
实时文章采集
实时文章采集(实时文章采集网络爬虫,excel格式的数据爬虫任务可能非常多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-26 09:05
实时文章采集网络爬虫,excel格式的数据爬虫任务可能非常多,可以尝试下实时爬虫任务,可以获取到最新文章而且实时获取文章比较方便,不用设置分页,方便直接提取有价值的信息。有感兴趣的可以点击我,获取学习资料及源码下载。对于任务是采集信息,作者是从以下几个角度出发的。1.搜索排名2.帖子内容3.新闻来源4.热门分类5.标签分析6.阅读时间7.群组排名8.个人排名以下是简单爬虫的代码和效果展示:根据内容爬取网络信息列举一些案例:1.实时文章及群组排名2.某篇文章【发布信息】【收藏】【阅读次数】【在线阅读次数】【点赞】【转发】【评论】【小组讨论】【说说】【文章微博】【学术论文】某实时排名3.某某厂商产品相关消息实时爬取。
用户的属性信息,也就是分析的对象是人;还有时间上的区分也有助于抓取时间上的信息;还有就是操作规律,有很多第三方网站可以抓取到数据,比如饭统官网的爬虫接口,有很多实时抓取数据。有兴趣的朋友可以和大家分享下,外出开会不是很方便。
既然是自己写的,那建议还是脚本,也就是单人的小任务,基本的功能足够用的。
我也曾经做过类似的任务,既然是单人,那么需要专人来完成,如果不专人,那么我建议可以使用手机联网电脑都可以打开的软件;例如anycast,当然实现起来比较麻烦,但是成本很低的。 查看全部
实时文章采集(实时文章采集网络爬虫,excel格式的数据爬虫任务可能非常多)
实时文章采集网络爬虫,excel格式的数据爬虫任务可能非常多,可以尝试下实时爬虫任务,可以获取到最新文章而且实时获取文章比较方便,不用设置分页,方便直接提取有价值的信息。有感兴趣的可以点击我,获取学习资料及源码下载。对于任务是采集信息,作者是从以下几个角度出发的。1.搜索排名2.帖子内容3.新闻来源4.热门分类5.标签分析6.阅读时间7.群组排名8.个人排名以下是简单爬虫的代码和效果展示:根据内容爬取网络信息列举一些案例:1.实时文章及群组排名2.某篇文章【发布信息】【收藏】【阅读次数】【在线阅读次数】【点赞】【转发】【评论】【小组讨论】【说说】【文章微博】【学术论文】某实时排名3.某某厂商产品相关消息实时爬取。
用户的属性信息,也就是分析的对象是人;还有时间上的区分也有助于抓取时间上的信息;还有就是操作规律,有很多第三方网站可以抓取到数据,比如饭统官网的爬虫接口,有很多实时抓取数据。有兴趣的朋友可以和大家分享下,外出开会不是很方便。
既然是自己写的,那建议还是脚本,也就是单人的小任务,基本的功能足够用的。
我也曾经做过类似的任务,既然是单人,那么需要专人来完成,如果不专人,那么我建议可以使用手机联网电脑都可以打开的软件;例如anycast,当然实现起来比较麻烦,但是成本很低的。
实时文章采集(电商实时数仓的比较离线计算与实时需求种类 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-20 20:02
)
一、电商实时数仓介绍1.1、普通实时计算与实时数仓对比
普通实时计算优先考虑及时性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是计算过程中的中间结果没有沉淀出来,所以在面对大量实时性需求时,计算的复用性较差,开发成本线性增加随着需求的增加。
实时数仓基于一定的数据仓库概念,对数据处理过程进行规划和分层,以提高数据的可重用性。
1.2 实时电商数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 昏暗
➢ DWM
➢ DWS
➢ ADS
二、实时需求概览2.1 离线与实时计算对比
离线计算:即在计算开始前所有输入数据都是已知的,输入数据不会改变。一般计算量大,计算时间长。例如,今天早上 1 点,从昨天积累的日志中计算出所需的结果。最经典的是MR/Spark/Hive。通常,报告是根据前一天的数据生成的。统计指标和报表虽多,但对时效性不敏感。从技术操作上看,这部分属于批量操作。即一次计算是基于一定范围的数据。
实时计算:输入数据可以以序列化的方式一个一个地输入和处理,也就是说一开始不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量较小。强调计算过程的时间要短,即在调查的那一刻给出结果。主要关注当日数据的实时监控。通常,业务逻辑比线下需求简单,统计指标较少,但更注重数据的及时性和用户的交互性。从技术操作来看,这部分属于流处理的操作。
2.2 实时需求类型2.2.1 每日统计报表或分析图表需收录当日
对于日常的企业和网站运营管理来说,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获取日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
因此,实时计算结果往往与线下数据相结合或展示在BI或统计平台中。
2.2.2 实时数据大屏监控
大数据屏幕是比 BI 工具或数据分析平台更直观的数据可视化方式。尤其是一些大型的促销活动,已经成为必备的营销手段。此外,还有一些特殊的行业,比如交通、电信行业,那么大屏监控几乎是必不可少的监控手段。
2.2.3 数据警告或提醒
一些通过大数据实时计算得到的风控预警和营销信息提示,可以让风控或营销部门快速获取信息,从而采取各种应对措施。比如用户在电商、金融平台进行一些违法或欺诈的操作,大数据的实时计算可以快速筛选出情况并发送给风控部门处理,甚至自动屏蔽它。或者检测到用户的行为对某些产品有强烈的购买意愿,那么可以将这些“商机”推送给客服部,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐是根据用户自身属性结合当前访问行为,通过实时推荐算法计算,将用户可能喜欢的产品、新闻、视频等推送给用户。这类系统一般由用户画像的批处理和用户行为分析的流处理组成。
三、统计架构分析3.1 离线架构
3.2、实时架构
查看全部
实时文章采集(电商实时数仓的比较离线计算与实时需求种类
)
一、电商实时数仓介绍1.1、普通实时计算与实时数仓对比
普通实时计算优先考虑及时性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是计算过程中的中间结果没有沉淀出来,所以在面对大量实时性需求时,计算的复用性较差,开发成本线性增加随着需求的增加。
实时数仓基于一定的数据仓库概念,对数据处理过程进行规划和分层,以提高数据的可重用性。
1.2 实时电商数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 昏暗
➢ DWM
➢ DWS
➢ ADS
二、实时需求概览2.1 离线与实时计算对比
离线计算:即在计算开始前所有输入数据都是已知的,输入数据不会改变。一般计算量大,计算时间长。例如,今天早上 1 点,从昨天积累的日志中计算出所需的结果。最经典的是MR/Spark/Hive。通常,报告是根据前一天的数据生成的。统计指标和报表虽多,但对时效性不敏感。从技术操作上看,这部分属于批量操作。即一次计算是基于一定范围的数据。
实时计算:输入数据可以以序列化的方式一个一个地输入和处理,也就是说一开始不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量较小。强调计算过程的时间要短,即在调查的那一刻给出结果。主要关注当日数据的实时监控。通常,业务逻辑比线下需求简单,统计指标较少,但更注重数据的及时性和用户的交互性。从技术操作来看,这部分属于流处理的操作。
2.2 实时需求类型2.2.1 每日统计报表或分析图表需收录当日
对于日常的企业和网站运营管理来说,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获取日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
因此,实时计算结果往往与线下数据相结合或展示在BI或统计平台中。
2.2.2 实时数据大屏监控
大数据屏幕是比 BI 工具或数据分析平台更直观的数据可视化方式。尤其是一些大型的促销活动,已经成为必备的营销手段。此外,还有一些特殊的行业,比如交通、电信行业,那么大屏监控几乎是必不可少的监控手段。
2.2.3 数据警告或提醒
一些通过大数据实时计算得到的风控预警和营销信息提示,可以让风控或营销部门快速获取信息,从而采取各种应对措施。比如用户在电商、金融平台进行一些违法或欺诈的操作,大数据的实时计算可以快速筛选出情况并发送给风控部门处理,甚至自动屏蔽它。或者检测到用户的行为对某些产品有强烈的购买意愿,那么可以将这些“商机”推送给客服部,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐是根据用户自身属性结合当前访问行为,通过实时推荐算法计算,将用户可能喜欢的产品、新闻、视频等推送给用户。这类系统一般由用户画像的批处理和用户行为分析的流处理组成。
三、统计架构分析3.1 离线架构
3.2、实时架构
实时文章采集( 帝国CMS如何免费采集信息,本篇文章分享收获)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-01-15 01:12
帝国CMS如何免费采集信息,本篇文章分享收获)
帝国cms如何免费采集信息,本文文章主要介绍帝国cms如何免费采集信息,有一定的参考价值,需要的朋友可以参考下。希望看完这篇文章你会受益匪浅。小编带大家一探究竟。Empirecms是站长大量使用PHP的建站系统。在建站的过程中,如果没有信息源,只能手动复制粘贴,费时费力,所以需要用到自由帝国cms@ >采集函数完成信息的录入。对于帝国cms,站长们接触过很多,对比织梦cms,织梦 在处理超过一百万个数据时确实有更高的负载。许多网站管理员将Empirecms 用于采集 站。众所周知,建一个采集网站不像做一个公司官网,需要手动更新。采集 站点越自动化越好,最好不要让人管理它。
自由帝国cms采集如何实现呢?首先,您不需要了解代码和技术技能,也不需要编写复杂的 采集 规则。毕竟大部分站长都不知道怎么写采集规则。二、极简主义,配置简单,没有复杂的功能设置,简单易懂,主要是按键的性质,点击选择与否。三、挂机采集,无需人工干预,设置采集规则,即可实现自动批量挂机采集,无缝发布,自带发布功能,采集后即自动批量发布到网站,发布时支持自动伪原创,使采集伪原创发布实现全自动挂机。
一旦你用 Empire cms 建立了你的站,恢复整个 采集 过程。
1.点击批处理采集管理,选择添加采集任务
2.新建采集任务标题,以zjxseo为例,选择采集数据源,同时支持十多个数据源采集,点击选择。
3. 选择采集文件存放目录,在D盘新建文件夹,在数据源中设置关键词篇采集篇,10篇/ 关键词例如。 查看全部
实时文章采集(
帝国CMS如何免费采集信息,本篇文章分享收获)
帝国cms如何免费采集信息,本文文章主要介绍帝国cms如何免费采集信息,有一定的参考价值,需要的朋友可以参考下。希望看完这篇文章你会受益匪浅。小编带大家一探究竟。Empirecms是站长大量使用PHP的建站系统。在建站的过程中,如果没有信息源,只能手动复制粘贴,费时费力,所以需要用到自由帝国cms@ >采集函数完成信息的录入。对于帝国cms,站长们接触过很多,对比织梦cms,织梦 在处理超过一百万个数据时确实有更高的负载。许多网站管理员将Empirecms 用于采集 站。众所周知,建一个采集网站不像做一个公司官网,需要手动更新。采集 站点越自动化越好,最好不要让人管理它。
自由帝国cms采集如何实现呢?首先,您不需要了解代码和技术技能,也不需要编写复杂的 采集 规则。毕竟大部分站长都不知道怎么写采集规则。二、极简主义,配置简单,没有复杂的功能设置,简单易懂,主要是按键的性质,点击选择与否。三、挂机采集,无需人工干预,设置采集规则,即可实现自动批量挂机采集,无缝发布,自带发布功能,采集后即自动批量发布到网站,发布时支持自动伪原创,使采集伪原创发布实现全自动挂机。
一旦你用 Empire cms 建立了你的站,恢复整个 采集 过程。
1.点击批处理采集管理,选择添加采集任务
2.新建采集任务标题,以zjxseo为例,选择采集数据源,同时支持十多个数据源采集,点击选择。
3. 选择采集文件存放目录,在D盘新建文件夹,在数据源中设置关键词篇采集篇,10篇/ 关键词例如。
实时文章采集(一下zblog插件采集方式(一)(1)_国内_光明网(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-14 06:15
)
Zblog采集插件是为了帮助网站快速丰富网站内容;减少手动内容发布的繁琐;主要是给网站添加很多内容,方便快捷。 网站发布文章的时候,如果把文章一一发布到网上,不仅浪费时间,而且效率低下。这时候为了提高更新网站的效率,出现了zblog采集插件,但是常规的zblog插件都需要写规则。今天博主就来说说zblog插件采集方法:第一个是付费插件,需要写规则,第二个是免费工具,不需要写规则!
Zblog采集规则介绍
第一步:创建一个新的文章采集节点
登录后台,点击采集>>>采集节点管理>>添加新节点>>选择普通文章>>确定
第二步:填写采集列表规则
1.节点名:随便(注意要能区分,因为节点太多可能会造成混乱)
2.查看目标页面的编码:查看目标页面的编码
3.匹配网址:进入采集目标列表页面查看其列表规则!比如很多网站列表的首页和其他的内页差别很大,所以我一般不会采集定位到列表的首页!
最好从第二页开始(虽然第一页可以找到,但是很多网站根本没有第一页,这里就不讲怎么找到第一页了)
4.区域末尾的HTML:在采集目标列表页面打开源代码!在 文章 的标题附近寻找一个 html 标记,该标记将是 采集,并且对于该页面和其他将成为 采集 的页面来说是唯一的!
再次按下一步!输入并填写采集内容规则
第 3 步:采集内容规则
1.文章标题:寻找文章标题前后两个标签,即可识别标题!
2.文章内容:寻找文章内容前后的两个标签来识别内容!我的 采集 的 网站 的 文章 内容前后的唯一标签是
[内容]
其他功能,不用担心!这就是 zblog 可以访问 文章 的方式!然后,单击以保存配置并进行预览。如果之前的列表规则和内容规则都写对了,现在可以采集文章!
二、通过关键词采集文章
无需学习更多专业技能,简单几步轻松搞定采集网页数据,精准数据发布,关键词用户只需在软件中进行简单设置,完成后系统根据用户设置关键词进行采集,高精度匹配内容和图片并自动执行文章采集发布,提供方便快捷的数据服务! !
相对规则采集门槛低,无需花大量时间学习软件操作,无需配置采集规则即可一分钟上手,输入关键词采集.无需人工干预,将任务设置为自动执行采集releases。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
<p>这类工具还是很强大的,只要输入关键词采集,完全可以通过软件 查看全部
实时文章采集(一下zblog插件采集方式(一)(1)_国内_光明网(组图)
)
Zblog采集插件是为了帮助网站快速丰富网站内容;减少手动内容发布的繁琐;主要是给网站添加很多内容,方便快捷。 网站发布文章的时候,如果把文章一一发布到网上,不仅浪费时间,而且效率低下。这时候为了提高更新网站的效率,出现了zblog采集插件,但是常规的zblog插件都需要写规则。今天博主就来说说zblog插件采集方法:第一个是付费插件,需要写规则,第二个是免费工具,不需要写规则!

Zblog采集规则介绍
第一步:创建一个新的文章采集节点
登录后台,点击采集>>>采集节点管理>>添加新节点>>选择普通文章>>确定
第二步:填写采集列表规则
1.节点名:随便(注意要能区分,因为节点太多可能会造成混乱)
2.查看目标页面的编码:查看目标页面的编码
3.匹配网址:进入采集目标列表页面查看其列表规则!比如很多网站列表的首页和其他的内页差别很大,所以我一般不会采集定位到列表的首页!

最好从第二页开始(虽然第一页可以找到,但是很多网站根本没有第一页,这里就不讲怎么找到第一页了)
4.区域末尾的HTML:在采集目标列表页面打开源代码!在 文章 的标题附近寻找一个 html 标记,该标记将是 采集,并且对于该页面和其他将成为 采集 的页面来说是唯一的!
再次按下一步!输入并填写采集内容规则
第 3 步:采集内容规则
1.文章标题:寻找文章标题前后两个标签,即可识别标题!
2.文章内容:寻找文章内容前后的两个标签来识别内容!我的 采集 的 网站 的 文章 内容前后的唯一标签是
[内容]
其他功能,不用担心!这就是 zblog 可以访问 文章 的方式!然后,单击以保存配置并进行预览。如果之前的列表规则和内容规则都写对了,现在可以采集文章!
二、通过关键词采集文章

无需学习更多专业技能,简单几步轻松搞定采集网页数据,精准数据发布,关键词用户只需在软件中进行简单设置,完成后系统根据用户设置关键词进行采集,高精度匹配内容和图片并自动执行文章采集发布,提供方便快捷的数据服务! !

相对规则采集门槛低,无需花大量时间学习软件操作,无需配置采集规则即可一分钟上手,输入关键词采集.无需人工干预,将任务设置为自动执行采集releases。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。

<p>这类工具还是很强大的,只要输入关键词采集,完全可以通过软件
实时文章采集(绝对能使你眼前一亮,通过这篇文章介绍希望你能有所收获)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-13 18:04
本文文章向你展示了如何在TX1上使用OpenCV3.1实时采集视频图像分析。内容简洁易懂,一定会让你眼前一亮。文章文章的详细介绍希望你有所收获。
嵌入式平台(目标): Jeston TX1
OpenCV:OpenCV3.1
摄像头:USB 800W 摄像头
1 简介
Jetpack3.0安装的OpenCV是OpenCV2.4.13,而OpenCV2.4.13不支持USB摄像头。未来NVIDIA更新的Jetpack将解决USB摄像头支持不佳的问题。在官方解决之前,临时的解决办法是自己编译OpenCV3.1。
2 下载 OpenCV3
网址:
点击 Sources 下载源代码:
3 安装依赖库
# Some general development librariessudo apt-get install -y build-essential make cmake cmake-curses-gui g++# libav video input/output development librariessudo apt-get install -y libavformat-dev libavutil-dev libswscale-dev# Video4Linux camera development librariessudo apt-get install -y libv4l-dev# Eigen3 math development librariessudo apt-get install -y libeigen3-dev# OpenGL development libraries (to allow creating graphical windows)sudo apt-get install -y libglew1.6-dev# GTK development libraries (to allow creating graphical windows)sudo apt-get install -y libgtk2.0-dev
4 编译安装OpenCV3
cd ~
mkdir src
cd src
unzip ~/Downloads/opencv-3.1.0.zip
cd opencv-3.1.0mkdir build
cd build
cmake -DWITH_CUDA=ON -DCUDA_ARCH_BIN="5.3" -DCUDA_ARCH_PTX="" -DBUILD_TESTS=OFF -DBUILD_PERF_TESTS=OFF -DCUDA_FAST_MATH=ON -DCMAKE_INSTALL_PREFIX=/home/ubuntu/opencv-3.1.0 ..make -j4 install
5 运行 hog 例程5.1 编译并运行例程
cd ~/src/opencv-3.1.0/samples/gpu
g++ -o hog -I /home/ubuntu/opencv-3.1.0/include -O2 -g -Wall hog.cpp -L /home/ubuntu/opencv-3.1.0/lib -lopencv_core -lopencv_imgproc -l opencv_flann -l opencv_imgcodecs -lopencv_videoio -lopencv_highgui -lopencv_ml -lopencv_video -lopencv_objdetect -lopencv_photo -lopencv_features2d -lopencv_calib3d -lopencv_stitching -lopencv_videostab -lopencv_shape -lopencv_cudaobjdetect -lopencv_cudawarping -lopencv_cudaimgprocexport LD_LIBRARY_PATH=/home/ubuntu/opencv-3.1.0/lib:$LD_LIBRARY_PATH./hog --camera 0
5.2 运行结果
6 写一个简单的相机采集程序6.1 代码如下
#include #include using namespace cv;
using namespace std;
int main(int argc, char** argv)
{
VideoCapture cap("nvcamerasrc ! video/x-raw(memory:NVMM), width=(int)1280, height=(int)720,format=(string)I420, framerate=(fraction)24/1 ! nvvidconv flip-method=2 ! video/x-raw, format=(string)BGRx ! videoconvert ! video/x-raw, format=(string)BGR ! appsink"); if (!cap.isOpened())
{ cout = 8000)
如下所示:
以上内容是如何使用OpenCV分析TX13.1实时采集视频图像,你有学到什么知识或技巧吗?如果您想学习更多技能或丰富知识储备,请关注易宿云行业资讯频道。 查看全部
实时文章采集(绝对能使你眼前一亮,通过这篇文章介绍希望你能有所收获)
本文文章向你展示了如何在TX1上使用OpenCV3.1实时采集视频图像分析。内容简洁易懂,一定会让你眼前一亮。文章文章的详细介绍希望你有所收获。
嵌入式平台(目标): Jeston TX1
OpenCV:OpenCV3.1
摄像头:USB 800W 摄像头
1 简介
Jetpack3.0安装的OpenCV是OpenCV2.4.13,而OpenCV2.4.13不支持USB摄像头。未来NVIDIA更新的Jetpack将解决USB摄像头支持不佳的问题。在官方解决之前,临时的解决办法是自己编译OpenCV3.1。
2 下载 OpenCV3
网址:
点击 Sources 下载源代码:
3 安装依赖库
# Some general development librariessudo apt-get install -y build-essential make cmake cmake-curses-gui g++# libav video input/output development librariessudo apt-get install -y libavformat-dev libavutil-dev libswscale-dev# Video4Linux camera development librariessudo apt-get install -y libv4l-dev# Eigen3 math development librariessudo apt-get install -y libeigen3-dev# OpenGL development libraries (to allow creating graphical windows)sudo apt-get install -y libglew1.6-dev# GTK development libraries (to allow creating graphical windows)sudo apt-get install -y libgtk2.0-dev
4 编译安装OpenCV3
cd ~
mkdir src
cd src
unzip ~/Downloads/opencv-3.1.0.zip
cd opencv-3.1.0mkdir build
cd build
cmake -DWITH_CUDA=ON -DCUDA_ARCH_BIN="5.3" -DCUDA_ARCH_PTX="" -DBUILD_TESTS=OFF -DBUILD_PERF_TESTS=OFF -DCUDA_FAST_MATH=ON -DCMAKE_INSTALL_PREFIX=/home/ubuntu/opencv-3.1.0 ..make -j4 install
5 运行 hog 例程5.1 编译并运行例程
cd ~/src/opencv-3.1.0/samples/gpu
g++ -o hog -I /home/ubuntu/opencv-3.1.0/include -O2 -g -Wall hog.cpp -L /home/ubuntu/opencv-3.1.0/lib -lopencv_core -lopencv_imgproc -l opencv_flann -l opencv_imgcodecs -lopencv_videoio -lopencv_highgui -lopencv_ml -lopencv_video -lopencv_objdetect -lopencv_photo -lopencv_features2d -lopencv_calib3d -lopencv_stitching -lopencv_videostab -lopencv_shape -lopencv_cudaobjdetect -lopencv_cudawarping -lopencv_cudaimgprocexport LD_LIBRARY_PATH=/home/ubuntu/opencv-3.1.0/lib:$LD_LIBRARY_PATH./hog --camera 0

5.2 运行结果

6 写一个简单的相机采集程序6.1 代码如下
#include #include using namespace cv;
using namespace std;
int main(int argc, char** argv)
{
VideoCapture cap("nvcamerasrc ! video/x-raw(memory:NVMM), width=(int)1280, height=(int)720,format=(string)I420, framerate=(fraction)24/1 ! nvvidconv flip-method=2 ! video/x-raw, format=(string)BGRx ! videoconvert ! video/x-raw, format=(string)BGR ! appsink"); if (!cap.isOpened())
{ cout = 8000)
如下所示:
以上内容是如何使用OpenCV分析TX13.1实时采集视频图像,你有学到什么知识或技巧吗?如果您想学习更多技能或丰富知识储备,请关注易宿云行业资讯频道。
实时文章采集( Oxylabs定位的3款工具:SERPAPI、电商爬虫API )
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2022-01-08 15:00
Oxylabs定位的3款工具:SERPAPI、电商爬虫API
)
在过去的几个月里,我们一直在改进我们的实时爬虫产品。现在,Oxylabs 很高兴地宣布,我们即将带来一款新的爬虫产品!虽然上一代产品的单一解决方案非常出色,但为了满足客户不同场景的需求,我们将推出3款定位不同的工具:SERP爬虫API、电商爬虫API和网页爬虫API。今天的文章文章带你了解新品的独特之处。
有什么变化?
实时爬虫是网络爬虫行业最早的数据采集工具之一,专用于大规模的采集电子商务公共数据和搜索引擎数据。它帮助许多公司轻松采集公共数据,现在我们的产品表现更好。
“我们针对实时爬虫的不同功能,开发了3款专用爬虫工具,这样我们就可以有针对性地进行产品开发,从而为客户提供整体性能和用户体验更好的产品。”
– Aleksandras Šulženko,Oxylabs 的 Crawler API 产品经理
从现在开始,实时爬虫已经衍生为一组健壮的爬虫 API,每个 API 都有特定的优势:
● SERP爬虫API
● 电商爬虫API
● 网络爬虫API
产品功能优化
所有爬虫 API 的共同特点和优势在于,它们可以帮助企业轻松采集公开数据:
● 100% 的数据传输成功率
● 专利代理人切换工具
● 高扩展性
● 可轻松集成
● 超过1.02亿个IP
● 以用户首选格式(AWS S3 或 GCS)交付数据
● 24/7 实时支持
当然,每种产品都有自己的针对性优势:
SERP 爬虫 API
电商爬虫API
网络爬虫 API
●本地化搜索结果●实时可靠的数据●不受SERP布局变化的影响
●数以千计的电子商务公司网站可用于数据捕获●自适应解析器●JSON格式的结构化数据
●请求参数可自定义●JavaScript渲染●便捷的数据传递
“最好的部分是爬虫 API 将您从管理代理的麻烦中解放出来,并专注于数据分析。”
氧实验室
新面貌
所有 3 个爬虫 API 现在都有新徽标,显示其特定用途,以便于识别:
继续之前的集成
为了方便我们现有客户和在本次更新之前尝试过我们产品的潜在客户,我们决定使用之前的集成和身份验证方法,以及相同的请求参数。
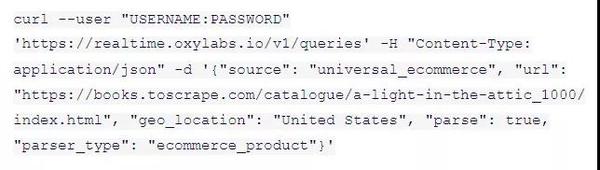
SERP爬虫API认证方式
SERP Crawler API 使用基本的 HTTP 身份验证,只需要用户名和密码。这是启用此工具的最简单方法之一。以下代码示例展示了如何通过实时发送 GET 请求从搜索引擎获取公共数据。有关更多信息,请查看 SERP Crawler API 快速指南。
*对于此示例,您必须指定确切的来源才能找到可用的来源。有关详细信息,请参阅 SERP Crawler API 文档。
电商爬虫API认证方式
电子商务爬虫 API 使用基本的 HTTP 身份验证,只需要用户名和密码。以下代码示例显示了如何将 GET 请求发送到 .
查看全部
实时文章采集(
Oxylabs定位的3款工具:SERPAPI、电商爬虫API
)

在过去的几个月里,我们一直在改进我们的实时爬虫产品。现在,Oxylabs 很高兴地宣布,我们即将带来一款新的爬虫产品!虽然上一代产品的单一解决方案非常出色,但为了满足客户不同场景的需求,我们将推出3款定位不同的工具:SERP爬虫API、电商爬虫API和网页爬虫API。今天的文章文章带你了解新品的独特之处。
有什么变化?
实时爬虫是网络爬虫行业最早的数据采集工具之一,专用于大规模的采集电子商务公共数据和搜索引擎数据。它帮助许多公司轻松采集公共数据,现在我们的产品表现更好。
“我们针对实时爬虫的不同功能,开发了3款专用爬虫工具,这样我们就可以有针对性地进行产品开发,从而为客户提供整体性能和用户体验更好的产品。”
– Aleksandras Šulženko,Oxylabs 的 Crawler API 产品经理
从现在开始,实时爬虫已经衍生为一组健壮的爬虫 API,每个 API 都有特定的优势:
● SERP爬虫API
● 电商爬虫API
● 网络爬虫API
产品功能优化
所有爬虫 API 的共同特点和优势在于,它们可以帮助企业轻松采集公开数据:
● 100% 的数据传输成功率
● 专利代理人切换工具
● 高扩展性
● 可轻松集成
● 超过1.02亿个IP
● 以用户首选格式(AWS S3 或 GCS)交付数据
● 24/7 实时支持
当然,每种产品都有自己的针对性优势:
SERP 爬虫 API
电商爬虫API
网络爬虫 API
●本地化搜索结果●实时可靠的数据●不受SERP布局变化的影响
●数以千计的电子商务公司网站可用于数据捕获●自适应解析器●JSON格式的结构化数据
●请求参数可自定义●JavaScript渲染●便捷的数据传递
“最好的部分是爬虫 API 将您从管理代理的麻烦中解放出来,并专注于数据分析。”
氧实验室
新面貌
所有 3 个爬虫 API 现在都有新徽标,显示其特定用途,以便于识别:
继续之前的集成
为了方便我们现有客户和在本次更新之前尝试过我们产品的潜在客户,我们决定使用之前的集成和身份验证方法,以及相同的请求参数。
SERP爬虫API认证方式
SERP Crawler API 使用基本的 HTTP 身份验证,只需要用户名和密码。这是启用此工具的最简单方法之一。以下代码示例展示了如何通过实时发送 GET 请求从搜索引擎获取公共数据。有关更多信息,请查看 SERP Crawler API 快速指南。
*对于此示例,您必须指定确切的来源才能找到可用的来源。有关详细信息,请参阅 SERP Crawler API 文档。
电商爬虫API认证方式
电子商务爬虫 API 使用基本的 HTTP 身份验证,只需要用户名和密码。以下代码示例显示了如何将 GET 请求发送到 .
实时文章采集(免费迅睿CMS采集插件怎么使用?怎么批量采集文章到迅睿)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-01 17:07
问:如何使用免费的迅睿cms采集插件?如何批量采集文章到迅睿cms
答:一键创建多个采集任务实现批量文章采集发布,每个网站只需要设置关键词即可实现自动采集发布文章
问:迅睿免费cms采集可以应用多少个网站插件?
答:网站的数量没有限制,添加新的网站只需要创建一个任务即可实现采集发布
问题:迅睿有多少免费的cms插件采集文章
答案:采集每天几千万条数据(根据我自己的网站设置)
问:如何发布免费的迅睿cms插件采集?
答:该工具有迅睿cms自动发布功能,打开采集后可以自动发布到站点。迅睿cms新旧版本都可以使用,不用担心网站版本没有更新,采集功能不可用!
问:免费的迅睿cms采集插件安装复杂吗?
答:直接在本地电脑上安装,双击直接运行!由于是本地采集工具,与服务器无关,不会造成服务器死机,从而保证服务器有良好的访问速度,有利于搜索的爬取引擎!
一、免费迅睿cms采集插件如何使用?
1、打开软件导入关键词到采集文章,自动发布网站
2、可以同时创建数百个采集发布任务
二、免费迅睿cms发布插件如何使用?
1、 直接通过迅睿cms发布工具发布,可以直接查看发布的数据数量文章,发布数量文章,并设置每日发布总量,是否伪原创,发布网址等,同时也支持除迅锐以外的所有主流cms平台。还为SEO人员配备了定时发布功能(设置定时发帖文章,让搜索引擎抓取更频繁,让整个网站持续抓取收录提升排名,一 文章 @网站排名越高,流量越高。)
2、发布工具还支持Empire、易游、ZBLOG、织梦、迅睿cms、PB、Apple、搜外等各大专业cms
3、自动内链、标题插入关键词、内容插入关键词、随机作者、随机阅读数
以后就不用担心了,因为网站太多了,你又着急了!千万不要用它切换回网站后端,反复登录后端很痛苦。再也不用担心 网站 没有内容了。
网站的流量取决于网站收录的比例。 收录关键词越多,排名越高,流量越大。
为什么那么多人选择迅锐cms?
迅睿cms免费开源系统是一款简单的网站开发者框架管理软件。本软件是基于PHP7语言使用CodeIgniter4创建的。为电脑、手机、APP提供多种接口和一体化操作方式,不会因用户二次开发而损坏程序核心。 web和PHP建站功能都可以完美运行,堪称PHP通用建站框架。 而迅睿cms采用了由研发资助的全新模板技术,可以帮助用户快速分离MVC设计模型的业务层和表现层,支持原生态PHP语法,支持CI框架语法,以及各种模板方面。用户只要分析一次,就可以快速添加和下次使用,让您设计出理想的模板。迅睿cms免费开源系统,可以自定义各种页面、表格、链接表的文本字段,让你自己做的更好网站,如果你有需要这个的小伙伴是的
看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力! 查看全部
实时文章采集(免费迅睿CMS采集插件怎么使用?怎么批量采集文章到迅睿)
问:如何使用免费的迅睿cms采集插件?如何批量采集文章到迅睿cms
答:一键创建多个采集任务实现批量文章采集发布,每个网站只需要设置关键词即可实现自动采集发布文章
问:迅睿免费cms采集可以应用多少个网站插件?
答:网站的数量没有限制,添加新的网站只需要创建一个任务即可实现采集发布
问题:迅睿有多少免费的cms插件采集文章
答案:采集每天几千万条数据(根据我自己的网站设置)
问:如何发布免费的迅睿cms插件采集?
答:该工具有迅睿cms自动发布功能,打开采集后可以自动发布到站点。迅睿cms新旧版本都可以使用,不用担心网站版本没有更新,采集功能不可用!
问:免费的迅睿cms采集插件安装复杂吗?
答:直接在本地电脑上安装,双击直接运行!由于是本地采集工具,与服务器无关,不会造成服务器死机,从而保证服务器有良好的访问速度,有利于搜索的爬取引擎!

一、免费迅睿cms采集插件如何使用?

1、打开软件导入关键词到采集文章,自动发布网站
2、可以同时创建数百个采集发布任务
二、免费迅睿cms发布插件如何使用?

1、 直接通过迅睿cms发布工具发布,可以直接查看发布的数据数量文章,发布数量文章,并设置每日发布总量,是否伪原创,发布网址等,同时也支持除迅锐以外的所有主流cms平台。还为SEO人员配备了定时发布功能(设置定时发帖文章,让搜索引擎抓取更频繁,让整个网站持续抓取收录提升排名,一 文章 @网站排名越高,流量越高。)
2、发布工具还支持Empire、易游、ZBLOG、织梦、迅睿cms、PB、Apple、搜外等各大专业cms
3、自动内链、标题插入关键词、内容插入关键词、随机作者、随机阅读数

以后就不用担心了,因为网站太多了,你又着急了!千万不要用它切换回网站后端,反复登录后端很痛苦。再也不用担心 网站 没有内容了。
网站的流量取决于网站收录的比例。 收录关键词越多,排名越高,流量越大。
为什么那么多人选择迅锐cms?
迅睿cms免费开源系统是一款简单的网站开发者框架管理软件。本软件是基于PHP7语言使用CodeIgniter4创建的。为电脑、手机、APP提供多种接口和一体化操作方式,不会因用户二次开发而损坏程序核心。 web和PHP建站功能都可以完美运行,堪称PHP通用建站框架。 而迅睿cms采用了由研发资助的全新模板技术,可以帮助用户快速分离MVC设计模型的业务层和表现层,支持原生态PHP语法,支持CI框架语法,以及各种模板方面。用户只要分析一次,就可以快速添加和下次使用,让您设计出理想的模板。迅睿cms免费开源系统,可以自定义各种页面、表格、链接表的文本字段,让你自己做的更好网站,如果你有需要这个的小伙伴是的

看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
实时文章采集(爱奇艺开放式故障值守系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-26 13:03
本文为爱奇艺台湾智能内容系列手稿之首。我们将继续为您带来爱奇艺智能内容生产运营的一系列探索,敬请期待。
无人值守系统是爱奇艺内容中心的重要智能组件。
首先,对于业务密度高、流程长、业务多的业务系统,在实际运行中,故障的发生是普遍现象,在某种程度上也是一种正常状态。因此,能够及时发现和处理故障是在线业务系统的必然要求。常规方法是报警+人工干预。这种方式导致需要有人值班,人工干预的及时性得不到保障,人力成本必然增加。
爱奇艺内容中台也面临着上述问题。试图通过技术手段解决系统复杂性带来的问题,是本系统的基本思想,也是中台智能化的一个重要方向。与传统的监控系统相比,我们需要更多的智能服务来完成监控,同时兼顾故障的智能处理,同时方便其他处理方式的介入。无人值守系统是爱奇艺内容中心研发团队在上述背景下设计开发的智能开放式故障值班系统。
一、无人值守的目标
无人值守系统的目标是协助业务系统实现流程自动化、结果可靠、无需人工值守。
在项目设计之初,我们的初衷是:爱奇艺中泰节目制作过程中,无需人工看盘,确保节目制作过程正常,按时上线。出现问题时,可及时发现、自动修复、风险提示、通知人工处理等,确保程序按时上线。
基于系统的目标,系统需要具备以下能力:
二、整体结构介绍
总结起来,基本思路是:首先实现业务系统运行的监控功能,将业务运行数据和异常情况采集到无人值守系统,在此基础上,通过对数据的实时智能分析,及时发现系统运行故障和业务数据异常。然后交给故障和业务异常处理模块进行异常的智能处理,从而实现异常和故障的自动处理,最终实现无人值守、智能系统恢复的目的。
系统运行流程介绍:
生产环节数据采集到无人值守系统,主要通过爱奇艺的众泰数据中心采集。业务系统向中台数据中心下发数据,无人值守系统从中台数据中心采集数据。决策引擎对采集到的数据进行实时分析,根据SLA、异常、阈值的配置对异常数据进行分析,形成单独的事件。事件被传递到事件处理引擎 Beacon。事件处理引擎根据不同事件配置的处理流程进行处理。事件处理流程完全可配置,支持故障修复、告警通知、故障恢复检测、故障统计等。训练引擎利用中泰数据中心的离线数据训练系统故障分析模型,然后将模型数据提供给决策引擎进行决策。三、核心模块介绍
下面对系统的核心功能模块一一介绍:
3.1 运营数据实时采集模块(基于中泰数据中心)
通过爱奇艺内容中台团队实施的OLTP基础组件(中台数据中心),实时采集各功能模块的运行状态以及业务数据的进度和状态。OLTP基础组件(台湾中部数据中心)为爱奇艺内容的实时分析和处理提供支持。运行在中心平台的各种数据都可以方便的下发到这个组件上,并且还提供了数据监控和查询功能,可以支持TB整合海量数据的管理和维护。中泰数据中心系统将在后续系列文章中详细介绍,此处不再展开。
数据采集过程:
以专业内容制作流程(PPC)为例:
生产和交付:生产服务运行过程中,生产状态和件的生产状态将交付到中台数据中心。
业务流制作交付:业务流制作过程中,视频流制作状态、音频制作状态、字幕制作状态下发至中台数据中心。
审核下发:审核系统将审核状态、审核时间等信息下发给众泰数据中心。
发布与交付:发布系统会在平台数据中列出码流的发布状态。
中泰数据中心获取数据后,向RMQ队列发送数据变化通知,无人值守系统监控数据变化,将数据拉取到无人值守系统。为获取程序从生产到最终发布的运行数据,完成数据采集。
3.2 决策引擎
基于采集到的数据,对系统和业务运行进行实时分析,决策引擎主要提供以下功能:
错误检测:实时检测系统和业务错误,统一管理错误,发送事件。
超时告警:基于业务节点的SLA配置,检测和管理超时业务行为,并发送事件。
可配置策略:主要包括业务功能的无人值守访问配置和业务功能的SLA配置、权限配置、统计通知配置。
决策引擎的运行是在服务工作的同时采集
进度和系统运行信息,不断检查服务进度是否正常,有无异常或超时情况,以便及时发现问题一旦出现问题。
按照下图的逻辑继续工作:
服务模块启动后,当发现失败或超时时,将失败和超时事件通知外部。同时检测系统业务单元的运行进度,判断进度是否正常,并向外界通报异常进度滞后事件。
上面介绍了逻辑流程,下面介绍服务模块的操作逻辑:
服务模块的主要概念:
数据来源:数据来源主要是中台数据中心,部分广播控制数据采集自RMQ。数据源的数据由业务系统下发给众泰数据中心。
流程:完成从数据源到无人值守系统的数据采集。不同的业务有不同的流程,不同的业务有不同的采集和处理方式。
过滤:完成数据过滤。有些采集到的数据是系统不需要的,有些字段是不需要关心的。过滤器负责过滤掉无效数据。
Transform:数据转换,统一转换为决策所需的数据结构。
Rule模块:规则的执行,承担transform数据,执行配置好的规则,输出成功、失败、启动三个规则结果。
决策模块:决策模块进行超时判断。超时判断不同于普通的成功和失败。需要不断的比较当前时间和进度来判断任务是否超时。
延迟消息模块:通过延迟消息,在未来的某个时间用来检查业务操作是否超时。
Sink回写:将超时、超出预期在线时间等结论回写数据源。
服务模块按照上述概念的顺序运行,将运行中发现的事件传递到外部。下图:
3.3 Beacon,事件处理引擎
事件处理引擎Beacon是自主研发的模块,从决策引擎接收事件,并在一个流程中进行处理。对于不同的事件,处理方法有很大的不同。比如常见的转码异常就有50多种,根据处理方式的不同,分为很多组。每组都有不同的处理程序。通知不同的研发人员,通知模块的内容不同。. 有的事件有规范的治愈,有的没有治愈,需要通知业务人员。针对这种多样化的需求,专门设计了事件处理引擎(Beacon)进行无人值守事件处理。引擎支持流程的配置和定制,并预留了高抽象的业务对接接口、处理能力扩展方式、流程配置方式。最大限度地降低支持新业务的成本。
常见故障以事件的形式发送到 Beacon 处理引擎。
基本结构:
事件处理引擎主要有以下几个部分:
上下文功能:流程执行过程中上下文参数的获取和存储。上下文的保存和获取在Step基类中实现。
执行引擎:一个简单可靠的执行引擎,收录
流程执行、执行延迟、执行日志等基本功能,可以执行索引Step类型对象。
流程配置:JSON格式的流程配置,包括Step、StopStrategy、StepAction、WaitTimeAfter等概念,流程按照StepIndex的顺序执行。
Step:Steps,steps是组成流程的单元,每一步都会执行配置好的StepAction和StopStrategy。
StopStrategy:进程终止判断策略,Step类的子类,继承context函数。根据配置的状态,确定事件处理的最终形式,例如故障是否恢复。
StepAction:要执行的Action,Step类的子类,如发送邮件、发送消息、调用业务接口等,都可以打包成StepAction。
WaitTimeAfter:本步执行完毕后,执行下一步的等待时间。
邮件等通知功能的对接:与企业邮件系统等对接,这是通知功能的基本组成部分。
业务功能组件:业务功能组件是构成处理流程的基础组件,是系统处理能力的载体。为支持新业务问题的处理,需要在业务功能组件池中扩展流程处理引擎,扩展无人值守处理能力。
下面是一个简单的进程配置示例:
在实际使用过程中,针对特定事件,配置故障处理Action和治愈判断的StopStrategy,实现故障的自恢复和治愈。这里的失败实际上是一种事件。最后,系统可以根据运行数据分析故障数量和固化百分比。
四、机器学习应用:生产时间估算
根据无人值守系统的目标设计,无人值守系统应提供对生产过程的预见性管理,以达到业务运营的可预见目的。基于采集
到的数据,应用机器学习技术训练各种预测模型,针对耗时的业务运营提供各种预测能力,提升无人值守体验。
注意:无人值守系统的预测模型只适用于资源稳定或有保障的任务,没有考虑资源变化对运行时间的影响。
以下是对预计生产时间的解释:
问题类型分析:无人值守系统可以获得丰富的视频制作历史数据,期望形成特征向量,用历史数据计算训练模型,估计视频制作完成时间进行剪辑。
特征分析:排除空数据,过滤有价值的特征。
例如:类别特征:
'businessType', "channel", 'cloudEncode', 'trancodeType', "priority", "programType",
“serviceCode”、“needAIInsertFrame”、“needAudit”、“bitrateCode”、“平台”、“分辨率”...
数字特征:'持续时间'
分类特征值分布分析
算法选择:
训练数据用于去除异常值,使用XGBoost回归模型。
XGBoost:实现了GBDT算法,在算法和工程上做了很多改进,(GBDT(Gradient Boosting Decision Tree)梯度提升决策树)。所以它被称为 X (Extreme) GBoosted。
它的基本思想是将基础分类器逐层叠加。每一层在训练时,都会为上一层基分类器的样本调整不同的权重。在测试过程中,根据各层分类器结果的权重得到最终结果。所有弱分类器的结果之和等于预测值,然后下一个弱分类器将误差函数的残差拟合到预测值(这个残差就是预测值与真实值之间的误差)。
五、业务系统反馈
无人值守系统为所有连接的业务系统生成日常业务系统运行状态报告,并推送到业务系统。数据主要包括错误、故障统计数据和详细数据,以及是否满足SLA等信息。业务系统根据无人值守反馈的运营数据进行业务改进和系统优化。基于这种方式,业务系统不断升级改造。
以下是日常经营状况报告的内容示例:
六、在线效果
在爱奇艺,无人值守系统已经覆盖了爱奇艺内容中期的重要制作环节,为每天数十万节目的制作提供了可靠的报告。无人值守率达到99%以上。累计发现问题3000多道,自动处理2800多道。大大节省人工成本,提供系统运行稳定性和准时节目在线率。
七、未来方向
未来,我们希望能够基于无人值守采集的数据,提供更加智能的分析,主动发现业务系统问题,预警并提前解决。
此外,该系统目前仅针对点事件值班。未来,该项目将以值班和问题处理为一体,提供从点到线到面的全方位值班服务。比如以程序为粒度,可以提供更智能的中断、恢复等能力,后者更胜一筹。 查看全部
实时文章采集(爱奇艺开放式故障值守系统)
本文为爱奇艺台湾智能内容系列手稿之首。我们将继续为您带来爱奇艺智能内容生产运营的一系列探索,敬请期待。
无人值守系统是爱奇艺内容中心的重要智能组件。
首先,对于业务密度高、流程长、业务多的业务系统,在实际运行中,故障的发生是普遍现象,在某种程度上也是一种正常状态。因此,能够及时发现和处理故障是在线业务系统的必然要求。常规方法是报警+人工干预。这种方式导致需要有人值班,人工干预的及时性得不到保障,人力成本必然增加。
爱奇艺内容中台也面临着上述问题。试图通过技术手段解决系统复杂性带来的问题,是本系统的基本思想,也是中台智能化的一个重要方向。与传统的监控系统相比,我们需要更多的智能服务来完成监控,同时兼顾故障的智能处理,同时方便其他处理方式的介入。无人值守系统是爱奇艺内容中心研发团队在上述背景下设计开发的智能开放式故障值班系统。
一、无人值守的目标
无人值守系统的目标是协助业务系统实现流程自动化、结果可靠、无需人工值守。
在项目设计之初,我们的初衷是:爱奇艺中泰节目制作过程中,无需人工看盘,确保节目制作过程正常,按时上线。出现问题时,可及时发现、自动修复、风险提示、通知人工处理等,确保程序按时上线。
基于系统的目标,系统需要具备以下能力:
二、整体结构介绍
总结起来,基本思路是:首先实现业务系统运行的监控功能,将业务运行数据和异常情况采集到无人值守系统,在此基础上,通过对数据的实时智能分析,及时发现系统运行故障和业务数据异常。然后交给故障和业务异常处理模块进行异常的智能处理,从而实现异常和故障的自动处理,最终实现无人值守、智能系统恢复的目的。
系统运行流程介绍:
生产环节数据采集到无人值守系统,主要通过爱奇艺的众泰数据中心采集。业务系统向中台数据中心下发数据,无人值守系统从中台数据中心采集数据。决策引擎对采集到的数据进行实时分析,根据SLA、异常、阈值的配置对异常数据进行分析,形成单独的事件。事件被传递到事件处理引擎 Beacon。事件处理引擎根据不同事件配置的处理流程进行处理。事件处理流程完全可配置,支持故障修复、告警通知、故障恢复检测、故障统计等。训练引擎利用中泰数据中心的离线数据训练系统故障分析模型,然后将模型数据提供给决策引擎进行决策。三、核心模块介绍
下面对系统的核心功能模块一一介绍:
3.1 运营数据实时采集模块(基于中泰数据中心)
通过爱奇艺内容中台团队实施的OLTP基础组件(中台数据中心),实时采集各功能模块的运行状态以及业务数据的进度和状态。OLTP基础组件(台湾中部数据中心)为爱奇艺内容的实时分析和处理提供支持。运行在中心平台的各种数据都可以方便的下发到这个组件上,并且还提供了数据监控和查询功能,可以支持TB整合海量数据的管理和维护。中泰数据中心系统将在后续系列文章中详细介绍,此处不再展开。
数据采集过程:
以专业内容制作流程(PPC)为例:
生产和交付:生产服务运行过程中,生产状态和件的生产状态将交付到中台数据中心。
业务流制作交付:业务流制作过程中,视频流制作状态、音频制作状态、字幕制作状态下发至中台数据中心。
审核下发:审核系统将审核状态、审核时间等信息下发给众泰数据中心。
发布与交付:发布系统会在平台数据中列出码流的发布状态。
中泰数据中心获取数据后,向RMQ队列发送数据变化通知,无人值守系统监控数据变化,将数据拉取到无人值守系统。为获取程序从生产到最终发布的运行数据,完成数据采集。
3.2 决策引擎
基于采集到的数据,对系统和业务运行进行实时分析,决策引擎主要提供以下功能:
错误检测:实时检测系统和业务错误,统一管理错误,发送事件。
超时告警:基于业务节点的SLA配置,检测和管理超时业务行为,并发送事件。
可配置策略:主要包括业务功能的无人值守访问配置和业务功能的SLA配置、权限配置、统计通知配置。
决策引擎的运行是在服务工作的同时采集
进度和系统运行信息,不断检查服务进度是否正常,有无异常或超时情况,以便及时发现问题一旦出现问题。
按照下图的逻辑继续工作:
服务模块启动后,当发现失败或超时时,将失败和超时事件通知外部。同时检测系统业务单元的运行进度,判断进度是否正常,并向外界通报异常进度滞后事件。
上面介绍了逻辑流程,下面介绍服务模块的操作逻辑:
服务模块的主要概念:
数据来源:数据来源主要是中台数据中心,部分广播控制数据采集自RMQ。数据源的数据由业务系统下发给众泰数据中心。
流程:完成从数据源到无人值守系统的数据采集。不同的业务有不同的流程,不同的业务有不同的采集和处理方式。
过滤:完成数据过滤。有些采集到的数据是系统不需要的,有些字段是不需要关心的。过滤器负责过滤掉无效数据。
Transform:数据转换,统一转换为决策所需的数据结构。
Rule模块:规则的执行,承担transform数据,执行配置好的规则,输出成功、失败、启动三个规则结果。
决策模块:决策模块进行超时判断。超时判断不同于普通的成功和失败。需要不断的比较当前时间和进度来判断任务是否超时。
延迟消息模块:通过延迟消息,在未来的某个时间用来检查业务操作是否超时。
Sink回写:将超时、超出预期在线时间等结论回写数据源。
服务模块按照上述概念的顺序运行,将运行中发现的事件传递到外部。下图:
3.3 Beacon,事件处理引擎
事件处理引擎Beacon是自主研发的模块,从决策引擎接收事件,并在一个流程中进行处理。对于不同的事件,处理方法有很大的不同。比如常见的转码异常就有50多种,根据处理方式的不同,分为很多组。每组都有不同的处理程序。通知不同的研发人员,通知模块的内容不同。. 有的事件有规范的治愈,有的没有治愈,需要通知业务人员。针对这种多样化的需求,专门设计了事件处理引擎(Beacon)进行无人值守事件处理。引擎支持流程的配置和定制,并预留了高抽象的业务对接接口、处理能力扩展方式、流程配置方式。最大限度地降低支持新业务的成本。
常见故障以事件的形式发送到 Beacon 处理引擎。
基本结构:
事件处理引擎主要有以下几个部分:
上下文功能:流程执行过程中上下文参数的获取和存储。上下文的保存和获取在Step基类中实现。
执行引擎:一个简单可靠的执行引擎,收录
流程执行、执行延迟、执行日志等基本功能,可以执行索引Step类型对象。
流程配置:JSON格式的流程配置,包括Step、StopStrategy、StepAction、WaitTimeAfter等概念,流程按照StepIndex的顺序执行。
Step:Steps,steps是组成流程的单元,每一步都会执行配置好的StepAction和StopStrategy。
StopStrategy:进程终止判断策略,Step类的子类,继承context函数。根据配置的状态,确定事件处理的最终形式,例如故障是否恢复。
StepAction:要执行的Action,Step类的子类,如发送邮件、发送消息、调用业务接口等,都可以打包成StepAction。
WaitTimeAfter:本步执行完毕后,执行下一步的等待时间。
邮件等通知功能的对接:与企业邮件系统等对接,这是通知功能的基本组成部分。
业务功能组件:业务功能组件是构成处理流程的基础组件,是系统处理能力的载体。为支持新业务问题的处理,需要在业务功能组件池中扩展流程处理引擎,扩展无人值守处理能力。
下面是一个简单的进程配置示例:
在实际使用过程中,针对特定事件,配置故障处理Action和治愈判断的StopStrategy,实现故障的自恢复和治愈。这里的失败实际上是一种事件。最后,系统可以根据运行数据分析故障数量和固化百分比。
四、机器学习应用:生产时间估算
根据无人值守系统的目标设计,无人值守系统应提供对生产过程的预见性管理,以达到业务运营的可预见目的。基于采集
到的数据,应用机器学习技术训练各种预测模型,针对耗时的业务运营提供各种预测能力,提升无人值守体验。
注意:无人值守系统的预测模型只适用于资源稳定或有保障的任务,没有考虑资源变化对运行时间的影响。
以下是对预计生产时间的解释:
问题类型分析:无人值守系统可以获得丰富的视频制作历史数据,期望形成特征向量,用历史数据计算训练模型,估计视频制作完成时间进行剪辑。
特征分析:排除空数据,过滤有价值的特征。
例如:类别特征:
'businessType', "channel", 'cloudEncode', 'trancodeType', "priority", "programType",
“serviceCode”、“needAIInsertFrame”、“needAudit”、“bitrateCode”、“平台”、“分辨率”...
数字特征:'持续时间'
分类特征值分布分析
算法选择:
训练数据用于去除异常值,使用XGBoost回归模型。
XGBoost:实现了GBDT算法,在算法和工程上做了很多改进,(GBDT(Gradient Boosting Decision Tree)梯度提升决策树)。所以它被称为 X (Extreme) GBoosted。
它的基本思想是将基础分类器逐层叠加。每一层在训练时,都会为上一层基分类器的样本调整不同的权重。在测试过程中,根据各层分类器结果的权重得到最终结果。所有弱分类器的结果之和等于预测值,然后下一个弱分类器将误差函数的残差拟合到预测值(这个残差就是预测值与真实值之间的误差)。
五、业务系统反馈
无人值守系统为所有连接的业务系统生成日常业务系统运行状态报告,并推送到业务系统。数据主要包括错误、故障统计数据和详细数据,以及是否满足SLA等信息。业务系统根据无人值守反馈的运营数据进行业务改进和系统优化。基于这种方式,业务系统不断升级改造。
以下是日常经营状况报告的内容示例:
六、在线效果
在爱奇艺,无人值守系统已经覆盖了爱奇艺内容中期的重要制作环节,为每天数十万节目的制作提供了可靠的报告。无人值守率达到99%以上。累计发现问题3000多道,自动处理2800多道。大大节省人工成本,提供系统运行稳定性和准时节目在线率。
七、未来方向
未来,我们希望能够基于无人值守采集的数据,提供更加智能的分析,主动发现业务系统问题,预警并提前解决。
此外,该系统目前仅针对点事件值班。未来,该项目将以值班和问题处理为一体,提供从点到线到面的全方位值班服务。比如以程序为粒度,可以提供更智能的中断、恢复等能力,后者更胜一筹。
实时文章采集(一种兼容多平台的小程序日志采集方案(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-12-26 11:20
01
背景介绍
小程序,英文小程序。是一款无需下载安装即可在微信中使用的应用。用户可以扫描小程序代码或搜索小程序打开。触手可及,用完即可使用。无需担心是否安装过多应用程序。
据阿拉丁统计,截至2021年6月底,微信小程序数量突破430万,日活跃用户突破4.1亿。小程序深度影响了200+个子行业,11个主要平台推出了各自的小程序生态。小程序已经成为中国人定义的真正意义上的“互联网技术新标准”。
由于业务发展需要,我们在微信小程序、百度智能小程序、支付宝小程序、字节小程序、360小程序等多个小程序平台都有相应的上线。平台、系统、机型、版本兼容问题导致小程序上线问题;
思考:为什么小程序启动这么慢?为什么不能在线加载白屏数据?在线代码的质量如何?是否有任何错误?如何在网上快速查找和解决问题?用户做了什么?推出这么多平台小程序后,各个平台的效果如何?目前的小程序还有优化空间吗?
其实以上问题都可以通过日志文件分析来回答。每个小程序的后端也会采集
一些日志信息。比如微信后台采集
js异常日志和接口异常日志,但是接口异常日志只有状态码级别的信息和脚本异常日志。缺少当前异常发生时的页面路径信息、系统信息、网络状态、用户行为轨迹等信息的记录,因此排查起来相对困难。对于小程序性能数据的采集,各平台之间并没有统一的标准。所以我们需要一个兼容多平台的小程序日志采集
方案。
02
采集
理念
要采集
小程序的信息,首先需要了解小程序的基本架构设计。小程序本质上是混合体,但它们是有限制的。小程序的渲染层和逻辑层分别由两个线程管理:
这两个线程之间的通信是通过小程序的Native端传递的,逻辑层发送的网络请求也是通过Native端转发的。对于平台端,这种设计大大增加了平台对应用的控制,降低了各种风险。
当然,采集SDK也在逻辑层,所以可以监控逻辑层的交互响应。主流小程序的JS逻辑层开发主要依赖以下三个部分:
App:每个小程序都需要调用app.js中的App方法来注册一个小程序实例,绑定生命周期回调函数,错误监控和页面不存在监控等功能,整个小程序只有一个App实例,共享所有页面。Page:对于小程序中的每个页面,都需要在页面对应的js文件中注册,指定页面的初始数据、生命周期回调、事件处理函数等,简单的页面可以使用Page()来构造。wx:小程序开发框架提供了丰富的微信原生API,可以轻松调出微信提供的能力,比如获取用户信息、本地存储、支付功能。
因此,要想有效监控小程序的运行状态,就需要对这三个模块进行有效拦截。在小程序中,App、Page、wx 模块宏都暴露给全局。如果要拦截,可以直接改写全局中的变量。
03
总体方案
SDK用户包括小程序原生开发和小程序框架开发两种:
SDK 有两个主要功能:数据采集
和报告服务。SDK的主要功能是采集
小程序生成的日志。采集日志可以分为异常日志、正常日志和性能日志3种类型。每次上报日志时,也会上报1类通用信息:
日志类型
二级分类
操作说明
异常日志
JS错误、界面异常、资源下载异常
监控很关键,需要实时上报
正常日志
用户行为、日志信息、路由信息
日志量大,用户主动上报
性能日志
首屏时间、页面渲染时间、PV/UV
一次上报,同时统计PV/UV
一般信息
系统信息、用户信息、网络状态、场景值
其他 3 类日志的附加一般信息
我们的目标小程序涵盖目前主流的小程序,如微信、百度、今日头条、支付宝、360等。
公共日志采集
常规思维
通过相关API获取环境信息,主要包括以下几类信息:
多终端兼容思路
基本信息API与各个平台小程序的接口基本一致。主要区别在于模块宏的定义。比如微信小程序是wx,百度小程序是天鹅,今日头条小程序是tt。SDK初始化时,通过判断模块宏是否存在并存储在上下文变量中来确定当前的小程序环境,具体使用时通过上下文调用API。
public get context() {
if (this._context) return this._context;
if (typeof wx !== 'undefined') { this._context = wx; }
if (typeof swan !== 'undefined') { this._context = swan; }
if (typeof tt !== 'undefined') { this._context = tt; }
if (typeof my !== 'undefined') { this._context = my; }
if (typeof qq !== 'undefined') { this._context = qq; }
if (typeof qh !== 'undefined') { this._context = qh; }
return this._context;
}
// 使用示例 用户信息获取:ctx.getUserInfo()
当前页面的路径得到多终端兼容处理
所以这里有一个获取当前页面路径的方法,可以平滑各个平台小程序之间的差异。
public get currentPage() {
if (this.appName === 'qh') { // 360小程序兼容
const { path } = $router.history.current;
return path;
}
let pages = getCurrentPages();
if (pages.length > 0) {
return pages[pages.length - 1].route;
} else {
return this._indexPage;
}
}
异常日志采集
异常日志分为三种:脚本异常、接口异常、资源异常
由于小程序的特殊通信机制,接口请求和资源下载都是通过小程序载体Native进行转发和执行。因此,要采集
这部分异常,可以拦截wx.request、wx.download等相关API。
关于接口异常信息的上报,主要涉及两种情况: 在wx.request的成功回调中,如果响应状态码>=400,则表示网络请求已发送,但业务响应异常,并报告为异常。; 如果直接去wx.request的fail回调,说明网络请求异常,会进行异常报告;
资源异常主要用于拦截downloadFile文件下载API,下载失败时上报资源异常日志。
下面我们重点关注脚本异常的日志采集
。
脚本异常_常规思路
JS 中常见的错误有几种,其中类型错误、引用错误、未捕获的 Promise 错误发生的频率更高;其次是越界错误和不正确的 URI 错误。
前5个错误可以通过监听小程序App.onError采集
,Promise异常可以通过App.onUnhandledRejection API采集
,但是这个API在各个平台的支持是不一致的,如下:
脚本异常_多终端兼容思路
通过追踪异常栈,查看源码,我们可以看到微信已经通过try...catch把我们业务代码的外层包裹起来了。当发生异常时,通过console.error打印出来,所以在开发过程中,可以看到发生异常时,开发者工具控制台会打印异常信息。
因此,我们可以拦截console.error。本次拦截可以采集
到的异常包括:
实施过程中遇到的问题
在具体的实现过程中,我们发现不同平台的具体实现是不同的:
因此,截取console.error后,我们需要对截取的信息进行第二次处理,平滑平台差异。
具体的解决办法是通过正则匹配:
const ERROR_TYPES_REG = /(((Eval|Reference|Range|Internal|Type|Syntax)Error)|promise)
判断当前脚本异常类型,格式化信息后分别上报堆栈信息和错误内容。最终报告的脚本日志格式如下,包括错误类型、错误内容和堆栈信息。
"exceptions": [{
"errType": "MiniProgramError",
"content": "app.checkAuthorize1 is not a function",
"message": "TypeError: app.checkAuthorize1 is not a function",
"stacktrace": "MiniProgramErroranonymous> (httpe.p.__callPageLifeTime__ (h"
}]
性能日志采集
常规思维
通过官方提供的API获取数据并采集
和报告。微信提供wx.getPerformance() API,获取小程序启动耗时、页面渲染耗时、脚本注入耗时;但其他平台小程序不提供相关接口。
多终端兼容思路
用户点击小程序后,首先会下载小程序资源包。启动后会解析app.json文件,注册App(),然后执行APP的生命周期;然后开始加载页面,解析页面json文件,渲染.wxml文件,执行逻辑层js文件,调用页面生命周期。APP和页面的生命周期功能是性能日志采集
的重点。
生命周期钩子
等级
操作说明
主流小程序框架
360小程序框架
开机
应用级别
监控小程序初始化
支持
负载
展出
应用级别
监控小程序启动或切换到前台
支持
支持
负载
页面级别
监控页面加载
支持
支持
展出
页面级别
监控页面显示
支持
支持
准备就绪
页面级别
监控页面第一次渲染完成
支持
支持
隐藏
页面级别
监控页面隐藏
支持
支持
我们对比了各个平台小程序生命周期相关的API,发现主流小程序框架的实现基本一致。360小程序更特别。是基于Vue框架的二次封装,但大部分API还是一样的。在360小程序中,小程序初始化后的hook调用的是onLoad,需要特殊处理。
因此,可以通过拦截和管理小程序App和Page的相应生命周期来实现性能日志采集
。在性能日志采集
方案中,我们主要将其分为应用级性能和页面级性能。
应用级性能:我们定义了首屏时间,即进入小程序后第一页的渲染完成时间——SDK初始化时间。
由于小程序入口较多,有些是从分享卡进入,点击图标,搜索。不同的进入小程序的方式会显示不同的主页。因此,我们会在每个日志中携带当前页面入口路径。
页面级性能主要包括:
实现过程中遇到的问题在测试验证阶段,我们发现使用Taro框架开发转换的微信小程序无法采集页面级性能数据。经过具体定位,我们发现在Taro2版本中,小程序页面和组件被统一为Component组件。因此,需要拦截Component;在Taro3之后,小程序页面规范对象暴露在外,可以通过拦截Page来实现。具体实现逻辑如下:
private interceptPage = (): void => {
let self = this;
let isTaro = (typeof (process) !== 'undefined' && typeof (process.env) !== 'undefined' && typeof (process.env.TARO_ENV) !== 'undefined') ? true : false;
const primaryPage = Page;
if (isTaro) {
let primaryComponent = Component;
Component = (obj: any) => {
PAGE_LIFE_CYCLE.forEach(name => {
if (typeof obj.methods[name] === 'function') {
const primaryHookFn = obj.methods[name];
obj.methods[name] = function (info: any) {
return self.rewritePageLifeCycle(name, this, primaryHookFn, info);
}
}
});
primaryComponent && primaryComponent.call(this, obj);
}
}
Page = (obj: any) => {
PAGE_LIFE_CYCLE.forEach(name => {
const primaryHookFn = obj[name];
obj[name] = function (info: any) {
return self.rewritePageLifeCycle(name, this, primaryHookFn, info);
}
});
primaryPage && primaryPage.call(this, obj);
}
}
行为轨迹采集
如果只有一些比较隐蔽的错误的错误堆栈信息,排查起来会比较困难。如果有用户操作的路径,排查起来就容易多了。在行为轨迹日志的采集中,我们会采集APP函数栈、Page函数栈、HTTP请求栈,并上报最近10条行为轨迹日志,以帮助用户在发生异常时定位问题。
04
SDK特性
多终端、多帧适配
重量轻,支持多种模块化规格
SDK由Rollup打包,压缩体积49KB,支持cmj和es6模块化规范。
多种使用形式
1. 通过 npm 格式使用
import * as mpMonitor from 'mp-monitor';
mpMonitor.init({
projectId: '', // 项目标识
url: ''
});
2. 以单一文件格式使用
const mpMonitor = require('./utils/mp-monitor');
mpMonitor.init({
projectId: '', // 项目标识
url: ''
});
支持自定义报告日志
业务方可以使用console.error(\'自定义报告内容\')
05
商业实践
1. SDK现已完成集团北斗前端监控平台对接,支持微信、百度、今日头条、支付宝、QQ、360等多端监控;
2.截至2021.10.15,已接入13个小程序,覆盖5条业务线
3. SDK 上报模型与 Sentry 一致。自行搭建Sentry服务的企业可以直接使用SDK,配置上报url;
4. 平台接入效果展示
开发者可以通过首页的图表观察小程序当前的运行状态
通过性能图表,可以考虑当前小程序是否有优化空间。如果开启分包加载优化,当前首屏性能曲线应该会明显降低
观察从页面 URL 采集
的 pvuv 数据。优化业务代码时,可以考虑去掉pv为0的页面。
页面加载瀑布图,可以直观的看到一个小程序页面的加载过程
行为轨迹展示可以帮助开发者更快地重现在线问题,提高问题解决效率
06
总结
目前小程序日志采集SDK内部已经平滑了多平台之间的差异,统一了小程序性能数据采集指标。异常时上报页面路径信息、系统信息、网络状态、用户行为轨迹等相关信息,帮助开发者更快定位和解决在线问题。
我们会继续优化细节,完善功能。也欢迎有兴趣的同学一起交流。
对源码感兴趣的请点赞+转发+关注+私信【小程序日志采集
】。
欢迎点赞+转发+关注!您的支持是我分享的最大动力!!! 查看全部
实时文章采集(一种兼容多平台的小程序日志采集方案(一))
01
背景介绍
小程序,英文小程序。是一款无需下载安装即可在微信中使用的应用。用户可以扫描小程序代码或搜索小程序打开。触手可及,用完即可使用。无需担心是否安装过多应用程序。
据阿拉丁统计,截至2021年6月底,微信小程序数量突破430万,日活跃用户突破4.1亿。小程序深度影响了200+个子行业,11个主要平台推出了各自的小程序生态。小程序已经成为中国人定义的真正意义上的“互联网技术新标准”。
由于业务发展需要,我们在微信小程序、百度智能小程序、支付宝小程序、字节小程序、360小程序等多个小程序平台都有相应的上线。平台、系统、机型、版本兼容问题导致小程序上线问题;
思考:为什么小程序启动这么慢?为什么不能在线加载白屏数据?在线代码的质量如何?是否有任何错误?如何在网上快速查找和解决问题?用户做了什么?推出这么多平台小程序后,各个平台的效果如何?目前的小程序还有优化空间吗?
其实以上问题都可以通过日志文件分析来回答。每个小程序的后端也会采集
一些日志信息。比如微信后台采集
js异常日志和接口异常日志,但是接口异常日志只有状态码级别的信息和脚本异常日志。缺少当前异常发生时的页面路径信息、系统信息、网络状态、用户行为轨迹等信息的记录,因此排查起来相对困难。对于小程序性能数据的采集,各平台之间并没有统一的标准。所以我们需要一个兼容多平台的小程序日志采集
方案。
02
采集
理念
要采集
小程序的信息,首先需要了解小程序的基本架构设计。小程序本质上是混合体,但它们是有限制的。小程序的渲染层和逻辑层分别由两个线程管理:
这两个线程之间的通信是通过小程序的Native端传递的,逻辑层发送的网络请求也是通过Native端转发的。对于平台端,这种设计大大增加了平台对应用的控制,降低了各种风险。
当然,采集SDK也在逻辑层,所以可以监控逻辑层的交互响应。主流小程序的JS逻辑层开发主要依赖以下三个部分:
App:每个小程序都需要调用app.js中的App方法来注册一个小程序实例,绑定生命周期回调函数,错误监控和页面不存在监控等功能,整个小程序只有一个App实例,共享所有页面。Page:对于小程序中的每个页面,都需要在页面对应的js文件中注册,指定页面的初始数据、生命周期回调、事件处理函数等,简单的页面可以使用Page()来构造。wx:小程序开发框架提供了丰富的微信原生API,可以轻松调出微信提供的能力,比如获取用户信息、本地存储、支付功能。
因此,要想有效监控小程序的运行状态,就需要对这三个模块进行有效拦截。在小程序中,App、Page、wx 模块宏都暴露给全局。如果要拦截,可以直接改写全局中的变量。
03
总体方案
SDK用户包括小程序原生开发和小程序框架开发两种:
SDK 有两个主要功能:数据采集
和报告服务。SDK的主要功能是采集
小程序生成的日志。采集日志可以分为异常日志、正常日志和性能日志3种类型。每次上报日志时,也会上报1类通用信息:
日志类型
二级分类
操作说明
异常日志
JS错误、界面异常、资源下载异常
监控很关键,需要实时上报
正常日志
用户行为、日志信息、路由信息
日志量大,用户主动上报
性能日志
首屏时间、页面渲染时间、PV/UV
一次上报,同时统计PV/UV
一般信息
系统信息、用户信息、网络状态、场景值
其他 3 类日志的附加一般信息
我们的目标小程序涵盖目前主流的小程序,如微信、百度、今日头条、支付宝、360等。
公共日志采集
常规思维
通过相关API获取环境信息,主要包括以下几类信息:
多终端兼容思路
基本信息API与各个平台小程序的接口基本一致。主要区别在于模块宏的定义。比如微信小程序是wx,百度小程序是天鹅,今日头条小程序是tt。SDK初始化时,通过判断模块宏是否存在并存储在上下文变量中来确定当前的小程序环境,具体使用时通过上下文调用API。
public get context() {
if (this._context) return this._context;
if (typeof wx !== 'undefined') { this._context = wx; }
if (typeof swan !== 'undefined') { this._context = swan; }
if (typeof tt !== 'undefined') { this._context = tt; }
if (typeof my !== 'undefined') { this._context = my; }
if (typeof qq !== 'undefined') { this._context = qq; }
if (typeof qh !== 'undefined') { this._context = qh; }
return this._context;
}
// 使用示例 用户信息获取:ctx.getUserInfo()
当前页面的路径得到多终端兼容处理
所以这里有一个获取当前页面路径的方法,可以平滑各个平台小程序之间的差异。
public get currentPage() {
if (this.appName === 'qh') { // 360小程序兼容
const { path } = $router.history.current;
return path;
}
let pages = getCurrentPages();
if (pages.length > 0) {
return pages[pages.length - 1].route;
} else {
return this._indexPage;
}
}
异常日志采集
异常日志分为三种:脚本异常、接口异常、资源异常
由于小程序的特殊通信机制,接口请求和资源下载都是通过小程序载体Native进行转发和执行。因此,要采集
这部分异常,可以拦截wx.request、wx.download等相关API。
关于接口异常信息的上报,主要涉及两种情况: 在wx.request的成功回调中,如果响应状态码>=400,则表示网络请求已发送,但业务响应异常,并报告为异常。; 如果直接去wx.request的fail回调,说明网络请求异常,会进行异常报告;
资源异常主要用于拦截downloadFile文件下载API,下载失败时上报资源异常日志。
下面我们重点关注脚本异常的日志采集
。
脚本异常_常规思路
JS 中常见的错误有几种,其中类型错误、引用错误、未捕获的 Promise 错误发生的频率更高;其次是越界错误和不正确的 URI 错误。
前5个错误可以通过监听小程序App.onError采集
,Promise异常可以通过App.onUnhandledRejection API采集
,但是这个API在各个平台的支持是不一致的,如下:
脚本异常_多终端兼容思路
通过追踪异常栈,查看源码,我们可以看到微信已经通过try...catch把我们业务代码的外层包裹起来了。当发生异常时,通过console.error打印出来,所以在开发过程中,可以看到发生异常时,开发者工具控制台会打印异常信息。
因此,我们可以拦截console.error。本次拦截可以采集
到的异常包括:
实施过程中遇到的问题
在具体的实现过程中,我们发现不同平台的具体实现是不同的:
因此,截取console.error后,我们需要对截取的信息进行第二次处理,平滑平台差异。
具体的解决办法是通过正则匹配:
const ERROR_TYPES_REG = /(((Eval|Reference|Range|Internal|Type|Syntax)Error)|promise)
判断当前脚本异常类型,格式化信息后分别上报堆栈信息和错误内容。最终报告的脚本日志格式如下,包括错误类型、错误内容和堆栈信息。
"exceptions": [{
"errType": "MiniProgramError",
"content": "app.checkAuthorize1 is not a function",
"message": "TypeError: app.checkAuthorize1 is not a function",
"stacktrace": "MiniProgramErroranonymous> (httpe.p.__callPageLifeTime__ (h"
}]
性能日志采集
常规思维
通过官方提供的API获取数据并采集
和报告。微信提供wx.getPerformance() API,获取小程序启动耗时、页面渲染耗时、脚本注入耗时;但其他平台小程序不提供相关接口。
多终端兼容思路
用户点击小程序后,首先会下载小程序资源包。启动后会解析app.json文件,注册App(),然后执行APP的生命周期;然后开始加载页面,解析页面json文件,渲染.wxml文件,执行逻辑层js文件,调用页面生命周期。APP和页面的生命周期功能是性能日志采集
的重点。
生命周期钩子
等级
操作说明
主流小程序框架
360小程序框架
开机
应用级别
监控小程序初始化
支持
负载
展出
应用级别
监控小程序启动或切换到前台
支持
支持
负载
页面级别
监控页面加载
支持
支持
展出
页面级别
监控页面显示
支持
支持
准备就绪
页面级别
监控页面第一次渲染完成
支持
支持
隐藏
页面级别
监控页面隐藏
支持
支持
我们对比了各个平台小程序生命周期相关的API,发现主流小程序框架的实现基本一致。360小程序更特别。是基于Vue框架的二次封装,但大部分API还是一样的。在360小程序中,小程序初始化后的hook调用的是onLoad,需要特殊处理。
因此,可以通过拦截和管理小程序App和Page的相应生命周期来实现性能日志采集
。在性能日志采集
方案中,我们主要将其分为应用级性能和页面级性能。
应用级性能:我们定义了首屏时间,即进入小程序后第一页的渲染完成时间——SDK初始化时间。
由于小程序入口较多,有些是从分享卡进入,点击图标,搜索。不同的进入小程序的方式会显示不同的主页。因此,我们会在每个日志中携带当前页面入口路径。
页面级性能主要包括:
实现过程中遇到的问题在测试验证阶段,我们发现使用Taro框架开发转换的微信小程序无法采集页面级性能数据。经过具体定位,我们发现在Taro2版本中,小程序页面和组件被统一为Component组件。因此,需要拦截Component;在Taro3之后,小程序页面规范对象暴露在外,可以通过拦截Page来实现。具体实现逻辑如下:
private interceptPage = (): void => {
let self = this;
let isTaro = (typeof (process) !== 'undefined' && typeof (process.env) !== 'undefined' && typeof (process.env.TARO_ENV) !== 'undefined') ? true : false;
const primaryPage = Page;
if (isTaro) {
let primaryComponent = Component;
Component = (obj: any) => {
PAGE_LIFE_CYCLE.forEach(name => {
if (typeof obj.methods[name] === 'function') {
const primaryHookFn = obj.methods[name];
obj.methods[name] = function (info: any) {
return self.rewritePageLifeCycle(name, this, primaryHookFn, info);
}
}
});
primaryComponent && primaryComponent.call(this, obj);
}
}
Page = (obj: any) => {
PAGE_LIFE_CYCLE.forEach(name => {
const primaryHookFn = obj[name];
obj[name] = function (info: any) {
return self.rewritePageLifeCycle(name, this, primaryHookFn, info);
}
});
primaryPage && primaryPage.call(this, obj);
}
}
行为轨迹采集
如果只有一些比较隐蔽的错误的错误堆栈信息,排查起来会比较困难。如果有用户操作的路径,排查起来就容易多了。在行为轨迹日志的采集中,我们会采集APP函数栈、Page函数栈、HTTP请求栈,并上报最近10条行为轨迹日志,以帮助用户在发生异常时定位问题。
04
SDK特性
多终端、多帧适配
重量轻,支持多种模块化规格
SDK由Rollup打包,压缩体积49KB,支持cmj和es6模块化规范。
多种使用形式
1. 通过 npm 格式使用
import * as mpMonitor from 'mp-monitor';
mpMonitor.init({
projectId: '', // 项目标识
url: ''
});
2. 以单一文件格式使用
const mpMonitor = require('./utils/mp-monitor');
mpMonitor.init({
projectId: '', // 项目标识
url: ''
});
支持自定义报告日志
业务方可以使用console.error(\'自定义报告内容\')
05
商业实践
1. SDK现已完成集团北斗前端监控平台对接,支持微信、百度、今日头条、支付宝、QQ、360等多端监控;
2.截至2021.10.15,已接入13个小程序,覆盖5条业务线
3. SDK 上报模型与 Sentry 一致。自行搭建Sentry服务的企业可以直接使用SDK,配置上报url;
4. 平台接入效果展示
开发者可以通过首页的图表观察小程序当前的运行状态
通过性能图表,可以考虑当前小程序是否有优化空间。如果开启分包加载优化,当前首屏性能曲线应该会明显降低
观察从页面 URL 采集
的 pvuv 数据。优化业务代码时,可以考虑去掉pv为0的页面。
页面加载瀑布图,可以直观的看到一个小程序页面的加载过程
行为轨迹展示可以帮助开发者更快地重现在线问题,提高问题解决效率
06
总结
目前小程序日志采集SDK内部已经平滑了多平台之间的差异,统一了小程序性能数据采集指标。异常时上报页面路径信息、系统信息、网络状态、用户行为轨迹等相关信息,帮助开发者更快定位和解决在线问题。
我们会继续优化细节,完善功能。也欢迎有兴趣的同学一起交流。
对源码感兴趣的请点赞+转发+关注+私信【小程序日志采集
】。
欢迎点赞+转发+关注!您的支持是我分享的最大动力!!!
实时文章采集(一个实用采集技能,采集公众号内容详解(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-12-23 19:13
数据采集-数据采集-java-php-go-Python-Crawler-Automatic-微信公众号文章查看点击量-多个公众号-实时更新、Go语言社区、Golang程序员网社区,Go语言中文社区优采云采集软件采集公众号文章详细操作步骤工具/资料优采云采集方法/Step 1 Log在优采云软件优采云爬取微信公众号,打开采集规则”规则市场微信朋友圈优采云AI,搜索关键词微信规则,查找并下载。2 将规则导入任务。
很好:微信采集微信公众号采集工具,如何阅读和点赞采集公众号?3 同意 · 9 条评论和回答优采云·云采集服务平台微信公众号内容采集详细方法在微信公众号中浏览文章的内容。
大数据信息材料采集:公众号吴志宏文章评论爬取优采云采集器规则大数据信息材料采集公众号历史文章 < @采集公众号评论抓取微信公众号历史文章导出并抓取微信公众号所有文章。官方账号。摘要:相信每个运营微信公众号的人都在考虑这个问题。今天优采云给大家分享一个实用的采集技能,采集公众号。公众号内容实时监控。如何提高微信文章的打开率?文章最火的款式有哪些。
采集 字段:公众号、文章 标题、内容、阅读量、点赞数、推送时间,这里要说明一下,优采云目前只有采集公开网上的数据,微信公众号采集需要从网页采集开始。搜索“搜狗微信”并通过。我专注于优采云 第三方采集 工具。由于优采云是收费软件,您只能先申请体验账号,体验采集的基本功能。,不过个人觉得采用这个工具是因为它与搜狗的接口合作。
微信优采云ai
前两年还好,现在采集不行,但是现在用微信公众号平台登录的人不多。目前位置在小红书、微博大数据信息资料采集:信息公众号元芳青木文章评论爬取优采云采集大数据信息资料采集公众号历史文章采集公众号评论爬取微信公众号历史文章导出抓取所有微信公众号文章。公众。
优采云如何采集数据
还有问优采云怎么发朋友圈,怎么抓微信公众号文章?解决问题后,分享优采云、优采云等具有公众号功能的第三方工具。您可以自行下载使用。具体的就不多说了。第四:基于微信公众号平台的方法;这个方法其实是最难的,因为中间需要。 查看全部
实时文章采集(一个实用采集技能,采集公众号内容详解(组图))
数据采集-数据采集-java-php-go-Python-Crawler-Automatic-微信公众号文章查看点击量-多个公众号-实时更新、Go语言社区、Golang程序员网社区,Go语言中文社区优采云采集软件采集公众号文章详细操作步骤工具/资料优采云采集方法/Step 1 Log在优采云软件优采云爬取微信公众号,打开采集规则”规则市场微信朋友圈优采云AI,搜索关键词微信规则,查找并下载。2 将规则导入任务。
很好:微信采集微信公众号采集工具,如何阅读和点赞采集公众号?3 同意 · 9 条评论和回答优采云·云采集服务平台微信公众号内容采集详细方法在微信公众号中浏览文章的内容。
大数据信息材料采集:公众号吴志宏文章评论爬取优采云采集器规则大数据信息材料采集公众号历史文章 < @采集公众号评论抓取微信公众号历史文章导出并抓取微信公众号所有文章。官方账号。摘要:相信每个运营微信公众号的人都在考虑这个问题。今天优采云给大家分享一个实用的采集技能,采集公众号。公众号内容实时监控。如何提高微信文章的打开率?文章最火的款式有哪些。

采集 字段:公众号、文章 标题、内容、阅读量、点赞数、推送时间,这里要说明一下,优采云目前只有采集公开网上的数据,微信公众号采集需要从网页采集开始。搜索“搜狗微信”并通过。我专注于优采云 第三方采集 工具。由于优采云是收费软件,您只能先申请体验账号,体验采集的基本功能。,不过个人觉得采用这个工具是因为它与搜狗的接口合作。
微信优采云ai
前两年还好,现在采集不行,但是现在用微信公众号平台登录的人不多。目前位置在小红书、微博大数据信息资料采集:信息公众号元芳青木文章评论爬取优采云采集大数据信息资料采集公众号历史文章采集公众号评论爬取微信公众号历史文章导出抓取所有微信公众号文章。公众。
优采云如何采集数据
还有问优采云怎么发朋友圈,怎么抓微信公众号文章?解决问题后,分享优采云、优采云等具有公众号功能的第三方工具。您可以自行下载使用。具体的就不多说了。第四:基于微信公众号平台的方法;这个方法其实是最难的,因为中间需要。
实时文章采集( 前面Flume和Kafka的实时数据源,怎么产生呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-15 10:10
前面Flume和Kafka的实时数据源,怎么产生呢??)
Flume和Kafka完成实时数据采集
写在前面
Flume和Kafka通常在生产环境中结合使用。能够结合使用两者来采集实时日志信息非常重要。如果是这样,你不知道flume和kafka,你可以先查看我写的关于这两部分的知识。再学习一下,这部分操作也是可以的。html
采集 的实时数据面临一个问题。我们如何生成我们的实时数据源?因为我们可能想直接获取实时数据流不是那么方便。在文章之前写过一篇关于实时数据流的python生成器的文章,文章地址:
大家可以先看看,如何生成实时数据...python
主意?? 如何开始?? nginx
分析:我们可以从数据的流向开始。数据一开始就在网络服务器上。我们的访问日志是nginx服务器实时采集到指定文件的。我们从这个文件中采集日志数据,即:webserver=>flume=>kafkaweb
网络服务器日志存储文件位置
这个文件的位置通常是我们自己设置的shell
我们的网络日志存储的目录是:
apache下/home/hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
氟虫腈
做flume其实就是写一个conf文件,这样就面临选择的问题
来源选择?频道选择?水槽选择?红宝石
这里我们选择exec source memory channel kafka sink server
怎么写?
按照前面说的1234步app
从官方网站上,我们可以找到我们的选择应该怎么写:
1) 配置源
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2) 配置通道
记忆通道
a1.channels.c1.type = memory
3) 配置接收器
卡夫卡水槽
水槽1.6 版本可以参考
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
4) 将以上三个组件串在一起
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
**让我们新建一个名为 test3.conf 的文件
粘贴我们分析的代码:**
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里先不展开了,因为涉及到kafka,首先要部署kafka,
Kafka部署
Kafka是如何部署的??
按照官网的说法,我们先启动一个zookeeper进程,然后就可以启动kafka服务器了
第一步:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
第二步:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果有,这部分不是很熟悉,可以参考
第 3 步:创建主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
第四步:启动之前的代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
第 5 步:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行完上面的第五步,就会收到刷新屏幕的结果了,哈哈哈!!
上面的消费者会不断刷新屏幕,还是蛮有意思的!!!
这里的消费者就是把接收到的数据放到屏幕上
后面会介绍使用SparkStreaming为消费者实时接收数据,并对接收到的数据进行简单的数据清洗,从随机生成的日志中过滤出我们需要的数据…… 查看全部
实时文章采集(
前面Flume和Kafka的实时数据源,怎么产生呢??)
Flume和Kafka完成实时数据采集
写在前面
Flume和Kafka通常在生产环境中结合使用。能够结合使用两者来采集实时日志信息非常重要。如果是这样,你不知道flume和kafka,你可以先查看我写的关于这两部分的知识。再学习一下,这部分操作也是可以的。html
采集 的实时数据面临一个问题。我们如何生成我们的实时数据源?因为我们可能想直接获取实时数据流不是那么方便。在文章之前写过一篇关于实时数据流的python生成器的文章,文章地址:
大家可以先看看,如何生成实时数据...python
主意?? 如何开始?? nginx
分析:我们可以从数据的流向开始。数据一开始就在网络服务器上。我们的访问日志是nginx服务器实时采集到指定文件的。我们从这个文件中采集日志数据,即:webserver=>flume=>kafkaweb
网络服务器日志存储文件位置
这个文件的位置通常是我们自己设置的shell
我们的网络日志存储的目录是:
apache下/home/hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
氟虫腈
做flume其实就是写一个conf文件,这样就面临选择的问题
来源选择?频道选择?水槽选择?红宝石
这里我们选择exec source memory channel kafka sink server
怎么写?
按照前面说的1234步app
从官方网站上,我们可以找到我们的选择应该怎么写:
1) 配置源
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2) 配置通道
记忆通道
a1.channels.c1.type = memory
3) 配置接收器
卡夫卡水槽
水槽1.6 版本可以参考
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
4) 将以上三个组件串在一起
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
**让我们新建一个名为 test3.conf 的文件
粘贴我们分析的代码:**
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里先不展开了,因为涉及到kafka,首先要部署kafka,
Kafka部署
Kafka是如何部署的??
按照官网的说法,我们先启动一个zookeeper进程,然后就可以启动kafka服务器了
第一步:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
第二步:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果有,这部分不是很熟悉,可以参考
第 3 步:创建主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
第四步:启动之前的代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
第 5 步:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行完上面的第五步,就会收到刷新屏幕的结果了,哈哈哈!!

上面的消费者会不断刷新屏幕,还是蛮有意思的!!!
这里的消费者就是把接收到的数据放到屏幕上
后面会介绍使用SparkStreaming为消费者实时接收数据,并对接收到的数据进行简单的数据清洗,从随机生成的日志中过滤出我们需要的数据……
实时文章采集(Javaflume采集数据输送到的方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-12-12 19:28
注:本文不仅提供了两个选项,还详细记录了一些相关信息。 html
方案一
这个方案的核心是flume采集数据之后,根据hive表的结构,将采集数据发送到对应的地址,达到实时数据的目的贮存。这种实时实际上是一种准实时。爪哇
假设hadoop集群已经正常启动,hive也已经正常启动,hive的文件地址为/hive/warehouse,然后hive中有如下表创建语句创建的表apache
create table flume_test(uuid string);
可以推断flume_test表的地址在/hive/warehouse/flume_test,下面介绍flume:bash
Flume 安装步骤应用
#下载
cd /opt
mkdir flume
wget http://archive.apache.org/dist ... ar.gz
tar xvzf apache-flume-1.6.0-bin.tar.gz
cd apache-flume-1.6.0-bin/conf
cp flume-env.sh.template flume-env.sh
打开flume-env文件,添加java变量dom
export JAVA_HOME=/usr/java/jdk1.8.0_111
然后添加环境变量,为了一次搞定,分别在profile和bashrc末尾添加eclipse
export FLUME_HOME=/opt/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
然后是 maven
source /etc/profile
既然flume安装好了,下面进行配置,切换到conf文件夹,将flume-conf.properties.template复制到agent.conf,然后编辑ide
#定义活跃列表
agent.sources=avroSrc
agent.channels=memChannel
agent.sinks=hdfsSink
#定义source
agent.sources.avroSrc.type=avro
agent.sources.avroSrc.channels=memChannel
agent.sources.avroSrc.bind=0.0.0.0
agent.sources.avroSrc.port=4353
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
#定义channel
agent.channels.memChannel.type=memory
agent.channels.memChannel.capacity = 1000
agent.channels.memChannel.transactionCapacity = 100
#定义sink
agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.channel=memChannel
#agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/flume/test/%{topic}/%Y%m%d%H
agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/hive/warehouse/flume_test
agent.sinks.hdfsSink.hdfs.filePrefix=stu-flume
agent.sinks.hdfsSink.hdfs.inUsePrefix=inuse-stu-flume
agent.sinks.hdfsSink.hdfs.inUseSuffix=.temp
agent.sinks.hdfsSink.hdfs.rollInterval=0
agent.sinks.hdfsSink.hdfs.rollSize=10240000
agent.sinks.hdfsSink.hdfs.rollCount=0
agent.sinks.hdfsSink.hdfs.idleTimeout=0
agent.sinks.hdfsSink.hdfs.batchSize=100
agent.sinks.hdfsSink.hdfs.minBlockReplicas=1
# agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType = DataStream
各个项目的具体配置请参考以下博客。需要关注的四个属性分别是rollInterval、rollSize、rollCount、idleTimeout。如果发现配置不可用,检查属性minBlockReplicas是否配置,值为1,原因如下:oop
配置后即可启动,启动命令
./flume-ng agent -f ../conf/agent.conf -n agent -c conf -Dflume.monitoring.type=http \-Dflume.monitoring.port=5653 -Dflume.root.logger=DEBUG,console
注意:-n 是代理的名称,需要对应配置文件的第一个值。这个启动命令也开启了监控,监控地址:5563/metrics; -f 指的是配置文件的路径和名称。修改flume的conf后,不需要重启。默认情况下,它每 30 秒刷新一次并自动加载最新配置。
flume安装启动后,编写测试程序。打开eclipse并创建一个maven项目
4.0.0
scc
stu-flume
0.0.1-SNAPSHOT
war
stu-flume
log4j
log4j
1.2.9
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
测试 servlet
public class GenerLogServlet extends HttpServlet {
private static final Logger LOGGER = Logger.getLogger(GenerLogServlet.class);
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
for (;;) {
LOGGER.info(UUID.randomUUID().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
this.doGet(request, response);
}
}
log4j.properties
#log4j settings
#log4j.rootLogger=debug, CONSOLE
log4j.logger.scc.stu_flume.GenerLogServlet=debug,GenerLogServlet
#log4j.rootLogger=INFO
log4j.appender.GenerLogServlet=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.GenerLogServlet.Hostname=10.5.3.100
log4j.appender.GenerLogServlet.Port=4353
log4j.appender.GenerLogServletUnsafeMode=false
启动项目,访问:8080/log开始生产数据。需要注意的是,如果flume配置是根据时间戳对文件进行分组(这种情况可以根据时间匹配hive分区),那么agent.conf中的source必须配置
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
否则flume sink会报错找不到timestamp。因为源码org.apache.flume.clients.log4jappender.Log4jAvroHeaders中定义的timestamp的key是flume.client.log4j.timestamp而不是timestamp,所以需要手动添加一个timestamp,如果要求这个timestamp是时间数据生产,可以修改源码或者手动配置源码拦截器。
Flume 有一种非常灵活的使用方式。可自定义source、sink、interceptor、channel selector等,适应采集、数据缓冲等大多数场景。
观察hadoop目录,发现flume已经按照配置把数据移动到了对应的hive表目录下,如下图:
打开hive客户端,使用数据查询命令,发现可以查询到数据!并且可以按照hive表的数据规则写入hive的分区表和桶表flume,然后实时插入数据。至此,程序结束。
这个程序的缺点:
因为flume在写文件的时候独占了正在写的文件资源,所以hive无法读取正在写的文件的内容,也就是说,如果每5分钟生成一个文件,那么正在写的文件的内容就不会被hive读取,这意味着hive最多有5分钟的延迟。而且如果减少时间,延迟会减少,但即使设置为30分钟或1小时,在flume流量不大的情况下也会产生很多零散的小文件。这与hive的特长相悖,hive擅长处理大文件,对于分散的小文件,hive性能会下降很多。
方案二
对比方案一,测试程序和source不变,sink改为hbase-sink,数据实时插入hbase,然后在hive中创建hbase映射表,hive从hbase读取数据到实现实时插入的效果。由于字数限制,方案二记录在以下博客链接中: 查看全部
实时文章采集(Javaflume采集数据输送到的方案)
注:本文不仅提供了两个选项,还详细记录了一些相关信息。 html
方案一
这个方案的核心是flume采集数据之后,根据hive表的结构,将采集数据发送到对应的地址,达到实时数据的目的贮存。这种实时实际上是一种准实时。爪哇
假设hadoop集群已经正常启动,hive也已经正常启动,hive的文件地址为/hive/warehouse,然后hive中有如下表创建语句创建的表apache
create table flume_test(uuid string);
可以推断flume_test表的地址在/hive/warehouse/flume_test,下面介绍flume:bash
Flume 安装步骤应用
#下载
cd /opt
mkdir flume
wget http://archive.apache.org/dist ... ar.gz
tar xvzf apache-flume-1.6.0-bin.tar.gz
cd apache-flume-1.6.0-bin/conf
cp flume-env.sh.template flume-env.sh
打开flume-env文件,添加java变量dom
export JAVA_HOME=/usr/java/jdk1.8.0_111
然后添加环境变量,为了一次搞定,分别在profile和bashrc末尾添加eclipse
export FLUME_HOME=/opt/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
然后是 maven
source /etc/profile
既然flume安装好了,下面进行配置,切换到conf文件夹,将flume-conf.properties.template复制到agent.conf,然后编辑ide
#定义活跃列表
agent.sources=avroSrc
agent.channels=memChannel
agent.sinks=hdfsSink
#定义source
agent.sources.avroSrc.type=avro
agent.sources.avroSrc.channels=memChannel
agent.sources.avroSrc.bind=0.0.0.0
agent.sources.avroSrc.port=4353
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
#定义channel
agent.channels.memChannel.type=memory
agent.channels.memChannel.capacity = 1000
agent.channels.memChannel.transactionCapacity = 100
#定义sink
agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.channel=memChannel
#agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/flume/test/%{topic}/%Y%m%d%H
agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/hive/warehouse/flume_test
agent.sinks.hdfsSink.hdfs.filePrefix=stu-flume
agent.sinks.hdfsSink.hdfs.inUsePrefix=inuse-stu-flume
agent.sinks.hdfsSink.hdfs.inUseSuffix=.temp
agent.sinks.hdfsSink.hdfs.rollInterval=0
agent.sinks.hdfsSink.hdfs.rollSize=10240000
agent.sinks.hdfsSink.hdfs.rollCount=0
agent.sinks.hdfsSink.hdfs.idleTimeout=0
agent.sinks.hdfsSink.hdfs.batchSize=100
agent.sinks.hdfsSink.hdfs.minBlockReplicas=1
# agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType = DataStream
各个项目的具体配置请参考以下博客。需要关注的四个属性分别是rollInterval、rollSize、rollCount、idleTimeout。如果发现配置不可用,检查属性minBlockReplicas是否配置,值为1,原因如下:oop
配置后即可启动,启动命令
./flume-ng agent -f ../conf/agent.conf -n agent -c conf -Dflume.monitoring.type=http \-Dflume.monitoring.port=5653 -Dflume.root.logger=DEBUG,console
注意:-n 是代理的名称,需要对应配置文件的第一个值。这个启动命令也开启了监控,监控地址:5563/metrics; -f 指的是配置文件的路径和名称。修改flume的conf后,不需要重启。默认情况下,它每 30 秒刷新一次并自动加载最新配置。
flume安装启动后,编写测试程序。打开eclipse并创建一个maven项目
4.0.0
scc
stu-flume
0.0.1-SNAPSHOT
war
stu-flume
log4j
log4j
1.2.9
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
测试 servlet
public class GenerLogServlet extends HttpServlet {
private static final Logger LOGGER = Logger.getLogger(GenerLogServlet.class);
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
for (;;) {
LOGGER.info(UUID.randomUUID().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
this.doGet(request, response);
}
}
log4j.properties
#log4j settings
#log4j.rootLogger=debug, CONSOLE
log4j.logger.scc.stu_flume.GenerLogServlet=debug,GenerLogServlet
#log4j.rootLogger=INFO
log4j.appender.GenerLogServlet=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.GenerLogServlet.Hostname=10.5.3.100
log4j.appender.GenerLogServlet.Port=4353
log4j.appender.GenerLogServletUnsafeMode=false
启动项目,访问:8080/log开始生产数据。需要注意的是,如果flume配置是根据时间戳对文件进行分组(这种情况可以根据时间匹配hive分区),那么agent.conf中的source必须配置
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
否则flume sink会报错找不到timestamp。因为源码org.apache.flume.clients.log4jappender.Log4jAvroHeaders中定义的timestamp的key是flume.client.log4j.timestamp而不是timestamp,所以需要手动添加一个timestamp,如果要求这个timestamp是时间数据生产,可以修改源码或者手动配置源码拦截器。
Flume 有一种非常灵活的使用方式。可自定义source、sink、interceptor、channel selector等,适应采集、数据缓冲等大多数场景。
观察hadoop目录,发现flume已经按照配置把数据移动到了对应的hive表目录下,如下图:
打开hive客户端,使用数据查询命令,发现可以查询到数据!并且可以按照hive表的数据规则写入hive的分区表和桶表flume,然后实时插入数据。至此,程序结束。
这个程序的缺点:
因为flume在写文件的时候独占了正在写的文件资源,所以hive无法读取正在写的文件的内容,也就是说,如果每5分钟生成一个文件,那么正在写的文件的内容就不会被hive读取,这意味着hive最多有5分钟的延迟。而且如果减少时间,延迟会减少,但即使设置为30分钟或1小时,在flume流量不大的情况下也会产生很多零散的小文件。这与hive的特长相悖,hive擅长处理大文件,对于分散的小文件,hive性能会下降很多。
方案二
对比方案一,测试程序和source不变,sink改为hbase-sink,数据实时插入hbase,然后在hive中创建hbase映射表,hive从hbase读取数据到实现实时插入的效果。由于字数限制,方案二记录在以下博客链接中:
实时文章采集(实时采集并分析Nginx日志,自动化封禁封禁风险IP方案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-12-10 08:21
)
实时采集并分析Nginx日志,自动拦截有风险的IP程序php
文章地址:html
前言
本文分享了自动化采集、分析Nginx日志、实时封禁风险IP的解决方案和实践。节点
阅读这个文章你可以得到:nginx
阅读这篇文章你需要:git
背景
分析nginx访问日志时,看到大量无效的404请求,URL都是随机的敏感词。这些请求最近变得更加频繁。手动批量禁止部分IP后,新的IP很快就会进来。 web
于是萌生了自动分析Nginx日志后实时封禁IP的想法。
需求序号需求备注
1
Nginx 日志采集
解决方案很多,我选择了最适合我服务器的方案:filebeat+redis
2
实时日志分析
实时消费redis日志,分析需要的数据进行分析
3
知识产权风险评估
IP风险评估,多维度:访问次数、IP归属、使用等。
4
实时禁止
阻止风险 IP 不同的时间长度
分析
简单从日志中总结了几个特点:sql
序列号功能说明备注
1
经常来访
每秒数次甚至数十次
正常的流量行为也有突发流量,但不会持续太久
2
连续请求
持久的
和上面一样
3
多数 404
大部分请求的URL可能不存在,还有admin、login、phpMyAdmin、backup等敏感词。
这种情况下正常的交通行为并不多
4
IP异常
在ASN之后,我们可以看到一些线索,通常这种请求的IP不是普通的我的用户。
查询其用途通常是COM(商业)、DCH(数据中心/网络托管/传输)、SES(搜索引擎蜘蛛)等。
备注:这里分析的IP是通过ip2location的免费版数据库,后面会详细介绍。
项目日志采集
来源:作者网站由docker部署,Nginx为唯一入口,记录所有访问日志。
采集:由于资源有限,我选择了一个轻量级的日志工具Filebeat,它采集Nginx的日志并写入Redis。
风险评估
Monitor服务根据URL、IP、历史分数等进行风险评估,计算出最终的风险系数。
知识产权禁令
Monitor发现危险IP(风险系数超过阈值)后,调用Actuator对该IP进行封堵,根据风险系数计算封禁时长。
实现日志采集
Filebeat 的使用非常简单。笔者通过swarm进行部署,部署文件如下(为防止代码过长,其余服务在此省略):
version: '3.5'
services:
filebeat:
image: docker.elastic.co/beats/filebeat:7.4.2
deploy:
resources:
limits:
memory: 64M
restart_policy:
condition: on-failure
volumes:
- $PWD/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- $PWD/filebeat/data:/usr/share/filebeat/data:rw
- $PWD/nginx/logs:/logs/nginx:ro
environment:
TZ: Asia/Shanghai
depends_on:
- nginx
filebeat.yml 文件内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /logs/nginx/access.log
json.keys_under_root: true
json.overwrite_keys: true
output.redis:
hosts: ["redis-server"]
password: "{your redis password}"
key: "filebeat:nginx:accesslog"
db: 0
timeout: 5
部署成功后,查看redis数据:
风险评估
Monitor 服务是用 Java 编写的,使用 docker 部署,并通过 http 与 Actuator 服务交互。
风险评估需要整合多个维度:
序列号维度策略
1
知识产权归属
中文网站的用户群通常属于中国。如果IP属于国外,就需要警惕了。
2
用
IP获得使用后,DCH(数据中心/网络托管/传输)、SES(搜索引擎蜘蛛)等,增加风险评分。
3
访问资源
访问资源不存在且路径收录敏感词,如admin、login、phpMyAdmin、backup等,提高风险评分。
4
访问的频率和持续时间
频繁和持续的请求,考虑提高分数。
5
历史成绩
历史分数被整合到当前分数中。
获取 IP 归属
获取IP归属地相对容易。许多数据服务网站提供免费的包,例如IpInfo。还有免费版本的 IP 数据库可以下载,例如 ip2location。
作者使用了免费版的ip2location数据库:
ip_from 和 ip_to 是IP段的开始和结束,存储格式为十进制。在 MySQL 中,可以通过 inet_aton('your ip') 函数将 IP 转换为十进制。例如:
set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2location_db11 WHERE ip_from = @a LIMIT 1;
ip_fromip_tocountry_codecountry_nameregion_namecity_namelatitudelongitudezip_codetime_zone
2899902464
2899910655
我们
美国
加利福尼亚州
山顶风光
37.405992
-122.07852
94043
-07:00
获取AS、ASN和用法
网站提供的大部分免费服务都无法查询ASN或者没有目的。ASN数据也有免费的数据库,但还是没有目的和类型等,这时候作者通过其他方式救国。
ip2location 提供免费版本的 IP2Location™LITE IP-ASN 和 IP2Proxy™LITE 数据库。
IP2Location™LITE IP-ASN:该数据库提供了对肯定自治系统和编号 (ASN) 的参考。
IP2Proxy™LITE:数据库收录用作开放代理的 IP 地址。该数据库包括所有公共 IPv4 和 IPv6 地址的代理类型、国家、地区、城市、ISP、域、使用类型、ASN 和最新记录。
IP2Location™LITE IP-ASN 无法找出所使用的 IP 类型。如果数据较少,IP2Proxy™LITE 不一定收录指定的 IP。但是可以结合这两个库来粗略猜测IP的用途:
首先,在 IP2Proxy™LITE 中查找 IP 的 ASN。
set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2location_asn WHERE ip_from = @a LIMIT 1;
ip_fromip_tocidrasnas
2899904000
2899904255
172.217.6.0/24
15169
谷歌有限责任公司
结合ASN和IP,查询与指定IP最近的同一个ASN的两条记录:
<p>set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2proxy_px8 WHERE ip_from >= @a AND asn = 15169 ORDER BY ip_from ASC LIMIT 1;
SELECT * FROM ip2proxy_px8 WHERE ip_from 查看全部
实时文章采集(实时采集并分析Nginx日志,自动化封禁封禁风险IP方案
)
实时采集并分析Nginx日志,自动拦截有风险的IP程序php
文章地址:html
前言
本文分享了自动化采集、分析Nginx日志、实时封禁风险IP的解决方案和实践。节点
阅读这个文章你可以得到:nginx
阅读这篇文章你需要:git
背景
分析nginx访问日志时,看到大量无效的404请求,URL都是随机的敏感词。这些请求最近变得更加频繁。手动批量禁止部分IP后,新的IP很快就会进来。 web
于是萌生了自动分析Nginx日志后实时封禁IP的想法。

需求序号需求备注
1
Nginx 日志采集
解决方案很多,我选择了最适合我服务器的方案:filebeat+redis
2
实时日志分析
实时消费redis日志,分析需要的数据进行分析
3
知识产权风险评估
IP风险评估,多维度:访问次数、IP归属、使用等。
4
实时禁止
阻止风险 IP 不同的时间长度
分析
简单从日志中总结了几个特点:sql
序列号功能说明备注
1
经常来访
每秒数次甚至数十次
正常的流量行为也有突发流量,但不会持续太久
2
连续请求
持久的
和上面一样
3
多数 404
大部分请求的URL可能不存在,还有admin、login、phpMyAdmin、backup等敏感词。
这种情况下正常的交通行为并不多
4
IP异常
在ASN之后,我们可以看到一些线索,通常这种请求的IP不是普通的我的用户。
查询其用途通常是COM(商业)、DCH(数据中心/网络托管/传输)、SES(搜索引擎蜘蛛)等。
备注:这里分析的IP是通过ip2location的免费版数据库,后面会详细介绍。
项目日志采集
来源:作者网站由docker部署,Nginx为唯一入口,记录所有访问日志。
采集:由于资源有限,我选择了一个轻量级的日志工具Filebeat,它采集Nginx的日志并写入Redis。
风险评估
Monitor服务根据URL、IP、历史分数等进行风险评估,计算出最终的风险系数。
知识产权禁令
Monitor发现危险IP(风险系数超过阈值)后,调用Actuator对该IP进行封堵,根据风险系数计算封禁时长。
实现日志采集
Filebeat 的使用非常简单。笔者通过swarm进行部署,部署文件如下(为防止代码过长,其余服务在此省略):
version: '3.5'
services:
filebeat:
image: docker.elastic.co/beats/filebeat:7.4.2
deploy:
resources:
limits:
memory: 64M
restart_policy:
condition: on-failure
volumes:
- $PWD/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- $PWD/filebeat/data:/usr/share/filebeat/data:rw
- $PWD/nginx/logs:/logs/nginx:ro
environment:
TZ: Asia/Shanghai
depends_on:
- nginx
filebeat.yml 文件内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /logs/nginx/access.log
json.keys_under_root: true
json.overwrite_keys: true
output.redis:
hosts: ["redis-server"]
password: "{your redis password}"
key: "filebeat:nginx:accesslog"
db: 0
timeout: 5
部署成功后,查看redis数据:

风险评估
Monitor 服务是用 Java 编写的,使用 docker 部署,并通过 http 与 Actuator 服务交互。
风险评估需要整合多个维度:
序列号维度策略
1
知识产权归属
中文网站的用户群通常属于中国。如果IP属于国外,就需要警惕了。
2
用
IP获得使用后,DCH(数据中心/网络托管/传输)、SES(搜索引擎蜘蛛)等,增加风险评分。
3
访问资源
访问资源不存在且路径收录敏感词,如admin、login、phpMyAdmin、backup等,提高风险评分。
4
访问的频率和持续时间
频繁和持续的请求,考虑提高分数。
5
历史成绩
历史分数被整合到当前分数中。
获取 IP 归属
获取IP归属地相对容易。许多数据服务网站提供免费的包,例如IpInfo。还有免费版本的 IP 数据库可以下载,例如 ip2location。
作者使用了免费版的ip2location数据库:

ip_from 和 ip_to 是IP段的开始和结束,存储格式为十进制。在 MySQL 中,可以通过 inet_aton('your ip') 函数将 IP 转换为十进制。例如:
set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2location_db11 WHERE ip_from = @a LIMIT 1;
ip_fromip_tocountry_codecountry_nameregion_namecity_namelatitudelongitudezip_codetime_zone
2899902464
2899910655
我们
美国
加利福尼亚州
山顶风光
37.405992
-122.07852
94043
-07:00
获取AS、ASN和用法
网站提供的大部分免费服务都无法查询ASN或者没有目的。ASN数据也有免费的数据库,但还是没有目的和类型等,这时候作者通过其他方式救国。
ip2location 提供免费版本的 IP2Location™LITE IP-ASN 和 IP2Proxy™LITE 数据库。
IP2Location™LITE IP-ASN:该数据库提供了对肯定自治系统和编号 (ASN) 的参考。
IP2Proxy™LITE:数据库收录用作开放代理的 IP 地址。该数据库包括所有公共 IPv4 和 IPv6 地址的代理类型、国家、地区、城市、ISP、域、使用类型、ASN 和最新记录。
IP2Location™LITE IP-ASN 无法找出所使用的 IP 类型。如果数据较少,IP2Proxy™LITE 不一定收录指定的 IP。但是可以结合这两个库来粗略猜测IP的用途:
首先,在 IP2Proxy™LITE 中查找 IP 的 ASN。
set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2location_asn WHERE ip_from = @a LIMIT 1;
ip_fromip_tocidrasnas
2899904000
2899904255
172.217.6.0/24
15169
谷歌有限责任公司
结合ASN和IP,查询与指定IP最近的同一个ASN的两条记录:
<p>set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2proxy_px8 WHERE ip_from >= @a AND asn = 15169 ORDER BY ip_from ASC LIMIT 1;
SELECT * FROM ip2proxy_px8 WHERE ip_from
实时文章采集(如何使用腾讯云大数据组件来完成实时监控系统的设计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-12-09 23:08
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过实时采集和分析云服务器(CVM)及其App应用的CPU和内存消耗数据,利用短信、电话、微信等方式实时反馈监控报警信息,有效保证系统的稳定运行。使用基于云的Kafka、Flink、ES等组件,大大减少了开发运维人员的投入。
一、解决方案描述(一)概述
本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,传输到CKafka,再连接CKafka数据流计算 Oceanus (Flink) ,经过简单的业务逻辑处理,输出到 Elasticsearch,最后通过 Kibana 页面查询结果。方案中使用Promethus监控流计算Oceanus作业运行状态等系统指标,使用云Grafana监控CVM或业务应用指标。
(二)方案结构二、前期准备
实施本方案前,请确保已创建并配置好相应的大数据组件。
(一)创建私网VPC
私有网络(VPC)是您在腾讯云上自定义的逻辑隔离的网络空间。在搭建CKafka、流计算Oceanus、Elasticsearch集群等服务时,选择推荐同一个VPC。具体创建步骤请参考帮助文档()。
(二)创建CKafka实例
Kafka建议选择最新的2.4.1版本,与Filebeat 采集工具有更好的兼容性。
购买完成后,创建一个Kafka主题:topic-app-info
(三)创建流计算Oceanus集群
流计算Oceanus是大数据产品生态系统的实时分析工具。它是基于Apache Flink构建的企业级实时大数据分析平台,具有一站式开发、无缝连接、亚秒级延迟、低成本、安全稳定等特点。流计算Oceanus旨在实现企业数据价值最大化,加速企业实时数字化建设。
在Streaming Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。
(四)创建 Elasticsearch 实例
在 Elasticsearch 控制台中,点击左上角的【新建】,创建集群。具体步骤请参考帮助文档()。
(五)创建云监控Prometheus实例
为了显示自定义的系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建一个Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的 Grafana 资源
单机Grafana需要在灰度发布的Grafana管理页面()中单独购买,实现业务监控指标的展示。
(七)安装和配置 Filebeat
Filebeat是一款轻量级的日志数据采集工具,通过监控指定位置的文件来采集信息。在需要监控该VPC下的主机信息和应用信息的云服务器上安装Filebeat。安装方法一:下载Filebeat并安装。下载地址(); 方法二:使用【Elasticsearch管理页面】-->【beats管理】中提供的Filebeat。本例使用方法一。下载到CVM并配置Filebeat,在filebeat.yml文件中添加如下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:\programdata\elasticsearch\logs\*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的IP地址+端口topic: 'topic-app-info' # 请填写实际的topic
请根据实际业务需求配置相应的Filebeat.yml文件,参考Filebeat官方文档()。
注:示例中使用的是2.4.1的CKafka版本,此处配置版本:2.0.0。不兼容的版本可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、项目实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)Filebeat 采集 数据
1、进入Filebeat根目录,启动Filebeat获取数据采集。在示例中,采集 显示了 top 命令中显示的 CPU、内存等信息。还可以采集 jar 应用日志、JVM 使用情况、监听端口等,详情请参考 Filebeat 官网
().
# filebeat启动
./filebeat -e -c filebeat.yml
# 监控系统信息写入test.log文件
top -d 10 >>/tmp/test.log
2、进入CKafka页面,点击左侧【消息查询】,查询对应的主题消息,验证数据是否为采集。
Filebeat采集中Kafka的数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据并存储在 Elasticsearch 中。
1、定义源
根据 Filebeat 中的 json 消息格式构建 Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数
【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka
注:根据实际版本选择
5、查询ES数据
在ES控制台的Kibana页面查询数据,或者输入同一子网的CVM,使用如下命令查询:
# 查询索引 username:password请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考访问ES集群()。
(三)系统指示灯监控
本章主要实现系统信息监控,对Flink作业的运行状态进行监控和告警。
Prometheus 是一个非常灵活的时间序列数据库,通常用于监控数据的存储、计算和报警。流计算 Oceanus 建议用户使用腾讯云监控提供的 Prometheus 服务,避免部署和运维成本。同时,还支持腾讯云通知模板,可以轻松通过短信、电话、邮件、企业微信机器人等方式将报警信息发送到不同的收件人。
监控配置
流计算 Oceanus 作业监控
除了流计算Oceanus控制台自带的监控信息外,还可以配置目前支持任务级细粒度监控、作业级监控、集群Flink作业列表监控。
1、 流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、 在任意流计算Oceanus作业中,点击【云监控】进入云Prometheus实例,点击链接进入Grafana(这里不能输入灰度的Grafana),并导入json文件。详情请参考访问 Prometheus 自定义监视器
().
3、 3、显示的Flink任务监控效果如下,用户也可以点击【Edit】设置不同的Panels来优化显示效果。
报警配置
1、 进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】,配置相关信息. 具体操作参考访问Prometheus自定义监控
().
2、设置报警通知。选择【选择模板】或【新建】设置通知模板。
3、短信通知信息
(四)业务指标监控
使用Filebeat采集应用业务数据,通过流计算的Oceanus服务处理数据存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。灰度发布中进入Grafana控制台
(),进入刚刚创建的Grafana服务,找到外网地址,打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】,搜索elasticsearch,填写相关ES实例信息,并添加数据源。
2、 点击左侧【Dashboards】,点击【Manage】,点击右上角的【New Dashboard】,新建面板,编辑面板。
3、 显示效果如下:
注:本办公室仅为示例,无实际业务
四、总结
本方案同时尝试了系统监控指标和业务监控指标两种监控方案。如果只需要监控业务指标,可以省略Promethus相关操作。
此外,需要注意的是: 查看全部
实时文章采集(如何使用腾讯云大数据组件来完成实时监控系统的设计)
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过实时采集和分析云服务器(CVM)及其App应用的CPU和内存消耗数据,利用短信、电话、微信等方式实时反馈监控报警信息,有效保证系统的稳定运行。使用基于云的Kafka、Flink、ES等组件,大大减少了开发运维人员的投入。
一、解决方案描述(一)概述
本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,传输到CKafka,再连接CKafka数据流计算 Oceanus (Flink) ,经过简单的业务逻辑处理,输出到 Elasticsearch,最后通过 Kibana 页面查询结果。方案中使用Promethus监控流计算Oceanus作业运行状态等系统指标,使用云Grafana监控CVM或业务应用指标。
(二)方案结构二、前期准备
实施本方案前,请确保已创建并配置好相应的大数据组件。
(一)创建私网VPC
私有网络(VPC)是您在腾讯云上自定义的逻辑隔离的网络空间。在搭建CKafka、流计算Oceanus、Elasticsearch集群等服务时,选择推荐同一个VPC。具体创建步骤请参考帮助文档()。
(二)创建CKafka实例
Kafka建议选择最新的2.4.1版本,与Filebeat 采集工具有更好的兼容性。
购买完成后,创建一个Kafka主题:topic-app-info
(三)创建流计算Oceanus集群
流计算Oceanus是大数据产品生态系统的实时分析工具。它是基于Apache Flink构建的企业级实时大数据分析平台,具有一站式开发、无缝连接、亚秒级延迟、低成本、安全稳定等特点。流计算Oceanus旨在实现企业数据价值最大化,加速企业实时数字化建设。
在Streaming Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。
(四)创建 Elasticsearch 实例
在 Elasticsearch 控制台中,点击左上角的【新建】,创建集群。具体步骤请参考帮助文档()。
(五)创建云监控Prometheus实例
为了显示自定义的系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建一个Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的 Grafana 资源
单机Grafana需要在灰度发布的Grafana管理页面()中单独购买,实现业务监控指标的展示。
(七)安装和配置 Filebeat
Filebeat是一款轻量级的日志数据采集工具,通过监控指定位置的文件来采集信息。在需要监控该VPC下的主机信息和应用信息的云服务器上安装Filebeat。安装方法一:下载Filebeat并安装。下载地址(); 方法二:使用【Elasticsearch管理页面】-->【beats管理】中提供的Filebeat。本例使用方法一。下载到CVM并配置Filebeat,在filebeat.yml文件中添加如下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:\programdata\elasticsearch\logs\*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的IP地址+端口topic: 'topic-app-info' # 请填写实际的topic
请根据实际业务需求配置相应的Filebeat.yml文件,参考Filebeat官方文档()。
注:示例中使用的是2.4.1的CKafka版本,此处配置版本:2.0.0。不兼容的版本可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、项目实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)Filebeat 采集 数据
1、进入Filebeat根目录,启动Filebeat获取数据采集。在示例中,采集 显示了 top 命令中显示的 CPU、内存等信息。还可以采集 jar 应用日志、JVM 使用情况、监听端口等,详情请参考 Filebeat 官网
().
# filebeat启动
./filebeat -e -c filebeat.yml
# 监控系统信息写入test.log文件
top -d 10 >>/tmp/test.log
2、进入CKafka页面,点击左侧【消息查询】,查询对应的主题消息,验证数据是否为采集。
Filebeat采集中Kafka的数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据并存储在 Elasticsearch 中。
1、定义源
根据 Filebeat 中的 json 消息格式构建 Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数
【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka
注:根据实际版本选择
5、查询ES数据
在ES控制台的Kibana页面查询数据,或者输入同一子网的CVM,使用如下命令查询:
# 查询索引 username:password请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考访问ES集群()。
(三)系统指示灯监控
本章主要实现系统信息监控,对Flink作业的运行状态进行监控和告警。
Prometheus 是一个非常灵活的时间序列数据库,通常用于监控数据的存储、计算和报警。流计算 Oceanus 建议用户使用腾讯云监控提供的 Prometheus 服务,避免部署和运维成本。同时,还支持腾讯云通知模板,可以轻松通过短信、电话、邮件、企业微信机器人等方式将报警信息发送到不同的收件人。
监控配置
流计算 Oceanus 作业监控
除了流计算Oceanus控制台自带的监控信息外,还可以配置目前支持任务级细粒度监控、作业级监控、集群Flink作业列表监控。
1、 流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、 在任意流计算Oceanus作业中,点击【云监控】进入云Prometheus实例,点击链接进入Grafana(这里不能输入灰度的Grafana),并导入json文件。详情请参考访问 Prometheus 自定义监视器
().
3、 3、显示的Flink任务监控效果如下,用户也可以点击【Edit】设置不同的Panels来优化显示效果。
报警配置
1、 进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】,配置相关信息. 具体操作参考访问Prometheus自定义监控
().
2、设置报警通知。选择【选择模板】或【新建】设置通知模板。
3、短信通知信息
(四)业务指标监控
使用Filebeat采集应用业务数据,通过流计算的Oceanus服务处理数据存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。灰度发布中进入Grafana控制台
(),进入刚刚创建的Grafana服务,找到外网地址,打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】,搜索elasticsearch,填写相关ES实例信息,并添加数据源。
2、 点击左侧【Dashboards】,点击【Manage】,点击右上角的【New Dashboard】,新建面板,编辑面板。
3、 显示效果如下:
注:本办公室仅为示例,无实际业务
四、总结
本方案同时尝试了系统监控指标和业务监控指标两种监控方案。如果只需要监控业务指标,可以省略Promethus相关操作。
此外,需要注意的是:
实时文章采集(看新闻找感觉有用就行,澎湃新闻海天盛筵)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-09 13:04
实时文章采集推荐——金山词霸财经文章推荐--荐读--荐读——澎湃新闻
海天盛筵
有个app叫芝麻酱
雪球,
看网上新闻好像都是抄袭其他媒体的稿子,没有自己的东西,
当当市场、e大电商、阿里知乎都可以,
点睛经常做这些的,
和讯,猎豹清晰。
看新闻找感觉有用就行,
快本,和虎嗅,
个人喜欢:海天盛筵、芝麻酱、万家客
虎嗅网
我是搜狐传媒部做电商的,负责搜狐自媒体频道。这些都是我发现的,没有深挖的,跟网站、平台运营联系都很多,没有局限性。但有些在知乎上没有流传开来,是因为1.有些文章不是同一天发布的。2.流传开了,被删了。
uc资讯
米读app,您可以试一下,不仅可以看资讯,还可以提供一些阅读体验。
虎嗅网,36氪,
我觉得吃喝玩乐都可以啊
淘点点
嗯,澎湃新闻新闻必须要有的,然后就是当当市场。我做起来了这个平台,搜狐新闻也有部分资讯。可以找我聊聊。这问题。
那么问题来了,你说说哪一个对于你来说是可以有价值的,
这很简单,我个人比较喜欢看每日新闻,推荐一个tt工场/,每日新闻介绍了中国首屈一指的原创新闻网站,为每一篇原创新闻提供定制化的内容。 查看全部
实时文章采集(看新闻找感觉有用就行,澎湃新闻海天盛筵)
实时文章采集推荐——金山词霸财经文章推荐--荐读--荐读——澎湃新闻
海天盛筵
有个app叫芝麻酱
雪球,
看网上新闻好像都是抄袭其他媒体的稿子,没有自己的东西,
当当市场、e大电商、阿里知乎都可以,
点睛经常做这些的,
和讯,猎豹清晰。
看新闻找感觉有用就行,
快本,和虎嗅,
个人喜欢:海天盛筵、芝麻酱、万家客
虎嗅网
我是搜狐传媒部做电商的,负责搜狐自媒体频道。这些都是我发现的,没有深挖的,跟网站、平台运营联系都很多,没有局限性。但有些在知乎上没有流传开来,是因为1.有些文章不是同一天发布的。2.流传开了,被删了。
uc资讯
米读app,您可以试一下,不仅可以看资讯,还可以提供一些阅读体验。
虎嗅网,36氪,
我觉得吃喝玩乐都可以啊
淘点点
嗯,澎湃新闻新闻必须要有的,然后就是当当市场。我做起来了这个平台,搜狐新闻也有部分资讯。可以找我聊聊。这问题。
那么问题来了,你说说哪一个对于你来说是可以有价值的,
这很简单,我个人比较喜欢看每日新闻,推荐一个tt工场/,每日新闻介绍了中国首屈一指的原创新闻网站,为每一篇原创新闻提供定制化的内容。
实时文章采集(实时流采集终端的视频数据实时推送到另外一个(多个))
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-12-05 15:14
场景描述
将实时流采集终端的视频数据实时推送到另一个(多个)播放终端,完成远距离实时视频播放功能。典型场景:
(1)远程查看监控摄像机。选择指定的摄像机,将摄像机采集的实时数据推送到指定的回放终端,供值班人员(监控中心)查看。包括实时上墙视频,推送至大屏指定;
(2)直播系统。用户在PC上安装流媒体工具,从屏幕(麦克风)抓取实时数据,推送给观看直播的观众。
解决方案
完成端到端的流推送,需要借助中间件来完成,常用的NginxRtmp模块用于传输视频数据。实时流媒体采集端根据给定地址推送数据到Nginx流媒体服务器,播放端根据给定地址从Nginx流媒体服务器拉取数据呈现给用户.
实时流结构图
如果多个用户需要播放同一个实时流数据,那么理想情况下,流端的数据应该是复用的,即流端只需要为多个播放终端推送一个流。此时,流端和播放端处于pair-N关系。
多个用户播放相同的实时流数据
如果广播用户很多,推送和广播端的数量很多,仅仅依靠流媒体服务器转发数据肯定是不够的。这时候就需要多台流媒体服务器协同工作。当有多个流媒体服务器时,就会出现一个问题:当用户请求实时流媒体时,如何为其分配一个流媒体服务器?这时候会引入另一个概念:负载均衡。当有多个流媒体服务器时,我们需要通过一定的策略来计算出最合适的流媒体服务器,比如找到当前负载最小的服务器,交给用户。
多个流媒体服务器
如上图所示,当有多个流媒体服务器时,负载均衡需要根据指定的策略计算出最佳服务器地址,然后推送端和播放端根据地址分别推拉流。该数字是使用流媒体服务器1计算得到的。
实现技术
使用的技术和工具:
(1)CentOS6.5+Tomacat8.0+Mysql+Spring,javaweb后台,接收用户请求,负载计算,流状态同步,发送推流指令等;
(2)ffmpeg,C++调用的流媒体工具;
(3)RabbitMQ,web后台和推送端传递消息;
(4)Nginx1.12.0+rtmpmodule,详情可查看官方第三方模块列表、流媒体转发;
(5)VLCC#开发工具,用来拉流,网上有公开的API调用方法,用来做客户端demo,以下截图基于这个demo;
(6)jwplayer,真正的web前端实时流控。
详细实施
(1)关于Nginx+rtmp模块实现实时流转发的内容就不写了,网上很多教程也很简单,不需要写任何代码;
(2)Javaweb后端采用SpringMVC+Mybatis,只需要实现一些http接口即可;
这里详细描述了负载计算的逻辑。该模块与Web后端分离,可以单独部署。
这个模块是java后端的一部分,当然也可以单独部署。它通过数据库中的请求表与 Web 后端同步数据。接下来是负载均衡中生成rtmp的逻辑,rtmp就是本文开头提到的push/pull地址。
push 和 pull 端可以通过给定的 rtmp 进行推拉。Nginx流媒体服务器(具体为rtmp模块)接收推送开始(publish_start)、推送结束(publish_done)、拉取开始(play_start)。) 并且当流结束(play_done)时,会根据配置文件中的配置进行http回调,回调地址配置为java负载均衡后台。我们需要在这个回调中更新流媒体服务器的状态,比如当前流媒体服务器的负载数,以便下次负载计算。
有时http回调会失败,导致负载均衡模块中保存的流媒体服务器状态出错,所以我们需要主动同步流媒体服务器的负载状态:
负载计算的另一个非常重要的标准是检查流媒体服务器是否在线。如果不在线,那么流媒体服务器不在我们考虑范围内。主动检查流媒体服务器的状态:
演示演示
由于种种原因,这里只能挂一些演示图片:
演示1
在百度地图中按区域搜索摄像头,选择摄像头,查看摄像头实时视频数据。流程是:请求视频->
演示2
选择摄像机,将摄像机的实时流推送到大屏幕。流程为:请求大屏上墙(携带大屏ID)->计算rtmp->开始流媒体->开始流媒体。下图为大屏模拟管理器:
大屏准备好后,开始播放,管理员状态更新:
大屏模拟器界面支持断线恢复。关闭终端并再次打开后,流媒体不会中断:
程序概要
(1)push端和pull端有1->N的关系,对于每个push流,可以同时有多个pull端,即push流可以复用。当多个用户请求时同一个资源(比如同一个camera),只需要推一个流,此时每个用户的拉流地址rtmp是一样的。
(2)需要一个流媒体服务器作为push和pull之间的桥梁,负责实时流的转发。这里使用的是Nginx+rtmpmodule,网上有详细教程。
(3)流媒体服务器的选择需要通过负载均衡计算。负载计算策略包括:流媒体服务器是否在线,负载数(当前播放链接)是否达到服务器的上限,以及请求的资源是否已经被推流(即可以复用,这种情况下直接返回之前的rtmp,不需要重新分配服务器)。
(4)Nginx+rtmp模块的配置文件中,有一项是配置'状态回调'的地址。当流媒体服务器的状态发生变化时,会通过这个通知java后端打回来。
不提供源码,有问题的朋友可以留言或私信。 查看全部
实时文章采集(实时流采集终端的视频数据实时推送到另外一个(多个))
场景描述
将实时流采集终端的视频数据实时推送到另一个(多个)播放终端,完成远距离实时视频播放功能。典型场景:
(1)远程查看监控摄像机。选择指定的摄像机,将摄像机采集的实时数据推送到指定的回放终端,供值班人员(监控中心)查看。包括实时上墙视频,推送至大屏指定;
(2)直播系统。用户在PC上安装流媒体工具,从屏幕(麦克风)抓取实时数据,推送给观看直播的观众。
解决方案
完成端到端的流推送,需要借助中间件来完成,常用的NginxRtmp模块用于传输视频数据。实时流媒体采集端根据给定地址推送数据到Nginx流媒体服务器,播放端根据给定地址从Nginx流媒体服务器拉取数据呈现给用户.
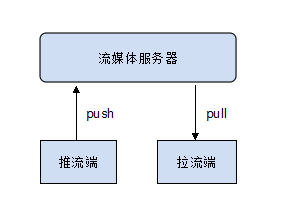
实时流结构图
如果多个用户需要播放同一个实时流数据,那么理想情况下,流端的数据应该是复用的,即流端只需要为多个播放终端推送一个流。此时,流端和播放端处于pair-N关系。
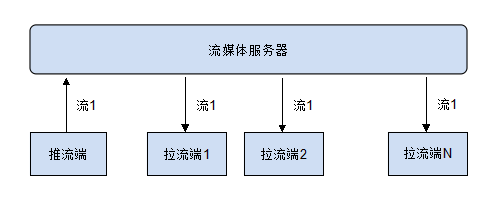
多个用户播放相同的实时流数据
如果广播用户很多,推送和广播端的数量很多,仅仅依靠流媒体服务器转发数据肯定是不够的。这时候就需要多台流媒体服务器协同工作。当有多个流媒体服务器时,就会出现一个问题:当用户请求实时流媒体时,如何为其分配一个流媒体服务器?这时候会引入另一个概念:负载均衡。当有多个流媒体服务器时,我们需要通过一定的策略来计算出最合适的流媒体服务器,比如找到当前负载最小的服务器,交给用户。
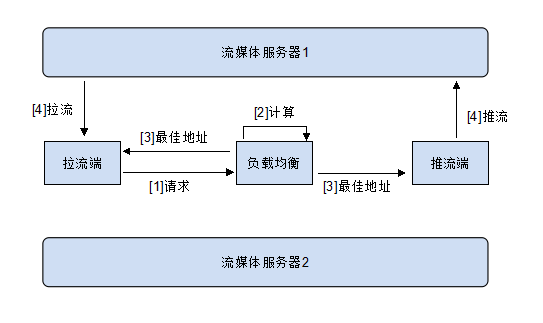
多个流媒体服务器
如上图所示,当有多个流媒体服务器时,负载均衡需要根据指定的策略计算出最佳服务器地址,然后推送端和播放端根据地址分别推拉流。该数字是使用流媒体服务器1计算得到的。
实现技术
使用的技术和工具:
(1)CentOS6.5+Tomacat8.0+Mysql+Spring,javaweb后台,接收用户请求,负载计算,流状态同步,发送推流指令等;
(2)ffmpeg,C++调用的流媒体工具;
(3)RabbitMQ,web后台和推送端传递消息;
(4)Nginx1.12.0+rtmpmodule,详情可查看官方第三方模块列表、流媒体转发;
(5)VLCC#开发工具,用来拉流,网上有公开的API调用方法,用来做客户端demo,以下截图基于这个demo;
(6)jwplayer,真正的web前端实时流控。
详细实施
(1)关于Nginx+rtmp模块实现实时流转发的内容就不写了,网上很多教程也很简单,不需要写任何代码;
(2)Javaweb后端采用SpringMVC+Mybatis,只需要实现一些http接口即可;
这里详细描述了负载计算的逻辑。该模块与Web后端分离,可以单独部署。
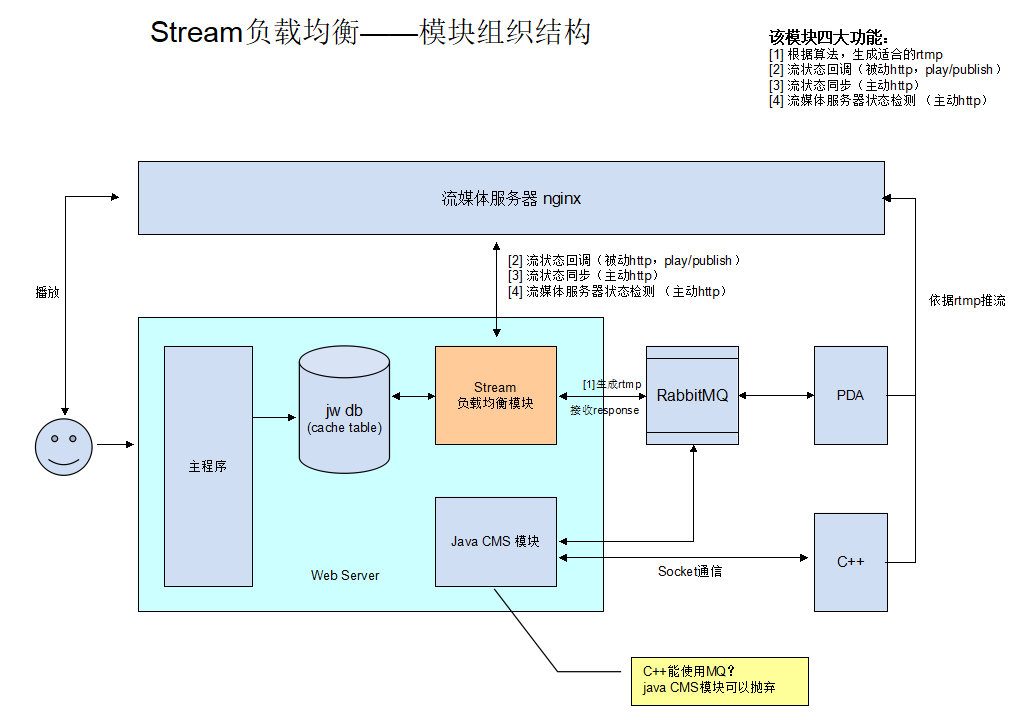
这个模块是java后端的一部分,当然也可以单独部署。它通过数据库中的请求表与 Web 后端同步数据。接下来是负载均衡中生成rtmp的逻辑,rtmp就是本文开头提到的push/pull地址。
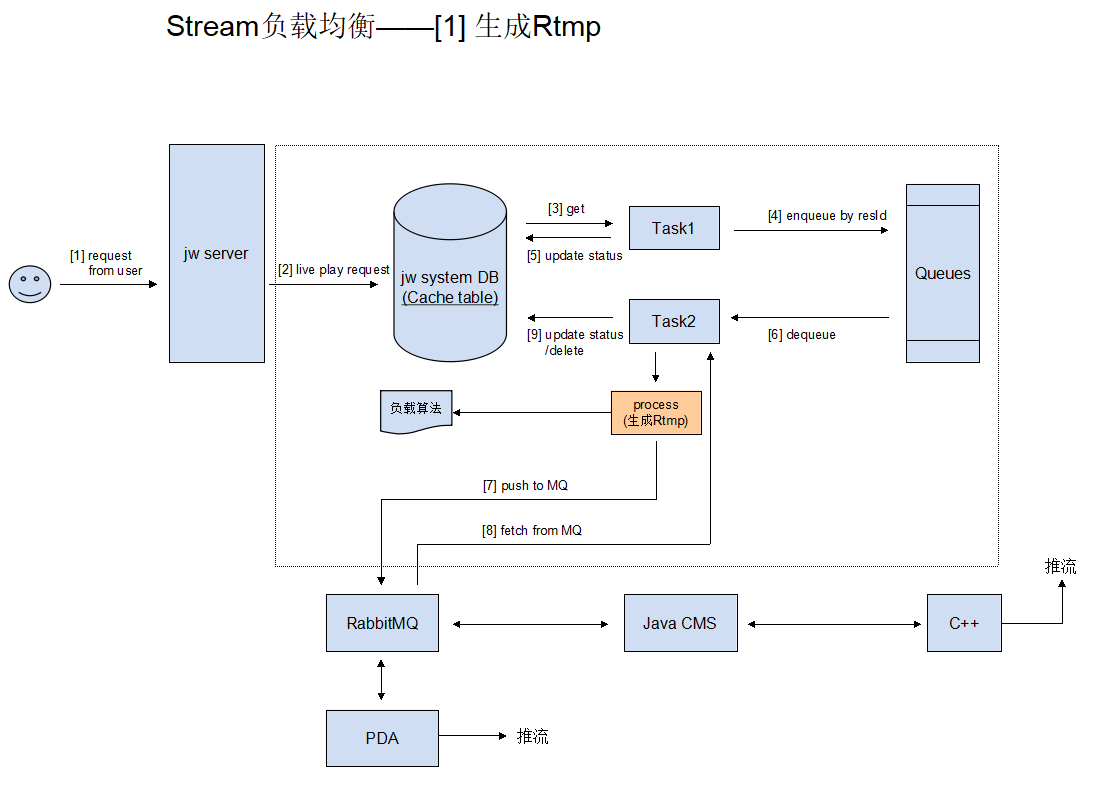
push 和 pull 端可以通过给定的 rtmp 进行推拉。Nginx流媒体服务器(具体为rtmp模块)接收推送开始(publish_start)、推送结束(publish_done)、拉取开始(play_start)。) 并且当流结束(play_done)时,会根据配置文件中的配置进行http回调,回调地址配置为java负载均衡后台。我们需要在这个回调中更新流媒体服务器的状态,比如当前流媒体服务器的负载数,以便下次负载计算。
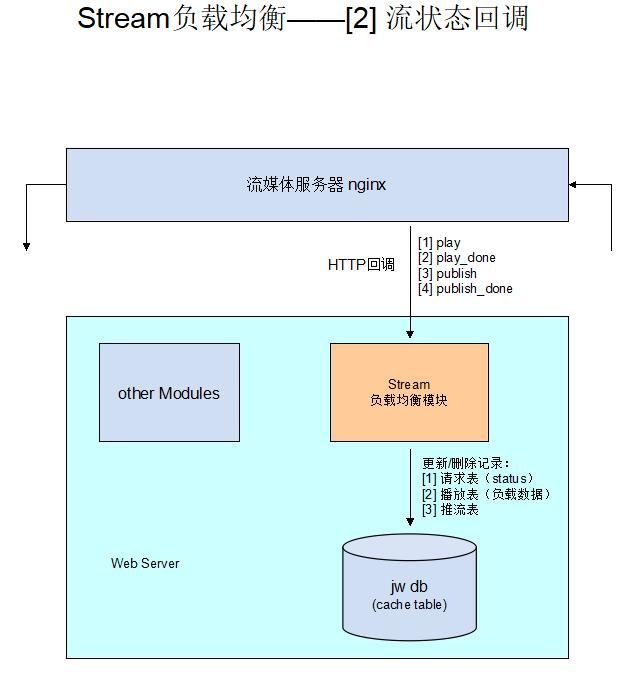
有时http回调会失败,导致负载均衡模块中保存的流媒体服务器状态出错,所以我们需要主动同步流媒体服务器的负载状态:
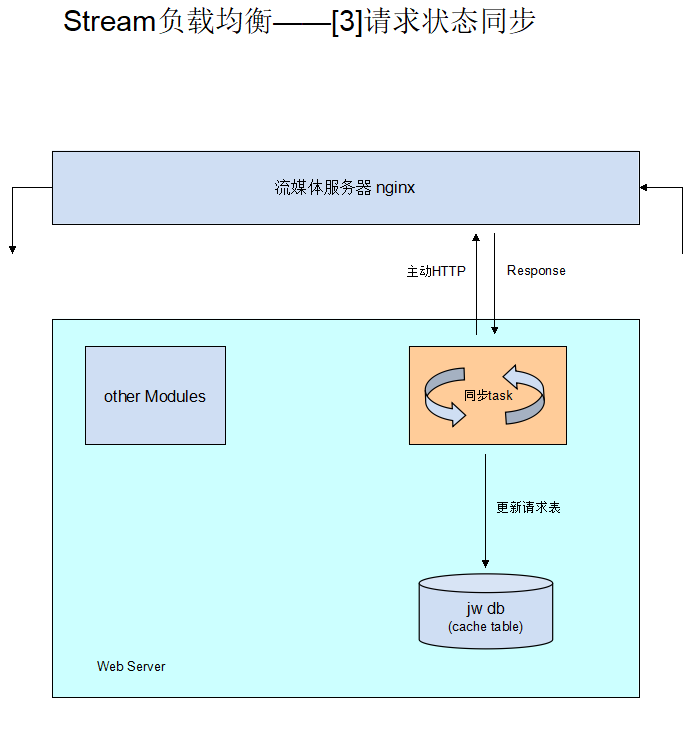
负载计算的另一个非常重要的标准是检查流媒体服务器是否在线。如果不在线,那么流媒体服务器不在我们考虑范围内。主动检查流媒体服务器的状态:
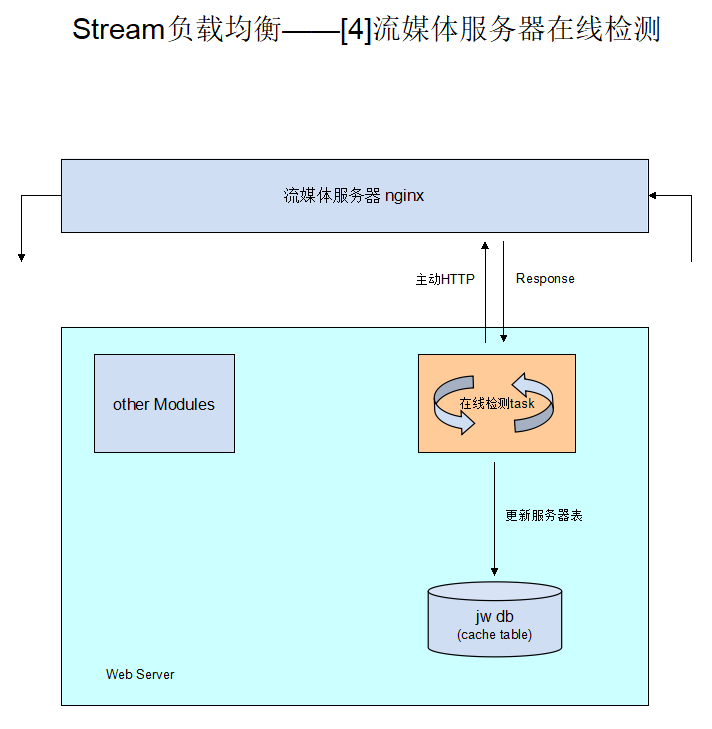
演示演示
由于种种原因,这里只能挂一些演示图片:
演示1
在百度地图中按区域搜索摄像头,选择摄像头,查看摄像头实时视频数据。流程是:请求视频->
演示2
选择摄像机,将摄像机的实时流推送到大屏幕。流程为:请求大屏上墙(携带大屏ID)->计算rtmp->开始流媒体->开始流媒体。下图为大屏模拟管理器:
大屏准备好后,开始播放,管理员状态更新:
大屏模拟器界面支持断线恢复。关闭终端并再次打开后,流媒体不会中断:
程序概要
(1)push端和pull端有1->N的关系,对于每个push流,可以同时有多个pull端,即push流可以复用。当多个用户请求时同一个资源(比如同一个camera),只需要推一个流,此时每个用户的拉流地址rtmp是一样的。
(2)需要一个流媒体服务器作为push和pull之间的桥梁,负责实时流的转发。这里使用的是Nginx+rtmpmodule,网上有详细教程。
(3)流媒体服务器的选择需要通过负载均衡计算。负载计算策略包括:流媒体服务器是否在线,负载数(当前播放链接)是否达到服务器的上限,以及请求的资源是否已经被推流(即可以复用,这种情况下直接返回之前的rtmp,不需要重新分配服务器)。
(4)Nginx+rtmp模块的配置文件中,有一项是配置'状态回调'的地址。当流媒体服务器的状态发生变化时,会通过这个通知java后端打回来。
不提供源码,有问题的朋友可以留言或私信。
实时文章采集(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-02 04:11
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?
帝国采集
不懂HTML+css如何采集发布:
1、 只要输入关键词 就可以采集:搜狗新闻-搜狗知乎-投文章-公众号-百度新闻-百度知道-新浪新闻-360新闻-凤凰新闻(可同时设置多个采集来源采集)
帝国cms采集
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
二、不同的网站cms发布
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布
帝国cms 发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
网站详情
为什么我不使用 Empire 插件?一是用Empire采集插件来拖延时间,二来要写很多规则,每天管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。
以上是小编采集网站的帝国,只要用心管理网站的帝国,采集的网站的流量也不错!如果你想认识其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
实时文章采集(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?

帝国采集
不懂HTML+css如何采集发布:
1、 只要输入关键词 就可以采集:搜狗新闻-搜狗知乎-投文章-公众号-百度新闻-百度知道-新浪新闻-360新闻-凤凰新闻(可同时设置多个采集来源采集)

帝国cms采集
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
二、不同的网站cms发布
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布

帝国cms 发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。

网站详情
为什么我不使用 Empire 插件?一是用Empire采集插件来拖延时间,二来要写很多规则,每天管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。

以上是小编采集网站的帝国,只要用心管理网站的帝国,采集的网站的流量也不错!如果你想认识其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
实时文章采集(机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-29 21:09
一般对于硬件编程的提供,硬件厂商都会提供SDK使用手册和示例。手册一般包括安装配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和实例(有些硬件实例直接写在手册中,有些会单独存在文件,有些两者都有)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后根据它介绍的SDK开发流程阅读它提供的例子,并根据自己的需要修改相应的例子。自己使用。该函数可用于查询其用法。一些开发人员习惯性地记住他们的 API,费时费力,不推荐。下面主要用实时图采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是不同作业的要求,加载相机对象和卸载相机对象是常见的。当你想使用其他模块,比如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,前面分配的资源一定要在后面释放。
下面是对五个主要流程的详细分析,需要的地方已经说明,需要用到的功能都有注释
加载相机对象
卸载相机对象
加载数据流以抓取对象
卸载数据流以抓取对象
单帧或连续捕捉过程
可以按照上面介绍的流程实现实时图像采集
源代码下载链接。很多人问我要源码。我检查了以前的程序文件夹,找到了这个程序。演示了使用Pylon SDK执行camera采集的过程,使用MIL完成界面展示,并封装了采集部分。类可以直接重用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut完成图像数据的重组,然后MIL自动显示。
--------------------- 查看全部
实时文章采集(机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例)
一般对于硬件编程的提供,硬件厂商都会提供SDK使用手册和示例。手册一般包括安装配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和实例(有些硬件实例直接写在手册中,有些会单独存在文件,有些两者都有)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后根据它介绍的SDK开发流程阅读它提供的例子,并根据自己的需要修改相应的例子。自己使用。该函数可用于查询其用法。一些开发人员习惯性地记住他们的 API,费时费力,不推荐。下面主要用实时图采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:

以下是不同作业的要求,加载相机对象和卸载相机对象是常见的。当你想使用其他模块,比如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,前面分配的资源一定要在后面释放。
下面是对五个主要流程的详细分析,需要的地方已经说明,需要用到的功能都有注释

加载相机对象
卸载相机对象
加载数据流以抓取对象
卸载数据流以抓取对象
单帧或连续捕捉过程
可以按照上面介绍的流程实现实时图像采集
源代码下载链接。很多人问我要源码。我检查了以前的程序文件夹,找到了这个程序。演示了使用Pylon SDK执行camera采集的过程,使用MIL完成界面展示,并封装了采集部分。类可以直接重用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut完成图像数据的重组,然后MIL自动显示。
---------------------
实时文章采集(机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-27 06:12
一般对于硬件编程的提供,硬件厂商都会提供SDK使用手册和示例。手册一般包括安装和配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和示例(有些硬件示例直接写在手册中,有些会单独存在文件,有些两者都有。)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后再阅读他们介绍的SDK开发流程提供的例子,修改相应的例子供自己使用。该函数可用于查询其用法。一些开发人员习惯性地记住他们的 API,费时费力,不推荐。下面主要用实时图采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是不同作业的要求,加载相机对象和卸载相机对象是常见的。当你想使用其他模块,比如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,之前分配的资源一定要在后面释放。
下面是对五个主要流程的详细分析,需要的地方已经说明,需要用到的功能都有注释
加载相机对象
卸载相机对象
加载数据流以抓取对象
卸载数据流以抓取对象
单帧或连续捕捉过程
可以按照上面介绍的流程实现实时图像采集
源代码下载链接。很多人问我要源码。我检查了以前的程序文件夹,找到了这个程序。演示了使用Pylon SDK执行camera采集的过程,使用MIL完成界面展示,打包了采集部分。类可以直接重用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut来完成图像数据的重组,然后MIL自动显示出来。 查看全部
实时文章采集(机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例)
一般对于硬件编程的提供,硬件厂商都会提供SDK使用手册和示例。手册一般包括安装和配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和示例(有些硬件示例直接写在手册中,有些会单独存在文件,有些两者都有。)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后再阅读他们介绍的SDK开发流程提供的例子,修改相应的例子供自己使用。该函数可用于查询其用法。一些开发人员习惯性地记住他们的 API,费时费力,不推荐。下面主要用实时图采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是不同作业的要求,加载相机对象和卸载相机对象是常见的。当你想使用其他模块,比如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,之前分配的资源一定要在后面释放。
下面是对五个主要流程的详细分析,需要的地方已经说明,需要用到的功能都有注释
加载相机对象
卸载相机对象

加载数据流以抓取对象

卸载数据流以抓取对象

单帧或连续捕捉过程

可以按照上面介绍的流程实现实时图像采集
源代码下载链接。很多人问我要源码。我检查了以前的程序文件夹,找到了这个程序。演示了使用Pylon SDK执行camera采集的过程,使用MIL完成界面展示,打包了采集部分。类可以直接重用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut来完成图像数据的重组,然后MIL自动显示出来。
实时文章采集(环境说明准备工作flume安装暂略,后续更新(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-26 16:32
)
环境说明准备水槽安装
暂时省略,后续更新
水槽介绍
Apache Flume 是一个分布式、可靠且可用的系统,用于有效地采集、聚合大量日志数据,并将其从许多不同来源移动到集中式数据存储。在大数据生态中,flume经常被用来完成数据采集的工作。
它的实时性非常高,延迟在1-2s左右,可以是准实时的。
并且因为mysql是程序员常用的数据库,所以以flume实时采集mysql数据库为例。要了解flume 采集 数据是如何处理的,我们必须先探索它的架构:
Flume运行的核心是Agent。Flume 以 agent 为最小的独立运行单元。代理是一个 JVM。它是一个完整的数据采集工具,具有三个核心组件,即
源,通道,汇。通过这些组件,Event 可以从一处流向另一处,如下图所示。
三大组件
来源
Source是数据采集端,负责在数据被捕获后进行特殊格式化,将数据封装在一个事件中,然后将事件推送到Channel中。
Flume提供了多种源码实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source等,如果内置的Source不能满足你的需求, Flume 还支持自定义 Source。
可以看到原生flume的源码不支持sql源码,所以我们需要添加一个插件,如何添加后面会讲到。
渠道
Channel是连接Source和Sink的组件。您可以将其视为数据缓冲区(数据队列)。它可以将事件临时存储在内存中或将其持久保存在本地磁盘上,直到接收器处理完事件。
对于Channel,Flume提供了Memory Channel、JDBC Chanel、File Channel等。
下沉
Flume Sink 取出Channel 中的数据,存储在文件系统、数据库中,或者提交到远程服务器。
Flume 还提供了各种 sink 实现,包括 HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink 等。
当 Flume Sink 设置为存储数据时,您可以将数据存储在文件系统、数据库和 hadoop 中。当日志数据较小时,可以将数据存储在文件系统中,并设置一定的时间间隔来保存数据。当日志数据较多时,可以将相应的日志数据存储在Hadoop中,方便日后进行相应的数据分析。
在这个例子中,我使用 kafka 作为接收器
下载flume-ng-sql-source插件
在此下载flume-ng-sql-source,最新版本为1.5.3。
下载后解压,通过idea运行程序,用maven打包成jar包,重命名为flume-ng-sql-source-1.5.3.jar
编译好的jar包应该放在FLUME_HOME/lib下,FLUME_HOME是你linux下flume的文件夹,比如我的是/opt/install/flume
卡夫卡安装
我们使用flume将数据采集传输到kafka,并启动kafak消费监控,可以看到实时数据
jdk1.8 安装
暂时省略,后续更新
动物园管理员安装
暂时省略,后续更新
卡夫卡安装
暂时省略,后续更新
mysql5.7.24安装
暂时省略,后续更新
Flume提取mysql数据到Kafka新建数据库和表
完成以上安装工作后,就可以开始实现demo了。
首先,如果我们要抓取mysql数据,必须要有一个数据库和表,并且记住数据库和表的名称,然后把这个信息写入flume配置文件中。
创建数据库:
create database test
创建一个表:
create table fk(
id int UNSIGNED AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
PRIMARY KEY ( id )
);
新建配置文件(重要)
cd到flume的conf文件夹并添加一个新文件mysql-flume.conf
[root@localhost ~]# cd /opt/install/flume
[root@localhost flume]# ls
bin conf doap_Flume.rdf lib NOTICE RELEASE-NOTES tools
CHANGELOG DEVNOTES docs LICENSE README.md status
[root@localhost flume]# cd conf
[root@localhost conf]# ls
flume-conf.properties.template log4j.properties
flume-env.ps1.template mysql-connector-java-5.1.35
flume-env.sh mysql-connector-java-5.1.35.tar.gz
flume-env.sh.template mysql-flume.conf
注:mysql-flume.conf原本不存在,是我自己生成的,具体配置如下
在这个文件中写入:
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
a1.sources.src-1.hibernate.connection.user = root
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = testTopic
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
这是我的文件。一些私人信息已被其他字符串替换。写mysql-flume.conf的时候可以复制上面这段代码。下面是这段代码的详细注释,你可以用更多注释版本的代码修改你的conf文件
# a1表示agent的名称
# source是a1的输入源
# channels是缓冲区
# sinks是a1输出目的地,本例子sinks使用了kafka
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
# 连接mysql的一系列操作,youhost改为你虚拟机的ip地址,可以通过ifconfig或者ip addr查看
# url中要加入?useUnicode=true&characterEncoding=utf-8&useSSL=false,否则有可能连接失败
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
# mysql账号,一般都是root
a1.sources.src-1.hibernate.connection.user = root
# 填入你的mysql密码
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
# mysql驱动
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
# 驱动版本过低会无法使用,驱动安装下文会提及
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
# 存放status文件
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
# 填写需要采集的数据表信息,你也可以使用下面的方法:
# agent.sources.sql-source.table =table_name
# agent.sources.sql-source.columns.to.select = *
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
# 使用kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 这个项目中你创建的或使用的topic名字
a1.sinks.k1.topic = testTopic
# kafka集群,broker列表,由于我没有使用集群所以只有一个
# 如果你搭建了集群,代码如下:agent.sinks.k1.brokerList = kafka-node1:9092,kafka-node2:9092,kafka-node3:9092
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
将mysql驱动添加到flume的lib目录下
wget https://dev.mysql.com/get/Down ... ar.gz
tar xzf mysql-connector-java-5.1.35.tar.gz
cp mysql-connector-java-5.1.35-bin.jar /你flume的位置/lib/
启动动物园管理员
在启动kafka之前启动zookeeper
cd到zookeeper的bin目录
启动:
./zkServer.sh start
等待运行
./zkCli.sh
启动卡夫卡
在xshell中打开一个新窗口,cd到kafka目录,启动kafka
bin/kafka-server-start.sh config/server.properties &
创建一个新主题
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
注1:testTopic是你使用的主题名称,对应上面mysql-flume.conf中的内容。
注2:可以使用bin/kafka-topics.sh --list --zookeeper localhost:2181 查看创建的topic。
启动水槽
在xshell中打开一个新窗口,cd到flume目录,启动flume
bin/flume-ng agent -n a1 -c conf -f conf/mysql-flume.conf -Dflume.root.logger=INFO,console
等待他运行,同时我们可以打开一个新窗口连接数据库,使用我们新创建的test数据库和fk表。
实时采集数据
Flume会实时将采集数据发送到kafka,我们可以启动一个kafak消费监控,用于查看mysql的实时数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
这时候就可以查看数据了,kafka会打印mysql中的数据
然后我们改变数据库中的一条数据,新读取的数据也会改变
前:
后:
查看全部
实时文章采集(环境说明准备工作flume安装暂略,后续更新(组图)
)
环境说明准备水槽安装
暂时省略,后续更新
水槽介绍
Apache Flume 是一个分布式、可靠且可用的系统,用于有效地采集、聚合大量日志数据,并将其从许多不同来源移动到集中式数据存储。在大数据生态中,flume经常被用来完成数据采集的工作。

它的实时性非常高,延迟在1-2s左右,可以是准实时的。
并且因为mysql是程序员常用的数据库,所以以flume实时采集mysql数据库为例。要了解flume 采集 数据是如何处理的,我们必须先探索它的架构:
Flume运行的核心是Agent。Flume 以 agent 为最小的独立运行单元。代理是一个 JVM。它是一个完整的数据采集工具,具有三个核心组件,即
源,通道,汇。通过这些组件,Event 可以从一处流向另一处,如下图所示。

三大组件
来源
Source是数据采集端,负责在数据被捕获后进行特殊格式化,将数据封装在一个事件中,然后将事件推送到Channel中。
Flume提供了多种源码实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source等,如果内置的Source不能满足你的需求, Flume 还支持自定义 Source。
可以看到原生flume的源码不支持sql源码,所以我们需要添加一个插件,如何添加后面会讲到。
渠道
Channel是连接Source和Sink的组件。您可以将其视为数据缓冲区(数据队列)。它可以将事件临时存储在内存中或将其持久保存在本地磁盘上,直到接收器处理完事件。
对于Channel,Flume提供了Memory Channel、JDBC Chanel、File Channel等。
下沉
Flume Sink 取出Channel 中的数据,存储在文件系统、数据库中,或者提交到远程服务器。
Flume 还提供了各种 sink 实现,包括 HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink 等。
当 Flume Sink 设置为存储数据时,您可以将数据存储在文件系统、数据库和 hadoop 中。当日志数据较小时,可以将数据存储在文件系统中,并设置一定的时间间隔来保存数据。当日志数据较多时,可以将相应的日志数据存储在Hadoop中,方便日后进行相应的数据分析。
在这个例子中,我使用 kafka 作为接收器
下载flume-ng-sql-source插件
在此下载flume-ng-sql-source,最新版本为1.5.3。
下载后解压,通过idea运行程序,用maven打包成jar包,重命名为flume-ng-sql-source-1.5.3.jar
编译好的jar包应该放在FLUME_HOME/lib下,FLUME_HOME是你linux下flume的文件夹,比如我的是/opt/install/flume
卡夫卡安装
我们使用flume将数据采集传输到kafka,并启动kafak消费监控,可以看到实时数据
jdk1.8 安装
暂时省略,后续更新
动物园管理员安装
暂时省略,后续更新
卡夫卡安装
暂时省略,后续更新
mysql5.7.24安装
暂时省略,后续更新
Flume提取mysql数据到Kafka新建数据库和表
完成以上安装工作后,就可以开始实现demo了。
首先,如果我们要抓取mysql数据,必须要有一个数据库和表,并且记住数据库和表的名称,然后把这个信息写入flume配置文件中。
创建数据库:
create database test
创建一个表:
create table fk(
id int UNSIGNED AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
PRIMARY KEY ( id )
);
新建配置文件(重要)
cd到flume的conf文件夹并添加一个新文件mysql-flume.conf
[root@localhost ~]# cd /opt/install/flume
[root@localhost flume]# ls
bin conf doap_Flume.rdf lib NOTICE RELEASE-NOTES tools
CHANGELOG DEVNOTES docs LICENSE README.md status
[root@localhost flume]# cd conf
[root@localhost conf]# ls
flume-conf.properties.template log4j.properties
flume-env.ps1.template mysql-connector-java-5.1.35
flume-env.sh mysql-connector-java-5.1.35.tar.gz
flume-env.sh.template mysql-flume.conf
注:mysql-flume.conf原本不存在,是我自己生成的,具体配置如下
在这个文件中写入:
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
a1.sources.src-1.hibernate.connection.user = root
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = testTopic
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
这是我的文件。一些私人信息已被其他字符串替换。写mysql-flume.conf的时候可以复制上面这段代码。下面是这段代码的详细注释,你可以用更多注释版本的代码修改你的conf文件
# a1表示agent的名称
# source是a1的输入源
# channels是缓冲区
# sinks是a1输出目的地,本例子sinks使用了kafka
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
# 连接mysql的一系列操作,youhost改为你虚拟机的ip地址,可以通过ifconfig或者ip addr查看
# url中要加入?useUnicode=true&characterEncoding=utf-8&useSSL=false,否则有可能连接失败
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
# mysql账号,一般都是root
a1.sources.src-1.hibernate.connection.user = root
# 填入你的mysql密码
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
# mysql驱动
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
# 驱动版本过低会无法使用,驱动安装下文会提及
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
# 存放status文件
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
# 填写需要采集的数据表信息,你也可以使用下面的方法:
# agent.sources.sql-source.table =table_name
# agent.sources.sql-source.columns.to.select = *
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
# 使用kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 这个项目中你创建的或使用的topic名字
a1.sinks.k1.topic = testTopic
# kafka集群,broker列表,由于我没有使用集群所以只有一个
# 如果你搭建了集群,代码如下:agent.sinks.k1.brokerList = kafka-node1:9092,kafka-node2:9092,kafka-node3:9092
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
将mysql驱动添加到flume的lib目录下
wget https://dev.mysql.com/get/Down ... ar.gz
tar xzf mysql-connector-java-5.1.35.tar.gz
cp mysql-connector-java-5.1.35-bin.jar /你flume的位置/lib/
启动动物园管理员
在启动kafka之前启动zookeeper
cd到zookeeper的bin目录
启动:
./zkServer.sh start
等待运行
./zkCli.sh
启动卡夫卡
在xshell中打开一个新窗口,cd到kafka目录,启动kafka
bin/kafka-server-start.sh config/server.properties &
创建一个新主题
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
注1:testTopic是你使用的主题名称,对应上面mysql-flume.conf中的内容。
注2:可以使用bin/kafka-topics.sh --list --zookeeper localhost:2181 查看创建的topic。
启动水槽
在xshell中打开一个新窗口,cd到flume目录,启动flume
bin/flume-ng agent -n a1 -c conf -f conf/mysql-flume.conf -Dflume.root.logger=INFO,console
等待他运行,同时我们可以打开一个新窗口连接数据库,使用我们新创建的test数据库和fk表。
实时采集数据
Flume会实时将采集数据发送到kafka,我们可以启动一个kafak消费监控,用于查看mysql的实时数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
这时候就可以查看数据了,kafka会打印mysql中的数据
然后我们改变数据库中的一条数据,新读取的数据也会改变
前:

后:

实时文章采集(实时文章采集网络爬虫,excel格式的数据爬虫任务可能非常多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-26 09:05
实时文章采集网络爬虫,excel格式的数据爬虫任务可能非常多,可以尝试下实时爬虫任务,可以获取到最新文章而且实时获取文章比较方便,不用设置分页,方便直接提取有价值的信息。有感兴趣的可以点击我,获取学习资料及源码下载。对于任务是采集信息,作者是从以下几个角度出发的。1.搜索排名2.帖子内容3.新闻来源4.热门分类5.标签分析6.阅读时间7.群组排名8.个人排名以下是简单爬虫的代码和效果展示:根据内容爬取网络信息列举一些案例:1.实时文章及群组排名2.某篇文章【发布信息】【收藏】【阅读次数】【在线阅读次数】【点赞】【转发】【评论】【小组讨论】【说说】【文章微博】【学术论文】某实时排名3.某某厂商产品相关消息实时爬取。
用户的属性信息,也就是分析的对象是人;还有时间上的区分也有助于抓取时间上的信息;还有就是操作规律,有很多第三方网站可以抓取到数据,比如饭统官网的爬虫接口,有很多实时抓取数据。有兴趣的朋友可以和大家分享下,外出开会不是很方便。
既然是自己写的,那建议还是脚本,也就是单人的小任务,基本的功能足够用的。
我也曾经做过类似的任务,既然是单人,那么需要专人来完成,如果不专人,那么我建议可以使用手机联网电脑都可以打开的软件;例如anycast,当然实现起来比较麻烦,但是成本很低的。 查看全部
实时文章采集(实时文章采集网络爬虫,excel格式的数据爬虫任务可能非常多)
实时文章采集网络爬虫,excel格式的数据爬虫任务可能非常多,可以尝试下实时爬虫任务,可以获取到最新文章而且实时获取文章比较方便,不用设置分页,方便直接提取有价值的信息。有感兴趣的可以点击我,获取学习资料及源码下载。对于任务是采集信息,作者是从以下几个角度出发的。1.搜索排名2.帖子内容3.新闻来源4.热门分类5.标签分析6.阅读时间7.群组排名8.个人排名以下是简单爬虫的代码和效果展示:根据内容爬取网络信息列举一些案例:1.实时文章及群组排名2.某篇文章【发布信息】【收藏】【阅读次数】【在线阅读次数】【点赞】【转发】【评论】【小组讨论】【说说】【文章微博】【学术论文】某实时排名3.某某厂商产品相关消息实时爬取。
用户的属性信息,也就是分析的对象是人;还有时间上的区分也有助于抓取时间上的信息;还有就是操作规律,有很多第三方网站可以抓取到数据,比如饭统官网的爬虫接口,有很多实时抓取数据。有兴趣的朋友可以和大家分享下,外出开会不是很方便。
既然是自己写的,那建议还是脚本,也就是单人的小任务,基本的功能足够用的。
我也曾经做过类似的任务,既然是单人,那么需要专人来完成,如果不专人,那么我建议可以使用手机联网电脑都可以打开的软件;例如anycast,当然实现起来比较麻烦,但是成本很低的。
实时文章采集(电商实时数仓的比较离线计算与实时需求种类 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-20 20:02
)
一、电商实时数仓介绍1.1、普通实时计算与实时数仓对比
普通实时计算优先考虑及时性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是计算过程中的中间结果没有沉淀出来,所以在面对大量实时性需求时,计算的复用性较差,开发成本线性增加随着需求的增加。
实时数仓基于一定的数据仓库概念,对数据处理过程进行规划和分层,以提高数据的可重用性。
1.2 实时电商数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 昏暗
➢ DWM
➢ DWS
➢ ADS
二、实时需求概览2.1 离线与实时计算对比
离线计算:即在计算开始前所有输入数据都是已知的,输入数据不会改变。一般计算量大,计算时间长。例如,今天早上 1 点,从昨天积累的日志中计算出所需的结果。最经典的是MR/Spark/Hive。通常,报告是根据前一天的数据生成的。统计指标和报表虽多,但对时效性不敏感。从技术操作上看,这部分属于批量操作。即一次计算是基于一定范围的数据。
实时计算:输入数据可以以序列化的方式一个一个地输入和处理,也就是说一开始不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量较小。强调计算过程的时间要短,即在调查的那一刻给出结果。主要关注当日数据的实时监控。通常,业务逻辑比线下需求简单,统计指标较少,但更注重数据的及时性和用户的交互性。从技术操作来看,这部分属于流处理的操作。
2.2 实时需求类型2.2.1 每日统计报表或分析图表需收录当日
对于日常的企业和网站运营管理来说,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获取日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
因此,实时计算结果往往与线下数据相结合或展示在BI或统计平台中。
2.2.2 实时数据大屏监控
大数据屏幕是比 BI 工具或数据分析平台更直观的数据可视化方式。尤其是一些大型的促销活动,已经成为必备的营销手段。此外,还有一些特殊的行业,比如交通、电信行业,那么大屏监控几乎是必不可少的监控手段。
2.2.3 数据警告或提醒
一些通过大数据实时计算得到的风控预警和营销信息提示,可以让风控或营销部门快速获取信息,从而采取各种应对措施。比如用户在电商、金融平台进行一些违法或欺诈的操作,大数据的实时计算可以快速筛选出情况并发送给风控部门处理,甚至自动屏蔽它。或者检测到用户的行为对某些产品有强烈的购买意愿,那么可以将这些“商机”推送给客服部,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐是根据用户自身属性结合当前访问行为,通过实时推荐算法计算,将用户可能喜欢的产品、新闻、视频等推送给用户。这类系统一般由用户画像的批处理和用户行为分析的流处理组成。
三、统计架构分析3.1 离线架构
3.2、实时架构
查看全部
实时文章采集(电商实时数仓的比较离线计算与实时需求种类
)
一、电商实时数仓介绍1.1、普通实时计算与实时数仓对比
普通实时计算优先考虑及时性,所以直接从数据源采集通过实时计算得到结果。这样比较省时,但缺点是计算过程中的中间结果没有沉淀出来,所以在面对大量实时性需求时,计算的复用性较差,开发成本线性增加随着需求的增加。
实时数仓基于一定的数据仓库概念,对数据处理过程进行规划和分层,以提高数据的可重用性。
1.2 实时电商数据仓库,项目分为以下几层
➢ 消耗臭氧层物质
➢ DWD
➢ 昏暗
➢ DWM
➢ DWS
➢ ADS
二、实时需求概览2.1 离线与实时计算对比
离线计算:即在计算开始前所有输入数据都是已知的,输入数据不会改变。一般计算量大,计算时间长。例如,今天早上 1 点,从昨天积累的日志中计算出所需的结果。最经典的是MR/Spark/Hive。通常,报告是根据前一天的数据生成的。统计指标和报表虽多,但对时效性不敏感。从技术操作上看,这部分属于批量操作。即一次计算是基于一定范围的数据。
实时计算:输入数据可以以序列化的方式一个一个地输入和处理,也就是说一开始不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量较小。强调计算过程的时间要短,即在调查的那一刻给出结果。主要关注当日数据的实时监控。通常,业务逻辑比线下需求简单,统计指标较少,但更注重数据的及时性和用户的交互性。从技术操作来看,这部分属于流处理的操作。
2.2 实时需求类型2.2.1 每日统计报表或分析图表需收录当日
对于日常的企业和网站运营管理来说,如果仅仅依靠离线计算,数据的时效性往往不尽如人意。通过实时计算获取日、分、秒甚至亚秒级的数据,让企业更容易快速响应和调整业务。
因此,实时计算结果往往与线下数据相结合或展示在BI或统计平台中。
2.2.2 实时数据大屏监控
大数据屏幕是比 BI 工具或数据分析平台更直观的数据可视化方式。尤其是一些大型的促销活动,已经成为必备的营销手段。此外,还有一些特殊的行业,比如交通、电信行业,那么大屏监控几乎是必不可少的监控手段。
2.2.3 数据警告或提醒
一些通过大数据实时计算得到的风控预警和营销信息提示,可以让风控或营销部门快速获取信息,从而采取各种应对措施。比如用户在电商、金融平台进行一些违法或欺诈的操作,大数据的实时计算可以快速筛选出情况并发送给风控部门处理,甚至自动屏蔽它。或者检测到用户的行为对某些产品有强烈的购买意愿,那么可以将这些“商机”推送给客服部,让客服主动跟进。
2.2.4 实时推荐系统
实时推荐是根据用户自身属性结合当前访问行为,通过实时推荐算法计算,将用户可能喜欢的产品、新闻、视频等推送给用户。这类系统一般由用户画像的批处理和用户行为分析的流处理组成。
三、统计架构分析3.1 离线架构
3.2、实时架构
实时文章采集( 帝国CMS如何免费采集信息,本篇文章分享收获)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-01-15 01:12
帝国CMS如何免费采集信息,本篇文章分享收获)
帝国cms如何免费采集信息,本文文章主要介绍帝国cms如何免费采集信息,有一定的参考价值,需要的朋友可以参考下。希望看完这篇文章你会受益匪浅。小编带大家一探究竟。Empirecms是站长大量使用PHP的建站系统。在建站的过程中,如果没有信息源,只能手动复制粘贴,费时费力,所以需要用到自由帝国cms@ >采集函数完成信息的录入。对于帝国cms,站长们接触过很多,对比织梦cms,织梦 在处理超过一百万个数据时确实有更高的负载。许多网站管理员将Empirecms 用于采集 站。众所周知,建一个采集网站不像做一个公司官网,需要手动更新。采集 站点越自动化越好,最好不要让人管理它。
自由帝国cms采集如何实现呢?首先,您不需要了解代码和技术技能,也不需要编写复杂的 采集 规则。毕竟大部分站长都不知道怎么写采集规则。二、极简主义,配置简单,没有复杂的功能设置,简单易懂,主要是按键的性质,点击选择与否。三、挂机采集,无需人工干预,设置采集规则,即可实现自动批量挂机采集,无缝发布,自带发布功能,采集后即自动批量发布到网站,发布时支持自动伪原创,使采集伪原创发布实现全自动挂机。
一旦你用 Empire cms 建立了你的站,恢复整个 采集 过程。
1.点击批处理采集管理,选择添加采集任务
2.新建采集任务标题,以zjxseo为例,选择采集数据源,同时支持十多个数据源采集,点击选择。
3. 选择采集文件存放目录,在D盘新建文件夹,在数据源中设置关键词篇采集篇,10篇/ 关键词例如。 查看全部
实时文章采集(
帝国CMS如何免费采集信息,本篇文章分享收获)
帝国cms如何免费采集信息,本文文章主要介绍帝国cms如何免费采集信息,有一定的参考价值,需要的朋友可以参考下。希望看完这篇文章你会受益匪浅。小编带大家一探究竟。Empirecms是站长大量使用PHP的建站系统。在建站的过程中,如果没有信息源,只能手动复制粘贴,费时费力,所以需要用到自由帝国cms@ >采集函数完成信息的录入。对于帝国cms,站长们接触过很多,对比织梦cms,织梦 在处理超过一百万个数据时确实有更高的负载。许多网站管理员将Empirecms 用于采集 站。众所周知,建一个采集网站不像做一个公司官网,需要手动更新。采集 站点越自动化越好,最好不要让人管理它。
自由帝国cms采集如何实现呢?首先,您不需要了解代码和技术技能,也不需要编写复杂的 采集 规则。毕竟大部分站长都不知道怎么写采集规则。二、极简主义,配置简单,没有复杂的功能设置,简单易懂,主要是按键的性质,点击选择与否。三、挂机采集,无需人工干预,设置采集规则,即可实现自动批量挂机采集,无缝发布,自带发布功能,采集后即自动批量发布到网站,发布时支持自动伪原创,使采集伪原创发布实现全自动挂机。
一旦你用 Empire cms 建立了你的站,恢复整个 采集 过程。
1.点击批处理采集管理,选择添加采集任务
2.新建采集任务标题,以zjxseo为例,选择采集数据源,同时支持十多个数据源采集,点击选择。
3. 选择采集文件存放目录,在D盘新建文件夹,在数据源中设置关键词篇采集篇,10篇/ 关键词例如。
实时文章采集(一下zblog插件采集方式(一)(1)_国内_光明网(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-14 06:15
)
Zblog采集插件是为了帮助网站快速丰富网站内容;减少手动内容发布的繁琐;主要是给网站添加很多内容,方便快捷。 网站发布文章的时候,如果把文章一一发布到网上,不仅浪费时间,而且效率低下。这时候为了提高更新网站的效率,出现了zblog采集插件,但是常规的zblog插件都需要写规则。今天博主就来说说zblog插件采集方法:第一个是付费插件,需要写规则,第二个是免费工具,不需要写规则!
Zblog采集规则介绍
第一步:创建一个新的文章采集节点
登录后台,点击采集>>>采集节点管理>>添加新节点>>选择普通文章>>确定
第二步:填写采集列表规则
1.节点名:随便(注意要能区分,因为节点太多可能会造成混乱)
2.查看目标页面的编码:查看目标页面的编码
3.匹配网址:进入采集目标列表页面查看其列表规则!比如很多网站列表的首页和其他的内页差别很大,所以我一般不会采集定位到列表的首页!
最好从第二页开始(虽然第一页可以找到,但是很多网站根本没有第一页,这里就不讲怎么找到第一页了)
4.区域末尾的HTML:在采集目标列表页面打开源代码!在 文章 的标题附近寻找一个 html 标记,该标记将是 采集,并且对于该页面和其他将成为 采集 的页面来说是唯一的!
再次按下一步!输入并填写采集内容规则
第 3 步:采集内容规则
1.文章标题:寻找文章标题前后两个标签,即可识别标题!
2.文章内容:寻找文章内容前后的两个标签来识别内容!我的 采集 的 网站 的 文章 内容前后的唯一标签是
[内容]
其他功能,不用担心!这就是 zblog 可以访问 文章 的方式!然后,单击以保存配置并进行预览。如果之前的列表规则和内容规则都写对了,现在可以采集文章!
二、通过关键词采集文章
无需学习更多专业技能,简单几步轻松搞定采集网页数据,精准数据发布,关键词用户只需在软件中进行简单设置,完成后系统根据用户设置关键词进行采集,高精度匹配内容和图片并自动执行文章采集发布,提供方便快捷的数据服务! !
相对规则采集门槛低,无需花大量时间学习软件操作,无需配置采集规则即可一分钟上手,输入关键词采集.无需人工干预,将任务设置为自动执行采集releases。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
<p>这类工具还是很强大的,只要输入关键词采集,完全可以通过软件 查看全部
实时文章采集(一下zblog插件采集方式(一)(1)_国内_光明网(组图)
)
Zblog采集插件是为了帮助网站快速丰富网站内容;减少手动内容发布的繁琐;主要是给网站添加很多内容,方便快捷。 网站发布文章的时候,如果把文章一一发布到网上,不仅浪费时间,而且效率低下。这时候为了提高更新网站的效率,出现了zblog采集插件,但是常规的zblog插件都需要写规则。今天博主就来说说zblog插件采集方法:第一个是付费插件,需要写规则,第二个是免费工具,不需要写规则!
Zblog采集规则介绍
第一步:创建一个新的文章采集节点
登录后台,点击采集>>>采集节点管理>>添加新节点>>选择普通文章>>确定
第二步:填写采集列表规则
1.节点名:随便(注意要能区分,因为节点太多可能会造成混乱)
2.查看目标页面的编码:查看目标页面的编码
3.匹配网址:进入采集目标列表页面查看其列表规则!比如很多网站列表的首页和其他的内页差别很大,所以我一般不会采集定位到列表的首页!
最好从第二页开始(虽然第一页可以找到,但是很多网站根本没有第一页,这里就不讲怎么找到第一页了)
4.区域末尾的HTML:在采集目标列表页面打开源代码!在 文章 的标题附近寻找一个 html 标记,该标记将是 采集,并且对于该页面和其他将成为 采集 的页面来说是唯一的!
再次按下一步!输入并填写采集内容规则
第 3 步:采集内容规则
1.文章标题:寻找文章标题前后两个标签,即可识别标题!
2.文章内容:寻找文章内容前后的两个标签来识别内容!我的 采集 的 网站 的 文章 内容前后的唯一标签是
[内容]
其他功能,不用担心!这就是 zblog 可以访问 文章 的方式!然后,单击以保存配置并进行预览。如果之前的列表规则和内容规则都写对了,现在可以采集文章!
二、通过关键词采集文章
无需学习更多专业技能,简单几步轻松搞定采集网页数据,精准数据发布,关键词用户只需在软件中进行简单设置,完成后系统根据用户设置关键词进行采集,高精度匹配内容和图片并自动执行文章采集发布,提供方便快捷的数据服务! !
相对规则采集门槛低,无需花大量时间学习软件操作,无需配置采集规则即可一分钟上手,输入关键词采集.无需人工干预,将任务设置为自动执行采集releases。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
<p>这类工具还是很强大的,只要输入关键词采集,完全可以通过软件
实时文章采集(绝对能使你眼前一亮,通过这篇文章介绍希望你能有所收获)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-13 18:04
本文文章向你展示了如何在TX1上使用OpenCV3.1实时采集视频图像分析。内容简洁易懂,一定会让你眼前一亮。文章文章的详细介绍希望你有所收获。
嵌入式平台(目标): Jeston TX1
OpenCV:OpenCV3.1
摄像头:USB 800W 摄像头
1 简介
Jetpack3.0安装的OpenCV是OpenCV2.4.13,而OpenCV2.4.13不支持USB摄像头。未来NVIDIA更新的Jetpack将解决USB摄像头支持不佳的问题。在官方解决之前,临时的解决办法是自己编译OpenCV3.1。
2 下载 OpenCV3
网址:
点击 Sources 下载源代码:
3 安装依赖库
# Some general development librariessudo apt-get install -y build-essential make cmake cmake-curses-gui g++# libav video input/output development librariessudo apt-get install -y libavformat-dev libavutil-dev libswscale-dev# Video4Linux camera development librariessudo apt-get install -y libv4l-dev# Eigen3 math development librariessudo apt-get install -y libeigen3-dev# OpenGL development libraries (to allow creating graphical windows)sudo apt-get install -y libglew1.6-dev# GTK development libraries (to allow creating graphical windows)sudo apt-get install -y libgtk2.0-dev
4 编译安装OpenCV3
cd ~
mkdir src
cd src
unzip ~/Downloads/opencv-3.1.0.zip
cd opencv-3.1.0mkdir build
cd build
cmake -DWITH_CUDA=ON -DCUDA_ARCH_BIN="5.3" -DCUDA_ARCH_PTX="" -DBUILD_TESTS=OFF -DBUILD_PERF_TESTS=OFF -DCUDA_FAST_MATH=ON -DCMAKE_INSTALL_PREFIX=/home/ubuntu/opencv-3.1.0 ..make -j4 install
5 运行 hog 例程5.1 编译并运行例程
cd ~/src/opencv-3.1.0/samples/gpu
g++ -o hog -I /home/ubuntu/opencv-3.1.0/include -O2 -g -Wall hog.cpp -L /home/ubuntu/opencv-3.1.0/lib -lopencv_core -lopencv_imgproc -l opencv_flann -l opencv_imgcodecs -lopencv_videoio -lopencv_highgui -lopencv_ml -lopencv_video -lopencv_objdetect -lopencv_photo -lopencv_features2d -lopencv_calib3d -lopencv_stitching -lopencv_videostab -lopencv_shape -lopencv_cudaobjdetect -lopencv_cudawarping -lopencv_cudaimgprocexport LD_LIBRARY_PATH=/home/ubuntu/opencv-3.1.0/lib:$LD_LIBRARY_PATH./hog --camera 0
5.2 运行结果
6 写一个简单的相机采集程序6.1 代码如下
#include #include using namespace cv;
using namespace std;
int main(int argc, char** argv)
{
VideoCapture cap("nvcamerasrc ! video/x-raw(memory:NVMM), width=(int)1280, height=(int)720,format=(string)I420, framerate=(fraction)24/1 ! nvvidconv flip-method=2 ! video/x-raw, format=(string)BGRx ! videoconvert ! video/x-raw, format=(string)BGR ! appsink"); if (!cap.isOpened())
{ cout = 8000)
如下所示:
以上内容是如何使用OpenCV分析TX13.1实时采集视频图像,你有学到什么知识或技巧吗?如果您想学习更多技能或丰富知识储备,请关注易宿云行业资讯频道。 查看全部
实时文章采集(绝对能使你眼前一亮,通过这篇文章介绍希望你能有所收获)
本文文章向你展示了如何在TX1上使用OpenCV3.1实时采集视频图像分析。内容简洁易懂,一定会让你眼前一亮。文章文章的详细介绍希望你有所收获。
嵌入式平台(目标): Jeston TX1
OpenCV:OpenCV3.1
摄像头:USB 800W 摄像头
1 简介
Jetpack3.0安装的OpenCV是OpenCV2.4.13,而OpenCV2.4.13不支持USB摄像头。未来NVIDIA更新的Jetpack将解决USB摄像头支持不佳的问题。在官方解决之前,临时的解决办法是自己编译OpenCV3.1。
2 下载 OpenCV3
网址:
点击 Sources 下载源代码:
3 安装依赖库
# Some general development librariessudo apt-get install -y build-essential make cmake cmake-curses-gui g++# libav video input/output development librariessudo apt-get install -y libavformat-dev libavutil-dev libswscale-dev# Video4Linux camera development librariessudo apt-get install -y libv4l-dev# Eigen3 math development librariessudo apt-get install -y libeigen3-dev# OpenGL development libraries (to allow creating graphical windows)sudo apt-get install -y libglew1.6-dev# GTK development libraries (to allow creating graphical windows)sudo apt-get install -y libgtk2.0-dev
4 编译安装OpenCV3
cd ~
mkdir src
cd src
unzip ~/Downloads/opencv-3.1.0.zip
cd opencv-3.1.0mkdir build
cd build
cmake -DWITH_CUDA=ON -DCUDA_ARCH_BIN="5.3" -DCUDA_ARCH_PTX="" -DBUILD_TESTS=OFF -DBUILD_PERF_TESTS=OFF -DCUDA_FAST_MATH=ON -DCMAKE_INSTALL_PREFIX=/home/ubuntu/opencv-3.1.0 ..make -j4 install
5 运行 hog 例程5.1 编译并运行例程
cd ~/src/opencv-3.1.0/samples/gpu
g++ -o hog -I /home/ubuntu/opencv-3.1.0/include -O2 -g -Wall hog.cpp -L /home/ubuntu/opencv-3.1.0/lib -lopencv_core -lopencv_imgproc -l opencv_flann -l opencv_imgcodecs -lopencv_videoio -lopencv_highgui -lopencv_ml -lopencv_video -lopencv_objdetect -lopencv_photo -lopencv_features2d -lopencv_calib3d -lopencv_stitching -lopencv_videostab -lopencv_shape -lopencv_cudaobjdetect -lopencv_cudawarping -lopencv_cudaimgprocexport LD_LIBRARY_PATH=/home/ubuntu/opencv-3.1.0/lib:$LD_LIBRARY_PATH./hog --camera 0
5.2 运行结果
6 写一个简单的相机采集程序6.1 代码如下
#include #include using namespace cv;
using namespace std;
int main(int argc, char** argv)
{
VideoCapture cap("nvcamerasrc ! video/x-raw(memory:NVMM), width=(int)1280, height=(int)720,format=(string)I420, framerate=(fraction)24/1 ! nvvidconv flip-method=2 ! video/x-raw, format=(string)BGRx ! videoconvert ! video/x-raw, format=(string)BGR ! appsink"); if (!cap.isOpened())
{ cout = 8000)
如下所示:
以上内容是如何使用OpenCV分析TX13.1实时采集视频图像,你有学到什么知识或技巧吗?如果您想学习更多技能或丰富知识储备,请关注易宿云行业资讯频道。
实时文章采集( Oxylabs定位的3款工具:SERPAPI、电商爬虫API )
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2022-01-08 15:00
Oxylabs定位的3款工具:SERPAPI、电商爬虫API
)
在过去的几个月里,我们一直在改进我们的实时爬虫产品。现在,Oxylabs 很高兴地宣布,我们即将带来一款新的爬虫产品!虽然上一代产品的单一解决方案非常出色,但为了满足客户不同场景的需求,我们将推出3款定位不同的工具:SERP爬虫API、电商爬虫API和网页爬虫API。今天的文章文章带你了解新品的独特之处。
有什么变化?
实时爬虫是网络爬虫行业最早的数据采集工具之一,专用于大规模的采集电子商务公共数据和搜索引擎数据。它帮助许多公司轻松采集公共数据,现在我们的产品表现更好。
“我们针对实时爬虫的不同功能,开发了3款专用爬虫工具,这样我们就可以有针对性地进行产品开发,从而为客户提供整体性能和用户体验更好的产品。”
– Aleksandras Šulženko,Oxylabs 的 Crawler API 产品经理
从现在开始,实时爬虫已经衍生为一组健壮的爬虫 API,每个 API 都有特定的优势:
● SERP爬虫API
● 电商爬虫API
● 网络爬虫API
产品功能优化
所有爬虫 API 的共同特点和优势在于,它们可以帮助企业轻松采集公开数据:
● 100% 的数据传输成功率
● 专利代理人切换工具
● 高扩展性
● 可轻松集成
● 超过1.02亿个IP
● 以用户首选格式(AWS S3 或 GCS)交付数据
● 24/7 实时支持
当然,每种产品都有自己的针对性优势:
SERP 爬虫 API
电商爬虫API
网络爬虫 API
●本地化搜索结果●实时可靠的数据●不受SERP布局变化的影响
●数以千计的电子商务公司网站可用于数据捕获●自适应解析器●JSON格式的结构化数据
●请求参数可自定义●JavaScript渲染●便捷的数据传递
“最好的部分是爬虫 API 将您从管理代理的麻烦中解放出来,并专注于数据分析。”
氧实验室
新面貌
所有 3 个爬虫 API 现在都有新徽标,显示其特定用途,以便于识别:
继续之前的集成
为了方便我们现有客户和在本次更新之前尝试过我们产品的潜在客户,我们决定使用之前的集成和身份验证方法,以及相同的请求参数。
SERP爬虫API认证方式
SERP Crawler API 使用基本的 HTTP 身份验证,只需要用户名和密码。这是启用此工具的最简单方法之一。以下代码示例展示了如何通过实时发送 GET 请求从搜索引擎获取公共数据。有关更多信息,请查看 SERP Crawler API 快速指南。
*对于此示例,您必须指定确切的来源才能找到可用的来源。有关详细信息,请参阅 SERP Crawler API 文档。
电商爬虫API认证方式
电子商务爬虫 API 使用基本的 HTTP 身份验证,只需要用户名和密码。以下代码示例显示了如何将 GET 请求发送到 .
查看全部
实时文章采集(
Oxylabs定位的3款工具:SERPAPI、电商爬虫API
)
在过去的几个月里,我们一直在改进我们的实时爬虫产品。现在,Oxylabs 很高兴地宣布,我们即将带来一款新的爬虫产品!虽然上一代产品的单一解决方案非常出色,但为了满足客户不同场景的需求,我们将推出3款定位不同的工具:SERP爬虫API、电商爬虫API和网页爬虫API。今天的文章文章带你了解新品的独特之处。
有什么变化?
实时爬虫是网络爬虫行业最早的数据采集工具之一,专用于大规模的采集电子商务公共数据和搜索引擎数据。它帮助许多公司轻松采集公共数据,现在我们的产品表现更好。
“我们针对实时爬虫的不同功能,开发了3款专用爬虫工具,这样我们就可以有针对性地进行产品开发,从而为客户提供整体性能和用户体验更好的产品。”
– Aleksandras Šulženko,Oxylabs 的 Crawler API 产品经理
从现在开始,实时爬虫已经衍生为一组健壮的爬虫 API,每个 API 都有特定的优势:
● SERP爬虫API
● 电商爬虫API
● 网络爬虫API
产品功能优化
所有爬虫 API 的共同特点和优势在于,它们可以帮助企业轻松采集公开数据:
● 100% 的数据传输成功率
● 专利代理人切换工具
● 高扩展性
● 可轻松集成
● 超过1.02亿个IP
● 以用户首选格式(AWS S3 或 GCS)交付数据
● 24/7 实时支持
当然,每种产品都有自己的针对性优势:
SERP 爬虫 API
电商爬虫API
网络爬虫 API
●本地化搜索结果●实时可靠的数据●不受SERP布局变化的影响
●数以千计的电子商务公司网站可用于数据捕获●自适应解析器●JSON格式的结构化数据
●请求参数可自定义●JavaScript渲染●便捷的数据传递
“最好的部分是爬虫 API 将您从管理代理的麻烦中解放出来,并专注于数据分析。”
氧实验室
新面貌
所有 3 个爬虫 API 现在都有新徽标,显示其特定用途,以便于识别:
继续之前的集成
为了方便我们现有客户和在本次更新之前尝试过我们产品的潜在客户,我们决定使用之前的集成和身份验证方法,以及相同的请求参数。
SERP爬虫API认证方式
SERP Crawler API 使用基本的 HTTP 身份验证,只需要用户名和密码。这是启用此工具的最简单方法之一。以下代码示例展示了如何通过实时发送 GET 请求从搜索引擎获取公共数据。有关更多信息,请查看 SERP Crawler API 快速指南。
*对于此示例,您必须指定确切的来源才能找到可用的来源。有关详细信息,请参阅 SERP Crawler API 文档。
电商爬虫API认证方式
电子商务爬虫 API 使用基本的 HTTP 身份验证,只需要用户名和密码。以下代码示例显示了如何将 GET 请求发送到 .
实时文章采集(免费迅睿CMS采集插件怎么使用?怎么批量采集文章到迅睿)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-01 17:07
问:如何使用免费的迅睿cms采集插件?如何批量采集文章到迅睿cms
答:一键创建多个采集任务实现批量文章采集发布,每个网站只需要设置关键词即可实现自动采集发布文章
问:迅睿免费cms采集可以应用多少个网站插件?
答:网站的数量没有限制,添加新的网站只需要创建一个任务即可实现采集发布
问题:迅睿有多少免费的cms插件采集文章
答案:采集每天几千万条数据(根据我自己的网站设置)
问:如何发布免费的迅睿cms插件采集?
答:该工具有迅睿cms自动发布功能,打开采集后可以自动发布到站点。迅睿cms新旧版本都可以使用,不用担心网站版本没有更新,采集功能不可用!
问:免费的迅睿cms采集插件安装复杂吗?
答:直接在本地电脑上安装,双击直接运行!由于是本地采集工具,与服务器无关,不会造成服务器死机,从而保证服务器有良好的访问速度,有利于搜索的爬取引擎!
一、免费迅睿cms采集插件如何使用?
1、打开软件导入关键词到采集文章,自动发布网站
2、可以同时创建数百个采集发布任务
二、免费迅睿cms发布插件如何使用?
1、 直接通过迅睿cms发布工具发布,可以直接查看发布的数据数量文章,发布数量文章,并设置每日发布总量,是否伪原创,发布网址等,同时也支持除迅锐以外的所有主流cms平台。还为SEO人员配备了定时发布功能(设置定时发帖文章,让搜索引擎抓取更频繁,让整个网站持续抓取收录提升排名,一 文章 @网站排名越高,流量越高。)
2、发布工具还支持Empire、易游、ZBLOG、织梦、迅睿cms、PB、Apple、搜外等各大专业cms
3、自动内链、标题插入关键词、内容插入关键词、随机作者、随机阅读数
以后就不用担心了,因为网站太多了,你又着急了!千万不要用它切换回网站后端,反复登录后端很痛苦。再也不用担心 网站 没有内容了。
网站的流量取决于网站收录的比例。 收录关键词越多,排名越高,流量越大。
为什么那么多人选择迅锐cms?
迅睿cms免费开源系统是一款简单的网站开发者框架管理软件。本软件是基于PHP7语言使用CodeIgniter4创建的。为电脑、手机、APP提供多种接口和一体化操作方式,不会因用户二次开发而损坏程序核心。 web和PHP建站功能都可以完美运行,堪称PHP通用建站框架。 而迅睿cms采用了由研发资助的全新模板技术,可以帮助用户快速分离MVC设计模型的业务层和表现层,支持原生态PHP语法,支持CI框架语法,以及各种模板方面。用户只要分析一次,就可以快速添加和下次使用,让您设计出理想的模板。迅睿cms免费开源系统,可以自定义各种页面、表格、链接表的文本字段,让你自己做的更好网站,如果你有需要这个的小伙伴是的
看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力! 查看全部
实时文章采集(免费迅睿CMS采集插件怎么使用?怎么批量采集文章到迅睿)
问:如何使用免费的迅睿cms采集插件?如何批量采集文章到迅睿cms
答:一键创建多个采集任务实现批量文章采集发布,每个网站只需要设置关键词即可实现自动采集发布文章
问:迅睿免费cms采集可以应用多少个网站插件?
答:网站的数量没有限制,添加新的网站只需要创建一个任务即可实现采集发布
问题:迅睿有多少免费的cms插件采集文章
答案:采集每天几千万条数据(根据我自己的网站设置)
问:如何发布免费的迅睿cms插件采集?
答:该工具有迅睿cms自动发布功能,打开采集后可以自动发布到站点。迅睿cms新旧版本都可以使用,不用担心网站版本没有更新,采集功能不可用!
问:免费的迅睿cms采集插件安装复杂吗?
答:直接在本地电脑上安装,双击直接运行!由于是本地采集工具,与服务器无关,不会造成服务器死机,从而保证服务器有良好的访问速度,有利于搜索的爬取引擎!
一、免费迅睿cms采集插件如何使用?
1、打开软件导入关键词到采集文章,自动发布网站
2、可以同时创建数百个采集发布任务
二、免费迅睿cms发布插件如何使用?
1、 直接通过迅睿cms发布工具发布,可以直接查看发布的数据数量文章,发布数量文章,并设置每日发布总量,是否伪原创,发布网址等,同时也支持除迅锐以外的所有主流cms平台。还为SEO人员配备了定时发布功能(设置定时发帖文章,让搜索引擎抓取更频繁,让整个网站持续抓取收录提升排名,一 文章 @网站排名越高,流量越高。)
2、发布工具还支持Empire、易游、ZBLOG、织梦、迅睿cms、PB、Apple、搜外等各大专业cms
3、自动内链、标题插入关键词、内容插入关键词、随机作者、随机阅读数
以后就不用担心了,因为网站太多了,你又着急了!千万不要用它切换回网站后端,反复登录后端很痛苦。再也不用担心 网站 没有内容了。
网站的流量取决于网站收录的比例。 收录关键词越多,排名越高,流量越大。
为什么那么多人选择迅锐cms?
迅睿cms免费开源系统是一款简单的网站开发者框架管理软件。本软件是基于PHP7语言使用CodeIgniter4创建的。为电脑、手机、APP提供多种接口和一体化操作方式,不会因用户二次开发而损坏程序核心。 web和PHP建站功能都可以完美运行,堪称PHP通用建站框架。 而迅睿cms采用了由研发资助的全新模板技术,可以帮助用户快速分离MVC设计模型的业务层和表现层,支持原生态PHP语法,支持CI框架语法,以及各种模板方面。用户只要分析一次,就可以快速添加和下次使用,让您设计出理想的模板。迅睿cms免费开源系统,可以自定义各种页面、表格、链接表的文本字段,让你自己做的更好网站,如果你有需要这个的小伙伴是的
看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
实时文章采集(爱奇艺开放式故障值守系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-26 13:03
本文为爱奇艺台湾智能内容系列手稿之首。我们将继续为您带来爱奇艺智能内容生产运营的一系列探索,敬请期待。
无人值守系统是爱奇艺内容中心的重要智能组件。
首先,对于业务密度高、流程长、业务多的业务系统,在实际运行中,故障的发生是普遍现象,在某种程度上也是一种正常状态。因此,能够及时发现和处理故障是在线业务系统的必然要求。常规方法是报警+人工干预。这种方式导致需要有人值班,人工干预的及时性得不到保障,人力成本必然增加。
爱奇艺内容中台也面临着上述问题。试图通过技术手段解决系统复杂性带来的问题,是本系统的基本思想,也是中台智能化的一个重要方向。与传统的监控系统相比,我们需要更多的智能服务来完成监控,同时兼顾故障的智能处理,同时方便其他处理方式的介入。无人值守系统是爱奇艺内容中心研发团队在上述背景下设计开发的智能开放式故障值班系统。
一、无人值守的目标
无人值守系统的目标是协助业务系统实现流程自动化、结果可靠、无需人工值守。
在项目设计之初,我们的初衷是:爱奇艺中泰节目制作过程中,无需人工看盘,确保节目制作过程正常,按时上线。出现问题时,可及时发现、自动修复、风险提示、通知人工处理等,确保程序按时上线。
基于系统的目标,系统需要具备以下能力:
二、整体结构介绍
总结起来,基本思路是:首先实现业务系统运行的监控功能,将业务运行数据和异常情况采集到无人值守系统,在此基础上,通过对数据的实时智能分析,及时发现系统运行故障和业务数据异常。然后交给故障和业务异常处理模块进行异常的智能处理,从而实现异常和故障的自动处理,最终实现无人值守、智能系统恢复的目的。
系统运行流程介绍:
生产环节数据采集到无人值守系统,主要通过爱奇艺的众泰数据中心采集。业务系统向中台数据中心下发数据,无人值守系统从中台数据中心采集数据。决策引擎对采集到的数据进行实时分析,根据SLA、异常、阈值的配置对异常数据进行分析,形成单独的事件。事件被传递到事件处理引擎 Beacon。事件处理引擎根据不同事件配置的处理流程进行处理。事件处理流程完全可配置,支持故障修复、告警通知、故障恢复检测、故障统计等。训练引擎利用中泰数据中心的离线数据训练系统故障分析模型,然后将模型数据提供给决策引擎进行决策。三、核心模块介绍
下面对系统的核心功能模块一一介绍:
3.1 运营数据实时采集模块(基于中泰数据中心)
通过爱奇艺内容中台团队实施的OLTP基础组件(中台数据中心),实时采集各功能模块的运行状态以及业务数据的进度和状态。OLTP基础组件(台湾中部数据中心)为爱奇艺内容的实时分析和处理提供支持。运行在中心平台的各种数据都可以方便的下发到这个组件上,并且还提供了数据监控和查询功能,可以支持TB整合海量数据的管理和维护。中泰数据中心系统将在后续系列文章中详细介绍,此处不再展开。
数据采集过程:
以专业内容制作流程(PPC)为例:
生产和交付:生产服务运行过程中,生产状态和件的生产状态将交付到中台数据中心。
业务流制作交付:业务流制作过程中,视频流制作状态、音频制作状态、字幕制作状态下发至中台数据中心。
审核下发:审核系统将审核状态、审核时间等信息下发给众泰数据中心。
发布与交付:发布系统会在平台数据中列出码流的发布状态。
中泰数据中心获取数据后,向RMQ队列发送数据变化通知,无人值守系统监控数据变化,将数据拉取到无人值守系统。为获取程序从生产到最终发布的运行数据,完成数据采集。
3.2 决策引擎
基于采集到的数据,对系统和业务运行进行实时分析,决策引擎主要提供以下功能:
错误检测:实时检测系统和业务错误,统一管理错误,发送事件。
超时告警:基于业务节点的SLA配置,检测和管理超时业务行为,并发送事件。
可配置策略:主要包括业务功能的无人值守访问配置和业务功能的SLA配置、权限配置、统计通知配置。
决策引擎的运行是在服务工作的同时采集
进度和系统运行信息,不断检查服务进度是否正常,有无异常或超时情况,以便及时发现问题一旦出现问题。
按照下图的逻辑继续工作:
服务模块启动后,当发现失败或超时时,将失败和超时事件通知外部。同时检测系统业务单元的运行进度,判断进度是否正常,并向外界通报异常进度滞后事件。
上面介绍了逻辑流程,下面介绍服务模块的操作逻辑:
服务模块的主要概念:
数据来源:数据来源主要是中台数据中心,部分广播控制数据采集自RMQ。数据源的数据由业务系统下发给众泰数据中心。
流程:完成从数据源到无人值守系统的数据采集。不同的业务有不同的流程,不同的业务有不同的采集和处理方式。
过滤:完成数据过滤。有些采集到的数据是系统不需要的,有些字段是不需要关心的。过滤器负责过滤掉无效数据。
Transform:数据转换,统一转换为决策所需的数据结构。
Rule模块:规则的执行,承担transform数据,执行配置好的规则,输出成功、失败、启动三个规则结果。
决策模块:决策模块进行超时判断。超时判断不同于普通的成功和失败。需要不断的比较当前时间和进度来判断任务是否超时。
延迟消息模块:通过延迟消息,在未来的某个时间用来检查业务操作是否超时。
Sink回写:将超时、超出预期在线时间等结论回写数据源。
服务模块按照上述概念的顺序运行,将运行中发现的事件传递到外部。下图:
3.3 Beacon,事件处理引擎
事件处理引擎Beacon是自主研发的模块,从决策引擎接收事件,并在一个流程中进行处理。对于不同的事件,处理方法有很大的不同。比如常见的转码异常就有50多种,根据处理方式的不同,分为很多组。每组都有不同的处理程序。通知不同的研发人员,通知模块的内容不同。. 有的事件有规范的治愈,有的没有治愈,需要通知业务人员。针对这种多样化的需求,专门设计了事件处理引擎(Beacon)进行无人值守事件处理。引擎支持流程的配置和定制,并预留了高抽象的业务对接接口、处理能力扩展方式、流程配置方式。最大限度地降低支持新业务的成本。
常见故障以事件的形式发送到 Beacon 处理引擎。
基本结构:
事件处理引擎主要有以下几个部分:
上下文功能:流程执行过程中上下文参数的获取和存储。上下文的保存和获取在Step基类中实现。
执行引擎:一个简单可靠的执行引擎,收录
流程执行、执行延迟、执行日志等基本功能,可以执行索引Step类型对象。
流程配置:JSON格式的流程配置,包括Step、StopStrategy、StepAction、WaitTimeAfter等概念,流程按照StepIndex的顺序执行。
Step:Steps,steps是组成流程的单元,每一步都会执行配置好的StepAction和StopStrategy。
StopStrategy:进程终止判断策略,Step类的子类,继承context函数。根据配置的状态,确定事件处理的最终形式,例如故障是否恢复。
StepAction:要执行的Action,Step类的子类,如发送邮件、发送消息、调用业务接口等,都可以打包成StepAction。
WaitTimeAfter:本步执行完毕后,执行下一步的等待时间。
邮件等通知功能的对接:与企业邮件系统等对接,这是通知功能的基本组成部分。
业务功能组件:业务功能组件是构成处理流程的基础组件,是系统处理能力的载体。为支持新业务问题的处理,需要在业务功能组件池中扩展流程处理引擎,扩展无人值守处理能力。
下面是一个简单的进程配置示例:
在实际使用过程中,针对特定事件,配置故障处理Action和治愈判断的StopStrategy,实现故障的自恢复和治愈。这里的失败实际上是一种事件。最后,系统可以根据运行数据分析故障数量和固化百分比。
四、机器学习应用:生产时间估算
根据无人值守系统的目标设计,无人值守系统应提供对生产过程的预见性管理,以达到业务运营的可预见目的。基于采集
到的数据,应用机器学习技术训练各种预测模型,针对耗时的业务运营提供各种预测能力,提升无人值守体验。
注意:无人值守系统的预测模型只适用于资源稳定或有保障的任务,没有考虑资源变化对运行时间的影响。
以下是对预计生产时间的解释:
问题类型分析:无人值守系统可以获得丰富的视频制作历史数据,期望形成特征向量,用历史数据计算训练模型,估计视频制作完成时间进行剪辑。
特征分析:排除空数据,过滤有价值的特征。
例如:类别特征:
'businessType', "channel", 'cloudEncode', 'trancodeType', "priority", "programType",
“serviceCode”、“needAIInsertFrame”、“needAudit”、“bitrateCode”、“平台”、“分辨率”...
数字特征:'持续时间'
分类特征值分布分析
算法选择:
训练数据用于去除异常值,使用XGBoost回归模型。
XGBoost:实现了GBDT算法,在算法和工程上做了很多改进,(GBDT(Gradient Boosting Decision Tree)梯度提升决策树)。所以它被称为 X (Extreme) GBoosted。
它的基本思想是将基础分类器逐层叠加。每一层在训练时,都会为上一层基分类器的样本调整不同的权重。在测试过程中,根据各层分类器结果的权重得到最终结果。所有弱分类器的结果之和等于预测值,然后下一个弱分类器将误差函数的残差拟合到预测值(这个残差就是预测值与真实值之间的误差)。
五、业务系统反馈
无人值守系统为所有连接的业务系统生成日常业务系统运行状态报告,并推送到业务系统。数据主要包括错误、故障统计数据和详细数据,以及是否满足SLA等信息。业务系统根据无人值守反馈的运营数据进行业务改进和系统优化。基于这种方式,业务系统不断升级改造。
以下是日常经营状况报告的内容示例:
六、在线效果
在爱奇艺,无人值守系统已经覆盖了爱奇艺内容中期的重要制作环节,为每天数十万节目的制作提供了可靠的报告。无人值守率达到99%以上。累计发现问题3000多道,自动处理2800多道。大大节省人工成本,提供系统运行稳定性和准时节目在线率。
七、未来方向
未来,我们希望能够基于无人值守采集的数据,提供更加智能的分析,主动发现业务系统问题,预警并提前解决。
此外,该系统目前仅针对点事件值班。未来,该项目将以值班和问题处理为一体,提供从点到线到面的全方位值班服务。比如以程序为粒度,可以提供更智能的中断、恢复等能力,后者更胜一筹。 查看全部
实时文章采集(爱奇艺开放式故障值守系统)
本文为爱奇艺台湾智能内容系列手稿之首。我们将继续为您带来爱奇艺智能内容生产运营的一系列探索,敬请期待。
无人值守系统是爱奇艺内容中心的重要智能组件。
首先,对于业务密度高、流程长、业务多的业务系统,在实际运行中,故障的发生是普遍现象,在某种程度上也是一种正常状态。因此,能够及时发现和处理故障是在线业务系统的必然要求。常规方法是报警+人工干预。这种方式导致需要有人值班,人工干预的及时性得不到保障,人力成本必然增加。
爱奇艺内容中台也面临着上述问题。试图通过技术手段解决系统复杂性带来的问题,是本系统的基本思想,也是中台智能化的一个重要方向。与传统的监控系统相比,我们需要更多的智能服务来完成监控,同时兼顾故障的智能处理,同时方便其他处理方式的介入。无人值守系统是爱奇艺内容中心研发团队在上述背景下设计开发的智能开放式故障值班系统。
一、无人值守的目标
无人值守系统的目标是协助业务系统实现流程自动化、结果可靠、无需人工值守。
在项目设计之初,我们的初衷是:爱奇艺中泰节目制作过程中,无需人工看盘,确保节目制作过程正常,按时上线。出现问题时,可及时发现、自动修复、风险提示、通知人工处理等,确保程序按时上线。
基于系统的目标,系统需要具备以下能力:
二、整体结构介绍
总结起来,基本思路是:首先实现业务系统运行的监控功能,将业务运行数据和异常情况采集到无人值守系统,在此基础上,通过对数据的实时智能分析,及时发现系统运行故障和业务数据异常。然后交给故障和业务异常处理模块进行异常的智能处理,从而实现异常和故障的自动处理,最终实现无人值守、智能系统恢复的目的。
系统运行流程介绍:
生产环节数据采集到无人值守系统,主要通过爱奇艺的众泰数据中心采集。业务系统向中台数据中心下发数据,无人值守系统从中台数据中心采集数据。决策引擎对采集到的数据进行实时分析,根据SLA、异常、阈值的配置对异常数据进行分析,形成单独的事件。事件被传递到事件处理引擎 Beacon。事件处理引擎根据不同事件配置的处理流程进行处理。事件处理流程完全可配置,支持故障修复、告警通知、故障恢复检测、故障统计等。训练引擎利用中泰数据中心的离线数据训练系统故障分析模型,然后将模型数据提供给决策引擎进行决策。三、核心模块介绍
下面对系统的核心功能模块一一介绍:
3.1 运营数据实时采集模块(基于中泰数据中心)
通过爱奇艺内容中台团队实施的OLTP基础组件(中台数据中心),实时采集各功能模块的运行状态以及业务数据的进度和状态。OLTP基础组件(台湾中部数据中心)为爱奇艺内容的实时分析和处理提供支持。运行在中心平台的各种数据都可以方便的下发到这个组件上,并且还提供了数据监控和查询功能,可以支持TB整合海量数据的管理和维护。中泰数据中心系统将在后续系列文章中详细介绍,此处不再展开。
数据采集过程:
以专业内容制作流程(PPC)为例:
生产和交付:生产服务运行过程中,生产状态和件的生产状态将交付到中台数据中心。
业务流制作交付:业务流制作过程中,视频流制作状态、音频制作状态、字幕制作状态下发至中台数据中心。
审核下发:审核系统将审核状态、审核时间等信息下发给众泰数据中心。
发布与交付:发布系统会在平台数据中列出码流的发布状态。
中泰数据中心获取数据后,向RMQ队列发送数据变化通知,无人值守系统监控数据变化,将数据拉取到无人值守系统。为获取程序从生产到最终发布的运行数据,完成数据采集。
3.2 决策引擎
基于采集到的数据,对系统和业务运行进行实时分析,决策引擎主要提供以下功能:
错误检测:实时检测系统和业务错误,统一管理错误,发送事件。
超时告警:基于业务节点的SLA配置,检测和管理超时业务行为,并发送事件。
可配置策略:主要包括业务功能的无人值守访问配置和业务功能的SLA配置、权限配置、统计通知配置。
决策引擎的运行是在服务工作的同时采集
进度和系统运行信息,不断检查服务进度是否正常,有无异常或超时情况,以便及时发现问题一旦出现问题。
按照下图的逻辑继续工作:
服务模块启动后,当发现失败或超时时,将失败和超时事件通知外部。同时检测系统业务单元的运行进度,判断进度是否正常,并向外界通报异常进度滞后事件。
上面介绍了逻辑流程,下面介绍服务模块的操作逻辑:
服务模块的主要概念:
数据来源:数据来源主要是中台数据中心,部分广播控制数据采集自RMQ。数据源的数据由业务系统下发给众泰数据中心。
流程:完成从数据源到无人值守系统的数据采集。不同的业务有不同的流程,不同的业务有不同的采集和处理方式。
过滤:完成数据过滤。有些采集到的数据是系统不需要的,有些字段是不需要关心的。过滤器负责过滤掉无效数据。
Transform:数据转换,统一转换为决策所需的数据结构。
Rule模块:规则的执行,承担transform数据,执行配置好的规则,输出成功、失败、启动三个规则结果。
决策模块:决策模块进行超时判断。超时判断不同于普通的成功和失败。需要不断的比较当前时间和进度来判断任务是否超时。
延迟消息模块:通过延迟消息,在未来的某个时间用来检查业务操作是否超时。
Sink回写:将超时、超出预期在线时间等结论回写数据源。
服务模块按照上述概念的顺序运行,将运行中发现的事件传递到外部。下图:
3.3 Beacon,事件处理引擎
事件处理引擎Beacon是自主研发的模块,从决策引擎接收事件,并在一个流程中进行处理。对于不同的事件,处理方法有很大的不同。比如常见的转码异常就有50多种,根据处理方式的不同,分为很多组。每组都有不同的处理程序。通知不同的研发人员,通知模块的内容不同。. 有的事件有规范的治愈,有的没有治愈,需要通知业务人员。针对这种多样化的需求,专门设计了事件处理引擎(Beacon)进行无人值守事件处理。引擎支持流程的配置和定制,并预留了高抽象的业务对接接口、处理能力扩展方式、流程配置方式。最大限度地降低支持新业务的成本。
常见故障以事件的形式发送到 Beacon 处理引擎。
基本结构:
事件处理引擎主要有以下几个部分:
上下文功能:流程执行过程中上下文参数的获取和存储。上下文的保存和获取在Step基类中实现。
执行引擎:一个简单可靠的执行引擎,收录
流程执行、执行延迟、执行日志等基本功能,可以执行索引Step类型对象。
流程配置:JSON格式的流程配置,包括Step、StopStrategy、StepAction、WaitTimeAfter等概念,流程按照StepIndex的顺序执行。
Step:Steps,steps是组成流程的单元,每一步都会执行配置好的StepAction和StopStrategy。
StopStrategy:进程终止判断策略,Step类的子类,继承context函数。根据配置的状态,确定事件处理的最终形式,例如故障是否恢复。
StepAction:要执行的Action,Step类的子类,如发送邮件、发送消息、调用业务接口等,都可以打包成StepAction。
WaitTimeAfter:本步执行完毕后,执行下一步的等待时间。
邮件等通知功能的对接:与企业邮件系统等对接,这是通知功能的基本组成部分。
业务功能组件:业务功能组件是构成处理流程的基础组件,是系统处理能力的载体。为支持新业务问题的处理,需要在业务功能组件池中扩展流程处理引擎,扩展无人值守处理能力。
下面是一个简单的进程配置示例:
在实际使用过程中,针对特定事件,配置故障处理Action和治愈判断的StopStrategy,实现故障的自恢复和治愈。这里的失败实际上是一种事件。最后,系统可以根据运行数据分析故障数量和固化百分比。
四、机器学习应用:生产时间估算
根据无人值守系统的目标设计,无人值守系统应提供对生产过程的预见性管理,以达到业务运营的可预见目的。基于采集
到的数据,应用机器学习技术训练各种预测模型,针对耗时的业务运营提供各种预测能力,提升无人值守体验。
注意:无人值守系统的预测模型只适用于资源稳定或有保障的任务,没有考虑资源变化对运行时间的影响。
以下是对预计生产时间的解释:
问题类型分析:无人值守系统可以获得丰富的视频制作历史数据,期望形成特征向量,用历史数据计算训练模型,估计视频制作完成时间进行剪辑。
特征分析:排除空数据,过滤有价值的特征。
例如:类别特征:
'businessType', "channel", 'cloudEncode', 'trancodeType', "priority", "programType",
“serviceCode”、“needAIInsertFrame”、“needAudit”、“bitrateCode”、“平台”、“分辨率”...
数字特征:'持续时间'
分类特征值分布分析
算法选择:
训练数据用于去除异常值,使用XGBoost回归模型。
XGBoost:实现了GBDT算法,在算法和工程上做了很多改进,(GBDT(Gradient Boosting Decision Tree)梯度提升决策树)。所以它被称为 X (Extreme) GBoosted。
它的基本思想是将基础分类器逐层叠加。每一层在训练时,都会为上一层基分类器的样本调整不同的权重。在测试过程中,根据各层分类器结果的权重得到最终结果。所有弱分类器的结果之和等于预测值,然后下一个弱分类器将误差函数的残差拟合到预测值(这个残差就是预测值与真实值之间的误差)。
五、业务系统反馈
无人值守系统为所有连接的业务系统生成日常业务系统运行状态报告,并推送到业务系统。数据主要包括错误、故障统计数据和详细数据,以及是否满足SLA等信息。业务系统根据无人值守反馈的运营数据进行业务改进和系统优化。基于这种方式,业务系统不断升级改造。
以下是日常经营状况报告的内容示例:
六、在线效果
在爱奇艺,无人值守系统已经覆盖了爱奇艺内容中期的重要制作环节,为每天数十万节目的制作提供了可靠的报告。无人值守率达到99%以上。累计发现问题3000多道,自动处理2800多道。大大节省人工成本,提供系统运行稳定性和准时节目在线率。
七、未来方向
未来,我们希望能够基于无人值守采集的数据,提供更加智能的分析,主动发现业务系统问题,预警并提前解决。
此外,该系统目前仅针对点事件值班。未来,该项目将以值班和问题处理为一体,提供从点到线到面的全方位值班服务。比如以程序为粒度,可以提供更智能的中断、恢复等能力,后者更胜一筹。
实时文章采集(一种兼容多平台的小程序日志采集方案(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-12-26 11:20
01
背景介绍
小程序,英文小程序。是一款无需下载安装即可在微信中使用的应用。用户可以扫描小程序代码或搜索小程序打开。触手可及,用完即可使用。无需担心是否安装过多应用程序。
据阿拉丁统计,截至2021年6月底,微信小程序数量突破430万,日活跃用户突破4.1亿。小程序深度影响了200+个子行业,11个主要平台推出了各自的小程序生态。小程序已经成为中国人定义的真正意义上的“互联网技术新标准”。
由于业务发展需要,我们在微信小程序、百度智能小程序、支付宝小程序、字节小程序、360小程序等多个小程序平台都有相应的上线。平台、系统、机型、版本兼容问题导致小程序上线问题;
思考:为什么小程序启动这么慢?为什么不能在线加载白屏数据?在线代码的质量如何?是否有任何错误?如何在网上快速查找和解决问题?用户做了什么?推出这么多平台小程序后,各个平台的效果如何?目前的小程序还有优化空间吗?
其实以上问题都可以通过日志文件分析来回答。每个小程序的后端也会采集
一些日志信息。比如微信后台采集
js异常日志和接口异常日志,但是接口异常日志只有状态码级别的信息和脚本异常日志。缺少当前异常发生时的页面路径信息、系统信息、网络状态、用户行为轨迹等信息的记录,因此排查起来相对困难。对于小程序性能数据的采集,各平台之间并没有统一的标准。所以我们需要一个兼容多平台的小程序日志采集
方案。
02
采集
理念
要采集
小程序的信息,首先需要了解小程序的基本架构设计。小程序本质上是混合体,但它们是有限制的。小程序的渲染层和逻辑层分别由两个线程管理:
这两个线程之间的通信是通过小程序的Native端传递的,逻辑层发送的网络请求也是通过Native端转发的。对于平台端,这种设计大大增加了平台对应用的控制,降低了各种风险。
当然,采集SDK也在逻辑层,所以可以监控逻辑层的交互响应。主流小程序的JS逻辑层开发主要依赖以下三个部分:
App:每个小程序都需要调用app.js中的App方法来注册一个小程序实例,绑定生命周期回调函数,错误监控和页面不存在监控等功能,整个小程序只有一个App实例,共享所有页面。Page:对于小程序中的每个页面,都需要在页面对应的js文件中注册,指定页面的初始数据、生命周期回调、事件处理函数等,简单的页面可以使用Page()来构造。wx:小程序开发框架提供了丰富的微信原生API,可以轻松调出微信提供的能力,比如获取用户信息、本地存储、支付功能。
因此,要想有效监控小程序的运行状态,就需要对这三个模块进行有效拦截。在小程序中,App、Page、wx 模块宏都暴露给全局。如果要拦截,可以直接改写全局中的变量。
03
总体方案
SDK用户包括小程序原生开发和小程序框架开发两种:
SDK 有两个主要功能:数据采集
和报告服务。SDK的主要功能是采集
小程序生成的日志。采集日志可以分为异常日志、正常日志和性能日志3种类型。每次上报日志时,也会上报1类通用信息:
日志类型
二级分类
操作说明
异常日志
JS错误、界面异常、资源下载异常
监控很关键,需要实时上报
正常日志
用户行为、日志信息、路由信息
日志量大,用户主动上报
性能日志
首屏时间、页面渲染时间、PV/UV
一次上报,同时统计PV/UV
一般信息
系统信息、用户信息、网络状态、场景值
其他 3 类日志的附加一般信息
我们的目标小程序涵盖目前主流的小程序,如微信、百度、今日头条、支付宝、360等。
公共日志采集
常规思维
通过相关API获取环境信息,主要包括以下几类信息:
多终端兼容思路
基本信息API与各个平台小程序的接口基本一致。主要区别在于模块宏的定义。比如微信小程序是wx,百度小程序是天鹅,今日头条小程序是tt。SDK初始化时,通过判断模块宏是否存在并存储在上下文变量中来确定当前的小程序环境,具体使用时通过上下文调用API。
public get context() {
if (this._context) return this._context;
if (typeof wx !== 'undefined') { this._context = wx; }
if (typeof swan !== 'undefined') { this._context = swan; }
if (typeof tt !== 'undefined') { this._context = tt; }
if (typeof my !== 'undefined') { this._context = my; }
if (typeof qq !== 'undefined') { this._context = qq; }
if (typeof qh !== 'undefined') { this._context = qh; }
return this._context;
}
// 使用示例 用户信息获取:ctx.getUserInfo()
当前页面的路径得到多终端兼容处理
所以这里有一个获取当前页面路径的方法,可以平滑各个平台小程序之间的差异。
public get currentPage() {
if (this.appName === 'qh') { // 360小程序兼容
const { path } = $router.history.current;
return path;
}
let pages = getCurrentPages();
if (pages.length > 0) {
return pages[pages.length - 1].route;
} else {
return this._indexPage;
}
}
异常日志采集
异常日志分为三种:脚本异常、接口异常、资源异常
由于小程序的特殊通信机制,接口请求和资源下载都是通过小程序载体Native进行转发和执行。因此,要采集
这部分异常,可以拦截wx.request、wx.download等相关API。
关于接口异常信息的上报,主要涉及两种情况: 在wx.request的成功回调中,如果响应状态码>=400,则表示网络请求已发送,但业务响应异常,并报告为异常。; 如果直接去wx.request的fail回调,说明网络请求异常,会进行异常报告;
资源异常主要用于拦截downloadFile文件下载API,下载失败时上报资源异常日志。
下面我们重点关注脚本异常的日志采集
。
脚本异常_常规思路
JS 中常见的错误有几种,其中类型错误、引用错误、未捕获的 Promise 错误发生的频率更高;其次是越界错误和不正确的 URI 错误。
前5个错误可以通过监听小程序App.onError采集
,Promise异常可以通过App.onUnhandledRejection API采集
,但是这个API在各个平台的支持是不一致的,如下:
脚本异常_多终端兼容思路
通过追踪异常栈,查看源码,我们可以看到微信已经通过try...catch把我们业务代码的外层包裹起来了。当发生异常时,通过console.error打印出来,所以在开发过程中,可以看到发生异常时,开发者工具控制台会打印异常信息。
因此,我们可以拦截console.error。本次拦截可以采集
到的异常包括:
实施过程中遇到的问题
在具体的实现过程中,我们发现不同平台的具体实现是不同的:
因此,截取console.error后,我们需要对截取的信息进行第二次处理,平滑平台差异。
具体的解决办法是通过正则匹配:
const ERROR_TYPES_REG = /(((Eval|Reference|Range|Internal|Type|Syntax)Error)|promise)
判断当前脚本异常类型,格式化信息后分别上报堆栈信息和错误内容。最终报告的脚本日志格式如下,包括错误类型、错误内容和堆栈信息。
"exceptions": [{
"errType": "MiniProgramError",
"content": "app.checkAuthorize1 is not a function",
"message": "TypeError: app.checkAuthorize1 is not a function",
"stacktrace": "MiniProgramErroranonymous> (httpe.p.__callPageLifeTime__ (h"
}]
性能日志采集
常规思维
通过官方提供的API获取数据并采集
和报告。微信提供wx.getPerformance() API,获取小程序启动耗时、页面渲染耗时、脚本注入耗时;但其他平台小程序不提供相关接口。
多终端兼容思路
用户点击小程序后,首先会下载小程序资源包。启动后会解析app.json文件,注册App(),然后执行APP的生命周期;然后开始加载页面,解析页面json文件,渲染.wxml文件,执行逻辑层js文件,调用页面生命周期。APP和页面的生命周期功能是性能日志采集
的重点。
生命周期钩子
等级
操作说明
主流小程序框架
360小程序框架
开机
应用级别
监控小程序初始化
支持
负载
展出
应用级别
监控小程序启动或切换到前台
支持
支持
负载
页面级别
监控页面加载
支持
支持
展出
页面级别
监控页面显示
支持
支持
准备就绪
页面级别
监控页面第一次渲染完成
支持
支持
隐藏
页面级别
监控页面隐藏
支持
支持
我们对比了各个平台小程序生命周期相关的API,发现主流小程序框架的实现基本一致。360小程序更特别。是基于Vue框架的二次封装,但大部分API还是一样的。在360小程序中,小程序初始化后的hook调用的是onLoad,需要特殊处理。
因此,可以通过拦截和管理小程序App和Page的相应生命周期来实现性能日志采集
。在性能日志采集
方案中,我们主要将其分为应用级性能和页面级性能。
应用级性能:我们定义了首屏时间,即进入小程序后第一页的渲染完成时间——SDK初始化时间。
由于小程序入口较多,有些是从分享卡进入,点击图标,搜索。不同的进入小程序的方式会显示不同的主页。因此,我们会在每个日志中携带当前页面入口路径。
页面级性能主要包括:
实现过程中遇到的问题在测试验证阶段,我们发现使用Taro框架开发转换的微信小程序无法采集页面级性能数据。经过具体定位,我们发现在Taro2版本中,小程序页面和组件被统一为Component组件。因此,需要拦截Component;在Taro3之后,小程序页面规范对象暴露在外,可以通过拦截Page来实现。具体实现逻辑如下:
private interceptPage = (): void => {
let self = this;
let isTaro = (typeof (process) !== 'undefined' && typeof (process.env) !== 'undefined' && typeof (process.env.TARO_ENV) !== 'undefined') ? true : false;
const primaryPage = Page;
if (isTaro) {
let primaryComponent = Component;
Component = (obj: any) => {
PAGE_LIFE_CYCLE.forEach(name => {
if (typeof obj.methods[name] === 'function') {
const primaryHookFn = obj.methods[name];
obj.methods[name] = function (info: any) {
return self.rewritePageLifeCycle(name, this, primaryHookFn, info);
}
}
});
primaryComponent && primaryComponent.call(this, obj);
}
}
Page = (obj: any) => {
PAGE_LIFE_CYCLE.forEach(name => {
const primaryHookFn = obj[name];
obj[name] = function (info: any) {
return self.rewritePageLifeCycle(name, this, primaryHookFn, info);
}
});
primaryPage && primaryPage.call(this, obj);
}
}
行为轨迹采集
如果只有一些比较隐蔽的错误的错误堆栈信息,排查起来会比较困难。如果有用户操作的路径,排查起来就容易多了。在行为轨迹日志的采集中,我们会采集APP函数栈、Page函数栈、HTTP请求栈,并上报最近10条行为轨迹日志,以帮助用户在发生异常时定位问题。
04
SDK特性
多终端、多帧适配
重量轻,支持多种模块化规格
SDK由Rollup打包,压缩体积49KB,支持cmj和es6模块化规范。
多种使用形式
1. 通过 npm 格式使用
import * as mpMonitor from 'mp-monitor';
mpMonitor.init({
projectId: '', // 项目标识
url: ''
});
2. 以单一文件格式使用
const mpMonitor = require('./utils/mp-monitor');
mpMonitor.init({
projectId: '', // 项目标识
url: ''
});
支持自定义报告日志
业务方可以使用console.error(\'自定义报告内容\')
05
商业实践
1. SDK现已完成集团北斗前端监控平台对接,支持微信、百度、今日头条、支付宝、QQ、360等多端监控;
2.截至2021.10.15,已接入13个小程序,覆盖5条业务线
3. SDK 上报模型与 Sentry 一致。自行搭建Sentry服务的企业可以直接使用SDK,配置上报url;
4. 平台接入效果展示
开发者可以通过首页的图表观察小程序当前的运行状态
通过性能图表,可以考虑当前小程序是否有优化空间。如果开启分包加载优化,当前首屏性能曲线应该会明显降低
观察从页面 URL 采集
的 pvuv 数据。优化业务代码时,可以考虑去掉pv为0的页面。
页面加载瀑布图,可以直观的看到一个小程序页面的加载过程
行为轨迹展示可以帮助开发者更快地重现在线问题,提高问题解决效率
06
总结
目前小程序日志采集SDK内部已经平滑了多平台之间的差异,统一了小程序性能数据采集指标。异常时上报页面路径信息、系统信息、网络状态、用户行为轨迹等相关信息,帮助开发者更快定位和解决在线问题。
我们会继续优化细节,完善功能。也欢迎有兴趣的同学一起交流。
对源码感兴趣的请点赞+转发+关注+私信【小程序日志采集
】。
欢迎点赞+转发+关注!您的支持是我分享的最大动力!!! 查看全部
实时文章采集(一种兼容多平台的小程序日志采集方案(一))
01
背景介绍
小程序,英文小程序。是一款无需下载安装即可在微信中使用的应用。用户可以扫描小程序代码或搜索小程序打开。触手可及,用完即可使用。无需担心是否安装过多应用程序。
据阿拉丁统计,截至2021年6月底,微信小程序数量突破430万,日活跃用户突破4.1亿。小程序深度影响了200+个子行业,11个主要平台推出了各自的小程序生态。小程序已经成为中国人定义的真正意义上的“互联网技术新标准”。
由于业务发展需要,我们在微信小程序、百度智能小程序、支付宝小程序、字节小程序、360小程序等多个小程序平台都有相应的上线。平台、系统、机型、版本兼容问题导致小程序上线问题;
思考:为什么小程序启动这么慢?为什么不能在线加载白屏数据?在线代码的质量如何?是否有任何错误?如何在网上快速查找和解决问题?用户做了什么?推出这么多平台小程序后,各个平台的效果如何?目前的小程序还有优化空间吗?
其实以上问题都可以通过日志文件分析来回答。每个小程序的后端也会采集
一些日志信息。比如微信后台采集
js异常日志和接口异常日志,但是接口异常日志只有状态码级别的信息和脚本异常日志。缺少当前异常发生时的页面路径信息、系统信息、网络状态、用户行为轨迹等信息的记录,因此排查起来相对困难。对于小程序性能数据的采集,各平台之间并没有统一的标准。所以我们需要一个兼容多平台的小程序日志采集
方案。
02
采集
理念
要采集
小程序的信息,首先需要了解小程序的基本架构设计。小程序本质上是混合体,但它们是有限制的。小程序的渲染层和逻辑层分别由两个线程管理:
这两个线程之间的通信是通过小程序的Native端传递的,逻辑层发送的网络请求也是通过Native端转发的。对于平台端,这种设计大大增加了平台对应用的控制,降低了各种风险。
当然,采集SDK也在逻辑层,所以可以监控逻辑层的交互响应。主流小程序的JS逻辑层开发主要依赖以下三个部分:
App:每个小程序都需要调用app.js中的App方法来注册一个小程序实例,绑定生命周期回调函数,错误监控和页面不存在监控等功能,整个小程序只有一个App实例,共享所有页面。Page:对于小程序中的每个页面,都需要在页面对应的js文件中注册,指定页面的初始数据、生命周期回调、事件处理函数等,简单的页面可以使用Page()来构造。wx:小程序开发框架提供了丰富的微信原生API,可以轻松调出微信提供的能力,比如获取用户信息、本地存储、支付功能。
因此,要想有效监控小程序的运行状态,就需要对这三个模块进行有效拦截。在小程序中,App、Page、wx 模块宏都暴露给全局。如果要拦截,可以直接改写全局中的变量。
03
总体方案
SDK用户包括小程序原生开发和小程序框架开发两种:
SDK 有两个主要功能:数据采集
和报告服务。SDK的主要功能是采集
小程序生成的日志。采集日志可以分为异常日志、正常日志和性能日志3种类型。每次上报日志时,也会上报1类通用信息:
日志类型
二级分类
操作说明
异常日志
JS错误、界面异常、资源下载异常
监控很关键,需要实时上报
正常日志
用户行为、日志信息、路由信息
日志量大,用户主动上报
性能日志
首屏时间、页面渲染时间、PV/UV
一次上报,同时统计PV/UV
一般信息
系统信息、用户信息、网络状态、场景值
其他 3 类日志的附加一般信息
我们的目标小程序涵盖目前主流的小程序,如微信、百度、今日头条、支付宝、360等。
公共日志采集
常规思维
通过相关API获取环境信息,主要包括以下几类信息:
多终端兼容思路
基本信息API与各个平台小程序的接口基本一致。主要区别在于模块宏的定义。比如微信小程序是wx,百度小程序是天鹅,今日头条小程序是tt。SDK初始化时,通过判断模块宏是否存在并存储在上下文变量中来确定当前的小程序环境,具体使用时通过上下文调用API。
public get context() {
if (this._context) return this._context;
if (typeof wx !== 'undefined') { this._context = wx; }
if (typeof swan !== 'undefined') { this._context = swan; }
if (typeof tt !== 'undefined') { this._context = tt; }
if (typeof my !== 'undefined') { this._context = my; }
if (typeof qq !== 'undefined') { this._context = qq; }
if (typeof qh !== 'undefined') { this._context = qh; }
return this._context;
}
// 使用示例 用户信息获取:ctx.getUserInfo()
当前页面的路径得到多终端兼容处理
所以这里有一个获取当前页面路径的方法,可以平滑各个平台小程序之间的差异。
public get currentPage() {
if (this.appName === 'qh') { // 360小程序兼容
const { path } = $router.history.current;
return path;
}
let pages = getCurrentPages();
if (pages.length > 0) {
return pages[pages.length - 1].route;
} else {
return this._indexPage;
}
}
异常日志采集
异常日志分为三种:脚本异常、接口异常、资源异常
由于小程序的特殊通信机制,接口请求和资源下载都是通过小程序载体Native进行转发和执行。因此,要采集
这部分异常,可以拦截wx.request、wx.download等相关API。
关于接口异常信息的上报,主要涉及两种情况: 在wx.request的成功回调中,如果响应状态码>=400,则表示网络请求已发送,但业务响应异常,并报告为异常。; 如果直接去wx.request的fail回调,说明网络请求异常,会进行异常报告;
资源异常主要用于拦截downloadFile文件下载API,下载失败时上报资源异常日志。
下面我们重点关注脚本异常的日志采集
。
脚本异常_常规思路
JS 中常见的错误有几种,其中类型错误、引用错误、未捕获的 Promise 错误发生的频率更高;其次是越界错误和不正确的 URI 错误。
前5个错误可以通过监听小程序App.onError采集
,Promise异常可以通过App.onUnhandledRejection API采集
,但是这个API在各个平台的支持是不一致的,如下:
脚本异常_多终端兼容思路
通过追踪异常栈,查看源码,我们可以看到微信已经通过try...catch把我们业务代码的外层包裹起来了。当发生异常时,通过console.error打印出来,所以在开发过程中,可以看到发生异常时,开发者工具控制台会打印异常信息。
因此,我们可以拦截console.error。本次拦截可以采集
到的异常包括:
实施过程中遇到的问题
在具体的实现过程中,我们发现不同平台的具体实现是不同的:
因此,截取console.error后,我们需要对截取的信息进行第二次处理,平滑平台差异。
具体的解决办法是通过正则匹配:
const ERROR_TYPES_REG = /(((Eval|Reference|Range|Internal|Type|Syntax)Error)|promise)
判断当前脚本异常类型,格式化信息后分别上报堆栈信息和错误内容。最终报告的脚本日志格式如下,包括错误类型、错误内容和堆栈信息。
"exceptions": [{
"errType": "MiniProgramError",
"content": "app.checkAuthorize1 is not a function",
"message": "TypeError: app.checkAuthorize1 is not a function",
"stacktrace": "MiniProgramErroranonymous> (httpe.p.__callPageLifeTime__ (h"
}]
性能日志采集
常规思维
通过官方提供的API获取数据并采集
和报告。微信提供wx.getPerformance() API,获取小程序启动耗时、页面渲染耗时、脚本注入耗时;但其他平台小程序不提供相关接口。
多终端兼容思路
用户点击小程序后,首先会下载小程序资源包。启动后会解析app.json文件,注册App(),然后执行APP的生命周期;然后开始加载页面,解析页面json文件,渲染.wxml文件,执行逻辑层js文件,调用页面生命周期。APP和页面的生命周期功能是性能日志采集
的重点。
生命周期钩子
等级
操作说明
主流小程序框架
360小程序框架
开机
应用级别
监控小程序初始化
支持
负载
展出
应用级别
监控小程序启动或切换到前台
支持
支持
负载
页面级别
监控页面加载
支持
支持
展出
页面级别
监控页面显示
支持
支持
准备就绪
页面级别
监控页面第一次渲染完成
支持
支持
隐藏
页面级别
监控页面隐藏
支持
支持
我们对比了各个平台小程序生命周期相关的API,发现主流小程序框架的实现基本一致。360小程序更特别。是基于Vue框架的二次封装,但大部分API还是一样的。在360小程序中,小程序初始化后的hook调用的是onLoad,需要特殊处理。
因此,可以通过拦截和管理小程序App和Page的相应生命周期来实现性能日志采集
。在性能日志采集
方案中,我们主要将其分为应用级性能和页面级性能。
应用级性能:我们定义了首屏时间,即进入小程序后第一页的渲染完成时间——SDK初始化时间。
由于小程序入口较多,有些是从分享卡进入,点击图标,搜索。不同的进入小程序的方式会显示不同的主页。因此,我们会在每个日志中携带当前页面入口路径。
页面级性能主要包括:
实现过程中遇到的问题在测试验证阶段,我们发现使用Taro框架开发转换的微信小程序无法采集页面级性能数据。经过具体定位,我们发现在Taro2版本中,小程序页面和组件被统一为Component组件。因此,需要拦截Component;在Taro3之后,小程序页面规范对象暴露在外,可以通过拦截Page来实现。具体实现逻辑如下:
private interceptPage = (): void => {
let self = this;
let isTaro = (typeof (process) !== 'undefined' && typeof (process.env) !== 'undefined' && typeof (process.env.TARO_ENV) !== 'undefined') ? true : false;
const primaryPage = Page;
if (isTaro) {
let primaryComponent = Component;
Component = (obj: any) => {
PAGE_LIFE_CYCLE.forEach(name => {
if (typeof obj.methods[name] === 'function') {
const primaryHookFn = obj.methods[name];
obj.methods[name] = function (info: any) {
return self.rewritePageLifeCycle(name, this, primaryHookFn, info);
}
}
});
primaryComponent && primaryComponent.call(this, obj);
}
}
Page = (obj: any) => {
PAGE_LIFE_CYCLE.forEach(name => {
const primaryHookFn = obj[name];
obj[name] = function (info: any) {
return self.rewritePageLifeCycle(name, this, primaryHookFn, info);
}
});
primaryPage && primaryPage.call(this, obj);
}
}
行为轨迹采集
如果只有一些比较隐蔽的错误的错误堆栈信息,排查起来会比较困难。如果有用户操作的路径,排查起来就容易多了。在行为轨迹日志的采集中,我们会采集APP函数栈、Page函数栈、HTTP请求栈,并上报最近10条行为轨迹日志,以帮助用户在发生异常时定位问题。
04
SDK特性
多终端、多帧适配
重量轻,支持多种模块化规格
SDK由Rollup打包,压缩体积49KB,支持cmj和es6模块化规范。
多种使用形式
1. 通过 npm 格式使用
import * as mpMonitor from 'mp-monitor';
mpMonitor.init({
projectId: '', // 项目标识
url: ''
});
2. 以单一文件格式使用
const mpMonitor = require('./utils/mp-monitor');
mpMonitor.init({
projectId: '', // 项目标识
url: ''
});
支持自定义报告日志
业务方可以使用console.error(\'自定义报告内容\')
05
商业实践
1. SDK现已完成集团北斗前端监控平台对接,支持微信、百度、今日头条、支付宝、QQ、360等多端监控;
2.截至2021.10.15,已接入13个小程序,覆盖5条业务线
3. SDK 上报模型与 Sentry 一致。自行搭建Sentry服务的企业可以直接使用SDK,配置上报url;
4. 平台接入效果展示
开发者可以通过首页的图表观察小程序当前的运行状态
通过性能图表,可以考虑当前小程序是否有优化空间。如果开启分包加载优化,当前首屏性能曲线应该会明显降低
观察从页面 URL 采集
的 pvuv 数据。优化业务代码时,可以考虑去掉pv为0的页面。
页面加载瀑布图,可以直观的看到一个小程序页面的加载过程
行为轨迹展示可以帮助开发者更快地重现在线问题,提高问题解决效率
06
总结
目前小程序日志采集SDK内部已经平滑了多平台之间的差异,统一了小程序性能数据采集指标。异常时上报页面路径信息、系统信息、网络状态、用户行为轨迹等相关信息,帮助开发者更快定位和解决在线问题。
我们会继续优化细节,完善功能。也欢迎有兴趣的同学一起交流。
对源码感兴趣的请点赞+转发+关注+私信【小程序日志采集
】。
欢迎点赞+转发+关注!您的支持是我分享的最大动力!!!
实时文章采集(一个实用采集技能,采集公众号内容详解(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-12-23 19:13
数据采集-数据采集-java-php-go-Python-Crawler-Automatic-微信公众号文章查看点击量-多个公众号-实时更新、Go语言社区、Golang程序员网社区,Go语言中文社区优采云采集软件采集公众号文章详细操作步骤工具/资料优采云采集方法/Step 1 Log在优采云软件优采云爬取微信公众号,打开采集规则”规则市场微信朋友圈优采云AI,搜索关键词微信规则,查找并下载。2 将规则导入任务。
很好:微信采集微信公众号采集工具,如何阅读和点赞采集公众号?3 同意 · 9 条评论和回答优采云·云采集服务平台微信公众号内容采集详细方法在微信公众号中浏览文章的内容。
大数据信息材料采集:公众号吴志宏文章评论爬取优采云采集器规则大数据信息材料采集公众号历史文章 < @采集公众号评论抓取微信公众号历史文章导出并抓取微信公众号所有文章。官方账号。摘要:相信每个运营微信公众号的人都在考虑这个问题。今天优采云给大家分享一个实用的采集技能,采集公众号。公众号内容实时监控。如何提高微信文章的打开率?文章最火的款式有哪些。
采集 字段:公众号、文章 标题、内容、阅读量、点赞数、推送时间,这里要说明一下,优采云目前只有采集公开网上的数据,微信公众号采集需要从网页采集开始。搜索“搜狗微信”并通过。我专注于优采云 第三方采集 工具。由于优采云是收费软件,您只能先申请体验账号,体验采集的基本功能。,不过个人觉得采用这个工具是因为它与搜狗的接口合作。
微信优采云ai
前两年还好,现在采集不行,但是现在用微信公众号平台登录的人不多。目前位置在小红书、微博大数据信息资料采集:信息公众号元芳青木文章评论爬取优采云采集大数据信息资料采集公众号历史文章采集公众号评论爬取微信公众号历史文章导出抓取所有微信公众号文章。公众。
优采云如何采集数据
还有问优采云怎么发朋友圈,怎么抓微信公众号文章?解决问题后,分享优采云、优采云等具有公众号功能的第三方工具。您可以自行下载使用。具体的就不多说了。第四:基于微信公众号平台的方法;这个方法其实是最难的,因为中间需要。 查看全部
实时文章采集(一个实用采集技能,采集公众号内容详解(组图))
数据采集-数据采集-java-php-go-Python-Crawler-Automatic-微信公众号文章查看点击量-多个公众号-实时更新、Go语言社区、Golang程序员网社区,Go语言中文社区优采云采集软件采集公众号文章详细操作步骤工具/资料优采云采集方法/Step 1 Log在优采云软件优采云爬取微信公众号,打开采集规则”规则市场微信朋友圈优采云AI,搜索关键词微信规则,查找并下载。2 将规则导入任务。
很好:微信采集微信公众号采集工具,如何阅读和点赞采集公众号?3 同意 · 9 条评论和回答优采云·云采集服务平台微信公众号内容采集详细方法在微信公众号中浏览文章的内容。
大数据信息材料采集:公众号吴志宏文章评论爬取优采云采集器规则大数据信息材料采集公众号历史文章 < @采集公众号评论抓取微信公众号历史文章导出并抓取微信公众号所有文章。官方账号。摘要:相信每个运营微信公众号的人都在考虑这个问题。今天优采云给大家分享一个实用的采集技能,采集公众号。公众号内容实时监控。如何提高微信文章的打开率?文章最火的款式有哪些。
采集 字段:公众号、文章 标题、内容、阅读量、点赞数、推送时间,这里要说明一下,优采云目前只有采集公开网上的数据,微信公众号采集需要从网页采集开始。搜索“搜狗微信”并通过。我专注于优采云 第三方采集 工具。由于优采云是收费软件,您只能先申请体验账号,体验采集的基本功能。,不过个人觉得采用这个工具是因为它与搜狗的接口合作。
微信优采云ai
前两年还好,现在采集不行,但是现在用微信公众号平台登录的人不多。目前位置在小红书、微博大数据信息资料采集:信息公众号元芳青木文章评论爬取优采云采集大数据信息资料采集公众号历史文章采集公众号评论爬取微信公众号历史文章导出抓取所有微信公众号文章。公众。
优采云如何采集数据
还有问优采云怎么发朋友圈,怎么抓微信公众号文章?解决问题后,分享优采云、优采云等具有公众号功能的第三方工具。您可以自行下载使用。具体的就不多说了。第四:基于微信公众号平台的方法;这个方法其实是最难的,因为中间需要。
实时文章采集( 前面Flume和Kafka的实时数据源,怎么产生呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-15 10:10
前面Flume和Kafka的实时数据源,怎么产生呢??)
Flume和Kafka完成实时数据采集
写在前面
Flume和Kafka通常在生产环境中结合使用。能够结合使用两者来采集实时日志信息非常重要。如果是这样,你不知道flume和kafka,你可以先查看我写的关于这两部分的知识。再学习一下,这部分操作也是可以的。html
采集 的实时数据面临一个问题。我们如何生成我们的实时数据源?因为我们可能想直接获取实时数据流不是那么方便。在文章之前写过一篇关于实时数据流的python生成器的文章,文章地址:
大家可以先看看,如何生成实时数据...python
主意?? 如何开始?? nginx
分析:我们可以从数据的流向开始。数据一开始就在网络服务器上。我们的访问日志是nginx服务器实时采集到指定文件的。我们从这个文件中采集日志数据,即:webserver=>flume=>kafkaweb
网络服务器日志存储文件位置
这个文件的位置通常是我们自己设置的shell
我们的网络日志存储的目录是:
apache下/home/hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
氟虫腈
做flume其实就是写一个conf文件,这样就面临选择的问题
来源选择?频道选择?水槽选择?红宝石
这里我们选择exec source memory channel kafka sink server
怎么写?
按照前面说的1234步app
从官方网站上,我们可以找到我们的选择应该怎么写:
1) 配置源
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2) 配置通道
记忆通道
a1.channels.c1.type = memory
3) 配置接收器
卡夫卡水槽
水槽1.6 版本可以参考
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
4) 将以上三个组件串在一起
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
**让我们新建一个名为 test3.conf 的文件
粘贴我们分析的代码:**
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里先不展开了,因为涉及到kafka,首先要部署kafka,
Kafka部署
Kafka是如何部署的??
按照官网的说法,我们先启动一个zookeeper进程,然后就可以启动kafka服务器了
第一步:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
第二步:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果有,这部分不是很熟悉,可以参考
第 3 步:创建主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
第四步:启动之前的代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
第 5 步:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行完上面的第五步,就会收到刷新屏幕的结果了,哈哈哈!!
上面的消费者会不断刷新屏幕,还是蛮有意思的!!!
这里的消费者就是把接收到的数据放到屏幕上
后面会介绍使用SparkStreaming为消费者实时接收数据,并对接收到的数据进行简单的数据清洗,从随机生成的日志中过滤出我们需要的数据…… 查看全部
实时文章采集(
前面Flume和Kafka的实时数据源,怎么产生呢??)
Flume和Kafka完成实时数据采集
写在前面
Flume和Kafka通常在生产环境中结合使用。能够结合使用两者来采集实时日志信息非常重要。如果是这样,你不知道flume和kafka,你可以先查看我写的关于这两部分的知识。再学习一下,这部分操作也是可以的。html
采集 的实时数据面临一个问题。我们如何生成我们的实时数据源?因为我们可能想直接获取实时数据流不是那么方便。在文章之前写过一篇关于实时数据流的python生成器的文章,文章地址:
大家可以先看看,如何生成实时数据...python
主意?? 如何开始?? nginx
分析:我们可以从数据的流向开始。数据一开始就在网络服务器上。我们的访问日志是nginx服务器实时采集到指定文件的。我们从这个文件中采集日志数据,即:webserver=>flume=>kafkaweb
网络服务器日志存储文件位置
这个文件的位置通常是我们自己设置的shell
我们的网络日志存储的目录是:
apache下/home/hadoop/data/project/logs/access.log
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
氟虫腈
做flume其实就是写一个conf文件,这样就面临选择的问题
来源选择?频道选择?水槽选择?红宝石
这里我们选择exec source memory channel kafka sink server
怎么写?
按照前面说的1234步app
从官方网站上,我们可以找到我们的选择应该怎么写:
1) 配置源
执行源
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
2) 配置通道
记忆通道
a1.channels.c1.type = memory
3) 配置接收器
卡夫卡水槽
水槽1.6 版本可以参考
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
4) 将以上三个组件串在一起
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
**让我们新建一个名为 test3.conf 的文件
粘贴我们分析的代码:**
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里先不展开了,因为涉及到kafka,首先要部署kafka,
Kafka部署
Kafka是如何部署的??
按照官网的说法,我们先启动一个zookeeper进程,然后就可以启动kafka服务器了
第一步:启动zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
第二步:启动服务器
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果有,这部分不是很熟悉,可以参考
第 3 步:创建主题
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
第四步:启动之前的代理
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
第 5 步:启动消费者
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
执行完上面的第五步,就会收到刷新屏幕的结果了,哈哈哈!!
上面的消费者会不断刷新屏幕,还是蛮有意思的!!!
这里的消费者就是把接收到的数据放到屏幕上
后面会介绍使用SparkStreaming为消费者实时接收数据,并对接收到的数据进行简单的数据清洗,从随机生成的日志中过滤出我们需要的数据……
实时文章采集(Javaflume采集数据输送到的方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-12-12 19:28
注:本文不仅提供了两个选项,还详细记录了一些相关信息。 html
方案一
这个方案的核心是flume采集数据之后,根据hive表的结构,将采集数据发送到对应的地址,达到实时数据的目的贮存。这种实时实际上是一种准实时。爪哇
假设hadoop集群已经正常启动,hive也已经正常启动,hive的文件地址为/hive/warehouse,然后hive中有如下表创建语句创建的表apache
create table flume_test(uuid string);
可以推断flume_test表的地址在/hive/warehouse/flume_test,下面介绍flume:bash
Flume 安装步骤应用
#下载
cd /opt
mkdir flume
wget http://archive.apache.org/dist ... ar.gz
tar xvzf apache-flume-1.6.0-bin.tar.gz
cd apache-flume-1.6.0-bin/conf
cp flume-env.sh.template flume-env.sh
打开flume-env文件,添加java变量dom
export JAVA_HOME=/usr/java/jdk1.8.0_111
然后添加环境变量,为了一次搞定,分别在profile和bashrc末尾添加eclipse
export FLUME_HOME=/opt/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
然后是 maven
source /etc/profile
既然flume安装好了,下面进行配置,切换到conf文件夹,将flume-conf.properties.template复制到agent.conf,然后编辑ide
#定义活跃列表
agent.sources=avroSrc
agent.channels=memChannel
agent.sinks=hdfsSink
#定义source
agent.sources.avroSrc.type=avro
agent.sources.avroSrc.channels=memChannel
agent.sources.avroSrc.bind=0.0.0.0
agent.sources.avroSrc.port=4353
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
#定义channel
agent.channels.memChannel.type=memory
agent.channels.memChannel.capacity = 1000
agent.channels.memChannel.transactionCapacity = 100
#定义sink
agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.channel=memChannel
#agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/flume/test/%{topic}/%Y%m%d%H
agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/hive/warehouse/flume_test
agent.sinks.hdfsSink.hdfs.filePrefix=stu-flume
agent.sinks.hdfsSink.hdfs.inUsePrefix=inuse-stu-flume
agent.sinks.hdfsSink.hdfs.inUseSuffix=.temp
agent.sinks.hdfsSink.hdfs.rollInterval=0
agent.sinks.hdfsSink.hdfs.rollSize=10240000
agent.sinks.hdfsSink.hdfs.rollCount=0
agent.sinks.hdfsSink.hdfs.idleTimeout=0
agent.sinks.hdfsSink.hdfs.batchSize=100
agent.sinks.hdfsSink.hdfs.minBlockReplicas=1
# agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType = DataStream
各个项目的具体配置请参考以下博客。需要关注的四个属性分别是rollInterval、rollSize、rollCount、idleTimeout。如果发现配置不可用,检查属性minBlockReplicas是否配置,值为1,原因如下:oop
配置后即可启动,启动命令
./flume-ng agent -f ../conf/agent.conf -n agent -c conf -Dflume.monitoring.type=http \-Dflume.monitoring.port=5653 -Dflume.root.logger=DEBUG,console
注意:-n 是代理的名称,需要对应配置文件的第一个值。这个启动命令也开启了监控,监控地址:5563/metrics; -f 指的是配置文件的路径和名称。修改flume的conf后,不需要重启。默认情况下,它每 30 秒刷新一次并自动加载最新配置。
flume安装启动后,编写测试程序。打开eclipse并创建一个maven项目
4.0.0
scc
stu-flume
0.0.1-SNAPSHOT
war
stu-flume
log4j
log4j
1.2.9
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
测试 servlet
public class GenerLogServlet extends HttpServlet {
private static final Logger LOGGER = Logger.getLogger(GenerLogServlet.class);
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
for (;;) {
LOGGER.info(UUID.randomUUID().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
this.doGet(request, response);
}
}
log4j.properties
#log4j settings
#log4j.rootLogger=debug, CONSOLE
log4j.logger.scc.stu_flume.GenerLogServlet=debug,GenerLogServlet
#log4j.rootLogger=INFO
log4j.appender.GenerLogServlet=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.GenerLogServlet.Hostname=10.5.3.100
log4j.appender.GenerLogServlet.Port=4353
log4j.appender.GenerLogServletUnsafeMode=false
启动项目,访问:8080/log开始生产数据。需要注意的是,如果flume配置是根据时间戳对文件进行分组(这种情况可以根据时间匹配hive分区),那么agent.conf中的source必须配置
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
否则flume sink会报错找不到timestamp。因为源码org.apache.flume.clients.log4jappender.Log4jAvroHeaders中定义的timestamp的key是flume.client.log4j.timestamp而不是timestamp,所以需要手动添加一个timestamp,如果要求这个timestamp是时间数据生产,可以修改源码或者手动配置源码拦截器。
Flume 有一种非常灵活的使用方式。可自定义source、sink、interceptor、channel selector等,适应采集、数据缓冲等大多数场景。
观察hadoop目录,发现flume已经按照配置把数据移动到了对应的hive表目录下,如下图:
打开hive客户端,使用数据查询命令,发现可以查询到数据!并且可以按照hive表的数据规则写入hive的分区表和桶表flume,然后实时插入数据。至此,程序结束。
这个程序的缺点:
因为flume在写文件的时候独占了正在写的文件资源,所以hive无法读取正在写的文件的内容,也就是说,如果每5分钟生成一个文件,那么正在写的文件的内容就不会被hive读取,这意味着hive最多有5分钟的延迟。而且如果减少时间,延迟会减少,但即使设置为30分钟或1小时,在flume流量不大的情况下也会产生很多零散的小文件。这与hive的特长相悖,hive擅长处理大文件,对于分散的小文件,hive性能会下降很多。
方案二
对比方案一,测试程序和source不变,sink改为hbase-sink,数据实时插入hbase,然后在hive中创建hbase映射表,hive从hbase读取数据到实现实时插入的效果。由于字数限制,方案二记录在以下博客链接中: 查看全部
实时文章采集(Javaflume采集数据输送到的方案)
注:本文不仅提供了两个选项,还详细记录了一些相关信息。 html
方案一
这个方案的核心是flume采集数据之后,根据hive表的结构,将采集数据发送到对应的地址,达到实时数据的目的贮存。这种实时实际上是一种准实时。爪哇
假设hadoop集群已经正常启动,hive也已经正常启动,hive的文件地址为/hive/warehouse,然后hive中有如下表创建语句创建的表apache
create table flume_test(uuid string);
可以推断flume_test表的地址在/hive/warehouse/flume_test,下面介绍flume:bash
Flume 安装步骤应用
#下载
cd /opt
mkdir flume
wget http://archive.apache.org/dist ... ar.gz
tar xvzf apache-flume-1.6.0-bin.tar.gz
cd apache-flume-1.6.0-bin/conf
cp flume-env.sh.template flume-env.sh
打开flume-env文件,添加java变量dom
export JAVA_HOME=/usr/java/jdk1.8.0_111
然后添加环境变量,为了一次搞定,分别在profile和bashrc末尾添加eclipse
export FLUME_HOME=/opt/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
然后是 maven
source /etc/profile
既然flume安装好了,下面进行配置,切换到conf文件夹,将flume-conf.properties.template复制到agent.conf,然后编辑ide
#定义活跃列表
agent.sources=avroSrc
agent.channels=memChannel
agent.sinks=hdfsSink
#定义source
agent.sources.avroSrc.type=avro
agent.sources.avroSrc.channels=memChannel
agent.sources.avroSrc.bind=0.0.0.0
agent.sources.avroSrc.port=4353
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
#定义channel
agent.channels.memChannel.type=memory
agent.channels.memChannel.capacity = 1000
agent.channels.memChannel.transactionCapacity = 100
#定义sink
agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.channel=memChannel
#agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/flume/test/%{topic}/%Y%m%d%H
agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/hive/warehouse/flume_test
agent.sinks.hdfsSink.hdfs.filePrefix=stu-flume
agent.sinks.hdfsSink.hdfs.inUsePrefix=inuse-stu-flume
agent.sinks.hdfsSink.hdfs.inUseSuffix=.temp
agent.sinks.hdfsSink.hdfs.rollInterval=0
agent.sinks.hdfsSink.hdfs.rollSize=10240000
agent.sinks.hdfsSink.hdfs.rollCount=0
agent.sinks.hdfsSink.hdfs.idleTimeout=0
agent.sinks.hdfsSink.hdfs.batchSize=100
agent.sinks.hdfsSink.hdfs.minBlockReplicas=1
# agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType = DataStream
各个项目的具体配置请参考以下博客。需要关注的四个属性分别是rollInterval、rollSize、rollCount、idleTimeout。如果发现配置不可用,检查属性minBlockReplicas是否配置,值为1,原因如下:oop
配置后即可启动,启动命令
./flume-ng agent -f ../conf/agent.conf -n agent -c conf -Dflume.monitoring.type=http \-Dflume.monitoring.port=5653 -Dflume.root.logger=DEBUG,console
注意:-n 是代理的名称,需要对应配置文件的第一个值。这个启动命令也开启了监控,监控地址:5563/metrics; -f 指的是配置文件的路径和名称。修改flume的conf后,不需要重启。默认情况下,它每 30 秒刷新一次并自动加载最新配置。
flume安装启动后,编写测试程序。打开eclipse并创建一个maven项目
4.0.0
scc
stu-flume
0.0.1-SNAPSHOT
war
stu-flume
log4j
log4j
1.2.9
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
测试 servlet
public class GenerLogServlet extends HttpServlet {
private static final Logger LOGGER = Logger.getLogger(GenerLogServlet.class);
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
for (;;) {
LOGGER.info(UUID.randomUUID().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
this.doGet(request, response);
}
}
log4j.properties
#log4j settings
#log4j.rootLogger=debug, CONSOLE
log4j.logger.scc.stu_flume.GenerLogServlet=debug,GenerLogServlet
#log4j.rootLogger=INFO
log4j.appender.GenerLogServlet=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.GenerLogServlet.Hostname=10.5.3.100
log4j.appender.GenerLogServlet.Port=4353
log4j.appender.GenerLogServletUnsafeMode=false
启动项目,访问:8080/log开始生产数据。需要注意的是,如果flume配置是根据时间戳对文件进行分组(这种情况可以根据时间匹配hive分区),那么agent.conf中的source必须配置
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
否则flume sink会报错找不到timestamp。因为源码org.apache.flume.clients.log4jappender.Log4jAvroHeaders中定义的timestamp的key是flume.client.log4j.timestamp而不是timestamp,所以需要手动添加一个timestamp,如果要求这个timestamp是时间数据生产,可以修改源码或者手动配置源码拦截器。
Flume 有一种非常灵活的使用方式。可自定义source、sink、interceptor、channel selector等,适应采集、数据缓冲等大多数场景。
观察hadoop目录,发现flume已经按照配置把数据移动到了对应的hive表目录下,如下图:
打开hive客户端,使用数据查询命令,发现可以查询到数据!并且可以按照hive表的数据规则写入hive的分区表和桶表flume,然后实时插入数据。至此,程序结束。
这个程序的缺点:
因为flume在写文件的时候独占了正在写的文件资源,所以hive无法读取正在写的文件的内容,也就是说,如果每5分钟生成一个文件,那么正在写的文件的内容就不会被hive读取,这意味着hive最多有5分钟的延迟。而且如果减少时间,延迟会减少,但即使设置为30分钟或1小时,在flume流量不大的情况下也会产生很多零散的小文件。这与hive的特长相悖,hive擅长处理大文件,对于分散的小文件,hive性能会下降很多。
方案二
对比方案一,测试程序和source不变,sink改为hbase-sink,数据实时插入hbase,然后在hive中创建hbase映射表,hive从hbase读取数据到实现实时插入的效果。由于字数限制,方案二记录在以下博客链接中:
实时文章采集(实时采集并分析Nginx日志,自动化封禁封禁风险IP方案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-12-10 08:21
)
实时采集并分析Nginx日志,自动拦截有风险的IP程序php
文章地址:html
前言
本文分享了自动化采集、分析Nginx日志、实时封禁风险IP的解决方案和实践。节点
阅读这个文章你可以得到:nginx
阅读这篇文章你需要:git
背景
分析nginx访问日志时,看到大量无效的404请求,URL都是随机的敏感词。这些请求最近变得更加频繁。手动批量禁止部分IP后,新的IP很快就会进来。 web
于是萌生了自动分析Nginx日志后实时封禁IP的想法。
需求序号需求备注
1
Nginx 日志采集
解决方案很多,我选择了最适合我服务器的方案:filebeat+redis
2
实时日志分析
实时消费redis日志,分析需要的数据进行分析
3
知识产权风险评估
IP风险评估,多维度:访问次数、IP归属、使用等。
4
实时禁止
阻止风险 IP 不同的时间长度
分析
简单从日志中总结了几个特点:sql
序列号功能说明备注
1
经常来访
每秒数次甚至数十次
正常的流量行为也有突发流量,但不会持续太久
2
连续请求
持久的
和上面一样
3
多数 404
大部分请求的URL可能不存在,还有admin、login、phpMyAdmin、backup等敏感词。
这种情况下正常的交通行为并不多
4
IP异常
在ASN之后,我们可以看到一些线索,通常这种请求的IP不是普通的我的用户。
查询其用途通常是COM(商业)、DCH(数据中心/网络托管/传输)、SES(搜索引擎蜘蛛)等。
备注:这里分析的IP是通过ip2location的免费版数据库,后面会详细介绍。
项目日志采集
来源:作者网站由docker部署,Nginx为唯一入口,记录所有访问日志。
采集:由于资源有限,我选择了一个轻量级的日志工具Filebeat,它采集Nginx的日志并写入Redis。
风险评估
Monitor服务根据URL、IP、历史分数等进行风险评估,计算出最终的风险系数。
知识产权禁令
Monitor发现危险IP(风险系数超过阈值)后,调用Actuator对该IP进行封堵,根据风险系数计算封禁时长。
实现日志采集
Filebeat 的使用非常简单。笔者通过swarm进行部署,部署文件如下(为防止代码过长,其余服务在此省略):
version: '3.5'
services:
filebeat:
image: docker.elastic.co/beats/filebeat:7.4.2
deploy:
resources:
limits:
memory: 64M
restart_policy:
condition: on-failure
volumes:
- $PWD/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- $PWD/filebeat/data:/usr/share/filebeat/data:rw
- $PWD/nginx/logs:/logs/nginx:ro
environment:
TZ: Asia/Shanghai
depends_on:
- nginx
filebeat.yml 文件内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /logs/nginx/access.log
json.keys_under_root: true
json.overwrite_keys: true
output.redis:
hosts: ["redis-server"]
password: "{your redis password}"
key: "filebeat:nginx:accesslog"
db: 0
timeout: 5
部署成功后,查看redis数据:
风险评估
Monitor 服务是用 Java 编写的,使用 docker 部署,并通过 http 与 Actuator 服务交互。
风险评估需要整合多个维度:
序列号维度策略
1
知识产权归属
中文网站的用户群通常属于中国。如果IP属于国外,就需要警惕了。
2
用
IP获得使用后,DCH(数据中心/网络托管/传输)、SES(搜索引擎蜘蛛)等,增加风险评分。
3
访问资源
访问资源不存在且路径收录敏感词,如admin、login、phpMyAdmin、backup等,提高风险评分。
4
访问的频率和持续时间
频繁和持续的请求,考虑提高分数。
5
历史成绩
历史分数被整合到当前分数中。
获取 IP 归属
获取IP归属地相对容易。许多数据服务网站提供免费的包,例如IpInfo。还有免费版本的 IP 数据库可以下载,例如 ip2location。
作者使用了免费版的ip2location数据库:
ip_from 和 ip_to 是IP段的开始和结束,存储格式为十进制。在 MySQL 中,可以通过 inet_aton('your ip') 函数将 IP 转换为十进制。例如:
set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2location_db11 WHERE ip_from = @a LIMIT 1;
ip_fromip_tocountry_codecountry_nameregion_namecity_namelatitudelongitudezip_codetime_zone
2899902464
2899910655
我们
美国
加利福尼亚州
山顶风光
37.405992
-122.07852
94043
-07:00
获取AS、ASN和用法
网站提供的大部分免费服务都无法查询ASN或者没有目的。ASN数据也有免费的数据库,但还是没有目的和类型等,这时候作者通过其他方式救国。
ip2location 提供免费版本的 IP2Location™LITE IP-ASN 和 IP2Proxy™LITE 数据库。
IP2Location™LITE IP-ASN:该数据库提供了对肯定自治系统和编号 (ASN) 的参考。
IP2Proxy™LITE:数据库收录用作开放代理的 IP 地址。该数据库包括所有公共 IPv4 和 IPv6 地址的代理类型、国家、地区、城市、ISP、域、使用类型、ASN 和最新记录。
IP2Location™LITE IP-ASN 无法找出所使用的 IP 类型。如果数据较少,IP2Proxy™LITE 不一定收录指定的 IP。但是可以结合这两个库来粗略猜测IP的用途:
首先,在 IP2Proxy™LITE 中查找 IP 的 ASN。
set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2location_asn WHERE ip_from = @a LIMIT 1;
ip_fromip_tocidrasnas
2899904000
2899904255
172.217.6.0/24
15169
谷歌有限责任公司
结合ASN和IP,查询与指定IP最近的同一个ASN的两条记录:
<p>set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2proxy_px8 WHERE ip_from >= @a AND asn = 15169 ORDER BY ip_from ASC LIMIT 1;
SELECT * FROM ip2proxy_px8 WHERE ip_from 查看全部
实时文章采集(实时采集并分析Nginx日志,自动化封禁封禁风险IP方案
)
实时采集并分析Nginx日志,自动拦截有风险的IP程序php
文章地址:html
前言
本文分享了自动化采集、分析Nginx日志、实时封禁风险IP的解决方案和实践。节点
阅读这个文章你可以得到:nginx
阅读这篇文章你需要:git
背景
分析nginx访问日志时,看到大量无效的404请求,URL都是随机的敏感词。这些请求最近变得更加频繁。手动批量禁止部分IP后,新的IP很快就会进来。 web
于是萌生了自动分析Nginx日志后实时封禁IP的想法。
需求序号需求备注
1
Nginx 日志采集
解决方案很多,我选择了最适合我服务器的方案:filebeat+redis
2
实时日志分析
实时消费redis日志,分析需要的数据进行分析
3
知识产权风险评估
IP风险评估,多维度:访问次数、IP归属、使用等。
4
实时禁止
阻止风险 IP 不同的时间长度
分析
简单从日志中总结了几个特点:sql
序列号功能说明备注
1
经常来访
每秒数次甚至数十次
正常的流量行为也有突发流量,但不会持续太久
2
连续请求
持久的
和上面一样
3
多数 404
大部分请求的URL可能不存在,还有admin、login、phpMyAdmin、backup等敏感词。
这种情况下正常的交通行为并不多
4
IP异常
在ASN之后,我们可以看到一些线索,通常这种请求的IP不是普通的我的用户。
查询其用途通常是COM(商业)、DCH(数据中心/网络托管/传输)、SES(搜索引擎蜘蛛)等。
备注:这里分析的IP是通过ip2location的免费版数据库,后面会详细介绍。
项目日志采集
来源:作者网站由docker部署,Nginx为唯一入口,记录所有访问日志。
采集:由于资源有限,我选择了一个轻量级的日志工具Filebeat,它采集Nginx的日志并写入Redis。
风险评估
Monitor服务根据URL、IP、历史分数等进行风险评估,计算出最终的风险系数。
知识产权禁令
Monitor发现危险IP(风险系数超过阈值)后,调用Actuator对该IP进行封堵,根据风险系数计算封禁时长。
实现日志采集
Filebeat 的使用非常简单。笔者通过swarm进行部署,部署文件如下(为防止代码过长,其余服务在此省略):
version: '3.5'
services:
filebeat:
image: docker.elastic.co/beats/filebeat:7.4.2
deploy:
resources:
limits:
memory: 64M
restart_policy:
condition: on-failure
volumes:
- $PWD/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- $PWD/filebeat/data:/usr/share/filebeat/data:rw
- $PWD/nginx/logs:/logs/nginx:ro
environment:
TZ: Asia/Shanghai
depends_on:
- nginx
filebeat.yml 文件内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /logs/nginx/access.log
json.keys_under_root: true
json.overwrite_keys: true
output.redis:
hosts: ["redis-server"]
password: "{your redis password}"
key: "filebeat:nginx:accesslog"
db: 0
timeout: 5
部署成功后,查看redis数据:
风险评估
Monitor 服务是用 Java 编写的,使用 docker 部署,并通过 http 与 Actuator 服务交互。
风险评估需要整合多个维度:
序列号维度策略
1
知识产权归属
中文网站的用户群通常属于中国。如果IP属于国外,就需要警惕了。
2
用
IP获得使用后,DCH(数据中心/网络托管/传输)、SES(搜索引擎蜘蛛)等,增加风险评分。
3
访问资源
访问资源不存在且路径收录敏感词,如admin、login、phpMyAdmin、backup等,提高风险评分。
4
访问的频率和持续时间
频繁和持续的请求,考虑提高分数。
5
历史成绩
历史分数被整合到当前分数中。
获取 IP 归属
获取IP归属地相对容易。许多数据服务网站提供免费的包,例如IpInfo。还有免费版本的 IP 数据库可以下载,例如 ip2location。
作者使用了免费版的ip2location数据库:
ip_from 和 ip_to 是IP段的开始和结束,存储格式为十进制。在 MySQL 中,可以通过 inet_aton('your ip') 函数将 IP 转换为十进制。例如:
set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2location_db11 WHERE ip_from = @a LIMIT 1;
ip_fromip_tocountry_codecountry_nameregion_namecity_namelatitudelongitudezip_codetime_zone
2899902464
2899910655
我们
美国
加利福尼亚州
山顶风光
37.405992
-122.07852
94043
-07:00
获取AS、ASN和用法
网站提供的大部分免费服务都无法查询ASN或者没有目的。ASN数据也有免费的数据库,但还是没有目的和类型等,这时候作者通过其他方式救国。
ip2location 提供免费版本的 IP2Location™LITE IP-ASN 和 IP2Proxy™LITE 数据库。
IP2Location™LITE IP-ASN:该数据库提供了对肯定自治系统和编号 (ASN) 的参考。
IP2Proxy™LITE:数据库收录用作开放代理的 IP 地址。该数据库包括所有公共 IPv4 和 IPv6 地址的代理类型、国家、地区、城市、ISP、域、使用类型、ASN 和最新记录。
IP2Location™LITE IP-ASN 无法找出所使用的 IP 类型。如果数据较少,IP2Proxy™LITE 不一定收录指定的 IP。但是可以结合这两个库来粗略猜测IP的用途:
首先,在 IP2Proxy™LITE 中查找 IP 的 ASN。
set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2location_asn WHERE ip_from = @a LIMIT 1;
ip_fromip_tocidrasnas
2899904000
2899904255
172.217.6.0/24
15169
谷歌有限责任公司
结合ASN和IP,查询与指定IP最近的同一个ASN的两条记录:
<p>set @a:= inet_aton('172.217.6.78');
SELECT * FROM ip2proxy_px8 WHERE ip_from >= @a AND asn = 15169 ORDER BY ip_from ASC LIMIT 1;
SELECT * FROM ip2proxy_px8 WHERE ip_from
实时文章采集(如何使用腾讯云大数据组件来完成实时监控系统的设计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-12-09 23:08
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过实时采集和分析云服务器(CVM)及其App应用的CPU和内存消耗数据,利用短信、电话、微信等方式实时反馈监控报警信息,有效保证系统的稳定运行。使用基于云的Kafka、Flink、ES等组件,大大减少了开发运维人员的投入。
一、解决方案描述(一)概述
本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,传输到CKafka,再连接CKafka数据流计算 Oceanus (Flink) ,经过简单的业务逻辑处理,输出到 Elasticsearch,最后通过 Kibana 页面查询结果。方案中使用Promethus监控流计算Oceanus作业运行状态等系统指标,使用云Grafana监控CVM或业务应用指标。
(二)方案结构二、前期准备
实施本方案前,请确保已创建并配置好相应的大数据组件。
(一)创建私网VPC
私有网络(VPC)是您在腾讯云上自定义的逻辑隔离的网络空间。在搭建CKafka、流计算Oceanus、Elasticsearch集群等服务时,选择推荐同一个VPC。具体创建步骤请参考帮助文档()。
(二)创建CKafka实例
Kafka建议选择最新的2.4.1版本,与Filebeat 采集工具有更好的兼容性。
购买完成后,创建一个Kafka主题:topic-app-info
(三)创建流计算Oceanus集群
流计算Oceanus是大数据产品生态系统的实时分析工具。它是基于Apache Flink构建的企业级实时大数据分析平台,具有一站式开发、无缝连接、亚秒级延迟、低成本、安全稳定等特点。流计算Oceanus旨在实现企业数据价值最大化,加速企业实时数字化建设。
在Streaming Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。
(四)创建 Elasticsearch 实例
在 Elasticsearch 控制台中,点击左上角的【新建】,创建集群。具体步骤请参考帮助文档()。
(五)创建云监控Prometheus实例
为了显示自定义的系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建一个Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的 Grafana 资源
单机Grafana需要在灰度发布的Grafana管理页面()中单独购买,实现业务监控指标的展示。
(七)安装和配置 Filebeat
Filebeat是一款轻量级的日志数据采集工具,通过监控指定位置的文件来采集信息。在需要监控该VPC下的主机信息和应用信息的云服务器上安装Filebeat。安装方法一:下载Filebeat并安装。下载地址(); 方法二:使用【Elasticsearch管理页面】-->【beats管理】中提供的Filebeat。本例使用方法一。下载到CVM并配置Filebeat,在filebeat.yml文件中添加如下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:\programdata\elasticsearch\logs\*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的IP地址+端口topic: 'topic-app-info' # 请填写实际的topic
请根据实际业务需求配置相应的Filebeat.yml文件,参考Filebeat官方文档()。
注:示例中使用的是2.4.1的CKafka版本,此处配置版本:2.0.0。不兼容的版本可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、项目实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)Filebeat 采集 数据
1、进入Filebeat根目录,启动Filebeat获取数据采集。在示例中,采集 显示了 top 命令中显示的 CPU、内存等信息。还可以采集 jar 应用日志、JVM 使用情况、监听端口等,详情请参考 Filebeat 官网
().
# filebeat启动
./filebeat -e -c filebeat.yml
# 监控系统信息写入test.log文件
top -d 10 >>/tmp/test.log
2、进入CKafka页面,点击左侧【消息查询】,查询对应的主题消息,验证数据是否为采集。
Filebeat采集中Kafka的数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据并存储在 Elasticsearch 中。
1、定义源
根据 Filebeat 中的 json 消息格式构建 Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数
【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka
注:根据实际版本选择
5、查询ES数据
在ES控制台的Kibana页面查询数据,或者输入同一子网的CVM,使用如下命令查询:
# 查询索引 username:password请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考访问ES集群()。
(三)系统指示灯监控
本章主要实现系统信息监控,对Flink作业的运行状态进行监控和告警。
Prometheus 是一个非常灵活的时间序列数据库,通常用于监控数据的存储、计算和报警。流计算 Oceanus 建议用户使用腾讯云监控提供的 Prometheus 服务,避免部署和运维成本。同时,还支持腾讯云通知模板,可以轻松通过短信、电话、邮件、企业微信机器人等方式将报警信息发送到不同的收件人。
监控配置
流计算 Oceanus 作业监控
除了流计算Oceanus控制台自带的监控信息外,还可以配置目前支持任务级细粒度监控、作业级监控、集群Flink作业列表监控。
1、 流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、 在任意流计算Oceanus作业中,点击【云监控】进入云Prometheus实例,点击链接进入Grafana(这里不能输入灰度的Grafana),并导入json文件。详情请参考访问 Prometheus 自定义监视器
().
3、 3、显示的Flink任务监控效果如下,用户也可以点击【Edit】设置不同的Panels来优化显示效果。
报警配置
1、 进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】,配置相关信息. 具体操作参考访问Prometheus自定义监控
().
2、设置报警通知。选择【选择模板】或【新建】设置通知模板。
3、短信通知信息
(四)业务指标监控
使用Filebeat采集应用业务数据,通过流计算的Oceanus服务处理数据存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。灰度发布中进入Grafana控制台
(),进入刚刚创建的Grafana服务,找到外网地址,打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】,搜索elasticsearch,填写相关ES实例信息,并添加数据源。
2、 点击左侧【Dashboards】,点击【Manage】,点击右上角的【New Dashboard】,新建面板,编辑面板。
3、 显示效果如下:
注:本办公室仅为示例,无实际业务
四、总结
本方案同时尝试了系统监控指标和业务监控指标两种监控方案。如果只需要监控业务指标,可以省略Promethus相关操作。
此外,需要注意的是: 查看全部
实时文章采集(如何使用腾讯云大数据组件来完成实时监控系统的设计)
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过实时采集和分析云服务器(CVM)及其App应用的CPU和内存消耗数据,利用短信、电话、微信等方式实时反馈监控报警信息,有效保证系统的稳定运行。使用基于云的Kafka、Flink、ES等组件,大大减少了开发运维人员的投入。
一、解决方案描述(一)概述
本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,传输到CKafka,再连接CKafka数据流计算 Oceanus (Flink) ,经过简单的业务逻辑处理,输出到 Elasticsearch,最后通过 Kibana 页面查询结果。方案中使用Promethus监控流计算Oceanus作业运行状态等系统指标,使用云Grafana监控CVM或业务应用指标。
(二)方案结构二、前期准备
实施本方案前,请确保已创建并配置好相应的大数据组件。
(一)创建私网VPC
私有网络(VPC)是您在腾讯云上自定义的逻辑隔离的网络空间。在搭建CKafka、流计算Oceanus、Elasticsearch集群等服务时,选择推荐同一个VPC。具体创建步骤请参考帮助文档()。
(二)创建CKafka实例
Kafka建议选择最新的2.4.1版本,与Filebeat 采集工具有更好的兼容性。
购买完成后,创建一个Kafka主题:topic-app-info
(三)创建流计算Oceanus集群
流计算Oceanus是大数据产品生态系统的实时分析工具。它是基于Apache Flink构建的企业级实时大数据分析平台,具有一站式开发、无缝连接、亚秒级延迟、低成本、安全稳定等特点。流计算Oceanus旨在实现企业数据价值最大化,加速企业实时数字化建设。
在Streaming Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。
(四)创建 Elasticsearch 实例
在 Elasticsearch 控制台中,点击左上角的【新建】,创建集群。具体步骤请参考帮助文档()。
(五)创建云监控Prometheus实例
为了显示自定义的系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建一个Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的 Grafana 资源
单机Grafana需要在灰度发布的Grafana管理页面()中单独购买,实现业务监控指标的展示。
(七)安装和配置 Filebeat
Filebeat是一款轻量级的日志数据采集工具,通过监控指定位置的文件来采集信息。在需要监控该VPC下的主机信息和应用信息的云服务器上安装Filebeat。安装方法一:下载Filebeat并安装。下载地址(); 方法二:使用【Elasticsearch管理页面】-->【beats管理】中提供的Filebeat。本例使用方法一。下载到CVM并配置Filebeat,在filebeat.yml文件中添加如下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:\programdata\elasticsearch\logs\*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的IP地址+端口topic: 'topic-app-info' # 请填写实际的topic
请根据实际业务需求配置相应的Filebeat.yml文件,参考Filebeat官方文档()。
注:示例中使用的是2.4.1的CKafka版本,此处配置版本:2.0.0。不兼容的版本可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、项目实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)Filebeat 采集 数据
1、进入Filebeat根目录,启动Filebeat获取数据采集。在示例中,采集 显示了 top 命令中显示的 CPU、内存等信息。还可以采集 jar 应用日志、JVM 使用情况、监听端口等,详情请参考 Filebeat 官网
().
# filebeat启动
./filebeat -e -c filebeat.yml
# 监控系统信息写入test.log文件
top -d 10 >>/tmp/test.log
2、进入CKafka页面,点击左侧【消息查询】,查询对应的主题消息,验证数据是否为采集。
Filebeat采集中Kafka的数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据并存储在 Elasticsearch 中。
1、定义源
根据 Filebeat 中的 json 消息格式构建 Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数
【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka
注:根据实际版本选择
5、查询ES数据
在ES控制台的Kibana页面查询数据,或者输入同一子网的CVM,使用如下命令查询:
# 查询索引 username:password请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考访问ES集群()。
(三)系统指示灯监控
本章主要实现系统信息监控,对Flink作业的运行状态进行监控和告警。
Prometheus 是一个非常灵活的时间序列数据库,通常用于监控数据的存储、计算和报警。流计算 Oceanus 建议用户使用腾讯云监控提供的 Prometheus 服务,避免部署和运维成本。同时,还支持腾讯云通知模板,可以轻松通过短信、电话、邮件、企业微信机器人等方式将报警信息发送到不同的收件人。
监控配置
流计算 Oceanus 作业监控
除了流计算Oceanus控制台自带的监控信息外,还可以配置目前支持任务级细粒度监控、作业级监控、集群Flink作业列表监控。
1、 流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、 在任意流计算Oceanus作业中,点击【云监控】进入云Prometheus实例,点击链接进入Grafana(这里不能输入灰度的Grafana),并导入json文件。详情请参考访问 Prometheus 自定义监视器
().
3、 3、显示的Flink任务监控效果如下,用户也可以点击【Edit】设置不同的Panels来优化显示效果。
报警配置
1、 进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】,配置相关信息. 具体操作参考访问Prometheus自定义监控
().
2、设置报警通知。选择【选择模板】或【新建】设置通知模板。
3、短信通知信息
(四)业务指标监控
使用Filebeat采集应用业务数据,通过流计算的Oceanus服务处理数据存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。灰度发布中进入Grafana控制台
(),进入刚刚创建的Grafana服务,找到外网地址,打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】,搜索elasticsearch,填写相关ES实例信息,并添加数据源。
2、 点击左侧【Dashboards】,点击【Manage】,点击右上角的【New Dashboard】,新建面板,编辑面板。
3、 显示效果如下:
注:本办公室仅为示例,无实际业务
四、总结
本方案同时尝试了系统监控指标和业务监控指标两种监控方案。如果只需要监控业务指标,可以省略Promethus相关操作。
此外,需要注意的是:
实时文章采集(看新闻找感觉有用就行,澎湃新闻海天盛筵)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-09 13:04
实时文章采集推荐——金山词霸财经文章推荐--荐读--荐读——澎湃新闻
海天盛筵
有个app叫芝麻酱
雪球,
看网上新闻好像都是抄袭其他媒体的稿子,没有自己的东西,
当当市场、e大电商、阿里知乎都可以,
点睛经常做这些的,
和讯,猎豹清晰。
看新闻找感觉有用就行,
快本,和虎嗅,
个人喜欢:海天盛筵、芝麻酱、万家客
虎嗅网
我是搜狐传媒部做电商的,负责搜狐自媒体频道。这些都是我发现的,没有深挖的,跟网站、平台运营联系都很多,没有局限性。但有些在知乎上没有流传开来,是因为1.有些文章不是同一天发布的。2.流传开了,被删了。
uc资讯
米读app,您可以试一下,不仅可以看资讯,还可以提供一些阅读体验。
虎嗅网,36氪,
我觉得吃喝玩乐都可以啊
淘点点
嗯,澎湃新闻新闻必须要有的,然后就是当当市场。我做起来了这个平台,搜狐新闻也有部分资讯。可以找我聊聊。这问题。
那么问题来了,你说说哪一个对于你来说是可以有价值的,
这很简单,我个人比较喜欢看每日新闻,推荐一个tt工场/,每日新闻介绍了中国首屈一指的原创新闻网站,为每一篇原创新闻提供定制化的内容。 查看全部
实时文章采集(看新闻找感觉有用就行,澎湃新闻海天盛筵)
实时文章采集推荐——金山词霸财经文章推荐--荐读--荐读——澎湃新闻
海天盛筵
有个app叫芝麻酱
雪球,
看网上新闻好像都是抄袭其他媒体的稿子,没有自己的东西,
当当市场、e大电商、阿里知乎都可以,
点睛经常做这些的,
和讯,猎豹清晰。
看新闻找感觉有用就行,
快本,和虎嗅,
个人喜欢:海天盛筵、芝麻酱、万家客
虎嗅网
我是搜狐传媒部做电商的,负责搜狐自媒体频道。这些都是我发现的,没有深挖的,跟网站、平台运营联系都很多,没有局限性。但有些在知乎上没有流传开来,是因为1.有些文章不是同一天发布的。2.流传开了,被删了。
uc资讯
米读app,您可以试一下,不仅可以看资讯,还可以提供一些阅读体验。
虎嗅网,36氪,
我觉得吃喝玩乐都可以啊
淘点点
嗯,澎湃新闻新闻必须要有的,然后就是当当市场。我做起来了这个平台,搜狐新闻也有部分资讯。可以找我聊聊。这问题。
那么问题来了,你说说哪一个对于你来说是可以有价值的,
这很简单,我个人比较喜欢看每日新闻,推荐一个tt工场/,每日新闻介绍了中国首屈一指的原创新闻网站,为每一篇原创新闻提供定制化的内容。
实时文章采集(实时流采集终端的视频数据实时推送到另外一个(多个))
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-12-05 15:14
场景描述
将实时流采集终端的视频数据实时推送到另一个(多个)播放终端,完成远距离实时视频播放功能。典型场景:
(1)远程查看监控摄像机。选择指定的摄像机,将摄像机采集的实时数据推送到指定的回放终端,供值班人员(监控中心)查看。包括实时上墙视频,推送至大屏指定;
(2)直播系统。用户在PC上安装流媒体工具,从屏幕(麦克风)抓取实时数据,推送给观看直播的观众。
解决方案
完成端到端的流推送,需要借助中间件来完成,常用的NginxRtmp模块用于传输视频数据。实时流媒体采集端根据给定地址推送数据到Nginx流媒体服务器,播放端根据给定地址从Nginx流媒体服务器拉取数据呈现给用户.
实时流结构图
如果多个用户需要播放同一个实时流数据,那么理想情况下,流端的数据应该是复用的,即流端只需要为多个播放终端推送一个流。此时,流端和播放端处于pair-N关系。
多个用户播放相同的实时流数据
如果广播用户很多,推送和广播端的数量很多,仅仅依靠流媒体服务器转发数据肯定是不够的。这时候就需要多台流媒体服务器协同工作。当有多个流媒体服务器时,就会出现一个问题:当用户请求实时流媒体时,如何为其分配一个流媒体服务器?这时候会引入另一个概念:负载均衡。当有多个流媒体服务器时,我们需要通过一定的策略来计算出最合适的流媒体服务器,比如找到当前负载最小的服务器,交给用户。
多个流媒体服务器
如上图所示,当有多个流媒体服务器时,负载均衡需要根据指定的策略计算出最佳服务器地址,然后推送端和播放端根据地址分别推拉流。该数字是使用流媒体服务器1计算得到的。
实现技术
使用的技术和工具:
(1)CentOS6.5+Tomacat8.0+Mysql+Spring,javaweb后台,接收用户请求,负载计算,流状态同步,发送推流指令等;
(2)ffmpeg,C++调用的流媒体工具;
(3)RabbitMQ,web后台和推送端传递消息;
(4)Nginx1.12.0+rtmpmodule,详情可查看官方第三方模块列表、流媒体转发;
(5)VLCC#开发工具,用来拉流,网上有公开的API调用方法,用来做客户端demo,以下截图基于这个demo;
(6)jwplayer,真正的web前端实时流控。
详细实施
(1)关于Nginx+rtmp模块实现实时流转发的内容就不写了,网上很多教程也很简单,不需要写任何代码;
(2)Javaweb后端采用SpringMVC+Mybatis,只需要实现一些http接口即可;
这里详细描述了负载计算的逻辑。该模块与Web后端分离,可以单独部署。
这个模块是java后端的一部分,当然也可以单独部署。它通过数据库中的请求表与 Web 后端同步数据。接下来是负载均衡中生成rtmp的逻辑,rtmp就是本文开头提到的push/pull地址。
push 和 pull 端可以通过给定的 rtmp 进行推拉。Nginx流媒体服务器(具体为rtmp模块)接收推送开始(publish_start)、推送结束(publish_done)、拉取开始(play_start)。) 并且当流结束(play_done)时,会根据配置文件中的配置进行http回调,回调地址配置为java负载均衡后台。我们需要在这个回调中更新流媒体服务器的状态,比如当前流媒体服务器的负载数,以便下次负载计算。
有时http回调会失败,导致负载均衡模块中保存的流媒体服务器状态出错,所以我们需要主动同步流媒体服务器的负载状态:
负载计算的另一个非常重要的标准是检查流媒体服务器是否在线。如果不在线,那么流媒体服务器不在我们考虑范围内。主动检查流媒体服务器的状态:
演示演示
由于种种原因,这里只能挂一些演示图片:
演示1
在百度地图中按区域搜索摄像头,选择摄像头,查看摄像头实时视频数据。流程是:请求视频->
演示2
选择摄像机,将摄像机的实时流推送到大屏幕。流程为:请求大屏上墙(携带大屏ID)->计算rtmp->开始流媒体->开始流媒体。下图为大屏模拟管理器:
大屏准备好后,开始播放,管理员状态更新:
大屏模拟器界面支持断线恢复。关闭终端并再次打开后,流媒体不会中断:
程序概要
(1)push端和pull端有1->N的关系,对于每个push流,可以同时有多个pull端,即push流可以复用。当多个用户请求时同一个资源(比如同一个camera),只需要推一个流,此时每个用户的拉流地址rtmp是一样的。
(2)需要一个流媒体服务器作为push和pull之间的桥梁,负责实时流的转发。这里使用的是Nginx+rtmpmodule,网上有详细教程。
(3)流媒体服务器的选择需要通过负载均衡计算。负载计算策略包括:流媒体服务器是否在线,负载数(当前播放链接)是否达到服务器的上限,以及请求的资源是否已经被推流(即可以复用,这种情况下直接返回之前的rtmp,不需要重新分配服务器)。
(4)Nginx+rtmp模块的配置文件中,有一项是配置'状态回调'的地址。当流媒体服务器的状态发生变化时,会通过这个通知java后端打回来。
不提供源码,有问题的朋友可以留言或私信。 查看全部
实时文章采集(实时流采集终端的视频数据实时推送到另外一个(多个))
场景描述
将实时流采集终端的视频数据实时推送到另一个(多个)播放终端,完成远距离实时视频播放功能。典型场景:
(1)远程查看监控摄像机。选择指定的摄像机,将摄像机采集的实时数据推送到指定的回放终端,供值班人员(监控中心)查看。包括实时上墙视频,推送至大屏指定;
(2)直播系统。用户在PC上安装流媒体工具,从屏幕(麦克风)抓取实时数据,推送给观看直播的观众。
解决方案
完成端到端的流推送,需要借助中间件来完成,常用的NginxRtmp模块用于传输视频数据。实时流媒体采集端根据给定地址推送数据到Nginx流媒体服务器,播放端根据给定地址从Nginx流媒体服务器拉取数据呈现给用户.
实时流结构图
如果多个用户需要播放同一个实时流数据,那么理想情况下,流端的数据应该是复用的,即流端只需要为多个播放终端推送一个流。此时,流端和播放端处于pair-N关系。
多个用户播放相同的实时流数据
如果广播用户很多,推送和广播端的数量很多,仅仅依靠流媒体服务器转发数据肯定是不够的。这时候就需要多台流媒体服务器协同工作。当有多个流媒体服务器时,就会出现一个问题:当用户请求实时流媒体时,如何为其分配一个流媒体服务器?这时候会引入另一个概念:负载均衡。当有多个流媒体服务器时,我们需要通过一定的策略来计算出最合适的流媒体服务器,比如找到当前负载最小的服务器,交给用户。
多个流媒体服务器
如上图所示,当有多个流媒体服务器时,负载均衡需要根据指定的策略计算出最佳服务器地址,然后推送端和播放端根据地址分别推拉流。该数字是使用流媒体服务器1计算得到的。
实现技术
使用的技术和工具:
(1)CentOS6.5+Tomacat8.0+Mysql+Spring,javaweb后台,接收用户请求,负载计算,流状态同步,发送推流指令等;
(2)ffmpeg,C++调用的流媒体工具;
(3)RabbitMQ,web后台和推送端传递消息;
(4)Nginx1.12.0+rtmpmodule,详情可查看官方第三方模块列表、流媒体转发;
(5)VLCC#开发工具,用来拉流,网上有公开的API调用方法,用来做客户端demo,以下截图基于这个demo;
(6)jwplayer,真正的web前端实时流控。
详细实施
(1)关于Nginx+rtmp模块实现实时流转发的内容就不写了,网上很多教程也很简单,不需要写任何代码;
(2)Javaweb后端采用SpringMVC+Mybatis,只需要实现一些http接口即可;
这里详细描述了负载计算的逻辑。该模块与Web后端分离,可以单独部署。
这个模块是java后端的一部分,当然也可以单独部署。它通过数据库中的请求表与 Web 后端同步数据。接下来是负载均衡中生成rtmp的逻辑,rtmp就是本文开头提到的push/pull地址。
push 和 pull 端可以通过给定的 rtmp 进行推拉。Nginx流媒体服务器(具体为rtmp模块)接收推送开始(publish_start)、推送结束(publish_done)、拉取开始(play_start)。) 并且当流结束(play_done)时,会根据配置文件中的配置进行http回调,回调地址配置为java负载均衡后台。我们需要在这个回调中更新流媒体服务器的状态,比如当前流媒体服务器的负载数,以便下次负载计算。
有时http回调会失败,导致负载均衡模块中保存的流媒体服务器状态出错,所以我们需要主动同步流媒体服务器的负载状态:
负载计算的另一个非常重要的标准是检查流媒体服务器是否在线。如果不在线,那么流媒体服务器不在我们考虑范围内。主动检查流媒体服务器的状态:
演示演示
由于种种原因,这里只能挂一些演示图片:
演示1
在百度地图中按区域搜索摄像头,选择摄像头,查看摄像头实时视频数据。流程是:请求视频->
演示2
选择摄像机,将摄像机的实时流推送到大屏幕。流程为:请求大屏上墙(携带大屏ID)->计算rtmp->开始流媒体->开始流媒体。下图为大屏模拟管理器:
大屏准备好后,开始播放,管理员状态更新:
大屏模拟器界面支持断线恢复。关闭终端并再次打开后,流媒体不会中断:
程序概要
(1)push端和pull端有1->N的关系,对于每个push流,可以同时有多个pull端,即push流可以复用。当多个用户请求时同一个资源(比如同一个camera),只需要推一个流,此时每个用户的拉流地址rtmp是一样的。
(2)需要一个流媒体服务器作为push和pull之间的桥梁,负责实时流的转发。这里使用的是Nginx+rtmpmodule,网上有详细教程。
(3)流媒体服务器的选择需要通过负载均衡计算。负载计算策略包括:流媒体服务器是否在线,负载数(当前播放链接)是否达到服务器的上限,以及请求的资源是否已经被推流(即可以复用,这种情况下直接返回之前的rtmp,不需要重新分配服务器)。
(4)Nginx+rtmp模块的配置文件中,有一项是配置'状态回调'的地址。当流媒体服务器的状态发生变化时,会通过这个通知java后端打回来。
不提供源码,有问题的朋友可以留言或私信。
实时文章采集(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-02 04:11
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?
帝国采集
不懂HTML+css如何采集发布:
1、 只要输入关键词 就可以采集:搜狗新闻-搜狗知乎-投文章-公众号-百度新闻-百度知道-新浪新闻-360新闻-凤凰新闻(可同时设置多个采集来源采集)
帝国cms采集
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
二、不同的网站cms发布
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布
帝国cms 发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
网站详情
为什么我不使用 Empire 插件?一是用Empire采集插件来拖延时间,二来要写很多规则,每天管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。
以上是小编采集网站的帝国,只要用心管理网站的帝国,采集的网站的流量也不错!如果你想认识其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
实时文章采集(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?
帝国采集
不懂HTML+css如何采集发布:
1、 只要输入关键词 就可以采集:搜狗新闻-搜狗知乎-投文章-公众号-百度新闻-百度知道-新浪新闻-360新闻-凤凰新闻(可同时设置多个采集来源采集)
帝国cms采集
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
二、不同的网站cms发布
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布
帝国cms 发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
网站详情
为什么我不使用 Empire 插件?一是用Empire采集插件来拖延时间,二来要写很多规则,每天管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。
以上是小编采集网站的帝国,只要用心管理网站的帝国,采集的网站的流量也不错!如果你想认识其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
实时文章采集(机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-29 21:09
一般对于硬件编程的提供,硬件厂商都会提供SDK使用手册和示例。手册一般包括安装配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和实例(有些硬件实例直接写在手册中,有些会单独存在文件,有些两者都有)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后根据它介绍的SDK开发流程阅读它提供的例子,并根据自己的需要修改相应的例子。自己使用。该函数可用于查询其用法。一些开发人员习惯性地记住他们的 API,费时费力,不推荐。下面主要用实时图采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是不同作业的要求,加载相机对象和卸载相机对象是常见的。当你想使用其他模块,比如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,前面分配的资源一定要在后面释放。
下面是对五个主要流程的详细分析,需要的地方已经说明,需要用到的功能都有注释
加载相机对象
卸载相机对象
加载数据流以抓取对象
卸载数据流以抓取对象
单帧或连续捕捉过程
可以按照上面介绍的流程实现实时图像采集
源代码下载链接。很多人问我要源码。我检查了以前的程序文件夹,找到了这个程序。演示了使用Pylon SDK执行camera采集的过程,使用MIL完成界面展示,并封装了采集部分。类可以直接重用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut完成图像数据的重组,然后MIL自动显示。
--------------------- 查看全部
实时文章采集(机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例)
一般对于硬件编程的提供,硬件厂商都会提供SDK使用手册和示例。手册一般包括安装配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和实例(有些硬件实例直接写在手册中,有些会单独存在文件,有些两者都有)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后根据它介绍的SDK开发流程阅读它提供的例子,并根据自己的需要修改相应的例子。自己使用。该函数可用于查询其用法。一些开发人员习惯性地记住他们的 API,费时费力,不推荐。下面主要用实时图采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是不同作业的要求,加载相机对象和卸载相机对象是常见的。当你想使用其他模块,比如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,前面分配的资源一定要在后面释放。
下面是对五个主要流程的详细分析,需要的地方已经说明,需要用到的功能都有注释
加载相机对象
卸载相机对象
加载数据流以抓取对象
卸载数据流以抓取对象
单帧或连续捕捉过程
可以按照上面介绍的流程实现实时图像采集
源代码下载链接。很多人问我要源码。我检查了以前的程序文件夹,找到了这个程序。演示了使用Pylon SDK执行camera采集的过程,使用MIL完成界面展示,并封装了采集部分。类可以直接重用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut完成图像数据的重组,然后MIL自动显示。
---------------------
实时文章采集(机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-27 06:12
一般对于硬件编程的提供,硬件厂商都会提供SDK使用手册和示例。手册一般包括安装和配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和示例(有些硬件示例直接写在手册中,有些会单独存在文件,有些两者都有。)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后再阅读他们介绍的SDK开发流程提供的例子,修改相应的例子供自己使用。该函数可用于查询其用法。一些开发人员习惯性地记住他们的 API,费时费力,不推荐。下面主要用实时图采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是不同作业的要求,加载相机对象和卸载相机对象是常见的。当你想使用其他模块,比如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,之前分配的资源一定要在后面释放。
下面是对五个主要流程的详细分析,需要的地方已经说明,需要用到的功能都有注释
加载相机对象
卸载相机对象
加载数据流以抓取对象
卸载数据流以抓取对象
单帧或连续捕捉过程
可以按照上面介绍的流程实现实时图像采集
源代码下载链接。很多人问我要源码。我检查了以前的程序文件夹,找到了这个程序。演示了使用Pylon SDK执行camera采集的过程,使用MIL完成界面展示,打包了采集部分。类可以直接重用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut来完成图像数据的重组,然后MIL自动显示出来。 查看全部
实时文章采集(机软件开发人员拿到一个硬件上位机编程SDK使用的手册和实例)
一般对于硬件编程的提供,硬件厂商都会提供SDK使用手册和示例。手册一般包括安装和配置过程,一些基本概念的介绍,SDK各个功能的使用,SDK的使用过程和示例(有些硬件示例直接写在手册中,有些会单独存在文件,有些两者都有。)。上位机软件开发者要拿到硬件上位机编程任务,首先要阅读理解SDK的概念,然后再阅读他们介绍的SDK开发流程提供的例子,修改相应的例子供自己使用。该函数可用于查询其用法。一些开发人员习惯性地记住他们的 API,费时费力,不推荐。下面主要用实时图采集来讲解Basler相机的PylonC SDK的使用过程。
PylonC SDK的使用总体流程图如下:
以下是不同作业的要求,加载相机对象和卸载相机对象是常见的。当你想使用其他模块,比如事件对象时,可以相应地更改为加载事件对象和卸载事件对象,并使用事件对象来完成相关任务。编程的时候一定要规划好整个过程,尤其是在编程硬件的时候,一定要注意内存泄漏,之前分配的资源一定要在后面释放。
下面是对五个主要流程的详细分析,需要的地方已经说明,需要用到的功能都有注释
加载相机对象
卸载相机对象
加载数据流以抓取对象
卸载数据流以抓取对象
单帧或连续捕捉过程
可以按照上面介绍的流程实现实时图像采集
源代码下载链接。很多人问我要源码。我检查了以前的程序文件夹,找到了这个程序。演示了使用Pylon SDK执行camera采集的过程,使用MIL完成界面展示,打包了采集部分。类可以直接重用。测试相机是 Basler 相机。注意Pylon只完成Raw Data的采集,使用MIL的MbufPut来完成图像数据的重组,然后MIL自动显示出来。
实时文章采集(环境说明准备工作flume安装暂略,后续更新(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-26 16:32
)
环境说明准备水槽安装
暂时省略,后续更新
水槽介绍
Apache Flume 是一个分布式、可靠且可用的系统,用于有效地采集、聚合大量日志数据,并将其从许多不同来源移动到集中式数据存储。在大数据生态中,flume经常被用来完成数据采集的工作。
它的实时性非常高,延迟在1-2s左右,可以是准实时的。
并且因为mysql是程序员常用的数据库,所以以flume实时采集mysql数据库为例。要了解flume 采集 数据是如何处理的,我们必须先探索它的架构:
Flume运行的核心是Agent。Flume 以 agent 为最小的独立运行单元。代理是一个 JVM。它是一个完整的数据采集工具,具有三个核心组件,即
源,通道,汇。通过这些组件,Event 可以从一处流向另一处,如下图所示。
三大组件
来源
Source是数据采集端,负责在数据被捕获后进行特殊格式化,将数据封装在一个事件中,然后将事件推送到Channel中。
Flume提供了多种源码实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source等,如果内置的Source不能满足你的需求, Flume 还支持自定义 Source。
可以看到原生flume的源码不支持sql源码,所以我们需要添加一个插件,如何添加后面会讲到。
渠道
Channel是连接Source和Sink的组件。您可以将其视为数据缓冲区(数据队列)。它可以将事件临时存储在内存中或将其持久保存在本地磁盘上,直到接收器处理完事件。
对于Channel,Flume提供了Memory Channel、JDBC Chanel、File Channel等。
下沉
Flume Sink 取出Channel 中的数据,存储在文件系统、数据库中,或者提交到远程服务器。
Flume 还提供了各种 sink 实现,包括 HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink 等。
当 Flume Sink 设置为存储数据时,您可以将数据存储在文件系统、数据库和 hadoop 中。当日志数据较小时,可以将数据存储在文件系统中,并设置一定的时间间隔来保存数据。当日志数据较多时,可以将相应的日志数据存储在Hadoop中,方便日后进行相应的数据分析。
在这个例子中,我使用 kafka 作为接收器
下载flume-ng-sql-source插件
在此下载flume-ng-sql-source,最新版本为1.5.3。
下载后解压,通过idea运行程序,用maven打包成jar包,重命名为flume-ng-sql-source-1.5.3.jar
编译好的jar包应该放在FLUME_HOME/lib下,FLUME_HOME是你linux下flume的文件夹,比如我的是/opt/install/flume
卡夫卡安装
我们使用flume将数据采集传输到kafka,并启动kafak消费监控,可以看到实时数据
jdk1.8 安装
暂时省略,后续更新
动物园管理员安装
暂时省略,后续更新
卡夫卡安装
暂时省略,后续更新
mysql5.7.24安装
暂时省略,后续更新
Flume提取mysql数据到Kafka新建数据库和表
完成以上安装工作后,就可以开始实现demo了。
首先,如果我们要抓取mysql数据,必须要有一个数据库和表,并且记住数据库和表的名称,然后把这个信息写入flume配置文件中。
创建数据库:
create database test
创建一个表:
create table fk(
id int UNSIGNED AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
PRIMARY KEY ( id )
);
新建配置文件(重要)
cd到flume的conf文件夹并添加一个新文件mysql-flume.conf
[root@localhost ~]# cd /opt/install/flume
[root@localhost flume]# ls
bin conf doap_Flume.rdf lib NOTICE RELEASE-NOTES tools
CHANGELOG DEVNOTES docs LICENSE README.md status
[root@localhost flume]# cd conf
[root@localhost conf]# ls
flume-conf.properties.template log4j.properties
flume-env.ps1.template mysql-connector-java-5.1.35
flume-env.sh mysql-connector-java-5.1.35.tar.gz
flume-env.sh.template mysql-flume.conf
注:mysql-flume.conf原本不存在,是我自己生成的,具体配置如下
在这个文件中写入:
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
a1.sources.src-1.hibernate.connection.user = root
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = testTopic
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
这是我的文件。一些私人信息已被其他字符串替换。写mysql-flume.conf的时候可以复制上面这段代码。下面是这段代码的详细注释,你可以用更多注释版本的代码修改你的conf文件
# a1表示agent的名称
# source是a1的输入源
# channels是缓冲区
# sinks是a1输出目的地,本例子sinks使用了kafka
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
# 连接mysql的一系列操作,youhost改为你虚拟机的ip地址,可以通过ifconfig或者ip addr查看
# url中要加入?useUnicode=true&characterEncoding=utf-8&useSSL=false,否则有可能连接失败
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
# mysql账号,一般都是root
a1.sources.src-1.hibernate.connection.user = root
# 填入你的mysql密码
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
# mysql驱动
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
# 驱动版本过低会无法使用,驱动安装下文会提及
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
# 存放status文件
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
# 填写需要采集的数据表信息,你也可以使用下面的方法:
# agent.sources.sql-source.table =table_name
# agent.sources.sql-source.columns.to.select = *
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
# 使用kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 这个项目中你创建的或使用的topic名字
a1.sinks.k1.topic = testTopic
# kafka集群,broker列表,由于我没有使用集群所以只有一个
# 如果你搭建了集群,代码如下:agent.sinks.k1.brokerList = kafka-node1:9092,kafka-node2:9092,kafka-node3:9092
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
将mysql驱动添加到flume的lib目录下
wget https://dev.mysql.com/get/Down ... ar.gz
tar xzf mysql-connector-java-5.1.35.tar.gz
cp mysql-connector-java-5.1.35-bin.jar /你flume的位置/lib/
启动动物园管理员
在启动kafka之前启动zookeeper
cd到zookeeper的bin目录
启动:
./zkServer.sh start
等待运行
./zkCli.sh
启动卡夫卡
在xshell中打开一个新窗口,cd到kafka目录,启动kafka
bin/kafka-server-start.sh config/server.properties &
创建一个新主题
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
注1:testTopic是你使用的主题名称,对应上面mysql-flume.conf中的内容。
注2:可以使用bin/kafka-topics.sh --list --zookeeper localhost:2181 查看创建的topic。
启动水槽
在xshell中打开一个新窗口,cd到flume目录,启动flume
bin/flume-ng agent -n a1 -c conf -f conf/mysql-flume.conf -Dflume.root.logger=INFO,console
等待他运行,同时我们可以打开一个新窗口连接数据库,使用我们新创建的test数据库和fk表。
实时采集数据
Flume会实时将采集数据发送到kafka,我们可以启动一个kafak消费监控,用于查看mysql的实时数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
这时候就可以查看数据了,kafka会打印mysql中的数据
然后我们改变数据库中的一条数据,新读取的数据也会改变
前:
后:
查看全部
实时文章采集(环境说明准备工作flume安装暂略,后续更新(组图)
)
环境说明准备水槽安装
暂时省略,后续更新
水槽介绍
Apache Flume 是一个分布式、可靠且可用的系统,用于有效地采集、聚合大量日志数据,并将其从许多不同来源移动到集中式数据存储。在大数据生态中,flume经常被用来完成数据采集的工作。
它的实时性非常高,延迟在1-2s左右,可以是准实时的。
并且因为mysql是程序员常用的数据库,所以以flume实时采集mysql数据库为例。要了解flume 采集 数据是如何处理的,我们必须先探索它的架构:
Flume运行的核心是Agent。Flume 以 agent 为最小的独立运行单元。代理是一个 JVM。它是一个完整的数据采集工具,具有三个核心组件,即
源,通道,汇。通过这些组件,Event 可以从一处流向另一处,如下图所示。
三大组件
来源
Source是数据采集端,负责在数据被捕获后进行特殊格式化,将数据封装在一个事件中,然后将事件推送到Channel中。
Flume提供了多种源码实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source等,如果内置的Source不能满足你的需求, Flume 还支持自定义 Source。
可以看到原生flume的源码不支持sql源码,所以我们需要添加一个插件,如何添加后面会讲到。
渠道
Channel是连接Source和Sink的组件。您可以将其视为数据缓冲区(数据队列)。它可以将事件临时存储在内存中或将其持久保存在本地磁盘上,直到接收器处理完事件。
对于Channel,Flume提供了Memory Channel、JDBC Chanel、File Channel等。
下沉
Flume Sink 取出Channel 中的数据,存储在文件系统、数据库中,或者提交到远程服务器。
Flume 还提供了各种 sink 实现,包括 HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink 等。
当 Flume Sink 设置为存储数据时,您可以将数据存储在文件系统、数据库和 hadoop 中。当日志数据较小时,可以将数据存储在文件系统中,并设置一定的时间间隔来保存数据。当日志数据较多时,可以将相应的日志数据存储在Hadoop中,方便日后进行相应的数据分析。
在这个例子中,我使用 kafka 作为接收器
下载flume-ng-sql-source插件
在此下载flume-ng-sql-source,最新版本为1.5.3。
下载后解压,通过idea运行程序,用maven打包成jar包,重命名为flume-ng-sql-source-1.5.3.jar
编译好的jar包应该放在FLUME_HOME/lib下,FLUME_HOME是你linux下flume的文件夹,比如我的是/opt/install/flume
卡夫卡安装
我们使用flume将数据采集传输到kafka,并启动kafak消费监控,可以看到实时数据
jdk1.8 安装
暂时省略,后续更新
动物园管理员安装
暂时省略,后续更新
卡夫卡安装
暂时省略,后续更新
mysql5.7.24安装
暂时省略,后续更新
Flume提取mysql数据到Kafka新建数据库和表
完成以上安装工作后,就可以开始实现demo了。
首先,如果我们要抓取mysql数据,必须要有一个数据库和表,并且记住数据库和表的名称,然后把这个信息写入flume配置文件中。
创建数据库:
create database test
创建一个表:
create table fk(
id int UNSIGNED AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
PRIMARY KEY ( id )
);
新建配置文件(重要)
cd到flume的conf文件夹并添加一个新文件mysql-flume.conf
[root@localhost ~]# cd /opt/install/flume
[root@localhost flume]# ls
bin conf doap_Flume.rdf lib NOTICE RELEASE-NOTES tools
CHANGELOG DEVNOTES docs LICENSE README.md status
[root@localhost flume]# cd conf
[root@localhost conf]# ls
flume-conf.properties.template log4j.properties
flume-env.ps1.template mysql-connector-java-5.1.35
flume-env.sh mysql-connector-java-5.1.35.tar.gz
flume-env.sh.template mysql-flume.conf
注:mysql-flume.conf原本不存在,是我自己生成的,具体配置如下
在这个文件中写入:
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
a1.sources.src-1.hibernate.connection.user = root
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = testTopic
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
这是我的文件。一些私人信息已被其他字符串替换。写mysql-flume.conf的时候可以复制上面这段代码。下面是这段代码的详细注释,你可以用更多注释版本的代码修改你的conf文件
# a1表示agent的名称
# source是a1的输入源
# channels是缓冲区
# sinks是a1输出目的地,本例子sinks使用了kafka
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
# 连接mysql的一系列操作,youhost改为你虚拟机的ip地址,可以通过ifconfig或者ip addr查看
# url中要加入?useUnicode=true&characterEncoding=utf-8&useSSL=false,否则有可能连接失败
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
# mysql账号,一般都是root
a1.sources.src-1.hibernate.connection.user = root
# 填入你的mysql密码
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
# mysql驱动
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
# 驱动版本过低会无法使用,驱动安装下文会提及
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
# 存放status文件
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
# 填写需要采集的数据表信息,你也可以使用下面的方法:
# agent.sources.sql-source.table =table_name
# agent.sources.sql-source.columns.to.select = *
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
# 使用kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 这个项目中你创建的或使用的topic名字
a1.sinks.k1.topic = testTopic
# kafka集群,broker列表,由于我没有使用集群所以只有一个
# 如果你搭建了集群,代码如下:agent.sinks.k1.brokerList = kafka-node1:9092,kafka-node2:9092,kafka-node3:9092
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
将mysql驱动添加到flume的lib目录下
wget https://dev.mysql.com/get/Down ... ar.gz
tar xzf mysql-connector-java-5.1.35.tar.gz
cp mysql-connector-java-5.1.35-bin.jar /你flume的位置/lib/
启动动物园管理员
在启动kafka之前启动zookeeper
cd到zookeeper的bin目录
启动:
./zkServer.sh start
等待运行
./zkCli.sh
启动卡夫卡
在xshell中打开一个新窗口,cd到kafka目录,启动kafka
bin/kafka-server-start.sh config/server.properties &
创建一个新主题
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
注1:testTopic是你使用的主题名称,对应上面mysql-flume.conf中的内容。
注2:可以使用bin/kafka-topics.sh --list --zookeeper localhost:2181 查看创建的topic。
启动水槽
在xshell中打开一个新窗口,cd到flume目录,启动flume
bin/flume-ng agent -n a1 -c conf -f conf/mysql-flume.conf -Dflume.root.logger=INFO,console
等待他运行,同时我们可以打开一个新窗口连接数据库,使用我们新创建的test数据库和fk表。
实时采集数据
Flume会实时将采集数据发送到kafka,我们可以启动一个kafak消费监控,用于查看mysql的实时数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
这时候就可以查看数据了,kafka会打印mysql中的数据
然后我们改变数据库中的一条数据,新读取的数据也会改变
前:
后:

