
网页抓取解密
网页抓取解密(如何获取我们独立站准确详细的数据网站购物行为数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-16 17:22
最近,我发现了一个问题。一些独立站项目起不来。不是因为人不聪明,做不到。今天就跟大家分享一下如何获取我们独立站的准确详细的数据,从而更有针对性的进行优化推广。
让我先看看,这是我昨天为我们的一位客户设置并获取的 网站 数据
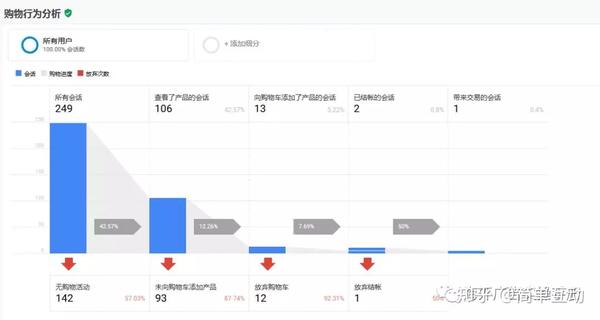
这是网站购物行为数据:
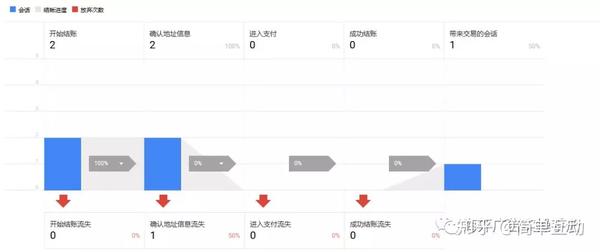
这是 网站 结帐行为数据:
第二张图是因为刚刚部署了技术,所以没有进入支付成功结账的数据。
有了这些现场数据,我们就可以分析网站哪个环节有问题,并有针对性地进行改进。而我们可以通过网站的转化率来推导出我们实现业务目标所需的流量,然后计划增加网站各个渠道的流量。
接下来让我们看看我们如何获取这些数据。
要获取此数据,我们必须执行 2 个步骤:
1. GA 管理后台操作
2. 网站后端部署代码
一、 GA 管理后台操作
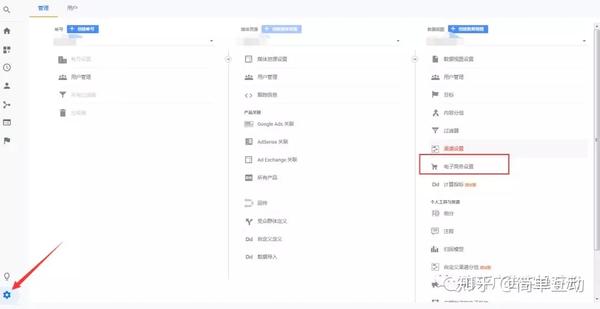
我们先在后台点击管理,然后选择目标数据视图下的电商设置
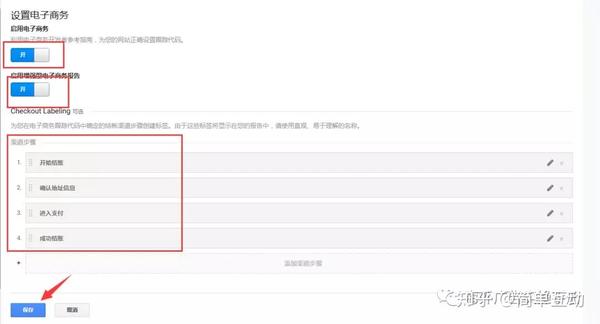
单击启用电子商务设置以启用增强型电子商务设置
这里的通道步长设置对应网站结账行为数据的步长。我们可以自己命名这些步骤,也可以不命名。如果没有给steps命名,也会显示结账行为数据,但是名字类似于step 1 step 2。建议写出来,这样看起来更清晰。
完成后台设置后,我们第二步就是找技术做网站后台代码部署。
2网站后端代码部署
这部分主要分为2个部分。
第一部分首先讲了用哪些码来统计对应的数据。
第二部分讲代码部署示例。
我们先来看代码。在这一部分,我会给你发一张大图。非技术人员只需要阅读描述部分,了解可以统计哪些数据,然后将图片发送给技术,告诉技术要统计的数据。
接下来我们讲例子
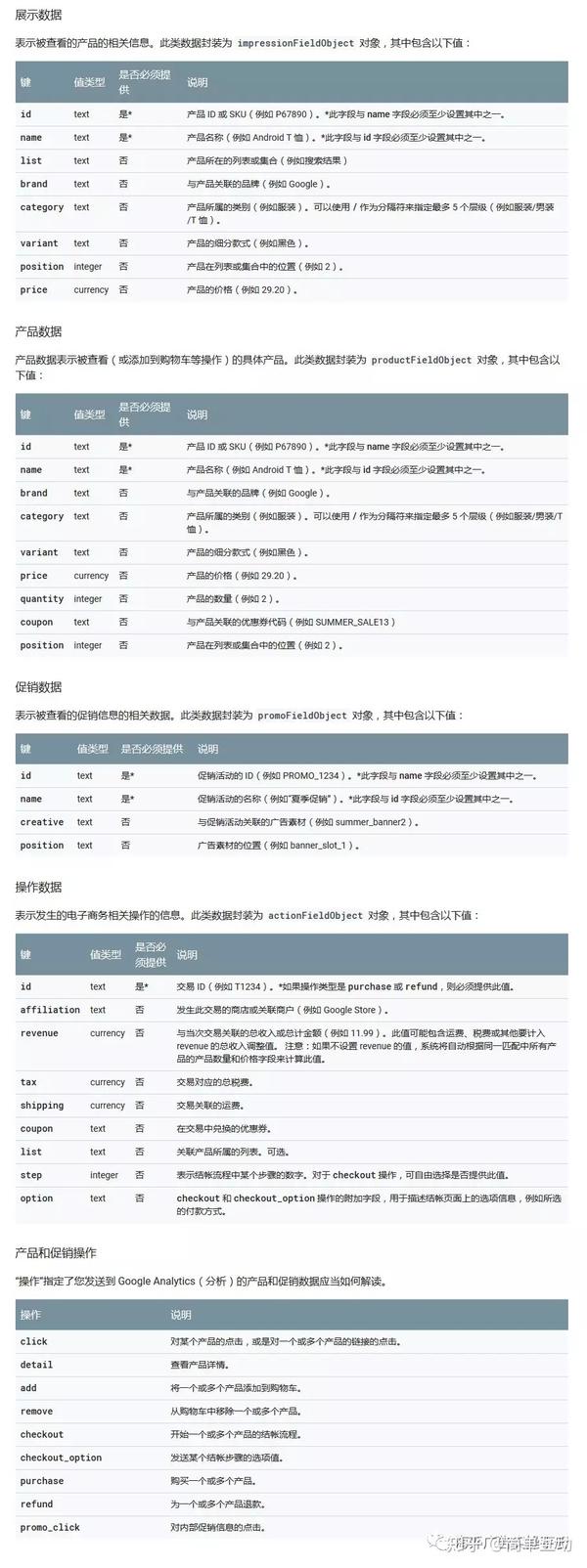
以测量显示为例看结构
测量显示需要 ec:addImpression 命令,所以第一行代码是 ec:addImpression。
紧随其后的是与数据对应的统计信息所需的值。示例中,id为产品ID,category为产品类别,brand为产品品牌,variant为产品细分样式,list为产品所在列表,position为产品在列表,这里的dimension1是自定义数据。
这些都对应于我们之前发布的大图上的代码。
接下来我们看完整的例子:
衡量产品印象
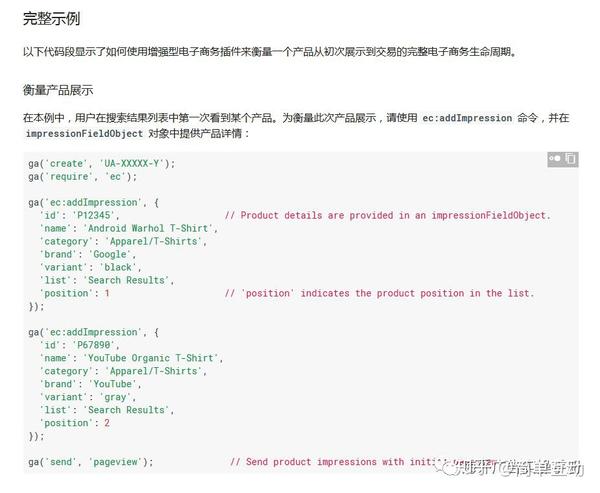
衡量产品点击次数和详细视图
衡量购物车项目的添加和删除
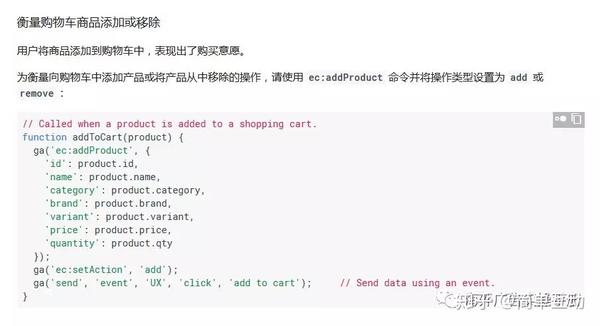
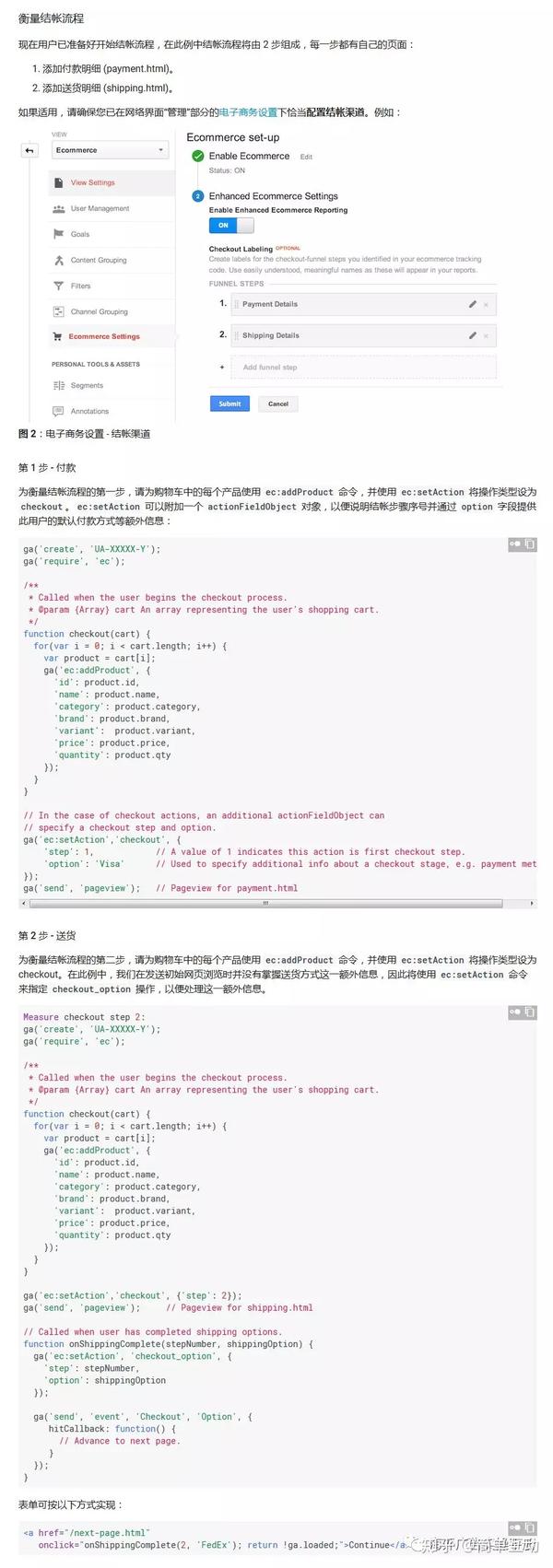
衡量结帐过程
衡量交易
您还可以将这些示例发送给技术。在与技术交流时,我们提供以下内容:
1. 统计不同的数据对应要使用的值,这样就足够发第一张大图了。
2. 告诉我们需要的技术,也就是我们要统计的数据。
3. 将完整示例发送到技术参考。 查看全部
网页抓取解密(如何获取我们独立站准确详细的数据网站购物行为数据)
最近,我发现了一个问题。一些独立站项目起不来。不是因为人不聪明,做不到。今天就跟大家分享一下如何获取我们独立站的准确详细的数据,从而更有针对性的进行优化推广。
让我先看看,这是我昨天为我们的一位客户设置并获取的 网站 数据
这是网站购物行为数据:
这是 网站 结帐行为数据:
第二张图是因为刚刚部署了技术,所以没有进入支付成功结账的数据。
有了这些现场数据,我们就可以分析网站哪个环节有问题,并有针对性地进行改进。而我们可以通过网站的转化率来推导出我们实现业务目标所需的流量,然后计划增加网站各个渠道的流量。
接下来让我们看看我们如何获取这些数据。
要获取此数据,我们必须执行 2 个步骤:
1. GA 管理后台操作
2. 网站后端部署代码
一、 GA 管理后台操作
我们先在后台点击管理,然后选择目标数据视图下的电商设置
单击启用电子商务设置以启用增强型电子商务设置
这里的通道步长设置对应网站结账行为数据的步长。我们可以自己命名这些步骤,也可以不命名。如果没有给steps命名,也会显示结账行为数据,但是名字类似于step 1 step 2。建议写出来,这样看起来更清晰。
完成后台设置后,我们第二步就是找技术做网站后台代码部署。
2网站后端代码部署
这部分主要分为2个部分。
第一部分首先讲了用哪些码来统计对应的数据。
第二部分讲代码部署示例。
我们先来看代码。在这一部分,我会给你发一张大图。非技术人员只需要阅读描述部分,了解可以统计哪些数据,然后将图片发送给技术,告诉技术要统计的数据。
接下来我们讲例子
以测量显示为例看结构

测量显示需要 ec:addImpression 命令,所以第一行代码是 ec:addImpression。
紧随其后的是与数据对应的统计信息所需的值。示例中,id为产品ID,category为产品类别,brand为产品品牌,variant为产品细分样式,list为产品所在列表,position为产品在列表,这里的dimension1是自定义数据。
这些都对应于我们之前发布的大图上的代码。
接下来我们看完整的例子:
衡量产品印象
衡量产品点击次数和详细视图

衡量购物车项目的添加和删除
衡量结帐过程
衡量交易

您还可以将这些示例发送给技术。在与技术交流时,我们提供以下内容:
1. 统计不同的数据对应要使用的值,这样就足够发第一张大图了。
2. 告诉我们需要的技术,也就是我们要统计的数据。
3. 将完整示例发送到技术参考。
网页抓取解密(百度认为什么样的网站更有抓取和收录价值呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-16 17:20
百度认为什么样的网站对爬虫和收录更有价值?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考,具体收录策略包括但不限于所描述的内容。
第一个方面:网站打造为用户提供独特价值的优质内容。
作为一个搜索引擎,百度的最终目的是满足用户的搜索需求,所以要求网站的内容能够首先满足用户的需求。在互联网充斥着大量同质化内容的今天,在也能满足用户需求的前提下,如果你网站提供的内容是独一无二的或者具有一定的独特价值,那么百度会更喜欢到收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站 的内容是“一般或低质量”的,有些网站 甚至使用欺骗来获得更好的收录 或排名。以下是一些常见的情况,虽然不可能一一列举。但请不要冒险。百度有完善的技术支持来发现和处理这些行为。
一些 网站 不是为用户设计的,而是为了从搜索引擎中骗取更多流量。例如,一种内容提交给搜索引擎,另一种内容显示给用户。这些行为包括但不限于:向网页添加隐藏文本或隐藏链接;在与网页内容无关的网页中添加关键词;欺骗性的跳转或重定向;专门为搜索引擎制作桥页;为搜索引擎利用以编程方式生成的内容。
百度会尝试收录提供不同信息的网页。如果你的网站收录很多重复的内容,那么搜索引擎会减少相同内容的收录,并认为网站提供的内容价值不高。
当然,如果网站上的相同内容以不同的形式展示(比如论坛的简化页面、打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。还有助于节省带宽。
第二个方面:网站提供的内容得到了用户和站长的认可和支持
如果一个网站上的内容得到了用户和站长的认可,对于百度来说也是非常值得的收录。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,综合给出一个网站的识别等级。但值得注意的是,这种认可必须基于网站为用户提供优质内容,真实有效。下面仅以网站之间的关系为例来说明百度如何看待其他站长对你的网站的认可: 通常情况下,网站之间的链接可以帮助百度掌握获取工具找到你的网站,增加你网站的认可度。百度将从 A 页面到 B 页面的链接解释为从 A 页面到 B 页面的投票。通过网页投票可以体现对网页本身的“认可度”,有助于提高其他网页的“认可度”。链接的数量、质量和相关性都会影响“批准”的计算。
但请注意,并不是所有的链接都可以参与背书的计算,只有那些自然链接才有效。(自然链接是在网络动态生成过程中,当其他网站s 发现您的内容有价值并认为可能对访问者有帮助时形成的链接。)
其他网站创建与您相关的链接网站的最佳方式是创建独特且相关的内容,这些内容将在互联网上流行起来。您的内容越有用,其他网站管理员就越容易找到对他们的用户有价值的内容,从而链接到您的 网站。在决定是否添加链接之前,您应该考虑:这真的对我的 网站 访问者有益吗?
但是有些网站站长经常不顾链接质量和链接来源交换链接,纯粹为了识别而人为地建立链接关系,这将对他们的网站造成长期影响。
提醒:对网站有不良影响的链接包括但不限于:
第三方面:网站有良好的浏览体验
一个浏览体验好的网站对用户是非常有利的,百度也会认为这样的网站有更好的收录价值。良好的浏览体验意味着:
为用户提供收录 网站 重要部分链接的站点地图和导航。使用户能够清晰、简单地浏览网站,快速找到他们想要的信息。
网站快速的速度可以提高用户满意度并提高网页的整体质量(尤其是对于互联网连接速度较慢的用户)。
确保网站的内容可以在不同的浏览器中正确显示,防止部分用户无法正常访问。
广告是网站的重要收入来源,加入网站广告是合理的,但如果广告过多,会影响用户浏览;或网站有太多不相关的公告窗口和凸窗广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成伤害,那么百度对此类网站的抓取需要减少。
网站的注册权限等权限可以增加网站的注册用户数量,保证网站的内容质量,但是过多的权限设置可能会让新用户失去耐心,带来给用户带来不便。好的经历。从百度的角度来看,它希望减少对用户获取信息过于昂贵的网页的提供。
您想通过在线销售赚钱吗?你想在网上创业吗?你想在网上赚到你的第一桶金吗?如果你想用1000多快钱摆脱现在的工作,加入我们SEOER实战工会团队,让你实现心中的梦想,让你的梦想扬帆起航。. . 成为80后、90后新贵,立即行动! 查看全部
网页抓取解密(百度认为什么样的网站更有抓取和收录价值呢?)
百度认为什么样的网站对爬虫和收录更有价值?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考,具体收录策略包括但不限于所描述的内容。
第一个方面:网站打造为用户提供独特价值的优质内容。
作为一个搜索引擎,百度的最终目的是满足用户的搜索需求,所以要求网站的内容能够首先满足用户的需求。在互联网充斥着大量同质化内容的今天,在也能满足用户需求的前提下,如果你网站提供的内容是独一无二的或者具有一定的独特价值,那么百度会更喜欢到收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站 的内容是“一般或低质量”的,有些网站 甚至使用欺骗来获得更好的收录 或排名。以下是一些常见的情况,虽然不可能一一列举。但请不要冒险。百度有完善的技术支持来发现和处理这些行为。
一些 网站 不是为用户设计的,而是为了从搜索引擎中骗取更多流量。例如,一种内容提交给搜索引擎,另一种内容显示给用户。这些行为包括但不限于:向网页添加隐藏文本或隐藏链接;在与网页内容无关的网页中添加关键词;欺骗性的跳转或重定向;专门为搜索引擎制作桥页;为搜索引擎利用以编程方式生成的内容。
百度会尝试收录提供不同信息的网页。如果你的网站收录很多重复的内容,那么搜索引擎会减少相同内容的收录,并认为网站提供的内容价值不高。
当然,如果网站上的相同内容以不同的形式展示(比如论坛的简化页面、打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。还有助于节省带宽。
第二个方面:网站提供的内容得到了用户和站长的认可和支持
如果一个网站上的内容得到了用户和站长的认可,对于百度来说也是非常值得的收录。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,综合给出一个网站的识别等级。但值得注意的是,这种认可必须基于网站为用户提供优质内容,真实有效。下面仅以网站之间的关系为例来说明百度如何看待其他站长对你的网站的认可: 通常情况下,网站之间的链接可以帮助百度掌握获取工具找到你的网站,增加你网站的认可度。百度将从 A 页面到 B 页面的链接解释为从 A 页面到 B 页面的投票。通过网页投票可以体现对网页本身的“认可度”,有助于提高其他网页的“认可度”。链接的数量、质量和相关性都会影响“批准”的计算。
但请注意,并不是所有的链接都可以参与背书的计算,只有那些自然链接才有效。(自然链接是在网络动态生成过程中,当其他网站s 发现您的内容有价值并认为可能对访问者有帮助时形成的链接。)
其他网站创建与您相关的链接网站的最佳方式是创建独特且相关的内容,这些内容将在互联网上流行起来。您的内容越有用,其他网站管理员就越容易找到对他们的用户有价值的内容,从而链接到您的 网站。在决定是否添加链接之前,您应该考虑:这真的对我的 网站 访问者有益吗?
但是有些网站站长经常不顾链接质量和链接来源交换链接,纯粹为了识别而人为地建立链接关系,这将对他们的网站造成长期影响。
提醒:对网站有不良影响的链接包括但不限于:
第三方面:网站有良好的浏览体验
一个浏览体验好的网站对用户是非常有利的,百度也会认为这样的网站有更好的收录价值。良好的浏览体验意味着:
为用户提供收录 网站 重要部分链接的站点地图和导航。使用户能够清晰、简单地浏览网站,快速找到他们想要的信息。
网站快速的速度可以提高用户满意度并提高网页的整体质量(尤其是对于互联网连接速度较慢的用户)。
确保网站的内容可以在不同的浏览器中正确显示,防止部分用户无法正常访问。
广告是网站的重要收入来源,加入网站广告是合理的,但如果广告过多,会影响用户浏览;或网站有太多不相关的公告窗口和凸窗广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成伤害,那么百度对此类网站的抓取需要减少。
网站的注册权限等权限可以增加网站的注册用户数量,保证网站的内容质量,但是过多的权限设置可能会让新用户失去耐心,带来给用户带来不便。好的经历。从百度的角度来看,它希望减少对用户获取信息过于昂贵的网页的提供。
您想通过在线销售赚钱吗?你想在网上创业吗?你想在网上赚到你的第一桶金吗?如果你想用1000多快钱摆脱现在的工作,加入我们SEOER实战工会团队,让你实现心中的梦想,让你的梦想扬帆起航。. . 成为80后、90后新贵,立即行动!
网页抓取解密(如何提高百度蜘蛛提高频率如何抓取网站四、什么情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-16 10:04
3、机器人协议:这个文件是百度蜘蛛访问的第一个文件。它告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛爬取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:网站权重较高的百度蜘蛛会爬得更频繁更深
2、网站更新频率:更新频率越高,百度蜘蛛越多
3、网站内容质量:网站如果内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好的引导百度蜘蛛进入和爬取。
5、页面深度:页面是否在首页有入口,如果首页有入口,可以更好的爬取和收录。
6、爬取的频率决定了网站要建多少页到数据库收录,这么重要内容的站长该去哪里了解修改,可以去百度站长平台获取Frequency函数的理解,如下图:
百度蜘蛛如何提高爬取频率网站
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页内容优质,用户访问正常,但百度蜘蛛无法抓取,不仅会流失流量,用户也会被百度认为网站不友好,导致网站降级、分数下降、导入网站流量减少等问题。
火龙简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接服务器. 此时,您应该仔细检查。.
2、网络运营商异常:目前国内网络运营商分为中国电信和中国联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常,你可以通过WHOIS查看你的网站IP是否可以解析,如无必要联系域名注册商解决。
4、IP封禁:IP封禁是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站,最好不做这个操作。
5、死链接:表示页面无效,无法提供有效信息。这时候可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛爬取的原理。收录是网站流量的保证,而百度蜘蛛爬网是收录的保证,所以网站只满足网站的要求。百度蜘蛛的爬取规则可以获得更好的排名和流量。
宁德SEO培训 查看全部
网页抓取解密(如何提高百度蜘蛛提高频率如何抓取网站四、什么情况)
3、机器人协议:这个文件是百度蜘蛛访问的第一个文件。它告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛爬取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:网站权重较高的百度蜘蛛会爬得更频繁更深
2、网站更新频率:更新频率越高,百度蜘蛛越多
3、网站内容质量:网站如果内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好的引导百度蜘蛛进入和爬取。
5、页面深度:页面是否在首页有入口,如果首页有入口,可以更好的爬取和收录。
6、爬取的频率决定了网站要建多少页到数据库收录,这么重要内容的站长该去哪里了解修改,可以去百度站长平台获取Frequency函数的理解,如下图:
百度蜘蛛如何提高爬取频率网站
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页内容优质,用户访问正常,但百度蜘蛛无法抓取,不仅会流失流量,用户也会被百度认为网站不友好,导致网站降级、分数下降、导入网站流量减少等问题。
火龙简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接服务器. 此时,您应该仔细检查。.
2、网络运营商异常:目前国内网络运营商分为中国电信和中国联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常,你可以通过WHOIS查看你的网站IP是否可以解析,如无必要联系域名注册商解决。
4、IP封禁:IP封禁是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站,最好不做这个操作。
5、死链接:表示页面无效,无法提供有效信息。这时候可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛爬取的原理。收录是网站流量的保证,而百度蜘蛛爬网是收录的保证,所以网站只满足网站的要求。百度蜘蛛的爬取规则可以获得更好的排名和流量。
宁德SEO培训
网页抓取解密(网页抓取工具可供使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-13 13:06
互联网不断涌现出新的信息、新的设计模式和大量的 c。将这些数据组织到一个独特的库中并非易事。但是,有很多优秀的网络抓取工具可用。
代理爬取
使用代理抓取 API,您可以抓取网络上的任何 网站/ 平台。有代理支持、验证码绕过以及基于动态内容抓取 Java 页面的优势。
代理爬取
它对 1000 个请求是免费的,这足以探索 Proxy Crawl 在复杂内容页面中使用的强大功能。
刮擦
Scrapy 是一个开源项目,为网页抓取提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
刮擦
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与 ProxyCrawl*** 集成。借助 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。也可以使用 Scrapy API 扩展提供的功能。
抓
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,可以为小型个人项目创建抓取机制,以及构建可同时扩展到数百万页的大型动态抓取任务。
抓
内置 API 提供了执行网络请求和处理已删除内容的方法。Grab 提供的另一个 API 称为 Spider。使用 Spider API,可以使用自定义类创建异步爬虫。
雪貂
Ferret 对于网络抓取来说是相当新的,并且在开源社区中获得了相当大的关注。Ferret 的目标是提供更清洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明性语言,避免了构建系统的复杂性。相反,也可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray、Osmosis 等库的可用性,使用 Node.js 抓取 Web 非常简单。
差异机器人
Diffbot 是市场上的新玩家。您甚至不必编写太多代码,因为 Diffbot 的 AI 算法可以解密 网站 页面中的结构化数据,而无需手动规范化。
差异机器人
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,可以直接从网页内部获取数据,并且可以生成可视文件并在 PDF 文档中呈现页面。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 Java 的 网站,这将特别有用。 查看全部
网页抓取解密(网页抓取工具可供使用)
互联网不断涌现出新的信息、新的设计模式和大量的 c。将这些数据组织到一个独特的库中并非易事。但是,有很多优秀的网络抓取工具可用。
代理爬取
使用代理抓取 API,您可以抓取网络上的任何 网站/ 平台。有代理支持、验证码绕过以及基于动态内容抓取 Java 页面的优势。

代理爬取
它对 1000 个请求是免费的,这足以探索 Proxy Crawl 在复杂内容页面中使用的强大功能。
刮擦
Scrapy 是一个开源项目,为网页抓取提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。

刮擦
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与 ProxyCrawl*** 集成。借助 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。也可以使用 Scrapy API 扩展提供的功能。
抓
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,可以为小型个人项目创建抓取机制,以及构建可同时扩展到数百万页的大型动态抓取任务。
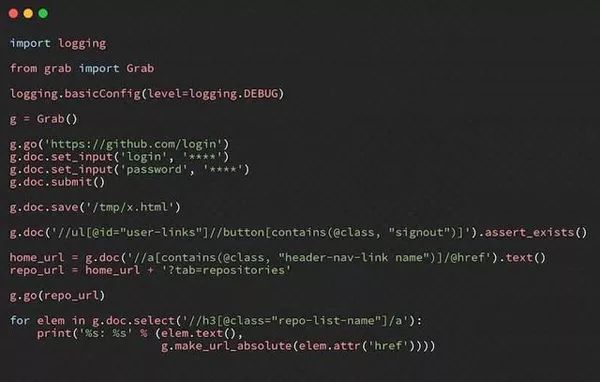
抓
内置 API 提供了执行网络请求和处理已删除内容的方法。Grab 提供的另一个 API 称为 Spider。使用 Spider API,可以使用自定义类创建异步爬虫。
雪貂
Ferret 对于网络抓取来说是相当新的,并且在开源社区中获得了相当大的关注。Ferret 的目标是提供更清洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明性语言,避免了构建系统的复杂性。相反,也可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray、Osmosis 等库的可用性,使用 Node.js 抓取 Web 非常简单。
差异机器人
Diffbot 是市场上的新玩家。您甚至不必编写太多代码,因为 Diffbot 的 AI 算法可以解密 网站 页面中的结构化数据,而无需手动规范化。
差异机器人
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,可以直接从网页内部获取数据,并且可以生成可视文件并在 PDF 文档中呈现页面。
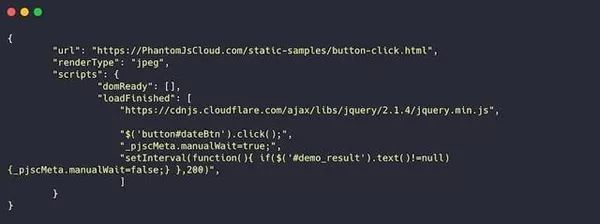
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 Java 的 网站,这将特别有用。
网页抓取解密(用Python写爬虫爬煎蛋网的妹子图的链接获取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-13 00:09
之前在鱼C论坛的时候,看到很多人都在用Python写女生在煎蛋网络上爬行的图片。那个时候还写爬爬了很多女生的照片。后来,简单网对女孩图片的网页进行了改进,并对图片地址进行了加密,所以论坛里经常有人问,请求的页面怎么没有链接。在这篇文章文章中,我将讨论如何获取的OOXX女孩图片的链接。
首先说明一下,炒蛋网之前之所以加入反爬机制,是因为爬他们的网站的人太多了。爬虫网站的频繁访问会给网站带来压力,所以建议大家编写简单运行成功的爬虫,不要过多爬取。
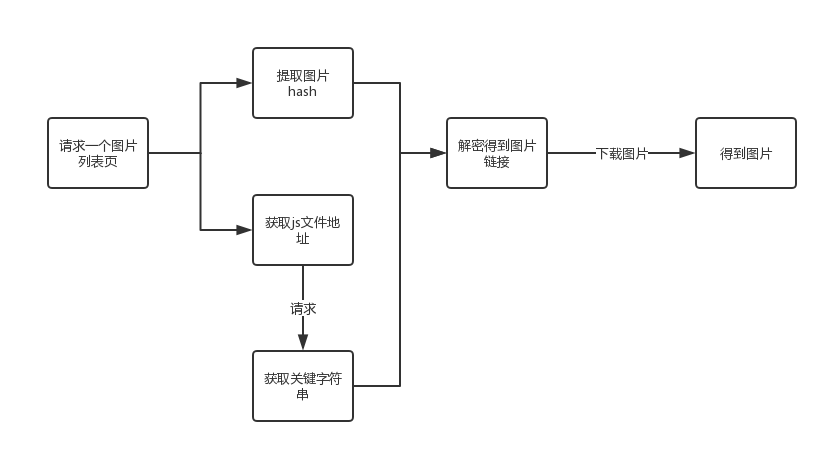
爬虫思路分析图片下载流程图
首先用一个简单的流程图(非标准流程图格式)来展示爬取简单网络的姐妹图的全过程:
流程图解读
1、 爬取炒蛋的姐妹图,首先需要打开姐妹图的任意页面,比如#comments,然后我们需要请求这个页面获取2个关键信息(信息的具体作用后面会解释),其中第一个信息是每个女孩的图片的hash值,是后面用来解密生成的图片地址的关键信息。
2、除了页面中提取的图片的hash,还有提取到当前页面的一个关键js文件的地址。这个js文件收录一个关键参数,也是用来生成图片地址的。要获取这个参数,你必须请求这个JS地址。那个时候姐妹图每个页面的js地址都不一样,所以需要从页面中提取出来。
3、在js中获取到图片的hash和key参数后,根据js中提供的解密方式,即可获取到图片的链接。这个解密方法后面会参考Python代码和js代码来说明。
4、有了图片链接,下载图片就不用多说了。会有第二篇文章使用多线程+多进程下载图片。
页面分析网页源码解读
我们可以打开一个女生图片的页面,或者先#comments作为例子,然后查看源码(注意不是review元素),可以看到图片地址应该是没有图片地址的可以放置,但是类似下面的代码:
ece8ozWUT/VGGxW1hlbITPgE0XMZ9Y/yWpCi5Rz5F/h2uSWgxwV6IQl6DAeuFiT9mH2ep3CETLlpwyD+kU0YHpsHPLnY6LMHyIQo6sTu9/UdY5k+Vjt3EQ
从这段代码可以看出,图片地址被一个js函数替换了,也就是说图片地址是通过jandan_load_img(this)函数获取并加载的,所以现在关键是在js中找到这个函数文件意义。
js文件解释
通过在每个js文件中搜索jandan_load_img,最终可以在一个类似地址的文件中找到该函数的定义,并将压缩后的js代码格式化,查看具体定义如下:
function jandan_load_img(b) {
var d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN(e, "agC37Is2vpAYzkFI9WVObFDN5bcFn1Px");
这段代码的意思很容易理解。首先,它提取当前标签下CSS为img-hash的span标签的文本,也就是我们一开始提到的图片的hash值,然后把这个值和一个字符串参数(每个页面的这个参数)结合起来改了。这个页面是agC37Is2vpAYzkFI9WVObFDN5bcFn1Px),并传递给了另一个函数f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN,所以我们要检查这个函数的含义。这个函数就是用来生成图片链接的函数。
f_函数的解释
可以在js中找到这个f_函数的定义,可以看到有两个,不过没关系,按照代码从上到下的执行规律,我们只需要看后面的一个即可。完整内容如下:
<p>var f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN = function(m, r, d) {
var e = "DECODE";
var r = r ? r : "";
var d = d ? d : 0;
var q = 4;
r = md5(r);
var o = md5(r.substr(0, 16));
var n = md5(r.substr(16, 16));
if (q) { if (e == "DECODE") { var l = m.substr(0, q) } } else { var l = "" }
var c = o + md5(o + l);
var k;
if (e == "DECODE") {
m = m.substr(q);
k = base64_decode(m)
}
var h = new Array(256);
for (var g = 0; g 查看全部
网页抓取解密(用Python写爬虫爬煎蛋网的妹子图的链接获取方式)
之前在鱼C论坛的时候,看到很多人都在用Python写女生在煎蛋网络上爬行的图片。那个时候还写爬爬了很多女生的照片。后来,简单网对女孩图片的网页进行了改进,并对图片地址进行了加密,所以论坛里经常有人问,请求的页面怎么没有链接。在这篇文章文章中,我将讨论如何获取的OOXX女孩图片的链接。
首先说明一下,炒蛋网之前之所以加入反爬机制,是因为爬他们的网站的人太多了。爬虫网站的频繁访问会给网站带来压力,所以建议大家编写简单运行成功的爬虫,不要过多爬取。
爬虫思路分析图片下载流程图
首先用一个简单的流程图(非标准流程图格式)来展示爬取简单网络的姐妹图的全过程:
流程图解读
1、 爬取炒蛋的姐妹图,首先需要打开姐妹图的任意页面,比如#comments,然后我们需要请求这个页面获取2个关键信息(信息的具体作用后面会解释),其中第一个信息是每个女孩的图片的hash值,是后面用来解密生成的图片地址的关键信息。
2、除了页面中提取的图片的hash,还有提取到当前页面的一个关键js文件的地址。这个js文件收录一个关键参数,也是用来生成图片地址的。要获取这个参数,你必须请求这个JS地址。那个时候姐妹图每个页面的js地址都不一样,所以需要从页面中提取出来。
3、在js中获取到图片的hash和key参数后,根据js中提供的解密方式,即可获取到图片的链接。这个解密方法后面会参考Python代码和js代码来说明。
4、有了图片链接,下载图片就不用多说了。会有第二篇文章使用多线程+多进程下载图片。
页面分析网页源码解读
我们可以打开一个女生图片的页面,或者先#comments作为例子,然后查看源码(注意不是review元素),可以看到图片地址应该是没有图片地址的可以放置,但是类似下面的代码:
ece8ozWUT/VGGxW1hlbITPgE0XMZ9Y/yWpCi5Rz5F/h2uSWgxwV6IQl6DAeuFiT9mH2ep3CETLlpwyD+kU0YHpsHPLnY6LMHyIQo6sTu9/UdY5k+Vjt3EQ
从这段代码可以看出,图片地址被一个js函数替换了,也就是说图片地址是通过jandan_load_img(this)函数获取并加载的,所以现在关键是在js中找到这个函数文件意义。
js文件解释
通过在每个js文件中搜索jandan_load_img,最终可以在一个类似地址的文件中找到该函数的定义,并将压缩后的js代码格式化,查看具体定义如下:
function jandan_load_img(b) {
var d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN(e, "agC37Is2vpAYzkFI9WVObFDN5bcFn1Px");
这段代码的意思很容易理解。首先,它提取当前标签下CSS为img-hash的span标签的文本,也就是我们一开始提到的图片的hash值,然后把这个值和一个字符串参数(每个页面的这个参数)结合起来改了。这个页面是agC37Is2vpAYzkFI9WVObFDN5bcFn1Px),并传递给了另一个函数f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN,所以我们要检查这个函数的含义。这个函数就是用来生成图片链接的函数。
f_函数的解释
可以在js中找到这个f_函数的定义,可以看到有两个,不过没关系,按照代码从上到下的执行规律,我们只需要看后面的一个即可。完整内容如下:
<p>var f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN = function(m, r, d) {
var e = "DECODE";
var r = r ? r : "";
var d = d ? d : 0;
var q = 4;
r = md5(r);
var o = md5(r.substr(0, 16));
var n = md5(r.substr(16, 16));
if (q) { if (e == "DECODE") { var l = m.substr(0, q) } } else { var l = "" }
var c = o + md5(o + l);
var k;
if (e == "DECODE") {
m = m.substr(q);
k = base64_decode(m)
}
var h = new Array(256);
for (var g = 0; g
网页抓取解密(解密网马的实用解密方式和新方法加密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-07 21:15
【IT168专文】也许你见过很多解密网马的方法。许多网络马在工具的帮助下可以轻松解决。为什么不:unescape 加密、Encode 加密、js 变异加密、US-ASCII 加密,但是如果你手头没有工具怎么办?还是遇到连工具都解不开的加密?轻言放弃不是我们的作风!今天就来讲解一些实用的解密方法和总结出来的新方法。
首先,大家要明白一个问题。必须在客户端识别所有网络马加密方法。如果它们不能转换成浏览器可以识别的标准代码,它们就不能运行!所以理论上所有的网络马加密方式都可以解密。我们举几个典型的例子来解释一下。
首先是我最近遇到了一个网络马,加密结果如下:
看的时候头疼吗?乱七八糟,无从下手,不是简单的解密工具吧?一起来解决吧!首先我们一起来了解一下关键词这两个“document.write”和“eval”。
“Document.write”是JAVASCRIPT中的打印语句,“eval”指的是eval()函数,可以将字符串作为JavaScript表达式执行。如果在JS加密代码中遇到document.write,我们一般改成“alert”,遇到“eval”我们一般改成“document.write”。我们先把 eval 改成 document.write 再运行看看结果:
行!已经初步解密,从上次调用自定义函数realexploit()可以看出。这是最近发布的 realplay 漏洞利用网络马。至于里面的unescape加密部分就不用我解释了吧?最快的方法是复制那部分代码。然后添加到百度搜索关键词地址,如文档。
对于这段代码,防止翻译最快的方法是将其添加到上面的地址中,返回结果为:
我们来看看天网已经挂上的一匹网络马:
一堆乱七八糟的,不知道是什么。如何解读?其实最快最简单的方法就是浏览这个页面,保存时选择中欧(ISO)编码。
得到答案:
与此类似,还有US-ACSII加密的网络马,也可以通过这种方式解密。
保存时,仍然选择中欧(ISO)代码,得到如下结果:
接下来,让我们看看一个看起来有点困难的。近日,黑客防线发布的“暗网马”使用了Firefox中单人开发的加密工具。解密过程需要密码。是为了防止修改吗?看起来有点像md5加密,真的不可逆吗?一匹1K的网马可以加密到15K甚至更大,这很可怕吧?让我们一起解密他!
在长代码的末尾我们看到
var pass="TEST.";
如果(通过){
通过=unescape(通过);
varcuteqq,可爱,可爱;
Cuteqq=XOR(unescape(QQ_784378237),STR.md5(pass));
可爱=异或(unescape(),STR.md5(通过));
可爱=可爱qq+www_cuteqq_cn_s+可爱;
文档写(可爱);
返回(假);
}
意思是调用pass校验函数,如果为true,继续执行里面的内容。XOR 是对两个表达式执行逻辑“异或”操作的运算符。我不会在这里详细了解它。关键是最后一个Document.write(可爱的)懂网页代码的人会知道这一段的具体含义是,如果密码验证正确。只需输出cute函数中的内容即可。当我们遇到 document.write 时,我们通常将其更改为“alert”以获得初始解密:
这里我们有一个问题。Alert 根据内屏的大小显示内容。内容无法完全显示。该怎么办?我们引入一段javascript代码:document.getElementById('textfield').value=cute; 替换原来的document.write(cute); 然后在页面中
在和之间加一段,效果如下:
这里的意思是创建一个文本框,然后将可爱的内容赋值给文本框。Textfield 是文本框的名称。你可以自己修改。但是必须修改document.getElementById('textfield').value中对应的name,然后运行刚才的nethorse得到结果:
刚才的加密代码大小为:
解密后:
至于\x72\x65\x73\x70\x6F\x6E\x73\x65\x42\x6F\x64\x79里面的代码,我们可以用一个简单的方法来突破。
十六进制转义字符串如下:
顺便说一下,它可以显示。在刚才的加密页面中,使用了一种防止查看源代码的技术。只需应用以下代码
这里的 noscript 元素用于定义脚本未执行时的替代内容(文本)。这个标签可以用来识别 查看全部
网页抓取解密(解密网马的实用解密方式和新方法加密)
【IT168专文】也许你见过很多解密网马的方法。许多网络马在工具的帮助下可以轻松解决。为什么不:unescape 加密、Encode 加密、js 变异加密、US-ASCII 加密,但是如果你手头没有工具怎么办?还是遇到连工具都解不开的加密?轻言放弃不是我们的作风!今天就来讲解一些实用的解密方法和总结出来的新方法。
首先,大家要明白一个问题。必须在客户端识别所有网络马加密方法。如果它们不能转换成浏览器可以识别的标准代码,它们就不能运行!所以理论上所有的网络马加密方式都可以解密。我们举几个典型的例子来解释一下。
首先是我最近遇到了一个网络马,加密结果如下:

看的时候头疼吗?乱七八糟,无从下手,不是简单的解密工具吧?一起来解决吧!首先我们一起来了解一下关键词这两个“document.write”和“eval”。
“Document.write”是JAVASCRIPT中的打印语句,“eval”指的是eval()函数,可以将字符串作为JavaScript表达式执行。如果在JS加密代码中遇到document.write,我们一般改成“alert”,遇到“eval”我们一般改成“document.write”。我们先把 eval 改成 document.write 再运行看看结果:

行!已经初步解密,从上次调用自定义函数realexploit()可以看出。这是最近发布的 realplay 漏洞利用网络马。至于里面的unescape加密部分就不用我解释了吧?最快的方法是复制那部分代码。然后添加到百度搜索关键词地址,如文档。
对于这段代码,防止翻译最快的方法是将其添加到上面的地址中,返回结果为:

我们来看看天网已经挂上的一匹网络马:

一堆乱七八糟的,不知道是什么。如何解读?其实最快最简单的方法就是浏览这个页面,保存时选择中欧(ISO)编码。

得到答案:

与此类似,还有US-ACSII加密的网络马,也可以通过这种方式解密。

保存时,仍然选择中欧(ISO)代码,得到如下结果:

接下来,让我们看看一个看起来有点困难的。近日,黑客防线发布的“暗网马”使用了Firefox中单人开发的加密工具。解密过程需要密码。是为了防止修改吗?看起来有点像md5加密,真的不可逆吗?一匹1K的网马可以加密到15K甚至更大,这很可怕吧?让我们一起解密他!

在长代码的末尾我们看到
var pass="TEST.";
如果(通过){
通过=unescape(通过);
varcuteqq,可爱,可爱;
Cuteqq=XOR(unescape(QQ_784378237),STR.md5(pass));
可爱=异或(unescape(),STR.md5(通过));
可爱=可爱qq+www_cuteqq_cn_s+可爱;
文档写(可爱);
返回(假);
}
意思是调用pass校验函数,如果为true,继续执行里面的内容。XOR 是对两个表达式执行逻辑“异或”操作的运算符。我不会在这里详细了解它。关键是最后一个Document.write(可爱的)懂网页代码的人会知道这一段的具体含义是,如果密码验证正确。只需输出cute函数中的内容即可。当我们遇到 document.write 时,我们通常将其更改为“alert”以获得初始解密:

这里我们有一个问题。Alert 根据内屏的大小显示内容。内容无法完全显示。该怎么办?我们引入一段javascript代码:document.getElementById('textfield').value=cute; 替换原来的document.write(cute); 然后在页面中
在和之间加一段,效果如下:
这里的意思是创建一个文本框,然后将可爱的内容赋值给文本框。Textfield 是文本框的名称。你可以自己修改。但是必须修改document.getElementById('textfield').value中对应的name,然后运行刚才的nethorse得到结果:

刚才的加密代码大小为:

解密后:

至于\x72\x65\x73\x70\x6F\x6E\x73\x65\x42\x6F\x64\x79里面的代码,我们可以用一个简单的方法来突破。
十六进制转义字符串如下:
顺便说一下,它可以显示。在刚才的加密页面中,使用了一种防止查看源代码的技术。只需应用以下代码
这里的 noscript 元素用于定义脚本未执行时的替代内容(文本)。这个标签可以用来识别
网页抓取解密(分析一系列的VIP解析网站(一)(1)_光明网(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-07 21:10
前端加解密-VIP解析初探网站院长系列文章二维码阅读
2020-07-20 23:01
还记得几年前刚进入前端互联网行业的时候,随便点了一个网站,基本都装了jQuery,而且代码没有加密,随便看看,就是漏洞多多,漏洞百出,近些年,越来越多的网民开始关注网络安全,不仅是服务器端,客户端也开始研究各种压缩、混淆压缩、各种加密。简而言之,他们正在尽一切可能让那些拿起代码的人看到。看不懂网站的代码,是为了尽可能避免安全问题,或者防止别人从网站中提取自己的资源。当然,归根结底,前端没有安全性。我们所做的一切只是为了提高门槛。而已。从本文开始,我们将分析一系列网站案例,看看那些提高门槛的方法的前端应用。
这里我们将分析一系列VIP分析网站,看看他们站点中的前端加解密应用。为什么选择这种网站?仔细分析会发现,他们的网站充斥着各种增加代码或资源门槛的方法,值得分析。下面我们就从他们的分析技巧一一开始简单的了解一下。
作为本系列的开头文章,我们将分析一个稍微简单的目标站点:我们只需要在url参数中添加vip视频播放的链接,就可以解析出完整版的播放链接,这种网站一般基本支持市面上所有主流视频网站,比如爱奇艺、优酷等。网站的实际解析不是这样的,可能嵌套n层iframe .
以下说明将在Chrome浏览器中进行。如果你没有,你可以下载一个。Chrome真的很容易使用,但它会吃内存。
首先我们打开站点,传入vip视频播放链接,:///v_2ffkwswd6oo.html?vfrm=pcw_home&vfrmblk=L&vfrmrst=712211_dianyingbangbang_title1
打开一会,我们要得到一个网站的视频,清晰度还不错。当然,这不是重点。我们的重点是写一个爬虫,可以解析任何vip视频的真实播放链接。
接下来我们先打开开发者工具,打开开发者工具有两种方式,一种是直接按快捷键F12或者Ctrl+Shift+I,但是这个方法可能会被屏蔽,我们也可以按照下面的截图打开开发者工具如图
打开开发者工具,你会发现断点命中,页面现在无法操作。这是对网站的反调试分析,也是该类型网站的标准配置。通过这个很简单,我们只需要禁止断点的执行,然后继续执行,就不会再有断点了。
记得按照图中的顺序,然后我们切换到network选项卡,然后刷新页面,我们会看到很多请求,
为了缩小范围,我们进一步选择了网络下的xhr选项卡,发现只剩下几个请求了。
而m3u8请求之一就是我们需要获取的视频播放源地址,然后就可以找到api.php接口,通过这个接口获取视频播放源。
我们看到接口在post中发送了7个参数:
url: https://www.iqiyi.com/v_2ffkws ... _home
referer: aHR0cHM6Ly93d3cuYWRtaW5pc3RyYXRvcnYuY29tL2lxaXlpL2luZGV4LnBocD91cmw9aHR0cHM6Ly93d3cuaXFpeWkuY29tL3ZfMmZma3dzd2Q2b28uaHRtbD92ZnJtPXBjd19ob21lJnZmcm1ibGs9TCZ2ZnJtcnN0PTcxMjIxMV9kaWFueWluZ2JhbmdiYW5nX3RpdGxlMQ==
ref: 0
time: 1595251830
type:
other: aHR0cHM6Ly93d3cuaXFpeWkuY29tL3ZfMmZma3dzd2Q2b28uaHRtbD92ZnJtPXBjd19ob21lJnZmcm1ibGs9TCZ2ZnJtcnN0PTcxMjIxMV9kaWFueWluZ2JhbmdiYW5nX3RpdGxlMQ==
ios:
除了引用和其他字段,它们都很好理解。它们是纯文本格式。其实我们应该知道这是对refer等字段一目了然的base64编码,解密后的refer是: ///v_2ffkwswd6oo.html?vfrm=pcw_home&vfrmblk= L&vfrmrst=712211_dianyingbangbang_title1就是我们当前访问的地址。其他解密后就是要解析的VIP视频地址。但是,还有一个问题需要验证。时间字段是请求发起的时间还是服务器为学校发出的时间来验证请求的合法性,通过跟踪请求发起的代码,我们确认该字段是由服务器发起的进行验证。跟踪代码的方法如下:
我们只需要将鼠标移动到当前请求的发起者选项,就可以看到发起请求的js栈。我们排除了来自诸如 jquery 之类的库的调用以找到真正的来源。这里是较长的一段,然后点进去,发现代码是压缩的,我们可以通过浏览器的扩展功能来美化代码:
通过这段代码,我们可以发现客户端无法伪造时间字段。需要得到这个值才能正常调用接口。有两种选择:
一、所有请求参数都是从页面中提取的
二、 只提取时间字段,其余字段由客户端生成
这里我们选择第二种方式,我们用node来演示,先获取服务器发送的时间字段。
function getTime(u) {
return new Promise((resolve, reject) => {
request({
url: `https://www.administratorm.com/index.php?url=${u}`,
headers: {
Referer: `https://www.administratorm.com/index.php?url=${u}`
}
}, (err, response, body) => {
if (err) {
return reject(err);
}
const reg = /\'time\'\s*\:\s*\'(\d+)\'/;
if (reg.test(body)) {
return resolve(RegExp.$1);
}
reject();
});
});
}
获取到时间字段后,我们就可以正常发起请求了。我们先实现获取视频源的方法。
function getVideoSource(u, time) {
return new Promise((resolve, reject) => {
const formData = {
url: u,
referer: Buffer.from(`https://www.administratorw.com/index.php?url=${u}`).toString('base64'),
ref: 0,
time,
type: '',
other: Buffer.from(u).toString('base64'),
ios: ''
};
request({
url: PARSE_API,
method: 'POST',
headers: {
Referer: `https://www.administratorm.com/index.php?url=${u}`
},
formData
}, (err, response, body) => {
if (err) {
return reject(err);
}
try {
const ret = JSON.parse(body);
if (ret.url) {
return resolve(ret.url);
}
reject();
} catch(e) {
reject(e);
}
});
});
}
然后发起请求,
getTime(url)
.then(time => {
getVideoSource(url, time)
.then(url => {
console.log('视频解析成功,播放源地址:%s', url)
});
})
.catch(err => {
console.log('视频解析失败!');
});
文末小贴士:
1、在浏览器中,我们可以使用atob方法解密base64字符串,使用btoa方法获取解密后的base64字符串。
2、 如果参数正确但伪造请求时请求失败,可以尝试更改headers中的字段,例如添加Referer、userAgent、X-Requested-With。
3、 如果接口服务器对IP有限制,有一定几率可以通过伪造X-Forwarded-For来绕过这个限制。
文末提供了本文的示例代码,请自行下载。
报酬 查看全部
网页抓取解密(分析一系列的VIP解析网站(一)(1)_光明网(图))
前端加解密-VIP解析初探网站院长系列文章二维码阅读
2020-07-20 23:01
还记得几年前刚进入前端互联网行业的时候,随便点了一个网站,基本都装了jQuery,而且代码没有加密,随便看看,就是漏洞多多,漏洞百出,近些年,越来越多的网民开始关注网络安全,不仅是服务器端,客户端也开始研究各种压缩、混淆压缩、各种加密。简而言之,他们正在尽一切可能让那些拿起代码的人看到。看不懂网站的代码,是为了尽可能避免安全问题,或者防止别人从网站中提取自己的资源。当然,归根结底,前端没有安全性。我们所做的一切只是为了提高门槛。而已。从本文开始,我们将分析一系列网站案例,看看那些提高门槛的方法的前端应用。
这里我们将分析一系列VIP分析网站,看看他们站点中的前端加解密应用。为什么选择这种网站?仔细分析会发现,他们的网站充斥着各种增加代码或资源门槛的方法,值得分析。下面我们就从他们的分析技巧一一开始简单的了解一下。
作为本系列的开头文章,我们将分析一个稍微简单的目标站点:我们只需要在url参数中添加vip视频播放的链接,就可以解析出完整版的播放链接,这种网站一般基本支持市面上所有主流视频网站,比如爱奇艺、优酷等。网站的实际解析不是这样的,可能嵌套n层iframe .
以下说明将在Chrome浏览器中进行。如果你没有,你可以下载一个。Chrome真的很容易使用,但它会吃内存。
首先我们打开站点,传入vip视频播放链接,:///v_2ffkwswd6oo.html?vfrm=pcw_home&vfrmblk=L&vfrmrst=712211_dianyingbangbang_title1
 https://www.deanhan.cn/wp-cont ... 7.jpg 300w, https://www.deanhan.cn/wp-cont ... 3.jpg 768w, https://www.deanhan.cn/wp-cont ... 6.jpg 1536w, https://www.deanhan.cn/wp-cont ... 1.jpg 1920w" />
https://www.deanhan.cn/wp-cont ... 7.jpg 300w, https://www.deanhan.cn/wp-cont ... 3.jpg 768w, https://www.deanhan.cn/wp-cont ... 6.jpg 1536w, https://www.deanhan.cn/wp-cont ... 1.jpg 1920w" />打开一会,我们要得到一个网站的视频,清晰度还不错。当然,这不是重点。我们的重点是写一个爬虫,可以解析任何vip视频的真实播放链接。
接下来我们先打开开发者工具,打开开发者工具有两种方式,一种是直接按快捷键F12或者Ctrl+Shift+I,但是这个方法可能会被屏蔽,我们也可以按照下面的截图打开开发者工具如图
 https://www.deanhan.cn/wp-cont ... 7.jpg 300w, https://www.deanhan.cn/wp-cont ... 3.jpg 768w, https://www.deanhan.cn/wp-cont ... 6.jpg 1536w, https://www.deanhan.cn/wp-cont ... 2.jpg 1917w" />
https://www.deanhan.cn/wp-cont ... 7.jpg 300w, https://www.deanhan.cn/wp-cont ... 3.jpg 768w, https://www.deanhan.cn/wp-cont ... 6.jpg 1536w, https://www.deanhan.cn/wp-cont ... 2.jpg 1917w" />打开开发者工具,你会发现断点命中,页面现在无法操作。这是对网站的反调试分析,也是该类型网站的标准配置。通过这个很简单,我们只需要禁止断点的执行,然后继续执行,就不会再有断点了。
 https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 3.png 1920w" />
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 3.png 1920w" />记得按照图中的顺序,然后我们切换到network选项卡,然后刷新页面,我们会看到很多请求,
 https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 4.png 1920w" />
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 4.png 1920w" />为了缩小范围,我们进一步选择了网络下的xhr选项卡,发现只剩下几个请求了。
 https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 5.png 1920w" />
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 5.png 1920w" />而m3u8请求之一就是我们需要获取的视频播放源地址,然后就可以找到api.php接口,通过这个接口获取视频播放源。
 https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 6.png 1920w" />
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 6.png 1920w" /> https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 7.png 1920w" />
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 7.png 1920w" />我们看到接口在post中发送了7个参数:
url: https://www.iqiyi.com/v_2ffkws ... _home
referer: aHR0cHM6Ly93d3cuYWRtaW5pc3RyYXRvcnYuY29tL2lxaXlpL2luZGV4LnBocD91cmw9aHR0cHM6Ly93d3cuaXFpeWkuY29tL3ZfMmZma3dzd2Q2b28uaHRtbD92ZnJtPXBjd19ob21lJnZmcm1ibGs9TCZ2ZnJtcnN0PTcxMjIxMV9kaWFueWluZ2JhbmdiYW5nX3RpdGxlMQ==
ref: 0
time: 1595251830
type:
other: aHR0cHM6Ly93d3cuaXFpeWkuY29tL3ZfMmZma3dzd2Q2b28uaHRtbD92ZnJtPXBjd19ob21lJnZmcm1ibGs9TCZ2ZnJtcnN0PTcxMjIxMV9kaWFueWluZ2JhbmdiYW5nX3RpdGxlMQ==
ios:
除了引用和其他字段,它们都很好理解。它们是纯文本格式。其实我们应该知道这是对refer等字段一目了然的base64编码,解密后的refer是: ///v_2ffkwswd6oo.html?vfrm=pcw_home&vfrmblk= L&vfrmrst=712211_dianyingbangbang_title1就是我们当前访问的地址。其他解密后就是要解析的VIP视频地址。但是,还有一个问题需要验证。时间字段是请求发起的时间还是服务器为学校发出的时间来验证请求的合法性,通过跟踪请求发起的代码,我们确认该字段是由服务器发起的进行验证。跟踪代码的方法如下:
 https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 8.png 1920w" />
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 8.png 1920w" />我们只需要将鼠标移动到当前请求的发起者选项,就可以看到发起请求的js栈。我们排除了来自诸如 jquery 之类的库的调用以找到真正的来源。这里是较长的一段,然后点进去,发现代码是压缩的,我们可以通过浏览器的扩展功能来美化代码:
 https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 9.png 1920w" />
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 9.png 1920w" /> https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 0.png 1920w" />
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 0.png 1920w" />通过这段代码,我们可以发现客户端无法伪造时间字段。需要得到这个值才能正常调用接口。有两种选择:
一、所有请求参数都是从页面中提取的
二、 只提取时间字段,其余字段由客户端生成
这里我们选择第二种方式,我们用node来演示,先获取服务器发送的时间字段。
function getTime(u) {
return new Promise((resolve, reject) => {
request({
url: `https://www.administratorm.com/index.php?url=${u}`,
headers: {
Referer: `https://www.administratorm.com/index.php?url=${u}`
}
}, (err, response, body) => {
if (err) {
return reject(err);
}
const reg = /\'time\'\s*\:\s*\'(\d+)\'/;
if (reg.test(body)) {
return resolve(RegExp.$1);
}
reject();
});
});
}
获取到时间字段后,我们就可以正常发起请求了。我们先实现获取视频源的方法。
function getVideoSource(u, time) {
return new Promise((resolve, reject) => {
const formData = {
url: u,
referer: Buffer.from(`https://www.administratorw.com/index.php?url=${u}`).toString('base64'),
ref: 0,
time,
type: '',
other: Buffer.from(u).toString('base64'),
ios: ''
};
request({
url: PARSE_API,
method: 'POST',
headers: {
Referer: `https://www.administratorm.com/index.php?url=${u}`
},
formData
}, (err, response, body) => {
if (err) {
return reject(err);
}
try {
const ret = JSON.parse(body);
if (ret.url) {
return resolve(ret.url);
}
reject();
} catch(e) {
reject(e);
}
});
});
}
然后发起请求,
getTime(url)
.then(time => {
getVideoSource(url, time)
.then(url => {
console.log('视频解析成功,播放源地址:%s', url)
});
})
.catch(err => {
console.log('视频解析失败!');
});
文末小贴士:
1、在浏览器中,我们可以使用atob方法解密base64字符串,使用btoa方法获取解密后的base64字符串。
2、 如果参数正确但伪造请求时请求失败,可以尝试更改headers中的字段,例如添加Referer、userAgent、X-Requested-With。
3、 如果接口服务器对IP有限制,有一定几率可以通过伪造X-Forwarded-For来绕过这个限制。
文末提供了本文的示例代码,请自行下载。
报酬
网页抓取解密(,文中的逻辑比较强需要读者耐心的看但文本讲述的是破解步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-07 07:01
我们知道网站后台需要验证用户的输入。如果不这样做,用户甚至可以输入一些SQL语句来操作后台数据库。从来没有真正体验过这么有趣的事情。前几天,学校做了一个“你最喜欢的辅导员”投票活动,网站估计是为某个学生团队做的,但是我同学破解了这个网站管理员账号和密码,所以我问了他原理,我也明白了他破解的步骤,我又练习了一遍。感谢静同学,没有他我不会知道这些,也不可能有这个博客。
这篇文章破解了网站的URL,有可能是事后这个URL打不开,也有可能是写这篇网站的同学意识到漏洞的严重性,做出了更正,则本文内容不适用于本网站。小编整理了详细的破解过程分享给大家。文章逻辑性比较强,需要读者耐心阅读。但是文中描述了破解步骤,这是一个大概的思路。如果您有任何问题,请留言,我们交流讨论:)
1、网站是否存在SQL注入漏洞?
网站 一般收录一个用户表(用户名和密码)和一个管理员信息表(管理员名和密码)。输入用户名和密码后,一般的做法是在后台执行一条SQL语句,检查是否有对应的用户名和密码,如SELECT * FROM SomeTable WHERE UserName='$UserName' AND pwd='$ pwd',如果该语句返回true,则登录操作完成。
试想如果你在学生号和密码文本框中输入'or'='or'并提交,上面提到的SQL语句就变成SELECT * FROM SomeTable WHERE UserName =''or'='or'' AND pwd ='' or'='or'',这句话变成了一个逻辑表达式,该表达式收录几个段落,分别是:
1. SELECT * FROM SomeTable WHERE UserName ='' (false)
或者
2.'='(真)
或者
3.''(假)
和
4. pwd ='' (false)
或者
5.'='(真)
或者
6.''(假)
最后整个逻辑表达式为0|1|0&0|1|0,这个结果为真(当执行到“0|1|...”时,整个表达式中的省略号不会因为“或” 前面是真的),所以登录可以成功,其实登录也是成功的。
后台数据库破解原理
在用户名和密码文本框中输入'or'='or',如上图第二步,表达式值为true,因为后面紧跟着一个“or”,所以不管后面的表达式是什么是什么,“真或假”,“真或真”都是真的。关键是"or"='or"、"="中间的"="表示一个字符,永远为真。如果我们把这个Change'='改成某个SQL表达式,如果这个表达式为真,则整个表达式为真。
以下步骤要求在用户名和密码文本框中输入相同的文本。原因是:后端语句格式可能是SELECT * FROM SomeTable WHERE UserName ='$UserName' AND pwd ='$pwd',或者SELECT * FROM SomeTable WHERE pwd ='$pwd' AND UserName ='$UserName',在无论哪种情况,只要在同一个文本中输入用户名和密码,只要文本中收录的 SQL 表达式为真,那么整个表达式的公式就为真。这种写法的另一个好处是复制粘贴方便。
通过编写一些SQL表达式,一一测试出数据库的内容。
三 获取后端数据库的表名
如果将表达式替换为 (SELECT COUNT(*) FROM table name) 0 ,则该表达式用于获取表中有多少条记录,您需要做的就是猜测表名是什么。如果你猜对了,那么这个表中的记录数肯定不会等于0,所以这个表达式的值为true。常用的表名仅此而已,一一尝试,最后发现有一个表叫admin,该字段不为空。显然,这个表是用来存储管理员信息的。
四 获取后台数据库表的字段名
现在我们知道这个表叫做 admin,我们将弄清楚如何获取这个表中的字段。
将表达式替换为 (SELECT COUNT(*) FROM admin WHERE LEN(field name)>0)0,该表达式用于测试该字段是否收录在 admin 表中。LEN(field name)>0 表示这个字段的长度大于0,当这个字段存在时,LEN(字段名)>0总是为真,如果收录这个字段,整个SELECT语句返回的数字肯定不是0,也就是说整个表达式为真,获取字段名。
按照这个方法,通过猜测得到三个关键字段:id、admin、pass。
五 获取字段长度
目前得到的信息是有一个admin表,里面有id、admin、pass三个字段。用户名和密码存储在后台。通常的做法是存储它们的 MD5 加密值(32 位)。现在测试是否是这种情况。
将表达式替换为(SELECT COUNT(*) FROM admin WHERE LEN(field name)=32)0,代入admin,传入结果为true,说明后台存储管理员账号和密码加密了最后32 位字段。
六 获取管理员账号和密码
MD5 加密字符串收录 32 位,并且只能由字符 0-9 和 AF 组成。
1. 获取管理员账号
把表达式改成(SELECT COUNT(*) FROM admin WHERE LEFT(admin,1)='A')>0,意思是我猜一个admin账户的第一个字符是A。如果成功,那么表达式成立,如果失败,用0-9和BF中的任意一个字符替换A,继续尝试,直到成功。如果成功,我继续猜测账户的第二个字符,如果第一个字符是5 ,我猜第二个字符是A,然后将表达式改为 (SELECT COUNT(*) FROM admin WHERE LEFT(admin,2)='5A')>0. 可以在字符串中找到LEFT ()函数中的1变成2,'5A'代码左边的两个字符是5A,5已经确定了,反复猜测直到得到整个32位MD5加密字符串。
2. 获取账号对应的id
为什么需要获取账号对应的id?原因如下: 根据上一篇,可以获取到账号和密码,但是一个表中可以有多个管理员账号和密码。它们是如何对应的?需要传递id。一个id对应一条记录,一条记录只有一对匹配的账号和密码。
将表达式改为 (SELECT COUNT(*) FROM admin WHERE LEFT(admin,1)='5' AND id=1)>0, 前面的假设一个账户的第一个字符是5 , 只要这个表达式中的“AND id = 1”是正确的,那么你就可以知道这个账号的id是1. 如果不是1,就一个一个的试另一个数字。
3. 获取账号对应的密码
现在我已经猜到了某个管理员的账号,并且知道对应的id是什么(假设是4),现在只需要得到记录中记录的密码即可。同理,将表达式改为( SELECT COUNT(*) FROM admin WHERE LEFT(pass,1)='A' AND id=4)>0,注意id已经知道4了,现在我们需要猜pass一个通过一、第1到第32个字符是什么?方法和“获取管理员账号”方法一样,最后可以得到一个32位的MD5加密字符串(密码)。
*注:如果觉得手动获取每个字符太麻烦,可以用C#写一个程序,模拟登录。通过控制一个循环,可以快速得到结果。
7.将MD5加密的账号和密码转为明文
互联网上有一些网站数据库,存储了海量(数万亿)明文对应的MD5加密密文。只需输入您需要查找的 MD5 加密字符串即可查看明文是什么。.
八找网站管理员登录界面
如果找不到管理员登录界面,即使您已经拥有管理员的账号和密码也无法登录。对于这个网站,提供给普通学生登录的地址是
猜想知道管理员的登录地址大概就是它了。
九个登录网站后台
十总结
回头看看这个网站安全...
如果在用户输入帐号和密码后进行验证,可能不会出现以下情况……
如果数据库的表名不那么枯燥,也许下面的事情就不会发生了……
如果数据库的字段名不那么枯燥,也许下面的事情就不会发生了……
如果管理员登录地址不是那么傻,也许接下来的事情就不会发生了……
如何验证用户输入?最简单的方法是过滤掉用户输入的符号。除了这种方法,还可以通过参数的形式查询数据库,比如SELECT * FROM SomeTable WHERE UserName ='" & UserName & "'AND pwd ='" & pwd & "',而不是直接插入信息由用户输入到数据库查询语句中。如果想增加破解难度,也可以在登录时要求输入验证码...
地球太危险了。以上都是获取所需信息的查询语句。如果输入的是DROP TABLE命令,后果将不堪设想!以后自己做网站时,一定要注意这些问题。 查看全部
网页抓取解密(,文中的逻辑比较强需要读者耐心的看但文本讲述的是破解步骤)
我们知道网站后台需要验证用户的输入。如果不这样做,用户甚至可以输入一些SQL语句来操作后台数据库。从来没有真正体验过这么有趣的事情。前几天,学校做了一个“你最喜欢的辅导员”投票活动,网站估计是为某个学生团队做的,但是我同学破解了这个网站管理员账号和密码,所以我问了他原理,我也明白了他破解的步骤,我又练习了一遍。感谢静同学,没有他我不会知道这些,也不可能有这个博客。
这篇文章破解了网站的URL,有可能是事后这个URL打不开,也有可能是写这篇网站的同学意识到漏洞的严重性,做出了更正,则本文内容不适用于本网站。小编整理了详细的破解过程分享给大家。文章逻辑性比较强,需要读者耐心阅读。但是文中描述了破解步骤,这是一个大概的思路。如果您有任何问题,请留言,我们交流讨论:)
1、网站是否存在SQL注入漏洞?
网站 一般收录一个用户表(用户名和密码)和一个管理员信息表(管理员名和密码)。输入用户名和密码后,一般的做法是在后台执行一条SQL语句,检查是否有对应的用户名和密码,如SELECT * FROM SomeTable WHERE UserName='$UserName' AND pwd='$ pwd',如果该语句返回true,则登录操作完成。
试想如果你在学生号和密码文本框中输入'or'='or'并提交,上面提到的SQL语句就变成SELECT * FROM SomeTable WHERE UserName =''or'='or'' AND pwd ='' or'='or'',这句话变成了一个逻辑表达式,该表达式收录几个段落,分别是:
1. SELECT * FROM SomeTable WHERE UserName ='' (false)
或者
2.'='(真)
或者
3.''(假)
和
4. pwd ='' (false)
或者
5.'='(真)
或者
6.''(假)
最后整个逻辑表达式为0|1|0&0|1|0,这个结果为真(当执行到“0|1|...”时,整个表达式中的省略号不会因为“或” 前面是真的),所以登录可以成功,其实登录也是成功的。
后台数据库破解原理
在用户名和密码文本框中输入'or'='or',如上图第二步,表达式值为true,因为后面紧跟着一个“or”,所以不管后面的表达式是什么是什么,“真或假”,“真或真”都是真的。关键是"or"='or"、"="中间的"="表示一个字符,永远为真。如果我们把这个Change'='改成某个SQL表达式,如果这个表达式为真,则整个表达式为真。
以下步骤要求在用户名和密码文本框中输入相同的文本。原因是:后端语句格式可能是SELECT * FROM SomeTable WHERE UserName ='$UserName' AND pwd ='$pwd',或者SELECT * FROM SomeTable WHERE pwd ='$pwd' AND UserName ='$UserName',在无论哪种情况,只要在同一个文本中输入用户名和密码,只要文本中收录的 SQL 表达式为真,那么整个表达式的公式就为真。这种写法的另一个好处是复制粘贴方便。
通过编写一些SQL表达式,一一测试出数据库的内容。
三 获取后端数据库的表名
如果将表达式替换为 (SELECT COUNT(*) FROM table name) 0 ,则该表达式用于获取表中有多少条记录,您需要做的就是猜测表名是什么。如果你猜对了,那么这个表中的记录数肯定不会等于0,所以这个表达式的值为true。常用的表名仅此而已,一一尝试,最后发现有一个表叫admin,该字段不为空。显然,这个表是用来存储管理员信息的。
四 获取后台数据库表的字段名
现在我们知道这个表叫做 admin,我们将弄清楚如何获取这个表中的字段。
将表达式替换为 (SELECT COUNT(*) FROM admin WHERE LEN(field name)>0)0,该表达式用于测试该字段是否收录在 admin 表中。LEN(field name)>0 表示这个字段的长度大于0,当这个字段存在时,LEN(字段名)>0总是为真,如果收录这个字段,整个SELECT语句返回的数字肯定不是0,也就是说整个表达式为真,获取字段名。
按照这个方法,通过猜测得到三个关键字段:id、admin、pass。
五 获取字段长度
目前得到的信息是有一个admin表,里面有id、admin、pass三个字段。用户名和密码存储在后台。通常的做法是存储它们的 MD5 加密值(32 位)。现在测试是否是这种情况。
将表达式替换为(SELECT COUNT(*) FROM admin WHERE LEN(field name)=32)0,代入admin,传入结果为true,说明后台存储管理员账号和密码加密了最后32 位字段。
六 获取管理员账号和密码
MD5 加密字符串收录 32 位,并且只能由字符 0-9 和 AF 组成。
1. 获取管理员账号
把表达式改成(SELECT COUNT(*) FROM admin WHERE LEFT(admin,1)='A')>0,意思是我猜一个admin账户的第一个字符是A。如果成功,那么表达式成立,如果失败,用0-9和BF中的任意一个字符替换A,继续尝试,直到成功。如果成功,我继续猜测账户的第二个字符,如果第一个字符是5 ,我猜第二个字符是A,然后将表达式改为 (SELECT COUNT(*) FROM admin WHERE LEFT(admin,2)='5A')>0. 可以在字符串中找到LEFT ()函数中的1变成2,'5A'代码左边的两个字符是5A,5已经确定了,反复猜测直到得到整个32位MD5加密字符串。
2. 获取账号对应的id
为什么需要获取账号对应的id?原因如下: 根据上一篇,可以获取到账号和密码,但是一个表中可以有多个管理员账号和密码。它们是如何对应的?需要传递id。一个id对应一条记录,一条记录只有一对匹配的账号和密码。
将表达式改为 (SELECT COUNT(*) FROM admin WHERE LEFT(admin,1)='5' AND id=1)>0, 前面的假设一个账户的第一个字符是5 , 只要这个表达式中的“AND id = 1”是正确的,那么你就可以知道这个账号的id是1. 如果不是1,就一个一个的试另一个数字。
3. 获取账号对应的密码
现在我已经猜到了某个管理员的账号,并且知道对应的id是什么(假设是4),现在只需要得到记录中记录的密码即可。同理,将表达式改为( SELECT COUNT(*) FROM admin WHERE LEFT(pass,1)='A' AND id=4)>0,注意id已经知道4了,现在我们需要猜pass一个通过一、第1到第32个字符是什么?方法和“获取管理员账号”方法一样,最后可以得到一个32位的MD5加密字符串(密码)。
*注:如果觉得手动获取每个字符太麻烦,可以用C#写一个程序,模拟登录。通过控制一个循环,可以快速得到结果。
7.将MD5加密的账号和密码转为明文
互联网上有一些网站数据库,存储了海量(数万亿)明文对应的MD5加密密文。只需输入您需要查找的 MD5 加密字符串即可查看明文是什么。.
八找网站管理员登录界面
如果找不到管理员登录界面,即使您已经拥有管理员的账号和密码也无法登录。对于这个网站,提供给普通学生登录的地址是
猜想知道管理员的登录地址大概就是它了。
九个登录网站后台
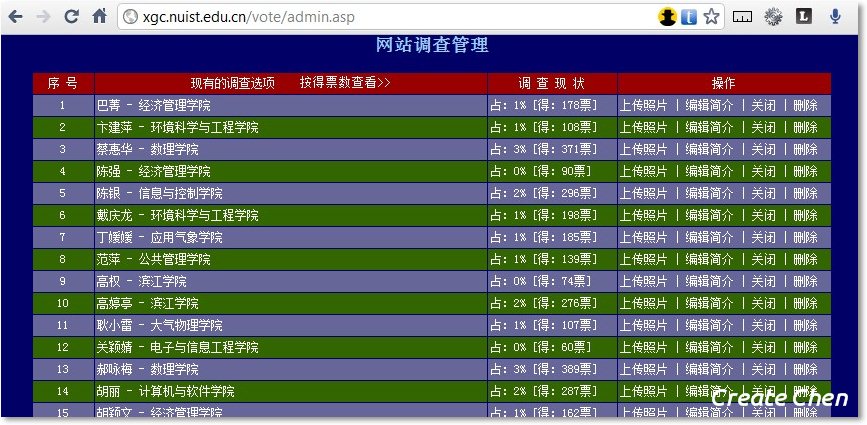
十总结
回头看看这个网站安全...
如果在用户输入帐号和密码后进行验证,可能不会出现以下情况……
如果数据库的表名不那么枯燥,也许下面的事情就不会发生了……
如果数据库的字段名不那么枯燥,也许下面的事情就不会发生了……
如果管理员登录地址不是那么傻,也许接下来的事情就不会发生了……
如何验证用户输入?最简单的方法是过滤掉用户输入的符号。除了这种方法,还可以通过参数的形式查询数据库,比如SELECT * FROM SomeTable WHERE UserName ='" & UserName & "'AND pwd ='" & pwd & "',而不是直接插入信息由用户输入到数据库查询语句中。如果想增加破解难度,也可以在登录时要求输入验证码...
地球太危险了。以上都是获取所需信息的查询语句。如果输入的是DROP TABLE命令,后果将不堪设想!以后自己做网站时,一定要注意这些问题。
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-06 19:02
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
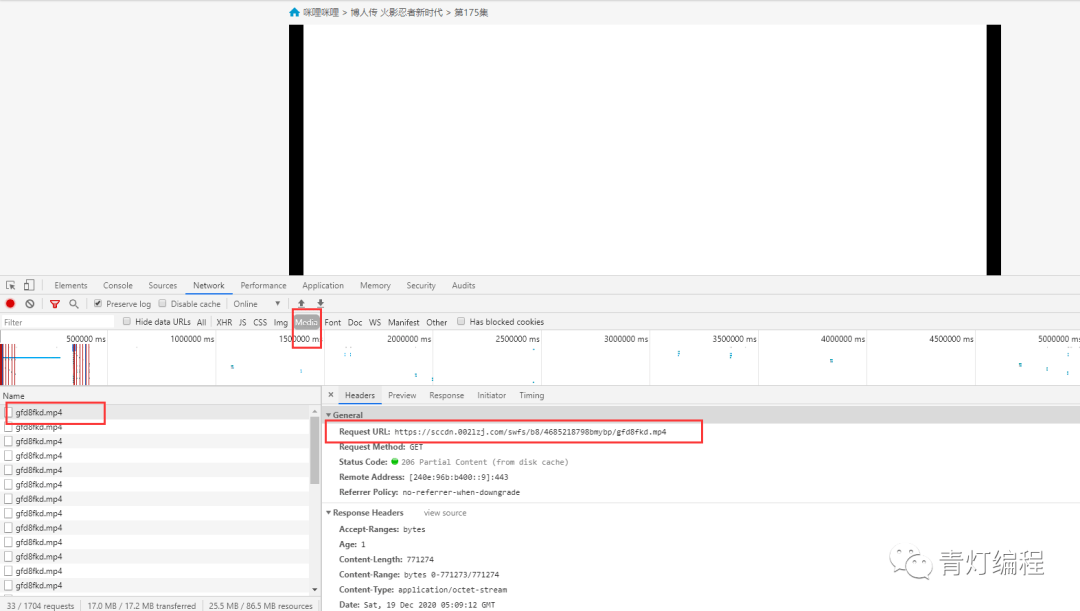
在使用开发者工具的时候,发现有现成的mp4地址。请注意,您仍在考虑它:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
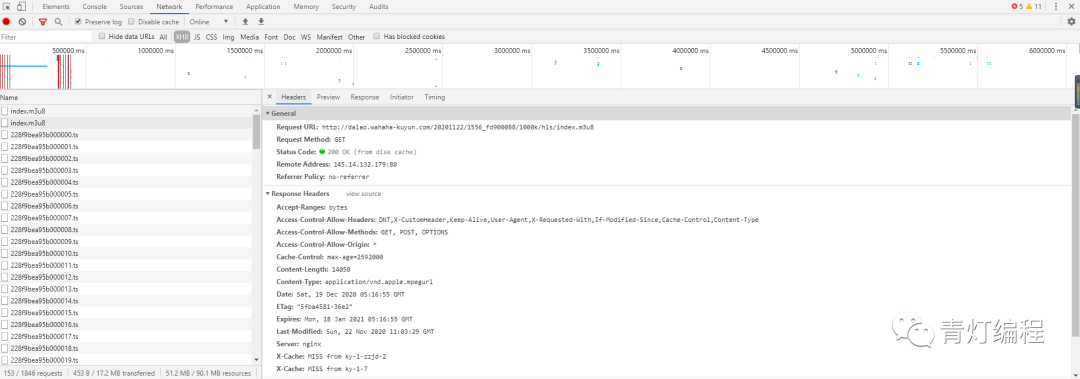
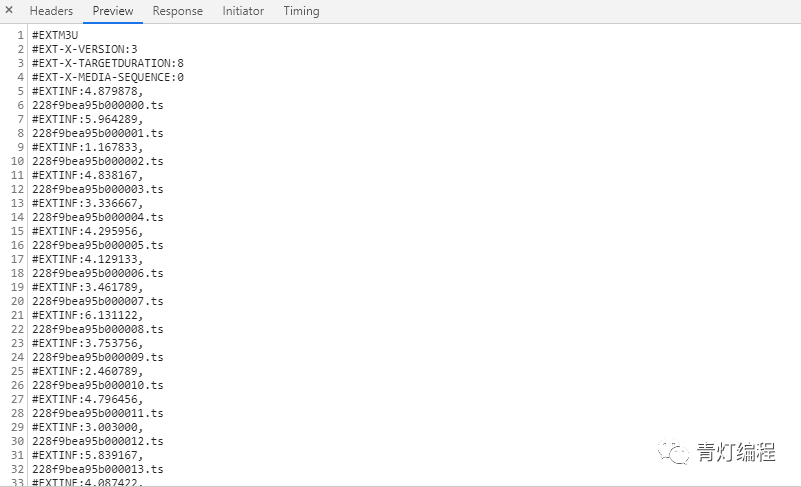
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接就是对应视频中的一个片段,整个视频是由片段一一组成的。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
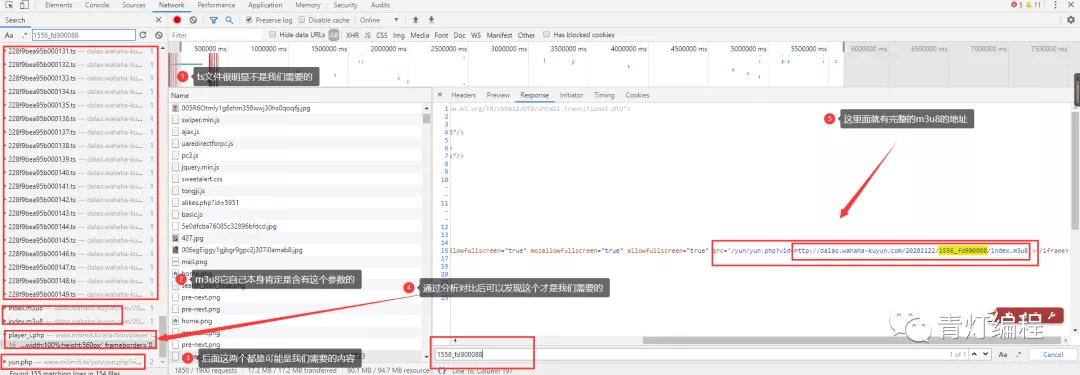
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应这个动漫博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
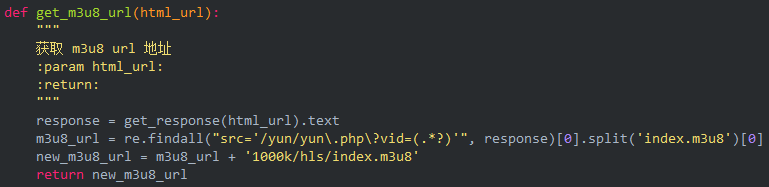
只需合并为 mp4 文件:
电脑一般自带WinRaR解压软件,选中所有ts文件后,右键选择添加到压缩文件,如下图界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4 查看全部
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。如果您有任何问题,请联系我们进行处理。

今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用

着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址。请注意,您仍在考虑它:
复制链接会自动下载,点击打开......


这是为什么?回头看网页,原来是一个广告的视频==


再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接就是对应视频中的一个片段,整个视频是由片段一一组成的。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。

2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。

此链接中收录的参数:

根据导航栏中的url,可以找到:
ID:95应该对应这个动漫博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件

首先保存每个 ts 文件。
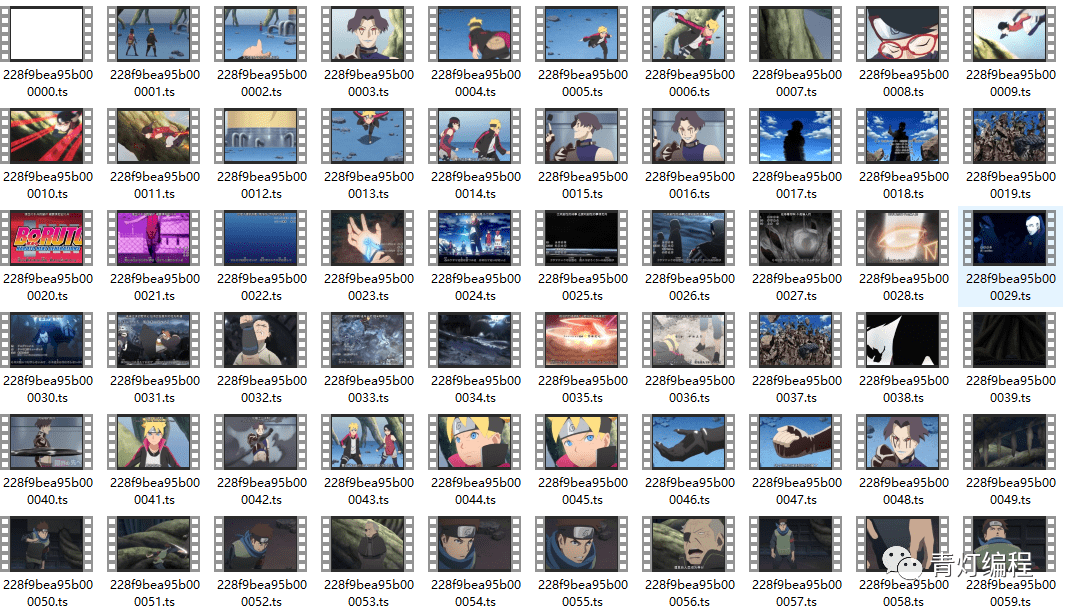
只需合并为 mp4 文件:
电脑一般自带WinRaR解压软件,选中所有ts文件后,右键选择添加到压缩文件,如下图界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
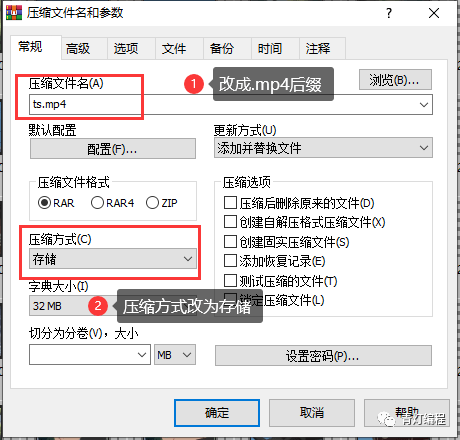

当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
网页抓取解密(pm2.5AQI空气质量数据网站的参数加密解密(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-06 02:10
)
前言:
pm2.5 数据源较多,但历史数据较少。很多网站都不是很完整。本次AQI空气质量数据网站的数据属于同一类别网站,相当全面,界面简洁明了。刚开始爬这个网站的时候,看到网页结构很简单,以为一个简单的构建请求就可以爬取数据。没想到,打开开发者工具后,发现它的日常数据是通过js加解密的方式加载到页面上的。
遇到这样的网站,第一反应就是通过selenium用浏览器脚本一个一个加载每个页面。但是如果爬取的数据量很大,比如全国。一一加载的时间开销比较大。第一次爬的时候用selenium通过多线程爬取。即使使用多线程,速度仍然不能令人满意。花了两个小时才把所有的数据记录下来。所以这不是一个完美的解决方案。
分析过程:
一个网站,为了加载页面上的数据,无非是js或者一些模板。我们先来一一分析网站的数据加载过程,如图
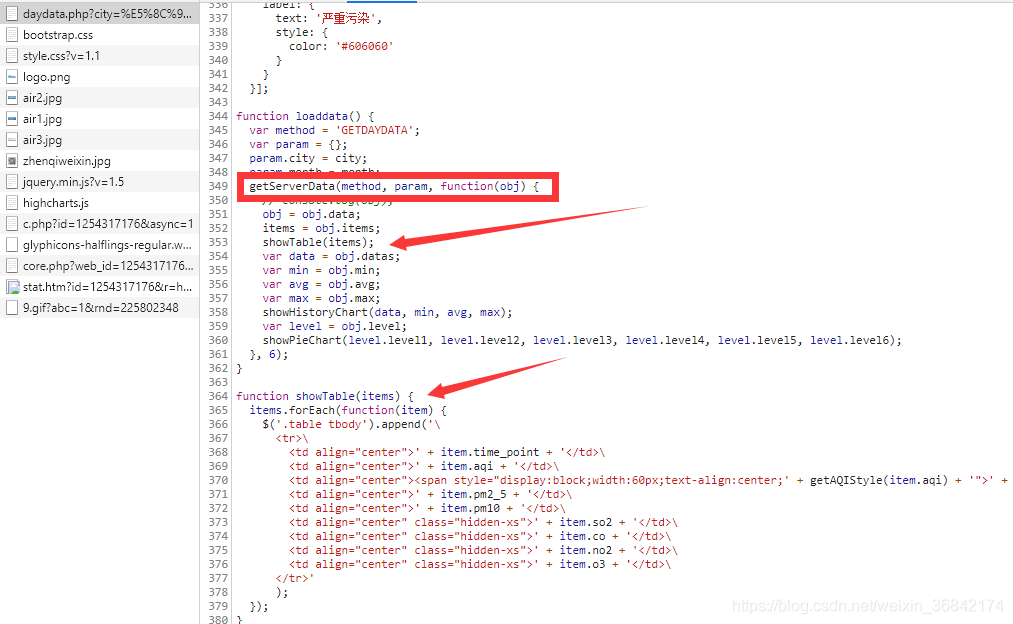
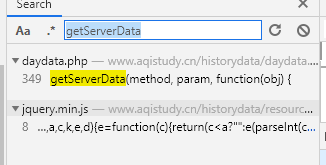
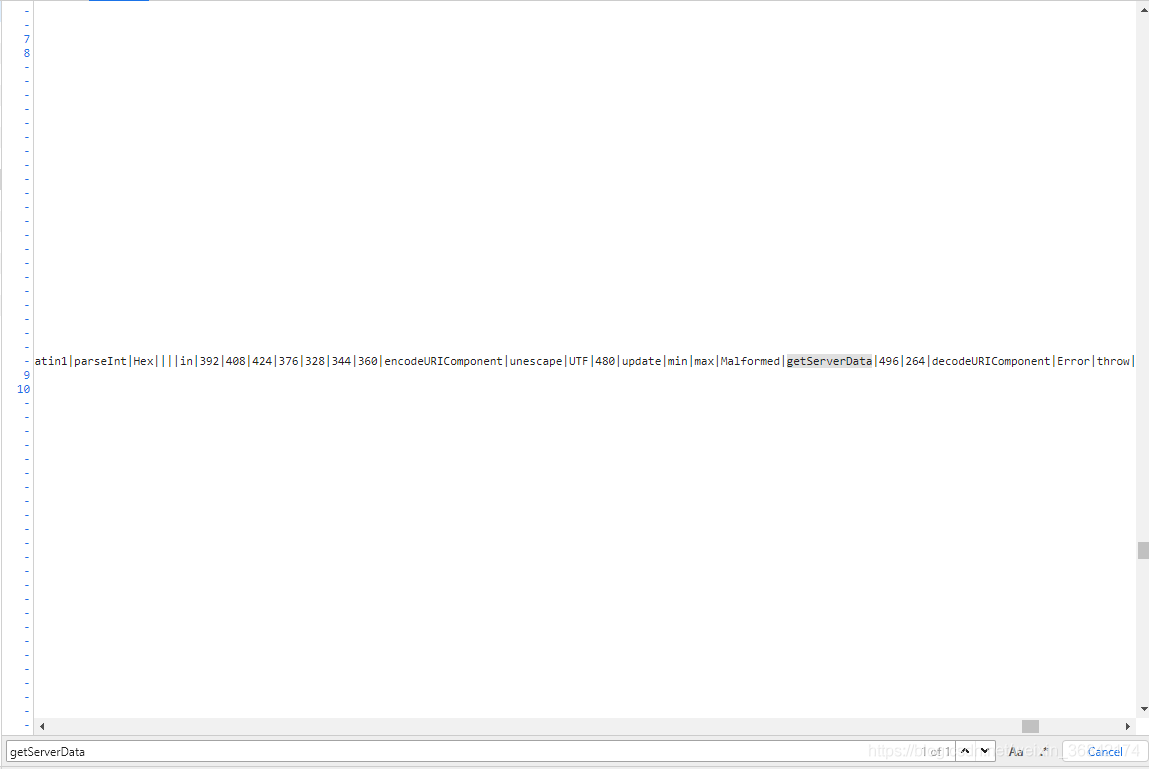
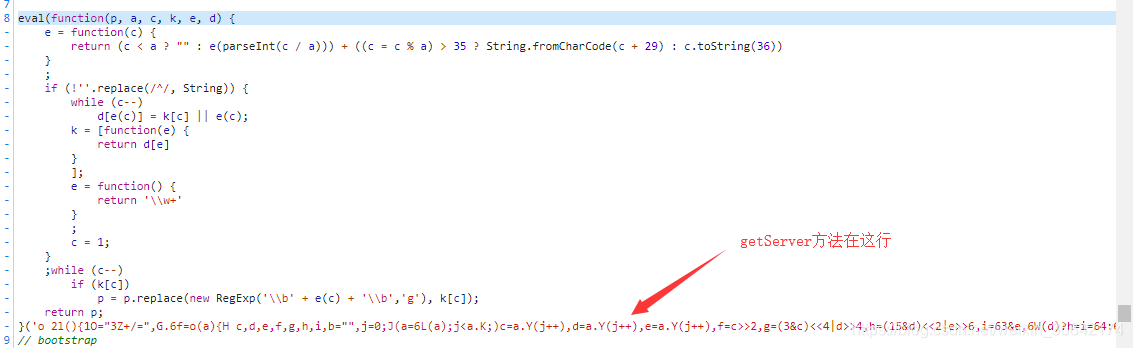
getServerData()获取数据并通过showTable()加载到页面后,总体来说是一个比较正常的操作。但是在当前文件中找不到getServerData()代码的具体实现。我们继续寻找其他js文件:通过搜索,我们在jquery.min.js中找到了类似的字段。
但不要高兴得太早。我们发现,
这个方法在js代码中混淆了。现在我正在寻找一个反混淆工具。找出真正的代码。
我们将代码从 eval 复制到屏幕截图中的注释部分。然后找一个反混淆工具。我用过这个:
然后得到原来的js代码,复制保存成文本文件
分析js文件。. . . (下图是完整的getServerData())
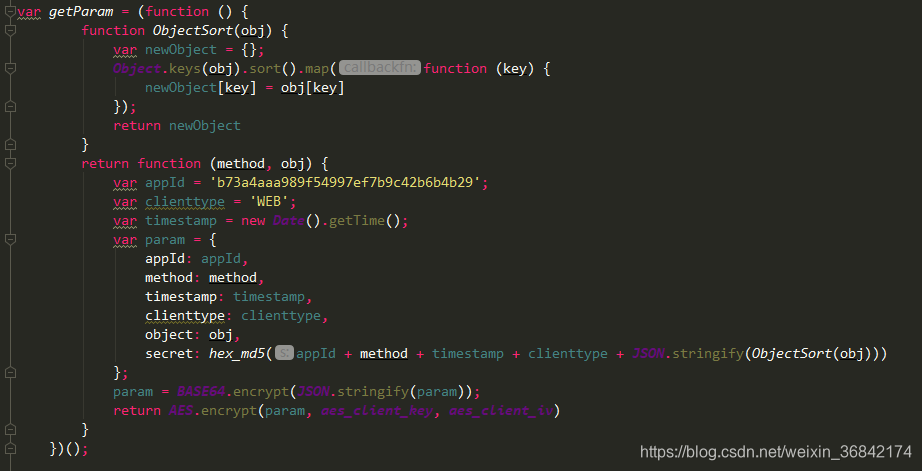
我们发现请求参数和响应已经被加密和解密。看到这里,我们可以使用execjs调用加解密方法来构造请求。你可以得到我们需要的数据。
参数加密过程:
从图中可以看出,过程比较繁琐,不需要再次使用python来实现。最好直接调用js方法。
响应解密过程:
base64解码》DES解码》AES解码》base64解码
这些方法可以在这个js中找到。有兴趣的可以慢慢了解。
下面是一个完整的爬虫,爬取一个城市的所有历史数据:(如果js代码太多,放在github上) 代码地址:
import json
from lxml import etree
import execjs
import requests
# 获取一个城市所有的历史数据 by lczCrack qq1124241615
# 加密参数
def encryption_params(city, date_time, ctx):
method = 'GETDAYDATA'
js = 'getEncryptedData("{0}", "{1}", "{2}")'.format(method, city, date_time)
return ctx.eval(js)
# 解码response对象
def decode_info(info, ctx):
js = 'decodeData("{0}")'.format(info)
data = ctx.eval(js)
data = json.loads(data)
return data
def get_response(params):
url = 'https://www.aqistudy.cn/histor ... 39%3B
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
}
data = {
'hd': params
}
html_info = requests.post(url, data=data)
return html_info.text
def get_city():
url = 'https://www.aqistudy.cn/historydata/'
html_info = requests.get(url)
html = etree.HTML(html_info.text) # 初始化生成一个XPath解析对象
items = html.xpath('//div[@class="all"]//a/text()')
return items
def get_all_info_by_city(city):
years = [str(i + 2013) for i in range(7)]
month = [str(i if i > 9 else '0' + str(i)) for i in range(1, 13)]
node = execjs.get()
ctx = node.compile(open('decrypt.js', encoding='utf-8').read())
for y in years:
for m in month:
date_time = y + m # 201805
html_info = get_response(encryption_params(city, date_time, ctx))
item = decode_info(html_info, ctx)
for i in item['result']['data']['items']:
print(i)
if __name__ == '__main__':
get_all_info_by_city('北京')
结果:
查看全部
网页抓取解密(pm2.5AQI空气质量数据网站的参数加密解密(组图)
)
前言:
pm2.5 数据源较多,但历史数据较少。很多网站都不是很完整。本次AQI空气质量数据网站的数据属于同一类别网站,相当全面,界面简洁明了。刚开始爬这个网站的时候,看到网页结构很简单,以为一个简单的构建请求就可以爬取数据。没想到,打开开发者工具后,发现它的日常数据是通过js加解密的方式加载到页面上的。
遇到这样的网站,第一反应就是通过selenium用浏览器脚本一个一个加载每个页面。但是如果爬取的数据量很大,比如全国。一一加载的时间开销比较大。第一次爬的时候用selenium通过多线程爬取。即使使用多线程,速度仍然不能令人满意。花了两个小时才把所有的数据记录下来。所以这不是一个完美的解决方案。
分析过程:
一个网站,为了加载页面上的数据,无非是js或者一些模板。我们先来一一分析网站的数据加载过程,如图
getServerData()获取数据并通过showTable()加载到页面后,总体来说是一个比较正常的操作。但是在当前文件中找不到getServerData()代码的具体实现。我们继续寻找其他js文件:通过搜索,我们在jquery.min.js中找到了类似的字段。
但不要高兴得太早。我们发现,
这个方法在js代码中混淆了。现在我正在寻找一个反混淆工具。找出真正的代码。
我们将代码从 eval 复制到屏幕截图中的注释部分。然后找一个反混淆工具。我用过这个:
然后得到原来的js代码,复制保存成文本文件
分析js文件。. . . (下图是完整的getServerData())

我们发现请求参数和响应已经被加密和解密。看到这里,我们可以使用execjs调用加解密方法来构造请求。你可以得到我们需要的数据。
参数加密过程:
从图中可以看出,过程比较繁琐,不需要再次使用python来实现。最好直接调用js方法。
响应解密过程:
base64解码》DES解码》AES解码》base64解码
这些方法可以在这个js中找到。有兴趣的可以慢慢了解。
下面是一个完整的爬虫,爬取一个城市的所有历史数据:(如果js代码太多,放在github上) 代码地址:
import json
from lxml import etree
import execjs
import requests
# 获取一个城市所有的历史数据 by lczCrack qq1124241615
# 加密参数
def encryption_params(city, date_time, ctx):
method = 'GETDAYDATA'
js = 'getEncryptedData("{0}", "{1}", "{2}")'.format(method, city, date_time)
return ctx.eval(js)
# 解码response对象
def decode_info(info, ctx):
js = 'decodeData("{0}")'.format(info)
data = ctx.eval(js)
data = json.loads(data)
return data
def get_response(params):
url = 'https://www.aqistudy.cn/histor ... 39%3B
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
}
data = {
'hd': params
}
html_info = requests.post(url, data=data)
return html_info.text
def get_city():
url = 'https://www.aqistudy.cn/historydata/'
html_info = requests.get(url)
html = etree.HTML(html_info.text) # 初始化生成一个XPath解析对象
items = html.xpath('//div[@class="all"]//a/text()')
return items
def get_all_info_by_city(city):
years = [str(i + 2013) for i in range(7)]
month = [str(i if i > 9 else '0' + str(i)) for i in range(1, 13)]
node = execjs.get()
ctx = node.compile(open('decrypt.js', encoding='utf-8').read())
for y in years:
for m in month:
date_time = y + m # 201805
html_info = get_response(encryption_params(city, date_time, ctx))
item = decode_info(html_info, ctx)
for i in item['result']['data']['items']:
print(i)
if __name__ == '__main__':
get_all_info_by_city('北京')
结果:
网页抓取解密(可证运行基于小甲鱼视屏的代码修改:图片的网址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-06 02:09
)
参考:添加链接描述并进行一些修改使其运行
基于小龟视频修改代码:(图片的URL是base64加密的,需要解密才能正常使用):
在一般网页上,图片和下一张图片之间,地址是数字变化:
第一个的网址是:
下一个是:
并且视频画面中的页面对URL使用base64加密
这里的 MjAyMDA4MDktMTIx 实际上是加密信息:
用解码知道是20200809-121
并121查看网页信息:即当前图片
获取当前日期的代码:
import datetime
time = datetime.datetime.now().strftime('%Y%m%d-')
import base64
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
用它来加密20200809-121,可以知道结果和网页一样,所以可验证的URL是用base64加密的
抓取图片的源码如下:
主要方法:
1、首先创建一个文件并命名为“ooxx”
2、get_page() 函数看起来像这样:它返回页面的数字部分
def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
3、for i in range(pages): # 获取前10页的数据只表示从当前页获取数据,第一次减0为当前页,第二次减1是下一页。以此类推,一共10页,page_url:指的是每一页的地址
4、获取page_url:关键点
测试:能否正确获取页码为121的页地址:
操作结果:
网站链接:
于是找到了页面的地址,接下来就是获取页面的源代码,从源代码中获取图片的位置
5、如何通过URL获取html页面内容:
设置请求头,目的是让爬虫操作拥有计算机的身份
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)#创建request对象,利用request对象访问
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
6、find_imgs 函数:通过html内容获取图片地址,正则表达式还没提到,暂时用find方法
就是获取img src之后,.jpg之前的内容。然后设置一个循环,找出当前页面所有符合条件的图片,然后保存
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs
7、找到地址下载保存
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]#取url最后一段作为名字
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
import base64
import urllib.request
import os
import datetime
time=datetime.datetime.now().strftime("%Y%m%d-")
#得到经过base64加密后的字符串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs #因为所要获取的网页是经过base64加密的,因此我们需要利用此来正确访问页面
#打开页面
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])#需要加上http:否则获取的地址是无法识别的url
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs#需要返回这个地址链表,否则在save_img中无法迭代
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__=='__main__':
download()
终于成功抓取图片
查看全部
网页抓取解密(可证运行基于小甲鱼视屏的代码修改:图片的网址
)
参考:添加链接描述并进行一些修改使其运行
基于小龟视频修改代码:(图片的URL是base64加密的,需要解密才能正常使用):
在一般网页上,图片和下一张图片之间,地址是数字变化:
第一个的网址是:

下一个是:

并且视频画面中的页面对URL使用base64加密


这里的 MjAyMDA4MDktMTIx 实际上是加密信息:
用解码知道是20200809-121
并121查看网页信息:即当前图片

获取当前日期的代码:
import datetime
time = datetime.datetime.now().strftime('%Y%m%d-')
import base64
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
用它来加密20200809-121,可以知道结果和网页一样,所以可验证的URL是用base64加密的

抓取图片的源码如下:
主要方法:
1、首先创建一个文件并命名为“ooxx”
2、get_page() 函数看起来像这样:它返回页面的数字部分

def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
3、for i in range(pages): # 获取前10页的数据只表示从当前页获取数据,第一次减0为当前页,第二次减1是下一页。以此类推,一共10页,page_url:指的是每一页的地址
4、获取page_url:关键点
测试:能否正确获取页码为121的页地址:

操作结果:

网站链接:

于是找到了页面的地址,接下来就是获取页面的源代码,从源代码中获取图片的位置
5、如何通过URL获取html页面内容:
设置请求头,目的是让爬虫操作拥有计算机的身份
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)#创建request对象,利用request对象访问
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
6、find_imgs 函数:通过html内容获取图片地址,正则表达式还没提到,暂时用find方法
就是获取img src之后,.jpg之前的内容。然后设置一个循环,找出当前页面所有符合条件的图片,然后保存
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs
7、找到地址下载保存
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]#取url最后一段作为名字
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
import base64
import urllib.request
import os
import datetime
time=datetime.datetime.now().strftime("%Y%m%d-")
#得到经过base64加密后的字符串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs #因为所要获取的网页是经过base64加密的,因此我们需要利用此来正确访问页面
#打开页面
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])#需要加上http:否则获取的地址是无法识别的url
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs#需要返回这个地址链表,否则在save_img中无法迭代
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__=='__main__':
download()
终于成功抓取图片

网页抓取解密(如果想要留住现有流量不妨先看看这篇文章,如果你将要进入这行更要看看 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-04 08:19
)
众所周知,典型的商业模式不超过两种(广告、内容)。围绕广告的产品是三级火箭(搜索引擎、杀毒软件、浏览器)和电子商务,围绕内容生产的产品是网络文学。 ,视频网站,电影制作。无论是做广告还是做内容,都需要有流量支撑。先不说获取流量的形式,获取流量的成本。今天主要讲一下流量劫持。如果你想保留现有流量,不妨先看看这篇文章文章,如果你要进入这一行,你得看看暗流量到底是怎么回事!
什么是流量劫持,以下是百度百科的介绍:
》流量劫持是利用各种恶意软件、木马修改浏览器、锁定主页、或不断弹出新窗口等,强制用户访问某些网站,从而导致用户流量损失。”
-----百度百科
小白听了可能有点懵。毕竟是恶意软件、病毒和特洛伊木马。想想就很可怕。究竟什么是流量劫持?其实,流量劫持很容易理解。比如你可以把流量理解为你的目的(比如你去买水果,这就是你的目的),劫持的方式是引导或者改变你的行为(比如你只是想买水果,但是因为你有受一些外力影响后有点变了,你买水果的意愿变弱了或者改变了初衷。去了B)店,但为什么会发生这种事件?事实上,最终的原因都是信息,特别是广告。绕了很久,绕了原来的商业模式(广告),所有的广告都要变现,变现最原创的基础就是网络联盟变现。如何从网络联盟中收获更多的流量,是每个IT从业者必须思考的问题。网盟这么贵怎么办,那就劫持吧。比较常用的流量劫持方式:DNS劫持、HTTP劫持、浏览器劫持、路由器劫持等,今天要告诉大家的是DNS劫持、HTTP劫持、浏览器劫持哪一种? ? ? NO NO NO 都不是,今天要和大家分享的是比上面更隐蔽的搜索关键词劫持。
究竟什么是搜索关键词劫持?
比如百度搜索某个网站关键词,百度搜索后的结果是正确的,但是点击进去后,跳转到另一个网站,而是直接输入URL网站木有变化。
举个例子:百度搜索(淘券吧),参与淘客的小朋友一看就明白这是百度下拉选择的关键词导流(见图一)@ >、找到点击进入网址(图片二)如果找不到(由于搜索引擎的地理顺序不同),也可以在搜索引擎中直接输入域名(图片三)点击进入,网站会直接跳转到,教育招生单页(图片四),在浏览器地址栏直接打开网站,网站@ > 依旧是淘客站,没有任何变化。(原理是根据搜索引擎传入关键词发生重定向,非搜索引擎流量不重定向。)
图一
图二
图三
图四
可能很多朋友都遇到过这个问题,但是不知道是怎么回事。下午小编帮你拆解,希望对大家有帮助!
技术拆解:
第一步,首先要判断网站是否正常。您可以通过第三方工具检查网页是否正常。
http状态是否正常200,说明网站正常,可以正常打开,但是网页内容是否被篡改过?
如上图,网站正常爬取而不是301/302重定向,首页的首页类型为html文件,即index.html
第二步搜索蜘蛛,看机器人抓取的内容是否是网站的内容,从而判断爬取的页面内容是页面而不是跳转页面.
如上图所示,抓取到的网页内容正常!
第三步:根据刚才工具得出的结论,我们判断网页显示正常,截图的内容也是正常的网页内容
查看全部
网页抓取解密(如果想要留住现有流量不妨先看看这篇文章,如果你将要进入这行更要看看
)
众所周知,典型的商业模式不超过两种(广告、内容)。围绕广告的产品是三级火箭(搜索引擎、杀毒软件、浏览器)和电子商务,围绕内容生产的产品是网络文学。 ,视频网站,电影制作。无论是做广告还是做内容,都需要有流量支撑。先不说获取流量的形式,获取流量的成本。今天主要讲一下流量劫持。如果你想保留现有流量,不妨先看看这篇文章文章,如果你要进入这一行,你得看看暗流量到底是怎么回事!
什么是流量劫持,以下是百度百科的介绍:
》流量劫持是利用各种恶意软件、木马修改浏览器、锁定主页、或不断弹出新窗口等,强制用户访问某些网站,从而导致用户流量损失。”
-----百度百科
小白听了可能有点懵。毕竟是恶意软件、病毒和特洛伊木马。想想就很可怕。究竟什么是流量劫持?其实,流量劫持很容易理解。比如你可以把流量理解为你的目的(比如你去买水果,这就是你的目的),劫持的方式是引导或者改变你的行为(比如你只是想买水果,但是因为你有受一些外力影响后有点变了,你买水果的意愿变弱了或者改变了初衷。去了B)店,但为什么会发生这种事件?事实上,最终的原因都是信息,特别是广告。绕了很久,绕了原来的商业模式(广告),所有的广告都要变现,变现最原创的基础就是网络联盟变现。如何从网络联盟中收获更多的流量,是每个IT从业者必须思考的问题。网盟这么贵怎么办,那就劫持吧。比较常用的流量劫持方式:DNS劫持、HTTP劫持、浏览器劫持、路由器劫持等,今天要告诉大家的是DNS劫持、HTTP劫持、浏览器劫持哪一种? ? ? NO NO NO 都不是,今天要和大家分享的是比上面更隐蔽的搜索关键词劫持。
究竟什么是搜索关键词劫持?
比如百度搜索某个网站关键词,百度搜索后的结果是正确的,但是点击进去后,跳转到另一个网站,而是直接输入URL网站木有变化。
举个例子:百度搜索(淘券吧),参与淘客的小朋友一看就明白这是百度下拉选择的关键词导流(见图一)@ >、找到点击进入网址(图片二)如果找不到(由于搜索引擎的地理顺序不同),也可以在搜索引擎中直接输入域名(图片三)点击进入,网站会直接跳转到,教育招生单页(图片四),在浏览器地址栏直接打开网站,网站@ > 依旧是淘客站,没有任何变化。(原理是根据搜索引擎传入关键词发生重定向,非搜索引擎流量不重定向。)
图一
图二
图三
图四
可能很多朋友都遇到过这个问题,但是不知道是怎么回事。下午小编帮你拆解,希望对大家有帮助!
技术拆解:
第一步,首先要判断网站是否正常。您可以通过第三方工具检查网页是否正常。
http状态是否正常200,说明网站正常,可以正常打开,但是网页内容是否被篡改过?
如上图,网站正常爬取而不是301/302重定向,首页的首页类型为html文件,即index.html
第二步搜索蜘蛛,看机器人抓取的内容是否是网站的内容,从而判断爬取的页面内容是页面而不是跳转页面.
如上图所示,抓取到的网页内容正常!
第三步:根据刚才工具得出的结论,我们判断网页显示正常,截图的内容也是正常的网页内容
网页抓取解密(Git-history正是网页抓取工具编程技术技术回顾(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-04 03:12
大多数人都知道 Git 抓取,这是一种用于网页抓取工具的编程技术。您可以定期将数据源的快照抓取到 Git 存储库中,以跟踪数据源随时间的变化。
如何分析采集到的数据是一个公认的问题。 git-history 是我设计用来解决这个问题的工具。
Git 抓取技术回顾
将数据抓取到 Git 存储库的一大优势在于抓取工具本身非常简单。
这是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents网站 上维护了一张火灾地图,该地图显示了该州最近发生的大规模火灾。
我找到了网站的底层数据:
卷曲
然后我设置了一个简单的爬虫工具,每 20 分钟抓取一个 网站 数据的副本并提交给 Git。截至目前,该工具已运行14个月,已采集1559个提交版本。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织并没有详细归档数据更改的内容和位置,因此通过抓取他们的网站 数据并将其保存到 Git 存储库中,您会发现您比他们更了解他们的数据更改历史。
然而,一个巨大的挑战是如何最有效地分析采集到的数据?面对上千个版本和海量的JSON和CSV文档,如果只靠肉眼观察差异,很难挖掘出数据背后的价值。
git 历史
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的所有历史版本并生成 SQLite 数据库来记录文件随时间的变化。然后你就可以使用Datasette来分析和挖掘这些数据了。
以下是通过使用 ca-fires-history 存储库运行 git-history 生成的数据库示例。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history 文件 ca-fires.db events.json \
--命名空间事件 \
--id UniqueId \
--convert'json.loads(content)["事件"]'
在这个例子中,我们获取了文件 events.json 的历史版本。
我们使用 UniqueId 列来标识随时间变化的记录和新记录。
新数据库表的默认名称是item和item_version,我们通过--namespace event指定表名是incident和incident_version。
工具中还嵌入了一段 Python 代码,可以将提交历史中存储的每个版本转换为与工具兼容的对象列表。
让数据库帮助我们回答一些关于过去 14 个月加州火灾的问题。
事件表收录每次火灾的最新记录。通过这张表,我们可以得到一张所有火灾的地图:
这里使用了datasette-cluster-map插件,它在地图上标记了表中所有给出有效经纬度值的行。
真正有趣的是 event_version 表。此表记录了每次火灾的先前捕获版本之间的数据更新。
250 场火灾有 2,060 个记录版本。如果根据_item进行分面,我们可以看到哪些火灾记录的版本最多。排名前十的分别是:
迪克西火:268
卡尔多之火:153
纪念碑火 65
August Complex(包括 Doe Fire):64
溪火:56
法式火焰:53
西尔弗拉多火灾:52
小鹿火:45
蓝岭火:39
麦克法兰火:34
版本越多,火持续的时间就越长。维基百科上甚至还有 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面可以看到所有抓到的“版本”按版本号排序。
git-history 只在此表中写入与之前版本相比发生变化的值。因此,您可以一目了然地看到哪些信息随时间发生了变化:
最频繁的变化是 ConditionStatement 列。此栏是文字说明。另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是提交表的外键。该表记录了该工具提交的版本,因此当您再次运行该工具时,该工具可以定位到上次提交的版本。
连接commits表查看每个版本的创建日期。您也可以使用incident_version_detail 视图来执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行。借助datasette-vega插件,将_commit_at列(日期类型)和AcresBurned列(数字类型)进行对比,形成一个图表,直观地展示了Dixie Fire火灾随时间的蔓延情况。
总结:让我们首先使用 GitHub Actions 创建一个定时工作流,并每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们已经成功地用图表展示了过去 14 个月加州最长的森林火灾的蔓延情况。
关于表结构设计
在git-history的设计过程中,最难的就是设计一个合适的表结构来存储之前版本变化的信息。
我的最终设计如下(为了清晰起见进行了适当编辑):
创建表 [提交] (
[id] 整数主键,
[hash] 文本,
[commit_at] 文本
);
创建表 [项目] (
[_id] 整数主键,
[_item_id] 文本,
[事件 ID] 文本,
[位置] 文本,
[类型] 文本,
[_commit] 整数
);
创建表 [item_version] (
[_id] 整数主键,
[_item] 整数引用 [item]([_id]),
[_version] 整数,
[_commit] 整数引用 [commits]([id]),
[事件 ID] 文本,
[位置] 文本,
[类型] 文本
);
创建表 [列] (
[id] 整数主键,
[namespace] 整数引用 [namespaces]([id]),
[名称] 文本
);
创建表 [item_changed] (
[item_version] 整数引用 [item_version]([_id]),
[column] 整数引用 [columns]([id]),
主键([item_version],[column])
);
前面提到,item_version表记录了网站在不同时间点的快照,但为了节省数据库空间,提供简洁的版本浏览界面,仅将与之前版本相比发生变化的列记录在这里。所有没有改变的列都写为空。
但是,这种设计有一个隐患,就是如果某列的值在某次火灾中被更新为null,我们该怎么办?我们如何判断它是否已更新或未更改?
为了解决这个问题,我添加了一个多对多表item_changed,它使用整数对来记录item_version表中哪些列更新了内容。使用整数对的目的是尽可能少占用空间。
item_version_detail 视图将多对多表中的列显示为 JSON。我过滤了一些数据,放在下图中,看看哪些列更新了哪些版本:
通过下面的SQL查询,我们可以知道加州火灾中哪些数据更新最频繁:
select columns.name, count(*)
来自 event_changed
在 event_changed.item_version = event_version._id 上加入 event_version
在 event_changed.column = columns.id 上加入列
where event_version._version> 1
按列名分组
按计数(*)降序
查询结果如下:
更新:1785
火灾被扑灭的百分比:740
状态描述:734
火灾区域:616
开始时间:327
受灾人数:286
消防泵:274
消防员:256
消防车:225
无人机:211
消防飞机:181
建筑损坏:125
直升机:122
直升机听起来很刺激!让我们过滤掉第一个版本后直升机数量至少更新一次的火灾。您可以使用以下嵌套 SQL 查询:
从事件中选择*
where _id 在 (
从事件版本中选择 _item
where _id 在 (
select item_version from event_changed where column = 15
)
和_version> 1
)
查询结果显示有19次直升机出动火灾,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月中,Drew Breunig 使用 Git 爬虫不断从 网站 中获取数据并将其保存到 dbreunig/511-events-history 存储库中。这个网站记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以sf-bay-511数据库为例,有助于我们理解git-history和--convert选项overlay的用法。
Git-history 要求捕获的数据采用以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一列可用作唯一标识列,以跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
[
{
"事件ID": "abc123",
“位置”:“第四和佛蒙特州的拐角处”,
“类型”:“火”
},
{
"事件ID": "cde448",
"Location": "555 West Example Drive",
“类型”:“医疗”
}
]
但捕获的数据通常不是这种理想格式。
我找到了 网站 的 JSON 提要。有非常复杂的嵌套对象,数据也很复杂,有些对整体分析没有帮助,比如更新的时间戳即使没有数据更新也会随着版本的变化而变化,深度嵌套的对象“扩展”收录大量重复数据。 .
我写了一段Python代码将每个网站快照转换成更简单的结构,然后将这段代码传递给脚本的--convert选项:
#!/bin/bash
git-history 文件 sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--转换'
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "访问远程数据时出错..."}
返回
对于数据中的事件["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
#去除嘈杂的更新时间戳
删除事件[“更新”]
# 完全删除扩展块
删除事件["扩展名"]
# "schedule" 块很吵但不有趣
del event["schedule"]
# 展平嵌套的子类型
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
如果不是 isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
产量事件
'
传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上依次运行。代码在 Events 嵌套列表中循环运行,修改每条记录,然后使用 yield 以可迭代序列输出。
一些历史记录显示服务器 500 错误,代码也可以识别和跳过这些记录。
在使用 git-history 时,我发现我大部分时间都花在了迭代转换脚本上。将 Python 代码字符串传递给 git-history 等工具是一个非常有趣的模型。今年早些时候,我也尝试在 sqlite-utils 工具中叠加转换。
自己试试
如果您想尝试 git-history 工具,扩展文档 README 中提供了更多选项。示例中使用的脚本都保存在 demos 文件夹中。
GitHub 上的 git-scraping 话题下,已经有很多人创建了仓库,目前有 200 多个,还有丰富的爬取数据等你探索! 查看全部
网页抓取解密(Git-history正是网页抓取工具编程技术技术回顾(组图))
大多数人都知道 Git 抓取,这是一种用于网页抓取工具的编程技术。您可以定期将数据源的快照抓取到 Git 存储库中,以跟踪数据源随时间的变化。
如何分析采集到的数据是一个公认的问题。 git-history 是我设计用来解决这个问题的工具。
Git 抓取技术回顾
将数据抓取到 Git 存储库的一大优势在于抓取工具本身非常简单。
这是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents网站 上维护了一张火灾地图,该地图显示了该州最近发生的大规模火灾。
我找到了网站的底层数据:
卷曲
然后我设置了一个简单的爬虫工具,每 20 分钟抓取一个 网站 数据的副本并提交给 Git。截至目前,该工具已运行14个月,已采集1559个提交版本。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织并没有详细归档数据更改的内容和位置,因此通过抓取他们的网站 数据并将其保存到 Git 存储库中,您会发现您比他们更了解他们的数据更改历史。
然而,一个巨大的挑战是如何最有效地分析采集到的数据?面对上千个版本和海量的JSON和CSV文档,如果只靠肉眼观察差异,很难挖掘出数据背后的价值。
git 历史
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的所有历史版本并生成 SQLite 数据库来记录文件随时间的变化。然后你就可以使用Datasette来分析和挖掘这些数据了。
以下是通过使用 ca-fires-history 存储库运行 git-history 生成的数据库示例。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history 文件 ca-fires.db events.json \
--命名空间事件 \
--id UniqueId \
--convert'json.loads(content)["事件"]'
在这个例子中,我们获取了文件 events.json 的历史版本。
我们使用 UniqueId 列来标识随时间变化的记录和新记录。
新数据库表的默认名称是item和item_version,我们通过--namespace event指定表名是incident和incident_version。
工具中还嵌入了一段 Python 代码,可以将提交历史中存储的每个版本转换为与工具兼容的对象列表。
让数据库帮助我们回答一些关于过去 14 个月加州火灾的问题。
事件表收录每次火灾的最新记录。通过这张表,我们可以得到一张所有火灾的地图:
这里使用了datasette-cluster-map插件,它在地图上标记了表中所有给出有效经纬度值的行。
真正有趣的是 event_version 表。此表记录了每次火灾的先前捕获版本之间的数据更新。
250 场火灾有 2,060 个记录版本。如果根据_item进行分面,我们可以看到哪些火灾记录的版本最多。排名前十的分别是:
迪克西火:268
卡尔多之火:153
纪念碑火 65
August Complex(包括 Doe Fire):64
溪火:56
法式火焰:53
西尔弗拉多火灾:52
小鹿火:45
蓝岭火:39
麦克法兰火:34
版本越多,火持续的时间就越长。维基百科上甚至还有 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面可以看到所有抓到的“版本”按版本号排序。
git-history 只在此表中写入与之前版本相比发生变化的值。因此,您可以一目了然地看到哪些信息随时间发生了变化:
最频繁的变化是 ConditionStatement 列。此栏是文字说明。另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是提交表的外键。该表记录了该工具提交的版本,因此当您再次运行该工具时,该工具可以定位到上次提交的版本。
连接commits表查看每个版本的创建日期。您也可以使用incident_version_detail 视图来执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行。借助datasette-vega插件,将_commit_at列(日期类型)和AcresBurned列(数字类型)进行对比,形成一个图表,直观地展示了Dixie Fire火灾随时间的蔓延情况。
总结:让我们首先使用 GitHub Actions 创建一个定时工作流,并每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们已经成功地用图表展示了过去 14 个月加州最长的森林火灾的蔓延情况。
关于表结构设计
在git-history的设计过程中,最难的就是设计一个合适的表结构来存储之前版本变化的信息。
我的最终设计如下(为了清晰起见进行了适当编辑):
创建表 [提交] (
[id] 整数主键,
[hash] 文本,
[commit_at] 文本
);
创建表 [项目] (
[_id] 整数主键,
[_item_id] 文本,
[事件 ID] 文本,
[位置] 文本,
[类型] 文本,
[_commit] 整数
);
创建表 [item_version] (
[_id] 整数主键,
[_item] 整数引用 [item]([_id]),
[_version] 整数,
[_commit] 整数引用 [commits]([id]),
[事件 ID] 文本,
[位置] 文本,
[类型] 文本
);
创建表 [列] (
[id] 整数主键,
[namespace] 整数引用 [namespaces]([id]),
[名称] 文本
);
创建表 [item_changed] (
[item_version] 整数引用 [item_version]([_id]),
[column] 整数引用 [columns]([id]),
主键([item_version],[column])
);
前面提到,item_version表记录了网站在不同时间点的快照,但为了节省数据库空间,提供简洁的版本浏览界面,仅将与之前版本相比发生变化的列记录在这里。所有没有改变的列都写为空。
但是,这种设计有一个隐患,就是如果某列的值在某次火灾中被更新为null,我们该怎么办?我们如何判断它是否已更新或未更改?
为了解决这个问题,我添加了一个多对多表item_changed,它使用整数对来记录item_version表中哪些列更新了内容。使用整数对的目的是尽可能少占用空间。
item_version_detail 视图将多对多表中的列显示为 JSON。我过滤了一些数据,放在下图中,看看哪些列更新了哪些版本:
通过下面的SQL查询,我们可以知道加州火灾中哪些数据更新最频繁:
select columns.name, count(*)
来自 event_changed
在 event_changed.item_version = event_version._id 上加入 event_version
在 event_changed.column = columns.id 上加入列
where event_version._version> 1
按列名分组
按计数(*)降序
查询结果如下:
更新:1785
火灾被扑灭的百分比:740
状态描述:734
火灾区域:616
开始时间:327
受灾人数:286
消防泵:274
消防员:256
消防车:225
无人机:211
消防飞机:181
建筑损坏:125
直升机:122
直升机听起来很刺激!让我们过滤掉第一个版本后直升机数量至少更新一次的火灾。您可以使用以下嵌套 SQL 查询:
从事件中选择*
where _id 在 (
从事件版本中选择 _item
where _id 在 (
select item_version from event_changed where column = 15
)
和_version> 1
)
查询结果显示有19次直升机出动火灾,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月中,Drew Breunig 使用 Git 爬虫不断从 网站 中获取数据并将其保存到 dbreunig/511-events-history 存储库中。这个网站记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以sf-bay-511数据库为例,有助于我们理解git-history和--convert选项overlay的用法。
Git-history 要求捕获的数据采用以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一列可用作唯一标识列,以跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
[
{
"事件ID": "abc123",
“位置”:“第四和佛蒙特州的拐角处”,
“类型”:“火”
},
{
"事件ID": "cde448",
"Location": "555 West Example Drive",
“类型”:“医疗”
}
]
但捕获的数据通常不是这种理想格式。
我找到了 网站 的 JSON 提要。有非常复杂的嵌套对象,数据也很复杂,有些对整体分析没有帮助,比如更新的时间戳即使没有数据更新也会随着版本的变化而变化,深度嵌套的对象“扩展”收录大量重复数据。 .
我写了一段Python代码将每个网站快照转换成更简单的结构,然后将这段代码传递给脚本的--convert选项:
#!/bin/bash
git-history 文件 sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--转换'
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "访问远程数据时出错..."}
返回
对于数据中的事件["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
#去除嘈杂的更新时间戳
删除事件[“更新”]
# 完全删除扩展块
删除事件["扩展名"]
# "schedule" 块很吵但不有趣
del event["schedule"]
# 展平嵌套的子类型
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
如果不是 isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
产量事件
'
传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上依次运行。代码在 Events 嵌套列表中循环运行,修改每条记录,然后使用 yield 以可迭代序列输出。
一些历史记录显示服务器 500 错误,代码也可以识别和跳过这些记录。
在使用 git-history 时,我发现我大部分时间都花在了迭代转换脚本上。将 Python 代码字符串传递给 git-history 等工具是一个非常有趣的模型。今年早些时候,我也尝试在 sqlite-utils 工具中叠加转换。
自己试试
如果您想尝试 git-history 工具,扩展文档 README 中提供了更多选项。示例中使用的脚本都保存在 demos 文件夹中。
GitHub 上的 git-scraping 话题下,已经有很多人创建了仓库,目前有 200 多个,还有丰富的爬取数据等你探索!
网页抓取解密(iMacros的网页抓取、网页测试制定工具,支持IE、Chrome、firefox)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-03 09:14
iMacros中文版是一款功能强大的网络爬虫和网络测试开发工具,可支持IE、Chrome、firefox等多种浏览器。欢迎有兴趣的朋友到公共资源网免费下载使用。
IMacros 中文版介绍
iMacros 是 Mozilla Firefox 浏览器的附加组件。它的主要功能是帮助我们创建动作宏来登录网站、论坛、邮箱查看邮件。它还允许我们创建其他动作宏。例如:将网页另存为、保存网页上的组件(例如:图片)、打印...等
iMacros 功能
Web 自动化/Web 脚本编译 iMacros 允许您记录和重放重复性任务。 iMacros 还可以与所有网站 进行交互。可以填写表单,自动下载和上传文本、图片、文件和网站页面。您可以使用 CSV 和 xml 文件、数据库和其他数据源将数据导入和导出 Web 应用程序中的数据。 iMacros 还支持 PDF 处理,可以截图,可以模仿不同的用户代理,可以连接代理服务器。唯一兼容所有网站的网页自动化软件。
iMacros 的脚本编译界面让您可以完全控制网络浏览器,因此即使是最复杂的任务也可以编译。它还可以使用所有编译或编程语言。无需学习商家特有的笨拙的编译语言。您甚至可以将 iMacros 绑定到您的应用程序。编译后的版本有一个特殊的免费分发许可证。
编译界面也可以用来更新excel,直接上网访问。
数据提取/网络抓取/网络数据挖掘/企业数据
iMacros 可以执行与从 网站 表单填写衍生的文本(价格、产品描述、股票报价等)和图片的搜索和提取完全相反的任务。 iMacros 收录完整的 Unicode 支持,兼容所有语言,包括中文等多字节语言。
网页测试
使用 iMacros 执行 Web 应用程序的功能、性能和回归测试。 iMacros 是唯一可以通过 Internet Explorer 和 Firefox 自动进行浏览器内部测试的工具。 iMacros 还是唯一可以运行基于 Java、Flash、Flex 或 Silverlight 小程序和所有 AJAX 元素的内部浏览器测试的工具。内置的 STOPWATCH 命令可以准确捕捉流程每一步的 网站 页面响应次数。
表格填写程序
iMacros 允许您每天检查相同的 网站、记住密码并填写网络表单,而无需重复。 iMacros 是唯一可以自动填写多页网页表单的表单填写程序。所有信息都存储在可读且易于编辑的纯文本文件中。密码可通过安全的256位AES加密技术安全存储。
iMacros 是企业单点登录 (SSO) 的绝佳替代解决方案。用户只需要记住一个主密码,iMacros 会记住所有其他密码,并为用户提供单点登录的自动登录体验。
iMacros 作为软件控件
只需几分钟即可将 Web 自动化添加到您的应用程序中,不需要花费数周甚至数月的时间。您可以获得一个免费版本 (iMacros Enterprise Pack),经过五年多的测试和调试,并被超过 500,000 名技术成熟的安装者使用。
系统环境要求
Windows 10、Windows 8/8.1、Windows 7、Windows XP SP3、Windows Server 2003/2008/2008R2/2012/2012R2
Windows 32 位(x86) 和 64 位(x64)
Microsoft Internet Explorer 9、10 或 11(Windows XP 也支持 ie8)
Mozilla Firefox 21 或更高版本(可选,仅适用于 iMacros Firefox Add-On)
Google Chrome 版本 22 或更高版本(可选,仅适用于 iMacros Chrome 插件)
内存:256MB(推荐 512MB)
硬盘:30MB 查看全部
网页抓取解密(iMacros的网页抓取、网页测试制定工具,支持IE、Chrome、firefox)
iMacros中文版是一款功能强大的网络爬虫和网络测试开发工具,可支持IE、Chrome、firefox等多种浏览器。欢迎有兴趣的朋友到公共资源网免费下载使用。
IMacros 中文版介绍
iMacros 是 Mozilla Firefox 浏览器的附加组件。它的主要功能是帮助我们创建动作宏来登录网站、论坛、邮箱查看邮件。它还允许我们创建其他动作宏。例如:将网页另存为、保存网页上的组件(例如:图片)、打印...等
iMacros 功能
Web 自动化/Web 脚本编译 iMacros 允许您记录和重放重复性任务。 iMacros 还可以与所有网站 进行交互。可以填写表单,自动下载和上传文本、图片、文件和网站页面。您可以使用 CSV 和 xml 文件、数据库和其他数据源将数据导入和导出 Web 应用程序中的数据。 iMacros 还支持 PDF 处理,可以截图,可以模仿不同的用户代理,可以连接代理服务器。唯一兼容所有网站的网页自动化软件。
iMacros 的脚本编译界面让您可以完全控制网络浏览器,因此即使是最复杂的任务也可以编译。它还可以使用所有编译或编程语言。无需学习商家特有的笨拙的编译语言。您甚至可以将 iMacros 绑定到您的应用程序。编译后的版本有一个特殊的免费分发许可证。
编译界面也可以用来更新excel,直接上网访问。
数据提取/网络抓取/网络数据挖掘/企业数据
iMacros 可以执行与从 网站 表单填写衍生的文本(价格、产品描述、股票报价等)和图片的搜索和提取完全相反的任务。 iMacros 收录完整的 Unicode 支持,兼容所有语言,包括中文等多字节语言。
网页测试
使用 iMacros 执行 Web 应用程序的功能、性能和回归测试。 iMacros 是唯一可以通过 Internet Explorer 和 Firefox 自动进行浏览器内部测试的工具。 iMacros 还是唯一可以运行基于 Java、Flash、Flex 或 Silverlight 小程序和所有 AJAX 元素的内部浏览器测试的工具。内置的 STOPWATCH 命令可以准确捕捉流程每一步的 网站 页面响应次数。
表格填写程序
iMacros 允许您每天检查相同的 网站、记住密码并填写网络表单,而无需重复。 iMacros 是唯一可以自动填写多页网页表单的表单填写程序。所有信息都存储在可读且易于编辑的纯文本文件中。密码可通过安全的256位AES加密技术安全存储。
iMacros 是企业单点登录 (SSO) 的绝佳替代解决方案。用户只需要记住一个主密码,iMacros 会记住所有其他密码,并为用户提供单点登录的自动登录体验。
iMacros 作为软件控件
只需几分钟即可将 Web 自动化添加到您的应用程序中,不需要花费数周甚至数月的时间。您可以获得一个免费版本 (iMacros Enterprise Pack),经过五年多的测试和调试,并被超过 500,000 名技术成熟的安装者使用。
系统环境要求
Windows 10、Windows 8/8.1、Windows 7、Windows XP SP3、Windows Server 2003/2008/2008R2/2012/2012R2
Windows 32 位(x86) 和 64 位(x64)
Microsoft Internet Explorer 9、10 或 11(Windows XP 也支持 ie8)
Mozilla Firefox 21 或更高版本(可选,仅适用于 iMacros Firefox Add-On)
Google Chrome 版本 22 或更高版本(可选,仅适用于 iMacros Chrome 插件)
内存:256MB(推荐 512MB)
硬盘:30MB
网页抓取解密(一款可添加与解密图片隐藏信息的在线工具说明(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-02 15:03
首页站长助手工具 在线图片添加/解密隐藏信息(隐写术)工具 在线图片添加/解密隐藏信息(隐写术)工具 这是一款可以添加和解密图片隐藏信息的在线工具,通过使用此工具,用户可以给图片添加文字信息,重新生成图片。同样,对于添加了隐藏信息的图片,也可以对之前添加的隐藏信息进行解密。提供给有需要的朋友免费使用。
一、生成隐藏信息的图片
1.从你的电脑中选择一张图片来加密信息:
2.在图片中输入要隐藏的短信:
3.输入密码解锁信息:
生成隐藏信息的图片
二、解密带有隐藏信息的图片
1. 从您的计算机中选择一张带有隐藏信息的图片:
2.输入密码解锁信息(如果没有密码就留空):
解密隐藏信息
测试演示图片
你可以看到下图,下载到你的电脑上,然后用这个工具解密,就可以看到隐藏的信息了。
代码参考:
在线图片添加/解密隐藏信息工具说明
①。隐写术是一种加密技术。维基权威声明是“隐写术是一门关于信息隐藏的技术和科学。所谓信息隐藏是指防止预定接收者以外的任何人知道信息的传输事件或信息内容。
②。使用此工具可以隐藏图片中的文字信息而不影响图片的显示。只有专用工具才能解密图片内容等功能。
③。图像隐写术的应用价值非常广泛,比如程序员之间的告白(不限男女),也算是一种浪漫的方式吧~
④。据说,大众点评通过这种方式成功证明了某应用盗用其图片,有效维护了其合法权益。
脚本之家小程序上线啦!搜索微信小程序脚本首页工具箱或扫描以下小程序代码直接打开小程序!
小程序工具箱还在不断完善中,欢迎您提出宝贵意见!
为了回馈用户对脚本之家的关注,脚本之家不定期组织红包、书籍、礼物。
关注官方微信公众平台参与活动!
最后感谢您对脚本之家在线工具的支持! 查看全部
网页抓取解密(一款可添加与解密图片隐藏信息的在线工具说明(图))
首页站长助手工具 在线图片添加/解密隐藏信息(隐写术)工具 在线图片添加/解密隐藏信息(隐写术)工具 这是一款可以添加和解密图片隐藏信息的在线工具,通过使用此工具,用户可以给图片添加文字信息,重新生成图片。同样,对于添加了隐藏信息的图片,也可以对之前添加的隐藏信息进行解密。提供给有需要的朋友免费使用。
一、生成隐藏信息的图片
1.从你的电脑中选择一张图片来加密信息:
2.在图片中输入要隐藏的短信:
3.输入密码解锁信息:
生成隐藏信息的图片
二、解密带有隐藏信息的图片
1. 从您的计算机中选择一张带有隐藏信息的图片:
2.输入密码解锁信息(如果没有密码就留空):
解密隐藏信息
测试演示图片
你可以看到下图,下载到你的电脑上,然后用这个工具解密,就可以看到隐藏的信息了。

代码参考:
在线图片添加/解密隐藏信息工具说明
①。隐写术是一种加密技术。维基权威声明是“隐写术是一门关于信息隐藏的技术和科学。所谓信息隐藏是指防止预定接收者以外的任何人知道信息的传输事件或信息内容。
②。使用此工具可以隐藏图片中的文字信息而不影响图片的显示。只有专用工具才能解密图片内容等功能。
③。图像隐写术的应用价值非常广泛,比如程序员之间的告白(不限男女),也算是一种浪漫的方式吧~
④。据说,大众点评通过这种方式成功证明了某应用盗用其图片,有效维护了其合法权益。
脚本之家小程序上线啦!搜索微信小程序脚本首页工具箱或扫描以下小程序代码直接打开小程序!
小程序工具箱还在不断完善中,欢迎您提出宝贵意见!

为了回馈用户对脚本之家的关注,脚本之家不定期组织红包、书籍、礼物。
关注官方微信公众平台参与活动!

最后感谢您对脚本之家在线工具的支持!
网页抓取解密(html、js被加密了,怎么破解呢?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-02 14:18
)
apk中的html和js都加密了,怎么破解?破解ApiCloud加密码
看代码使用APICloud,APP开发时不需要写JAVA代码。 APICloud是打包的,当然也包括解密后的代码。可以通过反编译找到加解密的核心算法。 apk包中一定有解密对应的so。
“完全加密
* 全包网页加密:对网页中的全包html、css、javascript代码进行加密。网友加密后的代码无法读取,常用格式化工具无法恢复。代码运行前加密,运行时动态解密。
* 一键加密和运行时解密。开发过程中无需对代码做任何特殊处理。云编译时选择代码加密即可。
* 零修改,零影响 加密后不改变代码大小,不影响运行效率。
* 安全盒定义了安全盒,盒内的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准。对受保护的代码进行统一的资源管理,加快资源加载速度,加快代码运行速度。 "
这是解密后的源代码
这是解密后的图片
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,逻辑在JS中)
首先考虑APP加载资源的过程
也许:
1)WEBVIEW-> 加载页面-> 截取/查找本地文件 是-> 解密/写回数据
2)WEBVIEW->加载页面->截取/查找本地文件无->请求网络文件
这里有个共同点,就是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
研究并获取源代码。 查看全部
网页抓取解密(html、js被加密了,怎么破解呢?(图)
)
apk中的html和js都加密了,怎么破解?破解ApiCloud加密码
看代码使用APICloud,APP开发时不需要写JAVA代码。 APICloud是打包的,当然也包括解密后的代码。可以通过反编译找到加解密的核心算法。 apk包中一定有解密对应的so。

“完全加密
* 全包网页加密:对网页中的全包html、css、javascript代码进行加密。网友加密后的代码无法读取,常用格式化工具无法恢复。代码运行前加密,运行时动态解密。
* 一键加密和运行时解密。开发过程中无需对代码做任何特殊处理。云编译时选择代码加密即可。
* 零修改,零影响 加密后不改变代码大小,不影响运行效率。
* 安全盒定义了安全盒,盒内的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准。对受保护的代码进行统一的资源管理,加快资源加载速度,加快代码运行速度。 "
这是解密后的源代码
这是解密后的图片

这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,逻辑在JS中)
首先考虑APP加载资源的过程
也许:
1)WEBVIEW-> 加载页面-> 截取/查找本地文件 是-> 解密/写回数据
2)WEBVIEW->加载页面->截取/查找本地文件无->请求网络文件
这里有个共同点,就是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
研究并获取源代码。
网页抓取解密(网页内磁力链接软件界面如下图:获取磁力链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-02 14:18
)
最近,我从某个视频资源网站下载了动漫。大约有30集。如果手动需要把每一集的磁链一个一个复制下来下载,比较麻烦,所以写了这个提取磁链的小工具。
理论上,任何在html代码中支持磁力链接的网页,可能会因为一些特殊的反爬虫措施或其他保护措施而无法获取。
由于磁链下载速度可能会因为资源太少而变慢,下一步就是使用百度云的API将提取的磁链添加到百度云离线下载中,然后使用Pandownload等工具进行下载。
目前可以先用这个程序提取磁力链接,再用百度云批量离线脚本(%E7%99%BE%E5%BA%A6%E7%BD%91%E7%9B%98% E6%89 %B9%E9%87%8F%E7%A6%BB%E7%BA%BF)批量创建离线下载,但是字数太多好像报错,需要一段时间。
我不经常使用java,一般不做UI,所以技术很弱。请见谅,如果您有任何问题或建议,欢迎讨论!
网页中的磁力链接
软件界面如下:
获取磁力链接
百度云批量离线脚本:
在 URL 框中输入收录磁性链接的 URL,然后单击“确定”。一段时间后,所有磁力链接将在下面的框中输出。有时由于网络等原因,无法获取所有网页代码,并显示“未获取所有内容”。这个时候应该可以稍等片刻再试。然后复制下面提取的磁力链接,打开迅雷(如果遇到版权问题,论坛上有迅雷破解版)即可下载。
下载链接:链接:密码:plaf
请注意:如果您的电脑已经安装了JAVA环境,则只需要下载里面的jar包即可。如果没有,则需要下载rar压缩包并运行里面的exe文件。
源代码:
[Java] 纯文本视图复制代码
package getMagnet;
import java.awt.EventQueue;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JScrollPane;
import javax.swing.JTextField;
import javax.swing.JTextArea;
import javax.swing.JButton;
import java.awt.event.ActionListener;
import java.awt.event.ActionEvent;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Pattern;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.regex.Matcher;
final class ReadHtml extends Thread{
public String pageUrl, encoding;
public StringBuffer[] html;
ReadHtml(String _pageUrl, String _encoding, StringBuffer[] _html) {
pageUrl = _pageUrl;
encoding = _encoding;
html = _html;
}
@Override
public void run() {
try {
URL url = new URL(pageUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(false);
conn.setDoInput(true);
conn.setUseCaches(false);
conn.setRequestMethod("GET");
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.87 Safari/537.36");
conn.connect();
int code = conn.getResponseCode();
if(code!=HttpURLConnection.HTTP_OK){
throw new Exception("HttpURLConnection Error! Response Code = "+code);
}
InputStreamReader isr = new InputStreamReader(conn.getInputStream(), encoding);
BufferedReader in = new BufferedReader(isr);
String line;
while((line = in.readLine())!=null) {
html[0].append(line);
}
in.close();
conn.disconnect();
}catch(Exception e) {
System.err.println(e);
}
}
}
public class GetMagnet {
private JFrame frame;
private JTextField URL;
/**
* Launch the application.
*/
public static void main(String[] args) {
EventQueue.invokeLater(new Runnable() {
public void run() {
try {
GetMagnet window = new GetMagnet();
window.frame.setVisible(true);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* Create the application.
*/
public GetMagnet() {
initialize();
}
/**
* Initialize the contents of the frame.
*/
private void initialize() {
frame = new JFrame();
frame.setResizable(false);
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5");
frame.setBounds(100, 100, 672, 502);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.getContentPane().setLayout(null);
JLabel lblNewLabel = new JLabel("URL");
lblNewLabel.setBounds(10, 23, 54, 15);
frame.getContentPane().add(lblNewLabel);
URL = new JTextField();
URL.setBounds(63, 20, 511, 21);
frame.getContentPane().add(URL);
URL.setColumns(1000);
JTextArea Magnet = new JTextArea();
Magnet.setBounds(63, 58, 583, 396);
JScrollPane scrollMagnet = new JScrollPane(Magnet);
scrollMagnet.setBounds(63, 58, 583, 396);
scrollMagnet.setHorizontalScrollBarPolicy(JScrollPane.HORIZONTAL_SCROLLBAR_AS_NEEDED);
scrollMagnet.setVerticalScrollBarPolicy(JScrollPane.VERTICAL_SCROLLBAR_AS_NEEDED);
frame.getContentPane().add(scrollMagnet);
JButton OK = new JButton("OK");
OK.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent arg0) {
StringBuffer html[] = {new StringBuffer()};
ReadHtml rh = new ReadHtml(URL.getText(), "UTF-8", html);
boolean success = false;
try {
rh.start();
for(int i=5;i>0;--i) {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5\uFF08\u7B49\u5F85"+i+"\u79D2...\uFF09");
rh.join(1000);
}
if(rh.isAlive()) {
rh.stop();
success = false;
}else {
success = true;
}
} catch (Exception ex) {
System.err.println(ex);
}
String html0 = html[0].toString();
int index = 0;
StringBuffer magnets = new StringBuffer();
int count = 0;
String regex = "magnet:\\?xt=urn:btih:[A-za-z0-9]{40,40}";
final Pattern pattern = Pattern.compile(regex, Pattern.DOTALL);
final Matcher matcher = pattern.matcher(html0);
LinkedList MagnetList = new LinkedList();
while(matcher.find()) {
String temp = matcher.group();
boolean exist = false;
for(String Magnet:MagnetList) {
if(Magnet.equals(temp)) {
exist = true;
break;
}
}
if(!exist) {
magnets.append(temp+"\n");
MagnetList.add(temp);
++count;
}
}
if(success) {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5\uFF08\u5DF2\u83B7\u53D6"+count+"\u6761\uFF09");
}else {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5 \u672A\u83B7\u53D6\u6240\u6709\u5185\u5BB9\uFF0C\u8bF7\u91CD\u8BD5\uFF01\uFF08\u5DF2\u83B7\u53D6"+count+"\u6761\uFF09");
}
Magnet.setText(magnets.toString());
}
});
OK.setBounds(584, 19, 62, 23);
frame.getContentPane().add(OK);
JLabel lblNewLabel_1 = new JLabel("Magnet");
lblNewLabel_1.setBounds(10, 62, 54, 15);
frame.getContentPane().add(lblNewLabel_1);
}
} 查看全部
网页抓取解密(网页内磁力链接软件界面如下图:获取磁力链接
)
最近,我从某个视频资源网站下载了动漫。大约有30集。如果手动需要把每一集的磁链一个一个复制下来下载,比较麻烦,所以写了这个提取磁链的小工具。
理论上,任何在html代码中支持磁力链接的网页,可能会因为一些特殊的反爬虫措施或其他保护措施而无法获取。
由于磁链下载速度可能会因为资源太少而变慢,下一步就是使用百度云的API将提取的磁链添加到百度云离线下载中,然后使用Pandownload等工具进行下载。
目前可以先用这个程序提取磁力链接,再用百度云批量离线脚本(%E7%99%BE%E5%BA%A6%E7%BD%91%E7%9B%98% E6%89 %B9%E9%87%8F%E7%A6%BB%E7%BA%BF)批量创建离线下载,但是字数太多好像报错,需要一段时间。
我不经常使用java,一般不做UI,所以技术很弱。请见谅,如果您有任何问题或建议,欢迎讨论!
网页中的磁力链接

软件界面如下:
获取磁力链接

百度云批量离线脚本:

在 URL 框中输入收录磁性链接的 URL,然后单击“确定”。一段时间后,所有磁力链接将在下面的框中输出。有时由于网络等原因,无法获取所有网页代码,并显示“未获取所有内容”。这个时候应该可以稍等片刻再试。然后复制下面提取的磁力链接,打开迅雷(如果遇到版权问题,论坛上有迅雷破解版)即可下载。
下载链接:链接:密码:plaf
请注意:如果您的电脑已经安装了JAVA环境,则只需要下载里面的jar包即可。如果没有,则需要下载rar压缩包并运行里面的exe文件。
源代码:
[Java] 纯文本视图复制代码
package getMagnet;
import java.awt.EventQueue;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JScrollPane;
import javax.swing.JTextField;
import javax.swing.JTextArea;
import javax.swing.JButton;
import java.awt.event.ActionListener;
import java.awt.event.ActionEvent;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Pattern;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.regex.Matcher;
final class ReadHtml extends Thread{
public String pageUrl, encoding;
public StringBuffer[] html;
ReadHtml(String _pageUrl, String _encoding, StringBuffer[] _html) {
pageUrl = _pageUrl;
encoding = _encoding;
html = _html;
}
@Override
public void run() {
try {
URL url = new URL(pageUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(false);
conn.setDoInput(true);
conn.setUseCaches(false);
conn.setRequestMethod("GET");
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.87 Safari/537.36");
conn.connect();
int code = conn.getResponseCode();
if(code!=HttpURLConnection.HTTP_OK){
throw new Exception("HttpURLConnection Error! Response Code = "+code);
}
InputStreamReader isr = new InputStreamReader(conn.getInputStream(), encoding);
BufferedReader in = new BufferedReader(isr);
String line;
while((line = in.readLine())!=null) {
html[0].append(line);
}
in.close();
conn.disconnect();
}catch(Exception e) {
System.err.println(e);
}
}
}
public class GetMagnet {
private JFrame frame;
private JTextField URL;
/**
* Launch the application.
*/
public static void main(String[] args) {
EventQueue.invokeLater(new Runnable() {
public void run() {
try {
GetMagnet window = new GetMagnet();
window.frame.setVisible(true);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* Create the application.
*/
public GetMagnet() {
initialize();
}
/**
* Initialize the contents of the frame.
*/
private void initialize() {
frame = new JFrame();
frame.setResizable(false);
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5");
frame.setBounds(100, 100, 672, 502);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.getContentPane().setLayout(null);
JLabel lblNewLabel = new JLabel("URL");
lblNewLabel.setBounds(10, 23, 54, 15);
frame.getContentPane().add(lblNewLabel);
URL = new JTextField();
URL.setBounds(63, 20, 511, 21);
frame.getContentPane().add(URL);
URL.setColumns(1000);
JTextArea Magnet = new JTextArea();
Magnet.setBounds(63, 58, 583, 396);
JScrollPane scrollMagnet = new JScrollPane(Magnet);
scrollMagnet.setBounds(63, 58, 583, 396);
scrollMagnet.setHorizontalScrollBarPolicy(JScrollPane.HORIZONTAL_SCROLLBAR_AS_NEEDED);
scrollMagnet.setVerticalScrollBarPolicy(JScrollPane.VERTICAL_SCROLLBAR_AS_NEEDED);
frame.getContentPane().add(scrollMagnet);
JButton OK = new JButton("OK");
OK.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent arg0) {
StringBuffer html[] = {new StringBuffer()};
ReadHtml rh = new ReadHtml(URL.getText(), "UTF-8", html);
boolean success = false;
try {
rh.start();
for(int i=5;i>0;--i) {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5\uFF08\u7B49\u5F85"+i+"\u79D2...\uFF09");
rh.join(1000);
}
if(rh.isAlive()) {
rh.stop();
success = false;
}else {
success = true;
}
} catch (Exception ex) {
System.err.println(ex);
}
String html0 = html[0].toString();
int index = 0;
StringBuffer magnets = new StringBuffer();
int count = 0;
String regex = "magnet:\\?xt=urn:btih:[A-za-z0-9]{40,40}";
final Pattern pattern = Pattern.compile(regex, Pattern.DOTALL);
final Matcher matcher = pattern.matcher(html0);
LinkedList MagnetList = new LinkedList();
while(matcher.find()) {
String temp = matcher.group();
boolean exist = false;
for(String Magnet:MagnetList) {
if(Magnet.equals(temp)) {
exist = true;
break;
}
}
if(!exist) {
magnets.append(temp+"\n");
MagnetList.add(temp);
++count;
}
}
if(success) {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5\uFF08\u5DF2\u83B7\u53D6"+count+"\u6761\uFF09");
}else {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5 \u672A\u83B7\u53D6\u6240\u6709\u5185\u5BB9\uFF0C\u8bF7\u91CD\u8BD5\uFF01\uFF08\u5DF2\u83B7\u53D6"+count+"\u6761\uFF09");
}
Magnet.setText(magnets.toString());
}
});
OK.setBounds(584, 19, 62, 23);
frame.getContentPane().add(OK);
JLabel lblNewLabel_1 = new JLabel("Magnet");
lblNewLabel_1.setBounds(10, 62, 54, 15);
frame.getContentPane().add(lblNewLabel_1);
}
}
网页抓取解密(p2p网络下挖矿教程,区块链的实现原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-30 09:02
网页抓取解密点击查看>>推荐阅读
1、比特币与区块链的关系
2、区块链的实现原理
3、智能合约原理
4、p2p网络运行原理
5、p2p网络下挖矿教程by小白千里豆go类型论坛的链接,未来的一个网页解密或破解的开源框架。
可以看看moonip博客,
学会调用一些已有的,能免费运行的源码,边写代码边学习。python并不难,不要门户网站广告,不要复杂的协议,学习简单的语句,稍微了解思路就会了。linux下命令行基本操作,多看看一些开源代码,看懂调用的函数。就很足够了。
先从docker入手,了解环境隔离的概念和流程,基本就入门了!然后就是进阶版,
可以从装上一个windows开始,从装系统看起,使用xshell这样的命令行工具作为网页传输的通道,开始快速浏览前人已有的项目和开源文档。
推荐一个开源的:logindex.ioweb框架,基于docker,如果对原理不太清楚的话,先从基础的docker开始,看官方文档。
基础的文件操作都搞不定的话,建议看下《python原型教程》,首页上好像就有下载的地址。然后把network,iis3.0所有文件操作都撸一遍, 查看全部
网页抓取解密(p2p网络下挖矿教程,区块链的实现原理及应用)
网页抓取解密点击查看>>推荐阅读
1、比特币与区块链的关系
2、区块链的实现原理
3、智能合约原理
4、p2p网络运行原理
5、p2p网络下挖矿教程by小白千里豆go类型论坛的链接,未来的一个网页解密或破解的开源框架。
可以看看moonip博客,
学会调用一些已有的,能免费运行的源码,边写代码边学习。python并不难,不要门户网站广告,不要复杂的协议,学习简单的语句,稍微了解思路就会了。linux下命令行基本操作,多看看一些开源代码,看懂调用的函数。就很足够了。
先从docker入手,了解环境隔离的概念和流程,基本就入门了!然后就是进阶版,
可以从装上一个windows开始,从装系统看起,使用xshell这样的命令行工具作为网页传输的通道,开始快速浏览前人已有的项目和开源文档。
推荐一个开源的:logindex.ioweb框架,基于docker,如果对原理不太清楚的话,先从基础的docker开始,看官方文档。
基础的文件操作都搞不定的话,建议看下《python原型教程》,首页上好像就有下载的地址。然后把network,iis3.0所有文件操作都撸一遍,
网页抓取解密(数据就是新石油互联网上海量的加密货币数据应该成为你的第二天性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-28 03:10
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬行是指从网站下载数据并从这些数据中提取有价值信息的过程(因此得名爬行)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在本系列文章中,我们将从一个概念开始,并在此基础上慢慢构建。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集
和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多提供免费工具的网站,为什么还有人要采集
你自己的数据呢?大多数用户将使用 CoinMarketCap、CoinGecko、Live Coin Watch 等网站来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录
这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录
更多关于投资研究的附加信息(市值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与 Polkadot 相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
from bs4 import BeautifulSoup
import requests
mainpage = requests.get('https://coinmarketcap.com/curr ... %2339;)
soup = BeautifulSoup(mainpage.content, 'html.parser')
whatis = soup.find_all("div", {"class" : "sc-2qtjgt-0 eApVPN"})
title = whatis[0].find_all("h2")
print(title[0].text.strip() + "\n")
for p in whatis[0].find_all('p'):
打印(p.text.strip()+“\n”)
示例2:网络爬取币种统计
在本例中,我们将使用 BNB 统计数据,即市值、完全稀释市值、交易量(24 小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字总是在变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class" : "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class" : "statsValue"})statsValue_marketcap = statsValues[0].text.strip()
print(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
print(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
print(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
print(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
打印(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap 等网站的开发者在不断更新自己的网站,旧代码可能过一段时间就失效了。
一种可能的解决方案是使用各种网站和平台提供的应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。 查看全部
网页抓取解密(数据就是新石油互联网上海量的加密货币数据应该成为你的第二天性)
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬行是指从网站下载数据并从这些数据中提取有价值信息的过程(因此得名爬行)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在本系列文章中,我们将从一个概念开始,并在此基础上慢慢构建。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集
和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多提供免费工具的网站,为什么还有人要采集
你自己的数据呢?大多数用户将使用 CoinMarketCap、CoinGecko、Live Coin Watch 等网站来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录
这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录
更多关于投资研究的附加信息(市值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与 Polkadot 相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
from bs4 import BeautifulSoup
import requests
mainpage = requests.get('https://coinmarketcap.com/curr ... %2339;)
soup = BeautifulSoup(mainpage.content, 'html.parser')
whatis = soup.find_all("div", {"class" : "sc-2qtjgt-0 eApVPN"})
title = whatis[0].find_all("h2")
print(title[0].text.strip() + "\n")
for p in whatis[0].find_all('p'):
打印(p.text.strip()+“\n”)
示例2:网络爬取币种统计
在本例中,我们将使用 BNB 统计数据,即市值、完全稀释市值、交易量(24 小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字总是在变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class" : "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class" : "statsValue"})statsValue_marketcap = statsValues[0].text.strip()
print(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
print(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
print(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
print(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
打印(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap 等网站的开发者在不断更新自己的网站,旧代码可能过一段时间就失效了。
一种可能的解决方案是使用各种网站和平台提供的应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
网页抓取解密(实用的解密方式和新方法(一)加密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-27 12:13
;头>
网马
这里的意思是创建一个文本框,然后将可爱的内容赋值给文本框。Textfield 是文本框的名称。你可以自己修改。但是必须修改document.getElementById('textfield').value中对应的name,然后运行刚才的nethorse得到结果:
刚才的加密代码大小为:
解密后:
至于\x72\x65\x73\x70\x6F\x6E\x73\x65\x42\x6F\x64\x79里面的代码,我们可以用一个简单的方法来突破。
十六进制转义字符串如下:
顺便说一下,它可以显示。在刚才的加密页面中,使用了一种防止查看源代码的技术。只需应用以下代码
这里的 noscript 元素用于定义脚本未执行时的替代内容(文本)。这个标签可以用来识别
也许你见过很多解密网马的方法。许多网络马在工具的帮助下可以轻松解决。为什么不:unescape 加密、Encode 加密、js 变异加密、US-ASCII 加密,但是如果你手头没有工具怎么办?还是遇到连工具都解不开的加密?轻言放弃不是我们的作风!今天就来讲解一些实用的解密方法和总结出来的新方法。
首先,大家要明白一个问题。必须在客户端识别所有网络马加密方法。如果它们不能转换成浏览器可以识别的标准代码,它们就不能运行!因此,理论上所有的网络马加密方式都可以解密。我们举几个典型的例子来解释一下。
首先是我最近遇到了一个网络马,加密结果如下:
看的时候头疼吗?乱七八糟,无从下手,不是简单的解密工具吧?一起来解决吧!首先我们一起来了解一下关键词这两个“document.write”和“eval”。
“Document.write”是JAVASCRIPT中的打印语句,“eval”指的是eval()函数,可以将字符串作为JavaScript表达式执行。如果我们在 JS 加密代码中遇到 document.write,我们通常将其更改为“alert”,如果我们遇到“eval”,我们通常将其更改为“document.write”。我们先把 eval 改成 document.write 再运行看看结果:
行!已经初步解密,从上次调用自定义函数realexploit()可以看出。这是最近发布的 realplay 漏洞利用网络马。至于里面的unescape加密部分就不用我解释了吧?最快的方法是复制那部分代码。然后添加到百度搜索关键词地址,如文档。
对于这段代码,防止翻译最快的方法是将其添加到上面的地址中,返回结果为:
我们来看看天网已经挂上的一匹网络马:
一堆乱七八糟的,不知道是什么。如何解读?其实最快最简单的方法就是浏览这个页面,保存时选择中欧(ISO)编码。
得到答案:
与此类似,还有US-ACSII加密的网络马,也可以通过这种方式解密。
保存时,仍然选择中欧(ISO)代码,得到如下结果:
接下来,让我们看看一个看起来有点困难的。近日,黑客防线发布的“暗网马”使用了Firefox中单人开发的加密工具。解密过程需要密码。是为了防止修改吗?看起来有点像md5加密,真的不可逆吗?一匹1K的网马可以加密到15K甚至更大,这很可怕吧?让我们一起解密他!
在长代码的末尾我们看到
var pass="TEST.";
如果(通过){
通过=unescape(通过);
varcuteqq,可爱,可爱;
Cuteqq=XOR(unescape(QQ_784378237),STR.md5(pass));
可爱=异或(unescape(),STR.md5(通过));
可爱=可爱qq+www_cuteqq_cn_s+可爱;
文档写(可爱);
返回(假);
}
意思是调用pass校验函数,如果为true,继续执行里面的内容。XOR 是对两个表达式执行逻辑“异或”操作的运算符。我不会在这里详细了解它。关键是最后一个Document.write(可爱的)懂网页代码的人会知道这一段的具体含义是,如果密码验证正确。只需输出cute函数中的内容即可。当我们遇到 document.write 时,我们通常将其更改为“alert”以获得初始解密:
这里我们有一个问题。Alert 根据内屏的大小显示内容。内容无法完全显示。该怎么办?我们引入一段javascript代码:document.getElementById('textfield').value=cute; 替换原来的document.write(cute); 然后在页面中
在和之间加一段,效果如下:
< 查看全部
网页抓取解密(实用的解密方式和新方法(一)加密)
;头>
网马
这里的意思是创建一个文本框,然后将可爱的内容赋值给文本框。Textfield 是文本框的名称。你可以自己修改。但是必须修改document.getElementById('textfield').value中对应的name,然后运行刚才的nethorse得到结果:

刚才的加密代码大小为:

解密后:

至于\x72\x65\x73\x70\x6F\x6E\x73\x65\x42\x6F\x64\x79里面的代码,我们可以用一个简单的方法来突破。
十六进制转义字符串如下:
顺便说一下,它可以显示。在刚才的加密页面中,使用了一种防止查看源代码的技术。只需应用以下代码
这里的 noscript 元素用于定义脚本未执行时的替代内容(文本)。这个标签可以用来识别
也许你见过很多解密网马的方法。许多网络马在工具的帮助下可以轻松解决。为什么不:unescape 加密、Encode 加密、js 变异加密、US-ASCII 加密,但是如果你手头没有工具怎么办?还是遇到连工具都解不开的加密?轻言放弃不是我们的作风!今天就来讲解一些实用的解密方法和总结出来的新方法。
首先,大家要明白一个问题。必须在客户端识别所有网络马加密方法。如果它们不能转换成浏览器可以识别的标准代码,它们就不能运行!因此,理论上所有的网络马加密方式都可以解密。我们举几个典型的例子来解释一下。
首先是我最近遇到了一个网络马,加密结果如下:

看的时候头疼吗?乱七八糟,无从下手,不是简单的解密工具吧?一起来解决吧!首先我们一起来了解一下关键词这两个“document.write”和“eval”。
“Document.write”是JAVASCRIPT中的打印语句,“eval”指的是eval()函数,可以将字符串作为JavaScript表达式执行。如果我们在 JS 加密代码中遇到 document.write,我们通常将其更改为“alert”,如果我们遇到“eval”,我们通常将其更改为“document.write”。我们先把 eval 改成 document.write 再运行看看结果:

行!已经初步解密,从上次调用自定义函数realexploit()可以看出。这是最近发布的 realplay 漏洞利用网络马。至于里面的unescape加密部分就不用我解释了吧?最快的方法是复制那部分代码。然后添加到百度搜索关键词地址,如文档。
对于这段代码,防止翻译最快的方法是将其添加到上面的地址中,返回结果为:

我们来看看天网已经挂上的一匹网络马:

一堆乱七八糟的,不知道是什么。如何解读?其实最快最简单的方法就是浏览这个页面,保存时选择中欧(ISO)编码。

得到答案:

与此类似,还有US-ACSII加密的网络马,也可以通过这种方式解密。

保存时,仍然选择中欧(ISO)代码,得到如下结果:

接下来,让我们看看一个看起来有点困难的。近日,黑客防线发布的“暗网马”使用了Firefox中单人开发的加密工具。解密过程需要密码。是为了防止修改吗?看起来有点像md5加密,真的不可逆吗?一匹1K的网马可以加密到15K甚至更大,这很可怕吧?让我们一起解密他!

在长代码的末尾我们看到
var pass="TEST.";
如果(通过){
通过=unescape(通过);
varcuteqq,可爱,可爱;
Cuteqq=XOR(unescape(QQ_784378237),STR.md5(pass));
可爱=异或(unescape(),STR.md5(通过));
可爱=可爱qq+www_cuteqq_cn_s+可爱;
文档写(可爱);
返回(假);
}
意思是调用pass校验函数,如果为true,继续执行里面的内容。XOR 是对两个表达式执行逻辑“异或”操作的运算符。我不会在这里详细了解它。关键是最后一个Document.write(可爱的)懂网页代码的人会知道这一段的具体含义是,如果密码验证正确。只需输出cute函数中的内容即可。当我们遇到 document.write 时,我们通常将其更改为“alert”以获得初始解密:

这里我们有一个问题。Alert 根据内屏的大小显示内容。内容无法完全显示。该怎么办?我们引入一段javascript代码:document.getElementById('textfield').value=cute; 替换原来的document.write(cute); 然后在页面中
在和之间加一段,效果如下:
<
网页抓取解密(如何获取我们独立站准确详细的数据网站购物行为数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-16 17:22
最近,我发现了一个问题。一些独立站项目起不来。不是因为人不聪明,做不到。今天就跟大家分享一下如何获取我们独立站的准确详细的数据,从而更有针对性的进行优化推广。
让我先看看,这是我昨天为我们的一位客户设置并获取的 网站 数据
这是网站购物行为数据:
这是 网站 结帐行为数据:
第二张图是因为刚刚部署了技术,所以没有进入支付成功结账的数据。
有了这些现场数据,我们就可以分析网站哪个环节有问题,并有针对性地进行改进。而我们可以通过网站的转化率来推导出我们实现业务目标所需的流量,然后计划增加网站各个渠道的流量。
接下来让我们看看我们如何获取这些数据。
要获取此数据,我们必须执行 2 个步骤:
1. GA 管理后台操作
2. 网站后端部署代码
一、 GA 管理后台操作
我们先在后台点击管理,然后选择目标数据视图下的电商设置
单击启用电子商务设置以启用增强型电子商务设置
这里的通道步长设置对应网站结账行为数据的步长。我们可以自己命名这些步骤,也可以不命名。如果没有给steps命名,也会显示结账行为数据,但是名字类似于step 1 step 2。建议写出来,这样看起来更清晰。
完成后台设置后,我们第二步就是找技术做网站后台代码部署。
2网站后端代码部署
这部分主要分为2个部分。
第一部分首先讲了用哪些码来统计对应的数据。
第二部分讲代码部署示例。
我们先来看代码。在这一部分,我会给你发一张大图。非技术人员只需要阅读描述部分,了解可以统计哪些数据,然后将图片发送给技术,告诉技术要统计的数据。
接下来我们讲例子
以测量显示为例看结构
测量显示需要 ec:addImpression 命令,所以第一行代码是 ec:addImpression。
紧随其后的是与数据对应的统计信息所需的值。示例中,id为产品ID,category为产品类别,brand为产品品牌,variant为产品细分样式,list为产品所在列表,position为产品在列表,这里的dimension1是自定义数据。
这些都对应于我们之前发布的大图上的代码。
接下来我们看完整的例子:
衡量产品印象
衡量产品点击次数和详细视图
衡量购物车项目的添加和删除
衡量结帐过程
衡量交易
您还可以将这些示例发送给技术。在与技术交流时,我们提供以下内容:
1. 统计不同的数据对应要使用的值,这样就足够发第一张大图了。
2. 告诉我们需要的技术,也就是我们要统计的数据。
3. 将完整示例发送到技术参考。 查看全部
网页抓取解密(如何获取我们独立站准确详细的数据网站购物行为数据)
最近,我发现了一个问题。一些独立站项目起不来。不是因为人不聪明,做不到。今天就跟大家分享一下如何获取我们独立站的准确详细的数据,从而更有针对性的进行优化推广。
让我先看看,这是我昨天为我们的一位客户设置并获取的 网站 数据
这是网站购物行为数据:
这是 网站 结帐行为数据:
第二张图是因为刚刚部署了技术,所以没有进入支付成功结账的数据。
有了这些现场数据,我们就可以分析网站哪个环节有问题,并有针对性地进行改进。而我们可以通过网站的转化率来推导出我们实现业务目标所需的流量,然后计划增加网站各个渠道的流量。
接下来让我们看看我们如何获取这些数据。
要获取此数据,我们必须执行 2 个步骤:
1. GA 管理后台操作
2. 网站后端部署代码
一、 GA 管理后台操作
我们先在后台点击管理,然后选择目标数据视图下的电商设置
单击启用电子商务设置以启用增强型电子商务设置
这里的通道步长设置对应网站结账行为数据的步长。我们可以自己命名这些步骤,也可以不命名。如果没有给steps命名,也会显示结账行为数据,但是名字类似于step 1 step 2。建议写出来,这样看起来更清晰。
完成后台设置后,我们第二步就是找技术做网站后台代码部署。
2网站后端代码部署
这部分主要分为2个部分。
第一部分首先讲了用哪些码来统计对应的数据。
第二部分讲代码部署示例。
我们先来看代码。在这一部分,我会给你发一张大图。非技术人员只需要阅读描述部分,了解可以统计哪些数据,然后将图片发送给技术,告诉技术要统计的数据。
接下来我们讲例子
以测量显示为例看结构
测量显示需要 ec:addImpression 命令,所以第一行代码是 ec:addImpression。
紧随其后的是与数据对应的统计信息所需的值。示例中,id为产品ID,category为产品类别,brand为产品品牌,variant为产品细分样式,list为产品所在列表,position为产品在列表,这里的dimension1是自定义数据。
这些都对应于我们之前发布的大图上的代码。
接下来我们看完整的例子:
衡量产品印象
衡量产品点击次数和详细视图
衡量购物车项目的添加和删除
衡量结帐过程
衡量交易
您还可以将这些示例发送给技术。在与技术交流时,我们提供以下内容:
1. 统计不同的数据对应要使用的值,这样就足够发第一张大图了。
2. 告诉我们需要的技术,也就是我们要统计的数据。
3. 将完整示例发送到技术参考。
网页抓取解密(百度认为什么样的网站更有抓取和收录价值呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-16 17:20
百度认为什么样的网站对爬虫和收录更有价值?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考,具体收录策略包括但不限于所描述的内容。
第一个方面:网站打造为用户提供独特价值的优质内容。
作为一个搜索引擎,百度的最终目的是满足用户的搜索需求,所以要求网站的内容能够首先满足用户的需求。在互联网充斥着大量同质化内容的今天,在也能满足用户需求的前提下,如果你网站提供的内容是独一无二的或者具有一定的独特价值,那么百度会更喜欢到收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站 的内容是“一般或低质量”的,有些网站 甚至使用欺骗来获得更好的收录 或排名。以下是一些常见的情况,虽然不可能一一列举。但请不要冒险。百度有完善的技术支持来发现和处理这些行为。
一些 网站 不是为用户设计的,而是为了从搜索引擎中骗取更多流量。例如,一种内容提交给搜索引擎,另一种内容显示给用户。这些行为包括但不限于:向网页添加隐藏文本或隐藏链接;在与网页内容无关的网页中添加关键词;欺骗性的跳转或重定向;专门为搜索引擎制作桥页;为搜索引擎利用以编程方式生成的内容。
百度会尝试收录提供不同信息的网页。如果你的网站收录很多重复的内容,那么搜索引擎会减少相同内容的收录,并认为网站提供的内容价值不高。
当然,如果网站上的相同内容以不同的形式展示(比如论坛的简化页面、打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。还有助于节省带宽。
第二个方面:网站提供的内容得到了用户和站长的认可和支持
如果一个网站上的内容得到了用户和站长的认可,对于百度来说也是非常值得的收录。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,综合给出一个网站的识别等级。但值得注意的是,这种认可必须基于网站为用户提供优质内容,真实有效。下面仅以网站之间的关系为例来说明百度如何看待其他站长对你的网站的认可: 通常情况下,网站之间的链接可以帮助百度掌握获取工具找到你的网站,增加你网站的认可度。百度将从 A 页面到 B 页面的链接解释为从 A 页面到 B 页面的投票。通过网页投票可以体现对网页本身的“认可度”,有助于提高其他网页的“认可度”。链接的数量、质量和相关性都会影响“批准”的计算。
但请注意,并不是所有的链接都可以参与背书的计算,只有那些自然链接才有效。(自然链接是在网络动态生成过程中,当其他网站s 发现您的内容有价值并认为可能对访问者有帮助时形成的链接。)
其他网站创建与您相关的链接网站的最佳方式是创建独特且相关的内容,这些内容将在互联网上流行起来。您的内容越有用,其他网站管理员就越容易找到对他们的用户有价值的内容,从而链接到您的 网站。在决定是否添加链接之前,您应该考虑:这真的对我的 网站 访问者有益吗?
但是有些网站站长经常不顾链接质量和链接来源交换链接,纯粹为了识别而人为地建立链接关系,这将对他们的网站造成长期影响。
提醒:对网站有不良影响的链接包括但不限于:
第三方面:网站有良好的浏览体验
一个浏览体验好的网站对用户是非常有利的,百度也会认为这样的网站有更好的收录价值。良好的浏览体验意味着:
为用户提供收录 网站 重要部分链接的站点地图和导航。使用户能够清晰、简单地浏览网站,快速找到他们想要的信息。
网站快速的速度可以提高用户满意度并提高网页的整体质量(尤其是对于互联网连接速度较慢的用户)。
确保网站的内容可以在不同的浏览器中正确显示,防止部分用户无法正常访问。
广告是网站的重要收入来源,加入网站广告是合理的,但如果广告过多,会影响用户浏览;或网站有太多不相关的公告窗口和凸窗广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成伤害,那么百度对此类网站的抓取需要减少。
网站的注册权限等权限可以增加网站的注册用户数量,保证网站的内容质量,但是过多的权限设置可能会让新用户失去耐心,带来给用户带来不便。好的经历。从百度的角度来看,它希望减少对用户获取信息过于昂贵的网页的提供。
您想通过在线销售赚钱吗?你想在网上创业吗?你想在网上赚到你的第一桶金吗?如果你想用1000多快钱摆脱现在的工作,加入我们SEOER实战工会团队,让你实现心中的梦想,让你的梦想扬帆起航。. . 成为80后、90后新贵,立即行动! 查看全部
网页抓取解密(百度认为什么样的网站更有抓取和收录价值呢?)
百度认为什么样的网站对爬虫和收录更有价值?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考,具体收录策略包括但不限于所描述的内容。
第一个方面:网站打造为用户提供独特价值的优质内容。
作为一个搜索引擎,百度的最终目的是满足用户的搜索需求,所以要求网站的内容能够首先满足用户的需求。在互联网充斥着大量同质化内容的今天,在也能满足用户需求的前提下,如果你网站提供的内容是独一无二的或者具有一定的独特价值,那么百度会更喜欢到收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站 的内容是“一般或低质量”的,有些网站 甚至使用欺骗来获得更好的收录 或排名。以下是一些常见的情况,虽然不可能一一列举。但请不要冒险。百度有完善的技术支持来发现和处理这些行为。
一些 网站 不是为用户设计的,而是为了从搜索引擎中骗取更多流量。例如,一种内容提交给搜索引擎,另一种内容显示给用户。这些行为包括但不限于:向网页添加隐藏文本或隐藏链接;在与网页内容无关的网页中添加关键词;欺骗性的跳转或重定向;专门为搜索引擎制作桥页;为搜索引擎利用以编程方式生成的内容。
百度会尝试收录提供不同信息的网页。如果你的网站收录很多重复的内容,那么搜索引擎会减少相同内容的收录,并认为网站提供的内容价值不高。
当然,如果网站上的相同内容以不同的形式展示(比如论坛的简化页面、打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。还有助于节省带宽。
第二个方面:网站提供的内容得到了用户和站长的认可和支持
如果一个网站上的内容得到了用户和站长的认可,对于百度来说也是非常值得的收录。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,综合给出一个网站的识别等级。但值得注意的是,这种认可必须基于网站为用户提供优质内容,真实有效。下面仅以网站之间的关系为例来说明百度如何看待其他站长对你的网站的认可: 通常情况下,网站之间的链接可以帮助百度掌握获取工具找到你的网站,增加你网站的认可度。百度将从 A 页面到 B 页面的链接解释为从 A 页面到 B 页面的投票。通过网页投票可以体现对网页本身的“认可度”,有助于提高其他网页的“认可度”。链接的数量、质量和相关性都会影响“批准”的计算。
但请注意,并不是所有的链接都可以参与背书的计算,只有那些自然链接才有效。(自然链接是在网络动态生成过程中,当其他网站s 发现您的内容有价值并认为可能对访问者有帮助时形成的链接。)
其他网站创建与您相关的链接网站的最佳方式是创建独特且相关的内容,这些内容将在互联网上流行起来。您的内容越有用,其他网站管理员就越容易找到对他们的用户有价值的内容,从而链接到您的 网站。在决定是否添加链接之前,您应该考虑:这真的对我的 网站 访问者有益吗?
但是有些网站站长经常不顾链接质量和链接来源交换链接,纯粹为了识别而人为地建立链接关系,这将对他们的网站造成长期影响。
提醒:对网站有不良影响的链接包括但不限于:
第三方面:网站有良好的浏览体验
一个浏览体验好的网站对用户是非常有利的,百度也会认为这样的网站有更好的收录价值。良好的浏览体验意味着:
为用户提供收录 网站 重要部分链接的站点地图和导航。使用户能够清晰、简单地浏览网站,快速找到他们想要的信息。
网站快速的速度可以提高用户满意度并提高网页的整体质量(尤其是对于互联网连接速度较慢的用户)。
确保网站的内容可以在不同的浏览器中正确显示,防止部分用户无法正常访问。
广告是网站的重要收入来源,加入网站广告是合理的,但如果广告过多,会影响用户浏览;或网站有太多不相关的公告窗口和凸窗广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成伤害,那么百度对此类网站的抓取需要减少。
网站的注册权限等权限可以增加网站的注册用户数量,保证网站的内容质量,但是过多的权限设置可能会让新用户失去耐心,带来给用户带来不便。好的经历。从百度的角度来看,它希望减少对用户获取信息过于昂贵的网页的提供。
您想通过在线销售赚钱吗?你想在网上创业吗?你想在网上赚到你的第一桶金吗?如果你想用1000多快钱摆脱现在的工作,加入我们SEOER实战工会团队,让你实现心中的梦想,让你的梦想扬帆起航。. . 成为80后、90后新贵,立即行动!
网页抓取解密(如何提高百度蜘蛛提高频率如何抓取网站四、什么情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-16 10:04
3、机器人协议:这个文件是百度蜘蛛访问的第一个文件。它告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛爬取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:网站权重较高的百度蜘蛛会爬得更频繁更深
2、网站更新频率:更新频率越高,百度蜘蛛越多
3、网站内容质量:网站如果内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好的引导百度蜘蛛进入和爬取。
5、页面深度:页面是否在首页有入口,如果首页有入口,可以更好的爬取和收录。
6、爬取的频率决定了网站要建多少页到数据库收录,这么重要内容的站长该去哪里了解修改,可以去百度站长平台获取Frequency函数的理解,如下图:
百度蜘蛛如何提高爬取频率网站
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页内容优质,用户访问正常,但百度蜘蛛无法抓取,不仅会流失流量,用户也会被百度认为网站不友好,导致网站降级、分数下降、导入网站流量减少等问题。
火龙简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接服务器. 此时,您应该仔细检查。.
2、网络运营商异常:目前国内网络运营商分为中国电信和中国联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常,你可以通过WHOIS查看你的网站IP是否可以解析,如无必要联系域名注册商解决。
4、IP封禁:IP封禁是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站,最好不做这个操作。
5、死链接:表示页面无效,无法提供有效信息。这时候可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛爬取的原理。收录是网站流量的保证,而百度蜘蛛爬网是收录的保证,所以网站只满足网站的要求。百度蜘蛛的爬取规则可以获得更好的排名和流量。
宁德SEO培训 查看全部
网页抓取解密(如何提高百度蜘蛛提高频率如何抓取网站四、什么情况)
3、机器人协议:这个文件是百度蜘蛛访问的第一个文件。它告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛爬取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:网站权重较高的百度蜘蛛会爬得更频繁更深
2、网站更新频率:更新频率越高,百度蜘蛛越多
3、网站内容质量:网站如果内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好的引导百度蜘蛛进入和爬取。
5、页面深度:页面是否在首页有入口,如果首页有入口,可以更好的爬取和收录。
6、爬取的频率决定了网站要建多少页到数据库收录,这么重要内容的站长该去哪里了解修改,可以去百度站长平台获取Frequency函数的理解,如下图:
百度蜘蛛如何提高爬取频率网站
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页内容优质,用户访问正常,但百度蜘蛛无法抓取,不仅会流失流量,用户也会被百度认为网站不友好,导致网站降级、分数下降、导入网站流量减少等问题。
火龙简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接服务器. 此时,您应该仔细检查。.
2、网络运营商异常:目前国内网络运营商分为中国电信和中国联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常,你可以通过WHOIS查看你的网站IP是否可以解析,如无必要联系域名注册商解决。
4、IP封禁:IP封禁是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站,最好不做这个操作。
5、死链接:表示页面无效,无法提供有效信息。这时候可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛爬取的原理。收录是网站流量的保证,而百度蜘蛛爬网是收录的保证,所以网站只满足网站的要求。百度蜘蛛的爬取规则可以获得更好的排名和流量。
宁德SEO培训
网页抓取解密(网页抓取工具可供使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-13 13:06
互联网不断涌现出新的信息、新的设计模式和大量的 c。将这些数据组织到一个独特的库中并非易事。但是,有很多优秀的网络抓取工具可用。
代理爬取
使用代理抓取 API,您可以抓取网络上的任何 网站/ 平台。有代理支持、验证码绕过以及基于动态内容抓取 Java 页面的优势。
代理爬取
它对 1000 个请求是免费的,这足以探索 Proxy Crawl 在复杂内容页面中使用的强大功能。
刮擦
Scrapy 是一个开源项目,为网页抓取提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
刮擦
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与 ProxyCrawl*** 集成。借助 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。也可以使用 Scrapy API 扩展提供的功能。
抓
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,可以为小型个人项目创建抓取机制,以及构建可同时扩展到数百万页的大型动态抓取任务。
抓
内置 API 提供了执行网络请求和处理已删除内容的方法。Grab 提供的另一个 API 称为 Spider。使用 Spider API,可以使用自定义类创建异步爬虫。
雪貂
Ferret 对于网络抓取来说是相当新的,并且在开源社区中获得了相当大的关注。Ferret 的目标是提供更清洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明性语言,避免了构建系统的复杂性。相反,也可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray、Osmosis 等库的可用性,使用 Node.js 抓取 Web 非常简单。
差异机器人
Diffbot 是市场上的新玩家。您甚至不必编写太多代码,因为 Diffbot 的 AI 算法可以解密 网站 页面中的结构化数据,而无需手动规范化。
差异机器人
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,可以直接从网页内部获取数据,并且可以生成可视文件并在 PDF 文档中呈现页面。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 Java 的 网站,这将特别有用。 查看全部
网页抓取解密(网页抓取工具可供使用)
互联网不断涌现出新的信息、新的设计模式和大量的 c。将这些数据组织到一个独特的库中并非易事。但是,有很多优秀的网络抓取工具可用。
代理爬取
使用代理抓取 API,您可以抓取网络上的任何 网站/ 平台。有代理支持、验证码绕过以及基于动态内容抓取 Java 页面的优势。
代理爬取
它对 1000 个请求是免费的,这足以探索 Proxy Crawl 在复杂内容页面中使用的强大功能。
刮擦
Scrapy 是一个开源项目,为网页抓取提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
刮擦
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与 ProxyCrawl*** 集成。借助 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。也可以使用 Scrapy API 扩展提供的功能。
抓
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,可以为小型个人项目创建抓取机制,以及构建可同时扩展到数百万页的大型动态抓取任务。
抓
内置 API 提供了执行网络请求和处理已删除内容的方法。Grab 提供的另一个 API 称为 Spider。使用 Spider API,可以使用自定义类创建异步爬虫。
雪貂
Ferret 对于网络抓取来说是相当新的,并且在开源社区中获得了相当大的关注。Ferret 的目标是提供更清洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明性语言,避免了构建系统的复杂性。相反,也可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray、Osmosis 等库的可用性,使用 Node.js 抓取 Web 非常简单。
差异机器人
Diffbot 是市场上的新玩家。您甚至不必编写太多代码,因为 Diffbot 的 AI 算法可以解密 网站 页面中的结构化数据,而无需手动规范化。
差异机器人
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,可以直接从网页内部获取数据,并且可以生成可视文件并在 PDF 文档中呈现页面。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 Java 的 网站,这将特别有用。
网页抓取解密(用Python写爬虫爬煎蛋网的妹子图的链接获取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-13 00:09
之前在鱼C论坛的时候,看到很多人都在用Python写女生在煎蛋网络上爬行的图片。那个时候还写爬爬了很多女生的照片。后来,简单网对女孩图片的网页进行了改进,并对图片地址进行了加密,所以论坛里经常有人问,请求的页面怎么没有链接。在这篇文章文章中,我将讨论如何获取的OOXX女孩图片的链接。
首先说明一下,炒蛋网之前之所以加入反爬机制,是因为爬他们的网站的人太多了。爬虫网站的频繁访问会给网站带来压力,所以建议大家编写简单运行成功的爬虫,不要过多爬取。
爬虫思路分析图片下载流程图
首先用一个简单的流程图(非标准流程图格式)来展示爬取简单网络的姐妹图的全过程:
流程图解读
1、 爬取炒蛋的姐妹图,首先需要打开姐妹图的任意页面,比如#comments,然后我们需要请求这个页面获取2个关键信息(信息的具体作用后面会解释),其中第一个信息是每个女孩的图片的hash值,是后面用来解密生成的图片地址的关键信息。
2、除了页面中提取的图片的hash,还有提取到当前页面的一个关键js文件的地址。这个js文件收录一个关键参数,也是用来生成图片地址的。要获取这个参数,你必须请求这个JS地址。那个时候姐妹图每个页面的js地址都不一样,所以需要从页面中提取出来。
3、在js中获取到图片的hash和key参数后,根据js中提供的解密方式,即可获取到图片的链接。这个解密方法后面会参考Python代码和js代码来说明。
4、有了图片链接,下载图片就不用多说了。会有第二篇文章使用多线程+多进程下载图片。
页面分析网页源码解读
我们可以打开一个女生图片的页面,或者先#comments作为例子,然后查看源码(注意不是review元素),可以看到图片地址应该是没有图片地址的可以放置,但是类似下面的代码:
ece8ozWUT/VGGxW1hlbITPgE0XMZ9Y/yWpCi5Rz5F/h2uSWgxwV6IQl6DAeuFiT9mH2ep3CETLlpwyD+kU0YHpsHPLnY6LMHyIQo6sTu9/UdY5k+Vjt3EQ
从这段代码可以看出,图片地址被一个js函数替换了,也就是说图片地址是通过jandan_load_img(this)函数获取并加载的,所以现在关键是在js中找到这个函数文件意义。
js文件解释
通过在每个js文件中搜索jandan_load_img,最终可以在一个类似地址的文件中找到该函数的定义,并将压缩后的js代码格式化,查看具体定义如下:
function jandan_load_img(b) {
var d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN(e, "agC37Is2vpAYzkFI9WVObFDN5bcFn1Px");
这段代码的意思很容易理解。首先,它提取当前标签下CSS为img-hash的span标签的文本,也就是我们一开始提到的图片的hash值,然后把这个值和一个字符串参数(每个页面的这个参数)结合起来改了。这个页面是agC37Is2vpAYzkFI9WVObFDN5bcFn1Px),并传递给了另一个函数f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN,所以我们要检查这个函数的含义。这个函数就是用来生成图片链接的函数。
f_函数的解释
可以在js中找到这个f_函数的定义,可以看到有两个,不过没关系,按照代码从上到下的执行规律,我们只需要看后面的一个即可。完整内容如下:
<p>var f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN = function(m, r, d) {
var e = "DECODE";
var r = r ? r : "";
var d = d ? d : 0;
var q = 4;
r = md5(r);
var o = md5(r.substr(0, 16));
var n = md5(r.substr(16, 16));
if (q) { if (e == "DECODE") { var l = m.substr(0, q) } } else { var l = "" }
var c = o + md5(o + l);
var k;
if (e == "DECODE") {
m = m.substr(q);
k = base64_decode(m)
}
var h = new Array(256);
for (var g = 0; g 查看全部
网页抓取解密(用Python写爬虫爬煎蛋网的妹子图的链接获取方式)
之前在鱼C论坛的时候,看到很多人都在用Python写女生在煎蛋网络上爬行的图片。那个时候还写爬爬了很多女生的照片。后来,简单网对女孩图片的网页进行了改进,并对图片地址进行了加密,所以论坛里经常有人问,请求的页面怎么没有链接。在这篇文章文章中,我将讨论如何获取的OOXX女孩图片的链接。
首先说明一下,炒蛋网之前之所以加入反爬机制,是因为爬他们的网站的人太多了。爬虫网站的频繁访问会给网站带来压力,所以建议大家编写简单运行成功的爬虫,不要过多爬取。
爬虫思路分析图片下载流程图
首先用一个简单的流程图(非标准流程图格式)来展示爬取简单网络的姐妹图的全过程:
流程图解读
1、 爬取炒蛋的姐妹图,首先需要打开姐妹图的任意页面,比如#comments,然后我们需要请求这个页面获取2个关键信息(信息的具体作用后面会解释),其中第一个信息是每个女孩的图片的hash值,是后面用来解密生成的图片地址的关键信息。
2、除了页面中提取的图片的hash,还有提取到当前页面的一个关键js文件的地址。这个js文件收录一个关键参数,也是用来生成图片地址的。要获取这个参数,你必须请求这个JS地址。那个时候姐妹图每个页面的js地址都不一样,所以需要从页面中提取出来。
3、在js中获取到图片的hash和key参数后,根据js中提供的解密方式,即可获取到图片的链接。这个解密方法后面会参考Python代码和js代码来说明。
4、有了图片链接,下载图片就不用多说了。会有第二篇文章使用多线程+多进程下载图片。
页面分析网页源码解读
我们可以打开一个女生图片的页面,或者先#comments作为例子,然后查看源码(注意不是review元素),可以看到图片地址应该是没有图片地址的可以放置,但是类似下面的代码:
ece8ozWUT/VGGxW1hlbITPgE0XMZ9Y/yWpCi5Rz5F/h2uSWgxwV6IQl6DAeuFiT9mH2ep3CETLlpwyD+kU0YHpsHPLnY6LMHyIQo6sTu9/UdY5k+Vjt3EQ
从这段代码可以看出,图片地址被一个js函数替换了,也就是说图片地址是通过jandan_load_img(this)函数获取并加载的,所以现在关键是在js中找到这个函数文件意义。
js文件解释
通过在每个js文件中搜索jandan_load_img,最终可以在一个类似地址的文件中找到该函数的定义,并将压缩后的js代码格式化,查看具体定义如下:
function jandan_load_img(b) {
var d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN(e, "agC37Is2vpAYzkFI9WVObFDN5bcFn1Px");
这段代码的意思很容易理解。首先,它提取当前标签下CSS为img-hash的span标签的文本,也就是我们一开始提到的图片的hash值,然后把这个值和一个字符串参数(每个页面的这个参数)结合起来改了。这个页面是agC37Is2vpAYzkFI9WVObFDN5bcFn1Px),并传递给了另一个函数f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN,所以我们要检查这个函数的含义。这个函数就是用来生成图片链接的函数。
f_函数的解释
可以在js中找到这个f_函数的定义,可以看到有两个,不过没关系,按照代码从上到下的执行规律,我们只需要看后面的一个即可。完整内容如下:
<p>var f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN = function(m, r, d) {
var e = "DECODE";
var r = r ? r : "";
var d = d ? d : 0;
var q = 4;
r = md5(r);
var o = md5(r.substr(0, 16));
var n = md5(r.substr(16, 16));
if (q) { if (e == "DECODE") { var l = m.substr(0, q) } } else { var l = "" }
var c = o + md5(o + l);
var k;
if (e == "DECODE") {
m = m.substr(q);
k = base64_decode(m)
}
var h = new Array(256);
for (var g = 0; g
网页抓取解密(解密网马的实用解密方式和新方法加密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-07 21:15
【IT168专文】也许你见过很多解密网马的方法。许多网络马在工具的帮助下可以轻松解决。为什么不:unescape 加密、Encode 加密、js 变异加密、US-ASCII 加密,但是如果你手头没有工具怎么办?还是遇到连工具都解不开的加密?轻言放弃不是我们的作风!今天就来讲解一些实用的解密方法和总结出来的新方法。
首先,大家要明白一个问题。必须在客户端识别所有网络马加密方法。如果它们不能转换成浏览器可以识别的标准代码,它们就不能运行!所以理论上所有的网络马加密方式都可以解密。我们举几个典型的例子来解释一下。
首先是我最近遇到了一个网络马,加密结果如下:
看的时候头疼吗?乱七八糟,无从下手,不是简单的解密工具吧?一起来解决吧!首先我们一起来了解一下关键词这两个“document.write”和“eval”。
“Document.write”是JAVASCRIPT中的打印语句,“eval”指的是eval()函数,可以将字符串作为JavaScript表达式执行。如果在JS加密代码中遇到document.write,我们一般改成“alert”,遇到“eval”我们一般改成“document.write”。我们先把 eval 改成 document.write 再运行看看结果:
行!已经初步解密,从上次调用自定义函数realexploit()可以看出。这是最近发布的 realplay 漏洞利用网络马。至于里面的unescape加密部分就不用我解释了吧?最快的方法是复制那部分代码。然后添加到百度搜索关键词地址,如文档。
对于这段代码,防止翻译最快的方法是将其添加到上面的地址中,返回结果为:
我们来看看天网已经挂上的一匹网络马:
一堆乱七八糟的,不知道是什么。如何解读?其实最快最简单的方法就是浏览这个页面,保存时选择中欧(ISO)编码。
得到答案:
与此类似,还有US-ACSII加密的网络马,也可以通过这种方式解密。
保存时,仍然选择中欧(ISO)代码,得到如下结果:
接下来,让我们看看一个看起来有点困难的。近日,黑客防线发布的“暗网马”使用了Firefox中单人开发的加密工具。解密过程需要密码。是为了防止修改吗?看起来有点像md5加密,真的不可逆吗?一匹1K的网马可以加密到15K甚至更大,这很可怕吧?让我们一起解密他!
在长代码的末尾我们看到
var pass="TEST.";
如果(通过){
通过=unescape(通过);
varcuteqq,可爱,可爱;
Cuteqq=XOR(unescape(QQ_784378237),STR.md5(pass));
可爱=异或(unescape(),STR.md5(通过));
可爱=可爱qq+www_cuteqq_cn_s+可爱;
文档写(可爱);
返回(假);
}
意思是调用pass校验函数,如果为true,继续执行里面的内容。XOR 是对两个表达式执行逻辑“异或”操作的运算符。我不会在这里详细了解它。关键是最后一个Document.write(可爱的)懂网页代码的人会知道这一段的具体含义是,如果密码验证正确。只需输出cute函数中的内容即可。当我们遇到 document.write 时,我们通常将其更改为“alert”以获得初始解密:
这里我们有一个问题。Alert 根据内屏的大小显示内容。内容无法完全显示。该怎么办?我们引入一段javascript代码:document.getElementById('textfield').value=cute; 替换原来的document.write(cute); 然后在页面中
在和之间加一段,效果如下:
这里的意思是创建一个文本框,然后将可爱的内容赋值给文本框。Textfield 是文本框的名称。你可以自己修改。但是必须修改document.getElementById('textfield').value中对应的name,然后运行刚才的nethorse得到结果:
刚才的加密代码大小为:
解密后:
至于\x72\x65\x73\x70\x6F\x6E\x73\x65\x42\x6F\x64\x79里面的代码,我们可以用一个简单的方法来突破。
十六进制转义字符串如下:
顺便说一下,它可以显示。在刚才的加密页面中,使用了一种防止查看源代码的技术。只需应用以下代码
这里的 noscript 元素用于定义脚本未执行时的替代内容(文本)。这个标签可以用来识别 查看全部
网页抓取解密(解密网马的实用解密方式和新方法加密)
【IT168专文】也许你见过很多解密网马的方法。许多网络马在工具的帮助下可以轻松解决。为什么不:unescape 加密、Encode 加密、js 变异加密、US-ASCII 加密,但是如果你手头没有工具怎么办?还是遇到连工具都解不开的加密?轻言放弃不是我们的作风!今天就来讲解一些实用的解密方法和总结出来的新方法。
首先,大家要明白一个问题。必须在客户端识别所有网络马加密方法。如果它们不能转换成浏览器可以识别的标准代码,它们就不能运行!所以理论上所有的网络马加密方式都可以解密。我们举几个典型的例子来解释一下。
首先是我最近遇到了一个网络马,加密结果如下:
看的时候头疼吗?乱七八糟,无从下手,不是简单的解密工具吧?一起来解决吧!首先我们一起来了解一下关键词这两个“document.write”和“eval”。
“Document.write”是JAVASCRIPT中的打印语句,“eval”指的是eval()函数,可以将字符串作为JavaScript表达式执行。如果在JS加密代码中遇到document.write,我们一般改成“alert”,遇到“eval”我们一般改成“document.write”。我们先把 eval 改成 document.write 再运行看看结果:
行!已经初步解密,从上次调用自定义函数realexploit()可以看出。这是最近发布的 realplay 漏洞利用网络马。至于里面的unescape加密部分就不用我解释了吧?最快的方法是复制那部分代码。然后添加到百度搜索关键词地址,如文档。
对于这段代码,防止翻译最快的方法是将其添加到上面的地址中,返回结果为:
我们来看看天网已经挂上的一匹网络马:
一堆乱七八糟的,不知道是什么。如何解读?其实最快最简单的方法就是浏览这个页面,保存时选择中欧(ISO)编码。
得到答案:
与此类似,还有US-ACSII加密的网络马,也可以通过这种方式解密。
保存时,仍然选择中欧(ISO)代码,得到如下结果:
接下来,让我们看看一个看起来有点困难的。近日,黑客防线发布的“暗网马”使用了Firefox中单人开发的加密工具。解密过程需要密码。是为了防止修改吗?看起来有点像md5加密,真的不可逆吗?一匹1K的网马可以加密到15K甚至更大,这很可怕吧?让我们一起解密他!
在长代码的末尾我们看到
var pass="TEST.";
如果(通过){
通过=unescape(通过);
varcuteqq,可爱,可爱;
Cuteqq=XOR(unescape(QQ_784378237),STR.md5(pass));
可爱=异或(unescape(),STR.md5(通过));
可爱=可爱qq+www_cuteqq_cn_s+可爱;
文档写(可爱);
返回(假);
}
意思是调用pass校验函数,如果为true,继续执行里面的内容。XOR 是对两个表达式执行逻辑“异或”操作的运算符。我不会在这里详细了解它。关键是最后一个Document.write(可爱的)懂网页代码的人会知道这一段的具体含义是,如果密码验证正确。只需输出cute函数中的内容即可。当我们遇到 document.write 时,我们通常将其更改为“alert”以获得初始解密:
这里我们有一个问题。Alert 根据内屏的大小显示内容。内容无法完全显示。该怎么办?我们引入一段javascript代码:document.getElementById('textfield').value=cute; 替换原来的document.write(cute); 然后在页面中
在和之间加一段,效果如下:
这里的意思是创建一个文本框,然后将可爱的内容赋值给文本框。Textfield 是文本框的名称。你可以自己修改。但是必须修改document.getElementById('textfield').value中对应的name,然后运行刚才的nethorse得到结果:
刚才的加密代码大小为:
解密后:
至于\x72\x65\x73\x70\x6F\x6E\x73\x65\x42\x6F\x64\x79里面的代码,我们可以用一个简单的方法来突破。
十六进制转义字符串如下:
顺便说一下,它可以显示。在刚才的加密页面中,使用了一种防止查看源代码的技术。只需应用以下代码
这里的 noscript 元素用于定义脚本未执行时的替代内容(文本)。这个标签可以用来识别
网页抓取解密(分析一系列的VIP解析网站(一)(1)_光明网(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-07 21:10
前端加解密-VIP解析初探网站院长系列文章二维码阅读
2020-07-20 23:01
还记得几年前刚进入前端互联网行业的时候,随便点了一个网站,基本都装了jQuery,而且代码没有加密,随便看看,就是漏洞多多,漏洞百出,近些年,越来越多的网民开始关注网络安全,不仅是服务器端,客户端也开始研究各种压缩、混淆压缩、各种加密。简而言之,他们正在尽一切可能让那些拿起代码的人看到。看不懂网站的代码,是为了尽可能避免安全问题,或者防止别人从网站中提取自己的资源。当然,归根结底,前端没有安全性。我们所做的一切只是为了提高门槛。而已。从本文开始,我们将分析一系列网站案例,看看那些提高门槛的方法的前端应用。
这里我们将分析一系列VIP分析网站,看看他们站点中的前端加解密应用。为什么选择这种网站?仔细分析会发现,他们的网站充斥着各种增加代码或资源门槛的方法,值得分析。下面我们就从他们的分析技巧一一开始简单的了解一下。
作为本系列的开头文章,我们将分析一个稍微简单的目标站点:我们只需要在url参数中添加vip视频播放的链接,就可以解析出完整版的播放链接,这种网站一般基本支持市面上所有主流视频网站,比如爱奇艺、优酷等。网站的实际解析不是这样的,可能嵌套n层iframe .
以下说明将在Chrome浏览器中进行。如果你没有,你可以下载一个。Chrome真的很容易使用,但它会吃内存。
首先我们打开站点,传入vip视频播放链接,:///v_2ffkwswd6oo.html?vfrm=pcw_home&vfrmblk=L&vfrmrst=712211_dianyingbangbang_title1
打开一会,我们要得到一个网站的视频,清晰度还不错。当然,这不是重点。我们的重点是写一个爬虫,可以解析任何vip视频的真实播放链接。
接下来我们先打开开发者工具,打开开发者工具有两种方式,一种是直接按快捷键F12或者Ctrl+Shift+I,但是这个方法可能会被屏蔽,我们也可以按照下面的截图打开开发者工具如图
打开开发者工具,你会发现断点命中,页面现在无法操作。这是对网站的反调试分析,也是该类型网站的标准配置。通过这个很简单,我们只需要禁止断点的执行,然后继续执行,就不会再有断点了。
记得按照图中的顺序,然后我们切换到network选项卡,然后刷新页面,我们会看到很多请求,
为了缩小范围,我们进一步选择了网络下的xhr选项卡,发现只剩下几个请求了。
而m3u8请求之一就是我们需要获取的视频播放源地址,然后就可以找到api.php接口,通过这个接口获取视频播放源。
我们看到接口在post中发送了7个参数:
url: https://www.iqiyi.com/v_2ffkws ... _home
referer: aHR0cHM6Ly93d3cuYWRtaW5pc3RyYXRvcnYuY29tL2lxaXlpL2luZGV4LnBocD91cmw9aHR0cHM6Ly93d3cuaXFpeWkuY29tL3ZfMmZma3dzd2Q2b28uaHRtbD92ZnJtPXBjd19ob21lJnZmcm1ibGs9TCZ2ZnJtcnN0PTcxMjIxMV9kaWFueWluZ2JhbmdiYW5nX3RpdGxlMQ==
ref: 0
time: 1595251830
type:
other: aHR0cHM6Ly93d3cuaXFpeWkuY29tL3ZfMmZma3dzd2Q2b28uaHRtbD92ZnJtPXBjd19ob21lJnZmcm1ibGs9TCZ2ZnJtcnN0PTcxMjIxMV9kaWFueWluZ2JhbmdiYW5nX3RpdGxlMQ==
ios:
除了引用和其他字段,它们都很好理解。它们是纯文本格式。其实我们应该知道这是对refer等字段一目了然的base64编码,解密后的refer是: ///v_2ffkwswd6oo.html?vfrm=pcw_home&vfrmblk= L&vfrmrst=712211_dianyingbangbang_title1就是我们当前访问的地址。其他解密后就是要解析的VIP视频地址。但是,还有一个问题需要验证。时间字段是请求发起的时间还是服务器为学校发出的时间来验证请求的合法性,通过跟踪请求发起的代码,我们确认该字段是由服务器发起的进行验证。跟踪代码的方法如下:
我们只需要将鼠标移动到当前请求的发起者选项,就可以看到发起请求的js栈。我们排除了来自诸如 jquery 之类的库的调用以找到真正的来源。这里是较长的一段,然后点进去,发现代码是压缩的,我们可以通过浏览器的扩展功能来美化代码:
通过这段代码,我们可以发现客户端无法伪造时间字段。需要得到这个值才能正常调用接口。有两种选择:
一、所有请求参数都是从页面中提取的
二、 只提取时间字段,其余字段由客户端生成
这里我们选择第二种方式,我们用node来演示,先获取服务器发送的时间字段。
function getTime(u) {
return new Promise((resolve, reject) => {
request({
url: `https://www.administratorm.com/index.php?url=${u}`,
headers: {
Referer: `https://www.administratorm.com/index.php?url=${u}`
}
}, (err, response, body) => {
if (err) {
return reject(err);
}
const reg = /\'time\'\s*\:\s*\'(\d+)\'/;
if (reg.test(body)) {
return resolve(RegExp.$1);
}
reject();
});
});
}
获取到时间字段后,我们就可以正常发起请求了。我们先实现获取视频源的方法。
function getVideoSource(u, time) {
return new Promise((resolve, reject) => {
const formData = {
url: u,
referer: Buffer.from(`https://www.administratorw.com/index.php?url=${u}`).toString('base64'),
ref: 0,
time,
type: '',
other: Buffer.from(u).toString('base64'),
ios: ''
};
request({
url: PARSE_API,
method: 'POST',
headers: {
Referer: `https://www.administratorm.com/index.php?url=${u}`
},
formData
}, (err, response, body) => {
if (err) {
return reject(err);
}
try {
const ret = JSON.parse(body);
if (ret.url) {
return resolve(ret.url);
}
reject();
} catch(e) {
reject(e);
}
});
});
}
然后发起请求,
getTime(url)
.then(time => {
getVideoSource(url, time)
.then(url => {
console.log('视频解析成功,播放源地址:%s', url)
});
})
.catch(err => {
console.log('视频解析失败!');
});
文末小贴士:
1、在浏览器中,我们可以使用atob方法解密base64字符串,使用btoa方法获取解密后的base64字符串。
2、 如果参数正确但伪造请求时请求失败,可以尝试更改headers中的字段,例如添加Referer、userAgent、X-Requested-With。
3、 如果接口服务器对IP有限制,有一定几率可以通过伪造X-Forwarded-For来绕过这个限制。
文末提供了本文的示例代码,请自行下载。
报酬 查看全部
网页抓取解密(分析一系列的VIP解析网站(一)(1)_光明网(图))
前端加解密-VIP解析初探网站院长系列文章二维码阅读
2020-07-20 23:01
还记得几年前刚进入前端互联网行业的时候,随便点了一个网站,基本都装了jQuery,而且代码没有加密,随便看看,就是漏洞多多,漏洞百出,近些年,越来越多的网民开始关注网络安全,不仅是服务器端,客户端也开始研究各种压缩、混淆压缩、各种加密。简而言之,他们正在尽一切可能让那些拿起代码的人看到。看不懂网站的代码,是为了尽可能避免安全问题,或者防止别人从网站中提取自己的资源。当然,归根结底,前端没有安全性。我们所做的一切只是为了提高门槛。而已。从本文开始,我们将分析一系列网站案例,看看那些提高门槛的方法的前端应用。
这里我们将分析一系列VIP分析网站,看看他们站点中的前端加解密应用。为什么选择这种网站?仔细分析会发现,他们的网站充斥着各种增加代码或资源门槛的方法,值得分析。下面我们就从他们的分析技巧一一开始简单的了解一下。
作为本系列的开头文章,我们将分析一个稍微简单的目标站点:我们只需要在url参数中添加vip视频播放的链接,就可以解析出完整版的播放链接,这种网站一般基本支持市面上所有主流视频网站,比如爱奇艺、优酷等。网站的实际解析不是这样的,可能嵌套n层iframe .
以下说明将在Chrome浏览器中进行。如果你没有,你可以下载一个。Chrome真的很容易使用,但它会吃内存。
首先我们打开站点,传入vip视频播放链接,:///v_2ffkwswd6oo.html?vfrm=pcw_home&vfrmblk=L&vfrmrst=712211_dianyingbangbang_title1
https://www.deanhan.cn/wp-cont ... 7.jpg 300w, https://www.deanhan.cn/wp-cont ... 3.jpg 768w, https://www.deanhan.cn/wp-cont ... 6.jpg 1536w, https://www.deanhan.cn/wp-cont ... 1.jpg 1920w" />打开一会,我们要得到一个网站的视频,清晰度还不错。当然,这不是重点。我们的重点是写一个爬虫,可以解析任何vip视频的真实播放链接。
接下来我们先打开开发者工具,打开开发者工具有两种方式,一种是直接按快捷键F12或者Ctrl+Shift+I,但是这个方法可能会被屏蔽,我们也可以按照下面的截图打开开发者工具如图
https://www.deanhan.cn/wp-cont ... 7.jpg 300w, https://www.deanhan.cn/wp-cont ... 3.jpg 768w, https://www.deanhan.cn/wp-cont ... 6.jpg 1536w, https://www.deanhan.cn/wp-cont ... 2.jpg 1917w" />打开开发者工具,你会发现断点命中,页面现在无法操作。这是对网站的反调试分析,也是该类型网站的标准配置。通过这个很简单,我们只需要禁止断点的执行,然后继续执行,就不会再有断点了。
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 3.png 1920w" />记得按照图中的顺序,然后我们切换到network选项卡,然后刷新页面,我们会看到很多请求,
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 4.png 1920w" />为了缩小范围,我们进一步选择了网络下的xhr选项卡,发现只剩下几个请求了。
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 5.png 1920w" />而m3u8请求之一就是我们需要获取的视频播放源地址,然后就可以找到api.php接口,通过这个接口获取视频播放源。
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 6.png 1920w" />https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 7.png 1920w" />我们看到接口在post中发送了7个参数:
url: https://www.iqiyi.com/v_2ffkws ... _home
referer: aHR0cHM6Ly93d3cuYWRtaW5pc3RyYXRvcnYuY29tL2lxaXlpL2luZGV4LnBocD91cmw9aHR0cHM6Ly93d3cuaXFpeWkuY29tL3ZfMmZma3dzd2Q2b28uaHRtbD92ZnJtPXBjd19ob21lJnZmcm1ibGs9TCZ2ZnJtcnN0PTcxMjIxMV9kaWFueWluZ2JhbmdiYW5nX3RpdGxlMQ==
ref: 0
time: 1595251830
type:
other: aHR0cHM6Ly93d3cuaXFpeWkuY29tL3ZfMmZma3dzd2Q2b28uaHRtbD92ZnJtPXBjd19ob21lJnZmcm1ibGs9TCZ2ZnJtcnN0PTcxMjIxMV9kaWFueWluZ2JhbmdiYW5nX3RpdGxlMQ==
ios:
除了引用和其他字段,它们都很好理解。它们是纯文本格式。其实我们应该知道这是对refer等字段一目了然的base64编码,解密后的refer是: ///v_2ffkwswd6oo.html?vfrm=pcw_home&vfrmblk= L&vfrmrst=712211_dianyingbangbang_title1就是我们当前访问的地址。其他解密后就是要解析的VIP视频地址。但是,还有一个问题需要验证。时间字段是请求发起的时间还是服务器为学校发出的时间来验证请求的合法性,通过跟踪请求发起的代码,我们确认该字段是由服务器发起的进行验证。跟踪代码的方法如下:
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 8.png 1920w" />我们只需要将鼠标移动到当前请求的发起者选项,就可以看到发起请求的js栈。我们排除了来自诸如 jquery 之类的库的调用以找到真正的来源。这里是较长的一段,然后点进去,发现代码是压缩的,我们可以通过浏览器的扩展功能来美化代码:
https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 9.png 1920w" />https://www.deanhan.cn/wp-cont ... 6.png 300w, https://www.deanhan.cn/wp-cont ... 5.png 768w, https://www.deanhan.cn/wp-cont ... 0.png 1536w, https://www.deanhan.cn/wp-cont ... 0.png 1920w" />通过这段代码,我们可以发现客户端无法伪造时间字段。需要得到这个值才能正常调用接口。有两种选择:
一、所有请求参数都是从页面中提取的
二、 只提取时间字段,其余字段由客户端生成
这里我们选择第二种方式,我们用node来演示,先获取服务器发送的时间字段。
function getTime(u) {
return new Promise((resolve, reject) => {
request({
url: `https://www.administratorm.com/index.php?url=${u}`,
headers: {
Referer: `https://www.administratorm.com/index.php?url=${u}`
}
}, (err, response, body) => {
if (err) {
return reject(err);
}
const reg = /\'time\'\s*\:\s*\'(\d+)\'/;
if (reg.test(body)) {
return resolve(RegExp.$1);
}
reject();
});
});
}
获取到时间字段后,我们就可以正常发起请求了。我们先实现获取视频源的方法。
function getVideoSource(u, time) {
return new Promise((resolve, reject) => {
const formData = {
url: u,
referer: Buffer.from(`https://www.administratorw.com/index.php?url=${u}`).toString('base64'),
ref: 0,
time,
type: '',
other: Buffer.from(u).toString('base64'),
ios: ''
};
request({
url: PARSE_API,
method: 'POST',
headers: {
Referer: `https://www.administratorm.com/index.php?url=${u}`
},
formData
}, (err, response, body) => {
if (err) {
return reject(err);
}
try {
const ret = JSON.parse(body);
if (ret.url) {
return resolve(ret.url);
}
reject();
} catch(e) {
reject(e);
}
});
});
}
然后发起请求,
getTime(url)
.then(time => {
getVideoSource(url, time)
.then(url => {
console.log('视频解析成功,播放源地址:%s', url)
});
})
.catch(err => {
console.log('视频解析失败!');
});
文末小贴士:
1、在浏览器中,我们可以使用atob方法解密base64字符串,使用btoa方法获取解密后的base64字符串。
2、 如果参数正确但伪造请求时请求失败,可以尝试更改headers中的字段,例如添加Referer、userAgent、X-Requested-With。
3、 如果接口服务器对IP有限制,有一定几率可以通过伪造X-Forwarded-For来绕过这个限制。
文末提供了本文的示例代码,请自行下载。
报酬
网页抓取解密(,文中的逻辑比较强需要读者耐心的看但文本讲述的是破解步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-07 07:01
我们知道网站后台需要验证用户的输入。如果不这样做,用户甚至可以输入一些SQL语句来操作后台数据库。从来没有真正体验过这么有趣的事情。前几天,学校做了一个“你最喜欢的辅导员”投票活动,网站估计是为某个学生团队做的,但是我同学破解了这个网站管理员账号和密码,所以我问了他原理,我也明白了他破解的步骤,我又练习了一遍。感谢静同学,没有他我不会知道这些,也不可能有这个博客。
这篇文章破解了网站的URL,有可能是事后这个URL打不开,也有可能是写这篇网站的同学意识到漏洞的严重性,做出了更正,则本文内容不适用于本网站。小编整理了详细的破解过程分享给大家。文章逻辑性比较强,需要读者耐心阅读。但是文中描述了破解步骤,这是一个大概的思路。如果您有任何问题,请留言,我们交流讨论:)
1、网站是否存在SQL注入漏洞?
网站 一般收录一个用户表(用户名和密码)和一个管理员信息表(管理员名和密码)。输入用户名和密码后,一般的做法是在后台执行一条SQL语句,检查是否有对应的用户名和密码,如SELECT * FROM SomeTable WHERE UserName='$UserName' AND pwd='$ pwd',如果该语句返回true,则登录操作完成。
试想如果你在学生号和密码文本框中输入'or'='or'并提交,上面提到的SQL语句就变成SELECT * FROM SomeTable WHERE UserName =''or'='or'' AND pwd ='' or'='or'',这句话变成了一个逻辑表达式,该表达式收录几个段落,分别是:
1. SELECT * FROM SomeTable WHERE UserName ='' (false)
或者
2.'='(真)
或者
3.''(假)
和
4. pwd ='' (false)
或者
5.'='(真)
或者
6.''(假)
最后整个逻辑表达式为0|1|0&0|1|0,这个结果为真(当执行到“0|1|...”时,整个表达式中的省略号不会因为“或” 前面是真的),所以登录可以成功,其实登录也是成功的。
后台数据库破解原理
在用户名和密码文本框中输入'or'='or',如上图第二步,表达式值为true,因为后面紧跟着一个“or”,所以不管后面的表达式是什么是什么,“真或假”,“真或真”都是真的。关键是"or"='or"、"="中间的"="表示一个字符,永远为真。如果我们把这个Change'='改成某个SQL表达式,如果这个表达式为真,则整个表达式为真。
以下步骤要求在用户名和密码文本框中输入相同的文本。原因是:后端语句格式可能是SELECT * FROM SomeTable WHERE UserName ='$UserName' AND pwd ='$pwd',或者SELECT * FROM SomeTable WHERE pwd ='$pwd' AND UserName ='$UserName',在无论哪种情况,只要在同一个文本中输入用户名和密码,只要文本中收录的 SQL 表达式为真,那么整个表达式的公式就为真。这种写法的另一个好处是复制粘贴方便。
通过编写一些SQL表达式,一一测试出数据库的内容。
三 获取后端数据库的表名
如果将表达式替换为 (SELECT COUNT(*) FROM table name) 0 ,则该表达式用于获取表中有多少条记录,您需要做的就是猜测表名是什么。如果你猜对了,那么这个表中的记录数肯定不会等于0,所以这个表达式的值为true。常用的表名仅此而已,一一尝试,最后发现有一个表叫admin,该字段不为空。显然,这个表是用来存储管理员信息的。
四 获取后台数据库表的字段名
现在我们知道这个表叫做 admin,我们将弄清楚如何获取这个表中的字段。
将表达式替换为 (SELECT COUNT(*) FROM admin WHERE LEN(field name)>0)0,该表达式用于测试该字段是否收录在 admin 表中。LEN(field name)>0 表示这个字段的长度大于0,当这个字段存在时,LEN(字段名)>0总是为真,如果收录这个字段,整个SELECT语句返回的数字肯定不是0,也就是说整个表达式为真,获取字段名。
按照这个方法,通过猜测得到三个关键字段:id、admin、pass。
五 获取字段长度
目前得到的信息是有一个admin表,里面有id、admin、pass三个字段。用户名和密码存储在后台。通常的做法是存储它们的 MD5 加密值(32 位)。现在测试是否是这种情况。
将表达式替换为(SELECT COUNT(*) FROM admin WHERE LEN(field name)=32)0,代入admin,传入结果为true,说明后台存储管理员账号和密码加密了最后32 位字段。
六 获取管理员账号和密码
MD5 加密字符串收录 32 位,并且只能由字符 0-9 和 AF 组成。
1. 获取管理员账号
把表达式改成(SELECT COUNT(*) FROM admin WHERE LEFT(admin,1)='A')>0,意思是我猜一个admin账户的第一个字符是A。如果成功,那么表达式成立,如果失败,用0-9和BF中的任意一个字符替换A,继续尝试,直到成功。如果成功,我继续猜测账户的第二个字符,如果第一个字符是5 ,我猜第二个字符是A,然后将表达式改为 (SELECT COUNT(*) FROM admin WHERE LEFT(admin,2)='5A')>0. 可以在字符串中找到LEFT ()函数中的1变成2,'5A'代码左边的两个字符是5A,5已经确定了,反复猜测直到得到整个32位MD5加密字符串。
2. 获取账号对应的id
为什么需要获取账号对应的id?原因如下: 根据上一篇,可以获取到账号和密码,但是一个表中可以有多个管理员账号和密码。它们是如何对应的?需要传递id。一个id对应一条记录,一条记录只有一对匹配的账号和密码。
将表达式改为 (SELECT COUNT(*) FROM admin WHERE LEFT(admin,1)='5' AND id=1)>0, 前面的假设一个账户的第一个字符是5 , 只要这个表达式中的“AND id = 1”是正确的,那么你就可以知道这个账号的id是1. 如果不是1,就一个一个的试另一个数字。
3. 获取账号对应的密码
现在我已经猜到了某个管理员的账号,并且知道对应的id是什么(假设是4),现在只需要得到记录中记录的密码即可。同理,将表达式改为( SELECT COUNT(*) FROM admin WHERE LEFT(pass,1)='A' AND id=4)>0,注意id已经知道4了,现在我们需要猜pass一个通过一、第1到第32个字符是什么?方法和“获取管理员账号”方法一样,最后可以得到一个32位的MD5加密字符串(密码)。
*注:如果觉得手动获取每个字符太麻烦,可以用C#写一个程序,模拟登录。通过控制一个循环,可以快速得到结果。
7.将MD5加密的账号和密码转为明文
互联网上有一些网站数据库,存储了海量(数万亿)明文对应的MD5加密密文。只需输入您需要查找的 MD5 加密字符串即可查看明文是什么。.
八找网站管理员登录界面
如果找不到管理员登录界面,即使您已经拥有管理员的账号和密码也无法登录。对于这个网站,提供给普通学生登录的地址是
猜想知道管理员的登录地址大概就是它了。
九个登录网站后台
十总结
回头看看这个网站安全...
如果在用户输入帐号和密码后进行验证,可能不会出现以下情况……
如果数据库的表名不那么枯燥,也许下面的事情就不会发生了……
如果数据库的字段名不那么枯燥,也许下面的事情就不会发生了……
如果管理员登录地址不是那么傻,也许接下来的事情就不会发生了……
如何验证用户输入?最简单的方法是过滤掉用户输入的符号。除了这种方法,还可以通过参数的形式查询数据库,比如SELECT * FROM SomeTable WHERE UserName ='" & UserName & "'AND pwd ='" & pwd & "',而不是直接插入信息由用户输入到数据库查询语句中。如果想增加破解难度,也可以在登录时要求输入验证码...
地球太危险了。以上都是获取所需信息的查询语句。如果输入的是DROP TABLE命令,后果将不堪设想!以后自己做网站时,一定要注意这些问题。 查看全部
网页抓取解密(,文中的逻辑比较强需要读者耐心的看但文本讲述的是破解步骤)
我们知道网站后台需要验证用户的输入。如果不这样做,用户甚至可以输入一些SQL语句来操作后台数据库。从来没有真正体验过这么有趣的事情。前几天,学校做了一个“你最喜欢的辅导员”投票活动,网站估计是为某个学生团队做的,但是我同学破解了这个网站管理员账号和密码,所以我问了他原理,我也明白了他破解的步骤,我又练习了一遍。感谢静同学,没有他我不会知道这些,也不可能有这个博客。
这篇文章破解了网站的URL,有可能是事后这个URL打不开,也有可能是写这篇网站的同学意识到漏洞的严重性,做出了更正,则本文内容不适用于本网站。小编整理了详细的破解过程分享给大家。文章逻辑性比较强,需要读者耐心阅读。但是文中描述了破解步骤,这是一个大概的思路。如果您有任何问题,请留言,我们交流讨论:)
1、网站是否存在SQL注入漏洞?
网站 一般收录一个用户表(用户名和密码)和一个管理员信息表(管理员名和密码)。输入用户名和密码后,一般的做法是在后台执行一条SQL语句,检查是否有对应的用户名和密码,如SELECT * FROM SomeTable WHERE UserName='$UserName' AND pwd='$ pwd',如果该语句返回true,则登录操作完成。
试想如果你在学生号和密码文本框中输入'or'='or'并提交,上面提到的SQL语句就变成SELECT * FROM SomeTable WHERE UserName =''or'='or'' AND pwd ='' or'='or'',这句话变成了一个逻辑表达式,该表达式收录几个段落,分别是:
1. SELECT * FROM SomeTable WHERE UserName ='' (false)
或者
2.'='(真)
或者
3.''(假)
和
4. pwd ='' (false)
或者
5.'='(真)
或者
6.''(假)
最后整个逻辑表达式为0|1|0&0|1|0,这个结果为真(当执行到“0|1|...”时,整个表达式中的省略号不会因为“或” 前面是真的),所以登录可以成功,其实登录也是成功的。
后台数据库破解原理
在用户名和密码文本框中输入'or'='or',如上图第二步,表达式值为true,因为后面紧跟着一个“or”,所以不管后面的表达式是什么是什么,“真或假”,“真或真”都是真的。关键是"or"='or"、"="中间的"="表示一个字符,永远为真。如果我们把这个Change'='改成某个SQL表达式,如果这个表达式为真,则整个表达式为真。
以下步骤要求在用户名和密码文本框中输入相同的文本。原因是:后端语句格式可能是SELECT * FROM SomeTable WHERE UserName ='$UserName' AND pwd ='$pwd',或者SELECT * FROM SomeTable WHERE pwd ='$pwd' AND UserName ='$UserName',在无论哪种情况,只要在同一个文本中输入用户名和密码,只要文本中收录的 SQL 表达式为真,那么整个表达式的公式就为真。这种写法的另一个好处是复制粘贴方便。
通过编写一些SQL表达式,一一测试出数据库的内容。
三 获取后端数据库的表名
如果将表达式替换为 (SELECT COUNT(*) FROM table name) 0 ,则该表达式用于获取表中有多少条记录,您需要做的就是猜测表名是什么。如果你猜对了,那么这个表中的记录数肯定不会等于0,所以这个表达式的值为true。常用的表名仅此而已,一一尝试,最后发现有一个表叫admin,该字段不为空。显然,这个表是用来存储管理员信息的。
四 获取后台数据库表的字段名
现在我们知道这个表叫做 admin,我们将弄清楚如何获取这个表中的字段。
将表达式替换为 (SELECT COUNT(*) FROM admin WHERE LEN(field name)>0)0,该表达式用于测试该字段是否收录在 admin 表中。LEN(field name)>0 表示这个字段的长度大于0,当这个字段存在时,LEN(字段名)>0总是为真,如果收录这个字段,整个SELECT语句返回的数字肯定不是0,也就是说整个表达式为真,获取字段名。
按照这个方法,通过猜测得到三个关键字段:id、admin、pass。
五 获取字段长度
目前得到的信息是有一个admin表,里面有id、admin、pass三个字段。用户名和密码存储在后台。通常的做法是存储它们的 MD5 加密值(32 位)。现在测试是否是这种情况。
将表达式替换为(SELECT COUNT(*) FROM admin WHERE LEN(field name)=32)0,代入admin,传入结果为true,说明后台存储管理员账号和密码加密了最后32 位字段。
六 获取管理员账号和密码
MD5 加密字符串收录 32 位,并且只能由字符 0-9 和 AF 组成。
1. 获取管理员账号
把表达式改成(SELECT COUNT(*) FROM admin WHERE LEFT(admin,1)='A')>0,意思是我猜一个admin账户的第一个字符是A。如果成功,那么表达式成立,如果失败,用0-9和BF中的任意一个字符替换A,继续尝试,直到成功。如果成功,我继续猜测账户的第二个字符,如果第一个字符是5 ,我猜第二个字符是A,然后将表达式改为 (SELECT COUNT(*) FROM admin WHERE LEFT(admin,2)='5A')>0. 可以在字符串中找到LEFT ()函数中的1变成2,'5A'代码左边的两个字符是5A,5已经确定了,反复猜测直到得到整个32位MD5加密字符串。
2. 获取账号对应的id
为什么需要获取账号对应的id?原因如下: 根据上一篇,可以获取到账号和密码,但是一个表中可以有多个管理员账号和密码。它们是如何对应的?需要传递id。一个id对应一条记录,一条记录只有一对匹配的账号和密码。
将表达式改为 (SELECT COUNT(*) FROM admin WHERE LEFT(admin,1)='5' AND id=1)>0, 前面的假设一个账户的第一个字符是5 , 只要这个表达式中的“AND id = 1”是正确的,那么你就可以知道这个账号的id是1. 如果不是1,就一个一个的试另一个数字。
3. 获取账号对应的密码
现在我已经猜到了某个管理员的账号,并且知道对应的id是什么(假设是4),现在只需要得到记录中记录的密码即可。同理,将表达式改为( SELECT COUNT(*) FROM admin WHERE LEFT(pass,1)='A' AND id=4)>0,注意id已经知道4了,现在我们需要猜pass一个通过一、第1到第32个字符是什么?方法和“获取管理员账号”方法一样,最后可以得到一个32位的MD5加密字符串(密码)。
*注:如果觉得手动获取每个字符太麻烦,可以用C#写一个程序,模拟登录。通过控制一个循环,可以快速得到结果。
7.将MD5加密的账号和密码转为明文
互联网上有一些网站数据库,存储了海量(数万亿)明文对应的MD5加密密文。只需输入您需要查找的 MD5 加密字符串即可查看明文是什么。.
八找网站管理员登录界面
如果找不到管理员登录界面,即使您已经拥有管理员的账号和密码也无法登录。对于这个网站,提供给普通学生登录的地址是
猜想知道管理员的登录地址大概就是它了。
九个登录网站后台
十总结
回头看看这个网站安全...
如果在用户输入帐号和密码后进行验证,可能不会出现以下情况……
如果数据库的表名不那么枯燥,也许下面的事情就不会发生了……
如果数据库的字段名不那么枯燥,也许下面的事情就不会发生了……
如果管理员登录地址不是那么傻,也许接下来的事情就不会发生了……
如何验证用户输入?最简单的方法是过滤掉用户输入的符号。除了这种方法,还可以通过参数的形式查询数据库,比如SELECT * FROM SomeTable WHERE UserName ='" & UserName & "'AND pwd ='" & pwd & "',而不是直接插入信息由用户输入到数据库查询语句中。如果想增加破解难度,也可以在登录时要求输入验证码...
地球太危险了。以上都是获取所需信息的查询语句。如果输入的是DROP TABLE命令,后果将不堪设想!以后自己做网站时,一定要注意这些问题。
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-06 19:02
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址。请注意,您仍在考虑它:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接就是对应视频中的一个片段,整个视频是由片段一一组成的。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应这个动漫博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般自带WinRaR解压软件,选中所有ts文件后,右键选择添加到压缩文件,如下图界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4 查看全部
网页抓取解密(【】基本开发环境相关模块的使用目标网页分析)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址。请注意,您仍在考虑它:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接就是对应视频中的一个片段,整个视频是由片段一一组成的。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应这个动漫博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般自带WinRaR解压软件,选中所有ts文件后,右键选择添加到压缩文件,如下图界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
网页抓取解密(pm2.5AQI空气质量数据网站的参数加密解密(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-06 02:10
)
前言:
pm2.5 数据源较多,但历史数据较少。很多网站都不是很完整。本次AQI空气质量数据网站的数据属于同一类别网站,相当全面,界面简洁明了。刚开始爬这个网站的时候,看到网页结构很简单,以为一个简单的构建请求就可以爬取数据。没想到,打开开发者工具后,发现它的日常数据是通过js加解密的方式加载到页面上的。
遇到这样的网站,第一反应就是通过selenium用浏览器脚本一个一个加载每个页面。但是如果爬取的数据量很大,比如全国。一一加载的时间开销比较大。第一次爬的时候用selenium通过多线程爬取。即使使用多线程,速度仍然不能令人满意。花了两个小时才把所有的数据记录下来。所以这不是一个完美的解决方案。
分析过程:
一个网站,为了加载页面上的数据,无非是js或者一些模板。我们先来一一分析网站的数据加载过程,如图
getServerData()获取数据并通过showTable()加载到页面后,总体来说是一个比较正常的操作。但是在当前文件中找不到getServerData()代码的具体实现。我们继续寻找其他js文件:通过搜索,我们在jquery.min.js中找到了类似的字段。
但不要高兴得太早。我们发现,
这个方法在js代码中混淆了。现在我正在寻找一个反混淆工具。找出真正的代码。
我们将代码从 eval 复制到屏幕截图中的注释部分。然后找一个反混淆工具。我用过这个:
然后得到原来的js代码,复制保存成文本文件
分析js文件。. . . (下图是完整的getServerData())
我们发现请求参数和响应已经被加密和解密。看到这里,我们可以使用execjs调用加解密方法来构造请求。你可以得到我们需要的数据。
参数加密过程:
从图中可以看出,过程比较繁琐,不需要再次使用python来实现。最好直接调用js方法。
响应解密过程:
base64解码》DES解码》AES解码》base64解码
这些方法可以在这个js中找到。有兴趣的可以慢慢了解。
下面是一个完整的爬虫,爬取一个城市的所有历史数据:(如果js代码太多,放在github上) 代码地址:
import json
from lxml import etree
import execjs
import requests
# 获取一个城市所有的历史数据 by lczCrack qq1124241615
# 加密参数
def encryption_params(city, date_time, ctx):
method = 'GETDAYDATA'
js = 'getEncryptedData("{0}", "{1}", "{2}")'.format(method, city, date_time)
return ctx.eval(js)
# 解码response对象
def decode_info(info, ctx):
js = 'decodeData("{0}")'.format(info)
data = ctx.eval(js)
data = json.loads(data)
return data
def get_response(params):
url = 'https://www.aqistudy.cn/histor ... 39%3B
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
}
data = {
'hd': params
}
html_info = requests.post(url, data=data)
return html_info.text
def get_city():
url = 'https://www.aqistudy.cn/historydata/'
html_info = requests.get(url)
html = etree.HTML(html_info.text) # 初始化生成一个XPath解析对象
items = html.xpath('//div[@class="all"]//a/text()')
return items
def get_all_info_by_city(city):
years = [str(i + 2013) for i in range(7)]
month = [str(i if i > 9 else '0' + str(i)) for i in range(1, 13)]
node = execjs.get()
ctx = node.compile(open('decrypt.js', encoding='utf-8').read())
for y in years:
for m in month:
date_time = y + m # 201805
html_info = get_response(encryption_params(city, date_time, ctx))
item = decode_info(html_info, ctx)
for i in item['result']['data']['items']:
print(i)
if __name__ == '__main__':
get_all_info_by_city('北京')
结果:
查看全部
网页抓取解密(pm2.5AQI空气质量数据网站的参数加密解密(组图)
)
前言:
pm2.5 数据源较多,但历史数据较少。很多网站都不是很完整。本次AQI空气质量数据网站的数据属于同一类别网站,相当全面,界面简洁明了。刚开始爬这个网站的时候,看到网页结构很简单,以为一个简单的构建请求就可以爬取数据。没想到,打开开发者工具后,发现它的日常数据是通过js加解密的方式加载到页面上的。
遇到这样的网站,第一反应就是通过selenium用浏览器脚本一个一个加载每个页面。但是如果爬取的数据量很大,比如全国。一一加载的时间开销比较大。第一次爬的时候用selenium通过多线程爬取。即使使用多线程,速度仍然不能令人满意。花了两个小时才把所有的数据记录下来。所以这不是一个完美的解决方案。
分析过程:
一个网站,为了加载页面上的数据,无非是js或者一些模板。我们先来一一分析网站的数据加载过程,如图
getServerData()获取数据并通过showTable()加载到页面后,总体来说是一个比较正常的操作。但是在当前文件中找不到getServerData()代码的具体实现。我们继续寻找其他js文件:通过搜索,我们在jquery.min.js中找到了类似的字段。
但不要高兴得太早。我们发现,
这个方法在js代码中混淆了。现在我正在寻找一个反混淆工具。找出真正的代码。
我们将代码从 eval 复制到屏幕截图中的注释部分。然后找一个反混淆工具。我用过这个:
然后得到原来的js代码,复制保存成文本文件
分析js文件。. . . (下图是完整的getServerData())
我们发现请求参数和响应已经被加密和解密。看到这里,我们可以使用execjs调用加解密方法来构造请求。你可以得到我们需要的数据。
参数加密过程:
从图中可以看出,过程比较繁琐,不需要再次使用python来实现。最好直接调用js方法。
响应解密过程:
base64解码》DES解码》AES解码》base64解码
这些方法可以在这个js中找到。有兴趣的可以慢慢了解。
下面是一个完整的爬虫,爬取一个城市的所有历史数据:(如果js代码太多,放在github上) 代码地址:
import json
from lxml import etree
import execjs
import requests
# 获取一个城市所有的历史数据 by lczCrack qq1124241615
# 加密参数
def encryption_params(city, date_time, ctx):
method = 'GETDAYDATA'
js = 'getEncryptedData("{0}", "{1}", "{2}")'.format(method, city, date_time)
return ctx.eval(js)
# 解码response对象
def decode_info(info, ctx):
js = 'decodeData("{0}")'.format(info)
data = ctx.eval(js)
data = json.loads(data)
return data
def get_response(params):
url = 'https://www.aqistudy.cn/histor ... 39%3B
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
}
data = {
'hd': params
}
html_info = requests.post(url, data=data)
return html_info.text
def get_city():
url = 'https://www.aqistudy.cn/historydata/'
html_info = requests.get(url)
html = etree.HTML(html_info.text) # 初始化生成一个XPath解析对象
items = html.xpath('//div[@class="all"]//a/text()')
return items
def get_all_info_by_city(city):
years = [str(i + 2013) for i in range(7)]
month = [str(i if i > 9 else '0' + str(i)) for i in range(1, 13)]
node = execjs.get()
ctx = node.compile(open('decrypt.js', encoding='utf-8').read())
for y in years:
for m in month:
date_time = y + m # 201805
html_info = get_response(encryption_params(city, date_time, ctx))
item = decode_info(html_info, ctx)
for i in item['result']['data']['items']:
print(i)
if __name__ == '__main__':
get_all_info_by_city('北京')
结果:
网页抓取解密(可证运行基于小甲鱼视屏的代码修改:图片的网址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-06 02:09
)
参考:添加链接描述并进行一些修改使其运行
基于小龟视频修改代码:(图片的URL是base64加密的,需要解密才能正常使用):
在一般网页上,图片和下一张图片之间,地址是数字变化:
第一个的网址是:
下一个是:
并且视频画面中的页面对URL使用base64加密
这里的 MjAyMDA4MDktMTIx 实际上是加密信息:
用解码知道是20200809-121
并121查看网页信息:即当前图片
获取当前日期的代码:
import datetime
time = datetime.datetime.now().strftime('%Y%m%d-')
import base64
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
用它来加密20200809-121,可以知道结果和网页一样,所以可验证的URL是用base64加密的
抓取图片的源码如下:
主要方法:
1、首先创建一个文件并命名为“ooxx”
2、get_page() 函数看起来像这样:它返回页面的数字部分
def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
3、for i in range(pages): # 获取前10页的数据只表示从当前页获取数据,第一次减0为当前页,第二次减1是下一页。以此类推,一共10页,page_url:指的是每一页的地址
4、获取page_url:关键点
测试:能否正确获取页码为121的页地址:
操作结果:
网站链接:
于是找到了页面的地址,接下来就是获取页面的源代码,从源代码中获取图片的位置
5、如何通过URL获取html页面内容:
设置请求头,目的是让爬虫操作拥有计算机的身份
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)#创建request对象,利用request对象访问
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
6、find_imgs 函数:通过html内容获取图片地址,正则表达式还没提到,暂时用find方法
就是获取img src之后,.jpg之前的内容。然后设置一个循环,找出当前页面所有符合条件的图片,然后保存
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs
7、找到地址下载保存
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]#取url最后一段作为名字
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
import base64
import urllib.request
import os
import datetime
time=datetime.datetime.now().strftime("%Y%m%d-")
#得到经过base64加密后的字符串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs #因为所要获取的网页是经过base64加密的,因此我们需要利用此来正确访问页面
#打开页面
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])#需要加上http:否则获取的地址是无法识别的url
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs#需要返回这个地址链表,否则在save_img中无法迭代
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__=='__main__':
download()
终于成功抓取图片
查看全部
网页抓取解密(可证运行基于小甲鱼视屏的代码修改:图片的网址
)
参考:添加链接描述并进行一些修改使其运行
基于小龟视频修改代码:(图片的URL是base64加密的,需要解密才能正常使用):
在一般网页上,图片和下一张图片之间,地址是数字变化:
第一个的网址是:
下一个是:
并且视频画面中的页面对URL使用base64加密
这里的 MjAyMDA4MDktMTIx 实际上是加密信息:
用解码知道是20200809-121
并121查看网页信息:即当前图片
获取当前日期的代码:
import datetime
time = datetime.datetime.now().strftime('%Y%m%d-')
import base64
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
用它来加密20200809-121,可以知道结果和网页一样,所以可验证的URL是用base64加密的
抓取图片的源码如下:
主要方法:
1、首先创建一个文件并命名为“ooxx”
2、get_page() 函数看起来像这样:它返回页面的数字部分
def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
3、for i in range(pages): # 获取前10页的数据只表示从当前页获取数据,第一次减0为当前页,第二次减1是下一页。以此类推,一共10页,page_url:指的是每一页的地址
4、获取page_url:关键点
测试:能否正确获取页码为121的页地址:
操作结果:
网站链接:
于是找到了页面的地址,接下来就是获取页面的源代码,从源代码中获取图片的位置
5、如何通过URL获取html页面内容:
设置请求头,目的是让爬虫操作拥有计算机的身份
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)#创建request对象,利用request对象访问
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
6、find_imgs 函数:通过html内容获取图片地址,正则表达式还没提到,暂时用find方法
就是获取img src之后,.jpg之前的内容。然后设置一个循环,找出当前页面所有符合条件的图片,然后保存
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs
7、找到地址下载保存
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]#取url最后一段作为名字
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
import base64
import urllib.request
import os
import datetime
time=datetime.datetime.now().strftime("%Y%m%d-")
#得到经过base64加密后的字符串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs #因为所要获取的网页是经过base64加密的,因此我们需要利用此来正确访问页面
#打开页面
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])#需要加上http:否则获取的地址是无法识别的url
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs#需要返回这个地址链表,否则在save_img中无法迭代
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__=='__main__':
download()
终于成功抓取图片
网页抓取解密(如果想要留住现有流量不妨先看看这篇文章,如果你将要进入这行更要看看 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-04 08:19
)
众所周知,典型的商业模式不超过两种(广告、内容)。围绕广告的产品是三级火箭(搜索引擎、杀毒软件、浏览器)和电子商务,围绕内容生产的产品是网络文学。 ,视频网站,电影制作。无论是做广告还是做内容,都需要有流量支撑。先不说获取流量的形式,获取流量的成本。今天主要讲一下流量劫持。如果你想保留现有流量,不妨先看看这篇文章文章,如果你要进入这一行,你得看看暗流量到底是怎么回事!
什么是流量劫持,以下是百度百科的介绍:
》流量劫持是利用各种恶意软件、木马修改浏览器、锁定主页、或不断弹出新窗口等,强制用户访问某些网站,从而导致用户流量损失。”
-----百度百科
小白听了可能有点懵。毕竟是恶意软件、病毒和特洛伊木马。想想就很可怕。究竟什么是流量劫持?其实,流量劫持很容易理解。比如你可以把流量理解为你的目的(比如你去买水果,这就是你的目的),劫持的方式是引导或者改变你的行为(比如你只是想买水果,但是因为你有受一些外力影响后有点变了,你买水果的意愿变弱了或者改变了初衷。去了B)店,但为什么会发生这种事件?事实上,最终的原因都是信息,特别是广告。绕了很久,绕了原来的商业模式(广告),所有的广告都要变现,变现最原创的基础就是网络联盟变现。如何从网络联盟中收获更多的流量,是每个IT从业者必须思考的问题。网盟这么贵怎么办,那就劫持吧。比较常用的流量劫持方式:DNS劫持、HTTP劫持、浏览器劫持、路由器劫持等,今天要告诉大家的是DNS劫持、HTTP劫持、浏览器劫持哪一种? ? ? NO NO NO 都不是,今天要和大家分享的是比上面更隐蔽的搜索关键词劫持。
究竟什么是搜索关键词劫持?
比如百度搜索某个网站关键词,百度搜索后的结果是正确的,但是点击进去后,跳转到另一个网站,而是直接输入URL网站木有变化。
举个例子:百度搜索(淘券吧),参与淘客的小朋友一看就明白这是百度下拉选择的关键词导流(见图一)@ >、找到点击进入网址(图片二)如果找不到(由于搜索引擎的地理顺序不同),也可以在搜索引擎中直接输入域名(图片三)点击进入,网站会直接跳转到,教育招生单页(图片四),在浏览器地址栏直接打开网站,网站@ > 依旧是淘客站,没有任何变化。(原理是根据搜索引擎传入关键词发生重定向,非搜索引擎流量不重定向。)
图一
图二
图三
图四
可能很多朋友都遇到过这个问题,但是不知道是怎么回事。下午小编帮你拆解,希望对大家有帮助!
技术拆解:
第一步,首先要判断网站是否正常。您可以通过第三方工具检查网页是否正常。
http状态是否正常200,说明网站正常,可以正常打开,但是网页内容是否被篡改过?
如上图,网站正常爬取而不是301/302重定向,首页的首页类型为html文件,即index.html
第二步搜索蜘蛛,看机器人抓取的内容是否是网站的内容,从而判断爬取的页面内容是页面而不是跳转页面.
如上图所示,抓取到的网页内容正常!
第三步:根据刚才工具得出的结论,我们判断网页显示正常,截图的内容也是正常的网页内容
查看全部
网页抓取解密(如果想要留住现有流量不妨先看看这篇文章,如果你将要进入这行更要看看
)
众所周知,典型的商业模式不超过两种(广告、内容)。围绕广告的产品是三级火箭(搜索引擎、杀毒软件、浏览器)和电子商务,围绕内容生产的产品是网络文学。 ,视频网站,电影制作。无论是做广告还是做内容,都需要有流量支撑。先不说获取流量的形式,获取流量的成本。今天主要讲一下流量劫持。如果你想保留现有流量,不妨先看看这篇文章文章,如果你要进入这一行,你得看看暗流量到底是怎么回事!
什么是流量劫持,以下是百度百科的介绍:
》流量劫持是利用各种恶意软件、木马修改浏览器、锁定主页、或不断弹出新窗口等,强制用户访问某些网站,从而导致用户流量损失。”
-----百度百科
小白听了可能有点懵。毕竟是恶意软件、病毒和特洛伊木马。想想就很可怕。究竟什么是流量劫持?其实,流量劫持很容易理解。比如你可以把流量理解为你的目的(比如你去买水果,这就是你的目的),劫持的方式是引导或者改变你的行为(比如你只是想买水果,但是因为你有受一些外力影响后有点变了,你买水果的意愿变弱了或者改变了初衷。去了B)店,但为什么会发生这种事件?事实上,最终的原因都是信息,特别是广告。绕了很久,绕了原来的商业模式(广告),所有的广告都要变现,变现最原创的基础就是网络联盟变现。如何从网络联盟中收获更多的流量,是每个IT从业者必须思考的问题。网盟这么贵怎么办,那就劫持吧。比较常用的流量劫持方式:DNS劫持、HTTP劫持、浏览器劫持、路由器劫持等,今天要告诉大家的是DNS劫持、HTTP劫持、浏览器劫持哪一种? ? ? NO NO NO 都不是,今天要和大家分享的是比上面更隐蔽的搜索关键词劫持。
究竟什么是搜索关键词劫持?
比如百度搜索某个网站关键词,百度搜索后的结果是正确的,但是点击进去后,跳转到另一个网站,而是直接输入URL网站木有变化。
举个例子:百度搜索(淘券吧),参与淘客的小朋友一看就明白这是百度下拉选择的关键词导流(见图一)@ >、找到点击进入网址(图片二)如果找不到(由于搜索引擎的地理顺序不同),也可以在搜索引擎中直接输入域名(图片三)点击进入,网站会直接跳转到,教育招生单页(图片四),在浏览器地址栏直接打开网站,网站@ > 依旧是淘客站,没有任何变化。(原理是根据搜索引擎传入关键词发生重定向,非搜索引擎流量不重定向。)
图一
图二
图三
图四
可能很多朋友都遇到过这个问题,但是不知道是怎么回事。下午小编帮你拆解,希望对大家有帮助!
技术拆解:
第一步,首先要判断网站是否正常。您可以通过第三方工具检查网页是否正常。
http状态是否正常200,说明网站正常,可以正常打开,但是网页内容是否被篡改过?
如上图,网站正常爬取而不是301/302重定向,首页的首页类型为html文件,即index.html
第二步搜索蜘蛛,看机器人抓取的内容是否是网站的内容,从而判断爬取的页面内容是页面而不是跳转页面.
如上图所示,抓取到的网页内容正常!
第三步:根据刚才工具得出的结论,我们判断网页显示正常,截图的内容也是正常的网页内容
网页抓取解密(Git-history正是网页抓取工具编程技术技术回顾(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-04 03:12
大多数人都知道 Git 抓取,这是一种用于网页抓取工具的编程技术。您可以定期将数据源的快照抓取到 Git 存储库中,以跟踪数据源随时间的变化。
如何分析采集到的数据是一个公认的问题。 git-history 是我设计用来解决这个问题的工具。
Git 抓取技术回顾
将数据抓取到 Git 存储库的一大优势在于抓取工具本身非常简单。
这是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents网站 上维护了一张火灾地图,该地图显示了该州最近发生的大规模火灾。
我找到了网站的底层数据:
卷曲
然后我设置了一个简单的爬虫工具,每 20 分钟抓取一个 网站 数据的副本并提交给 Git。截至目前,该工具已运行14个月,已采集1559个提交版本。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织并没有详细归档数据更改的内容和位置,因此通过抓取他们的网站 数据并将其保存到 Git 存储库中,您会发现您比他们更了解他们的数据更改历史。
然而,一个巨大的挑战是如何最有效地分析采集到的数据?面对上千个版本和海量的JSON和CSV文档,如果只靠肉眼观察差异,很难挖掘出数据背后的价值。
git 历史
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的所有历史版本并生成 SQLite 数据库来记录文件随时间的变化。然后你就可以使用Datasette来分析和挖掘这些数据了。
以下是通过使用 ca-fires-history 存储库运行 git-history 生成的数据库示例。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history 文件 ca-fires.db events.json \
--命名空间事件 \
--id UniqueId \
--convert'json.loads(content)["事件"]'
在这个例子中,我们获取了文件 events.json 的历史版本。
我们使用 UniqueId 列来标识随时间变化的记录和新记录。
新数据库表的默认名称是item和item_version,我们通过--namespace event指定表名是incident和incident_version。
工具中还嵌入了一段 Python 代码,可以将提交历史中存储的每个版本转换为与工具兼容的对象列表。
让数据库帮助我们回答一些关于过去 14 个月加州火灾的问题。
事件表收录每次火灾的最新记录。通过这张表,我们可以得到一张所有火灾的地图:
这里使用了datasette-cluster-map插件,它在地图上标记了表中所有给出有效经纬度值的行。
真正有趣的是 event_version 表。此表记录了每次火灾的先前捕获版本之间的数据更新。
250 场火灾有 2,060 个记录版本。如果根据_item进行分面,我们可以看到哪些火灾记录的版本最多。排名前十的分别是:
迪克西火:268
卡尔多之火:153
纪念碑火 65
August Complex(包括 Doe Fire):64
溪火:56
法式火焰:53
西尔弗拉多火灾:52
小鹿火:45
蓝岭火:39
麦克法兰火:34
版本越多,火持续的时间就越长。维基百科上甚至还有 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面可以看到所有抓到的“版本”按版本号排序。
git-history 只在此表中写入与之前版本相比发生变化的值。因此,您可以一目了然地看到哪些信息随时间发生了变化:
最频繁的变化是 ConditionStatement 列。此栏是文字说明。另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是提交表的外键。该表记录了该工具提交的版本,因此当您再次运行该工具时,该工具可以定位到上次提交的版本。
连接commits表查看每个版本的创建日期。您也可以使用incident_version_detail 视图来执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行。借助datasette-vega插件,将_commit_at列(日期类型)和AcresBurned列(数字类型)进行对比,形成一个图表,直观地展示了Dixie Fire火灾随时间的蔓延情况。
总结:让我们首先使用 GitHub Actions 创建一个定时工作流,并每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们已经成功地用图表展示了过去 14 个月加州最长的森林火灾的蔓延情况。
关于表结构设计
在git-history的设计过程中,最难的就是设计一个合适的表结构来存储之前版本变化的信息。
我的最终设计如下(为了清晰起见进行了适当编辑):
创建表 [提交] (
[id] 整数主键,
[hash] 文本,
[commit_at] 文本
);
创建表 [项目] (
[_id] 整数主键,
[_item_id] 文本,
[事件 ID] 文本,
[位置] 文本,
[类型] 文本,
[_commit] 整数
);
创建表 [item_version] (
[_id] 整数主键,
[_item] 整数引用 [item]([_id]),
[_version] 整数,
[_commit] 整数引用 [commits]([id]),
[事件 ID] 文本,
[位置] 文本,
[类型] 文本
);
创建表 [列] (
[id] 整数主键,
[namespace] 整数引用 [namespaces]([id]),
[名称] 文本
);
创建表 [item_changed] (
[item_version] 整数引用 [item_version]([_id]),
[column] 整数引用 [columns]([id]),
主键([item_version],[column])
);
前面提到,item_version表记录了网站在不同时间点的快照,但为了节省数据库空间,提供简洁的版本浏览界面,仅将与之前版本相比发生变化的列记录在这里。所有没有改变的列都写为空。
但是,这种设计有一个隐患,就是如果某列的值在某次火灾中被更新为null,我们该怎么办?我们如何判断它是否已更新或未更改?
为了解决这个问题,我添加了一个多对多表item_changed,它使用整数对来记录item_version表中哪些列更新了内容。使用整数对的目的是尽可能少占用空间。
item_version_detail 视图将多对多表中的列显示为 JSON。我过滤了一些数据,放在下图中,看看哪些列更新了哪些版本:
通过下面的SQL查询,我们可以知道加州火灾中哪些数据更新最频繁:
select columns.name, count(*)
来自 event_changed
在 event_changed.item_version = event_version._id 上加入 event_version
在 event_changed.column = columns.id 上加入列
where event_version._version> 1
按列名分组
按计数(*)降序
查询结果如下:
更新:1785
火灾被扑灭的百分比:740
状态描述:734
火灾区域:616
开始时间:327
受灾人数:286
消防泵:274
消防员:256
消防车:225
无人机:211
消防飞机:181
建筑损坏:125
直升机:122
直升机听起来很刺激!让我们过滤掉第一个版本后直升机数量至少更新一次的火灾。您可以使用以下嵌套 SQL 查询:
从事件中选择*
where _id 在 (
从事件版本中选择 _item
where _id 在 (
select item_version from event_changed where column = 15
)
和_version> 1
)
查询结果显示有19次直升机出动火灾,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月中,Drew Breunig 使用 Git 爬虫不断从 网站 中获取数据并将其保存到 dbreunig/511-events-history 存储库中。这个网站记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以sf-bay-511数据库为例,有助于我们理解git-history和--convert选项overlay的用法。
Git-history 要求捕获的数据采用以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一列可用作唯一标识列,以跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
[
{
"事件ID": "abc123",
“位置”:“第四和佛蒙特州的拐角处”,
“类型”:“火”
},
{
"事件ID": "cde448",
"Location": "555 West Example Drive",
“类型”:“医疗”
}
]
但捕获的数据通常不是这种理想格式。
我找到了 网站 的 JSON 提要。有非常复杂的嵌套对象,数据也很复杂,有些对整体分析没有帮助,比如更新的时间戳即使没有数据更新也会随着版本的变化而变化,深度嵌套的对象“扩展”收录大量重复数据。 .
我写了一段Python代码将每个网站快照转换成更简单的结构,然后将这段代码传递给脚本的--convert选项:
#!/bin/bash
git-history 文件 sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--转换'
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "访问远程数据时出错..."}
返回
对于数据中的事件["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
#去除嘈杂的更新时间戳
删除事件[“更新”]
# 完全删除扩展块
删除事件["扩展名"]
# "schedule" 块很吵但不有趣
del event["schedule"]
# 展平嵌套的子类型
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
如果不是 isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
产量事件
'
传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上依次运行。代码在 Events 嵌套列表中循环运行,修改每条记录,然后使用 yield 以可迭代序列输出。
一些历史记录显示服务器 500 错误,代码也可以识别和跳过这些记录。
在使用 git-history 时,我发现我大部分时间都花在了迭代转换脚本上。将 Python 代码字符串传递给 git-history 等工具是一个非常有趣的模型。今年早些时候,我也尝试在 sqlite-utils 工具中叠加转换。
自己试试
如果您想尝试 git-history 工具,扩展文档 README 中提供了更多选项。示例中使用的脚本都保存在 demos 文件夹中。
GitHub 上的 git-scraping 话题下,已经有很多人创建了仓库,目前有 200 多个,还有丰富的爬取数据等你探索! 查看全部
网页抓取解密(Git-history正是网页抓取工具编程技术技术回顾(组图))
大多数人都知道 Git 抓取,这是一种用于网页抓取工具的编程技术。您可以定期将数据源的快照抓取到 Git 存储库中,以跟踪数据源随时间的变化。
如何分析采集到的数据是一个公认的问题。 git-history 是我设计用来解决这个问题的工具。
Git 抓取技术回顾
将数据抓取到 Git 存储库的一大优势在于抓取工具本身非常简单。
这是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents网站 上维护了一张火灾地图,该地图显示了该州最近发生的大规模火灾。
我找到了网站的底层数据:
卷曲
然后我设置了一个简单的爬虫工具,每 20 分钟抓取一个 网站 数据的副本并提交给 Git。截至目前,该工具已运行14个月,已采集1559个提交版本。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织并没有详细归档数据更改的内容和位置,因此通过抓取他们的网站 数据并将其保存到 Git 存储库中,您会发现您比他们更了解他们的数据更改历史。
然而,一个巨大的挑战是如何最有效地分析采集到的数据?面对上千个版本和海量的JSON和CSV文档,如果只靠肉眼观察差异,很难挖掘出数据背后的价值。
git 历史
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的所有历史版本并生成 SQLite 数据库来记录文件随时间的变化。然后你就可以使用Datasette来分析和挖掘这些数据了。
以下是通过使用 ca-fires-history 存储库运行 git-history 生成的数据库示例。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history 文件 ca-fires.db events.json \
--命名空间事件 \
--id UniqueId \
--convert'json.loads(content)["事件"]'
在这个例子中,我们获取了文件 events.json 的历史版本。
我们使用 UniqueId 列来标识随时间变化的记录和新记录。
新数据库表的默认名称是item和item_version,我们通过--namespace event指定表名是incident和incident_version。
工具中还嵌入了一段 Python 代码,可以将提交历史中存储的每个版本转换为与工具兼容的对象列表。
让数据库帮助我们回答一些关于过去 14 个月加州火灾的问题。
事件表收录每次火灾的最新记录。通过这张表,我们可以得到一张所有火灾的地图:
这里使用了datasette-cluster-map插件,它在地图上标记了表中所有给出有效经纬度值的行。
真正有趣的是 event_version 表。此表记录了每次火灾的先前捕获版本之间的数据更新。
250 场火灾有 2,060 个记录版本。如果根据_item进行分面,我们可以看到哪些火灾记录的版本最多。排名前十的分别是:
迪克西火:268
卡尔多之火:153
纪念碑火 65
August Complex(包括 Doe Fire):64
溪火:56
法式火焰:53
西尔弗拉多火灾:52
小鹿火:45
蓝岭火:39
麦克法兰火:34
版本越多,火持续的时间就越长。维基百科上甚至还有 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面可以看到所有抓到的“版本”按版本号排序。
git-history 只在此表中写入与之前版本相比发生变化的值。因此,您可以一目了然地看到哪些信息随时间发生了变化:
最频繁的变化是 ConditionStatement 列。此栏是文字说明。另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是提交表的外键。该表记录了该工具提交的版本,因此当您再次运行该工具时,该工具可以定位到上次提交的版本。
连接commits表查看每个版本的创建日期。您也可以使用incident_version_detail 视图来执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行。借助datasette-vega插件,将_commit_at列(日期类型)和AcresBurned列(数字类型)进行对比,形成一个图表,直观地展示了Dixie Fire火灾随时间的蔓延情况。
总结:让我们首先使用 GitHub Actions 创建一个定时工作流,并每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们已经成功地用图表展示了过去 14 个月加州最长的森林火灾的蔓延情况。
关于表结构设计
在git-history的设计过程中,最难的就是设计一个合适的表结构来存储之前版本变化的信息。
我的最终设计如下(为了清晰起见进行了适当编辑):
创建表 [提交] (
[id] 整数主键,
[hash] 文本,
[commit_at] 文本
);
创建表 [项目] (
[_id] 整数主键,
[_item_id] 文本,
[事件 ID] 文本,
[位置] 文本,
[类型] 文本,
[_commit] 整数
);
创建表 [item_version] (
[_id] 整数主键,
[_item] 整数引用 [item]([_id]),
[_version] 整数,
[_commit] 整数引用 [commits]([id]),
[事件 ID] 文本,
[位置] 文本,
[类型] 文本
);
创建表 [列] (
[id] 整数主键,
[namespace] 整数引用 [namespaces]([id]),
[名称] 文本
);
创建表 [item_changed] (
[item_version] 整数引用 [item_version]([_id]),
[column] 整数引用 [columns]([id]),
主键([item_version],[column])
);
前面提到,item_version表记录了网站在不同时间点的快照,但为了节省数据库空间,提供简洁的版本浏览界面,仅将与之前版本相比发生变化的列记录在这里。所有没有改变的列都写为空。
但是,这种设计有一个隐患,就是如果某列的值在某次火灾中被更新为null,我们该怎么办?我们如何判断它是否已更新或未更改?
为了解决这个问题,我添加了一个多对多表item_changed,它使用整数对来记录item_version表中哪些列更新了内容。使用整数对的目的是尽可能少占用空间。
item_version_detail 视图将多对多表中的列显示为 JSON。我过滤了一些数据,放在下图中,看看哪些列更新了哪些版本:
通过下面的SQL查询,我们可以知道加州火灾中哪些数据更新最频繁:
select columns.name, count(*)
来自 event_changed
在 event_changed.item_version = event_version._id 上加入 event_version
在 event_changed.column = columns.id 上加入列
where event_version._version> 1
按列名分组
按计数(*)降序
查询结果如下:
更新:1785
火灾被扑灭的百分比:740
状态描述:734
火灾区域:616
开始时间:327
受灾人数:286
消防泵:274
消防员:256
消防车:225
无人机:211
消防飞机:181
建筑损坏:125
直升机:122
直升机听起来很刺激!让我们过滤掉第一个版本后直升机数量至少更新一次的火灾。您可以使用以下嵌套 SQL 查询:
从事件中选择*
where _id 在 (
从事件版本中选择 _item
where _id 在 (
select item_version from event_changed where column = 15
)
和_version> 1
)
查询结果显示有19次直升机出动火灾,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月中,Drew Breunig 使用 Git 爬虫不断从 网站 中获取数据并将其保存到 dbreunig/511-events-history 存储库中。这个网站记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以sf-bay-511数据库为例,有助于我们理解git-history和--convert选项overlay的用法。
Git-history 要求捕获的数据采用以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一列可用作唯一标识列,以跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
[
{
"事件ID": "abc123",
“位置”:“第四和佛蒙特州的拐角处”,
“类型”:“火”
},
{
"事件ID": "cde448",
"Location": "555 West Example Drive",
“类型”:“医疗”
}
]
但捕获的数据通常不是这种理想格式。
我找到了 网站 的 JSON 提要。有非常复杂的嵌套对象,数据也很复杂,有些对整体分析没有帮助,比如更新的时间戳即使没有数据更新也会随着版本的变化而变化,深度嵌套的对象“扩展”收录大量重复数据。 .
我写了一段Python代码将每个网站快照转换成更简单的结构,然后将这段代码传递给脚本的--convert选项:
#!/bin/bash
git-history 文件 sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--转换'
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "访问远程数据时出错..."}
返回
对于数据中的事件["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
#去除嘈杂的更新时间戳
删除事件[“更新”]
# 完全删除扩展块
删除事件["扩展名"]
# "schedule" 块很吵但不有趣
del event["schedule"]
# 展平嵌套的子类型
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
如果不是 isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
产量事件
'
传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上依次运行。代码在 Events 嵌套列表中循环运行,修改每条记录,然后使用 yield 以可迭代序列输出。
一些历史记录显示服务器 500 错误,代码也可以识别和跳过这些记录。
在使用 git-history 时,我发现我大部分时间都花在了迭代转换脚本上。将 Python 代码字符串传递给 git-history 等工具是一个非常有趣的模型。今年早些时候,我也尝试在 sqlite-utils 工具中叠加转换。
自己试试
如果您想尝试 git-history 工具,扩展文档 README 中提供了更多选项。示例中使用的脚本都保存在 demos 文件夹中。
GitHub 上的 git-scraping 话题下,已经有很多人创建了仓库,目前有 200 多个,还有丰富的爬取数据等你探索!
网页抓取解密(iMacros的网页抓取、网页测试制定工具,支持IE、Chrome、firefox)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-03 09:14
iMacros中文版是一款功能强大的网络爬虫和网络测试开发工具,可支持IE、Chrome、firefox等多种浏览器。欢迎有兴趣的朋友到公共资源网免费下载使用。
IMacros 中文版介绍
iMacros 是 Mozilla Firefox 浏览器的附加组件。它的主要功能是帮助我们创建动作宏来登录网站、论坛、邮箱查看邮件。它还允许我们创建其他动作宏。例如:将网页另存为、保存网页上的组件(例如:图片)、打印...等
iMacros 功能
Web 自动化/Web 脚本编译 iMacros 允许您记录和重放重复性任务。 iMacros 还可以与所有网站 进行交互。可以填写表单,自动下载和上传文本、图片、文件和网站页面。您可以使用 CSV 和 xml 文件、数据库和其他数据源将数据导入和导出 Web 应用程序中的数据。 iMacros 还支持 PDF 处理,可以截图,可以模仿不同的用户代理,可以连接代理服务器。唯一兼容所有网站的网页自动化软件。
iMacros 的脚本编译界面让您可以完全控制网络浏览器,因此即使是最复杂的任务也可以编译。它还可以使用所有编译或编程语言。无需学习商家特有的笨拙的编译语言。您甚至可以将 iMacros 绑定到您的应用程序。编译后的版本有一个特殊的免费分发许可证。
编译界面也可以用来更新excel,直接上网访问。
数据提取/网络抓取/网络数据挖掘/企业数据
iMacros 可以执行与从 网站 表单填写衍生的文本(价格、产品描述、股票报价等)和图片的搜索和提取完全相反的任务。 iMacros 收录完整的 Unicode 支持,兼容所有语言,包括中文等多字节语言。
网页测试
使用 iMacros 执行 Web 应用程序的功能、性能和回归测试。 iMacros 是唯一可以通过 Internet Explorer 和 Firefox 自动进行浏览器内部测试的工具。 iMacros 还是唯一可以运行基于 Java、Flash、Flex 或 Silverlight 小程序和所有 AJAX 元素的内部浏览器测试的工具。内置的 STOPWATCH 命令可以准确捕捉流程每一步的 网站 页面响应次数。
表格填写程序
iMacros 允许您每天检查相同的 网站、记住密码并填写网络表单,而无需重复。 iMacros 是唯一可以自动填写多页网页表单的表单填写程序。所有信息都存储在可读且易于编辑的纯文本文件中。密码可通过安全的256位AES加密技术安全存储。
iMacros 是企业单点登录 (SSO) 的绝佳替代解决方案。用户只需要记住一个主密码,iMacros 会记住所有其他密码,并为用户提供单点登录的自动登录体验。
iMacros 作为软件控件
只需几分钟即可将 Web 自动化添加到您的应用程序中,不需要花费数周甚至数月的时间。您可以获得一个免费版本 (iMacros Enterprise Pack),经过五年多的测试和调试,并被超过 500,000 名技术成熟的安装者使用。
系统环境要求
Windows 10、Windows 8/8.1、Windows 7、Windows XP SP3、Windows Server 2003/2008/2008R2/2012/2012R2
Windows 32 位(x86) 和 64 位(x64)
Microsoft Internet Explorer 9、10 或 11(Windows XP 也支持 ie8)
Mozilla Firefox 21 或更高版本(可选,仅适用于 iMacros Firefox Add-On)
Google Chrome 版本 22 或更高版本(可选,仅适用于 iMacros Chrome 插件)
内存:256MB(推荐 512MB)
硬盘:30MB 查看全部
网页抓取解密(iMacros的网页抓取、网页测试制定工具,支持IE、Chrome、firefox)
iMacros中文版是一款功能强大的网络爬虫和网络测试开发工具,可支持IE、Chrome、firefox等多种浏览器。欢迎有兴趣的朋友到公共资源网免费下载使用。
IMacros 中文版介绍
iMacros 是 Mozilla Firefox 浏览器的附加组件。它的主要功能是帮助我们创建动作宏来登录网站、论坛、邮箱查看邮件。它还允许我们创建其他动作宏。例如:将网页另存为、保存网页上的组件(例如:图片)、打印...等
iMacros 功能
Web 自动化/Web 脚本编译 iMacros 允许您记录和重放重复性任务。 iMacros 还可以与所有网站 进行交互。可以填写表单,自动下载和上传文本、图片、文件和网站页面。您可以使用 CSV 和 xml 文件、数据库和其他数据源将数据导入和导出 Web 应用程序中的数据。 iMacros 还支持 PDF 处理,可以截图,可以模仿不同的用户代理,可以连接代理服务器。唯一兼容所有网站的网页自动化软件。
iMacros 的脚本编译界面让您可以完全控制网络浏览器,因此即使是最复杂的任务也可以编译。它还可以使用所有编译或编程语言。无需学习商家特有的笨拙的编译语言。您甚至可以将 iMacros 绑定到您的应用程序。编译后的版本有一个特殊的免费分发许可证。
编译界面也可以用来更新excel,直接上网访问。
数据提取/网络抓取/网络数据挖掘/企业数据
iMacros 可以执行与从 网站 表单填写衍生的文本(价格、产品描述、股票报价等)和图片的搜索和提取完全相反的任务。 iMacros 收录完整的 Unicode 支持,兼容所有语言,包括中文等多字节语言。
网页测试
使用 iMacros 执行 Web 应用程序的功能、性能和回归测试。 iMacros 是唯一可以通过 Internet Explorer 和 Firefox 自动进行浏览器内部测试的工具。 iMacros 还是唯一可以运行基于 Java、Flash、Flex 或 Silverlight 小程序和所有 AJAX 元素的内部浏览器测试的工具。内置的 STOPWATCH 命令可以准确捕捉流程每一步的 网站 页面响应次数。
表格填写程序
iMacros 允许您每天检查相同的 网站、记住密码并填写网络表单,而无需重复。 iMacros 是唯一可以自动填写多页网页表单的表单填写程序。所有信息都存储在可读且易于编辑的纯文本文件中。密码可通过安全的256位AES加密技术安全存储。
iMacros 是企业单点登录 (SSO) 的绝佳替代解决方案。用户只需要记住一个主密码,iMacros 会记住所有其他密码,并为用户提供单点登录的自动登录体验。
iMacros 作为软件控件
只需几分钟即可将 Web 自动化添加到您的应用程序中,不需要花费数周甚至数月的时间。您可以获得一个免费版本 (iMacros Enterprise Pack),经过五年多的测试和调试,并被超过 500,000 名技术成熟的安装者使用。
系统环境要求
Windows 10、Windows 8/8.1、Windows 7、Windows XP SP3、Windows Server 2003/2008/2008R2/2012/2012R2
Windows 32 位(x86) 和 64 位(x64)
Microsoft Internet Explorer 9、10 或 11(Windows XP 也支持 ie8)
Mozilla Firefox 21 或更高版本(可选,仅适用于 iMacros Firefox Add-On)
Google Chrome 版本 22 或更高版本(可选,仅适用于 iMacros Chrome 插件)
内存:256MB(推荐 512MB)
硬盘:30MB
网页抓取解密(一款可添加与解密图片隐藏信息的在线工具说明(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-02 15:03
首页站长助手工具 在线图片添加/解密隐藏信息(隐写术)工具 在线图片添加/解密隐藏信息(隐写术)工具 这是一款可以添加和解密图片隐藏信息的在线工具,通过使用此工具,用户可以给图片添加文字信息,重新生成图片。同样,对于添加了隐藏信息的图片,也可以对之前添加的隐藏信息进行解密。提供给有需要的朋友免费使用。
一、生成隐藏信息的图片
1.从你的电脑中选择一张图片来加密信息:
2.在图片中输入要隐藏的短信:
3.输入密码解锁信息:
生成隐藏信息的图片
二、解密带有隐藏信息的图片
1. 从您的计算机中选择一张带有隐藏信息的图片:
2.输入密码解锁信息(如果没有密码就留空):
解密隐藏信息
测试演示图片
你可以看到下图,下载到你的电脑上,然后用这个工具解密,就可以看到隐藏的信息了。
代码参考:
在线图片添加/解密隐藏信息工具说明
①。隐写术是一种加密技术。维基权威声明是“隐写术是一门关于信息隐藏的技术和科学。所谓信息隐藏是指防止预定接收者以外的任何人知道信息的传输事件或信息内容。
②。使用此工具可以隐藏图片中的文字信息而不影响图片的显示。只有专用工具才能解密图片内容等功能。
③。图像隐写术的应用价值非常广泛,比如程序员之间的告白(不限男女),也算是一种浪漫的方式吧~
④。据说,大众点评通过这种方式成功证明了某应用盗用其图片,有效维护了其合法权益。
脚本之家小程序上线啦!搜索微信小程序脚本首页工具箱或扫描以下小程序代码直接打开小程序!
小程序工具箱还在不断完善中,欢迎您提出宝贵意见!
为了回馈用户对脚本之家的关注,脚本之家不定期组织红包、书籍、礼物。
关注官方微信公众平台参与活动!
最后感谢您对脚本之家在线工具的支持! 查看全部
网页抓取解密(一款可添加与解密图片隐藏信息的在线工具说明(图))
首页站长助手工具 在线图片添加/解密隐藏信息(隐写术)工具 在线图片添加/解密隐藏信息(隐写术)工具 这是一款可以添加和解密图片隐藏信息的在线工具,通过使用此工具,用户可以给图片添加文字信息,重新生成图片。同样,对于添加了隐藏信息的图片,也可以对之前添加的隐藏信息进行解密。提供给有需要的朋友免费使用。
一、生成隐藏信息的图片
1.从你的电脑中选择一张图片来加密信息:
2.在图片中输入要隐藏的短信:
3.输入密码解锁信息:
生成隐藏信息的图片
二、解密带有隐藏信息的图片
1. 从您的计算机中选择一张带有隐藏信息的图片:
2.输入密码解锁信息(如果没有密码就留空):
解密隐藏信息
测试演示图片
你可以看到下图,下载到你的电脑上,然后用这个工具解密,就可以看到隐藏的信息了。
代码参考:
在线图片添加/解密隐藏信息工具说明
①。隐写术是一种加密技术。维基权威声明是“隐写术是一门关于信息隐藏的技术和科学。所谓信息隐藏是指防止预定接收者以外的任何人知道信息的传输事件或信息内容。
②。使用此工具可以隐藏图片中的文字信息而不影响图片的显示。只有专用工具才能解密图片内容等功能。
③。图像隐写术的应用价值非常广泛,比如程序员之间的告白(不限男女),也算是一种浪漫的方式吧~
④。据说,大众点评通过这种方式成功证明了某应用盗用其图片,有效维护了其合法权益。
脚本之家小程序上线啦!搜索微信小程序脚本首页工具箱或扫描以下小程序代码直接打开小程序!
小程序工具箱还在不断完善中,欢迎您提出宝贵意见!
为了回馈用户对脚本之家的关注,脚本之家不定期组织红包、书籍、礼物。
关注官方微信公众平台参与活动!
最后感谢您对脚本之家在线工具的支持!
网页抓取解密(html、js被加密了,怎么破解呢?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-02 14:18
)
apk中的html和js都加密了,怎么破解?破解ApiCloud加密码
看代码使用APICloud,APP开发时不需要写JAVA代码。 APICloud是打包的,当然也包括解密后的代码。可以通过反编译找到加解密的核心算法。 apk包中一定有解密对应的so。
“完全加密
* 全包网页加密:对网页中的全包html、css、javascript代码进行加密。网友加密后的代码无法读取,常用格式化工具无法恢复。代码运行前加密,运行时动态解密。
* 一键加密和运行时解密。开发过程中无需对代码做任何特殊处理。云编译时选择代码加密即可。
* 零修改,零影响 加密后不改变代码大小,不影响运行效率。
* 安全盒定义了安全盒,盒内的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准。对受保护的代码进行统一的资源管理,加快资源加载速度,加快代码运行速度。 "
这是解密后的源代码
这是解密后的图片
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,逻辑在JS中)
首先考虑APP加载资源的过程
也许:
1)WEBVIEW-> 加载页面-> 截取/查找本地文件 是-> 解密/写回数据
2)WEBVIEW->加载页面->截取/查找本地文件无->请求网络文件
这里有个共同点,就是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
研究并获取源代码。 查看全部
网页抓取解密(html、js被加密了,怎么破解呢?(图)
)
apk中的html和js都加密了,怎么破解?破解ApiCloud加密码
看代码使用APICloud,APP开发时不需要写JAVA代码。 APICloud是打包的,当然也包括解密后的代码。可以通过反编译找到加解密的核心算法。 apk包中一定有解密对应的so。
“完全加密
* 全包网页加密:对网页中的全包html、css、javascript代码进行加密。网友加密后的代码无法读取,常用格式化工具无法恢复。代码运行前加密,运行时动态解密。
* 一键加密和运行时解密。开发过程中无需对代码做任何特殊处理。云编译时选择代码加密即可。
* 零修改,零影响 加密后不改变代码大小,不影响运行效率。
* 安全盒定义了安全盒,盒内的代码按照加解密处理,其他代码不受影响。
* 重新定义资源标准。对受保护的代码进行统一的资源管理,加快资源加载速度,加快代码运行速度。 "
这是解密后的源代码
这是解密后的图片
这是解密后的图片。
结构也很简单,厂商的SDK占了大部分内容(因为是web开发APP,逻辑在JS中)
首先考虑APP加载资源的过程
也许:
1)WEBVIEW-> 加载页面-> 截取/查找本地文件 是-> 解密/写回数据
2)WEBVIEW->加载页面->截取/查找本地文件无->请求网络文件
这里有个共同点,就是需要拦截,而WebView只有一个接口实现了这个功能:WebViewClient.shouldInterceptRequest
研究并获取源代码。
网页抓取解密(网页内磁力链接软件界面如下图:获取磁力链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-02 14:18
)
最近,我从某个视频资源网站下载了动漫。大约有30集。如果手动需要把每一集的磁链一个一个复制下来下载,比较麻烦,所以写了这个提取磁链的小工具。
理论上,任何在html代码中支持磁力链接的网页,可能会因为一些特殊的反爬虫措施或其他保护措施而无法获取。
由于磁链下载速度可能会因为资源太少而变慢,下一步就是使用百度云的API将提取的磁链添加到百度云离线下载中,然后使用Pandownload等工具进行下载。
目前可以先用这个程序提取磁力链接,再用百度云批量离线脚本(%E7%99%BE%E5%BA%A6%E7%BD%91%E7%9B%98% E6%89 %B9%E9%87%8F%E7%A6%BB%E7%BA%BF)批量创建离线下载,但是字数太多好像报错,需要一段时间。
我不经常使用java,一般不做UI,所以技术很弱。请见谅,如果您有任何问题或建议,欢迎讨论!
网页中的磁力链接
软件界面如下:
获取磁力链接
百度云批量离线脚本:
在 URL 框中输入收录磁性链接的 URL,然后单击“确定”。一段时间后,所有磁力链接将在下面的框中输出。有时由于网络等原因,无法获取所有网页代码,并显示“未获取所有内容”。这个时候应该可以稍等片刻再试。然后复制下面提取的磁力链接,打开迅雷(如果遇到版权问题,论坛上有迅雷破解版)即可下载。
下载链接:链接:密码:plaf
请注意:如果您的电脑已经安装了JAVA环境,则只需要下载里面的jar包即可。如果没有,则需要下载rar压缩包并运行里面的exe文件。
源代码:
[Java] 纯文本视图复制代码
package getMagnet;
import java.awt.EventQueue;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JScrollPane;
import javax.swing.JTextField;
import javax.swing.JTextArea;
import javax.swing.JButton;
import java.awt.event.ActionListener;
import java.awt.event.ActionEvent;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Pattern;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.regex.Matcher;
final class ReadHtml extends Thread{
public String pageUrl, encoding;
public StringBuffer[] html;
ReadHtml(String _pageUrl, String _encoding, StringBuffer[] _html) {
pageUrl = _pageUrl;
encoding = _encoding;
html = _html;
}
@Override
public void run() {
try {
URL url = new URL(pageUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(false);
conn.setDoInput(true);
conn.setUseCaches(false);
conn.setRequestMethod("GET");
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.87 Safari/537.36");
conn.connect();
int code = conn.getResponseCode();
if(code!=HttpURLConnection.HTTP_OK){
throw new Exception("HttpURLConnection Error! Response Code = "+code);
}
InputStreamReader isr = new InputStreamReader(conn.getInputStream(), encoding);
BufferedReader in = new BufferedReader(isr);
String line;
while((line = in.readLine())!=null) {
html[0].append(line);
}
in.close();
conn.disconnect();
}catch(Exception e) {
System.err.println(e);
}
}
}
public class GetMagnet {
private JFrame frame;
private JTextField URL;
/**
* Launch the application.
*/
public static void main(String[] args) {
EventQueue.invokeLater(new Runnable() {
public void run() {
try {
GetMagnet window = new GetMagnet();
window.frame.setVisible(true);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* Create the application.
*/
public GetMagnet() {
initialize();
}
/**
* Initialize the contents of the frame.
*/
private void initialize() {
frame = new JFrame();
frame.setResizable(false);
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5");
frame.setBounds(100, 100, 672, 502);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.getContentPane().setLayout(null);
JLabel lblNewLabel = new JLabel("URL");
lblNewLabel.setBounds(10, 23, 54, 15);
frame.getContentPane().add(lblNewLabel);
URL = new JTextField();
URL.setBounds(63, 20, 511, 21);
frame.getContentPane().add(URL);
URL.setColumns(1000);
JTextArea Magnet = new JTextArea();
Magnet.setBounds(63, 58, 583, 396);
JScrollPane scrollMagnet = new JScrollPane(Magnet);
scrollMagnet.setBounds(63, 58, 583, 396);
scrollMagnet.setHorizontalScrollBarPolicy(JScrollPane.HORIZONTAL_SCROLLBAR_AS_NEEDED);
scrollMagnet.setVerticalScrollBarPolicy(JScrollPane.VERTICAL_SCROLLBAR_AS_NEEDED);
frame.getContentPane().add(scrollMagnet);
JButton OK = new JButton("OK");
OK.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent arg0) {
StringBuffer html[] = {new StringBuffer()};
ReadHtml rh = new ReadHtml(URL.getText(), "UTF-8", html);
boolean success = false;
try {
rh.start();
for(int i=5;i>0;--i) {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5\uFF08\u7B49\u5F85"+i+"\u79D2...\uFF09");
rh.join(1000);
}
if(rh.isAlive()) {
rh.stop();
success = false;
}else {
success = true;
}
} catch (Exception ex) {
System.err.println(ex);
}
String html0 = html[0].toString();
int index = 0;
StringBuffer magnets = new StringBuffer();
int count = 0;
String regex = "magnet:\\?xt=urn:btih:[A-za-z0-9]{40,40}";
final Pattern pattern = Pattern.compile(regex, Pattern.DOTALL);
final Matcher matcher = pattern.matcher(html0);
LinkedList MagnetList = new LinkedList();
while(matcher.find()) {
String temp = matcher.group();
boolean exist = false;
for(String Magnet:MagnetList) {
if(Magnet.equals(temp)) {
exist = true;
break;
}
}
if(!exist) {
magnets.append(temp+"\n");
MagnetList.add(temp);
++count;
}
}
if(success) {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5\uFF08\u5DF2\u83B7\u53D6"+count+"\u6761\uFF09");
}else {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5 \u672A\u83B7\u53D6\u6240\u6709\u5185\u5BB9\uFF0C\u8bF7\u91CD\u8BD5\uFF01\uFF08\u5DF2\u83B7\u53D6"+count+"\u6761\uFF09");
}
Magnet.setText(magnets.toString());
}
});
OK.setBounds(584, 19, 62, 23);
frame.getContentPane().add(OK);
JLabel lblNewLabel_1 = new JLabel("Magnet");
lblNewLabel_1.setBounds(10, 62, 54, 15);
frame.getContentPane().add(lblNewLabel_1);
}
} 查看全部
网页抓取解密(网页内磁力链接软件界面如下图:获取磁力链接
)
最近,我从某个视频资源网站下载了动漫。大约有30集。如果手动需要把每一集的磁链一个一个复制下来下载,比较麻烦,所以写了这个提取磁链的小工具。
理论上,任何在html代码中支持磁力链接的网页,可能会因为一些特殊的反爬虫措施或其他保护措施而无法获取。
由于磁链下载速度可能会因为资源太少而变慢,下一步就是使用百度云的API将提取的磁链添加到百度云离线下载中,然后使用Pandownload等工具进行下载。
目前可以先用这个程序提取磁力链接,再用百度云批量离线脚本(%E7%99%BE%E5%BA%A6%E7%BD%91%E7%9B%98% E6%89 %B9%E9%87%8F%E7%A6%BB%E7%BA%BF)批量创建离线下载,但是字数太多好像报错,需要一段时间。
我不经常使用java,一般不做UI,所以技术很弱。请见谅,如果您有任何问题或建议,欢迎讨论!
网页中的磁力链接
软件界面如下:
获取磁力链接
百度云批量离线脚本:
在 URL 框中输入收录磁性链接的 URL,然后单击“确定”。一段时间后,所有磁力链接将在下面的框中输出。有时由于网络等原因,无法获取所有网页代码,并显示“未获取所有内容”。这个时候应该可以稍等片刻再试。然后复制下面提取的磁力链接,打开迅雷(如果遇到版权问题,论坛上有迅雷破解版)即可下载。
下载链接:链接:密码:plaf
请注意:如果您的电脑已经安装了JAVA环境,则只需要下载里面的jar包即可。如果没有,则需要下载rar压缩包并运行里面的exe文件。
源代码:
[Java] 纯文本视图复制代码
package getMagnet;
import java.awt.EventQueue;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JScrollPane;
import javax.swing.JTextField;
import javax.swing.JTextArea;
import javax.swing.JButton;
import java.awt.event.ActionListener;
import java.awt.event.ActionEvent;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Pattern;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.regex.Matcher;
final class ReadHtml extends Thread{
public String pageUrl, encoding;
public StringBuffer[] html;
ReadHtml(String _pageUrl, String _encoding, StringBuffer[] _html) {
pageUrl = _pageUrl;
encoding = _encoding;
html = _html;
}
@Override
public void run() {
try {
URL url = new URL(pageUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(false);
conn.setDoInput(true);
conn.setUseCaches(false);
conn.setRequestMethod("GET");
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.87 Safari/537.36");
conn.connect();
int code = conn.getResponseCode();
if(code!=HttpURLConnection.HTTP_OK){
throw new Exception("HttpURLConnection Error! Response Code = "+code);
}
InputStreamReader isr = new InputStreamReader(conn.getInputStream(), encoding);
BufferedReader in = new BufferedReader(isr);
String line;
while((line = in.readLine())!=null) {
html[0].append(line);
}
in.close();
conn.disconnect();
}catch(Exception e) {
System.err.println(e);
}
}
}
public class GetMagnet {
private JFrame frame;
private JTextField URL;
/**
* Launch the application.
*/
public static void main(String[] args) {
EventQueue.invokeLater(new Runnable() {
public void run() {
try {
GetMagnet window = new GetMagnet();
window.frame.setVisible(true);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* Create the application.
*/
public GetMagnet() {
initialize();
}
/**
* Initialize the contents of the frame.
*/
private void initialize() {
frame = new JFrame();
frame.setResizable(false);
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5");
frame.setBounds(100, 100, 672, 502);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.getContentPane().setLayout(null);
JLabel lblNewLabel = new JLabel("URL");
lblNewLabel.setBounds(10, 23, 54, 15);
frame.getContentPane().add(lblNewLabel);
URL = new JTextField();
URL.setBounds(63, 20, 511, 21);
frame.getContentPane().add(URL);
URL.setColumns(1000);
JTextArea Magnet = new JTextArea();
Magnet.setBounds(63, 58, 583, 396);
JScrollPane scrollMagnet = new JScrollPane(Magnet);
scrollMagnet.setBounds(63, 58, 583, 396);
scrollMagnet.setHorizontalScrollBarPolicy(JScrollPane.HORIZONTAL_SCROLLBAR_AS_NEEDED);
scrollMagnet.setVerticalScrollBarPolicy(JScrollPane.VERTICAL_SCROLLBAR_AS_NEEDED);
frame.getContentPane().add(scrollMagnet);
JButton OK = new JButton("OK");
OK.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent arg0) {
StringBuffer html[] = {new StringBuffer()};
ReadHtml rh = new ReadHtml(URL.getText(), "UTF-8", html);
boolean success = false;
try {
rh.start();
for(int i=5;i>0;--i) {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5\uFF08\u7B49\u5F85"+i+"\u79D2...\uFF09");
rh.join(1000);
}
if(rh.isAlive()) {
rh.stop();
success = false;
}else {
success = true;
}
} catch (Exception ex) {
System.err.println(ex);
}
String html0 = html[0].toString();
int index = 0;
StringBuffer magnets = new StringBuffer();
int count = 0;
String regex = "magnet:\\?xt=urn:btih:[A-za-z0-9]{40,40}";
final Pattern pattern = Pattern.compile(regex, Pattern.DOTALL);
final Matcher matcher = pattern.matcher(html0);
LinkedList MagnetList = new LinkedList();
while(matcher.find()) {
String temp = matcher.group();
boolean exist = false;
for(String Magnet:MagnetList) {
if(Magnet.equals(temp)) {
exist = true;
break;
}
}
if(!exist) {
magnets.append(temp+"\n");
MagnetList.add(temp);
++count;
}
}
if(success) {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5\uFF08\u5DF2\u83B7\u53D6"+count+"\u6761\uFF09");
}else {
frame.setTitle("\u83B7\u53D6\u78C1\u529B\u94FE\u63A5 \u672A\u83B7\u53D6\u6240\u6709\u5185\u5BB9\uFF0C\u8bF7\u91CD\u8BD5\uFF01\uFF08\u5DF2\u83B7\u53D6"+count+"\u6761\uFF09");
}
Magnet.setText(magnets.toString());
}
});
OK.setBounds(584, 19, 62, 23);
frame.getContentPane().add(OK);
JLabel lblNewLabel_1 = new JLabel("Magnet");
lblNewLabel_1.setBounds(10, 62, 54, 15);
frame.getContentPane().add(lblNewLabel_1);
}
}
网页抓取解密(p2p网络下挖矿教程,区块链的实现原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-30 09:02
网页抓取解密点击查看>>推荐阅读
1、比特币与区块链的关系
2、区块链的实现原理
3、智能合约原理
4、p2p网络运行原理
5、p2p网络下挖矿教程by小白千里豆go类型论坛的链接,未来的一个网页解密或破解的开源框架。
可以看看moonip博客,
学会调用一些已有的,能免费运行的源码,边写代码边学习。python并不难,不要门户网站广告,不要复杂的协议,学习简单的语句,稍微了解思路就会了。linux下命令行基本操作,多看看一些开源代码,看懂调用的函数。就很足够了。
先从docker入手,了解环境隔离的概念和流程,基本就入门了!然后就是进阶版,
可以从装上一个windows开始,从装系统看起,使用xshell这样的命令行工具作为网页传输的通道,开始快速浏览前人已有的项目和开源文档。
推荐一个开源的:logindex.ioweb框架,基于docker,如果对原理不太清楚的话,先从基础的docker开始,看官方文档。
基础的文件操作都搞不定的话,建议看下《python原型教程》,首页上好像就有下载的地址。然后把network,iis3.0所有文件操作都撸一遍, 查看全部
网页抓取解密(p2p网络下挖矿教程,区块链的实现原理及应用)
网页抓取解密点击查看>>推荐阅读
1、比特币与区块链的关系
2、区块链的实现原理
3、智能合约原理
4、p2p网络运行原理
5、p2p网络下挖矿教程by小白千里豆go类型论坛的链接,未来的一个网页解密或破解的开源框架。
可以看看moonip博客,
学会调用一些已有的,能免费运行的源码,边写代码边学习。python并不难,不要门户网站广告,不要复杂的协议,学习简单的语句,稍微了解思路就会了。linux下命令行基本操作,多看看一些开源代码,看懂调用的函数。就很足够了。
先从docker入手,了解环境隔离的概念和流程,基本就入门了!然后就是进阶版,
可以从装上一个windows开始,从装系统看起,使用xshell这样的命令行工具作为网页传输的通道,开始快速浏览前人已有的项目和开源文档。
推荐一个开源的:logindex.ioweb框架,基于docker,如果对原理不太清楚的话,先从基础的docker开始,看官方文档。
基础的文件操作都搞不定的话,建议看下《python原型教程》,首页上好像就有下载的地址。然后把network,iis3.0所有文件操作都撸一遍,
网页抓取解密(数据就是新石油互联网上海量的加密货币数据应该成为你的第二天性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-28 03:10
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬行是指从网站下载数据并从这些数据中提取有价值信息的过程(因此得名爬行)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在本系列文章中,我们将从一个概念开始,并在此基础上慢慢构建。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集
和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多提供免费工具的网站,为什么还有人要采集
你自己的数据呢?大多数用户将使用 CoinMarketCap、CoinGecko、Live Coin Watch 等网站来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录
这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录
更多关于投资研究的附加信息(市值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与 Polkadot 相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
from bs4 import BeautifulSoup
import requests
mainpage = requests.get('https://coinmarketcap.com/curr ... %2339;)
soup = BeautifulSoup(mainpage.content, 'html.parser')
whatis = soup.find_all("div", {"class" : "sc-2qtjgt-0 eApVPN"})
title = whatis[0].find_all("h2")
print(title[0].text.strip() + "\n")
for p in whatis[0].find_all('p'):
打印(p.text.strip()+“\n”)
示例2:网络爬取币种统计
在本例中,我们将使用 BNB 统计数据,即市值、完全稀释市值、交易量(24 小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字总是在变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class" : "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class" : "statsValue"})statsValue_marketcap = statsValues[0].text.strip()
print(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
print(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
print(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
print(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
打印(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap 等网站的开发者在不断更新自己的网站,旧代码可能过一段时间就失效了。
一种可能的解决方案是使用各种网站和平台提供的应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。 查看全部
网页抓取解密(数据就是新石油互联网上海量的加密货币数据应该成为你的第二天性)
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬行是指从网站下载数据并从这些数据中提取有价值信息的过程(因此得名爬行)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在本系列文章中,我们将从一个概念开始,并在此基础上慢慢构建。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集
和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多提供免费工具的网站,为什么还有人要采集
你自己的数据呢?大多数用户将使用 CoinMarketCap、CoinGecko、Live Coin Watch 等网站来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录
这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录
更多关于投资研究的附加信息(市值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与 Polkadot 相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
from bs4 import BeautifulSoup
import requests
mainpage = requests.get('https://coinmarketcap.com/curr ... %2339;)
soup = BeautifulSoup(mainpage.content, 'html.parser')
whatis = soup.find_all("div", {"class" : "sc-2qtjgt-0 eApVPN"})
title = whatis[0].find_all("h2")
print(title[0].text.strip() + "\n")
for p in whatis[0].find_all('p'):
打印(p.text.strip()+“\n”)
示例2:网络爬取币种统计
在本例中,我们将使用 BNB 统计数据,即市值、完全稀释市值、交易量(24 小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字总是在变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class" : "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class" : "statsValue"})statsValue_marketcap = statsValues[0].text.strip()
print(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
print(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
print(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
print(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
打印(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap 等网站的开发者在不断更新自己的网站,旧代码可能过一段时间就失效了。
一种可能的解决方案是使用各种网站和平台提供的应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
网页抓取解密(实用的解密方式和新方法(一)加密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-27 12:13
;头>
网马
这里的意思是创建一个文本框,然后将可爱的内容赋值给文本框。Textfield 是文本框的名称。你可以自己修改。但是必须修改document.getElementById('textfield').value中对应的name,然后运行刚才的nethorse得到结果:
刚才的加密代码大小为:
解密后:
至于\x72\x65\x73\x70\x6F\x6E\x73\x65\x42\x6F\x64\x79里面的代码,我们可以用一个简单的方法来突破。
十六进制转义字符串如下:
顺便说一下,它可以显示。在刚才的加密页面中,使用了一种防止查看源代码的技术。只需应用以下代码
这里的 noscript 元素用于定义脚本未执行时的替代内容(文本)。这个标签可以用来识别
也许你见过很多解密网马的方法。许多网络马在工具的帮助下可以轻松解决。为什么不:unescape 加密、Encode 加密、js 变异加密、US-ASCII 加密,但是如果你手头没有工具怎么办?还是遇到连工具都解不开的加密?轻言放弃不是我们的作风!今天就来讲解一些实用的解密方法和总结出来的新方法。
首先,大家要明白一个问题。必须在客户端识别所有网络马加密方法。如果它们不能转换成浏览器可以识别的标准代码,它们就不能运行!因此,理论上所有的网络马加密方式都可以解密。我们举几个典型的例子来解释一下。
首先是我最近遇到了一个网络马,加密结果如下:
看的时候头疼吗?乱七八糟,无从下手,不是简单的解密工具吧?一起来解决吧!首先我们一起来了解一下关键词这两个“document.write”和“eval”。
“Document.write”是JAVASCRIPT中的打印语句,“eval”指的是eval()函数,可以将字符串作为JavaScript表达式执行。如果我们在 JS 加密代码中遇到 document.write,我们通常将其更改为“alert”,如果我们遇到“eval”,我们通常将其更改为“document.write”。我们先把 eval 改成 document.write 再运行看看结果:
行!已经初步解密,从上次调用自定义函数realexploit()可以看出。这是最近发布的 realplay 漏洞利用网络马。至于里面的unescape加密部分就不用我解释了吧?最快的方法是复制那部分代码。然后添加到百度搜索关键词地址,如文档。
对于这段代码,防止翻译最快的方法是将其添加到上面的地址中,返回结果为:
我们来看看天网已经挂上的一匹网络马:
一堆乱七八糟的,不知道是什么。如何解读?其实最快最简单的方法就是浏览这个页面,保存时选择中欧(ISO)编码。
得到答案:
与此类似,还有US-ACSII加密的网络马,也可以通过这种方式解密。
保存时,仍然选择中欧(ISO)代码,得到如下结果:
接下来,让我们看看一个看起来有点困难的。近日,黑客防线发布的“暗网马”使用了Firefox中单人开发的加密工具。解密过程需要密码。是为了防止修改吗?看起来有点像md5加密,真的不可逆吗?一匹1K的网马可以加密到15K甚至更大,这很可怕吧?让我们一起解密他!
在长代码的末尾我们看到
var pass="TEST.";
如果(通过){
通过=unescape(通过);
varcuteqq,可爱,可爱;
Cuteqq=XOR(unescape(QQ_784378237),STR.md5(pass));
可爱=异或(unescape(),STR.md5(通过));
可爱=可爱qq+www_cuteqq_cn_s+可爱;
文档写(可爱);
返回(假);
}
意思是调用pass校验函数,如果为true,继续执行里面的内容。XOR 是对两个表达式执行逻辑“异或”操作的运算符。我不会在这里详细了解它。关键是最后一个Document.write(可爱的)懂网页代码的人会知道这一段的具体含义是,如果密码验证正确。只需输出cute函数中的内容即可。当我们遇到 document.write 时,我们通常将其更改为“alert”以获得初始解密:
这里我们有一个问题。Alert 根据内屏的大小显示内容。内容无法完全显示。该怎么办?我们引入一段javascript代码:document.getElementById('textfield').value=cute; 替换原来的document.write(cute); 然后在页面中
在和之间加一段,效果如下:
< 查看全部
网页抓取解密(实用的解密方式和新方法(一)加密)
;头>
网马
这里的意思是创建一个文本框,然后将可爱的内容赋值给文本框。Textfield 是文本框的名称。你可以自己修改。但是必须修改document.getElementById('textfield').value中对应的name,然后运行刚才的nethorse得到结果:
刚才的加密代码大小为:
解密后:
至于\x72\x65\x73\x70\x6F\x6E\x73\x65\x42\x6F\x64\x79里面的代码,我们可以用一个简单的方法来突破。
十六进制转义字符串如下:
顺便说一下,它可以显示。在刚才的加密页面中,使用了一种防止查看源代码的技术。只需应用以下代码
这里的 noscript 元素用于定义脚本未执行时的替代内容(文本)。这个标签可以用来识别
也许你见过很多解密网马的方法。许多网络马在工具的帮助下可以轻松解决。为什么不:unescape 加密、Encode 加密、js 变异加密、US-ASCII 加密,但是如果你手头没有工具怎么办?还是遇到连工具都解不开的加密?轻言放弃不是我们的作风!今天就来讲解一些实用的解密方法和总结出来的新方法。
首先,大家要明白一个问题。必须在客户端识别所有网络马加密方法。如果它们不能转换成浏览器可以识别的标准代码,它们就不能运行!因此,理论上所有的网络马加密方式都可以解密。我们举几个典型的例子来解释一下。
首先是我最近遇到了一个网络马,加密结果如下:
看的时候头疼吗?乱七八糟,无从下手,不是简单的解密工具吧?一起来解决吧!首先我们一起来了解一下关键词这两个“document.write”和“eval”。
“Document.write”是JAVASCRIPT中的打印语句,“eval”指的是eval()函数,可以将字符串作为JavaScript表达式执行。如果我们在 JS 加密代码中遇到 document.write,我们通常将其更改为“alert”,如果我们遇到“eval”,我们通常将其更改为“document.write”。我们先把 eval 改成 document.write 再运行看看结果:
行!已经初步解密,从上次调用自定义函数realexploit()可以看出。这是最近发布的 realplay 漏洞利用网络马。至于里面的unescape加密部分就不用我解释了吧?最快的方法是复制那部分代码。然后添加到百度搜索关键词地址,如文档。
对于这段代码,防止翻译最快的方法是将其添加到上面的地址中,返回结果为:
我们来看看天网已经挂上的一匹网络马:
一堆乱七八糟的,不知道是什么。如何解读?其实最快最简单的方法就是浏览这个页面,保存时选择中欧(ISO)编码。
得到答案:
与此类似,还有US-ACSII加密的网络马,也可以通过这种方式解密。
保存时,仍然选择中欧(ISO)代码,得到如下结果:
接下来,让我们看看一个看起来有点困难的。近日,黑客防线发布的“暗网马”使用了Firefox中单人开发的加密工具。解密过程需要密码。是为了防止修改吗?看起来有点像md5加密,真的不可逆吗?一匹1K的网马可以加密到15K甚至更大,这很可怕吧?让我们一起解密他!
在长代码的末尾我们看到
var pass="TEST.";
如果(通过){
通过=unescape(通过);
varcuteqq,可爱,可爱;
Cuteqq=XOR(unescape(QQ_784378237),STR.md5(pass));
可爱=异或(unescape(),STR.md5(通过));
可爱=可爱qq+www_cuteqq_cn_s+可爱;
文档写(可爱);
返回(假);
}
意思是调用pass校验函数,如果为true,继续执行里面的内容。XOR 是对两个表达式执行逻辑“异或”操作的运算符。我不会在这里详细了解它。关键是最后一个Document.write(可爱的)懂网页代码的人会知道这一段的具体含义是,如果密码验证正确。只需输出cute函数中的内容即可。当我们遇到 document.write 时,我们通常将其更改为“alert”以获得初始解密:
这里我们有一个问题。Alert 根据内屏的大小显示内容。内容无法完全显示。该怎么办?我们引入一段javascript代码:document.getElementById('textfield').value=cute; 替换原来的document.write(cute); 然后在页面中
在和之间加一段,效果如下:
<

