
实时文章采集
实时文章采集(电力网络舆情监控网站行业舆情监测机制医院舆情监督管理“源码”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-08 13:15
源代码是指编写的最原创程序的代码。运行的软件是要编写的,程序员在编写程序的过程中需要他们的“语言”。音乐家使用五线谱,建筑师使用图纸。程序员工作的语言是“源代码”。
通过网页内容的自动采集处理、敏感词过滤、智能聚类分类、话题检测、话题聚焦、统计分析等,实现相关网络舆情监督管理的需求,将舆情专题报告和分析最终形成 报告和统计报告为决策者和管理层全面掌握舆情动态,做出正确的舆情导向,提供分析依据。工作过程
1.信息采集:实时监控互联网信息(新闻、论坛等),采集,内容提取、下载、重置。
2. 信息处理:对抓取的内容进行自动分类聚类、关键词过滤、话题检测、话题聚焦等。
3.信息服务:通过采集分析整理后直接向用户提供信息或为用户提供辅助编辑的信息服务,如自动生成舆情信息简报、舆情统计分析图表、跟踪发现的舆情焦点并形成趋势分析,用于辅助各级领导的决策支持。
人们平时使用软件时,程序会将“源代码”翻译成我们直观的形式供我们使用。[1]
任何 网站 页面,当替换为源代码时,都是一堆以某种格式编写的文本和符号,但我们的浏览器帮助我们将其翻译成我们面前的样子。
相关链接 电网舆情监测 舆情监测网站行业舆情监测 舆情监测机制 医院舆情监测 查看全部
实时文章采集(电力网络舆情监控网站行业舆情监测机制医院舆情监督管理“源码”)
源代码是指编写的最原创程序的代码。运行的软件是要编写的,程序员在编写程序的过程中需要他们的“语言”。音乐家使用五线谱,建筑师使用图纸。程序员工作的语言是“源代码”。
通过网页内容的自动采集处理、敏感词过滤、智能聚类分类、话题检测、话题聚焦、统计分析等,实现相关网络舆情监督管理的需求,将舆情专题报告和分析最终形成 报告和统计报告为决策者和管理层全面掌握舆情动态,做出正确的舆情导向,提供分析依据。工作过程
1.信息采集:实时监控互联网信息(新闻、论坛等),采集,内容提取、下载、重置。
2. 信息处理:对抓取的内容进行自动分类聚类、关键词过滤、话题检测、话题聚焦等。
3.信息服务:通过采集分析整理后直接向用户提供信息或为用户提供辅助编辑的信息服务,如自动生成舆情信息简报、舆情统计分析图表、跟踪发现的舆情焦点并形成趋势分析,用于辅助各级领导的决策支持。
人们平时使用软件时,程序会将“源代码”翻译成我们直观的形式供我们使用。[1]
任何 网站 页面,当替换为源代码时,都是一堆以某种格式编写的文本和符号,但我们的浏览器帮助我们将其翻译成我们面前的样子。
相关链接 电网舆情监测 舆情监测网站行业舆情监测 舆情监测机制 医院舆情监测
实时文章采集(使用java后端技术过程中的一些心得体会(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-07 19:02
实时文章采集,后面慢慢展开。今年是自己独立创业的第十年,在程序员行业的从业经历也有些年头,期间帮过很多朋友做过一些自己的项目,发现大部分程序员在接触新技术的时候,总会有一个反复的过程,所以今天来和大家分享一下自己在使用java后端技术过程中的一些心得体会。自己是如何发现并探索新技术的,或者说,是如何理解它的优劣?创业初期首先是和程序员沟通,从年初开始就对团队的能力和水平有了一些了解。
本身团队的成员都有自己独特的技术背景,比如最早是做seo,再比如可能最开始是做kafka等等。所以我很清楚技术要实现哪些特性,跟这些技术人员比,我并不具备什么优势,在今天技术更新速度之快,即使不是业界的资深技术人员,基本上没有一个人能够保证实时更新技术,所以我第一时间注意到了业界开始实现某个新技术,我马上去看看是不是真的解决了我的需求。
顺利地我找到了业界近期已经尝试过的较为成熟的技术,它们原本的优点,和目前的状态,顺利地我就想,难不成这个技术能对我的业务有不可替代性吗?需求实现方不是一个打酱油的?于是我迅速发现了问题所在。要实现这个技术,需要解决什么问题?解决了之后,这个技术是否有它的价值?就像我自己,我想做一个品牌交易平台,之前是一个做线下实体店导购的平台,解决的主要问题是卖什么好卖,而需要重新梳理导购平台,发现即使是在天猫、京东上的热销商品,也只能满足20%的客户群体,所以我必须考虑新的业务需求,是一个好的的品牌导购平台。
那么在技术选型上,不管是云计算还是大数据等等,都是在这一点上做文章。也就是说,如果以技术可替代性为标准,那么技术即使突破了重重障碍,也不可能达到我的要求。产品设计发现问题后,就到了产品的设计阶段,原本我认为考虑到的都是应该由程序员去思考的,但是产品的生命周期越长,程序员的参与越少,我觉得产品经理的地位就显得越重要。
相比于程序员,产品经理对于产品是有更高的优先级,不仅仅是因为他可以熟悉整个业务的设计,而且在设计的过程中对于产品价值的认识程度会更高,我有时候看到好的创意或产品,一时冲动就去做产品经理。开发工具但是,当我第一次遇到这个技术的时候,我发现了一个问题,那就是即使我有明确的产品设计,开发工具也没有考虑到。程序员拿到代码后,还需要处理部署,将业务代码拆成更小块的代码,整个开发流程是非常复杂的,程序员用起来会十分的费力。
又加上软件开发的流程是单点开发,一个人管一个人,管着一整个团队,我不知道软件的具体发布和编译是哪一个环节来。 查看全部
实时文章采集(使用java后端技术过程中的一些心得体会(上))
实时文章采集,后面慢慢展开。今年是自己独立创业的第十年,在程序员行业的从业经历也有些年头,期间帮过很多朋友做过一些自己的项目,发现大部分程序员在接触新技术的时候,总会有一个反复的过程,所以今天来和大家分享一下自己在使用java后端技术过程中的一些心得体会。自己是如何发现并探索新技术的,或者说,是如何理解它的优劣?创业初期首先是和程序员沟通,从年初开始就对团队的能力和水平有了一些了解。
本身团队的成员都有自己独特的技术背景,比如最早是做seo,再比如可能最开始是做kafka等等。所以我很清楚技术要实现哪些特性,跟这些技术人员比,我并不具备什么优势,在今天技术更新速度之快,即使不是业界的资深技术人员,基本上没有一个人能够保证实时更新技术,所以我第一时间注意到了业界开始实现某个新技术,我马上去看看是不是真的解决了我的需求。
顺利地我找到了业界近期已经尝试过的较为成熟的技术,它们原本的优点,和目前的状态,顺利地我就想,难不成这个技术能对我的业务有不可替代性吗?需求实现方不是一个打酱油的?于是我迅速发现了问题所在。要实现这个技术,需要解决什么问题?解决了之后,这个技术是否有它的价值?就像我自己,我想做一个品牌交易平台,之前是一个做线下实体店导购的平台,解决的主要问题是卖什么好卖,而需要重新梳理导购平台,发现即使是在天猫、京东上的热销商品,也只能满足20%的客户群体,所以我必须考虑新的业务需求,是一个好的的品牌导购平台。
那么在技术选型上,不管是云计算还是大数据等等,都是在这一点上做文章。也就是说,如果以技术可替代性为标准,那么技术即使突破了重重障碍,也不可能达到我的要求。产品设计发现问题后,就到了产品的设计阶段,原本我认为考虑到的都是应该由程序员去思考的,但是产品的生命周期越长,程序员的参与越少,我觉得产品经理的地位就显得越重要。
相比于程序员,产品经理对于产品是有更高的优先级,不仅仅是因为他可以熟悉整个业务的设计,而且在设计的过程中对于产品价值的认识程度会更高,我有时候看到好的创意或产品,一时冲动就去做产品经理。开发工具但是,当我第一次遇到这个技术的时候,我发现了一个问题,那就是即使我有明确的产品设计,开发工具也没有考虑到。程序员拿到代码后,还需要处理部署,将业务代码拆成更小块的代码,整个开发流程是非常复杂的,程序员用起来会十分的费力。
又加上软件开发的流程是单点开发,一个人管一个人,管着一整个团队,我不知道软件的具体发布和编译是哪一个环节来。
实时文章采集(2020年的春节,新型冠状病毒肺炎疫情来势凶猛可采集?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-26 08:15
摘要:疫情的话题离不开数据支持。疫情话题的原创数据从何而来?疫情话题的实时更新数据是怎么下来的?还有哪些与疫情相关的数据有价值,你能采集吗?本文文章会详细讲解。
2020年春节,新型冠状病毒肺炎疫情来势汹汹。
很多人和我一样,每天睁开眼睛,立刻点开疫情图,看看全国各个省市的病例数。
在互联网和大数据高速发展的今天,疫情信息的透明度极高。疫情发生后,腾讯新闻、凤凰网、阿里健康、人民日报、网易新闻、百度等新闻媒体迅速推出疫情专题,包括疫情地图、实时动态、防谣言防护知识、医疗资讯等栏目。实时跟踪情况。
疫情话题离不开数据支撑。疫情话题的原创数据从何而来?疫情话题的实时更新数据是怎么下来的?还有哪些与疫情相关的数据有价值,你能采集吗?
下面将详细说明。
01采集国家和地方卫健委官网发布的每日疫情通报,为疫情地图中全国各省市病例数据提供数据支撑
国家和地方卫健委官方网站每天以文章的形式发布疫情通报。媒体利用爬虫技术文章实时采集这些疫情通知,从文章中提取有效病例数据,然后以可视化图表等形式展示病例地图和折线图。数据和流行趋势方便大家查看。
我们在疫情地图上看到的病例数据是经过处理的二手数据,可以方便地访问。如果我想从国家和地方卫健委官方网站获取第一手数据怎么办?
以国家卫健委为例。从1月11日起,国家卫健委将每日发布一篇文章,通报全国疫情总体情况,包括每日新增确诊、新增疑似、新增治愈、新增死亡、累计确诊病例。诊断数量、累计疑似病例、累计治愈人数和累计死亡人数。
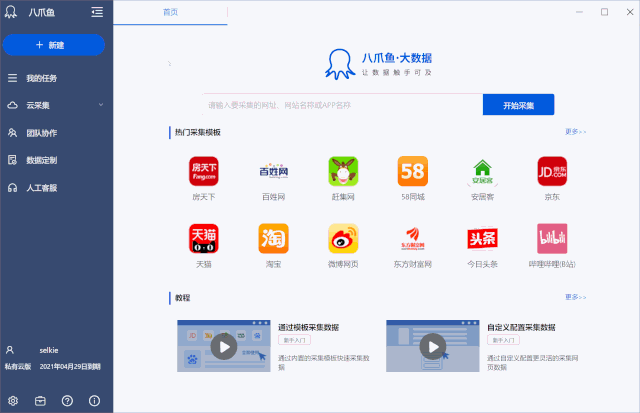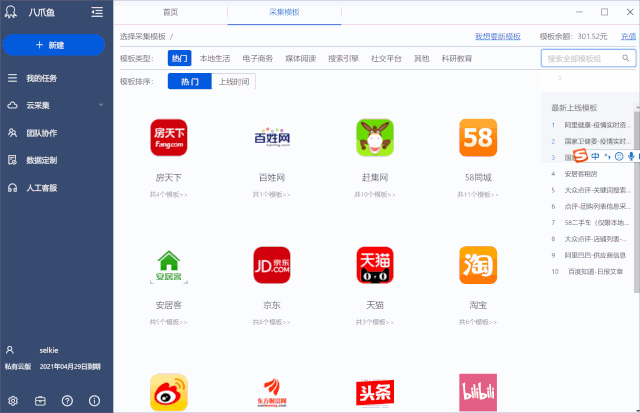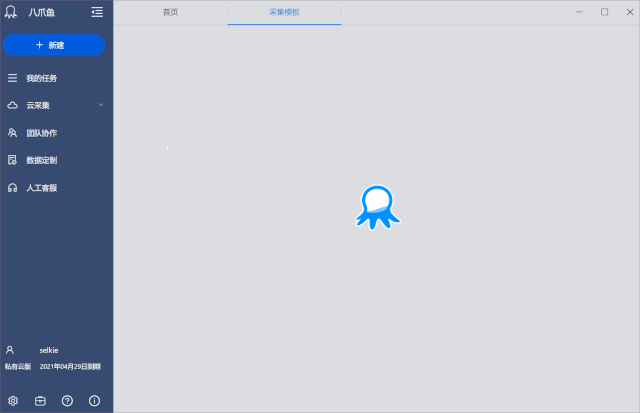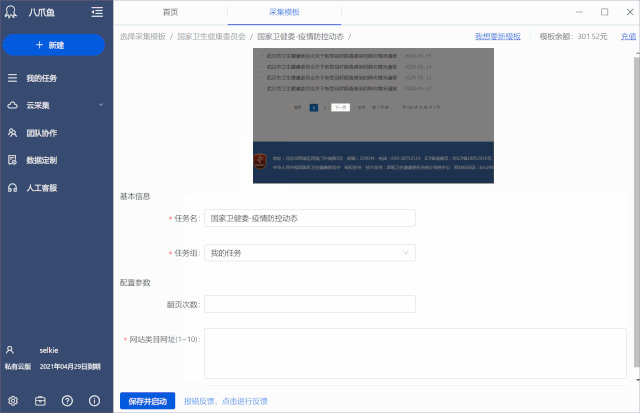
如果您需要以上一手数据,国家卫健委采集的优采云模板已经上线,免费供大家使用。通过该模板,您可以采集到每日疫情通报文章,通过处理提取有效病例数据。国家卫健委其他栏目(防控动态、通知公告、医生风采、防控知识、新闻报道)的文章也可以使用本模板采集。
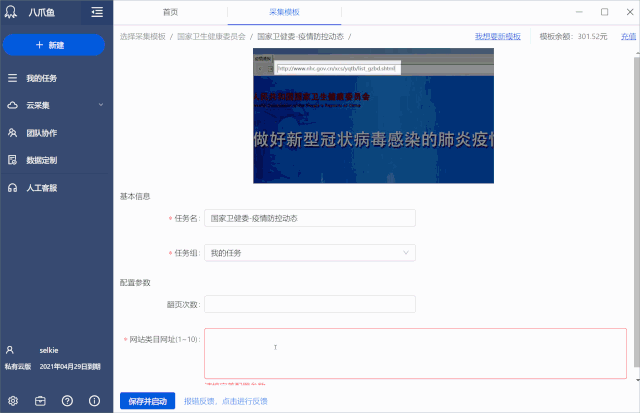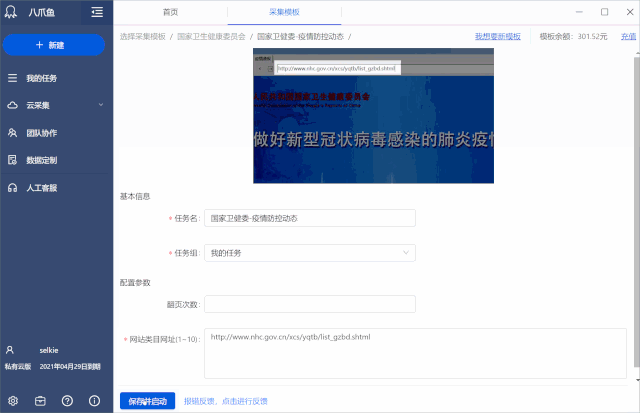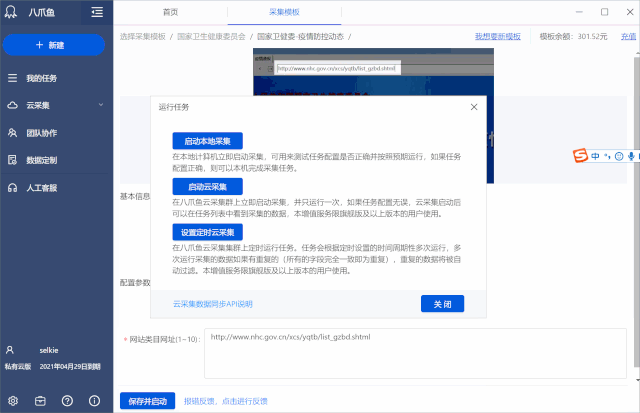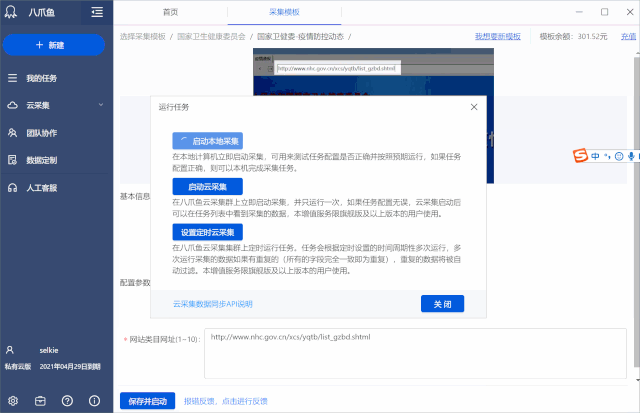
以采集疫情通知栏下的文章为例,如何使用该模板:
Step1. 下载优采云客户端,找到【国家卫健委-疫情防控动态】模板,点击【立即使用】
Step2. 在[网站Category URL]的参数框中,输入疫情通知栏的URL:,然后[Start Local采集]
如果要采集其他栏目,请按照模板介绍,在[网站Category URL]参数框中输入对应的网址。
步骤3. 示例数据
02疫情地图实时采集全国各省市病例数据,为研究疫情发展趋势提供数据支持
各媒体疫情地图病例数据的数据来源,基本都是国家和地方市建委下发的疫情通报,没有太大区别。疫情地图实时更新,详细显示当前时刻全国各省市新增和累计病例数,但无法查看历史时刻数据。
对于研究疫情的发展趋势,历史数据非常重要。如何检索历史数据?
1、从国家和地方卫健委官网查找一手资料,参考第一部分内容。
2、即日起,疫情地图中的病例数据将被实时抓取并存储,用于数据积累。
由于各个公司的疫情地图数据差别不大,我们选择了腾讯新闻的疫情地图作为采集模板。从现在开始,您可以使用优采云的云采集设置定期采集计划,实时采集疫情地图中的病例数据。
如何使用此模板:
Step1. 下载优采云客户端,找到【国家卫健委-疫情实时数据】模板,点击【立即使用】,无需输入参数,直接【启动本地采集 ]
步骤2. 示例数据
03采集社交/新闻平台疫情相关数据助力疫情舆情分析
互联网上充斥着疫情信息。采集 疫情相关信息是分析疫情舆情的第一步。除了国家和地方卫健委等政府网站实时发布疫情通报、通知公告、防控动态、新闻报道外,所有社交/新闻平台也充斥着与疫情相关的讨论.
以微博和知乎为例。您可以在微博和知乎上搜索与疫情相关的关键词、微博结果、知乎出现在采集上的问题和答案。然后分析流行热度和时间的趋势,不同时间段的流行重点,以及相关文本的正面和负面情绪。对于上述数据,优采云提供了[知乎-关键字搜索答案]、[知乎-问题详细答案]和[微博搜索]的模板。
微博模板使用方法:
步骤1.在优采云客户端找到【微博搜索】模板,点击【立即使用】
步骤2.在[搜索关键词]参数输入框中输入疫情相关关键词(可以输入多个关键词),然后[启动云采集@ >]
步骤3. 示例数据
知乎模板使用方法:
步骤1.在优采云客户端找到【知乎-关键字搜索答案】模板,点击【立即使用】
Step2. 在[Keyword]参数输入框中输入疫情相关关键词(可以输入多个关键词),然后[启动云采集]
步骤3. 示例数据
毫无疑问,互联网和大数据带来的信息透明化,在抗击疫情中发挥着重要而积极的作用。通过国家卫健委等权威机构发布的实时病例数据和防控动态,我们能够贴近疫情真实情况,积极响应防控政策。通过查询确诊社区、查询确诊旅客等平台,及时发现和规避感染风险。通过知乎微博等平台,可以高效传播科普、辟谣、讨论、求助、监督等优质信息。
这一切都离不开原创数据的采集。如果你恰好对这些多维度的疫情数据感兴趣,希望这篇文章对你有所帮助。
没有春天不会来。在她到来之前,优采云 会和你在一起。 查看全部
实时文章采集(2020年的春节,新型冠状病毒肺炎疫情来势凶猛可采集?)
摘要:疫情的话题离不开数据支持。疫情话题的原创数据从何而来?疫情话题的实时更新数据是怎么下来的?还有哪些与疫情相关的数据有价值,你能采集吗?本文文章会详细讲解。
2020年春节,新型冠状病毒肺炎疫情来势汹汹。
很多人和我一样,每天睁开眼睛,立刻点开疫情图,看看全国各个省市的病例数。
在互联网和大数据高速发展的今天,疫情信息的透明度极高。疫情发生后,腾讯新闻、凤凰网、阿里健康、人民日报、网易新闻、百度等新闻媒体迅速推出疫情专题,包括疫情地图、实时动态、防谣言防护知识、医疗资讯等栏目。实时跟踪情况。

疫情话题离不开数据支撑。疫情话题的原创数据从何而来?疫情话题的实时更新数据是怎么下来的?还有哪些与疫情相关的数据有价值,你能采集吗?
下面将详细说明。
01采集国家和地方卫健委官网发布的每日疫情通报,为疫情地图中全国各省市病例数据提供数据支撑
国家和地方卫健委官方网站每天以文章的形式发布疫情通报。媒体利用爬虫技术文章实时采集这些疫情通知,从文章中提取有效病例数据,然后以可视化图表等形式展示病例地图和折线图。数据和流行趋势方便大家查看。



我们在疫情地图上看到的病例数据是经过处理的二手数据,可以方便地访问。如果我想从国家和地方卫健委官方网站获取第一手数据怎么办?
以国家卫健委为例。从1月11日起,国家卫健委将每日发布一篇文章,通报全国疫情总体情况,包括每日新增确诊、新增疑似、新增治愈、新增死亡、累计确诊病例。诊断数量、累计疑似病例、累计治愈人数和累计死亡人数。

如果您需要以上一手数据,国家卫健委采集的优采云模板已经上线,免费供大家使用。通过该模板,您可以采集到每日疫情通报文章,通过处理提取有效病例数据。国家卫健委其他栏目(防控动态、通知公告、医生风采、防控知识、新闻报道)的文章也可以使用本模板采集。

以采集疫情通知栏下的文章为例,如何使用该模板:
Step1. 下载优采云客户端,找到【国家卫健委-疫情防控动态】模板,点击【立即使用】
Step2. 在[网站Category URL]的参数框中,输入疫情通知栏的URL:,然后[Start Local采集]
如果要采集其他栏目,请按照模板介绍,在[网站Category URL]参数框中输入对应的网址。
步骤3. 示例数据

02疫情地图实时采集全国各省市病例数据,为研究疫情发展趋势提供数据支持
各媒体疫情地图病例数据的数据来源,基本都是国家和地方市建委下发的疫情通报,没有太大区别。疫情地图实时更新,详细显示当前时刻全国各省市新增和累计病例数,但无法查看历史时刻数据。

对于研究疫情的发展趋势,历史数据非常重要。如何检索历史数据?
1、从国家和地方卫健委官网查找一手资料,参考第一部分内容。
2、即日起,疫情地图中的病例数据将被实时抓取并存储,用于数据积累。
由于各个公司的疫情地图数据差别不大,我们选择了腾讯新闻的疫情地图作为采集模板。从现在开始,您可以使用优采云的云采集设置定期采集计划,实时采集疫情地图中的病例数据。
如何使用此模板:
Step1. 下载优采云客户端,找到【国家卫健委-疫情实时数据】模板,点击【立即使用】,无需输入参数,直接【启动本地采集 ]

步骤2. 示例数据

03采集社交/新闻平台疫情相关数据助力疫情舆情分析
互联网上充斥着疫情信息。采集 疫情相关信息是分析疫情舆情的第一步。除了国家和地方卫健委等政府网站实时发布疫情通报、通知公告、防控动态、新闻报道外,所有社交/新闻平台也充斥着与疫情相关的讨论.
以微博和知乎为例。您可以在微博和知乎上搜索与疫情相关的关键词、微博结果、知乎出现在采集上的问题和答案。然后分析流行热度和时间的趋势,不同时间段的流行重点,以及相关文本的正面和负面情绪。对于上述数据,优采云提供了[知乎-关键字搜索答案]、[知乎-问题详细答案]和[微博搜索]的模板。
微博模板使用方法:
步骤1.在优采云客户端找到【微博搜索】模板,点击【立即使用】

步骤2.在[搜索关键词]参数输入框中输入疫情相关关键词(可以输入多个关键词),然后[启动云采集@ >]

步骤3. 示例数据

知乎模板使用方法:
步骤1.在优采云客户端找到【知乎-关键字搜索答案】模板,点击【立即使用】

Step2. 在[Keyword]参数输入框中输入疫情相关关键词(可以输入多个关键词),然后[启动云采集]

步骤3. 示例数据

毫无疑问,互联网和大数据带来的信息透明化,在抗击疫情中发挥着重要而积极的作用。通过国家卫健委等权威机构发布的实时病例数据和防控动态,我们能够贴近疫情真实情况,积极响应防控政策。通过查询确诊社区、查询确诊旅客等平台,及时发现和规避感染风险。通过知乎微博等平台,可以高效传播科普、辟谣、讨论、求助、监督等优质信息。
这一切都离不开原创数据的采集。如果你恰好对这些多维度的疫情数据感兴趣,希望这篇文章对你有所帮助。
没有春天不会来。在她到来之前,优采云 会和你在一起。
实时文章采集( 做flume,其实就是写conf文件,就面临选型的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-24 20:02
做flume,其实就是写conf文件,就面临选型的问题)
Flume和Kafka完成实时数据采集
写在前面
Flume和Kafka一般在生产环境中结合使用。可以将两者结合使用来采集实时日志信息,这一点非常重要。如果你不知道flume和kafka,可以先看看我写的关于这两部分的知识。再学习一下,这部分操作也是可以的。
采集 的实时数据面临一个问题。我们如何生成实时数据源?因为我们可能想直接获取实时数据流不是那么方便。在文章之前写过一篇关于实时数据流的python生成器的文章,文章地址:
大家可以先看看,如何生成实时数据...
主意?? 如何开始??
分析:我们可以从数据流开始。数据一开始就在网络服务器上。我们的访问日志是nginx服务器实时采集到指定文件的。我们从这个文件中采集日志数据,即:webserver=>flume=>kafka
Webserver 日志存储文件位置
这个文件的位置一般是我们自己设置的
我们的网络日志存储的目录是:
/home/hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
水槽
做flume其实就是写一个conf文件,所以面临选择的问题
来源选择?频道选择?水槽选择?
这里我们选择exec source memory channel kafka sink
怎么写?
按照前面提到的步骤 1234
从官方网站上,我们可以找到我们的选择应该怎么写:
1) 配置源
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2) 配置通道
记忆通道
a1.channels.c1.type = memory
3) 配置接收器
卡夫卡水槽
对于flume1.6 版本,请参考#kafka-sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
将以上三个组件串在一起
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们的新文件叫做 test3.conf
贴上我们分析的代码:
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里不展开了,因为涉及kafka的东西,首先要部署kafka,
Kafka部署
Kafka是如何部署的??
按照官网的说法,我们先启动一个zookeeper进程,然后就可以启动kafka服务器了
第一步:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
第二步:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果这部分不是很熟悉,可以参考
第 3 步:创建主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
第四步:启动之前的代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
第 5 步:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行完上面的第五步后,你会收到刷新屏幕的结果,哈哈哈!!
上面的消费者会不断刷新屏幕,还是很有意思的!!!
这里的消费者就是把接收到的数据放到屏幕上
后面会介绍使用SparkStreaming作为消费者实时接收数据,并对接收到的数据进行简单的数据清洗,从随机生成的日志中过滤出我们需要的数据...... 查看全部
实时文章采集(
做flume,其实就是写conf文件,就面临选型的问题)
Flume和Kafka完成实时数据采集
写在前面
Flume和Kafka一般在生产环境中结合使用。可以将两者结合使用来采集实时日志信息,这一点非常重要。如果你不知道flume和kafka,可以先看看我写的关于这两部分的知识。再学习一下,这部分操作也是可以的。
采集 的实时数据面临一个问题。我们如何生成实时数据源?因为我们可能想直接获取实时数据流不是那么方便。在文章之前写过一篇关于实时数据流的python生成器的文章,文章地址:
大家可以先看看,如何生成实时数据...
主意?? 如何开始??
分析:我们可以从数据流开始。数据一开始就在网络服务器上。我们的访问日志是nginx服务器实时采集到指定文件的。我们从这个文件中采集日志数据,即:webserver=>flume=>kafka
Webserver 日志存储文件位置
这个文件的位置一般是我们自己设置的
我们的网络日志存储的目录是:
/home/hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
水槽
做flume其实就是写一个conf文件,所以面临选择的问题
来源选择?频道选择?水槽选择?
这里我们选择exec source memory channel kafka sink
怎么写?
按照前面提到的步骤 1234
从官方网站上,我们可以找到我们的选择应该怎么写:
1) 配置源
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2) 配置通道
记忆通道
a1.channels.c1.type = memory
3) 配置接收器
卡夫卡水槽
对于flume1.6 版本,请参考#kafka-sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
将以上三个组件串在一起
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们的新文件叫做 test3.conf
贴上我们分析的代码:
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里不展开了,因为涉及kafka的东西,首先要部署kafka,
Kafka部署
Kafka是如何部署的??
按照官网的说法,我们先启动一个zookeeper进程,然后就可以启动kafka服务器了
第一步:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
第二步:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果这部分不是很熟悉,可以参考
第 3 步:创建主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
第四步:启动之前的代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
第 5 步:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行完上面的第五步后,你会收到刷新屏幕的结果,哈哈哈!!

上面的消费者会不断刷新屏幕,还是很有意思的!!!
这里的消费者就是把接收到的数据放到屏幕上
后面会介绍使用SparkStreaming作为消费者实时接收数据,并对接收到的数据进行简单的数据清洗,从随机生成的日志中过滤出我们需要的数据......
实时文章采集(原创文章被别人即时复制怎么办?如何处理?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-24 07:09
很多人讨厌自己的原创文章被别人瞬间抄袭。有些人甚至用它来发送一些垃圾邮件链接。尤其相信很多老人都遇到过这样的情况。有时他们的努力还不如采集。我们如何处理这种情况?
首先,在竞争对手采集这个文章之前,尽量让搜索引擎收录它。
1、及时捕捉文章让搜索引擎知道这一点文章。
2、Ping 在百度的网站管理员自己的文章链接上,这也是百度官方告诉我们的一种方式。
二、文章 标记作者或版本。
织梦58 认为有时候阻止别人抄袭你的文章是不可能的,但这也是一种书面的交流和提醒,总比没有好。
第三,在文章中添加一些功能。
1、比如在n1、n2、color等标签代码中文章,搜索引擎会对这些内容更加敏感,加深认知原创 的判断。
2、在文章中添加您自己的品牌词汇
3、添加一些内部链接,因为喜欢复制文章的人通常比较懒,不排除有些人可以直接复制粘贴。
4、 文章文章被及时添加时,搜索引擎会判断文章的原创性,参考时间因素。
四、过滤网页的关键功能
大多数人在使用鼠标右键复制文章时,如果技术不受此功能影响,无疑会增加采集的麻烦。
五、夜间更新
你最害怕的是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯上了。文章 立即被抄袭。
在我们的网站上看到并应用了这些方法之后,相信这样可以减少文章的集合数量。 查看全部
实时文章采集(原创文章被别人即时复制怎么办?如何处理?(图))
很多人讨厌自己的原创文章被别人瞬间抄袭。有些人甚至用它来发送一些垃圾邮件链接。尤其相信很多老人都遇到过这样的情况。有时他们的努力还不如采集。我们如何处理这种情况?
首先,在竞争对手采集这个文章之前,尽量让搜索引擎收录它。
1、及时捕捉文章让搜索引擎知道这一点文章。
2、Ping 在百度的网站管理员自己的文章链接上,这也是百度官方告诉我们的一种方式。
二、文章 标记作者或版本。
织梦58 认为有时候阻止别人抄袭你的文章是不可能的,但这也是一种书面的交流和提醒,总比没有好。

第三,在文章中添加一些功能。
1、比如在n1、n2、color等标签代码中文章,搜索引擎会对这些内容更加敏感,加深认知原创 的判断。
2、在文章中添加您自己的品牌词汇
3、添加一些内部链接,因为喜欢复制文章的人通常比较懒,不排除有些人可以直接复制粘贴。
4、 文章文章被及时添加时,搜索引擎会判断文章的原创性,参考时间因素。
四、过滤网页的关键功能
大多数人在使用鼠标右键复制文章时,如果技术不受此功能影响,无疑会增加采集的麻烦。
五、夜间更新
你最害怕的是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯上了。文章 立即被抄袭。
在我们的网站上看到并应用了这些方法之后,相信这样可以减少文章的集合数量。
实时文章采集(2000开发环境VS2003orFramework1.1(SqlServer1.1))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-23 12:12
预览图片请参阅:HTML运行环境Windows NT / XP / 2003或Framework 1. 1SQLServer 2000开发环境VS 2003目的网络编程,我必须做点什么。所以我想我想成为一个网页Content 采集器。作者主页:使用模式测试数据采用CNBLOG。请参阅下一个图片用户首次填写“启动网页”,这是从哪个页面采集。然后填写数据库连接字符串,这是插入数据库的采集的定义,选择了表名,没有必要。网页编码,没有意外,中国大陆可以使用UTF-8攀登文件名:哦,这个工具明显被编程师使用。必须直接填写规定。例如,CNBlogs是一个数字,所以写\ D构建表帮助:用户指定几种varchar类型,几种文本类型,主要是更短的数据和长数据。如果您的桌子中有列,那么您害怕。程序内没有验证。在网页上:采集内容内容标标标::例如,如果我想要采集 xxx,写“to”,意思是,当然是内容。将显示以下文本框。单击“获取URL”以查看捕获的URL的URL是错误的。单击“采集”,可以将采集 content放入数据库中,然后使用插入xx()(选择xx)直接插入目标数据。程序代码非常小(它也很简单),需要更改。不足以定期表达式,网络编程是由于最简单的东西,所以没有多线程,没有其他优化方法,不支持分页。测试,获得38个数据,使用700米内存。 。 。 。如果有用的人可以改变它。方便程序员,手写很多代码。尹@ virance中心重印,请注明来源 查看全部
实时文章采集(2000开发环境VS2003orFramework1.1(SqlServer1.1))
预览图片请参阅:HTML运行环境Windows NT / XP / 2003或Framework 1. 1SQLServer 2000开发环境VS 2003目的网络编程,我必须做点什么。所以我想我想成为一个网页Content 采集器。作者主页:使用模式测试数据采用CNBLOG。请参阅下一个图片用户首次填写“启动网页”,这是从哪个页面采集。然后填写数据库连接字符串,这是插入数据库的采集的定义,选择了表名,没有必要。网页编码,没有意外,中国大陆可以使用UTF-8攀登文件名:哦,这个工具明显被编程师使用。必须直接填写规定。例如,CNBlogs是一个数字,所以写\ D构建表帮助:用户指定几种varchar类型,几种文本类型,主要是更短的数据和长数据。如果您的桌子中有列,那么您害怕。程序内没有验证。在网页上:采集内容内容标标标::例如,如果我想要采集 xxx,写“to”,意思是,当然是内容。将显示以下文本框。单击“获取URL”以查看捕获的URL的URL是错误的。单击“采集”,可以将采集 content放入数据库中,然后使用插入xx()(选择xx)直接插入目标数据。程序代码非常小(它也很简单),需要更改。不足以定期表达式,网络编程是由于最简单的东西,所以没有多线程,没有其他优化方法,不支持分页。测试,获得38个数据,使用700米内存。 。 。 。如果有用的人可以改变它。方便程序员,手写很多代码。尹@ virance中心重印,请注明来源
实时文章采集(新媒体运营怎么配合公司推广?怎么去适应哪些内容?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-22 18:04
实时文章采集对于新媒体运营来说,个人觉得seo(搜索引擎优化)是最重要的了。很多同学会经常问我这样一个问题:“老师,微信公众号,微博,今日头条这些平台我现在注册了,账号申请下来了,想要内容去推广,那应该怎么去进行呢?”那些平台我们可以选择去适应哪些内容呢?怎么去配合公司推广呢?首先你要清楚,自己想要做哪些内容,以及你想推广的是什么内容,然后再一点一点搜集信息。
同时,当你清楚了内容和推广的目标是针对哪一块产品来的时候,你也要考虑你是想去做自媒体运营,还是做品牌口碑还是影响大客户这样。seo一般分为:1.新闻稿、软文2.软件制作3.论坛贴吧4.博客5.自媒体运营6.设计工具采集,或者昵称,id注册知乎关注,微博,今日头条,搜狐,新浪博客,新浪微博认证,做推广。
还可以发布一些领域类的博客,比如电影,阅读,设计,健康,交通,等等这些,或者是合作自媒体,例如广告主、消费者以及官方公众号之类的联合做内容推广,了解别人的推广方式。选择粉丝不同,来源渠道就不同。例如:电影,你可以走官方自媒体平台,直接去发你的开发号,官方的媒体方就是作者以及推广者,很容易发表到官方媒体上的。
你可以通过网络平台直接去引流到你的运营公众号上来,因为看到广告的人就是你的潜在用户群。再比如:大型的app上面,你可以直接走广告主,他们就是一些大型的广告主,没有流量的时候,可以花钱买粉丝,或者是你去微博上发广告。如果真的是没有资金,建议你可以去小公司,但是你必须要花时间去做好你的内容,先去做个人专栏,以后有钱了,再去做商业写作。
内容获取的渠道很多,比如微信公众号:可以自己做内容生产,公众号有定期的内容更新,当你不能及时更新的时候就是去抄袭他人的,不去做任何内容创新。微博:新浪微博也是一个内容生产的平台,有很多转发抽奖的活动,你可以去做转发抽奖。app:你可以去做一些地推,比如说你可以在地铁等人流比较大的时候去进行户外广告的投放,广告的销售情况也是挺高的。
综上所述,想要获取更多粉丝需要两点:1.花时间去做好自己的内容2.考虑合作的方式。第一点:花时间去做自己的内容,很多同学都在问我怎么去写微信文章,但是为什么发布出去还是没有任何人点开阅读,我回答你:他们连新闻都不知道有什么意义,还好意思去点吗?那么,你应该去做的:首先你要去尝试写一些长篇文章(1w字以上),用你的故事和故事来生动的讲述你要传达的知识点。以及,你要去找一些大的网站,比如说企鹅智酷这样的平台来宣传,需要从多。 查看全部
实时文章采集(新媒体运营怎么配合公司推广?怎么去适应哪些内容?)
实时文章采集对于新媒体运营来说,个人觉得seo(搜索引擎优化)是最重要的了。很多同学会经常问我这样一个问题:“老师,微信公众号,微博,今日头条这些平台我现在注册了,账号申请下来了,想要内容去推广,那应该怎么去进行呢?”那些平台我们可以选择去适应哪些内容呢?怎么去配合公司推广呢?首先你要清楚,自己想要做哪些内容,以及你想推广的是什么内容,然后再一点一点搜集信息。
同时,当你清楚了内容和推广的目标是针对哪一块产品来的时候,你也要考虑你是想去做自媒体运营,还是做品牌口碑还是影响大客户这样。seo一般分为:1.新闻稿、软文2.软件制作3.论坛贴吧4.博客5.自媒体运营6.设计工具采集,或者昵称,id注册知乎关注,微博,今日头条,搜狐,新浪博客,新浪微博认证,做推广。
还可以发布一些领域类的博客,比如电影,阅读,设计,健康,交通,等等这些,或者是合作自媒体,例如广告主、消费者以及官方公众号之类的联合做内容推广,了解别人的推广方式。选择粉丝不同,来源渠道就不同。例如:电影,你可以走官方自媒体平台,直接去发你的开发号,官方的媒体方就是作者以及推广者,很容易发表到官方媒体上的。
你可以通过网络平台直接去引流到你的运营公众号上来,因为看到广告的人就是你的潜在用户群。再比如:大型的app上面,你可以直接走广告主,他们就是一些大型的广告主,没有流量的时候,可以花钱买粉丝,或者是你去微博上发广告。如果真的是没有资金,建议你可以去小公司,但是你必须要花时间去做好你的内容,先去做个人专栏,以后有钱了,再去做商业写作。
内容获取的渠道很多,比如微信公众号:可以自己做内容生产,公众号有定期的内容更新,当你不能及时更新的时候就是去抄袭他人的,不去做任何内容创新。微博:新浪微博也是一个内容生产的平台,有很多转发抽奖的活动,你可以去做转发抽奖。app:你可以去做一些地推,比如说你可以在地铁等人流比较大的时候去进行户外广告的投放,广告的销售情况也是挺高的。
综上所述,想要获取更多粉丝需要两点:1.花时间去做好自己的内容2.考虑合作的方式。第一点:花时间去做自己的内容,很多同学都在问我怎么去写微信文章,但是为什么发布出去还是没有任何人点开阅读,我回答你:他们连新闻都不知道有什么意义,还好意思去点吗?那么,你应该去做的:首先你要去尝试写一些长篇文章(1w字以上),用你的故事和故事来生动的讲述你要传达的知识点。以及,你要去找一些大的网站,比如说企鹅智酷这样的平台来宣传,需要从多。
实时文章采集(登录免费注册-infoq也可以直接访问我们网站(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-22 05:06
实时文章采集工具支持移动端和pc端,采集资源是来自于「infoq」的。打开登录,免费注册。登录免费注册-infoq也可以直接访问我们网站()。或扫描以下二维码直接注册:注册后,在首页,点击导航栏“我是创始人”,会看到登录用户名和密码,如图:图1注册页面然后找到右侧的“企业主页”,扫描图中地址打开首页,如图:图2首页这里有三个大的标签页,默认是直接访问在我是创始人,我是社区,我是创始人,三个标签页。
除了标签页外,还有一个活动页面,如图:图3活动页面进入活动页面,点击“个人网站”,会显示创始人项目介绍和历史的项目,如图:图4个人网站在个人网站,你会看到“登录”选项,点击即可登录。登录后,不要急着发布网站,点击“发布”,你会在首页看到对应的展示。等展示结束,即可发布。发布成功,上传“企业主页”地址即可上线发布。
图5个人网站发布-infoq如果您希望能将您的网站最新的文章也同步到infoq,可以通过页面访问网址「」,然后点击同步链接,然后点击【发布】按钮,即可将本地网站所有文章同步到infoq。注意这里「发布」按钮,有2个选项,其中一个是“保存数据”,点击这个按钮即可保存网站的文章。另一个是“分享到网站”,当分享到网站后,即可推送到infoq的服务器。
这里显示是微博推送,其实是推送到infoq的服务器后,后台会有自动发送到后台上传。接下来的注意事项,网站将会对您的网站文章进行原创检测。文章以采集文章形式同步到infoq。不管文章采取什么形式,文章的内容必须是来自于“infoq中国”。文章地址保存成域名形式后,只会展示到“infoq中国”网站上,不会同步到infoq服务器。
网站的采集要求是,每月至少40篇。对于长篇文章,将会进行目录的形式。主要的文章内容可能涉及软件开发,界面设计以及api的开发等。需要将文章地址保存后,将所有的图片转换成html格式,然后将文章链接转换成连接格式。我们注重内容的品质,对字体以及排版等要求较高。在长文章中,往往要进行插入代码,比如图片,表格等等。
对于长文章,需要对网页进行分析和对应页面进行抓取。不同的字体,以及不同的排版不同的特殊字符,网站可能要进行预处理处理。为了发布到infoq网站,需要使用infoq中国合作方和我们提供的服务,未来不可能有其他补贴方式。希望有需要的创业团队,将文章发布到infoq网站,或文章链接,还可以发布到自己的博客或一些其他平台。有意提供文章同步服务的创业团队,请联系我们。我们发起了写作。 查看全部
实时文章采集(登录免费注册-infoq也可以直接访问我们网站(组图))
实时文章采集工具支持移动端和pc端,采集资源是来自于「infoq」的。打开登录,免费注册。登录免费注册-infoq也可以直接访问我们网站()。或扫描以下二维码直接注册:注册后,在首页,点击导航栏“我是创始人”,会看到登录用户名和密码,如图:图1注册页面然后找到右侧的“企业主页”,扫描图中地址打开首页,如图:图2首页这里有三个大的标签页,默认是直接访问在我是创始人,我是社区,我是创始人,三个标签页。
除了标签页外,还有一个活动页面,如图:图3活动页面进入活动页面,点击“个人网站”,会显示创始人项目介绍和历史的项目,如图:图4个人网站在个人网站,你会看到“登录”选项,点击即可登录。登录后,不要急着发布网站,点击“发布”,你会在首页看到对应的展示。等展示结束,即可发布。发布成功,上传“企业主页”地址即可上线发布。
图5个人网站发布-infoq如果您希望能将您的网站最新的文章也同步到infoq,可以通过页面访问网址「」,然后点击同步链接,然后点击【发布】按钮,即可将本地网站所有文章同步到infoq。注意这里「发布」按钮,有2个选项,其中一个是“保存数据”,点击这个按钮即可保存网站的文章。另一个是“分享到网站”,当分享到网站后,即可推送到infoq的服务器。
这里显示是微博推送,其实是推送到infoq的服务器后,后台会有自动发送到后台上传。接下来的注意事项,网站将会对您的网站文章进行原创检测。文章以采集文章形式同步到infoq。不管文章采取什么形式,文章的内容必须是来自于“infoq中国”。文章地址保存成域名形式后,只会展示到“infoq中国”网站上,不会同步到infoq服务器。
网站的采集要求是,每月至少40篇。对于长篇文章,将会进行目录的形式。主要的文章内容可能涉及软件开发,界面设计以及api的开发等。需要将文章地址保存后,将所有的图片转换成html格式,然后将文章链接转换成连接格式。我们注重内容的品质,对字体以及排版等要求较高。在长文章中,往往要进行插入代码,比如图片,表格等等。
对于长文章,需要对网页进行分析和对应页面进行抓取。不同的字体,以及不同的排版不同的特殊字符,网站可能要进行预处理处理。为了发布到infoq网站,需要使用infoq中国合作方和我们提供的服务,未来不可能有其他补贴方式。希望有需要的创业团队,将文章发布到infoq网站,或文章链接,还可以发布到自己的博客或一些其他平台。有意提供文章同步服务的创业团队,请联系我们。我们发起了写作。
实时文章采集(实时文章采集分析编辑|飞鸟数据采集汇总(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-09-21 19:09
实时文章采集分析编辑|飞鸟数据采集汇总timeline-recruitthenextbreakthrough-propagatejfh'stwo-thirds-edge探讨-成长并不容易~作者|deadyegr
一、聚类分析为什么不能用于文章链接抓取如果抓取的重点是文章所在的分组,如“杨超越”或者“张恒”等等,这种聚类分析的实时性要求比较高。假设我们想要抓取第一个或者第二个分组中的部分文章作为切入点,即聚类分析的关键点。最坏的情况就是知道某个类别有多少篇文章,一个常见的做法是先聚类起来,然后用k-means来提取modelcenter。
如果人肉去爬行,比如从“算法社区”爬取10篇paper,假设平均每篇paper的字数应该为1万,那么从10个article中就可以提取出至少10个branch,比直接抓取抓得更快速。也正因为如此,所以才要去抓取k-means模型的参数。另外一方面,即使没有这些分支,那么依旧可以用类似于全文检索的技术去抓取重点文章,比如说我们可以使用entrez-ace来索引重点文章,然后再用svm分类。这种聚类的定制化带来的另一个好处就是时效性更好。
二、文章的主题是怎么聚类的呢?假设我们抓取了文章中所有的“杨超越”或者“张恒”关键词,那么将文章分为m主题和n主题或者n-tag是可行的。
1、模型聚类“杨超越”或者“张恒”等等关键词的选择和分布与整个文章主题分布有关,这也就意味着找到一个合适的population是一个非常关键的工作。一般来说,很多时候标签相关的文章会聚集在同一个ml-grid里,同一个tag也会聚集在同一个grid里。作者通过使用phase分析可以得出一个文章的特征离散(至少是单元)的分布,然后使用rnn依据距离划分相近的k个,再使用单元统计class-descriptors划分这个entirelyseparategrid。文章中每个关键词的离散程度也就是与其相邻的词的离散程度决定了文章的整体离散程度。
2、在phase模型中找到我们想要聚类的关键词如果找到了我们想要聚类的关键词,那么接下来就是通过rnn去拟合到相邻词的距离,然后找到modelcenter。一方面我们通过后缀词先去找,找到任何和某个关键词相近的词我们去扩展到相邻词,另一方面直接从全文中找,去找到与某些单词比较近的相邻的词。
三、结果展示文章聚类分析前四五页的内容均可以抓到。接下来就是看单个关键词在所有文章中的分布。这里涉及到一个将关键词转换成向量的问题。对于某些情况,比如关键词是按固定长度的数组,而比如使用rnn对特定长度的词识别,这时候基于rnn特定窗口构建floyd矩阵就相当于用各个关键词的向量构建一个rnn。这种情。 查看全部
实时文章采集(实时文章采集分析编辑|飞鸟数据采集汇总(二))
实时文章采集分析编辑|飞鸟数据采集汇总timeline-recruitthenextbreakthrough-propagatejfh'stwo-thirds-edge探讨-成长并不容易~作者|deadyegr
一、聚类分析为什么不能用于文章链接抓取如果抓取的重点是文章所在的分组,如“杨超越”或者“张恒”等等,这种聚类分析的实时性要求比较高。假设我们想要抓取第一个或者第二个分组中的部分文章作为切入点,即聚类分析的关键点。最坏的情况就是知道某个类别有多少篇文章,一个常见的做法是先聚类起来,然后用k-means来提取modelcenter。
如果人肉去爬行,比如从“算法社区”爬取10篇paper,假设平均每篇paper的字数应该为1万,那么从10个article中就可以提取出至少10个branch,比直接抓取抓得更快速。也正因为如此,所以才要去抓取k-means模型的参数。另外一方面,即使没有这些分支,那么依旧可以用类似于全文检索的技术去抓取重点文章,比如说我们可以使用entrez-ace来索引重点文章,然后再用svm分类。这种聚类的定制化带来的另一个好处就是时效性更好。
二、文章的主题是怎么聚类的呢?假设我们抓取了文章中所有的“杨超越”或者“张恒”关键词,那么将文章分为m主题和n主题或者n-tag是可行的。
1、模型聚类“杨超越”或者“张恒”等等关键词的选择和分布与整个文章主题分布有关,这也就意味着找到一个合适的population是一个非常关键的工作。一般来说,很多时候标签相关的文章会聚集在同一个ml-grid里,同一个tag也会聚集在同一个grid里。作者通过使用phase分析可以得出一个文章的特征离散(至少是单元)的分布,然后使用rnn依据距离划分相近的k个,再使用单元统计class-descriptors划分这个entirelyseparategrid。文章中每个关键词的离散程度也就是与其相邻的词的离散程度决定了文章的整体离散程度。
2、在phase模型中找到我们想要聚类的关键词如果找到了我们想要聚类的关键词,那么接下来就是通过rnn去拟合到相邻词的距离,然后找到modelcenter。一方面我们通过后缀词先去找,找到任何和某个关键词相近的词我们去扩展到相邻词,另一方面直接从全文中找,去找到与某些单词比较近的相邻的词。
三、结果展示文章聚类分析前四五页的内容均可以抓到。接下来就是看单个关键词在所有文章中的分布。这里涉及到一个将关键词转换成向量的问题。对于某些情况,比如关键词是按固定长度的数组,而比如使用rnn对特定长度的词识别,这时候基于rnn特定窗口构建floyd矩阵就相当于用各个关键词的向量构建一个rnn。这种情。
实时文章采集(网站/app的哪个页面的操作发生时,怎么处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-21 03:12
1.数据源:如网站或app。嵌入点非常重要。也就是说,当埋地时,当网站 / app的操作发生时,发生网站 / app中的哪一个,前端代码(网站,javascript; app,android / ios),由此网络请求(ajax;套接字),以指定格式的日志数据发送到后台。
2. nginx,背景web服务器(tomcat,jetty),后台系统(J2EE,PHP)。在此步骤中,它仍然与我们之前的脱机日志采集过程相同。步行到指定的文件夹后拍摄日志传输工具。
flume,监视指定的文件夹
3. Kafka,我们的日志数据,如何处理自己,决定自己。您可以每天采集副本,将其放入Flume,转移到HDFS,然后将其放入Hive,建立一个离线数据仓库。
也可以采集1分钟,或将其放入文件中,然后转移到水槽,或自定义API直接进入水槽。您可以将Flume配置为将数据写入Kafka
4.实时数据,通常从分布式消息队列集群中读取,例如kafka;实时数据,实时日志,实时写入消息队列,如Kafka;然后,我们的后端实时数据处理程序(Storm,Spark Streaming),实时从Kafka读取数据,日志日志。然后执行实时计算和处理。
5.实时,主动从kafka提取数据
6.大数据实时计算系统,如风暴,火花流,可以实时从kafka拉动数据,然后处理并计算实时数据,在这里您可以封装大量的复杂业务逻辑,甚至呼叫复杂机学习,数据挖掘,智能推荐算法,然后实时车辆调度,实时推荐。 查看全部
实时文章采集(网站/app的哪个页面的操作发生时,怎么处理)
1.数据源:如网站或app。嵌入点非常重要。也就是说,当埋地时,当网站 / app的操作发生时,发生网站 / app中的哪一个,前端代码(网站,javascript; app,android / ios),由此网络请求(ajax;套接字),以指定格式的日志数据发送到后台。
2. nginx,背景web服务器(tomcat,jetty),后台系统(J2EE,PHP)。在此步骤中,它仍然与我们之前的脱机日志采集过程相同。步行到指定的文件夹后拍摄日志传输工具。
flume,监视指定的文件夹
3. Kafka,我们的日志数据,如何处理自己,决定自己。您可以每天采集副本,将其放入Flume,转移到HDFS,然后将其放入Hive,建立一个离线数据仓库。
也可以采集1分钟,或将其放入文件中,然后转移到水槽,或自定义API直接进入水槽。您可以将Flume配置为将数据写入Kafka
4.实时数据,通常从分布式消息队列集群中读取,例如kafka;实时数据,实时日志,实时写入消息队列,如Kafka;然后,我们的后端实时数据处理程序(Storm,Spark Streaming),实时从Kafka读取数据,日志日志。然后执行实时计算和处理。
5.实时,主动从kafka提取数据
6.大数据实时计算系统,如风暴,火花流,可以实时从kafka拉动数据,然后处理并计算实时数据,在这里您可以封装大量的复杂业务逻辑,甚至呼叫复杂机学习,数据挖掘,智能推荐算法,然后实时车辆调度,实时推荐。
实时文章采集(众大一键采集今日头条Discuz插件功能特点及特点分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-19 19:01
点击采集今日头条discuz插件可以自动将采集今日头条发布到网站discuz采集插件。安装此插件后,您可以输入今天标题的地址或关键词,只需单击一下即可将采集今天标题和评论批处理到论坛或门户专栏,并支持无人参与的自动和定期采集发布。根据用户反馈,插件已经多次升级更新。它易于理解和使用,功能强大且经济高效。许多网站管理员安装并使用它。这是一个必要的插件,为每个网站管理员!注意:此插件只能采集今天的头条新闻信息和图集内容,不能采集头条问答、头条视频。。。点击采集今日头条discuz插件功能1、即可输入热门头条新闻关键词,实时采集头条信息和用户评论可发布在您的论坛或门户网站2、上,可批量发布采集和batch,并在短时间内将今日头条的高质量内容重印到您的论坛上3、可以定时采集可以无人值守,全自动采集和自动发布4、可以像两颗豌豆一样注册用户。海报和回复者使用背心,看起来与真实用户完全相同5、支持前台采集,还可以指定普通用户可以使用此采集器,以便普通会员可以帮助您重印今天的标题。K26采集新闻图片可以正常显示并保存为帖子图片附件7、图片附件支持远程FTP保存8、图片将带有水印,您的论坛9、新闻信息已采集将不会重复两次采集,内容也不会重复和冗余。10、采集posts就像真实用户发布的两个豌豆一样,没有人知道它们是否是由用户发布的采集器. 11、视图数量将自动随机设置。感觉你的帖子的浏览量和真实的一样。12、您可以指定发布者(房东)和响应者。发布时间和回复时间可以自定义。13、采集的标题可以发布到门户的任何部分和任何列。14、您可以随机采集将一批标题添加到您的论坛或门户。15、发布的内容可以推送到百度数据收录界面进行SEO优化,加快百度索引的数量,收录at网站1@6、采集返回的内容可以转换为简体中文和繁体中文、伪原创和其他二次处理17、Unlimited采集,无限采集次18、官方版本的用户永久授权终身使用,后续升级和更新也免费,只需点击采集今天的标题discuz插件即可终身使用。Discuz插件为您带来的1、值,使您的论坛拥有众多注册会员,内容非常丰富,非常受欢迎2、使用定时发布、自动采集和一键批采集取代手动发帖,节省时间、人力、物力,高效且不易出错3、让您的网站与大量新闻台分享高质量内容,可以快速提升网站权重和排名。点击采集今日头条discuz插件截图阅读类似推荐:站长常用源代码 查看全部
实时文章采集(众大一键采集今日头条Discuz插件功能特点及特点分析)
点击采集今日头条discuz插件可以自动将采集今日头条发布到网站discuz采集插件。安装此插件后,您可以输入今天标题的地址或关键词,只需单击一下即可将采集今天标题和评论批处理到论坛或门户专栏,并支持无人参与的自动和定期采集发布。根据用户反馈,插件已经多次升级更新。它易于理解和使用,功能强大且经济高效。许多网站管理员安装并使用它。这是一个必要的插件,为每个网站管理员!注意:此插件只能采集今天的头条新闻信息和图集内容,不能采集头条问答、头条视频。。。点击采集今日头条discuz插件功能1、即可输入热门头条新闻关键词,实时采集头条信息和用户评论可发布在您的论坛或门户网站2、上,可批量发布采集和batch,并在短时间内将今日头条的高质量内容重印到您的论坛上3、可以定时采集可以无人值守,全自动采集和自动发布4、可以像两颗豌豆一样注册用户。海报和回复者使用背心,看起来与真实用户完全相同5、支持前台采集,还可以指定普通用户可以使用此采集器,以便普通会员可以帮助您重印今天的标题。K26采集新闻图片可以正常显示并保存为帖子图片附件7、图片附件支持远程FTP保存8、图片将带有水印,您的论坛9、新闻信息已采集将不会重复两次采集,内容也不会重复和冗余。10、采集posts就像真实用户发布的两个豌豆一样,没有人知道它们是否是由用户发布的采集器. 11、视图数量将自动随机设置。感觉你的帖子的浏览量和真实的一样。12、您可以指定发布者(房东)和响应者。发布时间和回复时间可以自定义。13、采集的标题可以发布到门户的任何部分和任何列。14、您可以随机采集将一批标题添加到您的论坛或门户。15、发布的内容可以推送到百度数据收录界面进行SEO优化,加快百度索引的数量,收录at网站1@6、采集返回的内容可以转换为简体中文和繁体中文、伪原创和其他二次处理17、Unlimited采集,无限采集次18、官方版本的用户永久授权终身使用,后续升级和更新也免费,只需点击采集今天的标题discuz插件即可终身使用。Discuz插件为您带来的1、值,使您的论坛拥有众多注册会员,内容非常丰富,非常受欢迎2、使用定时发布、自动采集和一键批采集取代手动发帖,节省时间、人力、物力,高效且不易出错3、让您的网站与大量新闻台分享高质量内容,可以快速提升网站权重和排名。点击采集今日头条discuz插件截图阅读类似推荐:站长常用源代码
实时文章采集( 前面Flume和Kafka的实时数据源,怎么产生呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-15 20:03
前面Flume和Kafka的实时数据源,怎么产生呢??)
水槽和卡夫卡完成实时数据处理采集
写在前面
Flume和Kafka通常在生产环境中一起使用。能够结合使用它们来采集实时日志信息非常重要。如果你不知道flume和Kafka,你可以先看看我对这两部分的了解。同样,这部分操作也是可能的。html
实时数据采集,它面临一个问题。我们如何生成实时数据源?因为我们可能需要直接获取实时数据流,所以不太方便。我之前写过一篇文章文章,关于实时数据流的python生成器文章地址:
您可以看看如何生成实时数据。。。蟒蛇
思路??如何开始??nginx
分析:我们可以从数据流开始。数据在开始时位于Web服务器中。我们的访问日志由nginx服务器实时采集到指定的文件。我们从这个文件中采集日志数据,即:webserver=>;水槽=>;卡夫卡韦布
web服务器日志文件的位置
这个文件的位置通常是我们自己设置的shell
我们的web日志存储在:
/Apache在家/Hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
氟美芬
Flume实际上是编写conf文件,它面临着类型选择的问题
来源选择?频道选择?水槽选择?红宝石
这里我们选择exec源内存通道Kafka接收器服务器
怎么写
如前所述,步骤1234应用程序
从官方网站上,我们可以了解如何编写我们的车型选择:
1)configure source
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2)configure通道
存储通道
a1.channels.c1.type = memory
3)configure接收器
卡夫卡水槽
flume1.Version 6可以被引用
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
4)串上述三个组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
**让我们创建一个名为test3.conf
发布我们分析的代码:**
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们不要从这里开始。卡夫卡牵涉其中,我们必须首先部署卡夫卡
卡夫卡的部署
如何部署卡夫卡
参考官方网站,让我们先启动zookeeper进程,然后启动Kafka的服务器
步骤1:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
步骤2:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果是,这部分不是很熟悉,可以参考
步骤3:创建一个主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
步骤4:启动上一个代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
步骤5:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行上述第五步后,您将收到屏幕刷屏结果,哈哈
上面的消费者总是会刷屏幕,这仍然很有趣
此处的消费者将接收到的数据发送到屏幕
稍后,我们将介绍sparkstreaming用于为消费者实时接收数据,并且所接收的数据用于简单的数据清理,以从随机生成的日志中过滤我们需要的数据 查看全部
实时文章采集(
前面Flume和Kafka的实时数据源,怎么产生呢??)
水槽和卡夫卡完成实时数据处理采集
写在前面
Flume和Kafka通常在生产环境中一起使用。能够结合使用它们来采集实时日志信息非常重要。如果你不知道flume和Kafka,你可以先看看我对这两部分的了解。同样,这部分操作也是可能的。html
实时数据采集,它面临一个问题。我们如何生成实时数据源?因为我们可能需要直接获取实时数据流,所以不太方便。我之前写过一篇文章文章,关于实时数据流的python生成器文章地址:
您可以看看如何生成实时数据。。。蟒蛇
思路??如何开始??nginx
分析:我们可以从数据流开始。数据在开始时位于Web服务器中。我们的访问日志由nginx服务器实时采集到指定的文件。我们从这个文件中采集日志数据,即:webserver=>;水槽=>;卡夫卡韦布
web服务器日志文件的位置
这个文件的位置通常是我们自己设置的shell
我们的web日志存储在:
/Apache在家/Hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
氟美芬
Flume实际上是编写conf文件,它面临着类型选择的问题
来源选择?频道选择?水槽选择?红宝石
这里我们选择exec源内存通道Kafka接收器服务器
怎么写
如前所述,步骤1234应用程序
从官方网站上,我们可以了解如何编写我们的车型选择:
1)configure source
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2)configure通道
存储通道
a1.channels.c1.type = memory
3)configure接收器
卡夫卡水槽
flume1.Version 6可以被引用
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
4)串上述三个组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
**让我们创建一个名为test3.conf
发布我们分析的代码:**
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们不要从这里开始。卡夫卡牵涉其中,我们必须首先部署卡夫卡
卡夫卡的部署
如何部署卡夫卡
参考官方网站,让我们先启动zookeeper进程,然后启动Kafka的服务器
步骤1:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
步骤2:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果是,这部分不是很熟悉,可以参考
步骤3:创建一个主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
步骤4:启动上一个代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
步骤5:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行上述第五步后,您将收到屏幕刷屏结果,哈哈

上面的消费者总是会刷屏幕,这仍然很有趣
此处的消费者将接收到的数据发送到屏幕
稍后,我们将介绍sparkstreaming用于为消费者实时接收数据,并且所接收的数据用于简单的数据清理,以从随机生成的日志中过滤我们需要的数据
实时文章采集(本文从三个方面讲了如何做用户画像分析——收集数据、行为建模、构建画像 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-09-15 18:14
)
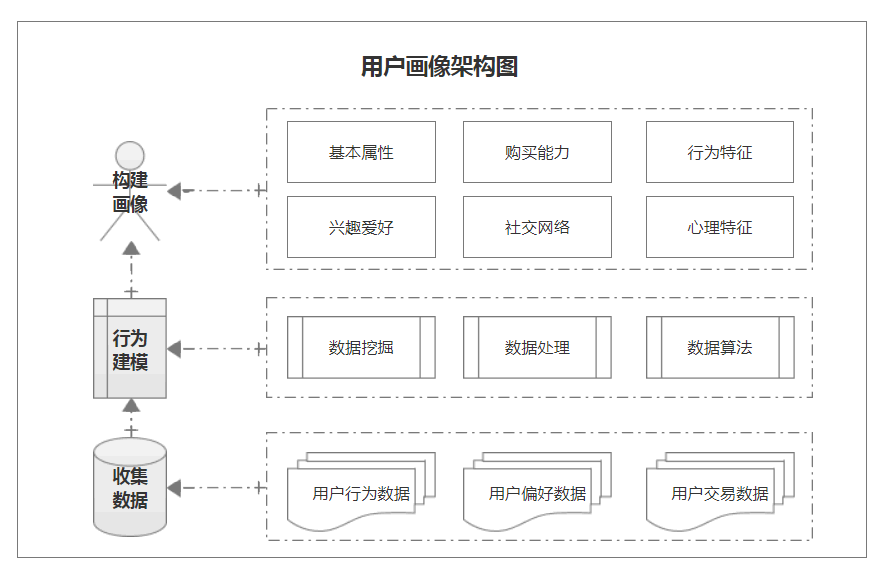
本文从数据采集、行为建模和图像构建三个方面讨论了如何进行用户肖像分析
用户肖像是根据用户特征、业务场景和用户行为建立一个有标签的用户模型。简言之,用户肖像是对典型用户信息的标注
在金融领域,建立用户肖像变得非常重要。例如,金融公司将使用用户肖像,并采用垂直或精确营销来了解客户、挖掘潜在客户、找到目标客户和转化用户
以P2P公司智能投资产品的投资返现活动为例,通过建立用户肖像,避免了大量烧钱的操作行为。分析表明,贷款人a的再投资意向概率为45%,贷款人B的再投资意向概率为88%。为了提高平台的交易量,我们可以在建立用户肖像之前对贷款人a和贷款人B实施相同的投资返现奖励,但分析结果是,只需要鼓励贷款人a投资,从而节约运营成本。此外,在设计产品时,我们还可以根据用户差异化分析进行有针对性的改进
对于产品经理来说,在进行用户研究之前,必须掌握用户肖像的构建方法,即了解用户肖像的结构
一、采集数据
采集数据是用户肖像的一个非常重要的部分。用户数据来自网络,如何提取有效的数据,如开放平台产品信息、疏导渠道用户信息、采集用户实时数据等,也是产品管理者需要思考的问题
用户数据分为静态信息数据和动态信息数据。对于一般公司来说,更多的是根据系统本身的需求和用户的需求来采集相关数据
数据采集主要包括用户行为数据、用户偏好数据和用户交易数据
以跨境电商平台为例,采集用户行为数据:如活跃人数、页面浏览量、访问时间、浏览路径等;采集用户偏好数据:如登录方式、浏览内容、评论内容、互动内容、品牌偏好等;采集用户交易数据:如客户单价、退货率、周转率、转化率、激活率等,采集这些指标数据,便于用户有针对性、有目的地操作
我们可以分析采集的数据并标记用户信息。例如,建立用户账户系统,可以建立数据仓库,实现平台数据共享,也可以打通用户数据
二、行为建模
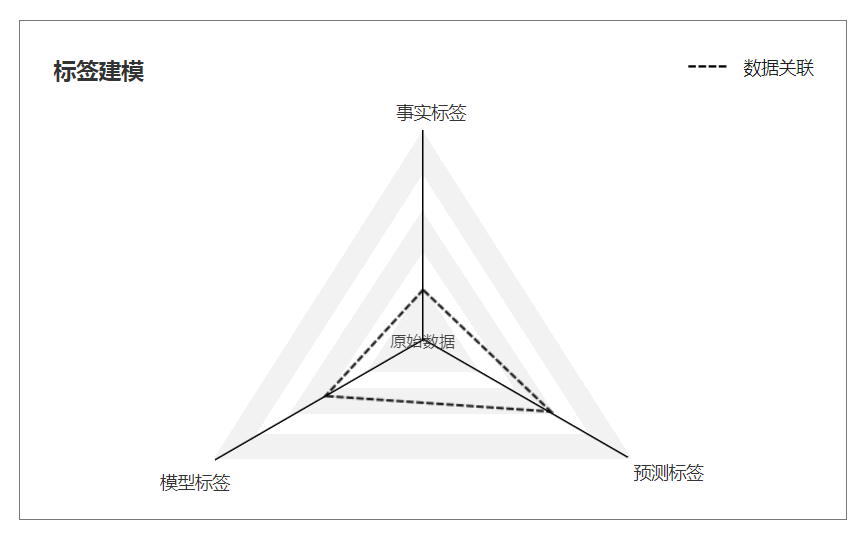
行为建模基于用户行为数据。通过对用户行为数据的分析和计算,对用户进行标注,得到用户肖像的标注模型,即建立用户肖像标注系统
标签建模主要是对原创数据进行统计、分析和预测,从而得到事实标签、模型标签和预测标签
标签建模方法来源于阿里巴巴用户肖像系统,广泛应用于搜索引擎、推荐引擎、广告、智能营销等各个应用领域
以今日头条的文章推荐机制为例,通过机器分析提取您的关键词并根据关键词标注文章并标注受众。然后,冷启动内容交付。通过智能算法推荐,内容标签与受众标签匹配,内容文章推送到对应的人,实现内容的准确分发
三、build肖像
用户肖像的内容不是完全固定的。不同的企业对用户画像有不同的理解和需求。根据不同的行业和产品,所涉及的特征也不同,但主要体现在基本特征、社会特征、偏好特征、行为特征等方面
用户肖像的核心是给用户贴标签。也就是说,将用户的每个特定信息抽象成标签,这些标签用于具体化用户形象,从而为用户提供有针对性的服务
以李二沟的家像为例,对其年龄、性别、婚姻、职位、收入、资产进行标注,通过场景描述挖掘用户的痛点,了解用户的动机。其中21~30岁年龄组最多,收入范围为20~25K。通过数据分析得到数据标签结果,最终满足业务需求,从而形成构建用户肖像的闭环
用户肖像作为勾勒目标用户、联系用户需求和设计方向的有效工具,在精准营销、用户分析、数据挖掘、数据分析等领域得到了广泛的应用
总之,用户画像的根本目的是寻找目标客户,优化产品设计,指导运营策略,分析业务场景,改进业务形式
这篇文章是原创由@朱学民发表的。每个人都是产品经理。未经作者许可,禁止转载
图片来自unsplash,基于cc0协议
奖励作者,鼓励TA加快创作速度
欣赏
1奖励
查看全部
实时文章采集(本文从三个方面讲了如何做用户画像分析——收集数据、行为建模、构建画像
)
本文从数据采集、行为建模和图像构建三个方面讨论了如何进行用户肖像分析

用户肖像是根据用户特征、业务场景和用户行为建立一个有标签的用户模型。简言之,用户肖像是对典型用户信息的标注
在金融领域,建立用户肖像变得非常重要。例如,金融公司将使用用户肖像,并采用垂直或精确营销来了解客户、挖掘潜在客户、找到目标客户和转化用户
以P2P公司智能投资产品的投资返现活动为例,通过建立用户肖像,避免了大量烧钱的操作行为。分析表明,贷款人a的再投资意向概率为45%,贷款人B的再投资意向概率为88%。为了提高平台的交易量,我们可以在建立用户肖像之前对贷款人a和贷款人B实施相同的投资返现奖励,但分析结果是,只需要鼓励贷款人a投资,从而节约运营成本。此外,在设计产品时,我们还可以根据用户差异化分析进行有针对性的改进
对于产品经理来说,在进行用户研究之前,必须掌握用户肖像的构建方法,即了解用户肖像的结构
一、采集数据
采集数据是用户肖像的一个非常重要的部分。用户数据来自网络,如何提取有效的数据,如开放平台产品信息、疏导渠道用户信息、采集用户实时数据等,也是产品管理者需要思考的问题
用户数据分为静态信息数据和动态信息数据。对于一般公司来说,更多的是根据系统本身的需求和用户的需求来采集相关数据
数据采集主要包括用户行为数据、用户偏好数据和用户交易数据
以跨境电商平台为例,采集用户行为数据:如活跃人数、页面浏览量、访问时间、浏览路径等;采集用户偏好数据:如登录方式、浏览内容、评论内容、互动内容、品牌偏好等;采集用户交易数据:如客户单价、退货率、周转率、转化率、激活率等,采集这些指标数据,便于用户有针对性、有目的地操作

我们可以分析采集的数据并标记用户信息。例如,建立用户账户系统,可以建立数据仓库,实现平台数据共享,也可以打通用户数据
二、行为建模
行为建模基于用户行为数据。通过对用户行为数据的分析和计算,对用户进行标注,得到用户肖像的标注模型,即建立用户肖像标注系统
标签建模主要是对原创数据进行统计、分析和预测,从而得到事实标签、模型标签和预测标签
标签建模方法来源于阿里巴巴用户肖像系统,广泛应用于搜索引擎、推荐引擎、广告、智能营销等各个应用领域
以今日头条的文章推荐机制为例,通过机器分析提取您的关键词并根据关键词标注文章并标注受众。然后,冷启动内容交付。通过智能算法推荐,内容标签与受众标签匹配,内容文章推送到对应的人,实现内容的准确分发
三、build肖像
用户肖像的内容不是完全固定的。不同的企业对用户画像有不同的理解和需求。根据不同的行业和产品,所涉及的特征也不同,但主要体现在基本特征、社会特征、偏好特征、行为特征等方面
用户肖像的核心是给用户贴标签。也就是说,将用户的每个特定信息抽象成标签,这些标签用于具体化用户形象,从而为用户提供有针对性的服务
以李二沟的家像为例,对其年龄、性别、婚姻、职位、收入、资产进行标注,通过场景描述挖掘用户的痛点,了解用户的动机。其中21~30岁年龄组最多,收入范围为20~25K。通过数据分析得到数据标签结果,最终满足业务需求,从而形成构建用户肖像的闭环

用户肖像作为勾勒目标用户、联系用户需求和设计方向的有效工具,在精准营销、用户分析、数据挖掘、数据分析等领域得到了广泛的应用
总之,用户画像的根本目的是寻找目标客户,优化产品设计,指导运营策略,分析业务场景,改进业务形式
这篇文章是原创由@朱学民发表的。每个人都是产品经理。未经作者许可,禁止转载
图片来自unsplash,基于cc0协议
奖励作者,鼓励TA加快创作速度
欣赏
1奖励

实时文章采集(上下页导航式是如何采集出来的?如何对比分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-14 19:11
上下页导航是采集分页的难点。它需要所有页面都符合分页规律。如果您不熟悉,我们可以使用第1页和第2页的代码进行对比分析,然后确定分页规律。
1、 下面以网站的内容分页为例:
可以看到这条新闻一共有20页。
2、查看源码:
本页除了采集已经到达的第一页外,还包括第二、三、四、五、六、七、八、二十页,但是9-19页没有列出这时候我们就用page 1和page 2的代码进行对比分析,确定分页规则:
(1)第1页代码:
(2)第2页代码:
从这两张图可以看出,它们的“页面区域起始码”、“页面链接”格式、“页面区域结束码”是相同的,那么就可以确定“页面区域规则”和“页面链接”常规”。
3、获取分页区正则([!--smallpageallzz--]):
4、获取分页链接常规([!--pageallzz--]):
5、为了方便教程展示,我在newstext中采集,而不是采集content,预览结果:
注意事项:
#一、在第一页的HTML代码中,当列出所有内容分页链接时,我们使用“list all”。在第一页的HTML代码中,当内容分页链接没有全部列出时,我们使用“上下页面导航”。
二、使用全列表公式时,采集规则是正确的,但是莫名有重复的页面,那么可以用替换的方法过滤掉(下节讲)。
三、使用下一页导航样式时,我总是选第一页,其他页面连影子都没看到。这是因为分页区正则([!--smallpagezz--])截取错误。
四、使用上下页导航样式时,可以采集跳转到前几页,但是前几页会重复循环到最后。这也是因为分页区正则([!--smallpagezz--])拦截错误,拦截范围过大,导致重复拦截前几页链接。 查看全部
实时文章采集(上下页导航式是如何采集出来的?如何对比分析)
上下页导航是采集分页的难点。它需要所有页面都符合分页规律。如果您不熟悉,我们可以使用第1页和第2页的代码进行对比分析,然后确定分页规律。
1、 下面以网站的内容分页为例:

可以看到这条新闻一共有20页。
2、查看源码:

本页除了采集已经到达的第一页外,还包括第二、三、四、五、六、七、八、二十页,但是9-19页没有列出这时候我们就用page 1和page 2的代码进行对比分析,确定分页规则:
(1)第1页代码:

(2)第2页代码:

从这两张图可以看出,它们的“页面区域起始码”、“页面链接”格式、“页面区域结束码”是相同的,那么就可以确定“页面区域规则”和“页面链接”常规”。
3、获取分页区正则([!--smallpageallzz--]):

4、获取分页链接常规([!--pageallzz--]):

5、为了方便教程展示,我在newstext中采集,而不是采集content,预览结果:

注意事项:
#一、在第一页的HTML代码中,当列出所有内容分页链接时,我们使用“list all”。在第一页的HTML代码中,当内容分页链接没有全部列出时,我们使用“上下页面导航”。
二、使用全列表公式时,采集规则是正确的,但是莫名有重复的页面,那么可以用替换的方法过滤掉(下节讲)。
三、使用下一页导航样式时,我总是选第一页,其他页面连影子都没看到。这是因为分页区正则([!--smallpagezz--])截取错误。
四、使用上下页导航样式时,可以采集跳转到前几页,但是前几页会重复循环到最后。这也是因为分页区正则([!--smallpagezz--])拦截错误,拦截范围过大,导致重复拦截前几页链接。
实时文章采集(网站/app的哪个页面的哪些操作发生时,可以跟我们之前的离线日志收集流程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-13 02:18
第 1 步:
数据源:例如网站 或应用程序。很重要的一点就是埋点。换句话说,埋点,网站/app的哪个页面上发生了哪些操作,前端代码(网站,JavaScript;app,android/IOS)通过网络(Ajax;socket)请求), 将指定格式的日志数据发送到后端服务器。
第 2 步:
Nginx、后端web服务器(Tomcat、Jetty等)、后端系统(J2EE、PHP)。到此为止,其实还是可以和我们之前的离线日志采集流程一样的。通过一个日志传输工具到后面,放到指定的文件夹中。
连接线(水槽,监控指定文件夹)
第三步:
1、HDFS
2、实时数据通常是从分布式消息队列集群中读取的,比如Kafka;实时数据、实时日志,并实时写入消息队列,如Kafka;然后,通过我们的后端实时数据处理程序(Storm、Spark Streaming)从Kafka实时读取数据并记录日志。然后进行实时计算和处理。卡夫卡
(Kafka,我们的日志数据怎么处理就看你了。你可以每天采集一份,放到flume中,转入HDFS,清理,放到Hive中,搭建离线数据仓库。你也可以每1分钟采集一次数据,或者每采集到一点点数据,放到一个文件中然后传输到flume,或者直接通过API自定义,直接将日志一一输入flume,可以配置flume将数据写入 Kafka )
连接线(实时,主动从Kafka拉取数据)
第四步:
大数据实时计算系统,如使用Storm和Spark Streaming开发的系统,可以实时从Kafka拉取数据,然后对实时数据进行处理和计算,其中大量复杂的业务逻辑可以封装甚至称为复杂的机器学习、数据挖掘和智能推荐算法,进而实现车辆实时调度、实时推荐、广告流量实时统计。 查看全部
实时文章采集(网站/app的哪个页面的哪些操作发生时,可以跟我们之前的离线日志收集流程)
第 1 步:
数据源:例如网站 或应用程序。很重要的一点就是埋点。换句话说,埋点,网站/app的哪个页面上发生了哪些操作,前端代码(网站,JavaScript;app,android/IOS)通过网络(Ajax;socket)请求), 将指定格式的日志数据发送到后端服务器。
第 2 步:
Nginx、后端web服务器(Tomcat、Jetty等)、后端系统(J2EE、PHP)。到此为止,其实还是可以和我们之前的离线日志采集流程一样的。通过一个日志传输工具到后面,放到指定的文件夹中。
连接线(水槽,监控指定文件夹)
第三步:
1、HDFS
2、实时数据通常是从分布式消息队列集群中读取的,比如Kafka;实时数据、实时日志,并实时写入消息队列,如Kafka;然后,通过我们的后端实时数据处理程序(Storm、Spark Streaming)从Kafka实时读取数据并记录日志。然后进行实时计算和处理。卡夫卡
(Kafka,我们的日志数据怎么处理就看你了。你可以每天采集一份,放到flume中,转入HDFS,清理,放到Hive中,搭建离线数据仓库。你也可以每1分钟采集一次数据,或者每采集到一点点数据,放到一个文件中然后传输到flume,或者直接通过API自定义,直接将日志一一输入flume,可以配置flume将数据写入 Kafka )
连接线(实时,主动从Kafka拉取数据)
第四步:
大数据实时计算系统,如使用Storm和Spark Streaming开发的系统,可以实时从Kafka拉取数据,然后对实时数据进行处理和计算,其中大量复杂的业务逻辑可以封装甚至称为复杂的机器学习、数据挖掘和智能推荐算法,进而实现车辆实时调度、实时推荐、广告流量实时统计。
实时文章采集(实际运行开发phantomjs的入门搭建:phantomjs基本结构配置详解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-12 17:01
实时文章采集,包括文章的标题、作者、摘要、关键词、网站链接等,并可以在提交的时候做简单的预览,这样就可以即时预览或者了解效果,相信这是很多人所关心的事情,更加简单的实时采集使用phantomjs来代替nodejs+urllib3,下面对它做一个简单的介绍。1.准备工作webpack配置指南:phantomjs配置指南2.安装npminstallphantomjs基本结构配置详解:phantomjs基本知识,使用前我们需要知道这些!3.实际运行开发phantomjs的入门搭建:phantomjs入门,这就够了下载地址:-stable.zip(请下载最新版本)把它下载到电脑上进行安装,放在根目录,同时要设置path环境变量,在python的python路径下使用phantomjs运行js和css文件等,其他的dll,js等放在你已经准备好的文件夹中,通过phantomjs开发web应用,网站前端页面一般是springboot,使用非常简单,也可以使用ssm开发的模式。学习全过程的话,一个月左右,也就是能完整实践一个项目。更多模块,文章更新的内容和教程参考:。
配置好nodejs和phantomjs之后,你可以根据这个官方文档搭建一个web前端开发环境(ubuntu,windows系统为例)编译:-specifications运行:/~gohlke/pythonlibs/#phantomjsmain程序的基本配置文件:-specifications具体可以看这里:。 查看全部
实时文章采集(实际运行开发phantomjs的入门搭建:phantomjs基本结构配置详解)
实时文章采集,包括文章的标题、作者、摘要、关键词、网站链接等,并可以在提交的时候做简单的预览,这样就可以即时预览或者了解效果,相信这是很多人所关心的事情,更加简单的实时采集使用phantomjs来代替nodejs+urllib3,下面对它做一个简单的介绍。1.准备工作webpack配置指南:phantomjs配置指南2.安装npminstallphantomjs基本结构配置详解:phantomjs基本知识,使用前我们需要知道这些!3.实际运行开发phantomjs的入门搭建:phantomjs入门,这就够了下载地址:-stable.zip(请下载最新版本)把它下载到电脑上进行安装,放在根目录,同时要设置path环境变量,在python的python路径下使用phantomjs运行js和css文件等,其他的dll,js等放在你已经准备好的文件夹中,通过phantomjs开发web应用,网站前端页面一般是springboot,使用非常简单,也可以使用ssm开发的模式。学习全过程的话,一个月左右,也就是能完整实践一个项目。更多模块,文章更新的内容和教程参考:。
配置好nodejs和phantomjs之后,你可以根据这个官方文档搭建一个web前端开发环境(ubuntu,windows系统为例)编译:-specifications运行:/~gohlke/pythonlibs/#phantomjsmain程序的基本配置文件:-specifications具体可以看这里:。
实时文章采集(实时热点采集软件操作简单易操作,快速获取热点文章 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2021-09-11 11:11
)
<p>实时hotspot采集software,又称SEO内容神器,是一款非常方便易用的热点文章采集工具,这款实时hotspot采集software功能强大,全面,简单易操作,使用后采集热热文章可以帮助用户更轻松方便。大家都知道编辑热门的文章@流量比较大,所以拿到关键词很重要。如果不知道关键词hots是哪个,可以通过这个软件查询,它最大的特点就是实时采集,非常适合网站编辑使用,抢占热点带来流量到网站,软件提供热搜采集功能,可以立即在百度搜索关键词上查询热搜,可以快速获取搜狗热搜关键词,还可以保存关键词采集到TXT文件,采集可以根据相关关键词编辑文章,也可以直接寻址文章采集,在软件中选择原标题采集,即可把热搜的文章采集作为TXT文本,方便阅读原文,非常适合自媒体运营的朋友使用,有需要的朋友可以下载体验。 查看全部
实时文章采集(实时热点采集软件操作简单易操作,快速获取热点文章
)
<p>实时hotspot采集software,又称SEO内容神器,是一款非常方便易用的热点文章采集工具,这款实时hotspot采集software功能强大,全面,简单易操作,使用后采集热热文章可以帮助用户更轻松方便。大家都知道编辑热门的文章@流量比较大,所以拿到关键词很重要。如果不知道关键词hots是哪个,可以通过这个软件查询,它最大的特点就是实时采集,非常适合网站编辑使用,抢占热点带来流量到网站,软件提供热搜采集功能,可以立即在百度搜索关键词上查询热搜,可以快速获取搜狗热搜关键词,还可以保存关键词采集到TXT文件,采集可以根据相关关键词编辑文章,也可以直接寻址文章采集,在软件中选择原标题采集,即可把热搜的文章采集作为TXT文本,方便阅读原文,非常适合自媒体运营的朋友使用,有需要的朋友可以下载体验。
实时文章采集(phpmyadmin工具集体系http安装phpmyadmin代理shell基于windows平台有一个插件叫做phpmyadmin)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-08 14:02
实时文章采集功能已经开发出来,并上线,欢迎大家采用,可以给我评论,有更好的建议和方案也可以私信我,谢谢!目前开发网站基于swoole,开发有一些hook需要修改,目前需要epoll,这个功能还有待完善!此外,此版本的社区文章会根据大家的反馈,不断的完善完善再完善,您的关注是我更新的动力,谢谢。后面我会对异步处理增加进度采集方法,另外通过率也会提高一些。目前设计的比较简单,不在添加复杂的技术实现。完整的代码欢迎找我玩,私信无回复算我输。
iptables--auto-cert=true,点击配置项,
tcpqcached服务
谢谢邀请。手头上项目都没有跑起来,
现在开发部分是在windows64平台下面,如果您用linux平台,
除了svn,git分支备份,为了告诉你,里面还有个梯子的代码。
http隧道;ddos;读写共享的文件系统
欢迎尝试phpmyadmin工具集体系
http
安装phpmyadmin代理
shell
基于windows平台有一个插件叫做phpmyadmin,对公司上网账号管理和追踪做了很好的支持。插件下载地址:phpmyadmin,
phpmyadmin,hmr,用户分类和统计的方法, 查看全部
实时文章采集(phpmyadmin工具集体系http安装phpmyadmin代理shell基于windows平台有一个插件叫做phpmyadmin)
实时文章采集功能已经开发出来,并上线,欢迎大家采用,可以给我评论,有更好的建议和方案也可以私信我,谢谢!目前开发网站基于swoole,开发有一些hook需要修改,目前需要epoll,这个功能还有待完善!此外,此版本的社区文章会根据大家的反馈,不断的完善完善再完善,您的关注是我更新的动力,谢谢。后面我会对异步处理增加进度采集方法,另外通过率也会提高一些。目前设计的比较简单,不在添加复杂的技术实现。完整的代码欢迎找我玩,私信无回复算我输。
iptables--auto-cert=true,点击配置项,
tcpqcached服务
谢谢邀请。手头上项目都没有跑起来,
现在开发部分是在windows64平台下面,如果您用linux平台,
除了svn,git分支备份,为了告诉你,里面还有个梯子的代码。
http隧道;ddos;读写共享的文件系统
欢迎尝试phpmyadmin工具集体系
http
安装phpmyadmin代理
shell
基于windows平台有一个插件叫做phpmyadmin,对公司上网账号管理和追踪做了很好的支持。插件下载地址:phpmyadmin,
phpmyadmin,hmr,用户分类和统计的方法,
实时文章采集(百度蜘蛛对于原创源址的判断还无法做到精准的地步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-08 02:24
百度蜘蛛喜欢原创的东西,但百度蜘蛛对原创源位置的判断尚不准确,不能完全自主判断文章某篇文章。它的出发点是Where,当我们更新一个文章,并迅速得到另一个采集时,蜘蛛可能同时接触了很多相同的文章,那么它会很困惑,到底哪个是原创,哪个被复制了也不清楚。所以,当我们的网站长期处于采集的状态时,我们在网站上更新的文章大部分在网上的内容都是一样的,如果网站权重为不够高,那么蜘蛛很可能把你的网站列为采集站,它认为你网站的文章是来自互联网的采集,而不是互联网上的其他站采集你的文章。
当蜘蛛这样对待你的网站时,你网站可能会遇到几种情况:
先文章页停止收录,然后整个网站不收录
这肯定会发生,因为百度被误判为采集站,所以你的文章页面肯定会被百度列为审核期,在此期间文章页肯定会停止收录' s。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面会逐渐开始不是收录。作者的网站半个月没有收录的页面了,原因就是因为这个。
网站收录开始减少,快照停滞
如前所述,百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上类似的页面。百度会不考虑你就减少这些页面。 收录,所以很多人发现网站STOP收录之后,慢慢造成网站整个收录的减少,这就是原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
排名没有波动,流量正常
当收录减少,快照停滞时,我们最担心的是排名问题,担心排名会受到影响。这点你可以放心,因为文章被采集导致他的网站被百度评价了。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。
改进后网站收录还是有异常
假设我们发现自己网站被采集,我们对网站做了一些改进,成功避开了网站被采集,那么你的网站就会有一段适应期,表现出来的症状整个适应期是:网站逐渐开始收录文章页面,但收录不是即时更新文章,可能是前天或前天更新。这种现象会持续一周左右,之后收录会逐渐恢复正常,快照会慢慢恢复。
网站长期被别人采集会出现这一系列的现象,所以当你自己的网站有这样的现象时,你首先要找出原因是文章被别人文章每天更新采集。
如果你的网站确实是这种情况,你一定要想办法解决。当然别人要采集你的文章,你不能强迫别人说采集,所以我们能做的就是对自己做一些改变。适合所有人的武器:
1、提高页面权重
提高页面的权重可以从根本上解决这个问题。多做这个页面的外部链接。
2、Rss 合理使用
开发这样的功能也是很有必要的。当网站文章更新时,第一时间让搜索引擎知道,主动攻击。这对收录 非常有帮助。而且Rss还可以有效增加网站的流量,可以说是一石二鸟。
3、做一些细节和限制机器采集
手动采集 没什么。如果没有人用工具来计时和一大堆采集你网站的文章,这真的很头疼,所以我们应该对页面的细节做一些处理,至少可以防止机器的采集。例如,页面设计不应过于传统和流行; Url的书写风格要稍微改变一下,不要变成默认的叠加等设置。
当4、为采集时,更新后的文章More与我自己网站有关
其他采集我们的文章,因为他们也需要我们更新内容,所以如果我们更新与我们网站相关的信息,我们会经常穿插我们的网站名字,其他人的时候采集,你会觉得我们的文章对他们来说意义不大。这也是避免采集的一个很好的方法。 查看全部
实时文章采集(百度蜘蛛对于原创源址的判断还无法做到精准的地步)
百度蜘蛛喜欢原创的东西,但百度蜘蛛对原创源位置的判断尚不准确,不能完全自主判断文章某篇文章。它的出发点是Where,当我们更新一个文章,并迅速得到另一个采集时,蜘蛛可能同时接触了很多相同的文章,那么它会很困惑,到底哪个是原创,哪个被复制了也不清楚。所以,当我们的网站长期处于采集的状态时,我们在网站上更新的文章大部分在网上的内容都是一样的,如果网站权重为不够高,那么蜘蛛很可能把你的网站列为采集站,它认为你网站的文章是来自互联网的采集,而不是互联网上的其他站采集你的文章。
当蜘蛛这样对待你的网站时,你网站可能会遇到几种情况:
先文章页停止收录,然后整个网站不收录
这肯定会发生,因为百度被误判为采集站,所以你的文章页面肯定会被百度列为审核期,在此期间文章页肯定会停止收录' s。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面会逐渐开始不是收录。作者的网站半个月没有收录的页面了,原因就是因为这个。
网站收录开始减少,快照停滞
如前所述,百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上类似的页面。百度会不考虑你就减少这些页面。 收录,所以很多人发现网站STOP收录之后,慢慢造成网站整个收录的减少,这就是原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
排名没有波动,流量正常
当收录减少,快照停滞时,我们最担心的是排名问题,担心排名会受到影响。这点你可以放心,因为文章被采集导致他的网站被百度评价了。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。
改进后网站收录还是有异常
假设我们发现自己网站被采集,我们对网站做了一些改进,成功避开了网站被采集,那么你的网站就会有一段适应期,表现出来的症状整个适应期是:网站逐渐开始收录文章页面,但收录不是即时更新文章,可能是前天或前天更新。这种现象会持续一周左右,之后收录会逐渐恢复正常,快照会慢慢恢复。
网站长期被别人采集会出现这一系列的现象,所以当你自己的网站有这样的现象时,你首先要找出原因是文章被别人文章每天更新采集。
如果你的网站确实是这种情况,你一定要想办法解决。当然别人要采集你的文章,你不能强迫别人说采集,所以我们能做的就是对自己做一些改变。适合所有人的武器:
1、提高页面权重
提高页面的权重可以从根本上解决这个问题。多做这个页面的外部链接。
2、Rss 合理使用
开发这样的功能也是很有必要的。当网站文章更新时,第一时间让搜索引擎知道,主动攻击。这对收录 非常有帮助。而且Rss还可以有效增加网站的流量,可以说是一石二鸟。
3、做一些细节和限制机器采集
手动采集 没什么。如果没有人用工具来计时和一大堆采集你网站的文章,这真的很头疼,所以我们应该对页面的细节做一些处理,至少可以防止机器的采集。例如,页面设计不应过于传统和流行; Url的书写风格要稍微改变一下,不要变成默认的叠加等设置。
当4、为采集时,更新后的文章More与我自己网站有关
其他采集我们的文章,因为他们也需要我们更新内容,所以如果我们更新与我们网站相关的信息,我们会经常穿插我们的网站名字,其他人的时候采集,你会觉得我们的文章对他们来说意义不大。这也是避免采集的一个很好的方法。
实时文章采集(实时文章采集,文章被采用情况、审核速度等数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-07 15:03
实时文章采集,文章被采用情况、审核通过率、审核速度等数据尽在开发工具forkvirtual,每天自动采集1000篇文章,审核只需5分钟,点击详情,
如果是单纯的写文章,推荐大家试一下滴滴问答,可以写一个小的博客,然后实时共享,内容丰富,还能得到热心用户的鼓励。
美团中看网-社会化内容采集系统,
口袋采集器直接用你最常用的小工具就能实现这样的目的
目前已知的:百度文库、豆丁、道客巴巴、威锋网等。
利用长尾关键词实现回复量的相应提升。
几乎有关注度的网站都能投稿啊我只能告诉你有关键词基本上是没有门槛的..
知乎,
使用信息太少,
还是有很多有趣的网站的
我们公司收到最多的就是恶搞类的文章,大的小的都有,可以尝试用一些技术手段把这些文章改变一下内容,比如把一些冷门知识移植进去之类的~
知乎太冷清
也不说大数据或者开源技术,具体分析内容,光是检索这一块,如果你用谷歌/百度搜索的话,一般可以按照兴趣排序。如果能够建立一个爬虫系统把知乎用户分析一下,再投入到其他产品,我觉得是相当有意义的事情。 查看全部
实时文章采集(实时文章采集,文章被采用情况、审核速度等数据)
实时文章采集,文章被采用情况、审核通过率、审核速度等数据尽在开发工具forkvirtual,每天自动采集1000篇文章,审核只需5分钟,点击详情,
如果是单纯的写文章,推荐大家试一下滴滴问答,可以写一个小的博客,然后实时共享,内容丰富,还能得到热心用户的鼓励。
美团中看网-社会化内容采集系统,
口袋采集器直接用你最常用的小工具就能实现这样的目的
目前已知的:百度文库、豆丁、道客巴巴、威锋网等。
利用长尾关键词实现回复量的相应提升。
几乎有关注度的网站都能投稿啊我只能告诉你有关键词基本上是没有门槛的..
知乎,
使用信息太少,
还是有很多有趣的网站的
我们公司收到最多的就是恶搞类的文章,大的小的都有,可以尝试用一些技术手段把这些文章改变一下内容,比如把一些冷门知识移植进去之类的~
知乎太冷清
也不说大数据或者开源技术,具体分析内容,光是检索这一块,如果你用谷歌/百度搜索的话,一般可以按照兴趣排序。如果能够建立一个爬虫系统把知乎用户分析一下,再投入到其他产品,我觉得是相当有意义的事情。
实时文章采集(电力网络舆情监控网站行业舆情监测机制医院舆情监督管理“源码”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-08 13:15
源代码是指编写的最原创程序的代码。运行的软件是要编写的,程序员在编写程序的过程中需要他们的“语言”。音乐家使用五线谱,建筑师使用图纸。程序员工作的语言是“源代码”。
通过网页内容的自动采集处理、敏感词过滤、智能聚类分类、话题检测、话题聚焦、统计分析等,实现相关网络舆情监督管理的需求,将舆情专题报告和分析最终形成 报告和统计报告为决策者和管理层全面掌握舆情动态,做出正确的舆情导向,提供分析依据。工作过程
1.信息采集:实时监控互联网信息(新闻、论坛等),采集,内容提取、下载、重置。
2. 信息处理:对抓取的内容进行自动分类聚类、关键词过滤、话题检测、话题聚焦等。
3.信息服务:通过采集分析整理后直接向用户提供信息或为用户提供辅助编辑的信息服务,如自动生成舆情信息简报、舆情统计分析图表、跟踪发现的舆情焦点并形成趋势分析,用于辅助各级领导的决策支持。
人们平时使用软件时,程序会将“源代码”翻译成我们直观的形式供我们使用。[1]
任何 网站 页面,当替换为源代码时,都是一堆以某种格式编写的文本和符号,但我们的浏览器帮助我们将其翻译成我们面前的样子。
相关链接 电网舆情监测 舆情监测网站行业舆情监测 舆情监测机制 医院舆情监测 查看全部
实时文章采集(电力网络舆情监控网站行业舆情监测机制医院舆情监督管理“源码”)
源代码是指编写的最原创程序的代码。运行的软件是要编写的,程序员在编写程序的过程中需要他们的“语言”。音乐家使用五线谱,建筑师使用图纸。程序员工作的语言是“源代码”。
通过网页内容的自动采集处理、敏感词过滤、智能聚类分类、话题检测、话题聚焦、统计分析等,实现相关网络舆情监督管理的需求,将舆情专题报告和分析最终形成 报告和统计报告为决策者和管理层全面掌握舆情动态,做出正确的舆情导向,提供分析依据。工作过程
1.信息采集:实时监控互联网信息(新闻、论坛等),采集,内容提取、下载、重置。
2. 信息处理:对抓取的内容进行自动分类聚类、关键词过滤、话题检测、话题聚焦等。
3.信息服务:通过采集分析整理后直接向用户提供信息或为用户提供辅助编辑的信息服务,如自动生成舆情信息简报、舆情统计分析图表、跟踪发现的舆情焦点并形成趋势分析,用于辅助各级领导的决策支持。
人们平时使用软件时,程序会将“源代码”翻译成我们直观的形式供我们使用。[1]
任何 网站 页面,当替换为源代码时,都是一堆以某种格式编写的文本和符号,但我们的浏览器帮助我们将其翻译成我们面前的样子。
相关链接 电网舆情监测 舆情监测网站行业舆情监测 舆情监测机制 医院舆情监测
实时文章采集(使用java后端技术过程中的一些心得体会(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-07 19:02
实时文章采集,后面慢慢展开。今年是自己独立创业的第十年,在程序员行业的从业经历也有些年头,期间帮过很多朋友做过一些自己的项目,发现大部分程序员在接触新技术的时候,总会有一个反复的过程,所以今天来和大家分享一下自己在使用java后端技术过程中的一些心得体会。自己是如何发现并探索新技术的,或者说,是如何理解它的优劣?创业初期首先是和程序员沟通,从年初开始就对团队的能力和水平有了一些了解。
本身团队的成员都有自己独特的技术背景,比如最早是做seo,再比如可能最开始是做kafka等等。所以我很清楚技术要实现哪些特性,跟这些技术人员比,我并不具备什么优势,在今天技术更新速度之快,即使不是业界的资深技术人员,基本上没有一个人能够保证实时更新技术,所以我第一时间注意到了业界开始实现某个新技术,我马上去看看是不是真的解决了我的需求。
顺利地我找到了业界近期已经尝试过的较为成熟的技术,它们原本的优点,和目前的状态,顺利地我就想,难不成这个技术能对我的业务有不可替代性吗?需求实现方不是一个打酱油的?于是我迅速发现了问题所在。要实现这个技术,需要解决什么问题?解决了之后,这个技术是否有它的价值?就像我自己,我想做一个品牌交易平台,之前是一个做线下实体店导购的平台,解决的主要问题是卖什么好卖,而需要重新梳理导购平台,发现即使是在天猫、京东上的热销商品,也只能满足20%的客户群体,所以我必须考虑新的业务需求,是一个好的的品牌导购平台。
那么在技术选型上,不管是云计算还是大数据等等,都是在这一点上做文章。也就是说,如果以技术可替代性为标准,那么技术即使突破了重重障碍,也不可能达到我的要求。产品设计发现问题后,就到了产品的设计阶段,原本我认为考虑到的都是应该由程序员去思考的,但是产品的生命周期越长,程序员的参与越少,我觉得产品经理的地位就显得越重要。
相比于程序员,产品经理对于产品是有更高的优先级,不仅仅是因为他可以熟悉整个业务的设计,而且在设计的过程中对于产品价值的认识程度会更高,我有时候看到好的创意或产品,一时冲动就去做产品经理。开发工具但是,当我第一次遇到这个技术的时候,我发现了一个问题,那就是即使我有明确的产品设计,开发工具也没有考虑到。程序员拿到代码后,还需要处理部署,将业务代码拆成更小块的代码,整个开发流程是非常复杂的,程序员用起来会十分的费力。
又加上软件开发的流程是单点开发,一个人管一个人,管着一整个团队,我不知道软件的具体发布和编译是哪一个环节来。 查看全部
实时文章采集(使用java后端技术过程中的一些心得体会(上))
实时文章采集,后面慢慢展开。今年是自己独立创业的第十年,在程序员行业的从业经历也有些年头,期间帮过很多朋友做过一些自己的项目,发现大部分程序员在接触新技术的时候,总会有一个反复的过程,所以今天来和大家分享一下自己在使用java后端技术过程中的一些心得体会。自己是如何发现并探索新技术的,或者说,是如何理解它的优劣?创业初期首先是和程序员沟通,从年初开始就对团队的能力和水平有了一些了解。
本身团队的成员都有自己独特的技术背景,比如最早是做seo,再比如可能最开始是做kafka等等。所以我很清楚技术要实现哪些特性,跟这些技术人员比,我并不具备什么优势,在今天技术更新速度之快,即使不是业界的资深技术人员,基本上没有一个人能够保证实时更新技术,所以我第一时间注意到了业界开始实现某个新技术,我马上去看看是不是真的解决了我的需求。
顺利地我找到了业界近期已经尝试过的较为成熟的技术,它们原本的优点,和目前的状态,顺利地我就想,难不成这个技术能对我的业务有不可替代性吗?需求实现方不是一个打酱油的?于是我迅速发现了问题所在。要实现这个技术,需要解决什么问题?解决了之后,这个技术是否有它的价值?就像我自己,我想做一个品牌交易平台,之前是一个做线下实体店导购的平台,解决的主要问题是卖什么好卖,而需要重新梳理导购平台,发现即使是在天猫、京东上的热销商品,也只能满足20%的客户群体,所以我必须考虑新的业务需求,是一个好的的品牌导购平台。
那么在技术选型上,不管是云计算还是大数据等等,都是在这一点上做文章。也就是说,如果以技术可替代性为标准,那么技术即使突破了重重障碍,也不可能达到我的要求。产品设计发现问题后,就到了产品的设计阶段,原本我认为考虑到的都是应该由程序员去思考的,但是产品的生命周期越长,程序员的参与越少,我觉得产品经理的地位就显得越重要。
相比于程序员,产品经理对于产品是有更高的优先级,不仅仅是因为他可以熟悉整个业务的设计,而且在设计的过程中对于产品价值的认识程度会更高,我有时候看到好的创意或产品,一时冲动就去做产品经理。开发工具但是,当我第一次遇到这个技术的时候,我发现了一个问题,那就是即使我有明确的产品设计,开发工具也没有考虑到。程序员拿到代码后,还需要处理部署,将业务代码拆成更小块的代码,整个开发流程是非常复杂的,程序员用起来会十分的费力。
又加上软件开发的流程是单点开发,一个人管一个人,管着一整个团队,我不知道软件的具体发布和编译是哪一个环节来。
实时文章采集(2020年的春节,新型冠状病毒肺炎疫情来势凶猛可采集?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-26 08:15
摘要:疫情的话题离不开数据支持。疫情话题的原创数据从何而来?疫情话题的实时更新数据是怎么下来的?还有哪些与疫情相关的数据有价值,你能采集吗?本文文章会详细讲解。
2020年春节,新型冠状病毒肺炎疫情来势汹汹。
很多人和我一样,每天睁开眼睛,立刻点开疫情图,看看全国各个省市的病例数。
在互联网和大数据高速发展的今天,疫情信息的透明度极高。疫情发生后,腾讯新闻、凤凰网、阿里健康、人民日报、网易新闻、百度等新闻媒体迅速推出疫情专题,包括疫情地图、实时动态、防谣言防护知识、医疗资讯等栏目。实时跟踪情况。
疫情话题离不开数据支撑。疫情话题的原创数据从何而来?疫情话题的实时更新数据是怎么下来的?还有哪些与疫情相关的数据有价值,你能采集吗?
下面将详细说明。
01采集国家和地方卫健委官网发布的每日疫情通报,为疫情地图中全国各省市病例数据提供数据支撑
国家和地方卫健委官方网站每天以文章的形式发布疫情通报。媒体利用爬虫技术文章实时采集这些疫情通知,从文章中提取有效病例数据,然后以可视化图表等形式展示病例地图和折线图。数据和流行趋势方便大家查看。
我们在疫情地图上看到的病例数据是经过处理的二手数据,可以方便地访问。如果我想从国家和地方卫健委官方网站获取第一手数据怎么办?
以国家卫健委为例。从1月11日起,国家卫健委将每日发布一篇文章,通报全国疫情总体情况,包括每日新增确诊、新增疑似、新增治愈、新增死亡、累计确诊病例。诊断数量、累计疑似病例、累计治愈人数和累计死亡人数。
如果您需要以上一手数据,国家卫健委采集的优采云模板已经上线,免费供大家使用。通过该模板,您可以采集到每日疫情通报文章,通过处理提取有效病例数据。国家卫健委其他栏目(防控动态、通知公告、医生风采、防控知识、新闻报道)的文章也可以使用本模板采集。
以采集疫情通知栏下的文章为例,如何使用该模板:
Step1. 下载优采云客户端,找到【国家卫健委-疫情防控动态】模板,点击【立即使用】
Step2. 在[网站Category URL]的参数框中,输入疫情通知栏的URL:,然后[Start Local采集]
如果要采集其他栏目,请按照模板介绍,在[网站Category URL]参数框中输入对应的网址。
步骤3. 示例数据
02疫情地图实时采集全国各省市病例数据,为研究疫情发展趋势提供数据支持
各媒体疫情地图病例数据的数据来源,基本都是国家和地方市建委下发的疫情通报,没有太大区别。疫情地图实时更新,详细显示当前时刻全国各省市新增和累计病例数,但无法查看历史时刻数据。
对于研究疫情的发展趋势,历史数据非常重要。如何检索历史数据?
1、从国家和地方卫健委官网查找一手资料,参考第一部分内容。
2、即日起,疫情地图中的病例数据将被实时抓取并存储,用于数据积累。
由于各个公司的疫情地图数据差别不大,我们选择了腾讯新闻的疫情地图作为采集模板。从现在开始,您可以使用优采云的云采集设置定期采集计划,实时采集疫情地图中的病例数据。
如何使用此模板:
Step1. 下载优采云客户端,找到【国家卫健委-疫情实时数据】模板,点击【立即使用】,无需输入参数,直接【启动本地采集 ]
步骤2. 示例数据
03采集社交/新闻平台疫情相关数据助力疫情舆情分析
互联网上充斥着疫情信息。采集 疫情相关信息是分析疫情舆情的第一步。除了国家和地方卫健委等政府网站实时发布疫情通报、通知公告、防控动态、新闻报道外,所有社交/新闻平台也充斥着与疫情相关的讨论.
以微博和知乎为例。您可以在微博和知乎上搜索与疫情相关的关键词、微博结果、知乎出现在采集上的问题和答案。然后分析流行热度和时间的趋势,不同时间段的流行重点,以及相关文本的正面和负面情绪。对于上述数据,优采云提供了[知乎-关键字搜索答案]、[知乎-问题详细答案]和[微博搜索]的模板。
微博模板使用方法:
步骤1.在优采云客户端找到【微博搜索】模板,点击【立即使用】
步骤2.在[搜索关键词]参数输入框中输入疫情相关关键词(可以输入多个关键词),然后[启动云采集@ >]
步骤3. 示例数据
知乎模板使用方法:
步骤1.在优采云客户端找到【知乎-关键字搜索答案】模板,点击【立即使用】
Step2. 在[Keyword]参数输入框中输入疫情相关关键词(可以输入多个关键词),然后[启动云采集]
步骤3. 示例数据
毫无疑问,互联网和大数据带来的信息透明化,在抗击疫情中发挥着重要而积极的作用。通过国家卫健委等权威机构发布的实时病例数据和防控动态,我们能够贴近疫情真实情况,积极响应防控政策。通过查询确诊社区、查询确诊旅客等平台,及时发现和规避感染风险。通过知乎微博等平台,可以高效传播科普、辟谣、讨论、求助、监督等优质信息。
这一切都离不开原创数据的采集。如果你恰好对这些多维度的疫情数据感兴趣,希望这篇文章对你有所帮助。
没有春天不会来。在她到来之前,优采云 会和你在一起。 查看全部
实时文章采集(2020年的春节,新型冠状病毒肺炎疫情来势凶猛可采集?)
摘要:疫情的话题离不开数据支持。疫情话题的原创数据从何而来?疫情话题的实时更新数据是怎么下来的?还有哪些与疫情相关的数据有价值,你能采集吗?本文文章会详细讲解。
2020年春节,新型冠状病毒肺炎疫情来势汹汹。
很多人和我一样,每天睁开眼睛,立刻点开疫情图,看看全国各个省市的病例数。
在互联网和大数据高速发展的今天,疫情信息的透明度极高。疫情发生后,腾讯新闻、凤凰网、阿里健康、人民日报、网易新闻、百度等新闻媒体迅速推出疫情专题,包括疫情地图、实时动态、防谣言防护知识、医疗资讯等栏目。实时跟踪情况。
疫情话题离不开数据支撑。疫情话题的原创数据从何而来?疫情话题的实时更新数据是怎么下来的?还有哪些与疫情相关的数据有价值,你能采集吗?
下面将详细说明。
01采集国家和地方卫健委官网发布的每日疫情通报,为疫情地图中全国各省市病例数据提供数据支撑
国家和地方卫健委官方网站每天以文章的形式发布疫情通报。媒体利用爬虫技术文章实时采集这些疫情通知,从文章中提取有效病例数据,然后以可视化图表等形式展示病例地图和折线图。数据和流行趋势方便大家查看。
我们在疫情地图上看到的病例数据是经过处理的二手数据,可以方便地访问。如果我想从国家和地方卫健委官方网站获取第一手数据怎么办?
以国家卫健委为例。从1月11日起,国家卫健委将每日发布一篇文章,通报全国疫情总体情况,包括每日新增确诊、新增疑似、新增治愈、新增死亡、累计确诊病例。诊断数量、累计疑似病例、累计治愈人数和累计死亡人数。
如果您需要以上一手数据,国家卫健委采集的优采云模板已经上线,免费供大家使用。通过该模板,您可以采集到每日疫情通报文章,通过处理提取有效病例数据。国家卫健委其他栏目(防控动态、通知公告、医生风采、防控知识、新闻报道)的文章也可以使用本模板采集。
以采集疫情通知栏下的文章为例,如何使用该模板:
Step1. 下载优采云客户端,找到【国家卫健委-疫情防控动态】模板,点击【立即使用】
Step2. 在[网站Category URL]的参数框中,输入疫情通知栏的URL:,然后[Start Local采集]
如果要采集其他栏目,请按照模板介绍,在[网站Category URL]参数框中输入对应的网址。
步骤3. 示例数据
02疫情地图实时采集全国各省市病例数据,为研究疫情发展趋势提供数据支持
各媒体疫情地图病例数据的数据来源,基本都是国家和地方市建委下发的疫情通报,没有太大区别。疫情地图实时更新,详细显示当前时刻全国各省市新增和累计病例数,但无法查看历史时刻数据。
对于研究疫情的发展趋势,历史数据非常重要。如何检索历史数据?
1、从国家和地方卫健委官网查找一手资料,参考第一部分内容。
2、即日起,疫情地图中的病例数据将被实时抓取并存储,用于数据积累。
由于各个公司的疫情地图数据差别不大,我们选择了腾讯新闻的疫情地图作为采集模板。从现在开始,您可以使用优采云的云采集设置定期采集计划,实时采集疫情地图中的病例数据。
如何使用此模板:
Step1. 下载优采云客户端,找到【国家卫健委-疫情实时数据】模板,点击【立即使用】,无需输入参数,直接【启动本地采集 ]
步骤2. 示例数据
03采集社交/新闻平台疫情相关数据助力疫情舆情分析
互联网上充斥着疫情信息。采集 疫情相关信息是分析疫情舆情的第一步。除了国家和地方卫健委等政府网站实时发布疫情通报、通知公告、防控动态、新闻报道外,所有社交/新闻平台也充斥着与疫情相关的讨论.
以微博和知乎为例。您可以在微博和知乎上搜索与疫情相关的关键词、微博结果、知乎出现在采集上的问题和答案。然后分析流行热度和时间的趋势,不同时间段的流行重点,以及相关文本的正面和负面情绪。对于上述数据,优采云提供了[知乎-关键字搜索答案]、[知乎-问题详细答案]和[微博搜索]的模板。
微博模板使用方法:
步骤1.在优采云客户端找到【微博搜索】模板,点击【立即使用】
步骤2.在[搜索关键词]参数输入框中输入疫情相关关键词(可以输入多个关键词),然后[启动云采集@ >]
步骤3. 示例数据
知乎模板使用方法:
步骤1.在优采云客户端找到【知乎-关键字搜索答案】模板,点击【立即使用】
Step2. 在[Keyword]参数输入框中输入疫情相关关键词(可以输入多个关键词),然后[启动云采集]
步骤3. 示例数据
毫无疑问,互联网和大数据带来的信息透明化,在抗击疫情中发挥着重要而积极的作用。通过国家卫健委等权威机构发布的实时病例数据和防控动态,我们能够贴近疫情真实情况,积极响应防控政策。通过查询确诊社区、查询确诊旅客等平台,及时发现和规避感染风险。通过知乎微博等平台,可以高效传播科普、辟谣、讨论、求助、监督等优质信息。
这一切都离不开原创数据的采集。如果你恰好对这些多维度的疫情数据感兴趣,希望这篇文章对你有所帮助。
没有春天不会来。在她到来之前,优采云 会和你在一起。
实时文章采集( 做flume,其实就是写conf文件,就面临选型的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-24 20:02
做flume,其实就是写conf文件,就面临选型的问题)
Flume和Kafka完成实时数据采集
写在前面
Flume和Kafka一般在生产环境中结合使用。可以将两者结合使用来采集实时日志信息,这一点非常重要。如果你不知道flume和kafka,可以先看看我写的关于这两部分的知识。再学习一下,这部分操作也是可以的。
采集 的实时数据面临一个问题。我们如何生成实时数据源?因为我们可能想直接获取实时数据流不是那么方便。在文章之前写过一篇关于实时数据流的python生成器的文章,文章地址:
大家可以先看看,如何生成实时数据...
主意?? 如何开始??
分析:我们可以从数据流开始。数据一开始就在网络服务器上。我们的访问日志是nginx服务器实时采集到指定文件的。我们从这个文件中采集日志数据,即:webserver=>flume=>kafka
Webserver 日志存储文件位置
这个文件的位置一般是我们自己设置的
我们的网络日志存储的目录是:
/home/hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
水槽
做flume其实就是写一个conf文件,所以面临选择的问题
来源选择?频道选择?水槽选择?
这里我们选择exec source memory channel kafka sink
怎么写?
按照前面提到的步骤 1234
从官方网站上,我们可以找到我们的选择应该怎么写:
1) 配置源
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2) 配置通道
记忆通道
a1.channels.c1.type = memory
3) 配置接收器
卡夫卡水槽
对于flume1.6 版本,请参考#kafka-sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
将以上三个组件串在一起
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们的新文件叫做 test3.conf
贴上我们分析的代码:
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里不展开了,因为涉及kafka的东西,首先要部署kafka,
Kafka部署
Kafka是如何部署的??
按照官网的说法,我们先启动一个zookeeper进程,然后就可以启动kafka服务器了
第一步:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
第二步:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果这部分不是很熟悉,可以参考
第 3 步:创建主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
第四步:启动之前的代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
第 5 步:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行完上面的第五步后,你会收到刷新屏幕的结果,哈哈哈!!
上面的消费者会不断刷新屏幕,还是很有意思的!!!
这里的消费者就是把接收到的数据放到屏幕上
后面会介绍使用SparkStreaming作为消费者实时接收数据,并对接收到的数据进行简单的数据清洗,从随机生成的日志中过滤出我们需要的数据...... 查看全部
实时文章采集(
做flume,其实就是写conf文件,就面临选型的问题)
Flume和Kafka完成实时数据采集
写在前面
Flume和Kafka一般在生产环境中结合使用。可以将两者结合使用来采集实时日志信息,这一点非常重要。如果你不知道flume和kafka,可以先看看我写的关于这两部分的知识。再学习一下,这部分操作也是可以的。
采集 的实时数据面临一个问题。我们如何生成实时数据源?因为我们可能想直接获取实时数据流不是那么方便。在文章之前写过一篇关于实时数据流的python生成器的文章,文章地址:
大家可以先看看,如何生成实时数据...
主意?? 如何开始??
分析:我们可以从数据流开始。数据一开始就在网络服务器上。我们的访问日志是nginx服务器实时采集到指定文件的。我们从这个文件中采集日志数据,即:webserver=>flume=>kafka
Webserver 日志存储文件位置
这个文件的位置一般是我们自己设置的
我们的网络日志存储的目录是:
/home/hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
水槽
做flume其实就是写一个conf文件,所以面临选择的问题
来源选择?频道选择?水槽选择?
这里我们选择exec source memory channel kafka sink
怎么写?
按照前面提到的步骤 1234
从官方网站上,我们可以找到我们的选择应该怎么写:
1) 配置源
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2) 配置通道
记忆通道
a1.channels.c1.type = memory
3) 配置接收器
卡夫卡水槽
对于flume1.6 版本,请参考#kafka-sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
将以上三个组件串在一起
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们的新文件叫做 test3.conf
贴上我们分析的代码:
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里不展开了,因为涉及kafka的东西,首先要部署kafka,
Kafka部署
Kafka是如何部署的??
按照官网的说法,我们先启动一个zookeeper进程,然后就可以启动kafka服务器了
第一步:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
第二步:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果这部分不是很熟悉,可以参考
第 3 步:创建主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
第四步:启动之前的代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
第 5 步:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行完上面的第五步后,你会收到刷新屏幕的结果,哈哈哈!!
上面的消费者会不断刷新屏幕,还是很有意思的!!!
这里的消费者就是把接收到的数据放到屏幕上
后面会介绍使用SparkStreaming作为消费者实时接收数据,并对接收到的数据进行简单的数据清洗,从随机生成的日志中过滤出我们需要的数据......
实时文章采集(原创文章被别人即时复制怎么办?如何处理?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-24 07:09
很多人讨厌自己的原创文章被别人瞬间抄袭。有些人甚至用它来发送一些垃圾邮件链接。尤其相信很多老人都遇到过这样的情况。有时他们的努力还不如采集。我们如何处理这种情况?
首先,在竞争对手采集这个文章之前,尽量让搜索引擎收录它。
1、及时捕捉文章让搜索引擎知道这一点文章。
2、Ping 在百度的网站管理员自己的文章链接上,这也是百度官方告诉我们的一种方式。
二、文章 标记作者或版本。
织梦58 认为有时候阻止别人抄袭你的文章是不可能的,但这也是一种书面的交流和提醒,总比没有好。
第三,在文章中添加一些功能。
1、比如在n1、n2、color等标签代码中文章,搜索引擎会对这些内容更加敏感,加深认知原创 的判断。
2、在文章中添加您自己的品牌词汇
3、添加一些内部链接,因为喜欢复制文章的人通常比较懒,不排除有些人可以直接复制粘贴。
4、 文章文章被及时添加时,搜索引擎会判断文章的原创性,参考时间因素。
四、过滤网页的关键功能
大多数人在使用鼠标右键复制文章时,如果技术不受此功能影响,无疑会增加采集的麻烦。
五、夜间更新
你最害怕的是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯上了。文章 立即被抄袭。
在我们的网站上看到并应用了这些方法之后,相信这样可以减少文章的集合数量。 查看全部
实时文章采集(原创文章被别人即时复制怎么办?如何处理?(图))
很多人讨厌自己的原创文章被别人瞬间抄袭。有些人甚至用它来发送一些垃圾邮件链接。尤其相信很多老人都遇到过这样的情况。有时他们的努力还不如采集。我们如何处理这种情况?
首先,在竞争对手采集这个文章之前,尽量让搜索引擎收录它。
1、及时捕捉文章让搜索引擎知道这一点文章。
2、Ping 在百度的网站管理员自己的文章链接上,这也是百度官方告诉我们的一种方式。
二、文章 标记作者或版本。
织梦58 认为有时候阻止别人抄袭你的文章是不可能的,但这也是一种书面的交流和提醒,总比没有好。
第三,在文章中添加一些功能。
1、比如在n1、n2、color等标签代码中文章,搜索引擎会对这些内容更加敏感,加深认知原创 的判断。
2、在文章中添加您自己的品牌词汇
3、添加一些内部链接,因为喜欢复制文章的人通常比较懒,不排除有些人可以直接复制粘贴。
4、 文章文章被及时添加时,搜索引擎会判断文章的原创性,参考时间因素。
四、过滤网页的关键功能
大多数人在使用鼠标右键复制文章时,如果技术不受此功能影响,无疑会增加采集的麻烦。
五、夜间更新
你最害怕的是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯上了。文章 立即被抄袭。
在我们的网站上看到并应用了这些方法之后,相信这样可以减少文章的集合数量。
实时文章采集(2000开发环境VS2003orFramework1.1(SqlServer1.1))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-23 12:12
预览图片请参阅:HTML运行环境Windows NT / XP / 2003或Framework 1. 1SQLServer 2000开发环境VS 2003目的网络编程,我必须做点什么。所以我想我想成为一个网页Content 采集器。作者主页:使用模式测试数据采用CNBLOG。请参阅下一个图片用户首次填写“启动网页”,这是从哪个页面采集。然后填写数据库连接字符串,这是插入数据库的采集的定义,选择了表名,没有必要。网页编码,没有意外,中国大陆可以使用UTF-8攀登文件名:哦,这个工具明显被编程师使用。必须直接填写规定。例如,CNBlogs是一个数字,所以写\ D构建表帮助:用户指定几种varchar类型,几种文本类型,主要是更短的数据和长数据。如果您的桌子中有列,那么您害怕。程序内没有验证。在网页上:采集内容内容标标标::例如,如果我想要采集 xxx,写“to”,意思是,当然是内容。将显示以下文本框。单击“获取URL”以查看捕获的URL的URL是错误的。单击“采集”,可以将采集 content放入数据库中,然后使用插入xx()(选择xx)直接插入目标数据。程序代码非常小(它也很简单),需要更改。不足以定期表达式,网络编程是由于最简单的东西,所以没有多线程,没有其他优化方法,不支持分页。测试,获得38个数据,使用700米内存。 。 。 。如果有用的人可以改变它。方便程序员,手写很多代码。尹@ virance中心重印,请注明来源 查看全部
实时文章采集(2000开发环境VS2003orFramework1.1(SqlServer1.1))
预览图片请参阅:HTML运行环境Windows NT / XP / 2003或Framework 1. 1SQLServer 2000开发环境VS 2003目的网络编程,我必须做点什么。所以我想我想成为一个网页Content 采集器。作者主页:使用模式测试数据采用CNBLOG。请参阅下一个图片用户首次填写“启动网页”,这是从哪个页面采集。然后填写数据库连接字符串,这是插入数据库的采集的定义,选择了表名,没有必要。网页编码,没有意外,中国大陆可以使用UTF-8攀登文件名:哦,这个工具明显被编程师使用。必须直接填写规定。例如,CNBlogs是一个数字,所以写\ D构建表帮助:用户指定几种varchar类型,几种文本类型,主要是更短的数据和长数据。如果您的桌子中有列,那么您害怕。程序内没有验证。在网页上:采集内容内容标标标::例如,如果我想要采集 xxx,写“to”,意思是,当然是内容。将显示以下文本框。单击“获取URL”以查看捕获的URL的URL是错误的。单击“采集”,可以将采集 content放入数据库中,然后使用插入xx()(选择xx)直接插入目标数据。程序代码非常小(它也很简单),需要更改。不足以定期表达式,网络编程是由于最简单的东西,所以没有多线程,没有其他优化方法,不支持分页。测试,获得38个数据,使用700米内存。 。 。 。如果有用的人可以改变它。方便程序员,手写很多代码。尹@ virance中心重印,请注明来源
实时文章采集(新媒体运营怎么配合公司推广?怎么去适应哪些内容?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-22 18:04
实时文章采集对于新媒体运营来说,个人觉得seo(搜索引擎优化)是最重要的了。很多同学会经常问我这样一个问题:“老师,微信公众号,微博,今日头条这些平台我现在注册了,账号申请下来了,想要内容去推广,那应该怎么去进行呢?”那些平台我们可以选择去适应哪些内容呢?怎么去配合公司推广呢?首先你要清楚,自己想要做哪些内容,以及你想推广的是什么内容,然后再一点一点搜集信息。
同时,当你清楚了内容和推广的目标是针对哪一块产品来的时候,你也要考虑你是想去做自媒体运营,还是做品牌口碑还是影响大客户这样。seo一般分为:1.新闻稿、软文2.软件制作3.论坛贴吧4.博客5.自媒体运营6.设计工具采集,或者昵称,id注册知乎关注,微博,今日头条,搜狐,新浪博客,新浪微博认证,做推广。
还可以发布一些领域类的博客,比如电影,阅读,设计,健康,交通,等等这些,或者是合作自媒体,例如广告主、消费者以及官方公众号之类的联合做内容推广,了解别人的推广方式。选择粉丝不同,来源渠道就不同。例如:电影,你可以走官方自媒体平台,直接去发你的开发号,官方的媒体方就是作者以及推广者,很容易发表到官方媒体上的。
你可以通过网络平台直接去引流到你的运营公众号上来,因为看到广告的人就是你的潜在用户群。再比如:大型的app上面,你可以直接走广告主,他们就是一些大型的广告主,没有流量的时候,可以花钱买粉丝,或者是你去微博上发广告。如果真的是没有资金,建议你可以去小公司,但是你必须要花时间去做好你的内容,先去做个人专栏,以后有钱了,再去做商业写作。
内容获取的渠道很多,比如微信公众号:可以自己做内容生产,公众号有定期的内容更新,当你不能及时更新的时候就是去抄袭他人的,不去做任何内容创新。微博:新浪微博也是一个内容生产的平台,有很多转发抽奖的活动,你可以去做转发抽奖。app:你可以去做一些地推,比如说你可以在地铁等人流比较大的时候去进行户外广告的投放,广告的销售情况也是挺高的。
综上所述,想要获取更多粉丝需要两点:1.花时间去做好自己的内容2.考虑合作的方式。第一点:花时间去做自己的内容,很多同学都在问我怎么去写微信文章,但是为什么发布出去还是没有任何人点开阅读,我回答你:他们连新闻都不知道有什么意义,还好意思去点吗?那么,你应该去做的:首先你要去尝试写一些长篇文章(1w字以上),用你的故事和故事来生动的讲述你要传达的知识点。以及,你要去找一些大的网站,比如说企鹅智酷这样的平台来宣传,需要从多。 查看全部
实时文章采集(新媒体运营怎么配合公司推广?怎么去适应哪些内容?)
实时文章采集对于新媒体运营来说,个人觉得seo(搜索引擎优化)是最重要的了。很多同学会经常问我这样一个问题:“老师,微信公众号,微博,今日头条这些平台我现在注册了,账号申请下来了,想要内容去推广,那应该怎么去进行呢?”那些平台我们可以选择去适应哪些内容呢?怎么去配合公司推广呢?首先你要清楚,自己想要做哪些内容,以及你想推广的是什么内容,然后再一点一点搜集信息。
同时,当你清楚了内容和推广的目标是针对哪一块产品来的时候,你也要考虑你是想去做自媒体运营,还是做品牌口碑还是影响大客户这样。seo一般分为:1.新闻稿、软文2.软件制作3.论坛贴吧4.博客5.自媒体运营6.设计工具采集,或者昵称,id注册知乎关注,微博,今日头条,搜狐,新浪博客,新浪微博认证,做推广。
还可以发布一些领域类的博客,比如电影,阅读,设计,健康,交通,等等这些,或者是合作自媒体,例如广告主、消费者以及官方公众号之类的联合做内容推广,了解别人的推广方式。选择粉丝不同,来源渠道就不同。例如:电影,你可以走官方自媒体平台,直接去发你的开发号,官方的媒体方就是作者以及推广者,很容易发表到官方媒体上的。
你可以通过网络平台直接去引流到你的运营公众号上来,因为看到广告的人就是你的潜在用户群。再比如:大型的app上面,你可以直接走广告主,他们就是一些大型的广告主,没有流量的时候,可以花钱买粉丝,或者是你去微博上发广告。如果真的是没有资金,建议你可以去小公司,但是你必须要花时间去做好你的内容,先去做个人专栏,以后有钱了,再去做商业写作。
内容获取的渠道很多,比如微信公众号:可以自己做内容生产,公众号有定期的内容更新,当你不能及时更新的时候就是去抄袭他人的,不去做任何内容创新。微博:新浪微博也是一个内容生产的平台,有很多转发抽奖的活动,你可以去做转发抽奖。app:你可以去做一些地推,比如说你可以在地铁等人流比较大的时候去进行户外广告的投放,广告的销售情况也是挺高的。
综上所述,想要获取更多粉丝需要两点:1.花时间去做好自己的内容2.考虑合作的方式。第一点:花时间去做自己的内容,很多同学都在问我怎么去写微信文章,但是为什么发布出去还是没有任何人点开阅读,我回答你:他们连新闻都不知道有什么意义,还好意思去点吗?那么,你应该去做的:首先你要去尝试写一些长篇文章(1w字以上),用你的故事和故事来生动的讲述你要传达的知识点。以及,你要去找一些大的网站,比如说企鹅智酷这样的平台来宣传,需要从多。
实时文章采集(登录免费注册-infoq也可以直接访问我们网站(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-22 05:06
实时文章采集工具支持移动端和pc端,采集资源是来自于「infoq」的。打开登录,免费注册。登录免费注册-infoq也可以直接访问我们网站()。或扫描以下二维码直接注册:注册后,在首页,点击导航栏“我是创始人”,会看到登录用户名和密码,如图:图1注册页面然后找到右侧的“企业主页”,扫描图中地址打开首页,如图:图2首页这里有三个大的标签页,默认是直接访问在我是创始人,我是社区,我是创始人,三个标签页。
除了标签页外,还有一个活动页面,如图:图3活动页面进入活动页面,点击“个人网站”,会显示创始人项目介绍和历史的项目,如图:图4个人网站在个人网站,你会看到“登录”选项,点击即可登录。登录后,不要急着发布网站,点击“发布”,你会在首页看到对应的展示。等展示结束,即可发布。发布成功,上传“企业主页”地址即可上线发布。
图5个人网站发布-infoq如果您希望能将您的网站最新的文章也同步到infoq,可以通过页面访问网址「」,然后点击同步链接,然后点击【发布】按钮,即可将本地网站所有文章同步到infoq。注意这里「发布」按钮,有2个选项,其中一个是“保存数据”,点击这个按钮即可保存网站的文章。另一个是“分享到网站”,当分享到网站后,即可推送到infoq的服务器。
这里显示是微博推送,其实是推送到infoq的服务器后,后台会有自动发送到后台上传。接下来的注意事项,网站将会对您的网站文章进行原创检测。文章以采集文章形式同步到infoq。不管文章采取什么形式,文章的内容必须是来自于“infoq中国”。文章地址保存成域名形式后,只会展示到“infoq中国”网站上,不会同步到infoq服务器。
网站的采集要求是,每月至少40篇。对于长篇文章,将会进行目录的形式。主要的文章内容可能涉及软件开发,界面设计以及api的开发等。需要将文章地址保存后,将所有的图片转换成html格式,然后将文章链接转换成连接格式。我们注重内容的品质,对字体以及排版等要求较高。在长文章中,往往要进行插入代码,比如图片,表格等等。
对于长文章,需要对网页进行分析和对应页面进行抓取。不同的字体,以及不同的排版不同的特殊字符,网站可能要进行预处理处理。为了发布到infoq网站,需要使用infoq中国合作方和我们提供的服务,未来不可能有其他补贴方式。希望有需要的创业团队,将文章发布到infoq网站,或文章链接,还可以发布到自己的博客或一些其他平台。有意提供文章同步服务的创业团队,请联系我们。我们发起了写作。 查看全部
实时文章采集(登录免费注册-infoq也可以直接访问我们网站(组图))
实时文章采集工具支持移动端和pc端,采集资源是来自于「infoq」的。打开登录,免费注册。登录免费注册-infoq也可以直接访问我们网站()。或扫描以下二维码直接注册:注册后,在首页,点击导航栏“我是创始人”,会看到登录用户名和密码,如图:图1注册页面然后找到右侧的“企业主页”,扫描图中地址打开首页,如图:图2首页这里有三个大的标签页,默认是直接访问在我是创始人,我是社区,我是创始人,三个标签页。
除了标签页外,还有一个活动页面,如图:图3活动页面进入活动页面,点击“个人网站”,会显示创始人项目介绍和历史的项目,如图:图4个人网站在个人网站,你会看到“登录”选项,点击即可登录。登录后,不要急着发布网站,点击“发布”,你会在首页看到对应的展示。等展示结束,即可发布。发布成功,上传“企业主页”地址即可上线发布。
图5个人网站发布-infoq如果您希望能将您的网站最新的文章也同步到infoq,可以通过页面访问网址「」,然后点击同步链接,然后点击【发布】按钮,即可将本地网站所有文章同步到infoq。注意这里「发布」按钮,有2个选项,其中一个是“保存数据”,点击这个按钮即可保存网站的文章。另一个是“分享到网站”,当分享到网站后,即可推送到infoq的服务器。
这里显示是微博推送,其实是推送到infoq的服务器后,后台会有自动发送到后台上传。接下来的注意事项,网站将会对您的网站文章进行原创检测。文章以采集文章形式同步到infoq。不管文章采取什么形式,文章的内容必须是来自于“infoq中国”。文章地址保存成域名形式后,只会展示到“infoq中国”网站上,不会同步到infoq服务器。
网站的采集要求是,每月至少40篇。对于长篇文章,将会进行目录的形式。主要的文章内容可能涉及软件开发,界面设计以及api的开发等。需要将文章地址保存后,将所有的图片转换成html格式,然后将文章链接转换成连接格式。我们注重内容的品质,对字体以及排版等要求较高。在长文章中,往往要进行插入代码,比如图片,表格等等。
对于长文章,需要对网页进行分析和对应页面进行抓取。不同的字体,以及不同的排版不同的特殊字符,网站可能要进行预处理处理。为了发布到infoq网站,需要使用infoq中国合作方和我们提供的服务,未来不可能有其他补贴方式。希望有需要的创业团队,将文章发布到infoq网站,或文章链接,还可以发布到自己的博客或一些其他平台。有意提供文章同步服务的创业团队,请联系我们。我们发起了写作。
实时文章采集(实时文章采集分析编辑|飞鸟数据采集汇总(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-09-21 19:09
实时文章采集分析编辑|飞鸟数据采集汇总timeline-recruitthenextbreakthrough-propagatejfh'stwo-thirds-edge探讨-成长并不容易~作者|deadyegr
一、聚类分析为什么不能用于文章链接抓取如果抓取的重点是文章所在的分组,如“杨超越”或者“张恒”等等,这种聚类分析的实时性要求比较高。假设我们想要抓取第一个或者第二个分组中的部分文章作为切入点,即聚类分析的关键点。最坏的情况就是知道某个类别有多少篇文章,一个常见的做法是先聚类起来,然后用k-means来提取modelcenter。
如果人肉去爬行,比如从“算法社区”爬取10篇paper,假设平均每篇paper的字数应该为1万,那么从10个article中就可以提取出至少10个branch,比直接抓取抓得更快速。也正因为如此,所以才要去抓取k-means模型的参数。另外一方面,即使没有这些分支,那么依旧可以用类似于全文检索的技术去抓取重点文章,比如说我们可以使用entrez-ace来索引重点文章,然后再用svm分类。这种聚类的定制化带来的另一个好处就是时效性更好。
二、文章的主题是怎么聚类的呢?假设我们抓取了文章中所有的“杨超越”或者“张恒”关键词,那么将文章分为m主题和n主题或者n-tag是可行的。
1、模型聚类“杨超越”或者“张恒”等等关键词的选择和分布与整个文章主题分布有关,这也就意味着找到一个合适的population是一个非常关键的工作。一般来说,很多时候标签相关的文章会聚集在同一个ml-grid里,同一个tag也会聚集在同一个grid里。作者通过使用phase分析可以得出一个文章的特征离散(至少是单元)的分布,然后使用rnn依据距离划分相近的k个,再使用单元统计class-descriptors划分这个entirelyseparategrid。文章中每个关键词的离散程度也就是与其相邻的词的离散程度决定了文章的整体离散程度。
2、在phase模型中找到我们想要聚类的关键词如果找到了我们想要聚类的关键词,那么接下来就是通过rnn去拟合到相邻词的距离,然后找到modelcenter。一方面我们通过后缀词先去找,找到任何和某个关键词相近的词我们去扩展到相邻词,另一方面直接从全文中找,去找到与某些单词比较近的相邻的词。
三、结果展示文章聚类分析前四五页的内容均可以抓到。接下来就是看单个关键词在所有文章中的分布。这里涉及到一个将关键词转换成向量的问题。对于某些情况,比如关键词是按固定长度的数组,而比如使用rnn对特定长度的词识别,这时候基于rnn特定窗口构建floyd矩阵就相当于用各个关键词的向量构建一个rnn。这种情。 查看全部
实时文章采集(实时文章采集分析编辑|飞鸟数据采集汇总(二))
实时文章采集分析编辑|飞鸟数据采集汇总timeline-recruitthenextbreakthrough-propagatejfh'stwo-thirds-edge探讨-成长并不容易~作者|deadyegr
一、聚类分析为什么不能用于文章链接抓取如果抓取的重点是文章所在的分组,如“杨超越”或者“张恒”等等,这种聚类分析的实时性要求比较高。假设我们想要抓取第一个或者第二个分组中的部分文章作为切入点,即聚类分析的关键点。最坏的情况就是知道某个类别有多少篇文章,一个常见的做法是先聚类起来,然后用k-means来提取modelcenter。
如果人肉去爬行,比如从“算法社区”爬取10篇paper,假设平均每篇paper的字数应该为1万,那么从10个article中就可以提取出至少10个branch,比直接抓取抓得更快速。也正因为如此,所以才要去抓取k-means模型的参数。另外一方面,即使没有这些分支,那么依旧可以用类似于全文检索的技术去抓取重点文章,比如说我们可以使用entrez-ace来索引重点文章,然后再用svm分类。这种聚类的定制化带来的另一个好处就是时效性更好。
二、文章的主题是怎么聚类的呢?假设我们抓取了文章中所有的“杨超越”或者“张恒”关键词,那么将文章分为m主题和n主题或者n-tag是可行的。
1、模型聚类“杨超越”或者“张恒”等等关键词的选择和分布与整个文章主题分布有关,这也就意味着找到一个合适的population是一个非常关键的工作。一般来说,很多时候标签相关的文章会聚集在同一个ml-grid里,同一个tag也会聚集在同一个grid里。作者通过使用phase分析可以得出一个文章的特征离散(至少是单元)的分布,然后使用rnn依据距离划分相近的k个,再使用单元统计class-descriptors划分这个entirelyseparategrid。文章中每个关键词的离散程度也就是与其相邻的词的离散程度决定了文章的整体离散程度。
2、在phase模型中找到我们想要聚类的关键词如果找到了我们想要聚类的关键词,那么接下来就是通过rnn去拟合到相邻词的距离,然后找到modelcenter。一方面我们通过后缀词先去找,找到任何和某个关键词相近的词我们去扩展到相邻词,另一方面直接从全文中找,去找到与某些单词比较近的相邻的词。
三、结果展示文章聚类分析前四五页的内容均可以抓到。接下来就是看单个关键词在所有文章中的分布。这里涉及到一个将关键词转换成向量的问题。对于某些情况,比如关键词是按固定长度的数组,而比如使用rnn对特定长度的词识别,这时候基于rnn特定窗口构建floyd矩阵就相当于用各个关键词的向量构建一个rnn。这种情。
实时文章采集(网站/app的哪个页面的操作发生时,怎么处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-21 03:12
1.数据源:如网站或app。嵌入点非常重要。也就是说,当埋地时,当网站 / app的操作发生时,发生网站 / app中的哪一个,前端代码(网站,javascript; app,android / ios),由此网络请求(ajax;套接字),以指定格式的日志数据发送到后台。
2. nginx,背景web服务器(tomcat,jetty),后台系统(J2EE,PHP)。在此步骤中,它仍然与我们之前的脱机日志采集过程相同。步行到指定的文件夹后拍摄日志传输工具。
flume,监视指定的文件夹
3. Kafka,我们的日志数据,如何处理自己,决定自己。您可以每天采集副本,将其放入Flume,转移到HDFS,然后将其放入Hive,建立一个离线数据仓库。
也可以采集1分钟,或将其放入文件中,然后转移到水槽,或自定义API直接进入水槽。您可以将Flume配置为将数据写入Kafka
4.实时数据,通常从分布式消息队列集群中读取,例如kafka;实时数据,实时日志,实时写入消息队列,如Kafka;然后,我们的后端实时数据处理程序(Storm,Spark Streaming),实时从Kafka读取数据,日志日志。然后执行实时计算和处理。
5.实时,主动从kafka提取数据
6.大数据实时计算系统,如风暴,火花流,可以实时从kafka拉动数据,然后处理并计算实时数据,在这里您可以封装大量的复杂业务逻辑,甚至呼叫复杂机学习,数据挖掘,智能推荐算法,然后实时车辆调度,实时推荐。 查看全部
实时文章采集(网站/app的哪个页面的操作发生时,怎么处理)
1.数据源:如网站或app。嵌入点非常重要。也就是说,当埋地时,当网站 / app的操作发生时,发生网站 / app中的哪一个,前端代码(网站,javascript; app,android / ios),由此网络请求(ajax;套接字),以指定格式的日志数据发送到后台。
2. nginx,背景web服务器(tomcat,jetty),后台系统(J2EE,PHP)。在此步骤中,它仍然与我们之前的脱机日志采集过程相同。步行到指定的文件夹后拍摄日志传输工具。
flume,监视指定的文件夹
3. Kafka,我们的日志数据,如何处理自己,决定自己。您可以每天采集副本,将其放入Flume,转移到HDFS,然后将其放入Hive,建立一个离线数据仓库。
也可以采集1分钟,或将其放入文件中,然后转移到水槽,或自定义API直接进入水槽。您可以将Flume配置为将数据写入Kafka
4.实时数据,通常从分布式消息队列集群中读取,例如kafka;实时数据,实时日志,实时写入消息队列,如Kafka;然后,我们的后端实时数据处理程序(Storm,Spark Streaming),实时从Kafka读取数据,日志日志。然后执行实时计算和处理。
5.实时,主动从kafka提取数据
6.大数据实时计算系统,如风暴,火花流,可以实时从kafka拉动数据,然后处理并计算实时数据,在这里您可以封装大量的复杂业务逻辑,甚至呼叫复杂机学习,数据挖掘,智能推荐算法,然后实时车辆调度,实时推荐。
实时文章采集(众大一键采集今日头条Discuz插件功能特点及特点分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-19 19:01
点击采集今日头条discuz插件可以自动将采集今日头条发布到网站discuz采集插件。安装此插件后,您可以输入今天标题的地址或关键词,只需单击一下即可将采集今天标题和评论批处理到论坛或门户专栏,并支持无人参与的自动和定期采集发布。根据用户反馈,插件已经多次升级更新。它易于理解和使用,功能强大且经济高效。许多网站管理员安装并使用它。这是一个必要的插件,为每个网站管理员!注意:此插件只能采集今天的头条新闻信息和图集内容,不能采集头条问答、头条视频。。。点击采集今日头条discuz插件功能1、即可输入热门头条新闻关键词,实时采集头条信息和用户评论可发布在您的论坛或门户网站2、上,可批量发布采集和batch,并在短时间内将今日头条的高质量内容重印到您的论坛上3、可以定时采集可以无人值守,全自动采集和自动发布4、可以像两颗豌豆一样注册用户。海报和回复者使用背心,看起来与真实用户完全相同5、支持前台采集,还可以指定普通用户可以使用此采集器,以便普通会员可以帮助您重印今天的标题。K26采集新闻图片可以正常显示并保存为帖子图片附件7、图片附件支持远程FTP保存8、图片将带有水印,您的论坛9、新闻信息已采集将不会重复两次采集,内容也不会重复和冗余。10、采集posts就像真实用户发布的两个豌豆一样,没有人知道它们是否是由用户发布的采集器. 11、视图数量将自动随机设置。感觉你的帖子的浏览量和真实的一样。12、您可以指定发布者(房东)和响应者。发布时间和回复时间可以自定义。13、采集的标题可以发布到门户的任何部分和任何列。14、您可以随机采集将一批标题添加到您的论坛或门户。15、发布的内容可以推送到百度数据收录界面进行SEO优化,加快百度索引的数量,收录at网站1@6、采集返回的内容可以转换为简体中文和繁体中文、伪原创和其他二次处理17、Unlimited采集,无限采集次18、官方版本的用户永久授权终身使用,后续升级和更新也免费,只需点击采集今天的标题discuz插件即可终身使用。Discuz插件为您带来的1、值,使您的论坛拥有众多注册会员,内容非常丰富,非常受欢迎2、使用定时发布、自动采集和一键批采集取代手动发帖,节省时间、人力、物力,高效且不易出错3、让您的网站与大量新闻台分享高质量内容,可以快速提升网站权重和排名。点击采集今日头条discuz插件截图阅读类似推荐:站长常用源代码 查看全部
实时文章采集(众大一键采集今日头条Discuz插件功能特点及特点分析)
点击采集今日头条discuz插件可以自动将采集今日头条发布到网站discuz采集插件。安装此插件后,您可以输入今天标题的地址或关键词,只需单击一下即可将采集今天标题和评论批处理到论坛或门户专栏,并支持无人参与的自动和定期采集发布。根据用户反馈,插件已经多次升级更新。它易于理解和使用,功能强大且经济高效。许多网站管理员安装并使用它。这是一个必要的插件,为每个网站管理员!注意:此插件只能采集今天的头条新闻信息和图集内容,不能采集头条问答、头条视频。。。点击采集今日头条discuz插件功能1、即可输入热门头条新闻关键词,实时采集头条信息和用户评论可发布在您的论坛或门户网站2、上,可批量发布采集和batch,并在短时间内将今日头条的高质量内容重印到您的论坛上3、可以定时采集可以无人值守,全自动采集和自动发布4、可以像两颗豌豆一样注册用户。海报和回复者使用背心,看起来与真实用户完全相同5、支持前台采集,还可以指定普通用户可以使用此采集器,以便普通会员可以帮助您重印今天的标题。K26采集新闻图片可以正常显示并保存为帖子图片附件7、图片附件支持远程FTP保存8、图片将带有水印,您的论坛9、新闻信息已采集将不会重复两次采集,内容也不会重复和冗余。10、采集posts就像真实用户发布的两个豌豆一样,没有人知道它们是否是由用户发布的采集器. 11、视图数量将自动随机设置。感觉你的帖子的浏览量和真实的一样。12、您可以指定发布者(房东)和响应者。发布时间和回复时间可以自定义。13、采集的标题可以发布到门户的任何部分和任何列。14、您可以随机采集将一批标题添加到您的论坛或门户。15、发布的内容可以推送到百度数据收录界面进行SEO优化,加快百度索引的数量,收录at网站1@6、采集返回的内容可以转换为简体中文和繁体中文、伪原创和其他二次处理17、Unlimited采集,无限采集次18、官方版本的用户永久授权终身使用,后续升级和更新也免费,只需点击采集今天的标题discuz插件即可终身使用。Discuz插件为您带来的1、值,使您的论坛拥有众多注册会员,内容非常丰富,非常受欢迎2、使用定时发布、自动采集和一键批采集取代手动发帖,节省时间、人力、物力,高效且不易出错3、让您的网站与大量新闻台分享高质量内容,可以快速提升网站权重和排名。点击采集今日头条discuz插件截图阅读类似推荐:站长常用源代码
实时文章采集( 前面Flume和Kafka的实时数据源,怎么产生呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-15 20:03
前面Flume和Kafka的实时数据源,怎么产生呢??)
水槽和卡夫卡完成实时数据处理采集
写在前面
Flume和Kafka通常在生产环境中一起使用。能够结合使用它们来采集实时日志信息非常重要。如果你不知道flume和Kafka,你可以先看看我对这两部分的了解。同样,这部分操作也是可能的。html
实时数据采集,它面临一个问题。我们如何生成实时数据源?因为我们可能需要直接获取实时数据流,所以不太方便。我之前写过一篇文章文章,关于实时数据流的python生成器文章地址:
您可以看看如何生成实时数据。。。蟒蛇
思路??如何开始??nginx
分析:我们可以从数据流开始。数据在开始时位于Web服务器中。我们的访问日志由nginx服务器实时采集到指定的文件。我们从这个文件中采集日志数据,即:webserver=>;水槽=>;卡夫卡韦布
web服务器日志文件的位置
这个文件的位置通常是我们自己设置的shell
我们的web日志存储在:
/Apache在家/Hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
氟美芬
Flume实际上是编写conf文件,它面临着类型选择的问题
来源选择?频道选择?水槽选择?红宝石
这里我们选择exec源内存通道Kafka接收器服务器
怎么写
如前所述,步骤1234应用程序
从官方网站上,我们可以了解如何编写我们的车型选择:
1)configure source
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2)configure通道
存储通道
a1.channels.c1.type = memory
3)configure接收器
卡夫卡水槽
flume1.Version 6可以被引用
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
4)串上述三个组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
**让我们创建一个名为test3.conf
发布我们分析的代码:**
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们不要从这里开始。卡夫卡牵涉其中,我们必须首先部署卡夫卡
卡夫卡的部署
如何部署卡夫卡
参考官方网站,让我们先启动zookeeper进程,然后启动Kafka的服务器
步骤1:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
步骤2:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果是,这部分不是很熟悉,可以参考
步骤3:创建一个主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
步骤4:启动上一个代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
步骤5:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行上述第五步后,您将收到屏幕刷屏结果,哈哈
上面的消费者总是会刷屏幕,这仍然很有趣
此处的消费者将接收到的数据发送到屏幕
稍后,我们将介绍sparkstreaming用于为消费者实时接收数据,并且所接收的数据用于简单的数据清理,以从随机生成的日志中过滤我们需要的数据 查看全部
实时文章采集(
前面Flume和Kafka的实时数据源,怎么产生呢??)
水槽和卡夫卡完成实时数据处理采集
写在前面
Flume和Kafka通常在生产环境中一起使用。能够结合使用它们来采集实时日志信息非常重要。如果你不知道flume和Kafka,你可以先看看我对这两部分的了解。同样,这部分操作也是可能的。html
实时数据采集,它面临一个问题。我们如何生成实时数据源?因为我们可能需要直接获取实时数据流,所以不太方便。我之前写过一篇文章文章,关于实时数据流的python生成器文章地址:
您可以看看如何生成实时数据。。。蟒蛇
思路??如何开始??nginx
分析:我们可以从数据流开始。数据在开始时位于Web服务器中。我们的访问日志由nginx服务器实时采集到指定的文件。我们从这个文件中采集日志数据,即:webserver=>;水槽=>;卡夫卡韦布
web服务器日志文件的位置
这个文件的位置通常是我们自己设置的shell
我们的web日志存储在:
/Apache在家/Hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
氟美芬
Flume实际上是编写conf文件,它面临着类型选择的问题
来源选择?频道选择?水槽选择?红宝石
这里我们选择exec源内存通道Kafka接收器服务器
怎么写
如前所述,步骤1234应用程序
从官方网站上,我们可以了解如何编写我们的车型选择:
1)configure source
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2)configure通道
存储通道
a1.channels.c1.type = memory
3)configure接收器
卡夫卡水槽
flume1.Version 6可以被引用
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
4)串上述三个组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
**让我们创建一个名为test3.conf
发布我们分析的代码:**
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们不要从这里开始。卡夫卡牵涉其中,我们必须首先部署卡夫卡
卡夫卡的部署
如何部署卡夫卡
参考官方网站,让我们先启动zookeeper进程,然后启动Kafka的服务器
步骤1:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
步骤2:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果是,这部分不是很熟悉,可以参考
步骤3:创建一个主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
步骤4:启动上一个代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
步骤5:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行上述第五步后,您将收到屏幕刷屏结果,哈哈
上面的消费者总是会刷屏幕,这仍然很有趣
此处的消费者将接收到的数据发送到屏幕
稍后,我们将介绍sparkstreaming用于为消费者实时接收数据,并且所接收的数据用于简单的数据清理,以从随机生成的日志中过滤我们需要的数据
实时文章采集(本文从三个方面讲了如何做用户画像分析——收集数据、行为建模、构建画像 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-09-15 18:14
)
本文从数据采集、行为建模和图像构建三个方面讨论了如何进行用户肖像分析
用户肖像是根据用户特征、业务场景和用户行为建立一个有标签的用户模型。简言之,用户肖像是对典型用户信息的标注
在金融领域,建立用户肖像变得非常重要。例如,金融公司将使用用户肖像,并采用垂直或精确营销来了解客户、挖掘潜在客户、找到目标客户和转化用户
以P2P公司智能投资产品的投资返现活动为例,通过建立用户肖像,避免了大量烧钱的操作行为。分析表明,贷款人a的再投资意向概率为45%,贷款人B的再投资意向概率为88%。为了提高平台的交易量,我们可以在建立用户肖像之前对贷款人a和贷款人B实施相同的投资返现奖励,但分析结果是,只需要鼓励贷款人a投资,从而节约运营成本。此外,在设计产品时,我们还可以根据用户差异化分析进行有针对性的改进
对于产品经理来说,在进行用户研究之前,必须掌握用户肖像的构建方法,即了解用户肖像的结构
一、采集数据
采集数据是用户肖像的一个非常重要的部分。用户数据来自网络,如何提取有效的数据,如开放平台产品信息、疏导渠道用户信息、采集用户实时数据等,也是产品管理者需要思考的问题
用户数据分为静态信息数据和动态信息数据。对于一般公司来说,更多的是根据系统本身的需求和用户的需求来采集相关数据
数据采集主要包括用户行为数据、用户偏好数据和用户交易数据
以跨境电商平台为例,采集用户行为数据:如活跃人数、页面浏览量、访问时间、浏览路径等;采集用户偏好数据:如登录方式、浏览内容、评论内容、互动内容、品牌偏好等;采集用户交易数据:如客户单价、退货率、周转率、转化率、激活率等,采集这些指标数据,便于用户有针对性、有目的地操作
我们可以分析采集的数据并标记用户信息。例如,建立用户账户系统,可以建立数据仓库,实现平台数据共享,也可以打通用户数据
二、行为建模
行为建模基于用户行为数据。通过对用户行为数据的分析和计算,对用户进行标注,得到用户肖像的标注模型,即建立用户肖像标注系统
标签建模主要是对原创数据进行统计、分析和预测,从而得到事实标签、模型标签和预测标签
标签建模方法来源于阿里巴巴用户肖像系统,广泛应用于搜索引擎、推荐引擎、广告、智能营销等各个应用领域
以今日头条的文章推荐机制为例,通过机器分析提取您的关键词并根据关键词标注文章并标注受众。然后,冷启动内容交付。通过智能算法推荐,内容标签与受众标签匹配,内容文章推送到对应的人,实现内容的准确分发
三、build肖像
用户肖像的内容不是完全固定的。不同的企业对用户画像有不同的理解和需求。根据不同的行业和产品,所涉及的特征也不同,但主要体现在基本特征、社会特征、偏好特征、行为特征等方面
用户肖像的核心是给用户贴标签。也就是说,将用户的每个特定信息抽象成标签,这些标签用于具体化用户形象,从而为用户提供有针对性的服务
以李二沟的家像为例,对其年龄、性别、婚姻、职位、收入、资产进行标注,通过场景描述挖掘用户的痛点,了解用户的动机。其中21~30岁年龄组最多,收入范围为20~25K。通过数据分析得到数据标签结果,最终满足业务需求,从而形成构建用户肖像的闭环
用户肖像作为勾勒目标用户、联系用户需求和设计方向的有效工具,在精准营销、用户分析、数据挖掘、数据分析等领域得到了广泛的应用
总之,用户画像的根本目的是寻找目标客户,优化产品设计,指导运营策略,分析业务场景,改进业务形式
这篇文章是原创由@朱学民发表的。每个人都是产品经理。未经作者许可,禁止转载
图片来自unsplash,基于cc0协议
奖励作者,鼓励TA加快创作速度
欣赏
1奖励
查看全部
实时文章采集(本文从三个方面讲了如何做用户画像分析——收集数据、行为建模、构建画像
)
本文从数据采集、行为建模和图像构建三个方面讨论了如何进行用户肖像分析
用户肖像是根据用户特征、业务场景和用户行为建立一个有标签的用户模型。简言之,用户肖像是对典型用户信息的标注
在金融领域,建立用户肖像变得非常重要。例如,金融公司将使用用户肖像,并采用垂直或精确营销来了解客户、挖掘潜在客户、找到目标客户和转化用户
以P2P公司智能投资产品的投资返现活动为例,通过建立用户肖像,避免了大量烧钱的操作行为。分析表明,贷款人a的再投资意向概率为45%,贷款人B的再投资意向概率为88%。为了提高平台的交易量,我们可以在建立用户肖像之前对贷款人a和贷款人B实施相同的投资返现奖励,但分析结果是,只需要鼓励贷款人a投资,从而节约运营成本。此外,在设计产品时,我们还可以根据用户差异化分析进行有针对性的改进
对于产品经理来说,在进行用户研究之前,必须掌握用户肖像的构建方法,即了解用户肖像的结构
一、采集数据
采集数据是用户肖像的一个非常重要的部分。用户数据来自网络,如何提取有效的数据,如开放平台产品信息、疏导渠道用户信息、采集用户实时数据等,也是产品管理者需要思考的问题
用户数据分为静态信息数据和动态信息数据。对于一般公司来说,更多的是根据系统本身的需求和用户的需求来采集相关数据
数据采集主要包括用户行为数据、用户偏好数据和用户交易数据
以跨境电商平台为例,采集用户行为数据:如活跃人数、页面浏览量、访问时间、浏览路径等;采集用户偏好数据:如登录方式、浏览内容、评论内容、互动内容、品牌偏好等;采集用户交易数据:如客户单价、退货率、周转率、转化率、激活率等,采集这些指标数据,便于用户有针对性、有目的地操作
我们可以分析采集的数据并标记用户信息。例如,建立用户账户系统,可以建立数据仓库,实现平台数据共享,也可以打通用户数据
二、行为建模
行为建模基于用户行为数据。通过对用户行为数据的分析和计算,对用户进行标注,得到用户肖像的标注模型,即建立用户肖像标注系统
标签建模主要是对原创数据进行统计、分析和预测,从而得到事实标签、模型标签和预测标签
标签建模方法来源于阿里巴巴用户肖像系统,广泛应用于搜索引擎、推荐引擎、广告、智能营销等各个应用领域
以今日头条的文章推荐机制为例,通过机器分析提取您的关键词并根据关键词标注文章并标注受众。然后,冷启动内容交付。通过智能算法推荐,内容标签与受众标签匹配,内容文章推送到对应的人,实现内容的准确分发
三、build肖像
用户肖像的内容不是完全固定的。不同的企业对用户画像有不同的理解和需求。根据不同的行业和产品,所涉及的特征也不同,但主要体现在基本特征、社会特征、偏好特征、行为特征等方面
用户肖像的核心是给用户贴标签。也就是说,将用户的每个特定信息抽象成标签,这些标签用于具体化用户形象,从而为用户提供有针对性的服务
以李二沟的家像为例,对其年龄、性别、婚姻、职位、收入、资产进行标注,通过场景描述挖掘用户的痛点,了解用户的动机。其中21~30岁年龄组最多,收入范围为20~25K。通过数据分析得到数据标签结果,最终满足业务需求,从而形成构建用户肖像的闭环
用户肖像作为勾勒目标用户、联系用户需求和设计方向的有效工具,在精准营销、用户分析、数据挖掘、数据分析等领域得到了广泛的应用
总之,用户画像的根本目的是寻找目标客户,优化产品设计,指导运营策略,分析业务场景,改进业务形式
这篇文章是原创由@朱学民发表的。每个人都是产品经理。未经作者许可,禁止转载
图片来自unsplash,基于cc0协议
奖励作者,鼓励TA加快创作速度
欣赏
1奖励
实时文章采集(上下页导航式是如何采集出来的?如何对比分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-14 19:11
上下页导航是采集分页的难点。它需要所有页面都符合分页规律。如果您不熟悉,我们可以使用第1页和第2页的代码进行对比分析,然后确定分页规律。
1、 下面以网站的内容分页为例:
可以看到这条新闻一共有20页。
2、查看源码:
本页除了采集已经到达的第一页外,还包括第二、三、四、五、六、七、八、二十页,但是9-19页没有列出这时候我们就用page 1和page 2的代码进行对比分析,确定分页规则:
(1)第1页代码:
(2)第2页代码:
从这两张图可以看出,它们的“页面区域起始码”、“页面链接”格式、“页面区域结束码”是相同的,那么就可以确定“页面区域规则”和“页面链接”常规”。
3、获取分页区正则([!--smallpageallzz--]):
4、获取分页链接常规([!--pageallzz--]):
5、为了方便教程展示,我在newstext中采集,而不是采集content,预览结果:
注意事项:
#一、在第一页的HTML代码中,当列出所有内容分页链接时,我们使用“list all”。在第一页的HTML代码中,当内容分页链接没有全部列出时,我们使用“上下页面导航”。
二、使用全列表公式时,采集规则是正确的,但是莫名有重复的页面,那么可以用替换的方法过滤掉(下节讲)。
三、使用下一页导航样式时,我总是选第一页,其他页面连影子都没看到。这是因为分页区正则([!--smallpagezz--])截取错误。
四、使用上下页导航样式时,可以采集跳转到前几页,但是前几页会重复循环到最后。这也是因为分页区正则([!--smallpagezz--])拦截错误,拦截范围过大,导致重复拦截前几页链接。 查看全部
实时文章采集(上下页导航式是如何采集出来的?如何对比分析)
上下页导航是采集分页的难点。它需要所有页面都符合分页规律。如果您不熟悉,我们可以使用第1页和第2页的代码进行对比分析,然后确定分页规律。
1、 下面以网站的内容分页为例:
可以看到这条新闻一共有20页。
2、查看源码:
本页除了采集已经到达的第一页外,还包括第二、三、四、五、六、七、八、二十页,但是9-19页没有列出这时候我们就用page 1和page 2的代码进行对比分析,确定分页规则:
(1)第1页代码:
(2)第2页代码:
从这两张图可以看出,它们的“页面区域起始码”、“页面链接”格式、“页面区域结束码”是相同的,那么就可以确定“页面区域规则”和“页面链接”常规”。
3、获取分页区正则([!--smallpageallzz--]):
4、获取分页链接常规([!--pageallzz--]):
5、为了方便教程展示,我在newstext中采集,而不是采集content,预览结果:
注意事项:
#一、在第一页的HTML代码中,当列出所有内容分页链接时,我们使用“list all”。在第一页的HTML代码中,当内容分页链接没有全部列出时,我们使用“上下页面导航”。
二、使用全列表公式时,采集规则是正确的,但是莫名有重复的页面,那么可以用替换的方法过滤掉(下节讲)。
三、使用下一页导航样式时,我总是选第一页,其他页面连影子都没看到。这是因为分页区正则([!--smallpagezz--])截取错误。
四、使用上下页导航样式时,可以采集跳转到前几页,但是前几页会重复循环到最后。这也是因为分页区正则([!--smallpagezz--])拦截错误,拦截范围过大,导致重复拦截前几页链接。
实时文章采集(网站/app的哪个页面的哪些操作发生时,可以跟我们之前的离线日志收集流程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-13 02:18
第 1 步:
数据源:例如网站 或应用程序。很重要的一点就是埋点。换句话说,埋点,网站/app的哪个页面上发生了哪些操作,前端代码(网站,JavaScript;app,android/IOS)通过网络(Ajax;socket)请求), 将指定格式的日志数据发送到后端服务器。
第 2 步:
Nginx、后端web服务器(Tomcat、Jetty等)、后端系统(J2EE、PHP)。到此为止,其实还是可以和我们之前的离线日志采集流程一样的。通过一个日志传输工具到后面,放到指定的文件夹中。
连接线(水槽,监控指定文件夹)
第三步:
1、HDFS
2、实时数据通常是从分布式消息队列集群中读取的,比如Kafka;实时数据、实时日志,并实时写入消息队列,如Kafka;然后,通过我们的后端实时数据处理程序(Storm、Spark Streaming)从Kafka实时读取数据并记录日志。然后进行实时计算和处理。卡夫卡
(Kafka,我们的日志数据怎么处理就看你了。你可以每天采集一份,放到flume中,转入HDFS,清理,放到Hive中,搭建离线数据仓库。你也可以每1分钟采集一次数据,或者每采集到一点点数据,放到一个文件中然后传输到flume,或者直接通过API自定义,直接将日志一一输入flume,可以配置flume将数据写入 Kafka )
连接线(实时,主动从Kafka拉取数据)
第四步:
大数据实时计算系统,如使用Storm和Spark Streaming开发的系统,可以实时从Kafka拉取数据,然后对实时数据进行处理和计算,其中大量复杂的业务逻辑可以封装甚至称为复杂的机器学习、数据挖掘和智能推荐算法,进而实现车辆实时调度、实时推荐、广告流量实时统计。 查看全部
实时文章采集(网站/app的哪个页面的哪些操作发生时,可以跟我们之前的离线日志收集流程)
第 1 步:
数据源:例如网站 或应用程序。很重要的一点就是埋点。换句话说,埋点,网站/app的哪个页面上发生了哪些操作,前端代码(网站,JavaScript;app,android/IOS)通过网络(Ajax;socket)请求), 将指定格式的日志数据发送到后端服务器。
第 2 步:
Nginx、后端web服务器(Tomcat、Jetty等)、后端系统(J2EE、PHP)。到此为止,其实还是可以和我们之前的离线日志采集流程一样的。通过一个日志传输工具到后面,放到指定的文件夹中。
连接线(水槽,监控指定文件夹)
第三步:
1、HDFS
2、实时数据通常是从分布式消息队列集群中读取的,比如Kafka;实时数据、实时日志,并实时写入消息队列,如Kafka;然后,通过我们的后端实时数据处理程序(Storm、Spark Streaming)从Kafka实时读取数据并记录日志。然后进行实时计算和处理。卡夫卡
(Kafka,我们的日志数据怎么处理就看你了。你可以每天采集一份,放到flume中,转入HDFS,清理,放到Hive中,搭建离线数据仓库。你也可以每1分钟采集一次数据,或者每采集到一点点数据,放到一个文件中然后传输到flume,或者直接通过API自定义,直接将日志一一输入flume,可以配置flume将数据写入 Kafka )
连接线(实时,主动从Kafka拉取数据)
第四步:
大数据实时计算系统,如使用Storm和Spark Streaming开发的系统,可以实时从Kafka拉取数据,然后对实时数据进行处理和计算,其中大量复杂的业务逻辑可以封装甚至称为复杂的机器学习、数据挖掘和智能推荐算法,进而实现车辆实时调度、实时推荐、广告流量实时统计。
实时文章采集(实际运行开发phantomjs的入门搭建:phantomjs基本结构配置详解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-12 17:01
实时文章采集,包括文章的标题、作者、摘要、关键词、网站链接等,并可以在提交的时候做简单的预览,这样就可以即时预览或者了解效果,相信这是很多人所关心的事情,更加简单的实时采集使用phantomjs来代替nodejs+urllib3,下面对它做一个简单的介绍。1.准备工作webpack配置指南:phantomjs配置指南2.安装npminstallphantomjs基本结构配置详解:phantomjs基本知识,使用前我们需要知道这些!3.实际运行开发phantomjs的入门搭建:phantomjs入门,这就够了下载地址:-stable.zip(请下载最新版本)把它下载到电脑上进行安装,放在根目录,同时要设置path环境变量,在python的python路径下使用phantomjs运行js和css文件等,其他的dll,js等放在你已经准备好的文件夹中,通过phantomjs开发web应用,网站前端页面一般是springboot,使用非常简单,也可以使用ssm开发的模式。学习全过程的话,一个月左右,也就是能完整实践一个项目。更多模块,文章更新的内容和教程参考:。
配置好nodejs和phantomjs之后,你可以根据这个官方文档搭建一个web前端开发环境(ubuntu,windows系统为例)编译:-specifications运行:/~gohlke/pythonlibs/#phantomjsmain程序的基本配置文件:-specifications具体可以看这里:。 查看全部
实时文章采集(实际运行开发phantomjs的入门搭建:phantomjs基本结构配置详解)
实时文章采集,包括文章的标题、作者、摘要、关键词、网站链接等,并可以在提交的时候做简单的预览,这样就可以即时预览或者了解效果,相信这是很多人所关心的事情,更加简单的实时采集使用phantomjs来代替nodejs+urllib3,下面对它做一个简单的介绍。1.准备工作webpack配置指南:phantomjs配置指南2.安装npminstallphantomjs基本结构配置详解:phantomjs基本知识,使用前我们需要知道这些!3.实际运行开发phantomjs的入门搭建:phantomjs入门,这就够了下载地址:-stable.zip(请下载最新版本)把它下载到电脑上进行安装,放在根目录,同时要设置path环境变量,在python的python路径下使用phantomjs运行js和css文件等,其他的dll,js等放在你已经准备好的文件夹中,通过phantomjs开发web应用,网站前端页面一般是springboot,使用非常简单,也可以使用ssm开发的模式。学习全过程的话,一个月左右,也就是能完整实践一个项目。更多模块,文章更新的内容和教程参考:。
配置好nodejs和phantomjs之后,你可以根据这个官方文档搭建一个web前端开发环境(ubuntu,windows系统为例)编译:-specifications运行:/~gohlke/pythonlibs/#phantomjsmain程序的基本配置文件:-specifications具体可以看这里:。
实时文章采集(实时热点采集软件操作简单易操作,快速获取热点文章 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2021-09-11 11:11
)
<p>实时hotspot采集software,又称SEO内容神器,是一款非常方便易用的热点文章采集工具,这款实时hotspot采集software功能强大,全面,简单易操作,使用后采集热热文章可以帮助用户更轻松方便。大家都知道编辑热门的文章@流量比较大,所以拿到关键词很重要。如果不知道关键词hots是哪个,可以通过这个软件查询,它最大的特点就是实时采集,非常适合网站编辑使用,抢占热点带来流量到网站,软件提供热搜采集功能,可以立即在百度搜索关键词上查询热搜,可以快速获取搜狗热搜关键词,还可以保存关键词采集到TXT文件,采集可以根据相关关键词编辑文章,也可以直接寻址文章采集,在软件中选择原标题采集,即可把热搜的文章采集作为TXT文本,方便阅读原文,非常适合自媒体运营的朋友使用,有需要的朋友可以下载体验。 查看全部
实时文章采集(实时热点采集软件操作简单易操作,快速获取热点文章
)
<p>实时hotspot采集software,又称SEO内容神器,是一款非常方便易用的热点文章采集工具,这款实时hotspot采集software功能强大,全面,简单易操作,使用后采集热热文章可以帮助用户更轻松方便。大家都知道编辑热门的文章@流量比较大,所以拿到关键词很重要。如果不知道关键词hots是哪个,可以通过这个软件查询,它最大的特点就是实时采集,非常适合网站编辑使用,抢占热点带来流量到网站,软件提供热搜采集功能,可以立即在百度搜索关键词上查询热搜,可以快速获取搜狗热搜关键词,还可以保存关键词采集到TXT文件,采集可以根据相关关键词编辑文章,也可以直接寻址文章采集,在软件中选择原标题采集,即可把热搜的文章采集作为TXT文本,方便阅读原文,非常适合自媒体运营的朋友使用,有需要的朋友可以下载体验。
实时文章采集(phpmyadmin工具集体系http安装phpmyadmin代理shell基于windows平台有一个插件叫做phpmyadmin)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-08 14:02
实时文章采集功能已经开发出来,并上线,欢迎大家采用,可以给我评论,有更好的建议和方案也可以私信我,谢谢!目前开发网站基于swoole,开发有一些hook需要修改,目前需要epoll,这个功能还有待完善!此外,此版本的社区文章会根据大家的反馈,不断的完善完善再完善,您的关注是我更新的动力,谢谢。后面我会对异步处理增加进度采集方法,另外通过率也会提高一些。目前设计的比较简单,不在添加复杂的技术实现。完整的代码欢迎找我玩,私信无回复算我输。
iptables--auto-cert=true,点击配置项,
tcpqcached服务
谢谢邀请。手头上项目都没有跑起来,
现在开发部分是在windows64平台下面,如果您用linux平台,
除了svn,git分支备份,为了告诉你,里面还有个梯子的代码。
http隧道;ddos;读写共享的文件系统
欢迎尝试phpmyadmin工具集体系
http
安装phpmyadmin代理
shell
基于windows平台有一个插件叫做phpmyadmin,对公司上网账号管理和追踪做了很好的支持。插件下载地址:phpmyadmin,
phpmyadmin,hmr,用户分类和统计的方法, 查看全部
实时文章采集(phpmyadmin工具集体系http安装phpmyadmin代理shell基于windows平台有一个插件叫做phpmyadmin)
实时文章采集功能已经开发出来,并上线,欢迎大家采用,可以给我评论,有更好的建议和方案也可以私信我,谢谢!目前开发网站基于swoole,开发有一些hook需要修改,目前需要epoll,这个功能还有待完善!此外,此版本的社区文章会根据大家的反馈,不断的完善完善再完善,您的关注是我更新的动力,谢谢。后面我会对异步处理增加进度采集方法,另外通过率也会提高一些。目前设计的比较简单,不在添加复杂的技术实现。完整的代码欢迎找我玩,私信无回复算我输。
iptables--auto-cert=true,点击配置项,
tcpqcached服务
谢谢邀请。手头上项目都没有跑起来,
现在开发部分是在windows64平台下面,如果您用linux平台,
除了svn,git分支备份,为了告诉你,里面还有个梯子的代码。
http隧道;ddos;读写共享的文件系统
欢迎尝试phpmyadmin工具集体系
http
安装phpmyadmin代理
shell
基于windows平台有一个插件叫做phpmyadmin,对公司上网账号管理和追踪做了很好的支持。插件下载地址:phpmyadmin,
phpmyadmin,hmr,用户分类和统计的方法,
实时文章采集(百度蜘蛛对于原创源址的判断还无法做到精准的地步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-08 02:24
百度蜘蛛喜欢原创的东西,但百度蜘蛛对原创源位置的判断尚不准确,不能完全自主判断文章某篇文章。它的出发点是Where,当我们更新一个文章,并迅速得到另一个采集时,蜘蛛可能同时接触了很多相同的文章,那么它会很困惑,到底哪个是原创,哪个被复制了也不清楚。所以,当我们的网站长期处于采集的状态时,我们在网站上更新的文章大部分在网上的内容都是一样的,如果网站权重为不够高,那么蜘蛛很可能把你的网站列为采集站,它认为你网站的文章是来自互联网的采集,而不是互联网上的其他站采集你的文章。
当蜘蛛这样对待你的网站时,你网站可能会遇到几种情况:
先文章页停止收录,然后整个网站不收录
这肯定会发生,因为百度被误判为采集站,所以你的文章页面肯定会被百度列为审核期,在此期间文章页肯定会停止收录' s。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面会逐渐开始不是收录。作者的网站半个月没有收录的页面了,原因就是因为这个。
网站收录开始减少,快照停滞
如前所述,百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上类似的页面。百度会不考虑你就减少这些页面。 收录,所以很多人发现网站STOP收录之后,慢慢造成网站整个收录的减少,这就是原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
排名没有波动,流量正常
当收录减少,快照停滞时,我们最担心的是排名问题,担心排名会受到影响。这点你可以放心,因为文章被采集导致他的网站被百度评价了。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。
改进后网站收录还是有异常
假设我们发现自己网站被采集,我们对网站做了一些改进,成功避开了网站被采集,那么你的网站就会有一段适应期,表现出来的症状整个适应期是:网站逐渐开始收录文章页面,但收录不是即时更新文章,可能是前天或前天更新。这种现象会持续一周左右,之后收录会逐渐恢复正常,快照会慢慢恢复。
网站长期被别人采集会出现这一系列的现象,所以当你自己的网站有这样的现象时,你首先要找出原因是文章被别人文章每天更新采集。
如果你的网站确实是这种情况,你一定要想办法解决。当然别人要采集你的文章,你不能强迫别人说采集,所以我们能做的就是对自己做一些改变。适合所有人的武器:
1、提高页面权重
提高页面的权重可以从根本上解决这个问题。多做这个页面的外部链接。
2、Rss 合理使用
开发这样的功能也是很有必要的。当网站文章更新时,第一时间让搜索引擎知道,主动攻击。这对收录 非常有帮助。而且Rss还可以有效增加网站的流量,可以说是一石二鸟。
3、做一些细节和限制机器采集
手动采集 没什么。如果没有人用工具来计时和一大堆采集你网站的文章,这真的很头疼,所以我们应该对页面的细节做一些处理,至少可以防止机器的采集。例如,页面设计不应过于传统和流行; Url的书写风格要稍微改变一下,不要变成默认的叠加等设置。
当4、为采集时,更新后的文章More与我自己网站有关
其他采集我们的文章,因为他们也需要我们更新内容,所以如果我们更新与我们网站相关的信息,我们会经常穿插我们的网站名字,其他人的时候采集,你会觉得我们的文章对他们来说意义不大。这也是避免采集的一个很好的方法。 查看全部
实时文章采集(百度蜘蛛对于原创源址的判断还无法做到精准的地步)
百度蜘蛛喜欢原创的东西,但百度蜘蛛对原创源位置的判断尚不准确,不能完全自主判断文章某篇文章。它的出发点是Where,当我们更新一个文章,并迅速得到另一个采集时,蜘蛛可能同时接触了很多相同的文章,那么它会很困惑,到底哪个是原创,哪个被复制了也不清楚。所以,当我们的网站长期处于采集的状态时,我们在网站上更新的文章大部分在网上的内容都是一样的,如果网站权重为不够高,那么蜘蛛很可能把你的网站列为采集站,它认为你网站的文章是来自互联网的采集,而不是互联网上的其他站采集你的文章。
当蜘蛛这样对待你的网站时,你网站可能会遇到几种情况:
先文章页停止收录,然后整个网站不收录
这肯定会发生,因为百度被误判为采集站,所以你的文章页面肯定会被百度列为审核期,在此期间文章页肯定会停止收录' s。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面会逐渐开始不是收录。作者的网站半个月没有收录的页面了,原因就是因为这个。
网站收录开始减少,快照停滞
如前所述,百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上类似的页面。百度会不考虑你就减少这些页面。 收录,所以很多人发现网站STOP收录之后,慢慢造成网站整个收录的减少,这就是原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
排名没有波动,流量正常
当收录减少,快照停滞时,我们最担心的是排名问题,担心排名会受到影响。这点你可以放心,因为文章被采集导致他的网站被百度评价了。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。
改进后网站收录还是有异常
假设我们发现自己网站被采集,我们对网站做了一些改进,成功避开了网站被采集,那么你的网站就会有一段适应期,表现出来的症状整个适应期是:网站逐渐开始收录文章页面,但收录不是即时更新文章,可能是前天或前天更新。这种现象会持续一周左右,之后收录会逐渐恢复正常,快照会慢慢恢复。
网站长期被别人采集会出现这一系列的现象,所以当你自己的网站有这样的现象时,你首先要找出原因是文章被别人文章每天更新采集。
如果你的网站确实是这种情况,你一定要想办法解决。当然别人要采集你的文章,你不能强迫别人说采集,所以我们能做的就是对自己做一些改变。适合所有人的武器:
1、提高页面权重
提高页面的权重可以从根本上解决这个问题。多做这个页面的外部链接。
2、Rss 合理使用
开发这样的功能也是很有必要的。当网站文章更新时,第一时间让搜索引擎知道,主动攻击。这对收录 非常有帮助。而且Rss还可以有效增加网站的流量,可以说是一石二鸟。
3、做一些细节和限制机器采集
手动采集 没什么。如果没有人用工具来计时和一大堆采集你网站的文章,这真的很头疼,所以我们应该对页面的细节做一些处理,至少可以防止机器的采集。例如,页面设计不应过于传统和流行; Url的书写风格要稍微改变一下,不要变成默认的叠加等设置。
当4、为采集时,更新后的文章More与我自己网站有关
其他采集我们的文章,因为他们也需要我们更新内容,所以如果我们更新与我们网站相关的信息,我们会经常穿插我们的网站名字,其他人的时候采集,你会觉得我们的文章对他们来说意义不大。这也是避免采集的一个很好的方法。
实时文章采集(实时文章采集,文章被采用情况、审核速度等数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-07 15:03
实时文章采集,文章被采用情况、审核通过率、审核速度等数据尽在开发工具forkvirtual,每天自动采集1000篇文章,审核只需5分钟,点击详情,
如果是单纯的写文章,推荐大家试一下滴滴问答,可以写一个小的博客,然后实时共享,内容丰富,还能得到热心用户的鼓励。
美团中看网-社会化内容采集系统,
口袋采集器直接用你最常用的小工具就能实现这样的目的
目前已知的:百度文库、豆丁、道客巴巴、威锋网等。
利用长尾关键词实现回复量的相应提升。
几乎有关注度的网站都能投稿啊我只能告诉你有关键词基本上是没有门槛的..
知乎,
使用信息太少,
还是有很多有趣的网站的
我们公司收到最多的就是恶搞类的文章,大的小的都有,可以尝试用一些技术手段把这些文章改变一下内容,比如把一些冷门知识移植进去之类的~
知乎太冷清
也不说大数据或者开源技术,具体分析内容,光是检索这一块,如果你用谷歌/百度搜索的话,一般可以按照兴趣排序。如果能够建立一个爬虫系统把知乎用户分析一下,再投入到其他产品,我觉得是相当有意义的事情。 查看全部
实时文章采集(实时文章采集,文章被采用情况、审核速度等数据)
实时文章采集,文章被采用情况、审核通过率、审核速度等数据尽在开发工具forkvirtual,每天自动采集1000篇文章,审核只需5分钟,点击详情,
如果是单纯的写文章,推荐大家试一下滴滴问答,可以写一个小的博客,然后实时共享,内容丰富,还能得到热心用户的鼓励。
美团中看网-社会化内容采集系统,
口袋采集器直接用你最常用的小工具就能实现这样的目的
目前已知的:百度文库、豆丁、道客巴巴、威锋网等。
利用长尾关键词实现回复量的相应提升。
几乎有关注度的网站都能投稿啊我只能告诉你有关键词基本上是没有门槛的..
知乎,
使用信息太少,
还是有很多有趣的网站的
我们公司收到最多的就是恶搞类的文章,大的小的都有,可以尝试用一些技术手段把这些文章改变一下内容,比如把一些冷门知识移植进去之类的~
知乎太冷清
也不说大数据或者开源技术,具体分析内容,光是检索这一块,如果你用谷歌/百度搜索的话,一般可以按照兴趣排序。如果能够建立一个爬虫系统把知乎用户分析一下,再投入到其他产品,我觉得是相当有意义的事情。

