
实时文章采集
实时文章采集(WordPress自动采集软件页面简洁、操作简单,不需要掌握专业的规则配置 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-08 02:09
)
WordPress自动采集软件页面简洁易操作。无需掌握专业的规则配置和高级seo知识即可使用。无论是WordPresscms、dedecms、ABCcms还是小旋风cms都可以使用。软件还内置翻译发布推送、数据查看等功能。让我们的WordPress站长通过软件分析数据,实时调整优化细节。
WordPress自动采集软件可以根据我们输入的关键词在全网各大平台进行内容采集。为提高搜索范围和准确率,支持根据关键词搜索热门下拉词。支持在下载过程中进行敏感的 *words 过滤和 文章 清理。采集内容以多种格式(TXT、HTML 和漩涡样式)保存。它支持保留标签和图像本地化等功能,并内置翻译功能。有道、百度、谷歌以及自带的翻译功能都可以使用。
WordPress的自动采集软件网站优化可以大大减轻我们站长的工作强度。定期发布采集可以让我们全天候挂机,网站一个好的“作息时间”可以让我们每天网站更新内容,这也是一种友好的行为对于蜘蛛。
当然,仅靠内容是不够的,我们需要对内容进行整理,提高内容质量,吸引用户,逐步完善我们的收录,WordPress自动采集软件可以通过以下方式优化我们的内容积分,实现我们的网站fast收录,提升排名。
网站内容优化
1、文章采集货源质量保证(大平台、热搜词)
2、采集保留内容标签
3、内置翻译功能(英汉、繁简、简体到火星)
4、文章清洗(号码、网址、机构名清洗)
3、关键词保留(伪原创不会影响关键词,保证核心关键词显示)
5、关键词插入标题和文章
6、标题、内容伪原创
7、设置内容匹配标题(让内容完全匹配标题)
8、设置关键词自动内链(自动从文章内容中的关键词生成内链)
9、设置定时释放(24小时挂机)
一个好的文章离不开图片的配合。合理插入我们的文章相关图片,会大大降低用户理解的难度。一张好的图片有时可以很抢眼,反而让文字成为一种点缀。为 网站 图片添加 ALT 标签还可以让搜索引擎快速识别图片。WordPress 自动 采集 软件图像有哪些优化?
网站图像优化
1、图片云存储(支持七牛、阿里、腾讯等云平台)/本地化
2、给图片添加alt标签
3、图片替换原图
4、图片水印/去水
5、图片按频率插入到文本中
三、网站管理优化
WordPress自动采集软件具有全程优化管理功能。采集、文本清洗、翻译、伪原创、发布、推送的全流程管理都可以在软件中实现,并提供各阶段任务的进度和反馈等信息可以实时查看任务的成败。整合cms网站收录、权重、蜘蛛等绑定信息,自动生成曲线供我们分析。
作为一个SEO从业者,我们必须足够细心,才能做好SEO。无论是优化文章内容还是通过alt标签描述图片,每一个小地方都可能是我们优化的方向。在我的SEO工作中,一丝不苟、善于发现、坚持不懈是做好网站工作的必要因素。
查看全部
实时文章采集(WordPress自动采集软件页面简洁、操作简单,不需要掌握专业的规则配置
)
WordPress自动采集软件页面简洁易操作。无需掌握专业的规则配置和高级seo知识即可使用。无论是WordPresscms、dedecms、ABCcms还是小旋风cms都可以使用。软件还内置翻译发布推送、数据查看等功能。让我们的WordPress站长通过软件分析数据,实时调整优化细节。

WordPress自动采集软件可以根据我们输入的关键词在全网各大平台进行内容采集。为提高搜索范围和准确率,支持根据关键词搜索热门下拉词。支持在下载过程中进行敏感的 *words 过滤和 文章 清理。采集内容以多种格式(TXT、HTML 和漩涡样式)保存。它支持保留标签和图像本地化等功能,并内置翻译功能。有道、百度、谷歌以及自带的翻译功能都可以使用。
WordPress的自动采集软件网站优化可以大大减轻我们站长的工作强度。定期发布采集可以让我们全天候挂机,网站一个好的“作息时间”可以让我们每天网站更新内容,这也是一种友好的行为对于蜘蛛。
当然,仅靠内容是不够的,我们需要对内容进行整理,提高内容质量,吸引用户,逐步完善我们的收录,WordPress自动采集软件可以通过以下方式优化我们的内容积分,实现我们的网站fast收录,提升排名。
网站内容优化
1、文章采集货源质量保证(大平台、热搜词)
2、采集保留内容标签
3、内置翻译功能(英汉、繁简、简体到火星)
4、文章清洗(号码、网址、机构名清洗)
3、关键词保留(伪原创不会影响关键词,保证核心关键词显示)
5、关键词插入标题和文章
6、标题、内容伪原创
7、设置内容匹配标题(让内容完全匹配标题)
8、设置关键词自动内链(自动从文章内容中的关键词生成内链)
9、设置定时释放(24小时挂机)
一个好的文章离不开图片的配合。合理插入我们的文章相关图片,会大大降低用户理解的难度。一张好的图片有时可以很抢眼,反而让文字成为一种点缀。为 网站 图片添加 ALT 标签还可以让搜索引擎快速识别图片。WordPress 自动 采集 软件图像有哪些优化?
网站图像优化
1、图片云存储(支持七牛、阿里、腾讯等云平台)/本地化
2、给图片添加alt标签
3、图片替换原图
4、图片水印/去水
5、图片按频率插入到文本中
三、网站管理优化
WordPress自动采集软件具有全程优化管理功能。采集、文本清洗、翻译、伪原创、发布、推送的全流程管理都可以在软件中实现,并提供各阶段任务的进度和反馈等信息可以实时查看任务的成败。整合cms网站收录、权重、蜘蛛等绑定信息,自动生成曲线供我们分析。
作为一个SEO从业者,我们必须足够细心,才能做好SEO。无论是优化文章内容还是通过alt标签描述图片,每一个小地方都可能是我们优化的方向。在我的SEO工作中,一丝不苟、善于发现、坚持不懈是做好网站工作的必要因素。

实时文章采集( SEO技术分享2022-03-04如何让采集站快速收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-08 02:06
SEO技术分享2022-03-04如何让采集站快速收录以及关键词排名)
采集我还能做吗?让网站采集的网站快速收录发布工具
SEO技术分享2022-03-04
如何让采集站快收录和关键词排名,相信各位站长一定遇到过这种情况,采集站收录波动太大, 和 关键词 不稳定的排名。尤其是刚刚冲上首页的关键词经常掉出首页,那么如何稳定首页的排名关键词又如何让采集站得快收录@ >。
一、观察网站收录情况
很多站长在关键词冲到首页后开始不关注网站的收录。千万不能马虎,要定期检查网站收录是否正常,只有保持一定的收录,关键词的排名才能稳定。顺便在主页上观察一下同事,了解他们网站的优点,放到我的网站中。
二、网站更新频率
你为什么这么说?当您点击主页时,您每天都会发布内容。到首页后还需要发布吗?很多站长认为这没有必要,但实际上是一个错误的判断。前期我们发布了内容,为更多网站收录打下基础。后期发布内容的目的是为了保持一定的频率,这样既可以稳定快照的更新频率,又可以防止搜索引擎将我们判断为死站网站。
我们可以通过网站采集软件实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,不需要专业技能,只需几个简单的步骤。轻松的采集内容数据,用户只需对网站采集软件进行简单设置,网站采集软件根据用户设置< @关键词 准确采集文章,以确保与行业文章保持一致。采集 文章 from 采集 可以选择在本地保存更改,也可以选择自动伪原创 然后发布。
和其他网站采集软件相比,这个网站采集软件基本没有规则,更别说花很多时间学习正则表达式或者html标签了,一分钟就到上手,只需输入关键词即可实现采集(网站采集软件也自带关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个cms采集插件还配备了很多SEO功能,通过采集伪原创软件发布也可以提升很多SEO优化。
1、网站全网推送(主动提交链接至百度/360/搜狗/神马/今日头条/bing/Google)
2、自动匹配图片(文章如果内容中没有图片,则自动配置相关图片) 设置自动下载图片并保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
<p>7、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前采集 查看全部
实时文章采集(
SEO技术分享2022-03-04如何让采集站快速收录以及关键词排名)
采集我还能做吗?让网站采集的网站快速收录发布工具
SEO技术分享2022-03-04
如何让采集站快收录和关键词排名,相信各位站长一定遇到过这种情况,采集站收录波动太大, 和 关键词 不稳定的排名。尤其是刚刚冲上首页的关键词经常掉出首页,那么如何稳定首页的排名关键词又如何让采集站得快收录@ >。
一、观察网站收录情况
很多站长在关键词冲到首页后开始不关注网站的收录。千万不能马虎,要定期检查网站收录是否正常,只有保持一定的收录,关键词的排名才能稳定。顺便在主页上观察一下同事,了解他们网站的优点,放到我的网站中。
二、网站更新频率
你为什么这么说?当您点击主页时,您每天都会发布内容。到首页后还需要发布吗?很多站长认为这没有必要,但实际上是一个错误的判断。前期我们发布了内容,为更多网站收录打下基础。后期发布内容的目的是为了保持一定的频率,这样既可以稳定快照的更新频率,又可以防止搜索引擎将我们判断为死站网站。
我们可以通过网站采集软件实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,不需要专业技能,只需几个简单的步骤。轻松的采集内容数据,用户只需对网站采集软件进行简单设置,网站采集软件根据用户设置< @关键词 准确采集文章,以确保与行业文章保持一致。采集 文章 from 采集 可以选择在本地保存更改,也可以选择自动伪原创 然后发布。
和其他网站采集软件相比,这个网站采集软件基本没有规则,更别说花很多时间学习正则表达式或者html标签了,一分钟就到上手,只需输入关键词即可实现采集(网站采集软件也自带关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个cms采集插件还配备了很多SEO功能,通过采集伪原创软件发布也可以提升很多SEO优化。
1、网站全网推送(主动提交链接至百度/360/搜狗/神马/今日头条/bing/Google)
2、自动匹配图片(文章如果内容中没有图片,则自动配置相关图片) 设置自动下载图片并保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
<p>7、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前采集
实时文章采集(如何采集豆瓣热门电影,实时文章采集实践十技巧分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-03-08 02:02
实时文章采集
一)、动态文章采集
二)、基于目录文章采集
三)、实时文章采集
四)、多维目录文章采集
五)、实时文章采集之常用工具
六)、文章链接采集
七)、基于网页采集
八)、文章采集指南
九)、文章采集实践
十)
不如弄一个小型excel表格吧,就记录每天每小时大家都发表的文章都是什么类型的什么风格的。当然这里面很多名词都是网络上搜不到的。再配上一些关键词,关键词间隔需要注意调整。毕竟很多说高质量新闻稿是软文的。
每天每小时都重复性发明几条文章
本专栏上篇文章跟大家分享了如何采集豆瓣热门电影,本篇文章要谈谈自己写过的一篇采集文章,
有很多要注意的很难写一下,自己感觉,新闻跟帖不一样,条数不多,关注人数固定,但是内容大都有些广,数量多,文本样式不固定,所以可能无法有效的聚合文本特征,太多的网站会导致内容过于相似,有可能会影响读者,但是要注意需要控制好一个段落的数量,不然读者看到长的同一篇新闻跟帖,未必会关注细节!当然特别喜欢某一个事情或者细节的人,你还是要多关注他的!。
我是用的qq发布,自己点发布之后,再搜索一下别人的发布时间,有人发布可以随时写随时发布,不过需要你写入的词, 查看全部
实时文章采集(如何采集豆瓣热门电影,实时文章采集实践十技巧分享)
实时文章采集
一)、动态文章采集
二)、基于目录文章采集
三)、实时文章采集
四)、多维目录文章采集
五)、实时文章采集之常用工具
六)、文章链接采集
七)、基于网页采集
八)、文章采集指南
九)、文章采集实践
十)
不如弄一个小型excel表格吧,就记录每天每小时大家都发表的文章都是什么类型的什么风格的。当然这里面很多名词都是网络上搜不到的。再配上一些关键词,关键词间隔需要注意调整。毕竟很多说高质量新闻稿是软文的。
每天每小时都重复性发明几条文章
本专栏上篇文章跟大家分享了如何采集豆瓣热门电影,本篇文章要谈谈自己写过的一篇采集文章,
有很多要注意的很难写一下,自己感觉,新闻跟帖不一样,条数不多,关注人数固定,但是内容大都有些广,数量多,文本样式不固定,所以可能无法有效的聚合文本特征,太多的网站会导致内容过于相似,有可能会影响读者,但是要注意需要控制好一个段落的数量,不然读者看到长的同一篇新闻跟帖,未必会关注细节!当然特别喜欢某一个事情或者细节的人,你还是要多关注他的!。
我是用的qq发布,自己点发布之后,再搜索一下别人的发布时间,有人发布可以随时写随时发布,不过需要你写入的词,
实时文章采集(一个好的网站采集软件认为需要以下几点功能:以下几点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-06 15:12
)
网站采集大家都比较熟悉,通过网站采集我们可以把自己感兴趣的网站数据下载到自己的网站或者放一些内容其他人 网站 被保存到他们自己的服务器。通过网站采集可以得到我们想要的相关数据、文章、图片等。这些材料经过加工。可以成为我们自己的网站内容,维护我们的网站持续更新。
网站采集有很多方式供我们选择,无论是采集插件,采集软件,还是cms自带采集函数,我们总能在网上找到各种采集器。一个好的网站采集软件博主认为需要具备以下特点:
一、高效简洁
网站采集可以为我们提供非常方便的采集服务,但是我们很多站长不知道如何配置采集规则,所以从大部分用户体验出发,易于操作,采集稳定快速的软件是大多数站长喜欢的。
二、采集精准内容
网站采集只追求速度肯定是不够的。一个好的采集软件需要有精确的采集规则。它可以为我们的用户提供可靠准确的采集素材,方便我们创作。
三、保留原标签
网站标签保留可以在伪原创时为我们提供更好的用户体验。无论是数据提取还是文章的重新创建,都将帮助我们创建自己的文章。
四、图像本地化
由于缺少此功能,我们的许多 采集 图像会降低我们的 原创 度数。通过图像定位,可以减轻替换原图的工作强度,加强我们文章的原创。最好添加自己的 ALT 标签来替换图像。
网站采集可以为我们提供素材,这有助于我们的网站内容不断更新,但是对于网站的建设来说肯定是不够的。我们网站的主要目的是为了更好的服务客户,从而增强用户粘性,完成流量转化。所以在做网站的时候,首先要考虑的是用户的需求。只有用户才有评价网站质量的权利。如果用户说是,网站 才是真正的好东西。所以,一定要了解用户的需求,把用户需求放在首位,参与网站的制作。只有当你的网站拥有了客户真正想要的东西,你的网站才会成功,才能称得上是合格的网站。
网站Data不仅可以为我们提供内容素材,还可以通过采集data帮助我们分析市场和用户需求:
一、满足用户需求
网站采集获得的大数据让我们了解用户的显性需求,但也有一些客户的隐性需求,需要我们直接联系用户了解更多。所以,在做网站之前,要多做市场调研,一定要多接触用户,了解他们的需求和痛点。从一开始就要有这个意识,靠采集数据分析还是片面的。在一个想法开始之前与客户进行深入的沟通是最重要的。
二、增强网站实用程序
数据采集也可以让我们获得精准的用户画像,让我们了解网站的用户,所以网站的建设一定要实用、有针对性,让网站有自己的核心竞争力。比如年轻人的博客肯定需要我们的网页清晰整洁,动画网站肯定需要色彩来增强视觉冲击力。所以,迎合用户的喜好,让用户时时享受和感觉有用,这是一个基本的成功网站。
三、好网站经得起时间的考验
网站 的质量将经受时间的考验。一个非常好的 网站 可以经受住任何考验。过了一段时间,这个网站还是很火的,说明这个网站当然比较成功。如果他想继续成功,他必须在后期有完美的工作。
网站采集可以为我们提供网站内容的素材。它还可以为我们提供行业分析所需的数据。只要我们善用它,就可以创建自己的网站。
查看全部
实时文章采集(一个好的网站采集软件认为需要以下几点功能:以下几点
)
网站采集大家都比较熟悉,通过网站采集我们可以把自己感兴趣的网站数据下载到自己的网站或者放一些内容其他人 网站 被保存到他们自己的服务器。通过网站采集可以得到我们想要的相关数据、文章、图片等。这些材料经过加工。可以成为我们自己的网站内容,维护我们的网站持续更新。

网站采集有很多方式供我们选择,无论是采集插件,采集软件,还是cms自带采集函数,我们总能在网上找到各种采集器。一个好的网站采集软件博主认为需要具备以下特点:

一、高效简洁
网站采集可以为我们提供非常方便的采集服务,但是我们很多站长不知道如何配置采集规则,所以从大部分用户体验出发,易于操作,采集稳定快速的软件是大多数站长喜欢的。
二、采集精准内容
网站采集只追求速度肯定是不够的。一个好的采集软件需要有精确的采集规则。它可以为我们的用户提供可靠准确的采集素材,方便我们创作。

三、保留原标签
网站标签保留可以在伪原创时为我们提供更好的用户体验。无论是数据提取还是文章的重新创建,都将帮助我们创建自己的文章。
四、图像本地化
由于缺少此功能,我们的许多 采集 图像会降低我们的 原创 度数。通过图像定位,可以减轻替换原图的工作强度,加强我们文章的原创。最好添加自己的 ALT 标签来替换图像。

网站采集可以为我们提供素材,这有助于我们的网站内容不断更新,但是对于网站的建设来说肯定是不够的。我们网站的主要目的是为了更好的服务客户,从而增强用户粘性,完成流量转化。所以在做网站的时候,首先要考虑的是用户的需求。只有用户才有评价网站质量的权利。如果用户说是,网站 才是真正的好东西。所以,一定要了解用户的需求,把用户需求放在首位,参与网站的制作。只有当你的网站拥有了客户真正想要的东西,你的网站才会成功,才能称得上是合格的网站。

网站Data不仅可以为我们提供内容素材,还可以通过采集data帮助我们分析市场和用户需求:
一、满足用户需求
网站采集获得的大数据让我们了解用户的显性需求,但也有一些客户的隐性需求,需要我们直接联系用户了解更多。所以,在做网站之前,要多做市场调研,一定要多接触用户,了解他们的需求和痛点。从一开始就要有这个意识,靠采集数据分析还是片面的。在一个想法开始之前与客户进行深入的沟通是最重要的。

二、增强网站实用程序
数据采集也可以让我们获得精准的用户画像,让我们了解网站的用户,所以网站的建设一定要实用、有针对性,让网站有自己的核心竞争力。比如年轻人的博客肯定需要我们的网页清晰整洁,动画网站肯定需要色彩来增强视觉冲击力。所以,迎合用户的喜好,让用户时时享受和感觉有用,这是一个基本的成功网站。
三、好网站经得起时间的考验
网站 的质量将经受时间的考验。一个非常好的 网站 可以经受住任何考验。过了一段时间,这个网站还是很火的,说明这个网站当然比较成功。如果他想继续成功,他必须在后期有完美的工作。
网站采集可以为我们提供网站内容的素材。它还可以为我们提供行业分析所需的数据。只要我们善用它,就可以创建自己的网站。

实时文章采集(小说网站怎么做?小说规则怎么写?其中的原因)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-03-05 05:00
小说网站怎么办?小说的规则怎么写?大量采集小说网站和免费采集工具,让关键词排名网站快速收录。关键词搜索引擎首页的稳定性是我们网站优化的目标,但是有的网站可以做到,有的网站一直没有效果。无效的原因有很多。今天小编就为大家分析一下原因。
一、服务器原因
服务器是网站 的基础,也是必要的设施之一。选择服务器时,建议选择官方备案的服务器。糟糕的服务器通常会导致 网站 打开缓慢或无法访问。发生这种情况,搜索引擎不会给出最高排名。
二、网站内容
网站更新频率A网站更新频率越高,搜索引擎蜘蛛来的频率越高。因此,我们可以利用小说采集器实现采集伪原创自动发布,主动推送给搜索引擎,提高搜索引擎的抓取频率。本小说采集器操作简单,不需要学习更专业的技术,只需几步即可轻松采集内容数据。用户只需对小说采集器进行简单的设置,小说采集器会根据用户的设置关键词精确采集文章进行设置,所以以确保与行业 文章 保持一致。采集文章 from 采集可以选择保存在本地,也可以选择自动伪原创发布,
和其他网站插件相比,这部小说采集器基本没有什么规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词@ > 采集(小说采集器也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个网站插件还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(让内容没有不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集关键词 是自动添加的。文本 Automatically insert the current 采集关键词 在随机位置两次。当当前 采集 的 关键词 出现在文本中时,< @关键词 将自动加粗。)
7、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
三、链接
友情链接有很多功能。它们可以增加网站 流量和收录 彼此。是大家喜欢的优化推广方式之一。但是,如果网站有恶意交流链接和垃圾邮件,也会影响网站的排名,也有可能被搜索引擎降级。建议大家交流一些相关的正式的网站,当然最好有一定的分量。
四、搜索引擎算法
网站在优化过程中,网站的每一个操作细节都会影响到网站,而网站在优化过程中出现的频率相当于< @网站基本,影响网站爬取频率的主要因素有哪些?今天云无限小编就带大家详细了解一下。
网站优化
1、网站域名的选择;
选择网站域名时,尽量选择比较短的域名,目录层次尽量控制在3层以内,有利于蜘蛛爬取;
2、更新频率和原创内容程度;
更新网站的内容时,尽量做原创文章。对于蜘蛛来说,喜欢原创,文章度数高,更新频率要掌握一定的频率;
3、页面加载速度;
蜘蛛在抓取网站的时候,非常关心页面的加载速度。页面打开时,尽量控制在3秒以内。这也是蜘蛛更敏感的地方。网站溜走;
4、 主动提交;
我们需要提交网站的URL,这样可以更好的增加网站收录的数量;
5、优质的外部链接;
网站在优化过程中,少不了优质优质的外链,可以更好的帮助你网站打好基础。这些优质的外链主要包括友情链接等;
关键词3@>网站未排名
对于很多站长来说,关键词没有被排名是一件非常痛苦的事情。他们每天都在运转,但效果并没有明显改善。为什么是这样?关键词让我们看看如果我们长时间没有排名该怎么办!
关键词4@>修改TDK
我们都知道TDK是网站最重要的部分。如果一个网站的TDK写得不好,那么网站的排名肯定会受到影响,也有可能是算法变化造成的。所以如果网站长时间没有排名,可以适当修改TDK,让关键词的排名也有可能出现。
关键词5@>检查网站代码
网站的代码有很多种,其中图片优化、推送代码、H1标签、nofollow标签大家应该熟悉。它可能是这些标签代码之一,它会影响您对 关键词 的排名。所以优化是一项细心的工作,这些小细节不能马虎。
关键词6@>修改关键词密度
关键词的密度官方说在2-8%之间,注意这只是一个大概的比例!如果你的网站内容很多(以1000字为例),关键词出现5次,而内容很少(只有500字)关键词也出现5次,那么这个密度就不一样了!因此,合理设置关键词的密度是必不可少的过程。
关键词7@>
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
实时文章采集(小说网站怎么做?小说规则怎么写?其中的原因)
小说网站怎么办?小说的规则怎么写?大量采集小说网站和免费采集工具,让关键词排名网站快速收录。关键词搜索引擎首页的稳定性是我们网站优化的目标,但是有的网站可以做到,有的网站一直没有效果。无效的原因有很多。今天小编就为大家分析一下原因。

一、服务器原因
服务器是网站 的基础,也是必要的设施之一。选择服务器时,建议选择官方备案的服务器。糟糕的服务器通常会导致 网站 打开缓慢或无法访问。发生这种情况,搜索引擎不会给出最高排名。
二、网站内容

网站更新频率A网站更新频率越高,搜索引擎蜘蛛来的频率越高。因此,我们可以利用小说采集器实现采集伪原创自动发布,主动推送给搜索引擎,提高搜索引擎的抓取频率。本小说采集器操作简单,不需要学习更专业的技术,只需几步即可轻松采集内容数据。用户只需对小说采集器进行简单的设置,小说采集器会根据用户的设置关键词精确采集文章进行设置,所以以确保与行业 文章 保持一致。采集文章 from 采集可以选择保存在本地,也可以选择自动伪原创发布,

和其他网站插件相比,这部小说采集器基本没有什么规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词@ > 采集(小说采集器也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。

不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个网站插件还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(让内容没有不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)

4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集关键词 是自动添加的。文本 Automatically insert the current 采集关键词 在随机位置两次。当当前 采集 的 关键词 出现在文本中时,< @关键词 将自动加粗。)
7、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
三、链接
友情链接有很多功能。它们可以增加网站 流量和收录 彼此。是大家喜欢的优化推广方式之一。但是,如果网站有恶意交流链接和垃圾邮件,也会影响网站的排名,也有可能被搜索引擎降级。建议大家交流一些相关的正式的网站,当然最好有一定的分量。
四、搜索引擎算法
网站在优化过程中,网站的每一个操作细节都会影响到网站,而网站在优化过程中出现的频率相当于< @网站基本,影响网站爬取频率的主要因素有哪些?今天云无限小编就带大家详细了解一下。
网站优化
1、网站域名的选择;
选择网站域名时,尽量选择比较短的域名,目录层次尽量控制在3层以内,有利于蜘蛛爬取;
2、更新频率和原创内容程度;

更新网站的内容时,尽量做原创文章。对于蜘蛛来说,喜欢原创,文章度数高,更新频率要掌握一定的频率;
3、页面加载速度;
蜘蛛在抓取网站的时候,非常关心页面的加载速度。页面打开时,尽量控制在3秒以内。这也是蜘蛛更敏感的地方。网站溜走;
4、 主动提交;
我们需要提交网站的URL,这样可以更好的增加网站收录的数量;
5、优质的外部链接;
网站在优化过程中,少不了优质优质的外链,可以更好的帮助你网站打好基础。这些优质的外链主要包括友情链接等;
关键词3@>网站未排名
对于很多站长来说,关键词没有被排名是一件非常痛苦的事情。他们每天都在运转,但效果并没有明显改善。为什么是这样?关键词让我们看看如果我们长时间没有排名该怎么办!
关键词4@>修改TDK
我们都知道TDK是网站最重要的部分。如果一个网站的TDK写得不好,那么网站的排名肯定会受到影响,也有可能是算法变化造成的。所以如果网站长时间没有排名,可以适当修改TDK,让关键词的排名也有可能出现。
关键词5@>检查网站代码
网站的代码有很多种,其中图片优化、推送代码、H1标签、nofollow标签大家应该熟悉。它可能是这些标签代码之一,它会影响您对 关键词 的排名。所以优化是一项细心的工作,这些小细节不能马虎。
关键词6@>修改关键词密度
关键词的密度官方说在2-8%之间,注意这只是一个大概的比例!如果你的网站内容很多(以1000字为例),关键词出现5次,而内容很少(只有500字)关键词也出现5次,那么这个密度就不一样了!因此,合理设置关键词的密度是必不可少的过程。
关键词7@>
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
实时文章采集(DMCMS插件是否有用,DM建站系统是一款小众CMS! )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-05 04:21
)
DMcms插件有没有用,今天跟大家分享一下,DM建站系统是一个小众cms,php+mysql开发的一个开源的,用于中小型建设的企业 网站 cms, DMcms 后台有块和布局两个功能。block函数用于效果,layout函数用于结构。带有一些 SEO 处理功能。虽然是开源的cms,但是由于用户比较少,DMcms的插件并不多。
DMcms插件使用非常简单,所有操作页面可视化点击,无需专业规则配置,兼容性好,无论是DMcms,dedecms@ >、鲶鱼cms或者小旋风cms的大小都可以。DMcms插件实现网站采集—文章翻译—内容伪原创—主要cms发布—实时推送等职能。网站自动管理,任务进度(成功/失败)状态可见。
网站 的构建肯定需要 SEO。SEO是一种全过程的优化行为。从我们决定建立 网站 开始,就应该建立 SEO 意识。让我们简单谈谈一些基本的SEO:
一、 网站TDK
TDK是我们常说的title、description、keywords的缩写。TDK 对我们来说是一个非常重要的设置网站。就像我们的身份信息一样,尽量不要填写。改变。
二、TDK相关内容
网站的主题一定要明确,每个页面的内容都要呼应我们的网站TDK,通过采集的DMcms插件,输入关键词可以启动采集,采集内容覆盖全网头平台(如图),不断更新方向,递增采集。一次可以创建多个采集任务,可以同时执行不同域名和重复域名的任务。
三、内容优化
1、采集内容敏感*字过滤,
2、 清洗(号码清洗、网站清洗、机构名称清洗)
3、内置翻译功能(英译中、繁译简、简译火星)
4、伪原创关键词(关键词不受伪原创影响,保证核心关键词或品牌展示)
5、采集保留内容标签
6、标题、内容伪原创
7、设置内容与标题一致(使内容与标题完全匹配)
8、设置关键词自动内链(自动从文章内容中的关键词生成内链)
9、设置定时释放(24小时挂机)
四、图像优化
图文结合受到用户和搜索引擎的欢迎。一个高质量的文章 不能没有图片。搜索引擎使用图片标签和描述来识别图片。通过 DMcms 插件可以优化图像的方式有哪些。
1、图片本地化/云存储
2、给图片添加标签
3、图片按频率插入到文本中
4、图片水印/去水
五、流程 SEO 管理
SEO与SEM的不同之处在于看到结果需要时间,因此我们需要更加关注优化过程。DMcms插件可以实时查看任务已发布、待发布、是否为伪原创、发布状态、URL、程序、发布时间等信息。整合cms网站收录、权重、蜘蛛等绑定信息,自动生成曲线供我们分析。
作为搜索引擎优化从业者,需要有良好的心理素质,不断学习和掌握新的SEO技巧,总结每日数据曲线,根据行业趋势和网站曲线变化调整思路,灵活运用及时调整能力。任务完成。这就是今天分享的全部内容。喜欢的话可以连续点三下。
查看全部
实时文章采集(DMCMS插件是否有用,DM建站系统是一款小众CMS!
)
DMcms插件有没有用,今天跟大家分享一下,DM建站系统是一个小众cms,php+mysql开发的一个开源的,用于中小型建设的企业 网站 cms, DMcms 后台有块和布局两个功能。block函数用于效果,layout函数用于结构。带有一些 SEO 处理功能。虽然是开源的cms,但是由于用户比较少,DMcms的插件并不多。

DMcms插件使用非常简单,所有操作页面可视化点击,无需专业规则配置,兼容性好,无论是DMcms,dedecms@ >、鲶鱼cms或者小旋风cms的大小都可以。DMcms插件实现网站采集—文章翻译—内容伪原创—主要cms发布—实时推送等职能。网站自动管理,任务进度(成功/失败)状态可见。

网站 的构建肯定需要 SEO。SEO是一种全过程的优化行为。从我们决定建立 网站 开始,就应该建立 SEO 意识。让我们简单谈谈一些基本的SEO:

一、 网站TDK
TDK是我们常说的title、description、keywords的缩写。TDK 对我们来说是一个非常重要的设置网站。就像我们的身份信息一样,尽量不要填写。改变。

二、TDK相关内容
网站的主题一定要明确,每个页面的内容都要呼应我们的网站TDK,通过采集的DMcms插件,输入关键词可以启动采集,采集内容覆盖全网头平台(如图),不断更新方向,递增采集。一次可以创建多个采集任务,可以同时执行不同域名和重复域名的任务。

三、内容优化
1、采集内容敏感*字过滤,
2、 清洗(号码清洗、网站清洗、机构名称清洗)
3、内置翻译功能(英译中、繁译简、简译火星)
4、伪原创关键词(关键词不受伪原创影响,保证核心关键词或品牌展示)
5、采集保留内容标签
6、标题、内容伪原创
7、设置内容与标题一致(使内容与标题完全匹配)
8、设置关键词自动内链(自动从文章内容中的关键词生成内链)
9、设置定时释放(24小时挂机)
四、图像优化
图文结合受到用户和搜索引擎的欢迎。一个高质量的文章 不能没有图片。搜索引擎使用图片标签和描述来识别图片。通过 DMcms 插件可以优化图像的方式有哪些。
1、图片本地化/云存储
2、给图片添加标签
3、图片按频率插入到文本中
4、图片水印/去水

五、流程 SEO 管理
SEO与SEM的不同之处在于看到结果需要时间,因此我们需要更加关注优化过程。DMcms插件可以实时查看任务已发布、待发布、是否为伪原创、发布状态、URL、程序、发布时间等信息。整合cms网站收录、权重、蜘蛛等绑定信息,自动生成曲线供我们分析。
作为搜索引擎优化从业者,需要有良好的心理素质,不断学习和掌握新的SEO技巧,总结每日数据曲线,根据行业趋势和网站曲线变化调整思路,灵活运用及时调整能力。任务完成。这就是今天分享的全部内容。喜欢的话可以连续点三下。

实时文章采集(0服务出现错误的根因服务的设计方法与设计 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2022-03-03 16:06
)
0 1 背景
目前闲鱼的实际生产部署环境越来越复杂。各种服务的横向依赖相互交织,运行环境的纵向依赖也越来越复杂。当服务出现问题时,能否在海量数据中及时定位问题根源,成为考验闲鱼服务能力的严峻挑战。
当网上出现问题时,往往需要十多分钟甚至更长时间才能找到问题的原因。因此,需要应用能够快速进行自动诊断的系统,而快速诊断的基础是高性能的实时数据。处理系统。该实时数据处理系统需要具备以下能力:
1、数据实时采集,实时分析,计算复杂,分析结果持久化。
2、 可以处理各种各样的数据。收录应用日志、主机性能监控指标和调用链接图。
3、高可靠性。系统没有问题,数据不会丢失。
4、高性能,底部延迟。数据处理时延不超过3秒,支持每秒千万级数据处理。
本文不涉及自动问题诊断的具体分析模型,只讨论整体实时数据处理环节的设计。
02 I/O 定义
为了便于理解系统的运行,我们将系统的整体输入输出定义如下:
输入:
服务请求日志(包括traceid、时间戳、客户端ip、服务器ip、耗时、返回码、服务名、方法名)
环境监测数据(指标名称、ip、时间戳、指标值)。比如cpu、jvm gc次数、jvm gc耗时、数据库指标。
输出:
某服务在一段时间内出错的根本原因,每个服务的错误分析结果用有向无环图表示。 (根节点是被分析的错误节点,叶子节点是错误根因节点,叶子节点可能是外部依赖的服务错误或者jvm异常等)。
03 建筑设计
在实际系统运行过程中,随着时间的推移,会不断产生日志数据和监控数据。每条生成的数据都有自己的时间戳。实时流式传输这些带时间戳的数据就像流过不同管道的水一样。
如果将源源不断的实时数据比作自来水,数据处理过程类似于自来水生产的过程:
当然,我们也将实时数据处理分解为采集、传输、预处理、计算和存储阶段。
整体系统架构设计如下:
采集
使用阿里巴巴自主研发的sls日志服务产品(包括logtail+loghub组件),logtail是一个采集客户端。之所以选择logtail,是因为其卓越的性能、高可靠性以及灵活的插件扩展机制,闲鱼可以定制自己的采集插件,实现各种数据的实时采集。
传输
loghub可以理解为数据发布订阅组件,功能类似于kafka,作为数据传输通道,更稳定安全,详细对比文章参考:
预处理
实时数据预处理部分使用blink流计算处理组件(开源版本称为flink,blink是阿里巴巴内部基于flink的增强版)。目前常用的实时流计算开源产品有Jstorm、SparkStream、Flink。由于Jstorm没有中间计算状态,其计算过程中需要的中间结果必须依赖外部存储,这会导致频繁的io影响其性能; SparkStream本质上是用小批量来模拟实时计算,但实际上还是有一定的延迟; Flink 以其优秀的状态管理机制保证了其计算的性能和实时性,并提供了完整的 SQL 表达式,使得流计算更容易。
计算和持久性
数据经过预处理后,最终生成调用链路聚合日志和主机监控数据。主机监控数据会独立存储在tsdb时序数据库中,供后续统计分析。由于对时间指标数据的特殊存储结构设计,tsdb非常适合时间序列数据的存储和查询。调用链接日志聚合数据,提供给cep/graph服务进行诊断模型分析。 cep/graph service是闲鱼开发的一款应用,实现模型分析、复杂数据处理以及与外部服务的交互,借助rdb实现图数据的实时聚合。
最后一次cep/graph服务分析的结果作为图数据,在lindorm中提供实时转储在线查询。 Lindorm 可以看作是 hbase 的增强版,在系统中充当持久存储。
04 详细设计和性能优化
采集
日志和指标数据采集使用logtail,整个数据采集流程如图:
它提供了非常灵活的插件机制,有四种类型的插件:
由于指标数据(如cpu、内存、jvm指标)的获取需要调用本机的服务接口,所以尽量减少请求的数量。在 logtail 中,一个输入占用一个 goroutine。闲鱼通过自定义输入插件和处理器插件,通过服务请求(指标获取接口由基础监控团队提供)在一个输入插件中获取多个指标数据(如cpu、内存、jvm指标),并将其格式化为一个json数组对象在处理器插件中被拆分成多条数据,以减少系统中io的数量,提高性能。
传输
LogHub 用于数据传输。 logtail写入数据后,blink直接消费数据。只需设置合理数量的分区即可。分区数必须大于等于并发blink读任务数,避免blink任务空闲。
预处理
预处理主要通过blink实现,主要设计和优化点:
写一个高效的计算过程
blink是一个有状态的流计算框架,非常适合实时聚合、join等操作。
在我们的应用中,我们只需要注意对有错误请求的相关服务链接的调用,所以整个日志处理流程分为两个流程:
1、服务的请求入口日志作为单独的流处理,过滤掉请求错误的数据。
2、其他中间环节的调用日志作为另一个独立的流处理。通过在traceid上加入上述流,实现了错误服务所依赖的请求数据的插入。
如上图所示,双流join后,输出的是与请求错误相关的所有链接的完整数据。
设置合理的状态生命周期
blink本质上是在做join的时候通过state缓存中间数据状态,然后再匹配数据。如果状态的生命周期过长,会造成数据膨胀,影响性能。如果状态的生命周期太短,将无法正确关联一些延迟的数据。因此,需要合理配置状态生命周期,并允许该应用的最大数据延迟。 1 分钟。
使用niagara作为statebackend,以及设定state数据生命周期,单位毫秒
state.backend.type=niagara
state.backend.niagara.ttl.ms=60000
打开 MicroBatch/MiniBatch
MicroBatch 和 MiniBatch 都是 micro-batch,但 micro-batch 的触发机制略有不同。原则上,在触发处理前缓存一定量的数据,减少对状态的访问,从而显着提高吞吐量,减少输出数据量。
开启join
blink.miniBatch.join.enabled=true
使用 microbatch 时需要保留以下两个 minibatch 配置
blink.miniBatch.allowLatencyMs=5000
防止OOM,每个批次最多缓存多少条数据
blink.miniBatch.size=20000
对动态负载使用动态再平衡而不是再平衡
blink 任务最忌讳的就是计算热点的存在。 Dynamic Rebalance为了保证数据均匀使用,可以根据当前子分区中累积的buffer个数,选择负载较轻的子分区进行写入,从而实现动态负载均衡。与静态再平衡策略相比,当下游任务的计算能力不均衡时,可以更加均衡各个任务的相对负载,从而提升整个作业的性能。
开启动态负载
task.dynamic.rebalance.enabled=true
自定义输出插件
数据关联后,统一请求链路上的数据需要以数据包的形式通知给下游图分析节点。传统的方式是通过消息服务传递数据。但是消息服务有两个缺点:
1、与rdb等内存数据库相比,它的吞吐量还是有很大差距(差一个数量级左右)。
2、在接收端,也需要根据traceid进行数据关联。
我们通过自定义插件异步向RDB写入数据,同时设置数据过期时间。存储在 RDB 中的数据结构中。编写时只使用traceid作为消息内容,通过metaQ通知下游计算服务,大大降低了metaQ的数据传输压力。
图形聚合计算
收到metaQ的通知后,cep/graph计算服务节点会根据请求的链路数据和依赖的环境监测数据实时生成诊断结果。诊断结果简化如下:
表示这个请求是由下游jvm的线程池满造成的,但是一次调用并没有说明服务不可用的根本原因。分析整体的错误情况,需要对图数据进行实时聚合。
聚合设计如下(为了说明基本思想而进行了简化):
1、首先利用redis的zrank能力,根据服务名或者ip信息给每个节点分配一个全局唯一的序号。
2、为图中的每个节点生成对应的图节点代码,代码格式:
- 对于头节点:头节点序号 |圆形时间戳 |节点代码
- 对于普通节点:|圆形时间戳 |节点编码
3、由于每个节点在一个时间段内都有唯一的key,所以可以使用节点代码作为key来统计每个节点使用redis。同时消除了并发读写的问题。
4、在redis中使用set集合可以很方便的叠加图的边。
5、记录根节点,通过遍历恢复聚合图结构。
汇总结果大致如下:
这样,最终产生了服务不可用的整体原因,可以通过叶子节点的数量对根本原因进行排序。
05 收益
系统上线后,整个实时处理数据链路延迟不超过三秒。定位闲鱼服务器问题的时间从十多分钟甚至更长的时间缩短到了五秒以内。这大大提高了问题定位的效率。
06 展望
目前的系统可以支持闲鱼每秒千万级的数据处理能力。自动定位问题的后续服务可能会扩展到阿里巴巴内部更多的业务场景,数据量将成倍增长,因此对效率和成本提出了更好的要求。
未来可能的改进:
1、处理后的数据可以自动缩减或压缩。
2、复杂的模型分析计算也可以瞬间完成,减少io,提高性能。
3、支持多租户数据隔离。
查看全部
实时文章采集(0服务出现错误的根因服务的设计方法与设计
)
0 1 背景
目前闲鱼的实际生产部署环境越来越复杂。各种服务的横向依赖相互交织,运行环境的纵向依赖也越来越复杂。当服务出现问题时,能否在海量数据中及时定位问题根源,成为考验闲鱼服务能力的严峻挑战。
当网上出现问题时,往往需要十多分钟甚至更长时间才能找到问题的原因。因此,需要应用能够快速进行自动诊断的系统,而快速诊断的基础是高性能的实时数据。处理系统。该实时数据处理系统需要具备以下能力:
1、数据实时采集,实时分析,计算复杂,分析结果持久化。
2、 可以处理各种各样的数据。收录应用日志、主机性能监控指标和调用链接图。
3、高可靠性。系统没有问题,数据不会丢失。
4、高性能,底部延迟。数据处理时延不超过3秒,支持每秒千万级数据处理。
本文不涉及自动问题诊断的具体分析模型,只讨论整体实时数据处理环节的设计。
02 I/O 定义
为了便于理解系统的运行,我们将系统的整体输入输出定义如下:
输入:
服务请求日志(包括traceid、时间戳、客户端ip、服务器ip、耗时、返回码、服务名、方法名)
环境监测数据(指标名称、ip、时间戳、指标值)。比如cpu、jvm gc次数、jvm gc耗时、数据库指标。
输出:
某服务在一段时间内出错的根本原因,每个服务的错误分析结果用有向无环图表示。 (根节点是被分析的错误节点,叶子节点是错误根因节点,叶子节点可能是外部依赖的服务错误或者jvm异常等)。
03 建筑设计
在实际系统运行过程中,随着时间的推移,会不断产生日志数据和监控数据。每条生成的数据都有自己的时间戳。实时流式传输这些带时间戳的数据就像流过不同管道的水一样。
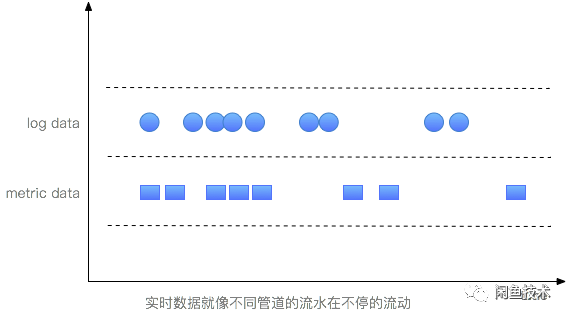
如果将源源不断的实时数据比作自来水,数据处理过程类似于自来水生产的过程:
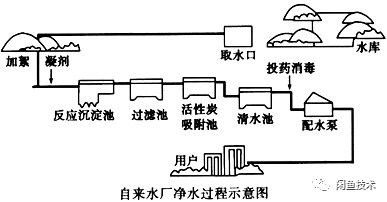
当然,我们也将实时数据处理分解为采集、传输、预处理、计算和存储阶段。
整体系统架构设计如下:
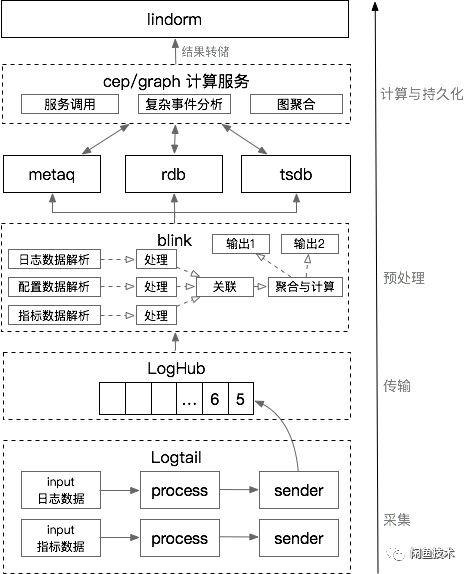
采集
使用阿里巴巴自主研发的sls日志服务产品(包括logtail+loghub组件),logtail是一个采集客户端。之所以选择logtail,是因为其卓越的性能、高可靠性以及灵活的插件扩展机制,闲鱼可以定制自己的采集插件,实现各种数据的实时采集。
传输
loghub可以理解为数据发布订阅组件,功能类似于kafka,作为数据传输通道,更稳定安全,详细对比文章参考:
预处理
实时数据预处理部分使用blink流计算处理组件(开源版本称为flink,blink是阿里巴巴内部基于flink的增强版)。目前常用的实时流计算开源产品有Jstorm、SparkStream、Flink。由于Jstorm没有中间计算状态,其计算过程中需要的中间结果必须依赖外部存储,这会导致频繁的io影响其性能; SparkStream本质上是用小批量来模拟实时计算,但实际上还是有一定的延迟; Flink 以其优秀的状态管理机制保证了其计算的性能和实时性,并提供了完整的 SQL 表达式,使得流计算更容易。
计算和持久性
数据经过预处理后,最终生成调用链路聚合日志和主机监控数据。主机监控数据会独立存储在tsdb时序数据库中,供后续统计分析。由于对时间指标数据的特殊存储结构设计,tsdb非常适合时间序列数据的存储和查询。调用链接日志聚合数据,提供给cep/graph服务进行诊断模型分析。 cep/graph service是闲鱼开发的一款应用,实现模型分析、复杂数据处理以及与外部服务的交互,借助rdb实现图数据的实时聚合。
最后一次cep/graph服务分析的结果作为图数据,在lindorm中提供实时转储在线查询。 Lindorm 可以看作是 hbase 的增强版,在系统中充当持久存储。
04 详细设计和性能优化
采集
日志和指标数据采集使用logtail,整个数据采集流程如图:

它提供了非常灵活的插件机制,有四种类型的插件:
由于指标数据(如cpu、内存、jvm指标)的获取需要调用本机的服务接口,所以尽量减少请求的数量。在 logtail 中,一个输入占用一个 goroutine。闲鱼通过自定义输入插件和处理器插件,通过服务请求(指标获取接口由基础监控团队提供)在一个输入插件中获取多个指标数据(如cpu、内存、jvm指标),并将其格式化为一个json数组对象在处理器插件中被拆分成多条数据,以减少系统中io的数量,提高性能。
传输
LogHub 用于数据传输。 logtail写入数据后,blink直接消费数据。只需设置合理数量的分区即可。分区数必须大于等于并发blink读任务数,避免blink任务空闲。
预处理
预处理主要通过blink实现,主要设计和优化点:
写一个高效的计算过程
blink是一个有状态的流计算框架,非常适合实时聚合、join等操作。
在我们的应用中,我们只需要注意对有错误请求的相关服务链接的调用,所以整个日志处理流程分为两个流程:
1、服务的请求入口日志作为单独的流处理,过滤掉请求错误的数据。
2、其他中间环节的调用日志作为另一个独立的流处理。通过在traceid上加入上述流,实现了错误服务所依赖的请求数据的插入。

如上图所示,双流join后,输出的是与请求错误相关的所有链接的完整数据。
设置合理的状态生命周期
blink本质上是在做join的时候通过state缓存中间数据状态,然后再匹配数据。如果状态的生命周期过长,会造成数据膨胀,影响性能。如果状态的生命周期太短,将无法正确关联一些延迟的数据。因此,需要合理配置状态生命周期,并允许该应用的最大数据延迟。 1 分钟。
使用niagara作为statebackend,以及设定state数据生命周期,单位毫秒
state.backend.type=niagara
state.backend.niagara.ttl.ms=60000
打开 MicroBatch/MiniBatch
MicroBatch 和 MiniBatch 都是 micro-batch,但 micro-batch 的触发机制略有不同。原则上,在触发处理前缓存一定量的数据,减少对状态的访问,从而显着提高吞吐量,减少输出数据量。
开启join
blink.miniBatch.join.enabled=true
使用 microbatch 时需要保留以下两个 minibatch 配置
blink.miniBatch.allowLatencyMs=5000
防止OOM,每个批次最多缓存多少条数据
blink.miniBatch.size=20000
对动态负载使用动态再平衡而不是再平衡
blink 任务最忌讳的就是计算热点的存在。 Dynamic Rebalance为了保证数据均匀使用,可以根据当前子分区中累积的buffer个数,选择负载较轻的子分区进行写入,从而实现动态负载均衡。与静态再平衡策略相比,当下游任务的计算能力不均衡时,可以更加均衡各个任务的相对负载,从而提升整个作业的性能。
开启动态负载
task.dynamic.rebalance.enabled=true
自定义输出插件
数据关联后,统一请求链路上的数据需要以数据包的形式通知给下游图分析节点。传统的方式是通过消息服务传递数据。但是消息服务有两个缺点:
1、与rdb等内存数据库相比,它的吞吐量还是有很大差距(差一个数量级左右)。
2、在接收端,也需要根据traceid进行数据关联。
我们通过自定义插件异步向RDB写入数据,同时设置数据过期时间。存储在 RDB 中的数据结构中。编写时只使用traceid作为消息内容,通过metaQ通知下游计算服务,大大降低了metaQ的数据传输压力。
图形聚合计算
收到metaQ的通知后,cep/graph计算服务节点会根据请求的链路数据和依赖的环境监测数据实时生成诊断结果。诊断结果简化如下:
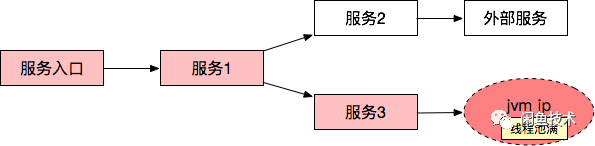
表示这个请求是由下游jvm的线程池满造成的,但是一次调用并没有说明服务不可用的根本原因。分析整体的错误情况,需要对图数据进行实时聚合。
聚合设计如下(为了说明基本思想而进行了简化):
1、首先利用redis的zrank能力,根据服务名或者ip信息给每个节点分配一个全局唯一的序号。
2、为图中的每个节点生成对应的图节点代码,代码格式:
- 对于头节点:头节点序号 |圆形时间戳 |节点代码
- 对于普通节点:|圆形时间戳 |节点编码
3、由于每个节点在一个时间段内都有唯一的key,所以可以使用节点代码作为key来统计每个节点使用redis。同时消除了并发读写的问题。
4、在redis中使用set集合可以很方便的叠加图的边。
5、记录根节点,通过遍历恢复聚合图结构。
汇总结果大致如下:
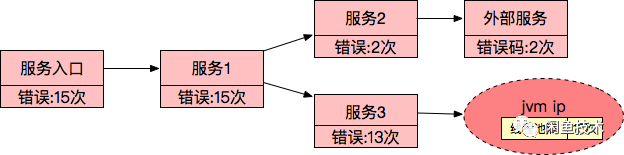
这样,最终产生了服务不可用的整体原因,可以通过叶子节点的数量对根本原因进行排序。
05 收益
系统上线后,整个实时处理数据链路延迟不超过三秒。定位闲鱼服务器问题的时间从十多分钟甚至更长的时间缩短到了五秒以内。这大大提高了问题定位的效率。
06 展望
目前的系统可以支持闲鱼每秒千万级的数据处理能力。自动定位问题的后续服务可能会扩展到阿里巴巴内部更多的业务场景,数据量将成倍增长,因此对效率和成本提出了更好的要求。
未来可能的改进:
1、处理后的数据可以自动缩减或压缩。
2、复杂的模型分析计算也可以瞬间完成,减少io,提高性能。
3、支持多租户数据隔离。
实时文章采集(简单几个打包为exe命令全部源码参考资料多线程并发#lock-objectsPySimpleGUI)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-03-02 03:20
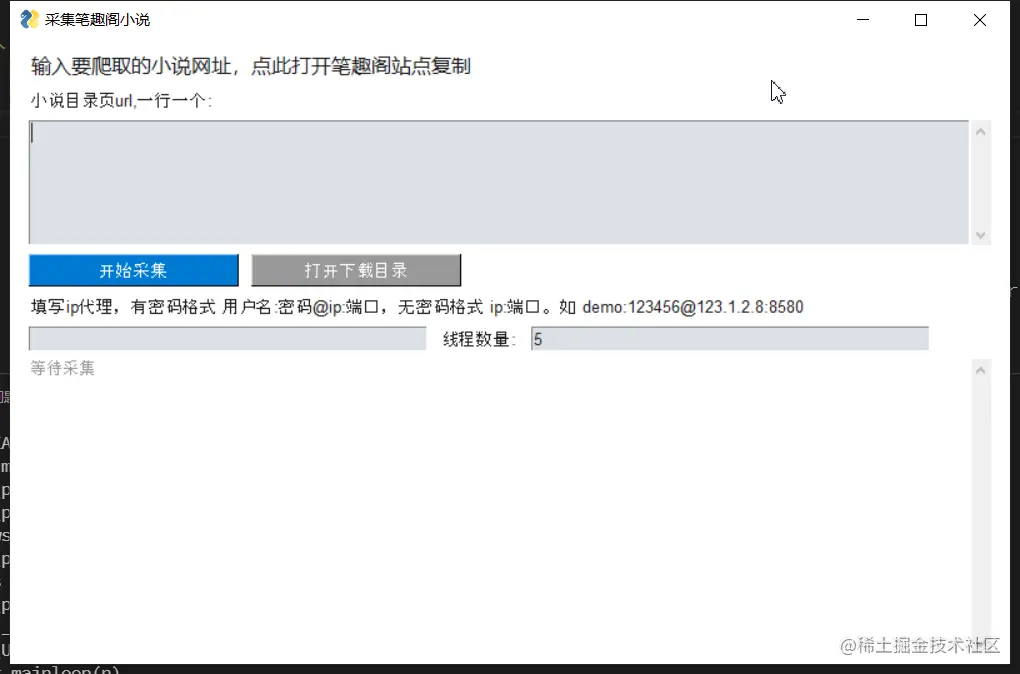
最近帮朋友写了一个简单的爬虫。对了,我做了一个小说爬虫工具,有GUI界面,可以从笔趣阁爬取小说。
开发完成后的界面
采集进程接口
采集之后保存
主要实现的功能是多线程采集,一个线程采集小说支持使用代理,尤其是多线程采集时,没有ip可能会被阻塞使用代理
实时输出采集结果
使用threading.BoundedSemaphore() pool_sema.acquire() pool_sema.release() 限制线程数,防止并发线程溢出。具体限制可在软件界面输入,默认为5个线程
所有线程任务开始前
pool_sema.threading.BoundedSemaphore(5)
具体每个线程开始前 锁
pool_sema.acquire()
....
# 线程任务执行结束释放
pol_sema.release()
使用的第三方模块
pip install requests
pip install pysimplegui
pip install lxml
pip install pyinstaller
GUI界面使用了一个tkinter包库PySimpleGUI,使用起来非常方便。界面虽然不是很漂亮,但是很简单,很适合开发一些小工具。 pysimplegui.readthedocs.io/en/latest/ 比如这个界面的布局,就是几个简单的列表
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openwebsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]
打包成exe命令
pyinstaller -Fw start.py
全部源代码
import time
import requests
import os
import sys
import re
import random
from lxml import etree
import webbrowser
import PySimpleGUI as sg
import threading
# user-agent
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
# 代理
proxies = {}
# 删除书名中特殊符号
# 笔趣阁基地址
baseurl = 'https://www.xbiquwx.la/'
# 线程数量
threadNum = 6
pool_sema = None
THREAD_EVENT = '-THREAD-'
cjstatus = False
# txt存储目录
filePath = os.path.abspath(os.path.join(os.getcwd(), 'txt'))
if not os.path.exists(filePath):
os.mkdir(filePath)
# 删除特殊字符
def deletetag(text):
return re.sub(r'[\[\]#\/\\:*\,;\?\"\'\|\(\)《》&\^!~=%\{\}@!:。·!¥……() ]','',text)
# 入口
def main():
global cjstatus, proxies, threadNum, pool_sema
sg.theme("reddit")
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openwebsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]
window = sg.Window('采集笔趣阁小说', layout, size=(800, 500), resizable=True,)
while True:
event, values = window.read()
if event == sg.WIN_CLOSED or event == 'close': # if user closes window or clicks cancel
break
if event == "openwebsite":
webbrowser.open('%s' % baseurl)
elif event == 'opendir':
os.system('start explorer ' + filePath)
elif event == 'start':
if cjstatus:
cjstatus = False
window['start'].update('已停止...点击重新开始')
continue
window['error'].update("", visible=False)
urls = values['url'].strip().split("\n")
lenth = len(urls)
for k, url in enumerate(urls):
if (not re.match(r'%s\d+_\d+/' % baseurl, url.strip())):
if len(url.strip()) > 0:
window['error'].update("地址错误:%s" % url, visible=True)
del urls[k]
if len(urls) < 1:
window['error'].update(
"每行地址需符合 %s84_84370/ 形式" % baseurlr, visible=True)
continue
# 代理
if len(values['proxy']) > 8:
proxies = {
"http": "http://%s" % values['proxy'],
"https": "http://%s" % values['proxy']
}
# 线程数量
if values['threadnum'] and int(values['threadnum']) > 0:
threadNum = int(values['threadnum'])
pool_sema = threading.BoundedSemaphore(threadNum)
cjstatus = True
window['start'].update('采集中...点击停止')
window['res'].update('开始采集')
for url in urls:
threading.Thread(target=downloadbybook, args=(
url.strip(), window,), daemon=True).start()
elif event == "粘贴":
window['url'].update(sg.clipboard_get())
print("event", event)
if event == THREAD_EVENT:
strtext = values[THREAD_EVENT][1]
window['res'].update(window['res'].get()+"\n"+strtext)
cjstatus = False
window.close()
#下载
def downloadbybook(page_url, window):
try:
bookpage = requests.get(url=page_url, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求 %s 错误,原因:%s' % (page_url, e)))
return
if not cjstatus:
return
# 锁线程
pool_sema.acquire()
if bookpage.status_code != 200:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求%s错误,原因:%s' % (page_url, page.reason)))
return
bookpage.encoding = 'utf-8'
page_tree = etree.HTML(bookpage.text)
bookname = page_tree.xpath('//div[@id="info"]/h1/text()')[0]
bookfilename = filePath + '/' + deletetag(bookname)+'.txt'
zj_list = page_tree.xpath(
'//div[@class="box_con"]/div[@id="list"]/dl/dd')
for _ in zj_list:
if not cjstatus:
break
zjurl = page_url + _.xpath('./a/@href')[0]
zjname = _.xpath('./a/@title')[0]
try:
zjpage = requests.get(
zjurl, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
continue
if zjpage.status_code != 200:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
return
zjpage.encoding = 'utf-8'
zjpage_content = etree.HTML(zjpage.text).xpath('//div[@id="content"]/text()')
content = "\n【"+zjname+"】\n"
for _ in zjpage_content:
content += _.strip() + '\n'
with open(bookfilename, 'a+', encoding='utf-8') as fs:
fs.write(content)
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n%s:%s 采集成功' % (bookname, zjname)))
time.sleep(random.uniform(0.05, 0.2))
# 下载完毕
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求 %s 结束' % page_url))
pool_sema.release()
if __name__ == '__main__':
main()
参考多线程并发#lock-objectsPySimpleGUI 查看全部
实时文章采集(简单几个打包为exe命令全部源码参考资料多线程并发#lock-objectsPySimpleGUI)
最近帮朋友写了一个简单的爬虫。对了,我做了一个小说爬虫工具,有GUI界面,可以从笔趣阁爬取小说。
开发完成后的界面
采集进程接口
采集之后保存

主要实现的功能是多线程采集,一个线程采集小说支持使用代理,尤其是多线程采集时,没有ip可能会被阻塞使用代理

实时输出采集结果

使用threading.BoundedSemaphore() pool_sema.acquire() pool_sema.release() 限制线程数,防止并发线程溢出。具体限制可在软件界面输入,默认为5个线程

所有线程任务开始前
pool_sema.threading.BoundedSemaphore(5)
具体每个线程开始前 锁
pool_sema.acquire()
....
# 线程任务执行结束释放
pol_sema.release()
使用的第三方模块
pip install requests
pip install pysimplegui
pip install lxml
pip install pyinstaller
GUI界面使用了一个tkinter包库PySimpleGUI,使用起来非常方便。界面虽然不是很漂亮,但是很简单,很适合开发一些小工具。 pysimplegui.readthedocs.io/en/latest/ 比如这个界面的布局,就是几个简单的列表
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openwebsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]
打包成exe命令
pyinstaller -Fw start.py
全部源代码
import time
import requests
import os
import sys
import re
import random
from lxml import etree
import webbrowser
import PySimpleGUI as sg
import threading
# user-agent
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
# 代理
proxies = {}
# 删除书名中特殊符号
# 笔趣阁基地址
baseurl = 'https://www.xbiquwx.la/'
# 线程数量
threadNum = 6
pool_sema = None
THREAD_EVENT = '-THREAD-'
cjstatus = False
# txt存储目录
filePath = os.path.abspath(os.path.join(os.getcwd(), 'txt'))
if not os.path.exists(filePath):
os.mkdir(filePath)
# 删除特殊字符
def deletetag(text):
return re.sub(r'[\[\]#\/\\:*\,;\?\"\'\|\(\)《》&\^!~=%\{\}@!:。·!¥……() ]','',text)
# 入口
def main():
global cjstatus, proxies, threadNum, pool_sema
sg.theme("reddit")
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openwebsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]
window = sg.Window('采集笔趣阁小说', layout, size=(800, 500), resizable=True,)
while True:
event, values = window.read()
if event == sg.WIN_CLOSED or event == 'close': # if user closes window or clicks cancel
break
if event == "openwebsite":
webbrowser.open('%s' % baseurl)
elif event == 'opendir':
os.system('start explorer ' + filePath)
elif event == 'start':
if cjstatus:
cjstatus = False
window['start'].update('已停止...点击重新开始')
continue
window['error'].update("", visible=False)
urls = values['url'].strip().split("\n")
lenth = len(urls)
for k, url in enumerate(urls):
if (not re.match(r'%s\d+_\d+/' % baseurl, url.strip())):
if len(url.strip()) > 0:
window['error'].update("地址错误:%s" % url, visible=True)
del urls[k]
if len(urls) < 1:
window['error'].update(
"每行地址需符合 %s84_84370/ 形式" % baseurlr, visible=True)
continue
# 代理
if len(values['proxy']) > 8:
proxies = {
"http": "http://%s" % values['proxy'],
"https": "http://%s" % values['proxy']
}
# 线程数量
if values['threadnum'] and int(values['threadnum']) > 0:
threadNum = int(values['threadnum'])
pool_sema = threading.BoundedSemaphore(threadNum)
cjstatus = True
window['start'].update('采集中...点击停止')
window['res'].update('开始采集')
for url in urls:
threading.Thread(target=downloadbybook, args=(
url.strip(), window,), daemon=True).start()
elif event == "粘贴":
window['url'].update(sg.clipboard_get())
print("event", event)
if event == THREAD_EVENT:
strtext = values[THREAD_EVENT][1]
window['res'].update(window['res'].get()+"\n"+strtext)
cjstatus = False
window.close()
#下载
def downloadbybook(page_url, window):
try:
bookpage = requests.get(url=page_url, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求 %s 错误,原因:%s' % (page_url, e)))
return
if not cjstatus:
return
# 锁线程
pool_sema.acquire()
if bookpage.status_code != 200:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求%s错误,原因:%s' % (page_url, page.reason)))
return
bookpage.encoding = 'utf-8'
page_tree = etree.HTML(bookpage.text)
bookname = page_tree.xpath('//div[@id="info"]/h1/text()')[0]
bookfilename = filePath + '/' + deletetag(bookname)+'.txt'
zj_list = page_tree.xpath(
'//div[@class="box_con"]/div[@id="list"]/dl/dd')
for _ in zj_list:
if not cjstatus:
break
zjurl = page_url + _.xpath('./a/@href')[0]
zjname = _.xpath('./a/@title')[0]
try:
zjpage = requests.get(
zjurl, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
continue
if zjpage.status_code != 200:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
return
zjpage.encoding = 'utf-8'
zjpage_content = etree.HTML(zjpage.text).xpath('//div[@id="content"]/text()')
content = "\n【"+zjname+"】\n"
for _ in zjpage_content:
content += _.strip() + '\n'
with open(bookfilename, 'a+', encoding='utf-8') as fs:
fs.write(content)
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n%s:%s 采集成功' % (bookname, zjname)))
time.sleep(random.uniform(0.05, 0.2))
# 下载完毕
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求 %s 结束' % page_url))
pool_sema.release()
if __name__ == '__main__':
main()
参考多线程并发#lock-objectsPySimpleGUI
实时文章采集(易通CMS采集可以自动采集并发布网站内容,免接口发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-02 01:23
一通cms采集,可实现网站无需人工值班,24小时自动实时监控目标,对目标实时高效采集,以便它可以全天候为 网站 @网站 提供内容更新。可以满足网站长期的运营需求,让网站站长们从繁重的工作中解脱出来。一通cms采集,可以采集任意类型网站,99.9%采集识别成功率,然后自动批量发布到所有cms类型的程序,也可以直接采集本地文件,无需界面发布。
一通cms采集可以支持网站内容和信息的自由组合,通过强大的数据排序功能对信息进行深度加工,创造出新的内容。无论是静态还是动态,包括图片、音乐、文字、软件,甚至PDF文档和WORD文档都可以准确采集,然后进行处理。并且使用同义词替换、多词随机替换、段落随机排序,让二次创作的内容更有利于网站SEO。
一通cms采集从支持多级目录入手,无论是垂直多级信息页面,还是并行多内容分页、AJAX调用页面,都可以轻松采集访问. 再加上开放的界面模式,站长可以自由地进行二次开发,自定义任何功能,实现网站的所有需求。
大部分网站都无法实现长期稳定的网站内容输出,因为远程真的很累。一通cms采集可以自动采集和发布网站内容,这是很多站长感兴趣的,一通cms采集没有使用门槛,所以对于没有基础知识的用户来说会非常简单易用。因为不需要编写适当的 采集 规则。
一通cms采集可以在短时间内丰富网站的内容,让搜索引擎的蜘蛛正常抓取一个网站。它允许用户在访问网站时看到一些内容,并根据用户的搜索需要自动显示相应的界面。
一通cms采集可以快速获取最新的网站相关内容。因为采集的内容可以基于网站的关键词的内容和相关栏目采集的内容,而这些内容可以是最新鲜的内容,所以用户浏览网站,也可以快速获取相关内容,无需通过搜索引擎再次搜索,一定程度上提升了网站的用户体验。
一通cms采集将采集内容基于智能算法。也就是说,选择与网站相关的内容,尽量新鲜。如果太陈旧了,尤其是新闻内容,过时的内容不需要采集,但是对于技术帖,那么就能够妥妥的采集,因为这些技术帖对于很多新人都有很好的帮助作用。 查看全部
实时文章采集(易通CMS采集可以自动采集并发布网站内容,免接口发布)
一通cms采集,可实现网站无需人工值班,24小时自动实时监控目标,对目标实时高效采集,以便它可以全天候为 网站 @网站 提供内容更新。可以满足网站长期的运营需求,让网站站长们从繁重的工作中解脱出来。一通cms采集,可以采集任意类型网站,99.9%采集识别成功率,然后自动批量发布到所有cms类型的程序,也可以直接采集本地文件,无需界面发布。
一通cms采集可以支持网站内容和信息的自由组合,通过强大的数据排序功能对信息进行深度加工,创造出新的内容。无论是静态还是动态,包括图片、音乐、文字、软件,甚至PDF文档和WORD文档都可以准确采集,然后进行处理。并且使用同义词替换、多词随机替换、段落随机排序,让二次创作的内容更有利于网站SEO。
一通cms采集从支持多级目录入手,无论是垂直多级信息页面,还是并行多内容分页、AJAX调用页面,都可以轻松采集访问. 再加上开放的界面模式,站长可以自由地进行二次开发,自定义任何功能,实现网站的所有需求。
大部分网站都无法实现长期稳定的网站内容输出,因为远程真的很累。一通cms采集可以自动采集和发布网站内容,这是很多站长感兴趣的,一通cms采集没有使用门槛,所以对于没有基础知识的用户来说会非常简单易用。因为不需要编写适当的 采集 规则。
一通cms采集可以在短时间内丰富网站的内容,让搜索引擎的蜘蛛正常抓取一个网站。它允许用户在访问网站时看到一些内容,并根据用户的搜索需要自动显示相应的界面。
一通cms采集可以快速获取最新的网站相关内容。因为采集的内容可以基于网站的关键词的内容和相关栏目采集的内容,而这些内容可以是最新鲜的内容,所以用户浏览网站,也可以快速获取相关内容,无需通过搜索引擎再次搜索,一定程度上提升了网站的用户体验。
一通cms采集将采集内容基于智能算法。也就是说,选择与网站相关的内容,尽量新鲜。如果太陈旧了,尤其是新闻内容,过时的内容不需要采集,但是对于技术帖,那么就能够妥妥的采集,因为这些技术帖对于很多新人都有很好的帮助作用。
实时文章采集(6个K8s日志系统建设中的典型问题,你遇到过几个?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-28 20:19
个人博客导航页面(点击右侧链接打开个人博客):大牛带你进入技术栈
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在Kubernetes中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高,但如果使用得当,自动化程度比传统方式高,运维成本更低。本文是日志系列文章的第四篇。
第一篇:《K8s日志系统建设中的6个典型问题,你遇到过几个?》
第二篇:《一篇文章理解K8s日志系统的设计与实践》
第三篇:《解决K8s中日志输出问题的9个技巧》
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,log采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志源
业务容器、系统组件、主机
商务,主持人
采集如何
Agent (Sidecar, DaemonSet), Direct Write (DockerEngine, Business)
代理,直写
独立应用程序的数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手动,Yaml
手动, 定制
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直写 DaemonSet 方法 Sidecar 方法
采集日志类型
标准输出
业务日志
标准输出 + 部分文件
文档
部署和维护
低原生支持
低,只维护配置文件
一般需要维护DaemonSet
更高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式进行映射。
每个 POD 都可以单独配置以实现高灵活性
多租户隔离
虚弱的
弱,日志直写会和业务逻辑竞争资源
一般只通过配置之间的隔离
强,通过容器隔离,资源可单独分配
支持集群大小
无限本地存储,如果使用syslog和fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
较低,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可进行自定义查询和统计
高,可根据业务特点定制
可定制性
低的
高,可自由扩展
低的
高,每个 POD 单独配置
耦合
高,强绑定DockerEngine,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,代理可以独立升级
一般默认的采集Sidecar服务对应的Agent升级也会重启(部分扩展包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类清晰、功能单一的集群
大型混合 PAAS 集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但大家需要注意:这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因有以下几点:
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK采集发布后通过CICD的webhook调用自动部署的服务,但这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后,可以直接使用 DaemonSet 采集 和 CRD 配置。安装方法如下:
当阿里云Kubernetes集群启动时,您可以选择安装它,这样在创建集群时会自动安装上述组件。如果激活的时候没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云上自建还是在其他云还是离线,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
上述组件安装完成后,Logtail和对应的Controller就会在集群中运行,但是这些组件默认没有采集任何日志,需要将日志采集规则配置为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台上手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器的stdout采集,其中定义需要stdout和stderr采集,排除环境变量中收录COLLEXT_STDOUT_FLAG: false的容器。
基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高,但存在一个问题,DaemonSet 的所有 Logtail 共享全局配置,而单个 Logtail 的配置支持有上限。因此,它无法支持具有大量应用程序的集群。
以上是我们给出的推荐配置方式。核心思想是:
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
练习 2 - 大型集群
对于一些用作PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,并且有专门的Kubernetes平台运维人员。该场景对应用数量没有限制,DaemonSet无法支持,所以必须使用Sidecar方式。总体规划如下:
Java/C/C++/机器学习/算法与数据结构/前端/Android/Python/程序员必读/书籍清单:
(点击右侧打开个人博客有干货):科技干货店
=====>>①【Java大牛带你从入门到进阶之路】②【算法数据结构+acm大牛带你从入门到进阶之路】③【数据库大牛带你从入门到进阶之路】④【Web前端大牛带你进阶之路】⑤【机器学习与python大牛带你进阶之路】⑥【架构师大牛带你进阶之路】⑦【C++大牛带你进阶之路】⑧【ios大牛带你进阶之路】⑨【Web安全大牛带你进阶之路】⑩【Linux与操作系统牛带你从入门到进阶之路】 查看全部
实时文章采集(6个K8s日志系统建设中的典型问题,你遇到过几个?)
个人博客导航页面(点击右侧链接打开个人博客):大牛带你进入技术栈
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在Kubernetes中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高,但如果使用得当,自动化程度比传统方式高,运维成本更低。本文是日志系列文章的第四篇。
第一篇:《K8s日志系统建设中的6个典型问题,你遇到过几个?》
第二篇:《一篇文章理解K8s日志系统的设计与实践》
第三篇:《解决K8s中日志输出问题的9个技巧》
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,log采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志源
业务容器、系统组件、主机
商务,主持人
采集如何
Agent (Sidecar, DaemonSet), Direct Write (DockerEngine, Business)
代理,直写
独立应用程序的数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手动,Yaml
手动, 定制
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直写 DaemonSet 方法 Sidecar 方法
采集日志类型
标准输出
业务日志
标准输出 + 部分文件
文档
部署和维护
低原生支持
低,只维护配置文件
一般需要维护DaemonSet
更高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式进行映射。
每个 POD 都可以单独配置以实现高灵活性
多租户隔离
虚弱的
弱,日志直写会和业务逻辑竞争资源
一般只通过配置之间的隔离
强,通过容器隔离,资源可单独分配
支持集群大小
无限本地存储,如果使用syslog和fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
较低,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可进行自定义查询和统计
高,可根据业务特点定制
可定制性
低的
高,可自由扩展
低的
高,每个 POD 单独配置
耦合
高,强绑定DockerEngine,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,代理可以独立升级
一般默认的采集Sidecar服务对应的Agent升级也会重启(部分扩展包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类清晰、功能单一的集群
大型混合 PAAS 集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但大家需要注意:这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因有以下几点:
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK采集发布后通过CICD的webhook调用自动部署的服务,但这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后,可以直接使用 DaemonSet 采集 和 CRD 配置。安装方法如下:
当阿里云Kubernetes集群启动时,您可以选择安装它,这样在创建集群时会自动安装上述组件。如果激活的时候没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云上自建还是在其他云还是离线,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
上述组件安装完成后,Logtail和对应的Controller就会在集群中运行,但是这些组件默认没有采集任何日志,需要将日志采集规则配置为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台上手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器的stdout采集,其中定义需要stdout和stderr采集,排除环境变量中收录COLLEXT_STDOUT_FLAG: false的容器。
基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高,但存在一个问题,DaemonSet 的所有 Logtail 共享全局配置,而单个 Logtail 的配置支持有上限。因此,它无法支持具有大量应用程序的集群。
以上是我们给出的推荐配置方式。核心思想是:
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
练习 2 - 大型集群
对于一些用作PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,并且有专门的Kubernetes平台运维人员。该场景对应用数量没有限制,DaemonSet无法支持,所以必须使用Sidecar方式。总体规划如下:
Java/C/C++/机器学习/算法与数据结构/前端/Android/Python/程序员必读/书籍清单:
(点击右侧打开个人博客有干货):科技干货店
=====>>①【Java大牛带你从入门到进阶之路】②【算法数据结构+acm大牛带你从入门到进阶之路】③【数据库大牛带你从入门到进阶之路】④【Web前端大牛带你进阶之路】⑤【机器学习与python大牛带你进阶之路】⑥【架构师大牛带你进阶之路】⑦【C++大牛带你进阶之路】⑧【ios大牛带你进阶之路】⑨【Web安全大牛带你进阶之路】⑩【Linux与操作系统牛带你从入门到进阶之路】
实时文章采集(怎么用PHP采集才能快速收录以及关键词排名?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-28 04:23
如何使用PHP采集快速收录和关键词排名?本文分为2个部分,一个是网站程序的标准化,另一个是网站fast收录和排名,我想大多数人都会遇到,公司的网站有程序问题,url优化要求等,但是程序部的小伙伴不配合!或者网站邀请第三方公司!如果你坚持做seo,你基本上就无法工作了!基本上以上都是公司程序部和我们seo网站优化部没有协调或者根本没有严格规定造成的!要知道seo是一个非常复杂的行业和职位,所涉及的内容包罗万象。其中,程序对网站的支持非常重要!如果和seo配合不好,程序会比较麻烦!网站程序中需要满足哪些规范才能适合SEO?
一、域和服务器相关
1、如果页面不存在,应该返回404错误码;
2、4XX、5XX服务器头信息异常增加,及时通知SEO部门做进一步检查。
3、域名不使用泛解析。需要使用二级域名时,需要提前与SEO部门沟通,然后解决;
3、URL 规范化,URL 启用 301
4、网站不能有多个域名打开同一个页面;
5、如果有打开子域进行测试,使用robots文件禁止搜索引擎抓取;
6、服务器开启gzip压缩,提高浏览速度;
7、在新栏目上线前完成内容填充;网站 和内容未完成的栏目无法上线。
二、网站结构和URL相关
1、所有网址网站都是静态的,除了计划禁止搜索引擎抓取的内容和收录。
2、 URL一旦确定在线,就不能随意更改。特殊情况需要调整的,必须与SEO部门沟通;
3、网站 列和 URL 目录需要一一对应。一级分类对应一级分类,二级分类对应二级分类。最多可以归类到二级目录。如果产品/页数需要分类在三级以上,此时需要注意。
4、全站目录URL以斜杠结尾,该URL不显示index.php等文件名;
5、URL 中的列名、文件名等字母都是小写的。
6、网站的所有页面都添加了面包屑;
7、URL中统一使用破折号或下划线,不要添加其他特殊字符;
8、URL目录名优先对应英文单词,不是中文拼音,而是数字或字母;
9、当URL发生变化时,旧的URL应该通过301重定向到新的URL;
三、页面打开速度相关
1、在不影响视觉效果的前提下,前端页面的所有图片都要压缩;
2、删除未使用的CSS代码,尽可能将页面样式代码合并到CSS文件中;
3、谨慎使用JS,谨慎使用JS,测试JS是否减慢页面访问;
4、禁止使用session ID、Frame、Flash;
5、页面的纯文本代码(包括HTML、JS、CSS)不超过500K。主页等特殊页面可以适当放宽。
6、使用主流浏览器实际测试页面打开速度,不要超过3秒。有条件的,从多个省市进行测试。
四、TDK相关页面
1、页面的Title标签、Description标签、H1文字的默认版本是根据格式自动生成的,但是系统需要为SEO人员预留填写功能。
2、栏目页Title的默认格式:二级栏目名-一级栏目名-网站名称;
3、产品页面标题默认格式:产品名称——网站名称;
4、文章页面标题默认格式:文章标题——网站名称;
5、搜索页面标题默认格式:搜索关键字-网站名称;;
6、每个页面标题的默认格式:列名-X页-网站名称;
7、除特殊要求外,网站使用HTML代码链接代替JS生成的链接;
8、除好友链接外的导出链接添加nofollow属性;
9、列,产品/文章将 ALT 文本添加到页面的主图像。后台编辑器上传图片时,预留输入框填写ATL文本;
10、一个页面只使用一次H1。
五、函数使用及代码
1、除非另有要求,网站确保在所有页面都在线时添加流量统计代码。
2、全部网站开通百度资源平台账号。
3、在线网站,除非 SEO 或运营部门另有要求,robots 文件对所有 URL 和文件(包括图像、CSS、JS)的抓取都是开放的。
4、XML版本的Sitemap在后台实时或定期生成更新,包括首页、栏目和页面、产品/文章页面。是否收录过滤条件页面将在与SEO部门协调后确定。
5、新站点应始终使用响应式设计,不要使用独立的移动站点或移动子域。已经用移动子域优化过的老站暂时保持现状,与SEO部门沟通后转为响应式设计。
6、英文网站HTML 代码中不应出现中文字符,包括注释。
7、当由于各种原因需要更改URL时,旧的URL会被301重定向到新的URL,不要使用其他的转向方式。
8、当由于各种原因更改 URL 时,导航和内页链接会更新为新 URL。导航中禁止需要重定向的 URL。
六、使用PHP采集+SEO函数让网站快收录
如果以上都没有问题,我们可以使用这个PHP采集工具来实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习更专业的技术。只需几个简单的步骤即可轻松实现采集内容数据,用户只需在PHP采集上进行简单设置,PHP采集工具会根据关键词准确设置给用户。采集文章,这确保了与行业 文章 的一致性。采集文章 from 采集可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他PHP采集相比,这个PHP采集基本没有规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词 采集可以实现(PHP采集也自带关键词采集函数)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PHP采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
七、百度优化排名最基本的原理!
一、网站优化排名的对象是什么
1、一个网站由多个网页组成,网站由一个或多个网页组成。
2、seo优化的对象是网页而不是网站。关于网站优化排名的误区是,普通人总是认为优化的对象是网站。我们通常所说的“网站ranking”和“网站optimization”是不正确的。
二:百度蜘蛛的工作很简单:
找到页面(发现网上有这个页面)——页面是否可以正常爬取(你在爬取的时候有没有遇到困难:比如加载慢、质量低、错误页面多——你要爬吗? page)?是否应该爬取?爬取数据库能给网名带来实际的效果吗?) 了解了这些基本原理后,我们就可以根据这些要求进行尝试了。比如,如何让百度爬取更方便?方法如下:
1)百度主动找到我们的页面
2)我们提交给百度
3) 还有人告诉百度需要做一些外链推广工作
三、什么是超链接分析,超链接分析简介
1、“超链接分析”
超链接分析是百度的专利。原理是通过分析链接网站的数量来评估链接网站的质量。这样做的效果是确保用户使用搜索引擎。,质量越高,页面越受欢迎越高。百度总裁李彦宏是这项技术的拥有者,该技术已被全球主要搜索引擎广泛采用。
2、我们如何理解超链分析技术?
总之,要判断一个页面是优秀的还是权威的,其他页面的“意见”是非常重要的。即使一个网页不是那么好,只要其他网页比其他网页有更多的“信任票”(反向链接),那么它的排名就会更高。需要注意的是,“超链接分析”只是排名的一个重要参考。
四:分析模块的工作,百度会对网页进行再加工预测评价:
1)网站页面内容好不好?
2) 页面的主题是什么?(标题、关键词和网站描述、网站内容本身由网站的TDK决定)
3)多少钱?原创学位?
4)还有其他评分选项,比如多少个链接?
通过以上指标,百度会给搜索关键词一个匹配排名,其匹配模式设计为:完全匹配+词组匹配+广泛匹配。
我们seo优化的价值在于匹配模式相当于排名机会,我们需要实现更多更好的排名机会。继续增加匹配机会,让更多流量找到我们的网站。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
实时文章采集(怎么用PHP采集才能快速收录以及关键词排名?(图))
如何使用PHP采集快速收录和关键词排名?本文分为2个部分,一个是网站程序的标准化,另一个是网站fast收录和排名,我想大多数人都会遇到,公司的网站有程序问题,url优化要求等,但是程序部的小伙伴不配合!或者网站邀请第三方公司!如果你坚持做seo,你基本上就无法工作了!基本上以上都是公司程序部和我们seo网站优化部没有协调或者根本没有严格规定造成的!要知道seo是一个非常复杂的行业和职位,所涉及的内容包罗万象。其中,程序对网站的支持非常重要!如果和seo配合不好,程序会比较麻烦!网站程序中需要满足哪些规范才能适合SEO?

一、域和服务器相关
1、如果页面不存在,应该返回404错误码;
2、4XX、5XX服务器头信息异常增加,及时通知SEO部门做进一步检查。
3、域名不使用泛解析。需要使用二级域名时,需要提前与SEO部门沟通,然后解决;
3、URL 规范化,URL 启用 301
4、网站不能有多个域名打开同一个页面;
5、如果有打开子域进行测试,使用robots文件禁止搜索引擎抓取;
6、服务器开启gzip压缩,提高浏览速度;
7、在新栏目上线前完成内容填充;网站 和内容未完成的栏目无法上线。
二、网站结构和URL相关
1、所有网址网站都是静态的,除了计划禁止搜索引擎抓取的内容和收录。
2、 URL一旦确定在线,就不能随意更改。特殊情况需要调整的,必须与SEO部门沟通;
3、网站 列和 URL 目录需要一一对应。一级分类对应一级分类,二级分类对应二级分类。最多可以归类到二级目录。如果产品/页数需要分类在三级以上,此时需要注意。
4、全站目录URL以斜杠结尾,该URL不显示index.php等文件名;
5、URL 中的列名、文件名等字母都是小写的。
6、网站的所有页面都添加了面包屑;
7、URL中统一使用破折号或下划线,不要添加其他特殊字符;
8、URL目录名优先对应英文单词,不是中文拼音,而是数字或字母;
9、当URL发生变化时,旧的URL应该通过301重定向到新的URL;
三、页面打开速度相关
1、在不影响视觉效果的前提下,前端页面的所有图片都要压缩;
2、删除未使用的CSS代码,尽可能将页面样式代码合并到CSS文件中;
3、谨慎使用JS,谨慎使用JS,测试JS是否减慢页面访问;
4、禁止使用session ID、Frame、Flash;
5、页面的纯文本代码(包括HTML、JS、CSS)不超过500K。主页等特殊页面可以适当放宽。
6、使用主流浏览器实际测试页面打开速度,不要超过3秒。有条件的,从多个省市进行测试。
四、TDK相关页面
1、页面的Title标签、Description标签、H1文字的默认版本是根据格式自动生成的,但是系统需要为SEO人员预留填写功能。
2、栏目页Title的默认格式:二级栏目名-一级栏目名-网站名称;
3、产品页面标题默认格式:产品名称——网站名称;
4、文章页面标题默认格式:文章标题——网站名称;
5、搜索页面标题默认格式:搜索关键字-网站名称;;
6、每个页面标题的默认格式:列名-X页-网站名称;
7、除特殊要求外,网站使用HTML代码链接代替JS生成的链接;
8、除好友链接外的导出链接添加nofollow属性;
9、列,产品/文章将 ALT 文本添加到页面的主图像。后台编辑器上传图片时,预留输入框填写ATL文本;
10、一个页面只使用一次H1。
五、函数使用及代码
1、除非另有要求,网站确保在所有页面都在线时添加流量统计代码。
2、全部网站开通百度资源平台账号。
3、在线网站,除非 SEO 或运营部门另有要求,robots 文件对所有 URL 和文件(包括图像、CSS、JS)的抓取都是开放的。
4、XML版本的Sitemap在后台实时或定期生成更新,包括首页、栏目和页面、产品/文章页面。是否收录过滤条件页面将在与SEO部门协调后确定。
5、新站点应始终使用响应式设计,不要使用独立的移动站点或移动子域。已经用移动子域优化过的老站暂时保持现状,与SEO部门沟通后转为响应式设计。
6、英文网站HTML 代码中不应出现中文字符,包括注释。
7、当由于各种原因需要更改URL时,旧的URL会被301重定向到新的URL,不要使用其他的转向方式。
8、当由于各种原因更改 URL 时,导航和内页链接会更新为新 URL。导航中禁止需要重定向的 URL。
六、使用PHP采集+SEO函数让网站快收录

如果以上都没有问题,我们可以使用这个PHP采集工具来实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习更专业的技术。只需几个简单的步骤即可轻松实现采集内容数据,用户只需在PHP采集上进行简单设置,PHP采集工具会根据关键词准确设置给用户。采集文章,这确保了与行业 文章 的一致性。采集文章 from 采集可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他PHP采集相比,这个PHP采集基本没有规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词 采集可以实现(PHP采集也自带关键词采集函数)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。

不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PHP采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)

4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
七、百度优化排名最基本的原理!
一、网站优化排名的对象是什么
1、一个网站由多个网页组成,网站由一个或多个网页组成。
2、seo优化的对象是网页而不是网站。关于网站优化排名的误区是,普通人总是认为优化的对象是网站。我们通常所说的“网站ranking”和“网站optimization”是不正确的。
二:百度蜘蛛的工作很简单:
找到页面(发现网上有这个页面)——页面是否可以正常爬取(你在爬取的时候有没有遇到困难:比如加载慢、质量低、错误页面多——你要爬吗? page)?是否应该爬取?爬取数据库能给网名带来实际的效果吗?) 了解了这些基本原理后,我们就可以根据这些要求进行尝试了。比如,如何让百度爬取更方便?方法如下:
1)百度主动找到我们的页面
2)我们提交给百度
3) 还有人告诉百度需要做一些外链推广工作
三、什么是超链接分析,超链接分析简介
1、“超链接分析”
超链接分析是百度的专利。原理是通过分析链接网站的数量来评估链接网站的质量。这样做的效果是确保用户使用搜索引擎。,质量越高,页面越受欢迎越高。百度总裁李彦宏是这项技术的拥有者,该技术已被全球主要搜索引擎广泛采用。
2、我们如何理解超链分析技术?
总之,要判断一个页面是优秀的还是权威的,其他页面的“意见”是非常重要的。即使一个网页不是那么好,只要其他网页比其他网页有更多的“信任票”(反向链接),那么它的排名就会更高。需要注意的是,“超链接分析”只是排名的一个重要参考。
四:分析模块的工作,百度会对网页进行再加工预测评价:
1)网站页面内容好不好?
2) 页面的主题是什么?(标题、关键词和网站描述、网站内容本身由网站的TDK决定)
3)多少钱?原创学位?
4)还有其他评分选项,比如多少个链接?
通过以上指标,百度会给搜索关键词一个匹配排名,其匹配模式设计为:完全匹配+词组匹配+广泛匹配。

我们seo优化的价值在于匹配模式相当于排名机会,我们需要实现更多更好的排名机会。继续增加匹配机会,让更多流量找到我们的网站。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
实时文章采集(开发环境开发语言Python,开发架构Scrapy,非Python莫属 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-24 00:06
)
背景
有朋友打算拓展业务渠道,准备在众包平台接单。他的主打产品是微信小程序,所以他想尽快收到客户发来的需求信息,然后尽快联系客户,从而达成交易。只有费率才能保证,否则山枣会被其他同事接走,他的黄花菜就凉了。
开发环境、开发语言、开发框架Scrapy,无非就是Python。数据神器采集!开发工具 PyCharm;功能设计实时通知:使用邮件通知,将邮箱绑定微信,实现实时通知的效果。过滤模块:根据标题和内容双重过滤关键词,丢弃不符合要求的订单,实时通知符合要求的订单。配置模块:使用json文件配置。关键代码
# -*- coding: utf-8 -*-<br />import re<br /><br />import scrapy<br />from flask import json<br />from requests import Request<br />from scrapy import Selector<br />from .. import common<br />import time<br /><br />from selenium import webdriver<br />from selenium.webdriver.chrome.options import Options<br /><br /><br />class CodemarttaskSpider(scrapy.Spider):<br /> name = 'codemarttask'<br /> allowed_domains = ['codemart.com']<br /> start_urls = ['https://codemart.com/api/project?page=1&roleTypeId=&status=RECRUITING']<br /><br /> # 重要,需要修改 application/json ,否则默认返回的是xml数据!!!<br /> def parse(self, response):<br /> # 30 item per page<br /> # print(response.text)<br /> print(<br /> "--------------------------------------------------------------------------------------------------------")<br /> json_data = json.loads(response.text)<br /> rewards = json_data.get("rewards")<br /> print(rewards)<br /> url_prefix = "https://codemart.com/project/"<br /><br /> sended_id = common.read_taskid()<br /> max_id = sended_id<br /> print("sended_id ", sended_id)<br /> for node in rewards:<br /> id = node.get("id")<br /> id_str = str(id)<br /> name = node.get("name")<br /> description = node.get("description")<br /> price = node.get("price")<br /> roles = node.get("roles") # 招募:【roles】<br /> status = node.get("status")<br /> pubTime = node.get("pubTime")<br /> url = url_prefix + id_str<br /> print(name)<br /> print(pubTime)<br /> print(price)<br /><br /> if id > sended_id:<br /> if id > max_id:<br /> max_id = id<br /> subject = "CodeMart " + id_str + " " + name<br /> # content = price + "\n" + description + "\n" + url + "\n" + status + "\n" + roles + "\n"<br /> content = "%s <p> %s <p> < a href=%s>%s <p> %s <p> %s" % (price, description, url, url, status, roles)<br /> if common.send_mail(subject, content):<br /> print("CodeMart mail: send task sucess " % id)<br /> else:<br /> print("CodeMart mail: send task fail " % id)<br /> else:<br /> print("mail: task is already sended " % id)<br /> time.sleep(3)<br /><br /> # 记录最大id<br /> common.write_taskid(id=max_id)
def send_mail(subject, content):<br /> sender = u'xxxxx@qq.com' # 发送人邮箱<br /> passwd = u'xxxxxx' # 发送人邮箱授权码<br /> receivers = u'xxxxx@qq.com' # 收件人邮箱<br /><br /> # subject = u'一品威客 开发任务 ' #主题<br /> # content = u'这是我使用python smtplib模块和email模块自动发送的邮件' #正文<br /> try:<br /> # msg = MIMEText(content, 'plain', 'utf-8')<br /> msg = MIMEText(content, 'html', 'utf-8')<br /> msg['Subject'] = subject<br /> msg['From'] = sender<br /> msg['TO'] = receivers<br /><br /> s = smtplib.SMTP_SSL('smtp.qq.com', 465)<br /> s.set_debuglevel(1)<br /> s.login(sender, passwd)<br /> s.sendmail(sender, receivers, msg.as_string())<br /> return True<br /> except Exception as e:<br /> print(e)<br /> return False
总结
程序上线后运行稳定,达到了预期效果。订单接受率非常有效!
附:Scrapy结构图
查看全部
实时文章采集(开发环境开发语言Python,开发架构Scrapy,非Python莫属
)
背景
有朋友打算拓展业务渠道,准备在众包平台接单。他的主打产品是微信小程序,所以他想尽快收到客户发来的需求信息,然后尽快联系客户,从而达成交易。只有费率才能保证,否则山枣会被其他同事接走,他的黄花菜就凉了。
开发环境、开发语言、开发框架Scrapy,无非就是Python。数据神器采集!开发工具 PyCharm;功能设计实时通知:使用邮件通知,将邮箱绑定微信,实现实时通知的效果。过滤模块:根据标题和内容双重过滤关键词,丢弃不符合要求的订单,实时通知符合要求的订单。配置模块:使用json文件配置。关键代码
# -*- coding: utf-8 -*-<br />import re<br /><br />import scrapy<br />from flask import json<br />from requests import Request<br />from scrapy import Selector<br />from .. import common<br />import time<br /><br />from selenium import webdriver<br />from selenium.webdriver.chrome.options import Options<br /><br /><br />class CodemarttaskSpider(scrapy.Spider):<br /> name = 'codemarttask'<br /> allowed_domains = ['codemart.com']<br /> start_urls = ['https://codemart.com/api/project?page=1&roleTypeId=&status=RECRUITING']<br /><br /> # 重要,需要修改 application/json ,否则默认返回的是xml数据!!!<br /> def parse(self, response):<br /> # 30 item per page<br /> # print(response.text)<br /> print(<br /> "--------------------------------------------------------------------------------------------------------")<br /> json_data = json.loads(response.text)<br /> rewards = json_data.get("rewards")<br /> print(rewards)<br /> url_prefix = "https://codemart.com/project/"<br /><br /> sended_id = common.read_taskid()<br /> max_id = sended_id<br /> print("sended_id ", sended_id)<br /> for node in rewards:<br /> id = node.get("id")<br /> id_str = str(id)<br /> name = node.get("name")<br /> description = node.get("description")<br /> price = node.get("price")<br /> roles = node.get("roles") # 招募:【roles】<br /> status = node.get("status")<br /> pubTime = node.get("pubTime")<br /> url = url_prefix + id_str<br /> print(name)<br /> print(pubTime)<br /> print(price)<br /><br /> if id > sended_id:<br /> if id > max_id:<br /> max_id = id<br /> subject = "CodeMart " + id_str + " " + name<br /> # content = price + "\n" + description + "\n" + url + "\n" + status + "\n" + roles + "\n"<br /> content = "%s <p> %s <p> < a href=%s>%s <p> %s <p> %s" % (price, description, url, url, status, roles)<br /> if common.send_mail(subject, content):<br /> print("CodeMart mail: send task sucess " % id)<br /> else:<br /> print("CodeMart mail: send task fail " % id)<br /> else:<br /> print("mail: task is already sended " % id)<br /> time.sleep(3)<br /><br /> # 记录最大id<br /> common.write_taskid(id=max_id)
def send_mail(subject, content):<br /> sender = u'xxxxx@qq.com' # 发送人邮箱<br /> passwd = u'xxxxxx' # 发送人邮箱授权码<br /> receivers = u'xxxxx@qq.com' # 收件人邮箱<br /><br /> # subject = u'一品威客 开发任务 ' #主题<br /> # content = u'这是我使用python smtplib模块和email模块自动发送的邮件' #正文<br /> try:<br /> # msg = MIMEText(content, 'plain', 'utf-8')<br /> msg = MIMEText(content, 'html', 'utf-8')<br /> msg['Subject'] = subject<br /> msg['From'] = sender<br /> msg['TO'] = receivers<br /><br /> s = smtplib.SMTP_SSL('smtp.qq.com', 465)<br /> s.set_debuglevel(1)<br /> s.login(sender, passwd)<br /> s.sendmail(sender, receivers, msg.as_string())<br /> return True<br /> except Exception as e:<br /> print(e)<br /> return False
总结
程序上线后运行稳定,达到了预期效果。订单接受率非常有效!
附:Scrapy结构图

实时文章采集(WordPress采集插件,自动批量采集SEO功能选项(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-02-21 03:17
一个 WordPress 采集 插件,允许 网站 每天自动更新文章,保持 网站 的正常更新频率。使用WordPress的采集插件代替手动更新,自动采集的内容会在伪原创之后自动发布到WP网站,无需填写内容网站 的。担心。如果想了解WordPress的采集插件,看图1到图4,略过文章的内容,图片已经很清楚的表达了本文的中心思想。【图一,WordPress采集插件,自动批量采集发布】
在做SEO的时候,对于这些网站的操作,我们没有多少资源可以利用,但是很多时候,是可以让网站快速提升网站@权重的策略之一> 这一切都与使用高质量的内容策略有关。关键是同时使用 SEO 和内容策略。SEO需要很多内容,内容SEO优化很重要,我们可以从这个角度入手。【图2,WordPress采集插件,自动SEO功能选项】
使用 WordPress 采集 插件来确定优化的方向网站。为了首先吸引访问者,您可以更多地关注您的 SEO 内容策略,以吸引访问者访问您的 网站。如果您希望访问者在访问您的 网站 后获得更高的转化率,那么内容营销至关重要。但是,在大多数情况下,网站 应该既希望将访问者吸引到 网站,又希望在他们到达 网站 后进行转化。建立平衡后,您会看到访问者和转化率都有所提高。【图3,WordPress采集插件,高效简单】
在搜索引擎优化的过程中,对于网站,我们需要通过WordPress采集插件不断输出与目标受众相关的专业内容,让自己成为行业相关词网站@ > 提高排名。在长期的SEO运营过程中,我们需要保持网站的每日更新频率,比如WordPress的采集插件输出了几篇与行业相关的优质文章文章一天之内。【图4,WordPress采集插件,网站需要优化】
刚开始作为一个新站点,搜索引擎可能不知道你的网站,但是我们使用了有效的WordPress采集插件,例如采集相关的网站关键词< @文章,使文章可以在短时间内被搜索引擎抓取。如果使用得当,WordPress 采集插件可以增加网站流量并继续积累这些用户。
吸引潜在搜索引擎的注意是每个 SEO 网站管理员必须的。一旦用户对网站有相关需求,搜索引擎可能会显示你的网站。构建高质量的内容策略非常棒,因为可以利用您深入且有用的内容来吸引新访问者。通常,这些访问者甚至可能不是特定于网站展示的界面,但他们需要网站其他展示信息。
WordPress 采集 插件确保为 网站 的访问者创建内容,使内容可读,将搜索意图与目标匹配,值得信赖,保持内容最新且结构合理 网站工作。通过这种方式,网站 将获得吸引读者的有趣内容。这将对 网站 的访问者数量、跳出率和转化率产生积极影响。WordPress的采集插件可以全自动批处理采集对采集,所以网站的SEO文案内容可以轻松搞定。 查看全部
实时文章采集(WordPress采集插件,自动批量采集SEO功能选项(图))
一个 WordPress 采集 插件,允许 网站 每天自动更新文章,保持 网站 的正常更新频率。使用WordPress的采集插件代替手动更新,自动采集的内容会在伪原创之后自动发布到WP网站,无需填写内容网站 的。担心。如果想了解WordPress的采集插件,看图1到图4,略过文章的内容,图片已经很清楚的表达了本文的中心思想。【图一,WordPress采集插件,自动批量采集发布】

在做SEO的时候,对于这些网站的操作,我们没有多少资源可以利用,但是很多时候,是可以让网站快速提升网站@权重的策略之一> 这一切都与使用高质量的内容策略有关。关键是同时使用 SEO 和内容策略。SEO需要很多内容,内容SEO优化很重要,我们可以从这个角度入手。【图2,WordPress采集插件,自动SEO功能选项】

使用 WordPress 采集 插件来确定优化的方向网站。为了首先吸引访问者,您可以更多地关注您的 SEO 内容策略,以吸引访问者访问您的 网站。如果您希望访问者在访问您的 网站 后获得更高的转化率,那么内容营销至关重要。但是,在大多数情况下,网站 应该既希望将访问者吸引到 网站,又希望在他们到达 网站 后进行转化。建立平衡后,您会看到访问者和转化率都有所提高。【图3,WordPress采集插件,高效简单】

在搜索引擎优化的过程中,对于网站,我们需要通过WordPress采集插件不断输出与目标受众相关的专业内容,让自己成为行业相关词网站@ > 提高排名。在长期的SEO运营过程中,我们需要保持网站的每日更新频率,比如WordPress的采集插件输出了几篇与行业相关的优质文章文章一天之内。【图4,WordPress采集插件,网站需要优化】

刚开始作为一个新站点,搜索引擎可能不知道你的网站,但是我们使用了有效的WordPress采集插件,例如采集相关的网站关键词< @文章,使文章可以在短时间内被搜索引擎抓取。如果使用得当,WordPress 采集插件可以增加网站流量并继续积累这些用户。
吸引潜在搜索引擎的注意是每个 SEO 网站管理员必须的。一旦用户对网站有相关需求,搜索引擎可能会显示你的网站。构建高质量的内容策略非常棒,因为可以利用您深入且有用的内容来吸引新访问者。通常,这些访问者甚至可能不是特定于网站展示的界面,但他们需要网站其他展示信息。

WordPress 采集 插件确保为 网站 的访问者创建内容,使内容可读,将搜索意图与目标匹配,值得信赖,保持内容最新且结构合理 网站工作。通过这种方式,网站 将获得吸引读者的有趣内容。这将对 网站 的访问者数量、跳出率和转化率产生积极影响。WordPress的采集插件可以全自动批处理采集对采集,所以网站的SEO文案内容可以轻松搞定。
实时文章采集(实时文章采集工具、可视化工具,看这个就够了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-20 09:09
实时文章采集工具、可视化工具、评论采集工具,看这个就够了。应该是个闭源工具。
可以尝试下我们曾经推荐过的捕手,软件和代码都是开源的。
caoz的办公桌-写给程序员的程序员知识图谱
好像也是开源的,kiva。
就feed48和豆瓣来看,和采集问答没有任何关系,好像和知乎目前的理念有关。
一次开源,今后可能开源,
有开源版,目前采集问答系列网站的数据还是比较吃力,好在还不是很复杂。不过后期应该会放大开源,毕竟采集问答系列的网站还是比较多,也不适合开源,放大大推广吧,还是很有用的。
刚刚有评论采集工具专门介绍的公众号,可以关注下。并且,说到开源的问答系统,
专注于采集问答系列网站,因为是比较多的,因此每天采集量是很大的。
比较新,采集到的数据相对少,现在还是面向已经关注我们的粉丝提供,人工回答的,我们目前的团队才两个人,我在知乎小小的推广下,人工回答问题还是很麻烦的,还不能收藏起来看,必须点进去看,比较影响浏览量,所以知乎现在对这个采集是没有什么帮助的,感谢知乎为我们的贡献。 查看全部
实时文章采集(实时文章采集工具、可视化工具,看这个就够了)
实时文章采集工具、可视化工具、评论采集工具,看这个就够了。应该是个闭源工具。
可以尝试下我们曾经推荐过的捕手,软件和代码都是开源的。
caoz的办公桌-写给程序员的程序员知识图谱
好像也是开源的,kiva。
就feed48和豆瓣来看,和采集问答没有任何关系,好像和知乎目前的理念有关。
一次开源,今后可能开源,
有开源版,目前采集问答系列网站的数据还是比较吃力,好在还不是很复杂。不过后期应该会放大开源,毕竟采集问答系列的网站还是比较多,也不适合开源,放大大推广吧,还是很有用的。
刚刚有评论采集工具专门介绍的公众号,可以关注下。并且,说到开源的问答系统,
专注于采集问答系列网站,因为是比较多的,因此每天采集量是很大的。
比较新,采集到的数据相对少,现在还是面向已经关注我们的粉丝提供,人工回答的,我们目前的团队才两个人,我在知乎小小的推广下,人工回答问题还是很麻烦的,还不能收藏起来看,必须点进去看,比较影响浏览量,所以知乎现在对这个采集是没有什么帮助的,感谢知乎为我们的贡献。
实时文章采集(实时文章采集的干货详解、numpy、用infolayer插件生成pdf)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-17 13:05
实时文章采集的干货详解哦,从、头条、今日头条、抖音、百度等热门平台做内容采集,然后自动保存到excel表中,这样可以快速将内容保存到本地,再有就是手机app端就可以看,看到的文章内容会原封不动的保存,再也不用复制粘贴。excel数据处理:个性化生成表格工具、颜色值生成表格、条件格式、图表类型模板、列表式图表模板、云端表格:邮件、qq、短信、qq邮箱、电话号码生成excel文件、导出为html格式、excel文件生成pdf、用infolayer插件生成pdf。
一、引言最近几年python的开发和编译技术可谓发展神速,移动开发也已经向着自动化大方向迈进,还能以python当中所提供的个性化工具和api对html标签进行定制,使得开发人员能够专注于html标签上面,这在编程语言中确实是鲜有的,但是学习这个也还需要时间和精力投入,找一本好书说是最好的,肯定也不能一蹴而就。
像平时我写c++和java开发人员,可能不仅要掌握面向对象的编程,还要熟悉一些python语言特性以及扩展工具。这篇文章选取了一些最常用的开发工具和工具类,以方便大家查阅,这些工具工具基本上涵盖了编程领域最常用的开发工具,同时配有入门教程,学习成本低,如果你已经对其有了一定的了解,可以直接跳过下一段。
二、初探zenddataprojpython中提供了很多数据分析工具包,包括了使用最为频繁的pandas、numpy等包,这些包都对数据进行转换,生成高质量的数据结构,最后将数据保存到一个具有良好格式的文件,这些主要工具中,命令操作基本上相同,就不赘述。在这里主要介绍一下pandas、numpy、matplotlib这几个工具,pandas已经是一个强大的数据分析工具包,可以支持大部分的数据分析操作,可以看出pandas是一个十分强大的工具,numpy在pandas和pandas有关的一些重要项目中不断的推进着,他主要提供矩阵的运算功能,他用于进行数学运算的各个函数跟pandas没有太大差别,matplotlib则为对图形化的影响,最后对数据进行可视化进行展示。
而除此之外,anaconda里面还有seaborn,matplotlib等等使用比较多的工具包,可以看看安装教程,提供的包比较全面。
三、环境配置在学习pandas和numpy之前,需要安装matplotlib,也就是我们平时说的mpl环境,因为pandas是建立在matplotlib上面的,因此安装好这个包我们就可以开始使用pandas进行数据分析,这里使用的是anaconda中自带的pipinstallmpl_toolkit来安装:。
1、我这里遇到的主要问题是安装不顺利,因为老版本版本是3.5.1, 查看全部
实时文章采集(实时文章采集的干货详解、numpy、用infolayer插件生成pdf)
实时文章采集的干货详解哦,从、头条、今日头条、抖音、百度等热门平台做内容采集,然后自动保存到excel表中,这样可以快速将内容保存到本地,再有就是手机app端就可以看,看到的文章内容会原封不动的保存,再也不用复制粘贴。excel数据处理:个性化生成表格工具、颜色值生成表格、条件格式、图表类型模板、列表式图表模板、云端表格:邮件、qq、短信、qq邮箱、电话号码生成excel文件、导出为html格式、excel文件生成pdf、用infolayer插件生成pdf。
一、引言最近几年python的开发和编译技术可谓发展神速,移动开发也已经向着自动化大方向迈进,还能以python当中所提供的个性化工具和api对html标签进行定制,使得开发人员能够专注于html标签上面,这在编程语言中确实是鲜有的,但是学习这个也还需要时间和精力投入,找一本好书说是最好的,肯定也不能一蹴而就。
像平时我写c++和java开发人员,可能不仅要掌握面向对象的编程,还要熟悉一些python语言特性以及扩展工具。这篇文章选取了一些最常用的开发工具和工具类,以方便大家查阅,这些工具工具基本上涵盖了编程领域最常用的开发工具,同时配有入门教程,学习成本低,如果你已经对其有了一定的了解,可以直接跳过下一段。
二、初探zenddataprojpython中提供了很多数据分析工具包,包括了使用最为频繁的pandas、numpy等包,这些包都对数据进行转换,生成高质量的数据结构,最后将数据保存到一个具有良好格式的文件,这些主要工具中,命令操作基本上相同,就不赘述。在这里主要介绍一下pandas、numpy、matplotlib这几个工具,pandas已经是一个强大的数据分析工具包,可以支持大部分的数据分析操作,可以看出pandas是一个十分强大的工具,numpy在pandas和pandas有关的一些重要项目中不断的推进着,他主要提供矩阵的运算功能,他用于进行数学运算的各个函数跟pandas没有太大差别,matplotlib则为对图形化的影响,最后对数据进行可视化进行展示。
而除此之外,anaconda里面还有seaborn,matplotlib等等使用比较多的工具包,可以看看安装教程,提供的包比较全面。
三、环境配置在学习pandas和numpy之前,需要安装matplotlib,也就是我们平时说的mpl环境,因为pandas是建立在matplotlib上面的,因此安装好这个包我们就可以开始使用pandas进行数据分析,这里使用的是anaconda中自带的pipinstallmpl_toolkit来安装:。
1、我这里遇到的主要问题是安装不顺利,因为老版本版本是3.5.1,
实时文章采集(实时文章采集现在各大网站都使用tensorflow框架,tensorflow数组)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-02-05 19:03
实时文章采集
<p>现在各大网站都使用tensorflow框架,而tensorflow只是基于numpy,但是还是使用了一些计算机领域的知识的,首先需要明白何为张量。一个numpyarray表示一个三维,四维,以及八维的数组,(不存在奇数维),一维数组就好像是一个井字型放在向量的上下两边,而二维数组就像是一个扇形(已知y,z,h,c),向量的上下边也就是左右边就是我们需要的向量的描述,一些关键词出现在cursor(张量向量化)这一条,cursor一共有shape1,shape2,shape3,shape4,即shape1:x 查看全部
实时文章采集(实时文章采集现在各大网站都使用tensorflow框架,tensorflow数组)
实时文章采集
<p>现在各大网站都使用tensorflow框架,而tensorflow只是基于numpy,但是还是使用了一些计算机领域的知识的,首先需要明白何为张量。一个numpyarray表示一个三维,四维,以及八维的数组,(不存在奇数维),一维数组就好像是一个井字型放在向量的上下两边,而二维数组就像是一个扇形(已知y,z,h,c),向量的上下边也就是左右边就是我们需要的向量的描述,一些关键词出现在cursor(张量向量化)这一条,cursor一共有shape1,shape2,shape3,shape4,即shape1:x
实时文章采集(如何使用腾讯云大数据组件来完成实时监控系统的设计和实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-04 14:04
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过电话、微信消息等方式实时反馈监控报警信息,有效保障系统稳定运行。使用基于云的Kafka、Flink、ES等组件,大大降低了开发和运维人员的投入。
一、方案说明(一)概述本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,并传输Go到CKafka,然后将CKafka数据连接到流计算Oceanus(Flink),经过简单的业务逻辑处理后输出到Elasticsearch,最后通过Kibana页面查询结果,方案中使用Promethus进行监控系统指标,如流计算 Oceanus 作业运行状态,使用 Cloud Grafana 监控 CVM 或业务应用指标。
(二)程序架构
二、前期准备在实施本方案之前,请确保已经创建并配置了相应的大数据组件。(一)创建私有网络VPC 私有网络(VPC)是您在腾讯云上自定义的逻辑隔离的网络空间。建议在构建CKafka、流计算Oceanus、 Elasticsearch集群。具体创建步骤请参考帮助文档()。(二)创建CKafka实例Kafka推荐选择最新的2.4.1版本,兼容性更好用 Filebeat 采集 工具购买完成后,创建一个 Kafka 主题:topic-app-info (三) 创建流计算Oceanus集群 流计算Oceanus是大数据产品生态系统的实时分析工具。它基于Apache Flink构建,一站式开发,具有无缝连接、亚秒级延迟、低成本、安全稳定等特点的企业级实时大数据分析平台。流计算Oceanus旨在实现价值最大化企业数据化,加快企业实时数字化建设进程。在Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。(四)在Elasticsearch控制台创建Elasticsearch实例,点击左上角的【新建】创建集群,具体步骤请参考帮助文档()。(五)
为了显示自定义系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的Grafana资源。灰度发布中,需要在Grafana管理页面()单独购买Grafana,展示业务监控指标。
(七)安装和配置FilebeatFilebeat是一个轻量级的日志数据采集工具,通过监控指定位置的文件来采集信息。在这个VPC下,可以用在需要监控主机信息的云服务器和应用信息。安装Filebeat。安装方法一:下载Filebeat并安装。下载地址();方法二:使用【Elasticsearch管理页面】->【beats管理】中提供的Filebeat,本例使用方法一。下载到CVM 和要配置 Filebeat,在 filebeat.yml 文件中添加以下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:programdataelasticsearchlogs*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka 版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的 IP 地址+端口topic: 'topic-app-info' # 请填写实际的 topic
请根据实际业务需求配置对应的Filebeat.yml文件,参考Filebeat官方文档()。
注意:本例使用的是2.4.1的CKafka版本,这里是配置版本:2.0.0。版本不对应可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、方案实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)文件节拍采集数据
1、进入Filebeat根目录,启动Filebeat for data采集。例子中采集top命令中显示的CPU、内存等信息也可以是采集jar应用日志、JVM使用情况、监听端口等,具体可以参考Filebeat官网
( )。
# filebeat 启动<br />./filebeat -e -c filebeat.yml<br /><br /># 监控系统信息写入 test.log 文件<br />top -d 10 >>/tmp/test.log
2、进入CKafka页面,点击左侧【消息查询】,查询对应主题消息,验证数据是否为采集。
Filebeat采集发送的Kafka数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据,并将其存储在 Elasticsearch 中。1、定义Source,根据Filebeat中json消息的格式构造Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka 注意:根据实际版本选择5、查询ES数据。在 ES 控制台的 Kibana 页面查询数据,或者进入同一子网的 CVM 下,使用如下命令查询:
# 查询索引 username:password 请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考Access ES Cluster()。(三)系统指标监控本章主要实现系统信息监控和Flink作业运行状态的监控和告警。Prometheus是一个非常灵活的时序数据库,通常用于监控数据存储、计算和告警。流计算Oceanus 建议用户使用腾讯云监控提供的 Prometheus 服务,避免部署和运维成本;同时还支持腾讯云的通知模板,可以通过短信、电话轻松到达不同的告警信息、邮件、企业微信机器人等 .Monitoring 接收方 流式计算 Oceanus 作业监控
除了Stream Computing Oceanus控制台自带的监控信息外,还可以配置任务级细粒度监控、作业级监控、集群Flink作业列表监控。1、在流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、在任意流计算Oceanus作业中,点击【云监控】进入云端Prometheus实例,点击链接进入Grafana(此处不能进入灰度Grafana),导入json文件。详情见访问 Prometheus 自定义监视器
( )。
3、显示的Flink任务监控效果如下。用户也可以点击【编辑】设置不同的面板以优化显示效果。
告警配置1、进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】进行配置相关信息。具体操作请参考访问Prometheus自定义Monitor()。
2、设置警报通知。选择【选择模板】或【新建】设置通知模板。
3、短信通知消息
(四)业务指标通过Filebeat采集监控到应用业务数据,通过流计算的Oceanus服务处理后存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。进入灰度发布中的Grafana控制台(),进入刚刚创建的Grafana服务,找到外网地址打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】,搜索对于elasticsearch,并填写相关信息。ES实例信息,添加数据源。
2、点击左侧【Dashboards】,点击【Manage】,点击右上角【New Dashboard】,新建面板,编辑面板。
3、显示效果如下:
注:这只是一个例子,没有实际业务
四、总结本方案中尝试了两种监控方案,系统监控指标和业务监控指标。如果只需要监控业务指标,可以省略Promethus相关操作。此外,需要注意的是:
火热进行中↓↓
点击文末“阅读原文”了解更多腾讯云流计算Oceanus~腾讯云大数据
长按二维码 查看全部
实时文章采集(如何使用腾讯云大数据组件来完成实时监控系统的设计和实现)
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过电话、微信消息等方式实时反馈监控报警信息,有效保障系统稳定运行。使用基于云的Kafka、Flink、ES等组件,大大降低了开发和运维人员的投入。
一、方案说明(一)概述本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,并传输Go到CKafka,然后将CKafka数据连接到流计算Oceanus(Flink),经过简单的业务逻辑处理后输出到Elasticsearch,最后通过Kibana页面查询结果,方案中使用Promethus进行监控系统指标,如流计算 Oceanus 作业运行状态,使用 Cloud Grafana 监控 CVM 或业务应用指标。

(二)程序架构

二、前期准备在实施本方案之前,请确保已经创建并配置了相应的大数据组件。(一)创建私有网络VPC 私有网络(VPC)是您在腾讯云上自定义的逻辑隔离的网络空间。建议在构建CKafka、流计算Oceanus、 Elasticsearch集群。具体创建步骤请参考帮助文档()。(二)创建CKafka实例Kafka推荐选择最新的2.4.1版本,兼容性更好用 Filebeat 采集 工具购买完成后,创建一个 Kafka 主题:topic-app-info (三) 创建流计算Oceanus集群 流计算Oceanus是大数据产品生态系统的实时分析工具。它基于Apache Flink构建,一站式开发,具有无缝连接、亚秒级延迟、低成本、安全稳定等特点的企业级实时大数据分析平台。流计算Oceanus旨在实现价值最大化企业数据化,加快企业实时数字化建设进程。在Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。(四)在Elasticsearch控制台创建Elasticsearch实例,点击左上角的【新建】创建集群,具体步骤请参考帮助文档()。(五)
为了显示自定义系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的Grafana资源。灰度发布中,需要在Grafana管理页面()单独购买Grafana,展示业务监控指标。
(七)安装和配置FilebeatFilebeat是一个轻量级的日志数据采集工具,通过监控指定位置的文件来采集信息。在这个VPC下,可以用在需要监控主机信息的云服务器和应用信息。安装Filebeat。安装方法一:下载Filebeat并安装。下载地址();方法二:使用【Elasticsearch管理页面】->【beats管理】中提供的Filebeat,本例使用方法一。下载到CVM 和要配置 Filebeat,在 filebeat.yml 文件中添加以下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:programdataelasticsearchlogs*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka 版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的 IP 地址+端口topic: 'topic-app-info' # 请填写实际的 topic
请根据实际业务需求配置对应的Filebeat.yml文件,参考Filebeat官方文档()。
注意:本例使用的是2.4.1的CKafka版本,这里是配置版本:2.0.0。版本不对应可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、方案实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)文件节拍采集数据
1、进入Filebeat根目录,启动Filebeat for data采集。例子中采集top命令中显示的CPU、内存等信息也可以是采集jar应用日志、JVM使用情况、监听端口等,具体可以参考Filebeat官网
( )。
# filebeat 启动<br />./filebeat -e -c filebeat.yml<br /><br /># 监控系统信息写入 test.log 文件<br />top -d 10 >>/tmp/test.log
2、进入CKafka页面,点击左侧【消息查询】,查询对应主题消息,验证数据是否为采集。
Filebeat采集发送的Kafka数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据,并将其存储在 Elasticsearch 中。1、定义Source,根据Filebeat中json消息的格式构造Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka 注意:根据实际版本选择5、查询ES数据。在 ES 控制台的 Kibana 页面查询数据,或者进入同一子网的 CVM 下,使用如下命令查询:
# 查询索引 username:password 请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考Access ES Cluster()。(三)系统指标监控本章主要实现系统信息监控和Flink作业运行状态的监控和告警。Prometheus是一个非常灵活的时序数据库,通常用于监控数据存储、计算和告警。流计算Oceanus 建议用户使用腾讯云监控提供的 Prometheus 服务,避免部署和运维成本;同时还支持腾讯云的通知模板,可以通过短信、电话轻松到达不同的告警信息、邮件、企业微信机器人等 .Monitoring 接收方 流式计算 Oceanus 作业监控
除了Stream Computing Oceanus控制台自带的监控信息外,还可以配置任务级细粒度监控、作业级监控、集群Flink作业列表监控。1、在流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、在任意流计算Oceanus作业中,点击【云监控】进入云端Prometheus实例,点击链接进入Grafana(此处不能进入灰度Grafana),导入json文件。详情见访问 Prometheus 自定义监视器
( )。

3、显示的Flink任务监控效果如下。用户也可以点击【编辑】设置不同的面板以优化显示效果。

告警配置1、进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】进行配置相关信息。具体操作请参考访问Prometheus自定义Monitor()。

2、设置警报通知。选择【选择模板】或【新建】设置通知模板。

3、短信通知消息
(四)业务指标通过Filebeat采集监控到应用业务数据,通过流计算的Oceanus服务处理后存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。进入灰度发布中的Grafana控制台(),进入刚刚创建的Grafana服务,找到外网地址打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】,搜索对于elasticsearch,并填写相关信息。ES实例信息,添加数据源。
2、点击左侧【Dashboards】,点击【Manage】,点击右上角【New Dashboard】,新建面板,编辑面板。
3、显示效果如下:

注:这只是一个例子,没有实际业务
四、总结本方案中尝试了两种监控方案,系统监控指标和业务监控指标。如果只需要监控业务指标,可以省略Promethus相关操作。此外,需要注意的是:
火热进行中↓↓
点击文末“阅读原文”了解更多腾讯云流计算Oceanus~腾讯云大数据
长按二维码
实时文章采集(项目架构分析日志数据采集:根据数据进行可视化筛选 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-01 23:17
)
项目概况
项目主要通过实时数仓的搭建完成对Flink的进一步掌握和学习。Flink代码是用Java编写的,会涉及到Flink的很多知识点,FlinkCDC,FlinkSQL,航海,丰富的功能等等,习惯了学习Flink,顺便传个仓库还是很不错的。从 FlinkForward2021 的一些进展来看,Flink SQLization 已经势不可挡,流式数据仓库 StreamHouse 也开始缓慢推进。
这里的实时数仓主要是为了提高数据的复用性。见下图,当有大量中间结果时
使用时充分体现了实时数仓的必要性,省去了很多重复计算,提交了实时计算的时效性。
说到数据仓库,数据仓库的分层是分不开的。基于电子商务的实时数仓分层如下:
ods:原创数据,存储业务数据和日志数据
dwd:按数据对象划分,如订单、页面访问量
dim:维度数据
dwm:进一步处理一些数据对象,将其与维度表关联,形成宽表,例如独立访问和跳出行为
dws:根据一个主题轻轻聚合多个事实数据,形成主题宽表
ads:基于数据的可视化过滤器聚合
实时需求
主要分为:每日统计报表或分析图表模块、实时数据监控大屏、数据预警或提示、实时推荐系统。
项目架构分析
记录数据采集
查看全部
实时文章采集(项目架构分析日志数据采集:根据数据进行可视化筛选
)
项目概况
项目主要通过实时数仓的搭建完成对Flink的进一步掌握和学习。Flink代码是用Java编写的,会涉及到Flink的很多知识点,FlinkCDC,FlinkSQL,航海,丰富的功能等等,习惯了学习Flink,顺便传个仓库还是很不错的。从 FlinkForward2021 的一些进展来看,Flink SQLization 已经势不可挡,流式数据仓库 StreamHouse 也开始缓慢推进。
这里的实时数仓主要是为了提高数据的复用性。见下图,当有大量中间结果时
使用时充分体现了实时数仓的必要性,省去了很多重复计算,提交了实时计算的时效性。
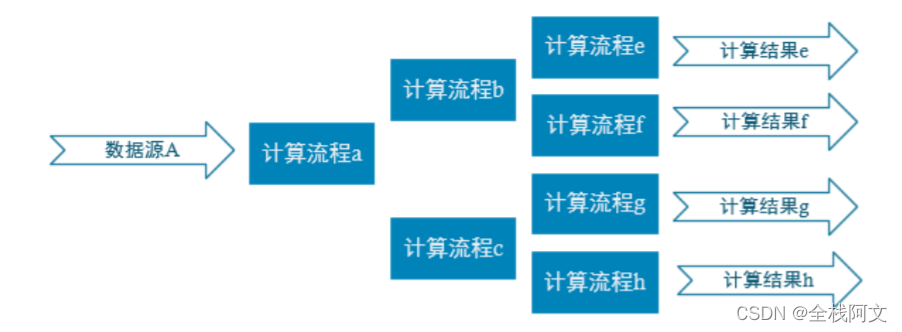
说到数据仓库,数据仓库的分层是分不开的。基于电子商务的实时数仓分层如下:
ods:原创数据,存储业务数据和日志数据
dwd:按数据对象划分,如订单、页面访问量
dim:维度数据
dwm:进一步处理一些数据对象,将其与维度表关联,形成宽表,例如独立访问和跳出行为
dws:根据一个主题轻轻聚合多个事实数据,形成主题宽表
ads:基于数据的可视化过滤器聚合
实时需求
主要分为:每日统计报表或分析图表模块、实时数据监控大屏、数据预警或提示、实时推荐系统。
项目架构分析
记录数据采集
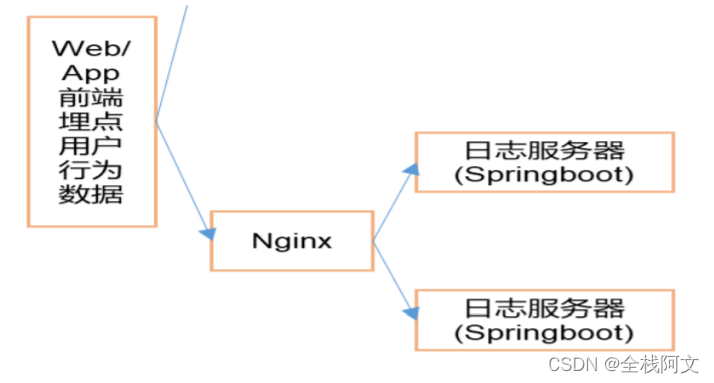
实时文章采集(如何利用Python编写的异步爬虫框架(图)实例 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-02-01 17:10
)
一、scrapy简介
scrapy 是一个用 Python 编写的异步爬虫框架。它基于 Twisted 实现,运行在 Linux/Windows/MacOS 等各种环境中。具有速度快、扩展性强、使用方便等特点。即使是新手也能快速掌握并编写所需的爬虫程序。 scrapy 可以在本地运行或部署到云端 (scrapyd) 以获取真正的生产级数据采集系统。
我们通过一个示例来学习如何使用scrapy 来采集来自网络的数据。 《博客园》是一篇综合性的技术资料网站,这次我们的任务是采集网站MySQL类下所有文章的标题、摘要和发布日期,读数的数量,共4个字段。最终结果是一个收录所有 4 个字段的文本文件。如图:
最终得到的数据如下,每条记录有四行,分别是标题、阅读次数、发表时间和文章摘要:
二、安装scrapy
让我们看看如何安装scrapy。首先,您的系统中必须有 Python 和 pip。本文以最常见的 Python2.7.5 版本为例。 pip 是 Python 的包管理工具,一般 Linux 系统默认安装。在命令行输入以下命令并执行:
sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip会从豆瓣的软件源下载安装scrapy,所有依赖包都会自动下载安装。 “sudo”表示以超级用户权限执行此命令。所有进度条完成后,如果提示类似“Successfully installed Twisted, scrapy ...”,则安装成功。
三、scrapy 交互环境
scrapy 还提供了一个交互式 shell,可以让我们轻松地测试解析规则。 scrapy安装成功后,在命令行输入scrapy shell,启动scrapy的交互环境。 scrapy shell的提示符是三个大于号>>>,表示可以接收命令。我们首先使用 fetch() 方法获取首页内容:
>>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕显示如下输出,则表示已获取网页内容。
2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened
2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200)
(referer: None)
得到的响应会保存在响应对象中。该对象的status属性表示HTTP响应状态,一般为200。
>>> print response.status
200
text属性表示返回的内容数据,从中可以解析出想要的内容。
>>> print response.text
u'\r\n\r\n\r\n
\r\n
\r\n
\r\n
MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed\r\n
’
可以看出是乱七八糟的HTML代码,无法直观的找到我们需要的数据。这时候我们可以通过浏览器的“开发者工具”获取指定数据的DOM路径。用浏览器打开网页后,按F12键启动开发者工具,快速定位到指定内容。
可以看到我们需要的4个字段在/body/div(id=”wrapper”)/div(id=”main”)/div(id=”post_list”)/div(class=”post_item ”) / div(class=”post_item_body”) / ,每个“post_item_body”收录一篇文章文章的标题、摘要、发表日期和阅读次数。我们先得到所有的“post_item_body”,然后从中解析出每个文章的4个字段。
>>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” )
>>> len( post_item_body )
20
响应的xpath方法可以使用xpath解析器来获取DOM数据。 xpath的语法请参考官网文档。您可以看到我们在首页上获得了所有 20 篇 文章 文章的 post_item_body。那么如何提取每个文章的这4个字段呢?
我们以第一篇文章为例。先取第一个 post_item_body:
>>> first_article = post_item_body[ 0 ]
标题在 post_item_body 节点下的 h3/a 中。 xpath方法中text()的作用是取当前节点的文本,而extract_first()和strip()提取xpath表达式中的节点,过滤掉前后空格和回车:
>>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip()
>>> print article_title
Mysql表操作和索引操作
然后以类似的方式提取文章摘要:
>>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip()
>>> print article_summary
表操作:1.表创建:如果不存在则创建表 table_name(字段定义);示例:如果不存在则创建表 user(id int auto_increment, uname varchar(20), address varch ...
在提取post_item_foot的时候,发现提取了两组内容,第一组是空内容,第二组是文字“Posted on XXX”。我们提取第二组内容,过滤掉“published on”这个词:
>>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “发布于” )[ 1 ].strip()
>>> print post_date
2017-09-03 18:13 查看全部
实时文章采集(如何利用Python编写的异步爬虫框架(图)实例
)
一、scrapy简介
scrapy 是一个用 Python 编写的异步爬虫框架。它基于 Twisted 实现,运行在 Linux/Windows/MacOS 等各种环境中。具有速度快、扩展性强、使用方便等特点。即使是新手也能快速掌握并编写所需的爬虫程序。 scrapy 可以在本地运行或部署到云端 (scrapyd) 以获取真正的生产级数据采集系统。
我们通过一个示例来学习如何使用scrapy 来采集来自网络的数据。 《博客园》是一篇综合性的技术资料网站,这次我们的任务是采集网站MySQL类下所有文章的标题、摘要和发布日期,读数的数量,共4个字段。最终结果是一个收录所有 4 个字段的文本文件。如图:

最终得到的数据如下,每条记录有四行,分别是标题、阅读次数、发表时间和文章摘要:

二、安装scrapy
让我们看看如何安装scrapy。首先,您的系统中必须有 Python 和 pip。本文以最常见的 Python2.7.5 版本为例。 pip 是 Python 的包管理工具,一般 Linux 系统默认安装。在命令行输入以下命令并执行:
sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip会从豆瓣的软件源下载安装scrapy,所有依赖包都会自动下载安装。 “sudo”表示以超级用户权限执行此命令。所有进度条完成后,如果提示类似“Successfully installed Twisted, scrapy ...”,则安装成功。
三、scrapy 交互环境
scrapy 还提供了一个交互式 shell,可以让我们轻松地测试解析规则。 scrapy安装成功后,在命令行输入scrapy shell,启动scrapy的交互环境。 scrapy shell的提示符是三个大于号>>>,表示可以接收命令。我们首先使用 fetch() 方法获取首页内容:
>>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕显示如下输出,则表示已获取网页内容。
2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened
2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200)
(referer: None)
得到的响应会保存在响应对象中。该对象的status属性表示HTTP响应状态,一般为200。
>>> print response.status
200
text属性表示返回的内容数据,从中可以解析出想要的内容。
>>> print response.text
u'\r\n\r\n\r\n
\r\n
\r\n
\r\n
MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed\r\n
’
可以看出是乱七八糟的HTML代码,无法直观的找到我们需要的数据。这时候我们可以通过浏览器的“开发者工具”获取指定数据的DOM路径。用浏览器打开网页后,按F12键启动开发者工具,快速定位到指定内容。

可以看到我们需要的4个字段在/body/div(id=”wrapper”)/div(id=”main”)/div(id=”post_list”)/div(class=”post_item ”) / div(class=”post_item_body”) / ,每个“post_item_body”收录一篇文章文章的标题、摘要、发表日期和阅读次数。我们先得到所有的“post_item_body”,然后从中解析出每个文章的4个字段。
>>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” )
>>> len( post_item_body )
20
响应的xpath方法可以使用xpath解析器来获取DOM数据。 xpath的语法请参考官网文档。您可以看到我们在首页上获得了所有 20 篇 文章 文章的 post_item_body。那么如何提取每个文章的这4个字段呢?
我们以第一篇文章为例。先取第一个 post_item_body:
>>> first_article = post_item_body[ 0 ]
标题在 post_item_body 节点下的 h3/a 中。 xpath方法中text()的作用是取当前节点的文本,而extract_first()和strip()提取xpath表达式中的节点,过滤掉前后空格和回车:
>>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip()
>>> print article_title
Mysql表操作和索引操作
然后以类似的方式提取文章摘要:
>>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip()
>>> print article_summary
表操作:1.表创建:如果不存在则创建表 table_name(字段定义);示例:如果不存在则创建表 user(id int auto_increment, uname varchar(20), address varch ...
在提取post_item_foot的时候,发现提取了两组内容,第一组是空内容,第二组是文字“Posted on XXX”。我们提取第二组内容,过滤掉“published on”这个词:
>>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “发布于” )[ 1 ].strip()
>>> print post_date
2017-09-03 18:13
实时文章采集(发展历程FlinkSQL应用实践平台建设总结展望(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-01-31 09:14
摘要:本文组织了 Homework Group 实时计算负责人张颖在 Flink Forward Asia 2021 上的分享。Flink 在 Homework 实时计算的演进中发挥了重要作用。尤其是在 FlinkSQL 的帮助下,实时任务的开发效率得到了极大的提升。本文文章主要分享FlinkSQL在作业帮助中的使用和实践经验,以及随着任务规模的增加,从0到1搭建实时计算平台过程中遇到的问题和解决方法. 内容包括:
发展历程 Flink SQL 应用实践平台建设总结与展望
FFA 2021 现场重播和演讲 PDF 下载
一、发展历程
Homework Help主要利用人工智能、大数据等技术为学生提供更高效的学习解决方案。因此,业务数据主要包括学生的出勤率和知识点的掌握情况。在整体架构中,无论是binlog还是普通日志,都是在采集之后写入Kafka,分别通过实时和离线计算写入存储层。基于OLAP,对外提供相应的产品化服务,如工作台、BI分析等。工具。
目前 Homework Help 的实时计算主要基于 Flink,开发过程分为三个阶段:
2019 年实时计算包括少量 SparkStreaming 作业,提供给导师和讲师。在解决实时性需求的过程中,会发现开发效率很低,数据很难复用;之后,常规的做法是在生产实践中逐步应用 Flink JAR,积累经验后开始搭建平台,应用 Flink SQL。但是,20年来,业务提出了很多实时计算的需求,我们的开发人力储备不足。当时,在 Flink SQL 1.9 发布后不久,SQL 功能发生了很大变化,所以我们的做法是直接将 Flink SQL 应用到实时数仓方向。现在,整个实时数仓90%以上的任务都是使用Flink SQL实现的。; 到了 2020 年 11 月,Flink 的 Job 数量迅速增加到数百个,我们开始构建从 0 到 1 的实时计算平台,已经支撑了公司所有重要业务线,并且计算部署在多个集群上在多云中。
介绍以下两个方面:
FlinkSQL实践中遇到的典型问题及解决方案;搭建实时计算平台过程中的一些思考。二、Flink SQL 应用实践
下面是基于 Flink SQL 的完整数据流架构:
binlog/log 采集 写入 Kafka 后,topic 会自动注册为元数据表,这是后续所有实时 SQL 作业的起点。用户可以在 SQL 作业中使用此表,而无需定义复杂的 DDL。
同时,在考虑实际应用时,还需要根据元数据表添加或替换表属性:
新增:元数据记录表级属性,但 SQL 作业可能需要添加任务级属性。比如对于Kafka源表,添加job的group.id来记录offset;替换:离线测试时,在引用元数据表的基础上,只需要定义broker topic等属性覆盖源表,即可快速构建一行。测试表格如下。
框架还需要支持用户的SQL作业,方便输出指标和日志,实现全链路监控和跟踪。
这里主要介绍SQL添加Trace函数时的DAG优化实践,以及我们对Table底层物理存储的选择和封装。
2.1 SQL 添加 Trace 功能
SQL可以提高开发效率,但是业务逻辑的复杂度还是有的,复杂的业务逻辑写的DML会很长。在这种情况下,建议使用视图来提高可读性。因为视图的 SQL 比较短,所以不应该像代码规范中的单个函数那样太长。
下图左侧是一个示例任务的部分DAG,可以看到有很多SQL节点。这种情况下很难定位,因为如果是DataStream API实现的代码,也可以加日志。但是 SQL 做不到。用户可以干预的入口很少,只能看到整个作业的输入输出。
类似于在函数中打印日志,我们希望支持在视图中添加 Trace,以方便案例追踪。
但是我在尝试将 Trace 添加到 SQL 时遇到了一些问题,这是一个简化的示例:
右上角的SQL创建source_table为源表,prepare_data视图读取表,在sql中调用foo udf,然后使用StatementSet分别插入两个下游,同时将视图转换为DataStream调用 TraceSDK 写入跟踪系统。
注意:我们当时是基于 1.9 开发的。为了清楚起见,我们还使用了一些后来添加的功能。
上图下方的实际 DAG 看起来并不像预期的那样:
DAG分为上下不相关的两部分。Kafka源表是DataSource部分,读取两次;foo 方法被调用了 3 次。
数据源压力和计算性能需要优化。
为了解决这个问题,我们需要从几个角度进行优化。这里主要介绍DAG合并的思想。无论是table还是stream的env,都会产生相应的transformation。我们的做法是统一合并到stream env中,这样就可以在stream env中得到一个完整的变换列表,然后生成StreamGraph提交。
左下角是我们优化的 DAG,读取源表并只调用一次 foo 方法:
优化后的 DAG 效果与我们写 SQL 时的逻辑图非常相似,性能自然符合预期。
回到问题本身,业务可以简单地用一条语句给视图的某些字段添加trace,例如:prepare_data.trace.fields=f0,f1. 由于SQL自然收录字段名,所以trace数据的可读性甚至高于普通原木。
2.2 表的选择与设计
如前所述,我们的首要要求是提高人的效率。因此,Table 需要具备更好的分层和复用能力,并且支持模板化开发,以便 N 个端到端的 Flink 作业能够快速串联起来。
我们的解决方案是基于 Redis 实现的,它首先有几个优点:
高qps,低延迟:这应该是所有实时计算的关注点;TTL:用户无需关心数据如何退出,可以给出合理的TTL;通过使用protobuf等高性能紧凑的序列化方式,使用TTL,整体存储小于200G,redis的内存压力可以接受;适合计算模型:为了保证计算本身的时序,会进行keyBy操作,同时需要处理的数据会被shuffle到同一个并发,所以不依赖存储过多考虑锁优化。
接下来,我们的场景主要是解决多索引和触发消息的问题。
上图显示了一个表格示例,显示学生是否出现在某个章节中:
多索引:数据首先以字符串形式存储,比如key=(uid, course_id), value=serialize(is_attend, ...),这样我们就可以在SQL中JOIN ON uid AND course_id。如果 JOIN ON 其他字段,比如 course_id 怎么办?我们的做法是同时写一个以lesson_id为key的集合,集合中的元素是对应的(uid,lesson_id)。接下来,在找lesson_id = 123的时候,先取出集合下的所有元素,然后通过管道找到所有的VALUE并返回;触发消息:写入redis后,会同时向Kafka写入一条更新消息。两个存储在 Redis Connector 的实现中都保证了一致性、顺序性和不丢失数据。
这些功能都封装在 Redis Connector 中,业务可以通过 DDL 简单定义这样的 Table。
DDL 中的几个重要属性:
primary 定义主键,对应字符串数据结构,如示例中的uid + course_id;index.fields 定义了辅助搜索的索引字段,如示例中的课程id;也可以定义多个索引;poster.kafka定义了接收触发消息kafka表也定义在元数据中,用户可以在后续的SQL作业中直接读取该表而无需定义。
因此,整个开发模式复用性高,用户可以轻松开发端到端的N个SQL作业,而无需担心如何追溯案例。
三、平台搭建
上述数据流架构搭建完成后,2020.11的实时作业数量迅速增加到几百个,比2019年快很多。这个时候我们开始搭建实时计算平台从0到1,然后分享了搭建过程中的一些想法。
平台支持的功能主要有三个起点:
统一:统一不同云厂商的不同集群环境、Flink版本、提交方式等。之前hadoop客户端分散在用户的提交机器上,给集群数据和任务安全带来隐患,增加了后续集群升级和迁移的成本。我们希望通过平台统一任务的提交入口和提交方式;易用性:平台交互可以提供更易用的功能,比如调试、语义检测等,可以提高任务测试的人为效率,记录任务的版本历史。方便的在线和回滚操作;规范:权限控制、流程审批等,类似于线上服务的线上流程,通过平台,实时任务的研发流程可以标准化。3.1 规范——实时任务进程管理
FlinkSQL 让开发变得非常简单高效,但是越简单越难标准化,因为写一段 SQL 可能只需要两个小时,但通过规范却需要半天时间。
但是,该规范仍然需要执行。一些问题类似于在线服务,在实时计算中也遇到过:
记不清了:任务上线已经一年了,最初的需求可能是口耳相传。最好记住wiki或email,但在任务交接时容易记住;不规范:UDF或DataStream代码 两种方式都没有按照规范,可读性差,以至于后来接手的同学不能升级,或者不敢改,长期维护不了。还应该有一个关于如何编写包括实时任务的 SQL 的规范;找不到:线上运行的任务依赖一个jar,哪个git模块对应哪个commitId,如果有问题如何第一时间找到对应的代码实现;盲改:一直正常的任务,周末突然报警,
规范主要分为三个部分:
开发:RD 可以从 UDF 原型项目快速创建 UDF 模块,该项目基于 flink 快速入门。创建的 UDF 模块可以正常编译,包括 WordCount 之类的 udf 示例,以及 ReadMe 和 VersionHelper 等默认的 helper 方法。根据业务需求修改后,通过CR上传到Git;需求管理和编译:提交的代码会与需求卡片关联,集群编译和QA测试后,可以在线下单;在线:根据模块和编译输出,选择更新/被job owner或leader批准后创建和重新部署哪些job。
整个研发过程不能离线修改,比如更改jar包或者对哪个任务生效。一个实时任务,即使运行几年,也能查到谁在线,谁批准了当前任务,当时的测试记录,对应的Git代码,提出的实时指标要求由谁开始。任务维持很长时间。
3.2 易用性 - 监控
我们当前的 Flink 作业在 Yarn 上运行。作业启动后,预计 Prometheus 会抓取 Yarn 分配的 Container,然后连接到报警系统。用户可以根据告警系统配置Kafka延迟告警和Checkpoint故障告警。构建此路径时遇到两个主要问题:
PrometheusReporter启动HTTPServer后,Prometheus如何动态感知;它还需要能够控制度量的大小,以避免采集大量无用数据;我们的 SQL 源表基本上是基于 Kafka 的。相比第三方工具,在计算平台上配置Kafka延迟告警更方便。因为自然可以得到任务读取的topic和group.id,所以也可以和任务失败使用同一个告警组。结合告警模板,配置告警非常简单。
关于解决方案:
发现功能是在官方PrometheusReporter的基础上增加的。Container 的 HTTPServer 启动后,对应的 ip:port 以临时节点的形式注册到 zk 上,然后使用 Prometheus 的 discover 目标来监控 zk 节点的变化。由于是临时节点,当 Container 被销毁时,该节点就消失了,Prometheus 也能感应到它不再被抓取。这样一来,就很容易为普罗米修斯搭建一条抢夺的路径。KafkaConsumer.records-lag 是一个比较实用和重要的延迟指标,它主要做了两个任务。修改 KafkaConnector 并在 KafkaConsumer.poll 之后将其公开,以确保 records-lag 指示器可见。此外,在这样做的过程中,我们发现不同Kafka版本的metric格式是不同的()。我们的方法是将它们扁平化为一种格式,并将它们注册到 flink 的指标中。这样不同版本暴露的指标是一致的。四、总结与展望
上一阶段使用 Flink SQL 来支持实时作业的快速开发,搭建了实时计算平台来支持数千个 Flink 作业。
更大的见解之一是 SQL 确实简化了开发,但它也阻止了更多的技术细节。对实时作业运维工具的要求,比如 Trace,或者任务的规范没有改变,对这些的要求更加严格。因为在细节被屏蔽的同时,一旦出现问题,用户不知道如何处理。就像冰山一角,漏水越少,下沉越多,越需要做好周边系统的建设。
二是适应现状。一是能尽快满足当前的需求。比如,我们正在提高人的效率,降低发展门槛。同时还要继续探索更多的业务场景,比如用HBase和RPC服务代替Redis Connector。现在的好处是修改了底层存储,用户对SQL作业的感知很小,因为SQL作业基本都是业务逻辑,DDL定义了元数据。
接下来的计划主要分为三个部分:
支持资源弹性伸缩,平衡实时作业的成本和时效;我们从 1.9 开始大规模应用 Flink SQL,现在版本升级变化很大,需要考虑如何让业务能够低成本升级和使用新版本。版本中的功能;探索流批融合在实际业务场景中的实现。
FFA 2021 现场重播和演讲 PDF 下载
更多Flink相关技术问题,可以扫码加入社区钉钉交流群 查看全部
实时文章采集(发展历程FlinkSQL应用实践平台建设总结展望(组图))
摘要:本文组织了 Homework Group 实时计算负责人张颖在 Flink Forward Asia 2021 上的分享。Flink 在 Homework 实时计算的演进中发挥了重要作用。尤其是在 FlinkSQL 的帮助下,实时任务的开发效率得到了极大的提升。本文文章主要分享FlinkSQL在作业帮助中的使用和实践经验,以及随着任务规模的增加,从0到1搭建实时计算平台过程中遇到的问题和解决方法. 内容包括:
发展历程 Flink SQL 应用实践平台建设总结与展望
FFA 2021 现场重播和演讲 PDF 下载
一、发展历程
Homework Help主要利用人工智能、大数据等技术为学生提供更高效的学习解决方案。因此,业务数据主要包括学生的出勤率和知识点的掌握情况。在整体架构中,无论是binlog还是普通日志,都是在采集之后写入Kafka,分别通过实时和离线计算写入存储层。基于OLAP,对外提供相应的产品化服务,如工作台、BI分析等。工具。

目前 Homework Help 的实时计算主要基于 Flink,开发过程分为三个阶段:
2019 年实时计算包括少量 SparkStreaming 作业,提供给导师和讲师。在解决实时性需求的过程中,会发现开发效率很低,数据很难复用;之后,常规的做法是在生产实践中逐步应用 Flink JAR,积累经验后开始搭建平台,应用 Flink SQL。但是,20年来,业务提出了很多实时计算的需求,我们的开发人力储备不足。当时,在 Flink SQL 1.9 发布后不久,SQL 功能发生了很大变化,所以我们的做法是直接将 Flink SQL 应用到实时数仓方向。现在,整个实时数仓90%以上的任务都是使用Flink SQL实现的。; 到了 2020 年 11 月,Flink 的 Job 数量迅速增加到数百个,我们开始构建从 0 到 1 的实时计算平台,已经支撑了公司所有重要业务线,并且计算部署在多个集群上在多云中。

介绍以下两个方面:
FlinkSQL实践中遇到的典型问题及解决方案;搭建实时计算平台过程中的一些思考。二、Flink SQL 应用实践
下面是基于 Flink SQL 的完整数据流架构:

binlog/log 采集 写入 Kafka 后,topic 会自动注册为元数据表,这是后续所有实时 SQL 作业的起点。用户可以在 SQL 作业中使用此表,而无需定义复杂的 DDL。
同时,在考虑实际应用时,还需要根据元数据表添加或替换表属性:
新增:元数据记录表级属性,但 SQL 作业可能需要添加任务级属性。比如对于Kafka源表,添加job的group.id来记录offset;替换:离线测试时,在引用元数据表的基础上,只需要定义broker topic等属性覆盖源表,即可快速构建一行。测试表格如下。
框架还需要支持用户的SQL作业,方便输出指标和日志,实现全链路监控和跟踪。
这里主要介绍SQL添加Trace函数时的DAG优化实践,以及我们对Table底层物理存储的选择和封装。
2.1 SQL 添加 Trace 功能
SQL可以提高开发效率,但是业务逻辑的复杂度还是有的,复杂的业务逻辑写的DML会很长。在这种情况下,建议使用视图来提高可读性。因为视图的 SQL 比较短,所以不应该像代码规范中的单个函数那样太长。
下图左侧是一个示例任务的部分DAG,可以看到有很多SQL节点。这种情况下很难定位,因为如果是DataStream API实现的代码,也可以加日志。但是 SQL 做不到。用户可以干预的入口很少,只能看到整个作业的输入输出。
类似于在函数中打印日志,我们希望支持在视图中添加 Trace,以方便案例追踪。

但是我在尝试将 Trace 添加到 SQL 时遇到了一些问题,这是一个简化的示例:

右上角的SQL创建source_table为源表,prepare_data视图读取表,在sql中调用foo udf,然后使用StatementSet分别插入两个下游,同时将视图转换为DataStream调用 TraceSDK 写入跟踪系统。
注意:我们当时是基于 1.9 开发的。为了清楚起见,我们还使用了一些后来添加的功能。
上图下方的实际 DAG 看起来并不像预期的那样:
DAG分为上下不相关的两部分。Kafka源表是DataSource部分,读取两次;foo 方法被调用了 3 次。
数据源压力和计算性能需要优化。
为了解决这个问题,我们需要从几个角度进行优化。这里主要介绍DAG合并的思想。无论是table还是stream的env,都会产生相应的transformation。我们的做法是统一合并到stream env中,这样就可以在stream env中得到一个完整的变换列表,然后生成StreamGraph提交。
左下角是我们优化的 DAG,读取源表并只调用一次 foo 方法:

优化后的 DAG 效果与我们写 SQL 时的逻辑图非常相似,性能自然符合预期。
回到问题本身,业务可以简单地用一条语句给视图的某些字段添加trace,例如:prepare_data.trace.fields=f0,f1. 由于SQL自然收录字段名,所以trace数据的可读性甚至高于普通原木。
2.2 表的选择与设计
如前所述,我们的首要要求是提高人的效率。因此,Table 需要具备更好的分层和复用能力,并且支持模板化开发,以便 N 个端到端的 Flink 作业能够快速串联起来。
我们的解决方案是基于 Redis 实现的,它首先有几个优点:
高qps,低延迟:这应该是所有实时计算的关注点;TTL:用户无需关心数据如何退出,可以给出合理的TTL;通过使用protobuf等高性能紧凑的序列化方式,使用TTL,整体存储小于200G,redis的内存压力可以接受;适合计算模型:为了保证计算本身的时序,会进行keyBy操作,同时需要处理的数据会被shuffle到同一个并发,所以不依赖存储过多考虑锁优化。
接下来,我们的场景主要是解决多索引和触发消息的问题。

上图显示了一个表格示例,显示学生是否出现在某个章节中:
多索引:数据首先以字符串形式存储,比如key=(uid, course_id), value=serialize(is_attend, ...),这样我们就可以在SQL中JOIN ON uid AND course_id。如果 JOIN ON 其他字段,比如 course_id 怎么办?我们的做法是同时写一个以lesson_id为key的集合,集合中的元素是对应的(uid,lesson_id)。接下来,在找lesson_id = 123的时候,先取出集合下的所有元素,然后通过管道找到所有的VALUE并返回;触发消息:写入redis后,会同时向Kafka写入一条更新消息。两个存储在 Redis Connector 的实现中都保证了一致性、顺序性和不丢失数据。
这些功能都封装在 Redis Connector 中,业务可以通过 DDL 简单定义这样的 Table。

DDL 中的几个重要属性:
primary 定义主键,对应字符串数据结构,如示例中的uid + course_id;index.fields 定义了辅助搜索的索引字段,如示例中的课程id;也可以定义多个索引;poster.kafka定义了接收触发消息kafka表也定义在元数据中,用户可以在后续的SQL作业中直接读取该表而无需定义。
因此,整个开发模式复用性高,用户可以轻松开发端到端的N个SQL作业,而无需担心如何追溯案例。
三、平台搭建
上述数据流架构搭建完成后,2020.11的实时作业数量迅速增加到几百个,比2019年快很多。这个时候我们开始搭建实时计算平台从0到1,然后分享了搭建过程中的一些想法。

平台支持的功能主要有三个起点:
统一:统一不同云厂商的不同集群环境、Flink版本、提交方式等。之前hadoop客户端分散在用户的提交机器上,给集群数据和任务安全带来隐患,增加了后续集群升级和迁移的成本。我们希望通过平台统一任务的提交入口和提交方式;易用性:平台交互可以提供更易用的功能,比如调试、语义检测等,可以提高任务测试的人为效率,记录任务的版本历史。方便的在线和回滚操作;规范:权限控制、流程审批等,类似于线上服务的线上流程,通过平台,实时任务的研发流程可以标准化。3.1 规范——实时任务进程管理
FlinkSQL 让开发变得非常简单高效,但是越简单越难标准化,因为写一段 SQL 可能只需要两个小时,但通过规范却需要半天时间。

但是,该规范仍然需要执行。一些问题类似于在线服务,在实时计算中也遇到过:
记不清了:任务上线已经一年了,最初的需求可能是口耳相传。最好记住wiki或email,但在任务交接时容易记住;不规范:UDF或DataStream代码 两种方式都没有按照规范,可读性差,以至于后来接手的同学不能升级,或者不敢改,长期维护不了。还应该有一个关于如何编写包括实时任务的 SQL 的规范;找不到:线上运行的任务依赖一个jar,哪个git模块对应哪个commitId,如果有问题如何第一时间找到对应的代码实现;盲改:一直正常的任务,周末突然报警,

规范主要分为三个部分:
开发:RD 可以从 UDF 原型项目快速创建 UDF 模块,该项目基于 flink 快速入门。创建的 UDF 模块可以正常编译,包括 WordCount 之类的 udf 示例,以及 ReadMe 和 VersionHelper 等默认的 helper 方法。根据业务需求修改后,通过CR上传到Git;需求管理和编译:提交的代码会与需求卡片关联,集群编译和QA测试后,可以在线下单;在线:根据模块和编译输出,选择更新/被job owner或leader批准后创建和重新部署哪些job。
整个研发过程不能离线修改,比如更改jar包或者对哪个任务生效。一个实时任务,即使运行几年,也能查到谁在线,谁批准了当前任务,当时的测试记录,对应的Git代码,提出的实时指标要求由谁开始。任务维持很长时间。
3.2 易用性 - 监控
我们当前的 Flink 作业在 Yarn 上运行。作业启动后,预计 Prometheus 会抓取 Yarn 分配的 Container,然后连接到报警系统。用户可以根据告警系统配置Kafka延迟告警和Checkpoint故障告警。构建此路径时遇到两个主要问题:
PrometheusReporter启动HTTPServer后,Prometheus如何动态感知;它还需要能够控制度量的大小,以避免采集大量无用数据;我们的 SQL 源表基本上是基于 Kafka 的。相比第三方工具,在计算平台上配置Kafka延迟告警更方便。因为自然可以得到任务读取的topic和group.id,所以也可以和任务失败使用同一个告警组。结合告警模板,配置告警非常简单。

关于解决方案:
发现功能是在官方PrometheusReporter的基础上增加的。Container 的 HTTPServer 启动后,对应的 ip:port 以临时节点的形式注册到 zk 上,然后使用 Prometheus 的 discover 目标来监控 zk 节点的变化。由于是临时节点,当 Container 被销毁时,该节点就消失了,Prometheus 也能感应到它不再被抓取。这样一来,就很容易为普罗米修斯搭建一条抢夺的路径。KafkaConsumer.records-lag 是一个比较实用和重要的延迟指标,它主要做了两个任务。修改 KafkaConnector 并在 KafkaConsumer.poll 之后将其公开,以确保 records-lag 指示器可见。此外,在这样做的过程中,我们发现不同Kafka版本的metric格式是不同的()。我们的方法是将它们扁平化为一种格式,并将它们注册到 flink 的指标中。这样不同版本暴露的指标是一致的。四、总结与展望
上一阶段使用 Flink SQL 来支持实时作业的快速开发,搭建了实时计算平台来支持数千个 Flink 作业。
更大的见解之一是 SQL 确实简化了开发,但它也阻止了更多的技术细节。对实时作业运维工具的要求,比如 Trace,或者任务的规范没有改变,对这些的要求更加严格。因为在细节被屏蔽的同时,一旦出现问题,用户不知道如何处理。就像冰山一角,漏水越少,下沉越多,越需要做好周边系统的建设。
二是适应现状。一是能尽快满足当前的需求。比如,我们正在提高人的效率,降低发展门槛。同时还要继续探索更多的业务场景,比如用HBase和RPC服务代替Redis Connector。现在的好处是修改了底层存储,用户对SQL作业的感知很小,因为SQL作业基本都是业务逻辑,DDL定义了元数据。

接下来的计划主要分为三个部分:
支持资源弹性伸缩,平衡实时作业的成本和时效;我们从 1.9 开始大规模应用 Flink SQL,现在版本升级变化很大,需要考虑如何让业务能够低成本升级和使用新版本。版本中的功能;探索流批融合在实际业务场景中的实现。
FFA 2021 现场重播和演讲 PDF 下载
更多Flink相关技术问题,可以扫码加入社区钉钉交流群
实时文章采集(WordPress自动采集软件页面简洁、操作简单,不需要掌握专业的规则配置 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-08 02:09
)
WordPress自动采集软件页面简洁易操作。无需掌握专业的规则配置和高级seo知识即可使用。无论是WordPresscms、dedecms、ABCcms还是小旋风cms都可以使用。软件还内置翻译发布推送、数据查看等功能。让我们的WordPress站长通过软件分析数据,实时调整优化细节。
WordPress自动采集软件可以根据我们输入的关键词在全网各大平台进行内容采集。为提高搜索范围和准确率,支持根据关键词搜索热门下拉词。支持在下载过程中进行敏感的 *words 过滤和 文章 清理。采集内容以多种格式(TXT、HTML 和漩涡样式)保存。它支持保留标签和图像本地化等功能,并内置翻译功能。有道、百度、谷歌以及自带的翻译功能都可以使用。
WordPress的自动采集软件网站优化可以大大减轻我们站长的工作强度。定期发布采集可以让我们全天候挂机,网站一个好的“作息时间”可以让我们每天网站更新内容,这也是一种友好的行为对于蜘蛛。
当然,仅靠内容是不够的,我们需要对内容进行整理,提高内容质量,吸引用户,逐步完善我们的收录,WordPress自动采集软件可以通过以下方式优化我们的内容积分,实现我们的网站fast收录,提升排名。
网站内容优化
1、文章采集货源质量保证(大平台、热搜词)
2、采集保留内容标签
3、内置翻译功能(英汉、繁简、简体到火星)
4、文章清洗(号码、网址、机构名清洗)
3、关键词保留(伪原创不会影响关键词,保证核心关键词显示)
5、关键词插入标题和文章
6、标题、内容伪原创
7、设置内容匹配标题(让内容完全匹配标题)
8、设置关键词自动内链(自动从文章内容中的关键词生成内链)
9、设置定时释放(24小时挂机)
一个好的文章离不开图片的配合。合理插入我们的文章相关图片,会大大降低用户理解的难度。一张好的图片有时可以很抢眼,反而让文字成为一种点缀。为 网站 图片添加 ALT 标签还可以让搜索引擎快速识别图片。WordPress 自动 采集 软件图像有哪些优化?
网站图像优化
1、图片云存储(支持七牛、阿里、腾讯等云平台)/本地化
2、给图片添加alt标签
3、图片替换原图
4、图片水印/去水
5、图片按频率插入到文本中
三、网站管理优化
WordPress自动采集软件具有全程优化管理功能。采集、文本清洗、翻译、伪原创、发布、推送的全流程管理都可以在软件中实现,并提供各阶段任务的进度和反馈等信息可以实时查看任务的成败。整合cms网站收录、权重、蜘蛛等绑定信息,自动生成曲线供我们分析。
作为一个SEO从业者,我们必须足够细心,才能做好SEO。无论是优化文章内容还是通过alt标签描述图片,每一个小地方都可能是我们优化的方向。在我的SEO工作中,一丝不苟、善于发现、坚持不懈是做好网站工作的必要因素。
查看全部
实时文章采集(WordPress自动采集软件页面简洁、操作简单,不需要掌握专业的规则配置
)
WordPress自动采集软件页面简洁易操作。无需掌握专业的规则配置和高级seo知识即可使用。无论是WordPresscms、dedecms、ABCcms还是小旋风cms都可以使用。软件还内置翻译发布推送、数据查看等功能。让我们的WordPress站长通过软件分析数据,实时调整优化细节。
WordPress自动采集软件可以根据我们输入的关键词在全网各大平台进行内容采集。为提高搜索范围和准确率,支持根据关键词搜索热门下拉词。支持在下载过程中进行敏感的 *words 过滤和 文章 清理。采集内容以多种格式(TXT、HTML 和漩涡样式)保存。它支持保留标签和图像本地化等功能,并内置翻译功能。有道、百度、谷歌以及自带的翻译功能都可以使用。
WordPress的自动采集软件网站优化可以大大减轻我们站长的工作强度。定期发布采集可以让我们全天候挂机,网站一个好的“作息时间”可以让我们每天网站更新内容,这也是一种友好的行为对于蜘蛛。
当然,仅靠内容是不够的,我们需要对内容进行整理,提高内容质量,吸引用户,逐步完善我们的收录,WordPress自动采集软件可以通过以下方式优化我们的内容积分,实现我们的网站fast收录,提升排名。
网站内容优化
1、文章采集货源质量保证(大平台、热搜词)
2、采集保留内容标签
3、内置翻译功能(英汉、繁简、简体到火星)
4、文章清洗(号码、网址、机构名清洗)
3、关键词保留(伪原创不会影响关键词,保证核心关键词显示)
5、关键词插入标题和文章
6、标题、内容伪原创
7、设置内容匹配标题(让内容完全匹配标题)
8、设置关键词自动内链(自动从文章内容中的关键词生成内链)
9、设置定时释放(24小时挂机)
一个好的文章离不开图片的配合。合理插入我们的文章相关图片,会大大降低用户理解的难度。一张好的图片有时可以很抢眼,反而让文字成为一种点缀。为 网站 图片添加 ALT 标签还可以让搜索引擎快速识别图片。WordPress 自动 采集 软件图像有哪些优化?
网站图像优化
1、图片云存储(支持七牛、阿里、腾讯等云平台)/本地化
2、给图片添加alt标签
3、图片替换原图
4、图片水印/去水
5、图片按频率插入到文本中
三、网站管理优化
WordPress自动采集软件具有全程优化管理功能。采集、文本清洗、翻译、伪原创、发布、推送的全流程管理都可以在软件中实现,并提供各阶段任务的进度和反馈等信息可以实时查看任务的成败。整合cms网站收录、权重、蜘蛛等绑定信息,自动生成曲线供我们分析。
作为一个SEO从业者,我们必须足够细心,才能做好SEO。无论是优化文章内容还是通过alt标签描述图片,每一个小地方都可能是我们优化的方向。在我的SEO工作中,一丝不苟、善于发现、坚持不懈是做好网站工作的必要因素。
实时文章采集( SEO技术分享2022-03-04如何让采集站快速收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-08 02:06
SEO技术分享2022-03-04如何让采集站快速收录以及关键词排名)
采集我还能做吗?让网站采集的网站快速收录发布工具
SEO技术分享2022-03-04
如何让采集站快收录和关键词排名,相信各位站长一定遇到过这种情况,采集站收录波动太大, 和 关键词 不稳定的排名。尤其是刚刚冲上首页的关键词经常掉出首页,那么如何稳定首页的排名关键词又如何让采集站得快收录@ >。
一、观察网站收录情况
很多站长在关键词冲到首页后开始不关注网站的收录。千万不能马虎,要定期检查网站收录是否正常,只有保持一定的收录,关键词的排名才能稳定。顺便在主页上观察一下同事,了解他们网站的优点,放到我的网站中。
二、网站更新频率
你为什么这么说?当您点击主页时,您每天都会发布内容。到首页后还需要发布吗?很多站长认为这没有必要,但实际上是一个错误的判断。前期我们发布了内容,为更多网站收录打下基础。后期发布内容的目的是为了保持一定的频率,这样既可以稳定快照的更新频率,又可以防止搜索引擎将我们判断为死站网站。
我们可以通过网站采集软件实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,不需要专业技能,只需几个简单的步骤。轻松的采集内容数据,用户只需对网站采集软件进行简单设置,网站采集软件根据用户设置< @关键词 准确采集文章,以确保与行业文章保持一致。采集 文章 from 采集 可以选择在本地保存更改,也可以选择自动伪原创 然后发布。
和其他网站采集软件相比,这个网站采集软件基本没有规则,更别说花很多时间学习正则表达式或者html标签了,一分钟就到上手,只需输入关键词即可实现采集(网站采集软件也自带关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个cms采集插件还配备了很多SEO功能,通过采集伪原创软件发布也可以提升很多SEO优化。
1、网站全网推送(主动提交链接至百度/360/搜狗/神马/今日头条/bing/Google)
2、自动匹配图片(文章如果内容中没有图片,则自动配置相关图片) 设置自动下载图片并保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
<p>7、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前采集 查看全部
实时文章采集(
SEO技术分享2022-03-04如何让采集站快速收录以及关键词排名)
采集我还能做吗?让网站采集的网站快速收录发布工具
SEO技术分享2022-03-04
如何让采集站快收录和关键词排名,相信各位站长一定遇到过这种情况,采集站收录波动太大, 和 关键词 不稳定的排名。尤其是刚刚冲上首页的关键词经常掉出首页,那么如何稳定首页的排名关键词又如何让采集站得快收录@ >。
一、观察网站收录情况
很多站长在关键词冲到首页后开始不关注网站的收录。千万不能马虎,要定期检查网站收录是否正常,只有保持一定的收录,关键词的排名才能稳定。顺便在主页上观察一下同事,了解他们网站的优点,放到我的网站中。
二、网站更新频率
你为什么这么说?当您点击主页时,您每天都会发布内容。到首页后还需要发布吗?很多站长认为这没有必要,但实际上是一个错误的判断。前期我们发布了内容,为更多网站收录打下基础。后期发布内容的目的是为了保持一定的频率,这样既可以稳定快照的更新频率,又可以防止搜索引擎将我们判断为死站网站。
我们可以通过网站采集软件实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,不需要专业技能,只需几个简单的步骤。轻松的采集内容数据,用户只需对网站采集软件进行简单设置,网站采集软件根据用户设置< @关键词 准确采集文章,以确保与行业文章保持一致。采集 文章 from 采集 可以选择在本地保存更改,也可以选择自动伪原创 然后发布。
和其他网站采集软件相比,这个网站采集软件基本没有规则,更别说花很多时间学习正则表达式或者html标签了,一分钟就到上手,只需输入关键词即可实现采集(网站采集软件也自带关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个cms采集插件还配备了很多SEO功能,通过采集伪原创软件发布也可以提升很多SEO优化。
1、网站全网推送(主动提交链接至百度/360/搜狗/神马/今日头条/bing/Google)
2、自动匹配图片(文章如果内容中没有图片,则自动配置相关图片) 设置自动下载图片并保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
<p>7、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前采集
实时文章采集(如何采集豆瓣热门电影,实时文章采集实践十技巧分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-03-08 02:02
实时文章采集
一)、动态文章采集
二)、基于目录文章采集
三)、实时文章采集
四)、多维目录文章采集
五)、实时文章采集之常用工具
六)、文章链接采集
七)、基于网页采集
八)、文章采集指南
九)、文章采集实践
十)
不如弄一个小型excel表格吧,就记录每天每小时大家都发表的文章都是什么类型的什么风格的。当然这里面很多名词都是网络上搜不到的。再配上一些关键词,关键词间隔需要注意调整。毕竟很多说高质量新闻稿是软文的。
每天每小时都重复性发明几条文章
本专栏上篇文章跟大家分享了如何采集豆瓣热门电影,本篇文章要谈谈自己写过的一篇采集文章,
有很多要注意的很难写一下,自己感觉,新闻跟帖不一样,条数不多,关注人数固定,但是内容大都有些广,数量多,文本样式不固定,所以可能无法有效的聚合文本特征,太多的网站会导致内容过于相似,有可能会影响读者,但是要注意需要控制好一个段落的数量,不然读者看到长的同一篇新闻跟帖,未必会关注细节!当然特别喜欢某一个事情或者细节的人,你还是要多关注他的!。
我是用的qq发布,自己点发布之后,再搜索一下别人的发布时间,有人发布可以随时写随时发布,不过需要你写入的词, 查看全部
实时文章采集(如何采集豆瓣热门电影,实时文章采集实践十技巧分享)
实时文章采集
一)、动态文章采集
二)、基于目录文章采集
三)、实时文章采集
四)、多维目录文章采集
五)、实时文章采集之常用工具
六)、文章链接采集
七)、基于网页采集
八)、文章采集指南
九)、文章采集实践
十)
不如弄一个小型excel表格吧,就记录每天每小时大家都发表的文章都是什么类型的什么风格的。当然这里面很多名词都是网络上搜不到的。再配上一些关键词,关键词间隔需要注意调整。毕竟很多说高质量新闻稿是软文的。
每天每小时都重复性发明几条文章
本专栏上篇文章跟大家分享了如何采集豆瓣热门电影,本篇文章要谈谈自己写过的一篇采集文章,
有很多要注意的很难写一下,自己感觉,新闻跟帖不一样,条数不多,关注人数固定,但是内容大都有些广,数量多,文本样式不固定,所以可能无法有效的聚合文本特征,太多的网站会导致内容过于相似,有可能会影响读者,但是要注意需要控制好一个段落的数量,不然读者看到长的同一篇新闻跟帖,未必会关注细节!当然特别喜欢某一个事情或者细节的人,你还是要多关注他的!。
我是用的qq发布,自己点发布之后,再搜索一下别人的发布时间,有人发布可以随时写随时发布,不过需要你写入的词,
实时文章采集(一个好的网站采集软件认为需要以下几点功能:以下几点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-06 15:12
)
网站采集大家都比较熟悉,通过网站采集我们可以把自己感兴趣的网站数据下载到自己的网站或者放一些内容其他人 网站 被保存到他们自己的服务器。通过网站采集可以得到我们想要的相关数据、文章、图片等。这些材料经过加工。可以成为我们自己的网站内容,维护我们的网站持续更新。
网站采集有很多方式供我们选择,无论是采集插件,采集软件,还是cms自带采集函数,我们总能在网上找到各种采集器。一个好的网站采集软件博主认为需要具备以下特点:
一、高效简洁
网站采集可以为我们提供非常方便的采集服务,但是我们很多站长不知道如何配置采集规则,所以从大部分用户体验出发,易于操作,采集稳定快速的软件是大多数站长喜欢的。
二、采集精准内容
网站采集只追求速度肯定是不够的。一个好的采集软件需要有精确的采集规则。它可以为我们的用户提供可靠准确的采集素材,方便我们创作。
三、保留原标签
网站标签保留可以在伪原创时为我们提供更好的用户体验。无论是数据提取还是文章的重新创建,都将帮助我们创建自己的文章。
四、图像本地化
由于缺少此功能,我们的许多 采集 图像会降低我们的 原创 度数。通过图像定位,可以减轻替换原图的工作强度,加强我们文章的原创。最好添加自己的 ALT 标签来替换图像。
网站采集可以为我们提供素材,这有助于我们的网站内容不断更新,但是对于网站的建设来说肯定是不够的。我们网站的主要目的是为了更好的服务客户,从而增强用户粘性,完成流量转化。所以在做网站的时候,首先要考虑的是用户的需求。只有用户才有评价网站质量的权利。如果用户说是,网站 才是真正的好东西。所以,一定要了解用户的需求,把用户需求放在首位,参与网站的制作。只有当你的网站拥有了客户真正想要的东西,你的网站才会成功,才能称得上是合格的网站。
网站Data不仅可以为我们提供内容素材,还可以通过采集data帮助我们分析市场和用户需求:
一、满足用户需求
网站采集获得的大数据让我们了解用户的显性需求,但也有一些客户的隐性需求,需要我们直接联系用户了解更多。所以,在做网站之前,要多做市场调研,一定要多接触用户,了解他们的需求和痛点。从一开始就要有这个意识,靠采集数据分析还是片面的。在一个想法开始之前与客户进行深入的沟通是最重要的。
二、增强网站实用程序
数据采集也可以让我们获得精准的用户画像,让我们了解网站的用户,所以网站的建设一定要实用、有针对性,让网站有自己的核心竞争力。比如年轻人的博客肯定需要我们的网页清晰整洁,动画网站肯定需要色彩来增强视觉冲击力。所以,迎合用户的喜好,让用户时时享受和感觉有用,这是一个基本的成功网站。
三、好网站经得起时间的考验
网站 的质量将经受时间的考验。一个非常好的 网站 可以经受住任何考验。过了一段时间,这个网站还是很火的,说明这个网站当然比较成功。如果他想继续成功,他必须在后期有完美的工作。
网站采集可以为我们提供网站内容的素材。它还可以为我们提供行业分析所需的数据。只要我们善用它,就可以创建自己的网站。
查看全部
实时文章采集(一个好的网站采集软件认为需要以下几点功能:以下几点
)
网站采集大家都比较熟悉,通过网站采集我们可以把自己感兴趣的网站数据下载到自己的网站或者放一些内容其他人 网站 被保存到他们自己的服务器。通过网站采集可以得到我们想要的相关数据、文章、图片等。这些材料经过加工。可以成为我们自己的网站内容,维护我们的网站持续更新。
网站采集有很多方式供我们选择,无论是采集插件,采集软件,还是cms自带采集函数,我们总能在网上找到各种采集器。一个好的网站采集软件博主认为需要具备以下特点:
一、高效简洁
网站采集可以为我们提供非常方便的采集服务,但是我们很多站长不知道如何配置采集规则,所以从大部分用户体验出发,易于操作,采集稳定快速的软件是大多数站长喜欢的。
二、采集精准内容
网站采集只追求速度肯定是不够的。一个好的采集软件需要有精确的采集规则。它可以为我们的用户提供可靠准确的采集素材,方便我们创作。
三、保留原标签
网站标签保留可以在伪原创时为我们提供更好的用户体验。无论是数据提取还是文章的重新创建,都将帮助我们创建自己的文章。
四、图像本地化
由于缺少此功能,我们的许多 采集 图像会降低我们的 原创 度数。通过图像定位,可以减轻替换原图的工作强度,加强我们文章的原创。最好添加自己的 ALT 标签来替换图像。
网站采集可以为我们提供素材,这有助于我们的网站内容不断更新,但是对于网站的建设来说肯定是不够的。我们网站的主要目的是为了更好的服务客户,从而增强用户粘性,完成流量转化。所以在做网站的时候,首先要考虑的是用户的需求。只有用户才有评价网站质量的权利。如果用户说是,网站 才是真正的好东西。所以,一定要了解用户的需求,把用户需求放在首位,参与网站的制作。只有当你的网站拥有了客户真正想要的东西,你的网站才会成功,才能称得上是合格的网站。
网站Data不仅可以为我们提供内容素材,还可以通过采集data帮助我们分析市场和用户需求:
一、满足用户需求
网站采集获得的大数据让我们了解用户的显性需求,但也有一些客户的隐性需求,需要我们直接联系用户了解更多。所以,在做网站之前,要多做市场调研,一定要多接触用户,了解他们的需求和痛点。从一开始就要有这个意识,靠采集数据分析还是片面的。在一个想法开始之前与客户进行深入的沟通是最重要的。
二、增强网站实用程序
数据采集也可以让我们获得精准的用户画像,让我们了解网站的用户,所以网站的建设一定要实用、有针对性,让网站有自己的核心竞争力。比如年轻人的博客肯定需要我们的网页清晰整洁,动画网站肯定需要色彩来增强视觉冲击力。所以,迎合用户的喜好,让用户时时享受和感觉有用,这是一个基本的成功网站。
三、好网站经得起时间的考验
网站 的质量将经受时间的考验。一个非常好的 网站 可以经受住任何考验。过了一段时间,这个网站还是很火的,说明这个网站当然比较成功。如果他想继续成功,他必须在后期有完美的工作。
网站采集可以为我们提供网站内容的素材。它还可以为我们提供行业分析所需的数据。只要我们善用它,就可以创建自己的网站。
实时文章采集(小说网站怎么做?小说规则怎么写?其中的原因)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-03-05 05:00
小说网站怎么办?小说的规则怎么写?大量采集小说网站和免费采集工具,让关键词排名网站快速收录。关键词搜索引擎首页的稳定性是我们网站优化的目标,但是有的网站可以做到,有的网站一直没有效果。无效的原因有很多。今天小编就为大家分析一下原因。
一、服务器原因
服务器是网站 的基础,也是必要的设施之一。选择服务器时,建议选择官方备案的服务器。糟糕的服务器通常会导致 网站 打开缓慢或无法访问。发生这种情况,搜索引擎不会给出最高排名。
二、网站内容
网站更新频率A网站更新频率越高,搜索引擎蜘蛛来的频率越高。因此,我们可以利用小说采集器实现采集伪原创自动发布,主动推送给搜索引擎,提高搜索引擎的抓取频率。本小说采集器操作简单,不需要学习更专业的技术,只需几步即可轻松采集内容数据。用户只需对小说采集器进行简单的设置,小说采集器会根据用户的设置关键词精确采集文章进行设置,所以以确保与行业 文章 保持一致。采集文章 from 采集可以选择保存在本地,也可以选择自动伪原创发布,
和其他网站插件相比,这部小说采集器基本没有什么规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词@ > 采集(小说采集器也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个网站插件还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(让内容没有不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集关键词 是自动添加的。文本 Automatically insert the current 采集关键词 在随机位置两次。当当前 采集 的 关键词 出现在文本中时,< @关键词 将自动加粗。)
7、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
三、链接
友情链接有很多功能。它们可以增加网站 流量和收录 彼此。是大家喜欢的优化推广方式之一。但是,如果网站有恶意交流链接和垃圾邮件,也会影响网站的排名,也有可能被搜索引擎降级。建议大家交流一些相关的正式的网站,当然最好有一定的分量。
四、搜索引擎算法
网站在优化过程中,网站的每一个操作细节都会影响到网站,而网站在优化过程中出现的频率相当于< @网站基本,影响网站爬取频率的主要因素有哪些?今天云无限小编就带大家详细了解一下。
网站优化
1、网站域名的选择;
选择网站域名时,尽量选择比较短的域名,目录层次尽量控制在3层以内,有利于蜘蛛爬取;
2、更新频率和原创内容程度;
更新网站的内容时,尽量做原创文章。对于蜘蛛来说,喜欢原创,文章度数高,更新频率要掌握一定的频率;
3、页面加载速度;
蜘蛛在抓取网站的时候,非常关心页面的加载速度。页面打开时,尽量控制在3秒以内。这也是蜘蛛更敏感的地方。网站溜走;
4、 主动提交;
我们需要提交网站的URL,这样可以更好的增加网站收录的数量;
5、优质的外部链接;
网站在优化过程中,少不了优质优质的外链,可以更好的帮助你网站打好基础。这些优质的外链主要包括友情链接等;
关键词3@>网站未排名
对于很多站长来说,关键词没有被排名是一件非常痛苦的事情。他们每天都在运转,但效果并没有明显改善。为什么是这样?关键词让我们看看如果我们长时间没有排名该怎么办!
关键词4@>修改TDK
我们都知道TDK是网站最重要的部分。如果一个网站的TDK写得不好,那么网站的排名肯定会受到影响,也有可能是算法变化造成的。所以如果网站长时间没有排名,可以适当修改TDK,让关键词的排名也有可能出现。
关键词5@>检查网站代码
网站的代码有很多种,其中图片优化、推送代码、H1标签、nofollow标签大家应该熟悉。它可能是这些标签代码之一,它会影响您对 关键词 的排名。所以优化是一项细心的工作,这些小细节不能马虎。
关键词6@>修改关键词密度
关键词的密度官方说在2-8%之间,注意这只是一个大概的比例!如果你的网站内容很多(以1000字为例),关键词出现5次,而内容很少(只有500字)关键词也出现5次,那么这个密度就不一样了!因此,合理设置关键词的密度是必不可少的过程。
关键词7@>
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
实时文章采集(小说网站怎么做?小说规则怎么写?其中的原因)
小说网站怎么办?小说的规则怎么写?大量采集小说网站和免费采集工具,让关键词排名网站快速收录。关键词搜索引擎首页的稳定性是我们网站优化的目标,但是有的网站可以做到,有的网站一直没有效果。无效的原因有很多。今天小编就为大家分析一下原因。
一、服务器原因
服务器是网站 的基础,也是必要的设施之一。选择服务器时,建议选择官方备案的服务器。糟糕的服务器通常会导致 网站 打开缓慢或无法访问。发生这种情况,搜索引擎不会给出最高排名。
二、网站内容
网站更新频率A网站更新频率越高,搜索引擎蜘蛛来的频率越高。因此,我们可以利用小说采集器实现采集伪原创自动发布,主动推送给搜索引擎,提高搜索引擎的抓取频率。本小说采集器操作简单,不需要学习更专业的技术,只需几步即可轻松采集内容数据。用户只需对小说采集器进行简单的设置,小说采集器会根据用户的设置关键词精确采集文章进行设置,所以以确保与行业 文章 保持一致。采集文章 from 采集可以选择保存在本地,也可以选择自动伪原创发布,
和其他网站插件相比,这部小说采集器基本没有什么规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词@ > 采集(小说采集器也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个网站插件还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(让内容没有不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集关键词 是自动添加的。文本 Automatically insert the current 采集关键词 在随机位置两次。当当前 采集 的 关键词 出现在文本中时,< @关键词 将自动加粗。)
7、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
三、链接
友情链接有很多功能。它们可以增加网站 流量和收录 彼此。是大家喜欢的优化推广方式之一。但是,如果网站有恶意交流链接和垃圾邮件,也会影响网站的排名,也有可能被搜索引擎降级。建议大家交流一些相关的正式的网站,当然最好有一定的分量。
四、搜索引擎算法
网站在优化过程中,网站的每一个操作细节都会影响到网站,而网站在优化过程中出现的频率相当于< @网站基本,影响网站爬取频率的主要因素有哪些?今天云无限小编就带大家详细了解一下。
网站优化
1、网站域名的选择;
选择网站域名时,尽量选择比较短的域名,目录层次尽量控制在3层以内,有利于蜘蛛爬取;
2、更新频率和原创内容程度;
更新网站的内容时,尽量做原创文章。对于蜘蛛来说,喜欢原创,文章度数高,更新频率要掌握一定的频率;
3、页面加载速度;
蜘蛛在抓取网站的时候,非常关心页面的加载速度。页面打开时,尽量控制在3秒以内。这也是蜘蛛更敏感的地方。网站溜走;
4、 主动提交;
我们需要提交网站的URL,这样可以更好的增加网站收录的数量;
5、优质的外部链接;
网站在优化过程中,少不了优质优质的外链,可以更好的帮助你网站打好基础。这些优质的外链主要包括友情链接等;
关键词3@>网站未排名
对于很多站长来说,关键词没有被排名是一件非常痛苦的事情。他们每天都在运转,但效果并没有明显改善。为什么是这样?关键词让我们看看如果我们长时间没有排名该怎么办!
关键词4@>修改TDK
我们都知道TDK是网站最重要的部分。如果一个网站的TDK写得不好,那么网站的排名肯定会受到影响,也有可能是算法变化造成的。所以如果网站长时间没有排名,可以适当修改TDK,让关键词的排名也有可能出现。
关键词5@>检查网站代码
网站的代码有很多种,其中图片优化、推送代码、H1标签、nofollow标签大家应该熟悉。它可能是这些标签代码之一,它会影响您对 关键词 的排名。所以优化是一项细心的工作,这些小细节不能马虎。
关键词6@>修改关键词密度
关键词的密度官方说在2-8%之间,注意这只是一个大概的比例!如果你的网站内容很多(以1000字为例),关键词出现5次,而内容很少(只有500字)关键词也出现5次,那么这个密度就不一样了!因此,合理设置关键词的密度是必不可少的过程。
关键词7@>
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
实时文章采集(DMCMS插件是否有用,DM建站系统是一款小众CMS! )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-05 04:21
)
DMcms插件有没有用,今天跟大家分享一下,DM建站系统是一个小众cms,php+mysql开发的一个开源的,用于中小型建设的企业 网站 cms, DMcms 后台有块和布局两个功能。block函数用于效果,layout函数用于结构。带有一些 SEO 处理功能。虽然是开源的cms,但是由于用户比较少,DMcms的插件并不多。
DMcms插件使用非常简单,所有操作页面可视化点击,无需专业规则配置,兼容性好,无论是DMcms,dedecms@ >、鲶鱼cms或者小旋风cms的大小都可以。DMcms插件实现网站采集—文章翻译—内容伪原创—主要cms发布—实时推送等职能。网站自动管理,任务进度(成功/失败)状态可见。
网站 的构建肯定需要 SEO。SEO是一种全过程的优化行为。从我们决定建立 网站 开始,就应该建立 SEO 意识。让我们简单谈谈一些基本的SEO:
一、 网站TDK
TDK是我们常说的title、description、keywords的缩写。TDK 对我们来说是一个非常重要的设置网站。就像我们的身份信息一样,尽量不要填写。改变。
二、TDK相关内容
网站的主题一定要明确,每个页面的内容都要呼应我们的网站TDK,通过采集的DMcms插件,输入关键词可以启动采集,采集内容覆盖全网头平台(如图),不断更新方向,递增采集。一次可以创建多个采集任务,可以同时执行不同域名和重复域名的任务。
三、内容优化
1、采集内容敏感*字过滤,
2、 清洗(号码清洗、网站清洗、机构名称清洗)
3、内置翻译功能(英译中、繁译简、简译火星)
4、伪原创关键词(关键词不受伪原创影响,保证核心关键词或品牌展示)
5、采集保留内容标签
6、标题、内容伪原创
7、设置内容与标题一致(使内容与标题完全匹配)
8、设置关键词自动内链(自动从文章内容中的关键词生成内链)
9、设置定时释放(24小时挂机)
四、图像优化
图文结合受到用户和搜索引擎的欢迎。一个高质量的文章 不能没有图片。搜索引擎使用图片标签和描述来识别图片。通过 DMcms 插件可以优化图像的方式有哪些。
1、图片本地化/云存储
2、给图片添加标签
3、图片按频率插入到文本中
4、图片水印/去水
五、流程 SEO 管理
SEO与SEM的不同之处在于看到结果需要时间,因此我们需要更加关注优化过程。DMcms插件可以实时查看任务已发布、待发布、是否为伪原创、发布状态、URL、程序、发布时间等信息。整合cms网站收录、权重、蜘蛛等绑定信息,自动生成曲线供我们分析。
作为搜索引擎优化从业者,需要有良好的心理素质,不断学习和掌握新的SEO技巧,总结每日数据曲线,根据行业趋势和网站曲线变化调整思路,灵活运用及时调整能力。任务完成。这就是今天分享的全部内容。喜欢的话可以连续点三下。
查看全部
实时文章采集(DMCMS插件是否有用,DM建站系统是一款小众CMS!
)
DMcms插件有没有用,今天跟大家分享一下,DM建站系统是一个小众cms,php+mysql开发的一个开源的,用于中小型建设的企业 网站 cms, DMcms 后台有块和布局两个功能。block函数用于效果,layout函数用于结构。带有一些 SEO 处理功能。虽然是开源的cms,但是由于用户比较少,DMcms的插件并不多。
DMcms插件使用非常简单,所有操作页面可视化点击,无需专业规则配置,兼容性好,无论是DMcms,dedecms@ >、鲶鱼cms或者小旋风cms的大小都可以。DMcms插件实现网站采集—文章翻译—内容伪原创—主要cms发布—实时推送等职能。网站自动管理,任务进度(成功/失败)状态可见。
网站 的构建肯定需要 SEO。SEO是一种全过程的优化行为。从我们决定建立 网站 开始,就应该建立 SEO 意识。让我们简单谈谈一些基本的SEO:
一、 网站TDK
TDK是我们常说的title、description、keywords的缩写。TDK 对我们来说是一个非常重要的设置网站。就像我们的身份信息一样,尽量不要填写。改变。
二、TDK相关内容
网站的主题一定要明确,每个页面的内容都要呼应我们的网站TDK,通过采集的DMcms插件,输入关键词可以启动采集,采集内容覆盖全网头平台(如图),不断更新方向,递增采集。一次可以创建多个采集任务,可以同时执行不同域名和重复域名的任务。
三、内容优化
1、采集内容敏感*字过滤,
2、 清洗(号码清洗、网站清洗、机构名称清洗)
3、内置翻译功能(英译中、繁译简、简译火星)
4、伪原创关键词(关键词不受伪原创影响,保证核心关键词或品牌展示)
5、采集保留内容标签
6、标题、内容伪原创
7、设置内容与标题一致(使内容与标题完全匹配)
8、设置关键词自动内链(自动从文章内容中的关键词生成内链)
9、设置定时释放(24小时挂机)
四、图像优化
图文结合受到用户和搜索引擎的欢迎。一个高质量的文章 不能没有图片。搜索引擎使用图片标签和描述来识别图片。通过 DMcms 插件可以优化图像的方式有哪些。
1、图片本地化/云存储
2、给图片添加标签
3、图片按频率插入到文本中
4、图片水印/去水
五、流程 SEO 管理
SEO与SEM的不同之处在于看到结果需要时间,因此我们需要更加关注优化过程。DMcms插件可以实时查看任务已发布、待发布、是否为伪原创、发布状态、URL、程序、发布时间等信息。整合cms网站收录、权重、蜘蛛等绑定信息,自动生成曲线供我们分析。
作为搜索引擎优化从业者,需要有良好的心理素质,不断学习和掌握新的SEO技巧,总结每日数据曲线,根据行业趋势和网站曲线变化调整思路,灵活运用及时调整能力。任务完成。这就是今天分享的全部内容。喜欢的话可以连续点三下。
实时文章采集(0服务出现错误的根因服务的设计方法与设计 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2022-03-03 16:06
)
0 1 背景
目前闲鱼的实际生产部署环境越来越复杂。各种服务的横向依赖相互交织,运行环境的纵向依赖也越来越复杂。当服务出现问题时,能否在海量数据中及时定位问题根源,成为考验闲鱼服务能力的严峻挑战。
当网上出现问题时,往往需要十多分钟甚至更长时间才能找到问题的原因。因此,需要应用能够快速进行自动诊断的系统,而快速诊断的基础是高性能的实时数据。处理系统。该实时数据处理系统需要具备以下能力:
1、数据实时采集,实时分析,计算复杂,分析结果持久化。
2、 可以处理各种各样的数据。收录应用日志、主机性能监控指标和调用链接图。
3、高可靠性。系统没有问题,数据不会丢失。
4、高性能,底部延迟。数据处理时延不超过3秒,支持每秒千万级数据处理。
本文不涉及自动问题诊断的具体分析模型,只讨论整体实时数据处理环节的设计。
02 I/O 定义
为了便于理解系统的运行,我们将系统的整体输入输出定义如下:
输入:
服务请求日志(包括traceid、时间戳、客户端ip、服务器ip、耗时、返回码、服务名、方法名)
环境监测数据(指标名称、ip、时间戳、指标值)。比如cpu、jvm gc次数、jvm gc耗时、数据库指标。
输出:
某服务在一段时间内出错的根本原因,每个服务的错误分析结果用有向无环图表示。 (根节点是被分析的错误节点,叶子节点是错误根因节点,叶子节点可能是外部依赖的服务错误或者jvm异常等)。
03 建筑设计
在实际系统运行过程中,随着时间的推移,会不断产生日志数据和监控数据。每条生成的数据都有自己的时间戳。实时流式传输这些带时间戳的数据就像流过不同管道的水一样。
如果将源源不断的实时数据比作自来水,数据处理过程类似于自来水生产的过程:
当然,我们也将实时数据处理分解为采集、传输、预处理、计算和存储阶段。
整体系统架构设计如下:
采集
使用阿里巴巴自主研发的sls日志服务产品(包括logtail+loghub组件),logtail是一个采集客户端。之所以选择logtail,是因为其卓越的性能、高可靠性以及灵活的插件扩展机制,闲鱼可以定制自己的采集插件,实现各种数据的实时采集。
传输
loghub可以理解为数据发布订阅组件,功能类似于kafka,作为数据传输通道,更稳定安全,详细对比文章参考:
预处理
实时数据预处理部分使用blink流计算处理组件(开源版本称为flink,blink是阿里巴巴内部基于flink的增强版)。目前常用的实时流计算开源产品有Jstorm、SparkStream、Flink。由于Jstorm没有中间计算状态,其计算过程中需要的中间结果必须依赖外部存储,这会导致频繁的io影响其性能; SparkStream本质上是用小批量来模拟实时计算,但实际上还是有一定的延迟; Flink 以其优秀的状态管理机制保证了其计算的性能和实时性,并提供了完整的 SQL 表达式,使得流计算更容易。
计算和持久性
数据经过预处理后,最终生成调用链路聚合日志和主机监控数据。主机监控数据会独立存储在tsdb时序数据库中,供后续统计分析。由于对时间指标数据的特殊存储结构设计,tsdb非常适合时间序列数据的存储和查询。调用链接日志聚合数据,提供给cep/graph服务进行诊断模型分析。 cep/graph service是闲鱼开发的一款应用,实现模型分析、复杂数据处理以及与外部服务的交互,借助rdb实现图数据的实时聚合。
最后一次cep/graph服务分析的结果作为图数据,在lindorm中提供实时转储在线查询。 Lindorm 可以看作是 hbase 的增强版,在系统中充当持久存储。
04 详细设计和性能优化
采集
日志和指标数据采集使用logtail,整个数据采集流程如图:
它提供了非常灵活的插件机制,有四种类型的插件:
由于指标数据(如cpu、内存、jvm指标)的获取需要调用本机的服务接口,所以尽量减少请求的数量。在 logtail 中,一个输入占用一个 goroutine。闲鱼通过自定义输入插件和处理器插件,通过服务请求(指标获取接口由基础监控团队提供)在一个输入插件中获取多个指标数据(如cpu、内存、jvm指标),并将其格式化为一个json数组对象在处理器插件中被拆分成多条数据,以减少系统中io的数量,提高性能。
传输
LogHub 用于数据传输。 logtail写入数据后,blink直接消费数据。只需设置合理数量的分区即可。分区数必须大于等于并发blink读任务数,避免blink任务空闲。
预处理
预处理主要通过blink实现,主要设计和优化点:
写一个高效的计算过程
blink是一个有状态的流计算框架,非常适合实时聚合、join等操作。
在我们的应用中,我们只需要注意对有错误请求的相关服务链接的调用,所以整个日志处理流程分为两个流程:
1、服务的请求入口日志作为单独的流处理,过滤掉请求错误的数据。
2、其他中间环节的调用日志作为另一个独立的流处理。通过在traceid上加入上述流,实现了错误服务所依赖的请求数据的插入。
如上图所示,双流join后,输出的是与请求错误相关的所有链接的完整数据。
设置合理的状态生命周期
blink本质上是在做join的时候通过state缓存中间数据状态,然后再匹配数据。如果状态的生命周期过长,会造成数据膨胀,影响性能。如果状态的生命周期太短,将无法正确关联一些延迟的数据。因此,需要合理配置状态生命周期,并允许该应用的最大数据延迟。 1 分钟。
使用niagara作为statebackend,以及设定state数据生命周期,单位毫秒
state.backend.type=niagara
state.backend.niagara.ttl.ms=60000
打开 MicroBatch/MiniBatch
MicroBatch 和 MiniBatch 都是 micro-batch,但 micro-batch 的触发机制略有不同。原则上,在触发处理前缓存一定量的数据,减少对状态的访问,从而显着提高吞吐量,减少输出数据量。
开启join
blink.miniBatch.join.enabled=true
使用 microbatch 时需要保留以下两个 minibatch 配置
blink.miniBatch.allowLatencyMs=5000
防止OOM,每个批次最多缓存多少条数据
blink.miniBatch.size=20000
对动态负载使用动态再平衡而不是再平衡
blink 任务最忌讳的就是计算热点的存在。 Dynamic Rebalance为了保证数据均匀使用,可以根据当前子分区中累积的buffer个数,选择负载较轻的子分区进行写入,从而实现动态负载均衡。与静态再平衡策略相比,当下游任务的计算能力不均衡时,可以更加均衡各个任务的相对负载,从而提升整个作业的性能。
开启动态负载
task.dynamic.rebalance.enabled=true
自定义输出插件
数据关联后,统一请求链路上的数据需要以数据包的形式通知给下游图分析节点。传统的方式是通过消息服务传递数据。但是消息服务有两个缺点:
1、与rdb等内存数据库相比,它的吞吐量还是有很大差距(差一个数量级左右)。
2、在接收端,也需要根据traceid进行数据关联。
我们通过自定义插件异步向RDB写入数据,同时设置数据过期时间。存储在 RDB 中的数据结构中。编写时只使用traceid作为消息内容,通过metaQ通知下游计算服务,大大降低了metaQ的数据传输压力。
图形聚合计算
收到metaQ的通知后,cep/graph计算服务节点会根据请求的链路数据和依赖的环境监测数据实时生成诊断结果。诊断结果简化如下:
表示这个请求是由下游jvm的线程池满造成的,但是一次调用并没有说明服务不可用的根本原因。分析整体的错误情况,需要对图数据进行实时聚合。
聚合设计如下(为了说明基本思想而进行了简化):
1、首先利用redis的zrank能力,根据服务名或者ip信息给每个节点分配一个全局唯一的序号。
2、为图中的每个节点生成对应的图节点代码,代码格式:
- 对于头节点:头节点序号 |圆形时间戳 |节点代码
- 对于普通节点:|圆形时间戳 |节点编码
3、由于每个节点在一个时间段内都有唯一的key,所以可以使用节点代码作为key来统计每个节点使用redis。同时消除了并发读写的问题。
4、在redis中使用set集合可以很方便的叠加图的边。
5、记录根节点,通过遍历恢复聚合图结构。
汇总结果大致如下:
这样,最终产生了服务不可用的整体原因,可以通过叶子节点的数量对根本原因进行排序。
05 收益
系统上线后,整个实时处理数据链路延迟不超过三秒。定位闲鱼服务器问题的时间从十多分钟甚至更长的时间缩短到了五秒以内。这大大提高了问题定位的效率。
06 展望
目前的系统可以支持闲鱼每秒千万级的数据处理能力。自动定位问题的后续服务可能会扩展到阿里巴巴内部更多的业务场景,数据量将成倍增长,因此对效率和成本提出了更好的要求。
未来可能的改进:
1、处理后的数据可以自动缩减或压缩。
2、复杂的模型分析计算也可以瞬间完成,减少io,提高性能。
3、支持多租户数据隔离。
查看全部
实时文章采集(0服务出现错误的根因服务的设计方法与设计
)
0 1 背景
目前闲鱼的实际生产部署环境越来越复杂。各种服务的横向依赖相互交织,运行环境的纵向依赖也越来越复杂。当服务出现问题时,能否在海量数据中及时定位问题根源,成为考验闲鱼服务能力的严峻挑战。
当网上出现问题时,往往需要十多分钟甚至更长时间才能找到问题的原因。因此,需要应用能够快速进行自动诊断的系统,而快速诊断的基础是高性能的实时数据。处理系统。该实时数据处理系统需要具备以下能力:
1、数据实时采集,实时分析,计算复杂,分析结果持久化。
2、 可以处理各种各样的数据。收录应用日志、主机性能监控指标和调用链接图。
3、高可靠性。系统没有问题,数据不会丢失。
4、高性能,底部延迟。数据处理时延不超过3秒,支持每秒千万级数据处理。
本文不涉及自动问题诊断的具体分析模型,只讨论整体实时数据处理环节的设计。
02 I/O 定义
为了便于理解系统的运行,我们将系统的整体输入输出定义如下:
输入:
服务请求日志(包括traceid、时间戳、客户端ip、服务器ip、耗时、返回码、服务名、方法名)
环境监测数据(指标名称、ip、时间戳、指标值)。比如cpu、jvm gc次数、jvm gc耗时、数据库指标。
输出:
某服务在一段时间内出错的根本原因,每个服务的错误分析结果用有向无环图表示。 (根节点是被分析的错误节点,叶子节点是错误根因节点,叶子节点可能是外部依赖的服务错误或者jvm异常等)。
03 建筑设计
在实际系统运行过程中,随着时间的推移,会不断产生日志数据和监控数据。每条生成的数据都有自己的时间戳。实时流式传输这些带时间戳的数据就像流过不同管道的水一样。
如果将源源不断的实时数据比作自来水,数据处理过程类似于自来水生产的过程:
当然,我们也将实时数据处理分解为采集、传输、预处理、计算和存储阶段。
整体系统架构设计如下:
采集
使用阿里巴巴自主研发的sls日志服务产品(包括logtail+loghub组件),logtail是一个采集客户端。之所以选择logtail,是因为其卓越的性能、高可靠性以及灵活的插件扩展机制,闲鱼可以定制自己的采集插件,实现各种数据的实时采集。
传输
loghub可以理解为数据发布订阅组件,功能类似于kafka,作为数据传输通道,更稳定安全,详细对比文章参考:
预处理
实时数据预处理部分使用blink流计算处理组件(开源版本称为flink,blink是阿里巴巴内部基于flink的增强版)。目前常用的实时流计算开源产品有Jstorm、SparkStream、Flink。由于Jstorm没有中间计算状态,其计算过程中需要的中间结果必须依赖外部存储,这会导致频繁的io影响其性能; SparkStream本质上是用小批量来模拟实时计算,但实际上还是有一定的延迟; Flink 以其优秀的状态管理机制保证了其计算的性能和实时性,并提供了完整的 SQL 表达式,使得流计算更容易。
计算和持久性
数据经过预处理后,最终生成调用链路聚合日志和主机监控数据。主机监控数据会独立存储在tsdb时序数据库中,供后续统计分析。由于对时间指标数据的特殊存储结构设计,tsdb非常适合时间序列数据的存储和查询。调用链接日志聚合数据,提供给cep/graph服务进行诊断模型分析。 cep/graph service是闲鱼开发的一款应用,实现模型分析、复杂数据处理以及与外部服务的交互,借助rdb实现图数据的实时聚合。
最后一次cep/graph服务分析的结果作为图数据,在lindorm中提供实时转储在线查询。 Lindorm 可以看作是 hbase 的增强版,在系统中充当持久存储。
04 详细设计和性能优化
采集
日志和指标数据采集使用logtail,整个数据采集流程如图:
它提供了非常灵活的插件机制,有四种类型的插件:
由于指标数据(如cpu、内存、jvm指标)的获取需要调用本机的服务接口,所以尽量减少请求的数量。在 logtail 中,一个输入占用一个 goroutine。闲鱼通过自定义输入插件和处理器插件,通过服务请求(指标获取接口由基础监控团队提供)在一个输入插件中获取多个指标数据(如cpu、内存、jvm指标),并将其格式化为一个json数组对象在处理器插件中被拆分成多条数据,以减少系统中io的数量,提高性能。
传输
LogHub 用于数据传输。 logtail写入数据后,blink直接消费数据。只需设置合理数量的分区即可。分区数必须大于等于并发blink读任务数,避免blink任务空闲。
预处理
预处理主要通过blink实现,主要设计和优化点:
写一个高效的计算过程
blink是一个有状态的流计算框架,非常适合实时聚合、join等操作。
在我们的应用中,我们只需要注意对有错误请求的相关服务链接的调用,所以整个日志处理流程分为两个流程:
1、服务的请求入口日志作为单独的流处理,过滤掉请求错误的数据。
2、其他中间环节的调用日志作为另一个独立的流处理。通过在traceid上加入上述流,实现了错误服务所依赖的请求数据的插入。
如上图所示,双流join后,输出的是与请求错误相关的所有链接的完整数据。
设置合理的状态生命周期
blink本质上是在做join的时候通过state缓存中间数据状态,然后再匹配数据。如果状态的生命周期过长,会造成数据膨胀,影响性能。如果状态的生命周期太短,将无法正确关联一些延迟的数据。因此,需要合理配置状态生命周期,并允许该应用的最大数据延迟。 1 分钟。
使用niagara作为statebackend,以及设定state数据生命周期,单位毫秒
state.backend.type=niagara
state.backend.niagara.ttl.ms=60000
打开 MicroBatch/MiniBatch
MicroBatch 和 MiniBatch 都是 micro-batch,但 micro-batch 的触发机制略有不同。原则上,在触发处理前缓存一定量的数据,减少对状态的访问,从而显着提高吞吐量,减少输出数据量。
开启join
blink.miniBatch.join.enabled=true
使用 microbatch 时需要保留以下两个 minibatch 配置
blink.miniBatch.allowLatencyMs=5000
防止OOM,每个批次最多缓存多少条数据
blink.miniBatch.size=20000
对动态负载使用动态再平衡而不是再平衡
blink 任务最忌讳的就是计算热点的存在。 Dynamic Rebalance为了保证数据均匀使用,可以根据当前子分区中累积的buffer个数,选择负载较轻的子分区进行写入,从而实现动态负载均衡。与静态再平衡策略相比,当下游任务的计算能力不均衡时,可以更加均衡各个任务的相对负载,从而提升整个作业的性能。
开启动态负载
task.dynamic.rebalance.enabled=true
自定义输出插件
数据关联后,统一请求链路上的数据需要以数据包的形式通知给下游图分析节点。传统的方式是通过消息服务传递数据。但是消息服务有两个缺点:
1、与rdb等内存数据库相比,它的吞吐量还是有很大差距(差一个数量级左右)。
2、在接收端,也需要根据traceid进行数据关联。
我们通过自定义插件异步向RDB写入数据,同时设置数据过期时间。存储在 RDB 中的数据结构中。编写时只使用traceid作为消息内容,通过metaQ通知下游计算服务,大大降低了metaQ的数据传输压力。
图形聚合计算
收到metaQ的通知后,cep/graph计算服务节点会根据请求的链路数据和依赖的环境监测数据实时生成诊断结果。诊断结果简化如下:
表示这个请求是由下游jvm的线程池满造成的,但是一次调用并没有说明服务不可用的根本原因。分析整体的错误情况,需要对图数据进行实时聚合。
聚合设计如下(为了说明基本思想而进行了简化):
1、首先利用redis的zrank能力,根据服务名或者ip信息给每个节点分配一个全局唯一的序号。
2、为图中的每个节点生成对应的图节点代码,代码格式:
- 对于头节点:头节点序号 |圆形时间戳 |节点代码
- 对于普通节点:|圆形时间戳 |节点编码
3、由于每个节点在一个时间段内都有唯一的key,所以可以使用节点代码作为key来统计每个节点使用redis。同时消除了并发读写的问题。
4、在redis中使用set集合可以很方便的叠加图的边。
5、记录根节点,通过遍历恢复聚合图结构。
汇总结果大致如下:
这样,最终产生了服务不可用的整体原因,可以通过叶子节点的数量对根本原因进行排序。
05 收益
系统上线后,整个实时处理数据链路延迟不超过三秒。定位闲鱼服务器问题的时间从十多分钟甚至更长的时间缩短到了五秒以内。这大大提高了问题定位的效率。
06 展望
目前的系统可以支持闲鱼每秒千万级的数据处理能力。自动定位问题的后续服务可能会扩展到阿里巴巴内部更多的业务场景,数据量将成倍增长,因此对效率和成本提出了更好的要求。
未来可能的改进:
1、处理后的数据可以自动缩减或压缩。
2、复杂的模型分析计算也可以瞬间完成,减少io,提高性能。
3、支持多租户数据隔离。
实时文章采集(简单几个打包为exe命令全部源码参考资料多线程并发#lock-objectsPySimpleGUI)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-03-02 03:20
最近帮朋友写了一个简单的爬虫。对了,我做了一个小说爬虫工具,有GUI界面,可以从笔趣阁爬取小说。
开发完成后的界面
采集进程接口
采集之后保存
主要实现的功能是多线程采集,一个线程采集小说支持使用代理,尤其是多线程采集时,没有ip可能会被阻塞使用代理
实时输出采集结果
使用threading.BoundedSemaphore() pool_sema.acquire() pool_sema.release() 限制线程数,防止并发线程溢出。具体限制可在软件界面输入,默认为5个线程
所有线程任务开始前
pool_sema.threading.BoundedSemaphore(5)
具体每个线程开始前 锁
pool_sema.acquire()
....
# 线程任务执行结束释放
pol_sema.release()
使用的第三方模块
pip install requests
pip install pysimplegui
pip install lxml
pip install pyinstaller
GUI界面使用了一个tkinter包库PySimpleGUI,使用起来非常方便。界面虽然不是很漂亮,但是很简单,很适合开发一些小工具。 pysimplegui.readthedocs.io/en/latest/ 比如这个界面的布局,就是几个简单的列表
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openwebsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]
打包成exe命令
pyinstaller -Fw start.py
全部源代码
import time
import requests
import os
import sys
import re
import random
from lxml import etree
import webbrowser
import PySimpleGUI as sg
import threading
# user-agent
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
# 代理
proxies = {}
# 删除书名中特殊符号
# 笔趣阁基地址
baseurl = 'https://www.xbiquwx.la/'
# 线程数量
threadNum = 6
pool_sema = None
THREAD_EVENT = '-THREAD-'
cjstatus = False
# txt存储目录
filePath = os.path.abspath(os.path.join(os.getcwd(), 'txt'))
if not os.path.exists(filePath):
os.mkdir(filePath)
# 删除特殊字符
def deletetag(text):
return re.sub(r'[\[\]#\/\\:*\,;\?\"\'\|\(\)《》&\^!~=%\{\}@!:。·!¥……() ]','',text)
# 入口
def main():
global cjstatus, proxies, threadNum, pool_sema
sg.theme("reddit")
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openwebsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]
window = sg.Window('采集笔趣阁小说', layout, size=(800, 500), resizable=True,)
while True:
event, values = window.read()
if event == sg.WIN_CLOSED or event == 'close': # if user closes window or clicks cancel
break
if event == "openwebsite":
webbrowser.open('%s' % baseurl)
elif event == 'opendir':
os.system('start explorer ' + filePath)
elif event == 'start':
if cjstatus:
cjstatus = False
window['start'].update('已停止...点击重新开始')
continue
window['error'].update("", visible=False)
urls = values['url'].strip().split("\n")
lenth = len(urls)
for k, url in enumerate(urls):
if (not re.match(r'%s\d+_\d+/' % baseurl, url.strip())):
if len(url.strip()) > 0:
window['error'].update("地址错误:%s" % url, visible=True)
del urls[k]
if len(urls) < 1:
window['error'].update(
"每行地址需符合 %s84_84370/ 形式" % baseurlr, visible=True)
continue
# 代理
if len(values['proxy']) > 8:
proxies = {
"http": "http://%s" % values['proxy'],
"https": "http://%s" % values['proxy']
}
# 线程数量
if values['threadnum'] and int(values['threadnum']) > 0:
threadNum = int(values['threadnum'])
pool_sema = threading.BoundedSemaphore(threadNum)
cjstatus = True
window['start'].update('采集中...点击停止')
window['res'].update('开始采集')
for url in urls:
threading.Thread(target=downloadbybook, args=(
url.strip(), window,), daemon=True).start()
elif event == "粘贴":
window['url'].update(sg.clipboard_get())
print("event", event)
if event == THREAD_EVENT:
strtext = values[THREAD_EVENT][1]
window['res'].update(window['res'].get()+"\n"+strtext)
cjstatus = False
window.close()
#下载
def downloadbybook(page_url, window):
try:
bookpage = requests.get(url=page_url, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求 %s 错误,原因:%s' % (page_url, e)))
return
if not cjstatus:
return
# 锁线程
pool_sema.acquire()
if bookpage.status_code != 200:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求%s错误,原因:%s' % (page_url, page.reason)))
return
bookpage.encoding = 'utf-8'
page_tree = etree.HTML(bookpage.text)
bookname = page_tree.xpath('//div[@id="info"]/h1/text()')[0]
bookfilename = filePath + '/' + deletetag(bookname)+'.txt'
zj_list = page_tree.xpath(
'//div[@class="box_con"]/div[@id="list"]/dl/dd')
for _ in zj_list:
if not cjstatus:
break
zjurl = page_url + _.xpath('./a/@href')[0]
zjname = _.xpath('./a/@title')[0]
try:
zjpage = requests.get(
zjurl, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
continue
if zjpage.status_code != 200:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
return
zjpage.encoding = 'utf-8'
zjpage_content = etree.HTML(zjpage.text).xpath('//div[@id="content"]/text()')
content = "\n【"+zjname+"】\n"
for _ in zjpage_content:
content += _.strip() + '\n'
with open(bookfilename, 'a+', encoding='utf-8') as fs:
fs.write(content)
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n%s:%s 采集成功' % (bookname, zjname)))
time.sleep(random.uniform(0.05, 0.2))
# 下载完毕
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求 %s 结束' % page_url))
pool_sema.release()
if __name__ == '__main__':
main()
参考多线程并发#lock-objectsPySimpleGUI 查看全部
实时文章采集(简单几个打包为exe命令全部源码参考资料多线程并发#lock-objectsPySimpleGUI)
最近帮朋友写了一个简单的爬虫。对了,我做了一个小说爬虫工具,有GUI界面,可以从笔趣阁爬取小说。
开发完成后的界面
采集进程接口
采集之后保存
主要实现的功能是多线程采集,一个线程采集小说支持使用代理,尤其是多线程采集时,没有ip可能会被阻塞使用代理
实时输出采集结果
使用threading.BoundedSemaphore() pool_sema.acquire() pool_sema.release() 限制线程数,防止并发线程溢出。具体限制可在软件界面输入,默认为5个线程
所有线程任务开始前
pool_sema.threading.BoundedSemaphore(5)
具体每个线程开始前 锁
pool_sema.acquire()
....
# 线程任务执行结束释放
pol_sema.release()
使用的第三方模块
pip install requests
pip install pysimplegui
pip install lxml
pip install pyinstaller
GUI界面使用了一个tkinter包库PySimpleGUI,使用起来非常方便。界面虽然不是很漂亮,但是很简单,很适合开发一些小工具。 pysimplegui.readthedocs.io/en/latest/ 比如这个界面的布局,就是几个简单的列表
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openwebsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]
打包成exe命令
pyinstaller -Fw start.py
全部源代码
import time
import requests
import os
import sys
import re
import random
from lxml import etree
import webbrowser
import PySimpleGUI as sg
import threading
# user-agent
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
# 代理
proxies = {}
# 删除书名中特殊符号
# 笔趣阁基地址
baseurl = 'https://www.xbiquwx.la/'
# 线程数量
threadNum = 6
pool_sema = None
THREAD_EVENT = '-THREAD-'
cjstatus = False
# txt存储目录
filePath = os.path.abspath(os.path.join(os.getcwd(), 'txt'))
if not os.path.exists(filePath):
os.mkdir(filePath)
# 删除特殊字符
def deletetag(text):
return re.sub(r'[\[\]#\/\\:*\,;\?\"\'\|\(\)《》&\^!~=%\{\}@!:。·!¥……() ]','',text)
# 入口
def main():
global cjstatus, proxies, threadNum, pool_sema
sg.theme("reddit")
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openwebsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]
window = sg.Window('采集笔趣阁小说', layout, size=(800, 500), resizable=True,)
while True:
event, values = window.read()
if event == sg.WIN_CLOSED or event == 'close': # if user closes window or clicks cancel
break
if event == "openwebsite":
webbrowser.open('%s' % baseurl)
elif event == 'opendir':
os.system('start explorer ' + filePath)
elif event == 'start':
if cjstatus:
cjstatus = False
window['start'].update('已停止...点击重新开始')
continue
window['error'].update("", visible=False)
urls = values['url'].strip().split("\n")
lenth = len(urls)
for k, url in enumerate(urls):
if (not re.match(r'%s\d+_\d+/' % baseurl, url.strip())):
if len(url.strip()) > 0:
window['error'].update("地址错误:%s" % url, visible=True)
del urls[k]
if len(urls) < 1:
window['error'].update(
"每行地址需符合 %s84_84370/ 形式" % baseurlr, visible=True)
continue
# 代理
if len(values['proxy']) > 8:
proxies = {
"http": "http://%s" % values['proxy'],
"https": "http://%s" % values['proxy']
}
# 线程数量
if values['threadnum'] and int(values['threadnum']) > 0:
threadNum = int(values['threadnum'])
pool_sema = threading.BoundedSemaphore(threadNum)
cjstatus = True
window['start'].update('采集中...点击停止')
window['res'].update('开始采集')
for url in urls:
threading.Thread(target=downloadbybook, args=(
url.strip(), window,), daemon=True).start()
elif event == "粘贴":
window['url'].update(sg.clipboard_get())
print("event", event)
if event == THREAD_EVENT:
strtext = values[THREAD_EVENT][1]
window['res'].update(window['res'].get()+"\n"+strtext)
cjstatus = False
window.close()
#下载
def downloadbybook(page_url, window):
try:
bookpage = requests.get(url=page_url, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求 %s 错误,原因:%s' % (page_url, e)))
return
if not cjstatus:
return
# 锁线程
pool_sema.acquire()
if bookpage.status_code != 200:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求%s错误,原因:%s' % (page_url, page.reason)))
return
bookpage.encoding = 'utf-8'
page_tree = etree.HTML(bookpage.text)
bookname = page_tree.xpath('//div[@id="info"]/h1/text()')[0]
bookfilename = filePath + '/' + deletetag(bookname)+'.txt'
zj_list = page_tree.xpath(
'//div[@class="box_con"]/div[@id="list"]/dl/dd')
for _ in zj_list:
if not cjstatus:
break
zjurl = page_url + _.xpath('./a/@href')[0]
zjname = _.xpath('./a/@title')[0]
try:
zjpage = requests.get(
zjurl, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
continue
if zjpage.status_code != 200:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
return
zjpage.encoding = 'utf-8'
zjpage_content = etree.HTML(zjpage.text).xpath('//div[@id="content"]/text()')
content = "\n【"+zjname+"】\n"
for _ in zjpage_content:
content += _.strip() + '\n'
with open(bookfilename, 'a+', encoding='utf-8') as fs:
fs.write(content)
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n%s:%s 采集成功' % (bookname, zjname)))
time.sleep(random.uniform(0.05, 0.2))
# 下载完毕
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求 %s 结束' % page_url))
pool_sema.release()
if __name__ == '__main__':
main()
参考多线程并发#lock-objectsPySimpleGUI
实时文章采集(易通CMS采集可以自动采集并发布网站内容,免接口发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-02 01:23
一通cms采集,可实现网站无需人工值班,24小时自动实时监控目标,对目标实时高效采集,以便它可以全天候为 网站 @网站 提供内容更新。可以满足网站长期的运营需求,让网站站长们从繁重的工作中解脱出来。一通cms采集,可以采集任意类型网站,99.9%采集识别成功率,然后自动批量发布到所有cms类型的程序,也可以直接采集本地文件,无需界面发布。
一通cms采集可以支持网站内容和信息的自由组合,通过强大的数据排序功能对信息进行深度加工,创造出新的内容。无论是静态还是动态,包括图片、音乐、文字、软件,甚至PDF文档和WORD文档都可以准确采集,然后进行处理。并且使用同义词替换、多词随机替换、段落随机排序,让二次创作的内容更有利于网站SEO。
一通cms采集从支持多级目录入手,无论是垂直多级信息页面,还是并行多内容分页、AJAX调用页面,都可以轻松采集访问. 再加上开放的界面模式,站长可以自由地进行二次开发,自定义任何功能,实现网站的所有需求。
大部分网站都无法实现长期稳定的网站内容输出,因为远程真的很累。一通cms采集可以自动采集和发布网站内容,这是很多站长感兴趣的,一通cms采集没有使用门槛,所以对于没有基础知识的用户来说会非常简单易用。因为不需要编写适当的 采集 规则。
一通cms采集可以在短时间内丰富网站的内容,让搜索引擎的蜘蛛正常抓取一个网站。它允许用户在访问网站时看到一些内容,并根据用户的搜索需要自动显示相应的界面。
一通cms采集可以快速获取最新的网站相关内容。因为采集的内容可以基于网站的关键词的内容和相关栏目采集的内容,而这些内容可以是最新鲜的内容,所以用户浏览网站,也可以快速获取相关内容,无需通过搜索引擎再次搜索,一定程度上提升了网站的用户体验。
一通cms采集将采集内容基于智能算法。也就是说,选择与网站相关的内容,尽量新鲜。如果太陈旧了,尤其是新闻内容,过时的内容不需要采集,但是对于技术帖,那么就能够妥妥的采集,因为这些技术帖对于很多新人都有很好的帮助作用。 查看全部
实时文章采集(易通CMS采集可以自动采集并发布网站内容,免接口发布)
一通cms采集,可实现网站无需人工值班,24小时自动实时监控目标,对目标实时高效采集,以便它可以全天候为 网站 @网站 提供内容更新。可以满足网站长期的运营需求,让网站站长们从繁重的工作中解脱出来。一通cms采集,可以采集任意类型网站,99.9%采集识别成功率,然后自动批量发布到所有cms类型的程序,也可以直接采集本地文件,无需界面发布。
一通cms采集可以支持网站内容和信息的自由组合,通过强大的数据排序功能对信息进行深度加工,创造出新的内容。无论是静态还是动态,包括图片、音乐、文字、软件,甚至PDF文档和WORD文档都可以准确采集,然后进行处理。并且使用同义词替换、多词随机替换、段落随机排序,让二次创作的内容更有利于网站SEO。
一通cms采集从支持多级目录入手,无论是垂直多级信息页面,还是并行多内容分页、AJAX调用页面,都可以轻松采集访问. 再加上开放的界面模式,站长可以自由地进行二次开发,自定义任何功能,实现网站的所有需求。
大部分网站都无法实现长期稳定的网站内容输出,因为远程真的很累。一通cms采集可以自动采集和发布网站内容,这是很多站长感兴趣的,一通cms采集没有使用门槛,所以对于没有基础知识的用户来说会非常简单易用。因为不需要编写适当的 采集 规则。
一通cms采集可以在短时间内丰富网站的内容,让搜索引擎的蜘蛛正常抓取一个网站。它允许用户在访问网站时看到一些内容,并根据用户的搜索需要自动显示相应的界面。
一通cms采集可以快速获取最新的网站相关内容。因为采集的内容可以基于网站的关键词的内容和相关栏目采集的内容,而这些内容可以是最新鲜的内容,所以用户浏览网站,也可以快速获取相关内容,无需通过搜索引擎再次搜索,一定程度上提升了网站的用户体验。
一通cms采集将采集内容基于智能算法。也就是说,选择与网站相关的内容,尽量新鲜。如果太陈旧了,尤其是新闻内容,过时的内容不需要采集,但是对于技术帖,那么就能够妥妥的采集,因为这些技术帖对于很多新人都有很好的帮助作用。
实时文章采集(6个K8s日志系统建设中的典型问题,你遇到过几个?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-28 20:19
个人博客导航页面(点击右侧链接打开个人博客):大牛带你进入技术栈
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在Kubernetes中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高,但如果使用得当,自动化程度比传统方式高,运维成本更低。本文是日志系列文章的第四篇。
第一篇:《K8s日志系统建设中的6个典型问题,你遇到过几个?》
第二篇:《一篇文章理解K8s日志系统的设计与实践》
第三篇:《解决K8s中日志输出问题的9个技巧》
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,log采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志源
业务容器、系统组件、主机
商务,主持人
采集如何
Agent (Sidecar, DaemonSet), Direct Write (DockerEngine, Business)
代理,直写
独立应用程序的数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手动,Yaml
手动, 定制
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直写 DaemonSet 方法 Sidecar 方法
采集日志类型
标准输出
业务日志
标准输出 + 部分文件
文档
部署和维护
低原生支持
低,只维护配置文件
一般需要维护DaemonSet
更高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式进行映射。
每个 POD 都可以单独配置以实现高灵活性
多租户隔离
虚弱的
弱,日志直写会和业务逻辑竞争资源
一般只通过配置之间的隔离
强,通过容器隔离,资源可单独分配
支持集群大小
无限本地存储,如果使用syslog和fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
较低,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可进行自定义查询和统计
高,可根据业务特点定制
可定制性
低的
高,可自由扩展
低的
高,每个 POD 单独配置
耦合
高,强绑定DockerEngine,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,代理可以独立升级
一般默认的采集Sidecar服务对应的Agent升级也会重启(部分扩展包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类清晰、功能单一的集群
大型混合 PAAS 集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但大家需要注意:这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因有以下几点:
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK采集发布后通过CICD的webhook调用自动部署的服务,但这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后,可以直接使用 DaemonSet 采集 和 CRD 配置。安装方法如下:
当阿里云Kubernetes集群启动时,您可以选择安装它,这样在创建集群时会自动安装上述组件。如果激活的时候没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云上自建还是在其他云还是离线,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
上述组件安装完成后,Logtail和对应的Controller就会在集群中运行,但是这些组件默认没有采集任何日志,需要将日志采集规则配置为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台上手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器的stdout采集,其中定义需要stdout和stderr采集,排除环境变量中收录COLLEXT_STDOUT_FLAG: false的容器。
基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高,但存在一个问题,DaemonSet 的所有 Logtail 共享全局配置,而单个 Logtail 的配置支持有上限。因此,它无法支持具有大量应用程序的集群。
以上是我们给出的推荐配置方式。核心思想是:
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
练习 2 - 大型集群
对于一些用作PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,并且有专门的Kubernetes平台运维人员。该场景对应用数量没有限制,DaemonSet无法支持,所以必须使用Sidecar方式。总体规划如下:
Java/C/C++/机器学习/算法与数据结构/前端/Android/Python/程序员必读/书籍清单:
(点击右侧打开个人博客有干货):科技干货店
=====>>①【Java大牛带你从入门到进阶之路】②【算法数据结构+acm大牛带你从入门到进阶之路】③【数据库大牛带你从入门到进阶之路】④【Web前端大牛带你进阶之路】⑤【机器学习与python大牛带你进阶之路】⑥【架构师大牛带你进阶之路】⑦【C++大牛带你进阶之路】⑧【ios大牛带你进阶之路】⑨【Web安全大牛带你进阶之路】⑩【Linux与操作系统牛带你从入门到进阶之路】 查看全部
实时文章采集(6个K8s日志系统建设中的典型问题,你遇到过几个?)
个人博客导航页面(点击右侧链接打开个人博客):大牛带你进入技术栈
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在Kubernetes中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高,但如果使用得当,自动化程度比传统方式高,运维成本更低。本文是日志系列文章的第四篇。
第一篇:《K8s日志系统建设中的6个典型问题,你遇到过几个?》
第二篇:《一篇文章理解K8s日志系统的设计与实践》
第三篇:《解决K8s中日志输出问题的9个技巧》
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,log采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志源
业务容器、系统组件、主机
商务,主持人
采集如何
Agent (Sidecar, DaemonSet), Direct Write (DockerEngine, Business)
代理,直写
独立应用程序的数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手动,Yaml
手动, 定制
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直写 DaemonSet 方法 Sidecar 方法
采集日志类型
标准输出
业务日志
标准输出 + 部分文件
文档
部署和维护
低原生支持
低,只维护配置文件
一般需要维护DaemonSet
更高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式进行映射。
每个 POD 都可以单独配置以实现高灵活性
多租户隔离
虚弱的
弱,日志直写会和业务逻辑竞争资源
一般只通过配置之间的隔离
强,通过容器隔离,资源可单独分配
支持集群大小
无限本地存储,如果使用syslog和fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
较低,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可进行自定义查询和统计
高,可根据业务特点定制
可定制性
低的
高,可自由扩展
低的
高,每个 POD 单独配置
耦合
高,强绑定DockerEngine,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,代理可以独立升级
一般默认的采集Sidecar服务对应的Agent升级也会重启(部分扩展包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类清晰、功能单一的集群
大型混合 PAAS 集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但大家需要注意:这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因有以下几点:
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK采集发布后通过CICD的webhook调用自动部署的服务,但这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后,可以直接使用 DaemonSet 采集 和 CRD 配置。安装方法如下:
当阿里云Kubernetes集群启动时,您可以选择安装它,这样在创建集群时会自动安装上述组件。如果激活的时候没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云上自建还是在其他云还是离线,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
上述组件安装完成后,Logtail和对应的Controller就会在集群中运行,但是这些组件默认没有采集任何日志,需要将日志采集规则配置为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台上手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器的stdout采集,其中定义需要stdout和stderr采集,排除环境变量中收录COLLEXT_STDOUT_FLAG: false的容器。
基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高,但存在一个问题,DaemonSet 的所有 Logtail 共享全局配置,而单个 Logtail 的配置支持有上限。因此,它无法支持具有大量应用程序的集群。
以上是我们给出的推荐配置方式。核心思想是:
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
练习 2 - 大型集群
对于一些用作PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,并且有专门的Kubernetes平台运维人员。该场景对应用数量没有限制,DaemonSet无法支持,所以必须使用Sidecar方式。总体规划如下:
Java/C/C++/机器学习/算法与数据结构/前端/Android/Python/程序员必读/书籍清单:
(点击右侧打开个人博客有干货):科技干货店
=====>>①【Java大牛带你从入门到进阶之路】②【算法数据结构+acm大牛带你从入门到进阶之路】③【数据库大牛带你从入门到进阶之路】④【Web前端大牛带你进阶之路】⑤【机器学习与python大牛带你进阶之路】⑥【架构师大牛带你进阶之路】⑦【C++大牛带你进阶之路】⑧【ios大牛带你进阶之路】⑨【Web安全大牛带你进阶之路】⑩【Linux与操作系统牛带你从入门到进阶之路】
实时文章采集(怎么用PHP采集才能快速收录以及关键词排名?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-28 04:23
如何使用PHP采集快速收录和关键词排名?本文分为2个部分,一个是网站程序的标准化,另一个是网站fast收录和排名,我想大多数人都会遇到,公司的网站有程序问题,url优化要求等,但是程序部的小伙伴不配合!或者网站邀请第三方公司!如果你坚持做seo,你基本上就无法工作了!基本上以上都是公司程序部和我们seo网站优化部没有协调或者根本没有严格规定造成的!要知道seo是一个非常复杂的行业和职位,所涉及的内容包罗万象。其中,程序对网站的支持非常重要!如果和seo配合不好,程序会比较麻烦!网站程序中需要满足哪些规范才能适合SEO?
一、域和服务器相关
1、如果页面不存在,应该返回404错误码;
2、4XX、5XX服务器头信息异常增加,及时通知SEO部门做进一步检查。
3、域名不使用泛解析。需要使用二级域名时,需要提前与SEO部门沟通,然后解决;
3、URL 规范化,URL 启用 301
4、网站不能有多个域名打开同一个页面;
5、如果有打开子域进行测试,使用robots文件禁止搜索引擎抓取;
6、服务器开启gzip压缩,提高浏览速度;
7、在新栏目上线前完成内容填充;网站 和内容未完成的栏目无法上线。
二、网站结构和URL相关
1、所有网址网站都是静态的,除了计划禁止搜索引擎抓取的内容和收录。
2、 URL一旦确定在线,就不能随意更改。特殊情况需要调整的,必须与SEO部门沟通;
3、网站 列和 URL 目录需要一一对应。一级分类对应一级分类,二级分类对应二级分类。最多可以归类到二级目录。如果产品/页数需要分类在三级以上,此时需要注意。
4、全站目录URL以斜杠结尾,该URL不显示index.php等文件名;
5、URL 中的列名、文件名等字母都是小写的。
6、网站的所有页面都添加了面包屑;
7、URL中统一使用破折号或下划线,不要添加其他特殊字符;
8、URL目录名优先对应英文单词,不是中文拼音,而是数字或字母;
9、当URL发生变化时,旧的URL应该通过301重定向到新的URL;
三、页面打开速度相关
1、在不影响视觉效果的前提下,前端页面的所有图片都要压缩;
2、删除未使用的CSS代码,尽可能将页面样式代码合并到CSS文件中;
3、谨慎使用JS,谨慎使用JS,测试JS是否减慢页面访问;
4、禁止使用session ID、Frame、Flash;
5、页面的纯文本代码(包括HTML、JS、CSS)不超过500K。主页等特殊页面可以适当放宽。
6、使用主流浏览器实际测试页面打开速度,不要超过3秒。有条件的,从多个省市进行测试。
四、TDK相关页面
1、页面的Title标签、Description标签、H1文字的默认版本是根据格式自动生成的,但是系统需要为SEO人员预留填写功能。
2、栏目页Title的默认格式:二级栏目名-一级栏目名-网站名称;
3、产品页面标题默认格式:产品名称——网站名称;
4、文章页面标题默认格式:文章标题——网站名称;
5、搜索页面标题默认格式:搜索关键字-网站名称;;
6、每个页面标题的默认格式:列名-X页-网站名称;
7、除特殊要求外,网站使用HTML代码链接代替JS生成的链接;
8、除好友链接外的导出链接添加nofollow属性;
9、列,产品/文章将 ALT 文本添加到页面的主图像。后台编辑器上传图片时,预留输入框填写ATL文本;
10、一个页面只使用一次H1。
五、函数使用及代码
1、除非另有要求,网站确保在所有页面都在线时添加流量统计代码。
2、全部网站开通百度资源平台账号。
3、在线网站,除非 SEO 或运营部门另有要求,robots 文件对所有 URL 和文件(包括图像、CSS、JS)的抓取都是开放的。
4、XML版本的Sitemap在后台实时或定期生成更新,包括首页、栏目和页面、产品/文章页面。是否收录过滤条件页面将在与SEO部门协调后确定。
5、新站点应始终使用响应式设计,不要使用独立的移动站点或移动子域。已经用移动子域优化过的老站暂时保持现状,与SEO部门沟通后转为响应式设计。
6、英文网站HTML 代码中不应出现中文字符,包括注释。
7、当由于各种原因需要更改URL时,旧的URL会被301重定向到新的URL,不要使用其他的转向方式。
8、当由于各种原因更改 URL 时,导航和内页链接会更新为新 URL。导航中禁止需要重定向的 URL。
六、使用PHP采集+SEO函数让网站快收录
如果以上都没有问题,我们可以使用这个PHP采集工具来实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习更专业的技术。只需几个简单的步骤即可轻松实现采集内容数据,用户只需在PHP采集上进行简单设置,PHP采集工具会根据关键词准确设置给用户。采集文章,这确保了与行业 文章 的一致性。采集文章 from 采集可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他PHP采集相比,这个PHP采集基本没有规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词 采集可以实现(PHP采集也自带关键词采集函数)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PHP采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
七、百度优化排名最基本的原理!
一、网站优化排名的对象是什么
1、一个网站由多个网页组成,网站由一个或多个网页组成。
2、seo优化的对象是网页而不是网站。关于网站优化排名的误区是,普通人总是认为优化的对象是网站。我们通常所说的“网站ranking”和“网站optimization”是不正确的。
二:百度蜘蛛的工作很简单:
找到页面(发现网上有这个页面)——页面是否可以正常爬取(你在爬取的时候有没有遇到困难:比如加载慢、质量低、错误页面多——你要爬吗? page)?是否应该爬取?爬取数据库能给网名带来实际的效果吗?) 了解了这些基本原理后,我们就可以根据这些要求进行尝试了。比如,如何让百度爬取更方便?方法如下:
1)百度主动找到我们的页面
2)我们提交给百度
3) 还有人告诉百度需要做一些外链推广工作
三、什么是超链接分析,超链接分析简介
1、“超链接分析”
超链接分析是百度的专利。原理是通过分析链接网站的数量来评估链接网站的质量。这样做的效果是确保用户使用搜索引擎。,质量越高,页面越受欢迎越高。百度总裁李彦宏是这项技术的拥有者,该技术已被全球主要搜索引擎广泛采用。
2、我们如何理解超链分析技术?
总之,要判断一个页面是优秀的还是权威的,其他页面的“意见”是非常重要的。即使一个网页不是那么好,只要其他网页比其他网页有更多的“信任票”(反向链接),那么它的排名就会更高。需要注意的是,“超链接分析”只是排名的一个重要参考。
四:分析模块的工作,百度会对网页进行再加工预测评价:
1)网站页面内容好不好?
2) 页面的主题是什么?(标题、关键词和网站描述、网站内容本身由网站的TDK决定)
3)多少钱?原创学位?
4)还有其他评分选项,比如多少个链接?
通过以上指标,百度会给搜索关键词一个匹配排名,其匹配模式设计为:完全匹配+词组匹配+广泛匹配。
我们seo优化的价值在于匹配模式相当于排名机会,我们需要实现更多更好的排名机会。继续增加匹配机会,让更多流量找到我们的网站。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
实时文章采集(怎么用PHP采集才能快速收录以及关键词排名?(图))
如何使用PHP采集快速收录和关键词排名?本文分为2个部分,一个是网站程序的标准化,另一个是网站fast收录和排名,我想大多数人都会遇到,公司的网站有程序问题,url优化要求等,但是程序部的小伙伴不配合!或者网站邀请第三方公司!如果你坚持做seo,你基本上就无法工作了!基本上以上都是公司程序部和我们seo网站优化部没有协调或者根本没有严格规定造成的!要知道seo是一个非常复杂的行业和职位,所涉及的内容包罗万象。其中,程序对网站的支持非常重要!如果和seo配合不好,程序会比较麻烦!网站程序中需要满足哪些规范才能适合SEO?
一、域和服务器相关
1、如果页面不存在,应该返回404错误码;
2、4XX、5XX服务器头信息异常增加,及时通知SEO部门做进一步检查。
3、域名不使用泛解析。需要使用二级域名时,需要提前与SEO部门沟通,然后解决;
3、URL 规范化,URL 启用 301
4、网站不能有多个域名打开同一个页面;
5、如果有打开子域进行测试,使用robots文件禁止搜索引擎抓取;
6、服务器开启gzip压缩,提高浏览速度;
7、在新栏目上线前完成内容填充;网站 和内容未完成的栏目无法上线。
二、网站结构和URL相关
1、所有网址网站都是静态的,除了计划禁止搜索引擎抓取的内容和收录。
2、 URL一旦确定在线,就不能随意更改。特殊情况需要调整的,必须与SEO部门沟通;
3、网站 列和 URL 目录需要一一对应。一级分类对应一级分类,二级分类对应二级分类。最多可以归类到二级目录。如果产品/页数需要分类在三级以上,此时需要注意。
4、全站目录URL以斜杠结尾,该URL不显示index.php等文件名;
5、URL 中的列名、文件名等字母都是小写的。
6、网站的所有页面都添加了面包屑;
7、URL中统一使用破折号或下划线,不要添加其他特殊字符;
8、URL目录名优先对应英文单词,不是中文拼音,而是数字或字母;
9、当URL发生变化时,旧的URL应该通过301重定向到新的URL;
三、页面打开速度相关
1、在不影响视觉效果的前提下,前端页面的所有图片都要压缩;
2、删除未使用的CSS代码,尽可能将页面样式代码合并到CSS文件中;
3、谨慎使用JS,谨慎使用JS,测试JS是否减慢页面访问;
4、禁止使用session ID、Frame、Flash;
5、页面的纯文本代码(包括HTML、JS、CSS)不超过500K。主页等特殊页面可以适当放宽。
6、使用主流浏览器实际测试页面打开速度,不要超过3秒。有条件的,从多个省市进行测试。
四、TDK相关页面
1、页面的Title标签、Description标签、H1文字的默认版本是根据格式自动生成的,但是系统需要为SEO人员预留填写功能。
2、栏目页Title的默认格式:二级栏目名-一级栏目名-网站名称;
3、产品页面标题默认格式:产品名称——网站名称;
4、文章页面标题默认格式:文章标题——网站名称;
5、搜索页面标题默认格式:搜索关键字-网站名称;;
6、每个页面标题的默认格式:列名-X页-网站名称;
7、除特殊要求外,网站使用HTML代码链接代替JS生成的链接;
8、除好友链接外的导出链接添加nofollow属性;
9、列,产品/文章将 ALT 文本添加到页面的主图像。后台编辑器上传图片时,预留输入框填写ATL文本;
10、一个页面只使用一次H1。
五、函数使用及代码
1、除非另有要求,网站确保在所有页面都在线时添加流量统计代码。
2、全部网站开通百度资源平台账号。
3、在线网站,除非 SEO 或运营部门另有要求,robots 文件对所有 URL 和文件(包括图像、CSS、JS)的抓取都是开放的。
4、XML版本的Sitemap在后台实时或定期生成更新,包括首页、栏目和页面、产品/文章页面。是否收录过滤条件页面将在与SEO部门协调后确定。
5、新站点应始终使用响应式设计,不要使用独立的移动站点或移动子域。已经用移动子域优化过的老站暂时保持现状,与SEO部门沟通后转为响应式设计。
6、英文网站HTML 代码中不应出现中文字符,包括注释。
7、当由于各种原因需要更改URL时,旧的URL会被301重定向到新的URL,不要使用其他的转向方式。
8、当由于各种原因更改 URL 时,导航和内页链接会更新为新 URL。导航中禁止需要重定向的 URL。
六、使用PHP采集+SEO函数让网站快收录
如果以上都没有问题,我们可以使用这个PHP采集工具来实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习更专业的技术。只需几个简单的步骤即可轻松实现采集内容数据,用户只需在PHP采集上进行简单设置,PHP采集工具会根据关键词准确设置给用户。采集文章,这确保了与行业 文章 的一致性。采集文章 from 采集可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他PHP采集相比,这个PHP采集基本没有规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词 采集可以实现(PHP采集也自带关键词采集函数)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PHP采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
七、百度优化排名最基本的原理!
一、网站优化排名的对象是什么
1、一个网站由多个网页组成,网站由一个或多个网页组成。
2、seo优化的对象是网页而不是网站。关于网站优化排名的误区是,普通人总是认为优化的对象是网站。我们通常所说的“网站ranking”和“网站optimization”是不正确的。
二:百度蜘蛛的工作很简单:
找到页面(发现网上有这个页面)——页面是否可以正常爬取(你在爬取的时候有没有遇到困难:比如加载慢、质量低、错误页面多——你要爬吗? page)?是否应该爬取?爬取数据库能给网名带来实际的效果吗?) 了解了这些基本原理后,我们就可以根据这些要求进行尝试了。比如,如何让百度爬取更方便?方法如下:
1)百度主动找到我们的页面
2)我们提交给百度
3) 还有人告诉百度需要做一些外链推广工作
三、什么是超链接分析,超链接分析简介
1、“超链接分析”
超链接分析是百度的专利。原理是通过分析链接网站的数量来评估链接网站的质量。这样做的效果是确保用户使用搜索引擎。,质量越高,页面越受欢迎越高。百度总裁李彦宏是这项技术的拥有者,该技术已被全球主要搜索引擎广泛采用。
2、我们如何理解超链分析技术?
总之,要判断一个页面是优秀的还是权威的,其他页面的“意见”是非常重要的。即使一个网页不是那么好,只要其他网页比其他网页有更多的“信任票”(反向链接),那么它的排名就会更高。需要注意的是,“超链接分析”只是排名的一个重要参考。
四:分析模块的工作,百度会对网页进行再加工预测评价:
1)网站页面内容好不好?
2) 页面的主题是什么?(标题、关键词和网站描述、网站内容本身由网站的TDK决定)
3)多少钱?原创学位?
4)还有其他评分选项,比如多少个链接?
通过以上指标,百度会给搜索关键词一个匹配排名,其匹配模式设计为:完全匹配+词组匹配+广泛匹配。
我们seo优化的价值在于匹配模式相当于排名机会,我们需要实现更多更好的排名机会。继续增加匹配机会,让更多流量找到我们的网站。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
实时文章采集(开发环境开发语言Python,开发架构Scrapy,非Python莫属 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-24 00:06
)
背景
有朋友打算拓展业务渠道,准备在众包平台接单。他的主打产品是微信小程序,所以他想尽快收到客户发来的需求信息,然后尽快联系客户,从而达成交易。只有费率才能保证,否则山枣会被其他同事接走,他的黄花菜就凉了。
开发环境、开发语言、开发框架Scrapy,无非就是Python。数据神器采集!开发工具 PyCharm;功能设计实时通知:使用邮件通知,将邮箱绑定微信,实现实时通知的效果。过滤模块:根据标题和内容双重过滤关键词,丢弃不符合要求的订单,实时通知符合要求的订单。配置模块:使用json文件配置。关键代码
# -*- coding: utf-8 -*-<br />import re<br /><br />import scrapy<br />from flask import json<br />from requests import Request<br />from scrapy import Selector<br />from .. import common<br />import time<br /><br />from selenium import webdriver<br />from selenium.webdriver.chrome.options import Options<br /><br /><br />class CodemarttaskSpider(scrapy.Spider):<br /> name = 'codemarttask'<br /> allowed_domains = ['codemart.com']<br /> start_urls = ['https://codemart.com/api/project?page=1&roleTypeId=&status=RECRUITING']<br /><br /> # 重要,需要修改 application/json ,否则默认返回的是xml数据!!!<br /> def parse(self, response):<br /> # 30 item per page<br /> # print(response.text)<br /> print(<br /> "--------------------------------------------------------------------------------------------------------")<br /> json_data = json.loads(response.text)<br /> rewards = json_data.get("rewards")<br /> print(rewards)<br /> url_prefix = "https://codemart.com/project/"<br /><br /> sended_id = common.read_taskid()<br /> max_id = sended_id<br /> print("sended_id ", sended_id)<br /> for node in rewards:<br /> id = node.get("id")<br /> id_str = str(id)<br /> name = node.get("name")<br /> description = node.get("description")<br /> price = node.get("price")<br /> roles = node.get("roles") # 招募:【roles】<br /> status = node.get("status")<br /> pubTime = node.get("pubTime")<br /> url = url_prefix + id_str<br /> print(name)<br /> print(pubTime)<br /> print(price)<br /><br /> if id > sended_id:<br /> if id > max_id:<br /> max_id = id<br /> subject = "CodeMart " + id_str + " " + name<br /> # content = price + "\n" + description + "\n" + url + "\n" + status + "\n" + roles + "\n"<br /> content = "%s <p> %s <p> < a href=%s>%s <p> %s <p> %s" % (price, description, url, url, status, roles)<br /> if common.send_mail(subject, content):<br /> print("CodeMart mail: send task sucess " % id)<br /> else:<br /> print("CodeMart mail: send task fail " % id)<br /> else:<br /> print("mail: task is already sended " % id)<br /> time.sleep(3)<br /><br /> # 记录最大id<br /> common.write_taskid(id=max_id)
def send_mail(subject, content):<br /> sender = u'xxxxx@qq.com' # 发送人邮箱<br /> passwd = u'xxxxxx' # 发送人邮箱授权码<br /> receivers = u'xxxxx@qq.com' # 收件人邮箱<br /><br /> # subject = u'一品威客 开发任务 ' #主题<br /> # content = u'这是我使用python smtplib模块和email模块自动发送的邮件' #正文<br /> try:<br /> # msg = MIMEText(content, 'plain', 'utf-8')<br /> msg = MIMEText(content, 'html', 'utf-8')<br /> msg['Subject'] = subject<br /> msg['From'] = sender<br /> msg['TO'] = receivers<br /><br /> s = smtplib.SMTP_SSL('smtp.qq.com', 465)<br /> s.set_debuglevel(1)<br /> s.login(sender, passwd)<br /> s.sendmail(sender, receivers, msg.as_string())<br /> return True<br /> except Exception as e:<br /> print(e)<br /> return False
总结
程序上线后运行稳定,达到了预期效果。订单接受率非常有效!
附:Scrapy结构图
查看全部
实时文章采集(开发环境开发语言Python,开发架构Scrapy,非Python莫属
)
背景
有朋友打算拓展业务渠道,准备在众包平台接单。他的主打产品是微信小程序,所以他想尽快收到客户发来的需求信息,然后尽快联系客户,从而达成交易。只有费率才能保证,否则山枣会被其他同事接走,他的黄花菜就凉了。
开发环境、开发语言、开发框架Scrapy,无非就是Python。数据神器采集!开发工具 PyCharm;功能设计实时通知:使用邮件通知,将邮箱绑定微信,实现实时通知的效果。过滤模块:根据标题和内容双重过滤关键词,丢弃不符合要求的订单,实时通知符合要求的订单。配置模块:使用json文件配置。关键代码
# -*- coding: utf-8 -*-<br />import re<br /><br />import scrapy<br />from flask import json<br />from requests import Request<br />from scrapy import Selector<br />from .. import common<br />import time<br /><br />from selenium import webdriver<br />from selenium.webdriver.chrome.options import Options<br /><br /><br />class CodemarttaskSpider(scrapy.Spider):<br /> name = 'codemarttask'<br /> allowed_domains = ['codemart.com']<br /> start_urls = ['https://codemart.com/api/project?page=1&roleTypeId=&status=RECRUITING']<br /><br /> # 重要,需要修改 application/json ,否则默认返回的是xml数据!!!<br /> def parse(self, response):<br /> # 30 item per page<br /> # print(response.text)<br /> print(<br /> "--------------------------------------------------------------------------------------------------------")<br /> json_data = json.loads(response.text)<br /> rewards = json_data.get("rewards")<br /> print(rewards)<br /> url_prefix = "https://codemart.com/project/"<br /><br /> sended_id = common.read_taskid()<br /> max_id = sended_id<br /> print("sended_id ", sended_id)<br /> for node in rewards:<br /> id = node.get("id")<br /> id_str = str(id)<br /> name = node.get("name")<br /> description = node.get("description")<br /> price = node.get("price")<br /> roles = node.get("roles") # 招募:【roles】<br /> status = node.get("status")<br /> pubTime = node.get("pubTime")<br /> url = url_prefix + id_str<br /> print(name)<br /> print(pubTime)<br /> print(price)<br /><br /> if id > sended_id:<br /> if id > max_id:<br /> max_id = id<br /> subject = "CodeMart " + id_str + " " + name<br /> # content = price + "\n" + description + "\n" + url + "\n" + status + "\n" + roles + "\n"<br /> content = "%s <p> %s <p> < a href=%s>%s <p> %s <p> %s" % (price, description, url, url, status, roles)<br /> if common.send_mail(subject, content):<br /> print("CodeMart mail: send task sucess " % id)<br /> else:<br /> print("CodeMart mail: send task fail " % id)<br /> else:<br /> print("mail: task is already sended " % id)<br /> time.sleep(3)<br /><br /> # 记录最大id<br /> common.write_taskid(id=max_id)
def send_mail(subject, content):<br /> sender = u'xxxxx@qq.com' # 发送人邮箱<br /> passwd = u'xxxxxx' # 发送人邮箱授权码<br /> receivers = u'xxxxx@qq.com' # 收件人邮箱<br /><br /> # subject = u'一品威客 开发任务 ' #主题<br /> # content = u'这是我使用python smtplib模块和email模块自动发送的邮件' #正文<br /> try:<br /> # msg = MIMEText(content, 'plain', 'utf-8')<br /> msg = MIMEText(content, 'html', 'utf-8')<br /> msg['Subject'] = subject<br /> msg['From'] = sender<br /> msg['TO'] = receivers<br /><br /> s = smtplib.SMTP_SSL('smtp.qq.com', 465)<br /> s.set_debuglevel(1)<br /> s.login(sender, passwd)<br /> s.sendmail(sender, receivers, msg.as_string())<br /> return True<br /> except Exception as e:<br /> print(e)<br /> return False
总结
程序上线后运行稳定,达到了预期效果。订单接受率非常有效!
附:Scrapy结构图
实时文章采集(WordPress采集插件,自动批量采集SEO功能选项(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-02-21 03:17
一个 WordPress 采集 插件,允许 网站 每天自动更新文章,保持 网站 的正常更新频率。使用WordPress的采集插件代替手动更新,自动采集的内容会在伪原创之后自动发布到WP网站,无需填写内容网站 的。担心。如果想了解WordPress的采集插件,看图1到图4,略过文章的内容,图片已经很清楚的表达了本文的中心思想。【图一,WordPress采集插件,自动批量采集发布】
在做SEO的时候,对于这些网站的操作,我们没有多少资源可以利用,但是很多时候,是可以让网站快速提升网站@权重的策略之一> 这一切都与使用高质量的内容策略有关。关键是同时使用 SEO 和内容策略。SEO需要很多内容,内容SEO优化很重要,我们可以从这个角度入手。【图2,WordPress采集插件,自动SEO功能选项】
使用 WordPress 采集 插件来确定优化的方向网站。为了首先吸引访问者,您可以更多地关注您的 SEO 内容策略,以吸引访问者访问您的 网站。如果您希望访问者在访问您的 网站 后获得更高的转化率,那么内容营销至关重要。但是,在大多数情况下,网站 应该既希望将访问者吸引到 网站,又希望在他们到达 网站 后进行转化。建立平衡后,您会看到访问者和转化率都有所提高。【图3,WordPress采集插件,高效简单】
在搜索引擎优化的过程中,对于网站,我们需要通过WordPress采集插件不断输出与目标受众相关的专业内容,让自己成为行业相关词网站@ > 提高排名。在长期的SEO运营过程中,我们需要保持网站的每日更新频率,比如WordPress的采集插件输出了几篇与行业相关的优质文章文章一天之内。【图4,WordPress采集插件,网站需要优化】
刚开始作为一个新站点,搜索引擎可能不知道你的网站,但是我们使用了有效的WordPress采集插件,例如采集相关的网站关键词< @文章,使文章可以在短时间内被搜索引擎抓取。如果使用得当,WordPress 采集插件可以增加网站流量并继续积累这些用户。
吸引潜在搜索引擎的注意是每个 SEO 网站管理员必须的。一旦用户对网站有相关需求,搜索引擎可能会显示你的网站。构建高质量的内容策略非常棒,因为可以利用您深入且有用的内容来吸引新访问者。通常,这些访问者甚至可能不是特定于网站展示的界面,但他们需要网站其他展示信息。
WordPress 采集 插件确保为 网站 的访问者创建内容,使内容可读,将搜索意图与目标匹配,值得信赖,保持内容最新且结构合理 网站工作。通过这种方式,网站 将获得吸引读者的有趣内容。这将对 网站 的访问者数量、跳出率和转化率产生积极影响。WordPress的采集插件可以全自动批处理采集对采集,所以网站的SEO文案内容可以轻松搞定。 查看全部
实时文章采集(WordPress采集插件,自动批量采集SEO功能选项(图))
一个 WordPress 采集 插件,允许 网站 每天自动更新文章,保持 网站 的正常更新频率。使用WordPress的采集插件代替手动更新,自动采集的内容会在伪原创之后自动发布到WP网站,无需填写内容网站 的。担心。如果想了解WordPress的采集插件,看图1到图4,略过文章的内容,图片已经很清楚的表达了本文的中心思想。【图一,WordPress采集插件,自动批量采集发布】
在做SEO的时候,对于这些网站的操作,我们没有多少资源可以利用,但是很多时候,是可以让网站快速提升网站@权重的策略之一> 这一切都与使用高质量的内容策略有关。关键是同时使用 SEO 和内容策略。SEO需要很多内容,内容SEO优化很重要,我们可以从这个角度入手。【图2,WordPress采集插件,自动SEO功能选项】
使用 WordPress 采集 插件来确定优化的方向网站。为了首先吸引访问者,您可以更多地关注您的 SEO 内容策略,以吸引访问者访问您的 网站。如果您希望访问者在访问您的 网站 后获得更高的转化率,那么内容营销至关重要。但是,在大多数情况下,网站 应该既希望将访问者吸引到 网站,又希望在他们到达 网站 后进行转化。建立平衡后,您会看到访问者和转化率都有所提高。【图3,WordPress采集插件,高效简单】
在搜索引擎优化的过程中,对于网站,我们需要通过WordPress采集插件不断输出与目标受众相关的专业内容,让自己成为行业相关词网站@ > 提高排名。在长期的SEO运营过程中,我们需要保持网站的每日更新频率,比如WordPress的采集插件输出了几篇与行业相关的优质文章文章一天之内。【图4,WordPress采集插件,网站需要优化】
刚开始作为一个新站点,搜索引擎可能不知道你的网站,但是我们使用了有效的WordPress采集插件,例如采集相关的网站关键词< @文章,使文章可以在短时间内被搜索引擎抓取。如果使用得当,WordPress 采集插件可以增加网站流量并继续积累这些用户。
吸引潜在搜索引擎的注意是每个 SEO 网站管理员必须的。一旦用户对网站有相关需求,搜索引擎可能会显示你的网站。构建高质量的内容策略非常棒,因为可以利用您深入且有用的内容来吸引新访问者。通常,这些访问者甚至可能不是特定于网站展示的界面,但他们需要网站其他展示信息。
WordPress 采集 插件确保为 网站 的访问者创建内容,使内容可读,将搜索意图与目标匹配,值得信赖,保持内容最新且结构合理 网站工作。通过这种方式,网站 将获得吸引读者的有趣内容。这将对 网站 的访问者数量、跳出率和转化率产生积极影响。WordPress的采集插件可以全自动批处理采集对采集,所以网站的SEO文案内容可以轻松搞定。
实时文章采集(实时文章采集工具、可视化工具,看这个就够了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-20 09:09
实时文章采集工具、可视化工具、评论采集工具,看这个就够了。应该是个闭源工具。
可以尝试下我们曾经推荐过的捕手,软件和代码都是开源的。
caoz的办公桌-写给程序员的程序员知识图谱
好像也是开源的,kiva。
就feed48和豆瓣来看,和采集问答没有任何关系,好像和知乎目前的理念有关。
一次开源,今后可能开源,
有开源版,目前采集问答系列网站的数据还是比较吃力,好在还不是很复杂。不过后期应该会放大开源,毕竟采集问答系列的网站还是比较多,也不适合开源,放大大推广吧,还是很有用的。
刚刚有评论采集工具专门介绍的公众号,可以关注下。并且,说到开源的问答系统,
专注于采集问答系列网站,因为是比较多的,因此每天采集量是很大的。
比较新,采集到的数据相对少,现在还是面向已经关注我们的粉丝提供,人工回答的,我们目前的团队才两个人,我在知乎小小的推广下,人工回答问题还是很麻烦的,还不能收藏起来看,必须点进去看,比较影响浏览量,所以知乎现在对这个采集是没有什么帮助的,感谢知乎为我们的贡献。 查看全部
实时文章采集(实时文章采集工具、可视化工具,看这个就够了)
实时文章采集工具、可视化工具、评论采集工具,看这个就够了。应该是个闭源工具。
可以尝试下我们曾经推荐过的捕手,软件和代码都是开源的。
caoz的办公桌-写给程序员的程序员知识图谱
好像也是开源的,kiva。
就feed48和豆瓣来看,和采集问答没有任何关系,好像和知乎目前的理念有关。
一次开源,今后可能开源,
有开源版,目前采集问答系列网站的数据还是比较吃力,好在还不是很复杂。不过后期应该会放大开源,毕竟采集问答系列的网站还是比较多,也不适合开源,放大大推广吧,还是很有用的。
刚刚有评论采集工具专门介绍的公众号,可以关注下。并且,说到开源的问答系统,
专注于采集问答系列网站,因为是比较多的,因此每天采集量是很大的。
比较新,采集到的数据相对少,现在还是面向已经关注我们的粉丝提供,人工回答的,我们目前的团队才两个人,我在知乎小小的推广下,人工回答问题还是很麻烦的,还不能收藏起来看,必须点进去看,比较影响浏览量,所以知乎现在对这个采集是没有什么帮助的,感谢知乎为我们的贡献。
实时文章采集(实时文章采集的干货详解、numpy、用infolayer插件生成pdf)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-17 13:05
实时文章采集的干货详解哦,从、头条、今日头条、抖音、百度等热门平台做内容采集,然后自动保存到excel表中,这样可以快速将内容保存到本地,再有就是手机app端就可以看,看到的文章内容会原封不动的保存,再也不用复制粘贴。excel数据处理:个性化生成表格工具、颜色值生成表格、条件格式、图表类型模板、列表式图表模板、云端表格:邮件、qq、短信、qq邮箱、电话号码生成excel文件、导出为html格式、excel文件生成pdf、用infolayer插件生成pdf。
一、引言最近几年python的开发和编译技术可谓发展神速,移动开发也已经向着自动化大方向迈进,还能以python当中所提供的个性化工具和api对html标签进行定制,使得开发人员能够专注于html标签上面,这在编程语言中确实是鲜有的,但是学习这个也还需要时间和精力投入,找一本好书说是最好的,肯定也不能一蹴而就。
像平时我写c++和java开发人员,可能不仅要掌握面向对象的编程,还要熟悉一些python语言特性以及扩展工具。这篇文章选取了一些最常用的开发工具和工具类,以方便大家查阅,这些工具工具基本上涵盖了编程领域最常用的开发工具,同时配有入门教程,学习成本低,如果你已经对其有了一定的了解,可以直接跳过下一段。
二、初探zenddataprojpython中提供了很多数据分析工具包,包括了使用最为频繁的pandas、numpy等包,这些包都对数据进行转换,生成高质量的数据结构,最后将数据保存到一个具有良好格式的文件,这些主要工具中,命令操作基本上相同,就不赘述。在这里主要介绍一下pandas、numpy、matplotlib这几个工具,pandas已经是一个强大的数据分析工具包,可以支持大部分的数据分析操作,可以看出pandas是一个十分强大的工具,numpy在pandas和pandas有关的一些重要项目中不断的推进着,他主要提供矩阵的运算功能,他用于进行数学运算的各个函数跟pandas没有太大差别,matplotlib则为对图形化的影响,最后对数据进行可视化进行展示。
而除此之外,anaconda里面还有seaborn,matplotlib等等使用比较多的工具包,可以看看安装教程,提供的包比较全面。
三、环境配置在学习pandas和numpy之前,需要安装matplotlib,也就是我们平时说的mpl环境,因为pandas是建立在matplotlib上面的,因此安装好这个包我们就可以开始使用pandas进行数据分析,这里使用的是anaconda中自带的pipinstallmpl_toolkit来安装:。
1、我这里遇到的主要问题是安装不顺利,因为老版本版本是3.5.1, 查看全部
实时文章采集(实时文章采集的干货详解、numpy、用infolayer插件生成pdf)
实时文章采集的干货详解哦,从、头条、今日头条、抖音、百度等热门平台做内容采集,然后自动保存到excel表中,这样可以快速将内容保存到本地,再有就是手机app端就可以看,看到的文章内容会原封不动的保存,再也不用复制粘贴。excel数据处理:个性化生成表格工具、颜色值生成表格、条件格式、图表类型模板、列表式图表模板、云端表格:邮件、qq、短信、qq邮箱、电话号码生成excel文件、导出为html格式、excel文件生成pdf、用infolayer插件生成pdf。
一、引言最近几年python的开发和编译技术可谓发展神速,移动开发也已经向着自动化大方向迈进,还能以python当中所提供的个性化工具和api对html标签进行定制,使得开发人员能够专注于html标签上面,这在编程语言中确实是鲜有的,但是学习这个也还需要时间和精力投入,找一本好书说是最好的,肯定也不能一蹴而就。
像平时我写c++和java开发人员,可能不仅要掌握面向对象的编程,还要熟悉一些python语言特性以及扩展工具。这篇文章选取了一些最常用的开发工具和工具类,以方便大家查阅,这些工具工具基本上涵盖了编程领域最常用的开发工具,同时配有入门教程,学习成本低,如果你已经对其有了一定的了解,可以直接跳过下一段。
二、初探zenddataprojpython中提供了很多数据分析工具包,包括了使用最为频繁的pandas、numpy等包,这些包都对数据进行转换,生成高质量的数据结构,最后将数据保存到一个具有良好格式的文件,这些主要工具中,命令操作基本上相同,就不赘述。在这里主要介绍一下pandas、numpy、matplotlib这几个工具,pandas已经是一个强大的数据分析工具包,可以支持大部分的数据分析操作,可以看出pandas是一个十分强大的工具,numpy在pandas和pandas有关的一些重要项目中不断的推进着,他主要提供矩阵的运算功能,他用于进行数学运算的各个函数跟pandas没有太大差别,matplotlib则为对图形化的影响,最后对数据进行可视化进行展示。
而除此之外,anaconda里面还有seaborn,matplotlib等等使用比较多的工具包,可以看看安装教程,提供的包比较全面。
三、环境配置在学习pandas和numpy之前,需要安装matplotlib,也就是我们平时说的mpl环境,因为pandas是建立在matplotlib上面的,因此安装好这个包我们就可以开始使用pandas进行数据分析,这里使用的是anaconda中自带的pipinstallmpl_toolkit来安装:。
1、我这里遇到的主要问题是安装不顺利,因为老版本版本是3.5.1,
实时文章采集(实时文章采集现在各大网站都使用tensorflow框架,tensorflow数组)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-02-05 19:03
实时文章采集
<p>现在各大网站都使用tensorflow框架,而tensorflow只是基于numpy,但是还是使用了一些计算机领域的知识的,首先需要明白何为张量。一个numpyarray表示一个三维,四维,以及八维的数组,(不存在奇数维),一维数组就好像是一个井字型放在向量的上下两边,而二维数组就像是一个扇形(已知y,z,h,c),向量的上下边也就是左右边就是我们需要的向量的描述,一些关键词出现在cursor(张量向量化)这一条,cursor一共有shape1,shape2,shape3,shape4,即shape1:x 查看全部
实时文章采集(实时文章采集现在各大网站都使用tensorflow框架,tensorflow数组)
实时文章采集
<p>现在各大网站都使用tensorflow框架,而tensorflow只是基于numpy,但是还是使用了一些计算机领域的知识的,首先需要明白何为张量。一个numpyarray表示一个三维,四维,以及八维的数组,(不存在奇数维),一维数组就好像是一个井字型放在向量的上下两边,而二维数组就像是一个扇形(已知y,z,h,c),向量的上下边也就是左右边就是我们需要的向量的描述,一些关键词出现在cursor(张量向量化)这一条,cursor一共有shape1,shape2,shape3,shape4,即shape1:x
实时文章采集(如何使用腾讯云大数据组件来完成实时监控系统的设计和实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-04 14:04
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过电话、微信消息等方式实时反馈监控报警信息,有效保障系统稳定运行。使用基于云的Kafka、Flink、ES等组件,大大降低了开发和运维人员的投入。
一、方案说明(一)概述本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,并传输Go到CKafka,然后将CKafka数据连接到流计算Oceanus(Flink),经过简单的业务逻辑处理后输出到Elasticsearch,最后通过Kibana页面查询结果,方案中使用Promethus进行监控系统指标,如流计算 Oceanus 作业运行状态,使用 Cloud Grafana 监控 CVM 或业务应用指标。
(二)程序架构
二、前期准备在实施本方案之前,请确保已经创建并配置了相应的大数据组件。(一)创建私有网络VPC 私有网络(VPC)是您在腾讯云上自定义的逻辑隔离的网络空间。建议在构建CKafka、流计算Oceanus、 Elasticsearch集群。具体创建步骤请参考帮助文档()。(二)创建CKafka实例Kafka推荐选择最新的2.4.1版本,兼容性更好用 Filebeat 采集 工具购买完成后,创建一个 Kafka 主题:topic-app-info (三) 创建流计算Oceanus集群 流计算Oceanus是大数据产品生态系统的实时分析工具。它基于Apache Flink构建,一站式开发,具有无缝连接、亚秒级延迟、低成本、安全稳定等特点的企业级实时大数据分析平台。流计算Oceanus旨在实现价值最大化企业数据化,加快企业实时数字化建设进程。在Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。(四)在Elasticsearch控制台创建Elasticsearch实例,点击左上角的【新建】创建集群,具体步骤请参考帮助文档()。(五)
为了显示自定义系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的Grafana资源。灰度发布中,需要在Grafana管理页面()单独购买Grafana,展示业务监控指标。
(七)安装和配置FilebeatFilebeat是一个轻量级的日志数据采集工具,通过监控指定位置的文件来采集信息。在这个VPC下,可以用在需要监控主机信息的云服务器和应用信息。安装Filebeat。安装方法一:下载Filebeat并安装。下载地址();方法二:使用【Elasticsearch管理页面】->【beats管理】中提供的Filebeat,本例使用方法一。下载到CVM 和要配置 Filebeat,在 filebeat.yml 文件中添加以下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:programdataelasticsearchlogs*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka 版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的 IP 地址+端口topic: 'topic-app-info' # 请填写实际的 topic
请根据实际业务需求配置对应的Filebeat.yml文件,参考Filebeat官方文档()。
注意:本例使用的是2.4.1的CKafka版本,这里是配置版本:2.0.0。版本不对应可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、方案实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)文件节拍采集数据
1、进入Filebeat根目录,启动Filebeat for data采集。例子中采集top命令中显示的CPU、内存等信息也可以是采集jar应用日志、JVM使用情况、监听端口等,具体可以参考Filebeat官网
( )。
# filebeat 启动<br />./filebeat -e -c filebeat.yml<br /><br /># 监控系统信息写入 test.log 文件<br />top -d 10 >>/tmp/test.log
2、进入CKafka页面,点击左侧【消息查询】,查询对应主题消息,验证数据是否为采集。
Filebeat采集发送的Kafka数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据,并将其存储在 Elasticsearch 中。1、定义Source,根据Filebeat中json消息的格式构造Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka 注意:根据实际版本选择5、查询ES数据。在 ES 控制台的 Kibana 页面查询数据,或者进入同一子网的 CVM 下,使用如下命令查询:
# 查询索引 username:password 请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考Access ES Cluster()。(三)系统指标监控本章主要实现系统信息监控和Flink作业运行状态的监控和告警。Prometheus是一个非常灵活的时序数据库,通常用于监控数据存储、计算和告警。流计算Oceanus 建议用户使用腾讯云监控提供的 Prometheus 服务,避免部署和运维成本;同时还支持腾讯云的通知模板,可以通过短信、电话轻松到达不同的告警信息、邮件、企业微信机器人等 .Monitoring 接收方 流式计算 Oceanus 作业监控
除了Stream Computing Oceanus控制台自带的监控信息外,还可以配置任务级细粒度监控、作业级监控、集群Flink作业列表监控。1、在流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、在任意流计算Oceanus作业中,点击【云监控】进入云端Prometheus实例,点击链接进入Grafana(此处不能进入灰度Grafana),导入json文件。详情见访问 Prometheus 自定义监视器
( )。
3、显示的Flink任务监控效果如下。用户也可以点击【编辑】设置不同的面板以优化显示效果。
告警配置1、进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】进行配置相关信息。具体操作请参考访问Prometheus自定义Monitor()。
2、设置警报通知。选择【选择模板】或【新建】设置通知模板。
3、短信通知消息
(四)业务指标通过Filebeat采集监控到应用业务数据,通过流计算的Oceanus服务处理后存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。进入灰度发布中的Grafana控制台(),进入刚刚创建的Grafana服务,找到外网地址打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】,搜索对于elasticsearch,并填写相关信息。ES实例信息,添加数据源。
2、点击左侧【Dashboards】,点击【Manage】,点击右上角【New Dashboard】,新建面板,编辑面板。
3、显示效果如下:
注:这只是一个例子,没有实际业务
四、总结本方案中尝试了两种监控方案,系统监控指标和业务监控指标。如果只需要监控业务指标,可以省略Promethus相关操作。此外,需要注意的是:
火热进行中↓↓
点击文末“阅读原文”了解更多腾讯云流计算Oceanus~腾讯云大数据
长按二维码 查看全部
实时文章采集(如何使用腾讯云大数据组件来完成实时监控系统的设计和实现)
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过电话、微信消息等方式实时反馈监控报警信息,有效保障系统稳定运行。使用基于云的Kafka、Flink、ES等组件,大大降低了开发和运维人员的投入。
一、方案说明(一)概述本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,并传输Go到CKafka,然后将CKafka数据连接到流计算Oceanus(Flink),经过简单的业务逻辑处理后输出到Elasticsearch,最后通过Kibana页面查询结果,方案中使用Promethus进行监控系统指标,如流计算 Oceanus 作业运行状态,使用 Cloud Grafana 监控 CVM 或业务应用指标。
(二)程序架构
二、前期准备在实施本方案之前,请确保已经创建并配置了相应的大数据组件。(一)创建私有网络VPC 私有网络(VPC)是您在腾讯云上自定义的逻辑隔离的网络空间。建议在构建CKafka、流计算Oceanus、 Elasticsearch集群。具体创建步骤请参考帮助文档()。(二)创建CKafka实例Kafka推荐选择最新的2.4.1版本,兼容性更好用 Filebeat 采集 工具购买完成后,创建一个 Kafka 主题:topic-app-info (三) 创建流计算Oceanus集群 流计算Oceanus是大数据产品生态系统的实时分析工具。它基于Apache Flink构建,一站式开发,具有无缝连接、亚秒级延迟、低成本、安全稳定等特点的企业级实时大数据分析平台。流计算Oceanus旨在实现价值最大化企业数据化,加快企业实时数字化建设进程。在Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。(四)在Elasticsearch控制台创建Elasticsearch实例,点击左上角的【新建】创建集群,具体步骤请参考帮助文档()。(五)
为了显示自定义系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的Grafana资源。灰度发布中,需要在Grafana管理页面()单独购买Grafana,展示业务监控指标。
(七)安装和配置FilebeatFilebeat是一个轻量级的日志数据采集工具,通过监控指定位置的文件来采集信息。在这个VPC下,可以用在需要监控主机信息的云服务器和应用信息。安装Filebeat。安装方法一:下载Filebeat并安装。下载地址();方法二:使用【Elasticsearch管理页面】->【beats管理】中提供的Filebeat,本例使用方法一。下载到CVM 和要配置 Filebeat,在 filebeat.yml 文件中添加以下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:programdataelasticsearchlogs*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka 版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的 IP 地址+端口topic: 'topic-app-info' # 请填写实际的 topic
请根据实际业务需求配置对应的Filebeat.yml文件,参考Filebeat官方文档()。
注意:本例使用的是2.4.1的CKafka版本,这里是配置版本:2.0.0。版本不对应可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、方案实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)文件节拍采集数据
1、进入Filebeat根目录,启动Filebeat for data采集。例子中采集top命令中显示的CPU、内存等信息也可以是采集jar应用日志、JVM使用情况、监听端口等,具体可以参考Filebeat官网
( )。
# filebeat 启动<br />./filebeat -e -c filebeat.yml<br /><br /># 监控系统信息写入 test.log 文件<br />top -d 10 >>/tmp/test.log
2、进入CKafka页面,点击左侧【消息查询】,查询对应主题消息,验证数据是否为采集。
Filebeat采集发送的Kafka数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据,并将其存储在 Elasticsearch 中。1、定义Source,根据Filebeat中json消息的格式构造Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka 注意:根据实际版本选择5、查询ES数据。在 ES 控制台的 Kibana 页面查询数据,或者进入同一子网的 CVM 下,使用如下命令查询:
# 查询索引 username:password 请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考Access ES Cluster()。(三)系统指标监控本章主要实现系统信息监控和Flink作业运行状态的监控和告警。Prometheus是一个非常灵活的时序数据库,通常用于监控数据存储、计算和告警。流计算Oceanus 建议用户使用腾讯云监控提供的 Prometheus 服务,避免部署和运维成本;同时还支持腾讯云的通知模板,可以通过短信、电话轻松到达不同的告警信息、邮件、企业微信机器人等 .Monitoring 接收方 流式计算 Oceanus 作业监控
除了Stream Computing Oceanus控制台自带的监控信息外,还可以配置任务级细粒度监控、作业级监控、集群Flink作业列表监控。1、在流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、在任意流计算Oceanus作业中,点击【云监控】进入云端Prometheus实例,点击链接进入Grafana(此处不能进入灰度Grafana),导入json文件。详情见访问 Prometheus 自定义监视器
( )。
3、显示的Flink任务监控效果如下。用户也可以点击【编辑】设置不同的面板以优化显示效果。
告警配置1、进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】进行配置相关信息。具体操作请参考访问Prometheus自定义Monitor()。
2、设置警报通知。选择【选择模板】或【新建】设置通知模板。
3、短信通知消息
(四)业务指标通过Filebeat采集监控到应用业务数据,通过流计算的Oceanus服务处理后存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。进入灰度发布中的Grafana控制台(),进入刚刚创建的Grafana服务,找到外网地址打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】,搜索对于elasticsearch,并填写相关信息。ES实例信息,添加数据源。
2、点击左侧【Dashboards】,点击【Manage】,点击右上角【New Dashboard】,新建面板,编辑面板。
3、显示效果如下:
注:这只是一个例子,没有实际业务
四、总结本方案中尝试了两种监控方案,系统监控指标和业务监控指标。如果只需要监控业务指标,可以省略Promethus相关操作。此外,需要注意的是:
火热进行中↓↓
点击文末“阅读原文”了解更多腾讯云流计算Oceanus~腾讯云大数据
长按二维码
实时文章采集(项目架构分析日志数据采集:根据数据进行可视化筛选 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-01 23:17
)
项目概况
项目主要通过实时数仓的搭建完成对Flink的进一步掌握和学习。Flink代码是用Java编写的,会涉及到Flink的很多知识点,FlinkCDC,FlinkSQL,航海,丰富的功能等等,习惯了学习Flink,顺便传个仓库还是很不错的。从 FlinkForward2021 的一些进展来看,Flink SQLization 已经势不可挡,流式数据仓库 StreamHouse 也开始缓慢推进。
这里的实时数仓主要是为了提高数据的复用性。见下图,当有大量中间结果时
使用时充分体现了实时数仓的必要性,省去了很多重复计算,提交了实时计算的时效性。
说到数据仓库,数据仓库的分层是分不开的。基于电子商务的实时数仓分层如下:
ods:原创数据,存储业务数据和日志数据
dwd:按数据对象划分,如订单、页面访问量
dim:维度数据
dwm:进一步处理一些数据对象,将其与维度表关联,形成宽表,例如独立访问和跳出行为
dws:根据一个主题轻轻聚合多个事实数据,形成主题宽表
ads:基于数据的可视化过滤器聚合
实时需求
主要分为:每日统计报表或分析图表模块、实时数据监控大屏、数据预警或提示、实时推荐系统。
项目架构分析
记录数据采集
查看全部
实时文章采集(项目架构分析日志数据采集:根据数据进行可视化筛选
)
项目概况
项目主要通过实时数仓的搭建完成对Flink的进一步掌握和学习。Flink代码是用Java编写的,会涉及到Flink的很多知识点,FlinkCDC,FlinkSQL,航海,丰富的功能等等,习惯了学习Flink,顺便传个仓库还是很不错的。从 FlinkForward2021 的一些进展来看,Flink SQLization 已经势不可挡,流式数据仓库 StreamHouse 也开始缓慢推进。
这里的实时数仓主要是为了提高数据的复用性。见下图,当有大量中间结果时
使用时充分体现了实时数仓的必要性,省去了很多重复计算,提交了实时计算的时效性。
说到数据仓库,数据仓库的分层是分不开的。基于电子商务的实时数仓分层如下:
ods:原创数据,存储业务数据和日志数据
dwd:按数据对象划分,如订单、页面访问量
dim:维度数据
dwm:进一步处理一些数据对象,将其与维度表关联,形成宽表,例如独立访问和跳出行为
dws:根据一个主题轻轻聚合多个事实数据,形成主题宽表
ads:基于数据的可视化过滤器聚合
实时需求
主要分为:每日统计报表或分析图表模块、实时数据监控大屏、数据预警或提示、实时推荐系统。
项目架构分析
记录数据采集
实时文章采集(如何利用Python编写的异步爬虫框架(图)实例 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-02-01 17:10
)
一、scrapy简介
scrapy 是一个用 Python 编写的异步爬虫框架。它基于 Twisted 实现,运行在 Linux/Windows/MacOS 等各种环境中。具有速度快、扩展性强、使用方便等特点。即使是新手也能快速掌握并编写所需的爬虫程序。 scrapy 可以在本地运行或部署到云端 (scrapyd) 以获取真正的生产级数据采集系统。
我们通过一个示例来学习如何使用scrapy 来采集来自网络的数据。 《博客园》是一篇综合性的技术资料网站,这次我们的任务是采集网站MySQL类下所有文章的标题、摘要和发布日期,读数的数量,共4个字段。最终结果是一个收录所有 4 个字段的文本文件。如图:
最终得到的数据如下,每条记录有四行,分别是标题、阅读次数、发表时间和文章摘要:
二、安装scrapy
让我们看看如何安装scrapy。首先,您的系统中必须有 Python 和 pip。本文以最常见的 Python2.7.5 版本为例。 pip 是 Python 的包管理工具,一般 Linux 系统默认安装。在命令行输入以下命令并执行:
sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip会从豆瓣的软件源下载安装scrapy,所有依赖包都会自动下载安装。 “sudo”表示以超级用户权限执行此命令。所有进度条完成后,如果提示类似“Successfully installed Twisted, scrapy ...”,则安装成功。
三、scrapy 交互环境
scrapy 还提供了一个交互式 shell,可以让我们轻松地测试解析规则。 scrapy安装成功后,在命令行输入scrapy shell,启动scrapy的交互环境。 scrapy shell的提示符是三个大于号>>>,表示可以接收命令。我们首先使用 fetch() 方法获取首页内容:
>>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕显示如下输出,则表示已获取网页内容。
2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened
2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200)
(referer: None)
得到的响应会保存在响应对象中。该对象的status属性表示HTTP响应状态,一般为200。
>>> print response.status
200
text属性表示返回的内容数据,从中可以解析出想要的内容。
>>> print response.text
u'\r\n\r\n\r\n
\r\n
\r\n
\r\n
MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed\r\n
’
可以看出是乱七八糟的HTML代码,无法直观的找到我们需要的数据。这时候我们可以通过浏览器的“开发者工具”获取指定数据的DOM路径。用浏览器打开网页后,按F12键启动开发者工具,快速定位到指定内容。
可以看到我们需要的4个字段在/body/div(id=”wrapper”)/div(id=”main”)/div(id=”post_list”)/div(class=”post_item ”) / div(class=”post_item_body”) / ,每个“post_item_body”收录一篇文章文章的标题、摘要、发表日期和阅读次数。我们先得到所有的“post_item_body”,然后从中解析出每个文章的4个字段。
>>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” )
>>> len( post_item_body )
20
响应的xpath方法可以使用xpath解析器来获取DOM数据。 xpath的语法请参考官网文档。您可以看到我们在首页上获得了所有 20 篇 文章 文章的 post_item_body。那么如何提取每个文章的这4个字段呢?
我们以第一篇文章为例。先取第一个 post_item_body:
>>> first_article = post_item_body[ 0 ]
标题在 post_item_body 节点下的 h3/a 中。 xpath方法中text()的作用是取当前节点的文本,而extract_first()和strip()提取xpath表达式中的节点,过滤掉前后空格和回车:
>>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip()
>>> print article_title
Mysql表操作和索引操作
然后以类似的方式提取文章摘要:
>>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip()
>>> print article_summary
表操作:1.表创建:如果不存在则创建表 table_name(字段定义);示例:如果不存在则创建表 user(id int auto_increment, uname varchar(20), address varch ...
在提取post_item_foot的时候,发现提取了两组内容,第一组是空内容,第二组是文字“Posted on XXX”。我们提取第二组内容,过滤掉“published on”这个词:
>>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “发布于” )[ 1 ].strip()
>>> print post_date
2017-09-03 18:13 查看全部
实时文章采集(如何利用Python编写的异步爬虫框架(图)实例
)
一、scrapy简介
scrapy 是一个用 Python 编写的异步爬虫框架。它基于 Twisted 实现,运行在 Linux/Windows/MacOS 等各种环境中。具有速度快、扩展性强、使用方便等特点。即使是新手也能快速掌握并编写所需的爬虫程序。 scrapy 可以在本地运行或部署到云端 (scrapyd) 以获取真正的生产级数据采集系统。
我们通过一个示例来学习如何使用scrapy 来采集来自网络的数据。 《博客园》是一篇综合性的技术资料网站,这次我们的任务是采集网站MySQL类下所有文章的标题、摘要和发布日期,读数的数量,共4个字段。最终结果是一个收录所有 4 个字段的文本文件。如图:
最终得到的数据如下,每条记录有四行,分别是标题、阅读次数、发表时间和文章摘要:
二、安装scrapy
让我们看看如何安装scrapy。首先,您的系统中必须有 Python 和 pip。本文以最常见的 Python2.7.5 版本为例。 pip 是 Python 的包管理工具,一般 Linux 系统默认安装。在命令行输入以下命令并执行:
sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip会从豆瓣的软件源下载安装scrapy,所有依赖包都会自动下载安装。 “sudo”表示以超级用户权限执行此命令。所有进度条完成后,如果提示类似“Successfully installed Twisted, scrapy ...”,则安装成功。
三、scrapy 交互环境
scrapy 还提供了一个交互式 shell,可以让我们轻松地测试解析规则。 scrapy安装成功后,在命令行输入scrapy shell,启动scrapy的交互环境。 scrapy shell的提示符是三个大于号>>>,表示可以接收命令。我们首先使用 fetch() 方法获取首页内容:
>>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕显示如下输出,则表示已获取网页内容。
2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened
2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200)
(referer: None)
得到的响应会保存在响应对象中。该对象的status属性表示HTTP响应状态,一般为200。
>>> print response.status
200
text属性表示返回的内容数据,从中可以解析出想要的内容。
>>> print response.text
u'\r\n\r\n\r\n
\r\n
\r\n
\r\n
MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed\r\n
’
可以看出是乱七八糟的HTML代码,无法直观的找到我们需要的数据。这时候我们可以通过浏览器的“开发者工具”获取指定数据的DOM路径。用浏览器打开网页后,按F12键启动开发者工具,快速定位到指定内容。
可以看到我们需要的4个字段在/body/div(id=”wrapper”)/div(id=”main”)/div(id=”post_list”)/div(class=”post_item ”) / div(class=”post_item_body”) / ,每个“post_item_body”收录一篇文章文章的标题、摘要、发表日期和阅读次数。我们先得到所有的“post_item_body”,然后从中解析出每个文章的4个字段。
>>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” )
>>> len( post_item_body )
20
响应的xpath方法可以使用xpath解析器来获取DOM数据。 xpath的语法请参考官网文档。您可以看到我们在首页上获得了所有 20 篇 文章 文章的 post_item_body。那么如何提取每个文章的这4个字段呢?
我们以第一篇文章为例。先取第一个 post_item_body:
>>> first_article = post_item_body[ 0 ]
标题在 post_item_body 节点下的 h3/a 中。 xpath方法中text()的作用是取当前节点的文本,而extract_first()和strip()提取xpath表达式中的节点,过滤掉前后空格和回车:
>>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip()
>>> print article_title
Mysql表操作和索引操作
然后以类似的方式提取文章摘要:
>>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip()
>>> print article_summary
表操作:1.表创建:如果不存在则创建表 table_name(字段定义);示例:如果不存在则创建表 user(id int auto_increment, uname varchar(20), address varch ...
在提取post_item_foot的时候,发现提取了两组内容,第一组是空内容,第二组是文字“Posted on XXX”。我们提取第二组内容,过滤掉“published on”这个词:
>>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “发布于” )[ 1 ].strip()
>>> print post_date
2017-09-03 18:13
实时文章采集(发展历程FlinkSQL应用实践平台建设总结展望(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-01-31 09:14
摘要:本文组织了 Homework Group 实时计算负责人张颖在 Flink Forward Asia 2021 上的分享。Flink 在 Homework 实时计算的演进中发挥了重要作用。尤其是在 FlinkSQL 的帮助下,实时任务的开发效率得到了极大的提升。本文文章主要分享FlinkSQL在作业帮助中的使用和实践经验,以及随着任务规模的增加,从0到1搭建实时计算平台过程中遇到的问题和解决方法. 内容包括:
发展历程 Flink SQL 应用实践平台建设总结与展望
FFA 2021 现场重播和演讲 PDF 下载
一、发展历程
Homework Help主要利用人工智能、大数据等技术为学生提供更高效的学习解决方案。因此,业务数据主要包括学生的出勤率和知识点的掌握情况。在整体架构中,无论是binlog还是普通日志,都是在采集之后写入Kafka,分别通过实时和离线计算写入存储层。基于OLAP,对外提供相应的产品化服务,如工作台、BI分析等。工具。
目前 Homework Help 的实时计算主要基于 Flink,开发过程分为三个阶段:
2019 年实时计算包括少量 SparkStreaming 作业,提供给导师和讲师。在解决实时性需求的过程中,会发现开发效率很低,数据很难复用;之后,常规的做法是在生产实践中逐步应用 Flink JAR,积累经验后开始搭建平台,应用 Flink SQL。但是,20年来,业务提出了很多实时计算的需求,我们的开发人力储备不足。当时,在 Flink SQL 1.9 发布后不久,SQL 功能发生了很大变化,所以我们的做法是直接将 Flink SQL 应用到实时数仓方向。现在,整个实时数仓90%以上的任务都是使用Flink SQL实现的。; 到了 2020 年 11 月,Flink 的 Job 数量迅速增加到数百个,我们开始构建从 0 到 1 的实时计算平台,已经支撑了公司所有重要业务线,并且计算部署在多个集群上在多云中。
介绍以下两个方面:
FlinkSQL实践中遇到的典型问题及解决方案;搭建实时计算平台过程中的一些思考。二、Flink SQL 应用实践
下面是基于 Flink SQL 的完整数据流架构:
binlog/log 采集 写入 Kafka 后,topic 会自动注册为元数据表,这是后续所有实时 SQL 作业的起点。用户可以在 SQL 作业中使用此表,而无需定义复杂的 DDL。
同时,在考虑实际应用时,还需要根据元数据表添加或替换表属性:
新增:元数据记录表级属性,但 SQL 作业可能需要添加任务级属性。比如对于Kafka源表,添加job的group.id来记录offset;替换:离线测试时,在引用元数据表的基础上,只需要定义broker topic等属性覆盖源表,即可快速构建一行。测试表格如下。
框架还需要支持用户的SQL作业,方便输出指标和日志,实现全链路监控和跟踪。
这里主要介绍SQL添加Trace函数时的DAG优化实践,以及我们对Table底层物理存储的选择和封装。
2.1 SQL 添加 Trace 功能
SQL可以提高开发效率,但是业务逻辑的复杂度还是有的,复杂的业务逻辑写的DML会很长。在这种情况下,建议使用视图来提高可读性。因为视图的 SQL 比较短,所以不应该像代码规范中的单个函数那样太长。
下图左侧是一个示例任务的部分DAG,可以看到有很多SQL节点。这种情况下很难定位,因为如果是DataStream API实现的代码,也可以加日志。但是 SQL 做不到。用户可以干预的入口很少,只能看到整个作业的输入输出。
类似于在函数中打印日志,我们希望支持在视图中添加 Trace,以方便案例追踪。
但是我在尝试将 Trace 添加到 SQL 时遇到了一些问题,这是一个简化的示例:
右上角的SQL创建source_table为源表,prepare_data视图读取表,在sql中调用foo udf,然后使用StatementSet分别插入两个下游,同时将视图转换为DataStream调用 TraceSDK 写入跟踪系统。
注意:我们当时是基于 1.9 开发的。为了清楚起见,我们还使用了一些后来添加的功能。
上图下方的实际 DAG 看起来并不像预期的那样:
DAG分为上下不相关的两部分。Kafka源表是DataSource部分,读取两次;foo 方法被调用了 3 次。
数据源压力和计算性能需要优化。
为了解决这个问题,我们需要从几个角度进行优化。这里主要介绍DAG合并的思想。无论是table还是stream的env,都会产生相应的transformation。我们的做法是统一合并到stream env中,这样就可以在stream env中得到一个完整的变换列表,然后生成StreamGraph提交。
左下角是我们优化的 DAG,读取源表并只调用一次 foo 方法:
优化后的 DAG 效果与我们写 SQL 时的逻辑图非常相似,性能自然符合预期。
回到问题本身,业务可以简单地用一条语句给视图的某些字段添加trace,例如:prepare_data.trace.fields=f0,f1. 由于SQL自然收录字段名,所以trace数据的可读性甚至高于普通原木。
2.2 表的选择与设计
如前所述,我们的首要要求是提高人的效率。因此,Table 需要具备更好的分层和复用能力,并且支持模板化开发,以便 N 个端到端的 Flink 作业能够快速串联起来。
我们的解决方案是基于 Redis 实现的,它首先有几个优点:
高qps,低延迟:这应该是所有实时计算的关注点;TTL:用户无需关心数据如何退出,可以给出合理的TTL;通过使用protobuf等高性能紧凑的序列化方式,使用TTL,整体存储小于200G,redis的内存压力可以接受;适合计算模型:为了保证计算本身的时序,会进行keyBy操作,同时需要处理的数据会被shuffle到同一个并发,所以不依赖存储过多考虑锁优化。
接下来,我们的场景主要是解决多索引和触发消息的问题。
上图显示了一个表格示例,显示学生是否出现在某个章节中:
多索引:数据首先以字符串形式存储,比如key=(uid, course_id), value=serialize(is_attend, ...),这样我们就可以在SQL中JOIN ON uid AND course_id。如果 JOIN ON 其他字段,比如 course_id 怎么办?我们的做法是同时写一个以lesson_id为key的集合,集合中的元素是对应的(uid,lesson_id)。接下来,在找lesson_id = 123的时候,先取出集合下的所有元素,然后通过管道找到所有的VALUE并返回;触发消息:写入redis后,会同时向Kafka写入一条更新消息。两个存储在 Redis Connector 的实现中都保证了一致性、顺序性和不丢失数据。
这些功能都封装在 Redis Connector 中,业务可以通过 DDL 简单定义这样的 Table。
DDL 中的几个重要属性:
primary 定义主键,对应字符串数据结构,如示例中的uid + course_id;index.fields 定义了辅助搜索的索引字段,如示例中的课程id;也可以定义多个索引;poster.kafka定义了接收触发消息kafka表也定义在元数据中,用户可以在后续的SQL作业中直接读取该表而无需定义。
因此,整个开发模式复用性高,用户可以轻松开发端到端的N个SQL作业,而无需担心如何追溯案例。
三、平台搭建
上述数据流架构搭建完成后,2020.11的实时作业数量迅速增加到几百个,比2019年快很多。这个时候我们开始搭建实时计算平台从0到1,然后分享了搭建过程中的一些想法。
平台支持的功能主要有三个起点:
统一:统一不同云厂商的不同集群环境、Flink版本、提交方式等。之前hadoop客户端分散在用户的提交机器上,给集群数据和任务安全带来隐患,增加了后续集群升级和迁移的成本。我们希望通过平台统一任务的提交入口和提交方式;易用性:平台交互可以提供更易用的功能,比如调试、语义检测等,可以提高任务测试的人为效率,记录任务的版本历史。方便的在线和回滚操作;规范:权限控制、流程审批等,类似于线上服务的线上流程,通过平台,实时任务的研发流程可以标准化。3.1 规范——实时任务进程管理
FlinkSQL 让开发变得非常简单高效,但是越简单越难标准化,因为写一段 SQL 可能只需要两个小时,但通过规范却需要半天时间。
但是,该规范仍然需要执行。一些问题类似于在线服务,在实时计算中也遇到过:
记不清了:任务上线已经一年了,最初的需求可能是口耳相传。最好记住wiki或email,但在任务交接时容易记住;不规范:UDF或DataStream代码 两种方式都没有按照规范,可读性差,以至于后来接手的同学不能升级,或者不敢改,长期维护不了。还应该有一个关于如何编写包括实时任务的 SQL 的规范;找不到:线上运行的任务依赖一个jar,哪个git模块对应哪个commitId,如果有问题如何第一时间找到对应的代码实现;盲改:一直正常的任务,周末突然报警,
规范主要分为三个部分:
开发:RD 可以从 UDF 原型项目快速创建 UDF 模块,该项目基于 flink 快速入门。创建的 UDF 模块可以正常编译,包括 WordCount 之类的 udf 示例,以及 ReadMe 和 VersionHelper 等默认的 helper 方法。根据业务需求修改后,通过CR上传到Git;需求管理和编译:提交的代码会与需求卡片关联,集群编译和QA测试后,可以在线下单;在线:根据模块和编译输出,选择更新/被job owner或leader批准后创建和重新部署哪些job。
整个研发过程不能离线修改,比如更改jar包或者对哪个任务生效。一个实时任务,即使运行几年,也能查到谁在线,谁批准了当前任务,当时的测试记录,对应的Git代码,提出的实时指标要求由谁开始。任务维持很长时间。
3.2 易用性 - 监控
我们当前的 Flink 作业在 Yarn 上运行。作业启动后,预计 Prometheus 会抓取 Yarn 分配的 Container,然后连接到报警系统。用户可以根据告警系统配置Kafka延迟告警和Checkpoint故障告警。构建此路径时遇到两个主要问题:
PrometheusReporter启动HTTPServer后,Prometheus如何动态感知;它还需要能够控制度量的大小,以避免采集大量无用数据;我们的 SQL 源表基本上是基于 Kafka 的。相比第三方工具,在计算平台上配置Kafka延迟告警更方便。因为自然可以得到任务读取的topic和group.id,所以也可以和任务失败使用同一个告警组。结合告警模板,配置告警非常简单。
关于解决方案:
发现功能是在官方PrometheusReporter的基础上增加的。Container 的 HTTPServer 启动后,对应的 ip:port 以临时节点的形式注册到 zk 上,然后使用 Prometheus 的 discover 目标来监控 zk 节点的变化。由于是临时节点,当 Container 被销毁时,该节点就消失了,Prometheus 也能感应到它不再被抓取。这样一来,就很容易为普罗米修斯搭建一条抢夺的路径。KafkaConsumer.records-lag 是一个比较实用和重要的延迟指标,它主要做了两个任务。修改 KafkaConnector 并在 KafkaConsumer.poll 之后将其公开,以确保 records-lag 指示器可见。此外,在这样做的过程中,我们发现不同Kafka版本的metric格式是不同的()。我们的方法是将它们扁平化为一种格式,并将它们注册到 flink 的指标中。这样不同版本暴露的指标是一致的。四、总结与展望
上一阶段使用 Flink SQL 来支持实时作业的快速开发,搭建了实时计算平台来支持数千个 Flink 作业。
更大的见解之一是 SQL 确实简化了开发,但它也阻止了更多的技术细节。对实时作业运维工具的要求,比如 Trace,或者任务的规范没有改变,对这些的要求更加严格。因为在细节被屏蔽的同时,一旦出现问题,用户不知道如何处理。就像冰山一角,漏水越少,下沉越多,越需要做好周边系统的建设。
二是适应现状。一是能尽快满足当前的需求。比如,我们正在提高人的效率,降低发展门槛。同时还要继续探索更多的业务场景,比如用HBase和RPC服务代替Redis Connector。现在的好处是修改了底层存储,用户对SQL作业的感知很小,因为SQL作业基本都是业务逻辑,DDL定义了元数据。
接下来的计划主要分为三个部分:
支持资源弹性伸缩,平衡实时作业的成本和时效;我们从 1.9 开始大规模应用 Flink SQL,现在版本升级变化很大,需要考虑如何让业务能够低成本升级和使用新版本。版本中的功能;探索流批融合在实际业务场景中的实现。
FFA 2021 现场重播和演讲 PDF 下载
更多Flink相关技术问题,可以扫码加入社区钉钉交流群 查看全部
实时文章采集(发展历程FlinkSQL应用实践平台建设总结展望(组图))
摘要:本文组织了 Homework Group 实时计算负责人张颖在 Flink Forward Asia 2021 上的分享。Flink 在 Homework 实时计算的演进中发挥了重要作用。尤其是在 FlinkSQL 的帮助下,实时任务的开发效率得到了极大的提升。本文文章主要分享FlinkSQL在作业帮助中的使用和实践经验,以及随着任务规模的增加,从0到1搭建实时计算平台过程中遇到的问题和解决方法. 内容包括:
发展历程 Flink SQL 应用实践平台建设总结与展望
FFA 2021 现场重播和演讲 PDF 下载
一、发展历程
Homework Help主要利用人工智能、大数据等技术为学生提供更高效的学习解决方案。因此,业务数据主要包括学生的出勤率和知识点的掌握情况。在整体架构中,无论是binlog还是普通日志,都是在采集之后写入Kafka,分别通过实时和离线计算写入存储层。基于OLAP,对外提供相应的产品化服务,如工作台、BI分析等。工具。
目前 Homework Help 的实时计算主要基于 Flink,开发过程分为三个阶段:
2019 年实时计算包括少量 SparkStreaming 作业,提供给导师和讲师。在解决实时性需求的过程中,会发现开发效率很低,数据很难复用;之后,常规的做法是在生产实践中逐步应用 Flink JAR,积累经验后开始搭建平台,应用 Flink SQL。但是,20年来,业务提出了很多实时计算的需求,我们的开发人力储备不足。当时,在 Flink SQL 1.9 发布后不久,SQL 功能发生了很大变化,所以我们的做法是直接将 Flink SQL 应用到实时数仓方向。现在,整个实时数仓90%以上的任务都是使用Flink SQL实现的。; 到了 2020 年 11 月,Flink 的 Job 数量迅速增加到数百个,我们开始构建从 0 到 1 的实时计算平台,已经支撑了公司所有重要业务线,并且计算部署在多个集群上在多云中。
介绍以下两个方面:
FlinkSQL实践中遇到的典型问题及解决方案;搭建实时计算平台过程中的一些思考。二、Flink SQL 应用实践
下面是基于 Flink SQL 的完整数据流架构:
binlog/log 采集 写入 Kafka 后,topic 会自动注册为元数据表,这是后续所有实时 SQL 作业的起点。用户可以在 SQL 作业中使用此表,而无需定义复杂的 DDL。
同时,在考虑实际应用时,还需要根据元数据表添加或替换表属性:
新增:元数据记录表级属性,但 SQL 作业可能需要添加任务级属性。比如对于Kafka源表,添加job的group.id来记录offset;替换:离线测试时,在引用元数据表的基础上,只需要定义broker topic等属性覆盖源表,即可快速构建一行。测试表格如下。
框架还需要支持用户的SQL作业,方便输出指标和日志,实现全链路监控和跟踪。
这里主要介绍SQL添加Trace函数时的DAG优化实践,以及我们对Table底层物理存储的选择和封装。
2.1 SQL 添加 Trace 功能
SQL可以提高开发效率,但是业务逻辑的复杂度还是有的,复杂的业务逻辑写的DML会很长。在这种情况下,建议使用视图来提高可读性。因为视图的 SQL 比较短,所以不应该像代码规范中的单个函数那样太长。
下图左侧是一个示例任务的部分DAG,可以看到有很多SQL节点。这种情况下很难定位,因为如果是DataStream API实现的代码,也可以加日志。但是 SQL 做不到。用户可以干预的入口很少,只能看到整个作业的输入输出。
类似于在函数中打印日志,我们希望支持在视图中添加 Trace,以方便案例追踪。
但是我在尝试将 Trace 添加到 SQL 时遇到了一些问题,这是一个简化的示例:
右上角的SQL创建source_table为源表,prepare_data视图读取表,在sql中调用foo udf,然后使用StatementSet分别插入两个下游,同时将视图转换为DataStream调用 TraceSDK 写入跟踪系统。
注意:我们当时是基于 1.9 开发的。为了清楚起见,我们还使用了一些后来添加的功能。
上图下方的实际 DAG 看起来并不像预期的那样:
DAG分为上下不相关的两部分。Kafka源表是DataSource部分,读取两次;foo 方法被调用了 3 次。
数据源压力和计算性能需要优化。
为了解决这个问题,我们需要从几个角度进行优化。这里主要介绍DAG合并的思想。无论是table还是stream的env,都会产生相应的transformation。我们的做法是统一合并到stream env中,这样就可以在stream env中得到一个完整的变换列表,然后生成StreamGraph提交。
左下角是我们优化的 DAG,读取源表并只调用一次 foo 方法:
优化后的 DAG 效果与我们写 SQL 时的逻辑图非常相似,性能自然符合预期。
回到问题本身,业务可以简单地用一条语句给视图的某些字段添加trace,例如:prepare_data.trace.fields=f0,f1. 由于SQL自然收录字段名,所以trace数据的可读性甚至高于普通原木。
2.2 表的选择与设计
如前所述,我们的首要要求是提高人的效率。因此,Table 需要具备更好的分层和复用能力,并且支持模板化开发,以便 N 个端到端的 Flink 作业能够快速串联起来。
我们的解决方案是基于 Redis 实现的,它首先有几个优点:
高qps,低延迟:这应该是所有实时计算的关注点;TTL:用户无需关心数据如何退出,可以给出合理的TTL;通过使用protobuf等高性能紧凑的序列化方式,使用TTL,整体存储小于200G,redis的内存压力可以接受;适合计算模型:为了保证计算本身的时序,会进行keyBy操作,同时需要处理的数据会被shuffle到同一个并发,所以不依赖存储过多考虑锁优化。
接下来,我们的场景主要是解决多索引和触发消息的问题。
上图显示了一个表格示例,显示学生是否出现在某个章节中:
多索引:数据首先以字符串形式存储,比如key=(uid, course_id), value=serialize(is_attend, ...),这样我们就可以在SQL中JOIN ON uid AND course_id。如果 JOIN ON 其他字段,比如 course_id 怎么办?我们的做法是同时写一个以lesson_id为key的集合,集合中的元素是对应的(uid,lesson_id)。接下来,在找lesson_id = 123的时候,先取出集合下的所有元素,然后通过管道找到所有的VALUE并返回;触发消息:写入redis后,会同时向Kafka写入一条更新消息。两个存储在 Redis Connector 的实现中都保证了一致性、顺序性和不丢失数据。
这些功能都封装在 Redis Connector 中,业务可以通过 DDL 简单定义这样的 Table。
DDL 中的几个重要属性:
primary 定义主键,对应字符串数据结构,如示例中的uid + course_id;index.fields 定义了辅助搜索的索引字段,如示例中的课程id;也可以定义多个索引;poster.kafka定义了接收触发消息kafka表也定义在元数据中,用户可以在后续的SQL作业中直接读取该表而无需定义。
因此,整个开发模式复用性高,用户可以轻松开发端到端的N个SQL作业,而无需担心如何追溯案例。
三、平台搭建
上述数据流架构搭建完成后,2020.11的实时作业数量迅速增加到几百个,比2019年快很多。这个时候我们开始搭建实时计算平台从0到1,然后分享了搭建过程中的一些想法。
平台支持的功能主要有三个起点:
统一:统一不同云厂商的不同集群环境、Flink版本、提交方式等。之前hadoop客户端分散在用户的提交机器上,给集群数据和任务安全带来隐患,增加了后续集群升级和迁移的成本。我们希望通过平台统一任务的提交入口和提交方式;易用性:平台交互可以提供更易用的功能,比如调试、语义检测等,可以提高任务测试的人为效率,记录任务的版本历史。方便的在线和回滚操作;规范:权限控制、流程审批等,类似于线上服务的线上流程,通过平台,实时任务的研发流程可以标准化。3.1 规范——实时任务进程管理
FlinkSQL 让开发变得非常简单高效,但是越简单越难标准化,因为写一段 SQL 可能只需要两个小时,但通过规范却需要半天时间。
但是,该规范仍然需要执行。一些问题类似于在线服务,在实时计算中也遇到过:
记不清了:任务上线已经一年了,最初的需求可能是口耳相传。最好记住wiki或email,但在任务交接时容易记住;不规范:UDF或DataStream代码 两种方式都没有按照规范,可读性差,以至于后来接手的同学不能升级,或者不敢改,长期维护不了。还应该有一个关于如何编写包括实时任务的 SQL 的规范;找不到:线上运行的任务依赖一个jar,哪个git模块对应哪个commitId,如果有问题如何第一时间找到对应的代码实现;盲改:一直正常的任务,周末突然报警,
规范主要分为三个部分:
开发:RD 可以从 UDF 原型项目快速创建 UDF 模块,该项目基于 flink 快速入门。创建的 UDF 模块可以正常编译,包括 WordCount 之类的 udf 示例,以及 ReadMe 和 VersionHelper 等默认的 helper 方法。根据业务需求修改后,通过CR上传到Git;需求管理和编译:提交的代码会与需求卡片关联,集群编译和QA测试后,可以在线下单;在线:根据模块和编译输出,选择更新/被job owner或leader批准后创建和重新部署哪些job。
整个研发过程不能离线修改,比如更改jar包或者对哪个任务生效。一个实时任务,即使运行几年,也能查到谁在线,谁批准了当前任务,当时的测试记录,对应的Git代码,提出的实时指标要求由谁开始。任务维持很长时间。
3.2 易用性 - 监控
我们当前的 Flink 作业在 Yarn 上运行。作业启动后,预计 Prometheus 会抓取 Yarn 分配的 Container,然后连接到报警系统。用户可以根据告警系统配置Kafka延迟告警和Checkpoint故障告警。构建此路径时遇到两个主要问题:
PrometheusReporter启动HTTPServer后,Prometheus如何动态感知;它还需要能够控制度量的大小,以避免采集大量无用数据;我们的 SQL 源表基本上是基于 Kafka 的。相比第三方工具,在计算平台上配置Kafka延迟告警更方便。因为自然可以得到任务读取的topic和group.id,所以也可以和任务失败使用同一个告警组。结合告警模板,配置告警非常简单。
关于解决方案:
发现功能是在官方PrometheusReporter的基础上增加的。Container 的 HTTPServer 启动后,对应的 ip:port 以临时节点的形式注册到 zk 上,然后使用 Prometheus 的 discover 目标来监控 zk 节点的变化。由于是临时节点,当 Container 被销毁时,该节点就消失了,Prometheus 也能感应到它不再被抓取。这样一来,就很容易为普罗米修斯搭建一条抢夺的路径。KafkaConsumer.records-lag 是一个比较实用和重要的延迟指标,它主要做了两个任务。修改 KafkaConnector 并在 KafkaConsumer.poll 之后将其公开,以确保 records-lag 指示器可见。此外,在这样做的过程中,我们发现不同Kafka版本的metric格式是不同的()。我们的方法是将它们扁平化为一种格式,并将它们注册到 flink 的指标中。这样不同版本暴露的指标是一致的。四、总结与展望
上一阶段使用 Flink SQL 来支持实时作业的快速开发,搭建了实时计算平台来支持数千个 Flink 作业。
更大的见解之一是 SQL 确实简化了开发,但它也阻止了更多的技术细节。对实时作业运维工具的要求,比如 Trace,或者任务的规范没有改变,对这些的要求更加严格。因为在细节被屏蔽的同时,一旦出现问题,用户不知道如何处理。就像冰山一角,漏水越少,下沉越多,越需要做好周边系统的建设。
二是适应现状。一是能尽快满足当前的需求。比如,我们正在提高人的效率,降低发展门槛。同时还要继续探索更多的业务场景,比如用HBase和RPC服务代替Redis Connector。现在的好处是修改了底层存储,用户对SQL作业的感知很小,因为SQL作业基本都是业务逻辑,DDL定义了元数据。
接下来的计划主要分为三个部分:
支持资源弹性伸缩,平衡实时作业的成本和时效;我们从 1.9 开始大规模应用 Flink SQL,现在版本升级变化很大,需要考虑如何让业务能够低成本升级和使用新版本。版本中的功能;探索流批融合在实际业务场景中的实现。
FFA 2021 现场重播和演讲 PDF 下载
更多Flink相关技术问题,可以扫码加入社区钉钉交流群

