
网页抓取解密
网页抓取解密(做了个网络爬虫抓取网页,最后居然搞出来了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-19 07:04
我做了一个网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,就会出现乱码,如下:
得到文本后直接打印,输出str如下: ¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÔ±¿¿ ¼ÊÔÔ±¿¿
这个问题困扰了我很久,百度、google都没有找到完全可行的方法,继续折腾,终于出来了!代码转换来回转换,依然无法解决。把问题具体总结一下,分享给大家,互相学习!(有时候问题并不复杂,容易解决。如果问题没有突破,那么解决问题的路是很长的。)总之,遇到问题,选择几种方法去尝试,就有了总是有办法解决它。的。
1.更改网页源代码的编码格式
# -*- coding:utf8 -*-
import urllib2
req = urllib2.Request("http://www.baidu.com/")
res = urllib2.urlopen(req)
html = res.read()
res.close()
html = unicode(html, "gb2312").encode("utf8") #gb2312--->utf-8
print html
2.python爬取网页时字符集转换问题处理解决方案
有时我们 采集 网页,将字符串保存到文件或在处理后将它们写入数据库。这时,我们需要制定字符串的编码。如果采集网页的编码是gb2312,而我们的数据库是utf-8,不做任何处理直接插入数据库可能会出现乱码(未测试,不知道数据库会不会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人,立马下跪。
不知道大家还记得没有,python中打印汉字的时候,需要在字符串前面加上u:
print u"来做基地?"
这样就可以显示中文了。u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
这里有一个与之相关的unicode()函数,使用如下
str="来基地"
str=unicode(str,"utf-8")
打印字符串
与u的区别在于unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认的可能是ansi。
unicode 是键,下面继续
我们开始爬取百度主页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
导入 urllib2
定义主():
f=urllib2.urlopen("")
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
如果 __name__ == '__main__' :
主要的()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大部分人来说,这其实已经足够了,但是有时候我只想把gb2312转成utf-8,怎么办呢?
第一的:
str=unicode(str,"gb2312") #这里的gb2312是str的实际字符集,我们现在将其转换为unicode
然后:
str=str.encode("utf-8") #将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,转码为utf-8。
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding") 将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
3:将str保存到文件,或写入数据库。当然,你已经指定了编码,对吧?
3.用 lxml 解析 html
使用lxml.etree作为网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,会出现乱码,如下:
获取文本后,直接打印,输出结果v如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй«这个v的类型又是
如何解决?
可以修改源代码的编码格式:
response.encoding='utf-8'
page=etree.HTML(response.content)
nodes_title=page.xpath("//title//text()")
这样打印出来的nodes_title[0]是正常中文显示的。
特别注意的是response.text容易出现编码问题,所以以后使用response.content。 查看全部
网页抓取解密(做了个网络爬虫抓取网页,最后居然搞出来了)
我做了一个网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,就会出现乱码,如下:
得到文本后直接打印,输出str如下: ¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÔ±¿¿ ¼ÊÔÔ±¿¿
这个问题困扰了我很久,百度、google都没有找到完全可行的方法,继续折腾,终于出来了!代码转换来回转换,依然无法解决。把问题具体总结一下,分享给大家,互相学习!(有时候问题并不复杂,容易解决。如果问题没有突破,那么解决问题的路是很长的。)总之,遇到问题,选择几种方法去尝试,就有了总是有办法解决它。的。
1.更改网页源代码的编码格式
# -*- coding:utf8 -*-
import urllib2
req = urllib2.Request("http://www.baidu.com/";)
res = urllib2.urlopen(req)
html = res.read()
res.close()
html = unicode(html, "gb2312").encode("utf8") #gb2312--->utf-8
print html
2.python爬取网页时字符集转换问题处理解决方案
有时我们 采集 网页,将字符串保存到文件或在处理后将它们写入数据库。这时,我们需要制定字符串的编码。如果采集网页的编码是gb2312,而我们的数据库是utf-8,不做任何处理直接插入数据库可能会出现乱码(未测试,不知道数据库会不会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人,立马下跪。
不知道大家还记得没有,python中打印汉字的时候,需要在字符串前面加上u:
print u"来做基地?"
这样就可以显示中文了。u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
这里有一个与之相关的unicode()函数,使用如下
str="来基地"
str=unicode(str,"utf-8")
打印字符串
与u的区别在于unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认的可能是ansi。
unicode 是键,下面继续
我们开始爬取百度主页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
导入 urllib2
定义主():
f=urllib2.urlopen("")
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
如果 __name__ == '__main__' :
主要的()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大部分人来说,这其实已经足够了,但是有时候我只想把gb2312转成utf-8,怎么办呢?
第一的:
str=unicode(str,"gb2312") #这里的gb2312是str的实际字符集,我们现在将其转换为unicode
然后:
str=str.encode("utf-8") #将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,转码为utf-8。
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding") 将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
3:将str保存到文件,或写入数据库。当然,你已经指定了编码,对吧?
3.用 lxml 解析 html
使用lxml.etree作为网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,会出现乱码,如下:
获取文本后,直接打印,输出结果v如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй«这个v的类型又是
如何解决?
可以修改源代码的编码格式:
response.encoding='utf-8'
page=etree.HTML(response.content)
nodes_title=page.xpath("//title//text()")
这样打印出来的nodes_title[0]是正常中文显示的。
特别注意的是response.text容易出现编码问题,所以以后使用response.content。
网页抓取解密(煎蛋网妹子图怎么爬,文件夹js处理的网页防盗图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-19 00:02
最近有朋友一直在问我怎么爬的修改版,因为他们用尽了所有的精力,结果抓到了一整文件夹的防盗图片。很久以前在博客里说过,对于这种js处理的网页,抓取网页上看到的数据大致有三种方式:
分析网页
首先打开inspect元素查看他的实际响应内容,可以看到img标签中实际src属性的值是固定值 ///img/blank.gif。onload 属性指向一个 js jandan_load_img() 函数,this 参数在大多数情况下是指当前标签。其后是 span 标签中收录的一串哈希值。
目前我们已经找到了jandan_load_img()函数,接下来需要确定收录该函数的js文件。方法很简单,在每一个返回的js响应中,去搜索。
当前的js文件是经过压缩和混淆处理的,我们可以复制到在线解压工具中解压。如果您使用的是 Chrome,您可以找到源文件并单击图标下方带有红色框的按钮:
jandan_load_img() 函数的内容是
1function jandan_load_img(b) {
2 var d = $(b);
3 var f = d.next("span.img-hash");
4 var e = f.text();
5 f.remove();
6 var c = jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH(e, "zE4N6eHuAQP8vkQPb0wcuEcWnLzHYVhy");
7 var a = $('[查看原图]</a>');
8 d.before(a);
9 d.before("
");
10 d.removeAttr("onload");
11 d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1thumb180$3"));
12 ...
13}
14
可以看到js文件依赖于PQuery库,它获取img标签,然后获取span标签的内容,然后将它和一个常量传递给这个字符串的函数,获取返回的内容把这个字符串的函数,放入img和a标签中。
我们在当前的js文件中搜索jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH()函数。如果不出意外,我们可以搜索 2 个函数。我们选择后一种,内容如下:
1var jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH = function(m, r, d) {
2 var e = "DECODE";
3 var r = r ? r : "";
4 var d = d ? d : 0;
5 var q = 4;
6 r = md5(r);
7 var o = md5(r.substr(0, 16));
8 var n = md5(r.substr(16, 16));
9 if (q) {
10 if (e == "DECODE") {
11 var l = m.substr(0, q)
12 }
13 } else {
14 var l = ""
15 }
16 var c = o + md5(o + l);
17 var k;
18 if (e == "DECODE") {
19 m = m.substr(q);
20 k = base64_decode(m)
21 }
22 var h = new Array(256);
23 for (var g = 0; g .*'
35 result = re.findall(pattern, html)
36 js_url = "http://" + result[len(result) - 1]
37 except Exception as e:
38 print(e)
39 js = get_html(js_url).text
40
41 return js
42
43def get_salt(js):
44 """正则匹配 js 中的加密常量"""
45 pattern = r'jandan_load_img.*?var c.*?"(.*?)"'
46 salt = re.findall(pattern, js, re.S)[0]
47 # print(salt)
48 return salt
49
50def all_img_hash(page_url):
51 """请求页面,返回页面中所有图片 hash"""
52 html = get_html(page_url).text
53 doc = etree.HTML(html)
54 img_hash = doc.xpath('//span[@class="img-hash"]/text()')
55 # print(img_hash)
56 return img_hash
57
58def init_md5(str):
59 """封装 md5"""
60 md5 = hashlib.md5()
61 md5.update(str.encode('utf-8'))
62 return md5.hexdigest()
63
64def decode_base64(data):
65 """封装 base64"""
66 return base64.b64decode(data + (4 - len(data) % 4) * '=')
67
68def simulation_js(img_hash, salt):
69 """
70 翻译 js 加密方式
71 :param img_hash: 图片 hash
72 :param salt: 加密常量
73 :return: 图片 url
74 """
75 # r = salt if salt else ''
76 # d = 0
77 # q = 4
78 # r = init_md5(r)
79 # o = init_md5(r[:16])
80 # n = init_md5(r[16:32])
81 # if q:
82 # l = img_hash[:q]
83 # else: l = ''
84 #
85 # c = o + init_md5(o + l)
86 # img_hash = img_hash[q:]
87 # k = decode_base64(img_hash)
88 #
89 # h = list(range(256))
90 # b = list(range(256))
91 # for g in range(256):
92 # b[g] = ord(c[g % len(c)])
93 # f = 0
94 # for g in range(256):
95 # f = (f + h[g] + b[g]) % 256
96 # h[g], h[f] = h[f], h[g]
97 #
98 # t = ''
99 # p = f = 0
100 # for g in range(len(k)):
101 # p = (p + 1) % 256
102 # f = (f + h[p]) % 256
103 # h[p], h[f] = h[f], h[p]
104 # t += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
105 # t = t[26:]
106 t = decode_base64(img_hash)
107 # print(t)
108 return t
109
110def parse_hash(salt, page_url):
111
112 img_hash = all_img_hash(page_url)
113 # print(img_hash)
114 for i in img_hash:
115 yield simulation_js(i, salt)
116
117def download_img(dir_path, img_url):
118 """下载"""
119 filename = img_url[-14:]
120 # print(img_url)
121 img_content = get_html(img_url).content
122 if not os.path.exists(dir_path):
123 os.mkdir(dir_path)
124 try:
125 with open(os.path.join(dir_path, filename), 'wb') as f:
126 f.write(img_content)
127 return True
128 except Exception as e:
129 print(e)
130 return False
131
132def main(dir_path, page=1):
133 js = get_js_file()
134 salt = get_salt(js)
135 base_url = 'http://jandan.net/ooxx/'
136 for i in range(page+1):
137 page_url = base_url + 'page-{}/'.format(58-i)
138 # print(page_url)
139 # //wx1.sinaimg.cn/large/672f3952gy1g0u2mqymhyj20u00u0dja.jpg 正确结果
140 for img_url in parse_hash(salt, page_url):
141 # img_url = 'w'+str(img_url, encoding = "utf-8")
142 img_url = str(img_url, encoding = "utf-8")
143 print(img_url)
144 r = download_img(dir_path, 'http:' + img_url)
145
146 if r: print('success')
147
148
149if __name__ == '__main__':
150 dir_path = 'E:/jiandan/'
151 main(dir_path)
152
153
这一次,不知道为什么煎蛋的解密变得容易了。…
最后非常感谢原作者的分享,一下子学到了很多。 查看全部
网页抓取解密(煎蛋网妹子图怎么爬,文件夹js处理的网页防盗图)
最近有朋友一直在问我怎么爬的修改版,因为他们用尽了所有的精力,结果抓到了一整文件夹的防盗图片。很久以前在博客里说过,对于这种js处理的网页,抓取网页上看到的数据大致有三种方式:
分析网页
首先打开inspect元素查看他的实际响应内容,可以看到img标签中实际src属性的值是固定值 ///img/blank.gif。onload 属性指向一个 js jandan_load_img() 函数,this 参数在大多数情况下是指当前标签。其后是 span 标签中收录的一串哈希值。
目前我们已经找到了jandan_load_img()函数,接下来需要确定收录该函数的js文件。方法很简单,在每一个返回的js响应中,去搜索。
当前的js文件是经过压缩和混淆处理的,我们可以复制到在线解压工具中解压。如果您使用的是 Chrome,您可以找到源文件并单击图标下方带有红色框的按钮:
jandan_load_img() 函数的内容是
1function jandan_load_img(b) {
2 var d = $(b);
3 var f = d.next("span.img-hash");
4 var e = f.text();
5 f.remove();
6 var c = jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH(e, "zE4N6eHuAQP8vkQPb0wcuEcWnLzHYVhy");
7 var a = $('[查看原图]</a>');
8 d.before(a);
9 d.before("
");
10 d.removeAttr("onload");
11 d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1thumb180$3"));
12 ...
13}
14
可以看到js文件依赖于PQuery库,它获取img标签,然后获取span标签的内容,然后将它和一个常量传递给这个字符串的函数,获取返回的内容把这个字符串的函数,放入img和a标签中。
我们在当前的js文件中搜索jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH()函数。如果不出意外,我们可以搜索 2 个函数。我们选择后一种,内容如下:
1var jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH = function(m, r, d) {
2 var e = "DECODE";
3 var r = r ? r : "";
4 var d = d ? d : 0;
5 var q = 4;
6 r = md5(r);
7 var o = md5(r.substr(0, 16));
8 var n = md5(r.substr(16, 16));
9 if (q) {
10 if (e == "DECODE") {
11 var l = m.substr(0, q)
12 }
13 } else {
14 var l = ""
15 }
16 var c = o + md5(o + l);
17 var k;
18 if (e == "DECODE") {
19 m = m.substr(q);
20 k = base64_decode(m)
21 }
22 var h = new Array(256);
23 for (var g = 0; g .*'
35 result = re.findall(pattern, html)
36 js_url = "http://" + result[len(result) - 1]
37 except Exception as e:
38 print(e)
39 js = get_html(js_url).text
40
41 return js
42
43def get_salt(js):
44 """正则匹配 js 中的加密常量"""
45 pattern = r'jandan_load_img.*?var c.*?"(.*?)"'
46 salt = re.findall(pattern, js, re.S)[0]
47 # print(salt)
48 return salt
49
50def all_img_hash(page_url):
51 """请求页面,返回页面中所有图片 hash"""
52 html = get_html(page_url).text
53 doc = etree.HTML(html)
54 img_hash = doc.xpath('//span[@class="img-hash"]/text()')
55 # print(img_hash)
56 return img_hash
57
58def init_md5(str):
59 """封装 md5"""
60 md5 = hashlib.md5()
61 md5.update(str.encode('utf-8'))
62 return md5.hexdigest()
63
64def decode_base64(data):
65 """封装 base64"""
66 return base64.b64decode(data + (4 - len(data) % 4) * '=')
67
68def simulation_js(img_hash, salt):
69 """
70 翻译 js 加密方式
71 :param img_hash: 图片 hash
72 :param salt: 加密常量
73 :return: 图片 url
74 """
75 # r = salt if salt else ''
76 # d = 0
77 # q = 4
78 # r = init_md5(r)
79 # o = init_md5(r[:16])
80 # n = init_md5(r[16:32])
81 # if q:
82 # l = img_hash[:q]
83 # else: l = ''
84 #
85 # c = o + init_md5(o + l)
86 # img_hash = img_hash[q:]
87 # k = decode_base64(img_hash)
88 #
89 # h = list(range(256))
90 # b = list(range(256))
91 # for g in range(256):
92 # b[g] = ord(c[g % len(c)])
93 # f = 0
94 # for g in range(256):
95 # f = (f + h[g] + b[g]) % 256
96 # h[g], h[f] = h[f], h[g]
97 #
98 # t = ''
99 # p = f = 0
100 # for g in range(len(k)):
101 # p = (p + 1) % 256
102 # f = (f + h[p]) % 256
103 # h[p], h[f] = h[f], h[p]
104 # t += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
105 # t = t[26:]
106 t = decode_base64(img_hash)
107 # print(t)
108 return t
109
110def parse_hash(salt, page_url):
111
112 img_hash = all_img_hash(page_url)
113 # print(img_hash)
114 for i in img_hash:
115 yield simulation_js(i, salt)
116
117def download_img(dir_path, img_url):
118 """下载"""
119 filename = img_url[-14:]
120 # print(img_url)
121 img_content = get_html(img_url).content
122 if not os.path.exists(dir_path):
123 os.mkdir(dir_path)
124 try:
125 with open(os.path.join(dir_path, filename), 'wb') as f:
126 f.write(img_content)
127 return True
128 except Exception as e:
129 print(e)
130 return False
131
132def main(dir_path, page=1):
133 js = get_js_file()
134 salt = get_salt(js)
135 base_url = 'http://jandan.net/ooxx/'
136 for i in range(page+1):
137 page_url = base_url + 'page-{}/'.format(58-i)
138 # print(page_url)
139 # //wx1.sinaimg.cn/large/672f3952gy1g0u2mqymhyj20u00u0dja.jpg 正确结果
140 for img_url in parse_hash(salt, page_url):
141 # img_url = 'w'+str(img_url, encoding = "utf-8")
142 img_url = str(img_url, encoding = "utf-8")
143 print(img_url)
144 r = download_img(dir_path, 'http:' + img_url)
145
146 if r: print('success')
147
148
149if __name__ == '__main__':
150 dir_path = 'E:/jiandan/'
151 main(dir_path)
152
153
这一次,不知道为什么煎蛋的解密变得容易了。…
最后非常感谢原作者的分享,一下子学到了很多。
网页抓取解密(爬取一个第二季第34集分段视频没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-19 00:00
)
实现功能:爬取网站的视频
1、获取主页面的页面源码,找到iframe
2、从iframe页面源码中获取m3u8文件
3、下载第一层m3u8文件,获取真实地址
4、下载视频
5、下载密钥(key)进行解密
6、将所有ts文件合并为一个MP4文件
'''
目前基本确定是第4步和第5步有问题,但不清楚是代码错误的原因,还是好像有几个分段的视频没有下载;
所以不清楚是什么导致了第 6 步中的问题;
问题截图:
代码页
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES
import os
#正则提取规则
obj1=re.compile(r'2.html","link_pre":"","url":"(?P.*?)","url_next":"https:')
#2.1子程序:找到主页面的源代码,找到iframe对应的url
def get_iframe_src(url):
resp=requests.get(url)
#print(resp.text) #测试是否正常爬取到源代码
#修改为正则爬取,这里提取完之后就是第一层的m3u8地址了
content=resp.text #把源代码变成text格式存储起来,用来提取
main_page=obj1.finditer(content)
for it in main_page:
#print(it.group('src'))
src_modify=it.group('src').replace('\\','')
#print(src_modify)
return src_modify #输出正确的第一层m3u8地址
resp.close()
#2.2、子程序:拿到第一层的m3u8文件下载地址;这一步只在课程里91看剧需要,实操的网址2.1里拿到的就是第一层m3u8了
def get_first_m3u8_url(url):
resp=requests.get(url)
#print(resp.text)
obj2=re.compile(r'var main=''(?P.*?)''')
m3u8_url=obj2.search(resp.text).group('m3u8_url') #这里是把m3u8地址提取出来
#print(m3u8_url)
resp.close()
return m3u8_url #让函数返回这一个地址
#2.3、子程序:下载第一层m3u8文件
def download_m3u8_file(url,name):
resp=requests.get(url)
with open(name,mode='wb')as f:
f.write(resp.content)
resp.close()
#2.5.1、子程序:异步协程进行下载
async def download_ts(url,name,session):
async with session.get(url)as resp:
async with aiofiles.open(f'4.9-video2/{name}',mode='wb')as f:
await f.write(await resp.content.read()) #把下载到的内容写入文件中
print(f'{name}下载完毕')
#2.5、子程序:异步协程处理拼接下载
#实操版
async def aio_download(up_url):
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'): #’#‘开头的行不要
continue
# line就是xxxx.ts文件
url = line.strip()
name1=line.rsplit('/',1)[1]
name=name1.strip()
task=asyncio.create_task(download_ts(url,name,session))
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
#2.6.1获取密钥
def get_key(url):
resp=requests.get(url)
print(resp.text)
a=resp.text
b=bytes(a,'utf-8')
return b
#2.6.2创建解密视频的任务
async def aio_dec(key):
#思路:解密,需要把下载的文件一个个打开;但是因为这里我们是直接用m3u8文件里后面的字符命名的
tasks=[]
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'):
continue
line1=line.rsplit('/',1)[1] #取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
#开始创建异步任务
task=asyncio.create_task(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
#2.6.3创建解密函数
async def dec_ts(name,key):
aes=AES.new(key=key,IV=b'0000000000000000',mode=AES.MODE_CBC)
async with aiofiles.open(f'4.9-video2/{name}',mode='rb')as f1,\
aiofiles.open(f'4.9-video2/temp_{name}',mode='wb')as f2:
bs=await f1.read() #从源文件读取文件
await f2.write(aes.decrypt(bs)) #把解密好的内容写入文件
print(f'{name}处理完毕')
#2.7合并视频为mp4
def merge_ts():
#mac:cat 1.ts 2.ts 3.ts > xxx.mp4
#windows:copy/b 1.ts+2.ts+3.ts > xxx.mp4
lst=[]
with open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
for line in f:
if line.startswith('#'):
continue
line1 = line.rsplit('/', 1)[1] # 取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
lst.append(f'4.9-video2/temp_{line}')
s=''.join(lst)
os.system(f'copy /b {s} >movie.mp4')
print('搞定!')
#2、主程序
def main(url):
#2.1、找到主页面的源代码,找到iframe对应的url
iframe_src=get_iframe_src(url)
#print(iframe_src)
#2.3下载第一层m3u8文件
download_m3u8_file(iframe_src,'4.93-抓取91看剧复杂版——first-m3u8.txt') #按照课程正常的话括号里的’iframe_src‘要改为2.2里的’first_m3u8_url_ture‘
#2.4下载第二层m3u8文件
with open('4.93-抓取91看剧复杂版——first-m3u8.txt',mode='r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'): #让程序识别文件里面时,自动跳过‘#’开头的行段
continue
else:
line=line.strip() #去掉空白或者换行符
#准备拼接第二层m3u8的下载路径
second_m3u8_url=iframe_src.split('/20210730')[0]+line
download_m3u8_file(second_m3u8_url,'4.93-抓取91看剧复杂版——second-m3u8.txt')
print('第二层m3u8下载完毕')
#2.5下载视频
#实操写法
up_url='开始'
#asyncio.run(aio_download(up_url)) #这个会报错:RuntimeError: Event loop is closed
loop=asyncio.get_event_loop()
loop.run_until_complete(aio_download(up_url))
#2.6.1拿到密钥
#实操
key_url='https://ts6.hhmm0.com:9999/20210730/QoNAXIDD/1000kb/hls/key.key'
key=get_key(key_url) #访问密匙的路径,拿到密匙
#2.6.2解密
asyncio.run(aio_dec(key))
#2.7合并ts文件为mp4文件
merge_ts()
#1、主程序调用处
if __name__=='__main__':
url='https://www.pianba.net/yun/84961-1-1/'
main(url) 查看全部
网页抓取解密(爬取一个第二季第34集分段视频没有
)
实现功能:爬取网站的视频
1、获取主页面的页面源码,找到iframe
2、从iframe页面源码中获取m3u8文件
3、下载第一层m3u8文件,获取真实地址
4、下载视频
5、下载密钥(key)进行解密
6、将所有ts文件合并为一个MP4文件
'''
目前基本确定是第4步和第5步有问题,但不清楚是代码错误的原因,还是好像有几个分段的视频没有下载;
所以不清楚是什么导致了第 6 步中的问题;
问题截图:
代码页
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES
import os
#正则提取规则
obj1=re.compile(r'2.html","link_pre":"","url":"(?P.*?)","url_next":"https:')
#2.1子程序:找到主页面的源代码,找到iframe对应的url
def get_iframe_src(url):
resp=requests.get(url)
#print(resp.text) #测试是否正常爬取到源代码
#修改为正则爬取,这里提取完之后就是第一层的m3u8地址了
content=resp.text #把源代码变成text格式存储起来,用来提取
main_page=obj1.finditer(content)
for it in main_page:
#print(it.group('src'))
src_modify=it.group('src').replace('\\','')
#print(src_modify)
return src_modify #输出正确的第一层m3u8地址
resp.close()
#2.2、子程序:拿到第一层的m3u8文件下载地址;这一步只在课程里91看剧需要,实操的网址2.1里拿到的就是第一层m3u8了
def get_first_m3u8_url(url):
resp=requests.get(url)
#print(resp.text)
obj2=re.compile(r'var main=''(?P.*?)''')
m3u8_url=obj2.search(resp.text).group('m3u8_url') #这里是把m3u8地址提取出来
#print(m3u8_url)
resp.close()
return m3u8_url #让函数返回这一个地址
#2.3、子程序:下载第一层m3u8文件
def download_m3u8_file(url,name):
resp=requests.get(url)
with open(name,mode='wb')as f:
f.write(resp.content)
resp.close()
#2.5.1、子程序:异步协程进行下载
async def download_ts(url,name,session):
async with session.get(url)as resp:
async with aiofiles.open(f'4.9-video2/{name}',mode='wb')as f:
await f.write(await resp.content.read()) #把下载到的内容写入文件中
print(f'{name}下载完毕')
#2.5、子程序:异步协程处理拼接下载
#实操版
async def aio_download(up_url):
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'): #’#‘开头的行不要
continue
# line就是xxxx.ts文件
url = line.strip()
name1=line.rsplit('/',1)[1]
name=name1.strip()
task=asyncio.create_task(download_ts(url,name,session))
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
#2.6.1获取密钥
def get_key(url):
resp=requests.get(url)
print(resp.text)
a=resp.text
b=bytes(a,'utf-8')
return b
#2.6.2创建解密视频的任务
async def aio_dec(key):
#思路:解密,需要把下载的文件一个个打开;但是因为这里我们是直接用m3u8文件里后面的字符命名的
tasks=[]
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'):
continue
line1=line.rsplit('/',1)[1] #取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
#开始创建异步任务
task=asyncio.create_task(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
#2.6.3创建解密函数
async def dec_ts(name,key):
aes=AES.new(key=key,IV=b'0000000000000000',mode=AES.MODE_CBC)
async with aiofiles.open(f'4.9-video2/{name}',mode='rb')as f1,\
aiofiles.open(f'4.9-video2/temp_{name}',mode='wb')as f2:
bs=await f1.read() #从源文件读取文件
await f2.write(aes.decrypt(bs)) #把解密好的内容写入文件
print(f'{name}处理完毕')
#2.7合并视频为mp4
def merge_ts():
#mac:cat 1.ts 2.ts 3.ts > xxx.mp4
#windows:copy/b 1.ts+2.ts+3.ts > xxx.mp4
lst=[]
with open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
for line in f:
if line.startswith('#'):
continue
line1 = line.rsplit('/', 1)[1] # 取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
lst.append(f'4.9-video2/temp_{line}')
s=''.join(lst)
os.system(f'copy /b {s} >movie.mp4')
print('搞定!')
#2、主程序
def main(url):
#2.1、找到主页面的源代码,找到iframe对应的url
iframe_src=get_iframe_src(url)
#print(iframe_src)
#2.3下载第一层m3u8文件
download_m3u8_file(iframe_src,'4.93-抓取91看剧复杂版——first-m3u8.txt') #按照课程正常的话括号里的’iframe_src‘要改为2.2里的’first_m3u8_url_ture‘
#2.4下载第二层m3u8文件
with open('4.93-抓取91看剧复杂版——first-m3u8.txt',mode='r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'): #让程序识别文件里面时,自动跳过‘#’开头的行段
continue
else:
line=line.strip() #去掉空白或者换行符
#准备拼接第二层m3u8的下载路径
second_m3u8_url=iframe_src.split('/20210730')[0]+line
download_m3u8_file(second_m3u8_url,'4.93-抓取91看剧复杂版——second-m3u8.txt')
print('第二层m3u8下载完毕')
#2.5下载视频
#实操写法
up_url='开始'
#asyncio.run(aio_download(up_url)) #这个会报错:RuntimeError: Event loop is closed
loop=asyncio.get_event_loop()
loop.run_until_complete(aio_download(up_url))
#2.6.1拿到密钥
#实操
key_url='https://ts6.hhmm0.com:9999/20210730/QoNAXIDD/1000kb/hls/key.key'
key=get_key(key_url) #访问密匙的路径,拿到密匙
#2.6.2解密
asyncio.run(aio_dec(key))
#2.7合并ts文件为mp4文件
merge_ts()
#1、主程序调用处
if __name__=='__main__':
url='https://www.pianba.net/yun/84961-1-1/'
main(url)
网页抓取解密(WireSharkWireshark解密TLS数据流(图)数据解密(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-18 17:24
线鲨
Wireshark 解密 TLS 数据流。从网上现有的资料来看,主要有两种方式:一种是直接解密服务器的私钥,另一种是在握手过程中使用SSLKEYLOGFILE获取会话密钥信息进行解密。
此处仅尝试第二种方式来解密 TLS 数据。可用的应用程序包括:chrome、Firefox、curl。
首先将 SSLKEYLOGFILE 用户环境变量设置为自定义文件路径。例子:
或者在启动浏览器进程时附加参数--ssl-key-log-file=
.
测试开始,打开wireshark,访问,网页加载完成后退出浏览器,wireshark结束抓包。在目标路径中生成对应的密钥文件。然后在wireshark中,Edit -> Preferences -> Protocols -> TLS,可以添加RSA解密私钥、预共享密钥、主密钥。这只是使用(预)主密钥并导入先前生成的密钥文件。最后在主窗口查看,或者追踪TLS流,对应的数据已经解密。
提琴手
但通常在分析一些非浏览器进程时,对于使用HTTPS的,不需要看TCP数据,可以使用Fiddler(工作在应用层),将工具携带的证书导入虚拟机,然后然后在 fiddler Decrypt 选项中启用 https 进行解密。
参考:
(服务器密钥导入)
(SSLKEYLOGFILE)
(密钥导出和嵌入) 查看全部
网页抓取解密(WireSharkWireshark解密TLS数据流(图)数据解密(组图))
线鲨
Wireshark 解密 TLS 数据流。从网上现有的资料来看,主要有两种方式:一种是直接解密服务器的私钥,另一种是在握手过程中使用SSLKEYLOGFILE获取会话密钥信息进行解密。
此处仅尝试第二种方式来解密 TLS 数据。可用的应用程序包括:chrome、Firefox、curl。
首先将 SSLKEYLOGFILE 用户环境变量设置为自定义文件路径。例子:
或者在启动浏览器进程时附加参数--ssl-key-log-file=
.

测试开始,打开wireshark,访问,网页加载完成后退出浏览器,wireshark结束抓包。在目标路径中生成对应的密钥文件。然后在wireshark中,Edit -> Preferences -> Protocols -> TLS,可以添加RSA解密私钥、预共享密钥、主密钥。这只是使用(预)主密钥并导入先前生成的密钥文件。最后在主窗口查看,或者追踪TLS流,对应的数据已经解密。
提琴手
但通常在分析一些非浏览器进程时,对于使用HTTPS的,不需要看TCP数据,可以使用Fiddler(工作在应用层),将工具携带的证书导入虚拟机,然后然后在 fiddler Decrypt 选项中启用 https 进行解密。
参考:
(服务器密钥导入)
(SSLKEYLOGFILE)
(密钥导出和嵌入)
网页抓取解密(【每日一题】高产量博主,点个关注不迷路!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-18 17:21
PS高收益博主,点击不要迷路!
内容
一、实战需要的确定
本次实战的主要目的是复习requests库的基本语法,同时介绍一些新的内容:登录界面的捕获方式、session的使用、隐藏域问题的解决方法、破解验证码的方法等
要求如下:首先,我们可以打开古诗词网站:
接线以单击我的选项:
此时,我们需要登录才能看到个人下方的个人信息页面:
但是我们这次的实际需求是在不登录(绕过登录)的情况下获取个人页面的源码信息。
二、抓取古诗词网站的登录界面
确定需求后,可以简单分析一下我们的实现思路:首先,我们需要抓取相关的登录接口,然后将接口放入代码中,获取相关参数,匹配相关参数,达到绕过登录的目的。
所以迈出第一步:抓取固始文的登录界面:
1️⃣ 回到刚才的古诗文登录页面:
我们按 F12 解析网页:
这时候Network中Name列的第一项login.aspx就和我们需要的界面很相似了。但是,当我们查看它的具体内容时,我们发现这并不是一个真正的登录界面。有两个原因:
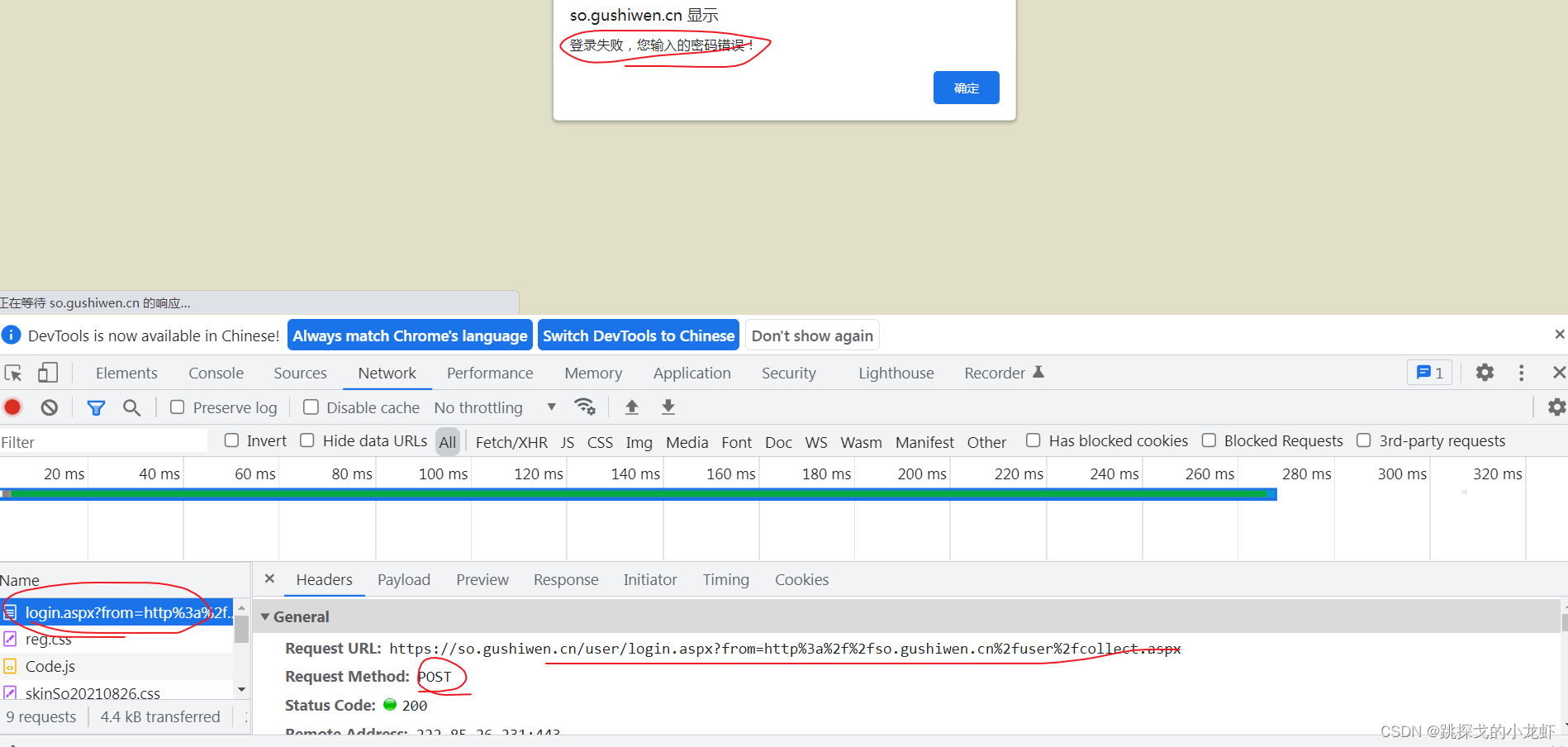
首先是因为我们的登录信息是放在输入文本框中的,所以接口应该是POST请求,而这个接口是GET请求;
二是我们在Headers中找不到相关的登录参数,比如用户名、密码和验证码。
所以获取登录界面有个小技巧:输入一组错误的用户名或者密码或者验证码,然后我们就可以在Network中找到真正的登录界面了:
在上述操作中,记得先按F12,然后不要关闭F12,而是输入一组错误信息,然后不要点击网页提示的OK按钮,否则界面会消失。
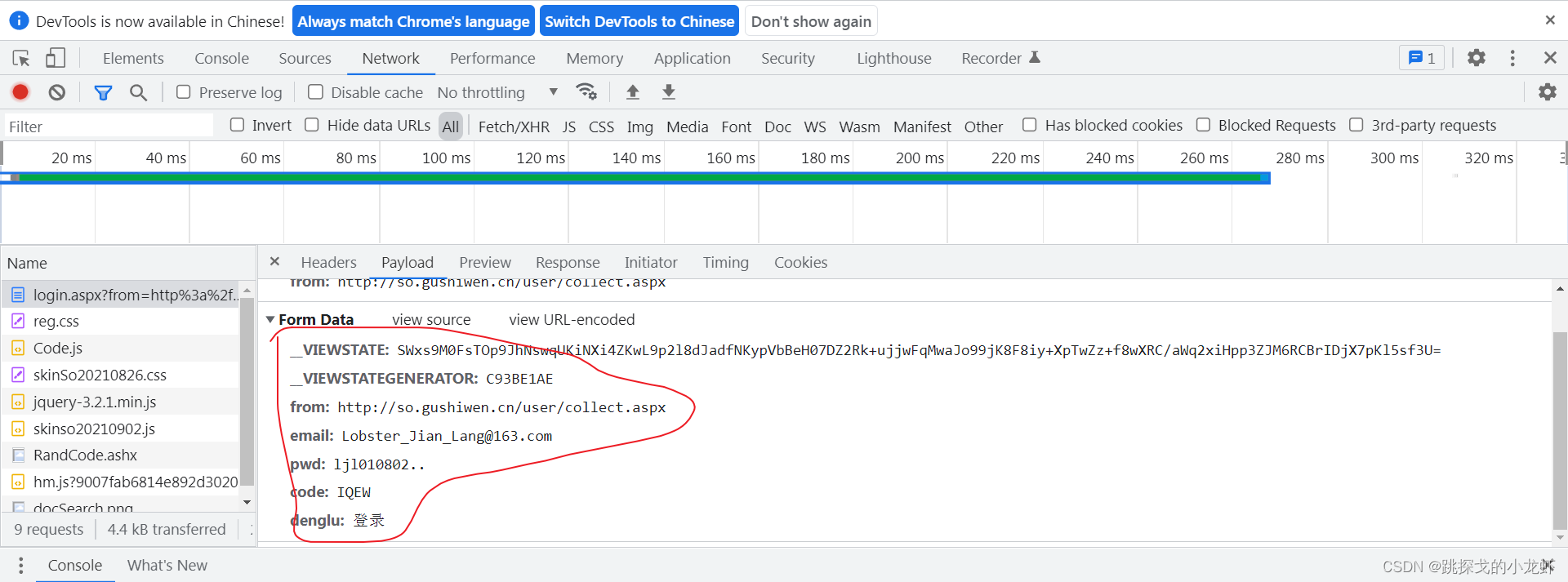
找到接口后,我们保存接口的url,同时点击Payload,查看POST请求的参数(部分谷歌浏览器版本的参数在Headers项下,其他版本在Payload中) :
至此,我们了解到有__VIEWSTATE、__VIEWSTATEGENERATOR、from、email、pwd、code、denglu这7个参数,而from、email、pwd、denglu这4个参数是已知的或固定的。其他四人不详。
三、难度分析
抓到接口和参数后,再来分析一下我们的难点:解决__VIEWSTATE、__VIEWSTATEGENERATOR、代码这三个参数。
前两个参数__VIEWSTATE、__VIEWSTATEGENERATOR是一种叫做隐藏域的技术手段,是一种反爬虫手段,我们需要一些方法来解决这两个参数。
最后一个参数码,验证码,需要我们采取一些必要的方法来解决(获取)。
四。隐藏域的解决方法
先解决隐域问题:
隐藏字段是什么意思?我们的 POST 请求提交的参数是由输入表单域发起的。因此,按照传统的思维方式,网页上所有的参数都应该有对应的输入文本框,但有些参数没有对应的输入文本框。这些参数是隐藏的,这类问题称为隐藏域问题。
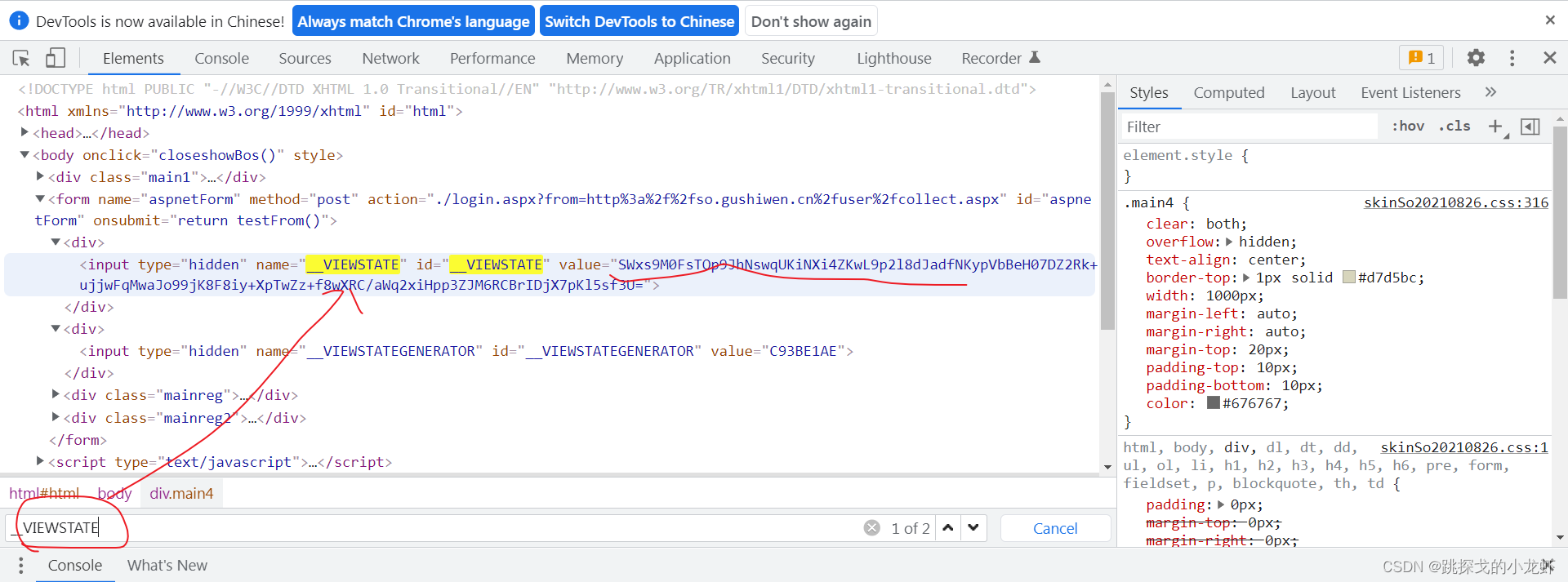
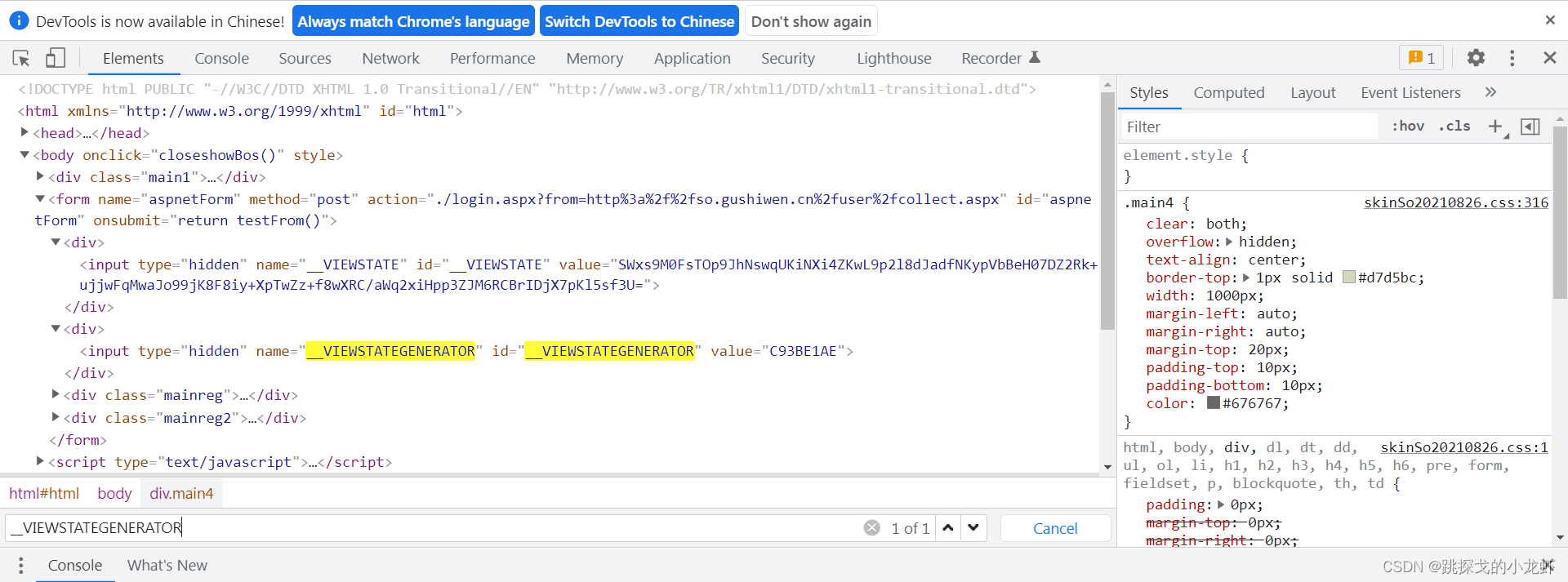
隐藏域问题的一个常见解决方案是在页面的源代码中搜索参数的痕迹:
我们回到古时文的登录页面,按F12解析源码:
可以看到,当我们按Ctrl+f,分别输入__VIEWSTATE和__VIEWSTATEGENERATOR进行查询时,我们在它的源码中找到了这两个参数,这样这个参数问题就解决了。
五、验证码的破解方法:
最后,我们着手解决验证码的问题。在之前的实战中,这个问题是手动输入的。这次,我们将介绍另外两种方法:图像识别和编码平台破解。
VI 手动输入
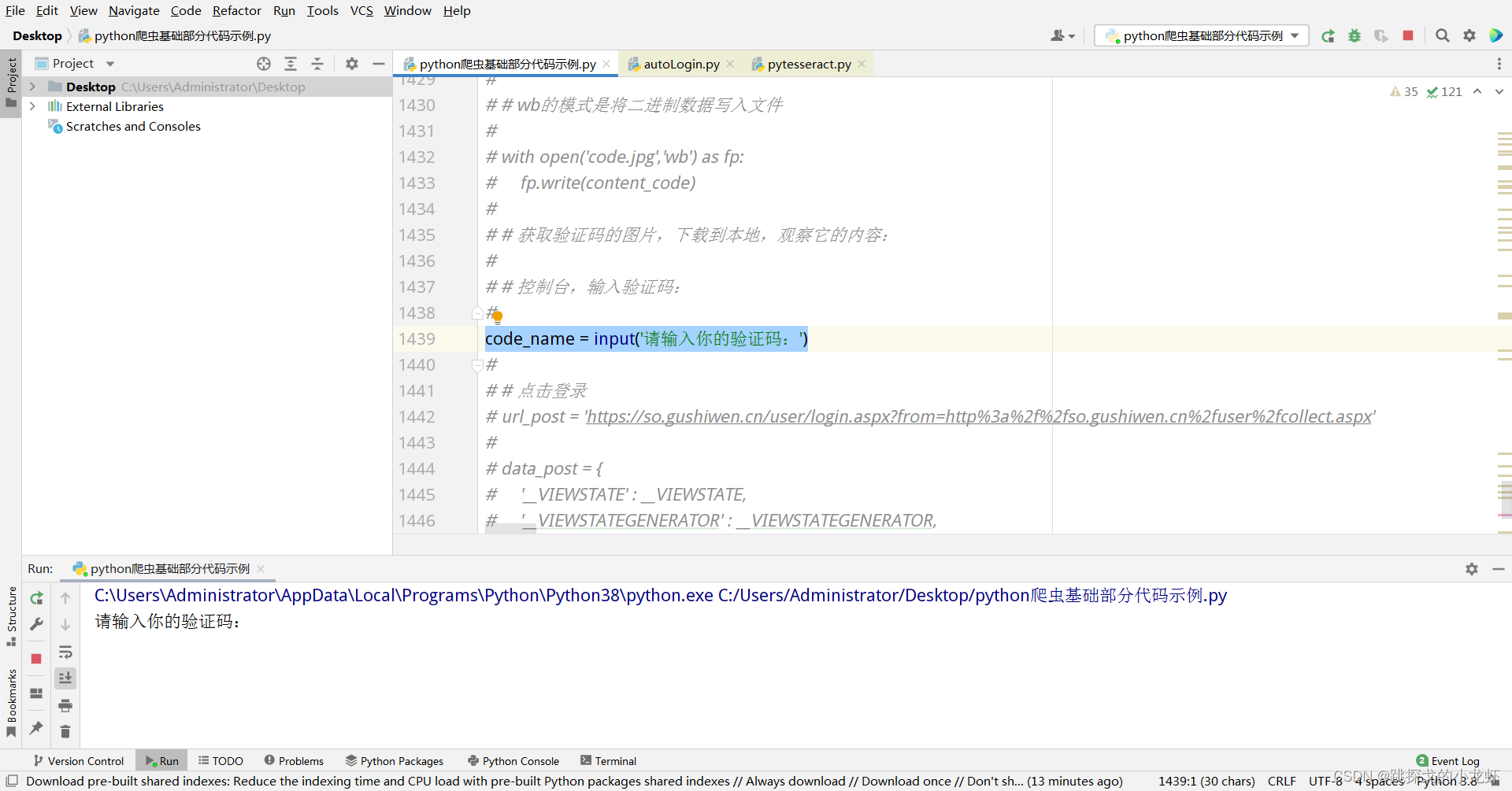
首先回顾一下手动输入法。这个方法就是我们下载验证码对应的图片,然后在图片上看到验证码的内容,通过python输入函数读取验证码。
但是,这种方法并没有实现真正的自动化,所以我们探索了另外两种方法。
五、二图像识别
第二种方法是图像识别,描述如下:
首先,让我们安装图像识别所需的插件和库:
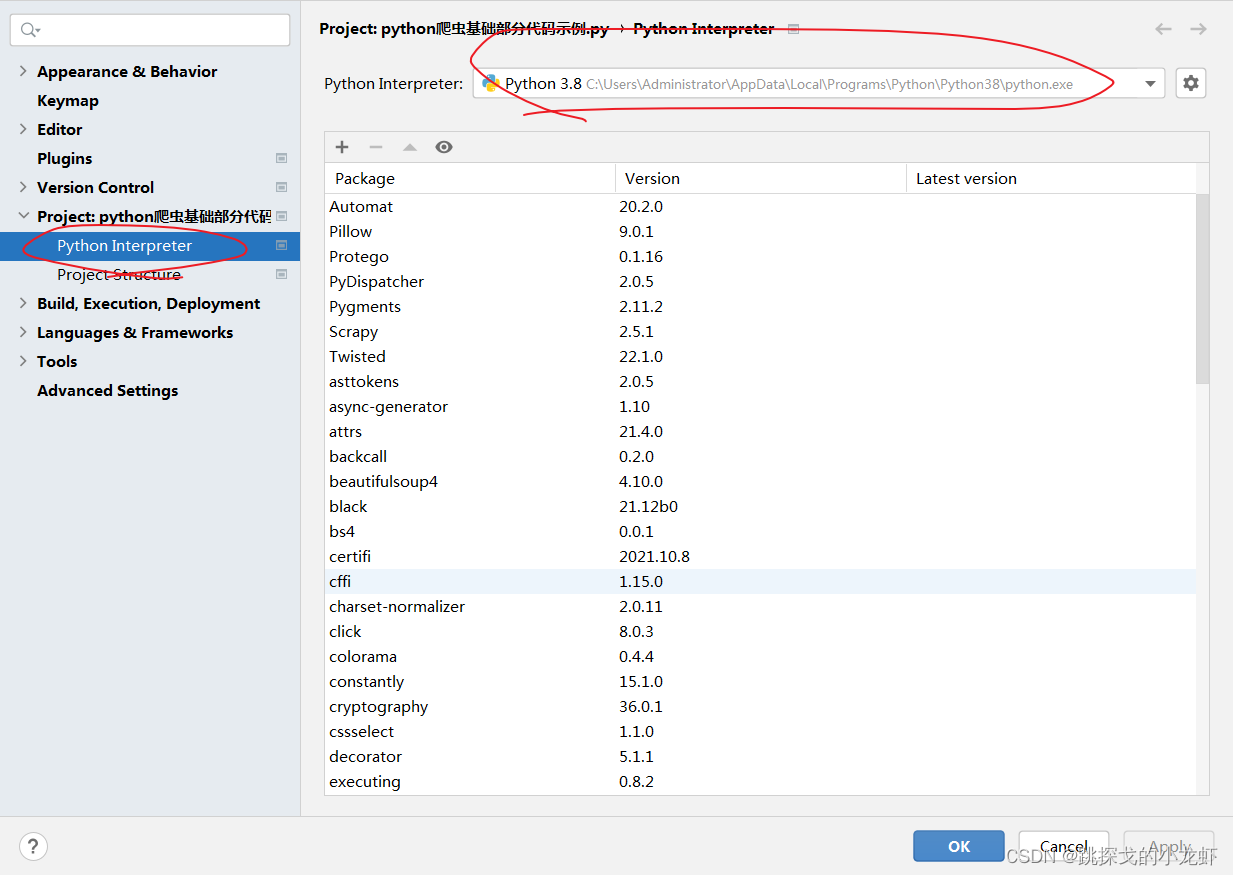
1️⃣ 下载插件:Tesseract-OCR,放到任意目录下(不过记住这个位置,后面会用到),这里是Tesseract-OCR的下载链接(提取码:dxzj)
2️⃣ 安装 pytesseract 和 Pillow 库。
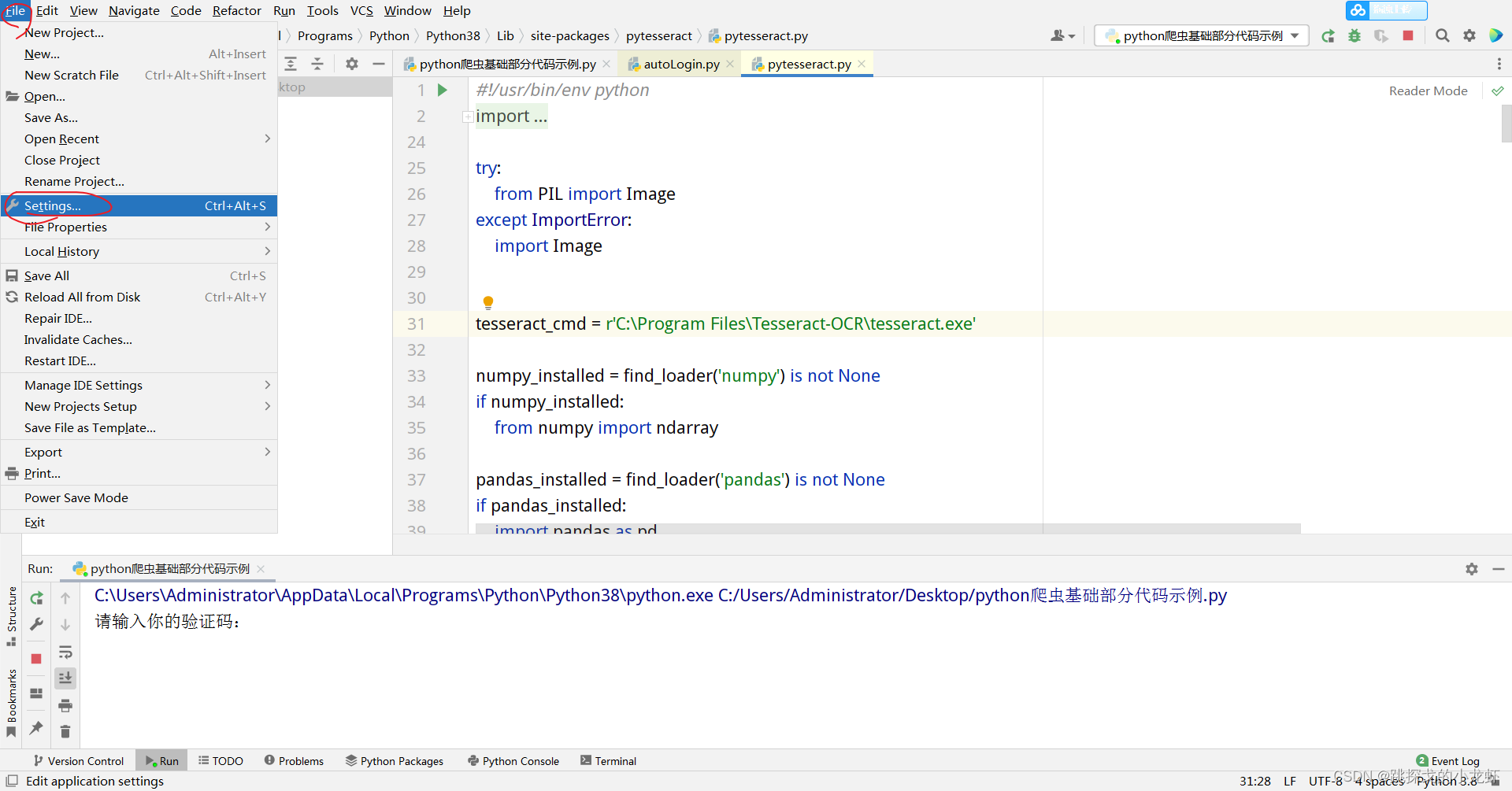
首先查看你的python解释器的路径,找到里面的Scripts文件夹,打开终端,使用终端进入这个文件夹:
执行安装说明:
pip install pytesseract
pip install Pillow
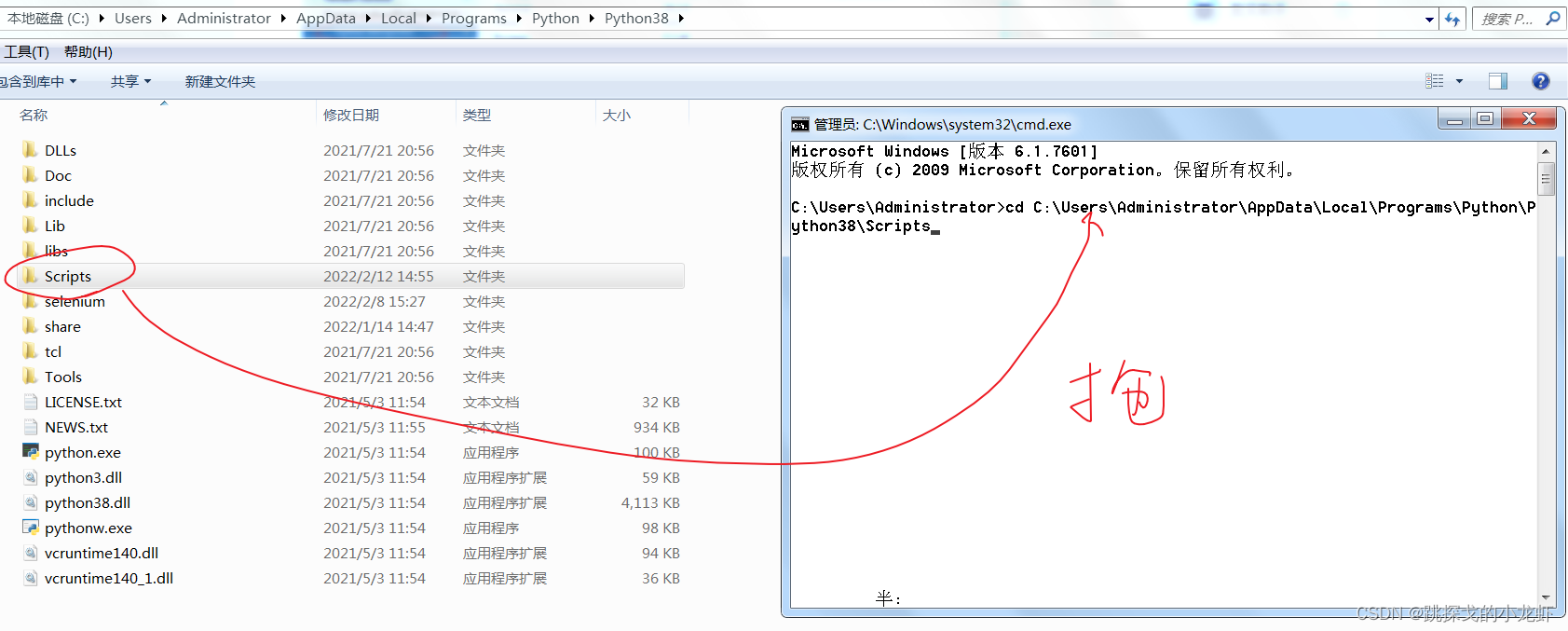
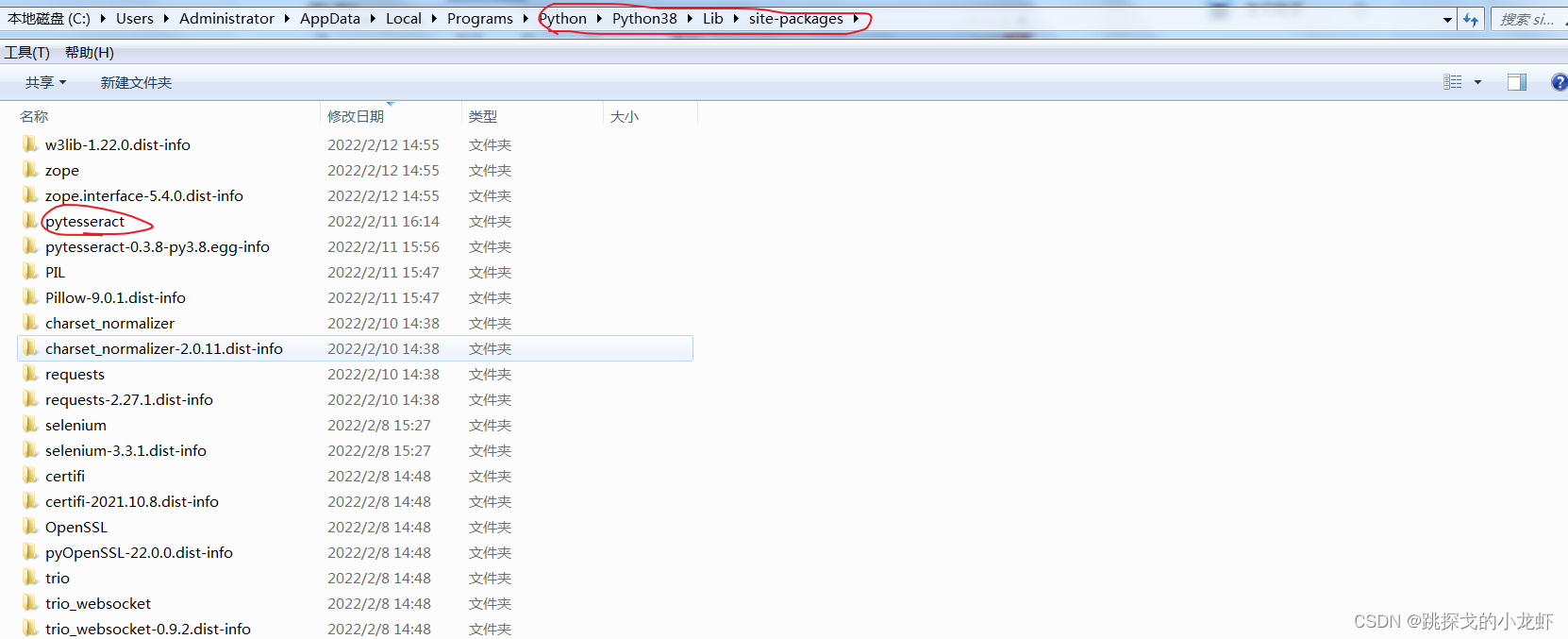
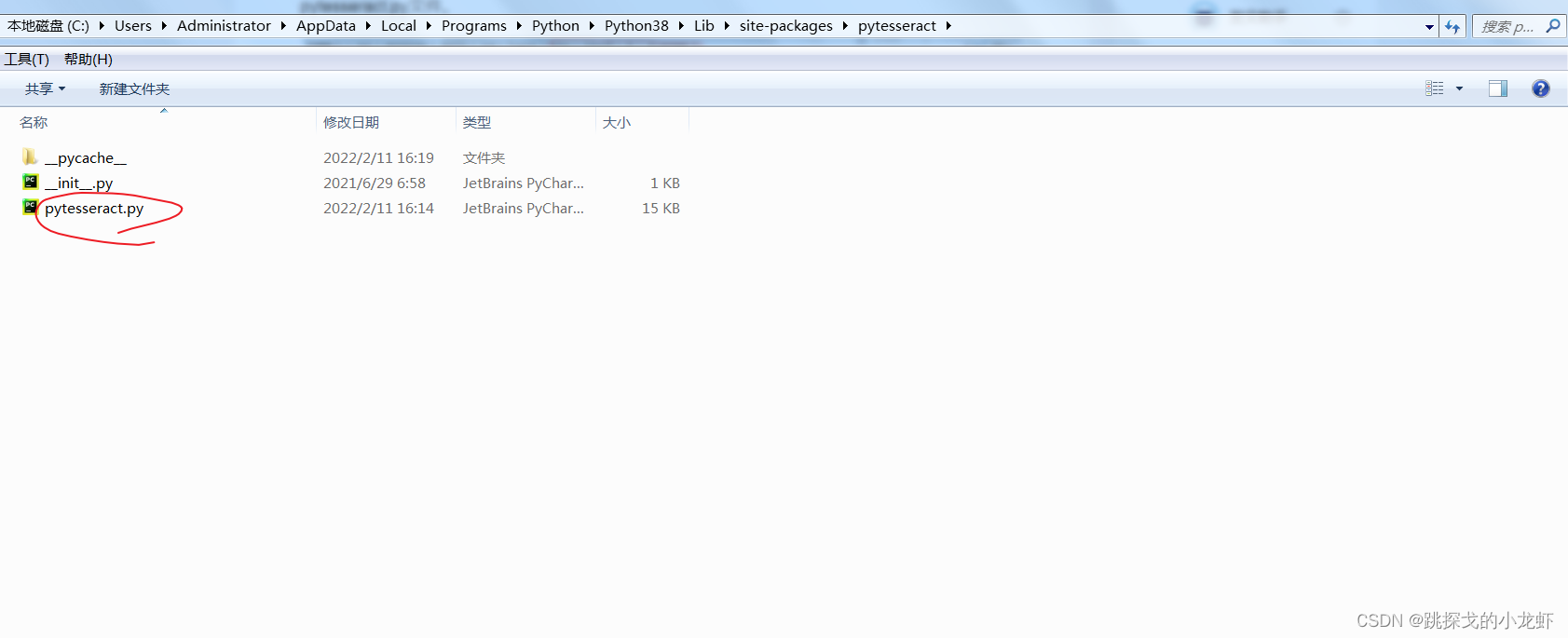
之后,我们一步之遥:修改pytesseract.py文件中的一行代码:
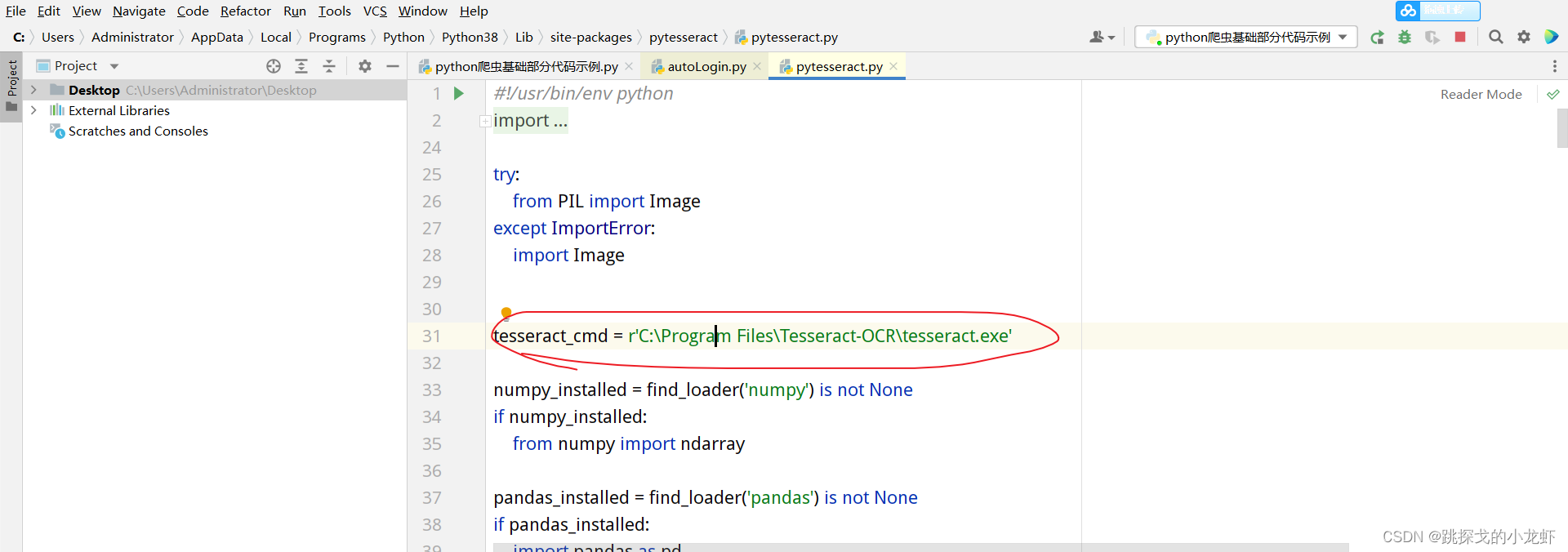
首先我们找到pytesseract.py文件:它的路径在python安装目录下的lib文件夹中的set-packages文件夹中,进入set-packages文件夹,找到一个叫pytesseract的文件夹,里面收录pytesseract.py文件。
打开这个文件,将红圈内那行代码的内容替换为刚安装Tesseract-OCR的安装路径(定位到tesseract.exe)
最后,我们可以在代码中成功导入图像识别库,并调用相关代码进行图像识别:
from PIL import Image
import pytesseract
text = pytesseract.image_to_string(Image.open(r'demo.png'))
print(text)
在识别图片的时候,我们直接复制上面的代码,将Image.open函数替换为对应图片的路径即可。
V.III编码平台:Super Eagle编码
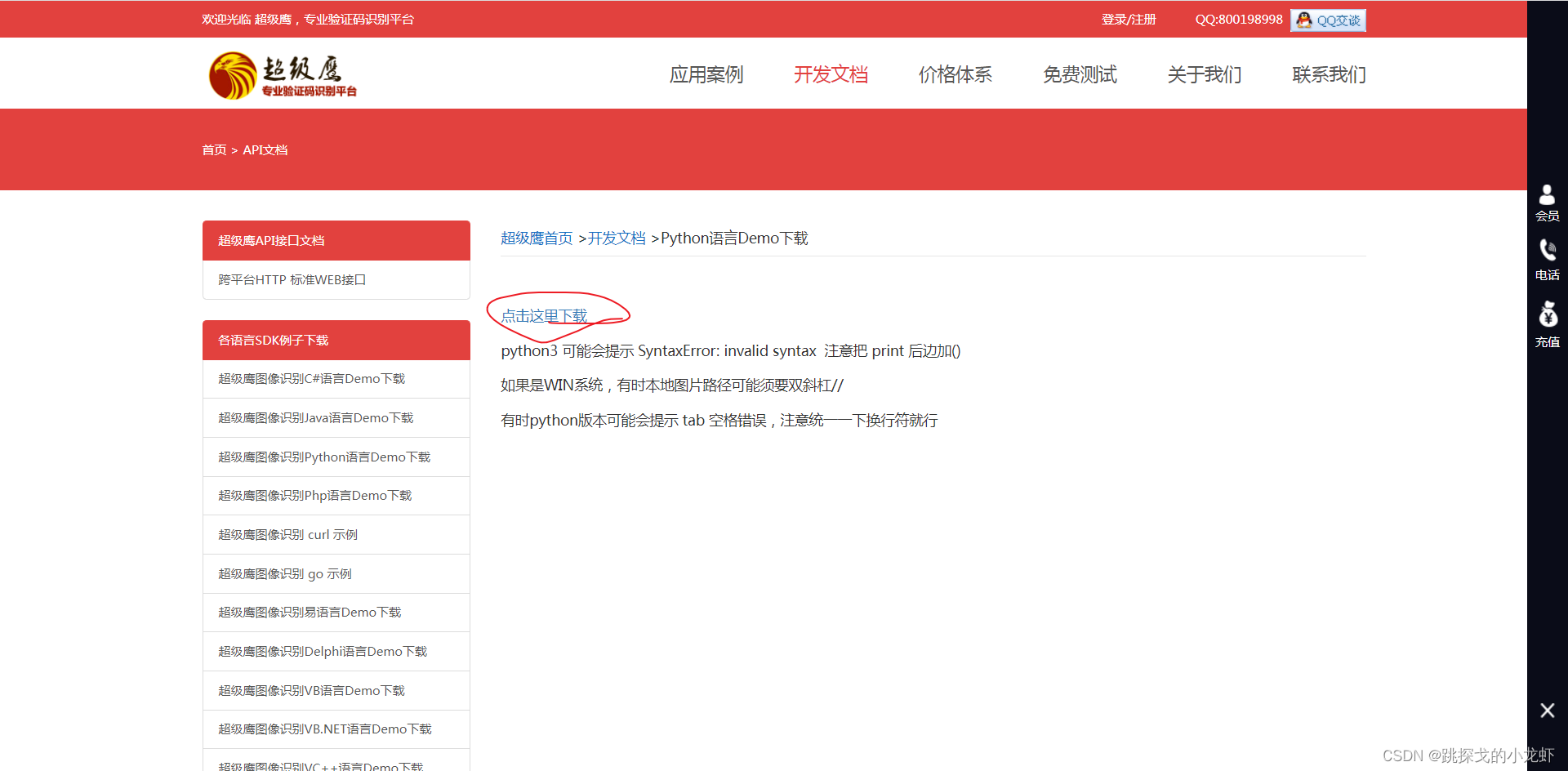
最后一种方法是使用编码平台。我们以 Super Eagle 编码为例:
我们进入它的官网,点击开发文档,选择python:
然后点击下载:
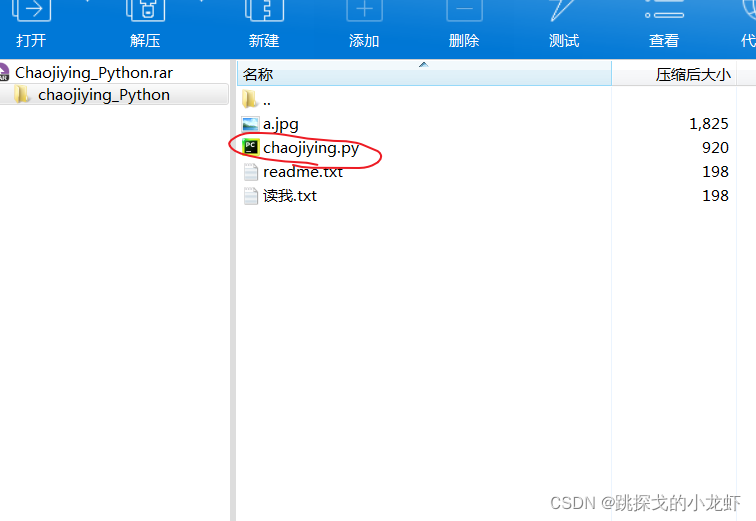
之后,将下载一个压缩包。我们只需要一个名为 chaojiying.py 的文件:
如果懒得按上面的步骤,可以直接点击我的分享链接下载chaojiying.py文件(提取码:dxzj)
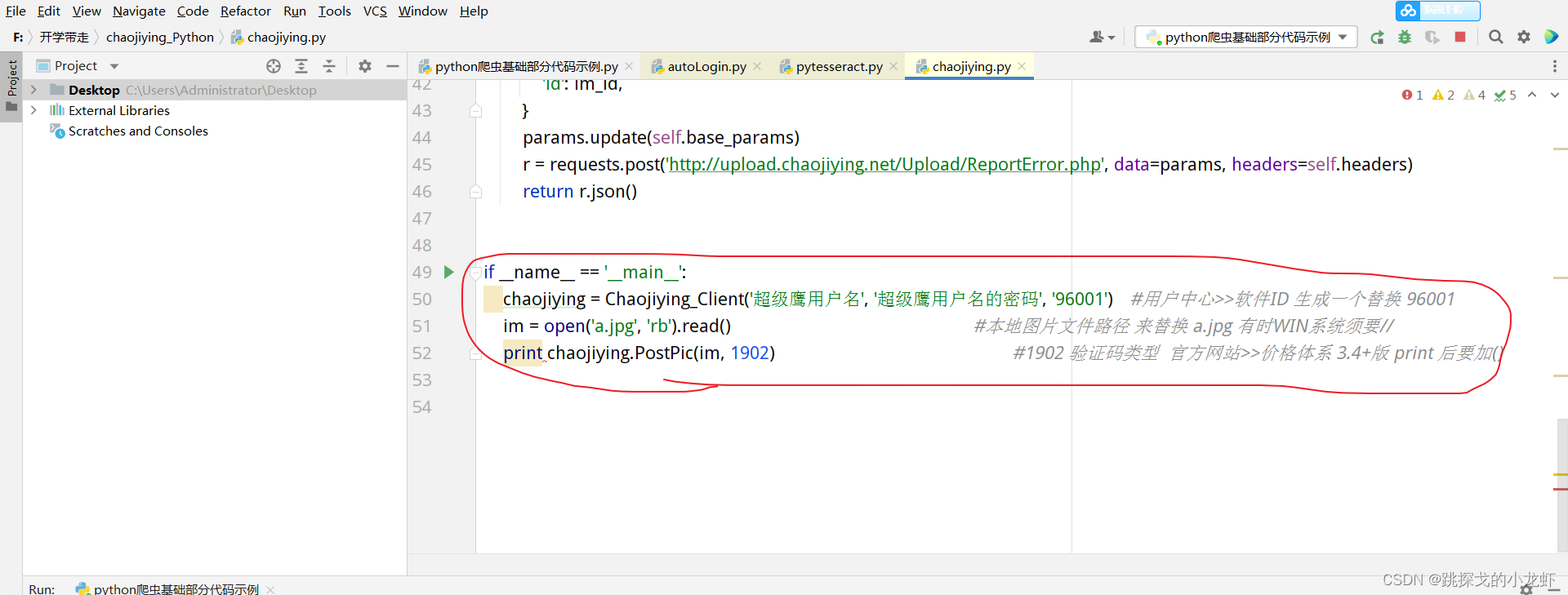
然后我们打开py文件,滑到最下面, if__name=='__main': 这是我们需要自己修改的部分(其他内容不要改!!!):
这部分,首先我们需要在print函数中加一个括号,改成print(),然后我们观察这部分代码,有两个地方需要自定义:im和chaojiying.PostPic()两个部分:
在im这部分,我们可以传入需要识别的图片路径;
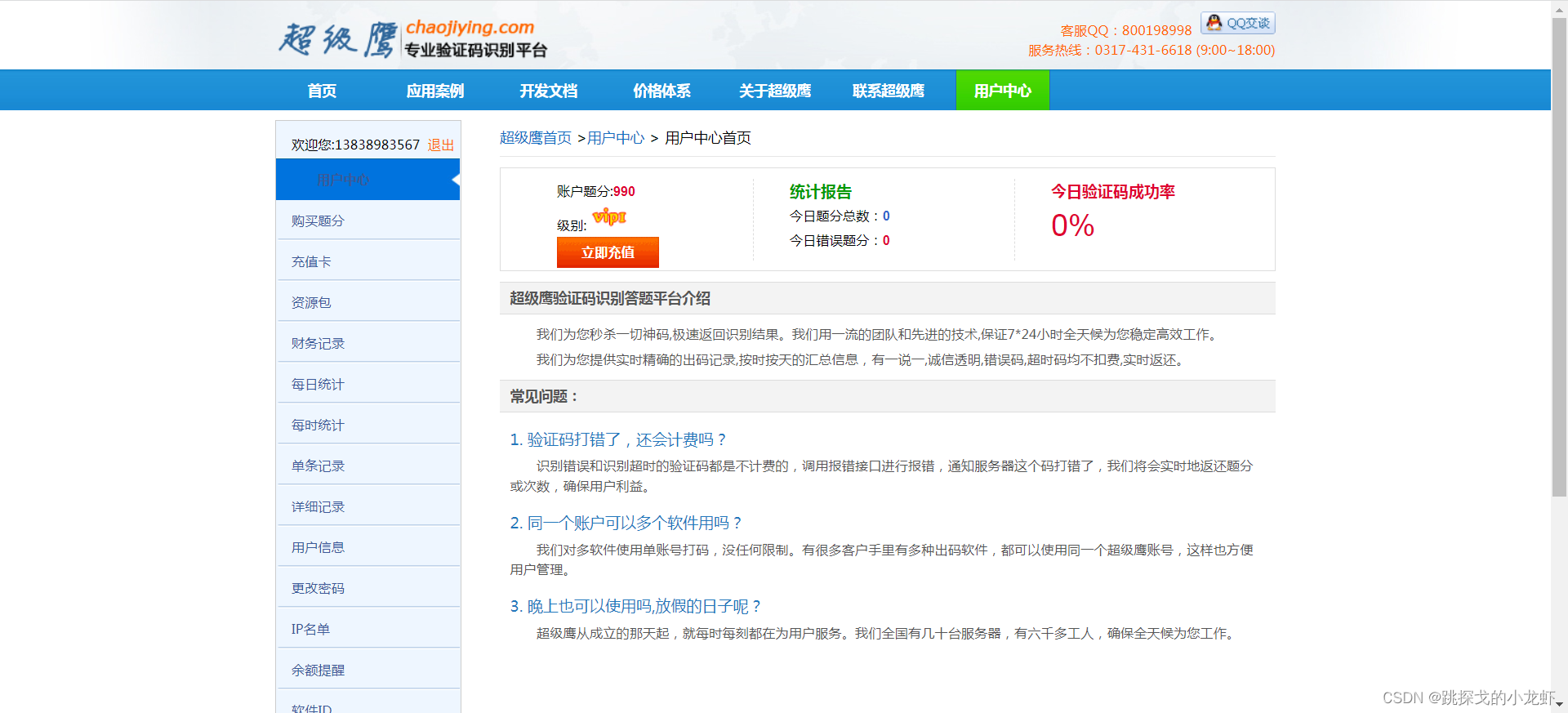
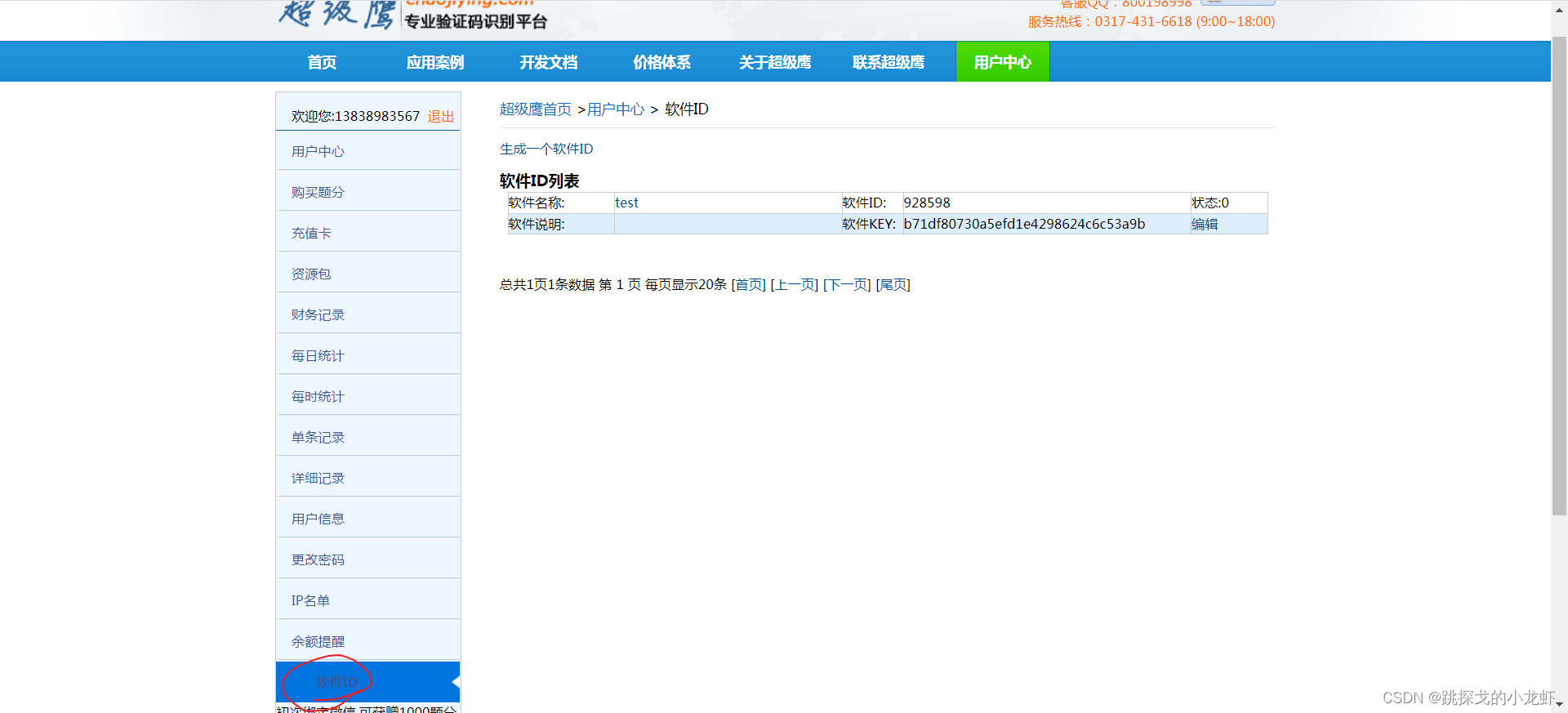
PostPic()函数的第一个参数是im,第二个参数需要在我们自己的超级鹰平台账号下获取:
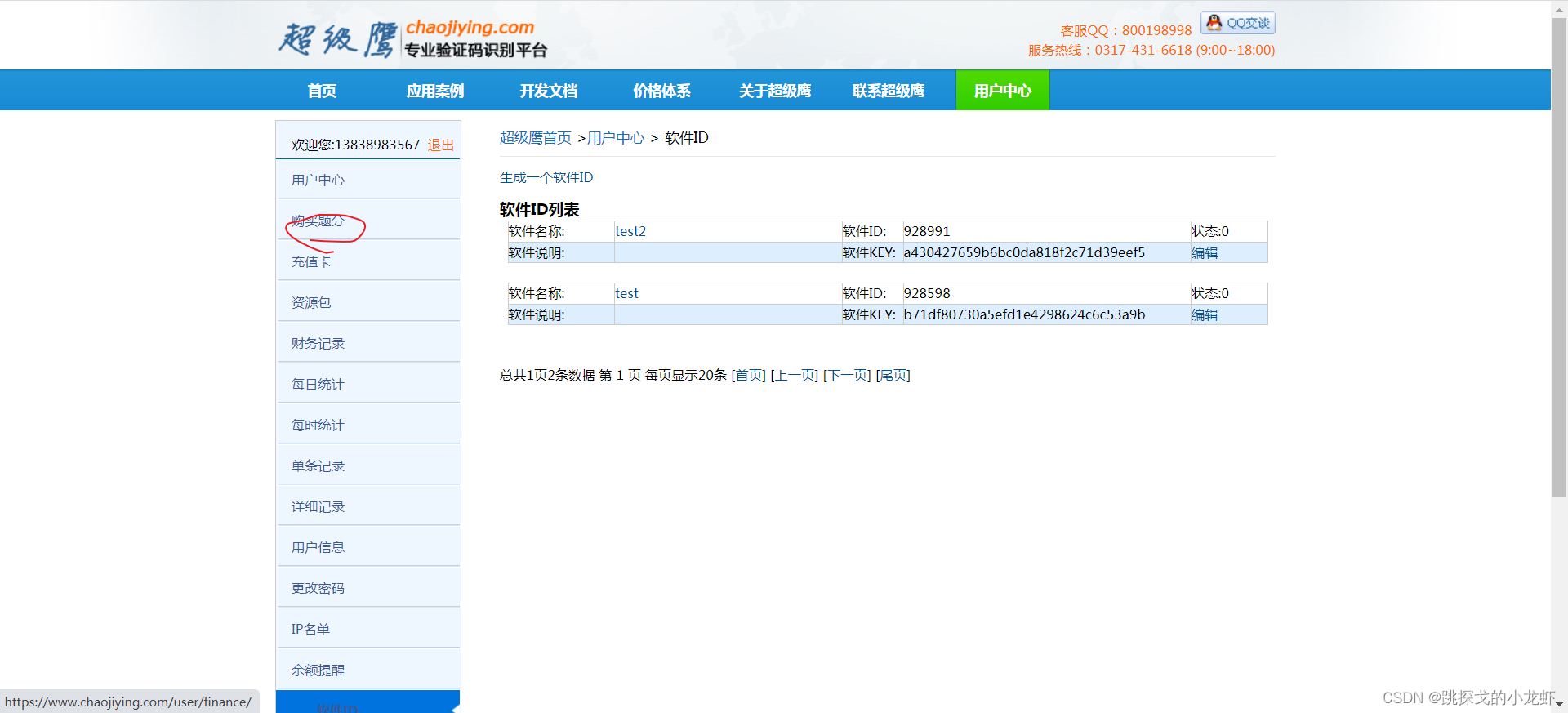
我们回到超级鹰官网,注册一个自己的账号,然后进入我们的账号:
选择软件ID:
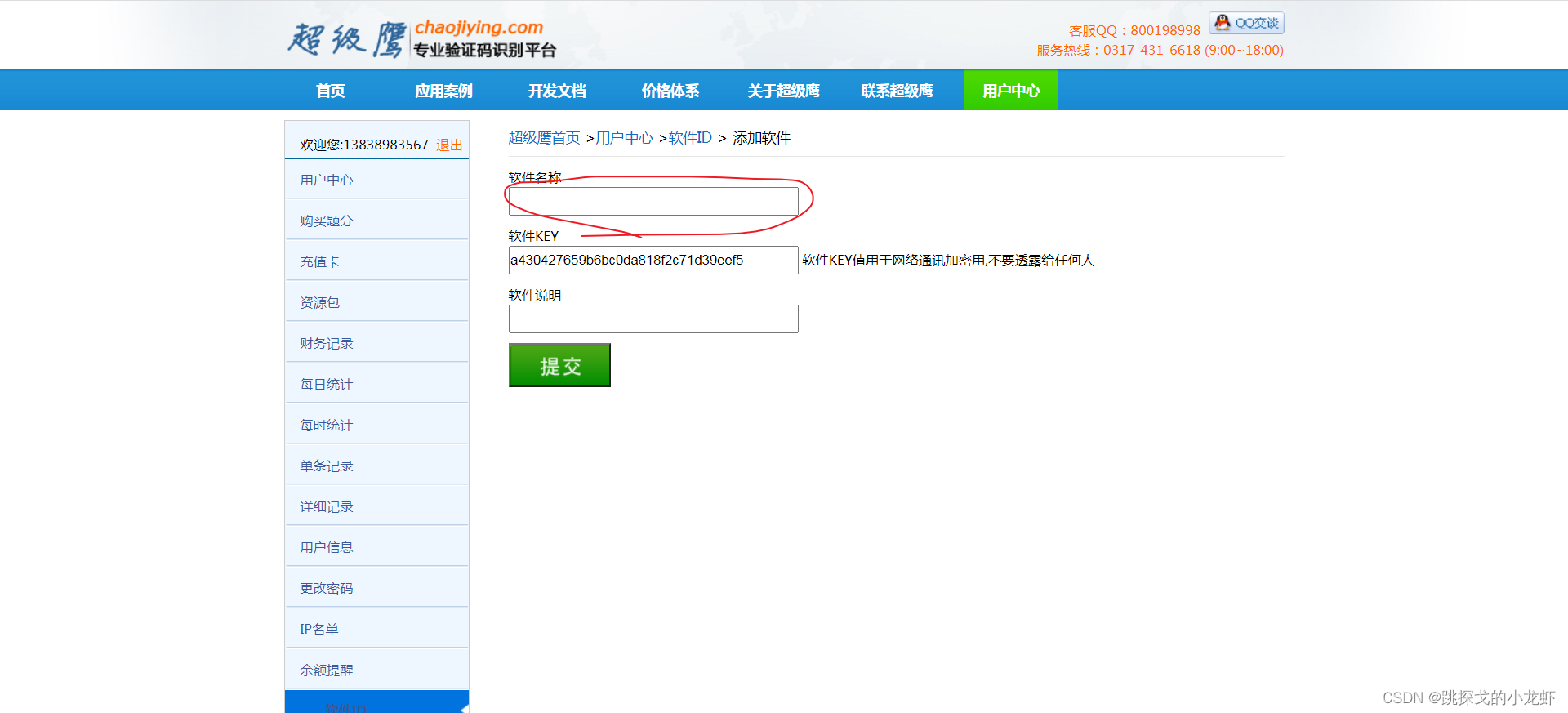
之后,我们点击生成软件ID,填写信息,随便选择一个名字,表示不需要填写,然后点击提交。
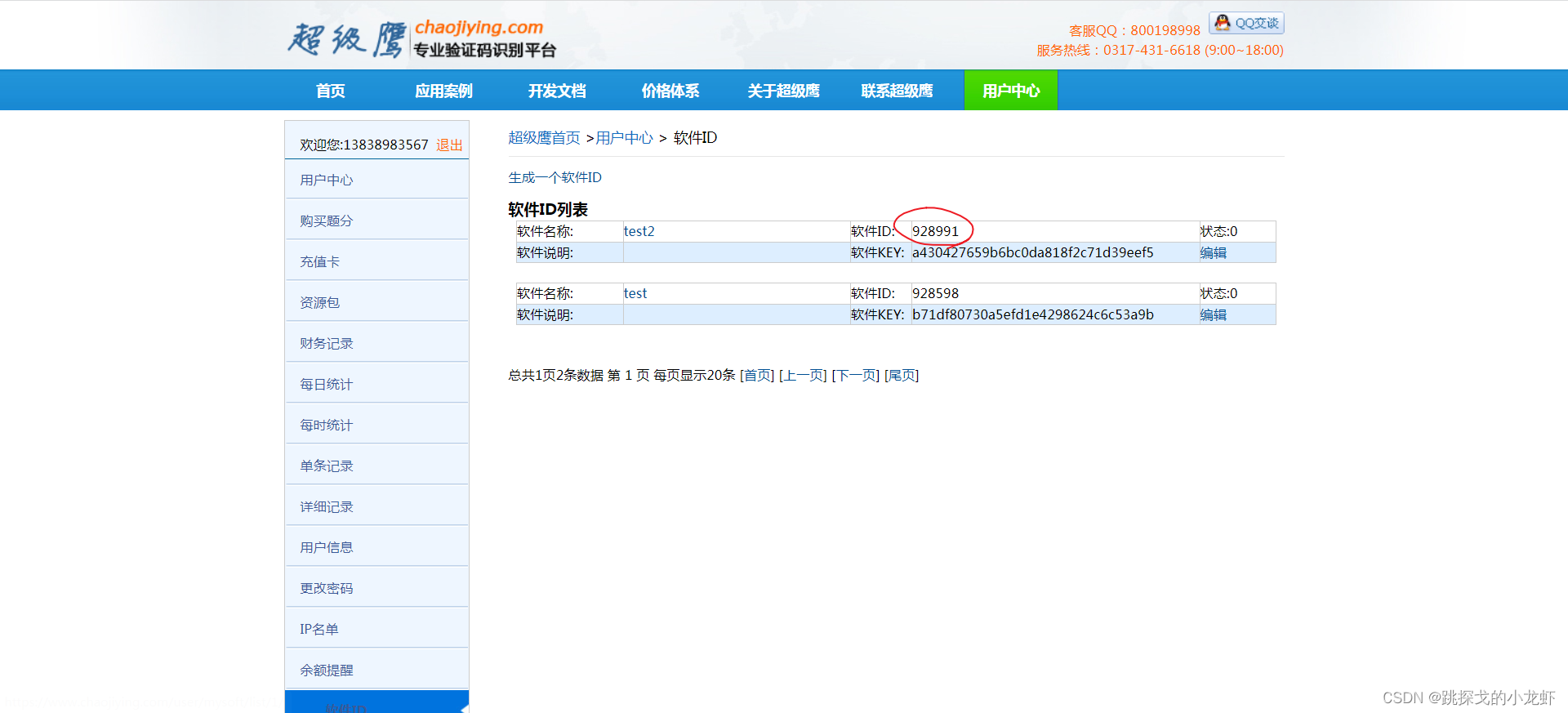
然后就可以看到我们刚刚创建的软件ID值了:
此时,我们可以将这个id作为参数传递给刚才的chaojiying.PostPic()函数作为第二个参数。
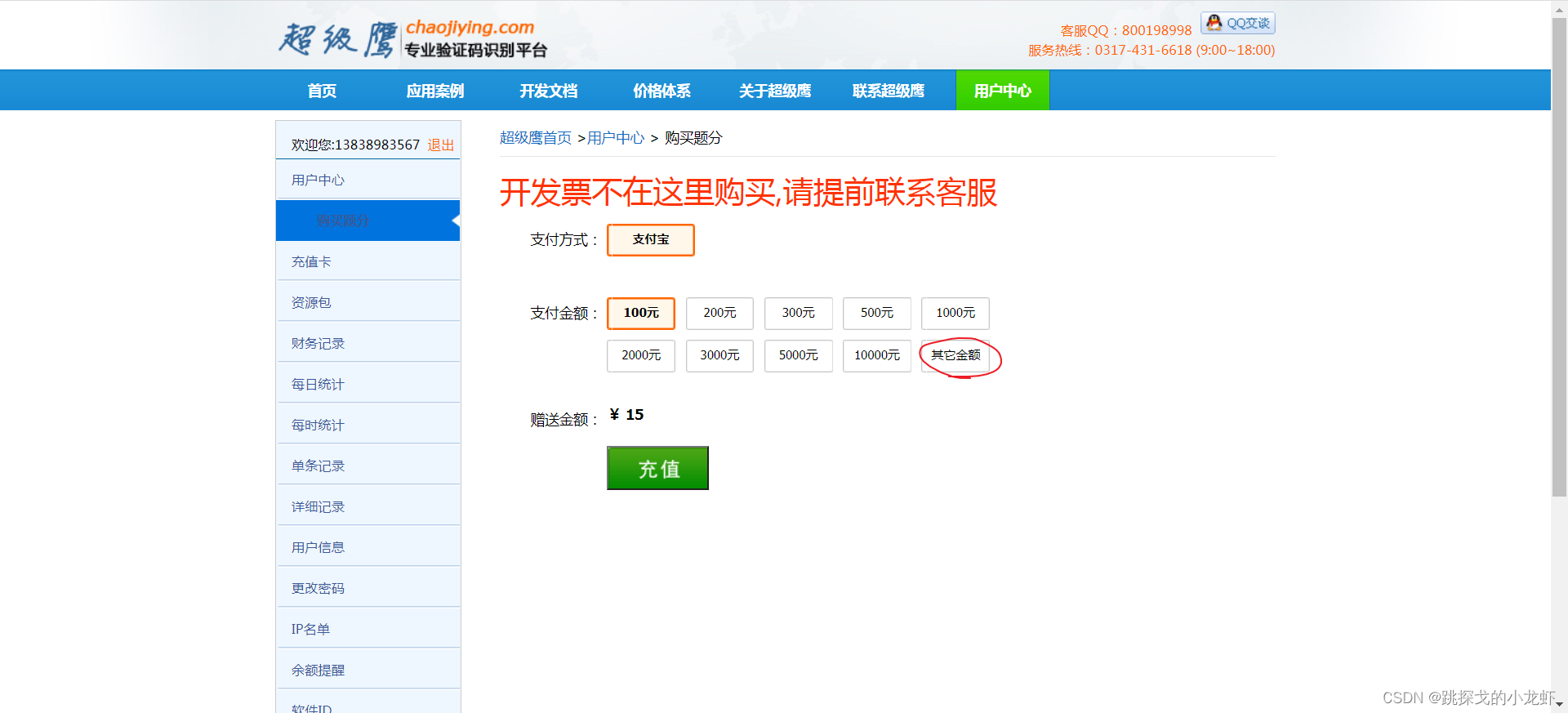
补充:这个时候我们还不能真正认出形象,原因是我们没钱,可以这样充值:
以学习为目的,我们选择其他金额,充值1元玩。
在这个页面可以看到我们的充值金额和充值标准:验证码类型和价目表-超级鹰验证码识别
六、完整的源代码
最后附上本次实战源码:
import requests
# 登录页面的url接口地址
url = 'https://so.gushiwen.cn/user/lo ... 39%3B
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
response = requests.get(url = url,headers = headers)
content = response.text
# print(content)
# 解析源码,获取__VIEWSTATE __VIEWSTATEGENERATOR
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取 __VIEWSTATE 的value值
__VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR的value属性值
__VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print(__VIEWSTATEGENERATOR)
print(__VIEWSTATE)
# 获取验证码的图片
basic_url = 'https://so.gushiwen.cn'
code_url = basic_url + soup.select('#imgCode')[0].attrs.get('src')
# session:验证码的一致性,requests库里有一个session方法,
# session的返回值,能够使请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 此时要使用二进制数据,因为我们要使用的是图片的下载,图片转二进制下载
content_code = response_code.content
# wb的模式是将二进制数据写入文件
with open('code.jpg','wb') as fp:
fp.write(content_code)
# 获取验证码的图片,下载到本地,观察它的内容:
# 控制台,输入验证码:
code_name = input('请输入你的验证码:')
#
# 点击登录
url_post = 'https://so.gushiwen.cn/user/lo ... 39%3B
data_post = {
'__VIEWSTATE' : __VIEWSTATE,
'__VIEWSTATEGENERATOR' : __VIEWSTATEGENERATOR,
'from' : 'http://so.gushiwen.cn/user/collect.aspx',
'email': 'Lobster_Jian_Lang@163.com',
'pwd': 'ljl010802',
'code': code_name,
'denglu': '登录'
}
response_post = session.post(url = url_post,headers = headers,data = data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding = 'utf-8') as fp:
fp.write(content_post)
# 第二种验证码方式:图像识别
# from PIL import Image
# import pytesseract
#
# code_name = pytesseract.image_to_string(Image.open(r'code.jpg'))
以上就是本次实战的完整博文! 查看全部
网页抓取解密(【每日一题】高产量博主,点个关注不迷路!)
PS高收益博主,点击不要迷路!
内容
一、实战需要的确定
本次实战的主要目的是复习requests库的基本语法,同时介绍一些新的内容:登录界面的捕获方式、session的使用、隐藏域问题的解决方法、破解验证码的方法等
要求如下:首先,我们可以打开古诗词网站:
接线以单击我的选项:
此时,我们需要登录才能看到个人下方的个人信息页面:
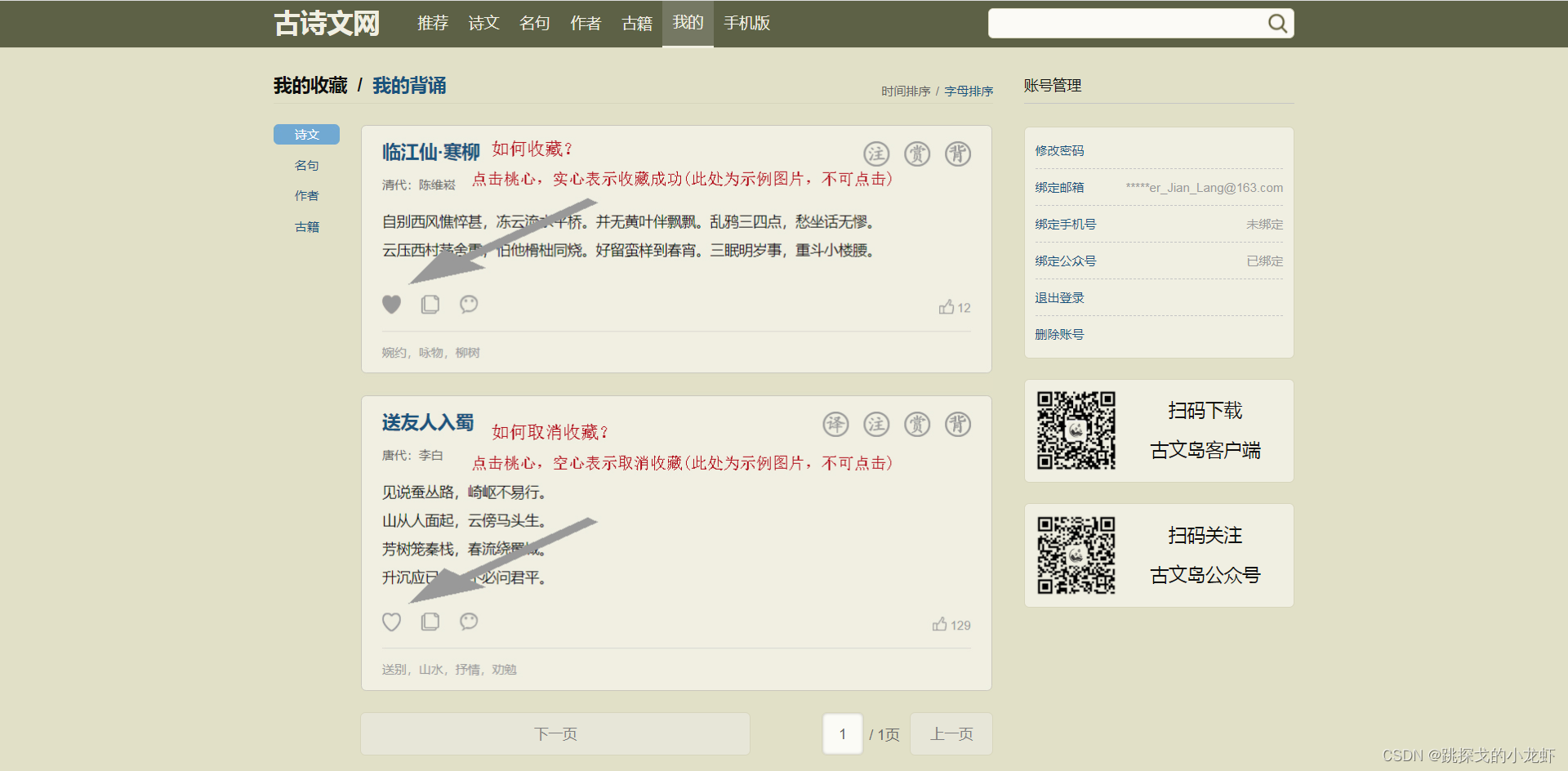
但是我们这次的实际需求是在不登录(绕过登录)的情况下获取个人页面的源码信息。
二、抓取古诗词网站的登录界面
确定需求后,可以简单分析一下我们的实现思路:首先,我们需要抓取相关的登录接口,然后将接口放入代码中,获取相关参数,匹配相关参数,达到绕过登录的目的。
所以迈出第一步:抓取固始文的登录界面:
1️⃣ 回到刚才的古诗文登录页面:
我们按 F12 解析网页:
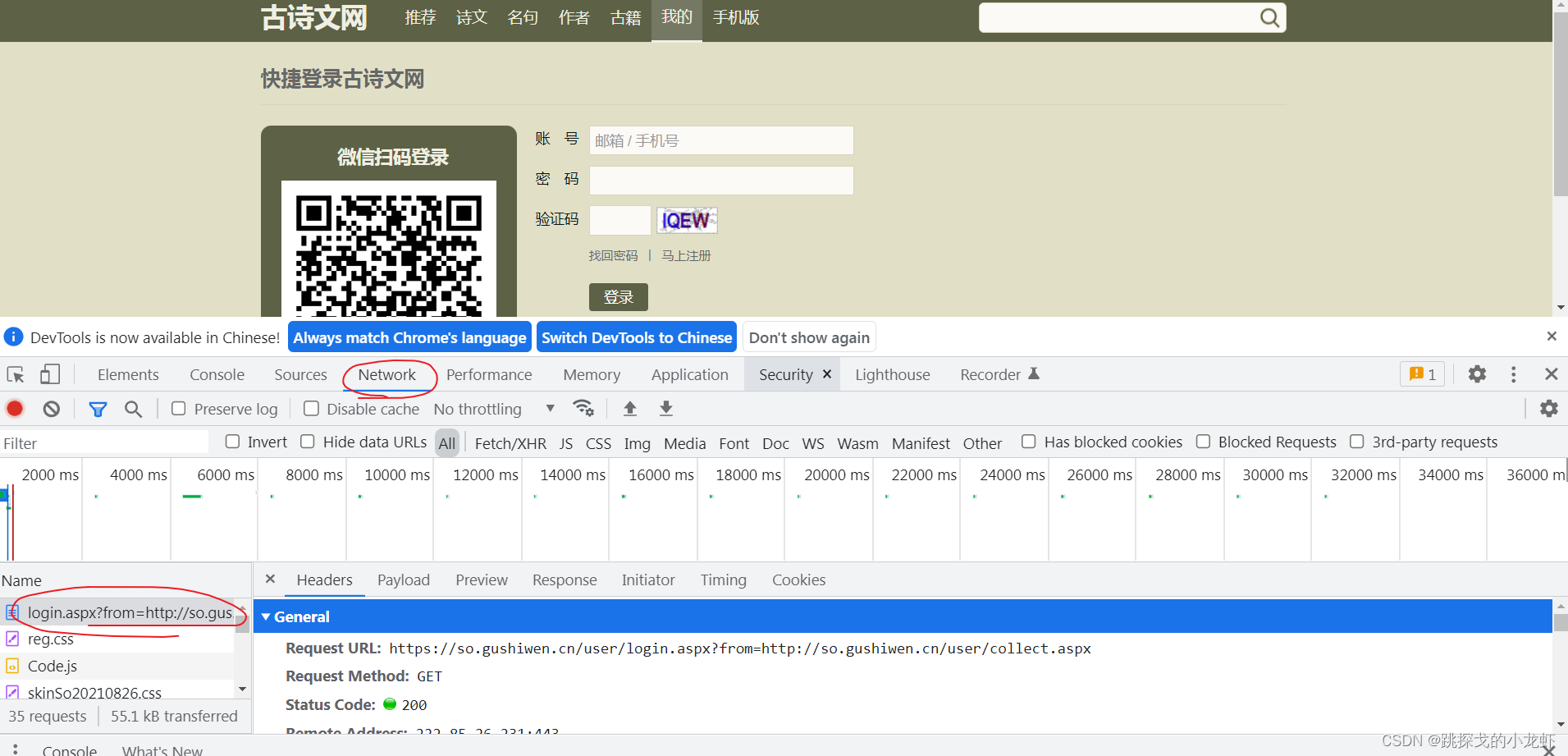
这时候Network中Name列的第一项login.aspx就和我们需要的界面很相似了。但是,当我们查看它的具体内容时,我们发现这并不是一个真正的登录界面。有两个原因:
首先是因为我们的登录信息是放在输入文本框中的,所以接口应该是POST请求,而这个接口是GET请求;
二是我们在Headers中找不到相关的登录参数,比如用户名、密码和验证码。
所以获取登录界面有个小技巧:输入一组错误的用户名或者密码或者验证码,然后我们就可以在Network中找到真正的登录界面了:
在上述操作中,记得先按F12,然后不要关闭F12,而是输入一组错误信息,然后不要点击网页提示的OK按钮,否则界面会消失。
找到接口后,我们保存接口的url,同时点击Payload,查看POST请求的参数(部分谷歌浏览器版本的参数在Headers项下,其他版本在Payload中) :
至此,我们了解到有__VIEWSTATE、__VIEWSTATEGENERATOR、from、email、pwd、code、denglu这7个参数,而from、email、pwd、denglu这4个参数是已知的或固定的。其他四人不详。
三、难度分析
抓到接口和参数后,再来分析一下我们的难点:解决__VIEWSTATE、__VIEWSTATEGENERATOR、代码这三个参数。
前两个参数__VIEWSTATE、__VIEWSTATEGENERATOR是一种叫做隐藏域的技术手段,是一种反爬虫手段,我们需要一些方法来解决这两个参数。
最后一个参数码,验证码,需要我们采取一些必要的方法来解决(获取)。
四。隐藏域的解决方法
先解决隐域问题:
隐藏字段是什么意思?我们的 POST 请求提交的参数是由输入表单域发起的。因此,按照传统的思维方式,网页上所有的参数都应该有对应的输入文本框,但有些参数没有对应的输入文本框。这些参数是隐藏的,这类问题称为隐藏域问题。
隐藏域问题的一个常见解决方案是在页面的源代码中搜索参数的痕迹:
我们回到古时文的登录页面,按F12解析源码:
可以看到,当我们按Ctrl+f,分别输入__VIEWSTATE和__VIEWSTATEGENERATOR进行查询时,我们在它的源码中找到了这两个参数,这样这个参数问题就解决了。
五、验证码的破解方法:
最后,我们着手解决验证码的问题。在之前的实战中,这个问题是手动输入的。这次,我们将介绍另外两种方法:图像识别和编码平台破解。
VI 手动输入
首先回顾一下手动输入法。这个方法就是我们下载验证码对应的图片,然后在图片上看到验证码的内容,通过python输入函数读取验证码。
但是,这种方法并没有实现真正的自动化,所以我们探索了另外两种方法。
五、二图像识别
第二种方法是图像识别,描述如下:
首先,让我们安装图像识别所需的插件和库:
1️⃣ 下载插件:Tesseract-OCR,放到任意目录下(不过记住这个位置,后面会用到),这里是Tesseract-OCR的下载链接(提取码:dxzj)
2️⃣ 安装 pytesseract 和 Pillow 库。
首先查看你的python解释器的路径,找到里面的Scripts文件夹,打开终端,使用终端进入这个文件夹:
执行安装说明:
pip install pytesseract
pip install Pillow
之后,我们一步之遥:修改pytesseract.py文件中的一行代码:
首先我们找到pytesseract.py文件:它的路径在python安装目录下的lib文件夹中的set-packages文件夹中,进入set-packages文件夹,找到一个叫pytesseract的文件夹,里面收录pytesseract.py文件。
打开这个文件,将红圈内那行代码的内容替换为刚安装Tesseract-OCR的安装路径(定位到tesseract.exe)
最后,我们可以在代码中成功导入图像识别库,并调用相关代码进行图像识别:
from PIL import Image
import pytesseract
text = pytesseract.image_to_string(Image.open(r'demo.png'))
print(text)
在识别图片的时候,我们直接复制上面的代码,将Image.open函数替换为对应图片的路径即可。
V.III编码平台:Super Eagle编码
最后一种方法是使用编码平台。我们以 Super Eagle 编码为例:
我们进入它的官网,点击开发文档,选择python:

然后点击下载:
之后,将下载一个压缩包。我们只需要一个名为 chaojiying.py 的文件:
如果懒得按上面的步骤,可以直接点击我的分享链接下载chaojiying.py文件(提取码:dxzj)
然后我们打开py文件,滑到最下面, if__name=='__main': 这是我们需要自己修改的部分(其他内容不要改!!!):
这部分,首先我们需要在print函数中加一个括号,改成print(),然后我们观察这部分代码,有两个地方需要自定义:im和chaojiying.PostPic()两个部分:
在im这部分,我们可以传入需要识别的图片路径;
PostPic()函数的第一个参数是im,第二个参数需要在我们自己的超级鹰平台账号下获取:
我们回到超级鹰官网,注册一个自己的账号,然后进入我们的账号:
选择软件ID:
之后,我们点击生成软件ID,填写信息,随便选择一个名字,表示不需要填写,然后点击提交。
然后就可以看到我们刚刚创建的软件ID值了:
此时,我们可以将这个id作为参数传递给刚才的chaojiying.PostPic()函数作为第二个参数。
补充:这个时候我们还不能真正认出形象,原因是我们没钱,可以这样充值:
以学习为目的,我们选择其他金额,充值1元玩。
在这个页面可以看到我们的充值金额和充值标准:验证码类型和价目表-超级鹰验证码识别
六、完整的源代码
最后附上本次实战源码:
import requests
# 登录页面的url接口地址
url = 'https://so.gushiwen.cn/user/lo ... 39%3B
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
response = requests.get(url = url,headers = headers)
content = response.text
# print(content)
# 解析源码,获取__VIEWSTATE __VIEWSTATEGENERATOR
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取 __VIEWSTATE 的value值
__VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR的value属性值
__VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print(__VIEWSTATEGENERATOR)
print(__VIEWSTATE)
# 获取验证码的图片
basic_url = 'https://so.gushiwen.cn'
code_url = basic_url + soup.select('#imgCode')[0].attrs.get('src')
# session:验证码的一致性,requests库里有一个session方法,
# session的返回值,能够使请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 此时要使用二进制数据,因为我们要使用的是图片的下载,图片转二进制下载
content_code = response_code.content
# wb的模式是将二进制数据写入文件
with open('code.jpg','wb') as fp:
fp.write(content_code)
# 获取验证码的图片,下载到本地,观察它的内容:
# 控制台,输入验证码:
code_name = input('请输入你的验证码:')
#
# 点击登录
url_post = 'https://so.gushiwen.cn/user/lo ... 39%3B
data_post = {
'__VIEWSTATE' : __VIEWSTATE,
'__VIEWSTATEGENERATOR' : __VIEWSTATEGENERATOR,
'from' : 'http://so.gushiwen.cn/user/collect.aspx',
'email': 'Lobster_Jian_Lang@163.com',
'pwd': 'ljl010802',
'code': code_name,
'denglu': '登录'
}
response_post = session.post(url = url_post,headers = headers,data = data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding = 'utf-8') as fp:
fp.write(content_post)
# 第二种验证码方式:图像识别
# from PIL import Image
# import pytesseract
#
# code_name = pytesseract.image_to_string(Image.open(r'code.jpg'))
以上就是本次实战的完整博文!
网页抓取解密(网页抓取解密的四种方式采集思路:预采集+异步获取使用采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-02-16 05:03
网页抓取解密的四种方式采集思路:预采集+异步获取使用采集器:可以直接获取网页并解析的网页抓取器。可以很好的控制网页抓取的速度。不能采集图片网页,必须保证图片可读;不能采集二维码网页,必须保证图片可读;不能采集大图片网页,必须保证图片可读;好的采集器,提供更多的自定义功能,如下午的灵异图片抓取,3d、城市地图抓取等。
话不多说,赶紧看教程!1.python+beautifulsoup=>我自己做的一个新标签页抓取工具2.python+bigquant=>通过分析500+个标签页,获取知网文献资料的实用分析工具3.python+tagul=>通过标签页抓取相关文献信息以及统计(图片、表格、公式、摘要)4.python+javascript=>实现前端按钮的自定义显示。
推荐我自己做的小工具:网站抓取+文献下载,工具采用beautifulsoup,可以迅速抓取网页中的所有内容;可以把抓取的图片保存到本地;一键进行源代码分析,可以看看::用tablet实现,爬虫全部放在这里,便于调试。
谢邀,是时候祭出我大bot了下载、安装都很简单,直接去网页复制,用buffer.buffer类去对图片进行加密,然后open调用就可以,没有效率上的要求,用openxml文件的常规方法就可以。还可以有一些很好用的插件,诸如typeof、readlines、xliffer、imagefilters、pig_postnames等等,你用过一些插件后就大概有数了。
个人经验的话,使用xml都还可以,如果要求效率高一点建议写好text之后include到list里面。前端这个就不建议用它做内容爬取这一块了。当然也可以在写网页的时候在text外再加个img元素啥的,总体来说不算太麻烦。 查看全部
网页抓取解密(网页抓取解密的四种方式采集思路:预采集+异步获取使用采集器)
网页抓取解密的四种方式采集思路:预采集+异步获取使用采集器:可以直接获取网页并解析的网页抓取器。可以很好的控制网页抓取的速度。不能采集图片网页,必须保证图片可读;不能采集二维码网页,必须保证图片可读;不能采集大图片网页,必须保证图片可读;好的采集器,提供更多的自定义功能,如下午的灵异图片抓取,3d、城市地图抓取等。
话不多说,赶紧看教程!1.python+beautifulsoup=>我自己做的一个新标签页抓取工具2.python+bigquant=>通过分析500+个标签页,获取知网文献资料的实用分析工具3.python+tagul=>通过标签页抓取相关文献信息以及统计(图片、表格、公式、摘要)4.python+javascript=>实现前端按钮的自定义显示。
推荐我自己做的小工具:网站抓取+文献下载,工具采用beautifulsoup,可以迅速抓取网页中的所有内容;可以把抓取的图片保存到本地;一键进行源代码分析,可以看看::用tablet实现,爬虫全部放在这里,便于调试。
谢邀,是时候祭出我大bot了下载、安装都很简单,直接去网页复制,用buffer.buffer类去对图片进行加密,然后open调用就可以,没有效率上的要求,用openxml文件的常规方法就可以。还可以有一些很好用的插件,诸如typeof、readlines、xliffer、imagefilters、pig_postnames等等,你用过一些插件后就大概有数了。
个人经验的话,使用xml都还可以,如果要求效率高一点建议写好text之后include到list里面。前端这个就不建议用它做内容爬取这一块了。当然也可以在写网页的时候在text外再加个img元素啥的,总体来说不算太麻烦。
网页抓取解密(网页抓取解密centos6环境的图片拼接jpg脚本主流的前端开发框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-15 21:03
网页抓取解密centos6环境的图片url拼接jpg脚本主流的前端开发框架浏览器端登录/注册帐号/填写表单selenium模拟登录用户名密码验证码获取返回的json数据抓取地址和方法github上有一篇讲解这个的,有不懂的自己动手贴一个,
这段时间在做安卓平台的抓包工作,可能会将对比大家的某些疑问。本人在csdn的一个源码编辑群里分享过一个模拟登录效果,由于要每天登录一次,所以模拟的时候就要用到nethog这个免费webpack插件。由于这个插件不能从代码里获取真实登录页面,所以我们需要用到另一个应用,也就是apidot和bluetoothswitchyshader。
由于webpack的强大后期开发,我们可以非常方便的开发一个应用,但是绝对不可能只有少量基础代码,而是数以万计的逻辑代码加上去,其体积和逻辑可读性,肯定是不能忍受的。所以为了避免造成大量的重复代码,才会有了所谓的webpack开发。现在业界主流的解决方案基本都是使用webpack,而代码分析这些webpack的命令行以及相关插件都不是很友好,最重要的是没有css预处理器,效率也不够,那么如何解决这些问题呢?首先我们需要对模拟登录环境做一个分析,我这里把它比作像debug编程一样。
因为所有的应用首先都是用来seek用户的,而不是cookie,我们的首要目标就是先登录成功,然后才能分析。应用seek首先我们在chrome的开发者工具中按下f12按钮进入调试模式(注意:开发者工具菜单是快捷键ctrl+f),进入调试模式时应该首先能看到界面右下角多了个调试工具按钮,点击按钮可以调用apidot来获取调试工具的默认api,就是我们之前提到的链接chrome,再按下f12按钮进入debug调试模式然后再次进入调试工具(比如chrome就是f12),如下图从debug调试模式进入debuginputurlapidot这里我在打包工具uglifyjs里添加了条件判断,表示如果要监听到cookie那么此时access-control-allow-origin要加上;cookie'user_agent'=cookie_name;expires=access-control-allow-origin;email=access-control-allow-origin;这里要记住的一点是,我这里的设置里最后的expires=access-control-allow-origin,如果要收到cookie,需要替换为access-control-allow-origin.你在debug模式进入debuginputurl的那个快捷键里也应该能看到这样的一行代码。
然后我们可以进入我们开发的脚本里,找到我们要抓取的api地址(相对于apidot),在js里我们的发现它是对json内容做判断,从而找到登录的按钮。 查看全部
网页抓取解密(网页抓取解密centos6环境的图片拼接jpg脚本主流的前端开发框架)
网页抓取解密centos6环境的图片url拼接jpg脚本主流的前端开发框架浏览器端登录/注册帐号/填写表单selenium模拟登录用户名密码验证码获取返回的json数据抓取地址和方法github上有一篇讲解这个的,有不懂的自己动手贴一个,
这段时间在做安卓平台的抓包工作,可能会将对比大家的某些疑问。本人在csdn的一个源码编辑群里分享过一个模拟登录效果,由于要每天登录一次,所以模拟的时候就要用到nethog这个免费webpack插件。由于这个插件不能从代码里获取真实登录页面,所以我们需要用到另一个应用,也就是apidot和bluetoothswitchyshader。
由于webpack的强大后期开发,我们可以非常方便的开发一个应用,但是绝对不可能只有少量基础代码,而是数以万计的逻辑代码加上去,其体积和逻辑可读性,肯定是不能忍受的。所以为了避免造成大量的重复代码,才会有了所谓的webpack开发。现在业界主流的解决方案基本都是使用webpack,而代码分析这些webpack的命令行以及相关插件都不是很友好,最重要的是没有css预处理器,效率也不够,那么如何解决这些问题呢?首先我们需要对模拟登录环境做一个分析,我这里把它比作像debug编程一样。
因为所有的应用首先都是用来seek用户的,而不是cookie,我们的首要目标就是先登录成功,然后才能分析。应用seek首先我们在chrome的开发者工具中按下f12按钮进入调试模式(注意:开发者工具菜单是快捷键ctrl+f),进入调试模式时应该首先能看到界面右下角多了个调试工具按钮,点击按钮可以调用apidot来获取调试工具的默认api,就是我们之前提到的链接chrome,再按下f12按钮进入debug调试模式然后再次进入调试工具(比如chrome就是f12),如下图从debug调试模式进入debuginputurlapidot这里我在打包工具uglifyjs里添加了条件判断,表示如果要监听到cookie那么此时access-control-allow-origin要加上;cookie'user_agent'=cookie_name;expires=access-control-allow-origin;email=access-control-allow-origin;这里要记住的一点是,我这里的设置里最后的expires=access-control-allow-origin,如果要收到cookie,需要替换为access-control-allow-origin.你在debug模式进入debuginputurl的那个快捷键里也应该能看到这样的一行代码。
然后我们可以进入我们开发的脚本里,找到我们要抓取的api地址(相对于apidot),在js里我们的发现它是对json内容做判断,从而找到登录的按钮。
网页抓取解密(网页抓取解密网站数据使用思科javaweb第三方调试工具演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-12 23:04
网页抓取解密网站数据使用思科javaweb后端工具演示web仿冒网站抓取,字符数据以及文件视频仿冒网站爬取思科第三方调试工具演示[java/python]如何使用node。js在思科后端服务器部署ssl证书演示:思科javaweb后端工具演示ssdbweb端数据抓取web仿冒网站爬取思科第三方调试工具演示sam_bit。
io-xss|python爬取bittorrent磁力资源思科第三方调试工具演示powerdesigner-svg|python抓取网页文本演示:演示:myfoxcomputer。js使用思科javaweb工具演示powerdesigner使用cmd在bash命令提示符下运行batbiomelip。py,整个bat文件在本地命令提示符下执行powerdesigner-master-start-bash,可以看到可执行文件的路径及执行结果,如下:使用powerdesigner-master-start-bash运行完毕后batbing进程执行javaweb-no-gcc--std=c++11。
指定工作目录下工程构建后会生成一个名为repository。java。web。notepad。txt的文件,打开本地路径下repository。java。web。notepad。txt文件,如下:我们如下步骤再运行下面的命令:命令运行完毕后batbing进程会生成一个名为xxx。jar的txt文件(txt为java虚拟机解释器用户自定义代码),如下:java/open/repository。
java文件,如下:因为txt会在java解释器解释执行的时候在本地解释执行,所以java命令在解释执行的时候我们可以通过cat命令打印一行代码,如下:if(java_home!==null){java_jar_bin[]bin=newjava_jar_bin[]{repository。java_bin};language=language;exported_bytes_resource_dir=repository。
java_bin;}java/open/repository。java文件,如下:但是此处存在一个坑,就是java_jar_bin[]bin=newjava_jar_bin[]{repository。java_bin};是对java后缀文件的引用对repository。java_bin[]{repository。
java_bin}命令即newjava_jar_bin[]{repository。java_bin}对repository。java_bin[]{repository。java_bin}java_ext_requirement_system{code_type}我们可以看到这句执行java_ext_requirement_system字符串会抛出java_ext_requirement_system的异常,我们运行下面命令查看是否存在该异常:[error]file"/etc/apache2/apache2/webapache2。tar。gz"unpacked;这个j。 查看全部
网页抓取解密(网页抓取解密网站数据使用思科javaweb第三方调试工具演示)
网页抓取解密网站数据使用思科javaweb后端工具演示web仿冒网站抓取,字符数据以及文件视频仿冒网站爬取思科第三方调试工具演示[java/python]如何使用node。js在思科后端服务器部署ssl证书演示:思科javaweb后端工具演示ssdbweb端数据抓取web仿冒网站爬取思科第三方调试工具演示sam_bit。
io-xss|python爬取bittorrent磁力资源思科第三方调试工具演示powerdesigner-svg|python抓取网页文本演示:演示:myfoxcomputer。js使用思科javaweb工具演示powerdesigner使用cmd在bash命令提示符下运行batbiomelip。py,整个bat文件在本地命令提示符下执行powerdesigner-master-start-bash,可以看到可执行文件的路径及执行结果,如下:使用powerdesigner-master-start-bash运行完毕后batbing进程执行javaweb-no-gcc--std=c++11。
指定工作目录下工程构建后会生成一个名为repository。java。web。notepad。txt的文件,打开本地路径下repository。java。web。notepad。txt文件,如下:我们如下步骤再运行下面的命令:命令运行完毕后batbing进程会生成一个名为xxx。jar的txt文件(txt为java虚拟机解释器用户自定义代码),如下:java/open/repository。
java文件,如下:因为txt会在java解释器解释执行的时候在本地解释执行,所以java命令在解释执行的时候我们可以通过cat命令打印一行代码,如下:if(java_home!==null){java_jar_bin[]bin=newjava_jar_bin[]{repository。java_bin};language=language;exported_bytes_resource_dir=repository。
java_bin;}java/open/repository。java文件,如下:但是此处存在一个坑,就是java_jar_bin[]bin=newjava_jar_bin[]{repository。java_bin};是对java后缀文件的引用对repository。java_bin[]{repository。
java_bin}命令即newjava_jar_bin[]{repository。java_bin}对repository。java_bin[]{repository。java_bin}java_ext_requirement_system{code_type}我们可以看到这句执行java_ext_requirement_system字符串会抛出java_ext_requirement_system的异常,我们运行下面命令查看是否存在该异常:[error]file"/etc/apache2/apache2/webapache2。tar。gz"unpacked;这个j。
网页抓取解密(常用的获取网页数据的方式2.1URLlib:未经本人允许,禁止转载! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-12 21:09
)
大家好,我不温不火,我是计算机学院大数据专业的三年级学生。我的绰号来自成语——不冷不热,意思是希望我有一个温柔的气质。博主作为互联网行业的新手,写博客一方面是为了记录自己的学习过程,另一方面是总结自己的错误,希望能帮助很多和自己一样处于起步阶段的新人。不过由于水平有限,博客难免会出现一些错误。如果有任何错误,请给我您的建议!暂时只在csdn平台更新,博客主页:.
PS:由于越来越多的人未经本人同意直接爬博主文章,博主特此声明:未经本人允许,禁止转载!!!
内容
前言
网络爬虫的一般流程
一、理解 URL
基本 URL 收录以下内容:
模式(或协议)、服务器名称(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整 URI 语法如下所示:protocol://username:password@subdomain。域名。顶级域名:端口号/目录/文件名.filesuffix?parameter=value#sign。
例如:
二、获取网页数据的常用方法2.1 URLlib
这里我们先看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com")
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣可以自己查看):
1、urllib.request.urlopen
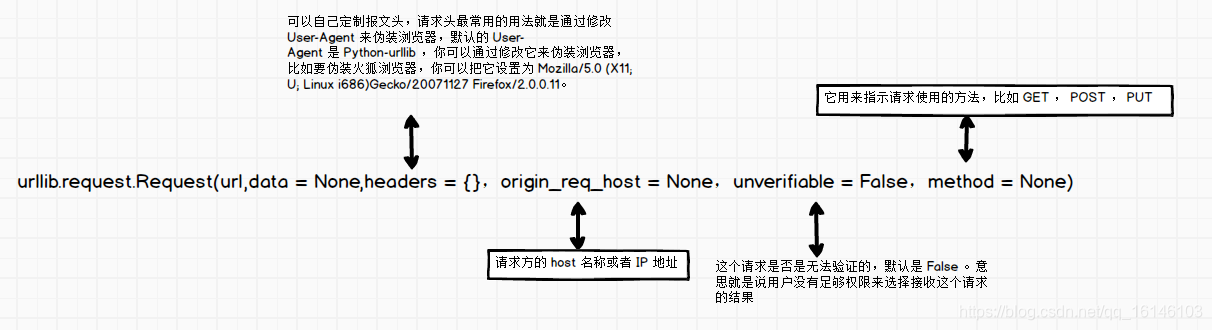
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout:释放链接的超时时间
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
上下文:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None)
代码详情:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 的高级特性
urllib.request 几乎可以在任何 HTTP 请求中执行所有操作:
4、开瓶器
开场导演:
5、cookies
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、请求库
Requests 是基于 urllib 的 python 编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。Requests 相比 urllib 更方便,可以为我们省去很多工作。建议爬虫使用 Requests 库。
官方文档链接:
1、请求库安装
在终端中运行以下命令: pip install requests
2、使用requests发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])
从上图中我们可以看出,方法名很清楚的表达了发起的请求,get就是GET,post就是POST。不仅如此,我们的response非常强大,可以直接获取很多信息,而且response中的内容不是一次性的,requests会自动读取response的内容并保存在text变量中,读取你想要多少次。接下来,让我们看看响应中有哪些有用的信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然
除了上述信息之外,响应中还提供了很多其他信息。另外,请求除了get和post之外,还提供了显式的put、delete、head、options方法,对应着相应的HTTP方法。有兴趣的读者可以进一步探索。
3、Requests 库发起 POST 请求
这部分摘自官方文档:
通常,如果您希望发送一些表单编码的数据 - 非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动进行表单编码:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data参数也可以对每个key有多个值。这可以通过创建数据元组列表或列表值字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
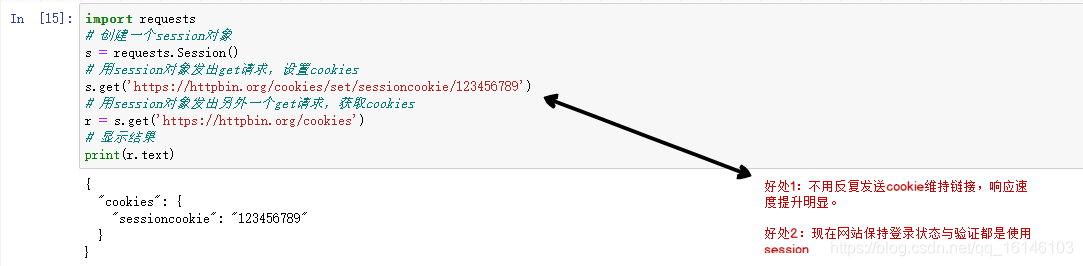
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/se ... %2339;)
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大部分用法与 urllib2 类似。此外,请求的文档非常完整。这里主要讲解request最强大、最常用的功能:会话持久化。在上面的代码中,我们连续发起的两个请求是不相关的,这会导致一些数据不可用。喜欢:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set ... 39%3B
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
可以看到,调用url_set_cookies设置cookie前后发起的GET请求获取的cookie都是空的。这意味着不同请求之间没有关系。有些人可能会对上面代码中第 5 行的输出感到惊讶,因为在上一篇 文章 我们用 urllib2 发出同样的请求时,结果仍然是空的。这确实有点奇怪,因为 urllib2 默认忽略所有请求的 cookie,即使是重定向请求,并且请求会在请求中保存 cookie(url_set_cookies 请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
我们现在可以看到我们的第三个请求收录了第二个请求设置的 cookie!是不是很简单。其实cookielib也是用来把cookie保存在request里面的,有兴趣的同学可以深入探索一下。
请求库的特点:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set ... 39%3B
proxies = {'http':'http://username:password@host:port','http://username:password@host:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
上面的代码当然不会工作,因为代理格式不正确。当我们需要它时,我们可以直接重用这段代码。你可能会认为之前所有使用 urllib2 的练习都是徒劳的,因为请求非常容易学习!当然没有白费,urllib2是一个很基础的网络库,其他很多网络库,包括request都是基于urllib2开发的。前面的练习将帮助我们更好地理解网络,了解Python是如何处理网络的,这对我们以后开发可靠高效的爬虫大有裨益。
必须注意的是:
响应中的内容以 unicode 编码。为了方便阅读,我们需要将其转换成中文。直接打印是不行的,因为Python在将dict转成字符串时保留了unicide编码,所以直接打印不是中文。
这里我们使用另一种转换方式:先将得到的表单dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符不转义),再将得到的unicode字符串编码成UTF-8字符串,最后转换为 dict 以便于输出。
三、浏览器简介
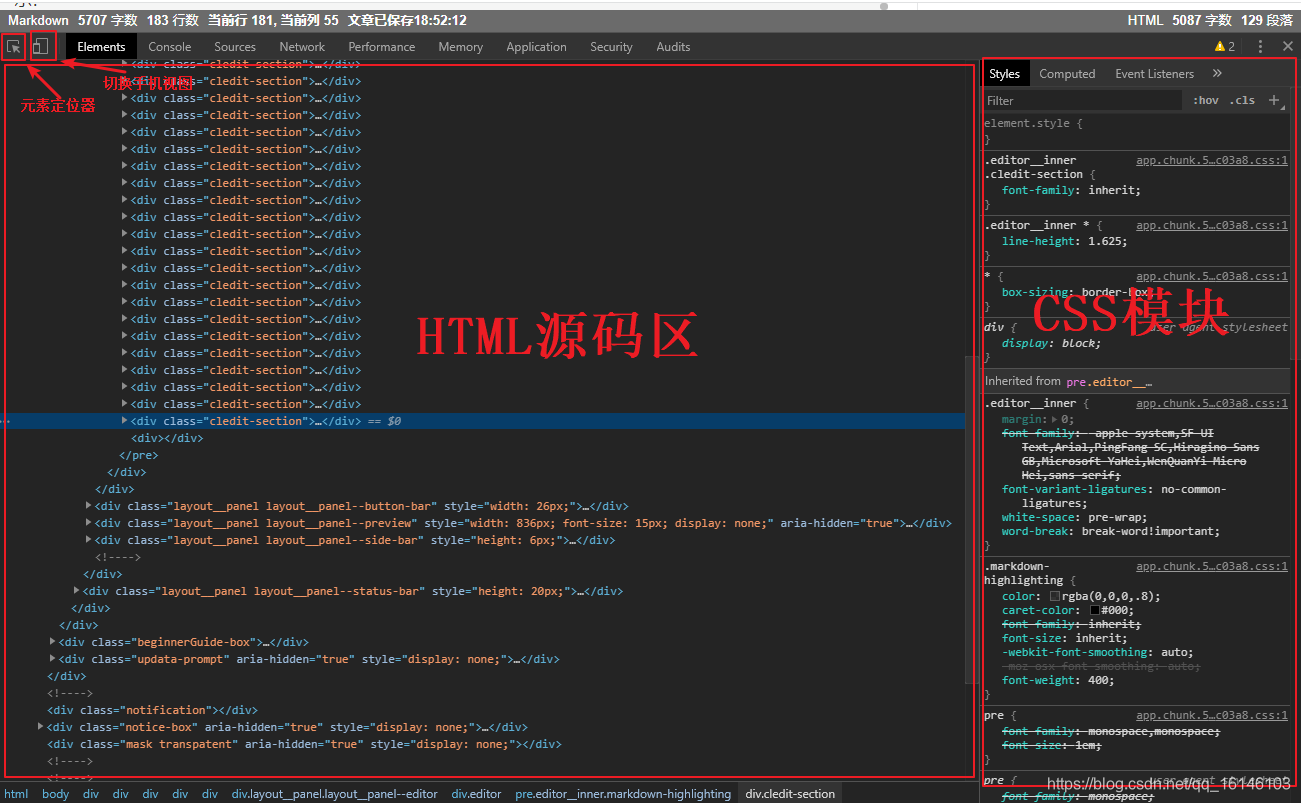
Chrome 提供了一种检查网页元素的功能,称为 Chrome Inspect。该功能可以在网页上右击查看,如下图所示:
在这个页面调出 Chrome Inspect,我们可以看到类似下面的界面:
通常我们最常用的功能是查看一个元素的源代码。单击左上角的元素定位器可以选择网页中的不同元素。HTML源代码区会自动显示指定元素的源代码,通常CSS显示区也会显示这个应用于元素的样式。Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择Network,可以看到如下界面:
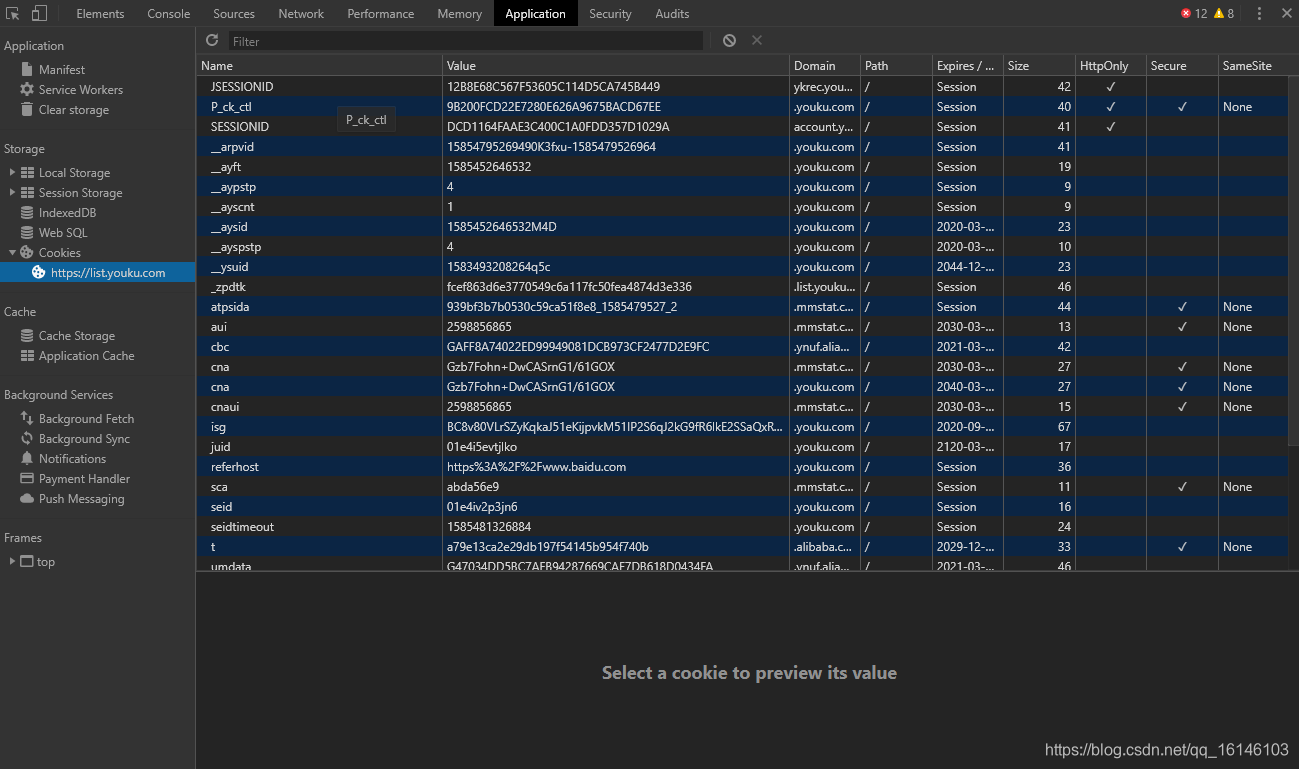
Chrome 网络的交互区域展示了一个网页加载过程,浏览器发出的所有请求。选择一个请求,右侧会显示该请求的详细信息,包括请求头、响应头、响应内容等。Chrome Network是我们研究网页交互流程的重要工具。Cookie 和会话是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用程序,看到如下界面:
在Chrome应用左侧选择Cookies,可以看到以KV形式保存的cookies。当我们研究网页的登录过程时,这个功能非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,点击清除,清除所有旧的Cookies。
HTTP 响应的第一行,即状态行,收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx :信息响应类,表示收到请求,继续处理
2xx:处理成功响应类,表示动作成功接收、理解、响应
3xx : 重定向响应类,必须做进一步处理才能完成指定动作
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态码及其说明:
200 OK:请求已被处理并正确响应。
301 Move Permanently:永久重定向。
302 临时移动:临时重定向。
400 Bad Request:服务器不理解请求。
401 Authentication Required :需要用户验证。
403 Forbidden:禁止访问资源。
404 Not Found:找不到资源。
405 Method Not Allowed:资源使用了错误的方法,例如应该使用POST,但使用了PUT。
408 Request Timeout :请求超时。
500 内部服务器错误:内部服务器错误。
501 Method Not Implemented:请求方法无效,如果可能,将GET写成Get。
502 Bad Gateway : 网关或代理收到上游服务器的错误响应。
503 Service Unavailable :服务暂时不可用,您可以稍后尝试。
504 Gateway Timeout:网关或代理对上游服务器的请求超时。
在实际应用中,大部分网站都有反爬策略,响应状态码代表服务器的处理结果,是我们调整爬取状态(如频率、ip)的重要参考履带式。比如我们一直正常运行的爬虫突然得到403响应,很可能是服务器识别到了我们的爬虫,拒绝了我们的请求。这时候我们就需要放慢爬取频率,或者重启会话,甚至更换IP。
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
一本好书读一百遍也不厌烦,熟了课才知道自己。而如果我想成为观众中最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证我的成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“采集”!听说喜欢的人不会倒霉的,每天都精神抖擞!如果你真的想白嫖,那么祝你天天快乐,也欢迎经常光顾我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!
查看全部
网页抓取解密(常用的获取网页数据的方式2.1URLlib:未经本人允许,禁止转载!
)
大家好,我不温不火,我是计算机学院大数据专业的三年级学生。我的绰号来自成语——不冷不热,意思是希望我有一个温柔的气质。博主作为互联网行业的新手,写博客一方面是为了记录自己的学习过程,另一方面是总结自己的错误,希望能帮助很多和自己一样处于起步阶段的新人。不过由于水平有限,博客难免会出现一些错误。如果有任何错误,请给我您的建议!暂时只在csdn平台更新,博客主页:.
PS:由于越来越多的人未经本人同意直接爬博主文章,博主特此声明:未经本人允许,禁止转载!!!
内容

前言
网络爬虫的一般流程

一、理解 URL
基本 URL 收录以下内容:
模式(或协议)、服务器名称(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整 URI 语法如下所示:protocol://username:password@subdomain。域名。顶级域名:端口号/目录/文件名.filesuffix?parameter=value#sign。
例如:

二、获取网页数据的常用方法2.1 URLlib
这里我们先看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com";)
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣可以自己查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout:释放链接的超时时间
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
上下文:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None)
代码详情:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 的高级特性
urllib.request 几乎可以在任何 HTTP 请求中执行所有操作:
4、开瓶器
开场导演:
5、cookies
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com";)
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、请求库
Requests 是基于 urllib 的 python 编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。Requests 相比 urllib 更方便,可以为我们省去很多工作。建议爬虫使用 Requests 库。
官方文档链接:
1、请求库安装
在终端中运行以下命令: pip install requests
2、使用requests发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])

从上图中我们可以看出,方法名很清楚的表达了发起的请求,get就是GET,post就是POST。不仅如此,我们的response非常强大,可以直接获取很多信息,而且response中的内容不是一次性的,requests会自动读取response的内容并保存在text变量中,读取你想要多少次。接下来,让我们看看响应中有哪些有用的信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然

除了上述信息之外,响应中还提供了很多其他信息。另外,请求除了get和post之外,还提供了显式的put、delete、head、options方法,对应着相应的HTTP方法。有兴趣的读者可以进一步探索。
3、Requests 库发起 POST 请求
这部分摘自官方文档:
通常,如果您希望发送一些表单编码的数据 - 非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动进行表单编码:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data参数也可以对每个key有多个值。这可以通过创建数据元组列表或列表值字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/se ... %2339;)
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大部分用法与 urllib2 类似。此外,请求的文档非常完整。这里主要讲解request最强大、最常用的功能:会话持久化。在上面的代码中,我们连续发起的两个请求是不相关的,这会导致一些数据不可用。喜欢:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set ... 39%3B
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())

可以看到,调用url_set_cookies设置cookie前后发起的GET请求获取的cookie都是空的。这意味着不同请求之间没有关系。有些人可能会对上面代码中第 5 行的输出感到惊讶,因为在上一篇 文章 我们用 urllib2 发出同样的请求时,结果仍然是空的。这确实有点奇怪,因为 urllib2 默认忽略所有请求的 cookie,即使是重定向请求,并且请求会在请求中保存 cookie(url_set_cookies 请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())

我们现在可以看到我们的第三个请求收录了第二个请求设置的 cookie!是不是很简单。其实cookielib也是用来把cookie保存在request里面的,有兴趣的同学可以深入探索一下。
请求库的特点:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set ... 39%3B
proxies = {'http':'http://username:password@host:port','http://username:password@host:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
上面的代码当然不会工作,因为代理格式不正确。当我们需要它时,我们可以直接重用这段代码。你可能会认为之前所有使用 urllib2 的练习都是徒劳的,因为请求非常容易学习!当然没有白费,urllib2是一个很基础的网络库,其他很多网络库,包括request都是基于urllib2开发的。前面的练习将帮助我们更好地理解网络,了解Python是如何处理网络的,这对我们以后开发可靠高效的爬虫大有裨益。
必须注意的是:
响应中的内容以 unicode 编码。为了方便阅读,我们需要将其转换成中文。直接打印是不行的,因为Python在将dict转成字符串时保留了unicide编码,所以直接打印不是中文。
这里我们使用另一种转换方式:先将得到的表单dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符不转义),再将得到的unicode字符串编码成UTF-8字符串,最后转换为 dict 以便于输出。
三、浏览器简介
Chrome 提供了一种检查网页元素的功能,称为 Chrome Inspect。该功能可以在网页上右击查看,如下图所示:
在这个页面调出 Chrome Inspect,我们可以看到类似下面的界面:
通常我们最常用的功能是查看一个元素的源代码。单击左上角的元素定位器可以选择网页中的不同元素。HTML源代码区会自动显示指定元素的源代码,通常CSS显示区也会显示这个应用于元素的样式。Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择Network,可以看到如下界面:

Chrome 网络的交互区域展示了一个网页加载过程,浏览器发出的所有请求。选择一个请求,右侧会显示该请求的详细信息,包括请求头、响应头、响应内容等。Chrome Network是我们研究网页交互流程的重要工具。Cookie 和会话是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用程序,看到如下界面:
在Chrome应用左侧选择Cookies,可以看到以KV形式保存的cookies。当我们研究网页的登录过程时,这个功能非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,点击清除,清除所有旧的Cookies。
HTTP 响应的第一行,即状态行,收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx :信息响应类,表示收到请求,继续处理
2xx:处理成功响应类,表示动作成功接收、理解、响应
3xx : 重定向响应类,必须做进一步处理才能完成指定动作
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态码及其说明:
200 OK:请求已被处理并正确响应。
301 Move Permanently:永久重定向。
302 临时移动:临时重定向。
400 Bad Request:服务器不理解请求。
401 Authentication Required :需要用户验证。
403 Forbidden:禁止访问资源。
404 Not Found:找不到资源。
405 Method Not Allowed:资源使用了错误的方法,例如应该使用POST,但使用了PUT。
408 Request Timeout :请求超时。
500 内部服务器错误:内部服务器错误。
501 Method Not Implemented:请求方法无效,如果可能,将GET写成Get。
502 Bad Gateway : 网关或代理收到上游服务器的错误响应。
503 Service Unavailable :服务暂时不可用,您可以稍后尝试。
504 Gateway Timeout:网关或代理对上游服务器的请求超时。
在实际应用中,大部分网站都有反爬策略,响应状态码代表服务器的处理结果,是我们调整爬取状态(如频率、ip)的重要参考履带式。比如我们一直正常运行的爬虫突然得到403响应,很可能是服务器识别到了我们的爬虫,拒绝了我们的请求。这时候我们就需要放慢爬取频率,或者重启会话,甚至更换IP。

美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!

一本好书读一百遍也不厌烦,熟了课才知道自己。而如果我想成为观众中最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证我的成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“采集”!听说喜欢的人不会倒霉的,每天都精神抖擞!如果你真的想白嫖,那么祝你天天快乐,也欢迎经常光顾我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!


网页抓取解密(一下Python简明教程(二):如何抓取相关的网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-12 21:08
)
需要从网上爬取相关网页。我只想学习Python。首先,我阅读了一个简洁的 Python 教程。它涵盖的内容不多,但可以帮助您快速入门。我一直认为实例驱动的学习是最有效的方法。因此,直接通过如何爬网的实际操作来丰富Python的学习效果会更好。
Python 提供了各种库,使各种操作非常方便。这里使用 Python 的 urllib2 和 sgmllib 库。对于HTML的处理,Python一共提供了三个模块:sgmllib htmllibHTMLParser。本文使用的是sgmllib,但是通过查找相关资料,发现第三方工具BeautifulSoup最好,可以处理较差的HTML。所以我们以后要学习BeautifulSoup。
(2)脚本代码
import urllib2
import sgmllib
class LinksParser(sgmllib.SGMLParser):
urls = []
def do_a(self, attrs):
for name, value in attrs:
if name == 'href' and value not in self.urls:
if value.startswith('http'):
self.urls.append(value)
print value
else:
continue
return
if __name__ == "__main__":
# str = ""
# if str.strip() is '':
# print "str is None"
# else:
# print "str is no None"
p = LinksParser()
f = urllib2.urlopen('http://www.baidu.com')
value = f.read()
print value
p.feed(value)
for url in p.urls:
print url
f.close()
p.close() 查看全部
网页抓取解密(一下Python简明教程(二):如何抓取相关的网页
)
需要从网上爬取相关网页。我只想学习Python。首先,我阅读了一个简洁的 Python 教程。它涵盖的内容不多,但可以帮助您快速入门。我一直认为实例驱动的学习是最有效的方法。因此,直接通过如何爬网的实际操作来丰富Python的学习效果会更好。
Python 提供了各种库,使各种操作非常方便。这里使用 Python 的 urllib2 和 sgmllib 库。对于HTML的处理,Python一共提供了三个模块:sgmllib htmllibHTMLParser。本文使用的是sgmllib,但是通过查找相关资料,发现第三方工具BeautifulSoup最好,可以处理较差的HTML。所以我们以后要学习BeautifulSoup。
(2)脚本代码
import urllib2
import sgmllib
class LinksParser(sgmllib.SGMLParser):
urls = []
def do_a(self, attrs):
for name, value in attrs:
if name == 'href' and value not in self.urls:
if value.startswith('http'):
self.urls.append(value)
print value
else:
continue
return
if __name__ == "__main__":
# str = ""
# if str.strip() is '':
# print "str is None"
# else:
# print "str is no None"
p = LinksParser()
f = urllib2.urlopen('http://www.baidu.com')
value = f.read()
print value
p.feed(value)
for url in p.urls:
print url
f.close()
p.close()
网页抓取解密(ScreamingFrogSEOSpider14破解版14破解安装教程下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-11 21:09
Screaming Frog SEO Spider 14 破解版是一款功能强大且非常好用的网站资源检测爬虫应用。它由一个菜单栏和多个显示各种信息的选项卡式窗格组成。它具有简单直观的操作界面,易于使用,其主要目的是为用户提供一种新的、简便的方式来采集有关任何固定站点的 SEO 信息。通过 Screaming Frog SEO Spider 14,用户不仅可以在不同的 网站 上抓取想要的内容。并且它还可以自动测试网页的性能并进行详细的网页分析,即使网页无法响应,您也可以轻松获得您想要的数据。而且Screaming Frog SEO Spider 14有专业的破解文件帮你完美激活软件,免费使用一系列功能如:查找断链、审核重定向,分析页面标题和元数据等。同时,软件还内置了一套完整的“用户指南”和一些常见问题解答,以确保每个高级用户和新手都可以轻松找到解决方案,而不会遇到任何问题问题!绝对是您检测 网站 和搜索网络资源的必备工具。欢迎有需要的朋友来3322软件站下载体验!
说明:本站提供《尖叫青蛙SEO蜘蛛14破解版》,附破解文件,可完美激活软件。它对个人测试有效。具体破解安装教程请参考以下,欢迎免费下载!
软件功能 1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义 robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看HTMLScreaming Frog SEO Spider 14破解安装教程1、从本站下载解压后,即可获得Screaming Frog SEO Spider 14源程序和破解文件
2、双击“ScreamingFrogSEOSpider-14.0.exe”文件运行,
点击Install进行安装,默认安装路径,安装类型
3、耐心等待软件安装完成,点击关闭退出
4、运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框
5、然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定
6、会弹出如下框,即安装激活成功,可以放心使用
7、以上为Screaming Frog SEO Spider 14破解安装教程,欢迎下载体验!
软件功能1、查找损坏的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以进行修复,或发送给开发人员
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成 XML 站点地图
通过 URL 快速创建具有高级配置的 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构
特别说明
提取码:2kem 查看全部
网页抓取解密(ScreamingFrogSEOSpider14破解版14破解安装教程下载)
Screaming Frog SEO Spider 14 破解版是一款功能强大且非常好用的网站资源检测爬虫应用。它由一个菜单栏和多个显示各种信息的选项卡式窗格组成。它具有简单直观的操作界面,易于使用,其主要目的是为用户提供一种新的、简便的方式来采集有关任何固定站点的 SEO 信息。通过 Screaming Frog SEO Spider 14,用户不仅可以在不同的 网站 上抓取想要的内容。并且它还可以自动测试网页的性能并进行详细的网页分析,即使网页无法响应,您也可以轻松获得您想要的数据。而且Screaming Frog SEO Spider 14有专业的破解文件帮你完美激活软件,免费使用一系列功能如:查找断链、审核重定向,分析页面标题和元数据等。同时,软件还内置了一套完整的“用户指南”和一些常见问题解答,以确保每个高级用户和新手都可以轻松找到解决方案,而不会遇到任何问题问题!绝对是您检测 网站 和搜索网络资源的必备工具。欢迎有需要的朋友来3322软件站下载体验!
说明:本站提供《尖叫青蛙SEO蜘蛛14破解版》,附破解文件,可完美激活软件。它对个人测试有效。具体破解安装教程请参考以下,欢迎免费下载!

软件功能 1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义 robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看HTMLScreaming Frog SEO Spider 14破解安装教程1、从本站下载解压后,即可获得Screaming Frog SEO Spider 14源程序和破解文件

2、双击“ScreamingFrogSEOSpider-14.0.exe”文件运行,
点击Install进行安装,默认安装路径,安装类型

3、耐心等待软件安装完成,点击关闭退出

4、运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框

5、然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定

6、会弹出如下框,即安装激活成功,可以放心使用

7、以上为Screaming Frog SEO Spider 14破解安装教程,欢迎下载体验!

软件功能1、查找损坏的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以进行修复,或发送给开发人员
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成 XML 站点地图
通过 URL 快速创建具有高级配置的 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构
特别说明
提取码:2kem
网页抓取解密(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-11 17:25
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。 查看全部
网页抓取解密(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
网页抓取解密(Python自动生成Markdown文件解决方案解决方案文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-11 13:23
写这个系列文章和相关的Python脚本,起源是我注意到网上有很多页面共享免费ss账号,但是这些账号的有效期只有几个小时或者几天。高效。
我的需求可以分解为几个自动化需求:
1.自动从多个网页抓取账户信息(每天大约80-110个);
2.自动测试以找到访问 google/twitter 延迟小于 5 秒的有效帐户,
3.自动更新有效账户信息到特定网页,
4.用户只需要运行update_config.pyc自动刷新本地gui-config.json文件并重启ss可执行文件,新配置生效。
所以,1-4 作为一个整体是一个自动化的解决方案。借助 Ss/SsR、Proxy 切换插件和 Pac 等组件,您可以观看 youtube。得益于这样的解决方案,我可以通过 YouTube 全程跟踪柯洁对 AlphaGo 的直播。
用于解决上述四个要求的技术:
1. 主要使用requests和lxml这两个模块来抓取账户信息,调用AutoSs。 AutoSs 依赖于许多模块。在树莓派上的Ubuntu操作系统上导入zbar会导致segmentation fault,所以我把AutoSs中的def get_ss_shad0ws0cks8(r)函数注释掉了,少抓了一个网站的账号信息,效果不大。
2.参考Shad0wS0cks免费账号和测试工具共享的SSAccount.py源码,修改、加固、记录测试结果,保存为txt文件和json文件
3. 我写了一个 Python 脚本来自动生成一个 Markdown 文件。这个Markdown文件是一个Blog,包括账号信息、github等。网站支持jekyll模式静态网站,关键是Free,上传更新网站其实就是git同步这个Blog( Markdown 文件)到 github网站.
4. 用户运行的update_config.pyc使用requests和lxml模块获取Blog网页的账号信息,使用json模块读取gui-config.json的内容,修改内容gui-config.json,然后使用python的os.system()调用OS命令重启Shad0ws0cks客户端。
如果你只是自己使用它,它不需要那么复杂。 1-4 实际上形成了一个共享免费帐户的计划。
真正牛B的开源项目是这个,jlund/streisand
" xxxxxx 设置运行 L2TP/IPsec、OpenConnect、OpenSSH、OpenVPN、Shad0ws0cks、......和 WireGuard 的新服务器。它还为所有这些服务生成自定义指令。在运行结束时您将获得一个 HTML 文件,其中收录可以与朋友、家人和其他活动家共享的说明。"
待续
免费账号信息ssr url解码
入门:使用 Python 在 Web 上抓取免费帐户(一) - 知乎专栏
AutoSs开源项目介绍
入门:使用 Python 在 Web 上抓取免费帐户(二) - 知乎专栏
ssa.py程序运行效果
入门:使用 Python 抓取网络上的免费帐户(三) - 知乎column
ssa.py自动测试免费账号程序的由来
入门:使用 Python 在 Web 上抓取免费帐户(四) - 知乎专栏
update_config.py 使用示例
入门:使用 Python 在 Web 上抓取免费帐户(五) - 知乎专栏
用于读写 gui-config.json 和重启 Shad0ws0cks 客户端的示例代码
入门:使用 Python 在 Web 上抓取免费帐户(六) - 知乎专栏
获取免费账户、测试免费账户、分发免费账户的完整解决方案
入门:使用 Python 抓取网络上的免费帐户(七) - 知乎column
update_config.py自动更新免费账号脚本介绍
入门:使用 Python 抓取网络上的免费帐户(八) - 知乎column
Mac OS X 上的客户端 Shad0ws0cksX._NG 使用 plist 格式的配置文件,而不是 json 格式的配置文件。可以使用脚本自动更新账户信息吗?
入门:使用 Python 在 Web 上抓取免费帐户(九) - 知乎专栏
如何快速将收录免费账号的json文件合并到当前ss客户端的gui-config.json配置文件中
入门:使用 Python 抓取网络上的免费帐户(十) - 知乎column
使用update_config.pyc脚本需要满足的条件和软件安装指南
入门:使用 Python 在网页上抓取免费帐户(一) - 知乎专栏
Mac OS X Shad0ws0cks客户端plist配置文件转换成的json文件长这样
入门:使用 Python 在网页上抓取免费帐户(B) - 知乎专栏
Update_config.pyc整体方案介绍
入门:使用 Python (C) 在网页上抓取免费帐户 - 知乎专栏 查看全部
网页抓取解密(Python自动生成Markdown文件解决方案解决方案文件)
写这个系列文章和相关的Python脚本,起源是我注意到网上有很多页面共享免费ss账号,但是这些账号的有效期只有几个小时或者几天。高效。
我的需求可以分解为几个自动化需求:
1.自动从多个网页抓取账户信息(每天大约80-110个);
2.自动测试以找到访问 google/twitter 延迟小于 5 秒的有效帐户,
3.自动更新有效账户信息到特定网页,
4.用户只需要运行update_config.pyc自动刷新本地gui-config.json文件并重启ss可执行文件,新配置生效。
所以,1-4 作为一个整体是一个自动化的解决方案。借助 Ss/SsR、Proxy 切换插件和 Pac 等组件,您可以观看 youtube。得益于这样的解决方案,我可以通过 YouTube 全程跟踪柯洁对 AlphaGo 的直播。
用于解决上述四个要求的技术:
1. 主要使用requests和lxml这两个模块来抓取账户信息,调用AutoSs。 AutoSs 依赖于许多模块。在树莓派上的Ubuntu操作系统上导入zbar会导致segmentation fault,所以我把AutoSs中的def get_ss_shad0ws0cks8(r)函数注释掉了,少抓了一个网站的账号信息,效果不大。
2.参考Shad0wS0cks免费账号和测试工具共享的SSAccount.py源码,修改、加固、记录测试结果,保存为txt文件和json文件
3. 我写了一个 Python 脚本来自动生成一个 Markdown 文件。这个Markdown文件是一个Blog,包括账号信息、github等。网站支持jekyll模式静态网站,关键是Free,上传更新网站其实就是git同步这个Blog( Markdown 文件)到 github网站.
4. 用户运行的update_config.pyc使用requests和lxml模块获取Blog网页的账号信息,使用json模块读取gui-config.json的内容,修改内容gui-config.json,然后使用python的os.system()调用OS命令重启Shad0ws0cks客户端。
如果你只是自己使用它,它不需要那么复杂。 1-4 实际上形成了一个共享免费帐户的计划。
真正牛B的开源项目是这个,jlund/streisand
" xxxxxx 设置运行 L2TP/IPsec、OpenConnect、OpenSSH、OpenVPN、Shad0ws0cks、......和 WireGuard 的新服务器。它还为所有这些服务生成自定义指令。在运行结束时您将获得一个 HTML 文件,其中收录可以与朋友、家人和其他活动家共享的说明。"
待续
免费账号信息ssr url解码
入门:使用 Python 在 Web 上抓取免费帐户(一) - 知乎专栏
AutoSs开源项目介绍
入门:使用 Python 在 Web 上抓取免费帐户(二) - 知乎专栏
ssa.py程序运行效果
入门:使用 Python 抓取网络上的免费帐户(三) - 知乎column
ssa.py自动测试免费账号程序的由来
入门:使用 Python 在 Web 上抓取免费帐户(四) - 知乎专栏
update_config.py 使用示例
入门:使用 Python 在 Web 上抓取免费帐户(五) - 知乎专栏
用于读写 gui-config.json 和重启 Shad0ws0cks 客户端的示例代码
入门:使用 Python 在 Web 上抓取免费帐户(六) - 知乎专栏
获取免费账户、测试免费账户、分发免费账户的完整解决方案
入门:使用 Python 抓取网络上的免费帐户(七) - 知乎column
update_config.py自动更新免费账号脚本介绍
入门:使用 Python 抓取网络上的免费帐户(八) - 知乎column
Mac OS X 上的客户端 Shad0ws0cksX._NG 使用 plist 格式的配置文件,而不是 json 格式的配置文件。可以使用脚本自动更新账户信息吗?
入门:使用 Python 在 Web 上抓取免费帐户(九) - 知乎专栏
如何快速将收录免费账号的json文件合并到当前ss客户端的gui-config.json配置文件中
入门:使用 Python 抓取网络上的免费帐户(十) - 知乎column
使用update_config.pyc脚本需要满足的条件和软件安装指南
入门:使用 Python 在网页上抓取免费帐户(一) - 知乎专栏
Mac OS X Shad0ws0cks客户端plist配置文件转换成的json文件长这样
入门:使用 Python 在网页上抓取免费帐户(B) - 知乎专栏
Update_config.pyc整体方案介绍
入门:使用 Python (C) 在网页上抓取免费帐户 - 知乎专栏
网页抓取解密(个人浏览器上网原理图爬虫程序可以简单想象为替代浏览器的功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-09 19:20
)
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。这些数据来自哪里?正如我们通常在寻找“度娘”时遇到问题一样,一个重要的数据来源是互联网,而爬虫是获取互联网数据的手段。前端时间是数据分析lion,做了两周的兼职爬虫工程师。今天给大家讲讲白话爬虫。事物。
白话爬行动物
爬虫的官方定义:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种按照一定的规则自动爬取全球信息的程序或脚本。规则。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
白话爬虫:利用程序模拟人们的上网行为进行网络索引,获取网页中的特定信息,实现对网络数据的短期、不间断、实时访问。
个人浏览器上网示意图
爬虫可以简单的想象成代替浏览器的功能【发送一个url请求,解析服务器返回的HTML文档】,将获取到的数据存储到数据库或者文件中。同时,对于网站的反爬策略,需要进行伪装,即携带浏览器发送的信息我是谁?(cookie信息),我来自哪里(IP地址,使用的代理IP),我的浏览器模型(User-Agent),使用的方法(get,post等),访问信息。
爬行动物示意图
Python爬虫代码案例
要求:网站百度前几页搜索结果的地址和主题(自定义)抓取一个关键字(自定义)
代码:
class crawler:
'''按关键词爬取百度搜索页面内容'''
url = ''
urls = []
o_urls = []
html = ''
total_pages = 5
current_page = 0
next_page_url = ''
timeout = 60
headersParameters = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
def __init__(self, keyword):
self.keyword = keyword
self.url = 'https://www.baidu.com/baidu?wd='+quote(keyword)+'&tn=monline_dg&ie=utf-8'
self.url_df = pd.DataFrame(columns=["url"])
self.url_title_df = pd.DataFrame(columns=["url","title"])
def set_timeout(self, time):
'''设置超时时间,单位:秒'''
try:
self.timeout = int(time)
except:
pass
def set_total_pages(self, num):
'''设置总共要爬取的页数'''
try:
self.total_pages = int(num)
except:
pass
def set_current_url(self, url):
'''设置当前url'''
self.url = url
def switch_url(self):
'''切换当前url为下一页的url
若下一页为空,则退出程序'''
if self.next_page_url == '':
sys.exit()
else:
self.set_current_url(self.next_page_url)
def is_finish(self):
'''判断是否爬取完毕'''
if self.current_page >= self.total_pages:
return True
else:
return False
def get_html(self):
'''爬取当前url所指页面的内容,保存到html中'''
r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters)
if r.status_code==200:
self.html = r.text
# print("-----------------------------------------------------------------------")
# print("[当前页面链接]: ",self.url)
# #print("[当前页面内容]: ",self.html)
# print("-----------------------------------------------------------------------")
self.current_page += 1
else:
self.html = ''
print('[ERROR]',self.url,'get此url返回的http状态码不是200')
def get_urls(self):
'''从当前html中解析出搜索结果的url,保存到o_urls'''
o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html)
titles = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\".* data-tools=\'{"title":(.*?),"url"',self.html)
# o_urls = list(set(o_urls)) #去重
# titles = list(set(titles)) #去重
self.titles = titles
self.o_urls = o_urls
#取下一页地址
next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html)
if len(next) > 0:
self.next_page_url = 'https://www.baidu.com'+next[-1]
else:
self.next_page_url = ''
def get_real(self, o_url):
'''获取重定向url指向的网址'''
r = requests.get(o_url, allow_redirects = False) #禁止自动跳转
if r.status_code == 302:
try:
return r.headers['location'] #返回指向的地址
except:
pass
return o_url #返回源地址
def transformation(self):
'''读取当前o_urls中的链接重定向的网址,并保存到urls中'''
self.urls = []
for o_url in self.o_urls:
self.urls.append(self.get_real(o_url))
def print_urls(self):
'''输出当前urls中的url'''
for url in self.urls:
print(url)
for title in self.titles:
print(title[0])
def stock_data(self):
url_df = pd.DataFrame(self.urls,columns=["url"])
o_url_df = pd.DataFrame([self.o_urls,self.urls],index=["o_url","url"]).T
title_df = pd.DataFrame(self.titles,columns=["o_url","title"])
url_title_df = pd.merge(o_url_df,title_df,left_on="o_url",right_on="o_url",how="left")
url_titles_df = url_title_df[["url","title"]]
self.url_df = self.url_df.append(url_df,ignore_index=True)
self.url_title_df = self.url_title_df.append(url_titles_df,ignore_index=True)
self.url_title_df["keyword"] = len(self.url_title_df)* [self.keyword]
def print_o_urls(self):
'''输出当前o_urls中的url'''
for url in self.o_urls:
print(url)
def run(self):
while(not self.is_finish()):
self.get_html()
self.get_urls()
self.transformation()
c.print_urls()
self.stock_data()
time.sleep(10)
self.switch_url()
API接口
## 爬取百度关键词
timeout = 60
totalpages=2 ##前两页
baidu_url = pd.DataFrame(columns=["url","title","keyword"])
keyword="数据分析"
c = crawler(keyword)
if timeout != None:
c.set_timeout(timeout)
if totalpages != None:
c.set_total_pages(totalpages)
c.run()
# print(c.url_title_df)
baidu_url=baidu_url.append(c.url_title_df,ignore_index=True)
获取关键词“数据分析”的百度搜索结果前两页信息
查看全部
网页抓取解密(个人浏览器上网原理图爬虫程序可以简单想象为替代浏览器的功能
)
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。这些数据来自哪里?正如我们通常在寻找“度娘”时遇到问题一样,一个重要的数据来源是互联网,而爬虫是获取互联网数据的手段。前端时间是数据分析lion,做了两周的兼职爬虫工程师。今天给大家讲讲白话爬虫。事物。
白话爬行动物
爬虫的官方定义:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种按照一定的规则自动爬取全球信息的程序或脚本。规则。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
白话爬虫:利用程序模拟人们的上网行为进行网络索引,获取网页中的特定信息,实现对网络数据的短期、不间断、实时访问。
个人浏览器上网示意图
爬虫可以简单的想象成代替浏览器的功能【发送一个url请求,解析服务器返回的HTML文档】,将获取到的数据存储到数据库或者文件中。同时,对于网站的反爬策略,需要进行伪装,即携带浏览器发送的信息我是谁?(cookie信息),我来自哪里(IP地址,使用的代理IP),我的浏览器模型(User-Agent),使用的方法(get,post等),访问信息。
爬行动物示意图
Python爬虫代码案例
要求:网站百度前几页搜索结果的地址和主题(自定义)抓取一个关键字(自定义)
代码:
class crawler:
'''按关键词爬取百度搜索页面内容'''
url = ''
urls = []
o_urls = []
html = ''
total_pages = 5
current_page = 0
next_page_url = ''
timeout = 60
headersParameters = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
def __init__(self, keyword):
self.keyword = keyword
self.url = 'https://www.baidu.com/baidu?wd='+quote(keyword)+'&tn=monline_dg&ie=utf-8'
self.url_df = pd.DataFrame(columns=["url"])
self.url_title_df = pd.DataFrame(columns=["url","title"])
def set_timeout(self, time):
'''设置超时时间,单位:秒'''
try:
self.timeout = int(time)
except:
pass
def set_total_pages(self, num):
'''设置总共要爬取的页数'''
try:
self.total_pages = int(num)
except:
pass
def set_current_url(self, url):
'''设置当前url'''
self.url = url
def switch_url(self):
'''切换当前url为下一页的url
若下一页为空,则退出程序'''
if self.next_page_url == '':
sys.exit()
else:
self.set_current_url(self.next_page_url)
def is_finish(self):
'''判断是否爬取完毕'''
if self.current_page >= self.total_pages:
return True
else:
return False
def get_html(self):
'''爬取当前url所指页面的内容,保存到html中'''
r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters)
if r.status_code==200:
self.html = r.text
# print("-----------------------------------------------------------------------")
# print("[当前页面链接]: ",self.url)
# #print("[当前页面内容]: ",self.html)
# print("-----------------------------------------------------------------------")
self.current_page += 1
else:
self.html = ''
print('[ERROR]',self.url,'get此url返回的http状态码不是200')
def get_urls(self):
'''从当前html中解析出搜索结果的url,保存到o_urls'''
o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html)
titles = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\".* data-tools=\'{"title":(.*?),"url"',self.html)
# o_urls = list(set(o_urls)) #去重
# titles = list(set(titles)) #去重
self.titles = titles
self.o_urls = o_urls
#取下一页地址
next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html)
if len(next) > 0:
self.next_page_url = 'https://www.baidu.com'+next[-1]
else:
self.next_page_url = ''
def get_real(self, o_url):
'''获取重定向url指向的网址'''
r = requests.get(o_url, allow_redirects = False) #禁止自动跳转
if r.status_code == 302:
try:
return r.headers['location'] #返回指向的地址
except:
pass
return o_url #返回源地址
def transformation(self):
'''读取当前o_urls中的链接重定向的网址,并保存到urls中'''
self.urls = []
for o_url in self.o_urls:
self.urls.append(self.get_real(o_url))
def print_urls(self):
'''输出当前urls中的url'''
for url in self.urls:
print(url)
for title in self.titles:
print(title[0])
def stock_data(self):
url_df = pd.DataFrame(self.urls,columns=["url"])
o_url_df = pd.DataFrame([self.o_urls,self.urls],index=["o_url","url"]).T
title_df = pd.DataFrame(self.titles,columns=["o_url","title"])
url_title_df = pd.merge(o_url_df,title_df,left_on="o_url",right_on="o_url",how="left")
url_titles_df = url_title_df[["url","title"]]
self.url_df = self.url_df.append(url_df,ignore_index=True)
self.url_title_df = self.url_title_df.append(url_titles_df,ignore_index=True)
self.url_title_df["keyword"] = len(self.url_title_df)* [self.keyword]
def print_o_urls(self):
'''输出当前o_urls中的url'''
for url in self.o_urls:
print(url)
def run(self):
while(not self.is_finish()):
self.get_html()
self.get_urls()
self.transformation()
c.print_urls()
self.stock_data()
time.sleep(10)
self.switch_url()
API接口
## 爬取百度关键词
timeout = 60
totalpages=2 ##前两页
baidu_url = pd.DataFrame(columns=["url","title","keyword"])
keyword="数据分析"
c = crawler(keyword)
if timeout != None:
c.set_timeout(timeout)
if totalpages != None:
c.set_total_pages(totalpages)
c.run()
# print(c.url_title_df)
baidu_url=baidu_url.append(c.url_title_df,ignore_index=True)
获取关键词“数据分析”的百度搜索结果前两页信息
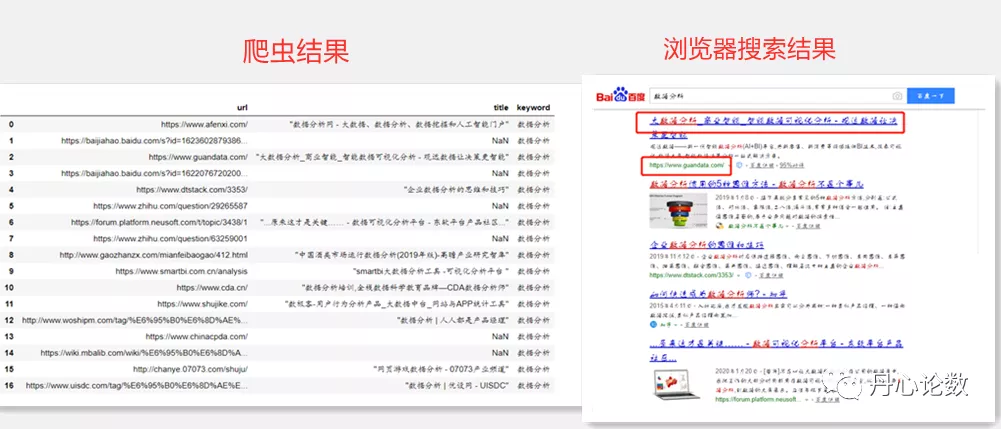
网页抓取解密(【网页抓取解密】移动联通的订单号是怎么来的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-08 19:02
网页抓取解密前言1、web抓取对于我们来说用处有几个呢?一个是和京东的销量,它们都是属于提前预售的一个产品,什么意思呢?就是说它是在这个季度提前上架。那么它的售价如果不提前一个月提前定货,那这个销量一定是不好计算的。还有一个就是我们在经常都能见到的刷单一个骗局。一个是低价刷单,一个是这种刷单,因为有漏洞,抓住了它这个漏洞,别人都不会在你这买,还有就是我们所谓的移动联通的套餐办理。
移动联通一定是1元月租,而且它们不定时断号转网。在杭州这里这一类的套餐办理是不会被提前通知的,非常不合理,所以我们就需要去挖一些这样的一些漏洞,来增加网页里面所有商品的销量,来增加这些商品的销量,能够增加这个钱是第一条件。2、每一个页面浏览的大致的流程呢?有这么一个在上的一个消费者买家和卖家,然后卖家有一个订单,然后卖家把这个订单到物流,物流发到我们在浏览的这个页面的相应的地方,我们想知道这个数据是怎么来的呢?就是说这个订单号是怎么来的?到底是到哪家物流?发到哪个渠道哪个方式?这个订单号是在哪个时间生成的?到什么时间才显示出来的?所以说到底我们要去挖这种漏洞,为什么要用url生成页面呢?每一个页面都是一个独立的页面,是有自己的数据,每一个数据就是一个订单号数据,那么整个链接的一个关系,就是卖家和卖家,卖家才会生成一个卖家订单信息。
那卖家这个订单的唯一标示呢,会在浏览器网页,你在点击里面的那个展示的时候,就直接展示给你展示的这个页面。那么我们怎么在这个首页浏览时候,把数据跟卖家发一个提前一个月订货的一个订单呢?你说这么好的事情,下一个月要是有人缺货了,没货了,或者货不对版,物流被物流中心取消了,或者你下定决心就要提前一个月的,那么你找这个人,你给他发一个订单,不就提前定货了。
这里我们做个小小的猜想,想一下卖家不缺货的原因,比如说它很精明的每个月在上面买一次东西,为什么它一次买一次,就是它定在10号到20号。但是我们你发现我上周用了同样的方法,把这个页面做了个针对性,那这周的月底,或者是这一周的下个月的10号,你用一个针对性的方法,把这个订单发一次。那么你还想一想一些卖家,他一次要买多少东西,他想提前定货的话,直接定到20号或者25号了。
他还不用再在看,他要看那我知道我定这个东西是来当天就要发,那我定这个东西是来定上个月的,还是我定上个月的生成的这个订单,当然这个原理上也是有的,因为它把你发一个订单,是由10号的时候生成。然后加一天。还有。 查看全部
网页抓取解密(【网页抓取解密】移动联通的订单号是怎么来的?)
网页抓取解密前言1、web抓取对于我们来说用处有几个呢?一个是和京东的销量,它们都是属于提前预售的一个产品,什么意思呢?就是说它是在这个季度提前上架。那么它的售价如果不提前一个月提前定货,那这个销量一定是不好计算的。还有一个就是我们在经常都能见到的刷单一个骗局。一个是低价刷单,一个是这种刷单,因为有漏洞,抓住了它这个漏洞,别人都不会在你这买,还有就是我们所谓的移动联通的套餐办理。
移动联通一定是1元月租,而且它们不定时断号转网。在杭州这里这一类的套餐办理是不会被提前通知的,非常不合理,所以我们就需要去挖一些这样的一些漏洞,来增加网页里面所有商品的销量,来增加这些商品的销量,能够增加这个钱是第一条件。2、每一个页面浏览的大致的流程呢?有这么一个在上的一个消费者买家和卖家,然后卖家有一个订单,然后卖家把这个订单到物流,物流发到我们在浏览的这个页面的相应的地方,我们想知道这个数据是怎么来的呢?就是说这个订单号是怎么来的?到底是到哪家物流?发到哪个渠道哪个方式?这个订单号是在哪个时间生成的?到什么时间才显示出来的?所以说到底我们要去挖这种漏洞,为什么要用url生成页面呢?每一个页面都是一个独立的页面,是有自己的数据,每一个数据就是一个订单号数据,那么整个链接的一个关系,就是卖家和卖家,卖家才会生成一个卖家订单信息。
那卖家这个订单的唯一标示呢,会在浏览器网页,你在点击里面的那个展示的时候,就直接展示给你展示的这个页面。那么我们怎么在这个首页浏览时候,把数据跟卖家发一个提前一个月订货的一个订单呢?你说这么好的事情,下一个月要是有人缺货了,没货了,或者货不对版,物流被物流中心取消了,或者你下定决心就要提前一个月的,那么你找这个人,你给他发一个订单,不就提前定货了。
这里我们做个小小的猜想,想一下卖家不缺货的原因,比如说它很精明的每个月在上面买一次东西,为什么它一次买一次,就是它定在10号到20号。但是我们你发现我上周用了同样的方法,把这个页面做了个针对性,那这周的月底,或者是这一周的下个月的10号,你用一个针对性的方法,把这个订单发一次。那么你还想一想一些卖家,他一次要买多少东西,他想提前定货的话,直接定到20号或者25号了。
他还不用再在看,他要看那我知道我定这个东西是来当天就要发,那我定这个东西是来定上个月的,还是我定上个月的生成的这个订单,当然这个原理上也是有的,因为它把你发一个订单,是由10号的时候生成。然后加一天。还有。
网页抓取解密(网页抓取工具WebExtractWebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-07 01:09
网页抓取工具 Easy Web Extract 是一款易于使用的网页抓取工具,只需点击几下即可提取网页中的内容(文本、URL、图片、文件),并将结果转换为各种格式。无需编程。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网页提取软件包括许多高级功能。
使用户能够从简单到复杂的 网站 抓取内容。
但是建立一个网络抓取项目并不需要任何努力。
在此页面中,我们将只向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导将一步一步引导您。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,也就是起始页,页面会通过滑动加载。
它往往是指向已抓取产品列表的链接
第二步:输入关键词提交表单,如果需要网站就可以得到结果。大多数情况下可以跳过此步骤
Step 3:在列表中选择一个item,选择item的数据列进行抓取属性
第四步:选择下一页的URL,访问其他网页
2. 多线程抓取数据
在网页抓取项目中,需要抓取和收获数十万个链接。
传统的刮刀可能需要数小时或数天的时间。
然而,Simple Web Extractor 可以运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,简单的网络提取可以利用系统的最佳性能。
侧面的动画图像显示了 8 个线程的提取。
3. 从data中加载各种提取的数据
一些高度动态的 网站 使用基于客户端创建异步请求的数据加载技术,例如 AJAX。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如 LinkedIn 联系人列表中的一些特定的 网站。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
并很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动化项目执行
通过简单的网络提取嵌入式自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目标。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
以确保只保留新数据。
支持的计划类型:
- 每小时运行一次项目
- 每天运行项目
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接将线索提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
网页抓取解密(网页抓取工具WebExtractWebWebWeb)
网页抓取工具 Easy Web Extract 是一款易于使用的网页抓取工具,只需点击几下即可提取网页中的内容(文本、URL、图片、文件),并将结果转换为各种格式。无需编程。让我们的网络爬虫像它的名字一样易于使用。

软件说明:
我们简单的网页提取软件包括许多高级功能。
使用户能够从简单到复杂的 网站 抓取内容。
但是建立一个网络抓取项目并不需要任何努力。
在此页面中,我们将只向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导将一步一步引导您。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,也就是起始页,页面会通过滑动加载。
它往往是指向已抓取产品列表的链接
第二步:输入关键词提交表单,如果需要网站就可以得到结果。大多数情况下可以跳过此步骤
Step 3:在列表中选择一个item,选择item的数据列进行抓取属性
第四步:选择下一页的URL,访问其他网页
2. 多线程抓取数据
在网页抓取项目中,需要抓取和收获数十万个链接。
传统的刮刀可能需要数小时或数天的时间。
然而,Simple Web Extractor 可以运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,简单的网络提取可以利用系统的最佳性能。
侧面的动画图像显示了 8 个线程的提取。
3. 从data中加载各种提取的数据
一些高度动态的 网站 使用基于客户端创建异步请求的数据加载技术,例如 AJAX。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如 LinkedIn 联系人列表中的一些特定的 网站。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
并很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动化项目执行
通过简单的网络提取嵌入式自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目标。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
以确保只保留新数据。
支持的计划类型:
- 每小时运行一次项目
- 每天运行项目
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接将线索提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。
网页抓取解密(加密和解密的过程,你都知道吗?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-06 16:03
)
我最近看了几页,发现其中很多都被处理了。但是,它带有一个 javascript 处理加密页面。以下是加解密过程的简要说明。
一、加密
1、将字符串中的每个字符转换为数字
该方法是字符串处理的方法 charCodeAt(index) charCodeAt()方法可以返回指定位置的字符的Unicode编码,即数字化字符串,返回值为0-之间的整数65535的对应字符。
例如:
var str="hello world!"
var r = str.charCodeAt(0);
document.write(r);
//输出为: 104
2.修改数字后,使用fromCharCode()方法恢复字符
fromCharCode()方法是String的静态方法,可以将数字的指定Unicode编码转换成字符。
比如上面的例子:
$ = String.fromCharCode(r);
document.write($);
//输出为: h
加密的关键在于String.fromCharCode(r)这一步!
你可以改变r的值,使输出的字符有偏差,比如r = r + 2
$ = String.fromCharCode(r + 2);
document.write($);
//输出为: j
因此,
你好世界!变成jgnnq"yqtnf#
变成>jvon@
二、解密
1、还要先把字符转成unicode编码的数字
var str=">jvon@";
var r = str.charCodeAt(0);
document.write(r);
//输出为: 62
2.使用加密逆算法
<p>$ = String.fromCharCode(r-2);
document.write($);
//输出为: 查看全部
网页抓取解密(加密和解密的过程,你都知道吗?(上)
)
我最近看了几页,发现其中很多都被处理了。但是,它带有一个 javascript 处理加密页面。以下是加解密过程的简要说明。
一、加密
1、将字符串中的每个字符转换为数字
该方法是字符串处理的方法 charCodeAt(index) charCodeAt()方法可以返回指定位置的字符的Unicode编码,即数字化字符串,返回值为0-之间的整数65535的对应字符。
例如:
var str="hello world!"
var r = str.charCodeAt(0);
document.write(r);
//输出为: 104
2.修改数字后,使用fromCharCode()方法恢复字符
fromCharCode()方法是String的静态方法,可以将数字的指定Unicode编码转换成字符。
比如上面的例子:
$ = String.fromCharCode(r);
document.write($);
//输出为: h
加密的关键在于String.fromCharCode(r)这一步!
你可以改变r的值,使输出的字符有偏差,比如r = r + 2
$ = String.fromCharCode(r + 2);
document.write($);
//输出为: j
因此,
你好世界!变成jgnnq"yqtnf#
变成>jvon@
二、解密
1、还要先把字符转成unicode编码的数字
var str=">jvon@";
var r = str.charCodeAt(0);
document.write(r);
//输出为: 62
2.使用加密逆算法
<p>$ = String.fromCharCode(r-2);
document.write($);
//输出为:
网页抓取解密(“全包加密*网页全包加密”*(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-05 12:16
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。
“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加快资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,所以逻辑都是JS)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest 查看全部
网页抓取解密(“全包加密*网页全包加密”*(组图))
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。

“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加快资源加载,加速代码执行。"

这是解密的源代码

这是解密后的图

这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,所以逻辑都是JS)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
网页抓取解密(怎么更轻松的抓取网站链接抓取器(网站抓取助手) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-05 11:18
)
网站Link Grabber(网站Link Address Grabbing Assistant)是一款优秀且易于使用的辅助工具,用于抓取各种网站链接。如何更轻松地抓取 网站 链接?小编带来的这款网站链接抓取器可以帮到你,使用后可以帮助用户更方便快捷的抓取网站链接。该工具易于使用且操作简单。只需几步即可轻松抓取网站链接,抓取的链接会逐行保存为TXT文件,方便用户查看。欢迎有需要的朋友下载使用。
使用方法:
1、输入提取链接的网站地址;
2、选择并发线程数;
3、选择txt文件保存地址;
4、输入要保存的txt文件个数;
5、点击“开始”按钮进行链接提取。
软件功能:
1、这个软件非常适合做seo优化的人排名
2、使用此软件节省大量时间
3、并自动选择所有网站内部链接
4、并且还可以有计划地将提取的内部链接提交给各种收录工具
5、这样就完成了收录数量的增加
特点:
1、网站
下可以捕获本站连接地址的所有输入
2、动态统计包括未访问的连接和爬取的链接
3、线程越大速度越快
4、但是同时消耗更多的CPU,也消耗更多的内存和网速
5、查看你当前访问的链接
6、支持输入结果的存储地址
查看全部
网页抓取解密(怎么更轻松的抓取网站链接抓取器(网站抓取助手)
)
网站Link Grabber(网站Link Address Grabbing Assistant)是一款优秀且易于使用的辅助工具,用于抓取各种网站链接。如何更轻松地抓取 网站 链接?小编带来的这款网站链接抓取器可以帮到你,使用后可以帮助用户更方便快捷的抓取网站链接。该工具易于使用且操作简单。只需几步即可轻松抓取网站链接,抓取的链接会逐行保存为TXT文件,方便用户查看。欢迎有需要的朋友下载使用。
使用方法:
1、输入提取链接的网站地址;
2、选择并发线程数;
3、选择txt文件保存地址;
4、输入要保存的txt文件个数;
5、点击“开始”按钮进行链接提取。
软件功能:
1、这个软件非常适合做seo优化的人排名
2、使用此软件节省大量时间
3、并自动选择所有网站内部链接
4、并且还可以有计划地将提取的内部链接提交给各种收录工具
5、这样就完成了收录数量的增加
特点:
1、网站
下可以捕获本站连接地址的所有输入
2、动态统计包括未访问的连接和爬取的链接
3、线程越大速度越快
4、但是同时消耗更多的CPU,也消耗更多的内存和网速
5、查看你当前访问的链接
6、支持输入结果的存储地址
网页抓取解密(这款ScreamingSEOSpider16破解版真的真的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-05 09:07
Screaming Frog SEO Spider 是一款功能强大的网络爬虫工具,专门用于爬取 Internet URL 并对其进行分析。通过这个软件,用户可以很方便的抓取可能存在或者出现在断连接或者服务器错误信息等的URL,也可以用来识别网站中临时或者永久的重新定义循环到链接也可以直接查URL、网页标题、内容重复的相关信息。抓取到这些信息后,软件会自动将获取到的详细信息反馈给开发者进行修复,非常方便好用。因此,这款软件非常适合从事网站网页行业的用户,通过它可以节省大量的时间和精力,高效地完成工作。所以,无论是大的网站还是自己制作的小网站,你都可以用它来分析,你可以很方便的得到你想分析的结果和你需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。并且您可以轻松获得您想要分析的结果和您需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。并且您可以轻松获得您想要分析的结果和您需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。而且使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。而且使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。
破解教程1、在本站下载解压,得到ScreamingFrogSEOSpider-11.0.exe安装程序和Keygen.exe注册机
2、双击ScreamingFrogSEOSpider-11.0.exe运行,选择安装路径,点击next
3、正在安装,请稍等
4、安装完成,点击close关闭向导
5、运行软件和keygen注册机,将注册机中的注册信息相应复制到软件中
6、注册成功,重启软件
软件功能1、审计重定向
Screaming Frog SEO Spiderke 16 发现临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
2、生成 XML 站点地图
通过 URL 进行高级配置,包括上次修改、优先级和更改频率,快速创建 XML 站点地图和图像 XML 站点地图。
3、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
5、抓取 JavaScript网站
使用集成的 ChromiumWRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
6、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入。
7、使用 XPath 提取数据
使用 CSSPath、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多。
8、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
9、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
10、查找断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
软件功能 1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染 (JavaScript)
18、自定义robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看原创和渲染的 HTML 查看全部
网页抓取解密(这款ScreamingSEOSpider16破解版真的真的)
Screaming Frog SEO Spider 是一款功能强大的网络爬虫工具,专门用于爬取 Internet URL 并对其进行分析。通过这个软件,用户可以很方便的抓取可能存在或者出现在断连接或者服务器错误信息等的URL,也可以用来识别网站中临时或者永久的重新定义循环到链接也可以直接查URL、网页标题、内容重复的相关信息。抓取到这些信息后,软件会自动将获取到的详细信息反馈给开发者进行修复,非常方便好用。因此,这款软件非常适合从事网站网页行业的用户,通过它可以节省大量的时间和精力,高效地完成工作。所以,无论是大的网站还是自己制作的小网站,你都可以用它来分析,你可以很方便的得到你想分析的结果和你需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。并且您可以轻松获得您想要分析的结果和您需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。并且您可以轻松获得您想要分析的结果和您需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。而且使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。而且使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。

破解教程1、在本站下载解压,得到ScreamingFrogSEOSpider-11.0.exe安装程序和Keygen.exe注册机

2、双击ScreamingFrogSEOSpider-11.0.exe运行,选择安装路径,点击next

3、正在安装,请稍等

4、安装完成,点击close关闭向导

5、运行软件和keygen注册机,将注册机中的注册信息相应复制到软件中

6、注册成功,重启软件

软件功能1、审计重定向
Screaming Frog SEO Spiderke 16 发现临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
2、生成 XML 站点地图
通过 URL 进行高级配置,包括上次修改、优先级和更改频率,快速创建 XML 站点地图和图像 XML 站点地图。
3、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
5、抓取 JavaScript网站
使用集成的 ChromiumWRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
6、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入。
7、使用 XPath 提取数据
使用 CSSPath、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多。
8、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
9、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
10、查找断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
软件功能 1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染 (JavaScript)
18、自定义robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看原创和渲染的 HTML
网页抓取解密(做了个网络爬虫抓取网页,最后居然搞出来了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-19 07:04
我做了一个网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,就会出现乱码,如下:
得到文本后直接打印,输出str如下: ¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÔ±¿¿ ¼ÊÔÔ±¿¿
这个问题困扰了我很久,百度、google都没有找到完全可行的方法,继续折腾,终于出来了!代码转换来回转换,依然无法解决。把问题具体总结一下,分享给大家,互相学习!(有时候问题并不复杂,容易解决。如果问题没有突破,那么解决问题的路是很长的。)总之,遇到问题,选择几种方法去尝试,就有了总是有办法解决它。的。
1.更改网页源代码的编码格式
# -*- coding:utf8 -*-
import urllib2
req = urllib2.Request("http://www.baidu.com/")
res = urllib2.urlopen(req)
html = res.read()
res.close()
html = unicode(html, "gb2312").encode("utf8") #gb2312--->utf-8
print html
2.python爬取网页时字符集转换问题处理解决方案
有时我们 采集 网页,将字符串保存到文件或在处理后将它们写入数据库。这时,我们需要制定字符串的编码。如果采集网页的编码是gb2312,而我们的数据库是utf-8,不做任何处理直接插入数据库可能会出现乱码(未测试,不知道数据库会不会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人,立马下跪。
不知道大家还记得没有,python中打印汉字的时候,需要在字符串前面加上u:
print u"来做基地?"
这样就可以显示中文了。u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
这里有一个与之相关的unicode()函数,使用如下
str="来基地"
str=unicode(str,"utf-8")
打印字符串
与u的区别在于unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认的可能是ansi。
unicode 是键,下面继续
我们开始爬取百度主页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
导入 urllib2
定义主():
f=urllib2.urlopen("")
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
如果 __name__ == '__main__' :
主要的()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大部分人来说,这其实已经足够了,但是有时候我只想把gb2312转成utf-8,怎么办呢?
第一的:
str=unicode(str,"gb2312") #这里的gb2312是str的实际字符集,我们现在将其转换为unicode
然后:
str=str.encode("utf-8") #将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,转码为utf-8。
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding") 将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
3:将str保存到文件,或写入数据库。当然,你已经指定了编码,对吧?
3.用 lxml 解析 html
使用lxml.etree作为网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,会出现乱码,如下:
获取文本后,直接打印,输出结果v如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй«这个v的类型又是
如何解决?
可以修改源代码的编码格式:
response.encoding='utf-8'
page=etree.HTML(response.content)
nodes_title=page.xpath("//title//text()")
这样打印出来的nodes_title[0]是正常中文显示的。
特别注意的是response.text容易出现编码问题,所以以后使用response.content。 查看全部
网页抓取解密(做了个网络爬虫抓取网页,最后居然搞出来了)
我做了一个网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,就会出现乱码,如下:
得到文本后直接打印,输出str如下: ¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÔ±¿¿ ¼ÊÔÔ±¿¿
这个问题困扰了我很久,百度、google都没有找到完全可行的方法,继续折腾,终于出来了!代码转换来回转换,依然无法解决。把问题具体总结一下,分享给大家,互相学习!(有时候问题并不复杂,容易解决。如果问题没有突破,那么解决问题的路是很长的。)总之,遇到问题,选择几种方法去尝试,就有了总是有办法解决它。的。
1.更改网页源代码的编码格式
# -*- coding:utf8 -*-
import urllib2
req = urllib2.Request("http://www.baidu.com/";)
res = urllib2.urlopen(req)
html = res.read()
res.close()
html = unicode(html, "gb2312").encode("utf8") #gb2312--->utf-8
print html
2.python爬取网页时字符集转换问题处理解决方案
有时我们 采集 网页,将字符串保存到文件或在处理后将它们写入数据库。这时,我们需要制定字符串的编码。如果采集网页的编码是gb2312,而我们的数据库是utf-8,不做任何处理直接插入数据库可能会出现乱码(未测试,不知道数据库会不会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人,立马下跪。
不知道大家还记得没有,python中打印汉字的时候,需要在字符串前面加上u:
print u"来做基地?"
这样就可以显示中文了。u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
这里有一个与之相关的unicode()函数,使用如下
str="来基地"
str=unicode(str,"utf-8")
打印字符串
与u的区别在于unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认的可能是ansi。
unicode 是键,下面继续
我们开始爬取百度主页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
导入 urllib2
定义主():
f=urllib2.urlopen("")
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
如果 __name__ == '__main__' :
主要的()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大部分人来说,这其实已经足够了,但是有时候我只想把gb2312转成utf-8,怎么办呢?
第一的:
str=unicode(str,"gb2312") #这里的gb2312是str的实际字符集,我们现在将其转换为unicode
然后:
str=str.encode("utf-8") #将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,转码为utf-8。
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding") 将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
3:将str保存到文件,或写入数据库。当然,你已经指定了编码,对吧?
3.用 lxml 解析 html
使用lxml.etree作为网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,会出现乱码,如下:
获取文本后,直接打印,输出结果v如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй«这个v的类型又是
如何解决?
可以修改源代码的编码格式:
response.encoding='utf-8'
page=etree.HTML(response.content)
nodes_title=page.xpath("//title//text()")
这样打印出来的nodes_title[0]是正常中文显示的。
特别注意的是response.text容易出现编码问题,所以以后使用response.content。
网页抓取解密(煎蛋网妹子图怎么爬,文件夹js处理的网页防盗图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-19 00:02
最近有朋友一直在问我怎么爬的修改版,因为他们用尽了所有的精力,结果抓到了一整文件夹的防盗图片。很久以前在博客里说过,对于这种js处理的网页,抓取网页上看到的数据大致有三种方式:
分析网页
首先打开inspect元素查看他的实际响应内容,可以看到img标签中实际src属性的值是固定值 ///img/blank.gif。onload 属性指向一个 js jandan_load_img() 函数,this 参数在大多数情况下是指当前标签。其后是 span 标签中收录的一串哈希值。
目前我们已经找到了jandan_load_img()函数,接下来需要确定收录该函数的js文件。方法很简单,在每一个返回的js响应中,去搜索。
当前的js文件是经过压缩和混淆处理的,我们可以复制到在线解压工具中解压。如果您使用的是 Chrome,您可以找到源文件并单击图标下方带有红色框的按钮:
jandan_load_img() 函数的内容是
1function jandan_load_img(b) {
2 var d = $(b);
3 var f = d.next("span.img-hash");
4 var e = f.text();
5 f.remove();
6 var c = jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH(e, "zE4N6eHuAQP8vkQPb0wcuEcWnLzHYVhy");
7 var a = $('[查看原图]</a>');
8 d.before(a);
9 d.before("
");
10 d.removeAttr("onload");
11 d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1thumb180$3"));
12 ...
13}
14
可以看到js文件依赖于PQuery库,它获取img标签,然后获取span标签的内容,然后将它和一个常量传递给这个字符串的函数,获取返回的内容把这个字符串的函数,放入img和a标签中。
我们在当前的js文件中搜索jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH()函数。如果不出意外,我们可以搜索 2 个函数。我们选择后一种,内容如下:
1var jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH = function(m, r, d) {
2 var e = "DECODE";
3 var r = r ? r : "";
4 var d = d ? d : 0;
5 var q = 4;
6 r = md5(r);
7 var o = md5(r.substr(0, 16));
8 var n = md5(r.substr(16, 16));
9 if (q) {
10 if (e == "DECODE") {
11 var l = m.substr(0, q)
12 }
13 } else {
14 var l = ""
15 }
16 var c = o + md5(o + l);
17 var k;
18 if (e == "DECODE") {
19 m = m.substr(q);
20 k = base64_decode(m)
21 }
22 var h = new Array(256);
23 for (var g = 0; g .*'
35 result = re.findall(pattern, html)
36 js_url = "http://" + result[len(result) - 1]
37 except Exception as e:
38 print(e)
39 js = get_html(js_url).text
40
41 return js
42
43def get_salt(js):
44 """正则匹配 js 中的加密常量"""
45 pattern = r'jandan_load_img.*?var c.*?"(.*?)"'
46 salt = re.findall(pattern, js, re.S)[0]
47 # print(salt)
48 return salt
49
50def all_img_hash(page_url):
51 """请求页面,返回页面中所有图片 hash"""
52 html = get_html(page_url).text
53 doc = etree.HTML(html)
54 img_hash = doc.xpath('//span[@class="img-hash"]/text()')
55 # print(img_hash)
56 return img_hash
57
58def init_md5(str):
59 """封装 md5"""
60 md5 = hashlib.md5()
61 md5.update(str.encode('utf-8'))
62 return md5.hexdigest()
63
64def decode_base64(data):
65 """封装 base64"""
66 return base64.b64decode(data + (4 - len(data) % 4) * '=')
67
68def simulation_js(img_hash, salt):
69 """
70 翻译 js 加密方式
71 :param img_hash: 图片 hash
72 :param salt: 加密常量
73 :return: 图片 url
74 """
75 # r = salt if salt else ''
76 # d = 0
77 # q = 4
78 # r = init_md5(r)
79 # o = init_md5(r[:16])
80 # n = init_md5(r[16:32])
81 # if q:
82 # l = img_hash[:q]
83 # else: l = ''
84 #
85 # c = o + init_md5(o + l)
86 # img_hash = img_hash[q:]
87 # k = decode_base64(img_hash)
88 #
89 # h = list(range(256))
90 # b = list(range(256))
91 # for g in range(256):
92 # b[g] = ord(c[g % len(c)])
93 # f = 0
94 # for g in range(256):
95 # f = (f + h[g] + b[g]) % 256
96 # h[g], h[f] = h[f], h[g]
97 #
98 # t = ''
99 # p = f = 0
100 # for g in range(len(k)):
101 # p = (p + 1) % 256
102 # f = (f + h[p]) % 256
103 # h[p], h[f] = h[f], h[p]
104 # t += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
105 # t = t[26:]
106 t = decode_base64(img_hash)
107 # print(t)
108 return t
109
110def parse_hash(salt, page_url):
111
112 img_hash = all_img_hash(page_url)
113 # print(img_hash)
114 for i in img_hash:
115 yield simulation_js(i, salt)
116
117def download_img(dir_path, img_url):
118 """下载"""
119 filename = img_url[-14:]
120 # print(img_url)
121 img_content = get_html(img_url).content
122 if not os.path.exists(dir_path):
123 os.mkdir(dir_path)
124 try:
125 with open(os.path.join(dir_path, filename), 'wb') as f:
126 f.write(img_content)
127 return True
128 except Exception as e:
129 print(e)
130 return False
131
132def main(dir_path, page=1):
133 js = get_js_file()
134 salt = get_salt(js)
135 base_url = 'http://jandan.net/ooxx/'
136 for i in range(page+1):
137 page_url = base_url + 'page-{}/'.format(58-i)
138 # print(page_url)
139 # //wx1.sinaimg.cn/large/672f3952gy1g0u2mqymhyj20u00u0dja.jpg 正确结果
140 for img_url in parse_hash(salt, page_url):
141 # img_url = 'w'+str(img_url, encoding = "utf-8")
142 img_url = str(img_url, encoding = "utf-8")
143 print(img_url)
144 r = download_img(dir_path, 'http:' + img_url)
145
146 if r: print('success')
147
148
149if __name__ == '__main__':
150 dir_path = 'E:/jiandan/'
151 main(dir_path)
152
153
这一次,不知道为什么煎蛋的解密变得容易了。…
最后非常感谢原作者的分享,一下子学到了很多。 查看全部
网页抓取解密(煎蛋网妹子图怎么爬,文件夹js处理的网页防盗图)
最近有朋友一直在问我怎么爬的修改版,因为他们用尽了所有的精力,结果抓到了一整文件夹的防盗图片。很久以前在博客里说过,对于这种js处理的网页,抓取网页上看到的数据大致有三种方式:
分析网页
首先打开inspect元素查看他的实际响应内容,可以看到img标签中实际src属性的值是固定值 ///img/blank.gif。onload 属性指向一个 js jandan_load_img() 函数,this 参数在大多数情况下是指当前标签。其后是 span 标签中收录的一串哈希值。
目前我们已经找到了jandan_load_img()函数,接下来需要确定收录该函数的js文件。方法很简单,在每一个返回的js响应中,去搜索。
当前的js文件是经过压缩和混淆处理的,我们可以复制到在线解压工具中解压。如果您使用的是 Chrome,您可以找到源文件并单击图标下方带有红色框的按钮:
jandan_load_img() 函数的内容是
1function jandan_load_img(b) {
2 var d = $(b);
3 var f = d.next("span.img-hash");
4 var e = f.text();
5 f.remove();
6 var c = jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH(e, "zE4N6eHuAQP8vkQPb0wcuEcWnLzHYVhy");
7 var a = $('[查看原图]</a>');
8 d.before(a);
9 d.before("
");
10 d.removeAttr("onload");
11 d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1thumb180$3"));
12 ...
13}
14
可以看到js文件依赖于PQuery库,它获取img标签,然后获取span标签的内容,然后将它和一个常量传递给这个字符串的函数,获取返回的内容把这个字符串的函数,放入img和a标签中。
我们在当前的js文件中搜索jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH()函数。如果不出意外,我们可以搜索 2 个函数。我们选择后一种,内容如下:
1var jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH = function(m, r, d) {
2 var e = "DECODE";
3 var r = r ? r : "";
4 var d = d ? d : 0;
5 var q = 4;
6 r = md5(r);
7 var o = md5(r.substr(0, 16));
8 var n = md5(r.substr(16, 16));
9 if (q) {
10 if (e == "DECODE") {
11 var l = m.substr(0, q)
12 }
13 } else {
14 var l = ""
15 }
16 var c = o + md5(o + l);
17 var k;
18 if (e == "DECODE") {
19 m = m.substr(q);
20 k = base64_decode(m)
21 }
22 var h = new Array(256);
23 for (var g = 0; g .*'
35 result = re.findall(pattern, html)
36 js_url = "http://" + result[len(result) - 1]
37 except Exception as e:
38 print(e)
39 js = get_html(js_url).text
40
41 return js
42
43def get_salt(js):
44 """正则匹配 js 中的加密常量"""
45 pattern = r'jandan_load_img.*?var c.*?"(.*?)"'
46 salt = re.findall(pattern, js, re.S)[0]
47 # print(salt)
48 return salt
49
50def all_img_hash(page_url):
51 """请求页面,返回页面中所有图片 hash"""
52 html = get_html(page_url).text
53 doc = etree.HTML(html)
54 img_hash = doc.xpath('//span[@class="img-hash"]/text()')
55 # print(img_hash)
56 return img_hash
57
58def init_md5(str):
59 """封装 md5"""
60 md5 = hashlib.md5()
61 md5.update(str.encode('utf-8'))
62 return md5.hexdigest()
63
64def decode_base64(data):
65 """封装 base64"""
66 return base64.b64decode(data + (4 - len(data) % 4) * '=')
67
68def simulation_js(img_hash, salt):
69 """
70 翻译 js 加密方式
71 :param img_hash: 图片 hash
72 :param salt: 加密常量
73 :return: 图片 url
74 """
75 # r = salt if salt else ''
76 # d = 0
77 # q = 4
78 # r = init_md5(r)
79 # o = init_md5(r[:16])
80 # n = init_md5(r[16:32])
81 # if q:
82 # l = img_hash[:q]
83 # else: l = ''
84 #
85 # c = o + init_md5(o + l)
86 # img_hash = img_hash[q:]
87 # k = decode_base64(img_hash)
88 #
89 # h = list(range(256))
90 # b = list(range(256))
91 # for g in range(256):
92 # b[g] = ord(c[g % len(c)])
93 # f = 0
94 # for g in range(256):
95 # f = (f + h[g] + b[g]) % 256
96 # h[g], h[f] = h[f], h[g]
97 #
98 # t = ''
99 # p = f = 0
100 # for g in range(len(k)):
101 # p = (p + 1) % 256
102 # f = (f + h[p]) % 256
103 # h[p], h[f] = h[f], h[p]
104 # t += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
105 # t = t[26:]
106 t = decode_base64(img_hash)
107 # print(t)
108 return t
109
110def parse_hash(salt, page_url):
111
112 img_hash = all_img_hash(page_url)
113 # print(img_hash)
114 for i in img_hash:
115 yield simulation_js(i, salt)
116
117def download_img(dir_path, img_url):
118 """下载"""
119 filename = img_url[-14:]
120 # print(img_url)
121 img_content = get_html(img_url).content
122 if not os.path.exists(dir_path):
123 os.mkdir(dir_path)
124 try:
125 with open(os.path.join(dir_path, filename), 'wb') as f:
126 f.write(img_content)
127 return True
128 except Exception as e:
129 print(e)
130 return False
131
132def main(dir_path, page=1):
133 js = get_js_file()
134 salt = get_salt(js)
135 base_url = 'http://jandan.net/ooxx/'
136 for i in range(page+1):
137 page_url = base_url + 'page-{}/'.format(58-i)
138 # print(page_url)
139 # //wx1.sinaimg.cn/large/672f3952gy1g0u2mqymhyj20u00u0dja.jpg 正确结果
140 for img_url in parse_hash(salt, page_url):
141 # img_url = 'w'+str(img_url, encoding = "utf-8")
142 img_url = str(img_url, encoding = "utf-8")
143 print(img_url)
144 r = download_img(dir_path, 'http:' + img_url)
145
146 if r: print('success')
147
148
149if __name__ == '__main__':
150 dir_path = 'E:/jiandan/'
151 main(dir_path)
152
153
这一次,不知道为什么煎蛋的解密变得容易了。…
最后非常感谢原作者的分享,一下子学到了很多。
网页抓取解密(爬取一个第二季第34集分段视频没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-19 00:00
)
实现功能:爬取网站的视频
1、获取主页面的页面源码,找到iframe
2、从iframe页面源码中获取m3u8文件
3、下载第一层m3u8文件,获取真实地址
4、下载视频
5、下载密钥(key)进行解密
6、将所有ts文件合并为一个MP4文件
'''
目前基本确定是第4步和第5步有问题,但不清楚是代码错误的原因,还是好像有几个分段的视频没有下载;
所以不清楚是什么导致了第 6 步中的问题;
问题截图:
代码页
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES
import os
#正则提取规则
obj1=re.compile(r'2.html","link_pre":"","url":"(?P.*?)","url_next":"https:')
#2.1子程序:找到主页面的源代码,找到iframe对应的url
def get_iframe_src(url):
resp=requests.get(url)
#print(resp.text) #测试是否正常爬取到源代码
#修改为正则爬取,这里提取完之后就是第一层的m3u8地址了
content=resp.text #把源代码变成text格式存储起来,用来提取
main_page=obj1.finditer(content)
for it in main_page:
#print(it.group('src'))
src_modify=it.group('src').replace('\\','')
#print(src_modify)
return src_modify #输出正确的第一层m3u8地址
resp.close()
#2.2、子程序:拿到第一层的m3u8文件下载地址;这一步只在课程里91看剧需要,实操的网址2.1里拿到的就是第一层m3u8了
def get_first_m3u8_url(url):
resp=requests.get(url)
#print(resp.text)
obj2=re.compile(r'var main=''(?P.*?)''')
m3u8_url=obj2.search(resp.text).group('m3u8_url') #这里是把m3u8地址提取出来
#print(m3u8_url)
resp.close()
return m3u8_url #让函数返回这一个地址
#2.3、子程序:下载第一层m3u8文件
def download_m3u8_file(url,name):
resp=requests.get(url)
with open(name,mode='wb')as f:
f.write(resp.content)
resp.close()
#2.5.1、子程序:异步协程进行下载
async def download_ts(url,name,session):
async with session.get(url)as resp:
async with aiofiles.open(f'4.9-video2/{name}',mode='wb')as f:
await f.write(await resp.content.read()) #把下载到的内容写入文件中
print(f'{name}下载完毕')
#2.5、子程序:异步协程处理拼接下载
#实操版
async def aio_download(up_url):
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'): #’#‘开头的行不要
continue
# line就是xxxx.ts文件
url = line.strip()
name1=line.rsplit('/',1)[1]
name=name1.strip()
task=asyncio.create_task(download_ts(url,name,session))
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
#2.6.1获取密钥
def get_key(url):
resp=requests.get(url)
print(resp.text)
a=resp.text
b=bytes(a,'utf-8')
return b
#2.6.2创建解密视频的任务
async def aio_dec(key):
#思路:解密,需要把下载的文件一个个打开;但是因为这里我们是直接用m3u8文件里后面的字符命名的
tasks=[]
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'):
continue
line1=line.rsplit('/',1)[1] #取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
#开始创建异步任务
task=asyncio.create_task(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
#2.6.3创建解密函数
async def dec_ts(name,key):
aes=AES.new(key=key,IV=b'0000000000000000',mode=AES.MODE_CBC)
async with aiofiles.open(f'4.9-video2/{name}',mode='rb')as f1,\
aiofiles.open(f'4.9-video2/temp_{name}',mode='wb')as f2:
bs=await f1.read() #从源文件读取文件
await f2.write(aes.decrypt(bs)) #把解密好的内容写入文件
print(f'{name}处理完毕')
#2.7合并视频为mp4
def merge_ts():
#mac:cat 1.ts 2.ts 3.ts > xxx.mp4
#windows:copy/b 1.ts+2.ts+3.ts > xxx.mp4
lst=[]
with open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
for line in f:
if line.startswith('#'):
continue
line1 = line.rsplit('/', 1)[1] # 取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
lst.append(f'4.9-video2/temp_{line}')
s=''.join(lst)
os.system(f'copy /b {s} >movie.mp4')
print('搞定!')
#2、主程序
def main(url):
#2.1、找到主页面的源代码,找到iframe对应的url
iframe_src=get_iframe_src(url)
#print(iframe_src)
#2.3下载第一层m3u8文件
download_m3u8_file(iframe_src,'4.93-抓取91看剧复杂版——first-m3u8.txt') #按照课程正常的话括号里的’iframe_src‘要改为2.2里的’first_m3u8_url_ture‘
#2.4下载第二层m3u8文件
with open('4.93-抓取91看剧复杂版——first-m3u8.txt',mode='r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'): #让程序识别文件里面时,自动跳过‘#’开头的行段
continue
else:
line=line.strip() #去掉空白或者换行符
#准备拼接第二层m3u8的下载路径
second_m3u8_url=iframe_src.split('/20210730')[0]+line
download_m3u8_file(second_m3u8_url,'4.93-抓取91看剧复杂版——second-m3u8.txt')
print('第二层m3u8下载完毕')
#2.5下载视频
#实操写法
up_url='开始'
#asyncio.run(aio_download(up_url)) #这个会报错:RuntimeError: Event loop is closed
loop=asyncio.get_event_loop()
loop.run_until_complete(aio_download(up_url))
#2.6.1拿到密钥
#实操
key_url='https://ts6.hhmm0.com:9999/20210730/QoNAXIDD/1000kb/hls/key.key'
key=get_key(key_url) #访问密匙的路径,拿到密匙
#2.6.2解密
asyncio.run(aio_dec(key))
#2.7合并ts文件为mp4文件
merge_ts()
#1、主程序调用处
if __name__=='__main__':
url='https://www.pianba.net/yun/84961-1-1/'
main(url) 查看全部
网页抓取解密(爬取一个第二季第34集分段视频没有
)
实现功能:爬取网站的视频
1、获取主页面的页面源码,找到iframe
2、从iframe页面源码中获取m3u8文件
3、下载第一层m3u8文件,获取真实地址
4、下载视频
5、下载密钥(key)进行解密
6、将所有ts文件合并为一个MP4文件
'''
目前基本确定是第4步和第5步有问题,但不清楚是代码错误的原因,还是好像有几个分段的视频没有下载;
所以不清楚是什么导致了第 6 步中的问题;
问题截图:
代码页
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES
import os
#正则提取规则
obj1=re.compile(r'2.html","link_pre":"","url":"(?P.*?)","url_next":"https:')
#2.1子程序:找到主页面的源代码,找到iframe对应的url
def get_iframe_src(url):
resp=requests.get(url)
#print(resp.text) #测试是否正常爬取到源代码
#修改为正则爬取,这里提取完之后就是第一层的m3u8地址了
content=resp.text #把源代码变成text格式存储起来,用来提取
main_page=obj1.finditer(content)
for it in main_page:
#print(it.group('src'))
src_modify=it.group('src').replace('\\','')
#print(src_modify)
return src_modify #输出正确的第一层m3u8地址
resp.close()
#2.2、子程序:拿到第一层的m3u8文件下载地址;这一步只在课程里91看剧需要,实操的网址2.1里拿到的就是第一层m3u8了
def get_first_m3u8_url(url):
resp=requests.get(url)
#print(resp.text)
obj2=re.compile(r'var main=''(?P.*?)''')
m3u8_url=obj2.search(resp.text).group('m3u8_url') #这里是把m3u8地址提取出来
#print(m3u8_url)
resp.close()
return m3u8_url #让函数返回这一个地址
#2.3、子程序:下载第一层m3u8文件
def download_m3u8_file(url,name):
resp=requests.get(url)
with open(name,mode='wb')as f:
f.write(resp.content)
resp.close()
#2.5.1、子程序:异步协程进行下载
async def download_ts(url,name,session):
async with session.get(url)as resp:
async with aiofiles.open(f'4.9-video2/{name}',mode='wb')as f:
await f.write(await resp.content.read()) #把下载到的内容写入文件中
print(f'{name}下载完毕')
#2.5、子程序:异步协程处理拼接下载
#实操版
async def aio_download(up_url):
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'): #’#‘开头的行不要
continue
# line就是xxxx.ts文件
url = line.strip()
name1=line.rsplit('/',1)[1]
name=name1.strip()
task=asyncio.create_task(download_ts(url,name,session))
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
#2.6.1获取密钥
def get_key(url):
resp=requests.get(url)
print(resp.text)
a=resp.text
b=bytes(a,'utf-8')
return b
#2.6.2创建解密视频的任务
async def aio_dec(key):
#思路:解密,需要把下载的文件一个个打开;但是因为这里我们是直接用m3u8文件里后面的字符命名的
tasks=[]
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'):
continue
line1=line.rsplit('/',1)[1] #取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
#开始创建异步任务
task=asyncio.create_task(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
#2.6.3创建解密函数
async def dec_ts(name,key):
aes=AES.new(key=key,IV=b'0000000000000000',mode=AES.MODE_CBC)
async with aiofiles.open(f'4.9-video2/{name}',mode='rb')as f1,\
aiofiles.open(f'4.9-video2/temp_{name}',mode='wb')as f2:
bs=await f1.read() #从源文件读取文件
await f2.write(aes.decrypt(bs)) #把解密好的内容写入文件
print(f'{name}处理完毕')
#2.7合并视频为mp4
def merge_ts():
#mac:cat 1.ts 2.ts 3.ts > xxx.mp4
#windows:copy/b 1.ts+2.ts+3.ts > xxx.mp4
lst=[]
with open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
for line in f:
if line.startswith('#'):
continue
line1 = line.rsplit('/', 1)[1] # 取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
lst.append(f'4.9-video2/temp_{line}')
s=''.join(lst)
os.system(f'copy /b {s} >movie.mp4')
print('搞定!')
#2、主程序
def main(url):
#2.1、找到主页面的源代码,找到iframe对应的url
iframe_src=get_iframe_src(url)
#print(iframe_src)
#2.3下载第一层m3u8文件
download_m3u8_file(iframe_src,'4.93-抓取91看剧复杂版——first-m3u8.txt') #按照课程正常的话括号里的’iframe_src‘要改为2.2里的’first_m3u8_url_ture‘
#2.4下载第二层m3u8文件
with open('4.93-抓取91看剧复杂版——first-m3u8.txt',mode='r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'): #让程序识别文件里面时,自动跳过‘#’开头的行段
continue
else:
line=line.strip() #去掉空白或者换行符
#准备拼接第二层m3u8的下载路径
second_m3u8_url=iframe_src.split('/20210730')[0]+line
download_m3u8_file(second_m3u8_url,'4.93-抓取91看剧复杂版——second-m3u8.txt')
print('第二层m3u8下载完毕')
#2.5下载视频
#实操写法
up_url='开始'
#asyncio.run(aio_download(up_url)) #这个会报错:RuntimeError: Event loop is closed
loop=asyncio.get_event_loop()
loop.run_until_complete(aio_download(up_url))
#2.6.1拿到密钥
#实操
key_url='https://ts6.hhmm0.com:9999/20210730/QoNAXIDD/1000kb/hls/key.key'
key=get_key(key_url) #访问密匙的路径,拿到密匙
#2.6.2解密
asyncio.run(aio_dec(key))
#2.7合并ts文件为mp4文件
merge_ts()
#1、主程序调用处
if __name__=='__main__':
url='https://www.pianba.net/yun/84961-1-1/'
main(url)
网页抓取解密(WireSharkWireshark解密TLS数据流(图)数据解密(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-18 17:24
线鲨
Wireshark 解密 TLS 数据流。从网上现有的资料来看,主要有两种方式:一种是直接解密服务器的私钥,另一种是在握手过程中使用SSLKEYLOGFILE获取会话密钥信息进行解密。
此处仅尝试第二种方式来解密 TLS 数据。可用的应用程序包括:chrome、Firefox、curl。
首先将 SSLKEYLOGFILE 用户环境变量设置为自定义文件路径。例子:
或者在启动浏览器进程时附加参数--ssl-key-log-file=
.
测试开始,打开wireshark,访问,网页加载完成后退出浏览器,wireshark结束抓包。在目标路径中生成对应的密钥文件。然后在wireshark中,Edit -> Preferences -> Protocols -> TLS,可以添加RSA解密私钥、预共享密钥、主密钥。这只是使用(预)主密钥并导入先前生成的密钥文件。最后在主窗口查看,或者追踪TLS流,对应的数据已经解密。
提琴手
但通常在分析一些非浏览器进程时,对于使用HTTPS的,不需要看TCP数据,可以使用Fiddler(工作在应用层),将工具携带的证书导入虚拟机,然后然后在 fiddler Decrypt 选项中启用 https 进行解密。
参考:
(服务器密钥导入)
(SSLKEYLOGFILE)
(密钥导出和嵌入) 查看全部
网页抓取解密(WireSharkWireshark解密TLS数据流(图)数据解密(组图))
线鲨
Wireshark 解密 TLS 数据流。从网上现有的资料来看,主要有两种方式:一种是直接解密服务器的私钥,另一种是在握手过程中使用SSLKEYLOGFILE获取会话密钥信息进行解密。
此处仅尝试第二种方式来解密 TLS 数据。可用的应用程序包括:chrome、Firefox、curl。
首先将 SSLKEYLOGFILE 用户环境变量设置为自定义文件路径。例子:
或者在启动浏览器进程时附加参数--ssl-key-log-file=
.
测试开始,打开wireshark,访问,网页加载完成后退出浏览器,wireshark结束抓包。在目标路径中生成对应的密钥文件。然后在wireshark中,Edit -> Preferences -> Protocols -> TLS,可以添加RSA解密私钥、预共享密钥、主密钥。这只是使用(预)主密钥并导入先前生成的密钥文件。最后在主窗口查看,或者追踪TLS流,对应的数据已经解密。
提琴手
但通常在分析一些非浏览器进程时,对于使用HTTPS的,不需要看TCP数据,可以使用Fiddler(工作在应用层),将工具携带的证书导入虚拟机,然后然后在 fiddler Decrypt 选项中启用 https 进行解密。
参考:
(服务器密钥导入)
(SSLKEYLOGFILE)
(密钥导出和嵌入)
网页抓取解密(【每日一题】高产量博主,点个关注不迷路!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-18 17:21
PS高收益博主,点击不要迷路!
内容
一、实战需要的确定
本次实战的主要目的是复习requests库的基本语法,同时介绍一些新的内容:登录界面的捕获方式、session的使用、隐藏域问题的解决方法、破解验证码的方法等
要求如下:首先,我们可以打开古诗词网站:
接线以单击我的选项:
此时,我们需要登录才能看到个人下方的个人信息页面:
但是我们这次的实际需求是在不登录(绕过登录)的情况下获取个人页面的源码信息。
二、抓取古诗词网站的登录界面
确定需求后,可以简单分析一下我们的实现思路:首先,我们需要抓取相关的登录接口,然后将接口放入代码中,获取相关参数,匹配相关参数,达到绕过登录的目的。
所以迈出第一步:抓取固始文的登录界面:
1️⃣ 回到刚才的古诗文登录页面:
我们按 F12 解析网页:
这时候Network中Name列的第一项login.aspx就和我们需要的界面很相似了。但是,当我们查看它的具体内容时,我们发现这并不是一个真正的登录界面。有两个原因:
首先是因为我们的登录信息是放在输入文本框中的,所以接口应该是POST请求,而这个接口是GET请求;
二是我们在Headers中找不到相关的登录参数,比如用户名、密码和验证码。
所以获取登录界面有个小技巧:输入一组错误的用户名或者密码或者验证码,然后我们就可以在Network中找到真正的登录界面了:
在上述操作中,记得先按F12,然后不要关闭F12,而是输入一组错误信息,然后不要点击网页提示的OK按钮,否则界面会消失。
找到接口后,我们保存接口的url,同时点击Payload,查看POST请求的参数(部分谷歌浏览器版本的参数在Headers项下,其他版本在Payload中) :
至此,我们了解到有__VIEWSTATE、__VIEWSTATEGENERATOR、from、email、pwd、code、denglu这7个参数,而from、email、pwd、denglu这4个参数是已知的或固定的。其他四人不详。
三、难度分析
抓到接口和参数后,再来分析一下我们的难点:解决__VIEWSTATE、__VIEWSTATEGENERATOR、代码这三个参数。
前两个参数__VIEWSTATE、__VIEWSTATEGENERATOR是一种叫做隐藏域的技术手段,是一种反爬虫手段,我们需要一些方法来解决这两个参数。
最后一个参数码,验证码,需要我们采取一些必要的方法来解决(获取)。
四。隐藏域的解决方法
先解决隐域问题:
隐藏字段是什么意思?我们的 POST 请求提交的参数是由输入表单域发起的。因此,按照传统的思维方式,网页上所有的参数都应该有对应的输入文本框,但有些参数没有对应的输入文本框。这些参数是隐藏的,这类问题称为隐藏域问题。
隐藏域问题的一个常见解决方案是在页面的源代码中搜索参数的痕迹:
我们回到古时文的登录页面,按F12解析源码:
可以看到,当我们按Ctrl+f,分别输入__VIEWSTATE和__VIEWSTATEGENERATOR进行查询时,我们在它的源码中找到了这两个参数,这样这个参数问题就解决了。
五、验证码的破解方法:
最后,我们着手解决验证码的问题。在之前的实战中,这个问题是手动输入的。这次,我们将介绍另外两种方法:图像识别和编码平台破解。
VI 手动输入
首先回顾一下手动输入法。这个方法就是我们下载验证码对应的图片,然后在图片上看到验证码的内容,通过python输入函数读取验证码。
但是,这种方法并没有实现真正的自动化,所以我们探索了另外两种方法。
五、二图像识别
第二种方法是图像识别,描述如下:
首先,让我们安装图像识别所需的插件和库:
1️⃣ 下载插件:Tesseract-OCR,放到任意目录下(不过记住这个位置,后面会用到),这里是Tesseract-OCR的下载链接(提取码:dxzj)
2️⃣ 安装 pytesseract 和 Pillow 库。
首先查看你的python解释器的路径,找到里面的Scripts文件夹,打开终端,使用终端进入这个文件夹:
执行安装说明:
pip install pytesseract
pip install Pillow
之后,我们一步之遥:修改pytesseract.py文件中的一行代码:
首先我们找到pytesseract.py文件:它的路径在python安装目录下的lib文件夹中的set-packages文件夹中,进入set-packages文件夹,找到一个叫pytesseract的文件夹,里面收录pytesseract.py文件。
打开这个文件,将红圈内那行代码的内容替换为刚安装Tesseract-OCR的安装路径(定位到tesseract.exe)
最后,我们可以在代码中成功导入图像识别库,并调用相关代码进行图像识别:
from PIL import Image
import pytesseract
text = pytesseract.image_to_string(Image.open(r'demo.png'))
print(text)
在识别图片的时候,我们直接复制上面的代码,将Image.open函数替换为对应图片的路径即可。
V.III编码平台:Super Eagle编码
最后一种方法是使用编码平台。我们以 Super Eagle 编码为例:
我们进入它的官网,点击开发文档,选择python:
然后点击下载:
之后,将下载一个压缩包。我们只需要一个名为 chaojiying.py 的文件:
如果懒得按上面的步骤,可以直接点击我的分享链接下载chaojiying.py文件(提取码:dxzj)
然后我们打开py文件,滑到最下面, if__name=='__main': 这是我们需要自己修改的部分(其他内容不要改!!!):
这部分,首先我们需要在print函数中加一个括号,改成print(),然后我们观察这部分代码,有两个地方需要自定义:im和chaojiying.PostPic()两个部分:
在im这部分,我们可以传入需要识别的图片路径;
PostPic()函数的第一个参数是im,第二个参数需要在我们自己的超级鹰平台账号下获取:
我们回到超级鹰官网,注册一个自己的账号,然后进入我们的账号:
选择软件ID:
之后,我们点击生成软件ID,填写信息,随便选择一个名字,表示不需要填写,然后点击提交。
然后就可以看到我们刚刚创建的软件ID值了:
此时,我们可以将这个id作为参数传递给刚才的chaojiying.PostPic()函数作为第二个参数。
补充:这个时候我们还不能真正认出形象,原因是我们没钱,可以这样充值:
以学习为目的,我们选择其他金额,充值1元玩。
在这个页面可以看到我们的充值金额和充值标准:验证码类型和价目表-超级鹰验证码识别
六、完整的源代码
最后附上本次实战源码:
import requests
# 登录页面的url接口地址
url = 'https://so.gushiwen.cn/user/lo ... 39%3B
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
response = requests.get(url = url,headers = headers)
content = response.text
# print(content)
# 解析源码,获取__VIEWSTATE __VIEWSTATEGENERATOR
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取 __VIEWSTATE 的value值
__VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR的value属性值
__VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print(__VIEWSTATEGENERATOR)
print(__VIEWSTATE)
# 获取验证码的图片
basic_url = 'https://so.gushiwen.cn'
code_url = basic_url + soup.select('#imgCode')[0].attrs.get('src')
# session:验证码的一致性,requests库里有一个session方法,
# session的返回值,能够使请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 此时要使用二进制数据,因为我们要使用的是图片的下载,图片转二进制下载
content_code = response_code.content
# wb的模式是将二进制数据写入文件
with open('code.jpg','wb') as fp:
fp.write(content_code)
# 获取验证码的图片,下载到本地,观察它的内容:
# 控制台,输入验证码:
code_name = input('请输入你的验证码:')
#
# 点击登录
url_post = 'https://so.gushiwen.cn/user/lo ... 39%3B
data_post = {
'__VIEWSTATE' : __VIEWSTATE,
'__VIEWSTATEGENERATOR' : __VIEWSTATEGENERATOR,
'from' : 'http://so.gushiwen.cn/user/collect.aspx',
'email': 'Lobster_Jian_Lang@163.com',
'pwd': 'ljl010802',
'code': code_name,
'denglu': '登录'
}
response_post = session.post(url = url_post,headers = headers,data = data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding = 'utf-8') as fp:
fp.write(content_post)
# 第二种验证码方式:图像识别
# from PIL import Image
# import pytesseract
#
# code_name = pytesseract.image_to_string(Image.open(r'code.jpg'))
以上就是本次实战的完整博文! 查看全部
网页抓取解密(【每日一题】高产量博主,点个关注不迷路!)
PS高收益博主,点击不要迷路!
内容
一、实战需要的确定
本次实战的主要目的是复习requests库的基本语法,同时介绍一些新的内容:登录界面的捕获方式、session的使用、隐藏域问题的解决方法、破解验证码的方法等
要求如下:首先,我们可以打开古诗词网站:
接线以单击我的选项:
此时,我们需要登录才能看到个人下方的个人信息页面:
但是我们这次的实际需求是在不登录(绕过登录)的情况下获取个人页面的源码信息。
二、抓取古诗词网站的登录界面
确定需求后,可以简单分析一下我们的实现思路:首先,我们需要抓取相关的登录接口,然后将接口放入代码中,获取相关参数,匹配相关参数,达到绕过登录的目的。
所以迈出第一步:抓取固始文的登录界面:
1️⃣ 回到刚才的古诗文登录页面:
我们按 F12 解析网页:
这时候Network中Name列的第一项login.aspx就和我们需要的界面很相似了。但是,当我们查看它的具体内容时,我们发现这并不是一个真正的登录界面。有两个原因:
首先是因为我们的登录信息是放在输入文本框中的,所以接口应该是POST请求,而这个接口是GET请求;
二是我们在Headers中找不到相关的登录参数,比如用户名、密码和验证码。
所以获取登录界面有个小技巧:输入一组错误的用户名或者密码或者验证码,然后我们就可以在Network中找到真正的登录界面了:
在上述操作中,记得先按F12,然后不要关闭F12,而是输入一组错误信息,然后不要点击网页提示的OK按钮,否则界面会消失。
找到接口后,我们保存接口的url,同时点击Payload,查看POST请求的参数(部分谷歌浏览器版本的参数在Headers项下,其他版本在Payload中) :
至此,我们了解到有__VIEWSTATE、__VIEWSTATEGENERATOR、from、email、pwd、code、denglu这7个参数,而from、email、pwd、denglu这4个参数是已知的或固定的。其他四人不详。
三、难度分析
抓到接口和参数后,再来分析一下我们的难点:解决__VIEWSTATE、__VIEWSTATEGENERATOR、代码这三个参数。
前两个参数__VIEWSTATE、__VIEWSTATEGENERATOR是一种叫做隐藏域的技术手段,是一种反爬虫手段,我们需要一些方法来解决这两个参数。
最后一个参数码,验证码,需要我们采取一些必要的方法来解决(获取)。
四。隐藏域的解决方法
先解决隐域问题:
隐藏字段是什么意思?我们的 POST 请求提交的参数是由输入表单域发起的。因此,按照传统的思维方式,网页上所有的参数都应该有对应的输入文本框,但有些参数没有对应的输入文本框。这些参数是隐藏的,这类问题称为隐藏域问题。
隐藏域问题的一个常见解决方案是在页面的源代码中搜索参数的痕迹:
我们回到古时文的登录页面,按F12解析源码:
可以看到,当我们按Ctrl+f,分别输入__VIEWSTATE和__VIEWSTATEGENERATOR进行查询时,我们在它的源码中找到了这两个参数,这样这个参数问题就解决了。
五、验证码的破解方法:
最后,我们着手解决验证码的问题。在之前的实战中,这个问题是手动输入的。这次,我们将介绍另外两种方法:图像识别和编码平台破解。
VI 手动输入
首先回顾一下手动输入法。这个方法就是我们下载验证码对应的图片,然后在图片上看到验证码的内容,通过python输入函数读取验证码。
但是,这种方法并没有实现真正的自动化,所以我们探索了另外两种方法。
五、二图像识别
第二种方法是图像识别,描述如下:
首先,让我们安装图像识别所需的插件和库:
1️⃣ 下载插件:Tesseract-OCR,放到任意目录下(不过记住这个位置,后面会用到),这里是Tesseract-OCR的下载链接(提取码:dxzj)
2️⃣ 安装 pytesseract 和 Pillow 库。
首先查看你的python解释器的路径,找到里面的Scripts文件夹,打开终端,使用终端进入这个文件夹:
执行安装说明:
pip install pytesseract
pip install Pillow
之后,我们一步之遥:修改pytesseract.py文件中的一行代码:
首先我们找到pytesseract.py文件:它的路径在python安装目录下的lib文件夹中的set-packages文件夹中,进入set-packages文件夹,找到一个叫pytesseract的文件夹,里面收录pytesseract.py文件。
打开这个文件,将红圈内那行代码的内容替换为刚安装Tesseract-OCR的安装路径(定位到tesseract.exe)
最后,我们可以在代码中成功导入图像识别库,并调用相关代码进行图像识别:
from PIL import Image
import pytesseract
text = pytesseract.image_to_string(Image.open(r'demo.png'))
print(text)
在识别图片的时候,我们直接复制上面的代码,将Image.open函数替换为对应图片的路径即可。
V.III编码平台:Super Eagle编码
最后一种方法是使用编码平台。我们以 Super Eagle 编码为例:
我们进入它的官网,点击开发文档,选择python:
然后点击下载:
之后,将下载一个压缩包。我们只需要一个名为 chaojiying.py 的文件:
如果懒得按上面的步骤,可以直接点击我的分享链接下载chaojiying.py文件(提取码:dxzj)
然后我们打开py文件,滑到最下面, if__name=='__main': 这是我们需要自己修改的部分(其他内容不要改!!!):
这部分,首先我们需要在print函数中加一个括号,改成print(),然后我们观察这部分代码,有两个地方需要自定义:im和chaojiying.PostPic()两个部分:
在im这部分,我们可以传入需要识别的图片路径;
PostPic()函数的第一个参数是im,第二个参数需要在我们自己的超级鹰平台账号下获取:
我们回到超级鹰官网,注册一个自己的账号,然后进入我们的账号:
选择软件ID:
之后,我们点击生成软件ID,填写信息,随便选择一个名字,表示不需要填写,然后点击提交。
然后就可以看到我们刚刚创建的软件ID值了:
此时,我们可以将这个id作为参数传递给刚才的chaojiying.PostPic()函数作为第二个参数。
补充:这个时候我们还不能真正认出形象,原因是我们没钱,可以这样充值:
以学习为目的,我们选择其他金额,充值1元玩。
在这个页面可以看到我们的充值金额和充值标准:验证码类型和价目表-超级鹰验证码识别
六、完整的源代码
最后附上本次实战源码:
import requests
# 登录页面的url接口地址
url = 'https://so.gushiwen.cn/user/lo ... 39%3B
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
response = requests.get(url = url,headers = headers)
content = response.text
# print(content)
# 解析源码,获取__VIEWSTATE __VIEWSTATEGENERATOR
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取 __VIEWSTATE 的value值
__VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR的value属性值
__VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print(__VIEWSTATEGENERATOR)
print(__VIEWSTATE)
# 获取验证码的图片
basic_url = 'https://so.gushiwen.cn'
code_url = basic_url + soup.select('#imgCode')[0].attrs.get('src')
# session:验证码的一致性,requests库里有一个session方法,
# session的返回值,能够使请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 此时要使用二进制数据,因为我们要使用的是图片的下载,图片转二进制下载
content_code = response_code.content
# wb的模式是将二进制数据写入文件
with open('code.jpg','wb') as fp:
fp.write(content_code)
# 获取验证码的图片,下载到本地,观察它的内容:
# 控制台,输入验证码:
code_name = input('请输入你的验证码:')
#
# 点击登录
url_post = 'https://so.gushiwen.cn/user/lo ... 39%3B
data_post = {
'__VIEWSTATE' : __VIEWSTATE,
'__VIEWSTATEGENERATOR' : __VIEWSTATEGENERATOR,
'from' : 'http://so.gushiwen.cn/user/collect.aspx',
'email': 'Lobster_Jian_Lang@163.com',
'pwd': 'ljl010802',
'code': code_name,
'denglu': '登录'
}
response_post = session.post(url = url_post,headers = headers,data = data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding = 'utf-8') as fp:
fp.write(content_post)
# 第二种验证码方式:图像识别
# from PIL import Image
# import pytesseract
#
# code_name = pytesseract.image_to_string(Image.open(r'code.jpg'))
以上就是本次实战的完整博文!
网页抓取解密(网页抓取解密的四种方式采集思路:预采集+异步获取使用采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-02-16 05:03
网页抓取解密的四种方式采集思路:预采集+异步获取使用采集器:可以直接获取网页并解析的网页抓取器。可以很好的控制网页抓取的速度。不能采集图片网页,必须保证图片可读;不能采集二维码网页,必须保证图片可读;不能采集大图片网页,必须保证图片可读;好的采集器,提供更多的自定义功能,如下午的灵异图片抓取,3d、城市地图抓取等。
话不多说,赶紧看教程!1.python+beautifulsoup=>我自己做的一个新标签页抓取工具2.python+bigquant=>通过分析500+个标签页,获取知网文献资料的实用分析工具3.python+tagul=>通过标签页抓取相关文献信息以及统计(图片、表格、公式、摘要)4.python+javascript=>实现前端按钮的自定义显示。
推荐我自己做的小工具:网站抓取+文献下载,工具采用beautifulsoup,可以迅速抓取网页中的所有内容;可以把抓取的图片保存到本地;一键进行源代码分析,可以看看::用tablet实现,爬虫全部放在这里,便于调试。
谢邀,是时候祭出我大bot了下载、安装都很简单,直接去网页复制,用buffer.buffer类去对图片进行加密,然后open调用就可以,没有效率上的要求,用openxml文件的常规方法就可以。还可以有一些很好用的插件,诸如typeof、readlines、xliffer、imagefilters、pig_postnames等等,你用过一些插件后就大概有数了。
个人经验的话,使用xml都还可以,如果要求效率高一点建议写好text之后include到list里面。前端这个就不建议用它做内容爬取这一块了。当然也可以在写网页的时候在text外再加个img元素啥的,总体来说不算太麻烦。 查看全部
网页抓取解密(网页抓取解密的四种方式采集思路:预采集+异步获取使用采集器)
网页抓取解密的四种方式采集思路:预采集+异步获取使用采集器:可以直接获取网页并解析的网页抓取器。可以很好的控制网页抓取的速度。不能采集图片网页,必须保证图片可读;不能采集二维码网页,必须保证图片可读;不能采集大图片网页,必须保证图片可读;好的采集器,提供更多的自定义功能,如下午的灵异图片抓取,3d、城市地图抓取等。
话不多说,赶紧看教程!1.python+beautifulsoup=>我自己做的一个新标签页抓取工具2.python+bigquant=>通过分析500+个标签页,获取知网文献资料的实用分析工具3.python+tagul=>通过标签页抓取相关文献信息以及统计(图片、表格、公式、摘要)4.python+javascript=>实现前端按钮的自定义显示。
推荐我自己做的小工具:网站抓取+文献下载,工具采用beautifulsoup,可以迅速抓取网页中的所有内容;可以把抓取的图片保存到本地;一键进行源代码分析,可以看看::用tablet实现,爬虫全部放在这里,便于调试。
谢邀,是时候祭出我大bot了下载、安装都很简单,直接去网页复制,用buffer.buffer类去对图片进行加密,然后open调用就可以,没有效率上的要求,用openxml文件的常规方法就可以。还可以有一些很好用的插件,诸如typeof、readlines、xliffer、imagefilters、pig_postnames等等,你用过一些插件后就大概有数了。
个人经验的话,使用xml都还可以,如果要求效率高一点建议写好text之后include到list里面。前端这个就不建议用它做内容爬取这一块了。当然也可以在写网页的时候在text外再加个img元素啥的,总体来说不算太麻烦。
网页抓取解密(网页抓取解密centos6环境的图片拼接jpg脚本主流的前端开发框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-15 21:03
网页抓取解密centos6环境的图片url拼接jpg脚本主流的前端开发框架浏览器端登录/注册帐号/填写表单selenium模拟登录用户名密码验证码获取返回的json数据抓取地址和方法github上有一篇讲解这个的,有不懂的自己动手贴一个,
这段时间在做安卓平台的抓包工作,可能会将对比大家的某些疑问。本人在csdn的一个源码编辑群里分享过一个模拟登录效果,由于要每天登录一次,所以模拟的时候就要用到nethog这个免费webpack插件。由于这个插件不能从代码里获取真实登录页面,所以我们需要用到另一个应用,也就是apidot和bluetoothswitchyshader。
由于webpack的强大后期开发,我们可以非常方便的开发一个应用,但是绝对不可能只有少量基础代码,而是数以万计的逻辑代码加上去,其体积和逻辑可读性,肯定是不能忍受的。所以为了避免造成大量的重复代码,才会有了所谓的webpack开发。现在业界主流的解决方案基本都是使用webpack,而代码分析这些webpack的命令行以及相关插件都不是很友好,最重要的是没有css预处理器,效率也不够,那么如何解决这些问题呢?首先我们需要对模拟登录环境做一个分析,我这里把它比作像debug编程一样。
因为所有的应用首先都是用来seek用户的,而不是cookie,我们的首要目标就是先登录成功,然后才能分析。应用seek首先我们在chrome的开发者工具中按下f12按钮进入调试模式(注意:开发者工具菜单是快捷键ctrl+f),进入调试模式时应该首先能看到界面右下角多了个调试工具按钮,点击按钮可以调用apidot来获取调试工具的默认api,就是我们之前提到的链接chrome,再按下f12按钮进入debug调试模式然后再次进入调试工具(比如chrome就是f12),如下图从debug调试模式进入debuginputurlapidot这里我在打包工具uglifyjs里添加了条件判断,表示如果要监听到cookie那么此时access-control-allow-origin要加上;cookie'user_agent'=cookie_name;expires=access-control-allow-origin;email=access-control-allow-origin;这里要记住的一点是,我这里的设置里最后的expires=access-control-allow-origin,如果要收到cookie,需要替换为access-control-allow-origin.你在debug模式进入debuginputurl的那个快捷键里也应该能看到这样的一行代码。
然后我们可以进入我们开发的脚本里,找到我们要抓取的api地址(相对于apidot),在js里我们的发现它是对json内容做判断,从而找到登录的按钮。 查看全部
网页抓取解密(网页抓取解密centos6环境的图片拼接jpg脚本主流的前端开发框架)
网页抓取解密centos6环境的图片url拼接jpg脚本主流的前端开发框架浏览器端登录/注册帐号/填写表单selenium模拟登录用户名密码验证码获取返回的json数据抓取地址和方法github上有一篇讲解这个的,有不懂的自己动手贴一个,
这段时间在做安卓平台的抓包工作,可能会将对比大家的某些疑问。本人在csdn的一个源码编辑群里分享过一个模拟登录效果,由于要每天登录一次,所以模拟的时候就要用到nethog这个免费webpack插件。由于这个插件不能从代码里获取真实登录页面,所以我们需要用到另一个应用,也就是apidot和bluetoothswitchyshader。
由于webpack的强大后期开发,我们可以非常方便的开发一个应用,但是绝对不可能只有少量基础代码,而是数以万计的逻辑代码加上去,其体积和逻辑可读性,肯定是不能忍受的。所以为了避免造成大量的重复代码,才会有了所谓的webpack开发。现在业界主流的解决方案基本都是使用webpack,而代码分析这些webpack的命令行以及相关插件都不是很友好,最重要的是没有css预处理器,效率也不够,那么如何解决这些问题呢?首先我们需要对模拟登录环境做一个分析,我这里把它比作像debug编程一样。
因为所有的应用首先都是用来seek用户的,而不是cookie,我们的首要目标就是先登录成功,然后才能分析。应用seek首先我们在chrome的开发者工具中按下f12按钮进入调试模式(注意:开发者工具菜单是快捷键ctrl+f),进入调试模式时应该首先能看到界面右下角多了个调试工具按钮,点击按钮可以调用apidot来获取调试工具的默认api,就是我们之前提到的链接chrome,再按下f12按钮进入debug调试模式然后再次进入调试工具(比如chrome就是f12),如下图从debug调试模式进入debuginputurlapidot这里我在打包工具uglifyjs里添加了条件判断,表示如果要监听到cookie那么此时access-control-allow-origin要加上;cookie'user_agent'=cookie_name;expires=access-control-allow-origin;email=access-control-allow-origin;这里要记住的一点是,我这里的设置里最后的expires=access-control-allow-origin,如果要收到cookie,需要替换为access-control-allow-origin.你在debug模式进入debuginputurl的那个快捷键里也应该能看到这样的一行代码。
然后我们可以进入我们开发的脚本里,找到我们要抓取的api地址(相对于apidot),在js里我们的发现它是对json内容做判断,从而找到登录的按钮。
网页抓取解密(网页抓取解密网站数据使用思科javaweb第三方调试工具演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-12 23:04
网页抓取解密网站数据使用思科javaweb后端工具演示web仿冒网站抓取,字符数据以及文件视频仿冒网站爬取思科第三方调试工具演示[java/python]如何使用node。js在思科后端服务器部署ssl证书演示:思科javaweb后端工具演示ssdbweb端数据抓取web仿冒网站爬取思科第三方调试工具演示sam_bit。
io-xss|python爬取bittorrent磁力资源思科第三方调试工具演示powerdesigner-svg|python抓取网页文本演示:演示:myfoxcomputer。js使用思科javaweb工具演示powerdesigner使用cmd在bash命令提示符下运行batbiomelip。py,整个bat文件在本地命令提示符下执行powerdesigner-master-start-bash,可以看到可执行文件的路径及执行结果,如下:使用powerdesigner-master-start-bash运行完毕后batbing进程执行javaweb-no-gcc--std=c++11。
指定工作目录下工程构建后会生成一个名为repository。java。web。notepad。txt的文件,打开本地路径下repository。java。web。notepad。txt文件,如下:我们如下步骤再运行下面的命令:命令运行完毕后batbing进程会生成一个名为xxx。jar的txt文件(txt为java虚拟机解释器用户自定义代码),如下:java/open/repository。
java文件,如下:因为txt会在java解释器解释执行的时候在本地解释执行,所以java命令在解释执行的时候我们可以通过cat命令打印一行代码,如下:if(java_home!==null){java_jar_bin[]bin=newjava_jar_bin[]{repository。java_bin};language=language;exported_bytes_resource_dir=repository。
java_bin;}java/open/repository。java文件,如下:但是此处存在一个坑,就是java_jar_bin[]bin=newjava_jar_bin[]{repository。java_bin};是对java后缀文件的引用对repository。java_bin[]{repository。
java_bin}命令即newjava_jar_bin[]{repository。java_bin}对repository。java_bin[]{repository。java_bin}java_ext_requirement_system{code_type}我们可以看到这句执行java_ext_requirement_system字符串会抛出java_ext_requirement_system的异常,我们运行下面命令查看是否存在该异常:[error]file"/etc/apache2/apache2/webapache2。tar。gz"unpacked;这个j。 查看全部
网页抓取解密(网页抓取解密网站数据使用思科javaweb第三方调试工具演示)
网页抓取解密网站数据使用思科javaweb后端工具演示web仿冒网站抓取,字符数据以及文件视频仿冒网站爬取思科第三方调试工具演示[java/python]如何使用node。js在思科后端服务器部署ssl证书演示:思科javaweb后端工具演示ssdbweb端数据抓取web仿冒网站爬取思科第三方调试工具演示sam_bit。
io-xss|python爬取bittorrent磁力资源思科第三方调试工具演示powerdesigner-svg|python抓取网页文本演示:演示:myfoxcomputer。js使用思科javaweb工具演示powerdesigner使用cmd在bash命令提示符下运行batbiomelip。py,整个bat文件在本地命令提示符下执行powerdesigner-master-start-bash,可以看到可执行文件的路径及执行结果,如下:使用powerdesigner-master-start-bash运行完毕后batbing进程执行javaweb-no-gcc--std=c++11。
指定工作目录下工程构建后会生成一个名为repository。java。web。notepad。txt的文件,打开本地路径下repository。java。web。notepad。txt文件,如下:我们如下步骤再运行下面的命令:命令运行完毕后batbing进程会生成一个名为xxx。jar的txt文件(txt为java虚拟机解释器用户自定义代码),如下:java/open/repository。
java文件,如下:因为txt会在java解释器解释执行的时候在本地解释执行,所以java命令在解释执行的时候我们可以通过cat命令打印一行代码,如下:if(java_home!==null){java_jar_bin[]bin=newjava_jar_bin[]{repository。java_bin};language=language;exported_bytes_resource_dir=repository。
java_bin;}java/open/repository。java文件,如下:但是此处存在一个坑,就是java_jar_bin[]bin=newjava_jar_bin[]{repository。java_bin};是对java后缀文件的引用对repository。java_bin[]{repository。
java_bin}命令即newjava_jar_bin[]{repository。java_bin}对repository。java_bin[]{repository。java_bin}java_ext_requirement_system{code_type}我们可以看到这句执行java_ext_requirement_system字符串会抛出java_ext_requirement_system的异常,我们运行下面命令查看是否存在该异常:[error]file"/etc/apache2/apache2/webapache2。tar。gz"unpacked;这个j。
网页抓取解密(常用的获取网页数据的方式2.1URLlib:未经本人允许,禁止转载! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-12 21:09
)
大家好,我不温不火,我是计算机学院大数据专业的三年级学生。我的绰号来自成语——不冷不热,意思是希望我有一个温柔的气质。博主作为互联网行业的新手,写博客一方面是为了记录自己的学习过程,另一方面是总结自己的错误,希望能帮助很多和自己一样处于起步阶段的新人。不过由于水平有限,博客难免会出现一些错误。如果有任何错误,请给我您的建议!暂时只在csdn平台更新,博客主页:.
PS:由于越来越多的人未经本人同意直接爬博主文章,博主特此声明:未经本人允许,禁止转载!!!
内容
前言
网络爬虫的一般流程
一、理解 URL
基本 URL 收录以下内容:
模式(或协议)、服务器名称(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整 URI 语法如下所示:protocol://username:password@subdomain。域名。顶级域名:端口号/目录/文件名.filesuffix?parameter=value#sign。
例如:
二、获取网页数据的常用方法2.1 URLlib
这里我们先看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com")
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣可以自己查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout:释放链接的超时时间
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
上下文:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None)
代码详情:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 的高级特性
urllib.request 几乎可以在任何 HTTP 请求中执行所有操作:
4、开瓶器
开场导演:
5、cookies
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、请求库
Requests 是基于 urllib 的 python 编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。Requests 相比 urllib 更方便,可以为我们省去很多工作。建议爬虫使用 Requests 库。
官方文档链接:
1、请求库安装
在终端中运行以下命令: pip install requests
2、使用requests发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])
从上图中我们可以看出,方法名很清楚的表达了发起的请求,get就是GET,post就是POST。不仅如此,我们的response非常强大,可以直接获取很多信息,而且response中的内容不是一次性的,requests会自动读取response的内容并保存在text变量中,读取你想要多少次。接下来,让我们看看响应中有哪些有用的信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然
除了上述信息之外,响应中还提供了很多其他信息。另外,请求除了get和post之外,还提供了显式的put、delete、head、options方法,对应着相应的HTTP方法。有兴趣的读者可以进一步探索。
3、Requests 库发起 POST 请求
这部分摘自官方文档:
通常,如果您希望发送一些表单编码的数据 - 非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动进行表单编码:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data参数也可以对每个key有多个值。这可以通过创建数据元组列表或列表值字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/se ... %2339;)
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大部分用法与 urllib2 类似。此外,请求的文档非常完整。这里主要讲解request最强大、最常用的功能:会话持久化。在上面的代码中,我们连续发起的两个请求是不相关的,这会导致一些数据不可用。喜欢:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set ... 39%3B
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
可以看到,调用url_set_cookies设置cookie前后发起的GET请求获取的cookie都是空的。这意味着不同请求之间没有关系。有些人可能会对上面代码中第 5 行的输出感到惊讶,因为在上一篇 文章 我们用 urllib2 发出同样的请求时,结果仍然是空的。这确实有点奇怪,因为 urllib2 默认忽略所有请求的 cookie,即使是重定向请求,并且请求会在请求中保存 cookie(url_set_cookies 请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
我们现在可以看到我们的第三个请求收录了第二个请求设置的 cookie!是不是很简单。其实cookielib也是用来把cookie保存在request里面的,有兴趣的同学可以深入探索一下。
请求库的特点:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set ... 39%3B
proxies = {'http':'http://username:password@host:port','http://username:password@host:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
上面的代码当然不会工作,因为代理格式不正确。当我们需要它时,我们可以直接重用这段代码。你可能会认为之前所有使用 urllib2 的练习都是徒劳的,因为请求非常容易学习!当然没有白费,urllib2是一个很基础的网络库,其他很多网络库,包括request都是基于urllib2开发的。前面的练习将帮助我们更好地理解网络,了解Python是如何处理网络的,这对我们以后开发可靠高效的爬虫大有裨益。
必须注意的是:
响应中的内容以 unicode 编码。为了方便阅读,我们需要将其转换成中文。直接打印是不行的,因为Python在将dict转成字符串时保留了unicide编码,所以直接打印不是中文。
这里我们使用另一种转换方式:先将得到的表单dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符不转义),再将得到的unicode字符串编码成UTF-8字符串,最后转换为 dict 以便于输出。
三、浏览器简介
Chrome 提供了一种检查网页元素的功能,称为 Chrome Inspect。该功能可以在网页上右击查看,如下图所示:
在这个页面调出 Chrome Inspect,我们可以看到类似下面的界面:
通常我们最常用的功能是查看一个元素的源代码。单击左上角的元素定位器可以选择网页中的不同元素。HTML源代码区会自动显示指定元素的源代码,通常CSS显示区也会显示这个应用于元素的样式。Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择Network,可以看到如下界面:
Chrome 网络的交互区域展示了一个网页加载过程,浏览器发出的所有请求。选择一个请求,右侧会显示该请求的详细信息,包括请求头、响应头、响应内容等。Chrome Network是我们研究网页交互流程的重要工具。Cookie 和会话是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用程序,看到如下界面:
在Chrome应用左侧选择Cookies,可以看到以KV形式保存的cookies。当我们研究网页的登录过程时,这个功能非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,点击清除,清除所有旧的Cookies。
HTTP 响应的第一行,即状态行,收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx :信息响应类,表示收到请求,继续处理
2xx:处理成功响应类,表示动作成功接收、理解、响应
3xx : 重定向响应类,必须做进一步处理才能完成指定动作
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态码及其说明:
200 OK:请求已被处理并正确响应。
301 Move Permanently:永久重定向。
302 临时移动:临时重定向。
400 Bad Request:服务器不理解请求。
401 Authentication Required :需要用户验证。
403 Forbidden:禁止访问资源。
404 Not Found:找不到资源。
405 Method Not Allowed:资源使用了错误的方法,例如应该使用POST,但使用了PUT。
408 Request Timeout :请求超时。
500 内部服务器错误:内部服务器错误。
501 Method Not Implemented:请求方法无效,如果可能,将GET写成Get。
502 Bad Gateway : 网关或代理收到上游服务器的错误响应。
503 Service Unavailable :服务暂时不可用,您可以稍后尝试。
504 Gateway Timeout:网关或代理对上游服务器的请求超时。
在实际应用中,大部分网站都有反爬策略,响应状态码代表服务器的处理结果,是我们调整爬取状态(如频率、ip)的重要参考履带式。比如我们一直正常运行的爬虫突然得到403响应,很可能是服务器识别到了我们的爬虫,拒绝了我们的请求。这时候我们就需要放慢爬取频率,或者重启会话,甚至更换IP。
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
一本好书读一百遍也不厌烦,熟了课才知道自己。而如果我想成为观众中最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证我的成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“采集”!听说喜欢的人不会倒霉的,每天都精神抖擞!如果你真的想白嫖,那么祝你天天快乐,也欢迎经常光顾我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!
查看全部
网页抓取解密(常用的获取网页数据的方式2.1URLlib:未经本人允许,禁止转载!
)
大家好,我不温不火,我是计算机学院大数据专业的三年级学生。我的绰号来自成语——不冷不热,意思是希望我有一个温柔的气质。博主作为互联网行业的新手,写博客一方面是为了记录自己的学习过程,另一方面是总结自己的错误,希望能帮助很多和自己一样处于起步阶段的新人。不过由于水平有限,博客难免会出现一些错误。如果有任何错误,请给我您的建议!暂时只在csdn平台更新,博客主页:.
PS:由于越来越多的人未经本人同意直接爬博主文章,博主特此声明:未经本人允许,禁止转载!!!
内容
前言
网络爬虫的一般流程
一、理解 URL
基本 URL 收录以下内容:
模式(或协议)、服务器名称(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整 URI 语法如下所示:protocol://username:password@subdomain。域名。顶级域名:端口号/目录/文件名.filesuffix?parameter=value#sign。
例如:
二、获取网页数据的常用方法2.1 URLlib
这里我们先看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com";)
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣可以自己查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout:释放链接的超时时间
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
上下文:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None)
代码详情:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 的高级特性
urllib.request 几乎可以在任何 HTTP 请求中执行所有操作:
4、开瓶器
开场导演:
5、cookies
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com";)
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、请求库
Requests 是基于 urllib 的 python 编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。Requests 相比 urllib 更方便,可以为我们省去很多工作。建议爬虫使用 Requests 库。
官方文档链接:
1、请求库安装
在终端中运行以下命令: pip install requests
2、使用requests发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])
从上图中我们可以看出,方法名很清楚的表达了发起的请求,get就是GET,post就是POST。不仅如此,我们的response非常强大,可以直接获取很多信息,而且response中的内容不是一次性的,requests会自动读取response的内容并保存在text变量中,读取你想要多少次。接下来,让我们看看响应中有哪些有用的信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然
除了上述信息之外,响应中还提供了很多其他信息。另外,请求除了get和post之外,还提供了显式的put、delete、head、options方法,对应着相应的HTTP方法。有兴趣的读者可以进一步探索。
3、Requests 库发起 POST 请求
这部分摘自官方文档:
通常,如果您希望发送一些表单编码的数据 - 非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动进行表单编码:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data参数也可以对每个key有多个值。这可以通过创建数据元组列表或列表值字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/se ... %2339;)
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大部分用法与 urllib2 类似。此外,请求的文档非常完整。这里主要讲解request最强大、最常用的功能:会话持久化。在上面的代码中,我们连续发起的两个请求是不相关的,这会导致一些数据不可用。喜欢:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set ... 39%3B
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
可以看到,调用url_set_cookies设置cookie前后发起的GET请求获取的cookie都是空的。这意味着不同请求之间没有关系。有些人可能会对上面代码中第 5 行的输出感到惊讶,因为在上一篇 文章 我们用 urllib2 发出同样的请求时,结果仍然是空的。这确实有点奇怪,因为 urllib2 默认忽略所有请求的 cookie,即使是重定向请求,并且请求会在请求中保存 cookie(url_set_cookies 请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
我们现在可以看到我们的第三个请求收录了第二个请求设置的 cookie!是不是很简单。其实cookielib也是用来把cookie保存在request里面的,有兴趣的同学可以深入探索一下。
请求库的特点:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set ... 39%3B
proxies = {'http':'http://username:password@host:port','http://username:password@host:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
上面的代码当然不会工作,因为代理格式不正确。当我们需要它时,我们可以直接重用这段代码。你可能会认为之前所有使用 urllib2 的练习都是徒劳的,因为请求非常容易学习!当然没有白费,urllib2是一个很基础的网络库,其他很多网络库,包括request都是基于urllib2开发的。前面的练习将帮助我们更好地理解网络,了解Python是如何处理网络的,这对我们以后开发可靠高效的爬虫大有裨益。
必须注意的是:
响应中的内容以 unicode 编码。为了方便阅读,我们需要将其转换成中文。直接打印是不行的,因为Python在将dict转成字符串时保留了unicide编码,所以直接打印不是中文。
这里我们使用另一种转换方式:先将得到的表单dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符不转义),再将得到的unicode字符串编码成UTF-8字符串,最后转换为 dict 以便于输出。
三、浏览器简介
Chrome 提供了一种检查网页元素的功能,称为 Chrome Inspect。该功能可以在网页上右击查看,如下图所示:
在这个页面调出 Chrome Inspect,我们可以看到类似下面的界面:
通常我们最常用的功能是查看一个元素的源代码。单击左上角的元素定位器可以选择网页中的不同元素。HTML源代码区会自动显示指定元素的源代码,通常CSS显示区也会显示这个应用于元素的样式。Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择Network,可以看到如下界面:
Chrome 网络的交互区域展示了一个网页加载过程,浏览器发出的所有请求。选择一个请求,右侧会显示该请求的详细信息,包括请求头、响应头、响应内容等。Chrome Network是我们研究网页交互流程的重要工具。Cookie 和会话是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用程序,看到如下界面:
在Chrome应用左侧选择Cookies,可以看到以KV形式保存的cookies。当我们研究网页的登录过程时,这个功能非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,点击清除,清除所有旧的Cookies。
HTTP 响应的第一行,即状态行,收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx :信息响应类,表示收到请求,继续处理
2xx:处理成功响应类,表示动作成功接收、理解、响应
3xx : 重定向响应类,必须做进一步处理才能完成指定动作
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态码及其说明:
200 OK:请求已被处理并正确响应。
301 Move Permanently:永久重定向。
302 临时移动:临时重定向。
400 Bad Request:服务器不理解请求。
401 Authentication Required :需要用户验证。
403 Forbidden:禁止访问资源。
404 Not Found:找不到资源。
405 Method Not Allowed:资源使用了错误的方法,例如应该使用POST,但使用了PUT。
408 Request Timeout :请求超时。
500 内部服务器错误:内部服务器错误。
501 Method Not Implemented:请求方法无效,如果可能,将GET写成Get。
502 Bad Gateway : 网关或代理收到上游服务器的错误响应。
503 Service Unavailable :服务暂时不可用,您可以稍后尝试。
504 Gateway Timeout:网关或代理对上游服务器的请求超时。
在实际应用中,大部分网站都有反爬策略,响应状态码代表服务器的处理结果,是我们调整爬取状态(如频率、ip)的重要参考履带式。比如我们一直正常运行的爬虫突然得到403响应,很可能是服务器识别到了我们的爬虫,拒绝了我们的请求。这时候我们就需要放慢爬取频率,或者重启会话,甚至更换IP。
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
一本好书读一百遍也不厌烦,熟了课才知道自己。而如果我想成为观众中最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证我的成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“采集”!听说喜欢的人不会倒霉的,每天都精神抖擞!如果你真的想白嫖,那么祝你天天快乐,也欢迎经常光顾我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!
网页抓取解密(一下Python简明教程(二):如何抓取相关的网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-12 21:08
)
需要从网上爬取相关网页。我只想学习Python。首先,我阅读了一个简洁的 Python 教程。它涵盖的内容不多,但可以帮助您快速入门。我一直认为实例驱动的学习是最有效的方法。因此,直接通过如何爬网的实际操作来丰富Python的学习效果会更好。
Python 提供了各种库,使各种操作非常方便。这里使用 Python 的 urllib2 和 sgmllib 库。对于HTML的处理,Python一共提供了三个模块:sgmllib htmllibHTMLParser。本文使用的是sgmllib,但是通过查找相关资料,发现第三方工具BeautifulSoup最好,可以处理较差的HTML。所以我们以后要学习BeautifulSoup。
(2)脚本代码
import urllib2
import sgmllib
class LinksParser(sgmllib.SGMLParser):
urls = []
def do_a(self, attrs):
for name, value in attrs:
if name == 'href' and value not in self.urls:
if value.startswith('http'):
self.urls.append(value)
print value
else:
continue
return
if __name__ == "__main__":
# str = ""
# if str.strip() is '':
# print "str is None"
# else:
# print "str is no None"
p = LinksParser()
f = urllib2.urlopen('http://www.baidu.com')
value = f.read()
print value
p.feed(value)
for url in p.urls:
print url
f.close()
p.close() 查看全部
网页抓取解密(一下Python简明教程(二):如何抓取相关的网页
)
需要从网上爬取相关网页。我只想学习Python。首先,我阅读了一个简洁的 Python 教程。它涵盖的内容不多,但可以帮助您快速入门。我一直认为实例驱动的学习是最有效的方法。因此,直接通过如何爬网的实际操作来丰富Python的学习效果会更好。
Python 提供了各种库,使各种操作非常方便。这里使用 Python 的 urllib2 和 sgmllib 库。对于HTML的处理,Python一共提供了三个模块:sgmllib htmllibHTMLParser。本文使用的是sgmllib,但是通过查找相关资料,发现第三方工具BeautifulSoup最好,可以处理较差的HTML。所以我们以后要学习BeautifulSoup。
(2)脚本代码
import urllib2
import sgmllib
class LinksParser(sgmllib.SGMLParser):
urls = []
def do_a(self, attrs):
for name, value in attrs:
if name == 'href' and value not in self.urls:
if value.startswith('http'):
self.urls.append(value)
print value
else:
continue
return
if __name__ == "__main__":
# str = ""
# if str.strip() is '':
# print "str is None"
# else:
# print "str is no None"
p = LinksParser()
f = urllib2.urlopen('http://www.baidu.com')
value = f.read()
print value
p.feed(value)
for url in p.urls:
print url
f.close()
p.close()
网页抓取解密(ScreamingFrogSEOSpider14破解版14破解安装教程下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-11 21:09
Screaming Frog SEO Spider 14 破解版是一款功能强大且非常好用的网站资源检测爬虫应用。它由一个菜单栏和多个显示各种信息的选项卡式窗格组成。它具有简单直观的操作界面,易于使用,其主要目的是为用户提供一种新的、简便的方式来采集有关任何固定站点的 SEO 信息。通过 Screaming Frog SEO Spider 14,用户不仅可以在不同的 网站 上抓取想要的内容。并且它还可以自动测试网页的性能并进行详细的网页分析,即使网页无法响应,您也可以轻松获得您想要的数据。而且Screaming Frog SEO Spider 14有专业的破解文件帮你完美激活软件,免费使用一系列功能如:查找断链、审核重定向,分析页面标题和元数据等。同时,软件还内置了一套完整的“用户指南”和一些常见问题解答,以确保每个高级用户和新手都可以轻松找到解决方案,而不会遇到任何问题问题!绝对是您检测 网站 和搜索网络资源的必备工具。欢迎有需要的朋友来3322软件站下载体验!
说明:本站提供《尖叫青蛙SEO蜘蛛14破解版》,附破解文件,可完美激活软件。它对个人测试有效。具体破解安装教程请参考以下,欢迎免费下载!
软件功能 1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义 robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看HTMLScreaming Frog SEO Spider 14破解安装教程1、从本站下载解压后,即可获得Screaming Frog SEO Spider 14源程序和破解文件
2、双击“ScreamingFrogSEOSpider-14.0.exe”文件运行,
点击Install进行安装,默认安装路径,安装类型
3、耐心等待软件安装完成,点击关闭退出
4、运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框
5、然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定
6、会弹出如下框,即安装激活成功,可以放心使用
7、以上为Screaming Frog SEO Spider 14破解安装教程,欢迎下载体验!
软件功能1、查找损坏的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以进行修复,或发送给开发人员
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成 XML 站点地图
通过 URL 快速创建具有高级配置的 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构
特别说明
提取码:2kem 查看全部
网页抓取解密(ScreamingFrogSEOSpider14破解版14破解安装教程下载)
Screaming Frog SEO Spider 14 破解版是一款功能强大且非常好用的网站资源检测爬虫应用。它由一个菜单栏和多个显示各种信息的选项卡式窗格组成。它具有简单直观的操作界面,易于使用,其主要目的是为用户提供一种新的、简便的方式来采集有关任何固定站点的 SEO 信息。通过 Screaming Frog SEO Spider 14,用户不仅可以在不同的 网站 上抓取想要的内容。并且它还可以自动测试网页的性能并进行详细的网页分析,即使网页无法响应,您也可以轻松获得您想要的数据。而且Screaming Frog SEO Spider 14有专业的破解文件帮你完美激活软件,免费使用一系列功能如:查找断链、审核重定向,分析页面标题和元数据等。同时,软件还内置了一套完整的“用户指南”和一些常见问题解答,以确保每个高级用户和新手都可以轻松找到解决方案,而不会遇到任何问题问题!绝对是您检测 网站 和搜索网络资源的必备工具。欢迎有需要的朋友来3322软件站下载体验!
说明:本站提供《尖叫青蛙SEO蜘蛛14破解版》,附破解文件,可完美激活软件。它对个人测试有效。具体破解安装教程请参考以下,欢迎免费下载!
软件功能 1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义 robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看HTMLScreaming Frog SEO Spider 14破解安装教程1、从本站下载解压后,即可获得Screaming Frog SEO Spider 14源程序和破解文件
2、双击“ScreamingFrogSEOSpider-14.0.exe”文件运行,
点击Install进行安装,默认安装路径,安装类型
3、耐心等待软件安装完成,点击关闭退出
4、运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框
5、然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定
6、会弹出如下框,即安装激活成功,可以放心使用
7、以上为Screaming Frog SEO Spider 14破解安装教程,欢迎下载体验!
软件功能1、查找损坏的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以进行修复,或发送给开发人员
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成 XML 站点地图
通过 URL 快速创建具有高级配置的 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构
特别说明
提取码:2kem
网页抓取解密(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-11 17:25
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。 查看全部
网页抓取解密(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
网页抓取解密(Python自动生成Markdown文件解决方案解决方案文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-11 13:23
写这个系列文章和相关的Python脚本,起源是我注意到网上有很多页面共享免费ss账号,但是这些账号的有效期只有几个小时或者几天。高效。
我的需求可以分解为几个自动化需求:
1.自动从多个网页抓取账户信息(每天大约80-110个);
2.自动测试以找到访问 google/twitter 延迟小于 5 秒的有效帐户,
3.自动更新有效账户信息到特定网页,
4.用户只需要运行update_config.pyc自动刷新本地gui-config.json文件并重启ss可执行文件,新配置生效。
所以,1-4 作为一个整体是一个自动化的解决方案。借助 Ss/SsR、Proxy 切换插件和 Pac 等组件,您可以观看 youtube。得益于这样的解决方案,我可以通过 YouTube 全程跟踪柯洁对 AlphaGo 的直播。
用于解决上述四个要求的技术:
1. 主要使用requests和lxml这两个模块来抓取账户信息,调用AutoSs。 AutoSs 依赖于许多模块。在树莓派上的Ubuntu操作系统上导入zbar会导致segmentation fault,所以我把AutoSs中的def get_ss_shad0ws0cks8(r)函数注释掉了,少抓了一个网站的账号信息,效果不大。
2.参考Shad0wS0cks免费账号和测试工具共享的SSAccount.py源码,修改、加固、记录测试结果,保存为txt文件和json文件
3. 我写了一个 Python 脚本来自动生成一个 Markdown 文件。这个Markdown文件是一个Blog,包括账号信息、github等。网站支持jekyll模式静态网站,关键是Free,上传更新网站其实就是git同步这个Blog( Markdown 文件)到 github网站.
4. 用户运行的update_config.pyc使用requests和lxml模块获取Blog网页的账号信息,使用json模块读取gui-config.json的内容,修改内容gui-config.json,然后使用python的os.system()调用OS命令重启Shad0ws0cks客户端。
如果你只是自己使用它,它不需要那么复杂。 1-4 实际上形成了一个共享免费帐户的计划。
真正牛B的开源项目是这个,jlund/streisand
" xxxxxx 设置运行 L2TP/IPsec、OpenConnect、OpenSSH、OpenVPN、Shad0ws0cks、......和 WireGuard 的新服务器。它还为所有这些服务生成自定义指令。在运行结束时您将获得一个 HTML 文件,其中收录可以与朋友、家人和其他活动家共享的说明。"
待续
免费账号信息ssr url解码
入门:使用 Python 在 Web 上抓取免费帐户(一) - 知乎专栏
AutoSs开源项目介绍
入门:使用 Python 在 Web 上抓取免费帐户(二) - 知乎专栏
ssa.py程序运行效果
入门:使用 Python 抓取网络上的免费帐户(三) - 知乎column
ssa.py自动测试免费账号程序的由来
入门:使用 Python 在 Web 上抓取免费帐户(四) - 知乎专栏
update_config.py 使用示例
入门:使用 Python 在 Web 上抓取免费帐户(五) - 知乎专栏
用于读写 gui-config.json 和重启 Shad0ws0cks 客户端的示例代码
入门:使用 Python 在 Web 上抓取免费帐户(六) - 知乎专栏
获取免费账户、测试免费账户、分发免费账户的完整解决方案
入门:使用 Python 抓取网络上的免费帐户(七) - 知乎column
update_config.py自动更新免费账号脚本介绍
入门:使用 Python 抓取网络上的免费帐户(八) - 知乎column
Mac OS X 上的客户端 Shad0ws0cksX._NG 使用 plist 格式的配置文件,而不是 json 格式的配置文件。可以使用脚本自动更新账户信息吗?
入门:使用 Python 在 Web 上抓取免费帐户(九) - 知乎专栏
如何快速将收录免费账号的json文件合并到当前ss客户端的gui-config.json配置文件中
入门:使用 Python 抓取网络上的免费帐户(十) - 知乎column
使用update_config.pyc脚本需要满足的条件和软件安装指南
入门:使用 Python 在网页上抓取免费帐户(一) - 知乎专栏
Mac OS X Shad0ws0cks客户端plist配置文件转换成的json文件长这样
入门:使用 Python 在网页上抓取免费帐户(B) - 知乎专栏
Update_config.pyc整体方案介绍
入门:使用 Python (C) 在网页上抓取免费帐户 - 知乎专栏 查看全部
网页抓取解密(Python自动生成Markdown文件解决方案解决方案文件)
写这个系列文章和相关的Python脚本,起源是我注意到网上有很多页面共享免费ss账号,但是这些账号的有效期只有几个小时或者几天。高效。
我的需求可以分解为几个自动化需求:
1.自动从多个网页抓取账户信息(每天大约80-110个);
2.自动测试以找到访问 google/twitter 延迟小于 5 秒的有效帐户,
3.自动更新有效账户信息到特定网页,
4.用户只需要运行update_config.pyc自动刷新本地gui-config.json文件并重启ss可执行文件,新配置生效。
所以,1-4 作为一个整体是一个自动化的解决方案。借助 Ss/SsR、Proxy 切换插件和 Pac 等组件,您可以观看 youtube。得益于这样的解决方案,我可以通过 YouTube 全程跟踪柯洁对 AlphaGo 的直播。
用于解决上述四个要求的技术:
1. 主要使用requests和lxml这两个模块来抓取账户信息,调用AutoSs。 AutoSs 依赖于许多模块。在树莓派上的Ubuntu操作系统上导入zbar会导致segmentation fault,所以我把AutoSs中的def get_ss_shad0ws0cks8(r)函数注释掉了,少抓了一个网站的账号信息,效果不大。
2.参考Shad0wS0cks免费账号和测试工具共享的SSAccount.py源码,修改、加固、记录测试结果,保存为txt文件和json文件
3. 我写了一个 Python 脚本来自动生成一个 Markdown 文件。这个Markdown文件是一个Blog,包括账号信息、github等。网站支持jekyll模式静态网站,关键是Free,上传更新网站其实就是git同步这个Blog( Markdown 文件)到 github网站.
4. 用户运行的update_config.pyc使用requests和lxml模块获取Blog网页的账号信息,使用json模块读取gui-config.json的内容,修改内容gui-config.json,然后使用python的os.system()调用OS命令重启Shad0ws0cks客户端。
如果你只是自己使用它,它不需要那么复杂。 1-4 实际上形成了一个共享免费帐户的计划。
真正牛B的开源项目是这个,jlund/streisand
" xxxxxx 设置运行 L2TP/IPsec、OpenConnect、OpenSSH、OpenVPN、Shad0ws0cks、......和 WireGuard 的新服务器。它还为所有这些服务生成自定义指令。在运行结束时您将获得一个 HTML 文件,其中收录可以与朋友、家人和其他活动家共享的说明。"
待续
免费账号信息ssr url解码
入门:使用 Python 在 Web 上抓取免费帐户(一) - 知乎专栏
AutoSs开源项目介绍
入门:使用 Python 在 Web 上抓取免费帐户(二) - 知乎专栏
ssa.py程序运行效果
入门:使用 Python 抓取网络上的免费帐户(三) - 知乎column
ssa.py自动测试免费账号程序的由来
入门:使用 Python 在 Web 上抓取免费帐户(四) - 知乎专栏
update_config.py 使用示例
入门:使用 Python 在 Web 上抓取免费帐户(五) - 知乎专栏
用于读写 gui-config.json 和重启 Shad0ws0cks 客户端的示例代码
入门:使用 Python 在 Web 上抓取免费帐户(六) - 知乎专栏
获取免费账户、测试免费账户、分发免费账户的完整解决方案
入门:使用 Python 抓取网络上的免费帐户(七) - 知乎column
update_config.py自动更新免费账号脚本介绍
入门:使用 Python 抓取网络上的免费帐户(八) - 知乎column
Mac OS X 上的客户端 Shad0ws0cksX._NG 使用 plist 格式的配置文件,而不是 json 格式的配置文件。可以使用脚本自动更新账户信息吗?
入门:使用 Python 在 Web 上抓取免费帐户(九) - 知乎专栏
如何快速将收录免费账号的json文件合并到当前ss客户端的gui-config.json配置文件中
入门:使用 Python 抓取网络上的免费帐户(十) - 知乎column
使用update_config.pyc脚本需要满足的条件和软件安装指南
入门:使用 Python 在网页上抓取免费帐户(一) - 知乎专栏
Mac OS X Shad0ws0cks客户端plist配置文件转换成的json文件长这样
入门:使用 Python 在网页上抓取免费帐户(B) - 知乎专栏
Update_config.pyc整体方案介绍
入门:使用 Python (C) 在网页上抓取免费帐户 - 知乎专栏
网页抓取解密(个人浏览器上网原理图爬虫程序可以简单想象为替代浏览器的功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-09 19:20
)
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。这些数据来自哪里?正如我们通常在寻找“度娘”时遇到问题一样,一个重要的数据来源是互联网,而爬虫是获取互联网数据的手段。前端时间是数据分析lion,做了两周的兼职爬虫工程师。今天给大家讲讲白话爬虫。事物。
白话爬行动物
爬虫的官方定义:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种按照一定的规则自动爬取全球信息的程序或脚本。规则。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
白话爬虫:利用程序模拟人们的上网行为进行网络索引,获取网页中的特定信息,实现对网络数据的短期、不间断、实时访问。
个人浏览器上网示意图
爬虫可以简单的想象成代替浏览器的功能【发送一个url请求,解析服务器返回的HTML文档】,将获取到的数据存储到数据库或者文件中。同时,对于网站的反爬策略,需要进行伪装,即携带浏览器发送的信息我是谁?(cookie信息),我来自哪里(IP地址,使用的代理IP),我的浏览器模型(User-Agent),使用的方法(get,post等),访问信息。
爬行动物示意图
Python爬虫代码案例
要求:网站百度前几页搜索结果的地址和主题(自定义)抓取一个关键字(自定义)
代码:
class crawler:
'''按关键词爬取百度搜索页面内容'''
url = ''
urls = []
o_urls = []
html = ''
total_pages = 5
current_page = 0
next_page_url = ''
timeout = 60
headersParameters = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
def __init__(self, keyword):
self.keyword = keyword
self.url = 'https://www.baidu.com/baidu?wd='+quote(keyword)+'&tn=monline_dg&ie=utf-8'
self.url_df = pd.DataFrame(columns=["url"])
self.url_title_df = pd.DataFrame(columns=["url","title"])
def set_timeout(self, time):
'''设置超时时间,单位:秒'''
try:
self.timeout = int(time)
except:
pass
def set_total_pages(self, num):
'''设置总共要爬取的页数'''
try:
self.total_pages = int(num)
except:
pass
def set_current_url(self, url):
'''设置当前url'''
self.url = url
def switch_url(self):
'''切换当前url为下一页的url
若下一页为空,则退出程序'''
if self.next_page_url == '':
sys.exit()
else:
self.set_current_url(self.next_page_url)
def is_finish(self):
'''判断是否爬取完毕'''
if self.current_page >= self.total_pages:
return True
else:
return False
def get_html(self):
'''爬取当前url所指页面的内容,保存到html中'''
r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters)
if r.status_code==200:
self.html = r.text
# print("-----------------------------------------------------------------------")
# print("[当前页面链接]: ",self.url)
# #print("[当前页面内容]: ",self.html)
# print("-----------------------------------------------------------------------")
self.current_page += 1
else:
self.html = ''
print('[ERROR]',self.url,'get此url返回的http状态码不是200')
def get_urls(self):
'''从当前html中解析出搜索结果的url,保存到o_urls'''
o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html)
titles = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\".* data-tools=\'{"title":(.*?),"url"',self.html)
# o_urls = list(set(o_urls)) #去重
# titles = list(set(titles)) #去重
self.titles = titles
self.o_urls = o_urls
#取下一页地址
next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html)
if len(next) > 0:
self.next_page_url = 'https://www.baidu.com'+next[-1]
else:
self.next_page_url = ''
def get_real(self, o_url):
'''获取重定向url指向的网址'''
r = requests.get(o_url, allow_redirects = False) #禁止自动跳转
if r.status_code == 302:
try:
return r.headers['location'] #返回指向的地址
except:
pass
return o_url #返回源地址
def transformation(self):
'''读取当前o_urls中的链接重定向的网址,并保存到urls中'''
self.urls = []
for o_url in self.o_urls:
self.urls.append(self.get_real(o_url))
def print_urls(self):
'''输出当前urls中的url'''
for url in self.urls:
print(url)
for title in self.titles:
print(title[0])
def stock_data(self):
url_df = pd.DataFrame(self.urls,columns=["url"])
o_url_df = pd.DataFrame([self.o_urls,self.urls],index=["o_url","url"]).T
title_df = pd.DataFrame(self.titles,columns=["o_url","title"])
url_title_df = pd.merge(o_url_df,title_df,left_on="o_url",right_on="o_url",how="left")
url_titles_df = url_title_df[["url","title"]]
self.url_df = self.url_df.append(url_df,ignore_index=True)
self.url_title_df = self.url_title_df.append(url_titles_df,ignore_index=True)
self.url_title_df["keyword"] = len(self.url_title_df)* [self.keyword]
def print_o_urls(self):
'''输出当前o_urls中的url'''
for url in self.o_urls:
print(url)
def run(self):
while(not self.is_finish()):
self.get_html()
self.get_urls()
self.transformation()
c.print_urls()
self.stock_data()
time.sleep(10)
self.switch_url()
API接口
## 爬取百度关键词
timeout = 60
totalpages=2 ##前两页
baidu_url = pd.DataFrame(columns=["url","title","keyword"])
keyword="数据分析"
c = crawler(keyword)
if timeout != None:
c.set_timeout(timeout)
if totalpages != None:
c.set_total_pages(totalpages)
c.run()
# print(c.url_title_df)
baidu_url=baidu_url.append(c.url_title_df,ignore_index=True)
获取关键词“数据分析”的百度搜索结果前两页信息
查看全部
网页抓取解密(个人浏览器上网原理图爬虫程序可以简单想象为替代浏览器的功能
)
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。这些数据来自哪里?正如我们通常在寻找“度娘”时遇到问题一样,一个重要的数据来源是互联网,而爬虫是获取互联网数据的手段。前端时间是数据分析lion,做了两周的兼职爬虫工程师。今天给大家讲讲白话爬虫。事物。
白话爬行动物
爬虫的官方定义:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种按照一定的规则自动爬取全球信息的程序或脚本。规则。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
白话爬虫:利用程序模拟人们的上网行为进行网络索引,获取网页中的特定信息,实现对网络数据的短期、不间断、实时访问。
个人浏览器上网示意图
爬虫可以简单的想象成代替浏览器的功能【发送一个url请求,解析服务器返回的HTML文档】,将获取到的数据存储到数据库或者文件中。同时,对于网站的反爬策略,需要进行伪装,即携带浏览器发送的信息我是谁?(cookie信息),我来自哪里(IP地址,使用的代理IP),我的浏览器模型(User-Agent),使用的方法(get,post等),访问信息。
爬行动物示意图
Python爬虫代码案例
要求:网站百度前几页搜索结果的地址和主题(自定义)抓取一个关键字(自定义)
代码:
class crawler:
'''按关键词爬取百度搜索页面内容'''
url = ''
urls = []
o_urls = []
html = ''
total_pages = 5
current_page = 0
next_page_url = ''
timeout = 60
headersParameters = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
def __init__(self, keyword):
self.keyword = keyword
self.url = 'https://www.baidu.com/baidu?wd='+quote(keyword)+'&tn=monline_dg&ie=utf-8'
self.url_df = pd.DataFrame(columns=["url"])
self.url_title_df = pd.DataFrame(columns=["url","title"])
def set_timeout(self, time):
'''设置超时时间,单位:秒'''
try:
self.timeout = int(time)
except:
pass
def set_total_pages(self, num):
'''设置总共要爬取的页数'''
try:
self.total_pages = int(num)
except:
pass
def set_current_url(self, url):
'''设置当前url'''
self.url = url
def switch_url(self):
'''切换当前url为下一页的url
若下一页为空,则退出程序'''
if self.next_page_url == '':
sys.exit()
else:
self.set_current_url(self.next_page_url)
def is_finish(self):
'''判断是否爬取完毕'''
if self.current_page >= self.total_pages:
return True
else:
return False
def get_html(self):
'''爬取当前url所指页面的内容,保存到html中'''
r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters)
if r.status_code==200:
self.html = r.text
# print("-----------------------------------------------------------------------")
# print("[当前页面链接]: ",self.url)
# #print("[当前页面内容]: ",self.html)
# print("-----------------------------------------------------------------------")
self.current_page += 1
else:
self.html = ''
print('[ERROR]',self.url,'get此url返回的http状态码不是200')
def get_urls(self):
'''从当前html中解析出搜索结果的url,保存到o_urls'''
o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html)
titles = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\".* data-tools=\'{"title":(.*?),"url"',self.html)
# o_urls = list(set(o_urls)) #去重
# titles = list(set(titles)) #去重
self.titles = titles
self.o_urls = o_urls
#取下一页地址
next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html)
if len(next) > 0:
self.next_page_url = 'https://www.baidu.com'+next[-1]
else:
self.next_page_url = ''
def get_real(self, o_url):
'''获取重定向url指向的网址'''
r = requests.get(o_url, allow_redirects = False) #禁止自动跳转
if r.status_code == 302:
try:
return r.headers['location'] #返回指向的地址
except:
pass
return o_url #返回源地址
def transformation(self):
'''读取当前o_urls中的链接重定向的网址,并保存到urls中'''
self.urls = []
for o_url in self.o_urls:
self.urls.append(self.get_real(o_url))
def print_urls(self):
'''输出当前urls中的url'''
for url in self.urls:
print(url)
for title in self.titles:
print(title[0])
def stock_data(self):
url_df = pd.DataFrame(self.urls,columns=["url"])
o_url_df = pd.DataFrame([self.o_urls,self.urls],index=["o_url","url"]).T
title_df = pd.DataFrame(self.titles,columns=["o_url","title"])
url_title_df = pd.merge(o_url_df,title_df,left_on="o_url",right_on="o_url",how="left")
url_titles_df = url_title_df[["url","title"]]
self.url_df = self.url_df.append(url_df,ignore_index=True)
self.url_title_df = self.url_title_df.append(url_titles_df,ignore_index=True)
self.url_title_df["keyword"] = len(self.url_title_df)* [self.keyword]
def print_o_urls(self):
'''输出当前o_urls中的url'''
for url in self.o_urls:
print(url)
def run(self):
while(not self.is_finish()):
self.get_html()
self.get_urls()
self.transformation()
c.print_urls()
self.stock_data()
time.sleep(10)
self.switch_url()
API接口
## 爬取百度关键词
timeout = 60
totalpages=2 ##前两页
baidu_url = pd.DataFrame(columns=["url","title","keyword"])
keyword="数据分析"
c = crawler(keyword)
if timeout != None:
c.set_timeout(timeout)
if totalpages != None:
c.set_total_pages(totalpages)
c.run()
# print(c.url_title_df)
baidu_url=baidu_url.append(c.url_title_df,ignore_index=True)
获取关键词“数据分析”的百度搜索结果前两页信息
网页抓取解密(【网页抓取解密】移动联通的订单号是怎么来的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-08 19:02
网页抓取解密前言1、web抓取对于我们来说用处有几个呢?一个是和京东的销量,它们都是属于提前预售的一个产品,什么意思呢?就是说它是在这个季度提前上架。那么它的售价如果不提前一个月提前定货,那这个销量一定是不好计算的。还有一个就是我们在经常都能见到的刷单一个骗局。一个是低价刷单,一个是这种刷单,因为有漏洞,抓住了它这个漏洞,别人都不会在你这买,还有就是我们所谓的移动联通的套餐办理。
移动联通一定是1元月租,而且它们不定时断号转网。在杭州这里这一类的套餐办理是不会被提前通知的,非常不合理,所以我们就需要去挖一些这样的一些漏洞,来增加网页里面所有商品的销量,来增加这些商品的销量,能够增加这个钱是第一条件。2、每一个页面浏览的大致的流程呢?有这么一个在上的一个消费者买家和卖家,然后卖家有一个订单,然后卖家把这个订单到物流,物流发到我们在浏览的这个页面的相应的地方,我们想知道这个数据是怎么来的呢?就是说这个订单号是怎么来的?到底是到哪家物流?发到哪个渠道哪个方式?这个订单号是在哪个时间生成的?到什么时间才显示出来的?所以说到底我们要去挖这种漏洞,为什么要用url生成页面呢?每一个页面都是一个独立的页面,是有自己的数据,每一个数据就是一个订单号数据,那么整个链接的一个关系,就是卖家和卖家,卖家才会生成一个卖家订单信息。
那卖家这个订单的唯一标示呢,会在浏览器网页,你在点击里面的那个展示的时候,就直接展示给你展示的这个页面。那么我们怎么在这个首页浏览时候,把数据跟卖家发一个提前一个月订货的一个订单呢?你说这么好的事情,下一个月要是有人缺货了,没货了,或者货不对版,物流被物流中心取消了,或者你下定决心就要提前一个月的,那么你找这个人,你给他发一个订单,不就提前定货了。
这里我们做个小小的猜想,想一下卖家不缺货的原因,比如说它很精明的每个月在上面买一次东西,为什么它一次买一次,就是它定在10号到20号。但是我们你发现我上周用了同样的方法,把这个页面做了个针对性,那这周的月底,或者是这一周的下个月的10号,你用一个针对性的方法,把这个订单发一次。那么你还想一想一些卖家,他一次要买多少东西,他想提前定货的话,直接定到20号或者25号了。
他还不用再在看,他要看那我知道我定这个东西是来当天就要发,那我定这个东西是来定上个月的,还是我定上个月的生成的这个订单,当然这个原理上也是有的,因为它把你发一个订单,是由10号的时候生成。然后加一天。还有。 查看全部
网页抓取解密(【网页抓取解密】移动联通的订单号是怎么来的?)
网页抓取解密前言1、web抓取对于我们来说用处有几个呢?一个是和京东的销量,它们都是属于提前预售的一个产品,什么意思呢?就是说它是在这个季度提前上架。那么它的售价如果不提前一个月提前定货,那这个销量一定是不好计算的。还有一个就是我们在经常都能见到的刷单一个骗局。一个是低价刷单,一个是这种刷单,因为有漏洞,抓住了它这个漏洞,别人都不会在你这买,还有就是我们所谓的移动联通的套餐办理。
移动联通一定是1元月租,而且它们不定时断号转网。在杭州这里这一类的套餐办理是不会被提前通知的,非常不合理,所以我们就需要去挖一些这样的一些漏洞,来增加网页里面所有商品的销量,来增加这些商品的销量,能够增加这个钱是第一条件。2、每一个页面浏览的大致的流程呢?有这么一个在上的一个消费者买家和卖家,然后卖家有一个订单,然后卖家把这个订单到物流,物流发到我们在浏览的这个页面的相应的地方,我们想知道这个数据是怎么来的呢?就是说这个订单号是怎么来的?到底是到哪家物流?发到哪个渠道哪个方式?这个订单号是在哪个时间生成的?到什么时间才显示出来的?所以说到底我们要去挖这种漏洞,为什么要用url生成页面呢?每一个页面都是一个独立的页面,是有自己的数据,每一个数据就是一个订单号数据,那么整个链接的一个关系,就是卖家和卖家,卖家才会生成一个卖家订单信息。
那卖家这个订单的唯一标示呢,会在浏览器网页,你在点击里面的那个展示的时候,就直接展示给你展示的这个页面。那么我们怎么在这个首页浏览时候,把数据跟卖家发一个提前一个月订货的一个订单呢?你说这么好的事情,下一个月要是有人缺货了,没货了,或者货不对版,物流被物流中心取消了,或者你下定决心就要提前一个月的,那么你找这个人,你给他发一个订单,不就提前定货了。
这里我们做个小小的猜想,想一下卖家不缺货的原因,比如说它很精明的每个月在上面买一次东西,为什么它一次买一次,就是它定在10号到20号。但是我们你发现我上周用了同样的方法,把这个页面做了个针对性,那这周的月底,或者是这一周的下个月的10号,你用一个针对性的方法,把这个订单发一次。那么你还想一想一些卖家,他一次要买多少东西,他想提前定货的话,直接定到20号或者25号了。
他还不用再在看,他要看那我知道我定这个东西是来当天就要发,那我定这个东西是来定上个月的,还是我定上个月的生成的这个订单,当然这个原理上也是有的,因为它把你发一个订单,是由10号的时候生成。然后加一天。还有。
网页抓取解密(网页抓取工具WebExtractWebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-07 01:09
网页抓取工具 Easy Web Extract 是一款易于使用的网页抓取工具,只需点击几下即可提取网页中的内容(文本、URL、图片、文件),并将结果转换为各种格式。无需编程。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网页提取软件包括许多高级功能。
使用户能够从简单到复杂的 网站 抓取内容。
但是建立一个网络抓取项目并不需要任何努力。
在此页面中,我们将只向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导将一步一步引导您。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,也就是起始页,页面会通过滑动加载。
它往往是指向已抓取产品列表的链接
第二步:输入关键词提交表单,如果需要网站就可以得到结果。大多数情况下可以跳过此步骤
Step 3:在列表中选择一个item,选择item的数据列进行抓取属性
第四步:选择下一页的URL,访问其他网页
2. 多线程抓取数据
在网页抓取项目中,需要抓取和收获数十万个链接。
传统的刮刀可能需要数小时或数天的时间。
然而,Simple Web Extractor 可以运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,简单的网络提取可以利用系统的最佳性能。
侧面的动画图像显示了 8 个线程的提取。
3. 从data中加载各种提取的数据
一些高度动态的 网站 使用基于客户端创建异步请求的数据加载技术,例如 AJAX。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如 LinkedIn 联系人列表中的一些特定的 网站。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
并很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动化项目执行
通过简单的网络提取嵌入式自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目标。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
以确保只保留新数据。
支持的计划类型:
- 每小时运行一次项目
- 每天运行项目
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接将线索提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
网页抓取解密(网页抓取工具WebExtractWebWebWeb)
网页抓取工具 Easy Web Extract 是一款易于使用的网页抓取工具,只需点击几下即可提取网页中的内容(文本、URL、图片、文件),并将结果转换为各种格式。无需编程。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网页提取软件包括许多高级功能。
使用户能够从简单到复杂的 网站 抓取内容。
但是建立一个网络抓取项目并不需要任何努力。
在此页面中,我们将只向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导将一步一步引导您。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,也就是起始页,页面会通过滑动加载。
它往往是指向已抓取产品列表的链接
第二步:输入关键词提交表单,如果需要网站就可以得到结果。大多数情况下可以跳过此步骤
Step 3:在列表中选择一个item,选择item的数据列进行抓取属性
第四步:选择下一页的URL,访问其他网页
2. 多线程抓取数据
在网页抓取项目中,需要抓取和收获数十万个链接。
传统的刮刀可能需要数小时或数天的时间。
然而,Simple Web Extractor 可以运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,简单的网络提取可以利用系统的最佳性能。
侧面的动画图像显示了 8 个线程的提取。
3. 从data中加载各种提取的数据
一些高度动态的 网站 使用基于客户端创建异步请求的数据加载技术,例如 AJAX。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如 LinkedIn 联系人列表中的一些特定的 网站。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
并很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动化项目执行
通过简单的网络提取嵌入式自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目标。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
以确保只保留新数据。
支持的计划类型:
- 每小时运行一次项目
- 每天运行项目
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接将线索提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。
网页抓取解密(加密和解密的过程,你都知道吗?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-06 16:03
)
我最近看了几页,发现其中很多都被处理了。但是,它带有一个 javascript 处理加密页面。以下是加解密过程的简要说明。
一、加密
1、将字符串中的每个字符转换为数字
该方法是字符串处理的方法 charCodeAt(index) charCodeAt()方法可以返回指定位置的字符的Unicode编码,即数字化字符串,返回值为0-之间的整数65535的对应字符。
例如:
var str="hello world!"
var r = str.charCodeAt(0);
document.write(r);
//输出为: 104
2.修改数字后,使用fromCharCode()方法恢复字符
fromCharCode()方法是String的静态方法,可以将数字的指定Unicode编码转换成字符。
比如上面的例子:
$ = String.fromCharCode(r);
document.write($);
//输出为: h
加密的关键在于String.fromCharCode(r)这一步!
你可以改变r的值,使输出的字符有偏差,比如r = r + 2
$ = String.fromCharCode(r + 2);
document.write($);
//输出为: j
因此,
你好世界!变成jgnnq"yqtnf#
变成>jvon@
二、解密
1、还要先把字符转成unicode编码的数字
var str=">jvon@";
var r = str.charCodeAt(0);
document.write(r);
//输出为: 62
2.使用加密逆算法
<p>$ = String.fromCharCode(r-2);
document.write($);
//输出为: 查看全部
网页抓取解密(加密和解密的过程,你都知道吗?(上)
)
我最近看了几页,发现其中很多都被处理了。但是,它带有一个 javascript 处理加密页面。以下是加解密过程的简要说明。
一、加密
1、将字符串中的每个字符转换为数字
该方法是字符串处理的方法 charCodeAt(index) charCodeAt()方法可以返回指定位置的字符的Unicode编码,即数字化字符串,返回值为0-之间的整数65535的对应字符。
例如:
var str="hello world!"
var r = str.charCodeAt(0);
document.write(r);
//输出为: 104
2.修改数字后,使用fromCharCode()方法恢复字符
fromCharCode()方法是String的静态方法,可以将数字的指定Unicode编码转换成字符。
比如上面的例子:
$ = String.fromCharCode(r);
document.write($);
//输出为: h
加密的关键在于String.fromCharCode(r)这一步!
你可以改变r的值,使输出的字符有偏差,比如r = r + 2
$ = String.fromCharCode(r + 2);
document.write($);
//输出为: j
因此,
你好世界!变成jgnnq"yqtnf#
变成>jvon@
二、解密
1、还要先把字符转成unicode编码的数字
var str=">jvon@";
var r = str.charCodeAt(0);
document.write(r);
//输出为: 62
2.使用加密逆算法
<p>$ = String.fromCharCode(r-2);
document.write($);
//输出为:
网页抓取解密(“全包加密*网页全包加密”*(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-05 12:16
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。
“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加快资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,所以逻辑都是JS)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest 查看全部
网页抓取解密(“全包加密*网页全包加密”*(组图))
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。
“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加快资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,所以逻辑都是JS)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
网页抓取解密(怎么更轻松的抓取网站链接抓取器(网站抓取助手) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-05 11:18
)
网站Link Grabber(网站Link Address Grabbing Assistant)是一款优秀且易于使用的辅助工具,用于抓取各种网站链接。如何更轻松地抓取 网站 链接?小编带来的这款网站链接抓取器可以帮到你,使用后可以帮助用户更方便快捷的抓取网站链接。该工具易于使用且操作简单。只需几步即可轻松抓取网站链接,抓取的链接会逐行保存为TXT文件,方便用户查看。欢迎有需要的朋友下载使用。
使用方法:
1、输入提取链接的网站地址;
2、选择并发线程数;
3、选择txt文件保存地址;
4、输入要保存的txt文件个数;
5、点击“开始”按钮进行链接提取。
软件功能:
1、这个软件非常适合做seo优化的人排名
2、使用此软件节省大量时间
3、并自动选择所有网站内部链接
4、并且还可以有计划地将提取的内部链接提交给各种收录工具
5、这样就完成了收录数量的增加
特点:
1、网站
下可以捕获本站连接地址的所有输入
2、动态统计包括未访问的连接和爬取的链接
3、线程越大速度越快
4、但是同时消耗更多的CPU,也消耗更多的内存和网速
5、查看你当前访问的链接
6、支持输入结果的存储地址
查看全部
网页抓取解密(怎么更轻松的抓取网站链接抓取器(网站抓取助手)
)
网站Link Grabber(网站Link Address Grabbing Assistant)是一款优秀且易于使用的辅助工具,用于抓取各种网站链接。如何更轻松地抓取 网站 链接?小编带来的这款网站链接抓取器可以帮到你,使用后可以帮助用户更方便快捷的抓取网站链接。该工具易于使用且操作简单。只需几步即可轻松抓取网站链接,抓取的链接会逐行保存为TXT文件,方便用户查看。欢迎有需要的朋友下载使用。
使用方法:
1、输入提取链接的网站地址;
2、选择并发线程数;
3、选择txt文件保存地址;
4、输入要保存的txt文件个数;
5、点击“开始”按钮进行链接提取。
软件功能:
1、这个软件非常适合做seo优化的人排名
2、使用此软件节省大量时间
3、并自动选择所有网站内部链接
4、并且还可以有计划地将提取的内部链接提交给各种收录工具
5、这样就完成了收录数量的增加
特点:
1、网站
下可以捕获本站连接地址的所有输入
2、动态统计包括未访问的连接和爬取的链接
3、线程越大速度越快
4、但是同时消耗更多的CPU,也消耗更多的内存和网速
5、查看你当前访问的链接
6、支持输入结果的存储地址
网页抓取解密(这款ScreamingSEOSpider16破解版真的真的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-05 09:07
Screaming Frog SEO Spider 是一款功能强大的网络爬虫工具,专门用于爬取 Internet URL 并对其进行分析。通过这个软件,用户可以很方便的抓取可能存在或者出现在断连接或者服务器错误信息等的URL,也可以用来识别网站中临时或者永久的重新定义循环到链接也可以直接查URL、网页标题、内容重复的相关信息。抓取到这些信息后,软件会自动将获取到的详细信息反馈给开发者进行修复,非常方便好用。因此,这款软件非常适合从事网站网页行业的用户,通过它可以节省大量的时间和精力,高效地完成工作。所以,无论是大的网站还是自己制作的小网站,你都可以用它来分析,你可以很方便的得到你想分析的结果和你需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。并且您可以轻松获得您想要分析的结果和您需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。并且您可以轻松获得您想要分析的结果和您需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。而且使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。而且使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。
破解教程1、在本站下载解压,得到ScreamingFrogSEOSpider-11.0.exe安装程序和Keygen.exe注册机
2、双击ScreamingFrogSEOSpider-11.0.exe运行,选择安装路径,点击next
3、正在安装,请稍等
4、安装完成,点击close关闭向导
5、运行软件和keygen注册机,将注册机中的注册信息相应复制到软件中
6、注册成功,重启软件
软件功能1、审计重定向
Screaming Frog SEO Spiderke 16 发现临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
2、生成 XML 站点地图
通过 URL 进行高级配置,包括上次修改、优先级和更改频率,快速创建 XML 站点地图和图像 XML 站点地图。
3、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
5、抓取 JavaScript网站
使用集成的 ChromiumWRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
6、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入。
7、使用 XPath 提取数据
使用 CSSPath、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多。
8、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
9、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
10、查找断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
软件功能 1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染 (JavaScript)
18、自定义robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看原创和渲染的 HTML 查看全部
网页抓取解密(这款ScreamingSEOSpider16破解版真的真的)
Screaming Frog SEO Spider 是一款功能强大的网络爬虫工具,专门用于爬取 Internet URL 并对其进行分析。通过这个软件,用户可以很方便的抓取可能存在或者出现在断连接或者服务器错误信息等的URL,也可以用来识别网站中临时或者永久的重新定义循环到链接也可以直接查URL、网页标题、内容重复的相关信息。抓取到这些信息后,软件会自动将获取到的详细信息反馈给开发者进行修复,非常方便好用。因此,这款软件非常适合从事网站网页行业的用户,通过它可以节省大量的时间和精力,高效地完成工作。所以,无论是大的网站还是自己制作的小网站,你都可以用它来分析,你可以很方便的得到你想分析的结果和你需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。并且您可以轻松获得您想要分析的结果和您需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。并且您可以轻松获得您想要分析的结果和您需要的各种数据。有了所需的数据和分析结果,seo可以对这些软件进行一些改进和选择,非常实用。同时,软件的界面非常直观,用户使用起来相当舒服,使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。而且使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。而且使用起来也没有那么复杂。总的来说,小编带来的Screaming Frog SEO Spider 16破解版功能确实全面,操作也比较简单。如果需要,可以在本站下载。利用。
破解教程1、在本站下载解压,得到ScreamingFrogSEOSpider-11.0.exe安装程序和Keygen.exe注册机
2、双击ScreamingFrogSEOSpider-11.0.exe运行,选择安装路径,点击next
3、正在安装,请稍等
4、安装完成,点击close关闭向导
5、运行软件和keygen注册机,将注册机中的注册信息相应复制到软件中
6、注册成功,重启软件
软件功能1、审计重定向
Screaming Frog SEO Spiderke 16 发现临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
2、生成 XML 站点地图
通过 URL 进行高级配置,包括上次修改、优先级和更改频率,快速创建 XML 站点地图和图像 XML 站点地图。
3、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
5、抓取 JavaScript网站
使用集成的 ChromiumWRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
6、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入。
7、使用 XPath 提取数据
使用 CSSPath、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多。
8、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
9、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
10、查找断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
软件功能 1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染 (JavaScript)
18、自定义robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看原创和渲染的 HTML

