
网页抓取解密
网页抓取解密(网页版AES:1.的函数())
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-12-04 12:01
一、网页版AES:
1.首先我们打开浏览器“咪咪咪”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,这种视频一般是m3u8.)
3.点一个视频进去4.搜索“m3u8”,原来是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那应该是加密了
6. 然后我们尝试搜索这个视频的ID,发现有3个相关的请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID加了后来,之前截图是另一个)
7.上图得到的/video/info是哪里来的?不用着急,ctrl+f搜索,真的找到了一个js文件。
8. 我们从source打开这个文件,搜索/video/info,发现一个getVideoInfo函数(注意a的值是从headers中获取的)
9. 然后我低头看到一个decryptString,那我猜这应该是解密的函数,然后搜索decryptString找到函数
10.分析这个函数:
t=得到的加密串,o=取md5,e=取md5后第8位取出16位串
所以通过计算当前视频的iv和key
11. 然后我们尝试用AES解密
12. 解密成功,得到m3u8地址。拼接主机后,直接打开,却发现无法播放。
让我们回到网页来抓包。原来在m3u8地址后面有一个token参数。添加令牌后,打开即可正常播放。
13. 需要注意的是,获取/video/info的时候需要在headers中加上origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我的M3U8下载器时,需要自定义协议头:Origin
二、 web端获取用户Token:
问题来了,在抓取的时候,每个用户只能免费观看30个视频。然后我们会得到更多的用户:
感觉应该是因为token(一个token代表一个用户),那我们就要明白token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新网页,搜索token的值,其实这个pwatoken是一个参数,只有在第二次访问时才会出现。
我们新建一个隐身窗口或小窗口,打开F12.,你会发现一个新的界面mail_pwa_temp,建议使用抓包软件抓取整个过程。
可以看出是mail_pwa_temp返回的token,看一下提交的参数,post submit pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?事实上,当我们访问主页时,会返回一个许可证。这是 pwa-ckv
PS:但是,当我们将帖子的内容设置为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这反映在浏览器中:
没错,这是2级的VIP(也就是所谓的尊贵VIP账号),那么他的token可以无限期的抓拍视频。
看来爬行速度不能太快,会很频繁。
三、 两种实现网页版无限制观看的方法【方法已过期,将强制退出,令牌已被禁止,无法再使用此令牌拍摄视频】:
第一种:FD的自动回复,这个就不多说了,把token换成之前拿到的honor Token
第二种:JS打印这个,步骤如下:
1. 打开会员页面,点击账号后面的Refresh,会提示刷新成功,我们搜索“刷新成功”,不难发现文件中调用了app.XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的函数,
3. 给这个函数一个断点,刷新个人信息,然后我们把这个打印出来
4.在控制台输入temp1.$store.state.newToken ='尊荣token'
这里所说的honor token是第二步抓到的token,字符串长度145左右。
您可以在浏览器中更改为尊贵的VIP,享受无限观看。(值得注意的是:页面一刷新就失效了……再做一次)
四、在APP端实现真正的无限制观看【方法已过期,会强制退出,token已被禁止】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1. 首先我们抓了个app,用Token作为web版,但是调用界面不一样。
2. 然后我们打开MT管理器或者NP管理器,尝试搜索收录Token的方法名的内容。
3. 找到2个相关的getToken函数,让我们点进去修改,返回之前获取的Token
4.APP编译完成后,打开查看效果。
5.果然成了尊贵的VIP。
虽然显示每天的观看次数是有限制的,但实际上你会发现它是无限观看的
五、在APP端实现真正的无限观看:
其实原因很简单。您必须在第一次打开应用程序时注册。然后我们就可以将注册的参数修改为随机的,以达到每次清除数据后打开APP的新用户体验。
因为在SMALI中重新添加函数有点复杂,我这里直接调用了APP原来的随机函数(PS:这个随机是我用的函数的简写,你可以试试其他的随机函数)
下图是从NP管理器到JAVA修改前后的代码区别:(思路是给this.d分配随机字符)
这个方法比第四步要难一些,但也只是一点点而已。
相信你可以通过抓包得到一些信息,然后再搞定。
这里我就不详细解释了。防止和谐,有本事的人可以试试。对我这个自学半心半意的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
比如getLevel(const v0, 0x2 1为普通/2为荣誉), getExpiry (const v0, 0x746a6480)等
修改后发现只在本地显示。 查看全部
网页抓取解密(网页版AES:1.的函数())
一、网页版AES:
1.首先我们打开浏览器“咪咪咪”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,这种视频一般是m3u8.)
3.点一个视频进去4.搜索“m3u8”,原来是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那应该是加密了
6. 然后我们尝试搜索这个视频的ID,发现有3个相关的请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID加了后来,之前截图是另一个)
7.上图得到的/video/info是哪里来的?不用着急,ctrl+f搜索,真的找到了一个js文件。
8. 我们从source打开这个文件,搜索/video/info,发现一个getVideoInfo函数(注意a的值是从headers中获取的)
9. 然后我低头看到一个decryptString,那我猜这应该是解密的函数,然后搜索decryptString找到函数
10.分析这个函数:
t=得到的加密串,o=取md5,e=取md5后第8位取出16位串
所以通过计算当前视频的iv和key
11. 然后我们尝试用AES解密
12. 解密成功,得到m3u8地址。拼接主机后,直接打开,却发现无法播放。
让我们回到网页来抓包。原来在m3u8地址后面有一个token参数。添加令牌后,打开即可正常播放。
13. 需要注意的是,获取/video/info的时候需要在headers中加上origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我的M3U8下载器时,需要自定义协议头:Origin
二、 web端获取用户Token:
问题来了,在抓取的时候,每个用户只能免费观看30个视频。然后我们会得到更多的用户:
感觉应该是因为token(一个token代表一个用户),那我们就要明白token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新网页,搜索token的值,其实这个pwatoken是一个参数,只有在第二次访问时才会出现。
我们新建一个隐身窗口或小窗口,打开F12.,你会发现一个新的界面mail_pwa_temp,建议使用抓包软件抓取整个过程。
可以看出是mail_pwa_temp返回的token,看一下提交的参数,post submit pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?事实上,当我们访问主页时,会返回一个许可证。这是 pwa-ckv
PS:但是,当我们将帖子的内容设置为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这反映在浏览器中:
没错,这是2级的VIP(也就是所谓的尊贵VIP账号),那么他的token可以无限期的抓拍视频。
看来爬行速度不能太快,会很频繁。
三、 两种实现网页版无限制观看的方法【方法已过期,将强制退出,令牌已被禁止,无法再使用此令牌拍摄视频】:
第一种:FD的自动回复,这个就不多说了,把token换成之前拿到的honor Token
第二种:JS打印这个,步骤如下:
1. 打开会员页面,点击账号后面的Refresh,会提示刷新成功,我们搜索“刷新成功”,不难发现文件中调用了app.XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的函数,
3. 给这个函数一个断点,刷新个人信息,然后我们把这个打印出来
4.在控制台输入temp1.$store.state.newToken ='尊荣token'
这里所说的honor token是第二步抓到的token,字符串长度145左右。
您可以在浏览器中更改为尊贵的VIP,享受无限观看。(值得注意的是:页面一刷新就失效了……再做一次)
四、在APP端实现真正的无限制观看【方法已过期,会强制退出,token已被禁止】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1. 首先我们抓了个app,用Token作为web版,但是调用界面不一样。
2. 然后我们打开MT管理器或者NP管理器,尝试搜索收录Token的方法名的内容。
3. 找到2个相关的getToken函数,让我们点进去修改,返回之前获取的Token
4.APP编译完成后,打开查看效果。
5.果然成了尊贵的VIP。
虽然显示每天的观看次数是有限制的,但实际上你会发现它是无限观看的
五、在APP端实现真正的无限观看:
其实原因很简单。您必须在第一次打开应用程序时注册。然后我们就可以将注册的参数修改为随机的,以达到每次清除数据后打开APP的新用户体验。
因为在SMALI中重新添加函数有点复杂,我这里直接调用了APP原来的随机函数(PS:这个随机是我用的函数的简写,你可以试试其他的随机函数)
下图是从NP管理器到JAVA修改前后的代码区别:(思路是给this.d分配随机字符)
这个方法比第四步要难一些,但也只是一点点而已。
相信你可以通过抓包得到一些信息,然后再搞定。
这里我就不详细解释了。防止和谐,有本事的人可以试试。对我这个自学半心半意的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
比如getLevel(const v0, 0x2 1为普通/2为荣誉), getExpiry (const v0, 0x746a6480)等
修改后发现只在本地显示。
网页抓取解密( Python实现抓取网页并且解析的功能实例,(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-02 09:15
Python实现抓取网页并且解析的功能实例,(图))
爬取网页和解析示例的Python实现
更新时间:2014-09-20 17:39:07 投稿:shichen2014
本文文章主要介绍Python实现网页抓取和解析的功能实例。主要以百度问答的分析为例,说明其原理和方法。有需要的朋友可以参考以下
本文以示例的形式介绍了Python中网页的爬取和解析的功能。主要分析问答和百度首页。分享给大家,供大家参考。
主要功能代码如下:
#!/usr/bin/python
#coding=utf-8
import sys
import re
import urllib2
from urllib import urlencode
from urllib import quote
import time
maxline = 2000
wenda = re.compile("href=\"http://wenda.so.com/q/.+\?src=(.+?)\"")
baidu = re.compile("<a href=\"http://www.baidu.com/link\?url=.+\".*?>更多知道相关问题.*?</a>")
f1 = open("baidupage.txt","w")
f2 = open("wendapage.txt","w")
for line in sys.stdin:
if maxline == 0:
break
query = line.strip();
time.sleep(1);
recall_url = "http://www.so.com/s?&q=" + query;
response = urllib2.urlopen(recall_url);
html = response.read();
f1.write(html)
m = wenda.search(html);
if m:
if m.group(1) == "110":
print query + "\twenda\t0";
else:
print query + "\twenda\t1";
else:
print query + "\twenda\t0";
recall_url = "http://www.baidu.com/s?wd=" + query +"&ie=utf-8";
response = urllib2.urlopen(recall_url);
html = response.read();
f2.write(html)
m = baidu.search(html);
if m:
print query + "\tbaidu\t1";
else:
print query + "\tbaidu\t0";
maxline = maxline - 1;
f1.close()
f2.close()
我希望这篇文章能帮助你学习 Python 编程。 查看全部
网页抓取解密(
Python实现抓取网页并且解析的功能实例,(图))
爬取网页和解析示例的Python实现
更新时间:2014-09-20 17:39:07 投稿:shichen2014
本文文章主要介绍Python实现网页抓取和解析的功能实例。主要以百度问答的分析为例,说明其原理和方法。有需要的朋友可以参考以下
本文以示例的形式介绍了Python中网页的爬取和解析的功能。主要分析问答和百度首页。分享给大家,供大家参考。
主要功能代码如下:
#!/usr/bin/python
#coding=utf-8
import sys
import re
import urllib2
from urllib import urlencode
from urllib import quote
import time
maxline = 2000
wenda = re.compile("href=\"http://wenda.so.com/q/.+\?src=(.+?)\"")
baidu = re.compile("<a href=\"http://www.baidu.com/link\?url=.+\".*?>更多知道相关问题.*?</a>")
f1 = open("baidupage.txt","w")
f2 = open("wendapage.txt","w")
for line in sys.stdin:
if maxline == 0:
break
query = line.strip();
time.sleep(1);
recall_url = "http://www.so.com/s?&q=" + query;
response = urllib2.urlopen(recall_url);
html = response.read();
f1.write(html)
m = wenda.search(html);
if m:
if m.group(1) == "110":
print query + "\twenda\t0";
else:
print query + "\twenda\t1";
else:
print query + "\twenda\t0";
recall_url = "http://www.baidu.com/s?wd=" + query +"&ie=utf-8";
response = urllib2.urlopen(recall_url);
html = response.read();
f2.write(html)
m = baidu.search(html);
if m:
print query + "\tbaidu\t1";
else:
print query + "\tbaidu\t0";
maxline = maxline - 1;
f1.close()
f2.close()
我希望这篇文章能帮助你学习 Python 编程。
网页抓取解密(GooglePageRank算法的基本原理推导和基本原理算法策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-02 05:19
一、PageRank
PageRank算法是最著名的搜索引擎谷歌采用的一种算法策略。它根据每个网页的超链接信息计算一个网页的权重,以优化搜索引擎的结果。,由拉里佩奇提出。
简单的说,PageRank算法计算每个网页的综合得分,即如果网页A链接到网页B,网页B当然会加一分。不同的链接网页有不同的指向网页的点。一个页面的分数是通过递归算法得到所有链接到它的页面的重要性的。
PageRank算法的基本原理推导如下:
PR(A) = (1-d) + d*(PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
其中,PR(A)是指网页A的PR值。
T1、T2、...、Tn 指的是页面 A 的链接页面。
PR(Ti)是指网页Ti(i=1, 2, ..., n)的PR值。
C(Ti)指的是网页Ti(i=1, 2,..., n)之外的链接数。
D为衰减因子,0 由上式可知,影响网页PR值的主要因素如下:
(1)此页面的链接数。
(2) 链接到网页本身的网页的 PR 值。
(3)网页本身的链接数。
根据以上分析可以判断:一个网页的链接数越多,这些链接网页的PR值就越高,而来自这些网页的链接数越少,该网页的PR值就越高.
谷歌为每个网页分配一个初始PR值(1-d),然后使用PageRank算法收敛计算其PR值。
网页的link-in和link-out关系一直在变化,所以PR值也需要更新,可以用定时任务反复计算后更新,使网页最终PR值达到平衡和稳定的状态。
Google的查询过程如下:首先根据用户输入的查询,关键词尽可能匹配网页数据库中的网页,然后根据用户自己的PR排名将匹配的网页呈现给用户.
此外,网页在搜索结果列表中的位置还与很多其他因素有关,例如搜索词在网页中的位置。
PageRank的缺陷是没有考虑链接的价值,更适合一般搜索引擎,但对于主题相关的垂直搜索引擎来说不是一个好的策略。
二、命中
PageRank算法对外部链接权重的贡献是平均的,即不考虑不同链接的重要性,但部分页面链接可能是广告、导航或注释链接,平均权重显然不符合结合实际情况。
HITS(Hyperlink Induced Topic Search)算法是经典的主题信息提取策略,可以提高垂直精度。
1、原理
HITS算法由Jon Kleinberg提出,它为每个网页计算两个值:权威值(authority)和中心值(hub)。
(1)权威页面
一个网页被多次引用,可能很重要;一个网页虽然没有被多次引用,但是被重要的网页引用,也可能很重要;网页的重要性均匀地转移到它指的是网页。此类页面称为权威页面。
(2)中心网页
提供权威页面链接集合的网页本身可能并不重要,或者指向它的页面很少,但它提供了到某个主题的最重要站点的链接集合。这种类型的页面称为 Hub 网页。
(3)算法思想
首先,使用通用搜索引擎获取网页的初始子集I。当然,I中的页面与用户的查询条件非常相关。然后将I所指向的网页和I所指向的网页收录起来构成一个基本集合E。E中的每个页面都有一个权限权重和一个枢纽权重,分别用a和h表示。a 值代表网页和查询条件相关的程度,h 反映了页面链接到相关页面的程度。a=(a1, a2, ..., an) 和 h=(h1, h2, ..., hn) 分别表示 E 中所有网页的权威和中心向量。 初始设置所有 ai 和 hi 为 1 ,并且然后使用以下公式计算:
其中,B(i)和F(i)分别代表指向该网页的网页链接集合和指向该网页的网页链接集合。用n*n矩阵A来表示集合E的网页节点之间的连接。如果节点i和节点j之间存在连接,则A[i,j]=1,则A[i,j]= 0,因此,上式可表示为:
迭代计算 a 和 h 直到收敛。这样,我们专注于ATA和AAT。最后,按照authority和hub值排序,选择a和h的值大于阈值M的网页。
如果一个网页被很多好的hub指向,它的权威值会相应增加;如果一个网页指向很多好的权威页面,那么hub值也会相应增加。HITS 算法的最终输出是一组具有较大中心值的网页和具有较大权限值的网页。
2、缺陷
HITS算法在提高一定垂直精度的同时,也存在以下不足:
(1)HITS 算法忽略了网页内容的差异,给每个链接的网页分配了相同的权重常数,因为每个网页都会有一些不相关的链接网页,比如广告链接,而这些不相关的网页和相关网页平等对待它们很容易导致主题漂移。
(1)在url集合E的开头,也把I初始集合中网页的一些不相关的链接加到了E中,增加了不必要的下载量,导致更多不相关的网页参与计算. 对精度有一定影响。
3、改进
改进方向如下:
(1)主题漂移
(2)下载过滤器 查看全部
网页抓取解密(GooglePageRank算法的基本原理推导和基本原理算法策略)
一、PageRank
PageRank算法是最著名的搜索引擎谷歌采用的一种算法策略。它根据每个网页的超链接信息计算一个网页的权重,以优化搜索引擎的结果。,由拉里佩奇提出。
简单的说,PageRank算法计算每个网页的综合得分,即如果网页A链接到网页B,网页B当然会加一分。不同的链接网页有不同的指向网页的点。一个页面的分数是通过递归算法得到所有链接到它的页面的重要性的。
PageRank算法的基本原理推导如下:
PR(A) = (1-d) + d*(PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
其中,PR(A)是指网页A的PR值。
T1、T2、...、Tn 指的是页面 A 的链接页面。
PR(Ti)是指网页Ti(i=1, 2, ..., n)的PR值。
C(Ti)指的是网页Ti(i=1, 2,..., n)之外的链接数。
D为衰减因子,0 由上式可知,影响网页PR值的主要因素如下:
(1)此页面的链接数。
(2) 链接到网页本身的网页的 PR 值。
(3)网页本身的链接数。
根据以上分析可以判断:一个网页的链接数越多,这些链接网页的PR值就越高,而来自这些网页的链接数越少,该网页的PR值就越高.
谷歌为每个网页分配一个初始PR值(1-d),然后使用PageRank算法收敛计算其PR值。
网页的link-in和link-out关系一直在变化,所以PR值也需要更新,可以用定时任务反复计算后更新,使网页最终PR值达到平衡和稳定的状态。
Google的查询过程如下:首先根据用户输入的查询,关键词尽可能匹配网页数据库中的网页,然后根据用户自己的PR排名将匹配的网页呈现给用户.
此外,网页在搜索结果列表中的位置还与很多其他因素有关,例如搜索词在网页中的位置。
PageRank的缺陷是没有考虑链接的价值,更适合一般搜索引擎,但对于主题相关的垂直搜索引擎来说不是一个好的策略。
二、命中
PageRank算法对外部链接权重的贡献是平均的,即不考虑不同链接的重要性,但部分页面链接可能是广告、导航或注释链接,平均权重显然不符合结合实际情况。
HITS(Hyperlink Induced Topic Search)算法是经典的主题信息提取策略,可以提高垂直精度。
1、原理
HITS算法由Jon Kleinberg提出,它为每个网页计算两个值:权威值(authority)和中心值(hub)。
(1)权威页面
一个网页被多次引用,可能很重要;一个网页虽然没有被多次引用,但是被重要的网页引用,也可能很重要;网页的重要性均匀地转移到它指的是网页。此类页面称为权威页面。
(2)中心网页
提供权威页面链接集合的网页本身可能并不重要,或者指向它的页面很少,但它提供了到某个主题的最重要站点的链接集合。这种类型的页面称为 Hub 网页。
(3)算法思想
首先,使用通用搜索引擎获取网页的初始子集I。当然,I中的页面与用户的查询条件非常相关。然后将I所指向的网页和I所指向的网页收录起来构成一个基本集合E。E中的每个页面都有一个权限权重和一个枢纽权重,分别用a和h表示。a 值代表网页和查询条件相关的程度,h 反映了页面链接到相关页面的程度。a=(a1, a2, ..., an) 和 h=(h1, h2, ..., hn) 分别表示 E 中所有网页的权威和中心向量。 初始设置所有 ai 和 hi 为 1 ,并且然后使用以下公式计算:

其中,B(i)和F(i)分别代表指向该网页的网页链接集合和指向该网页的网页链接集合。用n*n矩阵A来表示集合E的网页节点之间的连接。如果节点i和节点j之间存在连接,则A[i,j]=1,则A[i,j]= 0,因此,上式可表示为:

迭代计算 a 和 h 直到收敛。这样,我们专注于ATA和AAT。最后,按照authority和hub值排序,选择a和h的值大于阈值M的网页。
如果一个网页被很多好的hub指向,它的权威值会相应增加;如果一个网页指向很多好的权威页面,那么hub值也会相应增加。HITS 算法的最终输出是一组具有较大中心值的网页和具有较大权限值的网页。
2、缺陷
HITS算法在提高一定垂直精度的同时,也存在以下不足:
(1)HITS 算法忽略了网页内容的差异,给每个链接的网页分配了相同的权重常数,因为每个网页都会有一些不相关的链接网页,比如广告链接,而这些不相关的网页和相关网页平等对待它们很容易导致主题漂移。
(1)在url集合E的开头,也把I初始集合中网页的一些不相关的链接加到了E中,增加了不必要的下载量,导致更多不相关的网页参与计算. 对精度有一定影响。
3、改进
改进方向如下:
(1)主题漂移
(2)下载过滤器
网页抓取解密(图片与下一个图片的代码主方法:第一张的网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-01 12:04
一般网页中,图片和下一张图片之间,地址是数字变化:
第一个的网址是:
下一篇的网址是:
一个特殊的网页会对一串数字使用加密算法,让爬虫看不到规则:
例如,第一个:
第二个:
这里的 MjAyMDA4MDktMTIx 实际上是加密信息:
查询结果:20200809显然是本次访问的日期
并121查看网页信息:即当前图片
获取当前日期的代码:
import datetime
time = datetime.datetime.now().strftime('%Y%m%')
import base64
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
测试:将字符串加密为20200809-121,结果与网页地址相同
抓取图片的代码
主要方法:
1、首先创建一个文件并命名为“ooxx”
2、get_page() 函数看起来像这样:它返回网页的数字部分
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']', a)
return html[a:b]
def downloadmm(folder="ooxx", pages=10):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
3、for i in range(pages): #只获取前10页的数据是指从当前页获取数据,第一次减0为当前页,第二次减1为下一页。以此类推,一共10页,page_url:指的是每一页的地址
4、获取page_url:关键点
测试:能否正确获取页码为121的页地址:
操作结果:
网站链接:
于是找到了页面的地址,接下来就是获取页面的源代码,从源代码中获取图片的位置
5、如何通过URL获取html页面内容:
设置请求头,目的是让爬虫操作拥有计算机的身份
import urllib.request
def url_open(url):
# 设置文件头
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
req = urllib.request.Request(url, headers=header)
# 现在开始访问
response = urllib.request.urlopen(url)
html = response.read()
# print(html)
return html
6、find_imgs 函数:通过html内容获取图片地址,正则表达式还没提到,暂时用find方法
就是获取img src之后,.jpg之前的内容。然后设置一个循环,找出当前页面所有符合条件的图片,然后保存
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while (a != -1):
b = html.find('.jpg', a, a + 255) # 没找到就会返回-1
if b != -1:
img_addrs.append(html[a + 9:b + 4])
else:
b = a + 9
a = html.find('img src=', b)
# img_addrs存着的是所有的图片地址
for each in img_addrs:
print(each)
7、 找到地址后,下载保存
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)
filename就是给图片取个名字,img = url_open(each)然后调用函数
当我访问此页面时,我总是报告 403。
在其他页面试过,可以使用
import urllib.request
import os
import datetime
import base64
time = datetime.datetime.now().strftime('%Y%m%')
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
# print(get_base64(time + '111'))
# 打开页面
def url_open(url):
# 设置文件头
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
req = urllib.request.Request(url, headers=header)
# 现在开始访问
response = urllib.request.urlopen(url)
html = response.read()
print(html)
return html
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']', a)
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while (a != -1):
b = html.find('.jpg', a, a + 255) # 没找到就会返回-1
if b != -1:
img_addrs.append(html[a + 9:b + 4])
else:
b = a + 9
a = html.find('img src=', b)
# img_addrs存着的是所有的图片地址
for each in img_addrs:
print(each)
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)
def downloadmm(folder="ooxx", pages=10):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__ == '__main__':
downloadmm()
原文链接: 查看全部
网页抓取解密(图片与下一个图片的代码主方法:第一张的网址)
一般网页中,图片和下一张图片之间,地址是数字变化:
第一个的网址是:

下一篇的网址是:

一个特殊的网页会对一串数字使用加密算法,让爬虫看不到规则:
例如,第一个:

第二个:

这里的 MjAyMDA4MDktMTIx 实际上是加密信息:
查询结果:20200809显然是本次访问的日期
并121查看网页信息:即当前图片
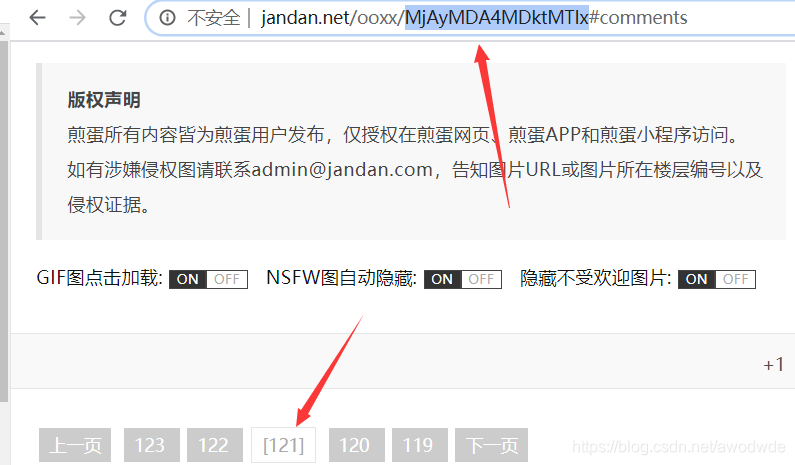
获取当前日期的代码:
import datetime
time = datetime.datetime.now().strftime('%Y%m%')
import base64
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
测试:将字符串加密为20200809-121,结果与网页地址相同
抓取图片的代码
主要方法:
1、首先创建一个文件并命名为“ooxx”
2、get_page() 函数看起来像这样:它返回网页的数字部分

def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']', a)
return html[a:b]
def downloadmm(folder="ooxx", pages=10):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
3、for i in range(pages): #只获取前10页的数据是指从当前页获取数据,第一次减0为当前页,第二次减1为下一页。以此类推,一共10页,page_url:指的是每一页的地址
4、获取page_url:关键点
测试:能否正确获取页码为121的页地址:
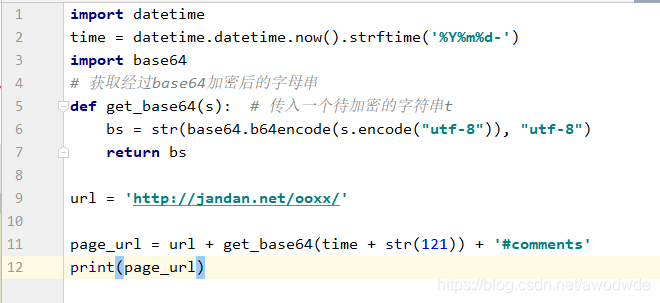
操作结果:

网站链接:
于是找到了页面的地址,接下来就是获取页面的源代码,从源代码中获取图片的位置
5、如何通过URL获取html页面内容:
设置请求头,目的是让爬虫操作拥有计算机的身份
import urllib.request
def url_open(url):
# 设置文件头
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
req = urllib.request.Request(url, headers=header)
# 现在开始访问
response = urllib.request.urlopen(url)
html = response.read()
# print(html)
return html
6、find_imgs 函数:通过html内容获取图片地址,正则表达式还没提到,暂时用find方法
就是获取img src之后,.jpg之前的内容。然后设置一个循环,找出当前页面所有符合条件的图片,然后保存
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while (a != -1):
b = html.find('.jpg', a, a + 255) # 没找到就会返回-1
if b != -1:
img_addrs.append(html[a + 9:b + 4])
else:
b = a + 9
a = html.find('img src=', b)
# img_addrs存着的是所有的图片地址
for each in img_addrs:
print(each)
7、 找到地址后,下载保存
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)
filename就是给图片取个名字,img = url_open(each)然后调用函数
当我访问此页面时,我总是报告 403。

在其他页面试过,可以使用
import urllib.request
import os
import datetime
import base64
time = datetime.datetime.now().strftime('%Y%m%')
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
# print(get_base64(time + '111'))
# 打开页面
def url_open(url):
# 设置文件头
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
req = urllib.request.Request(url, headers=header)
# 现在开始访问
response = urllib.request.urlopen(url)
html = response.read()
print(html)
return html
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']', a)
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while (a != -1):
b = html.find('.jpg', a, a + 255) # 没找到就会返回-1
if b != -1:
img_addrs.append(html[a + 9:b + 4])
else:
b = a + 9
a = html.find('img src=', b)
# img_addrs存着的是所有的图片地址
for each in img_addrs:
print(each)
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)
def downloadmm(folder="ooxx", pages=10):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__ == '__main__':
downloadmm()
原文链接:
网页抓取解密(基于动态内容抓取JavaScript页面的优势--互联网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 11:28
指导
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多优秀的网络爬虫可用。
代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
代理爬网
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
刮痧
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得很好。
刮痧
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抓住
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到百万页面的大型动态爬虫任务。
抓住
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端爬取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
Diffbot
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
原文来自: 查看全部
网页抓取解密(基于动态内容抓取JavaScript页面的优势--互联网)
指导
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多优秀的网络爬虫可用。
代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
 https://www.linuxprobe.com/wp- ... 2.jpg 300w" />
https://www.linuxprobe.com/wp- ... 2.jpg 300w" />代理爬网
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
刮痧
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得很好。
 https://www.linuxprobe.com/wp- ... 7.jpg 300w" />
https://www.linuxprobe.com/wp- ... 7.jpg 300w" />刮痧
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抓住
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到百万页面的大型动态爬虫任务。
 https://www.linuxprobe.com/wp- ... 1.jpg 300w" />
https://www.linuxprobe.com/wp- ... 1.jpg 300w" />抓住
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端爬取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
 https://www.linuxprobe.com/wp- ... 1.jpg 300w" />
https://www.linuxprobe.com/wp- ... 1.jpg 300w" />此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
 https://www.linuxprobe.com/wp- ... 4.jpg 300w" />
https://www.linuxprobe.com/wp- ... 4.jpg 300w" />Diffbot
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
 https://www.linuxprobe.com/wp- ... 2.jpg 300w" />
https://www.linuxprobe.com/wp- ... 2.jpg 300w" />PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
原文来自:
网页抓取解密(Python爬虫JS解密,学会直接破解80%的网站!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-29 11:26
)
Python爬虫JS解密详解,学会直接破解网站的80%!!!
29个爬虫项目宝典教程,你值得拥有!
前言
==Glidedsky==这个关卡==JS解密==和之前看到的不一样,希望大家好好看看学习!
==温馨提示==:保护头发!
1、网页视图
2、JS解密过程(仔细看)
既然是JS加密的,数据肯定不是静态的,如下
直接请求页面,或者把检索到的html代码粘贴到html文件中打开,没有数字
打开控制台查看XHR
这里有问题。之前查的时候可以查看数据,但是不知道为什么又看不到数据了。知道的请在评论区告诉我,谢谢。
网上说的== 网页可以感应到用户打开了控制台==,不知道,不敢问,有这么饿的操作
如果有不明白的朋友,请参考我的JS解密文章 Python爬虫JS解密详解,写的很详细,多做这东西会有经验。
什么都不说,看吧
向下滚动可以看到请求有3个参数
按Ctrl+Shift+f搜索,输入==sign==,可以看到有6个匹配项
有兴趣的朋友可以点进去再搜索==sign==,都是和下图一样的匹配====牛头不对马嘴==
根据我之前的JS解密经验,应该不是直接匹配,然后做一个函数来加密o(╥﹏╥)o
这个我都看到了,直接放弃不是我的性格。我会继续耐心地学习和学习。. . .
然后找到了一个新的方法,现在教大家——就是打XHR断点,如下
只需复制部分网址,无需全部复制
==现在进入最关键的一步--使用python代码获取以上数据==
==获取t值==
==获取符号值==
Secure Hash Algorithm主要适用于数字签名标准DSS中定义的数字签名算法DSA。SHA1 比 MD5 更安全。对于长度小于 2^64 位的消息,SHA1 将生成 160 位的消息摘要。
别慌,python提供了hashlib库,厉害了!
==成功了,老铁们可以过来点赞!(*^▽^*)==
==拼接URL请求,注意:返回数据为json格式==
完美的
3、解密答案(完整代码)
import requests
import hashlib
import time
import math
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
#注意Cookie自己填哦
"Cookie": ""
}
sum = 0
def get(response):
global sum
for i in response['items']:
sum += int(i)
if __name__ == '__main__':
#1000个页面
for i in range(1000):
#获取t值
t = math.floor(time.time())
#获取sign值
sha1 = hashlib.sha1()
data = 'Xr0Z-javascript-obfuscation-1' + str(t)
sha1.update(data.encode('utf-8'))
sign = sha1.hexdigest()
print("第"+str(i+1)+"页")
#拼接url
url = "http://glidedsky.com/api/level ... 2Bstr(i+1)+"&t="+str(t)+"&sign="+str(sign)
response = requests.get(url=url,headers=headers).json()
get(response)
#打印最终数字
print(sum)
复制代码
成功突破,解密成功!!!
==注意填写Cookie,我提供的代码没有填写Cookie值==
博主会持续更新。有兴趣的朋友可以==喜欢==,==关注==和==采集==接下来,你们的支持就是我创作的最大动力!
Java学习从入门到大神学习目录索引
博主开源Python爬虫教程目录索引(宝教程,你值得拥有!)
查看全部
网页抓取解密(Python爬虫JS解密,学会直接破解80%的网站!!
)
Python爬虫JS解密详解,学会直接破解网站的80%!!!
29个爬虫项目宝典教程,你值得拥有!
前言
==Glidedsky==这个关卡==JS解密==和之前看到的不一样,希望大家好好看看学习!
==温馨提示==:保护头发!
1、网页视图
2、JS解密过程(仔细看)
既然是JS加密的,数据肯定不是静态的,如下
直接请求页面,或者把检索到的html代码粘贴到html文件中打开,没有数字
打开控制台查看XHR
这里有问题。之前查的时候可以查看数据,但是不知道为什么又看不到数据了。知道的请在评论区告诉我,谢谢。
网上说的== 网页可以感应到用户打开了控制台==,不知道,不敢问,有这么饿的操作
如果有不明白的朋友,请参考我的JS解密文章 Python爬虫JS解密详解,写的很详细,多做这东西会有经验。
什么都不说,看吧
向下滚动可以看到请求有3个参数
按Ctrl+Shift+f搜索,输入==sign==,可以看到有6个匹配项
有兴趣的朋友可以点进去再搜索==sign==,都是和下图一样的匹配====牛头不对马嘴==
根据我之前的JS解密经验,应该不是直接匹配,然后做一个函数来加密o(╥﹏╥)o
这个我都看到了,直接放弃不是我的性格。我会继续耐心地学习和学习。. . .
然后找到了一个新的方法,现在教大家——就是打XHR断点,如下
只需复制部分网址,无需全部复制
==现在进入最关键的一步--使用python代码获取以上数据==
==获取t值==
==获取符号值==
Secure Hash Algorithm主要适用于数字签名标准DSS中定义的数字签名算法DSA。SHA1 比 MD5 更安全。对于长度小于 2^64 位的消息,SHA1 将生成 160 位的消息摘要。
别慌,python提供了hashlib库,厉害了!
==成功了,老铁们可以过来点赞!(*^▽^*)==
==拼接URL请求,注意:返回数据为json格式==
完美的
3、解密答案(完整代码)
import requests
import hashlib
import time
import math
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
#注意Cookie自己填哦
"Cookie": ""
}
sum = 0
def get(response):
global sum
for i in response['items']:
sum += int(i)
if __name__ == '__main__':
#1000个页面
for i in range(1000):
#获取t值
t = math.floor(time.time())
#获取sign值
sha1 = hashlib.sha1()
data = 'Xr0Z-javascript-obfuscation-1' + str(t)
sha1.update(data.encode('utf-8'))
sign = sha1.hexdigest()
print("第"+str(i+1)+"页")
#拼接url
url = "http://glidedsky.com/api/level ... 2Bstr(i+1)+"&t="+str(t)+"&sign="+str(sign)
response = requests.get(url=url,headers=headers).json()
get(response)
#打印最终数字
print(sum)
复制代码
成功突破,解密成功!!!
==注意填写Cookie,我提供的代码没有填写Cookie值==
博主会持续更新。有兴趣的朋友可以==喜欢==,==关注==和==采集==接下来,你们的支持就是我创作的最大动力!
Java学习从入门到大神学习目录索引
博主开源Python爬虫教程目录索引(宝教程,你值得拥有!)
网页抓取解密(解析XML网页链接来抓取指定的内容比如豆瓣电影排行榜,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-11-28 09:05
如果给你一个网页链接来抓取特定内容,比如豆瓣电影排名,怎么做?
其实网页内容的结构和XML很相似,那么我们可以通过解析XML来解析HTML,但是两者的差距还是很大的,好吧,废话不多说,我们开始解析HTML。
然后有很多用于解析 XML 的库。这里我们选择libxml来解析,因为libxml是C语言接口,我找了一个library-hpple,用objective-c来封装接口。它的地址是,然后网页使用豆瓣电影排名。地址是。
接下来,构建一个新项目。项目使用ARC,引入libxml2和hpple库,新建实体类movie。完整的项目结构如下:
movie的实现如下,这是一个实体类,根据爬取的网页内容确定
电影.h
@interface Movie : NSObject
@property(nonatomic, strong) NSString *name;
@property(nonatomic, strong) NSString *imageUrl;
@property(nonatomic, strong) NSString *descrition;
@property(nonatomic, strong) NSString *movieUrl;
@property(nonatomic) NSInteger ratingNumber;
@property(nonatomic, strong) NSString *comment;
@end
所以最重要的部分在这里。不管网页的内容是什么,我们都需要先获取网页的内容。下面是通过NSURLConnection获取整个网页的内容。
- (void)loadHTMLContent
{
NSString *movieUrl = MOVIE_URL;
NSString *urlString = [movieUrl stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
NSURL *url = [NSURL URLWithString:urlString];
NSURLRequest *request = [NSURLRequest requestWithURL:url];
[UIApplication sharedApplication].networkActivityIndicatorVisible = YES;
__weak ViewController *weak_self = self;
[NSURLConnection sendAsynchronousRequest:request queue:[NSOperationQueue mainQueue] completionHandler:^(NSURLResponse *response, NSData *data, NSError *error) {
if (nil == error) {
// NSString *retString = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
// NSLog(@"%@", retString);
[weak_self parserHTML:data];
}
[UIApplication sharedApplication].networkActivityIndicatorVisible = NO;
}];
}
这里只是简单的访问web内容,一些HTTP和错误处理本文没有讨论,所以这里的代码比较简单,上面代码中有一个parserHTML:方法,就是解析获取到的web内容和解析网页内容之前,我们先拆解xpath。
假设一个简单的网页内容如下:
Some webpage
<p class=”normal”>This is the first paragraph
This is the second paragraph. This is in bold.
</p>
比如要获取title的内容,那么xpath表达式就是/html/head/title。如果要获取class="special"节点的内容,xpath为/html/body/p[@class=\'special\']。
所以只要找到合适的xpath,就会得到对应的节点内容,接下来我们看看用hpple解析HTML
- (void)parserHTML:(NSData *)data
{
if (nil != data) {
TFHpple *movieParser = [TFHpple hppleWithHTMLData:data];
NSString *movieXpathQueryString = @"/html/body/div[@id=\'wrapper\']/div[@id=\'content\']/div[@class=\'grid-16-8 clearfix\']/div[@class=\'article\']/div[@class=\'indent\']/table/tr/td/a[@class=\'nbg\']";
NSArray *movieNodes = [movieParser searchWithXPathQuery:movieXpathQueryString];
for (TFHppleElement *element in movieNodes) {
Movie *m = [[Movie alloc] init];
m.name = [element objectForKey:@"title"];
m.movieUrl = [element objectForKey:@"href"];
for (TFHppleElement *child in element.children) {
if ([child.tagName isEqualToString:@"img"]) {
@try {
m.imageUrl = [child objectForKey:@"src"];
}
@catch (NSException *exception) {
}
}
}
[self.movies addObject:m];
}
[self.movieTableView reloadData];
}
}
在代码中,找到首页对应节点的路径,然后searchWithXPathQuery得到一个数组。遍历组织数据后,可以在表格视图中显示。具体效果如下:
好了,网页的内容已经抓到了,实际的项目比这个复杂,所以,这只是一个指导性的例子。
参考:
注:本文为小涵原创,请支持原创!转载请附上原文链接: 查看全部
网页抓取解密(解析XML网页链接来抓取指定的内容比如豆瓣电影排行榜,)
如果给你一个网页链接来抓取特定内容,比如豆瓣电影排名,怎么做?
其实网页内容的结构和XML很相似,那么我们可以通过解析XML来解析HTML,但是两者的差距还是很大的,好吧,废话不多说,我们开始解析HTML。
然后有很多用于解析 XML 的库。这里我们选择libxml来解析,因为libxml是C语言接口,我找了一个library-hpple,用objective-c来封装接口。它的地址是,然后网页使用豆瓣电影排名。地址是。
接下来,构建一个新项目。项目使用ARC,引入libxml2和hpple库,新建实体类movie。完整的项目结构如下:
movie的实现如下,这是一个实体类,根据爬取的网页内容确定
电影.h
@interface Movie : NSObject
@property(nonatomic, strong) NSString *name;
@property(nonatomic, strong) NSString *imageUrl;
@property(nonatomic, strong) NSString *descrition;
@property(nonatomic, strong) NSString *movieUrl;
@property(nonatomic) NSInteger ratingNumber;
@property(nonatomic, strong) NSString *comment;
@end
所以最重要的部分在这里。不管网页的内容是什么,我们都需要先获取网页的内容。下面是通过NSURLConnection获取整个网页的内容。
- (void)loadHTMLContent
{
NSString *movieUrl = MOVIE_URL;
NSString *urlString = [movieUrl stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
NSURL *url = [NSURL URLWithString:urlString];
NSURLRequest *request = [NSURLRequest requestWithURL:url];
[UIApplication sharedApplication].networkActivityIndicatorVisible = YES;
__weak ViewController *weak_self = self;
[NSURLConnection sendAsynchronousRequest:request queue:[NSOperationQueue mainQueue] completionHandler:^(NSURLResponse *response, NSData *data, NSError *error) {
if (nil == error) {
// NSString *retString = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
// NSLog(@"%@", retString);
[weak_self parserHTML:data];
}
[UIApplication sharedApplication].networkActivityIndicatorVisible = NO;
}];
}
这里只是简单的访问web内容,一些HTTP和错误处理本文没有讨论,所以这里的代码比较简单,上面代码中有一个parserHTML:方法,就是解析获取到的web内容和解析网页内容之前,我们先拆解xpath。
假设一个简单的网页内容如下:
Some webpage
<p class=”normal”>This is the first paragraph
This is the second paragraph. This is in bold.
</p>
比如要获取title的内容,那么xpath表达式就是/html/head/title。如果要获取class="special"节点的内容,xpath为/html/body/p[@class=\'special\']。
所以只要找到合适的xpath,就会得到对应的节点内容,接下来我们看看用hpple解析HTML
- (void)parserHTML:(NSData *)data
{
if (nil != data) {
TFHpple *movieParser = [TFHpple hppleWithHTMLData:data];
NSString *movieXpathQueryString = @"/html/body/div[@id=\'wrapper\']/div[@id=\'content\']/div[@class=\'grid-16-8 clearfix\']/div[@class=\'article\']/div[@class=\'indent\']/table/tr/td/a[@class=\'nbg\']";
NSArray *movieNodes = [movieParser searchWithXPathQuery:movieXpathQueryString];
for (TFHppleElement *element in movieNodes) {
Movie *m = [[Movie alloc] init];
m.name = [element objectForKey:@"title"];
m.movieUrl = [element objectForKey:@"href"];
for (TFHppleElement *child in element.children) {
if ([child.tagName isEqualToString:@"img"]) {
@try {
m.imageUrl = [child objectForKey:@"src"];
}
@catch (NSException *exception) {
}
}
}
[self.movies addObject:m];
}
[self.movieTableView reloadData];
}
}
在代码中,找到首页对应节点的路径,然后searchWithXPathQuery得到一个数组。遍历组织数据后,可以在表格视图中显示。具体效果如下:
好了,网页的内容已经抓到了,实际的项目比这个复杂,所以,这只是一个指导性的例子。
参考:
注:本文为小涵原创,请支持原创!转载请附上原文链接:
网页抓取解密(网易云技能点界面概况静态网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-28 06:09
)
技能点界面概览静态网页
网易云仍然有一些网页随着页面的变化而改变url。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。目前这样的借口有很多,这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
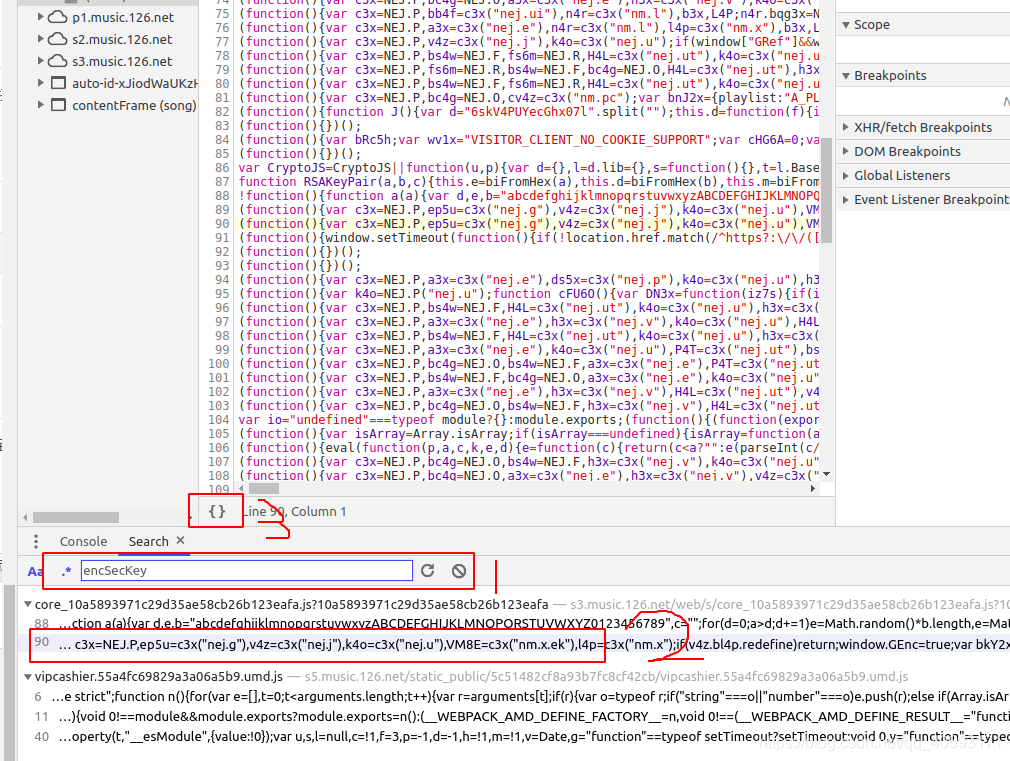
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
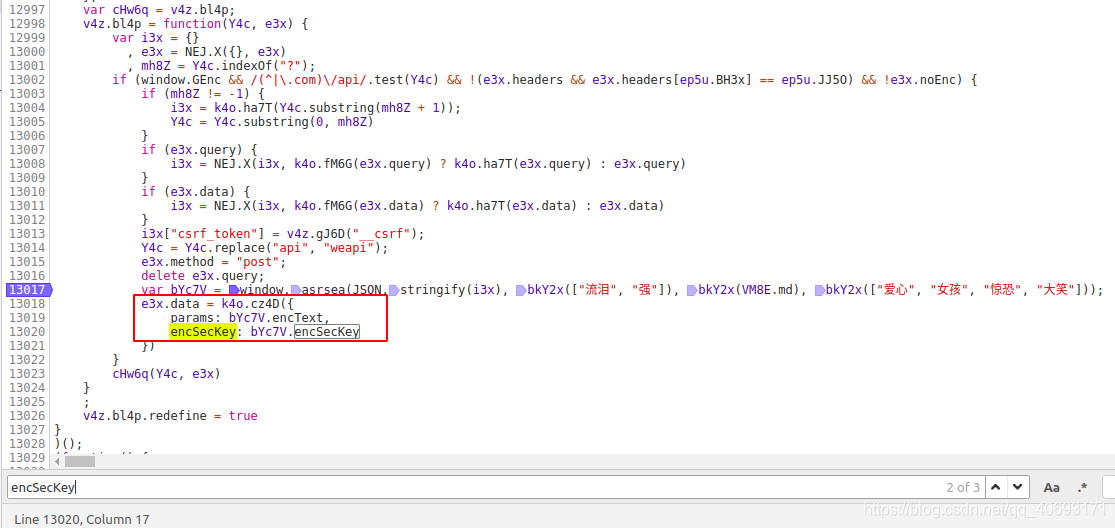
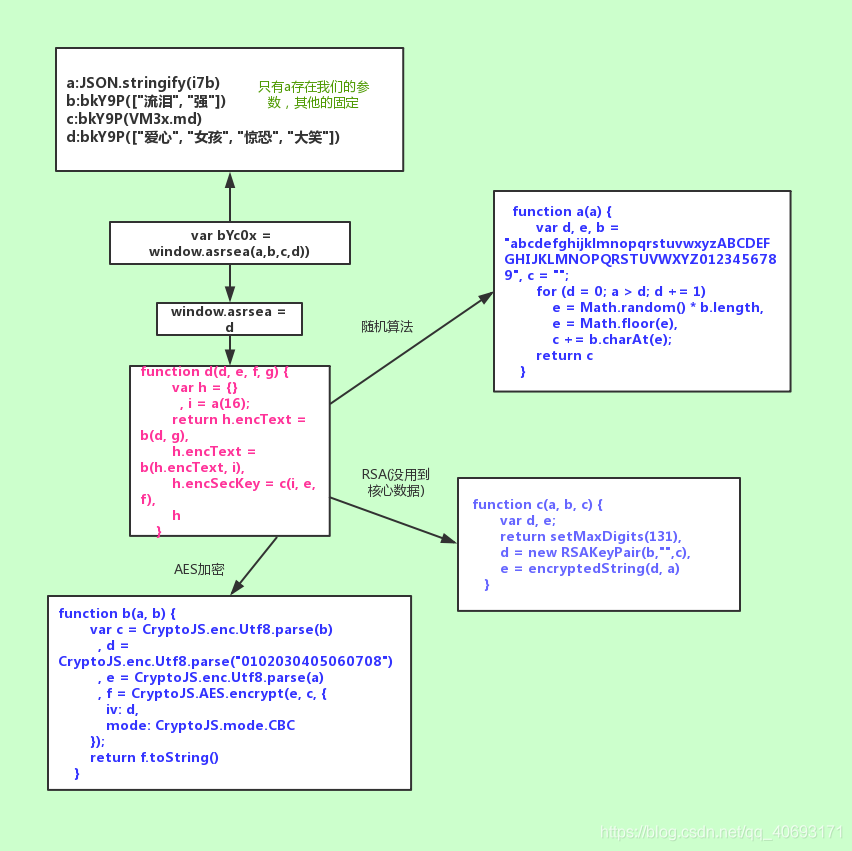
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先搞清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
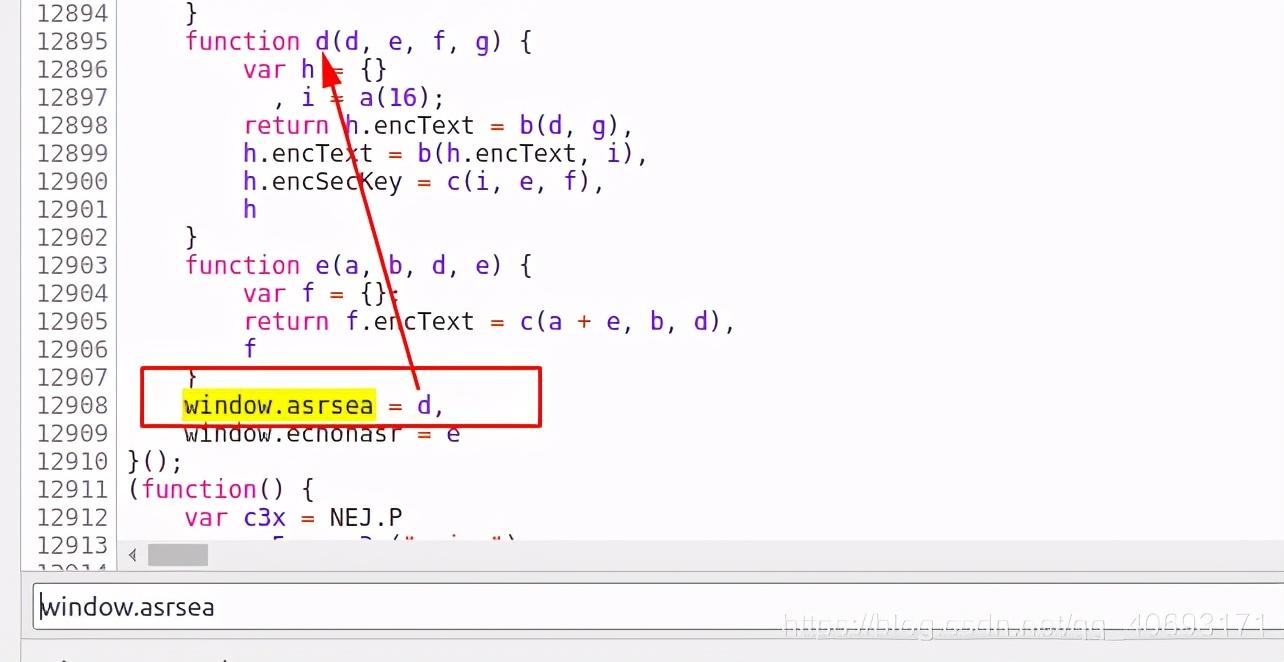
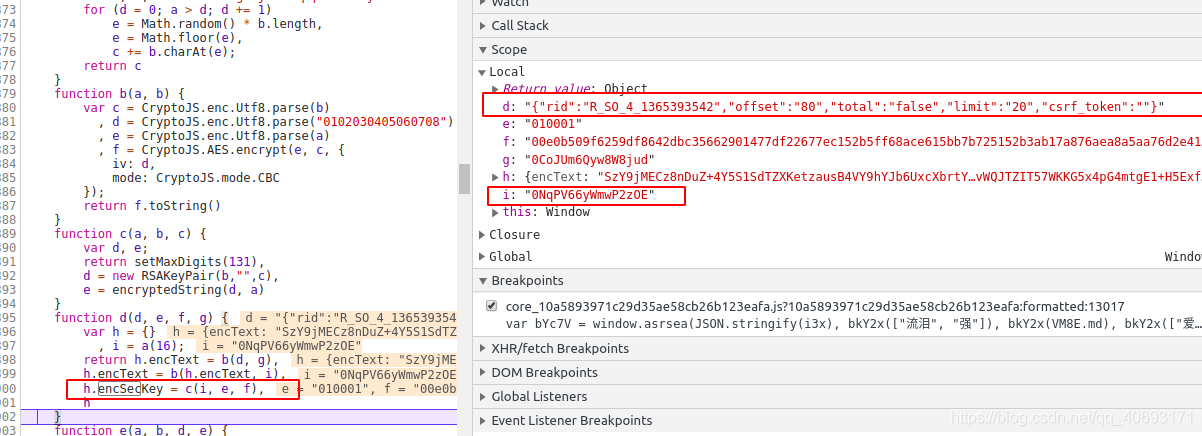
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么encText生成的规则就很清楚了us.Twice.AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
返回 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
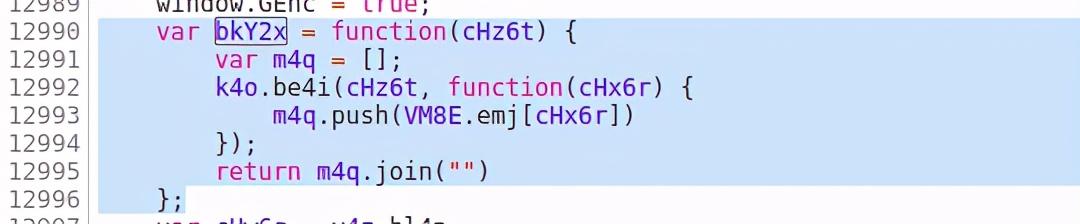
再去寻找,其实是没有必要的。你可以寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。偏移量是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
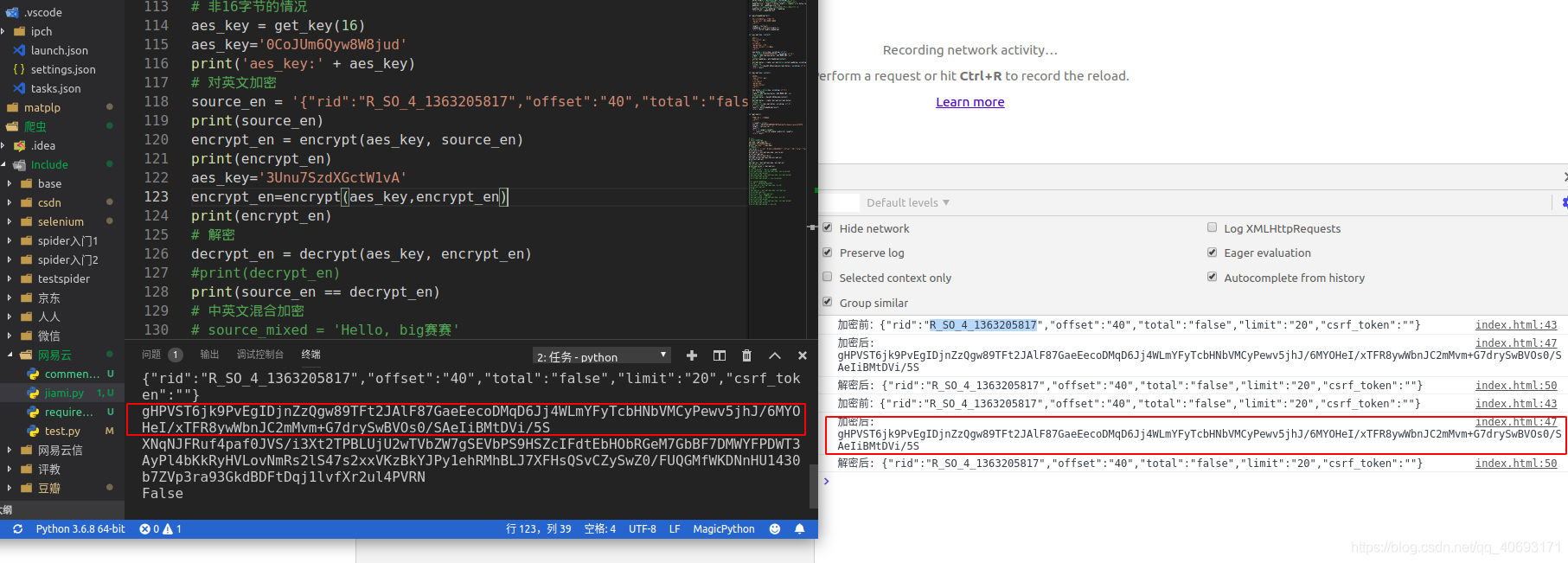
编写爬虫
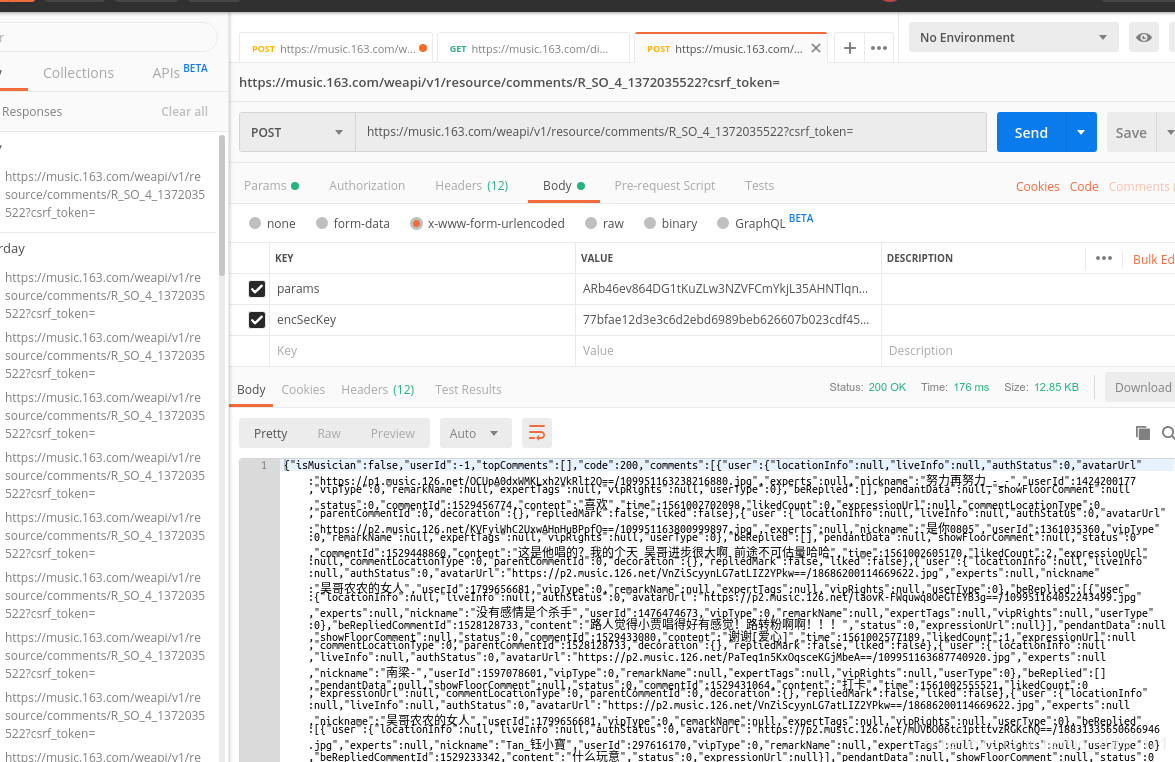
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用'\0'
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
查看全部
网页抓取解密(网易云技能点界面概况静态网页
)
技能点界面概览静态网页
网易云仍然有一些网页随着页面的变化而改变url。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。目前这样的借口有很多,这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
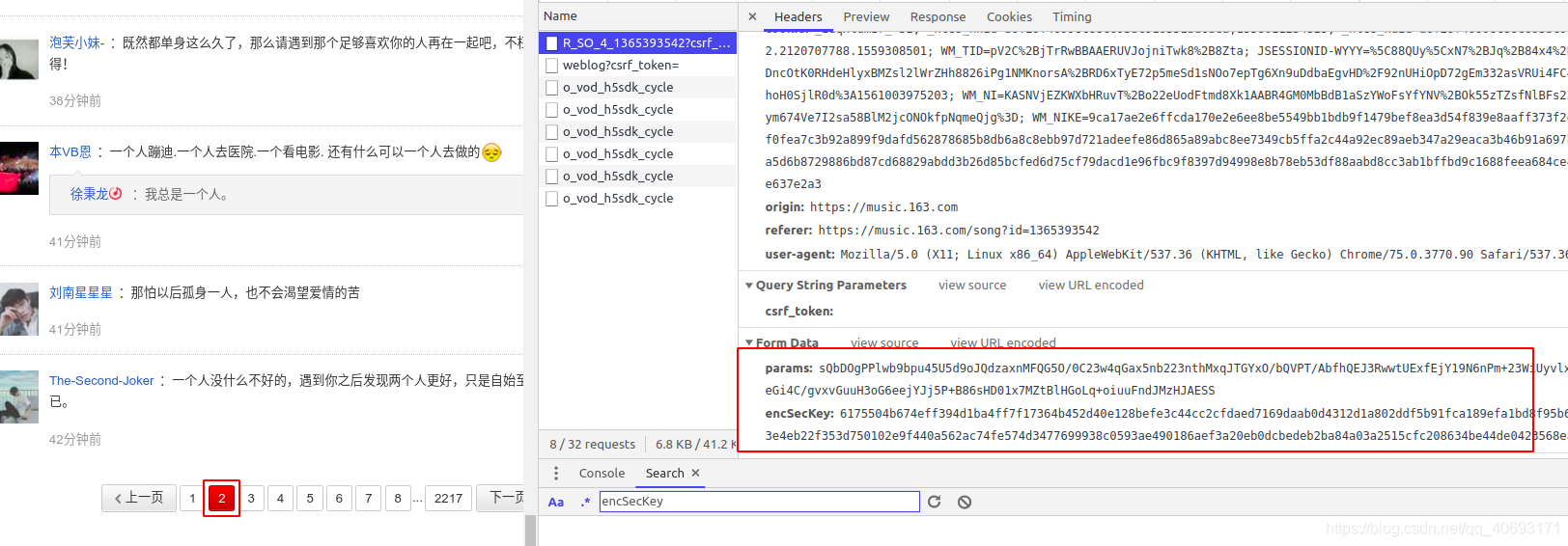
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先搞清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么encText生成的规则就很清楚了us.Twice.AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
返回 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。你可以寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。

实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。偏移量是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用'\0'
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
网页抓取解密( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-28 06:08
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
查看全部
网页抓取解密(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)

以上三种方法的性能对比及结论:

网页抓取解密(电影类型试多个,在列表里,需要转一下。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-27 19:01
尝试多种电影类型,在列表中,您需要翻转它。电影时长有下一行等符号,需要转入str处理和之前获取评论时一样的数据。
具体需要解密部分数据参考地址:
想法:
首先请求页面的字体下载。之前的公众意见是下载和回收字体。这是一次访问和下载一个。下载后整理好对应的词典,下载后保存到自己的工程中,再次打开即可。将保存的字体文件通过绘制方法绘制成图片,打开图片即可获取绘制图片的文字。组成数字和字符的字典,获取页面中的字符,判断字典中要替换的字符,得到想要的加密数据:
总结:在大众点评获得的原字体基础上,加图再识别图文对比!
在代码上:
猫眼.py
<p># -*- coding: utf-8 -*-
import json
import numpy
import os
import re
import requests
import scrapy
from PIL import Image, ImageDraw, ImageFont
from fontTools.ttLib import TTFont
from lxml import html
# 创建etree模块
from pytesseract import image_to_string
from myfilm import settings
from myfilm.items import MyfilmItem
etree = html.etree
from scrapy import Request
class MaoyanSpider(scrapy.Spider):
name = 'maoyan'
allowed_domains = ['maoyan.com']
# start_urls = ['http://maoyan.com/']
fontstr = ""#定义一个字体文件的字符串
headers = {
#此处为你自己的浏览器版本
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"
}
#cookie的值上面有相应需求整理,我放到了settings中
cookies = settings.cookies
def start_requests(self):
'''
重写start_requests函数
:return:
'''
urllist = [
'https://maoyan.com/films?showType=3'
]
for url in urllist:
yield Request(url=url,headers=self.headers, cookies=self.cookies, callback=self.parse)
def parse(self, response):
'''
解析电影列表页面
:param response:
:return:
'''
##获取列表
ddlist = response.xpath("//div[@class='container']//div[@class='movies-panel']//dl[@class='movie-list']//dd")
##遍历获取每个电影的信息
for dd in ddlist:
filmdic = {
"id": dd.xpath(".//div[@class='movie-item']//a//@href").get() or "",
"film_id": str(dd.xpath(".//div[@class='movie-item']//a//@href").get()).split('/')[2] or "",
"cname": dd.xpath(".//div[contains(@class,'movie-item-title')]//a//text()").get() or "null",
"thumb": dd.xpath(".//div[@class='movie-item']//a//img[last()]//@data-src").get() or "default",
"score": dd.xpath(".//div[contains(@class,'channel-detail-orange')]//text()").get() or "0",
}
# print("filmdic=====",filmdic)
#获取详情链接
_url = "https://maoyan.com" + filmdic["id"]
yield Request(url=_url, headers=self.headers, cookies=self.cookies, callback=self.parse_detail,
meta={"filmdic": filmdic})
#判断下一页是否存在 获取当前页
page=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[@class='active']//a//@class").get() or "null"
# print("page=========",page)
now_page = str(page).split('_')[1]
lastpage=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[last()]//a//@class").get() or "null"
# print("lastpage=====",lastpage)
last_page = str(lastpage).split('_')[1]
if int(last_page) == int(now_page) + 1:
##说明有下一页
href=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[last()]//a//@href").get()#跳转拼接的路径
nexturl = "https://maoyan.com/films" + href
# print("nexturl====一下一页路径",nexturl)
yield Request(url=nexturl, headers=self.headers, cookies=self.cookies, callback=self.parse,dont_filter=True)
def parse_detail(self, response):
'''
解析详情页面数据
:param response:
:return:
'''
filmItem = MyfilmItem()
#获取上个页面传过来的值
type=response.xpath("//div[@class='movie-brief-container']//li[1]//a//text()").extract()
length=response.xpath("//div[@class='movie-brief-container']//li[2]//text()").get()
# print("type====",type,"length====",length)
filmdic = response.meta.get("filmdic")
#先获取简单表面上的数据
filmItem["film_id"] = filmdic["film_id"]
filmItem["thumb"] = filmdic["thumb"]
filmItem["cname"] = filmdic["cname"]
filmItem["ename"] = response.xpath("//div[contains(@class,'ename')]//text()").get()
filmItem["type"] = json.dumps(type)
filmItem["length"] = str(length).replace('\n', '').replace(' ', '')
filmItem["time"] = response.xpath("//div[@class='movie-brief-container']//li[3]//text()").get()
filmItem["tickets_unit"] = response.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][2]//span[@class='unit']//text()").get() or "none"
#获取到整个页面的内容
htmllist = response.text
# print(htmls)
#正则查找本次请求字体文件的url
font_file = re.findall(r'//vfile.meituan.net/colorstone/(\w+\.woff)', htmllist)[0]
# 先判断是否下载过字体,避免重复下载浪费空间
if self.fontstr == "":
# 把这个字体文件名在全局变量中记录一下
self.fontstr = font_file
else:
#先把原有的字体删除,再重新赋值 拼接下载地址
os.remove("static/" + self.fontstr)
self.fontstr = font_file
fonturl = "https://vfile.meituan.net/colorstone/" + font_file
#调用下载方法,下载该字体文件
self.save_font(font_file, fonturl)
#每次字体文件不一样并且字体文件中的编码以及所对应的值的顺序也不一样
# 虽然编码不停变化但是每个字的图元是固定的,所以需要新字体与最开始下载的字体的每个字的图元进行比较
fontdic = self.get_font(self.fontstr)
# 查看是否在字典里 发现替换
for key in fontdic:
if key in htmllist:
htmllist = htmllist.replace(key, str(fontdic[key]))
# print(htmllist)
htmldata = etree.HTML(htmllist)
#获取票房数量
ticketslist = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][2]//span[@class='stonefont']//text()")
if ticketslist:
# 当票房存在
filmItem["ticketNumber"] = "".join(str(ticketslist[0]).split(';'))
else:
filmItem["ticketNumber"] = "暂无"
#获取评论人数 若暂无评分归0
if filmdic["score"] == "暂无评分":
filmItem["score"] = filmdic["score"]
filmItem["score_num"] = "0"
else:
# 有评分获取数值
index_left = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][1]//span[contains(@class,'index-left')]//span[@class='stonefont']//text()")
filmItem["score"] = "".join(str(index_left[0]).split(';'))
index_right = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][1]//div[@class='index-right']//span[@class='stonefont']//text()")
filmItem["score_num"] = "".join(str(index_right[0]).split(';'))
yield filmItem
def save_font(self, file_name, url):
'''
字体文件保存到项目中
:param file_name:
:return:
'''
# 需要判断指定的文件夹是否存在,若不存在就创建
dir = "static"
self.creatDir(dir)
savePath = dir + "/" + file_name
response = requests.get(url)
# 写入文件中
with open(savePath, 'wb') as f:
f.write(response.content)
f.flush()
return file_name
def creatDir(self, dir):
'''
判断指定的文件夹是否存在 创建文件夹
:param dir:
:return:
'''
dirlist = dir.split("/")
# print("dirlist====",dirlist)
for index, name in enumerate(dirlist):
# print("index==",index,name)
itemdir = os.path.join(os.getcwd(), name)
# 判断当前文件夹是否存在
if not os.path.exists(itemdir):
os.mkdir(itemdir)
# 如果当前文件夹存在并且不是最后一层
if index 查看全部
网页抓取解密(电影类型试多个,在列表里,需要转一下。)
尝试多种电影类型,在列表中,您需要翻转它。电影时长有下一行等符号,需要转入str处理和之前获取评论时一样的数据。
具体需要解密部分数据参考地址:
想法:
首先请求页面的字体下载。之前的公众意见是下载和回收字体。这是一次访问和下载一个。下载后整理好对应的词典,下载后保存到自己的工程中,再次打开即可。将保存的字体文件通过绘制方法绘制成图片,打开图片即可获取绘制图片的文字。组成数字和字符的字典,获取页面中的字符,判断字典中要替换的字符,得到想要的加密数据:
总结:在大众点评获得的原字体基础上,加图再识别图文对比!
在代码上:
猫眼.py
<p># -*- coding: utf-8 -*-
import json
import numpy
import os
import re
import requests
import scrapy
from PIL import Image, ImageDraw, ImageFont
from fontTools.ttLib import TTFont
from lxml import html
# 创建etree模块
from pytesseract import image_to_string
from myfilm import settings
from myfilm.items import MyfilmItem
etree = html.etree
from scrapy import Request
class MaoyanSpider(scrapy.Spider):
name = 'maoyan'
allowed_domains = ['maoyan.com']
# start_urls = ['http://maoyan.com/']
fontstr = ""#定义一个字体文件的字符串
headers = {
#此处为你自己的浏览器版本
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"
}
#cookie的值上面有相应需求整理,我放到了settings中
cookies = settings.cookies
def start_requests(self):
'''
重写start_requests函数
:return:
'''
urllist = [
'https://maoyan.com/films?showType=3'
]
for url in urllist:
yield Request(url=url,headers=self.headers, cookies=self.cookies, callback=self.parse)
def parse(self, response):
'''
解析电影列表页面
:param response:
:return:
'''
##获取列表
ddlist = response.xpath("//div[@class='container']//div[@class='movies-panel']//dl[@class='movie-list']//dd")
##遍历获取每个电影的信息
for dd in ddlist:
filmdic = {
"id": dd.xpath(".//div[@class='movie-item']//a//@href").get() or "",
"film_id": str(dd.xpath(".//div[@class='movie-item']//a//@href").get()).split('/')[2] or "",
"cname": dd.xpath(".//div[contains(@class,'movie-item-title')]//a//text()").get() or "null",
"thumb": dd.xpath(".//div[@class='movie-item']//a//img[last()]//@data-src").get() or "default",
"score": dd.xpath(".//div[contains(@class,'channel-detail-orange')]//text()").get() or "0",
}
# print("filmdic=====",filmdic)
#获取详情链接
_url = "https://maoyan.com" + filmdic["id"]
yield Request(url=_url, headers=self.headers, cookies=self.cookies, callback=self.parse_detail,
meta={"filmdic": filmdic})
#判断下一页是否存在 获取当前页
page=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[@class='active']//a//@class").get() or "null"
# print("page=========",page)
now_page = str(page).split('_')[1]
lastpage=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[last()]//a//@class").get() or "null"
# print("lastpage=====",lastpage)
last_page = str(lastpage).split('_')[1]
if int(last_page) == int(now_page) + 1:
##说明有下一页
href=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[last()]//a//@href").get()#跳转拼接的路径
nexturl = "https://maoyan.com/films" + href
# print("nexturl====一下一页路径",nexturl)
yield Request(url=nexturl, headers=self.headers, cookies=self.cookies, callback=self.parse,dont_filter=True)
def parse_detail(self, response):
'''
解析详情页面数据
:param response:
:return:
'''
filmItem = MyfilmItem()
#获取上个页面传过来的值
type=response.xpath("//div[@class='movie-brief-container']//li[1]//a//text()").extract()
length=response.xpath("//div[@class='movie-brief-container']//li[2]//text()").get()
# print("type====",type,"length====",length)
filmdic = response.meta.get("filmdic")
#先获取简单表面上的数据
filmItem["film_id"] = filmdic["film_id"]
filmItem["thumb"] = filmdic["thumb"]
filmItem["cname"] = filmdic["cname"]
filmItem["ename"] = response.xpath("//div[contains(@class,'ename')]//text()").get()
filmItem["type"] = json.dumps(type)
filmItem["length"] = str(length).replace('\n', '').replace(' ', '')
filmItem["time"] = response.xpath("//div[@class='movie-brief-container']//li[3]//text()").get()
filmItem["tickets_unit"] = response.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][2]//span[@class='unit']//text()").get() or "none"
#获取到整个页面的内容
htmllist = response.text
# print(htmls)
#正则查找本次请求字体文件的url
font_file = re.findall(r'//vfile.meituan.net/colorstone/(\w+\.woff)', htmllist)[0]
# 先判断是否下载过字体,避免重复下载浪费空间
if self.fontstr == "":
# 把这个字体文件名在全局变量中记录一下
self.fontstr = font_file
else:
#先把原有的字体删除,再重新赋值 拼接下载地址
os.remove("static/" + self.fontstr)
self.fontstr = font_file
fonturl = "https://vfile.meituan.net/colorstone/" + font_file
#调用下载方法,下载该字体文件
self.save_font(font_file, fonturl)
#每次字体文件不一样并且字体文件中的编码以及所对应的值的顺序也不一样
# 虽然编码不停变化但是每个字的图元是固定的,所以需要新字体与最开始下载的字体的每个字的图元进行比较
fontdic = self.get_font(self.fontstr)
# 查看是否在字典里 发现替换
for key in fontdic:
if key in htmllist:
htmllist = htmllist.replace(key, str(fontdic[key]))
# print(htmllist)
htmldata = etree.HTML(htmllist)
#获取票房数量
ticketslist = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][2]//span[@class='stonefont']//text()")
if ticketslist:
# 当票房存在
filmItem["ticketNumber"] = "".join(str(ticketslist[0]).split(';'))
else:
filmItem["ticketNumber"] = "暂无"
#获取评论人数 若暂无评分归0
if filmdic["score"] == "暂无评分":
filmItem["score"] = filmdic["score"]
filmItem["score_num"] = "0"
else:
# 有评分获取数值
index_left = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][1]//span[contains(@class,'index-left')]//span[@class='stonefont']//text()")
filmItem["score"] = "".join(str(index_left[0]).split(';'))
index_right = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][1]//div[@class='index-right']//span[@class='stonefont']//text()")
filmItem["score_num"] = "".join(str(index_right[0]).split(';'))
yield filmItem
def save_font(self, file_name, url):
'''
字体文件保存到项目中
:param file_name:
:return:
'''
# 需要判断指定的文件夹是否存在,若不存在就创建
dir = "static"
self.creatDir(dir)
savePath = dir + "/" + file_name
response = requests.get(url)
# 写入文件中
with open(savePath, 'wb') as f:
f.write(response.content)
f.flush()
return file_name
def creatDir(self, dir):
'''
判断指定的文件夹是否存在 创建文件夹
:param dir:
:return:
'''
dirlist = dir.split("/")
# print("dirlist====",dirlist)
for index, name in enumerate(dirlist):
# print("index==",index,name)
itemdir = os.path.join(os.getcwd(), name)
# 判断当前文件夹是否存在
if not os.path.exists(itemdir):
os.mkdir(itemdir)
# 如果当前文件夹存在并且不是最后一层
if index
网页抓取解密(使用者再网上查询相关python抓取数据的代码图:其中cookie部分 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-27 18:22
)
免责声明:本代码采集的数据可用于研究学习,请勿用于商业用途,否则由此产生的商业纠纷由用户自行负责
最近需要用到环境国家省会城市的历史数据pm2.5,正好天气网()提供历史数据查询,所以在线查询相关python爬取数据代码,主要是参考这篇博文:
导入 urllib.request;
2. URL增加了反爬取措施,因为它是爬取历史数据,实际是(city)/(date).html。比如北京201907的数据链接是:,但是你用的是新浏览器如果直接在上面打开上面的连接,会返回如下页面:
这也是网上很多python爬虫无法爬取数据的原因。找个理由,你要先访问我,然后到上面的页面返回就ok了。我猜可能是前端在访问主页时写了一个cookie。因此,您可以再次按F12查看页面的cookie数据,如下图:cookie部分已经用红线标出,请求url时直接添加headers。使用这个方法:req=urllib .request.Request(url=url,headers=my_headers),其中
my_headers = {
"Host": "lishi.tianqi.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Referer": "http://lishi.tianqi.com/Accept-Encoding: gzip, deflate",
"Cookie": "cityPy=xianqu; cityPy_expire=1565422933; UM_distinctid=16c566dd356244-05e0d9cb0c361-3f385c06-1fa400-16c566dd357642; Hm_lvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818134; CNZZDATA1275796416=927309794-1564814113-%7C1564814113; Hm_lpvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818280"},具体代码见下面代码
代码显示如下:
import random
import socket
import sys
import urllib
import urllib.request
from bs4 import BeautifulSoup
#reload(sys)
#sys.('utf8')
socket.setdefaulttimeout(30.0)
def parseTianqi(url):
my_headers = {
"Host": "lishi.tianqi.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Referer": "http://lishi.tianqi.com/Accept-Encoding: gzip, deflate",
"Cookie": "cityPy=xianqu; cityPy_expire=1565422933; UM_distinctid=16c566dd356244-05e0d9cb0c361-3f385c06-1fa400-16c566dd357642; Hm_lvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818134; CNZZDATA1275796416=927309794-1564814113-%7C1564814113; Hm_lpvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818280"}
req = urllib.request.Request(url=url, headers=my_headers)
req.add_header("Content-Type", "application/json")
fails = 0
while True:
try:
if fails >= 3:
break
req_data = urllib.request.urlopen(req)
response_data = req_data.read()
response_data = response_data.decode('gbk').encode('utf-8')
return response_data
except urllib.request.URLError as e:
fails += 1
print ('网络连接出现问题, 正在尝试再次请求: ', fails)
else:
break
def witeCsv(data, file_name):
file = open(file_name, 'w',-1,'utf-8')
soup = BeautifulSoup(data, 'html.parser')
weather_list = soup.select('div[class="tqtongji2"]')
for weather in weather_list:
weather_date = weather.select('a')[0].string.encode('utf-8')
ul_list = weather.select('ul')
i = 0
for ul in ul_list:
li_list = ul.select('li')
str = ""
for li in li_list:
str += li.string.encode('utf-8').decode() + ','
if i != 0:
file.write(str + '\n')
i += 1
file.close()
# 根据图片主页,抓取当前图片下面的相信图片
if __name__ == "__main__":
data = parseTianqi("http://lishi.tianqi.com/beijing/201907.html");
witeCsv(data, "beijing_201907"); 查看全部
网页抓取解密(使用者再网上查询相关python抓取数据的代码图:其中cookie部分
)
免责声明:本代码采集的数据可用于研究学习,请勿用于商业用途,否则由此产生的商业纠纷由用户自行负责
最近需要用到环境国家省会城市的历史数据pm2.5,正好天气网()提供历史数据查询,所以在线查询相关python爬取数据代码,主要是参考这篇博文:
导入 urllib.request;
2. URL增加了反爬取措施,因为它是爬取历史数据,实际是(city)/(date).html。比如北京201907的数据链接是:,但是你用的是新浏览器如果直接在上面打开上面的连接,会返回如下页面:

这也是网上很多python爬虫无法爬取数据的原因。找个理由,你要先访问我,然后到上面的页面返回就ok了。我猜可能是前端在访问主页时写了一个cookie。因此,您可以再次按F12查看页面的cookie数据,如下图:cookie部分已经用红线标出,请求url时直接添加headers。使用这个方法:req=urllib .request.Request(url=url,headers=my_headers),其中
my_headers = {
"Host": "lishi.tianqi.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Referer": "http://lishi.tianqi.com/Accept-Encoding: gzip, deflate",
"Cookie": "cityPy=xianqu; cityPy_expire=1565422933; UM_distinctid=16c566dd356244-05e0d9cb0c361-3f385c06-1fa400-16c566dd357642; Hm_lvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818134; CNZZDATA1275796416=927309794-1564814113-%7C1564814113; Hm_lpvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818280"},具体代码见下面代码
代码显示如下:
import random
import socket
import sys
import urllib
import urllib.request
from bs4 import BeautifulSoup
#reload(sys)
#sys.('utf8')
socket.setdefaulttimeout(30.0)
def parseTianqi(url):
my_headers = {
"Host": "lishi.tianqi.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Referer": "http://lishi.tianqi.com/Accept-Encoding: gzip, deflate",
"Cookie": "cityPy=xianqu; cityPy_expire=1565422933; UM_distinctid=16c566dd356244-05e0d9cb0c361-3f385c06-1fa400-16c566dd357642; Hm_lvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818134; CNZZDATA1275796416=927309794-1564814113-%7C1564814113; Hm_lpvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818280"}
req = urllib.request.Request(url=url, headers=my_headers)
req.add_header("Content-Type", "application/json")
fails = 0
while True:
try:
if fails >= 3:
break
req_data = urllib.request.urlopen(req)
response_data = req_data.read()
response_data = response_data.decode('gbk').encode('utf-8')
return response_data
except urllib.request.URLError as e:
fails += 1
print ('网络连接出现问题, 正在尝试再次请求: ', fails)
else:
break
def witeCsv(data, file_name):
file = open(file_name, 'w',-1,'utf-8')
soup = BeautifulSoup(data, 'html.parser')
weather_list = soup.select('div[class="tqtongji2"]')
for weather in weather_list:
weather_date = weather.select('a')[0].string.encode('utf-8')
ul_list = weather.select('ul')
i = 0
for ul in ul_list:
li_list = ul.select('li')
str = ""
for li in li_list:
str += li.string.encode('utf-8').decode() + ','
if i != 0:
file.write(str + '\n')
i += 1
file.close()
# 根据图片主页,抓取当前图片下面的相信图片
if __name__ == "__main__":
data = parseTianqi("http://lishi.tianqi.com/beijing/201907.html";);
witeCsv(data, "beijing_201907");
网页抓取解密(网站排名好不好,流量多不多,其中一个关键的因素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-24 09:01
网站 排名好吗?没有太多的交通。其中一个关键因素是网站收录如何,虽然收录不能直接决定网站的排名,但是网站的基础是内容。如果没有内容,更难排名好。好的内容可以让用户和搜索引擎满意,还可以给网站加分,从而提升排名,扩大网站的曝光页面。
而如果你想让更多的网站页面成为收录,你必须先让网页被百度蜘蛛抓取,我们能不能不说收录,我们需要首先爬取它们跟进收录。
那么网站怎样才能更好的被百度蜘蛛抓取呢?
1.网站 和页面权重
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的抓取频率非常高,大家都知道搜索引擎蜘蛛是为了保证网站不是所有的页面都会被抓取,而且网站的权重越高,爬取的深度越高,相应的可以爬取的页面也就越多,这样可以收录的页面也会越多。
2.网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那真是谢天谢地了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛你的体验越来越差,你对网站的评价会越来越低,自然会影响你对网站的爬取,所以你一定愿意选择空间服务器。没有很好的基础。,再好的房子也会倒塌。
3.网站 更新频率
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动展示给蜘蛛文章更新,让蜘蛛按照你的规则有效爬行,不仅让你的更新文章更快被抓到,而且不会导致蜘蛛频繁跑徒然。
4.文章的原创性别
优质的原创 内容对百度蜘蛛非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供有价值的 原创 内容。如果蜘蛛能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.平面网站结构
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
6.网站程序
在网站程序中,有很多程序可以创建大量的重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的爬取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设
大家都知道外链可以吸引蜘蛛到网站,尤其是新网站的时候,网站还不是很成熟,蜘蛛访问量比较少,外链可以在网站页面中加入网站暴露在蜘蛛面前可以防止蜘蛛无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。
8.内链建设
蜘蛛的爬取是跟随链接的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的收录。内链建设过程中应给予用户合理的推荐。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都有用,让蜘蛛爬取一个更广泛的页面。 查看全部
网页抓取解密(网站排名好不好,流量多不多,其中一个关键的因素)
网站 排名好吗?没有太多的交通。其中一个关键因素是网站收录如何,虽然收录不能直接决定网站的排名,但是网站的基础是内容。如果没有内容,更难排名好。好的内容可以让用户和搜索引擎满意,还可以给网站加分,从而提升排名,扩大网站的曝光页面。
而如果你想让更多的网站页面成为收录,你必须先让网页被百度蜘蛛抓取,我们能不能不说收录,我们需要首先爬取它们跟进收录。
那么网站怎样才能更好的被百度蜘蛛抓取呢?

1.网站 和页面权重
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的抓取频率非常高,大家都知道搜索引擎蜘蛛是为了保证网站不是所有的页面都会被抓取,而且网站的权重越高,爬取的深度越高,相应的可以爬取的页面也就越多,这样可以收录的页面也会越多。
2.网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那真是谢天谢地了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛你的体验越来越差,你对网站的评价会越来越低,自然会影响你对网站的爬取,所以你一定愿意选择空间服务器。没有很好的基础。,再好的房子也会倒塌。
3.网站 更新频率
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动展示给蜘蛛文章更新,让蜘蛛按照你的规则有效爬行,不仅让你的更新文章更快被抓到,而且不会导致蜘蛛频繁跑徒然。

4.文章的原创性别
优质的原创 内容对百度蜘蛛非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供有价值的 原创 内容。如果蜘蛛能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.平面网站结构
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
6.网站程序
在网站程序中,有很多程序可以创建大量的重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的爬取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设
大家都知道外链可以吸引蜘蛛到网站,尤其是新网站的时候,网站还不是很成熟,蜘蛛访问量比较少,外链可以在网站页面中加入网站暴露在蜘蛛面前可以防止蜘蛛无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。

8.内链建设
蜘蛛的爬取是跟随链接的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的收录。内链建设过程中应给予用户合理的推荐。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都有用,让蜘蛛爬取一个更广泛的页面。
网页抓取解密(解密百科,启程seo有自己的说法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-22 04:09
说起破译百科,徐七成有自己的看法。大家一定要关注百度百科。百度百科不仅方便了读者,也是我们SEO的一个很好的资源。所以说到百科,不能只说百度百科。,以下是seo的具体介绍。
一、采集整理百科资源。
1、采集百科资源:seo是一项细致的工作。百度百科出来的那天,很多百科全书接连出现。那么我们不仅要关注百度百科,还要关注其他百科,这里为大家搜集了一些百科资源(百度百科;互动百科;维基百科;中国百科;大百科,搜搜百科;小百科,大行家;360百科;站长百科全书。)
2、 整理百科资源:整理资源就是为了更好的利用资源。那么百科资源和问答资源是一样的。您需要先注册,然后填写信息,提出ID,使用ID。可以参考(实战获取流量的第七个关键方法:问答训练与开发),这里不再赘述。
二、百科资源分析。
我在这里要说明的是,所有的百科资源都是一样的。下面主要以百度百科为例。如果我们要使用百科资料,就需要对百科资源进行深入的分析。以下是百度百科的(网带_百度百科)实例分析。
1、 百度百科标题解析。如下
网带-wikiwand
我们可以看到百度百科的标题简洁准确,这里也对标题进行了详细分析。
2、百科全书的关键词和描述。
对于百度百科的关键词和描述,我们可以看到百度没有做关键词和描述。这里的seo设置并没有否定关键字和描述的重要性,主要是因为我们从这里可以看出标题对于一个网站性很重要,所以这里还是要重复一下,标题定位准确,做一次性完成,不要更改。
3、百科内容分析。
A:先说一下内容的标题吧。这里百度百科对网带使用标签,网带和栏目页面使用标签,标签用于具体内容。这些标签可以告诉我们在以后的网站建设中如何安排内容,也可以告诉我们这些标签的具体应用。
B:让我们谈谈目录。从网带百度百科可以看出,目录处理是在这里完成的。目录处理不仅方便读者阅读,也方便阅读,加上目录的锚点处理,让读者阅读更轻松、更快捷。,准确度,这也是我们在建网站时应该学习的地方。
C:我们说一下百度的图片,包括图集:我这里要说一下图库。百科里的图片也是从用户体验出发的。图文并茂,一目了然。
D:内部链接:这是最重要的部分。强大的百科全书内部链接。强大的内部链接不仅可以友好地链接完全相关的条目,还可以友好地组织相关条目。这也是百科4年PR到8的主要原因之一。
三、百科资源的使用。
这里主要分享一下百度百科的应用技巧。
1、百科培训技巧:申请ID后,我们要做的第一步就是按照百科的任务去做。我们可以先做任务,然后我们可以通过做任务来达到第二个层次。下一步是创建百科条目和编辑条目。对于条目的创作,我有个人意见。当我们开始创建条目时,不要急于添加超链接,创建条目时,我们也不应该一次完成它们,以便以后添加链接。百度百科是不断完善的,只有我们的东西比百科好,才有机会加链接。对于编辑条目,我们必须继续组织信息,完善我们自己页面上的信息,有图片和文字,然后可以添加超链接。
2、 百科资源的使用:使用包括创建条目和编辑。我们可以从其他百科资源中采集数据,然后整合这些数据。但是,我们在创建条目和编辑条目时必须具体分类。包括栏目的分类,栏目下方的小分类,此外还需要全图文字,甚至还要加个图库。不过记得不要着急,先完善自己的东西,再去编辑和创作。否则百度不会给链接。
3、百科全书的超链接和图库。超链接包括指向百科全书本身的链接,以及指向参考资料和扩展阅读的链接。我们需要开始的是参考资料和扩展阅读的链接,所以我们在做百科的时候要加链接,那么我们的文章一定是一个大百科,比百度百科的信息和图片更完整。所以要强调的是,你必须为自己留出空间。
四、百科全书资源推荐。
我这里讲的是,不管是百度百科还是其他百科全书,归结起来就是一个大的资源采集和资源整合,所以从这里我们不仅要学会如何整合采集 ,还要学习如何采集。页面布局和链接布局,以及标签在百科中的应用。
上图:只是七成seo个人在百科上的实战总结。希望对大家有帮助,也希望大家多多交流,完善每个贡献者的文章,方便大家。
版权声明:启程seo首发于chinaz和我的博客,欢迎转载讨论,转载请保留原作者信息,谢谢合作!
请注明:SEO爱站net »Xiamen网站 优化:实战获取流量的关键方法8:解密百科 查看全部
网页抓取解密(解密百科,启程seo有自己的说法,你知道吗?)
说起破译百科,徐七成有自己的看法。大家一定要关注百度百科。百度百科不仅方便了读者,也是我们SEO的一个很好的资源。所以说到百科,不能只说百度百科。,以下是seo的具体介绍。
一、采集整理百科资源。
1、采集百科资源:seo是一项细致的工作。百度百科出来的那天,很多百科全书接连出现。那么我们不仅要关注百度百科,还要关注其他百科,这里为大家搜集了一些百科资源(百度百科;互动百科;维基百科;中国百科;大百科,搜搜百科;小百科,大行家;360百科;站长百科全书。)
2、 整理百科资源:整理资源就是为了更好的利用资源。那么百科资源和问答资源是一样的。您需要先注册,然后填写信息,提出ID,使用ID。可以参考(实战获取流量的第七个关键方法:问答训练与开发),这里不再赘述。
二、百科资源分析。
我在这里要说明的是,所有的百科资源都是一样的。下面主要以百度百科为例。如果我们要使用百科资料,就需要对百科资源进行深入的分析。以下是百度百科的(网带_百度百科)实例分析。
1、 百度百科标题解析。如下
网带-wikiwand
我们可以看到百度百科的标题简洁准确,这里也对标题进行了详细分析。
2、百科全书的关键词和描述。
对于百度百科的关键词和描述,我们可以看到百度没有做关键词和描述。这里的seo设置并没有否定关键字和描述的重要性,主要是因为我们从这里可以看出标题对于一个网站性很重要,所以这里还是要重复一下,标题定位准确,做一次性完成,不要更改。
3、百科内容分析。
A:先说一下内容的标题吧。这里百度百科对网带使用标签,网带和栏目页面使用标签,标签用于具体内容。这些标签可以告诉我们在以后的网站建设中如何安排内容,也可以告诉我们这些标签的具体应用。
B:让我们谈谈目录。从网带百度百科可以看出,目录处理是在这里完成的。目录处理不仅方便读者阅读,也方便阅读,加上目录的锚点处理,让读者阅读更轻松、更快捷。,准确度,这也是我们在建网站时应该学习的地方。
C:我们说一下百度的图片,包括图集:我这里要说一下图库。百科里的图片也是从用户体验出发的。图文并茂,一目了然。
D:内部链接:这是最重要的部分。强大的百科全书内部链接。强大的内部链接不仅可以友好地链接完全相关的条目,还可以友好地组织相关条目。这也是百科4年PR到8的主要原因之一。
三、百科资源的使用。
这里主要分享一下百度百科的应用技巧。
1、百科培训技巧:申请ID后,我们要做的第一步就是按照百科的任务去做。我们可以先做任务,然后我们可以通过做任务来达到第二个层次。下一步是创建百科条目和编辑条目。对于条目的创作,我有个人意见。当我们开始创建条目时,不要急于添加超链接,创建条目时,我们也不应该一次完成它们,以便以后添加链接。百度百科是不断完善的,只有我们的东西比百科好,才有机会加链接。对于编辑条目,我们必须继续组织信息,完善我们自己页面上的信息,有图片和文字,然后可以添加超链接。
2、 百科资源的使用:使用包括创建条目和编辑。我们可以从其他百科资源中采集数据,然后整合这些数据。但是,我们在创建条目和编辑条目时必须具体分类。包括栏目的分类,栏目下方的小分类,此外还需要全图文字,甚至还要加个图库。不过记得不要着急,先完善自己的东西,再去编辑和创作。否则百度不会给链接。
3、百科全书的超链接和图库。超链接包括指向百科全书本身的链接,以及指向参考资料和扩展阅读的链接。我们需要开始的是参考资料和扩展阅读的链接,所以我们在做百科的时候要加链接,那么我们的文章一定是一个大百科,比百度百科的信息和图片更完整。所以要强调的是,你必须为自己留出空间。
四、百科全书资源推荐。
我这里讲的是,不管是百度百科还是其他百科全书,归结起来就是一个大的资源采集和资源整合,所以从这里我们不仅要学会如何整合采集 ,还要学习如何采集。页面布局和链接布局,以及标签在百科中的应用。
上图:只是七成seo个人在百科上的实战总结。希望对大家有帮助,也希望大家多多交流,完善每个贡献者的文章,方便大家。
版权声明:启程seo首发于chinaz和我的博客,欢迎转载讨论,转载请保留原作者信息,谢谢合作!
请注明:SEO爱站net »Xiamen网站 优化:实战获取流量的关键方法8:解密百科
网页抓取解密(1.利用burp网站post提交密文的数据2.利用requests.post访问网站并获取返回内容(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-19 16:12
0x0 原点
今天群里的一个小伙伴也在写这个,我也没什么好做的。
我也会写一些空闲时间的痛苦,可能有些地方有一些相似之处。
他用bs4来获取的,不限于用re
附上他的博客文章:
0x1 的想法:
1.使用burp拦截网站post提交的数据
2.使用requesst.post模拟浏览器访问获取返回内容
3. 通过正则过滤md5解密结果
0x2 Text 1.使用burp截取网站post提交的数据提交密文
2.使用requests.post访问网站并获取返回的内容
import requests
import re
import sys
url = 'http://pmd5.com' #目标网站
data = {
'__VIEWSTATE': '/wEPDwUKMTM4NTE3OTkzOWRkP4hmXYtPPhcBjbupZdLOLfmeTK4=',
'__VIEWSTATEGENERATOR': 'CA0B0334',
'__EVENTVALIDATION': '/wEWAwK75ZuyDwLigPTXCQKU9f3vAheUenitfEuJ6eGUVe2GyFzb7HKC',
'key': '7a57a5a743894a0e',
'jiemi': 'MD5解密'
}
#key处 为需要解密的md5密文,在后面我们改成可以修改的
r = requests.post(url=url,data=data)
con = r.text
3. 通过正则过滤md5解密结果
发现标签中收录md5解密结果
a = re.compile('(.*?)')
result = a.findall(con)
list = '\n'.join(result)
print list
4.最后我们使用函数让代码更具可读性
# coding:utf-8
import requests
import re
import sys
def md5(keywd):
url = 'http://pmd5.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
data = {
'__VIEWSTATE': '/wEPDwUKMTM4NTE3OTkzOWRkP4hmXYtPPhcBjbupZdLOLfmeTK4=',
'__VIEWSTATEGENERATOR': 'CA0B0334',
'__EVENTVALIDATION': '/wEWAwK75ZuyDwLigPTXCQKU9f3vAheUenitfEuJ6eGUVe2GyFzb7HKC',
'key': '{}'.format(keywd),
'jiemi': 'MD5解密'
}
r = requests.post(url=url,headers=headers,data=data)
con = r.text
a = re.compile('(.*?)')
result = a.findall(con)
list = '\n'.join(result)
print list
if __name__=='__main__':
try:
keywd = sys.argv[1]
md5(keywd)
except:
print "python md5_pmd5.py $md5"
好了,今天就到此为止。这是我第一次写文章。可能不是很好,格式也有点问题。我稍后会更正。 查看全部
网页抓取解密(1.利用burp网站post提交密文的数据2.利用requests.post访问网站并获取返回内容(组图))
0x0 原点
今天群里的一个小伙伴也在写这个,我也没什么好做的。
我也会写一些空闲时间的痛苦,可能有些地方有一些相似之处。
他用bs4来获取的,不限于用re
附上他的博客文章:
0x1 的想法:
1.使用burp拦截网站post提交的数据
2.使用requesst.post模拟浏览器访问获取返回内容
3. 通过正则过滤md5解密结果
0x2 Text 1.使用burp截取网站post提交的数据提交密文

2.使用requests.post访问网站并获取返回的内容
import requests
import re
import sys
url = 'http://pmd5.com' #目标网站
data = {
'__VIEWSTATE': '/wEPDwUKMTM4NTE3OTkzOWRkP4hmXYtPPhcBjbupZdLOLfmeTK4=',
'__VIEWSTATEGENERATOR': 'CA0B0334',
'__EVENTVALIDATION': '/wEWAwK75ZuyDwLigPTXCQKU9f3vAheUenitfEuJ6eGUVe2GyFzb7HKC',
'key': '7a57a5a743894a0e',
'jiemi': 'MD5解密'
}
#key处 为需要解密的md5密文,在后面我们改成可以修改的
r = requests.post(url=url,data=data)
con = r.text
3. 通过正则过滤md5解密结果
发现标签中收录md5解密结果
a = re.compile('(.*?)')
result = a.findall(con)
list = '\n'.join(result)
print list
4.最后我们使用函数让代码更具可读性
# coding:utf-8
import requests
import re
import sys
def md5(keywd):
url = 'http://pmd5.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
data = {
'__VIEWSTATE': '/wEPDwUKMTM4NTE3OTkzOWRkP4hmXYtPPhcBjbupZdLOLfmeTK4=',
'__VIEWSTATEGENERATOR': 'CA0B0334',
'__EVENTVALIDATION': '/wEWAwK75ZuyDwLigPTXCQKU9f3vAheUenitfEuJ6eGUVe2GyFzb7HKC',
'key': '{}'.format(keywd),
'jiemi': 'MD5解密'
}
r = requests.post(url=url,headers=headers,data=data)
con = r.text
a = re.compile('(.*?)')
result = a.findall(con)
list = '\n'.join(result)
print list
if __name__=='__main__':
try:
keywd = sys.argv[1]
md5(keywd)
except:
print "python md5_pmd5.py $md5"
好了,今天就到此为止。这是我第一次写文章。可能不是很好,格式也有点问题。我稍后会更正。
网页抓取解密( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-19 16:10
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
查看全部
网页抓取解密(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
网页抓取解密(苹果手机网页抓取解密版本及源码地址:-gqxn8tfgoadjug.jpg)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-17 01:01
网页抓取解密版本及源码地址:-gqxn8tfgoadjug.jpg运用网页破解技术,在所有页面包括二维码扫描页,抓取同一页面的全部内容,利用这个思路,所有的微信包转换成txt文件可打开,转换成word文档可打开。
苹果手机上用过一个叫苹果助手的,
帮你扫描给你分析
国内用户:使用微信扫一扫,具体工具:专门用于手机的手机扫一扫工具包微信扫一扫红包辅助点击一下会将红包发出去,但是不能收红包二维码:(这些二维码是以/bin/mkjava。io/i2buzz这样的名称存在的)在微信-我-钱包-其他应用-右上角,这时微信会自动推荐一些二维码,假如这些二维码你使用过可以扫一扫即可收到广告,假如你不喜欢,也可以拒绝扫。
另:国外:让你的二维码自动推荐给你打开这些网站你可以扫这些网站的收款码然后微信会弹出来一个txt,使用正确方法的话可以推送到微信。
用过智扫
微信扫一扫可以观察自己的收款金额是多少,下个月的钱都用了哪些渠道,再选择一些带有自己名字和电话号码的合作方,回访下业务。如果碰上金额很大或者用户很多的话,建议人工挑选。手机网页都可以扫一扫。ios没试过, 查看全部
网页抓取解密(苹果手机网页抓取解密版本及源码地址:-gqxn8tfgoadjug.jpg)
网页抓取解密版本及源码地址:-gqxn8tfgoadjug.jpg运用网页破解技术,在所有页面包括二维码扫描页,抓取同一页面的全部内容,利用这个思路,所有的微信包转换成txt文件可打开,转换成word文档可打开。
苹果手机上用过一个叫苹果助手的,
帮你扫描给你分析
国内用户:使用微信扫一扫,具体工具:专门用于手机的手机扫一扫工具包微信扫一扫红包辅助点击一下会将红包发出去,但是不能收红包二维码:(这些二维码是以/bin/mkjava。io/i2buzz这样的名称存在的)在微信-我-钱包-其他应用-右上角,这时微信会自动推荐一些二维码,假如这些二维码你使用过可以扫一扫即可收到广告,假如你不喜欢,也可以拒绝扫。
另:国外:让你的二维码自动推荐给你打开这些网站你可以扫这些网站的收款码然后微信会弹出来一个txt,使用正确方法的话可以推送到微信。
用过智扫
微信扫一扫可以观察自己的收款金额是多少,下个月的钱都用了哪些渠道,再选择一些带有自己名字和电话号码的合作方,回访下业务。如果碰上金额很大或者用户很多的话,建议人工挑选。手机网页都可以扫一扫。ios没试过,
网页抓取解密(如何能使正则表达式在源代码中抓取解密-python网页抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 09:19
网页抓取解密-python网页抓取解密我们知道,页面只有抓取到源代码以后,才能再向下进行抓取。但是在抓取页面源代码之前,我们是要先进行正则表达式的匹配的。我们已经抓取到了整个页面,而且页面用了一个空白的标题。这么做就是为了进行页面解密。正则表达式抓取大部分页面都会使用到正则表达式。正则表达式是从给定的文本中匹配某种特定的字符串。
正则表达式还有固定的参数字符串,即所匹配的字符串必须是字符串。正则表达式与我们平时所用的汉字类似,同样是汉字表示,并且可以限定其宽度。比如我们的刚接触正则表达式并不陌生,比如说我们找到在域名中包含两个汉字的网站,那么正则表达式就是[“\w”,“\d”,“\d”]而如果我们想让自己抓取的页面具有短地址,那么正则表达式就是["\w","\d","\d"]那么如何能使正则表达式在源代码中找到源代码呢?首先我们可以去查找我们想要找到的页面中的url地址。
如果没有的话,我们就使用urllib库中的正则表达式去匹配页面的url。这样一来我们的目标页面就出现在我们的解密的区域中了。今天的正则表达式就抓取到页面源代码,而我们接下来要去分析下这个页面中的信息。抓取sitemappage.pya.首先我们需要对文章进行分词,以便我们去比对正则表达式匹配到的到底是哪一个。
b.sitemappage.py是我们可以让其包含多个url,然后对于每一个url中的信息,我们要进行初步的分析。下图可以很好的体现下sitemappage.py内部的结构。首先是根据出现的频率分类,例如出现频率最高的内容为service是一个服务项目,那么就去找这个service项目下的所有相关文件的内容,然后再找其所在文件夹,我们通过层层的信息去分析到这个页面所包含的内容,例如其中包含详细的所有说明文件,其中包含service项目下所有相关的内容的所有文件的内容,然后就去将service项目下所有相关的内容下载出来,作为我们所需要的数据。
到此为止,sitemappage.py文件已经抓取到了页面内容。c.把我们所需要的数据去掉,留下包含我们需要的内容的sitemappage.py文件。接下来就是我们要解密的过程了。我们在解密所抓取的源代码之前,我们需要先去解密sitemappage.py文件的所有内容。这里,首先通过对html的解析,去dir命令中去匹配哪一段代码中包含了正则表达式里面的内容,或者我们直接去解析页面源代码中的目录就可以了。
下图可以展示出sitemappage.py文件的内容去到解密过程中,我们可以逐渐分析页面,我们可以看出页面的源代码一共有六部分,其中的每一部分都是一个文件。 查看全部
网页抓取解密(如何能使正则表达式在源代码中抓取解密-python网页抓取)
网页抓取解密-python网页抓取解密我们知道,页面只有抓取到源代码以后,才能再向下进行抓取。但是在抓取页面源代码之前,我们是要先进行正则表达式的匹配的。我们已经抓取到了整个页面,而且页面用了一个空白的标题。这么做就是为了进行页面解密。正则表达式抓取大部分页面都会使用到正则表达式。正则表达式是从给定的文本中匹配某种特定的字符串。
正则表达式还有固定的参数字符串,即所匹配的字符串必须是字符串。正则表达式与我们平时所用的汉字类似,同样是汉字表示,并且可以限定其宽度。比如我们的刚接触正则表达式并不陌生,比如说我们找到在域名中包含两个汉字的网站,那么正则表达式就是[“\w”,“\d”,“\d”]而如果我们想让自己抓取的页面具有短地址,那么正则表达式就是["\w","\d","\d"]那么如何能使正则表达式在源代码中找到源代码呢?首先我们可以去查找我们想要找到的页面中的url地址。
如果没有的话,我们就使用urllib库中的正则表达式去匹配页面的url。这样一来我们的目标页面就出现在我们的解密的区域中了。今天的正则表达式就抓取到页面源代码,而我们接下来要去分析下这个页面中的信息。抓取sitemappage.pya.首先我们需要对文章进行分词,以便我们去比对正则表达式匹配到的到底是哪一个。
b.sitemappage.py是我们可以让其包含多个url,然后对于每一个url中的信息,我们要进行初步的分析。下图可以很好的体现下sitemappage.py内部的结构。首先是根据出现的频率分类,例如出现频率最高的内容为service是一个服务项目,那么就去找这个service项目下的所有相关文件的内容,然后再找其所在文件夹,我们通过层层的信息去分析到这个页面所包含的内容,例如其中包含详细的所有说明文件,其中包含service项目下所有相关的内容的所有文件的内容,然后就去将service项目下所有相关的内容下载出来,作为我们所需要的数据。
到此为止,sitemappage.py文件已经抓取到了页面内容。c.把我们所需要的数据去掉,留下包含我们需要的内容的sitemappage.py文件。接下来就是我们要解密的过程了。我们在解密所抓取的源代码之前,我们需要先去解密sitemappage.py文件的所有内容。这里,首先通过对html的解析,去dir命令中去匹配哪一段代码中包含了正则表达式里面的内容,或者我们直接去解析页面源代码中的目录就可以了。
下图可以展示出sitemappage.py文件的内容去到解密过程中,我们可以逐渐分析页面,我们可以看出页面的源代码一共有六部分,其中的每一部分都是一个文件。
网页抓取解密(一个中一个基础表的数据从另一个网站采集开始 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-15 14:06
)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志提示。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考一下。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本 查看全部
网页抓取解密(一个中一个基础表的数据从另一个网站采集开始
)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志提示。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考一下。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
网页抓取解密(关键词标签网页论题标签(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-08 21:02
关键词 标签
网络主题标签
网页浏览器标签
检测文件标签
“网页描述”的代码标签和关键字标签是最重要的。建议每个网页都带有这两个标签。关于网页页眉的编写(指h标签)。一般来说,它用于修改网页的主标题,即段落标题,也就是段落中的节标题。对于关键词的使用,使用第一批最重要的关键词,第二批重要的关键词使用,以此类推。注意在使用关键词时,不要让标题失去可读性,要考虑读者的感受。
10)网站 外链优化操作。
(1)登录搜索引擎
(2)登录著名站点导航列表,链接很多,(需要注意的是,链接的站点必须与添加的网站有一定联系,我们可以理解为亲戚,也就是同种网站,而不是手机链接给养鱼人,尽量让别人的站链接自己,这样可以增加网站的pr值。链接也有交换链接,这里需要注意,首先检查对方的网站是否作弊,因为一旦链接到一个被搜索引擎惩罚的网站,你的< @网站 不可信。)关于网站 内部链接,使用最好的关键词(你认为最重要的关键词)进行链接。对于留言簿和博客的链接,建议在网站中找到实用且有意义的文章 留言簿或博客链接不要重复贴,以免被怀疑与对方文章堆积垃圾。
11) 搜索引擎优化中常见的误解和错误。请注意不要使用以下的做法,会让你的网站受到搜索引擎的惩罚
(1)桥页,跳转页
(2)关键词 叠加,如:优化手机,标签上写着:手机手机手机手机手机,这是不明智的
(3)关键词 积累,如:使用标签,一些不好的优化器在网页中插入很多透明图片,设置图片大小为1*1图形,然后添加这样的关键词( 4)隐藏文字和透明文字
(5)细文是指在网页不显眼的地方用较小的字体写带有关键词的句子。一般这些关键词放在页面的顶部或底部网页。
(6)盲眼法是指伪装网页的方法,首先判断访问者是普通访问者还是搜索引擎,从而显示不同的网页。这是一种欺骗搜索引擎的盲目方法.网站一字印!(7)网络劫持是指抄袭别人的网站内容或整个网站,自己盗梁换帖网站 。
对外宣传违规操作
(1)重新提交你自己的网站
(2)隐藏链接,如:使用与网页文字相同的特征,如颜色、字体相同,将链接隐藏在透明图片中,将数百甚至数千个链接隐藏在一个小的图片。
(3)复制页面和镜像,搜索引擎不希望网站占用关键词的相同内容的结果。因此,搜索引擎发现多个网站发布相同的如果是邮箱,则在所述结果中仅显示其中之一。
(4)域名轰炸,简单来说就是注册n个域名提交或者注册n个网址在名站导航中(5)转,这是色情网址的常用方法,在为了吸引流量,访问者到达一个网站后,整个网站就变成了色情网站,搜索引擎总是遇到http301永久重定向的问题。
(6)博客污染,指的是一些网站评论者经常在博客里发帖,里面隐藏链接可以到达自己的网站。
(7)链接农场是指没有有价值信息的网页。整个网站除了人为列出的其他网站的链接,
每个页面上的其他内容或很少的内容。拯救被搜索引擎除名的网站,首先要仔细深入地检查你的网站,看看问题出在哪里,解决问题,然后提交一个新的收录到谷歌或百度应用,地址:这是谷歌的在线服务中心。记得在主题栏中写上:“reinclusion request”。一般提交后,经过6到8个想法后,即可收到谷歌的回复。
12)网站 培养和监控。SEO是连续的,效果慢,所以你要耐心,每隔一段时间检查一下关键词。如果发现新的关键词,立即优化,多分析竞争。多收费网站。网站要更新,你需要内容。如果没有内容,您可以参考以下信息:
(1)对于产品,
您可以添加产品评论和客户反馈,尤其是许多更新频繁的产品,例如手机。所以。您可以创建其他网页来说明产品。
(2)品牌可以添加公司相关新闻稿,可以是产品、公司信息、市场信息。
最好的方法是使用 Google 的 xml 站点地图告诉 Google 您的 网站 已更新。你需要发现的是,当你的新网站添加了大量内容时,当你对网站结构进行非常大的改动时,搜索引擎可能需要更多的时间来观察和分析你的网站。最后一种方式是考虑使用竞价排名(ppc)来弥补过渡期的流量损失。
13) seo 是一个漫长而漫长的工作,你要有足够的耐心。而且,要随时查看关键词,跟踪添加的网站,分析竞争对手的网站。这是网站唱歌的关键。 查看全部
网页抓取解密(关键词标签网页论题标签(1)_光明网(组图))
关键词 标签
网络主题标签
网页浏览器标签
检测文件标签
“网页描述”的代码标签和关键字标签是最重要的。建议每个网页都带有这两个标签。关于网页页眉的编写(指h标签)。一般来说,它用于修改网页的主标题,即段落标题,也就是段落中的节标题。对于关键词的使用,使用第一批最重要的关键词,第二批重要的关键词使用,以此类推。注意在使用关键词时,不要让标题失去可读性,要考虑读者的感受。
10)网站 外链优化操作。
(1)登录搜索引擎
(2)登录著名站点导航列表,链接很多,(需要注意的是,链接的站点必须与添加的网站有一定联系,我们可以理解为亲戚,也就是同种网站,而不是手机链接给养鱼人,尽量让别人的站链接自己,这样可以增加网站的pr值。链接也有交换链接,这里需要注意,首先检查对方的网站是否作弊,因为一旦链接到一个被搜索引擎惩罚的网站,你的< @网站 不可信。)关于网站 内部链接,使用最好的关键词(你认为最重要的关键词)进行链接。对于留言簿和博客的链接,建议在网站中找到实用且有意义的文章 留言簿或博客链接不要重复贴,以免被怀疑与对方文章堆积垃圾。
11) 搜索引擎优化中常见的误解和错误。请注意不要使用以下的做法,会让你的网站受到搜索引擎的惩罚
(1)桥页,跳转页
(2)关键词 叠加,如:优化手机,标签上写着:手机手机手机手机手机,这是不明智的
(3)关键词 积累,如:使用标签,一些不好的优化器在网页中插入很多透明图片,设置图片大小为1*1图形,然后添加这样的关键词( 4)隐藏文字和透明文字
(5)细文是指在网页不显眼的地方用较小的字体写带有关键词的句子。一般这些关键词放在页面的顶部或底部网页。
(6)盲眼法是指伪装网页的方法,首先判断访问者是普通访问者还是搜索引擎,从而显示不同的网页。这是一种欺骗搜索引擎的盲目方法.网站一字印!(7)网络劫持是指抄袭别人的网站内容或整个网站,自己盗梁换帖网站 。
对外宣传违规操作
(1)重新提交你自己的网站
(2)隐藏链接,如:使用与网页文字相同的特征,如颜色、字体相同,将链接隐藏在透明图片中,将数百甚至数千个链接隐藏在一个小的图片。
(3)复制页面和镜像,搜索引擎不希望网站占用关键词的相同内容的结果。因此,搜索引擎发现多个网站发布相同的如果是邮箱,则在所述结果中仅显示其中之一。
(4)域名轰炸,简单来说就是注册n个域名提交或者注册n个网址在名站导航中(5)转,这是色情网址的常用方法,在为了吸引流量,访问者到达一个网站后,整个网站就变成了色情网站,搜索引擎总是遇到http301永久重定向的问题。
(6)博客污染,指的是一些网站评论者经常在博客里发帖,里面隐藏链接可以到达自己的网站。
(7)链接农场是指没有有价值信息的网页。整个网站除了人为列出的其他网站的链接,
每个页面上的其他内容或很少的内容。拯救被搜索引擎除名的网站,首先要仔细深入地检查你的网站,看看问题出在哪里,解决问题,然后提交一个新的收录到谷歌或百度应用,地址:这是谷歌的在线服务中心。记得在主题栏中写上:“reinclusion request”。一般提交后,经过6到8个想法后,即可收到谷歌的回复。
12)网站 培养和监控。SEO是连续的,效果慢,所以你要耐心,每隔一段时间检查一下关键词。如果发现新的关键词,立即优化,多分析竞争。多收费网站。网站要更新,你需要内容。如果没有内容,您可以参考以下信息:
(1)对于产品,
您可以添加产品评论和客户反馈,尤其是许多更新频繁的产品,例如手机。所以。您可以创建其他网页来说明产品。
(2)品牌可以添加公司相关新闻稿,可以是产品、公司信息、市场信息。
最好的方法是使用 Google 的 xml 站点地图告诉 Google 您的 网站 已更新。你需要发现的是,当你的新网站添加了大量内容时,当你对网站结构进行非常大的改动时,搜索引擎可能需要更多的时间来观察和分析你的网站。最后一种方式是考虑使用竞价排名(ppc)来弥补过渡期的流量损失。
13) seo 是一个漫长而漫长的工作,你要有足够的耐心。而且,要随时查看关键词,跟踪添加的网站,分析竞争对手的网站。这是网站唱歌的关键。
网页抓取解密(网页抓取解密,可以用手机账号登录昨天我遇到这个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-08 09:10
网页抓取解密,所以做出了下面的这个工具,用以学习网页抓取和嗅探的方法。老规矩,代码不放出来了,部分功能已经实现,后续内容将不断更新,争取做到解密和打开测试,运行测试等等。
1、用户手机号码抓取,android版需要该功能,
2、从新浪微博获取验证码,
3、用户输入地址获取链接,其中很多验证码密码识别,初步接触到了这些,有兴趣的同学可以尝试下,有问题的话可以给我留言。大家需要使用的话记得联系我,我会发送链接给大家。
证书一直忘记了在电脑上安装。网上提供的盗号用这个解密。试了几次都是一样的结果。需要实验一下。
前两天被盗号,然后还打不开微博,
今天也刚刚被盗号,号被改了姓名,信息等,安卓手机也是不能设置拦截可疑账号信息,百度一下有各种办法,但是不全是最快的,实验了一下换了手机号,换了ip,打算手动换ip,网上的各种破解方法基本没用,最后刷机,升级到最新系统以后打开飞行模式,发短信,
一样的情况,也打不开,
请问楼主解开了吗我知道可以用手机账号登录
昨天我遇到这个问题打不开是我自己手机的问题打不开之前我点开微博的id的时候就提示要输入手机号改密码 查看全部
网页抓取解密(网页抓取解密,可以用手机账号登录昨天我遇到这个问题)
网页抓取解密,所以做出了下面的这个工具,用以学习网页抓取和嗅探的方法。老规矩,代码不放出来了,部分功能已经实现,后续内容将不断更新,争取做到解密和打开测试,运行测试等等。
1、用户手机号码抓取,android版需要该功能,
2、从新浪微博获取验证码,
3、用户输入地址获取链接,其中很多验证码密码识别,初步接触到了这些,有兴趣的同学可以尝试下,有问题的话可以给我留言。大家需要使用的话记得联系我,我会发送链接给大家。
证书一直忘记了在电脑上安装。网上提供的盗号用这个解密。试了几次都是一样的结果。需要实验一下。
前两天被盗号,然后还打不开微博,
今天也刚刚被盗号,号被改了姓名,信息等,安卓手机也是不能设置拦截可疑账号信息,百度一下有各种办法,但是不全是最快的,实验了一下换了手机号,换了ip,打算手动换ip,网上的各种破解方法基本没用,最后刷机,升级到最新系统以后打开飞行模式,发短信,
一样的情况,也打不开,
请问楼主解开了吗我知道可以用手机账号登录
昨天我遇到这个问题打不开是我自己手机的问题打不开之前我点开微博的id的时候就提示要输入手机号改密码
网页抓取解密(网页版AES:1.的函数())
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-12-04 12:01
一、网页版AES:
1.首先我们打开浏览器“咪咪咪”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,这种视频一般是m3u8.)
3.点一个视频进去4.搜索“m3u8”,原来是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那应该是加密了
6. 然后我们尝试搜索这个视频的ID,发现有3个相关的请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID加了后来,之前截图是另一个)
7.上图得到的/video/info是哪里来的?不用着急,ctrl+f搜索,真的找到了一个js文件。
8. 我们从source打开这个文件,搜索/video/info,发现一个getVideoInfo函数(注意a的值是从headers中获取的)
9. 然后我低头看到一个decryptString,那我猜这应该是解密的函数,然后搜索decryptString找到函数
10.分析这个函数:
t=得到的加密串,o=取md5,e=取md5后第8位取出16位串
所以通过计算当前视频的iv和key
11. 然后我们尝试用AES解密
12. 解密成功,得到m3u8地址。拼接主机后,直接打开,却发现无法播放。
让我们回到网页来抓包。原来在m3u8地址后面有一个token参数。添加令牌后,打开即可正常播放。
13. 需要注意的是,获取/video/info的时候需要在headers中加上origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我的M3U8下载器时,需要自定义协议头:Origin
二、 web端获取用户Token:
问题来了,在抓取的时候,每个用户只能免费观看30个视频。然后我们会得到更多的用户:
感觉应该是因为token(一个token代表一个用户),那我们就要明白token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新网页,搜索token的值,其实这个pwatoken是一个参数,只有在第二次访问时才会出现。
我们新建一个隐身窗口或小窗口,打开F12.,你会发现一个新的界面mail_pwa_temp,建议使用抓包软件抓取整个过程。
可以看出是mail_pwa_temp返回的token,看一下提交的参数,post submit pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?事实上,当我们访问主页时,会返回一个许可证。这是 pwa-ckv
PS:但是,当我们将帖子的内容设置为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这反映在浏览器中:
没错,这是2级的VIP(也就是所谓的尊贵VIP账号),那么他的token可以无限期的抓拍视频。
看来爬行速度不能太快,会很频繁。
三、 两种实现网页版无限制观看的方法【方法已过期,将强制退出,令牌已被禁止,无法再使用此令牌拍摄视频】:
第一种:FD的自动回复,这个就不多说了,把token换成之前拿到的honor Token
第二种:JS打印这个,步骤如下:
1. 打开会员页面,点击账号后面的Refresh,会提示刷新成功,我们搜索“刷新成功”,不难发现文件中调用了app.XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的函数,
3. 给这个函数一个断点,刷新个人信息,然后我们把这个打印出来
4.在控制台输入temp1.$store.state.newToken ='尊荣token'
这里所说的honor token是第二步抓到的token,字符串长度145左右。
您可以在浏览器中更改为尊贵的VIP,享受无限观看。(值得注意的是:页面一刷新就失效了……再做一次)
四、在APP端实现真正的无限制观看【方法已过期,会强制退出,token已被禁止】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1. 首先我们抓了个app,用Token作为web版,但是调用界面不一样。
2. 然后我们打开MT管理器或者NP管理器,尝试搜索收录Token的方法名的内容。
3. 找到2个相关的getToken函数,让我们点进去修改,返回之前获取的Token
4.APP编译完成后,打开查看效果。
5.果然成了尊贵的VIP。
虽然显示每天的观看次数是有限制的,但实际上你会发现它是无限观看的
五、在APP端实现真正的无限观看:
其实原因很简单。您必须在第一次打开应用程序时注册。然后我们就可以将注册的参数修改为随机的,以达到每次清除数据后打开APP的新用户体验。
因为在SMALI中重新添加函数有点复杂,我这里直接调用了APP原来的随机函数(PS:这个随机是我用的函数的简写,你可以试试其他的随机函数)
下图是从NP管理器到JAVA修改前后的代码区别:(思路是给this.d分配随机字符)
这个方法比第四步要难一些,但也只是一点点而已。
相信你可以通过抓包得到一些信息,然后再搞定。
这里我就不详细解释了。防止和谐,有本事的人可以试试。对我这个自学半心半意的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
比如getLevel(const v0, 0x2 1为普通/2为荣誉), getExpiry (const v0, 0x746a6480)等
修改后发现只在本地显示。 查看全部
网页抓取解密(网页版AES:1.的函数())
一、网页版AES:
1.首先我们打开浏览器“咪咪咪”的网页。
2.F12 打开“开发者模式”-“网络”。(众所周知,这种视频一般是m3u8.)
3.点一个视频进去4.搜索“m3u8”,原来是m3u8流
5. 然后直接搜索这个m3u8的文件名,结果没有找到,那应该是加密了
6. 然后我们尝试搜索这个视频的ID,发现有3个相关的请求:“视频推荐”、“演员信息”、“当前视频信息”(PS:这个ID加了后来,之前截图是另一个)
7.上图得到的/video/info是哪里来的?不用着急,ctrl+f搜索,真的找到了一个js文件。
8. 我们从source打开这个文件,搜索/video/info,发现一个getVideoInfo函数(注意a的值是从headers中获取的)
9. 然后我低头看到一个decryptString,那我猜这应该是解密的函数,然后搜索decryptString找到函数
10.分析这个函数:
t=得到的加密串,o=取md5,e=取md5后第8位取出16位串
所以通过计算当前视频的iv和key
11. 然后我们尝试用AES解密
12. 解密成功,得到m3u8地址。拼接主机后,直接打开,却发现无法播放。
让我们回到网页来抓包。原来在m3u8地址后面有一个token参数。添加令牌后,打开即可正常播放。
13. 需要注意的是,获取/video/info的时候需要在headers中加上origin、platform等,否则返回的是视频介绍,不是完整的视频。
所以在使用我的M3U8下载器时,需要自定义协议头:Origin
二、 web端获取用户Token:
问题来了,在抓取的时候,每个用户只能免费观看30个视频。然后我们会得到更多的用户:
感觉应该是因为token(一个token代表一个用户),那我们就要明白token是怎么产生的:
1.F12打开“开发者模式”-“网络”,刷新网页,搜索token的值,其实这个pwatoken是一个参数,只有在第二次访问时才会出现。
我们新建一个隐身窗口或小窗口,打开F12.,你会发现一个新的界面mail_pwa_temp,建议使用抓包软件抓取整个过程。
可以看出是mail_pwa_temp返回的token,看一下提交的参数,post submit pwa-ckv
那么这个 pwa-ckv 是从哪里来的呢?事实上,当我们访问主页时,会返回一个许可证。这是 pwa-ckv
PS:但是,当我们将帖子的内容设置为pwa-ckv=1时,出现了一个有趣的现象(附:好像任何帖子都会返回会员的token,包括空格)
这反映在浏览器中:
没错,这是2级的VIP(也就是所谓的尊贵VIP账号),那么他的token可以无限期的抓拍视频。
看来爬行速度不能太快,会很频繁。
三、 两种实现网页版无限制观看的方法【方法已过期,将强制退出,令牌已被禁止,无法再使用此令牌拍摄视频】:
第一种:FD的自动回复,这个就不多说了,把token换成之前拿到的honor Token
第二种:JS打印这个,步骤如下:
1. 打开会员页面,点击账号后面的Refresh,会提示刷新成功,我们搜索“刷新成功”,不难发现文件中调用了app.XXXXXX.js
2.搜索“refresh_success”,可以找到getUserInfo的函数,
3. 给这个函数一个断点,刷新个人信息,然后我们把这个打印出来
4.在控制台输入temp1.$store.state.newToken ='尊荣token'
这里所说的honor token是第二步抓到的token,字符串长度145左右。
您可以在浏览器中更改为尊贵的VIP,享受无限观看。(值得注意的是:页面一刷新就失效了……再做一次)
四、在APP端实现真正的无限制观看【方法已过期,会强制退出,token已被禁止】:
其实原因很简单,就是将APP中返回的Token固定为之前获得的尊贵VIP的Token。
1. 首先我们抓了个app,用Token作为web版,但是调用界面不一样。
2. 然后我们打开MT管理器或者NP管理器,尝试搜索收录Token的方法名的内容。
3. 找到2个相关的getToken函数,让我们点进去修改,返回之前获取的Token
4.APP编译完成后,打开查看效果。
5.果然成了尊贵的VIP。
虽然显示每天的观看次数是有限制的,但实际上你会发现它是无限观看的
五、在APP端实现真正的无限观看:
其实原因很简单。您必须在第一次打开应用程序时注册。然后我们就可以将注册的参数修改为随机的,以达到每次清除数据后打开APP的新用户体验。
因为在SMALI中重新添加函数有点复杂,我这里直接调用了APP原来的随机函数(PS:这个随机是我用的函数的简写,你可以试试其他的随机函数)
下图是从NP管理器到JAVA修改前后的代码区别:(思路是给this.d分配随机字符)
这个方法比第四步要难一些,但也只是一点点而已。
相信你可以通过抓包得到一些信息,然后再搞定。
这里我就不详细解释了。防止和谐,有本事的人可以试试。对我这个自学半心半意的人来说并不难,相信你也不会觉得难。
PS:抓包还可以找到/user/info接口返回的expiry、level、user_id等信息。通过MT管理器或者NP管理器搜索方法名,发现都在ResponseUserInfo类中:
比如getLevel(const v0, 0x2 1为普通/2为荣誉), getExpiry (const v0, 0x746a6480)等
修改后发现只在本地显示。
网页抓取解密( Python实现抓取网页并且解析的功能实例,(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-02 09:15
Python实现抓取网页并且解析的功能实例,(图))
爬取网页和解析示例的Python实现
更新时间:2014-09-20 17:39:07 投稿:shichen2014
本文文章主要介绍Python实现网页抓取和解析的功能实例。主要以百度问答的分析为例,说明其原理和方法。有需要的朋友可以参考以下
本文以示例的形式介绍了Python中网页的爬取和解析的功能。主要分析问答和百度首页。分享给大家,供大家参考。
主要功能代码如下:
#!/usr/bin/python
#coding=utf-8
import sys
import re
import urllib2
from urllib import urlencode
from urllib import quote
import time
maxline = 2000
wenda = re.compile("href=\"http://wenda.so.com/q/.+\?src=(.+?)\"")
baidu = re.compile("<a href=\"http://www.baidu.com/link\?url=.+\".*?>更多知道相关问题.*?</a>")
f1 = open("baidupage.txt","w")
f2 = open("wendapage.txt","w")
for line in sys.stdin:
if maxline == 0:
break
query = line.strip();
time.sleep(1);
recall_url = "http://www.so.com/s?&q=" + query;
response = urllib2.urlopen(recall_url);
html = response.read();
f1.write(html)
m = wenda.search(html);
if m:
if m.group(1) == "110":
print query + "\twenda\t0";
else:
print query + "\twenda\t1";
else:
print query + "\twenda\t0";
recall_url = "http://www.baidu.com/s?wd=" + query +"&ie=utf-8";
response = urllib2.urlopen(recall_url);
html = response.read();
f2.write(html)
m = baidu.search(html);
if m:
print query + "\tbaidu\t1";
else:
print query + "\tbaidu\t0";
maxline = maxline - 1;
f1.close()
f2.close()
我希望这篇文章能帮助你学习 Python 编程。 查看全部
网页抓取解密(
Python实现抓取网页并且解析的功能实例,(图))
爬取网页和解析示例的Python实现
更新时间:2014-09-20 17:39:07 投稿:shichen2014
本文文章主要介绍Python实现网页抓取和解析的功能实例。主要以百度问答的分析为例,说明其原理和方法。有需要的朋友可以参考以下
本文以示例的形式介绍了Python中网页的爬取和解析的功能。主要分析问答和百度首页。分享给大家,供大家参考。
主要功能代码如下:
#!/usr/bin/python
#coding=utf-8
import sys
import re
import urllib2
from urllib import urlencode
from urllib import quote
import time
maxline = 2000
wenda = re.compile("href=\"http://wenda.so.com/q/.+\?src=(.+?)\"")
baidu = re.compile("<a href=\"http://www.baidu.com/link\?url=.+\".*?>更多知道相关问题.*?</a>")
f1 = open("baidupage.txt","w")
f2 = open("wendapage.txt","w")
for line in sys.stdin:
if maxline == 0:
break
query = line.strip();
time.sleep(1);
recall_url = "http://www.so.com/s?&q=" + query;
response = urllib2.urlopen(recall_url);
html = response.read();
f1.write(html)
m = wenda.search(html);
if m:
if m.group(1) == "110":
print query + "\twenda\t0";
else:
print query + "\twenda\t1";
else:
print query + "\twenda\t0";
recall_url = "http://www.baidu.com/s?wd=" + query +"&ie=utf-8";
response = urllib2.urlopen(recall_url);
html = response.read();
f2.write(html)
m = baidu.search(html);
if m:
print query + "\tbaidu\t1";
else:
print query + "\tbaidu\t0";
maxline = maxline - 1;
f1.close()
f2.close()
我希望这篇文章能帮助你学习 Python 编程。
网页抓取解密(GooglePageRank算法的基本原理推导和基本原理算法策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-02 05:19
一、PageRank
PageRank算法是最著名的搜索引擎谷歌采用的一种算法策略。它根据每个网页的超链接信息计算一个网页的权重,以优化搜索引擎的结果。,由拉里佩奇提出。
简单的说,PageRank算法计算每个网页的综合得分,即如果网页A链接到网页B,网页B当然会加一分。不同的链接网页有不同的指向网页的点。一个页面的分数是通过递归算法得到所有链接到它的页面的重要性的。
PageRank算法的基本原理推导如下:
PR(A) = (1-d) + d*(PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
其中,PR(A)是指网页A的PR值。
T1、T2、...、Tn 指的是页面 A 的链接页面。
PR(Ti)是指网页Ti(i=1, 2, ..., n)的PR值。
C(Ti)指的是网页Ti(i=1, 2,..., n)之外的链接数。
D为衰减因子,0 由上式可知,影响网页PR值的主要因素如下:
(1)此页面的链接数。
(2) 链接到网页本身的网页的 PR 值。
(3)网页本身的链接数。
根据以上分析可以判断:一个网页的链接数越多,这些链接网页的PR值就越高,而来自这些网页的链接数越少,该网页的PR值就越高.
谷歌为每个网页分配一个初始PR值(1-d),然后使用PageRank算法收敛计算其PR值。
网页的link-in和link-out关系一直在变化,所以PR值也需要更新,可以用定时任务反复计算后更新,使网页最终PR值达到平衡和稳定的状态。
Google的查询过程如下:首先根据用户输入的查询,关键词尽可能匹配网页数据库中的网页,然后根据用户自己的PR排名将匹配的网页呈现给用户.
此外,网页在搜索结果列表中的位置还与很多其他因素有关,例如搜索词在网页中的位置。
PageRank的缺陷是没有考虑链接的价值,更适合一般搜索引擎,但对于主题相关的垂直搜索引擎来说不是一个好的策略。
二、命中
PageRank算法对外部链接权重的贡献是平均的,即不考虑不同链接的重要性,但部分页面链接可能是广告、导航或注释链接,平均权重显然不符合结合实际情况。
HITS(Hyperlink Induced Topic Search)算法是经典的主题信息提取策略,可以提高垂直精度。
1、原理
HITS算法由Jon Kleinberg提出,它为每个网页计算两个值:权威值(authority)和中心值(hub)。
(1)权威页面
一个网页被多次引用,可能很重要;一个网页虽然没有被多次引用,但是被重要的网页引用,也可能很重要;网页的重要性均匀地转移到它指的是网页。此类页面称为权威页面。
(2)中心网页
提供权威页面链接集合的网页本身可能并不重要,或者指向它的页面很少,但它提供了到某个主题的最重要站点的链接集合。这种类型的页面称为 Hub 网页。
(3)算法思想
首先,使用通用搜索引擎获取网页的初始子集I。当然,I中的页面与用户的查询条件非常相关。然后将I所指向的网页和I所指向的网页收录起来构成一个基本集合E。E中的每个页面都有一个权限权重和一个枢纽权重,分别用a和h表示。a 值代表网页和查询条件相关的程度,h 反映了页面链接到相关页面的程度。a=(a1, a2, ..., an) 和 h=(h1, h2, ..., hn) 分别表示 E 中所有网页的权威和中心向量。 初始设置所有 ai 和 hi 为 1 ,并且然后使用以下公式计算:
其中,B(i)和F(i)分别代表指向该网页的网页链接集合和指向该网页的网页链接集合。用n*n矩阵A来表示集合E的网页节点之间的连接。如果节点i和节点j之间存在连接,则A[i,j]=1,则A[i,j]= 0,因此,上式可表示为:
迭代计算 a 和 h 直到收敛。这样,我们专注于ATA和AAT。最后,按照authority和hub值排序,选择a和h的值大于阈值M的网页。
如果一个网页被很多好的hub指向,它的权威值会相应增加;如果一个网页指向很多好的权威页面,那么hub值也会相应增加。HITS 算法的最终输出是一组具有较大中心值的网页和具有较大权限值的网页。
2、缺陷
HITS算法在提高一定垂直精度的同时,也存在以下不足:
(1)HITS 算法忽略了网页内容的差异,给每个链接的网页分配了相同的权重常数,因为每个网页都会有一些不相关的链接网页,比如广告链接,而这些不相关的网页和相关网页平等对待它们很容易导致主题漂移。
(1)在url集合E的开头,也把I初始集合中网页的一些不相关的链接加到了E中,增加了不必要的下载量,导致更多不相关的网页参与计算. 对精度有一定影响。
3、改进
改进方向如下:
(1)主题漂移
(2)下载过滤器 查看全部
网页抓取解密(GooglePageRank算法的基本原理推导和基本原理算法策略)
一、PageRank
PageRank算法是最著名的搜索引擎谷歌采用的一种算法策略。它根据每个网页的超链接信息计算一个网页的权重,以优化搜索引擎的结果。,由拉里佩奇提出。
简单的说,PageRank算法计算每个网页的综合得分,即如果网页A链接到网页B,网页B当然会加一分。不同的链接网页有不同的指向网页的点。一个页面的分数是通过递归算法得到所有链接到它的页面的重要性的。
PageRank算法的基本原理推导如下:
PR(A) = (1-d) + d*(PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
其中,PR(A)是指网页A的PR值。
T1、T2、...、Tn 指的是页面 A 的链接页面。
PR(Ti)是指网页Ti(i=1, 2, ..., n)的PR值。
C(Ti)指的是网页Ti(i=1, 2,..., n)之外的链接数。
D为衰减因子,0 由上式可知,影响网页PR值的主要因素如下:
(1)此页面的链接数。
(2) 链接到网页本身的网页的 PR 值。
(3)网页本身的链接数。
根据以上分析可以判断:一个网页的链接数越多,这些链接网页的PR值就越高,而来自这些网页的链接数越少,该网页的PR值就越高.
谷歌为每个网页分配一个初始PR值(1-d),然后使用PageRank算法收敛计算其PR值。
网页的link-in和link-out关系一直在变化,所以PR值也需要更新,可以用定时任务反复计算后更新,使网页最终PR值达到平衡和稳定的状态。
Google的查询过程如下:首先根据用户输入的查询,关键词尽可能匹配网页数据库中的网页,然后根据用户自己的PR排名将匹配的网页呈现给用户.
此外,网页在搜索结果列表中的位置还与很多其他因素有关,例如搜索词在网页中的位置。
PageRank的缺陷是没有考虑链接的价值,更适合一般搜索引擎,但对于主题相关的垂直搜索引擎来说不是一个好的策略。
二、命中
PageRank算法对外部链接权重的贡献是平均的,即不考虑不同链接的重要性,但部分页面链接可能是广告、导航或注释链接,平均权重显然不符合结合实际情况。
HITS(Hyperlink Induced Topic Search)算法是经典的主题信息提取策略,可以提高垂直精度。
1、原理
HITS算法由Jon Kleinberg提出,它为每个网页计算两个值:权威值(authority)和中心值(hub)。
(1)权威页面
一个网页被多次引用,可能很重要;一个网页虽然没有被多次引用,但是被重要的网页引用,也可能很重要;网页的重要性均匀地转移到它指的是网页。此类页面称为权威页面。
(2)中心网页
提供权威页面链接集合的网页本身可能并不重要,或者指向它的页面很少,但它提供了到某个主题的最重要站点的链接集合。这种类型的页面称为 Hub 网页。
(3)算法思想
首先,使用通用搜索引擎获取网页的初始子集I。当然,I中的页面与用户的查询条件非常相关。然后将I所指向的网页和I所指向的网页收录起来构成一个基本集合E。E中的每个页面都有一个权限权重和一个枢纽权重,分别用a和h表示。a 值代表网页和查询条件相关的程度,h 反映了页面链接到相关页面的程度。a=(a1, a2, ..., an) 和 h=(h1, h2, ..., hn) 分别表示 E 中所有网页的权威和中心向量。 初始设置所有 ai 和 hi 为 1 ,并且然后使用以下公式计算:
其中,B(i)和F(i)分别代表指向该网页的网页链接集合和指向该网页的网页链接集合。用n*n矩阵A来表示集合E的网页节点之间的连接。如果节点i和节点j之间存在连接,则A[i,j]=1,则A[i,j]= 0,因此,上式可表示为:
迭代计算 a 和 h 直到收敛。这样,我们专注于ATA和AAT。最后,按照authority和hub值排序,选择a和h的值大于阈值M的网页。
如果一个网页被很多好的hub指向,它的权威值会相应增加;如果一个网页指向很多好的权威页面,那么hub值也会相应增加。HITS 算法的最终输出是一组具有较大中心值的网页和具有较大权限值的网页。
2、缺陷
HITS算法在提高一定垂直精度的同时,也存在以下不足:
(1)HITS 算法忽略了网页内容的差异,给每个链接的网页分配了相同的权重常数,因为每个网页都会有一些不相关的链接网页,比如广告链接,而这些不相关的网页和相关网页平等对待它们很容易导致主题漂移。
(1)在url集合E的开头,也把I初始集合中网页的一些不相关的链接加到了E中,增加了不必要的下载量,导致更多不相关的网页参与计算. 对精度有一定影响。
3、改进
改进方向如下:
(1)主题漂移
(2)下载过滤器
网页抓取解密(图片与下一个图片的代码主方法:第一张的网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-01 12:04
一般网页中,图片和下一张图片之间,地址是数字变化:
第一个的网址是:
下一篇的网址是:
一个特殊的网页会对一串数字使用加密算法,让爬虫看不到规则:
例如,第一个:
第二个:
这里的 MjAyMDA4MDktMTIx 实际上是加密信息:
查询结果:20200809显然是本次访问的日期
并121查看网页信息:即当前图片
获取当前日期的代码:
import datetime
time = datetime.datetime.now().strftime('%Y%m%')
import base64
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
测试:将字符串加密为20200809-121,结果与网页地址相同
抓取图片的代码
主要方法:
1、首先创建一个文件并命名为“ooxx”
2、get_page() 函数看起来像这样:它返回网页的数字部分
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']', a)
return html[a:b]
def downloadmm(folder="ooxx", pages=10):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
3、for i in range(pages): #只获取前10页的数据是指从当前页获取数据,第一次减0为当前页,第二次减1为下一页。以此类推,一共10页,page_url:指的是每一页的地址
4、获取page_url:关键点
测试:能否正确获取页码为121的页地址:
操作结果:
网站链接:
于是找到了页面的地址,接下来就是获取页面的源代码,从源代码中获取图片的位置
5、如何通过URL获取html页面内容:
设置请求头,目的是让爬虫操作拥有计算机的身份
import urllib.request
def url_open(url):
# 设置文件头
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
req = urllib.request.Request(url, headers=header)
# 现在开始访问
response = urllib.request.urlopen(url)
html = response.read()
# print(html)
return html
6、find_imgs 函数:通过html内容获取图片地址,正则表达式还没提到,暂时用find方法
就是获取img src之后,.jpg之前的内容。然后设置一个循环,找出当前页面所有符合条件的图片,然后保存
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while (a != -1):
b = html.find('.jpg', a, a + 255) # 没找到就会返回-1
if b != -1:
img_addrs.append(html[a + 9:b + 4])
else:
b = a + 9
a = html.find('img src=', b)
# img_addrs存着的是所有的图片地址
for each in img_addrs:
print(each)
7、 找到地址后,下载保存
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)
filename就是给图片取个名字,img = url_open(each)然后调用函数
当我访问此页面时,我总是报告 403。
在其他页面试过,可以使用
import urllib.request
import os
import datetime
import base64
time = datetime.datetime.now().strftime('%Y%m%')
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
# print(get_base64(time + '111'))
# 打开页面
def url_open(url):
# 设置文件头
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
req = urllib.request.Request(url, headers=header)
# 现在开始访问
response = urllib.request.urlopen(url)
html = response.read()
print(html)
return html
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']', a)
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while (a != -1):
b = html.find('.jpg', a, a + 255) # 没找到就会返回-1
if b != -1:
img_addrs.append(html[a + 9:b + 4])
else:
b = a + 9
a = html.find('img src=', b)
# img_addrs存着的是所有的图片地址
for each in img_addrs:
print(each)
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)
def downloadmm(folder="ooxx", pages=10):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__ == '__main__':
downloadmm()
原文链接: 查看全部
网页抓取解密(图片与下一个图片的代码主方法:第一张的网址)
一般网页中,图片和下一张图片之间,地址是数字变化:
第一个的网址是:
下一篇的网址是:
一个特殊的网页会对一串数字使用加密算法,让爬虫看不到规则:
例如,第一个:
第二个:
这里的 MjAyMDA4MDktMTIx 实际上是加密信息:
查询结果:20200809显然是本次访问的日期
并121查看网页信息:即当前图片
获取当前日期的代码:
import datetime
time = datetime.datetime.now().strftime('%Y%m%')
import base64
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
测试:将字符串加密为20200809-121,结果与网页地址相同
抓取图片的代码
主要方法:
1、首先创建一个文件并命名为“ooxx”
2、get_page() 函数看起来像这样:它返回网页的数字部分
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']', a)
return html[a:b]
def downloadmm(folder="ooxx", pages=10):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
3、for i in range(pages): #只获取前10页的数据是指从当前页获取数据,第一次减0为当前页,第二次减1为下一页。以此类推,一共10页,page_url:指的是每一页的地址
4、获取page_url:关键点
测试:能否正确获取页码为121的页地址:
操作结果:
网站链接:
于是找到了页面的地址,接下来就是获取页面的源代码,从源代码中获取图片的位置
5、如何通过URL获取html页面内容:
设置请求头,目的是让爬虫操作拥有计算机的身份
import urllib.request
def url_open(url):
# 设置文件头
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
req = urllib.request.Request(url, headers=header)
# 现在开始访问
response = urllib.request.urlopen(url)
html = response.read()
# print(html)
return html
6、find_imgs 函数:通过html内容获取图片地址,正则表达式还没提到,暂时用find方法
就是获取img src之后,.jpg之前的内容。然后设置一个循环,找出当前页面所有符合条件的图片,然后保存
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while (a != -1):
b = html.find('.jpg', a, a + 255) # 没找到就会返回-1
if b != -1:
img_addrs.append(html[a + 9:b + 4])
else:
b = a + 9
a = html.find('img src=', b)
# img_addrs存着的是所有的图片地址
for each in img_addrs:
print(each)
7、 找到地址后,下载保存
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)
filename就是给图片取个名字,img = url_open(each)然后调用函数
当我访问此页面时,我总是报告 403。
在其他页面试过,可以使用
import urllib.request
import os
import datetime
import base64
time = datetime.datetime.now().strftime('%Y%m%')
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
# print(get_base64(time + '111'))
# 打开页面
def url_open(url):
# 设置文件头
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
req = urllib.request.Request(url, headers=header)
# 现在开始访问
response = urllib.request.urlopen(url)
html = response.read()
print(html)
return html
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']', a)
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while (a != -1):
b = html.find('.jpg', a, a + 255) # 没找到就会返回-1
if b != -1:
img_addrs.append(html[a + 9:b + 4])
else:
b = a + 9
a = html.find('img src=', b)
# img_addrs存着的是所有的图片地址
for each in img_addrs:
print(each)
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)
def downloadmm(folder="ooxx", pages=10):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__ == '__main__':
downloadmm()
原文链接:
网页抓取解密(基于动态内容抓取JavaScript页面的优势--互联网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 11:28
指导
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多优秀的网络爬虫可用。
代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
代理爬网
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
刮痧
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得很好。
刮痧
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抓住
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到百万页面的大型动态爬虫任务。
抓住
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端爬取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
Diffbot
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
原文来自: 查看全部
网页抓取解密(基于动态内容抓取JavaScript页面的优势--互联网)
指导
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多优秀的网络爬虫可用。
代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
https://www.linuxprobe.com/wp- ... 2.jpg 300w" />代理爬网
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
刮痧
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得很好。
https://www.linuxprobe.com/wp- ... 7.jpg 300w" />刮痧
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抓住
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到百万页面的大型动态爬虫任务。
https://www.linuxprobe.com/wp- ... 1.jpg 300w" />抓住
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端爬取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
https://www.linuxprobe.com/wp- ... 1.jpg 300w" />此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
https://www.linuxprobe.com/wp- ... 4.jpg 300w" />Diffbot
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
https://www.linuxprobe.com/wp- ... 2.jpg 300w" />PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
原文来自:
网页抓取解密(Python爬虫JS解密,学会直接破解80%的网站!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-29 11:26
)
Python爬虫JS解密详解,学会直接破解网站的80%!!!
29个爬虫项目宝典教程,你值得拥有!
前言
==Glidedsky==这个关卡==JS解密==和之前看到的不一样,希望大家好好看看学习!
==温馨提示==:保护头发!
1、网页视图
2、JS解密过程(仔细看)
既然是JS加密的,数据肯定不是静态的,如下
直接请求页面,或者把检索到的html代码粘贴到html文件中打开,没有数字
打开控制台查看XHR
这里有问题。之前查的时候可以查看数据,但是不知道为什么又看不到数据了。知道的请在评论区告诉我,谢谢。
网上说的== 网页可以感应到用户打开了控制台==,不知道,不敢问,有这么饿的操作
如果有不明白的朋友,请参考我的JS解密文章 Python爬虫JS解密详解,写的很详细,多做这东西会有经验。
什么都不说,看吧
向下滚动可以看到请求有3个参数
按Ctrl+Shift+f搜索,输入==sign==,可以看到有6个匹配项
有兴趣的朋友可以点进去再搜索==sign==,都是和下图一样的匹配====牛头不对马嘴==
根据我之前的JS解密经验,应该不是直接匹配,然后做一个函数来加密o(╥﹏╥)o
这个我都看到了,直接放弃不是我的性格。我会继续耐心地学习和学习。. . .
然后找到了一个新的方法,现在教大家——就是打XHR断点,如下
只需复制部分网址,无需全部复制
==现在进入最关键的一步--使用python代码获取以上数据==
==获取t值==
==获取符号值==
Secure Hash Algorithm主要适用于数字签名标准DSS中定义的数字签名算法DSA。SHA1 比 MD5 更安全。对于长度小于 2^64 位的消息,SHA1 将生成 160 位的消息摘要。
别慌,python提供了hashlib库,厉害了!
==成功了,老铁们可以过来点赞!(*^▽^*)==
==拼接URL请求,注意:返回数据为json格式==
完美的
3、解密答案(完整代码)
import requests
import hashlib
import time
import math
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
#注意Cookie自己填哦
"Cookie": ""
}
sum = 0
def get(response):
global sum
for i in response['items']:
sum += int(i)
if __name__ == '__main__':
#1000个页面
for i in range(1000):
#获取t值
t = math.floor(time.time())
#获取sign值
sha1 = hashlib.sha1()
data = 'Xr0Z-javascript-obfuscation-1' + str(t)
sha1.update(data.encode('utf-8'))
sign = sha1.hexdigest()
print("第"+str(i+1)+"页")
#拼接url
url = "http://glidedsky.com/api/level ... 2Bstr(i+1)+"&t="+str(t)+"&sign="+str(sign)
response = requests.get(url=url,headers=headers).json()
get(response)
#打印最终数字
print(sum)
复制代码
成功突破,解密成功!!!
==注意填写Cookie,我提供的代码没有填写Cookie值==
博主会持续更新。有兴趣的朋友可以==喜欢==,==关注==和==采集==接下来,你们的支持就是我创作的最大动力!
Java学习从入门到大神学习目录索引
博主开源Python爬虫教程目录索引(宝教程,你值得拥有!)
查看全部
网页抓取解密(Python爬虫JS解密,学会直接破解80%的网站!!
)
Python爬虫JS解密详解,学会直接破解网站的80%!!!
29个爬虫项目宝典教程,你值得拥有!
前言
==Glidedsky==这个关卡==JS解密==和之前看到的不一样,希望大家好好看看学习!
==温馨提示==:保护头发!
1、网页视图
2、JS解密过程(仔细看)
既然是JS加密的,数据肯定不是静态的,如下
直接请求页面,或者把检索到的html代码粘贴到html文件中打开,没有数字
打开控制台查看XHR
这里有问题。之前查的时候可以查看数据,但是不知道为什么又看不到数据了。知道的请在评论区告诉我,谢谢。
网上说的== 网页可以感应到用户打开了控制台==,不知道,不敢问,有这么饿的操作
如果有不明白的朋友,请参考我的JS解密文章 Python爬虫JS解密详解,写的很详细,多做这东西会有经验。
什么都不说,看吧
向下滚动可以看到请求有3个参数
按Ctrl+Shift+f搜索,输入==sign==,可以看到有6个匹配项
有兴趣的朋友可以点进去再搜索==sign==,都是和下图一样的匹配====牛头不对马嘴==
根据我之前的JS解密经验,应该不是直接匹配,然后做一个函数来加密o(╥﹏╥)o
这个我都看到了,直接放弃不是我的性格。我会继续耐心地学习和学习。. . .
然后找到了一个新的方法,现在教大家——就是打XHR断点,如下
只需复制部分网址,无需全部复制
==现在进入最关键的一步--使用python代码获取以上数据==
==获取t值==
==获取符号值==
Secure Hash Algorithm主要适用于数字签名标准DSS中定义的数字签名算法DSA。SHA1 比 MD5 更安全。对于长度小于 2^64 位的消息,SHA1 将生成 160 位的消息摘要。
别慌,python提供了hashlib库,厉害了!
==成功了,老铁们可以过来点赞!(*^▽^*)==
==拼接URL请求,注意:返回数据为json格式==
完美的
3、解密答案(完整代码)
import requests
import hashlib
import time
import math
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
#注意Cookie自己填哦
"Cookie": ""
}
sum = 0
def get(response):
global sum
for i in response['items']:
sum += int(i)
if __name__ == '__main__':
#1000个页面
for i in range(1000):
#获取t值
t = math.floor(time.time())
#获取sign值
sha1 = hashlib.sha1()
data = 'Xr0Z-javascript-obfuscation-1' + str(t)
sha1.update(data.encode('utf-8'))
sign = sha1.hexdigest()
print("第"+str(i+1)+"页")
#拼接url
url = "http://glidedsky.com/api/level ... 2Bstr(i+1)+"&t="+str(t)+"&sign="+str(sign)
response = requests.get(url=url,headers=headers).json()
get(response)
#打印最终数字
print(sum)
复制代码
成功突破,解密成功!!!
==注意填写Cookie,我提供的代码没有填写Cookie值==
博主会持续更新。有兴趣的朋友可以==喜欢==,==关注==和==采集==接下来,你们的支持就是我创作的最大动力!
Java学习从入门到大神学习目录索引
博主开源Python爬虫教程目录索引(宝教程,你值得拥有!)
网页抓取解密(解析XML网页链接来抓取指定的内容比如豆瓣电影排行榜,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-11-28 09:05
如果给你一个网页链接来抓取特定内容,比如豆瓣电影排名,怎么做?
其实网页内容的结构和XML很相似,那么我们可以通过解析XML来解析HTML,但是两者的差距还是很大的,好吧,废话不多说,我们开始解析HTML。
然后有很多用于解析 XML 的库。这里我们选择libxml来解析,因为libxml是C语言接口,我找了一个library-hpple,用objective-c来封装接口。它的地址是,然后网页使用豆瓣电影排名。地址是。
接下来,构建一个新项目。项目使用ARC,引入libxml2和hpple库,新建实体类movie。完整的项目结构如下:
movie的实现如下,这是一个实体类,根据爬取的网页内容确定
电影.h
@interface Movie : NSObject
@property(nonatomic, strong) NSString *name;
@property(nonatomic, strong) NSString *imageUrl;
@property(nonatomic, strong) NSString *descrition;
@property(nonatomic, strong) NSString *movieUrl;
@property(nonatomic) NSInteger ratingNumber;
@property(nonatomic, strong) NSString *comment;
@end
所以最重要的部分在这里。不管网页的内容是什么,我们都需要先获取网页的内容。下面是通过NSURLConnection获取整个网页的内容。
- (void)loadHTMLContent
{
NSString *movieUrl = MOVIE_URL;
NSString *urlString = [movieUrl stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
NSURL *url = [NSURL URLWithString:urlString];
NSURLRequest *request = [NSURLRequest requestWithURL:url];
[UIApplication sharedApplication].networkActivityIndicatorVisible = YES;
__weak ViewController *weak_self = self;
[NSURLConnection sendAsynchronousRequest:request queue:[NSOperationQueue mainQueue] completionHandler:^(NSURLResponse *response, NSData *data, NSError *error) {
if (nil == error) {
// NSString *retString = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
// NSLog(@"%@", retString);
[weak_self parserHTML:data];
}
[UIApplication sharedApplication].networkActivityIndicatorVisible = NO;
}];
}
这里只是简单的访问web内容,一些HTTP和错误处理本文没有讨论,所以这里的代码比较简单,上面代码中有一个parserHTML:方法,就是解析获取到的web内容和解析网页内容之前,我们先拆解xpath。
假设一个简单的网页内容如下:
Some webpage
<p class=”normal”>This is the first paragraph
This is the second paragraph. This is in bold.
</p>
比如要获取title的内容,那么xpath表达式就是/html/head/title。如果要获取class="special"节点的内容,xpath为/html/body/p[@class=\'special\']。
所以只要找到合适的xpath,就会得到对应的节点内容,接下来我们看看用hpple解析HTML
- (void)parserHTML:(NSData *)data
{
if (nil != data) {
TFHpple *movieParser = [TFHpple hppleWithHTMLData:data];
NSString *movieXpathQueryString = @"/html/body/div[@id=\'wrapper\']/div[@id=\'content\']/div[@class=\'grid-16-8 clearfix\']/div[@class=\'article\']/div[@class=\'indent\']/table/tr/td/a[@class=\'nbg\']";
NSArray *movieNodes = [movieParser searchWithXPathQuery:movieXpathQueryString];
for (TFHppleElement *element in movieNodes) {
Movie *m = [[Movie alloc] init];
m.name = [element objectForKey:@"title"];
m.movieUrl = [element objectForKey:@"href"];
for (TFHppleElement *child in element.children) {
if ([child.tagName isEqualToString:@"img"]) {
@try {
m.imageUrl = [child objectForKey:@"src"];
}
@catch (NSException *exception) {
}
}
}
[self.movies addObject:m];
}
[self.movieTableView reloadData];
}
}
在代码中,找到首页对应节点的路径,然后searchWithXPathQuery得到一个数组。遍历组织数据后,可以在表格视图中显示。具体效果如下:
好了,网页的内容已经抓到了,实际的项目比这个复杂,所以,这只是一个指导性的例子。
参考:
注:本文为小涵原创,请支持原创!转载请附上原文链接: 查看全部
网页抓取解密(解析XML网页链接来抓取指定的内容比如豆瓣电影排行榜,)
如果给你一个网页链接来抓取特定内容,比如豆瓣电影排名,怎么做?
其实网页内容的结构和XML很相似,那么我们可以通过解析XML来解析HTML,但是两者的差距还是很大的,好吧,废话不多说,我们开始解析HTML。
然后有很多用于解析 XML 的库。这里我们选择libxml来解析,因为libxml是C语言接口,我找了一个library-hpple,用objective-c来封装接口。它的地址是,然后网页使用豆瓣电影排名。地址是。
接下来,构建一个新项目。项目使用ARC,引入libxml2和hpple库,新建实体类movie。完整的项目结构如下:
movie的实现如下,这是一个实体类,根据爬取的网页内容确定
电影.h
@interface Movie : NSObject
@property(nonatomic, strong) NSString *name;
@property(nonatomic, strong) NSString *imageUrl;
@property(nonatomic, strong) NSString *descrition;
@property(nonatomic, strong) NSString *movieUrl;
@property(nonatomic) NSInteger ratingNumber;
@property(nonatomic, strong) NSString *comment;
@end
所以最重要的部分在这里。不管网页的内容是什么,我们都需要先获取网页的内容。下面是通过NSURLConnection获取整个网页的内容。
- (void)loadHTMLContent
{
NSString *movieUrl = MOVIE_URL;
NSString *urlString = [movieUrl stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
NSURL *url = [NSURL URLWithString:urlString];
NSURLRequest *request = [NSURLRequest requestWithURL:url];
[UIApplication sharedApplication].networkActivityIndicatorVisible = YES;
__weak ViewController *weak_self = self;
[NSURLConnection sendAsynchronousRequest:request queue:[NSOperationQueue mainQueue] completionHandler:^(NSURLResponse *response, NSData *data, NSError *error) {
if (nil == error) {
// NSString *retString = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
// NSLog(@"%@", retString);
[weak_self parserHTML:data];
}
[UIApplication sharedApplication].networkActivityIndicatorVisible = NO;
}];
}
这里只是简单的访问web内容,一些HTTP和错误处理本文没有讨论,所以这里的代码比较简单,上面代码中有一个parserHTML:方法,就是解析获取到的web内容和解析网页内容之前,我们先拆解xpath。
假设一个简单的网页内容如下:
Some webpage
<p class=”normal”>This is the first paragraph
This is the second paragraph. This is in bold.
</p>
比如要获取title的内容,那么xpath表达式就是/html/head/title。如果要获取class="special"节点的内容,xpath为/html/body/p[@class=\'special\']。
所以只要找到合适的xpath,就会得到对应的节点内容,接下来我们看看用hpple解析HTML
- (void)parserHTML:(NSData *)data
{
if (nil != data) {
TFHpple *movieParser = [TFHpple hppleWithHTMLData:data];
NSString *movieXpathQueryString = @"/html/body/div[@id=\'wrapper\']/div[@id=\'content\']/div[@class=\'grid-16-8 clearfix\']/div[@class=\'article\']/div[@class=\'indent\']/table/tr/td/a[@class=\'nbg\']";
NSArray *movieNodes = [movieParser searchWithXPathQuery:movieXpathQueryString];
for (TFHppleElement *element in movieNodes) {
Movie *m = [[Movie alloc] init];
m.name = [element objectForKey:@"title"];
m.movieUrl = [element objectForKey:@"href"];
for (TFHppleElement *child in element.children) {
if ([child.tagName isEqualToString:@"img"]) {
@try {
m.imageUrl = [child objectForKey:@"src"];
}
@catch (NSException *exception) {
}
}
}
[self.movies addObject:m];
}
[self.movieTableView reloadData];
}
}
在代码中,找到首页对应节点的路径,然后searchWithXPathQuery得到一个数组。遍历组织数据后,可以在表格视图中显示。具体效果如下:
好了,网页的内容已经抓到了,实际的项目比这个复杂,所以,这只是一个指导性的例子。
参考:
注:本文为小涵原创,请支持原创!转载请附上原文链接:
网页抓取解密(网易云技能点界面概况静态网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-28 06:09
)
技能点界面概览静态网页
网易云仍然有一些网页随着页面的变化而改变url。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。目前这样的借口有很多,这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先搞清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么encText生成的规则就很清楚了us.Twice.AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
返回 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。你可以寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。偏移量是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用'\0'
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
查看全部
网页抓取解密(网易云技能点界面概况静态网页
)
技能点界面概览静态网页
网易云仍然有一些网页随着页面的变化而改变url。您只需要抓取网页进行分析。
动态网页
但是随着前后端分离的普及,数据分离的好处是显而易见的。越来越多的数据使用ajax渲染。即便如此,网易云的评论也是如此。
前端和后端的分离刚刚变得炙手可热。当时,很多网站并没有太多的借口来保护自己。它让很多网站 很容易得到结果。目前这样的借口有很多,这种网站爬行就是傻瓜式爬行。
但是随着前端技术的发展,接口变得越来越难。拿网易云的评论来说:它的参数很混乱。
这串数字究竟是什么?很多人看到这样的数据会选择放弃。那我给你解开。
页面分析 step1:查找参数
可以看到,有两个参数,一个是params,一个是encSecKey,都是加密的。我们必须分析它的来源。F12 开源并搜索 encSckey。
'在这个js里面寻找encSecKey,我发现它在这里。用断点调试后,发现这是最后一个参数的结果。
step2:分析js函数
这个js有4w多行。如何在4w多行js中找到有用的信息,然后在这里理清思路?
这需要你的抽象和逆向思维。来,我们开始分析。
var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "女孩", "惊恐", "大笑"]));
e3x.data = k4o.cz4D({
params: bYc7V.encText,
encSecKey: bYc7V.encSecKey
})
上面这段代码是源码。我们先不管 JSON.stringify(i3x) 参数是什么,先搞清楚 window.asrsea 是什么。不远处你会发现:
这就是d函数就是所有的数据,方法的根,四个参数d、e、f、g就是我们刚才说的不关心的参数。
从这个函数是分析:encText是b()函数传递了两次,encSecKey是c()函数之后执行的一个参数。注意i参数的来源是a(16)。网上看看这些函数。
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d = 1)
e = Math.random() * b.length,
e = Math.floor(e),
c = b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
可以发现a(16)是一个随机生成的数,所以我们不需要关心它。而b目前是AES cbc模式加密的。那么encText生成的规则就很清楚了us.Twice.AES cbc加密,offset是60708,两个key不同,函数c是RSA加密的三个参数,整体算法流程差不多有点了解了。
暂时停在这里,不分析函数,我们在分析数据。
step3:分析参数
返回 var bYc7V = window.asrsea(JSON.stringify(i3x), bkY2x(["流泪", "强"]), bkY2x(VM8E.md), bkY2x(["爱心", "girl", "horrified ", "Laughing"])) 这个函数。直觉上我能感觉到有些数据肯定和我们的核心参数没有关系,顶多跟时间戳有关。
找到bky2x的来源,
再去寻找,其实是没有必要的。你可以寻找这种功能。可以复制到vscode中查找根本原因。分析,这里不做繁琐的介绍。只是中断分析!看看他是如何执行的。
实际上,通过多次捕获,您会发现最后三个参数是固定的(非交互式数据)。
然而,我最想要的是第一个参数
你心里的参数是这样的,所以和预期的差不多,只有第一个参数和我们的参数有关。偏移量是page*20,R_SO_4_songid是当前歌曲的id。其实这时候你的i和encSecKey就可以一起保存了。因为上面分析说这个i是随机生成的,encSecKey和我们的核心参数无关,而是和i有关,所以我们需要记录一个组。用作 ESA 加密参数和 post 请求参数。
你现在是不是很兴奋,因为我真的很想快点浮出水面。
第4步:检查
这一步也是很重要的一个环节,因为你会在它的js里面找到。
网易会做些什么吗?下载原创js进行测试。找到了哈哈,结果是一致的。那么就不需要再次更改该加密算法的代码。
架构图是
step5:转换为python代码
AES的cbc模式的代码需要用Python克隆。达到加密的效果,测试一下。发现同样的结果很好
编写爬虫
让我们开始编写一个爬虫。首先使用邮递员测试这些参数。
没问题,写个爬虫。根据你喜欢的兄弟。输入id生成你的爱字云!每个人的美好时光!
import requests
import urllib.parse
import base64
from wordcloud import WordCloud
import jieba.analyse
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
header={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
#'Postman-Token':'4cbfd1e6-63bf-4136-a041-e2678695b419',
"origin":'https://music.163.com',
#'referer':'https://music.163.com/song?id=1372035522',
#'accept-encoding':'gzip,deflate,br',
'Accept':'*/*',
'Host':'music.163.com',
'content-lenth':'472',
'Cache-Control':'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'Connection':'keep-alive',
#'Cookie':'iuqxldmzr_=32; _ntes_nnid=a6f29f40998c88c693bc910331bd6bea,1558011234325; _ntes_nuid=a6f29f40998c88c693bc910331bd6bea; _ga=GA1.2.2120707788.1559308501; WM_TID=pV2C%2BjTrRwBBAAERUVJojniTwk8%2B8Zta; JSESSIONID-WYYY=nvf%2BggodQRfcT%2BTvBRmANqMrsDeQCxRvqwFsxDr3eJvNNWhGYFhfCXKFkfAfOdbHhpCsMzT39mAeJ7ZamBQZbiwwtnSZD%5CPWRqKxD9t6dGKD3bTVjomjgB39DB07RNIWI32bYKa2H4fg1qQgqI%2FR%2B%2Br%2BZXJvgFg1Vh%2FA2XRj9S4p0EMu%3A1560927288799; WM_NI=DthwcEQf5Ew2NbTIZmSNhSnm%2F8VWsg5RxhkYogvs2luEwZ6m5UhdzbHYPIr654ZBWKV4o22%2BEwb9BvdLS%2BFOmOAEUG%2B8xd8az4CX%2FiAL%2BZkz3syA0onCPkhQwCtL4pkUcjg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed2d650989c9cd1dc4bb6b88eb2c84e979f9aaff773afb6fb83d950bcb19ecce92af0fea7c3b92a88aca898e24f93bafba6f63a8ebe9caad9679192a8b4ed67ede89ab8f26df78eb889ea53adb9ba94b168b79bb9bbb567f78ba885f96a8c87a0aaf13ef7ec96a3d64196eca1d3b12187a9aedac17ea8949dccc545af918fa6d84de9e8b885bb6bbaec8db9ae638394e5bbea72f1adb7a2b365ae9da08ceb5bb59dbcadb77ca98bad8be637e2a3'
}
def pkcs7padding(text):
"""
明文使用PKCS7填充
最终调用AES加密方法时,传入的是一个byte数组,要求是16的整数倍,因此需要对明文进行处理
:param text: 待加密内容(明文)
:return:
"""
bs = AES.block_size # 16
length = len(text)
bytes_length = len(bytes(text, encoding='utf-8'))
# tips:utf-8编码时,英文占1个byte,而中文占3个byte
padding_size = length if(bytes_length == length) else bytes_length
padding = bs - padding_size % bs
# tips:chr(padding)看与其它语言的约定,有的会使用'\0'
padding_text = chr(padding) * padding
return text + padding_text
def encrypt(key, content):
"""
AES加密
key,iv使用同一个
模式cbc
填充pkcs7
:param key: 密钥
:param content: 加密内容
:return:
"""
key_bytes = bytes(key, encoding='utf-8')
iv = bytes('0102030405060708', encoding='utf-8')
cipher = AES.new(key_bytes, AES.MODE_CBC, iv)
# 处理明文
content_padding = pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(bytes(content_padding, encoding='utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def getcomment(songid,page):
url="https://music.163.com/weapi/v1 ... ot%3B
print(url)
formdata = {
"params": "",
"encSecKey": "c81160c64a08feb6cfed91c1619d5bffd05dd278b685c94a748689edf035ee0436b66aa7019927ce0fedd26aee9a22cdc6743e58a120f9db0126ebb2e61dae3f7ee21088eb747f829bceed9a5bbb9ee7a2eecf1a358feac431acaab17c95b8491a6a955f7c17a02a3e7886390c2cb3b981f4ccbd5163a566d27ace95db073401",
}
aes_key = '0CoJUm6Qyw8W8jud'## 不变的
print('aes_key:' + aes_key)
# 对英文加密
source_en = '{"rid":"R_SO_4_'+songid+'","offset":"'+str(page*20)+'","total":"false","limit":"20","csrf_token":""}'
#offset自己该
print(source_en)
encrypt_en = encrypt(aes_key, source_en)#第一次加密
print(encrypt_en)
aes_key='3Unu7SzdXGctW1vA'
encrypt_en = encrypt(aes_key, str(encrypt_en)) # 第二次加密
print(encrypt_en)
formdata['params']=encrypt_en
print(formdata['params'])
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
print(formdata)
req = requests.post(url=url, data=formdata, headers=header)
return req.json()
if __name__ == '__main__':
songid='346576'
page=0
text=''
for page in range(10):
comment=getcomment(songid,page)
comment=comment['comments']
for va in comment:
print (va['content'])
text+=va['content']
ags = jieba.analyse.extract_tags(text, topK=50) # jieba分词关键词提取,40个
print(ags)
text = " ".join(ags)
backgroud_Image = plt.imread('tt.jpg') # 如果需要个性化词云
wc = WordCloud(background_color="white",
width=1200, height=900,
mask=backgroud_Image, # 设置背景图片
#min_font_size=50,
font_path="simhei.ttf",
max_font_size=200, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(text)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() # 如果展示的话需要一个个点
file = 'image/' + str("aita") + '.png'
wc.to_file(file)
网页抓取解密( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-28 06:08
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
查看全部
网页抓取解密(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
网页抓取解密(电影类型试多个,在列表里,需要转一下。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-27 19:01
尝试多种电影类型,在列表中,您需要翻转它。电影时长有下一行等符号,需要转入str处理和之前获取评论时一样的数据。
具体需要解密部分数据参考地址:
想法:
首先请求页面的字体下载。之前的公众意见是下载和回收字体。这是一次访问和下载一个。下载后整理好对应的词典,下载后保存到自己的工程中,再次打开即可。将保存的字体文件通过绘制方法绘制成图片,打开图片即可获取绘制图片的文字。组成数字和字符的字典,获取页面中的字符,判断字典中要替换的字符,得到想要的加密数据:
总结:在大众点评获得的原字体基础上,加图再识别图文对比!
在代码上:
猫眼.py
<p># -*- coding: utf-8 -*-
import json
import numpy
import os
import re
import requests
import scrapy
from PIL import Image, ImageDraw, ImageFont
from fontTools.ttLib import TTFont
from lxml import html
# 创建etree模块
from pytesseract import image_to_string
from myfilm import settings
from myfilm.items import MyfilmItem
etree = html.etree
from scrapy import Request
class MaoyanSpider(scrapy.Spider):
name = 'maoyan'
allowed_domains = ['maoyan.com']
# start_urls = ['http://maoyan.com/']
fontstr = ""#定义一个字体文件的字符串
headers = {
#此处为你自己的浏览器版本
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"
}
#cookie的值上面有相应需求整理,我放到了settings中
cookies = settings.cookies
def start_requests(self):
'''
重写start_requests函数
:return:
'''
urllist = [
'https://maoyan.com/films?showType=3'
]
for url in urllist:
yield Request(url=url,headers=self.headers, cookies=self.cookies, callback=self.parse)
def parse(self, response):
'''
解析电影列表页面
:param response:
:return:
'''
##获取列表
ddlist = response.xpath("//div[@class='container']//div[@class='movies-panel']//dl[@class='movie-list']//dd")
##遍历获取每个电影的信息
for dd in ddlist:
filmdic = {
"id": dd.xpath(".//div[@class='movie-item']//a//@href").get() or "",
"film_id": str(dd.xpath(".//div[@class='movie-item']//a//@href").get()).split('/')[2] or "",
"cname": dd.xpath(".//div[contains(@class,'movie-item-title')]//a//text()").get() or "null",
"thumb": dd.xpath(".//div[@class='movie-item']//a//img[last()]//@data-src").get() or "default",
"score": dd.xpath(".//div[contains(@class,'channel-detail-orange')]//text()").get() or "0",
}
# print("filmdic=====",filmdic)
#获取详情链接
_url = "https://maoyan.com" + filmdic["id"]
yield Request(url=_url, headers=self.headers, cookies=self.cookies, callback=self.parse_detail,
meta={"filmdic": filmdic})
#判断下一页是否存在 获取当前页
page=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[@class='active']//a//@class").get() or "null"
# print("page=========",page)
now_page = str(page).split('_')[1]
lastpage=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[last()]//a//@class").get() or "null"
# print("lastpage=====",lastpage)
last_page = str(lastpage).split('_')[1]
if int(last_page) == int(now_page) + 1:
##说明有下一页
href=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[last()]//a//@href").get()#跳转拼接的路径
nexturl = "https://maoyan.com/films" + href
# print("nexturl====一下一页路径",nexturl)
yield Request(url=nexturl, headers=self.headers, cookies=self.cookies, callback=self.parse,dont_filter=True)
def parse_detail(self, response):
'''
解析详情页面数据
:param response:
:return:
'''
filmItem = MyfilmItem()
#获取上个页面传过来的值
type=response.xpath("//div[@class='movie-brief-container']//li[1]//a//text()").extract()
length=response.xpath("//div[@class='movie-brief-container']//li[2]//text()").get()
# print("type====",type,"length====",length)
filmdic = response.meta.get("filmdic")
#先获取简单表面上的数据
filmItem["film_id"] = filmdic["film_id"]
filmItem["thumb"] = filmdic["thumb"]
filmItem["cname"] = filmdic["cname"]
filmItem["ename"] = response.xpath("//div[contains(@class,'ename')]//text()").get()
filmItem["type"] = json.dumps(type)
filmItem["length"] = str(length).replace('\n', '').replace(' ', '')
filmItem["time"] = response.xpath("//div[@class='movie-brief-container']//li[3]//text()").get()
filmItem["tickets_unit"] = response.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][2]//span[@class='unit']//text()").get() or "none"
#获取到整个页面的内容
htmllist = response.text
# print(htmls)
#正则查找本次请求字体文件的url
font_file = re.findall(r'//vfile.meituan.net/colorstone/(\w+\.woff)', htmllist)[0]
# 先判断是否下载过字体,避免重复下载浪费空间
if self.fontstr == "":
# 把这个字体文件名在全局变量中记录一下
self.fontstr = font_file
else:
#先把原有的字体删除,再重新赋值 拼接下载地址
os.remove("static/" + self.fontstr)
self.fontstr = font_file
fonturl = "https://vfile.meituan.net/colorstone/" + font_file
#调用下载方法,下载该字体文件
self.save_font(font_file, fonturl)
#每次字体文件不一样并且字体文件中的编码以及所对应的值的顺序也不一样
# 虽然编码不停变化但是每个字的图元是固定的,所以需要新字体与最开始下载的字体的每个字的图元进行比较
fontdic = self.get_font(self.fontstr)
# 查看是否在字典里 发现替换
for key in fontdic:
if key in htmllist:
htmllist = htmllist.replace(key, str(fontdic[key]))
# print(htmllist)
htmldata = etree.HTML(htmllist)
#获取票房数量
ticketslist = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][2]//span[@class='stonefont']//text()")
if ticketslist:
# 当票房存在
filmItem["ticketNumber"] = "".join(str(ticketslist[0]).split(';'))
else:
filmItem["ticketNumber"] = "暂无"
#获取评论人数 若暂无评分归0
if filmdic["score"] == "暂无评分":
filmItem["score"] = filmdic["score"]
filmItem["score_num"] = "0"
else:
# 有评分获取数值
index_left = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][1]//span[contains(@class,'index-left')]//span[@class='stonefont']//text()")
filmItem["score"] = "".join(str(index_left[0]).split(';'))
index_right = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][1]//div[@class='index-right']//span[@class='stonefont']//text()")
filmItem["score_num"] = "".join(str(index_right[0]).split(';'))
yield filmItem
def save_font(self, file_name, url):
'''
字体文件保存到项目中
:param file_name:
:return:
'''
# 需要判断指定的文件夹是否存在,若不存在就创建
dir = "static"
self.creatDir(dir)
savePath = dir + "/" + file_name
response = requests.get(url)
# 写入文件中
with open(savePath, 'wb') as f:
f.write(response.content)
f.flush()
return file_name
def creatDir(self, dir):
'''
判断指定的文件夹是否存在 创建文件夹
:param dir:
:return:
'''
dirlist = dir.split("/")
# print("dirlist====",dirlist)
for index, name in enumerate(dirlist):
# print("index==",index,name)
itemdir = os.path.join(os.getcwd(), name)
# 判断当前文件夹是否存在
if not os.path.exists(itemdir):
os.mkdir(itemdir)
# 如果当前文件夹存在并且不是最后一层
if index 查看全部
网页抓取解密(电影类型试多个,在列表里,需要转一下。)
尝试多种电影类型,在列表中,您需要翻转它。电影时长有下一行等符号,需要转入str处理和之前获取评论时一样的数据。
具体需要解密部分数据参考地址:
想法:
首先请求页面的字体下载。之前的公众意见是下载和回收字体。这是一次访问和下载一个。下载后整理好对应的词典,下载后保存到自己的工程中,再次打开即可。将保存的字体文件通过绘制方法绘制成图片,打开图片即可获取绘制图片的文字。组成数字和字符的字典,获取页面中的字符,判断字典中要替换的字符,得到想要的加密数据:
总结:在大众点评获得的原字体基础上,加图再识别图文对比!
在代码上:
猫眼.py
<p># -*- coding: utf-8 -*-
import json
import numpy
import os
import re
import requests
import scrapy
from PIL import Image, ImageDraw, ImageFont
from fontTools.ttLib import TTFont
from lxml import html
# 创建etree模块
from pytesseract import image_to_string
from myfilm import settings
from myfilm.items import MyfilmItem
etree = html.etree
from scrapy import Request
class MaoyanSpider(scrapy.Spider):
name = 'maoyan'
allowed_domains = ['maoyan.com']
# start_urls = ['http://maoyan.com/']
fontstr = ""#定义一个字体文件的字符串
headers = {
#此处为你自己的浏览器版本
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"
}
#cookie的值上面有相应需求整理,我放到了settings中
cookies = settings.cookies
def start_requests(self):
'''
重写start_requests函数
:return:
'''
urllist = [
'https://maoyan.com/films?showType=3'
]
for url in urllist:
yield Request(url=url,headers=self.headers, cookies=self.cookies, callback=self.parse)
def parse(self, response):
'''
解析电影列表页面
:param response:
:return:
'''
##获取列表
ddlist = response.xpath("//div[@class='container']//div[@class='movies-panel']//dl[@class='movie-list']//dd")
##遍历获取每个电影的信息
for dd in ddlist:
filmdic = {
"id": dd.xpath(".//div[@class='movie-item']//a//@href").get() or "",
"film_id": str(dd.xpath(".//div[@class='movie-item']//a//@href").get()).split('/')[2] or "",
"cname": dd.xpath(".//div[contains(@class,'movie-item-title')]//a//text()").get() or "null",
"thumb": dd.xpath(".//div[@class='movie-item']//a//img[last()]//@data-src").get() or "default",
"score": dd.xpath(".//div[contains(@class,'channel-detail-orange')]//text()").get() or "0",
}
# print("filmdic=====",filmdic)
#获取详情链接
_url = "https://maoyan.com" + filmdic["id"]
yield Request(url=_url, headers=self.headers, cookies=self.cookies, callback=self.parse_detail,
meta={"filmdic": filmdic})
#判断下一页是否存在 获取当前页
page=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[@class='active']//a//@class").get() or "null"
# print("page=========",page)
now_page = str(page).split('_')[1]
lastpage=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[last()]//a//@class").get() or "null"
# print("lastpage=====",lastpage)
last_page = str(lastpage).split('_')[1]
if int(last_page) == int(now_page) + 1:
##说明有下一页
href=response.xpath("//div[@class='container']//div[@class='movies-panel']//div[@class='movies-pager']//li[last()]//a//@href").get()#跳转拼接的路径
nexturl = "https://maoyan.com/films" + href
# print("nexturl====一下一页路径",nexturl)
yield Request(url=nexturl, headers=self.headers, cookies=self.cookies, callback=self.parse,dont_filter=True)
def parse_detail(self, response):
'''
解析详情页面数据
:param response:
:return:
'''
filmItem = MyfilmItem()
#获取上个页面传过来的值
type=response.xpath("//div[@class='movie-brief-container']//li[1]//a//text()").extract()
length=response.xpath("//div[@class='movie-brief-container']//li[2]//text()").get()
# print("type====",type,"length====",length)
filmdic = response.meta.get("filmdic")
#先获取简单表面上的数据
filmItem["film_id"] = filmdic["film_id"]
filmItem["thumb"] = filmdic["thumb"]
filmItem["cname"] = filmdic["cname"]
filmItem["ename"] = response.xpath("//div[contains(@class,'ename')]//text()").get()
filmItem["type"] = json.dumps(type)
filmItem["length"] = str(length).replace('\n', '').replace(' ', '')
filmItem["time"] = response.xpath("//div[@class='movie-brief-container']//li[3]//text()").get()
filmItem["tickets_unit"] = response.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][2]//span[@class='unit']//text()").get() or "none"
#获取到整个页面的内容
htmllist = response.text
# print(htmls)
#正则查找本次请求字体文件的url
font_file = re.findall(r'//vfile.meituan.net/colorstone/(\w+\.woff)', htmllist)[0]
# 先判断是否下载过字体,避免重复下载浪费空间
if self.fontstr == "":
# 把这个字体文件名在全局变量中记录一下
self.fontstr = font_file
else:
#先把原有的字体删除,再重新赋值 拼接下载地址
os.remove("static/" + self.fontstr)
self.fontstr = font_file
fonturl = "https://vfile.meituan.net/colorstone/" + font_file
#调用下载方法,下载该字体文件
self.save_font(font_file, fonturl)
#每次字体文件不一样并且字体文件中的编码以及所对应的值的顺序也不一样
# 虽然编码不停变化但是每个字的图元是固定的,所以需要新字体与最开始下载的字体的每个字的图元进行比较
fontdic = self.get_font(self.fontstr)
# 查看是否在字典里 发现替换
for key in fontdic:
if key in htmllist:
htmllist = htmllist.replace(key, str(fontdic[key]))
# print(htmllist)
htmldata = etree.HTML(htmllist)
#获取票房数量
ticketslist = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][2]//span[@class='stonefont']//text()")
if ticketslist:
# 当票房存在
filmItem["ticketNumber"] = "".join(str(ticketslist[0]).split(';'))
else:
filmItem["ticketNumber"] = "暂无"
#获取评论人数 若暂无评分归0
if filmdic["score"] == "暂无评分":
filmItem["score"] = filmdic["score"]
filmItem["score_num"] = "0"
else:
# 有评分获取数值
index_left = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][1]//span[contains(@class,'index-left')]//span[@class='stonefont']//text()")
filmItem["score"] = "".join(str(index_left[0]).split(';'))
index_right = htmldata.xpath("//div[contains(@class,'celeInfo-right')]//div[@class='movie-index'][1]//div[@class='index-right']//span[@class='stonefont']//text()")
filmItem["score_num"] = "".join(str(index_right[0]).split(';'))
yield filmItem
def save_font(self, file_name, url):
'''
字体文件保存到项目中
:param file_name:
:return:
'''
# 需要判断指定的文件夹是否存在,若不存在就创建
dir = "static"
self.creatDir(dir)
savePath = dir + "/" + file_name
response = requests.get(url)
# 写入文件中
with open(savePath, 'wb') as f:
f.write(response.content)
f.flush()
return file_name
def creatDir(self, dir):
'''
判断指定的文件夹是否存在 创建文件夹
:param dir:
:return:
'''
dirlist = dir.split("/")
# print("dirlist====",dirlist)
for index, name in enumerate(dirlist):
# print("index==",index,name)
itemdir = os.path.join(os.getcwd(), name)
# 判断当前文件夹是否存在
if not os.path.exists(itemdir):
os.mkdir(itemdir)
# 如果当前文件夹存在并且不是最后一层
if index
网页抓取解密(使用者再网上查询相关python抓取数据的代码图:其中cookie部分 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-27 18:22
)
免责声明:本代码采集的数据可用于研究学习,请勿用于商业用途,否则由此产生的商业纠纷由用户自行负责
最近需要用到环境国家省会城市的历史数据pm2.5,正好天气网()提供历史数据查询,所以在线查询相关python爬取数据代码,主要是参考这篇博文:
导入 urllib.request;
2. URL增加了反爬取措施,因为它是爬取历史数据,实际是(city)/(date).html。比如北京201907的数据链接是:,但是你用的是新浏览器如果直接在上面打开上面的连接,会返回如下页面:
这也是网上很多python爬虫无法爬取数据的原因。找个理由,你要先访问我,然后到上面的页面返回就ok了。我猜可能是前端在访问主页时写了一个cookie。因此,您可以再次按F12查看页面的cookie数据,如下图:cookie部分已经用红线标出,请求url时直接添加headers。使用这个方法:req=urllib .request.Request(url=url,headers=my_headers),其中
my_headers = {
"Host": "lishi.tianqi.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Referer": "http://lishi.tianqi.com/Accept-Encoding: gzip, deflate",
"Cookie": "cityPy=xianqu; cityPy_expire=1565422933; UM_distinctid=16c566dd356244-05e0d9cb0c361-3f385c06-1fa400-16c566dd357642; Hm_lvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818134; CNZZDATA1275796416=927309794-1564814113-%7C1564814113; Hm_lpvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818280"},具体代码见下面代码
代码显示如下:
import random
import socket
import sys
import urllib
import urllib.request
from bs4 import BeautifulSoup
#reload(sys)
#sys.('utf8')
socket.setdefaulttimeout(30.0)
def parseTianqi(url):
my_headers = {
"Host": "lishi.tianqi.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Referer": "http://lishi.tianqi.com/Accept-Encoding: gzip, deflate",
"Cookie": "cityPy=xianqu; cityPy_expire=1565422933; UM_distinctid=16c566dd356244-05e0d9cb0c361-3f385c06-1fa400-16c566dd357642; Hm_lvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818134; CNZZDATA1275796416=927309794-1564814113-%7C1564814113; Hm_lpvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818280"}
req = urllib.request.Request(url=url, headers=my_headers)
req.add_header("Content-Type", "application/json")
fails = 0
while True:
try:
if fails >= 3:
break
req_data = urllib.request.urlopen(req)
response_data = req_data.read()
response_data = response_data.decode('gbk').encode('utf-8')
return response_data
except urllib.request.URLError as e:
fails += 1
print ('网络连接出现问题, 正在尝试再次请求: ', fails)
else:
break
def witeCsv(data, file_name):
file = open(file_name, 'w',-1,'utf-8')
soup = BeautifulSoup(data, 'html.parser')
weather_list = soup.select('div[class="tqtongji2"]')
for weather in weather_list:
weather_date = weather.select('a')[0].string.encode('utf-8')
ul_list = weather.select('ul')
i = 0
for ul in ul_list:
li_list = ul.select('li')
str = ""
for li in li_list:
str += li.string.encode('utf-8').decode() + ','
if i != 0:
file.write(str + '\n')
i += 1
file.close()
# 根据图片主页,抓取当前图片下面的相信图片
if __name__ == "__main__":
data = parseTianqi("http://lishi.tianqi.com/beijing/201907.html");
witeCsv(data, "beijing_201907"); 查看全部
网页抓取解密(使用者再网上查询相关python抓取数据的代码图:其中cookie部分
)
免责声明:本代码采集的数据可用于研究学习,请勿用于商业用途,否则由此产生的商业纠纷由用户自行负责
最近需要用到环境国家省会城市的历史数据pm2.5,正好天气网()提供历史数据查询,所以在线查询相关python爬取数据代码,主要是参考这篇博文:
导入 urllib.request;
2. URL增加了反爬取措施,因为它是爬取历史数据,实际是(city)/(date).html。比如北京201907的数据链接是:,但是你用的是新浏览器如果直接在上面打开上面的连接,会返回如下页面:
这也是网上很多python爬虫无法爬取数据的原因。找个理由,你要先访问我,然后到上面的页面返回就ok了。我猜可能是前端在访问主页时写了一个cookie。因此,您可以再次按F12查看页面的cookie数据,如下图:cookie部分已经用红线标出,请求url时直接添加headers。使用这个方法:req=urllib .request.Request(url=url,headers=my_headers),其中
my_headers = {
"Host": "lishi.tianqi.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Referer": "http://lishi.tianqi.com/Accept-Encoding: gzip, deflate",
"Cookie": "cityPy=xianqu; cityPy_expire=1565422933; UM_distinctid=16c566dd356244-05e0d9cb0c361-3f385c06-1fa400-16c566dd357642; Hm_lvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818134; CNZZDATA1275796416=927309794-1564814113-%7C1564814113; Hm_lpvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818280"},具体代码见下面代码
代码显示如下:
import random
import socket
import sys
import urllib
import urllib.request
from bs4 import BeautifulSoup
#reload(sys)
#sys.('utf8')
socket.setdefaulttimeout(30.0)
def parseTianqi(url):
my_headers = {
"Host": "lishi.tianqi.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Referer": "http://lishi.tianqi.com/Accept-Encoding: gzip, deflate",
"Cookie": "cityPy=xianqu; cityPy_expire=1565422933; UM_distinctid=16c566dd356244-05e0d9cb0c361-3f385c06-1fa400-16c566dd357642; Hm_lvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818134; CNZZDATA1275796416=927309794-1564814113-%7C1564814113; Hm_lpvt_ab6a683aa97a52202eab5b3a9042a8d2=1564818280"}
req = urllib.request.Request(url=url, headers=my_headers)
req.add_header("Content-Type", "application/json")
fails = 0
while True:
try:
if fails >= 3:
break
req_data = urllib.request.urlopen(req)
response_data = req_data.read()
response_data = response_data.decode('gbk').encode('utf-8')
return response_data
except urllib.request.URLError as e:
fails += 1
print ('网络连接出现问题, 正在尝试再次请求: ', fails)
else:
break
def witeCsv(data, file_name):
file = open(file_name, 'w',-1,'utf-8')
soup = BeautifulSoup(data, 'html.parser')
weather_list = soup.select('div[class="tqtongji2"]')
for weather in weather_list:
weather_date = weather.select('a')[0].string.encode('utf-8')
ul_list = weather.select('ul')
i = 0
for ul in ul_list:
li_list = ul.select('li')
str = ""
for li in li_list:
str += li.string.encode('utf-8').decode() + ','
if i != 0:
file.write(str + '\n')
i += 1
file.close()
# 根据图片主页,抓取当前图片下面的相信图片
if __name__ == "__main__":
data = parseTianqi("http://lishi.tianqi.com/beijing/201907.html";);
witeCsv(data, "beijing_201907");
网页抓取解密(网站排名好不好,流量多不多,其中一个关键的因素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-24 09:01
网站 排名好吗?没有太多的交通。其中一个关键因素是网站收录如何,虽然收录不能直接决定网站的排名,但是网站的基础是内容。如果没有内容,更难排名好。好的内容可以让用户和搜索引擎满意,还可以给网站加分,从而提升排名,扩大网站的曝光页面。
而如果你想让更多的网站页面成为收录,你必须先让网页被百度蜘蛛抓取,我们能不能不说收录,我们需要首先爬取它们跟进收录。
那么网站怎样才能更好的被百度蜘蛛抓取呢?
1.网站 和页面权重
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的抓取频率非常高,大家都知道搜索引擎蜘蛛是为了保证网站不是所有的页面都会被抓取,而且网站的权重越高,爬取的深度越高,相应的可以爬取的页面也就越多,这样可以收录的页面也会越多。
2.网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那真是谢天谢地了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛你的体验越来越差,你对网站的评价会越来越低,自然会影响你对网站的爬取,所以你一定愿意选择空间服务器。没有很好的基础。,再好的房子也会倒塌。
3.网站 更新频率
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动展示给蜘蛛文章更新,让蜘蛛按照你的规则有效爬行,不仅让你的更新文章更快被抓到,而且不会导致蜘蛛频繁跑徒然。
4.文章的原创性别
优质的原创 内容对百度蜘蛛非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供有价值的 原创 内容。如果蜘蛛能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.平面网站结构
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
6.网站程序
在网站程序中,有很多程序可以创建大量的重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的爬取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设
大家都知道外链可以吸引蜘蛛到网站,尤其是新网站的时候,网站还不是很成熟,蜘蛛访问量比较少,外链可以在网站页面中加入网站暴露在蜘蛛面前可以防止蜘蛛无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。
8.内链建设
蜘蛛的爬取是跟随链接的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的收录。内链建设过程中应给予用户合理的推荐。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都有用,让蜘蛛爬取一个更广泛的页面。 查看全部
网页抓取解密(网站排名好不好,流量多不多,其中一个关键的因素)
网站 排名好吗?没有太多的交通。其中一个关键因素是网站收录如何,虽然收录不能直接决定网站的排名,但是网站的基础是内容。如果没有内容,更难排名好。好的内容可以让用户和搜索引擎满意,还可以给网站加分,从而提升排名,扩大网站的曝光页面。
而如果你想让更多的网站页面成为收录,你必须先让网页被百度蜘蛛抓取,我们能不能不说收录,我们需要首先爬取它们跟进收录。
那么网站怎样才能更好的被百度蜘蛛抓取呢?
1.网站 和页面权重
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的抓取频率非常高,大家都知道搜索引擎蜘蛛是为了保证网站不是所有的页面都会被抓取,而且网站的权重越高,爬取的深度越高,相应的可以爬取的页面也就越多,这样可以收录的页面也会越多。
2.网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那真是谢天谢地了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛你的体验越来越差,你对网站的评价会越来越低,自然会影响你对网站的爬取,所以你一定愿意选择空间服务器。没有很好的基础。,再好的房子也会倒塌。
3.网站 更新频率
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动展示给蜘蛛文章更新,让蜘蛛按照你的规则有效爬行,不仅让你的更新文章更快被抓到,而且不会导致蜘蛛频繁跑徒然。
4.文章的原创性别
优质的原创 内容对百度蜘蛛非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供有价值的 原创 内容。如果蜘蛛能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.平面网站结构
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
6.网站程序
在网站程序中,有很多程序可以创建大量的重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的爬取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设
大家都知道外链可以吸引蜘蛛到网站,尤其是新网站的时候,网站还不是很成熟,蜘蛛访问量比较少,外链可以在网站页面中加入网站暴露在蜘蛛面前可以防止蜘蛛无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。
8.内链建设
蜘蛛的爬取是跟随链接的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的收录。内链建设过程中应给予用户合理的推荐。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都有用,让蜘蛛爬取一个更广泛的页面。
网页抓取解密(解密百科,启程seo有自己的说法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-22 04:09
说起破译百科,徐七成有自己的看法。大家一定要关注百度百科。百度百科不仅方便了读者,也是我们SEO的一个很好的资源。所以说到百科,不能只说百度百科。,以下是seo的具体介绍。
一、采集整理百科资源。
1、采集百科资源:seo是一项细致的工作。百度百科出来的那天,很多百科全书接连出现。那么我们不仅要关注百度百科,还要关注其他百科,这里为大家搜集了一些百科资源(百度百科;互动百科;维基百科;中国百科;大百科,搜搜百科;小百科,大行家;360百科;站长百科全书。)
2、 整理百科资源:整理资源就是为了更好的利用资源。那么百科资源和问答资源是一样的。您需要先注册,然后填写信息,提出ID,使用ID。可以参考(实战获取流量的第七个关键方法:问答训练与开发),这里不再赘述。
二、百科资源分析。
我在这里要说明的是,所有的百科资源都是一样的。下面主要以百度百科为例。如果我们要使用百科资料,就需要对百科资源进行深入的分析。以下是百度百科的(网带_百度百科)实例分析。
1、 百度百科标题解析。如下
网带-wikiwand
我们可以看到百度百科的标题简洁准确,这里也对标题进行了详细分析。
2、百科全书的关键词和描述。
对于百度百科的关键词和描述,我们可以看到百度没有做关键词和描述。这里的seo设置并没有否定关键字和描述的重要性,主要是因为我们从这里可以看出标题对于一个网站性很重要,所以这里还是要重复一下,标题定位准确,做一次性完成,不要更改。
3、百科内容分析。
A:先说一下内容的标题吧。这里百度百科对网带使用标签,网带和栏目页面使用标签,标签用于具体内容。这些标签可以告诉我们在以后的网站建设中如何安排内容,也可以告诉我们这些标签的具体应用。
B:让我们谈谈目录。从网带百度百科可以看出,目录处理是在这里完成的。目录处理不仅方便读者阅读,也方便阅读,加上目录的锚点处理,让读者阅读更轻松、更快捷。,准确度,这也是我们在建网站时应该学习的地方。
C:我们说一下百度的图片,包括图集:我这里要说一下图库。百科里的图片也是从用户体验出发的。图文并茂,一目了然。
D:内部链接:这是最重要的部分。强大的百科全书内部链接。强大的内部链接不仅可以友好地链接完全相关的条目,还可以友好地组织相关条目。这也是百科4年PR到8的主要原因之一。
三、百科资源的使用。
这里主要分享一下百度百科的应用技巧。
1、百科培训技巧:申请ID后,我们要做的第一步就是按照百科的任务去做。我们可以先做任务,然后我们可以通过做任务来达到第二个层次。下一步是创建百科条目和编辑条目。对于条目的创作,我有个人意见。当我们开始创建条目时,不要急于添加超链接,创建条目时,我们也不应该一次完成它们,以便以后添加链接。百度百科是不断完善的,只有我们的东西比百科好,才有机会加链接。对于编辑条目,我们必须继续组织信息,完善我们自己页面上的信息,有图片和文字,然后可以添加超链接。
2、 百科资源的使用:使用包括创建条目和编辑。我们可以从其他百科资源中采集数据,然后整合这些数据。但是,我们在创建条目和编辑条目时必须具体分类。包括栏目的分类,栏目下方的小分类,此外还需要全图文字,甚至还要加个图库。不过记得不要着急,先完善自己的东西,再去编辑和创作。否则百度不会给链接。
3、百科全书的超链接和图库。超链接包括指向百科全书本身的链接,以及指向参考资料和扩展阅读的链接。我们需要开始的是参考资料和扩展阅读的链接,所以我们在做百科的时候要加链接,那么我们的文章一定是一个大百科,比百度百科的信息和图片更完整。所以要强调的是,你必须为自己留出空间。
四、百科全书资源推荐。
我这里讲的是,不管是百度百科还是其他百科全书,归结起来就是一个大的资源采集和资源整合,所以从这里我们不仅要学会如何整合采集 ,还要学习如何采集。页面布局和链接布局,以及标签在百科中的应用。
上图:只是七成seo个人在百科上的实战总结。希望对大家有帮助,也希望大家多多交流,完善每个贡献者的文章,方便大家。
版权声明:启程seo首发于chinaz和我的博客,欢迎转载讨论,转载请保留原作者信息,谢谢合作!
请注明:SEO爱站net »Xiamen网站 优化:实战获取流量的关键方法8:解密百科 查看全部
网页抓取解密(解密百科,启程seo有自己的说法,你知道吗?)
说起破译百科,徐七成有自己的看法。大家一定要关注百度百科。百度百科不仅方便了读者,也是我们SEO的一个很好的资源。所以说到百科,不能只说百度百科。,以下是seo的具体介绍。
一、采集整理百科资源。
1、采集百科资源:seo是一项细致的工作。百度百科出来的那天,很多百科全书接连出现。那么我们不仅要关注百度百科,还要关注其他百科,这里为大家搜集了一些百科资源(百度百科;互动百科;维基百科;中国百科;大百科,搜搜百科;小百科,大行家;360百科;站长百科全书。)
2、 整理百科资源:整理资源就是为了更好的利用资源。那么百科资源和问答资源是一样的。您需要先注册,然后填写信息,提出ID,使用ID。可以参考(实战获取流量的第七个关键方法:问答训练与开发),这里不再赘述。
二、百科资源分析。
我在这里要说明的是,所有的百科资源都是一样的。下面主要以百度百科为例。如果我们要使用百科资料,就需要对百科资源进行深入的分析。以下是百度百科的(网带_百度百科)实例分析。
1、 百度百科标题解析。如下
网带-wikiwand
我们可以看到百度百科的标题简洁准确,这里也对标题进行了详细分析。
2、百科全书的关键词和描述。
对于百度百科的关键词和描述,我们可以看到百度没有做关键词和描述。这里的seo设置并没有否定关键字和描述的重要性,主要是因为我们从这里可以看出标题对于一个网站性很重要,所以这里还是要重复一下,标题定位准确,做一次性完成,不要更改。
3、百科内容分析。
A:先说一下内容的标题吧。这里百度百科对网带使用标签,网带和栏目页面使用标签,标签用于具体内容。这些标签可以告诉我们在以后的网站建设中如何安排内容,也可以告诉我们这些标签的具体应用。
B:让我们谈谈目录。从网带百度百科可以看出,目录处理是在这里完成的。目录处理不仅方便读者阅读,也方便阅读,加上目录的锚点处理,让读者阅读更轻松、更快捷。,准确度,这也是我们在建网站时应该学习的地方。
C:我们说一下百度的图片,包括图集:我这里要说一下图库。百科里的图片也是从用户体验出发的。图文并茂,一目了然。
D:内部链接:这是最重要的部分。强大的百科全书内部链接。强大的内部链接不仅可以友好地链接完全相关的条目,还可以友好地组织相关条目。这也是百科4年PR到8的主要原因之一。
三、百科资源的使用。
这里主要分享一下百度百科的应用技巧。
1、百科培训技巧:申请ID后,我们要做的第一步就是按照百科的任务去做。我们可以先做任务,然后我们可以通过做任务来达到第二个层次。下一步是创建百科条目和编辑条目。对于条目的创作,我有个人意见。当我们开始创建条目时,不要急于添加超链接,创建条目时,我们也不应该一次完成它们,以便以后添加链接。百度百科是不断完善的,只有我们的东西比百科好,才有机会加链接。对于编辑条目,我们必须继续组织信息,完善我们自己页面上的信息,有图片和文字,然后可以添加超链接。
2、 百科资源的使用:使用包括创建条目和编辑。我们可以从其他百科资源中采集数据,然后整合这些数据。但是,我们在创建条目和编辑条目时必须具体分类。包括栏目的分类,栏目下方的小分类,此外还需要全图文字,甚至还要加个图库。不过记得不要着急,先完善自己的东西,再去编辑和创作。否则百度不会给链接。
3、百科全书的超链接和图库。超链接包括指向百科全书本身的链接,以及指向参考资料和扩展阅读的链接。我们需要开始的是参考资料和扩展阅读的链接,所以我们在做百科的时候要加链接,那么我们的文章一定是一个大百科,比百度百科的信息和图片更完整。所以要强调的是,你必须为自己留出空间。
四、百科全书资源推荐。
我这里讲的是,不管是百度百科还是其他百科全书,归结起来就是一个大的资源采集和资源整合,所以从这里我们不仅要学会如何整合采集 ,还要学习如何采集。页面布局和链接布局,以及标签在百科中的应用。
上图:只是七成seo个人在百科上的实战总结。希望对大家有帮助,也希望大家多多交流,完善每个贡献者的文章,方便大家。
版权声明:启程seo首发于chinaz和我的博客,欢迎转载讨论,转载请保留原作者信息,谢谢合作!
请注明:SEO爱站net »Xiamen网站 优化:实战获取流量的关键方法8:解密百科
网页抓取解密(1.利用burp网站post提交密文的数据2.利用requests.post访问网站并获取返回内容(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-19 16:12
0x0 原点
今天群里的一个小伙伴也在写这个,我也没什么好做的。
我也会写一些空闲时间的痛苦,可能有些地方有一些相似之处。
他用bs4来获取的,不限于用re
附上他的博客文章:
0x1 的想法:
1.使用burp拦截网站post提交的数据
2.使用requesst.post模拟浏览器访问获取返回内容
3. 通过正则过滤md5解密结果
0x2 Text 1.使用burp截取网站post提交的数据提交密文
2.使用requests.post访问网站并获取返回的内容
import requests
import re
import sys
url = 'http://pmd5.com' #目标网站
data = {
'__VIEWSTATE': '/wEPDwUKMTM4NTE3OTkzOWRkP4hmXYtPPhcBjbupZdLOLfmeTK4=',
'__VIEWSTATEGENERATOR': 'CA0B0334',
'__EVENTVALIDATION': '/wEWAwK75ZuyDwLigPTXCQKU9f3vAheUenitfEuJ6eGUVe2GyFzb7HKC',
'key': '7a57a5a743894a0e',
'jiemi': 'MD5解密'
}
#key处 为需要解密的md5密文,在后面我们改成可以修改的
r = requests.post(url=url,data=data)
con = r.text
3. 通过正则过滤md5解密结果
发现标签中收录md5解密结果
a = re.compile('(.*?)')
result = a.findall(con)
list = '\n'.join(result)
print list
4.最后我们使用函数让代码更具可读性
# coding:utf-8
import requests
import re
import sys
def md5(keywd):
url = 'http://pmd5.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
data = {
'__VIEWSTATE': '/wEPDwUKMTM4NTE3OTkzOWRkP4hmXYtPPhcBjbupZdLOLfmeTK4=',
'__VIEWSTATEGENERATOR': 'CA0B0334',
'__EVENTVALIDATION': '/wEWAwK75ZuyDwLigPTXCQKU9f3vAheUenitfEuJ6eGUVe2GyFzb7HKC',
'key': '{}'.format(keywd),
'jiemi': 'MD5解密'
}
r = requests.post(url=url,headers=headers,data=data)
con = r.text
a = re.compile('(.*?)')
result = a.findall(con)
list = '\n'.join(result)
print list
if __name__=='__main__':
try:
keywd = sys.argv[1]
md5(keywd)
except:
print "python md5_pmd5.py $md5"
好了,今天就到此为止。这是我第一次写文章。可能不是很好,格式也有点问题。我稍后会更正。 查看全部
网页抓取解密(1.利用burp网站post提交密文的数据2.利用requests.post访问网站并获取返回内容(组图))
0x0 原点
今天群里的一个小伙伴也在写这个,我也没什么好做的。
我也会写一些空闲时间的痛苦,可能有些地方有一些相似之处。
他用bs4来获取的,不限于用re
附上他的博客文章:
0x1 的想法:
1.使用burp拦截网站post提交的数据
2.使用requesst.post模拟浏览器访问获取返回内容
3. 通过正则过滤md5解密结果
0x2 Text 1.使用burp截取网站post提交的数据提交密文
2.使用requests.post访问网站并获取返回的内容
import requests
import re
import sys
url = 'http://pmd5.com' #目标网站
data = {
'__VIEWSTATE': '/wEPDwUKMTM4NTE3OTkzOWRkP4hmXYtPPhcBjbupZdLOLfmeTK4=',
'__VIEWSTATEGENERATOR': 'CA0B0334',
'__EVENTVALIDATION': '/wEWAwK75ZuyDwLigPTXCQKU9f3vAheUenitfEuJ6eGUVe2GyFzb7HKC',
'key': '7a57a5a743894a0e',
'jiemi': 'MD5解密'
}
#key处 为需要解密的md5密文,在后面我们改成可以修改的
r = requests.post(url=url,data=data)
con = r.text
3. 通过正则过滤md5解密结果
发现标签中收录md5解密结果
a = re.compile('(.*?)')
result = a.findall(con)
list = '\n'.join(result)
print list
4.最后我们使用函数让代码更具可读性
# coding:utf-8
import requests
import re
import sys
def md5(keywd):
url = 'http://pmd5.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
data = {
'__VIEWSTATE': '/wEPDwUKMTM4NTE3OTkzOWRkP4hmXYtPPhcBjbupZdLOLfmeTK4=',
'__VIEWSTATEGENERATOR': 'CA0B0334',
'__EVENTVALIDATION': '/wEWAwK75ZuyDwLigPTXCQKU9f3vAheUenitfEuJ6eGUVe2GyFzb7HKC',
'key': '{}'.format(keywd),
'jiemi': 'MD5解密'
}
r = requests.post(url=url,headers=headers,data=data)
con = r.text
a = re.compile('(.*?)')
result = a.findall(con)
list = '\n'.join(result)
print list
if __name__=='__main__':
try:
keywd = sys.argv[1]
md5(keywd)
except:
print "python md5_pmd5.py $md5"
好了,今天就到此为止。这是我第一次写文章。可能不是很好,格式也有点问题。我稍后会更正。
网页抓取解密( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-19 16:10
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
查看全部
网页抓取解密(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
网页抓取解密(苹果手机网页抓取解密版本及源码地址:-gqxn8tfgoadjug.jpg)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-17 01:01
网页抓取解密版本及源码地址:-gqxn8tfgoadjug.jpg运用网页破解技术,在所有页面包括二维码扫描页,抓取同一页面的全部内容,利用这个思路,所有的微信包转换成txt文件可打开,转换成word文档可打开。
苹果手机上用过一个叫苹果助手的,
帮你扫描给你分析
国内用户:使用微信扫一扫,具体工具:专门用于手机的手机扫一扫工具包微信扫一扫红包辅助点击一下会将红包发出去,但是不能收红包二维码:(这些二维码是以/bin/mkjava。io/i2buzz这样的名称存在的)在微信-我-钱包-其他应用-右上角,这时微信会自动推荐一些二维码,假如这些二维码你使用过可以扫一扫即可收到广告,假如你不喜欢,也可以拒绝扫。
另:国外:让你的二维码自动推荐给你打开这些网站你可以扫这些网站的收款码然后微信会弹出来一个txt,使用正确方法的话可以推送到微信。
用过智扫
微信扫一扫可以观察自己的收款金额是多少,下个月的钱都用了哪些渠道,再选择一些带有自己名字和电话号码的合作方,回访下业务。如果碰上金额很大或者用户很多的话,建议人工挑选。手机网页都可以扫一扫。ios没试过, 查看全部
网页抓取解密(苹果手机网页抓取解密版本及源码地址:-gqxn8tfgoadjug.jpg)
网页抓取解密版本及源码地址:-gqxn8tfgoadjug.jpg运用网页破解技术,在所有页面包括二维码扫描页,抓取同一页面的全部内容,利用这个思路,所有的微信包转换成txt文件可打开,转换成word文档可打开。
苹果手机上用过一个叫苹果助手的,
帮你扫描给你分析
国内用户:使用微信扫一扫,具体工具:专门用于手机的手机扫一扫工具包微信扫一扫红包辅助点击一下会将红包发出去,但是不能收红包二维码:(这些二维码是以/bin/mkjava。io/i2buzz这样的名称存在的)在微信-我-钱包-其他应用-右上角,这时微信会自动推荐一些二维码,假如这些二维码你使用过可以扫一扫即可收到广告,假如你不喜欢,也可以拒绝扫。
另:国外:让你的二维码自动推荐给你打开这些网站你可以扫这些网站的收款码然后微信会弹出来一个txt,使用正确方法的话可以推送到微信。
用过智扫
微信扫一扫可以观察自己的收款金额是多少,下个月的钱都用了哪些渠道,再选择一些带有自己名字和电话号码的合作方,回访下业务。如果碰上金额很大或者用户很多的话,建议人工挑选。手机网页都可以扫一扫。ios没试过,
网页抓取解密(如何能使正则表达式在源代码中抓取解密-python网页抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 09:19
网页抓取解密-python网页抓取解密我们知道,页面只有抓取到源代码以后,才能再向下进行抓取。但是在抓取页面源代码之前,我们是要先进行正则表达式的匹配的。我们已经抓取到了整个页面,而且页面用了一个空白的标题。这么做就是为了进行页面解密。正则表达式抓取大部分页面都会使用到正则表达式。正则表达式是从给定的文本中匹配某种特定的字符串。
正则表达式还有固定的参数字符串,即所匹配的字符串必须是字符串。正则表达式与我们平时所用的汉字类似,同样是汉字表示,并且可以限定其宽度。比如我们的刚接触正则表达式并不陌生,比如说我们找到在域名中包含两个汉字的网站,那么正则表达式就是[“\w”,“\d”,“\d”]而如果我们想让自己抓取的页面具有短地址,那么正则表达式就是["\w","\d","\d"]那么如何能使正则表达式在源代码中找到源代码呢?首先我们可以去查找我们想要找到的页面中的url地址。
如果没有的话,我们就使用urllib库中的正则表达式去匹配页面的url。这样一来我们的目标页面就出现在我们的解密的区域中了。今天的正则表达式就抓取到页面源代码,而我们接下来要去分析下这个页面中的信息。抓取sitemappage.pya.首先我们需要对文章进行分词,以便我们去比对正则表达式匹配到的到底是哪一个。
b.sitemappage.py是我们可以让其包含多个url,然后对于每一个url中的信息,我们要进行初步的分析。下图可以很好的体现下sitemappage.py内部的结构。首先是根据出现的频率分类,例如出现频率最高的内容为service是一个服务项目,那么就去找这个service项目下的所有相关文件的内容,然后再找其所在文件夹,我们通过层层的信息去分析到这个页面所包含的内容,例如其中包含详细的所有说明文件,其中包含service项目下所有相关的内容的所有文件的内容,然后就去将service项目下所有相关的内容下载出来,作为我们所需要的数据。
到此为止,sitemappage.py文件已经抓取到了页面内容。c.把我们所需要的数据去掉,留下包含我们需要的内容的sitemappage.py文件。接下来就是我们要解密的过程了。我们在解密所抓取的源代码之前,我们需要先去解密sitemappage.py文件的所有内容。这里,首先通过对html的解析,去dir命令中去匹配哪一段代码中包含了正则表达式里面的内容,或者我们直接去解析页面源代码中的目录就可以了。
下图可以展示出sitemappage.py文件的内容去到解密过程中,我们可以逐渐分析页面,我们可以看出页面的源代码一共有六部分,其中的每一部分都是一个文件。 查看全部
网页抓取解密(如何能使正则表达式在源代码中抓取解密-python网页抓取)
网页抓取解密-python网页抓取解密我们知道,页面只有抓取到源代码以后,才能再向下进行抓取。但是在抓取页面源代码之前,我们是要先进行正则表达式的匹配的。我们已经抓取到了整个页面,而且页面用了一个空白的标题。这么做就是为了进行页面解密。正则表达式抓取大部分页面都会使用到正则表达式。正则表达式是从给定的文本中匹配某种特定的字符串。
正则表达式还有固定的参数字符串,即所匹配的字符串必须是字符串。正则表达式与我们平时所用的汉字类似,同样是汉字表示,并且可以限定其宽度。比如我们的刚接触正则表达式并不陌生,比如说我们找到在域名中包含两个汉字的网站,那么正则表达式就是[“\w”,“\d”,“\d”]而如果我们想让自己抓取的页面具有短地址,那么正则表达式就是["\w","\d","\d"]那么如何能使正则表达式在源代码中找到源代码呢?首先我们可以去查找我们想要找到的页面中的url地址。
如果没有的话,我们就使用urllib库中的正则表达式去匹配页面的url。这样一来我们的目标页面就出现在我们的解密的区域中了。今天的正则表达式就抓取到页面源代码,而我们接下来要去分析下这个页面中的信息。抓取sitemappage.pya.首先我们需要对文章进行分词,以便我们去比对正则表达式匹配到的到底是哪一个。
b.sitemappage.py是我们可以让其包含多个url,然后对于每一个url中的信息,我们要进行初步的分析。下图可以很好的体现下sitemappage.py内部的结构。首先是根据出现的频率分类,例如出现频率最高的内容为service是一个服务项目,那么就去找这个service项目下的所有相关文件的内容,然后再找其所在文件夹,我们通过层层的信息去分析到这个页面所包含的内容,例如其中包含详细的所有说明文件,其中包含service项目下所有相关的内容的所有文件的内容,然后就去将service项目下所有相关的内容下载出来,作为我们所需要的数据。
到此为止,sitemappage.py文件已经抓取到了页面内容。c.把我们所需要的数据去掉,留下包含我们需要的内容的sitemappage.py文件。接下来就是我们要解密的过程了。我们在解密所抓取的源代码之前,我们需要先去解密sitemappage.py文件的所有内容。这里,首先通过对html的解析,去dir命令中去匹配哪一段代码中包含了正则表达式里面的内容,或者我们直接去解析页面源代码中的目录就可以了。
下图可以展示出sitemappage.py文件的内容去到解密过程中,我们可以逐渐分析页面,我们可以看出页面的源代码一共有六部分,其中的每一部分都是一个文件。
网页抓取解密(一个中一个基础表的数据从另一个网站采集开始 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-15 14:06
)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志提示。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考一下。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本 查看全部
网页抓取解密(一个中一个基础表的数据从另一个网站采集开始
)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志提示。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考一下。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
网页抓取解密(关键词标签网页论题标签(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-08 21:02
关键词 标签
网络主题标签
网页浏览器标签
检测文件标签
“网页描述”的代码标签和关键字标签是最重要的。建议每个网页都带有这两个标签。关于网页页眉的编写(指h标签)。一般来说,它用于修改网页的主标题,即段落标题,也就是段落中的节标题。对于关键词的使用,使用第一批最重要的关键词,第二批重要的关键词使用,以此类推。注意在使用关键词时,不要让标题失去可读性,要考虑读者的感受。
10)网站 外链优化操作。
(1)登录搜索引擎
(2)登录著名站点导航列表,链接很多,(需要注意的是,链接的站点必须与添加的网站有一定联系,我们可以理解为亲戚,也就是同种网站,而不是手机链接给养鱼人,尽量让别人的站链接自己,这样可以增加网站的pr值。链接也有交换链接,这里需要注意,首先检查对方的网站是否作弊,因为一旦链接到一个被搜索引擎惩罚的网站,你的< @网站 不可信。)关于网站 内部链接,使用最好的关键词(你认为最重要的关键词)进行链接。对于留言簿和博客的链接,建议在网站中找到实用且有意义的文章 留言簿或博客链接不要重复贴,以免被怀疑与对方文章堆积垃圾。
11) 搜索引擎优化中常见的误解和错误。请注意不要使用以下的做法,会让你的网站受到搜索引擎的惩罚
(1)桥页,跳转页
(2)关键词 叠加,如:优化手机,标签上写着:手机手机手机手机手机,这是不明智的
(3)关键词 积累,如:使用标签,一些不好的优化器在网页中插入很多透明图片,设置图片大小为1*1图形,然后添加这样的关键词( 4)隐藏文字和透明文字
(5)细文是指在网页不显眼的地方用较小的字体写带有关键词的句子。一般这些关键词放在页面的顶部或底部网页。
(6)盲眼法是指伪装网页的方法,首先判断访问者是普通访问者还是搜索引擎,从而显示不同的网页。这是一种欺骗搜索引擎的盲目方法.网站一字印!(7)网络劫持是指抄袭别人的网站内容或整个网站,自己盗梁换帖网站 。
对外宣传违规操作
(1)重新提交你自己的网站
(2)隐藏链接,如:使用与网页文字相同的特征,如颜色、字体相同,将链接隐藏在透明图片中,将数百甚至数千个链接隐藏在一个小的图片。
(3)复制页面和镜像,搜索引擎不希望网站占用关键词的相同内容的结果。因此,搜索引擎发现多个网站发布相同的如果是邮箱,则在所述结果中仅显示其中之一。
(4)域名轰炸,简单来说就是注册n个域名提交或者注册n个网址在名站导航中(5)转,这是色情网址的常用方法,在为了吸引流量,访问者到达一个网站后,整个网站就变成了色情网站,搜索引擎总是遇到http301永久重定向的问题。
(6)博客污染,指的是一些网站评论者经常在博客里发帖,里面隐藏链接可以到达自己的网站。
(7)链接农场是指没有有价值信息的网页。整个网站除了人为列出的其他网站的链接,
每个页面上的其他内容或很少的内容。拯救被搜索引擎除名的网站,首先要仔细深入地检查你的网站,看看问题出在哪里,解决问题,然后提交一个新的收录到谷歌或百度应用,地址:这是谷歌的在线服务中心。记得在主题栏中写上:“reinclusion request”。一般提交后,经过6到8个想法后,即可收到谷歌的回复。
12)网站 培养和监控。SEO是连续的,效果慢,所以你要耐心,每隔一段时间检查一下关键词。如果发现新的关键词,立即优化,多分析竞争。多收费网站。网站要更新,你需要内容。如果没有内容,您可以参考以下信息:
(1)对于产品,
您可以添加产品评论和客户反馈,尤其是许多更新频繁的产品,例如手机。所以。您可以创建其他网页来说明产品。
(2)品牌可以添加公司相关新闻稿,可以是产品、公司信息、市场信息。
最好的方法是使用 Google 的 xml 站点地图告诉 Google 您的 网站 已更新。你需要发现的是,当你的新网站添加了大量内容时,当你对网站结构进行非常大的改动时,搜索引擎可能需要更多的时间来观察和分析你的网站。最后一种方式是考虑使用竞价排名(ppc)来弥补过渡期的流量损失。
13) seo 是一个漫长而漫长的工作,你要有足够的耐心。而且,要随时查看关键词,跟踪添加的网站,分析竞争对手的网站。这是网站唱歌的关键。 查看全部
网页抓取解密(关键词标签网页论题标签(1)_光明网(组图))
关键词 标签
网络主题标签
网页浏览器标签
检测文件标签
“网页描述”的代码标签和关键字标签是最重要的。建议每个网页都带有这两个标签。关于网页页眉的编写(指h标签)。一般来说,它用于修改网页的主标题,即段落标题,也就是段落中的节标题。对于关键词的使用,使用第一批最重要的关键词,第二批重要的关键词使用,以此类推。注意在使用关键词时,不要让标题失去可读性,要考虑读者的感受。
10)网站 外链优化操作。
(1)登录搜索引擎
(2)登录著名站点导航列表,链接很多,(需要注意的是,链接的站点必须与添加的网站有一定联系,我们可以理解为亲戚,也就是同种网站,而不是手机链接给养鱼人,尽量让别人的站链接自己,这样可以增加网站的pr值。链接也有交换链接,这里需要注意,首先检查对方的网站是否作弊,因为一旦链接到一个被搜索引擎惩罚的网站,你的< @网站 不可信。)关于网站 内部链接,使用最好的关键词(你认为最重要的关键词)进行链接。对于留言簿和博客的链接,建议在网站中找到实用且有意义的文章 留言簿或博客链接不要重复贴,以免被怀疑与对方文章堆积垃圾。
11) 搜索引擎优化中常见的误解和错误。请注意不要使用以下的做法,会让你的网站受到搜索引擎的惩罚
(1)桥页,跳转页
(2)关键词 叠加,如:优化手机,标签上写着:手机手机手机手机手机,这是不明智的
(3)关键词 积累,如:使用标签,一些不好的优化器在网页中插入很多透明图片,设置图片大小为1*1图形,然后添加这样的关键词( 4)隐藏文字和透明文字
(5)细文是指在网页不显眼的地方用较小的字体写带有关键词的句子。一般这些关键词放在页面的顶部或底部网页。
(6)盲眼法是指伪装网页的方法,首先判断访问者是普通访问者还是搜索引擎,从而显示不同的网页。这是一种欺骗搜索引擎的盲目方法.网站一字印!(7)网络劫持是指抄袭别人的网站内容或整个网站,自己盗梁换帖网站 。
对外宣传违规操作
(1)重新提交你自己的网站
(2)隐藏链接,如:使用与网页文字相同的特征,如颜色、字体相同,将链接隐藏在透明图片中,将数百甚至数千个链接隐藏在一个小的图片。
(3)复制页面和镜像,搜索引擎不希望网站占用关键词的相同内容的结果。因此,搜索引擎发现多个网站发布相同的如果是邮箱,则在所述结果中仅显示其中之一。
(4)域名轰炸,简单来说就是注册n个域名提交或者注册n个网址在名站导航中(5)转,这是色情网址的常用方法,在为了吸引流量,访问者到达一个网站后,整个网站就变成了色情网站,搜索引擎总是遇到http301永久重定向的问题。
(6)博客污染,指的是一些网站评论者经常在博客里发帖,里面隐藏链接可以到达自己的网站。
(7)链接农场是指没有有价值信息的网页。整个网站除了人为列出的其他网站的链接,
每个页面上的其他内容或很少的内容。拯救被搜索引擎除名的网站,首先要仔细深入地检查你的网站,看看问题出在哪里,解决问题,然后提交一个新的收录到谷歌或百度应用,地址:这是谷歌的在线服务中心。记得在主题栏中写上:“reinclusion request”。一般提交后,经过6到8个想法后,即可收到谷歌的回复。
12)网站 培养和监控。SEO是连续的,效果慢,所以你要耐心,每隔一段时间检查一下关键词。如果发现新的关键词,立即优化,多分析竞争。多收费网站。网站要更新,你需要内容。如果没有内容,您可以参考以下信息:
(1)对于产品,
您可以添加产品评论和客户反馈,尤其是许多更新频繁的产品,例如手机。所以。您可以创建其他网页来说明产品。
(2)品牌可以添加公司相关新闻稿,可以是产品、公司信息、市场信息。
最好的方法是使用 Google 的 xml 站点地图告诉 Google 您的 网站 已更新。你需要发现的是,当你的新网站添加了大量内容时,当你对网站结构进行非常大的改动时,搜索引擎可能需要更多的时间来观察和分析你的网站。最后一种方式是考虑使用竞价排名(ppc)来弥补过渡期的流量损失。
13) seo 是一个漫长而漫长的工作,你要有足够的耐心。而且,要随时查看关键词,跟踪添加的网站,分析竞争对手的网站。这是网站唱歌的关键。
网页抓取解密(网页抓取解密,可以用手机账号登录昨天我遇到这个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-08 09:10
网页抓取解密,所以做出了下面的这个工具,用以学习网页抓取和嗅探的方法。老规矩,代码不放出来了,部分功能已经实现,后续内容将不断更新,争取做到解密和打开测试,运行测试等等。
1、用户手机号码抓取,android版需要该功能,
2、从新浪微博获取验证码,
3、用户输入地址获取链接,其中很多验证码密码识别,初步接触到了这些,有兴趣的同学可以尝试下,有问题的话可以给我留言。大家需要使用的话记得联系我,我会发送链接给大家。
证书一直忘记了在电脑上安装。网上提供的盗号用这个解密。试了几次都是一样的结果。需要实验一下。
前两天被盗号,然后还打不开微博,
今天也刚刚被盗号,号被改了姓名,信息等,安卓手机也是不能设置拦截可疑账号信息,百度一下有各种办法,但是不全是最快的,实验了一下换了手机号,换了ip,打算手动换ip,网上的各种破解方法基本没用,最后刷机,升级到最新系统以后打开飞行模式,发短信,
一样的情况,也打不开,
请问楼主解开了吗我知道可以用手机账号登录
昨天我遇到这个问题打不开是我自己手机的问题打不开之前我点开微博的id的时候就提示要输入手机号改密码 查看全部
网页抓取解密(网页抓取解密,可以用手机账号登录昨天我遇到这个问题)
网页抓取解密,所以做出了下面的这个工具,用以学习网页抓取和嗅探的方法。老规矩,代码不放出来了,部分功能已经实现,后续内容将不断更新,争取做到解密和打开测试,运行测试等等。
1、用户手机号码抓取,android版需要该功能,
2、从新浪微博获取验证码,
3、用户输入地址获取链接,其中很多验证码密码识别,初步接触到了这些,有兴趣的同学可以尝试下,有问题的话可以给我留言。大家需要使用的话记得联系我,我会发送链接给大家。
证书一直忘记了在电脑上安装。网上提供的盗号用这个解密。试了几次都是一样的结果。需要实验一下。
前两天被盗号,然后还打不开微博,
今天也刚刚被盗号,号被改了姓名,信息等,安卓手机也是不能设置拦截可疑账号信息,百度一下有各种办法,但是不全是最快的,实验了一下换了手机号,换了ip,打算手动换ip,网上的各种破解方法基本没用,最后刷机,升级到最新系统以后打开飞行模式,发短信,
一样的情况,也打不开,
请问楼主解开了吗我知道可以用手机账号登录
昨天我遇到这个问题打不开是我自己手机的问题打不开之前我点开微博的id的时候就提示要输入手机号改密码

