
网页抓取解密
网页抓取解密(搜索引擎的原理简单分为三段信息抓取、信息处理和查询服务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-10-14 02:00
专利名称:网络信息抓取方法
网络信息抓取方法
技术领域:
本发明涉及搜索引擎领域,尤其涉及一种搜索引擎的网页抓取技术。背景技术:
随着网络通信技术的飞速发展,互联网已经成为一个巨大的分布式信息空间,其中收录着潜在的有价值的知识。网络信息收录许多有用的、潜在的、但不容易发现的知识和模式。人们迫切需要发现和掌握能够获取这些知识和模式的方法和工具。互联网上的信息以网页形式存在,网页之间通过超链接相互连接,形成错综复杂的信息网络。在早期的互联网时代,人们查找信息非常不方便,导致了搜索引擎的出现。搜索引擎采集和发现互联网上的信息,理解、提取、组织和处理信息,为用户提供搜索服务。搜索引擎的原理简单地分为信息捕获、信息处理和查询服务三个部分。信息爬取是通过网络爬虫从一个或多个初始网页的网址中获取初始网页的网络信息,通过不断从当前网页中提取新的网址并放入队列中,获取更多的网页和网页。Internet 上的网络信息,直到满足系统的某个停止条件。信息处理是将网络信息获取后存储在搜索引擎的数据库中,然后对网络信息进行一定的处理,以方便检索。最后,查询服务会根据用户的需要反馈处理后的网络信息。然而,现有技术中搜索引擎处理的最小对象是网页。请参考图。参考图1,其示出了描绘因特网的现有搜索引擎的结构模型100。现有的搜索引擎将互联网的结构模型100描述为网页图模型。网页图100由多个网页节点和超链接边组成。搜索引擎在抓取信息的过程中将每个网页保存为一个网页节点,如图中节点102所示;然后通过超链接将各个网页节点连接为一个关系,如图中的边104所示;整个互联网存储为一个网页地图结构。需要说明的是,网页中的信息并非都是用户希望得到的信息。请参考图。2、图1显示了收录现有技术中的结构化信息块的网页200。网页200包括三部分网站分类导航信息块202、广告等网页200的信息块204和主题部分206。对于绝大多数用户来说,他们想要什么搜索的只是与关键字相关的主题部分206的信息,而对于网站分类导航信息块202和广告等信息204则不关心。像网页200的主题部分206这样的网络信息被称为结构化信息块。结构化信息块是指信息经过分析可以分解为多个相互关联的组件,每个组件都有清晰的层次结构,以及对由数据库管理的网页信息的使用和维护。例如,在关于笔记本的页面中,结构化信息块收录笔记
此“品牌、型号、CPU、内存、硬盘、显示屏……”信息;在有关房地产信息的页面上,其
结构化信息块收录物业的“类型、地区、地址、房型、面积、装修状况、租金、联系人、联系电话等。
话……”信息。可以看出,互联网上有海量的类似信息,用户想要直接获取。
信息。如果搜索引擎在信息抓取过程中使用图1所示的网页结构来描绘互联网,显然会导致查询结果中收录大量无用信息,导致准确率下降。而且,用超链接作为关系来存储各个网页节点之间的关系也是不合逻辑的。由于搜索引擎总是将网页地址作为搜索结果呈现给用户,当用户点击相关结果时,他们很可能就在超链接的旁边。网站是无用的广告网站,与用户的目标和期望相差很大,浪费用户的时间。因此,有必要提出一种新的技术方案来解决上述不足。
发明内容本节的目的是对本发明实施例的几个方面进行总结,并简要介绍一些优选实施例。为避免混淆本部分、说明书摘要和发明名称的目的,本申请部分和说明书摘要和发明名称可能会有所简化或省略,不得使用此类简化或省略以限制本发明的范围。本发明的一个目的是提供一种网络信息的抓取方法,通过该方法,搜索引擎可以抓取互联网中的结构化信息。为实现本发明的目的,根据本发明的一个方面,本发明提供了一种捕获网络信息的方法。并提取其中的结构化信息,将结构化信息存储为当前对象节点;将获取到的网页中的链接地址作为当前URL,继续从当前URL中获取网页,并分析捕获 获取网页并提取其结构化信息,将结构化信息存储为当前对象节点,定义并存储当前对象节点与现有对象节点的关系,重复此操作完成网络信息捕获。此外,有一个或多个初始 URL。更远,分析抓取的网页并提取其中的结构化信息是指提取抓取网页中的结构化信息块或抓取网页中的半结构化信息块和非结构化信息块。将结构化信息块转换为结构化信息块,每个结构化信息块作为一个对象节点。进一步地,可以从爬取的网页中提取一个或多个结构化信息块,每个结构化信息块作为一个对象节点。更远,当前对象节点与现有对象节点关系的定义和存储是指通过当前对象节点中的数据与现有对象节点之间的逻辑或语义关系,定义当前对象节点与现有对象节点之间的关系。现有对象节点和存储。进一步地,当前对象节点与现有对象节点之间关系的定义和存储意味着每次提取当前对象节点时,都必须与现有对象节点定义并存储关系。进一步地,如果不能从被爬取的网页中提取结构化信息,则将被爬取的网页视为伪对象节点。进一步地,网络信息捕获方法捕获的网络信息为对象图。更远,
要点ο与现有技术相比,本发明使用对象图来描绘互联网。搜索引擎处理的最小单位是对象节点,即结构化的信息块,它可以让用户直接获取有用的信息,剔除广告信息。和无用的信息;同时,每个对象节点之间的关系由逻辑或语义关系定义,每个对象节点之间的关系具有一定的逻辑或语义关系,可以使查询结果具有更好的准确率。
结合附图和以下详细描述,本发明将更容易理解,其中相同的附图标记对应相同的结构部件,其中
图1是现有的搜索引擎,描绘了互联网的结构模型;图2为现有技术中收录结构化信息块的网页;图3是本发明实施例中对象图的结构示意图;图4是使用本发明描述的对象图描绘互联网的示意图;和图。图5为本发明网络信息捕获方法一个实施例的方法流程图。
具体实施方式本发明的详细描述通过程序、步骤、逻辑块、流程或其他符号描述直接或间接模拟了本发明技术方案的运行。为了彻底理解本发明,在以下描述中陈述了许多具体细节。没有这些具体细节,本发明仍然可以实现。本领域技术人员在这里使用这些描述和陈述,有效地向本领域的其他技术人员介绍他们的工作性质。换句话说,为了避免混淆本发明的目的,由于众所周知的方法、流程、组件和电路已经很容易理解,因此不再详细描述。此处所称的“一个实施例”或“实施例”是指可包括在本发明的至少一种实施方式中的特定特征、结构或特性。本说明书中不同地方出现的“在一个实施例中”并不均指同一实施例,也不是与其他实施例分离或选择性地相互排斥的实施例。另外,一个或多个实施例的方法、流程图或功能框图中各模块的顺序并不总是指任何具体的顺序,并不构成对本发明的限制。本发明的网络信息采集方法可以通过计算机结合相关程序实现为信息采集模块,位于整个搜索引擎系统的信息抓取位置。在捕获网络信息时,以结构化信息块作为最小处理单元,将互联网描绘成对象图而不是网页图。为突出重点,下面仅对与本发明相关的网络信息采集技术进行说明,搜索引擎系统的其他方面本文不再赘述。
请参考图。参见图3,为本发明实施例中对象图的结构示意图。对象图300还包括图模型的两个基本元素,节点和边。我们定义对象图由若干对象节点(如图,节点304和节点310),以及连接两个对象节点的关系边(如图,边30)组成6)).其中,对象节点代表互联网网页中的结构化信息块,如图所示,网页302中的结构化信息块304为对象节点;主体部分图2中网页200的206为对象节点,在一个实施例中,对象节点可以表示产品的结构化信息,其中可以包括产品名称、产品价格、产品信息和产品产地等信息。在另一个实施例中,对象节点可以表示公司的结构化信息,可以包括公司名称、公司规模、公司注册日期、公司法人等信息。简而言之,对于不同的主题,对象节点可能代表不同的信息。连接两个对象节点的关系边表示两个对象节点之间的关系,通常是两个对象节点所表示的结构化信息的逻辑或语义关系。在一个实施例中,如果两个对象节点A和B所描述的主题是学术论文,则结构化信息可以包括论文的作者、论文出版商、论文发表时间、论文摘要等,
请参考图。请参考图4,其为本发明的对象图描绘互联网的示意图。因特网400包括许多互连的对象图。在一个实施例中,对象图402是与学术论文相关的对象节点和相关关系边的集合。在另一个实施例中,对象图404是代表学校所有人员的信息的集合,其中对象节点代表所有学生、教师和员工的个人信息,可能具有班级、年龄等逻辑关系;在另一个实施例中,对象图406表示一个博客网站的所有博客帖子,其中对象节点表示博客的正文、作者、时间等信息,其中关系端可以是作者的共同点爱好,同一出版时间等。每个对象图可能是一个主题或语义独立的集合,但它们是相互关联的。例如,对象图404中的学生或教师可以是对象图402中学术论文的作者,对象图406中的博客的所有者是对象图404的雇员等。总之,当通过对象图描述互联网时,希望每个对象节点都收录一个逻辑或语义独立的结构化信息块,每个对象节点之间的关系是逻辑或语义关系。显然,当通过对象图描绘互联网时,就相当于搜索引擎对互联网上的信息进行了预筛选和过滤。当用户搜索时,他们可以直接向用户反馈最重要或最想要的信息。请参考图。请参阅图5,其为本发明的网络信息撷取方法500的方法流程图。
方法500包括以下步骤。步骤502,以初始网址作为当前网址,从当前网址抓取网页,对抓取的网页进行分析,提取其中的结构化信息,并将结构化信息作为当前对象节点存储。搜索引擎可以从一个或多个初始 URL 开始抓取网页。网页被抓取后,必须提取网页中的结构化信息作为对象节点。在一个实施例中,在从网页中提取结构化信息之前,可以定义结构化信息模板。同样,如上所述,对于不同的数据主体,结构化信息模板的定义可以完全不同。例如,对于产品信息等主题,结构化信息可以包括产品名称、产品简介和产品。价格、产品信息、产品产地等信息字段。又例如,对于公司信息等主题,结构化信息可以包括公司名称、公司规模、公司注册日期、公司法人等信息字段。定义的结构化信息模板用于在网页中进行遍历搜索。如果网页中的部分数据可以与结构化信息模板匹配,则可以将这部分数据提取为网页中的结构化信息。在另一个实施例中,
在又一实施例中,结合多种网络结构化信息块提取技术,对网页进行综合处理,得到更多结构化信息块作为对象节点。在一个实施例中,如果从当前网页中提取出一个结构化信息,则将其视为当前的一个对象节点;如果从当前网页中提取出两个结构化信息,也将其视为当前两个对象节点,并定义当前两个对象节点之间的关系;如果结构化信息块不是从当前网页中提取出来的,则首先将其存储为伪对象节点。如果图 3 所示的网页 302 图3是商品导购页面,可以提取商品的结构化信息304,形成对象节点304;如果网页308是产品用户评价页面,则无法提取图3所示的网页312的结构。图3包括两个结构化信息块314和316,则形成两个对象节点。步骤504:将抓取到的网页中的链接地址作为当前URL,从当前URL继续抓取网页,分析抓取的网页并提取其结构化信息,并将结构化信息存储为当前URL。对象节点定义并存储当前对象节点与现有对象节点之间的关系,并重复该操作完成网络信息捕获。处理完一个页面后,根据该页面中的链接地址继续获取下一个页面,同时提取结构化信息。特别是,这个页面中的所有链接地址都必须按照一定的策略依次处理。比如可以使用I^ageRank算法的策略进行处理。
如果提取结构化信息块,则将其视为对象节点;如果当前网页没有从结构化信息块中提取出来,则首先将其视为伪对象节点。在一个实施例中,提取的每个新的对象节点都必须定义与现有对象节点的关系,该关系由每个对象节点中的结构化信息的相关数据或属性标签来确定是否收录相同的数据。或者同类型的数据,数据之间是否存在引用和继承关系来判断。例如,在一个实施例中,两个对象节点代表同一品牌的食品,因为两个对象节点的结构化信息包括相同的品牌数据,两个对象节点之间的关系被定义为相同的品牌。重复上面的504步,就可以对互联网上的整个网页进行一次处理,就可以得到一张物件图。我们也可以稍后去除object map中的fake object节点,然后优化object map中的object 节点之间的关系,以获得更准确的object graph。在一个具体实施例中,我们采用上述网络数据采集方法,利用计算机结合相关程序实现信息采集模块,该模块位于移动搜索引擎的信息采集位置,为用户提供吃、住、和运输。对于商品等生活信息的检索,用户输入关键词“无锡咖啡厅”后,他会直接在手机客户端获取无锡咖啡馆的相关信息,没有其他广告信息或无用信息。它不仅可以节省用户的时间,还可以充分利用手机较小的显示屏来显示更多有用的信息。
本发明的网络数据抓取方法的一个特点、优点或好处在于,不是直接抓取整个网页,而是对网页的数据进行分析提取,只抓取部分有用信息,从而使得可以减少存储的数据。也会大大减少,同时可以保证后续搜索更有针对性,搜索结果更准确。通过设置不同的主题,可以有针对性地抓取互联网上的数据,既保证了数据的全面性,又保证了数据的针对性。以上描述已经充分公开了本发明的具体实施例
. 需要指出的是,本领域技术人员已经熟悉本发明的具体实施例
所做的任何改变都不脱离本发明权利要求的范围。相应地,本发明权利要求的范围不限于具体实施例。
.
权限请求
1. 一种网络信息抓取方法,其特征在于以初始URL为当前URL,从当前URL中抓取网页,分析抓取的网页并提取结构化信息,将结构化信息存储为当前对象节点;将抓取到的网页中的一个链接地址作为当前URL,从当前URL继续抓取网页,分析抓取到的网页并提取其结构信息,结构化信息作为当前对象节点,当前对象之间的关系节点和已有的对象节点被定义和存储,重复这个操作完成网络信息的捕获。
2.如权利要求1所述的网络信息捕获方法,其特征在于,所述初始URL为一个或多个。
3.根据权利要求1所述的网络信息爬取方法,其特征在于,对爬取的网页进行分析并提取其中的结构化信息是指从爬取的网页块中提取结构化信息或将半结构化信息块和非结构化信息块进行转换将抓取到的网页中的信息转化为结构化信息块,每个结构化信息块作为一个对象节点。
4.根据权利要求1所述的网络信息爬取方法,其特征在于,可以从爬取的网页中提取一个或多个结构化信息块,每个结构化信息块作为一个对象节点。
5.根据权利要求1所述的网络信息捕获方法,其特征在于,当前对象节点与现有对象节点之间关系的定义和存储是指通过当前对象节点和现有对象节点。数据的逻辑或语义关系定义了当前对象节点与现有对象节点之间的关系并存储。
6.如权利要求1所述的网络信息抓取方法,其特征在于,定义和存储当前对象节点与现有对象节点之间的关系,是指每个当前对象节点都必须与现有对象节点一起提取。存在定义关系并存储它们的对象节点。
7.根据权利要求1所述的网络信息爬取方法,其特征在于,如果不能从被爬取的网页中提取结构化信息,则将被爬取的网页视为伪对象节点。
8.根据权利要求7所述的网络信息捕获方法,其特征在于,所述网络信息捕获方法捕获的网络信息为对象图。
9.根据权利要求8所述的网络信息捕获方法,其特征在于,所述网络信息捕获方法还包括去除获取的对象图中的伪对象节点。
全文摘要
本发明公开了一种网络信息的捕获方法。该方法包括使用初始URL作为当前URL,从当前URL中抓取网页,分析抓取的网页并提取其中的结构化信息,将结构化信息作为当前对象节点存储;将抓取到的网页中的链接地址作为当前网址,从当前网址继续抓取网页,对抓取到的网页进行分析,提取其结构化信息。将结构化信息存储为当前对象节点,定义并存储当前对象节点与现有对象节点之间的关系,重复此操作,完成网络信息捕获。
文件编号 G06F17/30GK102214179SQ20101014413
公布日期 2011 年 10 月 12 日 申请日期 2010 年 4 月 12 日 优先权日期 2010 年 4 月 12 日
发明人梁久珍、白玉钊、胡丽娟申请人: 查看全部
网页抓取解密(搜索引擎的原理简单分为三段信息抓取、信息处理和查询服务)
专利名称:网络信息抓取方法
网络信息抓取方法
技术领域:
本发明涉及搜索引擎领域,尤其涉及一种搜索引擎的网页抓取技术。背景技术:
随着网络通信技术的飞速发展,互联网已经成为一个巨大的分布式信息空间,其中收录着潜在的有价值的知识。网络信息收录许多有用的、潜在的、但不容易发现的知识和模式。人们迫切需要发现和掌握能够获取这些知识和模式的方法和工具。互联网上的信息以网页形式存在,网页之间通过超链接相互连接,形成错综复杂的信息网络。在早期的互联网时代,人们查找信息非常不方便,导致了搜索引擎的出现。搜索引擎采集和发现互联网上的信息,理解、提取、组织和处理信息,为用户提供搜索服务。搜索引擎的原理简单地分为信息捕获、信息处理和查询服务三个部分。信息爬取是通过网络爬虫从一个或多个初始网页的网址中获取初始网页的网络信息,通过不断从当前网页中提取新的网址并放入队列中,获取更多的网页和网页。Internet 上的网络信息,直到满足系统的某个停止条件。信息处理是将网络信息获取后存储在搜索引擎的数据库中,然后对网络信息进行一定的处理,以方便检索。最后,查询服务会根据用户的需要反馈处理后的网络信息。然而,现有技术中搜索引擎处理的最小对象是网页。请参考图。参考图1,其示出了描绘因特网的现有搜索引擎的结构模型100。现有的搜索引擎将互联网的结构模型100描述为网页图模型。网页图100由多个网页节点和超链接边组成。搜索引擎在抓取信息的过程中将每个网页保存为一个网页节点,如图中节点102所示;然后通过超链接将各个网页节点连接为一个关系,如图中的边104所示;整个互联网存储为一个网页地图结构。需要说明的是,网页中的信息并非都是用户希望得到的信息。请参考图。2、图1显示了收录现有技术中的结构化信息块的网页200。网页200包括三部分网站分类导航信息块202、广告等网页200的信息块204和主题部分206。对于绝大多数用户来说,他们想要什么搜索的只是与关键字相关的主题部分206的信息,而对于网站分类导航信息块202和广告等信息204则不关心。像网页200的主题部分206这样的网络信息被称为结构化信息块。结构化信息块是指信息经过分析可以分解为多个相互关联的组件,每个组件都有清晰的层次结构,以及对由数据库管理的网页信息的使用和维护。例如,在关于笔记本的页面中,结构化信息块收录笔记
此“品牌、型号、CPU、内存、硬盘、显示屏……”信息;在有关房地产信息的页面上,其
结构化信息块收录物业的“类型、地区、地址、房型、面积、装修状况、租金、联系人、联系电话等。
话……”信息。可以看出,互联网上有海量的类似信息,用户想要直接获取。
信息。如果搜索引擎在信息抓取过程中使用图1所示的网页结构来描绘互联网,显然会导致查询结果中收录大量无用信息,导致准确率下降。而且,用超链接作为关系来存储各个网页节点之间的关系也是不合逻辑的。由于搜索引擎总是将网页地址作为搜索结果呈现给用户,当用户点击相关结果时,他们很可能就在超链接的旁边。网站是无用的广告网站,与用户的目标和期望相差很大,浪费用户的时间。因此,有必要提出一种新的技术方案来解决上述不足。
发明内容本节的目的是对本发明实施例的几个方面进行总结,并简要介绍一些优选实施例。为避免混淆本部分、说明书摘要和发明名称的目的,本申请部分和说明书摘要和发明名称可能会有所简化或省略,不得使用此类简化或省略以限制本发明的范围。本发明的一个目的是提供一种网络信息的抓取方法,通过该方法,搜索引擎可以抓取互联网中的结构化信息。为实现本发明的目的,根据本发明的一个方面,本发明提供了一种捕获网络信息的方法。并提取其中的结构化信息,将结构化信息存储为当前对象节点;将获取到的网页中的链接地址作为当前URL,继续从当前URL中获取网页,并分析捕获 获取网页并提取其结构化信息,将结构化信息存储为当前对象节点,定义并存储当前对象节点与现有对象节点的关系,重复此操作完成网络信息捕获。此外,有一个或多个初始 URL。更远,分析抓取的网页并提取其中的结构化信息是指提取抓取网页中的结构化信息块或抓取网页中的半结构化信息块和非结构化信息块。将结构化信息块转换为结构化信息块,每个结构化信息块作为一个对象节点。进一步地,可以从爬取的网页中提取一个或多个结构化信息块,每个结构化信息块作为一个对象节点。更远,当前对象节点与现有对象节点关系的定义和存储是指通过当前对象节点中的数据与现有对象节点之间的逻辑或语义关系,定义当前对象节点与现有对象节点之间的关系。现有对象节点和存储。进一步地,当前对象节点与现有对象节点之间关系的定义和存储意味着每次提取当前对象节点时,都必须与现有对象节点定义并存储关系。进一步地,如果不能从被爬取的网页中提取结构化信息,则将被爬取的网页视为伪对象节点。进一步地,网络信息捕获方法捕获的网络信息为对象图。更远,
要点ο与现有技术相比,本发明使用对象图来描绘互联网。搜索引擎处理的最小单位是对象节点,即结构化的信息块,它可以让用户直接获取有用的信息,剔除广告信息。和无用的信息;同时,每个对象节点之间的关系由逻辑或语义关系定义,每个对象节点之间的关系具有一定的逻辑或语义关系,可以使查询结果具有更好的准确率。
结合附图和以下详细描述,本发明将更容易理解,其中相同的附图标记对应相同的结构部件,其中
图1是现有的搜索引擎,描绘了互联网的结构模型;图2为现有技术中收录结构化信息块的网页;图3是本发明实施例中对象图的结构示意图;图4是使用本发明描述的对象图描绘互联网的示意图;和图。图5为本发明网络信息捕获方法一个实施例的方法流程图。
具体实施方式本发明的详细描述通过程序、步骤、逻辑块、流程或其他符号描述直接或间接模拟了本发明技术方案的运行。为了彻底理解本发明,在以下描述中陈述了许多具体细节。没有这些具体细节,本发明仍然可以实现。本领域技术人员在这里使用这些描述和陈述,有效地向本领域的其他技术人员介绍他们的工作性质。换句话说,为了避免混淆本发明的目的,由于众所周知的方法、流程、组件和电路已经很容易理解,因此不再详细描述。此处所称的“一个实施例”或“实施例”是指可包括在本发明的至少一种实施方式中的特定特征、结构或特性。本说明书中不同地方出现的“在一个实施例中”并不均指同一实施例,也不是与其他实施例分离或选择性地相互排斥的实施例。另外,一个或多个实施例的方法、流程图或功能框图中各模块的顺序并不总是指任何具体的顺序,并不构成对本发明的限制。本发明的网络信息采集方法可以通过计算机结合相关程序实现为信息采集模块,位于整个搜索引擎系统的信息抓取位置。在捕获网络信息时,以结构化信息块作为最小处理单元,将互联网描绘成对象图而不是网页图。为突出重点,下面仅对与本发明相关的网络信息采集技术进行说明,搜索引擎系统的其他方面本文不再赘述。
请参考图。参见图3,为本发明实施例中对象图的结构示意图。对象图300还包括图模型的两个基本元素,节点和边。我们定义对象图由若干对象节点(如图,节点304和节点310),以及连接两个对象节点的关系边(如图,边30)组成6)).其中,对象节点代表互联网网页中的结构化信息块,如图所示,网页302中的结构化信息块304为对象节点;主体部分图2中网页200的206为对象节点,在一个实施例中,对象节点可以表示产品的结构化信息,其中可以包括产品名称、产品价格、产品信息和产品产地等信息。在另一个实施例中,对象节点可以表示公司的结构化信息,可以包括公司名称、公司规模、公司注册日期、公司法人等信息。简而言之,对于不同的主题,对象节点可能代表不同的信息。连接两个对象节点的关系边表示两个对象节点之间的关系,通常是两个对象节点所表示的结构化信息的逻辑或语义关系。在一个实施例中,如果两个对象节点A和B所描述的主题是学术论文,则结构化信息可以包括论文的作者、论文出版商、论文发表时间、论文摘要等,
请参考图。请参考图4,其为本发明的对象图描绘互联网的示意图。因特网400包括许多互连的对象图。在一个实施例中,对象图402是与学术论文相关的对象节点和相关关系边的集合。在另一个实施例中,对象图404是代表学校所有人员的信息的集合,其中对象节点代表所有学生、教师和员工的个人信息,可能具有班级、年龄等逻辑关系;在另一个实施例中,对象图406表示一个博客网站的所有博客帖子,其中对象节点表示博客的正文、作者、时间等信息,其中关系端可以是作者的共同点爱好,同一出版时间等。每个对象图可能是一个主题或语义独立的集合,但它们是相互关联的。例如,对象图404中的学生或教师可以是对象图402中学术论文的作者,对象图406中的博客的所有者是对象图404的雇员等。总之,当通过对象图描述互联网时,希望每个对象节点都收录一个逻辑或语义独立的结构化信息块,每个对象节点之间的关系是逻辑或语义关系。显然,当通过对象图描绘互联网时,就相当于搜索引擎对互联网上的信息进行了预筛选和过滤。当用户搜索时,他们可以直接向用户反馈最重要或最想要的信息。请参考图。请参阅图5,其为本发明的网络信息撷取方法500的方法流程图。
方法500包括以下步骤。步骤502,以初始网址作为当前网址,从当前网址抓取网页,对抓取的网页进行分析,提取其中的结构化信息,并将结构化信息作为当前对象节点存储。搜索引擎可以从一个或多个初始 URL 开始抓取网页。网页被抓取后,必须提取网页中的结构化信息作为对象节点。在一个实施例中,在从网页中提取结构化信息之前,可以定义结构化信息模板。同样,如上所述,对于不同的数据主体,结构化信息模板的定义可以完全不同。例如,对于产品信息等主题,结构化信息可以包括产品名称、产品简介和产品。价格、产品信息、产品产地等信息字段。又例如,对于公司信息等主题,结构化信息可以包括公司名称、公司规模、公司注册日期、公司法人等信息字段。定义的结构化信息模板用于在网页中进行遍历搜索。如果网页中的部分数据可以与结构化信息模板匹配,则可以将这部分数据提取为网页中的结构化信息。在另一个实施例中,
在又一实施例中,结合多种网络结构化信息块提取技术,对网页进行综合处理,得到更多结构化信息块作为对象节点。在一个实施例中,如果从当前网页中提取出一个结构化信息,则将其视为当前的一个对象节点;如果从当前网页中提取出两个结构化信息,也将其视为当前两个对象节点,并定义当前两个对象节点之间的关系;如果结构化信息块不是从当前网页中提取出来的,则首先将其存储为伪对象节点。如果图 3 所示的网页 302 图3是商品导购页面,可以提取商品的结构化信息304,形成对象节点304;如果网页308是产品用户评价页面,则无法提取图3所示的网页312的结构。图3包括两个结构化信息块314和316,则形成两个对象节点。步骤504:将抓取到的网页中的链接地址作为当前URL,从当前URL继续抓取网页,分析抓取的网页并提取其结构化信息,并将结构化信息存储为当前URL。对象节点定义并存储当前对象节点与现有对象节点之间的关系,并重复该操作完成网络信息捕获。处理完一个页面后,根据该页面中的链接地址继续获取下一个页面,同时提取结构化信息。特别是,这个页面中的所有链接地址都必须按照一定的策略依次处理。比如可以使用I^ageRank算法的策略进行处理。
如果提取结构化信息块,则将其视为对象节点;如果当前网页没有从结构化信息块中提取出来,则首先将其视为伪对象节点。在一个实施例中,提取的每个新的对象节点都必须定义与现有对象节点的关系,该关系由每个对象节点中的结构化信息的相关数据或属性标签来确定是否收录相同的数据。或者同类型的数据,数据之间是否存在引用和继承关系来判断。例如,在一个实施例中,两个对象节点代表同一品牌的食品,因为两个对象节点的结构化信息包括相同的品牌数据,两个对象节点之间的关系被定义为相同的品牌。重复上面的504步,就可以对互联网上的整个网页进行一次处理,就可以得到一张物件图。我们也可以稍后去除object map中的fake object节点,然后优化object map中的object 节点之间的关系,以获得更准确的object graph。在一个具体实施例中,我们采用上述网络数据采集方法,利用计算机结合相关程序实现信息采集模块,该模块位于移动搜索引擎的信息采集位置,为用户提供吃、住、和运输。对于商品等生活信息的检索,用户输入关键词“无锡咖啡厅”后,他会直接在手机客户端获取无锡咖啡馆的相关信息,没有其他广告信息或无用信息。它不仅可以节省用户的时间,还可以充分利用手机较小的显示屏来显示更多有用的信息。
本发明的网络数据抓取方法的一个特点、优点或好处在于,不是直接抓取整个网页,而是对网页的数据进行分析提取,只抓取部分有用信息,从而使得可以减少存储的数据。也会大大减少,同时可以保证后续搜索更有针对性,搜索结果更准确。通过设置不同的主题,可以有针对性地抓取互联网上的数据,既保证了数据的全面性,又保证了数据的针对性。以上描述已经充分公开了本发明的具体实施例
. 需要指出的是,本领域技术人员已经熟悉本发明的具体实施例
所做的任何改变都不脱离本发明权利要求的范围。相应地,本发明权利要求的范围不限于具体实施例。
.
权限请求
1. 一种网络信息抓取方法,其特征在于以初始URL为当前URL,从当前URL中抓取网页,分析抓取的网页并提取结构化信息,将结构化信息存储为当前对象节点;将抓取到的网页中的一个链接地址作为当前URL,从当前URL继续抓取网页,分析抓取到的网页并提取其结构信息,结构化信息作为当前对象节点,当前对象之间的关系节点和已有的对象节点被定义和存储,重复这个操作完成网络信息的捕获。
2.如权利要求1所述的网络信息捕获方法,其特征在于,所述初始URL为一个或多个。
3.根据权利要求1所述的网络信息爬取方法,其特征在于,对爬取的网页进行分析并提取其中的结构化信息是指从爬取的网页块中提取结构化信息或将半结构化信息块和非结构化信息块进行转换将抓取到的网页中的信息转化为结构化信息块,每个结构化信息块作为一个对象节点。
4.根据权利要求1所述的网络信息爬取方法,其特征在于,可以从爬取的网页中提取一个或多个结构化信息块,每个结构化信息块作为一个对象节点。
5.根据权利要求1所述的网络信息捕获方法,其特征在于,当前对象节点与现有对象节点之间关系的定义和存储是指通过当前对象节点和现有对象节点。数据的逻辑或语义关系定义了当前对象节点与现有对象节点之间的关系并存储。
6.如权利要求1所述的网络信息抓取方法,其特征在于,定义和存储当前对象节点与现有对象节点之间的关系,是指每个当前对象节点都必须与现有对象节点一起提取。存在定义关系并存储它们的对象节点。
7.根据权利要求1所述的网络信息爬取方法,其特征在于,如果不能从被爬取的网页中提取结构化信息,则将被爬取的网页视为伪对象节点。
8.根据权利要求7所述的网络信息捕获方法,其特征在于,所述网络信息捕获方法捕获的网络信息为对象图。
9.根据权利要求8所述的网络信息捕获方法,其特征在于,所述网络信息捕获方法还包括去除获取的对象图中的伪对象节点。
全文摘要
本发明公开了一种网络信息的捕获方法。该方法包括使用初始URL作为当前URL,从当前URL中抓取网页,分析抓取的网页并提取其中的结构化信息,将结构化信息作为当前对象节点存储;将抓取到的网页中的链接地址作为当前网址,从当前网址继续抓取网页,对抓取到的网页进行分析,提取其结构化信息。将结构化信息存储为当前对象节点,定义并存储当前对象节点与现有对象节点之间的关系,重复此操作,完成网络信息捕获。
文件编号 G06F17/30GK102214179SQ20101014413
公布日期 2011 年 10 月 12 日 申请日期 2010 年 4 月 12 日 优先权日期 2010 年 4 月 12 日
发明人梁久珍、白玉钊、胡丽娟申请人:
网页抓取解密( 图片来源网络抓取策略(一)(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-14 01:12
图片来源网络抓取策略(一)(1)_光明网(组图))
图片来源网络
爬取策略
在爬虫系统中,要爬取的URL是一个非常关键的部分。爬虫需要爬取的网页的网址排列在其中,形成一个队列结构。调度器每次从队列的头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被追加到待爬取的URL队列的末尾,从而形成一个爬行循环,整个爬虫系统可以说是由这个队列驱动的。
如何确定要抓取的URL队列中页面URL的顺序?如上所述,新下载页面中收录的链接将附加到队列的末尾。虽然这是一种确定队列的 URL 顺序的方法,但它不是唯一的方法。事实上,可以采用许多其他技术来保持队列等待被捕获。取URL进行排序。爬虫的不同爬取策略使用不同的方法来确定要爬取的 URL 队列中 URL 的优先级。
爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:首先选择重要的网页进行爬取。在爬虫系统中,所谓的网页重要性可以通过不同的方法来判断,但大多是按照网页的流行程度来定义的。
爬取策略的方法虽然有很多,但这里仅列举被证明有效或具有代表性的解决方案,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略、大站优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。搜索引擎爬虫一出现就被采用。新提出的爬取策略往往使用这种方法作为比较的基准。不过值得注意的是,这个策略也是一个非常强大的方法,很多新方法的实际效果不一定比广度优先遍历策略好,所以这个方法其实是很多爬虫采用的第一种爬行策略。
前面说过,“新下载的网页中收录的URL会被追加到待抓取的URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法并没有明确提出和使用网页的重要性作为衡量标准,而是机械地从新下载的网页中提取链接,作为URL的下载顺序附加到待抓取的URL队列中。下图是这个策略的示意图: 假设队列头部的网页是1号网页,从1号网页中提取3个分别指向2号、3号、4号的链接,因此它们按要捕获的数字顺序排列。在取队列中,图中网页的编号为待取队列中页面的序号,
实验表明,这种策略效果很好。虽然看起来很机械,但实际的网络抓取顺序基本上是按照网页的重要性排序的。为此,有研究人员认为,如果一个网页收录多个传入链接,则更容易被广度优先遍历策略及早捕获,而传入链接的数量从侧面反映了该网页的重要性,即,实际的宽度优先遍历策略 以上也暗示了一些网页优先级假设。
广度优先遍历策略
02 PageRank 策略不完整
PageRank 是一种著名的链接分析算法,可用于衡量网页的重要性。自然可以想到使用PageRank的思想来对URL的优先级进行排序。但是这里有一个问题。PageRank 是一种全局算法,这意味着当所有网页都被下载时,计算结果是可靠的。爬虫的目的是下载网页,运行时只能看到部分网页。,所以在爬行阶段的网页无法获得可靠的PageRank分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,将要爬取的URL队列中的URL加入到一个网页集合中,在其中计算PageRank,计算完成后,URL要抓取的队列将排队。里面的网页按照PageRank分数从高到低排序,形成的顺序就是爬虫接下来要爬取的URL列表。这就是为什么它被称为“不完整的 PageRank”。
如果每次抓取一个新的网页,所有下载的网页都重新计算为一个新的不完整的PageRank值,这显然效率太低,在现实中是不可行的。一个折衷的方法是:每当有足够K个新下载的网页时,对所有下载的网页重新计算一个新的不完整PageRank。这种计算效率勉强可以接受,但又带来了一个新问题:在开始下一轮PageRank计算之前,提取新下载网页中收录的链接。很有可能这些链接的重要性非常高,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 会为这些新提取的没有 PageRank 值的网页分配一个临时的 PageRank 值。本网页所有链接内传输的 PageRank 值汇总为临时 PageRank 值。如果这个值大于在要爬取的 URL 队列中计算的值,如果 PageRank 值高的页面出来,那么这个 URL 会先被下载。
下图是不完全PageRank策略的示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{P1,P2,P3},这3个网页中收录的链接指向{P4,P5,P6},形成了待抓取的URL队列。如何决定下载顺序?将这6个网页组成一个新的集合,计算这个集合的PageRank值,让P4、P5和P6得到各自对应的PageRank值,从大到小排序,然后就可以得到下载顺序获得。这里可以假设下载顺序为:P5、P4、P6。当P5页面被下载时,链接被提取并指向页面P8。此时,P8 被分配了一个临时的 PageRank 值。如果这个值大于 P4 和 P6 如果你有一个 PageRank 值,P8 将首先被下载。这样一个连续的循环就形成了不完全PageRank策略的计算思路。
不完全PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明,不完整的 PageRank 结果稍好一些,而一些实验结果则刚好相反。有研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大不同。不应将其作为计算 URL 在爬行过程中的重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC字面意思是“在线页面重要性计算”,可以看作是一种改进的PageRank算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当一个页面P被下载,P就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”分配给“空”。对于URL队列中待抓取的网页,它们是按照手头的现金量排序,现金最多的网页先下载。OPIC在其大框架上与PageRank基本相同。区别在于:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,有一个远程跳转到没有链接关系的网页的过程,而OPIC没有这个计算因素。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略好于广度优先遍历策略。
04 大站优先策略
大站优先策略的思路很简单:以网站为单位来衡量网页的重要性。对于URL队列中待抓取的网页,根据各自的网站进行分类,如果等待下载的是哪个网站,如果页面最多,先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略好于宽度优先遍历策略。
网页更新策略
互联网的动态特性是其显着特征。随时出现新页面,更改页面内容或删除现有页面。对于爬虫来说,并不是在本地抓取网页,即使完成了任务,也必须体现互联网的动态性。本地下载的页面可以看作是互联网页面的“镜子”,爬虫应该尽量保证一致性。可以假设这样一种情况:某个网页被删除或者内容发生了重大变化,搜索引擎仍然不知道这个引擎,仍然按照旧内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取过的网页,
网页更新策略的任务是决定何时重新抓取下载的网页,使本地下载的网页内容尽可能与互联网上的原创网页一致。常用的网页更新策略有3种:历史参考策略、用户体验策略和聚类抽样策略。
01 历史参考策略
历史参考策略是最直观的更新策略。它基于这样一个假设,即过去经常更新的网页在未来也会经常更新。因此,为了估计某个网页的更新时间,可以参考历史更新情况进行判断。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时会再次发生变化,以指导爬虫的抓取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,专注于内容变化检测和建模。优越的。
02用户体验策略
一般来说,搜索引擎用户提交查询后,可能会有上千条相关的搜索结果,但用户没有耐心等待看到排名靠后的搜索结果,可能只看前3页的搜索内容。用户体验策略就是利用用户的这个特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,那么以后更新这些过时的网页也是可以的。因此,判断网页何时更新取决于网页内容的变化(通常以搜索结果排名的变化来衡量)带来的搜索质量的变化。网页的影响越大,应该更新得越快。
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,作为判断爬虫何时重新抓取网页的参考依据。网页的影响越严重,就越优先安排重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略很大程度上依赖于网页的历史更新信息,因为这是后续计算的基础。但实际上,要为每个网页保存历史信息,搜索系统会增加很多额外的负担。从另一个角度来说,如果是第一个被爬取的网页,因为没有历史信息,无法按照这两个思路来估计更新周期。为了解决上述不足,提出了聚类抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测其更新周期。具有相似属性的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,并且同一类别的网页具有相同的更新频率。为了计算某个类别的更新周期,只需对该类别中的网页进行采样,并将这些采样网页的更新周期作为该类别中所有网页的更新周期。与前面介绍的两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,也可以根据所属类别进行更新。
下图描述了集群抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页都有相似的更新周期。从类别中提取出一部分最具代表性的网页(通常是提取离类别中心最近的那些网页),计算这些网页的更新周期,然后将该更新周期用于该类别中的所有网页,然后可以基于网页的类别 确定其更新周期。
聚类抽样策略
网页更新周期的属性特征分为静态特征和动态特征两大类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,例如图像数量的变化、图像数量的变化、链内和链外的变化。等待。基于这两种特征,可以对网页进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,有的研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一网站的网页具有相同的更新周期,则其中的网页网站是Sampling,计算更新周期,然后网站中的所有网页都会遵循这个更新周期。虽然这个假设很粗略,因为很明显同一网站内的网页更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类也非常困难。
如果你对爬虫感兴趣,还可以阅读:
全程干货| 爬虫技术原理入门,看这篇文章就知道了
网络爬虫 | 你不知道的暗网是如何爬取的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗? 查看全部
网页抓取解密(
图片来源网络抓取策略(一)(1)_光明网(组图))

图片来源网络
爬取策略
在爬虫系统中,要爬取的URL是一个非常关键的部分。爬虫需要爬取的网页的网址排列在其中,形成一个队列结构。调度器每次从队列的头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被追加到待爬取的URL队列的末尾,从而形成一个爬行循环,整个爬虫系统可以说是由这个队列驱动的。
如何确定要抓取的URL队列中页面URL的顺序?如上所述,新下载页面中收录的链接将附加到队列的末尾。虽然这是一种确定队列的 URL 顺序的方法,但它不是唯一的方法。事实上,可以采用许多其他技术来保持队列等待被捕获。取URL进行排序。爬虫的不同爬取策略使用不同的方法来确定要爬取的 URL 队列中 URL 的优先级。
爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:首先选择重要的网页进行爬取。在爬虫系统中,所谓的网页重要性可以通过不同的方法来判断,但大多是按照网页的流行程度来定义的。
爬取策略的方法虽然有很多,但这里仅列举被证明有效或具有代表性的解决方案,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略、大站优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。搜索引擎爬虫一出现就被采用。新提出的爬取策略往往使用这种方法作为比较的基准。不过值得注意的是,这个策略也是一个非常强大的方法,很多新方法的实际效果不一定比广度优先遍历策略好,所以这个方法其实是很多爬虫采用的第一种爬行策略。
前面说过,“新下载的网页中收录的URL会被追加到待抓取的URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法并没有明确提出和使用网页的重要性作为衡量标准,而是机械地从新下载的网页中提取链接,作为URL的下载顺序附加到待抓取的URL队列中。下图是这个策略的示意图: 假设队列头部的网页是1号网页,从1号网页中提取3个分别指向2号、3号、4号的链接,因此它们按要捕获的数字顺序排列。在取队列中,图中网页的编号为待取队列中页面的序号,
实验表明,这种策略效果很好。虽然看起来很机械,但实际的网络抓取顺序基本上是按照网页的重要性排序的。为此,有研究人员认为,如果一个网页收录多个传入链接,则更容易被广度优先遍历策略及早捕获,而传入链接的数量从侧面反映了该网页的重要性,即,实际的宽度优先遍历策略 以上也暗示了一些网页优先级假设。
广度优先遍历策略
02 PageRank 策略不完整
PageRank 是一种著名的链接分析算法,可用于衡量网页的重要性。自然可以想到使用PageRank的思想来对URL的优先级进行排序。但是这里有一个问题。PageRank 是一种全局算法,这意味着当所有网页都被下载时,计算结果是可靠的。爬虫的目的是下载网页,运行时只能看到部分网页。,所以在爬行阶段的网页无法获得可靠的PageRank分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,将要爬取的URL队列中的URL加入到一个网页集合中,在其中计算PageRank,计算完成后,URL要抓取的队列将排队。里面的网页按照PageRank分数从高到低排序,形成的顺序就是爬虫接下来要爬取的URL列表。这就是为什么它被称为“不完整的 PageRank”。
如果每次抓取一个新的网页,所有下载的网页都重新计算为一个新的不完整的PageRank值,这显然效率太低,在现实中是不可行的。一个折衷的方法是:每当有足够K个新下载的网页时,对所有下载的网页重新计算一个新的不完整PageRank。这种计算效率勉强可以接受,但又带来了一个新问题:在开始下一轮PageRank计算之前,提取新下载网页中收录的链接。很有可能这些链接的重要性非常高,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 会为这些新提取的没有 PageRank 值的网页分配一个临时的 PageRank 值。本网页所有链接内传输的 PageRank 值汇总为临时 PageRank 值。如果这个值大于在要爬取的 URL 队列中计算的值,如果 PageRank 值高的页面出来,那么这个 URL 会先被下载。
下图是不完全PageRank策略的示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{P1,P2,P3},这3个网页中收录的链接指向{P4,P5,P6},形成了待抓取的URL队列。如何决定下载顺序?将这6个网页组成一个新的集合,计算这个集合的PageRank值,让P4、P5和P6得到各自对应的PageRank值,从大到小排序,然后就可以得到下载顺序获得。这里可以假设下载顺序为:P5、P4、P6。当P5页面被下载时,链接被提取并指向页面P8。此时,P8 被分配了一个临时的 PageRank 值。如果这个值大于 P4 和 P6 如果你有一个 PageRank 值,P8 将首先被下载。这样一个连续的循环就形成了不完全PageRank策略的计算思路。
不完全PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明,不完整的 PageRank 结果稍好一些,而一些实验结果则刚好相反。有研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大不同。不应将其作为计算 URL 在爬行过程中的重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC字面意思是“在线页面重要性计算”,可以看作是一种改进的PageRank算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当一个页面P被下载,P就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”分配给“空”。对于URL队列中待抓取的网页,它们是按照手头的现金量排序,现金最多的网页先下载。OPIC在其大框架上与PageRank基本相同。区别在于:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,有一个远程跳转到没有链接关系的网页的过程,而OPIC没有这个计算因素。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略好于广度优先遍历策略。
04 大站优先策略
大站优先策略的思路很简单:以网站为单位来衡量网页的重要性。对于URL队列中待抓取的网页,根据各自的网站进行分类,如果等待下载的是哪个网站,如果页面最多,先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略好于宽度优先遍历策略。
网页更新策略
互联网的动态特性是其显着特征。随时出现新页面,更改页面内容或删除现有页面。对于爬虫来说,并不是在本地抓取网页,即使完成了任务,也必须体现互联网的动态性。本地下载的页面可以看作是互联网页面的“镜子”,爬虫应该尽量保证一致性。可以假设这样一种情况:某个网页被删除或者内容发生了重大变化,搜索引擎仍然不知道这个引擎,仍然按照旧内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取过的网页,
网页更新策略的任务是决定何时重新抓取下载的网页,使本地下载的网页内容尽可能与互联网上的原创网页一致。常用的网页更新策略有3种:历史参考策略、用户体验策略和聚类抽样策略。
01 历史参考策略
历史参考策略是最直观的更新策略。它基于这样一个假设,即过去经常更新的网页在未来也会经常更新。因此,为了估计某个网页的更新时间,可以参考历史更新情况进行判断。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时会再次发生变化,以指导爬虫的抓取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,专注于内容变化检测和建模。优越的。
02用户体验策略
一般来说,搜索引擎用户提交查询后,可能会有上千条相关的搜索结果,但用户没有耐心等待看到排名靠后的搜索结果,可能只看前3页的搜索内容。用户体验策略就是利用用户的这个特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,那么以后更新这些过时的网页也是可以的。因此,判断网页何时更新取决于网页内容的变化(通常以搜索结果排名的变化来衡量)带来的搜索质量的变化。网页的影响越大,应该更新得越快。
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,作为判断爬虫何时重新抓取网页的参考依据。网页的影响越严重,就越优先安排重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略很大程度上依赖于网页的历史更新信息,因为这是后续计算的基础。但实际上,要为每个网页保存历史信息,搜索系统会增加很多额外的负担。从另一个角度来说,如果是第一个被爬取的网页,因为没有历史信息,无法按照这两个思路来估计更新周期。为了解决上述不足,提出了聚类抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测其更新周期。具有相似属性的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,并且同一类别的网页具有相同的更新频率。为了计算某个类别的更新周期,只需对该类别中的网页进行采样,并将这些采样网页的更新周期作为该类别中所有网页的更新周期。与前面介绍的两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,也可以根据所属类别进行更新。
下图描述了集群抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页都有相似的更新周期。从类别中提取出一部分最具代表性的网页(通常是提取离类别中心最近的那些网页),计算这些网页的更新周期,然后将该更新周期用于该类别中的所有网页,然后可以基于网页的类别 确定其更新周期。
聚类抽样策略
网页更新周期的属性特征分为静态特征和动态特征两大类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,例如图像数量的变化、图像数量的变化、链内和链外的变化。等待。基于这两种特征,可以对网页进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,有的研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一网站的网页具有相同的更新周期,则其中的网页网站是Sampling,计算更新周期,然后网站中的所有网页都会遵循这个更新周期。虽然这个假设很粗略,因为很明显同一网站内的网页更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类也非常困难。
如果你对爬虫感兴趣,还可以阅读:
全程干货| 爬虫技术原理入门,看这篇文章就知道了
网络爬虫 | 你不知道的暗网是如何爬取的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗?
网页抓取解密(requestheaders属性简介压缩方法语言,以及服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-13 17:42
2、 服务器返回加密后的公钥,通常是SSL证书;
3、客户端从这个SSL证书中解析出公钥,随机生成一个密钥,用公钥加密后发送给服务器(这一步是安全的,因为只有服务器有私钥读取密钥);
4、服务器通过私钥解密密钥;
5、 客户端使用这个密钥对要传输的数据进行加密;
6、 服务器使用密钥解析数据。
(三)在网页上请求和返回
打开任意一个网页,F12,选择网络,清除刷新,就会出来一系列的请求数据。
头部是网络协议请求和对应的核心,它携带客户端浏览器、请求页面、服务器等信息。
请求头可以理解为用于在请求消息中向服务器传递附加信息,包括客户端可以接受的数据类型、压缩方式、语言,以及客户端计算机上保留的信息和发出的超链接源地址请求。下面是对请求头属性的介绍:
请求头属性介绍
响应头可以理解为用于在http请求中从服务器向浏览器传递额外的信息,主要包括服务器传递的数据类型、使用的压缩方式、语言、服务器和浏览器的信息响应请求的时间。以下是响应属性:
响应头属性介绍
页面数据的获取其实就是客户端向服务器发送请求,然后服务器根据请求返回数据的过程。这也是爬取数据的基本原理。
(四)ForeSpider爬虫工作流程
1.获取网页数据
爬虫对页面的获取,其实就是获取网页的源代码,然后从中提取出我们想要的数据。
ForeSpider爬虫工具中已经内置了爬虫脚本框架,您只需在爬虫软件中按照手动点击进入页面的流程进行配置即可。
案例一:采集凤凰日报
手动:打开网站→点击新闻列表中的一条新闻→打开新闻查看数据。
爬虫:创建任务→提取新闻列表链接→提取数据。
如下所示:
创建任务
提取列表链接
检索数据
案例二:采集孔子旧书网所有分类旧书信息
手册:选择图书类别→点击类别图书列表中的图书→打开图书界面查看数据。
爬虫:提取所有类别链接→提取类别的所有列表链接→提取数据。
提取所有类别链接
提取类别中的所有列表链接
提取产品数据
提取结果显示
2.采集数据
配置好爬虫后,点击启动采集。以案例2为例,如下图所示:
数据采集接口
采集数据到
3. 导出数据
采集数据整理好后,可以直接将数据导出为csv/excel格式。
导出数据
导出数据表 查看全部
网页抓取解密(requestheaders属性简介压缩方法语言,以及服务器)
2、 服务器返回加密后的公钥,通常是SSL证书;
3、客户端从这个SSL证书中解析出公钥,随机生成一个密钥,用公钥加密后发送给服务器(这一步是安全的,因为只有服务器有私钥读取密钥);
4、服务器通过私钥解密密钥;
5、 客户端使用这个密钥对要传输的数据进行加密;
6、 服务器使用密钥解析数据。
(三)在网页上请求和返回
打开任意一个网页,F12,选择网络,清除刷新,就会出来一系列的请求数据。
头部是网络协议请求和对应的核心,它携带客户端浏览器、请求页面、服务器等信息。
请求头可以理解为用于在请求消息中向服务器传递附加信息,包括客户端可以接受的数据类型、压缩方式、语言,以及客户端计算机上保留的信息和发出的超链接源地址请求。下面是对请求头属性的介绍:
请求头属性介绍
响应头可以理解为用于在http请求中从服务器向浏览器传递额外的信息,主要包括服务器传递的数据类型、使用的压缩方式、语言、服务器和浏览器的信息响应请求的时间。以下是响应属性:
响应头属性介绍
页面数据的获取其实就是客户端向服务器发送请求,然后服务器根据请求返回数据的过程。这也是爬取数据的基本原理。
(四)ForeSpider爬虫工作流程
1.获取网页数据
爬虫对页面的获取,其实就是获取网页的源代码,然后从中提取出我们想要的数据。
ForeSpider爬虫工具中已经内置了爬虫脚本框架,您只需在爬虫软件中按照手动点击进入页面的流程进行配置即可。
案例一:采集凤凰日报
手动:打开网站→点击新闻列表中的一条新闻→打开新闻查看数据。
爬虫:创建任务→提取新闻列表链接→提取数据。
如下所示:
创建任务
提取列表链接
检索数据
案例二:采集孔子旧书网所有分类旧书信息
手册:选择图书类别→点击类别图书列表中的图书→打开图书界面查看数据。
爬虫:提取所有类别链接→提取类别的所有列表链接→提取数据。
提取所有类别链接
提取类别中的所有列表链接
提取产品数据
提取结果显示
2.采集数据
配置好爬虫后,点击启动采集。以案例2为例,如下图所示:
数据采集接口
采集数据到
3. 导出数据
采集数据整理好后,可以直接将数据导出为csv/excel格式。
导出数据
导出数据表
网页抓取解密(网易云技能点界面概况静态网页(一)_软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-13 17:38
技能点界面概览
静态页面
网易云仍然有一些网页,其网址通常会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。目前这样的借口有很多,这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分辨率
step1:找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
查了一下这个js里面的encSecKey,发现是这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先弄清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么encText生成的规则就很清楚了us.Twice.AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点明白了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你想到的参数原来是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_+songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
源码github地址索要Star。 查看全部
网页抓取解密(网易云技能点界面概况静态网页(一)_软件)
技能点界面概览
静态页面
网易云仍然有一些网页,其网址通常会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。目前这样的借口有很多,这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分辨率
step1:找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
查了一下这个js里面的encSecKey,发现是这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先弄清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么encText生成的规则就很清楚了us.Twice.AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点明白了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你想到的参数原来是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_+songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
源码github地址索要Star。
网页抓取解密(Response.spiders.Selector.Spider.start_urls核心工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-13 17:35
环境准备:使用pip安装lxml和scrapyscrapy startproject amazon_comment,创建一个名为amazon_comment的scrapy爬虫项目。 scrapy的核心工作流程:在scrapy.spiders.Spider中有一个变量start_urls,它是一个数组类型,表示我们需要让爬虫从哪些链接开始爬取。 Spider会使用start_urls中的链接,用默认的回调函数parse生成一个Request,然后使用链接进行HTTP请求,获取HTTP响应内容,封装成Response对象,然后将Response对象作为参数传递到回调函数解析。 Spider 中的第一个 Request 是通过调用 start_requests() 方法获得的。 start_requests() 方法默认由 Spider 实现。我们一般不需要实现这个方法。在start_requests()方法中,Request请求是通过读取start_urls中的链接生成的,默认使用parse作为回调函数。获得Response对象后,我们可以重写回调函数:parse方法,或者在生成Request时指定我们想要的任何回调函数。
这样,Response就会作为参数传入我们指定的回调函数中(默认是parse方法)。然后,我们就可以在我们设置的回调函数中从Response对象中解析返回的网页header内容和网页body内容。最常见的就是使用scrapy提供的scrapy.selector.Selector从网页正文中提取我们想要的网页内容。我们设置的回调函数可以返回一个Item对象,或者一个dict,或者一个Request对象,或者一个收录这三样东西的可迭代对象。在使用 Selector 提取网页内容时,最常见的一种是使用 xpath 语法在网页中定位和提取我们想要的数据。如果回调函数返回一个Request对象,那么这个Request对象会被Scrapy处理(发送请求,得到Response,传递给回调函数进行处理)。如果我们设置的回调函数返回的是Item对象,那么scrapy会将Item传递给我们在scrapy中定义的Item Pipeline进行处理。因此,我们一般要实现ItemPipeline。最常见的是将 Item 对象放入 Item Pipeline 中。格式化成我们想要的格式,然后持久化到数据库中。
当我们实现scrapy.spiders.Spider时:
如果不需要登录,不需要设置header,而且只通过一个URL就可以访问一个网页,那么在scrapy.spiders的Spider类中,可以覆盖解析(响应)方法。
<p>如果不需要登录,需要设置header(一般设置User-Agent和Referer),以及通过url可以访问的网页,然后重写parse(response)方法,然后在scrapy.spiders的Spider类中,重写start_requests()方法,返回一个scrapy.http.Request对象,在该方法中设置了headers参数。 Request 对象还可以设置回调。如果设置了回调,start_requests方法返回Request对象后,scrapy会根据Request发起请求,获取scrapy.http.Response对象,然后将Response对象作为参数传递给回调方法,然后执行回调方法;如果没有设置回调,那么scrapy会根据Request发起请求,获取scrapy.http.Response对象,然后将Response对象作为参数传递给parse方法,然后执行parse方法。 查看全部
网页抓取解密(Response.spiders.Selector.Spider.start_urls核心工作流程)
环境准备:使用pip安装lxml和scrapyscrapy startproject amazon_comment,创建一个名为amazon_comment的scrapy爬虫项目。 scrapy的核心工作流程:在scrapy.spiders.Spider中有一个变量start_urls,它是一个数组类型,表示我们需要让爬虫从哪些链接开始爬取。 Spider会使用start_urls中的链接,用默认的回调函数parse生成一个Request,然后使用链接进行HTTP请求,获取HTTP响应内容,封装成Response对象,然后将Response对象作为参数传递到回调函数解析。 Spider 中的第一个 Request 是通过调用 start_requests() 方法获得的。 start_requests() 方法默认由 Spider 实现。我们一般不需要实现这个方法。在start_requests()方法中,Request请求是通过读取start_urls中的链接生成的,默认使用parse作为回调函数。获得Response对象后,我们可以重写回调函数:parse方法,或者在生成Request时指定我们想要的任何回调函数。
这样,Response就会作为参数传入我们指定的回调函数中(默认是parse方法)。然后,我们就可以在我们设置的回调函数中从Response对象中解析返回的网页header内容和网页body内容。最常见的就是使用scrapy提供的scrapy.selector.Selector从网页正文中提取我们想要的网页内容。我们设置的回调函数可以返回一个Item对象,或者一个dict,或者一个Request对象,或者一个收录这三样东西的可迭代对象。在使用 Selector 提取网页内容时,最常见的一种是使用 xpath 语法在网页中定位和提取我们想要的数据。如果回调函数返回一个Request对象,那么这个Request对象会被Scrapy处理(发送请求,得到Response,传递给回调函数进行处理)。如果我们设置的回调函数返回的是Item对象,那么scrapy会将Item传递给我们在scrapy中定义的Item Pipeline进行处理。因此,我们一般要实现ItemPipeline。最常见的是将 Item 对象放入 Item Pipeline 中。格式化成我们想要的格式,然后持久化到数据库中。
当我们实现scrapy.spiders.Spider时:
如果不需要登录,不需要设置header,而且只通过一个URL就可以访问一个网页,那么在scrapy.spiders的Spider类中,可以覆盖解析(响应)方法。
<p>如果不需要登录,需要设置header(一般设置User-Agent和Referer),以及通过url可以访问的网页,然后重写parse(response)方法,然后在scrapy.spiders的Spider类中,重写start_requests()方法,返回一个scrapy.http.Request对象,在该方法中设置了headers参数。 Request 对象还可以设置回调。如果设置了回调,start_requests方法返回Request对象后,scrapy会根据Request发起请求,获取scrapy.http.Response对象,然后将Response对象作为参数传递给回调方法,然后执行回调方法;如果没有设置回调,那么scrapy会根据Request发起请求,获取scrapy.http.Response对象,然后将Response对象作为参数传递给parse方法,然后执行parse方法。
网页抓取解密([Asm]纯文本驱动程序-2016年第三次模拟考试 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-13 14:14
)
[Asm] 纯文本视图复制代码
from selenium import webdriver
import time,re
start_url = "https://www.jijikb.com/play/52825-0-1.html" #一共5集
def get_start_m3u8(url):
#-----------------------------------------------------------------------------------------------------------------------
# chrome_options = webdriver.ChromeOptions()
# # 添加浏览器参数
# # 添加UA
# chrome_options.add_argument(
# 'User-Agent: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"'
# )
# # 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
# chrome_options.add_argument('--headless')
# # 以最高权限运行
# chrome_options.add_argument('--no-sandbox')
# chrome_options.add_argument("--disable-gpu")
# chrome_options.add_argument("--disable-dev-shm-usage")
# # 设置开发者模式启动,该模式下webdriver属性为正常值
# chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# driver = webdriver.Chrome(chrome_options= chrome_options)
#-----------------------------------------------------------------------------------------------------------------------
#创建浏览器对象
driver =webdriver.Chrome()
driver.get(start_url)
driver.find_element_by_id("details-button").click()
time.sleep(0.5)
driver.find_element_by_id('proceed-link').click()
time.sleep(1)
response = driver .page_source #获取首页的响应数据 首页有debuger 调试验证 用selenium 跳过
# print(response)
start_m3u8 = re.findall(r'id="forbaiducache">(.*?)',response)[0]
print(start_m3u8)
time.sleep(0.5)
print(driver.title)
driver.quit() #退出浏览器
return start_m3u8
if __name__ == '__main__':
get_start_m3u8(start_url)
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- -----------------------------------------
[Asm] 纯文本视图复制代码
import timeimport requests,os
import urllib3
import urllib.request
from startm3u8 import get_start_m3u8
import asyncio
import aiofile
import aiohttp
# start_url = "https://www.jijikb.com/play/52825-0-1.html" #一共5集
secend_m3u8 = "https://vod4.buycar5.cn/202106 ... ot%3B
headers = {
'Referer': 'https://vod4.buycar5.cn/',
'host':'vod4.buycar5.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
}
def response(url):
rep = requests.get(url=url,headers=headers,timeout = 20,verify =False) #使用Python3 requests发送HTTPS请求,已经关闭认证(verify=False)情况下,控制台会输出以下InsecureRequestWarning
rep.encoding = rep.apparent_encoding
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) ## 禁用安全请求警告
if rep.status_code == 200:
return rep
else:
print("----没有响应----")
def get_second_m3u8_url(url):
rep = requests.get(url)
print(rep)
with open('first.m3u8','w') as f:
f.write(rep.text)
with open('first.m3u8',"r") as r_f:
for line in r_f:
if line.startswith("#"):
continue
start_m3u8_url = "https://vod4.buycar5.cn" + line
return start_m3u8_url
def get_tc_url(resp):
with open('secend.m3u8', 'wb') as f:
f.write(resp)
tc_urls = []
with open('secend.m3u8',"r") as r_f:
for n in r_f:
if n.startswith("#"):
continue
else:
print(n)
tc_urls.append(n)
return tc_urls
async def mov_down(url,semaphore):
async with semaphore:
async with aiohttp.ClientSession() as session:
tc_name = url.split('/')[-1].strip()
print(tc_name,"---正在下载-----")
async with await session.get(url,headers=headers) as rep:
print(rep.status)
async with aiofile.async_open("mov2/"+tc_name,'wb') as p_f:
print("-----正在存储------")
rep1 = await rep.read()
await p_f.write(rep1)
print(tc_name,'----下载完成---')
"""
urllib.request.urlopen(url, data=None, [timeout, ])
传入的url就是你想抓取的地址;
data是指向服务器提交信息时传递的字典形式的信息,通常来说就是爬去需要登录的网址时传入的用户名和密码,可省略。
timeout参数指的是超时时间,也可省略。
"""
def main():
semaphore = asyncio.Semaphore(100) # 限制并发量为20
start_time = time.time()
if not os.path.exists('mov2'):
os.mkdir("mov2")
start_m3u8_url = get_start_m3u8(start_url)
secend_m3u8_url = get_second_m3u8_url(start_m3u8_url)
print(secend_m3u8_url)
resp = urllib.request.urlopen(secend_m3u8_url).read()
# resp =requests.get(url=secend_m3u8_url,headers=headers) #不知道为什么requests 请求不到
tc_urls = get_tc_url(resp)
tasks = []
for url in tc_urls:
task =asyncio.ensure_future(mov_down(url,semaphore))
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
print(time.time()-start_time)
if __name__ == '__main__':
loop = asyncio.get_event_loop() #建立事件循环
main()
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------
[Asm] 纯文本视图复制代码
import asyncioimport os,re
import requests
import aiofiles
from Crypto.Cipher import AES
#pycryptodome模块
# key_url = "https://ts4.chinalincoln.com:9 ... ot%3B
headers = {
'Referer': 'https://vod4.buycar5.cn/',
'host': 'vod4.buycar5.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
}
def get_key_url():
with open('secend.m3u8','r') as f:
ke = f.read()
key_url = re.findall(r'#EXT-X-KEY:METHOD=AES-128,URI="(?P.*?)"',str(ke))[0]
print(key_url)
return key_url
async def aio_dec(key): # METHOD=AES-128
#解密
tasks = []
print("-------1------")
with open("secend.m3u8",'r') as f:
for line in f:
if line.startswith("#"):
continue
line = line.split('/')[-1].strip()
#开始创建异步任务
print(line)
task = asyncio.ensure_future(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
# loop.run_until_complete(asyncio.wait(tasks))
# loop.close()
async def dec_ts(name,key): #解密
aes = AES.new(key=key,IV=b"0000000000000000",mode=AES.MODE_CBC) #IV偏移量 key多少位就是多少位前面写b
# print(aes)
async with aiofiles.open(f'mov2/{name}','rb') as f1:
bs= await f1.read() # 从原文件读取内容
print("-----2----")
async with aiofiles.open(f'mov2/temp_{name}','wb') as f2:
await f2.write(aes.decrypt(bs)) #解密好的内容用存入文件
os.remove(f'mov2/{name}')
print("-----3----")
print(f'{name}处理完毕')
def merge_ts(): #合并
#mac: cat 1.ts 2.ts 3.ts > xxx.mp4
#windows: copy/b 1.ts +2.ts +3.ts ... xxx.mp4
#copy /b 命令格式:copy /b 文件1+文件2+......文件N 合并后的文件名<BR>命令讲解:使用"+"将多个相同或不同格式的文件合并为一个文件。
lst = []
with open('secend.m3u8',mode="r",encoding='utf-8') as p_f:
for line in p_f:
if line.startswith("#"):
continue
line = line.split('/')[-1].strip()
lst.append(line)
s = "".join(lst)
os.system(f"copy /b {s} movie.mp4")
print("")
if __name__ == '__main__':
# loop = asyncio.get_event_loop()
key_url = get_key_url()
key = requests.get(url=key_url, headers=headers).text
# key ='39f98d719dbdfbde'
key = key.encode("utf-8")
print(key)
asyncio.run(aio_dec(key)) 查看全部
网页抓取解密([Asm]纯文本驱动程序-2016年第三次模拟考试
)
[Asm] 纯文本视图复制代码
from selenium import webdriver
import time,re
start_url = "https://www.jijikb.com/play/52825-0-1.html" #一共5集
def get_start_m3u8(url):
#-----------------------------------------------------------------------------------------------------------------------
# chrome_options = webdriver.ChromeOptions()
# # 添加浏览器参数
# # 添加UA
# chrome_options.add_argument(
# 'User-Agent: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"'
# )
# # 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
# chrome_options.add_argument('--headless')
# # 以最高权限运行
# chrome_options.add_argument('--no-sandbox')
# chrome_options.add_argument("--disable-gpu")
# chrome_options.add_argument("--disable-dev-shm-usage")
# # 设置开发者模式启动,该模式下webdriver属性为正常值
# chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# driver = webdriver.Chrome(chrome_options= chrome_options)
#-----------------------------------------------------------------------------------------------------------------------
#创建浏览器对象
driver =webdriver.Chrome()
driver.get(start_url)
driver.find_element_by_id("details-button").click()
time.sleep(0.5)
driver.find_element_by_id('proceed-link').click()
time.sleep(1)
response = driver .page_source #获取首页的响应数据 首页有debuger 调试验证 用selenium 跳过
# print(response)
start_m3u8 = re.findall(r'id="forbaiducache">(.*?)',response)[0]
print(start_m3u8)
time.sleep(0.5)
print(driver.title)
driver.quit() #退出浏览器
return start_m3u8
if __name__ == '__main__':
get_start_m3u8(start_url)
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- -----------------------------------------
[Asm] 纯文本视图复制代码
import timeimport requests,os
import urllib3
import urllib.request
from startm3u8 import get_start_m3u8
import asyncio
import aiofile
import aiohttp
# start_url = "https://www.jijikb.com/play/52825-0-1.html" #一共5集
secend_m3u8 = "https://vod4.buycar5.cn/202106 ... ot%3B
headers = {
'Referer': 'https://vod4.buycar5.cn/',
'host':'vod4.buycar5.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
}
def response(url):
rep = requests.get(url=url,headers=headers,timeout = 20,verify =False) #使用Python3 requests发送HTTPS请求,已经关闭认证(verify=False)情况下,控制台会输出以下InsecureRequestWarning
rep.encoding = rep.apparent_encoding
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) ## 禁用安全请求警告
if rep.status_code == 200:
return rep
else:
print("----没有响应----")
def get_second_m3u8_url(url):
rep = requests.get(url)
print(rep)
with open('first.m3u8','w') as f:
f.write(rep.text)
with open('first.m3u8',"r") as r_f:
for line in r_f:
if line.startswith("#"):
continue
start_m3u8_url = "https://vod4.buycar5.cn" + line
return start_m3u8_url
def get_tc_url(resp):
with open('secend.m3u8', 'wb') as f:
f.write(resp)
tc_urls = []
with open('secend.m3u8',"r") as r_f:
for n in r_f:
if n.startswith("#"):
continue
else:
print(n)
tc_urls.append(n)
return tc_urls
async def mov_down(url,semaphore):
async with semaphore:
async with aiohttp.ClientSession() as session:
tc_name = url.split('/')[-1].strip()
print(tc_name,"---正在下载-----")
async with await session.get(url,headers=headers) as rep:
print(rep.status)
async with aiofile.async_open("mov2/"+tc_name,'wb') as p_f:
print("-----正在存储------")
rep1 = await rep.read()
await p_f.write(rep1)
print(tc_name,'----下载完成---')
"""
urllib.request.urlopen(url, data=None, [timeout, ])
传入的url就是你想抓取的地址;
data是指向服务器提交信息时传递的字典形式的信息,通常来说就是爬去需要登录的网址时传入的用户名和密码,可省略。
timeout参数指的是超时时间,也可省略。
"""
def main():
semaphore = asyncio.Semaphore(100) # 限制并发量为20
start_time = time.time()
if not os.path.exists('mov2'):
os.mkdir("mov2")
start_m3u8_url = get_start_m3u8(start_url)
secend_m3u8_url = get_second_m3u8_url(start_m3u8_url)
print(secend_m3u8_url)
resp = urllib.request.urlopen(secend_m3u8_url).read()
# resp =requests.get(url=secend_m3u8_url,headers=headers) #不知道为什么requests 请求不到
tc_urls = get_tc_url(resp)
tasks = []
for url in tc_urls:
task =asyncio.ensure_future(mov_down(url,semaphore))
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
print(time.time()-start_time)
if __name__ == '__main__':
loop = asyncio.get_event_loop() #建立事件循环
main()
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------
[Asm] 纯文本视图复制代码
import asyncioimport os,re
import requests
import aiofiles
from Crypto.Cipher import AES
#pycryptodome模块
# key_url = "https://ts4.chinalincoln.com:9 ... ot%3B
headers = {
'Referer': 'https://vod4.buycar5.cn/',
'host': 'vod4.buycar5.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
}
def get_key_url():
with open('secend.m3u8','r') as f:
ke = f.read()
key_url = re.findall(r'#EXT-X-KEY:METHOD=AES-128,URI="(?P.*?)"',str(ke))[0]
print(key_url)
return key_url
async def aio_dec(key): # METHOD=AES-128
#解密
tasks = []
print("-------1------")
with open("secend.m3u8",'r') as f:
for line in f:
if line.startswith("#"):
continue
line = line.split('/')[-1].strip()
#开始创建异步任务
print(line)
task = asyncio.ensure_future(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
# loop.run_until_complete(asyncio.wait(tasks))
# loop.close()
async def dec_ts(name,key): #解密
aes = AES.new(key=key,IV=b"0000000000000000",mode=AES.MODE_CBC) #IV偏移量 key多少位就是多少位前面写b
# print(aes)
async with aiofiles.open(f'mov2/{name}','rb') as f1:
bs= await f1.read() # 从原文件读取内容
print("-----2----")
async with aiofiles.open(f'mov2/temp_{name}','wb') as f2:
await f2.write(aes.decrypt(bs)) #解密好的内容用存入文件
os.remove(f'mov2/{name}')
print("-----3----")
print(f'{name}处理完毕')
def merge_ts(): #合并
#mac: cat 1.ts 2.ts 3.ts > xxx.mp4
#windows: copy/b 1.ts +2.ts +3.ts ... xxx.mp4
#copy /b 命令格式:copy /b 文件1+文件2+......文件N 合并后的文件名<BR>命令讲解:使用"+"将多个相同或不同格式的文件合并为一个文件。
lst = []
with open('secend.m3u8',mode="r",encoding='utf-8') as p_f:
for line in p_f:
if line.startswith("#"):
continue
line = line.split('/')[-1].strip()
lst.append(line)
s = "".join(lst)
os.system(f"copy /b {s} movie.mp4")
print("")
if __name__ == '__main__':
# loop = asyncio.get_event_loop()
key_url = get_key_url()
key = requests.get(url=key_url, headers=headers).text
# key ='39f98d719dbdfbde'
key = key.encode("utf-8")
print(key)
asyncio.run(aio_dec(key))
网页抓取解密( 网站制作网站后还需要做哪些工作才可以让自己的网站在百度可以被搜索到呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-10-12 12:04
网站制作网站后还需要做哪些工作才可以让自己的网站在百度可以被搜索到呢)
当我们使用搜索引擎搜索某些产品时,会显示很多公司或个人的网站。网站的这种显示效果是如何产生的?网站制作网站后,我需要做什么工作才能让我的网站在百度上可以搜索到?下面为大家简单分析一下瑞易自助网站。
想要自己的网站可以百度搜索,一般有以下几种方式实现:
1、网站完成上线后,可以直接到百度门户提交。如果不知道在哪里提交,可以直接在百度上搜索“百度提交网站门户”。提交您自己的 网站 链接地址。该方法属于主动推送。因为网站刚刚上线,百度的数据库中没有你的网站的记录,所以不会直接抓取,也没有类抓取入口。这时候提交链接地址就相当于给了百度蜘蛛一个入口。
2、直接开启竞价,竞价可以让网站直接显示首页,但是网站竞价推广很费钱,按点击付费,关键词的重点激烈的竞争一次可能是几十个、几百个,这不是普通企业能够承受的。
3、seo 优化。这是非常实用的。它通过自然排名优化网站,将目标关键词推送到首页,但网站优化耗时较长,通常需要3-6个月才能达到最终效果。SEO优化一般按照关键词的流行度收费。
4、免费推广,通过外部链接推广网站,比如在一些流量大的论坛、贴吧、博客、分类信息网等发布一些相关内容,顺便说一下带上网站的链接,可以为网站做广告,增加蜘蛛爬到自己网站的几率。也可以在一些软文平台发布一些优质的原创文章,自带网站信息,如果你是收录,请阅读转载金额非常高。
简而言之,做网站的目的是为了推广营销,要推广就必须让用户搜索到。对于刚刚上线的新网站,希望几种自助建站方法对大家有所帮助。
更多关注 查看全部
网页抓取解密(
网站制作网站后还需要做哪些工作才可以让自己的网站在百度可以被搜索到呢)

当我们使用搜索引擎搜索某些产品时,会显示很多公司或个人的网站。网站的这种显示效果是如何产生的?网站制作网站后,我需要做什么工作才能让我的网站在百度上可以搜索到?下面为大家简单分析一下瑞易自助网站。
想要自己的网站可以百度搜索,一般有以下几种方式实现:
1、网站完成上线后,可以直接到百度门户提交。如果不知道在哪里提交,可以直接在百度上搜索“百度提交网站门户”。提交您自己的 网站 链接地址。该方法属于主动推送。因为网站刚刚上线,百度的数据库中没有你的网站的记录,所以不会直接抓取,也没有类抓取入口。这时候提交链接地址就相当于给了百度蜘蛛一个入口。
2、直接开启竞价,竞价可以让网站直接显示首页,但是网站竞价推广很费钱,按点击付费,关键词的重点激烈的竞争一次可能是几十个、几百个,这不是普通企业能够承受的。
3、seo 优化。这是非常实用的。它通过自然排名优化网站,将目标关键词推送到首页,但网站优化耗时较长,通常需要3-6个月才能达到最终效果。SEO优化一般按照关键词的流行度收费。
4、免费推广,通过外部链接推广网站,比如在一些流量大的论坛、贴吧、博客、分类信息网等发布一些相关内容,顺便说一下带上网站的链接,可以为网站做广告,增加蜘蛛爬到自己网站的几率。也可以在一些软文平台发布一些优质的原创文章,自带网站信息,如果你是收录,请阅读转载金额非常高。
简而言之,做网站的目的是为了推广营销,要推广就必须让用户搜索到。对于刚刚上线的新网站,希望几种自助建站方法对大家有所帮助。
更多关注
网页抓取解密(WebScraperforMac10分钟内轻松实现网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-12 12:00
摘要:WebScraper for Mac 是一款运行在 Mac 平台上的非常易用的数据提取工具。WebScraper 插件可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL。可以启动,操作简单,功能强大。
WebScraper for Mac 是一款非常实用的网站数据提取工具,运行在Mac平台上。WebScraper插件可以帮助您在10分钟内轻松抓取网页数据,只需输入起始网址即可启动,操作简单,功能强大。
【WebScraper官网售价25.00 USD】
WebScraper 4.8.4 for Mac 破解版介绍
WebScraper for Mac 是一个网站数据采集的工具。它可以通过使用将数据导出为 JSON 或 CSV 的极简应用程序来快速提取与网页相关的信息(包括文本内容),并为您提供以最少的努力从在线资源中快速提取内容的可能性。您可以完全控制将导出到 CSV 或 JSON 文件的数据。
使用多线程快速扫描任何网站
在 WebScraper 主窗口中,您必须指定要扫描的网页的 URL 地址以及完成此过程要使用的线程数。您可以使用简单的滑块调整后一个参数。
为避免任何不必要的扫描,您可以选择只抓取一页,然后单击鼠标即可开始该过程。在 Live View 窗口中,您可以看到每个链接返回的状态消息,这在处理调试任务时可能很有用。
提取各种类型的信息并将数据导出为 CSV 或 JSON
在“WebScraper 输出”面板中,您可以选择希望实用程序从网页中提取的信息类型:URL、标题、描述、与不同类别或 ID 关联的内容、标题、各种格式的页面内容(纯文本、HTML 或 Markdown)和最后修改日期。
您还可以选择输出文件格式(CSV 或 JSON),决定合并空白,并在文件超过特定大小时设置警报。如果选择 CSV 格式,则可以选择在列周围使用引号以及要使用的内容,而不是引号或行分隔符类型。
最后但并非最不重要的一点是,WebScraper 还允许您更改用户代理、设置链接和从主页点击的数量限制、您可以忽略查询字符串,并且您可以将根域的子域视为内部页面。
无需过多的用户交互即可轻松从在线资源中获取信息
WebScraper 为您提供了快速扫描 网站 并将其内容与其他附加内容一起输出到 JSON 文件的 CSV 的可能性。当您想离线访问数据而不存储整个页面时,此工具非常有用。
WebScraperVersion 4.8.4:Version 4.8.0:Version 4.7.1 的新特性:
WebScraper 4.8.4 for Mac 破解版下载 查看全部
网页抓取解密(WebScraperforMac10分钟内轻松实现网页数据的爬取)
摘要:WebScraper for Mac 是一款运行在 Mac 平台上的非常易用的数据提取工具。WebScraper 插件可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL。可以启动,操作简单,功能强大。
WebScraper for Mac 是一款非常实用的网站数据提取工具,运行在Mac平台上。WebScraper插件可以帮助您在10分钟内轻松抓取网页数据,只需输入起始网址即可启动,操作简单,功能强大。
【WebScraper官网售价25.00 USD】
WebScraper 4.8.4 for Mac 破解版介绍
WebScraper for Mac 是一个网站数据采集的工具。它可以通过使用将数据导出为 JSON 或 CSV 的极简应用程序来快速提取与网页相关的信息(包括文本内容),并为您提供以最少的努力从在线资源中快速提取内容的可能性。您可以完全控制将导出到 CSV 或 JSON 文件的数据。
使用多线程快速扫描任何网站
在 WebScraper 主窗口中,您必须指定要扫描的网页的 URL 地址以及完成此过程要使用的线程数。您可以使用简单的滑块调整后一个参数。
为避免任何不必要的扫描,您可以选择只抓取一页,然后单击鼠标即可开始该过程。在 Live View 窗口中,您可以看到每个链接返回的状态消息,这在处理调试任务时可能很有用。
提取各种类型的信息并将数据导出为 CSV 或 JSON
在“WebScraper 输出”面板中,您可以选择希望实用程序从网页中提取的信息类型:URL、标题、描述、与不同类别或 ID 关联的内容、标题、各种格式的页面内容(纯文本、HTML 或 Markdown)和最后修改日期。
您还可以选择输出文件格式(CSV 或 JSON),决定合并空白,并在文件超过特定大小时设置警报。如果选择 CSV 格式,则可以选择在列周围使用引号以及要使用的内容,而不是引号或行分隔符类型。
最后但并非最不重要的一点是,WebScraper 还允许您更改用户代理、设置链接和从主页点击的数量限制、您可以忽略查询字符串,并且您可以将根域的子域视为内部页面。
无需过多的用户交互即可轻松从在线资源中获取信息
WebScraper 为您提供了快速扫描 网站 并将其内容与其他附加内容一起输出到 JSON 文件的 CSV 的可能性。当您想离线访问数据而不存储整个页面时,此工具非常有用。
WebScraperVersion 4.8.4:Version 4.8.0:Version 4.7.1 的新特性:

WebScraper 4.8.4 for Mac 破解版下载
网页抓取解密(ASP.NETCore过渡阶段缓存的问题后.net)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-09 20:02
在解决了core中访问memcached缓存的问题后,我们开始向.net core迈进——将更多站点迁移到core。在迁移涉及获取用户登录信息的站点时,我们遇到了一个问题——如何在core和传统之间共享保存用户登录信息的cookie?
对于cookies的加解密,传统上采用对称加解密算法,而core采用基于公钥和私钥的非对称加解密算法。因此,core 无法解密传统生成的 cookie,也无法解密传统的 core 生成的 cookie。针对这个问题,.net社区有人提供了解决方案——将传统的加解密算法改为core(详见这里),但这需要修改传统站点的所有涉及获取用户登录信息的代码. 有些奢侈品不是万不得已,我们不想用它,我们必须另辟蹊径。
我们先把问题简化一下。根据我们迁移到 ASP.NET Core 过渡阶段的实际场景,用户登录操作是在传统站点上完成的。我们只需要解密核心站点上的cookie即可获取用户登录信息,无需加密。需要。由于core自身无法解密,可以让传统解密帮忙,core会通过web api将接收到的cookie发送给传统解密。简化后,问题变成-如何在核心接收传统cookie?如何拦截对cookies的核心解密操作?如何从 web api 中的 cookie 解密用户身份验证信息(FormsAuthenticationTicket)?在core中如何将FormsAuthenticationTicket转换成自己的认证信息(AuthenticationTicket)?让我们一一解决这些问题。
问题一:如何在core中接收传统的cookies?
这个问题很容易解决。只需将 Startup.cs 中 CookieAuthenticationOptions 的 CookieName 和 CookieDomain 设置为与传统相同即可。
var cookieOptions = new CookieAuthenticationOptions
{
CookieName = ".CnblogsCookie",
CookieDomain = ".cnblogs.com",
};
app.UseCookieAuthentication(cookieOptions);
问题二:如何拦截对cookies的核心解密操作?
这个问题很棘手。我们通过阅读Microsoft.AspNetCore.Authentication.Cookies的源代码,在CookieAuthenticationHandler.cs中找到了TicketDataFormat:
private async Task ReadCookieTicket()
{
var cookie = Options.CookieManager.GetRequestCookie(Context, Options.CookieName);
//...
var ticket = Options.TicketDataFormat.Unprotect(cookie, GetTlsTokenBinding());
//...
return AuthenticateResult.Success(ticket);
}
TicketDataFormat 的类型为 ISecureDataFormat 接口,解密 cookie 是调用该接口的 Unprotect 方法:
public interface ISecureDataFormat
{
string Protect(TData data);
string Protect(TData data, string purpose);
TData Unprotect(string protectedText);
TData Unprotect(string protectedText, string purpose);
}
而TicketDataFormat是CookieAuthenticationOptions的一个属性,我们可以直接修改这个属性值,使用我们自己的ISecureDataFormat接口实现(默认实现是SecureDataFormat),在Unprotect()方法的实现中读取protectedText参数值(这个应该是接收到的cookie 值)来达到拦截的目的,我们来试试。
定义一个 FormsAuthTicketDataFormat 类来实现 ISecureDataFormat 接口:
public class FormsAuthTicketDataFormat : ISecureDataFormat
{
//...
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
Console.WriteLine($"{nameof(Unprotect)}(\"{protectedText}\", \"{purpose}\")");
throw new NotImplementedException();
}
}
在 Startup.cs 中应用 FormsAuthTicketDataFormat:
var cookieOptions = new CookieAuthenticationOptions
{
//...
TicketDataFormat = new FormsAuthTicketDataFormat()
};
app.UseCookieAuthentication(cookieOptions);
经过测试验证,接收到的cookie值确实是传统生成的cookie值。
现在可以在 Unprotect() 方法中读取 cookie 值,然后可以通过 web api 将其发送到传统解密,因此我们继续下一个问题。
问题三:如何从web api中的cookie中解密用户认证信息(FormsAuthenticationTicket)?
这个问题也很容易解决,只要调用FormsAuthentication.Decrypt()方法解密,将FormsAuthenticationTicket的Name、IssueDate、Expiration值返回给core即可。
public IHttpActionResult GetTicket(string cookie)
{
var formsAuthTicket = FormsAuthentication.Decrypt(cookie);
return Ok(new
{
formsAuthTicket.Name,
formsAuthTicket.IssueDate,
formsAuthTicket.Expiration
});
}
核心通过调用web api对cookie进行解密,得到Name、IssueDate、Expiration三个值,所以FormsAuthTicketDataFormat.Unprotect()的实现代码变成了这样:
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
throw new NotImplementedException();
}
接下来,解决最后一个问题。
问题4:在core中如何将FormsAuthenticationTicket转换成自己的认证信息(AuthenticationTicket)?
由于Unprotect()方法的返回参数的类型是AuthenticationTicket,我们就不用换地方继续折腾这个方法了。现在我们有了 FormsAuthenticationTicket 的 Name、IssueDate 和 Expiration 三个值,我们需要根据它们创建一个有效的 AuthenticationTicket。
AuthenticationTicket 的构造函数有 3 个参数。第一个参数的类型是ClaimsPrincipal,与用户名相关联;第二个参数的类型是AuthenticationProperties,里面存放了cookie的生成时间和过期时间,第三个参数authenticationScheme设置为对应的值(这里设置为空字符串),代码如下:
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
//Get FormsAuthenticationTicket from asp.net web api
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
//Create AuthenticationTicket
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
var claimsPrincipal = new System.Security.Claims.ClaimsPrincipal(claimsIdentity);
var authProperties = new Microsoft.AspNetCore.Http.Authentication.AuthenticationProperties
{
IssuedUtc = issueDate,
ExpiresUtc = expiration
};
var ticket = new AuthenticationTicket(claimsPrincipal, authProperties, _authenticationScheme);
return ticket;
}
解决这4个问题后,你就大功告成了!在核心mvc控制器中可以显示当前登录用户名,如以下代码:
public IActionResult Index()
{
return Content(User.Identity.Name);
}
完整的相关实现代码如下:
启动文件
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
var cookieOptions = new CookieAuthenticationOptions
{
AutomaticAuthenticate = true,
AutomaticChallenge = true,
CookieHttpOnly = true,
CookieName = ".CnblogsCookie",
CookieDomain = ".cnblogs.com",
LoginPath = "/account/signin",
TicketDataFormat = new FormsAuthTicketDataFormat("")
};
app.UseCookieAuthentication(cookieOptions);
//...
}
FormAuthTicketDataFormat.cs
public class FormsAuthTicketDataFormat : ISecureDataFormat
{
private string _authenticationScheme;
public FormsAuthTicketDataFormat(string authenticationScheme)
{
_authenticationScheme = authenticationScheme;
}
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
//Get FormsAuthenticationTicket from asp.net web api
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
//Create AuthenticationTicket
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
var claimsPrincipal = new System.Security.Claims.ClaimsPrincipal(claimsIdentity);
var authProperties = new Microsoft.AspNetCore.Http.Authentication.AuthenticationProperties
{
IssuedUtc = issueDate,
ExpiresUtc = expiration
};
var ticket = new AuthenticationTicket(claimsPrincipal, authProperties, _authenticationScheme);
return ticket;
}
public string Protect(AuthenticationTicket data)
{
throw new NotImplementedException();
}
public string Protect(AuthenticationTicket data, string purpose)
{
throw new NotImplementedException();
}
public AuthenticationTicket Unprotect(string protectedText)
{
throw new NotImplementedException();
}
private FormsAuthTicketDto GetFormsAuthTicket(string cookie)
{
return new UserService().DecryptCookie(cookie).Result;
}
}
遗留问题:目前不适用于 [Authorize] 标签。
更新:
其余问题已解决,将在
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) });
到
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
即,将 authenticationType 的值设置为“Basic”。 查看全部
网页抓取解密(ASP.NETCore过渡阶段缓存的问题后.net)
在解决了core中访问memcached缓存的问题后,我们开始向.net core迈进——将更多站点迁移到core。在迁移涉及获取用户登录信息的站点时,我们遇到了一个问题——如何在core和传统之间共享保存用户登录信息的cookie?
对于cookies的加解密,传统上采用对称加解密算法,而core采用基于公钥和私钥的非对称加解密算法。因此,core 无法解密传统生成的 cookie,也无法解密传统的 core 生成的 cookie。针对这个问题,.net社区有人提供了解决方案——将传统的加解密算法改为core(详见这里),但这需要修改传统站点的所有涉及获取用户登录信息的代码. 有些奢侈品不是万不得已,我们不想用它,我们必须另辟蹊径。
我们先把问题简化一下。根据我们迁移到 ASP.NET Core 过渡阶段的实际场景,用户登录操作是在传统站点上完成的。我们只需要解密核心站点上的cookie即可获取用户登录信息,无需加密。需要。由于core自身无法解密,可以让传统解密帮忙,core会通过web api将接收到的cookie发送给传统解密。简化后,问题变成-如何在核心接收传统cookie?如何拦截对cookies的核心解密操作?如何从 web api 中的 cookie 解密用户身份验证信息(FormsAuthenticationTicket)?在core中如何将FormsAuthenticationTicket转换成自己的认证信息(AuthenticationTicket)?让我们一一解决这些问题。
问题一:如何在core中接收传统的cookies?
这个问题很容易解决。只需将 Startup.cs 中 CookieAuthenticationOptions 的 CookieName 和 CookieDomain 设置为与传统相同即可。
var cookieOptions = new CookieAuthenticationOptions
{
CookieName = ".CnblogsCookie",
CookieDomain = ".cnblogs.com",
};
app.UseCookieAuthentication(cookieOptions);
问题二:如何拦截对cookies的核心解密操作?
这个问题很棘手。我们通过阅读Microsoft.AspNetCore.Authentication.Cookies的源代码,在CookieAuthenticationHandler.cs中找到了TicketDataFormat:
private async Task ReadCookieTicket()
{
var cookie = Options.CookieManager.GetRequestCookie(Context, Options.CookieName);
//...
var ticket = Options.TicketDataFormat.Unprotect(cookie, GetTlsTokenBinding());
//...
return AuthenticateResult.Success(ticket);
}
TicketDataFormat 的类型为 ISecureDataFormat 接口,解密 cookie 是调用该接口的 Unprotect 方法:
public interface ISecureDataFormat
{
string Protect(TData data);
string Protect(TData data, string purpose);
TData Unprotect(string protectedText);
TData Unprotect(string protectedText, string purpose);
}
而TicketDataFormat是CookieAuthenticationOptions的一个属性,我们可以直接修改这个属性值,使用我们自己的ISecureDataFormat接口实现(默认实现是SecureDataFormat),在Unprotect()方法的实现中读取protectedText参数值(这个应该是接收到的cookie 值)来达到拦截的目的,我们来试试。
定义一个 FormsAuthTicketDataFormat 类来实现 ISecureDataFormat 接口:
public class FormsAuthTicketDataFormat : ISecureDataFormat
{
//...
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
Console.WriteLine($"{nameof(Unprotect)}(\"{protectedText}\", \"{purpose}\")");
throw new NotImplementedException();
}
}
在 Startup.cs 中应用 FormsAuthTicketDataFormat:
var cookieOptions = new CookieAuthenticationOptions
{
//...
TicketDataFormat = new FormsAuthTicketDataFormat()
};
app.UseCookieAuthentication(cookieOptions);
经过测试验证,接收到的cookie值确实是传统生成的cookie值。
现在可以在 Unprotect() 方法中读取 cookie 值,然后可以通过 web api 将其发送到传统解密,因此我们继续下一个问题。
问题三:如何从web api中的cookie中解密用户认证信息(FormsAuthenticationTicket)?
这个问题也很容易解决,只要调用FormsAuthentication.Decrypt()方法解密,将FormsAuthenticationTicket的Name、IssueDate、Expiration值返回给core即可。
public IHttpActionResult GetTicket(string cookie)
{
var formsAuthTicket = FormsAuthentication.Decrypt(cookie);
return Ok(new
{
formsAuthTicket.Name,
formsAuthTicket.IssueDate,
formsAuthTicket.Expiration
});
}
核心通过调用web api对cookie进行解密,得到Name、IssueDate、Expiration三个值,所以FormsAuthTicketDataFormat.Unprotect()的实现代码变成了这样:
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
throw new NotImplementedException();
}
接下来,解决最后一个问题。
问题4:在core中如何将FormsAuthenticationTicket转换成自己的认证信息(AuthenticationTicket)?
由于Unprotect()方法的返回参数的类型是AuthenticationTicket,我们就不用换地方继续折腾这个方法了。现在我们有了 FormsAuthenticationTicket 的 Name、IssueDate 和 Expiration 三个值,我们需要根据它们创建一个有效的 AuthenticationTicket。
AuthenticationTicket 的构造函数有 3 个参数。第一个参数的类型是ClaimsPrincipal,与用户名相关联;第二个参数的类型是AuthenticationProperties,里面存放了cookie的生成时间和过期时间,第三个参数authenticationScheme设置为对应的值(这里设置为空字符串),代码如下:
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
//Get FormsAuthenticationTicket from asp.net web api
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
//Create AuthenticationTicket
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
var claimsPrincipal = new System.Security.Claims.ClaimsPrincipal(claimsIdentity);
var authProperties = new Microsoft.AspNetCore.Http.Authentication.AuthenticationProperties
{
IssuedUtc = issueDate,
ExpiresUtc = expiration
};
var ticket = new AuthenticationTicket(claimsPrincipal, authProperties, _authenticationScheme);
return ticket;
}
解决这4个问题后,你就大功告成了!在核心mvc控制器中可以显示当前登录用户名,如以下代码:
public IActionResult Index()
{
return Content(User.Identity.Name);
}
完整的相关实现代码如下:
启动文件
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
var cookieOptions = new CookieAuthenticationOptions
{
AutomaticAuthenticate = true,
AutomaticChallenge = true,
CookieHttpOnly = true,
CookieName = ".CnblogsCookie",
CookieDomain = ".cnblogs.com",
LoginPath = "/account/signin",
TicketDataFormat = new FormsAuthTicketDataFormat("")
};
app.UseCookieAuthentication(cookieOptions);
//...
}
FormAuthTicketDataFormat.cs
public class FormsAuthTicketDataFormat : ISecureDataFormat
{
private string _authenticationScheme;
public FormsAuthTicketDataFormat(string authenticationScheme)
{
_authenticationScheme = authenticationScheme;
}
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
//Get FormsAuthenticationTicket from asp.net web api
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
//Create AuthenticationTicket
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
var claimsPrincipal = new System.Security.Claims.ClaimsPrincipal(claimsIdentity);
var authProperties = new Microsoft.AspNetCore.Http.Authentication.AuthenticationProperties
{
IssuedUtc = issueDate,
ExpiresUtc = expiration
};
var ticket = new AuthenticationTicket(claimsPrincipal, authProperties, _authenticationScheme);
return ticket;
}
public string Protect(AuthenticationTicket data)
{
throw new NotImplementedException();
}
public string Protect(AuthenticationTicket data, string purpose)
{
throw new NotImplementedException();
}
public AuthenticationTicket Unprotect(string protectedText)
{
throw new NotImplementedException();
}
private FormsAuthTicketDto GetFormsAuthTicket(string cookie)
{
return new UserService().DecryptCookie(cookie).Result;
}
}
遗留问题:目前不适用于 [Authorize] 标签。
更新:
其余问题已解决,将在
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) });
到
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
即,将 authenticationType 的值设置为“Basic”。
网页抓取解密(豆丁文档下载器是一款用于网络文档共享网站的专业工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2021-10-07 05:23
豆丁文档下载器是一款专业的网络文档下载工具。豆丁文档下载器可以为用户带来更好的文档抓取功能,支持多种文档共享网站,可以省去会员下载一些文档的麻烦,非常专业高效。
软件说明:
豆丁网免费下载器还支持百度、丁香、畅享、MBALib、HP009、MAX、Book118等图书馆文档的免费下载,无需注册和登录。下载的文档最终生成了高清pdf格式的文档。
软件特点:
1、支持百度、豆丁、丁香、畅享、MBALib、HP009、MAX、Book118等图书馆文档。
2、 无需积分,无需登录,即可免费下载百度文库和豆丁文库。
3、 支持多任务同时下载和断点续传。
4、生成的pdf文档质量和原文档一样。
指示:
1、输入要抓取的文档的网址
2、点击抓取文字
3、 捕获的文本会显示在下面的文本框中
4、用户可以自由复制文字
常见问题:
1、截取文字后段落格式乱了怎么办?
A、服务器转换成文本后,清除原来的格式。
2、为什么我不能下载全文?
答:服务器变化太大了。但是写文章就够了。
3、为什么这个程序有时候抓不到文字或者提示错误?
答:因为服务器没有将文档转换成文本,或者网络程序发生了不可预知的错误。
4、为什么有时候里面会有很多乱码或者无用的奇怪文字?
答:服务器转换错误,没办法。
5、这个程序可以直接下载文件吗?
答案:没有 查看全部
网页抓取解密(豆丁文档下载器是一款用于网络文档共享网站的专业工具)
豆丁文档下载器是一款专业的网络文档下载工具。豆丁文档下载器可以为用户带来更好的文档抓取功能,支持多种文档共享网站,可以省去会员下载一些文档的麻烦,非常专业高效。
软件说明:
豆丁网免费下载器还支持百度、丁香、畅享、MBALib、HP009、MAX、Book118等图书馆文档的免费下载,无需注册和登录。下载的文档最终生成了高清pdf格式的文档。

软件特点:
1、支持百度、豆丁、丁香、畅享、MBALib、HP009、MAX、Book118等图书馆文档。
2、 无需积分,无需登录,即可免费下载百度文库和豆丁文库。
3、 支持多任务同时下载和断点续传。
4、生成的pdf文档质量和原文档一样。

指示:
1、输入要抓取的文档的网址
2、点击抓取文字
3、 捕获的文本会显示在下面的文本框中
4、用户可以自由复制文字
常见问题:
1、截取文字后段落格式乱了怎么办?
A、服务器转换成文本后,清除原来的格式。
2、为什么我不能下载全文?
答:服务器变化太大了。但是写文章就够了。
3、为什么这个程序有时候抓不到文字或者提示错误?
答:因为服务器没有将文档转换成文本,或者网络程序发生了不可预知的错误。
4、为什么有时候里面会有很多乱码或者无用的奇怪文字?
答:服务器转换错误,没办法。
5、这个程序可以直接下载文件吗?
答案:没有
网页抓取解密(上一页没毛病云搜神器V1.0官方正版最新无限制破解版测试可用)
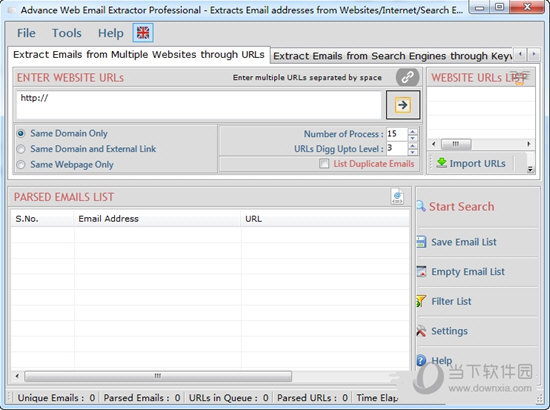
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-06 13:02
软件介绍: 上一页云搜索神器无错V1.0 官方正版最新无限破解版测试可用 下一页Advance Web Email Extractor(网络邮件抓取工具)V6. 3.3.35 最新无限制破解版正式版可供测试
本软件由七道奇为您精心采集,转载自网络。本软件收录为正式版,软件著作权归软件作者所有。本网站对其观点和内容不作任何评论。请读者自行判断。以下是其具体内容:
Advance Web Email Extractor 破解版是一款功能强大的网络邮箱爬取工具。该工具适用于销售人员。有了它,您可以从 Internet 获取客户邮箱。支持网页邮箱的自动抓取,非常方便快捷。并且软件内置破解工具,完全免费。
【特征】
根据您的搜索引擎关键字从 Internet 中提取所有电子邮件地址。
通过流行的搜索引擎(例如 Google、Yahoo、Bing、Excite、Lycos 等)从 Internet 中提取所有电子邮件地址。
它可以从列表中提取各种 URL/网站 电子邮件地址。
搜索引擎可以免费在线更新以获得最佳结果。
这是 Internet 上最快的电子邮件提取器。
它允许您添加扫描 URL 的配置,以便您可以非常快速地获得结果。
它可以过滤提取的电子邮件,仅过滤那些您确实不需要的电子邮件列表。
提取的电子邮件可以保存在 .CSV 和文本文件中。
它是从 网站 中提取电子邮件的最佳工具。
【下载链接】
Advance Web Email Extractor(网络邮箱抓取工具)V6.3.3.35破解免费版 查看全部
网页抓取解密(上一页没毛病云搜神器V1.0官方正版最新无限制破解版测试可用)
软件介绍: 上一页云搜索神器无错V1.0 官方正版最新无限破解版测试可用 下一页Advance Web Email Extractor(网络邮件抓取工具)V6. 3.3.35 最新无限制破解版正式版可供测试
本软件由七道奇为您精心采集,转载自网络。本软件收录为正式版,软件著作权归软件作者所有。本网站对其观点和内容不作任何评论。请读者自行判断。以下是其具体内容:
Advance Web Email Extractor 破解版是一款功能强大的网络邮箱爬取工具。该工具适用于销售人员。有了它,您可以从 Internet 获取客户邮箱。支持网页邮箱的自动抓取,非常方便快捷。并且软件内置破解工具,完全免费。
【特征】
根据您的搜索引擎关键字从 Internet 中提取所有电子邮件地址。
通过流行的搜索引擎(例如 Google、Yahoo、Bing、Excite、Lycos 等)从 Internet 中提取所有电子邮件地址。
它可以从列表中提取各种 URL/网站 电子邮件地址。
搜索引擎可以免费在线更新以获得最佳结果。
这是 Internet 上最快的电子邮件提取器。
它允许您添加扫描 URL 的配置,以便您可以非常快速地获得结果。
它可以过滤提取的电子邮件,仅过滤那些您确实不需要的电子邮件列表。
提取的电子邮件可以保存在 .CSV 和文本文件中。
它是从 网站 中提取电子邮件的最佳工具。
【下载链接】
Advance Web Email Extractor(网络邮箱抓取工具)V6.3.3.35破解免费版
网页抓取解密(EasyPlayer-RTSP-Android如何获取解码后的视频帧? )
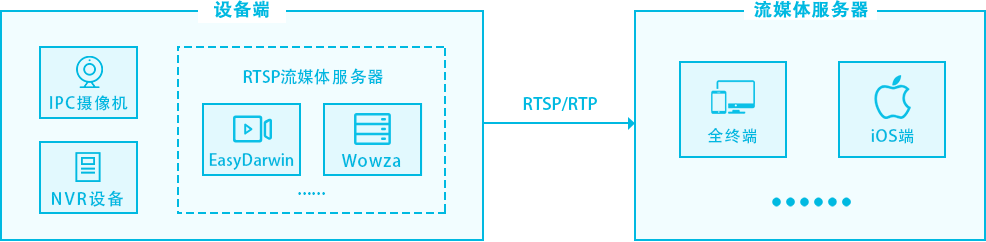
网站优化 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-10-06 06:28
)
应用场景
EasyPlayer-RTSP 多年来在与 VLC 进行基准测试的过程中积累了广泛的应用场景。EasyPlayer-RTSP底层和上层均为自主研发,具有自主知识产权,可实战测试。
EasyPlayer-RTSP 播放器
EasyPlayer-RTSP播放器是一套RTSP专用播放器,包括:Windows(支持IE插件、npapi插件)、Android、iOS三个平台。它是由清溪TSINGSEE开放平台开发和维护的,与市场上的不同。作为通用播放器的一部分,EasyPlayer-RTSP系列自2014年初开发以来,已广泛应用于各行各业(尤其是安防行业)。 主要原因是EasyPlayer-RTSP更精致,更专注,并且具有非常低的延迟。非常高的RTSP协议兼容性、编码数据分析等方面,都有非常大的优势。
EasyPlayer-RTSP-Android 解码获取视频帧问问题
EasyPlayer-RTSP-Android 如何获取解码后的视频帧?
分析问题
部分客户需要获取解码后的视频帧才能实现人脸识别。
解决这个问题
视频播放的实现在PlayFragment.java中,它有一个YUVExportFragment.java的子类,实现了接口EasyPlayerClient.I420DataCallback。您可以在 onI420Data 方法中获取解码后的视频帧:
深入阅读代码,你会发现在EasyPlayerClient.java中,硬解码和软解码两种方式都将解码后的视频帧传入onI420Data:
ByteBuffer buf = mDecoder.decodeFrameYUV(frameInfo, size);
if (i420callback != null && buf != null)
i420callback.onI420Data(buf);
if (buf != null)
mDecoder.releaseBuffer(buf);
ByteBuffer outputBuffer;
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.LOLLIPOP) {
outputBuffer = mCodec.getOutputBuffer(index);
} else {
outputBuffer = mCodec.getOutputBuffers()[index];
}
if (i420callback != null && outputBuffer != null) {
if (sliceHeight != realHeight) {
ByteBuffer tmp = ByteBuffer.allocateDirect(realWidth*realHeight*3/2);
outputBuffer.clear();
outputBuffer.limit(realWidth*realHeight);
tmp.put(outputBuffer);
outputBuffer.clear();
outputBuffer.position(realWidth * sliceHeight);
outputBuffer.limit((realWidth * sliceHeight + realWidth*realHeight /4));
tmp.put(outputBuffer);
outputBuffer.clear();
outputBuffer.position(realWidth * sliceHeight + realWidth*realHeight/4);
outputBuffer.limit((realWidth * sliceHeight + realWidth*realHeight/4 + realWidth*realHeight /4));
tmp.put(outputBuffer);
tmp.clear();
outputBuffer = tmp;
}
if (mColorFormat == COLOR_FormatYUV420SemiPlanar
|| mColorFormat == COLOR_FormatYUV420PackedSemiPlanar
|| mColorFormat == COLOR_TI_FormatYUV420PackedSemiPlanar) {
JNIUtil.yuvConvert2(outputBuffer, realWidth, realHeight, 4);
}
i420callback.onI420Data(outputBuffer);
} 查看全部
网页抓取解密(EasyPlayer-RTSP-Android如何获取解码后的视频帧?
)
应用场景
EasyPlayer-RTSP 多年来在与 VLC 进行基准测试的过程中积累了广泛的应用场景。EasyPlayer-RTSP底层和上层均为自主研发,具有自主知识产权,可实战测试。

EasyPlayer-RTSP 播放器
EasyPlayer-RTSP播放器是一套RTSP专用播放器,包括:Windows(支持IE插件、npapi插件)、Android、iOS三个平台。它是由清溪TSINGSEE开放平台开发和维护的,与市场上的不同。作为通用播放器的一部分,EasyPlayer-RTSP系列自2014年初开发以来,已广泛应用于各行各业(尤其是安防行业)。 主要原因是EasyPlayer-RTSP更精致,更专注,并且具有非常低的延迟。非常高的RTSP协议兼容性、编码数据分析等方面,都有非常大的优势。
EasyPlayer-RTSP-Android 解码获取视频帧问问题
EasyPlayer-RTSP-Android 如何获取解码后的视频帧?
分析问题
部分客户需要获取解码后的视频帧才能实现人脸识别。
解决这个问题
视频播放的实现在PlayFragment.java中,它有一个YUVExportFragment.java的子类,实现了接口EasyPlayerClient.I420DataCallback。您可以在 onI420Data 方法中获取解码后的视频帧:

深入阅读代码,你会发现在EasyPlayerClient.java中,硬解码和软解码两种方式都将解码后的视频帧传入onI420Data:
ByteBuffer buf = mDecoder.decodeFrameYUV(frameInfo, size);
if (i420callback != null && buf != null)
i420callback.onI420Data(buf);
if (buf != null)
mDecoder.releaseBuffer(buf);
ByteBuffer outputBuffer;
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.LOLLIPOP) {
outputBuffer = mCodec.getOutputBuffer(index);
} else {
outputBuffer = mCodec.getOutputBuffers()[index];
}
if (i420callback != null && outputBuffer != null) {
if (sliceHeight != realHeight) {
ByteBuffer tmp = ByteBuffer.allocateDirect(realWidth*realHeight*3/2);
outputBuffer.clear();
outputBuffer.limit(realWidth*realHeight);
tmp.put(outputBuffer);
outputBuffer.clear();
outputBuffer.position(realWidth * sliceHeight);
outputBuffer.limit((realWidth * sliceHeight + realWidth*realHeight /4));
tmp.put(outputBuffer);
outputBuffer.clear();
outputBuffer.position(realWidth * sliceHeight + realWidth*realHeight/4);
outputBuffer.limit((realWidth * sliceHeight + realWidth*realHeight/4 + realWidth*realHeight /4));
tmp.put(outputBuffer);
tmp.clear();
outputBuffer = tmp;
}
if (mColorFormat == COLOR_FormatYUV420SemiPlanar
|| mColorFormat == COLOR_FormatYUV420PackedSemiPlanar
|| mColorFormat == COLOR_TI_FormatYUV420PackedSemiPlanar) {
JNIUtil.yuvConvert2(outputBuffer, realWidth, realHeight, 4);
}
i420callback.onI420Data(outputBuffer);
}
网页抓取解密(Python一款IDE--网页请求监控工具发生的详细步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-06 06:26
)
1)首先,客户端和服务器需要建立连接。只需单击某个超链接,HTTP 工作就会开始。
2) 连接建立后,客户端向服务器发送请求。请求的格式为:统一资源标识符(URL)、协议版本号和 MIME 信息,包括请求修饰符、客户端信息和可能的内容。
3) 服务器收到请求后,会给出相应的响应信息。格式为状态行,包括信息的协议版本号、成功或错误码,MIME信息包括服务器信息、实体信息和可能性。内容。
4)客户端接收服务器返回的信息,通过浏览器显示在用户的显示屏上,然后客户端与服务器断开连接。
如果上述过程的某个步骤发生错误,则将导致错误的信息以显示屏幕输出的方式返回给客户端。对于用户来说,这些过程都是由HTTP本身完成的,用户只需要点击鼠标,等待信息显示出来。
二:了解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中;我们需要学习的是几个常用的函数。详情可上官网查看。
三:开发工具
Python自带一个编译器——IDLE,非常简洁;PyCharm - 具有良好交互性的 Python IDE;Fiddler - 一个网页请求监控工具,我们可以使用它来了解用户触发网页请求后发生的详细步骤;
简单的网络爬虫
代码
'''
第一个示例:简单的网页爬虫
爬取豆瓣首页
'''
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode('utf-8')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截取的部分结果如下:
查看全部
网页抓取解密(Python一款IDE--网页请求监控工具发生的详细步骤
)
1)首先,客户端和服务器需要建立连接。只需单击某个超链接,HTTP 工作就会开始。
2) 连接建立后,客户端向服务器发送请求。请求的格式为:统一资源标识符(URL)、协议版本号和 MIME 信息,包括请求修饰符、客户端信息和可能的内容。
3) 服务器收到请求后,会给出相应的响应信息。格式为状态行,包括信息的协议版本号、成功或错误码,MIME信息包括服务器信息、实体信息和可能性。内容。
4)客户端接收服务器返回的信息,通过浏览器显示在用户的显示屏上,然后客户端与服务器断开连接。
如果上述过程的某个步骤发生错误,则将导致错误的信息以显示屏幕输出的方式返回给客户端。对于用户来说,这些过程都是由HTTP本身完成的,用户只需要点击鼠标,等待信息显示出来。
二:了解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中;我们需要学习的是几个常用的函数。详情可上官网查看。
三:开发工具
Python自带一个编译器——IDLE,非常简洁;PyCharm - 具有良好交互性的 Python IDE;Fiddler - 一个网页请求监控工具,我们可以使用它来了解用户触发网页请求后发生的详细步骤;
简单的网络爬虫
代码
'''
第一个示例:简单的网页爬虫
爬取豆瓣首页
'''
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode('utf-8')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截取的部分结果如下:
网页抓取解密(如何找到需要的网页编码格式不一致与decode解决乱码问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-06 06:22
)
一、乱码问题说明
在爬虫或某些操作过程中,经常会出现中文乱码等问题,如下图所示
原因是向下爬行后,源页面代码与代码格式不一致
二、使用编码和解码来解决乱码问题
Python中字符串的内部表示是Unicode编码。在编码转换过程中,通常使用Unicode作为中间编码,即将其他编码字符串解码为Unicode,然后将其编码为另一种编码
decode的功能是将其他编码字符串转换为Unicode编码,例如STR1.decode('gb2312'),这意味着将gb2312编码字符串STR1转换为Unicode编码
Encode用于将Unicode编码转换为其他编码字符串,例如STR2.Encode('utf-8'),这意味着将Unicode编码字符串STR2转换为utf-8编码
decode中写的是您想要捕获的网页的代码,encode是您想要设置的代码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但也要注意:
如果字符串已经是Unicode,则解码将出错。因此,通常需要判断其编码方法是否为Unicode
Isinstance(s,Unicode)#用于确定它是否为Unicode
以非Unicode编码形式使用STR编码将报告错误
因此,最终的可靠代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到要抓取的目标网页的编码格式1、查看网页源代码
如果源代码中没有字符集编码格式,则可以使用以下方法
2、检查元素并查看响应标题
查看全部
网页抓取解密(如何找到需要的网页编码格式不一致与decode解决乱码问题
)
一、乱码问题说明
在爬虫或某些操作过程中,经常会出现中文乱码等问题,如下图所示
原因是向下爬行后,源页面代码与代码格式不一致
二、使用编码和解码来解决乱码问题
Python中字符串的内部表示是Unicode编码。在编码转换过程中,通常使用Unicode作为中间编码,即将其他编码字符串解码为Unicode,然后将其编码为另一种编码
decode的功能是将其他编码字符串转换为Unicode编码,例如STR1.decode('gb2312'),这意味着将gb2312编码字符串STR1转换为Unicode编码
Encode用于将Unicode编码转换为其他编码字符串,例如STR2.Encode('utf-8'),这意味着将Unicode编码字符串STR2转换为utf-8编码
decode中写的是您想要捕获的网页的代码,encode是您想要设置的代码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但也要注意:
如果字符串已经是Unicode,则解码将出错。因此,通常需要判断其编码方法是否为Unicode
Isinstance(s,Unicode)#用于确定它是否为Unicode
以非Unicode编码形式使用STR编码将报告错误
因此,最终的可靠代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到要抓取的目标网页的编码格式1、查看网页源代码
如果源代码中没有字符集编码格式,则可以使用以下方法
2、检查元素并查看响应标题
网页抓取解密(网络爬虫的处理对象是互联网通用的爬虫框架流程介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-05 20:01
搜索引擎的处理对象是互联网网页。网页的数量是数百亿,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统,将如此大量的网页数据传输到本地,并在本地形成互联网。网页镜像备份。
网络爬虫扮演这个角色。它是搜索引擎系统中非常关键和基本的组成部分。本文主要介绍与网络爬虫相关的技术。虽然爬虫技术经过几十年的发展在整体框架上已经比较成熟,但是随着网络的不断发展,也面临着一些具有挑战性的新问题。
下图展示了一个通用的爬虫框架流程。首先,从互联网页面中仔细选择一部分网页,将这些网页的链接地址作为种子URL,将这些种子URL放入URL队列中进行爬取。爬虫依次从待爬取的队列中读取URL,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
然后把它和网页的相对路径名给网页下载器,网页下载器负责下载页面的内容。对于本地下载的网页,一方面存储在页面库中,等待索引等后续处理;另一方面,将下载网页的网址放入已爬取的网址队列,记录爬虫系统已下载。网页网址,避免网页重复抓取。对于新下载的网页,提取其中收录的所有链接信息,并在抓取的URL队列中进行检查。如果发现该链接还没有被爬取,则将该URL放在待爬取的URL队列的末尾,然后在爬取调度中下载该URL对应的网页。通过这种方式,
对于爬虫来说,往往需要进行网络重复数据删除和网络反作弊。
以上就是一个通用爬虫的整体流程。如果从更宏观的角度考虑,动态抓取过程中的爬虫与互联网上所有网页的关系大致可以分为如图2-2所示的互联网页面。有5个部分:
1. 下载网页集合:爬虫从网上下载到本地索引的网页集合。
2.过期网页集合:由于网页数量最多,爬虫爬完一轮需要很长时间。在抓取过程中,许多下载的网页可能会过期。这是因为互联网网页处于不断动态变化的过程中,所以很容易产生本地网页内容与真实互联网网页的不一致。
3. 待下载网页集合:上图中待抓取的URL队列中的网页,这些网页会被爬虫下载。
4. 已知网页集合:这些网页没有被爬虫下载,也没有出现在待抓取的网址队列中,而是通过已经抓取的网页或待抓取的网址队列中的网页,它们总是可以在链接关系找到它们时,稍后被爬虫抓取并索引。
5. 未知网页集合:部分网页无法被爬虫抓取,这部分网页构成未知网页集合。事实上,这部分网页所占的比例很高。
根据应用的不同,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种:
1. 批量爬虫(Batch Crawler):批量爬虫有比较明确的爬取范围和目标。当爬虫到达设定的目标时,它停止爬虫过程。至于具体的目标,可能不一样,可能是设置一定数量的网页被爬取,也可能是设置爬取所消耗的时间等等。
2.增量爬虫(Incremental Crawler):增量爬虫与批量爬虫不同,它会不断地持续爬取,爬取的网页要定期更新,因为互联网的网页在不断变化,新网页很常见、要删除的网页或网页内容更改为通用。增量爬虫需要及时反映这种变化。因此,它们都在不断的爬取过程中,要么爬取新页面,要么更新现有页面。有网页。常见的商业搜索引擎爬虫基本都属于这一类。
3.Focused Crawter:垂直爬虫专注于特定主题内容或属于特定行业的网页。比如健康网站,只需要从网上找健康相关的页面即可。页面内容就够了,其他行业的内容不考虑。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定的行业或主题。从节省系统资源的角度考虑,不可能把所有的网页都下载下来然后过滤。这太浪费资源了。爬虫往往需要在爬取阶段动态识别某个 URL 是否与主题相关。并且尽量不要去抓取不相关的页面以节省资源。垂直搜索网站 查看全部
网页抓取解密(网络爬虫的处理对象是互联网通用的爬虫框架流程介绍)
搜索引擎的处理对象是互联网网页。网页的数量是数百亿,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统,将如此大量的网页数据传输到本地,并在本地形成互联网。网页镜像备份。
网络爬虫扮演这个角色。它是搜索引擎系统中非常关键和基本的组成部分。本文主要介绍与网络爬虫相关的技术。虽然爬虫技术经过几十年的发展在整体框架上已经比较成熟,但是随着网络的不断发展,也面临着一些具有挑战性的新问题。
下图展示了一个通用的爬虫框架流程。首先,从互联网页面中仔细选择一部分网页,将这些网页的链接地址作为种子URL,将这些种子URL放入URL队列中进行爬取。爬虫依次从待爬取的队列中读取URL,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
然后把它和网页的相对路径名给网页下载器,网页下载器负责下载页面的内容。对于本地下载的网页,一方面存储在页面库中,等待索引等后续处理;另一方面,将下载网页的网址放入已爬取的网址队列,记录爬虫系统已下载。网页网址,避免网页重复抓取。对于新下载的网页,提取其中收录的所有链接信息,并在抓取的URL队列中进行检查。如果发现该链接还没有被爬取,则将该URL放在待爬取的URL队列的末尾,然后在爬取调度中下载该URL对应的网页。通过这种方式,

对于爬虫来说,往往需要进行网络重复数据删除和网络反作弊。
以上就是一个通用爬虫的整体流程。如果从更宏观的角度考虑,动态抓取过程中的爬虫与互联网上所有网页的关系大致可以分为如图2-2所示的互联网页面。有5个部分:
1. 下载网页集合:爬虫从网上下载到本地索引的网页集合。
2.过期网页集合:由于网页数量最多,爬虫爬完一轮需要很长时间。在抓取过程中,许多下载的网页可能会过期。这是因为互联网网页处于不断动态变化的过程中,所以很容易产生本地网页内容与真实互联网网页的不一致。
3. 待下载网页集合:上图中待抓取的URL队列中的网页,这些网页会被爬虫下载。
4. 已知网页集合:这些网页没有被爬虫下载,也没有出现在待抓取的网址队列中,而是通过已经抓取的网页或待抓取的网址队列中的网页,它们总是可以在链接关系找到它们时,稍后被爬虫抓取并索引。
5. 未知网页集合:部分网页无法被爬虫抓取,这部分网页构成未知网页集合。事实上,这部分网页所占的比例很高。
根据应用的不同,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种:
1. 批量爬虫(Batch Crawler):批量爬虫有比较明确的爬取范围和目标。当爬虫到达设定的目标时,它停止爬虫过程。至于具体的目标,可能不一样,可能是设置一定数量的网页被爬取,也可能是设置爬取所消耗的时间等等。
2.增量爬虫(Incremental Crawler):增量爬虫与批量爬虫不同,它会不断地持续爬取,爬取的网页要定期更新,因为互联网的网页在不断变化,新网页很常见、要删除的网页或网页内容更改为通用。增量爬虫需要及时反映这种变化。因此,它们都在不断的爬取过程中,要么爬取新页面,要么更新现有页面。有网页。常见的商业搜索引擎爬虫基本都属于这一类。
3.Focused Crawter:垂直爬虫专注于特定主题内容或属于特定行业的网页。比如健康网站,只需要从网上找健康相关的页面即可。页面内容就够了,其他行业的内容不考虑。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定的行业或主题。从节省系统资源的角度考虑,不可能把所有的网页都下载下来然后过滤。这太浪费资源了。爬虫往往需要在爬取阶段动态识别某个 URL 是否与主题相关。并且尽量不要去抓取不相关的页面以节省资源。垂直搜索网站
网页抓取解密(腾讯课堂缓存文件分析进展缓存分析获取资源 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 739 次浏览 • 2021-10-05 20:00
)
背景
众所周知,腾讯课堂这样的视频是有时间限制的。
如果我付了钱并想永远保留它,我该怎么办?
录屏?也许这是一种思维方式。但是这个时间成本可能比较大。
接下来,我将提供一个解锁加密视频的思路,仅供参考。
发现
对分析过程不感兴趣的可以跳到最后一节
腾讯课堂网页版分析网络请求和过滤器关键词m3u8
直接复制这个url,发现可以下载一个m3u8文件,但是只有几十kb,显然不是视频。以文本方式打开文件,查找类似配置的相关信息。那么什么是m3u8?
关于 m3u8
详细请参考文档m3u8文件格式详细解释
m3u8文件作为媒体播放列表(Meida Playlist)时,其内部信息记录了一系列媒体片段资源。依次播放片段资源,充分展示多媒体资源。格式如下:
#EXTM3U
#EXT-X-TARGETDURATION:10
#EXTINF:9.009,
http://media.example.com/first.ts
#EXTINF:9.009,
http://media.example.com/second.ts
#EXTINF:3.003,
http://media.example.com/third.ts
分析网络请求并过滤关键词.ts
原来m3u8是一个媒体播放器列表,里面收录了多个ts播放片段资源,再看看.ts视频片段相关的请求
浏览器下载 .ts 视频文件
直接访问ts视频的url,发现可以直接下载ts视频文件。But when the player is selected to play, it cannot be played. 可以肯定视频是加密的。看一下m3u8文件(以文本模式查看):
......
#EXT-X-KEY:METHOD=AES-128,URI="https://ke.qq.com/cgi-bin/qclo ... ot%3B,IV=0x00000000000000000000000000000000
.......
METHOD:该值是一个可枚举的字符串,用于指定加密方法。AES-128:表示使用 AES-128 进行加密。
URI:指定密钥路径。密钥是一个 16 字节的数据。此键是必需参数,除非 METHOD 为 NONE。
IV:该值为 128 位十六进制值。AES-128 加密和解密需要相同的 16 字节 IV 值。使用不同的IV值可以增加密码的强度。
分析缓存文件分析进度获取缓存文件
腾讯课堂缓存文件存放在/sdcard/Android/data//files/tencentedu/video/txdownload/
可以通过adb把手机中的缓存文件拉到电脑上
adb pull /sdcard/Android/data/com.tencent.edu/files/tencentedu/video/txdownload/
分析缓存文件sqlite
既然是sqlite文件,放到Navicat或者Datagrip里看看
元数据和缓存,这里的重点是缓存表。从数据库中可以看出,数据库中插入了.ts视频文件片段、m3u8目录信息和解密密钥,与分析网页得到的数据基本一致。
分析ts片段
可以看出ts片段的格式是
https://1258712167.vod2.myqclo ... pegts
...
...
https://1258712167.vod2.myqclo ... pegts
开始和结束是连续的,并确定片段的开始和结束
修改链接为start=0&end=38045039(即end是最后一个片段的结尾),访问链接,但是提示需要签名信息。显然,它缺乏与符号相关的信息。可以轻松获取签到信息(ts从链接或m3u8文件中获取)
分析待解决问题的进度 破解加密缓存文件,从sqlite文件中获取必要信息
import sqlite3 as db
# 获取m3u8文件的下载链接,视频base_url,aes解密key
def get_url_key(sqlite_file):
con = db.connect(sqlite_file)
cu = con.cursor()
result = cu.execute('SELECT * FROM caches')
data = result.fetchall()
m3u8_url = data[0][0]
# video_base_url = data[2][0]
video_base_url = data[2][0].split("?")[0]
aes_key = data[1][1]
return m3u8_url, video_base_url, aes_key
拼接完整的视频剪辑链接
import m3u8
import re
def get_seg_uri(m3u8_file):
m3u8_obj = m3u8.load(m3u8_file)
seg_start_uri = m3u8_obj.segments[0].uri
seg_end_uri = m3u8_obj.segments[-1].uri
end_time = re.search('end=([0-9]*)', seg_end_uri).group(1)
pattern = r'end=[0-9]*'
seg_uri = re.sub(pattern, r'end={}'.format(end_time), seg_start_uri)
return seg_uri.split('?')[-1]
引入第三方库m3u8解析库,详细请参考m3u8解析库github地址
解密完整的视频文件
import os
from Crypto.Cipher import AES
import requests
import threading
THIS_FILE_PATH = os.path.dirname(os.path.realpath(__file__))
OUTPUT_FILE_PATH = os.path.join(THIS_FILE_PATH, 'output')
SQLITE_FILE_PATH = os.path.join(THIS_FILE_PATH, 'sqlite')
def decrypt_video(sqlite_file):
print("thread start......")
file_saved_name = sqlite_file.split('.')[0] + ".mp4"
m3u8_url, video_base_url, aes_key = get_url_key(os.path.join(SQLITE_FILE_PATH, sqlite_file))
# print(m3u8_url, video_base_url, aes_key, sep='\n')
seg_uri = get_seg_uri(m3u8_url)
video_url = video_base_url + '?' + seg_uri
# print(video_url)
res = requests.get(video_url, stream=True)
video_stream = b''
for chunk in res.iter_content(chunk_size=1024 * 20):
if chunk:
video_stream += chunk
decrypted_video = AES.new(aes_key, AES.MODE_CBC).decrypt(video_stream)
with open(os.path.join(OUTPUT_FILE_PATH, file_saved_name), 'ab') as f:
f.write(decrypted_video)
print("thread end .....")
for file in os.listdir(SQLITE_FILE_PATH):
if file.endswith('sqlite'):
decrypt_video_thread = threading.Thread(target=decrypt_video, args=(file,))
decrypt_video_thread.start()
介绍加密解密库Crypto。引导包遇到问题请参考python3中的Crypto ModuleNotFoundError
一些结论:下载完整视频然后解密是受网络影响的。考虑直接转到 sqlite 文件以获取完整视频。16byte的码流可以叠加合并得到完整的视频,但是声音不能同步。它放弃了通过单个 ts 段解密多个视频。把一个视频看成100+个片段很不方便。如果sqlite文件缓存很久,方法无效,sign等信息可能无效。如果要解密视频文件,需要有很多最近缓存的sqlite文件。视频网站的视频加解密方法与此类似,下面以开课为例,其他类型的网站视频如果需要,可以自己尝试
from Crypto.Cipher import AES
import requests
# key_url = "https://p.bokecc.com/servlet/h ... ot%3B
# key = requests.get(key_url)
# print(key.content)
# iv = 0x50E8E2C985FD43379C33DC5901307461
# iv = 0x50E8E2C985FD43379 # 取高16位
# iv = iv.to_bytes(length=16, byteorder='big')
# iv = b'0000000000000000' # 经过测试,iv在这里不起作用
for i in range(725):
video_url = "https://cd15-ccd1-2.play.bokec ... eo%3D{}&t=1601134081&key=B23C32BEF607876499FF469AA5B4B46C&tpl=10&tpt=112".format(i)
print("download video-{}....".format(i))
res = requests.get(video_url)
# hlskey通过key_url可下载到,也可通过requests.get下载,然后aes_key=key_res.content
with open("hlskey", "rb") as f:
key = f.read()
content_video_part = AES.new(key, AES.MODE_CBC).decrypt(res.content)
with open("kaikeba.mp4", 'ab') as f: # 追加保存解密结果
f.write(content_video_part)
写在最后
有任何问题请关注我的公众号CodeMonkeyJerry,欢迎留言
查看全部
网页抓取解密(腾讯课堂缓存文件分析进展缓存分析获取资源
)
背景
众所周知,腾讯课堂这样的视频是有时间限制的。
如果我付了钱并想永远保留它,我该怎么办?
录屏?也许这是一种思维方式。但是这个时间成本可能比较大。
接下来,我将提供一个解锁加密视频的思路,仅供参考。
发现
对分析过程不感兴趣的可以跳到最后一节
腾讯课堂网页版分析网络请求和过滤器关键词m3u8
直接复制这个url,发现可以下载一个m3u8文件,但是只有几十kb,显然不是视频。以文本方式打开文件,查找类似配置的相关信息。那么什么是m3u8?
关于 m3u8
详细请参考文档m3u8文件格式详细解释
m3u8文件作为媒体播放列表(Meida Playlist)时,其内部信息记录了一系列媒体片段资源。依次播放片段资源,充分展示多媒体资源。格式如下:
#EXTM3U
#EXT-X-TARGETDURATION:10
#EXTINF:9.009,
http://media.example.com/first.ts
#EXTINF:9.009,
http://media.example.com/second.ts
#EXTINF:3.003,
http://media.example.com/third.ts
分析网络请求并过滤关键词.ts
原来m3u8是一个媒体播放器列表,里面收录了多个ts播放片段资源,再看看.ts视频片段相关的请求
浏览器下载 .ts 视频文件
直接访问ts视频的url,发现可以直接下载ts视频文件。But when the player is selected to play, it cannot be played. 可以肯定视频是加密的。看一下m3u8文件(以文本模式查看):
......
#EXT-X-KEY:METHOD=AES-128,URI="https://ke.qq.com/cgi-bin/qclo ... ot%3B,IV=0x00000000000000000000000000000000
.......
METHOD:该值是一个可枚举的字符串,用于指定加密方法。AES-128:表示使用 AES-128 进行加密。
URI:指定密钥路径。密钥是一个 16 字节的数据。此键是必需参数,除非 METHOD 为 NONE。
IV:该值为 128 位十六进制值。AES-128 加密和解密需要相同的 16 字节 IV 值。使用不同的IV值可以增加密码的强度。
分析缓存文件分析进度获取缓存文件
腾讯课堂缓存文件存放在/sdcard/Android/data//files/tencentedu/video/txdownload/
可以通过adb把手机中的缓存文件拉到电脑上
adb pull /sdcard/Android/data/com.tencent.edu/files/tencentedu/video/txdownload/
分析缓存文件sqlite
既然是sqlite文件,放到Navicat或者Datagrip里看看

元数据和缓存,这里的重点是缓存表。从数据库中可以看出,数据库中插入了.ts视频文件片段、m3u8目录信息和解密密钥,与分析网页得到的数据基本一致。
分析ts片段
可以看出ts片段的格式是
https://1258712167.vod2.myqclo ... pegts
...
...
https://1258712167.vod2.myqclo ... pegts
开始和结束是连续的,并确定片段的开始和结束
修改链接为start=0&end=38045039(即end是最后一个片段的结尾),访问链接,但是提示需要签名信息。显然,它缺乏与符号相关的信息。可以轻松获取签到信息(ts从链接或m3u8文件中获取)
分析待解决问题的进度 破解加密缓存文件,从sqlite文件中获取必要信息
import sqlite3 as db
# 获取m3u8文件的下载链接,视频base_url,aes解密key
def get_url_key(sqlite_file):
con = db.connect(sqlite_file)
cu = con.cursor()
result = cu.execute('SELECT * FROM caches')
data = result.fetchall()
m3u8_url = data[0][0]
# video_base_url = data[2][0]
video_base_url = data[2][0].split("?")[0]
aes_key = data[1][1]
return m3u8_url, video_base_url, aes_key
拼接完整的视频剪辑链接
import m3u8
import re
def get_seg_uri(m3u8_file):
m3u8_obj = m3u8.load(m3u8_file)
seg_start_uri = m3u8_obj.segments[0].uri
seg_end_uri = m3u8_obj.segments[-1].uri
end_time = re.search('end=([0-9]*)', seg_end_uri).group(1)
pattern = r'end=[0-9]*'
seg_uri = re.sub(pattern, r'end={}'.format(end_time), seg_start_uri)
return seg_uri.split('?')[-1]
引入第三方库m3u8解析库,详细请参考m3u8解析库github地址
解密完整的视频文件
import os
from Crypto.Cipher import AES
import requests
import threading
THIS_FILE_PATH = os.path.dirname(os.path.realpath(__file__))
OUTPUT_FILE_PATH = os.path.join(THIS_FILE_PATH, 'output')
SQLITE_FILE_PATH = os.path.join(THIS_FILE_PATH, 'sqlite')
def decrypt_video(sqlite_file):
print("thread start......")
file_saved_name = sqlite_file.split('.')[0] + ".mp4"
m3u8_url, video_base_url, aes_key = get_url_key(os.path.join(SQLITE_FILE_PATH, sqlite_file))
# print(m3u8_url, video_base_url, aes_key, sep='\n')
seg_uri = get_seg_uri(m3u8_url)
video_url = video_base_url + '?' + seg_uri
# print(video_url)
res = requests.get(video_url, stream=True)
video_stream = b''
for chunk in res.iter_content(chunk_size=1024 * 20):
if chunk:
video_stream += chunk
decrypted_video = AES.new(aes_key, AES.MODE_CBC).decrypt(video_stream)
with open(os.path.join(OUTPUT_FILE_PATH, file_saved_name), 'ab') as f:
f.write(decrypted_video)
print("thread end .....")
for file in os.listdir(SQLITE_FILE_PATH):
if file.endswith('sqlite'):
decrypt_video_thread = threading.Thread(target=decrypt_video, args=(file,))
decrypt_video_thread.start()
介绍加密解密库Crypto。引导包遇到问题请参考python3中的Crypto ModuleNotFoundError
一些结论:下载完整视频然后解密是受网络影响的。考虑直接转到 sqlite 文件以获取完整视频。16byte的码流可以叠加合并得到完整的视频,但是声音不能同步。它放弃了通过单个 ts 段解密多个视频。把一个视频看成100+个片段很不方便。如果sqlite文件缓存很久,方法无效,sign等信息可能无效。如果要解密视频文件,需要有很多最近缓存的sqlite文件。视频网站的视频加解密方法与此类似,下面以开课为例,其他类型的网站视频如果需要,可以自己尝试
from Crypto.Cipher import AES
import requests
# key_url = "https://p.bokecc.com/servlet/h ... ot%3B
# key = requests.get(key_url)
# print(key.content)
# iv = 0x50E8E2C985FD43379C33DC5901307461
# iv = 0x50E8E2C985FD43379 # 取高16位
# iv = iv.to_bytes(length=16, byteorder='big')
# iv = b'0000000000000000' # 经过测试,iv在这里不起作用
for i in range(725):
video_url = "https://cd15-ccd1-2.play.bokec ... eo%3D{}&t=1601134081&key=B23C32BEF607876499FF469AA5B4B46C&tpl=10&tpt=112".format(i)
print("download video-{}....".format(i))
res = requests.get(video_url)
# hlskey通过key_url可下载到,也可通过requests.get下载,然后aes_key=key_res.content
with open("hlskey", "rb") as f:
key = f.read()
content_video_part = AES.new(key, AES.MODE_CBC).decrypt(res.content)
with open("kaikeba.mp4", 'ab') as f: # 追加保存解密结果
f.write(content_video_part)
写在最后
有任何问题请关注我的公众号CodeMonkeyJerry,欢迎留言

网页抓取解密(网页书籍抓取器(网页内容抓取工具)是一款很优秀好用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-10-03 22:21
)
网络图书爬虫(网络内容爬取工具)是一款非常好用的网络内容爬取助手。如何更轻松地抓取网页内容?编辑器带来的这个网络图书抓取器可以帮助您。它功能强大且易于操作。使用后,用户可以轻松快速地抓取网页内容。可以很好的帮助大家抓取指定网页的内容,比如抓取一些小说内容,然后通过合并功能合并成一个完整的小说文本。欢迎有需要的朋友下载使用。
软件特点:
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
使用说明:
网络图书抓取器可以提取和调整指定小说目录页的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
指示:
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击Start crawling开始下载。
软件介绍:
网络图书抓取器是一种可以帮助用户下载指定网页的某本书和某章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
查看全部
网页抓取解密(网页书籍抓取器(网页内容抓取工具)是一款很优秀好用
)
网络图书爬虫(网络内容爬取工具)是一款非常好用的网络内容爬取助手。如何更轻松地抓取网页内容?编辑器带来的这个网络图书抓取器可以帮助您。它功能强大且易于操作。使用后,用户可以轻松快速地抓取网页内容。可以很好的帮助大家抓取指定网页的内容,比如抓取一些小说内容,然后通过合并功能合并成一个完整的小说文本。欢迎有需要的朋友下载使用。
软件特点:
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
使用说明:
网络图书抓取器可以提取和调整指定小说目录页的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
指示:
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击Start crawling开始下载。
软件介绍:
网络图书抓取器是一种可以帮助用户下载指定网页的某本书和某章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
网页抓取解密(投稿作者为独立开发者朱鹏飞投稿的思路方法测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-10-02 19:04
投稿作者为独立开发者朱鹏飞。他说,“看完文章后,我立即按照他的思路和方法进行了测试,然后下载了十几个官方微信小游戏源代码,纯粹研究学习。截至目前,我推在了文章的时候(2018年1月1日23:50),微信官方已经修复了这个漏洞,但是我觉得文章还是可以分享给开发者的,安全问题真的不能忽略了.”
雷锋网也注意到,朱说,一些老版本的微信仍然可以抓包,获取包地址。
以下资料选自朱鹏飞文章:
一、发现
一早起来就查了V2EX。看到一个帖子“可以直接跳微信改分数,POST请求没有验证……”我好奇进去看了看。
发现不仅可以跳过小游戏直接改分数,连微信小程序和小游戏的源码都可以直接下载。只需要知道appid和版本号就可以直接构造后缀wxapkg源码包的下载地址,不需要任何验证。
虽然下载的源码包是加密的,但是解密方法已经被V2EXer发现了,并且写了一个解密后的Python脚本,运行源码包就可以解压到一个文件夹中。
二、转载
第一步,我先尝试用帖子作者拼接的跳转源包地址进行测试,发现无需任何验证即可下载。你只需要知道地址,直接在任何浏览器或下载工具中打开即可下载。
第二步,使用帖子中的解压Python脚本将源码包解压为源码。
第三步,在本地微信开发者工具中创建一个空白的小程序或小游戏项目,不要选择快速启动模板。
第四步,将解压后的源码复制到新创建的项目目录下,开发者工具会提示编译错误,这个只需要新建一个game.json文件即可。
文件内容不能为空。编写一对大括号或添加 deviceOrientation 配置。这句话的意思是游戏是垂直进行的。
保存后发现游戏还是无法编译,需要修改最后一项。单击开发者工具右上角的详细信息按钮,将调试基础库更改为游戏。
好的,它已经启动并运行:
版权所有文章雷锋网,未经授权禁止转载。有关详细信息,请参阅重印说明。 查看全部
网页抓取解密(投稿作者为独立开发者朱鹏飞投稿的思路方法测试)
投稿作者为独立开发者朱鹏飞。他说,“看完文章后,我立即按照他的思路和方法进行了测试,然后下载了十几个官方微信小游戏源代码,纯粹研究学习。截至目前,我推在了文章的时候(2018年1月1日23:50),微信官方已经修复了这个漏洞,但是我觉得文章还是可以分享给开发者的,安全问题真的不能忽略了.”
雷锋网也注意到,朱说,一些老版本的微信仍然可以抓包,获取包地址。
以下资料选自朱鹏飞文章:
一、发现
一早起来就查了V2EX。看到一个帖子“可以直接跳微信改分数,POST请求没有验证……”我好奇进去看了看。

发现不仅可以跳过小游戏直接改分数,连微信小程序和小游戏的源码都可以直接下载。只需要知道appid和版本号就可以直接构造后缀wxapkg源码包的下载地址,不需要任何验证。

虽然下载的源码包是加密的,但是解密方法已经被V2EXer发现了,并且写了一个解密后的Python脚本,运行源码包就可以解压到一个文件夹中。

二、转载
第一步,我先尝试用帖子作者拼接的跳转源包地址进行测试,发现无需任何验证即可下载。你只需要知道地址,直接在任何浏览器或下载工具中打开即可下载。

第二步,使用帖子中的解压Python脚本将源码包解压为源码。



第三步,在本地微信开发者工具中创建一个空白的小程序或小游戏项目,不要选择快速启动模板。

第四步,将解压后的源码复制到新创建的项目目录下,开发者工具会提示编译错误,这个只需要新建一个game.json文件即可。

文件内容不能为空。编写一对大括号或添加 deviceOrientation 配置。这句话的意思是游戏是垂直进行的。

保存后发现游戏还是无法编译,需要修改最后一项。单击开发者工具右上角的详细信息按钮,将调试基础库更改为游戏。

好的,它已经启动并运行:

版权所有文章雷锋网,未经授权禁止转载。有关详细信息,请参阅重印说明。
网页抓取解密(小程序授权登录的代码前,需要了解清楚openid与unionid的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-10-02 19:03
首先,“登录”、“授权”、“授权登录”都是同一个意思,不用担心。
在编写小程序授权登录的代码之前,需要了解openid和unionid的区别。下面是一个简单的介绍:
腾讯有“微信·开放平台”。只有企业才能注册账号,可以理解为微信系统中的顶级账号。官网地址:除了这个微信开放平台,还有一个叫“微信公众平台”,可以注册服务号、订阅号、小程序、企业微信四种帐号。也就是说,公众号(服务号和订阅号可以统称为公众号)占用一个帐号,小程序也占用一个帐号。在绑定开放平台之前,小程序授权登录只能获取用户的openid。官网地址:小程序可以绑定公众号,公众号可以绑定微信开放平台,小程序也可以绑定微信开放平台。(好像有点绕)简单来说就是所有公众平台账号都需要绑定“开放平台”才能获得unionid。这是打通同一个公司下所有微信公众号最有效的方式(官方推荐),具体可以用百度...一、 以下是小程序登录代码:
官方说明如何获取UnionID,如果开发者账号下有同一主题的公众号,且用户已关注该公众号。开发者可以通过wx.login+code2Session直接获取用户的UnionID,无需用户重新授权。
开发者账号下存在同一主题的公众号或移动应用,且用户已被授权登录该公众号或移动应用。用户的UnionID也可以通过code2session获取。
1/**
2 * Author: huanglp
3 * Date: 2018-11-28
4 */
5public class WeiXinUtils {
6
7 private static Logger log = LoggerFactory.getLogger(WeiXinUtils.class);
8
9 /**
10 * 通过前端传过来的code, 调用小程序登录接口, 获取到message并返回 (包含openid session_key等)
11 *
12 * @param code
13 * @return
14 */
15 public static JSONObject login(String code) {
16 log.info("==============小程序登录方法开始================");
17 WxMiniProperties properties = WeiXinPropertiesUtils.getWxMiniProperties();
18 String url = properties.getInterfaceUrl() + "/sns/jscode2session?appid="
19 + properties.getAppId() + "&secret=" + properties.getAppSecret()
20 + "&js_code=" + code + "&grant_type=authorization_code";
21 JSONObject message;
22 try {
23 // RestTemplate是Spring封装好的, 挺好用, 可做成单例模式
24 RestTemplate restTemplate = new RestTemplate();
25 String response = restTemplate.getForObject(url, String.class);
26 message = JSON.parseObject(response);
27 } catch (Exception e) {
28 log.error("微信服务器请求错误", e);
29 message = new JSONObject();
30 }
31 log.info("message:" + message.toString());
32 log.info("==============小程序登录方法结束================");
33 return message;
34
35 // 后续, 可获取openid session_key等数据, 以下代码一般放在Service层
36 //if (message.get("errcode") != null) {
37 // throw new ValidationException(message.toString());
38 //}
39 //String openid = message.get("openid").toString();
40 //String sessionKey = message.get("session_key").toString();
41 //...
42
43 }
44}
复制代码
1public class WeiXinPropertiesUtils {
2
3 // 微信小程序配置
4 private static WxMiniProperties miniProperties;
5 // 微信公众号配置
6 private static WxProperties wxProperties;
7
8 private static void init() {
9 if (miniProperties == null) {
10 miniProperties = ContextLoader.getCurrentWebApplicationContext()
11 .getBean(WxMiniProperties.class);
12 }
13 if (wxProperties == null) {
14 wxProperties = ContextLoader.getCurrentWebApplicationContext()
15 .getBean(WxProperties.class);
16 }
17 }
18
19 public static WxMiniProperties getWxMiniProperties() {
20 init();
21 return miniProperties;
22 }
23
24 public static WxProperties getWxProperties() {
25 init();
26 return wxProperties;
27 }
28}
复制代码
1@Data
2@Component
3@ConfigurationProperties(prefix = "luwei.module.wx-mini")
4public class WxMiniProperties {
5
6 private String appId;
7 private String appSecret;
8 private String interfaceUrl;
9
10}
复制代码
目前通过代码可以获取到用户的openid和session_key,但是如果不满足条件,即使小程序绑定微信开放平台也无法获取unionid,所以这种方法不稳定。建议使用解密方式获取数据。
1/**
2 * 通过encryptedData,sessionKey,iv获得解密信息, 拥有用户丰富的信息, 包含openid,unionid,昵称等
3 */
4public static JSONObject decryptWxData(String encryptedData, String sessionKey, String iv) throws Exception {
5 log.info("============小程序登录解析数据方法开始==========");
6 String result = AesCbcUtil.decrypt(encryptedData, sessionKey, iv, "UTF-8");
7 JSONObject userInfo = new JSONObject();
8 if (null != result && result.length() > 0) {
9 userInfo = JSONObject.parseObject(result);
10 }
11 log.info("result: " + userInfo);
12 log.info("============小程序登录解析数据方法结束==========");
13 return userInfo;
14}
复制代码
1package com.luwei.common.utils;
2
3import org.bouncycastle.jce.provider.BouncyCastleProvider;
4import org.apache.commons.codec.binary.Base64;
5import javax.crypto.Cipher;
6import javax.crypto.spec.IvParameterSpec;
7import javax.crypto.spec.SecretKeySpec;
8import java.security.AlgorithmParameters;
9import java.security.Security;
10
11/**
12 * Updated by huanglp
13 * Date: 2018-11-28
14 */
15public class AesCbcUtil {
16
17 static {
18 Security.addProvider(new BouncyCastleProvider());
19 }
20
21 /**
22 * AES解密
23 *
24 * @param data //被加密的数据
25 * @param key //加密秘钥
26 * @param iv //偏移量
27 * @param encoding //解密后的结果需要进行的编码
28 */
29 public static String decrypt(String data, String key, String iv, String encoding) {
30
31 // org.apache.commons.codec.binary.Base64
32 byte[] dataByte = Base64.decodeBase64(data);
33 byte[] keyByte = Base64.decodeBase64(key);
34 byte[] ivByte = Base64.decodeBase64(iv);
35
36 try {
37 Cipher cipher = Cipher.getInstance("AES/CBC/PKCS7Padding");
38 SecretKeySpec spec = new SecretKeySpec(keyByte, "AES");
39 AlgorithmParameters parameters = AlgorithmParameters.getInstance("AES");
40 parameters.init(new IvParameterSpec(ivByte));
41
42 cipher.init(Cipher.DECRYPT_MODE, spec, parameters);// 初始化
43 byte[] resultByte = cipher.doFinal(dataByte);
44 if (null != resultByte && resultByte.length > 0) {
45 return new String(resultByte, encoding);
46 }
47 return null;
48
49 } catch (Exception e) {
50 e.printStackTrace();
51 }
52
53 return null;
54 }
55}
复制代码
至此,已经获取到了JSONObject类型的userInfo,包括openid、unionid、昵称、头像等数据
之后可以将用户信息保存到数据库中,然后返回一个token给前端。Shiro 通过公司封装了一层。代码如下:
1...
2// 获得用户ID
3int userId = wxUser.getWxUserId();
4shiroTokenService.afterLogout(userId);
5String uuid = UUID.randomUUID().toString();
6String token = StringUtils.deleteAny(uuid, "-") + Long.toString(System.currentTimeMillis(), Character.MAX_RADIX);
7shiroTokenService.afterLogin(userId, token, null);
8return token;
复制代码
二、 以下为公众号(网页)授权码:
网页授权更简单,可以查看官方文档
需要添加riversoft相关依赖包,公众号网页授权,只需将公众号绑定到开放平台,即可获取unionid等用户信息。
1public static OpenUser webSiteLogin(String code, String state) {
2 log.info("============微信公众号(网页)授权开始===========");
3 WxProperties properties = WeiXinPropertiesUtils.getWxProperties();
4 AppSetting appSetting = new AppSetting(properties.getAppId(), properties.getAppSecret());
5 OpenOAuth2s openOAuth2s = OpenOAuth2s.with(appSetting);
6 AccessToken accessToken = openOAuth2s.getAccessToken(code);
7
8 // 获取用户信息
9 OpenUser openUser = openOAuth2s.userInfo(accessToken.getAccessToken(), accessToken.getOpenId());
10 log.info("============微信公众号(网页)授权结束===========");
11 return openUser;
12
13 // 后续, 可将用户信息保存
14 // 最后一步, 生成token后, 需重定向回页面
15 //return "redirect:" + state + "?token=" + token;
16}
复制代码
以下是我整理的微信公众号授权和小程序授权的一些经验和问题的总结。我希望你能从他们那里找到解决办法。 查看全部
网页抓取解密(小程序授权登录的代码前,需要了解清楚openid与unionid的区别)
首先,“登录”、“授权”、“授权登录”都是同一个意思,不用担心。
在编写小程序授权登录的代码之前,需要了解openid和unionid的区别。下面是一个简单的介绍:
腾讯有“微信·开放平台”。只有企业才能注册账号,可以理解为微信系统中的顶级账号。官网地址:除了这个微信开放平台,还有一个叫“微信公众平台”,可以注册服务号、订阅号、小程序、企业微信四种帐号。也就是说,公众号(服务号和订阅号可以统称为公众号)占用一个帐号,小程序也占用一个帐号。在绑定开放平台之前,小程序授权登录只能获取用户的openid。官网地址:小程序可以绑定公众号,公众号可以绑定微信开放平台,小程序也可以绑定微信开放平台。(好像有点绕)简单来说就是所有公众平台账号都需要绑定“开放平台”才能获得unionid。这是打通同一个公司下所有微信公众号最有效的方式(官方推荐),具体可以用百度...一、 以下是小程序登录代码:
官方说明如何获取UnionID,如果开发者账号下有同一主题的公众号,且用户已关注该公众号。开发者可以通过wx.login+code2Session直接获取用户的UnionID,无需用户重新授权。
开发者账号下存在同一主题的公众号或移动应用,且用户已被授权登录该公众号或移动应用。用户的UnionID也可以通过code2session获取。
1/**
2 * Author: huanglp
3 * Date: 2018-11-28
4 */
5public class WeiXinUtils {
6
7 private static Logger log = LoggerFactory.getLogger(WeiXinUtils.class);
8
9 /**
10 * 通过前端传过来的code, 调用小程序登录接口, 获取到message并返回 (包含openid session_key等)
11 *
12 * @param code
13 * @return
14 */
15 public static JSONObject login(String code) {
16 log.info("==============小程序登录方法开始================");
17 WxMiniProperties properties = WeiXinPropertiesUtils.getWxMiniProperties();
18 String url = properties.getInterfaceUrl() + "/sns/jscode2session?appid="
19 + properties.getAppId() + "&secret=" + properties.getAppSecret()
20 + "&js_code=" + code + "&grant_type=authorization_code";
21 JSONObject message;
22 try {
23 // RestTemplate是Spring封装好的, 挺好用, 可做成单例模式
24 RestTemplate restTemplate = new RestTemplate();
25 String response = restTemplate.getForObject(url, String.class);
26 message = JSON.parseObject(response);
27 } catch (Exception e) {
28 log.error("微信服务器请求错误", e);
29 message = new JSONObject();
30 }
31 log.info("message:" + message.toString());
32 log.info("==============小程序登录方法结束================");
33 return message;
34
35 // 后续, 可获取openid session_key等数据, 以下代码一般放在Service层
36 //if (message.get("errcode") != null) {
37 // throw new ValidationException(message.toString());
38 //}
39 //String openid = message.get("openid").toString();
40 //String sessionKey = message.get("session_key").toString();
41 //...
42
43 }
44}
复制代码
1public class WeiXinPropertiesUtils {
2
3 // 微信小程序配置
4 private static WxMiniProperties miniProperties;
5 // 微信公众号配置
6 private static WxProperties wxProperties;
7
8 private static void init() {
9 if (miniProperties == null) {
10 miniProperties = ContextLoader.getCurrentWebApplicationContext()
11 .getBean(WxMiniProperties.class);
12 }
13 if (wxProperties == null) {
14 wxProperties = ContextLoader.getCurrentWebApplicationContext()
15 .getBean(WxProperties.class);
16 }
17 }
18
19 public static WxMiniProperties getWxMiniProperties() {
20 init();
21 return miniProperties;
22 }
23
24 public static WxProperties getWxProperties() {
25 init();
26 return wxProperties;
27 }
28}
复制代码
1@Data
2@Component
3@ConfigurationProperties(prefix = "luwei.module.wx-mini")
4public class WxMiniProperties {
5
6 private String appId;
7 private String appSecret;
8 private String interfaceUrl;
9
10}
复制代码
目前通过代码可以获取到用户的openid和session_key,但是如果不满足条件,即使小程序绑定微信开放平台也无法获取unionid,所以这种方法不稳定。建议使用解密方式获取数据。
1/**
2 * 通过encryptedData,sessionKey,iv获得解密信息, 拥有用户丰富的信息, 包含openid,unionid,昵称等
3 */
4public static JSONObject decryptWxData(String encryptedData, String sessionKey, String iv) throws Exception {
5 log.info("============小程序登录解析数据方法开始==========");
6 String result = AesCbcUtil.decrypt(encryptedData, sessionKey, iv, "UTF-8");
7 JSONObject userInfo = new JSONObject();
8 if (null != result && result.length() > 0) {
9 userInfo = JSONObject.parseObject(result);
10 }
11 log.info("result: " + userInfo);
12 log.info("============小程序登录解析数据方法结束==========");
13 return userInfo;
14}
复制代码
1package com.luwei.common.utils;
2
3import org.bouncycastle.jce.provider.BouncyCastleProvider;
4import org.apache.commons.codec.binary.Base64;
5import javax.crypto.Cipher;
6import javax.crypto.spec.IvParameterSpec;
7import javax.crypto.spec.SecretKeySpec;
8import java.security.AlgorithmParameters;
9import java.security.Security;
10
11/**
12 * Updated by huanglp
13 * Date: 2018-11-28
14 */
15public class AesCbcUtil {
16
17 static {
18 Security.addProvider(new BouncyCastleProvider());
19 }
20
21 /**
22 * AES解密
23 *
24 * @param data //被加密的数据
25 * @param key //加密秘钥
26 * @param iv //偏移量
27 * @param encoding //解密后的结果需要进行的编码
28 */
29 public static String decrypt(String data, String key, String iv, String encoding) {
30
31 // org.apache.commons.codec.binary.Base64
32 byte[] dataByte = Base64.decodeBase64(data);
33 byte[] keyByte = Base64.decodeBase64(key);
34 byte[] ivByte = Base64.decodeBase64(iv);
35
36 try {
37 Cipher cipher = Cipher.getInstance("AES/CBC/PKCS7Padding");
38 SecretKeySpec spec = new SecretKeySpec(keyByte, "AES");
39 AlgorithmParameters parameters = AlgorithmParameters.getInstance("AES");
40 parameters.init(new IvParameterSpec(ivByte));
41
42 cipher.init(Cipher.DECRYPT_MODE, spec, parameters);// 初始化
43 byte[] resultByte = cipher.doFinal(dataByte);
44 if (null != resultByte && resultByte.length > 0) {
45 return new String(resultByte, encoding);
46 }
47 return null;
48
49 } catch (Exception e) {
50 e.printStackTrace();
51 }
52
53 return null;
54 }
55}
复制代码
至此,已经获取到了JSONObject类型的userInfo,包括openid、unionid、昵称、头像等数据
之后可以将用户信息保存到数据库中,然后返回一个token给前端。Shiro 通过公司封装了一层。代码如下:
1...
2// 获得用户ID
3int userId = wxUser.getWxUserId();
4shiroTokenService.afterLogout(userId);
5String uuid = UUID.randomUUID().toString();
6String token = StringUtils.deleteAny(uuid, "-") + Long.toString(System.currentTimeMillis(), Character.MAX_RADIX);
7shiroTokenService.afterLogin(userId, token, null);
8return token;
复制代码
二、 以下为公众号(网页)授权码:
网页授权更简单,可以查看官方文档
需要添加riversoft相关依赖包,公众号网页授权,只需将公众号绑定到开放平台,即可获取unionid等用户信息。
1public static OpenUser webSiteLogin(String code, String state) {
2 log.info("============微信公众号(网页)授权开始===========");
3 WxProperties properties = WeiXinPropertiesUtils.getWxProperties();
4 AppSetting appSetting = new AppSetting(properties.getAppId(), properties.getAppSecret());
5 OpenOAuth2s openOAuth2s = OpenOAuth2s.with(appSetting);
6 AccessToken accessToken = openOAuth2s.getAccessToken(code);
7
8 // 获取用户信息
9 OpenUser openUser = openOAuth2s.userInfo(accessToken.getAccessToken(), accessToken.getOpenId());
10 log.info("============微信公众号(网页)授权结束===========");
11 return openUser;
12
13 // 后续, 可将用户信息保存
14 // 最后一步, 生成token后, 需重定向回页面
15 //return "redirect:" + state + "?token=" + token;
16}
复制代码
以下是我整理的微信公众号授权和小程序授权的一些经验和问题的总结。我希望你能从他们那里找到解决办法。
网页抓取解密( Python页面抓取过程中乱码的原因与相应的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-02 19:02
Python页面抓取过程中乱码的原因与相应的解决方法)
python抓取并保存html页面时出现乱码问题的解决方法
更新时间:2016-07-01 11:23:47 作者:holybin
本文文章主要介绍了python爬取html页面时出现乱码问题的解决方法,并结合示例表单分析了python页面爬取过程中出现乱码的原因及相应的解决方法。有需要的朋友可以参考Down
本文示例介绍了python抓取并保存html页面时出现乱码问题的解决方法。分享给大家,供大家参考,如下:
使用Python抓取html页面并保存时,经常会出现抓取页面内容乱码的问题。出现这个问题的原因,一方面是代码中的编码设置有问题;另一方面,当编码设置正确时,网页的实际编码与标记的编码不匹配。html页面上标注的代码在这里:
复制代码代码如下:
这里有一个简单的解决方法:使用chardet来判断网页的真实编码,同时从url请求返回的info中判断出mark编码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(这里设置系统默认编码为utf-8)。
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'https://www.jb51.net'
download(url)
获取到的test.html文件打开如下,可以看到它是以UTF-8无BOM编码格式存储的,也就是我们设置的默认编码:
对Python相关内容感兴趣的读者可以查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》 ,《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页抓取解密(
Python页面抓取过程中乱码的原因与相应的解决方法)
python抓取并保存html页面时出现乱码问题的解决方法
更新时间:2016-07-01 11:23:47 作者:holybin
本文文章主要介绍了python爬取html页面时出现乱码问题的解决方法,并结合示例表单分析了python页面爬取过程中出现乱码的原因及相应的解决方法。有需要的朋友可以参考Down
本文示例介绍了python抓取并保存html页面时出现乱码问题的解决方法。分享给大家,供大家参考,如下:
使用Python抓取html页面并保存时,经常会出现抓取页面内容乱码的问题。出现这个问题的原因,一方面是代码中的编码设置有问题;另一方面,当编码设置正确时,网页的实际编码与标记的编码不匹配。html页面上标注的代码在这里:
复制代码代码如下:
这里有一个简单的解决方法:使用chardet来判断网页的真实编码,同时从url请求返回的info中判断出mark编码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(这里设置系统默认编码为utf-8)。
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'https://www.jb51.net'
download(url)
获取到的test.html文件打开如下,可以看到它是以UTF-8无BOM编码格式存储的,也就是我们设置的默认编码:

对Python相关内容感兴趣的读者可以查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》 ,《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。
网页抓取解密(搜索引擎的原理简单分为三段信息抓取、信息处理和查询服务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-10-14 02:00
专利名称:网络信息抓取方法
网络信息抓取方法
技术领域:
本发明涉及搜索引擎领域,尤其涉及一种搜索引擎的网页抓取技术。背景技术:
随着网络通信技术的飞速发展,互联网已经成为一个巨大的分布式信息空间,其中收录着潜在的有价值的知识。网络信息收录许多有用的、潜在的、但不容易发现的知识和模式。人们迫切需要发现和掌握能够获取这些知识和模式的方法和工具。互联网上的信息以网页形式存在,网页之间通过超链接相互连接,形成错综复杂的信息网络。在早期的互联网时代,人们查找信息非常不方便,导致了搜索引擎的出现。搜索引擎采集和发现互联网上的信息,理解、提取、组织和处理信息,为用户提供搜索服务。搜索引擎的原理简单地分为信息捕获、信息处理和查询服务三个部分。信息爬取是通过网络爬虫从一个或多个初始网页的网址中获取初始网页的网络信息,通过不断从当前网页中提取新的网址并放入队列中,获取更多的网页和网页。Internet 上的网络信息,直到满足系统的某个停止条件。信息处理是将网络信息获取后存储在搜索引擎的数据库中,然后对网络信息进行一定的处理,以方便检索。最后,查询服务会根据用户的需要反馈处理后的网络信息。然而,现有技术中搜索引擎处理的最小对象是网页。请参考图。参考图1,其示出了描绘因特网的现有搜索引擎的结构模型100。现有的搜索引擎将互联网的结构模型100描述为网页图模型。网页图100由多个网页节点和超链接边组成。搜索引擎在抓取信息的过程中将每个网页保存为一个网页节点,如图中节点102所示;然后通过超链接将各个网页节点连接为一个关系,如图中的边104所示;整个互联网存储为一个网页地图结构。需要说明的是,网页中的信息并非都是用户希望得到的信息。请参考图。2、图1显示了收录现有技术中的结构化信息块的网页200。网页200包括三部分网站分类导航信息块202、广告等网页200的信息块204和主题部分206。对于绝大多数用户来说,他们想要什么搜索的只是与关键字相关的主题部分206的信息,而对于网站分类导航信息块202和广告等信息204则不关心。像网页200的主题部分206这样的网络信息被称为结构化信息块。结构化信息块是指信息经过分析可以分解为多个相互关联的组件,每个组件都有清晰的层次结构,以及对由数据库管理的网页信息的使用和维护。例如,在关于笔记本的页面中,结构化信息块收录笔记
此“品牌、型号、CPU、内存、硬盘、显示屏……”信息;在有关房地产信息的页面上,其
结构化信息块收录物业的“类型、地区、地址、房型、面积、装修状况、租金、联系人、联系电话等。
话……”信息。可以看出,互联网上有海量的类似信息,用户想要直接获取。
信息。如果搜索引擎在信息抓取过程中使用图1所示的网页结构来描绘互联网,显然会导致查询结果中收录大量无用信息,导致准确率下降。而且,用超链接作为关系来存储各个网页节点之间的关系也是不合逻辑的。由于搜索引擎总是将网页地址作为搜索结果呈现给用户,当用户点击相关结果时,他们很可能就在超链接的旁边。网站是无用的广告网站,与用户的目标和期望相差很大,浪费用户的时间。因此,有必要提出一种新的技术方案来解决上述不足。
发明内容本节的目的是对本发明实施例的几个方面进行总结,并简要介绍一些优选实施例。为避免混淆本部分、说明书摘要和发明名称的目的,本申请部分和说明书摘要和发明名称可能会有所简化或省略,不得使用此类简化或省略以限制本发明的范围。本发明的一个目的是提供一种网络信息的抓取方法,通过该方法,搜索引擎可以抓取互联网中的结构化信息。为实现本发明的目的,根据本发明的一个方面,本发明提供了一种捕获网络信息的方法。并提取其中的结构化信息,将结构化信息存储为当前对象节点;将获取到的网页中的链接地址作为当前URL,继续从当前URL中获取网页,并分析捕获 获取网页并提取其结构化信息,将结构化信息存储为当前对象节点,定义并存储当前对象节点与现有对象节点的关系,重复此操作完成网络信息捕获。此外,有一个或多个初始 URL。更远,分析抓取的网页并提取其中的结构化信息是指提取抓取网页中的结构化信息块或抓取网页中的半结构化信息块和非结构化信息块。将结构化信息块转换为结构化信息块,每个结构化信息块作为一个对象节点。进一步地,可以从爬取的网页中提取一个或多个结构化信息块,每个结构化信息块作为一个对象节点。更远,当前对象节点与现有对象节点关系的定义和存储是指通过当前对象节点中的数据与现有对象节点之间的逻辑或语义关系,定义当前对象节点与现有对象节点之间的关系。现有对象节点和存储。进一步地,当前对象节点与现有对象节点之间关系的定义和存储意味着每次提取当前对象节点时,都必须与现有对象节点定义并存储关系。进一步地,如果不能从被爬取的网页中提取结构化信息,则将被爬取的网页视为伪对象节点。进一步地,网络信息捕获方法捕获的网络信息为对象图。更远,
要点ο与现有技术相比,本发明使用对象图来描绘互联网。搜索引擎处理的最小单位是对象节点,即结构化的信息块,它可以让用户直接获取有用的信息,剔除广告信息。和无用的信息;同时,每个对象节点之间的关系由逻辑或语义关系定义,每个对象节点之间的关系具有一定的逻辑或语义关系,可以使查询结果具有更好的准确率。
结合附图和以下详细描述,本发明将更容易理解,其中相同的附图标记对应相同的结构部件,其中
图1是现有的搜索引擎,描绘了互联网的结构模型;图2为现有技术中收录结构化信息块的网页;图3是本发明实施例中对象图的结构示意图;图4是使用本发明描述的对象图描绘互联网的示意图;和图。图5为本发明网络信息捕获方法一个实施例的方法流程图。
具体实施方式本发明的详细描述通过程序、步骤、逻辑块、流程或其他符号描述直接或间接模拟了本发明技术方案的运行。为了彻底理解本发明,在以下描述中陈述了许多具体细节。没有这些具体细节,本发明仍然可以实现。本领域技术人员在这里使用这些描述和陈述,有效地向本领域的其他技术人员介绍他们的工作性质。换句话说,为了避免混淆本发明的目的,由于众所周知的方法、流程、组件和电路已经很容易理解,因此不再详细描述。此处所称的“一个实施例”或“实施例”是指可包括在本发明的至少一种实施方式中的特定特征、结构或特性。本说明书中不同地方出现的“在一个实施例中”并不均指同一实施例,也不是与其他实施例分离或选择性地相互排斥的实施例。另外,一个或多个实施例的方法、流程图或功能框图中各模块的顺序并不总是指任何具体的顺序,并不构成对本发明的限制。本发明的网络信息采集方法可以通过计算机结合相关程序实现为信息采集模块,位于整个搜索引擎系统的信息抓取位置。在捕获网络信息时,以结构化信息块作为最小处理单元,将互联网描绘成对象图而不是网页图。为突出重点,下面仅对与本发明相关的网络信息采集技术进行说明,搜索引擎系统的其他方面本文不再赘述。
请参考图。参见图3,为本发明实施例中对象图的结构示意图。对象图300还包括图模型的两个基本元素,节点和边。我们定义对象图由若干对象节点(如图,节点304和节点310),以及连接两个对象节点的关系边(如图,边30)组成6)).其中,对象节点代表互联网网页中的结构化信息块,如图所示,网页302中的结构化信息块304为对象节点;主体部分图2中网页200的206为对象节点,在一个实施例中,对象节点可以表示产品的结构化信息,其中可以包括产品名称、产品价格、产品信息和产品产地等信息。在另一个实施例中,对象节点可以表示公司的结构化信息,可以包括公司名称、公司规模、公司注册日期、公司法人等信息。简而言之,对于不同的主题,对象节点可能代表不同的信息。连接两个对象节点的关系边表示两个对象节点之间的关系,通常是两个对象节点所表示的结构化信息的逻辑或语义关系。在一个实施例中,如果两个对象节点A和B所描述的主题是学术论文,则结构化信息可以包括论文的作者、论文出版商、论文发表时间、论文摘要等,
请参考图。请参考图4,其为本发明的对象图描绘互联网的示意图。因特网400包括许多互连的对象图。在一个实施例中,对象图402是与学术论文相关的对象节点和相关关系边的集合。在另一个实施例中,对象图404是代表学校所有人员的信息的集合,其中对象节点代表所有学生、教师和员工的个人信息,可能具有班级、年龄等逻辑关系;在另一个实施例中,对象图406表示一个博客网站的所有博客帖子,其中对象节点表示博客的正文、作者、时间等信息,其中关系端可以是作者的共同点爱好,同一出版时间等。每个对象图可能是一个主题或语义独立的集合,但它们是相互关联的。例如,对象图404中的学生或教师可以是对象图402中学术论文的作者,对象图406中的博客的所有者是对象图404的雇员等。总之,当通过对象图描述互联网时,希望每个对象节点都收录一个逻辑或语义独立的结构化信息块,每个对象节点之间的关系是逻辑或语义关系。显然,当通过对象图描绘互联网时,就相当于搜索引擎对互联网上的信息进行了预筛选和过滤。当用户搜索时,他们可以直接向用户反馈最重要或最想要的信息。请参考图。请参阅图5,其为本发明的网络信息撷取方法500的方法流程图。
方法500包括以下步骤。步骤502,以初始网址作为当前网址,从当前网址抓取网页,对抓取的网页进行分析,提取其中的结构化信息,并将结构化信息作为当前对象节点存储。搜索引擎可以从一个或多个初始 URL 开始抓取网页。网页被抓取后,必须提取网页中的结构化信息作为对象节点。在一个实施例中,在从网页中提取结构化信息之前,可以定义结构化信息模板。同样,如上所述,对于不同的数据主体,结构化信息模板的定义可以完全不同。例如,对于产品信息等主题,结构化信息可以包括产品名称、产品简介和产品。价格、产品信息、产品产地等信息字段。又例如,对于公司信息等主题,结构化信息可以包括公司名称、公司规模、公司注册日期、公司法人等信息字段。定义的结构化信息模板用于在网页中进行遍历搜索。如果网页中的部分数据可以与结构化信息模板匹配,则可以将这部分数据提取为网页中的结构化信息。在另一个实施例中,
在又一实施例中,结合多种网络结构化信息块提取技术,对网页进行综合处理,得到更多结构化信息块作为对象节点。在一个实施例中,如果从当前网页中提取出一个结构化信息,则将其视为当前的一个对象节点;如果从当前网页中提取出两个结构化信息,也将其视为当前两个对象节点,并定义当前两个对象节点之间的关系;如果结构化信息块不是从当前网页中提取出来的,则首先将其存储为伪对象节点。如果图 3 所示的网页 302 图3是商品导购页面,可以提取商品的结构化信息304,形成对象节点304;如果网页308是产品用户评价页面,则无法提取图3所示的网页312的结构。图3包括两个结构化信息块314和316,则形成两个对象节点。步骤504:将抓取到的网页中的链接地址作为当前URL,从当前URL继续抓取网页,分析抓取的网页并提取其结构化信息,并将结构化信息存储为当前URL。对象节点定义并存储当前对象节点与现有对象节点之间的关系,并重复该操作完成网络信息捕获。处理完一个页面后,根据该页面中的链接地址继续获取下一个页面,同时提取结构化信息。特别是,这个页面中的所有链接地址都必须按照一定的策略依次处理。比如可以使用I^ageRank算法的策略进行处理。
如果提取结构化信息块,则将其视为对象节点;如果当前网页没有从结构化信息块中提取出来,则首先将其视为伪对象节点。在一个实施例中,提取的每个新的对象节点都必须定义与现有对象节点的关系,该关系由每个对象节点中的结构化信息的相关数据或属性标签来确定是否收录相同的数据。或者同类型的数据,数据之间是否存在引用和继承关系来判断。例如,在一个实施例中,两个对象节点代表同一品牌的食品,因为两个对象节点的结构化信息包括相同的品牌数据,两个对象节点之间的关系被定义为相同的品牌。重复上面的504步,就可以对互联网上的整个网页进行一次处理,就可以得到一张物件图。我们也可以稍后去除object map中的fake object节点,然后优化object map中的object 节点之间的关系,以获得更准确的object graph。在一个具体实施例中,我们采用上述网络数据采集方法,利用计算机结合相关程序实现信息采集模块,该模块位于移动搜索引擎的信息采集位置,为用户提供吃、住、和运输。对于商品等生活信息的检索,用户输入关键词“无锡咖啡厅”后,他会直接在手机客户端获取无锡咖啡馆的相关信息,没有其他广告信息或无用信息。它不仅可以节省用户的时间,还可以充分利用手机较小的显示屏来显示更多有用的信息。
本发明的网络数据抓取方法的一个特点、优点或好处在于,不是直接抓取整个网页,而是对网页的数据进行分析提取,只抓取部分有用信息,从而使得可以减少存储的数据。也会大大减少,同时可以保证后续搜索更有针对性,搜索结果更准确。通过设置不同的主题,可以有针对性地抓取互联网上的数据,既保证了数据的全面性,又保证了数据的针对性。以上描述已经充分公开了本发明的具体实施例
. 需要指出的是,本领域技术人员已经熟悉本发明的具体实施例
所做的任何改变都不脱离本发明权利要求的范围。相应地,本发明权利要求的范围不限于具体实施例。
.
权限请求
1. 一种网络信息抓取方法,其特征在于以初始URL为当前URL,从当前URL中抓取网页,分析抓取的网页并提取结构化信息,将结构化信息存储为当前对象节点;将抓取到的网页中的一个链接地址作为当前URL,从当前URL继续抓取网页,分析抓取到的网页并提取其结构信息,结构化信息作为当前对象节点,当前对象之间的关系节点和已有的对象节点被定义和存储,重复这个操作完成网络信息的捕获。
2.如权利要求1所述的网络信息捕获方法,其特征在于,所述初始URL为一个或多个。
3.根据权利要求1所述的网络信息爬取方法,其特征在于,对爬取的网页进行分析并提取其中的结构化信息是指从爬取的网页块中提取结构化信息或将半结构化信息块和非结构化信息块进行转换将抓取到的网页中的信息转化为结构化信息块,每个结构化信息块作为一个对象节点。
4.根据权利要求1所述的网络信息爬取方法,其特征在于,可以从爬取的网页中提取一个或多个结构化信息块,每个结构化信息块作为一个对象节点。
5.根据权利要求1所述的网络信息捕获方法,其特征在于,当前对象节点与现有对象节点之间关系的定义和存储是指通过当前对象节点和现有对象节点。数据的逻辑或语义关系定义了当前对象节点与现有对象节点之间的关系并存储。
6.如权利要求1所述的网络信息抓取方法,其特征在于,定义和存储当前对象节点与现有对象节点之间的关系,是指每个当前对象节点都必须与现有对象节点一起提取。存在定义关系并存储它们的对象节点。
7.根据权利要求1所述的网络信息爬取方法,其特征在于,如果不能从被爬取的网页中提取结构化信息,则将被爬取的网页视为伪对象节点。
8.根据权利要求7所述的网络信息捕获方法,其特征在于,所述网络信息捕获方法捕获的网络信息为对象图。
9.根据权利要求8所述的网络信息捕获方法,其特征在于,所述网络信息捕获方法还包括去除获取的对象图中的伪对象节点。
全文摘要
本发明公开了一种网络信息的捕获方法。该方法包括使用初始URL作为当前URL,从当前URL中抓取网页,分析抓取的网页并提取其中的结构化信息,将结构化信息作为当前对象节点存储;将抓取到的网页中的链接地址作为当前网址,从当前网址继续抓取网页,对抓取到的网页进行分析,提取其结构化信息。将结构化信息存储为当前对象节点,定义并存储当前对象节点与现有对象节点之间的关系,重复此操作,完成网络信息捕获。
文件编号 G06F17/30GK102214179SQ20101014413
公布日期 2011 年 10 月 12 日 申请日期 2010 年 4 月 12 日 优先权日期 2010 年 4 月 12 日
发明人梁久珍、白玉钊、胡丽娟申请人: 查看全部
网页抓取解密(搜索引擎的原理简单分为三段信息抓取、信息处理和查询服务)
专利名称:网络信息抓取方法
网络信息抓取方法
技术领域:
本发明涉及搜索引擎领域,尤其涉及一种搜索引擎的网页抓取技术。背景技术:
随着网络通信技术的飞速发展,互联网已经成为一个巨大的分布式信息空间,其中收录着潜在的有价值的知识。网络信息收录许多有用的、潜在的、但不容易发现的知识和模式。人们迫切需要发现和掌握能够获取这些知识和模式的方法和工具。互联网上的信息以网页形式存在,网页之间通过超链接相互连接,形成错综复杂的信息网络。在早期的互联网时代,人们查找信息非常不方便,导致了搜索引擎的出现。搜索引擎采集和发现互联网上的信息,理解、提取、组织和处理信息,为用户提供搜索服务。搜索引擎的原理简单地分为信息捕获、信息处理和查询服务三个部分。信息爬取是通过网络爬虫从一个或多个初始网页的网址中获取初始网页的网络信息,通过不断从当前网页中提取新的网址并放入队列中,获取更多的网页和网页。Internet 上的网络信息,直到满足系统的某个停止条件。信息处理是将网络信息获取后存储在搜索引擎的数据库中,然后对网络信息进行一定的处理,以方便检索。最后,查询服务会根据用户的需要反馈处理后的网络信息。然而,现有技术中搜索引擎处理的最小对象是网页。请参考图。参考图1,其示出了描绘因特网的现有搜索引擎的结构模型100。现有的搜索引擎将互联网的结构模型100描述为网页图模型。网页图100由多个网页节点和超链接边组成。搜索引擎在抓取信息的过程中将每个网页保存为一个网页节点,如图中节点102所示;然后通过超链接将各个网页节点连接为一个关系,如图中的边104所示;整个互联网存储为一个网页地图结构。需要说明的是,网页中的信息并非都是用户希望得到的信息。请参考图。2、图1显示了收录现有技术中的结构化信息块的网页200。网页200包括三部分网站分类导航信息块202、广告等网页200的信息块204和主题部分206。对于绝大多数用户来说,他们想要什么搜索的只是与关键字相关的主题部分206的信息,而对于网站分类导航信息块202和广告等信息204则不关心。像网页200的主题部分206这样的网络信息被称为结构化信息块。结构化信息块是指信息经过分析可以分解为多个相互关联的组件,每个组件都有清晰的层次结构,以及对由数据库管理的网页信息的使用和维护。例如,在关于笔记本的页面中,结构化信息块收录笔记
此“品牌、型号、CPU、内存、硬盘、显示屏……”信息;在有关房地产信息的页面上,其
结构化信息块收录物业的“类型、地区、地址、房型、面积、装修状况、租金、联系人、联系电话等。
话……”信息。可以看出,互联网上有海量的类似信息,用户想要直接获取。
信息。如果搜索引擎在信息抓取过程中使用图1所示的网页结构来描绘互联网,显然会导致查询结果中收录大量无用信息,导致准确率下降。而且,用超链接作为关系来存储各个网页节点之间的关系也是不合逻辑的。由于搜索引擎总是将网页地址作为搜索结果呈现给用户,当用户点击相关结果时,他们很可能就在超链接的旁边。网站是无用的广告网站,与用户的目标和期望相差很大,浪费用户的时间。因此,有必要提出一种新的技术方案来解决上述不足。
发明内容本节的目的是对本发明实施例的几个方面进行总结,并简要介绍一些优选实施例。为避免混淆本部分、说明书摘要和发明名称的目的,本申请部分和说明书摘要和发明名称可能会有所简化或省略,不得使用此类简化或省略以限制本发明的范围。本发明的一个目的是提供一种网络信息的抓取方法,通过该方法,搜索引擎可以抓取互联网中的结构化信息。为实现本发明的目的,根据本发明的一个方面,本发明提供了一种捕获网络信息的方法。并提取其中的结构化信息,将结构化信息存储为当前对象节点;将获取到的网页中的链接地址作为当前URL,继续从当前URL中获取网页,并分析捕获 获取网页并提取其结构化信息,将结构化信息存储为当前对象节点,定义并存储当前对象节点与现有对象节点的关系,重复此操作完成网络信息捕获。此外,有一个或多个初始 URL。更远,分析抓取的网页并提取其中的结构化信息是指提取抓取网页中的结构化信息块或抓取网页中的半结构化信息块和非结构化信息块。将结构化信息块转换为结构化信息块,每个结构化信息块作为一个对象节点。进一步地,可以从爬取的网页中提取一个或多个结构化信息块,每个结构化信息块作为一个对象节点。更远,当前对象节点与现有对象节点关系的定义和存储是指通过当前对象节点中的数据与现有对象节点之间的逻辑或语义关系,定义当前对象节点与现有对象节点之间的关系。现有对象节点和存储。进一步地,当前对象节点与现有对象节点之间关系的定义和存储意味着每次提取当前对象节点时,都必须与现有对象节点定义并存储关系。进一步地,如果不能从被爬取的网页中提取结构化信息,则将被爬取的网页视为伪对象节点。进一步地,网络信息捕获方法捕获的网络信息为对象图。更远,
要点ο与现有技术相比,本发明使用对象图来描绘互联网。搜索引擎处理的最小单位是对象节点,即结构化的信息块,它可以让用户直接获取有用的信息,剔除广告信息。和无用的信息;同时,每个对象节点之间的关系由逻辑或语义关系定义,每个对象节点之间的关系具有一定的逻辑或语义关系,可以使查询结果具有更好的准确率。
结合附图和以下详细描述,本发明将更容易理解,其中相同的附图标记对应相同的结构部件,其中
图1是现有的搜索引擎,描绘了互联网的结构模型;图2为现有技术中收录结构化信息块的网页;图3是本发明实施例中对象图的结构示意图;图4是使用本发明描述的对象图描绘互联网的示意图;和图。图5为本发明网络信息捕获方法一个实施例的方法流程图。
具体实施方式本发明的详细描述通过程序、步骤、逻辑块、流程或其他符号描述直接或间接模拟了本发明技术方案的运行。为了彻底理解本发明,在以下描述中陈述了许多具体细节。没有这些具体细节,本发明仍然可以实现。本领域技术人员在这里使用这些描述和陈述,有效地向本领域的其他技术人员介绍他们的工作性质。换句话说,为了避免混淆本发明的目的,由于众所周知的方法、流程、组件和电路已经很容易理解,因此不再详细描述。此处所称的“一个实施例”或“实施例”是指可包括在本发明的至少一种实施方式中的特定特征、结构或特性。本说明书中不同地方出现的“在一个实施例中”并不均指同一实施例,也不是与其他实施例分离或选择性地相互排斥的实施例。另外,一个或多个实施例的方法、流程图或功能框图中各模块的顺序并不总是指任何具体的顺序,并不构成对本发明的限制。本发明的网络信息采集方法可以通过计算机结合相关程序实现为信息采集模块,位于整个搜索引擎系统的信息抓取位置。在捕获网络信息时,以结构化信息块作为最小处理单元,将互联网描绘成对象图而不是网页图。为突出重点,下面仅对与本发明相关的网络信息采集技术进行说明,搜索引擎系统的其他方面本文不再赘述。
请参考图。参见图3,为本发明实施例中对象图的结构示意图。对象图300还包括图模型的两个基本元素,节点和边。我们定义对象图由若干对象节点(如图,节点304和节点310),以及连接两个对象节点的关系边(如图,边30)组成6)).其中,对象节点代表互联网网页中的结构化信息块,如图所示,网页302中的结构化信息块304为对象节点;主体部分图2中网页200的206为对象节点,在一个实施例中,对象节点可以表示产品的结构化信息,其中可以包括产品名称、产品价格、产品信息和产品产地等信息。在另一个实施例中,对象节点可以表示公司的结构化信息,可以包括公司名称、公司规模、公司注册日期、公司法人等信息。简而言之,对于不同的主题,对象节点可能代表不同的信息。连接两个对象节点的关系边表示两个对象节点之间的关系,通常是两个对象节点所表示的结构化信息的逻辑或语义关系。在一个实施例中,如果两个对象节点A和B所描述的主题是学术论文,则结构化信息可以包括论文的作者、论文出版商、论文发表时间、论文摘要等,
请参考图。请参考图4,其为本发明的对象图描绘互联网的示意图。因特网400包括许多互连的对象图。在一个实施例中,对象图402是与学术论文相关的对象节点和相关关系边的集合。在另一个实施例中,对象图404是代表学校所有人员的信息的集合,其中对象节点代表所有学生、教师和员工的个人信息,可能具有班级、年龄等逻辑关系;在另一个实施例中,对象图406表示一个博客网站的所有博客帖子,其中对象节点表示博客的正文、作者、时间等信息,其中关系端可以是作者的共同点爱好,同一出版时间等。每个对象图可能是一个主题或语义独立的集合,但它们是相互关联的。例如,对象图404中的学生或教师可以是对象图402中学术论文的作者,对象图406中的博客的所有者是对象图404的雇员等。总之,当通过对象图描述互联网时,希望每个对象节点都收录一个逻辑或语义独立的结构化信息块,每个对象节点之间的关系是逻辑或语义关系。显然,当通过对象图描绘互联网时,就相当于搜索引擎对互联网上的信息进行了预筛选和过滤。当用户搜索时,他们可以直接向用户反馈最重要或最想要的信息。请参考图。请参阅图5,其为本发明的网络信息撷取方法500的方法流程图。
方法500包括以下步骤。步骤502,以初始网址作为当前网址,从当前网址抓取网页,对抓取的网页进行分析,提取其中的结构化信息,并将结构化信息作为当前对象节点存储。搜索引擎可以从一个或多个初始 URL 开始抓取网页。网页被抓取后,必须提取网页中的结构化信息作为对象节点。在一个实施例中,在从网页中提取结构化信息之前,可以定义结构化信息模板。同样,如上所述,对于不同的数据主体,结构化信息模板的定义可以完全不同。例如,对于产品信息等主题,结构化信息可以包括产品名称、产品简介和产品。价格、产品信息、产品产地等信息字段。又例如,对于公司信息等主题,结构化信息可以包括公司名称、公司规模、公司注册日期、公司法人等信息字段。定义的结构化信息模板用于在网页中进行遍历搜索。如果网页中的部分数据可以与结构化信息模板匹配,则可以将这部分数据提取为网页中的结构化信息。在另一个实施例中,
在又一实施例中,结合多种网络结构化信息块提取技术,对网页进行综合处理,得到更多结构化信息块作为对象节点。在一个实施例中,如果从当前网页中提取出一个结构化信息,则将其视为当前的一个对象节点;如果从当前网页中提取出两个结构化信息,也将其视为当前两个对象节点,并定义当前两个对象节点之间的关系;如果结构化信息块不是从当前网页中提取出来的,则首先将其存储为伪对象节点。如果图 3 所示的网页 302 图3是商品导购页面,可以提取商品的结构化信息304,形成对象节点304;如果网页308是产品用户评价页面,则无法提取图3所示的网页312的结构。图3包括两个结构化信息块314和316,则形成两个对象节点。步骤504:将抓取到的网页中的链接地址作为当前URL,从当前URL继续抓取网页,分析抓取的网页并提取其结构化信息,并将结构化信息存储为当前URL。对象节点定义并存储当前对象节点与现有对象节点之间的关系,并重复该操作完成网络信息捕获。处理完一个页面后,根据该页面中的链接地址继续获取下一个页面,同时提取结构化信息。特别是,这个页面中的所有链接地址都必须按照一定的策略依次处理。比如可以使用I^ageRank算法的策略进行处理。
如果提取结构化信息块,则将其视为对象节点;如果当前网页没有从结构化信息块中提取出来,则首先将其视为伪对象节点。在一个实施例中,提取的每个新的对象节点都必须定义与现有对象节点的关系,该关系由每个对象节点中的结构化信息的相关数据或属性标签来确定是否收录相同的数据。或者同类型的数据,数据之间是否存在引用和继承关系来判断。例如,在一个实施例中,两个对象节点代表同一品牌的食品,因为两个对象节点的结构化信息包括相同的品牌数据,两个对象节点之间的关系被定义为相同的品牌。重复上面的504步,就可以对互联网上的整个网页进行一次处理,就可以得到一张物件图。我们也可以稍后去除object map中的fake object节点,然后优化object map中的object 节点之间的关系,以获得更准确的object graph。在一个具体实施例中,我们采用上述网络数据采集方法,利用计算机结合相关程序实现信息采集模块,该模块位于移动搜索引擎的信息采集位置,为用户提供吃、住、和运输。对于商品等生活信息的检索,用户输入关键词“无锡咖啡厅”后,他会直接在手机客户端获取无锡咖啡馆的相关信息,没有其他广告信息或无用信息。它不仅可以节省用户的时间,还可以充分利用手机较小的显示屏来显示更多有用的信息。
本发明的网络数据抓取方法的一个特点、优点或好处在于,不是直接抓取整个网页,而是对网页的数据进行分析提取,只抓取部分有用信息,从而使得可以减少存储的数据。也会大大减少,同时可以保证后续搜索更有针对性,搜索结果更准确。通过设置不同的主题,可以有针对性地抓取互联网上的数据,既保证了数据的全面性,又保证了数据的针对性。以上描述已经充分公开了本发明的具体实施例
. 需要指出的是,本领域技术人员已经熟悉本发明的具体实施例
所做的任何改变都不脱离本发明权利要求的范围。相应地,本发明权利要求的范围不限于具体实施例。
.
权限请求
1. 一种网络信息抓取方法,其特征在于以初始URL为当前URL,从当前URL中抓取网页,分析抓取的网页并提取结构化信息,将结构化信息存储为当前对象节点;将抓取到的网页中的一个链接地址作为当前URL,从当前URL继续抓取网页,分析抓取到的网页并提取其结构信息,结构化信息作为当前对象节点,当前对象之间的关系节点和已有的对象节点被定义和存储,重复这个操作完成网络信息的捕获。
2.如权利要求1所述的网络信息捕获方法,其特征在于,所述初始URL为一个或多个。
3.根据权利要求1所述的网络信息爬取方法,其特征在于,对爬取的网页进行分析并提取其中的结构化信息是指从爬取的网页块中提取结构化信息或将半结构化信息块和非结构化信息块进行转换将抓取到的网页中的信息转化为结构化信息块,每个结构化信息块作为一个对象节点。
4.根据权利要求1所述的网络信息爬取方法,其特征在于,可以从爬取的网页中提取一个或多个结构化信息块,每个结构化信息块作为一个对象节点。
5.根据权利要求1所述的网络信息捕获方法,其特征在于,当前对象节点与现有对象节点之间关系的定义和存储是指通过当前对象节点和现有对象节点。数据的逻辑或语义关系定义了当前对象节点与现有对象节点之间的关系并存储。
6.如权利要求1所述的网络信息抓取方法,其特征在于,定义和存储当前对象节点与现有对象节点之间的关系,是指每个当前对象节点都必须与现有对象节点一起提取。存在定义关系并存储它们的对象节点。
7.根据权利要求1所述的网络信息爬取方法,其特征在于,如果不能从被爬取的网页中提取结构化信息,则将被爬取的网页视为伪对象节点。
8.根据权利要求7所述的网络信息捕获方法,其特征在于,所述网络信息捕获方法捕获的网络信息为对象图。
9.根据权利要求8所述的网络信息捕获方法,其特征在于,所述网络信息捕获方法还包括去除获取的对象图中的伪对象节点。
全文摘要
本发明公开了一种网络信息的捕获方法。该方法包括使用初始URL作为当前URL,从当前URL中抓取网页,分析抓取的网页并提取其中的结构化信息,将结构化信息作为当前对象节点存储;将抓取到的网页中的链接地址作为当前网址,从当前网址继续抓取网页,对抓取到的网页进行分析,提取其结构化信息。将结构化信息存储为当前对象节点,定义并存储当前对象节点与现有对象节点之间的关系,重复此操作,完成网络信息捕获。
文件编号 G06F17/30GK102214179SQ20101014413
公布日期 2011 年 10 月 12 日 申请日期 2010 年 4 月 12 日 优先权日期 2010 年 4 月 12 日
发明人梁久珍、白玉钊、胡丽娟申请人:
网页抓取解密( 图片来源网络抓取策略(一)(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-14 01:12
图片来源网络抓取策略(一)(1)_光明网(组图))
图片来源网络
爬取策略
在爬虫系统中,要爬取的URL是一个非常关键的部分。爬虫需要爬取的网页的网址排列在其中,形成一个队列结构。调度器每次从队列的头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被追加到待爬取的URL队列的末尾,从而形成一个爬行循环,整个爬虫系统可以说是由这个队列驱动的。
如何确定要抓取的URL队列中页面URL的顺序?如上所述,新下载页面中收录的链接将附加到队列的末尾。虽然这是一种确定队列的 URL 顺序的方法,但它不是唯一的方法。事实上,可以采用许多其他技术来保持队列等待被捕获。取URL进行排序。爬虫的不同爬取策略使用不同的方法来确定要爬取的 URL 队列中 URL 的优先级。
爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:首先选择重要的网页进行爬取。在爬虫系统中,所谓的网页重要性可以通过不同的方法来判断,但大多是按照网页的流行程度来定义的。
爬取策略的方法虽然有很多,但这里仅列举被证明有效或具有代表性的解决方案,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略、大站优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。搜索引擎爬虫一出现就被采用。新提出的爬取策略往往使用这种方法作为比较的基准。不过值得注意的是,这个策略也是一个非常强大的方法,很多新方法的实际效果不一定比广度优先遍历策略好,所以这个方法其实是很多爬虫采用的第一种爬行策略。
前面说过,“新下载的网页中收录的URL会被追加到待抓取的URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法并没有明确提出和使用网页的重要性作为衡量标准,而是机械地从新下载的网页中提取链接,作为URL的下载顺序附加到待抓取的URL队列中。下图是这个策略的示意图: 假设队列头部的网页是1号网页,从1号网页中提取3个分别指向2号、3号、4号的链接,因此它们按要捕获的数字顺序排列。在取队列中,图中网页的编号为待取队列中页面的序号,
实验表明,这种策略效果很好。虽然看起来很机械,但实际的网络抓取顺序基本上是按照网页的重要性排序的。为此,有研究人员认为,如果一个网页收录多个传入链接,则更容易被广度优先遍历策略及早捕获,而传入链接的数量从侧面反映了该网页的重要性,即,实际的宽度优先遍历策略 以上也暗示了一些网页优先级假设。
广度优先遍历策略
02 PageRank 策略不完整
PageRank 是一种著名的链接分析算法,可用于衡量网页的重要性。自然可以想到使用PageRank的思想来对URL的优先级进行排序。但是这里有一个问题。PageRank 是一种全局算法,这意味着当所有网页都被下载时,计算结果是可靠的。爬虫的目的是下载网页,运行时只能看到部分网页。,所以在爬行阶段的网页无法获得可靠的PageRank分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,将要爬取的URL队列中的URL加入到一个网页集合中,在其中计算PageRank,计算完成后,URL要抓取的队列将排队。里面的网页按照PageRank分数从高到低排序,形成的顺序就是爬虫接下来要爬取的URL列表。这就是为什么它被称为“不完整的 PageRank”。
如果每次抓取一个新的网页,所有下载的网页都重新计算为一个新的不完整的PageRank值,这显然效率太低,在现实中是不可行的。一个折衷的方法是:每当有足够K个新下载的网页时,对所有下载的网页重新计算一个新的不完整PageRank。这种计算效率勉强可以接受,但又带来了一个新问题:在开始下一轮PageRank计算之前,提取新下载网页中收录的链接。很有可能这些链接的重要性非常高,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 会为这些新提取的没有 PageRank 值的网页分配一个临时的 PageRank 值。本网页所有链接内传输的 PageRank 值汇总为临时 PageRank 值。如果这个值大于在要爬取的 URL 队列中计算的值,如果 PageRank 值高的页面出来,那么这个 URL 会先被下载。
下图是不完全PageRank策略的示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{P1,P2,P3},这3个网页中收录的链接指向{P4,P5,P6},形成了待抓取的URL队列。如何决定下载顺序?将这6个网页组成一个新的集合,计算这个集合的PageRank值,让P4、P5和P6得到各自对应的PageRank值,从大到小排序,然后就可以得到下载顺序获得。这里可以假设下载顺序为:P5、P4、P6。当P5页面被下载时,链接被提取并指向页面P8。此时,P8 被分配了一个临时的 PageRank 值。如果这个值大于 P4 和 P6 如果你有一个 PageRank 值,P8 将首先被下载。这样一个连续的循环就形成了不完全PageRank策略的计算思路。
不完全PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明,不完整的 PageRank 结果稍好一些,而一些实验结果则刚好相反。有研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大不同。不应将其作为计算 URL 在爬行过程中的重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC字面意思是“在线页面重要性计算”,可以看作是一种改进的PageRank算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当一个页面P被下载,P就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”分配给“空”。对于URL队列中待抓取的网页,它们是按照手头的现金量排序,现金最多的网页先下载。OPIC在其大框架上与PageRank基本相同。区别在于:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,有一个远程跳转到没有链接关系的网页的过程,而OPIC没有这个计算因素。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略好于广度优先遍历策略。
04 大站优先策略
大站优先策略的思路很简单:以网站为单位来衡量网页的重要性。对于URL队列中待抓取的网页,根据各自的网站进行分类,如果等待下载的是哪个网站,如果页面最多,先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略好于宽度优先遍历策略。
网页更新策略
互联网的动态特性是其显着特征。随时出现新页面,更改页面内容或删除现有页面。对于爬虫来说,并不是在本地抓取网页,即使完成了任务,也必须体现互联网的动态性。本地下载的页面可以看作是互联网页面的“镜子”,爬虫应该尽量保证一致性。可以假设这样一种情况:某个网页被删除或者内容发生了重大变化,搜索引擎仍然不知道这个引擎,仍然按照旧内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取过的网页,
网页更新策略的任务是决定何时重新抓取下载的网页,使本地下载的网页内容尽可能与互联网上的原创网页一致。常用的网页更新策略有3种:历史参考策略、用户体验策略和聚类抽样策略。
01 历史参考策略
历史参考策略是最直观的更新策略。它基于这样一个假设,即过去经常更新的网页在未来也会经常更新。因此,为了估计某个网页的更新时间,可以参考历史更新情况进行判断。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时会再次发生变化,以指导爬虫的抓取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,专注于内容变化检测和建模。优越的。
02用户体验策略
一般来说,搜索引擎用户提交查询后,可能会有上千条相关的搜索结果,但用户没有耐心等待看到排名靠后的搜索结果,可能只看前3页的搜索内容。用户体验策略就是利用用户的这个特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,那么以后更新这些过时的网页也是可以的。因此,判断网页何时更新取决于网页内容的变化(通常以搜索结果排名的变化来衡量)带来的搜索质量的变化。网页的影响越大,应该更新得越快。
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,作为判断爬虫何时重新抓取网页的参考依据。网页的影响越严重,就越优先安排重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略很大程度上依赖于网页的历史更新信息,因为这是后续计算的基础。但实际上,要为每个网页保存历史信息,搜索系统会增加很多额外的负担。从另一个角度来说,如果是第一个被爬取的网页,因为没有历史信息,无法按照这两个思路来估计更新周期。为了解决上述不足,提出了聚类抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测其更新周期。具有相似属性的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,并且同一类别的网页具有相同的更新频率。为了计算某个类别的更新周期,只需对该类别中的网页进行采样,并将这些采样网页的更新周期作为该类别中所有网页的更新周期。与前面介绍的两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,也可以根据所属类别进行更新。
下图描述了集群抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页都有相似的更新周期。从类别中提取出一部分最具代表性的网页(通常是提取离类别中心最近的那些网页),计算这些网页的更新周期,然后将该更新周期用于该类别中的所有网页,然后可以基于网页的类别 确定其更新周期。
聚类抽样策略
网页更新周期的属性特征分为静态特征和动态特征两大类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,例如图像数量的变化、图像数量的变化、链内和链外的变化。等待。基于这两种特征,可以对网页进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,有的研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一网站的网页具有相同的更新周期,则其中的网页网站是Sampling,计算更新周期,然后网站中的所有网页都会遵循这个更新周期。虽然这个假设很粗略,因为很明显同一网站内的网页更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类也非常困难。
如果你对爬虫感兴趣,还可以阅读:
全程干货| 爬虫技术原理入门,看这篇文章就知道了
网络爬虫 | 你不知道的暗网是如何爬取的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗? 查看全部
网页抓取解密(
图片来源网络抓取策略(一)(1)_光明网(组图))
图片来源网络
爬取策略
在爬虫系统中,要爬取的URL是一个非常关键的部分。爬虫需要爬取的网页的网址排列在其中,形成一个队列结构。调度器每次从队列的头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被追加到待爬取的URL队列的末尾,从而形成一个爬行循环,整个爬虫系统可以说是由这个队列驱动的。
如何确定要抓取的URL队列中页面URL的顺序?如上所述,新下载页面中收录的链接将附加到队列的末尾。虽然这是一种确定队列的 URL 顺序的方法,但它不是唯一的方法。事实上,可以采用许多其他技术来保持队列等待被捕获。取URL进行排序。爬虫的不同爬取策略使用不同的方法来确定要爬取的 URL 队列中 URL 的优先级。
爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:首先选择重要的网页进行爬取。在爬虫系统中,所谓的网页重要性可以通过不同的方法来判断,但大多是按照网页的流行程度来定义的。
爬取策略的方法虽然有很多,但这里仅列举被证明有效或具有代表性的解决方案,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略、大站优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。搜索引擎爬虫一出现就被采用。新提出的爬取策略往往使用这种方法作为比较的基准。不过值得注意的是,这个策略也是一个非常强大的方法,很多新方法的实际效果不一定比广度优先遍历策略好,所以这个方法其实是很多爬虫采用的第一种爬行策略。
前面说过,“新下载的网页中收录的URL会被追加到待抓取的URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法并没有明确提出和使用网页的重要性作为衡量标准,而是机械地从新下载的网页中提取链接,作为URL的下载顺序附加到待抓取的URL队列中。下图是这个策略的示意图: 假设队列头部的网页是1号网页,从1号网页中提取3个分别指向2号、3号、4号的链接,因此它们按要捕获的数字顺序排列。在取队列中,图中网页的编号为待取队列中页面的序号,
实验表明,这种策略效果很好。虽然看起来很机械,但实际的网络抓取顺序基本上是按照网页的重要性排序的。为此,有研究人员认为,如果一个网页收录多个传入链接,则更容易被广度优先遍历策略及早捕获,而传入链接的数量从侧面反映了该网页的重要性,即,实际的宽度优先遍历策略 以上也暗示了一些网页优先级假设。
广度优先遍历策略
02 PageRank 策略不完整
PageRank 是一种著名的链接分析算法,可用于衡量网页的重要性。自然可以想到使用PageRank的思想来对URL的优先级进行排序。但是这里有一个问题。PageRank 是一种全局算法,这意味着当所有网页都被下载时,计算结果是可靠的。爬虫的目的是下载网页,运行时只能看到部分网页。,所以在爬行阶段的网页无法获得可靠的PageRank分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,将要爬取的URL队列中的URL加入到一个网页集合中,在其中计算PageRank,计算完成后,URL要抓取的队列将排队。里面的网页按照PageRank分数从高到低排序,形成的顺序就是爬虫接下来要爬取的URL列表。这就是为什么它被称为“不完整的 PageRank”。
如果每次抓取一个新的网页,所有下载的网页都重新计算为一个新的不完整的PageRank值,这显然效率太低,在现实中是不可行的。一个折衷的方法是:每当有足够K个新下载的网页时,对所有下载的网页重新计算一个新的不完整PageRank。这种计算效率勉强可以接受,但又带来了一个新问题:在开始下一轮PageRank计算之前,提取新下载网页中收录的链接。很有可能这些链接的重要性非常高,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 会为这些新提取的没有 PageRank 值的网页分配一个临时的 PageRank 值。本网页所有链接内传输的 PageRank 值汇总为临时 PageRank 值。如果这个值大于在要爬取的 URL 队列中计算的值,如果 PageRank 值高的页面出来,那么这个 URL 会先被下载。
下图是不完全PageRank策略的示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{P1,P2,P3},这3个网页中收录的链接指向{P4,P5,P6},形成了待抓取的URL队列。如何决定下载顺序?将这6个网页组成一个新的集合,计算这个集合的PageRank值,让P4、P5和P6得到各自对应的PageRank值,从大到小排序,然后就可以得到下载顺序获得。这里可以假设下载顺序为:P5、P4、P6。当P5页面被下载时,链接被提取并指向页面P8。此时,P8 被分配了一个临时的 PageRank 值。如果这个值大于 P4 和 P6 如果你有一个 PageRank 值,P8 将首先被下载。这样一个连续的循环就形成了不完全PageRank策略的计算思路。
不完全PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明,不完整的 PageRank 结果稍好一些,而一些实验结果则刚好相反。有研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大不同。不应将其作为计算 URL 在爬行过程中的重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC字面意思是“在线页面重要性计算”,可以看作是一种改进的PageRank算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当一个页面P被下载,P就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”分配给“空”。对于URL队列中待抓取的网页,它们是按照手头的现金量排序,现金最多的网页先下载。OPIC在其大框架上与PageRank基本相同。区别在于:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,有一个远程跳转到没有链接关系的网页的过程,而OPIC没有这个计算因素。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略好于广度优先遍历策略。
04 大站优先策略
大站优先策略的思路很简单:以网站为单位来衡量网页的重要性。对于URL队列中待抓取的网页,根据各自的网站进行分类,如果等待下载的是哪个网站,如果页面最多,先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略好于宽度优先遍历策略。
网页更新策略
互联网的动态特性是其显着特征。随时出现新页面,更改页面内容或删除现有页面。对于爬虫来说,并不是在本地抓取网页,即使完成了任务,也必须体现互联网的动态性。本地下载的页面可以看作是互联网页面的“镜子”,爬虫应该尽量保证一致性。可以假设这样一种情况:某个网页被删除或者内容发生了重大变化,搜索引擎仍然不知道这个引擎,仍然按照旧内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取过的网页,
网页更新策略的任务是决定何时重新抓取下载的网页,使本地下载的网页内容尽可能与互联网上的原创网页一致。常用的网页更新策略有3种:历史参考策略、用户体验策略和聚类抽样策略。
01 历史参考策略
历史参考策略是最直观的更新策略。它基于这样一个假设,即过去经常更新的网页在未来也会经常更新。因此,为了估计某个网页的更新时间,可以参考历史更新情况进行判断。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时会再次发生变化,以指导爬虫的抓取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,专注于内容变化检测和建模。优越的。
02用户体验策略
一般来说,搜索引擎用户提交查询后,可能会有上千条相关的搜索结果,但用户没有耐心等待看到排名靠后的搜索结果,可能只看前3页的搜索内容。用户体验策略就是利用用户的这个特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,那么以后更新这些过时的网页也是可以的。因此,判断网页何时更新取决于网页内容的变化(通常以搜索结果排名的变化来衡量)带来的搜索质量的变化。网页的影响越大,应该更新得越快。
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,作为判断爬虫何时重新抓取网页的参考依据。网页的影响越严重,就越优先安排重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略很大程度上依赖于网页的历史更新信息,因为这是后续计算的基础。但实际上,要为每个网页保存历史信息,搜索系统会增加很多额外的负担。从另一个角度来说,如果是第一个被爬取的网页,因为没有历史信息,无法按照这两个思路来估计更新周期。为了解决上述不足,提出了聚类抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测其更新周期。具有相似属性的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,并且同一类别的网页具有相同的更新频率。为了计算某个类别的更新周期,只需对该类别中的网页进行采样,并将这些采样网页的更新周期作为该类别中所有网页的更新周期。与前面介绍的两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,也可以根据所属类别进行更新。
下图描述了集群抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页都有相似的更新周期。从类别中提取出一部分最具代表性的网页(通常是提取离类别中心最近的那些网页),计算这些网页的更新周期,然后将该更新周期用于该类别中的所有网页,然后可以基于网页的类别 确定其更新周期。
聚类抽样策略
网页更新周期的属性特征分为静态特征和动态特征两大类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,例如图像数量的变化、图像数量的变化、链内和链外的变化。等待。基于这两种特征,可以对网页进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,有的研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一网站的网页具有相同的更新周期,则其中的网页网站是Sampling,计算更新周期,然后网站中的所有网页都会遵循这个更新周期。虽然这个假设很粗略,因为很明显同一网站内的网页更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类也非常困难。
如果你对爬虫感兴趣,还可以阅读:
全程干货| 爬虫技术原理入门,看这篇文章就知道了
网络爬虫 | 你不知道的暗网是如何爬取的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗?
网页抓取解密(requestheaders属性简介压缩方法语言,以及服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-13 17:42
2、 服务器返回加密后的公钥,通常是SSL证书;
3、客户端从这个SSL证书中解析出公钥,随机生成一个密钥,用公钥加密后发送给服务器(这一步是安全的,因为只有服务器有私钥读取密钥);
4、服务器通过私钥解密密钥;
5、 客户端使用这个密钥对要传输的数据进行加密;
6、 服务器使用密钥解析数据。
(三)在网页上请求和返回
打开任意一个网页,F12,选择网络,清除刷新,就会出来一系列的请求数据。
头部是网络协议请求和对应的核心,它携带客户端浏览器、请求页面、服务器等信息。
请求头可以理解为用于在请求消息中向服务器传递附加信息,包括客户端可以接受的数据类型、压缩方式、语言,以及客户端计算机上保留的信息和发出的超链接源地址请求。下面是对请求头属性的介绍:
请求头属性介绍
响应头可以理解为用于在http请求中从服务器向浏览器传递额外的信息,主要包括服务器传递的数据类型、使用的压缩方式、语言、服务器和浏览器的信息响应请求的时间。以下是响应属性:
响应头属性介绍
页面数据的获取其实就是客户端向服务器发送请求,然后服务器根据请求返回数据的过程。这也是爬取数据的基本原理。
(四)ForeSpider爬虫工作流程
1.获取网页数据
爬虫对页面的获取,其实就是获取网页的源代码,然后从中提取出我们想要的数据。
ForeSpider爬虫工具中已经内置了爬虫脚本框架,您只需在爬虫软件中按照手动点击进入页面的流程进行配置即可。
案例一:采集凤凰日报
手动:打开网站→点击新闻列表中的一条新闻→打开新闻查看数据。
爬虫:创建任务→提取新闻列表链接→提取数据。
如下所示:
创建任务
提取列表链接
检索数据
案例二:采集孔子旧书网所有分类旧书信息
手册:选择图书类别→点击类别图书列表中的图书→打开图书界面查看数据。
爬虫:提取所有类别链接→提取类别的所有列表链接→提取数据。
提取所有类别链接
提取类别中的所有列表链接
提取产品数据
提取结果显示
2.采集数据
配置好爬虫后,点击启动采集。以案例2为例,如下图所示:
数据采集接口
采集数据到
3. 导出数据
采集数据整理好后,可以直接将数据导出为csv/excel格式。
导出数据
导出数据表 查看全部
网页抓取解密(requestheaders属性简介压缩方法语言,以及服务器)
2、 服务器返回加密后的公钥,通常是SSL证书;
3、客户端从这个SSL证书中解析出公钥,随机生成一个密钥,用公钥加密后发送给服务器(这一步是安全的,因为只有服务器有私钥读取密钥);
4、服务器通过私钥解密密钥;
5、 客户端使用这个密钥对要传输的数据进行加密;
6、 服务器使用密钥解析数据。
(三)在网页上请求和返回
打开任意一个网页,F12,选择网络,清除刷新,就会出来一系列的请求数据。
头部是网络协议请求和对应的核心,它携带客户端浏览器、请求页面、服务器等信息。
请求头可以理解为用于在请求消息中向服务器传递附加信息,包括客户端可以接受的数据类型、压缩方式、语言,以及客户端计算机上保留的信息和发出的超链接源地址请求。下面是对请求头属性的介绍:
请求头属性介绍
响应头可以理解为用于在http请求中从服务器向浏览器传递额外的信息,主要包括服务器传递的数据类型、使用的压缩方式、语言、服务器和浏览器的信息响应请求的时间。以下是响应属性:
响应头属性介绍
页面数据的获取其实就是客户端向服务器发送请求,然后服务器根据请求返回数据的过程。这也是爬取数据的基本原理。
(四)ForeSpider爬虫工作流程
1.获取网页数据
爬虫对页面的获取,其实就是获取网页的源代码,然后从中提取出我们想要的数据。
ForeSpider爬虫工具中已经内置了爬虫脚本框架,您只需在爬虫软件中按照手动点击进入页面的流程进行配置即可。
案例一:采集凤凰日报
手动:打开网站→点击新闻列表中的一条新闻→打开新闻查看数据。
爬虫:创建任务→提取新闻列表链接→提取数据。
如下所示:
创建任务
提取列表链接
检索数据
案例二:采集孔子旧书网所有分类旧书信息
手册:选择图书类别→点击类别图书列表中的图书→打开图书界面查看数据。
爬虫:提取所有类别链接→提取类别的所有列表链接→提取数据。
提取所有类别链接
提取类别中的所有列表链接
提取产品数据
提取结果显示
2.采集数据
配置好爬虫后,点击启动采集。以案例2为例,如下图所示:
数据采集接口
采集数据到
3. 导出数据
采集数据整理好后,可以直接将数据导出为csv/excel格式。
导出数据
导出数据表
网页抓取解密(网易云技能点界面概况静态网页(一)_软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-13 17:38
技能点界面概览
静态页面
网易云仍然有一些网页,其网址通常会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。目前这样的借口有很多,这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分辨率
step1:找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
查了一下这个js里面的encSecKey,发现是这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先弄清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么encText生成的规则就很清楚了us.Twice.AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点明白了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你想到的参数原来是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_+songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
源码github地址索要Star。 查看全部
网页抓取解密(网易云技能点界面概况静态网页(一)_软件)
技能点界面概览
静态页面
网易云仍然有一些网页,其网址通常会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。目前这样的借口有很多,这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分辨率
step1:找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
查了一下这个js里面的encSecKey,发现是这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先弄清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么encText生成的规则就很清楚了us.Twice.AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点明白了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你想到的参数原来是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_+songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
源码github地址索要Star。
网页抓取解密(Response.spiders.Selector.Spider.start_urls核心工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-13 17:35
环境准备:使用pip安装lxml和scrapyscrapy startproject amazon_comment,创建一个名为amazon_comment的scrapy爬虫项目。 scrapy的核心工作流程:在scrapy.spiders.Spider中有一个变量start_urls,它是一个数组类型,表示我们需要让爬虫从哪些链接开始爬取。 Spider会使用start_urls中的链接,用默认的回调函数parse生成一个Request,然后使用链接进行HTTP请求,获取HTTP响应内容,封装成Response对象,然后将Response对象作为参数传递到回调函数解析。 Spider 中的第一个 Request 是通过调用 start_requests() 方法获得的。 start_requests() 方法默认由 Spider 实现。我们一般不需要实现这个方法。在start_requests()方法中,Request请求是通过读取start_urls中的链接生成的,默认使用parse作为回调函数。获得Response对象后,我们可以重写回调函数:parse方法,或者在生成Request时指定我们想要的任何回调函数。
这样,Response就会作为参数传入我们指定的回调函数中(默认是parse方法)。然后,我们就可以在我们设置的回调函数中从Response对象中解析返回的网页header内容和网页body内容。最常见的就是使用scrapy提供的scrapy.selector.Selector从网页正文中提取我们想要的网页内容。我们设置的回调函数可以返回一个Item对象,或者一个dict,或者一个Request对象,或者一个收录这三样东西的可迭代对象。在使用 Selector 提取网页内容时,最常见的一种是使用 xpath 语法在网页中定位和提取我们想要的数据。如果回调函数返回一个Request对象,那么这个Request对象会被Scrapy处理(发送请求,得到Response,传递给回调函数进行处理)。如果我们设置的回调函数返回的是Item对象,那么scrapy会将Item传递给我们在scrapy中定义的Item Pipeline进行处理。因此,我们一般要实现ItemPipeline。最常见的是将 Item 对象放入 Item Pipeline 中。格式化成我们想要的格式,然后持久化到数据库中。
当我们实现scrapy.spiders.Spider时:
如果不需要登录,不需要设置header,而且只通过一个URL就可以访问一个网页,那么在scrapy.spiders的Spider类中,可以覆盖解析(响应)方法。
<p>如果不需要登录,需要设置header(一般设置User-Agent和Referer),以及通过url可以访问的网页,然后重写parse(response)方法,然后在scrapy.spiders的Spider类中,重写start_requests()方法,返回一个scrapy.http.Request对象,在该方法中设置了headers参数。 Request 对象还可以设置回调。如果设置了回调,start_requests方法返回Request对象后,scrapy会根据Request发起请求,获取scrapy.http.Response对象,然后将Response对象作为参数传递给回调方法,然后执行回调方法;如果没有设置回调,那么scrapy会根据Request发起请求,获取scrapy.http.Response对象,然后将Response对象作为参数传递给parse方法,然后执行parse方法。 查看全部
网页抓取解密(Response.spiders.Selector.Spider.start_urls核心工作流程)
环境准备:使用pip安装lxml和scrapyscrapy startproject amazon_comment,创建一个名为amazon_comment的scrapy爬虫项目。 scrapy的核心工作流程:在scrapy.spiders.Spider中有一个变量start_urls,它是一个数组类型,表示我们需要让爬虫从哪些链接开始爬取。 Spider会使用start_urls中的链接,用默认的回调函数parse生成一个Request,然后使用链接进行HTTP请求,获取HTTP响应内容,封装成Response对象,然后将Response对象作为参数传递到回调函数解析。 Spider 中的第一个 Request 是通过调用 start_requests() 方法获得的。 start_requests() 方法默认由 Spider 实现。我们一般不需要实现这个方法。在start_requests()方法中,Request请求是通过读取start_urls中的链接生成的,默认使用parse作为回调函数。获得Response对象后,我们可以重写回调函数:parse方法,或者在生成Request时指定我们想要的任何回调函数。
这样,Response就会作为参数传入我们指定的回调函数中(默认是parse方法)。然后,我们就可以在我们设置的回调函数中从Response对象中解析返回的网页header内容和网页body内容。最常见的就是使用scrapy提供的scrapy.selector.Selector从网页正文中提取我们想要的网页内容。我们设置的回调函数可以返回一个Item对象,或者一个dict,或者一个Request对象,或者一个收录这三样东西的可迭代对象。在使用 Selector 提取网页内容时,最常见的一种是使用 xpath 语法在网页中定位和提取我们想要的数据。如果回调函数返回一个Request对象,那么这个Request对象会被Scrapy处理(发送请求,得到Response,传递给回调函数进行处理)。如果我们设置的回调函数返回的是Item对象,那么scrapy会将Item传递给我们在scrapy中定义的Item Pipeline进行处理。因此,我们一般要实现ItemPipeline。最常见的是将 Item 对象放入 Item Pipeline 中。格式化成我们想要的格式,然后持久化到数据库中。
当我们实现scrapy.spiders.Spider时:
如果不需要登录,不需要设置header,而且只通过一个URL就可以访问一个网页,那么在scrapy.spiders的Spider类中,可以覆盖解析(响应)方法。
<p>如果不需要登录,需要设置header(一般设置User-Agent和Referer),以及通过url可以访问的网页,然后重写parse(response)方法,然后在scrapy.spiders的Spider类中,重写start_requests()方法,返回一个scrapy.http.Request对象,在该方法中设置了headers参数。 Request 对象还可以设置回调。如果设置了回调,start_requests方法返回Request对象后,scrapy会根据Request发起请求,获取scrapy.http.Response对象,然后将Response对象作为参数传递给回调方法,然后执行回调方法;如果没有设置回调,那么scrapy会根据Request发起请求,获取scrapy.http.Response对象,然后将Response对象作为参数传递给parse方法,然后执行parse方法。
网页抓取解密([Asm]纯文本驱动程序-2016年第三次模拟考试 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-13 14:14
)
[Asm] 纯文本视图复制代码
from selenium import webdriver
import time,re
start_url = "https://www.jijikb.com/play/52825-0-1.html" #一共5集
def get_start_m3u8(url):
#-----------------------------------------------------------------------------------------------------------------------
# chrome_options = webdriver.ChromeOptions()
# # 添加浏览器参数
# # 添加UA
# chrome_options.add_argument(
# 'User-Agent: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"'
# )
# # 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
# chrome_options.add_argument('--headless')
# # 以最高权限运行
# chrome_options.add_argument('--no-sandbox')
# chrome_options.add_argument("--disable-gpu")
# chrome_options.add_argument("--disable-dev-shm-usage")
# # 设置开发者模式启动,该模式下webdriver属性为正常值
# chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# driver = webdriver.Chrome(chrome_options= chrome_options)
#-----------------------------------------------------------------------------------------------------------------------
#创建浏览器对象
driver =webdriver.Chrome()
driver.get(start_url)
driver.find_element_by_id("details-button").click()
time.sleep(0.5)
driver.find_element_by_id('proceed-link').click()
time.sleep(1)
response = driver .page_source #获取首页的响应数据 首页有debuger 调试验证 用selenium 跳过
# print(response)
start_m3u8 = re.findall(r'id="forbaiducache">(.*?)',response)[0]
print(start_m3u8)
time.sleep(0.5)
print(driver.title)
driver.quit() #退出浏览器
return start_m3u8
if __name__ == '__main__':
get_start_m3u8(start_url)
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- -----------------------------------------
[Asm] 纯文本视图复制代码
import timeimport requests,os
import urllib3
import urllib.request
from startm3u8 import get_start_m3u8
import asyncio
import aiofile
import aiohttp
# start_url = "https://www.jijikb.com/play/52825-0-1.html" #一共5集
secend_m3u8 = "https://vod4.buycar5.cn/202106 ... ot%3B
headers = {
'Referer': 'https://vod4.buycar5.cn/',
'host':'vod4.buycar5.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
}
def response(url):
rep = requests.get(url=url,headers=headers,timeout = 20,verify =False) #使用Python3 requests发送HTTPS请求,已经关闭认证(verify=False)情况下,控制台会输出以下InsecureRequestWarning
rep.encoding = rep.apparent_encoding
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) ## 禁用安全请求警告
if rep.status_code == 200:
return rep
else:
print("----没有响应----")
def get_second_m3u8_url(url):
rep = requests.get(url)
print(rep)
with open('first.m3u8','w') as f:
f.write(rep.text)
with open('first.m3u8',"r") as r_f:
for line in r_f:
if line.startswith("#"):
continue
start_m3u8_url = "https://vod4.buycar5.cn" + line
return start_m3u8_url
def get_tc_url(resp):
with open('secend.m3u8', 'wb') as f:
f.write(resp)
tc_urls = []
with open('secend.m3u8',"r") as r_f:
for n in r_f:
if n.startswith("#"):
continue
else:
print(n)
tc_urls.append(n)
return tc_urls
async def mov_down(url,semaphore):
async with semaphore:
async with aiohttp.ClientSession() as session:
tc_name = url.split('/')[-1].strip()
print(tc_name,"---正在下载-----")
async with await session.get(url,headers=headers) as rep:
print(rep.status)
async with aiofile.async_open("mov2/"+tc_name,'wb') as p_f:
print("-----正在存储------")
rep1 = await rep.read()
await p_f.write(rep1)
print(tc_name,'----下载完成---')
"""
urllib.request.urlopen(url, data=None, [timeout, ])
传入的url就是你想抓取的地址;
data是指向服务器提交信息时传递的字典形式的信息,通常来说就是爬去需要登录的网址时传入的用户名和密码,可省略。
timeout参数指的是超时时间,也可省略。
"""
def main():
semaphore = asyncio.Semaphore(100) # 限制并发量为20
start_time = time.time()
if not os.path.exists('mov2'):
os.mkdir("mov2")
start_m3u8_url = get_start_m3u8(start_url)
secend_m3u8_url = get_second_m3u8_url(start_m3u8_url)
print(secend_m3u8_url)
resp = urllib.request.urlopen(secend_m3u8_url).read()
# resp =requests.get(url=secend_m3u8_url,headers=headers) #不知道为什么requests 请求不到
tc_urls = get_tc_url(resp)
tasks = []
for url in tc_urls:
task =asyncio.ensure_future(mov_down(url,semaphore))
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
print(time.time()-start_time)
if __name__ == '__main__':
loop = asyncio.get_event_loop() #建立事件循环
main()
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------
[Asm] 纯文本视图复制代码
import asyncioimport os,re
import requests
import aiofiles
from Crypto.Cipher import AES
#pycryptodome模块
# key_url = "https://ts4.chinalincoln.com:9 ... ot%3B
headers = {
'Referer': 'https://vod4.buycar5.cn/',
'host': 'vod4.buycar5.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
}
def get_key_url():
with open('secend.m3u8','r') as f:
ke = f.read()
key_url = re.findall(r'#EXT-X-KEY:METHOD=AES-128,URI="(?P.*?)"',str(ke))[0]
print(key_url)
return key_url
async def aio_dec(key): # METHOD=AES-128
#解密
tasks = []
print("-------1------")
with open("secend.m3u8",'r') as f:
for line in f:
if line.startswith("#"):
continue
line = line.split('/')[-1].strip()
#开始创建异步任务
print(line)
task = asyncio.ensure_future(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
# loop.run_until_complete(asyncio.wait(tasks))
# loop.close()
async def dec_ts(name,key): #解密
aes = AES.new(key=key,IV=b"0000000000000000",mode=AES.MODE_CBC) #IV偏移量 key多少位就是多少位前面写b
# print(aes)
async with aiofiles.open(f'mov2/{name}','rb') as f1:
bs= await f1.read() # 从原文件读取内容
print("-----2----")
async with aiofiles.open(f'mov2/temp_{name}','wb') as f2:
await f2.write(aes.decrypt(bs)) #解密好的内容用存入文件
os.remove(f'mov2/{name}')
print("-----3----")
print(f'{name}处理完毕')
def merge_ts(): #合并
#mac: cat 1.ts 2.ts 3.ts > xxx.mp4
#windows: copy/b 1.ts +2.ts +3.ts ... xxx.mp4
#copy /b 命令格式:copy /b 文件1+文件2+......文件N 合并后的文件名<BR>命令讲解:使用"+"将多个相同或不同格式的文件合并为一个文件。
lst = []
with open('secend.m3u8',mode="r",encoding='utf-8') as p_f:
for line in p_f:
if line.startswith("#"):
continue
line = line.split('/')[-1].strip()
lst.append(line)
s = "".join(lst)
os.system(f"copy /b {s} movie.mp4")
print("")
if __name__ == '__main__':
# loop = asyncio.get_event_loop()
key_url = get_key_url()
key = requests.get(url=key_url, headers=headers).text
# key ='39f98d719dbdfbde'
key = key.encode("utf-8")
print(key)
asyncio.run(aio_dec(key)) 查看全部
网页抓取解密([Asm]纯文本驱动程序-2016年第三次模拟考试
)
[Asm] 纯文本视图复制代码
from selenium import webdriver
import time,re
start_url = "https://www.jijikb.com/play/52825-0-1.html" #一共5集
def get_start_m3u8(url):
#-----------------------------------------------------------------------------------------------------------------------
# chrome_options = webdriver.ChromeOptions()
# # 添加浏览器参数
# # 添加UA
# chrome_options.add_argument(
# 'User-Agent: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"'
# )
# # 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
# chrome_options.add_argument('--headless')
# # 以最高权限运行
# chrome_options.add_argument('--no-sandbox')
# chrome_options.add_argument("--disable-gpu")
# chrome_options.add_argument("--disable-dev-shm-usage")
# # 设置开发者模式启动,该模式下webdriver属性为正常值
# chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# driver = webdriver.Chrome(chrome_options= chrome_options)
#-----------------------------------------------------------------------------------------------------------------------
#创建浏览器对象
driver =webdriver.Chrome()
driver.get(start_url)
driver.find_element_by_id("details-button").click()
time.sleep(0.5)
driver.find_element_by_id('proceed-link').click()
time.sleep(1)
response = driver .page_source #获取首页的响应数据 首页有debuger 调试验证 用selenium 跳过
# print(response)
start_m3u8 = re.findall(r'id="forbaiducache">(.*?)',response)[0]
print(start_m3u8)
time.sleep(0.5)
print(driver.title)
driver.quit() #退出浏览器
return start_m3u8
if __name__ == '__main__':
get_start_m3u8(start_url)
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- -----------------------------------------
[Asm] 纯文本视图复制代码
import timeimport requests,os
import urllib3
import urllib.request
from startm3u8 import get_start_m3u8
import asyncio
import aiofile
import aiohttp
# start_url = "https://www.jijikb.com/play/52825-0-1.html" #一共5集
secend_m3u8 = "https://vod4.buycar5.cn/202106 ... ot%3B
headers = {
'Referer': 'https://vod4.buycar5.cn/',
'host':'vod4.buycar5.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
}
def response(url):
rep = requests.get(url=url,headers=headers,timeout = 20,verify =False) #使用Python3 requests发送HTTPS请求,已经关闭认证(verify=False)情况下,控制台会输出以下InsecureRequestWarning
rep.encoding = rep.apparent_encoding
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) ## 禁用安全请求警告
if rep.status_code == 200:
return rep
else:
print("----没有响应----")
def get_second_m3u8_url(url):
rep = requests.get(url)
print(rep)
with open('first.m3u8','w') as f:
f.write(rep.text)
with open('first.m3u8',"r") as r_f:
for line in r_f:
if line.startswith("#"):
continue
start_m3u8_url = "https://vod4.buycar5.cn" + line
return start_m3u8_url
def get_tc_url(resp):
with open('secend.m3u8', 'wb') as f:
f.write(resp)
tc_urls = []
with open('secend.m3u8',"r") as r_f:
for n in r_f:
if n.startswith("#"):
continue
else:
print(n)
tc_urls.append(n)
return tc_urls
async def mov_down(url,semaphore):
async with semaphore:
async with aiohttp.ClientSession() as session:
tc_name = url.split('/')[-1].strip()
print(tc_name,"---正在下载-----")
async with await session.get(url,headers=headers) as rep:
print(rep.status)
async with aiofile.async_open("mov2/"+tc_name,'wb') as p_f:
print("-----正在存储------")
rep1 = await rep.read()
await p_f.write(rep1)
print(tc_name,'----下载完成---')
"""
urllib.request.urlopen(url, data=None, [timeout, ])
传入的url就是你想抓取的地址;
data是指向服务器提交信息时传递的字典形式的信息,通常来说就是爬去需要登录的网址时传入的用户名和密码,可省略。
timeout参数指的是超时时间,也可省略。
"""
def main():
semaphore = asyncio.Semaphore(100) # 限制并发量为20
start_time = time.time()
if not os.path.exists('mov2'):
os.mkdir("mov2")
start_m3u8_url = get_start_m3u8(start_url)
secend_m3u8_url = get_second_m3u8_url(start_m3u8_url)
print(secend_m3u8_url)
resp = urllib.request.urlopen(secend_m3u8_url).read()
# resp =requests.get(url=secend_m3u8_url,headers=headers) #不知道为什么requests 请求不到
tc_urls = get_tc_url(resp)
tasks = []
for url in tc_urls:
task =asyncio.ensure_future(mov_down(url,semaphore))
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
print(time.time()-start_time)
if __name__ == '__main__':
loop = asyncio.get_event_loop() #建立事件循环
main()
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------
[Asm] 纯文本视图复制代码
import asyncioimport os,re
import requests
import aiofiles
from Crypto.Cipher import AES
#pycryptodome模块
# key_url = "https://ts4.chinalincoln.com:9 ... ot%3B
headers = {
'Referer': 'https://vod4.buycar5.cn/',
'host': 'vod4.buycar5.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
}
def get_key_url():
with open('secend.m3u8','r') as f:
ke = f.read()
key_url = re.findall(r'#EXT-X-KEY:METHOD=AES-128,URI="(?P.*?)"',str(ke))[0]
print(key_url)
return key_url
async def aio_dec(key): # METHOD=AES-128
#解密
tasks = []
print("-------1------")
with open("secend.m3u8",'r') as f:
for line in f:
if line.startswith("#"):
continue
line = line.split('/')[-1].strip()
#开始创建异步任务
print(line)
task = asyncio.ensure_future(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
# loop.run_until_complete(asyncio.wait(tasks))
# loop.close()
async def dec_ts(name,key): #解密
aes = AES.new(key=key,IV=b"0000000000000000",mode=AES.MODE_CBC) #IV偏移量 key多少位就是多少位前面写b
# print(aes)
async with aiofiles.open(f'mov2/{name}','rb') as f1:
bs= await f1.read() # 从原文件读取内容
print("-----2----")
async with aiofiles.open(f'mov2/temp_{name}','wb') as f2:
await f2.write(aes.decrypt(bs)) #解密好的内容用存入文件
os.remove(f'mov2/{name}')
print("-----3----")
print(f'{name}处理完毕')
def merge_ts(): #合并
#mac: cat 1.ts 2.ts 3.ts > xxx.mp4
#windows: copy/b 1.ts +2.ts +3.ts ... xxx.mp4
#copy /b 命令格式:copy /b 文件1+文件2+......文件N 合并后的文件名<BR>命令讲解:使用"+"将多个相同或不同格式的文件合并为一个文件。
lst = []
with open('secend.m3u8',mode="r",encoding='utf-8') as p_f:
for line in p_f:
if line.startswith("#"):
continue
line = line.split('/')[-1].strip()
lst.append(line)
s = "".join(lst)
os.system(f"copy /b {s} movie.mp4")
print("")
if __name__ == '__main__':
# loop = asyncio.get_event_loop()
key_url = get_key_url()
key = requests.get(url=key_url, headers=headers).text
# key ='39f98d719dbdfbde'
key = key.encode("utf-8")
print(key)
asyncio.run(aio_dec(key))
网页抓取解密( 网站制作网站后还需要做哪些工作才可以让自己的网站在百度可以被搜索到呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-10-12 12:04
网站制作网站后还需要做哪些工作才可以让自己的网站在百度可以被搜索到呢)
当我们使用搜索引擎搜索某些产品时,会显示很多公司或个人的网站。网站的这种显示效果是如何产生的?网站制作网站后,我需要做什么工作才能让我的网站在百度上可以搜索到?下面为大家简单分析一下瑞易自助网站。
想要自己的网站可以百度搜索,一般有以下几种方式实现:
1、网站完成上线后,可以直接到百度门户提交。如果不知道在哪里提交,可以直接在百度上搜索“百度提交网站门户”。提交您自己的 网站 链接地址。该方法属于主动推送。因为网站刚刚上线,百度的数据库中没有你的网站的记录,所以不会直接抓取,也没有类抓取入口。这时候提交链接地址就相当于给了百度蜘蛛一个入口。
2、直接开启竞价,竞价可以让网站直接显示首页,但是网站竞价推广很费钱,按点击付费,关键词的重点激烈的竞争一次可能是几十个、几百个,这不是普通企业能够承受的。
3、seo 优化。这是非常实用的。它通过自然排名优化网站,将目标关键词推送到首页,但网站优化耗时较长,通常需要3-6个月才能达到最终效果。SEO优化一般按照关键词的流行度收费。
4、免费推广,通过外部链接推广网站,比如在一些流量大的论坛、贴吧、博客、分类信息网等发布一些相关内容,顺便说一下带上网站的链接,可以为网站做广告,增加蜘蛛爬到自己网站的几率。也可以在一些软文平台发布一些优质的原创文章,自带网站信息,如果你是收录,请阅读转载金额非常高。
简而言之,做网站的目的是为了推广营销,要推广就必须让用户搜索到。对于刚刚上线的新网站,希望几种自助建站方法对大家有所帮助。
更多关注 查看全部
网页抓取解密(
网站制作网站后还需要做哪些工作才可以让自己的网站在百度可以被搜索到呢)
当我们使用搜索引擎搜索某些产品时,会显示很多公司或个人的网站。网站的这种显示效果是如何产生的?网站制作网站后,我需要做什么工作才能让我的网站在百度上可以搜索到?下面为大家简单分析一下瑞易自助网站。
想要自己的网站可以百度搜索,一般有以下几种方式实现:
1、网站完成上线后,可以直接到百度门户提交。如果不知道在哪里提交,可以直接在百度上搜索“百度提交网站门户”。提交您自己的 网站 链接地址。该方法属于主动推送。因为网站刚刚上线,百度的数据库中没有你的网站的记录,所以不会直接抓取,也没有类抓取入口。这时候提交链接地址就相当于给了百度蜘蛛一个入口。
2、直接开启竞价,竞价可以让网站直接显示首页,但是网站竞价推广很费钱,按点击付费,关键词的重点激烈的竞争一次可能是几十个、几百个,这不是普通企业能够承受的。
3、seo 优化。这是非常实用的。它通过自然排名优化网站,将目标关键词推送到首页,但网站优化耗时较长,通常需要3-6个月才能达到最终效果。SEO优化一般按照关键词的流行度收费。
4、免费推广,通过外部链接推广网站,比如在一些流量大的论坛、贴吧、博客、分类信息网等发布一些相关内容,顺便说一下带上网站的链接,可以为网站做广告,增加蜘蛛爬到自己网站的几率。也可以在一些软文平台发布一些优质的原创文章,自带网站信息,如果你是收录,请阅读转载金额非常高。
简而言之,做网站的目的是为了推广营销,要推广就必须让用户搜索到。对于刚刚上线的新网站,希望几种自助建站方法对大家有所帮助。
更多关注
网页抓取解密(WebScraperforMac10分钟内轻松实现网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-12 12:00
摘要:WebScraper for Mac 是一款运行在 Mac 平台上的非常易用的数据提取工具。WebScraper 插件可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL。可以启动,操作简单,功能强大。
WebScraper for Mac 是一款非常实用的网站数据提取工具,运行在Mac平台上。WebScraper插件可以帮助您在10分钟内轻松抓取网页数据,只需输入起始网址即可启动,操作简单,功能强大。
【WebScraper官网售价25.00 USD】
WebScraper 4.8.4 for Mac 破解版介绍
WebScraper for Mac 是一个网站数据采集的工具。它可以通过使用将数据导出为 JSON 或 CSV 的极简应用程序来快速提取与网页相关的信息(包括文本内容),并为您提供以最少的努力从在线资源中快速提取内容的可能性。您可以完全控制将导出到 CSV 或 JSON 文件的数据。
使用多线程快速扫描任何网站
在 WebScraper 主窗口中,您必须指定要扫描的网页的 URL 地址以及完成此过程要使用的线程数。您可以使用简单的滑块调整后一个参数。
为避免任何不必要的扫描,您可以选择只抓取一页,然后单击鼠标即可开始该过程。在 Live View 窗口中,您可以看到每个链接返回的状态消息,这在处理调试任务时可能很有用。
提取各种类型的信息并将数据导出为 CSV 或 JSON
在“WebScraper 输出”面板中,您可以选择希望实用程序从网页中提取的信息类型:URL、标题、描述、与不同类别或 ID 关联的内容、标题、各种格式的页面内容(纯文本、HTML 或 Markdown)和最后修改日期。
您还可以选择输出文件格式(CSV 或 JSON),决定合并空白,并在文件超过特定大小时设置警报。如果选择 CSV 格式,则可以选择在列周围使用引号以及要使用的内容,而不是引号或行分隔符类型。
最后但并非最不重要的一点是,WebScraper 还允许您更改用户代理、设置链接和从主页点击的数量限制、您可以忽略查询字符串,并且您可以将根域的子域视为内部页面。
无需过多的用户交互即可轻松从在线资源中获取信息
WebScraper 为您提供了快速扫描 网站 并将其内容与其他附加内容一起输出到 JSON 文件的 CSV 的可能性。当您想离线访问数据而不存储整个页面时,此工具非常有用。
WebScraperVersion 4.8.4:Version 4.8.0:Version 4.7.1 的新特性:
WebScraper 4.8.4 for Mac 破解版下载 查看全部
网页抓取解密(WebScraperforMac10分钟内轻松实现网页数据的爬取)
摘要:WebScraper for Mac 是一款运行在 Mac 平台上的非常易用的数据提取工具。WebScraper 插件可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL。可以启动,操作简单,功能强大。
WebScraper for Mac 是一款非常实用的网站数据提取工具,运行在Mac平台上。WebScraper插件可以帮助您在10分钟内轻松抓取网页数据,只需输入起始网址即可启动,操作简单,功能强大。
【WebScraper官网售价25.00 USD】
WebScraper 4.8.4 for Mac 破解版介绍
WebScraper for Mac 是一个网站数据采集的工具。它可以通过使用将数据导出为 JSON 或 CSV 的极简应用程序来快速提取与网页相关的信息(包括文本内容),并为您提供以最少的努力从在线资源中快速提取内容的可能性。您可以完全控制将导出到 CSV 或 JSON 文件的数据。
使用多线程快速扫描任何网站
在 WebScraper 主窗口中,您必须指定要扫描的网页的 URL 地址以及完成此过程要使用的线程数。您可以使用简单的滑块调整后一个参数。
为避免任何不必要的扫描,您可以选择只抓取一页,然后单击鼠标即可开始该过程。在 Live View 窗口中,您可以看到每个链接返回的状态消息,这在处理调试任务时可能很有用。
提取各种类型的信息并将数据导出为 CSV 或 JSON
在“WebScraper 输出”面板中,您可以选择希望实用程序从网页中提取的信息类型:URL、标题、描述、与不同类别或 ID 关联的内容、标题、各种格式的页面内容(纯文本、HTML 或 Markdown)和最后修改日期。
您还可以选择输出文件格式(CSV 或 JSON),决定合并空白,并在文件超过特定大小时设置警报。如果选择 CSV 格式,则可以选择在列周围使用引号以及要使用的内容,而不是引号或行分隔符类型。
最后但并非最不重要的一点是,WebScraper 还允许您更改用户代理、设置链接和从主页点击的数量限制、您可以忽略查询字符串,并且您可以将根域的子域视为内部页面。
无需过多的用户交互即可轻松从在线资源中获取信息
WebScraper 为您提供了快速扫描 网站 并将其内容与其他附加内容一起输出到 JSON 文件的 CSV 的可能性。当您想离线访问数据而不存储整个页面时,此工具非常有用。
WebScraperVersion 4.8.4:Version 4.8.0:Version 4.7.1 的新特性:
WebScraper 4.8.4 for Mac 破解版下载
网页抓取解密(ASP.NETCore过渡阶段缓存的问题后.net)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-09 20:02
在解决了core中访问memcached缓存的问题后,我们开始向.net core迈进——将更多站点迁移到core。在迁移涉及获取用户登录信息的站点时,我们遇到了一个问题——如何在core和传统之间共享保存用户登录信息的cookie?
对于cookies的加解密,传统上采用对称加解密算法,而core采用基于公钥和私钥的非对称加解密算法。因此,core 无法解密传统生成的 cookie,也无法解密传统的 core 生成的 cookie。针对这个问题,.net社区有人提供了解决方案——将传统的加解密算法改为core(详见这里),但这需要修改传统站点的所有涉及获取用户登录信息的代码. 有些奢侈品不是万不得已,我们不想用它,我们必须另辟蹊径。
我们先把问题简化一下。根据我们迁移到 ASP.NET Core 过渡阶段的实际场景,用户登录操作是在传统站点上完成的。我们只需要解密核心站点上的cookie即可获取用户登录信息,无需加密。需要。由于core自身无法解密,可以让传统解密帮忙,core会通过web api将接收到的cookie发送给传统解密。简化后,问题变成-如何在核心接收传统cookie?如何拦截对cookies的核心解密操作?如何从 web api 中的 cookie 解密用户身份验证信息(FormsAuthenticationTicket)?在core中如何将FormsAuthenticationTicket转换成自己的认证信息(AuthenticationTicket)?让我们一一解决这些问题。
问题一:如何在core中接收传统的cookies?
这个问题很容易解决。只需将 Startup.cs 中 CookieAuthenticationOptions 的 CookieName 和 CookieDomain 设置为与传统相同即可。
var cookieOptions = new CookieAuthenticationOptions
{
CookieName = ".CnblogsCookie",
CookieDomain = ".cnblogs.com",
};
app.UseCookieAuthentication(cookieOptions);
问题二:如何拦截对cookies的核心解密操作?
这个问题很棘手。我们通过阅读Microsoft.AspNetCore.Authentication.Cookies的源代码,在CookieAuthenticationHandler.cs中找到了TicketDataFormat:
private async Task ReadCookieTicket()
{
var cookie = Options.CookieManager.GetRequestCookie(Context, Options.CookieName);
//...
var ticket = Options.TicketDataFormat.Unprotect(cookie, GetTlsTokenBinding());
//...
return AuthenticateResult.Success(ticket);
}
TicketDataFormat 的类型为 ISecureDataFormat 接口,解密 cookie 是调用该接口的 Unprotect 方法:
public interface ISecureDataFormat
{
string Protect(TData data);
string Protect(TData data, string purpose);
TData Unprotect(string protectedText);
TData Unprotect(string protectedText, string purpose);
}
而TicketDataFormat是CookieAuthenticationOptions的一个属性,我们可以直接修改这个属性值,使用我们自己的ISecureDataFormat接口实现(默认实现是SecureDataFormat),在Unprotect()方法的实现中读取protectedText参数值(这个应该是接收到的cookie 值)来达到拦截的目的,我们来试试。
定义一个 FormsAuthTicketDataFormat 类来实现 ISecureDataFormat 接口:
public class FormsAuthTicketDataFormat : ISecureDataFormat
{
//...
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
Console.WriteLine($"{nameof(Unprotect)}(\"{protectedText}\", \"{purpose}\")");
throw new NotImplementedException();
}
}
在 Startup.cs 中应用 FormsAuthTicketDataFormat:
var cookieOptions = new CookieAuthenticationOptions
{
//...
TicketDataFormat = new FormsAuthTicketDataFormat()
};
app.UseCookieAuthentication(cookieOptions);
经过测试验证,接收到的cookie值确实是传统生成的cookie值。
现在可以在 Unprotect() 方法中读取 cookie 值,然后可以通过 web api 将其发送到传统解密,因此我们继续下一个问题。
问题三:如何从web api中的cookie中解密用户认证信息(FormsAuthenticationTicket)?
这个问题也很容易解决,只要调用FormsAuthentication.Decrypt()方法解密,将FormsAuthenticationTicket的Name、IssueDate、Expiration值返回给core即可。
public IHttpActionResult GetTicket(string cookie)
{
var formsAuthTicket = FormsAuthentication.Decrypt(cookie);
return Ok(new
{
formsAuthTicket.Name,
formsAuthTicket.IssueDate,
formsAuthTicket.Expiration
});
}
核心通过调用web api对cookie进行解密,得到Name、IssueDate、Expiration三个值,所以FormsAuthTicketDataFormat.Unprotect()的实现代码变成了这样:
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
throw new NotImplementedException();
}
接下来,解决最后一个问题。
问题4:在core中如何将FormsAuthenticationTicket转换成自己的认证信息(AuthenticationTicket)?
由于Unprotect()方法的返回参数的类型是AuthenticationTicket,我们就不用换地方继续折腾这个方法了。现在我们有了 FormsAuthenticationTicket 的 Name、IssueDate 和 Expiration 三个值,我们需要根据它们创建一个有效的 AuthenticationTicket。
AuthenticationTicket 的构造函数有 3 个参数。第一个参数的类型是ClaimsPrincipal,与用户名相关联;第二个参数的类型是AuthenticationProperties,里面存放了cookie的生成时间和过期时间,第三个参数authenticationScheme设置为对应的值(这里设置为空字符串),代码如下:
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
//Get FormsAuthenticationTicket from asp.net web api
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
//Create AuthenticationTicket
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
var claimsPrincipal = new System.Security.Claims.ClaimsPrincipal(claimsIdentity);
var authProperties = new Microsoft.AspNetCore.Http.Authentication.AuthenticationProperties
{
IssuedUtc = issueDate,
ExpiresUtc = expiration
};
var ticket = new AuthenticationTicket(claimsPrincipal, authProperties, _authenticationScheme);
return ticket;
}
解决这4个问题后,你就大功告成了!在核心mvc控制器中可以显示当前登录用户名,如以下代码:
public IActionResult Index()
{
return Content(User.Identity.Name);
}
完整的相关实现代码如下:
启动文件
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
var cookieOptions = new CookieAuthenticationOptions
{
AutomaticAuthenticate = true,
AutomaticChallenge = true,
CookieHttpOnly = true,
CookieName = ".CnblogsCookie",
CookieDomain = ".cnblogs.com",
LoginPath = "/account/signin",
TicketDataFormat = new FormsAuthTicketDataFormat("")
};
app.UseCookieAuthentication(cookieOptions);
//...
}
FormAuthTicketDataFormat.cs
public class FormsAuthTicketDataFormat : ISecureDataFormat
{
private string _authenticationScheme;
public FormsAuthTicketDataFormat(string authenticationScheme)
{
_authenticationScheme = authenticationScheme;
}
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
//Get FormsAuthenticationTicket from asp.net web api
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
//Create AuthenticationTicket
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
var claimsPrincipal = new System.Security.Claims.ClaimsPrincipal(claimsIdentity);
var authProperties = new Microsoft.AspNetCore.Http.Authentication.AuthenticationProperties
{
IssuedUtc = issueDate,
ExpiresUtc = expiration
};
var ticket = new AuthenticationTicket(claimsPrincipal, authProperties, _authenticationScheme);
return ticket;
}
public string Protect(AuthenticationTicket data)
{
throw new NotImplementedException();
}
public string Protect(AuthenticationTicket data, string purpose)
{
throw new NotImplementedException();
}
public AuthenticationTicket Unprotect(string protectedText)
{
throw new NotImplementedException();
}
private FormsAuthTicketDto GetFormsAuthTicket(string cookie)
{
return new UserService().DecryptCookie(cookie).Result;
}
}
遗留问题:目前不适用于 [Authorize] 标签。
更新:
其余问题已解决,将在
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) });
到
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
即,将 authenticationType 的值设置为“Basic”。 查看全部
网页抓取解密(ASP.NETCore过渡阶段缓存的问题后.net)
在解决了core中访问memcached缓存的问题后,我们开始向.net core迈进——将更多站点迁移到core。在迁移涉及获取用户登录信息的站点时,我们遇到了一个问题——如何在core和传统之间共享保存用户登录信息的cookie?
对于cookies的加解密,传统上采用对称加解密算法,而core采用基于公钥和私钥的非对称加解密算法。因此,core 无法解密传统生成的 cookie,也无法解密传统的 core 生成的 cookie。针对这个问题,.net社区有人提供了解决方案——将传统的加解密算法改为core(详见这里),但这需要修改传统站点的所有涉及获取用户登录信息的代码. 有些奢侈品不是万不得已,我们不想用它,我们必须另辟蹊径。
我们先把问题简化一下。根据我们迁移到 ASP.NET Core 过渡阶段的实际场景,用户登录操作是在传统站点上完成的。我们只需要解密核心站点上的cookie即可获取用户登录信息,无需加密。需要。由于core自身无法解密,可以让传统解密帮忙,core会通过web api将接收到的cookie发送给传统解密。简化后,问题变成-如何在核心接收传统cookie?如何拦截对cookies的核心解密操作?如何从 web api 中的 cookie 解密用户身份验证信息(FormsAuthenticationTicket)?在core中如何将FormsAuthenticationTicket转换成自己的认证信息(AuthenticationTicket)?让我们一一解决这些问题。
问题一:如何在core中接收传统的cookies?
这个问题很容易解决。只需将 Startup.cs 中 CookieAuthenticationOptions 的 CookieName 和 CookieDomain 设置为与传统相同即可。
var cookieOptions = new CookieAuthenticationOptions
{
CookieName = ".CnblogsCookie",
CookieDomain = ".cnblogs.com",
};
app.UseCookieAuthentication(cookieOptions);
问题二:如何拦截对cookies的核心解密操作?
这个问题很棘手。我们通过阅读Microsoft.AspNetCore.Authentication.Cookies的源代码,在CookieAuthenticationHandler.cs中找到了TicketDataFormat:
private async Task ReadCookieTicket()
{
var cookie = Options.CookieManager.GetRequestCookie(Context, Options.CookieName);
//...
var ticket = Options.TicketDataFormat.Unprotect(cookie, GetTlsTokenBinding());
//...
return AuthenticateResult.Success(ticket);
}
TicketDataFormat 的类型为 ISecureDataFormat 接口,解密 cookie 是调用该接口的 Unprotect 方法:
public interface ISecureDataFormat
{
string Protect(TData data);
string Protect(TData data, string purpose);
TData Unprotect(string protectedText);
TData Unprotect(string protectedText, string purpose);
}
而TicketDataFormat是CookieAuthenticationOptions的一个属性,我们可以直接修改这个属性值,使用我们自己的ISecureDataFormat接口实现(默认实现是SecureDataFormat),在Unprotect()方法的实现中读取protectedText参数值(这个应该是接收到的cookie 值)来达到拦截的目的,我们来试试。
定义一个 FormsAuthTicketDataFormat 类来实现 ISecureDataFormat 接口:
public class FormsAuthTicketDataFormat : ISecureDataFormat
{
//...
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
Console.WriteLine($"{nameof(Unprotect)}(\"{protectedText}\", \"{purpose}\")");
throw new NotImplementedException();
}
}
在 Startup.cs 中应用 FormsAuthTicketDataFormat:
var cookieOptions = new CookieAuthenticationOptions
{
//...
TicketDataFormat = new FormsAuthTicketDataFormat()
};
app.UseCookieAuthentication(cookieOptions);
经过测试验证,接收到的cookie值确实是传统生成的cookie值。
现在可以在 Unprotect() 方法中读取 cookie 值,然后可以通过 web api 将其发送到传统解密,因此我们继续下一个问题。
问题三:如何从web api中的cookie中解密用户认证信息(FormsAuthenticationTicket)?
这个问题也很容易解决,只要调用FormsAuthentication.Decrypt()方法解密,将FormsAuthenticationTicket的Name、IssueDate、Expiration值返回给core即可。
public IHttpActionResult GetTicket(string cookie)
{
var formsAuthTicket = FormsAuthentication.Decrypt(cookie);
return Ok(new
{
formsAuthTicket.Name,
formsAuthTicket.IssueDate,
formsAuthTicket.Expiration
});
}
核心通过调用web api对cookie进行解密,得到Name、IssueDate、Expiration三个值,所以FormsAuthTicketDataFormat.Unprotect()的实现代码变成了这样:
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
throw new NotImplementedException();
}
接下来,解决最后一个问题。
问题4:在core中如何将FormsAuthenticationTicket转换成自己的认证信息(AuthenticationTicket)?
由于Unprotect()方法的返回参数的类型是AuthenticationTicket,我们就不用换地方继续折腾这个方法了。现在我们有了 FormsAuthenticationTicket 的 Name、IssueDate 和 Expiration 三个值,我们需要根据它们创建一个有效的 AuthenticationTicket。
AuthenticationTicket 的构造函数有 3 个参数。第一个参数的类型是ClaimsPrincipal,与用户名相关联;第二个参数的类型是AuthenticationProperties,里面存放了cookie的生成时间和过期时间,第三个参数authenticationScheme设置为对应的值(这里设置为空字符串),代码如下:
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
//Get FormsAuthenticationTicket from asp.net web api
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
//Create AuthenticationTicket
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
var claimsPrincipal = new System.Security.Claims.ClaimsPrincipal(claimsIdentity);
var authProperties = new Microsoft.AspNetCore.Http.Authentication.AuthenticationProperties
{
IssuedUtc = issueDate,
ExpiresUtc = expiration
};
var ticket = new AuthenticationTicket(claimsPrincipal, authProperties, _authenticationScheme);
return ticket;
}
解决这4个问题后,你就大功告成了!在核心mvc控制器中可以显示当前登录用户名,如以下代码:
public IActionResult Index()
{
return Content(User.Identity.Name);
}
完整的相关实现代码如下:
启动文件
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
var cookieOptions = new CookieAuthenticationOptions
{
AutomaticAuthenticate = true,
AutomaticChallenge = true,
CookieHttpOnly = true,
CookieName = ".CnblogsCookie",
CookieDomain = ".cnblogs.com",
LoginPath = "/account/signin",
TicketDataFormat = new FormsAuthTicketDataFormat("")
};
app.UseCookieAuthentication(cookieOptions);
//...
}
FormAuthTicketDataFormat.cs
public class FormsAuthTicketDataFormat : ISecureDataFormat
{
private string _authenticationScheme;
public FormsAuthTicketDataFormat(string authenticationScheme)
{
_authenticationScheme = authenticationScheme;
}
public AuthenticationTicket Unprotect(string protectedText, string purpose)
{
//Get FormsAuthenticationTicket from asp.net web api
var formsAuthTicket = GetFormsAuthTicket(protectedText);
var name = formsAuthTicket.Name;
DateTime issueDate = formsAuthTicket.IssueDate;
DateTime expiration = formsAuthTicket.Expiration;
//Create AuthenticationTicket
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
var claimsPrincipal = new System.Security.Claims.ClaimsPrincipal(claimsIdentity);
var authProperties = new Microsoft.AspNetCore.Http.Authentication.AuthenticationProperties
{
IssuedUtc = issueDate,
ExpiresUtc = expiration
};
var ticket = new AuthenticationTicket(claimsPrincipal, authProperties, _authenticationScheme);
return ticket;
}
public string Protect(AuthenticationTicket data)
{
throw new NotImplementedException();
}
public string Protect(AuthenticationTicket data, string purpose)
{
throw new NotImplementedException();
}
public AuthenticationTicket Unprotect(string protectedText)
{
throw new NotImplementedException();
}
private FormsAuthTicketDto GetFormsAuthTicket(string cookie)
{
return new UserService().DecryptCookie(cookie).Result;
}
}
遗留问题:目前不适用于 [Authorize] 标签。
更新:
其余问题已解决,将在
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) });
到
var claimsIdentity = new ClaimsIdentity(new Claim[] { new Claim(ClaimTypes.Name, name) }, "Basic");
即,将 authenticationType 的值设置为“Basic”。
网页抓取解密(豆丁文档下载器是一款用于网络文档共享网站的专业工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2021-10-07 05:23
豆丁文档下载器是一款专业的网络文档下载工具。豆丁文档下载器可以为用户带来更好的文档抓取功能,支持多种文档共享网站,可以省去会员下载一些文档的麻烦,非常专业高效。
软件说明:
豆丁网免费下载器还支持百度、丁香、畅享、MBALib、HP009、MAX、Book118等图书馆文档的免费下载,无需注册和登录。下载的文档最终生成了高清pdf格式的文档。
软件特点:
1、支持百度、豆丁、丁香、畅享、MBALib、HP009、MAX、Book118等图书馆文档。
2、 无需积分,无需登录,即可免费下载百度文库和豆丁文库。
3、 支持多任务同时下载和断点续传。
4、生成的pdf文档质量和原文档一样。
指示:
1、输入要抓取的文档的网址
2、点击抓取文字
3、 捕获的文本会显示在下面的文本框中
4、用户可以自由复制文字
常见问题:
1、截取文字后段落格式乱了怎么办?
A、服务器转换成文本后,清除原来的格式。
2、为什么我不能下载全文?
答:服务器变化太大了。但是写文章就够了。
3、为什么这个程序有时候抓不到文字或者提示错误?
答:因为服务器没有将文档转换成文本,或者网络程序发生了不可预知的错误。
4、为什么有时候里面会有很多乱码或者无用的奇怪文字?
答:服务器转换错误,没办法。
5、这个程序可以直接下载文件吗?
答案:没有 查看全部
网页抓取解密(豆丁文档下载器是一款用于网络文档共享网站的专业工具)
豆丁文档下载器是一款专业的网络文档下载工具。豆丁文档下载器可以为用户带来更好的文档抓取功能,支持多种文档共享网站,可以省去会员下载一些文档的麻烦,非常专业高效。
软件说明:
豆丁网免费下载器还支持百度、丁香、畅享、MBALib、HP009、MAX、Book118等图书馆文档的免费下载,无需注册和登录。下载的文档最终生成了高清pdf格式的文档。
软件特点:
1、支持百度、豆丁、丁香、畅享、MBALib、HP009、MAX、Book118等图书馆文档。
2、 无需积分,无需登录,即可免费下载百度文库和豆丁文库。
3、 支持多任务同时下载和断点续传。
4、生成的pdf文档质量和原文档一样。
指示:
1、输入要抓取的文档的网址
2、点击抓取文字
3、 捕获的文本会显示在下面的文本框中
4、用户可以自由复制文字
常见问题:
1、截取文字后段落格式乱了怎么办?
A、服务器转换成文本后,清除原来的格式。
2、为什么我不能下载全文?
答:服务器变化太大了。但是写文章就够了。
3、为什么这个程序有时候抓不到文字或者提示错误?
答:因为服务器没有将文档转换成文本,或者网络程序发生了不可预知的错误。
4、为什么有时候里面会有很多乱码或者无用的奇怪文字?
答:服务器转换错误,没办法。
5、这个程序可以直接下载文件吗?
答案:没有
网页抓取解密(上一页没毛病云搜神器V1.0官方正版最新无限制破解版测试可用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-06 13:02
软件介绍: 上一页云搜索神器无错V1.0 官方正版最新无限破解版测试可用 下一页Advance Web Email Extractor(网络邮件抓取工具)V6. 3.3.35 最新无限制破解版正式版可供测试
本软件由七道奇为您精心采集,转载自网络。本软件收录为正式版,软件著作权归软件作者所有。本网站对其观点和内容不作任何评论。请读者自行判断。以下是其具体内容:
Advance Web Email Extractor 破解版是一款功能强大的网络邮箱爬取工具。该工具适用于销售人员。有了它,您可以从 Internet 获取客户邮箱。支持网页邮箱的自动抓取,非常方便快捷。并且软件内置破解工具,完全免费。
【特征】
根据您的搜索引擎关键字从 Internet 中提取所有电子邮件地址。
通过流行的搜索引擎(例如 Google、Yahoo、Bing、Excite、Lycos 等)从 Internet 中提取所有电子邮件地址。
它可以从列表中提取各种 URL/网站 电子邮件地址。
搜索引擎可以免费在线更新以获得最佳结果。
这是 Internet 上最快的电子邮件提取器。
它允许您添加扫描 URL 的配置,以便您可以非常快速地获得结果。
它可以过滤提取的电子邮件,仅过滤那些您确实不需要的电子邮件列表。
提取的电子邮件可以保存在 .CSV 和文本文件中。
它是从 网站 中提取电子邮件的最佳工具。
【下载链接】
Advance Web Email Extractor(网络邮箱抓取工具)V6.3.3.35破解免费版 查看全部
网页抓取解密(上一页没毛病云搜神器V1.0官方正版最新无限制破解版测试可用)
软件介绍: 上一页云搜索神器无错V1.0 官方正版最新无限破解版测试可用 下一页Advance Web Email Extractor(网络邮件抓取工具)V6. 3.3.35 最新无限制破解版正式版可供测试
本软件由七道奇为您精心采集,转载自网络。本软件收录为正式版,软件著作权归软件作者所有。本网站对其观点和内容不作任何评论。请读者自行判断。以下是其具体内容:
Advance Web Email Extractor 破解版是一款功能强大的网络邮箱爬取工具。该工具适用于销售人员。有了它,您可以从 Internet 获取客户邮箱。支持网页邮箱的自动抓取,非常方便快捷。并且软件内置破解工具,完全免费。
【特征】
根据您的搜索引擎关键字从 Internet 中提取所有电子邮件地址。
通过流行的搜索引擎(例如 Google、Yahoo、Bing、Excite、Lycos 等)从 Internet 中提取所有电子邮件地址。
它可以从列表中提取各种 URL/网站 电子邮件地址。
搜索引擎可以免费在线更新以获得最佳结果。
这是 Internet 上最快的电子邮件提取器。
它允许您添加扫描 URL 的配置,以便您可以非常快速地获得结果。
它可以过滤提取的电子邮件,仅过滤那些您确实不需要的电子邮件列表。
提取的电子邮件可以保存在 .CSV 和文本文件中。
它是从 网站 中提取电子邮件的最佳工具。
【下载链接】
Advance Web Email Extractor(网络邮箱抓取工具)V6.3.3.35破解免费版
网页抓取解密(EasyPlayer-RTSP-Android如何获取解码后的视频帧? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-10-06 06:28
)
应用场景
EasyPlayer-RTSP 多年来在与 VLC 进行基准测试的过程中积累了广泛的应用场景。EasyPlayer-RTSP底层和上层均为自主研发,具有自主知识产权,可实战测试。
EasyPlayer-RTSP 播放器
EasyPlayer-RTSP播放器是一套RTSP专用播放器,包括:Windows(支持IE插件、npapi插件)、Android、iOS三个平台。它是由清溪TSINGSEE开放平台开发和维护的,与市场上的不同。作为通用播放器的一部分,EasyPlayer-RTSP系列自2014年初开发以来,已广泛应用于各行各业(尤其是安防行业)。 主要原因是EasyPlayer-RTSP更精致,更专注,并且具有非常低的延迟。非常高的RTSP协议兼容性、编码数据分析等方面,都有非常大的优势。
EasyPlayer-RTSP-Android 解码获取视频帧问问题
EasyPlayer-RTSP-Android 如何获取解码后的视频帧?
分析问题
部分客户需要获取解码后的视频帧才能实现人脸识别。
解决这个问题
视频播放的实现在PlayFragment.java中,它有一个YUVExportFragment.java的子类,实现了接口EasyPlayerClient.I420DataCallback。您可以在 onI420Data 方法中获取解码后的视频帧:
深入阅读代码,你会发现在EasyPlayerClient.java中,硬解码和软解码两种方式都将解码后的视频帧传入onI420Data:
ByteBuffer buf = mDecoder.decodeFrameYUV(frameInfo, size);
if (i420callback != null && buf != null)
i420callback.onI420Data(buf);
if (buf != null)
mDecoder.releaseBuffer(buf);
ByteBuffer outputBuffer;
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.LOLLIPOP) {
outputBuffer = mCodec.getOutputBuffer(index);
} else {
outputBuffer = mCodec.getOutputBuffers()[index];
}
if (i420callback != null && outputBuffer != null) {
if (sliceHeight != realHeight) {
ByteBuffer tmp = ByteBuffer.allocateDirect(realWidth*realHeight*3/2);
outputBuffer.clear();
outputBuffer.limit(realWidth*realHeight);
tmp.put(outputBuffer);
outputBuffer.clear();
outputBuffer.position(realWidth * sliceHeight);
outputBuffer.limit((realWidth * sliceHeight + realWidth*realHeight /4));
tmp.put(outputBuffer);
outputBuffer.clear();
outputBuffer.position(realWidth * sliceHeight + realWidth*realHeight/4);
outputBuffer.limit((realWidth * sliceHeight + realWidth*realHeight/4 + realWidth*realHeight /4));
tmp.put(outputBuffer);
tmp.clear();
outputBuffer = tmp;
}
if (mColorFormat == COLOR_FormatYUV420SemiPlanar
|| mColorFormat == COLOR_FormatYUV420PackedSemiPlanar
|| mColorFormat == COLOR_TI_FormatYUV420PackedSemiPlanar) {
JNIUtil.yuvConvert2(outputBuffer, realWidth, realHeight, 4);
}
i420callback.onI420Data(outputBuffer);
} 查看全部
网页抓取解密(EasyPlayer-RTSP-Android如何获取解码后的视频帧?
)
应用场景
EasyPlayer-RTSP 多年来在与 VLC 进行基准测试的过程中积累了广泛的应用场景。EasyPlayer-RTSP底层和上层均为自主研发,具有自主知识产权,可实战测试。
EasyPlayer-RTSP 播放器
EasyPlayer-RTSP播放器是一套RTSP专用播放器,包括:Windows(支持IE插件、npapi插件)、Android、iOS三个平台。它是由清溪TSINGSEE开放平台开发和维护的,与市场上的不同。作为通用播放器的一部分,EasyPlayer-RTSP系列自2014年初开发以来,已广泛应用于各行各业(尤其是安防行业)。 主要原因是EasyPlayer-RTSP更精致,更专注,并且具有非常低的延迟。非常高的RTSP协议兼容性、编码数据分析等方面,都有非常大的优势。
EasyPlayer-RTSP-Android 解码获取视频帧问问题
EasyPlayer-RTSP-Android 如何获取解码后的视频帧?
分析问题
部分客户需要获取解码后的视频帧才能实现人脸识别。
解决这个问题
视频播放的实现在PlayFragment.java中,它有一个YUVExportFragment.java的子类,实现了接口EasyPlayerClient.I420DataCallback。您可以在 onI420Data 方法中获取解码后的视频帧:
深入阅读代码,你会发现在EasyPlayerClient.java中,硬解码和软解码两种方式都将解码后的视频帧传入onI420Data:
ByteBuffer buf = mDecoder.decodeFrameYUV(frameInfo, size);
if (i420callback != null && buf != null)
i420callback.onI420Data(buf);
if (buf != null)
mDecoder.releaseBuffer(buf);
ByteBuffer outputBuffer;
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.LOLLIPOP) {
outputBuffer = mCodec.getOutputBuffer(index);
} else {
outputBuffer = mCodec.getOutputBuffers()[index];
}
if (i420callback != null && outputBuffer != null) {
if (sliceHeight != realHeight) {
ByteBuffer tmp = ByteBuffer.allocateDirect(realWidth*realHeight*3/2);
outputBuffer.clear();
outputBuffer.limit(realWidth*realHeight);
tmp.put(outputBuffer);
outputBuffer.clear();
outputBuffer.position(realWidth * sliceHeight);
outputBuffer.limit((realWidth * sliceHeight + realWidth*realHeight /4));
tmp.put(outputBuffer);
outputBuffer.clear();
outputBuffer.position(realWidth * sliceHeight + realWidth*realHeight/4);
outputBuffer.limit((realWidth * sliceHeight + realWidth*realHeight/4 + realWidth*realHeight /4));
tmp.put(outputBuffer);
tmp.clear();
outputBuffer = tmp;
}
if (mColorFormat == COLOR_FormatYUV420SemiPlanar
|| mColorFormat == COLOR_FormatYUV420PackedSemiPlanar
|| mColorFormat == COLOR_TI_FormatYUV420PackedSemiPlanar) {
JNIUtil.yuvConvert2(outputBuffer, realWidth, realHeight, 4);
}
i420callback.onI420Data(outputBuffer);
}
网页抓取解密(Python一款IDE--网页请求监控工具发生的详细步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-06 06:26
)
1)首先,客户端和服务器需要建立连接。只需单击某个超链接,HTTP 工作就会开始。
2) 连接建立后,客户端向服务器发送请求。请求的格式为:统一资源标识符(URL)、协议版本号和 MIME 信息,包括请求修饰符、客户端信息和可能的内容。
3) 服务器收到请求后,会给出相应的响应信息。格式为状态行,包括信息的协议版本号、成功或错误码,MIME信息包括服务器信息、实体信息和可能性。内容。
4)客户端接收服务器返回的信息,通过浏览器显示在用户的显示屏上,然后客户端与服务器断开连接。
如果上述过程的某个步骤发生错误,则将导致错误的信息以显示屏幕输出的方式返回给客户端。对于用户来说,这些过程都是由HTTP本身完成的,用户只需要点击鼠标,等待信息显示出来。
二:了解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中;我们需要学习的是几个常用的函数。详情可上官网查看。
三:开发工具
Python自带一个编译器——IDLE,非常简洁;PyCharm - 具有良好交互性的 Python IDE;Fiddler - 一个网页请求监控工具,我们可以使用它来了解用户触发网页请求后发生的详细步骤;
简单的网络爬虫
代码
'''
第一个示例:简单的网页爬虫
爬取豆瓣首页
'''
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode('utf-8')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截取的部分结果如下:
查看全部
网页抓取解密(Python一款IDE--网页请求监控工具发生的详细步骤
)
1)首先,客户端和服务器需要建立连接。只需单击某个超链接,HTTP 工作就会开始。
2) 连接建立后,客户端向服务器发送请求。请求的格式为:统一资源标识符(URL)、协议版本号和 MIME 信息,包括请求修饰符、客户端信息和可能的内容。
3) 服务器收到请求后,会给出相应的响应信息。格式为状态行,包括信息的协议版本号、成功或错误码,MIME信息包括服务器信息、实体信息和可能性。内容。
4)客户端接收服务器返回的信息,通过浏览器显示在用户的显示屏上,然后客户端与服务器断开连接。
如果上述过程的某个步骤发生错误,则将导致错误的信息以显示屏幕输出的方式返回给客户端。对于用户来说,这些过程都是由HTTP本身完成的,用户只需要点击鼠标,等待信息显示出来。
二:了解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中;我们需要学习的是几个常用的函数。详情可上官网查看。
三:开发工具
Python自带一个编译器——IDLE,非常简洁;PyCharm - 具有良好交互性的 Python IDE;Fiddler - 一个网页请求监控工具,我们可以使用它来了解用户触发网页请求后发生的详细步骤;
简单的网络爬虫
代码
'''
第一个示例:简单的网页爬虫
爬取豆瓣首页
'''
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode('utf-8')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截取的部分结果如下:
网页抓取解密(如何找到需要的网页编码格式不一致与decode解决乱码问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-06 06:22
)
一、乱码问题说明
在爬虫或某些操作过程中,经常会出现中文乱码等问题,如下图所示
原因是向下爬行后,源页面代码与代码格式不一致
二、使用编码和解码来解决乱码问题
Python中字符串的内部表示是Unicode编码。在编码转换过程中,通常使用Unicode作为中间编码,即将其他编码字符串解码为Unicode,然后将其编码为另一种编码
decode的功能是将其他编码字符串转换为Unicode编码,例如STR1.decode('gb2312'),这意味着将gb2312编码字符串STR1转换为Unicode编码
Encode用于将Unicode编码转换为其他编码字符串,例如STR2.Encode('utf-8'),这意味着将Unicode编码字符串STR2转换为utf-8编码
decode中写的是您想要捕获的网页的代码,encode是您想要设置的代码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但也要注意:
如果字符串已经是Unicode,则解码将出错。因此,通常需要判断其编码方法是否为Unicode
Isinstance(s,Unicode)#用于确定它是否为Unicode
以非Unicode编码形式使用STR编码将报告错误
因此,最终的可靠代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到要抓取的目标网页的编码格式1、查看网页源代码
如果源代码中没有字符集编码格式,则可以使用以下方法
2、检查元素并查看响应标题
查看全部
网页抓取解密(如何找到需要的网页编码格式不一致与decode解决乱码问题
)
一、乱码问题说明
在爬虫或某些操作过程中,经常会出现中文乱码等问题,如下图所示
原因是向下爬行后,源页面代码与代码格式不一致
二、使用编码和解码来解决乱码问题
Python中字符串的内部表示是Unicode编码。在编码转换过程中,通常使用Unicode作为中间编码,即将其他编码字符串解码为Unicode,然后将其编码为另一种编码
decode的功能是将其他编码字符串转换为Unicode编码,例如STR1.decode('gb2312'),这意味着将gb2312编码字符串STR1转换为Unicode编码
Encode用于将Unicode编码转换为其他编码字符串,例如STR2.Encode('utf-8'),这意味着将Unicode编码字符串STR2转换为utf-8编码
decode中写的是您想要捕获的网页的代码,encode是您想要设置的代码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但也要注意:
如果字符串已经是Unicode,则解码将出错。因此,通常需要判断其编码方法是否为Unicode
Isinstance(s,Unicode)#用于确定它是否为Unicode
以非Unicode编码形式使用STR编码将报告错误
因此,最终的可靠代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到要抓取的目标网页的编码格式1、查看网页源代码
如果源代码中没有字符集编码格式,则可以使用以下方法
2、检查元素并查看响应标题
网页抓取解密(网络爬虫的处理对象是互联网通用的爬虫框架流程介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-05 20:01
搜索引擎的处理对象是互联网网页。网页的数量是数百亿,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统,将如此大量的网页数据传输到本地,并在本地形成互联网。网页镜像备份。
网络爬虫扮演这个角色。它是搜索引擎系统中非常关键和基本的组成部分。本文主要介绍与网络爬虫相关的技术。虽然爬虫技术经过几十年的发展在整体框架上已经比较成熟,但是随着网络的不断发展,也面临着一些具有挑战性的新问题。
下图展示了一个通用的爬虫框架流程。首先,从互联网页面中仔细选择一部分网页,将这些网页的链接地址作为种子URL,将这些种子URL放入URL队列中进行爬取。爬虫依次从待爬取的队列中读取URL,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
然后把它和网页的相对路径名给网页下载器,网页下载器负责下载页面的内容。对于本地下载的网页,一方面存储在页面库中,等待索引等后续处理;另一方面,将下载网页的网址放入已爬取的网址队列,记录爬虫系统已下载。网页网址,避免网页重复抓取。对于新下载的网页,提取其中收录的所有链接信息,并在抓取的URL队列中进行检查。如果发现该链接还没有被爬取,则将该URL放在待爬取的URL队列的末尾,然后在爬取调度中下载该URL对应的网页。通过这种方式,
对于爬虫来说,往往需要进行网络重复数据删除和网络反作弊。
以上就是一个通用爬虫的整体流程。如果从更宏观的角度考虑,动态抓取过程中的爬虫与互联网上所有网页的关系大致可以分为如图2-2所示的互联网页面。有5个部分:
1. 下载网页集合:爬虫从网上下载到本地索引的网页集合。
2.过期网页集合:由于网页数量最多,爬虫爬完一轮需要很长时间。在抓取过程中,许多下载的网页可能会过期。这是因为互联网网页处于不断动态变化的过程中,所以很容易产生本地网页内容与真实互联网网页的不一致。
3. 待下载网页集合:上图中待抓取的URL队列中的网页,这些网页会被爬虫下载。
4. 已知网页集合:这些网页没有被爬虫下载,也没有出现在待抓取的网址队列中,而是通过已经抓取的网页或待抓取的网址队列中的网页,它们总是可以在链接关系找到它们时,稍后被爬虫抓取并索引。
5. 未知网页集合:部分网页无法被爬虫抓取,这部分网页构成未知网页集合。事实上,这部分网页所占的比例很高。
根据应用的不同,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种:
1. 批量爬虫(Batch Crawler):批量爬虫有比较明确的爬取范围和目标。当爬虫到达设定的目标时,它停止爬虫过程。至于具体的目标,可能不一样,可能是设置一定数量的网页被爬取,也可能是设置爬取所消耗的时间等等。
2.增量爬虫(Incremental Crawler):增量爬虫与批量爬虫不同,它会不断地持续爬取,爬取的网页要定期更新,因为互联网的网页在不断变化,新网页很常见、要删除的网页或网页内容更改为通用。增量爬虫需要及时反映这种变化。因此,它们都在不断的爬取过程中,要么爬取新页面,要么更新现有页面。有网页。常见的商业搜索引擎爬虫基本都属于这一类。
3.Focused Crawter:垂直爬虫专注于特定主题内容或属于特定行业的网页。比如健康网站,只需要从网上找健康相关的页面即可。页面内容就够了,其他行业的内容不考虑。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定的行业或主题。从节省系统资源的角度考虑,不可能把所有的网页都下载下来然后过滤。这太浪费资源了。爬虫往往需要在爬取阶段动态识别某个 URL 是否与主题相关。并且尽量不要去抓取不相关的页面以节省资源。垂直搜索网站 查看全部
网页抓取解密(网络爬虫的处理对象是互联网通用的爬虫框架流程介绍)
搜索引擎的处理对象是互联网网页。网页的数量是数百亿,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统,将如此大量的网页数据传输到本地,并在本地形成互联网。网页镜像备份。
网络爬虫扮演这个角色。它是搜索引擎系统中非常关键和基本的组成部分。本文主要介绍与网络爬虫相关的技术。虽然爬虫技术经过几十年的发展在整体框架上已经比较成熟,但是随着网络的不断发展,也面临着一些具有挑战性的新问题。
下图展示了一个通用的爬虫框架流程。首先,从互联网页面中仔细选择一部分网页,将这些网页的链接地址作为种子URL,将这些种子URL放入URL队列中进行爬取。爬虫依次从待爬取的队列中读取URL,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
然后把它和网页的相对路径名给网页下载器,网页下载器负责下载页面的内容。对于本地下载的网页,一方面存储在页面库中,等待索引等后续处理;另一方面,将下载网页的网址放入已爬取的网址队列,记录爬虫系统已下载。网页网址,避免网页重复抓取。对于新下载的网页,提取其中收录的所有链接信息,并在抓取的URL队列中进行检查。如果发现该链接还没有被爬取,则将该URL放在待爬取的URL队列的末尾,然后在爬取调度中下载该URL对应的网页。通过这种方式,
对于爬虫来说,往往需要进行网络重复数据删除和网络反作弊。
以上就是一个通用爬虫的整体流程。如果从更宏观的角度考虑,动态抓取过程中的爬虫与互联网上所有网页的关系大致可以分为如图2-2所示的互联网页面。有5个部分:
1. 下载网页集合:爬虫从网上下载到本地索引的网页集合。
2.过期网页集合:由于网页数量最多,爬虫爬完一轮需要很长时间。在抓取过程中,许多下载的网页可能会过期。这是因为互联网网页处于不断动态变化的过程中,所以很容易产生本地网页内容与真实互联网网页的不一致。
3. 待下载网页集合:上图中待抓取的URL队列中的网页,这些网页会被爬虫下载。
4. 已知网页集合:这些网页没有被爬虫下载,也没有出现在待抓取的网址队列中,而是通过已经抓取的网页或待抓取的网址队列中的网页,它们总是可以在链接关系找到它们时,稍后被爬虫抓取并索引。
5. 未知网页集合:部分网页无法被爬虫抓取,这部分网页构成未知网页集合。事实上,这部分网页所占的比例很高。
根据应用的不同,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种:
1. 批量爬虫(Batch Crawler):批量爬虫有比较明确的爬取范围和目标。当爬虫到达设定的目标时,它停止爬虫过程。至于具体的目标,可能不一样,可能是设置一定数量的网页被爬取,也可能是设置爬取所消耗的时间等等。
2.增量爬虫(Incremental Crawler):增量爬虫与批量爬虫不同,它会不断地持续爬取,爬取的网页要定期更新,因为互联网的网页在不断变化,新网页很常见、要删除的网页或网页内容更改为通用。增量爬虫需要及时反映这种变化。因此,它们都在不断的爬取过程中,要么爬取新页面,要么更新现有页面。有网页。常见的商业搜索引擎爬虫基本都属于这一类。
3.Focused Crawter:垂直爬虫专注于特定主题内容或属于特定行业的网页。比如健康网站,只需要从网上找健康相关的页面即可。页面内容就够了,其他行业的内容不考虑。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定的行业或主题。从节省系统资源的角度考虑,不可能把所有的网页都下载下来然后过滤。这太浪费资源了。爬虫往往需要在爬取阶段动态识别某个 URL 是否与主题相关。并且尽量不要去抓取不相关的页面以节省资源。垂直搜索网站
网页抓取解密(腾讯课堂缓存文件分析进展缓存分析获取资源 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 739 次浏览 • 2021-10-05 20:00
)
背景
众所周知,腾讯课堂这样的视频是有时间限制的。
如果我付了钱并想永远保留它,我该怎么办?
录屏?也许这是一种思维方式。但是这个时间成本可能比较大。
接下来,我将提供一个解锁加密视频的思路,仅供参考。
发现
对分析过程不感兴趣的可以跳到最后一节
腾讯课堂网页版分析网络请求和过滤器关键词m3u8
直接复制这个url,发现可以下载一个m3u8文件,但是只有几十kb,显然不是视频。以文本方式打开文件,查找类似配置的相关信息。那么什么是m3u8?
关于 m3u8
详细请参考文档m3u8文件格式详细解释
m3u8文件作为媒体播放列表(Meida Playlist)时,其内部信息记录了一系列媒体片段资源。依次播放片段资源,充分展示多媒体资源。格式如下:
#EXTM3U
#EXT-X-TARGETDURATION:10
#EXTINF:9.009,
http://media.example.com/first.ts
#EXTINF:9.009,
http://media.example.com/second.ts
#EXTINF:3.003,
http://media.example.com/third.ts
分析网络请求并过滤关键词.ts
原来m3u8是一个媒体播放器列表,里面收录了多个ts播放片段资源,再看看.ts视频片段相关的请求
浏览器下载 .ts 视频文件
直接访问ts视频的url,发现可以直接下载ts视频文件。But when the player is selected to play, it cannot be played. 可以肯定视频是加密的。看一下m3u8文件(以文本模式查看):
......
#EXT-X-KEY:METHOD=AES-128,URI="https://ke.qq.com/cgi-bin/qclo ... ot%3B,IV=0x00000000000000000000000000000000
.......
METHOD:该值是一个可枚举的字符串,用于指定加密方法。AES-128:表示使用 AES-128 进行加密。
URI:指定密钥路径。密钥是一个 16 字节的数据。此键是必需参数,除非 METHOD 为 NONE。
IV:该值为 128 位十六进制值。AES-128 加密和解密需要相同的 16 字节 IV 值。使用不同的IV值可以增加密码的强度。
分析缓存文件分析进度获取缓存文件
腾讯课堂缓存文件存放在/sdcard/Android/data//files/tencentedu/video/txdownload/
可以通过adb把手机中的缓存文件拉到电脑上
adb pull /sdcard/Android/data/com.tencent.edu/files/tencentedu/video/txdownload/
分析缓存文件sqlite
既然是sqlite文件,放到Navicat或者Datagrip里看看
元数据和缓存,这里的重点是缓存表。从数据库中可以看出,数据库中插入了.ts视频文件片段、m3u8目录信息和解密密钥,与分析网页得到的数据基本一致。
分析ts片段
可以看出ts片段的格式是
https://1258712167.vod2.myqclo ... pegts
...
...
https://1258712167.vod2.myqclo ... pegts
开始和结束是连续的,并确定片段的开始和结束
修改链接为start=0&end=38045039(即end是最后一个片段的结尾),访问链接,但是提示需要签名信息。显然,它缺乏与符号相关的信息。可以轻松获取签到信息(ts从链接或m3u8文件中获取)
分析待解决问题的进度 破解加密缓存文件,从sqlite文件中获取必要信息
import sqlite3 as db
# 获取m3u8文件的下载链接,视频base_url,aes解密key
def get_url_key(sqlite_file):
con = db.connect(sqlite_file)
cu = con.cursor()
result = cu.execute('SELECT * FROM caches')
data = result.fetchall()
m3u8_url = data[0][0]
# video_base_url = data[2][0]
video_base_url = data[2][0].split("?")[0]
aes_key = data[1][1]
return m3u8_url, video_base_url, aes_key
拼接完整的视频剪辑链接
import m3u8
import re
def get_seg_uri(m3u8_file):
m3u8_obj = m3u8.load(m3u8_file)
seg_start_uri = m3u8_obj.segments[0].uri
seg_end_uri = m3u8_obj.segments[-1].uri
end_time = re.search('end=([0-9]*)', seg_end_uri).group(1)
pattern = r'end=[0-9]*'
seg_uri = re.sub(pattern, r'end={}'.format(end_time), seg_start_uri)
return seg_uri.split('?')[-1]
引入第三方库m3u8解析库,详细请参考m3u8解析库github地址
解密完整的视频文件
import os
from Crypto.Cipher import AES
import requests
import threading
THIS_FILE_PATH = os.path.dirname(os.path.realpath(__file__))
OUTPUT_FILE_PATH = os.path.join(THIS_FILE_PATH, 'output')
SQLITE_FILE_PATH = os.path.join(THIS_FILE_PATH, 'sqlite')
def decrypt_video(sqlite_file):
print("thread start......")
file_saved_name = sqlite_file.split('.')[0] + ".mp4"
m3u8_url, video_base_url, aes_key = get_url_key(os.path.join(SQLITE_FILE_PATH, sqlite_file))
# print(m3u8_url, video_base_url, aes_key, sep='\n')
seg_uri = get_seg_uri(m3u8_url)
video_url = video_base_url + '?' + seg_uri
# print(video_url)
res = requests.get(video_url, stream=True)
video_stream = b''
for chunk in res.iter_content(chunk_size=1024 * 20):
if chunk:
video_stream += chunk
decrypted_video = AES.new(aes_key, AES.MODE_CBC).decrypt(video_stream)
with open(os.path.join(OUTPUT_FILE_PATH, file_saved_name), 'ab') as f:
f.write(decrypted_video)
print("thread end .....")
for file in os.listdir(SQLITE_FILE_PATH):
if file.endswith('sqlite'):
decrypt_video_thread = threading.Thread(target=decrypt_video, args=(file,))
decrypt_video_thread.start()
介绍加密解密库Crypto。引导包遇到问题请参考python3中的Crypto ModuleNotFoundError
一些结论:下载完整视频然后解密是受网络影响的。考虑直接转到 sqlite 文件以获取完整视频。16byte的码流可以叠加合并得到完整的视频,但是声音不能同步。它放弃了通过单个 ts 段解密多个视频。把一个视频看成100+个片段很不方便。如果sqlite文件缓存很久,方法无效,sign等信息可能无效。如果要解密视频文件,需要有很多最近缓存的sqlite文件。视频网站的视频加解密方法与此类似,下面以开课为例,其他类型的网站视频如果需要,可以自己尝试
from Crypto.Cipher import AES
import requests
# key_url = "https://p.bokecc.com/servlet/h ... ot%3B
# key = requests.get(key_url)
# print(key.content)
# iv = 0x50E8E2C985FD43379C33DC5901307461
# iv = 0x50E8E2C985FD43379 # 取高16位
# iv = iv.to_bytes(length=16, byteorder='big')
# iv = b'0000000000000000' # 经过测试,iv在这里不起作用
for i in range(725):
video_url = "https://cd15-ccd1-2.play.bokec ... eo%3D{}&t=1601134081&key=B23C32BEF607876499FF469AA5B4B46C&tpl=10&tpt=112".format(i)
print("download video-{}....".format(i))
res = requests.get(video_url)
# hlskey通过key_url可下载到,也可通过requests.get下载,然后aes_key=key_res.content
with open("hlskey", "rb") as f:
key = f.read()
content_video_part = AES.new(key, AES.MODE_CBC).decrypt(res.content)
with open("kaikeba.mp4", 'ab') as f: # 追加保存解密结果
f.write(content_video_part)
写在最后
有任何问题请关注我的公众号CodeMonkeyJerry,欢迎留言
查看全部
网页抓取解密(腾讯课堂缓存文件分析进展缓存分析获取资源
)
背景
众所周知,腾讯课堂这样的视频是有时间限制的。
如果我付了钱并想永远保留它,我该怎么办?
录屏?也许这是一种思维方式。但是这个时间成本可能比较大。
接下来,我将提供一个解锁加密视频的思路,仅供参考。
发现
对分析过程不感兴趣的可以跳到最后一节
腾讯课堂网页版分析网络请求和过滤器关键词m3u8
直接复制这个url,发现可以下载一个m3u8文件,但是只有几十kb,显然不是视频。以文本方式打开文件,查找类似配置的相关信息。那么什么是m3u8?
关于 m3u8
详细请参考文档m3u8文件格式详细解释
m3u8文件作为媒体播放列表(Meida Playlist)时,其内部信息记录了一系列媒体片段资源。依次播放片段资源,充分展示多媒体资源。格式如下:
#EXTM3U
#EXT-X-TARGETDURATION:10
#EXTINF:9.009,
http://media.example.com/first.ts
#EXTINF:9.009,
http://media.example.com/second.ts
#EXTINF:3.003,
http://media.example.com/third.ts
分析网络请求并过滤关键词.ts
原来m3u8是一个媒体播放器列表,里面收录了多个ts播放片段资源,再看看.ts视频片段相关的请求
浏览器下载 .ts 视频文件
直接访问ts视频的url,发现可以直接下载ts视频文件。But when the player is selected to play, it cannot be played. 可以肯定视频是加密的。看一下m3u8文件(以文本模式查看):
......
#EXT-X-KEY:METHOD=AES-128,URI="https://ke.qq.com/cgi-bin/qclo ... ot%3B,IV=0x00000000000000000000000000000000
.......
METHOD:该值是一个可枚举的字符串,用于指定加密方法。AES-128:表示使用 AES-128 进行加密。
URI:指定密钥路径。密钥是一个 16 字节的数据。此键是必需参数,除非 METHOD 为 NONE。
IV:该值为 128 位十六进制值。AES-128 加密和解密需要相同的 16 字节 IV 值。使用不同的IV值可以增加密码的强度。
分析缓存文件分析进度获取缓存文件
腾讯课堂缓存文件存放在/sdcard/Android/data//files/tencentedu/video/txdownload/
可以通过adb把手机中的缓存文件拉到电脑上
adb pull /sdcard/Android/data/com.tencent.edu/files/tencentedu/video/txdownload/
分析缓存文件sqlite
既然是sqlite文件,放到Navicat或者Datagrip里看看
元数据和缓存,这里的重点是缓存表。从数据库中可以看出,数据库中插入了.ts视频文件片段、m3u8目录信息和解密密钥,与分析网页得到的数据基本一致。
分析ts片段
可以看出ts片段的格式是
https://1258712167.vod2.myqclo ... pegts
...
...
https://1258712167.vod2.myqclo ... pegts
开始和结束是连续的,并确定片段的开始和结束
修改链接为start=0&end=38045039(即end是最后一个片段的结尾),访问链接,但是提示需要签名信息。显然,它缺乏与符号相关的信息。可以轻松获取签到信息(ts从链接或m3u8文件中获取)
分析待解决问题的进度 破解加密缓存文件,从sqlite文件中获取必要信息
import sqlite3 as db
# 获取m3u8文件的下载链接,视频base_url,aes解密key
def get_url_key(sqlite_file):
con = db.connect(sqlite_file)
cu = con.cursor()
result = cu.execute('SELECT * FROM caches')
data = result.fetchall()
m3u8_url = data[0][0]
# video_base_url = data[2][0]
video_base_url = data[2][0].split("?")[0]
aes_key = data[1][1]
return m3u8_url, video_base_url, aes_key
拼接完整的视频剪辑链接
import m3u8
import re
def get_seg_uri(m3u8_file):
m3u8_obj = m3u8.load(m3u8_file)
seg_start_uri = m3u8_obj.segments[0].uri
seg_end_uri = m3u8_obj.segments[-1].uri
end_time = re.search('end=([0-9]*)', seg_end_uri).group(1)
pattern = r'end=[0-9]*'
seg_uri = re.sub(pattern, r'end={}'.format(end_time), seg_start_uri)
return seg_uri.split('?')[-1]
引入第三方库m3u8解析库,详细请参考m3u8解析库github地址
解密完整的视频文件
import os
from Crypto.Cipher import AES
import requests
import threading
THIS_FILE_PATH = os.path.dirname(os.path.realpath(__file__))
OUTPUT_FILE_PATH = os.path.join(THIS_FILE_PATH, 'output')
SQLITE_FILE_PATH = os.path.join(THIS_FILE_PATH, 'sqlite')
def decrypt_video(sqlite_file):
print("thread start......")
file_saved_name = sqlite_file.split('.')[0] + ".mp4"
m3u8_url, video_base_url, aes_key = get_url_key(os.path.join(SQLITE_FILE_PATH, sqlite_file))
# print(m3u8_url, video_base_url, aes_key, sep='\n')
seg_uri = get_seg_uri(m3u8_url)
video_url = video_base_url + '?' + seg_uri
# print(video_url)
res = requests.get(video_url, stream=True)
video_stream = b''
for chunk in res.iter_content(chunk_size=1024 * 20):
if chunk:
video_stream += chunk
decrypted_video = AES.new(aes_key, AES.MODE_CBC).decrypt(video_stream)
with open(os.path.join(OUTPUT_FILE_PATH, file_saved_name), 'ab') as f:
f.write(decrypted_video)
print("thread end .....")
for file in os.listdir(SQLITE_FILE_PATH):
if file.endswith('sqlite'):
decrypt_video_thread = threading.Thread(target=decrypt_video, args=(file,))
decrypt_video_thread.start()
介绍加密解密库Crypto。引导包遇到问题请参考python3中的Crypto ModuleNotFoundError
一些结论:下载完整视频然后解密是受网络影响的。考虑直接转到 sqlite 文件以获取完整视频。16byte的码流可以叠加合并得到完整的视频,但是声音不能同步。它放弃了通过单个 ts 段解密多个视频。把一个视频看成100+个片段很不方便。如果sqlite文件缓存很久,方法无效,sign等信息可能无效。如果要解密视频文件,需要有很多最近缓存的sqlite文件。视频网站的视频加解密方法与此类似,下面以开课为例,其他类型的网站视频如果需要,可以自己尝试
from Crypto.Cipher import AES
import requests
# key_url = "https://p.bokecc.com/servlet/h ... ot%3B
# key = requests.get(key_url)
# print(key.content)
# iv = 0x50E8E2C985FD43379C33DC5901307461
# iv = 0x50E8E2C985FD43379 # 取高16位
# iv = iv.to_bytes(length=16, byteorder='big')
# iv = b'0000000000000000' # 经过测试,iv在这里不起作用
for i in range(725):
video_url = "https://cd15-ccd1-2.play.bokec ... eo%3D{}&t=1601134081&key=B23C32BEF607876499FF469AA5B4B46C&tpl=10&tpt=112".format(i)
print("download video-{}....".format(i))
res = requests.get(video_url)
# hlskey通过key_url可下载到,也可通过requests.get下载,然后aes_key=key_res.content
with open("hlskey", "rb") as f:
key = f.read()
content_video_part = AES.new(key, AES.MODE_CBC).decrypt(res.content)
with open("kaikeba.mp4", 'ab') as f: # 追加保存解密结果
f.write(content_video_part)
写在最后
有任何问题请关注我的公众号CodeMonkeyJerry,欢迎留言
网页抓取解密(网页书籍抓取器(网页内容抓取工具)是一款很优秀好用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-10-03 22:21
)
网络图书爬虫(网络内容爬取工具)是一款非常好用的网络内容爬取助手。如何更轻松地抓取网页内容?编辑器带来的这个网络图书抓取器可以帮助您。它功能强大且易于操作。使用后,用户可以轻松快速地抓取网页内容。可以很好的帮助大家抓取指定网页的内容,比如抓取一些小说内容,然后通过合并功能合并成一个完整的小说文本。欢迎有需要的朋友下载使用。
软件特点:
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
使用说明:
网络图书抓取器可以提取和调整指定小说目录页的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
指示:
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击Start crawling开始下载。
软件介绍:
网络图书抓取器是一种可以帮助用户下载指定网页的某本书和某章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
查看全部
网页抓取解密(网页书籍抓取器(网页内容抓取工具)是一款很优秀好用
)
网络图书爬虫(网络内容爬取工具)是一款非常好用的网络内容爬取助手。如何更轻松地抓取网页内容?编辑器带来的这个网络图书抓取器可以帮助您。它功能强大且易于操作。使用后,用户可以轻松快速地抓取网页内容。可以很好的帮助大家抓取指定网页的内容,比如抓取一些小说内容,然后通过合并功能合并成一个完整的小说文本。欢迎有需要的朋友下载使用。
软件特点:
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
使用说明:
网络图书抓取器可以提取和调整指定小说目录页的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
指示:
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击Start crawling开始下载。
软件介绍:
网络图书抓取器是一种可以帮助用户下载指定网页的某本书和某章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
网页抓取解密(投稿作者为独立开发者朱鹏飞投稿的思路方法测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-10-02 19:04
投稿作者为独立开发者朱鹏飞。他说,“看完文章后,我立即按照他的思路和方法进行了测试,然后下载了十几个官方微信小游戏源代码,纯粹研究学习。截至目前,我推在了文章的时候(2018年1月1日23:50),微信官方已经修复了这个漏洞,但是我觉得文章还是可以分享给开发者的,安全问题真的不能忽略了.”
雷锋网也注意到,朱说,一些老版本的微信仍然可以抓包,获取包地址。
以下资料选自朱鹏飞文章:
一、发现
一早起来就查了V2EX。看到一个帖子“可以直接跳微信改分数,POST请求没有验证……”我好奇进去看了看。
发现不仅可以跳过小游戏直接改分数,连微信小程序和小游戏的源码都可以直接下载。只需要知道appid和版本号就可以直接构造后缀wxapkg源码包的下载地址,不需要任何验证。
虽然下载的源码包是加密的,但是解密方法已经被V2EXer发现了,并且写了一个解密后的Python脚本,运行源码包就可以解压到一个文件夹中。
二、转载
第一步,我先尝试用帖子作者拼接的跳转源包地址进行测试,发现无需任何验证即可下载。你只需要知道地址,直接在任何浏览器或下载工具中打开即可下载。
第二步,使用帖子中的解压Python脚本将源码包解压为源码。
第三步,在本地微信开发者工具中创建一个空白的小程序或小游戏项目,不要选择快速启动模板。
第四步,将解压后的源码复制到新创建的项目目录下,开发者工具会提示编译错误,这个只需要新建一个game.json文件即可。
文件内容不能为空。编写一对大括号或添加 deviceOrientation 配置。这句话的意思是游戏是垂直进行的。
保存后发现游戏还是无法编译,需要修改最后一项。单击开发者工具右上角的详细信息按钮,将调试基础库更改为游戏。
好的,它已经启动并运行:
版权所有文章雷锋网,未经授权禁止转载。有关详细信息,请参阅重印说明。 查看全部
网页抓取解密(投稿作者为独立开发者朱鹏飞投稿的思路方法测试)
投稿作者为独立开发者朱鹏飞。他说,“看完文章后,我立即按照他的思路和方法进行了测试,然后下载了十几个官方微信小游戏源代码,纯粹研究学习。截至目前,我推在了文章的时候(2018年1月1日23:50),微信官方已经修复了这个漏洞,但是我觉得文章还是可以分享给开发者的,安全问题真的不能忽略了.”
雷锋网也注意到,朱说,一些老版本的微信仍然可以抓包,获取包地址。
以下资料选自朱鹏飞文章:
一、发现
一早起来就查了V2EX。看到一个帖子“可以直接跳微信改分数,POST请求没有验证……”我好奇进去看了看。
发现不仅可以跳过小游戏直接改分数,连微信小程序和小游戏的源码都可以直接下载。只需要知道appid和版本号就可以直接构造后缀wxapkg源码包的下载地址,不需要任何验证。
虽然下载的源码包是加密的,但是解密方法已经被V2EXer发现了,并且写了一个解密后的Python脚本,运行源码包就可以解压到一个文件夹中。
二、转载
第一步,我先尝试用帖子作者拼接的跳转源包地址进行测试,发现无需任何验证即可下载。你只需要知道地址,直接在任何浏览器或下载工具中打开即可下载。
第二步,使用帖子中的解压Python脚本将源码包解压为源码。
第三步,在本地微信开发者工具中创建一个空白的小程序或小游戏项目,不要选择快速启动模板。
第四步,将解压后的源码复制到新创建的项目目录下,开发者工具会提示编译错误,这个只需要新建一个game.json文件即可。
文件内容不能为空。编写一对大括号或添加 deviceOrientation 配置。这句话的意思是游戏是垂直进行的。
保存后发现游戏还是无法编译,需要修改最后一项。单击开发者工具右上角的详细信息按钮,将调试基础库更改为游戏。
好的,它已经启动并运行:
版权所有文章雷锋网,未经授权禁止转载。有关详细信息,请参阅重印说明。
网页抓取解密(小程序授权登录的代码前,需要了解清楚openid与unionid的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-10-02 19:03
首先,“登录”、“授权”、“授权登录”都是同一个意思,不用担心。
在编写小程序授权登录的代码之前,需要了解openid和unionid的区别。下面是一个简单的介绍:
腾讯有“微信·开放平台”。只有企业才能注册账号,可以理解为微信系统中的顶级账号。官网地址:除了这个微信开放平台,还有一个叫“微信公众平台”,可以注册服务号、订阅号、小程序、企业微信四种帐号。也就是说,公众号(服务号和订阅号可以统称为公众号)占用一个帐号,小程序也占用一个帐号。在绑定开放平台之前,小程序授权登录只能获取用户的openid。官网地址:小程序可以绑定公众号,公众号可以绑定微信开放平台,小程序也可以绑定微信开放平台。(好像有点绕)简单来说就是所有公众平台账号都需要绑定“开放平台”才能获得unionid。这是打通同一个公司下所有微信公众号最有效的方式(官方推荐),具体可以用百度...一、 以下是小程序登录代码:
官方说明如何获取UnionID,如果开发者账号下有同一主题的公众号,且用户已关注该公众号。开发者可以通过wx.login+code2Session直接获取用户的UnionID,无需用户重新授权。
开发者账号下存在同一主题的公众号或移动应用,且用户已被授权登录该公众号或移动应用。用户的UnionID也可以通过code2session获取。
1/**
2 * Author: huanglp
3 * Date: 2018-11-28
4 */
5public class WeiXinUtils {
6
7 private static Logger log = LoggerFactory.getLogger(WeiXinUtils.class);
8
9 /**
10 * 通过前端传过来的code, 调用小程序登录接口, 获取到message并返回 (包含openid session_key等)
11 *
12 * @param code
13 * @return
14 */
15 public static JSONObject login(String code) {
16 log.info("==============小程序登录方法开始================");
17 WxMiniProperties properties = WeiXinPropertiesUtils.getWxMiniProperties();
18 String url = properties.getInterfaceUrl() + "/sns/jscode2session?appid="
19 + properties.getAppId() + "&secret=" + properties.getAppSecret()
20 + "&js_code=" + code + "&grant_type=authorization_code";
21 JSONObject message;
22 try {
23 // RestTemplate是Spring封装好的, 挺好用, 可做成单例模式
24 RestTemplate restTemplate = new RestTemplate();
25 String response = restTemplate.getForObject(url, String.class);
26 message = JSON.parseObject(response);
27 } catch (Exception e) {
28 log.error("微信服务器请求错误", e);
29 message = new JSONObject();
30 }
31 log.info("message:" + message.toString());
32 log.info("==============小程序登录方法结束================");
33 return message;
34
35 // 后续, 可获取openid session_key等数据, 以下代码一般放在Service层
36 //if (message.get("errcode") != null) {
37 // throw new ValidationException(message.toString());
38 //}
39 //String openid = message.get("openid").toString();
40 //String sessionKey = message.get("session_key").toString();
41 //...
42
43 }
44}
复制代码
1public class WeiXinPropertiesUtils {
2
3 // 微信小程序配置
4 private static WxMiniProperties miniProperties;
5 // 微信公众号配置
6 private static WxProperties wxProperties;
7
8 private static void init() {
9 if (miniProperties == null) {
10 miniProperties = ContextLoader.getCurrentWebApplicationContext()
11 .getBean(WxMiniProperties.class);
12 }
13 if (wxProperties == null) {
14 wxProperties = ContextLoader.getCurrentWebApplicationContext()
15 .getBean(WxProperties.class);
16 }
17 }
18
19 public static WxMiniProperties getWxMiniProperties() {
20 init();
21 return miniProperties;
22 }
23
24 public static WxProperties getWxProperties() {
25 init();
26 return wxProperties;
27 }
28}
复制代码
1@Data
2@Component
3@ConfigurationProperties(prefix = "luwei.module.wx-mini")
4public class WxMiniProperties {
5
6 private String appId;
7 private String appSecret;
8 private String interfaceUrl;
9
10}
复制代码
目前通过代码可以获取到用户的openid和session_key,但是如果不满足条件,即使小程序绑定微信开放平台也无法获取unionid,所以这种方法不稳定。建议使用解密方式获取数据。
1/**
2 * 通过encryptedData,sessionKey,iv获得解密信息, 拥有用户丰富的信息, 包含openid,unionid,昵称等
3 */
4public static JSONObject decryptWxData(String encryptedData, String sessionKey, String iv) throws Exception {
5 log.info("============小程序登录解析数据方法开始==========");
6 String result = AesCbcUtil.decrypt(encryptedData, sessionKey, iv, "UTF-8");
7 JSONObject userInfo = new JSONObject();
8 if (null != result && result.length() > 0) {
9 userInfo = JSONObject.parseObject(result);
10 }
11 log.info("result: " + userInfo);
12 log.info("============小程序登录解析数据方法结束==========");
13 return userInfo;
14}
复制代码
1package com.luwei.common.utils;
2
3import org.bouncycastle.jce.provider.BouncyCastleProvider;
4import org.apache.commons.codec.binary.Base64;
5import javax.crypto.Cipher;
6import javax.crypto.spec.IvParameterSpec;
7import javax.crypto.spec.SecretKeySpec;
8import java.security.AlgorithmParameters;
9import java.security.Security;
10
11/**
12 * Updated by huanglp
13 * Date: 2018-11-28
14 */
15public class AesCbcUtil {
16
17 static {
18 Security.addProvider(new BouncyCastleProvider());
19 }
20
21 /**
22 * AES解密
23 *
24 * @param data //被加密的数据
25 * @param key //加密秘钥
26 * @param iv //偏移量
27 * @param encoding //解密后的结果需要进行的编码
28 */
29 public static String decrypt(String data, String key, String iv, String encoding) {
30
31 // org.apache.commons.codec.binary.Base64
32 byte[] dataByte = Base64.decodeBase64(data);
33 byte[] keyByte = Base64.decodeBase64(key);
34 byte[] ivByte = Base64.decodeBase64(iv);
35
36 try {
37 Cipher cipher = Cipher.getInstance("AES/CBC/PKCS7Padding");
38 SecretKeySpec spec = new SecretKeySpec(keyByte, "AES");
39 AlgorithmParameters parameters = AlgorithmParameters.getInstance("AES");
40 parameters.init(new IvParameterSpec(ivByte));
41
42 cipher.init(Cipher.DECRYPT_MODE, spec, parameters);// 初始化
43 byte[] resultByte = cipher.doFinal(dataByte);
44 if (null != resultByte && resultByte.length > 0) {
45 return new String(resultByte, encoding);
46 }
47 return null;
48
49 } catch (Exception e) {
50 e.printStackTrace();
51 }
52
53 return null;
54 }
55}
复制代码
至此,已经获取到了JSONObject类型的userInfo,包括openid、unionid、昵称、头像等数据
之后可以将用户信息保存到数据库中,然后返回一个token给前端。Shiro 通过公司封装了一层。代码如下:
1...
2// 获得用户ID
3int userId = wxUser.getWxUserId();
4shiroTokenService.afterLogout(userId);
5String uuid = UUID.randomUUID().toString();
6String token = StringUtils.deleteAny(uuid, "-") + Long.toString(System.currentTimeMillis(), Character.MAX_RADIX);
7shiroTokenService.afterLogin(userId, token, null);
8return token;
复制代码
二、 以下为公众号(网页)授权码:
网页授权更简单,可以查看官方文档
需要添加riversoft相关依赖包,公众号网页授权,只需将公众号绑定到开放平台,即可获取unionid等用户信息。
1public static OpenUser webSiteLogin(String code, String state) {
2 log.info("============微信公众号(网页)授权开始===========");
3 WxProperties properties = WeiXinPropertiesUtils.getWxProperties();
4 AppSetting appSetting = new AppSetting(properties.getAppId(), properties.getAppSecret());
5 OpenOAuth2s openOAuth2s = OpenOAuth2s.with(appSetting);
6 AccessToken accessToken = openOAuth2s.getAccessToken(code);
7
8 // 获取用户信息
9 OpenUser openUser = openOAuth2s.userInfo(accessToken.getAccessToken(), accessToken.getOpenId());
10 log.info("============微信公众号(网页)授权结束===========");
11 return openUser;
12
13 // 后续, 可将用户信息保存
14 // 最后一步, 生成token后, 需重定向回页面
15 //return "redirect:" + state + "?token=" + token;
16}
复制代码
以下是我整理的微信公众号授权和小程序授权的一些经验和问题的总结。我希望你能从他们那里找到解决办法。 查看全部
网页抓取解密(小程序授权登录的代码前,需要了解清楚openid与unionid的区别)
首先,“登录”、“授权”、“授权登录”都是同一个意思,不用担心。
在编写小程序授权登录的代码之前,需要了解openid和unionid的区别。下面是一个简单的介绍:
腾讯有“微信·开放平台”。只有企业才能注册账号,可以理解为微信系统中的顶级账号。官网地址:除了这个微信开放平台,还有一个叫“微信公众平台”,可以注册服务号、订阅号、小程序、企业微信四种帐号。也就是说,公众号(服务号和订阅号可以统称为公众号)占用一个帐号,小程序也占用一个帐号。在绑定开放平台之前,小程序授权登录只能获取用户的openid。官网地址:小程序可以绑定公众号,公众号可以绑定微信开放平台,小程序也可以绑定微信开放平台。(好像有点绕)简单来说就是所有公众平台账号都需要绑定“开放平台”才能获得unionid。这是打通同一个公司下所有微信公众号最有效的方式(官方推荐),具体可以用百度...一、 以下是小程序登录代码:
官方说明如何获取UnionID,如果开发者账号下有同一主题的公众号,且用户已关注该公众号。开发者可以通过wx.login+code2Session直接获取用户的UnionID,无需用户重新授权。
开发者账号下存在同一主题的公众号或移动应用,且用户已被授权登录该公众号或移动应用。用户的UnionID也可以通过code2session获取。
1/**
2 * Author: huanglp
3 * Date: 2018-11-28
4 */
5public class WeiXinUtils {
6
7 private static Logger log = LoggerFactory.getLogger(WeiXinUtils.class);
8
9 /**
10 * 通过前端传过来的code, 调用小程序登录接口, 获取到message并返回 (包含openid session_key等)
11 *
12 * @param code
13 * @return
14 */
15 public static JSONObject login(String code) {
16 log.info("==============小程序登录方法开始================");
17 WxMiniProperties properties = WeiXinPropertiesUtils.getWxMiniProperties();
18 String url = properties.getInterfaceUrl() + "/sns/jscode2session?appid="
19 + properties.getAppId() + "&secret=" + properties.getAppSecret()
20 + "&js_code=" + code + "&grant_type=authorization_code";
21 JSONObject message;
22 try {
23 // RestTemplate是Spring封装好的, 挺好用, 可做成单例模式
24 RestTemplate restTemplate = new RestTemplate();
25 String response = restTemplate.getForObject(url, String.class);
26 message = JSON.parseObject(response);
27 } catch (Exception e) {
28 log.error("微信服务器请求错误", e);
29 message = new JSONObject();
30 }
31 log.info("message:" + message.toString());
32 log.info("==============小程序登录方法结束================");
33 return message;
34
35 // 后续, 可获取openid session_key等数据, 以下代码一般放在Service层
36 //if (message.get("errcode") != null) {
37 // throw new ValidationException(message.toString());
38 //}
39 //String openid = message.get("openid").toString();
40 //String sessionKey = message.get("session_key").toString();
41 //...
42
43 }
44}
复制代码
1public class WeiXinPropertiesUtils {
2
3 // 微信小程序配置
4 private static WxMiniProperties miniProperties;
5 // 微信公众号配置
6 private static WxProperties wxProperties;
7
8 private static void init() {
9 if (miniProperties == null) {
10 miniProperties = ContextLoader.getCurrentWebApplicationContext()
11 .getBean(WxMiniProperties.class);
12 }
13 if (wxProperties == null) {
14 wxProperties = ContextLoader.getCurrentWebApplicationContext()
15 .getBean(WxProperties.class);
16 }
17 }
18
19 public static WxMiniProperties getWxMiniProperties() {
20 init();
21 return miniProperties;
22 }
23
24 public static WxProperties getWxProperties() {
25 init();
26 return wxProperties;
27 }
28}
复制代码
1@Data
2@Component
3@ConfigurationProperties(prefix = "luwei.module.wx-mini")
4public class WxMiniProperties {
5
6 private String appId;
7 private String appSecret;
8 private String interfaceUrl;
9
10}
复制代码
目前通过代码可以获取到用户的openid和session_key,但是如果不满足条件,即使小程序绑定微信开放平台也无法获取unionid,所以这种方法不稳定。建议使用解密方式获取数据。
1/**
2 * 通过encryptedData,sessionKey,iv获得解密信息, 拥有用户丰富的信息, 包含openid,unionid,昵称等
3 */
4public static JSONObject decryptWxData(String encryptedData, String sessionKey, String iv) throws Exception {
5 log.info("============小程序登录解析数据方法开始==========");
6 String result = AesCbcUtil.decrypt(encryptedData, sessionKey, iv, "UTF-8");
7 JSONObject userInfo = new JSONObject();
8 if (null != result && result.length() > 0) {
9 userInfo = JSONObject.parseObject(result);
10 }
11 log.info("result: " + userInfo);
12 log.info("============小程序登录解析数据方法结束==========");
13 return userInfo;
14}
复制代码
1package com.luwei.common.utils;
2
3import org.bouncycastle.jce.provider.BouncyCastleProvider;
4import org.apache.commons.codec.binary.Base64;
5import javax.crypto.Cipher;
6import javax.crypto.spec.IvParameterSpec;
7import javax.crypto.spec.SecretKeySpec;
8import java.security.AlgorithmParameters;
9import java.security.Security;
10
11/**
12 * Updated by huanglp
13 * Date: 2018-11-28
14 */
15public class AesCbcUtil {
16
17 static {
18 Security.addProvider(new BouncyCastleProvider());
19 }
20
21 /**
22 * AES解密
23 *
24 * @param data //被加密的数据
25 * @param key //加密秘钥
26 * @param iv //偏移量
27 * @param encoding //解密后的结果需要进行的编码
28 */
29 public static String decrypt(String data, String key, String iv, String encoding) {
30
31 // org.apache.commons.codec.binary.Base64
32 byte[] dataByte = Base64.decodeBase64(data);
33 byte[] keyByte = Base64.decodeBase64(key);
34 byte[] ivByte = Base64.decodeBase64(iv);
35
36 try {
37 Cipher cipher = Cipher.getInstance("AES/CBC/PKCS7Padding");
38 SecretKeySpec spec = new SecretKeySpec(keyByte, "AES");
39 AlgorithmParameters parameters = AlgorithmParameters.getInstance("AES");
40 parameters.init(new IvParameterSpec(ivByte));
41
42 cipher.init(Cipher.DECRYPT_MODE, spec, parameters);// 初始化
43 byte[] resultByte = cipher.doFinal(dataByte);
44 if (null != resultByte && resultByte.length > 0) {
45 return new String(resultByte, encoding);
46 }
47 return null;
48
49 } catch (Exception e) {
50 e.printStackTrace();
51 }
52
53 return null;
54 }
55}
复制代码
至此,已经获取到了JSONObject类型的userInfo,包括openid、unionid、昵称、头像等数据
之后可以将用户信息保存到数据库中,然后返回一个token给前端。Shiro 通过公司封装了一层。代码如下:
1...
2// 获得用户ID
3int userId = wxUser.getWxUserId();
4shiroTokenService.afterLogout(userId);
5String uuid = UUID.randomUUID().toString();
6String token = StringUtils.deleteAny(uuid, "-") + Long.toString(System.currentTimeMillis(), Character.MAX_RADIX);
7shiroTokenService.afterLogin(userId, token, null);
8return token;
复制代码
二、 以下为公众号(网页)授权码:
网页授权更简单,可以查看官方文档
需要添加riversoft相关依赖包,公众号网页授权,只需将公众号绑定到开放平台,即可获取unionid等用户信息。
1public static OpenUser webSiteLogin(String code, String state) {
2 log.info("============微信公众号(网页)授权开始===========");
3 WxProperties properties = WeiXinPropertiesUtils.getWxProperties();
4 AppSetting appSetting = new AppSetting(properties.getAppId(), properties.getAppSecret());
5 OpenOAuth2s openOAuth2s = OpenOAuth2s.with(appSetting);
6 AccessToken accessToken = openOAuth2s.getAccessToken(code);
7
8 // 获取用户信息
9 OpenUser openUser = openOAuth2s.userInfo(accessToken.getAccessToken(), accessToken.getOpenId());
10 log.info("============微信公众号(网页)授权结束===========");
11 return openUser;
12
13 // 后续, 可将用户信息保存
14 // 最后一步, 生成token后, 需重定向回页面
15 //return "redirect:" + state + "?token=" + token;
16}
复制代码
以下是我整理的微信公众号授权和小程序授权的一些经验和问题的总结。我希望你能从他们那里找到解决办法。
网页抓取解密( Python页面抓取过程中乱码的原因与相应的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-02 19:02
Python页面抓取过程中乱码的原因与相应的解决方法)
python抓取并保存html页面时出现乱码问题的解决方法
更新时间:2016-07-01 11:23:47 作者:holybin
本文文章主要介绍了python爬取html页面时出现乱码问题的解决方法,并结合示例表单分析了python页面爬取过程中出现乱码的原因及相应的解决方法。有需要的朋友可以参考Down
本文示例介绍了python抓取并保存html页面时出现乱码问题的解决方法。分享给大家,供大家参考,如下:
使用Python抓取html页面并保存时,经常会出现抓取页面内容乱码的问题。出现这个问题的原因,一方面是代码中的编码设置有问题;另一方面,当编码设置正确时,网页的实际编码与标记的编码不匹配。html页面上标注的代码在这里:
复制代码代码如下:
这里有一个简单的解决方法:使用chardet来判断网页的真实编码,同时从url请求返回的info中判断出mark编码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(这里设置系统默认编码为utf-8)。
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'https://www.jb51.net'
download(url)
获取到的test.html文件打开如下,可以看到它是以UTF-8无BOM编码格式存储的,也就是我们设置的默认编码:
对Python相关内容感兴趣的读者可以查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》 ,《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页抓取解密(
Python页面抓取过程中乱码的原因与相应的解决方法)
python抓取并保存html页面时出现乱码问题的解决方法
更新时间:2016-07-01 11:23:47 作者:holybin
本文文章主要介绍了python爬取html页面时出现乱码问题的解决方法,并结合示例表单分析了python页面爬取过程中出现乱码的原因及相应的解决方法。有需要的朋友可以参考Down
本文示例介绍了python抓取并保存html页面时出现乱码问题的解决方法。分享给大家,供大家参考,如下:
使用Python抓取html页面并保存时,经常会出现抓取页面内容乱码的问题。出现这个问题的原因,一方面是代码中的编码设置有问题;另一方面,当编码设置正确时,网页的实际编码与标记的编码不匹配。html页面上标注的代码在这里:
复制代码代码如下:
这里有一个简单的解决方法:使用chardet来判断网页的真实编码,同时从url请求返回的info中判断出mark编码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(这里设置系统默认编码为utf-8)。
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'https://www.jb51.net'
download(url)
获取到的test.html文件打开如下,可以看到它是以UTF-8无BOM编码格式存储的,也就是我们设置的默认编码:
对Python相关内容感兴趣的读者可以查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》 ,《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。

