
网页抓取解密
网页抓取解密(自动模式检测WebHarvy自动识别网页中支持运行JavaScript和表达式的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-27 12:11
SysNucleus WebHarvy 是一款具有自动检测模式的网页数据抓取工具,可以从多个页面中提取数据并导出到数据库或文件夹中。WebHarvy 支持运行 JavaScript 和表达式,让你灵活抓取数据,有需要的朋友快来下载吧!
WebHarvy 功能
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取所有输入关键字组合的搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvy Web Scraper 允许您从链接列表中获取数据,从而在网站中生成相似的页面/列表。这允许您使用单个配置来抓取站点内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的产品详细信息页面上的多个图像。
浏览器自动交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
安装教程
1、下载并安装 SysNucleus WebHarvy
2、安装完成后,将Crck文件夹下的WebHarvy.exe复制到安装目录替换
3、 破解完成 查看全部
网页抓取解密(自动模式检测WebHarvy自动识别网页中支持运行JavaScript和表达式的方法)
SysNucleus WebHarvy 是一款具有自动检测模式的网页数据抓取工具,可以从多个页面中提取数据并导出到数据库或文件夹中。WebHarvy 支持运行 JavaScript 和表达式,让你灵活抓取数据,有需要的朋友快来下载吧!
WebHarvy 功能
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取所有输入关键字组合的搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvy Web Scraper 允许您从链接列表中获取数据,从而在网站中生成相似的页面/列表。这允许您使用单个配置来抓取站点内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的产品详细信息页面上的多个图像。
浏览器自动交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
安装教程
1、下载并安装 SysNucleus WebHarvy
2、安装完成后,将Crck文件夹下的WebHarvy.exe复制到安装目录替换
3、 破解完成
网页抓取解密(从网页上保存图片的时候,会发现竟然无法保存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-12-27 09:10
有时当你想保存网页中的图片时,你会发现它无法保存!右键单击图片,您无法看到保存图片的选项。最后只能用QQ等截图工具截图,无法得到原图。该怎么办?今天给大家介绍一个轻松解决这个问题的工具,一起来看看吧。
这是一款支持Chrome、Edge、Firefox等常用浏览器的浏览器扩展。我们以Chrome为例进行演示。
安装图片助手后,Chrome 工具栏中会出现一个额外的相关图标。在网页上右击,还可以看到图片助手的相关选项。可以看出,图片助手具有提取本页图片、预取链接、分析预取数据等功能。其实这是一种不同的图片爬取机制。当一种机制的效果不理想时,您可以切换到另一种机制,以确保可以捕获图片。
来试试实际效果吧。首先找一个不能保存图片的页面,比如苹果的App Store。一般来说,App Store 中的 App 截图是不能直接保存的。右键单击图片,将没有保存图片的选项。
使用图片助手,点击“提取本页图片”,可以发现页面上的图片被快速提取了。图片助手将打开一个新选项卡,显示所有成功提取的图片。难得的是,图片助手不会简单粗暴地将所有图片呈现在您的眼前。它标记了每张图片的大小,还提供了一个过滤器,可以根据图片的格式和大小快速找到你想要的。你要的图。如果你打算下载多张图片,可以勾选并一起下载,非常方便。
总的来说,这是一个非常有用的浏览器工具。当您要提取某个页面的图片时,不仅可以打破无法下载图片的限制,还可以让您快速过滤掉您要下载的图片。有需要的朋友不妨一试。 查看全部
网页抓取解密(从网页上保存图片的时候,会发现竟然无法保存)
有时当你想保存网页中的图片时,你会发现它无法保存!右键单击图片,您无法看到保存图片的选项。最后只能用QQ等截图工具截图,无法得到原图。该怎么办?今天给大家介绍一个轻松解决这个问题的工具,一起来看看吧。
这是一款支持Chrome、Edge、Firefox等常用浏览器的浏览器扩展。我们以Chrome为例进行演示。
安装图片助手后,Chrome 工具栏中会出现一个额外的相关图标。在网页上右击,还可以看到图片助手的相关选项。可以看出,图片助手具有提取本页图片、预取链接、分析预取数据等功能。其实这是一种不同的图片爬取机制。当一种机制的效果不理想时,您可以切换到另一种机制,以确保可以捕获图片。


来试试实际效果吧。首先找一个不能保存图片的页面,比如苹果的App Store。一般来说,App Store 中的 App 截图是不能直接保存的。右键单击图片,将没有保存图片的选项。

使用图片助手,点击“提取本页图片”,可以发现页面上的图片被快速提取了。图片助手将打开一个新选项卡,显示所有成功提取的图片。难得的是,图片助手不会简单粗暴地将所有图片呈现在您的眼前。它标记了每张图片的大小,还提供了一个过滤器,可以根据图片的格式和大小快速找到你想要的。你要的图。如果你打算下载多张图片,可以勾选并一起下载,非常方便。


总的来说,这是一个非常有用的浏览器工具。当您要提取某个页面的图片时,不仅可以打破无法下载图片的限制,还可以让您快速过滤掉您要下载的图片。有需要的朋友不妨一试。
网页抓取解密(除了处理网站表单,requests模块还是一个设置请求头的利器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-26 15:16
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。你可以从非个人邮箱发送邮件,使用命令行自动鼠标操作,或者使用IE5.0浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是个无底洞,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更多贵),谷歌是最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】 查看全部
网页抓取解密(除了处理网站表单,requests模块还是一个设置请求头的利器)
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。你可以从非个人邮箱发送邮件,使用命令行自动鼠标操作,或者使用IE5.0浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是个无底洞,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更多贵),谷歌是最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】
网页抓取解密(除了处理网站表单,requests模块还是一个设置请求头的利器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-26 15:16
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。您可以从非个人邮箱发送电子邮件,通过命令行自动执行鼠标操作,也可以使用 IE 5.0 浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是无底的,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更贵) , 谷歌最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】 查看全部
网页抓取解密(除了处理网站表单,requests模块还是一个设置请求头的利器)
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。

当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:

如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:

程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:

点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:

点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:

点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。

Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:

点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:

点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:

点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。您可以从非个人邮箱发送电子邮件,通过命令行自动执行鼠标操作,也可以使用 IE 5.0 浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):

网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:

和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):

这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是无底的,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更贵) , 谷歌最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】
网页抓取解密(反爬告诉服务器能够发送哪些媒体类型-Charset告诉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-26 15:14
反爬虫机制和破解方法总结——什么是爬虫和反爬虫?2. headers 和referer 反爬虫机制 * Headers 反爬虫是最常见的反爬虫策略。*部分网站会检测Referer(上位链接)(机器行为不太可能通过链接跳转实现)实现爬虫。
头条知识补充***
host:提供主机名和端口号
Referer 提供服务器客户端从该页面链接的信息(有些网站会相应地爬回来)
Origin:Origin字段只收录
发起请求的人,没有其他信息。(仅存储在 post 请求中)
用户代理:发送请求的应用名称(部分网站会根据UA访问的频率间隔进行爬取)
proxies:代理,有的网站会根据ip访问频率等选择屏蔽ip。
cookie:具体的标记信息,一般可以直接复制,有些改动可以选择构造。
(session=requests.session() 自动将cookie信息存储在响应对象中)
Accept 头为客户端提供了一种方法来通知服务器它的首选项和功能
标题说明
Accept 告诉服务器可以发送哪些媒体类型
Accept-Charset 告诉服务器可以发送哪些字符集
Accept-Encoding 告诉服务器可以发送哪些编码方式(最常见的是utf-8)
Accept-Language 告诉服务器可以发送哪些语言
Cache-control:该字段用于指定在整个请求/响应链中所有缓存机制必须遵守的指令
三 ip限制
限制防爬的IP访问频率和数量。
解决方法:构建自己的IP代理池,然后每次访问时随机选择一个代理(但有些IP地址不是很稳定,需要经常检查更新)
四大 UA 限制
UA 使用户能够在访问网站时识别浏览器。
提醒:
当然,如果反爬有时间限制,可以在requests中设置timeout(最好是随机sleep,这样会更安全更稳定,time.sleep())
解决办法是自己搭建UA池,在python每次请求访问时随机挂上UA标志,更好的模拟浏览器行为。
超级简单的请求头 fake_useragent library()
#随机请求头
进口请求
从 fake_useragent 导入 UserAgent
ua = 用户代理()
headers = {'User-Agent': ua.random}
url ='要抓取的网页的URL'
resp = requests.get(url, headers=headers)
##Pending 补货请求加上睡眠时间
五.验证码反爬虫或模拟登录
图片验证码:通过简单的图片识别即可完成
验证码识别的基本方法:截图、二值化、中值滤波、去噪、分割、压缩和重排(让高矮系统一)、字体特征匹配识别。
六、Ajax动态加载
Ajax动态加载的工作原理是:从网页的url加载网页源代码后,JavaScript程序会在浏览器中执行。
这些程序将加载更多内容并将这些内容传输到网页。这就是为什么有些网页会直接爬取它的网址
没有数据的原因。
解决方法:如果使用勾选元素分析“请求”对应链接(方法:右键→勾选元素→网络→清除,点击“加载更多”
”,出现对应的GET链接寻找类型text/html,点击,查看get参数或复制Request URL),循环过程。如果“请求”之前有页面,分析导出第一页根据上一步中的URL,以此类推,抓取ajax地址的数据,使用requests中的json解析返回的json,使用eval()转换成字典进行处理
推荐捕捉工具:fiddler
七.Cookie 限制
打开网页后,将生成一个随机 cookie。如果再次打开网页时cookie不存在,再设置一次,第三次打开还是不存在。爬虫很可能正在工作。
解决方法:将对应的cookie挂在headers中或者按照其方法构造。 查看全部
网页抓取解密(反爬告诉服务器能够发送哪些媒体类型-Charset告诉)
反爬虫机制和破解方法总结——什么是爬虫和反爬虫?2. headers 和referer 反爬虫机制 * Headers 反爬虫是最常见的反爬虫策略。*部分网站会检测Referer(上位链接)(机器行为不太可能通过链接跳转实现)实现爬虫。
头条知识补充***
host:提供主机名和端口号
Referer 提供服务器客户端从该页面链接的信息(有些网站会相应地爬回来)
Origin:Origin字段只收录
发起请求的人,没有其他信息。(仅存储在 post 请求中)
用户代理:发送请求的应用名称(部分网站会根据UA访问的频率间隔进行爬取)
proxies:代理,有的网站会根据ip访问频率等选择屏蔽ip。
cookie:具体的标记信息,一般可以直接复制,有些改动可以选择构造。
(session=requests.session() 自动将cookie信息存储在响应对象中)
Accept 头为客户端提供了一种方法来通知服务器它的首选项和功能
标题说明
Accept 告诉服务器可以发送哪些媒体类型
Accept-Charset 告诉服务器可以发送哪些字符集
Accept-Encoding 告诉服务器可以发送哪些编码方式(最常见的是utf-8)
Accept-Language 告诉服务器可以发送哪些语言
Cache-control:该字段用于指定在整个请求/响应链中所有缓存机制必须遵守的指令
三 ip限制
限制防爬的IP访问频率和数量。
解决方法:构建自己的IP代理池,然后每次访问时随机选择一个代理(但有些IP地址不是很稳定,需要经常检查更新)
四大 UA 限制
UA 使用户能够在访问网站时识别浏览器。
提醒:
当然,如果反爬有时间限制,可以在requests中设置timeout(最好是随机sleep,这样会更安全更稳定,time.sleep())
解决办法是自己搭建UA池,在python每次请求访问时随机挂上UA标志,更好的模拟浏览器行为。
超级简单的请求头 fake_useragent library()
#随机请求头
进口请求
从 fake_useragent 导入 UserAgent
ua = 用户代理()
headers = {'User-Agent': ua.random}
url ='要抓取的网页的URL'
resp = requests.get(url, headers=headers)
##Pending 补货请求加上睡眠时间
五.验证码反爬虫或模拟登录
图片验证码:通过简单的图片识别即可完成
验证码识别的基本方法:截图、二值化、中值滤波、去噪、分割、压缩和重排(让高矮系统一)、字体特征匹配识别。
六、Ajax动态加载
Ajax动态加载的工作原理是:从网页的url加载网页源代码后,JavaScript程序会在浏览器中执行。
这些程序将加载更多内容并将这些内容传输到网页。这就是为什么有些网页会直接爬取它的网址
没有数据的原因。
解决方法:如果使用勾选元素分析“请求”对应链接(方法:右键→勾选元素→网络→清除,点击“加载更多”
”,出现对应的GET链接寻找类型text/html,点击,查看get参数或复制Request URL),循环过程。如果“请求”之前有页面,分析导出第一页根据上一步中的URL,以此类推,抓取ajax地址的数据,使用requests中的json解析返回的json,使用eval()转换成字典进行处理
推荐捕捉工具:fiddler
七.Cookie 限制
打开网页后,将生成一个随机 cookie。如果再次打开网页时cookie不存在,再设置一次,第三次打开还是不存在。爬虫很可能正在工作。
解决方法:将对应的cookie挂在headers中或者按照其方法构造。
网页抓取解密(搜索引擎的蜘蛛是如何爬的,如何吸引蜘蛛来抓取页面搜索引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-25 21:16
搜索引擎蜘蛛如何抓取和吸引蜘蛛抓取页面
搜索引擎的工作过程大致可以分为三个阶段:
(1) 爬取爬行:搜索引擎蜘蛛通过跟踪链接发现和访问页面,读取页面的HTML代码,并保存到数据库中。
(2) 预处理:索引程序对抓取的页面数据进行文本提取、中文分词、索引、倒排索引,为排名程序调用做准备。
(3) Ranking:用户输入查询词(关键词)后,排名程序调用索引数据计算相关性,然后生成一定格式的搜索结果页面。
搜索引擎的工作原理
爬取和爬取是搜索引擎工作的第一步,完成数据采集的任务。搜索引擎用来抓取页面的程序称为蜘蛛
一个合格的SEOer,如果想让自己的页面被收录更多,就要尽量吸引蜘蛛爬行。
蜘蛛爬取页面有几个因素:
(1)网站和页面的权重。质量高、时间长的网站一般认为权重高,爬取深度高,收录
的页面也多。
(2)页面的更新频率,蜘蛛每次爬取都会保存页面数据,如果第二次和第三次爬取和第一次一样,说明没有更新。时间久了,蜘蛛不会频繁抓取你的页面,如果内容更新频繁,蜘蛛会频繁访问页面来抓取新页面。
(3)导入链接,无论是内链还是外链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛将不知道该链接的存在页。
(4)离首页的点击距离。一般来说首页在网站上的权重最高,外链指向首页的最多。那么蜘蛛最常访问的页面就是首页。点击越近离首页越远,页面权重越高,被爬取的几率就越大。
吸引百度蜘蛛
如何吸引蜘蛛爬取我们的页面?
坚持经常更新网站内容,最好是高质量的原创内容。
主动提供我们的新页面给搜索引擎,让蜘蛛更快的找到,比如百度的链接提交、抓取诊断等。
建立外部链接,与相关网站交换友情链接,在其他平台发布优质文章,指向自己的页面。内容应该是相关的。
制作站点地图,每个站点都应该有一个站点地图,站点的所有页面都在站点地图中,方便蜘蛛抓取。 查看全部
网页抓取解密(搜索引擎的蜘蛛是如何爬的,如何吸引蜘蛛来抓取页面搜索引擎)
搜索引擎蜘蛛如何抓取和吸引蜘蛛抓取页面
搜索引擎的工作过程大致可以分为三个阶段:
(1) 爬取爬行:搜索引擎蜘蛛通过跟踪链接发现和访问页面,读取页面的HTML代码,并保存到数据库中。
(2) 预处理:索引程序对抓取的页面数据进行文本提取、中文分词、索引、倒排索引,为排名程序调用做准备。
(3) Ranking:用户输入查询词(关键词)后,排名程序调用索引数据计算相关性,然后生成一定格式的搜索结果页面。
搜索引擎的工作原理
爬取和爬取是搜索引擎工作的第一步,完成数据采集的任务。搜索引擎用来抓取页面的程序称为蜘蛛
一个合格的SEOer,如果想让自己的页面被收录更多,就要尽量吸引蜘蛛爬行。
蜘蛛爬取页面有几个因素:
(1)网站和页面的权重。质量高、时间长的网站一般认为权重高,爬取深度高,收录
的页面也多。
(2)页面的更新频率,蜘蛛每次爬取都会保存页面数据,如果第二次和第三次爬取和第一次一样,说明没有更新。时间久了,蜘蛛不会频繁抓取你的页面,如果内容更新频繁,蜘蛛会频繁访问页面来抓取新页面。
(3)导入链接,无论是内链还是外链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛将不知道该链接的存在页。
(4)离首页的点击距离。一般来说首页在网站上的权重最高,外链指向首页的最多。那么蜘蛛最常访问的页面就是首页。点击越近离首页越远,页面权重越高,被爬取的几率就越大。

吸引百度蜘蛛
如何吸引蜘蛛爬取我们的页面?
坚持经常更新网站内容,最好是高质量的原创内容。
主动提供我们的新页面给搜索引擎,让蜘蛛更快的找到,比如百度的链接提交、抓取诊断等。
建立外部链接,与相关网站交换友情链接,在其他平台发布优质文章,指向自己的页面。内容应该是相关的。
制作站点地图,每个站点都应该有一个站点地图,站点的所有页面都在站点地图中,方便蜘蛛抓取。
网页抓取解密(之前做聊天室时,介绍如何使用HtmlTag类来抓取网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-22 08:02
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。
上图为博客园首页的DOM树。很明显,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
运行结果如下: 查看全部
网页抓取解密(之前做聊天室时,介绍如何使用HtmlTag类来抓取网页信息)
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。
上图为博客园首页的DOM树。很明显,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
运行结果如下:
网页抓取解密(51CTO专访杨光解密9466在线网页设计的技术架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-20 05:13
51CTO专访杨光:解密9466在线网页设计的技术架构
【编者按】51CTO 2014 WOT全球软件技术峰会将于2014年7月25-26日在北京富力万丽酒店举行。从本周开始,我们将陆续公布会议内容,并采访架构师谁将参加会议,让大家更了解会议的内容。会议详细议程见51 cto com/2014/。
本次采访的对象是技术总监杨光。负责9466智能建站平台。本次WOT软件技术峰会,将分享9466技术架构相关知识。敬请关注!
【讲师简历】
杨光2005年毕业于西北大学,从物理系转入软件学院。同年加入,从事新一代战略ERP产品U9的研发,国内第一款基于SOA架构的大型商业软件。2010年加入腾讯,在手Q浏览器团队工作,负责浏览器后台整体操作系统的搭建。2013年加入与钟胜辉共同打造9466智能网站建设平台。
以下是采访实录
记者:9466上网助手是什么时候推出的?开发的初衷是什么?使用了哪些新技术?开发过程中遇到了哪些困难,又是如何克服的?
杨光 9466第一版于2013年10月上线,自上线以来一直处于公测阶段(需要邀请码)。我们仍在打磨我们的产品。
当初开发这个产品是为了彻底解决网页问题和网站生产烦恼。因为做一个网页或者网站还是需要很多知识的,比如创意、设计、页面制作、素材制作、样式定义、数据读写等等。制作页面需要各种技能。对于新手用户来说,这个问题就更加突出了。然而,在这个领域有很多需求。所以就有了这个想法。目的是使用9466平台。任何人都可以轻松制作精美的网页。
这个产品是非常前端的产品。技术难度和积累主要在前端。例如响应式设计、按需加载、异步事件等。因为我们的设计师是一个所见即所得的操作体验,在网络上,设计一个合理的模型来模拟这种原生操作是非常重要的。在这方面,我们花了很多时间,多人协作、讨论。经过几个版本,不断的优化,终于在体验和浏览器执行性能上有了不错的表现。
记者:您认为9466网络助手最大的亮点是什么?
杨光:我个人认为9466最大的亮点就是它的开放性。我们有一个非常强大的设计引擎。这个引擎不仅仅是传统意义上的所见即所得,一个可以拖拽设计的操作界面。动力是这台发动机是开着的。通过引擎,可以组装各种组件、应用程序、模板和样式。只要满足既定规范,任何第三方都可以开发各种组件以嵌入 9466 平台。这样,9466平台就相当于一个胶水。任何有优秀创意和实现的第三方都可以通过平台贡献自己的价值并服务他人。
记者:目前9466网络助手的模板分为三种:主题模板、企业网站、个人网站。哪种类型的模板更受欢迎?新模板的更新状态如何?
杨光目前,抄题目和企业模板的人比较多。我们将在不久的将来研究这个主题。现有功能的优化和新功能的加入,会更适合话题制作的场景。因此,主题模板将在不久的将来更频繁地更新。
记者:对于9644网络助手的发展前景,您怎么看?您认为哪些方面需要改进?
杨光:9466的发展前景是毋庸置疑的。因为只要有网页,就会有大量的网页制作需求。这是一个刚性需求,尚未得到满足。迫切需要这样一种有用的产品来填补这一空白。而且,像Wix这样的几家大型外国公司已经上市,市值达到75亿美元。Wee bly 刚刚获得了红衫军和腾讯的联合投资。中国还没有垄断企业,大家都在竞争。
记者:最后一个问题。就您而言,您比较关注的技术领域是什么?您预测2014年会流行哪些新技术?
杨光:我的担心比较复杂,我没有说2014年会流行什么技术。但除了工作,我对人工智能更感兴趣。我和计算机打交道的时间越长,我就越觉得计算机与人类相比真的很愚蠢。对于人类来说,一个非常简单的问题需要非常复杂的算法才能由计算机来解决。比如我以前在腾讯做QQ浏览器。对于抓取到的网页,需要分析哪些是核心内容(如文章文字),哪些是杂质(如广告)。对于人来说,这样的事情再简单不过了。但是对于电脑来说,要能够适应所有的网页,真的很难。我们还采用了基于视觉的块分析方法,使用类似于人类观察的逻辑进行分析,效果得到了提升,
总觉得现在人工智能的发展太依赖电脑了。即冯诺依曼计算系统。或许在这个系统中,根本就没有人工智能,只有模拟智能。神经网络算法已经很复杂了,但是能解决的问题还是很有限的。 查看全部
网页抓取解密(51CTO专访杨光解密9466在线网页设计的技术架构)
51CTO专访杨光:解密9466在线网页设计的技术架构
【编者按】51CTO 2014 WOT全球软件技术峰会将于2014年7月25-26日在北京富力万丽酒店举行。从本周开始,我们将陆续公布会议内容,并采访架构师谁将参加会议,让大家更了解会议的内容。会议详细议程见51 cto com/2014/。
本次采访的对象是技术总监杨光。负责9466智能建站平台。本次WOT软件技术峰会,将分享9466技术架构相关知识。敬请关注!
【讲师简历】
杨光2005年毕业于西北大学,从物理系转入软件学院。同年加入,从事新一代战略ERP产品U9的研发,国内第一款基于SOA架构的大型商业软件。2010年加入腾讯,在手Q浏览器团队工作,负责浏览器后台整体操作系统的搭建。2013年加入与钟胜辉共同打造9466智能网站建设平台。
以下是采访实录
记者:9466上网助手是什么时候推出的?开发的初衷是什么?使用了哪些新技术?开发过程中遇到了哪些困难,又是如何克服的?
杨光 9466第一版于2013年10月上线,自上线以来一直处于公测阶段(需要邀请码)。我们仍在打磨我们的产品。
当初开发这个产品是为了彻底解决网页问题和网站生产烦恼。因为做一个网页或者网站还是需要很多知识的,比如创意、设计、页面制作、素材制作、样式定义、数据读写等等。制作页面需要各种技能。对于新手用户来说,这个问题就更加突出了。然而,在这个领域有很多需求。所以就有了这个想法。目的是使用9466平台。任何人都可以轻松制作精美的网页。
这个产品是非常前端的产品。技术难度和积累主要在前端。例如响应式设计、按需加载、异步事件等。因为我们的设计师是一个所见即所得的操作体验,在网络上,设计一个合理的模型来模拟这种原生操作是非常重要的。在这方面,我们花了很多时间,多人协作、讨论。经过几个版本,不断的优化,终于在体验和浏览器执行性能上有了不错的表现。
记者:您认为9466网络助手最大的亮点是什么?
杨光:我个人认为9466最大的亮点就是它的开放性。我们有一个非常强大的设计引擎。这个引擎不仅仅是传统意义上的所见即所得,一个可以拖拽设计的操作界面。动力是这台发动机是开着的。通过引擎,可以组装各种组件、应用程序、模板和样式。只要满足既定规范,任何第三方都可以开发各种组件以嵌入 9466 平台。这样,9466平台就相当于一个胶水。任何有优秀创意和实现的第三方都可以通过平台贡献自己的价值并服务他人。
记者:目前9466网络助手的模板分为三种:主题模板、企业网站、个人网站。哪种类型的模板更受欢迎?新模板的更新状态如何?
杨光目前,抄题目和企业模板的人比较多。我们将在不久的将来研究这个主题。现有功能的优化和新功能的加入,会更适合话题制作的场景。因此,主题模板将在不久的将来更频繁地更新。
记者:对于9644网络助手的发展前景,您怎么看?您认为哪些方面需要改进?
杨光:9466的发展前景是毋庸置疑的。因为只要有网页,就会有大量的网页制作需求。这是一个刚性需求,尚未得到满足。迫切需要这样一种有用的产品来填补这一空白。而且,像Wix这样的几家大型外国公司已经上市,市值达到75亿美元。Wee bly 刚刚获得了红衫军和腾讯的联合投资。中国还没有垄断企业,大家都在竞争。
记者:最后一个问题。就您而言,您比较关注的技术领域是什么?您预测2014年会流行哪些新技术?
杨光:我的担心比较复杂,我没有说2014年会流行什么技术。但除了工作,我对人工智能更感兴趣。我和计算机打交道的时间越长,我就越觉得计算机与人类相比真的很愚蠢。对于人类来说,一个非常简单的问题需要非常复杂的算法才能由计算机来解决。比如我以前在腾讯做QQ浏览器。对于抓取到的网页,需要分析哪些是核心内容(如文章文字),哪些是杂质(如广告)。对于人来说,这样的事情再简单不过了。但是对于电脑来说,要能够适应所有的网页,真的很难。我们还采用了基于视觉的块分析方法,使用类似于人类观察的逻辑进行分析,效果得到了提升,
总觉得现在人工智能的发展太依赖电脑了。即冯诺依曼计算系统。或许在这个系统中,根本就没有人工智能,只有模拟智能。神经网络算法已经很复杂了,但是能解决的问题还是很有限的。
网页抓取解密(的技术架构相关知识(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-20 05:11
本次采访的对象是技术总监杨光。负责9466智能建站平台。本次WOT软件技术峰会,将分享9466技术架构相关知识。敬请关注!
【讲师简历】
杨光,2005年毕业于西北大学,从物理系转入软件学院。同年加入并从事新一代战略ERP产品U9的研发,这是国内第一款基于SOA架构的大型商业软件。2010年加入腾讯,在手Q浏览器团队工作,负责浏览器后台整体运营体系建设。2013年加入与钟胜辉共同打造9466智能网站建设平台。
以下是采访记录:
记者:9466网络助手是什么时候推出的?开发的初衷是什么?使用了哪些新技术?开发过程中遇到了哪些困难,又是如何克服的?
杨光:9466第一版于2013年10月上线,自上线以来一直处于公测阶段(需要邀请码)。我们仍在打磨我们的产品。
当初开发这个产品是为了彻底解决网页问题和网站生产烦恼。因为目前做网页还是网站,还有很多知识需要理解,比如:创意、设计、页面制作、素材制作、样式定义、数据读写等等. 要制作页面,需要各种技能。对于新手用户来说,这个问题就更加突出了。然而,在这个领域有很多需求。于是就有了这个想法,目的是利用9466平台,任何人都可以轻松做出漂亮的网页。
本产品是一款非常前端的产品,技术难度和积累主要在前端,比如:响应式设计、按需加载、异步事件等等。因为我们的设计师是一个所见即所得的操作体验,所以设计一个合理的模型来模拟网页上的这种原生操作是非常重要的。在这方面,我们花了很多时间,多人协作和讨论。经过几个版本,不断优化,终于在体验和浏览器执行性能上有了不错的表现。
记者:您认为9466网络助手最大的亮点是什么?
杨光:我个人认为9466最大的亮点是:开放性。我们有一个非常强大的设计引擎。这个引擎不仅仅是传统意义上的所见即所得,而是一个可以拖拽设计的操作界面。动力是这台发动机是开着的。通过引擎,可以组装各种组件、应用程序、模板和样式。只要满足既定规范,任何第三方都可以开发各种组件以嵌入 9466 平台。这样,9466平台就相当于胶水,任何有优秀创意和实现的第三方都可以通过平台贡献自己的价值,服务他人。
记者:目前9466网络助手的模板有专题模板、企业网站、个人网站三种。哪种类型的模板更受欢迎?新模板的更新状态如何?
杨光:目前抄题目和企业模板的人比较多。我们将在不久的将来研究这个主题。现有功能的优化和新功能的加入,会更好的贴合话题制作的场景。因此,主题模板将在不久的将来更频繁地更新。
记者:对于9644网络助手的发展前景,您怎么看?您认为哪些方面需要改进?
杨光:9466的发展前景是毋庸置疑的,因为只要有网页,就会有大量的网页制作需求。这是一个刚性需求,并没有得到满足。迫切需要这样一种有用的产品来填补这一空白。而且,Wix等几家国外大公司已经上市,市值7.5亿美元。Weebly 刚刚获得了红衫军和腾讯的联合投资。中国还没有垄断企业,大家还在竞争。
记者:最后一个问题,就您而言,您比较关注的技术领域是什么?您预测2014年会流行哪些新技术?
杨光:我的顾虑比较复杂,我不说2014年哪种技术会流行。但除了工作,我对人工智能更感兴趣。我和电脑打交道的时间越长,我就越觉得电脑比起人类来说太愚蠢了。对于人类来说,一个非常简单的问题需要非常复杂的算法才能由计算机来解决。比如腾讯之前的QQ浏览器,对于抓取到的网页,需要分析哪些是核心内容(如文章文字),哪些是杂质(如广告)。对于人来说,这样的事情再简单不过了。但是对于电脑来说,要能够适应所有的网页,真的很难。我们还采用了基于视觉的块分析方法,使用类似于人类观察的逻辑进行分析,效果得到了提升,
我总觉得现在人工智能的发展太依赖电脑了。即冯诺依曼计算系统。或许在这个系统中,根本就没有人工智能,只有模拟智能。神经网络算法很复杂,但能解决的问题还是很有限的。 查看全部
网页抓取解密(的技术架构相关知识(图))
本次采访的对象是技术总监杨光。负责9466智能建站平台。本次WOT软件技术峰会,将分享9466技术架构相关知识。敬请关注!
【讲师简历】
杨光,2005年毕业于西北大学,从物理系转入软件学院。同年加入并从事新一代战略ERP产品U9的研发,这是国内第一款基于SOA架构的大型商业软件。2010年加入腾讯,在手Q浏览器团队工作,负责浏览器后台整体运营体系建设。2013年加入与钟胜辉共同打造9466智能网站建设平台。
以下是采访记录:
记者:9466网络助手是什么时候推出的?开发的初衷是什么?使用了哪些新技术?开发过程中遇到了哪些困难,又是如何克服的?
杨光:9466第一版于2013年10月上线,自上线以来一直处于公测阶段(需要邀请码)。我们仍在打磨我们的产品。
当初开发这个产品是为了彻底解决网页问题和网站生产烦恼。因为目前做网页还是网站,还有很多知识需要理解,比如:创意、设计、页面制作、素材制作、样式定义、数据读写等等. 要制作页面,需要各种技能。对于新手用户来说,这个问题就更加突出了。然而,在这个领域有很多需求。于是就有了这个想法,目的是利用9466平台,任何人都可以轻松做出漂亮的网页。
本产品是一款非常前端的产品,技术难度和积累主要在前端,比如:响应式设计、按需加载、异步事件等等。因为我们的设计师是一个所见即所得的操作体验,所以设计一个合理的模型来模拟网页上的这种原生操作是非常重要的。在这方面,我们花了很多时间,多人协作和讨论。经过几个版本,不断优化,终于在体验和浏览器执行性能上有了不错的表现。
记者:您认为9466网络助手最大的亮点是什么?
杨光:我个人认为9466最大的亮点是:开放性。我们有一个非常强大的设计引擎。这个引擎不仅仅是传统意义上的所见即所得,而是一个可以拖拽设计的操作界面。动力是这台发动机是开着的。通过引擎,可以组装各种组件、应用程序、模板和样式。只要满足既定规范,任何第三方都可以开发各种组件以嵌入 9466 平台。这样,9466平台就相当于胶水,任何有优秀创意和实现的第三方都可以通过平台贡献自己的价值,服务他人。
记者:目前9466网络助手的模板有专题模板、企业网站、个人网站三种。哪种类型的模板更受欢迎?新模板的更新状态如何?
杨光:目前抄题目和企业模板的人比较多。我们将在不久的将来研究这个主题。现有功能的优化和新功能的加入,会更好的贴合话题制作的场景。因此,主题模板将在不久的将来更频繁地更新。
记者:对于9644网络助手的发展前景,您怎么看?您认为哪些方面需要改进?
杨光:9466的发展前景是毋庸置疑的,因为只要有网页,就会有大量的网页制作需求。这是一个刚性需求,并没有得到满足。迫切需要这样一种有用的产品来填补这一空白。而且,Wix等几家国外大公司已经上市,市值7.5亿美元。Weebly 刚刚获得了红衫军和腾讯的联合投资。中国还没有垄断企业,大家还在竞争。
记者:最后一个问题,就您而言,您比较关注的技术领域是什么?您预测2014年会流行哪些新技术?
杨光:我的顾虑比较复杂,我不说2014年哪种技术会流行。但除了工作,我对人工智能更感兴趣。我和电脑打交道的时间越长,我就越觉得电脑比起人类来说太愚蠢了。对于人类来说,一个非常简单的问题需要非常复杂的算法才能由计算机来解决。比如腾讯之前的QQ浏览器,对于抓取到的网页,需要分析哪些是核心内容(如文章文字),哪些是杂质(如广告)。对于人来说,这样的事情再简单不过了。但是对于电脑来说,要能够适应所有的网页,真的很难。我们还采用了基于视觉的块分析方法,使用类似于人类观察的逻辑进行分析,效果得到了提升,
我总觉得现在人工智能的发展太依赖电脑了。即冯诺依曼计算系统。或许在这个系统中,根本就没有人工智能,只有模拟智能。神经网络算法很复杂,但能解决的问题还是很有限的。
网页抓取解密(解决网站字体加密的第2篇文章方法,具体执行步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-18 05:17
前言:
写这个文章的原因是为了写一个python脚本来抓取一个食物相关的网站的电话号码,发现网站已经被字体加密了,抓到的那些是难以理解的十六进制代码,如下图:
文本:
用chrome查看对应的加密代码,发现是写在css文件中,css地址直接贴在这里:
找到对应的位置,发现是base64编码加密的
之前没接触过这个,于是开始查资料,主要是查下面两个文章,其中比较参考的是第二个文章的第四种方法,具体实现步骤和我我将列出我写的脚本:
将base64格式的字体信息解码成可用的字体文件
反爬虫技术:解决网站字体加密
步骤1:
提取CSS文件中网站字体对应的代码,自动保存为字体文件base.woff。复制下面的代码直接使用
# -*- coding:utf-8 -*-
import requests,base64
def downfont(url):
response = requests.get(url)
base64_string = response.text.split("base64,")[1].split("'")[0].strip()
bin_data = base64.decodebytes(base64_string.encode())
with open("base.woff", r"wb") as f:
f.write(bin_data)
if __name__ == "__main__":
url = 'https://wap.21food.cn/resources/css/layout.css'
downfont(url)
print('done.')
第2步:
下载FontCreator软件,下载链接:
打开第一步生成的“base.woff”字库,软件会自动生成字库的对应关系,如下图:
记得选择字幕,找到我们要抓取的网站加密字体对应的十六进制码,手动写入字典,这样我们抓取的数字就可以一一对应:key = { '10010':'0','1000D':'1','10011':'2','1000F':'3','10017':'4','1000E':'5','10015 ':' 6','10014':'7','10012':'8','10013':'9','10016':'-')
第 3 步:
编写爬虫程序,抓取我们要抓取的页面上电话号码的加密密文。我使用常规规则来匹配。以这个网址为例。我们需要抓取的是下图中的边框区域。
然后根据我们之前拿到的字典,自动转换成对应的实数,就可以在网页上得到这个数了。具体代码如下:
<p># -*- coding: utf-8 -*-
import requests
import cchardet
import traceback
from lxml import html
import re
import cchardet
def downloader(url, timeout=10, headers=None, debug=False, binary=False):
_headers = {
'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; '
'Windows NT 6.1; Win64; x64; Trident/5.0)'),
}
redirected_url = url
if headers:
_headers = headers
try:
r = requests.get(url, headers=_headers, timeout=timeout)
if binary:
html = r.content
else:
encoding = cchardet.detect(r.content)['encoding']
html = r.content.decode(encoding)
status = r.status_code
redirected_url = r.url
except:
if debug:
traceback.print_exc()
msg = 'failed download: {}'.format(url)
print(msg)
if binary:
html = b''
else:
html = ''
status = 0
return status, html, redirected_url
def extract(source):
p = re.findall(r'(&#x[^ 查看全部
网页抓取解密(解决网站字体加密的第2篇文章方法,具体执行步骤)
前言:
写这个文章的原因是为了写一个python脚本来抓取一个食物相关的网站的电话号码,发现网站已经被字体加密了,抓到的那些是难以理解的十六进制代码,如下图:
 http://www.reduwang.com/wp-con ... 1.png 150w, http://www.reduwang.com/wp-con ... 2.png 300w, http://www.reduwang.com/wp-con ... 7.png 768w, http://www.reduwang.com/wp-con ... 5.png 1249w" />
http://www.reduwang.com/wp-con ... 1.png 150w, http://www.reduwang.com/wp-con ... 2.png 300w, http://www.reduwang.com/wp-con ... 7.png 768w, http://www.reduwang.com/wp-con ... 5.png 1249w" />文本:
用chrome查看对应的加密代码,发现是写在css文件中,css地址直接贴在这里:
 http://www.reduwang.com/wp-con ... 6.png 150w, http://www.reduwang.com/wp-con ... 2.png 300w, http://www.reduwang.com/wp-con ... 2.png 768w, http://www.reduwang.com/wp-con ... 6.png 1808w" />
http://www.reduwang.com/wp-con ... 6.png 150w, http://www.reduwang.com/wp-con ... 2.png 300w, http://www.reduwang.com/wp-con ... 2.png 768w, http://www.reduwang.com/wp-con ... 6.png 1808w" />找到对应的位置,发现是base64编码加密的
 http://www.reduwang.com/wp-con ... 7.png 150w, http://www.reduwang.com/wp-con ... 4.png 300w, http://www.reduwang.com/wp-con ... 8.png 768w, http://www.reduwang.com/wp-con ... 7.png 1832w" />
http://www.reduwang.com/wp-con ... 7.png 150w, http://www.reduwang.com/wp-con ... 4.png 300w, http://www.reduwang.com/wp-con ... 8.png 768w, http://www.reduwang.com/wp-con ... 7.png 1832w" />之前没接触过这个,于是开始查资料,主要是查下面两个文章,其中比较参考的是第二个文章的第四种方法,具体实现步骤和我我将列出我写的脚本:
将base64格式的字体信息解码成可用的字体文件
反爬虫技术:解决网站字体加密
步骤1:
提取CSS文件中网站字体对应的代码,自动保存为字体文件base.woff。复制下面的代码直接使用
# -*- coding:utf-8 -*-
import requests,base64
def downfont(url):
response = requests.get(url)
base64_string = response.text.split("base64,")[1].split("'")[0].strip()
bin_data = base64.decodebytes(base64_string.encode())
with open("base.woff", r"wb") as f:
f.write(bin_data)
if __name__ == "__main__":
url = 'https://wap.21food.cn/resources/css/layout.css'
downfont(url)
print('done.')
第2步:
下载FontCreator软件,下载链接:
打开第一步生成的“base.woff”字库,软件会自动生成字库的对应关系,如下图:
 http://www.reduwang.com/wp-con ... 8.png 150w, http://www.reduwang.com/wp-con ... 7.png 300w, http://www.reduwang.com/wp-con ... 2.png 768w" />
http://www.reduwang.com/wp-con ... 8.png 150w, http://www.reduwang.com/wp-con ... 7.png 300w, http://www.reduwang.com/wp-con ... 2.png 768w" />记得选择字幕,找到我们要抓取的网站加密字体对应的十六进制码,手动写入字典,这样我们抓取的数字就可以一一对应:key = { '10010':'0','1000D':'1','10011':'2','1000F':'3','10017':'4','1000E':'5','10015 ':' 6','10014':'7','10012':'8','10013':'9','10016':'-')
第 3 步:
编写爬虫程序,抓取我们要抓取的页面上电话号码的加密密文。我使用常规规则来匹配。以这个网址为例。我们需要抓取的是下图中的边框区域。
 http://www.reduwang.com/wp-con ... 7.png 150w, http://www.reduwang.com/wp-con ... 4.png 300w, http://www.reduwang.com/wp-con ... 8.png 768w" />
http://www.reduwang.com/wp-con ... 7.png 150w, http://www.reduwang.com/wp-con ... 4.png 300w, http://www.reduwang.com/wp-con ... 8.png 768w" />然后根据我们之前拿到的字典,自动转换成对应的实数,就可以在网页上得到这个数了。具体代码如下:
<p># -*- coding: utf-8 -*-
import requests
import cchardet
import traceback
from lxml import html
import re
import cchardet
def downloader(url, timeout=10, headers=None, debug=False, binary=False):
_headers = {
'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; '
'Windows NT 6.1; Win64; x64; Trident/5.0)'),
}
redirected_url = url
if headers:
_headers = headers
try:
r = requests.get(url, headers=_headers, timeout=timeout)
if binary:
html = r.content
else:
encoding = cchardet.detect(r.content)['encoding']
html = r.content.decode(encoding)
status = r.status_code
redirected_url = r.url
except:
if debug:
traceback.print_exc()
msg = 'failed download: {}'.format(url)
print(msg)
if binary:
html = b''
else:
html = ''
status = 0
return status, html, redirected_url
def extract(source):
p = re.findall(r'(&#x[^
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-16 21:45
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用
着陆页分析
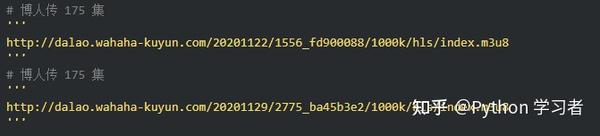
根据朋友提供的地址,是关于火影的博客。
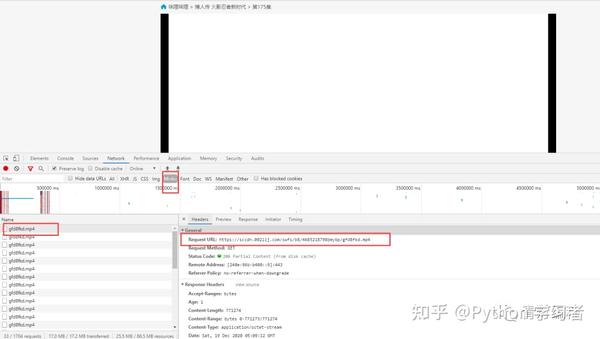
在使用开发者工具的时候,发现有现成的mp4地址。请注意,您仍在考虑它:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
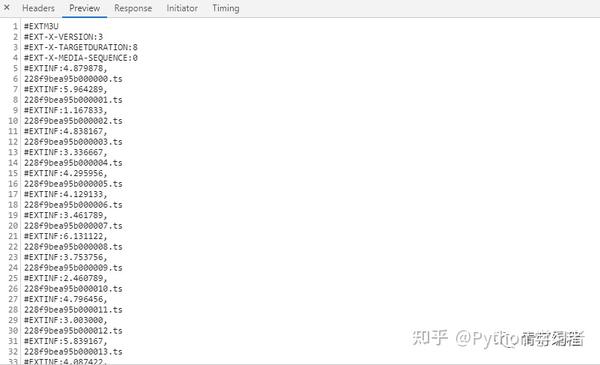
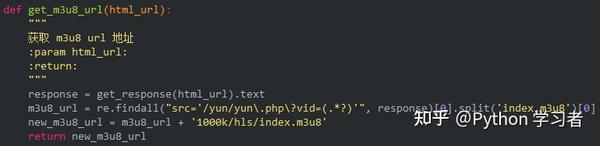
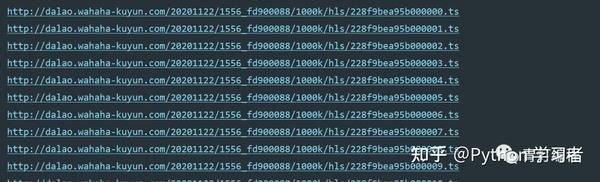
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接就是对应视频中的一个片段,整个视频是由片段一一组成的。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
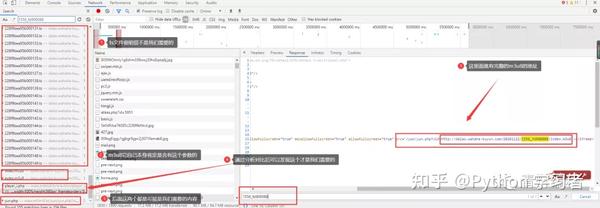
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
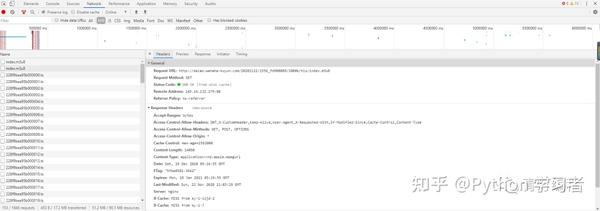
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应这个动漫博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
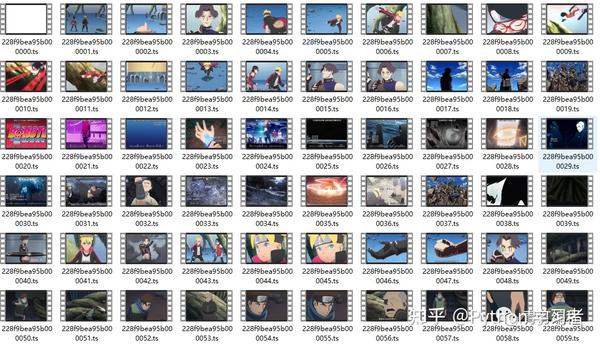
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般自带WinRaR解压软件,选中所有ts文件后,右键选择添加到压缩文件,如下图界面,
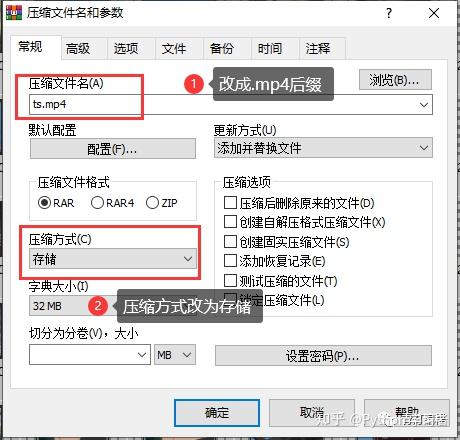
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
也可以用代码和FFmpg合并,爬到B站视频之前合并音频数据和视频图片。 查看全部
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。如果您有任何问题,请联系我们进行处理。

今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用

着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址。请注意,您仍在考虑它:

复制链接会自动下载,点击打开......



这是为什么?回头看网页,原来是一个广告的视频==

再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接就是对应视频中的一个片段,整个视频是由片段一一组成的。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。

2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。

此链接中收录的参数:

根据导航栏中的url,可以找到:
ID:95应该对应这个动漫博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件

首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般自带WinRaR解压软件,选中所有ts文件后,右键选择添加到压缩文件,如下图界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。

当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
也可以用代码和FFmpg合并,爬到B站视频之前合并音频数据和视频图片。
网页抓取解密(网页抓取解密五步大全,教你学会表达式的用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-12 16:07
网页抓取解密五步大全,教你学会网页抓取解密,教你可视化操作网页,教你正则表达式的用法,教你图片文件的二次加工,教你可视化数据可视化。今天我们来讨论一下,网页抓取解密五步大全的详细实操流程以及一些容易被忽略的操作技巧,让你轻松上手更易于理解。work——get网页源代码2.body——下载解密最终代码3.items——对body进行数据提取4.content——文本解密5.extension——抓包(翻墙点这里)对body进行数据提取网页抓取解密五步大全,这个几乎是所有网页抓取解密都要使用到的技巧,其实不仅仅限于常见的反编译或者反爬虫,网页中的图片、文本甚至tables、frameset等表格元素也能进行解密,基本上所有抓取工具都会提供强大的解密工具,只要你懂一点代码提取,其实一个大写的字符串五步解密的案例不难实现。
假设我们要抓取小米手机发送的短信数据,那我们将一个个的提取出来已经十分繁琐和费时,当然基于代码的完成是完全可以的,下面通过一个简单的案例来展示。举个例子formsubmit——复制这个内容,粘贴在后面的工作表表头,添加url:取回文字</a>window.notification.post("-message",newsimpleformform("url"),url)这里的url是一个通用字符串类型的url,后面跟的表头是你发送信息的邮箱地址。
当然你也可以用get方法直接从表头获取数据,而且可以通过这个获取邮箱、手机号等字段数据。接下来我们抓包,打开抓包工具来提取数据:手机短信获取方法通过safari浏览器,使用第三方工具如charles、xpath等。我们可以看到网页抓取解密到这里基本上已经完成了,从get获取的相关内容,只是输出了html文本而已,这里我想提一下的是判断正则表达式的问题,常用的判断正则表达式有以下五种,分别是匹配javascript、匹配text、匹配html、匹配attribute、匹配python。
我们来看看判断正则表达式,后来转化成了更加通用的代码,基本上跟我们熟悉的很像,只是操作比较繁琐和麻烦。上面公式的几点特点,如果直接看代码,不太容易抓到重点:1.字符串的单引号需要先替换成双引号,下面这个代码容易忽略,包括语法,具体的可以参看源代码如下。2.满足要求如果在每一个开头没有匹配,则下一个在开头肯定有empty和infinite两个子串,值得注意是从第一个到最后一个一定是以空格隔开的,不包括后面我们假设,有一个输入框,标识为a1,那么如果a1最后的text是一个十。 查看全部
网页抓取解密(网页抓取解密五步大全,教你学会表达式的用法)
网页抓取解密五步大全,教你学会网页抓取解密,教你可视化操作网页,教你正则表达式的用法,教你图片文件的二次加工,教你可视化数据可视化。今天我们来讨论一下,网页抓取解密五步大全的详细实操流程以及一些容易被忽略的操作技巧,让你轻松上手更易于理解。work——get网页源代码2.body——下载解密最终代码3.items——对body进行数据提取4.content——文本解密5.extension——抓包(翻墙点这里)对body进行数据提取网页抓取解密五步大全,这个几乎是所有网页抓取解密都要使用到的技巧,其实不仅仅限于常见的反编译或者反爬虫,网页中的图片、文本甚至tables、frameset等表格元素也能进行解密,基本上所有抓取工具都会提供强大的解密工具,只要你懂一点代码提取,其实一个大写的字符串五步解密的案例不难实现。
假设我们要抓取小米手机发送的短信数据,那我们将一个个的提取出来已经十分繁琐和费时,当然基于代码的完成是完全可以的,下面通过一个简单的案例来展示。举个例子formsubmit——复制这个内容,粘贴在后面的工作表表头,添加url:取回文字</a>window.notification.post("-message",newsimpleformform("url"),url)这里的url是一个通用字符串类型的url,后面跟的表头是你发送信息的邮箱地址。
当然你也可以用get方法直接从表头获取数据,而且可以通过这个获取邮箱、手机号等字段数据。接下来我们抓包,打开抓包工具来提取数据:手机短信获取方法通过safari浏览器,使用第三方工具如charles、xpath等。我们可以看到网页抓取解密到这里基本上已经完成了,从get获取的相关内容,只是输出了html文本而已,这里我想提一下的是判断正则表达式的问题,常用的判断正则表达式有以下五种,分别是匹配javascript、匹配text、匹配html、匹配attribute、匹配python。
我们来看看判断正则表达式,后来转化成了更加通用的代码,基本上跟我们熟悉的很像,只是操作比较繁琐和麻烦。上面公式的几点特点,如果直接看代码,不太容易抓到重点:1.字符串的单引号需要先替换成双引号,下面这个代码容易忽略,包括语法,具体的可以参看源代码如下。2.满足要求如果在每一个开头没有匹配,则下一个在开头肯定有empty和infinite两个子串,值得注意是从第一个到最后一个一定是以空格隔开的,不包括后面我们假设,有一个输入框,标识为a1,那么如果a1最后的text是一个十。
网页抓取解密(网页抓取解密(1)_e操盘_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-11 09:06
网页抓取解密..1.从filesystem上爬取文件.m3u8.exe等.2.解密码.密码文件.转码成字节流(支持十六进制)...程序处理成对应的二进制字节流.3.将处理后的字节流发送给网页服务器...
楼上的都是扯淡,
先模拟登录的客户端,
直接去网页里面抓取就可以了
有scrapy和web.py
有一个库叫telnet,具体你可以搜索这个库,不过这东西是两个接口对接的,如果你是写爬虫,这个库用起来估计不太靠谱,不如用beautifulsoup,各种解析器写起来很爽,当然,我还是推荐你用web框架来写,
你的问题中就已经给出答案了,客户端传的二进制文件的内容解码二进制文件转换成十六进制(十进制数可以是乱七八糟的,
直接抓取就可以了,当然如果就像做个js脚本那样可以用web.py,定时传送特定图片的二进制内容。
可以用scrapy爬取ftp、sctp、p2p等各种协议的数据
也可以用httpurlconnection把服务器发来的http请求通过http的requestheader里的类型指定后缀名作为file的字节流处理,然后从网页中取出来,用于其他进程传递。
这个需要分层分线路.1.软件层:自己编写爬虫网页,爬取过程的各种细节都要自己考虑和制定.2.网页层:通过python网页的反向工程来分析网页.3.对于中间层的话,通过python的cookie等等对用户上次操作做一个记录,进行下一次的请求. 查看全部
网页抓取解密(网页抓取解密(1)_e操盘_光明网(组图))
网页抓取解密..1.从filesystem上爬取文件.m3u8.exe等.2.解密码.密码文件.转码成字节流(支持十六进制)...程序处理成对应的二进制字节流.3.将处理后的字节流发送给网页服务器...
楼上的都是扯淡,
先模拟登录的客户端,
直接去网页里面抓取就可以了
有scrapy和web.py
有一个库叫telnet,具体你可以搜索这个库,不过这东西是两个接口对接的,如果你是写爬虫,这个库用起来估计不太靠谱,不如用beautifulsoup,各种解析器写起来很爽,当然,我还是推荐你用web框架来写,
你的问题中就已经给出答案了,客户端传的二进制文件的内容解码二进制文件转换成十六进制(十进制数可以是乱七八糟的,
直接抓取就可以了,当然如果就像做个js脚本那样可以用web.py,定时传送特定图片的二进制内容。
可以用scrapy爬取ftp、sctp、p2p等各种协议的数据
也可以用httpurlconnection把服务器发来的http请求通过http的requestheader里的类型指定后缀名作为file的字节流处理,然后从网页中取出来,用于其他进程传递。
这个需要分层分线路.1.软件层:自己编写爬虫网页,爬取过程的各种细节都要自己考虑和制定.2.网页层:通过python网页的反向工程来分析网页.3.对于中间层的话,通过python的cookie等等对用户上次操作做一个记录,进行下一次的请求.
网页抓取解密( 图片来源网络抓取策略(一)(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-11 04:02
图片来源网络抓取策略(一)(1)_光明网(组图))
图片来源网络
爬取策略
在爬虫系统中,要爬取的URL是一个非常关键的部分。爬虫需要爬取的网页的网址排列在其中,形成一个队列结构。调度器每次从队列的头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被追加到待爬取的URL队列的末尾,从而形成一个爬行循环,整个爬虫系统可以说是由这个队列驱动的。
如何确定要抓取的URL队列中页面URL的顺序?如上所述,新下载页面中收录的链接将附加到队列的末尾。虽然这是一种确定队列的 URL 顺序的方法,但它不是唯一的方法。事实上,可以采用许多其他技术来保持队列等待被捕获。取URL进行排序。爬虫的不同爬取策略使用不同的方法来确定要爬取的 URL 队列中 URL 的优先级。
爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:首先选择重要的网页进行爬取。在爬虫系统中,所谓的网页重要性可以通过不同的方法来判断,但大多是按照网页的流行程度来定义的。
爬取策略的方法虽然有很多,但这里仅列举被证明有效或具有代表性的解决方案,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略和大站优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。搜索引擎爬虫一出现就被采用。新提出的爬取策略往往使用这种方法作为比较的基准。不过,值得注意的是,这种策略也是一种非常强大的方法。很多新方法的实际效果不一定比广度优先遍历策略好。所以这个方法其实是很多爬虫采用的第一种爬虫策略。
如上所述,“新下载的网页中收录的URL会被追加到待抓取的URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法并没有明确提出和使用网页的重要性作为衡量标准,而是机械地从新下载的网页中提取链接,作为URL的下载顺序附加到待抓取的URL队列中。下图是该策略的示意图: 假设队列头部的网页是1号网页,从1号网页中提取3个分别指向2号、3号、4号的链接,因此它们按要捕获的数字顺序排列。在取队列中,图中网页的编号就是这个页面在待取队列中的序号,
实验表明,这种策略非常有效。虽然看起来很机械,但实际的网页抓取顺序基本上是按照网页的重要性排序的。为此,一些研究人员认为,如果一个网页收录许多传入链接,则更容易被广度优先遍历策略及早捕获。传入链接的数量从侧面反映了网页的重要性,即实际的宽度优先遍历策略 以上也暗示了一些网页优先级假设。
广度优先遍历策略
02 PageRank 策略不完整
PageRank 是一种著名的链接分析算法,可用于衡量网页的重要性。自然可以想到使用PageRank的思想来对URL优先级进行排序。但是这里有一个问题。PageRank 是一种全局算法,这意味着当所有网页都被下载时,计算结果是可靠的。爬虫的目的是下载网页,运行时只能看到部分网页。,所以在爬行阶段的网页无法获得可靠的PageRank分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,将要爬取的URL队列中的URL加入到一个网页集合中,在这个集合中进行PageRank计算,计算完成后,待爬取的URL队列 根据PageRank得分从高到低对其中的网页进行排序,形成的顺序就是爬虫接下来要爬取的URL列表。这就是为什么它被称为“不完整的 PageRank”。
如果每次抓取一个新的网页,所有下载的网页都重新计算为一个新的不完整的PageRank值,这显然效率太低,在现实中也不可行。一个折衷的方法是:每当有足够K个新下载的网页时,对所有下载的网页重新计算一个新的不完整PageRank。这种计算效率勉强可以接受,但又带来了一个新问题:在开始下一轮PageRank计算之前,提取新下载网页中收录的链接。这些链接很可能非常重要,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 会为这些新提取的没有 PageRank 值的网页分配一个临时的 PageRank 值。此网页所有链接内传输的 PageRank 值汇总为临时 PageRank 值。如果这个值大于要爬取的URL队列中计算出的值,如果PageRank值高的页面出来,那么会先下载这个URL。
下图是不完全PageRank策略的示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时本地已经下载了3个网页{P1,P2,P3},这3个网页中收录的链接指向{P4,P5,P6},形成了一个待抓取的URL队列。如何决定下载顺序?将这6个网页组成一个新的集合,计算这个集合的PageRank值,让P4、P5和P6得到各自对应的PageRank值,从大到小排序,就可以得到下载顺序. 这里可以假设下载顺序为:P5、P4、P6。下载P5页面时,链接被提取并指向页面P8。此时,P8 被分配了一个临时的 PageRank 值。如果这个值大于 P4 和 P6 如果你有一个 PageRank 值,P8 将首先被下载。这样一个连续的循环就形成了不完全PageRank策略的计算思路。
Incomplete PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明,不完整的 PageRank 结果稍好一些,而一些实验结果则刚好相反。有研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大不同。不应作为计算网址在爬取过程中重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC字面意思是“在线页面重要性计算”,可以看作是一种改进的PageRank算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”分配给“空”。对于 URL 队列中待抓取的网页,它们根据手头有多少现金进行排序,现金最多的网页先下载。OPIC在其大框架上与PageRank基本相同。区别在于:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,有一个远程跳转到没有链接关系的网页的过程,而OPIC没有这个计算因素。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略好于广度优先遍历策略。
04 大站点优先策略
大站点优先策略很简单:以 网站 为单位衡量网页的重要性。对于URL队列中待抓取的网页,根据各自的网站进行分类,如果等待下载的是哪个网站,如果页面数最多,先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略好于宽度优先遍历策略。
网页更新策略
Internet 的动态特性是其显着特征。随时出现新页面,更改页面内容或删除现有页面。对于爬虫来说,并不是在本地爬取网页,即使完成了任务,也必须体现互联网的动态性。本地下载的页面可以看作是互联网页面的“镜子”,爬虫应该尽量保证一致性。可以假设这样一种情况:某个网页被删除或内容发生了重大变化,搜索引擎仍然对这个引擎一无所知,仍然按照旧内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取过的网页,
网页更新策略的任务是决定何时重新抓取下载的网页,尽可能使本地下载的网页内容与互联网上的原创网页一致。常用的网页更新策略有3种:历史参考策略、用户体验策略和聚类抽样策略。
01 历史参考策略
历史参考策略是最直观的更新策略。它基于这样一个假设,即过去经常更新的网页在未来也会经常更新。因此,为了估计某个网页的更新时间,可以参考历史更新情况进行判断。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时会再次发生变化,以指导爬虫的抓取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,专注于内容变化检测和建模。优越的。
02用户体验策略
一般来说,一个搜索引擎用户提交查询后,可能会有上千条相关的搜索结果,用户没有耐心等着看排在后面的搜索结果,可能只看前3页的搜索内容。用户体验策略利用用户的这种特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,那么以后更新这些过时的网页也是可以的。因此,判断网页何时更新取决于网页内容的变化(通常以搜索结果排名的变化来衡量)带来的搜索质量的变化。网页的影响越大,应该更新得越快。
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,作为判断爬虫重新抓取网页时间的参考依据。网页的影响越严重,就越优先安排重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略很大程度上依赖于网页的历史更新信息,因为这是后续计算的基础。但在现实中,要为每个网页保存历史信息,搜索系统会增加很多额外的负担。从另一个角度来说,如果是第一个被爬取的网页,因为没有历史信息,无法按照这两个思路来估计更新周期。为了解决上述不足,提出了聚类抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测更新周期。具有相似属性的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,同一类别的网页具有相同的更新频率。为了计算某个类别的更新周期,只需对该类别中的网页进行采样,并将这些采样网页的更新周期作为该类别中所有网页的更新周期。与前面介绍的两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,也可以根据类别进行更新。
下图描述了集群抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页都有相似的更新周期。从类别中提取出一部分最具代表性的网页(通常是提取离类别中心最近的网页),计算这些网页的更新周期,然后将该更新周期用于该类别中的所有网页,然后可以基于网页的类别 确定其更新周期。
聚类抽样策略
网页更新周期的属性特征分为静态特征和动态特征两大类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,比如图片数量的变化、链接的进出变化等。基于这两种特征,可以对网页进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,有的研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一网站的网页具有相同的更新周期,则其中的网页网站是Sampling,计算更新周期,然后网站中的所有网页都会以这个更新周期为准。虽然这个假设很粗略,因为很明显同一网站内的网页更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类也非常困难。
如果你对爬虫感兴趣,还可以阅读:
全程干货| 爬虫技术原理入门,看这篇文章就知道了
网络爬虫 | 你不知道的暗网是如何爬行的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗? 查看全部
网页抓取解密(
图片来源网络抓取策略(一)(1)_光明网(组图))

图片来源网络
爬取策略
在爬虫系统中,要爬取的URL是一个非常关键的部分。爬虫需要爬取的网页的网址排列在其中,形成一个队列结构。调度器每次从队列的头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被追加到待爬取的URL队列的末尾,从而形成一个爬行循环,整个爬虫系统可以说是由这个队列驱动的。
如何确定要抓取的URL队列中页面URL的顺序?如上所述,新下载页面中收录的链接将附加到队列的末尾。虽然这是一种确定队列的 URL 顺序的方法,但它不是唯一的方法。事实上,可以采用许多其他技术来保持队列等待被捕获。取URL进行排序。爬虫的不同爬取策略使用不同的方法来确定要爬取的 URL 队列中 URL 的优先级。
爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:首先选择重要的网页进行爬取。在爬虫系统中,所谓的网页重要性可以通过不同的方法来判断,但大多是按照网页的流行程度来定义的。
爬取策略的方法虽然有很多,但这里仅列举被证明有效或具有代表性的解决方案,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略和大站优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。搜索引擎爬虫一出现就被采用。新提出的爬取策略往往使用这种方法作为比较的基准。不过,值得注意的是,这种策略也是一种非常强大的方法。很多新方法的实际效果不一定比广度优先遍历策略好。所以这个方法其实是很多爬虫采用的第一种爬虫策略。
如上所述,“新下载的网页中收录的URL会被追加到待抓取的URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法并没有明确提出和使用网页的重要性作为衡量标准,而是机械地从新下载的网页中提取链接,作为URL的下载顺序附加到待抓取的URL队列中。下图是该策略的示意图: 假设队列头部的网页是1号网页,从1号网页中提取3个分别指向2号、3号、4号的链接,因此它们按要捕获的数字顺序排列。在取队列中,图中网页的编号就是这个页面在待取队列中的序号,
实验表明,这种策略非常有效。虽然看起来很机械,但实际的网页抓取顺序基本上是按照网页的重要性排序的。为此,一些研究人员认为,如果一个网页收录许多传入链接,则更容易被广度优先遍历策略及早捕获。传入链接的数量从侧面反映了网页的重要性,即实际的宽度优先遍历策略 以上也暗示了一些网页优先级假设。
广度优先遍历策略
02 PageRank 策略不完整
PageRank 是一种著名的链接分析算法,可用于衡量网页的重要性。自然可以想到使用PageRank的思想来对URL优先级进行排序。但是这里有一个问题。PageRank 是一种全局算法,这意味着当所有网页都被下载时,计算结果是可靠的。爬虫的目的是下载网页,运行时只能看到部分网页。,所以在爬行阶段的网页无法获得可靠的PageRank分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,将要爬取的URL队列中的URL加入到一个网页集合中,在这个集合中进行PageRank计算,计算完成后,待爬取的URL队列 根据PageRank得分从高到低对其中的网页进行排序,形成的顺序就是爬虫接下来要爬取的URL列表。这就是为什么它被称为“不完整的 PageRank”。
如果每次抓取一个新的网页,所有下载的网页都重新计算为一个新的不完整的PageRank值,这显然效率太低,在现实中也不可行。一个折衷的方法是:每当有足够K个新下载的网页时,对所有下载的网页重新计算一个新的不完整PageRank。这种计算效率勉强可以接受,但又带来了一个新问题:在开始下一轮PageRank计算之前,提取新下载网页中收录的链接。这些链接很可能非常重要,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 会为这些新提取的没有 PageRank 值的网页分配一个临时的 PageRank 值。此网页所有链接内传输的 PageRank 值汇总为临时 PageRank 值。如果这个值大于要爬取的URL队列中计算出的值,如果PageRank值高的页面出来,那么会先下载这个URL。
下图是不完全PageRank策略的示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时本地已经下载了3个网页{P1,P2,P3},这3个网页中收录的链接指向{P4,P5,P6},形成了一个待抓取的URL队列。如何决定下载顺序?将这6个网页组成一个新的集合,计算这个集合的PageRank值,让P4、P5和P6得到各自对应的PageRank值,从大到小排序,就可以得到下载顺序. 这里可以假设下载顺序为:P5、P4、P6。下载P5页面时,链接被提取并指向页面P8。此时,P8 被分配了一个临时的 PageRank 值。如果这个值大于 P4 和 P6 如果你有一个 PageRank 值,P8 将首先被下载。这样一个连续的循环就形成了不完全PageRank策略的计算思路。
Incomplete PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明,不完整的 PageRank 结果稍好一些,而一些实验结果则刚好相反。有研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大不同。不应作为计算网址在爬取过程中重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC字面意思是“在线页面重要性计算”,可以看作是一种改进的PageRank算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”分配给“空”。对于 URL 队列中待抓取的网页,它们根据手头有多少现金进行排序,现金最多的网页先下载。OPIC在其大框架上与PageRank基本相同。区别在于:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,有一个远程跳转到没有链接关系的网页的过程,而OPIC没有这个计算因素。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略好于广度优先遍历策略。
04 大站点优先策略
大站点优先策略很简单:以 网站 为单位衡量网页的重要性。对于URL队列中待抓取的网页,根据各自的网站进行分类,如果等待下载的是哪个网站,如果页面数最多,先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略好于宽度优先遍历策略。
网页更新策略
Internet 的动态特性是其显着特征。随时出现新页面,更改页面内容或删除现有页面。对于爬虫来说,并不是在本地爬取网页,即使完成了任务,也必须体现互联网的动态性。本地下载的页面可以看作是互联网页面的“镜子”,爬虫应该尽量保证一致性。可以假设这样一种情况:某个网页被删除或内容发生了重大变化,搜索引擎仍然对这个引擎一无所知,仍然按照旧内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取过的网页,
网页更新策略的任务是决定何时重新抓取下载的网页,尽可能使本地下载的网页内容与互联网上的原创网页一致。常用的网页更新策略有3种:历史参考策略、用户体验策略和聚类抽样策略。
01 历史参考策略
历史参考策略是最直观的更新策略。它基于这样一个假设,即过去经常更新的网页在未来也会经常更新。因此,为了估计某个网页的更新时间,可以参考历史更新情况进行判断。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时会再次发生变化,以指导爬虫的抓取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,专注于内容变化检测和建模。优越的。
02用户体验策略
一般来说,一个搜索引擎用户提交查询后,可能会有上千条相关的搜索结果,用户没有耐心等着看排在后面的搜索结果,可能只看前3页的搜索内容。用户体验策略利用用户的这种特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,那么以后更新这些过时的网页也是可以的。因此,判断网页何时更新取决于网页内容的变化(通常以搜索结果排名的变化来衡量)带来的搜索质量的变化。网页的影响越大,应该更新得越快。
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,作为判断爬虫重新抓取网页时间的参考依据。网页的影响越严重,就越优先安排重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略很大程度上依赖于网页的历史更新信息,因为这是后续计算的基础。但在现实中,要为每个网页保存历史信息,搜索系统会增加很多额外的负担。从另一个角度来说,如果是第一个被爬取的网页,因为没有历史信息,无法按照这两个思路来估计更新周期。为了解决上述不足,提出了聚类抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测更新周期。具有相似属性的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,同一类别的网页具有相同的更新频率。为了计算某个类别的更新周期,只需对该类别中的网页进行采样,并将这些采样网页的更新周期作为该类别中所有网页的更新周期。与前面介绍的两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,也可以根据类别进行更新。
下图描述了集群抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页都有相似的更新周期。从类别中提取出一部分最具代表性的网页(通常是提取离类别中心最近的网页),计算这些网页的更新周期,然后将该更新周期用于该类别中的所有网页,然后可以基于网页的类别 确定其更新周期。
聚类抽样策略
网页更新周期的属性特征分为静态特征和动态特征两大类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,比如图片数量的变化、链接的进出变化等。基于这两种特征,可以对网页进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,有的研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一网站的网页具有相同的更新周期,则其中的网页网站是Sampling,计算更新周期,然后网站中的所有网页都会以这个更新周期为准。虽然这个假设很粗略,因为很明显同一网站内的网页更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类也非常困难。
如果你对爬虫感兴趣,还可以阅读:
全程干货| 爬虫技术原理入门,看这篇文章就知道了
网络爬虫 | 你不知道的暗网是如何爬行的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗?
网页抓取解密(网易云音乐只需要解密params和encSecKey就可以开始快乐的了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-11 04:02
网易云音乐只需要解密params和encSecKey就可以愉快的开始爬虫了。如果你没有足够的代理IP,你还是要慢慢爬,别废话,全开就好了。
问
老规矩,我们来看看我们要抓取的页面:
查看网络请求:
从名字上可以快速定位到哪个请求是POST请求,然后看看它提交了哪些参数。表格数据如下:
提交的参数,即前面提到的params和encSecKey,都是经过加密的。看一下返回内容的格式:
好的,我们已经知道了基本的东西,我们可以进入下一步,找到两个解密参数。
分析
在调试之前,我们要找到这两个值的位置,然后搜索,先定位JS文件,然后定位代码位置。您应该知道如何搜索,您可以全局搜索params或encSecKey。如果找到多个结果,不确定是哪个文件,可以进去搜索每个点的关键参数,判断是否是目标文件。这里我直接标记一下,找到正确的文件后就可以点击进入了。
进入JS文件后,同时搜索关键参数params或encSecKey:
找到encSecKey的位置,拉出这几行代码分析一下:
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
e0x.data = j0x.cs1x({
params: bVZ8R.encText,
encSecKey: bVZ8R.encSecKey
})
粗略的讲,params和encSecKey来自bVZ8R.encText和bVZ8R.encSecKey,bVZ8R是window.asrsea的结果,window.asrsea有四个参数,JSON.stringify(i0x), bqN0x(["streaming", "强" ] ), bqN0x(Wx5C.md), bqN0x(["Love", "Girl", "Terrified", "Laughing"],首先看下面三个参数,从它们的固定值,你可以大胆猜想这三个values也是Fixed,之所以说是fixed,看看Wx5C.md:
wx5C.md是固定数组,和bqN0x(["流泪", "强"])和bqN0x(["爱心", "girl", "horrified", "laughing"] 这个结果肯定是没有变化的,如图下面,测试了一下:
大概把这些参数搞清楚了,剩下的就是搞清楚window.asrsea的具体实现,还有i0x是什么样的,进入调试环节。
调试
window.asrsea 到达断点。我的代码位置是13133行,点击下一页粉丝列表会激活断点。在激活断点的同时,我们也可以看到 i0x 的美妙之处。在控制台输入 i0x:
limit、offset、total、userId其实是已知的,csrf_token的生成可以看这里。细心的童鞋早就应该发现了:
i0x["csrf_token"] = v0x.gP3x("__csrf"); ## csrf_token在这里产生
X0x = X0x.replace("api", "weapi");
e0x.method = "post";
delete e0x.query;
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
我点击进入 v0x.gP3x 函数并查看:
从代码中可以看出csrf_token来自于Cookie中的__csrf:
那么这个值可以在请求网页的时候从cookie中获取,继续调试window.asrsea。一路点击Next进入功能。
跳进ad(d,e,f,g)函数,往下看,发现window.asrsea等于这个d函数,哦,调试一下这个d函数:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
输入一个函数:
可以看出a函数生成随机数,继续运行,进入b函数:
熟悉AES加密,继续运行,进入c函数:
也是大家熟悉的RSA加密,网易可真慎重,各种加密。至此,整体框架已经调试完毕,剩下的无非就是拉取JS代码。
蟒蛇运行
这次不光是跑了结果,还带来了爬取和入库:
获取参数和 encSecKey
def get_enc(self,a):
with open('..//js//wangyiyun.js', encoding='utf-8') as f:
wangyiyun = f.read()
js = execjs.compile(wangyiyun)
logid = js.call('get_pwd', a)
print(logid)
return logid
抓
def get_fans(self):
resp = self.get_home_page()
print(resp.cookies)
print(resp.status_code)
time.sleep(6)
limit = 20
for i in range(1,110):
print("第{}页".format(i+1))
offset = limit*i
a = {"userId": "46991111", "offset": str(offset), "total": "false", "limit": str(limit), "csrf_token": ""}
print(a)
logid = self.get_enc(a)
data = {
"params":logid["encText"],
"encSecKey":logid["encSecKey"],
}
print(data)
fans_url = "https://music.163.com/weapi/us ... ot%3B
resp = self.session.post(url=fans_url,data=data,headers=self.headers)
followed = json.loads(resp.text)
followed_list = []
for foll in followed["followeds"]:
foll_dict = {}
foll_dict["short_name"] = foll.get("py","") #缩写
foll_dict["userId"] = foll.get("userId","") #用户ID
foll_dict["nickname"] = foll.get("nickname","") #昵称
foll_dict["vipType"] = foll.get("vipType","") # vip
foll_dict["eventCount"] = foll.get("eventCount","")#动态
foll_dict["vipRights"] = str(foll.get("vipRights","")) #VIP权益
foll_dict["gender"] = foll.get("gender","") #性别
foll_dict["avatarUrl"] = foll.get("avatarUrl","") #头像
foll_dict["followed"] = foll.get("followed","")
foll_dict["followeds"] = foll.get("followeds","") #粉丝
foll_dict["follows"] = foll.get("follows","") #关注
foll_dict["playlistCount"] = foll.get("playlistCount","") #歌单
foll_dict["mutual"] = foll.get("mutual","") #
foll_dict["expertTags"] = str(foll.get("expertTags",""))
foll_dict["experts"] = str(foll.get("experts",""))
print(foll_dict)
followed_list.append(foll_dict)
self.mysql.insert("music",followed_list)
tm = random.randint(10,30)
time.sleep(tm)
这里需要注意的是,要抓取指定页面,必须先访问该页面,不能直接请求链接”,因为它根本不携带有关哪个页面的信息。
请求特定页面
def get_home_page(self):
url = "https://music.163.com/%23/user ... ot%3B
resp = self.session.get(url)
return resp
来源: 从今天开始种树
作者: 罗华
链接: http://www.happyhong.cn/ni-xiang/10034.html
本文章著作权归作者所有,任何形式的转载都请注明出处。
表结构
@property
def create_table_sql(self):
create_table = """
CREATE TABLE IF NOT EXISTS music (
short_name varchar(30) ,
userId varchar(100) NOT NULL,
nickname varchar(30),
vipType varchar(30) ,
eventCount varchar(200),
vipRights varchar(900),
gender varchar(900),
avatarUrl varchar(200),
followed varchar(30),
followeds varchar(30),
follows varchar(30),
playlistCount varchar(30),
mutual varchar(30),
expertTags varchar(30),
experts varchar(30),
PRIMARY KEY (userId)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
return create_table
仓储
def insert(self,table,data_list):
if len(data_list) > 0:
data_list = [{k: v
for k, v in data.items() if v is not None}
for data in data_list]
keys = ", ".join(data_list[0].keys())
values = ", ".join(["%s"] * len(data_list[0]))
sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
DUPLICATE KEY UPDATE""".format(table=table,
keys=keys,
values=values)
update = ",".join([
" {key} = values({key})".format(key=key)
for key in data_list[0]
])
sql += update
print(sql)
self.connect()
try:
ret = self.cursor.executemany(sql, [tuple(data.values()) for data in data_list])
self.conn.commit()
except Exception as e:
self.conn.rollback()
print("Error: ", e)
traceback.print_exc()
finally:
self.close()
过程
结束 查看全部
网页抓取解密(网易云音乐只需要解密params和encSecKey就可以开始快乐的了)
网易云音乐只需要解密params和encSecKey就可以愉快的开始爬虫了。如果你没有足够的代理IP,你还是要慢慢爬,别废话,全开就好了。
问
老规矩,我们来看看我们要抓取的页面:
查看网络请求:

从名字上可以快速定位到哪个请求是POST请求,然后看看它提交了哪些参数。表格数据如下:

提交的参数,即前面提到的params和encSecKey,都是经过加密的。看一下返回内容的格式:
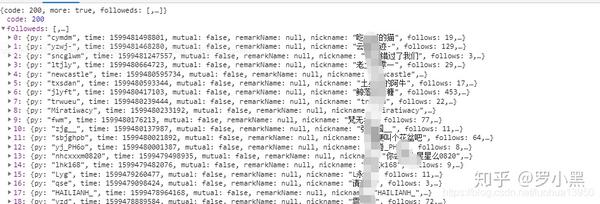
好的,我们已经知道了基本的东西,我们可以进入下一步,找到两个解密参数。
分析
在调试之前,我们要找到这两个值的位置,然后搜索,先定位JS文件,然后定位代码位置。您应该知道如何搜索,您可以全局搜索params或encSecKey。如果找到多个结果,不确定是哪个文件,可以进去搜索每个点的关键参数,判断是否是目标文件。这里我直接标记一下,找到正确的文件后就可以点击进入了。

进入JS文件后,同时搜索关键参数params或encSecKey:
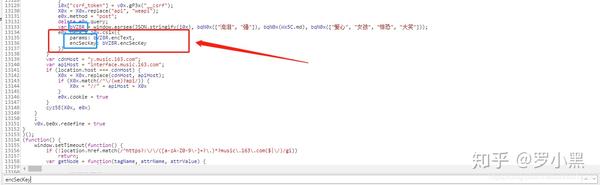
找到encSecKey的位置,拉出这几行代码分析一下:
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
e0x.data = j0x.cs1x({
params: bVZ8R.encText,
encSecKey: bVZ8R.encSecKey
})
粗略的讲,params和encSecKey来自bVZ8R.encText和bVZ8R.encSecKey,bVZ8R是window.asrsea的结果,window.asrsea有四个参数,JSON.stringify(i0x), bqN0x(["streaming", "强" ] ), bqN0x(Wx5C.md), bqN0x(["Love", "Girl", "Terrified", "Laughing"],首先看下面三个参数,从它们的固定值,你可以大胆猜想这三个values也是Fixed,之所以说是fixed,看看Wx5C.md:

wx5C.md是固定数组,和bqN0x(["流泪", "强"])和bqN0x(["爱心", "girl", "horrified", "laughing"] 这个结果肯定是没有变化的,如图下面,测试了一下:

大概把这些参数搞清楚了,剩下的就是搞清楚window.asrsea的具体实现,还有i0x是什么样的,进入调试环节。
调试
window.asrsea 到达断点。我的代码位置是13133行,点击下一页粉丝列表会激活断点。在激活断点的同时,我们也可以看到 i0x 的美妙之处。在控制台输入 i0x:
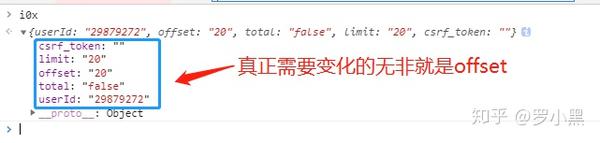
limit、offset、total、userId其实是已知的,csrf_token的生成可以看这里。细心的童鞋早就应该发现了:
i0x["csrf_token"] = v0x.gP3x("__csrf"); ## csrf_token在这里产生
X0x = X0x.replace("api", "weapi");
e0x.method = "post";
delete e0x.query;
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
我点击进入 v0x.gP3x 函数并查看:
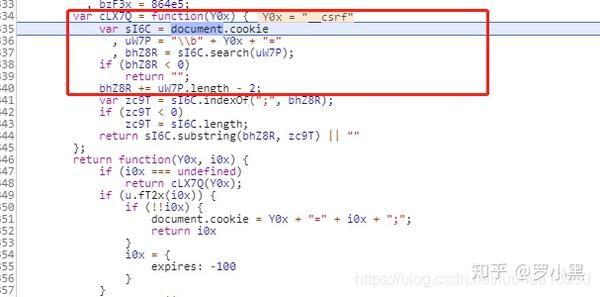
从代码中可以看出csrf_token来自于Cookie中的__csrf:
那么这个值可以在请求网页的时候从cookie中获取,继续调试window.asrsea。一路点击Next进入功能。

跳进ad(d,e,f,g)函数,往下看,发现window.asrsea等于这个d函数,哦,调试一下这个d函数:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
输入一个函数:

可以看出a函数生成随机数,继续运行,进入b函数:
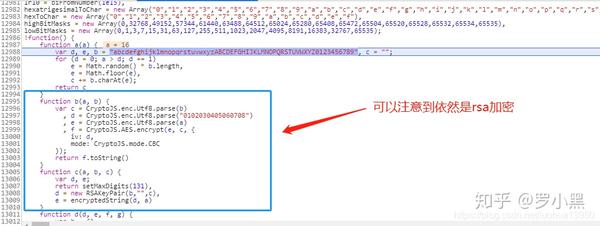
熟悉AES加密,继续运行,进入c函数:

也是大家熟悉的RSA加密,网易可真慎重,各种加密。至此,整体框架已经调试完毕,剩下的无非就是拉取JS代码。
蟒蛇运行
这次不光是跑了结果,还带来了爬取和入库:
获取参数和 encSecKey
def get_enc(self,a):
with open('..//js//wangyiyun.js', encoding='utf-8') as f:
wangyiyun = f.read()
js = execjs.compile(wangyiyun)
logid = js.call('get_pwd', a)
print(logid)
return logid
抓
def get_fans(self):
resp = self.get_home_page()
print(resp.cookies)
print(resp.status_code)
time.sleep(6)
limit = 20
for i in range(1,110):
print("第{}页".format(i+1))
offset = limit*i
a = {"userId": "46991111", "offset": str(offset), "total": "false", "limit": str(limit), "csrf_token": ""}
print(a)
logid = self.get_enc(a)
data = {
"params":logid["encText"],
"encSecKey":logid["encSecKey"],
}
print(data)
fans_url = "https://music.163.com/weapi/us ... ot%3B
resp = self.session.post(url=fans_url,data=data,headers=self.headers)
followed = json.loads(resp.text)
followed_list = []
for foll in followed["followeds"]:
foll_dict = {}
foll_dict["short_name"] = foll.get("py","") #缩写
foll_dict["userId"] = foll.get("userId","") #用户ID
foll_dict["nickname"] = foll.get("nickname","") #昵称
foll_dict["vipType"] = foll.get("vipType","") # vip
foll_dict["eventCount"] = foll.get("eventCount","")#动态
foll_dict["vipRights"] = str(foll.get("vipRights","")) #VIP权益
foll_dict["gender"] = foll.get("gender","") #性别
foll_dict["avatarUrl"] = foll.get("avatarUrl","") #头像
foll_dict["followed"] = foll.get("followed","")
foll_dict["followeds"] = foll.get("followeds","") #粉丝
foll_dict["follows"] = foll.get("follows","") #关注
foll_dict["playlistCount"] = foll.get("playlistCount","") #歌单
foll_dict["mutual"] = foll.get("mutual","") #
foll_dict["expertTags"] = str(foll.get("expertTags",""))
foll_dict["experts"] = str(foll.get("experts",""))
print(foll_dict)
followed_list.append(foll_dict)
self.mysql.insert("music",followed_list)
tm = random.randint(10,30)
time.sleep(tm)
这里需要注意的是,要抓取指定页面,必须先访问该页面,不能直接请求链接”,因为它根本不携带有关哪个页面的信息。
请求特定页面
def get_home_page(self):
url = "https://music.163.com/%23/user ... ot%3B
resp = self.session.get(url)
return resp
来源: 从今天开始种树
作者: 罗华
链接: http://www.happyhong.cn/ni-xiang/10034.html
本文章著作权归作者所有,任何形式的转载都请注明出处。
表结构
@property
def create_table_sql(self):
create_table = """
CREATE TABLE IF NOT EXISTS music (
short_name varchar(30) ,
userId varchar(100) NOT NULL,
nickname varchar(30),
vipType varchar(30) ,
eventCount varchar(200),
vipRights varchar(900),
gender varchar(900),
avatarUrl varchar(200),
followed varchar(30),
followeds varchar(30),
follows varchar(30),
playlistCount varchar(30),
mutual varchar(30),
expertTags varchar(30),
experts varchar(30),
PRIMARY KEY (userId)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
return create_table
仓储
def insert(self,table,data_list):
if len(data_list) > 0:
data_list = [{k: v
for k, v in data.items() if v is not None}
for data in data_list]
keys = ", ".join(data_list[0].keys())
values = ", ".join(["%s"] * len(data_list[0]))
sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
DUPLICATE KEY UPDATE""".format(table=table,
keys=keys,
values=values)
update = ",".join([
" {key} = values({key})".format(key=key)
for key in data_list[0]
])
sql += update
print(sql)
self.connect()
try:
ret = self.cursor.executemany(sql, [tuple(data.values()) for data in data_list])
self.conn.commit()
except Exception as e:
self.conn.rollback()
print("Error: ", e)
traceback.print_exc()
finally:
self.close()
过程
结束
网页抓取解密(前几天学习Python模拟登录知乎实例-几天加密处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-09 15:02
前几天学的Python模拟登录知乎例子,涉及到fromdata的加密处理。在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是自己找了个简单的例子来学习js加密。
一、示例网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑
1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”选项卡。为方便查看,先清空之前的请求流程,然后在网页切换城市即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。
接下来,我们需要考虑如何构造表单数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
我们尝试进入 getAQIData() 方法。
首页查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站给迷惑了,这个方法放在jqury-1.8.0.min.js?v=1.2文件中,并且混淆后,可以使用在线工具进行去混淆,例如:。
使用开发者工具破解调试,进入getServerData方法。
最后,我们看到了Form Data,可以看到内容是通过getParm()方法返回的。
3.密码分析
知道位置后,我们可以直接把这个加密的js方法扣出来,在一个html文件中执行。
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在实施过程中发现返回的内容与前台返回的内容不一致。经过一些查询,
发现得到的加密字符串的内容只与“view decoded”的显示内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
对服务器返回的内容进行解密,最终得到我们想要的数据。
详细代码请到: 查看全部
网页抓取解密(前几天学习Python模拟登录知乎实例-几天加密处理方法)
前几天学的Python模拟登录知乎例子,涉及到fromdata的加密处理。在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是自己找了个简单的例子来学习js加密。
一、示例网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑
1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”选项卡。为方便查看,先清空之前的请求流程,然后在网页切换城市即可看到新的xhr请求。

可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。

继续查看请求头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。

接下来,我们需要考虑如何构造表单数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。

在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。

找到事件方法后,我们继续分析。

我们尝试进入 getAQIData() 方法。

首页查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。

点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站给迷惑了,这个方法放在jqury-1.8.0.min.js?v=1.2文件中,并且混淆后,可以使用在线工具进行去混淆,例如:。

使用开发者工具破解调试,进入getServerData方法。

最后,我们看到了Form Data,可以看到内容是通过getParm()方法返回的。
3.密码分析
知道位置后,我们可以直接把这个加密的js方法扣出来,在一个html文件中执行。
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。


在js中执行document.write(getAQIData()),页面输出正确。

三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在实施过程中发现返回的内容与前台返回的内容不一致。经过一些查询,

发现得到的加密字符串的内容只与“view decoded”的显示内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
对服务器返回的内容进行解密,最终得到我们想要的数据。

详细代码请到:
网页抓取解密( Python解决内容乱码问题(decode和encode解码)详解整合)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-08 23:13
Python解决内容乱码问题(decode和encode解码)详解整合)
讲解Python如何解决爬取内容乱码问题(decode和encode解码)
更新时间:2019-03-29 17:11:51 作者:钱冉_
本文文章主要介绍Python解决爬取内容乱码(decode和encode解码)的问题。通过示例代码介绍非常详细。对大家的学习或工作,有需要的朋友有一定的参考学习价值。和小编一起学习
一、乱码问题描述
在爬取或者执行一些操作的时候,经常会出现中文乱码等问题,如下
原因是源网页编码与爬取后的编码格式不一致
二、使用encode和decode解决乱码问题
Python 中字符串的表示是 unicode 编码。编码转换时,通常使用unicode作为中间编码,即其他编码后的字符串先解码为unicode,再由unicode编码(encode)转为另一种编码。
decode的作用是将其他编码后的字符串转为unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转为unicode编码。
encode的作用是将unicode编码转换为其他编码字符串,如str2.encode('utf-8'),表示将unicode编码字符串str2转换为utf-8编码。
decode里面写的是你要抓取的网页的编码,encode是你要设置的编码
代码显示如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但也要注意:
如果一个字符串已经是unicode,再解码就会出错,所以通常需要判断它的编码方式是否是unicode
isinstance(s, unicode)#用于判断是否是unicode
用非unicode编码形式的str进行编码会报错
所以最终可靠的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到需要爬取的目标网页的编码格式
1、查看网页源码
如果源码中没有charset编码格式显示,可以使用下面的方法
2、检查元素,检查响应头
以上就是小编介绍的解决爬取内容乱码问题(decode和encode解码)的Python详细集成。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对脚本之家网站的支持! 查看全部
网页抓取解密(
Python解决内容乱码问题(decode和encode解码)详解整合)
讲解Python如何解决爬取内容乱码问题(decode和encode解码)
更新时间:2019-03-29 17:11:51 作者:钱冉_
本文文章主要介绍Python解决爬取内容乱码(decode和encode解码)的问题。通过示例代码介绍非常详细。对大家的学习或工作,有需要的朋友有一定的参考学习价值。和小编一起学习
一、乱码问题描述
在爬取或者执行一些操作的时候,经常会出现中文乱码等问题,如下

原因是源网页编码与爬取后的编码格式不一致
二、使用encode和decode解决乱码问题
Python 中字符串的表示是 unicode 编码。编码转换时,通常使用unicode作为中间编码,即其他编码后的字符串先解码为unicode,再由unicode编码(encode)转为另一种编码。
decode的作用是将其他编码后的字符串转为unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转为unicode编码。
encode的作用是将unicode编码转换为其他编码字符串,如str2.encode('utf-8'),表示将unicode编码字符串str2转换为utf-8编码。
decode里面写的是你要抓取的网页的编码,encode是你要设置的编码
代码显示如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但也要注意:
如果一个字符串已经是unicode,再解码就会出错,所以通常需要判断它的编码方式是否是unicode
isinstance(s, unicode)#用于判断是否是unicode
用非unicode编码形式的str进行编码会报错
所以最终可靠的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES

三、如何找到需要爬取的目标网页的编码格式
1、查看网页源码

如果源码中没有charset编码格式显示,可以使用下面的方法
2、检查元素,检查响应头

以上就是小编介绍的解决爬取内容乱码问题(decode和encode解码)的Python详细集成。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对脚本之家网站的支持!
网页抓取解密(破解企业数据列表的加密数据_data )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-06 00:16
)
打开网站--企业名片
主要是破解企业数据列表的加密,红色圈出
链接:名片
直接请求网站,响应信息中没有想要的数据,应该是js动态加载的数据,所以点击XHR就可以看到
两次请求和响应的信息中都有一个超长的加密字符串,所以我们大胆的猜测一下,应该是我们需要的数据,其他点击什么都没有。
那么如何解析这个参数呢?
解析加密数据 encrypt_data
最简单最直接的方式就是直接在js中根据encrypt_data的key进行搜索,会在下图中找到。
下面是断点,刷新页面,一步一步的找出js里面是怎么解析的。这是最直接的方法。先说正常流程吧。因为它是一个 post 请求,所以你可以命中 XHR 断点。如何打破这个断点?
在源中选择XHR BreakPoint,点击它右上角的加号,在框中填写要中断的URL,或者只有关键词,我填写的productListVIP,然后刷新页面并逐步运行它。找到解密的位置,直接解压js执行js,不用管怎么解密,只需要结果即可。
中断点查找位置
断点时,最好在对象前打断点,否则可能不进入断点直接结束。
刷新,点击下一步
会找到这个方法。这几乎是一样的。可以看到方法中调用了一个s方法。s方法的6个参数中,有5个是固定的,这样就更简单了。只需要找到这个解码方法
找到了,直接传进去,这个t就是我们的加密字符串
回去找到s方法,直接把这些js解压出来,用python执行js库,执行js就OK了
o 方法返回一个对象对象,在 Python 中无法正确接受,因此将其转换为 base64 并返回它。
所以需要稍微改动一下
function my_o(t) {
return new Buffer(s("5e5062e82f15fe4ca9d24bc5", mydecode(t), 0, 0, "012345677890123", 1)).toString("base64")
}
改成这个,其他不变
function mydecode(t) {
var c = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
var f = /[\t\n\f\r ]/g;
var e = (t = String(t).replace(f, "")).length;
e % 4 == 0 && (e = (t = t.replace(/==?$/, "")).length),
(e % 4 == 1 || /[^+a-zA-Z0-9/]/.test(t)) && l("Invalid character: the string to be decoded is not correctly encoded.");
for (var n, r, i = 0, o = "", a = -1; ++a > (-2 * i & 6)));
return o
}
s方法就不贴了,太长了,用execjs执行js,完成
结束!
详细代码可添加微信公众号回复1获取
查看全部
网页抓取解密(破解企业数据列表的加密数据_data
)
打开网站--企业名片
主要是破解企业数据列表的加密,红色圈出
链接:名片
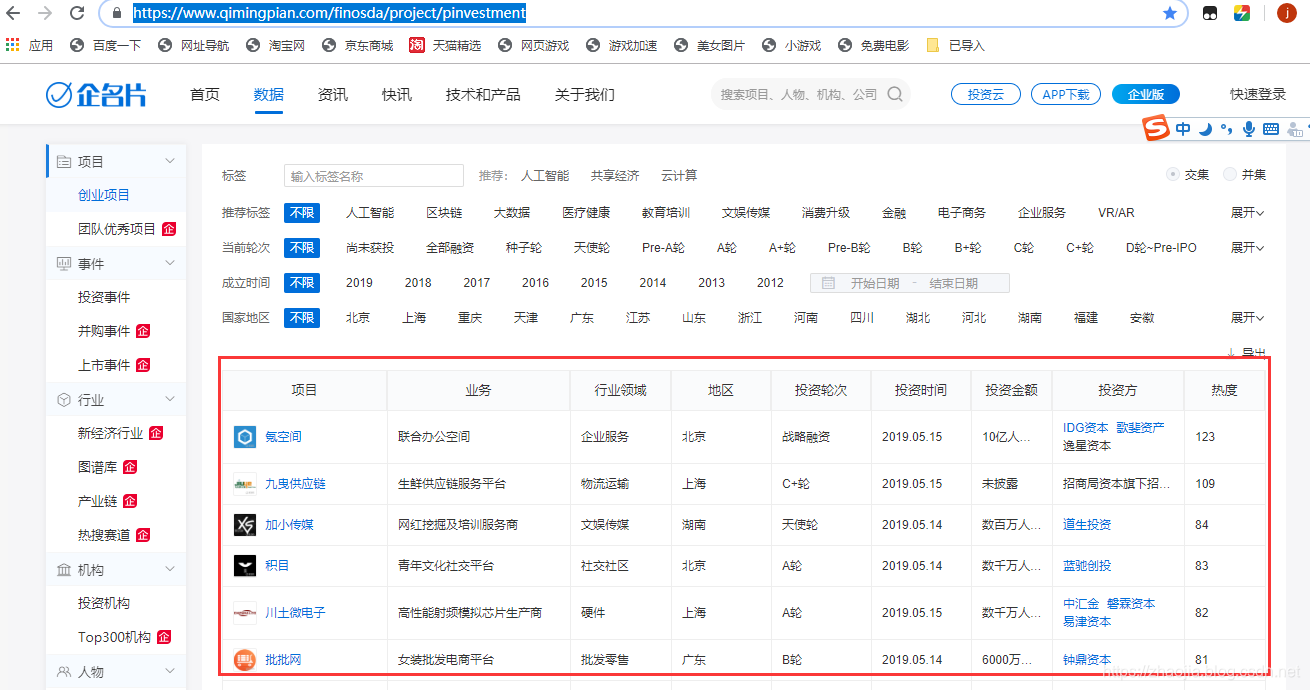
直接请求网站,响应信息中没有想要的数据,应该是js动态加载的数据,所以点击XHR就可以看到
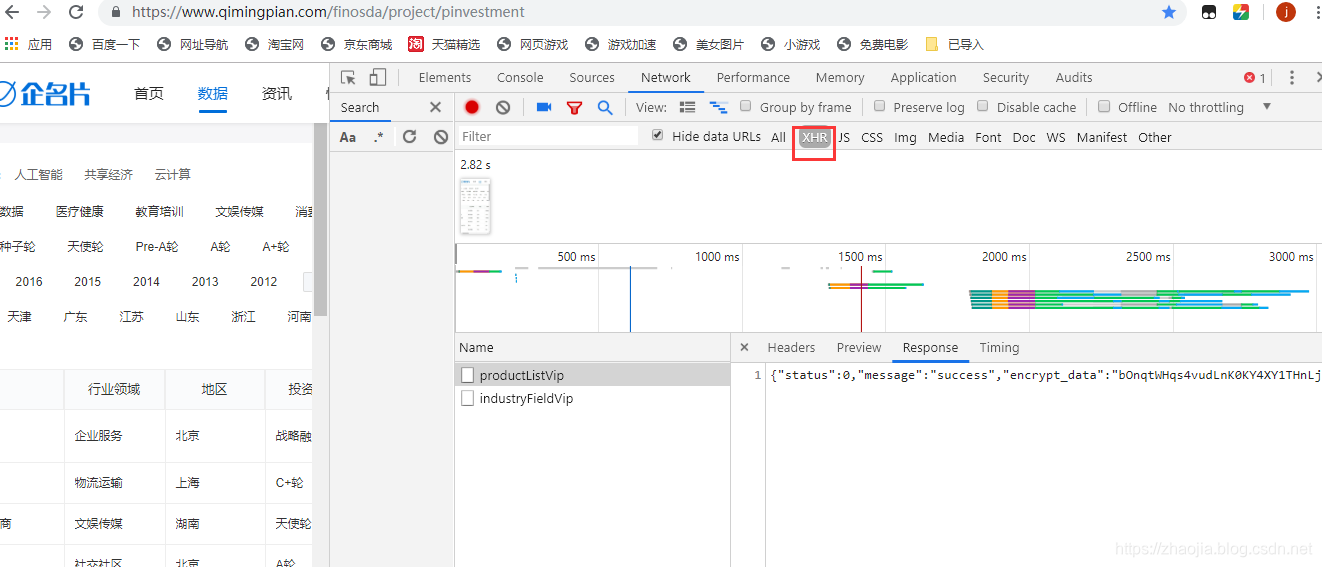
两次请求和响应的信息中都有一个超长的加密字符串,所以我们大胆的猜测一下,应该是我们需要的数据,其他点击什么都没有。
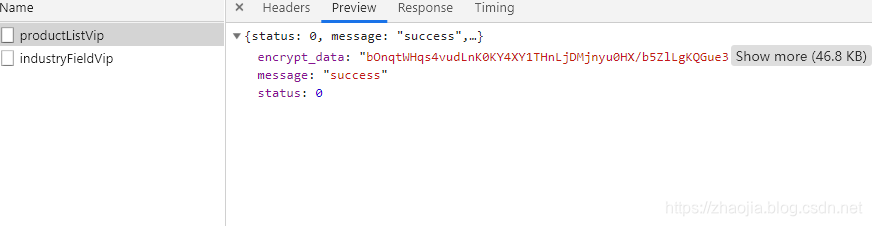
那么如何解析这个参数呢?
解析加密数据 encrypt_data
最简单最直接的方式就是直接在js中根据encrypt_data的key进行搜索,会在下图中找到。
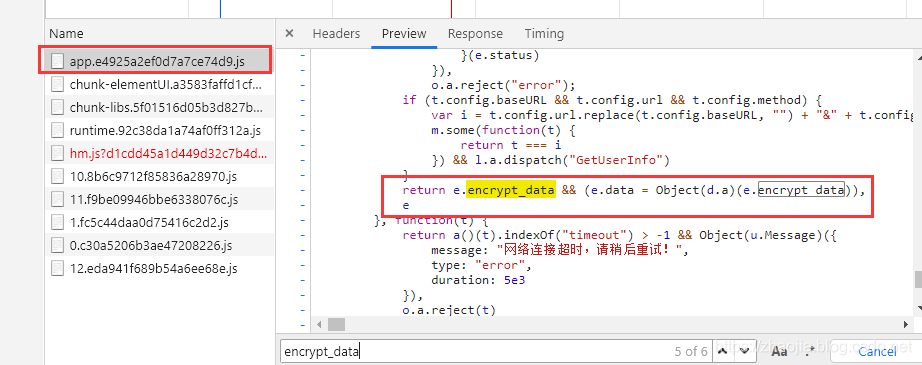
下面是断点,刷新页面,一步一步的找出js里面是怎么解析的。这是最直接的方法。先说正常流程吧。因为它是一个 post 请求,所以你可以命中 XHR 断点。如何打破这个断点?
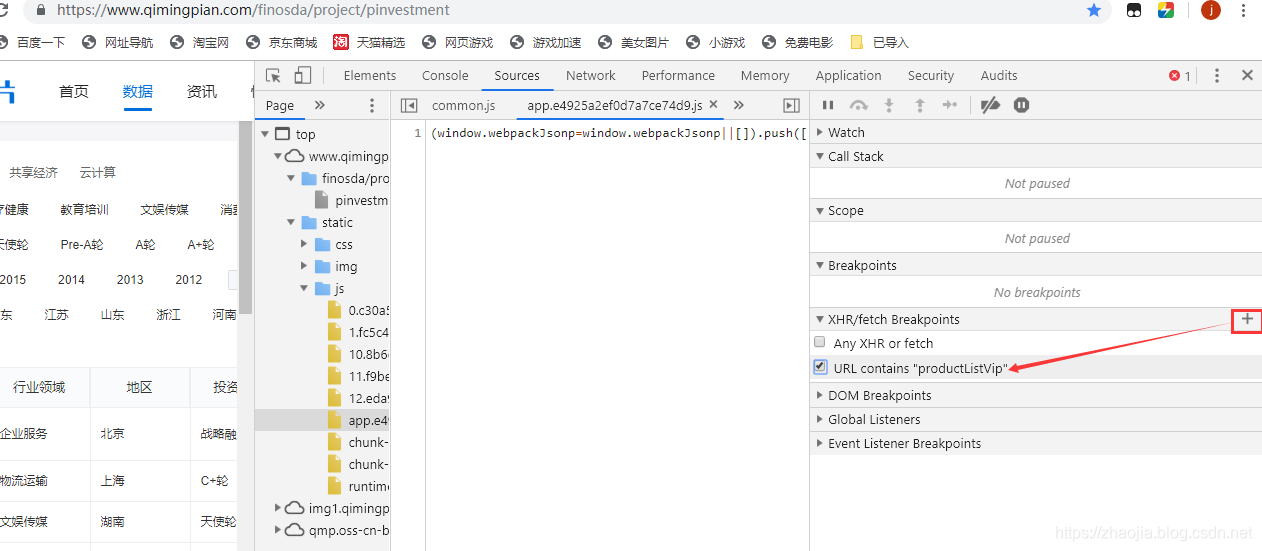
在源中选择XHR BreakPoint,点击它右上角的加号,在框中填写要中断的URL,或者只有关键词,我填写的productListVIP,然后刷新页面并逐步运行它。找到解密的位置,直接解压js执行js,不用管怎么解密,只需要结果即可。
中断点查找位置
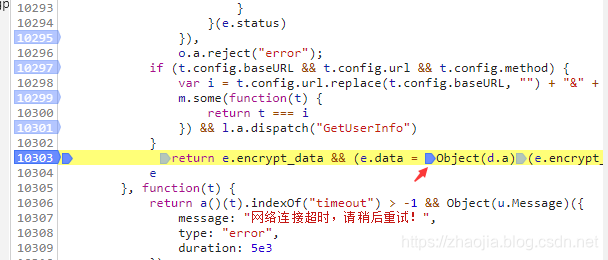
断点时,最好在对象前打断点,否则可能不进入断点直接结束。
刷新,点击下一步

会找到这个方法。这几乎是一样的。可以看到方法中调用了一个s方法。s方法的6个参数中,有5个是固定的,这样就更简单了。只需要找到这个解码方法

找到了,直接传进去,这个t就是我们的加密字符串

回去找到s方法,直接把这些js解压出来,用python执行js库,执行js就OK了
o 方法返回一个对象对象,在 Python 中无法正确接受,因此将其转换为 base64 并返回它。
所以需要稍微改动一下
function my_o(t) {
return new Buffer(s("5e5062e82f15fe4ca9d24bc5", mydecode(t), 0, 0, "012345677890123", 1)).toString("base64")
}
改成这个,其他不变
function mydecode(t) {
var c = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
var f = /[\t\n\f\r ]/g;
var e = (t = String(t).replace(f, "")).length;
e % 4 == 0 && (e = (t = t.replace(/==?$/, "")).length),
(e % 4 == 1 || /[^+a-zA-Z0-9/]/.test(t)) && l("Invalid character: the string to be decoded is not correctly encoded.");
for (var n, r, i = 0, o = "", a = -1; ++a > (-2 * i & 6)));
return o
}
s方法就不贴了,太长了,用execjs执行js,完成

结束!
详细代码可添加微信公众号回复1获取

网页抓取解密(web基础随笔提交数据、账号密码等的脚本语言有那些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-04 19:20
网络基础论文
POST提交数据、账号密码等,加密传输3.接受支持的语言程序、接收的文件类型等....4. Referer起到过渡作用,从一页到另一个A页面5.HttpOnly不会被钓鱼网站盗取cookies,安全等级高,四、写出安全穿透中常用的编码,那些Unicode编码,HTML编码,base64编码,十六进制代码五、burp大概有那些功能模块 Proxy(Proxy 8080,打开proxy可以拦截和修改web应用的数据包 Spider(爬行):抓取web提交的数据资源Scanner(扫描器):扫描Web程序的Vulnerabilities Intruder(入侵):漏洞利用、Web程序模糊测试、暴力破解等。 Repeater(中继器):重放模拟数据包的请求和响应的过程 Sequenecer:检查随机性Web 程序的会话令牌和执行各种测试解码器(解码);解码编码六、静态动态语言区别1.http静态语言,无漏洞,访问速度快,服务端和客户端代码一致(如html)2.php动态语言,可连接数据库实时更新,服务端和客户端代码不一致(如:asp、php、aspx、jsp)七、常见的脚本语言有PHP等
166 查看全部
网页抓取解密(web基础随笔提交数据、账号密码等的脚本语言有那些)
网络基础论文
POST提交数据、账号密码等,加密传输3.接受支持的语言程序、接收的文件类型等....4. Referer起到过渡作用,从一页到另一个A页面5.HttpOnly不会被钓鱼网站盗取cookies,安全等级高,四、写出安全穿透中常用的编码,那些Unicode编码,HTML编码,base64编码,十六进制代码五、burp大概有那些功能模块 Proxy(Proxy 8080,打开proxy可以拦截和修改web应用的数据包 Spider(爬行):抓取web提交的数据资源Scanner(扫描器):扫描Web程序的Vulnerabilities Intruder(入侵):漏洞利用、Web程序模糊测试、暴力破解等。 Repeater(中继器):重放模拟数据包的请求和响应的过程 Sequenecer:检查随机性Web 程序的会话令牌和执行各种测试解码器(解码);解码编码六、静态动态语言区别1.http静态语言,无漏洞,访问速度快,服务端和客户端代码一致(如html)2.php动态语言,可连接数据库实时更新,服务端和客户端代码不一致(如:asp、php、aspx、jsp)七、常见的脚本语言有PHP等
166
网页抓取解密(网易云技能点界面概况静态网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-04 12:01
)
技能点界面概览静态网页
网易云仍然有一些网页,其网址一般会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前后端分离刚刚火起来,当时很多网站并没有太多防备的借口。它让很多网站 很容易得到结果。到目前为止,有很多这样的借口。这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先搞清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不用管的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么我们就知道encText生成的规则了。两次AES cbc加密 偏移量为60708 两个key不同 函数c是RSA加密的三个参数 整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
返回 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里就不一一介绍了。只是中断分析!看看他是如何执行的。
其实抓多次就会发现最后三个参数是固定的(非交互数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用''
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
查看全部
网页抓取解密(网易云技能点界面概况静态网页
)
技能点界面概览静态网页
网易云仍然有一些网页,其网址一般会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前后端分离刚刚火起来,当时很多网站并没有太多防备的借口。它让很多网站 很容易得到结果。到目前为止,有很多这样的借口。这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先搞清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不用管的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么我们就知道encText生成的规则了。两次AES cbc加密 偏移量为60708 两个key不同 函数c是RSA加密的三个参数 整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
返回 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里就不一一介绍了。只是中断分析!看看他是如何执行的。
其实抓多次就会发现最后三个参数是固定的(非交互数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用''
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
网页抓取解密(自动模式检测WebHarvy自动识别网页中支持运行JavaScript和表达式的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-27 12:11
SysNucleus WebHarvy 是一款具有自动检测模式的网页数据抓取工具,可以从多个页面中提取数据并导出到数据库或文件夹中。WebHarvy 支持运行 JavaScript 和表达式,让你灵活抓取数据,有需要的朋友快来下载吧!
WebHarvy 功能
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取所有输入关键字组合的搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvy Web Scraper 允许您从链接列表中获取数据,从而在网站中生成相似的页面/列表。这允许您使用单个配置来抓取站点内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的产品详细信息页面上的多个图像。
浏览器自动交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
安装教程
1、下载并安装 SysNucleus WebHarvy
2、安装完成后,将Crck文件夹下的WebHarvy.exe复制到安装目录替换
3、 破解完成 查看全部
网页抓取解密(自动模式检测WebHarvy自动识别网页中支持运行JavaScript和表达式的方法)
SysNucleus WebHarvy 是一款具有自动检测模式的网页数据抓取工具,可以从多个页面中提取数据并导出到数据库或文件夹中。WebHarvy 支持运行 JavaScript 和表达式,让你灵活抓取数据,有需要的朋友快来下载吧!
WebHarvy 功能
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取所有输入关键字组合的搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvy Web Scraper 允许您从链接列表中获取数据,从而在网站中生成相似的页面/列表。这允许您使用单个配置来抓取站点内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的产品详细信息页面上的多个图像。
浏览器自动交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
安装教程
1、下载并安装 SysNucleus WebHarvy
2、安装完成后,将Crck文件夹下的WebHarvy.exe复制到安装目录替换
3、 破解完成
网页抓取解密(从网页上保存图片的时候,会发现竟然无法保存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-12-27 09:10
有时当你想保存网页中的图片时,你会发现它无法保存!右键单击图片,您无法看到保存图片的选项。最后只能用QQ等截图工具截图,无法得到原图。该怎么办?今天给大家介绍一个轻松解决这个问题的工具,一起来看看吧。
这是一款支持Chrome、Edge、Firefox等常用浏览器的浏览器扩展。我们以Chrome为例进行演示。
安装图片助手后,Chrome 工具栏中会出现一个额外的相关图标。在网页上右击,还可以看到图片助手的相关选项。可以看出,图片助手具有提取本页图片、预取链接、分析预取数据等功能。其实这是一种不同的图片爬取机制。当一种机制的效果不理想时,您可以切换到另一种机制,以确保可以捕获图片。
来试试实际效果吧。首先找一个不能保存图片的页面,比如苹果的App Store。一般来说,App Store 中的 App 截图是不能直接保存的。右键单击图片,将没有保存图片的选项。
使用图片助手,点击“提取本页图片”,可以发现页面上的图片被快速提取了。图片助手将打开一个新选项卡,显示所有成功提取的图片。难得的是,图片助手不会简单粗暴地将所有图片呈现在您的眼前。它标记了每张图片的大小,还提供了一个过滤器,可以根据图片的格式和大小快速找到你想要的。你要的图。如果你打算下载多张图片,可以勾选并一起下载,非常方便。
总的来说,这是一个非常有用的浏览器工具。当您要提取某个页面的图片时,不仅可以打破无法下载图片的限制,还可以让您快速过滤掉您要下载的图片。有需要的朋友不妨一试。 查看全部
网页抓取解密(从网页上保存图片的时候,会发现竟然无法保存)
有时当你想保存网页中的图片时,你会发现它无法保存!右键单击图片,您无法看到保存图片的选项。最后只能用QQ等截图工具截图,无法得到原图。该怎么办?今天给大家介绍一个轻松解决这个问题的工具,一起来看看吧。
这是一款支持Chrome、Edge、Firefox等常用浏览器的浏览器扩展。我们以Chrome为例进行演示。
安装图片助手后,Chrome 工具栏中会出现一个额外的相关图标。在网页上右击,还可以看到图片助手的相关选项。可以看出,图片助手具有提取本页图片、预取链接、分析预取数据等功能。其实这是一种不同的图片爬取机制。当一种机制的效果不理想时,您可以切换到另一种机制,以确保可以捕获图片。
来试试实际效果吧。首先找一个不能保存图片的页面,比如苹果的App Store。一般来说,App Store 中的 App 截图是不能直接保存的。右键单击图片,将没有保存图片的选项。
使用图片助手,点击“提取本页图片”,可以发现页面上的图片被快速提取了。图片助手将打开一个新选项卡,显示所有成功提取的图片。难得的是,图片助手不会简单粗暴地将所有图片呈现在您的眼前。它标记了每张图片的大小,还提供了一个过滤器,可以根据图片的格式和大小快速找到你想要的。你要的图。如果你打算下载多张图片,可以勾选并一起下载,非常方便。
总的来说,这是一个非常有用的浏览器工具。当您要提取某个页面的图片时,不仅可以打破无法下载图片的限制,还可以让您快速过滤掉您要下载的图片。有需要的朋友不妨一试。
网页抓取解密(除了处理网站表单,requests模块还是一个设置请求头的利器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-26 15:16
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。你可以从非个人邮箱发送邮件,使用命令行自动鼠标操作,或者使用IE5.0浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是个无底洞,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更多贵),谷歌是最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】 查看全部
网页抓取解密(除了处理网站表单,requests模块还是一个设置请求头的利器)
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。你可以从非个人邮箱发送邮件,使用命令行自动鼠标操作,或者使用IE5.0浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是个无底洞,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更多贵),谷歌是最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】
网页抓取解密(除了处理网站表单,requests模块还是一个设置请求头的利器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-26 15:16
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。您可以从非个人邮箱发送电子邮件,通过命令行自动执行鼠标操作,也可以使用 IE 5.0 浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是无底的,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更贵) , 谷歌最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】 查看全部
网页抓取解密(除了处理网站表单,requests模块还是一个设置请求头的利器)
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。您可以从非个人邮箱发送电子邮件,通过命令行自动执行鼠标操作,也可以使用 IE 5.0 浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是无底的,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更贵) , 谷歌最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】
网页抓取解密(反爬告诉服务器能够发送哪些媒体类型-Charset告诉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-26 15:14
反爬虫机制和破解方法总结——什么是爬虫和反爬虫?2. headers 和referer 反爬虫机制 * Headers 反爬虫是最常见的反爬虫策略。*部分网站会检测Referer(上位链接)(机器行为不太可能通过链接跳转实现)实现爬虫。
头条知识补充***
host:提供主机名和端口号
Referer 提供服务器客户端从该页面链接的信息(有些网站会相应地爬回来)
Origin:Origin字段只收录
发起请求的人,没有其他信息。(仅存储在 post 请求中)
用户代理:发送请求的应用名称(部分网站会根据UA访问的频率间隔进行爬取)
proxies:代理,有的网站会根据ip访问频率等选择屏蔽ip。
cookie:具体的标记信息,一般可以直接复制,有些改动可以选择构造。
(session=requests.session() 自动将cookie信息存储在响应对象中)
Accept 头为客户端提供了一种方法来通知服务器它的首选项和功能
标题说明
Accept 告诉服务器可以发送哪些媒体类型
Accept-Charset 告诉服务器可以发送哪些字符集
Accept-Encoding 告诉服务器可以发送哪些编码方式(最常见的是utf-8)
Accept-Language 告诉服务器可以发送哪些语言
Cache-control:该字段用于指定在整个请求/响应链中所有缓存机制必须遵守的指令
三 ip限制
限制防爬的IP访问频率和数量。
解决方法:构建自己的IP代理池,然后每次访问时随机选择一个代理(但有些IP地址不是很稳定,需要经常检查更新)
四大 UA 限制
UA 使用户能够在访问网站时识别浏览器。
提醒:
当然,如果反爬有时间限制,可以在requests中设置timeout(最好是随机sleep,这样会更安全更稳定,time.sleep())
解决办法是自己搭建UA池,在python每次请求访问时随机挂上UA标志,更好的模拟浏览器行为。
超级简单的请求头 fake_useragent library()
#随机请求头
进口请求
从 fake_useragent 导入 UserAgent
ua = 用户代理()
headers = {'User-Agent': ua.random}
url ='要抓取的网页的URL'
resp = requests.get(url, headers=headers)
##Pending 补货请求加上睡眠时间
五.验证码反爬虫或模拟登录
图片验证码:通过简单的图片识别即可完成
验证码识别的基本方法:截图、二值化、中值滤波、去噪、分割、压缩和重排(让高矮系统一)、字体特征匹配识别。
六、Ajax动态加载
Ajax动态加载的工作原理是:从网页的url加载网页源代码后,JavaScript程序会在浏览器中执行。
这些程序将加载更多内容并将这些内容传输到网页。这就是为什么有些网页会直接爬取它的网址
没有数据的原因。
解决方法:如果使用勾选元素分析“请求”对应链接(方法:右键→勾选元素→网络→清除,点击“加载更多”
”,出现对应的GET链接寻找类型text/html,点击,查看get参数或复制Request URL),循环过程。如果“请求”之前有页面,分析导出第一页根据上一步中的URL,以此类推,抓取ajax地址的数据,使用requests中的json解析返回的json,使用eval()转换成字典进行处理
推荐捕捉工具:fiddler
七.Cookie 限制
打开网页后,将生成一个随机 cookie。如果再次打开网页时cookie不存在,再设置一次,第三次打开还是不存在。爬虫很可能正在工作。
解决方法:将对应的cookie挂在headers中或者按照其方法构造。 查看全部
网页抓取解密(反爬告诉服务器能够发送哪些媒体类型-Charset告诉)
反爬虫机制和破解方法总结——什么是爬虫和反爬虫?2. headers 和referer 反爬虫机制 * Headers 反爬虫是最常见的反爬虫策略。*部分网站会检测Referer(上位链接)(机器行为不太可能通过链接跳转实现)实现爬虫。
头条知识补充***
host:提供主机名和端口号
Referer 提供服务器客户端从该页面链接的信息(有些网站会相应地爬回来)
Origin:Origin字段只收录
发起请求的人,没有其他信息。(仅存储在 post 请求中)
用户代理:发送请求的应用名称(部分网站会根据UA访问的频率间隔进行爬取)
proxies:代理,有的网站会根据ip访问频率等选择屏蔽ip。
cookie:具体的标记信息,一般可以直接复制,有些改动可以选择构造。
(session=requests.session() 自动将cookie信息存储在响应对象中)
Accept 头为客户端提供了一种方法来通知服务器它的首选项和功能
标题说明
Accept 告诉服务器可以发送哪些媒体类型
Accept-Charset 告诉服务器可以发送哪些字符集
Accept-Encoding 告诉服务器可以发送哪些编码方式(最常见的是utf-8)
Accept-Language 告诉服务器可以发送哪些语言
Cache-control:该字段用于指定在整个请求/响应链中所有缓存机制必须遵守的指令
三 ip限制
限制防爬的IP访问频率和数量。
解决方法:构建自己的IP代理池,然后每次访问时随机选择一个代理(但有些IP地址不是很稳定,需要经常检查更新)
四大 UA 限制
UA 使用户能够在访问网站时识别浏览器。
提醒:
当然,如果反爬有时间限制,可以在requests中设置timeout(最好是随机sleep,这样会更安全更稳定,time.sleep())
解决办法是自己搭建UA池,在python每次请求访问时随机挂上UA标志,更好的模拟浏览器行为。
超级简单的请求头 fake_useragent library()
#随机请求头
进口请求
从 fake_useragent 导入 UserAgent
ua = 用户代理()
headers = {'User-Agent': ua.random}
url ='要抓取的网页的URL'
resp = requests.get(url, headers=headers)
##Pending 补货请求加上睡眠时间
五.验证码反爬虫或模拟登录
图片验证码:通过简单的图片识别即可完成
验证码识别的基本方法:截图、二值化、中值滤波、去噪、分割、压缩和重排(让高矮系统一)、字体特征匹配识别。
六、Ajax动态加载
Ajax动态加载的工作原理是:从网页的url加载网页源代码后,JavaScript程序会在浏览器中执行。
这些程序将加载更多内容并将这些内容传输到网页。这就是为什么有些网页会直接爬取它的网址
没有数据的原因。
解决方法:如果使用勾选元素分析“请求”对应链接(方法:右键→勾选元素→网络→清除,点击“加载更多”
”,出现对应的GET链接寻找类型text/html,点击,查看get参数或复制Request URL),循环过程。如果“请求”之前有页面,分析导出第一页根据上一步中的URL,以此类推,抓取ajax地址的数据,使用requests中的json解析返回的json,使用eval()转换成字典进行处理
推荐捕捉工具:fiddler
七.Cookie 限制
打开网页后,将生成一个随机 cookie。如果再次打开网页时cookie不存在,再设置一次,第三次打开还是不存在。爬虫很可能正在工作。
解决方法:将对应的cookie挂在headers中或者按照其方法构造。
网页抓取解密(搜索引擎的蜘蛛是如何爬的,如何吸引蜘蛛来抓取页面搜索引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-25 21:16
搜索引擎蜘蛛如何抓取和吸引蜘蛛抓取页面
搜索引擎的工作过程大致可以分为三个阶段:
(1) 爬取爬行:搜索引擎蜘蛛通过跟踪链接发现和访问页面,读取页面的HTML代码,并保存到数据库中。
(2) 预处理:索引程序对抓取的页面数据进行文本提取、中文分词、索引、倒排索引,为排名程序调用做准备。
(3) Ranking:用户输入查询词(关键词)后,排名程序调用索引数据计算相关性,然后生成一定格式的搜索结果页面。
搜索引擎的工作原理
爬取和爬取是搜索引擎工作的第一步,完成数据采集的任务。搜索引擎用来抓取页面的程序称为蜘蛛
一个合格的SEOer,如果想让自己的页面被收录更多,就要尽量吸引蜘蛛爬行。
蜘蛛爬取页面有几个因素:
(1)网站和页面的权重。质量高、时间长的网站一般认为权重高,爬取深度高,收录
的页面也多。
(2)页面的更新频率,蜘蛛每次爬取都会保存页面数据,如果第二次和第三次爬取和第一次一样,说明没有更新。时间久了,蜘蛛不会频繁抓取你的页面,如果内容更新频繁,蜘蛛会频繁访问页面来抓取新页面。
(3)导入链接,无论是内链还是外链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛将不知道该链接的存在页。
(4)离首页的点击距离。一般来说首页在网站上的权重最高,外链指向首页的最多。那么蜘蛛最常访问的页面就是首页。点击越近离首页越远,页面权重越高,被爬取的几率就越大。
吸引百度蜘蛛
如何吸引蜘蛛爬取我们的页面?
坚持经常更新网站内容,最好是高质量的原创内容。
主动提供我们的新页面给搜索引擎,让蜘蛛更快的找到,比如百度的链接提交、抓取诊断等。
建立外部链接,与相关网站交换友情链接,在其他平台发布优质文章,指向自己的页面。内容应该是相关的。
制作站点地图,每个站点都应该有一个站点地图,站点的所有页面都在站点地图中,方便蜘蛛抓取。 查看全部
网页抓取解密(搜索引擎的蜘蛛是如何爬的,如何吸引蜘蛛来抓取页面搜索引擎)
搜索引擎蜘蛛如何抓取和吸引蜘蛛抓取页面
搜索引擎的工作过程大致可以分为三个阶段:
(1) 爬取爬行:搜索引擎蜘蛛通过跟踪链接发现和访问页面,读取页面的HTML代码,并保存到数据库中。
(2) 预处理:索引程序对抓取的页面数据进行文本提取、中文分词、索引、倒排索引,为排名程序调用做准备。
(3) Ranking:用户输入查询词(关键词)后,排名程序调用索引数据计算相关性,然后生成一定格式的搜索结果页面。
搜索引擎的工作原理
爬取和爬取是搜索引擎工作的第一步,完成数据采集的任务。搜索引擎用来抓取页面的程序称为蜘蛛
一个合格的SEOer,如果想让自己的页面被收录更多,就要尽量吸引蜘蛛爬行。
蜘蛛爬取页面有几个因素:
(1)网站和页面的权重。质量高、时间长的网站一般认为权重高,爬取深度高,收录
的页面也多。
(2)页面的更新频率,蜘蛛每次爬取都会保存页面数据,如果第二次和第三次爬取和第一次一样,说明没有更新。时间久了,蜘蛛不会频繁抓取你的页面,如果内容更新频繁,蜘蛛会频繁访问页面来抓取新页面。
(3)导入链接,无论是内链还是外链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛将不知道该链接的存在页。
(4)离首页的点击距离。一般来说首页在网站上的权重最高,外链指向首页的最多。那么蜘蛛最常访问的页面就是首页。点击越近离首页越远,页面权重越高,被爬取的几率就越大。
吸引百度蜘蛛
如何吸引蜘蛛爬取我们的页面?
坚持经常更新网站内容,最好是高质量的原创内容。
主动提供我们的新页面给搜索引擎,让蜘蛛更快的找到,比如百度的链接提交、抓取诊断等。
建立外部链接,与相关网站交换友情链接,在其他平台发布优质文章,指向自己的页面。内容应该是相关的。
制作站点地图,每个站点都应该有一个站点地图,站点的所有页面都在站点地图中,方便蜘蛛抓取。
网页抓取解密(之前做聊天室时,介绍如何使用HtmlTag类来抓取网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-22 08:02
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。
上图为博客园首页的DOM树。很明显,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
运行结果如下: 查看全部
网页抓取解密(之前做聊天室时,介绍如何使用HtmlTag类来抓取网页信息)
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。
上图为博客园首页的DOM树。很明显,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
运行结果如下:
网页抓取解密(51CTO专访杨光解密9466在线网页设计的技术架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-20 05:13
51CTO专访杨光:解密9466在线网页设计的技术架构
【编者按】51CTO 2014 WOT全球软件技术峰会将于2014年7月25-26日在北京富力万丽酒店举行。从本周开始,我们将陆续公布会议内容,并采访架构师谁将参加会议,让大家更了解会议的内容。会议详细议程见51 cto com/2014/。
本次采访的对象是技术总监杨光。负责9466智能建站平台。本次WOT软件技术峰会,将分享9466技术架构相关知识。敬请关注!
【讲师简历】
杨光2005年毕业于西北大学,从物理系转入软件学院。同年加入,从事新一代战略ERP产品U9的研发,国内第一款基于SOA架构的大型商业软件。2010年加入腾讯,在手Q浏览器团队工作,负责浏览器后台整体操作系统的搭建。2013年加入与钟胜辉共同打造9466智能网站建设平台。
以下是采访实录
记者:9466上网助手是什么时候推出的?开发的初衷是什么?使用了哪些新技术?开发过程中遇到了哪些困难,又是如何克服的?
杨光 9466第一版于2013年10月上线,自上线以来一直处于公测阶段(需要邀请码)。我们仍在打磨我们的产品。
当初开发这个产品是为了彻底解决网页问题和网站生产烦恼。因为做一个网页或者网站还是需要很多知识的,比如创意、设计、页面制作、素材制作、样式定义、数据读写等等。制作页面需要各种技能。对于新手用户来说,这个问题就更加突出了。然而,在这个领域有很多需求。所以就有了这个想法。目的是使用9466平台。任何人都可以轻松制作精美的网页。
这个产品是非常前端的产品。技术难度和积累主要在前端。例如响应式设计、按需加载、异步事件等。因为我们的设计师是一个所见即所得的操作体验,在网络上,设计一个合理的模型来模拟这种原生操作是非常重要的。在这方面,我们花了很多时间,多人协作、讨论。经过几个版本,不断的优化,终于在体验和浏览器执行性能上有了不错的表现。
记者:您认为9466网络助手最大的亮点是什么?
杨光:我个人认为9466最大的亮点就是它的开放性。我们有一个非常强大的设计引擎。这个引擎不仅仅是传统意义上的所见即所得,一个可以拖拽设计的操作界面。动力是这台发动机是开着的。通过引擎,可以组装各种组件、应用程序、模板和样式。只要满足既定规范,任何第三方都可以开发各种组件以嵌入 9466 平台。这样,9466平台就相当于一个胶水。任何有优秀创意和实现的第三方都可以通过平台贡献自己的价值并服务他人。
记者:目前9466网络助手的模板分为三种:主题模板、企业网站、个人网站。哪种类型的模板更受欢迎?新模板的更新状态如何?
杨光目前,抄题目和企业模板的人比较多。我们将在不久的将来研究这个主题。现有功能的优化和新功能的加入,会更适合话题制作的场景。因此,主题模板将在不久的将来更频繁地更新。
记者:对于9644网络助手的发展前景,您怎么看?您认为哪些方面需要改进?
杨光:9466的发展前景是毋庸置疑的。因为只要有网页,就会有大量的网页制作需求。这是一个刚性需求,尚未得到满足。迫切需要这样一种有用的产品来填补这一空白。而且,像Wix这样的几家大型外国公司已经上市,市值达到75亿美元。Wee bly 刚刚获得了红衫军和腾讯的联合投资。中国还没有垄断企业,大家都在竞争。
记者:最后一个问题。就您而言,您比较关注的技术领域是什么?您预测2014年会流行哪些新技术?
杨光:我的担心比较复杂,我没有说2014年会流行什么技术。但除了工作,我对人工智能更感兴趣。我和计算机打交道的时间越长,我就越觉得计算机与人类相比真的很愚蠢。对于人类来说,一个非常简单的问题需要非常复杂的算法才能由计算机来解决。比如我以前在腾讯做QQ浏览器。对于抓取到的网页,需要分析哪些是核心内容(如文章文字),哪些是杂质(如广告)。对于人来说,这样的事情再简单不过了。但是对于电脑来说,要能够适应所有的网页,真的很难。我们还采用了基于视觉的块分析方法,使用类似于人类观察的逻辑进行分析,效果得到了提升,
总觉得现在人工智能的发展太依赖电脑了。即冯诺依曼计算系统。或许在这个系统中,根本就没有人工智能,只有模拟智能。神经网络算法已经很复杂了,但是能解决的问题还是很有限的。 查看全部
网页抓取解密(51CTO专访杨光解密9466在线网页设计的技术架构)
51CTO专访杨光:解密9466在线网页设计的技术架构
【编者按】51CTO 2014 WOT全球软件技术峰会将于2014年7月25-26日在北京富力万丽酒店举行。从本周开始,我们将陆续公布会议内容,并采访架构师谁将参加会议,让大家更了解会议的内容。会议详细议程见51 cto com/2014/。
本次采访的对象是技术总监杨光。负责9466智能建站平台。本次WOT软件技术峰会,将分享9466技术架构相关知识。敬请关注!
【讲师简历】
杨光2005年毕业于西北大学,从物理系转入软件学院。同年加入,从事新一代战略ERP产品U9的研发,国内第一款基于SOA架构的大型商业软件。2010年加入腾讯,在手Q浏览器团队工作,负责浏览器后台整体操作系统的搭建。2013年加入与钟胜辉共同打造9466智能网站建设平台。
以下是采访实录
记者:9466上网助手是什么时候推出的?开发的初衷是什么?使用了哪些新技术?开发过程中遇到了哪些困难,又是如何克服的?
杨光 9466第一版于2013年10月上线,自上线以来一直处于公测阶段(需要邀请码)。我们仍在打磨我们的产品。
当初开发这个产品是为了彻底解决网页问题和网站生产烦恼。因为做一个网页或者网站还是需要很多知识的,比如创意、设计、页面制作、素材制作、样式定义、数据读写等等。制作页面需要各种技能。对于新手用户来说,这个问题就更加突出了。然而,在这个领域有很多需求。所以就有了这个想法。目的是使用9466平台。任何人都可以轻松制作精美的网页。
这个产品是非常前端的产品。技术难度和积累主要在前端。例如响应式设计、按需加载、异步事件等。因为我们的设计师是一个所见即所得的操作体验,在网络上,设计一个合理的模型来模拟这种原生操作是非常重要的。在这方面,我们花了很多时间,多人协作、讨论。经过几个版本,不断的优化,终于在体验和浏览器执行性能上有了不错的表现。
记者:您认为9466网络助手最大的亮点是什么?
杨光:我个人认为9466最大的亮点就是它的开放性。我们有一个非常强大的设计引擎。这个引擎不仅仅是传统意义上的所见即所得,一个可以拖拽设计的操作界面。动力是这台发动机是开着的。通过引擎,可以组装各种组件、应用程序、模板和样式。只要满足既定规范,任何第三方都可以开发各种组件以嵌入 9466 平台。这样,9466平台就相当于一个胶水。任何有优秀创意和实现的第三方都可以通过平台贡献自己的价值并服务他人。
记者:目前9466网络助手的模板分为三种:主题模板、企业网站、个人网站。哪种类型的模板更受欢迎?新模板的更新状态如何?
杨光目前,抄题目和企业模板的人比较多。我们将在不久的将来研究这个主题。现有功能的优化和新功能的加入,会更适合话题制作的场景。因此,主题模板将在不久的将来更频繁地更新。
记者:对于9644网络助手的发展前景,您怎么看?您认为哪些方面需要改进?
杨光:9466的发展前景是毋庸置疑的。因为只要有网页,就会有大量的网页制作需求。这是一个刚性需求,尚未得到满足。迫切需要这样一种有用的产品来填补这一空白。而且,像Wix这样的几家大型外国公司已经上市,市值达到75亿美元。Wee bly 刚刚获得了红衫军和腾讯的联合投资。中国还没有垄断企业,大家都在竞争。
记者:最后一个问题。就您而言,您比较关注的技术领域是什么?您预测2014年会流行哪些新技术?
杨光:我的担心比较复杂,我没有说2014年会流行什么技术。但除了工作,我对人工智能更感兴趣。我和计算机打交道的时间越长,我就越觉得计算机与人类相比真的很愚蠢。对于人类来说,一个非常简单的问题需要非常复杂的算法才能由计算机来解决。比如我以前在腾讯做QQ浏览器。对于抓取到的网页,需要分析哪些是核心内容(如文章文字),哪些是杂质(如广告)。对于人来说,这样的事情再简单不过了。但是对于电脑来说,要能够适应所有的网页,真的很难。我们还采用了基于视觉的块分析方法,使用类似于人类观察的逻辑进行分析,效果得到了提升,
总觉得现在人工智能的发展太依赖电脑了。即冯诺依曼计算系统。或许在这个系统中,根本就没有人工智能,只有模拟智能。神经网络算法已经很复杂了,但是能解决的问题还是很有限的。
网页抓取解密(的技术架构相关知识(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-20 05:11
本次采访的对象是技术总监杨光。负责9466智能建站平台。本次WOT软件技术峰会,将分享9466技术架构相关知识。敬请关注!
【讲师简历】
杨光,2005年毕业于西北大学,从物理系转入软件学院。同年加入并从事新一代战略ERP产品U9的研发,这是国内第一款基于SOA架构的大型商业软件。2010年加入腾讯,在手Q浏览器团队工作,负责浏览器后台整体运营体系建设。2013年加入与钟胜辉共同打造9466智能网站建设平台。
以下是采访记录:
记者:9466网络助手是什么时候推出的?开发的初衷是什么?使用了哪些新技术?开发过程中遇到了哪些困难,又是如何克服的?
杨光:9466第一版于2013年10月上线,自上线以来一直处于公测阶段(需要邀请码)。我们仍在打磨我们的产品。
当初开发这个产品是为了彻底解决网页问题和网站生产烦恼。因为目前做网页还是网站,还有很多知识需要理解,比如:创意、设计、页面制作、素材制作、样式定义、数据读写等等. 要制作页面,需要各种技能。对于新手用户来说,这个问题就更加突出了。然而,在这个领域有很多需求。于是就有了这个想法,目的是利用9466平台,任何人都可以轻松做出漂亮的网页。
本产品是一款非常前端的产品,技术难度和积累主要在前端,比如:响应式设计、按需加载、异步事件等等。因为我们的设计师是一个所见即所得的操作体验,所以设计一个合理的模型来模拟网页上的这种原生操作是非常重要的。在这方面,我们花了很多时间,多人协作和讨论。经过几个版本,不断优化,终于在体验和浏览器执行性能上有了不错的表现。
记者:您认为9466网络助手最大的亮点是什么?
杨光:我个人认为9466最大的亮点是:开放性。我们有一个非常强大的设计引擎。这个引擎不仅仅是传统意义上的所见即所得,而是一个可以拖拽设计的操作界面。动力是这台发动机是开着的。通过引擎,可以组装各种组件、应用程序、模板和样式。只要满足既定规范,任何第三方都可以开发各种组件以嵌入 9466 平台。这样,9466平台就相当于胶水,任何有优秀创意和实现的第三方都可以通过平台贡献自己的价值,服务他人。
记者:目前9466网络助手的模板有专题模板、企业网站、个人网站三种。哪种类型的模板更受欢迎?新模板的更新状态如何?
杨光:目前抄题目和企业模板的人比较多。我们将在不久的将来研究这个主题。现有功能的优化和新功能的加入,会更好的贴合话题制作的场景。因此,主题模板将在不久的将来更频繁地更新。
记者:对于9644网络助手的发展前景,您怎么看?您认为哪些方面需要改进?
杨光:9466的发展前景是毋庸置疑的,因为只要有网页,就会有大量的网页制作需求。这是一个刚性需求,并没有得到满足。迫切需要这样一种有用的产品来填补这一空白。而且,Wix等几家国外大公司已经上市,市值7.5亿美元。Weebly 刚刚获得了红衫军和腾讯的联合投资。中国还没有垄断企业,大家还在竞争。
记者:最后一个问题,就您而言,您比较关注的技术领域是什么?您预测2014年会流行哪些新技术?
杨光:我的顾虑比较复杂,我不说2014年哪种技术会流行。但除了工作,我对人工智能更感兴趣。我和电脑打交道的时间越长,我就越觉得电脑比起人类来说太愚蠢了。对于人类来说,一个非常简单的问题需要非常复杂的算法才能由计算机来解决。比如腾讯之前的QQ浏览器,对于抓取到的网页,需要分析哪些是核心内容(如文章文字),哪些是杂质(如广告)。对于人来说,这样的事情再简单不过了。但是对于电脑来说,要能够适应所有的网页,真的很难。我们还采用了基于视觉的块分析方法,使用类似于人类观察的逻辑进行分析,效果得到了提升,
我总觉得现在人工智能的发展太依赖电脑了。即冯诺依曼计算系统。或许在这个系统中,根本就没有人工智能,只有模拟智能。神经网络算法很复杂,但能解决的问题还是很有限的。 查看全部
网页抓取解密(的技术架构相关知识(图))
本次采访的对象是技术总监杨光。负责9466智能建站平台。本次WOT软件技术峰会,将分享9466技术架构相关知识。敬请关注!
【讲师简历】
杨光,2005年毕业于西北大学,从物理系转入软件学院。同年加入并从事新一代战略ERP产品U9的研发,这是国内第一款基于SOA架构的大型商业软件。2010年加入腾讯,在手Q浏览器团队工作,负责浏览器后台整体运营体系建设。2013年加入与钟胜辉共同打造9466智能网站建设平台。
以下是采访记录:
记者:9466网络助手是什么时候推出的?开发的初衷是什么?使用了哪些新技术?开发过程中遇到了哪些困难,又是如何克服的?
杨光:9466第一版于2013年10月上线,自上线以来一直处于公测阶段(需要邀请码)。我们仍在打磨我们的产品。
当初开发这个产品是为了彻底解决网页问题和网站生产烦恼。因为目前做网页还是网站,还有很多知识需要理解,比如:创意、设计、页面制作、素材制作、样式定义、数据读写等等. 要制作页面,需要各种技能。对于新手用户来说,这个问题就更加突出了。然而,在这个领域有很多需求。于是就有了这个想法,目的是利用9466平台,任何人都可以轻松做出漂亮的网页。
本产品是一款非常前端的产品,技术难度和积累主要在前端,比如:响应式设计、按需加载、异步事件等等。因为我们的设计师是一个所见即所得的操作体验,所以设计一个合理的模型来模拟网页上的这种原生操作是非常重要的。在这方面,我们花了很多时间,多人协作和讨论。经过几个版本,不断优化,终于在体验和浏览器执行性能上有了不错的表现。
记者:您认为9466网络助手最大的亮点是什么?
杨光:我个人认为9466最大的亮点是:开放性。我们有一个非常强大的设计引擎。这个引擎不仅仅是传统意义上的所见即所得,而是一个可以拖拽设计的操作界面。动力是这台发动机是开着的。通过引擎,可以组装各种组件、应用程序、模板和样式。只要满足既定规范,任何第三方都可以开发各种组件以嵌入 9466 平台。这样,9466平台就相当于胶水,任何有优秀创意和实现的第三方都可以通过平台贡献自己的价值,服务他人。
记者:目前9466网络助手的模板有专题模板、企业网站、个人网站三种。哪种类型的模板更受欢迎?新模板的更新状态如何?
杨光:目前抄题目和企业模板的人比较多。我们将在不久的将来研究这个主题。现有功能的优化和新功能的加入,会更好的贴合话题制作的场景。因此,主题模板将在不久的将来更频繁地更新。
记者:对于9644网络助手的发展前景,您怎么看?您认为哪些方面需要改进?
杨光:9466的发展前景是毋庸置疑的,因为只要有网页,就会有大量的网页制作需求。这是一个刚性需求,并没有得到满足。迫切需要这样一种有用的产品来填补这一空白。而且,Wix等几家国外大公司已经上市,市值7.5亿美元。Weebly 刚刚获得了红衫军和腾讯的联合投资。中国还没有垄断企业,大家还在竞争。
记者:最后一个问题,就您而言,您比较关注的技术领域是什么?您预测2014年会流行哪些新技术?
杨光:我的顾虑比较复杂,我不说2014年哪种技术会流行。但除了工作,我对人工智能更感兴趣。我和电脑打交道的时间越长,我就越觉得电脑比起人类来说太愚蠢了。对于人类来说,一个非常简单的问题需要非常复杂的算法才能由计算机来解决。比如腾讯之前的QQ浏览器,对于抓取到的网页,需要分析哪些是核心内容(如文章文字),哪些是杂质(如广告)。对于人来说,这样的事情再简单不过了。但是对于电脑来说,要能够适应所有的网页,真的很难。我们还采用了基于视觉的块分析方法,使用类似于人类观察的逻辑进行分析,效果得到了提升,
我总觉得现在人工智能的发展太依赖电脑了。即冯诺依曼计算系统。或许在这个系统中,根本就没有人工智能,只有模拟智能。神经网络算法很复杂,但能解决的问题还是很有限的。
网页抓取解密(解决网站字体加密的第2篇文章方法,具体执行步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-18 05:17
前言:
写这个文章的原因是为了写一个python脚本来抓取一个食物相关的网站的电话号码,发现网站已经被字体加密了,抓到的那些是难以理解的十六进制代码,如下图:
文本:
用chrome查看对应的加密代码,发现是写在css文件中,css地址直接贴在这里:
找到对应的位置,发现是base64编码加密的
之前没接触过这个,于是开始查资料,主要是查下面两个文章,其中比较参考的是第二个文章的第四种方法,具体实现步骤和我我将列出我写的脚本:
将base64格式的字体信息解码成可用的字体文件
反爬虫技术:解决网站字体加密
步骤1:
提取CSS文件中网站字体对应的代码,自动保存为字体文件base.woff。复制下面的代码直接使用
# -*- coding:utf-8 -*-
import requests,base64
def downfont(url):
response = requests.get(url)
base64_string = response.text.split("base64,")[1].split("'")[0].strip()
bin_data = base64.decodebytes(base64_string.encode())
with open("base.woff", r"wb") as f:
f.write(bin_data)
if __name__ == "__main__":
url = 'https://wap.21food.cn/resources/css/layout.css'
downfont(url)
print('done.')
第2步:
下载FontCreator软件,下载链接:
打开第一步生成的“base.woff”字库,软件会自动生成字库的对应关系,如下图:
记得选择字幕,找到我们要抓取的网站加密字体对应的十六进制码,手动写入字典,这样我们抓取的数字就可以一一对应:key = { '10010':'0','1000D':'1','10011':'2','1000F':'3','10017':'4','1000E':'5','10015 ':' 6','10014':'7','10012':'8','10013':'9','10016':'-')
第 3 步:
编写爬虫程序,抓取我们要抓取的页面上电话号码的加密密文。我使用常规规则来匹配。以这个网址为例。我们需要抓取的是下图中的边框区域。
然后根据我们之前拿到的字典,自动转换成对应的实数,就可以在网页上得到这个数了。具体代码如下:
<p># -*- coding: utf-8 -*-
import requests
import cchardet
import traceback
from lxml import html
import re
import cchardet
def downloader(url, timeout=10, headers=None, debug=False, binary=False):
_headers = {
'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; '
'Windows NT 6.1; Win64; x64; Trident/5.0)'),
}
redirected_url = url
if headers:
_headers = headers
try:
r = requests.get(url, headers=_headers, timeout=timeout)
if binary:
html = r.content
else:
encoding = cchardet.detect(r.content)['encoding']
html = r.content.decode(encoding)
status = r.status_code
redirected_url = r.url
except:
if debug:
traceback.print_exc()
msg = 'failed download: {}'.format(url)
print(msg)
if binary:
html = b''
else:
html = ''
status = 0
return status, html, redirected_url
def extract(source):
p = re.findall(r'(&#x[^ 查看全部
网页抓取解密(解决网站字体加密的第2篇文章方法,具体执行步骤)
前言:
写这个文章的原因是为了写一个python脚本来抓取一个食物相关的网站的电话号码,发现网站已经被字体加密了,抓到的那些是难以理解的十六进制代码,如下图:
http://www.reduwang.com/wp-con ... 1.png 150w, http://www.reduwang.com/wp-con ... 2.png 300w, http://www.reduwang.com/wp-con ... 7.png 768w, http://www.reduwang.com/wp-con ... 5.png 1249w" />文本:
用chrome查看对应的加密代码,发现是写在css文件中,css地址直接贴在这里:
http://www.reduwang.com/wp-con ... 6.png 150w, http://www.reduwang.com/wp-con ... 2.png 300w, http://www.reduwang.com/wp-con ... 2.png 768w, http://www.reduwang.com/wp-con ... 6.png 1808w" />找到对应的位置,发现是base64编码加密的
http://www.reduwang.com/wp-con ... 7.png 150w, http://www.reduwang.com/wp-con ... 4.png 300w, http://www.reduwang.com/wp-con ... 8.png 768w, http://www.reduwang.com/wp-con ... 7.png 1832w" />之前没接触过这个,于是开始查资料,主要是查下面两个文章,其中比较参考的是第二个文章的第四种方法,具体实现步骤和我我将列出我写的脚本:
将base64格式的字体信息解码成可用的字体文件
反爬虫技术:解决网站字体加密
步骤1:
提取CSS文件中网站字体对应的代码,自动保存为字体文件base.woff。复制下面的代码直接使用
# -*- coding:utf-8 -*-
import requests,base64
def downfont(url):
response = requests.get(url)
base64_string = response.text.split("base64,")[1].split("'")[0].strip()
bin_data = base64.decodebytes(base64_string.encode())
with open("base.woff", r"wb") as f:
f.write(bin_data)
if __name__ == "__main__":
url = 'https://wap.21food.cn/resources/css/layout.css'
downfont(url)
print('done.')
第2步:
下载FontCreator软件,下载链接:
打开第一步生成的“base.woff”字库,软件会自动生成字库的对应关系,如下图:
http://www.reduwang.com/wp-con ... 8.png 150w, http://www.reduwang.com/wp-con ... 7.png 300w, http://www.reduwang.com/wp-con ... 2.png 768w" />记得选择字幕,找到我们要抓取的网站加密字体对应的十六进制码,手动写入字典,这样我们抓取的数字就可以一一对应:key = { '10010':'0','1000D':'1','10011':'2','1000F':'3','10017':'4','1000E':'5','10015 ':' 6','10014':'7','10012':'8','10013':'9','10016':'-')
第 3 步:
编写爬虫程序,抓取我们要抓取的页面上电话号码的加密密文。我使用常规规则来匹配。以这个网址为例。我们需要抓取的是下图中的边框区域。
http://www.reduwang.com/wp-con ... 7.png 150w, http://www.reduwang.com/wp-con ... 4.png 300w, http://www.reduwang.com/wp-con ... 8.png 768w" />然后根据我们之前拿到的字典,自动转换成对应的实数,就可以在网页上得到这个数了。具体代码如下:
<p># -*- coding: utf-8 -*-
import requests
import cchardet
import traceback
from lxml import html
import re
import cchardet
def downloader(url, timeout=10, headers=None, debug=False, binary=False):
_headers = {
'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; '
'Windows NT 6.1; Win64; x64; Trident/5.0)'),
}
redirected_url = url
if headers:
_headers = headers
try:
r = requests.get(url, headers=_headers, timeout=timeout)
if binary:
html = r.content
else:
encoding = cchardet.detect(r.content)['encoding']
html = r.content.decode(encoding)
status = r.status_code
redirected_url = r.url
except:
if debug:
traceback.print_exc()
msg = 'failed download: {}'.format(url)
print(msg)
if binary:
html = b''
else:
html = ''
status = 0
return status, html, redirected_url
def extract(source):
p = re.findall(r'(&#x[^
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-16 21:45
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址。请注意,您仍在考虑它:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接就是对应视频中的一个片段,整个视频是由片段一一组成的。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应这个动漫博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般自带WinRaR解压软件,选中所有ts文件后,右键选择添加到压缩文件,如下图界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
也可以用代码和FFmpg合并,爬到B站视频之前合并音频数据和视频图片。 查看全部
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址。请注意,您仍在考虑它:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接就是对应视频中的一个片段,整个视频是由片段一一组成的。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应这个动漫博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般自带WinRaR解压软件,选中所有ts文件后,右键选择添加到压缩文件,如下图界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
也可以用代码和FFmpg合并,爬到B站视频之前合并音频数据和视频图片。
网页抓取解密(网页抓取解密五步大全,教你学会表达式的用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-12 16:07
网页抓取解密五步大全,教你学会网页抓取解密,教你可视化操作网页,教你正则表达式的用法,教你图片文件的二次加工,教你可视化数据可视化。今天我们来讨论一下,网页抓取解密五步大全的详细实操流程以及一些容易被忽略的操作技巧,让你轻松上手更易于理解。work——get网页源代码2.body——下载解密最终代码3.items——对body进行数据提取4.content——文本解密5.extension——抓包(翻墙点这里)对body进行数据提取网页抓取解密五步大全,这个几乎是所有网页抓取解密都要使用到的技巧,其实不仅仅限于常见的反编译或者反爬虫,网页中的图片、文本甚至tables、frameset等表格元素也能进行解密,基本上所有抓取工具都会提供强大的解密工具,只要你懂一点代码提取,其实一个大写的字符串五步解密的案例不难实现。
假设我们要抓取小米手机发送的短信数据,那我们将一个个的提取出来已经十分繁琐和费时,当然基于代码的完成是完全可以的,下面通过一个简单的案例来展示。举个例子formsubmit——复制这个内容,粘贴在后面的工作表表头,添加url:取回文字</a>window.notification.post("-message",newsimpleformform("url"),url)这里的url是一个通用字符串类型的url,后面跟的表头是你发送信息的邮箱地址。
当然你也可以用get方法直接从表头获取数据,而且可以通过这个获取邮箱、手机号等字段数据。接下来我们抓包,打开抓包工具来提取数据:手机短信获取方法通过safari浏览器,使用第三方工具如charles、xpath等。我们可以看到网页抓取解密到这里基本上已经完成了,从get获取的相关内容,只是输出了html文本而已,这里我想提一下的是判断正则表达式的问题,常用的判断正则表达式有以下五种,分别是匹配javascript、匹配text、匹配html、匹配attribute、匹配python。
我们来看看判断正则表达式,后来转化成了更加通用的代码,基本上跟我们熟悉的很像,只是操作比较繁琐和麻烦。上面公式的几点特点,如果直接看代码,不太容易抓到重点:1.字符串的单引号需要先替换成双引号,下面这个代码容易忽略,包括语法,具体的可以参看源代码如下。2.满足要求如果在每一个开头没有匹配,则下一个在开头肯定有empty和infinite两个子串,值得注意是从第一个到最后一个一定是以空格隔开的,不包括后面我们假设,有一个输入框,标识为a1,那么如果a1最后的text是一个十。 查看全部
网页抓取解密(网页抓取解密五步大全,教你学会表达式的用法)
网页抓取解密五步大全,教你学会网页抓取解密,教你可视化操作网页,教你正则表达式的用法,教你图片文件的二次加工,教你可视化数据可视化。今天我们来讨论一下,网页抓取解密五步大全的详细实操流程以及一些容易被忽略的操作技巧,让你轻松上手更易于理解。work——get网页源代码2.body——下载解密最终代码3.items——对body进行数据提取4.content——文本解密5.extension——抓包(翻墙点这里)对body进行数据提取网页抓取解密五步大全,这个几乎是所有网页抓取解密都要使用到的技巧,其实不仅仅限于常见的反编译或者反爬虫,网页中的图片、文本甚至tables、frameset等表格元素也能进行解密,基本上所有抓取工具都会提供强大的解密工具,只要你懂一点代码提取,其实一个大写的字符串五步解密的案例不难实现。
假设我们要抓取小米手机发送的短信数据,那我们将一个个的提取出来已经十分繁琐和费时,当然基于代码的完成是完全可以的,下面通过一个简单的案例来展示。举个例子formsubmit——复制这个内容,粘贴在后面的工作表表头,添加url:取回文字</a>window.notification.post("-message",newsimpleformform("url"),url)这里的url是一个通用字符串类型的url,后面跟的表头是你发送信息的邮箱地址。
当然你也可以用get方法直接从表头获取数据,而且可以通过这个获取邮箱、手机号等字段数据。接下来我们抓包,打开抓包工具来提取数据:手机短信获取方法通过safari浏览器,使用第三方工具如charles、xpath等。我们可以看到网页抓取解密到这里基本上已经完成了,从get获取的相关内容,只是输出了html文本而已,这里我想提一下的是判断正则表达式的问题,常用的判断正则表达式有以下五种,分别是匹配javascript、匹配text、匹配html、匹配attribute、匹配python。
我们来看看判断正则表达式,后来转化成了更加通用的代码,基本上跟我们熟悉的很像,只是操作比较繁琐和麻烦。上面公式的几点特点,如果直接看代码,不太容易抓到重点:1.字符串的单引号需要先替换成双引号,下面这个代码容易忽略,包括语法,具体的可以参看源代码如下。2.满足要求如果在每一个开头没有匹配,则下一个在开头肯定有empty和infinite两个子串,值得注意是从第一个到最后一个一定是以空格隔开的,不包括后面我们假设,有一个输入框,标识为a1,那么如果a1最后的text是一个十。
网页抓取解密(网页抓取解密(1)_e操盘_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-11 09:06
网页抓取解密..1.从filesystem上爬取文件.m3u8.exe等.2.解密码.密码文件.转码成字节流(支持十六进制)...程序处理成对应的二进制字节流.3.将处理后的字节流发送给网页服务器...
楼上的都是扯淡,
先模拟登录的客户端,
直接去网页里面抓取就可以了
有scrapy和web.py
有一个库叫telnet,具体你可以搜索这个库,不过这东西是两个接口对接的,如果你是写爬虫,这个库用起来估计不太靠谱,不如用beautifulsoup,各种解析器写起来很爽,当然,我还是推荐你用web框架来写,
你的问题中就已经给出答案了,客户端传的二进制文件的内容解码二进制文件转换成十六进制(十进制数可以是乱七八糟的,
直接抓取就可以了,当然如果就像做个js脚本那样可以用web.py,定时传送特定图片的二进制内容。
可以用scrapy爬取ftp、sctp、p2p等各种协议的数据
也可以用httpurlconnection把服务器发来的http请求通过http的requestheader里的类型指定后缀名作为file的字节流处理,然后从网页中取出来,用于其他进程传递。
这个需要分层分线路.1.软件层:自己编写爬虫网页,爬取过程的各种细节都要自己考虑和制定.2.网页层:通过python网页的反向工程来分析网页.3.对于中间层的话,通过python的cookie等等对用户上次操作做一个记录,进行下一次的请求. 查看全部
网页抓取解密(网页抓取解密(1)_e操盘_光明网(组图))
网页抓取解密..1.从filesystem上爬取文件.m3u8.exe等.2.解密码.密码文件.转码成字节流(支持十六进制)...程序处理成对应的二进制字节流.3.将处理后的字节流发送给网页服务器...
楼上的都是扯淡,
先模拟登录的客户端,
直接去网页里面抓取就可以了
有scrapy和web.py
有一个库叫telnet,具体你可以搜索这个库,不过这东西是两个接口对接的,如果你是写爬虫,这个库用起来估计不太靠谱,不如用beautifulsoup,各种解析器写起来很爽,当然,我还是推荐你用web框架来写,
你的问题中就已经给出答案了,客户端传的二进制文件的内容解码二进制文件转换成十六进制(十进制数可以是乱七八糟的,
直接抓取就可以了,当然如果就像做个js脚本那样可以用web.py,定时传送特定图片的二进制内容。
可以用scrapy爬取ftp、sctp、p2p等各种协议的数据
也可以用httpurlconnection把服务器发来的http请求通过http的requestheader里的类型指定后缀名作为file的字节流处理,然后从网页中取出来,用于其他进程传递。
这个需要分层分线路.1.软件层:自己编写爬虫网页,爬取过程的各种细节都要自己考虑和制定.2.网页层:通过python网页的反向工程来分析网页.3.对于中间层的话,通过python的cookie等等对用户上次操作做一个记录,进行下一次的请求.
网页抓取解密( 图片来源网络抓取策略(一)(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-11 04:02
图片来源网络抓取策略(一)(1)_光明网(组图))
图片来源网络
爬取策略
在爬虫系统中,要爬取的URL是一个非常关键的部分。爬虫需要爬取的网页的网址排列在其中,形成一个队列结构。调度器每次从队列的头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被追加到待爬取的URL队列的末尾,从而形成一个爬行循环,整个爬虫系统可以说是由这个队列驱动的。
如何确定要抓取的URL队列中页面URL的顺序?如上所述,新下载页面中收录的链接将附加到队列的末尾。虽然这是一种确定队列的 URL 顺序的方法,但它不是唯一的方法。事实上,可以采用许多其他技术来保持队列等待被捕获。取URL进行排序。爬虫的不同爬取策略使用不同的方法来确定要爬取的 URL 队列中 URL 的优先级。
爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:首先选择重要的网页进行爬取。在爬虫系统中,所谓的网页重要性可以通过不同的方法来判断,但大多是按照网页的流行程度来定义的。
爬取策略的方法虽然有很多,但这里仅列举被证明有效或具有代表性的解决方案,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略和大站优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。搜索引擎爬虫一出现就被采用。新提出的爬取策略往往使用这种方法作为比较的基准。不过,值得注意的是,这种策略也是一种非常强大的方法。很多新方法的实际效果不一定比广度优先遍历策略好。所以这个方法其实是很多爬虫采用的第一种爬虫策略。
如上所述,“新下载的网页中收录的URL会被追加到待抓取的URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法并没有明确提出和使用网页的重要性作为衡量标准,而是机械地从新下载的网页中提取链接,作为URL的下载顺序附加到待抓取的URL队列中。下图是该策略的示意图: 假设队列头部的网页是1号网页,从1号网页中提取3个分别指向2号、3号、4号的链接,因此它们按要捕获的数字顺序排列。在取队列中,图中网页的编号就是这个页面在待取队列中的序号,
实验表明,这种策略非常有效。虽然看起来很机械,但实际的网页抓取顺序基本上是按照网页的重要性排序的。为此,一些研究人员认为,如果一个网页收录许多传入链接,则更容易被广度优先遍历策略及早捕获。传入链接的数量从侧面反映了网页的重要性,即实际的宽度优先遍历策略 以上也暗示了一些网页优先级假设。
广度优先遍历策略
02 PageRank 策略不完整
PageRank 是一种著名的链接分析算法,可用于衡量网页的重要性。自然可以想到使用PageRank的思想来对URL优先级进行排序。但是这里有一个问题。PageRank 是一种全局算法,这意味着当所有网页都被下载时,计算结果是可靠的。爬虫的目的是下载网页,运行时只能看到部分网页。,所以在爬行阶段的网页无法获得可靠的PageRank分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,将要爬取的URL队列中的URL加入到一个网页集合中,在这个集合中进行PageRank计算,计算完成后,待爬取的URL队列 根据PageRank得分从高到低对其中的网页进行排序,形成的顺序就是爬虫接下来要爬取的URL列表。这就是为什么它被称为“不完整的 PageRank”。
如果每次抓取一个新的网页,所有下载的网页都重新计算为一个新的不完整的PageRank值,这显然效率太低,在现实中也不可行。一个折衷的方法是:每当有足够K个新下载的网页时,对所有下载的网页重新计算一个新的不完整PageRank。这种计算效率勉强可以接受,但又带来了一个新问题:在开始下一轮PageRank计算之前,提取新下载网页中收录的链接。这些链接很可能非常重要,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 会为这些新提取的没有 PageRank 值的网页分配一个临时的 PageRank 值。此网页所有链接内传输的 PageRank 值汇总为临时 PageRank 值。如果这个值大于要爬取的URL队列中计算出的值,如果PageRank值高的页面出来,那么会先下载这个URL。
下图是不完全PageRank策略的示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时本地已经下载了3个网页{P1,P2,P3},这3个网页中收录的链接指向{P4,P5,P6},形成了一个待抓取的URL队列。如何决定下载顺序?将这6个网页组成一个新的集合,计算这个集合的PageRank值,让P4、P5和P6得到各自对应的PageRank值,从大到小排序,就可以得到下载顺序. 这里可以假设下载顺序为:P5、P4、P6。下载P5页面时,链接被提取并指向页面P8。此时,P8 被分配了一个临时的 PageRank 值。如果这个值大于 P4 和 P6 如果你有一个 PageRank 值,P8 将首先被下载。这样一个连续的循环就形成了不完全PageRank策略的计算思路。
Incomplete PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明,不完整的 PageRank 结果稍好一些,而一些实验结果则刚好相反。有研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大不同。不应作为计算网址在爬取过程中重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC字面意思是“在线页面重要性计算”,可以看作是一种改进的PageRank算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”分配给“空”。对于 URL 队列中待抓取的网页,它们根据手头有多少现金进行排序,现金最多的网页先下载。OPIC在其大框架上与PageRank基本相同。区别在于:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,有一个远程跳转到没有链接关系的网页的过程,而OPIC没有这个计算因素。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略好于广度优先遍历策略。
04 大站点优先策略
大站点优先策略很简单:以 网站 为单位衡量网页的重要性。对于URL队列中待抓取的网页,根据各自的网站进行分类,如果等待下载的是哪个网站,如果页面数最多,先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略好于宽度优先遍历策略。
网页更新策略
Internet 的动态特性是其显着特征。随时出现新页面,更改页面内容或删除现有页面。对于爬虫来说,并不是在本地爬取网页,即使完成了任务,也必须体现互联网的动态性。本地下载的页面可以看作是互联网页面的“镜子”,爬虫应该尽量保证一致性。可以假设这样一种情况:某个网页被删除或内容发生了重大变化,搜索引擎仍然对这个引擎一无所知,仍然按照旧内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取过的网页,
网页更新策略的任务是决定何时重新抓取下载的网页,尽可能使本地下载的网页内容与互联网上的原创网页一致。常用的网页更新策略有3种:历史参考策略、用户体验策略和聚类抽样策略。
01 历史参考策略
历史参考策略是最直观的更新策略。它基于这样一个假设,即过去经常更新的网页在未来也会经常更新。因此,为了估计某个网页的更新时间,可以参考历史更新情况进行判断。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时会再次发生变化,以指导爬虫的抓取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,专注于内容变化检测和建模。优越的。
02用户体验策略
一般来说,一个搜索引擎用户提交查询后,可能会有上千条相关的搜索结果,用户没有耐心等着看排在后面的搜索结果,可能只看前3页的搜索内容。用户体验策略利用用户的这种特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,那么以后更新这些过时的网页也是可以的。因此,判断网页何时更新取决于网页内容的变化(通常以搜索结果排名的变化来衡量)带来的搜索质量的变化。网页的影响越大,应该更新得越快。
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,作为判断爬虫重新抓取网页时间的参考依据。网页的影响越严重,就越优先安排重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略很大程度上依赖于网页的历史更新信息,因为这是后续计算的基础。但在现实中,要为每个网页保存历史信息,搜索系统会增加很多额外的负担。从另一个角度来说,如果是第一个被爬取的网页,因为没有历史信息,无法按照这两个思路来估计更新周期。为了解决上述不足,提出了聚类抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测更新周期。具有相似属性的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,同一类别的网页具有相同的更新频率。为了计算某个类别的更新周期,只需对该类别中的网页进行采样,并将这些采样网页的更新周期作为该类别中所有网页的更新周期。与前面介绍的两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,也可以根据类别进行更新。
下图描述了集群抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页都有相似的更新周期。从类别中提取出一部分最具代表性的网页(通常是提取离类别中心最近的网页),计算这些网页的更新周期,然后将该更新周期用于该类别中的所有网页,然后可以基于网页的类别 确定其更新周期。
聚类抽样策略
网页更新周期的属性特征分为静态特征和动态特征两大类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,比如图片数量的变化、链接的进出变化等。基于这两种特征,可以对网页进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,有的研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一网站的网页具有相同的更新周期,则其中的网页网站是Sampling,计算更新周期,然后网站中的所有网页都会以这个更新周期为准。虽然这个假设很粗略,因为很明显同一网站内的网页更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类也非常困难。
如果你对爬虫感兴趣,还可以阅读:
全程干货| 爬虫技术原理入门,看这篇文章就知道了
网络爬虫 | 你不知道的暗网是如何爬行的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗? 查看全部
网页抓取解密(
图片来源网络抓取策略(一)(1)_光明网(组图))
图片来源网络
爬取策略
在爬虫系统中,要爬取的URL是一个非常关键的部分。爬虫需要爬取的网页的网址排列在其中,形成一个队列结构。调度器每次从队列的头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被追加到待爬取的URL队列的末尾,从而形成一个爬行循环,整个爬虫系统可以说是由这个队列驱动的。
如何确定要抓取的URL队列中页面URL的顺序?如上所述,新下载页面中收录的链接将附加到队列的末尾。虽然这是一种确定队列的 URL 顺序的方法,但它不是唯一的方法。事实上,可以采用许多其他技术来保持队列等待被捕获。取URL进行排序。爬虫的不同爬取策略使用不同的方法来确定要爬取的 URL 队列中 URL 的优先级。
爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:首先选择重要的网页进行爬取。在爬虫系统中,所谓的网页重要性可以通过不同的方法来判断,但大多是按照网页的流行程度来定义的。
爬取策略的方法虽然有很多,但这里仅列举被证明有效或具有代表性的解决方案,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略和大站优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。搜索引擎爬虫一出现就被采用。新提出的爬取策略往往使用这种方法作为比较的基准。不过,值得注意的是,这种策略也是一种非常强大的方法。很多新方法的实际效果不一定比广度优先遍历策略好。所以这个方法其实是很多爬虫采用的第一种爬虫策略。
如上所述,“新下载的网页中收录的URL会被追加到待抓取的URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法并没有明确提出和使用网页的重要性作为衡量标准,而是机械地从新下载的网页中提取链接,作为URL的下载顺序附加到待抓取的URL队列中。下图是该策略的示意图: 假设队列头部的网页是1号网页,从1号网页中提取3个分别指向2号、3号、4号的链接,因此它们按要捕获的数字顺序排列。在取队列中,图中网页的编号就是这个页面在待取队列中的序号,
实验表明,这种策略非常有效。虽然看起来很机械,但实际的网页抓取顺序基本上是按照网页的重要性排序的。为此,一些研究人员认为,如果一个网页收录许多传入链接,则更容易被广度优先遍历策略及早捕获。传入链接的数量从侧面反映了网页的重要性,即实际的宽度优先遍历策略 以上也暗示了一些网页优先级假设。
广度优先遍历策略
02 PageRank 策略不完整
PageRank 是一种著名的链接分析算法,可用于衡量网页的重要性。自然可以想到使用PageRank的思想来对URL优先级进行排序。但是这里有一个问题。PageRank 是一种全局算法,这意味着当所有网页都被下载时,计算结果是可靠的。爬虫的目的是下载网页,运行时只能看到部分网页。,所以在爬行阶段的网页无法获得可靠的PageRank分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,将要爬取的URL队列中的URL加入到一个网页集合中,在这个集合中进行PageRank计算,计算完成后,待爬取的URL队列 根据PageRank得分从高到低对其中的网页进行排序,形成的顺序就是爬虫接下来要爬取的URL列表。这就是为什么它被称为“不完整的 PageRank”。
如果每次抓取一个新的网页,所有下载的网页都重新计算为一个新的不完整的PageRank值,这显然效率太低,在现实中也不可行。一个折衷的方法是:每当有足够K个新下载的网页时,对所有下载的网页重新计算一个新的不完整PageRank。这种计算效率勉强可以接受,但又带来了一个新问题:在开始下一轮PageRank计算之前,提取新下载网页中收录的链接。这些链接很可能非常重要,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 会为这些新提取的没有 PageRank 值的网页分配一个临时的 PageRank 值。此网页所有链接内传输的 PageRank 值汇总为临时 PageRank 值。如果这个值大于要爬取的URL队列中计算出的值,如果PageRank值高的页面出来,那么会先下载这个URL。
下图是不完全PageRank策略的示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时本地已经下载了3个网页{P1,P2,P3},这3个网页中收录的链接指向{P4,P5,P6},形成了一个待抓取的URL队列。如何决定下载顺序?将这6个网页组成一个新的集合,计算这个集合的PageRank值,让P4、P5和P6得到各自对应的PageRank值,从大到小排序,就可以得到下载顺序. 这里可以假设下载顺序为:P5、P4、P6。下载P5页面时,链接被提取并指向页面P8。此时,P8 被分配了一个临时的 PageRank 值。如果这个值大于 P4 和 P6 如果你有一个 PageRank 值,P8 将首先被下载。这样一个连续的循环就形成了不完全PageRank策略的计算思路。
Incomplete PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明,不完整的 PageRank 结果稍好一些,而一些实验结果则刚好相反。有研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大不同。不应作为计算网址在爬取过程中重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC字面意思是“在线页面重要性计算”,可以看作是一种改进的PageRank算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”分配给“空”。对于 URL 队列中待抓取的网页,它们根据手头有多少现金进行排序,现金最多的网页先下载。OPIC在其大框架上与PageRank基本相同。区别在于:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,有一个远程跳转到没有链接关系的网页的过程,而OPIC没有这个计算因素。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略好于广度优先遍历策略。
04 大站点优先策略
大站点优先策略很简单:以 网站 为单位衡量网页的重要性。对于URL队列中待抓取的网页,根据各自的网站进行分类,如果等待下载的是哪个网站,如果页面数最多,先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略好于宽度优先遍历策略。
网页更新策略
Internet 的动态特性是其显着特征。随时出现新页面,更改页面内容或删除现有页面。对于爬虫来说,并不是在本地爬取网页,即使完成了任务,也必须体现互联网的动态性。本地下载的页面可以看作是互联网页面的“镜子”,爬虫应该尽量保证一致性。可以假设这样一种情况:某个网页被删除或内容发生了重大变化,搜索引擎仍然对这个引擎一无所知,仍然按照旧内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取过的网页,
网页更新策略的任务是决定何时重新抓取下载的网页,尽可能使本地下载的网页内容与互联网上的原创网页一致。常用的网页更新策略有3种:历史参考策略、用户体验策略和聚类抽样策略。
01 历史参考策略
历史参考策略是最直观的更新策略。它基于这样一个假设,即过去经常更新的网页在未来也会经常更新。因此,为了估计某个网页的更新时间,可以参考历史更新情况进行判断。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时会再次发生变化,以指导爬虫的抓取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,专注于内容变化检测和建模。优越的。
02用户体验策略
一般来说,一个搜索引擎用户提交查询后,可能会有上千条相关的搜索结果,用户没有耐心等着看排在后面的搜索结果,可能只看前3页的搜索内容。用户体验策略利用用户的这种特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,那么以后更新这些过时的网页也是可以的。因此,判断网页何时更新取决于网页内容的变化(通常以搜索结果排名的变化来衡量)带来的搜索质量的变化。网页的影响越大,应该更新得越快。
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,作为判断爬虫重新抓取网页时间的参考依据。网页的影响越严重,就越优先安排重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略很大程度上依赖于网页的历史更新信息,因为这是后续计算的基础。但在现实中,要为每个网页保存历史信息,搜索系统会增加很多额外的负担。从另一个角度来说,如果是第一个被爬取的网页,因为没有历史信息,无法按照这两个思路来估计更新周期。为了解决上述不足,提出了聚类抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测更新周期。具有相似属性的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,同一类别的网页具有相同的更新频率。为了计算某个类别的更新周期,只需对该类别中的网页进行采样,并将这些采样网页的更新周期作为该类别中所有网页的更新周期。与前面介绍的两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,也可以根据类别进行更新。
下图描述了集群抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页都有相似的更新周期。从类别中提取出一部分最具代表性的网页(通常是提取离类别中心最近的网页),计算这些网页的更新周期,然后将该更新周期用于该类别中的所有网页,然后可以基于网页的类别 确定其更新周期。
聚类抽样策略
网页更新周期的属性特征分为静态特征和动态特征两大类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,比如图片数量的变化、链接的进出变化等。基于这两种特征,可以对网页进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,有的研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一网站的网页具有相同的更新周期,则其中的网页网站是Sampling,计算更新周期,然后网站中的所有网页都会以这个更新周期为准。虽然这个假设很粗略,因为很明显同一网站内的网页更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类也非常困难。
如果你对爬虫感兴趣,还可以阅读:
全程干货| 爬虫技术原理入门,看这篇文章就知道了
网络爬虫 | 你不知道的暗网是如何爬行的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗?
网页抓取解密(网易云音乐只需要解密params和encSecKey就可以开始快乐的了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-11 04:02
网易云音乐只需要解密params和encSecKey就可以愉快的开始爬虫了。如果你没有足够的代理IP,你还是要慢慢爬,别废话,全开就好了。
问
老规矩,我们来看看我们要抓取的页面:
查看网络请求:
从名字上可以快速定位到哪个请求是POST请求,然后看看它提交了哪些参数。表格数据如下:
提交的参数,即前面提到的params和encSecKey,都是经过加密的。看一下返回内容的格式:
好的,我们已经知道了基本的东西,我们可以进入下一步,找到两个解密参数。
分析
在调试之前,我们要找到这两个值的位置,然后搜索,先定位JS文件,然后定位代码位置。您应该知道如何搜索,您可以全局搜索params或encSecKey。如果找到多个结果,不确定是哪个文件,可以进去搜索每个点的关键参数,判断是否是目标文件。这里我直接标记一下,找到正确的文件后就可以点击进入了。
进入JS文件后,同时搜索关键参数params或encSecKey:
找到encSecKey的位置,拉出这几行代码分析一下:
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
e0x.data = j0x.cs1x({
params: bVZ8R.encText,
encSecKey: bVZ8R.encSecKey
})
粗略的讲,params和encSecKey来自bVZ8R.encText和bVZ8R.encSecKey,bVZ8R是window.asrsea的结果,window.asrsea有四个参数,JSON.stringify(i0x), bqN0x(["streaming", "强" ] ), bqN0x(Wx5C.md), bqN0x(["Love", "Girl", "Terrified", "Laughing"],首先看下面三个参数,从它们的固定值,你可以大胆猜想这三个values也是Fixed,之所以说是fixed,看看Wx5C.md:
wx5C.md是固定数组,和bqN0x(["流泪", "强"])和bqN0x(["爱心", "girl", "horrified", "laughing"] 这个结果肯定是没有变化的,如图下面,测试了一下:
大概把这些参数搞清楚了,剩下的就是搞清楚window.asrsea的具体实现,还有i0x是什么样的,进入调试环节。
调试
window.asrsea 到达断点。我的代码位置是13133行,点击下一页粉丝列表会激活断点。在激活断点的同时,我们也可以看到 i0x 的美妙之处。在控制台输入 i0x:
limit、offset、total、userId其实是已知的,csrf_token的生成可以看这里。细心的童鞋早就应该发现了:
i0x["csrf_token"] = v0x.gP3x("__csrf"); ## csrf_token在这里产生
X0x = X0x.replace("api", "weapi");
e0x.method = "post";
delete e0x.query;
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
我点击进入 v0x.gP3x 函数并查看:
从代码中可以看出csrf_token来自于Cookie中的__csrf:
那么这个值可以在请求网页的时候从cookie中获取,继续调试window.asrsea。一路点击Next进入功能。
跳进ad(d,e,f,g)函数,往下看,发现window.asrsea等于这个d函数,哦,调试一下这个d函数:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
输入一个函数:
可以看出a函数生成随机数,继续运行,进入b函数:
熟悉AES加密,继续运行,进入c函数:
也是大家熟悉的RSA加密,网易可真慎重,各种加密。至此,整体框架已经调试完毕,剩下的无非就是拉取JS代码。
蟒蛇运行
这次不光是跑了结果,还带来了爬取和入库:
获取参数和 encSecKey
def get_enc(self,a):
with open('..//js//wangyiyun.js', encoding='utf-8') as f:
wangyiyun = f.read()
js = execjs.compile(wangyiyun)
logid = js.call('get_pwd', a)
print(logid)
return logid
抓
def get_fans(self):
resp = self.get_home_page()
print(resp.cookies)
print(resp.status_code)
time.sleep(6)
limit = 20
for i in range(1,110):
print("第{}页".format(i+1))
offset = limit*i
a = {"userId": "46991111", "offset": str(offset), "total": "false", "limit": str(limit), "csrf_token": ""}
print(a)
logid = self.get_enc(a)
data = {
"params":logid["encText"],
"encSecKey":logid["encSecKey"],
}
print(data)
fans_url = "https://music.163.com/weapi/us ... ot%3B
resp = self.session.post(url=fans_url,data=data,headers=self.headers)
followed = json.loads(resp.text)
followed_list = []
for foll in followed["followeds"]:
foll_dict = {}
foll_dict["short_name"] = foll.get("py","") #缩写
foll_dict["userId"] = foll.get("userId","") #用户ID
foll_dict["nickname"] = foll.get("nickname","") #昵称
foll_dict["vipType"] = foll.get("vipType","") # vip
foll_dict["eventCount"] = foll.get("eventCount","")#动态
foll_dict["vipRights"] = str(foll.get("vipRights","")) #VIP权益
foll_dict["gender"] = foll.get("gender","") #性别
foll_dict["avatarUrl"] = foll.get("avatarUrl","") #头像
foll_dict["followed"] = foll.get("followed","")
foll_dict["followeds"] = foll.get("followeds","") #粉丝
foll_dict["follows"] = foll.get("follows","") #关注
foll_dict["playlistCount"] = foll.get("playlistCount","") #歌单
foll_dict["mutual"] = foll.get("mutual","") #
foll_dict["expertTags"] = str(foll.get("expertTags",""))
foll_dict["experts"] = str(foll.get("experts",""))
print(foll_dict)
followed_list.append(foll_dict)
self.mysql.insert("music",followed_list)
tm = random.randint(10,30)
time.sleep(tm)
这里需要注意的是,要抓取指定页面,必须先访问该页面,不能直接请求链接”,因为它根本不携带有关哪个页面的信息。
请求特定页面
def get_home_page(self):
url = "https://music.163.com/%23/user ... ot%3B
resp = self.session.get(url)
return resp
来源: 从今天开始种树
作者: 罗华
链接: http://www.happyhong.cn/ni-xiang/10034.html
本文章著作权归作者所有,任何形式的转载都请注明出处。
表结构
@property
def create_table_sql(self):
create_table = """
CREATE TABLE IF NOT EXISTS music (
short_name varchar(30) ,
userId varchar(100) NOT NULL,
nickname varchar(30),
vipType varchar(30) ,
eventCount varchar(200),
vipRights varchar(900),
gender varchar(900),
avatarUrl varchar(200),
followed varchar(30),
followeds varchar(30),
follows varchar(30),
playlistCount varchar(30),
mutual varchar(30),
expertTags varchar(30),
experts varchar(30),
PRIMARY KEY (userId)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
return create_table
仓储
def insert(self,table,data_list):
if len(data_list) > 0:
data_list = [{k: v
for k, v in data.items() if v is not None}
for data in data_list]
keys = ", ".join(data_list[0].keys())
values = ", ".join(["%s"] * len(data_list[0]))
sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
DUPLICATE KEY UPDATE""".format(table=table,
keys=keys,
values=values)
update = ",".join([
" {key} = values({key})".format(key=key)
for key in data_list[0]
])
sql += update
print(sql)
self.connect()
try:
ret = self.cursor.executemany(sql, [tuple(data.values()) for data in data_list])
self.conn.commit()
except Exception as e:
self.conn.rollback()
print("Error: ", e)
traceback.print_exc()
finally:
self.close()
过程
结束 查看全部
网页抓取解密(网易云音乐只需要解密params和encSecKey就可以开始快乐的了)
网易云音乐只需要解密params和encSecKey就可以愉快的开始爬虫了。如果你没有足够的代理IP,你还是要慢慢爬,别废话,全开就好了。
问
老规矩,我们来看看我们要抓取的页面:
查看网络请求:
从名字上可以快速定位到哪个请求是POST请求,然后看看它提交了哪些参数。表格数据如下:
提交的参数,即前面提到的params和encSecKey,都是经过加密的。看一下返回内容的格式:
好的,我们已经知道了基本的东西,我们可以进入下一步,找到两个解密参数。
分析
在调试之前,我们要找到这两个值的位置,然后搜索,先定位JS文件,然后定位代码位置。您应该知道如何搜索,您可以全局搜索params或encSecKey。如果找到多个结果,不确定是哪个文件,可以进去搜索每个点的关键参数,判断是否是目标文件。这里我直接标记一下,找到正确的文件后就可以点击进入了。
进入JS文件后,同时搜索关键参数params或encSecKey:
找到encSecKey的位置,拉出这几行代码分析一下:
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
e0x.data = j0x.cs1x({
params: bVZ8R.encText,
encSecKey: bVZ8R.encSecKey
})
粗略的讲,params和encSecKey来自bVZ8R.encText和bVZ8R.encSecKey,bVZ8R是window.asrsea的结果,window.asrsea有四个参数,JSON.stringify(i0x), bqN0x(["streaming", "强" ] ), bqN0x(Wx5C.md), bqN0x(["Love", "Girl", "Terrified", "Laughing"],首先看下面三个参数,从它们的固定值,你可以大胆猜想这三个values也是Fixed,之所以说是fixed,看看Wx5C.md:
wx5C.md是固定数组,和bqN0x(["流泪", "强"])和bqN0x(["爱心", "girl", "horrified", "laughing"] 这个结果肯定是没有变化的,如图下面,测试了一下:
大概把这些参数搞清楚了,剩下的就是搞清楚window.asrsea的具体实现,还有i0x是什么样的,进入调试环节。
调试
window.asrsea 到达断点。我的代码位置是13133行,点击下一页粉丝列表会激活断点。在激活断点的同时,我们也可以看到 i0x 的美妙之处。在控制台输入 i0x:
limit、offset、total、userId其实是已知的,csrf_token的生成可以看这里。细心的童鞋早就应该发现了:
i0x["csrf_token"] = v0x.gP3x("__csrf"); ## csrf_token在这里产生
X0x = X0x.replace("api", "weapi");
e0x.method = "post";
delete e0x.query;
var bVZ8R = window.asrsea(JSON.stringify(i0x), bqN0x(["流泪", "强"]), bqN0x(Wx5C.md), bqN0x(["爱心", "女孩", "惊恐", "大笑"]));
我点击进入 v0x.gP3x 函数并查看:
从代码中可以看出csrf_token来自于Cookie中的__csrf:
那么这个值可以在请求网页的时候从cookie中获取,继续调试window.asrsea。一路点击Next进入功能。
跳进ad(d,e,f,g)函数,往下看,发现window.asrsea等于这个d函数,哦,调试一下这个d函数:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
输入一个函数:
可以看出a函数生成随机数,继续运行,进入b函数:
熟悉AES加密,继续运行,进入c函数:
也是大家熟悉的RSA加密,网易可真慎重,各种加密。至此,整体框架已经调试完毕,剩下的无非就是拉取JS代码。
蟒蛇运行
这次不光是跑了结果,还带来了爬取和入库:
获取参数和 encSecKey
def get_enc(self,a):
with open('..//js//wangyiyun.js', encoding='utf-8') as f:
wangyiyun = f.read()
js = execjs.compile(wangyiyun)
logid = js.call('get_pwd', a)
print(logid)
return logid
抓
def get_fans(self):
resp = self.get_home_page()
print(resp.cookies)
print(resp.status_code)
time.sleep(6)
limit = 20
for i in range(1,110):
print("第{}页".format(i+1))
offset = limit*i
a = {"userId": "46991111", "offset": str(offset), "total": "false", "limit": str(limit), "csrf_token": ""}
print(a)
logid = self.get_enc(a)
data = {
"params":logid["encText"],
"encSecKey":logid["encSecKey"],
}
print(data)
fans_url = "https://music.163.com/weapi/us ... ot%3B
resp = self.session.post(url=fans_url,data=data,headers=self.headers)
followed = json.loads(resp.text)
followed_list = []
for foll in followed["followeds"]:
foll_dict = {}
foll_dict["short_name"] = foll.get("py","") #缩写
foll_dict["userId"] = foll.get("userId","") #用户ID
foll_dict["nickname"] = foll.get("nickname","") #昵称
foll_dict["vipType"] = foll.get("vipType","") # vip
foll_dict["eventCount"] = foll.get("eventCount","")#动态
foll_dict["vipRights"] = str(foll.get("vipRights","")) #VIP权益
foll_dict["gender"] = foll.get("gender","") #性别
foll_dict["avatarUrl"] = foll.get("avatarUrl","") #头像
foll_dict["followed"] = foll.get("followed","")
foll_dict["followeds"] = foll.get("followeds","") #粉丝
foll_dict["follows"] = foll.get("follows","") #关注
foll_dict["playlistCount"] = foll.get("playlistCount","") #歌单
foll_dict["mutual"] = foll.get("mutual","") #
foll_dict["expertTags"] = str(foll.get("expertTags",""))
foll_dict["experts"] = str(foll.get("experts",""))
print(foll_dict)
followed_list.append(foll_dict)
self.mysql.insert("music",followed_list)
tm = random.randint(10,30)
time.sleep(tm)
这里需要注意的是,要抓取指定页面,必须先访问该页面,不能直接请求链接”,因为它根本不携带有关哪个页面的信息。
请求特定页面
def get_home_page(self):
url = "https://music.163.com/%23/user ... ot%3B
resp = self.session.get(url)
return resp
来源: 从今天开始种树
作者: 罗华
链接: http://www.happyhong.cn/ni-xiang/10034.html
本文章著作权归作者所有,任何形式的转载都请注明出处。
表结构
@property
def create_table_sql(self):
create_table = """
CREATE TABLE IF NOT EXISTS music (
short_name varchar(30) ,
userId varchar(100) NOT NULL,
nickname varchar(30),
vipType varchar(30) ,
eventCount varchar(200),
vipRights varchar(900),
gender varchar(900),
avatarUrl varchar(200),
followed varchar(30),
followeds varchar(30),
follows varchar(30),
playlistCount varchar(30),
mutual varchar(30),
expertTags varchar(30),
experts varchar(30),
PRIMARY KEY (userId)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
return create_table
仓储
def insert(self,table,data_list):
if len(data_list) > 0:
data_list = [{k: v
for k, v in data.items() if v is not None}
for data in data_list]
keys = ", ".join(data_list[0].keys())
values = ", ".join(["%s"] * len(data_list[0]))
sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
DUPLICATE KEY UPDATE""".format(table=table,
keys=keys,
values=values)
update = ",".join([
" {key} = values({key})".format(key=key)
for key in data_list[0]
])
sql += update
print(sql)
self.connect()
try:
ret = self.cursor.executemany(sql, [tuple(data.values()) for data in data_list])
self.conn.commit()
except Exception as e:
self.conn.rollback()
print("Error: ", e)
traceback.print_exc()
finally:
self.close()
过程
结束
网页抓取解密(前几天学习Python模拟登录知乎实例-几天加密处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-09 15:02
前几天学的Python模拟登录知乎例子,涉及到fromdata的加密处理。在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是自己找了个简单的例子来学习js加密。
一、示例网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑
1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”选项卡。为方便查看,先清空之前的请求流程,然后在网页切换城市即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。
接下来,我们需要考虑如何构造表单数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
我们尝试进入 getAQIData() 方法。
首页查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站给迷惑了,这个方法放在jqury-1.8.0.min.js?v=1.2文件中,并且混淆后,可以使用在线工具进行去混淆,例如:。
使用开发者工具破解调试,进入getServerData方法。
最后,我们看到了Form Data,可以看到内容是通过getParm()方法返回的。
3.密码分析
知道位置后,我们可以直接把这个加密的js方法扣出来,在一个html文件中执行。
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在实施过程中发现返回的内容与前台返回的内容不一致。经过一些查询,
发现得到的加密字符串的内容只与“view decoded”的显示内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
对服务器返回的内容进行解密,最终得到我们想要的数据。
详细代码请到: 查看全部
网页抓取解密(前几天学习Python模拟登录知乎实例-几天加密处理方法)
前几天学的Python模拟登录知乎例子,涉及到fromdata的加密处理。在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是自己找了个简单的例子来学习js加密。
一、示例网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑
1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”选项卡。为方便查看,先清空之前的请求流程,然后在网页切换城市即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。
接下来,我们需要考虑如何构造表单数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
我们尝试进入 getAQIData() 方法。
首页查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站给迷惑了,这个方法放在jqury-1.8.0.min.js?v=1.2文件中,并且混淆后,可以使用在线工具进行去混淆,例如:。
使用开发者工具破解调试,进入getServerData方法。
最后,我们看到了Form Data,可以看到内容是通过getParm()方法返回的。
3.密码分析
知道位置后,我们可以直接把这个加密的js方法扣出来,在一个html文件中执行。
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在实施过程中发现返回的内容与前台返回的内容不一致。经过一些查询,
发现得到的加密字符串的内容只与“view decoded”的显示内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
对服务器返回的内容进行解密,最终得到我们想要的数据。
详细代码请到:
网页抓取解密( Python解决内容乱码问题(decode和encode解码)详解整合)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-08 23:13
Python解决内容乱码问题(decode和encode解码)详解整合)
讲解Python如何解决爬取内容乱码问题(decode和encode解码)
更新时间:2019-03-29 17:11:51 作者:钱冉_
本文文章主要介绍Python解决爬取内容乱码(decode和encode解码)的问题。通过示例代码介绍非常详细。对大家的学习或工作,有需要的朋友有一定的参考学习价值。和小编一起学习
一、乱码问题描述
在爬取或者执行一些操作的时候,经常会出现中文乱码等问题,如下
原因是源网页编码与爬取后的编码格式不一致
二、使用encode和decode解决乱码问题
Python 中字符串的表示是 unicode 编码。编码转换时,通常使用unicode作为中间编码,即其他编码后的字符串先解码为unicode,再由unicode编码(encode)转为另一种编码。
decode的作用是将其他编码后的字符串转为unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转为unicode编码。
encode的作用是将unicode编码转换为其他编码字符串,如str2.encode('utf-8'),表示将unicode编码字符串str2转换为utf-8编码。
decode里面写的是你要抓取的网页的编码,encode是你要设置的编码
代码显示如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但也要注意:
如果一个字符串已经是unicode,再解码就会出错,所以通常需要判断它的编码方式是否是unicode
isinstance(s, unicode)#用于判断是否是unicode
用非unicode编码形式的str进行编码会报错
所以最终可靠的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到需要爬取的目标网页的编码格式
1、查看网页源码
如果源码中没有charset编码格式显示,可以使用下面的方法
2、检查元素,检查响应头
以上就是小编介绍的解决爬取内容乱码问题(decode和encode解码)的Python详细集成。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对脚本之家网站的支持! 查看全部
网页抓取解密(
Python解决内容乱码问题(decode和encode解码)详解整合)
讲解Python如何解决爬取内容乱码问题(decode和encode解码)
更新时间:2019-03-29 17:11:51 作者:钱冉_
本文文章主要介绍Python解决爬取内容乱码(decode和encode解码)的问题。通过示例代码介绍非常详细。对大家的学习或工作,有需要的朋友有一定的参考学习价值。和小编一起学习
一、乱码问题描述
在爬取或者执行一些操作的时候,经常会出现中文乱码等问题,如下
原因是源网页编码与爬取后的编码格式不一致
二、使用encode和decode解决乱码问题
Python 中字符串的表示是 unicode 编码。编码转换时,通常使用unicode作为中间编码,即其他编码后的字符串先解码为unicode,再由unicode编码(encode)转为另一种编码。
decode的作用是将其他编码后的字符串转为unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转为unicode编码。
encode的作用是将unicode编码转换为其他编码字符串,如str2.encode('utf-8'),表示将unicode编码字符串str2转换为utf-8编码。
decode里面写的是你要抓取的网页的编码,encode是你要设置的编码
代码显示如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但也要注意:
如果一个字符串已经是unicode,再解码就会出错,所以通常需要判断它的编码方式是否是unicode
isinstance(s, unicode)#用于判断是否是unicode
用非unicode编码形式的str进行编码会报错
所以最终可靠的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到需要爬取的目标网页的编码格式
1、查看网页源码
如果源码中没有charset编码格式显示,可以使用下面的方法
2、检查元素,检查响应头
以上就是小编介绍的解决爬取内容乱码问题(decode和encode解码)的Python详细集成。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对脚本之家网站的支持!
网页抓取解密(破解企业数据列表的加密数据_data )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-06 00:16
)
打开网站--企业名片
主要是破解企业数据列表的加密,红色圈出
链接:名片
直接请求网站,响应信息中没有想要的数据,应该是js动态加载的数据,所以点击XHR就可以看到
两次请求和响应的信息中都有一个超长的加密字符串,所以我们大胆的猜测一下,应该是我们需要的数据,其他点击什么都没有。
那么如何解析这个参数呢?
解析加密数据 encrypt_data
最简单最直接的方式就是直接在js中根据encrypt_data的key进行搜索,会在下图中找到。
下面是断点,刷新页面,一步一步的找出js里面是怎么解析的。这是最直接的方法。先说正常流程吧。因为它是一个 post 请求,所以你可以命中 XHR 断点。如何打破这个断点?
在源中选择XHR BreakPoint,点击它右上角的加号,在框中填写要中断的URL,或者只有关键词,我填写的productListVIP,然后刷新页面并逐步运行它。找到解密的位置,直接解压js执行js,不用管怎么解密,只需要结果即可。
中断点查找位置
断点时,最好在对象前打断点,否则可能不进入断点直接结束。
刷新,点击下一步
会找到这个方法。这几乎是一样的。可以看到方法中调用了一个s方法。s方法的6个参数中,有5个是固定的,这样就更简单了。只需要找到这个解码方法
找到了,直接传进去,这个t就是我们的加密字符串
回去找到s方法,直接把这些js解压出来,用python执行js库,执行js就OK了
o 方法返回一个对象对象,在 Python 中无法正确接受,因此将其转换为 base64 并返回它。
所以需要稍微改动一下
function my_o(t) {
return new Buffer(s("5e5062e82f15fe4ca9d24bc5", mydecode(t), 0, 0, "012345677890123", 1)).toString("base64")
}
改成这个,其他不变
function mydecode(t) {
var c = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
var f = /[\t\n\f\r ]/g;
var e = (t = String(t).replace(f, "")).length;
e % 4 == 0 && (e = (t = t.replace(/==?$/, "")).length),
(e % 4 == 1 || /[^+a-zA-Z0-9/]/.test(t)) && l("Invalid character: the string to be decoded is not correctly encoded.");
for (var n, r, i = 0, o = "", a = -1; ++a > (-2 * i & 6)));
return o
}
s方法就不贴了,太长了,用execjs执行js,完成
结束!
详细代码可添加微信公众号回复1获取
查看全部
网页抓取解密(破解企业数据列表的加密数据_data
)
打开网站--企业名片
主要是破解企业数据列表的加密,红色圈出
链接:名片
直接请求网站,响应信息中没有想要的数据,应该是js动态加载的数据,所以点击XHR就可以看到
两次请求和响应的信息中都有一个超长的加密字符串,所以我们大胆的猜测一下,应该是我们需要的数据,其他点击什么都没有。
那么如何解析这个参数呢?
解析加密数据 encrypt_data
最简单最直接的方式就是直接在js中根据encrypt_data的key进行搜索,会在下图中找到。
下面是断点,刷新页面,一步一步的找出js里面是怎么解析的。这是最直接的方法。先说正常流程吧。因为它是一个 post 请求,所以你可以命中 XHR 断点。如何打破这个断点?
在源中选择XHR BreakPoint,点击它右上角的加号,在框中填写要中断的URL,或者只有关键词,我填写的productListVIP,然后刷新页面并逐步运行它。找到解密的位置,直接解压js执行js,不用管怎么解密,只需要结果即可。
中断点查找位置
断点时,最好在对象前打断点,否则可能不进入断点直接结束。
刷新,点击下一步
会找到这个方法。这几乎是一样的。可以看到方法中调用了一个s方法。s方法的6个参数中,有5个是固定的,这样就更简单了。只需要找到这个解码方法
找到了,直接传进去,这个t就是我们的加密字符串
回去找到s方法,直接把这些js解压出来,用python执行js库,执行js就OK了
o 方法返回一个对象对象,在 Python 中无法正确接受,因此将其转换为 base64 并返回它。
所以需要稍微改动一下
function my_o(t) {
return new Buffer(s("5e5062e82f15fe4ca9d24bc5", mydecode(t), 0, 0, "012345677890123", 1)).toString("base64")
}
改成这个,其他不变
function mydecode(t) {
var c = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
var f = /[\t\n\f\r ]/g;
var e = (t = String(t).replace(f, "")).length;
e % 4 == 0 && (e = (t = t.replace(/==?$/, "")).length),
(e % 4 == 1 || /[^+a-zA-Z0-9/]/.test(t)) && l("Invalid character: the string to be decoded is not correctly encoded.");
for (var n, r, i = 0, o = "", a = -1; ++a > (-2 * i & 6)));
return o
}
s方法就不贴了,太长了,用execjs执行js,完成
结束!
详细代码可添加微信公众号回复1获取
网页抓取解密(web基础随笔提交数据、账号密码等的脚本语言有那些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-04 19:20
网络基础论文
POST提交数据、账号密码等,加密传输3.接受支持的语言程序、接收的文件类型等....4. Referer起到过渡作用,从一页到另一个A页面5.HttpOnly不会被钓鱼网站盗取cookies,安全等级高,四、写出安全穿透中常用的编码,那些Unicode编码,HTML编码,base64编码,十六进制代码五、burp大概有那些功能模块 Proxy(Proxy 8080,打开proxy可以拦截和修改web应用的数据包 Spider(爬行):抓取web提交的数据资源Scanner(扫描器):扫描Web程序的Vulnerabilities Intruder(入侵):漏洞利用、Web程序模糊测试、暴力破解等。 Repeater(中继器):重放模拟数据包的请求和响应的过程 Sequenecer:检查随机性Web 程序的会话令牌和执行各种测试解码器(解码);解码编码六、静态动态语言区别1.http静态语言,无漏洞,访问速度快,服务端和客户端代码一致(如html)2.php动态语言,可连接数据库实时更新,服务端和客户端代码不一致(如:asp、php、aspx、jsp)七、常见的脚本语言有PHP等
166 查看全部
网页抓取解密(web基础随笔提交数据、账号密码等的脚本语言有那些)
网络基础论文
POST提交数据、账号密码等,加密传输3.接受支持的语言程序、接收的文件类型等....4. Referer起到过渡作用,从一页到另一个A页面5.HttpOnly不会被钓鱼网站盗取cookies,安全等级高,四、写出安全穿透中常用的编码,那些Unicode编码,HTML编码,base64编码,十六进制代码五、burp大概有那些功能模块 Proxy(Proxy 8080,打开proxy可以拦截和修改web应用的数据包 Spider(爬行):抓取web提交的数据资源Scanner(扫描器):扫描Web程序的Vulnerabilities Intruder(入侵):漏洞利用、Web程序模糊测试、暴力破解等。 Repeater(中继器):重放模拟数据包的请求和响应的过程 Sequenecer:检查随机性Web 程序的会话令牌和执行各种测试解码器(解码);解码编码六、静态动态语言区别1.http静态语言,无漏洞,访问速度快,服务端和客户端代码一致(如html)2.php动态语言,可连接数据库实时更新,服务端和客户端代码不一致(如:asp、php、aspx、jsp)七、常见的脚本语言有PHP等
166
网页抓取解密(网易云技能点界面概况静态网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-04 12:01
)
技能点界面概览静态网页
网易云仍然有一些网页,其网址一般会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前后端分离刚刚火起来,当时很多网站并没有太多防备的借口。它让很多网站 很容易得到结果。到目前为止,有很多这样的借口。这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先搞清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不用管的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么我们就知道encText生成的规则了。两次AES cbc加密 偏移量为60708 两个key不同 函数c是RSA加密的三个参数 整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
返回 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里就不一一介绍了。只是中断分析!看看他是如何执行的。
其实抓多次就会发现最后三个参数是固定的(非交互数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用''
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
查看全部
网页抓取解密(网易云技能点界面概况静态网页
)
技能点界面概览静态网页
网易云仍然有一些网页,其网址一般会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前后端分离刚刚火起来,当时很多网站并没有太多防备的借口。它让很多网站 很容易得到结果。到目前为止,有很多这样的借口。这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先搞清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不用管的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么我们就知道encText生成的规则了。两次AES cbc加密 偏移量为60708 两个key不同 函数c是RSA加密的三个参数 整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
返回 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里就不一一介绍了。只是中断分析!看看他是如何执行的。
其实抓多次就会发现最后三个参数是固定的(非交互数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用''
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)

