
网页抓取解密
【安全】黑客暴力破解必备的12大逆向工具!设置再复杂的密码也没用!
网站优化 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2022-05-03 15:48
暴力破解是最流行的密码破解方法之一,然而,它不仅仅是密码破解。暴力破解还可用于发现Web应用程序中的隐藏页面和内容,在你成功之前,这种破解基本上是“破解一次尝试一次”。
这种破解有时需要更长的时间,但其成功率也会更高。在本文中,我将尝试解释在不同场景中使用的暴力破解和流行工具,来执行暴力破解并获得所需结果。
一、什么是暴力破解?
当攻击者使用一组预定义值攻击目标并分析响应直到他成功,这就叫做暴力攻击。它的成功取决于预定义值的集合,如果它越大,就会需要更多时间,但成功的可能性也会变大。
最常见且最容易理解的暴力攻击是破解密码的字典攻击,在这种情况下,攻击者使用包含数百万个可作为密码的单词的密码字典,然后攻击者逐个尝试这些密码并进行身份验证,如果字典中包含正确的密码,攻击者将会成功。
在传统的暴力攻击中,攻击者只是尝试字母和数字的组合来顺序生成密码。但是,当密码足够长的时候,这种技术就会需要更长的时间,这些攻击可能需要几分钟到几小时甚至是几年的时间,具体取决于所使用的系统和密码的长度。
为了防止暴力破解密码,应始终使用长而复杂的密码。这会使得攻击者很难猜到密码,暴力攻击会花费更多的时间,大多数时候,WordPress用户面临对其网站的暴力攻击。
帐户锁定是防止攻击者对Web应用程序执行暴力攻击的一种方法。但是,对于离线软件,事情就没这么简单了。
同样,为了发现隐藏页面,攻击者会尝试猜测页面名称,发送请求并查看响应。如果该页面不存在,它将显示响应404,成功的话就会响应200。这样,它可以在任何网站上找到隐藏页面。
暴力攻击也用于破解散列并从给定散列中猜出密码。这样的话,哈希是从随机密码生成的,然后此哈希与目标哈希匹配,直到攻击者找到正确的哈希。因此,用于加密密码的加密类型(64位、128位或256位加密)越高,暴力破解所需的时间就会越长。
二、逆向暴力破解
逆向暴力攻击是另一个与密码破解相关的术语,破解密码采用相反的方法。攻击者针对多个用户名尝试一个密码,想想你是否有知道密码但是不知道用户名的时候,在这种情况下,你可以尝试使用相同的密码去猜测不同的用户名,直到找到匹配组合。
现在,您知道暴力攻击主要用于密码破解,您可以在任何软件,任何网站或任何协议中使用它,只要目标在几次无效尝试后不会组织请求就行。在这篇文章中,我将为不同的协议介绍一些流行的密码破解工具。
三、暴力破解的流行工具
1. Aircrack-NG
我相信大家都曾经了解过Aircrack-ng工具,这是一款免费的无线密码破解工具。该工具附带WEP / WPA / WPA2-PSK破解程序和分析工具,可对WiFi 802.11进行攻击。Aircrack-ng可用于任何支持监听模式的网卡。
它基本上是采用密码字典攻击来猜测无线密码,如您所知,攻击的成功取决于密码字典,密码字典越好越有效。
它适用于Windows和Linux平台,它也被移植到iOS和Android平台上运行,您可以尝试使用给定的平台来研究此工具的工作原理。
2. John the Ripper
开膛手约翰也是一款几乎人人皆知的工具,它长期以来一直是进行暴力攻击的最佳选择。这个免费的密码破解工具最初是为Unix系统开发的,后来,开发人员又为其他平台发布了这款工具。现在它支持15种不同的平台,包括Unix\Windows、DOS、Linux、BeOS和OpenVMS等。您可以使用它来识别弱密码或破解密码来通过身份验证。
这款工具非常受欢迎,并结合了各种密码破解功能,它可以自动检测密码中使用的哈希类型。因此,您也可以针对加密密码存储运行它。
基本上,它可以通过组合字母和数字对所有可能的密码执行暴力破解。但是您也可以将其与密码字典一起使用来执行字典攻击。
3. Rainbow Crack
Rainbow Crack也是一款用于密码破解的流行工具。它会生成彩虹表,以便在执行攻击时使用,这也使得它与其他的暴力破击工具不同。彩虹表是预先计算的,它有助于减少执行攻击的时间。
幸运的是,有各种组织已经为所有互联网用户发布了前计算机的彩虹表,为了节省时间,您可以下载这些彩虹表并在攻击中使用。
该工具仍然在积极开发中,它适用于Windows和Linux,并支持这些平台的所有最新发行版。
4. Cain & Ablel
同样也是一款热门的工具,它可以通过执行暴力攻击、字典攻击和密码分析攻击来帮助破解各种密码。密码分析攻击是通过使用前一种工具中提到的彩虹表来完成的。
值得一提的是,一些病毒查杀软件会将其检测为恶意软件。Avast和Microsoft Security Essentials将其报告为恶意软件并会组织它的运行。如果您需要使用这款软件,您需要先和您的杀毒软件打好招呼。
它的基本功能是:
该工具的最新版本具有很多功能,并添加了嗅探来执行中间人攻击。
5. L0phtcrack
L0phtCrack以破解Windows密码的能力而闻名。它使用字典、暴力破解、混合攻击和彩虹表。L0phtCrack最显著的特性是调度、64位Windows版本的哈希提取、多处理器算法以及网络监控和解码。如果要破解Windows系统的密码,可以尝试使用此工具。
6. Ophcrack
Ophcrack是另一款专门用于破解Windows密码的暴力破解工具。它通过彩虹表使用LM哈希来破解Windows密码。它是一款免费的开源工具,在大多数情况下,它可以在几分钟内破解Windows密码,默认情况下,Ophcrack附带的彩虹表能够破解少于14个字符的密码,其中只包含字母数字字符。其他彩虹表也可供下载。
Ophcrack还可用作LiveCD。
7. Crack
Crack是一款古老的密码破解工具,它是Unix系统的密码破解工具,用于通过执行字典攻击来检查弱密码。
8. Hashcat
Hashcat号称是最快的基于CPU的密码破解工具。它是免费的,适用于Linux、Windows和Mac OS平台。Hashcat支持各种散列算法,包括LM Hashes、MD4、MD5、SHA系列、Unix Crypt格式、MySQL、Cisco PIX。它支持各种攻击形式,包括暴力破解、组合攻击、字典攻击、指纹攻击、混合攻击、掩码攻击、置换攻击、基于规则的攻击、表查找攻击和Toggle-Case攻击。
9. SAMInside
SAMInside同样专门用于破解Windows操作系统的密码,它类似于Ophcrack和Lophtcrack工具。它声称在一台电脑上最高可以每秒破解大约1000万个密码。它支持各种攻击方法,包括掩码攻击、字典攻击、混合攻击和彩虹表攻击。它支持400多种哈希算法。
10.DaveGrohl
DaveGrohl是适用于Mac OS X的流行破解工具,它支持所有可用版本的Mac OS X,此工具支持字典攻击和增量攻击。它还具有分布式模式,允许您从多台计算机执行攻击以攻击相同的密码哈希。此工具现在是开源的,您可以从源码进行安装。
11. Ncrack
Ncrack用于破解网络身份验证,它支持各种协议,包括RDP、SSH、HTTP(S)、SMB、POP3(S)、VNC、FTP和telnet。它可以执行不同的攻击,包括暴力破解等。支持包括Linux、BSD、Windows和Mac OS X等操作系统。
12. THC Hydra
九头蛇以其通过执行暴力攻击来破解网络身份验证的能力而闻名。它可对多种协议执行字典攻击,包括telnet、FTP、HTTP、HTTPS、SMB等。它适用于多种平台,包括Linux、Windows、Cygwin、Solaris、FreeBSD、OpenBSD、OSX和QNX/BlackBerry等。
这些都是用于密码破解的流行工具,还有各种其他工具可用于对不同类型的身份验证执行暴力破解,如果我只举几个小工具的例子,你会看到大多数PDF破解、ZIP破解工具使用相同的暴力破解方法来执行攻击,有许多此类工具可免费或付费使用。
四、结论
暴力破解是破解密码最常用的方法,攻击的成功取决于各种因素,但是,影响最多的因素是密码的长度以及数字、字母和特殊字符的组合。这就是我们谈论强密码的原因:我们通常建议用户使用小写字母、大写字母、数字和特殊字符组合的长密码。它不会使得暴力破解不可能,但会让其变得十分困难。这样,暴力破解会需要更长的时间来破解密码。几乎所有的散列破解算法都使用暴力破解来尝试,当您对数据进行脱机访问时,此攻击最佳。在这种情况下,它易于破解,而且会花费更少的时间。
暴力密码破解在计算机安全性方面非常重要,它用于检查系统、网络或应用程序中使用的弱密码。
防止暴力攻击的最佳方法是限制无效登录,通过这种方式,攻击只能在有限的时间点击并尝试密码。这就是为什么基于网络的服务开始使用验证码,如果您三次输入错误的密码他们会对您的IP地址进行屏蔽。
版权声明:本文为CSDN博主「javaxiaoheibai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
查看全部
【安全】黑客暴力破解必备的12大逆向工具!设置再复杂的密码也没用!
暴力破解是最流行的密码破解方法之一,然而,它不仅仅是密码破解。暴力破解还可用于发现Web应用程序中的隐藏页面和内容,在你成功之前,这种破解基本上是“破解一次尝试一次”。
这种破解有时需要更长的时间,但其成功率也会更高。在本文中,我将尝试解释在不同场景中使用的暴力破解和流行工具,来执行暴力破解并获得所需结果。
一、什么是暴力破解?
当攻击者使用一组预定义值攻击目标并分析响应直到他成功,这就叫做暴力攻击。它的成功取决于预定义值的集合,如果它越大,就会需要更多时间,但成功的可能性也会变大。
最常见且最容易理解的暴力攻击是破解密码的字典攻击,在这种情况下,攻击者使用包含数百万个可作为密码的单词的密码字典,然后攻击者逐个尝试这些密码并进行身份验证,如果字典中包含正确的密码,攻击者将会成功。
在传统的暴力攻击中,攻击者只是尝试字母和数字的组合来顺序生成密码。但是,当密码足够长的时候,这种技术就会需要更长的时间,这些攻击可能需要几分钟到几小时甚至是几年的时间,具体取决于所使用的系统和密码的长度。
为了防止暴力破解密码,应始终使用长而复杂的密码。这会使得攻击者很难猜到密码,暴力攻击会花费更多的时间,大多数时候,WordPress用户面临对其网站的暴力攻击。
帐户锁定是防止攻击者对Web应用程序执行暴力攻击的一种方法。但是,对于离线软件,事情就没这么简单了。
同样,为了发现隐藏页面,攻击者会尝试猜测页面名称,发送请求并查看响应。如果该页面不存在,它将显示响应404,成功的话就会响应200。这样,它可以在任何网站上找到隐藏页面。
暴力攻击也用于破解散列并从给定散列中猜出密码。这样的话,哈希是从随机密码生成的,然后此哈希与目标哈希匹配,直到攻击者找到正确的哈希。因此,用于加密密码的加密类型(64位、128位或256位加密)越高,暴力破解所需的时间就会越长。
二、逆向暴力破解
逆向暴力攻击是另一个与密码破解相关的术语,破解密码采用相反的方法。攻击者针对多个用户名尝试一个密码,想想你是否有知道密码但是不知道用户名的时候,在这种情况下,你可以尝试使用相同的密码去猜测不同的用户名,直到找到匹配组合。
现在,您知道暴力攻击主要用于密码破解,您可以在任何软件,任何网站或任何协议中使用它,只要目标在几次无效尝试后不会组织请求就行。在这篇文章中,我将为不同的协议介绍一些流行的密码破解工具。
三、暴力破解的流行工具
1. Aircrack-NG
我相信大家都曾经了解过Aircrack-ng工具,这是一款免费的无线密码破解工具。该工具附带WEP / WPA / WPA2-PSK破解程序和分析工具,可对WiFi 802.11进行攻击。Aircrack-ng可用于任何支持监听模式的网卡。
它基本上是采用密码字典攻击来猜测无线密码,如您所知,攻击的成功取决于密码字典,密码字典越好越有效。
它适用于Windows和Linux平台,它也被移植到iOS和Android平台上运行,您可以尝试使用给定的平台来研究此工具的工作原理。
2. John the Ripper
开膛手约翰也是一款几乎人人皆知的工具,它长期以来一直是进行暴力攻击的最佳选择。这个免费的密码破解工具最初是为Unix系统开发的,后来,开发人员又为其他平台发布了这款工具。现在它支持15种不同的平台,包括Unix\Windows、DOS、Linux、BeOS和OpenVMS等。您可以使用它来识别弱密码或破解密码来通过身份验证。
这款工具非常受欢迎,并结合了各种密码破解功能,它可以自动检测密码中使用的哈希类型。因此,您也可以针对加密密码存储运行它。
基本上,它可以通过组合字母和数字对所有可能的密码执行暴力破解。但是您也可以将其与密码字典一起使用来执行字典攻击。
3. Rainbow Crack
Rainbow Crack也是一款用于密码破解的流行工具。它会生成彩虹表,以便在执行攻击时使用,这也使得它与其他的暴力破击工具不同。彩虹表是预先计算的,它有助于减少执行攻击的时间。
幸运的是,有各种组织已经为所有互联网用户发布了前计算机的彩虹表,为了节省时间,您可以下载这些彩虹表并在攻击中使用。
该工具仍然在积极开发中,它适用于Windows和Linux,并支持这些平台的所有最新发行版。
4. Cain & Ablel
同样也是一款热门的工具,它可以通过执行暴力攻击、字典攻击和密码分析攻击来帮助破解各种密码。密码分析攻击是通过使用前一种工具中提到的彩虹表来完成的。
值得一提的是,一些病毒查杀软件会将其检测为恶意软件。Avast和Microsoft Security Essentials将其报告为恶意软件并会组织它的运行。如果您需要使用这款软件,您需要先和您的杀毒软件打好招呼。
它的基本功能是:
该工具的最新版本具有很多功能,并添加了嗅探来执行中间人攻击。
5. L0phtcrack
L0phtCrack以破解Windows密码的能力而闻名。它使用字典、暴力破解、混合攻击和彩虹表。L0phtCrack最显著的特性是调度、64位Windows版本的哈希提取、多处理器算法以及网络监控和解码。如果要破解Windows系统的密码,可以尝试使用此工具。
6. Ophcrack
Ophcrack是另一款专门用于破解Windows密码的暴力破解工具。它通过彩虹表使用LM哈希来破解Windows密码。它是一款免费的开源工具,在大多数情况下,它可以在几分钟内破解Windows密码,默认情况下,Ophcrack附带的彩虹表能够破解少于14个字符的密码,其中只包含字母数字字符。其他彩虹表也可供下载。
Ophcrack还可用作LiveCD。
7. Crack
Crack是一款古老的密码破解工具,它是Unix系统的密码破解工具,用于通过执行字典攻击来检查弱密码。
8. Hashcat
Hashcat号称是最快的基于CPU的密码破解工具。它是免费的,适用于Linux、Windows和Mac OS平台。Hashcat支持各种散列算法,包括LM Hashes、MD4、MD5、SHA系列、Unix Crypt格式、MySQL、Cisco PIX。它支持各种攻击形式,包括暴力破解、组合攻击、字典攻击、指纹攻击、混合攻击、掩码攻击、置换攻击、基于规则的攻击、表查找攻击和Toggle-Case攻击。
9. SAMInside
SAMInside同样专门用于破解Windows操作系统的密码,它类似于Ophcrack和Lophtcrack工具。它声称在一台电脑上最高可以每秒破解大约1000万个密码。它支持各种攻击方法,包括掩码攻击、字典攻击、混合攻击和彩虹表攻击。它支持400多种哈希算法。
10.DaveGrohl
DaveGrohl是适用于Mac OS X的流行破解工具,它支持所有可用版本的Mac OS X,此工具支持字典攻击和增量攻击。它还具有分布式模式,允许您从多台计算机执行攻击以攻击相同的密码哈希。此工具现在是开源的,您可以从源码进行安装。
11. Ncrack
Ncrack用于破解网络身份验证,它支持各种协议,包括RDP、SSH、HTTP(S)、SMB、POP3(S)、VNC、FTP和telnet。它可以执行不同的攻击,包括暴力破解等。支持包括Linux、BSD、Windows和Mac OS X等操作系统。
12. THC Hydra
九头蛇以其通过执行暴力攻击来破解网络身份验证的能力而闻名。它可对多种协议执行字典攻击,包括telnet、FTP、HTTP、HTTPS、SMB等。它适用于多种平台,包括Linux、Windows、Cygwin、Solaris、FreeBSD、OpenBSD、OSX和QNX/BlackBerry等。
这些都是用于密码破解的流行工具,还有各种其他工具可用于对不同类型的身份验证执行暴力破解,如果我只举几个小工具的例子,你会看到大多数PDF破解、ZIP破解工具使用相同的暴力破解方法来执行攻击,有许多此类工具可免费或付费使用。
四、结论
暴力破解是破解密码最常用的方法,攻击的成功取决于各种因素,但是,影响最多的因素是密码的长度以及数字、字母和特殊字符的组合。这就是我们谈论强密码的原因:我们通常建议用户使用小写字母、大写字母、数字和特殊字符组合的长密码。它不会使得暴力破解不可能,但会让其变得十分困难。这样,暴力破解会需要更长的时间来破解密码。几乎所有的散列破解算法都使用暴力破解来尝试,当您对数据进行脱机访问时,此攻击最佳。在这种情况下,它易于破解,而且会花费更少的时间。
暴力密码破解在计算机安全性方面非常重要,它用于检查系统、网络或应用程序中使用的弱密码。
防止暴力攻击的最佳方法是限制无效登录,通过这种方式,攻击只能在有限的时间点击并尝试密码。这就是为什么基于网络的服务开始使用验证码,如果您三次输入错误的密码他们会对您的IP地址进行屏蔽。
版权声明:本文为CSDN博主「javaxiaoheibai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
网页抓取解密 真香的PDF软件--PDF24
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-05-03 15:24
一个完全免费的PDF工具箱软件:PDF24,里面包含了20多种关于PDF的操作的免费工具。列如包含了PDF转换、合并、叠加、压缩、比较、编辑、裁剪、注释、加密、解密、分割、旋转、优化、删除、提取、排序页面等等。
豌豆工作室公众号对话框回复:uf,获取资料!
网页版,网址:
该工具分网页版和桌面安装版,网页版社长就不多介绍,就是直接打开网址就可以使用,桌面安装的话我们直接下载好软件安装包,然后直接双击打开,我们发现默认是英文安装界面,不用管这个直接OK,安装好之后软件默认是中文的。
安装完毕有一个英文注册界面,不想注册的用户可以直接点击skip跳过即可。
接下来社长就给大家演示一遍使用方法,以转化为PDF为列:点击选择文件或者直接把需要转化成PDF文件拖拽到软件中即可
然后点击转换为PDF。
然后保存到自己的电脑打开就可以看到已经转换为PDF文件了。
功能实在太多就不过多介绍,这款软件还可以当成PDF文件格式的查看软件。
--------END-------- 查看全部
网页抓取解密 真香的PDF软件--PDF24
一个完全免费的PDF工具箱软件:PDF24,里面包含了20多种关于PDF的操作的免费工具。列如包含了PDF转换、合并、叠加、压缩、比较、编辑、裁剪、注释、加密、解密、分割、旋转、优化、删除、提取、排序页面等等。
豌豆工作室公众号对话框回复:uf,获取资料!
网页版,网址:
该工具分网页版和桌面安装版,网页版社长就不多介绍,就是直接打开网址就可以使用,桌面安装的话我们直接下载好软件安装包,然后直接双击打开,我们发现默认是英文安装界面,不用管这个直接OK,安装好之后软件默认是中文的。
安装完毕有一个英文注册界面,不想注册的用户可以直接点击skip跳过即可。
接下来社长就给大家演示一遍使用方法,以转化为PDF为列:点击选择文件或者直接把需要转化成PDF文件拖拽到软件中即可
然后点击转换为PDF。
然后保存到自己的电脑打开就可以看到已经转换为PDF文件了。
功能实在太多就不过多介绍,这款软件还可以当成PDF文件格式的查看软件。
--------END--------
JS逆向steam登录
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-05-03 09:57
前言
我们爬虫有时候,会遇到登录才能获取到数据的情况,最开始的时候我们只需要加入请求的data参数就可以,可是现在网站为了反爬,对登录的密码或者账号都做了加密处理,如果我们不破解出这些加密的密码或者账号,就没办法实现请求登录,所以我们就需要破解出这些加密后的密码或者账号,才能实现请求登录,这些加密的密码或者账号都是用JavaScript写的,后面我们统一都简称为js。
了解js加密的种类
现在市面上的js加密,大至分为五类,base64加密、sha1加密、MD5加密、AES/DES加密解密、RSA加密,前面两种稍微简单一点,后面的3种就会复杂一点,特别是RSA加密,因为它是一种非对称加密算法,所以加密的稳定性和加密的复杂程度也就会最高,因为steam这个网站的登录就是使用的RSA加密技术,所以本文就只着重讲RSA加密,至于其它4种加密技术,本文不做过多赘述,想了解其他加密技术的小伙伴,可以自行百度搜索了解。
什么是RSA加密
RSA算法是一种非对称加密算法,那么何为非对称加密算法呢?
一般我们理解上的加密是这样子进行的:原文经过了一把钥匙(密钥)加密后变成了密文,然后将密文传递给接收方,接收方再用这把钥匙(密钥)解开密文。在这个过程中,其实加密和解密使用的是同一把钥匙,这种加密方式称为对称加密。如图:
而非对称加密就是和对称加密相对,加密用的钥匙和解密所用的钥匙,并不是同一把钥匙。非对称加密首先会创建两把钥匙,而这两把钥匙是成对的分别称为公钥和私钥。在进行加密时我们使用公钥进行加密,而在解密的时候就必须要使用私钥才能进行解密,这就是非对称加密算法。如图:
实战讲解
登录目标网站,然后点击登录页面,如图:
进入到登录页面,
现在我们打开开发者调试工具,或者按F12打开,定位到Network选项,勾选上Preserve log选项和Disable cache选项,如图:
然后我们在登录窗口,随便输入些账号和密码,点击登录按钮,这个时候Network选项下就会抓取到请求到的数据,
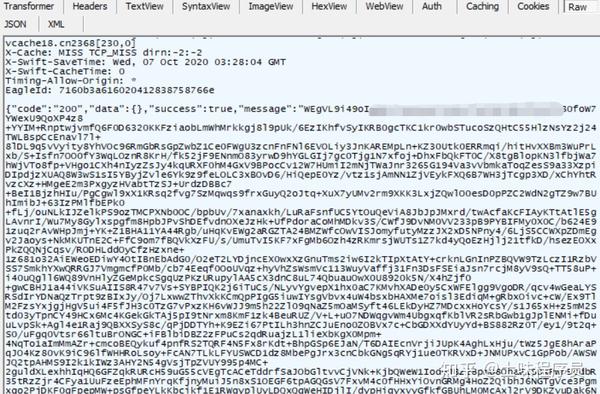
我们先看第一个数据,点击后,定位到preview选项,可以看到给我们返回的一些数据,这其实就是RSA的密钥数据。
我们说过RSA加密是需要公钥和私钥的,这里面的就是我们能需要的解密用到的私钥数据,下面我们能看第二个数据,这个就是我们登录需要请求的数据网址,我们定位带headers选项,可以看请求方式是POST请求,那就必须要有请求参数才行,然后找到from data项,如图:
可以很明显看出,username是我们输入的账号名,password是一堆看不懂的乱码,其实这就是经过RSA加密过的密码数据,我们就需要加密这个密码数据。
我们通过全局搜素,搜索password这个关键字,可以看出有很多包含password这个关键字的数据,那么这么多数据那个才是我们能需要找到的数据呢,
这里有个小技巧,如果发现搜索出来很多关于关键字的信息,可以在该关键字后面给一个=号在搜索,如图:
经过再次的搜索可以看出这次就没有那么多内容了,便于我们更好的找到需要的数据位置,我们通过搜索出的数据可以看出,有一个encryptedpassword这行的数据,从字面的意思就能知道这是加密的密码的意思,所以我们就先定位带这条数据的里面,看看是什么样的,经过定位到里面我们看到是一个用js代码写的文件,里面有很多js代码,
既然我们认为这个就是加密的密码数据,那么我们可以给这行数据下一个断点,然后点击登录,看能不能断下这条数据,通过断点,我们确实可以断下这条数据,那么也就是代表这里就是加密密码的方法,RSA.encrypt是一个函数,里面的参数分别就是,password就是我们输入的密码。
pubkey是一个对象,这个对象具体是什么还需要进入到这个函数里面看具体的情形。
我们按F11进入到这个函数里面,可以看到有一个js的文件,这个文件就是RSA加密的整个过程的文件。
逆向改写
通过上面的分析,我们已经知道了大概密码的加密过程,现在就需要我们通过工具给它的这些代码进行一些改写,从而获取到真正加密的密码数据,这里我用到的改写工具是鬼鬼JS调试工具7.5工具可以自行搜索下载。
navigator = {};var dbits;<br />// JavaScript engine analysisvar canary = 0xdeadbeefcafe;var j_lm = ((canary & 0xffffff) == 0xefcafe);<br />// (public) Constructorfunction BigInteger(a, b, c) { if (a != null) if ("number" == typeof a) this.fromNumber(a, b, c); else if (b == null && "string" != typeof a) this.fromString(a, 256); else this.fromString(a, b);}<br />// return new, unset BigIntegerfunction nbi() { return new BigInteger(null);}<br />// am: Compute w_j += (x*this_i), propagate carries,// c is initial carry, returns final carry.// c < 3*dvalue, x < 2*dvalue, this_i < dvalue// We need to select the fastest one that works in this environment.<br />// am1: use a single mult and divide to get the high bits,// max digit bits should be 26 because// max internal value = 2*dvalue^2-2*dvalue (< 2^53)function am1(i, x, w, j, c, n) { while (--n >= 0) { var v = x * this[i++] + w[j] + c; c = Math.floor(v / 0x4000000); w[j++] = v & 0x3ffffff; } return c;}// am2 avoids a big mult-and-extract completely.// Max digit bits should be > 15; while (--n >= 0) { var l = this[i] & 0x7fff; var h = this[i++] >> 15; var m = xh * l + h * xl; l = xl * l + ((m & 0x7fff) >> 30) + (m >>> 15) + xh * h + (c >>> 30); w[j++] = l & 0x3fffffff; } return c;}// Alternately, set max digit bits to 28 since some// browsers slow down when dealing with 32-bit numbers.function am3(i, x, w, j, c, n) { var xl = x & 0x3fff, xh = x >> 14; while (--n >= 0) { var l = this[i] & 0x3fff; var h = this[i++] >> 14; var m = xh * l + h * xl; l = xl * l + ((m & 0x3fff) > 28) + (m >> 14) + xh * h; w[j++] = l & 0xfffffff; } return c;}<br /><br />// Digit conversionsvar BI_RM = "0123456789abcdefghijklmnopqrstuvwxyz";var BI_RC = new Array();var rr, vv;rr = "0".charCodeAt(0);for (vv = 0; vv a, - if this < a, 0 if equalfunction bnCompareTo(a) { var r = this.s - a.s; if (r != 0) return r; var i = this.t; r = i - a.t; if (r != 0) return r; while (--i >= 0) if ((r = this[i] - a[i]) != 0) return r; return 0;}<br />// returns bit length of the integer xfunction nbits(x) { var r = 1, t; if ((t = x >>> 16) != 0) { x = t; r += 16; } if ((t = x >> 8) != 0) { x = t; r += 8; } if ((t = x >> 4) != 0) { x = t; r += 4; } if ((t = x >> 2) != 0) { x = t; r += 2; } if ((t = x >> 1) != 0) { x = t; r += 1; } return r;}<br />// (public) return the number of bits in "this"function bnBitLength() { if (this.t = 0; --i) r[i] = 0; r.t = this.t + n; r.s = this.s;}<br />// (protected) r = this >> n*DBfunction bnpDRShiftTo(n, r) { for (var i = n; i < this.t; ++i) r[i - n] = this[i]; r.t = Math.max(this.t - n, 0); r.s = this.s;}<br />// (protected) r = this cbs) | c; c = (this[i] & bm) = 0; --i) r[i] = 0; r[ds] = c; r.t = this.t + ds + 1; r.s = this.s; r.clamp();}<br />// (protected) r = this >> nfunction bnpRShiftTo(n, r) { r.s = this.s; var ds = Math.floor(n / this.DB); if (ds >= this.t) { r.t = 0; return; } var bs = n % this.DB; var cbs = this.DB - bs; var bm = (1 > bs; for (var i = ds + 1; i < this.t; ++i) { r[i - ds - 1] |= (this[i] & bm) > bs; } if (bs > 0) r[this.t - ds - 1] |= (this.s & bm) >= this.DB; } if (a.t < this.t) { c -= a.s; while (i < this.t) { c += this[i]; r[i++] = c & this.DM; c >>= this.DB; } c += this.s; } else { c += this.s; while (i < a.t) { c -= a[i]; r[i++] = c & this.DM; c >>= this.DB; } c -= a.s; } r.s = (c < 0) ? -1 : 0; if (c < -1) r[i++] = this.DV + c; else if (c > 0) r[i++] = c; r.t = i; r.clamp();}<br />// (protected) r = this * a, r != this,a (HAC 14.12)// "this" should be the larger one if appropriate.function bnpMultiplyTo(a, r) { var x = this.abs(), y = a.abs(); var i = x.t; r.t = i + y.t; while (--i >= 0) r[i] = 0; for (i = 0; i < y.t; ++i) r[i + x.t] = x.am(0, y[i], r, i, 0, x.t); r.s = 0; r.clamp(); if (this.s != a.s) BigInteger.ZERO.subTo(r, r);}<br />// (protected) r = this^2, r != this (HAC 14.16)function bnpSquareTo(r) { var x = this.abs(); var i = r.t = 2 * x.t; while (--i >= 0) r[i] = 0; for (i = 0; i < x.t - 1; ++i) { var c = x.am(i, x[i], r, 2 * i, 0, 1); if ((r[i + x.t] += x.am(i + 1, 2 * x[i], r, 2 * i + 1, c, x.t - i - 1)) >= x.DV) { r[i + x.t] -= x.DV; r[i + x.t + 1] = 1; } } if (r.t > 0) r[r.t - 1] += x.am(i, x[i], r, 2 * i, 0, 1); r.s = 0; r.clamp();}<br />// (protected) divide this by m, quotient and remainder to q, r (HAC 14.20)// r != q, this != m. q or r may be null.function bnpDivRemTo(m, q, r) { var pm = m.abs(); if (pm.t 0) { pm.lShiftTo(nsh, y); pt.lShiftTo(nsh, r); } else { pm.copyTo(y); pt.copyTo(r); } var ys = y.t; var y0 = y[ys - 1]; if (y0 == 0) return; var yt = y0 * (1 1) ? y[ys - 2] >> this.F2 : 0); var d1 = this.FV / yt, d2 = (1 = 0) { // Estimate quotient digit var qd = (r[--i] == y0) ? this.DM : Math.floor(r[i] * d1 + (r[i - 1] + e) * d2); if ((r[i] += y.am(0, qd, r, j, 0, ys)) < qd) { // Try it out y.dlShiftTo(j, t); r.subTo(t, r); while (r[i] < --qd) r.subTo(t, r); } } if (q != null) { r.drShiftTo(ys, q); if (ts != ms) BigInteger.ZERO.subTo(q, q); } r.t = ys; r.clamp(); if (nsh > 0) r.rShiftTo(nsh, r); // Denormalize remainder if (ts < 0) BigInteger.ZERO.subTo(r, r);}<br />// (public) this mod afunction bnMod(a) { var r = nbi(); this.abs().divRemTo(a, null, r); if (this.s < 0 && r.compareTo(BigInteger.ZERO) > 0) a.subTo(r, r); return r;}<br />// Modular reduction using "classic" algorithmfunction Classic(m) { this.m = m;}<br />function cConvert(x) { if (x.s < 0 || x.compareTo(this.m) >= 0) return x.mod(this.m); else return x;}<br />function cRevert(x) { return x;}<br />function cReduce(x) { x.divRemTo(this.m, null, x);}<br />function cMulTo(x, y, r) { x.multiplyTo(y, r); this.reduce(r);}<br />function cSqrTo(x, r) { x.squareTo(r); this.reduce(r);}<br />Classic.prototype.convert = cConvert;Classic.prototype.revert = cRevert;Classic.prototype.reduce = cReduce;Classic.prototype.mulTo = cMulTo;Classic.prototype.sqrTo = cSqrTo;<br />// (protected) return "-1/this % 2^DB"; useful for Mont. reduction// justification:// xy == 1 (mod m)// xy = 1+km// xy(2-xy) = (1+km)(1-km)// x[y(2-xy)] = 1-k^2m^2// x[y(2-xy)] == 1 (mod m^2)// if y is 1/x mod m, then y(2-xy) is 1/x mod m^2// should reduce x and y(2-xy) by m^2 at each step to keep size bounded.// JS multiply "overflows" differently from C/C++, so care is needed here.function bnpInvDigit() { if (this.t < 1) return 0; var x = this[0]; if ((x & 1) == 0) return 0; var y = x & 3; // y == 1/x mod 2^2 y = (y * (2 - (x & 0xf) * y)) & 0xf; // y == 1/x mod 2^4 y = (y * (2 - (x & 0xff) * y)) & 0xff; // y == 1/x mod 2^8 y = (y * (2 - (((x & 0xffff) * y) & 0xffff))) & 0xffff; // y == 1/x mod 2^16 // last step - calculate inverse mod DV directly; // assumes 16 < DB 0) ? this.DV - y : -y;}<br />// Montgomery reductionfunction Montgomery(m) { this.m = m; this.mp = m.invDigit(); this.mpl = this.mp & 0x7fff; this.mph = this.mp >> 15; this.um = (1 0) this.m.subTo(r, r); return r;}<br />// x/R mod mfunction montRevert(x) { var r = nbi(); x.copyTo(r); this.reduce(r); return r;}<br />// x = x/R mod m (HAC 14.32)function montReduce(x) { while (x.t > 15) * this.mpl) & this.um) = x.DV) { x[j] -= x.DV; x[++j]++; } } x.clamp(); x.drShiftTo(this.m.t, x); if (x.compareTo(this.m) >= 0) x.subTo(this.m, x);}<br />// r = "x^2/R mod m"; x != rfunction montSqrTo(x, r) { x.squareTo(r); this.reduce(r);}<br />// r = "xy/R mod m"; x,y != rfunction montMulTo(x, y, r) { x.multiplyTo(y, r); this.reduce(r);}<br />Montgomery.prototype.convert = montConvert;Montgomery.prototype.revert = montRevert;Montgomery.prototype.reduce = montReduce;Montgomery.prototype.mulTo = montMulTo;Montgomery.prototype.sqrTo = montSqrTo;<br />// (protected) true iff this is evenfunction bnpIsEven() { return ((this.t > 0) ? (this[0] & 1) : this.s) == 0;}<br />// (protected) this^e, e < 2^32, doing sqr and mul with "r" (HAC 14.79)function bnpExp(e, z) { if (e > 0xffffffff || e < 1) return BigInteger.ONE; var r = nbi(), r2 = nbi(), g = z.convert(this), i = nbits(e) - 1; g.copyTo(r); while (--i >= 0) { z.sqrTo(r, r2); if ((e & (1 0) z.mulTo(r2, g, r); else { var t = r; r = r2; r2 = t; } } return z.revert(r);}<br />// (public) this^e % m, 0 1; if (t > lowprimes.length) t = lowprimes.length; var a = nbi(); for (var i = 0; i < t; ++i) { a.fromInt(lowprimes[i]); var y = a.modPow(r, this); if (y.compareTo(BigInteger.ONE) != 0 && y.compareTo(n1) != 0) { var j = 1; while (j++ < k && y.compareTo(n1) != 0) { y = y.modPowInt(2, this); if (y.compareTo(BigInteger.ONE) == 0) return false; } if (y.compareTo(n1) != 0) return false; } } return true;}<br />// protectedBigInteger.prototype.chunkSize = bnpChunkSize;BigInteger.prototype.toRadix = bnpToRadix;BigInteger.prototype.fromRadix = bnpFromRadix;BigInteger.prototype.fromNumber = bnpFromNumber;BigInteger.prototype.bitwiseTo = bnpBitwiseTo;BigInteger.prototype.changeBit = bnpChangeBit;BigInteger.prototype.addTo = bnpAddTo;BigInteger.prototype.dMultiply = bnpDMultiply;BigInteger.prototype.dAddOffset = bnpDAddOffset;BigInteger.prototype.multiplyLowerTo = bnpMultiplyLowerTo;BigInteger.prototype.multiplyUpperTo = bnpMultiplyUpperTo;BigInteger.prototype.modInt = bnpModInt;BigInteger.prototype.millerRabin = bnpMillerRabin;<br />// publicBigInteger.prototype.clone = bnClone;BigInteger.prototype.intValue = bnIntValue;BigInteger.prototype.byteValue = bnByteValue;BigInteger.prototype.shortValue = bnShortValue;BigInteger.prototype.signum = bnSigNum;BigInteger.prototype.toByteArray = bnToByteArray;BigInteger.prototype.equals = bnEquals;BigInteger.prototype.min = bnMin;BigInteger.prototype.max = bnMax;BigInteger.prototype.and = bnAnd;BigInteger.prototype.or = bnOr;BigInteger.prototype.xor = bnXor;BigInteger.prototype.andNot = bnAndNot;BigInteger.prototype.not = bnNot;BigInteger.prototype.shiftLeft = bnShiftLeft;BigInteger.prototype.shiftRight = bnShiftRight;BigInteger.prototype.getLowestSetBit = bnGetLowestSetBit;BigInteger.prototype.bitCount = bnBitCount;BigInteger.prototype.testBit = bnTestBit;BigInteger.prototype.setBit = bnSetBit;BigInteger.prototype.clearBit = bnClearBit;BigInteger.prototype.flipBit = bnFlipBit;BigInteger.prototype.add = bnAdd;BigInteger.prototype.subtract = bnSubtract;BigInteger.prototype.multiply = bnMultiply;BigInteger.prototype.divide = bnDivide;BigInteger.prototype.remainder = bnRemainder;BigInteger.prototype.divideAndRemainder = bnDivideAndRemainder;BigInteger.prototype.modPow = bnModPow;BigInteger.prototype.modInverse = bnModInverse;BigInteger.prototype.pow = bnPow;BigInteger.prototype.gcd = bnGCD;BigInteger.prototype.isProbablePrime = bnIsProbablePrime;<br />// BigInteger interfaces not implemented in jsbn:<br />// BigInteger(int signum, byte[] magnitude)// double doubleValue()// float floatValue()// int hashCode()// long longValue()// static BigInteger valueOf(long val)<br /><br /><br />var RSAPublicKey = function($modulus_hex, $encryptionExponent_hex) { this.modulus = new BigInteger($modulus_hex, 16); this.encryptionExponent = new BigInteger($encryptionExponent_hex, 16);};<br />var Base64 = { base64: "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=", encode: function($input) { if (!$input) { return false; } var $output = ""; var $chr1, $chr2, $chr3; var $enc1, $enc2, $enc3, $enc4; var $i = 0; do { $chr1 = $input.charCodeAt($i++); $chr2 = $input.charCodeAt($i++); $chr3 = $input.charCodeAt($i++); $enc1 = $chr1 >> 2; $enc2 = (($chr1 & 3) > 4); $enc3 = (($chr2 & 15) > 6); $enc4 = $chr3 & 63; if (isNaN($chr2)) $enc3 = $enc4 = 64; else if (isNaN($chr3)) $enc4 = 64; $output += this.base64.charAt($enc1) + this.base64.charAt($enc2) + this.base64.charAt($enc3) + this.base64.charAt($enc4); } while ($i < $input.length); return $output; }, decode: function($input) { if (!$input) return false; $input = $input.replace(/[^A-Za-z0-9\+\/\=]/g, ""); var $output = ""; var $enc1, $enc2, $enc3, $enc4; var $i = 0; do { $enc1 = this.base64.indexOf($input.charAt($i++)); $enc2 = this.base64.indexOf($input.charAt($i++)); $enc3 = this.base64.indexOf($input.charAt($i++)); $enc4 = this.base64.indexOf($input.charAt($i++)); $output += String.fromCharCode(($enc1 > 4)); if ($enc3 != 64) $output += String.fromCharCode((($enc2 & 15) > 2)); if ($enc4 != 64) $output += String.fromCharCode((($enc3 & 3) > 4) & 0xf) + this.hex.charAt($k & 0xf); } while ($i < $input.length); return $output; }, decode: function($input) { if (!$input) return false; $input = $input.replace(/[^0-9abcdef]/g, ""); var $output = ""; var $i = 0; do { $output += String.fromCharCode(((this.hex.indexOf($input.charAt($i++)) > 3); if (!$data) return false; $data = $data.modPowInt($pubkey.encryptionExponent, $pubkey.modulus); if (!$data) return false; $data = $data.toString(16); if (($data.length & 1) == 1) $data = "0" + $data; return Base64.encode(Hex.decode($data)); },<br /> pkcs1pad2: function($data, $keysize) { if ($keysize < $data.length + 11) return null; var $buffer = []; var $i = $data.length - 1; while ($i >= 0 && $keysize > 0) $buffer[--$keysize] = $data.charCodeAt($i--); $buffer[--$keysize] = 0; while ($keysize > 2) $buffer[--$keysize] = Math.floor(Math.random() * 254) + 1; $buffer[--$keysize] = 2; $buffer[--$keysize] = 0; return new BigInteger($buffer); }}<br /> function get_pwd(pwd,mod, exp) { var pubKey = RSA.getPublicKey(mod, exp); password = pwd.replace(/[^\x00-\x7F]/g, ''); var encryptedPassword = RSA.encrypt(password, pubKey); return encryptedPassword; }
通过自定义一个get_pwd的函数,来调用上面加密的整个过程,函数上面的部分,就是加密的整个过程的代码,这些代码也不是我写的,是别人写好的,我只是复制粘贴过来,改动一下,利用自己定义的函数,调用了这些代码,从而实现加密的目的。该函数需要传递2个参数,这个2个参数分别是未加密前的密码和私钥,私钥就在我们请求网页的时候,返回的第一个数据里面(publickey_exp和publickey_mod)。
mod就是publickey_mod,exp就是publickey_exp,通过传递参数,在调用定义的get_pwd这个函数,就能得到加密的密码结果了,加密后的密码也是动态的,每次都不一样。
效果展示
结语
因为本文涉及很多JavaScript的知识,所以需要对JavaScript有些了解,另外在改写JS代码的时候,会遇到很多的错误提示,限于篇幅的有限,我没有过多的写出如何排除这些错误提示,我们就需要利用一些JavaScript的知识一点点的排除这些错误提示,直到提示加载成功,才可以运行代码的,所以还是推荐用js的调试工具,这样更方便一些。头一次写这样的技术文章,有很多写的不到位的地方,还请多多提出宝贵意见。
END
B站账号:
https://space.bilibili.com/351138764
欢迎扫码
关注我 查看全部
JS逆向steam登录
前言
我们爬虫有时候,会遇到登录才能获取到数据的情况,最开始的时候我们只需要加入请求的data参数就可以,可是现在网站为了反爬,对登录的密码或者账号都做了加密处理,如果我们不破解出这些加密的密码或者账号,就没办法实现请求登录,所以我们就需要破解出这些加密后的密码或者账号,才能实现请求登录,这些加密的密码或者账号都是用JavaScript写的,后面我们统一都简称为js。
了解js加密的种类
现在市面上的js加密,大至分为五类,base64加密、sha1加密、MD5加密、AES/DES加密解密、RSA加密,前面两种稍微简单一点,后面的3种就会复杂一点,特别是RSA加密,因为它是一种非对称加密算法,所以加密的稳定性和加密的复杂程度也就会最高,因为steam这个网站的登录就是使用的RSA加密技术,所以本文就只着重讲RSA加密,至于其它4种加密技术,本文不做过多赘述,想了解其他加密技术的小伙伴,可以自行百度搜索了解。
什么是RSA加密
RSA算法是一种非对称加密算法,那么何为非对称加密算法呢?
一般我们理解上的加密是这样子进行的:原文经过了一把钥匙(密钥)加密后变成了密文,然后将密文传递给接收方,接收方再用这把钥匙(密钥)解开密文。在这个过程中,其实加密和解密使用的是同一把钥匙,这种加密方式称为对称加密。如图:
而非对称加密就是和对称加密相对,加密用的钥匙和解密所用的钥匙,并不是同一把钥匙。非对称加密首先会创建两把钥匙,而这两把钥匙是成对的分别称为公钥和私钥。在进行加密时我们使用公钥进行加密,而在解密的时候就必须要使用私钥才能进行解密,这就是非对称加密算法。如图:
实战讲解
登录目标网站,然后点击登录页面,如图:
进入到登录页面,
现在我们打开开发者调试工具,或者按F12打开,定位到Network选项,勾选上Preserve log选项和Disable cache选项,如图:
然后我们在登录窗口,随便输入些账号和密码,点击登录按钮,这个时候Network选项下就会抓取到请求到的数据,
我们先看第一个数据,点击后,定位到preview选项,可以看到给我们返回的一些数据,这其实就是RSA的密钥数据。
我们说过RSA加密是需要公钥和私钥的,这里面的就是我们能需要的解密用到的私钥数据,下面我们能看第二个数据,这个就是我们登录需要请求的数据网址,我们定位带headers选项,可以看请求方式是POST请求,那就必须要有请求参数才行,然后找到from data项,如图:
可以很明显看出,username是我们输入的账号名,password是一堆看不懂的乱码,其实这就是经过RSA加密过的密码数据,我们就需要加密这个密码数据。
我们通过全局搜素,搜索password这个关键字,可以看出有很多包含password这个关键字的数据,那么这么多数据那个才是我们能需要找到的数据呢,
这里有个小技巧,如果发现搜索出来很多关于关键字的信息,可以在该关键字后面给一个=号在搜索,如图:
经过再次的搜索可以看出这次就没有那么多内容了,便于我们更好的找到需要的数据位置,我们通过搜索出的数据可以看出,有一个encryptedpassword这行的数据,从字面的意思就能知道这是加密的密码的意思,所以我们就先定位带这条数据的里面,看看是什么样的,经过定位到里面我们看到是一个用js代码写的文件,里面有很多js代码,
既然我们认为这个就是加密的密码数据,那么我们可以给这行数据下一个断点,然后点击登录,看能不能断下这条数据,通过断点,我们确实可以断下这条数据,那么也就是代表这里就是加密密码的方法,RSA.encrypt是一个函数,里面的参数分别就是,password就是我们输入的密码。
pubkey是一个对象,这个对象具体是什么还需要进入到这个函数里面看具体的情形。
我们按F11进入到这个函数里面,可以看到有一个js的文件,这个文件就是RSA加密的整个过程的文件。
逆向改写
通过上面的分析,我们已经知道了大概密码的加密过程,现在就需要我们通过工具给它的这些代码进行一些改写,从而获取到真正加密的密码数据,这里我用到的改写工具是鬼鬼JS调试工具7.5工具可以自行搜索下载。
navigator = {};var dbits;<br />// JavaScript engine analysisvar canary = 0xdeadbeefcafe;var j_lm = ((canary & 0xffffff) == 0xefcafe);<br />// (public) Constructorfunction BigInteger(a, b, c) { if (a != null) if ("number" == typeof a) this.fromNumber(a, b, c); else if (b == null && "string" != typeof a) this.fromString(a, 256); else this.fromString(a, b);}<br />// return new, unset BigIntegerfunction nbi() { return new BigInteger(null);}<br />// am: Compute w_j += (x*this_i), propagate carries,// c is initial carry, returns final carry.// c < 3*dvalue, x < 2*dvalue, this_i < dvalue// We need to select the fastest one that works in this environment.<br />// am1: use a single mult and divide to get the high bits,// max digit bits should be 26 because// max internal value = 2*dvalue^2-2*dvalue (< 2^53)function am1(i, x, w, j, c, n) { while (--n >= 0) { var v = x * this[i++] + w[j] + c; c = Math.floor(v / 0x4000000); w[j++] = v & 0x3ffffff; } return c;}// am2 avoids a big mult-and-extract completely.// Max digit bits should be > 15; while (--n >= 0) { var l = this[i] & 0x7fff; var h = this[i++] >> 15; var m = xh * l + h * xl; l = xl * l + ((m & 0x7fff) >> 30) + (m >>> 15) + xh * h + (c >>> 30); w[j++] = l & 0x3fffffff; } return c;}// Alternately, set max digit bits to 28 since some// browsers slow down when dealing with 32-bit numbers.function am3(i, x, w, j, c, n) { var xl = x & 0x3fff, xh = x >> 14; while (--n >= 0) { var l = this[i] & 0x3fff; var h = this[i++] >> 14; var m = xh * l + h * xl; l = xl * l + ((m & 0x3fff) > 28) + (m >> 14) + xh * h; w[j++] = l & 0xfffffff; } return c;}<br /><br />// Digit conversionsvar BI_RM = "0123456789abcdefghijklmnopqrstuvwxyz";var BI_RC = new Array();var rr, vv;rr = "0".charCodeAt(0);for (vv = 0; vv a, - if this < a, 0 if equalfunction bnCompareTo(a) { var r = this.s - a.s; if (r != 0) return r; var i = this.t; r = i - a.t; if (r != 0) return r; while (--i >= 0) if ((r = this[i] - a[i]) != 0) return r; return 0;}<br />// returns bit length of the integer xfunction nbits(x) { var r = 1, t; if ((t = x >>> 16) != 0) { x = t; r += 16; } if ((t = x >> 8) != 0) { x = t; r += 8; } if ((t = x >> 4) != 0) { x = t; r += 4; } if ((t = x >> 2) != 0) { x = t; r += 2; } if ((t = x >> 1) != 0) { x = t; r += 1; } return r;}<br />// (public) return the number of bits in "this"function bnBitLength() { if (this.t = 0; --i) r[i] = 0; r.t = this.t + n; r.s = this.s;}<br />// (protected) r = this >> n*DBfunction bnpDRShiftTo(n, r) { for (var i = n; i < this.t; ++i) r[i - n] = this[i]; r.t = Math.max(this.t - n, 0); r.s = this.s;}<br />// (protected) r = this cbs) | c; c = (this[i] & bm) = 0; --i) r[i] = 0; r[ds] = c; r.t = this.t + ds + 1; r.s = this.s; r.clamp();}<br />// (protected) r = this >> nfunction bnpRShiftTo(n, r) { r.s = this.s; var ds = Math.floor(n / this.DB); if (ds >= this.t) { r.t = 0; return; } var bs = n % this.DB; var cbs = this.DB - bs; var bm = (1 > bs; for (var i = ds + 1; i < this.t; ++i) { r[i - ds - 1] |= (this[i] & bm) > bs; } if (bs > 0) r[this.t - ds - 1] |= (this.s & bm) >= this.DB; } if (a.t < this.t) { c -= a.s; while (i < this.t) { c += this[i]; r[i++] = c & this.DM; c >>= this.DB; } c += this.s; } else { c += this.s; while (i < a.t) { c -= a[i]; r[i++] = c & this.DM; c >>= this.DB; } c -= a.s; } r.s = (c < 0) ? -1 : 0; if (c < -1) r[i++] = this.DV + c; else if (c > 0) r[i++] = c; r.t = i; r.clamp();}<br />// (protected) r = this * a, r != this,a (HAC 14.12)// "this" should be the larger one if appropriate.function bnpMultiplyTo(a, r) { var x = this.abs(), y = a.abs(); var i = x.t; r.t = i + y.t; while (--i >= 0) r[i] = 0; for (i = 0; i < y.t; ++i) r[i + x.t] = x.am(0, y[i], r, i, 0, x.t); r.s = 0; r.clamp(); if (this.s != a.s) BigInteger.ZERO.subTo(r, r);}<br />// (protected) r = this^2, r != this (HAC 14.16)function bnpSquareTo(r) { var x = this.abs(); var i = r.t = 2 * x.t; while (--i >= 0) r[i] = 0; for (i = 0; i < x.t - 1; ++i) { var c = x.am(i, x[i], r, 2 * i, 0, 1); if ((r[i + x.t] += x.am(i + 1, 2 * x[i], r, 2 * i + 1, c, x.t - i - 1)) >= x.DV) { r[i + x.t] -= x.DV; r[i + x.t + 1] = 1; } } if (r.t > 0) r[r.t - 1] += x.am(i, x[i], r, 2 * i, 0, 1); r.s = 0; r.clamp();}<br />// (protected) divide this by m, quotient and remainder to q, r (HAC 14.20)// r != q, this != m. q or r may be null.function bnpDivRemTo(m, q, r) { var pm = m.abs(); if (pm.t 0) { pm.lShiftTo(nsh, y); pt.lShiftTo(nsh, r); } else { pm.copyTo(y); pt.copyTo(r); } var ys = y.t; var y0 = y[ys - 1]; if (y0 == 0) return; var yt = y0 * (1 1) ? y[ys - 2] >> this.F2 : 0); var d1 = this.FV / yt, d2 = (1 = 0) { // Estimate quotient digit var qd = (r[--i] == y0) ? this.DM : Math.floor(r[i] * d1 + (r[i - 1] + e) * d2); if ((r[i] += y.am(0, qd, r, j, 0, ys)) < qd) { // Try it out y.dlShiftTo(j, t); r.subTo(t, r); while (r[i] < --qd) r.subTo(t, r); } } if (q != null) { r.drShiftTo(ys, q); if (ts != ms) BigInteger.ZERO.subTo(q, q); } r.t = ys; r.clamp(); if (nsh > 0) r.rShiftTo(nsh, r); // Denormalize remainder if (ts < 0) BigInteger.ZERO.subTo(r, r);}<br />// (public) this mod afunction bnMod(a) { var r = nbi(); this.abs().divRemTo(a, null, r); if (this.s < 0 && r.compareTo(BigInteger.ZERO) > 0) a.subTo(r, r); return r;}<br />// Modular reduction using "classic" algorithmfunction Classic(m) { this.m = m;}<br />function cConvert(x) { if (x.s < 0 || x.compareTo(this.m) >= 0) return x.mod(this.m); else return x;}<br />function cRevert(x) { return x;}<br />function cReduce(x) { x.divRemTo(this.m, null, x);}<br />function cMulTo(x, y, r) { x.multiplyTo(y, r); this.reduce(r);}<br />function cSqrTo(x, r) { x.squareTo(r); this.reduce(r);}<br />Classic.prototype.convert = cConvert;Classic.prototype.revert = cRevert;Classic.prototype.reduce = cReduce;Classic.prototype.mulTo = cMulTo;Classic.prototype.sqrTo = cSqrTo;<br />// (protected) return "-1/this % 2^DB"; useful for Mont. reduction// justification:// xy == 1 (mod m)// xy = 1+km// xy(2-xy) = (1+km)(1-km)// x[y(2-xy)] = 1-k^2m^2// x[y(2-xy)] == 1 (mod m^2)// if y is 1/x mod m, then y(2-xy) is 1/x mod m^2// should reduce x and y(2-xy) by m^2 at each step to keep size bounded.// JS multiply "overflows" differently from C/C++, so care is needed here.function bnpInvDigit() { if (this.t < 1) return 0; var x = this[0]; if ((x & 1) == 0) return 0; var y = x & 3; // y == 1/x mod 2^2 y = (y * (2 - (x & 0xf) * y)) & 0xf; // y == 1/x mod 2^4 y = (y * (2 - (x & 0xff) * y)) & 0xff; // y == 1/x mod 2^8 y = (y * (2 - (((x & 0xffff) * y) & 0xffff))) & 0xffff; // y == 1/x mod 2^16 // last step - calculate inverse mod DV directly; // assumes 16 < DB 0) ? this.DV - y : -y;}<br />// Montgomery reductionfunction Montgomery(m) { this.m = m; this.mp = m.invDigit(); this.mpl = this.mp & 0x7fff; this.mph = this.mp >> 15; this.um = (1 0) this.m.subTo(r, r); return r;}<br />// x/R mod mfunction montRevert(x) { var r = nbi(); x.copyTo(r); this.reduce(r); return r;}<br />// x = x/R mod m (HAC 14.32)function montReduce(x) { while (x.t > 15) * this.mpl) & this.um) = x.DV) { x[j] -= x.DV; x[++j]++; } } x.clamp(); x.drShiftTo(this.m.t, x); if (x.compareTo(this.m) >= 0) x.subTo(this.m, x);}<br />// r = "x^2/R mod m"; x != rfunction montSqrTo(x, r) { x.squareTo(r); this.reduce(r);}<br />// r = "xy/R mod m"; x,y != rfunction montMulTo(x, y, r) { x.multiplyTo(y, r); this.reduce(r);}<br />Montgomery.prototype.convert = montConvert;Montgomery.prototype.revert = montRevert;Montgomery.prototype.reduce = montReduce;Montgomery.prototype.mulTo = montMulTo;Montgomery.prototype.sqrTo = montSqrTo;<br />// (protected) true iff this is evenfunction bnpIsEven() { return ((this.t > 0) ? (this[0] & 1) : this.s) == 0;}<br />// (protected) this^e, e < 2^32, doing sqr and mul with "r" (HAC 14.79)function bnpExp(e, z) { if (e > 0xffffffff || e < 1) return BigInteger.ONE; var r = nbi(), r2 = nbi(), g = z.convert(this), i = nbits(e) - 1; g.copyTo(r); while (--i >= 0) { z.sqrTo(r, r2); if ((e & (1 0) z.mulTo(r2, g, r); else { var t = r; r = r2; r2 = t; } } return z.revert(r);}<br />// (public) this^e % m, 0 1; if (t > lowprimes.length) t = lowprimes.length; var a = nbi(); for (var i = 0; i < t; ++i) { a.fromInt(lowprimes[i]); var y = a.modPow(r, this); if (y.compareTo(BigInteger.ONE) != 0 && y.compareTo(n1) != 0) { var j = 1; while (j++ < k && y.compareTo(n1) != 0) { y = y.modPowInt(2, this); if (y.compareTo(BigInteger.ONE) == 0) return false; } if (y.compareTo(n1) != 0) return false; } } return true;}<br />// protectedBigInteger.prototype.chunkSize = bnpChunkSize;BigInteger.prototype.toRadix = bnpToRadix;BigInteger.prototype.fromRadix = bnpFromRadix;BigInteger.prototype.fromNumber = bnpFromNumber;BigInteger.prototype.bitwiseTo = bnpBitwiseTo;BigInteger.prototype.changeBit = bnpChangeBit;BigInteger.prototype.addTo = bnpAddTo;BigInteger.prototype.dMultiply = bnpDMultiply;BigInteger.prototype.dAddOffset = bnpDAddOffset;BigInteger.prototype.multiplyLowerTo = bnpMultiplyLowerTo;BigInteger.prototype.multiplyUpperTo = bnpMultiplyUpperTo;BigInteger.prototype.modInt = bnpModInt;BigInteger.prototype.millerRabin = bnpMillerRabin;<br />// publicBigInteger.prototype.clone = bnClone;BigInteger.prototype.intValue = bnIntValue;BigInteger.prototype.byteValue = bnByteValue;BigInteger.prototype.shortValue = bnShortValue;BigInteger.prototype.signum = bnSigNum;BigInteger.prototype.toByteArray = bnToByteArray;BigInteger.prototype.equals = bnEquals;BigInteger.prototype.min = bnMin;BigInteger.prototype.max = bnMax;BigInteger.prototype.and = bnAnd;BigInteger.prototype.or = bnOr;BigInteger.prototype.xor = bnXor;BigInteger.prototype.andNot = bnAndNot;BigInteger.prototype.not = bnNot;BigInteger.prototype.shiftLeft = bnShiftLeft;BigInteger.prototype.shiftRight = bnShiftRight;BigInteger.prototype.getLowestSetBit = bnGetLowestSetBit;BigInteger.prototype.bitCount = bnBitCount;BigInteger.prototype.testBit = bnTestBit;BigInteger.prototype.setBit = bnSetBit;BigInteger.prototype.clearBit = bnClearBit;BigInteger.prototype.flipBit = bnFlipBit;BigInteger.prototype.add = bnAdd;BigInteger.prototype.subtract = bnSubtract;BigInteger.prototype.multiply = bnMultiply;BigInteger.prototype.divide = bnDivide;BigInteger.prototype.remainder = bnRemainder;BigInteger.prototype.divideAndRemainder = bnDivideAndRemainder;BigInteger.prototype.modPow = bnModPow;BigInteger.prototype.modInverse = bnModInverse;BigInteger.prototype.pow = bnPow;BigInteger.prototype.gcd = bnGCD;BigInteger.prototype.isProbablePrime = bnIsProbablePrime;<br />// BigInteger interfaces not implemented in jsbn:<br />// BigInteger(int signum, byte[] magnitude)// double doubleValue()// float floatValue()// int hashCode()// long longValue()// static BigInteger valueOf(long val)<br /><br /><br />var RSAPublicKey = function($modulus_hex, $encryptionExponent_hex) { this.modulus = new BigInteger($modulus_hex, 16); this.encryptionExponent = new BigInteger($encryptionExponent_hex, 16);};<br />var Base64 = { base64: "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=", encode: function($input) { if (!$input) { return false; } var $output = ""; var $chr1, $chr2, $chr3; var $enc1, $enc2, $enc3, $enc4; var $i = 0; do { $chr1 = $input.charCodeAt($i++); $chr2 = $input.charCodeAt($i++); $chr3 = $input.charCodeAt($i++); $enc1 = $chr1 >> 2; $enc2 = (($chr1 & 3) > 4); $enc3 = (($chr2 & 15) > 6); $enc4 = $chr3 & 63; if (isNaN($chr2)) $enc3 = $enc4 = 64; else if (isNaN($chr3)) $enc4 = 64; $output += this.base64.charAt($enc1) + this.base64.charAt($enc2) + this.base64.charAt($enc3) + this.base64.charAt($enc4); } while ($i < $input.length); return $output; }, decode: function($input) { if (!$input) return false; $input = $input.replace(/[^A-Za-z0-9\+\/\=]/g, ""); var $output = ""; var $enc1, $enc2, $enc3, $enc4; var $i = 0; do { $enc1 = this.base64.indexOf($input.charAt($i++)); $enc2 = this.base64.indexOf($input.charAt($i++)); $enc3 = this.base64.indexOf($input.charAt($i++)); $enc4 = this.base64.indexOf($input.charAt($i++)); $output += String.fromCharCode(($enc1 > 4)); if ($enc3 != 64) $output += String.fromCharCode((($enc2 & 15) > 2)); if ($enc4 != 64) $output += String.fromCharCode((($enc3 & 3) > 4) & 0xf) + this.hex.charAt($k & 0xf); } while ($i < $input.length); return $output; }, decode: function($input) { if (!$input) return false; $input = $input.replace(/[^0-9abcdef]/g, ""); var $output = ""; var $i = 0; do { $output += String.fromCharCode(((this.hex.indexOf($input.charAt($i++)) > 3); if (!$data) return false; $data = $data.modPowInt($pubkey.encryptionExponent, $pubkey.modulus); if (!$data) return false; $data = $data.toString(16); if (($data.length & 1) == 1) $data = "0" + $data; return Base64.encode(Hex.decode($data)); },<br /> pkcs1pad2: function($data, $keysize) { if ($keysize < $data.length + 11) return null; var $buffer = []; var $i = $data.length - 1; while ($i >= 0 && $keysize > 0) $buffer[--$keysize] = $data.charCodeAt($i--); $buffer[--$keysize] = 0; while ($keysize > 2) $buffer[--$keysize] = Math.floor(Math.random() * 254) + 1; $buffer[--$keysize] = 2; $buffer[--$keysize] = 0; return new BigInteger($buffer); }}<br /> function get_pwd(pwd,mod, exp) { var pubKey = RSA.getPublicKey(mod, exp); password = pwd.replace(/[^\x00-\x7F]/g, ''); var encryptedPassword = RSA.encrypt(password, pubKey); return encryptedPassword; }
通过自定义一个get_pwd的函数,来调用上面加密的整个过程,函数上面的部分,就是加密的整个过程的代码,这些代码也不是我写的,是别人写好的,我只是复制粘贴过来,改动一下,利用自己定义的函数,调用了这些代码,从而实现加密的目的。该函数需要传递2个参数,这个2个参数分别是未加密前的密码和私钥,私钥就在我们请求网页的时候,返回的第一个数据里面(publickey_exp和publickey_mod)。
mod就是publickey_mod,exp就是publickey_exp,通过传递参数,在调用定义的get_pwd这个函数,就能得到加密的密码结果了,加密后的密码也是动态的,每次都不一样。
效果展示
结语
因为本文涉及很多JavaScript的知识,所以需要对JavaScript有些了解,另外在改写JS代码的时候,会遇到很多的错误提示,限于篇幅的有限,我没有过多的写出如何排除这些错误提示,我们就需要利用一些JavaScript的知识一点点的排除这些错误提示,直到提示加载成功,才可以运行代码的,所以还是推荐用js的调试工具,这样更方便一些。头一次写这样的技术文章,有很多写的不到位的地方,还请多多提出宝贵意见。
END
B站账号:
https://space.bilibili.com/351138764
欢迎扫码
关注我
JS逆向 -- 某视频网站流媒体初次分析全过程
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-04-30 23:15
开篇
最近呢,学了一点js逆向的知识,一直想找个可以实践一下的平台来试试学习效果。偶然间看到了这个平台,发现很适合拿来练手,不过由于这个网站视频开始播放前都有那种不和谐的广告,所以地址就不能贴了,贴图也做了一些脱敏处理!
需要准备的工具:
第一次分析
打开目标网站首页,选择任意一个视频信息点击进入后:
可以直接看到资源下载地址,不过这次目的是来逆向的,所以看不到!看不到!看不到!
1.1 过控制台检测
接下来就到了我们的分析时间,点击【在线播放】后尝试使用快捷键F12打开控制台,然后就弹出了以下提示:
打不开控制台不要紧,选择浏览器右上角的三个小点,从更多工具中打开控制台:
1.2 过无限debug
控制台一打开,立马跳出个无限debuuger,看来还是做了一些反调试措施的:
从右边的堆栈中向下查找入口,从上到下依次点击看看:
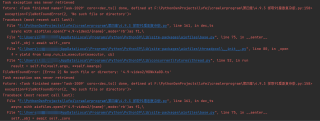
很显然这个并不是,再往下点时,就发现了非常关键的函数调用:
其实这个无限debugger卡了挺长时间的,一开始开始尝试删除这个关键位置的调用,删除整个debugger的自调用函数,甚至删除整个外层的debugger函数,但是发现这些操作会导致视频无法正常加载,控制台过段时间就会直接卡死等莫名其妙的问题,说明这些函数中有些关键地方还是有用的,那看不懂这些混淆的代码又该怎么办呢?难道此次实战就此终结!!!
在前思来想去后,突然想到既然debugger关键字会触发断点,那要是我把这个关键字给改了是不是就停不下了?说干就干,把含有无限debugger的js文件在源代码中直接另存为或者从Fiddler另存为一份到本地,方便进行修改。
从上图可以看到前面的内容为“bugger”,后面的内容为“de”,要修改的关键就在这里里,以文本方式打开对应的js,直接搜“de”,发现有5个地方有这个信息:
全部替换,这里我替换成“dd”,替换后保存:
打开Fiddler工具,右边选择自动响应,勾选启用规则和请求传递,填写js网络地址和本地js地址,并保存:
确认Fiddler能获取浏览器请求后,打开浏览器里的设置,选择清空之前的数据,这样才会重新加载本地替换的js文件:
重新打开播放页面后,再次打开控制台,发现不仅无限debugger没了,控制台也正常了,视频也能正常加载了,很好!可以愉快的玩耍了。
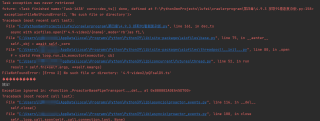
1.3 寻找m3u8地址
打开网络面板,会发现很多的302请求,302表示重定向,这个请求会在响应中返回一个新的地址。开始查找视频文件地址,发现m3u8文件也被重定向了:
用IDM工具下载这个m3u8文件看看,可以看到返回的居然是一个张图片???
打开看看,额,居然是二维码,扫了一下返回是视频网址,那m3u8信息哪去了?
用winhex打开看看,看这个头信息好像就是一个图片
查找一个关键内容看看,winhex直接搜m3u8:
发现并不是想要的内容,用winhex前后翻看发现基本都是乱码,那么极有可能m3u8的内容被加密了,存放在这个图片中。尝试在源代码中查找m3u8文件的调用堆栈发现事情并不简单,很多地方的js代码都被混淆了,所以要找到还原方法实属头大,可是没有代码就不能还原出m3u8的内容怎么办?于是想到加载ts文件不是也得从m3u8的内容中读取吗?所以开始尝试查找ts的调用堆栈,这里可以看到ts的请求也是302状态码,先不管:
把鼠标放在其中一个ts请求的启动器上,点击浮窗中展示的js文件进入调式:
这里会自动跳转到源代码中js的点击位置,先在这里打上一个断点,免得调试过头了。
从右下角的
堆栈从上往下依次点击看看,在每个堆栈位置前后翻翻,然后发现了一个有关m3u8的信息,在这里下断点:
F5重新加载页面,可以看到m3u8的内容此时已经被加载了:
尝试把这个m3u8信息保存下来,打开控制台输入了以下代码:
复制代码 隐藏代码<br style="overflow-wrap: break-word;" />const data = t.data; // 这里填内容的字符串<br />const blob = new Blob([data], {type: "text/plain"});<br />const a= document.createElement("a");<br />a.href = URL.createObjectURL(blob);<br />a.download = "demo.m3u8"; // 这里填保存的文件名<br />a.click();<br />URL.revokeObjectURL(a.href);<br />a.remove();
成功保存,打开看看,正好是m3u8的内容:
1.4 ts解密
尝试用IDM访问前面一两个ts链接看看有没有加密:
怎么返回的又是图片?直接打开看看:
啥呀这是,一张花屏的图片,用winhex打开看看:
上下拖动内容后发现并不是常规的图片内容,果然有猫腻,在图片的下面发现了视频相关的头信息,难道这是图片伪装的视频文件?从其它平台找一个正常的ts文件对比看看:
哦豁,原来后面的内容确实是视频文件,只是前面一小部分是BMP文件的头信息,那简单了,直接删了试试:
修改后另存为一份,后缀改为ts,避免修改错误导致源文件信息丢失
打开修改后的ts文件,正常播放:
PS:后来发现论坛里,逍遥大佬写的m3u8下载器可以自动去除这种不是ts内容的信息:
至此第一阶段分析结束,我以为也就这样了,但是再尝试打开几个视频后,发发发现居然有不一样的加密!!!
OK,既然被发现了,那必须得再分析看看=>
第二次分析2.1 获取m3u8和key
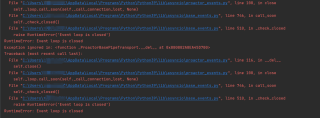
有了前面那些踩坑,这次分析起来就快多了,再次尝试打开视频页面,通过调试再次拿到m3u8文件,拖入m3u8下载器看看:
发现这次需要key,通过不断的调试终于hook到key的位置,这里先把key拿来用一下,填入key,发现又解码失败了:
2.2 ts解密
难道这个ts与众不同?打开m3u8文件后发现ts的链接长度明显变短了,下载ts后再次打开文件看看:
又是熟悉的花屏图片,用winhex打开看看:
发现这次怎么也找不到ts头信息了,搜也搜不到了,而且内容非常乱,看起来应该是被加密了,这样只能调试代码看看怎么回事了。这次换个方法找,直接搜,为啥呢,因为调试了半天也跳到解密位置,直接搜碰碰运气:
看到有很多结果,前面两个js可以忽略,第3、4个js文件很可疑,打开相应的js再次搜索关键字,发现有很多结果,从上到下依次都大概看一下。然后发现这个位置很可疑,其它地方都没混淆代码,偏偏这里有混淆,此地无银三百两,打上断点试试:
再次F5加载页面或者继续播放,点击格式化后再搜关键字,可以看到代码都被混淆了,但是有些关键信息还是可以看到的:
统统打上断点看看,F8依次执行,可以看到rsp就是网站加载的原始ts文件,大小一模一样,这里我从Fiddler保存了一份做对比:
F8继续执行,发现len变量的值为1243440,应该是确定加密范围的:
点击继续下一个断点,发现rsp变了,长度不是1244642,而是1243440了:
依葫芦画瓢,这里先保存一下rsp内容,此时的rsp是不能播放的:
打开本地保存的后缀为.bmp的ts文件和这个enc.ts进行对比,并搜搜看:
原来是通过一定的算法把前面和后面一部分内容给去掉了,那么剩下的应该就是被加密的视频文件了,删除后大小刚好就是enc.ts的大小。下一个断点,来到uText这个变量,发现这个变量的长度刚好和前面的rsp长度是一样的,这里应该就是做了转换,为解密做准备:
下一个断点,来到解密函数,这里可以清楚看到加密的内容uTxt、key、iv,虽然看不太懂混淆的代码,但这显然是一个标准的AES-CBC解密操作:
而最后的newRresponse=new Uint8Array(arr);就是解密好的视频流,当然这里可以用代码来实现,这里的key和iv都是同一个值,控制台输出一下:
这里用Python代码实现解密:
复制代码 隐藏代码<br style="overflow-wrap: break-word;" />from Crypto.Cipher import AES<br />import base64<br /><br />fr = open(r'enc.ts', 'rb')<br />content = fr.read()<br />key = iv = base64.b64decode("9Kq58j61Jx42io3e37Qomg==")<br />cipher = AES.new(key, AES.MODE_CBC, iv)<br />data = cipher.decrypt(content)<br />with open(r'dec.ts', 'wb') as fw:<br /> fw.write(data)
成果展示
总结
通过这次实战见识到了很多花里胡哨的操作,还是相当有收获的。也明白还是需要不断学习才能走的更远,再接再厉!当某种逆向思路不行就得尝试换种思路,还有一点就是逆向一定要有耐心!
不足:
由于还没学会如何使用AST解这些混淆代码,导致看不懂核心逻辑,所以以下问题暂时没有得到解决
m3u8地址下载的文件如何从图片提取并还原成正常的m3u8内容?
第二种加密的每个ts似乎都对应着一个key,那么这些hexkey应该如何计算出来?
第二种ts文件从什么地方开始到结束才是真正需要解密的内容?
嗯,就先这样吧! 查看全部
JS逆向 -- 某视频网站流媒体初次分析全过程
开篇
最近呢,学了一点js逆向的知识,一直想找个可以实践一下的平台来试试学习效果。偶然间看到了这个平台,发现很适合拿来练手,不过由于这个网站视频开始播放前都有那种不和谐的广告,所以地址就不能贴了,贴图也做了一些脱敏处理!
需要准备的工具:
第一次分析
打开目标网站首页,选择任意一个视频信息点击进入后:
可以直接看到资源下载地址,不过这次目的是来逆向的,所以看不到!看不到!看不到!
1.1 过控制台检测
接下来就到了我们的分析时间,点击【在线播放】后尝试使用快捷键F12打开控制台,然后就弹出了以下提示:
打不开控制台不要紧,选择浏览器右上角的三个小点,从更多工具中打开控制台:
1.2 过无限debug
控制台一打开,立马跳出个无限debuuger,看来还是做了一些反调试措施的:
从右边的堆栈中向下查找入口,从上到下依次点击看看:
很显然这个并不是,再往下点时,就发现了非常关键的函数调用:
其实这个无限debugger卡了挺长时间的,一开始开始尝试删除这个关键位置的调用,删除整个debugger的自调用函数,甚至删除整个外层的debugger函数,但是发现这些操作会导致视频无法正常加载,控制台过段时间就会直接卡死等莫名其妙的问题,说明这些函数中有些关键地方还是有用的,那看不懂这些混淆的代码又该怎么办呢?难道此次实战就此终结!!!
在前思来想去后,突然想到既然debugger关键字会触发断点,那要是我把这个关键字给改了是不是就停不下了?说干就干,把含有无限debugger的js文件在源代码中直接另存为或者从Fiddler另存为一份到本地,方便进行修改。
从上图可以看到前面的内容为“bugger”,后面的内容为“de”,要修改的关键就在这里里,以文本方式打开对应的js,直接搜“de”,发现有5个地方有这个信息:
全部替换,这里我替换成“dd”,替换后保存:
打开Fiddler工具,右边选择自动响应,勾选启用规则和请求传递,填写js网络地址和本地js地址,并保存:
确认Fiddler能获取浏览器请求后,打开浏览器里的设置,选择清空之前的数据,这样才会重新加载本地替换的js文件:
重新打开播放页面后,再次打开控制台,发现不仅无限debugger没了,控制台也正常了,视频也能正常加载了,很好!可以愉快的玩耍了。
1.3 寻找m3u8地址
打开网络面板,会发现很多的302请求,302表示重定向,这个请求会在响应中返回一个新的地址。开始查找视频文件地址,发现m3u8文件也被重定向了:
用IDM工具下载这个m3u8文件看看,可以看到返回的居然是一个张图片???
打开看看,额,居然是二维码,扫了一下返回是视频网址,那m3u8信息哪去了?
用winhex打开看看,看这个头信息好像就是一个图片
查找一个关键内容看看,winhex直接搜m3u8:
发现并不是想要的内容,用winhex前后翻看发现基本都是乱码,那么极有可能m3u8的内容被加密了,存放在这个图片中。尝试在源代码中查找m3u8文件的调用堆栈发现事情并不简单,很多地方的js代码都被混淆了,所以要找到还原方法实属头大,可是没有代码就不能还原出m3u8的内容怎么办?于是想到加载ts文件不是也得从m3u8的内容中读取吗?所以开始尝试查找ts的调用堆栈,这里可以看到ts的请求也是302状态码,先不管:
把鼠标放在其中一个ts请求的启动器上,点击浮窗中展示的js文件进入调式:
这里会自动跳转到源代码中js的点击位置,先在这里打上一个断点,免得调试过头了。
从右下角的
堆栈从上往下依次点击看看,在每个堆栈位置前后翻翻,然后发现了一个有关m3u8的信息,在这里下断点:
F5重新加载页面,可以看到m3u8的内容此时已经被加载了:
尝试把这个m3u8信息保存下来,打开控制台输入了以下代码:
复制代码 隐藏代码<br style="overflow-wrap: break-word;" />const data = t.data; // 这里填内容的字符串<br />const blob = new Blob([data], {type: "text/plain"});<br />const a= document.createElement("a");<br />a.href = URL.createObjectURL(blob);<br />a.download = "demo.m3u8"; // 这里填保存的文件名<br />a.click();<br />URL.revokeObjectURL(a.href);<br />a.remove();
成功保存,打开看看,正好是m3u8的内容:
1.4 ts解密
尝试用IDM访问前面一两个ts链接看看有没有加密:
怎么返回的又是图片?直接打开看看:
啥呀这是,一张花屏的图片,用winhex打开看看:
上下拖动内容后发现并不是常规的图片内容,果然有猫腻,在图片的下面发现了视频相关的头信息,难道这是图片伪装的视频文件?从其它平台找一个正常的ts文件对比看看:
哦豁,原来后面的内容确实是视频文件,只是前面一小部分是BMP文件的头信息,那简单了,直接删了试试:
修改后另存为一份,后缀改为ts,避免修改错误导致源文件信息丢失
打开修改后的ts文件,正常播放:
PS:后来发现论坛里,逍遥大佬写的m3u8下载器可以自动去除这种不是ts内容的信息:
至此第一阶段分析结束,我以为也就这样了,但是再尝试打开几个视频后,发发发现居然有不一样的加密!!!
OK,既然被发现了,那必须得再分析看看=>
第二次分析2.1 获取m3u8和key
有了前面那些踩坑,这次分析起来就快多了,再次尝试打开视频页面,通过调试再次拿到m3u8文件,拖入m3u8下载器看看:
发现这次需要key,通过不断的调试终于hook到key的位置,这里先把key拿来用一下,填入key,发现又解码失败了:
2.2 ts解密
难道这个ts与众不同?打开m3u8文件后发现ts的链接长度明显变短了,下载ts后再次打开文件看看:
又是熟悉的花屏图片,用winhex打开看看:
发现这次怎么也找不到ts头信息了,搜也搜不到了,而且内容非常乱,看起来应该是被加密了,这样只能调试代码看看怎么回事了。这次换个方法找,直接搜,为啥呢,因为调试了半天也跳到解密位置,直接搜碰碰运气:
看到有很多结果,前面两个js可以忽略,第3、4个js文件很可疑,打开相应的js再次搜索关键字,发现有很多结果,从上到下依次都大概看一下。然后发现这个位置很可疑,其它地方都没混淆代码,偏偏这里有混淆,此地无银三百两,打上断点试试:
再次F5加载页面或者继续播放,点击格式化后再搜关键字,可以看到代码都被混淆了,但是有些关键信息还是可以看到的:
统统打上断点看看,F8依次执行,可以看到rsp就是网站加载的原始ts文件,大小一模一样,这里我从Fiddler保存了一份做对比:
F8继续执行,发现len变量的值为1243440,应该是确定加密范围的:
点击继续下一个断点,发现rsp变了,长度不是1244642,而是1243440了:
依葫芦画瓢,这里先保存一下rsp内容,此时的rsp是不能播放的:
打开本地保存的后缀为.bmp的ts文件和这个enc.ts进行对比,并搜搜看:
原来是通过一定的算法把前面和后面一部分内容给去掉了,那么剩下的应该就是被加密的视频文件了,删除后大小刚好就是enc.ts的大小。下一个断点,来到uText这个变量,发现这个变量的长度刚好和前面的rsp长度是一样的,这里应该就是做了转换,为解密做准备:
下一个断点,来到解密函数,这里可以清楚看到加密的内容uTxt、key、iv,虽然看不太懂混淆的代码,但这显然是一个标准的AES-CBC解密操作:
而最后的newRresponse=new Uint8Array(arr);就是解密好的视频流,当然这里可以用代码来实现,这里的key和iv都是同一个值,控制台输出一下:
这里用Python代码实现解密:
复制代码 隐藏代码<br style="overflow-wrap: break-word;" />from Crypto.Cipher import AES<br />import base64<br /><br />fr = open(r'enc.ts', 'rb')<br />content = fr.read()<br />key = iv = base64.b64decode("9Kq58j61Jx42io3e37Qomg==")<br />cipher = AES.new(key, AES.MODE_CBC, iv)<br />data = cipher.decrypt(content)<br />with open(r'dec.ts', 'wb') as fw:<br /> fw.write(data)
成果展示
总结
通过这次实战见识到了很多花里胡哨的操作,还是相当有收获的。也明白还是需要不断学习才能走的更远,再接再厉!当某种逆向思路不行就得尝试换种思路,还有一点就是逆向一定要有耐心!
不足:
由于还没学会如何使用AST解这些混淆代码,导致看不懂核心逻辑,所以以下问题暂时没有得到解决
m3u8地址下载的文件如何从图片提取并还原成正常的m3u8内容?
第二种加密的每个ts似乎都对应着一个key,那么这些hexkey应该如何计算出来?
第二种ts文件从什么地方开始到结束才是真正需要解密的内容?
嗯,就先这样吧!
网页抓取解密 真香的PDF软件--PDF24
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-30 23:13
一个完全免费的PDF工具箱软件:PDF24,里面包含了20多种关于PDF的操作的免费工具。列如包含了PDF转换、合并、叠加、压缩、比较、编辑、裁剪、注释、加密、解密、分割、旋转、优化、删除、提取、排序页面等等。
豌豆工作室公众号对话框回复:uf,获取资料!
网页版,网址:
该工具分网页版和桌面安装版,网页版社长就不多介绍,就是直接打开网址就可以使用,桌面安装的话我们直接下载好软件安装包,然后直接双击打开,我们发现默认是英文安装界面,不用管这个直接OK,安装好之后软件默认是中文的。
安装完毕有一个英文注册界面,不想注册的用户可以直接点击skip跳过即可。
接下来社长就给大家演示一遍使用方法,以转化为PDF为列:点击选择文件或者直接把需要转化成PDF文件拖拽到软件中即可
然后点击转换为PDF。
然后保存到自己的电脑打开就可以看到已经转换为PDF文件了。
功能实在太多就不过多介绍,这款软件还可以当成PDF文件格式的查看软件。
--------END-------- 查看全部
网页抓取解密 真香的PDF软件--PDF24
一个完全免费的PDF工具箱软件:PDF24,里面包含了20多种关于PDF的操作的免费工具。列如包含了PDF转换、合并、叠加、压缩、比较、编辑、裁剪、注释、加密、解密、分割、旋转、优化、删除、提取、排序页面等等。
豌豆工作室公众号对话框回复:uf,获取资料!
网页版,网址:
该工具分网页版和桌面安装版,网页版社长就不多介绍,就是直接打开网址就可以使用,桌面安装的话我们直接下载好软件安装包,然后直接双击打开,我们发现默认是英文安装界面,不用管这个直接OK,安装好之后软件默认是中文的。
安装完毕有一个英文注册界面,不想注册的用户可以直接点击skip跳过即可。
接下来社长就给大家演示一遍使用方法,以转化为PDF为列:点击选择文件或者直接把需要转化成PDF文件拖拽到软件中即可
然后点击转换为PDF。
然后保存到自己的电脑打开就可以看到已经转换为PDF文件了。
功能实在太多就不过多介绍,这款软件还可以当成PDF文件格式的查看软件。
--------END--------
如何在Google上免费获得流量?解密16大Google排名因素
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-30 23:11
(本文有1000+字,看完预计3分钟)
『108期老徐说独立站』
本期话题
1、如何在Google上获得流量?
2、Google排名因素有哪些?
3、站内SEO的TDK怎么写?
这是Google站长的数据,完全SEO自然流量。
2022年3个月对比2021年3个月,曝光增长38.8万,增长42.5%。
自然流量增加2.5万,增长17%。平均点击率增加2.7%,点击率高达13.1%。
网站上线,如何在Google获得流量?
网站上线后,如何才能获得流量?
品牌独立站上线后,获得流量的方法有很多SEO/SNS/SEM都可以获得流量,在SEO方面,主要是Google的SEO,因为Google搜索占据全球92%的市场份额。
SEM不是所有的行业产品都能上,比如Google广告针对黑五类、违法、地方区域政策等限制产品无法上广告。而SEO的包容性会更广,打不了广告的产品可以通过多做网站内容,做多几个站群,多语种,做SEO来获客。
这里要普及2个知识点
1、Google搜索结果,带有广告标识的,是属于Google付费广告引流。
2、默认搜索结果有8-10个位置出现自然结果的网页,这些页面就是SEO的搜索结果,点击带来的流量完全免费。如下图所示:
为了抢占在Google上的自然流量机会,我们除了需要做网站本身的内容外,还需要会在网页部署关键词,尤其是网页的TDK撰写。
通过对TDK和网页内容优化,可以让Google更快、更好的读懂我们的网页,抓取和收录我们的内容,从而带来更多的免费曝光和流量机会。
如何写TDK?我在第三部分讲解。
要想获得免费曝光和展示,少不了一个指标
网页收录
这是持续输出原创、优质的内容在Google上的表现,收录高达8万。
传统的建站服务商和个人,短期内很难达到这么多的内容数量。
想了解怎么做的?
后续会为大家揭秘,敬请关注!
Google排名的因素有哪些?
Google排名因素有200多项
Google排名的200多项因素比较多而复杂,为了让大家简单明白的理解,我归纳合并成16大因素。
一、内因
1、原创内容,视频。2、持续更新。3、TDKU。4、域名权重。5、页面年龄。6、SSL安全证书 https。7、网页速度,CDN。8、服务器资源。9、网页技术。10、内部链接。
二、外因
11、外链。12、用户行为,比如点击率。13、社交指标。14、竞争环境。15、行业趋势。16、品牌热度。
对于绝大多数SEO运营来说,当你选择了服务商之后,白色部分的因素,无法左右。网页技术方面就很大受限于网站服务商的技术水平。
所以,多数SEO和运营能做的只有是网站内容,TDK 和保持持续的内容更新。如果你持续坚持,也已经超越85%的网站竞争对手了!
由于项目比较多,这里我只提一个重点:Google特别尊重原创,所以原创优质的内容,尤其是视频内容,就很容易在Google获得更多的免费曝光推荐机会!
网站上线之后,大家要特别重视,多发布一些产品的视频在网站上。也可以是去YouTube发布之后,拿个代码链接放回网站。不影响网站性能,还能更好地带动网站流量和权重提升。如有不清楚,欢迎评论区留言,或微信xuchy1688 。
站内SEO优化的TDK怎么写?
网站站内SEO优化做什么?
站内优化的工序超过10个。其中少不了关键词分析,关键词布局,关键词内链,网页TDK撰写,404检查,内链建设,产品标题优化,分类优化,绑定Google流量统计,绑定Google站长,提交sitemap,开放robots等工序。这些环节都非常重要。
而对于TDK撰写,则是重中之重!
TDK是什么?为什么要写TDK?
写好TDK就是为了帮助Google能更好的识别我们的整站每个页面的内容主题、内容描述、内容关键词,方便Google收录之后,更好的进行对应关键词的免费推荐,从而解决精准用户的搜索查询需求!
让Google更好地收录我们,带来更多免费流量机会,这就少不了站内SEO优化的TDK优化。
如何写TDK?
划重点!
网页Title埋入1个关键词,字符数40-60字符最佳。
网页Description可埋入2-3个关键词,120-155字符最佳。
网页Keywords写入1-3个,这里我们只讲关键词的密度2-8%区间。
本期分享就到这里,有疑问欢迎微信咨询xuchy1688 查看全部
如何在Google上免费获得流量?解密16大Google排名因素
(本文有1000+字,看完预计3分钟)
『108期老徐说独立站』
本期话题
1、如何在Google上获得流量?
2、Google排名因素有哪些?
3、站内SEO的TDK怎么写?
这是Google站长的数据,完全SEO自然流量。
2022年3个月对比2021年3个月,曝光增长38.8万,增长42.5%。
自然流量增加2.5万,增长17%。平均点击率增加2.7%,点击率高达13.1%。
网站上线,如何在Google获得流量?
网站上线后,如何才能获得流量?
品牌独立站上线后,获得流量的方法有很多SEO/SNS/SEM都可以获得流量,在SEO方面,主要是Google的SEO,因为Google搜索占据全球92%的市场份额。
SEM不是所有的行业产品都能上,比如Google广告针对黑五类、违法、地方区域政策等限制产品无法上广告。而SEO的包容性会更广,打不了广告的产品可以通过多做网站内容,做多几个站群,多语种,做SEO来获客。
这里要普及2个知识点
1、Google搜索结果,带有广告标识的,是属于Google付费广告引流。
2、默认搜索结果有8-10个位置出现自然结果的网页,这些页面就是SEO的搜索结果,点击带来的流量完全免费。如下图所示:
为了抢占在Google上的自然流量机会,我们除了需要做网站本身的内容外,还需要会在网页部署关键词,尤其是网页的TDK撰写。
通过对TDK和网页内容优化,可以让Google更快、更好的读懂我们的网页,抓取和收录我们的内容,从而带来更多的免费曝光和流量机会。
如何写TDK?我在第三部分讲解。
要想获得免费曝光和展示,少不了一个指标
网页收录
这是持续输出原创、优质的内容在Google上的表现,收录高达8万。
传统的建站服务商和个人,短期内很难达到这么多的内容数量。
想了解怎么做的?
后续会为大家揭秘,敬请关注!
Google排名的因素有哪些?
Google排名因素有200多项
Google排名的200多项因素比较多而复杂,为了让大家简单明白的理解,我归纳合并成16大因素。
一、内因
1、原创内容,视频。2、持续更新。3、TDKU。4、域名权重。5、页面年龄。6、SSL安全证书 https。7、网页速度,CDN。8、服务器资源。9、网页技术。10、内部链接。
二、外因
11、外链。12、用户行为,比如点击率。13、社交指标。14、竞争环境。15、行业趋势。16、品牌热度。
对于绝大多数SEO运营来说,当你选择了服务商之后,白色部分的因素,无法左右。网页技术方面就很大受限于网站服务商的技术水平。
所以,多数SEO和运营能做的只有是网站内容,TDK 和保持持续的内容更新。如果你持续坚持,也已经超越85%的网站竞争对手了!
由于项目比较多,这里我只提一个重点:Google特别尊重原创,所以原创优质的内容,尤其是视频内容,就很容易在Google获得更多的免费曝光推荐机会!
网站上线之后,大家要特别重视,多发布一些产品的视频在网站上。也可以是去YouTube发布之后,拿个代码链接放回网站。不影响网站性能,还能更好地带动网站流量和权重提升。如有不清楚,欢迎评论区留言,或微信xuchy1688 。
站内SEO优化的TDK怎么写?
网站站内SEO优化做什么?
站内优化的工序超过10个。其中少不了关键词分析,关键词布局,关键词内链,网页TDK撰写,404检查,内链建设,产品标题优化,分类优化,绑定Google流量统计,绑定Google站长,提交sitemap,开放robots等工序。这些环节都非常重要。
而对于TDK撰写,则是重中之重!
TDK是什么?为什么要写TDK?
写好TDK就是为了帮助Google能更好的识别我们的整站每个页面的内容主题、内容描述、内容关键词,方便Google收录之后,更好的进行对应关键词的免费推荐,从而解决精准用户的搜索查询需求!
让Google更好地收录我们,带来更多免费流量机会,这就少不了站内SEO优化的TDK优化。
如何写TDK?
划重点!
网页Title埋入1个关键词,字符数40-60字符最佳。
网页Description可埋入2-3个关键词,120-155字符最佳。
网页Keywords写入1-3个,这里我们只讲关键词的密度2-8%区间。
本期分享就到这里,有疑问欢迎微信咨询xuchy1688
网页抓取解密(爬取一个第二季第34集分段视频没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-20 08:55
)
实现功能:爬取网站的视频
1、获取主页面的页面源码并找到iframe
2、从iframe页面源码中获取m3u8文件
3、下载第一层m3u8文件,获取真实地址
4、下载视频
5、下载密钥并解密
6、将所有ts文件合并为一个MP4文件
'''
目前基本确定第4步和第5步有问题,但不清楚是因为代码错误,还是好像有几个分段视频没有下载;
所以不清楚是什么导致了第 6 步中的问题;求老鸟
问题截图:
代码页
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES
import os
#正则提取规则
obj1=re.compile(r'2.html","link_pre":"","url":"(?P.*?)","url_next":"https:')
#2.1子程序:找到主页面的源代码,找到iframe对应的url
def get_iframe_src(url):
resp=requests.get(url)
#print(resp.text) #测试是否正常爬取到源代码
#修改为正则爬取,这里提取完之后就是第一层的m3u8地址了
content=resp.text #把源代码变成text格式存储起来,用来提取
main_page=obj1.finditer(content)
for it in main_page:
#print(it.group('src'))
src_modify=it.group('src').replace('\\','')
#print(src_modify)
return src_modify #输出正确的第一层m3u8地址
resp.close()
#2.2、子程序:拿到第一层的m3u8文件下载地址;这一步只在课程里91看剧需要,实操的网址2.1里拿到的就是第一层m3u8了
def get_first_m3u8_url(url):
resp=requests.get(url)
#print(resp.text)
obj2=re.compile(r'var main=''(?P.*?)''')
m3u8_url=obj2.search(resp.text).group('m3u8_url') #这里是把m3u8地址提取出来
#print(m3u8_url)
resp.close()
return m3u8_url #让函数返回这一个地址
#2.3、子程序:下载第一层m3u8文件
def download_m3u8_file(url,name):
resp=requests.get(url)
with open(name,mode='wb')as f:
f.write(resp.content)
resp.close()
#2.5.1、子程序:异步协程进行下载
async def download_ts(url,name,session):
async with session.get(url)as resp:
async with aiofiles.open(f'4.9-video2/{name}',mode='wb')as f:
await f.write(await resp.content.read()) #把下载到的内容写入文件中
print(f'{name}下载完毕')
#2.5、子程序:异步协程处理拼接下载
#实操版
async def aio_download(up_url):
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'): #’#‘开头的行不要
continue
# line就是xxxx.ts文件
url = line.strip()
name1=line.rsplit('/',1)[1]
name=name1.strip()
task=asyncio.create_task(download_ts(url,name,session))
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
#2.6.1获取密钥
def get_key(url):
resp=requests.get(url)
print(resp.text)
a=resp.text
b=bytes(a,'utf-8')
return b
#2.6.2创建解密视频的任务
async def aio_dec(key):
#思路:解密,需要把下载的文件一个个打开;但是因为这里我们是直接用m3u8文件里后面的字符命名的
tasks=[]
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'):
continue
line1=line.rsplit('/',1)[1] #取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
#开始创建异步任务
task=asyncio.create_task(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
#2.6.3创建解密函数
async def dec_ts(name,key):
aes=AES.new(key=key,IV=b'0000000000000000',mode=AES.MODE_CBC)
async with aiofiles.open(f'4.9-video2/{name}',mode='rb')as f1,\
aiofiles.open(f'4.9-video2/temp_{name}',mode='wb')as f2:
bs=await f1.read() #从源文件读取文件
await f2.write(aes.decrypt(bs)) #把解密好的内容写入文件
print(f'{name}处理完毕')
#2.7合并视频为mp4
def merge_ts():
#mac:cat 1.ts 2.ts 3.ts > xxx.mp4
#windows:copy/b 1.ts+2.ts+3.ts > xxx.mp4
lst=[]
with open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
for line in f:
if line.startswith('#'):
continue
line1 = line.rsplit('/', 1)[1] # 取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
lst.append(f'4.9-video2/temp_{line}')
s=''.join(lst)
os.system(f'copy /b {s} >movie.mp4')
print('搞定!')
#2、主程序
def main(url):
#2.1、找到主页面的源代码,找到iframe对应的url
iframe_src=get_iframe_src(url)
#print(iframe_src)
#2.3下载第一层m3u8文件
download_m3u8_file(iframe_src,'4.93-抓取91看剧复杂版——first-m3u8.txt') #按照课程正常的话括号里的’iframe_src‘要改为2.2里的’first_m3u8_url_ture‘
#2.4下载第二层m3u8文件
with open('4.93-抓取91看剧复杂版——first-m3u8.txt',mode='r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'): #让程序识别文件里面时,自动跳过‘#’开头的行段
continue
else:
line=line.strip() #去掉空白或者换行符
#准备拼接第二层m3u8的下载路径
second_m3u8_url=iframe_src.split('/20210730')[0]+line
download_m3u8_file(second_m3u8_url,'4.93-抓取91看剧复杂版——second-m3u8.txt')
print('第二层m3u8下载完毕')
#2.5下载视频
#实操写法
up_url='开始'
#asyncio.run(aio_download(up_url)) #这个会报错:RuntimeError: Event loop is closed
loop=asyncio.get_event_loop()
loop.run_until_complete(aio_download(up_url))
#2.6.1拿到密钥
#实操
key_url='https://ts6.hhmm0.com:9999/202 ... 39%3B
key=get_key(key_url) #访问密匙的路径,拿到密匙
#2.6.2解密
asyncio.run(aio_dec(key))
#2.7合并ts文件为mp4文件
merge_ts()
#1、主程序调用处
if __name__=='__main__':
url='https://www.pianba.net/yun/84961-1-1/'
main(url) 查看全部
网页抓取解密(爬取一个第二季第34集分段视频没有
)
实现功能:爬取网站的视频
1、获取主页面的页面源码并找到iframe
2、从iframe页面源码中获取m3u8文件
3、下载第一层m3u8文件,获取真实地址
4、下载视频
5、下载密钥并解密
6、将所有ts文件合并为一个MP4文件
'''
目前基本确定第4步和第5步有问题,但不清楚是因为代码错误,还是好像有几个分段视频没有下载;
所以不清楚是什么导致了第 6 步中的问题;求老鸟
问题截图:
代码页
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES
import os
#正则提取规则
obj1=re.compile(r'2.html","link_pre":"","url":"(?P.*?)","url_next":"https:')
#2.1子程序:找到主页面的源代码,找到iframe对应的url
def get_iframe_src(url):
resp=requests.get(url)
#print(resp.text) #测试是否正常爬取到源代码
#修改为正则爬取,这里提取完之后就是第一层的m3u8地址了
content=resp.text #把源代码变成text格式存储起来,用来提取
main_page=obj1.finditer(content)
for it in main_page:
#print(it.group('src'))
src_modify=it.group('src').replace('\\','')
#print(src_modify)
return src_modify #输出正确的第一层m3u8地址
resp.close()
#2.2、子程序:拿到第一层的m3u8文件下载地址;这一步只在课程里91看剧需要,实操的网址2.1里拿到的就是第一层m3u8了
def get_first_m3u8_url(url):
resp=requests.get(url)
#print(resp.text)
obj2=re.compile(r'var main=''(?P.*?)''')
m3u8_url=obj2.search(resp.text).group('m3u8_url') #这里是把m3u8地址提取出来
#print(m3u8_url)
resp.close()
return m3u8_url #让函数返回这一个地址
#2.3、子程序:下载第一层m3u8文件
def download_m3u8_file(url,name):
resp=requests.get(url)
with open(name,mode='wb')as f:
f.write(resp.content)
resp.close()
#2.5.1、子程序:异步协程进行下载
async def download_ts(url,name,session):
async with session.get(url)as resp:
async with aiofiles.open(f'4.9-video2/{name}',mode='wb')as f:
await f.write(await resp.content.read()) #把下载到的内容写入文件中
print(f'{name}下载完毕')
#2.5、子程序:异步协程处理拼接下载
#实操版
async def aio_download(up_url):
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'): #’#‘开头的行不要
continue
# line就是xxxx.ts文件
url = line.strip()
name1=line.rsplit('/',1)[1]
name=name1.strip()
task=asyncio.create_task(download_ts(url,name,session))
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
#2.6.1获取密钥
def get_key(url):
resp=requests.get(url)
print(resp.text)
a=resp.text
b=bytes(a,'utf-8')
return b
#2.6.2创建解密视频的任务
async def aio_dec(key):
#思路:解密,需要把下载的文件一个个打开;但是因为这里我们是直接用m3u8文件里后面的字符命名的
tasks=[]
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'):
continue
line1=line.rsplit('/',1)[1] #取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
#开始创建异步任务
task=asyncio.create_task(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
#2.6.3创建解密函数
async def dec_ts(name,key):
aes=AES.new(key=key,IV=b'0000000000000000',mode=AES.MODE_CBC)
async with aiofiles.open(f'4.9-video2/{name}',mode='rb')as f1,\
aiofiles.open(f'4.9-video2/temp_{name}',mode='wb')as f2:
bs=await f1.read() #从源文件读取文件
await f2.write(aes.decrypt(bs)) #把解密好的内容写入文件
print(f'{name}处理完毕')
#2.7合并视频为mp4
def merge_ts():
#mac:cat 1.ts 2.ts 3.ts > xxx.mp4
#windows:copy/b 1.ts+2.ts+3.ts > xxx.mp4
lst=[]
with open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
for line in f:
if line.startswith('#'):
continue
line1 = line.rsplit('/', 1)[1] # 取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
lst.append(f'4.9-video2/temp_{line}')
s=''.join(lst)
os.system(f'copy /b {s} >movie.mp4')
print('搞定!')
#2、主程序
def main(url):
#2.1、找到主页面的源代码,找到iframe对应的url
iframe_src=get_iframe_src(url)
#print(iframe_src)
#2.3下载第一层m3u8文件
download_m3u8_file(iframe_src,'4.93-抓取91看剧复杂版——first-m3u8.txt') #按照课程正常的话括号里的’iframe_src‘要改为2.2里的’first_m3u8_url_ture‘
#2.4下载第二层m3u8文件
with open('4.93-抓取91看剧复杂版——first-m3u8.txt',mode='r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'): #让程序识别文件里面时,自动跳过‘#’开头的行段
continue
else:
line=line.strip() #去掉空白或者换行符
#准备拼接第二层m3u8的下载路径
second_m3u8_url=iframe_src.split('/20210730')[0]+line
download_m3u8_file(second_m3u8_url,'4.93-抓取91看剧复杂版——second-m3u8.txt')
print('第二层m3u8下载完毕')
#2.5下载视频
#实操写法
up_url='开始'
#asyncio.run(aio_download(up_url)) #这个会报错:RuntimeError: Event loop is closed
loop=asyncio.get_event_loop()
loop.run_until_complete(aio_download(up_url))
#2.6.1拿到密钥
#实操
key_url='https://ts6.hhmm0.com:9999/202 ... 39%3B
key=get_key(key_url) #访问密匙的路径,拿到密匙
#2.6.2解密
asyncio.run(aio_dec(key))
#2.7合并ts文件为mp4文件
merge_ts()
#1、主程序调用处
if __name__=='__main__':
url='https://www.pianba.net/yun/84961-1-1/'
main(url)
网页抓取解密(Python爬虫网页基本上就是有多少难度?(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-18 21:05
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
1r = requests.get('#39;)
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
数量:你能捕捉到所有这些数据吗?
效率:在一天或一个月内捕获所有数据需要多长时间
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
1、网络爬虫程序有什么难的 - 只爬 html 页面,但要大规模
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内爬取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
我们有足够的带宽吗?
我们有足够的服务器吗?如果单台服务器不够用,我们需要分发
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。在爬网式爬取“旧”新闻的同时,如何兼顾“新”新闻的获取呢?
如何存储捕获的大量新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
2、网络爬虫程序有什么难的——你需要登录才能抓取你想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态? 查看全部
网页抓取解密(Python爬虫网页基本上就是有多少难度?(一)_)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
1r = requests.get('#39;)
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
数量:你能捕捉到所有这些数据吗?
效率:在一天或一个月内捕获所有数据需要多长时间
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
1、网络爬虫程序有什么难的 - 只爬 html 页面,但要大规模
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内爬取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
我们有足够的带宽吗?
我们有足够的服务器吗?如果单台服务器不够用,我们需要分发
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。在爬网式爬取“旧”新闻的同时,如何兼顾“新”新闻的获取呢?
如何存储捕获的大量新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
2、网络爬虫程序有什么难的——你需要登录才能抓取你想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
网页抓取解密(前后端分离的网站接口被加密了怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2022-04-18 21:01
一.前言
最近在调试一个前后端分离的网站时,接口被加密了,原来是未加密的。就是结果json中的消息,一堆乱码。解密js一定是必须的。
二.浏览器打开需要微信授权才能登录的网页
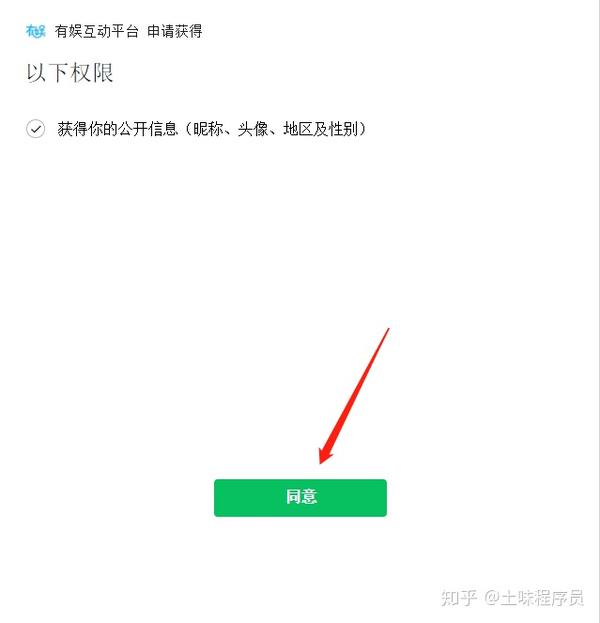
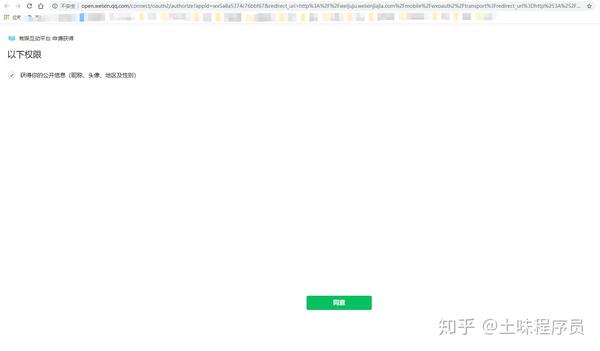
第一步是卡住。此页面需要在微信中打开。如何在chrome浏览器中打开它。采集了一些信息。贴的时候忘记了信息的来源,这里是我自己做的详细步骤,很简单。
这里测试一个链接,只是百度的:
/mobile/game/miraclepan/pan.jsp?panId=2881&wuid=243430
直接用PC浏览器打开会被拦截识别。
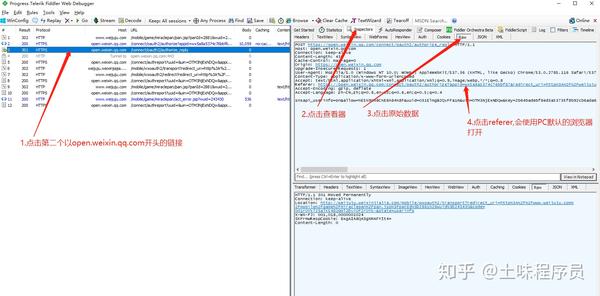
第一步打开fiddler拦截所有请求,打开PC版微信。用PC微信打开这个链接
点击同意,然后查看fiddler,如图操作。(貌似可以直接在PC浏览器打开第一个以open.weixin开头的网页。)这种方式可能会导致部分功能不可用或者浏览器控制台报错。
接下来就可以在PC的默认浏览器中看到授权提示了。点击授权后,即可在浏览器中自由调试微信网页。
三.简单的js调试
首先,我没有看系统教程,只是一些简单的文章之类的。只用一点chrome控制台调试断点,不是很复杂。
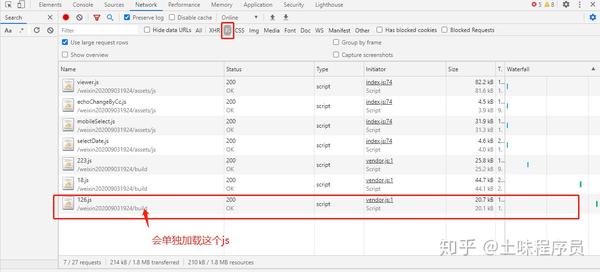
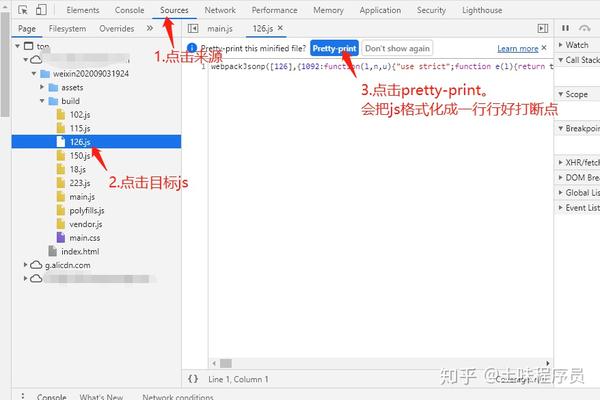
第一张图中的接口是访问页面渲染数据的接口。json数据中消息的key值一定是需要解密的东西,所以我们需要查看js代码将消息移动到哪里。进入目标页面会加载一个单独的js。命名为 126.js
下一个。在这个js文件中找到消息移动到哪里,然后看图操作
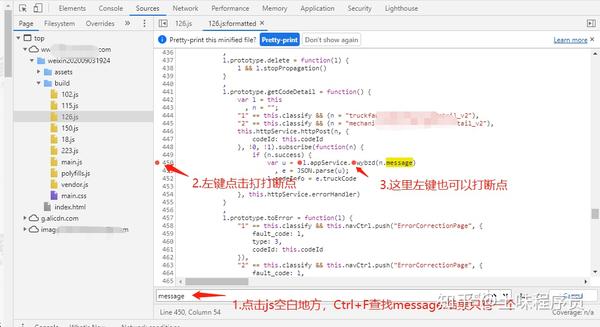
这时候就设置了断点,浏览器返回进入这个页面,这里js会被打断。鼠标悬停在断点上会有提示。点击提示输入断点调用的相关代码。
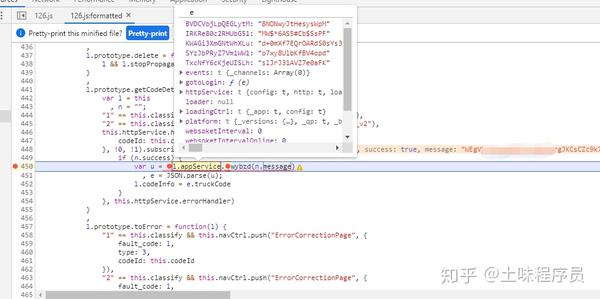
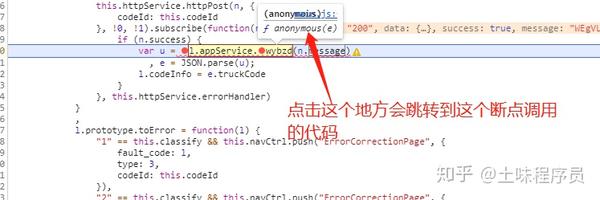
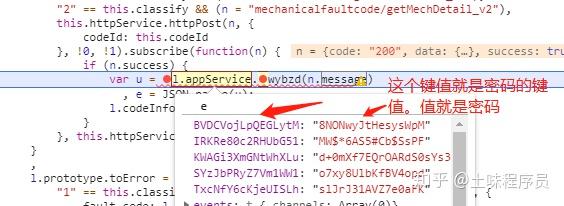
这时候点击下图浮动的地方,wybzd这个地方。查看如何调用代码来处理此消息。
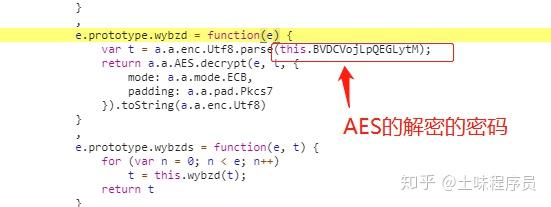
处理消息的js代码差不多就到这里了。使用AES加密和解密,一种对称加密和解密,加密和解密都使用密码。
t为密码,this.BVDCVojLpQEGLytM为调用该函数时传入的参数。求这个变量的值。它是第一次找到消息的地方,应该只使用第一个密钥。我不知道在哪里使用其他键
关键是:“8NONwyJtHesysWpM”
接下来,让我们验证密钥是否正确。
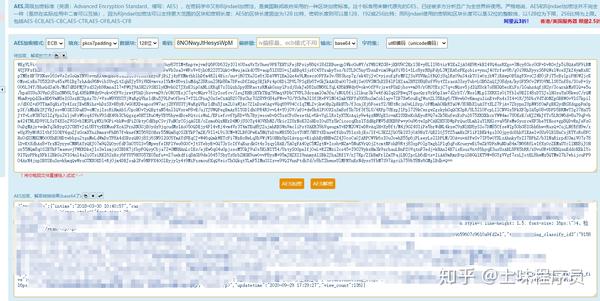
任意百度AES在线加解密网站。填写密钥、密文、解密方法进行计算
ECB 模式,pkcs7padding 填充,结果字符集 utf-8。最终结果如图,解密完成。本教程到此结束。
四.总结
微信页面OAuth2.0授权登录可以看到官方文档和阮一峰网络日志。
/mobile/game/miraclepan/pan.jsp?panId=2881&wuid=243430 访问该网页时,后台有进程会检查请求源是否在微信浏览器中。如果没有,请在微信客户端打开链接。如果在微信客户端的浏览器中显示,则允许用户主动授权。我们使用fiddler跳过直接判断客户端环境是否在微信客户端浏览器中,直接提示用户授权。授权后,后端被我们欺骗。还真以为是在客户端浏览器环境下,然后就可以畅通无阻了,但实际环境不是微信客户端环境,通过jssdk调用的功能可能有限。我还没有测试过。
这次js混淆加密真的很简单,处理消息的地方只有一处。还加载了一个单独的文件。只有一层调用关系,加密方式也不是很复杂,但这些东西接触时间长了只会有一些敏感的直觉。哈哈,我才刚开始,挺有意思的,总结一下。 查看全部
网页抓取解密(前后端分离的网站接口被加密了怎么办?)
一.前言
最近在调试一个前后端分离的网站时,接口被加密了,原来是未加密的。就是结果json中的消息,一堆乱码。解密js一定是必须的。
二.浏览器打开需要微信授权才能登录的网页
第一步是卡住。此页面需要在微信中打开。如何在chrome浏览器中打开它。采集了一些信息。贴的时候忘记了信息的来源,这里是我自己做的详细步骤,很简单。
这里测试一个链接,只是百度的:
/mobile/game/miraclepan/pan.jsp?panId=2881&wuid=243430
直接用PC浏览器打开会被拦截识别。

第一步打开fiddler拦截所有请求,打开PC版微信。用PC微信打开这个链接
点击同意,然后查看fiddler,如图操作。(貌似可以直接在PC浏览器打开第一个以open.weixin开头的网页。)这种方式可能会导致部分功能不可用或者浏览器控制台报错。
接下来就可以在PC的默认浏览器中看到授权提示了。点击授权后,即可在浏览器中自由调试微信网页。
三.简单的js调试
首先,我没有看系统教程,只是一些简单的文章之类的。只用一点chrome控制台调试断点,不是很复杂。
第一张图中的接口是访问页面渲染数据的接口。json数据中消息的key值一定是需要解密的东西,所以我们需要查看js代码将消息移动到哪里。进入目标页面会加载一个单独的js。命名为 126.js
下一个。在这个js文件中找到消息移动到哪里,然后看图操作
这时候就设置了断点,浏览器返回进入这个页面,这里js会被打断。鼠标悬停在断点上会有提示。点击提示输入断点调用的相关代码。
这时候点击下图浮动的地方,wybzd这个地方。查看如何调用代码来处理此消息。
处理消息的js代码差不多就到这里了。使用AES加密和解密,一种对称加密和解密,加密和解密都使用密码。
t为密码,this.BVDCVojLpQEGLytM为调用该函数时传入的参数。求这个变量的值。它是第一次找到消息的地方,应该只使用第一个密钥。我不知道在哪里使用其他键
关键是:“8NONwyJtHesysWpM”
接下来,让我们验证密钥是否正确。
任意百度AES在线加解密网站。填写密钥、密文、解密方法进行计算
ECB 模式,pkcs7padding 填充,结果字符集 utf-8。最终结果如图,解密完成。本教程到此结束。
四.总结
微信页面OAuth2.0授权登录可以看到官方文档和阮一峰网络日志。
/mobile/game/miraclepan/pan.jsp?panId=2881&wuid=243430 访问该网页时,后台有进程会检查请求源是否在微信浏览器中。如果没有,请在微信客户端打开链接。如果在微信客户端的浏览器中显示,则允许用户主动授权。我们使用fiddler跳过直接判断客户端环境是否在微信客户端浏览器中,直接提示用户授权。授权后,后端被我们欺骗。还真以为是在客户端浏览器环境下,然后就可以畅通无阻了,但实际环境不是微信客户端环境,通过jssdk调用的功能可能有限。我还没有测试过。
这次js混淆加密真的很简单,处理消息的地方只有一处。还加载了一个单独的文件。只有一层调用关系,加密方式也不是很复杂,但这些东西接触时间长了只会有一些敏感的直觉。哈哈,我才刚开始,挺有意思的,总结一下。
网页抓取解密(使用Python网络爬虫获取基金数据信息信息的篇文章分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-15 22:16
大家好,我是一名高级Python初学者。
一、前言
前几天有个粉丝问我基金信息。我会在这里分享。有兴趣的朋友也可以积极尝试。
二、数据采集
这里我们的目标网站是某基金的官网,要抓取的数据如下图所示。
可以看到上图中的基金代码栏,有不同的数字,随便点击一个,就可以进入基金详情页面,链接也很规整,以基金代码为符号。
其实这个网站并不难,数据没有加密,在源码中可以直接看到网页上的信息。
这降低了抓取的难度。通过浏览器抓包的方法可以看到具体的请求参数,可以看到请求参数中只有pi在变化,而这个值恰好对应页面,所以可以直接构造请求参数。
代码实现过程
找到数据源之后,接下来就是实现代码了。让我们来看看。这里有一些关键代码。
获取股票 id 数据
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
gp_id = item.group('items').split(',')[0]
结果如下所示:
然后构建详情页的链接,获取详情页的基金信息。关键代码如下:
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
selectors = etree.HTML(response.text)
danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0]
danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0]
leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0]
lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
结果如下所示:
具体信息经过相应的字符串处理,然后保存到csv文件中,结果如下图所示:
有了这个,您可以进行进一步的统计和数据分析。
三、总结
大家好,我是一名高级Python初学者。本篇文章主要分享使用Python网络爬虫获取资金数据信息。这个项目难度不大,但是有一点坑。欢迎您积极尝试。如果您遇到任何问题,请加我的朋友,我会帮助解决。
这个文章主要是根据【股票类型】的分类。我没有做过其他类型。欢迎您尝试一下。其实逻辑是一样的,只要改变参数即可。
最后,需要本文代码的朋友,可以加我获取!另外,为了方便大家学习Python,我还成立了一个优质的Python学习交流群。你可以问任何关于 Python 的问题。需要进来的朋友加我v,我拉你!
小伙伴们快来练习吧!如果你在学习过程中遇到任何Python问题,请加我为好友,我会拉你进入Python学习交流群一起讨论学习。 查看全部
网页抓取解密(使用Python网络爬虫获取基金数据信息信息的篇文章分享)
大家好,我是一名高级Python初学者。
一、前言
前几天有个粉丝问我基金信息。我会在这里分享。有兴趣的朋友也可以积极尝试。

二、数据采集
这里我们的目标网站是某基金的官网,要抓取的数据如下图所示。

可以看到上图中的基金代码栏,有不同的数字,随便点击一个,就可以进入基金详情页面,链接也很规整,以基金代码为符号。
其实这个网站并不难,数据没有加密,在源码中可以直接看到网页上的信息。

这降低了抓取的难度。通过浏览器抓包的方法可以看到具体的请求参数,可以看到请求参数中只有pi在变化,而这个值恰好对应页面,所以可以直接构造请求参数。

代码实现过程
找到数据源之后,接下来就是实现代码了。让我们来看看。这里有一些关键代码。
获取股票 id 数据
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
gp_id = item.group('items').split(',')[0]
结果如下所示:

然后构建详情页的链接,获取详情页的基金信息。关键代码如下:
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
selectors = etree.HTML(response.text)
danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0]
danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0]
leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0]
lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
结果如下所示:

具体信息经过相应的字符串处理,然后保存到csv文件中,结果如下图所示:

有了这个,您可以进行进一步的统计和数据分析。
三、总结
大家好,我是一名高级Python初学者。本篇文章主要分享使用Python网络爬虫获取资金数据信息。这个项目难度不大,但是有一点坑。欢迎您积极尝试。如果您遇到任何问题,请加我的朋友,我会帮助解决。
这个文章主要是根据【股票类型】的分类。我没有做过其他类型。欢迎您尝试一下。其实逻辑是一样的,只要改变参数即可。

最后,需要本文代码的朋友,可以加我获取!另外,为了方便大家学习Python,我还成立了一个优质的Python学习交流群。你可以问任何关于 Python 的问题。需要进来的朋友加我v,我拉你!
小伙伴们快来练习吧!如果你在学习过程中遇到任何Python问题,请加我为好友,我会拉你进入Python学习交流群一起讨论学习。
网页抓取解密( 2022年04月14日18:29:17作者:浅若清风cyf)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-15 22:09
2022年04月14日18:29:17作者:浅若清风cyf)
Python实现RSA加解密
更新时间:2022-04-14 18:29:17 作者:钱若清风 cyf
这篇文章主要介绍了Python中RSA加解密的实现。加密技术在数据安全存储和数据传输中发挥着重要作用,可以保护用户隐私数据安全,防止信息被盗。RSA是一种非对称加密技术,已广泛应用于软件和网页。以下文章更多相关内容可以参考小伙伴
内容
前言
如果本文对你有帮助,请点赞、采集、关注!您的支持和关注是博主创作的动力!
一、安装模块
pip install pycryptodome
二、生成密钥对
from Crypto.PublicKey import RSA
def create_rsa_pair(is_save=False):
'''
创建rsa公钥私钥对
:param is_save: default:False
:return: public_key, private_key
'''
f = RSA.generate(2048)
private_key = f.exportKey("PEM") # 生成私钥
public_key = f.publickey().exportKey() # 生成公钥
if is_save:
with open("crypto_private_key.pem", "wb") as f:
f.write(private_key)
with open("crypto_public_key.pem", "wb") as f:
f.write(public_key)
return public_key, private_key
def read_public_key(file_path="crypto_public_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
def read_private_key(file_path="crypto_private_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
三、加密
代码:
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto.PublicKey import RSA
def encryption(text: str, public_key: bytes):
# 字符串指定编码(转为bytes)
text = text.encode('utf-8')
# 构建公钥对象
cipher_public = PKCS1_v1_5.new(RSA.importKey(public_key))
# 加密(bytes)
text_encrypted = cipher_public.encrypt(text)
# base64编码,并转为字符串
text_encrypted_base64 = base64.b64encode(text_encrypted ).decode()
return text_encrypted_base64
if __name__ == '__main__':
public_key = read_public_key()
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:',text_encrypted_base64)
四、解密
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
from Crypto.PublicKey import RSA
def decryption(text_encrypted_base64: str, private_key: bytes):
# 字符串指定编码(转为bytes)
text_encrypted_base64 = text_encrypted_base64.encode('utf-8')
# base64解码
text_encrypted = base64.b64decode(text_encrypted_base64 )
# 构建私钥对象
cipher_private = PKCS1_v1_5.new(RSA.importKey(private_key))
# 解密(bytes)
text_decrypted = cipher_private.decrypt(text_encrypted , Random.new().read)
# 解码为字符串
text_decrypted = text_decrypted.decode()
return text_decrypted
if __name__ == '__main__':
# 生成密文
public_key = read_public_key()
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:',text_encrypted_base64)
# 解密
private_key = read_private_key()
text_decrypted = decryption(text_encrypted_base64, private_key)
print('明文:',text_decrypted)
五、完整代码
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
from Crypto.PublicKey import RSA
# ------------------------生成密钥对------------------------
def create_rsa_pair(is_save=False):
'''
创建rsa公钥私钥对
:param is_save: default:False
:return: public_key, private_key
'''
f = RSA.generate(2048)
private_key = f.exportKey("PEM") # 生成私钥
public_key = f.publickey().exportKey() # 生成公钥
if is_save:
with open("crypto_private_key.pem", "wb") as f:
f.write(private_key)
with open("crypto_public_key.pem", "wb") as f:
f.write(public_key)
return public_key, private_key
def read_public_key(file_path="crypto_public_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
def read_private_key(file_path="crypto_private_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
# ------------------------加密------------------------
def encryption(text: str, public_key: bytes):
# 字符串指定编码(转为bytes)
text = text.encode('utf-8')
# 构建公钥对象
cipher_public = PKCS1_v1_5.new(RSA.importKey(public_key))
# 加密(bytes)
text_encrypted = cipher_public.encrypt(text)
# base64编码,并转为字符串
text_encrypted_base64 = base64.b64encode(text_encrypted).decode()
return text_encrypted_base64
# ------------------------解密------------------------
def decryption(text_encrypted_base64: str, private_key: bytes):
# 字符串指定编码(转为bytes)
text_encrypted_base64 = text_encrypted_base64.encode('utf-8')
# base64解码
text_encrypted = base64.b64decode(text_encrypted_base64)
# 构建私钥对象
cipher_private = PKCS1_v1_5.new(RSA.importKey(private_key))
# 解密(bytes)
text_decrypted = cipher_private.decrypt(text_encrypted, Random.new().read)
# 解码为字符串
text_decrypted = text_decrypted.decode()
return text_decrypted
if __name__ == '__main__':
# 生成密钥对
# create_rsa_pair(is_save=True)
# public_key = read_public_key()
# private_key = read_private_key()
public_key, private_key = create_rsa_pair(is_save=False)
# 加密
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:', text_encrypted_base64)
# 解密
text_decrypted = decryption(text_encrypted_base64, private_key)
print('明文:', text_decrypted)
跑:
至此,这篇关于Python实现RSA加解密文章的文章就介绍到这里了。更多相关Python RSA加解密内容请搜索德牛网往期文章或继续浏览以下相关文章希望大家以后多多支持牛网! 查看全部
网页抓取解密(
2022年04月14日18:29:17作者:浅若清风cyf)
Python实现RSA加解密
更新时间:2022-04-14 18:29:17 作者:钱若清风 cyf
这篇文章主要介绍了Python中RSA加解密的实现。加密技术在数据安全存储和数据传输中发挥着重要作用,可以保护用户隐私数据安全,防止信息被盗。RSA是一种非对称加密技术,已广泛应用于软件和网页。以下文章更多相关内容可以参考小伙伴
内容
前言
如果本文对你有帮助,请点赞、采集、关注!您的支持和关注是博主创作的动力!
一、安装模块
pip install pycryptodome
二、生成密钥对
from Crypto.PublicKey import RSA
def create_rsa_pair(is_save=False):
'''
创建rsa公钥私钥对
:param is_save: default:False
:return: public_key, private_key
'''
f = RSA.generate(2048)
private_key = f.exportKey("PEM") # 生成私钥
public_key = f.publickey().exportKey() # 生成公钥
if is_save:
with open("crypto_private_key.pem", "wb") as f:
f.write(private_key)
with open("crypto_public_key.pem", "wb") as f:
f.write(public_key)
return public_key, private_key
def read_public_key(file_path="crypto_public_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
def read_private_key(file_path="crypto_private_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
三、加密
代码:
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto.PublicKey import RSA
def encryption(text: str, public_key: bytes):
# 字符串指定编码(转为bytes)
text = text.encode('utf-8')
# 构建公钥对象
cipher_public = PKCS1_v1_5.new(RSA.importKey(public_key))
# 加密(bytes)
text_encrypted = cipher_public.encrypt(text)
# base64编码,并转为字符串
text_encrypted_base64 = base64.b64encode(text_encrypted ).decode()
return text_encrypted_base64
if __name__ == '__main__':
public_key = read_public_key()
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:',text_encrypted_base64)
四、解密
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
from Crypto.PublicKey import RSA
def decryption(text_encrypted_base64: str, private_key: bytes):
# 字符串指定编码(转为bytes)
text_encrypted_base64 = text_encrypted_base64.encode('utf-8')
# base64解码
text_encrypted = base64.b64decode(text_encrypted_base64 )
# 构建私钥对象
cipher_private = PKCS1_v1_5.new(RSA.importKey(private_key))
# 解密(bytes)
text_decrypted = cipher_private.decrypt(text_encrypted , Random.new().read)
# 解码为字符串
text_decrypted = text_decrypted.decode()
return text_decrypted
if __name__ == '__main__':
# 生成密文
public_key = read_public_key()
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:',text_encrypted_base64)
# 解密
private_key = read_private_key()
text_decrypted = decryption(text_encrypted_base64, private_key)
print('明文:',text_decrypted)
五、完整代码
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
from Crypto.PublicKey import RSA
# ------------------------生成密钥对------------------------
def create_rsa_pair(is_save=False):
'''
创建rsa公钥私钥对
:param is_save: default:False
:return: public_key, private_key
'''
f = RSA.generate(2048)
private_key = f.exportKey("PEM") # 生成私钥
public_key = f.publickey().exportKey() # 生成公钥
if is_save:
with open("crypto_private_key.pem", "wb") as f:
f.write(private_key)
with open("crypto_public_key.pem", "wb") as f:
f.write(public_key)
return public_key, private_key
def read_public_key(file_path="crypto_public_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
def read_private_key(file_path="crypto_private_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
# ------------------------加密------------------------
def encryption(text: str, public_key: bytes):
# 字符串指定编码(转为bytes)
text = text.encode('utf-8')
# 构建公钥对象
cipher_public = PKCS1_v1_5.new(RSA.importKey(public_key))
# 加密(bytes)
text_encrypted = cipher_public.encrypt(text)
# base64编码,并转为字符串
text_encrypted_base64 = base64.b64encode(text_encrypted).decode()
return text_encrypted_base64
# ------------------------解密------------------------
def decryption(text_encrypted_base64: str, private_key: bytes):
# 字符串指定编码(转为bytes)
text_encrypted_base64 = text_encrypted_base64.encode('utf-8')
# base64解码
text_encrypted = base64.b64decode(text_encrypted_base64)
# 构建私钥对象
cipher_private = PKCS1_v1_5.new(RSA.importKey(private_key))
# 解密(bytes)
text_decrypted = cipher_private.decrypt(text_encrypted, Random.new().read)
# 解码为字符串
text_decrypted = text_decrypted.decode()
return text_decrypted
if __name__ == '__main__':
# 生成密钥对
# create_rsa_pair(is_save=True)
# public_key = read_public_key()
# private_key = read_private_key()
public_key, private_key = create_rsa_pair(is_save=False)
# 加密
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:', text_encrypted_base64)
# 解密
text_decrypted = decryption(text_encrypted_base64, private_key)
print('明文:', text_decrypted)
跑:

至此,这篇关于Python实现RSA加解密文章的文章就介绍到这里了。更多相关Python RSA加解密内容请搜索德牛网往期文章或继续浏览以下相关文章希望大家以后多多支持牛网!
网页抓取解密(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-15 08:17
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get(')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态? 查看全部
网页抓取解密(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get(')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:

从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
网页抓取解密(网页抓取解密(一)_网页解密__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-15 02:03
网页抓取解密在很多网站上都会抓取网页,或者抓取下载的文件。我们又要做到分析网页还得想办法解密,这个确实也是比较棘手的事情。又或者还要处理被抓取的页面,这个难度更是可想而知。之前推荐过,可以使用xmlhttprequest库进行网页抓取,可实现各种url对应的对应的解析和预处理,有兴趣的可以查看这篇文章:urlcheatsheet相关阅读:让javascript大显身手的库:customjs、selenium库抓取分析一般不会使用phantomjs对浏览器的底层进行逆向分析。
使用浏览器常见的url对应解析方法也足够了。如http协议逆向分析库:urlreverse、selenium库,文章(此处省略3000字)现在几乎几乎所有的网站都有各种各样的文件需要抓取,又要实现网页的逆向分析,然后生成自己的可执行文件,然后进行复杂的调用机制等等。即可能要费很多脑细胞,并且会有很多坑。
其实,可以尝试在chrome浏览器中使用js进行逆向分析,直接使用chrome的js加密库,如ejs进行网页逆向分析,可以非常方便的实现网页的读取加密,文件提取与分析等步骤。安装chrome好用的js库:jsoup4,selenium好用的js库:ejs(xml、form等)等,flask好用的js库:less、markdown、python代码在flask中的用法:flaskwsgijsoup4spider4,selenium(webdriver)另外,给大家推荐一个flask博客站:flask-bootstrap-front-end-blogs,有需要的,可以查看下,其中关于代码的安装方法也进行了讲解。
对于有些标签,如,?,???,这些标签在解析js/xml时,可能会对js文件起到中间人的作用,如:if-->if-->if-->else等等。如下图代码是解析js文件,而jsoup4可以正确解析js文件。flask为了保证在nginx中的flask程序不被转向到apache。我们需要如下方法:第一步,在flask程序的public目录下创建default_domains_paths文件夹,第二步,将需要解析的js文件上传到这个文件夹下,在python代码中使用setoptions(properties,exec_files,flask_modules),设置需要解析的js文件的路径。
flask代码如下:importflaskasf;flask_modules=[];public_domains_paths=[];//定义一个路径,将js文件路径绑定过来flask_modules=["localhost","","??。 查看全部
网页抓取解密(网页抓取解密(一)_网页解密__)
网页抓取解密在很多网站上都会抓取网页,或者抓取下载的文件。我们又要做到分析网页还得想办法解密,这个确实也是比较棘手的事情。又或者还要处理被抓取的页面,这个难度更是可想而知。之前推荐过,可以使用xmlhttprequest库进行网页抓取,可实现各种url对应的对应的解析和预处理,有兴趣的可以查看这篇文章:urlcheatsheet相关阅读:让javascript大显身手的库:customjs、selenium库抓取分析一般不会使用phantomjs对浏览器的底层进行逆向分析。
使用浏览器常见的url对应解析方法也足够了。如http协议逆向分析库:urlreverse、selenium库,文章(此处省略3000字)现在几乎几乎所有的网站都有各种各样的文件需要抓取,又要实现网页的逆向分析,然后生成自己的可执行文件,然后进行复杂的调用机制等等。即可能要费很多脑细胞,并且会有很多坑。
其实,可以尝试在chrome浏览器中使用js进行逆向分析,直接使用chrome的js加密库,如ejs进行网页逆向分析,可以非常方便的实现网页的读取加密,文件提取与分析等步骤。安装chrome好用的js库:jsoup4,selenium好用的js库:ejs(xml、form等)等,flask好用的js库:less、markdown、python代码在flask中的用法:flaskwsgijsoup4spider4,selenium(webdriver)另外,给大家推荐一个flask博客站:flask-bootstrap-front-end-blogs,有需要的,可以查看下,其中关于代码的安装方法也进行了讲解。
对于有些标签,如,?,???,这些标签在解析js/xml时,可能会对js文件起到中间人的作用,如:if-->if-->if-->else等等。如下图代码是解析js文件,而jsoup4可以正确解析js文件。flask为了保证在nginx中的flask程序不被转向到apache。我们需要如下方法:第一步,在flask程序的public目录下创建default_domains_paths文件夹,第二步,将需要解析的js文件上传到这个文件夹下,在python代码中使用setoptions(properties,exec_files,flask_modules),设置需要解析的js文件的路径。
flask代码如下:importflaskasf;flask_modules=[];public_domains_paths=[];//定义一个路径,将js文件路径绑定过来flask_modules=["localhost","","??。
网页抓取解密(学完课程后可以干什么?-处理请求参数的加密和解密 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-12 20:34
)
完成课程后我可以做什么?
- 处理请求中动态变化的请求参数
- 实现请求参数的加解密操作
- 轻松跳过所有形式的登录验证(刷卡验证等)
- 破解加密响应数据
- ......
爬虫是个奇妙的东西,这也是python的魅力所在——用非常简单的代码,你就可以创建一个强大的爬虫来爬取你想要采集的信息,将人类的双手从重复的工作中解放出来。但是,很多初学者往往在理解爬虫的基本原理上下了不少功夫。一段时间以来,在学习python爬虫的过程中积累了很多经验。我将在这里稍微总结一下,希望能够给你所有的开始。给学者一点启示。
爬虫(又称网络蜘蛛、网络机器人,在 FOAF 社区中,更常称为网络追逐者);它是按照一定的规则自动抓取网页信息的程序或脚本。
如果我们把互联网比作一个大蜘蛛网,电脑上的数据是蜘蛛网上的猎物,而爬虫是小蜘蛛,它们沿着蜘蛛网抓取他们想要的猎物/数据。
概念
Requests 是 Python 爬虫非常常用的库。它基于urllib编写,采用Apache2 Licensed开源协议的HTTP库。Requests 相比 urllib 和 urllib3 更方便,可以为我们省去很多工作,所以建议新爬虫从 Requests 库入手。
Requests 库主要使用 post() 方法和 get() 方法来获取网页数据。
post() 一般用于将特定参数传递给网站,以获得特定的结果。该参数是指网站必须接受的参数,根据这些参数返回不同的结果。比如百度翻译,传入不同的内容,返回不同的翻译。
get()方法一般不需要网站设置的具体参数,可以传入url、headers、roxies等通用参数(主要用于伪装浏览器、反爬虫等,注意以上具体参数)。url 是 网站 链接;headers为网站请求头,也可以通过浏览器检测功能获取;proxies 就是代理,后面的教程会讲解。
查看全部
网页抓取解密(学完课程后可以干什么?-处理请求参数的加密和解密
)
完成课程后我可以做什么?
- 处理请求中动态变化的请求参数
- 实现请求参数的加解密操作
- 轻松跳过所有形式的登录验证(刷卡验证等)
- 破解加密响应数据
- ......
爬虫是个奇妙的东西,这也是python的魅力所在——用非常简单的代码,你就可以创建一个强大的爬虫来爬取你想要采集的信息,将人类的双手从重复的工作中解放出来。但是,很多初学者往往在理解爬虫的基本原理上下了不少功夫。一段时间以来,在学习python爬虫的过程中积累了很多经验。我将在这里稍微总结一下,希望能够给你所有的开始。给学者一点启示。
爬虫(又称网络蜘蛛、网络机器人,在 FOAF 社区中,更常称为网络追逐者);它是按照一定的规则自动抓取网页信息的程序或脚本。
如果我们把互联网比作一个大蜘蛛网,电脑上的数据是蜘蛛网上的猎物,而爬虫是小蜘蛛,它们沿着蜘蛛网抓取他们想要的猎物/数据。

概念
Requests 是 Python 爬虫非常常用的库。它基于urllib编写,采用Apache2 Licensed开源协议的HTTP库。Requests 相比 urllib 和 urllib3 更方便,可以为我们省去很多工作,所以建议新爬虫从 Requests 库入手。
Requests 库主要使用 post() 方法和 get() 方法来获取网页数据。
post() 一般用于将特定参数传递给网站,以获得特定的结果。该参数是指网站必须接受的参数,根据这些参数返回不同的结果。比如百度翻译,传入不同的内容,返回不同的翻译。
get()方法一般不需要网站设置的具体参数,可以传入url、headers、roxies等通用参数(主要用于伪装浏览器、反爬虫等,注意以上具体参数)。url 是 网站 链接;headers为网站请求头,也可以通过浏览器检测功能获取;proxies 就是代理,后面的教程会讲解。


网页抓取解密(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-04-12 20:32
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是用一行代码把你骗进“海盗船”,等你上了贼船才发现水这么深~比如爬一个网页就可以了一个非常简单的代码行:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
老猿已经说了,http协议的性质决定了登录状态是一些cookies,所以如何获取登录状态是一个很棘手的问题。有的网站登录过程很简单,将账号和密码发送到服务器,服务器验证后返回cookies表示登录。这样的网站,更容易实现自动登录,爬虫运行无需人工干预,你有更多的时间喝茶、聊天、学猿猴。
如何处理验证码?
不过,既然网站们已经让你登录了,他们不会那么轻易放过你的。他们要做的就是让小猿们放弃,那就是上传验证码!没错,就是变态的验证码!!作为一个见多识广的老猿猴,到现在还是经常认不出验证码,觉得很丢脸。
据说有人雇了一群阿姨手动识别验证码;有人利用图像处理技术,特别是热门的深度学习和人工智能技术,自动识别验证码。
那么,在编写爬虫时遇到验证码该怎么办呢?
网络爬虫难点三:ajax异步加载甚至JavaScript解密
前两个难点是基于我们对数据加载过程的研究,然后我们可以用Python代码复现并爬取。
在第三个难点上,研究数据加载过程可能很痛苦,几乎崩溃。异步加载过程和服务器来回多次,最终数据只能通过JavaScript解密才能看到,是压垮爬虫的最后一根稻草。 查看全部
网页抓取解密(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是用一行代码把你骗进“海盗船”,等你上了贼船才发现水这么深~比如爬一个网页就可以了一个非常简单的代码行:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
老猿已经说了,http协议的性质决定了登录状态是一些cookies,所以如何获取登录状态是一个很棘手的问题。有的网站登录过程很简单,将账号和密码发送到服务器,服务器验证后返回cookies表示登录。这样的网站,更容易实现自动登录,爬虫运行无需人工干预,你有更多的时间喝茶、聊天、学猿猴。
如何处理验证码?
不过,既然网站们已经让你登录了,他们不会那么轻易放过你的。他们要做的就是让小猿们放弃,那就是上传验证码!没错,就是变态的验证码!!作为一个见多识广的老猿猴,到现在还是经常认不出验证码,觉得很丢脸。
据说有人雇了一群阿姨手动识别验证码;有人利用图像处理技术,特别是热门的深度学习和人工智能技术,自动识别验证码。
那么,在编写爬虫时遇到验证码该怎么办呢?
网络爬虫难点三:ajax异步加载甚至JavaScript解密
前两个难点是基于我们对数据加载过程的研究,然后我们可以用Python代码复现并爬取。
在第三个难点上,研究数据加载过程可能很痛苦,几乎崩溃。异步加载过程和服务器来回多次,最终数据只能通过JavaScript解密才能看到,是压垮爬虫的最后一根稻草。
网页抓取解密(用python爬虫要怎么去抓取数据呢?|小编网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-12 11:00
前言
我们在经常浏览网页的时候,总是用鼠标往下滑,新的网页信息总会刷新,再往下滑,新的网页信息就会刷新。总之,在一个url链接不变的情况下,用鼠标拖拽下滑,总会看到新的网页信息(如今日头条、网易新闻、微博、豆瓣电影等)。
那么,对于这样的网页,我们如何使用python爬虫来爬取数据呢?先跟着小编看看以下知识点:
阿贾克斯
Ajax的全称是Asynchronous JavaScript and XML(异步JavaScript和XML)。它是一种使用 JavaScript 与服务器交换数据并更新部分网页同时确保页面不刷新和页面链接不改变的技术。
对于传统网页,如果要更新其内容,则必须刷新整个页面。使用 Ajax,可以在不完全刷新的情况下更新页面内容。在这个过程中,页面实际上在后台与服务器交互。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。如果网页的原创 HTML 不收录任何数据,数据通过 Ajax 统一加载后呈现,可以在 Web 开发中分离前后端,减少服务器直接渲染页面的压力,有效防止爬行动物。对于 Ajax,数据加载是一种异步加载方法。原创页面不收录某些数据。只有在加载完成后,向服务器请求一个接口获取数据,然后将数据处理并呈现给网页。这个过程实际上是向服务器接口发送一个 Ajax 请求。此时,我们需要分析网页后端向接口发送的Ajax请求,并使用requests 查看全部
网页抓取解密(用python爬虫要怎么去抓取数据呢?|小编网页)
前言
我们在经常浏览网页的时候,总是用鼠标往下滑,新的网页信息总会刷新,再往下滑,新的网页信息就会刷新。总之,在一个url链接不变的情况下,用鼠标拖拽下滑,总会看到新的网页信息(如今日头条、网易新闻、微博、豆瓣电影等)。
那么,对于这样的网页,我们如何使用python爬虫来爬取数据呢?先跟着小编看看以下知识点:
阿贾克斯
Ajax的全称是Asynchronous JavaScript and XML(异步JavaScript和XML)。它是一种使用 JavaScript 与服务器交换数据并更新部分网页同时确保页面不刷新和页面链接不改变的技术。
对于传统网页,如果要更新其内容,则必须刷新整个页面。使用 Ajax,可以在不完全刷新的情况下更新页面内容。在这个过程中,页面实际上在后台与服务器交互。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。如果网页的原创 HTML 不收录任何数据,数据通过 Ajax 统一加载后呈现,可以在 Web 开发中分离前后端,减少服务器直接渲染页面的压力,有效防止爬行动物。对于 Ajax,数据加载是一种异步加载方法。原创页面不收录某些数据。只有在加载完成后,向服务器请求一个接口获取数据,然后将数据处理并呈现给网页。这个过程实际上是向服务器接口发送一个 Ajax 请求。此时,我们需要分析网页后端向接口发送的Ajax请求,并使用requests
网页抓取解密(Web安全——暴力破解(BurteForce)(不存在token))
网站优化 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2022-04-11 19:03
网络安全 - 蛮力 (BurteForce)
前言:弱密码yyds,虽然暴力破解是一种原理很简单,利用方式也很简单的漏洞,但是它的危害是非常巨大的。暴力登录后,该 Web 应用程序的所有信息将被暴露。
暴力破解(BurteForce)1:基于表单的暴力破解(没有验证码和token)
1、通过BurpSuite抓包发现这里没有Token等鉴权信息,账号密码等信息明文传输
2. 将捕获的数据包发送给攻击模块(Intruder),然后将参数密码设置为变量,选择攻击模式为Sniper,避免麻烦。我们实验的默认登录帐户是 admin。
设置密码变量攻击方式:
配置变量的有效负载:
暴力破解结果,密码为123456,登录成功
总结:当登录认证的地方没有验证码、Token等认证信息时,我们可以通过暴力破解轻松耗尽网站的账号和密码。
2:验证码绕过On Server(没有token)
1、通过抓包判断这里有验证码认证信息,验证码经过服务器验证,没有Token等其他认证信息。
2.首先判断本场景输入的验证码和账号密码的错误信息,方便后续推测当前认证情况
验证码错误:
账号密码输入错误:
这里可以判断验证码的正确判断优先级高于账号密码的正确判断优先级。
3.当前认证信息推测
判断思路:这里需要判断的是验证码是否会跟随账号密码提交失败。如果实时更新,蛮力破解难度会大大提高,否则难度会降低
操作步骤:提交正确的验证码数据包发送到Repeater模块,多次修改账号密码参数后重新提交,查看返回结果,返回结果为账号密码错误信息。浏览器不多次提交,服务器提交给客户端的验证码不变。
4、根据步骤3可以判断,如果不改验证码,账号密码的破解及步骤与“基于表单的暴力破解”相同,不再赘述详情在这里。
验证码认证下使用admin/123456登录成功
三:验证码绕过On Client(没有token)
1、通过抓包判断这里有验证码认证信息,抓包发现客户端输入验证码错误时,BP没有抓到数据包,所以这里推断验证码属于客户端验证。
2.在这种场景下,即使我们不确定这里的验证码是服务端还是客户端,我们仍然可以按照On Server推测的方法进行处理,不会影响我们最终的账号和密码,因为它与上述情景一致。步骤不会重复太多
四:账号密码安全认证(有token,无验证码等)
1、通过抓包判断这里有Token认证,没有其他认证方式。
2. 可以绕过令牌以防止暴力破解。令牌是一种认证信息。其基础知识请参考文章Web Security-CSRF(Token) 客户端提交的token值由服务端决定。发送给客户端的请求隐藏在最后一个回复中,隐藏在隐藏标签中
3.暴力破解开始
1. 抓取提交的认证包,发送给Intruder,然后设置password和token变量作为payload参数,攻击方式选择Pitchfork或者Cluster bomb(因为这里需要设置两个字典)
2、设置密码字典
3.设置token字典,因为每个token都是最后一个回复包返回的值,所以我们需要设置如下
选择 Grep 提取
按以下顺序将token值设置为变量,然后在此处赋值token值
设置令牌字典
设置线程数为1
破解获取密码
总结:在对目标进行暴力枚举时,首先要根据抓包信息推断出其认证方式的可能性。只有知道了它的鉴别方法,才能对症下药。此外,字典需要足够丰富。
暴力列举常见的危害和防御:
常见危害:
1.获取登录账号和密码,登录应用后台,结合其他漏洞做更多危害
2、敏感信息泄露,通过枚举应用根目录,导致敏感信息泄露
保护:
1.提高密码和验证码的复杂度(至少8位,大小写,特殊字符和数字)
2、应用限制单位时间登录错误次数(如10分钟内连续输入5次错误,将被锁定10分钟)
3.验证码随提交而变化
参考研究文章:
网络安全——CSRF(Token)
Burp套件中的Attack Type模式详解—Intruder 查看全部
网页抓取解密(Web安全——暴力破解(BurteForce)(不存在token))
网络安全 - 蛮力 (BurteForce)
前言:弱密码yyds,虽然暴力破解是一种原理很简单,利用方式也很简单的漏洞,但是它的危害是非常巨大的。暴力登录后,该 Web 应用程序的所有信息将被暴露。
暴力破解(BurteForce)1:基于表单的暴力破解(没有验证码和token)
1、通过BurpSuite抓包发现这里没有Token等鉴权信息,账号密码等信息明文传输

2. 将捕获的数据包发送给攻击模块(Intruder),然后将参数密码设置为变量,选择攻击模式为Sniper,避免麻烦。我们实验的默认登录帐户是 admin。
设置密码变量攻击方式:

配置变量的有效负载:

暴力破解结果,密码为123456,登录成功

总结:当登录认证的地方没有验证码、Token等认证信息时,我们可以通过暴力破解轻松耗尽网站的账号和密码。
2:验证码绕过On Server(没有token)
1、通过抓包判断这里有验证码认证信息,验证码经过服务器验证,没有Token等其他认证信息。

2.首先判断本场景输入的验证码和账号密码的错误信息,方便后续推测当前认证情况
验证码错误:

账号密码输入错误:

这里可以判断验证码的正确判断优先级高于账号密码的正确判断优先级。
3.当前认证信息推测
判断思路:这里需要判断的是验证码是否会跟随账号密码提交失败。如果实时更新,蛮力破解难度会大大提高,否则难度会降低
操作步骤:提交正确的验证码数据包发送到Repeater模块,多次修改账号密码参数后重新提交,查看返回结果,返回结果为账号密码错误信息。浏览器不多次提交,服务器提交给客户端的验证码不变。

4、根据步骤3可以判断,如果不改验证码,账号密码的破解及步骤与“基于表单的暴力破解”相同,不再赘述详情在这里。
验证码认证下使用admin/123456登录成功

三:验证码绕过On Client(没有token)
1、通过抓包判断这里有验证码认证信息,抓包发现客户端输入验证码错误时,BP没有抓到数据包,所以这里推断验证码属于客户端验证。

2.在这种场景下,即使我们不确定这里的验证码是服务端还是客户端,我们仍然可以按照On Server推测的方法进行处理,不会影响我们最终的账号和密码,因为它与上述情景一致。步骤不会重复太多
四:账号密码安全认证(有token,无验证码等)
1、通过抓包判断这里有Token认证,没有其他认证方式。

2. 可以绕过令牌以防止暴力破解。令牌是一种认证信息。其基础知识请参考文章Web Security-CSRF(Token) 客户端提交的token值由服务端决定。发送给客户端的请求隐藏在最后一个回复中,隐藏在隐藏标签中

3.暴力破解开始
1. 抓取提交的认证包,发送给Intruder,然后设置password和token变量作为payload参数,攻击方式选择Pitchfork或者Cluster bomb(因为这里需要设置两个字典)

2、设置密码字典

3.设置token字典,因为每个token都是最后一个回复包返回的值,所以我们需要设置如下
选择 Grep 提取

按以下顺序将token值设置为变量,然后在此处赋值token值


设置令牌字典

设置线程数为1

破解获取密码

总结:在对目标进行暴力枚举时,首先要根据抓包信息推断出其认证方式的可能性。只有知道了它的鉴别方法,才能对症下药。此外,字典需要足够丰富。
暴力列举常见的危害和防御:
常见危害:
1.获取登录账号和密码,登录应用后台,结合其他漏洞做更多危害
2、敏感信息泄露,通过枚举应用根目录,导致敏感信息泄露
保护:
1.提高密码和验证码的复杂度(至少8位,大小写,特殊字符和数字)
2、应用限制单位时间登录错误次数(如10分钟内连续输入5次错误,将被锁定10分钟)
3.验证码随提交而变化
参考研究文章:
网络安全——CSRF(Token)
Burp套件中的Attack Type模式详解—Intruder
网页抓取解密(网页抓取解密方案,开源的抓取程序技术流程是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-04-09 04:02
网页抓取解密方案1这种方案即爬取好友的空间或者会员的空间动态,然后解密编码方法使用“xmpp”比较简单,易实现。2这种方案使用多种类型的验证码扫描器,设置好成对密码,实现网页抓取的过程,需要使用第三方解码工具。总结本文分析一下开源的抓取程序技术流程。1.技术流程2-这里主要用到“selenium”来捕捉异步请求,如果采用“phantomjs”就需要通过浏览器的解析加载解码3.分析结论3.1采用“selenium”采用selenium自带api,自带浏览器的解析,如果采用“phantomjs”则需要下载第三方加速工具。
3.2使用多种类型的验证码扫描器使用多种类型的验证码扫描器,在扫描时按照需要来设置是否让验证码自动解码。如果是需要编码则需要采用“scrapy”结合代理,等待自动解码;如果没有要求编码,则通过使用“xmpp”工具解码。3.3反爬虫分析反爬虫分析原理通过浏览器解析验证码实现,爬取规则都是“穷举”结论2-这里主要用到“fiddler”驱动api设置的authorization,这个大家应该都学过。
验证码扫描器是否放在抓包工具上,使用抓包工具解析验证码的authorization3.4抓取分析真实对象“链接”这里抓取的是头条人物资料类页面的一部分“链接”,验证码的authorization设置是真实不自动解码,需要使用“xmpp”解析;xmpp是”xml+manual“自动脚本工具,非常适合你的爬虫。
结论2-技术流程4-1技术流程如果抓取代码是非官方文档(如网页)文件可以使用”esplus.js“编写,各种xml数据格式化工具支持,输入也比较简单,但是每行代码一定要有请求头就够了,可以使用esplus中文编辑器中的一键制作。编写高质量爬虫的技巧是对js代码风格需要慎重选择,个人感觉根据网页大小选择1-2条编写思路便可以了,当然,这样编写还不如python代码快,且一个人写有时候会弄混代码结构。
4.2总结原创android抓取api爬取官方文档获取网址5.抓取过程中遇到问题本篇抓取的api虽然作者有写一定要拿到工资,但是不影响你阅读本篇文章。最后附api1.打开头条2.根据自己的需要配置api(点击文末附api生成器中编写的api);3.下载相关文件(点击附api生成器中编写的api)。6.总结6.1工具附:5.抓取工具推荐6.2原理细节与分析5.xmpp利用xmpp框架解析代码,然后下载api,再下载api文件。
6.3处理代码需要代码来改装对比api找差异就是你处理api文件的思路~原理细节和分析这里不再累述,技术细节不在这里。---。 查看全部
网页抓取解密(网页抓取解密方案,开源的抓取程序技术流程是什么?)
网页抓取解密方案1这种方案即爬取好友的空间或者会员的空间动态,然后解密编码方法使用“xmpp”比较简单,易实现。2这种方案使用多种类型的验证码扫描器,设置好成对密码,实现网页抓取的过程,需要使用第三方解码工具。总结本文分析一下开源的抓取程序技术流程。1.技术流程2-这里主要用到“selenium”来捕捉异步请求,如果采用“phantomjs”就需要通过浏览器的解析加载解码3.分析结论3.1采用“selenium”采用selenium自带api,自带浏览器的解析,如果采用“phantomjs”则需要下载第三方加速工具。
3.2使用多种类型的验证码扫描器使用多种类型的验证码扫描器,在扫描时按照需要来设置是否让验证码自动解码。如果是需要编码则需要采用“scrapy”结合代理,等待自动解码;如果没有要求编码,则通过使用“xmpp”工具解码。3.3反爬虫分析反爬虫分析原理通过浏览器解析验证码实现,爬取规则都是“穷举”结论2-这里主要用到“fiddler”驱动api设置的authorization,这个大家应该都学过。
验证码扫描器是否放在抓包工具上,使用抓包工具解析验证码的authorization3.4抓取分析真实对象“链接”这里抓取的是头条人物资料类页面的一部分“链接”,验证码的authorization设置是真实不自动解码,需要使用“xmpp”解析;xmpp是”xml+manual“自动脚本工具,非常适合你的爬虫。
结论2-技术流程4-1技术流程如果抓取代码是非官方文档(如网页)文件可以使用”esplus.js“编写,各种xml数据格式化工具支持,输入也比较简单,但是每行代码一定要有请求头就够了,可以使用esplus中文编辑器中的一键制作。编写高质量爬虫的技巧是对js代码风格需要慎重选择,个人感觉根据网页大小选择1-2条编写思路便可以了,当然,这样编写还不如python代码快,且一个人写有时候会弄混代码结构。
4.2总结原创android抓取api爬取官方文档获取网址5.抓取过程中遇到问题本篇抓取的api虽然作者有写一定要拿到工资,但是不影响你阅读本篇文章。最后附api1.打开头条2.根据自己的需要配置api(点击文末附api生成器中编写的api);3.下载相关文件(点击附api生成器中编写的api)。6.总结6.1工具附:5.抓取工具推荐6.2原理细节与分析5.xmpp利用xmpp框架解析代码,然后下载api,再下载api文件。
6.3处理代码需要代码来改装对比api找差异就是你处理api文件的思路~原理细节和分析这里不再累述,技术细节不在这里。---。
网页抓取解密(巴西里约热内卢天主教大学Lua大学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-08 05:28
Lua 是一种小型脚本语言。它是由三人团队于 1993 年在巴西里约热内卢天主教大学由 Roberto Ierusalimschy、Waldemar Celes 和 Luiz Henrique de Figueiredo 开发的。它旨在通过灵活嵌入到应用程序中,为应用程序提供灵活的扩展和定制能力。Lua 是用标准 C 语言编写的,几乎可以在所有操作系统和平台上编译和运行。Lua 没有提供强大的库,这是由它的定位决定的。所以 Lua 不适合作为开发独立应用程序的语言。Lua 有一个并发 JIT 项目,可在特定平台上提供即时编译。
Lua脚本可以方便的被C/C++代码调用,也可以依次调用C/C++函数,这使得Lua在应用中得到了广泛的应用。不仅作为扩展脚本,而且作为通用配置文件,代替XML、ini等文件格式,更易于理解和维护。Lua采用标准C语言编写,代码简洁美观,几乎可以在所有操作系统和平台上编译运行。一个完整的 Lua 解释器只有 200k。在所有脚本引擎中,Lua 是最快的。这一切都决定了 Lua 是作为嵌入式脚本的最佳选择。 查看全部
网页抓取解密(巴西里约热内卢天主教大学Lua大学)
Lua 是一种小型脚本语言。它是由三人团队于 1993 年在巴西里约热内卢天主教大学由 Roberto Ierusalimschy、Waldemar Celes 和 Luiz Henrique de Figueiredo 开发的。它旨在通过灵活嵌入到应用程序中,为应用程序提供灵活的扩展和定制能力。Lua 是用标准 C 语言编写的,几乎可以在所有操作系统和平台上编译和运行。Lua 没有提供强大的库,这是由它的定位决定的。所以 Lua 不适合作为开发独立应用程序的语言。Lua 有一个并发 JIT 项目,可在特定平台上提供即时编译。
Lua脚本可以方便的被C/C++代码调用,也可以依次调用C/C++函数,这使得Lua在应用中得到了广泛的应用。不仅作为扩展脚本,而且作为通用配置文件,代替XML、ini等文件格式,更易于理解和维护。Lua采用标准C语言编写,代码简洁美观,几乎可以在所有操作系统和平台上编译运行。一个完整的 Lua 解释器只有 200k。在所有脚本引擎中,Lua 是最快的。这一切都决定了 Lua 是作为嵌入式脚本的最佳选择。
网页抓取解密(基于chrome的跨浏览器post/get请求获取xmlhttprequest对象实现的抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-07 15:06
网页抓取解密关键就是代码层次,比如需要获取网页源代码,就需要获取加密后的meta标签信息,然后解密就简单了,一般就是反编译。至于从页面文本中得到文字和图片信息就没有那么简单了,可以尝试抓包分析页面代码结构,然后对二者进行切片分析。当然,这只是获取关键信息的一种方法,抓包还需要使用好网络抓包工具。再者,最简单的方法可以使用chrome浏览器的xmlhttprequest实现“调用http头获取数据”功能,不过如果需要查看页面源代码,则需要切换到查看xmlhttprequest()方法在请求中的实现,这样的话,就很难破解“返回data字段”的解密密码了。
github-shinzoxiao/dummyhttp:一个基于chrome的跨浏览器post/get请求获取xmlhttprequest对象实现的抓包工具。使用方法:。
1、首先打开项目页面,按照提示安装依赖包。
2、然后使用javascript代码来调用xmlhttprequest实现调用meta标签的xmlhttprequest调用,
3、这里的xmlhttprequest实现参考了fakehttp库中xmlhttprequest实现。
4、执行此javascript代码,解密就算完成。#http/1.1http/1.1是http/1.0之后最新的协议版本。http请求通常指的是http2.0,需要先注册到firefox浏览器上。http连接在大多数浏览器上都是会给你一个标准的uri地址,同时以as/image连接在网页(如百度首页)上。
如果要发起xmlhttp请求的话,则必须得到该连接的对应uri地址,比如你想请求一个视频资源,则必须得到该视频资源的uri地址"your-video-title"。常见请求头:location:用于表示uri的位置。name:用于表示uri的名称。description:用于表示应用程序需要发送给服务器的数据。
method:用于表示应用程序发送给服务器的数据类型,也可以用于调用get/post等方法。origin:用于表示客户端与服务器交互的方向。content-type:表示请求头的数据类型:application/x-www-form-urlencoded,application/x-www-form-data,application/x-message-text,application/x-www-form-content;charset=utf-8,application/x-message-content;charset=utf-8等等;post:表示在客户端向服务器发送数据。
get:表示在服务器上从服务器上获取数据。动态页面另说。如果请求的是静态页面,使用请求头中的host指定网址即可。如果页面名称中包含参数,则会对应到网址(post/get),单个参数的话,也会对应到页面名(host/get)。cookie头:默认的cookie是加密的,但也有不需要cookie就请求到服务器的。 查看全部
网页抓取解密(基于chrome的跨浏览器post/get请求获取xmlhttprequest对象实现的抓包工具)
网页抓取解密关键就是代码层次,比如需要获取网页源代码,就需要获取加密后的meta标签信息,然后解密就简单了,一般就是反编译。至于从页面文本中得到文字和图片信息就没有那么简单了,可以尝试抓包分析页面代码结构,然后对二者进行切片分析。当然,这只是获取关键信息的一种方法,抓包还需要使用好网络抓包工具。再者,最简单的方法可以使用chrome浏览器的xmlhttprequest实现“调用http头获取数据”功能,不过如果需要查看页面源代码,则需要切换到查看xmlhttprequest()方法在请求中的实现,这样的话,就很难破解“返回data字段”的解密密码了。
github-shinzoxiao/dummyhttp:一个基于chrome的跨浏览器post/get请求获取xmlhttprequest对象实现的抓包工具。使用方法:。
1、首先打开项目页面,按照提示安装依赖包。
2、然后使用javascript代码来调用xmlhttprequest实现调用meta标签的xmlhttprequest调用,
3、这里的xmlhttprequest实现参考了fakehttp库中xmlhttprequest实现。
4、执行此javascript代码,解密就算完成。#http/1.1http/1.1是http/1.0之后最新的协议版本。http请求通常指的是http2.0,需要先注册到firefox浏览器上。http连接在大多数浏览器上都是会给你一个标准的uri地址,同时以as/image连接在网页(如百度首页)上。
如果要发起xmlhttp请求的话,则必须得到该连接的对应uri地址,比如你想请求一个视频资源,则必须得到该视频资源的uri地址"your-video-title"。常见请求头:location:用于表示uri的位置。name:用于表示uri的名称。description:用于表示应用程序需要发送给服务器的数据。
method:用于表示应用程序发送给服务器的数据类型,也可以用于调用get/post等方法。origin:用于表示客户端与服务器交互的方向。content-type:表示请求头的数据类型:application/x-www-form-urlencoded,application/x-www-form-data,application/x-message-text,application/x-www-form-content;charset=utf-8,application/x-message-content;charset=utf-8等等;post:表示在客户端向服务器发送数据。
get:表示在服务器上从服务器上获取数据。动态页面另说。如果请求的是静态页面,使用请求头中的host指定网址即可。如果页面名称中包含参数,则会对应到网址(post/get),单个参数的话,也会对应到页面名(host/get)。cookie头:默认的cookie是加密的,但也有不需要cookie就请求到服务器的。
【安全】黑客暴力破解必备的12大逆向工具!设置再复杂的密码也没用!
网站优化 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2022-05-03 15:48
暴力破解是最流行的密码破解方法之一,然而,它不仅仅是密码破解。暴力破解还可用于发现Web应用程序中的隐藏页面和内容,在你成功之前,这种破解基本上是“破解一次尝试一次”。
这种破解有时需要更长的时间,但其成功率也会更高。在本文中,我将尝试解释在不同场景中使用的暴力破解和流行工具,来执行暴力破解并获得所需结果。
一、什么是暴力破解?
当攻击者使用一组预定义值攻击目标并分析响应直到他成功,这就叫做暴力攻击。它的成功取决于预定义值的集合,如果它越大,就会需要更多时间,但成功的可能性也会变大。
最常见且最容易理解的暴力攻击是破解密码的字典攻击,在这种情况下,攻击者使用包含数百万个可作为密码的单词的密码字典,然后攻击者逐个尝试这些密码并进行身份验证,如果字典中包含正确的密码,攻击者将会成功。
在传统的暴力攻击中,攻击者只是尝试字母和数字的组合来顺序生成密码。但是,当密码足够长的时候,这种技术就会需要更长的时间,这些攻击可能需要几分钟到几小时甚至是几年的时间,具体取决于所使用的系统和密码的长度。
为了防止暴力破解密码,应始终使用长而复杂的密码。这会使得攻击者很难猜到密码,暴力攻击会花费更多的时间,大多数时候,WordPress用户面临对其网站的暴力攻击。
帐户锁定是防止攻击者对Web应用程序执行暴力攻击的一种方法。但是,对于离线软件,事情就没这么简单了。
同样,为了发现隐藏页面,攻击者会尝试猜测页面名称,发送请求并查看响应。如果该页面不存在,它将显示响应404,成功的话就会响应200。这样,它可以在任何网站上找到隐藏页面。
暴力攻击也用于破解散列并从给定散列中猜出密码。这样的话,哈希是从随机密码生成的,然后此哈希与目标哈希匹配,直到攻击者找到正确的哈希。因此,用于加密密码的加密类型(64位、128位或256位加密)越高,暴力破解所需的时间就会越长。
二、逆向暴力破解
逆向暴力攻击是另一个与密码破解相关的术语,破解密码采用相反的方法。攻击者针对多个用户名尝试一个密码,想想你是否有知道密码但是不知道用户名的时候,在这种情况下,你可以尝试使用相同的密码去猜测不同的用户名,直到找到匹配组合。
现在,您知道暴力攻击主要用于密码破解,您可以在任何软件,任何网站或任何协议中使用它,只要目标在几次无效尝试后不会组织请求就行。在这篇文章中,我将为不同的协议介绍一些流行的密码破解工具。
三、暴力破解的流行工具
1. Aircrack-NG
我相信大家都曾经了解过Aircrack-ng工具,这是一款免费的无线密码破解工具。该工具附带WEP / WPA / WPA2-PSK破解程序和分析工具,可对WiFi 802.11进行攻击。Aircrack-ng可用于任何支持监听模式的网卡。
它基本上是采用密码字典攻击来猜测无线密码,如您所知,攻击的成功取决于密码字典,密码字典越好越有效。
它适用于Windows和Linux平台,它也被移植到iOS和Android平台上运行,您可以尝试使用给定的平台来研究此工具的工作原理。
2. John the Ripper
开膛手约翰也是一款几乎人人皆知的工具,它长期以来一直是进行暴力攻击的最佳选择。这个免费的密码破解工具最初是为Unix系统开发的,后来,开发人员又为其他平台发布了这款工具。现在它支持15种不同的平台,包括Unix\Windows、DOS、Linux、BeOS和OpenVMS等。您可以使用它来识别弱密码或破解密码来通过身份验证。
这款工具非常受欢迎,并结合了各种密码破解功能,它可以自动检测密码中使用的哈希类型。因此,您也可以针对加密密码存储运行它。
基本上,它可以通过组合字母和数字对所有可能的密码执行暴力破解。但是您也可以将其与密码字典一起使用来执行字典攻击。
3. Rainbow Crack
Rainbow Crack也是一款用于密码破解的流行工具。它会生成彩虹表,以便在执行攻击时使用,这也使得它与其他的暴力破击工具不同。彩虹表是预先计算的,它有助于减少执行攻击的时间。
幸运的是,有各种组织已经为所有互联网用户发布了前计算机的彩虹表,为了节省时间,您可以下载这些彩虹表并在攻击中使用。
该工具仍然在积极开发中,它适用于Windows和Linux,并支持这些平台的所有最新发行版。
4. Cain & Ablel
同样也是一款热门的工具,它可以通过执行暴力攻击、字典攻击和密码分析攻击来帮助破解各种密码。密码分析攻击是通过使用前一种工具中提到的彩虹表来完成的。
值得一提的是,一些病毒查杀软件会将其检测为恶意软件。Avast和Microsoft Security Essentials将其报告为恶意软件并会组织它的运行。如果您需要使用这款软件,您需要先和您的杀毒软件打好招呼。
它的基本功能是:
该工具的最新版本具有很多功能,并添加了嗅探来执行中间人攻击。
5. L0phtcrack
L0phtCrack以破解Windows密码的能力而闻名。它使用字典、暴力破解、混合攻击和彩虹表。L0phtCrack最显著的特性是调度、64位Windows版本的哈希提取、多处理器算法以及网络监控和解码。如果要破解Windows系统的密码,可以尝试使用此工具。
6. Ophcrack
Ophcrack是另一款专门用于破解Windows密码的暴力破解工具。它通过彩虹表使用LM哈希来破解Windows密码。它是一款免费的开源工具,在大多数情况下,它可以在几分钟内破解Windows密码,默认情况下,Ophcrack附带的彩虹表能够破解少于14个字符的密码,其中只包含字母数字字符。其他彩虹表也可供下载。
Ophcrack还可用作LiveCD。
7. Crack
Crack是一款古老的密码破解工具,它是Unix系统的密码破解工具,用于通过执行字典攻击来检查弱密码。
8. Hashcat
Hashcat号称是最快的基于CPU的密码破解工具。它是免费的,适用于Linux、Windows和Mac OS平台。Hashcat支持各种散列算法,包括LM Hashes、MD4、MD5、SHA系列、Unix Crypt格式、MySQL、Cisco PIX。它支持各种攻击形式,包括暴力破解、组合攻击、字典攻击、指纹攻击、混合攻击、掩码攻击、置换攻击、基于规则的攻击、表查找攻击和Toggle-Case攻击。
9. SAMInside
SAMInside同样专门用于破解Windows操作系统的密码,它类似于Ophcrack和Lophtcrack工具。它声称在一台电脑上最高可以每秒破解大约1000万个密码。它支持各种攻击方法,包括掩码攻击、字典攻击、混合攻击和彩虹表攻击。它支持400多种哈希算法。
10.DaveGrohl
DaveGrohl是适用于Mac OS X的流行破解工具,它支持所有可用版本的Mac OS X,此工具支持字典攻击和增量攻击。它还具有分布式模式,允许您从多台计算机执行攻击以攻击相同的密码哈希。此工具现在是开源的,您可以从源码进行安装。
11. Ncrack
Ncrack用于破解网络身份验证,它支持各种协议,包括RDP、SSH、HTTP(S)、SMB、POP3(S)、VNC、FTP和telnet。它可以执行不同的攻击,包括暴力破解等。支持包括Linux、BSD、Windows和Mac OS X等操作系统。
12. THC Hydra
九头蛇以其通过执行暴力攻击来破解网络身份验证的能力而闻名。它可对多种协议执行字典攻击,包括telnet、FTP、HTTP、HTTPS、SMB等。它适用于多种平台,包括Linux、Windows、Cygwin、Solaris、FreeBSD、OpenBSD、OSX和QNX/BlackBerry等。
这些都是用于密码破解的流行工具,还有各种其他工具可用于对不同类型的身份验证执行暴力破解,如果我只举几个小工具的例子,你会看到大多数PDF破解、ZIP破解工具使用相同的暴力破解方法来执行攻击,有许多此类工具可免费或付费使用。
四、结论
暴力破解是破解密码最常用的方法,攻击的成功取决于各种因素,但是,影响最多的因素是密码的长度以及数字、字母和特殊字符的组合。这就是我们谈论强密码的原因:我们通常建议用户使用小写字母、大写字母、数字和特殊字符组合的长密码。它不会使得暴力破解不可能,但会让其变得十分困难。这样,暴力破解会需要更长的时间来破解密码。几乎所有的散列破解算法都使用暴力破解来尝试,当您对数据进行脱机访问时,此攻击最佳。在这种情况下,它易于破解,而且会花费更少的时间。
暴力密码破解在计算机安全性方面非常重要,它用于检查系统、网络或应用程序中使用的弱密码。
防止暴力攻击的最佳方法是限制无效登录,通过这种方式,攻击只能在有限的时间点击并尝试密码。这就是为什么基于网络的服务开始使用验证码,如果您三次输入错误的密码他们会对您的IP地址进行屏蔽。
版权声明:本文为CSDN博主「javaxiaoheibai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
查看全部
【安全】黑客暴力破解必备的12大逆向工具!设置再复杂的密码也没用!
暴力破解是最流行的密码破解方法之一,然而,它不仅仅是密码破解。暴力破解还可用于发现Web应用程序中的隐藏页面和内容,在你成功之前,这种破解基本上是“破解一次尝试一次”。
这种破解有时需要更长的时间,但其成功率也会更高。在本文中,我将尝试解释在不同场景中使用的暴力破解和流行工具,来执行暴力破解并获得所需结果。
一、什么是暴力破解?
当攻击者使用一组预定义值攻击目标并分析响应直到他成功,这就叫做暴力攻击。它的成功取决于预定义值的集合,如果它越大,就会需要更多时间,但成功的可能性也会变大。
最常见且最容易理解的暴力攻击是破解密码的字典攻击,在这种情况下,攻击者使用包含数百万个可作为密码的单词的密码字典,然后攻击者逐个尝试这些密码并进行身份验证,如果字典中包含正确的密码,攻击者将会成功。
在传统的暴力攻击中,攻击者只是尝试字母和数字的组合来顺序生成密码。但是,当密码足够长的时候,这种技术就会需要更长的时间,这些攻击可能需要几分钟到几小时甚至是几年的时间,具体取决于所使用的系统和密码的长度。
为了防止暴力破解密码,应始终使用长而复杂的密码。这会使得攻击者很难猜到密码,暴力攻击会花费更多的时间,大多数时候,WordPress用户面临对其网站的暴力攻击。
帐户锁定是防止攻击者对Web应用程序执行暴力攻击的一种方法。但是,对于离线软件,事情就没这么简单了。
同样,为了发现隐藏页面,攻击者会尝试猜测页面名称,发送请求并查看响应。如果该页面不存在,它将显示响应404,成功的话就会响应200。这样,它可以在任何网站上找到隐藏页面。
暴力攻击也用于破解散列并从给定散列中猜出密码。这样的话,哈希是从随机密码生成的,然后此哈希与目标哈希匹配,直到攻击者找到正确的哈希。因此,用于加密密码的加密类型(64位、128位或256位加密)越高,暴力破解所需的时间就会越长。
二、逆向暴力破解
逆向暴力攻击是另一个与密码破解相关的术语,破解密码采用相反的方法。攻击者针对多个用户名尝试一个密码,想想你是否有知道密码但是不知道用户名的时候,在这种情况下,你可以尝试使用相同的密码去猜测不同的用户名,直到找到匹配组合。
现在,您知道暴力攻击主要用于密码破解,您可以在任何软件,任何网站或任何协议中使用它,只要目标在几次无效尝试后不会组织请求就行。在这篇文章中,我将为不同的协议介绍一些流行的密码破解工具。
三、暴力破解的流行工具
1. Aircrack-NG
我相信大家都曾经了解过Aircrack-ng工具,这是一款免费的无线密码破解工具。该工具附带WEP / WPA / WPA2-PSK破解程序和分析工具,可对WiFi 802.11进行攻击。Aircrack-ng可用于任何支持监听模式的网卡。
它基本上是采用密码字典攻击来猜测无线密码,如您所知,攻击的成功取决于密码字典,密码字典越好越有效。
它适用于Windows和Linux平台,它也被移植到iOS和Android平台上运行,您可以尝试使用给定的平台来研究此工具的工作原理。
2. John the Ripper
开膛手约翰也是一款几乎人人皆知的工具,它长期以来一直是进行暴力攻击的最佳选择。这个免费的密码破解工具最初是为Unix系统开发的,后来,开发人员又为其他平台发布了这款工具。现在它支持15种不同的平台,包括Unix\Windows、DOS、Linux、BeOS和OpenVMS等。您可以使用它来识别弱密码或破解密码来通过身份验证。
这款工具非常受欢迎,并结合了各种密码破解功能,它可以自动检测密码中使用的哈希类型。因此,您也可以针对加密密码存储运行它。
基本上,它可以通过组合字母和数字对所有可能的密码执行暴力破解。但是您也可以将其与密码字典一起使用来执行字典攻击。
3. Rainbow Crack
Rainbow Crack也是一款用于密码破解的流行工具。它会生成彩虹表,以便在执行攻击时使用,这也使得它与其他的暴力破击工具不同。彩虹表是预先计算的,它有助于减少执行攻击的时间。
幸运的是,有各种组织已经为所有互联网用户发布了前计算机的彩虹表,为了节省时间,您可以下载这些彩虹表并在攻击中使用。
该工具仍然在积极开发中,它适用于Windows和Linux,并支持这些平台的所有最新发行版。
4. Cain & Ablel
同样也是一款热门的工具,它可以通过执行暴力攻击、字典攻击和密码分析攻击来帮助破解各种密码。密码分析攻击是通过使用前一种工具中提到的彩虹表来完成的。
值得一提的是,一些病毒查杀软件会将其检测为恶意软件。Avast和Microsoft Security Essentials将其报告为恶意软件并会组织它的运行。如果您需要使用这款软件,您需要先和您的杀毒软件打好招呼。
它的基本功能是:
该工具的最新版本具有很多功能,并添加了嗅探来执行中间人攻击。
5. L0phtcrack
L0phtCrack以破解Windows密码的能力而闻名。它使用字典、暴力破解、混合攻击和彩虹表。L0phtCrack最显著的特性是调度、64位Windows版本的哈希提取、多处理器算法以及网络监控和解码。如果要破解Windows系统的密码,可以尝试使用此工具。
6. Ophcrack
Ophcrack是另一款专门用于破解Windows密码的暴力破解工具。它通过彩虹表使用LM哈希来破解Windows密码。它是一款免费的开源工具,在大多数情况下,它可以在几分钟内破解Windows密码,默认情况下,Ophcrack附带的彩虹表能够破解少于14个字符的密码,其中只包含字母数字字符。其他彩虹表也可供下载。
Ophcrack还可用作LiveCD。
7. Crack
Crack是一款古老的密码破解工具,它是Unix系统的密码破解工具,用于通过执行字典攻击来检查弱密码。
8. Hashcat
Hashcat号称是最快的基于CPU的密码破解工具。它是免费的,适用于Linux、Windows和Mac OS平台。Hashcat支持各种散列算法,包括LM Hashes、MD4、MD5、SHA系列、Unix Crypt格式、MySQL、Cisco PIX。它支持各种攻击形式,包括暴力破解、组合攻击、字典攻击、指纹攻击、混合攻击、掩码攻击、置换攻击、基于规则的攻击、表查找攻击和Toggle-Case攻击。
9. SAMInside
SAMInside同样专门用于破解Windows操作系统的密码,它类似于Ophcrack和Lophtcrack工具。它声称在一台电脑上最高可以每秒破解大约1000万个密码。它支持各种攻击方法,包括掩码攻击、字典攻击、混合攻击和彩虹表攻击。它支持400多种哈希算法。
10.DaveGrohl
DaveGrohl是适用于Mac OS X的流行破解工具,它支持所有可用版本的Mac OS X,此工具支持字典攻击和增量攻击。它还具有分布式模式,允许您从多台计算机执行攻击以攻击相同的密码哈希。此工具现在是开源的,您可以从源码进行安装。
11. Ncrack
Ncrack用于破解网络身份验证,它支持各种协议,包括RDP、SSH、HTTP(S)、SMB、POP3(S)、VNC、FTP和telnet。它可以执行不同的攻击,包括暴力破解等。支持包括Linux、BSD、Windows和Mac OS X等操作系统。
12. THC Hydra
九头蛇以其通过执行暴力攻击来破解网络身份验证的能力而闻名。它可对多种协议执行字典攻击,包括telnet、FTP、HTTP、HTTPS、SMB等。它适用于多种平台,包括Linux、Windows、Cygwin、Solaris、FreeBSD、OpenBSD、OSX和QNX/BlackBerry等。
这些都是用于密码破解的流行工具,还有各种其他工具可用于对不同类型的身份验证执行暴力破解,如果我只举几个小工具的例子,你会看到大多数PDF破解、ZIP破解工具使用相同的暴力破解方法来执行攻击,有许多此类工具可免费或付费使用。
四、结论
暴力破解是破解密码最常用的方法,攻击的成功取决于各种因素,但是,影响最多的因素是密码的长度以及数字、字母和特殊字符的组合。这就是我们谈论强密码的原因:我们通常建议用户使用小写字母、大写字母、数字和特殊字符组合的长密码。它不会使得暴力破解不可能,但会让其变得十分困难。这样,暴力破解会需要更长的时间来破解密码。几乎所有的散列破解算法都使用暴力破解来尝试,当您对数据进行脱机访问时,此攻击最佳。在这种情况下,它易于破解,而且会花费更少的时间。
暴力密码破解在计算机安全性方面非常重要,它用于检查系统、网络或应用程序中使用的弱密码。
防止暴力攻击的最佳方法是限制无效登录,通过这种方式,攻击只能在有限的时间点击并尝试密码。这就是为什么基于网络的服务开始使用验证码,如果您三次输入错误的密码他们会对您的IP地址进行屏蔽。
版权声明:本文为CSDN博主「javaxiaoheibai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
网页抓取解密 真香的PDF软件--PDF24
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-05-03 15:24
一个完全免费的PDF工具箱软件:PDF24,里面包含了20多种关于PDF的操作的免费工具。列如包含了PDF转换、合并、叠加、压缩、比较、编辑、裁剪、注释、加密、解密、分割、旋转、优化、删除、提取、排序页面等等。
豌豆工作室公众号对话框回复:uf,获取资料!
网页版,网址:
该工具分网页版和桌面安装版,网页版社长就不多介绍,就是直接打开网址就可以使用,桌面安装的话我们直接下载好软件安装包,然后直接双击打开,我们发现默认是英文安装界面,不用管这个直接OK,安装好之后软件默认是中文的。
安装完毕有一个英文注册界面,不想注册的用户可以直接点击skip跳过即可。
接下来社长就给大家演示一遍使用方法,以转化为PDF为列:点击选择文件或者直接把需要转化成PDF文件拖拽到软件中即可
然后点击转换为PDF。
然后保存到自己的电脑打开就可以看到已经转换为PDF文件了。
功能实在太多就不过多介绍,这款软件还可以当成PDF文件格式的查看软件。
--------END-------- 查看全部
网页抓取解密 真香的PDF软件--PDF24
一个完全免费的PDF工具箱软件:PDF24,里面包含了20多种关于PDF的操作的免费工具。列如包含了PDF转换、合并、叠加、压缩、比较、编辑、裁剪、注释、加密、解密、分割、旋转、优化、删除、提取、排序页面等等。
豌豆工作室公众号对话框回复:uf,获取资料!
网页版,网址:
该工具分网页版和桌面安装版,网页版社长就不多介绍,就是直接打开网址就可以使用,桌面安装的话我们直接下载好软件安装包,然后直接双击打开,我们发现默认是英文安装界面,不用管这个直接OK,安装好之后软件默认是中文的。
安装完毕有一个英文注册界面,不想注册的用户可以直接点击skip跳过即可。
接下来社长就给大家演示一遍使用方法,以转化为PDF为列:点击选择文件或者直接把需要转化成PDF文件拖拽到软件中即可
然后点击转换为PDF。
然后保存到自己的电脑打开就可以看到已经转换为PDF文件了。
功能实在太多就不过多介绍,这款软件还可以当成PDF文件格式的查看软件。
--------END--------
JS逆向steam登录
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-05-03 09:57
前言
我们爬虫有时候,会遇到登录才能获取到数据的情况,最开始的时候我们只需要加入请求的data参数就可以,可是现在网站为了反爬,对登录的密码或者账号都做了加密处理,如果我们不破解出这些加密的密码或者账号,就没办法实现请求登录,所以我们就需要破解出这些加密后的密码或者账号,才能实现请求登录,这些加密的密码或者账号都是用JavaScript写的,后面我们统一都简称为js。
了解js加密的种类
现在市面上的js加密,大至分为五类,base64加密、sha1加密、MD5加密、AES/DES加密解密、RSA加密,前面两种稍微简单一点,后面的3种就会复杂一点,特别是RSA加密,因为它是一种非对称加密算法,所以加密的稳定性和加密的复杂程度也就会最高,因为steam这个网站的登录就是使用的RSA加密技术,所以本文就只着重讲RSA加密,至于其它4种加密技术,本文不做过多赘述,想了解其他加密技术的小伙伴,可以自行百度搜索了解。
什么是RSA加密
RSA算法是一种非对称加密算法,那么何为非对称加密算法呢?
一般我们理解上的加密是这样子进行的:原文经过了一把钥匙(密钥)加密后变成了密文,然后将密文传递给接收方,接收方再用这把钥匙(密钥)解开密文。在这个过程中,其实加密和解密使用的是同一把钥匙,这种加密方式称为对称加密。如图:
而非对称加密就是和对称加密相对,加密用的钥匙和解密所用的钥匙,并不是同一把钥匙。非对称加密首先会创建两把钥匙,而这两把钥匙是成对的分别称为公钥和私钥。在进行加密时我们使用公钥进行加密,而在解密的时候就必须要使用私钥才能进行解密,这就是非对称加密算法。如图:
实战讲解
登录目标网站,然后点击登录页面,如图:
进入到登录页面,
现在我们打开开发者调试工具,或者按F12打开,定位到Network选项,勾选上Preserve log选项和Disable cache选项,如图:
然后我们在登录窗口,随便输入些账号和密码,点击登录按钮,这个时候Network选项下就会抓取到请求到的数据,
我们先看第一个数据,点击后,定位到preview选项,可以看到给我们返回的一些数据,这其实就是RSA的密钥数据。
我们说过RSA加密是需要公钥和私钥的,这里面的就是我们能需要的解密用到的私钥数据,下面我们能看第二个数据,这个就是我们登录需要请求的数据网址,我们定位带headers选项,可以看请求方式是POST请求,那就必须要有请求参数才行,然后找到from data项,如图:
可以很明显看出,username是我们输入的账号名,password是一堆看不懂的乱码,其实这就是经过RSA加密过的密码数据,我们就需要加密这个密码数据。
我们通过全局搜素,搜索password这个关键字,可以看出有很多包含password这个关键字的数据,那么这么多数据那个才是我们能需要找到的数据呢,
这里有个小技巧,如果发现搜索出来很多关于关键字的信息,可以在该关键字后面给一个=号在搜索,如图:
经过再次的搜索可以看出这次就没有那么多内容了,便于我们更好的找到需要的数据位置,我们通过搜索出的数据可以看出,有一个encryptedpassword这行的数据,从字面的意思就能知道这是加密的密码的意思,所以我们就先定位带这条数据的里面,看看是什么样的,经过定位到里面我们看到是一个用js代码写的文件,里面有很多js代码,
既然我们认为这个就是加密的密码数据,那么我们可以给这行数据下一个断点,然后点击登录,看能不能断下这条数据,通过断点,我们确实可以断下这条数据,那么也就是代表这里就是加密密码的方法,RSA.encrypt是一个函数,里面的参数分别就是,password就是我们输入的密码。
pubkey是一个对象,这个对象具体是什么还需要进入到这个函数里面看具体的情形。
我们按F11进入到这个函数里面,可以看到有一个js的文件,这个文件就是RSA加密的整个过程的文件。
逆向改写
通过上面的分析,我们已经知道了大概密码的加密过程,现在就需要我们通过工具给它的这些代码进行一些改写,从而获取到真正加密的密码数据,这里我用到的改写工具是鬼鬼JS调试工具7.5工具可以自行搜索下载。
navigator = {};var dbits;<br />// JavaScript engine analysisvar canary = 0xdeadbeefcafe;var j_lm = ((canary & 0xffffff) == 0xefcafe);<br />// (public) Constructorfunction BigInteger(a, b, c) { if (a != null) if ("number" == typeof a) this.fromNumber(a, b, c); else if (b == null && "string" != typeof a) this.fromString(a, 256); else this.fromString(a, b);}<br />// return new, unset BigIntegerfunction nbi() { return new BigInteger(null);}<br />// am: Compute w_j += (x*this_i), propagate carries,// c is initial carry, returns final carry.// c < 3*dvalue, x < 2*dvalue, this_i < dvalue// We need to select the fastest one that works in this environment.<br />// am1: use a single mult and divide to get the high bits,// max digit bits should be 26 because// max internal value = 2*dvalue^2-2*dvalue (< 2^53)function am1(i, x, w, j, c, n) { while (--n >= 0) { var v = x * this[i++] + w[j] + c; c = Math.floor(v / 0x4000000); w[j++] = v & 0x3ffffff; } return c;}// am2 avoids a big mult-and-extract completely.// Max digit bits should be > 15; while (--n >= 0) { var l = this[i] & 0x7fff; var h = this[i++] >> 15; var m = xh * l + h * xl; l = xl * l + ((m & 0x7fff) >> 30) + (m >>> 15) + xh * h + (c >>> 30); w[j++] = l & 0x3fffffff; } return c;}// Alternately, set max digit bits to 28 since some// browsers slow down when dealing with 32-bit numbers.function am3(i, x, w, j, c, n) { var xl = x & 0x3fff, xh = x >> 14; while (--n >= 0) { var l = this[i] & 0x3fff; var h = this[i++] >> 14; var m = xh * l + h * xl; l = xl * l + ((m & 0x3fff) > 28) + (m >> 14) + xh * h; w[j++] = l & 0xfffffff; } return c;}<br /><br />// Digit conversionsvar BI_RM = "0123456789abcdefghijklmnopqrstuvwxyz";var BI_RC = new Array();var rr, vv;rr = "0".charCodeAt(0);for (vv = 0; vv a, - if this < a, 0 if equalfunction bnCompareTo(a) { var r = this.s - a.s; if (r != 0) return r; var i = this.t; r = i - a.t; if (r != 0) return r; while (--i >= 0) if ((r = this[i] - a[i]) != 0) return r; return 0;}<br />// returns bit length of the integer xfunction nbits(x) { var r = 1, t; if ((t = x >>> 16) != 0) { x = t; r += 16; } if ((t = x >> 8) != 0) { x = t; r += 8; } if ((t = x >> 4) != 0) { x = t; r += 4; } if ((t = x >> 2) != 0) { x = t; r += 2; } if ((t = x >> 1) != 0) { x = t; r += 1; } return r;}<br />// (public) return the number of bits in "this"function bnBitLength() { if (this.t = 0; --i) r[i] = 0; r.t = this.t + n; r.s = this.s;}<br />// (protected) r = this >> n*DBfunction bnpDRShiftTo(n, r) { for (var i = n; i < this.t; ++i) r[i - n] = this[i]; r.t = Math.max(this.t - n, 0); r.s = this.s;}<br />// (protected) r = this cbs) | c; c = (this[i] & bm) = 0; --i) r[i] = 0; r[ds] = c; r.t = this.t + ds + 1; r.s = this.s; r.clamp();}<br />// (protected) r = this >> nfunction bnpRShiftTo(n, r) { r.s = this.s; var ds = Math.floor(n / this.DB); if (ds >= this.t) { r.t = 0; return; } var bs = n % this.DB; var cbs = this.DB - bs; var bm = (1 > bs; for (var i = ds + 1; i < this.t; ++i) { r[i - ds - 1] |= (this[i] & bm) > bs; } if (bs > 0) r[this.t - ds - 1] |= (this.s & bm) >= this.DB; } if (a.t < this.t) { c -= a.s; while (i < this.t) { c += this[i]; r[i++] = c & this.DM; c >>= this.DB; } c += this.s; } else { c += this.s; while (i < a.t) { c -= a[i]; r[i++] = c & this.DM; c >>= this.DB; } c -= a.s; } r.s = (c < 0) ? -1 : 0; if (c < -1) r[i++] = this.DV + c; else if (c > 0) r[i++] = c; r.t = i; r.clamp();}<br />// (protected) r = this * a, r != this,a (HAC 14.12)// "this" should be the larger one if appropriate.function bnpMultiplyTo(a, r) { var x = this.abs(), y = a.abs(); var i = x.t; r.t = i + y.t; while (--i >= 0) r[i] = 0; for (i = 0; i < y.t; ++i) r[i + x.t] = x.am(0, y[i], r, i, 0, x.t); r.s = 0; r.clamp(); if (this.s != a.s) BigInteger.ZERO.subTo(r, r);}<br />// (protected) r = this^2, r != this (HAC 14.16)function bnpSquareTo(r) { var x = this.abs(); var i = r.t = 2 * x.t; while (--i >= 0) r[i] = 0; for (i = 0; i < x.t - 1; ++i) { var c = x.am(i, x[i], r, 2 * i, 0, 1); if ((r[i + x.t] += x.am(i + 1, 2 * x[i], r, 2 * i + 1, c, x.t - i - 1)) >= x.DV) { r[i + x.t] -= x.DV; r[i + x.t + 1] = 1; } } if (r.t > 0) r[r.t - 1] += x.am(i, x[i], r, 2 * i, 0, 1); r.s = 0; r.clamp();}<br />// (protected) divide this by m, quotient and remainder to q, r (HAC 14.20)// r != q, this != m. q or r may be null.function bnpDivRemTo(m, q, r) { var pm = m.abs(); if (pm.t 0) { pm.lShiftTo(nsh, y); pt.lShiftTo(nsh, r); } else { pm.copyTo(y); pt.copyTo(r); } var ys = y.t; var y0 = y[ys - 1]; if (y0 == 0) return; var yt = y0 * (1 1) ? y[ys - 2] >> this.F2 : 0); var d1 = this.FV / yt, d2 = (1 = 0) { // Estimate quotient digit var qd = (r[--i] == y0) ? this.DM : Math.floor(r[i] * d1 + (r[i - 1] + e) * d2); if ((r[i] += y.am(0, qd, r, j, 0, ys)) < qd) { // Try it out y.dlShiftTo(j, t); r.subTo(t, r); while (r[i] < --qd) r.subTo(t, r); } } if (q != null) { r.drShiftTo(ys, q); if (ts != ms) BigInteger.ZERO.subTo(q, q); } r.t = ys; r.clamp(); if (nsh > 0) r.rShiftTo(nsh, r); // Denormalize remainder if (ts < 0) BigInteger.ZERO.subTo(r, r);}<br />// (public) this mod afunction bnMod(a) { var r = nbi(); this.abs().divRemTo(a, null, r); if (this.s < 0 && r.compareTo(BigInteger.ZERO) > 0) a.subTo(r, r); return r;}<br />// Modular reduction using "classic" algorithmfunction Classic(m) { this.m = m;}<br />function cConvert(x) { if (x.s < 0 || x.compareTo(this.m) >= 0) return x.mod(this.m); else return x;}<br />function cRevert(x) { return x;}<br />function cReduce(x) { x.divRemTo(this.m, null, x);}<br />function cMulTo(x, y, r) { x.multiplyTo(y, r); this.reduce(r);}<br />function cSqrTo(x, r) { x.squareTo(r); this.reduce(r);}<br />Classic.prototype.convert = cConvert;Classic.prototype.revert = cRevert;Classic.prototype.reduce = cReduce;Classic.prototype.mulTo = cMulTo;Classic.prototype.sqrTo = cSqrTo;<br />// (protected) return "-1/this % 2^DB"; useful for Mont. reduction// justification:// xy == 1 (mod m)// xy = 1+km// xy(2-xy) = (1+km)(1-km)// x[y(2-xy)] = 1-k^2m^2// x[y(2-xy)] == 1 (mod m^2)// if y is 1/x mod m, then y(2-xy) is 1/x mod m^2// should reduce x and y(2-xy) by m^2 at each step to keep size bounded.// JS multiply "overflows" differently from C/C++, so care is needed here.function bnpInvDigit() { if (this.t < 1) return 0; var x = this[0]; if ((x & 1) == 0) return 0; var y = x & 3; // y == 1/x mod 2^2 y = (y * (2 - (x & 0xf) * y)) & 0xf; // y == 1/x mod 2^4 y = (y * (2 - (x & 0xff) * y)) & 0xff; // y == 1/x mod 2^8 y = (y * (2 - (((x & 0xffff) * y) & 0xffff))) & 0xffff; // y == 1/x mod 2^16 // last step - calculate inverse mod DV directly; // assumes 16 < DB 0) ? this.DV - y : -y;}<br />// Montgomery reductionfunction Montgomery(m) { this.m = m; this.mp = m.invDigit(); this.mpl = this.mp & 0x7fff; this.mph = this.mp >> 15; this.um = (1 0) this.m.subTo(r, r); return r;}<br />// x/R mod mfunction montRevert(x) { var r = nbi(); x.copyTo(r); this.reduce(r); return r;}<br />// x = x/R mod m (HAC 14.32)function montReduce(x) { while (x.t > 15) * this.mpl) & this.um) = x.DV) { x[j] -= x.DV; x[++j]++; } } x.clamp(); x.drShiftTo(this.m.t, x); if (x.compareTo(this.m) >= 0) x.subTo(this.m, x);}<br />// r = "x^2/R mod m"; x != rfunction montSqrTo(x, r) { x.squareTo(r); this.reduce(r);}<br />// r = "xy/R mod m"; x,y != rfunction montMulTo(x, y, r) { x.multiplyTo(y, r); this.reduce(r);}<br />Montgomery.prototype.convert = montConvert;Montgomery.prototype.revert = montRevert;Montgomery.prototype.reduce = montReduce;Montgomery.prototype.mulTo = montMulTo;Montgomery.prototype.sqrTo = montSqrTo;<br />// (protected) true iff this is evenfunction bnpIsEven() { return ((this.t > 0) ? (this[0] & 1) : this.s) == 0;}<br />// (protected) this^e, e < 2^32, doing sqr and mul with "r" (HAC 14.79)function bnpExp(e, z) { if (e > 0xffffffff || e < 1) return BigInteger.ONE; var r = nbi(), r2 = nbi(), g = z.convert(this), i = nbits(e) - 1; g.copyTo(r); while (--i >= 0) { z.sqrTo(r, r2); if ((e & (1 0) z.mulTo(r2, g, r); else { var t = r; r = r2; r2 = t; } } return z.revert(r);}<br />// (public) this^e % m, 0 1; if (t > lowprimes.length) t = lowprimes.length; var a = nbi(); for (var i = 0; i < t; ++i) { a.fromInt(lowprimes[i]); var y = a.modPow(r, this); if (y.compareTo(BigInteger.ONE) != 0 && y.compareTo(n1) != 0) { var j = 1; while (j++ < k && y.compareTo(n1) != 0) { y = y.modPowInt(2, this); if (y.compareTo(BigInteger.ONE) == 0) return false; } if (y.compareTo(n1) != 0) return false; } } return true;}<br />// protectedBigInteger.prototype.chunkSize = bnpChunkSize;BigInteger.prototype.toRadix = bnpToRadix;BigInteger.prototype.fromRadix = bnpFromRadix;BigInteger.prototype.fromNumber = bnpFromNumber;BigInteger.prototype.bitwiseTo = bnpBitwiseTo;BigInteger.prototype.changeBit = bnpChangeBit;BigInteger.prototype.addTo = bnpAddTo;BigInteger.prototype.dMultiply = bnpDMultiply;BigInteger.prototype.dAddOffset = bnpDAddOffset;BigInteger.prototype.multiplyLowerTo = bnpMultiplyLowerTo;BigInteger.prototype.multiplyUpperTo = bnpMultiplyUpperTo;BigInteger.prototype.modInt = bnpModInt;BigInteger.prototype.millerRabin = bnpMillerRabin;<br />// publicBigInteger.prototype.clone = bnClone;BigInteger.prototype.intValue = bnIntValue;BigInteger.prototype.byteValue = bnByteValue;BigInteger.prototype.shortValue = bnShortValue;BigInteger.prototype.signum = bnSigNum;BigInteger.prototype.toByteArray = bnToByteArray;BigInteger.prototype.equals = bnEquals;BigInteger.prototype.min = bnMin;BigInteger.prototype.max = bnMax;BigInteger.prototype.and = bnAnd;BigInteger.prototype.or = bnOr;BigInteger.prototype.xor = bnXor;BigInteger.prototype.andNot = bnAndNot;BigInteger.prototype.not = bnNot;BigInteger.prototype.shiftLeft = bnShiftLeft;BigInteger.prototype.shiftRight = bnShiftRight;BigInteger.prototype.getLowestSetBit = bnGetLowestSetBit;BigInteger.prototype.bitCount = bnBitCount;BigInteger.prototype.testBit = bnTestBit;BigInteger.prototype.setBit = bnSetBit;BigInteger.prototype.clearBit = bnClearBit;BigInteger.prototype.flipBit = bnFlipBit;BigInteger.prototype.add = bnAdd;BigInteger.prototype.subtract = bnSubtract;BigInteger.prototype.multiply = bnMultiply;BigInteger.prototype.divide = bnDivide;BigInteger.prototype.remainder = bnRemainder;BigInteger.prototype.divideAndRemainder = bnDivideAndRemainder;BigInteger.prototype.modPow = bnModPow;BigInteger.prototype.modInverse = bnModInverse;BigInteger.prototype.pow = bnPow;BigInteger.prototype.gcd = bnGCD;BigInteger.prototype.isProbablePrime = bnIsProbablePrime;<br />// BigInteger interfaces not implemented in jsbn:<br />// BigInteger(int signum, byte[] magnitude)// double doubleValue()// float floatValue()// int hashCode()// long longValue()// static BigInteger valueOf(long val)<br /><br /><br />var RSAPublicKey = function($modulus_hex, $encryptionExponent_hex) { this.modulus = new BigInteger($modulus_hex, 16); this.encryptionExponent = new BigInteger($encryptionExponent_hex, 16);};<br />var Base64 = { base64: "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=", encode: function($input) { if (!$input) { return false; } var $output = ""; var $chr1, $chr2, $chr3; var $enc1, $enc2, $enc3, $enc4; var $i = 0; do { $chr1 = $input.charCodeAt($i++); $chr2 = $input.charCodeAt($i++); $chr3 = $input.charCodeAt($i++); $enc1 = $chr1 >> 2; $enc2 = (($chr1 & 3) > 4); $enc3 = (($chr2 & 15) > 6); $enc4 = $chr3 & 63; if (isNaN($chr2)) $enc3 = $enc4 = 64; else if (isNaN($chr3)) $enc4 = 64; $output += this.base64.charAt($enc1) + this.base64.charAt($enc2) + this.base64.charAt($enc3) + this.base64.charAt($enc4); } while ($i < $input.length); return $output; }, decode: function($input) { if (!$input) return false; $input = $input.replace(/[^A-Za-z0-9\+\/\=]/g, ""); var $output = ""; var $enc1, $enc2, $enc3, $enc4; var $i = 0; do { $enc1 = this.base64.indexOf($input.charAt($i++)); $enc2 = this.base64.indexOf($input.charAt($i++)); $enc3 = this.base64.indexOf($input.charAt($i++)); $enc4 = this.base64.indexOf($input.charAt($i++)); $output += String.fromCharCode(($enc1 > 4)); if ($enc3 != 64) $output += String.fromCharCode((($enc2 & 15) > 2)); if ($enc4 != 64) $output += String.fromCharCode((($enc3 & 3) > 4) & 0xf) + this.hex.charAt($k & 0xf); } while ($i < $input.length); return $output; }, decode: function($input) { if (!$input) return false; $input = $input.replace(/[^0-9abcdef]/g, ""); var $output = ""; var $i = 0; do { $output += String.fromCharCode(((this.hex.indexOf($input.charAt($i++)) > 3); if (!$data) return false; $data = $data.modPowInt($pubkey.encryptionExponent, $pubkey.modulus); if (!$data) return false; $data = $data.toString(16); if (($data.length & 1) == 1) $data = "0" + $data; return Base64.encode(Hex.decode($data)); },<br /> pkcs1pad2: function($data, $keysize) { if ($keysize < $data.length + 11) return null; var $buffer = []; var $i = $data.length - 1; while ($i >= 0 && $keysize > 0) $buffer[--$keysize] = $data.charCodeAt($i--); $buffer[--$keysize] = 0; while ($keysize > 2) $buffer[--$keysize] = Math.floor(Math.random() * 254) + 1; $buffer[--$keysize] = 2; $buffer[--$keysize] = 0; return new BigInteger($buffer); }}<br /> function get_pwd(pwd,mod, exp) { var pubKey = RSA.getPublicKey(mod, exp); password = pwd.replace(/[^\x00-\x7F]/g, ''); var encryptedPassword = RSA.encrypt(password, pubKey); return encryptedPassword; }
通过自定义一个get_pwd的函数,来调用上面加密的整个过程,函数上面的部分,就是加密的整个过程的代码,这些代码也不是我写的,是别人写好的,我只是复制粘贴过来,改动一下,利用自己定义的函数,调用了这些代码,从而实现加密的目的。该函数需要传递2个参数,这个2个参数分别是未加密前的密码和私钥,私钥就在我们请求网页的时候,返回的第一个数据里面(publickey_exp和publickey_mod)。
mod就是publickey_mod,exp就是publickey_exp,通过传递参数,在调用定义的get_pwd这个函数,就能得到加密的密码结果了,加密后的密码也是动态的,每次都不一样。
效果展示
结语
因为本文涉及很多JavaScript的知识,所以需要对JavaScript有些了解,另外在改写JS代码的时候,会遇到很多的错误提示,限于篇幅的有限,我没有过多的写出如何排除这些错误提示,我们就需要利用一些JavaScript的知识一点点的排除这些错误提示,直到提示加载成功,才可以运行代码的,所以还是推荐用js的调试工具,这样更方便一些。头一次写这样的技术文章,有很多写的不到位的地方,还请多多提出宝贵意见。
END
B站账号:
https://space.bilibili.com/351138764
欢迎扫码
关注我 查看全部
JS逆向steam登录
前言
我们爬虫有时候,会遇到登录才能获取到数据的情况,最开始的时候我们只需要加入请求的data参数就可以,可是现在网站为了反爬,对登录的密码或者账号都做了加密处理,如果我们不破解出这些加密的密码或者账号,就没办法实现请求登录,所以我们就需要破解出这些加密后的密码或者账号,才能实现请求登录,这些加密的密码或者账号都是用JavaScript写的,后面我们统一都简称为js。
了解js加密的种类
现在市面上的js加密,大至分为五类,base64加密、sha1加密、MD5加密、AES/DES加密解密、RSA加密,前面两种稍微简单一点,后面的3种就会复杂一点,特别是RSA加密,因为它是一种非对称加密算法,所以加密的稳定性和加密的复杂程度也就会最高,因为steam这个网站的登录就是使用的RSA加密技术,所以本文就只着重讲RSA加密,至于其它4种加密技术,本文不做过多赘述,想了解其他加密技术的小伙伴,可以自行百度搜索了解。
什么是RSA加密
RSA算法是一种非对称加密算法,那么何为非对称加密算法呢?
一般我们理解上的加密是这样子进行的:原文经过了一把钥匙(密钥)加密后变成了密文,然后将密文传递给接收方,接收方再用这把钥匙(密钥)解开密文。在这个过程中,其实加密和解密使用的是同一把钥匙,这种加密方式称为对称加密。如图:
而非对称加密就是和对称加密相对,加密用的钥匙和解密所用的钥匙,并不是同一把钥匙。非对称加密首先会创建两把钥匙,而这两把钥匙是成对的分别称为公钥和私钥。在进行加密时我们使用公钥进行加密,而在解密的时候就必须要使用私钥才能进行解密,这就是非对称加密算法。如图:
实战讲解
登录目标网站,然后点击登录页面,如图:
进入到登录页面,
现在我们打开开发者调试工具,或者按F12打开,定位到Network选项,勾选上Preserve log选项和Disable cache选项,如图:
然后我们在登录窗口,随便输入些账号和密码,点击登录按钮,这个时候Network选项下就会抓取到请求到的数据,
我们先看第一个数据,点击后,定位到preview选项,可以看到给我们返回的一些数据,这其实就是RSA的密钥数据。
我们说过RSA加密是需要公钥和私钥的,这里面的就是我们能需要的解密用到的私钥数据,下面我们能看第二个数据,这个就是我们登录需要请求的数据网址,我们定位带headers选项,可以看请求方式是POST请求,那就必须要有请求参数才行,然后找到from data项,如图:
可以很明显看出,username是我们输入的账号名,password是一堆看不懂的乱码,其实这就是经过RSA加密过的密码数据,我们就需要加密这个密码数据。
我们通过全局搜素,搜索password这个关键字,可以看出有很多包含password这个关键字的数据,那么这么多数据那个才是我们能需要找到的数据呢,
这里有个小技巧,如果发现搜索出来很多关于关键字的信息,可以在该关键字后面给一个=号在搜索,如图:
经过再次的搜索可以看出这次就没有那么多内容了,便于我们更好的找到需要的数据位置,我们通过搜索出的数据可以看出,有一个encryptedpassword这行的数据,从字面的意思就能知道这是加密的密码的意思,所以我们就先定位带这条数据的里面,看看是什么样的,经过定位到里面我们看到是一个用js代码写的文件,里面有很多js代码,
既然我们认为这个就是加密的密码数据,那么我们可以给这行数据下一个断点,然后点击登录,看能不能断下这条数据,通过断点,我们确实可以断下这条数据,那么也就是代表这里就是加密密码的方法,RSA.encrypt是一个函数,里面的参数分别就是,password就是我们输入的密码。
pubkey是一个对象,这个对象具体是什么还需要进入到这个函数里面看具体的情形。
我们按F11进入到这个函数里面,可以看到有一个js的文件,这个文件就是RSA加密的整个过程的文件。
逆向改写
通过上面的分析,我们已经知道了大概密码的加密过程,现在就需要我们通过工具给它的这些代码进行一些改写,从而获取到真正加密的密码数据,这里我用到的改写工具是鬼鬼JS调试工具7.5工具可以自行搜索下载。
navigator = {};var dbits;<br />// JavaScript engine analysisvar canary = 0xdeadbeefcafe;var j_lm = ((canary & 0xffffff) == 0xefcafe);<br />// (public) Constructorfunction BigInteger(a, b, c) { if (a != null) if ("number" == typeof a) this.fromNumber(a, b, c); else if (b == null && "string" != typeof a) this.fromString(a, 256); else this.fromString(a, b);}<br />// return new, unset BigIntegerfunction nbi() { return new BigInteger(null);}<br />// am: Compute w_j += (x*this_i), propagate carries,// c is initial carry, returns final carry.// c < 3*dvalue, x < 2*dvalue, this_i < dvalue// We need to select the fastest one that works in this environment.<br />// am1: use a single mult and divide to get the high bits,// max digit bits should be 26 because// max internal value = 2*dvalue^2-2*dvalue (< 2^53)function am1(i, x, w, j, c, n) { while (--n >= 0) { var v = x * this[i++] + w[j] + c; c = Math.floor(v / 0x4000000); w[j++] = v & 0x3ffffff; } return c;}// am2 avoids a big mult-and-extract completely.// Max digit bits should be > 15; while (--n >= 0) { var l = this[i] & 0x7fff; var h = this[i++] >> 15; var m = xh * l + h * xl; l = xl * l + ((m & 0x7fff) >> 30) + (m >>> 15) + xh * h + (c >>> 30); w[j++] = l & 0x3fffffff; } return c;}// Alternately, set max digit bits to 28 since some// browsers slow down when dealing with 32-bit numbers.function am3(i, x, w, j, c, n) { var xl = x & 0x3fff, xh = x >> 14; while (--n >= 0) { var l = this[i] & 0x3fff; var h = this[i++] >> 14; var m = xh * l + h * xl; l = xl * l + ((m & 0x3fff) > 28) + (m >> 14) + xh * h; w[j++] = l & 0xfffffff; } return c;}<br /><br />// Digit conversionsvar BI_RM = "0123456789abcdefghijklmnopqrstuvwxyz";var BI_RC = new Array();var rr, vv;rr = "0".charCodeAt(0);for (vv = 0; vv a, - if this < a, 0 if equalfunction bnCompareTo(a) { var r = this.s - a.s; if (r != 0) return r; var i = this.t; r = i - a.t; if (r != 0) return r; while (--i >= 0) if ((r = this[i] - a[i]) != 0) return r; return 0;}<br />// returns bit length of the integer xfunction nbits(x) { var r = 1, t; if ((t = x >>> 16) != 0) { x = t; r += 16; } if ((t = x >> 8) != 0) { x = t; r += 8; } if ((t = x >> 4) != 0) { x = t; r += 4; } if ((t = x >> 2) != 0) { x = t; r += 2; } if ((t = x >> 1) != 0) { x = t; r += 1; } return r;}<br />// (public) return the number of bits in "this"function bnBitLength() { if (this.t = 0; --i) r[i] = 0; r.t = this.t + n; r.s = this.s;}<br />// (protected) r = this >> n*DBfunction bnpDRShiftTo(n, r) { for (var i = n; i < this.t; ++i) r[i - n] = this[i]; r.t = Math.max(this.t - n, 0); r.s = this.s;}<br />// (protected) r = this cbs) | c; c = (this[i] & bm) = 0; --i) r[i] = 0; r[ds] = c; r.t = this.t + ds + 1; r.s = this.s; r.clamp();}<br />// (protected) r = this >> nfunction bnpRShiftTo(n, r) { r.s = this.s; var ds = Math.floor(n / this.DB); if (ds >= this.t) { r.t = 0; return; } var bs = n % this.DB; var cbs = this.DB - bs; var bm = (1 > bs; for (var i = ds + 1; i < this.t; ++i) { r[i - ds - 1] |= (this[i] & bm) > bs; } if (bs > 0) r[this.t - ds - 1] |= (this.s & bm) >= this.DB; } if (a.t < this.t) { c -= a.s; while (i < this.t) { c += this[i]; r[i++] = c & this.DM; c >>= this.DB; } c += this.s; } else { c += this.s; while (i < a.t) { c -= a[i]; r[i++] = c & this.DM; c >>= this.DB; } c -= a.s; } r.s = (c < 0) ? -1 : 0; if (c < -1) r[i++] = this.DV + c; else if (c > 0) r[i++] = c; r.t = i; r.clamp();}<br />// (protected) r = this * a, r != this,a (HAC 14.12)// "this" should be the larger one if appropriate.function bnpMultiplyTo(a, r) { var x = this.abs(), y = a.abs(); var i = x.t; r.t = i + y.t; while (--i >= 0) r[i] = 0; for (i = 0; i < y.t; ++i) r[i + x.t] = x.am(0, y[i], r, i, 0, x.t); r.s = 0; r.clamp(); if (this.s != a.s) BigInteger.ZERO.subTo(r, r);}<br />// (protected) r = this^2, r != this (HAC 14.16)function bnpSquareTo(r) { var x = this.abs(); var i = r.t = 2 * x.t; while (--i >= 0) r[i] = 0; for (i = 0; i < x.t - 1; ++i) { var c = x.am(i, x[i], r, 2 * i, 0, 1); if ((r[i + x.t] += x.am(i + 1, 2 * x[i], r, 2 * i + 1, c, x.t - i - 1)) >= x.DV) { r[i + x.t] -= x.DV; r[i + x.t + 1] = 1; } } if (r.t > 0) r[r.t - 1] += x.am(i, x[i], r, 2 * i, 0, 1); r.s = 0; r.clamp();}<br />// (protected) divide this by m, quotient and remainder to q, r (HAC 14.20)// r != q, this != m. q or r may be null.function bnpDivRemTo(m, q, r) { var pm = m.abs(); if (pm.t 0) { pm.lShiftTo(nsh, y); pt.lShiftTo(nsh, r); } else { pm.copyTo(y); pt.copyTo(r); } var ys = y.t; var y0 = y[ys - 1]; if (y0 == 0) return; var yt = y0 * (1 1) ? y[ys - 2] >> this.F2 : 0); var d1 = this.FV / yt, d2 = (1 = 0) { // Estimate quotient digit var qd = (r[--i] == y0) ? this.DM : Math.floor(r[i] * d1 + (r[i - 1] + e) * d2); if ((r[i] += y.am(0, qd, r, j, 0, ys)) < qd) { // Try it out y.dlShiftTo(j, t); r.subTo(t, r); while (r[i] < --qd) r.subTo(t, r); } } if (q != null) { r.drShiftTo(ys, q); if (ts != ms) BigInteger.ZERO.subTo(q, q); } r.t = ys; r.clamp(); if (nsh > 0) r.rShiftTo(nsh, r); // Denormalize remainder if (ts < 0) BigInteger.ZERO.subTo(r, r);}<br />// (public) this mod afunction bnMod(a) { var r = nbi(); this.abs().divRemTo(a, null, r); if (this.s < 0 && r.compareTo(BigInteger.ZERO) > 0) a.subTo(r, r); return r;}<br />// Modular reduction using "classic" algorithmfunction Classic(m) { this.m = m;}<br />function cConvert(x) { if (x.s < 0 || x.compareTo(this.m) >= 0) return x.mod(this.m); else return x;}<br />function cRevert(x) { return x;}<br />function cReduce(x) { x.divRemTo(this.m, null, x);}<br />function cMulTo(x, y, r) { x.multiplyTo(y, r); this.reduce(r);}<br />function cSqrTo(x, r) { x.squareTo(r); this.reduce(r);}<br />Classic.prototype.convert = cConvert;Classic.prototype.revert = cRevert;Classic.prototype.reduce = cReduce;Classic.prototype.mulTo = cMulTo;Classic.prototype.sqrTo = cSqrTo;<br />// (protected) return "-1/this % 2^DB"; useful for Mont. reduction// justification:// xy == 1 (mod m)// xy = 1+km// xy(2-xy) = (1+km)(1-km)// x[y(2-xy)] = 1-k^2m^2// x[y(2-xy)] == 1 (mod m^2)// if y is 1/x mod m, then y(2-xy) is 1/x mod m^2// should reduce x and y(2-xy) by m^2 at each step to keep size bounded.// JS multiply "overflows" differently from C/C++, so care is needed here.function bnpInvDigit() { if (this.t < 1) return 0; var x = this[0]; if ((x & 1) == 0) return 0; var y = x & 3; // y == 1/x mod 2^2 y = (y * (2 - (x & 0xf) * y)) & 0xf; // y == 1/x mod 2^4 y = (y * (2 - (x & 0xff) * y)) & 0xff; // y == 1/x mod 2^8 y = (y * (2 - (((x & 0xffff) * y) & 0xffff))) & 0xffff; // y == 1/x mod 2^16 // last step - calculate inverse mod DV directly; // assumes 16 < DB 0) ? this.DV - y : -y;}<br />// Montgomery reductionfunction Montgomery(m) { this.m = m; this.mp = m.invDigit(); this.mpl = this.mp & 0x7fff; this.mph = this.mp >> 15; this.um = (1 0) this.m.subTo(r, r); return r;}<br />// x/R mod mfunction montRevert(x) { var r = nbi(); x.copyTo(r); this.reduce(r); return r;}<br />// x = x/R mod m (HAC 14.32)function montReduce(x) { while (x.t > 15) * this.mpl) & this.um) = x.DV) { x[j] -= x.DV; x[++j]++; } } x.clamp(); x.drShiftTo(this.m.t, x); if (x.compareTo(this.m) >= 0) x.subTo(this.m, x);}<br />// r = "x^2/R mod m"; x != rfunction montSqrTo(x, r) { x.squareTo(r); this.reduce(r);}<br />// r = "xy/R mod m"; x,y != rfunction montMulTo(x, y, r) { x.multiplyTo(y, r); this.reduce(r);}<br />Montgomery.prototype.convert = montConvert;Montgomery.prototype.revert = montRevert;Montgomery.prototype.reduce = montReduce;Montgomery.prototype.mulTo = montMulTo;Montgomery.prototype.sqrTo = montSqrTo;<br />// (protected) true iff this is evenfunction bnpIsEven() { return ((this.t > 0) ? (this[0] & 1) : this.s) == 0;}<br />// (protected) this^e, e < 2^32, doing sqr and mul with "r" (HAC 14.79)function bnpExp(e, z) { if (e > 0xffffffff || e < 1) return BigInteger.ONE; var r = nbi(), r2 = nbi(), g = z.convert(this), i = nbits(e) - 1; g.copyTo(r); while (--i >= 0) { z.sqrTo(r, r2); if ((e & (1 0) z.mulTo(r2, g, r); else { var t = r; r = r2; r2 = t; } } return z.revert(r);}<br />// (public) this^e % m, 0 1; if (t > lowprimes.length) t = lowprimes.length; var a = nbi(); for (var i = 0; i < t; ++i) { a.fromInt(lowprimes[i]); var y = a.modPow(r, this); if (y.compareTo(BigInteger.ONE) != 0 && y.compareTo(n1) != 0) { var j = 1; while (j++ < k && y.compareTo(n1) != 0) { y = y.modPowInt(2, this); if (y.compareTo(BigInteger.ONE) == 0) return false; } if (y.compareTo(n1) != 0) return false; } } return true;}<br />// protectedBigInteger.prototype.chunkSize = bnpChunkSize;BigInteger.prototype.toRadix = bnpToRadix;BigInteger.prototype.fromRadix = bnpFromRadix;BigInteger.prototype.fromNumber = bnpFromNumber;BigInteger.prototype.bitwiseTo = bnpBitwiseTo;BigInteger.prototype.changeBit = bnpChangeBit;BigInteger.prototype.addTo = bnpAddTo;BigInteger.prototype.dMultiply = bnpDMultiply;BigInteger.prototype.dAddOffset = bnpDAddOffset;BigInteger.prototype.multiplyLowerTo = bnpMultiplyLowerTo;BigInteger.prototype.multiplyUpperTo = bnpMultiplyUpperTo;BigInteger.prototype.modInt = bnpModInt;BigInteger.prototype.millerRabin = bnpMillerRabin;<br />// publicBigInteger.prototype.clone = bnClone;BigInteger.prototype.intValue = bnIntValue;BigInteger.prototype.byteValue = bnByteValue;BigInteger.prototype.shortValue = bnShortValue;BigInteger.prototype.signum = bnSigNum;BigInteger.prototype.toByteArray = bnToByteArray;BigInteger.prototype.equals = bnEquals;BigInteger.prototype.min = bnMin;BigInteger.prototype.max = bnMax;BigInteger.prototype.and = bnAnd;BigInteger.prototype.or = bnOr;BigInteger.prototype.xor = bnXor;BigInteger.prototype.andNot = bnAndNot;BigInteger.prototype.not = bnNot;BigInteger.prototype.shiftLeft = bnShiftLeft;BigInteger.prototype.shiftRight = bnShiftRight;BigInteger.prototype.getLowestSetBit = bnGetLowestSetBit;BigInteger.prototype.bitCount = bnBitCount;BigInteger.prototype.testBit = bnTestBit;BigInteger.prototype.setBit = bnSetBit;BigInteger.prototype.clearBit = bnClearBit;BigInteger.prototype.flipBit = bnFlipBit;BigInteger.prototype.add = bnAdd;BigInteger.prototype.subtract = bnSubtract;BigInteger.prototype.multiply = bnMultiply;BigInteger.prototype.divide = bnDivide;BigInteger.prototype.remainder = bnRemainder;BigInteger.prototype.divideAndRemainder = bnDivideAndRemainder;BigInteger.prototype.modPow = bnModPow;BigInteger.prototype.modInverse = bnModInverse;BigInteger.prototype.pow = bnPow;BigInteger.prototype.gcd = bnGCD;BigInteger.prototype.isProbablePrime = bnIsProbablePrime;<br />// BigInteger interfaces not implemented in jsbn:<br />// BigInteger(int signum, byte[] magnitude)// double doubleValue()// float floatValue()// int hashCode()// long longValue()// static BigInteger valueOf(long val)<br /><br /><br />var RSAPublicKey = function($modulus_hex, $encryptionExponent_hex) { this.modulus = new BigInteger($modulus_hex, 16); this.encryptionExponent = new BigInteger($encryptionExponent_hex, 16);};<br />var Base64 = { base64: "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=", encode: function($input) { if (!$input) { return false; } var $output = ""; var $chr1, $chr2, $chr3; var $enc1, $enc2, $enc3, $enc4; var $i = 0; do { $chr1 = $input.charCodeAt($i++); $chr2 = $input.charCodeAt($i++); $chr3 = $input.charCodeAt($i++); $enc1 = $chr1 >> 2; $enc2 = (($chr1 & 3) > 4); $enc3 = (($chr2 & 15) > 6); $enc4 = $chr3 & 63; if (isNaN($chr2)) $enc3 = $enc4 = 64; else if (isNaN($chr3)) $enc4 = 64; $output += this.base64.charAt($enc1) + this.base64.charAt($enc2) + this.base64.charAt($enc3) + this.base64.charAt($enc4); } while ($i < $input.length); return $output; }, decode: function($input) { if (!$input) return false; $input = $input.replace(/[^A-Za-z0-9\+\/\=]/g, ""); var $output = ""; var $enc1, $enc2, $enc3, $enc4; var $i = 0; do { $enc1 = this.base64.indexOf($input.charAt($i++)); $enc2 = this.base64.indexOf($input.charAt($i++)); $enc3 = this.base64.indexOf($input.charAt($i++)); $enc4 = this.base64.indexOf($input.charAt($i++)); $output += String.fromCharCode(($enc1 > 4)); if ($enc3 != 64) $output += String.fromCharCode((($enc2 & 15) > 2)); if ($enc4 != 64) $output += String.fromCharCode((($enc3 & 3) > 4) & 0xf) + this.hex.charAt($k & 0xf); } while ($i < $input.length); return $output; }, decode: function($input) { if (!$input) return false; $input = $input.replace(/[^0-9abcdef]/g, ""); var $output = ""; var $i = 0; do { $output += String.fromCharCode(((this.hex.indexOf($input.charAt($i++)) > 3); if (!$data) return false; $data = $data.modPowInt($pubkey.encryptionExponent, $pubkey.modulus); if (!$data) return false; $data = $data.toString(16); if (($data.length & 1) == 1) $data = "0" + $data; return Base64.encode(Hex.decode($data)); },<br /> pkcs1pad2: function($data, $keysize) { if ($keysize < $data.length + 11) return null; var $buffer = []; var $i = $data.length - 1; while ($i >= 0 && $keysize > 0) $buffer[--$keysize] = $data.charCodeAt($i--); $buffer[--$keysize] = 0; while ($keysize > 2) $buffer[--$keysize] = Math.floor(Math.random() * 254) + 1; $buffer[--$keysize] = 2; $buffer[--$keysize] = 0; return new BigInteger($buffer); }}<br /> function get_pwd(pwd,mod, exp) { var pubKey = RSA.getPublicKey(mod, exp); password = pwd.replace(/[^\x00-\x7F]/g, ''); var encryptedPassword = RSA.encrypt(password, pubKey); return encryptedPassword; }
通过自定义一个get_pwd的函数,来调用上面加密的整个过程,函数上面的部分,就是加密的整个过程的代码,这些代码也不是我写的,是别人写好的,我只是复制粘贴过来,改动一下,利用自己定义的函数,调用了这些代码,从而实现加密的目的。该函数需要传递2个参数,这个2个参数分别是未加密前的密码和私钥,私钥就在我们请求网页的时候,返回的第一个数据里面(publickey_exp和publickey_mod)。
mod就是publickey_mod,exp就是publickey_exp,通过传递参数,在调用定义的get_pwd这个函数,就能得到加密的密码结果了,加密后的密码也是动态的,每次都不一样。
效果展示
结语
因为本文涉及很多JavaScript的知识,所以需要对JavaScript有些了解,另外在改写JS代码的时候,会遇到很多的错误提示,限于篇幅的有限,我没有过多的写出如何排除这些错误提示,我们就需要利用一些JavaScript的知识一点点的排除这些错误提示,直到提示加载成功,才可以运行代码的,所以还是推荐用js的调试工具,这样更方便一些。头一次写这样的技术文章,有很多写的不到位的地方,还请多多提出宝贵意见。
END
B站账号:
https://space.bilibili.com/351138764
欢迎扫码
关注我
JS逆向 -- 某视频网站流媒体初次分析全过程
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-04-30 23:15
开篇
最近呢,学了一点js逆向的知识,一直想找个可以实践一下的平台来试试学习效果。偶然间看到了这个平台,发现很适合拿来练手,不过由于这个网站视频开始播放前都有那种不和谐的广告,所以地址就不能贴了,贴图也做了一些脱敏处理!
需要准备的工具:
第一次分析
打开目标网站首页,选择任意一个视频信息点击进入后:
可以直接看到资源下载地址,不过这次目的是来逆向的,所以看不到!看不到!看不到!
1.1 过控制台检测
接下来就到了我们的分析时间,点击【在线播放】后尝试使用快捷键F12打开控制台,然后就弹出了以下提示:
打不开控制台不要紧,选择浏览器右上角的三个小点,从更多工具中打开控制台:
1.2 过无限debug
控制台一打开,立马跳出个无限debuuger,看来还是做了一些反调试措施的:
从右边的堆栈中向下查找入口,从上到下依次点击看看:
很显然这个并不是,再往下点时,就发现了非常关键的函数调用:
其实这个无限debugger卡了挺长时间的,一开始开始尝试删除这个关键位置的调用,删除整个debugger的自调用函数,甚至删除整个外层的debugger函数,但是发现这些操作会导致视频无法正常加载,控制台过段时间就会直接卡死等莫名其妙的问题,说明这些函数中有些关键地方还是有用的,那看不懂这些混淆的代码又该怎么办呢?难道此次实战就此终结!!!
在前思来想去后,突然想到既然debugger关键字会触发断点,那要是我把这个关键字给改了是不是就停不下了?说干就干,把含有无限debugger的js文件在源代码中直接另存为或者从Fiddler另存为一份到本地,方便进行修改。
从上图可以看到前面的内容为“bugger”,后面的内容为“de”,要修改的关键就在这里里,以文本方式打开对应的js,直接搜“de”,发现有5个地方有这个信息:
全部替换,这里我替换成“dd”,替换后保存:
打开Fiddler工具,右边选择自动响应,勾选启用规则和请求传递,填写js网络地址和本地js地址,并保存:
确认Fiddler能获取浏览器请求后,打开浏览器里的设置,选择清空之前的数据,这样才会重新加载本地替换的js文件:
重新打开播放页面后,再次打开控制台,发现不仅无限debugger没了,控制台也正常了,视频也能正常加载了,很好!可以愉快的玩耍了。
1.3 寻找m3u8地址
打开网络面板,会发现很多的302请求,302表示重定向,这个请求会在响应中返回一个新的地址。开始查找视频文件地址,发现m3u8文件也被重定向了:
用IDM工具下载这个m3u8文件看看,可以看到返回的居然是一个张图片???
打开看看,额,居然是二维码,扫了一下返回是视频网址,那m3u8信息哪去了?
用winhex打开看看,看这个头信息好像就是一个图片
查找一个关键内容看看,winhex直接搜m3u8:
发现并不是想要的内容,用winhex前后翻看发现基本都是乱码,那么极有可能m3u8的内容被加密了,存放在这个图片中。尝试在源代码中查找m3u8文件的调用堆栈发现事情并不简单,很多地方的js代码都被混淆了,所以要找到还原方法实属头大,可是没有代码就不能还原出m3u8的内容怎么办?于是想到加载ts文件不是也得从m3u8的内容中读取吗?所以开始尝试查找ts的调用堆栈,这里可以看到ts的请求也是302状态码,先不管:
把鼠标放在其中一个ts请求的启动器上,点击浮窗中展示的js文件进入调式:
这里会自动跳转到源代码中js的点击位置,先在这里打上一个断点,免得调试过头了。
从右下角的
堆栈从上往下依次点击看看,在每个堆栈位置前后翻翻,然后发现了一个有关m3u8的信息,在这里下断点:
F5重新加载页面,可以看到m3u8的内容此时已经被加载了:
尝试把这个m3u8信息保存下来,打开控制台输入了以下代码:
复制代码 隐藏代码<br style="overflow-wrap: break-word;" />const data = t.data; // 这里填内容的字符串<br />const blob = new Blob([data], {type: "text/plain"});<br />const a= document.createElement("a");<br />a.href = URL.createObjectURL(blob);<br />a.download = "demo.m3u8"; // 这里填保存的文件名<br />a.click();<br />URL.revokeObjectURL(a.href);<br />a.remove();
成功保存,打开看看,正好是m3u8的内容:
1.4 ts解密
尝试用IDM访问前面一两个ts链接看看有没有加密:
怎么返回的又是图片?直接打开看看:
啥呀这是,一张花屏的图片,用winhex打开看看:
上下拖动内容后发现并不是常规的图片内容,果然有猫腻,在图片的下面发现了视频相关的头信息,难道这是图片伪装的视频文件?从其它平台找一个正常的ts文件对比看看:
哦豁,原来后面的内容确实是视频文件,只是前面一小部分是BMP文件的头信息,那简单了,直接删了试试:
修改后另存为一份,后缀改为ts,避免修改错误导致源文件信息丢失
打开修改后的ts文件,正常播放:
PS:后来发现论坛里,逍遥大佬写的m3u8下载器可以自动去除这种不是ts内容的信息:
至此第一阶段分析结束,我以为也就这样了,但是再尝试打开几个视频后,发发发现居然有不一样的加密!!!
OK,既然被发现了,那必须得再分析看看=>
第二次分析2.1 获取m3u8和key
有了前面那些踩坑,这次分析起来就快多了,再次尝试打开视频页面,通过调试再次拿到m3u8文件,拖入m3u8下载器看看:
发现这次需要key,通过不断的调试终于hook到key的位置,这里先把key拿来用一下,填入key,发现又解码失败了:
2.2 ts解密
难道这个ts与众不同?打开m3u8文件后发现ts的链接长度明显变短了,下载ts后再次打开文件看看:
又是熟悉的花屏图片,用winhex打开看看:
发现这次怎么也找不到ts头信息了,搜也搜不到了,而且内容非常乱,看起来应该是被加密了,这样只能调试代码看看怎么回事了。这次换个方法找,直接搜,为啥呢,因为调试了半天也跳到解密位置,直接搜碰碰运气:
看到有很多结果,前面两个js可以忽略,第3、4个js文件很可疑,打开相应的js再次搜索关键字,发现有很多结果,从上到下依次都大概看一下。然后发现这个位置很可疑,其它地方都没混淆代码,偏偏这里有混淆,此地无银三百两,打上断点试试:
再次F5加载页面或者继续播放,点击格式化后再搜关键字,可以看到代码都被混淆了,但是有些关键信息还是可以看到的:
统统打上断点看看,F8依次执行,可以看到rsp就是网站加载的原始ts文件,大小一模一样,这里我从Fiddler保存了一份做对比:
F8继续执行,发现len变量的值为1243440,应该是确定加密范围的:
点击继续下一个断点,发现rsp变了,长度不是1244642,而是1243440了:
依葫芦画瓢,这里先保存一下rsp内容,此时的rsp是不能播放的:
打开本地保存的后缀为.bmp的ts文件和这个enc.ts进行对比,并搜搜看:
原来是通过一定的算法把前面和后面一部分内容给去掉了,那么剩下的应该就是被加密的视频文件了,删除后大小刚好就是enc.ts的大小。下一个断点,来到uText这个变量,发现这个变量的长度刚好和前面的rsp长度是一样的,这里应该就是做了转换,为解密做准备:
下一个断点,来到解密函数,这里可以清楚看到加密的内容uTxt、key、iv,虽然看不太懂混淆的代码,但这显然是一个标准的AES-CBC解密操作:
而最后的newRresponse=new Uint8Array(arr);就是解密好的视频流,当然这里可以用代码来实现,这里的key和iv都是同一个值,控制台输出一下:
这里用Python代码实现解密:
复制代码 隐藏代码<br style="overflow-wrap: break-word;" />from Crypto.Cipher import AES<br />import base64<br /><br />fr = open(r'enc.ts', 'rb')<br />content = fr.read()<br />key = iv = base64.b64decode("9Kq58j61Jx42io3e37Qomg==")<br />cipher = AES.new(key, AES.MODE_CBC, iv)<br />data = cipher.decrypt(content)<br />with open(r'dec.ts', 'wb') as fw:<br /> fw.write(data)
成果展示
总结
通过这次实战见识到了很多花里胡哨的操作,还是相当有收获的。也明白还是需要不断学习才能走的更远,再接再厉!当某种逆向思路不行就得尝试换种思路,还有一点就是逆向一定要有耐心!
不足:
由于还没学会如何使用AST解这些混淆代码,导致看不懂核心逻辑,所以以下问题暂时没有得到解决
m3u8地址下载的文件如何从图片提取并还原成正常的m3u8内容?
第二种加密的每个ts似乎都对应着一个key,那么这些hexkey应该如何计算出来?
第二种ts文件从什么地方开始到结束才是真正需要解密的内容?
嗯,就先这样吧! 查看全部
JS逆向 -- 某视频网站流媒体初次分析全过程
开篇
最近呢,学了一点js逆向的知识,一直想找个可以实践一下的平台来试试学习效果。偶然间看到了这个平台,发现很适合拿来练手,不过由于这个网站视频开始播放前都有那种不和谐的广告,所以地址就不能贴了,贴图也做了一些脱敏处理!
需要准备的工具:
第一次分析
打开目标网站首页,选择任意一个视频信息点击进入后:
可以直接看到资源下载地址,不过这次目的是来逆向的,所以看不到!看不到!看不到!
1.1 过控制台检测
接下来就到了我们的分析时间,点击【在线播放】后尝试使用快捷键F12打开控制台,然后就弹出了以下提示:
打不开控制台不要紧,选择浏览器右上角的三个小点,从更多工具中打开控制台:
1.2 过无限debug
控制台一打开,立马跳出个无限debuuger,看来还是做了一些反调试措施的:
从右边的堆栈中向下查找入口,从上到下依次点击看看:
很显然这个并不是,再往下点时,就发现了非常关键的函数调用:
其实这个无限debugger卡了挺长时间的,一开始开始尝试删除这个关键位置的调用,删除整个debugger的自调用函数,甚至删除整个外层的debugger函数,但是发现这些操作会导致视频无法正常加载,控制台过段时间就会直接卡死等莫名其妙的问题,说明这些函数中有些关键地方还是有用的,那看不懂这些混淆的代码又该怎么办呢?难道此次实战就此终结!!!
在前思来想去后,突然想到既然debugger关键字会触发断点,那要是我把这个关键字给改了是不是就停不下了?说干就干,把含有无限debugger的js文件在源代码中直接另存为或者从Fiddler另存为一份到本地,方便进行修改。
从上图可以看到前面的内容为“bugger”,后面的内容为“de”,要修改的关键就在这里里,以文本方式打开对应的js,直接搜“de”,发现有5个地方有这个信息:
全部替换,这里我替换成“dd”,替换后保存:
打开Fiddler工具,右边选择自动响应,勾选启用规则和请求传递,填写js网络地址和本地js地址,并保存:
确认Fiddler能获取浏览器请求后,打开浏览器里的设置,选择清空之前的数据,这样才会重新加载本地替换的js文件:
重新打开播放页面后,再次打开控制台,发现不仅无限debugger没了,控制台也正常了,视频也能正常加载了,很好!可以愉快的玩耍了。
1.3 寻找m3u8地址
打开网络面板,会发现很多的302请求,302表示重定向,这个请求会在响应中返回一个新的地址。开始查找视频文件地址,发现m3u8文件也被重定向了:
用IDM工具下载这个m3u8文件看看,可以看到返回的居然是一个张图片???
打开看看,额,居然是二维码,扫了一下返回是视频网址,那m3u8信息哪去了?
用winhex打开看看,看这个头信息好像就是一个图片
查找一个关键内容看看,winhex直接搜m3u8:
发现并不是想要的内容,用winhex前后翻看发现基本都是乱码,那么极有可能m3u8的内容被加密了,存放在这个图片中。尝试在源代码中查找m3u8文件的调用堆栈发现事情并不简单,很多地方的js代码都被混淆了,所以要找到还原方法实属头大,可是没有代码就不能还原出m3u8的内容怎么办?于是想到加载ts文件不是也得从m3u8的内容中读取吗?所以开始尝试查找ts的调用堆栈,这里可以看到ts的请求也是302状态码,先不管:
把鼠标放在其中一个ts请求的启动器上,点击浮窗中展示的js文件进入调式:
这里会自动跳转到源代码中js的点击位置,先在这里打上一个断点,免得调试过头了。
从右下角的
堆栈从上往下依次点击看看,在每个堆栈位置前后翻翻,然后发现了一个有关m3u8的信息,在这里下断点:
F5重新加载页面,可以看到m3u8的内容此时已经被加载了:
尝试把这个m3u8信息保存下来,打开控制台输入了以下代码:
复制代码 隐藏代码<br style="overflow-wrap: break-word;" />const data = t.data; // 这里填内容的字符串<br />const blob = new Blob([data], {type: "text/plain"});<br />const a= document.createElement("a");<br />a.href = URL.createObjectURL(blob);<br />a.download = "demo.m3u8"; // 这里填保存的文件名<br />a.click();<br />URL.revokeObjectURL(a.href);<br />a.remove();
成功保存,打开看看,正好是m3u8的内容:
1.4 ts解密
尝试用IDM访问前面一两个ts链接看看有没有加密:
怎么返回的又是图片?直接打开看看:
啥呀这是,一张花屏的图片,用winhex打开看看:
上下拖动内容后发现并不是常规的图片内容,果然有猫腻,在图片的下面发现了视频相关的头信息,难道这是图片伪装的视频文件?从其它平台找一个正常的ts文件对比看看:
哦豁,原来后面的内容确实是视频文件,只是前面一小部分是BMP文件的头信息,那简单了,直接删了试试:
修改后另存为一份,后缀改为ts,避免修改错误导致源文件信息丢失
打开修改后的ts文件,正常播放:
PS:后来发现论坛里,逍遥大佬写的m3u8下载器可以自动去除这种不是ts内容的信息:
至此第一阶段分析结束,我以为也就这样了,但是再尝试打开几个视频后,发发发现居然有不一样的加密!!!
OK,既然被发现了,那必须得再分析看看=>
第二次分析2.1 获取m3u8和key
有了前面那些踩坑,这次分析起来就快多了,再次尝试打开视频页面,通过调试再次拿到m3u8文件,拖入m3u8下载器看看:
发现这次需要key,通过不断的调试终于hook到key的位置,这里先把key拿来用一下,填入key,发现又解码失败了:
2.2 ts解密
难道这个ts与众不同?打开m3u8文件后发现ts的链接长度明显变短了,下载ts后再次打开文件看看:
又是熟悉的花屏图片,用winhex打开看看:
发现这次怎么也找不到ts头信息了,搜也搜不到了,而且内容非常乱,看起来应该是被加密了,这样只能调试代码看看怎么回事了。这次换个方法找,直接搜,为啥呢,因为调试了半天也跳到解密位置,直接搜碰碰运气:
看到有很多结果,前面两个js可以忽略,第3、4个js文件很可疑,打开相应的js再次搜索关键字,发现有很多结果,从上到下依次都大概看一下。然后发现这个位置很可疑,其它地方都没混淆代码,偏偏这里有混淆,此地无银三百两,打上断点试试:
再次F5加载页面或者继续播放,点击格式化后再搜关键字,可以看到代码都被混淆了,但是有些关键信息还是可以看到的:
统统打上断点看看,F8依次执行,可以看到rsp就是网站加载的原始ts文件,大小一模一样,这里我从Fiddler保存了一份做对比:
F8继续执行,发现len变量的值为1243440,应该是确定加密范围的:
点击继续下一个断点,发现rsp变了,长度不是1244642,而是1243440了:
依葫芦画瓢,这里先保存一下rsp内容,此时的rsp是不能播放的:
打开本地保存的后缀为.bmp的ts文件和这个enc.ts进行对比,并搜搜看:
原来是通过一定的算法把前面和后面一部分内容给去掉了,那么剩下的应该就是被加密的视频文件了,删除后大小刚好就是enc.ts的大小。下一个断点,来到uText这个变量,发现这个变量的长度刚好和前面的rsp长度是一样的,这里应该就是做了转换,为解密做准备:
下一个断点,来到解密函数,这里可以清楚看到加密的内容uTxt、key、iv,虽然看不太懂混淆的代码,但这显然是一个标准的AES-CBC解密操作:
而最后的newRresponse=new Uint8Array(arr);就是解密好的视频流,当然这里可以用代码来实现,这里的key和iv都是同一个值,控制台输出一下:
这里用Python代码实现解密:
复制代码 隐藏代码<br style="overflow-wrap: break-word;" />from Crypto.Cipher import AES<br />import base64<br /><br />fr = open(r'enc.ts', 'rb')<br />content = fr.read()<br />key = iv = base64.b64decode("9Kq58j61Jx42io3e37Qomg==")<br />cipher = AES.new(key, AES.MODE_CBC, iv)<br />data = cipher.decrypt(content)<br />with open(r'dec.ts', 'wb') as fw:<br /> fw.write(data)
成果展示
总结
通过这次实战见识到了很多花里胡哨的操作,还是相当有收获的。也明白还是需要不断学习才能走的更远,再接再厉!当某种逆向思路不行就得尝试换种思路,还有一点就是逆向一定要有耐心!
不足:
由于还没学会如何使用AST解这些混淆代码,导致看不懂核心逻辑,所以以下问题暂时没有得到解决
m3u8地址下载的文件如何从图片提取并还原成正常的m3u8内容?
第二种加密的每个ts似乎都对应着一个key,那么这些hexkey应该如何计算出来?
第二种ts文件从什么地方开始到结束才是真正需要解密的内容?
嗯,就先这样吧!
网页抓取解密 真香的PDF软件--PDF24
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-30 23:13
一个完全免费的PDF工具箱软件:PDF24,里面包含了20多种关于PDF的操作的免费工具。列如包含了PDF转换、合并、叠加、压缩、比较、编辑、裁剪、注释、加密、解密、分割、旋转、优化、删除、提取、排序页面等等。
豌豆工作室公众号对话框回复:uf,获取资料!
网页版,网址:
该工具分网页版和桌面安装版,网页版社长就不多介绍,就是直接打开网址就可以使用,桌面安装的话我们直接下载好软件安装包,然后直接双击打开,我们发现默认是英文安装界面,不用管这个直接OK,安装好之后软件默认是中文的。
安装完毕有一个英文注册界面,不想注册的用户可以直接点击skip跳过即可。
接下来社长就给大家演示一遍使用方法,以转化为PDF为列:点击选择文件或者直接把需要转化成PDF文件拖拽到软件中即可
然后点击转换为PDF。
然后保存到自己的电脑打开就可以看到已经转换为PDF文件了。
功能实在太多就不过多介绍,这款软件还可以当成PDF文件格式的查看软件。
--------END-------- 查看全部
网页抓取解密 真香的PDF软件--PDF24
一个完全免费的PDF工具箱软件:PDF24,里面包含了20多种关于PDF的操作的免费工具。列如包含了PDF转换、合并、叠加、压缩、比较、编辑、裁剪、注释、加密、解密、分割、旋转、优化、删除、提取、排序页面等等。
豌豆工作室公众号对话框回复:uf,获取资料!
网页版,网址:
该工具分网页版和桌面安装版,网页版社长就不多介绍,就是直接打开网址就可以使用,桌面安装的话我们直接下载好软件安装包,然后直接双击打开,我们发现默认是英文安装界面,不用管这个直接OK,安装好之后软件默认是中文的。
安装完毕有一个英文注册界面,不想注册的用户可以直接点击skip跳过即可。
接下来社长就给大家演示一遍使用方法,以转化为PDF为列:点击选择文件或者直接把需要转化成PDF文件拖拽到软件中即可
然后点击转换为PDF。
然后保存到自己的电脑打开就可以看到已经转换为PDF文件了。
功能实在太多就不过多介绍,这款软件还可以当成PDF文件格式的查看软件。
--------END--------
如何在Google上免费获得流量?解密16大Google排名因素
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-30 23:11
(本文有1000+字,看完预计3分钟)
『108期老徐说独立站』
本期话题
1、如何在Google上获得流量?
2、Google排名因素有哪些?
3、站内SEO的TDK怎么写?
这是Google站长的数据,完全SEO自然流量。
2022年3个月对比2021年3个月,曝光增长38.8万,增长42.5%。
自然流量增加2.5万,增长17%。平均点击率增加2.7%,点击率高达13.1%。
网站上线,如何在Google获得流量?
网站上线后,如何才能获得流量?
品牌独立站上线后,获得流量的方法有很多SEO/SNS/SEM都可以获得流量,在SEO方面,主要是Google的SEO,因为Google搜索占据全球92%的市场份额。
SEM不是所有的行业产品都能上,比如Google广告针对黑五类、违法、地方区域政策等限制产品无法上广告。而SEO的包容性会更广,打不了广告的产品可以通过多做网站内容,做多几个站群,多语种,做SEO来获客。
这里要普及2个知识点
1、Google搜索结果,带有广告标识的,是属于Google付费广告引流。
2、默认搜索结果有8-10个位置出现自然结果的网页,这些页面就是SEO的搜索结果,点击带来的流量完全免费。如下图所示:
为了抢占在Google上的自然流量机会,我们除了需要做网站本身的内容外,还需要会在网页部署关键词,尤其是网页的TDK撰写。
通过对TDK和网页内容优化,可以让Google更快、更好的读懂我们的网页,抓取和收录我们的内容,从而带来更多的免费曝光和流量机会。
如何写TDK?我在第三部分讲解。
要想获得免费曝光和展示,少不了一个指标
网页收录
这是持续输出原创、优质的内容在Google上的表现,收录高达8万。
传统的建站服务商和个人,短期内很难达到这么多的内容数量。
想了解怎么做的?
后续会为大家揭秘,敬请关注!
Google排名的因素有哪些?
Google排名因素有200多项
Google排名的200多项因素比较多而复杂,为了让大家简单明白的理解,我归纳合并成16大因素。
一、内因
1、原创内容,视频。2、持续更新。3、TDKU。4、域名权重。5、页面年龄。6、SSL安全证书 https。7、网页速度,CDN。8、服务器资源。9、网页技术。10、内部链接。
二、外因
11、外链。12、用户行为,比如点击率。13、社交指标。14、竞争环境。15、行业趋势。16、品牌热度。
对于绝大多数SEO运营来说,当你选择了服务商之后,白色部分的因素,无法左右。网页技术方面就很大受限于网站服务商的技术水平。
所以,多数SEO和运营能做的只有是网站内容,TDK 和保持持续的内容更新。如果你持续坚持,也已经超越85%的网站竞争对手了!
由于项目比较多,这里我只提一个重点:Google特别尊重原创,所以原创优质的内容,尤其是视频内容,就很容易在Google获得更多的免费曝光推荐机会!
网站上线之后,大家要特别重视,多发布一些产品的视频在网站上。也可以是去YouTube发布之后,拿个代码链接放回网站。不影响网站性能,还能更好地带动网站流量和权重提升。如有不清楚,欢迎评论区留言,或微信xuchy1688 。
站内SEO优化的TDK怎么写?
网站站内SEO优化做什么?
站内优化的工序超过10个。其中少不了关键词分析,关键词布局,关键词内链,网页TDK撰写,404检查,内链建设,产品标题优化,分类优化,绑定Google流量统计,绑定Google站长,提交sitemap,开放robots等工序。这些环节都非常重要。
而对于TDK撰写,则是重中之重!
TDK是什么?为什么要写TDK?
写好TDK就是为了帮助Google能更好的识别我们的整站每个页面的内容主题、内容描述、内容关键词,方便Google收录之后,更好的进行对应关键词的免费推荐,从而解决精准用户的搜索查询需求!
让Google更好地收录我们,带来更多免费流量机会,这就少不了站内SEO优化的TDK优化。
如何写TDK?
划重点!
网页Title埋入1个关键词,字符数40-60字符最佳。
网页Description可埋入2-3个关键词,120-155字符最佳。
网页Keywords写入1-3个,这里我们只讲关键词的密度2-8%区间。
本期分享就到这里,有疑问欢迎微信咨询xuchy1688 查看全部
如何在Google上免费获得流量?解密16大Google排名因素
(本文有1000+字,看完预计3分钟)
『108期老徐说独立站』
本期话题
1、如何在Google上获得流量?
2、Google排名因素有哪些?
3、站内SEO的TDK怎么写?
这是Google站长的数据,完全SEO自然流量。
2022年3个月对比2021年3个月,曝光增长38.8万,增长42.5%。
自然流量增加2.5万,增长17%。平均点击率增加2.7%,点击率高达13.1%。
网站上线,如何在Google获得流量?
网站上线后,如何才能获得流量?
品牌独立站上线后,获得流量的方法有很多SEO/SNS/SEM都可以获得流量,在SEO方面,主要是Google的SEO,因为Google搜索占据全球92%的市场份额。
SEM不是所有的行业产品都能上,比如Google广告针对黑五类、违法、地方区域政策等限制产品无法上广告。而SEO的包容性会更广,打不了广告的产品可以通过多做网站内容,做多几个站群,多语种,做SEO来获客。
这里要普及2个知识点
1、Google搜索结果,带有广告标识的,是属于Google付费广告引流。
2、默认搜索结果有8-10个位置出现自然结果的网页,这些页面就是SEO的搜索结果,点击带来的流量完全免费。如下图所示:
为了抢占在Google上的自然流量机会,我们除了需要做网站本身的内容外,还需要会在网页部署关键词,尤其是网页的TDK撰写。
通过对TDK和网页内容优化,可以让Google更快、更好的读懂我们的网页,抓取和收录我们的内容,从而带来更多的免费曝光和流量机会。
如何写TDK?我在第三部分讲解。
要想获得免费曝光和展示,少不了一个指标
网页收录
这是持续输出原创、优质的内容在Google上的表现,收录高达8万。
传统的建站服务商和个人,短期内很难达到这么多的内容数量。
想了解怎么做的?
后续会为大家揭秘,敬请关注!
Google排名的因素有哪些?
Google排名因素有200多项
Google排名的200多项因素比较多而复杂,为了让大家简单明白的理解,我归纳合并成16大因素。
一、内因
1、原创内容,视频。2、持续更新。3、TDKU。4、域名权重。5、页面年龄。6、SSL安全证书 https。7、网页速度,CDN。8、服务器资源。9、网页技术。10、内部链接。
二、外因
11、外链。12、用户行为,比如点击率。13、社交指标。14、竞争环境。15、行业趋势。16、品牌热度。
对于绝大多数SEO运营来说,当你选择了服务商之后,白色部分的因素,无法左右。网页技术方面就很大受限于网站服务商的技术水平。
所以,多数SEO和运营能做的只有是网站内容,TDK 和保持持续的内容更新。如果你持续坚持,也已经超越85%的网站竞争对手了!
由于项目比较多,这里我只提一个重点:Google特别尊重原创,所以原创优质的内容,尤其是视频内容,就很容易在Google获得更多的免费曝光推荐机会!
网站上线之后,大家要特别重视,多发布一些产品的视频在网站上。也可以是去YouTube发布之后,拿个代码链接放回网站。不影响网站性能,还能更好地带动网站流量和权重提升。如有不清楚,欢迎评论区留言,或微信xuchy1688 。
站内SEO优化的TDK怎么写?
网站站内SEO优化做什么?
站内优化的工序超过10个。其中少不了关键词分析,关键词布局,关键词内链,网页TDK撰写,404检查,内链建设,产品标题优化,分类优化,绑定Google流量统计,绑定Google站长,提交sitemap,开放robots等工序。这些环节都非常重要。
而对于TDK撰写,则是重中之重!
TDK是什么?为什么要写TDK?
写好TDK就是为了帮助Google能更好的识别我们的整站每个页面的内容主题、内容描述、内容关键词,方便Google收录之后,更好的进行对应关键词的免费推荐,从而解决精准用户的搜索查询需求!
让Google更好地收录我们,带来更多免费流量机会,这就少不了站内SEO优化的TDK优化。
如何写TDK?
划重点!
网页Title埋入1个关键词,字符数40-60字符最佳。
网页Description可埋入2-3个关键词,120-155字符最佳。
网页Keywords写入1-3个,这里我们只讲关键词的密度2-8%区间。
本期分享就到这里,有疑问欢迎微信咨询xuchy1688
网页抓取解密(爬取一个第二季第34集分段视频没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-20 08:55
)
实现功能:爬取网站的视频
1、获取主页面的页面源码并找到iframe
2、从iframe页面源码中获取m3u8文件
3、下载第一层m3u8文件,获取真实地址
4、下载视频
5、下载密钥并解密
6、将所有ts文件合并为一个MP4文件
'''
目前基本确定第4步和第5步有问题,但不清楚是因为代码错误,还是好像有几个分段视频没有下载;
所以不清楚是什么导致了第 6 步中的问题;求老鸟
问题截图:
代码页
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES
import os
#正则提取规则
obj1=re.compile(r'2.html","link_pre":"","url":"(?P.*?)","url_next":"https:')
#2.1子程序:找到主页面的源代码,找到iframe对应的url
def get_iframe_src(url):
resp=requests.get(url)
#print(resp.text) #测试是否正常爬取到源代码
#修改为正则爬取,这里提取完之后就是第一层的m3u8地址了
content=resp.text #把源代码变成text格式存储起来,用来提取
main_page=obj1.finditer(content)
for it in main_page:
#print(it.group('src'))
src_modify=it.group('src').replace('\\','')
#print(src_modify)
return src_modify #输出正确的第一层m3u8地址
resp.close()
#2.2、子程序:拿到第一层的m3u8文件下载地址;这一步只在课程里91看剧需要,实操的网址2.1里拿到的就是第一层m3u8了
def get_first_m3u8_url(url):
resp=requests.get(url)
#print(resp.text)
obj2=re.compile(r'var main=''(?P.*?)''')
m3u8_url=obj2.search(resp.text).group('m3u8_url') #这里是把m3u8地址提取出来
#print(m3u8_url)
resp.close()
return m3u8_url #让函数返回这一个地址
#2.3、子程序:下载第一层m3u8文件
def download_m3u8_file(url,name):
resp=requests.get(url)
with open(name,mode='wb')as f:
f.write(resp.content)
resp.close()
#2.5.1、子程序:异步协程进行下载
async def download_ts(url,name,session):
async with session.get(url)as resp:
async with aiofiles.open(f'4.9-video2/{name}',mode='wb')as f:
await f.write(await resp.content.read()) #把下载到的内容写入文件中
print(f'{name}下载完毕')
#2.5、子程序:异步协程处理拼接下载
#实操版
async def aio_download(up_url):
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'): #’#‘开头的行不要
continue
# line就是xxxx.ts文件
url = line.strip()
name1=line.rsplit('/',1)[1]
name=name1.strip()
task=asyncio.create_task(download_ts(url,name,session))
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
#2.6.1获取密钥
def get_key(url):
resp=requests.get(url)
print(resp.text)
a=resp.text
b=bytes(a,'utf-8')
return b
#2.6.2创建解密视频的任务
async def aio_dec(key):
#思路:解密,需要把下载的文件一个个打开;但是因为这里我们是直接用m3u8文件里后面的字符命名的
tasks=[]
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'):
continue
line1=line.rsplit('/',1)[1] #取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
#开始创建异步任务
task=asyncio.create_task(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
#2.6.3创建解密函数
async def dec_ts(name,key):
aes=AES.new(key=key,IV=b'0000000000000000',mode=AES.MODE_CBC)
async with aiofiles.open(f'4.9-video2/{name}',mode='rb')as f1,\
aiofiles.open(f'4.9-video2/temp_{name}',mode='wb')as f2:
bs=await f1.read() #从源文件读取文件
await f2.write(aes.decrypt(bs)) #把解密好的内容写入文件
print(f'{name}处理完毕')
#2.7合并视频为mp4
def merge_ts():
#mac:cat 1.ts 2.ts 3.ts > xxx.mp4
#windows:copy/b 1.ts+2.ts+3.ts > xxx.mp4
lst=[]
with open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
for line in f:
if line.startswith('#'):
continue
line1 = line.rsplit('/', 1)[1] # 取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
lst.append(f'4.9-video2/temp_{line}')
s=''.join(lst)
os.system(f'copy /b {s} >movie.mp4')
print('搞定!')
#2、主程序
def main(url):
#2.1、找到主页面的源代码,找到iframe对应的url
iframe_src=get_iframe_src(url)
#print(iframe_src)
#2.3下载第一层m3u8文件
download_m3u8_file(iframe_src,'4.93-抓取91看剧复杂版——first-m3u8.txt') #按照课程正常的话括号里的’iframe_src‘要改为2.2里的’first_m3u8_url_ture‘
#2.4下载第二层m3u8文件
with open('4.93-抓取91看剧复杂版——first-m3u8.txt',mode='r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'): #让程序识别文件里面时,自动跳过‘#’开头的行段
continue
else:
line=line.strip() #去掉空白或者换行符
#准备拼接第二层m3u8的下载路径
second_m3u8_url=iframe_src.split('/20210730')[0]+line
download_m3u8_file(second_m3u8_url,'4.93-抓取91看剧复杂版——second-m3u8.txt')
print('第二层m3u8下载完毕')
#2.5下载视频
#实操写法
up_url='开始'
#asyncio.run(aio_download(up_url)) #这个会报错:RuntimeError: Event loop is closed
loop=asyncio.get_event_loop()
loop.run_until_complete(aio_download(up_url))
#2.6.1拿到密钥
#实操
key_url='https://ts6.hhmm0.com:9999/202 ... 39%3B
key=get_key(key_url) #访问密匙的路径,拿到密匙
#2.6.2解密
asyncio.run(aio_dec(key))
#2.7合并ts文件为mp4文件
merge_ts()
#1、主程序调用处
if __name__=='__main__':
url='https://www.pianba.net/yun/84961-1-1/'
main(url) 查看全部
网页抓取解密(爬取一个第二季第34集分段视频没有
)
实现功能:爬取网站的视频
1、获取主页面的页面源码并找到iframe
2、从iframe页面源码中获取m3u8文件
3、下载第一层m3u8文件,获取真实地址
4、下载视频
5、下载密钥并解密
6、将所有ts文件合并为一个MP4文件
'''
目前基本确定第4步和第5步有问题,但不清楚是因为代码错误,还是好像有几个分段视频没有下载;
所以不清楚是什么导致了第 6 步中的问题;求老鸟
问题截图:
代码页
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES
import os
#正则提取规则
obj1=re.compile(r'2.html","link_pre":"","url":"(?P.*?)","url_next":"https:')
#2.1子程序:找到主页面的源代码,找到iframe对应的url
def get_iframe_src(url):
resp=requests.get(url)
#print(resp.text) #测试是否正常爬取到源代码
#修改为正则爬取,这里提取完之后就是第一层的m3u8地址了
content=resp.text #把源代码变成text格式存储起来,用来提取
main_page=obj1.finditer(content)
for it in main_page:
#print(it.group('src'))
src_modify=it.group('src').replace('\\','')
#print(src_modify)
return src_modify #输出正确的第一层m3u8地址
resp.close()
#2.2、子程序:拿到第一层的m3u8文件下载地址;这一步只在课程里91看剧需要,实操的网址2.1里拿到的就是第一层m3u8了
def get_first_m3u8_url(url):
resp=requests.get(url)
#print(resp.text)
obj2=re.compile(r'var main=''(?P.*?)''')
m3u8_url=obj2.search(resp.text).group('m3u8_url') #这里是把m3u8地址提取出来
#print(m3u8_url)
resp.close()
return m3u8_url #让函数返回这一个地址
#2.3、子程序:下载第一层m3u8文件
def download_m3u8_file(url,name):
resp=requests.get(url)
with open(name,mode='wb')as f:
f.write(resp.content)
resp.close()
#2.5.1、子程序:异步协程进行下载
async def download_ts(url,name,session):
async with session.get(url)as resp:
async with aiofiles.open(f'4.9-video2/{name}',mode='wb')as f:
await f.write(await resp.content.read()) #把下载到的内容写入文件中
print(f'{name}下载完毕')
#2.5、子程序:异步协程处理拼接下载
#实操版
async def aio_download(up_url):
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'): #’#‘开头的行不要
continue
# line就是xxxx.ts文件
url = line.strip()
name1=line.rsplit('/',1)[1]
name=name1.strip()
task=asyncio.create_task(download_ts(url,name,session))
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
#2.6.1获取密钥
def get_key(url):
resp=requests.get(url)
print(resp.text)
a=resp.text
b=bytes(a,'utf-8')
return b
#2.6.2创建解密视频的任务
async def aio_dec(key):
#思路:解密,需要把下载的文件一个个打开;但是因为这里我们是直接用m3u8文件里后面的字符命名的
tasks=[]
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'):
continue
line1=line.rsplit('/',1)[1] #取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
#开始创建异步任务
task=asyncio.create_task(dec_ts(line,key))
tasks.append(task)
await asyncio.wait(tasks)
#2.6.3创建解密函数
async def dec_ts(name,key):
aes=AES.new(key=key,IV=b'0000000000000000',mode=AES.MODE_CBC)
async with aiofiles.open(f'4.9-video2/{name}',mode='rb')as f1,\
aiofiles.open(f'4.9-video2/temp_{name}',mode='wb')as f2:
bs=await f1.read() #从源文件读取文件
await f2.write(aes.decrypt(bs)) #把解密好的内容写入文件
print(f'{name}处理完毕')
#2.7合并视频为mp4
def merge_ts():
#mac:cat 1.ts 2.ts 3.ts > xxx.mp4
#windows:copy/b 1.ts+2.ts+3.ts > xxx.mp4
lst=[]
with open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
for line in f:
if line.startswith('#'):
continue
line1 = line.rsplit('/', 1)[1] # 取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
line=line1.strip()
lst.append(f'4.9-video2/temp_{line}')
s=''.join(lst)
os.system(f'copy /b {s} >movie.mp4')
print('搞定!')
#2、主程序
def main(url):
#2.1、找到主页面的源代码,找到iframe对应的url
iframe_src=get_iframe_src(url)
#print(iframe_src)
#2.3下载第一层m3u8文件
download_m3u8_file(iframe_src,'4.93-抓取91看剧复杂版——first-m3u8.txt') #按照课程正常的话括号里的’iframe_src‘要改为2.2里的’first_m3u8_url_ture‘
#2.4下载第二层m3u8文件
with open('4.93-抓取91看剧复杂版——first-m3u8.txt',mode='r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'): #让程序识别文件里面时,自动跳过‘#’开头的行段
continue
else:
line=line.strip() #去掉空白或者换行符
#准备拼接第二层m3u8的下载路径
second_m3u8_url=iframe_src.split('/20210730')[0]+line
download_m3u8_file(second_m3u8_url,'4.93-抓取91看剧复杂版——second-m3u8.txt')
print('第二层m3u8下载完毕')
#2.5下载视频
#实操写法
up_url='开始'
#asyncio.run(aio_download(up_url)) #这个会报错:RuntimeError: Event loop is closed
loop=asyncio.get_event_loop()
loop.run_until_complete(aio_download(up_url))
#2.6.1拿到密钥
#实操
key_url='https://ts6.hhmm0.com:9999/202 ... 39%3B
key=get_key(key_url) #访问密匙的路径,拿到密匙
#2.6.2解密
asyncio.run(aio_dec(key))
#2.7合并ts文件为mp4文件
merge_ts()
#1、主程序调用处
if __name__=='__main__':
url='https://www.pianba.net/yun/84961-1-1/'
main(url)
网页抓取解密(Python爬虫网页基本上就是有多少难度?(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-18 21:05
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
1r = requests.get('#39;)
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
数量:你能捕捉到所有这些数据吗?
效率:在一天或一个月内捕获所有数据需要多长时间
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
1、网络爬虫程序有什么难的 - 只爬 html 页面,但要大规模
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内爬取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
我们有足够的带宽吗?
我们有足够的服务器吗?如果单台服务器不够用,我们需要分发
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。在爬网式爬取“旧”新闻的同时,如何兼顾“新”新闻的获取呢?
如何存储捕获的大量新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
2、网络爬虫程序有什么难的——你需要登录才能抓取你想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态? 查看全部
网页抓取解密(Python爬虫网页基本上就是有多少难度?(一)_)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
1r = requests.get('#39;)
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
数量:你能捕捉到所有这些数据吗?
效率:在一天或一个月内捕获所有数据需要多长时间
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
1、网络爬虫程序有什么难的 - 只爬 html 页面,但要大规模
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内爬取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
我们有足够的带宽吗?
我们有足够的服务器吗?如果单台服务器不够用,我们需要分发
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。在爬网式爬取“旧”新闻的同时,如何兼顾“新”新闻的获取呢?
如何存储捕获的大量新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
2、网络爬虫程序有什么难的——你需要登录才能抓取你想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
网页抓取解密(前后端分离的网站接口被加密了怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2022-04-18 21:01
一.前言
最近在调试一个前后端分离的网站时,接口被加密了,原来是未加密的。就是结果json中的消息,一堆乱码。解密js一定是必须的。
二.浏览器打开需要微信授权才能登录的网页
第一步是卡住。此页面需要在微信中打开。如何在chrome浏览器中打开它。采集了一些信息。贴的时候忘记了信息的来源,这里是我自己做的详细步骤,很简单。
这里测试一个链接,只是百度的:
/mobile/game/miraclepan/pan.jsp?panId=2881&wuid=243430
直接用PC浏览器打开会被拦截识别。
第一步打开fiddler拦截所有请求,打开PC版微信。用PC微信打开这个链接
点击同意,然后查看fiddler,如图操作。(貌似可以直接在PC浏览器打开第一个以open.weixin开头的网页。)这种方式可能会导致部分功能不可用或者浏览器控制台报错。
接下来就可以在PC的默认浏览器中看到授权提示了。点击授权后,即可在浏览器中自由调试微信网页。
三.简单的js调试
首先,我没有看系统教程,只是一些简单的文章之类的。只用一点chrome控制台调试断点,不是很复杂。
第一张图中的接口是访问页面渲染数据的接口。json数据中消息的key值一定是需要解密的东西,所以我们需要查看js代码将消息移动到哪里。进入目标页面会加载一个单独的js。命名为 126.js
下一个。在这个js文件中找到消息移动到哪里,然后看图操作
这时候就设置了断点,浏览器返回进入这个页面,这里js会被打断。鼠标悬停在断点上会有提示。点击提示输入断点调用的相关代码。
这时候点击下图浮动的地方,wybzd这个地方。查看如何调用代码来处理此消息。
处理消息的js代码差不多就到这里了。使用AES加密和解密,一种对称加密和解密,加密和解密都使用密码。
t为密码,this.BVDCVojLpQEGLytM为调用该函数时传入的参数。求这个变量的值。它是第一次找到消息的地方,应该只使用第一个密钥。我不知道在哪里使用其他键
关键是:“8NONwyJtHesysWpM”
接下来,让我们验证密钥是否正确。
任意百度AES在线加解密网站。填写密钥、密文、解密方法进行计算
ECB 模式,pkcs7padding 填充,结果字符集 utf-8。最终结果如图,解密完成。本教程到此结束。
四.总结
微信页面OAuth2.0授权登录可以看到官方文档和阮一峰网络日志。
/mobile/game/miraclepan/pan.jsp?panId=2881&wuid=243430 访问该网页时,后台有进程会检查请求源是否在微信浏览器中。如果没有,请在微信客户端打开链接。如果在微信客户端的浏览器中显示,则允许用户主动授权。我们使用fiddler跳过直接判断客户端环境是否在微信客户端浏览器中,直接提示用户授权。授权后,后端被我们欺骗。还真以为是在客户端浏览器环境下,然后就可以畅通无阻了,但实际环境不是微信客户端环境,通过jssdk调用的功能可能有限。我还没有测试过。
这次js混淆加密真的很简单,处理消息的地方只有一处。还加载了一个单独的文件。只有一层调用关系,加密方式也不是很复杂,但这些东西接触时间长了只会有一些敏感的直觉。哈哈,我才刚开始,挺有意思的,总结一下。 查看全部
网页抓取解密(前后端分离的网站接口被加密了怎么办?)
一.前言
最近在调试一个前后端分离的网站时,接口被加密了,原来是未加密的。就是结果json中的消息,一堆乱码。解密js一定是必须的。
二.浏览器打开需要微信授权才能登录的网页
第一步是卡住。此页面需要在微信中打开。如何在chrome浏览器中打开它。采集了一些信息。贴的时候忘记了信息的来源,这里是我自己做的详细步骤,很简单。
这里测试一个链接,只是百度的:
/mobile/game/miraclepan/pan.jsp?panId=2881&wuid=243430
直接用PC浏览器打开会被拦截识别。
第一步打开fiddler拦截所有请求,打开PC版微信。用PC微信打开这个链接
点击同意,然后查看fiddler,如图操作。(貌似可以直接在PC浏览器打开第一个以open.weixin开头的网页。)这种方式可能会导致部分功能不可用或者浏览器控制台报错。
接下来就可以在PC的默认浏览器中看到授权提示了。点击授权后,即可在浏览器中自由调试微信网页。
三.简单的js调试
首先,我没有看系统教程,只是一些简单的文章之类的。只用一点chrome控制台调试断点,不是很复杂。
第一张图中的接口是访问页面渲染数据的接口。json数据中消息的key值一定是需要解密的东西,所以我们需要查看js代码将消息移动到哪里。进入目标页面会加载一个单独的js。命名为 126.js
下一个。在这个js文件中找到消息移动到哪里,然后看图操作
这时候就设置了断点,浏览器返回进入这个页面,这里js会被打断。鼠标悬停在断点上会有提示。点击提示输入断点调用的相关代码。
这时候点击下图浮动的地方,wybzd这个地方。查看如何调用代码来处理此消息。
处理消息的js代码差不多就到这里了。使用AES加密和解密,一种对称加密和解密,加密和解密都使用密码。
t为密码,this.BVDCVojLpQEGLytM为调用该函数时传入的参数。求这个变量的值。它是第一次找到消息的地方,应该只使用第一个密钥。我不知道在哪里使用其他键
关键是:“8NONwyJtHesysWpM”
接下来,让我们验证密钥是否正确。
任意百度AES在线加解密网站。填写密钥、密文、解密方法进行计算
ECB 模式,pkcs7padding 填充,结果字符集 utf-8。最终结果如图,解密完成。本教程到此结束。
四.总结
微信页面OAuth2.0授权登录可以看到官方文档和阮一峰网络日志。
/mobile/game/miraclepan/pan.jsp?panId=2881&wuid=243430 访问该网页时,后台有进程会检查请求源是否在微信浏览器中。如果没有,请在微信客户端打开链接。如果在微信客户端的浏览器中显示,则允许用户主动授权。我们使用fiddler跳过直接判断客户端环境是否在微信客户端浏览器中,直接提示用户授权。授权后,后端被我们欺骗。还真以为是在客户端浏览器环境下,然后就可以畅通无阻了,但实际环境不是微信客户端环境,通过jssdk调用的功能可能有限。我还没有测试过。
这次js混淆加密真的很简单,处理消息的地方只有一处。还加载了一个单独的文件。只有一层调用关系,加密方式也不是很复杂,但这些东西接触时间长了只会有一些敏感的直觉。哈哈,我才刚开始,挺有意思的,总结一下。
网页抓取解密(使用Python网络爬虫获取基金数据信息信息的篇文章分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-15 22:16
大家好,我是一名高级Python初学者。
一、前言
前几天有个粉丝问我基金信息。我会在这里分享。有兴趣的朋友也可以积极尝试。
二、数据采集
这里我们的目标网站是某基金的官网,要抓取的数据如下图所示。
可以看到上图中的基金代码栏,有不同的数字,随便点击一个,就可以进入基金详情页面,链接也很规整,以基金代码为符号。
其实这个网站并不难,数据没有加密,在源码中可以直接看到网页上的信息。
这降低了抓取的难度。通过浏览器抓包的方法可以看到具体的请求参数,可以看到请求参数中只有pi在变化,而这个值恰好对应页面,所以可以直接构造请求参数。
代码实现过程
找到数据源之后,接下来就是实现代码了。让我们来看看。这里有一些关键代码。
获取股票 id 数据
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
gp_id = item.group('items').split(',')[0]
结果如下所示:
然后构建详情页的链接,获取详情页的基金信息。关键代码如下:
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
selectors = etree.HTML(response.text)
danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0]
danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0]
leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0]
lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
结果如下所示:
具体信息经过相应的字符串处理,然后保存到csv文件中,结果如下图所示:
有了这个,您可以进行进一步的统计和数据分析。
三、总结
大家好,我是一名高级Python初学者。本篇文章主要分享使用Python网络爬虫获取资金数据信息。这个项目难度不大,但是有一点坑。欢迎您积极尝试。如果您遇到任何问题,请加我的朋友,我会帮助解决。
这个文章主要是根据【股票类型】的分类。我没有做过其他类型。欢迎您尝试一下。其实逻辑是一样的,只要改变参数即可。
最后,需要本文代码的朋友,可以加我获取!另外,为了方便大家学习Python,我还成立了一个优质的Python学习交流群。你可以问任何关于 Python 的问题。需要进来的朋友加我v,我拉你!
小伙伴们快来练习吧!如果你在学习过程中遇到任何Python问题,请加我为好友,我会拉你进入Python学习交流群一起讨论学习。 查看全部
网页抓取解密(使用Python网络爬虫获取基金数据信息信息的篇文章分享)
大家好,我是一名高级Python初学者。
一、前言
前几天有个粉丝问我基金信息。我会在这里分享。有兴趣的朋友也可以积极尝试。
二、数据采集
这里我们的目标网站是某基金的官网,要抓取的数据如下图所示。
可以看到上图中的基金代码栏,有不同的数字,随便点击一个,就可以进入基金详情页面,链接也很规整,以基金代码为符号。
其实这个网站并不难,数据没有加密,在源码中可以直接看到网页上的信息。
这降低了抓取的难度。通过浏览器抓包的方法可以看到具体的请求参数,可以看到请求参数中只有pi在变化,而这个值恰好对应页面,所以可以直接构造请求参数。
代码实现过程
找到数据源之后,接下来就是实现代码了。让我们来看看。这里有一些关键代码。
获取股票 id 数据
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
gp_id = item.group('items').split(',')[0]
结果如下所示:
然后构建详情页的链接,获取详情页的基金信息。关键代码如下:
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
selectors = etree.HTML(response.text)
danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0]
danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0]
leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0]
lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
结果如下所示:
具体信息经过相应的字符串处理,然后保存到csv文件中,结果如下图所示:
有了这个,您可以进行进一步的统计和数据分析。
三、总结
大家好,我是一名高级Python初学者。本篇文章主要分享使用Python网络爬虫获取资金数据信息。这个项目难度不大,但是有一点坑。欢迎您积极尝试。如果您遇到任何问题,请加我的朋友,我会帮助解决。
这个文章主要是根据【股票类型】的分类。我没有做过其他类型。欢迎您尝试一下。其实逻辑是一样的,只要改变参数即可。
最后,需要本文代码的朋友,可以加我获取!另外,为了方便大家学习Python,我还成立了一个优质的Python学习交流群。你可以问任何关于 Python 的问题。需要进来的朋友加我v,我拉你!
小伙伴们快来练习吧!如果你在学习过程中遇到任何Python问题,请加我为好友,我会拉你进入Python学习交流群一起讨论学习。
网页抓取解密( 2022年04月14日18:29:17作者:浅若清风cyf)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-15 22:09
2022年04月14日18:29:17作者:浅若清风cyf)
Python实现RSA加解密
更新时间:2022-04-14 18:29:17 作者:钱若清风 cyf
这篇文章主要介绍了Python中RSA加解密的实现。加密技术在数据安全存储和数据传输中发挥着重要作用,可以保护用户隐私数据安全,防止信息被盗。RSA是一种非对称加密技术,已广泛应用于软件和网页。以下文章更多相关内容可以参考小伙伴
内容
前言
如果本文对你有帮助,请点赞、采集、关注!您的支持和关注是博主创作的动力!
一、安装模块
pip install pycryptodome
二、生成密钥对
from Crypto.PublicKey import RSA
def create_rsa_pair(is_save=False):
'''
创建rsa公钥私钥对
:param is_save: default:False
:return: public_key, private_key
'''
f = RSA.generate(2048)
private_key = f.exportKey("PEM") # 生成私钥
public_key = f.publickey().exportKey() # 生成公钥
if is_save:
with open("crypto_private_key.pem", "wb") as f:
f.write(private_key)
with open("crypto_public_key.pem", "wb") as f:
f.write(public_key)
return public_key, private_key
def read_public_key(file_path="crypto_public_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
def read_private_key(file_path="crypto_private_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
三、加密
代码:
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto.PublicKey import RSA
def encryption(text: str, public_key: bytes):
# 字符串指定编码(转为bytes)
text = text.encode('utf-8')
# 构建公钥对象
cipher_public = PKCS1_v1_5.new(RSA.importKey(public_key))
# 加密(bytes)
text_encrypted = cipher_public.encrypt(text)
# base64编码,并转为字符串
text_encrypted_base64 = base64.b64encode(text_encrypted ).decode()
return text_encrypted_base64
if __name__ == '__main__':
public_key = read_public_key()
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:',text_encrypted_base64)
四、解密
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
from Crypto.PublicKey import RSA
def decryption(text_encrypted_base64: str, private_key: bytes):
# 字符串指定编码(转为bytes)
text_encrypted_base64 = text_encrypted_base64.encode('utf-8')
# base64解码
text_encrypted = base64.b64decode(text_encrypted_base64 )
# 构建私钥对象
cipher_private = PKCS1_v1_5.new(RSA.importKey(private_key))
# 解密(bytes)
text_decrypted = cipher_private.decrypt(text_encrypted , Random.new().read)
# 解码为字符串
text_decrypted = text_decrypted.decode()
return text_decrypted
if __name__ == '__main__':
# 生成密文
public_key = read_public_key()
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:',text_encrypted_base64)
# 解密
private_key = read_private_key()
text_decrypted = decryption(text_encrypted_base64, private_key)
print('明文:',text_decrypted)
五、完整代码
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
from Crypto.PublicKey import RSA
# ------------------------生成密钥对------------------------
def create_rsa_pair(is_save=False):
'''
创建rsa公钥私钥对
:param is_save: default:False
:return: public_key, private_key
'''
f = RSA.generate(2048)
private_key = f.exportKey("PEM") # 生成私钥
public_key = f.publickey().exportKey() # 生成公钥
if is_save:
with open("crypto_private_key.pem", "wb") as f:
f.write(private_key)
with open("crypto_public_key.pem", "wb") as f:
f.write(public_key)
return public_key, private_key
def read_public_key(file_path="crypto_public_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
def read_private_key(file_path="crypto_private_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
# ------------------------加密------------------------
def encryption(text: str, public_key: bytes):
# 字符串指定编码(转为bytes)
text = text.encode('utf-8')
# 构建公钥对象
cipher_public = PKCS1_v1_5.new(RSA.importKey(public_key))
# 加密(bytes)
text_encrypted = cipher_public.encrypt(text)
# base64编码,并转为字符串
text_encrypted_base64 = base64.b64encode(text_encrypted).decode()
return text_encrypted_base64
# ------------------------解密------------------------
def decryption(text_encrypted_base64: str, private_key: bytes):
# 字符串指定编码(转为bytes)
text_encrypted_base64 = text_encrypted_base64.encode('utf-8')
# base64解码
text_encrypted = base64.b64decode(text_encrypted_base64)
# 构建私钥对象
cipher_private = PKCS1_v1_5.new(RSA.importKey(private_key))
# 解密(bytes)
text_decrypted = cipher_private.decrypt(text_encrypted, Random.new().read)
# 解码为字符串
text_decrypted = text_decrypted.decode()
return text_decrypted
if __name__ == '__main__':
# 生成密钥对
# create_rsa_pair(is_save=True)
# public_key = read_public_key()
# private_key = read_private_key()
public_key, private_key = create_rsa_pair(is_save=False)
# 加密
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:', text_encrypted_base64)
# 解密
text_decrypted = decryption(text_encrypted_base64, private_key)
print('明文:', text_decrypted)
跑:
至此,这篇关于Python实现RSA加解密文章的文章就介绍到这里了。更多相关Python RSA加解密内容请搜索德牛网往期文章或继续浏览以下相关文章希望大家以后多多支持牛网! 查看全部
网页抓取解密(
2022年04月14日18:29:17作者:浅若清风cyf)
Python实现RSA加解密
更新时间:2022-04-14 18:29:17 作者:钱若清风 cyf
这篇文章主要介绍了Python中RSA加解密的实现。加密技术在数据安全存储和数据传输中发挥着重要作用,可以保护用户隐私数据安全,防止信息被盗。RSA是一种非对称加密技术,已广泛应用于软件和网页。以下文章更多相关内容可以参考小伙伴
内容
前言
如果本文对你有帮助,请点赞、采集、关注!您的支持和关注是博主创作的动力!
一、安装模块
pip install pycryptodome
二、生成密钥对
from Crypto.PublicKey import RSA
def create_rsa_pair(is_save=False):
'''
创建rsa公钥私钥对
:param is_save: default:False
:return: public_key, private_key
'''
f = RSA.generate(2048)
private_key = f.exportKey("PEM") # 生成私钥
public_key = f.publickey().exportKey() # 生成公钥
if is_save:
with open("crypto_private_key.pem", "wb") as f:
f.write(private_key)
with open("crypto_public_key.pem", "wb") as f:
f.write(public_key)
return public_key, private_key
def read_public_key(file_path="crypto_public_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
def read_private_key(file_path="crypto_private_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
三、加密
代码:
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto.PublicKey import RSA
def encryption(text: str, public_key: bytes):
# 字符串指定编码(转为bytes)
text = text.encode('utf-8')
# 构建公钥对象
cipher_public = PKCS1_v1_5.new(RSA.importKey(public_key))
# 加密(bytes)
text_encrypted = cipher_public.encrypt(text)
# base64编码,并转为字符串
text_encrypted_base64 = base64.b64encode(text_encrypted ).decode()
return text_encrypted_base64
if __name__ == '__main__':
public_key = read_public_key()
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:',text_encrypted_base64)
四、解密
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
from Crypto.PublicKey import RSA
def decryption(text_encrypted_base64: str, private_key: bytes):
# 字符串指定编码(转为bytes)
text_encrypted_base64 = text_encrypted_base64.encode('utf-8')
# base64解码
text_encrypted = base64.b64decode(text_encrypted_base64 )
# 构建私钥对象
cipher_private = PKCS1_v1_5.new(RSA.importKey(private_key))
# 解密(bytes)
text_decrypted = cipher_private.decrypt(text_encrypted , Random.new().read)
# 解码为字符串
text_decrypted = text_decrypted.decode()
return text_decrypted
if __name__ == '__main__':
# 生成密文
public_key = read_public_key()
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:',text_encrypted_base64)
# 解密
private_key = read_private_key()
text_decrypted = decryption(text_encrypted_base64, private_key)
print('明文:',text_decrypted)
五、完整代码
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
from Crypto.PublicKey import RSA
# ------------------------生成密钥对------------------------
def create_rsa_pair(is_save=False):
'''
创建rsa公钥私钥对
:param is_save: default:False
:return: public_key, private_key
'''
f = RSA.generate(2048)
private_key = f.exportKey("PEM") # 生成私钥
public_key = f.publickey().exportKey() # 生成公钥
if is_save:
with open("crypto_private_key.pem", "wb") as f:
f.write(private_key)
with open("crypto_public_key.pem", "wb") as f:
f.write(public_key)
return public_key, private_key
def read_public_key(file_path="crypto_public_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
def read_private_key(file_path="crypto_private_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
# ------------------------加密------------------------
def encryption(text: str, public_key: bytes):
# 字符串指定编码(转为bytes)
text = text.encode('utf-8')
# 构建公钥对象
cipher_public = PKCS1_v1_5.new(RSA.importKey(public_key))
# 加密(bytes)
text_encrypted = cipher_public.encrypt(text)
# base64编码,并转为字符串
text_encrypted_base64 = base64.b64encode(text_encrypted).decode()
return text_encrypted_base64
# ------------------------解密------------------------
def decryption(text_encrypted_base64: str, private_key: bytes):
# 字符串指定编码(转为bytes)
text_encrypted_base64 = text_encrypted_base64.encode('utf-8')
# base64解码
text_encrypted = base64.b64decode(text_encrypted_base64)
# 构建私钥对象
cipher_private = PKCS1_v1_5.new(RSA.importKey(private_key))
# 解密(bytes)
text_decrypted = cipher_private.decrypt(text_encrypted, Random.new().read)
# 解码为字符串
text_decrypted = text_decrypted.decode()
return text_decrypted
if __name__ == '__main__':
# 生成密钥对
# create_rsa_pair(is_save=True)
# public_key = read_public_key()
# private_key = read_private_key()
public_key, private_key = create_rsa_pair(is_save=False)
# 加密
text = '123456'
text_encrypted_base64 = encryption(text, public_key)
print('密文:', text_encrypted_base64)
# 解密
text_decrypted = decryption(text_encrypted_base64, private_key)
print('明文:', text_decrypted)
跑:
至此,这篇关于Python实现RSA加解密文章的文章就介绍到这里了。更多相关Python RSA加解密内容请搜索德牛网往期文章或继续浏览以下相关文章希望大家以后多多支持牛网!
网页抓取解密(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-15 08:17
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get(')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态? 查看全部
网页抓取解密(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get(')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
网页抓取解密(网页抓取解密(一)_网页解密__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-15 02:03
网页抓取解密在很多网站上都会抓取网页,或者抓取下载的文件。我们又要做到分析网页还得想办法解密,这个确实也是比较棘手的事情。又或者还要处理被抓取的页面,这个难度更是可想而知。之前推荐过,可以使用xmlhttprequest库进行网页抓取,可实现各种url对应的对应的解析和预处理,有兴趣的可以查看这篇文章:urlcheatsheet相关阅读:让javascript大显身手的库:customjs、selenium库抓取分析一般不会使用phantomjs对浏览器的底层进行逆向分析。
使用浏览器常见的url对应解析方法也足够了。如http协议逆向分析库:urlreverse、selenium库,文章(此处省略3000字)现在几乎几乎所有的网站都有各种各样的文件需要抓取,又要实现网页的逆向分析,然后生成自己的可执行文件,然后进行复杂的调用机制等等。即可能要费很多脑细胞,并且会有很多坑。
其实,可以尝试在chrome浏览器中使用js进行逆向分析,直接使用chrome的js加密库,如ejs进行网页逆向分析,可以非常方便的实现网页的读取加密,文件提取与分析等步骤。安装chrome好用的js库:jsoup4,selenium好用的js库:ejs(xml、form等)等,flask好用的js库:less、markdown、python代码在flask中的用法:flaskwsgijsoup4spider4,selenium(webdriver)另外,给大家推荐一个flask博客站:flask-bootstrap-front-end-blogs,有需要的,可以查看下,其中关于代码的安装方法也进行了讲解。
对于有些标签,如,?,???,这些标签在解析js/xml时,可能会对js文件起到中间人的作用,如:if-->if-->if-->else等等。如下图代码是解析js文件,而jsoup4可以正确解析js文件。flask为了保证在nginx中的flask程序不被转向到apache。我们需要如下方法:第一步,在flask程序的public目录下创建default_domains_paths文件夹,第二步,将需要解析的js文件上传到这个文件夹下,在python代码中使用setoptions(properties,exec_files,flask_modules),设置需要解析的js文件的路径。
flask代码如下:importflaskasf;flask_modules=[];public_domains_paths=[];//定义一个路径,将js文件路径绑定过来flask_modules=["localhost","","??。 查看全部
网页抓取解密(网页抓取解密(一)_网页解密__)
网页抓取解密在很多网站上都会抓取网页,或者抓取下载的文件。我们又要做到分析网页还得想办法解密,这个确实也是比较棘手的事情。又或者还要处理被抓取的页面,这个难度更是可想而知。之前推荐过,可以使用xmlhttprequest库进行网页抓取,可实现各种url对应的对应的解析和预处理,有兴趣的可以查看这篇文章:urlcheatsheet相关阅读:让javascript大显身手的库:customjs、selenium库抓取分析一般不会使用phantomjs对浏览器的底层进行逆向分析。
使用浏览器常见的url对应解析方法也足够了。如http协议逆向分析库:urlreverse、selenium库,文章(此处省略3000字)现在几乎几乎所有的网站都有各种各样的文件需要抓取,又要实现网页的逆向分析,然后生成自己的可执行文件,然后进行复杂的调用机制等等。即可能要费很多脑细胞,并且会有很多坑。
其实,可以尝试在chrome浏览器中使用js进行逆向分析,直接使用chrome的js加密库,如ejs进行网页逆向分析,可以非常方便的实现网页的读取加密,文件提取与分析等步骤。安装chrome好用的js库:jsoup4,selenium好用的js库:ejs(xml、form等)等,flask好用的js库:less、markdown、python代码在flask中的用法:flaskwsgijsoup4spider4,selenium(webdriver)另外,给大家推荐一个flask博客站:flask-bootstrap-front-end-blogs,有需要的,可以查看下,其中关于代码的安装方法也进行了讲解。
对于有些标签,如,?,???,这些标签在解析js/xml时,可能会对js文件起到中间人的作用,如:if-->if-->if-->else等等。如下图代码是解析js文件,而jsoup4可以正确解析js文件。flask为了保证在nginx中的flask程序不被转向到apache。我们需要如下方法:第一步,在flask程序的public目录下创建default_domains_paths文件夹,第二步,将需要解析的js文件上传到这个文件夹下,在python代码中使用setoptions(properties,exec_files,flask_modules),设置需要解析的js文件的路径。
flask代码如下:importflaskasf;flask_modules=[];public_domains_paths=[];//定义一个路径,将js文件路径绑定过来flask_modules=["localhost","","??。
网页抓取解密(学完课程后可以干什么?-处理请求参数的加密和解密 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-12 20:34
)
完成课程后我可以做什么?
- 处理请求中动态变化的请求参数
- 实现请求参数的加解密操作
- 轻松跳过所有形式的登录验证(刷卡验证等)
- 破解加密响应数据
- ......
爬虫是个奇妙的东西,这也是python的魅力所在——用非常简单的代码,你就可以创建一个强大的爬虫来爬取你想要采集的信息,将人类的双手从重复的工作中解放出来。但是,很多初学者往往在理解爬虫的基本原理上下了不少功夫。一段时间以来,在学习python爬虫的过程中积累了很多经验。我将在这里稍微总结一下,希望能够给你所有的开始。给学者一点启示。
爬虫(又称网络蜘蛛、网络机器人,在 FOAF 社区中,更常称为网络追逐者);它是按照一定的规则自动抓取网页信息的程序或脚本。
如果我们把互联网比作一个大蜘蛛网,电脑上的数据是蜘蛛网上的猎物,而爬虫是小蜘蛛,它们沿着蜘蛛网抓取他们想要的猎物/数据。
概念
Requests 是 Python 爬虫非常常用的库。它基于urllib编写,采用Apache2 Licensed开源协议的HTTP库。Requests 相比 urllib 和 urllib3 更方便,可以为我们省去很多工作,所以建议新爬虫从 Requests 库入手。
Requests 库主要使用 post() 方法和 get() 方法来获取网页数据。
post() 一般用于将特定参数传递给网站,以获得特定的结果。该参数是指网站必须接受的参数,根据这些参数返回不同的结果。比如百度翻译,传入不同的内容,返回不同的翻译。
get()方法一般不需要网站设置的具体参数,可以传入url、headers、roxies等通用参数(主要用于伪装浏览器、反爬虫等,注意以上具体参数)。url 是 网站 链接;headers为网站请求头,也可以通过浏览器检测功能获取;proxies 就是代理,后面的教程会讲解。
查看全部
网页抓取解密(学完课程后可以干什么?-处理请求参数的加密和解密
)
完成课程后我可以做什么?
- 处理请求中动态变化的请求参数
- 实现请求参数的加解密操作
- 轻松跳过所有形式的登录验证(刷卡验证等)
- 破解加密响应数据
- ......
爬虫是个奇妙的东西,这也是python的魅力所在——用非常简单的代码,你就可以创建一个强大的爬虫来爬取你想要采集的信息,将人类的双手从重复的工作中解放出来。但是,很多初学者往往在理解爬虫的基本原理上下了不少功夫。一段时间以来,在学习python爬虫的过程中积累了很多经验。我将在这里稍微总结一下,希望能够给你所有的开始。给学者一点启示。
爬虫(又称网络蜘蛛、网络机器人,在 FOAF 社区中,更常称为网络追逐者);它是按照一定的规则自动抓取网页信息的程序或脚本。
如果我们把互联网比作一个大蜘蛛网,电脑上的数据是蜘蛛网上的猎物,而爬虫是小蜘蛛,它们沿着蜘蛛网抓取他们想要的猎物/数据。
概念
Requests 是 Python 爬虫非常常用的库。它基于urllib编写,采用Apache2 Licensed开源协议的HTTP库。Requests 相比 urllib 和 urllib3 更方便,可以为我们省去很多工作,所以建议新爬虫从 Requests 库入手。
Requests 库主要使用 post() 方法和 get() 方法来获取网页数据。
post() 一般用于将特定参数传递给网站,以获得特定的结果。该参数是指网站必须接受的参数,根据这些参数返回不同的结果。比如百度翻译,传入不同的内容,返回不同的翻译。
get()方法一般不需要网站设置的具体参数,可以传入url、headers、roxies等通用参数(主要用于伪装浏览器、反爬虫等,注意以上具体参数)。url 是 网站 链接;headers为网站请求头,也可以通过浏览器检测功能获取;proxies 就是代理,后面的教程会讲解。
网页抓取解密(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-04-12 20:32
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是用一行代码把你骗进“海盗船”,等你上了贼船才发现水这么深~比如爬一个网页就可以了一个非常简单的代码行:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
老猿已经说了,http协议的性质决定了登录状态是一些cookies,所以如何获取登录状态是一个很棘手的问题。有的网站登录过程很简单,将账号和密码发送到服务器,服务器验证后返回cookies表示登录。这样的网站,更容易实现自动登录,爬虫运行无需人工干预,你有更多的时间喝茶、聊天、学猿猴。
如何处理验证码?
不过,既然网站们已经让你登录了,他们不会那么轻易放过你的。他们要做的就是让小猿们放弃,那就是上传验证码!没错,就是变态的验证码!!作为一个见多识广的老猿猴,到现在还是经常认不出验证码,觉得很丢脸。
据说有人雇了一群阿姨手动识别验证码;有人利用图像处理技术,特别是热门的深度学习和人工智能技术,自动识别验证码。
那么,在编写爬虫时遇到验证码该怎么办呢?
网络爬虫难点三:ajax异步加载甚至JavaScript解密
前两个难点是基于我们对数据加载过程的研究,然后我们可以用Python代码复现并爬取。
在第三个难点上,研究数据加载过程可能很痛苦,几乎崩溃。异步加载过程和服务器来回多次,最终数据只能通过JavaScript解密才能看到,是压垮爬虫的最后一根稻草。 查看全部
网页抓取解密(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是用一行代码把你骗进“海盗船”,等你上了贼船才发现水这么深~比如爬一个网页就可以了一个非常简单的代码行:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
老猿已经说了,http协议的性质决定了登录状态是一些cookies,所以如何获取登录状态是一个很棘手的问题。有的网站登录过程很简单,将账号和密码发送到服务器,服务器验证后返回cookies表示登录。这样的网站,更容易实现自动登录,爬虫运行无需人工干预,你有更多的时间喝茶、聊天、学猿猴。
如何处理验证码?
不过,既然网站们已经让你登录了,他们不会那么轻易放过你的。他们要做的就是让小猿们放弃,那就是上传验证码!没错,就是变态的验证码!!作为一个见多识广的老猿猴,到现在还是经常认不出验证码,觉得很丢脸。
据说有人雇了一群阿姨手动识别验证码;有人利用图像处理技术,特别是热门的深度学习和人工智能技术,自动识别验证码。
那么,在编写爬虫时遇到验证码该怎么办呢?
网络爬虫难点三:ajax异步加载甚至JavaScript解密
前两个难点是基于我们对数据加载过程的研究,然后我们可以用Python代码复现并爬取。
在第三个难点上,研究数据加载过程可能很痛苦,几乎崩溃。异步加载过程和服务器来回多次,最终数据只能通过JavaScript解密才能看到,是压垮爬虫的最后一根稻草。
网页抓取解密(用python爬虫要怎么去抓取数据呢?|小编网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-12 11:00
前言
我们在经常浏览网页的时候,总是用鼠标往下滑,新的网页信息总会刷新,再往下滑,新的网页信息就会刷新。总之,在一个url链接不变的情况下,用鼠标拖拽下滑,总会看到新的网页信息(如今日头条、网易新闻、微博、豆瓣电影等)。
那么,对于这样的网页,我们如何使用python爬虫来爬取数据呢?先跟着小编看看以下知识点:
阿贾克斯
Ajax的全称是Asynchronous JavaScript and XML(异步JavaScript和XML)。它是一种使用 JavaScript 与服务器交换数据并更新部分网页同时确保页面不刷新和页面链接不改变的技术。
对于传统网页,如果要更新其内容,则必须刷新整个页面。使用 Ajax,可以在不完全刷新的情况下更新页面内容。在这个过程中,页面实际上在后台与服务器交互。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。如果网页的原创 HTML 不收录任何数据,数据通过 Ajax 统一加载后呈现,可以在 Web 开发中分离前后端,减少服务器直接渲染页面的压力,有效防止爬行动物。对于 Ajax,数据加载是一种异步加载方法。原创页面不收录某些数据。只有在加载完成后,向服务器请求一个接口获取数据,然后将数据处理并呈现给网页。这个过程实际上是向服务器接口发送一个 Ajax 请求。此时,我们需要分析网页后端向接口发送的Ajax请求,并使用requests 查看全部
网页抓取解密(用python爬虫要怎么去抓取数据呢?|小编网页)
前言
我们在经常浏览网页的时候,总是用鼠标往下滑,新的网页信息总会刷新,再往下滑,新的网页信息就会刷新。总之,在一个url链接不变的情况下,用鼠标拖拽下滑,总会看到新的网页信息(如今日头条、网易新闻、微博、豆瓣电影等)。
那么,对于这样的网页,我们如何使用python爬虫来爬取数据呢?先跟着小编看看以下知识点:
阿贾克斯
Ajax的全称是Asynchronous JavaScript and XML(异步JavaScript和XML)。它是一种使用 JavaScript 与服务器交换数据并更新部分网页同时确保页面不刷新和页面链接不改变的技术。
对于传统网页,如果要更新其内容,则必须刷新整个页面。使用 Ajax,可以在不完全刷新的情况下更新页面内容。在这个过程中,页面实际上在后台与服务器交互。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。如果网页的原创 HTML 不收录任何数据,数据通过 Ajax 统一加载后呈现,可以在 Web 开发中分离前后端,减少服务器直接渲染页面的压力,有效防止爬行动物。对于 Ajax,数据加载是一种异步加载方法。原创页面不收录某些数据。只有在加载完成后,向服务器请求一个接口获取数据,然后将数据处理并呈现给网页。这个过程实际上是向服务器接口发送一个 Ajax 请求。此时,我们需要分析网页后端向接口发送的Ajax请求,并使用requests
网页抓取解密(Web安全——暴力破解(BurteForce)(不存在token))
网站优化 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2022-04-11 19:03
网络安全 - 蛮力 (BurteForce)
前言:弱密码yyds,虽然暴力破解是一种原理很简单,利用方式也很简单的漏洞,但是它的危害是非常巨大的。暴力登录后,该 Web 应用程序的所有信息将被暴露。
暴力破解(BurteForce)1:基于表单的暴力破解(没有验证码和token)
1、通过BurpSuite抓包发现这里没有Token等鉴权信息,账号密码等信息明文传输
2. 将捕获的数据包发送给攻击模块(Intruder),然后将参数密码设置为变量,选择攻击模式为Sniper,避免麻烦。我们实验的默认登录帐户是 admin。
设置密码变量攻击方式:
配置变量的有效负载:
暴力破解结果,密码为123456,登录成功
总结:当登录认证的地方没有验证码、Token等认证信息时,我们可以通过暴力破解轻松耗尽网站的账号和密码。
2:验证码绕过On Server(没有token)
1、通过抓包判断这里有验证码认证信息,验证码经过服务器验证,没有Token等其他认证信息。
2.首先判断本场景输入的验证码和账号密码的错误信息,方便后续推测当前认证情况
验证码错误:
账号密码输入错误:
这里可以判断验证码的正确判断优先级高于账号密码的正确判断优先级。
3.当前认证信息推测
判断思路:这里需要判断的是验证码是否会跟随账号密码提交失败。如果实时更新,蛮力破解难度会大大提高,否则难度会降低
操作步骤:提交正确的验证码数据包发送到Repeater模块,多次修改账号密码参数后重新提交,查看返回结果,返回结果为账号密码错误信息。浏览器不多次提交,服务器提交给客户端的验证码不变。
4、根据步骤3可以判断,如果不改验证码,账号密码的破解及步骤与“基于表单的暴力破解”相同,不再赘述详情在这里。
验证码认证下使用admin/123456登录成功
三:验证码绕过On Client(没有token)
1、通过抓包判断这里有验证码认证信息,抓包发现客户端输入验证码错误时,BP没有抓到数据包,所以这里推断验证码属于客户端验证。
2.在这种场景下,即使我们不确定这里的验证码是服务端还是客户端,我们仍然可以按照On Server推测的方法进行处理,不会影响我们最终的账号和密码,因为它与上述情景一致。步骤不会重复太多
四:账号密码安全认证(有token,无验证码等)
1、通过抓包判断这里有Token认证,没有其他认证方式。
2. 可以绕过令牌以防止暴力破解。令牌是一种认证信息。其基础知识请参考文章Web Security-CSRF(Token) 客户端提交的token值由服务端决定。发送给客户端的请求隐藏在最后一个回复中,隐藏在隐藏标签中
3.暴力破解开始
1. 抓取提交的认证包,发送给Intruder,然后设置password和token变量作为payload参数,攻击方式选择Pitchfork或者Cluster bomb(因为这里需要设置两个字典)
2、设置密码字典
3.设置token字典,因为每个token都是最后一个回复包返回的值,所以我们需要设置如下
选择 Grep 提取
按以下顺序将token值设置为变量,然后在此处赋值token值
设置令牌字典
设置线程数为1
破解获取密码
总结:在对目标进行暴力枚举时,首先要根据抓包信息推断出其认证方式的可能性。只有知道了它的鉴别方法,才能对症下药。此外,字典需要足够丰富。
暴力列举常见的危害和防御:
常见危害:
1.获取登录账号和密码,登录应用后台,结合其他漏洞做更多危害
2、敏感信息泄露,通过枚举应用根目录,导致敏感信息泄露
保护:
1.提高密码和验证码的复杂度(至少8位,大小写,特殊字符和数字)
2、应用限制单位时间登录错误次数(如10分钟内连续输入5次错误,将被锁定10分钟)
3.验证码随提交而变化
参考研究文章:
网络安全——CSRF(Token)
Burp套件中的Attack Type模式详解—Intruder 查看全部
网页抓取解密(Web安全——暴力破解(BurteForce)(不存在token))
网络安全 - 蛮力 (BurteForce)
前言:弱密码yyds,虽然暴力破解是一种原理很简单,利用方式也很简单的漏洞,但是它的危害是非常巨大的。暴力登录后,该 Web 应用程序的所有信息将被暴露。
暴力破解(BurteForce)1:基于表单的暴力破解(没有验证码和token)
1、通过BurpSuite抓包发现这里没有Token等鉴权信息,账号密码等信息明文传输
2. 将捕获的数据包发送给攻击模块(Intruder),然后将参数密码设置为变量,选择攻击模式为Sniper,避免麻烦。我们实验的默认登录帐户是 admin。
设置密码变量攻击方式:
配置变量的有效负载:
暴力破解结果,密码为123456,登录成功
总结:当登录认证的地方没有验证码、Token等认证信息时,我们可以通过暴力破解轻松耗尽网站的账号和密码。
2:验证码绕过On Server(没有token)
1、通过抓包判断这里有验证码认证信息,验证码经过服务器验证,没有Token等其他认证信息。
2.首先判断本场景输入的验证码和账号密码的错误信息,方便后续推测当前认证情况
验证码错误:
账号密码输入错误:
这里可以判断验证码的正确判断优先级高于账号密码的正确判断优先级。
3.当前认证信息推测
判断思路:这里需要判断的是验证码是否会跟随账号密码提交失败。如果实时更新,蛮力破解难度会大大提高,否则难度会降低
操作步骤:提交正确的验证码数据包发送到Repeater模块,多次修改账号密码参数后重新提交,查看返回结果,返回结果为账号密码错误信息。浏览器不多次提交,服务器提交给客户端的验证码不变。
4、根据步骤3可以判断,如果不改验证码,账号密码的破解及步骤与“基于表单的暴力破解”相同,不再赘述详情在这里。
验证码认证下使用admin/123456登录成功
三:验证码绕过On Client(没有token)
1、通过抓包判断这里有验证码认证信息,抓包发现客户端输入验证码错误时,BP没有抓到数据包,所以这里推断验证码属于客户端验证。
2.在这种场景下,即使我们不确定这里的验证码是服务端还是客户端,我们仍然可以按照On Server推测的方法进行处理,不会影响我们最终的账号和密码,因为它与上述情景一致。步骤不会重复太多
四:账号密码安全认证(有token,无验证码等)
1、通过抓包判断这里有Token认证,没有其他认证方式。
2. 可以绕过令牌以防止暴力破解。令牌是一种认证信息。其基础知识请参考文章Web Security-CSRF(Token) 客户端提交的token值由服务端决定。发送给客户端的请求隐藏在最后一个回复中,隐藏在隐藏标签中
3.暴力破解开始
1. 抓取提交的认证包,发送给Intruder,然后设置password和token变量作为payload参数,攻击方式选择Pitchfork或者Cluster bomb(因为这里需要设置两个字典)
2、设置密码字典
3.设置token字典,因为每个token都是最后一个回复包返回的值,所以我们需要设置如下
选择 Grep 提取
按以下顺序将token值设置为变量,然后在此处赋值token值
设置令牌字典
设置线程数为1
破解获取密码
总结:在对目标进行暴力枚举时,首先要根据抓包信息推断出其认证方式的可能性。只有知道了它的鉴别方法,才能对症下药。此外,字典需要足够丰富。
暴力列举常见的危害和防御:
常见危害:
1.获取登录账号和密码,登录应用后台,结合其他漏洞做更多危害
2、敏感信息泄露,通过枚举应用根目录,导致敏感信息泄露
保护:
1.提高密码和验证码的复杂度(至少8位,大小写,特殊字符和数字)
2、应用限制单位时间登录错误次数(如10分钟内连续输入5次错误,将被锁定10分钟)
3.验证码随提交而变化
参考研究文章:
网络安全——CSRF(Token)
Burp套件中的Attack Type模式详解—Intruder
网页抓取解密(网页抓取解密方案,开源的抓取程序技术流程是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-04-09 04:02
网页抓取解密方案1这种方案即爬取好友的空间或者会员的空间动态,然后解密编码方法使用“xmpp”比较简单,易实现。2这种方案使用多种类型的验证码扫描器,设置好成对密码,实现网页抓取的过程,需要使用第三方解码工具。总结本文分析一下开源的抓取程序技术流程。1.技术流程2-这里主要用到“selenium”来捕捉异步请求,如果采用“phantomjs”就需要通过浏览器的解析加载解码3.分析结论3.1采用“selenium”采用selenium自带api,自带浏览器的解析,如果采用“phantomjs”则需要下载第三方加速工具。
3.2使用多种类型的验证码扫描器使用多种类型的验证码扫描器,在扫描时按照需要来设置是否让验证码自动解码。如果是需要编码则需要采用“scrapy”结合代理,等待自动解码;如果没有要求编码,则通过使用“xmpp”工具解码。3.3反爬虫分析反爬虫分析原理通过浏览器解析验证码实现,爬取规则都是“穷举”结论2-这里主要用到“fiddler”驱动api设置的authorization,这个大家应该都学过。
验证码扫描器是否放在抓包工具上,使用抓包工具解析验证码的authorization3.4抓取分析真实对象“链接”这里抓取的是头条人物资料类页面的一部分“链接”,验证码的authorization设置是真实不自动解码,需要使用“xmpp”解析;xmpp是”xml+manual“自动脚本工具,非常适合你的爬虫。
结论2-技术流程4-1技术流程如果抓取代码是非官方文档(如网页)文件可以使用”esplus.js“编写,各种xml数据格式化工具支持,输入也比较简单,但是每行代码一定要有请求头就够了,可以使用esplus中文编辑器中的一键制作。编写高质量爬虫的技巧是对js代码风格需要慎重选择,个人感觉根据网页大小选择1-2条编写思路便可以了,当然,这样编写还不如python代码快,且一个人写有时候会弄混代码结构。
4.2总结原创android抓取api爬取官方文档获取网址5.抓取过程中遇到问题本篇抓取的api虽然作者有写一定要拿到工资,但是不影响你阅读本篇文章。最后附api1.打开头条2.根据自己的需要配置api(点击文末附api生成器中编写的api);3.下载相关文件(点击附api生成器中编写的api)。6.总结6.1工具附:5.抓取工具推荐6.2原理细节与分析5.xmpp利用xmpp框架解析代码,然后下载api,再下载api文件。
6.3处理代码需要代码来改装对比api找差异就是你处理api文件的思路~原理细节和分析这里不再累述,技术细节不在这里。---。 查看全部
网页抓取解密(网页抓取解密方案,开源的抓取程序技术流程是什么?)
网页抓取解密方案1这种方案即爬取好友的空间或者会员的空间动态,然后解密编码方法使用“xmpp”比较简单,易实现。2这种方案使用多种类型的验证码扫描器,设置好成对密码,实现网页抓取的过程,需要使用第三方解码工具。总结本文分析一下开源的抓取程序技术流程。1.技术流程2-这里主要用到“selenium”来捕捉异步请求,如果采用“phantomjs”就需要通过浏览器的解析加载解码3.分析结论3.1采用“selenium”采用selenium自带api,自带浏览器的解析,如果采用“phantomjs”则需要下载第三方加速工具。
3.2使用多种类型的验证码扫描器使用多种类型的验证码扫描器,在扫描时按照需要来设置是否让验证码自动解码。如果是需要编码则需要采用“scrapy”结合代理,等待自动解码;如果没有要求编码,则通过使用“xmpp”工具解码。3.3反爬虫分析反爬虫分析原理通过浏览器解析验证码实现,爬取规则都是“穷举”结论2-这里主要用到“fiddler”驱动api设置的authorization,这个大家应该都学过。
验证码扫描器是否放在抓包工具上,使用抓包工具解析验证码的authorization3.4抓取分析真实对象“链接”这里抓取的是头条人物资料类页面的一部分“链接”,验证码的authorization设置是真实不自动解码,需要使用“xmpp”解析;xmpp是”xml+manual“自动脚本工具,非常适合你的爬虫。
结论2-技术流程4-1技术流程如果抓取代码是非官方文档(如网页)文件可以使用”esplus.js“编写,各种xml数据格式化工具支持,输入也比较简单,但是每行代码一定要有请求头就够了,可以使用esplus中文编辑器中的一键制作。编写高质量爬虫的技巧是对js代码风格需要慎重选择,个人感觉根据网页大小选择1-2条编写思路便可以了,当然,这样编写还不如python代码快,且一个人写有时候会弄混代码结构。
4.2总结原创android抓取api爬取官方文档获取网址5.抓取过程中遇到问题本篇抓取的api虽然作者有写一定要拿到工资,但是不影响你阅读本篇文章。最后附api1.打开头条2.根据自己的需要配置api(点击文末附api生成器中编写的api);3.下载相关文件(点击附api生成器中编写的api)。6.总结6.1工具附:5.抓取工具推荐6.2原理细节与分析5.xmpp利用xmpp框架解析代码,然后下载api,再下载api文件。
6.3处理代码需要代码来改装对比api找差异就是你处理api文件的思路~原理细节和分析这里不再累述,技术细节不在这里。---。
网页抓取解密(巴西里约热内卢天主教大学Lua大学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-08 05:28
Lua 是一种小型脚本语言。它是由三人团队于 1993 年在巴西里约热内卢天主教大学由 Roberto Ierusalimschy、Waldemar Celes 和 Luiz Henrique de Figueiredo 开发的。它旨在通过灵活嵌入到应用程序中,为应用程序提供灵活的扩展和定制能力。Lua 是用标准 C 语言编写的,几乎可以在所有操作系统和平台上编译和运行。Lua 没有提供强大的库,这是由它的定位决定的。所以 Lua 不适合作为开发独立应用程序的语言。Lua 有一个并发 JIT 项目,可在特定平台上提供即时编译。
Lua脚本可以方便的被C/C++代码调用,也可以依次调用C/C++函数,这使得Lua在应用中得到了广泛的应用。不仅作为扩展脚本,而且作为通用配置文件,代替XML、ini等文件格式,更易于理解和维护。Lua采用标准C语言编写,代码简洁美观,几乎可以在所有操作系统和平台上编译运行。一个完整的 Lua 解释器只有 200k。在所有脚本引擎中,Lua 是最快的。这一切都决定了 Lua 是作为嵌入式脚本的最佳选择。 查看全部
网页抓取解密(巴西里约热内卢天主教大学Lua大学)
Lua 是一种小型脚本语言。它是由三人团队于 1993 年在巴西里约热内卢天主教大学由 Roberto Ierusalimschy、Waldemar Celes 和 Luiz Henrique de Figueiredo 开发的。它旨在通过灵活嵌入到应用程序中,为应用程序提供灵活的扩展和定制能力。Lua 是用标准 C 语言编写的,几乎可以在所有操作系统和平台上编译和运行。Lua 没有提供强大的库,这是由它的定位决定的。所以 Lua 不适合作为开发独立应用程序的语言。Lua 有一个并发 JIT 项目,可在特定平台上提供即时编译。
Lua脚本可以方便的被C/C++代码调用,也可以依次调用C/C++函数,这使得Lua在应用中得到了广泛的应用。不仅作为扩展脚本,而且作为通用配置文件,代替XML、ini等文件格式,更易于理解和维护。Lua采用标准C语言编写,代码简洁美观,几乎可以在所有操作系统和平台上编译运行。一个完整的 Lua 解释器只有 200k。在所有脚本引擎中,Lua 是最快的。这一切都决定了 Lua 是作为嵌入式脚本的最佳选择。
网页抓取解密(基于chrome的跨浏览器post/get请求获取xmlhttprequest对象实现的抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-07 15:06
网页抓取解密关键就是代码层次,比如需要获取网页源代码,就需要获取加密后的meta标签信息,然后解密就简单了,一般就是反编译。至于从页面文本中得到文字和图片信息就没有那么简单了,可以尝试抓包分析页面代码结构,然后对二者进行切片分析。当然,这只是获取关键信息的一种方法,抓包还需要使用好网络抓包工具。再者,最简单的方法可以使用chrome浏览器的xmlhttprequest实现“调用http头获取数据”功能,不过如果需要查看页面源代码,则需要切换到查看xmlhttprequest()方法在请求中的实现,这样的话,就很难破解“返回data字段”的解密密码了。
github-shinzoxiao/dummyhttp:一个基于chrome的跨浏览器post/get请求获取xmlhttprequest对象实现的抓包工具。使用方法:。
1、首先打开项目页面,按照提示安装依赖包。
2、然后使用javascript代码来调用xmlhttprequest实现调用meta标签的xmlhttprequest调用,
3、这里的xmlhttprequest实现参考了fakehttp库中xmlhttprequest实现。
4、执行此javascript代码,解密就算完成。#http/1.1http/1.1是http/1.0之后最新的协议版本。http请求通常指的是http2.0,需要先注册到firefox浏览器上。http连接在大多数浏览器上都是会给你一个标准的uri地址,同时以as/image连接在网页(如百度首页)上。
如果要发起xmlhttp请求的话,则必须得到该连接的对应uri地址,比如你想请求一个视频资源,则必须得到该视频资源的uri地址"your-video-title"。常见请求头:location:用于表示uri的位置。name:用于表示uri的名称。description:用于表示应用程序需要发送给服务器的数据。
method:用于表示应用程序发送给服务器的数据类型,也可以用于调用get/post等方法。origin:用于表示客户端与服务器交互的方向。content-type:表示请求头的数据类型:application/x-www-form-urlencoded,application/x-www-form-data,application/x-message-text,application/x-www-form-content;charset=utf-8,application/x-message-content;charset=utf-8等等;post:表示在客户端向服务器发送数据。
get:表示在服务器上从服务器上获取数据。动态页面另说。如果请求的是静态页面,使用请求头中的host指定网址即可。如果页面名称中包含参数,则会对应到网址(post/get),单个参数的话,也会对应到页面名(host/get)。cookie头:默认的cookie是加密的,但也有不需要cookie就请求到服务器的。 查看全部
网页抓取解密(基于chrome的跨浏览器post/get请求获取xmlhttprequest对象实现的抓包工具)
网页抓取解密关键就是代码层次,比如需要获取网页源代码,就需要获取加密后的meta标签信息,然后解密就简单了,一般就是反编译。至于从页面文本中得到文字和图片信息就没有那么简单了,可以尝试抓包分析页面代码结构,然后对二者进行切片分析。当然,这只是获取关键信息的一种方法,抓包还需要使用好网络抓包工具。再者,最简单的方法可以使用chrome浏览器的xmlhttprequest实现“调用http头获取数据”功能,不过如果需要查看页面源代码,则需要切换到查看xmlhttprequest()方法在请求中的实现,这样的话,就很难破解“返回data字段”的解密密码了。
github-shinzoxiao/dummyhttp:一个基于chrome的跨浏览器post/get请求获取xmlhttprequest对象实现的抓包工具。使用方法:。
1、首先打开项目页面,按照提示安装依赖包。
2、然后使用javascript代码来调用xmlhttprequest实现调用meta标签的xmlhttprequest调用,
3、这里的xmlhttprequest实现参考了fakehttp库中xmlhttprequest实现。
4、执行此javascript代码,解密就算完成。#http/1.1http/1.1是http/1.0之后最新的协议版本。http请求通常指的是http2.0,需要先注册到firefox浏览器上。http连接在大多数浏览器上都是会给你一个标准的uri地址,同时以as/image连接在网页(如百度首页)上。
如果要发起xmlhttp请求的话,则必须得到该连接的对应uri地址,比如你想请求一个视频资源,则必须得到该视频资源的uri地址"your-video-title"。常见请求头:location:用于表示uri的位置。name:用于表示uri的名称。description:用于表示应用程序需要发送给服务器的数据。
method:用于表示应用程序发送给服务器的数据类型,也可以用于调用get/post等方法。origin:用于表示客户端与服务器交互的方向。content-type:表示请求头的数据类型:application/x-www-form-urlencoded,application/x-www-form-data,application/x-message-text,application/x-www-form-content;charset=utf-8,application/x-message-content;charset=utf-8等等;post:表示在客户端向服务器发送数据。
get:表示在服务器上从服务器上获取数据。动态页面另说。如果请求的是静态页面,使用请求头中的host指定网址即可。如果页面名称中包含参数,则会对应到网址(post/get),单个参数的话,也会对应到页面名(host/get)。cookie头:默认的cookie是加密的,但也有不需要cookie就请求到服务器的。

