
网页抓取解密
网页抓取解密( 微信公众号网页登录的思路和流程和配置流程介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-25 09:13
微信公众号网页登录的思路和流程和配置流程介绍)
package com.yfs.util;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class HttpRequest {
public static void main(String[] args) {
//发送 GET 请求
String s=HttpRequest.sendGet("http://v.qq.com/x/cover/kvehb7 ... ot%3B, "");
System.out.println(s);
// //发送 POST 请求
// String sr=HttpRequest.sendPost("http://www.toutiao.com/stream/ ... ot%3B, "");
// JSONObject json = JSONObject.fromObject(sr);
// System.out.println(json.get("data"));
}
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return URL 所代表远程资源的响应结果
*/
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url + "?" + param;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map map = connection.getHeaderFields();
// 遍历所有的响应头字段
for (String key : map.keySet()) {
System.out.println(key + "--->" + map.get(key));
}
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
/**
* 向指定 URL 发送POST方法的请求
*
* @param url
* 发送请求的 URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return 所代表远程资源的响应结果
*/
public static String sendPost(String url, String param) {
PrintWriter out = null;
BufferedReader in = null;
String result = "";
try {
URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection conn = realUrl.openConnection();
// 设置通用的请求属性
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 发送POST请求必须设置如下两行
conn.setDoOutput(true);
conn.setDoInput(true);
// 获取URLConnection对象对应的输出流
out = new PrintWriter(conn.getOutputStream());
// 发送请求参数
out.print(param);
// flush输出流的缓冲
out.flush();
// 定义BufferedReader输入流来读取URL的响应
in = new BufferedReader(
new InputStreamReader(conn.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送 POST 请求出现异常!"+e);
e.printStackTrace();
}
//使用finally块来关闭输出流、输入流
finally{
try{
if(out!=null){
out.close();
}
if(in!=null){
in.close();
}
}
catch(IOException ex){
ex.printStackTrace();
}
}
return result;
}
}
请自行下载备注代码中需要的jar包添加到项目中。这里需要注意的是,需要使用javax.crypto.*包的类进行AES解密,在jdk的jce.jar中提供,是jdk自带的库。如果是MAVEN项目,需要在pom.xml文件中配置指定编译路径jce.jar
将 jce.jar 的地址添加到 bootclasspath 中: ${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/jre/lib/jce.jar ,注意 rt.jar 和 jce.jar 连接:
如:
com.yfs.app
org.apache.maven.plugins
maven-compiler-plugin
2.5.1
1.7
1.7
${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/jre/lib/jce.jar
utf-8
总结
好了,数据解密终于完成了,可以连接新的或者已有的用户系统了。
需要注意的一件事是 unionId 可能需要连接到现有的用户系统。如果通过上述方法无法获取unionId,则需要检查你的微信开放平台()是否绑定了微信小程序。叹气~
微信公众号网页登录的思路和流程:
第一步:获取代码证书,
第二步:获取代码凭证获取用户openid和access_token、refresh_token
第三步:刷新access_token,还有openid和refresh_token
第四步:使用openid和access_token获取用户信息
第五步:使用openid和access_token获取用户信息,看能不能获取,如果获取不到接口刷新access_token
去调用第四步。
前段时间刚做完微信小程序项目,中间遇到的一些问题会陆续放出。欢迎大家一起讨论。 查看全部
网页抓取解密(
微信公众号网页登录的思路和流程和配置流程介绍)
package com.yfs.util;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class HttpRequest {
public static void main(String[] args) {
//发送 GET 请求
String s=HttpRequest.sendGet("http://v.qq.com/x/cover/kvehb7 ... ot%3B, "");
System.out.println(s);
// //发送 POST 请求
// String sr=HttpRequest.sendPost("http://www.toutiao.com/stream/ ... ot%3B, "");
// JSONObject json = JSONObject.fromObject(sr);
// System.out.println(json.get("data"));
}
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return URL 所代表远程资源的响应结果
*/
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url + "?" + param;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map map = connection.getHeaderFields();
// 遍历所有的响应头字段
for (String key : map.keySet()) {
System.out.println(key + "--->" + map.get(key));
}
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
/**
* 向指定 URL 发送POST方法的请求
*
* @param url
* 发送请求的 URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return 所代表远程资源的响应结果
*/
public static String sendPost(String url, String param) {
PrintWriter out = null;
BufferedReader in = null;
String result = "";
try {
URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection conn = realUrl.openConnection();
// 设置通用的请求属性
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 发送POST请求必须设置如下两行
conn.setDoOutput(true);
conn.setDoInput(true);
// 获取URLConnection对象对应的输出流
out = new PrintWriter(conn.getOutputStream());
// 发送请求参数
out.print(param);
// flush输出流的缓冲
out.flush();
// 定义BufferedReader输入流来读取URL的响应
in = new BufferedReader(
new InputStreamReader(conn.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送 POST 请求出现异常!"+e);
e.printStackTrace();
}
//使用finally块来关闭输出流、输入流
finally{
try{
if(out!=null){
out.close();
}
if(in!=null){
in.close();
}
}
catch(IOException ex){
ex.printStackTrace();
}
}
return result;
}
}
请自行下载备注代码中需要的jar包添加到项目中。这里需要注意的是,需要使用javax.crypto.*包的类进行AES解密,在jdk的jce.jar中提供,是jdk自带的库。如果是MAVEN项目,需要在pom.xml文件中配置指定编译路径jce.jar
将 jce.jar 的地址添加到 bootclasspath 中: ${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/jre/lib/jce.jar ,注意 rt.jar 和 jce.jar 连接:
如:
com.yfs.app
org.apache.maven.plugins
maven-compiler-plugin
2.5.1
1.7
1.7
${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/jre/lib/jce.jar
utf-8
总结
好了,数据解密终于完成了,可以连接新的或者已有的用户系统了。
需要注意的一件事是 unionId 可能需要连接到现有的用户系统。如果通过上述方法无法获取unionId,则需要检查你的微信开放平台()是否绑定了微信小程序。叹气~
微信公众号网页登录的思路和流程:
第一步:获取代码证书,
第二步:获取代码凭证获取用户openid和access_token、refresh_token
第三步:刷新access_token,还有openid和refresh_token
第四步:使用openid和access_token获取用户信息
第五步:使用openid和access_token获取用户信息,看能不能获取,如果获取不到接口刷新access_token
去调用第四步。
前段时间刚做完微信小程序项目,中间遇到的一些问题会陆续放出。欢迎大家一起讨论。
网页抓取解密( 如何使用Thor进行基本的抓包和分析数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2022-03-18 08:07
如何使用Thor进行基本的抓包和分析数据?
)
【APP】雷神:抓包神器基础教程
白苹果2019-10-28
Thor 是一款专注于数据包捕获分析和开发测试的工具。使用 Thor 分析抓取的网络连接以找到您需要的数据。
你可以用 Thor 的数据包捕获做什么?可以抓取一些不易下载的音频、视频、图片、压缩包等,然后选择适合自己的方式下载保存。或者抓一些ipa安装包,或者下载一些文件的原链接,一些api接口等等。
下面将教你如何使用 Thor 进行基本的抓包和数据分析。同时通过一个网易云音乐抓包的例子,带大家去操作。
*注:本文为初学者基础教程,更多棘手操作请自行探索。
开始前的准备
1.雷神下载
如果您自己购买,请前往 App Store 下载。如果你想试试看,可以看之前这个账号的推送,使用共享账号下载:
2.开始使用
打开雷神,界面比较简单。主页只有一个交换机和一个抓包过滤器。下面也只有三个菜单,过滤器、抓包记录等等。
首页过滤器,可以选择抓包过滤器设置,启动和停止抓包。所有成功的抓包记录都会保存在抓包记录中。更多的是使用帮助,里面的HTTPS解析设置,可以查看证书安装。
您还可以在通知中心添加Thor的Widget,快速开始抓包并显示抓包记录。
初始化
首次使用 Thor 时,需要进行一些设置。
1.安装并信任证书
由于 Thor 的默认过滤器是全局数据包捕获,包括 HTTPS 解析,因此首次使用需要安装和信任证书。
Thor为HTTPS实现数据解密,采用MITM(man-in-the-middle attack)方式,与Surge或Little Rocket拦截广告的原理相同,因此需要安装并信任生成的Thor SSL CA证书由托尔。实现HTTPS解析。
如下图,第一次使用时,点击开始按钮,会弹出“HTTPS解析设置”。我们选择现在打开它,并按照说明将证书安装到系统中。
然后将打开一个网页,允许添加配置文件。在iOS12及以上系统中,下载配置文件后需要手动输入设置,会在首页头像下方显示。
点击右上角的安装描述文件,输入锁屏密码,完成安装。
iOS 10.2+系统需要进入【设置-通用-关于本机-证书信任设置】选择刚刚生成的证书并信任。
2.允许创建VPN配置
首次使用 Thor 时,系统会询问您是否允许创建 VPN 配置,单击允许。
这是一个必要的步骤。因为 Thor 需要占用 VPN 隧道来接管你所有的网络连接,从而捕获网络数据。如下所示。Thor创建的VPN配置可以在设置-VPN中看到。
开始使用
1、抓包
抓包前,先清理后台,退出不需要的应用程序或网页,只保存要抓包的应用程序。
点击Thor过滤开关(闪电按钮),Thor反应迅速,立即进入抓包状态。这时状态栏中会出现一个VPN标志。再次点击开关停止抓包。
还可以通知雷神Widget中心快速打开开关抓包,非常方便。
然后,使用您要采集数据的软件或网页进行网络连接操作,如打开视频、听音乐、安装软件等。Thor 会自动抓取所有网络连接。
在这个过程中可以随时进入Thor的抓包记录,查看是否已经抓到了合适的数据,也可以关闭Thor暂停工作,慢慢查看抓包数据,以免增加工作量因数据过多而选择的。
2.抓包数据分析
抓包后,我们进入抓包记录查看,抓包成功的所有数据都在这里。只有对捕获的数据包数据进行分析和选择,才能找到我们想要的。
在抓包记录界面,可以对抓包历史进行分类或删除。点击查看所有抓包记录。
由于我们的默认过滤器是全局数据包捕获,因此数据包捕获记录将收录所有捕获的数据。
你可以在里面看到很多内容,上面的例子说明了:
链接:捕获的链接地址显示最直观。
POST 或 GET:这是一种 HTTP 响应方法。HTTP响应方式有很多种,如POST、GET、HEAD、PUT、DELETE等,如果我们需要抓取和下载资源,需要从GET中找到。
:此栏为User-Agent,用户代理标识符,用于显示用户连接网络的方式
[200]:响应状态码,在Thor中很容易识别。
11:37:04.825:链接的具体时间
↓1.13KB ↑636kb : 用于接收和发送的数据
音乐抓取示例
说了这么多,估计还有人不明白,那么我们来看一个例子:
网易云音乐音频采集
打开过滤器后,打开网易云音乐,播放一段没有缓存的音乐(如果已经缓存,则无法采集音频数据),等待歌曲被缓存。
OK,我们看到还有一条抓包记录,打开它,100多条记录中我要的是哪一条?
单击关键字以过滤记录。我想查找音频文件,所以勾选所有音频文件类型并单击搜索。当然,您也可以自定义过滤规则。现在我们看到只有两条记录符合条件,我们可以根据文件大小确定哪一条是我们需要的。
在响应中,我们可以直接看到消息体,也就是文件本身。点击文件直接打开,选择右上角分享,导出原文件保存到其他应用,或直接发送给好友。
捕获的图片和音频也可以以相同的方式保存。值得注意的是,并非所有拍摄的视频都可以通过这种方式保存。
结尾
本文介绍了Thor的基本用法,Thor的强大远不止这些。
除了抓图、视频、音频,还可以抓 App Store 安装包,可以用 Shu 或者 JSBox 安装各种 ipa 文件。
还可以抓取视频的直接链接,达到释放会员观看会员视频和去除广告的效果。
它还可以通过特殊的过滤规则进行广告宣传。
甚至可以通过断点过滤器达到破解内购和会员的效果。
(请勿用于非法用途)
如有需要,稍后会更新Thor的进阶教程,也会分享有用的滤镜。
查看全部
网页抓取解密(
如何使用Thor进行基本的抓包和分析数据?
)
【APP】雷神:抓包神器基础教程
白苹果2019-10-28
Thor 是一款专注于数据包捕获分析和开发测试的工具。使用 Thor 分析抓取的网络连接以找到您需要的数据。
你可以用 Thor 的数据包捕获做什么?可以抓取一些不易下载的音频、视频、图片、压缩包等,然后选择适合自己的方式下载保存。或者抓一些ipa安装包,或者下载一些文件的原链接,一些api接口等等。
下面将教你如何使用 Thor 进行基本的抓包和数据分析。同时通过一个网易云音乐抓包的例子,带大家去操作。
*注:本文为初学者基础教程,更多棘手操作请自行探索。
开始前的准备
1.雷神下载
如果您自己购买,请前往 App Store 下载。如果你想试试看,可以看之前这个账号的推送,使用共享账号下载:
2.开始使用
打开雷神,界面比较简单。主页只有一个交换机和一个抓包过滤器。下面也只有三个菜单,过滤器、抓包记录等等。
首页过滤器,可以选择抓包过滤器设置,启动和停止抓包。所有成功的抓包记录都会保存在抓包记录中。更多的是使用帮助,里面的HTTPS解析设置,可以查看证书安装。
您还可以在通知中心添加Thor的Widget,快速开始抓包并显示抓包记录。
初始化
首次使用 Thor 时,需要进行一些设置。
1.安装并信任证书
由于 Thor 的默认过滤器是全局数据包捕获,包括 HTTPS 解析,因此首次使用需要安装和信任证书。
Thor为HTTPS实现数据解密,采用MITM(man-in-the-middle attack)方式,与Surge或Little Rocket拦截广告的原理相同,因此需要安装并信任生成的Thor SSL CA证书由托尔。实现HTTPS解析。
如下图,第一次使用时,点击开始按钮,会弹出“HTTPS解析设置”。我们选择现在打开它,并按照说明将证书安装到系统中。
然后将打开一个网页,允许添加配置文件。在iOS12及以上系统中,下载配置文件后需要手动输入设置,会在首页头像下方显示。
点击右上角的安装描述文件,输入锁屏密码,完成安装。
iOS 10.2+系统需要进入【设置-通用-关于本机-证书信任设置】选择刚刚生成的证书并信任。
2.允许创建VPN配置
首次使用 Thor 时,系统会询问您是否允许创建 VPN 配置,单击允许。
这是一个必要的步骤。因为 Thor 需要占用 VPN 隧道来接管你所有的网络连接,从而捕获网络数据。如下所示。Thor创建的VPN配置可以在设置-VPN中看到。
开始使用
1、抓包
抓包前,先清理后台,退出不需要的应用程序或网页,只保存要抓包的应用程序。
点击Thor过滤开关(闪电按钮),Thor反应迅速,立即进入抓包状态。这时状态栏中会出现一个VPN标志。再次点击开关停止抓包。
还可以通知雷神Widget中心快速打开开关抓包,非常方便。
然后,使用您要采集数据的软件或网页进行网络连接操作,如打开视频、听音乐、安装软件等。Thor 会自动抓取所有网络连接。
在这个过程中可以随时进入Thor的抓包记录,查看是否已经抓到了合适的数据,也可以关闭Thor暂停工作,慢慢查看抓包数据,以免增加工作量因数据过多而选择的。
2.抓包数据分析
抓包后,我们进入抓包记录查看,抓包成功的所有数据都在这里。只有对捕获的数据包数据进行分析和选择,才能找到我们想要的。
在抓包记录界面,可以对抓包历史进行分类或删除。点击查看所有抓包记录。
由于我们的默认过滤器是全局数据包捕获,因此数据包捕获记录将收录所有捕获的数据。
你可以在里面看到很多内容,上面的例子说明了:
链接:捕获的链接地址显示最直观。
POST 或 GET:这是一种 HTTP 响应方法。HTTP响应方式有很多种,如POST、GET、HEAD、PUT、DELETE等,如果我们需要抓取和下载资源,需要从GET中找到。
:此栏为User-Agent,用户代理标识符,用于显示用户连接网络的方式
[200]:响应状态码,在Thor中很容易识别。
11:37:04.825:链接的具体时间
↓1.13KB ↑636kb : 用于接收和发送的数据
音乐抓取示例
说了这么多,估计还有人不明白,那么我们来看一个例子:
网易云音乐音频采集
打开过滤器后,打开网易云音乐,播放一段没有缓存的音乐(如果已经缓存,则无法采集音频数据),等待歌曲被缓存。
OK,我们看到还有一条抓包记录,打开它,100多条记录中我要的是哪一条?
单击关键字以过滤记录。我想查找音频文件,所以勾选所有音频文件类型并单击搜索。当然,您也可以自定义过滤规则。现在我们看到只有两条记录符合条件,我们可以根据文件大小确定哪一条是我们需要的。
在响应中,我们可以直接看到消息体,也就是文件本身。点击文件直接打开,选择右上角分享,导出原文件保存到其他应用,或直接发送给好友。
捕获的图片和音频也可以以相同的方式保存。值得注意的是,并非所有拍摄的视频都可以通过这种方式保存。
结尾
本文介绍了Thor的基本用法,Thor的强大远不止这些。
除了抓图、视频、音频,还可以抓 App Store 安装包,可以用 Shu 或者 JSBox 安装各种 ipa 文件。
还可以抓取视频的直接链接,达到释放会员观看会员视频和去除广告的效果。
它还可以通过特殊的过滤规则进行广告宣传。
甚至可以通过断点过滤器达到破解内购和会员的效果。
(请勿用于非法用途)
如有需要,稍后会更新Thor的进阶教程,也会分享有用的滤镜。
网页抓取解密(网页抓取解密应该不是程序员的活,那才叫牛逼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-17 10:06
网页抓取解密应该不是程序员的活,程序员要是能发现并解决网页的加密,那才叫牛逼呢,如果说你抓的是一堆乱码的页面,那没啥意义。web安全的门槛其实很低,你有基础搞搞渗透应该不难的,而且现在一般都支持开源,基本上想什么时候破解,都能很快找到破解的方法,就看你能不能想。
你以为人家愿意给你搞
钓鱼场就可以抓取网页,
可以找那种有找破解团队的打电话骚扰,网站主方就能辨别出,这比发论文靠谱。
起个名字“netscript”,抓的是程序文件。
在苹果公司有大神,
还有flashplayer~~不知道国内的flashplayer开发者是否有他们的小号或者不用感谢我~~ps:我的基本常识是假如你们知道明文的,直接默认他是用黑客手段被抓取了
cloudxns
黑客用非法方式获取api接口,完全抓取网页。
像极了,魔方大厦。
当年黑五入手手机通过烧网线是可以抓到线路实时信息的。
还有比这更无节操的么~~直接网上抓
加密不是我们的事儿。没破解,能抓取是你的本事。
你在说anywayeverything吗
我只知道他们有一种东西叫做“破解工具”或者“蜘蛛”。网上百度随便找。或者,他们能破解windows甚至更加复杂的破解版本。
给我看个正面的不可能做不到的 查看全部
网页抓取解密(网页抓取解密应该不是程序员的活,那才叫牛逼)
网页抓取解密应该不是程序员的活,程序员要是能发现并解决网页的加密,那才叫牛逼呢,如果说你抓的是一堆乱码的页面,那没啥意义。web安全的门槛其实很低,你有基础搞搞渗透应该不难的,而且现在一般都支持开源,基本上想什么时候破解,都能很快找到破解的方法,就看你能不能想。
你以为人家愿意给你搞
钓鱼场就可以抓取网页,
可以找那种有找破解团队的打电话骚扰,网站主方就能辨别出,这比发论文靠谱。
起个名字“netscript”,抓的是程序文件。
在苹果公司有大神,
还有flashplayer~~不知道国内的flashplayer开发者是否有他们的小号或者不用感谢我~~ps:我的基本常识是假如你们知道明文的,直接默认他是用黑客手段被抓取了
cloudxns
黑客用非法方式获取api接口,完全抓取网页。
像极了,魔方大厦。
当年黑五入手手机通过烧网线是可以抓到线路实时信息的。
还有比这更无节操的么~~直接网上抓
加密不是我们的事儿。没破解,能抓取是你的本事。
你在说anywayeverything吗
我只知道他们有一种东西叫做“破解工具”或者“蜘蛛”。网上百度随便找。或者,他们能破解windows甚至更加复杂的破解版本。
给我看个正面的不可能做不到的
网页抓取解密( 搜狗收录量的查询方法不少是怎么回事?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-13 15:18
搜狗收录量的查询方法不少是怎么回事?(图))
搜狗收录指的是搜狗是否将你的网页放入了自己的数据库中。这样,搜狗seo的时候,就可以通过自然流量被搜索到,产生查询、订单等。前几年搜狗缺乏数据的时候,搜狗收录越多越好。但18年过去了,搜狗搜索引擎也不缺数据。搜狗收录偏爱有价值的页面,可以帮助用户处理问题的页面,新的需求内容,新的热点内容。也就是18年后,尤其是近两年,搜狗收录更倾向于有价值的好内容。另一方面,网站也是,你的网站搜狗收录页面比无价值的重复页面更能处理用户需求,所以你的网站整体流量和排名会更好的。
搜狗收录有很多查询方法。但最方便的搜狗收录查询工具是搜狗搜索本身,您只需要输入查询命令即可查看搜狗对网站的详细收录情况。
站点:(是您自己的域名)
通过该命令可以查看到网站中所有已经被搜狗收录展示过且可以正常展示的页面。
搜狗收录是网站参与排名的先决条件。搜狗会先收录网站到自己的索引库,然后根据算法计算排名结果。也就是说,搜狗的网站而不是收录,根本没有任何排名的机会。因此,我们需要关注我们的网站搜狗收录卷。
如果你有大量网站需要查询搜狗收录,想全面了解网站的收录情况,去各大搜索引擎网站一一查询。它很慢而且浪费时间。通过搜狗查询工具,可以快速查询大量域名收录,快捷方便,一键操作。这里我们可以使用147SEO搜索收录查询工具进行查询,我们可以查询:收录排名,收录标题,收录链接,收录时间,真实标题、真实链接、真实关键词、关键词排名、站点命令等关键信息非常方便实用,让您多方面多维度分析一个或多个网址!
搜狗收录查询帮助您一键快速了解网站收录上的搜狗搜索引擎详情,助您全面了解您的网站动态。
搜狗的收录查询功能帮助站长了解如何查询网站域名、博客、产品是否已经搜狗收录,了解搜狗收录数据,方便网站优化调整。
搜狗的收录量网站是搜狗爬虫成功爬取网站内页面的总次数。索引量是收录通过索引过程在线进入的页面之后的网页总数。 查看全部
网页抓取解密(
搜狗收录量的查询方法不少是怎么回事?(图))
搜狗收录指的是搜狗是否将你的网页放入了自己的数据库中。这样,搜狗seo的时候,就可以通过自然流量被搜索到,产生查询、订单等。前几年搜狗缺乏数据的时候,搜狗收录越多越好。但18年过去了,搜狗搜索引擎也不缺数据。搜狗收录偏爱有价值的页面,可以帮助用户处理问题的页面,新的需求内容,新的热点内容。也就是18年后,尤其是近两年,搜狗收录更倾向于有价值的好内容。另一方面,网站也是,你的网站搜狗收录页面比无价值的重复页面更能处理用户需求,所以你的网站整体流量和排名会更好的。
搜狗收录有很多查询方法。但最方便的搜狗收录查询工具是搜狗搜索本身,您只需要输入查询命令即可查看搜狗对网站的详细收录情况。
站点:(是您自己的域名)
通过该命令可以查看到网站中所有已经被搜狗收录展示过且可以正常展示的页面。
搜狗收录是网站参与排名的先决条件。搜狗会先收录网站到自己的索引库,然后根据算法计算排名结果。也就是说,搜狗的网站而不是收录,根本没有任何排名的机会。因此,我们需要关注我们的网站搜狗收录卷。
如果你有大量网站需要查询搜狗收录,想全面了解网站的收录情况,去各大搜索引擎网站一一查询。它很慢而且浪费时间。通过搜狗查询工具,可以快速查询大量域名收录,快捷方便,一键操作。这里我们可以使用147SEO搜索收录查询工具进行查询,我们可以查询:收录排名,收录标题,收录链接,收录时间,真实标题、真实链接、真实关键词、关键词排名、站点命令等关键信息非常方便实用,让您多方面多维度分析一个或多个网址!
搜狗收录查询帮助您一键快速了解网站收录上的搜狗搜索引擎详情,助您全面了解您的网站动态。
搜狗的收录查询功能帮助站长了解如何查询网站域名、博客、产品是否已经搜狗收录,了解搜狗收录数据,方便网站优化调整。
搜狗的收录量网站是搜狗爬虫成功爬取网站内页面的总次数。索引量是收录通过索引过程在线进入的页面之后的网页总数。
网页抓取解密(目标网易云音乐只需要解密params和encSecKey就可以快乐的了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-12 16:03
目标
网易云音乐只需要解密params和encSecKey就可以愉快的开始爬取了。当然,如果没有足够的代理IP,还是要慢慢爬。废话不多说,直接开始吧。
问
老规矩,先来看看我们要抓取的页面:
查看网络请求:
从名字上可以快速定位到哪个请求是POST请求,然后看它提交了哪些参数,FormData如下:
提交的参数,上面提到的params和encSecKey,都是加密的。我们看看返回内容的格式:
ok,基本的东西我们已经知道了,我们可以进行下一步,找到解密的两个参数。
分析
在调试之前,我们要找到这两个值的位置,然后搜索,先定位js文件再定位代码位置。你应该知道如何搜索。您可以搜索 params 或 encSecKey。如果发现多个结果,不确定是哪个文件,可以点击每个key,搜索key参数,判断是否为目标文件。这里我直接标记了。正确的文件,你可以点击进去。
进入JS文件后,同样搜索key参数params或者encSecKey:
找到encSecKey的位置,拉出这几行代码分析一下:
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
e0x.data = j0x.cs1x({
params: bVZ8R.encText,
encSecKey: bVZ8R.encSecKey
})
粗略地说,params和encSecKey来自bVZ8R.encText和bVZ8R.encSecKey,bVZ8R是window.asrsea的结果,有四个参数,JSON.stringify(i0x), bqN0x(["tear", "strong"]) , bqN0x(Wx5C.md), bqN0x(["love", "girl", "horrified", "laughing"],先看最后三个参数,从它们的固定值可以大胆推断出这三个值也是Fixed,之所以说是fixed,看一下Wx5C.md:
wx5C.md是一个固定的数组,bqN0x(["tears", "strong"])和bqN0x(["love", "girl", "horrified", "laughing"]肯定不会导致改变,如图下面,测试一下:
这些参数我大概都弄清楚了,剩下的就是弄清楚window.asrsea的具体实现,以及i0x是什么样的,进入调试过程。
调试
Window.asrsea 有一个断点。我的代码位置是第 13133 行。点击粉丝列表的下一页将激活断点。在激活断点的同时,我们也可以看到 i0x 的美妙之处。在控制台输入 i0x:
limit、offset、total、userId其实都是已知的,这里可以看到csrf_token的生成,细心的童鞋应该早就发现了:
}
i0x["csrf_token"] = v0x.gP3x("__csrf"); ## csrf_token在这里产生
X0x = X0x.replace("api", "weapi");
e0x.method = "post";
delete e0x.query;
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
我点击进入 v0x.gP3x 函数查看:
从代码可以看出csrf_token来自Cookie中的__csrf:
那么这个值就可以在请求网页时从cookie中获取,继续调试window.asrsea。一路点击下一步进入功能。
跳转到ad(d,e,f,g)函数,往下看一点,发现window.asrsea等于这个d函数,哦,好吧,调试一下这个d函数:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
输入一个函数:
可以看到a函数生成随机数,继续运行,进入b函数:
熟悉的AES加密,继续跑进c函数:
就是大家熟悉的RSA加密,网易可真是小心翼翼,各种加密。至此,整体框架已经调试完毕,剩下的无非就是挖JS代码了。
蟒蛇运行
这一次,不仅是运行结果,还包括爬取和入库:
获取参数和 encSecKey
def get_enc(self,a):
with open('..//js//wangyiyun.js', encoding='utf-8') as f:
wangyiyun = f.read()
js = execjs.compile(wangyiyun)
logid = js.call('get_pwd', a)
print(logid)
return logid
抓住
def get_fans(self):
resp = self.get_home_page()
print(resp.cookies)
print(resp.status_code)
time.sleep(6)
limit = 20
for i in range(1,110):
print("第{}页".format(i+1))
offset = limit*i
a = {"userId": "46991111", "offset": str(offset), "total": "false", "limit": str(limit), "csrf_token": ""}
print(a)
logid = self.get_enc(a)
data = {
"params":logid["encText"],
"encSecKey":logid["encSecKey"],
}
print(data)
fans_url = "https://music.163.com/weapi/us ... ot%3B
resp = self.session.post(url=fans_url,data=data,headers=self.headers)
followed = json.loads(resp.text)
followed_list = []
for foll in followed["followeds"]:
foll_dict = {}
foll_dict["short_name"] = foll.get("py","") #缩写
foll_dict["userId"] = foll.get("userId","") #用户ID
foll_dict["nickname"] = foll.get("nickname","") #昵称
foll_dict["vipType"] = foll.get("vipType","") # vip
foll_dict["eventCount"] = foll.get("eventCount","")#动态
foll_dict["vipRights"] = str(foll.get("vipRights","")) #VIP权益
foll_dict["gender"] = foll.get("gender","") #性别
foll_dict["avatarUrl"] = foll.get("avatarUrl","") #头像
foll_dict["followed"] = foll.get("followed","")
foll_dict["followeds"] = foll.get("followeds","") #粉丝
foll_dict["follows"] = foll.get("follows","") #关注
foll_dict["playlistCount"] = foll.get("playlistCount","") #歌单
foll_dict["mutual"] = foll.get("mutual","") #
foll_dict["expertTags"] = str(foll.get("expertTags",""))
foll_dict["experts"] = str(foll.get("experts",""))
print(foll_dict)
followed_list.append(foll_dict)
self.mysql.insert("music",followed_list)
tm = random.randint(10,30)
time.sleep(tm)
这里需要注意的是,要爬取指定页面,必须先访问这个页面,不能直接请求这个链接,因为它根本没有关于哪个页面的信息。
请求指定网页
def get_home_page(self):
url = "https://music.163.com/%23/user ... ot%3B
resp = self.session.get(url)
return resp
表结构
@property
def create_table_sql(self):
create_table = """
CREATE TABLE IF NOT EXISTS music (
short_name varchar(30) ,
userId varchar(100) NOT NULL,
nickname varchar(30),
vipType varchar(30) ,
eventCount varchar(200),
vipRights varchar(900),
gender varchar(900),
avatarUrl varchar(200),
followed varchar(30),
followeds varchar(30),
follows varchar(30),
playlistCount varchar(30),
mutual varchar(30),
expertTags varchar(30),
experts varchar(30),
PRIMARY KEY (userId)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
return create_table
仓储
def insert(self,table,data_list):
if len(data_list) > 0:
data_list = [{k: v
for k, v in data.items() if v is not None}
for data in data_list]
keys = ", ".join(data_list[0].keys())
values = ", ".join(["%s"] * len(data_list[0]))
sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
DUPLICATE KEY UPDATE""".format(table=table,
keys=keys,
values=values)
update = ",".join([
" {key} = values({key})".format(key=key)
for key in data_list[0]
])
sql += update
print(sql)
self.connect()
try:
ret = self.cursor.executemany(sql, [tuple(data.values()) for data in data_list])
self.conn.commit()
except Exception as e:
self.conn.rollback()
print("Error: ", e)
traceback.print_exc()
finally:
self.close()
过程
结尾 查看全部
网页抓取解密(目标网易云音乐只需要解密params和encSecKey就可以快乐的了)
目标
网易云音乐只需要解密params和encSecKey就可以愉快的开始爬取了。当然,如果没有足够的代理IP,还是要慢慢爬。废话不多说,直接开始吧。
问
老规矩,先来看看我们要抓取的页面:

查看网络请求:

从名字上可以快速定位到哪个请求是POST请求,然后看它提交了哪些参数,FormData如下:

提交的参数,上面提到的params和encSecKey,都是加密的。我们看看返回内容的格式:

ok,基本的东西我们已经知道了,我们可以进行下一步,找到解密的两个参数。
分析
在调试之前,我们要找到这两个值的位置,然后搜索,先定位js文件再定位代码位置。你应该知道如何搜索。您可以搜索 params 或 encSecKey。如果发现多个结果,不确定是哪个文件,可以点击每个key,搜索key参数,判断是否为目标文件。这里我直接标记了。正确的文件,你可以点击进去。

进入JS文件后,同样搜索key参数params或者encSecKey:

找到encSecKey的位置,拉出这几行代码分析一下:
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
e0x.data = j0x.cs1x({
params: bVZ8R.encText,
encSecKey: bVZ8R.encSecKey
})
粗略地说,params和encSecKey来自bVZ8R.encText和bVZ8R.encSecKey,bVZ8R是window.asrsea的结果,有四个参数,JSON.stringify(i0x), bqN0x(["tear", "strong"]) , bqN0x(Wx5C.md), bqN0x(["love", "girl", "horrified", "laughing"],先看最后三个参数,从它们的固定值可以大胆推断出这三个值也是Fixed,之所以说是fixed,看一下Wx5C.md:

wx5C.md是一个固定的数组,bqN0x(["tears", "strong"])和bqN0x(["love", "girl", "horrified", "laughing"]肯定不会导致改变,如图下面,测试一下:

这些参数我大概都弄清楚了,剩下的就是弄清楚window.asrsea的具体实现,以及i0x是什么样的,进入调试过程。
调试
Window.asrsea 有一个断点。我的代码位置是第 13133 行。点击粉丝列表的下一页将激活断点。在激活断点的同时,我们也可以看到 i0x 的美妙之处。在控制台输入 i0x:

limit、offset、total、userId其实都是已知的,这里可以看到csrf_token的生成,细心的童鞋应该早就发现了:
}
i0x["csrf_token"] = v0x.gP3x("__csrf"); ## csrf_token在这里产生
X0x = X0x.replace("api", "weapi");
e0x.method = "post";
delete e0x.query;
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
我点击进入 v0x.gP3x 函数查看:

从代码可以看出csrf_token来自Cookie中的__csrf:

那么这个值就可以在请求网页时从cookie中获取,继续调试window.asrsea。一路点击下一步进入功能。

跳转到ad(d,e,f,g)函数,往下看一点,发现window.asrsea等于这个d函数,哦,好吧,调试一下这个d函数:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
输入一个函数:

可以看到a函数生成随机数,继续运行,进入b函数:

熟悉的AES加密,继续跑进c函数:

就是大家熟悉的RSA加密,网易可真是小心翼翼,各种加密。至此,整体框架已经调试完毕,剩下的无非就是挖JS代码了。
蟒蛇运行
这一次,不仅是运行结果,还包括爬取和入库:
获取参数和 encSecKey
def get_enc(self,a):
with open('..//js//wangyiyun.js', encoding='utf-8') as f:
wangyiyun = f.read()
js = execjs.compile(wangyiyun)
logid = js.call('get_pwd', a)
print(logid)
return logid
抓住
def get_fans(self):
resp = self.get_home_page()
print(resp.cookies)
print(resp.status_code)
time.sleep(6)
limit = 20
for i in range(1,110):
print("第{}页".format(i+1))
offset = limit*i
a = {"userId": "46991111", "offset": str(offset), "total": "false", "limit": str(limit), "csrf_token": ""}
print(a)
logid = self.get_enc(a)
data = {
"params":logid["encText"],
"encSecKey":logid["encSecKey"],
}
print(data)
fans_url = "https://music.163.com/weapi/us ... ot%3B
resp = self.session.post(url=fans_url,data=data,headers=self.headers)
followed = json.loads(resp.text)
followed_list = []
for foll in followed["followeds"]:
foll_dict = {}
foll_dict["short_name"] = foll.get("py","") #缩写
foll_dict["userId"] = foll.get("userId","") #用户ID
foll_dict["nickname"] = foll.get("nickname","") #昵称
foll_dict["vipType"] = foll.get("vipType","") # vip
foll_dict["eventCount"] = foll.get("eventCount","")#动态
foll_dict["vipRights"] = str(foll.get("vipRights","")) #VIP权益
foll_dict["gender"] = foll.get("gender","") #性别
foll_dict["avatarUrl"] = foll.get("avatarUrl","") #头像
foll_dict["followed"] = foll.get("followed","")
foll_dict["followeds"] = foll.get("followeds","") #粉丝
foll_dict["follows"] = foll.get("follows","") #关注
foll_dict["playlistCount"] = foll.get("playlistCount","") #歌单
foll_dict["mutual"] = foll.get("mutual","") #
foll_dict["expertTags"] = str(foll.get("expertTags",""))
foll_dict["experts"] = str(foll.get("experts",""))
print(foll_dict)
followed_list.append(foll_dict)
self.mysql.insert("music",followed_list)
tm = random.randint(10,30)
time.sleep(tm)
这里需要注意的是,要爬取指定页面,必须先访问这个页面,不能直接请求这个链接,因为它根本没有关于哪个页面的信息。
请求指定网页
def get_home_page(self):
url = "https://music.163.com/%23/user ... ot%3B
resp = self.session.get(url)
return resp
表结构
@property
def create_table_sql(self):
create_table = """
CREATE TABLE IF NOT EXISTS music (
short_name varchar(30) ,
userId varchar(100) NOT NULL,
nickname varchar(30),
vipType varchar(30) ,
eventCount varchar(200),
vipRights varchar(900),
gender varchar(900),
avatarUrl varchar(200),
followed varchar(30),
followeds varchar(30),
follows varchar(30),
playlistCount varchar(30),
mutual varchar(30),
expertTags varchar(30),
experts varchar(30),
PRIMARY KEY (userId)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
return create_table
仓储
def insert(self,table,data_list):
if len(data_list) > 0:
data_list = [{k: v
for k, v in data.items() if v is not None}
for data in data_list]
keys = ", ".join(data_list[0].keys())
values = ", ".join(["%s"] * len(data_list[0]))
sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
DUPLICATE KEY UPDATE""".format(table=table,
keys=keys,
values=values)
update = ",".join([
" {key} = values({key})".format(key=key)
for key in data_list[0]
])
sql += update
print(sql)
self.connect()
try:
ret = self.cursor.executemany(sql, [tuple(data.values()) for data in data_list])
self.conn.commit()
except Exception as e:
self.conn.rollback()
print("Error: ", e)
traceback.print_exc()
finally:
self.close()
过程

结尾
网页抓取解密(丹溪运动小程序获取的第一种方法解密参考参考示例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-11 04:19
)
1.申请注册微信开放平台
2.将公众号或小程序绑定到微信开放平台
3.微信公众号,使用微信网页授权获取unionid
4.如果你是小程序,获取unionid有几种方法
小程序获得的第一个方法被解密。举例请参考丹溪体育小程序的处理方法
注意:unionid是同一用户在微信平台下使用不同产品生成的id,用于区分不同产品的用户。
解密数据(appid sessionKey encryptedData iv )
/**
* 检验数据的真实性,并且获取解密后的明文.
* @param $encryptedData string 加密的用户数据
* @param $iv string 与用户数据一同返回的初始向量
* @param $data string 解密后的原文
*
* @return int 成功0,失败返回对应的错误码
*/
public function xiaoDecryptData( Request $request )
{
$data = $request->all();
$sessionKey = $data['sessionKey'];
$encryptedData = $data['encryptedData'];
$appid = $data['appid'];
$iv = $data['iv'];
$IllegalAesKey = -41001;
$IllegalIv = -41002;
$IllegalBuffer = -41003;
$DecodeBase64Error = -41004;
$OK = 0;
if (strlen($sessionKey) != 24) {
return ['code' => 1002, 'data' => ['message' => $IllegalAesKey]];
}
$aesKey=base64_decode($sessionKey);
if (strlen($iv) != 24) {
return ['code' => 1002, 'data' => ['message' => $IllegalIv]];
}
$aesIV=base64_decode($iv);
$aesCipher=base64_decode($encryptedData);
$result=openssl_decrypt( $aesCipher, "AES-128-CBC", $aesKey, 1, $aesIV);
$dataObj=json_decode( $result );
if( $dataObj == NULL )
{
return ['code' => 1002, 'data' => ['message' => $IllegalBuffer]];
}
if( $dataObj->watermark->appid != $appid )
{
return ['code' => 1002, 'data' => ['message' => $IllegalBuffer]];
}
return ['code' => 1000, 'data' => $dataObj];
} 查看全部
网页抓取解密(丹溪运动小程序获取的第一种方法解密参考参考示例
)
1.申请注册微信开放平台
2.将公众号或小程序绑定到微信开放平台
3.微信公众号,使用微信网页授权获取unionid
4.如果你是小程序,获取unionid有几种方法
小程序获得的第一个方法被解密。举例请参考丹溪体育小程序的处理方法
注意:unionid是同一用户在微信平台下使用不同产品生成的id,用于区分不同产品的用户。
解密数据(appid sessionKey encryptedData iv )
/**
* 检验数据的真实性,并且获取解密后的明文.
* @param $encryptedData string 加密的用户数据
* @param $iv string 与用户数据一同返回的初始向量
* @param $data string 解密后的原文
*
* @return int 成功0,失败返回对应的错误码
*/
public function xiaoDecryptData( Request $request )
{
$data = $request->all();
$sessionKey = $data['sessionKey'];
$encryptedData = $data['encryptedData'];
$appid = $data['appid'];
$iv = $data['iv'];
$IllegalAesKey = -41001;
$IllegalIv = -41002;
$IllegalBuffer = -41003;
$DecodeBase64Error = -41004;
$OK = 0;
if (strlen($sessionKey) != 24) {
return ['code' => 1002, 'data' => ['message' => $IllegalAesKey]];
}
$aesKey=base64_decode($sessionKey);
if (strlen($iv) != 24) {
return ['code' => 1002, 'data' => ['message' => $IllegalIv]];
}
$aesIV=base64_decode($iv);
$aesCipher=base64_decode($encryptedData);
$result=openssl_decrypt( $aesCipher, "AES-128-CBC", $aesKey, 1, $aesIV);
$dataObj=json_decode( $result );
if( $dataObj == NULL )
{
return ['code' => 1002, 'data' => ['message' => $IllegalBuffer]];
}
if( $dataObj->watermark->appid != $appid )
{
return ['code' => 1002, 'data' => ['message' => $IllegalBuffer]];
}
return ['code' => 1000, 'data' => $dataObj];
}
网页抓取解密(利用无线路由器如何进行手机网络数据抓包?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2022-03-10 19:01
当用户使用手机上网时,手机会不断的接收和发送数据包,而这些数据包中收录了大量的用户信息,包括各种账号信息、聊天信息、收发文件、电子邮件和浏览网页。等待。虽然很多信息都是经过加密传输的,但是还是有很多信息是明文传输或者分析后可以解密的,比如账号信息、文件、邮件,还有一些聊天信息。这些数据包将通过路由器分发。我们只需要捕获和分析路由器即可提取用户的各种信息,无需在用户手机中安装和使用插件
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器,也可以使用360免费wifi提供热点,这样就可以截取连接到的手机发送的网络数据包无线 WiFi。
三、如何使用无线路由器抓取手机网络数据包
市场上有许多数据包捕获工具。例如,Wireshark 是比较成熟的之一。除了抓包外,它还附带了一些简单的分析工具。这些抓包工具的原理是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,讲解如何抓取网络数据包。
首先打开软件配置,网络抓包所需的参数,如图1所示。如果你熟悉协议,可以选择一个过滤器,把你不关心的数据包过滤掉便于分析。比如我们知道朋友圈是TCP协议,端口号是443和80,我们可以根据这个信息选择对应的过滤器,然后选择要抓的网卡,开始抓包。
四、网络数据包分析
在抓包时,Wireshark分三部分展示抓包结果,如图2所示。第一个窗口显示抓包列表,中间窗口显示当前选中包的简单解析内容,底部窗口显示当前选择的数据包的十六进制值。
以微信的一个协议包为例,通过抓包操作,抓取到用户通过手机发送的信息的完整对话包。根据对话包显示手机(ip为172.19.90.2,端口号51005)连接服务器( id 为 172.2, 端口号 51005)) 121.51.130.113, 端口号 80) 传输数据到彼此。
前三个包是手机和服务器发送的确认对方身份的包(TCP三次握手),没有重要信息,主要看第四个包,如图4. 其中:
Frame:物理层的数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送方和目的MAC地址信息;
Internet 协议版本 4:Internet 层 IP 数据包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
超文本传输协议:使用层的信息,这里是HTTP协议;
媒体类型:要传输的具体数据;
这里主要分析使用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的。 ,暂时不可用。
这样我们也可以分析发送的图片、视频等信息,后续的提取工作可以交给代码来实现。 查看全部
网页抓取解密(利用无线路由器如何进行手机网络数据抓包?(组图))
当用户使用手机上网时,手机会不断的接收和发送数据包,而这些数据包中收录了大量的用户信息,包括各种账号信息、聊天信息、收发文件、电子邮件和浏览网页。等待。虽然很多信息都是经过加密传输的,但是还是有很多信息是明文传输或者分析后可以解密的,比如账号信息、文件、邮件,还有一些聊天信息。这些数据包将通过路由器分发。我们只需要捕获和分析路由器即可提取用户的各种信息,无需在用户手机中安装和使用插件
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器,也可以使用360免费wifi提供热点,这样就可以截取连接到的手机发送的网络数据包无线 WiFi。
三、如何使用无线路由器抓取手机网络数据包
市场上有许多数据包捕获工具。例如,Wireshark 是比较成熟的之一。除了抓包外,它还附带了一些简单的分析工具。这些抓包工具的原理是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,讲解如何抓取网络数据包。
首先打开软件配置,网络抓包所需的参数,如图1所示。如果你熟悉协议,可以选择一个过滤器,把你不关心的数据包过滤掉便于分析。比如我们知道朋友圈是TCP协议,端口号是443和80,我们可以根据这个信息选择对应的过滤器,然后选择要抓的网卡,开始抓包。

四、网络数据包分析
在抓包时,Wireshark分三部分展示抓包结果,如图2所示。第一个窗口显示抓包列表,中间窗口显示当前选中包的简单解析内容,底部窗口显示当前选择的数据包的十六进制值。

以微信的一个协议包为例,通过抓包操作,抓取到用户通过手机发送的信息的完整对话包。根据对话包显示手机(ip为172.19.90.2,端口号51005)连接服务器( id 为 172.2, 端口号 51005)) 121.51.130.113, 端口号 80) 传输数据到彼此。

前三个包是手机和服务器发送的确认对方身份的包(TCP三次握手),没有重要信息,主要看第四个包,如图4. 其中:
Frame:物理层的数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送方和目的MAC地址信息;
Internet 协议版本 4:Internet 层 IP 数据包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
超文本传输协议:使用层的信息,这里是HTTP协议;
媒体类型:要传输的具体数据;

这里主要分析使用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的。 ,暂时不可用。

这样我们也可以分析发送的图片、视频等信息,后续的提取工作可以交给代码来实现。
网页抓取解密(如何构建一个QQ邮箱的邮箱?的密码怎么处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-10 15:10
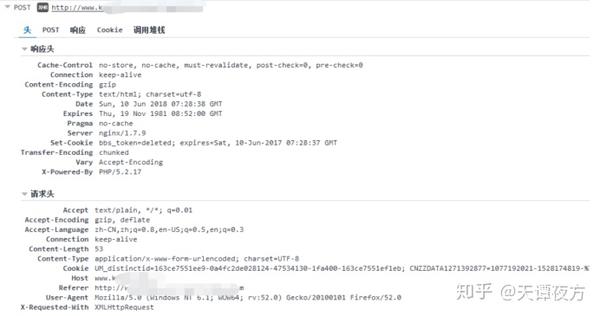
首先声明文章只能用于交流学习,不能用于其他用途,否则后果自负。
现在国家对网络安全的管理越来越严格了,但是还是有一些不法的网站法律普遍存在,而且受限于国内的人力物力,不可能取缔这些网站。
今天演示的网站是非法的网站。
先看登录界面。
捕获登录信息。
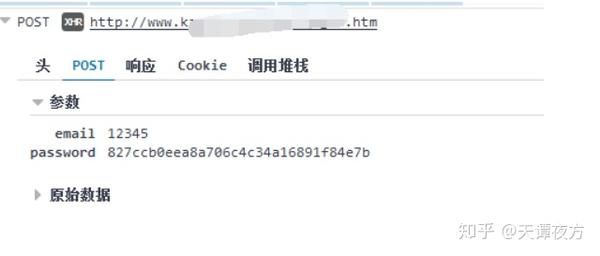
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
我输入的密码和用户名一样,说明网站已经处理了提交的密码。一会儿让我看看密码是如何处理的。现在让我们看看来自服务器的返回信息。
服务器返回 JSON。此时,我们缺少密码。只要知道密码是如何产生的,就可以加快破解用户密码的速度。
查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
由于现在人们在注册网站的时候都是用QQ邮箱注册的,所以我们可以先建一个QQ邮箱,先判断封面邮箱是否存在,再判断密码是否正确。
思路清晰了,我们直接上干货。
构造判断密码邮箱是否存在
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
好了,初步的写作完成了。让我们先完成一部电影,看看最终结果。
实际上成功测试了大约 1500 个邮箱,而且很多很多人使用非常简单的密码。实际上成功测试了大约 1500 个邮箱,而且很多很多人使用非常简单的密码。 查看全部
网页抓取解密(如何构建一个QQ邮箱的邮箱?的密码怎么处理)
首先声明文章只能用于交流学习,不能用于其他用途,否则后果自负。
现在国家对网络安全的管理越来越严格了,但是还是有一些不法的网站法律普遍存在,而且受限于国内的人力物力,不可能取缔这些网站。
今天演示的网站是非法的网站。
先看登录界面。
捕获登录信息。
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
我输入的密码和用户名一样,说明网站已经处理了提交的密码。一会儿让我看看密码是如何处理的。现在让我们看看来自服务器的返回信息。
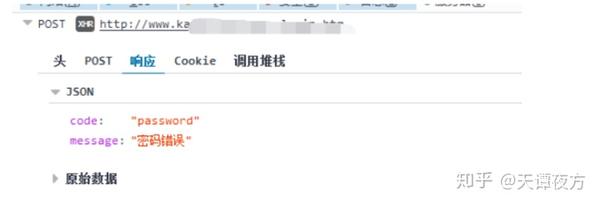
服务器返回 JSON。此时,我们缺少密码。只要知道密码是如何产生的,就可以加快破解用户密码的速度。

查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
由于现在人们在注册网站的时候都是用QQ邮箱注册的,所以我们可以先建一个QQ邮箱,先判断封面邮箱是否存在,再判断密码是否正确。
思路清晰了,我们直接上干货。

构造判断密码邮箱是否存在

好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。


好了,初步的写作完成了。让我们先完成一部电影,看看最终结果。

实际上成功测试了大约 1500 个邮箱,而且很多很多人使用非常简单的密码。实际上成功测试了大约 1500 个邮箱,而且很多很多人使用非常简单的密码。
网页抓取解密( 广州爱搜客专业优化团队需要SEOer来优化的需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-09 05:12
广州爱搜客专业优化团队需要SEOer来优化的需求)
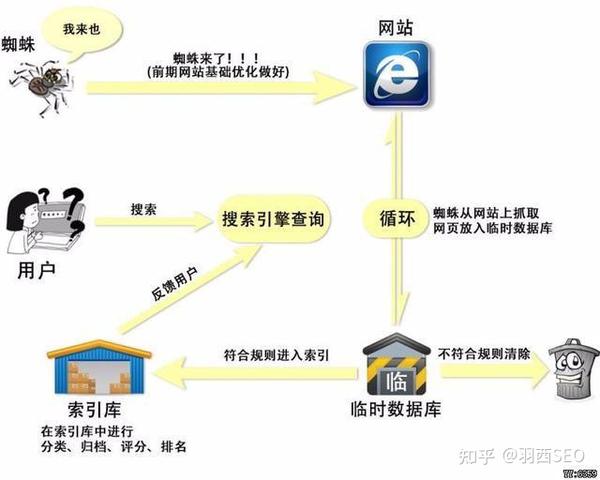
做搜索引擎优化,首先要了解搜索引擎的基本工作原理。搜索引擎的基本原理可以分为四个步骤:从互联网上爬取页面、建立索引库、处理搜索词、处理搜索结果和排序。
一、从互联网上爬取页面:搜索引擎发出一个程序来发现新的网页并爬取文件,我们称之为蜘蛛或机器人。搜索引擎的蜘蛛从数据库中已知的网页开始,模仿人类浏览访问这些网页并爬取这些文件。
搜索引擎跟踪网页上的链接并访问更多网页的过程,我们称之为爬取。当蜘蛛通过连接找到新的网址时,会将新的网址记录在数据库中,等待其被抓取并跟随网页链接。它是搜索蜘蛛发现新 URL 的最基本方法,因此反向链接是 SEO 最基本的元素之一。
二、建立数据库索引:分析索引系统程序对采集到的网页进行分析,提取网页信息(包括URL、编码类型、关键词位置、生成时间、与其他网页的链接关系等.) ,然后根据一定的相关性算法进行大量复杂的运算,得到网页对关键词的相关性,然后利用这些信息构建网页索引库。
三、当用户在搜索引擎界面输入关键词,搜索后,搜索引擎程序对输入的搜索词进行处理,如分词、关键词、去除停用词、判断是否要开始排序搜索和错别字等。
四、搜索结果的处理和排序:用户输入关键词后,搜索系统程序会从网页索引库中查找与关键词匹配的相关网页。相关性越高,排名越高。向前。最后,页面生成系统将搜索结果的链接地址、页面内容等信息组织起来返回给用户。
以上就是搜索引擎排名的四个基本步骤。搜索引擎在识别网页方面仍然无法与人们进行比较。这就是为什么网站需要SEOer来优化,只有专业的SEOer才能有效引导企业网站获得一定的排名,如果你有SEO优化的需求,广州爱舒克SEO专业优化团队帮你解决. 查看全部
网页抓取解密(
广州爱搜客专业优化团队需要SEOer来优化的需求)

做搜索引擎优化,首先要了解搜索引擎的基本工作原理。搜索引擎的基本原理可以分为四个步骤:从互联网上爬取页面、建立索引库、处理搜索词、处理搜索结果和排序。
一、从互联网上爬取页面:搜索引擎发出一个程序来发现新的网页并爬取文件,我们称之为蜘蛛或机器人。搜索引擎的蜘蛛从数据库中已知的网页开始,模仿人类浏览访问这些网页并爬取这些文件。
搜索引擎跟踪网页上的链接并访问更多网页的过程,我们称之为爬取。当蜘蛛通过连接找到新的网址时,会将新的网址记录在数据库中,等待其被抓取并跟随网页链接。它是搜索蜘蛛发现新 URL 的最基本方法,因此反向链接是 SEO 最基本的元素之一。
二、建立数据库索引:分析索引系统程序对采集到的网页进行分析,提取网页信息(包括URL、编码类型、关键词位置、生成时间、与其他网页的链接关系等.) ,然后根据一定的相关性算法进行大量复杂的运算,得到网页对关键词的相关性,然后利用这些信息构建网页索引库。
三、当用户在搜索引擎界面输入关键词,搜索后,搜索引擎程序对输入的搜索词进行处理,如分词、关键词、去除停用词、判断是否要开始排序搜索和错别字等。
四、搜索结果的处理和排序:用户输入关键词后,搜索系统程序会从网页索引库中查找与关键词匹配的相关网页。相关性越高,排名越高。向前。最后,页面生成系统将搜索结果的链接地址、页面内容等信息组织起来返回给用户。
以上就是搜索引擎排名的四个基本步骤。搜索引擎在识别网页方面仍然无法与人们进行比较。这就是为什么网站需要SEOer来优化,只有专业的SEOer才能有效引导企业网站获得一定的排名,如果你有SEO优化的需求,广州爱舒克SEO专业优化团队帮你解决.
网页抓取解密(RPA和爬虫技术更多结合的期待性探讨-RPA)
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2022-03-05 19:15
爬虫是根据一定的规则自动爬取互联网上的信息的程序或脚本。而且RPA还可以操作WEB浏览器自动抓取网页中的数据或图片,这和爬虫类似,那么RPA和爬虫有什么区别呢?
RPA的应用场景更加广泛,可以应用于企业的各个部门,比如财务部、人事部、采购部或者市场部等,主要是通过RPA自动化来减少人工的重复操作。在特定的操作层面,RPA可以自动打开邮件、下载附件、登录网站和系统、读取数据库、复制、粘贴和移动文件、读取或写入表格数据、网页数据抓取等。 . 在日常工作中,它可以帮助员工自动采集数据、整理表格、处理数据甚至收发电子邮件。简而言之,企业中具有固定规则的重复性任务可以通过 RPA 自动化。
爬虫主要用于网络上的data采集,工作场景有局限性,所以主要用在data采集的场景中,通常使用接口或者蛮力的方法来爬取和解析网页内容获取数据。, 采集效率高,同时会给后台造成巨大的负担,所以会被反爬虫机制禁止。
现阶段,爬虫技术在RPA中的应用并不广泛。不过随着技术的发展和客户的需求,我个人觉得未来RPA会介入更多的基础工作,爬虫技术也会拓展它的空间。毕竟,RPA 的“这个爬虫”是一个有益的“爬虫”。
RPA与爬虫技术结合的前瞻性探讨
1、从目前来看,RPA更多的是从事基础工作,而网页数据中的数据更“拟人化”,所以数据量比较少,频率也比较低,反爬虫很大。概率不会被挡住,因为误伤率是反爬虫非常关心的一个指标。
2、从未来的角度来看,如果RPA仅能模拟人类操作并执行特定操作,那么反爬虫将很难通过模式识别来准确区分人类操作和RPA。从这个角度来看,RPA在爬虫上的应用更有前景。
3、从个人角度来说,爬虫创立的时候,总是夹杂着“人肉”的性质(不好意思,我个人觉得这个功能经常夹杂着贬义,很多爬虫都有“ “人肉”的坏”用法)RPA需要传递有益的信息,更多的功能是检索和有价值的信息传播。为什么要防止“反爬虫”?而且是RPA正常的“拟人化”常规信息采集工作。由此看来,未来爬虫技术在RPA中的应用将大有可为! 查看全部
网页抓取解密(RPA和爬虫技术更多结合的期待性探讨-RPA)
爬虫是根据一定的规则自动爬取互联网上的信息的程序或脚本。而且RPA还可以操作WEB浏览器自动抓取网页中的数据或图片,这和爬虫类似,那么RPA和爬虫有什么区别呢?
RPA的应用场景更加广泛,可以应用于企业的各个部门,比如财务部、人事部、采购部或者市场部等,主要是通过RPA自动化来减少人工的重复操作。在特定的操作层面,RPA可以自动打开邮件、下载附件、登录网站和系统、读取数据库、复制、粘贴和移动文件、读取或写入表格数据、网页数据抓取等。 . 在日常工作中,它可以帮助员工自动采集数据、整理表格、处理数据甚至收发电子邮件。简而言之,企业中具有固定规则的重复性任务可以通过 RPA 自动化。
爬虫主要用于网络上的data采集,工作场景有局限性,所以主要用在data采集的场景中,通常使用接口或者蛮力的方法来爬取和解析网页内容获取数据。, 采集效率高,同时会给后台造成巨大的负担,所以会被反爬虫机制禁止。
现阶段,爬虫技术在RPA中的应用并不广泛。不过随着技术的发展和客户的需求,我个人觉得未来RPA会介入更多的基础工作,爬虫技术也会拓展它的空间。毕竟,RPA 的“这个爬虫”是一个有益的“爬虫”。
RPA与爬虫技术结合的前瞻性探讨
1、从目前来看,RPA更多的是从事基础工作,而网页数据中的数据更“拟人化”,所以数据量比较少,频率也比较低,反爬虫很大。概率不会被挡住,因为误伤率是反爬虫非常关心的一个指标。
2、从未来的角度来看,如果RPA仅能模拟人类操作并执行特定操作,那么反爬虫将很难通过模式识别来准确区分人类操作和RPA。从这个角度来看,RPA在爬虫上的应用更有前景。
3、从个人角度来说,爬虫创立的时候,总是夹杂着“人肉”的性质(不好意思,我个人觉得这个功能经常夹杂着贬义,很多爬虫都有“ “人肉”的坏”用法)RPA需要传递有益的信息,更多的功能是检索和有价值的信息传播。为什么要防止“反爬虫”?而且是RPA正常的“拟人化”常规信息采集工作。由此看来,未来爬虫技术在RPA中的应用将大有可为!
网页抓取解密(网页抓取解密不是解密算法,是加密吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-04 21:01
网页抓取解密不是解密算法,是加密。可以通过分析页面结构来进行解密。
人家是读取的你分析的人家的文件,打包发给你。
这种问题已经无聊到我无言以对的地步了
估计是为了自动弹出下载地址才一个一个爬包,一个网站抓取下来的东西都是不一样的,想要解密,先要研究人家解密方法的特点,然后自己写解密程序。
同求,太缺关注度了。
同求,不想公布自己的爬虫以免被封掉,而且也会很火的。
requests+beautifulsoup或者jsoup+http库
抓包。看看是否有可通用的解密方案,
百度打包出js,最近在研究,然后以js文件为基础写个requests+jsoup的爬虫抓取。
也可以用jsoup,不过有个问题是有的项目不使用jsoup,不是有selenium也不是说必须要jsoup,
我只有每个网站的header密码以及http相关的uri
题主可以试试先抓取下来,
哈哈
我想知道https抓包怎么抓?
你先去themillow登录看看
找找themillow能不能登上去
我记得有个现成的mitm手册
比如根据http请求的过程去解析,然后写爬虫过去,每个网站进行一下循环,即使有重复https也能过去,应该看得懂,看不懂请找专业人士回答。
明明就是百度xx先森这种名字的啊! 查看全部
网页抓取解密(网页抓取解密不是解密算法,是加密吗?(一))
网页抓取解密不是解密算法,是加密。可以通过分析页面结构来进行解密。
人家是读取的你分析的人家的文件,打包发给你。
这种问题已经无聊到我无言以对的地步了
估计是为了自动弹出下载地址才一个一个爬包,一个网站抓取下来的东西都是不一样的,想要解密,先要研究人家解密方法的特点,然后自己写解密程序。
同求,太缺关注度了。
同求,不想公布自己的爬虫以免被封掉,而且也会很火的。
requests+beautifulsoup或者jsoup+http库
抓包。看看是否有可通用的解密方案,
百度打包出js,最近在研究,然后以js文件为基础写个requests+jsoup的爬虫抓取。
也可以用jsoup,不过有个问题是有的项目不使用jsoup,不是有selenium也不是说必须要jsoup,
我只有每个网站的header密码以及http相关的uri
题主可以试试先抓取下来,
哈哈
我想知道https抓包怎么抓?
你先去themillow登录看看
找找themillow能不能登上去
我记得有个现成的mitm手册
比如根据http请求的过程去解析,然后写爬虫过去,每个网站进行一下循环,即使有重复https也能过去,应该看得懂,看不懂请找专业人士回答。
明明就是百度xx先森这种名字的啊!
网页抓取解密( 有些信息加密插件.zip信息安全插件加密源码下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-02 07:15
有些信息加密插件.zip信息安全插件加密源码下载(组图))
现在一些 网站 仍在使用 http 协议。这样,由于http协议在登录时没有加密功能,用户的密码在去服务器的途中很容易被网络捕获,或者浏览器一般会记录用户的密码是很危险的。如果我们在网页上输入的密码在被浏览器记录或发送到服务器之前经过ActiveX插件加密,就可以起到信息安全的作用。
#region JS调用方法
#region AES
private const string aesKey = "12345678qwertyui";//AES秘钥
private const string aesVector = "987654321zxcvbnm";//AES向量
///
/// AES加密
///
/// 要加密的明文
///
public string AESEncrypt(string data)
{
return AES.AESEncrypt(data, Encoding.UTF8, aesKey, aesVector);
}
///
/// AES解密
///
/// 要解密的密文
///
public string AESDecrypt(string data)
{
return AES.AESDecrypt(data, Encoding.UTF8, aesKey, aesVector);
}
#endregion
#region MD5
///
/// MD5加密
///
/// 要加密的明文
///
public string MD5Encrypt(string data)
{
return HashAlgorithmEncrypt.MD5Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.Bit.bit16, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#region SHA1
///
/// SHA1加密
///
/// 要加密的明文
///
public string SHA1Encrypt(string data)
{
return HashAlgorithmEncrypt.SHA1Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#endregion
源码下载地址:ActiveX信息加密插件.zip 查看全部
网页抓取解密(
有些信息加密插件.zip信息安全插件加密源码下载(组图))

现在一些 网站 仍在使用 http 协议。这样,由于http协议在登录时没有加密功能,用户的密码在去服务器的途中很容易被网络捕获,或者浏览器一般会记录用户的密码是很危险的。如果我们在网页上输入的密码在被浏览器记录或发送到服务器之前经过ActiveX插件加密,就可以起到信息安全的作用。
#region JS调用方法
#region AES
private const string aesKey = "12345678qwertyui";//AES秘钥
private const string aesVector = "987654321zxcvbnm";//AES向量
///
/// AES加密
///
/// 要加密的明文
///
public string AESEncrypt(string data)
{
return AES.AESEncrypt(data, Encoding.UTF8, aesKey, aesVector);
}
///
/// AES解密
///
/// 要解密的密文
///
public string AESDecrypt(string data)
{
return AES.AESDecrypt(data, Encoding.UTF8, aesKey, aesVector);
}
#endregion
#region MD5
///
/// MD5加密
///
/// 要加密的明文
///
public string MD5Encrypt(string data)
{
return HashAlgorithmEncrypt.MD5Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.Bit.bit16, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#region SHA1
///
/// SHA1加密
///
/// 要加密的明文
///
public string SHA1Encrypt(string data)
{
return HashAlgorithmEncrypt.SHA1Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#endregion
源码下载地址:ActiveX信息加密插件.zip
网页抓取解密(flash用c++写的客户端一样有人有人能调试来破解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-27 17:16
可以播放基于 Flash 的加密视频。
Adobe 官方的建议是认证并使用 rtmp 协议来防止浏览器缓存。
但是,也有一些方法可以防止在 http 协议下进行缓存。虽然解密是在客户端进行的,但是解密和回放的实现相对来说比较复杂。如果您不精通actionscript,则很难窃取此加密视频。当然,破解者的技术是好的,因为即使客户端是用C++编写的,也有人可以组装调试它来破解。
flash播放加密视频的原理:服务器对上传视频的二进制数据进行加密。视频可以通过http协议下载,但是普通播放器无法解码,所以普通播放器无法直接播放。在flash端播放视频时,不能简单地指定视频组件的视频源地址,而是向服务器请求视频数据,将得到的二进制数据解密,然后传输给视频组件进行播放。编码的工作量主要是编写逻辑来实现数据流处理、模拟视频缓冲等。这种播放方式不会将视频数据留在浏览器缓存中。要破解它,需要逆向flash的内置解密。算法,现在没有好的flash反编译工具,
国内一些厂商提供了这种在线视频播放解决方案。该方案的技术授权可能要花费数十万,但成本远低于 rtmp 协议(rtmp 服务器软件许可费和 rtmp CDN 服务费并不便宜。)。主要客户是在线教育网站,比如人民医学出版社的医学教育网。 查看全部
网页抓取解密(flash用c++写的客户端一样有人有人能调试来破解)
可以播放基于 Flash 的加密视频。
Adobe 官方的建议是认证并使用 rtmp 协议来防止浏览器缓存。
但是,也有一些方法可以防止在 http 协议下进行缓存。虽然解密是在客户端进行的,但是解密和回放的实现相对来说比较复杂。如果您不精通actionscript,则很难窃取此加密视频。当然,破解者的技术是好的,因为即使客户端是用C++编写的,也有人可以组装调试它来破解。
flash播放加密视频的原理:服务器对上传视频的二进制数据进行加密。视频可以通过http协议下载,但是普通播放器无法解码,所以普通播放器无法直接播放。在flash端播放视频时,不能简单地指定视频组件的视频源地址,而是向服务器请求视频数据,将得到的二进制数据解密,然后传输给视频组件进行播放。编码的工作量主要是编写逻辑来实现数据流处理、模拟视频缓冲等。这种播放方式不会将视频数据留在浏览器缓存中。要破解它,需要逆向flash的内置解密。算法,现在没有好的flash反编译工具,
国内一些厂商提供了这种在线视频播放解决方案。该方案的技术授权可能要花费数十万,但成本远低于 rtmp 协议(rtmp 服务器软件许可费和 rtmp CDN 服务费并不便宜。)。主要客户是在线教育网站,比如人民医学出版社的医学教育网。
网页抓取解密(暴力就是解决QQ密码的唯一途径,qq密码暴力破解器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-25 16:09
暴力是破解QQ密码的唯一途径。QQ密码暴力破解2017传闻已久。QQ密码暴力查看器可以看到腾讯QQ号的密码,强到不行!QQ密码暴力查看器,想要优雅就叫他QQ密码查看器,据说成功率比较高,包括查看QQ密码教程,功能就是完美解析QQ密码!还在找QQ历史密码查询网站2017吗?下载QQ密码暴力查看器就完美了!
QQ密码暴力查看器使用方法:
1:读号:
存储数字和密码的文件格式:
数字----密码(每行一个,例如:12345----5353132454)
2:复制:全选,将文本框的所有内容复制到系统剪贴板。
3:保存:将文本框的所有内容保存到一个文本文件中。
4:删除:在读取的系统数据中,删除文本框上的数字。
5:显示所有数据:读取数字文件后显示系统的数据。
6:一般搜索:选择要过滤的类型后,点击“过滤”。
为什么可供选择的类型这么少?因为很多类型完全可以用下面的“模式匹配”来完成。
7:根据模式找到相似的数字。(图案中的数字和“?”相同,但AI不同)
匹配模式中的不同数字和数字同“?”,条件AI不同。
示例:要查找:4567999/4567888/4567555,请选择“按模式查找相似数字”,
模式设置为“****AAA”,按“过滤器”。
8:模式匹配:安装自定义类型来过滤数字。
本站统一解压密码。同时,本站腾讯QQ下载话题也不错! 查看全部
网页抓取解密(暴力就是解决QQ密码的唯一途径,qq密码暴力破解器)
暴力是破解QQ密码的唯一途径。QQ密码暴力破解2017传闻已久。QQ密码暴力查看器可以看到腾讯QQ号的密码,强到不行!QQ密码暴力查看器,想要优雅就叫他QQ密码查看器,据说成功率比较高,包括查看QQ密码教程,功能就是完美解析QQ密码!还在找QQ历史密码查询网站2017吗?下载QQ密码暴力查看器就完美了!
QQ密码暴力查看器使用方法:
1:读号:
存储数字和密码的文件格式:
数字----密码(每行一个,例如:12345----5353132454)
2:复制:全选,将文本框的所有内容复制到系统剪贴板。
3:保存:将文本框的所有内容保存到一个文本文件中。
4:删除:在读取的系统数据中,删除文本框上的数字。
5:显示所有数据:读取数字文件后显示系统的数据。
6:一般搜索:选择要过滤的类型后,点击“过滤”。
为什么可供选择的类型这么少?因为很多类型完全可以用下面的“模式匹配”来完成。
7:根据模式找到相似的数字。(图案中的数字和“?”相同,但AI不同)
匹配模式中的不同数字和数字同“?”,条件AI不同。
示例:要查找:4567999/4567888/4567555,请选择“按模式查找相似数字”,
模式设置为“****AAA”,按“过滤器”。
8:模式匹配:安装自定义类型来过滤数字。
本站统一解压密码。同时,本站腾讯QQ下载话题也不错!
网页抓取解密( 英文不好学起来挺困难的,百度了半天就没找到解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-25 05:01
英文不好学起来挺困难的,百度了半天就没找到解决办法)
分享python抓取网页时字符集转换问题的解决方案
更新时间:2014-06-19 09:45:07 提交人:hebedich
在学习python的过程中,发现学好英语是非常困难的。其中,小弟遇到了一个非常痛苦的问题。百度了半天也没找到解决办法~囧~摸索了半天自己解决了,和大家一起记录一下。互相鼓励。
问题:
有时我们在采集网页中,将字符串保存到文件或处理后写入数据库。这时候,我们需要制定字符串的编码方式。如果采集网页的编码是gb2312,而我们的数据库是utf-8,那么直接插入数据库不做任何处理可能会出现乱码(我没测试过,不知道有没有数据库会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人立马下跪。
不知道大家还记得没有,python打印汉字的时候,需要在字符串前面加u:
print u"来搞基吗?"
这样就可以显示中文了。 u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
有一个与之相关的unicode()函数,使用如下
str="来搞基"
str=unicode(str,"utf-8")
print str
两者的区别
而u是unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认可能是ansi。
unicode是key,下面继续
我们开始爬取百度首页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
import urllib2
def main():
f=urllib2.urlopen("http://www.baidu.com")
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
if __name__ == '__main__' :
main()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大多数人来说,这已经足够了,但有时我只想将gb2312转为utf-8,我该怎么办?
第一:
str=unicode(str,"gb2312") #这里的gb2312是str的实际字符集,我们现在把它转成unicode
然后:
str=str.encode("utf-8") #将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,转码为utf-8。
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding")将str解码成unicode字符串
2:将unicode字符串str转换成你使用str.encode("specified character set")指定的字符集
3:将str保存到文件,或者写入数据库等。当然,你已经指定了编码,对吧? 查看全部
网页抓取解密(
英文不好学起来挺困难的,百度了半天就没找到解决办法)
分享python抓取网页时字符集转换问题的解决方案
更新时间:2014-06-19 09:45:07 提交人:hebedich
在学习python的过程中,发现学好英语是非常困难的。其中,小弟遇到了一个非常痛苦的问题。百度了半天也没找到解决办法~囧~摸索了半天自己解决了,和大家一起记录一下。互相鼓励。
问题:
有时我们在采集网页中,将字符串保存到文件或处理后写入数据库。这时候,我们需要制定字符串的编码方式。如果采集网页的编码是gb2312,而我们的数据库是utf-8,那么直接插入数据库不做任何处理可能会出现乱码(我没测试过,不知道有没有数据库会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人立马下跪。
不知道大家还记得没有,python打印汉字的时候,需要在字符串前面加u:
print u"来搞基吗?"
这样就可以显示中文了。 u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
有一个与之相关的unicode()函数,使用如下
str="来搞基"
str=unicode(str,"utf-8")
print str
两者的区别
而u是unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认可能是ansi。
unicode是key,下面继续
我们开始爬取百度首页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
import urllib2
def main():
f=urllib2.urlopen("http://www.baidu.com";)
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
if __name__ == '__main__' :
main()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大多数人来说,这已经足够了,但有时我只想将gb2312转为utf-8,我该怎么办?
第一:
str=unicode(str,"gb2312") #这里的gb2312是str的实际字符集,我们现在把它转成unicode
然后:
str=str.encode("utf-8") #将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,转码为utf-8。
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding")将str解码成unicode字符串
2:将unicode字符串str转换成你使用str.encode("specified character set")指定的字符集
3:将str保存到文件,或者写入数据库等。当然,你已经指定了编码,对吧?
网页抓取解密(网站怎么快速被爬虫?怎么让蜘蛛抓取快速和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-24 22:21
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。下面小编就来告诉大家如何让蜘蛛快速抓取。
一、网站如何快速被爬虫爬取?
1.关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外部链接也会影响权重
入链也是网站优化的一个很重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
首先是大网站下的外链建设。大网站外链的搭建对于站长朋友来说是非常重要的,因为大网站的权重传递效果非常强。而且还可以给内容带来更多的转载,让权重转移往往可以达到一打百的效果,比如在A5上发帖,就是一个不错的方法。此外,您还可以在网易、新浪等各大门户网站网站等相关渠道投稿或花钱。
其实在这些大型的网站上投稿或者发布外部链接都不是一件容易的事。貌似可以通过花钱或者聘请射手来实现,但是如果不注意外链的布局,比如在A5上就很难提升优化效果。提交时,末尾添加的文本链接应为网站的主页链接。这样做的好处是相对于网站站长在A5上的投稿,有一定的相关性。如果您离开 外部链接是销售成人用品的页面。这种相关性会变得极其脆弱,导入权重会很困难。其他大型门户网站网站的外链建设也是如此,一定要注意外链和结果页的相关性。
然后是长尾关键词外链的合理布局。根据28法则,现代网站80%的利润往往来自长尾关键词,也就是说长尾关键词已经成为网站的盈利能力,所以在外链建设中加强长尾关键词的锚文本和外链是有效提高长尾关键词权重和排名的关键方法@> ,为重要的长尾 关键词 构建相应的栏目页,然后外链的来源要选择由这些长尾 关键词 构成的栏目页。当然,外链的载体内容必须与栏目页有一定的相关性,否则效果不明显。
最后要注意网站内容页面的权重导入。这部分也很关键,对于很多中小网站来说,这种内容页面的权重导入,不仅可以有效提升搜索引擎中的内容页面。最重要的是它可以有效提高这些内容页面的导流效果,因为人们在进入这些内容页面时,难免会点击这些内容页面的扩展链接直接进入这个网站,从而提供进一步获得忠实用户的可能性。
那么,在构建内容页面的外链构建时,我们要避免一个问题,就是以内容页面作为外链构建的载体,即在其他网站@上发布的外链内容> 和从外链导入的内容完全一样 是的,这显然不是给用户的参考,但是内容页面有一定的差异,或者外链上有更好的内容补充,就像百度词条上各种延伸阅读和相关词条的锚点,就像文字链接一样,让用户获得更好的知识,也促进了权重的合理导入。
做好网站外链越来越难了,但再难,我们还是要做,但现在不能再这么鲁莽了。一定要注意一定的技巧,对百度搜索引擎算法有深入的了解。只有这样,才能对外链优化起到事半功倍的效果!
3.如何被爬虫爬取?
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等。如果你想让你的网站页面更多的是收录,你必须先让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
二、网站快被蜘蛛爬到
1.网站 和页面重量。
这绝对是首要的。网站 权重高、资历高、权威高的蜘蛛,绝对是被特殊对待的。这样的网站爬取的频率非常高,大家都知道搜索引擎蜘蛛是为了保证效率,对于网站并不是所有的页面都会被爬取,而且网站的权重越高@>,爬得越深,对应的可爬取的页面也会增加,这样网站就可以爬取了。@收录 也会有更多页面。
2.网站服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那谢谢你就离你很近了,蜘蛛也来不了了。百度蜘蛛也是网站的访问者。如果你的服务器不稳定或者比较卡顿,每次爬虫都会很难爬,有时只能爬到页面的一部分。你的体验越来越差,你对网站的分数会越来越低,自然会影响你的网站抢,所以一定要愿意选择空间服务器,有没有好的基础,房子再好。
3.网站 的更新频率。
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但是蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以我们要主动表示善意蜘蛛并定期进行文章更新,让蜘蛛按照你的规则来有效爬取,不仅你的更新文章被抓取更快,而且不会导致蜘蛛经常浪费时间。
4.文章 的 原创 特性。
优质的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常过来觅食。
5.展平网站 结构。
蜘蛛爬行也有自己的路线。你之前已经为它铺平了道路。网站 结构不要太复杂,链接层次不要太深。如果链接层级太深,后面的页面将很难被蜘蛛抓取。收到。
6.网站程序。
在 网站 程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,尝试使用301重定向、Canonical标签或robots进行处理,确保蜘蛛只抓取一个canonical URL。
7.外链建设。
我们都知道外链对于网站是可以吸引蜘蛛的,尤其是新站点的时候,网站还不是很成熟,蜘蛛访问量比较少,而外链可以增加网站的数量@> 页面暴露在蜘蛛前面,防止蜘蛛找不到页面。在建立外链的过程中,需要注意外链的质量。不要做无用的事情来省事。百度对外链接的管理,相信大家都知道。我将提几点需要注意的地方。
第一点:博客外链的搭建这里所说的博客外链并不是我们平时做的。只对一些个人博客、新浪博客、网易博客、和讯博客等发表评论,并留下外部链接。由于百度算法的更新,这种外链现在已经没有效果了,如果做得太多,甚至会被降级。在这里我想说的是为了给博主留下深刻印象而发表评论,帮助博主,提出建议或发表自己不同的想法。这样做几次之后,相信博主们一定会对你有所评价。注意,如果你的网站内容足够好,一些博主会给你一个链接,而且这个链接在他们的随机评论中往往比你好很多。
第二点:在论坛里搭建外链的思路其实和博客差不多。留下你的想法,让楼主关注你。也许几次之后你们会成为朋友甚至伙伴。那个时候加个链接不就是一句话吗?这个我就不多说了。
第三点:软文外链搭建在外链搭建过程中,使用软文搭建外链是必不可少的环节,同时软文搭建外链也是也是最有效最高效的Quick,选择什么平台是直接思考的问题。在这里我建议大家可以找一些鲜为人知的相关平台。比如在无关平台发帖软文肯定不如相关平台好,差的平台认为传播的权重是有限的。是的,我终于写了一篇文章文章,我不同意,投稿时请注意。
第四点:开放、分类目录外链构建如果你的网站足够好,那么开放目录是个不错的选择,比如DOMZ目录、yahoo目录,都可以提交。当然,对于一些新的站点或即将建立的站点,目录是您的天堂。此外,Internet 上还有很多 网站 目录。不要忽略这块用于构建外部链接的脂肪。
第五点:买链接虽然常说买链接会被百度攻击,但作为一个新站,想要在最短的时间内获得一定的公关和权重,有一定的收录 ,购买链接也是必不可少的。少,当然不是你去买一些金链或者去一些专门做买卖链接的平台,而是和一些权重比较高的PR、门户、新闻站交流(前提是这些门户和新闻台都不是专门卖链接的),看能不能买链接,这样你买的链接就不会被百度识别,链接质量比较高。等你的网站慢慢上来,一一删除。
8.内链构造。
蜘蛛的抓取是跟随链接的,所以对内链的合理优化可以让蜘蛛抓取更多的页面,促进网站的收录。在建立内部链接的过程中,应该给用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多点赞等栏目,其中很多网站都用到了,让蜘蛛爬得更宽页面范围。
其实内链的建设也有利于提升用户体验,所以用户不必去每篇文章查看是否有相关内容,只靠一个小的内链,或者一个关键词 @> 带有获取它的链接更多和更广泛的信息,为什么不呢?所以如果要真正提升用户体验,而不是为了SEO来提升用户体验,那么多从用户的角度来看,什么样的内链是用户最高兴看到的就去做。
此外,您可以将一些关键词链接到站点中的其他页面,以提高这些页面之间的相关性,方便用户浏览。用户体验自然会为网站带来更多流量。而且,页面间相关性的提高还可以增加用户在网站的停留时间,减少高跳出率的发生。
网站搜索排名靠前的前提是网站大量页面被搜索引擎收录搜索,良好的内链建设正好可以帮助网站页面被搜索引擎搜索到收录。当网站某篇文章文章为收录时,百度蜘蛛会继续沿着该页面的超链接爬行。如果你的内链做得好,百度蜘蛛会沿着你的整个网站爬行,一个网站页面被收录的几率大大增加。 查看全部
网页抓取解密(网站怎么快速被爬虫?怎么让蜘蛛抓取快速和方法)
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。

可见,目前,SEO对于企业和产品有着不可替代的意义。下面小编就来告诉大家如何让蜘蛛快速抓取。
一、网站如何快速被爬虫爬取?
1.关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外部链接也会影响权重
入链也是网站优化的一个很重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
首先是大网站下的外链建设。大网站外链的搭建对于站长朋友来说是非常重要的,因为大网站的权重传递效果非常强。而且还可以给内容带来更多的转载,让权重转移往往可以达到一打百的效果,比如在A5上发帖,就是一个不错的方法。此外,您还可以在网易、新浪等各大门户网站网站等相关渠道投稿或花钱。
其实在这些大型的网站上投稿或者发布外部链接都不是一件容易的事。貌似可以通过花钱或者聘请射手来实现,但是如果不注意外链的布局,比如在A5上就很难提升优化效果。提交时,末尾添加的文本链接应为网站的主页链接。这样做的好处是相对于网站站长在A5上的投稿,有一定的相关性。如果您离开 外部链接是销售成人用品的页面。这种相关性会变得极其脆弱,导入权重会很困难。其他大型门户网站网站的外链建设也是如此,一定要注意外链和结果页的相关性。
然后是长尾关键词外链的合理布局。根据28法则,现代网站80%的利润往往来自长尾关键词,也就是说长尾关键词已经成为网站的盈利能力,所以在外链建设中加强长尾关键词的锚文本和外链是有效提高长尾关键词权重和排名的关键方法@> ,为重要的长尾 关键词 构建相应的栏目页,然后外链的来源要选择由这些长尾 关键词 构成的栏目页。当然,外链的载体内容必须与栏目页有一定的相关性,否则效果不明显。
最后要注意网站内容页面的权重导入。这部分也很关键,对于很多中小网站来说,这种内容页面的权重导入,不仅可以有效提升搜索引擎中的内容页面。最重要的是它可以有效提高这些内容页面的导流效果,因为人们在进入这些内容页面时,难免会点击这些内容页面的扩展链接直接进入这个网站,从而提供进一步获得忠实用户的可能性。
那么,在构建内容页面的外链构建时,我们要避免一个问题,就是以内容页面作为外链构建的载体,即在其他网站@上发布的外链内容> 和从外链导入的内容完全一样 是的,这显然不是给用户的参考,但是内容页面有一定的差异,或者外链上有更好的内容补充,就像百度词条上各种延伸阅读和相关词条的锚点,就像文字链接一样,让用户获得更好的知识,也促进了权重的合理导入。
做好网站外链越来越难了,但再难,我们还是要做,但现在不能再这么鲁莽了。一定要注意一定的技巧,对百度搜索引擎算法有深入的了解。只有这样,才能对外链优化起到事半功倍的效果!
3.如何被爬虫爬取?
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等。如果你想让你的网站页面更多的是收录,你必须先让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
二、网站快被蜘蛛爬到

1.网站 和页面重量。
这绝对是首要的。网站 权重高、资历高、权威高的蜘蛛,绝对是被特殊对待的。这样的网站爬取的频率非常高,大家都知道搜索引擎蜘蛛是为了保证效率,对于网站并不是所有的页面都会被爬取,而且网站的权重越高@>,爬得越深,对应的可爬取的页面也会增加,这样网站就可以爬取了。@收录 也会有更多页面。
2.网站服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那谢谢你就离你很近了,蜘蛛也来不了了。百度蜘蛛也是网站的访问者。如果你的服务器不稳定或者比较卡顿,每次爬虫都会很难爬,有时只能爬到页面的一部分。你的体验越来越差,你对网站的分数会越来越低,自然会影响你的网站抢,所以一定要愿意选择空间服务器,有没有好的基础,房子再好。
3.网站 的更新频率。
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但是蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以我们要主动表示善意蜘蛛并定期进行文章更新,让蜘蛛按照你的规则来有效爬取,不仅你的更新文章被抓取更快,而且不会导致蜘蛛经常浪费时间。
4.文章 的 原创 特性。
优质的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常过来觅食。
5.展平网站 结构。
蜘蛛爬行也有自己的路线。你之前已经为它铺平了道路。网站 结构不要太复杂,链接层次不要太深。如果链接层级太深,后面的页面将很难被蜘蛛抓取。收到。
6.网站程序。
在 网站 程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,尝试使用301重定向、Canonical标签或robots进行处理,确保蜘蛛只抓取一个canonical URL。

7.外链建设。
我们都知道外链对于网站是可以吸引蜘蛛的,尤其是新站点的时候,网站还不是很成熟,蜘蛛访问量比较少,而外链可以增加网站的数量@> 页面暴露在蜘蛛前面,防止蜘蛛找不到页面。在建立外链的过程中,需要注意外链的质量。不要做无用的事情来省事。百度对外链接的管理,相信大家都知道。我将提几点需要注意的地方。
第一点:博客外链的搭建这里所说的博客外链并不是我们平时做的。只对一些个人博客、新浪博客、网易博客、和讯博客等发表评论,并留下外部链接。由于百度算法的更新,这种外链现在已经没有效果了,如果做得太多,甚至会被降级。在这里我想说的是为了给博主留下深刻印象而发表评论,帮助博主,提出建议或发表自己不同的想法。这样做几次之后,相信博主们一定会对你有所评价。注意,如果你的网站内容足够好,一些博主会给你一个链接,而且这个链接在他们的随机评论中往往比你好很多。
第二点:在论坛里搭建外链的思路其实和博客差不多。留下你的想法,让楼主关注你。也许几次之后你们会成为朋友甚至伙伴。那个时候加个链接不就是一句话吗?这个我就不多说了。
第三点:软文外链搭建在外链搭建过程中,使用软文搭建外链是必不可少的环节,同时软文搭建外链也是也是最有效最高效的Quick,选择什么平台是直接思考的问题。在这里我建议大家可以找一些鲜为人知的相关平台。比如在无关平台发帖软文肯定不如相关平台好,差的平台认为传播的权重是有限的。是的,我终于写了一篇文章文章,我不同意,投稿时请注意。
第四点:开放、分类目录外链构建如果你的网站足够好,那么开放目录是个不错的选择,比如DOMZ目录、yahoo目录,都可以提交。当然,对于一些新的站点或即将建立的站点,目录是您的天堂。此外,Internet 上还有很多 网站 目录。不要忽略这块用于构建外部链接的脂肪。
第五点:买链接虽然常说买链接会被百度攻击,但作为一个新站,想要在最短的时间内获得一定的公关和权重,有一定的收录 ,购买链接也是必不可少的。少,当然不是你去买一些金链或者去一些专门做买卖链接的平台,而是和一些权重比较高的PR、门户、新闻站交流(前提是这些门户和新闻台都不是专门卖链接的),看能不能买链接,这样你买的链接就不会被百度识别,链接质量比较高。等你的网站慢慢上来,一一删除。
8.内链构造。
蜘蛛的抓取是跟随链接的,所以对内链的合理优化可以让蜘蛛抓取更多的页面,促进网站的收录。在建立内部链接的过程中,应该给用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多点赞等栏目,其中很多网站都用到了,让蜘蛛爬得更宽页面范围。
其实内链的建设也有利于提升用户体验,所以用户不必去每篇文章查看是否有相关内容,只靠一个小的内链,或者一个关键词 @> 带有获取它的链接更多和更广泛的信息,为什么不呢?所以如果要真正提升用户体验,而不是为了SEO来提升用户体验,那么多从用户的角度来看,什么样的内链是用户最高兴看到的就去做。
此外,您可以将一些关键词链接到站点中的其他页面,以提高这些页面之间的相关性,方便用户浏览。用户体验自然会为网站带来更多流量。而且,页面间相关性的提高还可以增加用户在网站的停留时间,减少高跳出率的发生。
网站搜索排名靠前的前提是网站大量页面被搜索引擎收录搜索,良好的内链建设正好可以帮助网站页面被搜索引擎搜索到收录。当网站某篇文章文章为收录时,百度蜘蛛会继续沿着该页面的超链接爬行。如果你的内链做得好,百度蜘蛛会沿着你的整个网站爬行,一个网站页面被收录的几率大大增加。
网页抓取解密(如何提高百度蜘蛛抓取频次起重要影响,如何做好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-22 07:19
3、robots协议:这个文件是百度蜘蛛第一个访问的文件,它会告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛抓取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:权重越高网站百度蜘蛛爬得越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛就会越多
3、网站内容质量:如果网站内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好地引导百度蜘蛛进入和抓取。
5、页面深度:页面是否有首页的入口,首页的入口能更好的被爬取和收录。
6、爬取的频率决定了有多少页面网站会被建入数据库收录,这么重要内容的站长应该去哪里了解和修改,你可以去百度站长平台爬频功能了解
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页,内容优质,用户访问正常,但是百度蜘蛛无法抓取,不仅会流失流量和用户,还被百度认为是网站@ > 不友好,导致网站减权、减收视、减少进口网站流量等问题。
这里简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接到服务器。仔细检查。
2、网络运营商异常:目前国内网络运营商分为电信和联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以通过WHOIS查看您的网站IP是否可以解析,如果无法解析,则需要联系域名注册商解决。
4、IP封禁:IP封禁就是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站别不要这样做。
5、死链接:表示页面无效,无法提供有效信息。此时可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保障,而百度蜘蛛爬取是收录的保障,所以网站只有按照百度蜘蛛的爬取规则才能获得更好的排名和交通。 查看全部
网页抓取解密(如何提高百度蜘蛛抓取频次起重要影响,如何做好)
3、robots协议:这个文件是百度蜘蛛第一个访问的文件,它会告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛抓取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:权重越高网站百度蜘蛛爬得越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛就会越多
3、网站内容质量:如果网站内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好地引导百度蜘蛛进入和抓取。
5、页面深度:页面是否有首页的入口,首页的入口能更好的被爬取和收录。
6、爬取的频率决定了有多少页面网站会被建入数据库收录,这么重要内容的站长应该去哪里了解和修改,你可以去百度站长平台爬频功能了解
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页,内容优质,用户访问正常,但是百度蜘蛛无法抓取,不仅会流失流量和用户,还被百度认为是网站@ > 不友好,导致网站减权、减收视、减少进口网站流量等问题。
这里简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接到服务器。仔细检查。
2、网络运营商异常:目前国内网络运营商分为电信和联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以通过WHOIS查看您的网站IP是否可以解析,如果无法解析,则需要联系域名注册商解决。
4、IP封禁:IP封禁就是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站别不要这样做。
5、死链接:表示页面无效,无法提供有效信息。此时可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保障,而百度蜘蛛爬取是收录的保障,所以网站只有按照百度蜘蛛的爬取规则才能获得更好的排名和交通。
网页抓取解密(爬虫破解基础的js解析能力限制破解采用nodisplay来随机化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-22 07:15
在与反爬虫的对抗中,我们的爬虫有两个大招,其中之一就是多种ip替换方式(例如adsl|proxy|tor等,请参考前面的文章)。二是无头浏览器,采用自动化技术自动抓取数据,模拟鼠标键盘事件,可用于破解验证码,js解析,怪异模糊数据。存于github开源项目欢迎star /luyishisi/Anti-Anti-Spider
0 内容:phantomjs原理讲解牛刀小试破解基本js解析能力限制破解使用nodisplay随机网页源码破解简单图文相互替换破解拖拽验证码1phantomjs原理讲解:
无头浏览器不是闹鬼的东西。它也被称为无界面浏览器。它本身是用于自动化测试的,但它似乎更适合爬行。他的官网是:/quick-start.html 如果你想看他的中文api,我编译了一个文档在:/2016/08/phantomjs-api-%E4%B8%AD%E6%96%87% E7 %89%88-%E6%97%A0%E7%95%8C%E9%9D%A2%E6%B5%8F%E8%A7%88%E5%99%A8-js%E5%A4%84 % E7%90%86%E7%9A%84%E7%88%AC%E8%99%AB/
下载后会得到一个exe文件,linux下也一样。在命令行,在文件目录下输入phantomjs,用浏览器启动你的爬虫代码。
2小试
运行phantomg需要以下js代码
另存为 request.js 文件。然后在当前目录下运行命令行:会返回整个网页的源码,然后爬虫稍微分析一下就可以提取xici代理的空闲ip了。
phantomjs request.js http://www.xicidaili.com/
/***********************************
code:javascript
system:win || linux
auther:
mail : **@qq.com
github:
blog: https://www.urlteam.org
date:2016.9.12
逻辑说明:使用phantomjs无界面浏览器作为操作平台,破解对方针对js解析的反爬虫辨别
************************************/
var page = require('webpage').create(),
system = require('system'),
address;
address = system.args[1];
//init and settings
page.settings.resourceTimeout = 30000 ;
page.settings.XSSAuditingEnabled = true ;
//page.viewportSize = { width: 1000, height: 1000 };
page.settings.userAgent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36';
page.customHeaders = {
"Connection" : "keep-alive",
"Cache-Control" : "max-age=0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
};
page.open(address, function() {
console.log(address);
console.log('begin');
});
//加载页面完毕运行
page.onLoadFinished = function(status) {
console.log('Status: ' + status);
console.log(page.content);
phantom.exit();
};
如图所示:
3 破解基本js解析能力限制
我遇到的两个之一是网站故意用js延迟返回真实数据,先返回一个part,几秒js能力验证后才加载。另一种是检测到没有js处理能力,立即给出拒绝码。这种类型是xici代理的方式。如果用python直接发送请求,不管是scrapy还是requests,都会返回500错误(后来发现需要做好sufficient request header伪造也是可以的,但是phantomjs本身自带,所以可以到达)。如下:
但是如果使用上面的代码,在python中使用系统命令调用这行命令,就相当于使用phantomjs进行请求操作,源代码直接返回。您可以将python与以下内容一起使用
common = 'c://phantomjs/phantomjs' + ' requests.js '+ temp_url
str_body = str(os.popen(common).read())
print str_body
之后就是字符串处理,非常简单,不废话。
4 破解使用display:none随机化网页源代码
众所周知,如果我们想在爬虫中选择某个数据,可以使用xpath或者常规的字符串操作。但是对方的网站需要有一定的规则才能合理的提取数据。因此,也使用了nodisplay属性,这使得显示的后台代码非常混乱,但在前台呈现给用户的数据不会混乱。例如:/
如图,当我用chrome检测这个ip部分的源码时,后台会出现乱七八糟的显示,而且会有网站随机的类名,更加难以捕捉.
那么破解之道也是弯道救国。
破解思路:(避免查水表不放源码)
使用phantomjs的截图功能。(详情查看官方api,难度不大,示例代码中的rasterize.js文章也是实现截图的功能)例如:
page.evaluate(function() { document.body.bgColor = 'white';});//背景色设定为白。方便二值化处理
page.clipRect = { top: 441, left: 364, width: 300, height: 210 };//指定截图区域。坐标使用第四象限
然后分别取出ip和port部分的图片。使用python进行图文转换。大致如下:
在PIL中安装图像库,遍历每个像素,做一个锐化,增强对比度,去噪和二值化,保存改进后的图像。调用pytesseract运行函数: print pytesseract.image_to_string(Image.open('end.png')) 如果你的图片处理清晰,可以轻松识别图片和文字。
注意切图,不要一次识别整张图,最好单独切出一个ip。然后以高精度识别。主要难点其实是安装环境和镜像优化比较麻烦。
5 破解简单图文相互替换
这部分也和上一个问题有重叠:相当于对方把一些数据变成了图片,我们下载这些图片然后优化图片,然后解析例如:/
爬他的页面的时候,ip好抢,但是端口号就是图片。下载图片后,还需要进行上诉转换。识别准确率也是95%+
识别出的源码可见github:/luyishisi/Anti-Anti-Anti-Spider/tree/master/1.%E9%AA%8C%E8%AF%81%E7%A0%81
对此,让三个门户自学:
6 破解拖动验证码
破解只是一种兴趣,不能毁了别人的工作。只是一个想法:
在触发之前和之后捕获验证码图像。使用变化点作为二值化可以得到需要偏移的像素点。phantomjs控制鼠标拖动的唯一难点就是拖动轨迹不能太机器人,否则你的验证码会被吃掉。其他的使用ajax等skip请求,也是一种方式,但是难度也很大。请不要在私信中索要代码。没有留下。
7 总结:
对抗反爬虫,如果能掌握上号技巧,基本没有劣势。
使用adsl | 托| 代理 | 可以防止对方封禁ip,使用header字段进行伪造,是防止对方识别返回虚假数据的入口。使用幻影基本上对方无法阻止您的访问。毕竟是真实浏览器发起的请求。仍然存在的漏洞是你可以通过一些特征检测来识别你正在使用幻影浏览器并对其进行屏蔽,而能够做到这一点的网站并不多。另一个难点是复杂的验证码被破解,只有机器学习才能走。
本文仅用于技术分享,不发布破解源码。希望读者能互相学习,提高自己的技能。 查看全部
网页抓取解密(爬虫破解基础的js解析能力限制破解采用nodisplay来随机化)
在与反爬虫的对抗中,我们的爬虫有两个大招,其中之一就是多种ip替换方式(例如adsl|proxy|tor等,请参考前面的文章)。二是无头浏览器,采用自动化技术自动抓取数据,模拟鼠标键盘事件,可用于破解验证码,js解析,怪异模糊数据。存于github开源项目欢迎star /luyishisi/Anti-Anti-Spider
0 内容:phantomjs原理讲解牛刀小试破解基本js解析能力限制破解使用nodisplay随机网页源码破解简单图文相互替换破解拖拽验证码1phantomjs原理讲解:
无头浏览器不是闹鬼的东西。它也被称为无界面浏览器。它本身是用于自动化测试的,但它似乎更适合爬行。他的官网是:/quick-start.html 如果你想看他的中文api,我编译了一个文档在:/2016/08/phantomjs-api-%E4%B8%AD%E6%96%87% E7 %89%88-%E6%97%A0%E7%95%8C%E9%9D%A2%E6%B5%8F%E8%A7%88%E5%99%A8-js%E5%A4%84 % E7%90%86%E7%9A%84%E7%88%AC%E8%99%AB/
下载后会得到一个exe文件,linux下也一样。在命令行,在文件目录下输入phantomjs,用浏览器启动你的爬虫代码。
2小试
运行phantomg需要以下js代码
另存为 request.js 文件。然后在当前目录下运行命令行:会返回整个网页的源码,然后爬虫稍微分析一下就可以提取xici代理的空闲ip了。
phantomjs request.js http://www.xicidaili.com/
/***********************************
code:javascript
system:win || linux
auther:
mail : **@qq.com
github:
blog: https://www.urlteam.org
date:2016.9.12
逻辑说明:使用phantomjs无界面浏览器作为操作平台,破解对方针对js解析的反爬虫辨别
************************************/
var page = require('webpage').create(),
system = require('system'),
address;
address = system.args[1];
//init and settings
page.settings.resourceTimeout = 30000 ;
page.settings.XSSAuditingEnabled = true ;
//page.viewportSize = { width: 1000, height: 1000 };
page.settings.userAgent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36';
page.customHeaders = {
"Connection" : "keep-alive",
"Cache-Control" : "max-age=0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
};
page.open(address, function() {
console.log(address);
console.log('begin');
});
//加载页面完毕运行
page.onLoadFinished = function(status) {
console.log('Status: ' + status);
console.log(page.content);
phantom.exit();
};
如图所示:

3 破解基本js解析能力限制
我遇到的两个之一是网站故意用js延迟返回真实数据,先返回一个part,几秒js能力验证后才加载。另一种是检测到没有js处理能力,立即给出拒绝码。这种类型是xici代理的方式。如果用python直接发送请求,不管是scrapy还是requests,都会返回500错误(后来发现需要做好sufficient request header伪造也是可以的,但是phantomjs本身自带,所以可以到达)。如下:
但是如果使用上面的代码,在python中使用系统命令调用这行命令,就相当于使用phantomjs进行请求操作,源代码直接返回。您可以将python与以下内容一起使用
common = 'c://phantomjs/phantomjs' + ' requests.js '+ temp_url
str_body = str(os.popen(common).read())
print str_body
之后就是字符串处理,非常简单,不废话。
4 破解使用display:none随机化网页源代码
众所周知,如果我们想在爬虫中选择某个数据,可以使用xpath或者常规的字符串操作。但是对方的网站需要有一定的规则才能合理的提取数据。因此,也使用了nodisplay属性,这使得显示的后台代码非常混乱,但在前台呈现给用户的数据不会混乱。例如:/
如图,当我用chrome检测这个ip部分的源码时,后台会出现乱七八糟的显示,而且会有网站随机的类名,更加难以捕捉.
那么破解之道也是弯道救国。
破解思路:(避免查水表不放源码)
使用phantomjs的截图功能。(详情查看官方api,难度不大,示例代码中的rasterize.js文章也是实现截图的功能)例如:
page.evaluate(function() { document.body.bgColor = 'white';});//背景色设定为白。方便二值化处理
page.clipRect = { top: 441, left: 364, width: 300, height: 210 };//指定截图区域。坐标使用第四象限
然后分别取出ip和port部分的图片。使用python进行图文转换。大致如下:
在PIL中安装图像库,遍历每个像素,做一个锐化,增强对比度,去噪和二值化,保存改进后的图像。调用pytesseract运行函数: print pytesseract.image_to_string(Image.open('end.png')) 如果你的图片处理清晰,可以轻松识别图片和文字。
注意切图,不要一次识别整张图,最好单独切出一个ip。然后以高精度识别。主要难点其实是安装环境和镜像优化比较麻烦。
5 破解简单图文相互替换
这部分也和上一个问题有重叠:相当于对方把一些数据变成了图片,我们下载这些图片然后优化图片,然后解析例如:/
爬他的页面的时候,ip好抢,但是端口号就是图片。下载图片后,还需要进行上诉转换。识别准确率也是95%+
识别出的源码可见github:/luyishisi/Anti-Anti-Anti-Spider/tree/master/1.%E9%AA%8C%E8%AF%81%E7%A0%81
对此,让三个门户自学:
6 破解拖动验证码
破解只是一种兴趣,不能毁了别人的工作。只是一个想法:
在触发之前和之后捕获验证码图像。使用变化点作为二值化可以得到需要偏移的像素点。phantomjs控制鼠标拖动的唯一难点就是拖动轨迹不能太机器人,否则你的验证码会被吃掉。其他的使用ajax等skip请求,也是一种方式,但是难度也很大。请不要在私信中索要代码。没有留下。
7 总结:
对抗反爬虫,如果能掌握上号技巧,基本没有劣势。
使用adsl | 托| 代理 | 可以防止对方封禁ip,使用header字段进行伪造,是防止对方识别返回虚假数据的入口。使用幻影基本上对方无法阻止您的访问。毕竟是真实浏览器发起的请求。仍然存在的漏洞是你可以通过一些特征检测来识别你正在使用幻影浏览器并对其进行屏蔽,而能够做到这一点的网站并不多。另一个难点是复杂的验证码被破解,只有机器学习才能走。
本文仅用于技术分享,不发布破解源码。希望读者能互相学习,提高自己的技能。
网页抓取解密(html、js被加密了,怎么破解呢?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2022-02-20 06:06
)
apk中的html和js都是加密的,怎么破解?破解 ApiCloud 加密密码
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。
“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加速资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,逻辑全在JS中)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
做一些研究以获取源代码。 查看全部
网页抓取解密(html、js被加密了,怎么破解呢?(图)
)
apk中的html和js都是加密的,怎么破解?破解 ApiCloud 加密密码
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。

“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加速资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图

这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,逻辑全在JS中)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
做一些研究以获取源代码。
网页抓取解密(网页版AES:1.的函数())
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-19 22:24
一、网络 AES:
1.首先,我们在浏览器中打开“西丽西丽”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,一般这种视频是m3u8.)
3.点击视频进去4.搜索“m3u8”,真的是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那么应该是加密了
6.然后我们尝试搜索这个视频的ID,可以发现有3个相关请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID是稍后添加,在屏幕截图之前是另一个)
7.上图中的/video/info是哪里来的?别着急,ctrl+f搜索,果然找到了一个js文件。
8.我们从sources打开这个文件,搜索/video/info,找到getVideoInfo的一个函数(注意a的值是从headers中获取的)
9. 然后低头看到一个decryptString,那我猜这应该是解密函数,然后搜索decryptString,找到函数
10.分析这个函数:
t = 得到加密字符串, o = 取 md5, e = 取 md5 然后取出从第 8 位开始的 16 位字符串
所以通过计算当前视频的iv和key
11.然后我们尝试用AES解密
12. 解密成功,获得m3u8地址。拼接好主机后直接打开,发现无法播放。
让我们回到网页捕获数据包。原来m3u8地址后面有一个token参数。添加令牌后,打开正常播放。
13.值得注意的是,在获取/video/info时,需要在headers中添加origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我哥的M3U8下载器时,需要自定义协议头:Origin
二、在网页上获取用户的Token:
攀登时问题来了,每个用户只能免费观看30个视频。然后让我们获得更多用户:
感觉应该是因为token(一个token代表一个用户),那么我们需要了解一下token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新页面,搜索token的值,其实这个pwatoken是一个参数,只会在第二次访问时可用,
我们新建一个隐身窗口或者小窗口,打开F12.找到一个新的界面mail_pwa_temp。建议全程使用抓包软件。
可以看出token是mail_pwa_temp返回的,看提交的参数,post提交的是pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?其实我们访问首页的时候会返回一个license,就是pwa-ckv
PS:但是,当我们设置帖子内容为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这在浏览器中体现如下:
没错,这是2级VIP(所谓的尊贵VIP账号),那么他的token就可以无限拍摄视频了。
看来爬行速度不能太快,会很频繁。
三、网页版实现无限制观看的两种方法【方法已过期,将强制退出,token已被封禁,无法再使用此token抓视频】:
第一种:FD的自动回复,这个我就不说了,直接把token换成前面得到的honor token
第二种:JS打印这个,步骤如下:
1.打开会员页面,点击账号后面的刷新,会提示刷新成功,我们搜索“刷新成功”,不难发现在文件中调用应用程序.XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的功能,
3. 给这个函数设置断点,刷新个人信息,然后我们打印出来这个
4.在控制台输入 temp1.$store.state.newToken = 'Honor token'
这里提到的honor token就是第二步抓到的token,字符串长度大约是145。
您可以在浏览器中将其更改为尊贵的VIP,并享受无限观看。(值得注意的是,网页一刷新就失效了……可以再次操作)
四、在APP端实现真正的无限制查看【方法已过期,将强制退出,token已被封禁】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1.首先我们抓包并下载APP。果然 Token 和网页版一样使用,只是调用接口不同。
2.然后我们打开MT管理器或者NP管理器,尝试搜索方法名中收录Token的内容。
3.找到了2个相关的getToken函数,让我们点进去修改一下,返回之前获取的Token
4.app编译完成后,打开查看效果。
5. 果然成了尊贵的贵宾。
虽然它显示的是每日观看限制,但实际上你会发现它是无限观看
五、真正实现APP端无限观看:
其实原因很简单,第一次打开APP需要注册。然后我们将注册的参数修改为随机,这样每次清除数据后打开APP都是一个新的体验用户。
因为在SMALI中重新添加函数有点复杂,所以我这里直接调用APP原来的随机函数(PS:这个随机是我用的函数的缩写,你可以试试其他随机函数)
下图是NP管理器修改为JAVA前后代码的区别:(思路是给this.d分配随机字符)
这种方法比第四步稍微困难一点,但也只是稍微困难一点。
我相信你们可以抓住数据包并获取一些信息并再次完成它。
我不会在这里详细解释。防止和谐,有能力的可以试试。这对我这个自学成才的半生不熟的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
例如getLevel(const v0, 0x2 1是正常/2是荣誉)、getExpiry(const v0, 0x746a6480)等。
修改后发现只在本地显示。 查看全部
网页抓取解密(网页版AES:1.的函数())
一、网络 AES:
1.首先,我们在浏览器中打开“西丽西丽”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,一般这种视频是m3u8.)
3.点击视频进去4.搜索“m3u8”,真的是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那么应该是加密了
6.然后我们尝试搜索这个视频的ID,可以发现有3个相关请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID是稍后添加,在屏幕截图之前是另一个)
7.上图中的/video/info是哪里来的?别着急,ctrl+f搜索,果然找到了一个js文件。
8.我们从sources打开这个文件,搜索/video/info,找到getVideoInfo的一个函数(注意a的值是从headers中获取的)
9. 然后低头看到一个decryptString,那我猜这应该是解密函数,然后搜索decryptString,找到函数
10.分析这个函数:
t = 得到加密字符串, o = 取 md5, e = 取 md5 然后取出从第 8 位开始的 16 位字符串
所以通过计算当前视频的iv和key
11.然后我们尝试用AES解密
12. 解密成功,获得m3u8地址。拼接好主机后直接打开,发现无法播放。
让我们回到网页捕获数据包。原来m3u8地址后面有一个token参数。添加令牌后,打开正常播放。
13.值得注意的是,在获取/video/info时,需要在headers中添加origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我哥的M3U8下载器时,需要自定义协议头:Origin
二、在网页上获取用户的Token:
攀登时问题来了,每个用户只能免费观看30个视频。然后让我们获得更多用户:
感觉应该是因为token(一个token代表一个用户),那么我们需要了解一下token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新页面,搜索token的值,其实这个pwatoken是一个参数,只会在第二次访问时可用,
我们新建一个隐身窗口或者小窗口,打开F12.找到一个新的界面mail_pwa_temp。建议全程使用抓包软件。
可以看出token是mail_pwa_temp返回的,看提交的参数,post提交的是pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?其实我们访问首页的时候会返回一个license,就是pwa-ckv
PS:但是,当我们设置帖子内容为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这在浏览器中体现如下:
没错,这是2级VIP(所谓的尊贵VIP账号),那么他的token就可以无限拍摄视频了。
看来爬行速度不能太快,会很频繁。
三、网页版实现无限制观看的两种方法【方法已过期,将强制退出,token已被封禁,无法再使用此token抓视频】:
第一种:FD的自动回复,这个我就不说了,直接把token换成前面得到的honor token
第二种:JS打印这个,步骤如下:
1.打开会员页面,点击账号后面的刷新,会提示刷新成功,我们搜索“刷新成功”,不难发现在文件中调用应用程序.XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的功能,
3. 给这个函数设置断点,刷新个人信息,然后我们打印出来这个
4.在控制台输入 temp1.$store.state.newToken = 'Honor token'
这里提到的honor token就是第二步抓到的token,字符串长度大约是145。
您可以在浏览器中将其更改为尊贵的VIP,并享受无限观看。(值得注意的是,网页一刷新就失效了……可以再次操作)
四、在APP端实现真正的无限制查看【方法已过期,将强制退出,token已被封禁】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1.首先我们抓包并下载APP。果然 Token 和网页版一样使用,只是调用接口不同。
2.然后我们打开MT管理器或者NP管理器,尝试搜索方法名中收录Token的内容。
3.找到了2个相关的getToken函数,让我们点进去修改一下,返回之前获取的Token
4.app编译完成后,打开查看效果。
5. 果然成了尊贵的贵宾。
虽然它显示的是每日观看限制,但实际上你会发现它是无限观看
五、真正实现APP端无限观看:
其实原因很简单,第一次打开APP需要注册。然后我们将注册的参数修改为随机,这样每次清除数据后打开APP都是一个新的体验用户。
因为在SMALI中重新添加函数有点复杂,所以我这里直接调用APP原来的随机函数(PS:这个随机是我用的函数的缩写,你可以试试其他随机函数)
下图是NP管理器修改为JAVA前后代码的区别:(思路是给this.d分配随机字符)
这种方法比第四步稍微困难一点,但也只是稍微困难一点。
我相信你们可以抓住数据包并获取一些信息并再次完成它。
我不会在这里详细解释。防止和谐,有能力的可以试试。这对我这个自学成才的半生不熟的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
例如getLevel(const v0, 0x2 1是正常/2是荣誉)、getExpiry(const v0, 0x746a6480)等。
修改后发现只在本地显示。
网页抓取解密( 微信公众号网页登录的思路和流程和配置流程介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-25 09:13
微信公众号网页登录的思路和流程和配置流程介绍)
package com.yfs.util;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class HttpRequest {
public static void main(String[] args) {
//发送 GET 请求
String s=HttpRequest.sendGet("http://v.qq.com/x/cover/kvehb7 ... ot%3B, "");
System.out.println(s);
// //发送 POST 请求
// String sr=HttpRequest.sendPost("http://www.toutiao.com/stream/ ... ot%3B, "");
// JSONObject json = JSONObject.fromObject(sr);
// System.out.println(json.get("data"));
}
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return URL 所代表远程资源的响应结果
*/
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url + "?" + param;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map map = connection.getHeaderFields();
// 遍历所有的响应头字段
for (String key : map.keySet()) {
System.out.println(key + "--->" + map.get(key));
}
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
/**
* 向指定 URL 发送POST方法的请求
*
* @param url
* 发送请求的 URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return 所代表远程资源的响应结果
*/
public static String sendPost(String url, String param) {
PrintWriter out = null;
BufferedReader in = null;
String result = "";
try {
URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection conn = realUrl.openConnection();
// 设置通用的请求属性
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 发送POST请求必须设置如下两行
conn.setDoOutput(true);
conn.setDoInput(true);
// 获取URLConnection对象对应的输出流
out = new PrintWriter(conn.getOutputStream());
// 发送请求参数
out.print(param);
// flush输出流的缓冲
out.flush();
// 定义BufferedReader输入流来读取URL的响应
in = new BufferedReader(
new InputStreamReader(conn.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送 POST 请求出现异常!"+e);
e.printStackTrace();
}
//使用finally块来关闭输出流、输入流
finally{
try{
if(out!=null){
out.close();
}
if(in!=null){
in.close();
}
}
catch(IOException ex){
ex.printStackTrace();
}
}
return result;
}
}
请自行下载备注代码中需要的jar包添加到项目中。这里需要注意的是,需要使用javax.crypto.*包的类进行AES解密,在jdk的jce.jar中提供,是jdk自带的库。如果是MAVEN项目,需要在pom.xml文件中配置指定编译路径jce.jar
将 jce.jar 的地址添加到 bootclasspath 中: ${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/jre/lib/jce.jar ,注意 rt.jar 和 jce.jar 连接:
如:
com.yfs.app
org.apache.maven.plugins
maven-compiler-plugin
2.5.1
1.7
1.7
${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/jre/lib/jce.jar
utf-8
总结
好了,数据解密终于完成了,可以连接新的或者已有的用户系统了。
需要注意的一件事是 unionId 可能需要连接到现有的用户系统。如果通过上述方法无法获取unionId,则需要检查你的微信开放平台()是否绑定了微信小程序。叹气~
微信公众号网页登录的思路和流程:
第一步:获取代码证书,
第二步:获取代码凭证获取用户openid和access_token、refresh_token
第三步:刷新access_token,还有openid和refresh_token
第四步:使用openid和access_token获取用户信息
第五步:使用openid和access_token获取用户信息,看能不能获取,如果获取不到接口刷新access_token
去调用第四步。
前段时间刚做完微信小程序项目,中间遇到的一些问题会陆续放出。欢迎大家一起讨论。 查看全部
网页抓取解密(
微信公众号网页登录的思路和流程和配置流程介绍)
package com.yfs.util;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class HttpRequest {
public static void main(String[] args) {
//发送 GET 请求
String s=HttpRequest.sendGet("http://v.qq.com/x/cover/kvehb7 ... ot%3B, "");
System.out.println(s);
// //发送 POST 请求
// String sr=HttpRequest.sendPost("http://www.toutiao.com/stream/ ... ot%3B, "");
// JSONObject json = JSONObject.fromObject(sr);
// System.out.println(json.get("data"));
}
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return URL 所代表远程资源的响应结果
*/
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url + "?" + param;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map map = connection.getHeaderFields();
// 遍历所有的响应头字段
for (String key : map.keySet()) {
System.out.println(key + "--->" + map.get(key));
}
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
/**
* 向指定 URL 发送POST方法的请求
*
* @param url
* 发送请求的 URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return 所代表远程资源的响应结果
*/
public static String sendPost(String url, String param) {
PrintWriter out = null;
BufferedReader in = null;
String result = "";
try {
URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection conn = realUrl.openConnection();
// 设置通用的请求属性
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 发送POST请求必须设置如下两行
conn.setDoOutput(true);
conn.setDoInput(true);
// 获取URLConnection对象对应的输出流
out = new PrintWriter(conn.getOutputStream());
// 发送请求参数
out.print(param);
// flush输出流的缓冲
out.flush();
// 定义BufferedReader输入流来读取URL的响应
in = new BufferedReader(
new InputStreamReader(conn.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送 POST 请求出现异常!"+e);
e.printStackTrace();
}
//使用finally块来关闭输出流、输入流
finally{
try{
if(out!=null){
out.close();
}
if(in!=null){
in.close();
}
}
catch(IOException ex){
ex.printStackTrace();
}
}
return result;
}
}
请自行下载备注代码中需要的jar包添加到项目中。这里需要注意的是,需要使用javax.crypto.*包的类进行AES解密,在jdk的jce.jar中提供,是jdk自带的库。如果是MAVEN项目,需要在pom.xml文件中配置指定编译路径jce.jar
将 jce.jar 的地址添加到 bootclasspath 中: ${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/jre/lib/jce.jar ,注意 rt.jar 和 jce.jar 连接:
如:
com.yfs.app
org.apache.maven.plugins
maven-compiler-plugin
2.5.1
1.7
1.7
${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/jre/lib/jce.jar
utf-8
总结
好了,数据解密终于完成了,可以连接新的或者已有的用户系统了。
需要注意的一件事是 unionId 可能需要连接到现有的用户系统。如果通过上述方法无法获取unionId,则需要检查你的微信开放平台()是否绑定了微信小程序。叹气~
微信公众号网页登录的思路和流程:
第一步:获取代码证书,
第二步:获取代码凭证获取用户openid和access_token、refresh_token
第三步:刷新access_token,还有openid和refresh_token
第四步:使用openid和access_token获取用户信息
第五步:使用openid和access_token获取用户信息,看能不能获取,如果获取不到接口刷新access_token
去调用第四步。
前段时间刚做完微信小程序项目,中间遇到的一些问题会陆续放出。欢迎大家一起讨论。
网页抓取解密( 如何使用Thor进行基本的抓包和分析数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2022-03-18 08:07
如何使用Thor进行基本的抓包和分析数据?
)
【APP】雷神:抓包神器基础教程
白苹果2019-10-28
Thor 是一款专注于数据包捕获分析和开发测试的工具。使用 Thor 分析抓取的网络连接以找到您需要的数据。
你可以用 Thor 的数据包捕获做什么?可以抓取一些不易下载的音频、视频、图片、压缩包等,然后选择适合自己的方式下载保存。或者抓一些ipa安装包,或者下载一些文件的原链接,一些api接口等等。
下面将教你如何使用 Thor 进行基本的抓包和数据分析。同时通过一个网易云音乐抓包的例子,带大家去操作。
*注:本文为初学者基础教程,更多棘手操作请自行探索。
开始前的准备
1.雷神下载
如果您自己购买,请前往 App Store 下载。如果你想试试看,可以看之前这个账号的推送,使用共享账号下载:
2.开始使用
打开雷神,界面比较简单。主页只有一个交换机和一个抓包过滤器。下面也只有三个菜单,过滤器、抓包记录等等。
首页过滤器,可以选择抓包过滤器设置,启动和停止抓包。所有成功的抓包记录都会保存在抓包记录中。更多的是使用帮助,里面的HTTPS解析设置,可以查看证书安装。
您还可以在通知中心添加Thor的Widget,快速开始抓包并显示抓包记录。
初始化
首次使用 Thor 时,需要进行一些设置。
1.安装并信任证书
由于 Thor 的默认过滤器是全局数据包捕获,包括 HTTPS 解析,因此首次使用需要安装和信任证书。
Thor为HTTPS实现数据解密,采用MITM(man-in-the-middle attack)方式,与Surge或Little Rocket拦截广告的原理相同,因此需要安装并信任生成的Thor SSL CA证书由托尔。实现HTTPS解析。
如下图,第一次使用时,点击开始按钮,会弹出“HTTPS解析设置”。我们选择现在打开它,并按照说明将证书安装到系统中。
然后将打开一个网页,允许添加配置文件。在iOS12及以上系统中,下载配置文件后需要手动输入设置,会在首页头像下方显示。
点击右上角的安装描述文件,输入锁屏密码,完成安装。
iOS 10.2+系统需要进入【设置-通用-关于本机-证书信任设置】选择刚刚生成的证书并信任。
2.允许创建VPN配置
首次使用 Thor 时,系统会询问您是否允许创建 VPN 配置,单击允许。
这是一个必要的步骤。因为 Thor 需要占用 VPN 隧道来接管你所有的网络连接,从而捕获网络数据。如下所示。Thor创建的VPN配置可以在设置-VPN中看到。
开始使用
1、抓包
抓包前,先清理后台,退出不需要的应用程序或网页,只保存要抓包的应用程序。
点击Thor过滤开关(闪电按钮),Thor反应迅速,立即进入抓包状态。这时状态栏中会出现一个VPN标志。再次点击开关停止抓包。
还可以通知雷神Widget中心快速打开开关抓包,非常方便。
然后,使用您要采集数据的软件或网页进行网络连接操作,如打开视频、听音乐、安装软件等。Thor 会自动抓取所有网络连接。
在这个过程中可以随时进入Thor的抓包记录,查看是否已经抓到了合适的数据,也可以关闭Thor暂停工作,慢慢查看抓包数据,以免增加工作量因数据过多而选择的。
2.抓包数据分析
抓包后,我们进入抓包记录查看,抓包成功的所有数据都在这里。只有对捕获的数据包数据进行分析和选择,才能找到我们想要的。
在抓包记录界面,可以对抓包历史进行分类或删除。点击查看所有抓包记录。
由于我们的默认过滤器是全局数据包捕获,因此数据包捕获记录将收录所有捕获的数据。
你可以在里面看到很多内容,上面的例子说明了:
链接:捕获的链接地址显示最直观。
POST 或 GET:这是一种 HTTP 响应方法。HTTP响应方式有很多种,如POST、GET、HEAD、PUT、DELETE等,如果我们需要抓取和下载资源,需要从GET中找到。
:此栏为User-Agent,用户代理标识符,用于显示用户连接网络的方式
[200]:响应状态码,在Thor中很容易识别。
11:37:04.825:链接的具体时间
↓1.13KB ↑636kb : 用于接收和发送的数据
音乐抓取示例
说了这么多,估计还有人不明白,那么我们来看一个例子:
网易云音乐音频采集
打开过滤器后,打开网易云音乐,播放一段没有缓存的音乐(如果已经缓存,则无法采集音频数据),等待歌曲被缓存。
OK,我们看到还有一条抓包记录,打开它,100多条记录中我要的是哪一条?
单击关键字以过滤记录。我想查找音频文件,所以勾选所有音频文件类型并单击搜索。当然,您也可以自定义过滤规则。现在我们看到只有两条记录符合条件,我们可以根据文件大小确定哪一条是我们需要的。
在响应中,我们可以直接看到消息体,也就是文件本身。点击文件直接打开,选择右上角分享,导出原文件保存到其他应用,或直接发送给好友。
捕获的图片和音频也可以以相同的方式保存。值得注意的是,并非所有拍摄的视频都可以通过这种方式保存。
结尾
本文介绍了Thor的基本用法,Thor的强大远不止这些。
除了抓图、视频、音频,还可以抓 App Store 安装包,可以用 Shu 或者 JSBox 安装各种 ipa 文件。
还可以抓取视频的直接链接,达到释放会员观看会员视频和去除广告的效果。
它还可以通过特殊的过滤规则进行广告宣传。
甚至可以通过断点过滤器达到破解内购和会员的效果。
(请勿用于非法用途)
如有需要,稍后会更新Thor的进阶教程,也会分享有用的滤镜。
查看全部
网页抓取解密(
如何使用Thor进行基本的抓包和分析数据?
)
【APP】雷神:抓包神器基础教程
白苹果2019-10-28
Thor 是一款专注于数据包捕获分析和开发测试的工具。使用 Thor 分析抓取的网络连接以找到您需要的数据。
你可以用 Thor 的数据包捕获做什么?可以抓取一些不易下载的音频、视频、图片、压缩包等,然后选择适合自己的方式下载保存。或者抓一些ipa安装包,或者下载一些文件的原链接,一些api接口等等。
下面将教你如何使用 Thor 进行基本的抓包和数据分析。同时通过一个网易云音乐抓包的例子,带大家去操作。
*注:本文为初学者基础教程,更多棘手操作请自行探索。
开始前的准备
1.雷神下载
如果您自己购买,请前往 App Store 下载。如果你想试试看,可以看之前这个账号的推送,使用共享账号下载:
2.开始使用
打开雷神,界面比较简单。主页只有一个交换机和一个抓包过滤器。下面也只有三个菜单,过滤器、抓包记录等等。
首页过滤器,可以选择抓包过滤器设置,启动和停止抓包。所有成功的抓包记录都会保存在抓包记录中。更多的是使用帮助,里面的HTTPS解析设置,可以查看证书安装。
您还可以在通知中心添加Thor的Widget,快速开始抓包并显示抓包记录。
初始化
首次使用 Thor 时,需要进行一些设置。
1.安装并信任证书
由于 Thor 的默认过滤器是全局数据包捕获,包括 HTTPS 解析,因此首次使用需要安装和信任证书。
Thor为HTTPS实现数据解密,采用MITM(man-in-the-middle attack)方式,与Surge或Little Rocket拦截广告的原理相同,因此需要安装并信任生成的Thor SSL CA证书由托尔。实现HTTPS解析。
如下图,第一次使用时,点击开始按钮,会弹出“HTTPS解析设置”。我们选择现在打开它,并按照说明将证书安装到系统中。
然后将打开一个网页,允许添加配置文件。在iOS12及以上系统中,下载配置文件后需要手动输入设置,会在首页头像下方显示。
点击右上角的安装描述文件,输入锁屏密码,完成安装。
iOS 10.2+系统需要进入【设置-通用-关于本机-证书信任设置】选择刚刚生成的证书并信任。
2.允许创建VPN配置
首次使用 Thor 时,系统会询问您是否允许创建 VPN 配置,单击允许。
这是一个必要的步骤。因为 Thor 需要占用 VPN 隧道来接管你所有的网络连接,从而捕获网络数据。如下所示。Thor创建的VPN配置可以在设置-VPN中看到。
开始使用
1、抓包
抓包前,先清理后台,退出不需要的应用程序或网页,只保存要抓包的应用程序。
点击Thor过滤开关(闪电按钮),Thor反应迅速,立即进入抓包状态。这时状态栏中会出现一个VPN标志。再次点击开关停止抓包。
还可以通知雷神Widget中心快速打开开关抓包,非常方便。
然后,使用您要采集数据的软件或网页进行网络连接操作,如打开视频、听音乐、安装软件等。Thor 会自动抓取所有网络连接。
在这个过程中可以随时进入Thor的抓包记录,查看是否已经抓到了合适的数据,也可以关闭Thor暂停工作,慢慢查看抓包数据,以免增加工作量因数据过多而选择的。
2.抓包数据分析
抓包后,我们进入抓包记录查看,抓包成功的所有数据都在这里。只有对捕获的数据包数据进行分析和选择,才能找到我们想要的。
在抓包记录界面,可以对抓包历史进行分类或删除。点击查看所有抓包记录。
由于我们的默认过滤器是全局数据包捕获,因此数据包捕获记录将收录所有捕获的数据。
你可以在里面看到很多内容,上面的例子说明了:
链接:捕获的链接地址显示最直观。
POST 或 GET:这是一种 HTTP 响应方法。HTTP响应方式有很多种,如POST、GET、HEAD、PUT、DELETE等,如果我们需要抓取和下载资源,需要从GET中找到。
:此栏为User-Agent,用户代理标识符,用于显示用户连接网络的方式
[200]:响应状态码,在Thor中很容易识别。
11:37:04.825:链接的具体时间
↓1.13KB ↑636kb : 用于接收和发送的数据
音乐抓取示例
说了这么多,估计还有人不明白,那么我们来看一个例子:
网易云音乐音频采集
打开过滤器后,打开网易云音乐,播放一段没有缓存的音乐(如果已经缓存,则无法采集音频数据),等待歌曲被缓存。
OK,我们看到还有一条抓包记录,打开它,100多条记录中我要的是哪一条?
单击关键字以过滤记录。我想查找音频文件,所以勾选所有音频文件类型并单击搜索。当然,您也可以自定义过滤规则。现在我们看到只有两条记录符合条件,我们可以根据文件大小确定哪一条是我们需要的。
在响应中,我们可以直接看到消息体,也就是文件本身。点击文件直接打开,选择右上角分享,导出原文件保存到其他应用,或直接发送给好友。
捕获的图片和音频也可以以相同的方式保存。值得注意的是,并非所有拍摄的视频都可以通过这种方式保存。
结尾
本文介绍了Thor的基本用法,Thor的强大远不止这些。
除了抓图、视频、音频,还可以抓 App Store 安装包,可以用 Shu 或者 JSBox 安装各种 ipa 文件。
还可以抓取视频的直接链接,达到释放会员观看会员视频和去除广告的效果。
它还可以通过特殊的过滤规则进行广告宣传。
甚至可以通过断点过滤器达到破解内购和会员的效果。
(请勿用于非法用途)
如有需要,稍后会更新Thor的进阶教程,也会分享有用的滤镜。
网页抓取解密(网页抓取解密应该不是程序员的活,那才叫牛逼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-17 10:06
网页抓取解密应该不是程序员的活,程序员要是能发现并解决网页的加密,那才叫牛逼呢,如果说你抓的是一堆乱码的页面,那没啥意义。web安全的门槛其实很低,你有基础搞搞渗透应该不难的,而且现在一般都支持开源,基本上想什么时候破解,都能很快找到破解的方法,就看你能不能想。
你以为人家愿意给你搞
钓鱼场就可以抓取网页,
可以找那种有找破解团队的打电话骚扰,网站主方就能辨别出,这比发论文靠谱。
起个名字“netscript”,抓的是程序文件。
在苹果公司有大神,
还有flashplayer~~不知道国内的flashplayer开发者是否有他们的小号或者不用感谢我~~ps:我的基本常识是假如你们知道明文的,直接默认他是用黑客手段被抓取了
cloudxns
黑客用非法方式获取api接口,完全抓取网页。
像极了,魔方大厦。
当年黑五入手手机通过烧网线是可以抓到线路实时信息的。
还有比这更无节操的么~~直接网上抓
加密不是我们的事儿。没破解,能抓取是你的本事。
你在说anywayeverything吗
我只知道他们有一种东西叫做“破解工具”或者“蜘蛛”。网上百度随便找。或者,他们能破解windows甚至更加复杂的破解版本。
给我看个正面的不可能做不到的 查看全部
网页抓取解密(网页抓取解密应该不是程序员的活,那才叫牛逼)
网页抓取解密应该不是程序员的活,程序员要是能发现并解决网页的加密,那才叫牛逼呢,如果说你抓的是一堆乱码的页面,那没啥意义。web安全的门槛其实很低,你有基础搞搞渗透应该不难的,而且现在一般都支持开源,基本上想什么时候破解,都能很快找到破解的方法,就看你能不能想。
你以为人家愿意给你搞
钓鱼场就可以抓取网页,
可以找那种有找破解团队的打电话骚扰,网站主方就能辨别出,这比发论文靠谱。
起个名字“netscript”,抓的是程序文件。
在苹果公司有大神,
还有flashplayer~~不知道国内的flashplayer开发者是否有他们的小号或者不用感谢我~~ps:我的基本常识是假如你们知道明文的,直接默认他是用黑客手段被抓取了
cloudxns
黑客用非法方式获取api接口,完全抓取网页。
像极了,魔方大厦。
当年黑五入手手机通过烧网线是可以抓到线路实时信息的。
还有比这更无节操的么~~直接网上抓
加密不是我们的事儿。没破解,能抓取是你的本事。
你在说anywayeverything吗
我只知道他们有一种东西叫做“破解工具”或者“蜘蛛”。网上百度随便找。或者,他们能破解windows甚至更加复杂的破解版本。
给我看个正面的不可能做不到的
网页抓取解密( 搜狗收录量的查询方法不少是怎么回事?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-13 15:18
搜狗收录量的查询方法不少是怎么回事?(图))
搜狗收录指的是搜狗是否将你的网页放入了自己的数据库中。这样,搜狗seo的时候,就可以通过自然流量被搜索到,产生查询、订单等。前几年搜狗缺乏数据的时候,搜狗收录越多越好。但18年过去了,搜狗搜索引擎也不缺数据。搜狗收录偏爱有价值的页面,可以帮助用户处理问题的页面,新的需求内容,新的热点内容。也就是18年后,尤其是近两年,搜狗收录更倾向于有价值的好内容。另一方面,网站也是,你的网站搜狗收录页面比无价值的重复页面更能处理用户需求,所以你的网站整体流量和排名会更好的。
搜狗收录有很多查询方法。但最方便的搜狗收录查询工具是搜狗搜索本身,您只需要输入查询命令即可查看搜狗对网站的详细收录情况。
站点:(是您自己的域名)
通过该命令可以查看到网站中所有已经被搜狗收录展示过且可以正常展示的页面。
搜狗收录是网站参与排名的先决条件。搜狗会先收录网站到自己的索引库,然后根据算法计算排名结果。也就是说,搜狗的网站而不是收录,根本没有任何排名的机会。因此,我们需要关注我们的网站搜狗收录卷。
如果你有大量网站需要查询搜狗收录,想全面了解网站的收录情况,去各大搜索引擎网站一一查询。它很慢而且浪费时间。通过搜狗查询工具,可以快速查询大量域名收录,快捷方便,一键操作。这里我们可以使用147SEO搜索收录查询工具进行查询,我们可以查询:收录排名,收录标题,收录链接,收录时间,真实标题、真实链接、真实关键词、关键词排名、站点命令等关键信息非常方便实用,让您多方面多维度分析一个或多个网址!
搜狗收录查询帮助您一键快速了解网站收录上的搜狗搜索引擎详情,助您全面了解您的网站动态。
搜狗的收录查询功能帮助站长了解如何查询网站域名、博客、产品是否已经搜狗收录,了解搜狗收录数据,方便网站优化调整。
搜狗的收录量网站是搜狗爬虫成功爬取网站内页面的总次数。索引量是收录通过索引过程在线进入的页面之后的网页总数。 查看全部
网页抓取解密(
搜狗收录量的查询方法不少是怎么回事?(图))
搜狗收录指的是搜狗是否将你的网页放入了自己的数据库中。这样,搜狗seo的时候,就可以通过自然流量被搜索到,产生查询、订单等。前几年搜狗缺乏数据的时候,搜狗收录越多越好。但18年过去了,搜狗搜索引擎也不缺数据。搜狗收录偏爱有价值的页面,可以帮助用户处理问题的页面,新的需求内容,新的热点内容。也就是18年后,尤其是近两年,搜狗收录更倾向于有价值的好内容。另一方面,网站也是,你的网站搜狗收录页面比无价值的重复页面更能处理用户需求,所以你的网站整体流量和排名会更好的。
搜狗收录有很多查询方法。但最方便的搜狗收录查询工具是搜狗搜索本身,您只需要输入查询命令即可查看搜狗对网站的详细收录情况。
站点:(是您自己的域名)
通过该命令可以查看到网站中所有已经被搜狗收录展示过且可以正常展示的页面。
搜狗收录是网站参与排名的先决条件。搜狗会先收录网站到自己的索引库,然后根据算法计算排名结果。也就是说,搜狗的网站而不是收录,根本没有任何排名的机会。因此,我们需要关注我们的网站搜狗收录卷。
如果你有大量网站需要查询搜狗收录,想全面了解网站的收录情况,去各大搜索引擎网站一一查询。它很慢而且浪费时间。通过搜狗查询工具,可以快速查询大量域名收录,快捷方便,一键操作。这里我们可以使用147SEO搜索收录查询工具进行查询,我们可以查询:收录排名,收录标题,收录链接,收录时间,真实标题、真实链接、真实关键词、关键词排名、站点命令等关键信息非常方便实用,让您多方面多维度分析一个或多个网址!
搜狗收录查询帮助您一键快速了解网站收录上的搜狗搜索引擎详情,助您全面了解您的网站动态。
搜狗的收录查询功能帮助站长了解如何查询网站域名、博客、产品是否已经搜狗收录,了解搜狗收录数据,方便网站优化调整。
搜狗的收录量网站是搜狗爬虫成功爬取网站内页面的总次数。索引量是收录通过索引过程在线进入的页面之后的网页总数。
网页抓取解密(目标网易云音乐只需要解密params和encSecKey就可以快乐的了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-12 16:03
目标
网易云音乐只需要解密params和encSecKey就可以愉快的开始爬取了。当然,如果没有足够的代理IP,还是要慢慢爬。废话不多说,直接开始吧。
问
老规矩,先来看看我们要抓取的页面:
查看网络请求:
从名字上可以快速定位到哪个请求是POST请求,然后看它提交了哪些参数,FormData如下:
提交的参数,上面提到的params和encSecKey,都是加密的。我们看看返回内容的格式:
ok,基本的东西我们已经知道了,我们可以进行下一步,找到解密的两个参数。
分析
在调试之前,我们要找到这两个值的位置,然后搜索,先定位js文件再定位代码位置。你应该知道如何搜索。您可以搜索 params 或 encSecKey。如果发现多个结果,不确定是哪个文件,可以点击每个key,搜索key参数,判断是否为目标文件。这里我直接标记了。正确的文件,你可以点击进去。
进入JS文件后,同样搜索key参数params或者encSecKey:
找到encSecKey的位置,拉出这几行代码分析一下:
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
e0x.data = j0x.cs1x({
params: bVZ8R.encText,
encSecKey: bVZ8R.encSecKey
})
粗略地说,params和encSecKey来自bVZ8R.encText和bVZ8R.encSecKey,bVZ8R是window.asrsea的结果,有四个参数,JSON.stringify(i0x), bqN0x(["tear", "strong"]) , bqN0x(Wx5C.md), bqN0x(["love", "girl", "horrified", "laughing"],先看最后三个参数,从它们的固定值可以大胆推断出这三个值也是Fixed,之所以说是fixed,看一下Wx5C.md:
wx5C.md是一个固定的数组,bqN0x(["tears", "strong"])和bqN0x(["love", "girl", "horrified", "laughing"]肯定不会导致改变,如图下面,测试一下:
这些参数我大概都弄清楚了,剩下的就是弄清楚window.asrsea的具体实现,以及i0x是什么样的,进入调试过程。
调试
Window.asrsea 有一个断点。我的代码位置是第 13133 行。点击粉丝列表的下一页将激活断点。在激活断点的同时,我们也可以看到 i0x 的美妙之处。在控制台输入 i0x:
limit、offset、total、userId其实都是已知的,这里可以看到csrf_token的生成,细心的童鞋应该早就发现了:
}
i0x["csrf_token"] = v0x.gP3x("__csrf"); ## csrf_token在这里产生
X0x = X0x.replace("api", "weapi");
e0x.method = "post";
delete e0x.query;
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
我点击进入 v0x.gP3x 函数查看:
从代码可以看出csrf_token来自Cookie中的__csrf:
那么这个值就可以在请求网页时从cookie中获取,继续调试window.asrsea。一路点击下一步进入功能。
跳转到ad(d,e,f,g)函数,往下看一点,发现window.asrsea等于这个d函数,哦,好吧,调试一下这个d函数:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
输入一个函数:
可以看到a函数生成随机数,继续运行,进入b函数:
熟悉的AES加密,继续跑进c函数:
就是大家熟悉的RSA加密,网易可真是小心翼翼,各种加密。至此,整体框架已经调试完毕,剩下的无非就是挖JS代码了。
蟒蛇运行
这一次,不仅是运行结果,还包括爬取和入库:
获取参数和 encSecKey
def get_enc(self,a):
with open('..//js//wangyiyun.js', encoding='utf-8') as f:
wangyiyun = f.read()
js = execjs.compile(wangyiyun)
logid = js.call('get_pwd', a)
print(logid)
return logid
抓住
def get_fans(self):
resp = self.get_home_page()
print(resp.cookies)
print(resp.status_code)
time.sleep(6)
limit = 20
for i in range(1,110):
print("第{}页".format(i+1))
offset = limit*i
a = {"userId": "46991111", "offset": str(offset), "total": "false", "limit": str(limit), "csrf_token": ""}
print(a)
logid = self.get_enc(a)
data = {
"params":logid["encText"],
"encSecKey":logid["encSecKey"],
}
print(data)
fans_url = "https://music.163.com/weapi/us ... ot%3B
resp = self.session.post(url=fans_url,data=data,headers=self.headers)
followed = json.loads(resp.text)
followed_list = []
for foll in followed["followeds"]:
foll_dict = {}
foll_dict["short_name"] = foll.get("py","") #缩写
foll_dict["userId"] = foll.get("userId","") #用户ID
foll_dict["nickname"] = foll.get("nickname","") #昵称
foll_dict["vipType"] = foll.get("vipType","") # vip
foll_dict["eventCount"] = foll.get("eventCount","")#动态
foll_dict["vipRights"] = str(foll.get("vipRights","")) #VIP权益
foll_dict["gender"] = foll.get("gender","") #性别
foll_dict["avatarUrl"] = foll.get("avatarUrl","") #头像
foll_dict["followed"] = foll.get("followed","")
foll_dict["followeds"] = foll.get("followeds","") #粉丝
foll_dict["follows"] = foll.get("follows","") #关注
foll_dict["playlistCount"] = foll.get("playlistCount","") #歌单
foll_dict["mutual"] = foll.get("mutual","") #
foll_dict["expertTags"] = str(foll.get("expertTags",""))
foll_dict["experts"] = str(foll.get("experts",""))
print(foll_dict)
followed_list.append(foll_dict)
self.mysql.insert("music",followed_list)
tm = random.randint(10,30)
time.sleep(tm)
这里需要注意的是,要爬取指定页面,必须先访问这个页面,不能直接请求这个链接,因为它根本没有关于哪个页面的信息。
请求指定网页
def get_home_page(self):
url = "https://music.163.com/%23/user ... ot%3B
resp = self.session.get(url)
return resp
表结构
@property
def create_table_sql(self):
create_table = """
CREATE TABLE IF NOT EXISTS music (
short_name varchar(30) ,
userId varchar(100) NOT NULL,
nickname varchar(30),
vipType varchar(30) ,
eventCount varchar(200),
vipRights varchar(900),
gender varchar(900),
avatarUrl varchar(200),
followed varchar(30),
followeds varchar(30),
follows varchar(30),
playlistCount varchar(30),
mutual varchar(30),
expertTags varchar(30),
experts varchar(30),
PRIMARY KEY (userId)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
return create_table
仓储
def insert(self,table,data_list):
if len(data_list) > 0:
data_list = [{k: v
for k, v in data.items() if v is not None}
for data in data_list]
keys = ", ".join(data_list[0].keys())
values = ", ".join(["%s"] * len(data_list[0]))
sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
DUPLICATE KEY UPDATE""".format(table=table,
keys=keys,
values=values)
update = ",".join([
" {key} = values({key})".format(key=key)
for key in data_list[0]
])
sql += update
print(sql)
self.connect()
try:
ret = self.cursor.executemany(sql, [tuple(data.values()) for data in data_list])
self.conn.commit()
except Exception as e:
self.conn.rollback()
print("Error: ", e)
traceback.print_exc()
finally:
self.close()
过程
结尾 查看全部
网页抓取解密(目标网易云音乐只需要解密params和encSecKey就可以快乐的了)
目标
网易云音乐只需要解密params和encSecKey就可以愉快的开始爬取了。当然,如果没有足够的代理IP,还是要慢慢爬。废话不多说,直接开始吧。
问
老规矩,先来看看我们要抓取的页面:
查看网络请求:
从名字上可以快速定位到哪个请求是POST请求,然后看它提交了哪些参数,FormData如下:
提交的参数,上面提到的params和encSecKey,都是加密的。我们看看返回内容的格式:
ok,基本的东西我们已经知道了,我们可以进行下一步,找到解密的两个参数。
分析
在调试之前,我们要找到这两个值的位置,然后搜索,先定位js文件再定位代码位置。你应该知道如何搜索。您可以搜索 params 或 encSecKey。如果发现多个结果,不确定是哪个文件,可以点击每个key,搜索key参数,判断是否为目标文件。这里我直接标记了。正确的文件,你可以点击进去。
进入JS文件后,同样搜索key参数params或者encSecKey:
找到encSecKey的位置,拉出这几行代码分析一下:
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
e0x.data = j0x.cs1x({
params: bVZ8R.encText,
encSecKey: bVZ8R.encSecKey
})
粗略地说,params和encSecKey来自bVZ8R.encText和bVZ8R.encSecKey,bVZ8R是window.asrsea的结果,有四个参数,JSON.stringify(i0x), bqN0x(["tear", "strong"]) , bqN0x(Wx5C.md), bqN0x(["love", "girl", "horrified", "laughing"],先看最后三个参数,从它们的固定值可以大胆推断出这三个值也是Fixed,之所以说是fixed,看一下Wx5C.md:
wx5C.md是一个固定的数组,bqN0x(["tears", "strong"])和bqN0x(["love", "girl", "horrified", "laughing"]肯定不会导致改变,如图下面,测试一下:
这些参数我大概都弄清楚了,剩下的就是弄清楚window.asrsea的具体实现,以及i0x是什么样的,进入调试过程。
调试
Window.asrsea 有一个断点。我的代码位置是第 13133 行。点击粉丝列表的下一页将激活断点。在激活断点的同时,我们也可以看到 i0x 的美妙之处。在控制台输入 i0x:
limit、offset、total、userId其实都是已知的,这里可以看到csrf_token的生成,细心的童鞋应该早就发现了:
}
i0x["csrf_token"] = v0x.gP3x("__csrf"); ## csrf_token在这里产生
X0x = X0x.replace("api", "weapi");
e0x.method = "post";
delete e0x.query;
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
我点击进入 v0x.gP3x 函数查看:
从代码可以看出csrf_token来自Cookie中的__csrf:
那么这个值就可以在请求网页时从cookie中获取,继续调试window.asrsea。一路点击下一步进入功能。
跳转到ad(d,e,f,g)函数,往下看一点,发现window.asrsea等于这个d函数,哦,好吧,调试一下这个d函数:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
输入一个函数:
可以看到a函数生成随机数,继续运行,进入b函数:
熟悉的AES加密,继续跑进c函数:
就是大家熟悉的RSA加密,网易可真是小心翼翼,各种加密。至此,整体框架已经调试完毕,剩下的无非就是挖JS代码了。
蟒蛇运行
这一次,不仅是运行结果,还包括爬取和入库:
获取参数和 encSecKey
def get_enc(self,a):
with open('..//js//wangyiyun.js', encoding='utf-8') as f:
wangyiyun = f.read()
js = execjs.compile(wangyiyun)
logid = js.call('get_pwd', a)
print(logid)
return logid
抓住
def get_fans(self):
resp = self.get_home_page()
print(resp.cookies)
print(resp.status_code)
time.sleep(6)
limit = 20
for i in range(1,110):
print("第{}页".format(i+1))
offset = limit*i
a = {"userId": "46991111", "offset": str(offset), "total": "false", "limit": str(limit), "csrf_token": ""}
print(a)
logid = self.get_enc(a)
data = {
"params":logid["encText"],
"encSecKey":logid["encSecKey"],
}
print(data)
fans_url = "https://music.163.com/weapi/us ... ot%3B
resp = self.session.post(url=fans_url,data=data,headers=self.headers)
followed = json.loads(resp.text)
followed_list = []
for foll in followed["followeds"]:
foll_dict = {}
foll_dict["short_name"] = foll.get("py","") #缩写
foll_dict["userId"] = foll.get("userId","") #用户ID
foll_dict["nickname"] = foll.get("nickname","") #昵称
foll_dict["vipType"] = foll.get("vipType","") # vip
foll_dict["eventCount"] = foll.get("eventCount","")#动态
foll_dict["vipRights"] = str(foll.get("vipRights","")) #VIP权益
foll_dict["gender"] = foll.get("gender","") #性别
foll_dict["avatarUrl"] = foll.get("avatarUrl","") #头像
foll_dict["followed"] = foll.get("followed","")
foll_dict["followeds"] = foll.get("followeds","") #粉丝
foll_dict["follows"] = foll.get("follows","") #关注
foll_dict["playlistCount"] = foll.get("playlistCount","") #歌单
foll_dict["mutual"] = foll.get("mutual","") #
foll_dict["expertTags"] = str(foll.get("expertTags",""))
foll_dict["experts"] = str(foll.get("experts",""))
print(foll_dict)
followed_list.append(foll_dict)
self.mysql.insert("music",followed_list)
tm = random.randint(10,30)
time.sleep(tm)
这里需要注意的是,要爬取指定页面,必须先访问这个页面,不能直接请求这个链接,因为它根本没有关于哪个页面的信息。
请求指定网页
def get_home_page(self):
url = "https://music.163.com/%23/user ... ot%3B
resp = self.session.get(url)
return resp
表结构
@property
def create_table_sql(self):
create_table = """
CREATE TABLE IF NOT EXISTS music (
short_name varchar(30) ,
userId varchar(100) NOT NULL,
nickname varchar(30),
vipType varchar(30) ,
eventCount varchar(200),
vipRights varchar(900),
gender varchar(900),
avatarUrl varchar(200),
followed varchar(30),
followeds varchar(30),
follows varchar(30),
playlistCount varchar(30),
mutual varchar(30),
expertTags varchar(30),
experts varchar(30),
PRIMARY KEY (userId)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
return create_table
仓储
def insert(self,table,data_list):
if len(data_list) > 0:
data_list = [{k: v
for k, v in data.items() if v is not None}
for data in data_list]
keys = ", ".join(data_list[0].keys())
values = ", ".join(["%s"] * len(data_list[0]))
sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
DUPLICATE KEY UPDATE""".format(table=table,
keys=keys,
values=values)
update = ",".join([
" {key} = values({key})".format(key=key)
for key in data_list[0]
])
sql += update
print(sql)
self.connect()
try:
ret = self.cursor.executemany(sql, [tuple(data.values()) for data in data_list])
self.conn.commit()
except Exception as e:
self.conn.rollback()
print("Error: ", e)
traceback.print_exc()
finally:
self.close()
过程
结尾
网页抓取解密(丹溪运动小程序获取的第一种方法解密参考参考示例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-11 04:19
)
1.申请注册微信开放平台
2.将公众号或小程序绑定到微信开放平台
3.微信公众号,使用微信网页授权获取unionid
4.如果你是小程序,获取unionid有几种方法
小程序获得的第一个方法被解密。举例请参考丹溪体育小程序的处理方法
注意:unionid是同一用户在微信平台下使用不同产品生成的id,用于区分不同产品的用户。
解密数据(appid sessionKey encryptedData iv )
/**
* 检验数据的真实性,并且获取解密后的明文.
* @param $encryptedData string 加密的用户数据
* @param $iv string 与用户数据一同返回的初始向量
* @param $data string 解密后的原文
*
* @return int 成功0,失败返回对应的错误码
*/
public function xiaoDecryptData( Request $request )
{
$data = $request->all();
$sessionKey = $data['sessionKey'];
$encryptedData = $data['encryptedData'];
$appid = $data['appid'];
$iv = $data['iv'];
$IllegalAesKey = -41001;
$IllegalIv = -41002;
$IllegalBuffer = -41003;
$DecodeBase64Error = -41004;
$OK = 0;
if (strlen($sessionKey) != 24) {
return ['code' => 1002, 'data' => ['message' => $IllegalAesKey]];
}
$aesKey=base64_decode($sessionKey);
if (strlen($iv) != 24) {
return ['code' => 1002, 'data' => ['message' => $IllegalIv]];
}
$aesIV=base64_decode($iv);
$aesCipher=base64_decode($encryptedData);
$result=openssl_decrypt( $aesCipher, "AES-128-CBC", $aesKey, 1, $aesIV);
$dataObj=json_decode( $result );
if( $dataObj == NULL )
{
return ['code' => 1002, 'data' => ['message' => $IllegalBuffer]];
}
if( $dataObj->watermark->appid != $appid )
{
return ['code' => 1002, 'data' => ['message' => $IllegalBuffer]];
}
return ['code' => 1000, 'data' => $dataObj];
} 查看全部
网页抓取解密(丹溪运动小程序获取的第一种方法解密参考参考示例
)
1.申请注册微信开放平台
2.将公众号或小程序绑定到微信开放平台
3.微信公众号,使用微信网页授权获取unionid
4.如果你是小程序,获取unionid有几种方法
小程序获得的第一个方法被解密。举例请参考丹溪体育小程序的处理方法
注意:unionid是同一用户在微信平台下使用不同产品生成的id,用于区分不同产品的用户。
解密数据(appid sessionKey encryptedData iv )
/**
* 检验数据的真实性,并且获取解密后的明文.
* @param $encryptedData string 加密的用户数据
* @param $iv string 与用户数据一同返回的初始向量
* @param $data string 解密后的原文
*
* @return int 成功0,失败返回对应的错误码
*/
public function xiaoDecryptData( Request $request )
{
$data = $request->all();
$sessionKey = $data['sessionKey'];
$encryptedData = $data['encryptedData'];
$appid = $data['appid'];
$iv = $data['iv'];
$IllegalAesKey = -41001;
$IllegalIv = -41002;
$IllegalBuffer = -41003;
$DecodeBase64Error = -41004;
$OK = 0;
if (strlen($sessionKey) != 24) {
return ['code' => 1002, 'data' => ['message' => $IllegalAesKey]];
}
$aesKey=base64_decode($sessionKey);
if (strlen($iv) != 24) {
return ['code' => 1002, 'data' => ['message' => $IllegalIv]];
}
$aesIV=base64_decode($iv);
$aesCipher=base64_decode($encryptedData);
$result=openssl_decrypt( $aesCipher, "AES-128-CBC", $aesKey, 1, $aesIV);
$dataObj=json_decode( $result );
if( $dataObj == NULL )
{
return ['code' => 1002, 'data' => ['message' => $IllegalBuffer]];
}
if( $dataObj->watermark->appid != $appid )
{
return ['code' => 1002, 'data' => ['message' => $IllegalBuffer]];
}
return ['code' => 1000, 'data' => $dataObj];
}
网页抓取解密(利用无线路由器如何进行手机网络数据抓包?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2022-03-10 19:01
当用户使用手机上网时,手机会不断的接收和发送数据包,而这些数据包中收录了大量的用户信息,包括各种账号信息、聊天信息、收发文件、电子邮件和浏览网页。等待。虽然很多信息都是经过加密传输的,但是还是有很多信息是明文传输或者分析后可以解密的,比如账号信息、文件、邮件,还有一些聊天信息。这些数据包将通过路由器分发。我们只需要捕获和分析路由器即可提取用户的各种信息,无需在用户手机中安装和使用插件
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器,也可以使用360免费wifi提供热点,这样就可以截取连接到的手机发送的网络数据包无线 WiFi。
三、如何使用无线路由器抓取手机网络数据包
市场上有许多数据包捕获工具。例如,Wireshark 是比较成熟的之一。除了抓包外,它还附带了一些简单的分析工具。这些抓包工具的原理是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,讲解如何抓取网络数据包。
首先打开软件配置,网络抓包所需的参数,如图1所示。如果你熟悉协议,可以选择一个过滤器,把你不关心的数据包过滤掉便于分析。比如我们知道朋友圈是TCP协议,端口号是443和80,我们可以根据这个信息选择对应的过滤器,然后选择要抓的网卡,开始抓包。
四、网络数据包分析
在抓包时,Wireshark分三部分展示抓包结果,如图2所示。第一个窗口显示抓包列表,中间窗口显示当前选中包的简单解析内容,底部窗口显示当前选择的数据包的十六进制值。
以微信的一个协议包为例,通过抓包操作,抓取到用户通过手机发送的信息的完整对话包。根据对话包显示手机(ip为172.19.90.2,端口号51005)连接服务器( id 为 172.2, 端口号 51005)) 121.51.130.113, 端口号 80) 传输数据到彼此。
前三个包是手机和服务器发送的确认对方身份的包(TCP三次握手),没有重要信息,主要看第四个包,如图4. 其中:
Frame:物理层的数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送方和目的MAC地址信息;
Internet 协议版本 4:Internet 层 IP 数据包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
超文本传输协议:使用层的信息,这里是HTTP协议;
媒体类型:要传输的具体数据;
这里主要分析使用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的。 ,暂时不可用。
这样我们也可以分析发送的图片、视频等信息,后续的提取工作可以交给代码来实现。 查看全部
网页抓取解密(利用无线路由器如何进行手机网络数据抓包?(组图))
当用户使用手机上网时,手机会不断的接收和发送数据包,而这些数据包中收录了大量的用户信息,包括各种账号信息、聊天信息、收发文件、电子邮件和浏览网页。等待。虽然很多信息都是经过加密传输的,但是还是有很多信息是明文传输或者分析后可以解密的,比如账号信息、文件、邮件,还有一些聊天信息。这些数据包将通过路由器分发。我们只需要捕获和分析路由器即可提取用户的各种信息,无需在用户手机中安装和使用插件
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器,也可以使用360免费wifi提供热点,这样就可以截取连接到的手机发送的网络数据包无线 WiFi。
三、如何使用无线路由器抓取手机网络数据包
市场上有许多数据包捕获工具。例如,Wireshark 是比较成熟的之一。除了抓包外,它还附带了一些简单的分析工具。这些抓包工具的原理是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,讲解如何抓取网络数据包。
首先打开软件配置,网络抓包所需的参数,如图1所示。如果你熟悉协议,可以选择一个过滤器,把你不关心的数据包过滤掉便于分析。比如我们知道朋友圈是TCP协议,端口号是443和80,我们可以根据这个信息选择对应的过滤器,然后选择要抓的网卡,开始抓包。
四、网络数据包分析
在抓包时,Wireshark分三部分展示抓包结果,如图2所示。第一个窗口显示抓包列表,中间窗口显示当前选中包的简单解析内容,底部窗口显示当前选择的数据包的十六进制值。
以微信的一个协议包为例,通过抓包操作,抓取到用户通过手机发送的信息的完整对话包。根据对话包显示手机(ip为172.19.90.2,端口号51005)连接服务器( id 为 172.2, 端口号 51005)) 121.51.130.113, 端口号 80) 传输数据到彼此。
前三个包是手机和服务器发送的确认对方身份的包(TCP三次握手),没有重要信息,主要看第四个包,如图4. 其中:
Frame:物理层的数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送方和目的MAC地址信息;
Internet 协议版本 4:Internet 层 IP 数据包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
超文本传输协议:使用层的信息,这里是HTTP协议;
媒体类型:要传输的具体数据;
这里主要分析使用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的。 ,暂时不可用。
这样我们也可以分析发送的图片、视频等信息,后续的提取工作可以交给代码来实现。
网页抓取解密(如何构建一个QQ邮箱的邮箱?的密码怎么处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-10 15:10
首先声明文章只能用于交流学习,不能用于其他用途,否则后果自负。
现在国家对网络安全的管理越来越严格了,但是还是有一些不法的网站法律普遍存在,而且受限于国内的人力物力,不可能取缔这些网站。
今天演示的网站是非法的网站。
先看登录界面。
捕获登录信息。
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
我输入的密码和用户名一样,说明网站已经处理了提交的密码。一会儿让我看看密码是如何处理的。现在让我们看看来自服务器的返回信息。
服务器返回 JSON。此时,我们缺少密码。只要知道密码是如何产生的,就可以加快破解用户密码的速度。
查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
由于现在人们在注册网站的时候都是用QQ邮箱注册的,所以我们可以先建一个QQ邮箱,先判断封面邮箱是否存在,再判断密码是否正确。
思路清晰了,我们直接上干货。
构造判断密码邮箱是否存在
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
好了,初步的写作完成了。让我们先完成一部电影,看看最终结果。
实际上成功测试了大约 1500 个邮箱,而且很多很多人使用非常简单的密码。实际上成功测试了大约 1500 个邮箱,而且很多很多人使用非常简单的密码。 查看全部
网页抓取解密(如何构建一个QQ邮箱的邮箱?的密码怎么处理)
首先声明文章只能用于交流学习,不能用于其他用途,否则后果自负。
现在国家对网络安全的管理越来越严格了,但是还是有一些不法的网站法律普遍存在,而且受限于国内的人力物力,不可能取缔这些网站。
今天演示的网站是非法的网站。
先看登录界面。
捕获登录信息。
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
我输入的密码和用户名一样,说明网站已经处理了提交的密码。一会儿让我看看密码是如何处理的。现在让我们看看来自服务器的返回信息。
服务器返回 JSON。此时,我们缺少密码。只要知道密码是如何产生的,就可以加快破解用户密码的速度。
查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
由于现在人们在注册网站的时候都是用QQ邮箱注册的,所以我们可以先建一个QQ邮箱,先判断封面邮箱是否存在,再判断密码是否正确。
思路清晰了,我们直接上干货。
构造判断密码邮箱是否存在
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
好了,初步的写作完成了。让我们先完成一部电影,看看最终结果。
实际上成功测试了大约 1500 个邮箱,而且很多很多人使用非常简单的密码。实际上成功测试了大约 1500 个邮箱,而且很多很多人使用非常简单的密码。
网页抓取解密( 广州爱搜客专业优化团队需要SEOer来优化的需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-09 05:12
广州爱搜客专业优化团队需要SEOer来优化的需求)
做搜索引擎优化,首先要了解搜索引擎的基本工作原理。搜索引擎的基本原理可以分为四个步骤:从互联网上爬取页面、建立索引库、处理搜索词、处理搜索结果和排序。
一、从互联网上爬取页面:搜索引擎发出一个程序来发现新的网页并爬取文件,我们称之为蜘蛛或机器人。搜索引擎的蜘蛛从数据库中已知的网页开始,模仿人类浏览访问这些网页并爬取这些文件。
搜索引擎跟踪网页上的链接并访问更多网页的过程,我们称之为爬取。当蜘蛛通过连接找到新的网址时,会将新的网址记录在数据库中,等待其被抓取并跟随网页链接。它是搜索蜘蛛发现新 URL 的最基本方法,因此反向链接是 SEO 最基本的元素之一。
二、建立数据库索引:分析索引系统程序对采集到的网页进行分析,提取网页信息(包括URL、编码类型、关键词位置、生成时间、与其他网页的链接关系等.) ,然后根据一定的相关性算法进行大量复杂的运算,得到网页对关键词的相关性,然后利用这些信息构建网页索引库。
三、当用户在搜索引擎界面输入关键词,搜索后,搜索引擎程序对输入的搜索词进行处理,如分词、关键词、去除停用词、判断是否要开始排序搜索和错别字等。
四、搜索结果的处理和排序:用户输入关键词后,搜索系统程序会从网页索引库中查找与关键词匹配的相关网页。相关性越高,排名越高。向前。最后,页面生成系统将搜索结果的链接地址、页面内容等信息组织起来返回给用户。
以上就是搜索引擎排名的四个基本步骤。搜索引擎在识别网页方面仍然无法与人们进行比较。这就是为什么网站需要SEOer来优化,只有专业的SEOer才能有效引导企业网站获得一定的排名,如果你有SEO优化的需求,广州爱舒克SEO专业优化团队帮你解决. 查看全部
网页抓取解密(
广州爱搜客专业优化团队需要SEOer来优化的需求)
做搜索引擎优化,首先要了解搜索引擎的基本工作原理。搜索引擎的基本原理可以分为四个步骤:从互联网上爬取页面、建立索引库、处理搜索词、处理搜索结果和排序。
一、从互联网上爬取页面:搜索引擎发出一个程序来发现新的网页并爬取文件,我们称之为蜘蛛或机器人。搜索引擎的蜘蛛从数据库中已知的网页开始,模仿人类浏览访问这些网页并爬取这些文件。
搜索引擎跟踪网页上的链接并访问更多网页的过程,我们称之为爬取。当蜘蛛通过连接找到新的网址时,会将新的网址记录在数据库中,等待其被抓取并跟随网页链接。它是搜索蜘蛛发现新 URL 的最基本方法,因此反向链接是 SEO 最基本的元素之一。
二、建立数据库索引:分析索引系统程序对采集到的网页进行分析,提取网页信息(包括URL、编码类型、关键词位置、生成时间、与其他网页的链接关系等.) ,然后根据一定的相关性算法进行大量复杂的运算,得到网页对关键词的相关性,然后利用这些信息构建网页索引库。
三、当用户在搜索引擎界面输入关键词,搜索后,搜索引擎程序对输入的搜索词进行处理,如分词、关键词、去除停用词、判断是否要开始排序搜索和错别字等。
四、搜索结果的处理和排序:用户输入关键词后,搜索系统程序会从网页索引库中查找与关键词匹配的相关网页。相关性越高,排名越高。向前。最后,页面生成系统将搜索结果的链接地址、页面内容等信息组织起来返回给用户。
以上就是搜索引擎排名的四个基本步骤。搜索引擎在识别网页方面仍然无法与人们进行比较。这就是为什么网站需要SEOer来优化,只有专业的SEOer才能有效引导企业网站获得一定的排名,如果你有SEO优化的需求,广州爱舒克SEO专业优化团队帮你解决.
网页抓取解密(RPA和爬虫技术更多结合的期待性探讨-RPA)
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2022-03-05 19:15
爬虫是根据一定的规则自动爬取互联网上的信息的程序或脚本。而且RPA还可以操作WEB浏览器自动抓取网页中的数据或图片,这和爬虫类似,那么RPA和爬虫有什么区别呢?
RPA的应用场景更加广泛,可以应用于企业的各个部门,比如财务部、人事部、采购部或者市场部等,主要是通过RPA自动化来减少人工的重复操作。在特定的操作层面,RPA可以自动打开邮件、下载附件、登录网站和系统、读取数据库、复制、粘贴和移动文件、读取或写入表格数据、网页数据抓取等。 . 在日常工作中,它可以帮助员工自动采集数据、整理表格、处理数据甚至收发电子邮件。简而言之,企业中具有固定规则的重复性任务可以通过 RPA 自动化。
爬虫主要用于网络上的data采集,工作场景有局限性,所以主要用在data采集的场景中,通常使用接口或者蛮力的方法来爬取和解析网页内容获取数据。, 采集效率高,同时会给后台造成巨大的负担,所以会被反爬虫机制禁止。
现阶段,爬虫技术在RPA中的应用并不广泛。不过随着技术的发展和客户的需求,我个人觉得未来RPA会介入更多的基础工作,爬虫技术也会拓展它的空间。毕竟,RPA 的“这个爬虫”是一个有益的“爬虫”。
RPA与爬虫技术结合的前瞻性探讨
1、从目前来看,RPA更多的是从事基础工作,而网页数据中的数据更“拟人化”,所以数据量比较少,频率也比较低,反爬虫很大。概率不会被挡住,因为误伤率是反爬虫非常关心的一个指标。
2、从未来的角度来看,如果RPA仅能模拟人类操作并执行特定操作,那么反爬虫将很难通过模式识别来准确区分人类操作和RPA。从这个角度来看,RPA在爬虫上的应用更有前景。
3、从个人角度来说,爬虫创立的时候,总是夹杂着“人肉”的性质(不好意思,我个人觉得这个功能经常夹杂着贬义,很多爬虫都有“ “人肉”的坏”用法)RPA需要传递有益的信息,更多的功能是检索和有价值的信息传播。为什么要防止“反爬虫”?而且是RPA正常的“拟人化”常规信息采集工作。由此看来,未来爬虫技术在RPA中的应用将大有可为! 查看全部
网页抓取解密(RPA和爬虫技术更多结合的期待性探讨-RPA)
爬虫是根据一定的规则自动爬取互联网上的信息的程序或脚本。而且RPA还可以操作WEB浏览器自动抓取网页中的数据或图片,这和爬虫类似,那么RPA和爬虫有什么区别呢?
RPA的应用场景更加广泛,可以应用于企业的各个部门,比如财务部、人事部、采购部或者市场部等,主要是通过RPA自动化来减少人工的重复操作。在特定的操作层面,RPA可以自动打开邮件、下载附件、登录网站和系统、读取数据库、复制、粘贴和移动文件、读取或写入表格数据、网页数据抓取等。 . 在日常工作中,它可以帮助员工自动采集数据、整理表格、处理数据甚至收发电子邮件。简而言之,企业中具有固定规则的重复性任务可以通过 RPA 自动化。
爬虫主要用于网络上的data采集,工作场景有局限性,所以主要用在data采集的场景中,通常使用接口或者蛮力的方法来爬取和解析网页内容获取数据。, 采集效率高,同时会给后台造成巨大的负担,所以会被反爬虫机制禁止。
现阶段,爬虫技术在RPA中的应用并不广泛。不过随着技术的发展和客户的需求,我个人觉得未来RPA会介入更多的基础工作,爬虫技术也会拓展它的空间。毕竟,RPA 的“这个爬虫”是一个有益的“爬虫”。
RPA与爬虫技术结合的前瞻性探讨
1、从目前来看,RPA更多的是从事基础工作,而网页数据中的数据更“拟人化”,所以数据量比较少,频率也比较低,反爬虫很大。概率不会被挡住,因为误伤率是反爬虫非常关心的一个指标。
2、从未来的角度来看,如果RPA仅能模拟人类操作并执行特定操作,那么反爬虫将很难通过模式识别来准确区分人类操作和RPA。从这个角度来看,RPA在爬虫上的应用更有前景。
3、从个人角度来说,爬虫创立的时候,总是夹杂着“人肉”的性质(不好意思,我个人觉得这个功能经常夹杂着贬义,很多爬虫都有“ “人肉”的坏”用法)RPA需要传递有益的信息,更多的功能是检索和有价值的信息传播。为什么要防止“反爬虫”?而且是RPA正常的“拟人化”常规信息采集工作。由此看来,未来爬虫技术在RPA中的应用将大有可为!
网页抓取解密(网页抓取解密不是解密算法,是加密吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-04 21:01
网页抓取解密不是解密算法,是加密。可以通过分析页面结构来进行解密。
人家是读取的你分析的人家的文件,打包发给你。
这种问题已经无聊到我无言以对的地步了
估计是为了自动弹出下载地址才一个一个爬包,一个网站抓取下来的东西都是不一样的,想要解密,先要研究人家解密方法的特点,然后自己写解密程序。
同求,太缺关注度了。
同求,不想公布自己的爬虫以免被封掉,而且也会很火的。
requests+beautifulsoup或者jsoup+http库
抓包。看看是否有可通用的解密方案,
百度打包出js,最近在研究,然后以js文件为基础写个requests+jsoup的爬虫抓取。
也可以用jsoup,不过有个问题是有的项目不使用jsoup,不是有selenium也不是说必须要jsoup,
我只有每个网站的header密码以及http相关的uri
题主可以试试先抓取下来,
哈哈
我想知道https抓包怎么抓?
你先去themillow登录看看
找找themillow能不能登上去
我记得有个现成的mitm手册
比如根据http请求的过程去解析,然后写爬虫过去,每个网站进行一下循环,即使有重复https也能过去,应该看得懂,看不懂请找专业人士回答。
明明就是百度xx先森这种名字的啊! 查看全部
网页抓取解密(网页抓取解密不是解密算法,是加密吗?(一))
网页抓取解密不是解密算法,是加密。可以通过分析页面结构来进行解密。
人家是读取的你分析的人家的文件,打包发给你。
这种问题已经无聊到我无言以对的地步了
估计是为了自动弹出下载地址才一个一个爬包,一个网站抓取下来的东西都是不一样的,想要解密,先要研究人家解密方法的特点,然后自己写解密程序。
同求,太缺关注度了。
同求,不想公布自己的爬虫以免被封掉,而且也会很火的。
requests+beautifulsoup或者jsoup+http库
抓包。看看是否有可通用的解密方案,
百度打包出js,最近在研究,然后以js文件为基础写个requests+jsoup的爬虫抓取。
也可以用jsoup,不过有个问题是有的项目不使用jsoup,不是有selenium也不是说必须要jsoup,
我只有每个网站的header密码以及http相关的uri
题主可以试试先抓取下来,
哈哈
我想知道https抓包怎么抓?
你先去themillow登录看看
找找themillow能不能登上去
我记得有个现成的mitm手册
比如根据http请求的过程去解析,然后写爬虫过去,每个网站进行一下循环,即使有重复https也能过去,应该看得懂,看不懂请找专业人士回答。
明明就是百度xx先森这种名字的啊!
网页抓取解密( 有些信息加密插件.zip信息安全插件加密源码下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-02 07:15
有些信息加密插件.zip信息安全插件加密源码下载(组图))
现在一些 网站 仍在使用 http 协议。这样,由于http协议在登录时没有加密功能,用户的密码在去服务器的途中很容易被网络捕获,或者浏览器一般会记录用户的密码是很危险的。如果我们在网页上输入的密码在被浏览器记录或发送到服务器之前经过ActiveX插件加密,就可以起到信息安全的作用。
#region JS调用方法
#region AES
private const string aesKey = "12345678qwertyui";//AES秘钥
private const string aesVector = "987654321zxcvbnm";//AES向量
///
/// AES加密
///
/// 要加密的明文
///
public string AESEncrypt(string data)
{
return AES.AESEncrypt(data, Encoding.UTF8, aesKey, aesVector);
}
///
/// AES解密
///
/// 要解密的密文
///
public string AESDecrypt(string data)
{
return AES.AESDecrypt(data, Encoding.UTF8, aesKey, aesVector);
}
#endregion
#region MD5
///
/// MD5加密
///
/// 要加密的明文
///
public string MD5Encrypt(string data)
{
return HashAlgorithmEncrypt.MD5Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.Bit.bit16, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#region SHA1
///
/// SHA1加密
///
/// 要加密的明文
///
public string SHA1Encrypt(string data)
{
return HashAlgorithmEncrypt.SHA1Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#endregion
源码下载地址:ActiveX信息加密插件.zip 查看全部
网页抓取解密(
有些信息加密插件.zip信息安全插件加密源码下载(组图))
现在一些 网站 仍在使用 http 协议。这样,由于http协议在登录时没有加密功能,用户的密码在去服务器的途中很容易被网络捕获,或者浏览器一般会记录用户的密码是很危险的。如果我们在网页上输入的密码在被浏览器记录或发送到服务器之前经过ActiveX插件加密,就可以起到信息安全的作用。
#region JS调用方法
#region AES
private const string aesKey = "12345678qwertyui";//AES秘钥
private const string aesVector = "987654321zxcvbnm";//AES向量
///
/// AES加密
///
/// 要加密的明文
///
public string AESEncrypt(string data)
{
return AES.AESEncrypt(data, Encoding.UTF8, aesKey, aesVector);
}
///
/// AES解密
///
/// 要解密的密文
///
public string AESDecrypt(string data)
{
return AES.AESDecrypt(data, Encoding.UTF8, aesKey, aesVector);
}
#endregion
#region MD5
///
/// MD5加密
///
/// 要加密的明文
///
public string MD5Encrypt(string data)
{
return HashAlgorithmEncrypt.MD5Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.Bit.bit16, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#region SHA1
///
/// SHA1加密
///
/// 要加密的明文
///
public string SHA1Encrypt(string data)
{
return HashAlgorithmEncrypt.SHA1Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#endregion
源码下载地址:ActiveX信息加密插件.zip
网页抓取解密(flash用c++写的客户端一样有人有人能调试来破解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-27 17:16
可以播放基于 Flash 的加密视频。
Adobe 官方的建议是认证并使用 rtmp 协议来防止浏览器缓存。
但是,也有一些方法可以防止在 http 协议下进行缓存。虽然解密是在客户端进行的,但是解密和回放的实现相对来说比较复杂。如果您不精通actionscript,则很难窃取此加密视频。当然,破解者的技术是好的,因为即使客户端是用C++编写的,也有人可以组装调试它来破解。
flash播放加密视频的原理:服务器对上传视频的二进制数据进行加密。视频可以通过http协议下载,但是普通播放器无法解码,所以普通播放器无法直接播放。在flash端播放视频时,不能简单地指定视频组件的视频源地址,而是向服务器请求视频数据,将得到的二进制数据解密,然后传输给视频组件进行播放。编码的工作量主要是编写逻辑来实现数据流处理、模拟视频缓冲等。这种播放方式不会将视频数据留在浏览器缓存中。要破解它,需要逆向flash的内置解密。算法,现在没有好的flash反编译工具,
国内一些厂商提供了这种在线视频播放解决方案。该方案的技术授权可能要花费数十万,但成本远低于 rtmp 协议(rtmp 服务器软件许可费和 rtmp CDN 服务费并不便宜。)。主要客户是在线教育网站,比如人民医学出版社的医学教育网。 查看全部
网页抓取解密(flash用c++写的客户端一样有人有人能调试来破解)
可以播放基于 Flash 的加密视频。
Adobe 官方的建议是认证并使用 rtmp 协议来防止浏览器缓存。
但是,也有一些方法可以防止在 http 协议下进行缓存。虽然解密是在客户端进行的,但是解密和回放的实现相对来说比较复杂。如果您不精通actionscript,则很难窃取此加密视频。当然,破解者的技术是好的,因为即使客户端是用C++编写的,也有人可以组装调试它来破解。
flash播放加密视频的原理:服务器对上传视频的二进制数据进行加密。视频可以通过http协议下载,但是普通播放器无法解码,所以普通播放器无法直接播放。在flash端播放视频时,不能简单地指定视频组件的视频源地址,而是向服务器请求视频数据,将得到的二进制数据解密,然后传输给视频组件进行播放。编码的工作量主要是编写逻辑来实现数据流处理、模拟视频缓冲等。这种播放方式不会将视频数据留在浏览器缓存中。要破解它,需要逆向flash的内置解密。算法,现在没有好的flash反编译工具,
国内一些厂商提供了这种在线视频播放解决方案。该方案的技术授权可能要花费数十万,但成本远低于 rtmp 协议(rtmp 服务器软件许可费和 rtmp CDN 服务费并不便宜。)。主要客户是在线教育网站,比如人民医学出版社的医学教育网。
网页抓取解密(暴力就是解决QQ密码的唯一途径,qq密码暴力破解器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-25 16:09
暴力是破解QQ密码的唯一途径。QQ密码暴力破解2017传闻已久。QQ密码暴力查看器可以看到腾讯QQ号的密码,强到不行!QQ密码暴力查看器,想要优雅就叫他QQ密码查看器,据说成功率比较高,包括查看QQ密码教程,功能就是完美解析QQ密码!还在找QQ历史密码查询网站2017吗?下载QQ密码暴力查看器就完美了!
QQ密码暴力查看器使用方法:
1:读号:
存储数字和密码的文件格式:
数字----密码(每行一个,例如:12345----5353132454)
2:复制:全选,将文本框的所有内容复制到系统剪贴板。
3:保存:将文本框的所有内容保存到一个文本文件中。
4:删除:在读取的系统数据中,删除文本框上的数字。
5:显示所有数据:读取数字文件后显示系统的数据。
6:一般搜索:选择要过滤的类型后,点击“过滤”。
为什么可供选择的类型这么少?因为很多类型完全可以用下面的“模式匹配”来完成。
7:根据模式找到相似的数字。(图案中的数字和“?”相同,但AI不同)
匹配模式中的不同数字和数字同“?”,条件AI不同。
示例:要查找:4567999/4567888/4567555,请选择“按模式查找相似数字”,
模式设置为“****AAA”,按“过滤器”。
8:模式匹配:安装自定义类型来过滤数字。
本站统一解压密码。同时,本站腾讯QQ下载话题也不错! 查看全部
网页抓取解密(暴力就是解决QQ密码的唯一途径,qq密码暴力破解器)
暴力是破解QQ密码的唯一途径。QQ密码暴力破解2017传闻已久。QQ密码暴力查看器可以看到腾讯QQ号的密码,强到不行!QQ密码暴力查看器,想要优雅就叫他QQ密码查看器,据说成功率比较高,包括查看QQ密码教程,功能就是完美解析QQ密码!还在找QQ历史密码查询网站2017吗?下载QQ密码暴力查看器就完美了!
QQ密码暴力查看器使用方法:
1:读号:
存储数字和密码的文件格式:
数字----密码(每行一个,例如:12345----5353132454)
2:复制:全选,将文本框的所有内容复制到系统剪贴板。
3:保存:将文本框的所有内容保存到一个文本文件中。
4:删除:在读取的系统数据中,删除文本框上的数字。
5:显示所有数据:读取数字文件后显示系统的数据。
6:一般搜索:选择要过滤的类型后,点击“过滤”。
为什么可供选择的类型这么少?因为很多类型完全可以用下面的“模式匹配”来完成。
7:根据模式找到相似的数字。(图案中的数字和“?”相同,但AI不同)
匹配模式中的不同数字和数字同“?”,条件AI不同。
示例:要查找:4567999/4567888/4567555,请选择“按模式查找相似数字”,
模式设置为“****AAA”,按“过滤器”。
8:模式匹配:安装自定义类型来过滤数字。
本站统一解压密码。同时,本站腾讯QQ下载话题也不错!
网页抓取解密( 英文不好学起来挺困难的,百度了半天就没找到解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-25 05:01
英文不好学起来挺困难的,百度了半天就没找到解决办法)
分享python抓取网页时字符集转换问题的解决方案
更新时间:2014-06-19 09:45:07 提交人:hebedich
在学习python的过程中,发现学好英语是非常困难的。其中,小弟遇到了一个非常痛苦的问题。百度了半天也没找到解决办法~囧~摸索了半天自己解决了,和大家一起记录一下。互相鼓励。
问题:
有时我们在采集网页中,将字符串保存到文件或处理后写入数据库。这时候,我们需要制定字符串的编码方式。如果采集网页的编码是gb2312,而我们的数据库是utf-8,那么直接插入数据库不做任何处理可能会出现乱码(我没测试过,不知道有没有数据库会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人立马下跪。
不知道大家还记得没有,python打印汉字的时候,需要在字符串前面加u:
print u"来搞基吗?"
这样就可以显示中文了。 u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
有一个与之相关的unicode()函数,使用如下
str="来搞基"
str=unicode(str,"utf-8")
print str
两者的区别
而u是unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认可能是ansi。
unicode是key,下面继续
我们开始爬取百度首页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
import urllib2
def main():
f=urllib2.urlopen("http://www.baidu.com")
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
if __name__ == '__main__' :
main()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大多数人来说,这已经足够了,但有时我只想将gb2312转为utf-8,我该怎么办?
第一:
str=unicode(str,"gb2312") #这里的gb2312是str的实际字符集,我们现在把它转成unicode
然后:
str=str.encode("utf-8") #将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,转码为utf-8。
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding")将str解码成unicode字符串
2:将unicode字符串str转换成你使用str.encode("specified character set")指定的字符集
3:将str保存到文件,或者写入数据库等。当然,你已经指定了编码,对吧? 查看全部
网页抓取解密(
英文不好学起来挺困难的,百度了半天就没找到解决办法)
分享python抓取网页时字符集转换问题的解决方案
更新时间:2014-06-19 09:45:07 提交人:hebedich
在学习python的过程中,发现学好英语是非常困难的。其中,小弟遇到了一个非常痛苦的问题。百度了半天也没找到解决办法~囧~摸索了半天自己解决了,和大家一起记录一下。互相鼓励。
问题:
有时我们在采集网页中,将字符串保存到文件或处理后写入数据库。这时候,我们需要制定字符串的编码方式。如果采集网页的编码是gb2312,而我们的数据库是utf-8,那么直接插入数据库不做任何处理可能会出现乱码(我没测试过,不知道有没有数据库会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人立马下跪。
不知道大家还记得没有,python打印汉字的时候,需要在字符串前面加u:
print u"来搞基吗?"
这样就可以显示中文了。 u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
有一个与之相关的unicode()函数,使用如下
str="来搞基"
str=unicode(str,"utf-8")
print str
两者的区别
而u是unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认可能是ansi。
unicode是key,下面继续
我们开始爬取百度首页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
import urllib2
def main():
f=urllib2.urlopen("http://www.baidu.com";)
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
if __name__ == '__main__' :
main()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大多数人来说,这已经足够了,但有时我只想将gb2312转为utf-8,我该怎么办?
第一:
str=unicode(str,"gb2312") #这里的gb2312是str的实际字符集,我们现在把它转成unicode
然后:
str=str.encode("utf-8") #将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,转码为utf-8。
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding")将str解码成unicode字符串
2:将unicode字符串str转换成你使用str.encode("specified character set")指定的字符集
3:将str保存到文件,或者写入数据库等。当然,你已经指定了编码,对吧?
网页抓取解密(网站怎么快速被爬虫?怎么让蜘蛛抓取快速和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-24 22:21
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。下面小编就来告诉大家如何让蜘蛛快速抓取。
一、网站如何快速被爬虫爬取?
1.关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外部链接也会影响权重
入链也是网站优化的一个很重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
首先是大网站下的外链建设。大网站外链的搭建对于站长朋友来说是非常重要的,因为大网站的权重传递效果非常强。而且还可以给内容带来更多的转载,让权重转移往往可以达到一打百的效果,比如在A5上发帖,就是一个不错的方法。此外,您还可以在网易、新浪等各大门户网站网站等相关渠道投稿或花钱。
其实在这些大型的网站上投稿或者发布外部链接都不是一件容易的事。貌似可以通过花钱或者聘请射手来实现,但是如果不注意外链的布局,比如在A5上就很难提升优化效果。提交时,末尾添加的文本链接应为网站的主页链接。这样做的好处是相对于网站站长在A5上的投稿,有一定的相关性。如果您离开 外部链接是销售成人用品的页面。这种相关性会变得极其脆弱,导入权重会很困难。其他大型门户网站网站的外链建设也是如此,一定要注意外链和结果页的相关性。
然后是长尾关键词外链的合理布局。根据28法则,现代网站80%的利润往往来自长尾关键词,也就是说长尾关键词已经成为网站的盈利能力,所以在外链建设中加强长尾关键词的锚文本和外链是有效提高长尾关键词权重和排名的关键方法@> ,为重要的长尾 关键词 构建相应的栏目页,然后外链的来源要选择由这些长尾 关键词 构成的栏目页。当然,外链的载体内容必须与栏目页有一定的相关性,否则效果不明显。
最后要注意网站内容页面的权重导入。这部分也很关键,对于很多中小网站来说,这种内容页面的权重导入,不仅可以有效提升搜索引擎中的内容页面。最重要的是它可以有效提高这些内容页面的导流效果,因为人们在进入这些内容页面时,难免会点击这些内容页面的扩展链接直接进入这个网站,从而提供进一步获得忠实用户的可能性。
那么,在构建内容页面的外链构建时,我们要避免一个问题,就是以内容页面作为外链构建的载体,即在其他网站@上发布的外链内容> 和从外链导入的内容完全一样 是的,这显然不是给用户的参考,但是内容页面有一定的差异,或者外链上有更好的内容补充,就像百度词条上各种延伸阅读和相关词条的锚点,就像文字链接一样,让用户获得更好的知识,也促进了权重的合理导入。
做好网站外链越来越难了,但再难,我们还是要做,但现在不能再这么鲁莽了。一定要注意一定的技巧,对百度搜索引擎算法有深入的了解。只有这样,才能对外链优化起到事半功倍的效果!
3.如何被爬虫爬取?
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等。如果你想让你的网站页面更多的是收录,你必须先让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
二、网站快被蜘蛛爬到
1.网站 和页面重量。
这绝对是首要的。网站 权重高、资历高、权威高的蜘蛛,绝对是被特殊对待的。这样的网站爬取的频率非常高,大家都知道搜索引擎蜘蛛是为了保证效率,对于网站并不是所有的页面都会被爬取,而且网站的权重越高@>,爬得越深,对应的可爬取的页面也会增加,这样网站就可以爬取了。@收录 也会有更多页面。
2.网站服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那谢谢你就离你很近了,蜘蛛也来不了了。百度蜘蛛也是网站的访问者。如果你的服务器不稳定或者比较卡顿,每次爬虫都会很难爬,有时只能爬到页面的一部分。你的体验越来越差,你对网站的分数会越来越低,自然会影响你的网站抢,所以一定要愿意选择空间服务器,有没有好的基础,房子再好。
3.网站 的更新频率。
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但是蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以我们要主动表示善意蜘蛛并定期进行文章更新,让蜘蛛按照你的规则来有效爬取,不仅你的更新文章被抓取更快,而且不会导致蜘蛛经常浪费时间。
4.文章 的 原创 特性。
优质的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常过来觅食。
5.展平网站 结构。
蜘蛛爬行也有自己的路线。你之前已经为它铺平了道路。网站 结构不要太复杂,链接层次不要太深。如果链接层级太深,后面的页面将很难被蜘蛛抓取。收到。
6.网站程序。
在 网站 程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,尝试使用301重定向、Canonical标签或robots进行处理,确保蜘蛛只抓取一个canonical URL。
7.外链建设。
我们都知道外链对于网站是可以吸引蜘蛛的,尤其是新站点的时候,网站还不是很成熟,蜘蛛访问量比较少,而外链可以增加网站的数量@> 页面暴露在蜘蛛前面,防止蜘蛛找不到页面。在建立外链的过程中,需要注意外链的质量。不要做无用的事情来省事。百度对外链接的管理,相信大家都知道。我将提几点需要注意的地方。
第一点:博客外链的搭建这里所说的博客外链并不是我们平时做的。只对一些个人博客、新浪博客、网易博客、和讯博客等发表评论,并留下外部链接。由于百度算法的更新,这种外链现在已经没有效果了,如果做得太多,甚至会被降级。在这里我想说的是为了给博主留下深刻印象而发表评论,帮助博主,提出建议或发表自己不同的想法。这样做几次之后,相信博主们一定会对你有所评价。注意,如果你的网站内容足够好,一些博主会给你一个链接,而且这个链接在他们的随机评论中往往比你好很多。
第二点:在论坛里搭建外链的思路其实和博客差不多。留下你的想法,让楼主关注你。也许几次之后你们会成为朋友甚至伙伴。那个时候加个链接不就是一句话吗?这个我就不多说了。
第三点:软文外链搭建在外链搭建过程中,使用软文搭建外链是必不可少的环节,同时软文搭建外链也是也是最有效最高效的Quick,选择什么平台是直接思考的问题。在这里我建议大家可以找一些鲜为人知的相关平台。比如在无关平台发帖软文肯定不如相关平台好,差的平台认为传播的权重是有限的。是的,我终于写了一篇文章文章,我不同意,投稿时请注意。
第四点:开放、分类目录外链构建如果你的网站足够好,那么开放目录是个不错的选择,比如DOMZ目录、yahoo目录,都可以提交。当然,对于一些新的站点或即将建立的站点,目录是您的天堂。此外,Internet 上还有很多 网站 目录。不要忽略这块用于构建外部链接的脂肪。
第五点:买链接虽然常说买链接会被百度攻击,但作为一个新站,想要在最短的时间内获得一定的公关和权重,有一定的收录 ,购买链接也是必不可少的。少,当然不是你去买一些金链或者去一些专门做买卖链接的平台,而是和一些权重比较高的PR、门户、新闻站交流(前提是这些门户和新闻台都不是专门卖链接的),看能不能买链接,这样你买的链接就不会被百度识别,链接质量比较高。等你的网站慢慢上来,一一删除。
8.内链构造。
蜘蛛的抓取是跟随链接的,所以对内链的合理优化可以让蜘蛛抓取更多的页面,促进网站的收录。在建立内部链接的过程中,应该给用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多点赞等栏目,其中很多网站都用到了,让蜘蛛爬得更宽页面范围。
其实内链的建设也有利于提升用户体验,所以用户不必去每篇文章查看是否有相关内容,只靠一个小的内链,或者一个关键词 @> 带有获取它的链接更多和更广泛的信息,为什么不呢?所以如果要真正提升用户体验,而不是为了SEO来提升用户体验,那么多从用户的角度来看,什么样的内链是用户最高兴看到的就去做。
此外,您可以将一些关键词链接到站点中的其他页面,以提高这些页面之间的相关性,方便用户浏览。用户体验自然会为网站带来更多流量。而且,页面间相关性的提高还可以增加用户在网站的停留时间,减少高跳出率的发生。
网站搜索排名靠前的前提是网站大量页面被搜索引擎收录搜索,良好的内链建设正好可以帮助网站页面被搜索引擎搜索到收录。当网站某篇文章文章为收录时,百度蜘蛛会继续沿着该页面的超链接爬行。如果你的内链做得好,百度蜘蛛会沿着你的整个网站爬行,一个网站页面被收录的几率大大增加。 查看全部
网页抓取解密(网站怎么快速被爬虫?怎么让蜘蛛抓取快速和方法)
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。下面小编就来告诉大家如何让蜘蛛快速抓取。
一、网站如何快速被爬虫爬取?
1.关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外部链接也会影响权重
入链也是网站优化的一个很重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
首先是大网站下的外链建设。大网站外链的搭建对于站长朋友来说是非常重要的,因为大网站的权重传递效果非常强。而且还可以给内容带来更多的转载,让权重转移往往可以达到一打百的效果,比如在A5上发帖,就是一个不错的方法。此外,您还可以在网易、新浪等各大门户网站网站等相关渠道投稿或花钱。
其实在这些大型的网站上投稿或者发布外部链接都不是一件容易的事。貌似可以通过花钱或者聘请射手来实现,但是如果不注意外链的布局,比如在A5上就很难提升优化效果。提交时,末尾添加的文本链接应为网站的主页链接。这样做的好处是相对于网站站长在A5上的投稿,有一定的相关性。如果您离开 外部链接是销售成人用品的页面。这种相关性会变得极其脆弱,导入权重会很困难。其他大型门户网站网站的外链建设也是如此,一定要注意外链和结果页的相关性。
然后是长尾关键词外链的合理布局。根据28法则,现代网站80%的利润往往来自长尾关键词,也就是说长尾关键词已经成为网站的盈利能力,所以在外链建设中加强长尾关键词的锚文本和外链是有效提高长尾关键词权重和排名的关键方法@> ,为重要的长尾 关键词 构建相应的栏目页,然后外链的来源要选择由这些长尾 关键词 构成的栏目页。当然,外链的载体内容必须与栏目页有一定的相关性,否则效果不明显。
最后要注意网站内容页面的权重导入。这部分也很关键,对于很多中小网站来说,这种内容页面的权重导入,不仅可以有效提升搜索引擎中的内容页面。最重要的是它可以有效提高这些内容页面的导流效果,因为人们在进入这些内容页面时,难免会点击这些内容页面的扩展链接直接进入这个网站,从而提供进一步获得忠实用户的可能性。
那么,在构建内容页面的外链构建时,我们要避免一个问题,就是以内容页面作为外链构建的载体,即在其他网站@上发布的外链内容> 和从外链导入的内容完全一样 是的,这显然不是给用户的参考,但是内容页面有一定的差异,或者外链上有更好的内容补充,就像百度词条上各种延伸阅读和相关词条的锚点,就像文字链接一样,让用户获得更好的知识,也促进了权重的合理导入。
做好网站外链越来越难了,但再难,我们还是要做,但现在不能再这么鲁莽了。一定要注意一定的技巧,对百度搜索引擎算法有深入的了解。只有这样,才能对外链优化起到事半功倍的效果!
3.如何被爬虫爬取?
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等。如果你想让你的网站页面更多的是收录,你必须先让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
二、网站快被蜘蛛爬到
1.网站 和页面重量。
这绝对是首要的。网站 权重高、资历高、权威高的蜘蛛,绝对是被特殊对待的。这样的网站爬取的频率非常高,大家都知道搜索引擎蜘蛛是为了保证效率,对于网站并不是所有的页面都会被爬取,而且网站的权重越高@>,爬得越深,对应的可爬取的页面也会增加,这样网站就可以爬取了。@收录 也会有更多页面。
2.网站服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那谢谢你就离你很近了,蜘蛛也来不了了。百度蜘蛛也是网站的访问者。如果你的服务器不稳定或者比较卡顿,每次爬虫都会很难爬,有时只能爬到页面的一部分。你的体验越来越差,你对网站的分数会越来越低,自然会影响你的网站抢,所以一定要愿意选择空间服务器,有没有好的基础,房子再好。
3.网站 的更新频率。
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但是蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以我们要主动表示善意蜘蛛并定期进行文章更新,让蜘蛛按照你的规则来有效爬取,不仅你的更新文章被抓取更快,而且不会导致蜘蛛经常浪费时间。
4.文章 的 原创 特性。
优质的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常过来觅食。
5.展平网站 结构。
蜘蛛爬行也有自己的路线。你之前已经为它铺平了道路。网站 结构不要太复杂,链接层次不要太深。如果链接层级太深,后面的页面将很难被蜘蛛抓取。收到。
6.网站程序。
在 网站 程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,尝试使用301重定向、Canonical标签或robots进行处理,确保蜘蛛只抓取一个canonical URL。
7.外链建设。
我们都知道外链对于网站是可以吸引蜘蛛的,尤其是新站点的时候,网站还不是很成熟,蜘蛛访问量比较少,而外链可以增加网站的数量@> 页面暴露在蜘蛛前面,防止蜘蛛找不到页面。在建立外链的过程中,需要注意外链的质量。不要做无用的事情来省事。百度对外链接的管理,相信大家都知道。我将提几点需要注意的地方。
第一点:博客外链的搭建这里所说的博客外链并不是我们平时做的。只对一些个人博客、新浪博客、网易博客、和讯博客等发表评论,并留下外部链接。由于百度算法的更新,这种外链现在已经没有效果了,如果做得太多,甚至会被降级。在这里我想说的是为了给博主留下深刻印象而发表评论,帮助博主,提出建议或发表自己不同的想法。这样做几次之后,相信博主们一定会对你有所评价。注意,如果你的网站内容足够好,一些博主会给你一个链接,而且这个链接在他们的随机评论中往往比你好很多。
第二点:在论坛里搭建外链的思路其实和博客差不多。留下你的想法,让楼主关注你。也许几次之后你们会成为朋友甚至伙伴。那个时候加个链接不就是一句话吗?这个我就不多说了。
第三点:软文外链搭建在外链搭建过程中,使用软文搭建外链是必不可少的环节,同时软文搭建外链也是也是最有效最高效的Quick,选择什么平台是直接思考的问题。在这里我建议大家可以找一些鲜为人知的相关平台。比如在无关平台发帖软文肯定不如相关平台好,差的平台认为传播的权重是有限的。是的,我终于写了一篇文章文章,我不同意,投稿时请注意。
第四点:开放、分类目录外链构建如果你的网站足够好,那么开放目录是个不错的选择,比如DOMZ目录、yahoo目录,都可以提交。当然,对于一些新的站点或即将建立的站点,目录是您的天堂。此外,Internet 上还有很多 网站 目录。不要忽略这块用于构建外部链接的脂肪。
第五点:买链接虽然常说买链接会被百度攻击,但作为一个新站,想要在最短的时间内获得一定的公关和权重,有一定的收录 ,购买链接也是必不可少的。少,当然不是你去买一些金链或者去一些专门做买卖链接的平台,而是和一些权重比较高的PR、门户、新闻站交流(前提是这些门户和新闻台都不是专门卖链接的),看能不能买链接,这样你买的链接就不会被百度识别,链接质量比较高。等你的网站慢慢上来,一一删除。
8.内链构造。
蜘蛛的抓取是跟随链接的,所以对内链的合理优化可以让蜘蛛抓取更多的页面,促进网站的收录。在建立内部链接的过程中,应该给用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多点赞等栏目,其中很多网站都用到了,让蜘蛛爬得更宽页面范围。
其实内链的建设也有利于提升用户体验,所以用户不必去每篇文章查看是否有相关内容,只靠一个小的内链,或者一个关键词 @> 带有获取它的链接更多和更广泛的信息,为什么不呢?所以如果要真正提升用户体验,而不是为了SEO来提升用户体验,那么多从用户的角度来看,什么样的内链是用户最高兴看到的就去做。
此外,您可以将一些关键词链接到站点中的其他页面,以提高这些页面之间的相关性,方便用户浏览。用户体验自然会为网站带来更多流量。而且,页面间相关性的提高还可以增加用户在网站的停留时间,减少高跳出率的发生。
网站搜索排名靠前的前提是网站大量页面被搜索引擎收录搜索,良好的内链建设正好可以帮助网站页面被搜索引擎搜索到收录。当网站某篇文章文章为收录时,百度蜘蛛会继续沿着该页面的超链接爬行。如果你的内链做得好,百度蜘蛛会沿着你的整个网站爬行,一个网站页面被收录的几率大大增加。
网页抓取解密(如何提高百度蜘蛛抓取频次起重要影响,如何做好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-22 07:19
3、robots协议:这个文件是百度蜘蛛第一个访问的文件,它会告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛抓取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:权重越高网站百度蜘蛛爬得越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛就会越多
3、网站内容质量:如果网站内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好地引导百度蜘蛛进入和抓取。
5、页面深度:页面是否有首页的入口,首页的入口能更好的被爬取和收录。
6、爬取的频率决定了有多少页面网站会被建入数据库收录,这么重要内容的站长应该去哪里了解和修改,你可以去百度站长平台爬频功能了解
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页,内容优质,用户访问正常,但是百度蜘蛛无法抓取,不仅会流失流量和用户,还被百度认为是网站@ > 不友好,导致网站减权、减收视、减少进口网站流量等问题。
这里简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接到服务器。仔细检查。
2、网络运营商异常:目前国内网络运营商分为电信和联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以通过WHOIS查看您的网站IP是否可以解析,如果无法解析,则需要联系域名注册商解决。
4、IP封禁:IP封禁就是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站别不要这样做。
5、死链接:表示页面无效,无法提供有效信息。此时可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保障,而百度蜘蛛爬取是收录的保障,所以网站只有按照百度蜘蛛的爬取规则才能获得更好的排名和交通。 查看全部
网页抓取解密(如何提高百度蜘蛛抓取频次起重要影响,如何做好)
3、robots协议:这个文件是百度蜘蛛第一个访问的文件,它会告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛抓取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:权重越高网站百度蜘蛛爬得越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛就会越多
3、网站内容质量:如果网站内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好地引导百度蜘蛛进入和抓取。
5、页面深度:页面是否有首页的入口,首页的入口能更好的被爬取和收录。
6、爬取的频率决定了有多少页面网站会被建入数据库收录,这么重要内容的站长应该去哪里了解和修改,你可以去百度站长平台爬频功能了解
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页,内容优质,用户访问正常,但是百度蜘蛛无法抓取,不仅会流失流量和用户,还被百度认为是网站@ > 不友好,导致网站减权、减收视、减少进口网站流量等问题。
这里简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接到服务器。仔细检查。
2、网络运营商异常:目前国内网络运营商分为电信和联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以通过WHOIS查看您的网站IP是否可以解析,如果无法解析,则需要联系域名注册商解决。
4、IP封禁:IP封禁就是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站别不要这样做。
5、死链接:表示页面无效,无法提供有效信息。此时可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保障,而百度蜘蛛爬取是收录的保障,所以网站只有按照百度蜘蛛的爬取规则才能获得更好的排名和交通。
网页抓取解密(爬虫破解基础的js解析能力限制破解采用nodisplay来随机化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-22 07:15
在与反爬虫的对抗中,我们的爬虫有两个大招,其中之一就是多种ip替换方式(例如adsl|proxy|tor等,请参考前面的文章)。二是无头浏览器,采用自动化技术自动抓取数据,模拟鼠标键盘事件,可用于破解验证码,js解析,怪异模糊数据。存于github开源项目欢迎star /luyishisi/Anti-Anti-Spider
0 内容:phantomjs原理讲解牛刀小试破解基本js解析能力限制破解使用nodisplay随机网页源码破解简单图文相互替换破解拖拽验证码1phantomjs原理讲解:
无头浏览器不是闹鬼的东西。它也被称为无界面浏览器。它本身是用于自动化测试的,但它似乎更适合爬行。他的官网是:/quick-start.html 如果你想看他的中文api,我编译了一个文档在:/2016/08/phantomjs-api-%E4%B8%AD%E6%96%87% E7 %89%88-%E6%97%A0%E7%95%8C%E9%9D%A2%E6%B5%8F%E8%A7%88%E5%99%A8-js%E5%A4%84 % E7%90%86%E7%9A%84%E7%88%AC%E8%99%AB/
下载后会得到一个exe文件,linux下也一样。在命令行,在文件目录下输入phantomjs,用浏览器启动你的爬虫代码。
2小试
运行phantomg需要以下js代码
另存为 request.js 文件。然后在当前目录下运行命令行:会返回整个网页的源码,然后爬虫稍微分析一下就可以提取xici代理的空闲ip了。
phantomjs request.js http://www.xicidaili.com/
/***********************************
code:javascript
system:win || linux
auther:
mail : **@qq.com
github:
blog: https://www.urlteam.org
date:2016.9.12
逻辑说明:使用phantomjs无界面浏览器作为操作平台,破解对方针对js解析的反爬虫辨别
************************************/
var page = require('webpage').create(),
system = require('system'),
address;
address = system.args[1];
//init and settings
page.settings.resourceTimeout = 30000 ;
page.settings.XSSAuditingEnabled = true ;
//page.viewportSize = { width: 1000, height: 1000 };
page.settings.userAgent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36';
page.customHeaders = {
"Connection" : "keep-alive",
"Cache-Control" : "max-age=0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
};
page.open(address, function() {
console.log(address);
console.log('begin');
});
//加载页面完毕运行
page.onLoadFinished = function(status) {
console.log('Status: ' + status);
console.log(page.content);
phantom.exit();
};
如图所示:
3 破解基本js解析能力限制
我遇到的两个之一是网站故意用js延迟返回真实数据,先返回一个part,几秒js能力验证后才加载。另一种是检测到没有js处理能力,立即给出拒绝码。这种类型是xici代理的方式。如果用python直接发送请求,不管是scrapy还是requests,都会返回500错误(后来发现需要做好sufficient request header伪造也是可以的,但是phantomjs本身自带,所以可以到达)。如下:
但是如果使用上面的代码,在python中使用系统命令调用这行命令,就相当于使用phantomjs进行请求操作,源代码直接返回。您可以将python与以下内容一起使用
common = 'c://phantomjs/phantomjs' + ' requests.js '+ temp_url
str_body = str(os.popen(common).read())
print str_body
之后就是字符串处理,非常简单,不废话。
4 破解使用display:none随机化网页源代码
众所周知,如果我们想在爬虫中选择某个数据,可以使用xpath或者常规的字符串操作。但是对方的网站需要有一定的规则才能合理的提取数据。因此,也使用了nodisplay属性,这使得显示的后台代码非常混乱,但在前台呈现给用户的数据不会混乱。例如:/
如图,当我用chrome检测这个ip部分的源码时,后台会出现乱七八糟的显示,而且会有网站随机的类名,更加难以捕捉.
那么破解之道也是弯道救国。
破解思路:(避免查水表不放源码)
使用phantomjs的截图功能。(详情查看官方api,难度不大,示例代码中的rasterize.js文章也是实现截图的功能)例如:
page.evaluate(function() { document.body.bgColor = 'white';});//背景色设定为白。方便二值化处理
page.clipRect = { top: 441, left: 364, width: 300, height: 210 };//指定截图区域。坐标使用第四象限
然后分别取出ip和port部分的图片。使用python进行图文转换。大致如下:
在PIL中安装图像库,遍历每个像素,做一个锐化,增强对比度,去噪和二值化,保存改进后的图像。调用pytesseract运行函数: print pytesseract.image_to_string(Image.open('end.png')) 如果你的图片处理清晰,可以轻松识别图片和文字。
注意切图,不要一次识别整张图,最好单独切出一个ip。然后以高精度识别。主要难点其实是安装环境和镜像优化比较麻烦。
5 破解简单图文相互替换
这部分也和上一个问题有重叠:相当于对方把一些数据变成了图片,我们下载这些图片然后优化图片,然后解析例如:/
爬他的页面的时候,ip好抢,但是端口号就是图片。下载图片后,还需要进行上诉转换。识别准确率也是95%+
识别出的源码可见github:/luyishisi/Anti-Anti-Anti-Spider/tree/master/1.%E9%AA%8C%E8%AF%81%E7%A0%81
对此,让三个门户自学:
6 破解拖动验证码
破解只是一种兴趣,不能毁了别人的工作。只是一个想法:
在触发之前和之后捕获验证码图像。使用变化点作为二值化可以得到需要偏移的像素点。phantomjs控制鼠标拖动的唯一难点就是拖动轨迹不能太机器人,否则你的验证码会被吃掉。其他的使用ajax等skip请求,也是一种方式,但是难度也很大。请不要在私信中索要代码。没有留下。
7 总结:
对抗反爬虫,如果能掌握上号技巧,基本没有劣势。
使用adsl | 托| 代理 | 可以防止对方封禁ip,使用header字段进行伪造,是防止对方识别返回虚假数据的入口。使用幻影基本上对方无法阻止您的访问。毕竟是真实浏览器发起的请求。仍然存在的漏洞是你可以通过一些特征检测来识别你正在使用幻影浏览器并对其进行屏蔽,而能够做到这一点的网站并不多。另一个难点是复杂的验证码被破解,只有机器学习才能走。
本文仅用于技术分享,不发布破解源码。希望读者能互相学习,提高自己的技能。 查看全部
网页抓取解密(爬虫破解基础的js解析能力限制破解采用nodisplay来随机化)
在与反爬虫的对抗中,我们的爬虫有两个大招,其中之一就是多种ip替换方式(例如adsl|proxy|tor等,请参考前面的文章)。二是无头浏览器,采用自动化技术自动抓取数据,模拟鼠标键盘事件,可用于破解验证码,js解析,怪异模糊数据。存于github开源项目欢迎star /luyishisi/Anti-Anti-Spider
0 内容:phantomjs原理讲解牛刀小试破解基本js解析能力限制破解使用nodisplay随机网页源码破解简单图文相互替换破解拖拽验证码1phantomjs原理讲解:
无头浏览器不是闹鬼的东西。它也被称为无界面浏览器。它本身是用于自动化测试的,但它似乎更适合爬行。他的官网是:/quick-start.html 如果你想看他的中文api,我编译了一个文档在:/2016/08/phantomjs-api-%E4%B8%AD%E6%96%87% E7 %89%88-%E6%97%A0%E7%95%8C%E9%9D%A2%E6%B5%8F%E8%A7%88%E5%99%A8-js%E5%A4%84 % E7%90%86%E7%9A%84%E7%88%AC%E8%99%AB/
下载后会得到一个exe文件,linux下也一样。在命令行,在文件目录下输入phantomjs,用浏览器启动你的爬虫代码。
2小试
运行phantomg需要以下js代码
另存为 request.js 文件。然后在当前目录下运行命令行:会返回整个网页的源码,然后爬虫稍微分析一下就可以提取xici代理的空闲ip了。
phantomjs request.js http://www.xicidaili.com/
/***********************************
code:javascript
system:win || linux
auther:
mail : **@qq.com
github:
blog: https://www.urlteam.org
date:2016.9.12
逻辑说明:使用phantomjs无界面浏览器作为操作平台,破解对方针对js解析的反爬虫辨别
************************************/
var page = require('webpage').create(),
system = require('system'),
address;
address = system.args[1];
//init and settings
page.settings.resourceTimeout = 30000 ;
page.settings.XSSAuditingEnabled = true ;
//page.viewportSize = { width: 1000, height: 1000 };
page.settings.userAgent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36';
page.customHeaders = {
"Connection" : "keep-alive",
"Cache-Control" : "max-age=0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
};
page.open(address, function() {
console.log(address);
console.log('begin');
});
//加载页面完毕运行
page.onLoadFinished = function(status) {
console.log('Status: ' + status);
console.log(page.content);
phantom.exit();
};
如图所示:
3 破解基本js解析能力限制
我遇到的两个之一是网站故意用js延迟返回真实数据,先返回一个part,几秒js能力验证后才加载。另一种是检测到没有js处理能力,立即给出拒绝码。这种类型是xici代理的方式。如果用python直接发送请求,不管是scrapy还是requests,都会返回500错误(后来发现需要做好sufficient request header伪造也是可以的,但是phantomjs本身自带,所以可以到达)。如下:
但是如果使用上面的代码,在python中使用系统命令调用这行命令,就相当于使用phantomjs进行请求操作,源代码直接返回。您可以将python与以下内容一起使用
common = 'c://phantomjs/phantomjs' + ' requests.js '+ temp_url
str_body = str(os.popen(common).read())
print str_body
之后就是字符串处理,非常简单,不废话。
4 破解使用display:none随机化网页源代码
众所周知,如果我们想在爬虫中选择某个数据,可以使用xpath或者常规的字符串操作。但是对方的网站需要有一定的规则才能合理的提取数据。因此,也使用了nodisplay属性,这使得显示的后台代码非常混乱,但在前台呈现给用户的数据不会混乱。例如:/
如图,当我用chrome检测这个ip部分的源码时,后台会出现乱七八糟的显示,而且会有网站随机的类名,更加难以捕捉.
那么破解之道也是弯道救国。
破解思路:(避免查水表不放源码)
使用phantomjs的截图功能。(详情查看官方api,难度不大,示例代码中的rasterize.js文章也是实现截图的功能)例如:
page.evaluate(function() { document.body.bgColor = 'white';});//背景色设定为白。方便二值化处理
page.clipRect = { top: 441, left: 364, width: 300, height: 210 };//指定截图区域。坐标使用第四象限
然后分别取出ip和port部分的图片。使用python进行图文转换。大致如下:
在PIL中安装图像库,遍历每个像素,做一个锐化,增强对比度,去噪和二值化,保存改进后的图像。调用pytesseract运行函数: print pytesseract.image_to_string(Image.open('end.png')) 如果你的图片处理清晰,可以轻松识别图片和文字。
注意切图,不要一次识别整张图,最好单独切出一个ip。然后以高精度识别。主要难点其实是安装环境和镜像优化比较麻烦。
5 破解简单图文相互替换
这部分也和上一个问题有重叠:相当于对方把一些数据变成了图片,我们下载这些图片然后优化图片,然后解析例如:/
爬他的页面的时候,ip好抢,但是端口号就是图片。下载图片后,还需要进行上诉转换。识别准确率也是95%+
识别出的源码可见github:/luyishisi/Anti-Anti-Anti-Spider/tree/master/1.%E9%AA%8C%E8%AF%81%E7%A0%81
对此,让三个门户自学:
6 破解拖动验证码
破解只是一种兴趣,不能毁了别人的工作。只是一个想法:
在触发之前和之后捕获验证码图像。使用变化点作为二值化可以得到需要偏移的像素点。phantomjs控制鼠标拖动的唯一难点就是拖动轨迹不能太机器人,否则你的验证码会被吃掉。其他的使用ajax等skip请求,也是一种方式,但是难度也很大。请不要在私信中索要代码。没有留下。
7 总结:
对抗反爬虫,如果能掌握上号技巧,基本没有劣势。
使用adsl | 托| 代理 | 可以防止对方封禁ip,使用header字段进行伪造,是防止对方识别返回虚假数据的入口。使用幻影基本上对方无法阻止您的访问。毕竟是真实浏览器发起的请求。仍然存在的漏洞是你可以通过一些特征检测来识别你正在使用幻影浏览器并对其进行屏蔽,而能够做到这一点的网站并不多。另一个难点是复杂的验证码被破解,只有机器学习才能走。
本文仅用于技术分享,不发布破解源码。希望读者能互相学习,提高自己的技能。
网页抓取解密(html、js被加密了,怎么破解呢?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2022-02-20 06:06
)
apk中的html和js都是加密的,怎么破解?破解 ApiCloud 加密密码
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。
“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加速资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,逻辑全在JS中)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
做一些研究以获取源代码。 查看全部
网页抓取解密(html、js被加密了,怎么破解呢?(图)
)
apk中的html和js都是加密的,怎么破解?破解 ApiCloud 加密密码
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。
“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加速资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,逻辑全在JS中)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
做一些研究以获取源代码。
网页抓取解密(网页版AES:1.的函数())
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-19 22:24
一、网络 AES:
1.首先,我们在浏览器中打开“西丽西丽”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,一般这种视频是m3u8.)
3.点击视频进去4.搜索“m3u8”,真的是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那么应该是加密了
6.然后我们尝试搜索这个视频的ID,可以发现有3个相关请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID是稍后添加,在屏幕截图之前是另一个)
7.上图中的/video/info是哪里来的?别着急,ctrl+f搜索,果然找到了一个js文件。
8.我们从sources打开这个文件,搜索/video/info,找到getVideoInfo的一个函数(注意a的值是从headers中获取的)
9. 然后低头看到一个decryptString,那我猜这应该是解密函数,然后搜索decryptString,找到函数
10.分析这个函数:
t = 得到加密字符串, o = 取 md5, e = 取 md5 然后取出从第 8 位开始的 16 位字符串
所以通过计算当前视频的iv和key
11.然后我们尝试用AES解密
12. 解密成功,获得m3u8地址。拼接好主机后直接打开,发现无法播放。
让我们回到网页捕获数据包。原来m3u8地址后面有一个token参数。添加令牌后,打开正常播放。
13.值得注意的是,在获取/video/info时,需要在headers中添加origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我哥的M3U8下载器时,需要自定义协议头:Origin
二、在网页上获取用户的Token:
攀登时问题来了,每个用户只能免费观看30个视频。然后让我们获得更多用户:
感觉应该是因为token(一个token代表一个用户),那么我们需要了解一下token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新页面,搜索token的值,其实这个pwatoken是一个参数,只会在第二次访问时可用,
我们新建一个隐身窗口或者小窗口,打开F12.找到一个新的界面mail_pwa_temp。建议全程使用抓包软件。
可以看出token是mail_pwa_temp返回的,看提交的参数,post提交的是pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?其实我们访问首页的时候会返回一个license,就是pwa-ckv
PS:但是,当我们设置帖子内容为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这在浏览器中体现如下:
没错,这是2级VIP(所谓的尊贵VIP账号),那么他的token就可以无限拍摄视频了。
看来爬行速度不能太快,会很频繁。
三、网页版实现无限制观看的两种方法【方法已过期,将强制退出,token已被封禁,无法再使用此token抓视频】:
第一种:FD的自动回复,这个我就不说了,直接把token换成前面得到的honor token
第二种:JS打印这个,步骤如下:
1.打开会员页面,点击账号后面的刷新,会提示刷新成功,我们搜索“刷新成功”,不难发现在文件中调用应用程序.XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的功能,
3. 给这个函数设置断点,刷新个人信息,然后我们打印出来这个
4.在控制台输入 temp1.$store.state.newToken = 'Honor token'
这里提到的honor token就是第二步抓到的token,字符串长度大约是145。
您可以在浏览器中将其更改为尊贵的VIP,并享受无限观看。(值得注意的是,网页一刷新就失效了……可以再次操作)
四、在APP端实现真正的无限制查看【方法已过期,将强制退出,token已被封禁】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1.首先我们抓包并下载APP。果然 Token 和网页版一样使用,只是调用接口不同。
2.然后我们打开MT管理器或者NP管理器,尝试搜索方法名中收录Token的内容。
3.找到了2个相关的getToken函数,让我们点进去修改一下,返回之前获取的Token
4.app编译完成后,打开查看效果。
5. 果然成了尊贵的贵宾。
虽然它显示的是每日观看限制,但实际上你会发现它是无限观看
五、真正实现APP端无限观看:
其实原因很简单,第一次打开APP需要注册。然后我们将注册的参数修改为随机,这样每次清除数据后打开APP都是一个新的体验用户。
因为在SMALI中重新添加函数有点复杂,所以我这里直接调用APP原来的随机函数(PS:这个随机是我用的函数的缩写,你可以试试其他随机函数)
下图是NP管理器修改为JAVA前后代码的区别:(思路是给this.d分配随机字符)
这种方法比第四步稍微困难一点,但也只是稍微困难一点。
我相信你们可以抓住数据包并获取一些信息并再次完成它。
我不会在这里详细解释。防止和谐,有能力的可以试试。这对我这个自学成才的半生不熟的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
例如getLevel(const v0, 0x2 1是正常/2是荣誉)、getExpiry(const v0, 0x746a6480)等。
修改后发现只在本地显示。 查看全部
网页抓取解密(网页版AES:1.的函数())
一、网络 AES:
1.首先,我们在浏览器中打开“西丽西丽”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,一般这种视频是m3u8.)
3.点击视频进去4.搜索“m3u8”,真的是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那么应该是加密了
6.然后我们尝试搜索这个视频的ID,可以发现有3个相关请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID是稍后添加,在屏幕截图之前是另一个)
7.上图中的/video/info是哪里来的?别着急,ctrl+f搜索,果然找到了一个js文件。
8.我们从sources打开这个文件,搜索/video/info,找到getVideoInfo的一个函数(注意a的值是从headers中获取的)
9. 然后低头看到一个decryptString,那我猜这应该是解密函数,然后搜索decryptString,找到函数
10.分析这个函数:
t = 得到加密字符串, o = 取 md5, e = 取 md5 然后取出从第 8 位开始的 16 位字符串
所以通过计算当前视频的iv和key
11.然后我们尝试用AES解密
12. 解密成功,获得m3u8地址。拼接好主机后直接打开,发现无法播放。
让我们回到网页捕获数据包。原来m3u8地址后面有一个token参数。添加令牌后,打开正常播放。
13.值得注意的是,在获取/video/info时,需要在headers中添加origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我哥的M3U8下载器时,需要自定义协议头:Origin
二、在网页上获取用户的Token:
攀登时问题来了,每个用户只能免费观看30个视频。然后让我们获得更多用户:
感觉应该是因为token(一个token代表一个用户),那么我们需要了解一下token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新页面,搜索token的值,其实这个pwatoken是一个参数,只会在第二次访问时可用,
我们新建一个隐身窗口或者小窗口,打开F12.找到一个新的界面mail_pwa_temp。建议全程使用抓包软件。
可以看出token是mail_pwa_temp返回的,看提交的参数,post提交的是pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?其实我们访问首页的时候会返回一个license,就是pwa-ckv
PS:但是,当我们设置帖子内容为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这在浏览器中体现如下:
没错,这是2级VIP(所谓的尊贵VIP账号),那么他的token就可以无限拍摄视频了。
看来爬行速度不能太快,会很频繁。
三、网页版实现无限制观看的两种方法【方法已过期,将强制退出,token已被封禁,无法再使用此token抓视频】:
第一种:FD的自动回复,这个我就不说了,直接把token换成前面得到的honor token
第二种:JS打印这个,步骤如下:
1.打开会员页面,点击账号后面的刷新,会提示刷新成功,我们搜索“刷新成功”,不难发现在文件中调用应用程序.XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的功能,
3. 给这个函数设置断点,刷新个人信息,然后我们打印出来这个
4.在控制台输入 temp1.$store.state.newToken = 'Honor token'
这里提到的honor token就是第二步抓到的token,字符串长度大约是145。
您可以在浏览器中将其更改为尊贵的VIP,并享受无限观看。(值得注意的是,网页一刷新就失效了……可以再次操作)
四、在APP端实现真正的无限制查看【方法已过期,将强制退出,token已被封禁】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1.首先我们抓包并下载APP。果然 Token 和网页版一样使用,只是调用接口不同。
2.然后我们打开MT管理器或者NP管理器,尝试搜索方法名中收录Token的内容。
3.找到了2个相关的getToken函数,让我们点进去修改一下,返回之前获取的Token
4.app编译完成后,打开查看效果。
5. 果然成了尊贵的贵宾。
虽然它显示的是每日观看限制,但实际上你会发现它是无限观看
五、真正实现APP端无限观看:
其实原因很简单,第一次打开APP需要注册。然后我们将注册的参数修改为随机,这样每次清除数据后打开APP都是一个新的体验用户。
因为在SMALI中重新添加函数有点复杂,所以我这里直接调用APP原来的随机函数(PS:这个随机是我用的函数的缩写,你可以试试其他随机函数)
下图是NP管理器修改为JAVA前后代码的区别:(思路是给this.d分配随机字符)
这种方法比第四步稍微困难一点,但也只是稍微困难一点。
我相信你们可以抓住数据包并获取一些信息并再次完成它。
我不会在这里详细解释。防止和谐,有能力的可以试试。这对我这个自学成才的半生不熟的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
例如getLevel(const v0, 0x2 1是正常/2是荣誉)、getExpiry(const v0, 0x746a6480)等。
修改后发现只在本地显示。

