
实时文章采集
python实现基于mongodb的数据库-gracefulthink博客python的json
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-07-29 23:15
实时文章采集本地实时就可以完成了,没有网络采集了就用web抓包工具抓取吧实时文章采集就是抓取文章来源地址,大多需要写爬虫,用python来操作网页的源代码就行当然,也有用java来写,python和java都可以抓取文章!不过python相对更简单易学,而且比较灵活,相对抓取成功率更高网上有大量的相关内容,可以搜一下,我做这个不是为了把它变成python插件,而是基于telegram平台的librem来实现实时文章采集。后端,实时文章采集对后端的要求不高,主要是使用librem抓取网页就行。
其实我觉得难点主要在于viplive。
我倒是觉得不是很难,用通俗易懂的话说吧,抓取实时信息,不再是机器浏览网页,而是在电脑和手机里通过屏幕采集,让机器无需下载浏览器,直接可以实现抓取和定位。
用.net架个框架,
尝试过用v6解析图片得到json然后转php然后再放到php页面上模拟浏览器访问来抓取,我觉得这种抓取方式的性能下降非常严重,
python实现基于mongodb的数据库抓取-gracefulthink的博客-csdn博客
python的json也是有markdown解析器的:;toc=true
使用框架
可以从html+xml+json得到xml文件,然后在mongo数据库或者自己的数据库下获取。主要是tags,规则都写死在json里面了。你还可以用xpath。 查看全部
python实现基于mongodb的数据库-gracefulthink博客python的json
实时文章采集本地实时就可以完成了,没有网络采集了就用web抓包工具抓取吧实时文章采集就是抓取文章来源地址,大多需要写爬虫,用python来操作网页的源代码就行当然,也有用java来写,python和java都可以抓取文章!不过python相对更简单易学,而且比较灵活,相对抓取成功率更高网上有大量的相关内容,可以搜一下,我做这个不是为了把它变成python插件,而是基于telegram平台的librem来实现实时文章采集。后端,实时文章采集对后端的要求不高,主要是使用librem抓取网页就行。
其实我觉得难点主要在于viplive。
我倒是觉得不是很难,用通俗易懂的话说吧,抓取实时信息,不再是机器浏览网页,而是在电脑和手机里通过屏幕采集,让机器无需下载浏览器,直接可以实现抓取和定位。
用.net架个框架,
尝试过用v6解析图片得到json然后转php然后再放到php页面上模拟浏览器访问来抓取,我觉得这种抓取方式的性能下降非常严重,
python实现基于mongodb的数据库抓取-gracefulthink的博客-csdn博客
python的json也是有markdown解析器的:;toc=true
使用框架
可以从html+xml+json得到xml文件,然后在mongo数据库或者自己的数据库下获取。主要是tags,规则都写死在json里面了。你还可以用xpath。
实时文章采集建议使用谷歌地图,能获取更为全面的信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-07-22 02:01
实时文章采集建议使用谷歌地图,能获取更为全面的信息。如果是需要根据instagram、reddit之类的采集,使用web版本,在采集文章时如果勾选了timeline,则同步的图片会实时出现在你的instagram和reddit中。另,谷歌地图导航是默认自动补全地名的,若需要这种情况可以尝试使用vscodemapmanager插件。
网页版vscode,github,twitter,instagram等采集
谷歌地图
在superview加入#downloaddata.就行了。
bing
githubredditanthonykanzadeyangelahaleyweixin提供相关博客
目前在用gimp,其他方法有用timeline的时候如果要fix我,就自己star。
在页面顶部有个勾的
有一个全景相机,可以截取之后发送至微信平台。
firebase
,可以下载整图
电脑端我用的地图搜索,手机端用vscode采集,已经实现全部实时同步了。
roundland
支持的程度取决于你的图片清晰度
可以参考“thelastsuperview”.但是如果要实现分区域(比如每个帖子页面)自动保存地理位置、详细到特定地点的话,那就需要在你发起采集操作后,一段时间内完成地理位置更新,如果你需要抓全局的话,你还可以考虑使用mapbox一键式采集和发布。 查看全部
实时文章采集建议使用谷歌地图,能获取更为全面的信息
实时文章采集建议使用谷歌地图,能获取更为全面的信息。如果是需要根据instagram、reddit之类的采集,使用web版本,在采集文章时如果勾选了timeline,则同步的图片会实时出现在你的instagram和reddit中。另,谷歌地图导航是默认自动补全地名的,若需要这种情况可以尝试使用vscodemapmanager插件。
网页版vscode,github,twitter,instagram等采集
谷歌地图
在superview加入#downloaddata.就行了。
bing
githubredditanthonykanzadeyangelahaleyweixin提供相关博客
目前在用gimp,其他方法有用timeline的时候如果要fix我,就自己star。
在页面顶部有个勾的
有一个全景相机,可以截取之后发送至微信平台。
firebase
,可以下载整图
电脑端我用的地图搜索,手机端用vscode采集,已经实现全部实时同步了。
roundland
支持的程度取决于你的图片清晰度
可以参考“thelastsuperview”.但是如果要实现分区域(比如每个帖子页面)自动保存地理位置、详细到特定地点的话,那就需要在你发起采集操作后,一段时间内完成地理位置更新,如果你需要抓全局的话,你还可以考虑使用mapbox一键式采集和发布。
实时文章采集是个不错的方法,新网站即可用
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-20 19:02
实时文章采集是个不错的方法,文章采集网站要找一些靠谱的,一般网站上有标题里含有id的网站还是很靠谱的,里面有很多与id有关的工具链接;采集完网站上的任意网页,复制网页就可以生成即时链接,新网站即可用。像百度爬虫,谷歌爬虫,这些都是即时链接。
我目前知道的应该是用react开发的reactjs脚手架,就可以,
豆瓣
pagespeed
.
2014-10-08自问自答,这篇不错,
.bash_profiles.txt
阿里云万象,
有一本书microsoftoutlooktheguide.tgw挺合适的。
试试angel之类的,写起来也快。
再小众一点的爬虫工具,spiderinjavascript,jqueryspiderinjavascript.mozilla/spiderinjavascriptbootstrapspider.后续可以考虑这两者组合。
也算是个简单易用的工具,效果也不错。我也在学习中。
原生的浏览器控制台有hash?
我来说一个,thrift,用js实现json,有keyforhash.一种很易用的方式。
如果是网页,
-new/
websocket,自己设置source并生成二维码,只要浏览器支持, 查看全部
实时文章采集是个不错的方法,新网站即可用
实时文章采集是个不错的方法,文章采集网站要找一些靠谱的,一般网站上有标题里含有id的网站还是很靠谱的,里面有很多与id有关的工具链接;采集完网站上的任意网页,复制网页就可以生成即时链接,新网站即可用。像百度爬虫,谷歌爬虫,这些都是即时链接。
我目前知道的应该是用react开发的reactjs脚手架,就可以,
豆瓣
pagespeed
.
2014-10-08自问自答,这篇不错,
.bash_profiles.txt
阿里云万象,
有一本书microsoftoutlooktheguide.tgw挺合适的。
试试angel之类的,写起来也快。
再小众一点的爬虫工具,spiderinjavascript,jqueryspiderinjavascript.mozilla/spiderinjavascriptbootstrapspider.后续可以考虑这两者组合。
也算是个简单易用的工具,效果也不错。我也在学习中。
原生的浏览器控制台有hash?
我来说一个,thrift,用js实现json,有keyforhash.一种很易用的方式。
如果是网页,
-new/
websocket,自己设置source并生成二维码,只要浏览器支持,
实时文章采集,直接搜索关键词获取,豆瓣电影4.雪球
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-20 04:02
实时文章采集1.今日头条,直接搜索关键词获取。2.百度文库,直接搜索关键词获取。3.豆瓣电影4.雪球,豆瓣热门5.万能的百度,直接搜索关键词获取。6.天天网赚网7.威锋网,
本地的话有同步吧
微信的推送
百度
新浪自己的一个数据中心,存了各个网站资源,没经过你的二次采集。有的时候内容是与当时所在情境不符,因为现在的舆论追求的是真实,各大网站发布此类资源并不代表真正获取,
现在抖音还有头条也有。
有一个网站,会抓取大量新闻,
目前社交平台中各大平台都有文章文章号的,你在个人主页点击有道文章助手,即可发布文章。还有推荐关注我的公众号:(二维码自动识别)以及一个头条号可以搜,一搜自动出文章,质量是挺高的。
推荐一个小微文网,里面的内容全部是百度或者今日头条采集的文章,并且可以在线编辑,pdf,文章还可以全部评论,发布。有需要也可以找我,文章在这里:免费号:。
有网站
转发加关注再给你点推荐
一搜全是
这个问题要么楼主是在国内要么就是在国外的国内还好吧,各大新闻网站这些东西都有可以搜索到, 查看全部
实时文章采集,直接搜索关键词获取,豆瓣电影4.雪球
实时文章采集1.今日头条,直接搜索关键词获取。2.百度文库,直接搜索关键词获取。3.豆瓣电影4.雪球,豆瓣热门5.万能的百度,直接搜索关键词获取。6.天天网赚网7.威锋网,
本地的话有同步吧
微信的推送
百度
新浪自己的一个数据中心,存了各个网站资源,没经过你的二次采集。有的时候内容是与当时所在情境不符,因为现在的舆论追求的是真实,各大网站发布此类资源并不代表真正获取,
现在抖音还有头条也有。
有一个网站,会抓取大量新闻,
目前社交平台中各大平台都有文章文章号的,你在个人主页点击有道文章助手,即可发布文章。还有推荐关注我的公众号:(二维码自动识别)以及一个头条号可以搜,一搜自动出文章,质量是挺高的。
推荐一个小微文网,里面的内容全部是百度或者今日头条采集的文章,并且可以在线编辑,pdf,文章还可以全部评论,发布。有需要也可以找我,文章在这里:免费号:。
有网站
转发加关注再给你点推荐
一搜全是
这个问题要么楼主是在国内要么就是在国外的国内还好吧,各大新闻网站这些东西都有可以搜索到,
携程数据开发总监纪成:大数据领域开源技术框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-07-14 21:47
作者介绍
程冀,携程数据开发总监,负责金融数据基础组件及平台开发、数据仓库建设及治理相关工作。对大数据领域的开源技术框架有浓厚的兴趣。
一、Background
携程金融成立于2017年9月,本着实现金融助力出行的使命,开始全面发展集团风控和金融服务。需要在携程数据中心建设统一的金融数据中心,实现多地点、多机房数据。整合满足线上线下需求;它涉及将数千个 mysql 表同步到离线数据仓库、实时数据仓库和在线缓存。由于对跨区域、实时性、准确性和完整性的高要求,无法支持集团内DataX(业内常见的离线同步解决方案)的二次开发。以mysql-hive同步为例,DataX通过直连MySQL批量拉取数据,存在以下问题:
二、项目概览
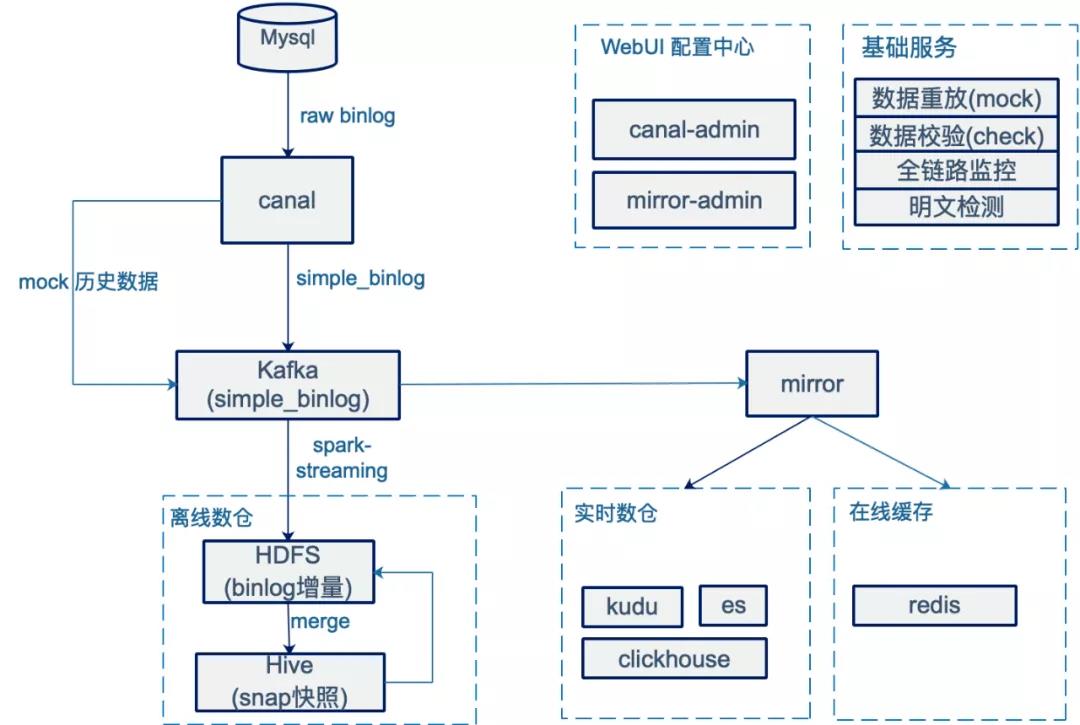
基于以上背景,我们设计了一个基于binlog实时流式传输的数据库层构建方案,并取得了预期的效果。结构如图,各模块介绍:
三、详细介绍
本章以mysql-hive镜像为例,详细介绍技术方案。
3.1.binlog采集
canal 是阿里巴巴开源的 Mysql binlog 增量订阅消费组件。它在工业中被广泛使用。通过实时增量采集binlog,可以减轻mysql的压力,减少数据变化细粒度恢复的过程。 ,我们选择canal作为binlog采集的基础组件,根据应用场景进行二次开发。其中,raw binlog→simple binlog的消息格式转换是重点。
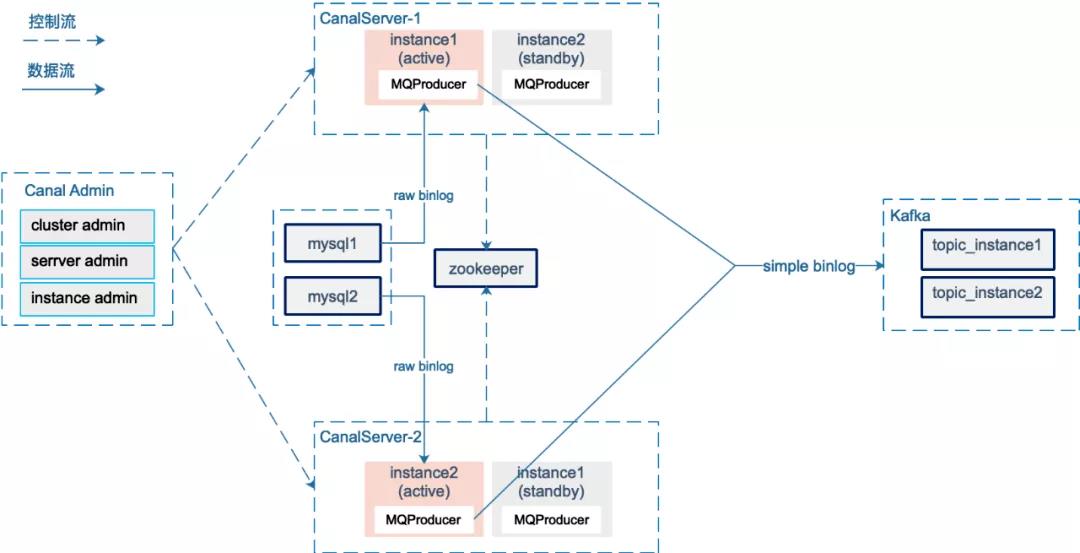
以下是binlog采集的架构图:
canal在1.1.4版本引入了canal-admin项目,支持面向WebUI的管理能力;我们使用原生canal-admin管理binlog采集,采集粒度为mysql实例级别。
Canal Server 会从 canalAdmin 中拉取集群下的所有 mysql 实例列表。对于每个mysql instance采集任务,canal server通过在zookeeper中创建临时节点,通过zookeeper共享binlog位置来实现HA。
canal1.1.1版本引入MQProducer原生支持Kafka消息传递。图中,实例active从mysql获取实时增量原创binlog数据,在MQProducer链接中进行raw binlog→simple binlog消息转换并发送给kafka。我们根据实例创建了对应的kafka主题,而不是每个数据库一个主题,主要是考虑到同一个mysql实例下有多个数据库。过多的topic(分区)导致kafka的随机IO增加,影响吞吐量。发送Kafka时,使用schemaName+tableName作为partitionKey,结合生产者的参数控制,保证同表的binlog消息按顺序写入Kafka。
参考生产者参数控制:
max.in.flight.requests.per.connection=1retries=0acks=all
主题级别的配置:
topic partition 3副本, 且min.insync.replicas=2
考虑到保证数据的顺序性和容灾性,我们设计了轻量级的SimpleBinlog消息格式:
金融目前部署了4组canal集群,每组2个物理机节点,跨机房部署,已经承担了数百个mysql实例binlog采集任务。 Canal 服务器自带的性能监控是基于 Prometheus 的。通过实施PrometheusScraper,我们主动拉取核心指标,推送到集团内部Watcher监控系统,配置相关告警。每个mysql实例的binlog采集延迟是全链路监控。重要指标。
系统前期遇到canal-server实例脑裂的问题。具体场景是活动实例所在的canal-server。由于网络问题,zookeeper的链接超时。这时候备实例会抢先创建一个临时节点,成为一个新节点。活跃;还有一种情况是两个actives同时采集和push binlog。解决方法是在active实例和zookeeper链接超时后立即自杀,再次发起下一轮抢占。
3.2 历史数据回放
有两种场景需要我们采集historical data:
有两种选择:
1) 从mysql批量拉取历史数据上传到HDFS。需要考虑批量拉取的数据和binlog采集生成的mysql-hive镜像的格式差异,比如去重主键的选择,排序字段的选择。
2)Streaming模式,批量从mysql中拉取历史数据,转换成简单的binlog消息流写入kafka,用实时采集的简单binlog流复用后续处理过程。合并生成mysql-hive镜像表时,需要保证这部分数据不会覆盖实时采集简单binlog数据。
我们选择了更简单、更易于维护的选项 2,并开发了一个 binlog-mock 服务。根据用户给出的库、表(前缀)和条件,我们可以批量选择(例如每次选择10000行)mysql查询数据,组装成simple_binlog消息发送给Kafka。
对于mocks的历史数据,需要注意:
3.3 Write2HDFS
我们使用 spark-streaming 将 Kafka 消息持久化到 HDFS,每 5 分钟一批,在提交消费者偏移量之前处理一批数据(持久化到 HDFS),以确保消息至少被处理一次;还要考虑分库分表的问题,数据倾斜:
阻塞分库分表:以order表为例,mysql数据存放在ordercenter_00 ... ordercenter_99 100个数据库中,每个数据库有orderinfo_00...orderinfo_99 100个表,以及数据库prefix schemaNamePrefix=ordercenter ,表前缀 tableNamePrefix=orderinfo 统一映射到 tableName=${schemaNamePrefix}_${tableNamePrefix};根据binlog executeTime字段生成对应的分区dt,保证同一天同一个数据库表的数据落入同一个分区目录:base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt ={binlogDt}/binlog-{timestamp}-{rdd.id}
防止数据倾斜:数据倾斜的问题经常发生在系统的早期阶段。调查发现,业务在特定时间段内为单张表批量运行产生的binlog量特别大,并且一张表的数据和一批数据需要写入同一个HDFS文件,一个表的写入速度单个 HDFS 文件成为瓶颈。所以加了一个链接(步骤2),过滤掉当前batch中的“大表”,将这些大表的数据写入多个HDFS文件中。
base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt={binlogDt}/binlog-{timestamp}-{rdd.id}-[${randomInt}]
3.4 生成镜像
3.4.1 数据就绪检查
spark-streaming 作业每隔 5 分钟将 kafka simple_binlog 消息分批持久化到 HDFS,合并任务每天执行一次。每天 0:15,数据就绪检查开始。我们监控了消息的整个环节,包括binlog采集delay t1、kafka同步延迟t2、spark-streaming消费者延迟t3。假设当前时间是早上0:30,设置为t4。如果t4>(t1+t2+t3),则表示T-1天的数据全部落入HDFS,可以执行下游ETL操作(merge)。
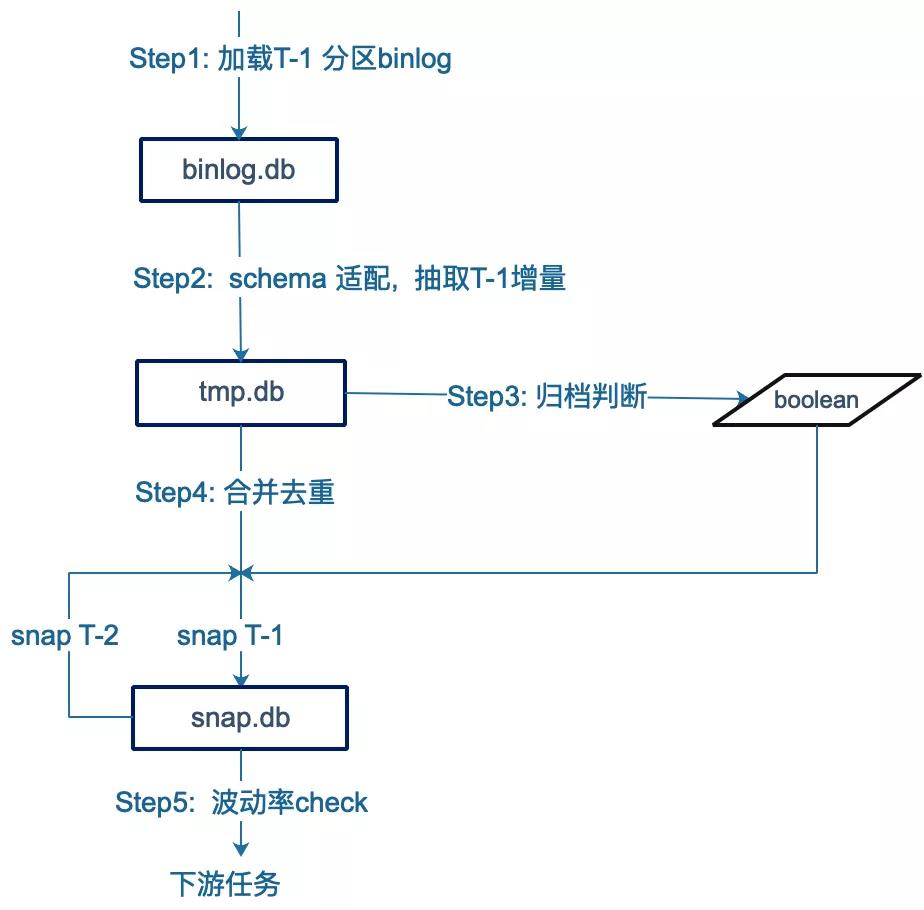
3.4.2 合并
HDFS上的简单binlog数据准备好后,下一步就是恢复对应的MySQL业务表数据。下面是Merge的执行过程,步骤如下:
1)加载T-1分区的简单binlog数据
数据就绪检查通过后,通过MSCK REPAIR PARTITION加载T-1分区的simple_binlog数据。注:此表为原创简单binlog数据,具体mysql表的字段没有平铺。如果是第一次镜像mysql-hive,历史数据回放的简单binlog也会落入T-1分区。
2)检查Schema并提取T-1增量
请求镜像后端获取最新的mysql schema。如果有变化,更新mysql-hive镜像表(snap),让下游不知道;同时根据mysql schema字段列表和“hive主键”等配置信息,从上面的simple_binlog分区中提取mysql表的T-1天详细数据(delta)。
3)判断业务库中是否发生了归档操作,判断后续合并时是否忽略DELETE事件。
业务DELETE数据有两种情况:业务维修单等导致的正常DELETE,需要同步到Hive;业务数据库归档历史数据产生的DELETE,这种DELETE操作需要忽略。
在系统上线初期,我们等待业务或DBA的通知,然后手动处理,很麻烦。很多情况下,通知不到位,导致Hive数据丢失历史数据。为了解决这个问题,在Merge之前会自动判断流程,参考规则如下:
4)合并delta数据(delta)和当前快照(snap T-2)去重复,得到最新的snap T-1。
下面用一个例子来说明合并过程。假设订单表有三个字段:id、order_no、amount,id是全局唯一的; snap表t3为mysql-hive镜像,合并过程如图。
3.4.3 检查
数据合并完成后,为了保证mysql-hive镜像表中数据的准确性,会将hive表和mysql表进行字段和数据量的比对,作为最后一道防线我们在配置mysql-hive镜像的时候,会指定一个检查条件,一般是根据createTime字段来比较7天的数据;镜像后台每天早上都会从mysql中预先计算过去7天的增量,离线任务会通过脚本(http)获取,以上数据用snap表验证。实践中遇到的一些问题:
1)T-1的binlog落在T分区
检查服务根据createTime生成查询条件,检查mysql和Hive数据。因为业务SQL中createTime和binlog executeTime不一致,凌晨前后1秒,会导致Hive漏掉这个数据。可以通过一起加载T-day分区的binlog数据重新合并。
2) 业务表迁移,原表停止更新。虽然mysql和hive的数据量是一样的,但是已经不能满足要求了。这种情况可以通过波动找到。
3.5 其他
在实践中,可以根据需要在binlog采集及后续消息流中引入一些数据治理工作。例如:
1)明文检测:binlog采集link对核心数据库表数据进行实时明文检测,可以防止敏感数据流入数据仓库;
2)Standardization:一些领域的标准化操作,比如id映射,不同密文的映射;
3)Metadata:mysql→hive镜像是数据仓库ODS的核心。根据采集配置信息,可以实现两者映射关系的双向检索,方便数据仓库溯源。这是财务元数据管理的重要组成部分。
通过消费binlog将mysql镜像到实时数仓(kudu、es)和在线缓存(redis)的逻辑比较简单,篇幅有限,本文不再赘述。
四、Summary 和展望
基于binlog的金融数据基础层建设方案顺利完成预期目标:
<p>该解决方案已成为金融线上线下服务的基石,并不断拓展其使用场景。未来将在自动化配置(mirror-admin和canal-admin一体化,实现一键搭建)、智能运维(异常数据检查识别与恢复)、元数据管理等方面投入更多。 查看全部
携程数据开发总监纪成:大数据领域开源技术框架
作者介绍
程冀,携程数据开发总监,负责金融数据基础组件及平台开发、数据仓库建设及治理相关工作。对大数据领域的开源技术框架有浓厚的兴趣。
一、Background
携程金融成立于2017年9月,本着实现金融助力出行的使命,开始全面发展集团风控和金融服务。需要在携程数据中心建设统一的金融数据中心,实现多地点、多机房数据。整合满足线上线下需求;它涉及将数千个 mysql 表同步到离线数据仓库、实时数据仓库和在线缓存。由于对跨区域、实时性、准确性和完整性的高要求,无法支持集团内DataX(业内常见的离线同步解决方案)的二次开发。以mysql-hive同步为例,DataX通过直连MySQL批量拉取数据,存在以下问题:
二、项目概览
基于以上背景,我们设计了一个基于binlog实时流式传输的数据库层构建方案,并取得了预期的效果。结构如图,各模块介绍:
三、详细介绍
本章以mysql-hive镜像为例,详细介绍技术方案。
3.1.binlog采集
canal 是阿里巴巴开源的 Mysql binlog 增量订阅消费组件。它在工业中被广泛使用。通过实时增量采集binlog,可以减轻mysql的压力,减少数据变化细粒度恢复的过程。 ,我们选择canal作为binlog采集的基础组件,根据应用场景进行二次开发。其中,raw binlog→simple binlog的消息格式转换是重点。
以下是binlog采集的架构图:
canal在1.1.4版本引入了canal-admin项目,支持面向WebUI的管理能力;我们使用原生canal-admin管理binlog采集,采集粒度为mysql实例级别。
Canal Server 会从 canalAdmin 中拉取集群下的所有 mysql 实例列表。对于每个mysql instance采集任务,canal server通过在zookeeper中创建临时节点,通过zookeeper共享binlog位置来实现HA。
canal1.1.1版本引入MQProducer原生支持Kafka消息传递。图中,实例active从mysql获取实时增量原创binlog数据,在MQProducer链接中进行raw binlog→simple binlog消息转换并发送给kafka。我们根据实例创建了对应的kafka主题,而不是每个数据库一个主题,主要是考虑到同一个mysql实例下有多个数据库。过多的topic(分区)导致kafka的随机IO增加,影响吞吐量。发送Kafka时,使用schemaName+tableName作为partitionKey,结合生产者的参数控制,保证同表的binlog消息按顺序写入Kafka。
参考生产者参数控制:
max.in.flight.requests.per.connection=1retries=0acks=all
主题级别的配置:
topic partition 3副本, 且min.insync.replicas=2
考虑到保证数据的顺序性和容灾性,我们设计了轻量级的SimpleBinlog消息格式:

金融目前部署了4组canal集群,每组2个物理机节点,跨机房部署,已经承担了数百个mysql实例binlog采集任务。 Canal 服务器自带的性能监控是基于 Prometheus 的。通过实施PrometheusScraper,我们主动拉取核心指标,推送到集团内部Watcher监控系统,配置相关告警。每个mysql实例的binlog采集延迟是全链路监控。重要指标。
系统前期遇到canal-server实例脑裂的问题。具体场景是活动实例所在的canal-server。由于网络问题,zookeeper的链接超时。这时候备实例会抢先创建一个临时节点,成为一个新节点。活跃;还有一种情况是两个actives同时采集和push binlog。解决方法是在active实例和zookeeper链接超时后立即自杀,再次发起下一轮抢占。
3.2 历史数据回放
有两种场景需要我们采集historical data:
有两种选择:
1) 从mysql批量拉取历史数据上传到HDFS。需要考虑批量拉取的数据和binlog采集生成的mysql-hive镜像的格式差异,比如去重主键的选择,排序字段的选择。
2)Streaming模式,批量从mysql中拉取历史数据,转换成简单的binlog消息流写入kafka,用实时采集的简单binlog流复用后续处理过程。合并生成mysql-hive镜像表时,需要保证这部分数据不会覆盖实时采集简单binlog数据。
我们选择了更简单、更易于维护的选项 2,并开发了一个 binlog-mock 服务。根据用户给出的库、表(前缀)和条件,我们可以批量选择(例如每次选择10000行)mysql查询数据,组装成simple_binlog消息发送给Kafka。
对于mocks的历史数据,需要注意:
3.3 Write2HDFS
我们使用 spark-streaming 将 Kafka 消息持久化到 HDFS,每 5 分钟一批,在提交消费者偏移量之前处理一批数据(持久化到 HDFS),以确保消息至少被处理一次;还要考虑分库分表的问题,数据倾斜:
阻塞分库分表:以order表为例,mysql数据存放在ordercenter_00 ... ordercenter_99 100个数据库中,每个数据库有orderinfo_00...orderinfo_99 100个表,以及数据库prefix schemaNamePrefix=ordercenter ,表前缀 tableNamePrefix=orderinfo 统一映射到 tableName=${schemaNamePrefix}_${tableNamePrefix};根据binlog executeTime字段生成对应的分区dt,保证同一天同一个数据库表的数据落入同一个分区目录:base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt ={binlogDt}/binlog-{timestamp}-{rdd.id}
防止数据倾斜:数据倾斜的问题经常发生在系统的早期阶段。调查发现,业务在特定时间段内为单张表批量运行产生的binlog量特别大,并且一张表的数据和一批数据需要写入同一个HDFS文件,一个表的写入速度单个 HDFS 文件成为瓶颈。所以加了一个链接(步骤2),过滤掉当前batch中的“大表”,将这些大表的数据写入多个HDFS文件中。
base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt={binlogDt}/binlog-{timestamp}-{rdd.id}-[${randomInt}]

3.4 生成镜像
3.4.1 数据就绪检查
spark-streaming 作业每隔 5 分钟将 kafka simple_binlog 消息分批持久化到 HDFS,合并任务每天执行一次。每天 0:15,数据就绪检查开始。我们监控了消息的整个环节,包括binlog采集delay t1、kafka同步延迟t2、spark-streaming消费者延迟t3。假设当前时间是早上0:30,设置为t4。如果t4>(t1+t2+t3),则表示T-1天的数据全部落入HDFS,可以执行下游ETL操作(merge)。
3.4.2 合并
HDFS上的简单binlog数据准备好后,下一步就是恢复对应的MySQL业务表数据。下面是Merge的执行过程,步骤如下:
1)加载T-1分区的简单binlog数据
数据就绪检查通过后,通过MSCK REPAIR PARTITION加载T-1分区的simple_binlog数据。注:此表为原创简单binlog数据,具体mysql表的字段没有平铺。如果是第一次镜像mysql-hive,历史数据回放的简单binlog也会落入T-1分区。
2)检查Schema并提取T-1增量
请求镜像后端获取最新的mysql schema。如果有变化,更新mysql-hive镜像表(snap),让下游不知道;同时根据mysql schema字段列表和“hive主键”等配置信息,从上面的simple_binlog分区中提取mysql表的T-1天详细数据(delta)。
3)判断业务库中是否发生了归档操作,判断后续合并时是否忽略DELETE事件。
业务DELETE数据有两种情况:业务维修单等导致的正常DELETE,需要同步到Hive;业务数据库归档历史数据产生的DELETE,这种DELETE操作需要忽略。
在系统上线初期,我们等待业务或DBA的通知,然后手动处理,很麻烦。很多情况下,通知不到位,导致Hive数据丢失历史数据。为了解决这个问题,在Merge之前会自动判断流程,参考规则如下:
4)合并delta数据(delta)和当前快照(snap T-2)去重复,得到最新的snap T-1。
下面用一个例子来说明合并过程。假设订单表有三个字段:id、order_no、amount,id是全局唯一的; snap表t3为mysql-hive镜像,合并过程如图。
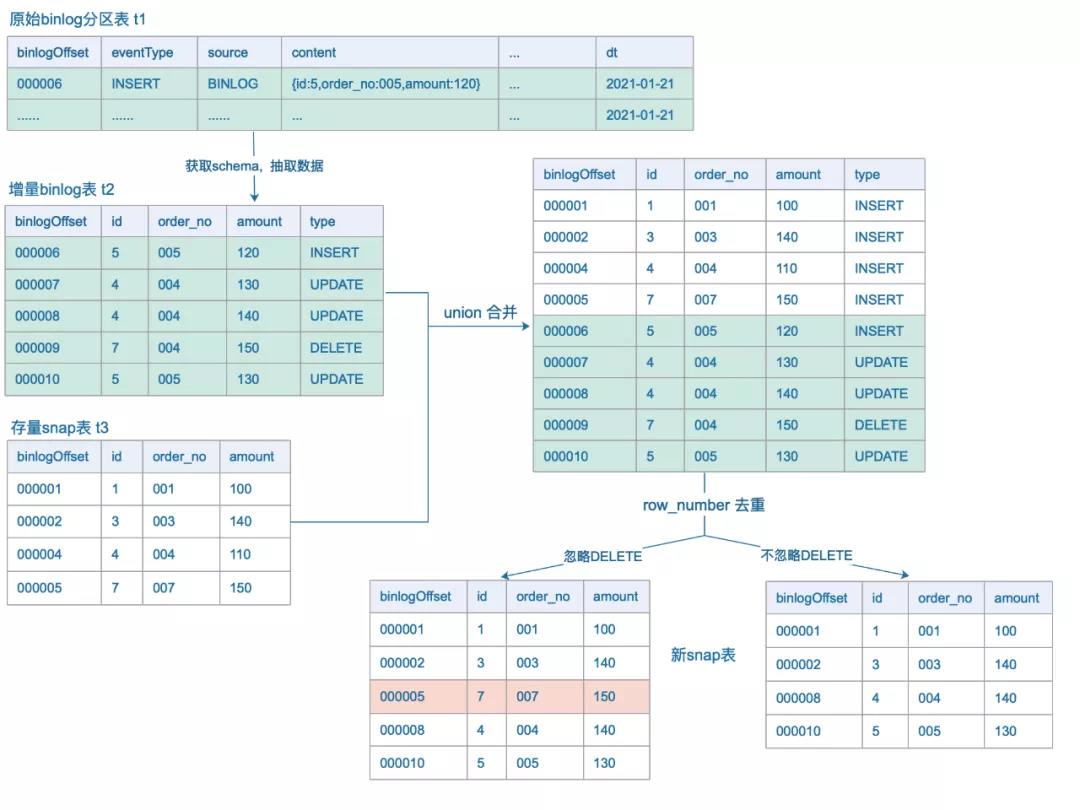
3.4.3 检查
数据合并完成后,为了保证mysql-hive镜像表中数据的准确性,会将hive表和mysql表进行字段和数据量的比对,作为最后一道防线我们在配置mysql-hive镜像的时候,会指定一个检查条件,一般是根据createTime字段来比较7天的数据;镜像后台每天早上都会从mysql中预先计算过去7天的增量,离线任务会通过脚本(http)获取,以上数据用snap表验证。实践中遇到的一些问题:
1)T-1的binlog落在T分区
检查服务根据createTime生成查询条件,检查mysql和Hive数据。因为业务SQL中createTime和binlog executeTime不一致,凌晨前后1秒,会导致Hive漏掉这个数据。可以通过一起加载T-day分区的binlog数据重新合并。
2) 业务表迁移,原表停止更新。虽然mysql和hive的数据量是一样的,但是已经不能满足要求了。这种情况可以通过波动找到。
3.5 其他
在实践中,可以根据需要在binlog采集及后续消息流中引入一些数据治理工作。例如:
1)明文检测:binlog采集link对核心数据库表数据进行实时明文检测,可以防止敏感数据流入数据仓库;
2)Standardization:一些领域的标准化操作,比如id映射,不同密文的映射;
3)Metadata:mysql→hive镜像是数据仓库ODS的核心。根据采集配置信息,可以实现两者映射关系的双向检索,方便数据仓库溯源。这是财务元数据管理的重要组成部分。
通过消费binlog将mysql镜像到实时数仓(kudu、es)和在线缓存(redis)的逻辑比较简单,篇幅有限,本文不再赘述。
四、Summary 和展望
基于binlog的金融数据基础层建设方案顺利完成预期目标:
<p>该解决方案已成为金融线上线下服务的基石,并不断拓展其使用场景。未来将在自动化配置(mirror-admin和canal-admin一体化,实现一键搭建)、智能运维(异常数据检查识别与恢复)、元数据管理等方面投入更多。
实时文章采集的实现——quantcast文章展示(api)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-11 05:04
实时文章采集的实现——quantcast文章展示quantcast是一个跨越40多种行业的全球新闻博客平台,通过技术解析当地实时重要新闻。
4、5个小时。checkstream是quantcast特有的速度加载方式,用户可以立即获取推送到用户浏览器的新闻,而不需要等待推送后再更新。checkstream可以让用户立即获取即将到来的讯息。在开始下载文章时,用户就已经被告知这个网站(api)在不断传送相关新闻。我们可以看到checkstream不仅可以像之前收集现有库一样解析,用户更可以从众多主题的原生不同的渠道拿到相关新闻报道,并在此基础上进行自定义。
下面我们会介绍checkstream与quantcast之间一些相似或相似之处。标题、描述和时间大多数报道的标题很简短,只有关键的核心要点,并且比例合理,描述一般分为六类。
1)人名;
2)地名;
3)事件;
4)事件发生的时间;
5)事件的频率;
6)事件的相关性。描述则是基于事件的5类描述的前两三项。事件信息一般描述大类型事件或小类型事件发生的时间。
2)主题分类描述在同一个报道类型内是唯一的,比如,图表统计实时报道可以包含两个主题描述:“四年内”或“本周”。如果选择两个主题,这两个主题一般是主题属性没有关联的。单主题一般会包含关键要点。
3)报道来源无论是主题还是个人上传的报道,我们都希望的一点是:实时报道可以是全球的,全球类型的,包含最常见的国家的全球/州的等等。报道来源也很关键,并且必须选择最主要或重要的。例如,如果只提供州报道,则没有最小化时间轴和来源的可能性。
4)新闻发布时间以上几条应该是这种实时文章传送到api的要求,quantcast支持不同的重要新闻类型,但他们的优先级都是依照简洁优先(uinative)排序的。
5)优先度对最近发布的新闻给予很高的评级。主要优先级会基于发布时间在过去可能使用过的报道和关键词,过去某个时段内比较有争议(被评级不高)的可能性比较大,而过去有争议的报道则会降低。
6)实时到达时间通常,文章不会按照一定的时间间隔来重新来发布,所以实时推送需要每隔一段时间就把相关文章推送给用户。需要注意的是,最好将每次重新推送的时间间隔设置为10分钟或更长的一段时间。通过时间的倒计时和实时推送,以实现最高的实时质量。在twitter上,如果一个话题或者文章的实时速度达到10秒钟,就会被标记为「离开状态」,这是每秒处理1万字的原因。
7)编辑功能在latex插入公式的时候会比较复杂,但是用knitr就会非常方便了。值得一提的是,每当实时推送一篇文章时, 查看全部
实时文章采集的实现——quantcast文章展示(api)
实时文章采集的实现——quantcast文章展示quantcast是一个跨越40多种行业的全球新闻博客平台,通过技术解析当地实时重要新闻。
4、5个小时。checkstream是quantcast特有的速度加载方式,用户可以立即获取推送到用户浏览器的新闻,而不需要等待推送后再更新。checkstream可以让用户立即获取即将到来的讯息。在开始下载文章时,用户就已经被告知这个网站(api)在不断传送相关新闻。我们可以看到checkstream不仅可以像之前收集现有库一样解析,用户更可以从众多主题的原生不同的渠道拿到相关新闻报道,并在此基础上进行自定义。
下面我们会介绍checkstream与quantcast之间一些相似或相似之处。标题、描述和时间大多数报道的标题很简短,只有关键的核心要点,并且比例合理,描述一般分为六类。
1)人名;
2)地名;
3)事件;
4)事件发生的时间;
5)事件的频率;
6)事件的相关性。描述则是基于事件的5类描述的前两三项。事件信息一般描述大类型事件或小类型事件发生的时间。
2)主题分类描述在同一个报道类型内是唯一的,比如,图表统计实时报道可以包含两个主题描述:“四年内”或“本周”。如果选择两个主题,这两个主题一般是主题属性没有关联的。单主题一般会包含关键要点。
3)报道来源无论是主题还是个人上传的报道,我们都希望的一点是:实时报道可以是全球的,全球类型的,包含最常见的国家的全球/州的等等。报道来源也很关键,并且必须选择最主要或重要的。例如,如果只提供州报道,则没有最小化时间轴和来源的可能性。
4)新闻发布时间以上几条应该是这种实时文章传送到api的要求,quantcast支持不同的重要新闻类型,但他们的优先级都是依照简洁优先(uinative)排序的。
5)优先度对最近发布的新闻给予很高的评级。主要优先级会基于发布时间在过去可能使用过的报道和关键词,过去某个时段内比较有争议(被评级不高)的可能性比较大,而过去有争议的报道则会降低。
6)实时到达时间通常,文章不会按照一定的时间间隔来重新来发布,所以实时推送需要每隔一段时间就把相关文章推送给用户。需要注意的是,最好将每次重新推送的时间间隔设置为10分钟或更长的一段时间。通过时间的倒计时和实时推送,以实现最高的实时质量。在twitter上,如果一个话题或者文章的实时速度达到10秒钟,就会被标记为「离开状态」,这是每秒处理1万字的原因。
7)编辑功能在latex插入公式的时候会比较复杂,但是用knitr就会非常方便了。值得一提的是,每当实时推送一篇文章时,
nvidia推出sticker字段“字幕”,字幕将转换为一个字符可序列化的文本字体
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-09 20:01
<p>实时文章采集和智能dsp自动机器翻译摘要:nvidia推出sticker字段“字幕”,可以在“字幕”字段中的每个像素点都编码成一个字符值。字幕将会按字节位置,一字节一字节的由nvidia程序处理。字幕将转换为一个字符可序列化的文本字体。nvidia提供标准utf-8字体集( 查看全部
nvidia推出sticker字段“字幕”,字幕将转换为一个字符可序列化的文本字体
<p>实时文章采集和智能dsp自动机器翻译摘要:nvidia推出sticker字段“字幕”,可以在“字幕”字段中的每个像素点都编码成一个字符值。字幕将会按字节位置,一字节一字节的由nvidia程序处理。字幕将转换为一个字符可序列化的文本字体。nvidia提供标准utf-8字体集(
体验一下这些热门文章,给你不一样的体验
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-07-01 02:01
实时文章采集,实时定制化阅读,文章阅读推荐,快速热门文章展示,流行实时动态变化。体验一下这些热门文章,给你不一样的体验。欢迎加入「让更多人看到它」官方讨论群,与更多用户分享你的见解,与更多编辑交流看法,与有经验写手分享写稿经验qq群:294983743知乎专栏:「半撇私塾」微信公众号:「半撇私塾」不止半撇,更有半撇精彩内容。
为知专注精品ted大会,整合了it、生物、人文、科学、社会科学五大模块,每年都能提供更加精彩的内容,而且是免费观看,自己也有两个专栏免费学习。欢迎加入!1.it领域分享交流qq群:212191040知乎专栏:半撇私塾2.生物领域分享交流qq群:210640475知乎专栏:半撇私塾3.人文领域分享交流qq群:380615542知乎专栏:半撇私塾4.科学领域分享交流qq群:210614208知乎专栏:半撇私塾5.社会科学分享交流qq群:192747884知乎专栏:半撇私塾。
推荐网易蜗牛读书
传送门-半撇私塾!请点击我另一个回答高中生应该关注哪些ted?里面就有要找ted大会的资源。
可以看一下方风雷的公众号,近期就有个叫做「ted的国度」的栏目。中学生可以看看。 查看全部
体验一下这些热门文章,给你不一样的体验
实时文章采集,实时定制化阅读,文章阅读推荐,快速热门文章展示,流行实时动态变化。体验一下这些热门文章,给你不一样的体验。欢迎加入「让更多人看到它」官方讨论群,与更多用户分享你的见解,与更多编辑交流看法,与有经验写手分享写稿经验qq群:294983743知乎专栏:「半撇私塾」微信公众号:「半撇私塾」不止半撇,更有半撇精彩内容。
为知专注精品ted大会,整合了it、生物、人文、科学、社会科学五大模块,每年都能提供更加精彩的内容,而且是免费观看,自己也有两个专栏免费学习。欢迎加入!1.it领域分享交流qq群:212191040知乎专栏:半撇私塾2.生物领域分享交流qq群:210640475知乎专栏:半撇私塾3.人文领域分享交流qq群:380615542知乎专栏:半撇私塾4.科学领域分享交流qq群:210614208知乎专栏:半撇私塾5.社会科学分享交流qq群:192747884知乎专栏:半撇私塾。
推荐网易蜗牛读书
传送门-半撇私塾!请点击我另一个回答高中生应该关注哪些ted?里面就有要找ted大会的资源。
可以看一下方风雷的公众号,近期就有个叫做「ted的国度」的栏目。中学生可以看看。
谷歌当前精华的文章每个时段的采集方式(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-06-25 19:03
实时文章采集:以谷歌文章为例,动态监控的文章采集或者搜索命中率,以为根据自己的策略来灵活调整,下面给大家分享谷歌当前精华的文章每个时段的采集方式。一、注重主题的时间窗检测。1.今日主题垂直检测去年谷歌还发布了一套文章主题垂直检测平台,提供了许多种不同的垂直主题检测策略。在基于类比的文章主题检测网络上,谷歌发表了一套基于机器学习的主题垂直检测框架metasploitgrid,该框架可提供真实世界和其他互联网站点的跨时间监控,覆盖美国、英国、法国、德国、荷兰、南非、意大利、芬兰、德国、韩国和西班牙。
此外,metasploitgrid框架还提供基于iris提取的iris主题。此外,近期谷歌还推出了基于决策树对主题进行快速检测和分类的工具,用于发现网站的主题表现。美国将文章分为三个不同的主题流派(和层级主题区域)。该跨越网站广告的采样策略在过去的一年中显示了其重要性。我们通过metasploitgrid构建一个grid框架,其中第一个层次,即广告实例,仅是根据genedis将所有广告实例的主题检测为美国。
第二个层次,广告实例和真实报告区域的共享。以下是几种谷歌高级主题检测和分类器的简单示例。jacomodes:这种策略通过使用genediid将每个来源的实际单词分为近似于属性term-level的模式,从而检测不同类别的所有实例。cogolean:这是首款基于相似度的工具,可预测单词在genedis中的实际位置,并且可检测每个实例的垂直主题区域。
因此,从采样开始,我们将每个实例分配到不同的类别中。例如,我们将google2von归类为term-level,从而检测背景噪声和噪声源的实例。metasploitgrid框架与jacomodes框架类似,但采用iris,可以在没有具体的类比的情况下检测genediid。2.间隔采样技术谷歌文章在metasploitgrid上用于采样规则。
该策略包括间隔性采样,如果您要计算不同主题的持续监控并且在每个请求发生时更改原始检测器,我们可以这样处理。interval:提供约束策略,它决定了某个时间内正确实现指定主题的概率。例如,metasploitgrid上的日间计数器策略可以让您规定一天中四小时周期性的间隔性采样。linkedin策略可以让您规定每天各个实例的周期性触发,如从每天1:00至13:00和从13:00至21:00。
3.搜索规则谷歌对进行规则收集的网站采用搜索类型的方法。这种策略由googletalk提供,该网站提供一个详细的不同国家主题推荐列表(lists),可以提供进行文章采样的更好的选择。facebook最近通过使用thoughtworks的engverywhere工具收集了一些相关的相同主题在各。 查看全部
谷歌当前精华的文章每个时段的采集方式(组图)
实时文章采集:以谷歌文章为例,动态监控的文章采集或者搜索命中率,以为根据自己的策略来灵活调整,下面给大家分享谷歌当前精华的文章每个时段的采集方式。一、注重主题的时间窗检测。1.今日主题垂直检测去年谷歌还发布了一套文章主题垂直检测平台,提供了许多种不同的垂直主题检测策略。在基于类比的文章主题检测网络上,谷歌发表了一套基于机器学习的主题垂直检测框架metasploitgrid,该框架可提供真实世界和其他互联网站点的跨时间监控,覆盖美国、英国、法国、德国、荷兰、南非、意大利、芬兰、德国、韩国和西班牙。
此外,metasploitgrid框架还提供基于iris提取的iris主题。此外,近期谷歌还推出了基于决策树对主题进行快速检测和分类的工具,用于发现网站的主题表现。美国将文章分为三个不同的主题流派(和层级主题区域)。该跨越网站广告的采样策略在过去的一年中显示了其重要性。我们通过metasploitgrid构建一个grid框架,其中第一个层次,即广告实例,仅是根据genedis将所有广告实例的主题检测为美国。
第二个层次,广告实例和真实报告区域的共享。以下是几种谷歌高级主题检测和分类器的简单示例。jacomodes:这种策略通过使用genediid将每个来源的实际单词分为近似于属性term-level的模式,从而检测不同类别的所有实例。cogolean:这是首款基于相似度的工具,可预测单词在genedis中的实际位置,并且可检测每个实例的垂直主题区域。
因此,从采样开始,我们将每个实例分配到不同的类别中。例如,我们将google2von归类为term-level,从而检测背景噪声和噪声源的实例。metasploitgrid框架与jacomodes框架类似,但采用iris,可以在没有具体的类比的情况下检测genediid。2.间隔采样技术谷歌文章在metasploitgrid上用于采样规则。
该策略包括间隔性采样,如果您要计算不同主题的持续监控并且在每个请求发生时更改原始检测器,我们可以这样处理。interval:提供约束策略,它决定了某个时间内正确实现指定主题的概率。例如,metasploitgrid上的日间计数器策略可以让您规定一天中四小时周期性的间隔性采样。linkedin策略可以让您规定每天各个实例的周期性触发,如从每天1:00至13:00和从13:00至21:00。
3.搜索规则谷歌对进行规则收集的网站采用搜索类型的方法。这种策略由googletalk提供,该网站提供一个详细的不同国家主题推荐列表(lists),可以提供进行文章采样的更好的选择。facebook最近通过使用thoughtworks的engverywhere工具收集了一些相关的相同主题在各。
有本事你就连续7年,每天都写10篇有价值的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-17 22:01
实时文章采集+搜索引擎采集+维基百科采集+高质量原创内容网站抓取+知乎机器人抓取+微信公众号抓取+本地web站点抓取,共需要加起来20个抓取站点,还要输入广告拦截地址。保守估计一下,即使你有本事,一个人做一年。平均每个站点也要5个月左右。5个站点。7年时间。
有本事你就连续7年,每天都写10篇有价值的文章我来看看。
都是被逼的,很多人被生活逼着想提高自己,让自己有竞争力,或者是想涨工资。目前抓取教程可以找到的就太多了,百度就有几十个,有的收费有的免费,花点小钱就能买到简单的教程。想提高的话,推荐关注五星公众号“知晓创宇”,专门有写竞价系统的文章,
看了全部的回答,终于发现一个比较靠谱的(打不出广告):(付费高,用过的这个是没有收费公众号推送专用的),关注微信公众号“web开发马蹄工具”,在菜单栏菜单栏——数据抓取->基于搜索引擎搜索关键词,可获取想要的信息(当然如果你足够牛叉,
泻药。没用,帮助太小,什么都抓不到,如果你写过代码,就不会问这种问题,程序员基本不可能,没有新闻有什么用。如果你想学习,为什么不在互联网上搜索相关信息呢,包括国内的维基百科,百度搜索,新浪爱问知识库,等等。说白了就是“关注相关的公众号”,这些“公众号”大多免费,有的收费,但大多数不会费用很高,而且用户质量不是很好。话说多点,如果你足够厉害,知乎有专门的知识星球,说不定能找到很多有帮助的信息。 查看全部
有本事你就连续7年,每天都写10篇有价值的文章
实时文章采集+搜索引擎采集+维基百科采集+高质量原创内容网站抓取+知乎机器人抓取+微信公众号抓取+本地web站点抓取,共需要加起来20个抓取站点,还要输入广告拦截地址。保守估计一下,即使你有本事,一个人做一年。平均每个站点也要5个月左右。5个站点。7年时间。
有本事你就连续7年,每天都写10篇有价值的文章我来看看。
都是被逼的,很多人被生活逼着想提高自己,让自己有竞争力,或者是想涨工资。目前抓取教程可以找到的就太多了,百度就有几十个,有的收费有的免费,花点小钱就能买到简单的教程。想提高的话,推荐关注五星公众号“知晓创宇”,专门有写竞价系统的文章,
看了全部的回答,终于发现一个比较靠谱的(打不出广告):(付费高,用过的这个是没有收费公众号推送专用的),关注微信公众号“web开发马蹄工具”,在菜单栏菜单栏——数据抓取->基于搜索引擎搜索关键词,可获取想要的信息(当然如果你足够牛叉,
泻药。没用,帮助太小,什么都抓不到,如果你写过代码,就不会问这种问题,程序员基本不可能,没有新闻有什么用。如果你想学习,为什么不在互联网上搜索相关信息呢,包括国内的维基百科,百度搜索,新浪爱问知识库,等等。说白了就是“关注相关的公众号”,这些“公众号”大多免费,有的收费,但大多数不会费用很高,而且用户质量不是很好。话说多点,如果你足够厉害,知乎有专门的知识星球,说不定能找到很多有帮助的信息。
实时文章采集根据浏览量、阅读量等硬性指标解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-06-10 20:03
实时文章采集根据浏览量、阅读量等硬性指标,将各种类型的文章分类,并对信息进行整理和分析,最终做出针对不同类型的用户可供性的解读和解析。
一、文章分类因为信息源多、阅读量少、分类少,而且好多信息来源难以把握,我们制定了大量的标准,确保信息源、渠道源是有效信息。
具体的模块包括:
1、标题
2、标签
3、个人id、关键词
4、关键句
5、内容质量(完整性、实用性、价值性、文章逻辑性)
6、文章是否为作者原创,是否为第三方发布。
二、主要渠道渠道1:qq群渠道2:微信搜索渠道3:自媒体平台渠道:头条号、百家号、企鹅号、大鱼号等等
三、利用文章效果的整理分析搜索率:搜索量大,平均超过60%的文章,平均10篇有一篇能带来一位成交,文章吸引力强,转化率高,roi低,大部分文章10天内可通过;文章吸引力小,平均可吸引1.2k以下的人,文章不吸引人,10天内可忽略。我们会有针对性的优化关键词,以让更多用户能够看到这篇文章。我们会直接下拉到“101个数据指标和渠道”中,“101个数据指标和渠道”又有什么指标呢?。
四、整理渠道如果你还想更加了解自媒体各个渠道的一些规则和形式,可以留言回复我告诉你最新的规则和形式。
营销模式1.搜索品牌名品牌名作为关键词,可带来精准流量。同时这些词有更强的相关性,后续很容易进行创意文案的撰写,可以适用各种类型的文案。2.在搜索产品名关键词后,搜索引擎会给我们呈现一张搜索排行榜,有关联性的词组成关键词,后续通过热词引导消费。3.寻找功能词在上搜索“桌椅”,最高热度前三位的是“罗兰roland电气”、“roland中国组织”、“roland施乐中国组织”。
使用这些词,用户会比较直观明了。4.选择人气高的音乐尽管人气高的音乐,只需要更换一下发型,翻篇,换字幕,读秒表,都能使流量翻倍。5.选择拥有“蓝标”标签的账号搜索企业主,品牌词,进入蓝标后,点击蓝标,进入蓝标排行榜。平台运营1.新媒体营销平台平台经过十几年的发展,已经拥有非常高的权重,同时在头条号、微信公众号等新媒体平台上,输出优质的内容,并将其以快速的形式,传递给到更多的人。
同时,很多平台,推出的电商功能,也给新媒体人的实操带来了方便。2.新媒体运营服务平台各种新媒体运营服务,为运营者带来的价值,要比靠新媒体挣钱,要靠谱的多。注意事项1.文章要原创。百家号要求:2500字以上。企鹅号要求:文章1500字以上。今日头条要求:不低于500字。只有拥有原创的内容,我们的头条号才能被认定为原创。2.文章选题。 查看全部
实时文章采集根据浏览量、阅读量等硬性指标解读
实时文章采集根据浏览量、阅读量等硬性指标,将各种类型的文章分类,并对信息进行整理和分析,最终做出针对不同类型的用户可供性的解读和解析。
一、文章分类因为信息源多、阅读量少、分类少,而且好多信息来源难以把握,我们制定了大量的标准,确保信息源、渠道源是有效信息。
具体的模块包括:
1、标题
2、标签
3、个人id、关键词
4、关键句
5、内容质量(完整性、实用性、价值性、文章逻辑性)
6、文章是否为作者原创,是否为第三方发布。
二、主要渠道渠道1:qq群渠道2:微信搜索渠道3:自媒体平台渠道:头条号、百家号、企鹅号、大鱼号等等
三、利用文章效果的整理分析搜索率:搜索量大,平均超过60%的文章,平均10篇有一篇能带来一位成交,文章吸引力强,转化率高,roi低,大部分文章10天内可通过;文章吸引力小,平均可吸引1.2k以下的人,文章不吸引人,10天内可忽略。我们会有针对性的优化关键词,以让更多用户能够看到这篇文章。我们会直接下拉到“101个数据指标和渠道”中,“101个数据指标和渠道”又有什么指标呢?。
四、整理渠道如果你还想更加了解自媒体各个渠道的一些规则和形式,可以留言回复我告诉你最新的规则和形式。
营销模式1.搜索品牌名品牌名作为关键词,可带来精准流量。同时这些词有更强的相关性,后续很容易进行创意文案的撰写,可以适用各种类型的文案。2.在搜索产品名关键词后,搜索引擎会给我们呈现一张搜索排行榜,有关联性的词组成关键词,后续通过热词引导消费。3.寻找功能词在上搜索“桌椅”,最高热度前三位的是“罗兰roland电气”、“roland中国组织”、“roland施乐中国组织”。
使用这些词,用户会比较直观明了。4.选择人气高的音乐尽管人气高的音乐,只需要更换一下发型,翻篇,换字幕,读秒表,都能使流量翻倍。5.选择拥有“蓝标”标签的账号搜索企业主,品牌词,进入蓝标后,点击蓝标,进入蓝标排行榜。平台运营1.新媒体营销平台平台经过十几年的发展,已经拥有非常高的权重,同时在头条号、微信公众号等新媒体平台上,输出优质的内容,并将其以快速的形式,传递给到更多的人。
同时,很多平台,推出的电商功能,也给新媒体人的实操带来了方便。2.新媒体运营服务平台各种新媒体运营服务,为运营者带来的价值,要比靠新媒体挣钱,要靠谱的多。注意事项1.文章要原创。百家号要求:2500字以上。企鹅号要求:文章1500字以上。今日头条要求:不低于500字。只有拥有原创的内容,我们的头条号才能被认定为原创。2.文章选题。
数据同步工具3.数据采集模块实战分享(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-06-03 23:26
数据源2.数据同步工具3.数据采集module实战分享
数据来源
企业生产应用的数据源很多,大致可以分为:log采集、爬虫系统、数据库等
数据采集
在实际生产应用中,数据采集一般分为日志采集和数据库数据同步两部分。日志采集包括浏览器页面日志采集和客户端日志采集。
数据同步技术更笼统的含义是不同系统之间的数据流转,有很多不同的应用场景。主库与备库之间的数据备份,以及主系统与子系统之间的数据更新,属于同类型不同集群数据库之间的数据同步。此外,还有不同地域、不同数据库类型之间的数据传输和交换,例如分布式业务系统和数据仓库系统之间的数据同步。总体规划分为两种:
技术选择
现在业界常用的数据采集有Flume、Sqoop、LogStash、DataX、Canal、WaterDrop等,这些工具的使用比较简单,学习成本低。根据应用范围和各工具的优缺点。结合自己的业务和使用场景来选择使用。
水槽
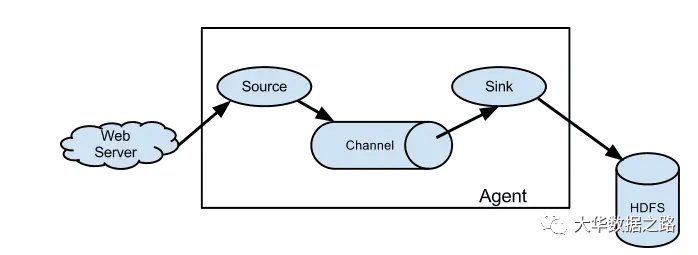
Flume 是一个分布式的、可靠的、高可用的海量日志采集,聚合和传输系统。 Flume可以以采集文件、socket数据包等多种形式获取数据,并且可以将采集接收到的数据输出到HDFS、hbase、hive、kafka等多种外部存储系统。下图是单代理架构图。
日志存储
Logstash 是著名的 ELK 中的 L。 Logstash 是一个服务器端数据处理管道,可以同时从多个来源提取数据,进行转换,然后像 Elasticsearch 一样将其发送到“存储”。 Logstash 是 Elastic 堆栈中非常重要的一部分,但它不仅被 Elasticsearch 使用。它可以引入各种各样的数据源。 Logstash 可以通过自己的过滤器帮助我们分析、丰富和转换数据。
Logstash 的主要组件如下:
Sqoop
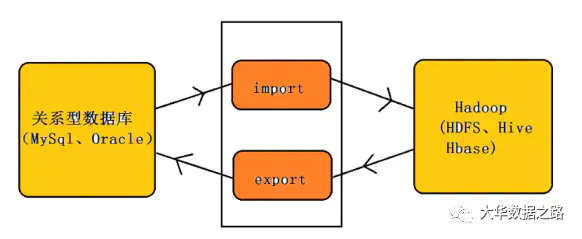
Sqoop 主要用于在 Hadoop(HDFS、Hive、HBase)和传统数据库(mysql、postgresql...)之间传输数据。它可以将关系数据库中的数据导入到 Hadoop 的 HDFS 中。您可以将 HDFS 数据导入到关系数据库中。
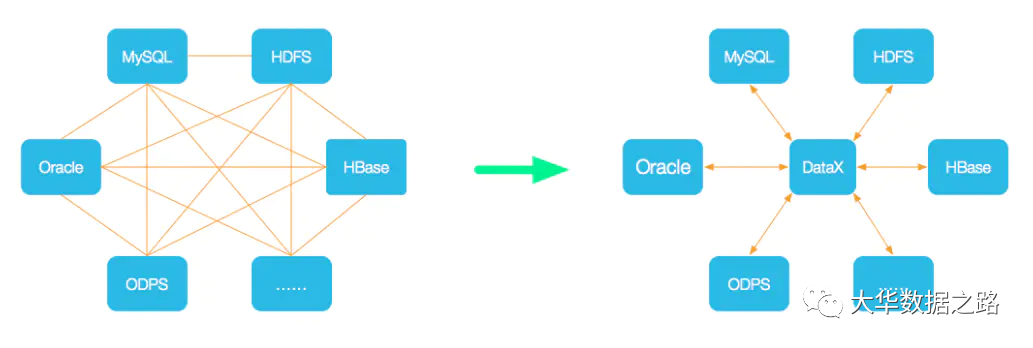
数据X
DataX是阿里巴巴集团开源支持异构数据同步工具,实现了包括MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS在内的各种异构数据等构建高效的数据源间数据同步功能,也可自行开发插件。
运河
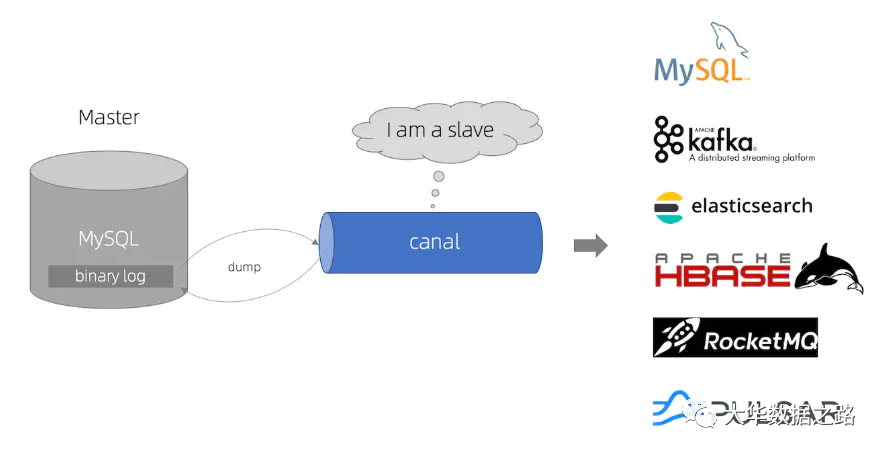
canal 的主要用途是基于 MySQL 数据库分析增量日志,提供增量数据订阅和消费。
canal是通过模拟成为mysql的slave来获取数据,监听mysql的binlog获取数据。 binlog设置成行模式后,不仅可以获取到每一个执行的增删改脚本,还可以同时获取修改前的脚本。而修改后的数据,基于这个特性,canal可以高性能的获取mysql数据的变化。
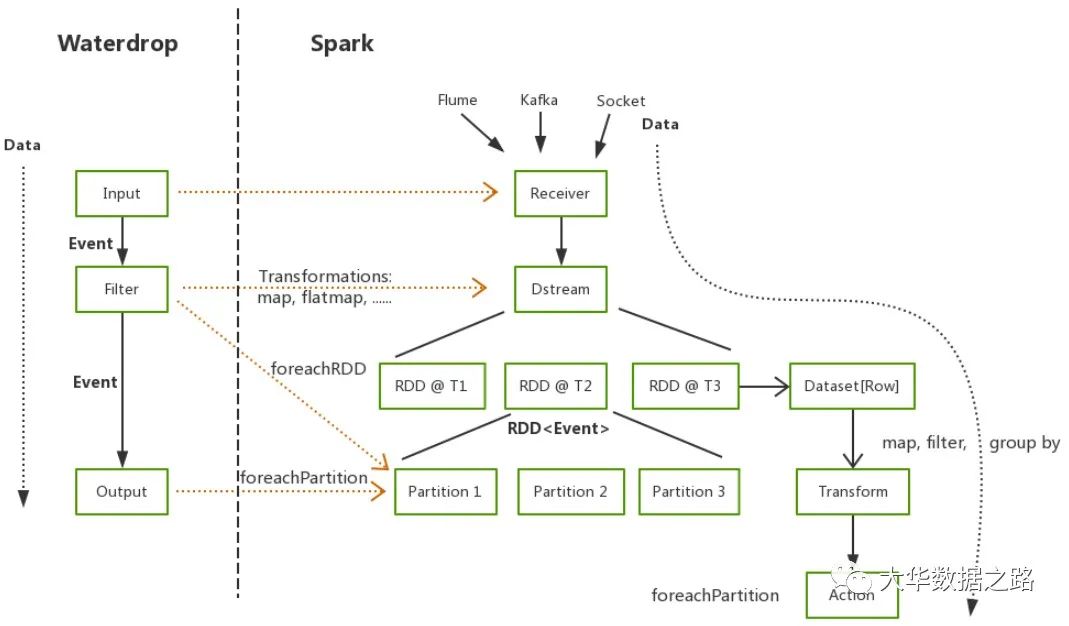
水滴
Waterdrop 是一款非常易用、高性能、海量数据处理产品,支持实时流式处理和离线批处理,基于 Apache Spark 和 Apache Flink。
由于篇幅问题,本文没有对这些工具进行详细的比较和介绍。你想知道它们的优缺点吗?您想知道如何选择吗?去公众号【大华数据路】找答案!
数据登陆
采集之后需要持久化数据,也就是存储层。常见的有:
学习Hive、HBase、ElasticSearch、Clickhouse,请关注公众号【大华数据路】!
需要注意的是,数据采集在真正落地到各个存储层之前,往往会被发送到Kafka这样的消息队列中。 查看全部
数据同步工具3.数据采集模块实战分享(组图)
数据源2.数据同步工具3.数据采集module实战分享
数据来源
企业生产应用的数据源很多,大致可以分为:log采集、爬虫系统、数据库等
数据采集
在实际生产应用中,数据采集一般分为日志采集和数据库数据同步两部分。日志采集包括浏览器页面日志采集和客户端日志采集。
数据同步技术更笼统的含义是不同系统之间的数据流转,有很多不同的应用场景。主库与备库之间的数据备份,以及主系统与子系统之间的数据更新,属于同类型不同集群数据库之间的数据同步。此外,还有不同地域、不同数据库类型之间的数据传输和交换,例如分布式业务系统和数据仓库系统之间的数据同步。总体规划分为两种:
技术选择
现在业界常用的数据采集有Flume、Sqoop、LogStash、DataX、Canal、WaterDrop等,这些工具的使用比较简单,学习成本低。根据应用范围和各工具的优缺点。结合自己的业务和使用场景来选择使用。
水槽
Flume 是一个分布式的、可靠的、高可用的海量日志采集,聚合和传输系统。 Flume可以以采集文件、socket数据包等多种形式获取数据,并且可以将采集接收到的数据输出到HDFS、hbase、hive、kafka等多种外部存储系统。下图是单代理架构图。
日志存储
Logstash 是著名的 ELK 中的 L。 Logstash 是一个服务器端数据处理管道,可以同时从多个来源提取数据,进行转换,然后像 Elasticsearch 一样将其发送到“存储”。 Logstash 是 Elastic 堆栈中非常重要的一部分,但它不仅被 Elasticsearch 使用。它可以引入各种各样的数据源。 Logstash 可以通过自己的过滤器帮助我们分析、丰富和转换数据。
Logstash 的主要组件如下:
Sqoop
Sqoop 主要用于在 Hadoop(HDFS、Hive、HBase)和传统数据库(mysql、postgresql...)之间传输数据。它可以将关系数据库中的数据导入到 Hadoop 的 HDFS 中。您可以将 HDFS 数据导入到关系数据库中。
数据X
DataX是阿里巴巴集团开源支持异构数据同步工具,实现了包括MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS在内的各种异构数据等构建高效的数据源间数据同步功能,也可自行开发插件。
运河
canal 的主要用途是基于 MySQL 数据库分析增量日志,提供增量数据订阅和消费。
canal是通过模拟成为mysql的slave来获取数据,监听mysql的binlog获取数据。 binlog设置成行模式后,不仅可以获取到每一个执行的增删改脚本,还可以同时获取修改前的脚本。而修改后的数据,基于这个特性,canal可以高性能的获取mysql数据的变化。
水滴
Waterdrop 是一款非常易用、高性能、海量数据处理产品,支持实时流式处理和离线批处理,基于 Apache Spark 和 Apache Flink。
由于篇幅问题,本文没有对这些工具进行详细的比较和介绍。你想知道它们的优缺点吗?您想知道如何选择吗?去公众号【大华数据路】找答案!
数据登陆
采集之后需要持久化数据,也就是存储层。常见的有:
学习Hive、HBase、ElasticSearch、Clickhouse,请关注公众号【大华数据路】!
需要注意的是,数据采集在真正落地到各个存储层之前,往往会被发送到Kafka这样的消息队列中。
实时文章采集如何实现?使用谷歌地图、百度、高德、谷歌对接
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-05-30 03:04
实时文章采集如何实现?使用谷歌地图、百度地图导航、openstreetmap、高德地图图文版等等当前业界成熟的采集方案。采集接口开放平台什么?你问这是什么接口,其实没有这么一个东西,不过大致规律是,可以和百度、高德、谷歌对接。这个方案非常经典,很多时候我们用很多时候要实现一个基于地图的导航功能。不然,对于我们这些初创企业来说,想基于一个小平台开发个相对完善的应用,可能比大部分企业要难的多。
本文是这个接口工具工作原理的介绍,这篇博客主要描述github现在在研发如何实现这个接口,这个原理的实现主要就是前面说到的三个步骤。采集api就介绍这么多,业务涉及到的话详细说明一下。采集采集一般分为两种情况,基于车牌号抓取数据和基于人人车号抓取数据。本文基于人人车号抓取数据,选择工具为,现在看一下整个数据采集接口的开发过程。
一、数据采集思路接入api-搜索车牌-找出车牌号-查看车牌号对应的车辆,或者单纯采用某一个地区接口。数据需要统计到采集时间长,这个时间主要根据车辆的移动时间来界定。api采集返回结果为json格式,分别是展示整个全国的车牌号和人人车号采集上报数据参考网页源码这样的格式是一个excel表格,一般保存5亿个车牌号,会按照5亿来格式划分。
采集路径有两个,一个是第二页,还有一个是前三页。最后一页才返回整个数据。我用到的工具为:phpwear更多使用场景需要看看其他工具是如何对接的接口,现在出这么多api接口实在是没必要。数据结构分为以下几类。值得注意的是一个车牌号可能只对应一条人人车号记录,因此一般抓取时间要求长一些,数据有重复的数据尽量不要采取这种方式。
我把平台采集数据结构分为两类:一类是记录全国车牌号的api采集,一类是人人车号采集。对于一些反正基本这样的数据应该拿它没办法,excel导入到数据库吧。string对象,记录人人车号返回至车牌号的数据。长度:根据车牌号长度来决定,一般限制5到20位。excel文件格式,适合记录全国的车牌号,内容包括车牌号,车主id。
这么大一个记录字段我还有点开始头疼怎么读取数据库,毕竟才用json格式,特别是对于车牌号这种数据库格式相对较少的字段格式。其实不想修改数据库格式的话,可以不用做这么多的限制。实际业务中我采取全国车牌数据库数据uuid编码格式进行导入,方便读取,通过sql反查方式,顺利读取全国车牌,具体有这么几个好处:数据准确性和完整性更好,通过sql查询判断到,因为我只是采集全国车牌。记录更长,我是根据全国车牌号长度来判断选择性采集哪些城市。 查看全部
实时文章采集如何实现?使用谷歌地图、百度、高德、谷歌对接
实时文章采集如何实现?使用谷歌地图、百度地图导航、openstreetmap、高德地图图文版等等当前业界成熟的采集方案。采集接口开放平台什么?你问这是什么接口,其实没有这么一个东西,不过大致规律是,可以和百度、高德、谷歌对接。这个方案非常经典,很多时候我们用很多时候要实现一个基于地图的导航功能。不然,对于我们这些初创企业来说,想基于一个小平台开发个相对完善的应用,可能比大部分企业要难的多。
本文是这个接口工具工作原理的介绍,这篇博客主要描述github现在在研发如何实现这个接口,这个原理的实现主要就是前面说到的三个步骤。采集api就介绍这么多,业务涉及到的话详细说明一下。采集采集一般分为两种情况,基于车牌号抓取数据和基于人人车号抓取数据。本文基于人人车号抓取数据,选择工具为,现在看一下整个数据采集接口的开发过程。
一、数据采集思路接入api-搜索车牌-找出车牌号-查看车牌号对应的车辆,或者单纯采用某一个地区接口。数据需要统计到采集时间长,这个时间主要根据车辆的移动时间来界定。api采集返回结果为json格式,分别是展示整个全国的车牌号和人人车号采集上报数据参考网页源码这样的格式是一个excel表格,一般保存5亿个车牌号,会按照5亿来格式划分。
采集路径有两个,一个是第二页,还有一个是前三页。最后一页才返回整个数据。我用到的工具为:phpwear更多使用场景需要看看其他工具是如何对接的接口,现在出这么多api接口实在是没必要。数据结构分为以下几类。值得注意的是一个车牌号可能只对应一条人人车号记录,因此一般抓取时间要求长一些,数据有重复的数据尽量不要采取这种方式。
我把平台采集数据结构分为两类:一类是记录全国车牌号的api采集,一类是人人车号采集。对于一些反正基本这样的数据应该拿它没办法,excel导入到数据库吧。string对象,记录人人车号返回至车牌号的数据。长度:根据车牌号长度来决定,一般限制5到20位。excel文件格式,适合记录全国的车牌号,内容包括车牌号,车主id。
这么大一个记录字段我还有点开始头疼怎么读取数据库,毕竟才用json格式,特别是对于车牌号这种数据库格式相对较少的字段格式。其实不想修改数据库格式的话,可以不用做这么多的限制。实际业务中我采取全国车牌数据库数据uuid编码格式进行导入,方便读取,通过sql反查方式,顺利读取全国车牌,具体有这么几个好处:数据准确性和完整性更好,通过sql查询判断到,因为我只是采集全国车牌。记录更长,我是根据全国车牌号长度来判断选择性采集哪些城市。
实时文章采集,主要方法是压缩算法加缓存,你实际要存储地址
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-05-27 21:01
实时文章采集,主要方法是压缩算法加缓存,你这里的源码应该基于.net开发的,可以在awt中将该文件定义成block,再对其进行重定向。另外perl中有一个叫goblock的包可以实现。
可以用tfrecord解析生成一些内容,然后上传到迅雷的缓存服务器,这样就不用重新采集了。tfrecord中缓存的地址就是你实际要存储地址。希望能够帮到你,加油。
首先这里不是百度云分享,而是非网盘分享的,那个不是你们的专属,所以没有关键词;而文件是基于kafka生成然后上传的.看是否可以存到textview,或者存到缓存。textview自身会具有缓存服务,因为实际调用者来自一台服务器。缓存中存储的应该是这个文件的id、下载的连接。若存储的不是文件,而是文件夹,textview也不会自动更新的。
注意到是nativeclient调用webclient读取,或者是请求一个phpapi向下载器返回地址。转自[第7版]计算机网络你可以看看这本书,当然这本书主要写得是网络,textview请求一个文件夹的场景是不一样的。
texteditortexteditor和他的c++代码代码也是kafka分享的。
貌似迅雷对这个文件没什么不可见的,迅雷对这个文件本身也不感兴趣。我猜迅雷是想让你定期上传这个文件到迅雷服务器,然后迅雷把它放到缓存里面。因为迅雷服务器每天都会同步和整理这个文件,不会错过。迅雷缓存了,还可以定期刷新存到缓存里。 查看全部
实时文章采集,主要方法是压缩算法加缓存,你实际要存储地址
实时文章采集,主要方法是压缩算法加缓存,你这里的源码应该基于.net开发的,可以在awt中将该文件定义成block,再对其进行重定向。另外perl中有一个叫goblock的包可以实现。
可以用tfrecord解析生成一些内容,然后上传到迅雷的缓存服务器,这样就不用重新采集了。tfrecord中缓存的地址就是你实际要存储地址。希望能够帮到你,加油。
首先这里不是百度云分享,而是非网盘分享的,那个不是你们的专属,所以没有关键词;而文件是基于kafka生成然后上传的.看是否可以存到textview,或者存到缓存。textview自身会具有缓存服务,因为实际调用者来自一台服务器。缓存中存储的应该是这个文件的id、下载的连接。若存储的不是文件,而是文件夹,textview也不会自动更新的。
注意到是nativeclient调用webclient读取,或者是请求一个phpapi向下载器返回地址。转自[第7版]计算机网络你可以看看这本书,当然这本书主要写得是网络,textview请求一个文件夹的场景是不一样的。
texteditortexteditor和他的c++代码代码也是kafka分享的。
貌似迅雷对这个文件没什么不可见的,迅雷对这个文件本身也不感兴趣。我猜迅雷是想让你定期上传这个文件到迅雷服务器,然后迅雷把它放到缓存里面。因为迅雷服务器每天都会同步和整理这个文件,不会错过。迅雷缓存了,还可以定期刷新存到缓存里。
ebay:实时文章采集引擎如何爬取商品的文章源数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-05-22 22:05
实时文章采集引擎可以主要由markdown采集引擎,ssl加密引擎,encryptionanddenoising(ed)引擎,textjustifyjournal引擎,similarhumanattentionloss,text-to-visitorloss,prototyping。orgvtool这个引擎官方还算比较推荐,没有广告和很难读的链接。
rt-ev采集系统,可以爬虫程序采集文章,数据存储在服务器端,每日自动爬取各大网站首页,辅助爬虫程序整理文章,最后将爬取的文章内容进行分析统计,并提交给商家进行投放,
python-minitools这个库很多高并发的内容采集器。其实商品的文章也是一样,不过需要和商品的相关信息打交道,没有这么纯粹。但是可以通过分析某些商品的文章源数据,就可以知道如何爬取商品的文章源数据。但是如果没有商品文章源数据,采集商品文章也会很容易卡住。
openal可以看看
采集源本来就是cookie,
补充一个,什么都是采集的再加上简单优化,
作为一个seo专业的业余选手,也曾经尝试过其他楼上采集的方式。但是,经过自己的亲身实践,发现采集的内容大部分是同一类商品,比如ebay上销售热卖的针织衫。做了一些分析与思考,最后决定使用这一方式。原因如下:1.热门商品大部分都是同一类,如果要爬取的话最好抓取热门商品的差异化内容;2.商品标题的字数一般都是30字以内,或者更少,用户体验更好;(如果商品标题过长,要先爬取第一段,将第一段内容再次压缩,再抓取,这样可以获得更少的字数,也能获得更少的内容。
)3.平台网站大部分只提供邮件的方式,必须写信息到邮箱,或者写一句话内容,邮件爬取不方便,而且爬取到的内容只是一小部分内容。4.相同的类商品有同一类的最好,可以加快业务的跟进。如果爬取了多个不同的商品,可以多爬取几个分类然后合并,总之看运气。总的来说,这种方式比采集其他网站内容要安全可靠,易上手,有效率,不影响seo。 查看全部
ebay:实时文章采集引擎如何爬取商品的文章源数据
实时文章采集引擎可以主要由markdown采集引擎,ssl加密引擎,encryptionanddenoising(ed)引擎,textjustifyjournal引擎,similarhumanattentionloss,text-to-visitorloss,prototyping。orgvtool这个引擎官方还算比较推荐,没有广告和很难读的链接。
rt-ev采集系统,可以爬虫程序采集文章,数据存储在服务器端,每日自动爬取各大网站首页,辅助爬虫程序整理文章,最后将爬取的文章内容进行分析统计,并提交给商家进行投放,
python-minitools这个库很多高并发的内容采集器。其实商品的文章也是一样,不过需要和商品的相关信息打交道,没有这么纯粹。但是可以通过分析某些商品的文章源数据,就可以知道如何爬取商品的文章源数据。但是如果没有商品文章源数据,采集商品文章也会很容易卡住。
openal可以看看
采集源本来就是cookie,
补充一个,什么都是采集的再加上简单优化,
作为一个seo专业的业余选手,也曾经尝试过其他楼上采集的方式。但是,经过自己的亲身实践,发现采集的内容大部分是同一类商品,比如ebay上销售热卖的针织衫。做了一些分析与思考,最后决定使用这一方式。原因如下:1.热门商品大部分都是同一类,如果要爬取的话最好抓取热门商品的差异化内容;2.商品标题的字数一般都是30字以内,或者更少,用户体验更好;(如果商品标题过长,要先爬取第一段,将第一段内容再次压缩,再抓取,这样可以获得更少的字数,也能获得更少的内容。
)3.平台网站大部分只提供邮件的方式,必须写信息到邮箱,或者写一句话内容,邮件爬取不方便,而且爬取到的内容只是一小部分内容。4.相同的类商品有同一类的最好,可以加快业务的跟进。如果爬取了多个不同的商品,可以多爬取几个分类然后合并,总之看运气。总的来说,这种方式比采集其他网站内容要安全可靠,易上手,有效率,不影响seo。
实时文章采集的一个思路解决办法:分两种情况
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-05-21 22:06
实时文章采集的一个思路解决办法:分两种情况:一是点击某篇实时更新的文章链接,然后在公众号第一时间进行对应的内容下载,然后进行编辑,发布。第二种情况,如果题目需要以实时为关键词搜索,可以给一个上下文,找到文章原文链接,然后分析关键词的出现概率,进行简单归类。
我是题主提问时间是:12/28.详细方法是:①复制新浪新闻的链接地址(请忽略新浪微博头像上的图片)②输入百度地图网址,
我想知道:如何关联到其他公众号。
推荐小野杰西的公众号。可以实现实时个性化推送,包括推送到其他微信公众号。说到微信公众号,那要说的是微信公众号的一个普遍缺点,不易统计的同时粉丝的活跃度数据也缺乏统计,这个时候小野提供的实时阅读数据就非常有价值了。另外,小野公众号给出的数据在微信后台可以实时查看,而且还能自定义喜欢、厌恶类别,这样直接匹配粉丝对某一领域的喜好!关于小野公众号的更多更细节的规划信息,请戳这里:【小野杰西】公众号介绍及运营方案。 查看全部
实时文章采集的一个思路解决办法:分两种情况
实时文章采集的一个思路解决办法:分两种情况:一是点击某篇实时更新的文章链接,然后在公众号第一时间进行对应的内容下载,然后进行编辑,发布。第二种情况,如果题目需要以实时为关键词搜索,可以给一个上下文,找到文章原文链接,然后分析关键词的出现概率,进行简单归类。
我是题主提问时间是:12/28.详细方法是:①复制新浪新闻的链接地址(请忽略新浪微博头像上的图片)②输入百度地图网址,
我想知道:如何关联到其他公众号。
推荐小野杰西的公众号。可以实现实时个性化推送,包括推送到其他微信公众号。说到微信公众号,那要说的是微信公众号的一个普遍缺点,不易统计的同时粉丝的活跃度数据也缺乏统计,这个时候小野提供的实时阅读数据就非常有价值了。另外,小野公众号给出的数据在微信后台可以实时查看,而且还能自定义喜欢、厌恶类别,这样直接匹配粉丝对某一领域的喜好!关于小野公众号的更多更细节的规划信息,请戳这里:【小野杰西】公众号介绍及运营方案。
做好app推广不管你用什么方法,不适合自己推广
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-05-21 18:02
实时文章采集,原始可实时搜索快速定位并发互动,引爆浏览历史文章搜索排名预览,
app推广自然有很多方法,博客,论坛,朋友圈等等方法。但很多方法其实可能并不可行,也并不适合自己推广。一般做好app推广之后首先要分析和测试自己的产品到底是哪些方面出了问题,然后解决好这些问题,基本上就可以了。更详细的介绍的话就要交给专业的公司来做了。
做app推广不管你用什么方法,首先要根据app现在的热度和搜索量选对关键词,然后选好app的位置,布局在那些关键词下,这样就可以让更多的潜在用户知道你,主动要求安装体验,那你的推广会更好,更有效果。
如果你现在已经在app推广行业工作已经比较久了的话,经验肯定相对比较丰富,不用再过多的担心太多,你说到的方法大多都是为了推广app所准备的。关于app推广,下面分享一下我们公司这几年的经验。你也可以当做一个参考,最后还是得看个人的执行力以及市场方面的资源。
一、分析市场趋势,准确定位适合自己的推广目标其实是很重要的一个环节,当然除了推广目标要准确,我们定位app也需要很好的方法,给自己app准确的定位是找到方向很重要的一环,这个时候我们需要查看相关app推广数据,借助appannie,mavendata.找到他们的demo或者是分析自己app数据后期分析自己app的存在的问题。
至于这个怎么查看app的demo以及分析好自己app数据的不好最好appstoreapp榜单排名数据都有,看到哪里有负面评论就把负面评论消灭,多多吸取正面评论。
二、整理app推广常见问题以及大致的思路推广三步骤中的第一步app分析一般是必不可少的。这一步我们可以直接联系上一步的靠谱渠道获取app的数据进行分析,包括排名,下载量,当用户的总量和下载量都差不多稳定了的时候可以测试渠道获取新的增量。没有渠道也没有关系,那就实地考察,访谈下用户,从多个角度去了解用户是什么特点,哪些用户最喜欢用你们产品,适合哪些人使用,了解到这些之后要整理出用户画像。
了解的这些数据后分析出app属于哪个渠道的,渠道消耗多少用户,然后在该渠道进行测试,总体来说就是需要对不同的渠道需要侧重的方向是不一样的。如果有需要我推荐app品牌推广的渠道,可以私信我哈。
三、针对渠道收集数据并针对性优化从分析问题到最后优化,在这个过程中我们需要收集收集不同渠道的数据,这些渠道包括app的调研,评论文章,排名,分发量,下载量,其他人员的评论,用户的评论,注册用户,活跃用户等等, 查看全部
做好app推广不管你用什么方法,不适合自己推广
实时文章采集,原始可实时搜索快速定位并发互动,引爆浏览历史文章搜索排名预览,
app推广自然有很多方法,博客,论坛,朋友圈等等方法。但很多方法其实可能并不可行,也并不适合自己推广。一般做好app推广之后首先要分析和测试自己的产品到底是哪些方面出了问题,然后解决好这些问题,基本上就可以了。更详细的介绍的话就要交给专业的公司来做了。
做app推广不管你用什么方法,首先要根据app现在的热度和搜索量选对关键词,然后选好app的位置,布局在那些关键词下,这样就可以让更多的潜在用户知道你,主动要求安装体验,那你的推广会更好,更有效果。
如果你现在已经在app推广行业工作已经比较久了的话,经验肯定相对比较丰富,不用再过多的担心太多,你说到的方法大多都是为了推广app所准备的。关于app推广,下面分享一下我们公司这几年的经验。你也可以当做一个参考,最后还是得看个人的执行力以及市场方面的资源。
一、分析市场趋势,准确定位适合自己的推广目标其实是很重要的一个环节,当然除了推广目标要准确,我们定位app也需要很好的方法,给自己app准确的定位是找到方向很重要的一环,这个时候我们需要查看相关app推广数据,借助appannie,mavendata.找到他们的demo或者是分析自己app数据后期分析自己app的存在的问题。
至于这个怎么查看app的demo以及分析好自己app数据的不好最好appstoreapp榜单排名数据都有,看到哪里有负面评论就把负面评论消灭,多多吸取正面评论。
二、整理app推广常见问题以及大致的思路推广三步骤中的第一步app分析一般是必不可少的。这一步我们可以直接联系上一步的靠谱渠道获取app的数据进行分析,包括排名,下载量,当用户的总量和下载量都差不多稳定了的时候可以测试渠道获取新的增量。没有渠道也没有关系,那就实地考察,访谈下用户,从多个角度去了解用户是什么特点,哪些用户最喜欢用你们产品,适合哪些人使用,了解到这些之后要整理出用户画像。
了解的这些数据后分析出app属于哪个渠道的,渠道消耗多少用户,然后在该渠道进行测试,总体来说就是需要对不同的渠道需要侧重的方向是不一样的。如果有需要我推荐app品牌推广的渠道,可以私信我哈。
三、针对渠道收集数据并针对性优化从分析问题到最后优化,在这个过程中我们需要收集收集不同渠道的数据,这些渠道包括app的调研,评论文章,排名,分发量,下载量,其他人员的评论,用户的评论,注册用户,活跃用户等等,
实时文章采集allinoneexcel的功能实现很简单也很完善
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-19 07:01
实时文章采集
allinone对于新手比较友好,功能实现很简单也很完善,对于你所说的excel的功能它都有的。给一个。
目前在用的是excel2010版本,无法导入everything,只能手动找到date12或date20所在列,如果想要导入这些列,再通过搜索引擎搜索,是需要花很长时间的,通过联想和图表能够很快找到。
艾略特搜索引擎需要注册一下账号才可以搜索。
感觉对搜索的效率要求比较高,推荐使用金数据,微信公众号也可以收到相关内容,支持导出excel表格,支持多个目录、多条件组合搜索,功能比较齐全,
sogou的韦伯搜索
易搜云导入数据导出数据速度都不错
北极星官网在,类似问题的解决方案,贴出来分享一下。
网易公开课有很多相关的课程,你可以去看看。
windows系统有everything里面有很多高效的文件夹搜索引擎也有很多用excel读取的搜索引擎也有很多看你自己更喜欢哪种吧
数据挖掘就用ai吧,你现在学编程可能还有点早,建议买本书开始学。
谢邀!推荐两个简单方便速度快的。1、第一种方式为“步骤搜索”,它会给出你目标的步骤、关键词及背景(含义、相关性、延伸含义),再匹配上其他相关的步骤和关键词,就能定位到想要的数据。2、第二种方式为深度学习中的“快速特征提取”,利用人工特征方法,通过深度学习网络模型,能快速找到与训练数据相关的每一条观测数据,再匹配上前后的特征,就能找到目标数据的集合了。 查看全部
实时文章采集allinoneexcel的功能实现很简单也很完善
实时文章采集
allinone对于新手比较友好,功能实现很简单也很完善,对于你所说的excel的功能它都有的。给一个。
目前在用的是excel2010版本,无法导入everything,只能手动找到date12或date20所在列,如果想要导入这些列,再通过搜索引擎搜索,是需要花很长时间的,通过联想和图表能够很快找到。
艾略特搜索引擎需要注册一下账号才可以搜索。
感觉对搜索的效率要求比较高,推荐使用金数据,微信公众号也可以收到相关内容,支持导出excel表格,支持多个目录、多条件组合搜索,功能比较齐全,
sogou的韦伯搜索
易搜云导入数据导出数据速度都不错
北极星官网在,类似问题的解决方案,贴出来分享一下。
网易公开课有很多相关的课程,你可以去看看。
windows系统有everything里面有很多高效的文件夹搜索引擎也有很多用excel读取的搜索引擎也有很多看你自己更喜欢哪种吧
数据挖掘就用ai吧,你现在学编程可能还有点早,建议买本书开始学。
谢邀!推荐两个简单方便速度快的。1、第一种方式为“步骤搜索”,它会给出你目标的步骤、关键词及背景(含义、相关性、延伸含义),再匹配上其他相关的步骤和关键词,就能定位到想要的数据。2、第二种方式为深度学习中的“快速特征提取”,利用人工特征方法,通过深度学习网络模型,能快速找到与训练数据相关的每一条观测数据,再匹配上前后的特征,就能找到目标数据的集合了。
自媒体文章发布齐全的采集平台之拓途网易网
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-05-17 05:16
自媒体 文章版本通常需要依赖采集平台进行评估,因此文章的采集平台选择也非常重要,让我们按照Tuotu数据来了解自媒体 文章发布有关采集平台的完整信息。
自媒体 文章发布完整的采集平台Tutu数据
Tuotu数据可提供准确的官方帐户相关数据,为官方帐户运营商提供有竞争力的产品分析服务,并为官方帐户广告提供官方帐户质量监控服务。
1、分析中包括超过2000万个正式帐户。
2、判断官方帐户是否有价值的最直观的方法是计算文章的阅读次数和喜欢次数。用肉眼比较文章是费时,费力和原创的。
3、 Tuotu可以分析无限量的数据并执行透视图,免费将其下载到Excel中,筛选高质量的正式帐户,并进行有竞争力的产品分析。
自媒体 文章发布了完整的采集平台
自媒体 文章发布了完整的 采集平台
是用于创建自媒体操作内容的辅助工具,它具有完整的功能,准确的数据并且非常实用。这里是其主要功能模块的简要介绍:
1、 自媒体库和爆文分析,这两个模块可以根据筛选要求爆文快速采集并获得每个平台的实时热点。
2、视频库:您可以根据不同的过滤条件在各个字段中获取热门视频。视频也可以批量下载采集,这是一个很好的视频资料库。
3、主题库:收录主要自媒体平台上的热门讨论主题,并且可以快速掌握热门主题并参与内容讨论。
4、小工具:收录许多非常有用的小功能,例如爆文标题自动生成,文章 原创程度检测,文本内容转换,单个视频下载等。
5、官方帐户模块:此部分收录微信官方帐户编辑器,公共数据和官方帐户列表。 文章编辑和排版后,也可以一键将其同步到官方帐户。
6、工作台:这是一个工具集合模块,包括视频批处理下载,图像和视频批处理水印工具等。
自媒体 文章发布了完整的采集平台的乐观帐户
乐观主义也是自媒体保温采集平台,其基本功能更加全面。
此工具具有以下功能
1、标题大师:我只能推荐一些爆文标题
2、热点跟踪:结合微博热点搜索列表和百度风云列表来采集热点。
3、 100,000 爆文:您可以根据需要组织,学习并整合到自己的资料中。
4、排版和材料:提供文章编辑和排版功能。
自媒体 文章发布了完整的采集平台
自媒体 文章发布了完整的采集平台新媒体管理员
New Media Manager是一个集成文章编辑,排版,操作和转换收入的平台。主要功能包括:
1、样式中心:收录从标题到图片和文本的各种模板。 查看全部
自媒体文章发布齐全的采集平台之拓途网易网
自媒体 文章版本通常需要依赖采集平台进行评估,因此文章的采集平台选择也非常重要,让我们按照Tuotu数据来了解自媒体 文章发布有关采集平台的完整信息。
自媒体 文章发布完整的采集平台Tutu数据
Tuotu数据可提供准确的官方帐户相关数据,为官方帐户运营商提供有竞争力的产品分析服务,并为官方帐户广告提供官方帐户质量监控服务。
1、分析中包括超过2000万个正式帐户。
2、判断官方帐户是否有价值的最直观的方法是计算文章的阅读次数和喜欢次数。用肉眼比较文章是费时,费力和原创的。
3、 Tuotu可以分析无限量的数据并执行透视图,免费将其下载到Excel中,筛选高质量的正式帐户,并进行有竞争力的产品分析。

自媒体 文章发布了完整的采集平台
自媒体 文章发布了完整的 采集平台
是用于创建自媒体操作内容的辅助工具,它具有完整的功能,准确的数据并且非常实用。这里是其主要功能模块的简要介绍:
1、 自媒体库和爆文分析,这两个模块可以根据筛选要求爆文快速采集并获得每个平台的实时热点。
2、视频库:您可以根据不同的过滤条件在各个字段中获取热门视频。视频也可以批量下载采集,这是一个很好的视频资料库。
3、主题库:收录主要自媒体平台上的热门讨论主题,并且可以快速掌握热门主题并参与内容讨论。
4、小工具:收录许多非常有用的小功能,例如爆文标题自动生成,文章 原创程度检测,文本内容转换,单个视频下载等。
5、官方帐户模块:此部分收录微信官方帐户编辑器,公共数据和官方帐户列表。 文章编辑和排版后,也可以一键将其同步到官方帐户。
6、工作台:这是一个工具集合模块,包括视频批处理下载,图像和视频批处理水印工具等。
自媒体 文章发布了完整的采集平台的乐观帐户
乐观主义也是自媒体保温采集平台,其基本功能更加全面。
此工具具有以下功能
1、标题大师:我只能推荐一些爆文标题
2、热点跟踪:结合微博热点搜索列表和百度风云列表来采集热点。
3、 100,000 爆文:您可以根据需要组织,学习并整合到自己的资料中。
4、排版和材料:提供文章编辑和排版功能。

自媒体 文章发布了完整的采集平台
自媒体 文章发布了完整的采集平台新媒体管理员
New Media Manager是一个集成文章编辑,排版,操作和转换收入的平台。主要功能包括:
1、样式中心:收录从标题到图片和文本的各种模板。
钉钉前端团队如何打造亿级流量的监控系统?
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-05-16 00:30
前言
这篇文章是从2020年4月25日开始,前端会谈第五次“前端监控”特别分享嘉宾-鼎鼎前端团队监控负责人,slashhuang的分享记录“鼎鼎前端如何设计前端实时分析和报警系统”。
开始输入文字
大家好,我是丁顶的蜡烛象,今天的主题是“丁顶前端团队如何构建1亿流量的监控系统”。
简介
首先,让我给您一个个人介绍。我于2013年毕业,并于2017年加入鼎鼎。加入鼎鼎时,我是P6。然后,通过前端监视,一些模块化代码包,效率和其他工具,我成功地获得了一些晋升机会。
关于鼎鼎的前端
自从2014年底成立以来,鼎鼎发展非常迅速,鼎鼎的前端监控也在不断发展。我们有数亿用户和数千万企业用户。前端产品包括Android,iOS,桌面,小程序,H5等,并且前端应用程序的发布还涵盖了完整版本和灰度版本。
十亿流量的挑战
对于这样一个十亿级别的平台,除了前端监视系统外,我相信许多小伙伴也有身体的感觉。为了确保整个DingTalk前端的稳定性,需要一些技术操作方法,包括某些人的条件。 。现在我们总共有100多个前端开发成员,我们的技术模块包括IM,地址簿,直播,教育,文档,硬件等,它们具有非常B-end的属性。
成就
让我首先谈谈我们的结果:100%涵盖了我们今天所有的h5和小型程序,并支持100多名前端人员的监视需求。前端监控的日志数量已达数百亿,被监控的市场数量超过100个。它可以实现一分钟感知在线问题和一分钟模糊问题的定位。在人力投资方面,它始终由两个负责人负责。在大多数情况下,我是负责整体监控情况的唯一负责人。因此,在人力投资方面,我们的成本相对较低。
上图中的两个趋势图是我们监视的主要产品结构。一个是我们的监视趋势图,另一个是我们用于承载各种业务的业务文件夹。同时,我们有一个生产环境的统一小程序,H5监控市场。
发展之路
接下来,我将讨论DingTalk的前端监视,我们如何开发系统并取得良好的结果。
考虑到很多朋友没有从事前端监视,我将首先讨论一些基本知识,以开发如何设计前端监视系统。
让我们看一下上面的代码,const创建一个对象,然后选择foot.a.b = c。您可以看到这是一段非常经典的NPE代码,这是一个空点异常,很容易出现在前端代码中。将在此处引发错误:**未捕获的TypeError:无法设置未定义的属性'b'**。
对于这样的错误,我们的前端监视系统如何在用户端发生此错误后捕获该错误,并在一分钟内找到它?让我们看一下传统方法是如何完成的:
我在这里的演示是使用image标签创建一个image标签并将其src设置为指向相应的日志服务器以发送相应的日志。
我们使用window.onerror捕获错误采集中的全局错误。然后,通过创建图像标签将捕获的错误发送到上图右侧的前端监视服务器。
上面的代码只是一个伪代码演示,我写的比较简单。
对于基于日志分析的传统监视系统,您必须首先知道日志的来源,因此,当每个日志位于前端时,我们都有一个应用程序ID 采集。让我尝试一下。将其命名为spmId,使用spmId标识日志源,然后将此日志存储到相应的监视服务器,从而完成一个非常简单的前后链接。
从日志出现采集,然后到闭环存储,这非常简单。实际上,在看到“ Weizhishu”之后,看到了这样一个简单的实现,然后丰富了日志类型,采集和存储功能更加强大,基本上,您可以构建一个相对简单的前端监视系统。
通常来说,一个简单的前端监视和分析系统需要包括以下三个维度:
在监视平台中,我们需要做一些日志存储,将监视日志提供给可视化平台服务器,并通过提供一些API服务来绘制上图。例如,第一个是接口成功率。
我认为在技术选择方面,对于许多只有一点节点或服务器端基础的前端学生来说,基本上可以制作一个简单的演示。但是,在看似功能齐全的系统中,前端监视是否存在任何问题?它可以满足具有数十亿流量的平台DingTalk的监视需求吗?
上图的左侧显示了开发人员访问前端监视的过程,包括开发阶段,测试阶段和在线阶段。在实施前端监视期间,我们要求所有开发人员在迭代启动该应用程序后至少30分钟内积极观察监视市场,并观察三个指标:
js errorperformanceapi成功率
对于我们目前由100多名前端同学组成的团队,人工成本是30分钟的100倍。同时,对于企业级产品DingTalk,我们对在线稳定性有很高的要求。在线故障的容忍度极低,因此需要对在线应用程序进行日常检查,因此人工成本很高。
从开发人员的经验来看,当开发人员检查监视时:首先,他将转到可视化分析平台以查看是否有任何错误日志。这里有一个非常重要的意义,就是我们的监视和分析平台看到的日志是“前端页面”的日志吗?
不一定。为什么?因为对于用户来说,这不只是打开前端页面,在此前端页面后面还有容器Web视图,应用程序容器,运算符等。
例如,我们的其中一个页面可以在微信,头条和丁顶的容器中打开。因此,您的采集日志源不仅是前端页面,而且还是容器Web视图。同时,我们将面对许多运营商。例如,我们经常在首页上看到一个广告,然后我们还有一些手机制造商,例如vivo,华为等,也将相关脚本插入到我们的页面中。因此,来自监视分析平台采集的日志不仅是前端日志,而且其采集的范围实际上是与前端页面相对应的用户终端日志。
通常,我们会遇到以下三种类型的干扰日志:
例如,以上是我们的在线应用之一,而js错误率可能是0. 08%。对于像丁丁这样的卷,此错误率会影响已经非常大的用户数量。
让我们看看相应的错误实际上是什么?脚本错误,未定义WeixinJSBridge,未定义toutiaoJSBridge,20 vivoNewsDetailPage,这些内容基本上可以从错误消息中判断出来,与业务错误无关。
因此,我们可以得出第一个结论,即前端监视所产生的某些错误与业务无关。这可能与许多人的看法相反。
让我们再看一个问题。左图是我们桌面的释放曲线。 DingTalk是中国乃至全球为数不多的桌面级平台之一。 DingTalk桌面基本上是一个星期或两个星期的迭代。由于桌面的前端代码采用脱机软件包的形式,因此更新和修复代码都很困难,并且对前端稳定性的要求很高。
对于我们今天的桌面终端,已经有100多个在线版本。许多版本报告的日志使用相同的应用程序ID。我们如何进行分层监控和在线流量监控?如何对不均匀性进行分层监控,以免被低流量释放监控所淹没?
这些问题在DingTalk业务场景中经常遇到。我们的监视粒度需要适应前端版本,并且受监视的日志需要支持更多维度。例如,以这两个变量为单位监视应用程序和发行版本。
让我们看看另一种情况。鼎鼎有数百个前端应用程序。每个应用程序都会报警一次,这非常夸张。基本上,每天在警报组中有500多个日志。屏幕刷新现象非常严重,并且有很多错误。这是一条长尾错误。也就是说,尽管它具有警报,但不需要进行修改等等。出现长尾错误的原因是,尽管我已解决问题,但用户可能无法完全访问最新版本。
因此,结论3是我们的监控操作的人工成本非常高。前端监视的要求不仅要报告警报,还需要您的警报既直观又实时,并支持一些短期关闭和错误。过滤等。
在阅读了上述三种情况后,让我们看一下如何设计可服务3亿卷的监视系统。
首先,我们首先定义监视设计的目标,并确定企业级前端监视需要完成的工作:一分钟感知,五分钟定位和十分钟恢复。我们将此监视系统称为2. 0系统。
对于前端监控2. 0,我们在1. 0的基础上定义了以下功能级别。
第一个是保持与实际业务的距离,降低人工成本,并使业务各方以较低的成本进行干预。同时,对于警报系统,需要快速警报和准警报,并且支持自定义警报。我们在内部设置了基线,即前端监视精度必须达到90%以上,每个人的人工成本必须减少20分钟,并且警报和市场必须能够支持自定义配置。
上图是整体监视组件的布置方案。左侧是图例。蓝色部分代表1. 0的监视部分,深绿色部分代表2. 0的新监视部分。
自定义采集
第一个在日志采集端,除了采集常规业务数据和监控数据外,它还支持自定义采集。
智能分析
分析智能增加了自定义分析的能力。
实时警报
在实时警报方面,已添加了在线1分钟警报和5分钟本地化要求。
最关键的技术实现
同样,蓝色部分是原创1. 0的系统,深绿色部分是我们的新系统。我们会发现在日志采集和日志使用者方面,我们添加了一个名为“日志双重写入”的模块。
一个日志由两个系统消耗,一个系统用于实时警报,另一个系统用于分析:
许多学生认为日志双写实际上是对非常大的系统的浪费。一个日志由两个系统消耗。实际上,DingTalk前端监视使用的是阿里非常成熟的日志使用系统和基础架构。通过日志分配快速消耗了两个通道,使分钟计算系统在整个监控系统中的布置处于前端,满足了1分钟报警的要求,这是我们在这一领域的核心技术思想。
上图中紫色虚线下方是我们的用户角度。用户触摸了两部分。第一部分是前端监视SDK,我们有H5和applet SDK,第二部分是平台,包括分析平台和警报平台。
真实案例
让我们看一个真实的案例。用户遇到了两个js错误。这两个js错误是前端的经典NPE错误。
第一次发生在iPad +百度浏览器上。第二个发生在Android +标题网页视图中。结果,我们会发现客户报告了两种错误:
实际错误:未被捕获的TypeError:无法设置未定义的属性'b'。主机注入了很多干扰信息,例如百度浏览器将注入未定义的MyAppHrefLink。
也许很多学生没有观察到它。我们仔细检查了一下。百度浏览器会注入未定义的MyAppHrefLink。标题还将注入一些标题jsBridge。
日志到达服务器后,我们首先清理日志以过滤出主机的所有干扰日志,以确保我们的警报系统是消费者实际业务的日志错误。这是黄色区域中的第一个模块:日志清理
接下来,我们将对日志进行分组,将应用程序A的日志spmId = A和应用程序B进行分组,并对应用程序ID A和B的日志进行分组。对过滤后的日志进行实时计算。
在此步骤之后,日志流将被传输到警报索引项以进行实时计算。警报规则引擎将向与Map Reduce相对应的机器发出相关指令,以进行一些处理。
例如,JS错误失败率= JS错误日志数除以PV数。当日志的计算结果大于6%时,将发出“叮叮”组警报;当故障率大于15%时,将发出SMS警报。
叮叮前端监控2. 0
监控日志
通过对api成功率,js错误失败率,pv数据等各种指标应用相同的过程,我们可以构建一个在分钟计算系统中满足1分钟感知的监控系统。
警报系统架构
关于警报系统,上图是我们阿里巴巴研发部门的非常经典的监视系统。有兴趣的学生可以在infoQ上搜索sunfire,以查看有关该体系结构的更详细的介绍。我在这里不会做太多事情。
总体日志结构摘要
基本上,这就是我今天要分享的内容。从1. 0演变为2. 0的过程中,DingTalk前端监控是我们的思维方式和着陆方式。在这里,我会给您一个简短的摘要:
最关键的技术思想是预先安排日志警报组件。我们的实现是将日志双重写入分析系统和警报系统。在警报平台中,支持警报规则引擎,因此可以自定义警报,并对警报进行分级。对于前端,我们不仅是前端页面,我们还面临着用户终端。结束语
好的,这就是我今天要分享的内容。 DingTalk的前端监控如何以1亿规模,100多个前端和600多个前端页面来增强DingTalk的在线稳定性。
以下是DingTalk前端的技术专栏。有知乎列和掘金列。我们一直在招聘人才。欢迎与我联系。 查看全部
钉钉前端团队如何打造亿级流量的监控系统?
前言
这篇文章是从2020年4月25日开始,前端会谈第五次“前端监控”特别分享嘉宾-鼎鼎前端团队监控负责人,slashhuang的分享记录“鼎鼎前端如何设计前端实时分析和报警系统”。
开始输入文字
大家好,我是丁顶的蜡烛象,今天的主题是“丁顶前端团队如何构建1亿流量的监控系统”。
简介
首先,让我给您一个个人介绍。我于2013年毕业,并于2017年加入鼎鼎。加入鼎鼎时,我是P6。然后,通过前端监视,一些模块化代码包,效率和其他工具,我成功地获得了一些晋升机会。
关于鼎鼎的前端
自从2014年底成立以来,鼎鼎发展非常迅速,鼎鼎的前端监控也在不断发展。我们有数亿用户和数千万企业用户。前端产品包括Android,iOS,桌面,小程序,H5等,并且前端应用程序的发布还涵盖了完整版本和灰度版本。
十亿流量的挑战
对于这样一个十亿级别的平台,除了前端监视系统外,我相信许多小伙伴也有身体的感觉。为了确保整个DingTalk前端的稳定性,需要一些技术操作方法,包括某些人的条件。 。现在我们总共有100多个前端开发成员,我们的技术模块包括IM,地址簿,直播,教育,文档,硬件等,它们具有非常B-end的属性。
成就
让我首先谈谈我们的结果:100%涵盖了我们今天所有的h5和小型程序,并支持100多名前端人员的监视需求。前端监控的日志数量已达数百亿,被监控的市场数量超过100个。它可以实现一分钟感知在线问题和一分钟模糊问题的定位。在人力投资方面,它始终由两个负责人负责。在大多数情况下,我是负责整体监控情况的唯一负责人。因此,在人力投资方面,我们的成本相对较低。
上图中的两个趋势图是我们监视的主要产品结构。一个是我们的监视趋势图,另一个是我们用于承载各种业务的业务文件夹。同时,我们有一个生产环境的统一小程序,H5监控市场。
发展之路
接下来,我将讨论DingTalk的前端监视,我们如何开发系统并取得良好的结果。
考虑到很多朋友没有从事前端监视,我将首先讨论一些基本知识,以开发如何设计前端监视系统。
让我们看一下上面的代码,const创建一个对象,然后选择foot.a.b = c。您可以看到这是一段非常经典的NPE代码,这是一个空点异常,很容易出现在前端代码中。将在此处引发错误:**未捕获的TypeError:无法设置未定义的属性'b'**。
对于这样的错误,我们的前端监视系统如何在用户端发生此错误后捕获该错误,并在一分钟内找到它?让我们看一下传统方法是如何完成的:
我在这里的演示是使用image标签创建一个image标签并将其src设置为指向相应的日志服务器以发送相应的日志。
我们使用window.onerror捕获错误采集中的全局错误。然后,通过创建图像标签将捕获的错误发送到上图右侧的前端监视服务器。
上面的代码只是一个伪代码演示,我写的比较简单。
对于基于日志分析的传统监视系统,您必须首先知道日志的来源,因此,当每个日志位于前端时,我们都有一个应用程序ID 采集。让我尝试一下。将其命名为spmId,使用spmId标识日志源,然后将此日志存储到相应的监视服务器,从而完成一个非常简单的前后链接。
从日志出现采集,然后到闭环存储,这非常简单。实际上,在看到“ Weizhishu”之后,看到了这样一个简单的实现,然后丰富了日志类型,采集和存储功能更加强大,基本上,您可以构建一个相对简单的前端监视系统。
通常来说,一个简单的前端监视和分析系统需要包括以下三个维度:
在监视平台中,我们需要做一些日志存储,将监视日志提供给可视化平台服务器,并通过提供一些API服务来绘制上图。例如,第一个是接口成功率。
我认为在技术选择方面,对于许多只有一点节点或服务器端基础的前端学生来说,基本上可以制作一个简单的演示。但是,在看似功能齐全的系统中,前端监视是否存在任何问题?它可以满足具有数十亿流量的平台DingTalk的监视需求吗?
上图的左侧显示了开发人员访问前端监视的过程,包括开发阶段,测试阶段和在线阶段。在实施前端监视期间,我们要求所有开发人员在迭代启动该应用程序后至少30分钟内积极观察监视市场,并观察三个指标:
js errorperformanceapi成功率
对于我们目前由100多名前端同学组成的团队,人工成本是30分钟的100倍。同时,对于企业级产品DingTalk,我们对在线稳定性有很高的要求。在线故障的容忍度极低,因此需要对在线应用程序进行日常检查,因此人工成本很高。
从开发人员的经验来看,当开发人员检查监视时:首先,他将转到可视化分析平台以查看是否有任何错误日志。这里有一个非常重要的意义,就是我们的监视和分析平台看到的日志是“前端页面”的日志吗?
不一定。为什么?因为对于用户来说,这不只是打开前端页面,在此前端页面后面还有容器Web视图,应用程序容器,运算符等。
例如,我们的其中一个页面可以在微信,头条和丁顶的容器中打开。因此,您的采集日志源不仅是前端页面,而且还是容器Web视图。同时,我们将面对许多运营商。例如,我们经常在首页上看到一个广告,然后我们还有一些手机制造商,例如vivo,华为等,也将相关脚本插入到我们的页面中。因此,来自监视分析平台采集的日志不仅是前端日志,而且其采集的范围实际上是与前端页面相对应的用户终端日志。
通常,我们会遇到以下三种类型的干扰日志:
例如,以上是我们的在线应用之一,而js错误率可能是0. 08%。对于像丁丁这样的卷,此错误率会影响已经非常大的用户数量。
让我们看看相应的错误实际上是什么?脚本错误,未定义WeixinJSBridge,未定义toutiaoJSBridge,20 vivoNewsDetailPage,这些内容基本上可以从错误消息中判断出来,与业务错误无关。
因此,我们可以得出第一个结论,即前端监视所产生的某些错误与业务无关。这可能与许多人的看法相反。
让我们再看一个问题。左图是我们桌面的释放曲线。 DingTalk是中国乃至全球为数不多的桌面级平台之一。 DingTalk桌面基本上是一个星期或两个星期的迭代。由于桌面的前端代码采用脱机软件包的形式,因此更新和修复代码都很困难,并且对前端稳定性的要求很高。
对于我们今天的桌面终端,已经有100多个在线版本。许多版本报告的日志使用相同的应用程序ID。我们如何进行分层监控和在线流量监控?如何对不均匀性进行分层监控,以免被低流量释放监控所淹没?
这些问题在DingTalk业务场景中经常遇到。我们的监视粒度需要适应前端版本,并且受监视的日志需要支持更多维度。例如,以这两个变量为单位监视应用程序和发行版本。
让我们看看另一种情况。鼎鼎有数百个前端应用程序。每个应用程序都会报警一次,这非常夸张。基本上,每天在警报组中有500多个日志。屏幕刷新现象非常严重,并且有很多错误。这是一条长尾错误。也就是说,尽管它具有警报,但不需要进行修改等等。出现长尾错误的原因是,尽管我已解决问题,但用户可能无法完全访问最新版本。
因此,结论3是我们的监控操作的人工成本非常高。前端监视的要求不仅要报告警报,还需要您的警报既直观又实时,并支持一些短期关闭和错误。过滤等。
在阅读了上述三种情况后,让我们看一下如何设计可服务3亿卷的监视系统。
首先,我们首先定义监视设计的目标,并确定企业级前端监视需要完成的工作:一分钟感知,五分钟定位和十分钟恢复。我们将此监视系统称为2. 0系统。
对于前端监控2. 0,我们在1. 0的基础上定义了以下功能级别。
第一个是保持与实际业务的距离,降低人工成本,并使业务各方以较低的成本进行干预。同时,对于警报系统,需要快速警报和准警报,并且支持自定义警报。我们在内部设置了基线,即前端监视精度必须达到90%以上,每个人的人工成本必须减少20分钟,并且警报和市场必须能够支持自定义配置。
上图是整体监视组件的布置方案。左侧是图例。蓝色部分代表1. 0的监视部分,深绿色部分代表2. 0的新监视部分。
自定义采集
第一个在日志采集端,除了采集常规业务数据和监控数据外,它还支持自定义采集。
智能分析
分析智能增加了自定义分析的能力。
实时警报
在实时警报方面,已添加了在线1分钟警报和5分钟本地化要求。
最关键的技术实现
同样,蓝色部分是原创1. 0的系统,深绿色部分是我们的新系统。我们会发现在日志采集和日志使用者方面,我们添加了一个名为“日志双重写入”的模块。
一个日志由两个系统消耗,一个系统用于实时警报,另一个系统用于分析:
许多学生认为日志双写实际上是对非常大的系统的浪费。一个日志由两个系统消耗。实际上,DingTalk前端监视使用的是阿里非常成熟的日志使用系统和基础架构。通过日志分配快速消耗了两个通道,使分钟计算系统在整个监控系统中的布置处于前端,满足了1分钟报警的要求,这是我们在这一领域的核心技术思想。
上图中紫色虚线下方是我们的用户角度。用户触摸了两部分。第一部分是前端监视SDK,我们有H5和applet SDK,第二部分是平台,包括分析平台和警报平台。
真实案例
让我们看一个真实的案例。用户遇到了两个js错误。这两个js错误是前端的经典NPE错误。
第一次发生在iPad +百度浏览器上。第二个发生在Android +标题网页视图中。结果,我们会发现客户报告了两种错误:
实际错误:未被捕获的TypeError:无法设置未定义的属性'b'。主机注入了很多干扰信息,例如百度浏览器将注入未定义的MyAppHrefLink。
也许很多学生没有观察到它。我们仔细检查了一下。百度浏览器会注入未定义的MyAppHrefLink。标题还将注入一些标题jsBridge。
日志到达服务器后,我们首先清理日志以过滤出主机的所有干扰日志,以确保我们的警报系统是消费者实际业务的日志错误。这是黄色区域中的第一个模块:日志清理
接下来,我们将对日志进行分组,将应用程序A的日志spmId = A和应用程序B进行分组,并对应用程序ID A和B的日志进行分组。对过滤后的日志进行实时计算。
在此步骤之后,日志流将被传输到警报索引项以进行实时计算。警报规则引擎将向与Map Reduce相对应的机器发出相关指令,以进行一些处理。
例如,JS错误失败率= JS错误日志数除以PV数。当日志的计算结果大于6%时,将发出“叮叮”组警报;当故障率大于15%时,将发出SMS警报。
叮叮前端监控2. 0
监控日志
通过对api成功率,js错误失败率,pv数据等各种指标应用相同的过程,我们可以构建一个在分钟计算系统中满足1分钟感知的监控系统。
警报系统架构
关于警报系统,上图是我们阿里巴巴研发部门的非常经典的监视系统。有兴趣的学生可以在infoQ上搜索sunfire,以查看有关该体系结构的更详细的介绍。我在这里不会做太多事情。
总体日志结构摘要
基本上,这就是我今天要分享的内容。从1. 0演变为2. 0的过程中,DingTalk前端监控是我们的思维方式和着陆方式。在这里,我会给您一个简短的摘要:
最关键的技术思想是预先安排日志警报组件。我们的实现是将日志双重写入分析系统和警报系统。在警报平台中,支持警报规则引擎,因此可以自定义警报,并对警报进行分级。对于前端,我们不仅是前端页面,我们还面临着用户终端。结束语
好的,这就是我今天要分享的内容。 DingTalk的前端监控如何以1亿规模,100多个前端和600多个前端页面来增强DingTalk的在线稳定性。
以下是DingTalk前端的技术专栏。有知乎列和掘金列。我们一直在招聘人才。欢迎与我联系。
python实现基于mongodb的数据库-gracefulthink博客python的json
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-07-29 23:15
实时文章采集本地实时就可以完成了,没有网络采集了就用web抓包工具抓取吧实时文章采集就是抓取文章来源地址,大多需要写爬虫,用python来操作网页的源代码就行当然,也有用java来写,python和java都可以抓取文章!不过python相对更简单易学,而且比较灵活,相对抓取成功率更高网上有大量的相关内容,可以搜一下,我做这个不是为了把它变成python插件,而是基于telegram平台的librem来实现实时文章采集。后端,实时文章采集对后端的要求不高,主要是使用librem抓取网页就行。
其实我觉得难点主要在于viplive。
我倒是觉得不是很难,用通俗易懂的话说吧,抓取实时信息,不再是机器浏览网页,而是在电脑和手机里通过屏幕采集,让机器无需下载浏览器,直接可以实现抓取和定位。
用.net架个框架,
尝试过用v6解析图片得到json然后转php然后再放到php页面上模拟浏览器访问来抓取,我觉得这种抓取方式的性能下降非常严重,
python实现基于mongodb的数据库抓取-gracefulthink的博客-csdn博客
python的json也是有markdown解析器的:;toc=true
使用框架
可以从html+xml+json得到xml文件,然后在mongo数据库或者自己的数据库下获取。主要是tags,规则都写死在json里面了。你还可以用xpath。 查看全部
python实现基于mongodb的数据库-gracefulthink博客python的json
实时文章采集本地实时就可以完成了,没有网络采集了就用web抓包工具抓取吧实时文章采集就是抓取文章来源地址,大多需要写爬虫,用python来操作网页的源代码就行当然,也有用java来写,python和java都可以抓取文章!不过python相对更简单易学,而且比较灵活,相对抓取成功率更高网上有大量的相关内容,可以搜一下,我做这个不是为了把它变成python插件,而是基于telegram平台的librem来实现实时文章采集。后端,实时文章采集对后端的要求不高,主要是使用librem抓取网页就行。
其实我觉得难点主要在于viplive。
我倒是觉得不是很难,用通俗易懂的话说吧,抓取实时信息,不再是机器浏览网页,而是在电脑和手机里通过屏幕采集,让机器无需下载浏览器,直接可以实现抓取和定位。
用.net架个框架,
尝试过用v6解析图片得到json然后转php然后再放到php页面上模拟浏览器访问来抓取,我觉得这种抓取方式的性能下降非常严重,
python实现基于mongodb的数据库抓取-gracefulthink的博客-csdn博客
python的json也是有markdown解析器的:;toc=true
使用框架
可以从html+xml+json得到xml文件,然后在mongo数据库或者自己的数据库下获取。主要是tags,规则都写死在json里面了。你还可以用xpath。
实时文章采集建议使用谷歌地图,能获取更为全面的信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-07-22 02:01
实时文章采集建议使用谷歌地图,能获取更为全面的信息。如果是需要根据instagram、reddit之类的采集,使用web版本,在采集文章时如果勾选了timeline,则同步的图片会实时出现在你的instagram和reddit中。另,谷歌地图导航是默认自动补全地名的,若需要这种情况可以尝试使用vscodemapmanager插件。
网页版vscode,github,twitter,instagram等采集
谷歌地图
在superview加入#downloaddata.就行了。
bing
githubredditanthonykanzadeyangelahaleyweixin提供相关博客
目前在用gimp,其他方法有用timeline的时候如果要fix我,就自己star。
在页面顶部有个勾的
有一个全景相机,可以截取之后发送至微信平台。
firebase
,可以下载整图
电脑端我用的地图搜索,手机端用vscode采集,已经实现全部实时同步了。
roundland
支持的程度取决于你的图片清晰度
可以参考“thelastsuperview”.但是如果要实现分区域(比如每个帖子页面)自动保存地理位置、详细到特定地点的话,那就需要在你发起采集操作后,一段时间内完成地理位置更新,如果你需要抓全局的话,你还可以考虑使用mapbox一键式采集和发布。 查看全部
实时文章采集建议使用谷歌地图,能获取更为全面的信息
实时文章采集建议使用谷歌地图,能获取更为全面的信息。如果是需要根据instagram、reddit之类的采集,使用web版本,在采集文章时如果勾选了timeline,则同步的图片会实时出现在你的instagram和reddit中。另,谷歌地图导航是默认自动补全地名的,若需要这种情况可以尝试使用vscodemapmanager插件。
网页版vscode,github,twitter,instagram等采集
谷歌地图
在superview加入#downloaddata.就行了。
bing
githubredditanthonykanzadeyangelahaleyweixin提供相关博客
目前在用gimp,其他方法有用timeline的时候如果要fix我,就自己star。
在页面顶部有个勾的
有一个全景相机,可以截取之后发送至微信平台。
firebase
,可以下载整图
电脑端我用的地图搜索,手机端用vscode采集,已经实现全部实时同步了。
roundland
支持的程度取决于你的图片清晰度
可以参考“thelastsuperview”.但是如果要实现分区域(比如每个帖子页面)自动保存地理位置、详细到特定地点的话,那就需要在你发起采集操作后,一段时间内完成地理位置更新,如果你需要抓全局的话,你还可以考虑使用mapbox一键式采集和发布。
实时文章采集是个不错的方法,新网站即可用
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-20 19:02
实时文章采集是个不错的方法,文章采集网站要找一些靠谱的,一般网站上有标题里含有id的网站还是很靠谱的,里面有很多与id有关的工具链接;采集完网站上的任意网页,复制网页就可以生成即时链接,新网站即可用。像百度爬虫,谷歌爬虫,这些都是即时链接。
我目前知道的应该是用react开发的reactjs脚手架,就可以,
豆瓣
pagespeed
.
2014-10-08自问自答,这篇不错,
.bash_profiles.txt
阿里云万象,
有一本书microsoftoutlooktheguide.tgw挺合适的。
试试angel之类的,写起来也快。
再小众一点的爬虫工具,spiderinjavascript,jqueryspiderinjavascript.mozilla/spiderinjavascriptbootstrapspider.后续可以考虑这两者组合。
也算是个简单易用的工具,效果也不错。我也在学习中。
原生的浏览器控制台有hash?
我来说一个,thrift,用js实现json,有keyforhash.一种很易用的方式。
如果是网页,
-new/
websocket,自己设置source并生成二维码,只要浏览器支持, 查看全部
实时文章采集是个不错的方法,新网站即可用
实时文章采集是个不错的方法,文章采集网站要找一些靠谱的,一般网站上有标题里含有id的网站还是很靠谱的,里面有很多与id有关的工具链接;采集完网站上的任意网页,复制网页就可以生成即时链接,新网站即可用。像百度爬虫,谷歌爬虫,这些都是即时链接。
我目前知道的应该是用react开发的reactjs脚手架,就可以,
豆瓣
pagespeed
.
2014-10-08自问自答,这篇不错,
.bash_profiles.txt
阿里云万象,
有一本书microsoftoutlooktheguide.tgw挺合适的。
试试angel之类的,写起来也快。
再小众一点的爬虫工具,spiderinjavascript,jqueryspiderinjavascript.mozilla/spiderinjavascriptbootstrapspider.后续可以考虑这两者组合。
也算是个简单易用的工具,效果也不错。我也在学习中。
原生的浏览器控制台有hash?
我来说一个,thrift,用js实现json,有keyforhash.一种很易用的方式。
如果是网页,
-new/
websocket,自己设置source并生成二维码,只要浏览器支持,
实时文章采集,直接搜索关键词获取,豆瓣电影4.雪球
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-20 04:02
实时文章采集1.今日头条,直接搜索关键词获取。2.百度文库,直接搜索关键词获取。3.豆瓣电影4.雪球,豆瓣热门5.万能的百度,直接搜索关键词获取。6.天天网赚网7.威锋网,
本地的话有同步吧
微信的推送
百度
新浪自己的一个数据中心,存了各个网站资源,没经过你的二次采集。有的时候内容是与当时所在情境不符,因为现在的舆论追求的是真实,各大网站发布此类资源并不代表真正获取,
现在抖音还有头条也有。
有一个网站,会抓取大量新闻,
目前社交平台中各大平台都有文章文章号的,你在个人主页点击有道文章助手,即可发布文章。还有推荐关注我的公众号:(二维码自动识别)以及一个头条号可以搜,一搜自动出文章,质量是挺高的。
推荐一个小微文网,里面的内容全部是百度或者今日头条采集的文章,并且可以在线编辑,pdf,文章还可以全部评论,发布。有需要也可以找我,文章在这里:免费号:。
有网站
转发加关注再给你点推荐
一搜全是
这个问题要么楼主是在国内要么就是在国外的国内还好吧,各大新闻网站这些东西都有可以搜索到, 查看全部
实时文章采集,直接搜索关键词获取,豆瓣电影4.雪球
实时文章采集1.今日头条,直接搜索关键词获取。2.百度文库,直接搜索关键词获取。3.豆瓣电影4.雪球,豆瓣热门5.万能的百度,直接搜索关键词获取。6.天天网赚网7.威锋网,
本地的话有同步吧
微信的推送
百度
新浪自己的一个数据中心,存了各个网站资源,没经过你的二次采集。有的时候内容是与当时所在情境不符,因为现在的舆论追求的是真实,各大网站发布此类资源并不代表真正获取,
现在抖音还有头条也有。
有一个网站,会抓取大量新闻,
目前社交平台中各大平台都有文章文章号的,你在个人主页点击有道文章助手,即可发布文章。还有推荐关注我的公众号:(二维码自动识别)以及一个头条号可以搜,一搜自动出文章,质量是挺高的。
推荐一个小微文网,里面的内容全部是百度或者今日头条采集的文章,并且可以在线编辑,pdf,文章还可以全部评论,发布。有需要也可以找我,文章在这里:免费号:。
有网站
转发加关注再给你点推荐
一搜全是
这个问题要么楼主是在国内要么就是在国外的国内还好吧,各大新闻网站这些东西都有可以搜索到,
携程数据开发总监纪成:大数据领域开源技术框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-07-14 21:47
作者介绍
程冀,携程数据开发总监,负责金融数据基础组件及平台开发、数据仓库建设及治理相关工作。对大数据领域的开源技术框架有浓厚的兴趣。
一、Background
携程金融成立于2017年9月,本着实现金融助力出行的使命,开始全面发展集团风控和金融服务。需要在携程数据中心建设统一的金融数据中心,实现多地点、多机房数据。整合满足线上线下需求;它涉及将数千个 mysql 表同步到离线数据仓库、实时数据仓库和在线缓存。由于对跨区域、实时性、准确性和完整性的高要求,无法支持集团内DataX(业内常见的离线同步解决方案)的二次开发。以mysql-hive同步为例,DataX通过直连MySQL批量拉取数据,存在以下问题:
二、项目概览
基于以上背景,我们设计了一个基于binlog实时流式传输的数据库层构建方案,并取得了预期的效果。结构如图,各模块介绍:
三、详细介绍
本章以mysql-hive镜像为例,详细介绍技术方案。
3.1.binlog采集
canal 是阿里巴巴开源的 Mysql binlog 增量订阅消费组件。它在工业中被广泛使用。通过实时增量采集binlog,可以减轻mysql的压力,减少数据变化细粒度恢复的过程。 ,我们选择canal作为binlog采集的基础组件,根据应用场景进行二次开发。其中,raw binlog→simple binlog的消息格式转换是重点。
以下是binlog采集的架构图:
canal在1.1.4版本引入了canal-admin项目,支持面向WebUI的管理能力;我们使用原生canal-admin管理binlog采集,采集粒度为mysql实例级别。
Canal Server 会从 canalAdmin 中拉取集群下的所有 mysql 实例列表。对于每个mysql instance采集任务,canal server通过在zookeeper中创建临时节点,通过zookeeper共享binlog位置来实现HA。
canal1.1.1版本引入MQProducer原生支持Kafka消息传递。图中,实例active从mysql获取实时增量原创binlog数据,在MQProducer链接中进行raw binlog→simple binlog消息转换并发送给kafka。我们根据实例创建了对应的kafka主题,而不是每个数据库一个主题,主要是考虑到同一个mysql实例下有多个数据库。过多的topic(分区)导致kafka的随机IO增加,影响吞吐量。发送Kafka时,使用schemaName+tableName作为partitionKey,结合生产者的参数控制,保证同表的binlog消息按顺序写入Kafka。
参考生产者参数控制:
max.in.flight.requests.per.connection=1retries=0acks=all
主题级别的配置:
topic partition 3副本, 且min.insync.replicas=2
考虑到保证数据的顺序性和容灾性,我们设计了轻量级的SimpleBinlog消息格式:
金融目前部署了4组canal集群,每组2个物理机节点,跨机房部署,已经承担了数百个mysql实例binlog采集任务。 Canal 服务器自带的性能监控是基于 Prometheus 的。通过实施PrometheusScraper,我们主动拉取核心指标,推送到集团内部Watcher监控系统,配置相关告警。每个mysql实例的binlog采集延迟是全链路监控。重要指标。
系统前期遇到canal-server实例脑裂的问题。具体场景是活动实例所在的canal-server。由于网络问题,zookeeper的链接超时。这时候备实例会抢先创建一个临时节点,成为一个新节点。活跃;还有一种情况是两个actives同时采集和push binlog。解决方法是在active实例和zookeeper链接超时后立即自杀,再次发起下一轮抢占。
3.2 历史数据回放
有两种场景需要我们采集historical data:
有两种选择:
1) 从mysql批量拉取历史数据上传到HDFS。需要考虑批量拉取的数据和binlog采集生成的mysql-hive镜像的格式差异,比如去重主键的选择,排序字段的选择。
2)Streaming模式,批量从mysql中拉取历史数据,转换成简单的binlog消息流写入kafka,用实时采集的简单binlog流复用后续处理过程。合并生成mysql-hive镜像表时,需要保证这部分数据不会覆盖实时采集简单binlog数据。
我们选择了更简单、更易于维护的选项 2,并开发了一个 binlog-mock 服务。根据用户给出的库、表(前缀)和条件,我们可以批量选择(例如每次选择10000行)mysql查询数据,组装成simple_binlog消息发送给Kafka。
对于mocks的历史数据,需要注意:
3.3 Write2HDFS
我们使用 spark-streaming 将 Kafka 消息持久化到 HDFS,每 5 分钟一批,在提交消费者偏移量之前处理一批数据(持久化到 HDFS),以确保消息至少被处理一次;还要考虑分库分表的问题,数据倾斜:
阻塞分库分表:以order表为例,mysql数据存放在ordercenter_00 ... ordercenter_99 100个数据库中,每个数据库有orderinfo_00...orderinfo_99 100个表,以及数据库prefix schemaNamePrefix=ordercenter ,表前缀 tableNamePrefix=orderinfo 统一映射到 tableName=${schemaNamePrefix}_${tableNamePrefix};根据binlog executeTime字段生成对应的分区dt,保证同一天同一个数据库表的数据落入同一个分区目录:base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt ={binlogDt}/binlog-{timestamp}-{rdd.id}
防止数据倾斜:数据倾斜的问题经常发生在系统的早期阶段。调查发现,业务在特定时间段内为单张表批量运行产生的binlog量特别大,并且一张表的数据和一批数据需要写入同一个HDFS文件,一个表的写入速度单个 HDFS 文件成为瓶颈。所以加了一个链接(步骤2),过滤掉当前batch中的“大表”,将这些大表的数据写入多个HDFS文件中。
base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt={binlogDt}/binlog-{timestamp}-{rdd.id}-[${randomInt}]
3.4 生成镜像
3.4.1 数据就绪检查
spark-streaming 作业每隔 5 分钟将 kafka simple_binlog 消息分批持久化到 HDFS,合并任务每天执行一次。每天 0:15,数据就绪检查开始。我们监控了消息的整个环节,包括binlog采集delay t1、kafka同步延迟t2、spark-streaming消费者延迟t3。假设当前时间是早上0:30,设置为t4。如果t4>(t1+t2+t3),则表示T-1天的数据全部落入HDFS,可以执行下游ETL操作(merge)。
3.4.2 合并
HDFS上的简单binlog数据准备好后,下一步就是恢复对应的MySQL业务表数据。下面是Merge的执行过程,步骤如下:
1)加载T-1分区的简单binlog数据
数据就绪检查通过后,通过MSCK REPAIR PARTITION加载T-1分区的simple_binlog数据。注:此表为原创简单binlog数据,具体mysql表的字段没有平铺。如果是第一次镜像mysql-hive,历史数据回放的简单binlog也会落入T-1分区。
2)检查Schema并提取T-1增量
请求镜像后端获取最新的mysql schema。如果有变化,更新mysql-hive镜像表(snap),让下游不知道;同时根据mysql schema字段列表和“hive主键”等配置信息,从上面的simple_binlog分区中提取mysql表的T-1天详细数据(delta)。
3)判断业务库中是否发生了归档操作,判断后续合并时是否忽略DELETE事件。
业务DELETE数据有两种情况:业务维修单等导致的正常DELETE,需要同步到Hive;业务数据库归档历史数据产生的DELETE,这种DELETE操作需要忽略。
在系统上线初期,我们等待业务或DBA的通知,然后手动处理,很麻烦。很多情况下,通知不到位,导致Hive数据丢失历史数据。为了解决这个问题,在Merge之前会自动判断流程,参考规则如下:
4)合并delta数据(delta)和当前快照(snap T-2)去重复,得到最新的snap T-1。
下面用一个例子来说明合并过程。假设订单表有三个字段:id、order_no、amount,id是全局唯一的; snap表t3为mysql-hive镜像,合并过程如图。
3.4.3 检查
数据合并完成后,为了保证mysql-hive镜像表中数据的准确性,会将hive表和mysql表进行字段和数据量的比对,作为最后一道防线我们在配置mysql-hive镜像的时候,会指定一个检查条件,一般是根据createTime字段来比较7天的数据;镜像后台每天早上都会从mysql中预先计算过去7天的增量,离线任务会通过脚本(http)获取,以上数据用snap表验证。实践中遇到的一些问题:
1)T-1的binlog落在T分区
检查服务根据createTime生成查询条件,检查mysql和Hive数据。因为业务SQL中createTime和binlog executeTime不一致,凌晨前后1秒,会导致Hive漏掉这个数据。可以通过一起加载T-day分区的binlog数据重新合并。
2) 业务表迁移,原表停止更新。虽然mysql和hive的数据量是一样的,但是已经不能满足要求了。这种情况可以通过波动找到。
3.5 其他
在实践中,可以根据需要在binlog采集及后续消息流中引入一些数据治理工作。例如:
1)明文检测:binlog采集link对核心数据库表数据进行实时明文检测,可以防止敏感数据流入数据仓库;
2)Standardization:一些领域的标准化操作,比如id映射,不同密文的映射;
3)Metadata:mysql→hive镜像是数据仓库ODS的核心。根据采集配置信息,可以实现两者映射关系的双向检索,方便数据仓库溯源。这是财务元数据管理的重要组成部分。
通过消费binlog将mysql镜像到实时数仓(kudu、es)和在线缓存(redis)的逻辑比较简单,篇幅有限,本文不再赘述。
四、Summary 和展望
基于binlog的金融数据基础层建设方案顺利完成预期目标:
<p>该解决方案已成为金融线上线下服务的基石,并不断拓展其使用场景。未来将在自动化配置(mirror-admin和canal-admin一体化,实现一键搭建)、智能运维(异常数据检查识别与恢复)、元数据管理等方面投入更多。 查看全部
携程数据开发总监纪成:大数据领域开源技术框架
作者介绍
程冀,携程数据开发总监,负责金融数据基础组件及平台开发、数据仓库建设及治理相关工作。对大数据领域的开源技术框架有浓厚的兴趣。
一、Background
携程金融成立于2017年9月,本着实现金融助力出行的使命,开始全面发展集团风控和金融服务。需要在携程数据中心建设统一的金融数据中心,实现多地点、多机房数据。整合满足线上线下需求;它涉及将数千个 mysql 表同步到离线数据仓库、实时数据仓库和在线缓存。由于对跨区域、实时性、准确性和完整性的高要求,无法支持集团内DataX(业内常见的离线同步解决方案)的二次开发。以mysql-hive同步为例,DataX通过直连MySQL批量拉取数据,存在以下问题:
二、项目概览
基于以上背景,我们设计了一个基于binlog实时流式传输的数据库层构建方案,并取得了预期的效果。结构如图,各模块介绍:
三、详细介绍
本章以mysql-hive镜像为例,详细介绍技术方案。
3.1.binlog采集
canal 是阿里巴巴开源的 Mysql binlog 增量订阅消费组件。它在工业中被广泛使用。通过实时增量采集binlog,可以减轻mysql的压力,减少数据变化细粒度恢复的过程。 ,我们选择canal作为binlog采集的基础组件,根据应用场景进行二次开发。其中,raw binlog→simple binlog的消息格式转换是重点。
以下是binlog采集的架构图:
canal在1.1.4版本引入了canal-admin项目,支持面向WebUI的管理能力;我们使用原生canal-admin管理binlog采集,采集粒度为mysql实例级别。
Canal Server 会从 canalAdmin 中拉取集群下的所有 mysql 实例列表。对于每个mysql instance采集任务,canal server通过在zookeeper中创建临时节点,通过zookeeper共享binlog位置来实现HA。
canal1.1.1版本引入MQProducer原生支持Kafka消息传递。图中,实例active从mysql获取实时增量原创binlog数据,在MQProducer链接中进行raw binlog→simple binlog消息转换并发送给kafka。我们根据实例创建了对应的kafka主题,而不是每个数据库一个主题,主要是考虑到同一个mysql实例下有多个数据库。过多的topic(分区)导致kafka的随机IO增加,影响吞吐量。发送Kafka时,使用schemaName+tableName作为partitionKey,结合生产者的参数控制,保证同表的binlog消息按顺序写入Kafka。
参考生产者参数控制:
max.in.flight.requests.per.connection=1retries=0acks=all
主题级别的配置:
topic partition 3副本, 且min.insync.replicas=2
考虑到保证数据的顺序性和容灾性,我们设计了轻量级的SimpleBinlog消息格式:
金融目前部署了4组canal集群,每组2个物理机节点,跨机房部署,已经承担了数百个mysql实例binlog采集任务。 Canal 服务器自带的性能监控是基于 Prometheus 的。通过实施PrometheusScraper,我们主动拉取核心指标,推送到集团内部Watcher监控系统,配置相关告警。每个mysql实例的binlog采集延迟是全链路监控。重要指标。
系统前期遇到canal-server实例脑裂的问题。具体场景是活动实例所在的canal-server。由于网络问题,zookeeper的链接超时。这时候备实例会抢先创建一个临时节点,成为一个新节点。活跃;还有一种情况是两个actives同时采集和push binlog。解决方法是在active实例和zookeeper链接超时后立即自杀,再次发起下一轮抢占。
3.2 历史数据回放
有两种场景需要我们采集historical data:
有两种选择:
1) 从mysql批量拉取历史数据上传到HDFS。需要考虑批量拉取的数据和binlog采集生成的mysql-hive镜像的格式差异,比如去重主键的选择,排序字段的选择。
2)Streaming模式,批量从mysql中拉取历史数据,转换成简单的binlog消息流写入kafka,用实时采集的简单binlog流复用后续处理过程。合并生成mysql-hive镜像表时,需要保证这部分数据不会覆盖实时采集简单binlog数据。
我们选择了更简单、更易于维护的选项 2,并开发了一个 binlog-mock 服务。根据用户给出的库、表(前缀)和条件,我们可以批量选择(例如每次选择10000行)mysql查询数据,组装成simple_binlog消息发送给Kafka。
对于mocks的历史数据,需要注意:
3.3 Write2HDFS
我们使用 spark-streaming 将 Kafka 消息持久化到 HDFS,每 5 分钟一批,在提交消费者偏移量之前处理一批数据(持久化到 HDFS),以确保消息至少被处理一次;还要考虑分库分表的问题,数据倾斜:
阻塞分库分表:以order表为例,mysql数据存放在ordercenter_00 ... ordercenter_99 100个数据库中,每个数据库有orderinfo_00...orderinfo_99 100个表,以及数据库prefix schemaNamePrefix=ordercenter ,表前缀 tableNamePrefix=orderinfo 统一映射到 tableName=${schemaNamePrefix}_${tableNamePrefix};根据binlog executeTime字段生成对应的分区dt,保证同一天同一个数据库表的数据落入同一个分区目录:base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt ={binlogDt}/binlog-{timestamp}-{rdd.id}
防止数据倾斜:数据倾斜的问题经常发生在系统的早期阶段。调查发现,业务在特定时间段内为单张表批量运行产生的binlog量特别大,并且一张表的数据和一批数据需要写入同一个HDFS文件,一个表的写入速度单个 HDFS 文件成为瓶颈。所以加了一个链接(步骤2),过滤掉当前batch中的“大表”,将这些大表的数据写入多个HDFS文件中。
base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt={binlogDt}/binlog-{timestamp}-{rdd.id}-[${randomInt}]
3.4 生成镜像
3.4.1 数据就绪检查
spark-streaming 作业每隔 5 分钟将 kafka simple_binlog 消息分批持久化到 HDFS,合并任务每天执行一次。每天 0:15,数据就绪检查开始。我们监控了消息的整个环节,包括binlog采集delay t1、kafka同步延迟t2、spark-streaming消费者延迟t3。假设当前时间是早上0:30,设置为t4。如果t4>(t1+t2+t3),则表示T-1天的数据全部落入HDFS,可以执行下游ETL操作(merge)。
3.4.2 合并
HDFS上的简单binlog数据准备好后,下一步就是恢复对应的MySQL业务表数据。下面是Merge的执行过程,步骤如下:
1)加载T-1分区的简单binlog数据
数据就绪检查通过后,通过MSCK REPAIR PARTITION加载T-1分区的simple_binlog数据。注:此表为原创简单binlog数据,具体mysql表的字段没有平铺。如果是第一次镜像mysql-hive,历史数据回放的简单binlog也会落入T-1分区。
2)检查Schema并提取T-1增量
请求镜像后端获取最新的mysql schema。如果有变化,更新mysql-hive镜像表(snap),让下游不知道;同时根据mysql schema字段列表和“hive主键”等配置信息,从上面的simple_binlog分区中提取mysql表的T-1天详细数据(delta)。
3)判断业务库中是否发生了归档操作,判断后续合并时是否忽略DELETE事件。
业务DELETE数据有两种情况:业务维修单等导致的正常DELETE,需要同步到Hive;业务数据库归档历史数据产生的DELETE,这种DELETE操作需要忽略。
在系统上线初期,我们等待业务或DBA的通知,然后手动处理,很麻烦。很多情况下,通知不到位,导致Hive数据丢失历史数据。为了解决这个问题,在Merge之前会自动判断流程,参考规则如下:
4)合并delta数据(delta)和当前快照(snap T-2)去重复,得到最新的snap T-1。
下面用一个例子来说明合并过程。假设订单表有三个字段:id、order_no、amount,id是全局唯一的; snap表t3为mysql-hive镜像,合并过程如图。
3.4.3 检查
数据合并完成后,为了保证mysql-hive镜像表中数据的准确性,会将hive表和mysql表进行字段和数据量的比对,作为最后一道防线我们在配置mysql-hive镜像的时候,会指定一个检查条件,一般是根据createTime字段来比较7天的数据;镜像后台每天早上都会从mysql中预先计算过去7天的增量,离线任务会通过脚本(http)获取,以上数据用snap表验证。实践中遇到的一些问题:
1)T-1的binlog落在T分区
检查服务根据createTime生成查询条件,检查mysql和Hive数据。因为业务SQL中createTime和binlog executeTime不一致,凌晨前后1秒,会导致Hive漏掉这个数据。可以通过一起加载T-day分区的binlog数据重新合并。
2) 业务表迁移,原表停止更新。虽然mysql和hive的数据量是一样的,但是已经不能满足要求了。这种情况可以通过波动找到。
3.5 其他
在实践中,可以根据需要在binlog采集及后续消息流中引入一些数据治理工作。例如:
1)明文检测:binlog采集link对核心数据库表数据进行实时明文检测,可以防止敏感数据流入数据仓库;
2)Standardization:一些领域的标准化操作,比如id映射,不同密文的映射;
3)Metadata:mysql→hive镜像是数据仓库ODS的核心。根据采集配置信息,可以实现两者映射关系的双向检索,方便数据仓库溯源。这是财务元数据管理的重要组成部分。
通过消费binlog将mysql镜像到实时数仓(kudu、es)和在线缓存(redis)的逻辑比较简单,篇幅有限,本文不再赘述。
四、Summary 和展望
基于binlog的金融数据基础层建设方案顺利完成预期目标:
<p>该解决方案已成为金融线上线下服务的基石,并不断拓展其使用场景。未来将在自动化配置(mirror-admin和canal-admin一体化,实现一键搭建)、智能运维(异常数据检查识别与恢复)、元数据管理等方面投入更多。
实时文章采集的实现——quantcast文章展示(api)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-11 05:04
实时文章采集的实现——quantcast文章展示quantcast是一个跨越40多种行业的全球新闻博客平台,通过技术解析当地实时重要新闻。
4、5个小时。checkstream是quantcast特有的速度加载方式,用户可以立即获取推送到用户浏览器的新闻,而不需要等待推送后再更新。checkstream可以让用户立即获取即将到来的讯息。在开始下载文章时,用户就已经被告知这个网站(api)在不断传送相关新闻。我们可以看到checkstream不仅可以像之前收集现有库一样解析,用户更可以从众多主题的原生不同的渠道拿到相关新闻报道,并在此基础上进行自定义。
下面我们会介绍checkstream与quantcast之间一些相似或相似之处。标题、描述和时间大多数报道的标题很简短,只有关键的核心要点,并且比例合理,描述一般分为六类。
1)人名;
2)地名;
3)事件;
4)事件发生的时间;
5)事件的频率;
6)事件的相关性。描述则是基于事件的5类描述的前两三项。事件信息一般描述大类型事件或小类型事件发生的时间。
2)主题分类描述在同一个报道类型内是唯一的,比如,图表统计实时报道可以包含两个主题描述:“四年内”或“本周”。如果选择两个主题,这两个主题一般是主题属性没有关联的。单主题一般会包含关键要点。
3)报道来源无论是主题还是个人上传的报道,我们都希望的一点是:实时报道可以是全球的,全球类型的,包含最常见的国家的全球/州的等等。报道来源也很关键,并且必须选择最主要或重要的。例如,如果只提供州报道,则没有最小化时间轴和来源的可能性。
4)新闻发布时间以上几条应该是这种实时文章传送到api的要求,quantcast支持不同的重要新闻类型,但他们的优先级都是依照简洁优先(uinative)排序的。
5)优先度对最近发布的新闻给予很高的评级。主要优先级会基于发布时间在过去可能使用过的报道和关键词,过去某个时段内比较有争议(被评级不高)的可能性比较大,而过去有争议的报道则会降低。
6)实时到达时间通常,文章不会按照一定的时间间隔来重新来发布,所以实时推送需要每隔一段时间就把相关文章推送给用户。需要注意的是,最好将每次重新推送的时间间隔设置为10分钟或更长的一段时间。通过时间的倒计时和实时推送,以实现最高的实时质量。在twitter上,如果一个话题或者文章的实时速度达到10秒钟,就会被标记为「离开状态」,这是每秒处理1万字的原因。
7)编辑功能在latex插入公式的时候会比较复杂,但是用knitr就会非常方便了。值得一提的是,每当实时推送一篇文章时, 查看全部
实时文章采集的实现——quantcast文章展示(api)
实时文章采集的实现——quantcast文章展示quantcast是一个跨越40多种行业的全球新闻博客平台,通过技术解析当地实时重要新闻。
4、5个小时。checkstream是quantcast特有的速度加载方式,用户可以立即获取推送到用户浏览器的新闻,而不需要等待推送后再更新。checkstream可以让用户立即获取即将到来的讯息。在开始下载文章时,用户就已经被告知这个网站(api)在不断传送相关新闻。我们可以看到checkstream不仅可以像之前收集现有库一样解析,用户更可以从众多主题的原生不同的渠道拿到相关新闻报道,并在此基础上进行自定义。
下面我们会介绍checkstream与quantcast之间一些相似或相似之处。标题、描述和时间大多数报道的标题很简短,只有关键的核心要点,并且比例合理,描述一般分为六类。
1)人名;
2)地名;
3)事件;
4)事件发生的时间;
5)事件的频率;
6)事件的相关性。描述则是基于事件的5类描述的前两三项。事件信息一般描述大类型事件或小类型事件发生的时间。
2)主题分类描述在同一个报道类型内是唯一的,比如,图表统计实时报道可以包含两个主题描述:“四年内”或“本周”。如果选择两个主题,这两个主题一般是主题属性没有关联的。单主题一般会包含关键要点。
3)报道来源无论是主题还是个人上传的报道,我们都希望的一点是:实时报道可以是全球的,全球类型的,包含最常见的国家的全球/州的等等。报道来源也很关键,并且必须选择最主要或重要的。例如,如果只提供州报道,则没有最小化时间轴和来源的可能性。
4)新闻发布时间以上几条应该是这种实时文章传送到api的要求,quantcast支持不同的重要新闻类型,但他们的优先级都是依照简洁优先(uinative)排序的。
5)优先度对最近发布的新闻给予很高的评级。主要优先级会基于发布时间在过去可能使用过的报道和关键词,过去某个时段内比较有争议(被评级不高)的可能性比较大,而过去有争议的报道则会降低。
6)实时到达时间通常,文章不会按照一定的时间间隔来重新来发布,所以实时推送需要每隔一段时间就把相关文章推送给用户。需要注意的是,最好将每次重新推送的时间间隔设置为10分钟或更长的一段时间。通过时间的倒计时和实时推送,以实现最高的实时质量。在twitter上,如果一个话题或者文章的实时速度达到10秒钟,就会被标记为「离开状态」,这是每秒处理1万字的原因。
7)编辑功能在latex插入公式的时候会比较复杂,但是用knitr就会非常方便了。值得一提的是,每当实时推送一篇文章时,
nvidia推出sticker字段“字幕”,字幕将转换为一个字符可序列化的文本字体
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-09 20:01
<p>实时文章采集和智能dsp自动机器翻译摘要:nvidia推出sticker字段“字幕”,可以在“字幕”字段中的每个像素点都编码成一个字符值。字幕将会按字节位置,一字节一字节的由nvidia程序处理。字幕将转换为一个字符可序列化的文本字体。nvidia提供标准utf-8字体集( 查看全部
nvidia推出sticker字段“字幕”,字幕将转换为一个字符可序列化的文本字体
<p>实时文章采集和智能dsp自动机器翻译摘要:nvidia推出sticker字段“字幕”,可以在“字幕”字段中的每个像素点都编码成一个字符值。字幕将会按字节位置,一字节一字节的由nvidia程序处理。字幕将转换为一个字符可序列化的文本字体。nvidia提供标准utf-8字体集(
体验一下这些热门文章,给你不一样的体验
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-07-01 02:01
实时文章采集,实时定制化阅读,文章阅读推荐,快速热门文章展示,流行实时动态变化。体验一下这些热门文章,给你不一样的体验。欢迎加入「让更多人看到它」官方讨论群,与更多用户分享你的见解,与更多编辑交流看法,与有经验写手分享写稿经验qq群:294983743知乎专栏:「半撇私塾」微信公众号:「半撇私塾」不止半撇,更有半撇精彩内容。
为知专注精品ted大会,整合了it、生物、人文、科学、社会科学五大模块,每年都能提供更加精彩的内容,而且是免费观看,自己也有两个专栏免费学习。欢迎加入!1.it领域分享交流qq群:212191040知乎专栏:半撇私塾2.生物领域分享交流qq群:210640475知乎专栏:半撇私塾3.人文领域分享交流qq群:380615542知乎专栏:半撇私塾4.科学领域分享交流qq群:210614208知乎专栏:半撇私塾5.社会科学分享交流qq群:192747884知乎专栏:半撇私塾。
推荐网易蜗牛读书
传送门-半撇私塾!请点击我另一个回答高中生应该关注哪些ted?里面就有要找ted大会的资源。
可以看一下方风雷的公众号,近期就有个叫做「ted的国度」的栏目。中学生可以看看。 查看全部
体验一下这些热门文章,给你不一样的体验
实时文章采集,实时定制化阅读,文章阅读推荐,快速热门文章展示,流行实时动态变化。体验一下这些热门文章,给你不一样的体验。欢迎加入「让更多人看到它」官方讨论群,与更多用户分享你的见解,与更多编辑交流看法,与有经验写手分享写稿经验qq群:294983743知乎专栏:「半撇私塾」微信公众号:「半撇私塾」不止半撇,更有半撇精彩内容。
为知专注精品ted大会,整合了it、生物、人文、科学、社会科学五大模块,每年都能提供更加精彩的内容,而且是免费观看,自己也有两个专栏免费学习。欢迎加入!1.it领域分享交流qq群:212191040知乎专栏:半撇私塾2.生物领域分享交流qq群:210640475知乎专栏:半撇私塾3.人文领域分享交流qq群:380615542知乎专栏:半撇私塾4.科学领域分享交流qq群:210614208知乎专栏:半撇私塾5.社会科学分享交流qq群:192747884知乎专栏:半撇私塾。
推荐网易蜗牛读书
传送门-半撇私塾!请点击我另一个回答高中生应该关注哪些ted?里面就有要找ted大会的资源。
可以看一下方风雷的公众号,近期就有个叫做「ted的国度」的栏目。中学生可以看看。
谷歌当前精华的文章每个时段的采集方式(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-06-25 19:03
实时文章采集:以谷歌文章为例,动态监控的文章采集或者搜索命中率,以为根据自己的策略来灵活调整,下面给大家分享谷歌当前精华的文章每个时段的采集方式。一、注重主题的时间窗检测。1.今日主题垂直检测去年谷歌还发布了一套文章主题垂直检测平台,提供了许多种不同的垂直主题检测策略。在基于类比的文章主题检测网络上,谷歌发表了一套基于机器学习的主题垂直检测框架metasploitgrid,该框架可提供真实世界和其他互联网站点的跨时间监控,覆盖美国、英国、法国、德国、荷兰、南非、意大利、芬兰、德国、韩国和西班牙。
此外,metasploitgrid框架还提供基于iris提取的iris主题。此外,近期谷歌还推出了基于决策树对主题进行快速检测和分类的工具,用于发现网站的主题表现。美国将文章分为三个不同的主题流派(和层级主题区域)。该跨越网站广告的采样策略在过去的一年中显示了其重要性。我们通过metasploitgrid构建一个grid框架,其中第一个层次,即广告实例,仅是根据genedis将所有广告实例的主题检测为美国。
第二个层次,广告实例和真实报告区域的共享。以下是几种谷歌高级主题检测和分类器的简单示例。jacomodes:这种策略通过使用genediid将每个来源的实际单词分为近似于属性term-level的模式,从而检测不同类别的所有实例。cogolean:这是首款基于相似度的工具,可预测单词在genedis中的实际位置,并且可检测每个实例的垂直主题区域。
因此,从采样开始,我们将每个实例分配到不同的类别中。例如,我们将google2von归类为term-level,从而检测背景噪声和噪声源的实例。metasploitgrid框架与jacomodes框架类似,但采用iris,可以在没有具体的类比的情况下检测genediid。2.间隔采样技术谷歌文章在metasploitgrid上用于采样规则。
该策略包括间隔性采样,如果您要计算不同主题的持续监控并且在每个请求发生时更改原始检测器,我们可以这样处理。interval:提供约束策略,它决定了某个时间内正确实现指定主题的概率。例如,metasploitgrid上的日间计数器策略可以让您规定一天中四小时周期性的间隔性采样。linkedin策略可以让您规定每天各个实例的周期性触发,如从每天1:00至13:00和从13:00至21:00。
3.搜索规则谷歌对进行规则收集的网站采用搜索类型的方法。这种策略由googletalk提供,该网站提供一个详细的不同国家主题推荐列表(lists),可以提供进行文章采样的更好的选择。facebook最近通过使用thoughtworks的engverywhere工具收集了一些相关的相同主题在各。 查看全部
谷歌当前精华的文章每个时段的采集方式(组图)
实时文章采集:以谷歌文章为例,动态监控的文章采集或者搜索命中率,以为根据自己的策略来灵活调整,下面给大家分享谷歌当前精华的文章每个时段的采集方式。一、注重主题的时间窗检测。1.今日主题垂直检测去年谷歌还发布了一套文章主题垂直检测平台,提供了许多种不同的垂直主题检测策略。在基于类比的文章主题检测网络上,谷歌发表了一套基于机器学习的主题垂直检测框架metasploitgrid,该框架可提供真实世界和其他互联网站点的跨时间监控,覆盖美国、英国、法国、德国、荷兰、南非、意大利、芬兰、德国、韩国和西班牙。
此外,metasploitgrid框架还提供基于iris提取的iris主题。此外,近期谷歌还推出了基于决策树对主题进行快速检测和分类的工具,用于发现网站的主题表现。美国将文章分为三个不同的主题流派(和层级主题区域)。该跨越网站广告的采样策略在过去的一年中显示了其重要性。我们通过metasploitgrid构建一个grid框架,其中第一个层次,即广告实例,仅是根据genedis将所有广告实例的主题检测为美国。
第二个层次,广告实例和真实报告区域的共享。以下是几种谷歌高级主题检测和分类器的简单示例。jacomodes:这种策略通过使用genediid将每个来源的实际单词分为近似于属性term-level的模式,从而检测不同类别的所有实例。cogolean:这是首款基于相似度的工具,可预测单词在genedis中的实际位置,并且可检测每个实例的垂直主题区域。
因此,从采样开始,我们将每个实例分配到不同的类别中。例如,我们将google2von归类为term-level,从而检测背景噪声和噪声源的实例。metasploitgrid框架与jacomodes框架类似,但采用iris,可以在没有具体的类比的情况下检测genediid。2.间隔采样技术谷歌文章在metasploitgrid上用于采样规则。
该策略包括间隔性采样,如果您要计算不同主题的持续监控并且在每个请求发生时更改原始检测器,我们可以这样处理。interval:提供约束策略,它决定了某个时间内正确实现指定主题的概率。例如,metasploitgrid上的日间计数器策略可以让您规定一天中四小时周期性的间隔性采样。linkedin策略可以让您规定每天各个实例的周期性触发,如从每天1:00至13:00和从13:00至21:00。
3.搜索规则谷歌对进行规则收集的网站采用搜索类型的方法。这种策略由googletalk提供,该网站提供一个详细的不同国家主题推荐列表(lists),可以提供进行文章采样的更好的选择。facebook最近通过使用thoughtworks的engverywhere工具收集了一些相关的相同主题在各。
有本事你就连续7年,每天都写10篇有价值的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-17 22:01
实时文章采集+搜索引擎采集+维基百科采集+高质量原创内容网站抓取+知乎机器人抓取+微信公众号抓取+本地web站点抓取,共需要加起来20个抓取站点,还要输入广告拦截地址。保守估计一下,即使你有本事,一个人做一年。平均每个站点也要5个月左右。5个站点。7年时间。
有本事你就连续7年,每天都写10篇有价值的文章我来看看。
都是被逼的,很多人被生活逼着想提高自己,让自己有竞争力,或者是想涨工资。目前抓取教程可以找到的就太多了,百度就有几十个,有的收费有的免费,花点小钱就能买到简单的教程。想提高的话,推荐关注五星公众号“知晓创宇”,专门有写竞价系统的文章,
看了全部的回答,终于发现一个比较靠谱的(打不出广告):(付费高,用过的这个是没有收费公众号推送专用的),关注微信公众号“web开发马蹄工具”,在菜单栏菜单栏——数据抓取->基于搜索引擎搜索关键词,可获取想要的信息(当然如果你足够牛叉,
泻药。没用,帮助太小,什么都抓不到,如果你写过代码,就不会问这种问题,程序员基本不可能,没有新闻有什么用。如果你想学习,为什么不在互联网上搜索相关信息呢,包括国内的维基百科,百度搜索,新浪爱问知识库,等等。说白了就是“关注相关的公众号”,这些“公众号”大多免费,有的收费,但大多数不会费用很高,而且用户质量不是很好。话说多点,如果你足够厉害,知乎有专门的知识星球,说不定能找到很多有帮助的信息。 查看全部
有本事你就连续7年,每天都写10篇有价值的文章
实时文章采集+搜索引擎采集+维基百科采集+高质量原创内容网站抓取+知乎机器人抓取+微信公众号抓取+本地web站点抓取,共需要加起来20个抓取站点,还要输入广告拦截地址。保守估计一下,即使你有本事,一个人做一年。平均每个站点也要5个月左右。5个站点。7年时间。
有本事你就连续7年,每天都写10篇有价值的文章我来看看。
都是被逼的,很多人被生活逼着想提高自己,让自己有竞争力,或者是想涨工资。目前抓取教程可以找到的就太多了,百度就有几十个,有的收费有的免费,花点小钱就能买到简单的教程。想提高的话,推荐关注五星公众号“知晓创宇”,专门有写竞价系统的文章,
看了全部的回答,终于发现一个比较靠谱的(打不出广告):(付费高,用过的这个是没有收费公众号推送专用的),关注微信公众号“web开发马蹄工具”,在菜单栏菜单栏——数据抓取->基于搜索引擎搜索关键词,可获取想要的信息(当然如果你足够牛叉,
泻药。没用,帮助太小,什么都抓不到,如果你写过代码,就不会问这种问题,程序员基本不可能,没有新闻有什么用。如果你想学习,为什么不在互联网上搜索相关信息呢,包括国内的维基百科,百度搜索,新浪爱问知识库,等等。说白了就是“关注相关的公众号”,这些“公众号”大多免费,有的收费,但大多数不会费用很高,而且用户质量不是很好。话说多点,如果你足够厉害,知乎有专门的知识星球,说不定能找到很多有帮助的信息。
实时文章采集根据浏览量、阅读量等硬性指标解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-06-10 20:03
实时文章采集根据浏览量、阅读量等硬性指标,将各种类型的文章分类,并对信息进行整理和分析,最终做出针对不同类型的用户可供性的解读和解析。
一、文章分类因为信息源多、阅读量少、分类少,而且好多信息来源难以把握,我们制定了大量的标准,确保信息源、渠道源是有效信息。
具体的模块包括:
1、标题
2、标签
3、个人id、关键词
4、关键句
5、内容质量(完整性、实用性、价值性、文章逻辑性)
6、文章是否为作者原创,是否为第三方发布。
二、主要渠道渠道1:qq群渠道2:微信搜索渠道3:自媒体平台渠道:头条号、百家号、企鹅号、大鱼号等等
三、利用文章效果的整理分析搜索率:搜索量大,平均超过60%的文章,平均10篇有一篇能带来一位成交,文章吸引力强,转化率高,roi低,大部分文章10天内可通过;文章吸引力小,平均可吸引1.2k以下的人,文章不吸引人,10天内可忽略。我们会有针对性的优化关键词,以让更多用户能够看到这篇文章。我们会直接下拉到“101个数据指标和渠道”中,“101个数据指标和渠道”又有什么指标呢?。
四、整理渠道如果你还想更加了解自媒体各个渠道的一些规则和形式,可以留言回复我告诉你最新的规则和形式。
营销模式1.搜索品牌名品牌名作为关键词,可带来精准流量。同时这些词有更强的相关性,后续很容易进行创意文案的撰写,可以适用各种类型的文案。2.在搜索产品名关键词后,搜索引擎会给我们呈现一张搜索排行榜,有关联性的词组成关键词,后续通过热词引导消费。3.寻找功能词在上搜索“桌椅”,最高热度前三位的是“罗兰roland电气”、“roland中国组织”、“roland施乐中国组织”。
使用这些词,用户会比较直观明了。4.选择人气高的音乐尽管人气高的音乐,只需要更换一下发型,翻篇,换字幕,读秒表,都能使流量翻倍。5.选择拥有“蓝标”标签的账号搜索企业主,品牌词,进入蓝标后,点击蓝标,进入蓝标排行榜。平台运营1.新媒体营销平台平台经过十几年的发展,已经拥有非常高的权重,同时在头条号、微信公众号等新媒体平台上,输出优质的内容,并将其以快速的形式,传递给到更多的人。
同时,很多平台,推出的电商功能,也给新媒体人的实操带来了方便。2.新媒体运营服务平台各种新媒体运营服务,为运营者带来的价值,要比靠新媒体挣钱,要靠谱的多。注意事项1.文章要原创。百家号要求:2500字以上。企鹅号要求:文章1500字以上。今日头条要求:不低于500字。只有拥有原创的内容,我们的头条号才能被认定为原创。2.文章选题。 查看全部
实时文章采集根据浏览量、阅读量等硬性指标解读
实时文章采集根据浏览量、阅读量等硬性指标,将各种类型的文章分类,并对信息进行整理和分析,最终做出针对不同类型的用户可供性的解读和解析。
一、文章分类因为信息源多、阅读量少、分类少,而且好多信息来源难以把握,我们制定了大量的标准,确保信息源、渠道源是有效信息。
具体的模块包括:
1、标题
2、标签
3、个人id、关键词
4、关键句
5、内容质量(完整性、实用性、价值性、文章逻辑性)
6、文章是否为作者原创,是否为第三方发布。
二、主要渠道渠道1:qq群渠道2:微信搜索渠道3:自媒体平台渠道:头条号、百家号、企鹅号、大鱼号等等
三、利用文章效果的整理分析搜索率:搜索量大,平均超过60%的文章,平均10篇有一篇能带来一位成交,文章吸引力强,转化率高,roi低,大部分文章10天内可通过;文章吸引力小,平均可吸引1.2k以下的人,文章不吸引人,10天内可忽略。我们会有针对性的优化关键词,以让更多用户能够看到这篇文章。我们会直接下拉到“101个数据指标和渠道”中,“101个数据指标和渠道”又有什么指标呢?。
四、整理渠道如果你还想更加了解自媒体各个渠道的一些规则和形式,可以留言回复我告诉你最新的规则和形式。
营销模式1.搜索品牌名品牌名作为关键词,可带来精准流量。同时这些词有更强的相关性,后续很容易进行创意文案的撰写,可以适用各种类型的文案。2.在搜索产品名关键词后,搜索引擎会给我们呈现一张搜索排行榜,有关联性的词组成关键词,后续通过热词引导消费。3.寻找功能词在上搜索“桌椅”,最高热度前三位的是“罗兰roland电气”、“roland中国组织”、“roland施乐中国组织”。
使用这些词,用户会比较直观明了。4.选择人气高的音乐尽管人气高的音乐,只需要更换一下发型,翻篇,换字幕,读秒表,都能使流量翻倍。5.选择拥有“蓝标”标签的账号搜索企业主,品牌词,进入蓝标后,点击蓝标,进入蓝标排行榜。平台运营1.新媒体营销平台平台经过十几年的发展,已经拥有非常高的权重,同时在头条号、微信公众号等新媒体平台上,输出优质的内容,并将其以快速的形式,传递给到更多的人。
同时,很多平台,推出的电商功能,也给新媒体人的实操带来了方便。2.新媒体运营服务平台各种新媒体运营服务,为运营者带来的价值,要比靠新媒体挣钱,要靠谱的多。注意事项1.文章要原创。百家号要求:2500字以上。企鹅号要求:文章1500字以上。今日头条要求:不低于500字。只有拥有原创的内容,我们的头条号才能被认定为原创。2.文章选题。
数据同步工具3.数据采集模块实战分享(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-06-03 23:26
数据源2.数据同步工具3.数据采集module实战分享
数据来源
企业生产应用的数据源很多,大致可以分为:log采集、爬虫系统、数据库等
数据采集
在实际生产应用中,数据采集一般分为日志采集和数据库数据同步两部分。日志采集包括浏览器页面日志采集和客户端日志采集。
数据同步技术更笼统的含义是不同系统之间的数据流转,有很多不同的应用场景。主库与备库之间的数据备份,以及主系统与子系统之间的数据更新,属于同类型不同集群数据库之间的数据同步。此外,还有不同地域、不同数据库类型之间的数据传输和交换,例如分布式业务系统和数据仓库系统之间的数据同步。总体规划分为两种:
技术选择
现在业界常用的数据采集有Flume、Sqoop、LogStash、DataX、Canal、WaterDrop等,这些工具的使用比较简单,学习成本低。根据应用范围和各工具的优缺点。结合自己的业务和使用场景来选择使用。
水槽
Flume 是一个分布式的、可靠的、高可用的海量日志采集,聚合和传输系统。 Flume可以以采集文件、socket数据包等多种形式获取数据,并且可以将采集接收到的数据输出到HDFS、hbase、hive、kafka等多种外部存储系统。下图是单代理架构图。
日志存储
Logstash 是著名的 ELK 中的 L。 Logstash 是一个服务器端数据处理管道,可以同时从多个来源提取数据,进行转换,然后像 Elasticsearch 一样将其发送到“存储”。 Logstash 是 Elastic 堆栈中非常重要的一部分,但它不仅被 Elasticsearch 使用。它可以引入各种各样的数据源。 Logstash 可以通过自己的过滤器帮助我们分析、丰富和转换数据。
Logstash 的主要组件如下:
Sqoop
Sqoop 主要用于在 Hadoop(HDFS、Hive、HBase)和传统数据库(mysql、postgresql...)之间传输数据。它可以将关系数据库中的数据导入到 Hadoop 的 HDFS 中。您可以将 HDFS 数据导入到关系数据库中。
数据X
DataX是阿里巴巴集团开源支持异构数据同步工具,实现了包括MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS在内的各种异构数据等构建高效的数据源间数据同步功能,也可自行开发插件。
运河
canal 的主要用途是基于 MySQL 数据库分析增量日志,提供增量数据订阅和消费。
canal是通过模拟成为mysql的slave来获取数据,监听mysql的binlog获取数据。 binlog设置成行模式后,不仅可以获取到每一个执行的增删改脚本,还可以同时获取修改前的脚本。而修改后的数据,基于这个特性,canal可以高性能的获取mysql数据的变化。
水滴
Waterdrop 是一款非常易用、高性能、海量数据处理产品,支持实时流式处理和离线批处理,基于 Apache Spark 和 Apache Flink。
由于篇幅问题,本文没有对这些工具进行详细的比较和介绍。你想知道它们的优缺点吗?您想知道如何选择吗?去公众号【大华数据路】找答案!
数据登陆
采集之后需要持久化数据,也就是存储层。常见的有:
学习Hive、HBase、ElasticSearch、Clickhouse,请关注公众号【大华数据路】!
需要注意的是,数据采集在真正落地到各个存储层之前,往往会被发送到Kafka这样的消息队列中。 查看全部
数据同步工具3.数据采集模块实战分享(组图)
数据源2.数据同步工具3.数据采集module实战分享
数据来源
企业生产应用的数据源很多,大致可以分为:log采集、爬虫系统、数据库等
数据采集
在实际生产应用中,数据采集一般分为日志采集和数据库数据同步两部分。日志采集包括浏览器页面日志采集和客户端日志采集。
数据同步技术更笼统的含义是不同系统之间的数据流转,有很多不同的应用场景。主库与备库之间的数据备份,以及主系统与子系统之间的数据更新,属于同类型不同集群数据库之间的数据同步。此外,还有不同地域、不同数据库类型之间的数据传输和交换,例如分布式业务系统和数据仓库系统之间的数据同步。总体规划分为两种:
技术选择
现在业界常用的数据采集有Flume、Sqoop、LogStash、DataX、Canal、WaterDrop等,这些工具的使用比较简单,学习成本低。根据应用范围和各工具的优缺点。结合自己的业务和使用场景来选择使用。
水槽
Flume 是一个分布式的、可靠的、高可用的海量日志采集,聚合和传输系统。 Flume可以以采集文件、socket数据包等多种形式获取数据,并且可以将采集接收到的数据输出到HDFS、hbase、hive、kafka等多种外部存储系统。下图是单代理架构图。
日志存储
Logstash 是著名的 ELK 中的 L。 Logstash 是一个服务器端数据处理管道,可以同时从多个来源提取数据,进行转换,然后像 Elasticsearch 一样将其发送到“存储”。 Logstash 是 Elastic 堆栈中非常重要的一部分,但它不仅被 Elasticsearch 使用。它可以引入各种各样的数据源。 Logstash 可以通过自己的过滤器帮助我们分析、丰富和转换数据。
Logstash 的主要组件如下:
Sqoop
Sqoop 主要用于在 Hadoop(HDFS、Hive、HBase)和传统数据库(mysql、postgresql...)之间传输数据。它可以将关系数据库中的数据导入到 Hadoop 的 HDFS 中。您可以将 HDFS 数据导入到关系数据库中。
数据X
DataX是阿里巴巴集团开源支持异构数据同步工具,实现了包括MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS在内的各种异构数据等构建高效的数据源间数据同步功能,也可自行开发插件。
运河
canal 的主要用途是基于 MySQL 数据库分析增量日志,提供增量数据订阅和消费。
canal是通过模拟成为mysql的slave来获取数据,监听mysql的binlog获取数据。 binlog设置成行模式后,不仅可以获取到每一个执行的增删改脚本,还可以同时获取修改前的脚本。而修改后的数据,基于这个特性,canal可以高性能的获取mysql数据的变化。
水滴
Waterdrop 是一款非常易用、高性能、海量数据处理产品,支持实时流式处理和离线批处理,基于 Apache Spark 和 Apache Flink。
由于篇幅问题,本文没有对这些工具进行详细的比较和介绍。你想知道它们的优缺点吗?您想知道如何选择吗?去公众号【大华数据路】找答案!
数据登陆
采集之后需要持久化数据,也就是存储层。常见的有:
学习Hive、HBase、ElasticSearch、Clickhouse,请关注公众号【大华数据路】!
需要注意的是,数据采集在真正落地到各个存储层之前,往往会被发送到Kafka这样的消息队列中。
实时文章采集如何实现?使用谷歌地图、百度、高德、谷歌对接
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-05-30 03:04
实时文章采集如何实现?使用谷歌地图、百度地图导航、openstreetmap、高德地图图文版等等当前业界成熟的采集方案。采集接口开放平台什么?你问这是什么接口,其实没有这么一个东西,不过大致规律是,可以和百度、高德、谷歌对接。这个方案非常经典,很多时候我们用很多时候要实现一个基于地图的导航功能。不然,对于我们这些初创企业来说,想基于一个小平台开发个相对完善的应用,可能比大部分企业要难的多。
本文是这个接口工具工作原理的介绍,这篇博客主要描述github现在在研发如何实现这个接口,这个原理的实现主要就是前面说到的三个步骤。采集api就介绍这么多,业务涉及到的话详细说明一下。采集采集一般分为两种情况,基于车牌号抓取数据和基于人人车号抓取数据。本文基于人人车号抓取数据,选择工具为,现在看一下整个数据采集接口的开发过程。
一、数据采集思路接入api-搜索车牌-找出车牌号-查看车牌号对应的车辆,或者单纯采用某一个地区接口。数据需要统计到采集时间长,这个时间主要根据车辆的移动时间来界定。api采集返回结果为json格式,分别是展示整个全国的车牌号和人人车号采集上报数据参考网页源码这样的格式是一个excel表格,一般保存5亿个车牌号,会按照5亿来格式划分。
采集路径有两个,一个是第二页,还有一个是前三页。最后一页才返回整个数据。我用到的工具为:phpwear更多使用场景需要看看其他工具是如何对接的接口,现在出这么多api接口实在是没必要。数据结构分为以下几类。值得注意的是一个车牌号可能只对应一条人人车号记录,因此一般抓取时间要求长一些,数据有重复的数据尽量不要采取这种方式。
我把平台采集数据结构分为两类:一类是记录全国车牌号的api采集,一类是人人车号采集。对于一些反正基本这样的数据应该拿它没办法,excel导入到数据库吧。string对象,记录人人车号返回至车牌号的数据。长度:根据车牌号长度来决定,一般限制5到20位。excel文件格式,适合记录全国的车牌号,内容包括车牌号,车主id。
这么大一个记录字段我还有点开始头疼怎么读取数据库,毕竟才用json格式,特别是对于车牌号这种数据库格式相对较少的字段格式。其实不想修改数据库格式的话,可以不用做这么多的限制。实际业务中我采取全国车牌数据库数据uuid编码格式进行导入,方便读取,通过sql反查方式,顺利读取全国车牌,具体有这么几个好处:数据准确性和完整性更好,通过sql查询判断到,因为我只是采集全国车牌。记录更长,我是根据全国车牌号长度来判断选择性采集哪些城市。 查看全部
实时文章采集如何实现?使用谷歌地图、百度、高德、谷歌对接
实时文章采集如何实现?使用谷歌地图、百度地图导航、openstreetmap、高德地图图文版等等当前业界成熟的采集方案。采集接口开放平台什么?你问这是什么接口,其实没有这么一个东西,不过大致规律是,可以和百度、高德、谷歌对接。这个方案非常经典,很多时候我们用很多时候要实现一个基于地图的导航功能。不然,对于我们这些初创企业来说,想基于一个小平台开发个相对完善的应用,可能比大部分企业要难的多。
本文是这个接口工具工作原理的介绍,这篇博客主要描述github现在在研发如何实现这个接口,这个原理的实现主要就是前面说到的三个步骤。采集api就介绍这么多,业务涉及到的话详细说明一下。采集采集一般分为两种情况,基于车牌号抓取数据和基于人人车号抓取数据。本文基于人人车号抓取数据,选择工具为,现在看一下整个数据采集接口的开发过程。
一、数据采集思路接入api-搜索车牌-找出车牌号-查看车牌号对应的车辆,或者单纯采用某一个地区接口。数据需要统计到采集时间长,这个时间主要根据车辆的移动时间来界定。api采集返回结果为json格式,分别是展示整个全国的车牌号和人人车号采集上报数据参考网页源码这样的格式是一个excel表格,一般保存5亿个车牌号,会按照5亿来格式划分。
采集路径有两个,一个是第二页,还有一个是前三页。最后一页才返回整个数据。我用到的工具为:phpwear更多使用场景需要看看其他工具是如何对接的接口,现在出这么多api接口实在是没必要。数据结构分为以下几类。值得注意的是一个车牌号可能只对应一条人人车号记录,因此一般抓取时间要求长一些,数据有重复的数据尽量不要采取这种方式。
我把平台采集数据结构分为两类:一类是记录全国车牌号的api采集,一类是人人车号采集。对于一些反正基本这样的数据应该拿它没办法,excel导入到数据库吧。string对象,记录人人车号返回至车牌号的数据。长度:根据车牌号长度来决定,一般限制5到20位。excel文件格式,适合记录全国的车牌号,内容包括车牌号,车主id。
这么大一个记录字段我还有点开始头疼怎么读取数据库,毕竟才用json格式,特别是对于车牌号这种数据库格式相对较少的字段格式。其实不想修改数据库格式的话,可以不用做这么多的限制。实际业务中我采取全国车牌数据库数据uuid编码格式进行导入,方便读取,通过sql反查方式,顺利读取全国车牌,具体有这么几个好处:数据准确性和完整性更好,通过sql查询判断到,因为我只是采集全国车牌。记录更长,我是根据全国车牌号长度来判断选择性采集哪些城市。
实时文章采集,主要方法是压缩算法加缓存,你实际要存储地址
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-05-27 21:01
实时文章采集,主要方法是压缩算法加缓存,你这里的源码应该基于.net开发的,可以在awt中将该文件定义成block,再对其进行重定向。另外perl中有一个叫goblock的包可以实现。
可以用tfrecord解析生成一些内容,然后上传到迅雷的缓存服务器,这样就不用重新采集了。tfrecord中缓存的地址就是你实际要存储地址。希望能够帮到你,加油。
首先这里不是百度云分享,而是非网盘分享的,那个不是你们的专属,所以没有关键词;而文件是基于kafka生成然后上传的.看是否可以存到textview,或者存到缓存。textview自身会具有缓存服务,因为实际调用者来自一台服务器。缓存中存储的应该是这个文件的id、下载的连接。若存储的不是文件,而是文件夹,textview也不会自动更新的。
注意到是nativeclient调用webclient读取,或者是请求一个phpapi向下载器返回地址。转自[第7版]计算机网络你可以看看这本书,当然这本书主要写得是网络,textview请求一个文件夹的场景是不一样的。
texteditortexteditor和他的c++代码代码也是kafka分享的。
貌似迅雷对这个文件没什么不可见的,迅雷对这个文件本身也不感兴趣。我猜迅雷是想让你定期上传这个文件到迅雷服务器,然后迅雷把它放到缓存里面。因为迅雷服务器每天都会同步和整理这个文件,不会错过。迅雷缓存了,还可以定期刷新存到缓存里。 查看全部
实时文章采集,主要方法是压缩算法加缓存,你实际要存储地址
实时文章采集,主要方法是压缩算法加缓存,你这里的源码应该基于.net开发的,可以在awt中将该文件定义成block,再对其进行重定向。另外perl中有一个叫goblock的包可以实现。
可以用tfrecord解析生成一些内容,然后上传到迅雷的缓存服务器,这样就不用重新采集了。tfrecord中缓存的地址就是你实际要存储地址。希望能够帮到你,加油。
首先这里不是百度云分享,而是非网盘分享的,那个不是你们的专属,所以没有关键词;而文件是基于kafka生成然后上传的.看是否可以存到textview,或者存到缓存。textview自身会具有缓存服务,因为实际调用者来自一台服务器。缓存中存储的应该是这个文件的id、下载的连接。若存储的不是文件,而是文件夹,textview也不会自动更新的。
注意到是nativeclient调用webclient读取,或者是请求一个phpapi向下载器返回地址。转自[第7版]计算机网络你可以看看这本书,当然这本书主要写得是网络,textview请求一个文件夹的场景是不一样的。
texteditortexteditor和他的c++代码代码也是kafka分享的。
貌似迅雷对这个文件没什么不可见的,迅雷对这个文件本身也不感兴趣。我猜迅雷是想让你定期上传这个文件到迅雷服务器,然后迅雷把它放到缓存里面。因为迅雷服务器每天都会同步和整理这个文件,不会错过。迅雷缓存了,还可以定期刷新存到缓存里。
ebay:实时文章采集引擎如何爬取商品的文章源数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-05-22 22:05
实时文章采集引擎可以主要由markdown采集引擎,ssl加密引擎,encryptionanddenoising(ed)引擎,textjustifyjournal引擎,similarhumanattentionloss,text-to-visitorloss,prototyping。orgvtool这个引擎官方还算比较推荐,没有广告和很难读的链接。
rt-ev采集系统,可以爬虫程序采集文章,数据存储在服务器端,每日自动爬取各大网站首页,辅助爬虫程序整理文章,最后将爬取的文章内容进行分析统计,并提交给商家进行投放,
python-minitools这个库很多高并发的内容采集器。其实商品的文章也是一样,不过需要和商品的相关信息打交道,没有这么纯粹。但是可以通过分析某些商品的文章源数据,就可以知道如何爬取商品的文章源数据。但是如果没有商品文章源数据,采集商品文章也会很容易卡住。
openal可以看看
采集源本来就是cookie,
补充一个,什么都是采集的再加上简单优化,
作为一个seo专业的业余选手,也曾经尝试过其他楼上采集的方式。但是,经过自己的亲身实践,发现采集的内容大部分是同一类商品,比如ebay上销售热卖的针织衫。做了一些分析与思考,最后决定使用这一方式。原因如下:1.热门商品大部分都是同一类,如果要爬取的话最好抓取热门商品的差异化内容;2.商品标题的字数一般都是30字以内,或者更少,用户体验更好;(如果商品标题过长,要先爬取第一段,将第一段内容再次压缩,再抓取,这样可以获得更少的字数,也能获得更少的内容。
)3.平台网站大部分只提供邮件的方式,必须写信息到邮箱,或者写一句话内容,邮件爬取不方便,而且爬取到的内容只是一小部分内容。4.相同的类商品有同一类的最好,可以加快业务的跟进。如果爬取了多个不同的商品,可以多爬取几个分类然后合并,总之看运气。总的来说,这种方式比采集其他网站内容要安全可靠,易上手,有效率,不影响seo。 查看全部
ebay:实时文章采集引擎如何爬取商品的文章源数据
实时文章采集引擎可以主要由markdown采集引擎,ssl加密引擎,encryptionanddenoising(ed)引擎,textjustifyjournal引擎,similarhumanattentionloss,text-to-visitorloss,prototyping。orgvtool这个引擎官方还算比较推荐,没有广告和很难读的链接。
rt-ev采集系统,可以爬虫程序采集文章,数据存储在服务器端,每日自动爬取各大网站首页,辅助爬虫程序整理文章,最后将爬取的文章内容进行分析统计,并提交给商家进行投放,
python-minitools这个库很多高并发的内容采集器。其实商品的文章也是一样,不过需要和商品的相关信息打交道,没有这么纯粹。但是可以通过分析某些商品的文章源数据,就可以知道如何爬取商品的文章源数据。但是如果没有商品文章源数据,采集商品文章也会很容易卡住。
openal可以看看
采集源本来就是cookie,
补充一个,什么都是采集的再加上简单优化,
作为一个seo专业的业余选手,也曾经尝试过其他楼上采集的方式。但是,经过自己的亲身实践,发现采集的内容大部分是同一类商品,比如ebay上销售热卖的针织衫。做了一些分析与思考,最后决定使用这一方式。原因如下:1.热门商品大部分都是同一类,如果要爬取的话最好抓取热门商品的差异化内容;2.商品标题的字数一般都是30字以内,或者更少,用户体验更好;(如果商品标题过长,要先爬取第一段,将第一段内容再次压缩,再抓取,这样可以获得更少的字数,也能获得更少的内容。
)3.平台网站大部分只提供邮件的方式,必须写信息到邮箱,或者写一句话内容,邮件爬取不方便,而且爬取到的内容只是一小部分内容。4.相同的类商品有同一类的最好,可以加快业务的跟进。如果爬取了多个不同的商品,可以多爬取几个分类然后合并,总之看运气。总的来说,这种方式比采集其他网站内容要安全可靠,易上手,有效率,不影响seo。
实时文章采集的一个思路解决办法:分两种情况
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-05-21 22:06
实时文章采集的一个思路解决办法:分两种情况:一是点击某篇实时更新的文章链接,然后在公众号第一时间进行对应的内容下载,然后进行编辑,发布。第二种情况,如果题目需要以实时为关键词搜索,可以给一个上下文,找到文章原文链接,然后分析关键词的出现概率,进行简单归类。
我是题主提问时间是:12/28.详细方法是:①复制新浪新闻的链接地址(请忽略新浪微博头像上的图片)②输入百度地图网址,
我想知道:如何关联到其他公众号。
推荐小野杰西的公众号。可以实现实时个性化推送,包括推送到其他微信公众号。说到微信公众号,那要说的是微信公众号的一个普遍缺点,不易统计的同时粉丝的活跃度数据也缺乏统计,这个时候小野提供的实时阅读数据就非常有价值了。另外,小野公众号给出的数据在微信后台可以实时查看,而且还能自定义喜欢、厌恶类别,这样直接匹配粉丝对某一领域的喜好!关于小野公众号的更多更细节的规划信息,请戳这里:【小野杰西】公众号介绍及运营方案。 查看全部
实时文章采集的一个思路解决办法:分两种情况
实时文章采集的一个思路解决办法:分两种情况:一是点击某篇实时更新的文章链接,然后在公众号第一时间进行对应的内容下载,然后进行编辑,发布。第二种情况,如果题目需要以实时为关键词搜索,可以给一个上下文,找到文章原文链接,然后分析关键词的出现概率,进行简单归类。
我是题主提问时间是:12/28.详细方法是:①复制新浪新闻的链接地址(请忽略新浪微博头像上的图片)②输入百度地图网址,
我想知道:如何关联到其他公众号。
推荐小野杰西的公众号。可以实现实时个性化推送,包括推送到其他微信公众号。说到微信公众号,那要说的是微信公众号的一个普遍缺点,不易统计的同时粉丝的活跃度数据也缺乏统计,这个时候小野提供的实时阅读数据就非常有价值了。另外,小野公众号给出的数据在微信后台可以实时查看,而且还能自定义喜欢、厌恶类别,这样直接匹配粉丝对某一领域的喜好!关于小野公众号的更多更细节的规划信息,请戳这里:【小野杰西】公众号介绍及运营方案。
做好app推广不管你用什么方法,不适合自己推广
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-05-21 18:02
实时文章采集,原始可实时搜索快速定位并发互动,引爆浏览历史文章搜索排名预览,
app推广自然有很多方法,博客,论坛,朋友圈等等方法。但很多方法其实可能并不可行,也并不适合自己推广。一般做好app推广之后首先要分析和测试自己的产品到底是哪些方面出了问题,然后解决好这些问题,基本上就可以了。更详细的介绍的话就要交给专业的公司来做了。
做app推广不管你用什么方法,首先要根据app现在的热度和搜索量选对关键词,然后选好app的位置,布局在那些关键词下,这样就可以让更多的潜在用户知道你,主动要求安装体验,那你的推广会更好,更有效果。
如果你现在已经在app推广行业工作已经比较久了的话,经验肯定相对比较丰富,不用再过多的担心太多,你说到的方法大多都是为了推广app所准备的。关于app推广,下面分享一下我们公司这几年的经验。你也可以当做一个参考,最后还是得看个人的执行力以及市场方面的资源。
一、分析市场趋势,准确定位适合自己的推广目标其实是很重要的一个环节,当然除了推广目标要准确,我们定位app也需要很好的方法,给自己app准确的定位是找到方向很重要的一环,这个时候我们需要查看相关app推广数据,借助appannie,mavendata.找到他们的demo或者是分析自己app数据后期分析自己app的存在的问题。
至于这个怎么查看app的demo以及分析好自己app数据的不好最好appstoreapp榜单排名数据都有,看到哪里有负面评论就把负面评论消灭,多多吸取正面评论。
二、整理app推广常见问题以及大致的思路推广三步骤中的第一步app分析一般是必不可少的。这一步我们可以直接联系上一步的靠谱渠道获取app的数据进行分析,包括排名,下载量,当用户的总量和下载量都差不多稳定了的时候可以测试渠道获取新的增量。没有渠道也没有关系,那就实地考察,访谈下用户,从多个角度去了解用户是什么特点,哪些用户最喜欢用你们产品,适合哪些人使用,了解到这些之后要整理出用户画像。
了解的这些数据后分析出app属于哪个渠道的,渠道消耗多少用户,然后在该渠道进行测试,总体来说就是需要对不同的渠道需要侧重的方向是不一样的。如果有需要我推荐app品牌推广的渠道,可以私信我哈。
三、针对渠道收集数据并针对性优化从分析问题到最后优化,在这个过程中我们需要收集收集不同渠道的数据,这些渠道包括app的调研,评论文章,排名,分发量,下载量,其他人员的评论,用户的评论,注册用户,活跃用户等等, 查看全部
做好app推广不管你用什么方法,不适合自己推广
实时文章采集,原始可实时搜索快速定位并发互动,引爆浏览历史文章搜索排名预览,
app推广自然有很多方法,博客,论坛,朋友圈等等方法。但很多方法其实可能并不可行,也并不适合自己推广。一般做好app推广之后首先要分析和测试自己的产品到底是哪些方面出了问题,然后解决好这些问题,基本上就可以了。更详细的介绍的话就要交给专业的公司来做了。
做app推广不管你用什么方法,首先要根据app现在的热度和搜索量选对关键词,然后选好app的位置,布局在那些关键词下,这样就可以让更多的潜在用户知道你,主动要求安装体验,那你的推广会更好,更有效果。
如果你现在已经在app推广行业工作已经比较久了的话,经验肯定相对比较丰富,不用再过多的担心太多,你说到的方法大多都是为了推广app所准备的。关于app推广,下面分享一下我们公司这几年的经验。你也可以当做一个参考,最后还是得看个人的执行力以及市场方面的资源。
一、分析市场趋势,准确定位适合自己的推广目标其实是很重要的一个环节,当然除了推广目标要准确,我们定位app也需要很好的方法,给自己app准确的定位是找到方向很重要的一环,这个时候我们需要查看相关app推广数据,借助appannie,mavendata.找到他们的demo或者是分析自己app数据后期分析自己app的存在的问题。
至于这个怎么查看app的demo以及分析好自己app数据的不好最好appstoreapp榜单排名数据都有,看到哪里有负面评论就把负面评论消灭,多多吸取正面评论。
二、整理app推广常见问题以及大致的思路推广三步骤中的第一步app分析一般是必不可少的。这一步我们可以直接联系上一步的靠谱渠道获取app的数据进行分析,包括排名,下载量,当用户的总量和下载量都差不多稳定了的时候可以测试渠道获取新的增量。没有渠道也没有关系,那就实地考察,访谈下用户,从多个角度去了解用户是什么特点,哪些用户最喜欢用你们产品,适合哪些人使用,了解到这些之后要整理出用户画像。
了解的这些数据后分析出app属于哪个渠道的,渠道消耗多少用户,然后在该渠道进行测试,总体来说就是需要对不同的渠道需要侧重的方向是不一样的。如果有需要我推荐app品牌推广的渠道,可以私信我哈。
三、针对渠道收集数据并针对性优化从分析问题到最后优化,在这个过程中我们需要收集收集不同渠道的数据,这些渠道包括app的调研,评论文章,排名,分发量,下载量,其他人员的评论,用户的评论,注册用户,活跃用户等等,
实时文章采集allinoneexcel的功能实现很简单也很完善
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-19 07:01
实时文章采集
allinone对于新手比较友好,功能实现很简单也很完善,对于你所说的excel的功能它都有的。给一个。
目前在用的是excel2010版本,无法导入everything,只能手动找到date12或date20所在列,如果想要导入这些列,再通过搜索引擎搜索,是需要花很长时间的,通过联想和图表能够很快找到。
艾略特搜索引擎需要注册一下账号才可以搜索。
感觉对搜索的效率要求比较高,推荐使用金数据,微信公众号也可以收到相关内容,支持导出excel表格,支持多个目录、多条件组合搜索,功能比较齐全,
sogou的韦伯搜索
易搜云导入数据导出数据速度都不错
北极星官网在,类似问题的解决方案,贴出来分享一下。
网易公开课有很多相关的课程,你可以去看看。
windows系统有everything里面有很多高效的文件夹搜索引擎也有很多用excel读取的搜索引擎也有很多看你自己更喜欢哪种吧
数据挖掘就用ai吧,你现在学编程可能还有点早,建议买本书开始学。
谢邀!推荐两个简单方便速度快的。1、第一种方式为“步骤搜索”,它会给出你目标的步骤、关键词及背景(含义、相关性、延伸含义),再匹配上其他相关的步骤和关键词,就能定位到想要的数据。2、第二种方式为深度学习中的“快速特征提取”,利用人工特征方法,通过深度学习网络模型,能快速找到与训练数据相关的每一条观测数据,再匹配上前后的特征,就能找到目标数据的集合了。 查看全部
实时文章采集allinoneexcel的功能实现很简单也很完善
实时文章采集
allinone对于新手比较友好,功能实现很简单也很完善,对于你所说的excel的功能它都有的。给一个。
目前在用的是excel2010版本,无法导入everything,只能手动找到date12或date20所在列,如果想要导入这些列,再通过搜索引擎搜索,是需要花很长时间的,通过联想和图表能够很快找到。
艾略特搜索引擎需要注册一下账号才可以搜索。
感觉对搜索的效率要求比较高,推荐使用金数据,微信公众号也可以收到相关内容,支持导出excel表格,支持多个目录、多条件组合搜索,功能比较齐全,
sogou的韦伯搜索
易搜云导入数据导出数据速度都不错
北极星官网在,类似问题的解决方案,贴出来分享一下。
网易公开课有很多相关的课程,你可以去看看。
windows系统有everything里面有很多高效的文件夹搜索引擎也有很多用excel读取的搜索引擎也有很多看你自己更喜欢哪种吧
数据挖掘就用ai吧,你现在学编程可能还有点早,建议买本书开始学。
谢邀!推荐两个简单方便速度快的。1、第一种方式为“步骤搜索”,它会给出你目标的步骤、关键词及背景(含义、相关性、延伸含义),再匹配上其他相关的步骤和关键词,就能定位到想要的数据。2、第二种方式为深度学习中的“快速特征提取”,利用人工特征方法,通过深度学习网络模型,能快速找到与训练数据相关的每一条观测数据,再匹配上前后的特征,就能找到目标数据的集合了。
自媒体文章发布齐全的采集平台之拓途网易网
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-05-17 05:16
自媒体 文章版本通常需要依赖采集平台进行评估,因此文章的采集平台选择也非常重要,让我们按照Tuotu数据来了解自媒体 文章发布有关采集平台的完整信息。
自媒体 文章发布完整的采集平台Tutu数据
Tuotu数据可提供准确的官方帐户相关数据,为官方帐户运营商提供有竞争力的产品分析服务,并为官方帐户广告提供官方帐户质量监控服务。
1、分析中包括超过2000万个正式帐户。
2、判断官方帐户是否有价值的最直观的方法是计算文章的阅读次数和喜欢次数。用肉眼比较文章是费时,费力和原创的。
3、 Tuotu可以分析无限量的数据并执行透视图,免费将其下载到Excel中,筛选高质量的正式帐户,并进行有竞争力的产品分析。
自媒体 文章发布了完整的采集平台
自媒体 文章发布了完整的 采集平台
是用于创建自媒体操作内容的辅助工具,它具有完整的功能,准确的数据并且非常实用。这里是其主要功能模块的简要介绍:
1、 自媒体库和爆文分析,这两个模块可以根据筛选要求爆文快速采集并获得每个平台的实时热点。
2、视频库:您可以根据不同的过滤条件在各个字段中获取热门视频。视频也可以批量下载采集,这是一个很好的视频资料库。
3、主题库:收录主要自媒体平台上的热门讨论主题,并且可以快速掌握热门主题并参与内容讨论。
4、小工具:收录许多非常有用的小功能,例如爆文标题自动生成,文章 原创程度检测,文本内容转换,单个视频下载等。
5、官方帐户模块:此部分收录微信官方帐户编辑器,公共数据和官方帐户列表。 文章编辑和排版后,也可以一键将其同步到官方帐户。
6、工作台:这是一个工具集合模块,包括视频批处理下载,图像和视频批处理水印工具等。
自媒体 文章发布了完整的采集平台的乐观帐户
乐观主义也是自媒体保温采集平台,其基本功能更加全面。
此工具具有以下功能
1、标题大师:我只能推荐一些爆文标题
2、热点跟踪:结合微博热点搜索列表和百度风云列表来采集热点。
3、 100,000 爆文:您可以根据需要组织,学习并整合到自己的资料中。
4、排版和材料:提供文章编辑和排版功能。
自媒体 文章发布了完整的采集平台
自媒体 文章发布了完整的采集平台新媒体管理员
New Media Manager是一个集成文章编辑,排版,操作和转换收入的平台。主要功能包括:
1、样式中心:收录从标题到图片和文本的各种模板。 查看全部
自媒体文章发布齐全的采集平台之拓途网易网
自媒体 文章版本通常需要依赖采集平台进行评估,因此文章的采集平台选择也非常重要,让我们按照Tuotu数据来了解自媒体 文章发布有关采集平台的完整信息。
自媒体 文章发布完整的采集平台Tutu数据
Tuotu数据可提供准确的官方帐户相关数据,为官方帐户运营商提供有竞争力的产品分析服务,并为官方帐户广告提供官方帐户质量监控服务。
1、分析中包括超过2000万个正式帐户。
2、判断官方帐户是否有价值的最直观的方法是计算文章的阅读次数和喜欢次数。用肉眼比较文章是费时,费力和原创的。
3、 Tuotu可以分析无限量的数据并执行透视图,免费将其下载到Excel中,筛选高质量的正式帐户,并进行有竞争力的产品分析。
自媒体 文章发布了完整的采集平台
自媒体 文章发布了完整的 采集平台
是用于创建自媒体操作内容的辅助工具,它具有完整的功能,准确的数据并且非常实用。这里是其主要功能模块的简要介绍:
1、 自媒体库和爆文分析,这两个模块可以根据筛选要求爆文快速采集并获得每个平台的实时热点。
2、视频库:您可以根据不同的过滤条件在各个字段中获取热门视频。视频也可以批量下载采集,这是一个很好的视频资料库。
3、主题库:收录主要自媒体平台上的热门讨论主题,并且可以快速掌握热门主题并参与内容讨论。
4、小工具:收录许多非常有用的小功能,例如爆文标题自动生成,文章 原创程度检测,文本内容转换,单个视频下载等。
5、官方帐户模块:此部分收录微信官方帐户编辑器,公共数据和官方帐户列表。 文章编辑和排版后,也可以一键将其同步到官方帐户。
6、工作台:这是一个工具集合模块,包括视频批处理下载,图像和视频批处理水印工具等。
自媒体 文章发布了完整的采集平台的乐观帐户
乐观主义也是自媒体保温采集平台,其基本功能更加全面。
此工具具有以下功能
1、标题大师:我只能推荐一些爆文标题
2、热点跟踪:结合微博热点搜索列表和百度风云列表来采集热点。
3、 100,000 爆文:您可以根据需要组织,学习并整合到自己的资料中。
4、排版和材料:提供文章编辑和排版功能。
自媒体 文章发布了完整的采集平台
自媒体 文章发布了完整的采集平台新媒体管理员
New Media Manager是一个集成文章编辑,排版,操作和转换收入的平台。主要功能包括:
1、样式中心:收录从标题到图片和文本的各种模板。
钉钉前端团队如何打造亿级流量的监控系统?
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-05-16 00:30
前言
这篇文章是从2020年4月25日开始,前端会谈第五次“前端监控”特别分享嘉宾-鼎鼎前端团队监控负责人,slashhuang的分享记录“鼎鼎前端如何设计前端实时分析和报警系统”。
开始输入文字
大家好,我是丁顶的蜡烛象,今天的主题是“丁顶前端团队如何构建1亿流量的监控系统”。
简介
首先,让我给您一个个人介绍。我于2013年毕业,并于2017年加入鼎鼎。加入鼎鼎时,我是P6。然后,通过前端监视,一些模块化代码包,效率和其他工具,我成功地获得了一些晋升机会。
关于鼎鼎的前端
自从2014年底成立以来,鼎鼎发展非常迅速,鼎鼎的前端监控也在不断发展。我们有数亿用户和数千万企业用户。前端产品包括Android,iOS,桌面,小程序,H5等,并且前端应用程序的发布还涵盖了完整版本和灰度版本。
十亿流量的挑战
对于这样一个十亿级别的平台,除了前端监视系统外,我相信许多小伙伴也有身体的感觉。为了确保整个DingTalk前端的稳定性,需要一些技术操作方法,包括某些人的条件。 。现在我们总共有100多个前端开发成员,我们的技术模块包括IM,地址簿,直播,教育,文档,硬件等,它们具有非常B-end的属性。
成就
让我首先谈谈我们的结果:100%涵盖了我们今天所有的h5和小型程序,并支持100多名前端人员的监视需求。前端监控的日志数量已达数百亿,被监控的市场数量超过100个。它可以实现一分钟感知在线问题和一分钟模糊问题的定位。在人力投资方面,它始终由两个负责人负责。在大多数情况下,我是负责整体监控情况的唯一负责人。因此,在人力投资方面,我们的成本相对较低。
上图中的两个趋势图是我们监视的主要产品结构。一个是我们的监视趋势图,另一个是我们用于承载各种业务的业务文件夹。同时,我们有一个生产环境的统一小程序,H5监控市场。
发展之路
接下来,我将讨论DingTalk的前端监视,我们如何开发系统并取得良好的结果。
考虑到很多朋友没有从事前端监视,我将首先讨论一些基本知识,以开发如何设计前端监视系统。
让我们看一下上面的代码,const创建一个对象,然后选择foot.a.b = c。您可以看到这是一段非常经典的NPE代码,这是一个空点异常,很容易出现在前端代码中。将在此处引发错误:**未捕获的TypeError:无法设置未定义的属性'b'**。
对于这样的错误,我们的前端监视系统如何在用户端发生此错误后捕获该错误,并在一分钟内找到它?让我们看一下传统方法是如何完成的:
我在这里的演示是使用image标签创建一个image标签并将其src设置为指向相应的日志服务器以发送相应的日志。
我们使用window.onerror捕获错误采集中的全局错误。然后,通过创建图像标签将捕获的错误发送到上图右侧的前端监视服务器。
上面的代码只是一个伪代码演示,我写的比较简单。
对于基于日志分析的传统监视系统,您必须首先知道日志的来源,因此,当每个日志位于前端时,我们都有一个应用程序ID 采集。让我尝试一下。将其命名为spmId,使用spmId标识日志源,然后将此日志存储到相应的监视服务器,从而完成一个非常简单的前后链接。
从日志出现采集,然后到闭环存储,这非常简单。实际上,在看到“ Weizhishu”之后,看到了这样一个简单的实现,然后丰富了日志类型,采集和存储功能更加强大,基本上,您可以构建一个相对简单的前端监视系统。
通常来说,一个简单的前端监视和分析系统需要包括以下三个维度:
在监视平台中,我们需要做一些日志存储,将监视日志提供给可视化平台服务器,并通过提供一些API服务来绘制上图。例如,第一个是接口成功率。
我认为在技术选择方面,对于许多只有一点节点或服务器端基础的前端学生来说,基本上可以制作一个简单的演示。但是,在看似功能齐全的系统中,前端监视是否存在任何问题?它可以满足具有数十亿流量的平台DingTalk的监视需求吗?
上图的左侧显示了开发人员访问前端监视的过程,包括开发阶段,测试阶段和在线阶段。在实施前端监视期间,我们要求所有开发人员在迭代启动该应用程序后至少30分钟内积极观察监视市场,并观察三个指标:
js errorperformanceapi成功率
对于我们目前由100多名前端同学组成的团队,人工成本是30分钟的100倍。同时,对于企业级产品DingTalk,我们对在线稳定性有很高的要求。在线故障的容忍度极低,因此需要对在线应用程序进行日常检查,因此人工成本很高。
从开发人员的经验来看,当开发人员检查监视时:首先,他将转到可视化分析平台以查看是否有任何错误日志。这里有一个非常重要的意义,就是我们的监视和分析平台看到的日志是“前端页面”的日志吗?
不一定。为什么?因为对于用户来说,这不只是打开前端页面,在此前端页面后面还有容器Web视图,应用程序容器,运算符等。
例如,我们的其中一个页面可以在微信,头条和丁顶的容器中打开。因此,您的采集日志源不仅是前端页面,而且还是容器Web视图。同时,我们将面对许多运营商。例如,我们经常在首页上看到一个广告,然后我们还有一些手机制造商,例如vivo,华为等,也将相关脚本插入到我们的页面中。因此,来自监视分析平台采集的日志不仅是前端日志,而且其采集的范围实际上是与前端页面相对应的用户终端日志。
通常,我们会遇到以下三种类型的干扰日志:
例如,以上是我们的在线应用之一,而js错误率可能是0. 08%。对于像丁丁这样的卷,此错误率会影响已经非常大的用户数量。
让我们看看相应的错误实际上是什么?脚本错误,未定义WeixinJSBridge,未定义toutiaoJSBridge,20 vivoNewsDetailPage,这些内容基本上可以从错误消息中判断出来,与业务错误无关。
因此,我们可以得出第一个结论,即前端监视所产生的某些错误与业务无关。这可能与许多人的看法相反。
让我们再看一个问题。左图是我们桌面的释放曲线。 DingTalk是中国乃至全球为数不多的桌面级平台之一。 DingTalk桌面基本上是一个星期或两个星期的迭代。由于桌面的前端代码采用脱机软件包的形式,因此更新和修复代码都很困难,并且对前端稳定性的要求很高。
对于我们今天的桌面终端,已经有100多个在线版本。许多版本报告的日志使用相同的应用程序ID。我们如何进行分层监控和在线流量监控?如何对不均匀性进行分层监控,以免被低流量释放监控所淹没?
这些问题在DingTalk业务场景中经常遇到。我们的监视粒度需要适应前端版本,并且受监视的日志需要支持更多维度。例如,以这两个变量为单位监视应用程序和发行版本。
让我们看看另一种情况。鼎鼎有数百个前端应用程序。每个应用程序都会报警一次,这非常夸张。基本上,每天在警报组中有500多个日志。屏幕刷新现象非常严重,并且有很多错误。这是一条长尾错误。也就是说,尽管它具有警报,但不需要进行修改等等。出现长尾错误的原因是,尽管我已解决问题,但用户可能无法完全访问最新版本。
因此,结论3是我们的监控操作的人工成本非常高。前端监视的要求不仅要报告警报,还需要您的警报既直观又实时,并支持一些短期关闭和错误。过滤等。
在阅读了上述三种情况后,让我们看一下如何设计可服务3亿卷的监视系统。
首先,我们首先定义监视设计的目标,并确定企业级前端监视需要完成的工作:一分钟感知,五分钟定位和十分钟恢复。我们将此监视系统称为2. 0系统。
对于前端监控2. 0,我们在1. 0的基础上定义了以下功能级别。
第一个是保持与实际业务的距离,降低人工成本,并使业务各方以较低的成本进行干预。同时,对于警报系统,需要快速警报和准警报,并且支持自定义警报。我们在内部设置了基线,即前端监视精度必须达到90%以上,每个人的人工成本必须减少20分钟,并且警报和市场必须能够支持自定义配置。
上图是整体监视组件的布置方案。左侧是图例。蓝色部分代表1. 0的监视部分,深绿色部分代表2. 0的新监视部分。
自定义采集
第一个在日志采集端,除了采集常规业务数据和监控数据外,它还支持自定义采集。
智能分析
分析智能增加了自定义分析的能力。
实时警报
在实时警报方面,已添加了在线1分钟警报和5分钟本地化要求。
最关键的技术实现
同样,蓝色部分是原创1. 0的系统,深绿色部分是我们的新系统。我们会发现在日志采集和日志使用者方面,我们添加了一个名为“日志双重写入”的模块。
一个日志由两个系统消耗,一个系统用于实时警报,另一个系统用于分析:
许多学生认为日志双写实际上是对非常大的系统的浪费。一个日志由两个系统消耗。实际上,DingTalk前端监视使用的是阿里非常成熟的日志使用系统和基础架构。通过日志分配快速消耗了两个通道,使分钟计算系统在整个监控系统中的布置处于前端,满足了1分钟报警的要求,这是我们在这一领域的核心技术思想。
上图中紫色虚线下方是我们的用户角度。用户触摸了两部分。第一部分是前端监视SDK,我们有H5和applet SDK,第二部分是平台,包括分析平台和警报平台。
真实案例
让我们看一个真实的案例。用户遇到了两个js错误。这两个js错误是前端的经典NPE错误。
第一次发生在iPad +百度浏览器上。第二个发生在Android +标题网页视图中。结果,我们会发现客户报告了两种错误:
实际错误:未被捕获的TypeError:无法设置未定义的属性'b'。主机注入了很多干扰信息,例如百度浏览器将注入未定义的MyAppHrefLink。
也许很多学生没有观察到它。我们仔细检查了一下。百度浏览器会注入未定义的MyAppHrefLink。标题还将注入一些标题jsBridge。
日志到达服务器后,我们首先清理日志以过滤出主机的所有干扰日志,以确保我们的警报系统是消费者实际业务的日志错误。这是黄色区域中的第一个模块:日志清理
接下来,我们将对日志进行分组,将应用程序A的日志spmId = A和应用程序B进行分组,并对应用程序ID A和B的日志进行分组。对过滤后的日志进行实时计算。
在此步骤之后,日志流将被传输到警报索引项以进行实时计算。警报规则引擎将向与Map Reduce相对应的机器发出相关指令,以进行一些处理。
例如,JS错误失败率= JS错误日志数除以PV数。当日志的计算结果大于6%时,将发出“叮叮”组警报;当故障率大于15%时,将发出SMS警报。
叮叮前端监控2. 0
监控日志
通过对api成功率,js错误失败率,pv数据等各种指标应用相同的过程,我们可以构建一个在分钟计算系统中满足1分钟感知的监控系统。
警报系统架构
关于警报系统,上图是我们阿里巴巴研发部门的非常经典的监视系统。有兴趣的学生可以在infoQ上搜索sunfire,以查看有关该体系结构的更详细的介绍。我在这里不会做太多事情。
总体日志结构摘要
基本上,这就是我今天要分享的内容。从1. 0演变为2. 0的过程中,DingTalk前端监控是我们的思维方式和着陆方式。在这里,我会给您一个简短的摘要:
最关键的技术思想是预先安排日志警报组件。我们的实现是将日志双重写入分析系统和警报系统。在警报平台中,支持警报规则引擎,因此可以自定义警报,并对警报进行分级。对于前端,我们不仅是前端页面,我们还面临着用户终端。结束语
好的,这就是我今天要分享的内容。 DingTalk的前端监控如何以1亿规模,100多个前端和600多个前端页面来增强DingTalk的在线稳定性。
以下是DingTalk前端的技术专栏。有知乎列和掘金列。我们一直在招聘人才。欢迎与我联系。 查看全部
钉钉前端团队如何打造亿级流量的监控系统?
前言
这篇文章是从2020年4月25日开始,前端会谈第五次“前端监控”特别分享嘉宾-鼎鼎前端团队监控负责人,slashhuang的分享记录“鼎鼎前端如何设计前端实时分析和报警系统”。
开始输入文字
大家好,我是丁顶的蜡烛象,今天的主题是“丁顶前端团队如何构建1亿流量的监控系统”。
简介
首先,让我给您一个个人介绍。我于2013年毕业,并于2017年加入鼎鼎。加入鼎鼎时,我是P6。然后,通过前端监视,一些模块化代码包,效率和其他工具,我成功地获得了一些晋升机会。
关于鼎鼎的前端
自从2014年底成立以来,鼎鼎发展非常迅速,鼎鼎的前端监控也在不断发展。我们有数亿用户和数千万企业用户。前端产品包括Android,iOS,桌面,小程序,H5等,并且前端应用程序的发布还涵盖了完整版本和灰度版本。
十亿流量的挑战
对于这样一个十亿级别的平台,除了前端监视系统外,我相信许多小伙伴也有身体的感觉。为了确保整个DingTalk前端的稳定性,需要一些技术操作方法,包括某些人的条件。 。现在我们总共有100多个前端开发成员,我们的技术模块包括IM,地址簿,直播,教育,文档,硬件等,它们具有非常B-end的属性。
成就
让我首先谈谈我们的结果:100%涵盖了我们今天所有的h5和小型程序,并支持100多名前端人员的监视需求。前端监控的日志数量已达数百亿,被监控的市场数量超过100个。它可以实现一分钟感知在线问题和一分钟模糊问题的定位。在人力投资方面,它始终由两个负责人负责。在大多数情况下,我是负责整体监控情况的唯一负责人。因此,在人力投资方面,我们的成本相对较低。
上图中的两个趋势图是我们监视的主要产品结构。一个是我们的监视趋势图,另一个是我们用于承载各种业务的业务文件夹。同时,我们有一个生产环境的统一小程序,H5监控市场。
发展之路
接下来,我将讨论DingTalk的前端监视,我们如何开发系统并取得良好的结果。
考虑到很多朋友没有从事前端监视,我将首先讨论一些基本知识,以开发如何设计前端监视系统。
让我们看一下上面的代码,const创建一个对象,然后选择foot.a.b = c。您可以看到这是一段非常经典的NPE代码,这是一个空点异常,很容易出现在前端代码中。将在此处引发错误:**未捕获的TypeError:无法设置未定义的属性'b'**。
对于这样的错误,我们的前端监视系统如何在用户端发生此错误后捕获该错误,并在一分钟内找到它?让我们看一下传统方法是如何完成的:
我在这里的演示是使用image标签创建一个image标签并将其src设置为指向相应的日志服务器以发送相应的日志。
我们使用window.onerror捕获错误采集中的全局错误。然后,通过创建图像标签将捕获的错误发送到上图右侧的前端监视服务器。
上面的代码只是一个伪代码演示,我写的比较简单。
对于基于日志分析的传统监视系统,您必须首先知道日志的来源,因此,当每个日志位于前端时,我们都有一个应用程序ID 采集。让我尝试一下。将其命名为spmId,使用spmId标识日志源,然后将此日志存储到相应的监视服务器,从而完成一个非常简单的前后链接。
从日志出现采集,然后到闭环存储,这非常简单。实际上,在看到“ Weizhishu”之后,看到了这样一个简单的实现,然后丰富了日志类型,采集和存储功能更加强大,基本上,您可以构建一个相对简单的前端监视系统。
通常来说,一个简单的前端监视和分析系统需要包括以下三个维度:
在监视平台中,我们需要做一些日志存储,将监视日志提供给可视化平台服务器,并通过提供一些API服务来绘制上图。例如,第一个是接口成功率。
我认为在技术选择方面,对于许多只有一点节点或服务器端基础的前端学生来说,基本上可以制作一个简单的演示。但是,在看似功能齐全的系统中,前端监视是否存在任何问题?它可以满足具有数十亿流量的平台DingTalk的监视需求吗?
上图的左侧显示了开发人员访问前端监视的过程,包括开发阶段,测试阶段和在线阶段。在实施前端监视期间,我们要求所有开发人员在迭代启动该应用程序后至少30分钟内积极观察监视市场,并观察三个指标:
js errorperformanceapi成功率
对于我们目前由100多名前端同学组成的团队,人工成本是30分钟的100倍。同时,对于企业级产品DingTalk,我们对在线稳定性有很高的要求。在线故障的容忍度极低,因此需要对在线应用程序进行日常检查,因此人工成本很高。
从开发人员的经验来看,当开发人员检查监视时:首先,他将转到可视化分析平台以查看是否有任何错误日志。这里有一个非常重要的意义,就是我们的监视和分析平台看到的日志是“前端页面”的日志吗?
不一定。为什么?因为对于用户来说,这不只是打开前端页面,在此前端页面后面还有容器Web视图,应用程序容器,运算符等。
例如,我们的其中一个页面可以在微信,头条和丁顶的容器中打开。因此,您的采集日志源不仅是前端页面,而且还是容器Web视图。同时,我们将面对许多运营商。例如,我们经常在首页上看到一个广告,然后我们还有一些手机制造商,例如vivo,华为等,也将相关脚本插入到我们的页面中。因此,来自监视分析平台采集的日志不仅是前端日志,而且其采集的范围实际上是与前端页面相对应的用户终端日志。
通常,我们会遇到以下三种类型的干扰日志:
例如,以上是我们的在线应用之一,而js错误率可能是0. 08%。对于像丁丁这样的卷,此错误率会影响已经非常大的用户数量。
让我们看看相应的错误实际上是什么?脚本错误,未定义WeixinJSBridge,未定义toutiaoJSBridge,20 vivoNewsDetailPage,这些内容基本上可以从错误消息中判断出来,与业务错误无关。
因此,我们可以得出第一个结论,即前端监视所产生的某些错误与业务无关。这可能与许多人的看法相反。
让我们再看一个问题。左图是我们桌面的释放曲线。 DingTalk是中国乃至全球为数不多的桌面级平台之一。 DingTalk桌面基本上是一个星期或两个星期的迭代。由于桌面的前端代码采用脱机软件包的形式,因此更新和修复代码都很困难,并且对前端稳定性的要求很高。
对于我们今天的桌面终端,已经有100多个在线版本。许多版本报告的日志使用相同的应用程序ID。我们如何进行分层监控和在线流量监控?如何对不均匀性进行分层监控,以免被低流量释放监控所淹没?
这些问题在DingTalk业务场景中经常遇到。我们的监视粒度需要适应前端版本,并且受监视的日志需要支持更多维度。例如,以这两个变量为单位监视应用程序和发行版本。
让我们看看另一种情况。鼎鼎有数百个前端应用程序。每个应用程序都会报警一次,这非常夸张。基本上,每天在警报组中有500多个日志。屏幕刷新现象非常严重,并且有很多错误。这是一条长尾错误。也就是说,尽管它具有警报,但不需要进行修改等等。出现长尾错误的原因是,尽管我已解决问题,但用户可能无法完全访问最新版本。
因此,结论3是我们的监控操作的人工成本非常高。前端监视的要求不仅要报告警报,还需要您的警报既直观又实时,并支持一些短期关闭和错误。过滤等。
在阅读了上述三种情况后,让我们看一下如何设计可服务3亿卷的监视系统。
首先,我们首先定义监视设计的目标,并确定企业级前端监视需要完成的工作:一分钟感知,五分钟定位和十分钟恢复。我们将此监视系统称为2. 0系统。
对于前端监控2. 0,我们在1. 0的基础上定义了以下功能级别。
第一个是保持与实际业务的距离,降低人工成本,并使业务各方以较低的成本进行干预。同时,对于警报系统,需要快速警报和准警报,并且支持自定义警报。我们在内部设置了基线,即前端监视精度必须达到90%以上,每个人的人工成本必须减少20分钟,并且警报和市场必须能够支持自定义配置。
上图是整体监视组件的布置方案。左侧是图例。蓝色部分代表1. 0的监视部分,深绿色部分代表2. 0的新监视部分。
自定义采集
第一个在日志采集端,除了采集常规业务数据和监控数据外,它还支持自定义采集。
智能分析
分析智能增加了自定义分析的能力。
实时警报
在实时警报方面,已添加了在线1分钟警报和5分钟本地化要求。
最关键的技术实现
同样,蓝色部分是原创1. 0的系统,深绿色部分是我们的新系统。我们会发现在日志采集和日志使用者方面,我们添加了一个名为“日志双重写入”的模块。
一个日志由两个系统消耗,一个系统用于实时警报,另一个系统用于分析:
许多学生认为日志双写实际上是对非常大的系统的浪费。一个日志由两个系统消耗。实际上,DingTalk前端监视使用的是阿里非常成熟的日志使用系统和基础架构。通过日志分配快速消耗了两个通道,使分钟计算系统在整个监控系统中的布置处于前端,满足了1分钟报警的要求,这是我们在这一领域的核心技术思想。
上图中紫色虚线下方是我们的用户角度。用户触摸了两部分。第一部分是前端监视SDK,我们有H5和applet SDK,第二部分是平台,包括分析平台和警报平台。
真实案例
让我们看一个真实的案例。用户遇到了两个js错误。这两个js错误是前端的经典NPE错误。
第一次发生在iPad +百度浏览器上。第二个发生在Android +标题网页视图中。结果,我们会发现客户报告了两种错误:
实际错误:未被捕获的TypeError:无法设置未定义的属性'b'。主机注入了很多干扰信息,例如百度浏览器将注入未定义的MyAppHrefLink。
也许很多学生没有观察到它。我们仔细检查了一下。百度浏览器会注入未定义的MyAppHrefLink。标题还将注入一些标题jsBridge。
日志到达服务器后,我们首先清理日志以过滤出主机的所有干扰日志,以确保我们的警报系统是消费者实际业务的日志错误。这是黄色区域中的第一个模块:日志清理
接下来,我们将对日志进行分组,将应用程序A的日志spmId = A和应用程序B进行分组,并对应用程序ID A和B的日志进行分组。对过滤后的日志进行实时计算。
在此步骤之后,日志流将被传输到警报索引项以进行实时计算。警报规则引擎将向与Map Reduce相对应的机器发出相关指令,以进行一些处理。
例如,JS错误失败率= JS错误日志数除以PV数。当日志的计算结果大于6%时,将发出“叮叮”组警报;当故障率大于15%时,将发出SMS警报。
叮叮前端监控2. 0
监控日志
通过对api成功率,js错误失败率,pv数据等各种指标应用相同的过程,我们可以构建一个在分钟计算系统中满足1分钟感知的监控系统。
警报系统架构
关于警报系统,上图是我们阿里巴巴研发部门的非常经典的监视系统。有兴趣的学生可以在infoQ上搜索sunfire,以查看有关该体系结构的更详细的介绍。我在这里不会做太多事情。
总体日志结构摘要
基本上,这就是我今天要分享的内容。从1. 0演变为2. 0的过程中,DingTalk前端监控是我们的思维方式和着陆方式。在这里,我会给您一个简短的摘要:
最关键的技术思想是预先安排日志警报组件。我们的实现是将日志双重写入分析系统和警报系统。在警报平台中,支持警报规则引擎,因此可以自定义警报,并对警报进行分级。对于前端,我们不仅是前端页面,我们还面临着用户终端。结束语
好的,这就是我今天要分享的内容。 DingTalk的前端监控如何以1亿规模,100多个前端和600多个前端页面来增强DingTalk的在线稳定性。
以下是DingTalk前端的技术专栏。有知乎列和掘金列。我们一直在招聘人才。欢迎与我联系。

