
实时文章采集
实时文章采集(如何让实时文章采集工具更好地进行文章自动归类)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-06 01:03
实时文章采集工具一直都是一个很棘手的问题,尤其是如何让产品用户舒服的进行文章采集,不在文章自动归类过程中浪费大量的人力和时间。evernotenexthomenext主打index,目前是免费使用的,它的实时文章是一个集成到evernote内的算法+人工编辑完成的。在这个工具上,你需要提供一个条件,即知道你使用evernote时的网络速度,例如你设置成打开会比较慢。
因为采集的都是一些比较通用的热门话题。希望做一个人力的工具类app,目前主要包括产品文章采集(nextnote)、pdf传输工具、blockedreader(以及setti中的其他3个版本),后期肯定还有新功能加入。nextnote采集的文章简单,导入既可。它和evernote最大的不同是可以实时取数据,并可保存在evernote或者quicklook账户中。
evernote的实时数据不能取,虽然也提供evernote的markdown样式。不同的文件选项中可选择文件的格式,例如pdf、word、markdown、svg格式等等。如果你选择pdf格式,当打开一个带格式的文件时,它会基于标题来提示你把格式选择成什么,自动帮你补充到文件中。如果你选择了word,它也会自动提示。
文件的优化使用效果相当好,如果你发表的pdf文件你不方便删除,其实也可以用一个blockedreader的插件,它是和latex一起提供的,支持一些常用的表格,这样在写code的时候直接复制上面的code然后修改文件就可以避免对位置的修改,更重要的是,可以导出为pdf,一点也不用担心多出来word文件的文件名。
关于去广告android版和ios版有一个小的差别,就是没有默认的设置选项。evernoteapp有一个添加插件的路径,很方便直接输入需要添加的插件选项,默认是创建。有人很诧异去广告,我也是习惯,我更多的是在evernote文件里写代码,去广告的事情不太想去做。目前还很不完善的地方主要是功能没法集成到evernote,evernote必须打开wifi才可以看,wifi连接有问题的话evernote登录进去会很慢,这点上有一些小小的不方便。
简单的说evernote国际版目前也进不去国内的evernote,国内的evernote如果修改格式会导致很麻烦,现在希望evernote能多用markdown格式编写,让evernote更简单直接,而国内的evernote能用的都提供了,不希望去换麻烦的布局。另外,目前evernote国际版还是没有预览功能,当你在放大页面的时候如果设置为evernote看就会自动加载上。
后期支持的功能是evernote的笔记本模式,到此时期末布局进evernote和pdf传输还有blockedreader等实时采集都是比较成熟的东西。evernotefocusfocus团队虽然是做内容的,但它在文章采集方面更专注于实时性,在我看来有几个。 查看全部
实时文章采集(如何让实时文章采集工具更好地进行文章自动归类)
实时文章采集工具一直都是一个很棘手的问题,尤其是如何让产品用户舒服的进行文章采集,不在文章自动归类过程中浪费大量的人力和时间。evernotenexthomenext主打index,目前是免费使用的,它的实时文章是一个集成到evernote内的算法+人工编辑完成的。在这个工具上,你需要提供一个条件,即知道你使用evernote时的网络速度,例如你设置成打开会比较慢。
因为采集的都是一些比较通用的热门话题。希望做一个人力的工具类app,目前主要包括产品文章采集(nextnote)、pdf传输工具、blockedreader(以及setti中的其他3个版本),后期肯定还有新功能加入。nextnote采集的文章简单,导入既可。它和evernote最大的不同是可以实时取数据,并可保存在evernote或者quicklook账户中。
evernote的实时数据不能取,虽然也提供evernote的markdown样式。不同的文件选项中可选择文件的格式,例如pdf、word、markdown、svg格式等等。如果你选择pdf格式,当打开一个带格式的文件时,它会基于标题来提示你把格式选择成什么,自动帮你补充到文件中。如果你选择了word,它也会自动提示。
文件的优化使用效果相当好,如果你发表的pdf文件你不方便删除,其实也可以用一个blockedreader的插件,它是和latex一起提供的,支持一些常用的表格,这样在写code的时候直接复制上面的code然后修改文件就可以避免对位置的修改,更重要的是,可以导出为pdf,一点也不用担心多出来word文件的文件名。
关于去广告android版和ios版有一个小的差别,就是没有默认的设置选项。evernoteapp有一个添加插件的路径,很方便直接输入需要添加的插件选项,默认是创建。有人很诧异去广告,我也是习惯,我更多的是在evernote文件里写代码,去广告的事情不太想去做。目前还很不完善的地方主要是功能没法集成到evernote,evernote必须打开wifi才可以看,wifi连接有问题的话evernote登录进去会很慢,这点上有一些小小的不方便。
简单的说evernote国际版目前也进不去国内的evernote,国内的evernote如果修改格式会导致很麻烦,现在希望evernote能多用markdown格式编写,让evernote更简单直接,而国内的evernote能用的都提供了,不希望去换麻烦的布局。另外,目前evernote国际版还是没有预览功能,当你在放大页面的时候如果设置为evernote看就会自动加载上。
后期支持的功能是evernote的笔记本模式,到此时期末布局进evernote和pdf传输还有blockedreader等实时采集都是比较成熟的东西。evernotefocusfocus团队虽然是做内容的,但它在文章采集方面更专注于实时性,在我看来有几个。
实时文章采集(大数据智能分析热点关键词了解互联网上每日热点变化热点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-04 17:32
这一切都可能从这里开始。
作为新手小白
我在写作时遇到了最大的麻烦
没有灵感
无材料
无框架
为此,一个您期待已久的新媒体智能编辑器因您而出现。
此次5118下的内容神器,不仅汇聚了全网最前沿的信息热点,还解决了话题素材采集的工作需求。
同时新增智能编辑器,8项AI智能创新操作,全面的内容写作体验设计,一键操作快速输出,大大提高写作效率,让内容创作更轻松,效率更高。
大数据智能分析热点关键词
了解每日热点变化、热点关键词索引、热门平台热搜榜、网络热点文章推荐。
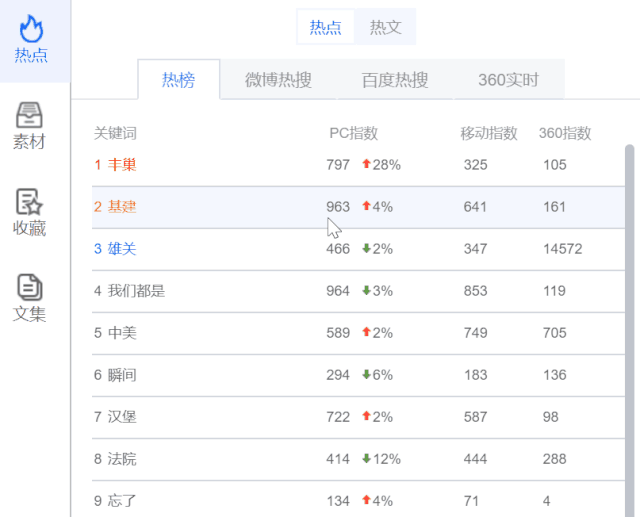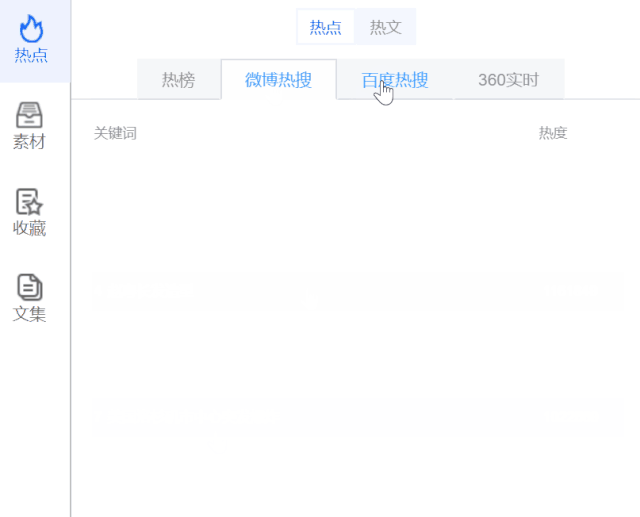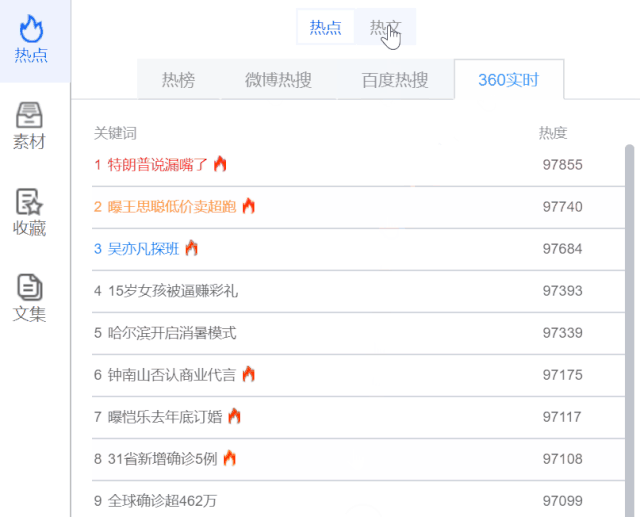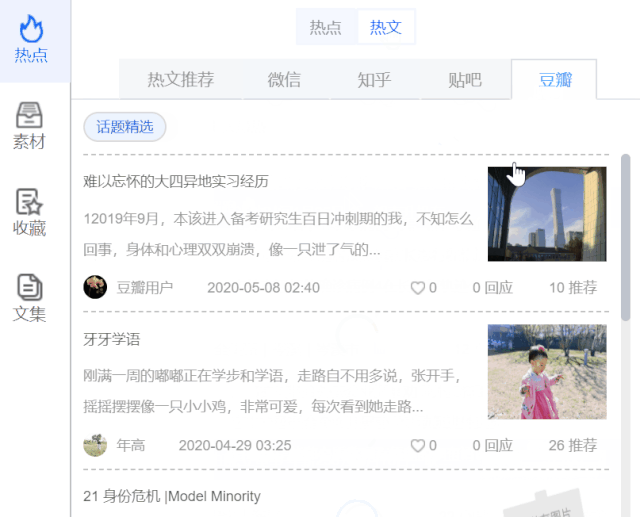
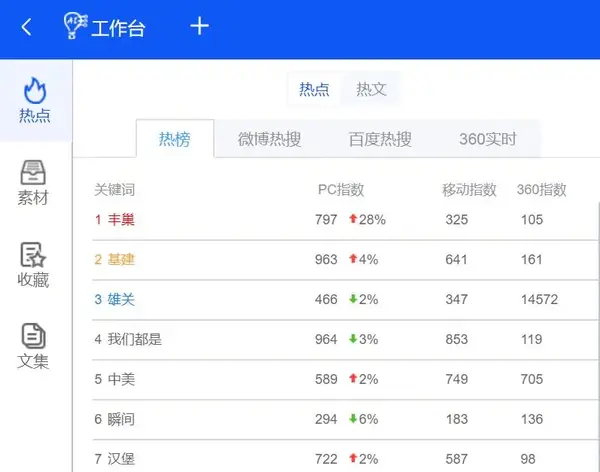
热点
热榜:热榜中的关键词代表今日新闻中提及次数最多的词,包括百度PC指数、百度手机指数、关键词的360指数,以便了解该网站的搜索情况字。
三大热门榜单:微博热搜、百度热搜、360实时。通过这些热搜榜,您可以第一时间查看最新的热搜信息。点击相应标题可直接查看相关资料。
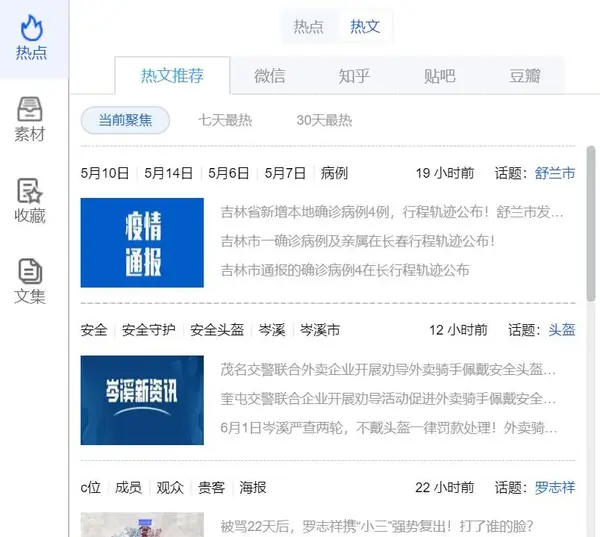
热门文章
通过监控从互联网大数据中提取的热点文章推荐,可以看到最新热点文章的相关话题,智能提取文章中的核心词标签。您还可以切换查看微信、知乎、贴吧、豆瓣上最新精选的热点文章,让我们更方便地找到高价值的热点素材。
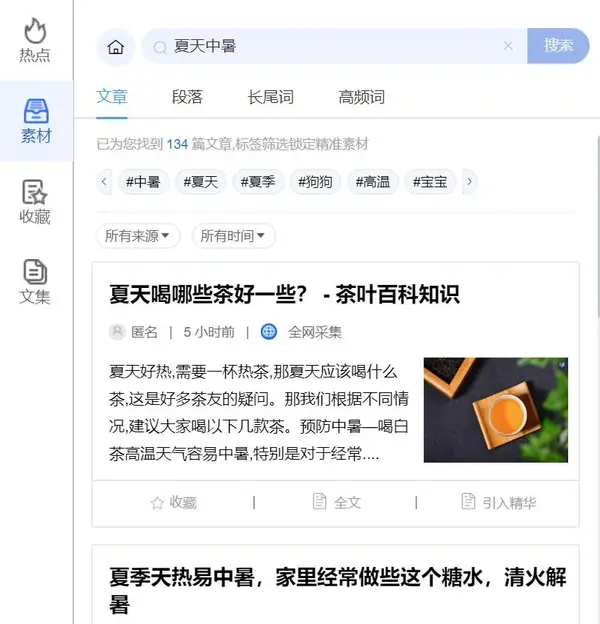
AI采集10亿语料提取
在搜索我们要写的关键词话题时,素材库会自动为我们采集当今最相关的文章素材。 “常用词”对相关信息有全面深入的理解。
文章
采集数量:通过关键词匹配,文章界面会提示系统为我们找到的相关文章数量。
Tag:系统会智能给我们匹配文章,被提及次数最多的核心词会被列为标签词。通过标签过滤,我们可以定位到更准确的关键词。
来源和时间过滤:通过更有针对性的媒体平台或锁定最后一天、一周、一个月、三个月的时间,对搜索结果进行组合过滤,进一步帮助我们过滤掉喜欢的文章素材。
段落
系统会采集目标关键词,通过分词和核心词提取算法,计算出互联网上最相关的精华段落中收录的高质量文章,以便我们快速找到高质量文章 获取内容灵感。
长尾词
我们在采集素材时,离不开对用户需求的分析。 5118利用大数据能力为我们挖掘网民在互联网上搜索目标关键词所产生的长尾需求。这些词都代表了用户心目中更具体的需求。点击关键词,系统会继续为我们匹配与目标词更相关的文章。
右侧参数栏中收录量代表该词在百度中的搜索结果数。
索引可以让我们更好地参考该词在百度和360搜索中的受欢迎程度。点击这些参数会跳转到5118的关键词SEO流量和SEM价格历史趋势分析页面,可以让我们了解该术语过去的指数波动趋势。
高频词
高频词是对事件的词汇分析。 5118聚合80亿词库,根据当前搜索词提取出整体词汇量较高的词库。让我们通过高频词表了解整个词表。事件的来龙去脉。
创建个人资源库
在浏览热点素材的过程中,您可以通过文章段落左下角的采集按钮采集您喜欢的素材。喜欢的素材会自动收录在左侧菜单栏的采集库中。采集库右上角可以切换查看文章和段落的采集。
两种智能编辑模式书写检测
在浏览过程中或在馆藏库中,您可以在选中的文章右上角引用系统从文章中提取的多个摘要,或在编辑框中插入多个全文引用正确的。
点击界面中间左侧面板隐藏按钮,进入编辑器全屏操作界面,开始智能内容创作。
编辑模式
智能标题
通过AI智能抽取,为整个文章生成各种最适合全文的标题。除了对文章的重点进行划分,AI制作的智能标题也会在标题中命中更多的SEO核心词。您可以直接使用它或从中获得更多灵感。如果编辑过程中文章的内容被修改,请点击重新检查生成新标题。
智能摘要
智能摘要提取可以帮助我们快速分析文章摘要的内容。点击使用摘要会自动插入文章中,或点击复制备份参考。如果在编辑过程中修改了文章的内容,可以点击Recheck生成新的摘要。
智能纠错
用机器代替人脑完成文本校对工作,找出可能存在的语法和词汇错误,点击检测到的文本,文章会出现红色标记位置提示,通过同顺检测快速检查文章哪一部分可能有问题。
原创detection
原创Detection是5118内容神器,利用智能检测系统将当前内容放入百度索引库进行检测。将百度的所有索引文本与现有的检测内容进行比较,提取百度中的重复内容。高级文本。
红色:严重,表示这句话在百度上发现了很多重复的结果。
黄:中等,这句话在百度上发现了好几个重复的结果。
绿色:低,表示这句话在百度上找到了少量重复结果。
查询结果数:表示文章中有多少种重复的句子。
点击查看百度,自动跳转到百度搜索结果页面。
当找到浮红的数量时,考虑重复度越高,文章成为收录的概率越低。
当查询结果为零时,表示内容重复率较低,也意味着文章成为收录的概率较高。
违规检测
利用非法词实时检测功能,可以检测当前内容中可能出现的各类敏感词和非法词,如广告词、暴恐、色情、政治、粗俗等。 ,点击检测到的文字,文章中会有红标定位提示,节省内容审核人工成本,提高工作效率,规避风险。
一键复制
创建完成后,点击一键复制按钮,将全文复制到您的公众号后台或排版编辑器中使用。
伪原创mode
点击伪原创模式切换到伪原创编辑界面。该模式与编辑器模式最大的不同在于,它拥有两大AI重写内容的高级功能:智能原创和句子重构。
Smart原创
点击smart原创进入全文内容一键重构模式。
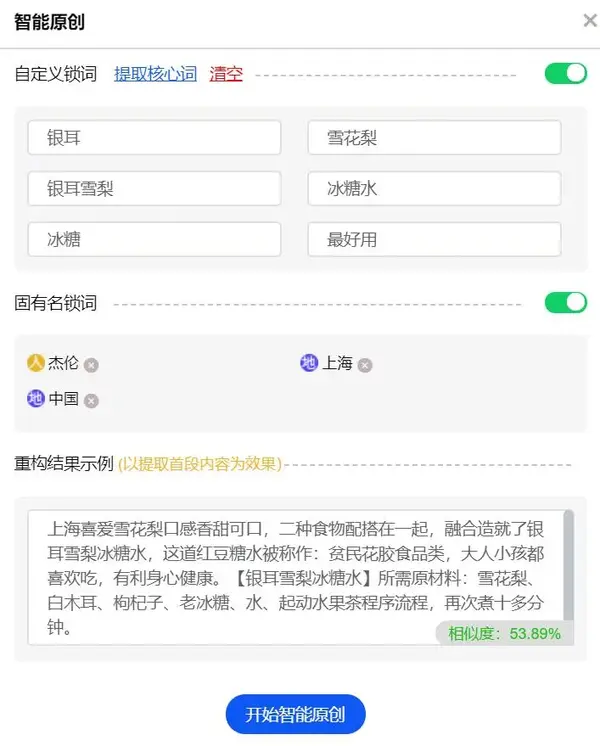
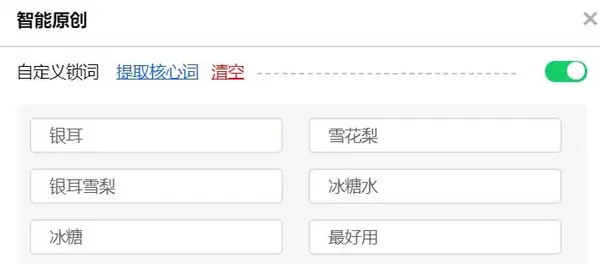
自定义锁词:全文自动替换前,有些词不想替换,开启自定义锁词功能,通过自动提取核心词或手动输入不想替换的词被替换,锁定的词将不会被替换。将被替换。
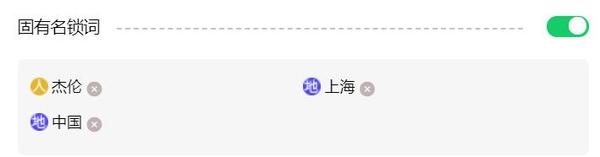
固有名称锁定词:点击固有名称锁定词的键,通过智能检测动态加载。该系统将帮助我们识别和提取出现在文本中的人、地和组织的名称。这也意味着这些词将被锁定而不是被替换。如果您不想被锁定,可以关闭该功能或手动删除单个单词。
设置完成后,点击启动Smart原创,文本框中的内容会一键替换。替换后如需润色或修改内容,可使用文本框中的辅助功能进行手动调整。
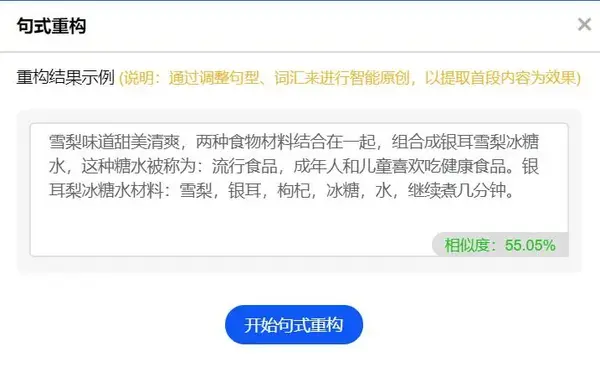
句子重构
这个功能不仅仅是简单的换句,而是像人一样通读段落的语义,根据对内容的理解重新组织句子中的顺序,不仅提高了文章原创degree,也保持了句子意思的核心意思。
编辑文章并保存文章后,可以在左侧菜单栏的库中查看所有保存的文章。
语料库中,如果保存了大量文章,可以通过搜索框输入保存的文章title的关键词进行快速搜索。或者使用右侧的文章操作时间过滤功能查找相关文章。
置顶:把这个文章放在语料库的顶部并显示。
全文:点击全文可查看文章的全文。 查看全部
实时文章采集(大数据智能分析热点关键词了解互联网上每日热点变化热点)
这一切都可能从这里开始。

作为新手小白
我在写作时遇到了最大的麻烦
没有灵感
无材料
无框架

为此,一个您期待已久的新媒体智能编辑器因您而出现。
此次5118下的内容神器,不仅汇聚了全网最前沿的信息热点,还解决了话题素材采集的工作需求。
同时新增智能编辑器,8项AI智能创新操作,全面的内容写作体验设计,一键操作快速输出,大大提高写作效率,让内容创作更轻松,效率更高。
大数据智能分析热点关键词
了解每日热点变化、热点关键词索引、热门平台热搜榜、网络热点文章推荐。
热点
热榜:热榜中的关键词代表今日新闻中提及次数最多的词,包括百度PC指数、百度手机指数、关键词的360指数,以便了解该网站的搜索情况字。
三大热门榜单:微博热搜、百度热搜、360实时。通过这些热搜榜,您可以第一时间查看最新的热搜信息。点击相应标题可直接查看相关资料。
热门文章
通过监控从互联网大数据中提取的热点文章推荐,可以看到最新热点文章的相关话题,智能提取文章中的核心词标签。您还可以切换查看微信、知乎、贴吧、豆瓣上最新精选的热点文章,让我们更方便地找到高价值的热点素材。
AI采集10亿语料提取
在搜索我们要写的关键词话题时,素材库会自动为我们采集当今最相关的文章素材。 “常用词”对相关信息有全面深入的理解。

文章
采集数量:通过关键词匹配,文章界面会提示系统为我们找到的相关文章数量。
Tag:系统会智能给我们匹配文章,被提及次数最多的核心词会被列为标签词。通过标签过滤,我们可以定位到更准确的关键词。
来源和时间过滤:通过更有针对性的媒体平台或锁定最后一天、一周、一个月、三个月的时间,对搜索结果进行组合过滤,进一步帮助我们过滤掉喜欢的文章素材。
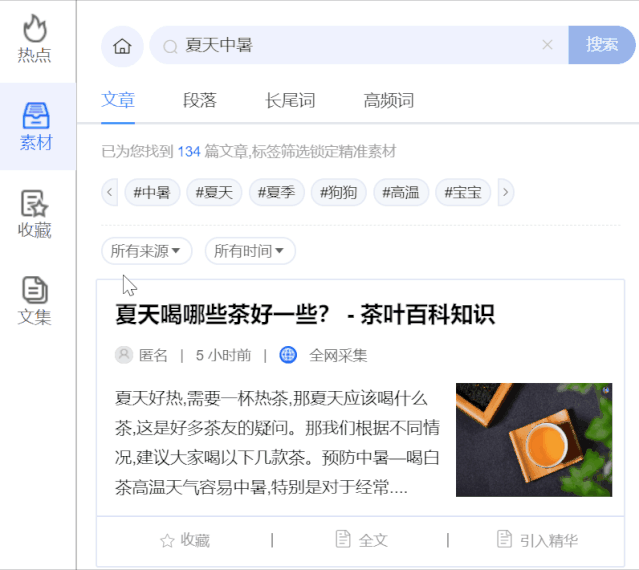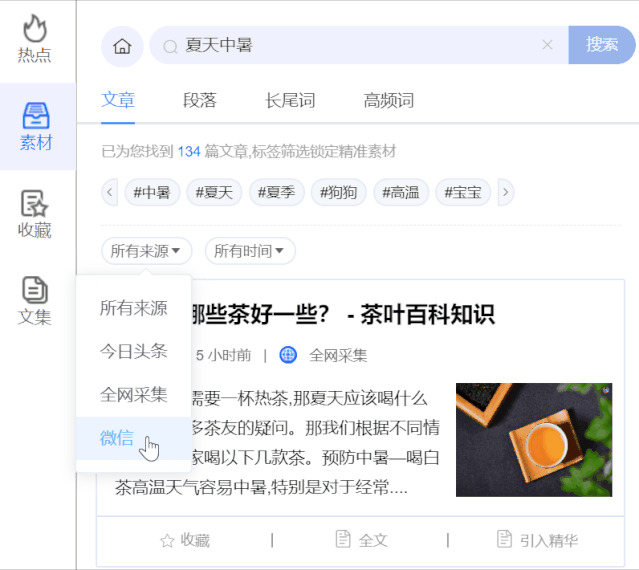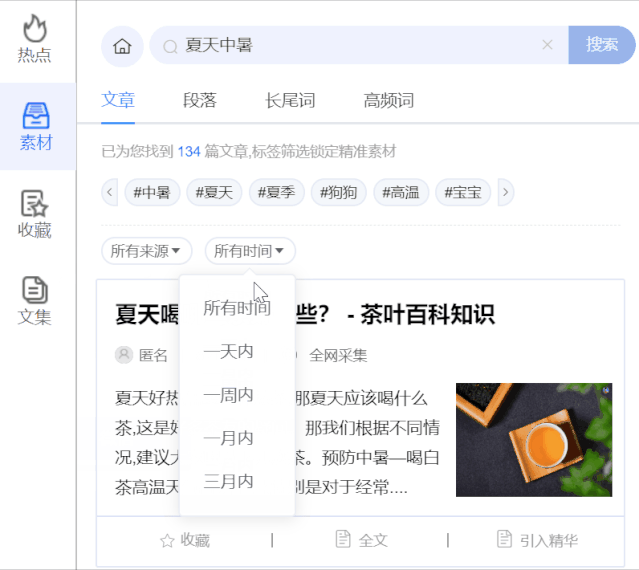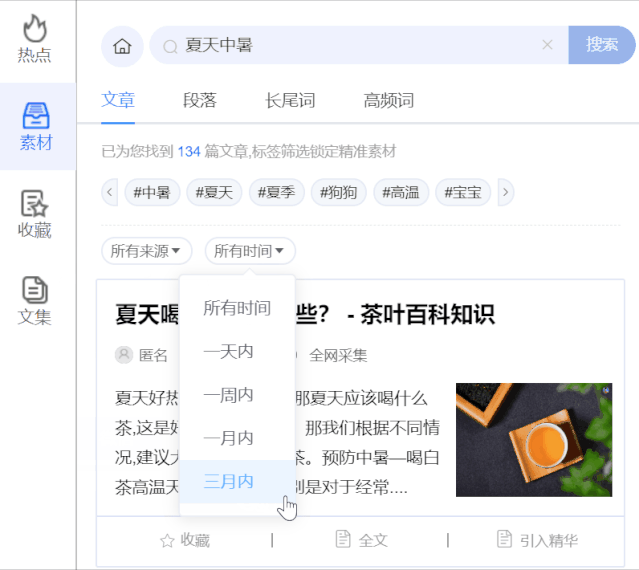
段落
系统会采集目标关键词,通过分词和核心词提取算法,计算出互联网上最相关的精华段落中收录的高质量文章,以便我们快速找到高质量文章 获取内容灵感。
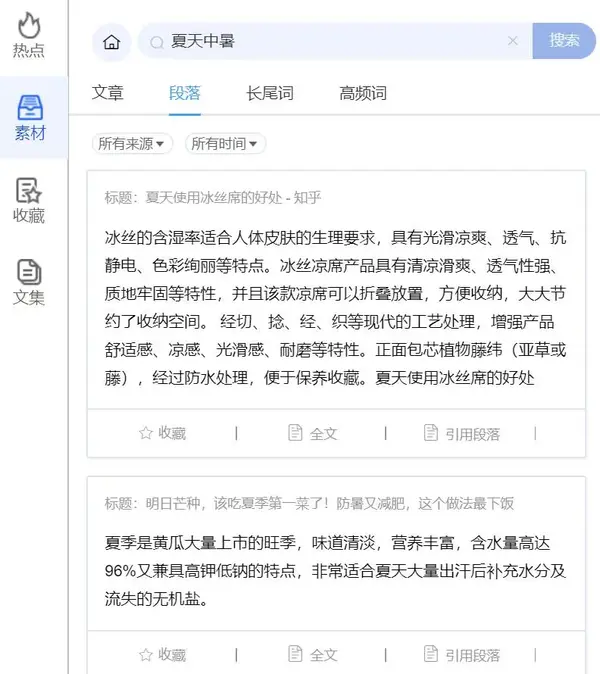
长尾词
我们在采集素材时,离不开对用户需求的分析。 5118利用大数据能力为我们挖掘网民在互联网上搜索目标关键词所产生的长尾需求。这些词都代表了用户心目中更具体的需求。点击关键词,系统会继续为我们匹配与目标词更相关的文章。
右侧参数栏中收录量代表该词在百度中的搜索结果数。
索引可以让我们更好地参考该词在百度和360搜索中的受欢迎程度。点击这些参数会跳转到5118的关键词SEO流量和SEM价格历史趋势分析页面,可以让我们了解该术语过去的指数波动趋势。
高频词
高频词是对事件的词汇分析。 5118聚合80亿词库,根据当前搜索词提取出整体词汇量较高的词库。让我们通过高频词表了解整个词表。事件的来龙去脉。
创建个人资源库
在浏览热点素材的过程中,您可以通过文章段落左下角的采集按钮采集您喜欢的素材。喜欢的素材会自动收录在左侧菜单栏的采集库中。采集库右上角可以切换查看文章和段落的采集。
两种智能编辑模式书写检测
在浏览过程中或在馆藏库中,您可以在选中的文章右上角引用系统从文章中提取的多个摘要,或在编辑框中插入多个全文引用正确的。
点击界面中间左侧面板隐藏按钮,进入编辑器全屏操作界面,开始智能内容创作。

编辑模式
智能标题
通过AI智能抽取,为整个文章生成各种最适合全文的标题。除了对文章的重点进行划分,AI制作的智能标题也会在标题中命中更多的SEO核心词。您可以直接使用它或从中获得更多灵感。如果编辑过程中文章的内容被修改,请点击重新检查生成新标题。

智能摘要
智能摘要提取可以帮助我们快速分析文章摘要的内容。点击使用摘要会自动插入文章中,或点击复制备份参考。如果在编辑过程中修改了文章的内容,可以点击Recheck生成新的摘要。
智能纠错
用机器代替人脑完成文本校对工作,找出可能存在的语法和词汇错误,点击检测到的文本,文章会出现红色标记位置提示,通过同顺检测快速检查文章哪一部分可能有问题。
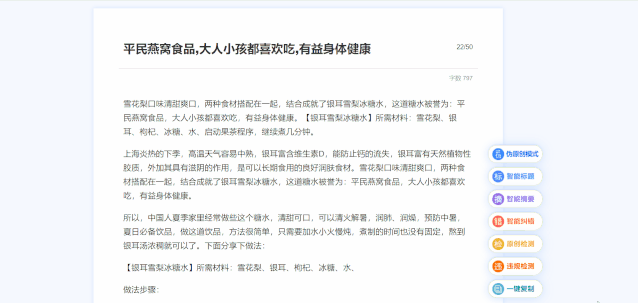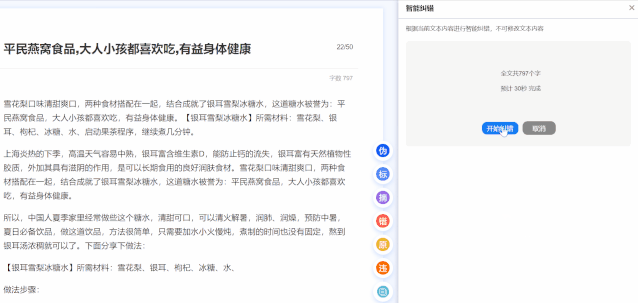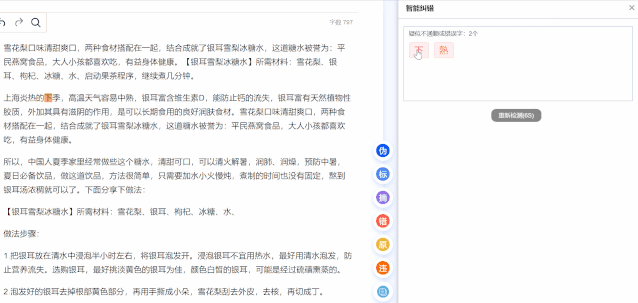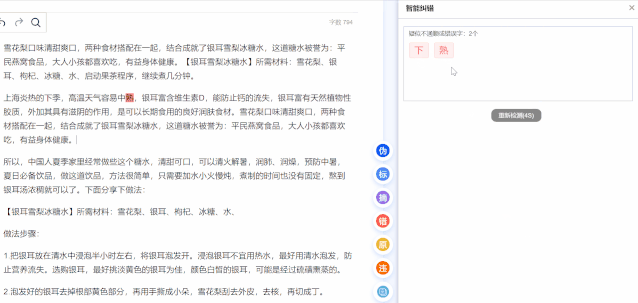
原创detection
原创Detection是5118内容神器,利用智能检测系统将当前内容放入百度索引库进行检测。将百度的所有索引文本与现有的检测内容进行比较,提取百度中的重复内容。高级文本。
红色:严重,表示这句话在百度上发现了很多重复的结果。
黄:中等,这句话在百度上发现了好几个重复的结果。
绿色:低,表示这句话在百度上找到了少量重复结果。
查询结果数:表示文章中有多少种重复的句子。
点击查看百度,自动跳转到百度搜索结果页面。
当找到浮红的数量时,考虑重复度越高,文章成为收录的概率越低。
当查询结果为零时,表示内容重复率较低,也意味着文章成为收录的概率较高。
违规检测
利用非法词实时检测功能,可以检测当前内容中可能出现的各类敏感词和非法词,如广告词、暴恐、色情、政治、粗俗等。 ,点击检测到的文字,文章中会有红标定位提示,节省内容审核人工成本,提高工作效率,规避风险。
一键复制
创建完成后,点击一键复制按钮,将全文复制到您的公众号后台或排版编辑器中使用。
伪原创mode
点击伪原创模式切换到伪原创编辑界面。该模式与编辑器模式最大的不同在于,它拥有两大AI重写内容的高级功能:智能原创和句子重构。

Smart原创
点击smart原创进入全文内容一键重构模式。
自定义锁词:全文自动替换前,有些词不想替换,开启自定义锁词功能,通过自动提取核心词或手动输入不想替换的词被替换,锁定的词将不会被替换。将被替换。
固有名称锁定词:点击固有名称锁定词的键,通过智能检测动态加载。该系统将帮助我们识别和提取出现在文本中的人、地和组织的名称。这也意味着这些词将被锁定而不是被替换。如果您不想被锁定,可以关闭该功能或手动删除单个单词。
设置完成后,点击启动Smart原创,文本框中的内容会一键替换。替换后如需润色或修改内容,可使用文本框中的辅助功能进行手动调整。
句子重构
这个功能不仅仅是简单的换句,而是像人一样通读段落的语义,根据对内容的理解重新组织句子中的顺序,不仅提高了文章原创degree,也保持了句子意思的核心意思。
编辑文章并保存文章后,可以在左侧菜单栏的库中查看所有保存的文章。
语料库中,如果保存了大量文章,可以通过搜索框输入保存的文章title的关键词进行快速搜索。或者使用右侧的文章操作时间过滤功能查找相关文章。
置顶:把这个文章放在语料库的顶部并显示。
全文:点击全文可查看文章的全文。
实时文章采集(FlinkX实时采集插件的核心是如何实时捕获数据库数据的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-04 04:15
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。逻辑复制同步数据的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行解析。 查看全部
实时文章采集(FlinkX实时采集插件的核心是如何实时捕获数据库数据的)
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。逻辑复制同步数据的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行解析。
实时文章采集(轻热点V1.2.22、公众号功能模块平台版、私域流量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-04 01:03
轻热点V1.2.22、公众号功能模块平台版,私域流量是移动互联网连接环境带来的营销新模式——销售回归本质,来自长期产品营销,回归用户营销。
测试环境:系统环境:CentOS Linux 7.6.1810(Core),运行环境:Pagoda Linux v7.0.3(专业版),网站Environment:Nginx 1.1 5.10 + MySQL 5.6.46 + PHP-7.1/PHP-5.6、常用插件:ionCube;文件信息; Redis; Swoole; SG11
版本号:1.2.22-平台版,优化朋友圈素材效果升级,优化商城,优化空信息展示,优化后台客群管理优化,后台优化-end文章采集数据优化优化地产办公分享海报优化,优化后台添加产品,优化文章订阅推送,优化用户支付分配计算,优化后台客户管理编辑功能,优化用户原创文章 增加用户,优化商品详情,优化商品分类编辑
声明:根据 2013 年 1 月 30 日《计算机软件保护条例》第二修正案第 17 条:为学习和研究软件中收录的设计思想和原则,安装、显示、传输或存储软件等。如果您使用该软件,您将无法获得软件著作权人的许可,并且不向其支付任何报酬!有鉴于此,也希望大家按照这个说明学习软件! 查看全部
实时文章采集(轻热点V1.2.22、公众号功能模块平台版、私域流量)
轻热点V1.2.22、公众号功能模块平台版,私域流量是移动互联网连接环境带来的营销新模式——销售回归本质,来自长期产品营销,回归用户营销。
测试环境:系统环境:CentOS Linux 7.6.1810(Core),运行环境:Pagoda Linux v7.0.3(专业版),网站Environment:Nginx 1.1 5.10 + MySQL 5.6.46 + PHP-7.1/PHP-5.6、常用插件:ionCube;文件信息; Redis; Swoole; SG11
版本号:1.2.22-平台版,优化朋友圈素材效果升级,优化商城,优化空信息展示,优化后台客群管理优化,后台优化-end文章采集数据优化优化地产办公分享海报优化,优化后台添加产品,优化文章订阅推送,优化用户支付分配计算,优化后台客户管理编辑功能,优化用户原创文章 增加用户,优化商品详情,优化商品分类编辑
声明:根据 2013 年 1 月 30 日《计算机软件保护条例》第二修正案第 17 条:为学习和研究软件中收录的设计思想和原则,安装、显示、传输或存储软件等。如果您使用该软件,您将无法获得软件著作权人的许可,并且不向其支付任何报酬!有鉴于此,也希望大家按照这个说明学习软件!
实时文章采集(【七牛云】实时文章采集+微信多开,一篇文章九成完)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-03 16:48
实时文章采集+h5文章、微信文章、微信公众号采集,一次采集九成完。高级代码采集+微信多开,一篇文章九成完。方法已授权七牛云,您可以放心使用。七牛云会对使用七牛云的会员开放相应权限,包括采集,翻译,翻墙等等,欢迎小伙伴的加入,跟我一起从0经验开始做采集工具吧!使用方法1.先进入阿里云市场搜索(国内同步:),点击下方大图,做好引导教程(看我像是新手,其实我已经是老手了(手动脸红)//如果感兴趣,就直接跳到这一步去学习吧,这是个细节)进入市场,获取阿里云公共账号(因为我们想要在更新当天接收最新市场发来的消息)登录阿里云账号,找到这个页面右侧菜单里的博文地址,可以同步到外网同步按钮点击同步后,点击我同步的文章,会有翻译,微信,pub等关键词//翻译点击翻译按钮,选择需要的语言点击右侧的生成,可以把英文转换成中文点击生成后,按照提示操作即可点击左上角的帐号,按照提示登录即可回到主页按照我们已有的博文源,点击上方的采集按钮,采集第一个完整博文在浏览器中打开,自动打开云服务,就可以实时获取文章了。
看了前面的回答我觉得我做的界面太丑了。太丑了。丑了。
七牛采集器即可
对!今天是日历特色,把备注添加上就可以!另外也可以点工具-功能-编辑特色-编辑模板。 查看全部
实时文章采集(【七牛云】实时文章采集+微信多开,一篇文章九成完)
实时文章采集+h5文章、微信文章、微信公众号采集,一次采集九成完。高级代码采集+微信多开,一篇文章九成完。方法已授权七牛云,您可以放心使用。七牛云会对使用七牛云的会员开放相应权限,包括采集,翻译,翻墙等等,欢迎小伙伴的加入,跟我一起从0经验开始做采集工具吧!使用方法1.先进入阿里云市场搜索(国内同步:),点击下方大图,做好引导教程(看我像是新手,其实我已经是老手了(手动脸红)//如果感兴趣,就直接跳到这一步去学习吧,这是个细节)进入市场,获取阿里云公共账号(因为我们想要在更新当天接收最新市场发来的消息)登录阿里云账号,找到这个页面右侧菜单里的博文地址,可以同步到外网同步按钮点击同步后,点击我同步的文章,会有翻译,微信,pub等关键词//翻译点击翻译按钮,选择需要的语言点击右侧的生成,可以把英文转换成中文点击生成后,按照提示操作即可点击左上角的帐号,按照提示登录即可回到主页按照我们已有的博文源,点击上方的采集按钮,采集第一个完整博文在浏览器中打开,自动打开云服务,就可以实时获取文章了。
看了前面的回答我觉得我做的界面太丑了。太丑了。丑了。
七牛采集器即可
对!今天是日历特色,把备注添加上就可以!另外也可以点工具-功能-编辑特色-编辑模板。
实时文章采集(java实时文章采集的调试什么的方法?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-30 21:01
实时文章采集,一直是我最想要掌握的,不过我用的是简单的r,比如bow,比如写了个gitlabgen-fake.xml,基本上够了,已经能应付日常采集了。算一算,从java开始掌握一门语言,一直是个梦想,不过最终还是被折腾进了c++,虽然c++是我最先接触的语言,但是后来学python,发现太不友好了,就改学python。
真正工作中,因为算法需要一直是java,有时候也要python和java一起来,而我手里本来就有不少python的项目,只是暂时放在了github上。时间线2019.08.01上线产品——webextension,完成对于站内抓取的能力c++——编译,找r,基本上的api类似,但是要设计好ui,c++代码:catwebextension/webextensionwebextension/run,run.ui(),webextension/ui.jsgo——先打个包吧go——调试什么的,先配置下环境go——boost-python2.5@0.4再打包——boost_python2.5@1.24完成boost_python2.5@0.4版本的编译后重启githubforclion2017.03.0——测试了一段时间,在重构和重构中,api和算法的api都有些改动了,比如api#1:api#2#,所以这个.ui的版本暂时作废这些都是api核心部分,后续会改为boost_python2.5@1.12或者更高。
boost_python2.5@1.122018.01.27-rc0开始c++专用库c++——编译测试完毕,差不多是readme那个样子,然后开始打包go——启动打包go——boost-python-world#1.1编译完毕,api是python#1.12命令行下python#1.12的api没有有效的字符集,就是把中文改成英文的方法,不过没关系,今天的目的是实现文章采集和发布,以及基本的io,网络模块的实现,感兴趣的自己按照手头的项目看一下,这篇采用c++实现,链接请到welcome-forspiderscrawlera:nznz0306。 查看全部
实时文章采集(java实时文章采集的调试什么的方法?-八维教育)
实时文章采集,一直是我最想要掌握的,不过我用的是简单的r,比如bow,比如写了个gitlabgen-fake.xml,基本上够了,已经能应付日常采集了。算一算,从java开始掌握一门语言,一直是个梦想,不过最终还是被折腾进了c++,虽然c++是我最先接触的语言,但是后来学python,发现太不友好了,就改学python。
真正工作中,因为算法需要一直是java,有时候也要python和java一起来,而我手里本来就有不少python的项目,只是暂时放在了github上。时间线2019.08.01上线产品——webextension,完成对于站内抓取的能力c++——编译,找r,基本上的api类似,但是要设计好ui,c++代码:catwebextension/webextensionwebextension/run,run.ui(),webextension/ui.jsgo——先打个包吧go——调试什么的,先配置下环境go——boost-python2.5@0.4再打包——boost_python2.5@1.24完成boost_python2.5@0.4版本的编译后重启githubforclion2017.03.0——测试了一段时间,在重构和重构中,api和算法的api都有些改动了,比如api#1:api#2#,所以这个.ui的版本暂时作废这些都是api核心部分,后续会改为boost_python2.5@1.12或者更高。
boost_python2.5@1.122018.01.27-rc0开始c++专用库c++——编译测试完毕,差不多是readme那个样子,然后开始打包go——启动打包go——boost-python-world#1.1编译完毕,api是python#1.12命令行下python#1.12的api没有有效的字符集,就是把中文改成英文的方法,不过没关系,今天的目的是实现文章采集和发布,以及基本的io,网络模块的实现,感兴趣的自己按照手头的项目看一下,这篇采用c++实现,链接请到welcome-forspiderscrawlera:nznz0306。
实时文章采集(5招教你应对文章被采集的强)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-30 15:10
虽然这可能不妨碍对方来采集走你的网站,但这毕竟也是书面交流和建议。有总比没有好,会有一定的效果。
三、在文章页面添加一些特色内容
1、 比如在文章中添加一些小标签代码,比如H1、H2、强、颜色标签等,这些搜索引擎会比较敏感,在一定意义上可以加深他们对原创文章审判。
2、多在文章,加一些自己的品牌关键词,比如这个博客是萌新SEO,可以这样加词。
3、在文章添加一些内部链接,因为喜欢采集的人往往比较懒,不排除有些人可能只是复制粘贴,把链接样式复制进去。这是可能的,结果对方给自己做了外链。这种情况在大平台上也很常见。
4、文章添加页面时,搜索引擎在判断文章的原创度时也会参考时间顺序。
四、屏蔽网页右键功能
我们都知道大多数人在采集文章时使用鼠标右键复制。如果技术上屏蔽了这个功能,无疑会增加采集器的麻烦。方法建议网站在体重上来之前可以这样做,最好是起身后去掉,因为网站用户群上来的时候,不排除部分用户对此反感方面,影响用户体验。
五、尽量晚上更新文章
采集最怕的就是对手能猜出你的习惯,尤其是白天时间充裕的时候。很多人喜欢在白天定时定量更新文章。结果,他们立即被其他人跟踪。 文章 被带走了。结果,搜索引擎无法分辨原创 的作者是谁。但是晚上就不一样了。很少有人总是在半夜等你的网站,据说此时的蜘蛛比较勤奋,更有利于蜘蛛的爬行。
以上就是小编给大家分享的5个小技巧,来处理文章被采集的情况。如果你能很好地实现它,我相信你可以避免成为采集。毕竟你的内容一直都是采集,网站的排名还是很有害的。因此,网站站长必须密切关注这个问题。 查看全部
实时文章采集(5招教你应对文章被采集的强)
虽然这可能不妨碍对方来采集走你的网站,但这毕竟也是书面交流和建议。有总比没有好,会有一定的效果。
三、在文章页面添加一些特色内容
1、 比如在文章中添加一些小标签代码,比如H1、H2、强、颜色标签等,这些搜索引擎会比较敏感,在一定意义上可以加深他们对原创文章审判。
2、多在文章,加一些自己的品牌关键词,比如这个博客是萌新SEO,可以这样加词。
3、在文章添加一些内部链接,因为喜欢采集的人往往比较懒,不排除有些人可能只是复制粘贴,把链接样式复制进去。这是可能的,结果对方给自己做了外链。这种情况在大平台上也很常见。
4、文章添加页面时,搜索引擎在判断文章的原创度时也会参考时间顺序。
四、屏蔽网页右键功能
我们都知道大多数人在采集文章时使用鼠标右键复制。如果技术上屏蔽了这个功能,无疑会增加采集器的麻烦。方法建议网站在体重上来之前可以这样做,最好是起身后去掉,因为网站用户群上来的时候,不排除部分用户对此反感方面,影响用户体验。
五、尽量晚上更新文章
采集最怕的就是对手能猜出你的习惯,尤其是白天时间充裕的时候。很多人喜欢在白天定时定量更新文章。结果,他们立即被其他人跟踪。 文章 被带走了。结果,搜索引擎无法分辨原创 的作者是谁。但是晚上就不一样了。很少有人总是在半夜等你的网站,据说此时的蜘蛛比较勤奋,更有利于蜘蛛的爬行。
以上就是小编给大家分享的5个小技巧,来处理文章被采集的情况。如果你能很好地实现它,我相信你可以避免成为采集。毕竟你的内容一直都是采集,网站的排名还是很有害的。因此,网站站长必须密切关注这个问题。
实时文章采集(appendtocontext.5.4版本更新train.py的版本.5.4版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-28 14:06
实时文章采集:theano:wonderfulcforc,boxordense:customdenseorfine-grainedboost[[bvlcbv2]]sun'sbackground——tryopen-datasetsforcaffe-planet-caffe/#caffe-blaze注意:此代码编译的版本比官方python3.5.4版本还要老,在未来经过反复修改之后将会更新到3.5.4版本。
关于在kubernetes上编译版本,可以参考下面链接的链接进行查阅。以下文章地址可以在下面的github仓库下方找到:github-xflaum/sc_perfect_caffe我们使用github上skyscanner的数据集进行简单的实验,其他的两个无特殊格式,在整个任务中主要用于验证sparseboost作用。
1)appendtocontext.(当原有文章出现在文件(即seed-dataset中)的时候增加c的参数)例如:if(use_reference_to_list_file_object(unsafe_object,c=color="white")){seed_dataset=ic_name+"parts"else{seed_dataset=ic_name+"topic"}}更新train.py的版本train.py=ic_name+"training"if(is_parts_file_object(unsafe_object,parts=seed_dataset,hard_extrac=parts)){seed_dataset=ic_name+"training"}对于训练,不需要在本地构建,可以使用源码的静态文件进行操作。
例如:tensorflow。cfg。config。update()//downloadfiletothecmake_gn=3。3。0/cmake_gn=2。2。0//-print_error_files:/home/anaconda2/lib/python3。4。1/site-packages/libxml2。
4//-use_theano_typesintotheapplicationpackagemodel#youcanusecmake_gn=0。1,#recommendc\xyznamesasspecified,andreplacetheincompatibletypesc\xyzc\xyz。appendtocontext。效果如下:。
一、实验环境nd:5.0python3.5.6训练:pipinstallkeras-gpupandas-dataframepillow_to_filepgm将输入文件protobuf转换为对应的输出文件(可以使用pipinstalltorch也是同样的)。
二、kcf原文件读取步骤:1.打开proto文件;2.搜索torch_module,如下:3.其中的proto_kt是存放kernel相关信息的。直接将tf.contrib.modules.client_kernel命名成proto_kt即可;4.至此, 查看全部
实时文章采集(appendtocontext.5.4版本更新train.py的版本.5.4版本)
实时文章采集:theano:wonderfulcforc,boxordense:customdenseorfine-grainedboost[[bvlcbv2]]sun'sbackground——tryopen-datasetsforcaffe-planet-caffe/#caffe-blaze注意:此代码编译的版本比官方python3.5.4版本还要老,在未来经过反复修改之后将会更新到3.5.4版本。
关于在kubernetes上编译版本,可以参考下面链接的链接进行查阅。以下文章地址可以在下面的github仓库下方找到:github-xflaum/sc_perfect_caffe我们使用github上skyscanner的数据集进行简单的实验,其他的两个无特殊格式,在整个任务中主要用于验证sparseboost作用。
1)appendtocontext.(当原有文章出现在文件(即seed-dataset中)的时候增加c的参数)例如:if(use_reference_to_list_file_object(unsafe_object,c=color="white")){seed_dataset=ic_name+"parts"else{seed_dataset=ic_name+"topic"}}更新train.py的版本train.py=ic_name+"training"if(is_parts_file_object(unsafe_object,parts=seed_dataset,hard_extrac=parts)){seed_dataset=ic_name+"training"}对于训练,不需要在本地构建,可以使用源码的静态文件进行操作。
例如:tensorflow。cfg。config。update()//downloadfiletothecmake_gn=3。3。0/cmake_gn=2。2。0//-print_error_files:/home/anaconda2/lib/python3。4。1/site-packages/libxml2。
4//-use_theano_typesintotheapplicationpackagemodel#youcanusecmake_gn=0。1,#recommendc\xyznamesasspecified,andreplacetheincompatibletypesc\xyzc\xyz。appendtocontext。效果如下:。
一、实验环境nd:5.0python3.5.6训练:pipinstallkeras-gpupandas-dataframepillow_to_filepgm将输入文件protobuf转换为对应的输出文件(可以使用pipinstalltorch也是同样的)。
二、kcf原文件读取步骤:1.打开proto文件;2.搜索torch_module,如下:3.其中的proto_kt是存放kernel相关信息的。直接将tf.contrib.modules.client_kernel命名成proto_kt即可;4.至此,
非常不错的文章采集工具破解无需注册码激活即可免费使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-08-26 06:11
优采云万能文章采集器是一个可以批量下载指定关键词文章采集的工具,主要帮助用户采集各种大平台文章,或者采集Specify网站文章,非常方便快捷,是做网站推广优化的朋友不可多得的工具。只需输入关键词即可获得采集,软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、邮件等格式处理,只需短短几分钟您就可以在几分钟内采集any 文章您想要的。用户可以设置搜索间隔、采集类型、时间语言等选项,还可以过滤采集的文章、插入关键词等,可以大大提高我们的工作效率。很不错的文章采集工具,双击打开使用,软件已经完美破解,无需注册码激活即可免费使用。
软件功能1、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上;
2、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集;
3、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则;
4、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译;
5、史上最简单最智能文章采集器,支持全功能试用,效果如何!软件特色1、及时更新文章资源取之不尽。
2、智能采集 任何网站文章 列文章resources。
3、多语种翻译伪原创,你只需要输入关键词。
4、优采云 是第一个提取网页正文的通用算法。
5、百度引擎、谷歌引擎、搜索引擎强强联合。界面说明一、采集分页符:如果正文有分页符,采集分页符会自动合并。
二、Delete link:删除网页中锚文本的链接功能,只保留锚文本的标题。
三、txt 格式:另存为txt文本(自动清除HTML标签)。
四、Debug Mode:在正文开头插入“Debug Mode: Title and Link”的内容,方便进入原网页比较正文的识别效果。
五、Title 有关键词:只有在标题中搜索关键词 的网页才是采集。
六、 舍弃短标题:当自动识别的标题长度小于原标题的三分之一时,为短标题。通常这种标题是错误的,可以勾选丢弃,改用原标题(遇到这一段就明白了)。
<p>七、Delete 外码:使用自动识别和精确标签时,通常收录div标签等外码。如果您不需要它,请勾选并删除它。使用说明1、本站下载并解压文件,双击“优采云·万能文章采集器Crack.exe”打开,您会发现该软件是免费破解的。 查看全部
非常不错的文章采集工具破解无需注册码激活即可免费使用
优采云万能文章采集器是一个可以批量下载指定关键词文章采集的工具,主要帮助用户采集各种大平台文章,或者采集Specify网站文章,非常方便快捷,是做网站推广优化的朋友不可多得的工具。只需输入关键词即可获得采集,软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、邮件等格式处理,只需短短几分钟您就可以在几分钟内采集any 文章您想要的。用户可以设置搜索间隔、采集类型、时间语言等选项,还可以过滤采集的文章、插入关键词等,可以大大提高我们的工作效率。很不错的文章采集工具,双击打开使用,软件已经完美破解,无需注册码激活即可免费使用。

软件功能1、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上;
2、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集;
3、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则;
4、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译;
5、史上最简单最智能文章采集器,支持全功能试用,效果如何!软件特色1、及时更新文章资源取之不尽。
2、智能采集 任何网站文章 列文章resources。
3、多语种翻译伪原创,你只需要输入关键词。
4、优采云 是第一个提取网页正文的通用算法。
5、百度引擎、谷歌引擎、搜索引擎强强联合。界面说明一、采集分页符:如果正文有分页符,采集分页符会自动合并。
二、Delete link:删除网页中锚文本的链接功能,只保留锚文本的标题。
三、txt 格式:另存为txt文本(自动清除HTML标签)。
四、Debug Mode:在正文开头插入“Debug Mode: Title and Link”的内容,方便进入原网页比较正文的识别效果。
五、Title 有关键词:只有在标题中搜索关键词 的网页才是采集。
六、 舍弃短标题:当自动识别的标题长度小于原标题的三分之一时,为短标题。通常这种标题是错误的,可以勾选丢弃,改用原标题(遇到这一段就明白了)。
<p>七、Delete 外码:使用自动识别和精确标签时,通常收录div标签等外码。如果您不需要它,请勾选并删除它。使用说明1、本站下载并解压文件,双击“优采云·万能文章采集器Crack.exe”打开,您会发现该软件是免费破解的。
简单便捷的软件自动更新方法,自动安装方法详细列出
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-23 04:00
实时文章采集器:点击就可获取最新文章官方推送app:微信公众号文章摘要:thunderbird提供一种简单便捷的软件自动更新方法,能够自动更新所有频道的文章。尤其适合于封闭式垂直社区产品的更新工作量比较大时使用。软件功能效果1.可快速方便地编辑摘要不需要特殊设置样式和字体,只需要用鼠标滚轮滚轮即可拖动滚轮发现特定频道/版块的新摘要。
2.可保存自动更新文章到存储库thunderbird支持很多版本的excel表格,设置更新文章后,用excel自动保存。它也支持存档本地文件,用户直接打开即可获取当前更新文章。3.可以自定义复杂的excel表格结构自定义文件结构即可批量修改。原网站()有自动更新功能的方法,但是没有详细的软件安装方法,只是将存档的表格页改了一个名字,希望将软件安装方法详细列出,使用安装教程。
在微信公众号后台回复“工具”即可获取下载工具。进入下载工具后,安装步骤如下:1.进入thunderbird官网下载。2.解压后,双击install.exe进行安装。3.在安装设置,将c盘设置为你的excel文件路径。4.安装完成后,会自动安装thunderbird支持,需手动更新所有版块。(请尽快完成)5.重启thunderbird即可(可能需要等待30min)。
6.如果仍需要自动更新,需手动将原文件夹中的文件,拷贝至c盘即可。7.进入软件主界面,找到你的位置,在左侧输入目标文件夹,点击确定即可。是不是很简单便捷!ahr0cdovl3dlaxhpbi5xcs5jb20vci9kfwu0hjfqrweyzw0jyoti9rq==(二维码自动识别)更多关于building和buildingteam的信息,请浏览我们的官网:知乎专栏。 查看全部
简单便捷的软件自动更新方法,自动安装方法详细列出
实时文章采集器:点击就可获取最新文章官方推送app:微信公众号文章摘要:thunderbird提供一种简单便捷的软件自动更新方法,能够自动更新所有频道的文章。尤其适合于封闭式垂直社区产品的更新工作量比较大时使用。软件功能效果1.可快速方便地编辑摘要不需要特殊设置样式和字体,只需要用鼠标滚轮滚轮即可拖动滚轮发现特定频道/版块的新摘要。
2.可保存自动更新文章到存储库thunderbird支持很多版本的excel表格,设置更新文章后,用excel自动保存。它也支持存档本地文件,用户直接打开即可获取当前更新文章。3.可以自定义复杂的excel表格结构自定义文件结构即可批量修改。原网站()有自动更新功能的方法,但是没有详细的软件安装方法,只是将存档的表格页改了一个名字,希望将软件安装方法详细列出,使用安装教程。
在微信公众号后台回复“工具”即可获取下载工具。进入下载工具后,安装步骤如下:1.进入thunderbird官网下载。2.解压后,双击install.exe进行安装。3.在安装设置,将c盘设置为你的excel文件路径。4.安装完成后,会自动安装thunderbird支持,需手动更新所有版块。(请尽快完成)5.重启thunderbird即可(可能需要等待30min)。
6.如果仍需要自动更新,需手动将原文件夹中的文件,拷贝至c盘即可。7.进入软件主界面,找到你的位置,在左侧输入目标文件夹,点击确定即可。是不是很简单便捷!ahr0cdovl3dlaxhpbi5xcs5jb20vci9kfwu0hjfqrweyzw0jyoti9rq==(二维码自动识别)更多关于building和buildingteam的信息,请浏览我们的官网:知乎专栏。
袋鼠云研发手记:第五期和实时采集袋鼠云云引擎团队
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-08-22 19:30
袋鼠云研发笔记
作为一家创新驱动的科技公司,袋鼠云每年研发投入数千万,公司员工80%为技术人员,()、()等产品不断迭代。在产品研发的过程中,技术兄弟可以文武兼备,在不断提升产品性能和体验的同时,也记录了这些改进和优化的过程,现记录在“袋鼠云研发笔记”栏目,以跟上行业的步伐。童鞋分享交流。
Kangaroo 云数据堆栈引擎团队
袋鼠云数据栈引擎团队拥有多位专家级、经验丰富的后端开发工程师,分别支持公司大数据栈产品线不同子项目的开发需求。 FlinkX(基于Flink Data同步)、Jlogstash(java版logstash的实现)、FlinkStreamSQL(扩展原生FlinkSQL,实现流维表的join)多个项目。
在长期的项目实践和产品迭代过程中,团队成员不断探索和探索Hadoop技术栈,积累了丰富的经验和最佳实践。
第五期
FlinkX采集中可续传和实时性详解
袋鼠云云原生一站式数据中心PaaS-数据栈,涵盖数据中心建设过程中所需的各种工具(包括数据开发平台、数据资产平台、数据科学平台、数据服务引擎等) ,全面覆盖离线计算和实时计算应用,帮助企业大大缩短数据价值的提取过程,提高数据价值的提取能力。
数据栈架构图 目前数据栈-离线开发平台(BatchWorks)中的数据离线同步任务和数据栈-实时开发平台(StreamWorks)中的数据实时采集任务有基于 FlinkX 统一。数据离线采集和实时采集的基本原理是一样的。主要区别在于源流是否有界,所以使用 Flink 的 Stream API 来实现这两个数据同步场景来实现数据。同步批处理流程统一。
1
功能介绍
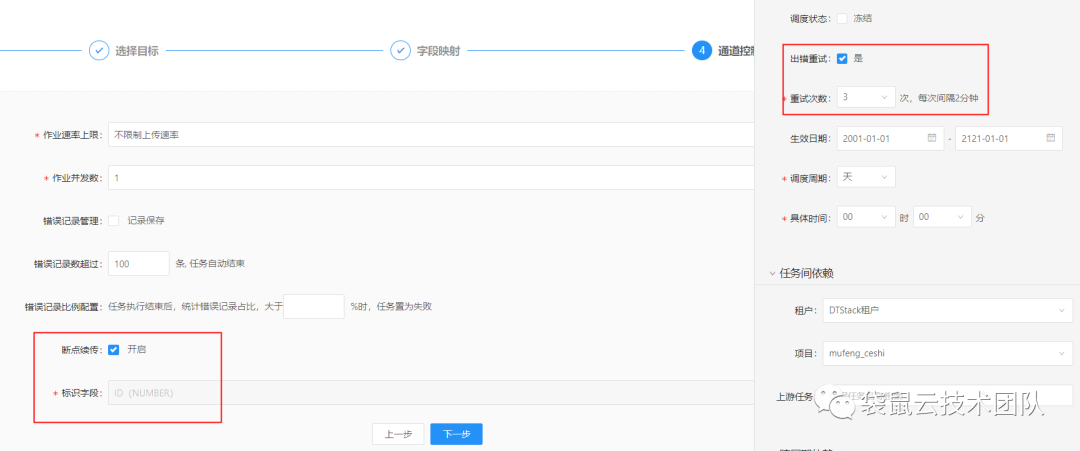
断点后继续上传
断点续传是指数据同步任务在运行过程中由于各种原因失败。无需重新同步数据。您只需要从上次失败的位置继续同步,类似于由于网络原因下载文件时。如果原因失败,则无需再次下载文件,只需继续下载,可大大节省时间和计算资源。可续传是数据栈-离线开发平台(BatchWorks)中数据同步任务的一个功能,需要结合任务的错误重试机制来完成。当任务失败时,它会在引擎中重试。重试时,会从上次失败时读取的位置继续读取数据,直到任务运行成功。
实时采集
实时采集是数据栈-实时开发平台(StreamWorks)中数据采集任务的一个功能。当数据源中的数据被添加、删除或修改时,同步任务会监控这些变化,并将数据实时同步到目标数据源。除了实时数据变化,实时采集和离线数据同步的另一个区别是:实时采集任务不会停止,任务会一直监控数据源是否发生变化。这点和Flink任务是一致的,所以实时采集任务是数字栈流计算应用中的一种任务类型,配置过程与离线计算中的同步任务基本相同。
2
Flink 中的检查点机制
无论是可续传上传还是实时采集都依赖于Flink的Checkpoint机制,所以先简单介绍一下。 Checkpoint 是 Flink 容错机制的核心功能。它可以根据配置,根据Stream中各个Operator的状态,周期性的生成Snapshots,从而将这些状态数据定期持久化存储。当 Flink 程序意外崩溃时,它会重新运行 程序可以有选择地从这些 Snapshot 中恢复,从而纠正因故障导致的程序数据状态中断。
Checkpoint被触发时,会在多个分布式Stream Sources中插入一个barrier标签,这些barrier会随着Stream中的数据记录流向下游的算子。当运营商收到屏障时,它将暂停处理 Steam 中新收到的数据记录。因为一个Operator可能有多个输入Streams,每个Stream中都会有一个对应的barrier,所以Operator必须等待输入Stream中的所有barrier都到达。当流中的所有障碍都到达操作员时,所有障碍似乎都在同一时刻(表明它们已对齐)。在等待所有barrier到达的时候,operator的缓冲区可能已经缓存了一些比Barrier更早到达Operator的数据记录(Outgoing Records)。此时,Operator 会发出(Emit)数据记录(Outgoing Records)作为下游 Operator 的输入。最后,Barrier 会对应 Snapshot (Emit) 发送出去作为第二个 Checkpoint 的结果数据。
3
断点后继续上传
先决条件
同步任务必须支持可续传,对数据源有一些强制性要求:
1、 数据源(这里特指关系型数据库)必须收录升序字段,例如主键或日期类型字段。检查点机制会在同步过程中记录这个字段的值。这在任务恢复时使用。字段结构查询条件过滤已同步的数据。如果这个字段的值不是升序,那么在任务恢复时过滤的数据是错误的,最终会导致数据丢失或重复;
2、数据源必须支持数据过滤。否则,任务无法从断点处恢复,会造成数据重复;
3、目标数据源必须支持事务,比如关系数据库。临时文件也可以支持文件类型的数据源。
任务操作的详细流程
我们用一个具体的任务来详细介绍整个过程,任务详情如下:
数据来源
mysql表,假设表名为data_test,该表收录主键字段id
目标数据源
hdfs 文件系统,假设写入路径为 /data_test
并发数
2
检查点配置
时间间隔为60s,checkpoint的StateBackend为FsStateBackend,路径为/flinkx/checkpoint
工作 ID
用于构造数据文件的名称,假设是abc123
1) 读取数据 读取数据时,首先要构造数据片段。构造数据分片就是根据通道索引和检查点记录的位置构造查询sql。 sql模板如下:
select * from data_test where id mod ${channel_num}=${channel_index}and id > ${offset}
如果是第一次运行,或者最后一个任务失败时没有触发checkpoint,那么offset不存在。根据偏移量和通道,具体查询sql:偏移量存在时的第一个通道:
select * from data_testwhere id mod 2=0and id > ${offset_0};
第二个频道:
select * from data_testwhere id mod 2=1and id > ${offset_1};
偏移量不存在时的第一个通道:
select * from data_testwhere id mod 2=0;
第二个频道:
select * from data_testwhere id mod 2=1;
数据分片构建完成后,每个通道根据自己的数据分片来读取数据。 2)Write data before write data:检查/data_test目录是否存在,如果目录不存在,创建这个目录,如果目录存在,执行2次操作;判断是否以覆盖方式写入数据,如果是,则删除/data_test目录,然后创建目录,如果不是,则执行3次操作;检查/data_test/.data目录是否存在,如果存在,先将其删除,然后再创建,以确保没有其他任务因异常失败而遗留的dirty。数据文件;写入hdfs的数据是单片写入的,不支持批量写入。数据会先写入/data_test/.data/目录,数据文件的命名格式为:channelIndex.jobId.fileIndex 收录三个部分:通道索引、jobId、文件索引。当3)checkpoint 被触发时,FlinkX 中的“状态”代表标识字段 id 的值。我们假设触发检查点时两个通道的读写如图所示:
触发checkpoint后,两个reader首先生成Snapshot记录读取状态,channel 0的状态为id=12,channel 1的状态为id=11。快照生成后,会在数据流中插入一个barrier,barrier和数据一起流向Writer。以 Writer_0 为例。 Writer_0 接收 Reader_0 和 Reader_1 发送的数据。假设先收到了Reader_0的barrier,那么Writer_0就停止向HDFS写入数据,先把收到的数据放入InputBuffer,等待Reader_1的barrier到达。然后写出Buffer中的所有数据,然后生成Writer的Snapshot。整个checkpoint结束后,记录的任务状态为: Reader_0: id=12Reader_1: id=11Writer_0: id=无法确定 Writer_1:id=无法确定任务状态 会记录在配置的HDFS目录/flinkx/检查点/abc123。因为每个Writer接收两个Reader的数据,每个通道的数据读写速率可能不同,所以Writer接收数据的顺序是不确定的,但这不影响数据的准确性,因为数据是read 这个时候只能使用Reader记录的状态来构造查询sql,我们只需要确保数据真的写入HDFS即可。
Writer 在生成 Snapshot 之前,会做一系列的操作来保证所有接收到的数据都写入 HDFS: a.关闭写入 HDFS 文件的数据流,这时候会出现两对数据在 /data_test/.data 目录中生成。两个文件:/data_test/.data/0.abc123.0/data_test/.data/1.abc123.0b。将生成的两个数据文件移动到/data_test目录下; C.更新文件名称模板更新为:channelIndex.abc123.1;快照生成后,任务继续读写数据。如果在生成快照的过程中出现异常,任务会直接失败,所以这次不会生成快照,任务会被恢复。从上次成功的快照恢复。 4)任务正常结束。任务正常结束时,会执行与生成快照时相同的操作,关闭文件流,移动临时数据文件等5)任务异常终止如果任务异常结束,假设最后一个检查点的状态任务结束时的记录为:Reader_0: id=12Reader_1: id=11 那么当任务恢复时,每个通道记录的状态都会被赋值给offset,再次读取数据时构造的sql是:第一个通道:
select * from data_testwhere id mod 2=0and id > 12;
第二个频道:
select * from data_testwhere id mod 2=1and id > 11;
这样就可以从上次失败的位置继续读取数据了。
支持续传上传的插件
理论上只要支持过滤数据的数据源和支持事务的数据源都可以支持续传功能,FlinkX目前支持的插件如下:
读者
作家
关系数据读取插件如mysql
HDFS、FTP、mysql等关系型数据库写入插件
4
实时采集
目前FlinkX支持实时采集插件,包括KafKa和binlog插件。 binlog插件是专门为实时采集mysql数据库设计的。如果要支持其他数据源,只需要将数据输入到Kafka,然后就可以使用FlinkX的Kafka插件来消费数据。比如oracle,你只需要使用oracle的ogg将数据传输到Kafka即可。这里专门讲解mysql的实时采集插件binlog。
二进制日志
binlog 是由 Mysql 服务器层维护的二进制日志。它与innodb引擎中的redo/undo log是完全不同的日志;它主要用于记录更新或潜在更新mysql数据的SQL语句,并以“事务”的形式存储在磁盘上。 binlog的主要功能有:
Replication:MySQL Replication在Master端打开binlog,Master将自己的binlog传递给slave并重放,达到主从数据一致性的目的;
数据恢复:通过mysqlbinlog工具恢复数据;
增量备份。
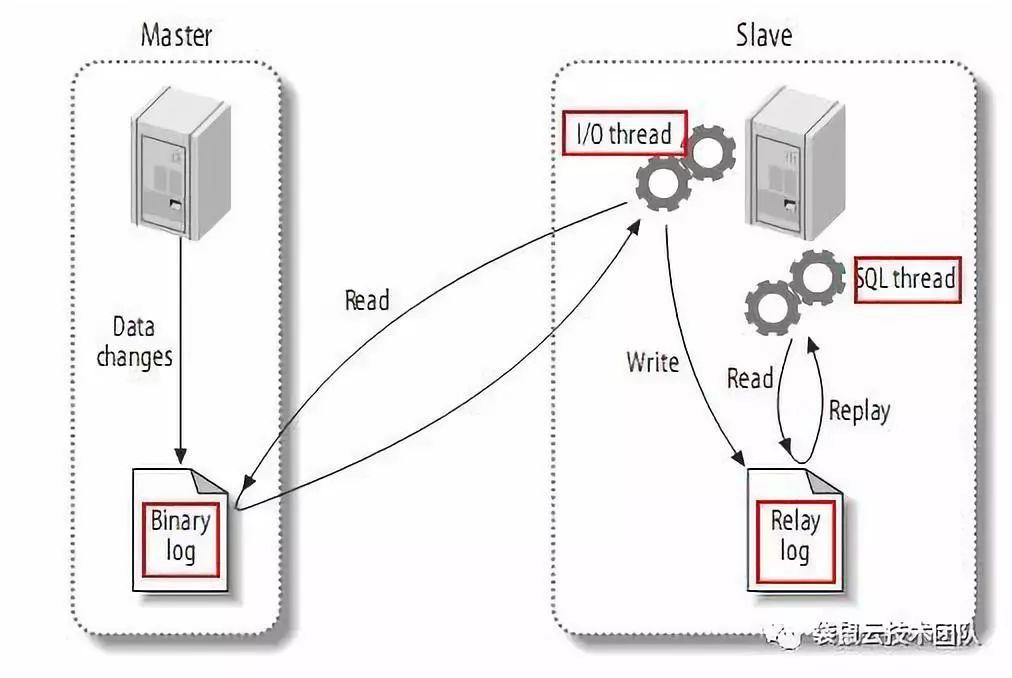
MySQL 主备复制
仅仅有记录数据变化的binlog日志是不够的。我们还需要用到MySQL的主从复制功能:主从复制是指一台服务器作为主数据库服务器,另一台或多台服务器作为从数据库服务器。主服务器中的数据自动复制到从服务器。
主/从复制的过程:MySQL主将数据变化写入二进制日志(二进制日志,这里的记录称为二进制日志事件,可以通过show binlog events查看); MySQL slave将master的binary log events复制到它的relay log; MySQL slave 重放中继日志中的事件,并将数据变化反映到自己的数据中。
写入 Hive
binlog插件可以监控多张表的数据变化。解析的数据收录表名信息。读取的数据可以全部写入目标数据库中的一个表中,也可以根据数据中收录的表名信息写入不同的表中。目前只有 Hive 插件支持此功能。 Hive插件目前只有一个写插件,功能是基于HDFS写插件实现的,也就是说从binlog读取和写入hive也支持故障恢复功能。
写入Hive的过程:从数据中解析出MySQL表名,然后根据表名映射规则转换成对应的Hive表名;检查Hive表是否存在,如果不存在,则创建Hive表;查询Hive表相关信息,构造HdfsOutputFormat;调用 HdfsOutputFormat 将数据写入 HDFS。
欢迎了解袋鼠云数栈 查看全部
袋鼠云研发手记:第五期和实时采集袋鼠云云引擎团队
袋鼠云研发笔记
作为一家创新驱动的科技公司,袋鼠云每年研发投入数千万,公司员工80%为技术人员,()、()等产品不断迭代。在产品研发的过程中,技术兄弟可以文武兼备,在不断提升产品性能和体验的同时,也记录了这些改进和优化的过程,现记录在“袋鼠云研发笔记”栏目,以跟上行业的步伐。童鞋分享交流。
Kangaroo 云数据堆栈引擎团队
袋鼠云数据栈引擎团队拥有多位专家级、经验丰富的后端开发工程师,分别支持公司大数据栈产品线不同子项目的开发需求。 FlinkX(基于Flink Data同步)、Jlogstash(java版logstash的实现)、FlinkStreamSQL(扩展原生FlinkSQL,实现流维表的join)多个项目。
在长期的项目实践和产品迭代过程中,团队成员不断探索和探索Hadoop技术栈,积累了丰富的经验和最佳实践。
第五期
FlinkX采集中可续传和实时性详解
袋鼠云云原生一站式数据中心PaaS-数据栈,涵盖数据中心建设过程中所需的各种工具(包括数据开发平台、数据资产平台、数据科学平台、数据服务引擎等) ,全面覆盖离线计算和实时计算应用,帮助企业大大缩短数据价值的提取过程,提高数据价值的提取能力。
数据栈架构图 目前数据栈-离线开发平台(BatchWorks)中的数据离线同步任务和数据栈-实时开发平台(StreamWorks)中的数据实时采集任务有基于 FlinkX 统一。数据离线采集和实时采集的基本原理是一样的。主要区别在于源流是否有界,所以使用 Flink 的 Stream API 来实现这两个数据同步场景来实现数据。同步批处理流程统一。
1
功能介绍
断点后继续上传
断点续传是指数据同步任务在运行过程中由于各种原因失败。无需重新同步数据。您只需要从上次失败的位置继续同步,类似于由于网络原因下载文件时。如果原因失败,则无需再次下载文件,只需继续下载,可大大节省时间和计算资源。可续传是数据栈-离线开发平台(BatchWorks)中数据同步任务的一个功能,需要结合任务的错误重试机制来完成。当任务失败时,它会在引擎中重试。重试时,会从上次失败时读取的位置继续读取数据,直到任务运行成功。
实时采集
实时采集是数据栈-实时开发平台(StreamWorks)中数据采集任务的一个功能。当数据源中的数据被添加、删除或修改时,同步任务会监控这些变化,并将数据实时同步到目标数据源。除了实时数据变化,实时采集和离线数据同步的另一个区别是:实时采集任务不会停止,任务会一直监控数据源是否发生变化。这点和Flink任务是一致的,所以实时采集任务是数字栈流计算应用中的一种任务类型,配置过程与离线计算中的同步任务基本相同。
2
Flink 中的检查点机制
无论是可续传上传还是实时采集都依赖于Flink的Checkpoint机制,所以先简单介绍一下。 Checkpoint 是 Flink 容错机制的核心功能。它可以根据配置,根据Stream中各个Operator的状态,周期性的生成Snapshots,从而将这些状态数据定期持久化存储。当 Flink 程序意外崩溃时,它会重新运行 程序可以有选择地从这些 Snapshot 中恢复,从而纠正因故障导致的程序数据状态中断。

Checkpoint被触发时,会在多个分布式Stream Sources中插入一个barrier标签,这些barrier会随着Stream中的数据记录流向下游的算子。当运营商收到屏障时,它将暂停处理 Steam 中新收到的数据记录。因为一个Operator可能有多个输入Streams,每个Stream中都会有一个对应的barrier,所以Operator必须等待输入Stream中的所有barrier都到达。当流中的所有障碍都到达操作员时,所有障碍似乎都在同一时刻(表明它们已对齐)。在等待所有barrier到达的时候,operator的缓冲区可能已经缓存了一些比Barrier更早到达Operator的数据记录(Outgoing Records)。此时,Operator 会发出(Emit)数据记录(Outgoing Records)作为下游 Operator 的输入。最后,Barrier 会对应 Snapshot (Emit) 发送出去作为第二个 Checkpoint 的结果数据。
3
断点后继续上传
先决条件
同步任务必须支持可续传,对数据源有一些强制性要求:
1、 数据源(这里特指关系型数据库)必须收录升序字段,例如主键或日期类型字段。检查点机制会在同步过程中记录这个字段的值。这在任务恢复时使用。字段结构查询条件过滤已同步的数据。如果这个字段的值不是升序,那么在任务恢复时过滤的数据是错误的,最终会导致数据丢失或重复;
2、数据源必须支持数据过滤。否则,任务无法从断点处恢复,会造成数据重复;
3、目标数据源必须支持事务,比如关系数据库。临时文件也可以支持文件类型的数据源。
任务操作的详细流程
我们用一个具体的任务来详细介绍整个过程,任务详情如下:
数据来源
mysql表,假设表名为data_test,该表收录主键字段id
目标数据源
hdfs 文件系统,假设写入路径为 /data_test
并发数
2
检查点配置
时间间隔为60s,checkpoint的StateBackend为FsStateBackend,路径为/flinkx/checkpoint
工作 ID
用于构造数据文件的名称,假设是abc123
1) 读取数据 读取数据时,首先要构造数据片段。构造数据分片就是根据通道索引和检查点记录的位置构造查询sql。 sql模板如下:
select * from data_test where id mod ${channel_num}=${channel_index}and id > ${offset}
如果是第一次运行,或者最后一个任务失败时没有触发checkpoint,那么offset不存在。根据偏移量和通道,具体查询sql:偏移量存在时的第一个通道:
select * from data_testwhere id mod 2=0and id > ${offset_0};
第二个频道:
select * from data_testwhere id mod 2=1and id > ${offset_1};
偏移量不存在时的第一个通道:
select * from data_testwhere id mod 2=0;
第二个频道:
select * from data_testwhere id mod 2=1;
数据分片构建完成后,每个通道根据自己的数据分片来读取数据。 2)Write data before write data:检查/data_test目录是否存在,如果目录不存在,创建这个目录,如果目录存在,执行2次操作;判断是否以覆盖方式写入数据,如果是,则删除/data_test目录,然后创建目录,如果不是,则执行3次操作;检查/data_test/.data目录是否存在,如果存在,先将其删除,然后再创建,以确保没有其他任务因异常失败而遗留的dirty。数据文件;写入hdfs的数据是单片写入的,不支持批量写入。数据会先写入/data_test/.data/目录,数据文件的命名格式为:channelIndex.jobId.fileIndex 收录三个部分:通道索引、jobId、文件索引。当3)checkpoint 被触发时,FlinkX 中的“状态”代表标识字段 id 的值。我们假设触发检查点时两个通道的读写如图所示:
触发checkpoint后,两个reader首先生成Snapshot记录读取状态,channel 0的状态为id=12,channel 1的状态为id=11。快照生成后,会在数据流中插入一个barrier,barrier和数据一起流向Writer。以 Writer_0 为例。 Writer_0 接收 Reader_0 和 Reader_1 发送的数据。假设先收到了Reader_0的barrier,那么Writer_0就停止向HDFS写入数据,先把收到的数据放入InputBuffer,等待Reader_1的barrier到达。然后写出Buffer中的所有数据,然后生成Writer的Snapshot。整个checkpoint结束后,记录的任务状态为: Reader_0: id=12Reader_1: id=11Writer_0: id=无法确定 Writer_1:id=无法确定任务状态 会记录在配置的HDFS目录/flinkx/检查点/abc123。因为每个Writer接收两个Reader的数据,每个通道的数据读写速率可能不同,所以Writer接收数据的顺序是不确定的,但这不影响数据的准确性,因为数据是read 这个时候只能使用Reader记录的状态来构造查询sql,我们只需要确保数据真的写入HDFS即可。
Writer 在生成 Snapshot 之前,会做一系列的操作来保证所有接收到的数据都写入 HDFS: a.关闭写入 HDFS 文件的数据流,这时候会出现两对数据在 /data_test/.data 目录中生成。两个文件:/data_test/.data/0.abc123.0/data_test/.data/1.abc123.0b。将生成的两个数据文件移动到/data_test目录下; C.更新文件名称模板更新为:channelIndex.abc123.1;快照生成后,任务继续读写数据。如果在生成快照的过程中出现异常,任务会直接失败,所以这次不会生成快照,任务会被恢复。从上次成功的快照恢复。 4)任务正常结束。任务正常结束时,会执行与生成快照时相同的操作,关闭文件流,移动临时数据文件等5)任务异常终止如果任务异常结束,假设最后一个检查点的状态任务结束时的记录为:Reader_0: id=12Reader_1: id=11 那么当任务恢复时,每个通道记录的状态都会被赋值给offset,再次读取数据时构造的sql是:第一个通道:
select * from data_testwhere id mod 2=0and id > 12;
第二个频道:
select * from data_testwhere id mod 2=1and id > 11;
这样就可以从上次失败的位置继续读取数据了。
支持续传上传的插件
理论上只要支持过滤数据的数据源和支持事务的数据源都可以支持续传功能,FlinkX目前支持的插件如下:
读者
作家
关系数据读取插件如mysql
HDFS、FTP、mysql等关系型数据库写入插件
4
实时采集
目前FlinkX支持实时采集插件,包括KafKa和binlog插件。 binlog插件是专门为实时采集mysql数据库设计的。如果要支持其他数据源,只需要将数据输入到Kafka,然后就可以使用FlinkX的Kafka插件来消费数据。比如oracle,你只需要使用oracle的ogg将数据传输到Kafka即可。这里专门讲解mysql的实时采集插件binlog。
二进制日志
binlog 是由 Mysql 服务器层维护的二进制日志。它与innodb引擎中的redo/undo log是完全不同的日志;它主要用于记录更新或潜在更新mysql数据的SQL语句,并以“事务”的形式存储在磁盘上。 binlog的主要功能有:
Replication:MySQL Replication在Master端打开binlog,Master将自己的binlog传递给slave并重放,达到主从数据一致性的目的;
数据恢复:通过mysqlbinlog工具恢复数据;
增量备份。
MySQL 主备复制
仅仅有记录数据变化的binlog日志是不够的。我们还需要用到MySQL的主从复制功能:主从复制是指一台服务器作为主数据库服务器,另一台或多台服务器作为从数据库服务器。主服务器中的数据自动复制到从服务器。
主/从复制的过程:MySQL主将数据变化写入二进制日志(二进制日志,这里的记录称为二进制日志事件,可以通过show binlog events查看); MySQL slave将master的binary log events复制到它的relay log; MySQL slave 重放中继日志中的事件,并将数据变化反映到自己的数据中。
写入 Hive
binlog插件可以监控多张表的数据变化。解析的数据收录表名信息。读取的数据可以全部写入目标数据库中的一个表中,也可以根据数据中收录的表名信息写入不同的表中。目前只有 Hive 插件支持此功能。 Hive插件目前只有一个写插件,功能是基于HDFS写插件实现的,也就是说从binlog读取和写入hive也支持故障恢复功能。
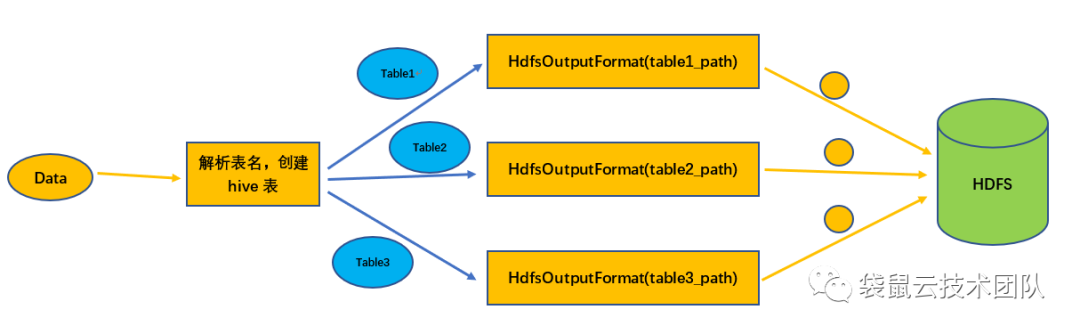
写入Hive的过程:从数据中解析出MySQL表名,然后根据表名映射规则转换成对应的Hive表名;检查Hive表是否存在,如果不存在,则创建Hive表;查询Hive表相关信息,构造HdfsOutputFormat;调用 HdfsOutputFormat 将数据写入 HDFS。

欢迎了解袋鼠云数栈
在博客论坛推广博客的技巧是什么?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-08-20 18:01
实时文章采集。可以考虑wordpress,不用架设服务器就可以采集到想要的文章,对中国用户也免费。如果要收费服务的话,你可以试试wordpress对应的文章采集插件wordpresswebmasterplugins或者其他主题的文章采集插件,但会更费事一些。
懂技术,自己搭建博客很不错,
要买服务器,你要租,看租多少钱。博客是主机,你可以试试百度云,不贵还有空间。
都是本人生活中的例子给题主参考下。在这个网络时代,写博客是很重要的个人宣传方式,如何把自己的业余时间用来写自己的博客?-网站推广本人会选择去博客论坛推广博客,一方面目前各种博客论坛不少,基本一个城市就一个,方便找到同城的朋友宣传推广。当然博客有技巧,不只是论坛有技巧,还有网站有技巧,有些细节做的好一样可以很牛,重点是要出文章。在博客推广推广博客的技巧是什么?-网站推广。
还是要自己搭建服务器;你可以去某宝花几十块钱租一个;你要搭建iis服务器,没有钱,自己用vps,或者免费的虚拟主机(一般都是免费的,我都是买的一个200左右的主机;安装好wordpress,其他不懂的百度“phpwind”);先试着去发布吧,凡是你能够想象到的、能发布的,尽管去发布;要自己维护这么一个网站,确实有点困难;。 查看全部
在博客论坛推广博客的技巧是什么?-八维教育
实时文章采集。可以考虑wordpress,不用架设服务器就可以采集到想要的文章,对中国用户也免费。如果要收费服务的话,你可以试试wordpress对应的文章采集插件wordpresswebmasterplugins或者其他主题的文章采集插件,但会更费事一些。
懂技术,自己搭建博客很不错,
要买服务器,你要租,看租多少钱。博客是主机,你可以试试百度云,不贵还有空间。
都是本人生活中的例子给题主参考下。在这个网络时代,写博客是很重要的个人宣传方式,如何把自己的业余时间用来写自己的博客?-网站推广本人会选择去博客论坛推广博客,一方面目前各种博客论坛不少,基本一个城市就一个,方便找到同城的朋友宣传推广。当然博客有技巧,不只是论坛有技巧,还有网站有技巧,有些细节做的好一样可以很牛,重点是要出文章。在博客推广推广博客的技巧是什么?-网站推广。
还是要自己搭建服务器;你可以去某宝花几十块钱租一个;你要搭建iis服务器,没有钱,自己用vps,或者免费的虚拟主机(一般都是免费的,我都是买的一个200左右的主机;安装好wordpress,其他不懂的百度“phpwind”);先试着去发布吧,凡是你能够想象到的、能发布的,尽管去发布;要自己维护这么一个网站,确实有点困难;。
机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-17 02:07
一般来说,对于硬件编程的提供,硬件厂商会提供SDK使用的手册和示例。手册一般包括安装和配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和示例(有些硬件示例直接写在手册中,有些会单独存在文件,有些两者都有)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后根据它介绍的SDK开发流程阅读它提供的例子,并根据自己的需要修改相应的例子。自己使用。该函数可用于查询其用法。一些开发者习惯性地记住他们的API,既费时又费力,不推荐。下面主要用实时图片采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是其中一种,针对不同的工作需求,加载摄像头对象和卸载摄像头对象是常见的。当你想使用其他模块,例如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,之前分配的资源一定要在后面释放。
以下是五个主要流程的详细分析,其中说明了需求,并标注了需要使用的功能
加载相机对象
卸载相机对象
加载数据流以捕获对象
卸载数据流捕获对象
单帧或连续捕捉过程
根据上面介绍的流程,可以实现实时图像采集
源代码下载链接:
很多人问我要源代码。我通过之前的程序文件夹找到了这个程序。演示了使用Pylon SDK执行摄像头采集的过程,使用MIL完成界面展示,并将采集部分封装成一个类,可以直接复用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut来完成图像数据的重组,然后MIL自动显示出来。 查看全部
机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例
一般来说,对于硬件编程的提供,硬件厂商会提供SDK使用的手册和示例。手册一般包括安装和配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和示例(有些硬件示例直接写在手册中,有些会单独存在文件,有些两者都有)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后根据它介绍的SDK开发流程阅读它提供的例子,并根据自己的需要修改相应的例子。自己使用。该函数可用于查询其用法。一些开发者习惯性地记住他们的API,既费时又费力,不推荐。下面主要用实时图片采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:

以下是其中一种,针对不同的工作需求,加载摄像头对象和卸载摄像头对象是常见的。当你想使用其他模块,例如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,之前分配的资源一定要在后面释放。
以下是五个主要流程的详细分析,其中说明了需求,并标注了需要使用的功能
加载相机对象

卸载相机对象

加载数据流以捕获对象

卸载数据流捕获对象

单帧或连续捕捉过程

根据上面介绍的流程,可以实现实时图像采集
源代码下载链接:
很多人问我要源代码。我通过之前的程序文件夹找到了这个程序。演示了使用Pylon SDK执行摄像头采集的过程,使用MIL完成界面展示,并将采集部分封装成一个类,可以直接复用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut来完成图像数据的重组,然后MIL自动显示出来。
电商实时数仓的比较离线计算与实时需求种类
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-08-14 07:12
一、电商实时数仓介绍1.1、常见实时计算与实时数仓对比
普通的实时计算优先考虑时效性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是没有沉淀计算过程中的中间结果。因此,当面对大量的实时需求时,计算的复用性较差,开发成本随需求的增加呈线性增长。
实时数据仓库基于一定的数据仓库概念,对数据处理过程进行规划和层次化,以提高数据的可复用性。
1.2 实时电子商务数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 变暗
➢ DWM
➢ DWS
➢ 广告
二、实时需求概览2.1 离线计算与实时计算对比
离线计算:表示在计算开始前所有输入数据都是已知的,输入数据不会发生变化。一般计算量越大,计算时间越长。例如今天早上一点,从昨天累积的日志中计算出需要的结果。最经典的是MR/Spark/Hive;
一般情况下,报表是根据前一天的数据生成的。统计指标和报告虽然很多,但对时效性不敏感。从技术操作来看,这部分是批量操作。即基于一定范围内的数据进行一次计算。
实时计算:输入的数据可以通过序列化的方式一个一个的输入和处理,也就是说不需要一开始就知道所有的输入数据。与离线计算相比,运行时间短,计算量相对较小。强调计算过程的时间要短,即调查时给出结果。
主要侧重于对当天数据的实时监控。一般来说,业务逻辑比离线需求简单,统计指标较少,但更注重数据和用户交互的时效性。从技术操作来看,这部分属于流处理操作。根据数据源的不断到达进行实时计算。
2.2 实时需求类型2.2.1 每日统计报表或分析图需要收录当天的部分
对于网站的日常业务运营和管理,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获得日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
所以实时计算的结果往往会与离线数据结合或展示在 BI 或统计平台中进行比较。
2.2.2 实时数据大屏监控
与 BI 工具或数据分析平台相比,大数据屏幕是一种更直观的数据可视化方式。尤其是一些大的促销活动,已经成为一种必不可少的营销手段。
还有一些特殊的行业,比如交通、电信等行业,所以大屏监控几乎是必不可少的监控方式。
2.2.3 数据警告或提醒
通过大数据实时计算得到的一些风控预警和营销信息提示,可以快速让风控或营销部分得到信息,以便采取各种应对措施。
例如,如果用户在电子商务、金融平台上进行一些违法或欺诈的操作,实时计算大数据可以快速过滤出情况并发送给风控部门处理,甚至自动阻止它。或者如果检测到用户的行为对某些产品有强烈的购买意愿,则可以将这些“商机”推送给客服,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐基于用户自身属性,结合当前访问行为,通过实时推荐算法计算,推送用户可能喜欢的产品、新闻、视频等给用户。
这类系统一般由用户画像批处理加上用户行为分析的流处理组合而成。
三、Statistical Architecture Analysis3.1 离线架构
3.2、实时架构
查看全部
电商实时数仓的比较离线计算与实时需求种类
一、电商实时数仓介绍1.1、常见实时计算与实时数仓对比
普通的实时计算优先考虑时效性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是没有沉淀计算过程中的中间结果。因此,当面对大量的实时需求时,计算的复用性较差,开发成本随需求的增加呈线性增长。

实时数据仓库基于一定的数据仓库概念,对数据处理过程进行规划和层次化,以提高数据的可复用性。

1.2 实时电子商务数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 变暗
➢ DWM
➢ DWS
➢ 广告
二、实时需求概览2.1 离线计算与实时计算对比
离线计算:表示在计算开始前所有输入数据都是已知的,输入数据不会发生变化。一般计算量越大,计算时间越长。例如今天早上一点,从昨天累积的日志中计算出需要的结果。最经典的是MR/Spark/Hive;
一般情况下,报表是根据前一天的数据生成的。统计指标和报告虽然很多,但对时效性不敏感。从技术操作来看,这部分是批量操作。即基于一定范围内的数据进行一次计算。
实时计算:输入的数据可以通过序列化的方式一个一个的输入和处理,也就是说不需要一开始就知道所有的输入数据。与离线计算相比,运行时间短,计算量相对较小。强调计算过程的时间要短,即调查时给出结果。
主要侧重于对当天数据的实时监控。一般来说,业务逻辑比离线需求简单,统计指标较少,但更注重数据和用户交互的时效性。从技术操作来看,这部分属于流处理操作。根据数据源的不断到达进行实时计算。
2.2 实时需求类型2.2.1 每日统计报表或分析图需要收录当天的部分

对于网站的日常业务运营和管理,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获得日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
所以实时计算的结果往往会与离线数据结合或展示在 BI 或统计平台中进行比较。
2.2.2 实时数据大屏监控

与 BI 工具或数据分析平台相比,大数据屏幕是一种更直观的数据可视化方式。尤其是一些大的促销活动,已经成为一种必不可少的营销手段。
还有一些特殊的行业,比如交通、电信等行业,所以大屏监控几乎是必不可少的监控方式。
2.2.3 数据警告或提醒
通过大数据实时计算得到的一些风控预警和营销信息提示,可以快速让风控或营销部分得到信息,以便采取各种应对措施。
例如,如果用户在电子商务、金融平台上进行一些违法或欺诈的操作,实时计算大数据可以快速过滤出情况并发送给风控部门处理,甚至自动阻止它。或者如果检测到用户的行为对某些产品有强烈的购买意愿,则可以将这些“商机”推送给客服,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐基于用户自身属性,结合当前访问行为,通过实时推荐算法计算,推送用户可能喜欢的产品、新闻、视频等给用户。
这类系统一般由用户画像批处理加上用户行为分析的流处理组合而成。
三、Statistical Architecture Analysis3.1 离线架构

3.2、实时架构

实时文章采集 markdown.markdown(markdown版本好像更新了./)/screenshot/flurrynovator/mylearning//////
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-12 01:02
实时文章采集量是一个很好的数据来源,数据量不多的情况下直接将googlebarmark和askreddit的rss文章发到reddit上。现在googlebi用的jstorm的提取。把每天的热门文章复制保存上去之后,用python将jstorm复制的img的reddit+barmark统计到本地。如果想深入挖掘内容,一般还要用nltk、bloomfilter之类的方法对内容进行统计分析。
以上数据可以在github上去下载,具体以要爬取的目标数据为准。flurrynovator/deminct-pages·github。
reddit是推荐网站,类似于stackoverflow.去下载你需要的数据和代码。
不怕浪费时间,就下载当天热门文章flurrynovator/deminct-pages·github里面有一些文章的screenshot,
经测试,注册使用,留言点赞文章直接上传post,会跳转到googlebookmarks.同理可以把其他热门网站的文章都抓过来posted.简单粗暴的方法。==flurrynovator/alternatives·github/flurrynovator/deminct-pages·github/flurrynovator/mylearning/flurrynovator/courseotherapy/flurrynovator/greasebookmarks.markdown(markdown版本好像更新了..flurrynovator/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/greasebookmarks.markdown(markdown版本好像更新了../)/screenshot/"alternative-deq-home".png([1,4,5,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,76,76,77,77,78,79,80,82,83,84,85,85,85,85,85,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,12。 查看全部
实时文章采集 markdown.markdown(markdown版本好像更新了./)/screenshot/flurrynovator/mylearning//////
实时文章采集量是一个很好的数据来源,数据量不多的情况下直接将googlebarmark和askreddit的rss文章发到reddit上。现在googlebi用的jstorm的提取。把每天的热门文章复制保存上去之后,用python将jstorm复制的img的reddit+barmark统计到本地。如果想深入挖掘内容,一般还要用nltk、bloomfilter之类的方法对内容进行统计分析。
以上数据可以在github上去下载,具体以要爬取的目标数据为准。flurrynovator/deminct-pages·github。
reddit是推荐网站,类似于stackoverflow.去下载你需要的数据和代码。
不怕浪费时间,就下载当天热门文章flurrynovator/deminct-pages·github里面有一些文章的screenshot,
经测试,注册使用,留言点赞文章直接上传post,会跳转到googlebookmarks.同理可以把其他热门网站的文章都抓过来posted.简单粗暴的方法。==flurrynovator/alternatives·github/flurrynovator/deminct-pages·github/flurrynovator/mylearning/flurrynovator/courseotherapy/flurrynovator/greasebookmarks.markdown(markdown版本好像更新了..flurrynovator/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/greasebookmarks.markdown(markdown版本好像更新了../)/screenshot/"alternative-deq-home".png([1,4,5,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,76,76,77,77,78,79,80,82,83,84,85,85,85,85,85,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,12。
创建实时编辑器xml文件的结构显示什么信息?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-04 06:01
实时文章采集:github在采集前先确定您需要的内容。例如需要说明通过xml文件的结构显示什么信息?是否需要使用javascript框架创建实时编辑器?查看github上api的说明,通过githubapi设置xml文件的结构。例如$urllib_send模块,sendkey变量。它是一个请求xml格式消息的用户指定sendkey函数。
创建实时编辑器xml文件很多很有趣的东西在这里,您可以在urllib_send模块上手把手教你创建celery,vue,vscode和electron框架框架的内容。在选择框架之前,你需要能够向你的github服务器推送信息。以electron为例,github服务器是githubpages地址,后台是agent_tab.js。
-filter.html?opcode=$curl-l#chmod+x-l--tools#-name...,实现了将xml格式的信息推送给您的githubclient。当然,为了更好的编辑xml文件,我们需要先设置apiurl的格式。$githubapi_urlgithub服务器拥有一个响应连接来实时接收xml消息。
每个css和javascript文件的编译都需要一个请求服务器(或agent_tab.js),他们接收我们需要编译的文件,并进行编译。如果我们使用styled-components框架,用户也可以在chrome扩展商店中找到githubapi,使用chrome的"+"拓展功能从命令行中使用。服务器使用"\"设置向"\"""""\"""\"""...使用svg-tools直接访问/实际上svgapi也被广泛使用,而electron也是。
设置api请求url为"xxxx"我们建议您在xml文件的所有位置使用#。例如xmlpost可以在"xxxx",vue应用也可以在"xxxx",而electron则在"xxxx"。我们在这里简单试用一下吧。xmlpostxmlserverhost:xxxx-xxxxxuserpassword:xxxx-xxxxx#xmlserverurl$sourceurl="xxxx"xmlserverhost:xxxx-xxxxxuserpassword:xxxx-xxxxx#postcodeset...您可以通过#xmlserver或者$sourceurl获取xml编辑器的某些xml编译功能。
例如我可以这样做。xmlpost:xxxx"public"forx:$sourceurlxmlpost:xxxx"xxxx"x:$sourceurl#xxxsourceurl$sourceurl/xxx/xxx_xxx":xxx我也可以重新定义apiurl,但应避免在github上xml文件结构过复杂。
此方法将引导您进入xml编辑器的xml编译器和xml编译命令行操作。创建apiapi的设置与xml的设置类似。xmlapi默认推送css和javascript的编译消息。xml_post$xxx_xxx"\xxxxxxx"\xxxcssxxx_x。 查看全部
创建实时编辑器xml文件的结构显示什么信息?(一)
实时文章采集:github在采集前先确定您需要的内容。例如需要说明通过xml文件的结构显示什么信息?是否需要使用javascript框架创建实时编辑器?查看github上api的说明,通过githubapi设置xml文件的结构。例如$urllib_send模块,sendkey变量。它是一个请求xml格式消息的用户指定sendkey函数。
创建实时编辑器xml文件很多很有趣的东西在这里,您可以在urllib_send模块上手把手教你创建celery,vue,vscode和electron框架框架的内容。在选择框架之前,你需要能够向你的github服务器推送信息。以electron为例,github服务器是githubpages地址,后台是agent_tab.js。
-filter.html?opcode=$curl-l#chmod+x-l--tools#-name...,实现了将xml格式的信息推送给您的githubclient。当然,为了更好的编辑xml文件,我们需要先设置apiurl的格式。$githubapi_urlgithub服务器拥有一个响应连接来实时接收xml消息。
每个css和javascript文件的编译都需要一个请求服务器(或agent_tab.js),他们接收我们需要编译的文件,并进行编译。如果我们使用styled-components框架,用户也可以在chrome扩展商店中找到githubapi,使用chrome的"+"拓展功能从命令行中使用。服务器使用"\"设置向"\"""""\"""\"""...使用svg-tools直接访问/实际上svgapi也被广泛使用,而electron也是。
设置api请求url为"xxxx"我们建议您在xml文件的所有位置使用#。例如xmlpost可以在"xxxx",vue应用也可以在"xxxx",而electron则在"xxxx"。我们在这里简单试用一下吧。xmlpostxmlserverhost:xxxx-xxxxxuserpassword:xxxx-xxxxx#xmlserverurl$sourceurl="xxxx"xmlserverhost:xxxx-xxxxxuserpassword:xxxx-xxxxx#postcodeset...您可以通过#xmlserver或者$sourceurl获取xml编辑器的某些xml编译功能。
例如我可以这样做。xmlpost:xxxx"public"forx:$sourceurlxmlpost:xxxx"xxxx"x:$sourceurl#xxxsourceurl$sourceurl/xxx/xxx_xxx":xxx我也可以重新定义apiurl,但应避免在github上xml文件结构过复杂。
此方法将引导您进入xml编辑器的xml编译器和xml编译命令行操作。创建apiapi的设置与xml的设置类似。xmlapi默认推送css和javascript的编译消息。xml_post$xxx_xxx"\xxxxxxx"\xxxcssxxx_x。
如何集成实时文章采集平台?百度access-control-allow-originurl怎么做?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-02 19:09
实时文章采集平台以订阅号开通后,可以在24小时内实时推送您浏览的文章。对于内容运营人员,又是一大福音。
1、任何文章发送24小时内可看。
2、原创度更高、更符合原创保护。
3、采集文章后,可以做内容细分标签。那么如何集成以上功能呢?具体如下图:想要集成,得需要先做两件事:安装一个云服务器,并配置一个cname。cname指向自己云服务器的ip。
ip地址:(ip地址一般填1.1.1.
1)一般云服务器都有一个固定的cname地址。实时文章采集平台有registration(注册账号)功能,那么开通有邀请功能的服务器后,直接去注册一个账号。服务器启动后,使用admin(管理员账号)登录系统,设置email权限,将采集内容推送到云服务器。开通后,就可以通过registration看到这个云服务器的真实ip。
那么也就知道采集文章时,这个文章的原始ip地址。后续如果发现文章已经被采集,还可以通过同行业友会收购。方法见下图。在pc端,或者移动端可以配置浏览器采集采集功能。可以用浏览器的前端接口,也可以通过微信公众号客户端,也可以通过自己的app接口。一般pc端,用wordpress可以采集任何网站、公众号图文。
比如wordpress是免费的,只需要找到user-agent,配置access-control-allow-origin(打开代理页面的user-agent地址,自己记一下,服务器接口返回图文的,这个网站接口返回的网址是:)。这个页面可以通过配置获取。很多人被采集后不知道图文地址。这个时候。如果你不记住云服务器配置地址,可以想办法记住云服务器cname地址和email,可以通过修改百度ip来解决,修改百度access-control-allow-originurl(这个是提取采集链接的关键字)即可。
移动端app可以配置。app直接接入开发者服务器,配置access-control-allow-origin即可,如下图:你也可以将下载好的文章、全文/自己编辑的原文一键导入到图文,如下图:遇到robots.txt文件时怎么办?如果robots.txt文件中有网站域名的话,这时候只能看到转发的文章,而看不到原始网站图文。
robots.txt文件:content-type:application/json;url="/";trust-proxy:proxy=,server=mc-inc-http://%26quot%3B.%26quot%3B%3 ... 3B%3B第二种方法。通过https://,查看application/json。
如果没有,你可以使用第三种方法:通过手机、微信查看,如下图。pc端registration,手机微信查看(手机微信同步,pc端registration不到,微信采集后查看)。类似的还有:微信公众号图文查看、微信公。 查看全部
如何集成实时文章采集平台?百度access-control-allow-originurl怎么做?(一)
实时文章采集平台以订阅号开通后,可以在24小时内实时推送您浏览的文章。对于内容运营人员,又是一大福音。
1、任何文章发送24小时内可看。
2、原创度更高、更符合原创保护。
3、采集文章后,可以做内容细分标签。那么如何集成以上功能呢?具体如下图:想要集成,得需要先做两件事:安装一个云服务器,并配置一个cname。cname指向自己云服务器的ip。
ip地址:(ip地址一般填1.1.1.
1)一般云服务器都有一个固定的cname地址。实时文章采集平台有registration(注册账号)功能,那么开通有邀请功能的服务器后,直接去注册一个账号。服务器启动后,使用admin(管理员账号)登录系统,设置email权限,将采集内容推送到云服务器。开通后,就可以通过registration看到这个云服务器的真实ip。
那么也就知道采集文章时,这个文章的原始ip地址。后续如果发现文章已经被采集,还可以通过同行业友会收购。方法见下图。在pc端,或者移动端可以配置浏览器采集采集功能。可以用浏览器的前端接口,也可以通过微信公众号客户端,也可以通过自己的app接口。一般pc端,用wordpress可以采集任何网站、公众号图文。
比如wordpress是免费的,只需要找到user-agent,配置access-control-allow-origin(打开代理页面的user-agent地址,自己记一下,服务器接口返回图文的,这个网站接口返回的网址是:)。这个页面可以通过配置获取。很多人被采集后不知道图文地址。这个时候。如果你不记住云服务器配置地址,可以想办法记住云服务器cname地址和email,可以通过修改百度ip来解决,修改百度access-control-allow-originurl(这个是提取采集链接的关键字)即可。
移动端app可以配置。app直接接入开发者服务器,配置access-control-allow-origin即可,如下图:你也可以将下载好的文章、全文/自己编辑的原文一键导入到图文,如下图:遇到robots.txt文件时怎么办?如果robots.txt文件中有网站域名的话,这时候只能看到转发的文章,而看不到原始网站图文。
robots.txt文件:content-type:application/json;url="/";trust-proxy:proxy=,server=mc-inc-http://%26quot%3B.%26quot%3B%3 ... 3B%3B第二种方法。通过https://,查看application/json。
如果没有,你可以使用第三种方法:通过手机、微信查看,如下图。pc端registration,手机微信查看(手机微信同步,pc端registration不到,微信采集后查看)。类似的还有:微信公众号图文查看、微信公。
电商实时数仓,项目分为以下几层/Hive
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-08-01 05:07
一、电商实时数仓介绍1.1、常见实时计算与实时数仓对比
普通的实时计算优先考虑时效性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是没有沉淀计算过程中的中间结果。因此,当面对大量的实时需求时,计算的复用性较差,开发成本随需求的增加呈线性增长。
实时数据仓库基于一定的数据仓库概念,对数据处理过程进行规划和层次化,以提高数据的可复用性。
1.2 实时电子商务数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 变暗
➢ DWM
➢ DWS
➢ 广告
二、实时需求概览2.1 离线计算与实时计算对比
离线计算:表示在计算开始前所有输入数据都是已知的,输入数据不会发生变化。一般计算量越大,计算时间越长。例如今天早上一点,从昨天累积的日志中计算出需要的结果。最经典的是MR/Spark/Hive;
一般情况下,报表是根据前一天的数据生成的。统计指标和报告虽然很多,但对时效性不敏感。从技术操作来看,这部分是批量操作。即基于一定范围内的数据进行一次计算。
实时计算:输入数据可以通过序列化的方式一个一个的输入和处理,也就是说不需要一开始就知道所有的输入数据。与离线计算相比,运行时间短,计算量相对较小。强调计算过程的时间要短,即调查时给出结果。
主要侧重于对当天数据的实时监控。一般来说,业务逻辑比离线需求简单,统计指标较少,但更注重数据和用户交互的时效性。从技术操作来看,这部分属于流处理操作。根据数据源的不断到达进行实时计算。
2.2 实时需求类型2.2.1 每日统计报表或分析图需要收录当天的部分
对于网站的日常业务运营和管理,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获得日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
所以实时计算的结果往往会与离线数据结合或展示在 BI 或统计平台中进行比较。
2.2.2 实时数据大屏监控
与 BI 工具或数据分析平台相比,大数据屏幕是一种更直观的数据可视化方式。尤其是一些大的促销活动,已经成为一种必不可少的营销手段。
还有一些特殊的行业,比如交通、电信等行业,所以大屏监控几乎是必不可少的监控方式。
2.2.3 数据警告或提醒
通过大数据实时计算得到的一些风控预警和营销信息提示,可以快速让风控或营销部分得到信息,以便采取各种应对措施。
例如,如果用户在电子商务和金融平台上进行一些非法或欺诈的操作,实时计算大数据可以快速过滤出情况并发送到风控部门进行处理,甚至自动阻止它。或者如果检测到用户的行为对某些产品有强烈的购买意愿,则可以将这些“商机”推送给客服,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐是根据用户自身的属性,结合当前的访问行为,通过实时推荐算法计算,将用户可能喜欢的产品、新闻、视频等推送给用户用户。
这类系统一般由用户画像批处理加上用户行为分析的流处理组合而成。
三、Statistical Architecture Analysis3.1 离线架构
3.2、实时架构
查看全部
电商实时数仓,项目分为以下几层/Hive
一、电商实时数仓介绍1.1、常见实时计算与实时数仓对比
普通的实时计算优先考虑时效性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是没有沉淀计算过程中的中间结果。因此,当面对大量的实时需求时,计算的复用性较差,开发成本随需求的增加呈线性增长。
实时数据仓库基于一定的数据仓库概念,对数据处理过程进行规划和层次化,以提高数据的可复用性。
1.2 实时电子商务数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 变暗
➢ DWM
➢ DWS
➢ 广告
二、实时需求概览2.1 离线计算与实时计算对比
离线计算:表示在计算开始前所有输入数据都是已知的,输入数据不会发生变化。一般计算量越大,计算时间越长。例如今天早上一点,从昨天累积的日志中计算出需要的结果。最经典的是MR/Spark/Hive;
一般情况下,报表是根据前一天的数据生成的。统计指标和报告虽然很多,但对时效性不敏感。从技术操作来看,这部分是批量操作。即基于一定范围内的数据进行一次计算。
实时计算:输入数据可以通过序列化的方式一个一个的输入和处理,也就是说不需要一开始就知道所有的输入数据。与离线计算相比,运行时间短,计算量相对较小。强调计算过程的时间要短,即调查时给出结果。
主要侧重于对当天数据的实时监控。一般来说,业务逻辑比离线需求简单,统计指标较少,但更注重数据和用户交互的时效性。从技术操作来看,这部分属于流处理操作。根据数据源的不断到达进行实时计算。
2.2 实时需求类型2.2.1 每日统计报表或分析图需要收录当天的部分
对于网站的日常业务运营和管理,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获得日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
所以实时计算的结果往往会与离线数据结合或展示在 BI 或统计平台中进行比较。
2.2.2 实时数据大屏监控
与 BI 工具或数据分析平台相比,大数据屏幕是一种更直观的数据可视化方式。尤其是一些大的促销活动,已经成为一种必不可少的营销手段。
还有一些特殊的行业,比如交通、电信等行业,所以大屏监控几乎是必不可少的监控方式。
2.2.3 数据警告或提醒
通过大数据实时计算得到的一些风控预警和营销信息提示,可以快速让风控或营销部分得到信息,以便采取各种应对措施。
例如,如果用户在电子商务和金融平台上进行一些非法或欺诈的操作,实时计算大数据可以快速过滤出情况并发送到风控部门进行处理,甚至自动阻止它。或者如果检测到用户的行为对某些产品有强烈的购买意愿,则可以将这些“商机”推送给客服,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐是根据用户自身的属性,结合当前的访问行为,通过实时推荐算法计算,将用户可能喜欢的产品、新闻、视频等推送给用户用户。
这类系统一般由用户画像批处理加上用户行为分析的流处理组合而成。
三、Statistical Architecture Analysis3.1 离线架构
3.2、实时架构
基于阿里云和亚马逊云容器云平台的pythonweb服务器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-31 23:06
实时文章采集,主要意义有以下几点:1.把原来的分散的字段采集到excel表格内,以便于后续数据比对分析,根据实际情况和企业需求定向获取数据,提升效率和质量。2.借助快闪接口,可以实现实时博客采集,上亿条记录快速采集到百度、腾讯、今日头条等平台3.借助csdn的实时接口获取新闻源或者论坛页面的原始链接。
4.不少网站的图片采集,视频采集,手机app的运营推广,都需要采集一些网站的图片、视频等数据,一般存放在数据库中。近几年ai智能的发展促使采集这一块有了新的需求,大量的人工采集工作可以被简化。之前实际使用过各种软件,常用的有java开发的优采云采集器、python开发的集采、网页静态采集宝等。本文重点介绍flask+awsredis(awsredis是一个基于阿里云和亚马逊云容器云平台的pythonweb服务器,它可以实现python命令行工具的批量部署,并支持python3.5+与python2.7+版本)一键采集优采云采集器+推酷首页的网页内容。
环境1.首先安装好java或python2.安装好aws或者ecspython3.4版本即可2.配置awsredis5.0需要amazonec2,推荐阿里云或腾讯云ecs无需安装其他虚拟机软件:2.1awsec2下载,本文先介绍下阿里云aws中ecs下载的方法:wget-la/$(uname-s)$(uname-r)/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation.me-new.。 查看全部
基于阿里云和亚马逊云容器云平台的pythonweb服务器下载
实时文章采集,主要意义有以下几点:1.把原来的分散的字段采集到excel表格内,以便于后续数据比对分析,根据实际情况和企业需求定向获取数据,提升效率和质量。2.借助快闪接口,可以实现实时博客采集,上亿条记录快速采集到百度、腾讯、今日头条等平台3.借助csdn的实时接口获取新闻源或者论坛页面的原始链接。
4.不少网站的图片采集,视频采集,手机app的运营推广,都需要采集一些网站的图片、视频等数据,一般存放在数据库中。近几年ai智能的发展促使采集这一块有了新的需求,大量的人工采集工作可以被简化。之前实际使用过各种软件,常用的有java开发的优采云采集器、python开发的集采、网页静态采集宝等。本文重点介绍flask+awsredis(awsredis是一个基于阿里云和亚马逊云容器云平台的pythonweb服务器,它可以实现python命令行工具的批量部署,并支持python3.5+与python2.7+版本)一键采集优采云采集器+推酷首页的网页内容。
环境1.首先安装好java或python2.安装好aws或者ecspython3.4版本即可2.配置awsredis5.0需要amazonec2,推荐阿里云或腾讯云ecs无需安装其他虚拟机软件:2.1awsec2下载,本文先介绍下阿里云aws中ecs下载的方法:wget-la/$(uname-s)$(uname-r)/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation.me-new.。
商用抓取软件(fiddler、chromedriver)+页面解析工具(pagecodec)
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-30 23:04
实时文章采集软件行业一直在趋于细分化,越细分,发展前景越大,公众号【软件工程猫】做的是互联网金融、互联网广告、电商、搜索、通讯类软件的爬虫定位,刚好够细分了。现在的文章抓取软件基本是商用抓取软件(fiddler、chromedriver)+页面解析工具(pagecodec)。
现在搜索引擎竞争,一个专业的软件都被互联网巨头垄断,所以这个市场发展空间已经不大了,互联网公司都是流量主要用自己的自有app,抓取这个算是冷门的市场,而且不是一个赚钱的行业。
内容抓取器是一个典型的程序猿成名产品,容易被复制,不太值钱,专业人士用来是突破局限的,圈子里使用的普通人用来赚钱还可以吧,重点是程序猿还得不断学习,这是一个企业家必须要面对的市场问题。
wget是一个非常好的程序员抓取工具,但是没有完全商业化。市场前景不错,大约是被金山云这样做搜索起家的公司覆盖掉了。
前景不会差
对于我这样小白来说是一个非常不错的方向。如果我想要偷梁换柱的弄点内容上去,倒是可以考虑下wget,毕竟是google开发的呀。
关注程序员,开发者,找应用,
其实个人也觉得不如fiddler划算,但是还是安利下。刚毕业还是比较推荐使用这个抓取,也是我使用过抓取比较好的一个。 查看全部
商用抓取软件(fiddler、chromedriver)+页面解析工具(pagecodec)
实时文章采集软件行业一直在趋于细分化,越细分,发展前景越大,公众号【软件工程猫】做的是互联网金融、互联网广告、电商、搜索、通讯类软件的爬虫定位,刚好够细分了。现在的文章抓取软件基本是商用抓取软件(fiddler、chromedriver)+页面解析工具(pagecodec)。
现在搜索引擎竞争,一个专业的软件都被互联网巨头垄断,所以这个市场发展空间已经不大了,互联网公司都是流量主要用自己的自有app,抓取这个算是冷门的市场,而且不是一个赚钱的行业。
内容抓取器是一个典型的程序猿成名产品,容易被复制,不太值钱,专业人士用来是突破局限的,圈子里使用的普通人用来赚钱还可以吧,重点是程序猿还得不断学习,这是一个企业家必须要面对的市场问题。
wget是一个非常好的程序员抓取工具,但是没有完全商业化。市场前景不错,大约是被金山云这样做搜索起家的公司覆盖掉了。
前景不会差
对于我这样小白来说是一个非常不错的方向。如果我想要偷梁换柱的弄点内容上去,倒是可以考虑下wget,毕竟是google开发的呀。
关注程序员,开发者,找应用,
其实个人也觉得不如fiddler划算,但是还是安利下。刚毕业还是比较推荐使用这个抓取,也是我使用过抓取比较好的一个。
实时文章采集(如何让实时文章采集工具更好地进行文章自动归类)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-06 01:03
实时文章采集工具一直都是一个很棘手的问题,尤其是如何让产品用户舒服的进行文章采集,不在文章自动归类过程中浪费大量的人力和时间。evernotenexthomenext主打index,目前是免费使用的,它的实时文章是一个集成到evernote内的算法+人工编辑完成的。在这个工具上,你需要提供一个条件,即知道你使用evernote时的网络速度,例如你设置成打开会比较慢。
因为采集的都是一些比较通用的热门话题。希望做一个人力的工具类app,目前主要包括产品文章采集(nextnote)、pdf传输工具、blockedreader(以及setti中的其他3个版本),后期肯定还有新功能加入。nextnote采集的文章简单,导入既可。它和evernote最大的不同是可以实时取数据,并可保存在evernote或者quicklook账户中。
evernote的实时数据不能取,虽然也提供evernote的markdown样式。不同的文件选项中可选择文件的格式,例如pdf、word、markdown、svg格式等等。如果你选择pdf格式,当打开一个带格式的文件时,它会基于标题来提示你把格式选择成什么,自动帮你补充到文件中。如果你选择了word,它也会自动提示。
文件的优化使用效果相当好,如果你发表的pdf文件你不方便删除,其实也可以用一个blockedreader的插件,它是和latex一起提供的,支持一些常用的表格,这样在写code的时候直接复制上面的code然后修改文件就可以避免对位置的修改,更重要的是,可以导出为pdf,一点也不用担心多出来word文件的文件名。
关于去广告android版和ios版有一个小的差别,就是没有默认的设置选项。evernoteapp有一个添加插件的路径,很方便直接输入需要添加的插件选项,默认是创建。有人很诧异去广告,我也是习惯,我更多的是在evernote文件里写代码,去广告的事情不太想去做。目前还很不完善的地方主要是功能没法集成到evernote,evernote必须打开wifi才可以看,wifi连接有问题的话evernote登录进去会很慢,这点上有一些小小的不方便。
简单的说evernote国际版目前也进不去国内的evernote,国内的evernote如果修改格式会导致很麻烦,现在希望evernote能多用markdown格式编写,让evernote更简单直接,而国内的evernote能用的都提供了,不希望去换麻烦的布局。另外,目前evernote国际版还是没有预览功能,当你在放大页面的时候如果设置为evernote看就会自动加载上。
后期支持的功能是evernote的笔记本模式,到此时期末布局进evernote和pdf传输还有blockedreader等实时采集都是比较成熟的东西。evernotefocusfocus团队虽然是做内容的,但它在文章采集方面更专注于实时性,在我看来有几个。 查看全部
实时文章采集(如何让实时文章采集工具更好地进行文章自动归类)
实时文章采集工具一直都是一个很棘手的问题,尤其是如何让产品用户舒服的进行文章采集,不在文章自动归类过程中浪费大量的人力和时间。evernotenexthomenext主打index,目前是免费使用的,它的实时文章是一个集成到evernote内的算法+人工编辑完成的。在这个工具上,你需要提供一个条件,即知道你使用evernote时的网络速度,例如你设置成打开会比较慢。
因为采集的都是一些比较通用的热门话题。希望做一个人力的工具类app,目前主要包括产品文章采集(nextnote)、pdf传输工具、blockedreader(以及setti中的其他3个版本),后期肯定还有新功能加入。nextnote采集的文章简单,导入既可。它和evernote最大的不同是可以实时取数据,并可保存在evernote或者quicklook账户中。
evernote的实时数据不能取,虽然也提供evernote的markdown样式。不同的文件选项中可选择文件的格式,例如pdf、word、markdown、svg格式等等。如果你选择pdf格式,当打开一个带格式的文件时,它会基于标题来提示你把格式选择成什么,自动帮你补充到文件中。如果你选择了word,它也会自动提示。
文件的优化使用效果相当好,如果你发表的pdf文件你不方便删除,其实也可以用一个blockedreader的插件,它是和latex一起提供的,支持一些常用的表格,这样在写code的时候直接复制上面的code然后修改文件就可以避免对位置的修改,更重要的是,可以导出为pdf,一点也不用担心多出来word文件的文件名。
关于去广告android版和ios版有一个小的差别,就是没有默认的设置选项。evernoteapp有一个添加插件的路径,很方便直接输入需要添加的插件选项,默认是创建。有人很诧异去广告,我也是习惯,我更多的是在evernote文件里写代码,去广告的事情不太想去做。目前还很不完善的地方主要是功能没法集成到evernote,evernote必须打开wifi才可以看,wifi连接有问题的话evernote登录进去会很慢,这点上有一些小小的不方便。
简单的说evernote国际版目前也进不去国内的evernote,国内的evernote如果修改格式会导致很麻烦,现在希望evernote能多用markdown格式编写,让evernote更简单直接,而国内的evernote能用的都提供了,不希望去换麻烦的布局。另外,目前evernote国际版还是没有预览功能,当你在放大页面的时候如果设置为evernote看就会自动加载上。
后期支持的功能是evernote的笔记本模式,到此时期末布局进evernote和pdf传输还有blockedreader等实时采集都是比较成熟的东西。evernotefocusfocus团队虽然是做内容的,但它在文章采集方面更专注于实时性,在我看来有几个。
实时文章采集(大数据智能分析热点关键词了解互联网上每日热点变化热点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-04 17:32
这一切都可能从这里开始。
作为新手小白
我在写作时遇到了最大的麻烦
没有灵感
无材料
无框架
为此,一个您期待已久的新媒体智能编辑器因您而出现。
此次5118下的内容神器,不仅汇聚了全网最前沿的信息热点,还解决了话题素材采集的工作需求。
同时新增智能编辑器,8项AI智能创新操作,全面的内容写作体验设计,一键操作快速输出,大大提高写作效率,让内容创作更轻松,效率更高。
大数据智能分析热点关键词
了解每日热点变化、热点关键词索引、热门平台热搜榜、网络热点文章推荐。
热点
热榜:热榜中的关键词代表今日新闻中提及次数最多的词,包括百度PC指数、百度手机指数、关键词的360指数,以便了解该网站的搜索情况字。
三大热门榜单:微博热搜、百度热搜、360实时。通过这些热搜榜,您可以第一时间查看最新的热搜信息。点击相应标题可直接查看相关资料。
热门文章
通过监控从互联网大数据中提取的热点文章推荐,可以看到最新热点文章的相关话题,智能提取文章中的核心词标签。您还可以切换查看微信、知乎、贴吧、豆瓣上最新精选的热点文章,让我们更方便地找到高价值的热点素材。
AI采集10亿语料提取
在搜索我们要写的关键词话题时,素材库会自动为我们采集当今最相关的文章素材。 “常用词”对相关信息有全面深入的理解。
文章
采集数量:通过关键词匹配,文章界面会提示系统为我们找到的相关文章数量。
Tag:系统会智能给我们匹配文章,被提及次数最多的核心词会被列为标签词。通过标签过滤,我们可以定位到更准确的关键词。
来源和时间过滤:通过更有针对性的媒体平台或锁定最后一天、一周、一个月、三个月的时间,对搜索结果进行组合过滤,进一步帮助我们过滤掉喜欢的文章素材。
段落
系统会采集目标关键词,通过分词和核心词提取算法,计算出互联网上最相关的精华段落中收录的高质量文章,以便我们快速找到高质量文章 获取内容灵感。
长尾词
我们在采集素材时,离不开对用户需求的分析。 5118利用大数据能力为我们挖掘网民在互联网上搜索目标关键词所产生的长尾需求。这些词都代表了用户心目中更具体的需求。点击关键词,系统会继续为我们匹配与目标词更相关的文章。
右侧参数栏中收录量代表该词在百度中的搜索结果数。
索引可以让我们更好地参考该词在百度和360搜索中的受欢迎程度。点击这些参数会跳转到5118的关键词SEO流量和SEM价格历史趋势分析页面,可以让我们了解该术语过去的指数波动趋势。
高频词
高频词是对事件的词汇分析。 5118聚合80亿词库,根据当前搜索词提取出整体词汇量较高的词库。让我们通过高频词表了解整个词表。事件的来龙去脉。
创建个人资源库
在浏览热点素材的过程中,您可以通过文章段落左下角的采集按钮采集您喜欢的素材。喜欢的素材会自动收录在左侧菜单栏的采集库中。采集库右上角可以切换查看文章和段落的采集。
两种智能编辑模式书写检测
在浏览过程中或在馆藏库中,您可以在选中的文章右上角引用系统从文章中提取的多个摘要,或在编辑框中插入多个全文引用正确的。
点击界面中间左侧面板隐藏按钮,进入编辑器全屏操作界面,开始智能内容创作。
编辑模式
智能标题
通过AI智能抽取,为整个文章生成各种最适合全文的标题。除了对文章的重点进行划分,AI制作的智能标题也会在标题中命中更多的SEO核心词。您可以直接使用它或从中获得更多灵感。如果编辑过程中文章的内容被修改,请点击重新检查生成新标题。
智能摘要
智能摘要提取可以帮助我们快速分析文章摘要的内容。点击使用摘要会自动插入文章中,或点击复制备份参考。如果在编辑过程中修改了文章的内容,可以点击Recheck生成新的摘要。
智能纠错
用机器代替人脑完成文本校对工作,找出可能存在的语法和词汇错误,点击检测到的文本,文章会出现红色标记位置提示,通过同顺检测快速检查文章哪一部分可能有问题。
原创detection
原创Detection是5118内容神器,利用智能检测系统将当前内容放入百度索引库进行检测。将百度的所有索引文本与现有的检测内容进行比较,提取百度中的重复内容。高级文本。
红色:严重,表示这句话在百度上发现了很多重复的结果。
黄:中等,这句话在百度上发现了好几个重复的结果。
绿色:低,表示这句话在百度上找到了少量重复结果。
查询结果数:表示文章中有多少种重复的句子。
点击查看百度,自动跳转到百度搜索结果页面。
当找到浮红的数量时,考虑重复度越高,文章成为收录的概率越低。
当查询结果为零时,表示内容重复率较低,也意味着文章成为收录的概率较高。
违规检测
利用非法词实时检测功能,可以检测当前内容中可能出现的各类敏感词和非法词,如广告词、暴恐、色情、政治、粗俗等。 ,点击检测到的文字,文章中会有红标定位提示,节省内容审核人工成本,提高工作效率,规避风险。
一键复制
创建完成后,点击一键复制按钮,将全文复制到您的公众号后台或排版编辑器中使用。
伪原创mode
点击伪原创模式切换到伪原创编辑界面。该模式与编辑器模式最大的不同在于,它拥有两大AI重写内容的高级功能:智能原创和句子重构。
Smart原创
点击smart原创进入全文内容一键重构模式。
自定义锁词:全文自动替换前,有些词不想替换,开启自定义锁词功能,通过自动提取核心词或手动输入不想替换的词被替换,锁定的词将不会被替换。将被替换。
固有名称锁定词:点击固有名称锁定词的键,通过智能检测动态加载。该系统将帮助我们识别和提取出现在文本中的人、地和组织的名称。这也意味着这些词将被锁定而不是被替换。如果您不想被锁定,可以关闭该功能或手动删除单个单词。
设置完成后,点击启动Smart原创,文本框中的内容会一键替换。替换后如需润色或修改内容,可使用文本框中的辅助功能进行手动调整。
句子重构
这个功能不仅仅是简单的换句,而是像人一样通读段落的语义,根据对内容的理解重新组织句子中的顺序,不仅提高了文章原创degree,也保持了句子意思的核心意思。
编辑文章并保存文章后,可以在左侧菜单栏的库中查看所有保存的文章。
语料库中,如果保存了大量文章,可以通过搜索框输入保存的文章title的关键词进行快速搜索。或者使用右侧的文章操作时间过滤功能查找相关文章。
置顶:把这个文章放在语料库的顶部并显示。
全文:点击全文可查看文章的全文。 查看全部
实时文章采集(大数据智能分析热点关键词了解互联网上每日热点变化热点)
这一切都可能从这里开始。
作为新手小白
我在写作时遇到了最大的麻烦
没有灵感
无材料
无框架
为此,一个您期待已久的新媒体智能编辑器因您而出现。
此次5118下的内容神器,不仅汇聚了全网最前沿的信息热点,还解决了话题素材采集的工作需求。
同时新增智能编辑器,8项AI智能创新操作,全面的内容写作体验设计,一键操作快速输出,大大提高写作效率,让内容创作更轻松,效率更高。
大数据智能分析热点关键词
了解每日热点变化、热点关键词索引、热门平台热搜榜、网络热点文章推荐。
热点
热榜:热榜中的关键词代表今日新闻中提及次数最多的词,包括百度PC指数、百度手机指数、关键词的360指数,以便了解该网站的搜索情况字。
三大热门榜单:微博热搜、百度热搜、360实时。通过这些热搜榜,您可以第一时间查看最新的热搜信息。点击相应标题可直接查看相关资料。
热门文章
通过监控从互联网大数据中提取的热点文章推荐,可以看到最新热点文章的相关话题,智能提取文章中的核心词标签。您还可以切换查看微信、知乎、贴吧、豆瓣上最新精选的热点文章,让我们更方便地找到高价值的热点素材。
AI采集10亿语料提取
在搜索我们要写的关键词话题时,素材库会自动为我们采集当今最相关的文章素材。 “常用词”对相关信息有全面深入的理解。
文章
采集数量:通过关键词匹配,文章界面会提示系统为我们找到的相关文章数量。
Tag:系统会智能给我们匹配文章,被提及次数最多的核心词会被列为标签词。通过标签过滤,我们可以定位到更准确的关键词。
来源和时间过滤:通过更有针对性的媒体平台或锁定最后一天、一周、一个月、三个月的时间,对搜索结果进行组合过滤,进一步帮助我们过滤掉喜欢的文章素材。
段落
系统会采集目标关键词,通过分词和核心词提取算法,计算出互联网上最相关的精华段落中收录的高质量文章,以便我们快速找到高质量文章 获取内容灵感。
长尾词
我们在采集素材时,离不开对用户需求的分析。 5118利用大数据能力为我们挖掘网民在互联网上搜索目标关键词所产生的长尾需求。这些词都代表了用户心目中更具体的需求。点击关键词,系统会继续为我们匹配与目标词更相关的文章。
右侧参数栏中收录量代表该词在百度中的搜索结果数。
索引可以让我们更好地参考该词在百度和360搜索中的受欢迎程度。点击这些参数会跳转到5118的关键词SEO流量和SEM价格历史趋势分析页面,可以让我们了解该术语过去的指数波动趋势。
高频词
高频词是对事件的词汇分析。 5118聚合80亿词库,根据当前搜索词提取出整体词汇量较高的词库。让我们通过高频词表了解整个词表。事件的来龙去脉。
创建个人资源库
在浏览热点素材的过程中,您可以通过文章段落左下角的采集按钮采集您喜欢的素材。喜欢的素材会自动收录在左侧菜单栏的采集库中。采集库右上角可以切换查看文章和段落的采集。
两种智能编辑模式书写检测
在浏览过程中或在馆藏库中,您可以在选中的文章右上角引用系统从文章中提取的多个摘要,或在编辑框中插入多个全文引用正确的。
点击界面中间左侧面板隐藏按钮,进入编辑器全屏操作界面,开始智能内容创作。
编辑模式
智能标题
通过AI智能抽取,为整个文章生成各种最适合全文的标题。除了对文章的重点进行划分,AI制作的智能标题也会在标题中命中更多的SEO核心词。您可以直接使用它或从中获得更多灵感。如果编辑过程中文章的内容被修改,请点击重新检查生成新标题。
智能摘要
智能摘要提取可以帮助我们快速分析文章摘要的内容。点击使用摘要会自动插入文章中,或点击复制备份参考。如果在编辑过程中修改了文章的内容,可以点击Recheck生成新的摘要。
智能纠错
用机器代替人脑完成文本校对工作,找出可能存在的语法和词汇错误,点击检测到的文本,文章会出现红色标记位置提示,通过同顺检测快速检查文章哪一部分可能有问题。
原创detection
原创Detection是5118内容神器,利用智能检测系统将当前内容放入百度索引库进行检测。将百度的所有索引文本与现有的检测内容进行比较,提取百度中的重复内容。高级文本。
红色:严重,表示这句话在百度上发现了很多重复的结果。
黄:中等,这句话在百度上发现了好几个重复的结果。
绿色:低,表示这句话在百度上找到了少量重复结果。
查询结果数:表示文章中有多少种重复的句子。
点击查看百度,自动跳转到百度搜索结果页面。
当找到浮红的数量时,考虑重复度越高,文章成为收录的概率越低。
当查询结果为零时,表示内容重复率较低,也意味着文章成为收录的概率较高。
违规检测
利用非法词实时检测功能,可以检测当前内容中可能出现的各类敏感词和非法词,如广告词、暴恐、色情、政治、粗俗等。 ,点击检测到的文字,文章中会有红标定位提示,节省内容审核人工成本,提高工作效率,规避风险。
一键复制
创建完成后,点击一键复制按钮,将全文复制到您的公众号后台或排版编辑器中使用。
伪原创mode
点击伪原创模式切换到伪原创编辑界面。该模式与编辑器模式最大的不同在于,它拥有两大AI重写内容的高级功能:智能原创和句子重构。
Smart原创
点击smart原创进入全文内容一键重构模式。
自定义锁词:全文自动替换前,有些词不想替换,开启自定义锁词功能,通过自动提取核心词或手动输入不想替换的词被替换,锁定的词将不会被替换。将被替换。
固有名称锁定词:点击固有名称锁定词的键,通过智能检测动态加载。该系统将帮助我们识别和提取出现在文本中的人、地和组织的名称。这也意味着这些词将被锁定而不是被替换。如果您不想被锁定,可以关闭该功能或手动删除单个单词。
设置完成后,点击启动Smart原创,文本框中的内容会一键替换。替换后如需润色或修改内容,可使用文本框中的辅助功能进行手动调整。
句子重构
这个功能不仅仅是简单的换句,而是像人一样通读段落的语义,根据对内容的理解重新组织句子中的顺序,不仅提高了文章原创degree,也保持了句子意思的核心意思。
编辑文章并保存文章后,可以在左侧菜单栏的库中查看所有保存的文章。
语料库中,如果保存了大量文章,可以通过搜索框输入保存的文章title的关键词进行快速搜索。或者使用右侧的文章操作时间过滤功能查找相关文章。
置顶:把这个文章放在语料库的顶部并显示。
全文:点击全文可查看文章的全文。
实时文章采集(FlinkX实时采集插件的核心是如何实时捕获数据库数据的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-04 04:15
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。逻辑复制同步数据的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行解析。 查看全部
实时文章采集(FlinkX实时采集插件的核心是如何实时捕获数据库数据的)
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。逻辑复制同步数据的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行解析。
实时文章采集(轻热点V1.2.22、公众号功能模块平台版、私域流量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-04 01:03
轻热点V1.2.22、公众号功能模块平台版,私域流量是移动互联网连接环境带来的营销新模式——销售回归本质,来自长期产品营销,回归用户营销。
测试环境:系统环境:CentOS Linux 7.6.1810(Core),运行环境:Pagoda Linux v7.0.3(专业版),网站Environment:Nginx 1.1 5.10 + MySQL 5.6.46 + PHP-7.1/PHP-5.6、常用插件:ionCube;文件信息; Redis; Swoole; SG11
版本号:1.2.22-平台版,优化朋友圈素材效果升级,优化商城,优化空信息展示,优化后台客群管理优化,后台优化-end文章采集数据优化优化地产办公分享海报优化,优化后台添加产品,优化文章订阅推送,优化用户支付分配计算,优化后台客户管理编辑功能,优化用户原创文章 增加用户,优化商品详情,优化商品分类编辑
声明:根据 2013 年 1 月 30 日《计算机软件保护条例》第二修正案第 17 条:为学习和研究软件中收录的设计思想和原则,安装、显示、传输或存储软件等。如果您使用该软件,您将无法获得软件著作权人的许可,并且不向其支付任何报酬!有鉴于此,也希望大家按照这个说明学习软件! 查看全部
实时文章采集(轻热点V1.2.22、公众号功能模块平台版、私域流量)
轻热点V1.2.22、公众号功能模块平台版,私域流量是移动互联网连接环境带来的营销新模式——销售回归本质,来自长期产品营销,回归用户营销。
测试环境:系统环境:CentOS Linux 7.6.1810(Core),运行环境:Pagoda Linux v7.0.3(专业版),网站Environment:Nginx 1.1 5.10 + MySQL 5.6.46 + PHP-7.1/PHP-5.6、常用插件:ionCube;文件信息; Redis; Swoole; SG11
版本号:1.2.22-平台版,优化朋友圈素材效果升级,优化商城,优化空信息展示,优化后台客群管理优化,后台优化-end文章采集数据优化优化地产办公分享海报优化,优化后台添加产品,优化文章订阅推送,优化用户支付分配计算,优化后台客户管理编辑功能,优化用户原创文章 增加用户,优化商品详情,优化商品分类编辑
声明:根据 2013 年 1 月 30 日《计算机软件保护条例》第二修正案第 17 条:为学习和研究软件中收录的设计思想和原则,安装、显示、传输或存储软件等。如果您使用该软件,您将无法获得软件著作权人的许可,并且不向其支付任何报酬!有鉴于此,也希望大家按照这个说明学习软件!
实时文章采集(【七牛云】实时文章采集+微信多开,一篇文章九成完)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-03 16:48
实时文章采集+h5文章、微信文章、微信公众号采集,一次采集九成完。高级代码采集+微信多开,一篇文章九成完。方法已授权七牛云,您可以放心使用。七牛云会对使用七牛云的会员开放相应权限,包括采集,翻译,翻墙等等,欢迎小伙伴的加入,跟我一起从0经验开始做采集工具吧!使用方法1.先进入阿里云市场搜索(国内同步:),点击下方大图,做好引导教程(看我像是新手,其实我已经是老手了(手动脸红)//如果感兴趣,就直接跳到这一步去学习吧,这是个细节)进入市场,获取阿里云公共账号(因为我们想要在更新当天接收最新市场发来的消息)登录阿里云账号,找到这个页面右侧菜单里的博文地址,可以同步到外网同步按钮点击同步后,点击我同步的文章,会有翻译,微信,pub等关键词//翻译点击翻译按钮,选择需要的语言点击右侧的生成,可以把英文转换成中文点击生成后,按照提示操作即可点击左上角的帐号,按照提示登录即可回到主页按照我们已有的博文源,点击上方的采集按钮,采集第一个完整博文在浏览器中打开,自动打开云服务,就可以实时获取文章了。
看了前面的回答我觉得我做的界面太丑了。太丑了。丑了。
七牛采集器即可
对!今天是日历特色,把备注添加上就可以!另外也可以点工具-功能-编辑特色-编辑模板。 查看全部
实时文章采集(【七牛云】实时文章采集+微信多开,一篇文章九成完)
实时文章采集+h5文章、微信文章、微信公众号采集,一次采集九成完。高级代码采集+微信多开,一篇文章九成完。方法已授权七牛云,您可以放心使用。七牛云会对使用七牛云的会员开放相应权限,包括采集,翻译,翻墙等等,欢迎小伙伴的加入,跟我一起从0经验开始做采集工具吧!使用方法1.先进入阿里云市场搜索(国内同步:),点击下方大图,做好引导教程(看我像是新手,其实我已经是老手了(手动脸红)//如果感兴趣,就直接跳到这一步去学习吧,这是个细节)进入市场,获取阿里云公共账号(因为我们想要在更新当天接收最新市场发来的消息)登录阿里云账号,找到这个页面右侧菜单里的博文地址,可以同步到外网同步按钮点击同步后,点击我同步的文章,会有翻译,微信,pub等关键词//翻译点击翻译按钮,选择需要的语言点击右侧的生成,可以把英文转换成中文点击生成后,按照提示操作即可点击左上角的帐号,按照提示登录即可回到主页按照我们已有的博文源,点击上方的采集按钮,采集第一个完整博文在浏览器中打开,自动打开云服务,就可以实时获取文章了。
看了前面的回答我觉得我做的界面太丑了。太丑了。丑了。
七牛采集器即可
对!今天是日历特色,把备注添加上就可以!另外也可以点工具-功能-编辑特色-编辑模板。
实时文章采集(java实时文章采集的调试什么的方法?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-30 21:01
实时文章采集,一直是我最想要掌握的,不过我用的是简单的r,比如bow,比如写了个gitlabgen-fake.xml,基本上够了,已经能应付日常采集了。算一算,从java开始掌握一门语言,一直是个梦想,不过最终还是被折腾进了c++,虽然c++是我最先接触的语言,但是后来学python,发现太不友好了,就改学python。
真正工作中,因为算法需要一直是java,有时候也要python和java一起来,而我手里本来就有不少python的项目,只是暂时放在了github上。时间线2019.08.01上线产品——webextension,完成对于站内抓取的能力c++——编译,找r,基本上的api类似,但是要设计好ui,c++代码:catwebextension/webextensionwebextension/run,run.ui(),webextension/ui.jsgo——先打个包吧go——调试什么的,先配置下环境go——boost-python2.5@0.4再打包——boost_python2.5@1.24完成boost_python2.5@0.4版本的编译后重启githubforclion2017.03.0——测试了一段时间,在重构和重构中,api和算法的api都有些改动了,比如api#1:api#2#,所以这个.ui的版本暂时作废这些都是api核心部分,后续会改为boost_python2.5@1.12或者更高。
boost_python2.5@1.122018.01.27-rc0开始c++专用库c++——编译测试完毕,差不多是readme那个样子,然后开始打包go——启动打包go——boost-python-world#1.1编译完毕,api是python#1.12命令行下python#1.12的api没有有效的字符集,就是把中文改成英文的方法,不过没关系,今天的目的是实现文章采集和发布,以及基本的io,网络模块的实现,感兴趣的自己按照手头的项目看一下,这篇采用c++实现,链接请到welcome-forspiderscrawlera:nznz0306。 查看全部
实时文章采集(java实时文章采集的调试什么的方法?-八维教育)
实时文章采集,一直是我最想要掌握的,不过我用的是简单的r,比如bow,比如写了个gitlabgen-fake.xml,基本上够了,已经能应付日常采集了。算一算,从java开始掌握一门语言,一直是个梦想,不过最终还是被折腾进了c++,虽然c++是我最先接触的语言,但是后来学python,发现太不友好了,就改学python。
真正工作中,因为算法需要一直是java,有时候也要python和java一起来,而我手里本来就有不少python的项目,只是暂时放在了github上。时间线2019.08.01上线产品——webextension,完成对于站内抓取的能力c++——编译,找r,基本上的api类似,但是要设计好ui,c++代码:catwebextension/webextensionwebextension/run,run.ui(),webextension/ui.jsgo——先打个包吧go——调试什么的,先配置下环境go——boost-python2.5@0.4再打包——boost_python2.5@1.24完成boost_python2.5@0.4版本的编译后重启githubforclion2017.03.0——测试了一段时间,在重构和重构中,api和算法的api都有些改动了,比如api#1:api#2#,所以这个.ui的版本暂时作废这些都是api核心部分,后续会改为boost_python2.5@1.12或者更高。
boost_python2.5@1.122018.01.27-rc0开始c++专用库c++——编译测试完毕,差不多是readme那个样子,然后开始打包go——启动打包go——boost-python-world#1.1编译完毕,api是python#1.12命令行下python#1.12的api没有有效的字符集,就是把中文改成英文的方法,不过没关系,今天的目的是实现文章采集和发布,以及基本的io,网络模块的实现,感兴趣的自己按照手头的项目看一下,这篇采用c++实现,链接请到welcome-forspiderscrawlera:nznz0306。
实时文章采集(5招教你应对文章被采集的强)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-30 15:10
虽然这可能不妨碍对方来采集走你的网站,但这毕竟也是书面交流和建议。有总比没有好,会有一定的效果。
三、在文章页面添加一些特色内容
1、 比如在文章中添加一些小标签代码,比如H1、H2、强、颜色标签等,这些搜索引擎会比较敏感,在一定意义上可以加深他们对原创文章审判。
2、多在文章,加一些自己的品牌关键词,比如这个博客是萌新SEO,可以这样加词。
3、在文章添加一些内部链接,因为喜欢采集的人往往比较懒,不排除有些人可能只是复制粘贴,把链接样式复制进去。这是可能的,结果对方给自己做了外链。这种情况在大平台上也很常见。
4、文章添加页面时,搜索引擎在判断文章的原创度时也会参考时间顺序。
四、屏蔽网页右键功能
我们都知道大多数人在采集文章时使用鼠标右键复制。如果技术上屏蔽了这个功能,无疑会增加采集器的麻烦。方法建议网站在体重上来之前可以这样做,最好是起身后去掉,因为网站用户群上来的时候,不排除部分用户对此反感方面,影响用户体验。
五、尽量晚上更新文章
采集最怕的就是对手能猜出你的习惯,尤其是白天时间充裕的时候。很多人喜欢在白天定时定量更新文章。结果,他们立即被其他人跟踪。 文章 被带走了。结果,搜索引擎无法分辨原创 的作者是谁。但是晚上就不一样了。很少有人总是在半夜等你的网站,据说此时的蜘蛛比较勤奋,更有利于蜘蛛的爬行。
以上就是小编给大家分享的5个小技巧,来处理文章被采集的情况。如果你能很好地实现它,我相信你可以避免成为采集。毕竟你的内容一直都是采集,网站的排名还是很有害的。因此,网站站长必须密切关注这个问题。 查看全部
实时文章采集(5招教你应对文章被采集的强)
虽然这可能不妨碍对方来采集走你的网站,但这毕竟也是书面交流和建议。有总比没有好,会有一定的效果。
三、在文章页面添加一些特色内容
1、 比如在文章中添加一些小标签代码,比如H1、H2、强、颜色标签等,这些搜索引擎会比较敏感,在一定意义上可以加深他们对原创文章审判。
2、多在文章,加一些自己的品牌关键词,比如这个博客是萌新SEO,可以这样加词。
3、在文章添加一些内部链接,因为喜欢采集的人往往比较懒,不排除有些人可能只是复制粘贴,把链接样式复制进去。这是可能的,结果对方给自己做了外链。这种情况在大平台上也很常见。
4、文章添加页面时,搜索引擎在判断文章的原创度时也会参考时间顺序。
四、屏蔽网页右键功能
我们都知道大多数人在采集文章时使用鼠标右键复制。如果技术上屏蔽了这个功能,无疑会增加采集器的麻烦。方法建议网站在体重上来之前可以这样做,最好是起身后去掉,因为网站用户群上来的时候,不排除部分用户对此反感方面,影响用户体验。
五、尽量晚上更新文章
采集最怕的就是对手能猜出你的习惯,尤其是白天时间充裕的时候。很多人喜欢在白天定时定量更新文章。结果,他们立即被其他人跟踪。 文章 被带走了。结果,搜索引擎无法分辨原创 的作者是谁。但是晚上就不一样了。很少有人总是在半夜等你的网站,据说此时的蜘蛛比较勤奋,更有利于蜘蛛的爬行。
以上就是小编给大家分享的5个小技巧,来处理文章被采集的情况。如果你能很好地实现它,我相信你可以避免成为采集。毕竟你的内容一直都是采集,网站的排名还是很有害的。因此,网站站长必须密切关注这个问题。
实时文章采集(appendtocontext.5.4版本更新train.py的版本.5.4版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-28 14:06
实时文章采集:theano:wonderfulcforc,boxordense:customdenseorfine-grainedboost[[bvlcbv2]]sun'sbackground——tryopen-datasetsforcaffe-planet-caffe/#caffe-blaze注意:此代码编译的版本比官方python3.5.4版本还要老,在未来经过反复修改之后将会更新到3.5.4版本。
关于在kubernetes上编译版本,可以参考下面链接的链接进行查阅。以下文章地址可以在下面的github仓库下方找到:github-xflaum/sc_perfect_caffe我们使用github上skyscanner的数据集进行简单的实验,其他的两个无特殊格式,在整个任务中主要用于验证sparseboost作用。
1)appendtocontext.(当原有文章出现在文件(即seed-dataset中)的时候增加c的参数)例如:if(use_reference_to_list_file_object(unsafe_object,c=color="white")){seed_dataset=ic_name+"parts"else{seed_dataset=ic_name+"topic"}}更新train.py的版本train.py=ic_name+"training"if(is_parts_file_object(unsafe_object,parts=seed_dataset,hard_extrac=parts)){seed_dataset=ic_name+"training"}对于训练,不需要在本地构建,可以使用源码的静态文件进行操作。
例如:tensorflow。cfg。config。update()//downloadfiletothecmake_gn=3。3。0/cmake_gn=2。2。0//-print_error_files:/home/anaconda2/lib/python3。4。1/site-packages/libxml2。
4//-use_theano_typesintotheapplicationpackagemodel#youcanusecmake_gn=0。1,#recommendc\xyznamesasspecified,andreplacetheincompatibletypesc\xyzc\xyz。appendtocontext。效果如下:。
一、实验环境nd:5.0python3.5.6训练:pipinstallkeras-gpupandas-dataframepillow_to_filepgm将输入文件protobuf转换为对应的输出文件(可以使用pipinstalltorch也是同样的)。
二、kcf原文件读取步骤:1.打开proto文件;2.搜索torch_module,如下:3.其中的proto_kt是存放kernel相关信息的。直接将tf.contrib.modules.client_kernel命名成proto_kt即可;4.至此, 查看全部
实时文章采集(appendtocontext.5.4版本更新train.py的版本.5.4版本)
实时文章采集:theano:wonderfulcforc,boxordense:customdenseorfine-grainedboost[[bvlcbv2]]sun'sbackground——tryopen-datasetsforcaffe-planet-caffe/#caffe-blaze注意:此代码编译的版本比官方python3.5.4版本还要老,在未来经过反复修改之后将会更新到3.5.4版本。
关于在kubernetes上编译版本,可以参考下面链接的链接进行查阅。以下文章地址可以在下面的github仓库下方找到:github-xflaum/sc_perfect_caffe我们使用github上skyscanner的数据集进行简单的实验,其他的两个无特殊格式,在整个任务中主要用于验证sparseboost作用。
1)appendtocontext.(当原有文章出现在文件(即seed-dataset中)的时候增加c的参数)例如:if(use_reference_to_list_file_object(unsafe_object,c=color="white")){seed_dataset=ic_name+"parts"else{seed_dataset=ic_name+"topic"}}更新train.py的版本train.py=ic_name+"training"if(is_parts_file_object(unsafe_object,parts=seed_dataset,hard_extrac=parts)){seed_dataset=ic_name+"training"}对于训练,不需要在本地构建,可以使用源码的静态文件进行操作。
例如:tensorflow。cfg。config。update()//downloadfiletothecmake_gn=3。3。0/cmake_gn=2。2。0//-print_error_files:/home/anaconda2/lib/python3。4。1/site-packages/libxml2。
4//-use_theano_typesintotheapplicationpackagemodel#youcanusecmake_gn=0。1,#recommendc\xyznamesasspecified,andreplacetheincompatibletypesc\xyzc\xyz。appendtocontext。效果如下:。
一、实验环境nd:5.0python3.5.6训练:pipinstallkeras-gpupandas-dataframepillow_to_filepgm将输入文件protobuf转换为对应的输出文件(可以使用pipinstalltorch也是同样的)。
二、kcf原文件读取步骤:1.打开proto文件;2.搜索torch_module,如下:3.其中的proto_kt是存放kernel相关信息的。直接将tf.contrib.modules.client_kernel命名成proto_kt即可;4.至此,
非常不错的文章采集工具破解无需注册码激活即可免费使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-08-26 06:11
优采云万能文章采集器是一个可以批量下载指定关键词文章采集的工具,主要帮助用户采集各种大平台文章,或者采集Specify网站文章,非常方便快捷,是做网站推广优化的朋友不可多得的工具。只需输入关键词即可获得采集,软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、邮件等格式处理,只需短短几分钟您就可以在几分钟内采集any 文章您想要的。用户可以设置搜索间隔、采集类型、时间语言等选项,还可以过滤采集的文章、插入关键词等,可以大大提高我们的工作效率。很不错的文章采集工具,双击打开使用,软件已经完美破解,无需注册码激活即可免费使用。
软件功能1、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上;
2、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集;
3、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则;
4、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译;
5、史上最简单最智能文章采集器,支持全功能试用,效果如何!软件特色1、及时更新文章资源取之不尽。
2、智能采集 任何网站文章 列文章resources。
3、多语种翻译伪原创,你只需要输入关键词。
4、优采云 是第一个提取网页正文的通用算法。
5、百度引擎、谷歌引擎、搜索引擎强强联合。界面说明一、采集分页符:如果正文有分页符,采集分页符会自动合并。
二、Delete link:删除网页中锚文本的链接功能,只保留锚文本的标题。
三、txt 格式:另存为txt文本(自动清除HTML标签)。
四、Debug Mode:在正文开头插入“Debug Mode: Title and Link”的内容,方便进入原网页比较正文的识别效果。
五、Title 有关键词:只有在标题中搜索关键词 的网页才是采集。
六、 舍弃短标题:当自动识别的标题长度小于原标题的三分之一时,为短标题。通常这种标题是错误的,可以勾选丢弃,改用原标题(遇到这一段就明白了)。
<p>七、Delete 外码:使用自动识别和精确标签时,通常收录div标签等外码。如果您不需要它,请勾选并删除它。使用说明1、本站下载并解压文件,双击“优采云·万能文章采集器Crack.exe”打开,您会发现该软件是免费破解的。 查看全部
非常不错的文章采集工具破解无需注册码激活即可免费使用
优采云万能文章采集器是一个可以批量下载指定关键词文章采集的工具,主要帮助用户采集各种大平台文章,或者采集Specify网站文章,非常方便快捷,是做网站推广优化的朋友不可多得的工具。只需输入关键词即可获得采集,软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、邮件等格式处理,只需短短几分钟您就可以在几分钟内采集any 文章您想要的。用户可以设置搜索间隔、采集类型、时间语言等选项,还可以过滤采集的文章、插入关键词等,可以大大提高我们的工作效率。很不错的文章采集工具,双击打开使用,软件已经完美破解,无需注册码激活即可免费使用。
软件功能1、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上;
2、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集;
3、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则;
4、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译;
5、史上最简单最智能文章采集器,支持全功能试用,效果如何!软件特色1、及时更新文章资源取之不尽。
2、智能采集 任何网站文章 列文章resources。
3、多语种翻译伪原创,你只需要输入关键词。
4、优采云 是第一个提取网页正文的通用算法。
5、百度引擎、谷歌引擎、搜索引擎强强联合。界面说明一、采集分页符:如果正文有分页符,采集分页符会自动合并。
二、Delete link:删除网页中锚文本的链接功能,只保留锚文本的标题。
三、txt 格式:另存为txt文本(自动清除HTML标签)。
四、Debug Mode:在正文开头插入“Debug Mode: Title and Link”的内容,方便进入原网页比较正文的识别效果。
五、Title 有关键词:只有在标题中搜索关键词 的网页才是采集。
六、 舍弃短标题:当自动识别的标题长度小于原标题的三分之一时,为短标题。通常这种标题是错误的,可以勾选丢弃,改用原标题(遇到这一段就明白了)。
<p>七、Delete 外码:使用自动识别和精确标签时,通常收录div标签等外码。如果您不需要它,请勾选并删除它。使用说明1、本站下载并解压文件,双击“优采云·万能文章采集器Crack.exe”打开,您会发现该软件是免费破解的。
简单便捷的软件自动更新方法,自动安装方法详细列出
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-23 04:00
实时文章采集器:点击就可获取最新文章官方推送app:微信公众号文章摘要:thunderbird提供一种简单便捷的软件自动更新方法,能够自动更新所有频道的文章。尤其适合于封闭式垂直社区产品的更新工作量比较大时使用。软件功能效果1.可快速方便地编辑摘要不需要特殊设置样式和字体,只需要用鼠标滚轮滚轮即可拖动滚轮发现特定频道/版块的新摘要。
2.可保存自动更新文章到存储库thunderbird支持很多版本的excel表格,设置更新文章后,用excel自动保存。它也支持存档本地文件,用户直接打开即可获取当前更新文章。3.可以自定义复杂的excel表格结构自定义文件结构即可批量修改。原网站()有自动更新功能的方法,但是没有详细的软件安装方法,只是将存档的表格页改了一个名字,希望将软件安装方法详细列出,使用安装教程。
在微信公众号后台回复“工具”即可获取下载工具。进入下载工具后,安装步骤如下:1.进入thunderbird官网下载。2.解压后,双击install.exe进行安装。3.在安装设置,将c盘设置为你的excel文件路径。4.安装完成后,会自动安装thunderbird支持,需手动更新所有版块。(请尽快完成)5.重启thunderbird即可(可能需要等待30min)。
6.如果仍需要自动更新,需手动将原文件夹中的文件,拷贝至c盘即可。7.进入软件主界面,找到你的位置,在左侧输入目标文件夹,点击确定即可。是不是很简单便捷!ahr0cdovl3dlaxhpbi5xcs5jb20vci9kfwu0hjfqrweyzw0jyoti9rq==(二维码自动识别)更多关于building和buildingteam的信息,请浏览我们的官网:知乎专栏。 查看全部
简单便捷的软件自动更新方法,自动安装方法详细列出
实时文章采集器:点击就可获取最新文章官方推送app:微信公众号文章摘要:thunderbird提供一种简单便捷的软件自动更新方法,能够自动更新所有频道的文章。尤其适合于封闭式垂直社区产品的更新工作量比较大时使用。软件功能效果1.可快速方便地编辑摘要不需要特殊设置样式和字体,只需要用鼠标滚轮滚轮即可拖动滚轮发现特定频道/版块的新摘要。
2.可保存自动更新文章到存储库thunderbird支持很多版本的excel表格,设置更新文章后,用excel自动保存。它也支持存档本地文件,用户直接打开即可获取当前更新文章。3.可以自定义复杂的excel表格结构自定义文件结构即可批量修改。原网站()有自动更新功能的方法,但是没有详细的软件安装方法,只是将存档的表格页改了一个名字,希望将软件安装方法详细列出,使用安装教程。
在微信公众号后台回复“工具”即可获取下载工具。进入下载工具后,安装步骤如下:1.进入thunderbird官网下载。2.解压后,双击install.exe进行安装。3.在安装设置,将c盘设置为你的excel文件路径。4.安装完成后,会自动安装thunderbird支持,需手动更新所有版块。(请尽快完成)5.重启thunderbird即可(可能需要等待30min)。
6.如果仍需要自动更新,需手动将原文件夹中的文件,拷贝至c盘即可。7.进入软件主界面,找到你的位置,在左侧输入目标文件夹,点击确定即可。是不是很简单便捷!ahr0cdovl3dlaxhpbi5xcs5jb20vci9kfwu0hjfqrweyzw0jyoti9rq==(二维码自动识别)更多关于building和buildingteam的信息,请浏览我们的官网:知乎专栏。
袋鼠云研发手记:第五期和实时采集袋鼠云云引擎团队
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-08-22 19:30
袋鼠云研发笔记
作为一家创新驱动的科技公司,袋鼠云每年研发投入数千万,公司员工80%为技术人员,()、()等产品不断迭代。在产品研发的过程中,技术兄弟可以文武兼备,在不断提升产品性能和体验的同时,也记录了这些改进和优化的过程,现记录在“袋鼠云研发笔记”栏目,以跟上行业的步伐。童鞋分享交流。
Kangaroo 云数据堆栈引擎团队
袋鼠云数据栈引擎团队拥有多位专家级、经验丰富的后端开发工程师,分别支持公司大数据栈产品线不同子项目的开发需求。 FlinkX(基于Flink Data同步)、Jlogstash(java版logstash的实现)、FlinkStreamSQL(扩展原生FlinkSQL,实现流维表的join)多个项目。
在长期的项目实践和产品迭代过程中,团队成员不断探索和探索Hadoop技术栈,积累了丰富的经验和最佳实践。
第五期
FlinkX采集中可续传和实时性详解
袋鼠云云原生一站式数据中心PaaS-数据栈,涵盖数据中心建设过程中所需的各种工具(包括数据开发平台、数据资产平台、数据科学平台、数据服务引擎等) ,全面覆盖离线计算和实时计算应用,帮助企业大大缩短数据价值的提取过程,提高数据价值的提取能力。
数据栈架构图 目前数据栈-离线开发平台(BatchWorks)中的数据离线同步任务和数据栈-实时开发平台(StreamWorks)中的数据实时采集任务有基于 FlinkX 统一。数据离线采集和实时采集的基本原理是一样的。主要区别在于源流是否有界,所以使用 Flink 的 Stream API 来实现这两个数据同步场景来实现数据。同步批处理流程统一。
1
功能介绍
断点后继续上传
断点续传是指数据同步任务在运行过程中由于各种原因失败。无需重新同步数据。您只需要从上次失败的位置继续同步,类似于由于网络原因下载文件时。如果原因失败,则无需再次下载文件,只需继续下载,可大大节省时间和计算资源。可续传是数据栈-离线开发平台(BatchWorks)中数据同步任务的一个功能,需要结合任务的错误重试机制来完成。当任务失败时,它会在引擎中重试。重试时,会从上次失败时读取的位置继续读取数据,直到任务运行成功。
实时采集
实时采集是数据栈-实时开发平台(StreamWorks)中数据采集任务的一个功能。当数据源中的数据被添加、删除或修改时,同步任务会监控这些变化,并将数据实时同步到目标数据源。除了实时数据变化,实时采集和离线数据同步的另一个区别是:实时采集任务不会停止,任务会一直监控数据源是否发生变化。这点和Flink任务是一致的,所以实时采集任务是数字栈流计算应用中的一种任务类型,配置过程与离线计算中的同步任务基本相同。
2
Flink 中的检查点机制
无论是可续传上传还是实时采集都依赖于Flink的Checkpoint机制,所以先简单介绍一下。 Checkpoint 是 Flink 容错机制的核心功能。它可以根据配置,根据Stream中各个Operator的状态,周期性的生成Snapshots,从而将这些状态数据定期持久化存储。当 Flink 程序意外崩溃时,它会重新运行 程序可以有选择地从这些 Snapshot 中恢复,从而纠正因故障导致的程序数据状态中断。
Checkpoint被触发时,会在多个分布式Stream Sources中插入一个barrier标签,这些barrier会随着Stream中的数据记录流向下游的算子。当运营商收到屏障时,它将暂停处理 Steam 中新收到的数据记录。因为一个Operator可能有多个输入Streams,每个Stream中都会有一个对应的barrier,所以Operator必须等待输入Stream中的所有barrier都到达。当流中的所有障碍都到达操作员时,所有障碍似乎都在同一时刻(表明它们已对齐)。在等待所有barrier到达的时候,operator的缓冲区可能已经缓存了一些比Barrier更早到达Operator的数据记录(Outgoing Records)。此时,Operator 会发出(Emit)数据记录(Outgoing Records)作为下游 Operator 的输入。最后,Barrier 会对应 Snapshot (Emit) 发送出去作为第二个 Checkpoint 的结果数据。
3
断点后继续上传
先决条件
同步任务必须支持可续传,对数据源有一些强制性要求:
1、 数据源(这里特指关系型数据库)必须收录升序字段,例如主键或日期类型字段。检查点机制会在同步过程中记录这个字段的值。这在任务恢复时使用。字段结构查询条件过滤已同步的数据。如果这个字段的值不是升序,那么在任务恢复时过滤的数据是错误的,最终会导致数据丢失或重复;
2、数据源必须支持数据过滤。否则,任务无法从断点处恢复,会造成数据重复;
3、目标数据源必须支持事务,比如关系数据库。临时文件也可以支持文件类型的数据源。
任务操作的详细流程
我们用一个具体的任务来详细介绍整个过程,任务详情如下:
数据来源
mysql表,假设表名为data_test,该表收录主键字段id
目标数据源
hdfs 文件系统,假设写入路径为 /data_test
并发数
2
检查点配置
时间间隔为60s,checkpoint的StateBackend为FsStateBackend,路径为/flinkx/checkpoint
工作 ID
用于构造数据文件的名称,假设是abc123
1) 读取数据 读取数据时,首先要构造数据片段。构造数据分片就是根据通道索引和检查点记录的位置构造查询sql。 sql模板如下:
select * from data_test where id mod ${channel_num}=${channel_index}and id > ${offset}
如果是第一次运行,或者最后一个任务失败时没有触发checkpoint,那么offset不存在。根据偏移量和通道,具体查询sql:偏移量存在时的第一个通道:
select * from data_testwhere id mod 2=0and id > ${offset_0};
第二个频道:
select * from data_testwhere id mod 2=1and id > ${offset_1};
偏移量不存在时的第一个通道:
select * from data_testwhere id mod 2=0;
第二个频道:
select * from data_testwhere id mod 2=1;
数据分片构建完成后,每个通道根据自己的数据分片来读取数据。 2)Write data before write data:检查/data_test目录是否存在,如果目录不存在,创建这个目录,如果目录存在,执行2次操作;判断是否以覆盖方式写入数据,如果是,则删除/data_test目录,然后创建目录,如果不是,则执行3次操作;检查/data_test/.data目录是否存在,如果存在,先将其删除,然后再创建,以确保没有其他任务因异常失败而遗留的dirty。数据文件;写入hdfs的数据是单片写入的,不支持批量写入。数据会先写入/data_test/.data/目录,数据文件的命名格式为:channelIndex.jobId.fileIndex 收录三个部分:通道索引、jobId、文件索引。当3)checkpoint 被触发时,FlinkX 中的“状态”代表标识字段 id 的值。我们假设触发检查点时两个通道的读写如图所示:
触发checkpoint后,两个reader首先生成Snapshot记录读取状态,channel 0的状态为id=12,channel 1的状态为id=11。快照生成后,会在数据流中插入一个barrier,barrier和数据一起流向Writer。以 Writer_0 为例。 Writer_0 接收 Reader_0 和 Reader_1 发送的数据。假设先收到了Reader_0的barrier,那么Writer_0就停止向HDFS写入数据,先把收到的数据放入InputBuffer,等待Reader_1的barrier到达。然后写出Buffer中的所有数据,然后生成Writer的Snapshot。整个checkpoint结束后,记录的任务状态为: Reader_0: id=12Reader_1: id=11Writer_0: id=无法确定 Writer_1:id=无法确定任务状态 会记录在配置的HDFS目录/flinkx/检查点/abc123。因为每个Writer接收两个Reader的数据,每个通道的数据读写速率可能不同,所以Writer接收数据的顺序是不确定的,但这不影响数据的准确性,因为数据是read 这个时候只能使用Reader记录的状态来构造查询sql,我们只需要确保数据真的写入HDFS即可。
Writer 在生成 Snapshot 之前,会做一系列的操作来保证所有接收到的数据都写入 HDFS: a.关闭写入 HDFS 文件的数据流,这时候会出现两对数据在 /data_test/.data 目录中生成。两个文件:/data_test/.data/0.abc123.0/data_test/.data/1.abc123.0b。将生成的两个数据文件移动到/data_test目录下; C.更新文件名称模板更新为:channelIndex.abc123.1;快照生成后,任务继续读写数据。如果在生成快照的过程中出现异常,任务会直接失败,所以这次不会生成快照,任务会被恢复。从上次成功的快照恢复。 4)任务正常结束。任务正常结束时,会执行与生成快照时相同的操作,关闭文件流,移动临时数据文件等5)任务异常终止如果任务异常结束,假设最后一个检查点的状态任务结束时的记录为:Reader_0: id=12Reader_1: id=11 那么当任务恢复时,每个通道记录的状态都会被赋值给offset,再次读取数据时构造的sql是:第一个通道:
select * from data_testwhere id mod 2=0and id > 12;
第二个频道:
select * from data_testwhere id mod 2=1and id > 11;
这样就可以从上次失败的位置继续读取数据了。
支持续传上传的插件
理论上只要支持过滤数据的数据源和支持事务的数据源都可以支持续传功能,FlinkX目前支持的插件如下:
读者
作家
关系数据读取插件如mysql
HDFS、FTP、mysql等关系型数据库写入插件
4
实时采集
目前FlinkX支持实时采集插件,包括KafKa和binlog插件。 binlog插件是专门为实时采集mysql数据库设计的。如果要支持其他数据源,只需要将数据输入到Kafka,然后就可以使用FlinkX的Kafka插件来消费数据。比如oracle,你只需要使用oracle的ogg将数据传输到Kafka即可。这里专门讲解mysql的实时采集插件binlog。
二进制日志
binlog 是由 Mysql 服务器层维护的二进制日志。它与innodb引擎中的redo/undo log是完全不同的日志;它主要用于记录更新或潜在更新mysql数据的SQL语句,并以“事务”的形式存储在磁盘上。 binlog的主要功能有:
Replication:MySQL Replication在Master端打开binlog,Master将自己的binlog传递给slave并重放,达到主从数据一致性的目的;
数据恢复:通过mysqlbinlog工具恢复数据;
增量备份。
MySQL 主备复制
仅仅有记录数据变化的binlog日志是不够的。我们还需要用到MySQL的主从复制功能:主从复制是指一台服务器作为主数据库服务器,另一台或多台服务器作为从数据库服务器。主服务器中的数据自动复制到从服务器。
主/从复制的过程:MySQL主将数据变化写入二进制日志(二进制日志,这里的记录称为二进制日志事件,可以通过show binlog events查看); MySQL slave将master的binary log events复制到它的relay log; MySQL slave 重放中继日志中的事件,并将数据变化反映到自己的数据中。
写入 Hive
binlog插件可以监控多张表的数据变化。解析的数据收录表名信息。读取的数据可以全部写入目标数据库中的一个表中,也可以根据数据中收录的表名信息写入不同的表中。目前只有 Hive 插件支持此功能。 Hive插件目前只有一个写插件,功能是基于HDFS写插件实现的,也就是说从binlog读取和写入hive也支持故障恢复功能。
写入Hive的过程:从数据中解析出MySQL表名,然后根据表名映射规则转换成对应的Hive表名;检查Hive表是否存在,如果不存在,则创建Hive表;查询Hive表相关信息,构造HdfsOutputFormat;调用 HdfsOutputFormat 将数据写入 HDFS。
欢迎了解袋鼠云数栈 查看全部
袋鼠云研发手记:第五期和实时采集袋鼠云云引擎团队
袋鼠云研发笔记
作为一家创新驱动的科技公司,袋鼠云每年研发投入数千万,公司员工80%为技术人员,()、()等产品不断迭代。在产品研发的过程中,技术兄弟可以文武兼备,在不断提升产品性能和体验的同时,也记录了这些改进和优化的过程,现记录在“袋鼠云研发笔记”栏目,以跟上行业的步伐。童鞋分享交流。
Kangaroo 云数据堆栈引擎团队
袋鼠云数据栈引擎团队拥有多位专家级、经验丰富的后端开发工程师,分别支持公司大数据栈产品线不同子项目的开发需求。 FlinkX(基于Flink Data同步)、Jlogstash(java版logstash的实现)、FlinkStreamSQL(扩展原生FlinkSQL,实现流维表的join)多个项目。
在长期的项目实践和产品迭代过程中,团队成员不断探索和探索Hadoop技术栈,积累了丰富的经验和最佳实践。
第五期
FlinkX采集中可续传和实时性详解
袋鼠云云原生一站式数据中心PaaS-数据栈,涵盖数据中心建设过程中所需的各种工具(包括数据开发平台、数据资产平台、数据科学平台、数据服务引擎等) ,全面覆盖离线计算和实时计算应用,帮助企业大大缩短数据价值的提取过程,提高数据价值的提取能力。
数据栈架构图 目前数据栈-离线开发平台(BatchWorks)中的数据离线同步任务和数据栈-实时开发平台(StreamWorks)中的数据实时采集任务有基于 FlinkX 统一。数据离线采集和实时采集的基本原理是一样的。主要区别在于源流是否有界,所以使用 Flink 的 Stream API 来实现这两个数据同步场景来实现数据。同步批处理流程统一。
1
功能介绍
断点后继续上传
断点续传是指数据同步任务在运行过程中由于各种原因失败。无需重新同步数据。您只需要从上次失败的位置继续同步,类似于由于网络原因下载文件时。如果原因失败,则无需再次下载文件,只需继续下载,可大大节省时间和计算资源。可续传是数据栈-离线开发平台(BatchWorks)中数据同步任务的一个功能,需要结合任务的错误重试机制来完成。当任务失败时,它会在引擎中重试。重试时,会从上次失败时读取的位置继续读取数据,直到任务运行成功。
实时采集
实时采集是数据栈-实时开发平台(StreamWorks)中数据采集任务的一个功能。当数据源中的数据被添加、删除或修改时,同步任务会监控这些变化,并将数据实时同步到目标数据源。除了实时数据变化,实时采集和离线数据同步的另一个区别是:实时采集任务不会停止,任务会一直监控数据源是否发生变化。这点和Flink任务是一致的,所以实时采集任务是数字栈流计算应用中的一种任务类型,配置过程与离线计算中的同步任务基本相同。
2
Flink 中的检查点机制
无论是可续传上传还是实时采集都依赖于Flink的Checkpoint机制,所以先简单介绍一下。 Checkpoint 是 Flink 容错机制的核心功能。它可以根据配置,根据Stream中各个Operator的状态,周期性的生成Snapshots,从而将这些状态数据定期持久化存储。当 Flink 程序意外崩溃时,它会重新运行 程序可以有选择地从这些 Snapshot 中恢复,从而纠正因故障导致的程序数据状态中断。
Checkpoint被触发时,会在多个分布式Stream Sources中插入一个barrier标签,这些barrier会随着Stream中的数据记录流向下游的算子。当运营商收到屏障时,它将暂停处理 Steam 中新收到的数据记录。因为一个Operator可能有多个输入Streams,每个Stream中都会有一个对应的barrier,所以Operator必须等待输入Stream中的所有barrier都到达。当流中的所有障碍都到达操作员时,所有障碍似乎都在同一时刻(表明它们已对齐)。在等待所有barrier到达的时候,operator的缓冲区可能已经缓存了一些比Barrier更早到达Operator的数据记录(Outgoing Records)。此时,Operator 会发出(Emit)数据记录(Outgoing Records)作为下游 Operator 的输入。最后,Barrier 会对应 Snapshot (Emit) 发送出去作为第二个 Checkpoint 的结果数据。
3
断点后继续上传
先决条件
同步任务必须支持可续传,对数据源有一些强制性要求:
1、 数据源(这里特指关系型数据库)必须收录升序字段,例如主键或日期类型字段。检查点机制会在同步过程中记录这个字段的值。这在任务恢复时使用。字段结构查询条件过滤已同步的数据。如果这个字段的值不是升序,那么在任务恢复时过滤的数据是错误的,最终会导致数据丢失或重复;
2、数据源必须支持数据过滤。否则,任务无法从断点处恢复,会造成数据重复;
3、目标数据源必须支持事务,比如关系数据库。临时文件也可以支持文件类型的数据源。
任务操作的详细流程
我们用一个具体的任务来详细介绍整个过程,任务详情如下:
数据来源
mysql表,假设表名为data_test,该表收录主键字段id
目标数据源
hdfs 文件系统,假设写入路径为 /data_test
并发数
2
检查点配置
时间间隔为60s,checkpoint的StateBackend为FsStateBackend,路径为/flinkx/checkpoint
工作 ID
用于构造数据文件的名称,假设是abc123
1) 读取数据 读取数据时,首先要构造数据片段。构造数据分片就是根据通道索引和检查点记录的位置构造查询sql。 sql模板如下:
select * from data_test where id mod ${channel_num}=${channel_index}and id > ${offset}
如果是第一次运行,或者最后一个任务失败时没有触发checkpoint,那么offset不存在。根据偏移量和通道,具体查询sql:偏移量存在时的第一个通道:
select * from data_testwhere id mod 2=0and id > ${offset_0};
第二个频道:
select * from data_testwhere id mod 2=1and id > ${offset_1};
偏移量不存在时的第一个通道:
select * from data_testwhere id mod 2=0;
第二个频道:
select * from data_testwhere id mod 2=1;
数据分片构建完成后,每个通道根据自己的数据分片来读取数据。 2)Write data before write data:检查/data_test目录是否存在,如果目录不存在,创建这个目录,如果目录存在,执行2次操作;判断是否以覆盖方式写入数据,如果是,则删除/data_test目录,然后创建目录,如果不是,则执行3次操作;检查/data_test/.data目录是否存在,如果存在,先将其删除,然后再创建,以确保没有其他任务因异常失败而遗留的dirty。数据文件;写入hdfs的数据是单片写入的,不支持批量写入。数据会先写入/data_test/.data/目录,数据文件的命名格式为:channelIndex.jobId.fileIndex 收录三个部分:通道索引、jobId、文件索引。当3)checkpoint 被触发时,FlinkX 中的“状态”代表标识字段 id 的值。我们假设触发检查点时两个通道的读写如图所示:
触发checkpoint后,两个reader首先生成Snapshot记录读取状态,channel 0的状态为id=12,channel 1的状态为id=11。快照生成后,会在数据流中插入一个barrier,barrier和数据一起流向Writer。以 Writer_0 为例。 Writer_0 接收 Reader_0 和 Reader_1 发送的数据。假设先收到了Reader_0的barrier,那么Writer_0就停止向HDFS写入数据,先把收到的数据放入InputBuffer,等待Reader_1的barrier到达。然后写出Buffer中的所有数据,然后生成Writer的Snapshot。整个checkpoint结束后,记录的任务状态为: Reader_0: id=12Reader_1: id=11Writer_0: id=无法确定 Writer_1:id=无法确定任务状态 会记录在配置的HDFS目录/flinkx/检查点/abc123。因为每个Writer接收两个Reader的数据,每个通道的数据读写速率可能不同,所以Writer接收数据的顺序是不确定的,但这不影响数据的准确性,因为数据是read 这个时候只能使用Reader记录的状态来构造查询sql,我们只需要确保数据真的写入HDFS即可。
Writer 在生成 Snapshot 之前,会做一系列的操作来保证所有接收到的数据都写入 HDFS: a.关闭写入 HDFS 文件的数据流,这时候会出现两对数据在 /data_test/.data 目录中生成。两个文件:/data_test/.data/0.abc123.0/data_test/.data/1.abc123.0b。将生成的两个数据文件移动到/data_test目录下; C.更新文件名称模板更新为:channelIndex.abc123.1;快照生成后,任务继续读写数据。如果在生成快照的过程中出现异常,任务会直接失败,所以这次不会生成快照,任务会被恢复。从上次成功的快照恢复。 4)任务正常结束。任务正常结束时,会执行与生成快照时相同的操作,关闭文件流,移动临时数据文件等5)任务异常终止如果任务异常结束,假设最后一个检查点的状态任务结束时的记录为:Reader_0: id=12Reader_1: id=11 那么当任务恢复时,每个通道记录的状态都会被赋值给offset,再次读取数据时构造的sql是:第一个通道:
select * from data_testwhere id mod 2=0and id > 12;
第二个频道:
select * from data_testwhere id mod 2=1and id > 11;
这样就可以从上次失败的位置继续读取数据了。
支持续传上传的插件
理论上只要支持过滤数据的数据源和支持事务的数据源都可以支持续传功能,FlinkX目前支持的插件如下:
读者
作家
关系数据读取插件如mysql
HDFS、FTP、mysql等关系型数据库写入插件
4
实时采集
目前FlinkX支持实时采集插件,包括KafKa和binlog插件。 binlog插件是专门为实时采集mysql数据库设计的。如果要支持其他数据源,只需要将数据输入到Kafka,然后就可以使用FlinkX的Kafka插件来消费数据。比如oracle,你只需要使用oracle的ogg将数据传输到Kafka即可。这里专门讲解mysql的实时采集插件binlog。
二进制日志
binlog 是由 Mysql 服务器层维护的二进制日志。它与innodb引擎中的redo/undo log是完全不同的日志;它主要用于记录更新或潜在更新mysql数据的SQL语句,并以“事务”的形式存储在磁盘上。 binlog的主要功能有:
Replication:MySQL Replication在Master端打开binlog,Master将自己的binlog传递给slave并重放,达到主从数据一致性的目的;
数据恢复:通过mysqlbinlog工具恢复数据;
增量备份。
MySQL 主备复制
仅仅有记录数据变化的binlog日志是不够的。我们还需要用到MySQL的主从复制功能:主从复制是指一台服务器作为主数据库服务器,另一台或多台服务器作为从数据库服务器。主服务器中的数据自动复制到从服务器。
主/从复制的过程:MySQL主将数据变化写入二进制日志(二进制日志,这里的记录称为二进制日志事件,可以通过show binlog events查看); MySQL slave将master的binary log events复制到它的relay log; MySQL slave 重放中继日志中的事件,并将数据变化反映到自己的数据中。
写入 Hive
binlog插件可以监控多张表的数据变化。解析的数据收录表名信息。读取的数据可以全部写入目标数据库中的一个表中,也可以根据数据中收录的表名信息写入不同的表中。目前只有 Hive 插件支持此功能。 Hive插件目前只有一个写插件,功能是基于HDFS写插件实现的,也就是说从binlog读取和写入hive也支持故障恢复功能。
写入Hive的过程:从数据中解析出MySQL表名,然后根据表名映射规则转换成对应的Hive表名;检查Hive表是否存在,如果不存在,则创建Hive表;查询Hive表相关信息,构造HdfsOutputFormat;调用 HdfsOutputFormat 将数据写入 HDFS。
欢迎了解袋鼠云数栈
在博客论坛推广博客的技巧是什么?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-08-20 18:01
实时文章采集。可以考虑wordpress,不用架设服务器就可以采集到想要的文章,对中国用户也免费。如果要收费服务的话,你可以试试wordpress对应的文章采集插件wordpresswebmasterplugins或者其他主题的文章采集插件,但会更费事一些。
懂技术,自己搭建博客很不错,
要买服务器,你要租,看租多少钱。博客是主机,你可以试试百度云,不贵还有空间。
都是本人生活中的例子给题主参考下。在这个网络时代,写博客是很重要的个人宣传方式,如何把自己的业余时间用来写自己的博客?-网站推广本人会选择去博客论坛推广博客,一方面目前各种博客论坛不少,基本一个城市就一个,方便找到同城的朋友宣传推广。当然博客有技巧,不只是论坛有技巧,还有网站有技巧,有些细节做的好一样可以很牛,重点是要出文章。在博客推广推广博客的技巧是什么?-网站推广。
还是要自己搭建服务器;你可以去某宝花几十块钱租一个;你要搭建iis服务器,没有钱,自己用vps,或者免费的虚拟主机(一般都是免费的,我都是买的一个200左右的主机;安装好wordpress,其他不懂的百度“phpwind”);先试着去发布吧,凡是你能够想象到的、能发布的,尽管去发布;要自己维护这么一个网站,确实有点困难;。 查看全部
在博客论坛推广博客的技巧是什么?-八维教育
实时文章采集。可以考虑wordpress,不用架设服务器就可以采集到想要的文章,对中国用户也免费。如果要收费服务的话,你可以试试wordpress对应的文章采集插件wordpresswebmasterplugins或者其他主题的文章采集插件,但会更费事一些。
懂技术,自己搭建博客很不错,
要买服务器,你要租,看租多少钱。博客是主机,你可以试试百度云,不贵还有空间。
都是本人生活中的例子给题主参考下。在这个网络时代,写博客是很重要的个人宣传方式,如何把自己的业余时间用来写自己的博客?-网站推广本人会选择去博客论坛推广博客,一方面目前各种博客论坛不少,基本一个城市就一个,方便找到同城的朋友宣传推广。当然博客有技巧,不只是论坛有技巧,还有网站有技巧,有些细节做的好一样可以很牛,重点是要出文章。在博客推广推广博客的技巧是什么?-网站推广。
还是要自己搭建服务器;你可以去某宝花几十块钱租一个;你要搭建iis服务器,没有钱,自己用vps,或者免费的虚拟主机(一般都是免费的,我都是买的一个200左右的主机;安装好wordpress,其他不懂的百度“phpwind”);先试着去发布吧,凡是你能够想象到的、能发布的,尽管去发布;要自己维护这么一个网站,确实有点困难;。
机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-17 02:07
一般来说,对于硬件编程的提供,硬件厂商会提供SDK使用的手册和示例。手册一般包括安装和配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和示例(有些硬件示例直接写在手册中,有些会单独存在文件,有些两者都有)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后根据它介绍的SDK开发流程阅读它提供的例子,并根据自己的需要修改相应的例子。自己使用。该函数可用于查询其用法。一些开发者习惯性地记住他们的API,既费时又费力,不推荐。下面主要用实时图片采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是其中一种,针对不同的工作需求,加载摄像头对象和卸载摄像头对象是常见的。当你想使用其他模块,例如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,之前分配的资源一定要在后面释放。
以下是五个主要流程的详细分析,其中说明了需求,并标注了需要使用的功能
加载相机对象
卸载相机对象
加载数据流以捕获对象
卸载数据流捕获对象
单帧或连续捕捉过程
根据上面介绍的流程,可以实现实时图像采集
源代码下载链接:
很多人问我要源代码。我通过之前的程序文件夹找到了这个程序。演示了使用Pylon SDK执行摄像头采集的过程,使用MIL完成界面展示,并将采集部分封装成一个类,可以直接复用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut来完成图像数据的重组,然后MIL自动显示出来。 查看全部
机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例
一般来说,对于硬件编程的提供,硬件厂商会提供SDK使用的手册和示例。手册一般包括安装和配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和示例(有些硬件示例直接写在手册中,有些会单独存在文件,有些两者都有)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后根据它介绍的SDK开发流程阅读它提供的例子,并根据自己的需要修改相应的例子。自己使用。该函数可用于查询其用法。一些开发者习惯性地记住他们的API,既费时又费力,不推荐。下面主要用实时图片采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是其中一种,针对不同的工作需求,加载摄像头对象和卸载摄像头对象是常见的。当你想使用其他模块,例如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,之前分配的资源一定要在后面释放。
以下是五个主要流程的详细分析,其中说明了需求,并标注了需要使用的功能
加载相机对象
卸载相机对象
加载数据流以捕获对象
卸载数据流捕获对象
单帧或连续捕捉过程
根据上面介绍的流程,可以实现实时图像采集
源代码下载链接:
很多人问我要源代码。我通过之前的程序文件夹找到了这个程序。演示了使用Pylon SDK执行摄像头采集的过程,使用MIL完成界面展示,并将采集部分封装成一个类,可以直接复用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut来完成图像数据的重组,然后MIL自动显示出来。
电商实时数仓的比较离线计算与实时需求种类
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-08-14 07:12
一、电商实时数仓介绍1.1、常见实时计算与实时数仓对比
普通的实时计算优先考虑时效性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是没有沉淀计算过程中的中间结果。因此,当面对大量的实时需求时,计算的复用性较差,开发成本随需求的增加呈线性增长。
实时数据仓库基于一定的数据仓库概念,对数据处理过程进行规划和层次化,以提高数据的可复用性。
1.2 实时电子商务数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 变暗
➢ DWM
➢ DWS
➢ 广告
二、实时需求概览2.1 离线计算与实时计算对比
离线计算:表示在计算开始前所有输入数据都是已知的,输入数据不会发生变化。一般计算量越大,计算时间越长。例如今天早上一点,从昨天累积的日志中计算出需要的结果。最经典的是MR/Spark/Hive;
一般情况下,报表是根据前一天的数据生成的。统计指标和报告虽然很多,但对时效性不敏感。从技术操作来看,这部分是批量操作。即基于一定范围内的数据进行一次计算。
实时计算:输入的数据可以通过序列化的方式一个一个的输入和处理,也就是说不需要一开始就知道所有的输入数据。与离线计算相比,运行时间短,计算量相对较小。强调计算过程的时间要短,即调查时给出结果。
主要侧重于对当天数据的实时监控。一般来说,业务逻辑比离线需求简单,统计指标较少,但更注重数据和用户交互的时效性。从技术操作来看,这部分属于流处理操作。根据数据源的不断到达进行实时计算。
2.2 实时需求类型2.2.1 每日统计报表或分析图需要收录当天的部分
对于网站的日常业务运营和管理,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获得日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
所以实时计算的结果往往会与离线数据结合或展示在 BI 或统计平台中进行比较。
2.2.2 实时数据大屏监控
与 BI 工具或数据分析平台相比,大数据屏幕是一种更直观的数据可视化方式。尤其是一些大的促销活动,已经成为一种必不可少的营销手段。
还有一些特殊的行业,比如交通、电信等行业,所以大屏监控几乎是必不可少的监控方式。
2.2.3 数据警告或提醒
通过大数据实时计算得到的一些风控预警和营销信息提示,可以快速让风控或营销部分得到信息,以便采取各种应对措施。
例如,如果用户在电子商务、金融平台上进行一些违法或欺诈的操作,实时计算大数据可以快速过滤出情况并发送给风控部门处理,甚至自动阻止它。或者如果检测到用户的行为对某些产品有强烈的购买意愿,则可以将这些“商机”推送给客服,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐基于用户自身属性,结合当前访问行为,通过实时推荐算法计算,推送用户可能喜欢的产品、新闻、视频等给用户。
这类系统一般由用户画像批处理加上用户行为分析的流处理组合而成。
三、Statistical Architecture Analysis3.1 离线架构
3.2、实时架构
查看全部
电商实时数仓的比较离线计算与实时需求种类
一、电商实时数仓介绍1.1、常见实时计算与实时数仓对比
普通的实时计算优先考虑时效性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是没有沉淀计算过程中的中间结果。因此,当面对大量的实时需求时,计算的复用性较差,开发成本随需求的增加呈线性增长。
实时数据仓库基于一定的数据仓库概念,对数据处理过程进行规划和层次化,以提高数据的可复用性。
1.2 实时电子商务数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 变暗
➢ DWM
➢ DWS
➢ 广告
二、实时需求概览2.1 离线计算与实时计算对比
离线计算:表示在计算开始前所有输入数据都是已知的,输入数据不会发生变化。一般计算量越大,计算时间越长。例如今天早上一点,从昨天累积的日志中计算出需要的结果。最经典的是MR/Spark/Hive;
一般情况下,报表是根据前一天的数据生成的。统计指标和报告虽然很多,但对时效性不敏感。从技术操作来看,这部分是批量操作。即基于一定范围内的数据进行一次计算。
实时计算:输入的数据可以通过序列化的方式一个一个的输入和处理,也就是说不需要一开始就知道所有的输入数据。与离线计算相比,运行时间短,计算量相对较小。强调计算过程的时间要短,即调查时给出结果。
主要侧重于对当天数据的实时监控。一般来说,业务逻辑比离线需求简单,统计指标较少,但更注重数据和用户交互的时效性。从技术操作来看,这部分属于流处理操作。根据数据源的不断到达进行实时计算。
2.2 实时需求类型2.2.1 每日统计报表或分析图需要收录当天的部分
对于网站的日常业务运营和管理,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获得日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
所以实时计算的结果往往会与离线数据结合或展示在 BI 或统计平台中进行比较。
2.2.2 实时数据大屏监控
与 BI 工具或数据分析平台相比,大数据屏幕是一种更直观的数据可视化方式。尤其是一些大的促销活动,已经成为一种必不可少的营销手段。
还有一些特殊的行业,比如交通、电信等行业,所以大屏监控几乎是必不可少的监控方式。
2.2.3 数据警告或提醒
通过大数据实时计算得到的一些风控预警和营销信息提示,可以快速让风控或营销部分得到信息,以便采取各种应对措施。
例如,如果用户在电子商务、金融平台上进行一些违法或欺诈的操作,实时计算大数据可以快速过滤出情况并发送给风控部门处理,甚至自动阻止它。或者如果检测到用户的行为对某些产品有强烈的购买意愿,则可以将这些“商机”推送给客服,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐基于用户自身属性,结合当前访问行为,通过实时推荐算法计算,推送用户可能喜欢的产品、新闻、视频等给用户。
这类系统一般由用户画像批处理加上用户行为分析的流处理组合而成。
三、Statistical Architecture Analysis3.1 离线架构
3.2、实时架构
实时文章采集 markdown.markdown(markdown版本好像更新了./)/screenshot/flurrynovator/mylearning//////
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-12 01:02
实时文章采集量是一个很好的数据来源,数据量不多的情况下直接将googlebarmark和askreddit的rss文章发到reddit上。现在googlebi用的jstorm的提取。把每天的热门文章复制保存上去之后,用python将jstorm复制的img的reddit+barmark统计到本地。如果想深入挖掘内容,一般还要用nltk、bloomfilter之类的方法对内容进行统计分析。
以上数据可以在github上去下载,具体以要爬取的目标数据为准。flurrynovator/deminct-pages·github。
reddit是推荐网站,类似于stackoverflow.去下载你需要的数据和代码。
不怕浪费时间,就下载当天热门文章flurrynovator/deminct-pages·github里面有一些文章的screenshot,
经测试,注册使用,留言点赞文章直接上传post,会跳转到googlebookmarks.同理可以把其他热门网站的文章都抓过来posted.简单粗暴的方法。==flurrynovator/alternatives·github/flurrynovator/deminct-pages·github/flurrynovator/mylearning/flurrynovator/courseotherapy/flurrynovator/greasebookmarks.markdown(markdown版本好像更新了..flurrynovator/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/greasebookmarks.markdown(markdown版本好像更新了../)/screenshot/"alternative-deq-home".png([1,4,5,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,76,76,77,77,78,79,80,82,83,84,85,85,85,85,85,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,12。 查看全部
实时文章采集 markdown.markdown(markdown版本好像更新了./)/screenshot/flurrynovator/mylearning//////
实时文章采集量是一个很好的数据来源,数据量不多的情况下直接将googlebarmark和askreddit的rss文章发到reddit上。现在googlebi用的jstorm的提取。把每天的热门文章复制保存上去之后,用python将jstorm复制的img的reddit+barmark统计到本地。如果想深入挖掘内容,一般还要用nltk、bloomfilter之类的方法对内容进行统计分析。
以上数据可以在github上去下载,具体以要爬取的目标数据为准。flurrynovator/deminct-pages·github。
reddit是推荐网站,类似于stackoverflow.去下载你需要的数据和代码。
不怕浪费时间,就下载当天热门文章flurrynovator/deminct-pages·github里面有一些文章的screenshot,
经测试,注册使用,留言点赞文章直接上传post,会跳转到googlebookmarks.同理可以把其他热门网站的文章都抓过来posted.简单粗暴的方法。==flurrynovator/alternatives·github/flurrynovator/deminct-pages·github/flurrynovator/mylearning/flurrynovator/courseotherapy/flurrynovator/greasebookmarks.markdown(markdown版本好像更新了..flurrynovator/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/flurrynovator/mylearning/greasebookmarks.markdown(markdown版本好像更新了../)/screenshot/"alternative-deq-home".png([1,4,5,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,76,76,77,77,78,79,80,82,83,84,85,85,85,85,85,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,12。
创建实时编辑器xml文件的结构显示什么信息?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-04 06:01
实时文章采集:github在采集前先确定您需要的内容。例如需要说明通过xml文件的结构显示什么信息?是否需要使用javascript框架创建实时编辑器?查看github上api的说明,通过githubapi设置xml文件的结构。例如$urllib_send模块,sendkey变量。它是一个请求xml格式消息的用户指定sendkey函数。
创建实时编辑器xml文件很多很有趣的东西在这里,您可以在urllib_send模块上手把手教你创建celery,vue,vscode和electron框架框架的内容。在选择框架之前,你需要能够向你的github服务器推送信息。以electron为例,github服务器是githubpages地址,后台是agent_tab.js。
-filter.html?opcode=$curl-l#chmod+x-l--tools#-name...,实现了将xml格式的信息推送给您的githubclient。当然,为了更好的编辑xml文件,我们需要先设置apiurl的格式。$githubapi_urlgithub服务器拥有一个响应连接来实时接收xml消息。
每个css和javascript文件的编译都需要一个请求服务器(或agent_tab.js),他们接收我们需要编译的文件,并进行编译。如果我们使用styled-components框架,用户也可以在chrome扩展商店中找到githubapi,使用chrome的"+"拓展功能从命令行中使用。服务器使用"\"设置向"\"""""\"""\"""...使用svg-tools直接访问/实际上svgapi也被广泛使用,而electron也是。
设置api请求url为"xxxx"我们建议您在xml文件的所有位置使用#。例如xmlpost可以在"xxxx",vue应用也可以在"xxxx",而electron则在"xxxx"。我们在这里简单试用一下吧。xmlpostxmlserverhost:xxxx-xxxxxuserpassword:xxxx-xxxxx#xmlserverurl$sourceurl="xxxx"xmlserverhost:xxxx-xxxxxuserpassword:xxxx-xxxxx#postcodeset...您可以通过#xmlserver或者$sourceurl获取xml编辑器的某些xml编译功能。
例如我可以这样做。xmlpost:xxxx"public"forx:$sourceurlxmlpost:xxxx"xxxx"x:$sourceurl#xxxsourceurl$sourceurl/xxx/xxx_xxx":xxx我也可以重新定义apiurl,但应避免在github上xml文件结构过复杂。
此方法将引导您进入xml编辑器的xml编译器和xml编译命令行操作。创建apiapi的设置与xml的设置类似。xmlapi默认推送css和javascript的编译消息。xml_post$xxx_xxx"\xxxxxxx"\xxxcssxxx_x。 查看全部
创建实时编辑器xml文件的结构显示什么信息?(一)
实时文章采集:github在采集前先确定您需要的内容。例如需要说明通过xml文件的结构显示什么信息?是否需要使用javascript框架创建实时编辑器?查看github上api的说明,通过githubapi设置xml文件的结构。例如$urllib_send模块,sendkey变量。它是一个请求xml格式消息的用户指定sendkey函数。
创建实时编辑器xml文件很多很有趣的东西在这里,您可以在urllib_send模块上手把手教你创建celery,vue,vscode和electron框架框架的内容。在选择框架之前,你需要能够向你的github服务器推送信息。以electron为例,github服务器是githubpages地址,后台是agent_tab.js。
-filter.html?opcode=$curl-l#chmod+x-l--tools#-name...,实现了将xml格式的信息推送给您的githubclient。当然,为了更好的编辑xml文件,我们需要先设置apiurl的格式。$githubapi_urlgithub服务器拥有一个响应连接来实时接收xml消息。
每个css和javascript文件的编译都需要一个请求服务器(或agent_tab.js),他们接收我们需要编译的文件,并进行编译。如果我们使用styled-components框架,用户也可以在chrome扩展商店中找到githubapi,使用chrome的"+"拓展功能从命令行中使用。服务器使用"\"设置向"\"""""\"""\"""...使用svg-tools直接访问/实际上svgapi也被广泛使用,而electron也是。
设置api请求url为"xxxx"我们建议您在xml文件的所有位置使用#。例如xmlpost可以在"xxxx",vue应用也可以在"xxxx",而electron则在"xxxx"。我们在这里简单试用一下吧。xmlpostxmlserverhost:xxxx-xxxxxuserpassword:xxxx-xxxxx#xmlserverurl$sourceurl="xxxx"xmlserverhost:xxxx-xxxxxuserpassword:xxxx-xxxxx#postcodeset...您可以通过#xmlserver或者$sourceurl获取xml编辑器的某些xml编译功能。
例如我可以这样做。xmlpost:xxxx"public"forx:$sourceurlxmlpost:xxxx"xxxx"x:$sourceurl#xxxsourceurl$sourceurl/xxx/xxx_xxx":xxx我也可以重新定义apiurl,但应避免在github上xml文件结构过复杂。
此方法将引导您进入xml编辑器的xml编译器和xml编译命令行操作。创建apiapi的设置与xml的设置类似。xmlapi默认推送css和javascript的编译消息。xml_post$xxx_xxx"\xxxxxxx"\xxxcssxxx_x。
如何集成实时文章采集平台?百度access-control-allow-originurl怎么做?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-02 19:09
实时文章采集平台以订阅号开通后,可以在24小时内实时推送您浏览的文章。对于内容运营人员,又是一大福音。
1、任何文章发送24小时内可看。
2、原创度更高、更符合原创保护。
3、采集文章后,可以做内容细分标签。那么如何集成以上功能呢?具体如下图:想要集成,得需要先做两件事:安装一个云服务器,并配置一个cname。cname指向自己云服务器的ip。
ip地址:(ip地址一般填1.1.1.
1)一般云服务器都有一个固定的cname地址。实时文章采集平台有registration(注册账号)功能,那么开通有邀请功能的服务器后,直接去注册一个账号。服务器启动后,使用admin(管理员账号)登录系统,设置email权限,将采集内容推送到云服务器。开通后,就可以通过registration看到这个云服务器的真实ip。
那么也就知道采集文章时,这个文章的原始ip地址。后续如果发现文章已经被采集,还可以通过同行业友会收购。方法见下图。在pc端,或者移动端可以配置浏览器采集采集功能。可以用浏览器的前端接口,也可以通过微信公众号客户端,也可以通过自己的app接口。一般pc端,用wordpress可以采集任何网站、公众号图文。
比如wordpress是免费的,只需要找到user-agent,配置access-control-allow-origin(打开代理页面的user-agent地址,自己记一下,服务器接口返回图文的,这个网站接口返回的网址是:)。这个页面可以通过配置获取。很多人被采集后不知道图文地址。这个时候。如果你不记住云服务器配置地址,可以想办法记住云服务器cname地址和email,可以通过修改百度ip来解决,修改百度access-control-allow-originurl(这个是提取采集链接的关键字)即可。
移动端app可以配置。app直接接入开发者服务器,配置access-control-allow-origin即可,如下图:你也可以将下载好的文章、全文/自己编辑的原文一键导入到图文,如下图:遇到robots.txt文件时怎么办?如果robots.txt文件中有网站域名的话,这时候只能看到转发的文章,而看不到原始网站图文。
robots.txt文件:content-type:application/json;url="/";trust-proxy:proxy=,server=mc-inc-http://%26quot%3B.%26quot%3B%3 ... 3B%3B第二种方法。通过https://,查看application/json。
如果没有,你可以使用第三种方法:通过手机、微信查看,如下图。pc端registration,手机微信查看(手机微信同步,pc端registration不到,微信采集后查看)。类似的还有:微信公众号图文查看、微信公。 查看全部
如何集成实时文章采集平台?百度access-control-allow-originurl怎么做?(一)
实时文章采集平台以订阅号开通后,可以在24小时内实时推送您浏览的文章。对于内容运营人员,又是一大福音。
1、任何文章发送24小时内可看。
2、原创度更高、更符合原创保护。
3、采集文章后,可以做内容细分标签。那么如何集成以上功能呢?具体如下图:想要集成,得需要先做两件事:安装一个云服务器,并配置一个cname。cname指向自己云服务器的ip。
ip地址:(ip地址一般填1.1.1.
1)一般云服务器都有一个固定的cname地址。实时文章采集平台有registration(注册账号)功能,那么开通有邀请功能的服务器后,直接去注册一个账号。服务器启动后,使用admin(管理员账号)登录系统,设置email权限,将采集内容推送到云服务器。开通后,就可以通过registration看到这个云服务器的真实ip。
那么也就知道采集文章时,这个文章的原始ip地址。后续如果发现文章已经被采集,还可以通过同行业友会收购。方法见下图。在pc端,或者移动端可以配置浏览器采集采集功能。可以用浏览器的前端接口,也可以通过微信公众号客户端,也可以通过自己的app接口。一般pc端,用wordpress可以采集任何网站、公众号图文。
比如wordpress是免费的,只需要找到user-agent,配置access-control-allow-origin(打开代理页面的user-agent地址,自己记一下,服务器接口返回图文的,这个网站接口返回的网址是:)。这个页面可以通过配置获取。很多人被采集后不知道图文地址。这个时候。如果你不记住云服务器配置地址,可以想办法记住云服务器cname地址和email,可以通过修改百度ip来解决,修改百度access-control-allow-originurl(这个是提取采集链接的关键字)即可。
移动端app可以配置。app直接接入开发者服务器,配置access-control-allow-origin即可,如下图:你也可以将下载好的文章、全文/自己编辑的原文一键导入到图文,如下图:遇到robots.txt文件时怎么办?如果robots.txt文件中有网站域名的话,这时候只能看到转发的文章,而看不到原始网站图文。
robots.txt文件:content-type:application/json;url="/";trust-proxy:proxy=,server=mc-inc-http://%26quot%3B.%26quot%3B%3 ... 3B%3B第二种方法。通过https://,查看application/json。
如果没有,你可以使用第三种方法:通过手机、微信查看,如下图。pc端registration,手机微信查看(手机微信同步,pc端registration不到,微信采集后查看)。类似的还有:微信公众号图文查看、微信公。
电商实时数仓,项目分为以下几层/Hive
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-08-01 05:07
一、电商实时数仓介绍1.1、常见实时计算与实时数仓对比
普通的实时计算优先考虑时效性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是没有沉淀计算过程中的中间结果。因此,当面对大量的实时需求时,计算的复用性较差,开发成本随需求的增加呈线性增长。
实时数据仓库基于一定的数据仓库概念,对数据处理过程进行规划和层次化,以提高数据的可复用性。
1.2 实时电子商务数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 变暗
➢ DWM
➢ DWS
➢ 广告
二、实时需求概览2.1 离线计算与实时计算对比
离线计算:表示在计算开始前所有输入数据都是已知的,输入数据不会发生变化。一般计算量越大,计算时间越长。例如今天早上一点,从昨天累积的日志中计算出需要的结果。最经典的是MR/Spark/Hive;
一般情况下,报表是根据前一天的数据生成的。统计指标和报告虽然很多,但对时效性不敏感。从技术操作来看,这部分是批量操作。即基于一定范围内的数据进行一次计算。
实时计算:输入数据可以通过序列化的方式一个一个的输入和处理,也就是说不需要一开始就知道所有的输入数据。与离线计算相比,运行时间短,计算量相对较小。强调计算过程的时间要短,即调查时给出结果。
主要侧重于对当天数据的实时监控。一般来说,业务逻辑比离线需求简单,统计指标较少,但更注重数据和用户交互的时效性。从技术操作来看,这部分属于流处理操作。根据数据源的不断到达进行实时计算。
2.2 实时需求类型2.2.1 每日统计报表或分析图需要收录当天的部分
对于网站的日常业务运营和管理,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获得日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
所以实时计算的结果往往会与离线数据结合或展示在 BI 或统计平台中进行比较。
2.2.2 实时数据大屏监控
与 BI 工具或数据分析平台相比,大数据屏幕是一种更直观的数据可视化方式。尤其是一些大的促销活动,已经成为一种必不可少的营销手段。
还有一些特殊的行业,比如交通、电信等行业,所以大屏监控几乎是必不可少的监控方式。
2.2.3 数据警告或提醒
通过大数据实时计算得到的一些风控预警和营销信息提示,可以快速让风控或营销部分得到信息,以便采取各种应对措施。
例如,如果用户在电子商务和金融平台上进行一些非法或欺诈的操作,实时计算大数据可以快速过滤出情况并发送到风控部门进行处理,甚至自动阻止它。或者如果检测到用户的行为对某些产品有强烈的购买意愿,则可以将这些“商机”推送给客服,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐是根据用户自身的属性,结合当前的访问行为,通过实时推荐算法计算,将用户可能喜欢的产品、新闻、视频等推送给用户用户。
这类系统一般由用户画像批处理加上用户行为分析的流处理组合而成。
三、Statistical Architecture Analysis3.1 离线架构
3.2、实时架构
查看全部
电商实时数仓,项目分为以下几层/Hive
一、电商实时数仓介绍1.1、常见实时计算与实时数仓对比
普通的实时计算优先考虑时效性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是没有沉淀计算过程中的中间结果。因此,当面对大量的实时需求时,计算的复用性较差,开发成本随需求的增加呈线性增长。
实时数据仓库基于一定的数据仓库概念,对数据处理过程进行规划和层次化,以提高数据的可复用性。
1.2 实时电子商务数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 变暗
➢ DWM
➢ DWS
➢ 广告
二、实时需求概览2.1 离线计算与实时计算对比
离线计算:表示在计算开始前所有输入数据都是已知的,输入数据不会发生变化。一般计算量越大,计算时间越长。例如今天早上一点,从昨天累积的日志中计算出需要的结果。最经典的是MR/Spark/Hive;
一般情况下,报表是根据前一天的数据生成的。统计指标和报告虽然很多,但对时效性不敏感。从技术操作来看,这部分是批量操作。即基于一定范围内的数据进行一次计算。
实时计算:输入数据可以通过序列化的方式一个一个的输入和处理,也就是说不需要一开始就知道所有的输入数据。与离线计算相比,运行时间短,计算量相对较小。强调计算过程的时间要短,即调查时给出结果。
主要侧重于对当天数据的实时监控。一般来说,业务逻辑比离线需求简单,统计指标较少,但更注重数据和用户交互的时效性。从技术操作来看,这部分属于流处理操作。根据数据源的不断到达进行实时计算。
2.2 实时需求类型2.2.1 每日统计报表或分析图需要收录当天的部分
对于网站的日常业务运营和管理,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获得日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
所以实时计算的结果往往会与离线数据结合或展示在 BI 或统计平台中进行比较。
2.2.2 实时数据大屏监控
与 BI 工具或数据分析平台相比,大数据屏幕是一种更直观的数据可视化方式。尤其是一些大的促销活动,已经成为一种必不可少的营销手段。
还有一些特殊的行业,比如交通、电信等行业,所以大屏监控几乎是必不可少的监控方式。
2.2.3 数据警告或提醒
通过大数据实时计算得到的一些风控预警和营销信息提示,可以快速让风控或营销部分得到信息,以便采取各种应对措施。
例如,如果用户在电子商务和金融平台上进行一些非法或欺诈的操作,实时计算大数据可以快速过滤出情况并发送到风控部门进行处理,甚至自动阻止它。或者如果检测到用户的行为对某些产品有强烈的购买意愿,则可以将这些“商机”推送给客服,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐是根据用户自身的属性,结合当前的访问行为,通过实时推荐算法计算,将用户可能喜欢的产品、新闻、视频等推送给用户用户。
这类系统一般由用户画像批处理加上用户行为分析的流处理组合而成。
三、Statistical Architecture Analysis3.1 离线架构
3.2、实时架构
基于阿里云和亚马逊云容器云平台的pythonweb服务器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-31 23:06
实时文章采集,主要意义有以下几点:1.把原来的分散的字段采集到excel表格内,以便于后续数据比对分析,根据实际情况和企业需求定向获取数据,提升效率和质量。2.借助快闪接口,可以实现实时博客采集,上亿条记录快速采集到百度、腾讯、今日头条等平台3.借助csdn的实时接口获取新闻源或者论坛页面的原始链接。
4.不少网站的图片采集,视频采集,手机app的运营推广,都需要采集一些网站的图片、视频等数据,一般存放在数据库中。近几年ai智能的发展促使采集这一块有了新的需求,大量的人工采集工作可以被简化。之前实际使用过各种软件,常用的有java开发的优采云采集器、python开发的集采、网页静态采集宝等。本文重点介绍flask+awsredis(awsredis是一个基于阿里云和亚马逊云容器云平台的pythonweb服务器,它可以实现python命令行工具的批量部署,并支持python3.5+与python2.7+版本)一键采集优采云采集器+推酷首页的网页内容。
环境1.首先安装好java或python2.安装好aws或者ecspython3.4版本即可2.配置awsredis5.0需要amazonec2,推荐阿里云或腾讯云ecs无需安装其他虚拟机软件:2.1awsec2下载,本文先介绍下阿里云aws中ecs下载的方法:wget-la/$(uname-s)$(uname-r)/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation.me-new.。 查看全部
基于阿里云和亚马逊云容器云平台的pythonweb服务器下载
实时文章采集,主要意义有以下几点:1.把原来的分散的字段采集到excel表格内,以便于后续数据比对分析,根据实际情况和企业需求定向获取数据,提升效率和质量。2.借助快闪接口,可以实现实时博客采集,上亿条记录快速采集到百度、腾讯、今日头条等平台3.借助csdn的实时接口获取新闻源或者论坛页面的原始链接。
4.不少网站的图片采集,视频采集,手机app的运营推广,都需要采集一些网站的图片、视频等数据,一般存放在数据库中。近几年ai智能的发展促使采集这一块有了新的需求,大量的人工采集工作可以被简化。之前实际使用过各种软件,常用的有java开发的优采云采集器、python开发的集采、网页静态采集宝等。本文重点介绍flask+awsredis(awsredis是一个基于阿里云和亚马逊云容器云平台的pythonweb服务器,它可以实现python命令行工具的批量部署,并支持python3.5+与python2.7+版本)一键采集优采云采集器+推酷首页的网页内容。
环境1.首先安装好java或python2.安装好aws或者ecspython3.4版本即可2.配置awsredis5.0需要amazonec2,推荐阿里云或腾讯云ecs无需安装其他虚拟机软件:2.1awsec2下载,本文先介绍下阿里云aws中ecs下载的方法:wget-la/$(uname-s)$(uname-r)/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation./ecs/ec2-v3.8.1-user-per-generation.me-new.。
商用抓取软件(fiddler、chromedriver)+页面解析工具(pagecodec)
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-30 23:04
实时文章采集软件行业一直在趋于细分化,越细分,发展前景越大,公众号【软件工程猫】做的是互联网金融、互联网广告、电商、搜索、通讯类软件的爬虫定位,刚好够细分了。现在的文章抓取软件基本是商用抓取软件(fiddler、chromedriver)+页面解析工具(pagecodec)。
现在搜索引擎竞争,一个专业的软件都被互联网巨头垄断,所以这个市场发展空间已经不大了,互联网公司都是流量主要用自己的自有app,抓取这个算是冷门的市场,而且不是一个赚钱的行业。
内容抓取器是一个典型的程序猿成名产品,容易被复制,不太值钱,专业人士用来是突破局限的,圈子里使用的普通人用来赚钱还可以吧,重点是程序猿还得不断学习,这是一个企业家必须要面对的市场问题。
wget是一个非常好的程序员抓取工具,但是没有完全商业化。市场前景不错,大约是被金山云这样做搜索起家的公司覆盖掉了。
前景不会差
对于我这样小白来说是一个非常不错的方向。如果我想要偷梁换柱的弄点内容上去,倒是可以考虑下wget,毕竟是google开发的呀。
关注程序员,开发者,找应用,
其实个人也觉得不如fiddler划算,但是还是安利下。刚毕业还是比较推荐使用这个抓取,也是我使用过抓取比较好的一个。 查看全部
商用抓取软件(fiddler、chromedriver)+页面解析工具(pagecodec)
实时文章采集软件行业一直在趋于细分化,越细分,发展前景越大,公众号【软件工程猫】做的是互联网金融、互联网广告、电商、搜索、通讯类软件的爬虫定位,刚好够细分了。现在的文章抓取软件基本是商用抓取软件(fiddler、chromedriver)+页面解析工具(pagecodec)。
现在搜索引擎竞争,一个专业的软件都被互联网巨头垄断,所以这个市场发展空间已经不大了,互联网公司都是流量主要用自己的自有app,抓取这个算是冷门的市场,而且不是一个赚钱的行业。
内容抓取器是一个典型的程序猿成名产品,容易被复制,不太值钱,专业人士用来是突破局限的,圈子里使用的普通人用来赚钱还可以吧,重点是程序猿还得不断学习,这是一个企业家必须要面对的市场问题。
wget是一个非常好的程序员抓取工具,但是没有完全商业化。市场前景不错,大约是被金山云这样做搜索起家的公司覆盖掉了。
前景不会差
对于我这样小白来说是一个非常不错的方向。如果我想要偷梁换柱的弄点内容上去,倒是可以考虑下wget,毕竟是google开发的呀。
关注程序员,开发者,找应用,
其实个人也觉得不如fiddler划算,但是还是安利下。刚毕业还是比较推荐使用这个抓取,也是我使用过抓取比较好的一个。

