
实时文章采集
解决方案:使用LogHub进行日志实时采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-09-01 14:32
背景
“我要订购外卖”是基于平台的电子商务网站,用户,餐厅,送货人员等. 用户可以在网页,应用程序,微信,支付宝等上下订单;商家收到订单后开始处理,并自动通知周边快递;快递员将食物交付给用户.
操作要求
在操作过程中,发现了以下问题:
很难获得用户. 向渠道(网页,微信推送)投入大量广告费,接收一些用户,但无法判断每个渠道的有效性,用户常常抱怨交付缓慢,但是在哪个环节,订单的接收,分配,处理?如何优化?用户操作通常会参与一些优惠活动(发送优惠券),但无法获得效果. 计划问题,如何帮助商家在高峰时段提前库存?如何派遣更多快递员到指定地区?客户服务中,用户反馈说订单失败,用户背后的操作是什么?系统中有错误吗?数据采集难点
在数据操作过程中,第一步是如何集中采集分散的日志数据,这将面临以下挑战:
我们需要采集分散的外部和内部日志以进行统一管理. 过去,这部分工作需要很多工作,但现在可以通过LogHub 采集函数进行访问.
日志统一管理和配置创建管理日志项目项目,例如myorder
创建日志存储库Logstore,以从不同的数据源生成日志,例如:
如果需要清除原创数据和ETL,则可以创建一些中间结果日志存储区
(有关更多操作,请参阅快速启动/管理控制台)
用户提升日志采集
为了获取新用户,通常有两种方法:
网站注册时有直接优惠券
扫描其他渠道的QR码并放置优惠券
方法
定义以下注册服务器地址,并生成QR码(传单,网页)供用户注册和扫描. 当用户扫描此页面进行注册时,他知道该用户是通过特定来源输入并记录日志的.
http://examplewebsite/login%3F ... Dkd4b
服务器接受请求后,服务器将输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
采集方法:
应用程序将日志输出到硬盘,然后通过Logtail 采集应用程序通过SDK写入日志,请参见SDK服务器数据采集
支付宝/微信公众号编程是一种典型的Web端模式,通常有三种日志类型:
将练习日志写入本地文件,并通过Logtail配置正则表达式写入指定的Logstore. 日志可以在Docker中生成. 容器服务可用于集成日志服务. 可以使用Java程序Log4J Appender. 写); Log4J Appender C#,Python,Java,PHP,C等可以使用SDK写入Windows服务器. 您可以使用Logstash 采集终端用户日志访问Web / M网站页面的用户行为
页面用户行为集合可以分为两类:
页面与后台服务器之间的交互: 例如下订单,登录和注销. 该页面没有后台服务器交互: 该请求直接在前端处理,例如滚动,关闭页面等. 方法第一种方法可以引用服务器采集方法. 第二种方法可以使用Tracking Pixel / JS库采集页面行为,请参考Tracking Web界面服务器日志的操作和维护
例如:
不同网络环境下的方法数据采集
LogHub在每个区域提供访问点,每个区域提供三个访问点:
有关更多信息,请参阅网络访问,始终有一种适合您.
其他,请参阅LogHub完整采集方法. 查看日志实时消耗,涉及流计算,数据清理,数据仓库和索引查询等功能. 查看全部
使用LogHub实时记录采集
背景
“我要订购外卖”是基于平台的电子商务网站,用户,餐厅,送货人员等. 用户可以在网页,应用程序,微信,支付宝等上下订单;商家收到订单后开始处理,并自动通知周边快递;快递员将食物交付给用户.

操作要求
在操作过程中,发现了以下问题:
很难获得用户. 向渠道(网页,微信推送)投入大量广告费,接收一些用户,但无法判断每个渠道的有效性,用户常常抱怨交付缓慢,但是在哪个环节,订单的接收,分配,处理?如何优化?用户操作通常会参与一些优惠活动(发送优惠券),但无法获得效果. 计划问题,如何帮助商家在高峰时段提前库存?如何派遣更多快递员到指定地区?客户服务中,用户反馈说订单失败,用户背后的操作是什么?系统中有错误吗?数据采集难点
在数据操作过程中,第一步是如何集中采集分散的日志数据,这将面临以下挑战:
我们需要采集分散的外部和内部日志以进行统一管理. 过去,这部分工作需要很多工作,但现在可以通过LogHub 采集函数进行访问.
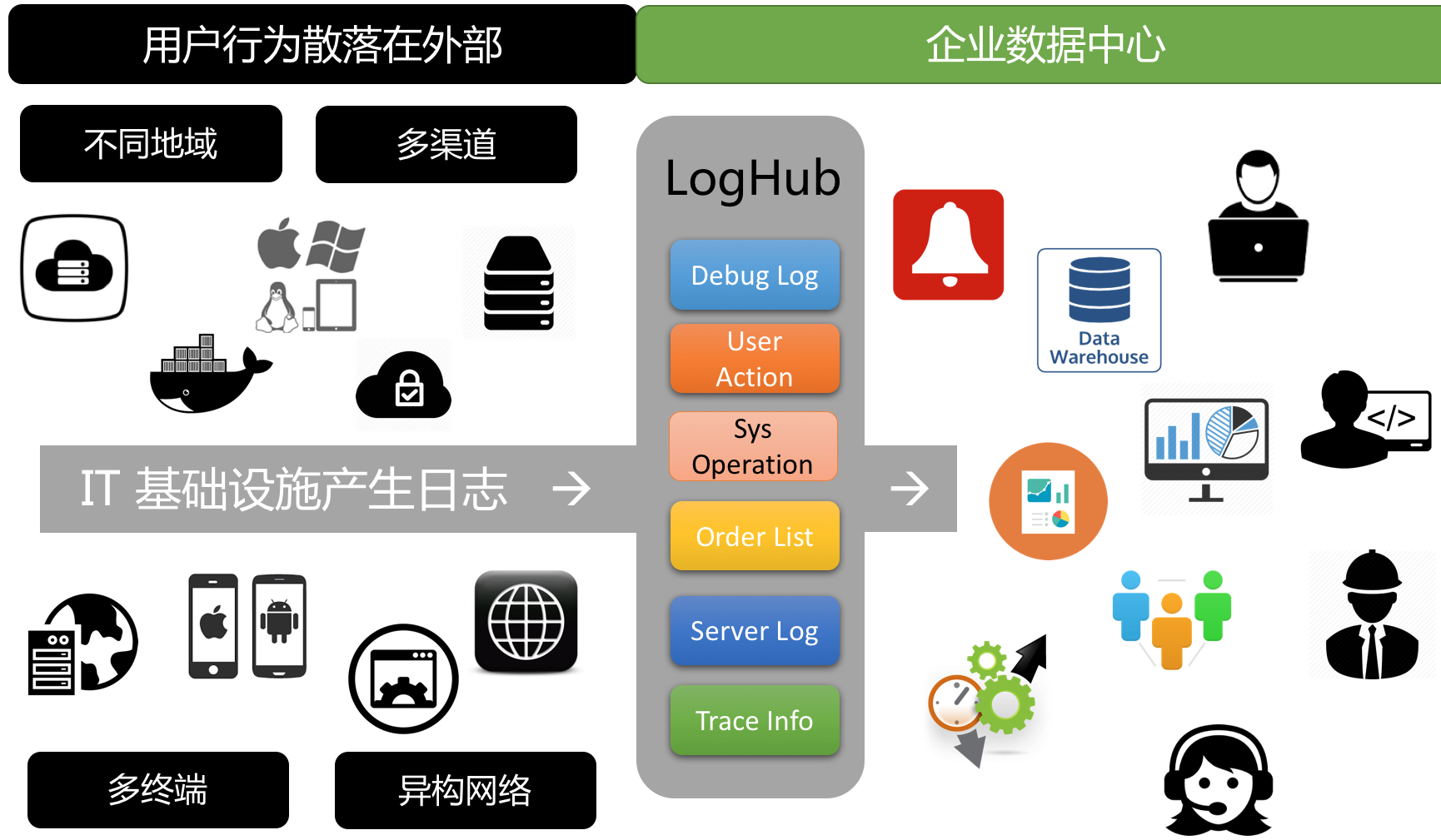
日志统一管理和配置创建管理日志项目项目,例如myorder
创建日志存储库Logstore,以从不同的数据源生成日志,例如:
如果需要清除原创数据和ETL,则可以创建一些中间结果日志存储区
(有关更多操作,请参阅快速启动/管理控制台)
用户提升日志采集
为了获取新用户,通常有两种方法:
网站注册时有直接优惠券
扫描其他渠道的QR码并放置优惠券
方法
定义以下注册服务器地址,并生成QR码(传单,网页)供用户注册和扫描. 当用户扫描此页面进行注册时,他知道该用户是通过特定来源输入并记录日志的.
http://examplewebsite/login%3F ... Dkd4b
服务器接受请求后,服务器将输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
采集方法:
应用程序将日志输出到硬盘,然后通过Logtail 采集应用程序通过SDK写入日志,请参见SDK服务器数据采集
支付宝/微信公众号编程是一种典型的Web端模式,通常有三种日志类型:
将练习日志写入本地文件,并通过Logtail配置正则表达式写入指定的Logstore. 日志可以在Docker中生成. 容器服务可用于集成日志服务. 可以使用Java程序Log4J Appender. 写); Log4J Appender C#,Python,Java,PHP,C等可以使用SDK写入Windows服务器. 您可以使用Logstash 采集终端用户日志访问Web / M网站页面的用户行为
页面用户行为集合可以分为两类:
页面与后台服务器之间的交互: 例如下订单,登录和注销. 该页面没有后台服务器交互: 该请求直接在前端处理,例如滚动,关闭页面等. 方法第一种方法可以引用服务器采集方法. 第二种方法可以使用Tracking Pixel / JS库采集页面行为,请参考Tracking Web界面服务器日志的操作和维护
例如:
不同网络环境下的方法数据采集
LogHub在每个区域提供访问点,每个区域提供三个访问点:
有关更多信息,请参阅网络访问,始终有一种适合您.
其他,请参阅LogHub完整采集方法. 查看日志实时消耗,涉及流计算,数据清理,数据仓库和索引查询等功能.
基于anyproxy的微信公众号文章爬取,收录阅读数点赞数
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-08-27 21:23
github项目地址
录制的视频:点击抵达
基本原理AnyProxy是一个阿里开源的HTTP代理服务器,类似fiddler和charles,但是提供了二次开发能力,可以编撰js代码改变http/https恳求和响应为了爬取一个微信公众号的全部文章,首先就是获取全部文章,然后一篇一篇去打开获取文章标题,作者,阅读数,点赞数(这两个只能在微信浏览器获取)每个微信公众号都提供查看历史消息的功能,点击去打开这个网页,不停下滚,可以查到全部发布文章。在这一步,基于anyproxy,修改了这个网页html,注入一段使页面不停往下滚动的js脚本,当滚到顶部,就获取了全部文章列表。 本质上是中间人攻击。
获取完全部文章的内容(包括url,标题,发布时间等等)后,下一步就是循环通知陌陌浏览器一个一个去打开这种文章网页。每个文章网页也注入js脚本,功能是不停的检测页面的点赞数和阅读数,检测到,就往某服务器发,后台每成功收到一个文章的点赞数和阅读数,就通知陌陌浏览器打开下一个url。这里我使用了socketio,实现陌陌浏览器和自建的koa服务器之间的通信。
如图所示:
获取文章列表演示
一篇一篇打开文章链接
如何运行
第一步,一定要安装成功anyproxy,这一步请详尽阅读anyproxy的官方教程,写的太详尽,要保证能成功代理https,能查看到https的body内容。
npm install
npm start
会手动打开一个result.html,实时查看爬取文章的内容
点击一个微信公众号,点击查看历史消息,之后历史页面会不停的滚动究竟,滚动完毕,就开始一篇一篇打开文章,爬取内容。
实时结果显示.jpg
具体过程
1.第一步,要获取一个公众号的全部历史文章。在早已设置好anyproxy代理的真机上,查看历史消息,这时陌陌会打开历史文章网页。
获取一个html文档:
,var msgList就是我们须要的历史文章数据,简单正则匹配下来,替代非法字符,JSON.parse转成我们须要的格式。 基于anyproxy,我们给这个html文档注入一段脚本,目的是使这个网页不停的往下自己滚动,触发浏览器去获得更多的文章。
var scrollKey = setInterval(function () {
window.scrollTo(0,document.body.scrollHeight);
},1000);
当网页滚究竟,再次获取文章,这个时侯,同样的是get恳求,但是返回了Content-Type为application/json的格式,这里同样的方式,正则匹配找出并低格成我们须要的格式
同时当can_msg_continue为0时,表示早已拉到底,获取了全部文章。
至此,获得了一个公众号的全部文章,包括文章标题,作者,url。但是没有阅读数和点赞数,这须要打开具体的文章链接,才能看得到。
我们还没获得阅读数和点赞数,接下来就是一步一步使微信浏览器不停地打开具体文章,触发陌陌浏览器获取阅读数和点赞数。这里使用了socket.io,让文章页面联接自定义的服务器,服务器主动通知浏览器下一个点开的文章链接,这样单向通信,一个循环才能获取具体文章的阅读数和点赞。
socket.on('url', function (data) {
window.location = data.url;
});
阅读数和点赞可以在浏览器端,不停检测dom元素是否渲染下来之后搜集发往服务器,也可以直接anyproxy检测下来(这里我采用前一种)。
key = setInterval(function () {
var readNum = $('#readNum3').text().trim();
if (!readNum) return;
var likeNum = $('#likeNum3').text().trim();
var postUser = $('#post-user').text().trim();
var postDate = $('#post-date').text().trim() || $('#publish_time').text().trim();
var activityName = $('#activity-name').text().trim();
var js_share_source = $('#js_share_source').attr('href');
socket.emit('crawler', {
readNum: readNum,
likeNum: likeNum,
postUser: postUser,
postDate: postDate,
activityName: activityName,
js_share_source: js_share_source
});
}, 1000); 查看全部
基于anyproxy的微信公众号文章爬取,收录阅读数点赞数
github项目地址
录制的视频:点击抵达
基本原理AnyProxy是一个阿里开源的HTTP代理服务器,类似fiddler和charles,但是提供了二次开发能力,可以编撰js代码改变http/https恳求和响应为了爬取一个微信公众号的全部文章,首先就是获取全部文章,然后一篇一篇去打开获取文章标题,作者,阅读数,点赞数(这两个只能在微信浏览器获取)每个微信公众号都提供查看历史消息的功能,点击去打开这个网页,不停下滚,可以查到全部发布文章。在这一步,基于anyproxy,修改了这个网页html,注入一段使页面不停往下滚动的js脚本,当滚到顶部,就获取了全部文章列表。 本质上是中间人攻击。
获取完全部文章的内容(包括url,标题,发布时间等等)后,下一步就是循环通知陌陌浏览器一个一个去打开这种文章网页。每个文章网页也注入js脚本,功能是不停的检测页面的点赞数和阅读数,检测到,就往某服务器发,后台每成功收到一个文章的点赞数和阅读数,就通知陌陌浏览器打开下一个url。这里我使用了socketio,实现陌陌浏览器和自建的koa服务器之间的通信。
如图所示:

获取文章列表演示

一篇一篇打开文章链接
如何运行
第一步,一定要安装成功anyproxy,这一步请详尽阅读anyproxy的官方教程,写的太详尽,要保证能成功代理https,能查看到https的body内容。
npm install
npm start
会手动打开一个result.html,实时查看爬取文章的内容
点击一个微信公众号,点击查看历史消息,之后历史页面会不停的滚动究竟,滚动完毕,就开始一篇一篇打开文章,爬取内容。

实时结果显示.jpg
具体过程
1.第一步,要获取一个公众号的全部历史文章。在早已设置好anyproxy代理的真机上,查看历史消息,这时陌陌会打开历史文章网页。
获取一个html文档:

,var msgList就是我们须要的历史文章数据,简单正则匹配下来,替代非法字符,JSON.parse转成我们须要的格式。 基于anyproxy,我们给这个html文档注入一段脚本,目的是使这个网页不停的往下自己滚动,触发浏览器去获得更多的文章。
var scrollKey = setInterval(function () {
window.scrollTo(0,document.body.scrollHeight);
},1000);
当网页滚究竟,再次获取文章,这个时侯,同样的是get恳求,但是返回了Content-Type为application/json的格式,这里同样的方式,正则匹配找出并低格成我们须要的格式

同时当can_msg_continue为0时,表示早已拉到底,获取了全部文章。
至此,获得了一个公众号的全部文章,包括文章标题,作者,url。但是没有阅读数和点赞数,这须要打开具体的文章链接,才能看得到。
我们还没获得阅读数和点赞数,接下来就是一步一步使微信浏览器不停地打开具体文章,触发陌陌浏览器获取阅读数和点赞数。这里使用了socket.io,让文章页面联接自定义的服务器,服务器主动通知浏览器下一个点开的文章链接,这样单向通信,一个循环才能获取具体文章的阅读数和点赞。
socket.on('url', function (data) {
window.location = data.url;
});
阅读数和点赞可以在浏览器端,不停检测dom元素是否渲染下来之后搜集发往服务器,也可以直接anyproxy检测下来(这里我采用前一种)。
key = setInterval(function () {
var readNum = $('#readNum3').text().trim();
if (!readNum) return;
var likeNum = $('#likeNum3').text().trim();
var postUser = $('#post-user').text().trim();
var postDate = $('#post-date').text().trim() || $('#publish_time').text().trim();
var activityName = $('#activity-name').text().trim();
var js_share_source = $('#js_share_source').attr('href');
socket.emit('crawler', {
readNum: readNum,
likeNum: likeNum,
postUser: postUser,
postDate: postDate,
activityName: activityName,
js_share_source: js_share_source
});
}, 1000);
爬一爬数据采集实战系列7「调度任务」:采集微博实时热搜榜信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-08-26 07:43
本篇教程为中级实战案例,用【调度】功能多次采集微博实时热搜榜数据。
##插件安装及菜鸟入门教程可以看订阅号第一篇文章 极简易用网页采集器:爬一爬数据采集实战教程
微博实时热搜榜每10min更新一次。如果想采集某个时间段内实时热搜榜的完整信息,需每隔十分钟自动运行,这样的效率极低,不可取。
实时热搜榜的入选规则
今天就教你们一个方式,用调度器定时采集数据。这样,只要我们设置好调度任务,让任务手动运行,我们就可以高枕无忧的打闹去了。
本例设置了在19:00--21:00期间每隔10分钟采集微博热搜榜数据。
操作步骤
1.确保帐号已登陆,打开须要采集的微博实时热搜榜网站,点击浏览器插件栏的“爬”字图标,启动插件。
2.点击页面上须要采集的信息。如果色调框没有收录所有的任务数据, 点击切换按键,切换算法,直到选中所有的任务数据。(注:下载为js-engine)
依次选定要抓取的元素
3.先点击“完成”按钮,再点击“测试”按钮,测试采集的数据是否就是您想要的。
测试数据
4.确认测试成功后,点击”OK”关闭测试窗口。填写任务名称(长度为4-32的字符,必填),并依照个人须要更改列名。
5.点击“提交”按钮,创建任务。
创建任务
6.任务创建成功后,在官网导航栏“任务”页面,点击”打开任务调度器”,调度页面便出现在浏览器标签页。
打开调度器
7.在所创建的任务后点击”管理”选项。
打开任务管理页面
8.点击”调度”选项,新建调度,设置定时任务。
新建调度任务
9.根据Cron表达式,设置任务抓取频度,如下图所示。具体可参考”教程中心”热门问题中的“什么是Cron表达式”。
(#注:本例设置的是 在19:00--21:00之间每隔10分抓取页面)
设置Cron表达式
10.调度配置成功后,任务按照设置频度手动运行。我们可在调度管理标签页面,看到任务的运行状态。(#注:在任务调度期间,该页面不关掉。)
查看调度状态
11.点击任务”数据”选项,我们可以看见多批次的数据。(#注:数据从19:00开始,每个批次间隔10分钟)
查看数据
Tips:
①本例下载器为js-engine
②为保证数据稳定,可将频度值大一点,预留足够的抓取时间。
③想看视频版调度教程,赶紧去官网教程中心吧。
④附Cron表达式的一些事例:
表达式
释义
提示
0 12 * * ?
每天12:00
相当于’0 12 */1 * ?’
15 10 ? * *
每天10:15
相当于’15 10 * * ?’或’15 10 */1 * ?’
* 14 * * ?
每天14:00到14:59,每隔1分钟
0/5 14 * * ?
每天14:00到14:59,每隔5分钟
相当于’*/5 14 * * ?’
0-5 14 * * ?
每天14:00到14:05,每隔1分钟
10,44 14 ? * 4
每周三14:10和14:44
15 10 15 * ?
每月15日的10:15
15 10 ? * 6L
每月最后一个周日的10:15
15 10 ? * 6#3
每月第三个周日的10:15 查看全部
爬一爬数据采集实战系列7「调度任务」:采集微博实时热搜榜信息
本篇教程为中级实战案例,用【调度】功能多次采集微博实时热搜榜数据。
##插件安装及菜鸟入门教程可以看订阅号第一篇文章 极简易用网页采集器:爬一爬数据采集实战教程
微博实时热搜榜每10min更新一次。如果想采集某个时间段内实时热搜榜的完整信息,需每隔十分钟自动运行,这样的效率极低,不可取。
实时热搜榜的入选规则
今天就教你们一个方式,用调度器定时采集数据。这样,只要我们设置好调度任务,让任务手动运行,我们就可以高枕无忧的打闹去了。
本例设置了在19:00--21:00期间每隔10分钟采集微博热搜榜数据。
操作步骤
1.确保帐号已登陆,打开须要采集的微博实时热搜榜网站,点击浏览器插件栏的“爬”字图标,启动插件。
2.点击页面上须要采集的信息。如果色调框没有收录所有的任务数据, 点击切换按键,切换算法,直到选中所有的任务数据。(注:下载为js-engine)
依次选定要抓取的元素
3.先点击“完成”按钮,再点击“测试”按钮,测试采集的数据是否就是您想要的。
测试数据
4.确认测试成功后,点击”OK”关闭测试窗口。填写任务名称(长度为4-32的字符,必填),并依照个人须要更改列名。
5.点击“提交”按钮,创建任务。
创建任务
6.任务创建成功后,在官网导航栏“任务”页面,点击”打开任务调度器”,调度页面便出现在浏览器标签页。
打开调度器
7.在所创建的任务后点击”管理”选项。
打开任务管理页面
8.点击”调度”选项,新建调度,设置定时任务。
新建调度任务
9.根据Cron表达式,设置任务抓取频度,如下图所示。具体可参考”教程中心”热门问题中的“什么是Cron表达式”。
(#注:本例设置的是 在19:00--21:00之间每隔10分抓取页面)
设置Cron表达式
10.调度配置成功后,任务按照设置频度手动运行。我们可在调度管理标签页面,看到任务的运行状态。(#注:在任务调度期间,该页面不关掉。)
查看调度状态
11.点击任务”数据”选项,我们可以看见多批次的数据。(#注:数据从19:00开始,每个批次间隔10分钟)
查看数据
Tips:
①本例下载器为js-engine
②为保证数据稳定,可将频度值大一点,预留足够的抓取时间。
③想看视频版调度教程,赶紧去官网教程中心吧。
④附Cron表达式的一些事例:
表达式
释义
提示
0 12 * * ?
每天12:00
相当于’0 12 */1 * ?’
15 10 ? * *
每天10:15
相当于’15 10 * * ?’或’15 10 */1 * ?’
* 14 * * ?
每天14:00到14:59,每隔1分钟
0/5 14 * * ?
每天14:00到14:59,每隔5分钟
相当于’*/5 14 * * ?’
0-5 14 * * ?
每天14:00到14:05,每隔1分钟
10,44 14 ? * 4
每周三14:10和14:44
15 10 15 * ?
每月15日的10:15
15 10 ? * 6L
每月最后一个周日的10:15
15 10 ? * 6#3
每月第三个周日的10:15
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-20 23:19
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
无敌企业名录搜索软件是一款针对B2B网站的企业信息进行实时采集整理的软件,支持定义多个条件采集数据,个性化的搜索方法使您采集的数据十分精准有效,采集的数据数组诸多,多种导入格式便捷您进行数据管理,形成高效确切的顾客资源,让您全面把握一手的市场顾客资料,是销售人员开发新顾客、企业进行网路营销、开拓市场查找顾客的必备神器!
产品功能及特性:
1、数据来自著名在线B2B网站(阿里巴巴、慧聪、马可波罗、环球贸易网、中国制造网等),来源权威、可靠、准确,让您把握最准确的企业信息;
2、软件实时采集最新最活跃的信息,保证数据的时效性、有效性;
3、多个条件精确定位准确度极高,只搜索您须要的数据名录;
4、搜索条件支持行业、二级行业、关键词、经营模式、省份、城市、地区等条件搜索;
5、数据字段齐全,收录公司名称、联系人、职务、电话、手机、邮箱、公司地址等大量数组;
6、数据手动除去重复,提高效率;
7、导出格式支持txt记事本和excel表格,方便举办任何营销工作。
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
无敌企业名录搜索软件 B2B网站企业信息实时采集V3.5营销版' />
下载 查看全部
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
无敌企业名录搜索软件是一款针对B2B网站的企业信息进行实时采集整理的软件,支持定义多个条件采集数据,个性化的搜索方法使您采集的数据十分精准有效,采集的数据数组诸多,多种导入格式便捷您进行数据管理,形成高效确切的顾客资源,让您全面把握一手的市场顾客资料,是销售人员开发新顾客、企业进行网路营销、开拓市场查找顾客的必备神器!
产品功能及特性:
1、数据来自著名在线B2B网站(阿里巴巴、慧聪、马可波罗、环球贸易网、中国制造网等),来源权威、可靠、准确,让您把握最准确的企业信息;
2、软件实时采集最新最活跃的信息,保证数据的时效性、有效性;
3、多个条件精确定位准确度极高,只搜索您须要的数据名录;
4、搜索条件支持行业、二级行业、关键词、经营模式、省份、城市、地区等条件搜索;
5、数据字段齐全,收录公司名称、联系人、职务、电话、手机、邮箱、公司地址等大量数组;
6、数据手动除去重复,提高效率;
7、导出格式支持txt记事本和excel表格,方便举办任何营销工作。
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版

无敌企业名录搜索软件 B2B网站企业信息实时采集V3.5营销版' />
下载
基于springboot的温湿度NBIOT采集实时显示
采集交流 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2020-08-17 19:53
这个项目就是之前说的要开源下来的一个结业项目,是我在学院期间做的一个项目,大家假如有须要可以随便下载,开源一起学习才有长足的进步
项目链接:
Gitee项目链接
演示地址:
演示地址
:8080
使用1234 123登录
底下是Readme.md
springboot后台联接立秋云介绍
后台基于spring boot的简单实现,前端模板使用springboot官方的折线图实现温湿度的动态监控,注意:需要配合硬件联接立秋云实现
软件构架
软件构架说明
安装教程安装IDEA 配置java环境,这些就不用说了。在IDEA中 导入项目 直接选择下载好的文件夹即可等待IDEA手动导出项目中的须要用到的依赖使用说明
项目需配置mysql数据库,localhost:3306,数据库名为login,账户为root,密码为123456,可以在application.yml中配置数据源。
当数据库中有login数据库时不需要再建表,后台使用jpa框架会手动创建须要用到的数据表,此项目会创建两个表,一个拿来温湿度储存数据,一个拿来储存用户
项目只需等待手动导出依赖文件而且配置好数据库后即可使用
项目中的GuYuNbiot是联接立秋云透传平台的,在Gylistener中请填入自己的春分的注册包,谷雨云的使用请移步:%E8%B0%B7%E9%9B%A8%E4%BA%91%E9%80%8F%E4%BC%A0%E5%B9%B3%E5%8F%B0%E6%8E%A5%E5%85%A5%E6%8C%87%E5%8D%97
项目须要用到硬件的联动,硬件发给谷雨云以后,通过春分云平台的透传能够实现后端图表的实时更新
项目中有许多善待改进的功能,比如在GyRecieveThread收到数据的数据库插入时,偶尔会报null,我这儿使用了
@PostConstruct//解决非controller类注入为null的问题
public void init(){
gyRecieveThread=this;
gyRecieveThread.dataService=this.dataService;
}
如果有更好的解决办法,可以联系我,多谢了。
项目说明
1.因为本人处在大四结业阶段,还是第一次学习springboot的缘由,项目中参考了网上的些许不错的代码,如有侵害请联系我,我会立刻删掉。
2.项目是springboot比较简单的应用,欢迎和我一样的初学者学习,如果有任何不懂的也可以联系我,一起开源学习交流就会长久的进步。
参与贡献Fork 本库房新建 Feat_xxx 分支递交代码新建 Pull Request码云特技使用 Readme_XXX.md 来支持不同的语言,例如 Readme_en.md, Readme_zh.md码云官方博客 你可以 这个地址来了解码云上的优秀开源项目GVP 全称是码云最有价值开源项目,是码云综合评定出的优秀开源项目码云官方提供的使用指南 码云封面人物是一档拿来展示码云会员风采的栏目 查看全部
基于springboot的温湿度NBIOT采集实时显示
这个项目就是之前说的要开源下来的一个结业项目,是我在学院期间做的一个项目,大家假如有须要可以随便下载,开源一起学习才有长足的进步
项目链接:
Gitee项目链接
演示地址:
演示地址
:8080
使用1234 123登录
底下是Readme.md
springboot后台联接立秋云介绍
后台基于spring boot的简单实现,前端模板使用springboot官方的折线图实现温湿度的动态监控,注意:需要配合硬件联接立秋云实现
软件构架
软件构架说明
安装教程安装IDEA 配置java环境,这些就不用说了。在IDEA中 导入项目 直接选择下载好的文件夹即可等待IDEA手动导出项目中的须要用到的依赖使用说明
项目需配置mysql数据库,localhost:3306,数据库名为login,账户为root,密码为123456,可以在application.yml中配置数据源。
当数据库中有login数据库时不需要再建表,后台使用jpa框架会手动创建须要用到的数据表,此项目会创建两个表,一个拿来温湿度储存数据,一个拿来储存用户
项目只需等待手动导出依赖文件而且配置好数据库后即可使用
项目中的GuYuNbiot是联接立秋云透传平台的,在Gylistener中请填入自己的春分的注册包,谷雨云的使用请移步:%E8%B0%B7%E9%9B%A8%E4%BA%91%E9%80%8F%E4%BC%A0%E5%B9%B3%E5%8F%B0%E6%8E%A5%E5%85%A5%E6%8C%87%E5%8D%97
项目须要用到硬件的联动,硬件发给谷雨云以后,通过春分云平台的透传能够实现后端图表的实时更新
项目中有许多善待改进的功能,比如在GyRecieveThread收到数据的数据库插入时,偶尔会报null,我这儿使用了
@PostConstruct//解决非controller类注入为null的问题
public void init(){
gyRecieveThread=this;
gyRecieveThread.dataService=this.dataService;
}
如果有更好的解决办法,可以联系我,多谢了。
项目说明
1.因为本人处在大四结业阶段,还是第一次学习springboot的缘由,项目中参考了网上的些许不错的代码,如有侵害请联系我,我会立刻删掉。
2.项目是springboot比较简单的应用,欢迎和我一样的初学者学习,如果有任何不懂的也可以联系我,一起开源学习交流就会长久的进步。
参与贡献Fork 本库房新建 Feat_xxx 分支递交代码新建 Pull Request码云特技使用 Readme_XXX.md 来支持不同的语言,例如 Readme_en.md, Readme_zh.md码云官方博客 你可以 这个地址来了解码云上的优秀开源项目GVP 全称是码云最有价值开源项目,是码云综合评定出的优秀开源项目码云官方提供的使用指南 码云封面人物是一档拿来展示码云会员风采的栏目
Python网路数据采集之读取文件|第05天
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-08-14 08:59
Date:2018-04-01
Mark:《Python网路数据采集》
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
Python网路数据采集之储存数据
读取文档文档编码
文档编码的方法一般可以依照文件的扩充名进行判定,虽然文件扩充名并不是由编码确定的,而是由开发者确定的。从最底层的角度看,所有文档都是由 0和 1 编码而成的。例如我我们将一个后缀为png的图片后缀改为.py。用编辑器打打开就完全不对了。
只要安装了合适的库, Python 就可以帮你处理任意类型的文档。纯文本文件、视频文件和图象文件的惟一区别,就是它们的 0和1 面向用户的转换方法不同。
纯文本
对于纯文本的文件获取的方法很简单,用 urlopen 获取了网页以后,我们会把它转变成 BeautifulSoup对象。
from urllib.request import urlopen
textPage = urlopen(
"http://www.pythonscraping.com/ ... 6quot;)
print(textPage.read())
CSV 文件
Python有一个标准库对CSV文件的处理非常的友好,可以处理各种的CSV文件。文档地址
读取CSV文件
Python 的csv 库主要是面向本地文件,就是说你的 CSV 文件得存贮在你的笔记本上。而进行网路数据采集的时侯,很多文件都是在线的。有几个参考解决办法:
例如获取网上的CSV文件,然后输出命令行。
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen("http://pythonscraping.com/file ... 6quot;).read().decode('ASCII','ignore')
dataFile = StringIO(data)
csvReader = csv.reader(dataFile)
for row in csvReader:
print(row)
输出的结果:
['Name', 'Year']
["Monty Python's Flying Circus", '1970']
['Another Monty Python Record', '1971']
["Monty Python's Previous Record", '1972']
['The Monty Python Matching Tie and Handkerchief', '1973']
['Monty Python Live at Drury Lane', '1974']
['An Album of the Soundtrack of the Trailer of the Film of Monty Python and the Holy Grail', '1975']
['Monty Python Live at City Center', '1977']
['The Monty Python Instant Record Collection', '1977']
["Monty Python's Life of Brian", '1979']
["Monty Python's Cotractual Obligation Album", '1980']
["Monty Python's The Meaning of Life", '1983']
['The Final Rip Off', '1987']
['Monty Python Sings', '1989']
['The Ultimate Monty Python Rip Off', '1994']
['Monty Python Sings Again', '2014']
PDF 文件
PDFMiner3K是一个非常好用的库(是PDFMiner的Python 3.x移植版)。它十分灵活,可以通过命令行使用,也可以整合到代码中。它还可以处理不同的语言编码,而且对网路文件的处理也十分便捷。
下载解压后用python setup.py install完成安装。
模块的源文件下载地址:
例如可以把任意 PDF 读成字符串,然后用 StringIO转换成文件对象。
from urllib.request import urlopen
from pdfminer.pdfinterp import PDFResourceManager, process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from io import StringIO
from io import open
def readPDF(pdfFile):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
process_pdf(rsrcmgr, device, pdfFile)
device.close()
content = retstr.getvalue() retstr.close()
return content
pdfFile = urlopen("http://pythonscraping.com/page ... 6quot;)
outputString = readPDF(pdfFile)
print(outputString)
pdfFile.close()
readPDF 函数最大的用处是,如果PDF文件在笔记本里,就可以直接把 urlopen返回的对象 pdfFile 替换成普通的 open() 文件对象:
pdfFile = open("./chapter1.pdf", 'rb')
如果本文对你有所帮助,欢迎喜欢或则评论;如果你也对网路采集感兴趣,可以点击关注,这样才能够收到后续的更新。感谢您的阅读。 查看全部
User:你好我是森林
Date:2018-04-01
Mark:《Python网路数据采集》
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
Python网路数据采集之储存数据
读取文档文档编码
文档编码的方法一般可以依照文件的扩充名进行判定,虽然文件扩充名并不是由编码确定的,而是由开发者确定的。从最底层的角度看,所有文档都是由 0和 1 编码而成的。例如我我们将一个后缀为png的图片后缀改为.py。用编辑器打打开就完全不对了。
只要安装了合适的库, Python 就可以帮你处理任意类型的文档。纯文本文件、视频文件和图象文件的惟一区别,就是它们的 0和1 面向用户的转换方法不同。
纯文本
对于纯文本的文件获取的方法很简单,用 urlopen 获取了网页以后,我们会把它转变成 BeautifulSoup对象。
from urllib.request import urlopen
textPage = urlopen(
"http://www.pythonscraping.com/ ... 6quot;)
print(textPage.read())
CSV 文件
Python有一个标准库对CSV文件的处理非常的友好,可以处理各种的CSV文件。文档地址
读取CSV文件
Python 的csv 库主要是面向本地文件,就是说你的 CSV 文件得存贮在你的笔记本上。而进行网路数据采集的时侯,很多文件都是在线的。有几个参考解决办法:
例如获取网上的CSV文件,然后输出命令行。
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen("http://pythonscraping.com/file ... 6quot;).read().decode('ASCII','ignore')
dataFile = StringIO(data)
csvReader = csv.reader(dataFile)
for row in csvReader:
print(row)
输出的结果:
['Name', 'Year']
["Monty Python's Flying Circus", '1970']
['Another Monty Python Record', '1971']
["Monty Python's Previous Record", '1972']
['The Monty Python Matching Tie and Handkerchief', '1973']
['Monty Python Live at Drury Lane', '1974']
['An Album of the Soundtrack of the Trailer of the Film of Monty Python and the Holy Grail', '1975']
['Monty Python Live at City Center', '1977']
['The Monty Python Instant Record Collection', '1977']
["Monty Python's Life of Brian", '1979']
["Monty Python's Cotractual Obligation Album", '1980']
["Monty Python's The Meaning of Life", '1983']
['The Final Rip Off', '1987']
['Monty Python Sings', '1989']
['The Ultimate Monty Python Rip Off', '1994']
['Monty Python Sings Again', '2014']
PDF 文件
PDFMiner3K是一个非常好用的库(是PDFMiner的Python 3.x移植版)。它十分灵活,可以通过命令行使用,也可以整合到代码中。它还可以处理不同的语言编码,而且对网路文件的处理也十分便捷。
下载解压后用python setup.py install完成安装。
模块的源文件下载地址:
例如可以把任意 PDF 读成字符串,然后用 StringIO转换成文件对象。
from urllib.request import urlopen
from pdfminer.pdfinterp import PDFResourceManager, process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from io import StringIO
from io import open
def readPDF(pdfFile):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
process_pdf(rsrcmgr, device, pdfFile)
device.close()
content = retstr.getvalue() retstr.close()
return content
pdfFile = urlopen("http://pythonscraping.com/page ... 6quot;)
outputString = readPDF(pdfFile)
print(outputString)
pdfFile.close()
readPDF 函数最大的用处是,如果PDF文件在笔记本里,就可以直接把 urlopen返回的对象 pdfFile 替换成普通的 open() 文件对象:
pdfFile = open("./chapter1.pdf", 'rb')
如果本文对你有所帮助,欢迎喜欢或则评论;如果你也对网路采集感兴趣,可以点击关注,这样才能够收到后续的更新。感谢您的阅读。
使用LogHub进行日志实时采集-阿里云开发者社区
采集交流 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2020-08-13 03:47
“我要点订餐“是一个平台型电商网站,用户、餐厅、配送员等。用户可以在网页、App、微信、支付宝等进行下单点菜;商家领到订单后开始加工,并手动通知周围的快递员;快递员将订餐送到用户手中。
运营需求
在营运的过程中,发现了如下的问题:
获取用户难,投放一笔不小的广告费对到渠道(网页、微信推送),收货了一些用户,但难以衡量各渠道的疗效用户时常埋怨送货慢,但慢在哪些环节,接单、配送、加工?如何优化?用户营运,经常搞一些让利活动(发送优惠券),但未能获得疗效调度问题,如何帮助店家在高峰时提早备货?如何调度更多的快递员到指定区域?客服服务,用户反馈下单失败,用户背后的操作是哪些?系统是否有错误?数据采集难点
在数据化营运的过程中,第一步是怎样将洒落日志数据集中搜集上去,其中会碰到如下挑战:
我们须要把飘散在外部、内部日志搜集上去,统一进行管理。在过去这块须要大量几种工作,现在可以通过LogHub采集功能完成统一接入。
日志统一管理、配置创建管理日志项目Project,例如叫myorder
为不同数据源形成日志创建日志库Logstore,例如:
如须要对原创数据进行清洗与ETL,可以创建一些中间结果logstore
(更多操作可以参见快速开始/管理控制台)
用户推广日志采集
为获取新用户,一般有2种形式:
网站注册时直接投放优惠券
其他渠道扫描二维码,投放优惠券
做法
定义如下注册服务器地址,生成二维码(传单、网页)供用户注册扫描。用户扫描该页面注册时,就晓得用户通过特定来源步入,并记录日志。
http://examplewebsite/login%3F ... Dkd4b
当服务端接受恳求时,服务器输出如下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
采集方法:
应用程序输出日志到硬碟,通过Logtail采集应用程序通过SDK写入,参见SDK服务端数据采集
支付宝/微信公众帐号编程是典型的Web端模式,一般会有三种类型日志:
做法日志讲到本地文件,通过Logtail配置正则表达式讲到指定LogstoreDocker中形成日志可以使用容器服务集成日志服务Java程序可以使用Log4J Appender日志不落盘, LogHub Producer Library(客户端高并发写入);Log4J AppenderC#、Python、Java、PHP、C等可以使用SDK写入Windows服务器可以使用Logstash采集终端用户日志接入Web/M 站页面用户行为
页面用户行为搜集可以分为两类:
页面与后台服务器交互:例如下单,登陆、退出等。页面无后台服务器交互:请求直接在后端处理,例如滚屏,关闭页面等。做法第一种可以参考服务端采集方法第二种可以使用Tracking Pixel/JS Library搜集页面行为,参考Tracking Web插口服务器日志运维
例如:
做法不同网路环境下数据采集
LogHub在各Region提供 访问点,每个Region提供三种形式接入点:
更多请参见网路接入,总有一款适宜你。
其他参见LogHub完整采集方式。参见日志实时消费,涉及流计算、数据清洗、数据库房和索引查询等功能。 查看全部
背景
“我要点订餐“是一个平台型电商网站,用户、餐厅、配送员等。用户可以在网页、App、微信、支付宝等进行下单点菜;商家领到订单后开始加工,并手动通知周围的快递员;快递员将订餐送到用户手中。
运营需求
在营运的过程中,发现了如下的问题:
获取用户难,投放一笔不小的广告费对到渠道(网页、微信推送),收货了一些用户,但难以衡量各渠道的疗效用户时常埋怨送货慢,但慢在哪些环节,接单、配送、加工?如何优化?用户营运,经常搞一些让利活动(发送优惠券),但未能获得疗效调度问题,如何帮助店家在高峰时提早备货?如何调度更多的快递员到指定区域?客服服务,用户反馈下单失败,用户背后的操作是哪些?系统是否有错误?数据采集难点
在数据化营运的过程中,第一步是怎样将洒落日志数据集中搜集上去,其中会碰到如下挑战:
我们须要把飘散在外部、内部日志搜集上去,统一进行管理。在过去这块须要大量几种工作,现在可以通过LogHub采集功能完成统一接入。
日志统一管理、配置创建管理日志项目Project,例如叫myorder
为不同数据源形成日志创建日志库Logstore,例如:
如须要对原创数据进行清洗与ETL,可以创建一些中间结果logstore
(更多操作可以参见快速开始/管理控制台)
用户推广日志采集
为获取新用户,一般有2种形式:
网站注册时直接投放优惠券
其他渠道扫描二维码,投放优惠券
做法
定义如下注册服务器地址,生成二维码(传单、网页)供用户注册扫描。用户扫描该页面注册时,就晓得用户通过特定来源步入,并记录日志。
http://examplewebsite/login%3F ... Dkd4b
当服务端接受恳求时,服务器输出如下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
采集方法:
应用程序输出日志到硬碟,通过Logtail采集应用程序通过SDK写入,参见SDK服务端数据采集
支付宝/微信公众帐号编程是典型的Web端模式,一般会有三种类型日志:
做法日志讲到本地文件,通过Logtail配置正则表达式讲到指定LogstoreDocker中形成日志可以使用容器服务集成日志服务Java程序可以使用Log4J Appender日志不落盘, LogHub Producer Library(客户端高并发写入);Log4J AppenderC#、Python、Java、PHP、C等可以使用SDK写入Windows服务器可以使用Logstash采集终端用户日志接入Web/M 站页面用户行为
页面用户行为搜集可以分为两类:
页面与后台服务器交互:例如下单,登陆、退出等。页面无后台服务器交互:请求直接在后端处理,例如滚屏,关闭页面等。做法第一种可以参考服务端采集方法第二种可以使用Tracking Pixel/JS Library搜集页面行为,参考Tracking Web插口服务器日志运维
例如:
做法不同网路环境下数据采集
LogHub在各Region提供 访问点,每个Region提供三种形式接入点:
更多请参见网路接入,总有一款适宜你。
其他参见LogHub完整采集方式。参见日志实时消费,涉及流计算、数据清洗、数据库房和索引查询等功能。
实现并口数据的接收功能、以及绘图工具进行数据显示
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-11 12:58
前言:这个小项目是自己的毕设,做的比较简单,之前记录是pyqt的环境配置,说实话,今天忽然听到自己也都忘得差不多了,看来还是要好好记录一下自己的知识。
这个项目分为了两个部份,其中下位机的数据采集是使用STM32L0系列的开发板作为了主控器,温度采集模块是DB18B20,还有一个GSM模块,用于发送邮件,比较简单的项目。上位机部份也就是使用pyserial模块来进行数据的接收,使用matplotlib模块来进行绘图。
下位机部份的代码还在,但是用于时间关系,开发板等东西已然送人了,所以这篇博客主要就讲一下上位机的程序开发,但是为了和上一篇博客中实现的疗效一样,我去找到了一个软件模拟下位机向PC端发送数据。
1.模拟软件向PC端发送数据–VSPD软件
找了一篇博客,收录VSPD使用教程,放上链接如下:
2.串口接收数据
今天打算把之前的代码用来跑一下,但是发觉出了一些小问题,这里也记载一下,被自己蠢哭的问题。
问题1:
pyserial模块的安装问题,换了环境,但是使用pip安装,以及在pycharm中进行安装,都没有成功,下载的包都是空的文件夹,其截图如下:
解决办法,去官网下载压缩包,然后解压到你的类库的Lib/site-packages目录下,然后运行命令进行安装;
#files
命令行安装
综上问题1解决
问题2(自己犯低级错误):
a.串口初始化部份
class MainWindow(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(MainWindow, self).__init__(parent)
self.setupUi(self)
### 1. 画图
self.my_graph_1 = MyMplCanvas()
self.left1.addWidget(self.my_graph_1)
self.t = [] ### 储存计数
self.m = [] ### 储存接收的数据
self.i = 0 ### 计数值
### 2. 串口部分
# 串口初始化为None
self.ser = None
# 设置窗口名称
self.setWindowTitle("Temperature--Serial")
# 刷新一下串口的列表
# self.refresh()
# 波特率
self.comboBox_2.addItem('115200')
self.comboBox_2.addItem('57600')
self.comboBox_2.addItem('9600')
self.comboBox_2.addItem('4800')
self.comboBox_2.addItem('2400')
self.comboBox_2.addItem('1200')
# 实例化一个定时器
self.timer = QTimer(self)
# 定时器调用读取串口接收数据
self.timer.timeout.connect(self.recv)
# 打开串口按钮
self.pushButton.clicked.connect(self.open)
# 关闭串口
self.pushButton_2.clicked.connect(self.close)
# 波特率修改
self.comboBox_2.activated.connect(self.baud_modify)
# 串口号修改
self.comboBox.activated.connect(self.com_modify)
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
b.数据接收及处理 查看全部
实现并口数据的接收功能、以及绘图工具进行数据显示
前言:这个小项目是自己的毕设,做的比较简单,之前记录是pyqt的环境配置,说实话,今天忽然听到自己也都忘得差不多了,看来还是要好好记录一下自己的知识。
这个项目分为了两个部份,其中下位机的数据采集是使用STM32L0系列的开发板作为了主控器,温度采集模块是DB18B20,还有一个GSM模块,用于发送邮件,比较简单的项目。上位机部份也就是使用pyserial模块来进行数据的接收,使用matplotlib模块来进行绘图。
下位机部份的代码还在,但是用于时间关系,开发板等东西已然送人了,所以这篇博客主要就讲一下上位机的程序开发,但是为了和上一篇博客中实现的疗效一样,我去找到了一个软件模拟下位机向PC端发送数据。
1.模拟软件向PC端发送数据–VSPD软件
找了一篇博客,收录VSPD使用教程,放上链接如下:
2.串口接收数据
今天打算把之前的代码用来跑一下,但是发觉出了一些小问题,这里也记载一下,被自己蠢哭的问题。
问题1:
pyserial模块的安装问题,换了环境,但是使用pip安装,以及在pycharm中进行安装,都没有成功,下载的包都是空的文件夹,其截图如下:
解决办法,去官网下载压缩包,然后解压到你的类库的Lib/site-packages目录下,然后运行命令进行安装;
#files
命令行安装
综上问题1解决
问题2(自己犯低级错误):
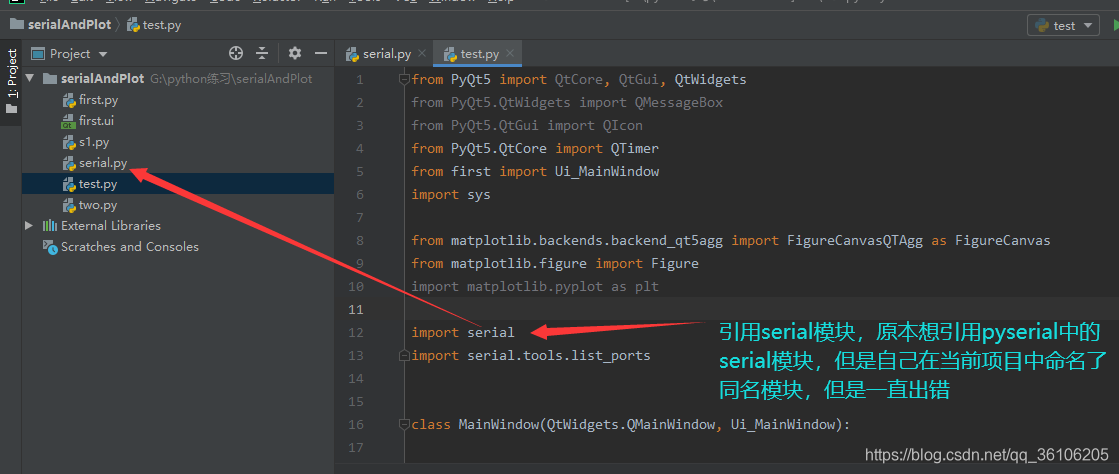
a.串口初始化部份
class MainWindow(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(MainWindow, self).__init__(parent)
self.setupUi(self)
### 1. 画图
self.my_graph_1 = MyMplCanvas()
self.left1.addWidget(self.my_graph_1)
self.t = [] ### 储存计数
self.m = [] ### 储存接收的数据
self.i = 0 ### 计数值
### 2. 串口部分
# 串口初始化为None
self.ser = None
# 设置窗口名称
self.setWindowTitle("Temperature--Serial")
# 刷新一下串口的列表
# self.refresh()
# 波特率
self.comboBox_2.addItem('115200')
self.comboBox_2.addItem('57600')
self.comboBox_2.addItem('9600')
self.comboBox_2.addItem('4800')
self.comboBox_2.addItem('2400')
self.comboBox_2.addItem('1200')
# 实例化一个定时器
self.timer = QTimer(self)
# 定时器调用读取串口接收数据
self.timer.timeout.connect(self.recv)
# 打开串口按钮
self.pushButton.clicked.connect(self.open)
# 关闭串口
self.pushButton_2.clicked.connect(self.close)
# 波特率修改
self.comboBox_2.activated.connect(self.baud_modify)
# 串口号修改
self.comboBox.activated.connect(self.com_modify)
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
b.数据接收及处理
系列文章:Kubernetes日志采集最佳实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-09 16:03
上一期主要介绍Kubernetes日志输出的一些注意事项,日志输出最终的目的还是做统一的采集和剖析。在Kubernetes中,日志采集和普通虚拟机的方法有很大不同,相对实现难度和布署代价也略大,但若使用恰当则比传统方法自动化程度更高、运维代价更低。
Kubernetes日志采集难点
在Kubernetes中,日志采集相比传统虚拟机、物理机方法要复杂好多,最根本的缘由是Kubernetes把底层异常屏蔽,提供愈发细细度的资源调度,向上提供稳定、动态的环境。因此日志采集面对的是愈发丰富、动态的环境,需要考虑的点也愈发的多。
例如:
对于运行时间太短的Job类应用,从启动到停止只有几秒的时间,如何保证日志采集的实时性才能跟上并且数据不丢?K8s通常推荐使用大尺寸节点,每个节点可以运行10-100+的容器,如何在资源消耗尽可能低的情况下采集100+的容器?在K8s中,应用都以yaml的形式布署,而日志采集还是以手工的配置文件方式为主,如何才能使日志采集以K8s的方法进行布署?Kubernetes传统方法
日志种类
文件、stdout、宿主机文件、journal
文件、journal
日志源
业务容器、系统组件、宿主机
业务、宿主机
采集方式
Agent(Sidecar、DaemonSet)、直写(DockerEngine、业务)
Agent、直写
单机应用数
10-100
1-10
应用动态性
高
低
节点动态性
高
低
采集部署形式
手动、Yaml
手动、自定义
采集方式:主动 or 被动
日志的采集方式分为被动采集和主动推送两种,在K8s中,被动采集一般分为Sidecar和DaemonSet两种形式,主动推送有DockerEngine推送和业务直写两种形式。
总结出来:DockerEngine直写通常不推荐;业务直写推荐在日志量极大的场景中使用;DaemonSet通常在中小型集群中使用;Sidecar推荐在超大型的集群中使用。详细的各类采集方式对比如下:
DockerEngine业务直写DaemonSet形式Sidecar形式
采集日志类型
标准输出
业务日志
标准输出+部分文件
文件
部署运维
低,原生支持
低,只需维护好配置文件即可
一般,需维护DaemonSet
较高,每个须要采集日志的POD都须要布署sidecar容器
日志分类储存
无法实现
业务独立配置
一般,可通过容器/路径等映射
每个POD可单独配置,灵活性高
多住户隔离
弱
弱,日志直写会和业务逻辑竞争资源
一般,只能通过配置间隔离
强,通过容器进行隔离,可单独分配资源
支持集群规模
本地储存无限制,若使用syslog、fluentd会有单点限制
无限制
取决于配置数
无限制
资源占用
低,docker
engine提供
整体最低,省去采集开销
较低,每个节点运行一个容器
较高,每个POD运行一个容器
查询便捷性
低,只能grep原创日志
高,可依照业务特性进行订制
较高,可进行自定义的查询、统计
高,可依照业务特性进行订制
可定制性
低
高,可自由扩充
低
高,每个POD单独配置
耦合度
高,与DockerEngine强绑定,修改须要重启DockerEngine
高,采集模块更改/升级须要重新发布业务
低,Agent可独立升级
一般,默认采集Agent升级对应Sidecar业务也会重启(有一些扩充包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类明晰、功能较单一的集群
大型、混合型、PAAS型集群
日志输出:Stdout or 文件
和虚拟机/物理机不同,K8s的容器提供标准输出和文件两种形式。在容器中,标准输出将日志直接输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,将日志接收后根据DockerEngine配置的LogDriver规则进行处理;日志复印到文件的形式和虚拟机/物理机基本类似,只是日志可以使用不同的储存形式,例如默认储存、EmptyDir、HostVolume、NFS等。
虽然使用Stdout复印日志是Docker官方推荐的方法,但你们须要注意这个推荐是基于容器只作为简单应用的场景,实际的业务场景中我们还是建议你们尽可能使用文件的形式,主要的缘由有以下几点:
Stdout性能问题,从应用输出stdout到服务端,中间会经过好几个流程(例如普遍使用的JSON LogDriver):应用stdout -> DockerEngine -> LogDriver -> 序列化成JSON -> 保存到文件 -> Agent采集文件 -> 解析JSON -> 上传服务端。整个流程相比文件的额外开支要多好多,在压测时,每秒10万行日志输出都会额外占用DockerEngine 1个CPU核。Stdout不支持分类,即所有的输出都混在一个流中,无法象文件一样分类输出,通常一个应用中有AccessLog、ErrorLog、InterfaceLog(调用外部插口的日志)、TraceLog等,而这种日志的格式、用途不一,如果混在同一个流上将很难采集和剖析。Stdout只支持容器的主程序输出,如果是daemon/fork形式运行的程序将难以使用stdout。文件的Dump形式支持各类策略,例如同步/异步写入、缓存大小、文件轮转策略、压缩策略、清除策略等,相对愈发灵活。
因此我们建议线上应用使用文件的形式输出日志,Stdout只在功能单一的应用或一些K8s系统/运维组件中使用。
CICD集成:Logging Operator
Kubernetes提供了标准化的业务布署形式,可以通过yaml(K8s API)来申明路由规则、暴露服务、挂载储存、运行业务、定义缩扩容规则等,所以Kubernetes很容易和CICD系统集成。而日志采集也是运维监控过程中的重要部份,业务上线后的所有日志都要进行实时的搜集。
原创的形式是在发布以后自动去布署日志采集的逻辑,这种方法须要手工干预,违背CICD自动化的宗旨;为了实现自动化,有人开始基于日志采集的API/SDK包装一个手动布署的服务,在发布后通过CICD的webhook触发调用,但这些方法的开发代价很高。
在Kubernetes中,日志最标准的集成方法是以一个新资源注册到Kubernetes系统中,以Operator(CRD)的形式来进行管理和维护。在这些形式下,CICD系统不需要额外的开发,只需在布署到Kubernetes系统时附加上日志相关的配置即可实现。
Kubernetes日志采集方案
早在Kubernetes出现之前,我们就开始为容器环境开发日志采集方案,随着K8s的逐步稳定,我们开始将好多业务迁移到K8s平台上,因此也基于之前的基础专门开发了一套K8s上的日志采集方案。主要具备的功能有:
支持各种数据的实时采集,包括容器文件、容器Stdout、宿主机文件、Journal、Event等;支持多种采集部署方法,包括DaemonSet、Sidecar、DockerEngine LogDriver等;支持对日志数据进行富化,包括附加Namespace、Pod、Container、Image、Node等信息;稳定、高可靠,基于阿里自研的Logtail采集Agent实现,目前全网已有几百万的布署实例;基于CRD进行扩充,可使用Kubernetes布署发布的形式来布署日志采集规则,与CICD完美集成。安装日志采集组件
目前这套采集方案早已对外开放,我们提供了一个Helm安装包,其中包括Logtail的DaemonSet、AliyunlogConfig的CRD申明以及CRD Controller,安装以后才能直接使用DaemonS优采云采集器以及CRD配置了。安装方法如下:
阿里云Kubernetes集群在开通的时侯可以勾选安装,这样在集群创建的时侯会手动安装上述组件。如果开通的时侯没有安装,则可以自动安装。如果是自建的Kubernetes,无论是在阿里云上自建还是在其他云或则是线下,也可以使用这样采集方案,具体安装方法参考[自建Kubernetes安装]()。
安装好上述组件然后,Logtail和对应的Controller都会运行在集群中,但默认这种组件并不会采集任何日志,需要配置日志采集规则来采集指定Pod的各种日志。
采集规则配置:环境变量 or CRD
除了在日志服务控制台上自动配置之外,对于Kubernetes还额外支持两种配置方法:环境变量和CRD。
环境变量是自swarm时代仍然使用的配置方法,只须要在想要采集的容器环境变量上申明须要采集的数据地址即可,Logtail会手动将这种数据采集到服务端。这种方法布署简单,学习成本低,很容易上手;但才能支持的配置规则极少,很多中级配置(例如解析方法、过滤方法、黑白名单等)都不支持,而且这些申明的方法不支持更改/删除,每次更改虽然都是创建1个新的采集配置,历史的采集配置须要自动清除,否则会导致资源浪费。
CRD配置方法是特别符合Kubernetes官方推荐的标准扩充方法,让采集配置以K8s资源的方法进行管理,通过向Kubernetes部署AliyunLogConfig这个特殊的CRD资源来申明须要采集的数据。例如下边的示例就是布署一个容器标准输出的采集,其中定义须要Stdout和Stderr都采集,并且排除环境变量中收录COLLEXT_STDOUT_FLAG:false的容器。
基于CRD的配置方法以Kubernetes标准扩充资源的方法进行管理,支持配置的增删改查完整语义,而且支持各类中级配置,是我们非常推荐的采集配置方法。
采集规则推荐的配置形式
实际应用场景中,一般都是使用DaemonSet或DaemonSet与Sidecar混用形式,DaemonSet的优势是资源利用率高,但有一个问题是DaemonSet的所有Logtail都共享全局配置,而单一的Logtail有配置支撑的上限,因此难以支撑应用数比较多的集群。
上述是我们给出的推荐配置形式,核心的思想是:
一个配置尽可能多的采集同类数据,减少配置数,降低DaemonSet压力;核心的应用采集要给以充分的资源,可以使用Sidecar形式;配置方法尽可能使用CRD形式;Sidecar因为每位Logtail是单独的配置,所以没有配置数的限制,这种比较适宜于超小型的集群使用。
实践1-中小型集群
绝大部分Kubernetes集群都属于中小型的,对于中小型没有明晰的定义,一般应用数在500以内,节点规模1000以内,没有职能明晰的Kubernetes平台运维。这种场景应用数不会非常多,DaemonSet可以支撑所有的采集配置:
绝大部分业务应用的数据使用DaemonS优采云采集器形式核心应用(对于采集可靠性要求比较高,例如订单/交易系统)使用Sidecar形式单独采集
实践2-大型集群
对于一些用作PAAS平台的小型/超大型集群,一般业务在1000以上,节点规模也在1000以上,有专门的Kubernetes平台运维人员。这种场景下应用数没有限制,DaemonSet难以支持,因此必须使用Sidecar形式,整体规划如下:
Kubernetes平台本身的系统组件日志、内核日志相对种类固定,这部份日志使用DaemonS优采云采集器,主要为平台的运维人员提供服务;各个业务的日志使用Sidecar形式采集,每个业务可以独立设置Sidecar的采集目的地址,为业务的DevOps人员提供足够的灵活性。
原文链接 查看全部
前言
上一期主要介绍Kubernetes日志输出的一些注意事项,日志输出最终的目的还是做统一的采集和剖析。在Kubernetes中,日志采集和普通虚拟机的方法有很大不同,相对实现难度和布署代价也略大,但若使用恰当则比传统方法自动化程度更高、运维代价更低。
Kubernetes日志采集难点
在Kubernetes中,日志采集相比传统虚拟机、物理机方法要复杂好多,最根本的缘由是Kubernetes把底层异常屏蔽,提供愈发细细度的资源调度,向上提供稳定、动态的环境。因此日志采集面对的是愈发丰富、动态的环境,需要考虑的点也愈发的多。
例如:
对于运行时间太短的Job类应用,从启动到停止只有几秒的时间,如何保证日志采集的实时性才能跟上并且数据不丢?K8s通常推荐使用大尺寸节点,每个节点可以运行10-100+的容器,如何在资源消耗尽可能低的情况下采集100+的容器?在K8s中,应用都以yaml的形式布署,而日志采集还是以手工的配置文件方式为主,如何才能使日志采集以K8s的方法进行布署?Kubernetes传统方法
日志种类
文件、stdout、宿主机文件、journal
文件、journal
日志源
业务容器、系统组件、宿主机
业务、宿主机
采集方式
Agent(Sidecar、DaemonSet)、直写(DockerEngine、业务)
Agent、直写
单机应用数
10-100
1-10
应用动态性
高
低
节点动态性
高
低
采集部署形式
手动、Yaml
手动、自定义
采集方式:主动 or 被动
日志的采集方式分为被动采集和主动推送两种,在K8s中,被动采集一般分为Sidecar和DaemonSet两种形式,主动推送有DockerEngine推送和业务直写两种形式。
总结出来:DockerEngine直写通常不推荐;业务直写推荐在日志量极大的场景中使用;DaemonSet通常在中小型集群中使用;Sidecar推荐在超大型的集群中使用。详细的各类采集方式对比如下:
DockerEngine业务直写DaemonSet形式Sidecar形式
采集日志类型
标准输出
业务日志
标准输出+部分文件
文件
部署运维
低,原生支持
低,只需维护好配置文件即可
一般,需维护DaemonSet
较高,每个须要采集日志的POD都须要布署sidecar容器
日志分类储存
无法实现
业务独立配置
一般,可通过容器/路径等映射
每个POD可单独配置,灵活性高
多住户隔离
弱
弱,日志直写会和业务逻辑竞争资源
一般,只能通过配置间隔离
强,通过容器进行隔离,可单独分配资源
支持集群规模
本地储存无限制,若使用syslog、fluentd会有单点限制
无限制
取决于配置数
无限制
资源占用
低,docker
engine提供
整体最低,省去采集开销
较低,每个节点运行一个容器
较高,每个POD运行一个容器
查询便捷性
低,只能grep原创日志
高,可依照业务特性进行订制
较高,可进行自定义的查询、统计
高,可依照业务特性进行订制
可定制性
低
高,可自由扩充
低
高,每个POD单独配置
耦合度
高,与DockerEngine强绑定,修改须要重启DockerEngine
高,采集模块更改/升级须要重新发布业务
低,Agent可独立升级
一般,默认采集Agent升级对应Sidecar业务也会重启(有一些扩充包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类明晰、功能较单一的集群
大型、混合型、PAAS型集群
日志输出:Stdout or 文件
和虚拟机/物理机不同,K8s的容器提供标准输出和文件两种形式。在容器中,标准输出将日志直接输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,将日志接收后根据DockerEngine配置的LogDriver规则进行处理;日志复印到文件的形式和虚拟机/物理机基本类似,只是日志可以使用不同的储存形式,例如默认储存、EmptyDir、HostVolume、NFS等。
虽然使用Stdout复印日志是Docker官方推荐的方法,但你们须要注意这个推荐是基于容器只作为简单应用的场景,实际的业务场景中我们还是建议你们尽可能使用文件的形式,主要的缘由有以下几点:
Stdout性能问题,从应用输出stdout到服务端,中间会经过好几个流程(例如普遍使用的JSON LogDriver):应用stdout -> DockerEngine -> LogDriver -> 序列化成JSON -> 保存到文件 -> Agent采集文件 -> 解析JSON -> 上传服务端。整个流程相比文件的额外开支要多好多,在压测时,每秒10万行日志输出都会额外占用DockerEngine 1个CPU核。Stdout不支持分类,即所有的输出都混在一个流中,无法象文件一样分类输出,通常一个应用中有AccessLog、ErrorLog、InterfaceLog(调用外部插口的日志)、TraceLog等,而这种日志的格式、用途不一,如果混在同一个流上将很难采集和剖析。Stdout只支持容器的主程序输出,如果是daemon/fork形式运行的程序将难以使用stdout。文件的Dump形式支持各类策略,例如同步/异步写入、缓存大小、文件轮转策略、压缩策略、清除策略等,相对愈发灵活。
因此我们建议线上应用使用文件的形式输出日志,Stdout只在功能单一的应用或一些K8s系统/运维组件中使用。
CICD集成:Logging Operator
Kubernetes提供了标准化的业务布署形式,可以通过yaml(K8s API)来申明路由规则、暴露服务、挂载储存、运行业务、定义缩扩容规则等,所以Kubernetes很容易和CICD系统集成。而日志采集也是运维监控过程中的重要部份,业务上线后的所有日志都要进行实时的搜集。
原创的形式是在发布以后自动去布署日志采集的逻辑,这种方法须要手工干预,违背CICD自动化的宗旨;为了实现自动化,有人开始基于日志采集的API/SDK包装一个手动布署的服务,在发布后通过CICD的webhook触发调用,但这些方法的开发代价很高。
在Kubernetes中,日志最标准的集成方法是以一个新资源注册到Kubernetes系统中,以Operator(CRD)的形式来进行管理和维护。在这些形式下,CICD系统不需要额外的开发,只需在布署到Kubernetes系统时附加上日志相关的配置即可实现。
Kubernetes日志采集方案
早在Kubernetes出现之前,我们就开始为容器环境开发日志采集方案,随着K8s的逐步稳定,我们开始将好多业务迁移到K8s平台上,因此也基于之前的基础专门开发了一套K8s上的日志采集方案。主要具备的功能有:
支持各种数据的实时采集,包括容器文件、容器Stdout、宿主机文件、Journal、Event等;支持多种采集部署方法,包括DaemonSet、Sidecar、DockerEngine LogDriver等;支持对日志数据进行富化,包括附加Namespace、Pod、Container、Image、Node等信息;稳定、高可靠,基于阿里自研的Logtail采集Agent实现,目前全网已有几百万的布署实例;基于CRD进行扩充,可使用Kubernetes布署发布的形式来布署日志采集规则,与CICD完美集成。安装日志采集组件
目前这套采集方案早已对外开放,我们提供了一个Helm安装包,其中包括Logtail的DaemonSet、AliyunlogConfig的CRD申明以及CRD Controller,安装以后才能直接使用DaemonS优采云采集器以及CRD配置了。安装方法如下:
阿里云Kubernetes集群在开通的时侯可以勾选安装,这样在集群创建的时侯会手动安装上述组件。如果开通的时侯没有安装,则可以自动安装。如果是自建的Kubernetes,无论是在阿里云上自建还是在其他云或则是线下,也可以使用这样采集方案,具体安装方法参考[自建Kubernetes安装]()。
安装好上述组件然后,Logtail和对应的Controller都会运行在集群中,但默认这种组件并不会采集任何日志,需要配置日志采集规则来采集指定Pod的各种日志。
采集规则配置:环境变量 or CRD
除了在日志服务控制台上自动配置之外,对于Kubernetes还额外支持两种配置方法:环境变量和CRD。
环境变量是自swarm时代仍然使用的配置方法,只须要在想要采集的容器环境变量上申明须要采集的数据地址即可,Logtail会手动将这种数据采集到服务端。这种方法布署简单,学习成本低,很容易上手;但才能支持的配置规则极少,很多中级配置(例如解析方法、过滤方法、黑白名单等)都不支持,而且这些申明的方法不支持更改/删除,每次更改虽然都是创建1个新的采集配置,历史的采集配置须要自动清除,否则会导致资源浪费。
CRD配置方法是特别符合Kubernetes官方推荐的标准扩充方法,让采集配置以K8s资源的方法进行管理,通过向Kubernetes部署AliyunLogConfig这个特殊的CRD资源来申明须要采集的数据。例如下边的示例就是布署一个容器标准输出的采集,其中定义须要Stdout和Stderr都采集,并且排除环境变量中收录COLLEXT_STDOUT_FLAG:false的容器。
基于CRD的配置方法以Kubernetes标准扩充资源的方法进行管理,支持配置的增删改查完整语义,而且支持各类中级配置,是我们非常推荐的采集配置方法。
采集规则推荐的配置形式
实际应用场景中,一般都是使用DaemonSet或DaemonSet与Sidecar混用形式,DaemonSet的优势是资源利用率高,但有一个问题是DaemonSet的所有Logtail都共享全局配置,而单一的Logtail有配置支撑的上限,因此难以支撑应用数比较多的集群。
上述是我们给出的推荐配置形式,核心的思想是:
一个配置尽可能多的采集同类数据,减少配置数,降低DaemonSet压力;核心的应用采集要给以充分的资源,可以使用Sidecar形式;配置方法尽可能使用CRD形式;Sidecar因为每位Logtail是单独的配置,所以没有配置数的限制,这种比较适宜于超小型的集群使用。
实践1-中小型集群
绝大部分Kubernetes集群都属于中小型的,对于中小型没有明晰的定义,一般应用数在500以内,节点规模1000以内,没有职能明晰的Kubernetes平台运维。这种场景应用数不会非常多,DaemonSet可以支撑所有的采集配置:
绝大部分业务应用的数据使用DaemonS优采云采集器形式核心应用(对于采集可靠性要求比较高,例如订单/交易系统)使用Sidecar形式单独采集
实践2-大型集群
对于一些用作PAAS平台的小型/超大型集群,一般业务在1000以上,节点规模也在1000以上,有专门的Kubernetes平台运维人员。这种场景下应用数没有限制,DaemonSet难以支持,因此必须使用Sidecar形式,整体规划如下:
Kubernetes平台本身的系统组件日志、内核日志相对种类固定,这部份日志使用DaemonS优采云采集器,主要为平台的运维人员提供服务;各个业务的日志使用Sidecar形式采集,每个业务可以独立设置Sidecar的采集目的地址,为业务的DevOps人员提供足够的灵活性。
原文链接
一种基于分布式的舆情数据实时采集方法和系统技术方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-09 15:04
全部详尽技术资料下载
【技术实现步骤摘要】
本专利技术涉及互联网舆情数据的分布式高并发采集方法及系统,特别的涉及目标数据的高效、实时采集技术实现方式及系统,尤其涉及一种基于分布式的舆情数据实时采集方法及系统。
技术介绍
舆情是在一定的社会空间内,围绕中介性社会风波的发生、发展和变化,民众对社会管理者形成和持有的社会政治心态。目前,网络成为反映社会舆情的主要载体之一,在舆情传播中起着重要的作用。而舆论危机的爆发使越来越多的人关注社会舆论的形成和发展。各级党政机关要及时了解信息,加强舆情监控,提高舆情应对能力和在新舆论环境中的执政能力,及时化解矛盾,处理好政府和民众的关系。企事业单位也须要关注网路舆情,利用市场已有的舆情剖析系统和服务平台,或者人员与工具结合,掌控网络舆情,辅助决策。如何从大量的网路数据中提取出关键信息,是当前技术研究的一个重点。传统的通用搜索引擎作为一个辅助检索信息的工具,成为用户访问网路的入口和手册。但是,这些通用的搜索引擎也存在着一定的局限性,1、通用搜索引擎所返回的结果收录大量用户不关心的网页。通用搜索引擎常常对信息浓度密集且具有一定结构的数据无能为力,不能挺好地发觉和获取关键信息。2、简单的基于互联网的数据采集系统,其采集方式单一,无法同时多任务执行,这就造成了数据的采集效率较低,无法满足数据的实时性。3、目前的其他舆情剖析监测系统,舆情数据大部分采用离线处理机制,在结构上就造成了其数据必然存在一定的信噪比。而随着网路技术的发展,信息更新的速率越来越快,低信噪比的舆情数据采集系统成为舆情剖析项目的急切需求。
技术实现思路
本专利技术的目的在于克服现有技术的不足,提供一种基于分布式的舆情数据实时采集方法及系统,爬取的数据可生成在线舆情大数据库,为相关政府及企业用户提供在线数据库服务。本专利技术的目的是通过以下技术方案来实现的:一种基于分布式的舆情数据实时采集方法,它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。所述的步骤S1包括以下子步骤:S11:将所有数据源站分为多类,针对每一类网站采集包括网站的网页地址、网页标题、关键字在内的信息构建类相关的关键字库;S12:根据每类网站的页面数据特性,事先定义好要爬取的数据数组;S13:当有新的目标网站需要采集时,获取包括目标网站地址、页面标题、页面关键字在内的与关键字库对应的信息,根据获得的信息与已有的泛型数据对目标网站进行分类;同时筛选出网站的文章列表地址,过滤包括广告在内的与舆情数据无关的页面,将筛选出的地址加入数据采集网站列表。
所述的步骤S2包括以下子步骤:S21:将分类后的舆情数据源网站以列表的形式传给数据采集服务器,数据采集服务器将采集任务分配到多台数据采集PC;针对每位源站,系统设置专门的爬虫进行数据爬取;S22:在数据爬取的过程中对源网站进行实时监控,系统在整个数据爬取过程中采用休眠机制循环访问网站页面,休眠时间依照网站的数据更新速率动态设置;当更新量达到采集阈值时,爬虫激活进行新一轮的数据采集;同时,在每一轮数据采集完成以后,系统标示最后的采集位置,日志文件记录本次循环共采集的数据条数,系统步入休眠状态。在数据爬取过程中,系统首先采用鞋厂设计模式将模拟访问不同的浏览器方式封装上去,并提供统一的实例化插口;在具体实例化的过程中,指定浏览器类型名称即可生产出对应的浏览器访问类;爬虫将按照数据源站的类型与复杂度生成对应的浏览器访问实例;同时,代理设置模块在浏览器访问过程中手动为程序分配IP地址。页面数据分为静态数据和动态数据;对于静态页面数据,爬虫调用模拟浏览器访问方式页面地址获取网页源数据;对于动态数据,爬虫在访问页面之前,需要通过抓包的方法找到动态数据返回链接,再调用浏览器访问方式获取页面数据。将URL地址储存队列方式封装上去,并提供统一的实例化插口;采用多级生产者消费者模式并发的爬取数据:一级生产者依据分配的数据源网站地址访问页面获取数据的一级URL地址,并将地址储存到数据队列当中;若当前地址页面不是正文地址,而是正文列表地址,系统将分配二级生成者从当前地址队列中获取URL地址进行数据爬取,直到获取到正文URL地址;消费者负责从正文地址队列中取出URL数据,访问页面获取正文页面内容;在此过程中,生产者和消费者彼此之间通过阻塞队列来进行通信;采用队列设置模块提供队列的存取操作,并初始化队列数据库并完善联接。
所述的步骤S3包括对动态网页数据的剖析和对静态页面数据的剖析,其中对于静态页面数据使用封装好的Xpath方式,给定数据项的路径地址即可获取到对应数据项;同时结合正则表达式,通过正则表达式过滤筛选数据,补充获取XPath未能解析到的数据;系统将解析到的数据形参给事前定义好的对应的数据项;对于动态网页数据,使用JSON方式获取字典格式的动态网页数据项。所述的步骤S4步骤包括:在数据采集之前,采用鞋厂设计模式,将每一类网站定义好的数据项以及保留数组封装成字典格式,并提供统一的数据插口;在数据采集完成后,根据数据源网站类别,系统调用对应的封装方式将采集到的数据封装为对应类的统一格式;在封装过程中使用UUID方式为每条数据生成惟一的标识符,方便后续的检索操作。所述的步骤S5包括:采用鞋厂设计模式将结果数据的储存操作封装为队列方式,采集到数据然后调用队列方式将数据输入数据库服务器;在数据库服务器中分别为每一类源数据网站设置对应的数据库,在数据储存时将数据存到对应的数据库;根据保存数据的不同采取不同的数据库,保存生产者和消费者之间的URL队列数据。所述的步骤S6包括:采用鞋厂模式将日志方式封装上去,提供统一的插口访问;日志采用logging模块给运行中的程序提供了一个标准的信息输出插口;系统开始运行的时侯即调用日志插口生成实例,在整个过程中记录每位模块的运行状态与结果;在每一轮爬虫程序执行完成时,将检测结果按天生成日志文件。
采用所述的方式的系统,所述的系统包括:数据打算模块,用于完成源站的分类以及目标数据项定义;更新检测模块,用于检测目标数据网站的更新情况。数据爬取模块,用于模拟浏览器环境访问源站目标页面并将页面数据获取到本地;代理设置模块,用于手动为服务器分配IP地址。队列设置模块,用于负责管理阻塞URL采集队列,以及结果数据储存队列,并进行去重操作;数据解析模块,用于通过剖析源数据,并从中解析出目标数据项;数据封装模块,用于将爬取到的数据项统一封装成标准格式输出;数据储存模块,用于将封装好的数据储存到在线舆情大数据库;日志生成模块,用于各环节检测状态的日志输出。本专利技术的有益疗效是:1. 系统构架先进,通过使用工厂模式作为系统的主要设计模式,能够快速生成新实例。将浏览器访问,日志生成,数据封装,代理设置以及队列设置等系统核心功能封装上去。增强了系统的可扩展性和可移植性,提高了代码的可重用性和系统的可维护性
【技术保护点】
一种基于分布式的舆情数据实时采集方法,其特点在于:它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。
【技术特点摘要】
1.一种基于分布式的舆情数据实时采集方法,其特点在于:它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。2.根据权力要求1所述的一种基于分布式的舆情数据实时采集方法,其特点在于:所述的步骤S1包括以下子步骤:S11:将所有数据源站分为多类,针对每一类网站采集包括网站的网页地址、网页标题、关键字在内的信息构建类相关的关键字库;S12:根据每类网站的页面数据特性,事先定义好要爬取的数据数组;S13:当有新的目标网站需要采集时,获取包括目标网站地址、页面标题、页面关键字在内的与关键字库对应的信息,根据获得的信息与已有的泛型数据对目标网站进行分类;同时筛选出网站的文章列表地址,过滤包括广告在内的与舆情数据无关的页面,将筛选出的地址加入数据采集网站列表。
3.根据权力要求1所述的一种基于分布式的舆情数据实时采集方法,其特点在于:所述的步骤S2包括以下子步骤:S21:将分类后的舆情数据源网站以列表的形式传给数据采集服务器,数据采集服务器将采集任务分配到多台数据采集PC;针对每位源站,系统设置专门的爬虫进行数据爬取;S22:在数据爬取的过程中对源网站进行实时监控,系统在整个数据爬取过程中采用休眠机制循环访问网站页面,休眠时间依照网站的数据更新速率动态设置;当更新量达到采集阈值时,爬虫激活进行新一轮的数据采集;同时,在每一轮数据采集完成以后,系统标示最后的采集位置,日志文件记录本次循环共采集的数据条数,系统步入休眠状态。4.根据权力要求1或3所述的一种基于分布式的舆情数据实时采集方法,其特点在于:在数据爬取过程中,系统首先采用鞋厂设计模式将模拟访问不同的浏览器方式封装上去,并提供统一的实例化插口;在具体实例化的过程中,指定浏览器类型名称即可生产出对应的浏览器访问类;爬虫将按照数据源站的类型与复杂度生成对应的浏览器访问实例;同时,代理设置模块在浏览器访问过程中手动为程序分配IP地址。5.根据权力要求1或3所述的一种基于分布式的舆情数据实时采集方法,其特点在于:将URL地址储存队列方式封装上去,并提供统一的实例化插口;采用多级生产者消费者模式并发的爬取数据:一级生产者依据分配的数据源网站地址访问页面获取数据的一级URL地址,并将地址储存到数据队列当中;若当前地址页面不是正文地址,而是正文列表地址,系统将分配二级生成者从当前地址队列中获取URL地址进行...
【专利技术属性】
技术研制人员:李平,陈雁,胡栋,代臻,刘婷,许斌,孙先,林辉,赵玲,
申请(专利权)人:西南石油大学,
类型:发明
国别省市:四川;51
全部详尽技术资料下载 我是这个专利的主人 查看全部
本发明专利技术公开了一种基于分布式的舆情数据实时采集方法及系统,方法包括以下步骤:S1:建立舆情数据网站类库,分类并定义爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,服务器分配相应的爬虫以休眠的模式循环地爬取数据;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。本发明专利技术构架先进,通过使用工厂模式作为系统的主要设计模式,能够快速生成新实例,将浏览器访问、日志生成、数据封装、代理设置以及队列设置等系统核心功能封装上去,增强系统的可扩展性和可移植性,提高代码的可重用性和系统的可维护性。

全部详尽技术资料下载
【技术实现步骤摘要】
本专利技术涉及互联网舆情数据的分布式高并发采集方法及系统,特别的涉及目标数据的高效、实时采集技术实现方式及系统,尤其涉及一种基于分布式的舆情数据实时采集方法及系统。
技术介绍
舆情是在一定的社会空间内,围绕中介性社会风波的发生、发展和变化,民众对社会管理者形成和持有的社会政治心态。目前,网络成为反映社会舆情的主要载体之一,在舆情传播中起着重要的作用。而舆论危机的爆发使越来越多的人关注社会舆论的形成和发展。各级党政机关要及时了解信息,加强舆情监控,提高舆情应对能力和在新舆论环境中的执政能力,及时化解矛盾,处理好政府和民众的关系。企事业单位也须要关注网路舆情,利用市场已有的舆情剖析系统和服务平台,或者人员与工具结合,掌控网络舆情,辅助决策。如何从大量的网路数据中提取出关键信息,是当前技术研究的一个重点。传统的通用搜索引擎作为一个辅助检索信息的工具,成为用户访问网路的入口和手册。但是,这些通用的搜索引擎也存在着一定的局限性,1、通用搜索引擎所返回的结果收录大量用户不关心的网页。通用搜索引擎常常对信息浓度密集且具有一定结构的数据无能为力,不能挺好地发觉和获取关键信息。2、简单的基于互联网的数据采集系统,其采集方式单一,无法同时多任务执行,这就造成了数据的采集效率较低,无法满足数据的实时性。3、目前的其他舆情剖析监测系统,舆情数据大部分采用离线处理机制,在结构上就造成了其数据必然存在一定的信噪比。而随着网路技术的发展,信息更新的速率越来越快,低信噪比的舆情数据采集系统成为舆情剖析项目的急切需求。
技术实现思路
本专利技术的目的在于克服现有技术的不足,提供一种基于分布式的舆情数据实时采集方法及系统,爬取的数据可生成在线舆情大数据库,为相关政府及企业用户提供在线数据库服务。本专利技术的目的是通过以下技术方案来实现的:一种基于分布式的舆情数据实时采集方法,它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。所述的步骤S1包括以下子步骤:S11:将所有数据源站分为多类,针对每一类网站采集包括网站的网页地址、网页标题、关键字在内的信息构建类相关的关键字库;S12:根据每类网站的页面数据特性,事先定义好要爬取的数据数组;S13:当有新的目标网站需要采集时,获取包括目标网站地址、页面标题、页面关键字在内的与关键字库对应的信息,根据获得的信息与已有的泛型数据对目标网站进行分类;同时筛选出网站的文章列表地址,过滤包括广告在内的与舆情数据无关的页面,将筛选出的地址加入数据采集网站列表。
所述的步骤S2包括以下子步骤:S21:将分类后的舆情数据源网站以列表的形式传给数据采集服务器,数据采集服务器将采集任务分配到多台数据采集PC;针对每位源站,系统设置专门的爬虫进行数据爬取;S22:在数据爬取的过程中对源网站进行实时监控,系统在整个数据爬取过程中采用休眠机制循环访问网站页面,休眠时间依照网站的数据更新速率动态设置;当更新量达到采集阈值时,爬虫激活进行新一轮的数据采集;同时,在每一轮数据采集完成以后,系统标示最后的采集位置,日志文件记录本次循环共采集的数据条数,系统步入休眠状态。在数据爬取过程中,系统首先采用鞋厂设计模式将模拟访问不同的浏览器方式封装上去,并提供统一的实例化插口;在具体实例化的过程中,指定浏览器类型名称即可生产出对应的浏览器访问类;爬虫将按照数据源站的类型与复杂度生成对应的浏览器访问实例;同时,代理设置模块在浏览器访问过程中手动为程序分配IP地址。页面数据分为静态数据和动态数据;对于静态页面数据,爬虫调用模拟浏览器访问方式页面地址获取网页源数据;对于动态数据,爬虫在访问页面之前,需要通过抓包的方法找到动态数据返回链接,再调用浏览器访问方式获取页面数据。将URL地址储存队列方式封装上去,并提供统一的实例化插口;采用多级生产者消费者模式并发的爬取数据:一级生产者依据分配的数据源网站地址访问页面获取数据的一级URL地址,并将地址储存到数据队列当中;若当前地址页面不是正文地址,而是正文列表地址,系统将分配二级生成者从当前地址队列中获取URL地址进行数据爬取,直到获取到正文URL地址;消费者负责从正文地址队列中取出URL数据,访问页面获取正文页面内容;在此过程中,生产者和消费者彼此之间通过阻塞队列来进行通信;采用队列设置模块提供队列的存取操作,并初始化队列数据库并完善联接。
所述的步骤S3包括对动态网页数据的剖析和对静态页面数据的剖析,其中对于静态页面数据使用封装好的Xpath方式,给定数据项的路径地址即可获取到对应数据项;同时结合正则表达式,通过正则表达式过滤筛选数据,补充获取XPath未能解析到的数据;系统将解析到的数据形参给事前定义好的对应的数据项;对于动态网页数据,使用JSON方式获取字典格式的动态网页数据项。所述的步骤S4步骤包括:在数据采集之前,采用鞋厂设计模式,将每一类网站定义好的数据项以及保留数组封装成字典格式,并提供统一的数据插口;在数据采集完成后,根据数据源网站类别,系统调用对应的封装方式将采集到的数据封装为对应类的统一格式;在封装过程中使用UUID方式为每条数据生成惟一的标识符,方便后续的检索操作。所述的步骤S5包括:采用鞋厂设计模式将结果数据的储存操作封装为队列方式,采集到数据然后调用队列方式将数据输入数据库服务器;在数据库服务器中分别为每一类源数据网站设置对应的数据库,在数据储存时将数据存到对应的数据库;根据保存数据的不同采取不同的数据库,保存生产者和消费者之间的URL队列数据。所述的步骤S6包括:采用鞋厂模式将日志方式封装上去,提供统一的插口访问;日志采用logging模块给运行中的程序提供了一个标准的信息输出插口;系统开始运行的时侯即调用日志插口生成实例,在整个过程中记录每位模块的运行状态与结果;在每一轮爬虫程序执行完成时,将检测结果按天生成日志文件。
采用所述的方式的系统,所述的系统包括:数据打算模块,用于完成源站的分类以及目标数据项定义;更新检测模块,用于检测目标数据网站的更新情况。数据爬取模块,用于模拟浏览器环境访问源站目标页面并将页面数据获取到本地;代理设置模块,用于手动为服务器分配IP地址。队列设置模块,用于负责管理阻塞URL采集队列,以及结果数据储存队列,并进行去重操作;数据解析模块,用于通过剖析源数据,并从中解析出目标数据项;数据封装模块,用于将爬取到的数据项统一封装成标准格式输出;数据储存模块,用于将封装好的数据储存到在线舆情大数据库;日志生成模块,用于各环节检测状态的日志输出。本专利技术的有益疗效是:1. 系统构架先进,通过使用工厂模式作为系统的主要设计模式,能够快速生成新实例。将浏览器访问,日志生成,数据封装,代理设置以及队列设置等系统核心功能封装上去。增强了系统的可扩展性和可移植性,提高了代码的可重用性和系统的可维护性
【技术保护点】
一种基于分布式的舆情数据实时采集方法,其特点在于:它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。
【技术特点摘要】
1.一种基于分布式的舆情数据实时采集方法,其特点在于:它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。2.根据权力要求1所述的一种基于分布式的舆情数据实时采集方法,其特点在于:所述的步骤S1包括以下子步骤:S11:将所有数据源站分为多类,针对每一类网站采集包括网站的网页地址、网页标题、关键字在内的信息构建类相关的关键字库;S12:根据每类网站的页面数据特性,事先定义好要爬取的数据数组;S13:当有新的目标网站需要采集时,获取包括目标网站地址、页面标题、页面关键字在内的与关键字库对应的信息,根据获得的信息与已有的泛型数据对目标网站进行分类;同时筛选出网站的文章列表地址,过滤包括广告在内的与舆情数据无关的页面,将筛选出的地址加入数据采集网站列表。
3.根据权力要求1所述的一种基于分布式的舆情数据实时采集方法,其特点在于:所述的步骤S2包括以下子步骤:S21:将分类后的舆情数据源网站以列表的形式传给数据采集服务器,数据采集服务器将采集任务分配到多台数据采集PC;针对每位源站,系统设置专门的爬虫进行数据爬取;S22:在数据爬取的过程中对源网站进行实时监控,系统在整个数据爬取过程中采用休眠机制循环访问网站页面,休眠时间依照网站的数据更新速率动态设置;当更新量达到采集阈值时,爬虫激活进行新一轮的数据采集;同时,在每一轮数据采集完成以后,系统标示最后的采集位置,日志文件记录本次循环共采集的数据条数,系统步入休眠状态。4.根据权力要求1或3所述的一种基于分布式的舆情数据实时采集方法,其特点在于:在数据爬取过程中,系统首先采用鞋厂设计模式将模拟访问不同的浏览器方式封装上去,并提供统一的实例化插口;在具体实例化的过程中,指定浏览器类型名称即可生产出对应的浏览器访问类;爬虫将按照数据源站的类型与复杂度生成对应的浏览器访问实例;同时,代理设置模块在浏览器访问过程中手动为程序分配IP地址。5.根据权力要求1或3所述的一种基于分布式的舆情数据实时采集方法,其特点在于:将URL地址储存队列方式封装上去,并提供统一的实例化插口;采用多级生产者消费者模式并发的爬取数据:一级生产者依据分配的数据源网站地址访问页面获取数据的一级URL地址,并将地址储存到数据队列当中;若当前地址页面不是正文地址,而是正文列表地址,系统将分配二级生成者从当前地址队列中获取URL地址进行...
【专利技术属性】
技术研制人员:李平,陈雁,胡栋,代臻,刘婷,许斌,孙先,林辉,赵玲,
申请(专利权)人:西南石油大学,
类型:发明
国别省市:四川;51
全部详尽技术资料下载 我是这个专利的主人
全网微博数据每日亿级实时采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2020-08-09 08:34
硬件配置
2台服务器,每台的配置如下
系统CPU显存硬碟
Ubuntu16.04E5-2630 v4 @ 2.20GHz * 832G1T
抓取速率
每台服务器满负荷运转:
每台服务器启动50个爬虫进程,两台共100个爬虫进程
每个进程的抓取情况:
可以看见每位进程,每分钟可以抓取300+页面。那么,一天共可以抓取:
300(pages/(process*min)) * 100(prcesses) * 60*24(mins/day) = 43,200,000(pages/day)
所以三天可以抓取4.3千万的页面
如果抓取用户个人信息,1(data/page) ,
则三天的数据抓取量是 43,200,000(pages/day) * 1(data/page) = 43,200,000(data/day) 4.3千万
如果抓取用户微博数据,10(data/page) ,
则三天的数据抓取量是 43,200,000(pages/day) * 10(data/page) = 432,000,000(data/day) 4.3亿
数据库统计
MongoDB IO量
每秒4500+的数据插入量,所以三天就是4亿+的数据采集入库量
用户个人信息数据
微博用户id采用海量采集的形式,目前早已拥有5.5千万有效真实用户的微博id,并且在不断下降中
发掘id有效id有效百分比
97,267,43555,832,4010.574
用户微博数据
实时抓取5.5千万+有效用户的微博,数据统计
微博发表日期为11.20~11.24日之间的微博
11.2011.2111.2211.2311.24
13,864,35918,438,46018,866,07218,143,92311,351,606
当前数据库总数:537,475,459 (5亿)
数据展示
用户数据
微博数据 查看全部
实验数据
硬件配置
2台服务器,每台的配置如下
系统CPU显存硬碟
Ubuntu16.04E5-2630 v4 @ 2.20GHz * 832G1T
抓取速率
每台服务器满负荷运转:
每台服务器启动50个爬虫进程,两台共100个爬虫进程
每个进程的抓取情况:
可以看见每位进程,每分钟可以抓取300+页面。那么,一天共可以抓取:
300(pages/(process*min)) * 100(prcesses) * 60*24(mins/day) = 43,200,000(pages/day)
所以三天可以抓取4.3千万的页面
如果抓取用户个人信息,1(data/page) ,
则三天的数据抓取量是 43,200,000(pages/day) * 1(data/page) = 43,200,000(data/day) 4.3千万
如果抓取用户微博数据,10(data/page) ,
则三天的数据抓取量是 43,200,000(pages/day) * 10(data/page) = 432,000,000(data/day) 4.3亿
数据库统计
MongoDB IO量
每秒4500+的数据插入量,所以三天就是4亿+的数据采集入库量
用户个人信息数据
微博用户id采用海量采集的形式,目前早已拥有5.5千万有效真实用户的微博id,并且在不断下降中
发掘id有效id有效百分比
97,267,43555,832,4010.574
用户微博数据
实时抓取5.5千万+有效用户的微博,数据统计
微博发表日期为11.20~11.24日之间的微博
11.2011.2111.2211.2311.24
13,864,35918,438,46018,866,07218,143,92311,351,606
当前数据库总数:537,475,459 (5亿)
数据展示
用户数据
微博数据
QQ群实时数据查询采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 570 次浏览 • 2020-08-09 01:47
软件功能
它可以根据关键字捕获组号,根据段落编号捕获组号和采集组,采集朋友的QQ号,支持将成员数保存为TXT,Excel格式,需要使用软件登录QQ帐户.
软件功能
1. 根据关键词采集组号: 输入关键词,省市等信息.
2. 根据号码段采集组号: 输入组号段以采集组名和对应于组号的创建者. 仅使用TM2009进行采集.
3. 采集QQ号: 可以根据城市,性别,年龄和在线状态采集QQ号.
4. 采集朋友的QQ数字: 提取朋友的数字并选择将其分组.
5. 采集组中的会员号: 您可以采集单个组中的成员,也可以采集所有加入的组.
6. 它支持以TXT和Excel格式保存,并可以使用灵活的保存格式模板导出为qq邮箱格式.
软件提示
该软件功能强大,易于操作,人性化的设计理念,并且操作页面的用户体验非常简洁,易于使用,并且完全是傻瓜式的操作模式.
软件屏幕截图
相关软件
起点QQ签名采集器: 这是起点QQ签名采集器,可以一键自动采集网络上的QQ签名,并支持导出到txt.
明智的QQ采集器: 这是明智的QQ采集器,可用于批量采集QQ的软件!可以根据地区,年龄,性别或关键字进行采集! 查看全部
这是QQ群组实时数据查询采集器,它是QQ群组号码的辅助软件.
软件功能
它可以根据关键字捕获组号,根据段落编号捕获组号和采集组,采集朋友的QQ号,支持将成员数保存为TXT,Excel格式,需要使用软件登录QQ帐户.
软件功能
1. 根据关键词采集组号: 输入关键词,省市等信息.
2. 根据号码段采集组号: 输入组号段以采集组名和对应于组号的创建者. 仅使用TM2009进行采集.
3. 采集QQ号: 可以根据城市,性别,年龄和在线状态采集QQ号.
4. 采集朋友的QQ数字: 提取朋友的数字并选择将其分组.
5. 采集组中的会员号: 您可以采集单个组中的成员,也可以采集所有加入的组.
6. 它支持以TXT和Excel格式保存,并可以使用灵活的保存格式模板导出为qq邮箱格式.
软件提示
该软件功能强大,易于操作,人性化的设计理念,并且操作页面的用户体验非常简洁,易于使用,并且完全是傻瓜式的操作模式.
软件屏幕截图

相关软件
起点QQ签名采集器: 这是起点QQ签名采集器,可以一键自动采集网络上的QQ签名,并支持导出到txt.
明智的QQ采集器: 这是明智的QQ采集器,可用于批量采集QQ的软件!可以根据地区,年龄,性别或关键字进行采集!
FileBeat + Kafka用于实时日志采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 731 次浏览 • 2020-08-07 08:16
在日志生成端(LogServer服务器)上,已部署FlumeAgent实时监视生成的日志,然后将其发送到Kafka. 经过观察,每个FlumeAgent占用大量系统资源(至少占CPU的50%或更多). 对于另一项业务,LogServer承受着巨大的压力,CPU资源特别紧张. 如果要实时采集和分析日志,则需要一个更轻量级且耗费资源较少的日志采集框架,因此我尝试了Filebeat.
Filebeat是使用go语言开发的开源文本日志采集器. 它重构了logstash采集器源代码,将其安装在日志生成服务器上以监视日志目录或特定的日志文件,并将它们发送到kastka上的logstash,elasticsearch和. Filebeat是一种数据采集解决方案,它替代了logstash-forwarder. 原因是logstash在jvm上运行并且消耗大量服务器资源(Flume也是一样). 由于Filebeat如此轻巧,因此不要期望它在日志采集过程中做更多的清理和转换工作. 它仅负责一件事,即有效且可靠地传输日志数据. 至于清洁和转换,您可以在此过程中进行后续操作.
Filebeat的官方网站地址是: 您可以下载Filebeat并在此地址查看文档.
Filebeat安装配置
Filebeat的安装和配置非常简单.
下载filebeat-5.6.3-linux-x86_64.tar.gz并将其解压缩.
输入filebeat-5.6.3-linux-x86_64目录并编辑配置文件filebeat.yml
配置输入并监视日志文件:
filebeat.prospectors:
-input_type: log
路径:
-/ data / dmp / openresty / logs / dmp_intf _ *. log
配置输出到Kafka
#——————————– Kafka输出——————————–
output.kafka:
主机: [“ datadev1: 9092”]
topic: lxw1234
required_acks: 1
PS: 假设您已经安装并配置了Kafka,并且已经建立了主题.
有关更多配置选项,请参阅官方文档.
需要大数据学习材料和交流学习的学生可以增加数据学习小组: 724693112有免费的材料,可以与一群学习大数据的小伙伴共享和共同努力
文件拍开始
在filebeat-5.6.3-linux-x86_64目录下,执行命令:
./ filebeat -e -c filebeat.yml以启动Filebeat.
启动后,Filebeat开始监视输入配置中的日志文件,并将消息发送到Kafka.
您可以在Kafka中启动Consumer来查看:
./ kafka-console-consumer.sh –bootstrap-server localhost: 9092 –topic lxw1234 –from-beginning
Filebeat邮件格式
在原创日志中,日志格式如下:
2017-11-09T15: 18: 05 + 08: 00 |〜| 127.0.0.1 |〜|-|〜| hy_xyz |〜| 200 |〜| 0.002
Filebeat将消息封装为JSON字符串,除了原创日志外,还收录其他信息.
@timestamp: 邮件发送时间
beat: Filebeat运行主机和版本信息
字段: 一些用户定义的变量和值非常有用,类似于Flume的静态拦截器
input_type: 输入类型
消息: 原创日志内容
offset: 此消息在原创日志文件中的偏移量
源: 日志文件
此外,Filebeat的CPU使用率:
初步试用后,以下问题尚待测试:
数据可靠性: 是否存在日志数据丢失或重复发送;
您可以自定义Filebeat的消息格式以删除一些多余和无用的项目吗? 查看全部
之前,我们其中一项业务的实时日志采集和处理架构大致如下:

在日志生成端(LogServer服务器)上,已部署FlumeAgent实时监视生成的日志,然后将其发送到Kafka. 经过观察,每个FlumeAgent占用大量系统资源(至少占CPU的50%或更多). 对于另一项业务,LogServer承受着巨大的压力,CPU资源特别紧张. 如果要实时采集和分析日志,则需要一个更轻量级且耗费资源较少的日志采集框架,因此我尝试了Filebeat.
Filebeat是使用go语言开发的开源文本日志采集器. 它重构了logstash采集器源代码,将其安装在日志生成服务器上以监视日志目录或特定的日志文件,并将它们发送到kastka上的logstash,elasticsearch和. Filebeat是一种数据采集解决方案,它替代了logstash-forwarder. 原因是logstash在jvm上运行并且消耗大量服务器资源(Flume也是一样). 由于Filebeat如此轻巧,因此不要期望它在日志采集过程中做更多的清理和转换工作. 它仅负责一件事,即有效且可靠地传输日志数据. 至于清洁和转换,您可以在此过程中进行后续操作.
Filebeat的官方网站地址是: 您可以下载Filebeat并在此地址查看文档.
Filebeat安装配置
Filebeat的安装和配置非常简单.
下载filebeat-5.6.3-linux-x86_64.tar.gz并将其解压缩.
输入filebeat-5.6.3-linux-x86_64目录并编辑配置文件filebeat.yml
配置输入并监视日志文件:
filebeat.prospectors:
-input_type: log
路径:
-/ data / dmp / openresty / logs / dmp_intf _ *. log
配置输出到Kafka
#——————————– Kafka输出——————————–
output.kafka:
主机: [“ datadev1: 9092”]
topic: lxw1234
required_acks: 1
PS: 假设您已经安装并配置了Kafka,并且已经建立了主题.
有关更多配置选项,请参阅官方文档.
需要大数据学习材料和交流学习的学生可以增加数据学习小组: 724693112有免费的材料,可以与一群学习大数据的小伙伴共享和共同努力
文件拍开始
在filebeat-5.6.3-linux-x86_64目录下,执行命令:
./ filebeat -e -c filebeat.yml以启动Filebeat.
启动后,Filebeat开始监视输入配置中的日志文件,并将消息发送到Kafka.
您可以在Kafka中启动Consumer来查看:
./ kafka-console-consumer.sh –bootstrap-server localhost: 9092 –topic lxw1234 –from-beginning
Filebeat邮件格式
在原创日志中,日志格式如下:
2017-11-09T15: 18: 05 + 08: 00 |〜| 127.0.0.1 |〜|-|〜| hy_xyz |〜| 200 |〜| 0.002
Filebeat将消息封装为JSON字符串,除了原创日志外,还收录其他信息.

@timestamp: 邮件发送时间
beat: Filebeat运行主机和版本信息
字段: 一些用户定义的变量和值非常有用,类似于Flume的静态拦截器
input_type: 输入类型
消息: 原创日志内容
offset: 此消息在原创日志文件中的偏移量
源: 日志文件
此外,Filebeat的CPU使用率:

初步试用后,以下问题尚待测试:
数据可靠性: 是否存在日志数据丢失或重复发送;
您可以自定义Filebeat的消息格式以删除一些多余和无用的项目吗?
实时视频IMU采集项目(1): 在Qt中使用FFmpeg库
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-07 08:15
要实现项目中视频流的实时传输和显示,最常见的是编码和解码操作. 如果您自己实现H.264的编码和解码,则将花费大量时间和精力. 因此,通常使用开源H.264编解码器. 所谓的编解码器是用于实现编码和解码,输入原创数据流以及输出H.264编码流的代码.
在Ubuntu16.04下安装FFmpeg
首先在官方网站上下载最新的FFmpeg压缩包源代码,然后使用以下命令解压缩:
$ tar xvf ffmpeg-3.4.2.tar.bz2
然后进入解压缩的文件夹以查看安装步骤:
$ cd ffmpeg-3.4.2
$ cat INSTALL.md
显示内容如下:
安装FFmpeg: 输入./configure创建配置. 配置列表
通过运行configure --help打印
选项.
可以从与FFmpeg源不同的目录中启动
configure,以在树外构建对象. 为此,请在启动配置时使用绝对路径,例如/ ffmpegdir / ffmpeg / configure. 然后键入make来构建FFmpeg. 需要GNU Make 3.81或更高版本. 键入make install以安装您构建的所有二进制文件和库.
注意
默认情况下,非系统依赖项(例如libx264,libvpx)处于禁用状态.
请按照上述步骤进行安装:
$ ./configure --prefix=/home/string/ffmpeg3.4.2 --enable-shared --disable-static
提醒: 找不到Yasm / nasm或太旧. 使用–disable-yasm进行严重破坏的构建.
发现未安装yasm,因此请安装yasm:
$ sudo apt-get install yasm
安装后,重新执行上述第一步以生成配置文件
$ make
$ make install
# 安装后,查看ffmpeg版本
cd ~/ffmpeg3.4.2/bin
./ffmpeg -version
安装成功.
Qt导入FFmpeg库
首先创建一个新的Qt项目,默认情况下每个人都会知道这一点. 下一步是根据先前的安装目录配置Qt pro文件. 如下图所示:
核心是添加FFmpeg库目录和库文件路径信息.
INCLUDEPATH += /home/string/ffmpeg3.4.2/include
LIBS += -L /home/string/ffmpeg3.4.2/lib -lavcodec -lswresample -lavutil -lavformat -lswscale
下一步是修改main.cpp文件,以测试FFmpeg文件是否成功导入.
<p># main.cpp
#include "mainwidget.h"
#include
#include
using namespace std;
// 由于建立的是C++工程,编译时使用的是C++编译器编译,
// 而FFmpeg是C的库,因此这里需要加上extern "C",否则会提示各种未定义
extern "C"
{
#include "libavcodec/avcodec.h"
#include "libavformat/avformat.h"
#include "libavfilter/avfilter.h"
#include "libswresample/swresample.h"
#include "libavdevice/avdevice.h"
}
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
MainWidget w;
w.show();
cout 查看全部
概述
要实现项目中视频流的实时传输和显示,最常见的是编码和解码操作. 如果您自己实现H.264的编码和解码,则将花费大量时间和精力. 因此,通常使用开源H.264编解码器. 所谓的编解码器是用于实现编码和解码,输入原创数据流以及输出H.264编码流的代码.
在Ubuntu16.04下安装FFmpeg
首先在官方网站上下载最新的FFmpeg压缩包源代码,然后使用以下命令解压缩:
$ tar xvf ffmpeg-3.4.2.tar.bz2
然后进入解压缩的文件夹以查看安装步骤:
$ cd ffmpeg-3.4.2
$ cat INSTALL.md
显示内容如下:
安装FFmpeg: 输入./configure创建配置. 配置列表
通过运行configure --help打印
选项.
可以从与FFmpeg源不同的目录中启动
configure,以在树外构建对象. 为此,请在启动配置时使用绝对路径,例如/ ffmpegdir / ffmpeg / configure. 然后键入make来构建FFmpeg. 需要GNU Make 3.81或更高版本. 键入make install以安装您构建的所有二进制文件和库.
注意
默认情况下,非系统依赖项(例如libx264,libvpx)处于禁用状态.
请按照上述步骤进行安装:
$ ./configure --prefix=/home/string/ffmpeg3.4.2 --enable-shared --disable-static
提醒: 找不到Yasm / nasm或太旧. 使用–disable-yasm进行严重破坏的构建.
发现未安装yasm,因此请安装yasm:
$ sudo apt-get install yasm
安装后,重新执行上述第一步以生成配置文件
$ make
$ make install
# 安装后,查看ffmpeg版本
cd ~/ffmpeg3.4.2/bin
./ffmpeg -version
安装成功.
Qt导入FFmpeg库
首先创建一个新的Qt项目,默认情况下每个人都会知道这一点. 下一步是根据先前的安装目录配置Qt pro文件. 如下图所示:

核心是添加FFmpeg库目录和库文件路径信息.
INCLUDEPATH += /home/string/ffmpeg3.4.2/include
LIBS += -L /home/string/ffmpeg3.4.2/lib -lavcodec -lswresample -lavutil -lavformat -lswscale
下一步是修改main.cpp文件,以测试FFmpeg文件是否成功导入.
<p># main.cpp
#include "mainwidget.h"
#include
#include
using namespace std;
// 由于建立的是C++工程,编译时使用的是C++编译器编译,
// 而FFmpeg是C的库,因此这里需要加上extern "C",否则会提示各种未定义
extern "C"
{
#include "libavcodec/avcodec.h"
#include "libavformat/avformat.h"
#include "libavfilter/avfilter.h"
#include "libswresample/swresample.h"
#include "libavdevice/avdevice.h"
}
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
MainWidget w;
w.show();
cout
[正版]采集所有者信息采集软件企业目录实时所有者信息采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-07 03:15
[Jigu客房新闻搜索营销软件]属于“ Jike营销软件”系列. 该软件是专业的所有者搜索软件和功能强大的所有者信息搜索和采集软件. 它可以自动采集最新的所有者目录,可以帮助您快速识别目标客户,进行充分的市场研究,为销售管理和营销管理做充分的准备,并为您提供直接与目标客户联系的机会. 搜索结果支持导出到Excel或一键导入到手机通讯簿. 该数据可用于研究或市场参考. (非个人隐私信息,该软件不生产,也不存储任何数据)
软件功能,只需用鼠标单击,无需编写任何采集规则,[它可以直接导出Excel文件,并且只需单击一下即可导入手机通讯录,适用于电话销售和微信营销. )
1. 实时采集,不是历史数据,而是官方网站的最新搜索数据.
2. 该操作简单易用,傻瓜式操作,分三个步骤完成(配置城市和行业词汇;单击以开始采集;导出数据). 无需手动编写任何规则. 操作就是这么简单.
3. 支持多省/多城市采集. (同时在多个城市中使用多个关键字)使搜索更加“简单,快速,有效”.
4. 快速搜索,极快的操作体验,流畅舒适.
5. 采集效率和数据完整性领先业界.
6. 及时处理客户反馈和建议还使该软件能够很好地处理许多细节.
7. 具有自动升级功能: 新版本正式发布后,客户端打开后将自动升级到最新版本.
该软件是许多批发商,电子商务业务推广和微型业务推广人员将业务量增加一倍的法宝. 它被各个行业的许多业务人员使用. 查看全部
[正版]采集所有者信息采集软件企业目录实时所有者信息采集软件
[Jigu客房新闻搜索营销软件]属于“ Jike营销软件”系列. 该软件是专业的所有者搜索软件和功能强大的所有者信息搜索和采集软件. 它可以自动采集最新的所有者目录,可以帮助您快速识别目标客户,进行充分的市场研究,为销售管理和营销管理做充分的准备,并为您提供直接与目标客户联系的机会. 搜索结果支持导出到Excel或一键导入到手机通讯簿. 该数据可用于研究或市场参考. (非个人隐私信息,该软件不生产,也不存储任何数据)
软件功能,只需用鼠标单击,无需编写任何采集规则,[它可以直接导出Excel文件,并且只需单击一下即可导入手机通讯录,适用于电话销售和微信营销. )
1. 实时采集,不是历史数据,而是官方网站的最新搜索数据.
2. 该操作简单易用,傻瓜式操作,分三个步骤完成(配置城市和行业词汇;单击以开始采集;导出数据). 无需手动编写任何规则. 操作就是这么简单.
3. 支持多省/多城市采集. (同时在多个城市中使用多个关键字)使搜索更加“简单,快速,有效”.
4. 快速搜索,极快的操作体验,流畅舒适.
5. 采集效率和数据完整性领先业界.
6. 及时处理客户反馈和建议还使该软件能够很好地处理许多细节.
7. 具有自动升级功能: 新版本正式发布后,客户端打开后将自动升级到最新版本.
该软件是许多批发商,电子商务业务推广和微型业务推广人员将业务量增加一倍的法宝. 它被各个行业的许多业务人员使用.
2020年7月的最新消息,优采云在微信公众号上批量采集最新文章(包括实时更新)的方法和思想
采集交流 • 优采云 发表了文章 • 0 个评论 • 484 次浏览 • 2020-08-06 21:21
首先谈谈我的需求:
获取约10个正式帐户的批文. 监视最新帖子,大概的想法是早上检查并在下午再次检查. 采集可用的新文章.
为什么要使用优采云?
该软件非常易于使用,具有自动URL重复数据删除功能. 重复的链接将被跳过,不再使用. 此外,优采云具有WordPress免登录发布界面. 我一直在为小白使用它. 我已经习惯了,很容易上手.
解决方案选择:
主要关注解决官方帐户的历史文章网址,即文章列表.
首先,我想在开始时使用它(这也是最在线的教程),但是事实证明,在Sogou官方帐户上的搜索不再显示某个特定官方帐户的最新文章. 据说它将在2019年之前无法使用,腾讯已关闭该界面.
2. 直接捕获微信数据包,使用fildder和其他数据包捕获工具,并与PC版微信配合捕获官方帐户URL. 这非常复杂. 我看了一轮教程,果断地放弃了,这超出了我的承受能力.
3. 使用第三方公共帐户数据查询平台. 该程序可以运行. 经过研究,我发现了三个.
1. 西瓜助手:
2. 小宝:
3. 一个同伴插件:
谈谈它们各自的优点和缺点:
西瓜助手,优点: 可以查询大量的官方账号,并且视觉更新很快. 就像普通网站的采集一样,官方帐户中的文章列表可以直接通过优采云采集. 缺点,收费和昂贵的批次. 普通版是每月99元.
小宝,优点,免费,您可以在登录时查看官方帐户数据,快速更新(基本上会有一天的间隔),并且该官方帐户收录更多内容. 缺点: 优采云无法直接采集列表,它是由js算法编写的.
Yiban插件,优点,免费,有财云可以直接采集列表. 缺点是,某些官方帐户无法找到数据,更新情况就像过山车,相隔一天,相隔半年.
我还体验了一个名为vread的平台,地址为: . 该平台具有部分官方帐户内容,并且还通过监视采集了最新的官方帐户文章. 优采云的优势可以直接采集. 缺点: 官方帐户收录的较少,需要您自己提交(我提交了一个,在前一天晚上提交,但第二天不收录)并收取费用. 每月12元. 尽管价格便宜,但它确实不像免费的一部分插件那样容易使用.
我在第三方平台上浪费了很多时间. 西瓜助理,我已经写好了优采云站的采集规则,目前正处于筛选官方账户的阶段. 结果,第二天,系统提示我升级我的会员资格以继续使用它. 操我,我的努力是徒劳的. 浪费时间.
一个合作伙伴插件,编写规则也很简单. 但是,我最终放弃了与官方帐户数据更新迷相同的操作.
小宝,这种机动性很好. 但是它呈现的列表是由js呈现的. 优采云无能为力. 它只能通过带有硒文本的python运行. 该硒仅仅是驱动浏览器打开网页的程序. 以这种方式捕获的结果是js算法完成时显示的结果.
我知道事实,但是去年我学习了python一两个星期,看了几节课,现在我完全忘记了. 因此,我再次学习了python,并首先在站点b上搜索了硒教程. 看了几次之后,我感到不舒服. 从硬盘上,我找到了一套“ Python3 Web Crawler实用案例”,该软件是去年由崔庆才先生下载的. 在实际的一章中有一个实际的课程: “第16类: 使用硒模拟浏览器获取淘宝商品和食品信息”. 这只是完美的教程. 阅读几次后,我在Internet上找到了一些源代码,然后就可以开始工作了.
安装python,pycharm等工具并不会多说,新手已经花了很多时间.
您认为最终计划已经完成吗?
否.
四个. 这不是源于Micro Treasure的官方帐户商品数据爬网的最新缺陷(没有那天,但只有昨天). 我也想找出是否还有更直接的方法. 确实如此. 那是微信公众号的官方运营平台.
您可以在此处管理材料,插入链接并引用其他官方帐户. 此处的官方帐户显示最新数据. 可以捕获一个小时前的文章.
但是,优采云无法在此处直接爬取列表. Python和硒仍然需要战斗. 经过一夜零一夜的研究.
我终于完成了这项任务.
最终的实施计划如下:
微信公众号操作平台,获取列表页面网址,该网址生成一个html文件并将其保存到本地网站(由phpstudy构建). 然后转到Ucai Cloud以提取这些html中的URL,然后采集一篇文章. (通过这种方式,优采云的效果与普通网站的采集效果相同).
为什么不直接使用python采集官方帐户的目标文章?因为我的技术不到位,所以要采集特定的文章,我必须了解图像下载和html标签处理. 我是新手,一点也不,我不知道学习需要多长时间. 此外,官方帐户文章的发布时间由js表示. 我可以通过优采云标签的方法直接从硒捕获的html信息中直接调用它.
我最近说过: python中的Selenium确实是人工制品!从理论上讲,任何东西都可以捕获! 查看全部
优采云采集微信官方帐户,许多网站建设者都希望使用此功能. 我在2020年4月写了这些内容,但今天是7月,根本没有问题. 我不必多说,只需直接交付干货即可.
首先谈谈我的需求:
获取约10个正式帐户的批文. 监视最新帖子,大概的想法是早上检查并在下午再次检查. 采集可用的新文章.
为什么要使用优采云?
该软件非常易于使用,具有自动URL重复数据删除功能. 重复的链接将被跳过,不再使用. 此外,优采云具有WordPress免登录发布界面. 我一直在为小白使用它. 我已经习惯了,很容易上手.
解决方案选择:
主要关注解决官方帐户的历史文章网址,即文章列表.
首先,我想在开始时使用它(这也是最在线的教程),但是事实证明,在Sogou官方帐户上的搜索不再显示某个特定官方帐户的最新文章. 据说它将在2019年之前无法使用,腾讯已关闭该界面.
2. 直接捕获微信数据包,使用fildder和其他数据包捕获工具,并与PC版微信配合捕获官方帐户URL. 这非常复杂. 我看了一轮教程,果断地放弃了,这超出了我的承受能力.
3. 使用第三方公共帐户数据查询平台. 该程序可以运行. 经过研究,我发现了三个.
1. 西瓜助手:
2. 小宝:

3. 一个同伴插件:

谈谈它们各自的优点和缺点:
西瓜助手,优点: 可以查询大量的官方账号,并且视觉更新很快. 就像普通网站的采集一样,官方帐户中的文章列表可以直接通过优采云采集. 缺点,收费和昂贵的批次. 普通版是每月99元.
小宝,优点,免费,您可以在登录时查看官方帐户数据,快速更新(基本上会有一天的间隔),并且该官方帐户收录更多内容. 缺点: 优采云无法直接采集列表,它是由js算法编写的.
Yiban插件,优点,免费,有财云可以直接采集列表. 缺点是,某些官方帐户无法找到数据,更新情况就像过山车,相隔一天,相隔半年.
我还体验了一个名为vread的平台,地址为: . 该平台具有部分官方帐户内容,并且还通过监视采集了最新的官方帐户文章. 优采云的优势可以直接采集. 缺点: 官方帐户收录的较少,需要您自己提交(我提交了一个,在前一天晚上提交,但第二天不收录)并收取费用. 每月12元. 尽管价格便宜,但它确实不像免费的一部分插件那样容易使用.
我在第三方平台上浪费了很多时间. 西瓜助理,我已经写好了优采云站的采集规则,目前正处于筛选官方账户的阶段. 结果,第二天,系统提示我升级我的会员资格以继续使用它. 操我,我的努力是徒劳的. 浪费时间.
一个合作伙伴插件,编写规则也很简单. 但是,我最终放弃了与官方帐户数据更新迷相同的操作.
小宝,这种机动性很好. 但是它呈现的列表是由js呈现的. 优采云无能为力. 它只能通过带有硒文本的python运行. 该硒仅仅是驱动浏览器打开网页的程序. 以这种方式捕获的结果是js算法完成时显示的结果.
我知道事实,但是去年我学习了python一两个星期,看了几节课,现在我完全忘记了. 因此,我再次学习了python,并首先在站点b上搜索了硒教程. 看了几次之后,我感到不舒服. 从硬盘上,我找到了一套“ Python3 Web Crawler实用案例”,该软件是去年由崔庆才先生下载的. 在实际的一章中有一个实际的课程: “第16类: 使用硒模拟浏览器获取淘宝商品和食品信息”. 这只是完美的教程. 阅读几次后,我在Internet上找到了一些源代码,然后就可以开始工作了.
安装python,pycharm等工具并不会多说,新手已经花了很多时间.
您认为最终计划已经完成吗?
否.
四个. 这不是源于Micro Treasure的官方帐户商品数据爬网的最新缺陷(没有那天,但只有昨天). 我也想找出是否还有更直接的方法. 确实如此. 那是微信公众号的官方运营平台.
您可以在此处管理材料,插入链接并引用其他官方帐户. 此处的官方帐户显示最新数据. 可以捕获一个小时前的文章.

但是,优采云无法在此处直接爬取列表. Python和硒仍然需要战斗. 经过一夜零一夜的研究.
我终于完成了这项任务.
最终的实施计划如下:
微信公众号操作平台,获取列表页面网址,该网址生成一个html文件并将其保存到本地网站(由phpstudy构建). 然后转到Ucai Cloud以提取这些html中的URL,然后采集一篇文章. (通过这种方式,优采云的效果与普通网站的采集效果相同).
为什么不直接使用python采集官方帐户的目标文章?因为我的技术不到位,所以要采集特定的文章,我必须了解图像下载和html标签处理. 我是新手,一点也不,我不知道学习需要多长时间. 此外,官方帐户文章的发布时间由js表示. 我可以通过优采云标签的方法直接从硒捕获的html信息中直接调用它.


我最近说过: python中的Selenium确实是人工制品!从理论上讲,任何东西都可以捕获!
Pylon使用实时图像捕获来解释PylonC SDK的使用过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2020-08-06 05:04
使用PylonC SDK的总体流程图如下:
以下是针对不同工作要求的其中之一,常见的是加载相机对象和卸载相机对象. 要使用其他模块,例如事件对象,可以相应地加载和卸载事件对象,并使用事件对象完成相关任务. 进行编程时,必须计划整个过程,尤其是在对硬件进行编程时,必须注意内存泄漏,并且之前分配的资源必须稍后释放.
以下是对五个主要过程的详细分析,其中解释了需求,并注释了需要使用的功能
加载相机对象
卸载相机对象
加载数据流以捕获对象
卸载数据流捕获对象
单帧或连续捕获过程
根据上述过程,可以实现实时图像采集
源代码下载链接. 许多人要求我提供源代码. 我浏览了之前的程序文件夹,找到了该程序. 它演示了使用Pylon SDK进行摄像机采集的过程. 使用MIL完成界面显示. 采集部分被封装到一个类中,可以直接重用. 测试相机是Basler相机. 请注意,Pylon仅完成原创数据的采集,使用MIL的MbufPut完成图像数据的重组,然后MIL自动显示.
---------------------
作者: 温英雄 查看全部
通常,对于硬件编程,硬件制造商将提供手册和示例供SDK使用. 该手册通常包括安装和配置过程,一些基本概念的介绍,SDK的每个功能的使用,SDK的使用过程和示例(一些硬件示例直接写在手册中,有些将单独存在文件,有些同时具有). 为了使上位计算机软件开发人员获得硬件主机编程任务,他们应该首先阅读并理解SDK概念,然后根据引入的SDK开发过程阅读SDK提供的示例,并修改相应的示例以供自己使用. . 该功能可用于查询其用法. 一些开发人员习惯性地记住他们的API,这既费时又费力,不建议使用. 下面主要说明带实时图像采集的Basler相机的PylonC SDK的使用过程.
使用PylonC SDK的总体流程图如下:

以下是针对不同工作要求的其中之一,常见的是加载相机对象和卸载相机对象. 要使用其他模块,例如事件对象,可以相应地加载和卸载事件对象,并使用事件对象完成相关任务. 进行编程时,必须计划整个过程,尤其是在对硬件进行编程时,必须注意内存泄漏,并且之前分配的资源必须稍后释放.
以下是对五个主要过程的详细分析,其中解释了需求,并注释了需要使用的功能

加载相机对象
卸载相机对象
加载数据流以捕获对象
卸载数据流捕获对象
单帧或连续捕获过程
根据上述过程,可以实现实时图像采集
源代码下载链接. 许多人要求我提供源代码. 我浏览了之前的程序文件夹,找到了该程序. 它演示了使用Pylon SDK进行摄像机采集的过程. 使用MIL完成界面显示. 采集部分被封装到一个类中,可以直接重用. 测试相机是Basler相机. 请注意,Pylon仅完成原创数据的采集,使用MIL的MbufPut完成图像数据的重组,然后MIL自动显示.
---------------------
作者: 温英雄
解决方案:使用LogHub进行日志实时采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-09-01 14:32
背景
“我要订购外卖”是基于平台的电子商务网站,用户,餐厅,送货人员等. 用户可以在网页,应用程序,微信,支付宝等上下订单;商家收到订单后开始处理,并自动通知周边快递;快递员将食物交付给用户.
操作要求
在操作过程中,发现了以下问题:
很难获得用户. 向渠道(网页,微信推送)投入大量广告费,接收一些用户,但无法判断每个渠道的有效性,用户常常抱怨交付缓慢,但是在哪个环节,订单的接收,分配,处理?如何优化?用户操作通常会参与一些优惠活动(发送优惠券),但无法获得效果. 计划问题,如何帮助商家在高峰时段提前库存?如何派遣更多快递员到指定地区?客户服务中,用户反馈说订单失败,用户背后的操作是什么?系统中有错误吗?数据采集难点
在数据操作过程中,第一步是如何集中采集分散的日志数据,这将面临以下挑战:
我们需要采集分散的外部和内部日志以进行统一管理. 过去,这部分工作需要很多工作,但现在可以通过LogHub 采集函数进行访问.
日志统一管理和配置创建管理日志项目项目,例如myorder
创建日志存储库Logstore,以从不同的数据源生成日志,例如:
如果需要清除原创数据和ETL,则可以创建一些中间结果日志存储区
(有关更多操作,请参阅快速启动/管理控制台)
用户提升日志采集
为了获取新用户,通常有两种方法:
网站注册时有直接优惠券
扫描其他渠道的QR码并放置优惠券
方法
定义以下注册服务器地址,并生成QR码(传单,网页)供用户注册和扫描. 当用户扫描此页面进行注册时,他知道该用户是通过特定来源输入并记录日志的.
http://examplewebsite/login%3F ... Dkd4b
服务器接受请求后,服务器将输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
采集方法:
应用程序将日志输出到硬盘,然后通过Logtail 采集应用程序通过SDK写入日志,请参见SDK服务器数据采集
支付宝/微信公众号编程是一种典型的Web端模式,通常有三种日志类型:
将练习日志写入本地文件,并通过Logtail配置正则表达式写入指定的Logstore. 日志可以在Docker中生成. 容器服务可用于集成日志服务. 可以使用Java程序Log4J Appender. 写); Log4J Appender C#,Python,Java,PHP,C等可以使用SDK写入Windows服务器. 您可以使用Logstash 采集终端用户日志访问Web / M网站页面的用户行为
页面用户行为集合可以分为两类:
页面与后台服务器之间的交互: 例如下订单,登录和注销. 该页面没有后台服务器交互: 该请求直接在前端处理,例如滚动,关闭页面等. 方法第一种方法可以引用服务器采集方法. 第二种方法可以使用Tracking Pixel / JS库采集页面行为,请参考Tracking Web界面服务器日志的操作和维护
例如:
不同网络环境下的方法数据采集
LogHub在每个区域提供访问点,每个区域提供三个访问点:
有关更多信息,请参阅网络访问,始终有一种适合您.
其他,请参阅LogHub完整采集方法. 查看日志实时消耗,涉及流计算,数据清理,数据仓库和索引查询等功能. 查看全部
使用LogHub实时记录采集
背景
“我要订购外卖”是基于平台的电子商务网站,用户,餐厅,送货人员等. 用户可以在网页,应用程序,微信,支付宝等上下订单;商家收到订单后开始处理,并自动通知周边快递;快递员将食物交付给用户.
操作要求
在操作过程中,发现了以下问题:
很难获得用户. 向渠道(网页,微信推送)投入大量广告费,接收一些用户,但无法判断每个渠道的有效性,用户常常抱怨交付缓慢,但是在哪个环节,订单的接收,分配,处理?如何优化?用户操作通常会参与一些优惠活动(发送优惠券),但无法获得效果. 计划问题,如何帮助商家在高峰时段提前库存?如何派遣更多快递员到指定地区?客户服务中,用户反馈说订单失败,用户背后的操作是什么?系统中有错误吗?数据采集难点
在数据操作过程中,第一步是如何集中采集分散的日志数据,这将面临以下挑战:
我们需要采集分散的外部和内部日志以进行统一管理. 过去,这部分工作需要很多工作,但现在可以通过LogHub 采集函数进行访问.
日志统一管理和配置创建管理日志项目项目,例如myorder
创建日志存储库Logstore,以从不同的数据源生成日志,例如:
如果需要清除原创数据和ETL,则可以创建一些中间结果日志存储区
(有关更多操作,请参阅快速启动/管理控制台)
用户提升日志采集
为了获取新用户,通常有两种方法:
网站注册时有直接优惠券
扫描其他渠道的QR码并放置优惠券
方法
定义以下注册服务器地址,并生成QR码(传单,网页)供用户注册和扫描. 当用户扫描此页面进行注册时,他知道该用户是通过特定来源输入并记录日志的.
http://examplewebsite/login%3F ... Dkd4b
服务器接受请求后,服务器将输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
采集方法:
应用程序将日志输出到硬盘,然后通过Logtail 采集应用程序通过SDK写入日志,请参见SDK服务器数据采集
支付宝/微信公众号编程是一种典型的Web端模式,通常有三种日志类型:
将练习日志写入本地文件,并通过Logtail配置正则表达式写入指定的Logstore. 日志可以在Docker中生成. 容器服务可用于集成日志服务. 可以使用Java程序Log4J Appender. 写); Log4J Appender C#,Python,Java,PHP,C等可以使用SDK写入Windows服务器. 您可以使用Logstash 采集终端用户日志访问Web / M网站页面的用户行为
页面用户行为集合可以分为两类:
页面与后台服务器之间的交互: 例如下订单,登录和注销. 该页面没有后台服务器交互: 该请求直接在前端处理,例如滚动,关闭页面等. 方法第一种方法可以引用服务器采集方法. 第二种方法可以使用Tracking Pixel / JS库采集页面行为,请参考Tracking Web界面服务器日志的操作和维护
例如:
不同网络环境下的方法数据采集
LogHub在每个区域提供访问点,每个区域提供三个访问点:
有关更多信息,请参阅网络访问,始终有一种适合您.
其他,请参阅LogHub完整采集方法. 查看日志实时消耗,涉及流计算,数据清理,数据仓库和索引查询等功能.
基于anyproxy的微信公众号文章爬取,收录阅读数点赞数
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-08-27 21:23
github项目地址
录制的视频:点击抵达
基本原理AnyProxy是一个阿里开源的HTTP代理服务器,类似fiddler和charles,但是提供了二次开发能力,可以编撰js代码改变http/https恳求和响应为了爬取一个微信公众号的全部文章,首先就是获取全部文章,然后一篇一篇去打开获取文章标题,作者,阅读数,点赞数(这两个只能在微信浏览器获取)每个微信公众号都提供查看历史消息的功能,点击去打开这个网页,不停下滚,可以查到全部发布文章。在这一步,基于anyproxy,修改了这个网页html,注入一段使页面不停往下滚动的js脚本,当滚到顶部,就获取了全部文章列表。 本质上是中间人攻击。
获取完全部文章的内容(包括url,标题,发布时间等等)后,下一步就是循环通知陌陌浏览器一个一个去打开这种文章网页。每个文章网页也注入js脚本,功能是不停的检测页面的点赞数和阅读数,检测到,就往某服务器发,后台每成功收到一个文章的点赞数和阅读数,就通知陌陌浏览器打开下一个url。这里我使用了socketio,实现陌陌浏览器和自建的koa服务器之间的通信。
如图所示:
获取文章列表演示
一篇一篇打开文章链接
如何运行
第一步,一定要安装成功anyproxy,这一步请详尽阅读anyproxy的官方教程,写的太详尽,要保证能成功代理https,能查看到https的body内容。
npm install
npm start
会手动打开一个result.html,实时查看爬取文章的内容
点击一个微信公众号,点击查看历史消息,之后历史页面会不停的滚动究竟,滚动完毕,就开始一篇一篇打开文章,爬取内容。
实时结果显示.jpg
具体过程
1.第一步,要获取一个公众号的全部历史文章。在早已设置好anyproxy代理的真机上,查看历史消息,这时陌陌会打开历史文章网页。
获取一个html文档:
,var msgList就是我们须要的历史文章数据,简单正则匹配下来,替代非法字符,JSON.parse转成我们须要的格式。 基于anyproxy,我们给这个html文档注入一段脚本,目的是使这个网页不停的往下自己滚动,触发浏览器去获得更多的文章。
var scrollKey = setInterval(function () {
window.scrollTo(0,document.body.scrollHeight);
},1000);
当网页滚究竟,再次获取文章,这个时侯,同样的是get恳求,但是返回了Content-Type为application/json的格式,这里同样的方式,正则匹配找出并低格成我们须要的格式
同时当can_msg_continue为0时,表示早已拉到底,获取了全部文章。
至此,获得了一个公众号的全部文章,包括文章标题,作者,url。但是没有阅读数和点赞数,这须要打开具体的文章链接,才能看得到。
我们还没获得阅读数和点赞数,接下来就是一步一步使微信浏览器不停地打开具体文章,触发陌陌浏览器获取阅读数和点赞数。这里使用了socket.io,让文章页面联接自定义的服务器,服务器主动通知浏览器下一个点开的文章链接,这样单向通信,一个循环才能获取具体文章的阅读数和点赞。
socket.on('url', function (data) {
window.location = data.url;
});
阅读数和点赞可以在浏览器端,不停检测dom元素是否渲染下来之后搜集发往服务器,也可以直接anyproxy检测下来(这里我采用前一种)。
key = setInterval(function () {
var readNum = $('#readNum3').text().trim();
if (!readNum) return;
var likeNum = $('#likeNum3').text().trim();
var postUser = $('#post-user').text().trim();
var postDate = $('#post-date').text().trim() || $('#publish_time').text().trim();
var activityName = $('#activity-name').text().trim();
var js_share_source = $('#js_share_source').attr('href');
socket.emit('crawler', {
readNum: readNum,
likeNum: likeNum,
postUser: postUser,
postDate: postDate,
activityName: activityName,
js_share_source: js_share_source
});
}, 1000); 查看全部
基于anyproxy的微信公众号文章爬取,收录阅读数点赞数
github项目地址
录制的视频:点击抵达
基本原理AnyProxy是一个阿里开源的HTTP代理服务器,类似fiddler和charles,但是提供了二次开发能力,可以编撰js代码改变http/https恳求和响应为了爬取一个微信公众号的全部文章,首先就是获取全部文章,然后一篇一篇去打开获取文章标题,作者,阅读数,点赞数(这两个只能在微信浏览器获取)每个微信公众号都提供查看历史消息的功能,点击去打开这个网页,不停下滚,可以查到全部发布文章。在这一步,基于anyproxy,修改了这个网页html,注入一段使页面不停往下滚动的js脚本,当滚到顶部,就获取了全部文章列表。 本质上是中间人攻击。
获取完全部文章的内容(包括url,标题,发布时间等等)后,下一步就是循环通知陌陌浏览器一个一个去打开这种文章网页。每个文章网页也注入js脚本,功能是不停的检测页面的点赞数和阅读数,检测到,就往某服务器发,后台每成功收到一个文章的点赞数和阅读数,就通知陌陌浏览器打开下一个url。这里我使用了socketio,实现陌陌浏览器和自建的koa服务器之间的通信。
如图所示:
获取文章列表演示
一篇一篇打开文章链接
如何运行
第一步,一定要安装成功anyproxy,这一步请详尽阅读anyproxy的官方教程,写的太详尽,要保证能成功代理https,能查看到https的body内容。
npm install
npm start
会手动打开一个result.html,实时查看爬取文章的内容
点击一个微信公众号,点击查看历史消息,之后历史页面会不停的滚动究竟,滚动完毕,就开始一篇一篇打开文章,爬取内容。
实时结果显示.jpg
具体过程
1.第一步,要获取一个公众号的全部历史文章。在早已设置好anyproxy代理的真机上,查看历史消息,这时陌陌会打开历史文章网页。
获取一个html文档:
,var msgList就是我们须要的历史文章数据,简单正则匹配下来,替代非法字符,JSON.parse转成我们须要的格式。 基于anyproxy,我们给这个html文档注入一段脚本,目的是使这个网页不停的往下自己滚动,触发浏览器去获得更多的文章。
var scrollKey = setInterval(function () {
window.scrollTo(0,document.body.scrollHeight);
},1000);
当网页滚究竟,再次获取文章,这个时侯,同样的是get恳求,但是返回了Content-Type为application/json的格式,这里同样的方式,正则匹配找出并低格成我们须要的格式
同时当can_msg_continue为0时,表示早已拉到底,获取了全部文章。
至此,获得了一个公众号的全部文章,包括文章标题,作者,url。但是没有阅读数和点赞数,这须要打开具体的文章链接,才能看得到。
我们还没获得阅读数和点赞数,接下来就是一步一步使微信浏览器不停地打开具体文章,触发陌陌浏览器获取阅读数和点赞数。这里使用了socket.io,让文章页面联接自定义的服务器,服务器主动通知浏览器下一个点开的文章链接,这样单向通信,一个循环才能获取具体文章的阅读数和点赞。
socket.on('url', function (data) {
window.location = data.url;
});
阅读数和点赞可以在浏览器端,不停检测dom元素是否渲染下来之后搜集发往服务器,也可以直接anyproxy检测下来(这里我采用前一种)。
key = setInterval(function () {
var readNum = $('#readNum3').text().trim();
if (!readNum) return;
var likeNum = $('#likeNum3').text().trim();
var postUser = $('#post-user').text().trim();
var postDate = $('#post-date').text().trim() || $('#publish_time').text().trim();
var activityName = $('#activity-name').text().trim();
var js_share_source = $('#js_share_source').attr('href');
socket.emit('crawler', {
readNum: readNum,
likeNum: likeNum,
postUser: postUser,
postDate: postDate,
activityName: activityName,
js_share_source: js_share_source
});
}, 1000);
爬一爬数据采集实战系列7「调度任务」:采集微博实时热搜榜信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-08-26 07:43
本篇教程为中级实战案例,用【调度】功能多次采集微博实时热搜榜数据。
##插件安装及菜鸟入门教程可以看订阅号第一篇文章 极简易用网页采集器:爬一爬数据采集实战教程
微博实时热搜榜每10min更新一次。如果想采集某个时间段内实时热搜榜的完整信息,需每隔十分钟自动运行,这样的效率极低,不可取。
实时热搜榜的入选规则
今天就教你们一个方式,用调度器定时采集数据。这样,只要我们设置好调度任务,让任务手动运行,我们就可以高枕无忧的打闹去了。
本例设置了在19:00--21:00期间每隔10分钟采集微博热搜榜数据。
操作步骤
1.确保帐号已登陆,打开须要采集的微博实时热搜榜网站,点击浏览器插件栏的“爬”字图标,启动插件。
2.点击页面上须要采集的信息。如果色调框没有收录所有的任务数据, 点击切换按键,切换算法,直到选中所有的任务数据。(注:下载为js-engine)
依次选定要抓取的元素
3.先点击“完成”按钮,再点击“测试”按钮,测试采集的数据是否就是您想要的。
测试数据
4.确认测试成功后,点击”OK”关闭测试窗口。填写任务名称(长度为4-32的字符,必填),并依照个人须要更改列名。
5.点击“提交”按钮,创建任务。
创建任务
6.任务创建成功后,在官网导航栏“任务”页面,点击”打开任务调度器”,调度页面便出现在浏览器标签页。
打开调度器
7.在所创建的任务后点击”管理”选项。
打开任务管理页面
8.点击”调度”选项,新建调度,设置定时任务。
新建调度任务
9.根据Cron表达式,设置任务抓取频度,如下图所示。具体可参考”教程中心”热门问题中的“什么是Cron表达式”。
(#注:本例设置的是 在19:00--21:00之间每隔10分抓取页面)
设置Cron表达式
10.调度配置成功后,任务按照设置频度手动运行。我们可在调度管理标签页面,看到任务的运行状态。(#注:在任务调度期间,该页面不关掉。)
查看调度状态
11.点击任务”数据”选项,我们可以看见多批次的数据。(#注:数据从19:00开始,每个批次间隔10分钟)
查看数据
Tips:
①本例下载器为js-engine
②为保证数据稳定,可将频度值大一点,预留足够的抓取时间。
③想看视频版调度教程,赶紧去官网教程中心吧。
④附Cron表达式的一些事例:
表达式
释义
提示
0 12 * * ?
每天12:00
相当于’0 12 */1 * ?’
15 10 ? * *
每天10:15
相当于’15 10 * * ?’或’15 10 */1 * ?’
* 14 * * ?
每天14:00到14:59,每隔1分钟
0/5 14 * * ?
每天14:00到14:59,每隔5分钟
相当于’*/5 14 * * ?’
0-5 14 * * ?
每天14:00到14:05,每隔1分钟
10,44 14 ? * 4
每周三14:10和14:44
15 10 15 * ?
每月15日的10:15
15 10 ? * 6L
每月最后一个周日的10:15
15 10 ? * 6#3
每月第三个周日的10:15 查看全部
爬一爬数据采集实战系列7「调度任务」:采集微博实时热搜榜信息
本篇教程为中级实战案例,用【调度】功能多次采集微博实时热搜榜数据。
##插件安装及菜鸟入门教程可以看订阅号第一篇文章 极简易用网页采集器:爬一爬数据采集实战教程
微博实时热搜榜每10min更新一次。如果想采集某个时间段内实时热搜榜的完整信息,需每隔十分钟自动运行,这样的效率极低,不可取。
实时热搜榜的入选规则
今天就教你们一个方式,用调度器定时采集数据。这样,只要我们设置好调度任务,让任务手动运行,我们就可以高枕无忧的打闹去了。
本例设置了在19:00--21:00期间每隔10分钟采集微博热搜榜数据。
操作步骤
1.确保帐号已登陆,打开须要采集的微博实时热搜榜网站,点击浏览器插件栏的“爬”字图标,启动插件。
2.点击页面上须要采集的信息。如果色调框没有收录所有的任务数据, 点击切换按键,切换算法,直到选中所有的任务数据。(注:下载为js-engine)
依次选定要抓取的元素
3.先点击“完成”按钮,再点击“测试”按钮,测试采集的数据是否就是您想要的。
测试数据
4.确认测试成功后,点击”OK”关闭测试窗口。填写任务名称(长度为4-32的字符,必填),并依照个人须要更改列名。
5.点击“提交”按钮,创建任务。
创建任务
6.任务创建成功后,在官网导航栏“任务”页面,点击”打开任务调度器”,调度页面便出现在浏览器标签页。
打开调度器
7.在所创建的任务后点击”管理”选项。
打开任务管理页面
8.点击”调度”选项,新建调度,设置定时任务。
新建调度任务
9.根据Cron表达式,设置任务抓取频度,如下图所示。具体可参考”教程中心”热门问题中的“什么是Cron表达式”。
(#注:本例设置的是 在19:00--21:00之间每隔10分抓取页面)
设置Cron表达式
10.调度配置成功后,任务按照设置频度手动运行。我们可在调度管理标签页面,看到任务的运行状态。(#注:在任务调度期间,该页面不关掉。)
查看调度状态
11.点击任务”数据”选项,我们可以看见多批次的数据。(#注:数据从19:00开始,每个批次间隔10分钟)
查看数据
Tips:
①本例下载器为js-engine
②为保证数据稳定,可将频度值大一点,预留足够的抓取时间。
③想看视频版调度教程,赶紧去官网教程中心吧。
④附Cron表达式的一些事例:
表达式
释义
提示
0 12 * * ?
每天12:00
相当于’0 12 */1 * ?’
15 10 ? * *
每天10:15
相当于’15 10 * * ?’或’15 10 */1 * ?’
* 14 * * ?
每天14:00到14:59,每隔1分钟
0/5 14 * * ?
每天14:00到14:59,每隔5分钟
相当于’*/5 14 * * ?’
0-5 14 * * ?
每天14:00到14:05,每隔1分钟
10,44 14 ? * 4
每周三14:10和14:44
15 10 15 * ?
每月15日的10:15
15 10 ? * 6L
每月最后一个周日的10:15
15 10 ? * 6#3
每月第三个周日的10:15
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-20 23:19
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
无敌企业名录搜索软件是一款针对B2B网站的企业信息进行实时采集整理的软件,支持定义多个条件采集数据,个性化的搜索方法使您采集的数据十分精准有效,采集的数据数组诸多,多种导入格式便捷您进行数据管理,形成高效确切的顾客资源,让您全面把握一手的市场顾客资料,是销售人员开发新顾客、企业进行网路营销、开拓市场查找顾客的必备神器!
产品功能及特性:
1、数据来自著名在线B2B网站(阿里巴巴、慧聪、马可波罗、环球贸易网、中国制造网等),来源权威、可靠、准确,让您把握最准确的企业信息;
2、软件实时采集最新最活跃的信息,保证数据的时效性、有效性;
3、多个条件精确定位准确度极高,只搜索您须要的数据名录;
4、搜索条件支持行业、二级行业、关键词、经营模式、省份、城市、地区等条件搜索;
5、数据字段齐全,收录公司名称、联系人、职务、电话、手机、邮箱、公司地址等大量数组;
6、数据手动除去重复,提高效率;
7、导出格式支持txt记事本和excel表格,方便举办任何营销工作。
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
无敌企业名录搜索软件 B2B网站企业信息实时采集V3.5营销版' />
下载 查看全部
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
无敌企业名录搜索软件是一款针对B2B网站的企业信息进行实时采集整理的软件,支持定义多个条件采集数据,个性化的搜索方法使您采集的数据十分精准有效,采集的数据数组诸多,多种导入格式便捷您进行数据管理,形成高效确切的顾客资源,让您全面把握一手的市场顾客资料,是销售人员开发新顾客、企业进行网路营销、开拓市场查找顾客的必备神器!
产品功能及特性:
1、数据来自著名在线B2B网站(阿里巴巴、慧聪、马可波罗、环球贸易网、中国制造网等),来源权威、可靠、准确,让您把握最准确的企业信息;
2、软件实时采集最新最活跃的信息,保证数据的时效性、有效性;
3、多个条件精确定位准确度极高,只搜索您须要的数据名录;
4、搜索条件支持行业、二级行业、关键词、经营模式、省份、城市、地区等条件搜索;
5、数据字段齐全,收录公司名称、联系人、职务、电话、手机、邮箱、公司地址等大量数组;
6、数据手动除去重复,提高效率;
7、导出格式支持txt记事本和excel表格,方便举办任何营销工作。
无敌企业名录搜索软件B2B网站企业信息实时采集V3.5破解版
无敌企业名录搜索软件 B2B网站企业信息实时采集V3.5营销版' />
下载
基于springboot的温湿度NBIOT采集实时显示
采集交流 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2020-08-17 19:53
这个项目就是之前说的要开源下来的一个结业项目,是我在学院期间做的一个项目,大家假如有须要可以随便下载,开源一起学习才有长足的进步
项目链接:
Gitee项目链接
演示地址:
演示地址
:8080
使用1234 123登录
底下是Readme.md
springboot后台联接立秋云介绍
后台基于spring boot的简单实现,前端模板使用springboot官方的折线图实现温湿度的动态监控,注意:需要配合硬件联接立秋云实现
软件构架
软件构架说明
安装教程安装IDEA 配置java环境,这些就不用说了。在IDEA中 导入项目 直接选择下载好的文件夹即可等待IDEA手动导出项目中的须要用到的依赖使用说明
项目需配置mysql数据库,localhost:3306,数据库名为login,账户为root,密码为123456,可以在application.yml中配置数据源。
当数据库中有login数据库时不需要再建表,后台使用jpa框架会手动创建须要用到的数据表,此项目会创建两个表,一个拿来温湿度储存数据,一个拿来储存用户
项目只需等待手动导出依赖文件而且配置好数据库后即可使用
项目中的GuYuNbiot是联接立秋云透传平台的,在Gylistener中请填入自己的春分的注册包,谷雨云的使用请移步:%E8%B0%B7%E9%9B%A8%E4%BA%91%E9%80%8F%E4%BC%A0%E5%B9%B3%E5%8F%B0%E6%8E%A5%E5%85%A5%E6%8C%87%E5%8D%97
项目须要用到硬件的联动,硬件发给谷雨云以后,通过春分云平台的透传能够实现后端图表的实时更新
项目中有许多善待改进的功能,比如在GyRecieveThread收到数据的数据库插入时,偶尔会报null,我这儿使用了
@PostConstruct//解决非controller类注入为null的问题
public void init(){
gyRecieveThread=this;
gyRecieveThread.dataService=this.dataService;
}
如果有更好的解决办法,可以联系我,多谢了。
项目说明
1.因为本人处在大四结业阶段,还是第一次学习springboot的缘由,项目中参考了网上的些许不错的代码,如有侵害请联系我,我会立刻删掉。
2.项目是springboot比较简单的应用,欢迎和我一样的初学者学习,如果有任何不懂的也可以联系我,一起开源学习交流就会长久的进步。
参与贡献Fork 本库房新建 Feat_xxx 分支递交代码新建 Pull Request码云特技使用 Readme_XXX.md 来支持不同的语言,例如 Readme_en.md, Readme_zh.md码云官方博客 你可以 这个地址来了解码云上的优秀开源项目GVP 全称是码云最有价值开源项目,是码云综合评定出的优秀开源项目码云官方提供的使用指南 码云封面人物是一档拿来展示码云会员风采的栏目 查看全部
基于springboot的温湿度NBIOT采集实时显示
这个项目就是之前说的要开源下来的一个结业项目,是我在学院期间做的一个项目,大家假如有须要可以随便下载,开源一起学习才有长足的进步
项目链接:
Gitee项目链接
演示地址:
演示地址
:8080
使用1234 123登录
底下是Readme.md
springboot后台联接立秋云介绍
后台基于spring boot的简单实现,前端模板使用springboot官方的折线图实现温湿度的动态监控,注意:需要配合硬件联接立秋云实现
软件构架
软件构架说明
安装教程安装IDEA 配置java环境,这些就不用说了。在IDEA中 导入项目 直接选择下载好的文件夹即可等待IDEA手动导出项目中的须要用到的依赖使用说明
项目需配置mysql数据库,localhost:3306,数据库名为login,账户为root,密码为123456,可以在application.yml中配置数据源。
当数据库中有login数据库时不需要再建表,后台使用jpa框架会手动创建须要用到的数据表,此项目会创建两个表,一个拿来温湿度储存数据,一个拿来储存用户
项目只需等待手动导出依赖文件而且配置好数据库后即可使用
项目中的GuYuNbiot是联接立秋云透传平台的,在Gylistener中请填入自己的春分的注册包,谷雨云的使用请移步:%E8%B0%B7%E9%9B%A8%E4%BA%91%E9%80%8F%E4%BC%A0%E5%B9%B3%E5%8F%B0%E6%8E%A5%E5%85%A5%E6%8C%87%E5%8D%97
项目须要用到硬件的联动,硬件发给谷雨云以后,通过春分云平台的透传能够实现后端图表的实时更新
项目中有许多善待改进的功能,比如在GyRecieveThread收到数据的数据库插入时,偶尔会报null,我这儿使用了
@PostConstruct//解决非controller类注入为null的问题
public void init(){
gyRecieveThread=this;
gyRecieveThread.dataService=this.dataService;
}
如果有更好的解决办法,可以联系我,多谢了。
项目说明
1.因为本人处在大四结业阶段,还是第一次学习springboot的缘由,项目中参考了网上的些许不错的代码,如有侵害请联系我,我会立刻删掉。
2.项目是springboot比较简单的应用,欢迎和我一样的初学者学习,如果有任何不懂的也可以联系我,一起开源学习交流就会长久的进步。
参与贡献Fork 本库房新建 Feat_xxx 分支递交代码新建 Pull Request码云特技使用 Readme_XXX.md 来支持不同的语言,例如 Readme_en.md, Readme_zh.md码云官方博客 你可以 这个地址来了解码云上的优秀开源项目GVP 全称是码云最有价值开源项目,是码云综合评定出的优秀开源项目码云官方提供的使用指南 码云封面人物是一档拿来展示码云会员风采的栏目
Python网路数据采集之读取文件|第05天
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-08-14 08:59
Date:2018-04-01
Mark:《Python网路数据采集》
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
Python网路数据采集之储存数据
读取文档文档编码
文档编码的方法一般可以依照文件的扩充名进行判定,虽然文件扩充名并不是由编码确定的,而是由开发者确定的。从最底层的角度看,所有文档都是由 0和 1 编码而成的。例如我我们将一个后缀为png的图片后缀改为.py。用编辑器打打开就完全不对了。
只要安装了合适的库, Python 就可以帮你处理任意类型的文档。纯文本文件、视频文件和图象文件的惟一区别,就是它们的 0和1 面向用户的转换方法不同。
纯文本
对于纯文本的文件获取的方法很简单,用 urlopen 获取了网页以后,我们会把它转变成 BeautifulSoup对象。
from urllib.request import urlopen
textPage = urlopen(
"http://www.pythonscraping.com/ ... 6quot;)
print(textPage.read())
CSV 文件
Python有一个标准库对CSV文件的处理非常的友好,可以处理各种的CSV文件。文档地址
读取CSV文件
Python 的csv 库主要是面向本地文件,就是说你的 CSV 文件得存贮在你的笔记本上。而进行网路数据采集的时侯,很多文件都是在线的。有几个参考解决办法:
例如获取网上的CSV文件,然后输出命令行。
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen("http://pythonscraping.com/file ... 6quot;).read().decode('ASCII','ignore')
dataFile = StringIO(data)
csvReader = csv.reader(dataFile)
for row in csvReader:
print(row)
输出的结果:
['Name', 'Year']
["Monty Python's Flying Circus", '1970']
['Another Monty Python Record', '1971']
["Monty Python's Previous Record", '1972']
['The Monty Python Matching Tie and Handkerchief', '1973']
['Monty Python Live at Drury Lane', '1974']
['An Album of the Soundtrack of the Trailer of the Film of Monty Python and the Holy Grail', '1975']
['Monty Python Live at City Center', '1977']
['The Monty Python Instant Record Collection', '1977']
["Monty Python's Life of Brian", '1979']
["Monty Python's Cotractual Obligation Album", '1980']
["Monty Python's The Meaning of Life", '1983']
['The Final Rip Off', '1987']
['Monty Python Sings', '1989']
['The Ultimate Monty Python Rip Off', '1994']
['Monty Python Sings Again', '2014']
PDF 文件
PDFMiner3K是一个非常好用的库(是PDFMiner的Python 3.x移植版)。它十分灵活,可以通过命令行使用,也可以整合到代码中。它还可以处理不同的语言编码,而且对网路文件的处理也十分便捷。
下载解压后用python setup.py install完成安装。
模块的源文件下载地址:
例如可以把任意 PDF 读成字符串,然后用 StringIO转换成文件对象。
from urllib.request import urlopen
from pdfminer.pdfinterp import PDFResourceManager, process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from io import StringIO
from io import open
def readPDF(pdfFile):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
process_pdf(rsrcmgr, device, pdfFile)
device.close()
content = retstr.getvalue() retstr.close()
return content
pdfFile = urlopen("http://pythonscraping.com/page ... 6quot;)
outputString = readPDF(pdfFile)
print(outputString)
pdfFile.close()
readPDF 函数最大的用处是,如果PDF文件在笔记本里,就可以直接把 urlopen返回的对象 pdfFile 替换成普通的 open() 文件对象:
pdfFile = open("./chapter1.pdf", 'rb')
如果本文对你有所帮助,欢迎喜欢或则评论;如果你也对网路采集感兴趣,可以点击关注,这样才能够收到后续的更新。感谢您的阅读。 查看全部
User:你好我是森林
Date:2018-04-01
Mark:《Python网路数据采集》
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
Python网路数据采集之储存数据
读取文档文档编码
文档编码的方法一般可以依照文件的扩充名进行判定,虽然文件扩充名并不是由编码确定的,而是由开发者确定的。从最底层的角度看,所有文档都是由 0和 1 编码而成的。例如我我们将一个后缀为png的图片后缀改为.py。用编辑器打打开就完全不对了。
只要安装了合适的库, Python 就可以帮你处理任意类型的文档。纯文本文件、视频文件和图象文件的惟一区别,就是它们的 0和1 面向用户的转换方法不同。
纯文本
对于纯文本的文件获取的方法很简单,用 urlopen 获取了网页以后,我们会把它转变成 BeautifulSoup对象。
from urllib.request import urlopen
textPage = urlopen(
"http://www.pythonscraping.com/ ... 6quot;)
print(textPage.read())
CSV 文件
Python有一个标准库对CSV文件的处理非常的友好,可以处理各种的CSV文件。文档地址
读取CSV文件
Python 的csv 库主要是面向本地文件,就是说你的 CSV 文件得存贮在你的笔记本上。而进行网路数据采集的时侯,很多文件都是在线的。有几个参考解决办法:
例如获取网上的CSV文件,然后输出命令行。
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen("http://pythonscraping.com/file ... 6quot;).read().decode('ASCII','ignore')
dataFile = StringIO(data)
csvReader = csv.reader(dataFile)
for row in csvReader:
print(row)
输出的结果:
['Name', 'Year']
["Monty Python's Flying Circus", '1970']
['Another Monty Python Record', '1971']
["Monty Python's Previous Record", '1972']
['The Monty Python Matching Tie and Handkerchief', '1973']
['Monty Python Live at Drury Lane', '1974']
['An Album of the Soundtrack of the Trailer of the Film of Monty Python and the Holy Grail', '1975']
['Monty Python Live at City Center', '1977']
['The Monty Python Instant Record Collection', '1977']
["Monty Python's Life of Brian", '1979']
["Monty Python's Cotractual Obligation Album", '1980']
["Monty Python's The Meaning of Life", '1983']
['The Final Rip Off', '1987']
['Monty Python Sings', '1989']
['The Ultimate Monty Python Rip Off', '1994']
['Monty Python Sings Again', '2014']
PDF 文件
PDFMiner3K是一个非常好用的库(是PDFMiner的Python 3.x移植版)。它十分灵活,可以通过命令行使用,也可以整合到代码中。它还可以处理不同的语言编码,而且对网路文件的处理也十分便捷。
下载解压后用python setup.py install完成安装。
模块的源文件下载地址:
例如可以把任意 PDF 读成字符串,然后用 StringIO转换成文件对象。
from urllib.request import urlopen
from pdfminer.pdfinterp import PDFResourceManager, process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from io import StringIO
from io import open
def readPDF(pdfFile):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
process_pdf(rsrcmgr, device, pdfFile)
device.close()
content = retstr.getvalue() retstr.close()
return content
pdfFile = urlopen("http://pythonscraping.com/page ... 6quot;)
outputString = readPDF(pdfFile)
print(outputString)
pdfFile.close()
readPDF 函数最大的用处是,如果PDF文件在笔记本里,就可以直接把 urlopen返回的对象 pdfFile 替换成普通的 open() 文件对象:
pdfFile = open("./chapter1.pdf", 'rb')
如果本文对你有所帮助,欢迎喜欢或则评论;如果你也对网路采集感兴趣,可以点击关注,这样才能够收到后续的更新。感谢您的阅读。
使用LogHub进行日志实时采集-阿里云开发者社区
采集交流 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2020-08-13 03:47
“我要点订餐“是一个平台型电商网站,用户、餐厅、配送员等。用户可以在网页、App、微信、支付宝等进行下单点菜;商家领到订单后开始加工,并手动通知周围的快递员;快递员将订餐送到用户手中。
运营需求
在营运的过程中,发现了如下的问题:
获取用户难,投放一笔不小的广告费对到渠道(网页、微信推送),收货了一些用户,但难以衡量各渠道的疗效用户时常埋怨送货慢,但慢在哪些环节,接单、配送、加工?如何优化?用户营运,经常搞一些让利活动(发送优惠券),但未能获得疗效调度问题,如何帮助店家在高峰时提早备货?如何调度更多的快递员到指定区域?客服服务,用户反馈下单失败,用户背后的操作是哪些?系统是否有错误?数据采集难点
在数据化营运的过程中,第一步是怎样将洒落日志数据集中搜集上去,其中会碰到如下挑战:
我们须要把飘散在外部、内部日志搜集上去,统一进行管理。在过去这块须要大量几种工作,现在可以通过LogHub采集功能完成统一接入。
日志统一管理、配置创建管理日志项目Project,例如叫myorder
为不同数据源形成日志创建日志库Logstore,例如:
如须要对原创数据进行清洗与ETL,可以创建一些中间结果logstore
(更多操作可以参见快速开始/管理控制台)
用户推广日志采集
为获取新用户,一般有2种形式:
网站注册时直接投放优惠券
其他渠道扫描二维码,投放优惠券
做法
定义如下注册服务器地址,生成二维码(传单、网页)供用户注册扫描。用户扫描该页面注册时,就晓得用户通过特定来源步入,并记录日志。
http://examplewebsite/login%3F ... Dkd4b
当服务端接受恳求时,服务器输出如下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
采集方法:
应用程序输出日志到硬碟,通过Logtail采集应用程序通过SDK写入,参见SDK服务端数据采集
支付宝/微信公众帐号编程是典型的Web端模式,一般会有三种类型日志:
做法日志讲到本地文件,通过Logtail配置正则表达式讲到指定LogstoreDocker中形成日志可以使用容器服务集成日志服务Java程序可以使用Log4J Appender日志不落盘, LogHub Producer Library(客户端高并发写入);Log4J AppenderC#、Python、Java、PHP、C等可以使用SDK写入Windows服务器可以使用Logstash采集终端用户日志接入Web/M 站页面用户行为
页面用户行为搜集可以分为两类:
页面与后台服务器交互:例如下单,登陆、退出等。页面无后台服务器交互:请求直接在后端处理,例如滚屏,关闭页面等。做法第一种可以参考服务端采集方法第二种可以使用Tracking Pixel/JS Library搜集页面行为,参考Tracking Web插口服务器日志运维
例如:
做法不同网路环境下数据采集
LogHub在各Region提供 访问点,每个Region提供三种形式接入点:
更多请参见网路接入,总有一款适宜你。
其他参见LogHub完整采集方式。参见日志实时消费,涉及流计算、数据清洗、数据库房和索引查询等功能。 查看全部
背景
“我要点订餐“是一个平台型电商网站,用户、餐厅、配送员等。用户可以在网页、App、微信、支付宝等进行下单点菜;商家领到订单后开始加工,并手动通知周围的快递员;快递员将订餐送到用户手中。
运营需求
在营运的过程中,发现了如下的问题:
获取用户难,投放一笔不小的广告费对到渠道(网页、微信推送),收货了一些用户,但难以衡量各渠道的疗效用户时常埋怨送货慢,但慢在哪些环节,接单、配送、加工?如何优化?用户营运,经常搞一些让利活动(发送优惠券),但未能获得疗效调度问题,如何帮助店家在高峰时提早备货?如何调度更多的快递员到指定区域?客服服务,用户反馈下单失败,用户背后的操作是哪些?系统是否有错误?数据采集难点
在数据化营运的过程中,第一步是怎样将洒落日志数据集中搜集上去,其中会碰到如下挑战:
我们须要把飘散在外部、内部日志搜集上去,统一进行管理。在过去这块须要大量几种工作,现在可以通过LogHub采集功能完成统一接入。
日志统一管理、配置创建管理日志项目Project,例如叫myorder
为不同数据源形成日志创建日志库Logstore,例如:
如须要对原创数据进行清洗与ETL,可以创建一些中间结果logstore
(更多操作可以参见快速开始/管理控制台)
用户推广日志采集
为获取新用户,一般有2种形式:
网站注册时直接投放优惠券
其他渠道扫描二维码,投放优惠券
做法
定义如下注册服务器地址,生成二维码(传单、网页)供用户注册扫描。用户扫描该页面注册时,就晓得用户通过特定来源步入,并记录日志。
http://examplewebsite/login%3F ... Dkd4b
当服务端接受恳求时,服务器输出如下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
采集方法:
应用程序输出日志到硬碟,通过Logtail采集应用程序通过SDK写入,参见SDK服务端数据采集
支付宝/微信公众帐号编程是典型的Web端模式,一般会有三种类型日志:
做法日志讲到本地文件,通过Logtail配置正则表达式讲到指定LogstoreDocker中形成日志可以使用容器服务集成日志服务Java程序可以使用Log4J Appender日志不落盘, LogHub Producer Library(客户端高并发写入);Log4J AppenderC#、Python、Java、PHP、C等可以使用SDK写入Windows服务器可以使用Logstash采集终端用户日志接入Web/M 站页面用户行为
页面用户行为搜集可以分为两类:
页面与后台服务器交互:例如下单,登陆、退出等。页面无后台服务器交互:请求直接在后端处理,例如滚屏,关闭页面等。做法第一种可以参考服务端采集方法第二种可以使用Tracking Pixel/JS Library搜集页面行为,参考Tracking Web插口服务器日志运维
例如:
做法不同网路环境下数据采集
LogHub在各Region提供 访问点,每个Region提供三种形式接入点:
更多请参见网路接入,总有一款适宜你。
其他参见LogHub完整采集方式。参见日志实时消费,涉及流计算、数据清洗、数据库房和索引查询等功能。
实现并口数据的接收功能、以及绘图工具进行数据显示
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-11 12:58
前言:这个小项目是自己的毕设,做的比较简单,之前记录是pyqt的环境配置,说实话,今天忽然听到自己也都忘得差不多了,看来还是要好好记录一下自己的知识。
这个项目分为了两个部份,其中下位机的数据采集是使用STM32L0系列的开发板作为了主控器,温度采集模块是DB18B20,还有一个GSM模块,用于发送邮件,比较简单的项目。上位机部份也就是使用pyserial模块来进行数据的接收,使用matplotlib模块来进行绘图。
下位机部份的代码还在,但是用于时间关系,开发板等东西已然送人了,所以这篇博客主要就讲一下上位机的程序开发,但是为了和上一篇博客中实现的疗效一样,我去找到了一个软件模拟下位机向PC端发送数据。
1.模拟软件向PC端发送数据–VSPD软件
找了一篇博客,收录VSPD使用教程,放上链接如下:
2.串口接收数据
今天打算把之前的代码用来跑一下,但是发觉出了一些小问题,这里也记载一下,被自己蠢哭的问题。
问题1:
pyserial模块的安装问题,换了环境,但是使用pip安装,以及在pycharm中进行安装,都没有成功,下载的包都是空的文件夹,其截图如下:
解决办法,去官网下载压缩包,然后解压到你的类库的Lib/site-packages目录下,然后运行命令进行安装;
#files
命令行安装
综上问题1解决
问题2(自己犯低级错误):
a.串口初始化部份
class MainWindow(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(MainWindow, self).__init__(parent)
self.setupUi(self)
### 1. 画图
self.my_graph_1 = MyMplCanvas()
self.left1.addWidget(self.my_graph_1)
self.t = [] ### 储存计数
self.m = [] ### 储存接收的数据
self.i = 0 ### 计数值
### 2. 串口部分
# 串口初始化为None
self.ser = None
# 设置窗口名称
self.setWindowTitle("Temperature--Serial")
# 刷新一下串口的列表
# self.refresh()
# 波特率
self.comboBox_2.addItem('115200')
self.comboBox_2.addItem('57600')
self.comboBox_2.addItem('9600')
self.comboBox_2.addItem('4800')
self.comboBox_2.addItem('2400')
self.comboBox_2.addItem('1200')
# 实例化一个定时器
self.timer = QTimer(self)
# 定时器调用读取串口接收数据
self.timer.timeout.connect(self.recv)
# 打开串口按钮
self.pushButton.clicked.connect(self.open)
# 关闭串口
self.pushButton_2.clicked.connect(self.close)
# 波特率修改
self.comboBox_2.activated.connect(self.baud_modify)
# 串口号修改
self.comboBox.activated.connect(self.com_modify)
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
b.数据接收及处理 查看全部
实现并口数据的接收功能、以及绘图工具进行数据显示
前言:这个小项目是自己的毕设,做的比较简单,之前记录是pyqt的环境配置,说实话,今天忽然听到自己也都忘得差不多了,看来还是要好好记录一下自己的知识。
这个项目分为了两个部份,其中下位机的数据采集是使用STM32L0系列的开发板作为了主控器,温度采集模块是DB18B20,还有一个GSM模块,用于发送邮件,比较简单的项目。上位机部份也就是使用pyserial模块来进行数据的接收,使用matplotlib模块来进行绘图。
下位机部份的代码还在,但是用于时间关系,开发板等东西已然送人了,所以这篇博客主要就讲一下上位机的程序开发,但是为了和上一篇博客中实现的疗效一样,我去找到了一个软件模拟下位机向PC端发送数据。
1.模拟软件向PC端发送数据–VSPD软件
找了一篇博客,收录VSPD使用教程,放上链接如下:
2.串口接收数据
今天打算把之前的代码用来跑一下,但是发觉出了一些小问题,这里也记载一下,被自己蠢哭的问题。
问题1:
pyserial模块的安装问题,换了环境,但是使用pip安装,以及在pycharm中进行安装,都没有成功,下载的包都是空的文件夹,其截图如下:
解决办法,去官网下载压缩包,然后解压到你的类库的Lib/site-packages目录下,然后运行命令进行安装;
#files
命令行安装
综上问题1解决
问题2(自己犯低级错误):
a.串口初始化部份
class MainWindow(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(MainWindow, self).__init__(parent)
self.setupUi(self)
### 1. 画图
self.my_graph_1 = MyMplCanvas()
self.left1.addWidget(self.my_graph_1)
self.t = [] ### 储存计数
self.m = [] ### 储存接收的数据
self.i = 0 ### 计数值
### 2. 串口部分
# 串口初始化为None
self.ser = None
# 设置窗口名称
self.setWindowTitle("Temperature--Serial")
# 刷新一下串口的列表
# self.refresh()
# 波特率
self.comboBox_2.addItem('115200')
self.comboBox_2.addItem('57600')
self.comboBox_2.addItem('9600')
self.comboBox_2.addItem('4800')
self.comboBox_2.addItem('2400')
self.comboBox_2.addItem('1200')
# 实例化一个定时器
self.timer = QTimer(self)
# 定时器调用读取串口接收数据
self.timer.timeout.connect(self.recv)
# 打开串口按钮
self.pushButton.clicked.connect(self.open)
# 关闭串口
self.pushButton_2.clicked.connect(self.close)
# 波特率修改
self.comboBox_2.activated.connect(self.baud_modify)
# 串口号修改
self.comboBox.activated.connect(self.com_modify)
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
b.数据接收及处理
系列文章:Kubernetes日志采集最佳实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-09 16:03
上一期主要介绍Kubernetes日志输出的一些注意事项,日志输出最终的目的还是做统一的采集和剖析。在Kubernetes中,日志采集和普通虚拟机的方法有很大不同,相对实现难度和布署代价也略大,但若使用恰当则比传统方法自动化程度更高、运维代价更低。
Kubernetes日志采集难点
在Kubernetes中,日志采集相比传统虚拟机、物理机方法要复杂好多,最根本的缘由是Kubernetes把底层异常屏蔽,提供愈发细细度的资源调度,向上提供稳定、动态的环境。因此日志采集面对的是愈发丰富、动态的环境,需要考虑的点也愈发的多。
例如:
对于运行时间太短的Job类应用,从启动到停止只有几秒的时间,如何保证日志采集的实时性才能跟上并且数据不丢?K8s通常推荐使用大尺寸节点,每个节点可以运行10-100+的容器,如何在资源消耗尽可能低的情况下采集100+的容器?在K8s中,应用都以yaml的形式布署,而日志采集还是以手工的配置文件方式为主,如何才能使日志采集以K8s的方法进行布署?Kubernetes传统方法
日志种类
文件、stdout、宿主机文件、journal
文件、journal
日志源
业务容器、系统组件、宿主机
业务、宿主机
采集方式
Agent(Sidecar、DaemonSet)、直写(DockerEngine、业务)
Agent、直写
单机应用数
10-100
1-10
应用动态性
高
低
节点动态性
高
低
采集部署形式
手动、Yaml
手动、自定义
采集方式:主动 or 被动
日志的采集方式分为被动采集和主动推送两种,在K8s中,被动采集一般分为Sidecar和DaemonSet两种形式,主动推送有DockerEngine推送和业务直写两种形式。
总结出来:DockerEngine直写通常不推荐;业务直写推荐在日志量极大的场景中使用;DaemonSet通常在中小型集群中使用;Sidecar推荐在超大型的集群中使用。详细的各类采集方式对比如下:
DockerEngine业务直写DaemonSet形式Sidecar形式
采集日志类型
标准输出
业务日志
标准输出+部分文件
文件
部署运维
低,原生支持
低,只需维护好配置文件即可
一般,需维护DaemonSet
较高,每个须要采集日志的POD都须要布署sidecar容器
日志分类储存
无法实现
业务独立配置
一般,可通过容器/路径等映射
每个POD可单独配置,灵活性高
多住户隔离
弱
弱,日志直写会和业务逻辑竞争资源
一般,只能通过配置间隔离
强,通过容器进行隔离,可单独分配资源
支持集群规模
本地储存无限制,若使用syslog、fluentd会有单点限制
无限制
取决于配置数
无限制
资源占用
低,docker
engine提供
整体最低,省去采集开销
较低,每个节点运行一个容器
较高,每个POD运行一个容器
查询便捷性
低,只能grep原创日志
高,可依照业务特性进行订制
较高,可进行自定义的查询、统计
高,可依照业务特性进行订制
可定制性
低
高,可自由扩充
低
高,每个POD单独配置
耦合度
高,与DockerEngine强绑定,修改须要重启DockerEngine
高,采集模块更改/升级须要重新发布业务
低,Agent可独立升级
一般,默认采集Agent升级对应Sidecar业务也会重启(有一些扩充包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类明晰、功能较单一的集群
大型、混合型、PAAS型集群
日志输出:Stdout or 文件
和虚拟机/物理机不同,K8s的容器提供标准输出和文件两种形式。在容器中,标准输出将日志直接输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,将日志接收后根据DockerEngine配置的LogDriver规则进行处理;日志复印到文件的形式和虚拟机/物理机基本类似,只是日志可以使用不同的储存形式,例如默认储存、EmptyDir、HostVolume、NFS等。
虽然使用Stdout复印日志是Docker官方推荐的方法,但你们须要注意这个推荐是基于容器只作为简单应用的场景,实际的业务场景中我们还是建议你们尽可能使用文件的形式,主要的缘由有以下几点:
Stdout性能问题,从应用输出stdout到服务端,中间会经过好几个流程(例如普遍使用的JSON LogDriver):应用stdout -> DockerEngine -> LogDriver -> 序列化成JSON -> 保存到文件 -> Agent采集文件 -> 解析JSON -> 上传服务端。整个流程相比文件的额外开支要多好多,在压测时,每秒10万行日志输出都会额外占用DockerEngine 1个CPU核。Stdout不支持分类,即所有的输出都混在一个流中,无法象文件一样分类输出,通常一个应用中有AccessLog、ErrorLog、InterfaceLog(调用外部插口的日志)、TraceLog等,而这种日志的格式、用途不一,如果混在同一个流上将很难采集和剖析。Stdout只支持容器的主程序输出,如果是daemon/fork形式运行的程序将难以使用stdout。文件的Dump形式支持各类策略,例如同步/异步写入、缓存大小、文件轮转策略、压缩策略、清除策略等,相对愈发灵活。
因此我们建议线上应用使用文件的形式输出日志,Stdout只在功能单一的应用或一些K8s系统/运维组件中使用。
CICD集成:Logging Operator
Kubernetes提供了标准化的业务布署形式,可以通过yaml(K8s API)来申明路由规则、暴露服务、挂载储存、运行业务、定义缩扩容规则等,所以Kubernetes很容易和CICD系统集成。而日志采集也是运维监控过程中的重要部份,业务上线后的所有日志都要进行实时的搜集。
原创的形式是在发布以后自动去布署日志采集的逻辑,这种方法须要手工干预,违背CICD自动化的宗旨;为了实现自动化,有人开始基于日志采集的API/SDK包装一个手动布署的服务,在发布后通过CICD的webhook触发调用,但这些方法的开发代价很高。
在Kubernetes中,日志最标准的集成方法是以一个新资源注册到Kubernetes系统中,以Operator(CRD)的形式来进行管理和维护。在这些形式下,CICD系统不需要额外的开发,只需在布署到Kubernetes系统时附加上日志相关的配置即可实现。
Kubernetes日志采集方案
早在Kubernetes出现之前,我们就开始为容器环境开发日志采集方案,随着K8s的逐步稳定,我们开始将好多业务迁移到K8s平台上,因此也基于之前的基础专门开发了一套K8s上的日志采集方案。主要具备的功能有:
支持各种数据的实时采集,包括容器文件、容器Stdout、宿主机文件、Journal、Event等;支持多种采集部署方法,包括DaemonSet、Sidecar、DockerEngine LogDriver等;支持对日志数据进行富化,包括附加Namespace、Pod、Container、Image、Node等信息;稳定、高可靠,基于阿里自研的Logtail采集Agent实现,目前全网已有几百万的布署实例;基于CRD进行扩充,可使用Kubernetes布署发布的形式来布署日志采集规则,与CICD完美集成。安装日志采集组件
目前这套采集方案早已对外开放,我们提供了一个Helm安装包,其中包括Logtail的DaemonSet、AliyunlogConfig的CRD申明以及CRD Controller,安装以后才能直接使用DaemonS优采云采集器以及CRD配置了。安装方法如下:
阿里云Kubernetes集群在开通的时侯可以勾选安装,这样在集群创建的时侯会手动安装上述组件。如果开通的时侯没有安装,则可以自动安装。如果是自建的Kubernetes,无论是在阿里云上自建还是在其他云或则是线下,也可以使用这样采集方案,具体安装方法参考[自建Kubernetes安装]()。
安装好上述组件然后,Logtail和对应的Controller都会运行在集群中,但默认这种组件并不会采集任何日志,需要配置日志采集规则来采集指定Pod的各种日志。
采集规则配置:环境变量 or CRD
除了在日志服务控制台上自动配置之外,对于Kubernetes还额外支持两种配置方法:环境变量和CRD。
环境变量是自swarm时代仍然使用的配置方法,只须要在想要采集的容器环境变量上申明须要采集的数据地址即可,Logtail会手动将这种数据采集到服务端。这种方法布署简单,学习成本低,很容易上手;但才能支持的配置规则极少,很多中级配置(例如解析方法、过滤方法、黑白名单等)都不支持,而且这些申明的方法不支持更改/删除,每次更改虽然都是创建1个新的采集配置,历史的采集配置须要自动清除,否则会导致资源浪费。
CRD配置方法是特别符合Kubernetes官方推荐的标准扩充方法,让采集配置以K8s资源的方法进行管理,通过向Kubernetes部署AliyunLogConfig这个特殊的CRD资源来申明须要采集的数据。例如下边的示例就是布署一个容器标准输出的采集,其中定义须要Stdout和Stderr都采集,并且排除环境变量中收录COLLEXT_STDOUT_FLAG:false的容器。
基于CRD的配置方法以Kubernetes标准扩充资源的方法进行管理,支持配置的增删改查完整语义,而且支持各类中级配置,是我们非常推荐的采集配置方法。
采集规则推荐的配置形式
实际应用场景中,一般都是使用DaemonSet或DaemonSet与Sidecar混用形式,DaemonSet的优势是资源利用率高,但有一个问题是DaemonSet的所有Logtail都共享全局配置,而单一的Logtail有配置支撑的上限,因此难以支撑应用数比较多的集群。
上述是我们给出的推荐配置形式,核心的思想是:
一个配置尽可能多的采集同类数据,减少配置数,降低DaemonSet压力;核心的应用采集要给以充分的资源,可以使用Sidecar形式;配置方法尽可能使用CRD形式;Sidecar因为每位Logtail是单独的配置,所以没有配置数的限制,这种比较适宜于超小型的集群使用。
实践1-中小型集群
绝大部分Kubernetes集群都属于中小型的,对于中小型没有明晰的定义,一般应用数在500以内,节点规模1000以内,没有职能明晰的Kubernetes平台运维。这种场景应用数不会非常多,DaemonSet可以支撑所有的采集配置:
绝大部分业务应用的数据使用DaemonS优采云采集器形式核心应用(对于采集可靠性要求比较高,例如订单/交易系统)使用Sidecar形式单独采集
实践2-大型集群
对于一些用作PAAS平台的小型/超大型集群,一般业务在1000以上,节点规模也在1000以上,有专门的Kubernetes平台运维人员。这种场景下应用数没有限制,DaemonSet难以支持,因此必须使用Sidecar形式,整体规划如下:
Kubernetes平台本身的系统组件日志、内核日志相对种类固定,这部份日志使用DaemonS优采云采集器,主要为平台的运维人员提供服务;各个业务的日志使用Sidecar形式采集,每个业务可以独立设置Sidecar的采集目的地址,为业务的DevOps人员提供足够的灵活性。
原文链接 查看全部
前言
上一期主要介绍Kubernetes日志输出的一些注意事项,日志输出最终的目的还是做统一的采集和剖析。在Kubernetes中,日志采集和普通虚拟机的方法有很大不同,相对实现难度和布署代价也略大,但若使用恰当则比传统方法自动化程度更高、运维代价更低。
Kubernetes日志采集难点
在Kubernetes中,日志采集相比传统虚拟机、物理机方法要复杂好多,最根本的缘由是Kubernetes把底层异常屏蔽,提供愈发细细度的资源调度,向上提供稳定、动态的环境。因此日志采集面对的是愈发丰富、动态的环境,需要考虑的点也愈发的多。
例如:
对于运行时间太短的Job类应用,从启动到停止只有几秒的时间,如何保证日志采集的实时性才能跟上并且数据不丢?K8s通常推荐使用大尺寸节点,每个节点可以运行10-100+的容器,如何在资源消耗尽可能低的情况下采集100+的容器?在K8s中,应用都以yaml的形式布署,而日志采集还是以手工的配置文件方式为主,如何才能使日志采集以K8s的方法进行布署?Kubernetes传统方法
日志种类
文件、stdout、宿主机文件、journal
文件、journal
日志源
业务容器、系统组件、宿主机
业务、宿主机
采集方式
Agent(Sidecar、DaemonSet)、直写(DockerEngine、业务)
Agent、直写
单机应用数
10-100
1-10
应用动态性
高
低
节点动态性
高
低
采集部署形式
手动、Yaml
手动、自定义
采集方式:主动 or 被动
日志的采集方式分为被动采集和主动推送两种,在K8s中,被动采集一般分为Sidecar和DaemonSet两种形式,主动推送有DockerEngine推送和业务直写两种形式。
总结出来:DockerEngine直写通常不推荐;业务直写推荐在日志量极大的场景中使用;DaemonSet通常在中小型集群中使用;Sidecar推荐在超大型的集群中使用。详细的各类采集方式对比如下:
DockerEngine业务直写DaemonSet形式Sidecar形式
采集日志类型
标准输出
业务日志
标准输出+部分文件
文件
部署运维
低,原生支持
低,只需维护好配置文件即可
一般,需维护DaemonSet
较高,每个须要采集日志的POD都须要布署sidecar容器
日志分类储存
无法实现
业务独立配置
一般,可通过容器/路径等映射
每个POD可单独配置,灵活性高
多住户隔离
弱
弱,日志直写会和业务逻辑竞争资源
一般,只能通过配置间隔离
强,通过容器进行隔离,可单独分配资源
支持集群规模
本地储存无限制,若使用syslog、fluentd会有单点限制
无限制
取决于配置数
无限制
资源占用
低,docker
engine提供
整体最低,省去采集开销
较低,每个节点运行一个容器
较高,每个POD运行一个容器
查询便捷性
低,只能grep原创日志
高,可依照业务特性进行订制
较高,可进行自定义的查询、统计
高,可依照业务特性进行订制
可定制性
低
高,可自由扩充
低
高,每个POD单独配置
耦合度
高,与DockerEngine强绑定,修改须要重启DockerEngine
高,采集模块更改/升级须要重新发布业务
低,Agent可独立升级
一般,默认采集Agent升级对应Sidecar业务也会重启(有一些扩充包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类明晰、功能较单一的集群
大型、混合型、PAAS型集群
日志输出:Stdout or 文件
和虚拟机/物理机不同,K8s的容器提供标准输出和文件两种形式。在容器中,标准输出将日志直接输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,将日志接收后根据DockerEngine配置的LogDriver规则进行处理;日志复印到文件的形式和虚拟机/物理机基本类似,只是日志可以使用不同的储存形式,例如默认储存、EmptyDir、HostVolume、NFS等。
虽然使用Stdout复印日志是Docker官方推荐的方法,但你们须要注意这个推荐是基于容器只作为简单应用的场景,实际的业务场景中我们还是建议你们尽可能使用文件的形式,主要的缘由有以下几点:
Stdout性能问题,从应用输出stdout到服务端,中间会经过好几个流程(例如普遍使用的JSON LogDriver):应用stdout -> DockerEngine -> LogDriver -> 序列化成JSON -> 保存到文件 -> Agent采集文件 -> 解析JSON -> 上传服务端。整个流程相比文件的额外开支要多好多,在压测时,每秒10万行日志输出都会额外占用DockerEngine 1个CPU核。Stdout不支持分类,即所有的输出都混在一个流中,无法象文件一样分类输出,通常一个应用中有AccessLog、ErrorLog、InterfaceLog(调用外部插口的日志)、TraceLog等,而这种日志的格式、用途不一,如果混在同一个流上将很难采集和剖析。Stdout只支持容器的主程序输出,如果是daemon/fork形式运行的程序将难以使用stdout。文件的Dump形式支持各类策略,例如同步/异步写入、缓存大小、文件轮转策略、压缩策略、清除策略等,相对愈发灵活。
因此我们建议线上应用使用文件的形式输出日志,Stdout只在功能单一的应用或一些K8s系统/运维组件中使用。
CICD集成:Logging Operator
Kubernetes提供了标准化的业务布署形式,可以通过yaml(K8s API)来申明路由规则、暴露服务、挂载储存、运行业务、定义缩扩容规则等,所以Kubernetes很容易和CICD系统集成。而日志采集也是运维监控过程中的重要部份,业务上线后的所有日志都要进行实时的搜集。
原创的形式是在发布以后自动去布署日志采集的逻辑,这种方法须要手工干预,违背CICD自动化的宗旨;为了实现自动化,有人开始基于日志采集的API/SDK包装一个手动布署的服务,在发布后通过CICD的webhook触发调用,但这些方法的开发代价很高。
在Kubernetes中,日志最标准的集成方法是以一个新资源注册到Kubernetes系统中,以Operator(CRD)的形式来进行管理和维护。在这些形式下,CICD系统不需要额外的开发,只需在布署到Kubernetes系统时附加上日志相关的配置即可实现。
Kubernetes日志采集方案
早在Kubernetes出现之前,我们就开始为容器环境开发日志采集方案,随着K8s的逐步稳定,我们开始将好多业务迁移到K8s平台上,因此也基于之前的基础专门开发了一套K8s上的日志采集方案。主要具备的功能有:
支持各种数据的实时采集,包括容器文件、容器Stdout、宿主机文件、Journal、Event等;支持多种采集部署方法,包括DaemonSet、Sidecar、DockerEngine LogDriver等;支持对日志数据进行富化,包括附加Namespace、Pod、Container、Image、Node等信息;稳定、高可靠,基于阿里自研的Logtail采集Agent实现,目前全网已有几百万的布署实例;基于CRD进行扩充,可使用Kubernetes布署发布的形式来布署日志采集规则,与CICD完美集成。安装日志采集组件
目前这套采集方案早已对外开放,我们提供了一个Helm安装包,其中包括Logtail的DaemonSet、AliyunlogConfig的CRD申明以及CRD Controller,安装以后才能直接使用DaemonS优采云采集器以及CRD配置了。安装方法如下:
阿里云Kubernetes集群在开通的时侯可以勾选安装,这样在集群创建的时侯会手动安装上述组件。如果开通的时侯没有安装,则可以自动安装。如果是自建的Kubernetes,无论是在阿里云上自建还是在其他云或则是线下,也可以使用这样采集方案,具体安装方法参考[自建Kubernetes安装]()。
安装好上述组件然后,Logtail和对应的Controller都会运行在集群中,但默认这种组件并不会采集任何日志,需要配置日志采集规则来采集指定Pod的各种日志。
采集规则配置:环境变量 or CRD
除了在日志服务控制台上自动配置之外,对于Kubernetes还额外支持两种配置方法:环境变量和CRD。
环境变量是自swarm时代仍然使用的配置方法,只须要在想要采集的容器环境变量上申明须要采集的数据地址即可,Logtail会手动将这种数据采集到服务端。这种方法布署简单,学习成本低,很容易上手;但才能支持的配置规则极少,很多中级配置(例如解析方法、过滤方法、黑白名单等)都不支持,而且这些申明的方法不支持更改/删除,每次更改虽然都是创建1个新的采集配置,历史的采集配置须要自动清除,否则会导致资源浪费。
CRD配置方法是特别符合Kubernetes官方推荐的标准扩充方法,让采集配置以K8s资源的方法进行管理,通过向Kubernetes部署AliyunLogConfig这个特殊的CRD资源来申明须要采集的数据。例如下边的示例就是布署一个容器标准输出的采集,其中定义须要Stdout和Stderr都采集,并且排除环境变量中收录COLLEXT_STDOUT_FLAG:false的容器。
基于CRD的配置方法以Kubernetes标准扩充资源的方法进行管理,支持配置的增删改查完整语义,而且支持各类中级配置,是我们非常推荐的采集配置方法。
采集规则推荐的配置形式
实际应用场景中,一般都是使用DaemonSet或DaemonSet与Sidecar混用形式,DaemonSet的优势是资源利用率高,但有一个问题是DaemonSet的所有Logtail都共享全局配置,而单一的Logtail有配置支撑的上限,因此难以支撑应用数比较多的集群。
上述是我们给出的推荐配置形式,核心的思想是:
一个配置尽可能多的采集同类数据,减少配置数,降低DaemonSet压力;核心的应用采集要给以充分的资源,可以使用Sidecar形式;配置方法尽可能使用CRD形式;Sidecar因为每位Logtail是单独的配置,所以没有配置数的限制,这种比较适宜于超小型的集群使用。
实践1-中小型集群
绝大部分Kubernetes集群都属于中小型的,对于中小型没有明晰的定义,一般应用数在500以内,节点规模1000以内,没有职能明晰的Kubernetes平台运维。这种场景应用数不会非常多,DaemonSet可以支撑所有的采集配置:
绝大部分业务应用的数据使用DaemonS优采云采集器形式核心应用(对于采集可靠性要求比较高,例如订单/交易系统)使用Sidecar形式单独采集
实践2-大型集群
对于一些用作PAAS平台的小型/超大型集群,一般业务在1000以上,节点规模也在1000以上,有专门的Kubernetes平台运维人员。这种场景下应用数没有限制,DaemonSet难以支持,因此必须使用Sidecar形式,整体规划如下:
Kubernetes平台本身的系统组件日志、内核日志相对种类固定,这部份日志使用DaemonS优采云采集器,主要为平台的运维人员提供服务;各个业务的日志使用Sidecar形式采集,每个业务可以独立设置Sidecar的采集目的地址,为业务的DevOps人员提供足够的灵活性。
原文链接
一种基于分布式的舆情数据实时采集方法和系统技术方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-09 15:04
全部详尽技术资料下载
【技术实现步骤摘要】
本专利技术涉及互联网舆情数据的分布式高并发采集方法及系统,特别的涉及目标数据的高效、实时采集技术实现方式及系统,尤其涉及一种基于分布式的舆情数据实时采集方法及系统。
技术介绍
舆情是在一定的社会空间内,围绕中介性社会风波的发生、发展和变化,民众对社会管理者形成和持有的社会政治心态。目前,网络成为反映社会舆情的主要载体之一,在舆情传播中起着重要的作用。而舆论危机的爆发使越来越多的人关注社会舆论的形成和发展。各级党政机关要及时了解信息,加强舆情监控,提高舆情应对能力和在新舆论环境中的执政能力,及时化解矛盾,处理好政府和民众的关系。企事业单位也须要关注网路舆情,利用市场已有的舆情剖析系统和服务平台,或者人员与工具结合,掌控网络舆情,辅助决策。如何从大量的网路数据中提取出关键信息,是当前技术研究的一个重点。传统的通用搜索引擎作为一个辅助检索信息的工具,成为用户访问网路的入口和手册。但是,这些通用的搜索引擎也存在着一定的局限性,1、通用搜索引擎所返回的结果收录大量用户不关心的网页。通用搜索引擎常常对信息浓度密集且具有一定结构的数据无能为力,不能挺好地发觉和获取关键信息。2、简单的基于互联网的数据采集系统,其采集方式单一,无法同时多任务执行,这就造成了数据的采集效率较低,无法满足数据的实时性。3、目前的其他舆情剖析监测系统,舆情数据大部分采用离线处理机制,在结构上就造成了其数据必然存在一定的信噪比。而随着网路技术的发展,信息更新的速率越来越快,低信噪比的舆情数据采集系统成为舆情剖析项目的急切需求。
技术实现思路
本专利技术的目的在于克服现有技术的不足,提供一种基于分布式的舆情数据实时采集方法及系统,爬取的数据可生成在线舆情大数据库,为相关政府及企业用户提供在线数据库服务。本专利技术的目的是通过以下技术方案来实现的:一种基于分布式的舆情数据实时采集方法,它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。所述的步骤S1包括以下子步骤:S11:将所有数据源站分为多类,针对每一类网站采集包括网站的网页地址、网页标题、关键字在内的信息构建类相关的关键字库;S12:根据每类网站的页面数据特性,事先定义好要爬取的数据数组;S13:当有新的目标网站需要采集时,获取包括目标网站地址、页面标题、页面关键字在内的与关键字库对应的信息,根据获得的信息与已有的泛型数据对目标网站进行分类;同时筛选出网站的文章列表地址,过滤包括广告在内的与舆情数据无关的页面,将筛选出的地址加入数据采集网站列表。
所述的步骤S2包括以下子步骤:S21:将分类后的舆情数据源网站以列表的形式传给数据采集服务器,数据采集服务器将采集任务分配到多台数据采集PC;针对每位源站,系统设置专门的爬虫进行数据爬取;S22:在数据爬取的过程中对源网站进行实时监控,系统在整个数据爬取过程中采用休眠机制循环访问网站页面,休眠时间依照网站的数据更新速率动态设置;当更新量达到采集阈值时,爬虫激活进行新一轮的数据采集;同时,在每一轮数据采集完成以后,系统标示最后的采集位置,日志文件记录本次循环共采集的数据条数,系统步入休眠状态。在数据爬取过程中,系统首先采用鞋厂设计模式将模拟访问不同的浏览器方式封装上去,并提供统一的实例化插口;在具体实例化的过程中,指定浏览器类型名称即可生产出对应的浏览器访问类;爬虫将按照数据源站的类型与复杂度生成对应的浏览器访问实例;同时,代理设置模块在浏览器访问过程中手动为程序分配IP地址。页面数据分为静态数据和动态数据;对于静态页面数据,爬虫调用模拟浏览器访问方式页面地址获取网页源数据;对于动态数据,爬虫在访问页面之前,需要通过抓包的方法找到动态数据返回链接,再调用浏览器访问方式获取页面数据。将URL地址储存队列方式封装上去,并提供统一的实例化插口;采用多级生产者消费者模式并发的爬取数据:一级生产者依据分配的数据源网站地址访问页面获取数据的一级URL地址,并将地址储存到数据队列当中;若当前地址页面不是正文地址,而是正文列表地址,系统将分配二级生成者从当前地址队列中获取URL地址进行数据爬取,直到获取到正文URL地址;消费者负责从正文地址队列中取出URL数据,访问页面获取正文页面内容;在此过程中,生产者和消费者彼此之间通过阻塞队列来进行通信;采用队列设置模块提供队列的存取操作,并初始化队列数据库并完善联接。
所述的步骤S3包括对动态网页数据的剖析和对静态页面数据的剖析,其中对于静态页面数据使用封装好的Xpath方式,给定数据项的路径地址即可获取到对应数据项;同时结合正则表达式,通过正则表达式过滤筛选数据,补充获取XPath未能解析到的数据;系统将解析到的数据形参给事前定义好的对应的数据项;对于动态网页数据,使用JSON方式获取字典格式的动态网页数据项。所述的步骤S4步骤包括:在数据采集之前,采用鞋厂设计模式,将每一类网站定义好的数据项以及保留数组封装成字典格式,并提供统一的数据插口;在数据采集完成后,根据数据源网站类别,系统调用对应的封装方式将采集到的数据封装为对应类的统一格式;在封装过程中使用UUID方式为每条数据生成惟一的标识符,方便后续的检索操作。所述的步骤S5包括:采用鞋厂设计模式将结果数据的储存操作封装为队列方式,采集到数据然后调用队列方式将数据输入数据库服务器;在数据库服务器中分别为每一类源数据网站设置对应的数据库,在数据储存时将数据存到对应的数据库;根据保存数据的不同采取不同的数据库,保存生产者和消费者之间的URL队列数据。所述的步骤S6包括:采用鞋厂模式将日志方式封装上去,提供统一的插口访问;日志采用logging模块给运行中的程序提供了一个标准的信息输出插口;系统开始运行的时侯即调用日志插口生成实例,在整个过程中记录每位模块的运行状态与结果;在每一轮爬虫程序执行完成时,将检测结果按天生成日志文件。
采用所述的方式的系统,所述的系统包括:数据打算模块,用于完成源站的分类以及目标数据项定义;更新检测模块,用于检测目标数据网站的更新情况。数据爬取模块,用于模拟浏览器环境访问源站目标页面并将页面数据获取到本地;代理设置模块,用于手动为服务器分配IP地址。队列设置模块,用于负责管理阻塞URL采集队列,以及结果数据储存队列,并进行去重操作;数据解析模块,用于通过剖析源数据,并从中解析出目标数据项;数据封装模块,用于将爬取到的数据项统一封装成标准格式输出;数据储存模块,用于将封装好的数据储存到在线舆情大数据库;日志生成模块,用于各环节检测状态的日志输出。本专利技术的有益疗效是:1. 系统构架先进,通过使用工厂模式作为系统的主要设计模式,能够快速生成新实例。将浏览器访问,日志生成,数据封装,代理设置以及队列设置等系统核心功能封装上去。增强了系统的可扩展性和可移植性,提高了代码的可重用性和系统的可维护性
【技术保护点】
一种基于分布式的舆情数据实时采集方法,其特点在于:它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。
【技术特点摘要】
1.一种基于分布式的舆情数据实时采集方法,其特点在于:它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。2.根据权力要求1所述的一种基于分布式的舆情数据实时采集方法,其特点在于:所述的步骤S1包括以下子步骤:S11:将所有数据源站分为多类,针对每一类网站采集包括网站的网页地址、网页标题、关键字在内的信息构建类相关的关键字库;S12:根据每类网站的页面数据特性,事先定义好要爬取的数据数组;S13:当有新的目标网站需要采集时,获取包括目标网站地址、页面标题、页面关键字在内的与关键字库对应的信息,根据获得的信息与已有的泛型数据对目标网站进行分类;同时筛选出网站的文章列表地址,过滤包括广告在内的与舆情数据无关的页面,将筛选出的地址加入数据采集网站列表。
3.根据权力要求1所述的一种基于分布式的舆情数据实时采集方法,其特点在于:所述的步骤S2包括以下子步骤:S21:将分类后的舆情数据源网站以列表的形式传给数据采集服务器,数据采集服务器将采集任务分配到多台数据采集PC;针对每位源站,系统设置专门的爬虫进行数据爬取;S22:在数据爬取的过程中对源网站进行实时监控,系统在整个数据爬取过程中采用休眠机制循环访问网站页面,休眠时间依照网站的数据更新速率动态设置;当更新量达到采集阈值时,爬虫激活进行新一轮的数据采集;同时,在每一轮数据采集完成以后,系统标示最后的采集位置,日志文件记录本次循环共采集的数据条数,系统步入休眠状态。4.根据权力要求1或3所述的一种基于分布式的舆情数据实时采集方法,其特点在于:在数据爬取过程中,系统首先采用鞋厂设计模式将模拟访问不同的浏览器方式封装上去,并提供统一的实例化插口;在具体实例化的过程中,指定浏览器类型名称即可生产出对应的浏览器访问类;爬虫将按照数据源站的类型与复杂度生成对应的浏览器访问实例;同时,代理设置模块在浏览器访问过程中手动为程序分配IP地址。5.根据权力要求1或3所述的一种基于分布式的舆情数据实时采集方法,其特点在于:将URL地址储存队列方式封装上去,并提供统一的实例化插口;采用多级生产者消费者模式并发的爬取数据:一级生产者依据分配的数据源网站地址访问页面获取数据的一级URL地址,并将地址储存到数据队列当中;若当前地址页面不是正文地址,而是正文列表地址,系统将分配二级生成者从当前地址队列中获取URL地址进行...
【专利技术属性】
技术研制人员:李平,陈雁,胡栋,代臻,刘婷,许斌,孙先,林辉,赵玲,
申请(专利权)人:西南石油大学,
类型:发明
国别省市:四川;51
全部详尽技术资料下载 我是这个专利的主人 查看全部
本发明专利技术公开了一种基于分布式的舆情数据实时采集方法及系统,方法包括以下步骤:S1:建立舆情数据网站类库,分类并定义爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,服务器分配相应的爬虫以休眠的模式循环地爬取数据;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。本发明专利技术构架先进,通过使用工厂模式作为系统的主要设计模式,能够快速生成新实例,将浏览器访问、日志生成、数据封装、代理设置以及队列设置等系统核心功能封装上去,增强系统的可扩展性和可移植性,提高代码的可重用性和系统的可维护性。
全部详尽技术资料下载
【技术实现步骤摘要】
本专利技术涉及互联网舆情数据的分布式高并发采集方法及系统,特别的涉及目标数据的高效、实时采集技术实现方式及系统,尤其涉及一种基于分布式的舆情数据实时采集方法及系统。
技术介绍
舆情是在一定的社会空间内,围绕中介性社会风波的发生、发展和变化,民众对社会管理者形成和持有的社会政治心态。目前,网络成为反映社会舆情的主要载体之一,在舆情传播中起着重要的作用。而舆论危机的爆发使越来越多的人关注社会舆论的形成和发展。各级党政机关要及时了解信息,加强舆情监控,提高舆情应对能力和在新舆论环境中的执政能力,及时化解矛盾,处理好政府和民众的关系。企事业单位也须要关注网路舆情,利用市场已有的舆情剖析系统和服务平台,或者人员与工具结合,掌控网络舆情,辅助决策。如何从大量的网路数据中提取出关键信息,是当前技术研究的一个重点。传统的通用搜索引擎作为一个辅助检索信息的工具,成为用户访问网路的入口和手册。但是,这些通用的搜索引擎也存在着一定的局限性,1、通用搜索引擎所返回的结果收录大量用户不关心的网页。通用搜索引擎常常对信息浓度密集且具有一定结构的数据无能为力,不能挺好地发觉和获取关键信息。2、简单的基于互联网的数据采集系统,其采集方式单一,无法同时多任务执行,这就造成了数据的采集效率较低,无法满足数据的实时性。3、目前的其他舆情剖析监测系统,舆情数据大部分采用离线处理机制,在结构上就造成了其数据必然存在一定的信噪比。而随着网路技术的发展,信息更新的速率越来越快,低信噪比的舆情数据采集系统成为舆情剖析项目的急切需求。
技术实现思路
本专利技术的目的在于克服现有技术的不足,提供一种基于分布式的舆情数据实时采集方法及系统,爬取的数据可生成在线舆情大数据库,为相关政府及企业用户提供在线数据库服务。本专利技术的目的是通过以下技术方案来实现的:一种基于分布式的舆情数据实时采集方法,它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。所述的步骤S1包括以下子步骤:S11:将所有数据源站分为多类,针对每一类网站采集包括网站的网页地址、网页标题、关键字在内的信息构建类相关的关键字库;S12:根据每类网站的页面数据特性,事先定义好要爬取的数据数组;S13:当有新的目标网站需要采集时,获取包括目标网站地址、页面标题、页面关键字在内的与关键字库对应的信息,根据获得的信息与已有的泛型数据对目标网站进行分类;同时筛选出网站的文章列表地址,过滤包括广告在内的与舆情数据无关的页面,将筛选出的地址加入数据采集网站列表。
所述的步骤S2包括以下子步骤:S21:将分类后的舆情数据源网站以列表的形式传给数据采集服务器,数据采集服务器将采集任务分配到多台数据采集PC;针对每位源站,系统设置专门的爬虫进行数据爬取;S22:在数据爬取的过程中对源网站进行实时监控,系统在整个数据爬取过程中采用休眠机制循环访问网站页面,休眠时间依照网站的数据更新速率动态设置;当更新量达到采集阈值时,爬虫激活进行新一轮的数据采集;同时,在每一轮数据采集完成以后,系统标示最后的采集位置,日志文件记录本次循环共采集的数据条数,系统步入休眠状态。在数据爬取过程中,系统首先采用鞋厂设计模式将模拟访问不同的浏览器方式封装上去,并提供统一的实例化插口;在具体实例化的过程中,指定浏览器类型名称即可生产出对应的浏览器访问类;爬虫将按照数据源站的类型与复杂度生成对应的浏览器访问实例;同时,代理设置模块在浏览器访问过程中手动为程序分配IP地址。页面数据分为静态数据和动态数据;对于静态页面数据,爬虫调用模拟浏览器访问方式页面地址获取网页源数据;对于动态数据,爬虫在访问页面之前,需要通过抓包的方法找到动态数据返回链接,再调用浏览器访问方式获取页面数据。将URL地址储存队列方式封装上去,并提供统一的实例化插口;采用多级生产者消费者模式并发的爬取数据:一级生产者依据分配的数据源网站地址访问页面获取数据的一级URL地址,并将地址储存到数据队列当中;若当前地址页面不是正文地址,而是正文列表地址,系统将分配二级生成者从当前地址队列中获取URL地址进行数据爬取,直到获取到正文URL地址;消费者负责从正文地址队列中取出URL数据,访问页面获取正文页面内容;在此过程中,生产者和消费者彼此之间通过阻塞队列来进行通信;采用队列设置模块提供队列的存取操作,并初始化队列数据库并完善联接。
所述的步骤S3包括对动态网页数据的剖析和对静态页面数据的剖析,其中对于静态页面数据使用封装好的Xpath方式,给定数据项的路径地址即可获取到对应数据项;同时结合正则表达式,通过正则表达式过滤筛选数据,补充获取XPath未能解析到的数据;系统将解析到的数据形参给事前定义好的对应的数据项;对于动态网页数据,使用JSON方式获取字典格式的动态网页数据项。所述的步骤S4步骤包括:在数据采集之前,采用鞋厂设计模式,将每一类网站定义好的数据项以及保留数组封装成字典格式,并提供统一的数据插口;在数据采集完成后,根据数据源网站类别,系统调用对应的封装方式将采集到的数据封装为对应类的统一格式;在封装过程中使用UUID方式为每条数据生成惟一的标识符,方便后续的检索操作。所述的步骤S5包括:采用鞋厂设计模式将结果数据的储存操作封装为队列方式,采集到数据然后调用队列方式将数据输入数据库服务器;在数据库服务器中分别为每一类源数据网站设置对应的数据库,在数据储存时将数据存到对应的数据库;根据保存数据的不同采取不同的数据库,保存生产者和消费者之间的URL队列数据。所述的步骤S6包括:采用鞋厂模式将日志方式封装上去,提供统一的插口访问;日志采用logging模块给运行中的程序提供了一个标准的信息输出插口;系统开始运行的时侯即调用日志插口生成实例,在整个过程中记录每位模块的运行状态与结果;在每一轮爬虫程序执行完成时,将检测结果按天生成日志文件。
采用所述的方式的系统,所述的系统包括:数据打算模块,用于完成源站的分类以及目标数据项定义;更新检测模块,用于检测目标数据网站的更新情况。数据爬取模块,用于模拟浏览器环境访问源站目标页面并将页面数据获取到本地;代理设置模块,用于手动为服务器分配IP地址。队列设置模块,用于负责管理阻塞URL采集队列,以及结果数据储存队列,并进行去重操作;数据解析模块,用于通过剖析源数据,并从中解析出目标数据项;数据封装模块,用于将爬取到的数据项统一封装成标准格式输出;数据储存模块,用于将封装好的数据储存到在线舆情大数据库;日志生成模块,用于各环节检测状态的日志输出。本专利技术的有益疗效是:1. 系统构架先进,通过使用工厂模式作为系统的主要设计模式,能够快速生成新实例。将浏览器访问,日志生成,数据封装,代理设置以及队列设置等系统核心功能封装上去。增强了系统的可扩展性和可移植性,提高了代码的可重用性和系统的可维护性
【技术保护点】
一种基于分布式的舆情数据实时采集方法,其特点在于:它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。
【技术特点摘要】
1.一种基于分布式的舆情数据实时采集方法,其特点在于:它包括以下步骤:S1:建立舆情数据网站类库,分类舆情数据源站,并定义每类网站的爬取数据项;S2:将数据采集网站列表传输给数据采集服务器,数据采集服务器分配相应的爬虫以休眠的模式循环地爬取目标网站数据,采集过程中使用生产者消费者模式并发执行采集任务;S3:对爬取到的源网页数据进行标签解析,定位目标数据项位置获取目标数据项;S4:将获取到的结果数据项封装成对应类的统一格式;S5:将封装后的数据存入对应的数据库;S6:生成检测日志文件。2.根据权力要求1所述的一种基于分布式的舆情数据实时采集方法,其特点在于:所述的步骤S1包括以下子步骤:S11:将所有数据源站分为多类,针对每一类网站采集包括网站的网页地址、网页标题、关键字在内的信息构建类相关的关键字库;S12:根据每类网站的页面数据特性,事先定义好要爬取的数据数组;S13:当有新的目标网站需要采集时,获取包括目标网站地址、页面标题、页面关键字在内的与关键字库对应的信息,根据获得的信息与已有的泛型数据对目标网站进行分类;同时筛选出网站的文章列表地址,过滤包括广告在内的与舆情数据无关的页面,将筛选出的地址加入数据采集网站列表。
3.根据权力要求1所述的一种基于分布式的舆情数据实时采集方法,其特点在于:所述的步骤S2包括以下子步骤:S21:将分类后的舆情数据源网站以列表的形式传给数据采集服务器,数据采集服务器将采集任务分配到多台数据采集PC;针对每位源站,系统设置专门的爬虫进行数据爬取;S22:在数据爬取的过程中对源网站进行实时监控,系统在整个数据爬取过程中采用休眠机制循环访问网站页面,休眠时间依照网站的数据更新速率动态设置;当更新量达到采集阈值时,爬虫激活进行新一轮的数据采集;同时,在每一轮数据采集完成以后,系统标示最后的采集位置,日志文件记录本次循环共采集的数据条数,系统步入休眠状态。4.根据权力要求1或3所述的一种基于分布式的舆情数据实时采集方法,其特点在于:在数据爬取过程中,系统首先采用鞋厂设计模式将模拟访问不同的浏览器方式封装上去,并提供统一的实例化插口;在具体实例化的过程中,指定浏览器类型名称即可生产出对应的浏览器访问类;爬虫将按照数据源站的类型与复杂度生成对应的浏览器访问实例;同时,代理设置模块在浏览器访问过程中手动为程序分配IP地址。5.根据权力要求1或3所述的一种基于分布式的舆情数据实时采集方法,其特点在于:将URL地址储存队列方式封装上去,并提供统一的实例化插口;采用多级生产者消费者模式并发的爬取数据:一级生产者依据分配的数据源网站地址访问页面获取数据的一级URL地址,并将地址储存到数据队列当中;若当前地址页面不是正文地址,而是正文列表地址,系统将分配二级生成者从当前地址队列中获取URL地址进行...
【专利技术属性】
技术研制人员:李平,陈雁,胡栋,代臻,刘婷,许斌,孙先,林辉,赵玲,
申请(专利权)人:西南石油大学,
类型:发明
国别省市:四川;51
全部详尽技术资料下载 我是这个专利的主人
全网微博数据每日亿级实时采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2020-08-09 08:34
硬件配置
2台服务器,每台的配置如下
系统CPU显存硬碟
Ubuntu16.04E5-2630 v4 @ 2.20GHz * 832G1T
抓取速率
每台服务器满负荷运转:
每台服务器启动50个爬虫进程,两台共100个爬虫进程
每个进程的抓取情况:
可以看见每位进程,每分钟可以抓取300+页面。那么,一天共可以抓取:
300(pages/(process*min)) * 100(prcesses) * 60*24(mins/day) = 43,200,000(pages/day)
所以三天可以抓取4.3千万的页面
如果抓取用户个人信息,1(data/page) ,
则三天的数据抓取量是 43,200,000(pages/day) * 1(data/page) = 43,200,000(data/day) 4.3千万
如果抓取用户微博数据,10(data/page) ,
则三天的数据抓取量是 43,200,000(pages/day) * 10(data/page) = 432,000,000(data/day) 4.3亿
数据库统计
MongoDB IO量
每秒4500+的数据插入量,所以三天就是4亿+的数据采集入库量
用户个人信息数据
微博用户id采用海量采集的形式,目前早已拥有5.5千万有效真实用户的微博id,并且在不断下降中
发掘id有效id有效百分比
97,267,43555,832,4010.574
用户微博数据
实时抓取5.5千万+有效用户的微博,数据统计
微博发表日期为11.20~11.24日之间的微博
11.2011.2111.2211.2311.24
13,864,35918,438,46018,866,07218,143,92311,351,606
当前数据库总数:537,475,459 (5亿)
数据展示
用户数据
微博数据 查看全部
实验数据
硬件配置
2台服务器,每台的配置如下
系统CPU显存硬碟
Ubuntu16.04E5-2630 v4 @ 2.20GHz * 832G1T
抓取速率
每台服务器满负荷运转:
每台服务器启动50个爬虫进程,两台共100个爬虫进程
每个进程的抓取情况:
可以看见每位进程,每分钟可以抓取300+页面。那么,一天共可以抓取:
300(pages/(process*min)) * 100(prcesses) * 60*24(mins/day) = 43,200,000(pages/day)
所以三天可以抓取4.3千万的页面
如果抓取用户个人信息,1(data/page) ,
则三天的数据抓取量是 43,200,000(pages/day) * 1(data/page) = 43,200,000(data/day) 4.3千万
如果抓取用户微博数据,10(data/page) ,
则三天的数据抓取量是 43,200,000(pages/day) * 10(data/page) = 432,000,000(data/day) 4.3亿
数据库统计
MongoDB IO量
每秒4500+的数据插入量,所以三天就是4亿+的数据采集入库量
用户个人信息数据
微博用户id采用海量采集的形式,目前早已拥有5.5千万有效真实用户的微博id,并且在不断下降中
发掘id有效id有效百分比
97,267,43555,832,4010.574
用户微博数据
实时抓取5.5千万+有效用户的微博,数据统计
微博发表日期为11.20~11.24日之间的微博
11.2011.2111.2211.2311.24
13,864,35918,438,46018,866,07218,143,92311,351,606
当前数据库总数:537,475,459 (5亿)
数据展示
用户数据
微博数据
QQ群实时数据查询采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 570 次浏览 • 2020-08-09 01:47
软件功能
它可以根据关键字捕获组号,根据段落编号捕获组号和采集组,采集朋友的QQ号,支持将成员数保存为TXT,Excel格式,需要使用软件登录QQ帐户.
软件功能
1. 根据关键词采集组号: 输入关键词,省市等信息.
2. 根据号码段采集组号: 输入组号段以采集组名和对应于组号的创建者. 仅使用TM2009进行采集.
3. 采集QQ号: 可以根据城市,性别,年龄和在线状态采集QQ号.
4. 采集朋友的QQ数字: 提取朋友的数字并选择将其分组.
5. 采集组中的会员号: 您可以采集单个组中的成员,也可以采集所有加入的组.
6. 它支持以TXT和Excel格式保存,并可以使用灵活的保存格式模板导出为qq邮箱格式.
软件提示
该软件功能强大,易于操作,人性化的设计理念,并且操作页面的用户体验非常简洁,易于使用,并且完全是傻瓜式的操作模式.
软件屏幕截图
相关软件
起点QQ签名采集器: 这是起点QQ签名采集器,可以一键自动采集网络上的QQ签名,并支持导出到txt.
明智的QQ采集器: 这是明智的QQ采集器,可用于批量采集QQ的软件!可以根据地区,年龄,性别或关键字进行采集! 查看全部
这是QQ群组实时数据查询采集器,它是QQ群组号码的辅助软件.
软件功能
它可以根据关键字捕获组号,根据段落编号捕获组号和采集组,采集朋友的QQ号,支持将成员数保存为TXT,Excel格式,需要使用软件登录QQ帐户.
软件功能
1. 根据关键词采集组号: 输入关键词,省市等信息.
2. 根据号码段采集组号: 输入组号段以采集组名和对应于组号的创建者. 仅使用TM2009进行采集.
3. 采集QQ号: 可以根据城市,性别,年龄和在线状态采集QQ号.
4. 采集朋友的QQ数字: 提取朋友的数字并选择将其分组.
5. 采集组中的会员号: 您可以采集单个组中的成员,也可以采集所有加入的组.
6. 它支持以TXT和Excel格式保存,并可以使用灵活的保存格式模板导出为qq邮箱格式.
软件提示
该软件功能强大,易于操作,人性化的设计理念,并且操作页面的用户体验非常简洁,易于使用,并且完全是傻瓜式的操作模式.
软件屏幕截图
相关软件
起点QQ签名采集器: 这是起点QQ签名采集器,可以一键自动采集网络上的QQ签名,并支持导出到txt.
明智的QQ采集器: 这是明智的QQ采集器,可用于批量采集QQ的软件!可以根据地区,年龄,性别或关键字进行采集!
FileBeat + Kafka用于实时日志采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 731 次浏览 • 2020-08-07 08:16
在日志生成端(LogServer服务器)上,已部署FlumeAgent实时监视生成的日志,然后将其发送到Kafka. 经过观察,每个FlumeAgent占用大量系统资源(至少占CPU的50%或更多). 对于另一项业务,LogServer承受着巨大的压力,CPU资源特别紧张. 如果要实时采集和分析日志,则需要一个更轻量级且耗费资源较少的日志采集框架,因此我尝试了Filebeat.
Filebeat是使用go语言开发的开源文本日志采集器. 它重构了logstash采集器源代码,将其安装在日志生成服务器上以监视日志目录或特定的日志文件,并将它们发送到kastka上的logstash,elasticsearch和. Filebeat是一种数据采集解决方案,它替代了logstash-forwarder. 原因是logstash在jvm上运行并且消耗大量服务器资源(Flume也是一样). 由于Filebeat如此轻巧,因此不要期望它在日志采集过程中做更多的清理和转换工作. 它仅负责一件事,即有效且可靠地传输日志数据. 至于清洁和转换,您可以在此过程中进行后续操作.
Filebeat的官方网站地址是: 您可以下载Filebeat并在此地址查看文档.
Filebeat安装配置
Filebeat的安装和配置非常简单.
下载filebeat-5.6.3-linux-x86_64.tar.gz并将其解压缩.
输入filebeat-5.6.3-linux-x86_64目录并编辑配置文件filebeat.yml
配置输入并监视日志文件:
filebeat.prospectors:
-input_type: log
路径:
-/ data / dmp / openresty / logs / dmp_intf _ *. log
配置输出到Kafka
#——————————– Kafka输出——————————–
output.kafka:
主机: [“ datadev1: 9092”]
topic: lxw1234
required_acks: 1
PS: 假设您已经安装并配置了Kafka,并且已经建立了主题.
有关更多配置选项,请参阅官方文档.
需要大数据学习材料和交流学习的学生可以增加数据学习小组: 724693112有免费的材料,可以与一群学习大数据的小伙伴共享和共同努力
文件拍开始
在filebeat-5.6.3-linux-x86_64目录下,执行命令:
./ filebeat -e -c filebeat.yml以启动Filebeat.
启动后,Filebeat开始监视输入配置中的日志文件,并将消息发送到Kafka.
您可以在Kafka中启动Consumer来查看:
./ kafka-console-consumer.sh –bootstrap-server localhost: 9092 –topic lxw1234 –from-beginning
Filebeat邮件格式
在原创日志中,日志格式如下:
2017-11-09T15: 18: 05 + 08: 00 |〜| 127.0.0.1 |〜|-|〜| hy_xyz |〜| 200 |〜| 0.002
Filebeat将消息封装为JSON字符串,除了原创日志外,还收录其他信息.
@timestamp: 邮件发送时间
beat: Filebeat运行主机和版本信息
字段: 一些用户定义的变量和值非常有用,类似于Flume的静态拦截器
input_type: 输入类型
消息: 原创日志内容
offset: 此消息在原创日志文件中的偏移量
源: 日志文件
此外,Filebeat的CPU使用率:
初步试用后,以下问题尚待测试:
数据可靠性: 是否存在日志数据丢失或重复发送;
您可以自定义Filebeat的消息格式以删除一些多余和无用的项目吗? 查看全部
之前,我们其中一项业务的实时日志采集和处理架构大致如下:
在日志生成端(LogServer服务器)上,已部署FlumeAgent实时监视生成的日志,然后将其发送到Kafka. 经过观察,每个FlumeAgent占用大量系统资源(至少占CPU的50%或更多). 对于另一项业务,LogServer承受着巨大的压力,CPU资源特别紧张. 如果要实时采集和分析日志,则需要一个更轻量级且耗费资源较少的日志采集框架,因此我尝试了Filebeat.
Filebeat是使用go语言开发的开源文本日志采集器. 它重构了logstash采集器源代码,将其安装在日志生成服务器上以监视日志目录或特定的日志文件,并将它们发送到kastka上的logstash,elasticsearch和. Filebeat是一种数据采集解决方案,它替代了logstash-forwarder. 原因是logstash在jvm上运行并且消耗大量服务器资源(Flume也是一样). 由于Filebeat如此轻巧,因此不要期望它在日志采集过程中做更多的清理和转换工作. 它仅负责一件事,即有效且可靠地传输日志数据. 至于清洁和转换,您可以在此过程中进行后续操作.
Filebeat的官方网站地址是: 您可以下载Filebeat并在此地址查看文档.
Filebeat安装配置
Filebeat的安装和配置非常简单.
下载filebeat-5.6.3-linux-x86_64.tar.gz并将其解压缩.
输入filebeat-5.6.3-linux-x86_64目录并编辑配置文件filebeat.yml
配置输入并监视日志文件:
filebeat.prospectors:
-input_type: log
路径:
-/ data / dmp / openresty / logs / dmp_intf _ *. log
配置输出到Kafka
#——————————– Kafka输出——————————–
output.kafka:
主机: [“ datadev1: 9092”]
topic: lxw1234
required_acks: 1
PS: 假设您已经安装并配置了Kafka,并且已经建立了主题.
有关更多配置选项,请参阅官方文档.
需要大数据学习材料和交流学习的学生可以增加数据学习小组: 724693112有免费的材料,可以与一群学习大数据的小伙伴共享和共同努力
文件拍开始
在filebeat-5.6.3-linux-x86_64目录下,执行命令:
./ filebeat -e -c filebeat.yml以启动Filebeat.
启动后,Filebeat开始监视输入配置中的日志文件,并将消息发送到Kafka.
您可以在Kafka中启动Consumer来查看:
./ kafka-console-consumer.sh –bootstrap-server localhost: 9092 –topic lxw1234 –from-beginning
Filebeat邮件格式
在原创日志中,日志格式如下:
2017-11-09T15: 18: 05 + 08: 00 |〜| 127.0.0.1 |〜|-|〜| hy_xyz |〜| 200 |〜| 0.002
Filebeat将消息封装为JSON字符串,除了原创日志外,还收录其他信息.
@timestamp: 邮件发送时间
beat: Filebeat运行主机和版本信息
字段: 一些用户定义的变量和值非常有用,类似于Flume的静态拦截器
input_type: 输入类型
消息: 原创日志内容
offset: 此消息在原创日志文件中的偏移量
源: 日志文件
此外,Filebeat的CPU使用率:
初步试用后,以下问题尚待测试:
数据可靠性: 是否存在日志数据丢失或重复发送;
您可以自定义Filebeat的消息格式以删除一些多余和无用的项目吗?
实时视频IMU采集项目(1): 在Qt中使用FFmpeg库
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-07 08:15
要实现项目中视频流的实时传输和显示,最常见的是编码和解码操作. 如果您自己实现H.264的编码和解码,则将花费大量时间和精力. 因此,通常使用开源H.264编解码器. 所谓的编解码器是用于实现编码和解码,输入原创数据流以及输出H.264编码流的代码.
在Ubuntu16.04下安装FFmpeg
首先在官方网站上下载最新的FFmpeg压缩包源代码,然后使用以下命令解压缩:
$ tar xvf ffmpeg-3.4.2.tar.bz2
然后进入解压缩的文件夹以查看安装步骤:
$ cd ffmpeg-3.4.2
$ cat INSTALL.md
显示内容如下:
安装FFmpeg: 输入./configure创建配置. 配置列表
通过运行configure --help打印
选项.
可以从与FFmpeg源不同的目录中启动
configure,以在树外构建对象. 为此,请在启动配置时使用绝对路径,例如/ ffmpegdir / ffmpeg / configure. 然后键入make来构建FFmpeg. 需要GNU Make 3.81或更高版本. 键入make install以安装您构建的所有二进制文件和库.
注意
默认情况下,非系统依赖项(例如libx264,libvpx)处于禁用状态.
请按照上述步骤进行安装:
$ ./configure --prefix=/home/string/ffmpeg3.4.2 --enable-shared --disable-static
提醒: 找不到Yasm / nasm或太旧. 使用–disable-yasm进行严重破坏的构建.
发现未安装yasm,因此请安装yasm:
$ sudo apt-get install yasm
安装后,重新执行上述第一步以生成配置文件
$ make
$ make install
# 安装后,查看ffmpeg版本
cd ~/ffmpeg3.4.2/bin
./ffmpeg -version
安装成功.
Qt导入FFmpeg库
首先创建一个新的Qt项目,默认情况下每个人都会知道这一点. 下一步是根据先前的安装目录配置Qt pro文件. 如下图所示:
核心是添加FFmpeg库目录和库文件路径信息.
INCLUDEPATH += /home/string/ffmpeg3.4.2/include
LIBS += -L /home/string/ffmpeg3.4.2/lib -lavcodec -lswresample -lavutil -lavformat -lswscale
下一步是修改main.cpp文件,以测试FFmpeg文件是否成功导入.
<p># main.cpp
#include "mainwidget.h"
#include
#include
using namespace std;
// 由于建立的是C++工程,编译时使用的是C++编译器编译,
// 而FFmpeg是C的库,因此这里需要加上extern "C",否则会提示各种未定义
extern "C"
{
#include "libavcodec/avcodec.h"
#include "libavformat/avformat.h"
#include "libavfilter/avfilter.h"
#include "libswresample/swresample.h"
#include "libavdevice/avdevice.h"
}
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
MainWidget w;
w.show();
cout 查看全部
概述
要实现项目中视频流的实时传输和显示,最常见的是编码和解码操作. 如果您自己实现H.264的编码和解码,则将花费大量时间和精力. 因此,通常使用开源H.264编解码器. 所谓的编解码器是用于实现编码和解码,输入原创数据流以及输出H.264编码流的代码.
在Ubuntu16.04下安装FFmpeg
首先在官方网站上下载最新的FFmpeg压缩包源代码,然后使用以下命令解压缩:
$ tar xvf ffmpeg-3.4.2.tar.bz2
然后进入解压缩的文件夹以查看安装步骤:
$ cd ffmpeg-3.4.2
$ cat INSTALL.md
显示内容如下:
安装FFmpeg: 输入./configure创建配置. 配置列表
通过运行configure --help打印
选项.
可以从与FFmpeg源不同的目录中启动
configure,以在树外构建对象. 为此,请在启动配置时使用绝对路径,例如/ ffmpegdir / ffmpeg / configure. 然后键入make来构建FFmpeg. 需要GNU Make 3.81或更高版本. 键入make install以安装您构建的所有二进制文件和库.
注意
默认情况下,非系统依赖项(例如libx264,libvpx)处于禁用状态.
请按照上述步骤进行安装:
$ ./configure --prefix=/home/string/ffmpeg3.4.2 --enable-shared --disable-static
提醒: 找不到Yasm / nasm或太旧. 使用–disable-yasm进行严重破坏的构建.
发现未安装yasm,因此请安装yasm:
$ sudo apt-get install yasm
安装后,重新执行上述第一步以生成配置文件
$ make
$ make install
# 安装后,查看ffmpeg版本
cd ~/ffmpeg3.4.2/bin
./ffmpeg -version
安装成功.
Qt导入FFmpeg库
首先创建一个新的Qt项目,默认情况下每个人都会知道这一点. 下一步是根据先前的安装目录配置Qt pro文件. 如下图所示:
核心是添加FFmpeg库目录和库文件路径信息.
INCLUDEPATH += /home/string/ffmpeg3.4.2/include
LIBS += -L /home/string/ffmpeg3.4.2/lib -lavcodec -lswresample -lavutil -lavformat -lswscale
下一步是修改main.cpp文件,以测试FFmpeg文件是否成功导入.
<p># main.cpp
#include "mainwidget.h"
#include
#include
using namespace std;
// 由于建立的是C++工程,编译时使用的是C++编译器编译,
// 而FFmpeg是C的库,因此这里需要加上extern "C",否则会提示各种未定义
extern "C"
{
#include "libavcodec/avcodec.h"
#include "libavformat/avformat.h"
#include "libavfilter/avfilter.h"
#include "libswresample/swresample.h"
#include "libavdevice/avdevice.h"
}
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
MainWidget w;
w.show();
cout
[正版]采集所有者信息采集软件企业目录实时所有者信息采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-07 03:15
[Jigu客房新闻搜索营销软件]属于“ Jike营销软件”系列. 该软件是专业的所有者搜索软件和功能强大的所有者信息搜索和采集软件. 它可以自动采集最新的所有者目录,可以帮助您快速识别目标客户,进行充分的市场研究,为销售管理和营销管理做充分的准备,并为您提供直接与目标客户联系的机会. 搜索结果支持导出到Excel或一键导入到手机通讯簿. 该数据可用于研究或市场参考. (非个人隐私信息,该软件不生产,也不存储任何数据)
软件功能,只需用鼠标单击,无需编写任何采集规则,[它可以直接导出Excel文件,并且只需单击一下即可导入手机通讯录,适用于电话销售和微信营销. )
1. 实时采集,不是历史数据,而是官方网站的最新搜索数据.
2. 该操作简单易用,傻瓜式操作,分三个步骤完成(配置城市和行业词汇;单击以开始采集;导出数据). 无需手动编写任何规则. 操作就是这么简单.
3. 支持多省/多城市采集. (同时在多个城市中使用多个关键字)使搜索更加“简单,快速,有效”.
4. 快速搜索,极快的操作体验,流畅舒适.
5. 采集效率和数据完整性领先业界.
6. 及时处理客户反馈和建议还使该软件能够很好地处理许多细节.
7. 具有自动升级功能: 新版本正式发布后,客户端打开后将自动升级到最新版本.
该软件是许多批发商,电子商务业务推广和微型业务推广人员将业务量增加一倍的法宝. 它被各个行业的许多业务人员使用. 查看全部
[正版]采集所有者信息采集软件企业目录实时所有者信息采集软件
[Jigu客房新闻搜索营销软件]属于“ Jike营销软件”系列. 该软件是专业的所有者搜索软件和功能强大的所有者信息搜索和采集软件. 它可以自动采集最新的所有者目录,可以帮助您快速识别目标客户,进行充分的市场研究,为销售管理和营销管理做充分的准备,并为您提供直接与目标客户联系的机会. 搜索结果支持导出到Excel或一键导入到手机通讯簿. 该数据可用于研究或市场参考. (非个人隐私信息,该软件不生产,也不存储任何数据)
软件功能,只需用鼠标单击,无需编写任何采集规则,[它可以直接导出Excel文件,并且只需单击一下即可导入手机通讯录,适用于电话销售和微信营销. )
1. 实时采集,不是历史数据,而是官方网站的最新搜索数据.
2. 该操作简单易用,傻瓜式操作,分三个步骤完成(配置城市和行业词汇;单击以开始采集;导出数据). 无需手动编写任何规则. 操作就是这么简单.
3. 支持多省/多城市采集. (同时在多个城市中使用多个关键字)使搜索更加“简单,快速,有效”.
4. 快速搜索,极快的操作体验,流畅舒适.
5. 采集效率和数据完整性领先业界.
6. 及时处理客户反馈和建议还使该软件能够很好地处理许多细节.
7. 具有自动升级功能: 新版本正式发布后,客户端打开后将自动升级到最新版本.
该软件是许多批发商,电子商务业务推广和微型业务推广人员将业务量增加一倍的法宝. 它被各个行业的许多业务人员使用.
2020年7月的最新消息,优采云在微信公众号上批量采集最新文章(包括实时更新)的方法和思想
采集交流 • 优采云 发表了文章 • 0 个评论 • 484 次浏览 • 2020-08-06 21:21
首先谈谈我的需求:
获取约10个正式帐户的批文. 监视最新帖子,大概的想法是早上检查并在下午再次检查. 采集可用的新文章.
为什么要使用优采云?
该软件非常易于使用,具有自动URL重复数据删除功能. 重复的链接将被跳过,不再使用. 此外,优采云具有WordPress免登录发布界面. 我一直在为小白使用它. 我已经习惯了,很容易上手.
解决方案选择:
主要关注解决官方帐户的历史文章网址,即文章列表.
首先,我想在开始时使用它(这也是最在线的教程),但是事实证明,在Sogou官方帐户上的搜索不再显示某个特定官方帐户的最新文章. 据说它将在2019年之前无法使用,腾讯已关闭该界面.
2. 直接捕获微信数据包,使用fildder和其他数据包捕获工具,并与PC版微信配合捕获官方帐户URL. 这非常复杂. 我看了一轮教程,果断地放弃了,这超出了我的承受能力.
3. 使用第三方公共帐户数据查询平台. 该程序可以运行. 经过研究,我发现了三个.
1. 西瓜助手:
2. 小宝:
3. 一个同伴插件:
谈谈它们各自的优点和缺点:
西瓜助手,优点: 可以查询大量的官方账号,并且视觉更新很快. 就像普通网站的采集一样,官方帐户中的文章列表可以直接通过优采云采集. 缺点,收费和昂贵的批次. 普通版是每月99元.
小宝,优点,免费,您可以在登录时查看官方帐户数据,快速更新(基本上会有一天的间隔),并且该官方帐户收录更多内容. 缺点: 优采云无法直接采集列表,它是由js算法编写的.
Yiban插件,优点,免费,有财云可以直接采集列表. 缺点是,某些官方帐户无法找到数据,更新情况就像过山车,相隔一天,相隔半年.
我还体验了一个名为vread的平台,地址为: . 该平台具有部分官方帐户内容,并且还通过监视采集了最新的官方帐户文章. 优采云的优势可以直接采集. 缺点: 官方帐户收录的较少,需要您自己提交(我提交了一个,在前一天晚上提交,但第二天不收录)并收取费用. 每月12元. 尽管价格便宜,但它确实不像免费的一部分插件那样容易使用.
我在第三方平台上浪费了很多时间. 西瓜助理,我已经写好了优采云站的采集规则,目前正处于筛选官方账户的阶段. 结果,第二天,系统提示我升级我的会员资格以继续使用它. 操我,我的努力是徒劳的. 浪费时间.
一个合作伙伴插件,编写规则也很简单. 但是,我最终放弃了与官方帐户数据更新迷相同的操作.
小宝,这种机动性很好. 但是它呈现的列表是由js呈现的. 优采云无能为力. 它只能通过带有硒文本的python运行. 该硒仅仅是驱动浏览器打开网页的程序. 以这种方式捕获的结果是js算法完成时显示的结果.
我知道事实,但是去年我学习了python一两个星期,看了几节课,现在我完全忘记了. 因此,我再次学习了python,并首先在站点b上搜索了硒教程. 看了几次之后,我感到不舒服. 从硬盘上,我找到了一套“ Python3 Web Crawler实用案例”,该软件是去年由崔庆才先生下载的. 在实际的一章中有一个实际的课程: “第16类: 使用硒模拟浏览器获取淘宝商品和食品信息”. 这只是完美的教程. 阅读几次后,我在Internet上找到了一些源代码,然后就可以开始工作了.
安装python,pycharm等工具并不会多说,新手已经花了很多时间.
您认为最终计划已经完成吗?
否.
四个. 这不是源于Micro Treasure的官方帐户商品数据爬网的最新缺陷(没有那天,但只有昨天). 我也想找出是否还有更直接的方法. 确实如此. 那是微信公众号的官方运营平台.
您可以在此处管理材料,插入链接并引用其他官方帐户. 此处的官方帐户显示最新数据. 可以捕获一个小时前的文章.
但是,优采云无法在此处直接爬取列表. Python和硒仍然需要战斗. 经过一夜零一夜的研究.
我终于完成了这项任务.
最终的实施计划如下:
微信公众号操作平台,获取列表页面网址,该网址生成一个html文件并将其保存到本地网站(由phpstudy构建). 然后转到Ucai Cloud以提取这些html中的URL,然后采集一篇文章. (通过这种方式,优采云的效果与普通网站的采集效果相同).
为什么不直接使用python采集官方帐户的目标文章?因为我的技术不到位,所以要采集特定的文章,我必须了解图像下载和html标签处理. 我是新手,一点也不,我不知道学习需要多长时间. 此外,官方帐户文章的发布时间由js表示. 我可以通过优采云标签的方法直接从硒捕获的html信息中直接调用它.
我最近说过: python中的Selenium确实是人工制品!从理论上讲,任何东西都可以捕获! 查看全部
优采云采集微信官方帐户,许多网站建设者都希望使用此功能. 我在2020年4月写了这些内容,但今天是7月,根本没有问题. 我不必多说,只需直接交付干货即可.
首先谈谈我的需求:
获取约10个正式帐户的批文. 监视最新帖子,大概的想法是早上检查并在下午再次检查. 采集可用的新文章.
为什么要使用优采云?
该软件非常易于使用,具有自动URL重复数据删除功能. 重复的链接将被跳过,不再使用. 此外,优采云具有WordPress免登录发布界面. 我一直在为小白使用它. 我已经习惯了,很容易上手.
解决方案选择:
主要关注解决官方帐户的历史文章网址,即文章列表.
首先,我想在开始时使用它(这也是最在线的教程),但是事实证明,在Sogou官方帐户上的搜索不再显示某个特定官方帐户的最新文章. 据说它将在2019年之前无法使用,腾讯已关闭该界面.
2. 直接捕获微信数据包,使用fildder和其他数据包捕获工具,并与PC版微信配合捕获官方帐户URL. 这非常复杂. 我看了一轮教程,果断地放弃了,这超出了我的承受能力.
3. 使用第三方公共帐户数据查询平台. 该程序可以运行. 经过研究,我发现了三个.
1. 西瓜助手:
2. 小宝:
3. 一个同伴插件:
谈谈它们各自的优点和缺点:
西瓜助手,优点: 可以查询大量的官方账号,并且视觉更新很快. 就像普通网站的采集一样,官方帐户中的文章列表可以直接通过优采云采集. 缺点,收费和昂贵的批次. 普通版是每月99元.
小宝,优点,免费,您可以在登录时查看官方帐户数据,快速更新(基本上会有一天的间隔),并且该官方帐户收录更多内容. 缺点: 优采云无法直接采集列表,它是由js算法编写的.
Yiban插件,优点,免费,有财云可以直接采集列表. 缺点是,某些官方帐户无法找到数据,更新情况就像过山车,相隔一天,相隔半年.
我还体验了一个名为vread的平台,地址为: . 该平台具有部分官方帐户内容,并且还通过监视采集了最新的官方帐户文章. 优采云的优势可以直接采集. 缺点: 官方帐户收录的较少,需要您自己提交(我提交了一个,在前一天晚上提交,但第二天不收录)并收取费用. 每月12元. 尽管价格便宜,但它确实不像免费的一部分插件那样容易使用.
我在第三方平台上浪费了很多时间. 西瓜助理,我已经写好了优采云站的采集规则,目前正处于筛选官方账户的阶段. 结果,第二天,系统提示我升级我的会员资格以继续使用它. 操我,我的努力是徒劳的. 浪费时间.
一个合作伙伴插件,编写规则也很简单. 但是,我最终放弃了与官方帐户数据更新迷相同的操作.
小宝,这种机动性很好. 但是它呈现的列表是由js呈现的. 优采云无能为力. 它只能通过带有硒文本的python运行. 该硒仅仅是驱动浏览器打开网页的程序. 以这种方式捕获的结果是js算法完成时显示的结果.
我知道事实,但是去年我学习了python一两个星期,看了几节课,现在我完全忘记了. 因此,我再次学习了python,并首先在站点b上搜索了硒教程. 看了几次之后,我感到不舒服. 从硬盘上,我找到了一套“ Python3 Web Crawler实用案例”,该软件是去年由崔庆才先生下载的. 在实际的一章中有一个实际的课程: “第16类: 使用硒模拟浏览器获取淘宝商品和食品信息”. 这只是完美的教程. 阅读几次后,我在Internet上找到了一些源代码,然后就可以开始工作了.
安装python,pycharm等工具并不会多说,新手已经花了很多时间.
您认为最终计划已经完成吗?
否.
四个. 这不是源于Micro Treasure的官方帐户商品数据爬网的最新缺陷(没有那天,但只有昨天). 我也想找出是否还有更直接的方法. 确实如此. 那是微信公众号的官方运营平台.
您可以在此处管理材料,插入链接并引用其他官方帐户. 此处的官方帐户显示最新数据. 可以捕获一个小时前的文章.
但是,优采云无法在此处直接爬取列表. Python和硒仍然需要战斗. 经过一夜零一夜的研究.
我终于完成了这项任务.
最终的实施计划如下:
微信公众号操作平台,获取列表页面网址,该网址生成一个html文件并将其保存到本地网站(由phpstudy构建). 然后转到Ucai Cloud以提取这些html中的URL,然后采集一篇文章. (通过这种方式,优采云的效果与普通网站的采集效果相同).
为什么不直接使用python采集官方帐户的目标文章?因为我的技术不到位,所以要采集特定的文章,我必须了解图像下载和html标签处理. 我是新手,一点也不,我不知道学习需要多长时间. 此外,官方帐户文章的发布时间由js表示. 我可以通过优采云标签的方法直接从硒捕获的html信息中直接调用它.
我最近说过: python中的Selenium确实是人工制品!从理论上讲,任何东西都可以捕获!
Pylon使用实时图像捕获来解释PylonC SDK的使用过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2020-08-06 05:04
使用PylonC SDK的总体流程图如下:
以下是针对不同工作要求的其中之一,常见的是加载相机对象和卸载相机对象. 要使用其他模块,例如事件对象,可以相应地加载和卸载事件对象,并使用事件对象完成相关任务. 进行编程时,必须计划整个过程,尤其是在对硬件进行编程时,必须注意内存泄漏,并且之前分配的资源必须稍后释放.
以下是对五个主要过程的详细分析,其中解释了需求,并注释了需要使用的功能
加载相机对象
卸载相机对象
加载数据流以捕获对象
卸载数据流捕获对象
单帧或连续捕获过程
根据上述过程,可以实现实时图像采集
源代码下载链接. 许多人要求我提供源代码. 我浏览了之前的程序文件夹,找到了该程序. 它演示了使用Pylon SDK进行摄像机采集的过程. 使用MIL完成界面显示. 采集部分被封装到一个类中,可以直接重用. 测试相机是Basler相机. 请注意,Pylon仅完成原创数据的采集,使用MIL的MbufPut完成图像数据的重组,然后MIL自动显示.
---------------------
作者: 温英雄 查看全部
通常,对于硬件编程,硬件制造商将提供手册和示例供SDK使用. 该手册通常包括安装和配置过程,一些基本概念的介绍,SDK的每个功能的使用,SDK的使用过程和示例(一些硬件示例直接写在手册中,有些将单独存在文件,有些同时具有). 为了使上位计算机软件开发人员获得硬件主机编程任务,他们应该首先阅读并理解SDK概念,然后根据引入的SDK开发过程阅读SDK提供的示例,并修改相应的示例以供自己使用. . 该功能可用于查询其用法. 一些开发人员习惯性地记住他们的API,这既费时又费力,不建议使用. 下面主要说明带实时图像采集的Basler相机的PylonC SDK的使用过程.
使用PylonC SDK的总体流程图如下:
以下是针对不同工作要求的其中之一,常见的是加载相机对象和卸载相机对象. 要使用其他模块,例如事件对象,可以相应地加载和卸载事件对象,并使用事件对象完成相关任务. 进行编程时,必须计划整个过程,尤其是在对硬件进行编程时,必须注意内存泄漏,并且之前分配的资源必须稍后释放.
以下是对五个主要过程的详细分析,其中解释了需求,并注释了需要使用的功能
加载相机对象
卸载相机对象
加载数据流以捕获对象
卸载数据流捕获对象
单帧或连续捕获过程
根据上述过程,可以实现实时图像采集
源代码下载链接. 许多人要求我提供源代码. 我浏览了之前的程序文件夹,找到了该程序. 它演示了使用Pylon SDK进行摄像机采集的过程. 使用MIL完成界面显示. 采集部分被封装到一个类中,可以直接重用. 测试相机是Basler相机. 请注意,Pylon仅完成原创数据的采集,使用MIL的MbufPut完成图像数据的重组,然后MIL自动显示.
---------------------
作者: 温英雄

