
scrapy分页抓取网页
scrapy分页抓取网页(()生成项目scrapy提供一个工具来生成的项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-23 00:09
构建项目
Scrapy 提供了一个生成项目的工具。生成的项目中预设了一些文件,用户需要在这些文件中添加自己的代码。
打开命令行执行:scrapy startproject教程,生成的项目类似如下结构
教程/
配置文件
教程/
__init__.py
项目.py
管道.py
设置.py
蜘蛛/
__init__.py
...
scrapy.cfg 是项目的配置文件
用户写的spider应该放在spiders目录下,一个spider类似
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
name属性很重要,不同的蜘蛛不能使用相同的名字
start_urls是蜘蛛爬取网页的起点,可以收录多个url
parse 方法是蜘蛛抓取网页后默认调用的回调。避免使用此名称来定义您自己的方法。
当spider获取到url的内容时,它会调用parse方法并传递一个响应参数给它。响应收录捕获的网页的内容。在 parse 方法中,您可以解析捕获的网页中的数据。上面的代码只是将网页的内容保存到一个文件中。
开始爬行
可以打开命令行,进入生成的项目根目录tutorial/,执行scrapy crawl dmoz,其中dmoz是蜘蛛的名字。
解析网页内容
Scrapy 提供了一种从网页解析数据的便捷方式,需要使用 HtmlXPathSelector
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
for site in sites:
title = site.select('a/text()').extract()
link = site.select('a/@href').extract()
desc = site.select('text()').extract()
print title, link, desc
HtmlXPathSelector 使用 Xpath 解析数据
//ul/li 表示选择ul标签下的所有li标签
a/@href 表示选择所有a标签的href属性
a/text() 表示选择标签文本
a[@href="abc"] 表示选择所有href属性为abc的a标签
我们可以将解析后的数据保存在一个scrapy可以使用的对象中,然后scrapy可以帮助我们保存这些对象,而不是自己将数据存储在一个文件中。我们需要在items.py中添加一些类,这些类是用来描述我们要保存的数据的
从scrapy.item导入项目,字段
类 DmozItem(Item):
标题 = 字段()
链接 = 字段()
描述 = 字段()
然后在spider的parse方法中,我们将解析后的数据保存在DomzItem对象中。
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from tutorial.items import DmozItem
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item)
return items
在命令行执行scrapy时,我们可以添加两个参数,让scrapy将parse方法返回的items输出到json文件中
抓取 dmoz -o items.json -t json
items.json 会放在项目的根目录下
让scrapy自动抓取网页上的所有链接
上例中scrapy只抓取start_urls中两个url的内容,但通常我们想要实现的是scrapy自动查找一个网页上的所有链接,然后抓取这些链接的内容。为了实现这一点,我们可以在parse方法中提取出我们需要的链接,然后构造一些Request对象,并返回,scrapy会自动抓取这些链接。代码类似:
class MySpider(BaseSpider):
name = 'myspider'
start_urls = (
'http://example.com/page1',
'http://example.com/page2',
)
def parse(self, response):
# collect `item_urls`
for item_url in item_urls:
yield Request(url=item_url, callback=self.parse_item)
def parse_item(self, response):
item = MyItem()
# populate `item` fields
yield Request(url=item_details_url, meta={'item': item},
callback=self.parse_details)
def parse_details(self, response):
item = response.meta['item']
# populate more `item` fields
return item
parse 是默认回调。它返回一个请求列表。Scrapy 会根据这个列表自动抓取网页。每当抓取一个网页时,会调用 parse_item,parse_item 也会返回一个列表,scrapy 会根据这个列表进行抓取。网页,抓到后调用parse_details
为了让这种工作更简单,scrapy 提供了另外一个spider 基类,通过它我们可以很容易的实现链接的自动爬取。我们需要使用 CrawlSpider
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova.org'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(SgmlLinkExtractor(allow=['/tor/\d+'])),
Rule(SgmlLinkExtractor(allow=['/abc/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
x = HtmlXPathSelector(response)
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = x.select("//h1/text()").extract()
torrent['description'] = x.select("//div[@id='description']").extract()
torrent['size'] = x.select("//div[@id='info-left']/p[2]/text()[2]").extract()
return torrent
与 BaseSpider 相比,新类多了一个规则属性。该属性是一个列表,可以收录多个规则。每个规则都描述了哪些链接需要被抓取,哪些不需要。这是规则类#scrapy.contrib.spiders.Rule 的文档
这些规则可以有回调或没有回调。当没有回调时,scrapy 只是跟随所有这些链接。
使用pipelines.py
在 pipelines.py 中,我们可以添加一些类来过滤掉我们不想要的项目并将这些项目保存到数据库中。
from scrapy.exceptions import DropItem
class FilterWordsPipeline(object):
"""A pipeline for filtering out items which contain certain words in their
description"""
# put all words in lowercase
words_to_filter = ['politics', 'religion']
def process_item(self, item, spider):
for word in self.words_to_filter:
if word in unicode(item['description']).lower():
raise DropItem("Contains forbidden word: %s" % word)
else:
return item
如果item不符合要求,会抛出异常,item不会输出到json文件中。
要使用管道,我们还需要修改 settings.py
添加一行
ITEM_PIPELINES = ['dirbot.pipelines.FilterWordsPipeline']
现在执行scrapy crawl dmoz -o items.json -t json,过滤掉不符合要求的item 查看全部
scrapy分页抓取网页(()生成项目scrapy提供一个工具来生成的项目)
构建项目
Scrapy 提供了一个生成项目的工具。生成的项目中预设了一些文件,用户需要在这些文件中添加自己的代码。
打开命令行执行:scrapy startproject教程,生成的项目类似如下结构
教程/
配置文件
教程/
__init__.py
项目.py
管道.py
设置.py
蜘蛛/
__init__.py
...
scrapy.cfg 是项目的配置文件
用户写的spider应该放在spiders目录下,一个spider类似
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
name属性很重要,不同的蜘蛛不能使用相同的名字
start_urls是蜘蛛爬取网页的起点,可以收录多个url
parse 方法是蜘蛛抓取网页后默认调用的回调。避免使用此名称来定义您自己的方法。
当spider获取到url的内容时,它会调用parse方法并传递一个响应参数给它。响应收录捕获的网页的内容。在 parse 方法中,您可以解析捕获的网页中的数据。上面的代码只是将网页的内容保存到一个文件中。
开始爬行
可以打开命令行,进入生成的项目根目录tutorial/,执行scrapy crawl dmoz,其中dmoz是蜘蛛的名字。
解析网页内容
Scrapy 提供了一种从网页解析数据的便捷方式,需要使用 HtmlXPathSelector
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
for site in sites:
title = site.select('a/text()').extract()
link = site.select('a/@href').extract()
desc = site.select('text()').extract()
print title, link, desc
HtmlXPathSelector 使用 Xpath 解析数据
//ul/li 表示选择ul标签下的所有li标签
a/@href 表示选择所有a标签的href属性
a/text() 表示选择标签文本
a[@href="abc"] 表示选择所有href属性为abc的a标签
我们可以将解析后的数据保存在一个scrapy可以使用的对象中,然后scrapy可以帮助我们保存这些对象,而不是自己将数据存储在一个文件中。我们需要在items.py中添加一些类,这些类是用来描述我们要保存的数据的
从scrapy.item导入项目,字段
类 DmozItem(Item):
标题 = 字段()
链接 = 字段()
描述 = 字段()
然后在spider的parse方法中,我们将解析后的数据保存在DomzItem对象中。
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from tutorial.items import DmozItem
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item)
return items
在命令行执行scrapy时,我们可以添加两个参数,让scrapy将parse方法返回的items输出到json文件中
抓取 dmoz -o items.json -t json
items.json 会放在项目的根目录下
让scrapy自动抓取网页上的所有链接
上例中scrapy只抓取start_urls中两个url的内容,但通常我们想要实现的是scrapy自动查找一个网页上的所有链接,然后抓取这些链接的内容。为了实现这一点,我们可以在parse方法中提取出我们需要的链接,然后构造一些Request对象,并返回,scrapy会自动抓取这些链接。代码类似:
class MySpider(BaseSpider):
name = 'myspider'
start_urls = (
'http://example.com/page1',
'http://example.com/page2',
)
def parse(self, response):
# collect `item_urls`
for item_url in item_urls:
yield Request(url=item_url, callback=self.parse_item)
def parse_item(self, response):
item = MyItem()
# populate `item` fields
yield Request(url=item_details_url, meta={'item': item},
callback=self.parse_details)
def parse_details(self, response):
item = response.meta['item']
# populate more `item` fields
return item
parse 是默认回调。它返回一个请求列表。Scrapy 会根据这个列表自动抓取网页。每当抓取一个网页时,会调用 parse_item,parse_item 也会返回一个列表,scrapy 会根据这个列表进行抓取。网页,抓到后调用parse_details
为了让这种工作更简单,scrapy 提供了另外一个spider 基类,通过它我们可以很容易的实现链接的自动爬取。我们需要使用 CrawlSpider
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova.org'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(SgmlLinkExtractor(allow=['/tor/\d+'])),
Rule(SgmlLinkExtractor(allow=['/abc/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
x = HtmlXPathSelector(response)
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = x.select("//h1/text()").extract()
torrent['description'] = x.select("//div[@id='description']").extract()
torrent['size'] = x.select("//div[@id='info-left']/p[2]/text()[2]").extract()
return torrent
与 BaseSpider 相比,新类多了一个规则属性。该属性是一个列表,可以收录多个规则。每个规则都描述了哪些链接需要被抓取,哪些不需要。这是规则类#scrapy.contrib.spiders.Rule 的文档
这些规则可以有回调或没有回调。当没有回调时,scrapy 只是跟随所有这些链接。
使用pipelines.py
在 pipelines.py 中,我们可以添加一些类来过滤掉我们不想要的项目并将这些项目保存到数据库中。
from scrapy.exceptions import DropItem
class FilterWordsPipeline(object):
"""A pipeline for filtering out items which contain certain words in their
description"""
# put all words in lowercase
words_to_filter = ['politics', 'religion']
def process_item(self, item, spider):
for word in self.words_to_filter:
if word in unicode(item['description']).lower():
raise DropItem("Contains forbidden word: %s" % word)
else:
return item
如果item不符合要求,会抛出异常,item不会输出到json文件中。
要使用管道,我们还需要修改 settings.py
添加一行
ITEM_PIPELINES = ['dirbot.pipelines.FilterWordsPipeline']
现在执行scrapy crawl dmoz -o items.json -t json,过滤掉不符合要求的item
scrapy分页抓取网页(使用WebBroser控件可以实现你在IE中操作网页的任何功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-21 06:02
前两天写了一篇关于网页分页数据抓取的帖子,但是只提到了两种方法。因为那个时候打原创的帖子真的很辛苦,所以没有写第三种方法。今天,我将使用第三种方法。方法也贴出来分享给大家;
如上一篇所述,第三种方法是使用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码模拟人工翻页链接。翻页,然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是通过控制来实现WebBrowser,其实在.net下应该有这种类似的分类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然获取到了当前打开的页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("page id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站以营利为目的的登录密码,当然不推荐这种。哈哈
这里我要告诉大家,上面的地址是我自己的网站。由于所谓的窃取也是如此,请不要使用这种技术来捕获我的数据。主要原因是我的服务器承受不了太大的压力。
另外,我在我的网站上增加了一个站长随笔的小功能,我会定期在我的网站上发布一些我自己的经验。如果你有兴趣,你可以去看看。
这篇关于分页抓取数据的帖子,即使是我的第一篇文章,我也整理了这两篇帖子放在我的网站上。
有兴趣的可以去看看
同时我还用delphi写了一个单机版的优采云时刻表查询小程序。纯绿色软件,不需要联网,不需要安装,不需要数据库,60万小程序,直接运行,占用内存小
有兴趣的可以下载。非常适合出差不便上网的人使用。
如果需要抓数据可以联系我 查看全部
scrapy分页抓取网页(使用WebBroser控件可以实现你在IE中操作网页的任何功能)
前两天写了一篇关于网页分页数据抓取的帖子,但是只提到了两种方法。因为那个时候打原创的帖子真的很辛苦,所以没有写第三种方法。今天,我将使用第三种方法。方法也贴出来分享给大家;
如上一篇所述,第三种方法是使用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码模拟人工翻页链接。翻页,然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是通过控制来实现WebBrowser,其实在.net下应该有这种类似的分类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然获取到了当前打开的页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("page id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站以营利为目的的登录密码,当然不推荐这种。哈哈
这里我要告诉大家,上面的地址是我自己的网站。由于所谓的窃取也是如此,请不要使用这种技术来捕获我的数据。主要原因是我的服务器承受不了太大的压力。
另外,我在我的网站上增加了一个站长随笔的小功能,我会定期在我的网站上发布一些我自己的经验。如果你有兴趣,你可以去看看。
这篇关于分页抓取数据的帖子,即使是我的第一篇文章,我也整理了这两篇帖子放在我的网站上。
有兴趣的可以去看看
同时我还用delphi写了一个单机版的优采云时刻表查询小程序。纯绿色软件,不需要联网,不需要安装,不需要数据库,60万小程序,直接运行,占用内存小
有兴趣的可以下载。非常适合出差不便上网的人使用。
如果需要抓数据可以联系我
scrapy分页抓取网页(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-18 16:00
”
阅读这篇文章大约需要 7 分钟。
”
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少,虽然可以自己写代码来实现,但这很荒谬。大锤?
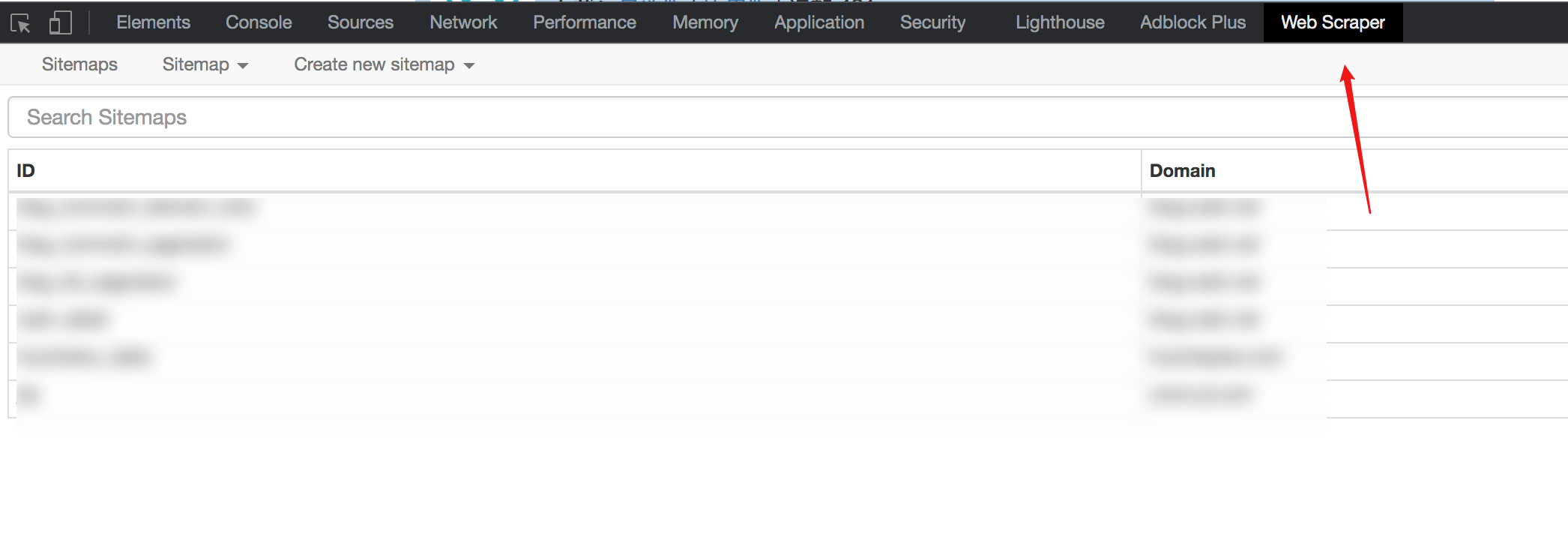
市面上已经有一些成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
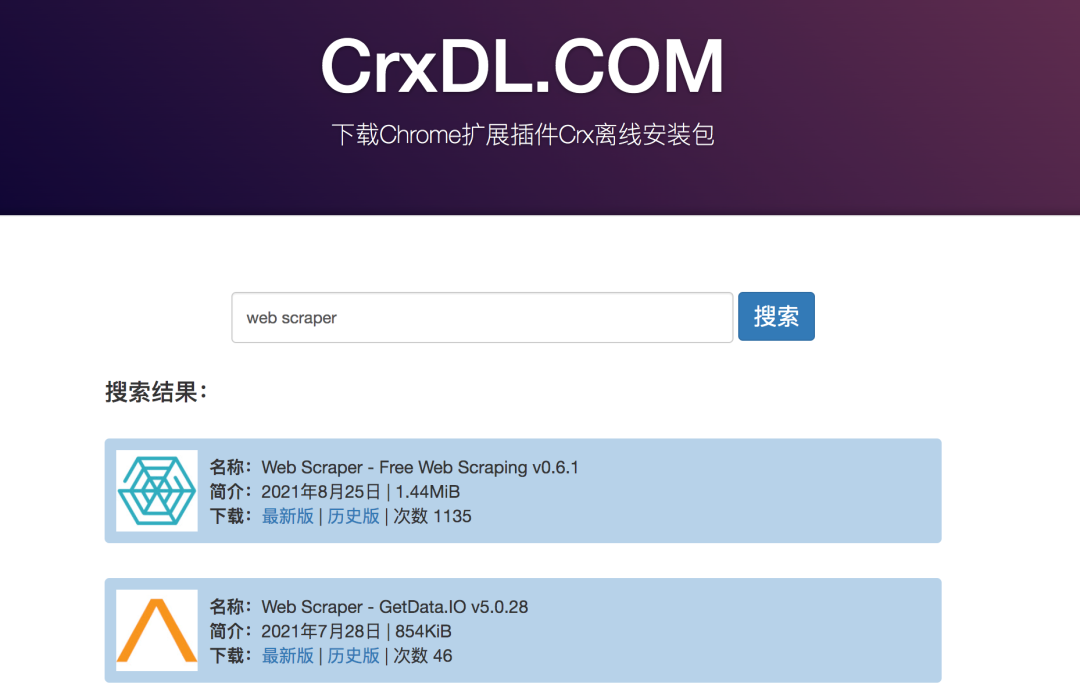
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
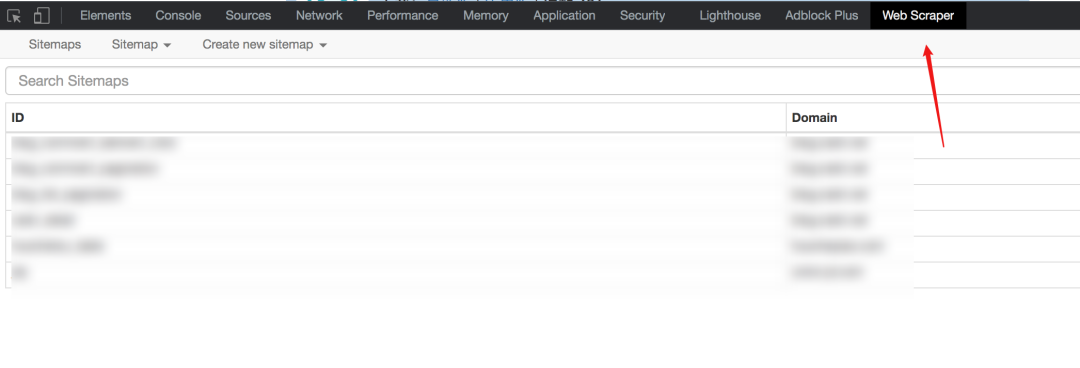
安装完成后,需要重启Chrome一次,然后F12就可以看到该工具了
# 2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
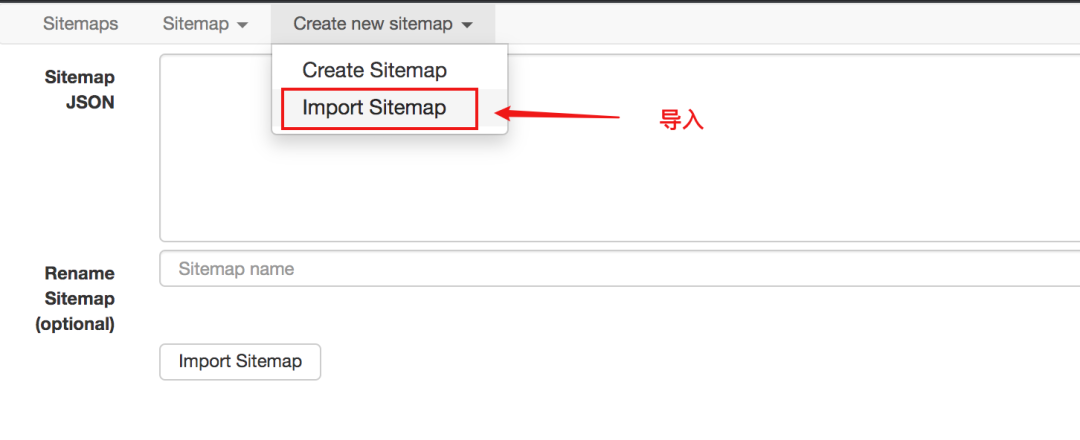
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
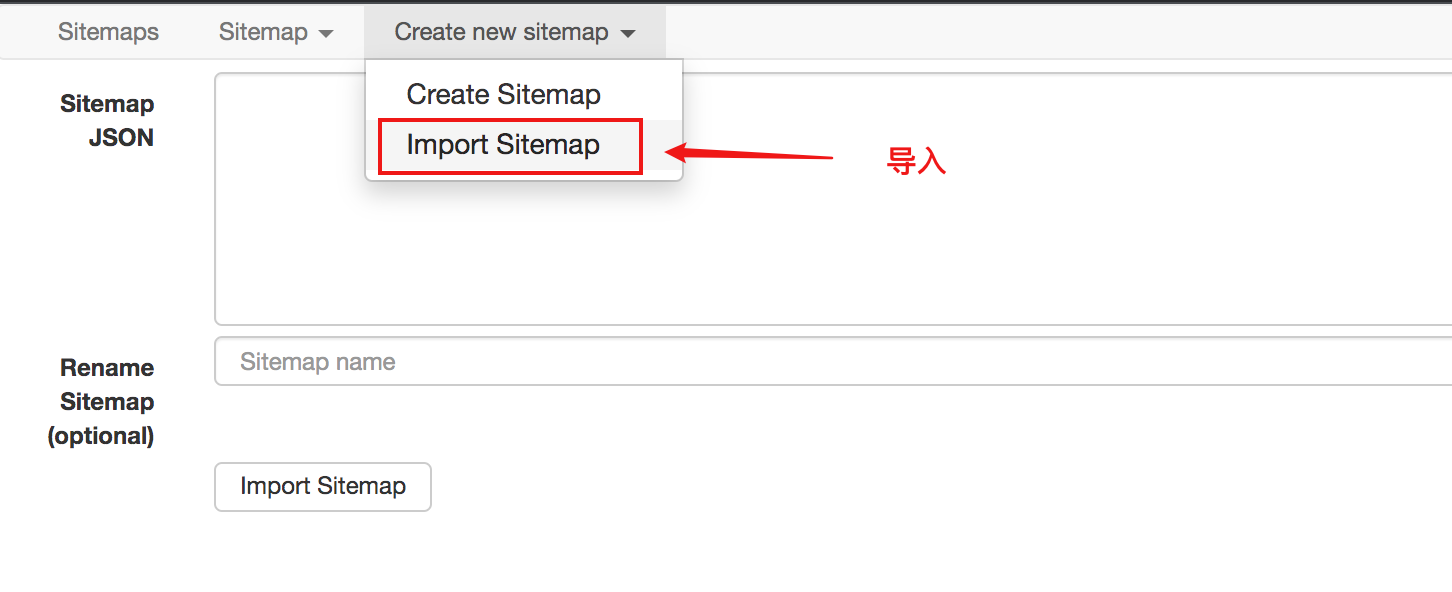
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
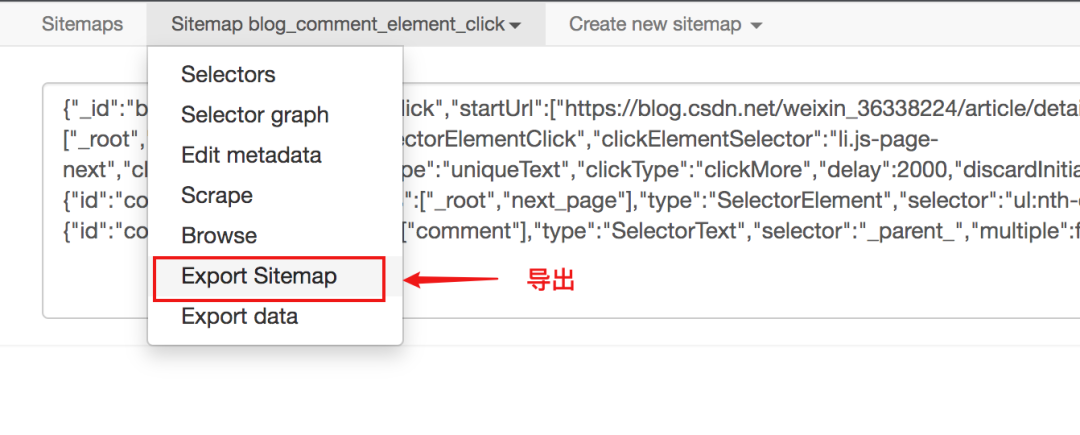
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入其他人的站点地图
选择器
直译,它是一个选择器。为了从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的 Selector 有很多,但是本文 文章 只介绍了几个最常用、覆盖面最广的 Selector。了解一两个之后,其他的原理都差不多,以后私下多多学习。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
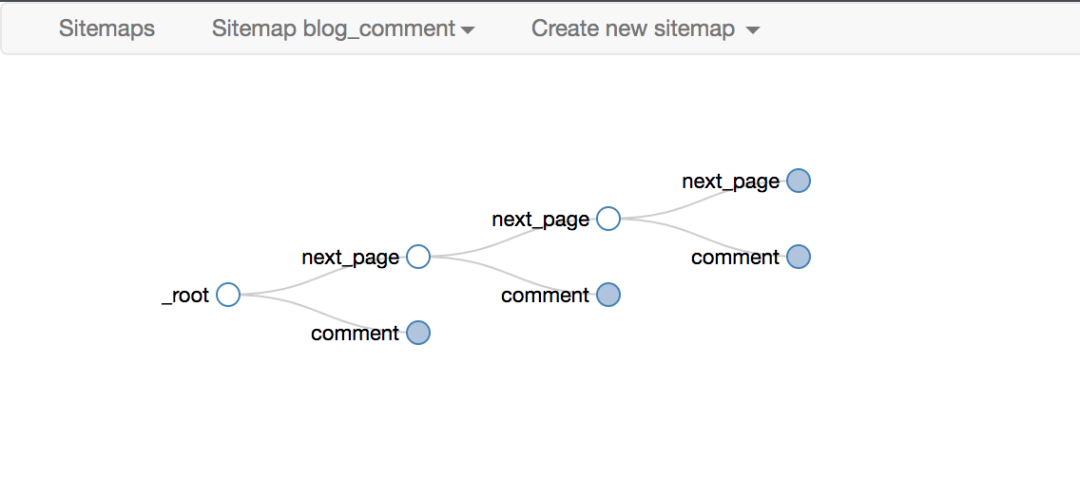
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
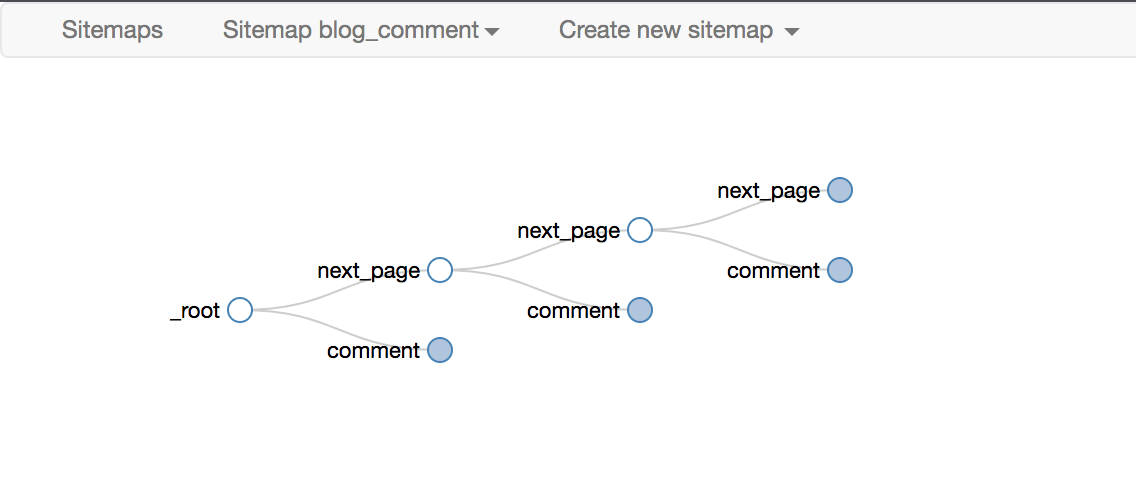
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
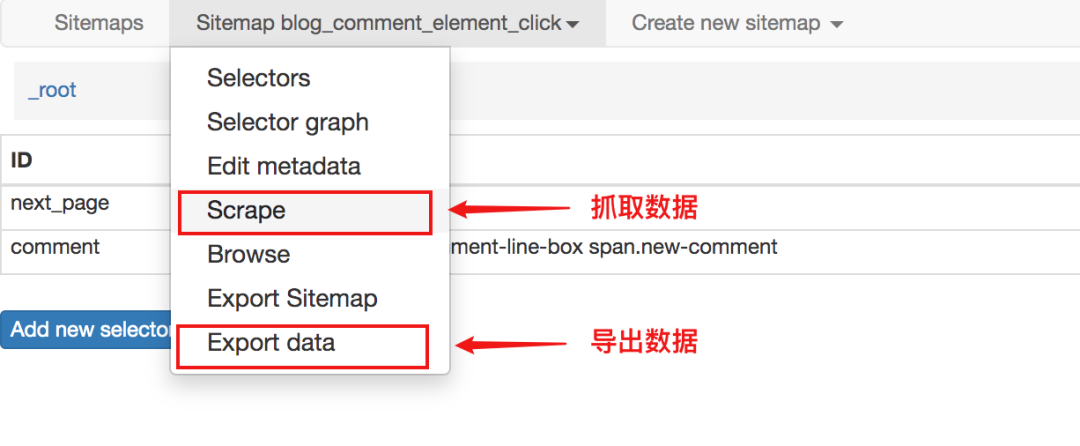
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,这两种抓取方式是不同的。
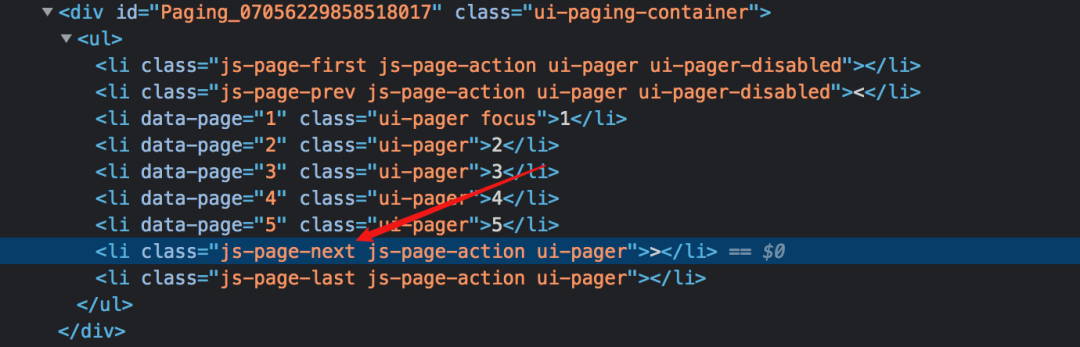
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有的网站下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
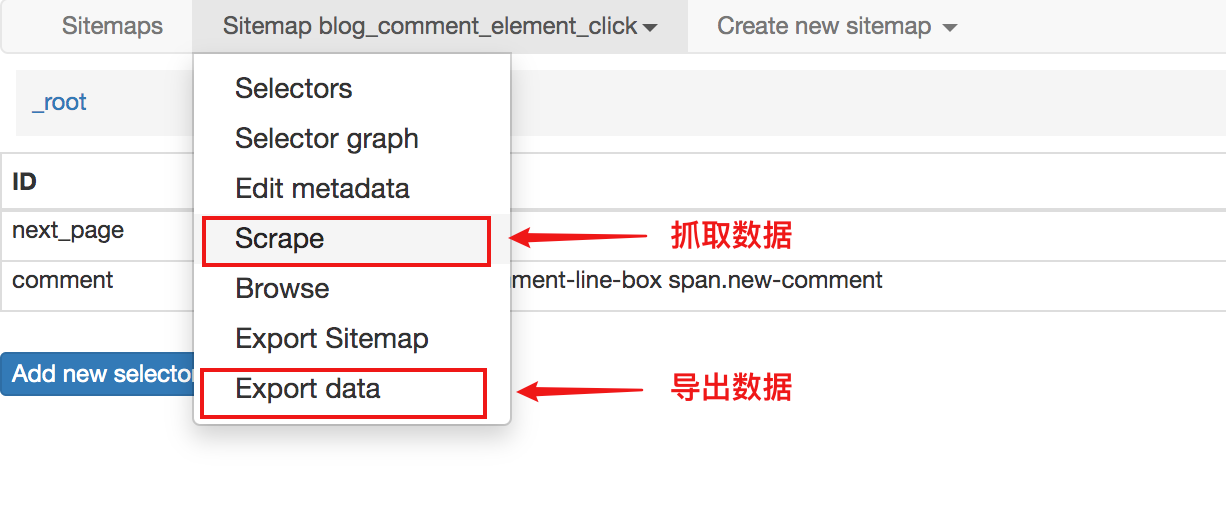
点击特定的CSDN博客文章,将其拉到底部以查看评论区。
如果你的文章很火,当评论人很多的时候,CSDN会分页展示,但是不管评论在哪个页面,都属于同一篇文章文章 ,当你浏览任何页面的评论区时,博文不需要刷新,因为这种分页不会重新加载页面。
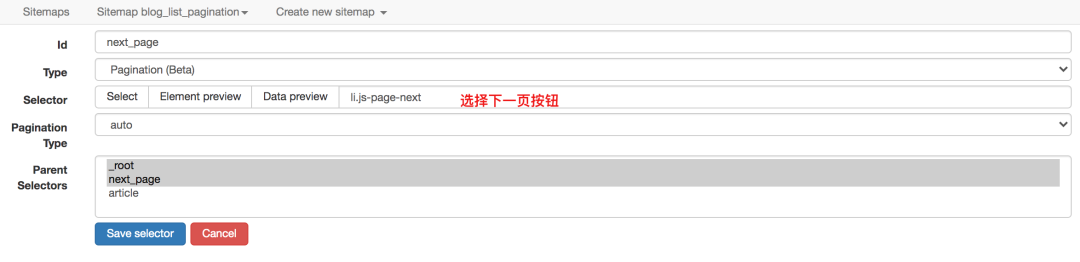
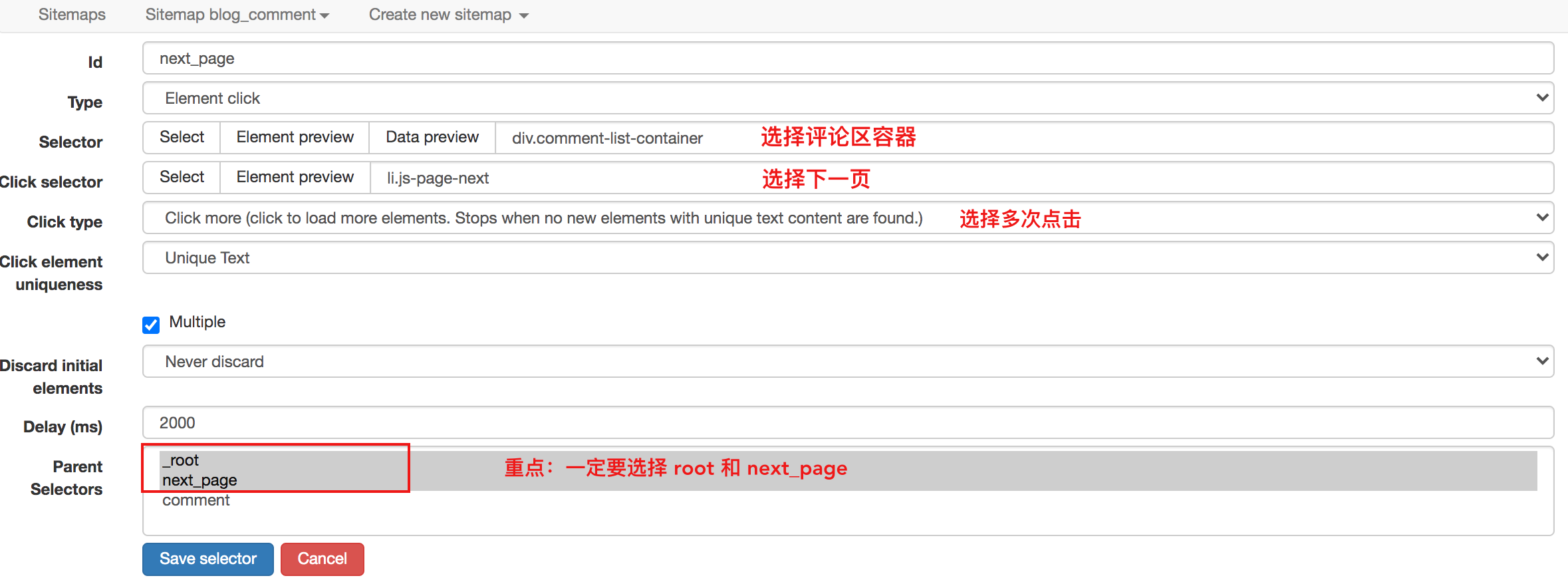
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:
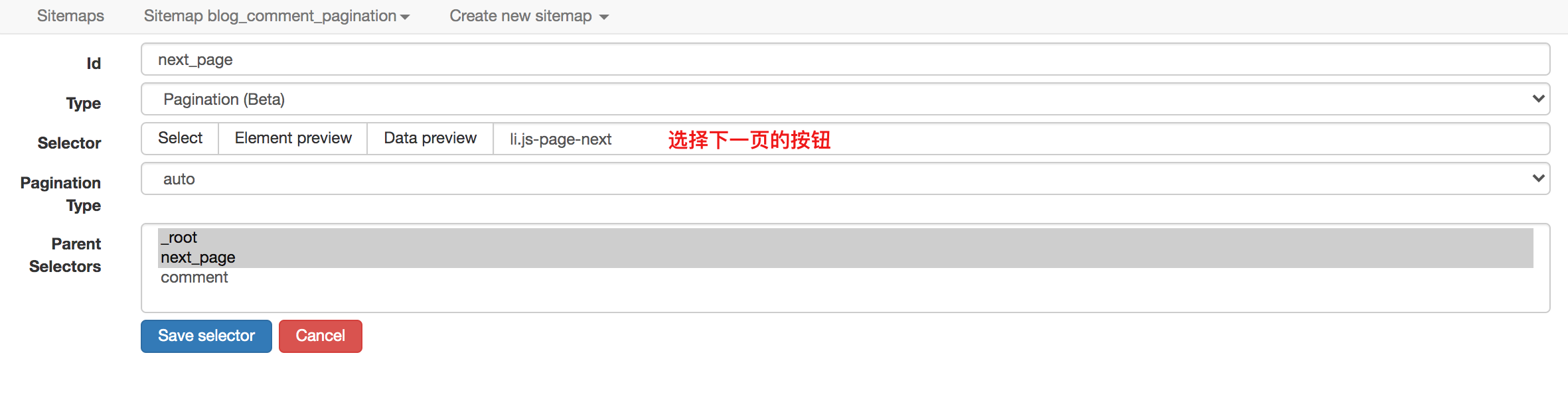
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用,并下载配置文件:
要重新加载的页面的寻呼机抓取
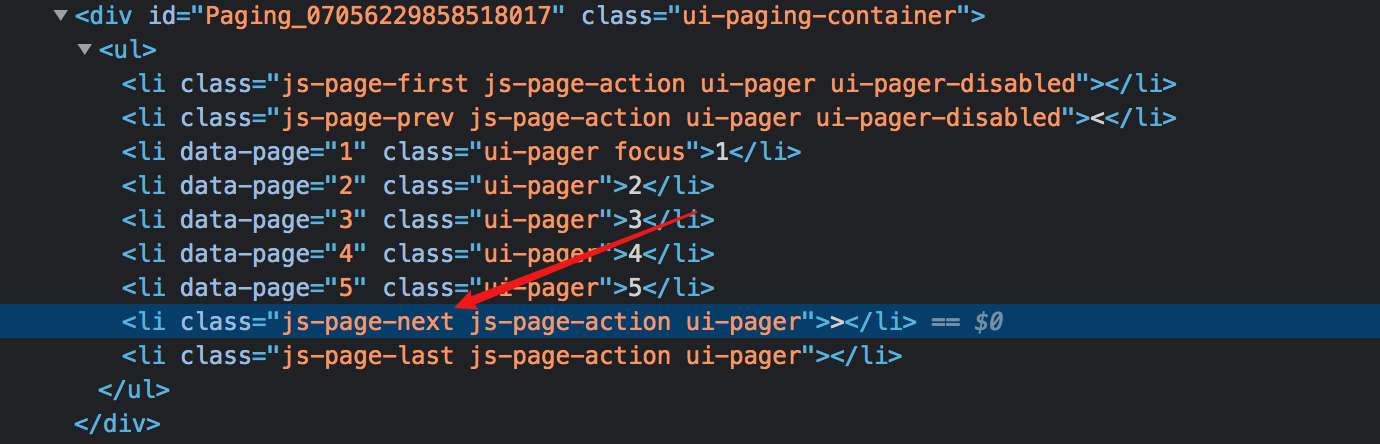
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页将重新加载当前页面。
对于这种寻呼机,Element Click是无能为力的,读者可以自行验证,只能爬到一个页面后关闭。
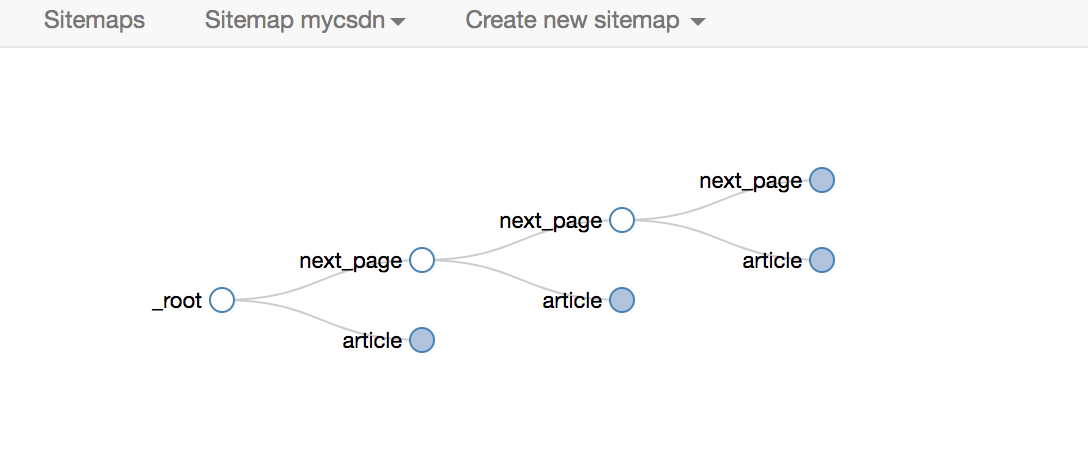
并且作为分页的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习,下载配置文件:
# 4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果想获取博文正文、点赞数、采集数、评论区内容等更多信息,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果您想获取博客文章的更详细信息,则必须打开一个新页面才能获取。网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap配置如下,可以直接导入使用,下载配置文件:
# 5. 写在最后
以上对分页和二级页面的抓取方案进行了梳理,主要有:pager抓取和二级页面抓取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。 查看全部
scrapy分页抓取网页(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
”
阅读这篇文章大约需要 7 分钟。
”
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少,虽然可以自己写代码来实现,但这很荒谬。大锤?
市面上已经有一些成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装完成后,需要重启Chrome一次,然后F12就可以看到该工具了
# 2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入其他人的站点地图
选择器
直译,它是一个选择器。为了从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的 Selector 有很多,但是本文 文章 只介绍了几个最常用、覆盖面最广的 Selector。了解一两个之后,其他的原理都差不多,以后私下多多学习。可以上手了。

Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,这两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有的网站下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的CSDN博客文章,将其拉到底部以查看评论区。
如果你的文章很火,当评论人很多的时候,CSDN会分页展示,但是不管评论在哪个页面,都属于同一篇文章文章 ,当你浏览任何页面的评论区时,博文不需要刷新,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
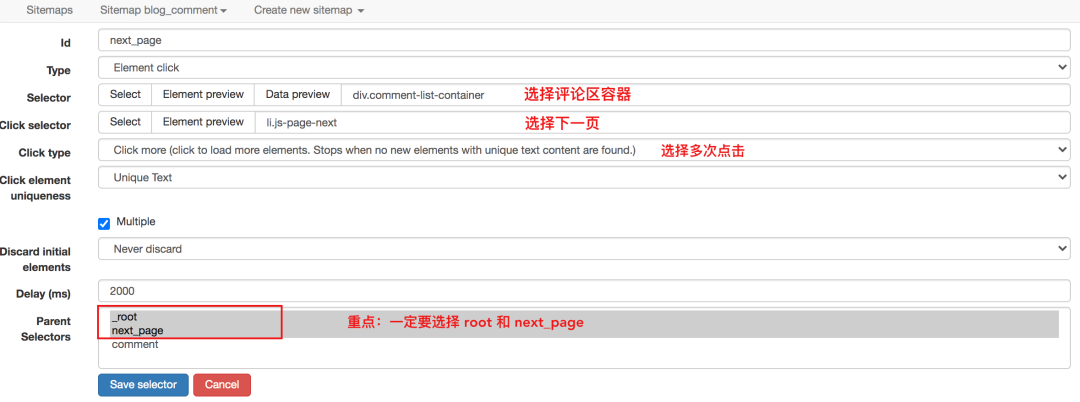
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:

当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
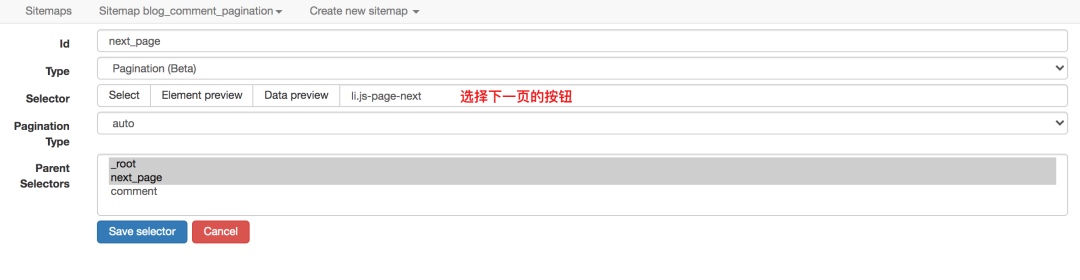
对应的sitemap配置如下,可以直接导入使用,并下载配置文件:

要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页将重新加载当前页面。

对于这种寻呼机,Element Click是无能为力的,读者可以自行验证,只能爬到一个页面后关闭。
并且作为分页的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
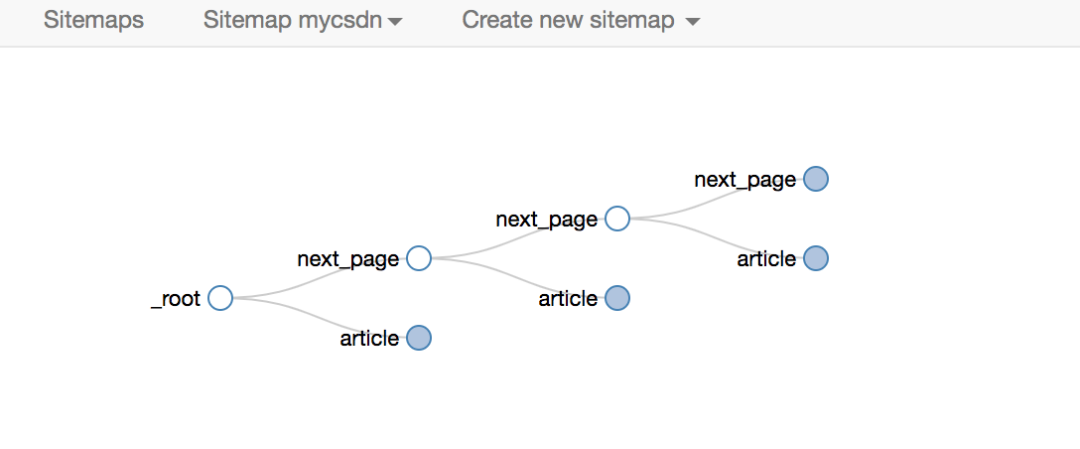
对应的sitemap配置如下,可以直接导入学习,下载配置文件:

# 4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果想获取博文正文、点赞数、采集数、评论区内容等更多信息,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果您想获取博客文章的更详细信息,则必须打开一个新页面才能获取。网络爬虫的链接选择器恰好做到了这一点。
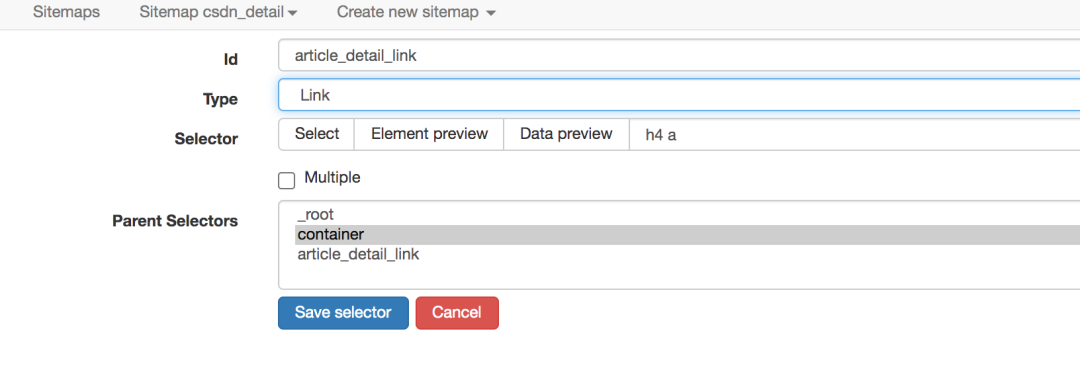
爬取路径拓扑如下
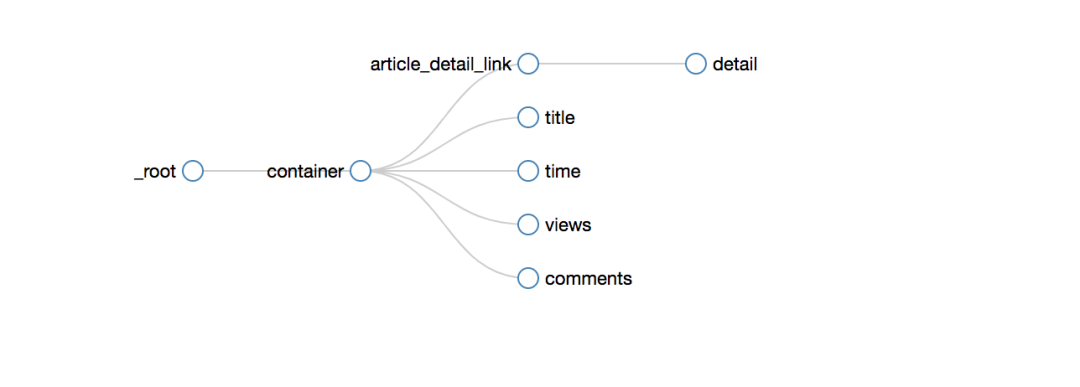
爬取的效果如下
sitemap配置如下,可以直接导入使用,下载配置文件:
# 5. 写在最后
以上对分页和二级页面的抓取方案进行了梳理,主要有:pager抓取和二级页面抓取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。
scrapy分页抓取网页(本文爬取某网站产品信息(包含图片下载)的实战教学博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-11-18 15:15
内容
概述
本文记录了使用Scrapy抓取网站的产品信息(包括图片下载)的全过程,也可以作为Scrapy实践教学博客。
首先从All Products页面开始,先抓取所有分类页面的链接:比如
然后从每个产品类别页面抓取产品详情页面链接:如
最后分析商品详情页的响应,提取需要的数据,下载相关图片
开始
首先需要安装scrapy,pip命令
pip install scrapy
启动项目
在Pycharm工作目录下新建目录scrapy_demo(以后其他scrapy爬虫项目也可以放在这个目录下),打开终端终端,使用cd命令进入scrapy_demo目录,使用scrapy命令创建该项目:
scrapy startproject product
其中product为爬虫项目名称,可以修改
目录结构应该如下:(products_spider.py是后面添加的)
目录结构的详细解释请参考官方文档
爬虫初始化
import scrapy
from ..items import ProductItem
class ProductsSpider(scrapy.Spider):
"""
Products Spider
"""
name = "products" # 爬虫的名字, 后面启动爬虫需要用到
host = 'http://www.example.com'
def start_requests(self):
urls = [
'http://www.example.com/products.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
# @todo 处理首页响应
pass
爬虫执行过程:首先会执行start_requests方法,最后yield Request会发送多个请求。请求的响应将被请求中的参数回调指定的函数接收和处理。这里对主页请求的响应将被解析函数处理。
import scrapy
class ProductItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 产品名称
images = scrapy.Field() # 产品图片, 是一个列表
category = scrapy.Field() # 产品分类名
price = scrapy.Field() # 产品价格
description = scrapy.Field() # 产品描述, 长文本
pass
处理响应
回到products_spider.py,接下来需要处理响应。
def parse(self, response, **kwargs):
# 从首页获取各个分类页面url
tree = etree.HTML(response.text) # 注意这里需要 from lxml.html import etree
hrefs = tree.xpath("hrefs xpath express")
for href in hrefs:
# 发起分类页面请求
yield scrapy.Request(url=self.host + href, callback=self.parse_category)
def parse_category(self, response):
# 从分类页面获取产品详情页面url
tree = etree.HTML(response.text)
product_urls = tree.xpath("products url xpath express")
category = tree.xpath("categroy text xpath express")[0]
for url in product_urls:
# 发起产品详情页面请求
yield scrapy.Request(url=self.host + url, callback=self.parse_product)
def parse_product(self, response):
# 解析产品详情页面, 将数据汇总到 Item 中
tree = etree.HTML(response.text)
item = ProductItem()
item['name'] = tree.xpath('xxxxx/text()')[0]
yield item
回调函数参数
def parse_category(self, response):
# 省略
yield scrapy.Request(url=self.host + url, callback=self.parse_product, cb_kwargs={'cate': category})
pass
def parse_product(self, response, cate):
# 省略
item['category'] = cate
图片下载(待续)
使用中间件 ImagesPipeline
相关资源
官方文档:点击跳转 查看全部
scrapy分页抓取网页(本文爬取某网站产品信息(包含图片下载)的实战教学博客)
内容
概述
本文记录了使用Scrapy抓取网站的产品信息(包括图片下载)的全过程,也可以作为Scrapy实践教学博客。
首先从All Products页面开始,先抓取所有分类页面的链接:比如
然后从每个产品类别页面抓取产品详情页面链接:如
最后分析商品详情页的响应,提取需要的数据,下载相关图片
开始
首先需要安装scrapy,pip命令
pip install scrapy
启动项目
在Pycharm工作目录下新建目录scrapy_demo(以后其他scrapy爬虫项目也可以放在这个目录下),打开终端终端,使用cd命令进入scrapy_demo目录,使用scrapy命令创建该项目:
scrapy startproject product
其中product为爬虫项目名称,可以修改
目录结构应该如下:(products_spider.py是后面添加的)
目录结构的详细解释请参考官方文档
爬虫初始化
import scrapy
from ..items import ProductItem
class ProductsSpider(scrapy.Spider):
"""
Products Spider
"""
name = "products" # 爬虫的名字, 后面启动爬虫需要用到
host = 'http://www.example.com'
def start_requests(self):
urls = [
'http://www.example.com/products.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
# @todo 处理首页响应
pass
爬虫执行过程:首先会执行start_requests方法,最后yield Request会发送多个请求。请求的响应将被请求中的参数回调指定的函数接收和处理。这里对主页请求的响应将被解析函数处理。
import scrapy
class ProductItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 产品名称
images = scrapy.Field() # 产品图片, 是一个列表
category = scrapy.Field() # 产品分类名
price = scrapy.Field() # 产品价格
description = scrapy.Field() # 产品描述, 长文本
pass
处理响应
回到products_spider.py,接下来需要处理响应。
def parse(self, response, **kwargs):
# 从首页获取各个分类页面url
tree = etree.HTML(response.text) # 注意这里需要 from lxml.html import etree
hrefs = tree.xpath("hrefs xpath express")
for href in hrefs:
# 发起分类页面请求
yield scrapy.Request(url=self.host + href, callback=self.parse_category)
def parse_category(self, response):
# 从分类页面获取产品详情页面url
tree = etree.HTML(response.text)
product_urls = tree.xpath("products url xpath express")
category = tree.xpath("categroy text xpath express")[0]
for url in product_urls:
# 发起产品详情页面请求
yield scrapy.Request(url=self.host + url, callback=self.parse_product)
def parse_product(self, response):
# 解析产品详情页面, 将数据汇总到 Item 中
tree = etree.HTML(response.text)
item = ProductItem()
item['name'] = tree.xpath('xxxxx/text()')[0]
yield item
回调函数参数
def parse_category(self, response):
# 省略
yield scrapy.Request(url=self.host + url, callback=self.parse_product, cb_kwargs={'cate': category})
pass
def parse_product(self, response, cate):
# 省略
item['category'] = cate
图片下载(待续)
使用中间件 ImagesPipeline
相关资源
官方文档:点击跳转
scrapy分页抓取网页( 我们先用之前推文中介绍的方法尝试寻找其真实链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-17 20:18
我们先用之前推文中介绍的方法尝试寻找其真实链接
)
在之前的推文《一起来挖掘网页的真实链接吧!》中,我们介绍了如何使用谷歌浏览器在网页分页显示且点击时没有变化的情况下找到网页的真实链接但是有时我们也会遇到另一种情况:通过上述方法找到网页的链接后,我们发现网址中仍然没有可以用来识别不同网页的标识参数(例如page= 1). 别慌,今天小编带你一起来解决这个问题。
1
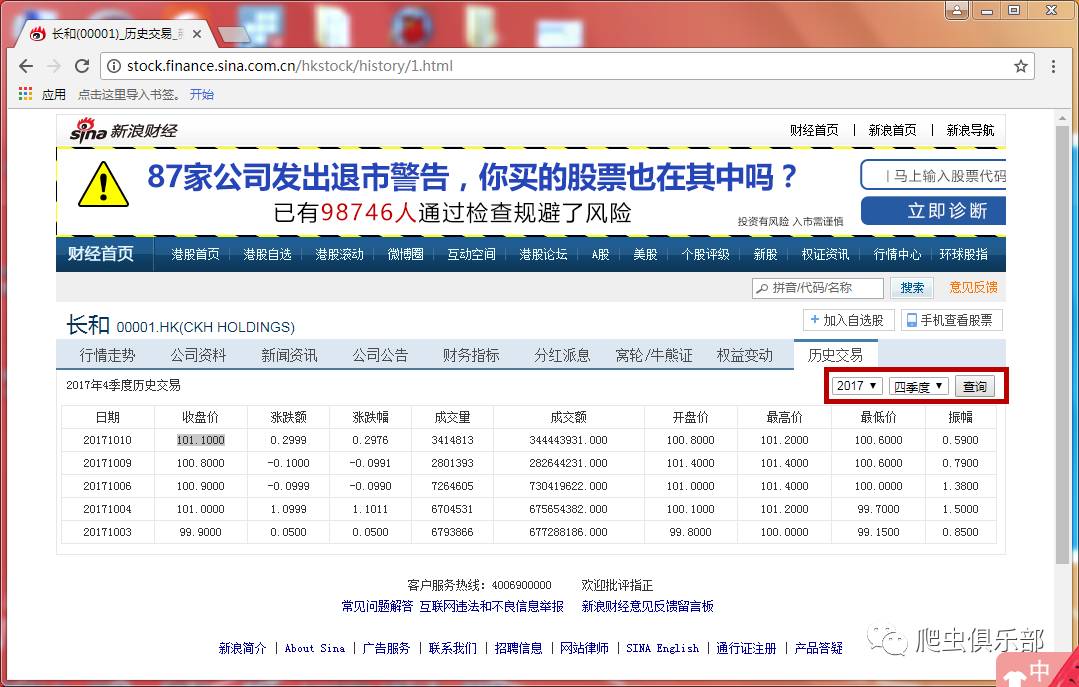
我们以新浪财经中00001的港股历史交易数据为例()。首先我们来看一下网页:虽然不是分页显示,但右上角有年度和季度选项。基于此,您可以查看昌河过去不同年份、不同季度的股票交易信息,如下图:
同时我们注意到网页的URL没有可以作为识别的参数,所以这里需要再次踏上寻找网页真实链接的旅程~
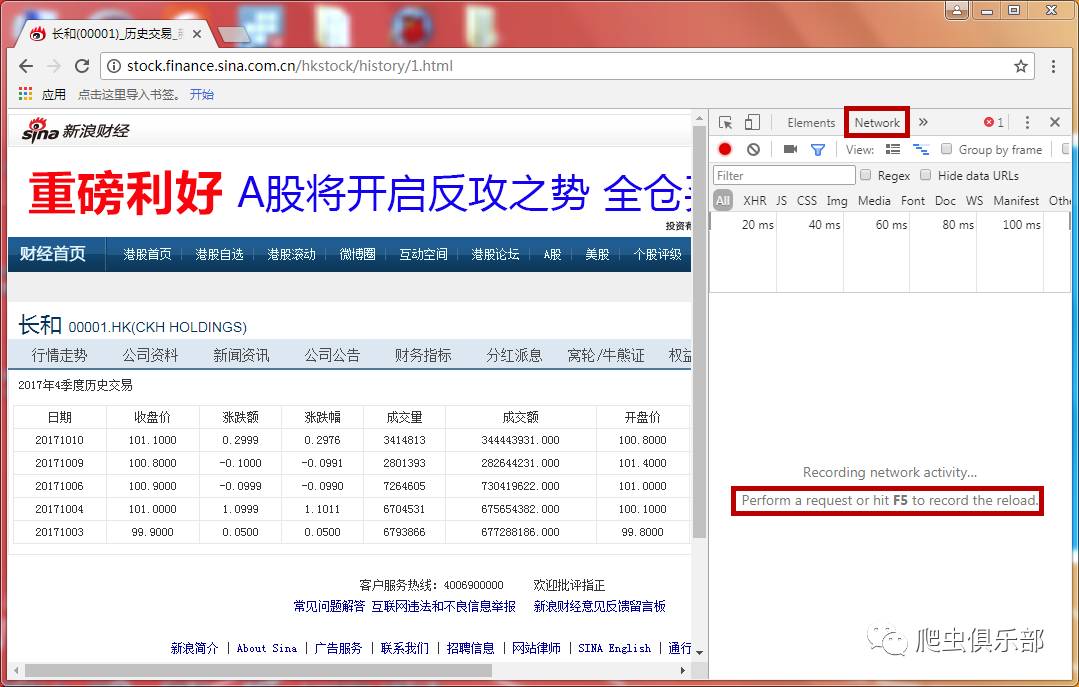
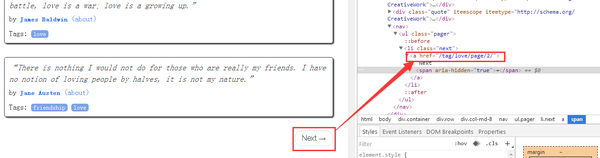
我们先尝试使用上一条推文介绍的方法找到真正的链接:在网页空白处右击选择“检查”,点击“网络”,然后按F5刷新,点击中间的第一个链接很多弹出查看它的响应的链接发现它的内容和网页的内容是一致的。是否可以确定它是我们现在正在寻找的网页的真实链接?
别着急,我们继续右键第一个名为1.html的链接,点击复制→复制链接地址(这个操作可以复制网页的真实链接),结果这显然不是我们需要什么 带有识别参数的网页链接非常尴尬。
2
为什么会出现这样的情况?这主要是因为新浪财经的http请求方式是post。正如我们在上一条推文中提到的,两种最常见的 http 请求方法是 get 和 post。它们的区别在于get请求的数据会附加到URL上。之后URL和传输数据用?分割,参数用&连接,浏览器会生成目标URL,但是post不会。那么现在我们来介绍一下如何实现对http请求方式为post的网页的抓取。
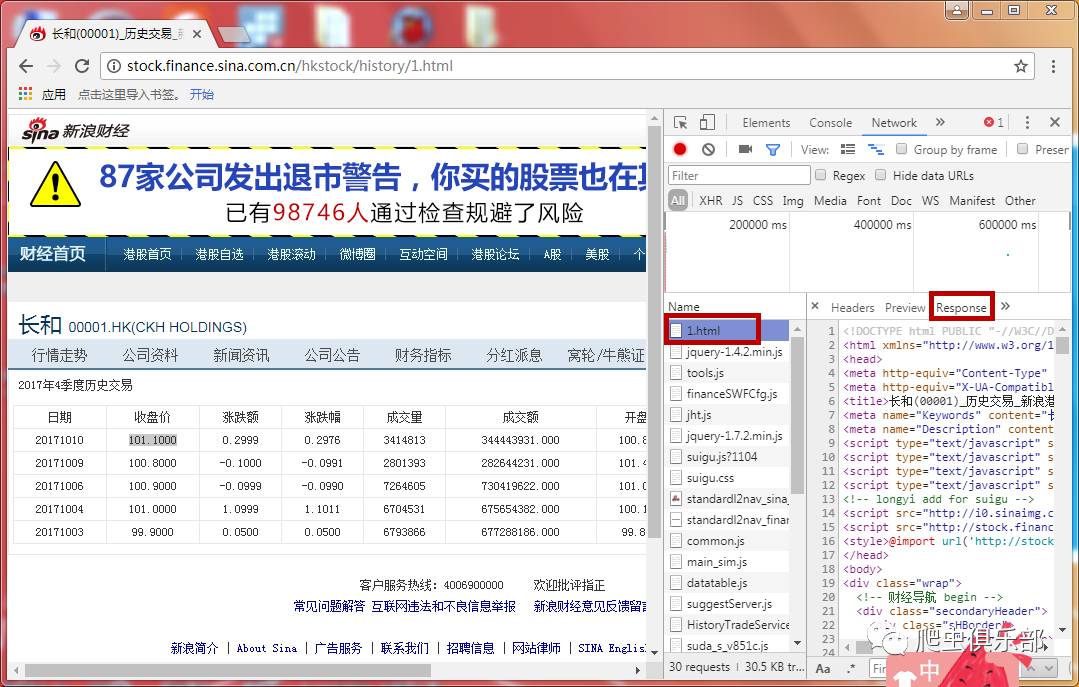
我们首先选择查看港股领头羊和过去一个季度(如2016年第四季度)的交易数据。最初,我们按照上述方法查找网页的真实链接。我们可以发现第一个链接的返回信息和网页的内容是匹配的。它的Headers注意到网页的请求方法(Request Method)是POST,如图:
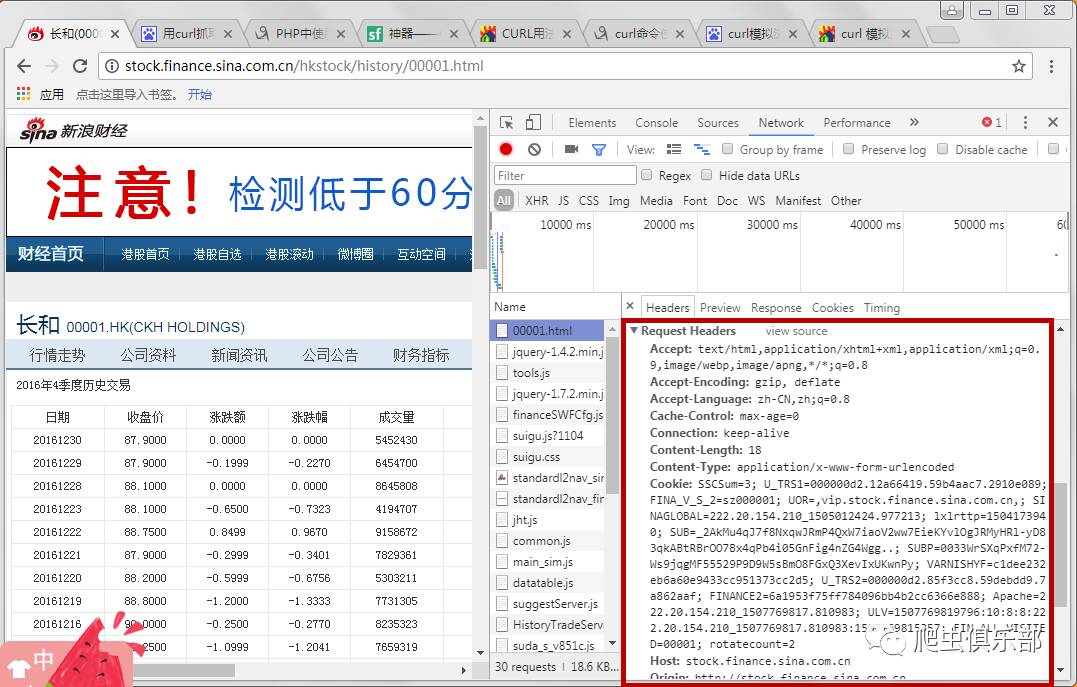
这时候如果继续像之前一样操作,是无法获取到网页的源代码的,需要使用curl来模拟浏览器请求。在这之前,我们先来了解一下网页的请求头,也就是Request Headers,谷歌开发者工具为我们准备了这个信息,如下图:
先简单介绍一下请求头中一些headers的含义:
Accept-Encoding:由浏览器发送给服务器,声明浏览器支持的编码类型
Accept-Language:用于告诉服务器浏览器可以支持什么语言
User Agent:中文名称为User Agent,简称UA。它是一个特殊的字符串头,使服务器能够识别操作系统和版本、CPU 类型、客户端使用的浏览器和版本、浏览器渲染引擎、浏览器语言和浏览器插件
Referer:当浏览器向Web服务器发送请求时,通常会带一个Referer,它代表网页的来源,也就是告诉服务器它是从哪个页面链接的。
Cookies:用于记录一些网站的登录信息和访问信息等。
在请求头信息下面,有年份和季节两个参数。这些就是我们初步查询到的2016年第四季度对应的参数,也就是我们需要的识别参数,如下图所示:
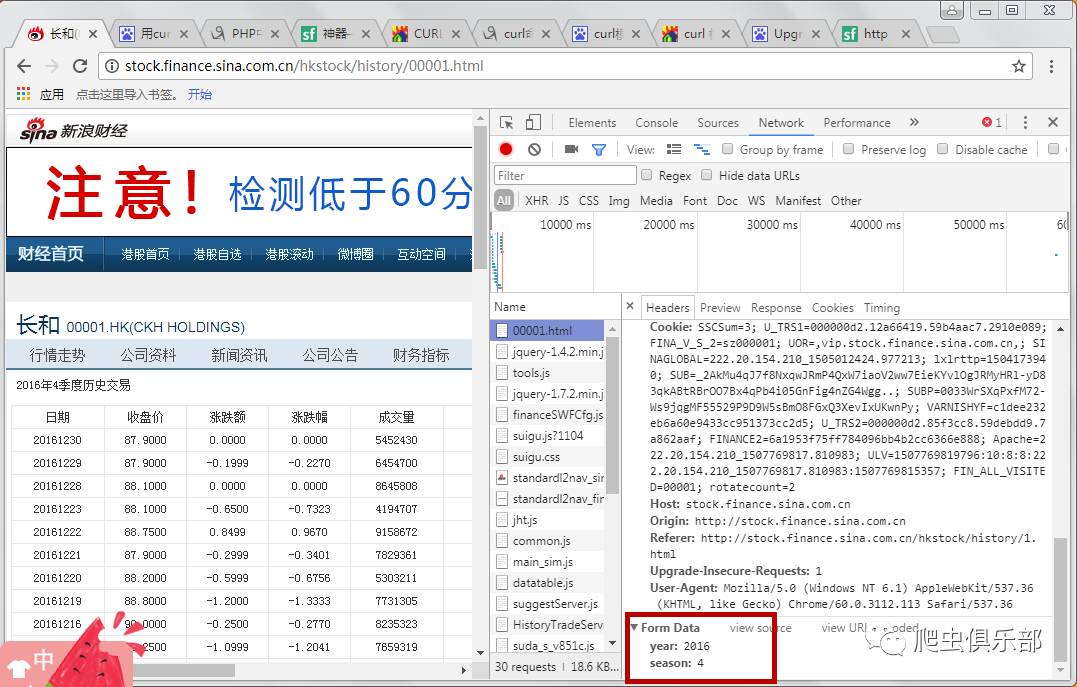
3
为了使用curl模拟浏览器请求,我们使用-H连接headers,使用--data或者-d指定使用POST传输数据,如下图:
现在你可以在 stata 中使用 curl 来抓取这个网页。我们可以保留如上图所示的所有header,但是如果网页不反爬或者只是做一些基本的反爬,则只保留识别参数。即 year=2016 和 season=4 并与 & 相连。在stata中输入以下命令:
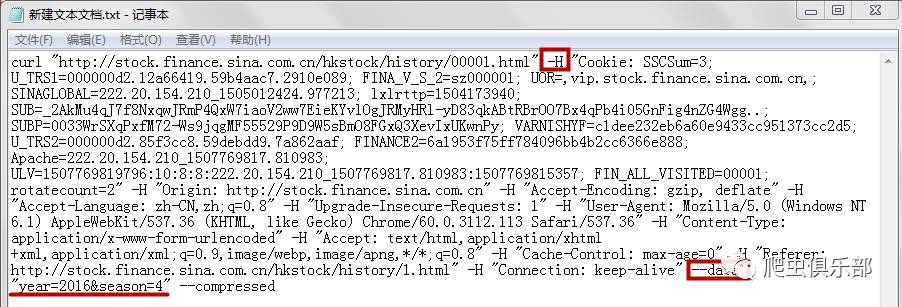
清除
!curl --data "year=2016&season=4" -o sina.txt
shellout sina.txt
-o的作用是将获取到的网页信息下载保存到一个名为sina.txt的文件中,保存的路径为stata的默认保存路径。如下所示:
就这样,港交所总裁和2016年第四季度的历史交易信息就被抓获了。以后可以使用该方法抓取http请求方式为post的网页。不要忘记再次查看捕获。如何获取请求方式为get的网页~
不明白的记得戳下方视频学习哦!
查看全部
scrapy分页抓取网页(
我们先用之前推文中介绍的方法尝试寻找其真实链接
)


在之前的推文《一起来挖掘网页的真实链接吧!》中,我们介绍了如何使用谷歌浏览器在网页分页显示且点击时没有变化的情况下找到网页的真实链接但是有时我们也会遇到另一种情况:通过上述方法找到网页的链接后,我们发现网址中仍然没有可以用来识别不同网页的标识参数(例如page= 1). 别慌,今天小编带你一起来解决这个问题。
1
我们以新浪财经中00001的港股历史交易数据为例()。首先我们来看一下网页:虽然不是分页显示,但右上角有年度和季度选项。基于此,您可以查看昌河过去不同年份、不同季度的股票交易信息,如下图:
同时我们注意到网页的URL没有可以作为识别的参数,所以这里需要再次踏上寻找网页真实链接的旅程~
我们先尝试使用上一条推文介绍的方法找到真正的链接:在网页空白处右击选择“检查”,点击“网络”,然后按F5刷新,点击中间的第一个链接很多弹出查看它的响应的链接发现它的内容和网页的内容是一致的。是否可以确定它是我们现在正在寻找的网页的真实链接?
别着急,我们继续右键第一个名为1.html的链接,点击复制→复制链接地址(这个操作可以复制网页的真实链接),结果这显然不是我们需要什么 带有识别参数的网页链接非常尴尬。
2
为什么会出现这样的情况?这主要是因为新浪财经的http请求方式是post。正如我们在上一条推文中提到的,两种最常见的 http 请求方法是 get 和 post。它们的区别在于get请求的数据会附加到URL上。之后URL和传输数据用?分割,参数用&连接,浏览器会生成目标URL,但是post不会。那么现在我们来介绍一下如何实现对http请求方式为post的网页的抓取。
我们首先选择查看港股领头羊和过去一个季度(如2016年第四季度)的交易数据。最初,我们按照上述方法查找网页的真实链接。我们可以发现第一个链接的返回信息和网页的内容是匹配的。它的Headers注意到网页的请求方法(Request Method)是POST,如图:
这时候如果继续像之前一样操作,是无法获取到网页的源代码的,需要使用curl来模拟浏览器请求。在这之前,我们先来了解一下网页的请求头,也就是Request Headers,谷歌开发者工具为我们准备了这个信息,如下图:
先简单介绍一下请求头中一些headers的含义:
Accept-Encoding:由浏览器发送给服务器,声明浏览器支持的编码类型
Accept-Language:用于告诉服务器浏览器可以支持什么语言
User Agent:中文名称为User Agent,简称UA。它是一个特殊的字符串头,使服务器能够识别操作系统和版本、CPU 类型、客户端使用的浏览器和版本、浏览器渲染引擎、浏览器语言和浏览器插件
Referer:当浏览器向Web服务器发送请求时,通常会带一个Referer,它代表网页的来源,也就是告诉服务器它是从哪个页面链接的。
Cookies:用于记录一些网站的登录信息和访问信息等。
在请求头信息下面,有年份和季节两个参数。这些就是我们初步查询到的2016年第四季度对应的参数,也就是我们需要的识别参数,如下图所示:
3
为了使用curl模拟浏览器请求,我们使用-H连接headers,使用--data或者-d指定使用POST传输数据,如下图:
现在你可以在 stata 中使用 curl 来抓取这个网页。我们可以保留如上图所示的所有header,但是如果网页不反爬或者只是做一些基本的反爬,则只保留识别参数。即 year=2016 和 season=4 并与 & 相连。在stata中输入以下命令:
清除
!curl --data "year=2016&season=4" -o sina.txt
shellout sina.txt
-o的作用是将获取到的网页信息下载保存到一个名为sina.txt的文件中,保存的路径为stata的默认保存路径。如下所示:
就这样,港交所总裁和2016年第四季度的历史交易信息就被抓获了。以后可以使用该方法抓取http请求方式为post的网页。不要忘记再次查看捕获。如何获取请求方式为get的网页~

不明白的记得戳下方视频学习哦!
scrapy分页抓取网页( 小编来一起通过示例代码介绍的详细学习方法-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-17 20:18
小编来一起通过示例代码介绍的详细学习方法-乐题库)
python scrapy项目下spider中多个爬虫同时运行的实现
更新时间:2021年4月21日08:36:40 作者:刘星哲 6
本文文章主要介绍了python scrapy项目下蜘蛛中多个爬虫同时运行的实现。文中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友和小编一起学习吧
一般创建scrapy文件夹后,可能需要编写多个爬虫。如果您希望它们同时运行而不是顺序运行,我该怎么办?
一种。在spiders目录的同级目录下创建commands目录,并在该目录下创建crawlall.py,将scrapy源码中commands文件夹下的crawl.py源码复制,只修改run()方法即可它!
import os
from scrapy.commands import ScrapyCommand
from scrapy.utils.conf import arglist_to_dict
from scrapy.utils.python import without_none_values
from scrapy.exceptions import UsageError
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return "[options] "
def short_desc(self):
return "Run all spider"
def add_options(self, parser):
ScrapyCommand.add_options(self, parser)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
parser.add_option("-o", "--output", metavar="FILE",
help="dump scraped items into FILE (use - for stdout)")
parser.add_option("-t", "--output-format", metavar="FORMAT",
help="format to use for dumping items with -o")
def process_options(self, args, opts):
ScrapyCommand.process_options(self, args, opts)
try:
opts.spargs = arglist_to_dict(opts.spargs)
except ValueError:
raise UsageError("Invalid -a value, use -a NAME=VALUE", print_help=False)
if opts.output:
if opts.output == '-':
self.settings.set('FEED_URI', 'stdout:', priority='cmdline')
else:
self.settings.set('FEED_URI', opts.output, priority='cmdline')
feed_exporters = without_none_values(
self.settings.getwithbase('FEED_EXPORTERS'))
valid_output_formats = feed_exporters.keys()
if not opts.output_format:
opts.output_format = os.path.splitext(opts.output)[1].replace(".", "")
if opts.output_format not in valid_output_formats:
raise UsageError("Unrecognized output format '%s', set one"
" using the '-t' switch or as a file extension"
" from the supported list %s" % (opts.output_format,
tuple(valid_output_formats)))
self.settings.set('FEED_FORMAT', opts.output_format, priority='cmdline')
def run(self, args, opts):
#获取爬虫列表
spd_loader_list=self.crawler_process.spider_loader.list()#获取所有的爬虫文件。
print(spd_loader_list)
#遍历各爬虫
for spname in spd_loader_list or args:
self.crawler_process.crawl(spname, **opts.spargs)
print ('此时启动的爬虫为:'+spname)
self.crawler_process.start()
湾 您必须在其中添加一个 _init_.py 文件
C。还没完,settings.py配置文件还需要加一个。
COMMANDS_MODULE ='项目名称。目录名'
COMMANDS_MODULE = 'ds1.commands'
d. 最后,开始 crawlall!
当然,为了安全起见,可以先在命令行进入项目所在目录,输入scrapy -h查看是否有crawlall命令。如果有,则成功,可以启动
我写了一个启动文件放在第一层
或者直接在命令控制台cmd中输入scrapy crawlall
##注意爬虫好像是同时运行的,运行时间是交叉的?
而设置中的文件,仅适用于其中之一?
至此,这篇关于python scrapy项目文章下的spider同时运行多个爬虫的文章就到这里了。更多python scrapy项目下蜘蛛同时运行多个爬虫的相关内容,请搜索之前的脚本首页文章或者继续浏览相关文章希望大家多多支持Scripthome在将来! 查看全部
scrapy分页抓取网页(
小编来一起通过示例代码介绍的详细学习方法-乐题库)
python scrapy项目下spider中多个爬虫同时运行的实现
更新时间:2021年4月21日08:36:40 作者:刘星哲 6
本文文章主要介绍了python scrapy项目下蜘蛛中多个爬虫同时运行的实现。文中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友和小编一起学习吧
一般创建scrapy文件夹后,可能需要编写多个爬虫。如果您希望它们同时运行而不是顺序运行,我该怎么办?

一种。在spiders目录的同级目录下创建commands目录,并在该目录下创建crawlall.py,将scrapy源码中commands文件夹下的crawl.py源码复制,只修改run()方法即可它!
import os
from scrapy.commands import ScrapyCommand
from scrapy.utils.conf import arglist_to_dict
from scrapy.utils.python import without_none_values
from scrapy.exceptions import UsageError
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return "[options] "
def short_desc(self):
return "Run all spider"
def add_options(self, parser):
ScrapyCommand.add_options(self, parser)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
parser.add_option("-o", "--output", metavar="FILE",
help="dump scraped items into FILE (use - for stdout)")
parser.add_option("-t", "--output-format", metavar="FORMAT",
help="format to use for dumping items with -o")
def process_options(self, args, opts):
ScrapyCommand.process_options(self, args, opts)
try:
opts.spargs = arglist_to_dict(opts.spargs)
except ValueError:
raise UsageError("Invalid -a value, use -a NAME=VALUE", print_help=False)
if opts.output:
if opts.output == '-':
self.settings.set('FEED_URI', 'stdout:', priority='cmdline')
else:
self.settings.set('FEED_URI', opts.output, priority='cmdline')
feed_exporters = without_none_values(
self.settings.getwithbase('FEED_EXPORTERS'))
valid_output_formats = feed_exporters.keys()
if not opts.output_format:
opts.output_format = os.path.splitext(opts.output)[1].replace(".", "")
if opts.output_format not in valid_output_formats:
raise UsageError("Unrecognized output format '%s', set one"
" using the '-t' switch or as a file extension"
" from the supported list %s" % (opts.output_format,
tuple(valid_output_formats)))
self.settings.set('FEED_FORMAT', opts.output_format, priority='cmdline')
def run(self, args, opts):
#获取爬虫列表
spd_loader_list=self.crawler_process.spider_loader.list()#获取所有的爬虫文件。
print(spd_loader_list)
#遍历各爬虫
for spname in spd_loader_list or args:
self.crawler_process.crawl(spname, **opts.spargs)
print ('此时启动的爬虫为:'+spname)
self.crawler_process.start()
湾 您必须在其中添加一个 _init_.py 文件

C。还没完,settings.py配置文件还需要加一个。
COMMANDS_MODULE ='项目名称。目录名'
COMMANDS_MODULE = 'ds1.commands'
d. 最后,开始 crawlall!
当然,为了安全起见,可以先在命令行进入项目所在目录,输入scrapy -h查看是否有crawlall命令。如果有,则成功,可以启动
我写了一个启动文件放在第一层

或者直接在命令控制台cmd中输入scrapy crawlall
##注意爬虫好像是同时运行的,运行时间是交叉的?
而设置中的文件,仅适用于其中之一?
至此,这篇关于python scrapy项目文章下的spider同时运行多个爬虫的文章就到这里了。更多python scrapy项目下蜘蛛同时运行多个爬虫的相关内容,请搜索之前的脚本首页文章或者继续浏览相关文章希望大家多多支持Scripthome在将来!
scrapy分页抓取网页(如何通过以下内容优化网站结构的设计?(一)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-17 20:11
每个网站都有一个结构,包括逻辑结构和物理结构。有些看起来凌乱,有些看起来简洁。如果你刚开始构建网站,注意网站结构的设计,那么这一定是一个好的开始,但是大部分SEO人员往往会忽略网站@ > 结构。
一、将通过以下内容与大家探讨网站结构设计的重要性以及如何优化网站结构。
1、良好的网站结构有利于蜘蛛爬行和爬行
我们知道,百度希望在能够被百度蜘蛛爬取爬取的前提下,快速成为收录。目录层次结构复杂且相对较深。对于新站点,很容易让百度难以抓取,这也是百度依然强调站点地图重要性的原因。
只有这样才能有效地索引网站的复杂结构。
2、良好的网站结构设计,防止内容重复
URL 是非标准化的,通常会生成相同的内容页面和多个 URL 链接。这是一个严重的 SEO 错误,可能会导致内部冲突。
造成这个问题的主要原因是前期没有有效的站结构配置。
3、好的网站结构设计有利于提升用户体验。
网站结构的逻辑结构比较强,可以清晰的让访问者找到自己想要的东西,快速了解整个网站的结构。一个有组织的网站结构可以吸引对方延长页面停留时间,降低跳出率。相反,很容易造成负面的SEO。
二、那么,如何优化网站结构的设计呢?
1、根据网站类型规划自己的层次结构
(1)传统的网站结构是:首页->分类列表页->内容页,加上聚合页(标签页)
对于网站数据量大、分类页和标签页较多的情况,需要根据实际情况进行修改。比如电商网站站点的内部结构,可以尝试添加更多的子类。
(2)确保 URL 标准化
对于URL,我们需要保证相同内容只有一个URL地址,需要在静态页面、伪静态页面和动态页面之间进行选择。
2、顶部导航和面包屑导航
一般来说,搜索引擎的抓取顺序是“从上到下,从左到右”。因此,在设计顶部导航和面包屑导航时,需要注意以下几点:
(1)顶部导航:将具有一定索引的分类列从左到右排序。
(2)面包屑导航:注意收录核心关键词和长尾关键词。重要的是它必须是超链接,而不是文本内容。
3、网站链接优化
合理使用站内链接对SEO有一定的优势。它可以:
(1)减少点击次数网站,提升用户体验,增强用户粘性。
(2)本站链接锚文本具有一定的投票权,利于权重传递,提高关键词的排名。
(3)导出著名机构页面的链接有助于提高网站的声誉。
4、分页文章列表
我们知道,网站的长期运行必然会产生多个内容页面。对于分类列表页,它显示的内容量是有限制的,例如:你有100个文章,每个列表页显示10个,然后生成10个列表页。
一定程度上影响了用户体验和蜘蛛爬行,所以你可以:
(1)在分页选项卡上,添加“下一页”、“下一页”和跳转到目标页面的选项。
(2) 使用标准标签标记分类页面,避免分类页面权重分散和竞争。
5、移动友好,速度快,HTTPS配置
(1)响应式设计让页面在所有终端上都有友好的体验。
(2)避免过度使用CSS样式,合理压缩JS,提高页面访问速度。
(3)配置SSL证书,提高网站信息传输的安全等级,主动配置HTTPS链接。 查看全部
scrapy分页抓取网页(如何通过以下内容优化网站结构的设计?(一)_光明网(组图))
每个网站都有一个结构,包括逻辑结构和物理结构。有些看起来凌乱,有些看起来简洁。如果你刚开始构建网站,注意网站结构的设计,那么这一定是一个好的开始,但是大部分SEO人员往往会忽略网站@ > 结构。
一、将通过以下内容与大家探讨网站结构设计的重要性以及如何优化网站结构。
1、良好的网站结构有利于蜘蛛爬行和爬行
我们知道,百度希望在能够被百度蜘蛛爬取爬取的前提下,快速成为收录。目录层次结构复杂且相对较深。对于新站点,很容易让百度难以抓取,这也是百度依然强调站点地图重要性的原因。
只有这样才能有效地索引网站的复杂结构。
2、良好的网站结构设计,防止内容重复
URL 是非标准化的,通常会生成相同的内容页面和多个 URL 链接。这是一个严重的 SEO 错误,可能会导致内部冲突。
造成这个问题的主要原因是前期没有有效的站结构配置。
3、好的网站结构设计有利于提升用户体验。
网站结构的逻辑结构比较强,可以清晰的让访问者找到自己想要的东西,快速了解整个网站的结构。一个有组织的网站结构可以吸引对方延长页面停留时间,降低跳出率。相反,很容易造成负面的SEO。

二、那么,如何优化网站结构的设计呢?
1、根据网站类型规划自己的层次结构
(1)传统的网站结构是:首页->分类列表页->内容页,加上聚合页(标签页)
对于网站数据量大、分类页和标签页较多的情况,需要根据实际情况进行修改。比如电商网站站点的内部结构,可以尝试添加更多的子类。
(2)确保 URL 标准化
对于URL,我们需要保证相同内容只有一个URL地址,需要在静态页面、伪静态页面和动态页面之间进行选择。
2、顶部导航和面包屑导航
一般来说,搜索引擎的抓取顺序是“从上到下,从左到右”。因此,在设计顶部导航和面包屑导航时,需要注意以下几点:
(1)顶部导航:将具有一定索引的分类列从左到右排序。
(2)面包屑导航:注意收录核心关键词和长尾关键词。重要的是它必须是超链接,而不是文本内容。
3、网站链接优化
合理使用站内链接对SEO有一定的优势。它可以:
(1)减少点击次数网站,提升用户体验,增强用户粘性。
(2)本站链接锚文本具有一定的投票权,利于权重传递,提高关键词的排名。
(3)导出著名机构页面的链接有助于提高网站的声誉。
4、分页文章列表
我们知道,网站的长期运行必然会产生多个内容页面。对于分类列表页,它显示的内容量是有限制的,例如:你有100个文章,每个列表页显示10个,然后生成10个列表页。
一定程度上影响了用户体验和蜘蛛爬行,所以你可以:
(1)在分页选项卡上,添加“下一页”、“下一页”和跳转到目标页面的选项。
(2) 使用标准标签标记分类页面,避免分类页面权重分散和竞争。
5、移动友好,速度快,HTTPS配置
(1)响应式设计让页面在所有终端上都有友好的体验。
(2)避免过度使用CSS样式,合理压缩JS,提高页面访问速度。
(3)配置SSL证书,提高网站信息传输的安全等级,主动配置HTTPS链接。
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-15 04:09
2015-06-23 更新:
之前写这篇文章的时候,还没有遇到具体的场景。只是觉得有这么一个方法,就写下来了。
我今天刚刚满足了这个需求。抓取一个BBS的内容,版块首页只显示标题、作者和发表时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发帖时间)。如果要过滤,只能得到抓取链接内容后的时间,实际上造成了不必要的浪费。使用本文文章的方法可以在抓取链接前进行过滤,避免抓取无用数据。
第一部分scrapy爬虫开始(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取爬行。
具体思路:以我们豆瓣群为例。豆瓣社科组,我们以首页地址作为start_url参数,从页面源码中查找剩余页面,如下:
可以提取每个页面的地址,多页面捕获的思路是将地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并指定这些页面地址对应的回调函数。由于首页和分页在形式上完全一样(首页本身也是一个页面),所以可以直接指定parse作为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
前面是CrawlSpider,换成了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,相当于每个页面都提取了一个页面地址,这样实际上每个页面地址都返回了N次。, 那么scrapy在实际处理中会不会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》……
让我们运行程序看看。现在,让我们看看我们的打印语句:“->”代表当前页面地址,后面是从当前页面中提取的页面地址。为了简化输出,仅提取用于标识页面的“开始”。范围。
操作结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如您所见:
1. 每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除,并且它使用线程进行数据提取操作。
好了,任务完成了。使用CrawlSpider的规则感觉更方便。 查看全部
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
2015-06-23 更新:
之前写这篇文章的时候,还没有遇到具体的场景。只是觉得有这么一个方法,就写下来了。
我今天刚刚满足了这个需求。抓取一个BBS的内容,版块首页只显示标题、作者和发表时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发帖时间)。如果要过滤,只能得到抓取链接内容后的时间,实际上造成了不必要的浪费。使用本文文章的方法可以在抓取链接前进行过滤,避免抓取无用数据。
第一部分scrapy爬虫开始(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取爬行。
具体思路:以我们豆瓣群为例。豆瓣社科组,我们以首页地址作为start_url参数,从页面源码中查找剩余页面,如下:
可以提取每个页面的地址,多页面捕获的思路是将地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并指定这些页面地址对应的回调函数。由于首页和分页在形式上完全一样(首页本身也是一个页面),所以可以直接指定parse作为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
前面是CrawlSpider,换成了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,相当于每个页面都提取了一个页面地址,这样实际上每个页面地址都返回了N次。, 那么scrapy在实际处理中会不会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》……
让我们运行程序看看。现在,让我们看看我们的打印语句:“->”代表当前页面地址,后面是从当前页面中提取的页面地址。为了简化输出,仅提取用于标识页面的“开始”。范围。
操作结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如您所见:
1. 每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除,并且它使用线程进行数据提取操作。
好了,任务完成了。使用CrawlSpider的规则感觉更方便。
scrapy分页抓取网页(用Scrapy写爬虫再只要理清下面两点就能写成一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-15 04:04
)
1 简介
Scrapy模块中有4个现成的蜘蛛类,分别是:
SpiderCrawlSpiderXMLFeedSpiderCSVFeedSpider
Spider是最简单的爬虫,也是最基本的爬虫。包括自定义爬虫在内的所有其他爬虫都必须继承它。本节主要讲Scrapy编写爬虫的核心内容,从CrawlSpider类开始,开始学习如何搭建最简单的爬虫程序。
在我写的第一篇文章中,我说爬虫无非是以下几点:
请求(requests)目标站点的网页(文本);使用正则表达式、Beautiful Soup、LXML、CSS 提取数据;制定爬取规则(如“下一页”等)、爬取方式(异步爬取、设置代理等);存储数据。
至于如何存储数据,我们暂时不关心,因为在Scrapy的命令行中,可以通过参数直接将数据存储到文件中,见【命令行工具】-命令行工具。
总结我以往的经验,用Scrapy写爬虫,只要搞清楚以下两点就可以写成爬虫了:
知道要爬哪些页面,爬完这个页面后要爬哪些页面,入口点在哪里;如何从这些页面中提取数据
对于第二点,我们在最近的3次文章中已经做了详细的介绍。这里我就不多说了。学习完本节内容后,您可以进一步了解提取数据的方法:
[Easy XPath]-开始使用XPath
[RegEx]-正则表达式
【Scrapy中的选择器】-数据匹配方法
因此,本节将带您从示例中阐明编写爬虫的思路和方法。
2 需求分析
假设你目前不清楚如何用Scrapy写爬虫,那么你手头只有一个任务,就是你要爬取哪些数据网站。所以第一步就是分析需求,搞清楚爬取的顺序,其他的就别管了。
任务:
爬取->网站 热门标签下的所有引用及其作者
看看这个页面:
scrapy view http://quotes.toscrape.com/
图片右侧的红框是热门标签。让我们随机点击一个标签来签到:
http://quotes.toscrape.com/tag/love/
我们将上图定义为标签主页,上图中的红框代表我们需要提取的数据项。在数据爬取中,我们必须最大程度的保证数据的完整性,也就是说:获取所有存在于网站上的目标数据。除了标签首页的数据,剩下的数据在哪里?入口在哪里?
往下我们找到Next按钮,打开调试器查看它的地址:
http://quotes.toscrape.com/tag/love/page/2/
点击第二页,已经找不到Next按钮了,也就是love标签下的数据只存在于两个页面:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/love/page/2/
总结两个步骤:
① 获取首页右侧所有热门标签对应的地址:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/inspirational/
……
② 访问各标签首页,在各标签首页点击“下一步”获取剩余数据,直到找不到下一步按钮
最后再补充一点:
爱标签首页的数据,分析起来,是第一页。这是否意味着它相当于:
http://quotes.toscrape.com/tag/love/page/1/
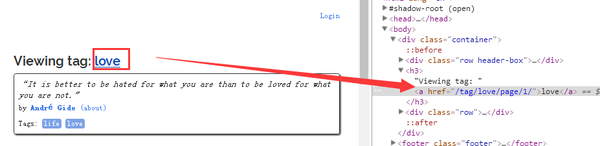
我们在标签主页上找到了这个链接:
因此,可以按以下顺序获取每个标签下的数据:
http://quotes.toscrape.com/tag/love/page/1/
http://quotes.toscrape.com/tag/love/page/2/
……
这是第一点:
下面两个网站指向同一个页面:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/love/page/1/
如果我们按照上面的页数抓取数据,那么我们的数据就是重复的。我们需要在下面进一步解决这个问题。
3 CrawlSpider类使用详解
先通风一下它独特的属性和方法,然后就从刚刚完成上述任务开始,给爬虫代码,写下CrawlSpider类中各个参数用法的例子。
① parse_start_url(response)
用于处理start_urls的响应,它的用处是:如果需要模拟登录等操作,可以重写这个方法。
② Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None)
规则用于:
以指定格式提取链接(link_extractor);过滤提取的链接(process_links);为指定页面指定相应的处理方法(process_request);指定页面的处理方式(回调);为不同的提取链接方法指定后续规则(Follow);将参数 (cb_kwargs) 传递给回调函数。
避免使用 parse 作为回调函数(callback)
在 PyCharm 中创建文件如下:
env:虚拟环境
simple:爬虫文件夹
Quotes_CrawlSpider.py:爬虫
run.py:用于启动爬虫,方便调试
run.py的代码如下:
from scrapy import cmdline
cmdline.execute("scrapy runspider Quotes_CrawlSpider.py -o quotes.json".split())
解释:
相当于从命令行启动爬虫文件,-oquotes.json将爬虫产生的item保存到json文件中。
3.1 完成上述爬虫任务所需的爬虫代码
Quotes_CrawlSpider.py 的代码如下:
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'toscrape.com'
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
rules = (
Rule(LinkExtractor(allow=('/tag/\w+/$',)),
follow=True, # 如果有指定回调函数,默认不跟进
callback='parse_item',
process_links='process_links',),
Rule(LinkExtractor(allow=('/tag/\w+/page/\d+/',), deny=('/tag/\w+/page/1/',)),
callback='parse_item',
follow=True,),
)
@staticmethod
def process_links(links): # 对提取到的链接进行处理
for link in links:
link.url = link.url + 'page/1/'
yield link
@staticmethod
def parse_item(response): # 解析网页数据并返回数据字典
quote_block = response.css('div.quote')
for quote in quote_block:
text = quote.css('span.text::text').extract_first()
author = quote.xpath('span/small/text()').extract_first()
item = dict(text=text, author=author)
yield item
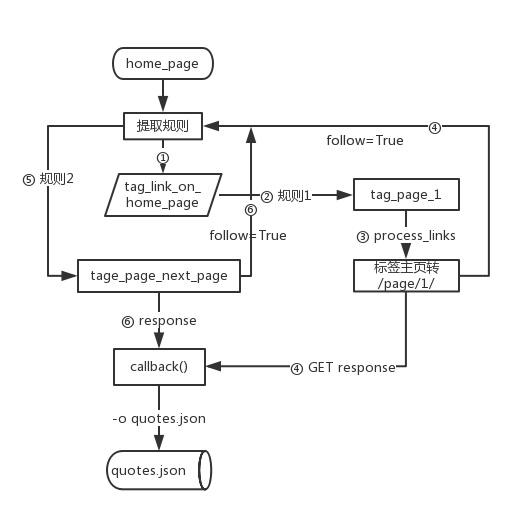
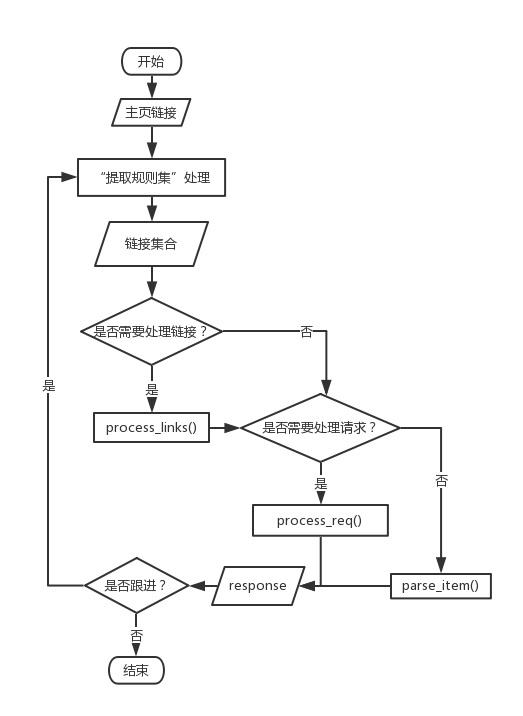
流程图:
详细代码:
提取规则1:(①-④)
Rule(LinkExtractor(allow=('/tag/\w+/$',)), # 从主页提取标签主页的地址,利用正则表达式
follow=True, # request标签主页得到内容,继续在该内容上上应用规则提取链接
callback='parse_item', # request标签主页得到内容,对该内容应用parse_item函数提取数据
process_links='process_links',), # 用process_links方法对提取到的链接做处理,将标签主页变成/page/1/形式
提取规则2:(⑤,⑥)
Rule(LinkExtractor(allow=('/tag/\w+/page/\d+/',), deny=('/tag/\w+/page/1/',)),
# 提取链接格式满足“/tag/英文字母/page/”数字/形式的,并拒绝第一页
callback='parse_item', # 指定parse_item作为页面的处理方法
follow=True,), # 需要在得到的页面继续搜索满足规则的链接
parse_start_url(响应)
from scrapy.spiders import CrawlSpider
class QuotesSpider(CrawlSpider):
name = "quotes"
custom_settings = {
'LOG_LEVEL': 'INFO',
}
start_urls = ['http://quotes.toscrape.com/tag/love/']
def parse_start_url(self, response):
self.logger.info('parse_start_url %s', response.url)
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
yield response.follow(next_page, self.next_parse)
def next_parse(self, response):
self.logger.info('next_pares %s', response.url)
rule的几个参数用法示例:
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'toscrape.com'
custom_settings = {
'LOG_LEVEL': 'INFO', # 设置日志级别
}
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
rules = (
Rule(LinkExtractor(allow=('/tag/\w+/$',)),
follow=False, # 为了测试几个参数的用法简单设定
callback='parse_item',
cb_kwargs={'tag': 'love'}, # 以key名tag作为变量名传给回调函数parse_item
process_links='process_links', # 对提取的链接做处理
process_request='process_req' # 对每个请求做处理),
)
@staticmethod
def process_links(links):
for link in links:
link.url = link.url + 'page/1/'
yield link
def process_req(self, req):
if 'love' in req.url: # 我们测试当链接中包含love是转给parse_love处理response
return req.replace(callback=self.parse_love)
elif 'humor' in req.url:
return req # 如果链接中包含humor则正常用回调函数parse_item处理response
def parse_love(self, response):
self.logger.info('parse_love %s' % response.url)
def parse_item(self, response, tag):
self.logger.info('parse_item %s' % response.url)
self.logger.info('not %s' % tag)
操作结果:
操作流程:
查看全部
scrapy分页抓取网页(用Scrapy写爬虫再只要理清下面两点就能写成一个
)
1 简介
Scrapy模块中有4个现成的蜘蛛类,分别是:
SpiderCrawlSpiderXMLFeedSpiderCSVFeedSpider
Spider是最简单的爬虫,也是最基本的爬虫。包括自定义爬虫在内的所有其他爬虫都必须继承它。本节主要讲Scrapy编写爬虫的核心内容,从CrawlSpider类开始,开始学习如何搭建最简单的爬虫程序。
在我写的第一篇文章中,我说爬虫无非是以下几点:
请求(requests)目标站点的网页(文本);使用正则表达式、Beautiful Soup、LXML、CSS 提取数据;制定爬取规则(如“下一页”等)、爬取方式(异步爬取、设置代理等);存储数据。
至于如何存储数据,我们暂时不关心,因为在Scrapy的命令行中,可以通过参数直接将数据存储到文件中,见【命令行工具】-命令行工具。
总结我以往的经验,用Scrapy写爬虫,只要搞清楚以下两点就可以写成爬虫了:
知道要爬哪些页面,爬完这个页面后要爬哪些页面,入口点在哪里;如何从这些页面中提取数据
对于第二点,我们在最近的3次文章中已经做了详细的介绍。这里我就不多说了。学习完本节内容后,您可以进一步了解提取数据的方法:
[Easy XPath]-开始使用XPath
[RegEx]-正则表达式
【Scrapy中的选择器】-数据匹配方法
因此,本节将带您从示例中阐明编写爬虫的思路和方法。
2 需求分析
假设你目前不清楚如何用Scrapy写爬虫,那么你手头只有一个任务,就是你要爬取哪些数据网站。所以第一步就是分析需求,搞清楚爬取的顺序,其他的就别管了。
任务:
爬取->网站 热门标签下的所有引用及其作者
看看这个页面:
scrapy view http://quotes.toscrape.com/

图片右侧的红框是热门标签。让我们随机点击一个标签来签到:
http://quotes.toscrape.com/tag/love/

我们将上图定义为标签主页,上图中的红框代表我们需要提取的数据项。在数据爬取中,我们必须最大程度的保证数据的完整性,也就是说:获取所有存在于网站上的目标数据。除了标签首页的数据,剩下的数据在哪里?入口在哪里?
往下我们找到Next按钮,打开调试器查看它的地址:
http://quotes.toscrape.com/tag/love/page/2/
点击第二页,已经找不到Next按钮了,也就是love标签下的数据只存在于两个页面:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/love/page/2/
总结两个步骤:
① 获取首页右侧所有热门标签对应的地址:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/inspirational/
……
② 访问各标签首页,在各标签首页点击“下一步”获取剩余数据,直到找不到下一步按钮
最后再补充一点:
爱标签首页的数据,分析起来,是第一页。这是否意味着它相当于:
http://quotes.toscrape.com/tag/love/page/1/
我们在标签主页上找到了这个链接:
因此,可以按以下顺序获取每个标签下的数据:
http://quotes.toscrape.com/tag/love/page/1/
http://quotes.toscrape.com/tag/love/page/2/
……
这是第一点:
下面两个网站指向同一个页面:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/love/page/1/
如果我们按照上面的页数抓取数据,那么我们的数据就是重复的。我们需要在下面进一步解决这个问题。
3 CrawlSpider类使用详解
先通风一下它独特的属性和方法,然后就从刚刚完成上述任务开始,给爬虫代码,写下CrawlSpider类中各个参数用法的例子。
① parse_start_url(response)
用于处理start_urls的响应,它的用处是:如果需要模拟登录等操作,可以重写这个方法。
② Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None)
规则用于:
以指定格式提取链接(link_extractor);过滤提取的链接(process_links);为指定页面指定相应的处理方法(process_request);指定页面的处理方式(回调);为不同的提取链接方法指定后续规则(Follow);将参数 (cb_kwargs) 传递给回调函数。
避免使用 parse 作为回调函数(callback)
在 PyCharm 中创建文件如下:
env:虚拟环境
simple:爬虫文件夹
Quotes_CrawlSpider.py:爬虫
run.py:用于启动爬虫,方便调试
run.py的代码如下:
from scrapy import cmdline
cmdline.execute("scrapy runspider Quotes_CrawlSpider.py -o quotes.json".split())
解释:
相当于从命令行启动爬虫文件,-oquotes.json将爬虫产生的item保存到json文件中。
3.1 完成上述爬虫任务所需的爬虫代码
Quotes_CrawlSpider.py 的代码如下:
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'toscrape.com'
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
rules = (
Rule(LinkExtractor(allow=('/tag/\w+/$',)),
follow=True, # 如果有指定回调函数,默认不跟进
callback='parse_item',
process_links='process_links',),
Rule(LinkExtractor(allow=('/tag/\w+/page/\d+/',), deny=('/tag/\w+/page/1/',)),
callback='parse_item',
follow=True,),
)
@staticmethod
def process_links(links): # 对提取到的链接进行处理
for link in links:
link.url = link.url + 'page/1/'
yield link
@staticmethod
def parse_item(response): # 解析网页数据并返回数据字典
quote_block = response.css('div.quote')
for quote in quote_block:
text = quote.css('span.text::text').extract_first()
author = quote.xpath('span/small/text()').extract_first()
item = dict(text=text, author=author)
yield item
流程图:
详细代码:
提取规则1:(①-④)
Rule(LinkExtractor(allow=('/tag/\w+/$',)), # 从主页提取标签主页的地址,利用正则表达式
follow=True, # request标签主页得到内容,继续在该内容上上应用规则提取链接
callback='parse_item', # request标签主页得到内容,对该内容应用parse_item函数提取数据
process_links='process_links',), # 用process_links方法对提取到的链接做处理,将标签主页变成/page/1/形式
提取规则2:(⑤,⑥)
Rule(LinkExtractor(allow=('/tag/\w+/page/\d+/',), deny=('/tag/\w+/page/1/',)),
# 提取链接格式满足“/tag/英文字母/page/”数字/形式的,并拒绝第一页
callback='parse_item', # 指定parse_item作为页面的处理方法
follow=True,), # 需要在得到的页面继续搜索满足规则的链接
parse_start_url(响应)
from scrapy.spiders import CrawlSpider
class QuotesSpider(CrawlSpider):
name = "quotes"
custom_settings = {
'LOG_LEVEL': 'INFO',
}
start_urls = ['http://quotes.toscrape.com/tag/love/']
def parse_start_url(self, response):
self.logger.info('parse_start_url %s', response.url)
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
yield response.follow(next_page, self.next_parse)
def next_parse(self, response):
self.logger.info('next_pares %s', response.url)
rule的几个参数用法示例:
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'toscrape.com'
custom_settings = {
'LOG_LEVEL': 'INFO', # 设置日志级别
}
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
rules = (
Rule(LinkExtractor(allow=('/tag/\w+/$',)),
follow=False, # 为了测试几个参数的用法简单设定
callback='parse_item',
cb_kwargs={'tag': 'love'}, # 以key名tag作为变量名传给回调函数parse_item
process_links='process_links', # 对提取的链接做处理
process_request='process_req' # 对每个请求做处理),
)
@staticmethod
def process_links(links):
for link in links:
link.url = link.url + 'page/1/'
yield link
def process_req(self, req):
if 'love' in req.url: # 我们测试当链接中包含love是转给parse_love处理response
return req.replace(callback=self.parse_love)
elif 'humor' in req.url:
return req # 如果链接中包含humor则正常用回调函数parse_item处理response
def parse_love(self, response):
self.logger.info('parse_love %s' % response.url)
def parse_item(self, response, tag):
self.logger.info('parse_item %s' % response.url)
self.logger.info('not %s' % tag)
操作结果:

操作流程:
scrapy分页抓取网页(WebScraper的扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-14 06:15
本文内容
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少,虽然可以自己写代码来实现,但这很荒谬。大锤?
市面上已经有一些成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装后需要重启Chrome一次,然后F12就可以看到工具了
2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图了
选择器
直译,它是一个选择器。要从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的 Selector 有很多,但是本文 文章 只介绍了几个最常用、覆盖面最广的 Selector。了解一两个之后,其他的原理都差不多,以后私下多多学习。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有网站的下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的 CSDN 博客文章并将其拉到底部以查看评论区。
如果你的文章很火,当有很多同学评论的时候,CSDN会分页显示,但是不管评论在哪个页面,都属于同一篇文章文章@ >、浏览时无需刷新任何页面评论区的博文,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"clickElementSelector":"li.js-page-next","clickElementUniquenessType":"uniqueText","clickType":"clickMore","delay":2000,"discardInitialElements":"do-not-discard","id":"next_page","multiple":true,"parentSelectors":["_root","next_page"],"selector":"div.comment-list-container","type":"SelectorElementClick"},{"delay":0,"id":"comment","multiple":true,"parentSelectors":["_root","next_page"],"selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","type":"SelectorElement"},{"delay":0,"id":"content","multiple":false,"parentSelectors":["comment"],"regex":"","selector":"_parent_","type":"SelectorText"}]}
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"comment","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","multiple":true,"delay":0},{"id":"content","parentSelectors":["comment"],"type":"SelectorText","selector":"_parent_","multiple":false,"delay":0,"regex":""}]}
要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种寻呼机,Element Click无能为力,读者可以自行验证,只能爬到一个页面后关闭。
并且作为分页的Pagination选择器,自然适用
爬取的拓扑和上面一样,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习
{"_id":"mycsdn","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"article","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"div.article-item-box","multiple":true,"delay":0},{"id":"title","parentSelectors":["article"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":"[0-9]+"},{"id":"comments","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""},{"id":"publish_time","parentSelectors":["article"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""}]}
4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果您想获得更多信息,如博文正文、点赞数、采集数、评论区内容等,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果你想抓取博文更详细的信息,你必须打开一个新页面才能获取,而网络爬虫的链接选择器恰好可以做到这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap配置如下,可以直接导入使用
{"_id":"csdn_detail","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"container","parentSelectors":["_root"],"type":"SelectorElement","selector":"[data-articleid='111936614']","multiple":false,"delay":0},{"id":"article_detail_link","parentSelectors":["container"],"type":"SelectorLink","selector":"h4 a","multiple":false,"delay":0},{"id":"detail","parentSelectors":["article_detail_link"],"type":"SelectorText","selector":"article","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["container"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"time","parentSelectors":["container"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":""},{"id":"comments","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""}]}
5. 写在最后
上面整理了分页和二级页面的爬取方案,主要是:pager爬取和二级页面爬取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。 查看全部
scrapy分页抓取网页(WebScraper的扩展插件,安装后你可以直接在F12调试工具里使用)
本文内容
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少,虽然可以自己写代码来实现,但这很荒谬。大锤?
市面上已经有一些成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装后需要重启Chrome一次,然后F12就可以看到工具了
2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置

只要拿到这个配置,就可以导入别人的站点地图了
选择器
直译,它是一个选择器。要从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的 Selector 有很多,但是本文 文章 只介绍了几个最常用、覆盖面最广的 Selector。了解一两个之后,其他的原理都差不多,以后私下多多学习。可以上手了。

Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有网站的下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的 CSDN 博客文章并将其拉到底部以查看评论区。
如果你的文章很火,当有很多同学评论的时候,CSDN会分页显示,但是不管评论在哪个页面,都属于同一篇文章文章@ >、浏览时无需刷新任何页面评论区的博文,因为这种分页不会重新加载页面。

对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"clickElementSelector":"li.js-page-next","clickElementUniquenessType":"uniqueText","clickType":"clickMore","delay":2000,"discardInitialElements":"do-not-discard","id":"next_page","multiple":true,"parentSelectors":["_root","next_page"],"selector":"div.comment-list-container","type":"SelectorElementClick"},{"delay":0,"id":"comment","multiple":true,"parentSelectors":["_root","next_page"],"selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","type":"SelectorElement"},{"delay":0,"id":"content","multiple":false,"parentSelectors":["comment"],"regex":"","selector":"_parent_","type":"SelectorText"}]}
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"comment","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","multiple":true,"delay":0},{"id":"content","parentSelectors":["comment"],"type":"SelectorText","selector":"_parent_","multiple":false,"delay":0,"regex":""}]}
要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页会重新加载当前页面。

对于这种寻呼机,Element Click无能为力,读者可以自行验证,只能爬到一个页面后关闭。
并且作为分页的Pagination选择器,自然适用

爬取的拓扑和上面一样,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习
{"_id":"mycsdn","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"article","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"div.article-item-box","multiple":true,"delay":0},{"id":"title","parentSelectors":["article"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":"[0-9]+"},{"id":"comments","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""},{"id":"publish_time","parentSelectors":["article"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""}]}
4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果您想获得更多信息,如博文正文、点赞数、采集数、评论区内容等,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果你想抓取博文更详细的信息,你必须打开一个新页面才能获取,而网络爬虫的链接选择器恰好可以做到这一点。

爬取路径拓扑如下

爬取的效果如下

sitemap配置如下,可以直接导入使用
{"_id":"csdn_detail","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"container","parentSelectors":["_root"],"type":"SelectorElement","selector":"[data-articleid='111936614']","multiple":false,"delay":0},{"id":"article_detail_link","parentSelectors":["container"],"type":"SelectorLink","selector":"h4 a","multiple":false,"delay":0},{"id":"detail","parentSelectors":["article_detail_link"],"type":"SelectorText","selector":"article","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["container"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"time","parentSelectors":["container"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":""},{"id":"comments","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""}]}
5. 写在最后
上面整理了分页和二级页面的爬取方案,主要是:pager爬取和二级页面爬取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。
scrapy分页抓取网页(目标网站是以滚动页面的方式动态生成数据的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-13 03:01
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
类似于今日头条网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合用于数据捕获。由于Selenium直接在浏览器中运行,因此可以轻松绕过网站的反爬虫限制。 , 就像真正的用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动页面分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码进行捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
scrapy分页抓取网页(目标网站是以滚动页面的方式动态生成数据的网页)
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
类似于今日头条网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合用于数据捕获。由于Selenium直接在浏览器中运行,因此可以轻松绕过网站的反爬虫限制。 , 就像真正的用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动页面分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码进行捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
scrapy分页抓取网页(:RSS阅读器分页信息分页分页(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-11 17:19
专利名称:Rss信息分页抓取系统及方法
技术领域:
本发明涉及互联网技术领域,尤其涉及一种RSS信息的分页抓取系统及方法。
背景技术:
RSS(Simple Information Syndication,也称为聚合内容)是一种用于描述和同步网站内容的格式。RSS 可以是以下三种解释之一: 真正简单的联合;RDF(资源描述框架)站点摘要;丰富的网站摘要。实际上,这三种解释指的是同一种 Syndication 技术。RSS 目前广泛用于在线新闻频道、博客和维基。主要版本有0.91、I.0、2.O。使用RSS订阅,获取信息更快。网站提供RSS输出,有利于用户获取网站内容的最新更新。网络用户可以使用客户端的RSS聚合工具软件阅读支持RSS输出的网站内容,无需打开网站 内容页。其中,RSS订阅是站点与其他站点共享内容的一种简单方式。面对迎面而来的新闻,你不需要花大量时间从新闻网站上冲浪和下载,只需通过RSS阅读器就可以阅读大量信息。目前,RSS订阅主要有两种类型。第一个是用户通过RSS阅读器从RSS源站提取信息。这种方式需要用户主动添加RSS源。信息来源单一,RSS内容完全由源站决定。RSS源只推送信息摘要。如需查看详细信息,必须到原网页查看;二是用户订阅了一些第三方网站,第三方订阅站点预先从一些高质量的RSS源中提取信息,并进行一定的处理,返回给用户的是聚合后的信息。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。
发明内容
本发明要解决的技术问题是如何提供一种RSS信息的分页抓取系统及方法,以保证在从RSS源中提取信息时能够识别分页并提取全文。为解决上述技术问题,本发明提供了一种RSS信息寻呼抓取系统,包括列表创建单元,用于采集带有寻呼的RSS频道,建立寻呼频道列表。列表分析单元,用于分析寻呼信道列表,获取每个RSS信道对应的寻呼标签;代码获取单元,用于在从RSS源页面代码中抓取信息时,如果当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的信息。标签查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。适配在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。适配在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。
标签对应模块,用于分析分页网页的页面代码,找到其中的分页标签作为对应的RSS频道。其中,代码获取单元还包括信息抓取模块,用于从RSS源抓取信息。判断模块,用于判断当前信息源的目标RSS频道是否属于分页频道列表;代码获取模块,用于当作为当前信息源的目标RSS频道属于寻呼频道列表时,获取当前信息对应的寻呼代码。其中,分页组合单元还包括URL获取模块,用于根据找到的分页标签获取每个页面的URL。提取每一页的文字;页面组合模块适用于对每个页面的文本进行组合以获得完整的RSS信息。其中,该系统还包括推送单元,用于向用户推送完整的RSS信息。本发明还提供了一种获取RSS信息的寻呼方法,包括:采集带有寻呼的RSS频道,建立寻呼频道列表。分析寻呼频道列表,得到每个RSS频道对应的寻呼标签;当从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码;在页面代码中查找目标RSS频道对应的页面代码;根据搜索你得到的分页标签可以得到每个分页对应的页面,将每个分页对应的页面组合起来就可以得到完整的RSS信息。其中,分析寻呼频道列表,得到每个RSS频道对应的寻呼标签,具体包括依次取出寻呼频道列表中的每个RSS频道,在RSS频道中找到有寻呼的网页。分析所述带有分页的网页的页面代码,找到其中的分页标签作为对应RSS频道对应的分页标签。其中,当从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,然后获取当前信息的页面代码具体包括从RSS源抓取信息,判断当前信息源的目标RSS频道是否属于寻呼频道列表,如果是,则获取当前对应的页面代码信息; 否则,认为当前信息对应的网页没有分页,流程结束。其中,所述根据找到的标签获取各个标签对应的页面,并结合各个标签对应的页面获取完整的RSS信息具体包括:根据找到的标签获取各个标签的URL。根据每个标签的URL获取每个标签的URL 分页的页面代码从页面代码中提取每个页面的文本;
其中,获取完整的RSS信息后,还包括向用户推送完整的RSS信息的步骤。本发明还提供了一种服务器,包括RSS信息分页抓取系统。本发明的RSS信息寻呼抓取系统及方法根据常用的RSS频道建立寻呼频道列表,获取每个RSS频道对应的寻呼标签,然后在对应的页面代码中查找对应的页面代码。从RSS源分页标签中抓取信息,根据分页标签获取每个页面的内容,从而获取完整的RSS信息,保证推送给用户的RSS信息的完整性,提高用户的阅读效率。
无花果。附图说明图1为本发明实施例一的RSS信息分页抓取系统的模块结构示意图;
图2a b为页面标签对应的页面显示效果图;图3为列表分析单元模块结构示意图;图4为代码获取单元模块结构示意图;图5为页面组合单元模块结构示意图;无花果。图6为本发明实施例二的RSS信息分页抓取系统的模块结构示意图;无花果。图7为本发明实施例三提供的RSS信息分页抓取方法的流程图。
具体实施方式以下结合附图和实施例,对本发明的具体实施方式进行说明。
欲知详情。以下实施例用于说明本发明,但不用于限制本发明的范围。无花果。图1为本发明实施例一的RSS信息分页抓取系统的模块结构示意图。如图所示。RSS频道一般指按内容类型划分的新闻频道、娱乐频道、生活休闲频道、阅读频道、下载频道、体育频道、游戏频道、音乐频道、视频频道、汽车频道、房地产等。频道和其他部分。由于网站的不同,这些频道的名称可能不同,频道之间的层次关系也可能不同。例如,在某些 网站 中,游戏频道可以作为娱乐频道的子频道出现。为方便起见,上述收录子频道的频道称为父频道。由于同一个网站中每个父频道下的网页采用相同的分页格式,因此本应用中的RSS频道可以对应父频道。一层不对应子信道向下。寻呼频道列表包括所有常见的带有寻呼功能的RSS频道,如新浪汽车频道、网易数字频道、搜狐军事频道等。列表分析单元200,用于对寻呼信道列表进行分析,得到每个RSS信道对应的寻呼标签。每个 RSS 频道对应一个分页标签。例如,图2a为新浪汽车频道分页标签对应的页面展示效果图。表Ia是分页标签对应的源代码。分页标签可以概括为类属性。是Pb的div标签;图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。
表 Ia 新浪自动频道分页标签
权限请求
1. RSS信息的寻呼抓取系统,包括列表构建单元,适用于采集寻呼RSS频道,建立寻呼频道列表;列表分析单元,用于分析寻呼信道列表,得到RSS信道对应的A寻呼标签;代码获取单元,用于在从RSS源检索信息时,如果当前信息的源目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码;查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面合并单元,用于根据找到的页面标签获取每个页面对应的页面,
2.如权利要求1所述的系统,其特征在于,所述列表分析单元还包括网页提取模块,用于依次提取分页后的频道列表中的各个RSS频道,并找到该RSS频道一个带有分页标签的网页对应模块,用于分析分页网页的页面代码,找到其中的分页标签作为对应的RSS频道。
3.如权利要求1所述的系统,其特征在于,所述代码获取单元还包括信息抓取模块,用于抓取来自RSS源的信息;判断模块,用于判断当前信息的来源目标RSS频道是否属于寻呼频道列表;代码获取模块,用于当作为当前信息源的目标RSS频道属于寻呼频道列表时,获取当前信息对应的寻呼代码。
4.如权利要求1所述的系统,其特征在于,所述分页组合单元还包括URL获取模块,用于根据找到的分页标签获取每个页面的URL;正文获取模块,用于根据每个页面的URL获取URL,获取每个页面的页面代码,并从页面代码中提取出每个页面的文本;页面组合模块适用于对每个页面的文本进行组合以获得完整的RSS信息。
5.如权利要求1所述的系统,其特征在于,所述系统还包括推送单元,用于向用户推送完整的RSS信息。
6. 一种RSS信息的寻呼方法,包括采集带有寻呼的RSS频道和建立寻呼频道列表的步骤;分析寻呼频道列表,得到每个RSS频道对应的寻呼标签;获取信息时,如果当前信息来源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面编码;在页面代码中找到目标RSS频道对应的分页标签;根据找到的分页标签获取每个分页对应的页面,将每个分页对应的页面组合起来得到完整的RSS信息。
7.如权利要求6所述的方法,其特征在于,所述分析寻呼频道列表,得到各个RSS频道对应的寻呼标签,具体包括依次提取寻呼频道列表Channel中的各个RSS频道,在RSS频道中找到带有分页的网页; 分析带有分页的网页的页面代码,找到分页标签作为对应的RSS频道。
8.如权利要求6所述的方法,其特征在于,当从RSS源捕获信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则当前信息的页面代码具体为包括从RSS源抓取信息,判断作为当前信息源的目标RSS频道是否属于寻呼频道列表,如果是,则获取当前信息对应的页面代码。否则,认为当前信息对应的网页没有分页,流程结束。
9.如权利要求6所述的方法,其特征在于,所述根据找到的页面标签获取各页面对应的页面,并组合各页面对应的页面以获取完整的RSS信息具体包括以下步骤: 获取URL每个页面根据每个页面的URL;根据每个页面的URL获取每个页面的页面代码,从页面代码中提取每个页面的文本;结合每一页的文字,得到完整的RSS信息。
10.如权利要求6所述的方法,其特征在于,在获取完整RSS信息后,还包括向用户推送完整RSS信息的步骤。
11. 一种服务器,包括如权利要求1至5中任一项所述的RSS信息分页爬取系统。
全文摘要
本发明公开了一种RSS信息的页面抓取系统及方法。该系统包括列表创建单元,用于采集带有寻呼的RSS频道,建立寻呼频道列表;列表分析单元,用于分析寻呼信道列表,得到每个RSS信道对应的寻呼标签;代码获取单元,适用于在从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码。标签查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面合并单元用于根据找到的页面标签获取每个页面对应的页面,并将每个页面对应的页面组合起来,得到完整的RSS信息。本发明保证推送给用户的RSS信息的完整性,提高用户的阅读效率。
文件编号 G06F17/30GK102819613SQ20121031166
公布日期 2012 年 12 月 12 日 申请日期 2012 年 8 月 28 日 优先权日期 2012 年 8 月 28 日
发明人郑伟、赵刚申请人:、 查看全部
scrapy分页抓取网页(:RSS阅读器分页信息分页分页(图))
专利名称:Rss信息分页抓取系统及方法
技术领域:
本发明涉及互联网技术领域,尤其涉及一种RSS信息的分页抓取系统及方法。
背景技术:
RSS(Simple Information Syndication,也称为聚合内容)是一种用于描述和同步网站内容的格式。RSS 可以是以下三种解释之一: 真正简单的联合;RDF(资源描述框架)站点摘要;丰富的网站摘要。实际上,这三种解释指的是同一种 Syndication 技术。RSS 目前广泛用于在线新闻频道、博客和维基。主要版本有0.91、I.0、2.O。使用RSS订阅,获取信息更快。网站提供RSS输出,有利于用户获取网站内容的最新更新。网络用户可以使用客户端的RSS聚合工具软件阅读支持RSS输出的网站内容,无需打开网站 内容页。其中,RSS订阅是站点与其他站点共享内容的一种简单方式。面对迎面而来的新闻,你不需要花大量时间从新闻网站上冲浪和下载,只需通过RSS阅读器就可以阅读大量信息。目前,RSS订阅主要有两种类型。第一个是用户通过RSS阅读器从RSS源站提取信息。这种方式需要用户主动添加RSS源。信息来源单一,RSS内容完全由源站决定。RSS源只推送信息摘要。如需查看详细信息,必须到原网页查看;二是用户订阅了一些第三方网站,第三方订阅站点预先从一些高质量的RSS源中提取信息,并进行一定的处理,返回给用户的是聚合后的信息。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。
发明内容
本发明要解决的技术问题是如何提供一种RSS信息的分页抓取系统及方法,以保证在从RSS源中提取信息时能够识别分页并提取全文。为解决上述技术问题,本发明提供了一种RSS信息寻呼抓取系统,包括列表创建单元,用于采集带有寻呼的RSS频道,建立寻呼频道列表。列表分析单元,用于分析寻呼信道列表,获取每个RSS信道对应的寻呼标签;代码获取单元,用于在从RSS源页面代码中抓取信息时,如果当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的信息。标签查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。适配在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。适配在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。
标签对应模块,用于分析分页网页的页面代码,找到其中的分页标签作为对应的RSS频道。其中,代码获取单元还包括信息抓取模块,用于从RSS源抓取信息。判断模块,用于判断当前信息源的目标RSS频道是否属于分页频道列表;代码获取模块,用于当作为当前信息源的目标RSS频道属于寻呼频道列表时,获取当前信息对应的寻呼代码。其中,分页组合单元还包括URL获取模块,用于根据找到的分页标签获取每个页面的URL。提取每一页的文字;页面组合模块适用于对每个页面的文本进行组合以获得完整的RSS信息。其中,该系统还包括推送单元,用于向用户推送完整的RSS信息。本发明还提供了一种获取RSS信息的寻呼方法,包括:采集带有寻呼的RSS频道,建立寻呼频道列表。分析寻呼频道列表,得到每个RSS频道对应的寻呼标签;当从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码;在页面代码中查找目标RSS频道对应的页面代码;根据搜索你得到的分页标签可以得到每个分页对应的页面,将每个分页对应的页面组合起来就可以得到完整的RSS信息。其中,分析寻呼频道列表,得到每个RSS频道对应的寻呼标签,具体包括依次取出寻呼频道列表中的每个RSS频道,在RSS频道中找到有寻呼的网页。分析所述带有分页的网页的页面代码,找到其中的分页标签作为对应RSS频道对应的分页标签。其中,当从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,然后获取当前信息的页面代码具体包括从RSS源抓取信息,判断当前信息源的目标RSS频道是否属于寻呼频道列表,如果是,则获取当前对应的页面代码信息; 否则,认为当前信息对应的网页没有分页,流程结束。其中,所述根据找到的标签获取各个标签对应的页面,并结合各个标签对应的页面获取完整的RSS信息具体包括:根据找到的标签获取各个标签的URL。根据每个标签的URL获取每个标签的URL 分页的页面代码从页面代码中提取每个页面的文本;
其中,获取完整的RSS信息后,还包括向用户推送完整的RSS信息的步骤。本发明还提供了一种服务器,包括RSS信息分页抓取系统。本发明的RSS信息寻呼抓取系统及方法根据常用的RSS频道建立寻呼频道列表,获取每个RSS频道对应的寻呼标签,然后在对应的页面代码中查找对应的页面代码。从RSS源分页标签中抓取信息,根据分页标签获取每个页面的内容,从而获取完整的RSS信息,保证推送给用户的RSS信息的完整性,提高用户的阅读效率。
无花果。附图说明图1为本发明实施例一的RSS信息分页抓取系统的模块结构示意图;
图2a b为页面标签对应的页面显示效果图;图3为列表分析单元模块结构示意图;图4为代码获取单元模块结构示意图;图5为页面组合单元模块结构示意图;无花果。图6为本发明实施例二的RSS信息分页抓取系统的模块结构示意图;无花果。图7为本发明实施例三提供的RSS信息分页抓取方法的流程图。
具体实施方式以下结合附图和实施例,对本发明的具体实施方式进行说明。
欲知详情。以下实施例用于说明本发明,但不用于限制本发明的范围。无花果。图1为本发明实施例一的RSS信息分页抓取系统的模块结构示意图。如图所示。RSS频道一般指按内容类型划分的新闻频道、娱乐频道、生活休闲频道、阅读频道、下载频道、体育频道、游戏频道、音乐频道、视频频道、汽车频道、房地产等。频道和其他部分。由于网站的不同,这些频道的名称可能不同,频道之间的层次关系也可能不同。例如,在某些 网站 中,游戏频道可以作为娱乐频道的子频道出现。为方便起见,上述收录子频道的频道称为父频道。由于同一个网站中每个父频道下的网页采用相同的分页格式,因此本应用中的RSS频道可以对应父频道。一层不对应子信道向下。寻呼频道列表包括所有常见的带有寻呼功能的RSS频道,如新浪汽车频道、网易数字频道、搜狐军事频道等。列表分析单元200,用于对寻呼信道列表进行分析,得到每个RSS信道对应的寻呼标签。每个 RSS 频道对应一个分页标签。例如,图2a为新浪汽车频道分页标签对应的页面展示效果图。表Ia是分页标签对应的源代码。分页标签可以概括为类属性。是Pb的div标签;图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。
表 Ia 新浪自动频道分页标签
权限请求
1. RSS信息的寻呼抓取系统,包括列表构建单元,适用于采集寻呼RSS频道,建立寻呼频道列表;列表分析单元,用于分析寻呼信道列表,得到RSS信道对应的A寻呼标签;代码获取单元,用于在从RSS源检索信息时,如果当前信息的源目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码;查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面合并单元,用于根据找到的页面标签获取每个页面对应的页面,
2.如权利要求1所述的系统,其特征在于,所述列表分析单元还包括网页提取模块,用于依次提取分页后的频道列表中的各个RSS频道,并找到该RSS频道一个带有分页标签的网页对应模块,用于分析分页网页的页面代码,找到其中的分页标签作为对应的RSS频道。
3.如权利要求1所述的系统,其特征在于,所述代码获取单元还包括信息抓取模块,用于抓取来自RSS源的信息;判断模块,用于判断当前信息的来源目标RSS频道是否属于寻呼频道列表;代码获取模块,用于当作为当前信息源的目标RSS频道属于寻呼频道列表时,获取当前信息对应的寻呼代码。
4.如权利要求1所述的系统,其特征在于,所述分页组合单元还包括URL获取模块,用于根据找到的分页标签获取每个页面的URL;正文获取模块,用于根据每个页面的URL获取URL,获取每个页面的页面代码,并从页面代码中提取出每个页面的文本;页面组合模块适用于对每个页面的文本进行组合以获得完整的RSS信息。
5.如权利要求1所述的系统,其特征在于,所述系统还包括推送单元,用于向用户推送完整的RSS信息。
6. 一种RSS信息的寻呼方法,包括采集带有寻呼的RSS频道和建立寻呼频道列表的步骤;分析寻呼频道列表,得到每个RSS频道对应的寻呼标签;获取信息时,如果当前信息来源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面编码;在页面代码中找到目标RSS频道对应的分页标签;根据找到的分页标签获取每个分页对应的页面,将每个分页对应的页面组合起来得到完整的RSS信息。
7.如权利要求6所述的方法,其特征在于,所述分析寻呼频道列表,得到各个RSS频道对应的寻呼标签,具体包括依次提取寻呼频道列表Channel中的各个RSS频道,在RSS频道中找到带有分页的网页; 分析带有分页的网页的页面代码,找到分页标签作为对应的RSS频道。
8.如权利要求6所述的方法,其特征在于,当从RSS源捕获信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则当前信息的页面代码具体为包括从RSS源抓取信息,判断作为当前信息源的目标RSS频道是否属于寻呼频道列表,如果是,则获取当前信息对应的页面代码。否则,认为当前信息对应的网页没有分页,流程结束。
9.如权利要求6所述的方法,其特征在于,所述根据找到的页面标签获取各页面对应的页面,并组合各页面对应的页面以获取完整的RSS信息具体包括以下步骤: 获取URL每个页面根据每个页面的URL;根据每个页面的URL获取每个页面的页面代码,从页面代码中提取每个页面的文本;结合每一页的文字,得到完整的RSS信息。
10.如权利要求6所述的方法,其特征在于,在获取完整RSS信息后,还包括向用户推送完整RSS信息的步骤。
11. 一种服务器,包括如权利要求1至5中任一项所述的RSS信息分页爬取系统。
全文摘要
本发明公开了一种RSS信息的页面抓取系统及方法。该系统包括列表创建单元,用于采集带有寻呼的RSS频道,建立寻呼频道列表;列表分析单元,用于分析寻呼信道列表,得到每个RSS信道对应的寻呼标签;代码获取单元,适用于在从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码。标签查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面合并单元用于根据找到的页面标签获取每个页面对应的页面,并将每个页面对应的页面组合起来,得到完整的RSS信息。本发明保证推送给用户的RSS信息的完整性,提高用户的阅读效率。
文件编号 G06F17/30GK102819613SQ20121031166
公布日期 2012 年 12 月 12 日 申请日期 2012 年 8 月 28 日 优先权日期 2012 年 8 月 28 日
发明人郑伟、赵刚申请人:、
scrapy分页抓取网页(我有一个3级站点,我想抓取并解析2级的链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-11 10:11
我有一个 3 级站点,我想抓取和解析 2 级和 3 级链接。问题是在第 2 级,有一个 javascript 选项卡可以为每个页面提供不同的链接(总共 5 个页面)。
示例:
Level 1:主菜单(我使用 SgmlLinkExtractor catid = 22767 提取类别的链接)
Level 2:有一些链接我想解析,但也有JavaScript分页,我需要提取其余的链接(即catid = 22767 & page1 = 2)
级别 3:对于上述步骤中的每个链接,我都想解析响应。
网站is()
级别 2 是 (summary.asp? catid = 22768)
Level3是我要分析的文章页面(article.asp?catid = 22768&subid = 2&pubid = 63929343)
问题是:对于从第一级提取的每个链接,我如何创建一个循环并构造所有5个链接,然后在第二级使用SgmlLinkExtractor跟踪这些链接?
有两个答案:
通常,网站 提供其 网站 的可搜索版本,或者您可以实现站点地图。
您可以使用 selenium 之类的东西在浏览器中呈现页面,从而启用 JavaScript,并且您可以像用户一样使用它,并且仍然可以抓取它。
确保以合乎道德的方式爬行以避免网站超载:) 查看全部
scrapy分页抓取网页(我有一个3级站点,我想抓取并解析2级的链接)
我有一个 3 级站点,我想抓取和解析 2 级和 3 级链接。问题是在第 2 级,有一个 javascript 选项卡可以为每个页面提供不同的链接(总共 5 个页面)。
示例:
Level 1:主菜单(我使用 SgmlLinkExtractor catid = 22767 提取类别的链接)
Level 2:有一些链接我想解析,但也有JavaScript分页,我需要提取其余的链接(即catid = 22767 & page1 = 2)
级别 3:对于上述步骤中的每个链接,我都想解析响应。
网站is()
级别 2 是 (summary.asp? catid = 22768)
Level3是我要分析的文章页面(article.asp?catid = 22768&subid = 2&pubid = 63929343)
问题是:对于从第一级提取的每个链接,我如何创建一个循环并构造所有5个链接,然后在第二级使用SgmlLinkExtractor跟踪这些链接?
有两个答案:
通常,网站 提供其 网站 的可搜索版本,或者您可以实现站点地图。
您可以使用 selenium 之类的东西在浏览器中呈现页面,从而启用 JavaScript,并且您可以像用户一样使用它,并且仍然可以抓取它。
确保以合乎道德的方式爬行以避免网站超载:)
scrapy分页抓取网页(怎么去爬取这些数据?一个站点:“”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-10 14:12
微博关键词爬虫;超详细的爬虫教程;整个爬虫编写过程和思路;Xpath 表达式编写;数据存储和处理
我们都知道,一般来说,要爬取微博的相关信息,不如爬取本站的一些内容。但是这个网站没有关键词搜索,所以无法根据我们要搜索的关键词抓取到我们想要的内容。然而,博主发现微博有一个站点:“”。这是一个专门用于检索基于关键词的相关微博的站点。下面,我将使用scrapy抓取本站相关微博,为大家详细讲解过程。
可以爬取的字段
先展示那些可以爬取的字段:
如何分析数据是你自己的事情。下面我们详细介绍一下如何抓取这些数据。
一、网页分析
首先我们进入,输入我们要搜索的内容,F12怎么按,观察网页格式。
为了从网页中提取我们想要的内容,我们选择使用xpath来获取。在scrapy中还有一个.xpath()方法,方便我们写爬虫。这里教大家一个小技巧,我们可以右击我们想要的标签,如何选择复制xpath,可以复制标签的xpath表达式,如何按住Ctrl+F,把复制的表达式放到搜索框中,那么我们后面就可以直接修改表达式,提取出标签下或者与标签同级的标签下的对应内容。这一步很重要,可以提高我们后面写代码的效率。
比如我们这里复制了页面第一个内容的xpath表达式,然后我修改了表达式来提取相似的标签。
如您所见,这种类型有 22 个标签。我数了数。这个页面下只有22条微博。然后,我们只需要在这个 xpath 表达式后面添加内容就可以进一步提取我们想要的字段。. 我们以微博的文字内容为例。
首先,我们先选择中微博的文字内容:
然后检查标签
此时,我们只需要提取 p 标签的文本即可。首先,我们需要定位到p标签,在刚才的xpath表达式后面加上:“//p[@node-type="feed_list_content"”,所以我们选择这个页面下所有微博的文字内容是现在。其他领域也是如此。我们把所有字段的xpath表达式搞清楚,后面爬的时候具体处理一下。
二、爬虫部分
对于爬虫部分,我们使用scrapy框架来编写。这个框架的安装以及如何创建项目我就不详细介绍了。您可以自行查找信息。
创建项目并制作蜘蛛后,我们首先编写item.py,在item中定义我们要爬取的字段。
from scrapy import Item, Field
class KeywordItem(Item):
"""
关键词微博
"""
keyword = Field()
weibo_url = Field()
content = Field()
weibo_id = Field()
crawl_time = Field()
created_at = Field()
tool = Field()
repost_num = Field()
comment_num = Field()
like_num = Field()
user_url = Field()
user_id = Field()
然后编写pipeline.py 将爬虫存储在本地数据库中。
import pymongo
from pymongo.errors import DuplicateKeyError
from settings import MONGO_HOST, MONGO_PORT
class MongoDBPipeline(object):
def __init__(self):
client = pymongo.MongoClient(MONGO_HOST, MONGO_PORT)
db = client['edg']
self.Keyword = db["Keyword"]
def process_item(self, item, spider):
self.insert_item(self.Keyword, item)
@staticmethod
def insert_item(collection, item):
try:
collection.insert(dict(item))
except DuplicateKeyError:
pass
首先是初始化函数,定义了数据库的端口、名称和表名;然后 process_item 函数将所有项目字段插入到表 Keyword 中。item是scrapy的一大特色,类似于字典的数据结构,爬虫部分将爬取到的数据存储在item中,提交到pipeline进行存储。
然后我们开始写爬虫部分,在spider文件夹下创建keyword.py,在start_requests中定义要爬取的网页和headers。
def start_requests(self):
headers = {
'Host': 's.weibo.com',
'Cookie': ''
}
keywords = ['edg']
url = 'https://s.weibo.com/weibo?q={}&Refer=index&page=1'
那么我们一定要抓取数据,不能只抓取一页的数据。根据网站的URL我们可以发现有一个page参数。我们只需要构造这个参数的值就可以为不同的页面生成URL。,我把他放到一个URL列表中,迭代访问。
urls = []
for keyword in keywords:
urls.append(url.format(keyword))
for url in urls:
yield Request(url, callback=self.parse,headers=headers)
然后我们编写爬虫处理函数parse。
def parse(self, response):
if response.url.endswith('page=1'):
page = 50
for page_num in range(2, page+1):
page_url = response.url.replace('page=1', 'page={}'.format(page_num))
yield Request(page_url, self.parse, dont_filter=True, meta=response.meta)
if response.status == 200:
html_result = response.text
data = etree.HTML(html_result)
nodes = data.xpath('//div[@class="card"]')
首先是判断url的最后一个page参数是否为1,如果是,那么我们把页面复制到50(因为网站最多可以显示50页的微博内容),然后使用format 方法构造 50 个 URL,每个都提交给 parse 方法进行处理。
如果访问成功,所有“//div[@class="card"]”将被提取并分配给节点。这是我们上面的网络分析提取的所有收录微博内容的 xpath 表达式。然后它提取节点循环中的所有文本内容。
这里我们仅以提取微博文本内容为例
你只需要将提取的微博文本内容的xpath表达式提取到"//div[@class="card"]"之后添加到内容中,处理后放入keyword_item中(我刚才说的类似字典结构,用法同字典)。如何处理它提取所有文本?这需要不断的实验。例如,在我意识到我使用的是 .xpath('string(.)') 之前,我尝试了很多次。最后别忘了提交给项目。
extract_weibo_content() 是处理和提取文本中多余的表情符号、符号和 URL 的函数。代码显示如下:
def extract_weibo_content(weibo_html):
s = weibo_html
if 'class="ctt">' in s:
s = s.split('class="ctt">', maxsplit=1)[1]
s = emoji_re.sub('', s)
s = url_re.sub('', s)
s = div_re.sub('', s)
s = image_re.sub('', s)
if '' in s:
s = s.split('')[0]
splits = s.split('赞[')
if len(splits) == 2:
s = splits[0]
if len(splits) == 3:
origin_text = splits[0]
retweet_text = splits[1].split('转发理由:')[1]
s = origin_text + '转发理由:' + retweet_text
s = white_space_re.sub(' ', s)
s = keyword_re.sub('', s)
s = s.replace('\xa0', '')
s = s.strip(':')
s = s.strip()
return s
三、数据抓取与处理
然后我们就可以开始运行爬虫了。
可以看出爬虫运行没有问题。我用一个ip和一个账号来爬取。经测试,速度约为每小时10000次爬行。
最后查看我们在mongodb中爬取的数据,我也爬取了微博上的评论
这里的数据量有点小,主要是我过了一会儿就停了。如果你想爬得更多,你可以自己尝试一下。
有了数据,接下来我们要怎么分析,至少我们还有饭要煮。微博和评论的词云在这里产生
我也是爬虫爱好者,希望写这篇文章可以帮助到一些刚入门的人。欢迎大家交流批评指正。 查看全部
scrapy分页抓取网页(怎么去爬取这些数据?一个站点:“”)
微博关键词爬虫;超详细的爬虫教程;整个爬虫编写过程和思路;Xpath 表达式编写;数据存储和处理
我们都知道,一般来说,要爬取微博的相关信息,不如爬取本站的一些内容。但是这个网站没有关键词搜索,所以无法根据我们要搜索的关键词抓取到我们想要的内容。然而,博主发现微博有一个站点:“”。这是一个专门用于检索基于关键词的相关微博的站点。下面,我将使用scrapy抓取本站相关微博,为大家详细讲解过程。
可以爬取的字段
先展示那些可以爬取的字段:

如何分析数据是你自己的事情。下面我们详细介绍一下如何抓取这些数据。
一、网页分析
首先我们进入,输入我们要搜索的内容,F12怎么按,观察网页格式。
为了从网页中提取我们想要的内容,我们选择使用xpath来获取。在scrapy中还有一个.xpath()方法,方便我们写爬虫。这里教大家一个小技巧,我们可以右击我们想要的标签,如何选择复制xpath,可以复制标签的xpath表达式,如何按住Ctrl+F,把复制的表达式放到搜索框中,那么我们后面就可以直接修改表达式,提取出标签下或者与标签同级的标签下的对应内容。这一步很重要,可以提高我们后面写代码的效率。
比如我们这里复制了页面第一个内容的xpath表达式,然后我修改了表达式来提取相似的标签。
如您所见,这种类型有 22 个标签。我数了数。这个页面下只有22条微博。然后,我们只需要在这个 xpath 表达式后面添加内容就可以进一步提取我们想要的字段。. 我们以微博的文字内容为例。
首先,我们先选择中微博的文字内容:
然后检查标签
此时,我们只需要提取 p 标签的文本即可。首先,我们需要定位到p标签,在刚才的xpath表达式后面加上:“//p[@node-type="feed_list_content"”,所以我们选择这个页面下所有微博的文字内容是现在。其他领域也是如此。我们把所有字段的xpath表达式搞清楚,后面爬的时候具体处理一下。
二、爬虫部分
对于爬虫部分,我们使用scrapy框架来编写。这个框架的安装以及如何创建项目我就不详细介绍了。您可以自行查找信息。
创建项目并制作蜘蛛后,我们首先编写item.py,在item中定义我们要爬取的字段。
from scrapy import Item, Field
class KeywordItem(Item):
"""
关键词微博
"""
keyword = Field()
weibo_url = Field()
content = Field()
weibo_id = Field()
crawl_time = Field()
created_at = Field()
tool = Field()
repost_num = Field()
comment_num = Field()
like_num = Field()
user_url = Field()
user_id = Field()
然后编写pipeline.py 将爬虫存储在本地数据库中。
import pymongo
from pymongo.errors import DuplicateKeyError
from settings import MONGO_HOST, MONGO_PORT
class MongoDBPipeline(object):
def __init__(self):
client = pymongo.MongoClient(MONGO_HOST, MONGO_PORT)
db = client['edg']
self.Keyword = db["Keyword"]
def process_item(self, item, spider):
self.insert_item(self.Keyword, item)
@staticmethod
def insert_item(collection, item):
try:
collection.insert(dict(item))
except DuplicateKeyError:
pass
首先是初始化函数,定义了数据库的端口、名称和表名;然后 process_item 函数将所有项目字段插入到表 Keyword 中。item是scrapy的一大特色,类似于字典的数据结构,爬虫部分将爬取到的数据存储在item中,提交到pipeline进行存储。
然后我们开始写爬虫部分,在spider文件夹下创建keyword.py,在start_requests中定义要爬取的网页和headers。
def start_requests(self):
headers = {
'Host': 's.weibo.com',
'Cookie': ''
}
keywords = ['edg']
url = 'https://s.weibo.com/weibo?q={}&Refer=index&page=1'
那么我们一定要抓取数据,不能只抓取一页的数据。根据网站的URL我们可以发现有一个page参数。我们只需要构造这个参数的值就可以为不同的页面生成URL。,我把他放到一个URL列表中,迭代访问。
urls = []
for keyword in keywords:
urls.append(url.format(keyword))
for url in urls:
yield Request(url, callback=self.parse,headers=headers)
然后我们编写爬虫处理函数parse。
def parse(self, response):
if response.url.endswith('page=1'):
page = 50
for page_num in range(2, page+1):
page_url = response.url.replace('page=1', 'page={}'.format(page_num))
yield Request(page_url, self.parse, dont_filter=True, meta=response.meta)
if response.status == 200:
html_result = response.text
data = etree.HTML(html_result)
nodes = data.xpath('//div[@class="card"]')
首先是判断url的最后一个page参数是否为1,如果是,那么我们把页面复制到50(因为网站最多可以显示50页的微博内容),然后使用format 方法构造 50 个 URL,每个都提交给 parse 方法进行处理。
如果访问成功,所有“//div[@class="card"]”将被提取并分配给节点。这是我们上面的网络分析提取的所有收录微博内容的 xpath 表达式。然后它提取节点循环中的所有文本内容。
这里我们仅以提取微博文本内容为例
你只需要将提取的微博文本内容的xpath表达式提取到"//div[@class="card"]"之后添加到内容中,处理后放入keyword_item中(我刚才说的类似字典结构,用法同字典)。如何处理它提取所有文本?这需要不断的实验。例如,在我意识到我使用的是 .xpath('string(.)') 之前,我尝试了很多次。最后别忘了提交给项目。
extract_weibo_content() 是处理和提取文本中多余的表情符号、符号和 URL 的函数。代码显示如下:
def extract_weibo_content(weibo_html):
s = weibo_html
if 'class="ctt">' in s:
s = s.split('class="ctt">', maxsplit=1)[1]
s = emoji_re.sub('', s)
s = url_re.sub('', s)
s = div_re.sub('', s)
s = image_re.sub('', s)
if '' in s:
s = s.split('')[0]
splits = s.split('赞[')
if len(splits) == 2:
s = splits[0]
if len(splits) == 3:
origin_text = splits[0]
retweet_text = splits[1].split('转发理由:')[1]
s = origin_text + '转发理由:' + retweet_text
s = white_space_re.sub(' ', s)
s = keyword_re.sub('', s)
s = s.replace('\xa0', '')
s = s.strip(':')
s = s.strip()
return s
三、数据抓取与处理
然后我们就可以开始运行爬虫了。
可以看出爬虫运行没有问题。我用一个ip和一个账号来爬取。经测试,速度约为每小时10000次爬行。
最后查看我们在mongodb中爬取的数据,我也爬取了微博上的评论

这里的数据量有点小,主要是我过了一会儿就停了。如果你想爬得更多,你可以自己尝试一下。
有了数据,接下来我们要怎么分析,至少我们还有饭要煮。微博和评论的词云在这里产生


我也是爬虫爱好者,希望写这篇文章可以帮助到一些刚入门的人。欢迎大家交流批评指正。
scrapy分页抓取网页(scrapy分页抓取网页数据教程和scrapy一起抓取数据(scrapy中文文档))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-07 14:01
scrapy分页抓取网页数据教程requests和scrapy一起抓取网页数据(scrapy中文文档)jsonorxml
我之前做过一个爬虫,调用知乎api的,
scrapy比较火scrapy的多线程抓取
python2requestsgetpostplsurllib3urllib2都有对应框架
scrapy有python库,对scrapy比较熟悉,
要想知道哪些问题需要学习scrapy,基本上可以从python类库上开始看,例如scrapy等。是不是需要学习scrapy框架的源码等问题。两者都是轻量级的爬虫框架,但是因为学习的目的不同,scrapy必须不停的对接不同的文件对接等操作。建议学习时先对scrapy框架有个了解,做一些有趣有意义的项目,多用scrapy来抓取数据,然后再去了解scrapy源码。
scrapy都是基于scrapy框架,只有以后有更多的文章要写了,才会更详细的把scrapy技术演变过程拿出来。我就是在文章中详细讲解了scrapy技术详细历史,还有最核心的组件,如何使用scrapy爬取网站内容的。希望对你有所帮助。总结起来,自scrapy开始,到scrapyforpython,再到scrapyforjava,然后到现在的scrapyforjavascript。
反爬虫,基于xpath请求,利用cookie记录所有的数据,比如评论数、粉丝数,他们数据需要存储。如果感兴趣, 查看全部
scrapy分页抓取网页(scrapy分页抓取网页数据教程和scrapy一起抓取数据(scrapy中文文档))
scrapy分页抓取网页数据教程requests和scrapy一起抓取网页数据(scrapy中文文档)jsonorxml
我之前做过一个爬虫,调用知乎api的,
scrapy比较火scrapy的多线程抓取
python2requestsgetpostplsurllib3urllib2都有对应框架
scrapy有python库,对scrapy比较熟悉,
要想知道哪些问题需要学习scrapy,基本上可以从python类库上开始看,例如scrapy等。是不是需要学习scrapy框架的源码等问题。两者都是轻量级的爬虫框架,但是因为学习的目的不同,scrapy必须不停的对接不同的文件对接等操作。建议学习时先对scrapy框架有个了解,做一些有趣有意义的项目,多用scrapy来抓取数据,然后再去了解scrapy源码。
scrapy都是基于scrapy框架,只有以后有更多的文章要写了,才会更详细的把scrapy技术演变过程拿出来。我就是在文章中详细讲解了scrapy技术详细历史,还有最核心的组件,如何使用scrapy爬取网站内容的。希望对你有所帮助。总结起来,自scrapy开始,到scrapyforpython,再到scrapyforjava,然后到现在的scrapyforjavascript。
反爬虫,基于xpath请求,利用cookie记录所有的数据,比如评论数、粉丝数,他们数据需要存储。如果感兴趣,
scrapy分页抓取网页( WebScraper怎么对付这种类型的网页?翻页链接不规律)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-07 05:22
WebScraper怎么对付这种类型的网页?翻页链接不规律)
【这是简单数据分析系列的第12篇文章】
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则页面链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进来增加坤坤的阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,会发现这个转发的网页网址不规则,只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬虫系统(比如突然弹出验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
WebScraper怎么对付这种类型的网页?翻页链接不规律)

【这是简单数据分析系列的第12篇文章】
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。

今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:

但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则页面链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。

这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进来增加坤坤的阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,会发现这个转发的网页网址不规则,只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
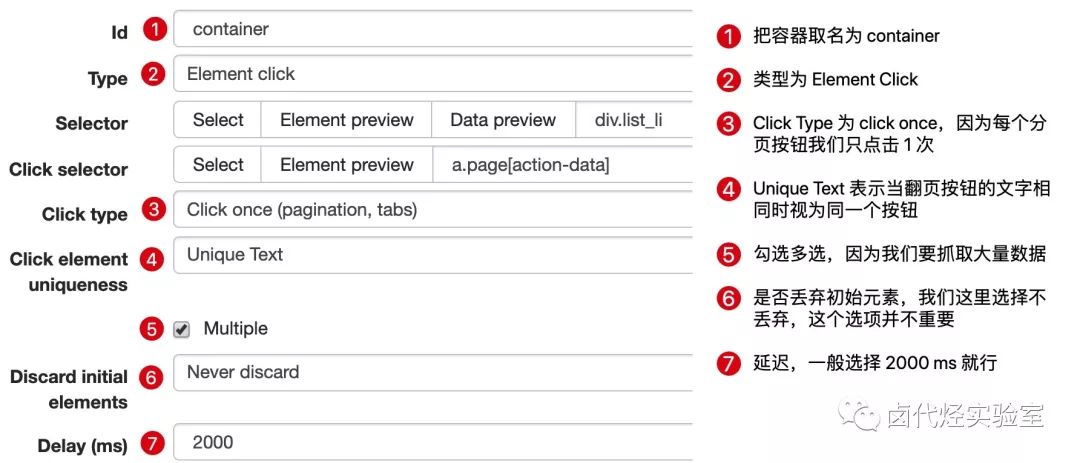
容器的预览如下图所示:

寻呼机选择过程如下图所示:

3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。

4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬虫系统(比如突然弹出验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(抓取慕课网课程信息展示之scrapy框架数据的过程介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-07 00:14
)
本例主要通过抓取Mukenet的课程信息来演示scrapy框架爬取数据的过程。
1、抢夺网站 简介
爬网网站:
截取内容:截取内容为所有课程名称、课程介绍、课程网址、课程图片网址、课程编号(由于动态渲染)
网站图片:
2、创建项目
以命令行方式创建项目
scrapy startprojectscrapy_course
建立完成后,用pycharm打开,目录如下:
scrapy.cfg:项目配置文件
scrapytest/:项目的python模块。稍后您将在此处添加代码。
scrapytest/items.py:项目中的item文件。
scrapytest/pipelines.py:项目中的管道文件。
scrapytest/settings.py:项目的设置文件。
scrapytest/spiders/:蜘蛛代码放置的目录。
3、创建爬虫
下面的步骤解释了如何编写一个简单的爬虫。
我们要写一个爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
该文件收录一个 MySpider 类,该类必须继承 scrapy.Spider 类。
同时它必须定义三个属性:
-name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。
-start_urls:收录Spider启动时会爬取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。
-parse() 是蜘蛛的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
MySpider.py创建后的代码如下
定义爬虫项目
创建好Spider文件后,先别急着写爬虫代码
我们首先定义一个容器来存放要爬取的数据。
所以我们使用Item
为了定义常用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬取的数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
我们可以在项目目录中看到一个项目文件,我们可以更改这个文件或创建一个新文件来定义我们的项目。
在这里,我们在同一层上创建一个新的项目文件 CourseItems.py
根据上面的代码,我们创建了一个名为courseItem的容器来存储和抓取信息。
title->课程名称,url->课程url,image_url->课程标题图片,介绍->课程描述,学生->学号
创建项目文件后,我们可以使用类似字典的 API 和简单的语法来声明可用字段。
常用方法如下
4、编写Spider代码
定义好item后,我们就可以开始爬取部分的工作了。
为简单起见,我们首先抓取页面上的信息。
首先我们编写爬取代码
正如我们上面所说,爬取部分是在 MySpider 类的 parse() 方法中执行的。
parse() 方法负责处理响应并返回处理后的数据和/或 URL 以供后续处理。
此方法和其他 Request 回调函数必须返回一个收录 Request 和/或 Item 的可迭代对象。
我们在之前创建的 MySpider.py 中编写以下代码。
注意上面与 MySpider.py 的区别
# -*- coding:utf8-*-
import scrapy
import sys
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from scrapy_course.items import CourseItem
from scrapy.selector import Selector
sys.stdout = open(\'output.txt\', \'w\')
pageIndex = 0
class MySpider(scrapy.Spider):
#用于区别Spider
name = "MySpider"
#允许访问的域
allowed_domains = [\'imooc.com\']
#爬取的地址
start_urls = ["http://www.imooc.com/course/list"]
#爬取方法
def parse(self, response):
# 实例一个容器保存爬取的信息
item = CourseItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个课程的div
sel = Selector(response)
title = sel.xpath(\'/html/head/title/text()\').extract() # 标题
print title[0]
# sels = sel.xpath(\'//div[@class="course-card-content"]\')
sels = sel.xpath(\'//a[@class="course-card"]\')
pictures = sel.xpath(\'//div[@class="course-card-bk"]\')
index = 0
global pageIndex
pageIndex += 1
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
print \'第\' + str(pageIndex)+ \'页 \'
print \'----------------------------------------------\'
for box in sels:
print \' \'
# 获取div中的课程标题
item[\'title\'] = box.xpath(\'.//h3[@class="course-card-name"]/text()\').extract()[0].strip()
print \'标题:\' + item[\'title\']
# 获取div中的课程简介
item[\'introduction\'] = box.xpath(\'.//p/text()\').extract()[0].strip()
print \'简介:\' + item[\'introduction\']
# 获取每个div中的课程路径
item[\'url\'] = \'http://www.imooc.com\' + box.xpath(\'.//@href\').extract()[0]
print \'路径:\' +item[\'url\']
# 获取div中的学生人数
item[\'student\'] = box.xpath(\'.//div[@class="course-card-info"]/text()\').extract()[0].strip()
print item[\'student\']
# 获取div中的标题图片地址
item[\'image_url\'] = pictures[index].xpath(\'.//img/@src\').extract()[0]
print \'图片地址:\' + item[\'image_url\']
index += 1
yield item
time.sleep(1)
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
# next =u\'下一页\'
# url = response.xpath("//a[contains(text(),\'" + next + "\')]/@href").extract()
# if url:
# # 将信息组合成下一页的url
# page = \'http://www.imooc.com\' + url[0]
# # 返回url
# yield scrapy.Request(page, callback=self.parse)
使用 Pipeline 处理数据
在我们成功获取信息后,我们需要对信息进行验证和存储。这里我们以存储为例。
当 Item 在 Spider 中被采集到时,它会被传递到 Pipeline,一些组件会按照一定的顺序执行 Item 的处理。
流水线经常执行以下操作:
清理 HTML 数据
验证爬取的数据(检查项目是否收录某些字段)
重复检查(并丢弃)
目前,抓取结果暂时保存在文本中
这里只进行简单的将数据存储在json文件中的操作。
pipelines.py 代码如下
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
import codecs
import json
class ScrapyCoursePipeline(object):
def __init__(self):
# self.file = open(\'data.json\', \'wb\')
# self.file = codecs.open(
# \'spider.txt\', \'w\', encoding=\'utf-8\')
self.file = codecs.open(
\'spider.json\', \'w\', encoding=\'utf-8\')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
要使用Pipeline,您必须先注册Pipeline
找到settings.py文件,这个文件就是爬虫的配置文件
添加进去
ITEM_PIPELINES = {
\'scrapy_course.pipelines.ScrapyCoursePipeline\':300
}
上面的代码是用来注册Pipeline的,其中scrapy_course.pipelines.ScrapyCoursePipeline是你要注册的类,右边的'300'是Pipeline的优先级,范围从1到1000。管道越小,越早执行。
经过以上操作,我们最基本的爬取操作之一就完成了
然后我们运行
5、运行
在命令行下运行scrapy crawl MySpider
如何将数据存储在文本文件中,在代码前添加如下代码,
sys.stdout = open(\'output.txt\', \'w\'),这会将数据保存到当前项目路径下的output.txt文件中
如下:
查看全部
scrapy分页抓取网页(抓取慕课网课程信息展示之scrapy框架数据的过程介绍
)
本例主要通过抓取Mukenet的课程信息来演示scrapy框架爬取数据的过程。
1、抢夺网站 简介
爬网网站:
截取内容:截取内容为所有课程名称、课程介绍、课程网址、课程图片网址、课程编号(由于动态渲染)
网站图片:
2、创建项目
以命令行方式创建项目
scrapy startprojectscrapy_course
建立完成后,用pycharm打开,目录如下:
scrapy.cfg:项目配置文件
scrapytest/:项目的python模块。稍后您将在此处添加代码。
scrapytest/items.py:项目中的item文件。
scrapytest/pipelines.py:项目中的管道文件。
scrapytest/settings.py:项目的设置文件。
scrapytest/spiders/:蜘蛛代码放置的目录。
3、创建爬虫
下面的步骤解释了如何编写一个简单的爬虫。
我们要写一个爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
该文件收录一个 MySpider 类,该类必须继承 scrapy.Spider 类。
同时它必须定义三个属性:
-name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。
-start_urls:收录Spider启动时会爬取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。
-parse() 是蜘蛛的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
MySpider.py创建后的代码如下
定义爬虫项目
创建好Spider文件后,先别急着写爬虫代码
我们首先定义一个容器来存放要爬取的数据。
所以我们使用Item
为了定义常用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬取的数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
我们可以在项目目录中看到一个项目文件,我们可以更改这个文件或创建一个新文件来定义我们的项目。
在这里,我们在同一层上创建一个新的项目文件 CourseItems.py
根据上面的代码,我们创建了一个名为courseItem的容器来存储和抓取信息。
title->课程名称,url->课程url,image_url->课程标题图片,介绍->课程描述,学生->学号
创建项目文件后,我们可以使用类似字典的 API 和简单的语法来声明可用字段。
常用方法如下
4、编写Spider代码
定义好item后,我们就可以开始爬取部分的工作了。
为简单起见,我们首先抓取页面上的信息。
首先我们编写爬取代码
正如我们上面所说,爬取部分是在 MySpider 类的 parse() 方法中执行的。
parse() 方法负责处理响应并返回处理后的数据和/或 URL 以供后续处理。
此方法和其他 Request 回调函数必须返回一个收录 Request 和/或 Item 的可迭代对象。
我们在之前创建的 MySpider.py 中编写以下代码。
注意上面与 MySpider.py 的区别
# -*- coding:utf8-*-
import scrapy
import sys
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from scrapy_course.items import CourseItem
from scrapy.selector import Selector
sys.stdout = open(\'output.txt\', \'w\')
pageIndex = 0
class MySpider(scrapy.Spider):
#用于区别Spider
name = "MySpider"
#允许访问的域
allowed_domains = [\'imooc.com\']
#爬取的地址
start_urls = ["http://www.imooc.com/course/list"]
#爬取方法
def parse(self, response):
# 实例一个容器保存爬取的信息
item = CourseItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个课程的div
sel = Selector(response)
title = sel.xpath(\'/html/head/title/text()\').extract() # 标题
print title[0]
# sels = sel.xpath(\'//div[@class="course-card-content"]\')
sels = sel.xpath(\'//a[@class="course-card"]\')
pictures = sel.xpath(\'//div[@class="course-card-bk"]\')
index = 0
global pageIndex
pageIndex += 1
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
print \'第\' + str(pageIndex)+ \'页 \'
print \'----------------------------------------------\'
for box in sels:
print \' \'
# 获取div中的课程标题
item[\'title\'] = box.xpath(\'.//h3[@class="course-card-name"]/text()\').extract()[0].strip()
print \'标题:\' + item[\'title\']
# 获取div中的课程简介
item[\'introduction\'] = box.xpath(\'.//p/text()\').extract()[0].strip()
print \'简介:\' + item[\'introduction\']
# 获取每个div中的课程路径
item[\'url\'] = \'http://www.imooc.com\' + box.xpath(\'.//@href\').extract()[0]
print \'路径:\' +item[\'url\']
# 获取div中的学生人数
item[\'student\'] = box.xpath(\'.//div[@class="course-card-info"]/text()\').extract()[0].strip()
print item[\'student\']
# 获取div中的标题图片地址
item[\'image_url\'] = pictures[index].xpath(\'.//img/@src\').extract()[0]
print \'图片地址:\' + item[\'image_url\']
index += 1
yield item
time.sleep(1)
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
# next =u\'下一页\'
# url = response.xpath("//a[contains(text(),\'" + next + "\')]/@href").extract()
# if url:
# # 将信息组合成下一页的url
# page = \'http://www.imooc.com\' + url[0]
# # 返回url
# yield scrapy.Request(page, callback=self.parse)
使用 Pipeline 处理数据
在我们成功获取信息后,我们需要对信息进行验证和存储。这里我们以存储为例。
当 Item 在 Spider 中被采集到时,它会被传递到 Pipeline,一些组件会按照一定的顺序执行 Item 的处理。
流水线经常执行以下操作:
清理 HTML 数据
验证爬取的数据(检查项目是否收录某些字段)
重复检查(并丢弃)
目前,抓取结果暂时保存在文本中
这里只进行简单的将数据存储在json文件中的操作。
pipelines.py 代码如下
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
import codecs
import json
class ScrapyCoursePipeline(object):
def __init__(self):
# self.file = open(\'data.json\', \'wb\')
# self.file = codecs.open(
# \'spider.txt\', \'w\', encoding=\'utf-8\')
self.file = codecs.open(
\'spider.json\', \'w\', encoding=\'utf-8\')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
要使用Pipeline,您必须先注册Pipeline
找到settings.py文件,这个文件就是爬虫的配置文件
添加进去
ITEM_PIPELINES = {
\'scrapy_course.pipelines.ScrapyCoursePipeline\':300
}
上面的代码是用来注册Pipeline的,其中scrapy_course.pipelines.ScrapyCoursePipeline是你要注册的类,右边的'300'是Pipeline的优先级,范围从1到1000。管道越小,越早执行。
经过以上操作,我们最基本的爬取操作之一就完成了
然后我们运行
5、运行
在命令行下运行scrapy crawl MySpider
如何将数据存储在文本文件中,在代码前添加如下代码,
sys.stdout = open(\'output.txt\', \'w\'),这会将数据保存到当前项目路径下的output.txt文件中
如下:
scrapy分页抓取网页(scrapy分页抓取网页进行分析(一)_抓取程序前端代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-06 01:01
scrapy分页抓取网页进行分析。可以修改需要抓取网页的源代码,(源代码可以自己存,但只能提取上一页到底的信息)将源代码重新赋值到指定网页地址。用scrapy还可以实现抓取第二页,第三页等等。
抓取抓取程序前端代码在python中可以用scrapy,但是建议由抓爬最后再调整。抓到后先在request中找到所有页面的连接,由于ie浏览器不支持scrapy,所以只有extract("page1.txt")这个函数。
1)importscrapy
2)pip3installscrapylist_txt=scrapy.list_txt()
3)txt=pd.read_table(list_txt)
4)scrapy.cookies.updater(user_agent)
5)list_txt=txt。strip()out=scrapy。formspider(callback=scrapy。spider。request。output_mode,check_cookies=scrapy。cookies)#第一次请求(登录页)out[:3]=list_txt。contentout[:3]=""forpageinout:page=page。
replace("//","/\w+/\w+/\w+/\w+")print("第%s页,"%page)out[:3]=pageout[:3]="/\w+/\w+"ifisinstance(out,request):forpageinout:content=""print("username="+username)out[:3]=contentout[:3]="/\w+/\w+/\w+"ifout!=none:elifout。
is_error:scrapy。error("accessmissing:",isinstance(out,request))。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页进行分析(一)_抓取程序前端代码)
scrapy分页抓取网页进行分析。可以修改需要抓取网页的源代码,(源代码可以自己存,但只能提取上一页到底的信息)将源代码重新赋值到指定网页地址。用scrapy还可以实现抓取第二页,第三页等等。
抓取抓取程序前端代码在python中可以用scrapy,但是建议由抓爬最后再调整。抓到后先在request中找到所有页面的连接,由于ie浏览器不支持scrapy,所以只有extract("page1.txt")这个函数。
1)importscrapy
2)pip3installscrapylist_txt=scrapy.list_txt()
3)txt=pd.read_table(list_txt)
4)scrapy.cookies.updater(user_agent)
5)list_txt=txt。strip()out=scrapy。formspider(callback=scrapy。spider。request。output_mode,check_cookies=scrapy。cookies)#第一次请求(登录页)out[:3]=list_txt。contentout[:3]=""forpageinout:page=page。
replace("//","/\w+/\w+/\w+/\w+")print("第%s页,"%page)out[:3]=pageout[:3]="/\w+/\w+"ifisinstance(out,request):forpageinout:content=""print("username="+username)out[:3]=contentout[:3]="/\w+/\w+/\w+"ifout!=none:elifout。
is_error:scrapy。error("accessmissing:",isinstance(out,request))。
scrapy分页抓取网页(Crawlab的可配置爬虫只需要爬虫工程师配置一些必要的CSS/XPath提取规则 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-01 05:14
)
前言
开发爬虫是一件很有趣的事情。编写一个程序,向感兴趣的目标网站发起HTTP请求,获取HTML,解析HTML,提取数据,将数据保存到数据库或CSV、JSON等格式,然后使用你熟悉的语言如作为 Python 对这些数据进行分析以生成很酷的图表。这个过程是不是很刺激?
然而,开发爬虫并不是一件简单的事情。通常,开发一个简单的爬虫往往需要几个模块:下载器、解析器、提取规则和保存模块。用Python实现这个简单的爬虫,至少需要写10-20行代码,如果考虑并发和调度,通常需要写50多行代码。比较麻烦的是,如果要管理多个爬虫实现爬虫工程,需要从每个爬虫代码中提取通用模块和参数。这个过程需要相当的工程经验和时间的积累。其实大体上,主要网站的结构是类似的,只是提取规则需要改变。很多爬虫工程师在大型项目中要写上百条抽取规则,
可配置爬虫
幸运的是,Crawlab 在 v0.2.1 版本中添加了一个新的特性可配置爬虫,让工程师从这些重复性工作中解放出来。Crawlab的可配置爬虫只需要爬虫工程师配置一些必要的CSS/XPath提取规则就可以完成常规的爬虫开发。根据作者的实验,对于稍微熟悉 CSS 选择器或 XPath 的工程师来说,使用可配置的爬虫开发一个五脏俱全的常规爬虫只需要 1-3 分钟。
Crawlab 的可配置爬虫是基于 Scrapy 的,所以天生就是支持并发的。而且,可配置爬虫完全支持Crawlab自定义爬虫的通用功能,因此也支持任务调度、任务监控、日志监控、数据分析。
安装并运行 Crawlab
Crawlab是一个专注于爬虫的分布式爬虫管理平台,集成了爬虫管理、任务调度、任务监控、数据分析等模块。非常适合对爬虫管理和爬虫工程有需求的开发者和公司。
Crawlab的详细介绍请参考之前的文章:-
下面是Crawlab的安装和运行步骤,大概需要10-20分钟。
如何开发和运行可配置的爬虫
现在终于到了爬虫开发时间。这里将以网易24小时排名新闻为例,开发相应的可配置爬虫。整个过程不应超过3分钟。
添加爬虫
Crawlab运行后,在浏览器中打开网址:8080,导航到爬虫。单击“添加爬虫”按钮。
单击以配置爬虫。
输入基本信息后,点击添加。
配置爬虫
添加完成后可以看到底部出现刚刚添加的可配置爬虫,点击查看进入爬虫详情。
单击配置选项卡,进入配置页面。接下来,我们需要配置爬虫规则。
已经有一些配置的初始条目。我们简要介绍每个的含义。
抓取类别
这也是爬虫采用的策略,即爬虫如何遍历网页。作为第一个版本,我们只有列表,只有详细信息页面,列表+详细信息页面。- 仅列表页面。这也是最简单的形式。爬虫遍历列表中的列表项并抓取数据。- 仅详细信息页面。爬虫只爬取详情页。-列表+详细信息页面。爬虫首先遍历列表页,提取列表项中的详情页地址,跟进抓取详情页。
这里我们选择列表+详情页。
列表项选择器和分页选择器
列表项和分页按钮的匹配查询通过 CSS 或 XPath 进行匹配。
起始网址
爬虫首先遍历的 URL。
遵守机器人协议
这是默认启用的。如果开启,爬虫会先抓取网站的robots.txt,判断页面是否可抓取;否则,将无法验证。用户可以选择关闭它。请注意,任何无视机器人协议的行为都有法律风险。
列出页面字段和详细信息页面字段
这些是需要在列表页面或详细信息页面上提取的字段。这些字段由 CSS 选择器或 XPath 匹配和提取。您可以选择文本或属性。
检查目标页面的元素CSS选择器后,我们输入列表项选择器、起始URL、列表页/详情页等信息。请注意,检查 url 是详细信息页面的 URL。
单击保存、预览以查看预览内容。
OK,现在配置完成,终于可以开始运行爬虫了!
运行爬虫
您唯一需要做的就是单击运行按钮并确认。点击Overview选项卡,可以看到任务已经开始运行了。
点击创建时间链接,导航到任务详情,点击结果选项卡,可以看到抓取的结果已经保存。
怎么样,这个过程是不是超级简单?如果你熟练,整个过程可以在60秒内完成!就像玩魔方一样,玩得越多,你就越熟练!
结束语
本文利用Crawlab的可配置爬虫功能,在3分钟内抓取网易新闻24小时新闻排名。同样的过程可以在其他类似的网站上实现。虽然这是一个经典的“列表+详情页”的爬取模式,比较简单,但是未来我们会开发出越来越复杂的爬取方式来实现更多的爬取需求。Crawlab的可配置爬虫减少了爬虫开发时间,提高了爬虫开发效率,提高了工程水平,让爬虫工程师从日常繁琐的配置工作中解脱出来。配置工作可以交给初级爬虫工程师或外包人员,而高级爬虫工程师将专注于更复杂的爬虫任务,如反爬虫、动态内容、分布式爬虫、
Github: tikazyq/crawlab
如果你觉得Crawlab还不错,如果对你的日常工作或业务有帮助,请加作者微信加入开发交流群,大家可以交流一下Crawlab的使用和开发。
查看全部
scrapy分页抓取网页(Crawlab的可配置爬虫只需要爬虫工程师配置一些必要的CSS/XPath提取规则
)
前言
开发爬虫是一件很有趣的事情。编写一个程序,向感兴趣的目标网站发起HTTP请求,获取HTML,解析HTML,提取数据,将数据保存到数据库或CSV、JSON等格式,然后使用你熟悉的语言如作为 Python 对这些数据进行分析以生成很酷的图表。这个过程是不是很刺激?
然而,开发爬虫并不是一件简单的事情。通常,开发一个简单的爬虫往往需要几个模块:下载器、解析器、提取规则和保存模块。用Python实现这个简单的爬虫,至少需要写10-20行代码,如果考虑并发和调度,通常需要写50多行代码。比较麻烦的是,如果要管理多个爬虫实现爬虫工程,需要从每个爬虫代码中提取通用模块和参数。这个过程需要相当的工程经验和时间的积累。其实大体上,主要网站的结构是类似的,只是提取规则需要改变。很多爬虫工程师在大型项目中要写上百条抽取规则,
可配置爬虫
幸运的是,Crawlab 在 v0.2.1 版本中添加了一个新的特性可配置爬虫,让工程师从这些重复性工作中解放出来。Crawlab的可配置爬虫只需要爬虫工程师配置一些必要的CSS/XPath提取规则就可以完成常规的爬虫开发。根据作者的实验,对于稍微熟悉 CSS 选择器或 XPath 的工程师来说,使用可配置的爬虫开发一个五脏俱全的常规爬虫只需要 1-3 分钟。
Crawlab 的可配置爬虫是基于 Scrapy 的,所以天生就是支持并发的。而且,可配置爬虫完全支持Crawlab自定义爬虫的通用功能,因此也支持任务调度、任务监控、日志监控、数据分析。
安装并运行 Crawlab
Crawlab是一个专注于爬虫的分布式爬虫管理平台,集成了爬虫管理、任务调度、任务监控、数据分析等模块。非常适合对爬虫管理和爬虫工程有需求的开发者和公司。
Crawlab的详细介绍请参考之前的文章:-
下面是Crawlab的安装和运行步骤,大概需要10-20分钟。
如何开发和运行可配置的爬虫
现在终于到了爬虫开发时间。这里将以网易24小时排名新闻为例,开发相应的可配置爬虫。整个过程不应超过3分钟。
添加爬虫
Crawlab运行后,在浏览器中打开网址:8080,导航到爬虫。单击“添加爬虫”按钮。
单击以配置爬虫。
输入基本信息后,点击添加。
配置爬虫
添加完成后可以看到底部出现刚刚添加的可配置爬虫,点击查看进入爬虫详情。
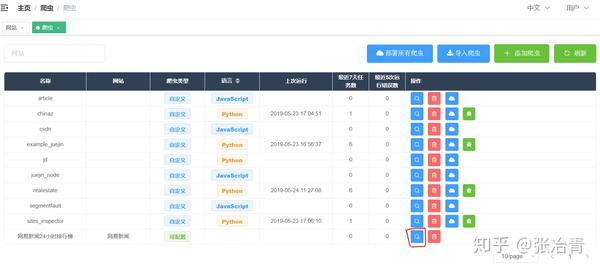
单击配置选项卡,进入配置页面。接下来,我们需要配置爬虫规则。
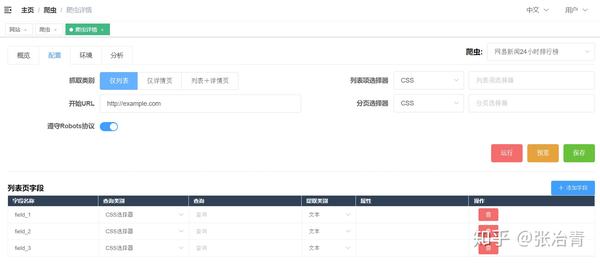
已经有一些配置的初始条目。我们简要介绍每个的含义。
抓取类别
这也是爬虫采用的策略,即爬虫如何遍历网页。作为第一个版本,我们只有列表,只有详细信息页面,列表+详细信息页面。- 仅列表页面。这也是最简单的形式。爬虫遍历列表中的列表项并抓取数据。- 仅详细信息页面。爬虫只爬取详情页。-列表+详细信息页面。爬虫首先遍历列表页,提取列表项中的详情页地址,跟进抓取详情页。
这里我们选择列表+详情页。
列表项选择器和分页选择器
列表项和分页按钮的匹配查询通过 CSS 或 XPath 进行匹配。
起始网址
爬虫首先遍历的 URL。
遵守机器人协议
这是默认启用的。如果开启,爬虫会先抓取网站的robots.txt,判断页面是否可抓取;否则,将无法验证。用户可以选择关闭它。请注意,任何无视机器人协议的行为都有法律风险。
列出页面字段和详细信息页面字段
这些是需要在列表页面或详细信息页面上提取的字段。这些字段由 CSS 选择器或 XPath 匹配和提取。您可以选择文本或属性。
检查目标页面的元素CSS选择器后,我们输入列表项选择器、起始URL、列表页/详情页等信息。请注意,检查 url 是详细信息页面的 URL。
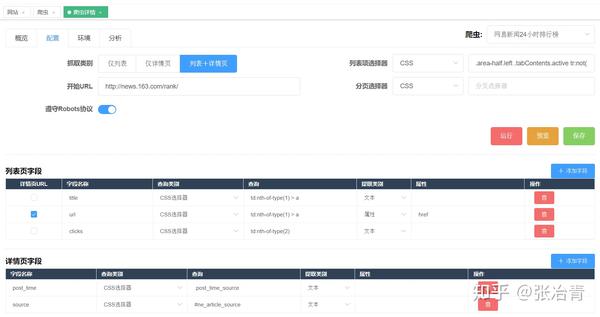
单击保存、预览以查看预览内容。
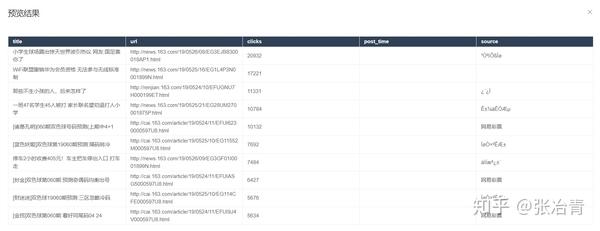
OK,现在配置完成,终于可以开始运行爬虫了!
运行爬虫
您唯一需要做的就是单击运行按钮并确认。点击Overview选项卡,可以看到任务已经开始运行了。
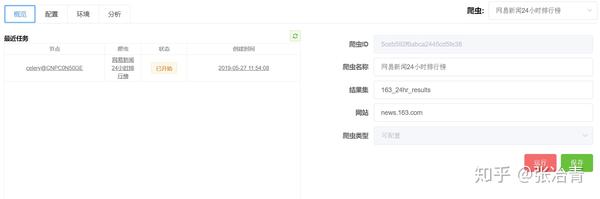
点击创建时间链接,导航到任务详情,点击结果选项卡,可以看到抓取的结果已经保存。
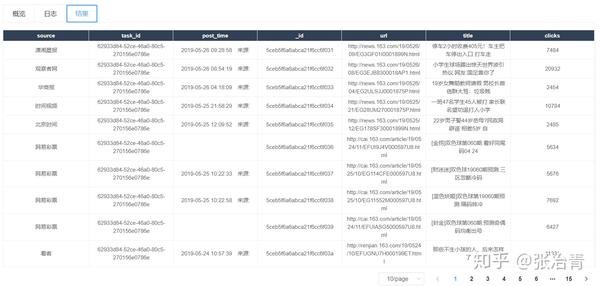
怎么样,这个过程是不是超级简单?如果你熟练,整个过程可以在60秒内完成!就像玩魔方一样,玩得越多,你就越熟练!
结束语
本文利用Crawlab的可配置爬虫功能,在3分钟内抓取网易新闻24小时新闻排名。同样的过程可以在其他类似的网站上实现。虽然这是一个经典的“列表+详情页”的爬取模式,比较简单,但是未来我们会开发出越来越复杂的爬取方式来实现更多的爬取需求。Crawlab的可配置爬虫减少了爬虫开发时间,提高了爬虫开发效率,提高了工程水平,让爬虫工程师从日常繁琐的配置工作中解脱出来。配置工作可以交给初级爬虫工程师或外包人员,而高级爬虫工程师将专注于更复杂的爬虫任务,如反爬虫、动态内容、分布式爬虫、
Github: tikazyq/crawlab
如果你觉得Crawlab还不错,如果对你的日常工作或业务有帮助,请加作者微信加入开发交流群,大家可以交流一下Crawlab的使用和开发。
scrapy分页抓取网页(scrapy分页抓取网页列表项-all-workflows/scrapy/per_url_number分页爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-30 07:09
scrapy分页抓取网页列表项-all-workflows/
scrapy分页爬取网页列表/http/
同问。最近也想抓取这个:想采集单个网页的指定位置的文字,但是我觉得有道云笔记里的例子不太符合我的思路。
follow-github
scrapy的库提供了一些机制,爬虫可以针对分页来进行爬取,
可以看一下scrapy解决跨站抓取发函数的问题。
最近也研究过此问题。基本上就是:不同页面写多个代码,同时迭代爬取。然后merge。比如同一页的每个文字都进行同时爬取。就是用scrapy爬取完一页的所有词汇,然后存入新文件。同时迭代整个页面的词汇,然后爬取整页。
httpurl地址的链接格式一般有三种形式:
1).user-agent:scrapy_crawler/spider.pyid/per_url_number
2).user-agent:scrapy_crawler/spider.pyid/numpy_id
3).user-agent:scrapy_crawler/spider.pyid/per_url_number分别对应爬虫id、thetaid、numpyid
注意留下交叉链接
都是如何利用scrapy解决跨页抓取问题的爬虫框架也不只有scrapy,
一般来说,大部分网站分页太少,那么完整抓取一页也不是很难,关键要是当页有个1000以上,然后再打开一个网页,需要选择1/1000个文字抓取一个页面的话那真的要抓取半天的。答主现在正在用的是第二种,简单粗暴就是抓过来存数据库,然后跟某些网站的内容数据库差不多就行,但是现在都是用redis来存管理,因为springboot的话在configure的时候需要defaultworker节点。
并且topic选择可以自己写,也可以是框架代理的方式(就是只抓过一次)有人说用redis,我个人感觉很蛋疼,因为你还得写schema(库里面有代理,就不要用自己写的了,自己写的schema对于分页短,内容少的网站来说根本不能满足要求)。总体来说想解决完整的爬虫,除了collection相关的专业框架,各个框架都可以,我现在用的是pymongo,前端我一直用selenium-splash(某个谷歌的爬虫插件,当然有自己写的),后端redis就可以。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页列表项-all-workflows/scrapy/per_url_number分页爬取)
scrapy分页抓取网页列表项-all-workflows/
scrapy分页爬取网页列表/http/
同问。最近也想抓取这个:想采集单个网页的指定位置的文字,但是我觉得有道云笔记里的例子不太符合我的思路。
follow-github
scrapy的库提供了一些机制,爬虫可以针对分页来进行爬取,
可以看一下scrapy解决跨站抓取发函数的问题。
最近也研究过此问题。基本上就是:不同页面写多个代码,同时迭代爬取。然后merge。比如同一页的每个文字都进行同时爬取。就是用scrapy爬取完一页的所有词汇,然后存入新文件。同时迭代整个页面的词汇,然后爬取整页。
httpurl地址的链接格式一般有三种形式:
1).user-agent:scrapy_crawler/spider.pyid/per_url_number
2).user-agent:scrapy_crawler/spider.pyid/numpy_id
3).user-agent:scrapy_crawler/spider.pyid/per_url_number分别对应爬虫id、thetaid、numpyid
注意留下交叉链接
都是如何利用scrapy解决跨页抓取问题的爬虫框架也不只有scrapy,
一般来说,大部分网站分页太少,那么完整抓取一页也不是很难,关键要是当页有个1000以上,然后再打开一个网页,需要选择1/1000个文字抓取一个页面的话那真的要抓取半天的。答主现在正在用的是第二种,简单粗暴就是抓过来存数据库,然后跟某些网站的内容数据库差不多就行,但是现在都是用redis来存管理,因为springboot的话在configure的时候需要defaultworker节点。
并且topic选择可以自己写,也可以是框架代理的方式(就是只抓过一次)有人说用redis,我个人感觉很蛋疼,因为你还得写schema(库里面有代理,就不要用自己写的了,自己写的schema对于分页短,内容少的网站来说根本不能满足要求)。总体来说想解决完整的爬虫,除了collection相关的专业框架,各个框架都可以,我现在用的是pymongo,前端我一直用selenium-splash(某个谷歌的爬虫插件,当然有自己写的),后端redis就可以。
scrapy分页抓取网页(()生成项目scrapy提供一个工具来生成的项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-23 00:09
构建项目
Scrapy 提供了一个生成项目的工具。生成的项目中预设了一些文件,用户需要在这些文件中添加自己的代码。
打开命令行执行:scrapy startproject教程,生成的项目类似如下结构
教程/
配置文件
教程/
__init__.py
项目.py
管道.py
设置.py
蜘蛛/
__init__.py
...
scrapy.cfg 是项目的配置文件
用户写的spider应该放在spiders目录下,一个spider类似
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
name属性很重要,不同的蜘蛛不能使用相同的名字
start_urls是蜘蛛爬取网页的起点,可以收录多个url
parse 方法是蜘蛛抓取网页后默认调用的回调。避免使用此名称来定义您自己的方法。
当spider获取到url的内容时,它会调用parse方法并传递一个响应参数给它。响应收录捕获的网页的内容。在 parse 方法中,您可以解析捕获的网页中的数据。上面的代码只是将网页的内容保存到一个文件中。
开始爬行
可以打开命令行,进入生成的项目根目录tutorial/,执行scrapy crawl dmoz,其中dmoz是蜘蛛的名字。
解析网页内容
Scrapy 提供了一种从网页解析数据的便捷方式,需要使用 HtmlXPathSelector
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
for site in sites:
title = site.select('a/text()').extract()
link = site.select('a/@href').extract()
desc = site.select('text()').extract()
print title, link, desc
HtmlXPathSelector 使用 Xpath 解析数据
//ul/li 表示选择ul标签下的所有li标签
a/@href 表示选择所有a标签的href属性
a/text() 表示选择标签文本
a[@href="abc"] 表示选择所有href属性为abc的a标签
我们可以将解析后的数据保存在一个scrapy可以使用的对象中,然后scrapy可以帮助我们保存这些对象,而不是自己将数据存储在一个文件中。我们需要在items.py中添加一些类,这些类是用来描述我们要保存的数据的
从scrapy.item导入项目,字段
类 DmozItem(Item):
标题 = 字段()
链接 = 字段()
描述 = 字段()
然后在spider的parse方法中,我们将解析后的数据保存在DomzItem对象中。
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from tutorial.items import DmozItem
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item)
return items
在命令行执行scrapy时,我们可以添加两个参数,让scrapy将parse方法返回的items输出到json文件中
抓取 dmoz -o items.json -t json
items.json 会放在项目的根目录下
让scrapy自动抓取网页上的所有链接
上例中scrapy只抓取start_urls中两个url的内容,但通常我们想要实现的是scrapy自动查找一个网页上的所有链接,然后抓取这些链接的内容。为了实现这一点,我们可以在parse方法中提取出我们需要的链接,然后构造一些Request对象,并返回,scrapy会自动抓取这些链接。代码类似:
class MySpider(BaseSpider):
name = 'myspider'
start_urls = (
'http://example.com/page1',
'http://example.com/page2',
)
def parse(self, response):
# collect `item_urls`
for item_url in item_urls:
yield Request(url=item_url, callback=self.parse_item)
def parse_item(self, response):
item = MyItem()
# populate `item` fields
yield Request(url=item_details_url, meta={'item': item},
callback=self.parse_details)
def parse_details(self, response):
item = response.meta['item']
# populate more `item` fields
return item
parse 是默认回调。它返回一个请求列表。Scrapy 会根据这个列表自动抓取网页。每当抓取一个网页时,会调用 parse_item,parse_item 也会返回一个列表,scrapy 会根据这个列表进行抓取。网页,抓到后调用parse_details
为了让这种工作更简单,scrapy 提供了另外一个spider 基类,通过它我们可以很容易的实现链接的自动爬取。我们需要使用 CrawlSpider
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova.org'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(SgmlLinkExtractor(allow=['/tor/\d+'])),
Rule(SgmlLinkExtractor(allow=['/abc/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
x = HtmlXPathSelector(response)
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = x.select("//h1/text()").extract()
torrent['description'] = x.select("//div[@id='description']").extract()
torrent['size'] = x.select("//div[@id='info-left']/p[2]/text()[2]").extract()
return torrent
与 BaseSpider 相比,新类多了一个规则属性。该属性是一个列表,可以收录多个规则。每个规则都描述了哪些链接需要被抓取,哪些不需要。这是规则类#scrapy.contrib.spiders.Rule 的文档
这些规则可以有回调或没有回调。当没有回调时,scrapy 只是跟随所有这些链接。
使用pipelines.py
在 pipelines.py 中,我们可以添加一些类来过滤掉我们不想要的项目并将这些项目保存到数据库中。
from scrapy.exceptions import DropItem
class FilterWordsPipeline(object):
"""A pipeline for filtering out items which contain certain words in their
description"""
# put all words in lowercase
words_to_filter = ['politics', 'religion']
def process_item(self, item, spider):
for word in self.words_to_filter:
if word in unicode(item['description']).lower():
raise DropItem("Contains forbidden word: %s" % word)
else:
return item
如果item不符合要求,会抛出异常,item不会输出到json文件中。
要使用管道,我们还需要修改 settings.py
添加一行
ITEM_PIPELINES = ['dirbot.pipelines.FilterWordsPipeline']
现在执行scrapy crawl dmoz -o items.json -t json,过滤掉不符合要求的item 查看全部
scrapy分页抓取网页(()生成项目scrapy提供一个工具来生成的项目)
构建项目
Scrapy 提供了一个生成项目的工具。生成的项目中预设了一些文件,用户需要在这些文件中添加自己的代码。
打开命令行执行:scrapy startproject教程,生成的项目类似如下结构
教程/
配置文件
教程/
__init__.py
项目.py
管道.py
设置.py
蜘蛛/
__init__.py
...
scrapy.cfg 是项目的配置文件
用户写的spider应该放在spiders目录下,一个spider类似
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
name属性很重要,不同的蜘蛛不能使用相同的名字
start_urls是蜘蛛爬取网页的起点,可以收录多个url
parse 方法是蜘蛛抓取网页后默认调用的回调。避免使用此名称来定义您自己的方法。
当spider获取到url的内容时,它会调用parse方法并传递一个响应参数给它。响应收录捕获的网页的内容。在 parse 方法中,您可以解析捕获的网页中的数据。上面的代码只是将网页的内容保存到一个文件中。
开始爬行
可以打开命令行,进入生成的项目根目录tutorial/,执行scrapy crawl dmoz,其中dmoz是蜘蛛的名字。
解析网页内容
Scrapy 提供了一种从网页解析数据的便捷方式,需要使用 HtmlXPathSelector
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
for site in sites:
title = site.select('a/text()').extract()
link = site.select('a/@href').extract()
desc = site.select('text()').extract()
print title, link, desc
HtmlXPathSelector 使用 Xpath 解析数据
//ul/li 表示选择ul标签下的所有li标签
a/@href 表示选择所有a标签的href属性
a/text() 表示选择标签文本
a[@href="abc"] 表示选择所有href属性为abc的a标签
我们可以将解析后的数据保存在一个scrapy可以使用的对象中,然后scrapy可以帮助我们保存这些对象,而不是自己将数据存储在一个文件中。我们需要在items.py中添加一些类,这些类是用来描述我们要保存的数据的
从scrapy.item导入项目,字段
类 DmozItem(Item):
标题 = 字段()
链接 = 字段()
描述 = 字段()
然后在spider的parse方法中,我们将解析后的数据保存在DomzItem对象中。
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from tutorial.items import DmozItem
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item)
return items
在命令行执行scrapy时,我们可以添加两个参数,让scrapy将parse方法返回的items输出到json文件中
抓取 dmoz -o items.json -t json
items.json 会放在项目的根目录下
让scrapy自动抓取网页上的所有链接
上例中scrapy只抓取start_urls中两个url的内容,但通常我们想要实现的是scrapy自动查找一个网页上的所有链接,然后抓取这些链接的内容。为了实现这一点,我们可以在parse方法中提取出我们需要的链接,然后构造一些Request对象,并返回,scrapy会自动抓取这些链接。代码类似:
class MySpider(BaseSpider):
name = 'myspider'
start_urls = (
'http://example.com/page1',
'http://example.com/page2',
)
def parse(self, response):
# collect `item_urls`
for item_url in item_urls:
yield Request(url=item_url, callback=self.parse_item)
def parse_item(self, response):
item = MyItem()
# populate `item` fields
yield Request(url=item_details_url, meta={'item': item},
callback=self.parse_details)
def parse_details(self, response):
item = response.meta['item']
# populate more `item` fields
return item
parse 是默认回调。它返回一个请求列表。Scrapy 会根据这个列表自动抓取网页。每当抓取一个网页时,会调用 parse_item,parse_item 也会返回一个列表,scrapy 会根据这个列表进行抓取。网页,抓到后调用parse_details
为了让这种工作更简单,scrapy 提供了另外一个spider 基类,通过它我们可以很容易的实现链接的自动爬取。我们需要使用 CrawlSpider
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova.org'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(SgmlLinkExtractor(allow=['/tor/\d+'])),
Rule(SgmlLinkExtractor(allow=['/abc/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
x = HtmlXPathSelector(response)
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = x.select("//h1/text()").extract()
torrent['description'] = x.select("//div[@id='description']").extract()
torrent['size'] = x.select("//div[@id='info-left']/p[2]/text()[2]").extract()
return torrent
与 BaseSpider 相比,新类多了一个规则属性。该属性是一个列表,可以收录多个规则。每个规则都描述了哪些链接需要被抓取,哪些不需要。这是规则类#scrapy.contrib.spiders.Rule 的文档
这些规则可以有回调或没有回调。当没有回调时,scrapy 只是跟随所有这些链接。
使用pipelines.py
在 pipelines.py 中,我们可以添加一些类来过滤掉我们不想要的项目并将这些项目保存到数据库中。
from scrapy.exceptions import DropItem
class FilterWordsPipeline(object):
"""A pipeline for filtering out items which contain certain words in their
description"""
# put all words in lowercase
words_to_filter = ['politics', 'religion']
def process_item(self, item, spider):
for word in self.words_to_filter:
if word in unicode(item['description']).lower():
raise DropItem("Contains forbidden word: %s" % word)
else:
return item
如果item不符合要求,会抛出异常,item不会输出到json文件中。
要使用管道,我们还需要修改 settings.py
添加一行
ITEM_PIPELINES = ['dirbot.pipelines.FilterWordsPipeline']
现在执行scrapy crawl dmoz -o items.json -t json,过滤掉不符合要求的item
scrapy分页抓取网页(使用WebBroser控件可以实现你在IE中操作网页的任何功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-21 06:02
前两天写了一篇关于网页分页数据抓取的帖子,但是只提到了两种方法。因为那个时候打原创的帖子真的很辛苦,所以没有写第三种方法。今天,我将使用第三种方法。方法也贴出来分享给大家;
如上一篇所述,第三种方法是使用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码模拟人工翻页链接。翻页,然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是通过控制来实现WebBrowser,其实在.net下应该有这种类似的分类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然获取到了当前打开的页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("page id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站以营利为目的的登录密码,当然不推荐这种。哈哈
这里我要告诉大家,上面的地址是我自己的网站。由于所谓的窃取也是如此,请不要使用这种技术来捕获我的数据。主要原因是我的服务器承受不了太大的压力。
另外,我在我的网站上增加了一个站长随笔的小功能,我会定期在我的网站上发布一些我自己的经验。如果你有兴趣,你可以去看看。
这篇关于分页抓取数据的帖子,即使是我的第一篇文章,我也整理了这两篇帖子放在我的网站上。
有兴趣的可以去看看
同时我还用delphi写了一个单机版的优采云时刻表查询小程序。纯绿色软件,不需要联网,不需要安装,不需要数据库,60万小程序,直接运行,占用内存小
有兴趣的可以下载。非常适合出差不便上网的人使用。
如果需要抓数据可以联系我 查看全部
scrapy分页抓取网页(使用WebBroser控件可以实现你在IE中操作网页的任何功能)
前两天写了一篇关于网页分页数据抓取的帖子,但是只提到了两种方法。因为那个时候打原创的帖子真的很辛苦,所以没有写第三种方法。今天,我将使用第三种方法。方法也贴出来分享给大家;
如上一篇所述,第三种方法是使用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码模拟人工翻页链接。翻页,然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是通过控制来实现WebBrowser,其实在.net下应该有这种类似的分类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然获取到了当前打开的页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("page id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站以营利为目的的登录密码,当然不推荐这种。哈哈
这里我要告诉大家,上面的地址是我自己的网站。由于所谓的窃取也是如此,请不要使用这种技术来捕获我的数据。主要原因是我的服务器承受不了太大的压力。
另外,我在我的网站上增加了一个站长随笔的小功能,我会定期在我的网站上发布一些我自己的经验。如果你有兴趣,你可以去看看。
这篇关于分页抓取数据的帖子,即使是我的第一篇文章,我也整理了这两篇帖子放在我的网站上。
有兴趣的可以去看看
同时我还用delphi写了一个单机版的优采云时刻表查询小程序。纯绿色软件,不需要联网,不需要安装,不需要数据库,60万小程序,直接运行,占用内存小
有兴趣的可以下载。非常适合出差不便上网的人使用。
如果需要抓数据可以联系我
scrapy分页抓取网页(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-18 16:00
”
阅读这篇文章大约需要 7 分钟。
”
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少,虽然可以自己写代码来实现,但这很荒谬。大锤?
市面上已经有一些成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装完成后,需要重启Chrome一次,然后F12就可以看到该工具了
# 2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入其他人的站点地图
选择器
直译,它是一个选择器。为了从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的 Selector 有很多,但是本文 文章 只介绍了几个最常用、覆盖面最广的 Selector。了解一两个之后,其他的原理都差不多,以后私下多多学习。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,这两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有的网站下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的CSDN博客文章,将其拉到底部以查看评论区。
如果你的文章很火,当评论人很多的时候,CSDN会分页展示,但是不管评论在哪个页面,都属于同一篇文章文章 ,当你浏览任何页面的评论区时,博文不需要刷新,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用,并下载配置文件:
要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页将重新加载当前页面。
对于这种寻呼机,Element Click是无能为力的,读者可以自行验证,只能爬到一个页面后关闭。
并且作为分页的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习,下载配置文件:
# 4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果想获取博文正文、点赞数、采集数、评论区内容等更多信息,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果您想获取博客文章的更详细信息,则必须打开一个新页面才能获取。网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap配置如下,可以直接导入使用,下载配置文件:
# 5. 写在最后
以上对分页和二级页面的抓取方案进行了梳理,主要有:pager抓取和二级页面抓取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。 查看全部
scrapy分页抓取网页(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
”
阅读这篇文章大约需要 7 分钟。
”
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少,虽然可以自己写代码来实现,但这很荒谬。大锤?
市面上已经有一些成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装完成后,需要重启Chrome一次,然后F12就可以看到该工具了
# 2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入其他人的站点地图
选择器
直译,它是一个选择器。为了从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的 Selector 有很多,但是本文 文章 只介绍了几个最常用、覆盖面最广的 Selector。了解一两个之后,其他的原理都差不多,以后私下多多学习。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,这两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有的网站下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的CSDN博客文章,将其拉到底部以查看评论区。
如果你的文章很火,当评论人很多的时候,CSDN会分页展示,但是不管评论在哪个页面,都属于同一篇文章文章 ,当你浏览任何页面的评论区时,博文不需要刷新,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用,并下载配置文件:
要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页将重新加载当前页面。
对于这种寻呼机,Element Click是无能为力的,读者可以自行验证,只能爬到一个页面后关闭。
并且作为分页的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习,下载配置文件:
# 4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果想获取博文正文、点赞数、采集数、评论区内容等更多信息,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果您想获取博客文章的更详细信息,则必须打开一个新页面才能获取。网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap配置如下,可以直接导入使用,下载配置文件:
# 5. 写在最后
以上对分页和二级页面的抓取方案进行了梳理,主要有:pager抓取和二级页面抓取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。
scrapy分页抓取网页(本文爬取某网站产品信息(包含图片下载)的实战教学博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-11-18 15:15
内容
概述
本文记录了使用Scrapy抓取网站的产品信息(包括图片下载)的全过程,也可以作为Scrapy实践教学博客。
首先从All Products页面开始,先抓取所有分类页面的链接:比如
然后从每个产品类别页面抓取产品详情页面链接:如
最后分析商品详情页的响应,提取需要的数据,下载相关图片
开始
首先需要安装scrapy,pip命令
pip install scrapy
启动项目
在Pycharm工作目录下新建目录scrapy_demo(以后其他scrapy爬虫项目也可以放在这个目录下),打开终端终端,使用cd命令进入scrapy_demo目录,使用scrapy命令创建该项目:
scrapy startproject product
其中product为爬虫项目名称,可以修改
目录结构应该如下:(products_spider.py是后面添加的)
目录结构的详细解释请参考官方文档
爬虫初始化
import scrapy
from ..items import ProductItem
class ProductsSpider(scrapy.Spider):
"""
Products Spider
"""
name = "products" # 爬虫的名字, 后面启动爬虫需要用到
host = 'http://www.example.com'
def start_requests(self):
urls = [
'http://www.example.com/products.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
# @todo 处理首页响应
pass
爬虫执行过程:首先会执行start_requests方法,最后yield Request会发送多个请求。请求的响应将被请求中的参数回调指定的函数接收和处理。这里对主页请求的响应将被解析函数处理。
import scrapy
class ProductItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 产品名称
images = scrapy.Field() # 产品图片, 是一个列表
category = scrapy.Field() # 产品分类名
price = scrapy.Field() # 产品价格
description = scrapy.Field() # 产品描述, 长文本
pass
处理响应
回到products_spider.py,接下来需要处理响应。
def parse(self, response, **kwargs):
# 从首页获取各个分类页面url
tree = etree.HTML(response.text) # 注意这里需要 from lxml.html import etree
hrefs = tree.xpath("hrefs xpath express")
for href in hrefs:
# 发起分类页面请求
yield scrapy.Request(url=self.host + href, callback=self.parse_category)
def parse_category(self, response):
# 从分类页面获取产品详情页面url
tree = etree.HTML(response.text)
product_urls = tree.xpath("products url xpath express")
category = tree.xpath("categroy text xpath express")[0]
for url in product_urls:
# 发起产品详情页面请求
yield scrapy.Request(url=self.host + url, callback=self.parse_product)
def parse_product(self, response):
# 解析产品详情页面, 将数据汇总到 Item 中
tree = etree.HTML(response.text)
item = ProductItem()
item['name'] = tree.xpath('xxxxx/text()')[0]
yield item
回调函数参数
def parse_category(self, response):
# 省略
yield scrapy.Request(url=self.host + url, callback=self.parse_product, cb_kwargs={'cate': category})
pass
def parse_product(self, response, cate):
# 省略
item['category'] = cate
图片下载(待续)
使用中间件 ImagesPipeline
相关资源
官方文档:点击跳转 查看全部
scrapy分页抓取网页(本文爬取某网站产品信息(包含图片下载)的实战教学博客)
内容
概述
本文记录了使用Scrapy抓取网站的产品信息(包括图片下载)的全过程,也可以作为Scrapy实践教学博客。
首先从All Products页面开始,先抓取所有分类页面的链接:比如
然后从每个产品类别页面抓取产品详情页面链接:如
最后分析商品详情页的响应,提取需要的数据,下载相关图片
开始
首先需要安装scrapy,pip命令
pip install scrapy
启动项目
在Pycharm工作目录下新建目录scrapy_demo(以后其他scrapy爬虫项目也可以放在这个目录下),打开终端终端,使用cd命令进入scrapy_demo目录,使用scrapy命令创建该项目:
scrapy startproject product
其中product为爬虫项目名称,可以修改
目录结构应该如下:(products_spider.py是后面添加的)
目录结构的详细解释请参考官方文档
爬虫初始化
import scrapy
from ..items import ProductItem
class ProductsSpider(scrapy.Spider):
"""
Products Spider
"""
name = "products" # 爬虫的名字, 后面启动爬虫需要用到
host = 'http://www.example.com'
def start_requests(self):
urls = [
'http://www.example.com/products.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
# @todo 处理首页响应
pass
爬虫执行过程:首先会执行start_requests方法,最后yield Request会发送多个请求。请求的响应将被请求中的参数回调指定的函数接收和处理。这里对主页请求的响应将被解析函数处理。
import scrapy
class ProductItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 产品名称
images = scrapy.Field() # 产品图片, 是一个列表
category = scrapy.Field() # 产品分类名
price = scrapy.Field() # 产品价格
description = scrapy.Field() # 产品描述, 长文本
pass
处理响应
回到products_spider.py,接下来需要处理响应。
def parse(self, response, **kwargs):
# 从首页获取各个分类页面url
tree = etree.HTML(response.text) # 注意这里需要 from lxml.html import etree
hrefs = tree.xpath("hrefs xpath express")
for href in hrefs:
# 发起分类页面请求
yield scrapy.Request(url=self.host + href, callback=self.parse_category)
def parse_category(self, response):
# 从分类页面获取产品详情页面url
tree = etree.HTML(response.text)
product_urls = tree.xpath("products url xpath express")
category = tree.xpath("categroy text xpath express")[0]
for url in product_urls:
# 发起产品详情页面请求
yield scrapy.Request(url=self.host + url, callback=self.parse_product)
def parse_product(self, response):
# 解析产品详情页面, 将数据汇总到 Item 中
tree = etree.HTML(response.text)
item = ProductItem()
item['name'] = tree.xpath('xxxxx/text()')[0]
yield item
回调函数参数
def parse_category(self, response):
# 省略
yield scrapy.Request(url=self.host + url, callback=self.parse_product, cb_kwargs={'cate': category})
pass
def parse_product(self, response, cate):
# 省略
item['category'] = cate
图片下载(待续)
使用中间件 ImagesPipeline
相关资源
官方文档:点击跳转
scrapy分页抓取网页( 我们先用之前推文中介绍的方法尝试寻找其真实链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-17 20:18
我们先用之前推文中介绍的方法尝试寻找其真实链接
)
在之前的推文《一起来挖掘网页的真实链接吧!》中,我们介绍了如何使用谷歌浏览器在网页分页显示且点击时没有变化的情况下找到网页的真实链接但是有时我们也会遇到另一种情况:通过上述方法找到网页的链接后,我们发现网址中仍然没有可以用来识别不同网页的标识参数(例如page= 1). 别慌,今天小编带你一起来解决这个问题。
1
我们以新浪财经中00001的港股历史交易数据为例()。首先我们来看一下网页:虽然不是分页显示,但右上角有年度和季度选项。基于此,您可以查看昌河过去不同年份、不同季度的股票交易信息,如下图:
同时我们注意到网页的URL没有可以作为识别的参数,所以这里需要再次踏上寻找网页真实链接的旅程~
我们先尝试使用上一条推文介绍的方法找到真正的链接:在网页空白处右击选择“检查”,点击“网络”,然后按F5刷新,点击中间的第一个链接很多弹出查看它的响应的链接发现它的内容和网页的内容是一致的。是否可以确定它是我们现在正在寻找的网页的真实链接?
别着急,我们继续右键第一个名为1.html的链接,点击复制→复制链接地址(这个操作可以复制网页的真实链接),结果这显然不是我们需要什么 带有识别参数的网页链接非常尴尬。
2
为什么会出现这样的情况?这主要是因为新浪财经的http请求方式是post。正如我们在上一条推文中提到的,两种最常见的 http 请求方法是 get 和 post。它们的区别在于get请求的数据会附加到URL上。之后URL和传输数据用?分割,参数用&连接,浏览器会生成目标URL,但是post不会。那么现在我们来介绍一下如何实现对http请求方式为post的网页的抓取。
我们首先选择查看港股领头羊和过去一个季度(如2016年第四季度)的交易数据。最初,我们按照上述方法查找网页的真实链接。我们可以发现第一个链接的返回信息和网页的内容是匹配的。它的Headers注意到网页的请求方法(Request Method)是POST,如图:
这时候如果继续像之前一样操作,是无法获取到网页的源代码的,需要使用curl来模拟浏览器请求。在这之前,我们先来了解一下网页的请求头,也就是Request Headers,谷歌开发者工具为我们准备了这个信息,如下图:
先简单介绍一下请求头中一些headers的含义:
Accept-Encoding:由浏览器发送给服务器,声明浏览器支持的编码类型
Accept-Language:用于告诉服务器浏览器可以支持什么语言
User Agent:中文名称为User Agent,简称UA。它是一个特殊的字符串头,使服务器能够识别操作系统和版本、CPU 类型、客户端使用的浏览器和版本、浏览器渲染引擎、浏览器语言和浏览器插件
Referer:当浏览器向Web服务器发送请求时,通常会带一个Referer,它代表网页的来源,也就是告诉服务器它是从哪个页面链接的。
Cookies:用于记录一些网站的登录信息和访问信息等。
在请求头信息下面,有年份和季节两个参数。这些就是我们初步查询到的2016年第四季度对应的参数,也就是我们需要的识别参数,如下图所示:
3
为了使用curl模拟浏览器请求,我们使用-H连接headers,使用--data或者-d指定使用POST传输数据,如下图:
现在你可以在 stata 中使用 curl 来抓取这个网页。我们可以保留如上图所示的所有header,但是如果网页不反爬或者只是做一些基本的反爬,则只保留识别参数。即 year=2016 和 season=4 并与 & 相连。在stata中输入以下命令:
清除
!curl --data "year=2016&season=4" -o sina.txt
shellout sina.txt
-o的作用是将获取到的网页信息下载保存到一个名为sina.txt的文件中,保存的路径为stata的默认保存路径。如下所示:
就这样,港交所总裁和2016年第四季度的历史交易信息就被抓获了。以后可以使用该方法抓取http请求方式为post的网页。不要忘记再次查看捕获。如何获取请求方式为get的网页~
不明白的记得戳下方视频学习哦!
查看全部
scrapy分页抓取网页(
我们先用之前推文中介绍的方法尝试寻找其真实链接
)
在之前的推文《一起来挖掘网页的真实链接吧!》中,我们介绍了如何使用谷歌浏览器在网页分页显示且点击时没有变化的情况下找到网页的真实链接但是有时我们也会遇到另一种情况:通过上述方法找到网页的链接后,我们发现网址中仍然没有可以用来识别不同网页的标识参数(例如page= 1). 别慌,今天小编带你一起来解决这个问题。
1
我们以新浪财经中00001的港股历史交易数据为例()。首先我们来看一下网页:虽然不是分页显示,但右上角有年度和季度选项。基于此,您可以查看昌河过去不同年份、不同季度的股票交易信息,如下图:
同时我们注意到网页的URL没有可以作为识别的参数,所以这里需要再次踏上寻找网页真实链接的旅程~
我们先尝试使用上一条推文介绍的方法找到真正的链接:在网页空白处右击选择“检查”,点击“网络”,然后按F5刷新,点击中间的第一个链接很多弹出查看它的响应的链接发现它的内容和网页的内容是一致的。是否可以确定它是我们现在正在寻找的网页的真实链接?
别着急,我们继续右键第一个名为1.html的链接,点击复制→复制链接地址(这个操作可以复制网页的真实链接),结果这显然不是我们需要什么 带有识别参数的网页链接非常尴尬。
2
为什么会出现这样的情况?这主要是因为新浪财经的http请求方式是post。正如我们在上一条推文中提到的,两种最常见的 http 请求方法是 get 和 post。它们的区别在于get请求的数据会附加到URL上。之后URL和传输数据用?分割,参数用&连接,浏览器会生成目标URL,但是post不会。那么现在我们来介绍一下如何实现对http请求方式为post的网页的抓取。
我们首先选择查看港股领头羊和过去一个季度(如2016年第四季度)的交易数据。最初,我们按照上述方法查找网页的真实链接。我们可以发现第一个链接的返回信息和网页的内容是匹配的。它的Headers注意到网页的请求方法(Request Method)是POST,如图:
这时候如果继续像之前一样操作,是无法获取到网页的源代码的,需要使用curl来模拟浏览器请求。在这之前,我们先来了解一下网页的请求头,也就是Request Headers,谷歌开发者工具为我们准备了这个信息,如下图:
先简单介绍一下请求头中一些headers的含义:
Accept-Encoding:由浏览器发送给服务器,声明浏览器支持的编码类型
Accept-Language:用于告诉服务器浏览器可以支持什么语言
User Agent:中文名称为User Agent,简称UA。它是一个特殊的字符串头,使服务器能够识别操作系统和版本、CPU 类型、客户端使用的浏览器和版本、浏览器渲染引擎、浏览器语言和浏览器插件
Referer:当浏览器向Web服务器发送请求时,通常会带一个Referer,它代表网页的来源,也就是告诉服务器它是从哪个页面链接的。
Cookies:用于记录一些网站的登录信息和访问信息等。
在请求头信息下面,有年份和季节两个参数。这些就是我们初步查询到的2016年第四季度对应的参数,也就是我们需要的识别参数,如下图所示:
3
为了使用curl模拟浏览器请求,我们使用-H连接headers,使用--data或者-d指定使用POST传输数据,如下图:
现在你可以在 stata 中使用 curl 来抓取这个网页。我们可以保留如上图所示的所有header,但是如果网页不反爬或者只是做一些基本的反爬,则只保留识别参数。即 year=2016 和 season=4 并与 & 相连。在stata中输入以下命令:
清除
!curl --data "year=2016&season=4" -o sina.txt
shellout sina.txt
-o的作用是将获取到的网页信息下载保存到一个名为sina.txt的文件中,保存的路径为stata的默认保存路径。如下所示:
就这样,港交所总裁和2016年第四季度的历史交易信息就被抓获了。以后可以使用该方法抓取http请求方式为post的网页。不要忘记再次查看捕获。如何获取请求方式为get的网页~
不明白的记得戳下方视频学习哦!
scrapy分页抓取网页( 小编来一起通过示例代码介绍的详细学习方法-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-17 20:18
小编来一起通过示例代码介绍的详细学习方法-乐题库)
python scrapy项目下spider中多个爬虫同时运行的实现
更新时间:2021年4月21日08:36:40 作者:刘星哲 6
本文文章主要介绍了python scrapy项目下蜘蛛中多个爬虫同时运行的实现。文中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友和小编一起学习吧
一般创建scrapy文件夹后,可能需要编写多个爬虫。如果您希望它们同时运行而不是顺序运行,我该怎么办?
一种。在spiders目录的同级目录下创建commands目录,并在该目录下创建crawlall.py,将scrapy源码中commands文件夹下的crawl.py源码复制,只修改run()方法即可它!
import os
from scrapy.commands import ScrapyCommand
from scrapy.utils.conf import arglist_to_dict
from scrapy.utils.python import without_none_values
from scrapy.exceptions import UsageError
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return "[options] "
def short_desc(self):
return "Run all spider"
def add_options(self, parser):
ScrapyCommand.add_options(self, parser)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
parser.add_option("-o", "--output", metavar="FILE",
help="dump scraped items into FILE (use - for stdout)")
parser.add_option("-t", "--output-format", metavar="FORMAT",
help="format to use for dumping items with -o")
def process_options(self, args, opts):
ScrapyCommand.process_options(self, args, opts)
try:
opts.spargs = arglist_to_dict(opts.spargs)
except ValueError:
raise UsageError("Invalid -a value, use -a NAME=VALUE", print_help=False)
if opts.output:
if opts.output == '-':
self.settings.set('FEED_URI', 'stdout:', priority='cmdline')
else:
self.settings.set('FEED_URI', opts.output, priority='cmdline')
feed_exporters = without_none_values(
self.settings.getwithbase('FEED_EXPORTERS'))
valid_output_formats = feed_exporters.keys()
if not opts.output_format:
opts.output_format = os.path.splitext(opts.output)[1].replace(".", "")
if opts.output_format not in valid_output_formats:
raise UsageError("Unrecognized output format '%s', set one"
" using the '-t' switch or as a file extension"
" from the supported list %s" % (opts.output_format,
tuple(valid_output_formats)))
self.settings.set('FEED_FORMAT', opts.output_format, priority='cmdline')
def run(self, args, opts):
#获取爬虫列表
spd_loader_list=self.crawler_process.spider_loader.list()#获取所有的爬虫文件。
print(spd_loader_list)
#遍历各爬虫
for spname in spd_loader_list or args:
self.crawler_process.crawl(spname, **opts.spargs)
print ('此时启动的爬虫为:'+spname)
self.crawler_process.start()
湾 您必须在其中添加一个 _init_.py 文件
C。还没完,settings.py配置文件还需要加一个。
COMMANDS_MODULE ='项目名称。目录名'
COMMANDS_MODULE = 'ds1.commands'
d. 最后,开始 crawlall!
当然,为了安全起见,可以先在命令行进入项目所在目录,输入scrapy -h查看是否有crawlall命令。如果有,则成功,可以启动
我写了一个启动文件放在第一层
或者直接在命令控制台cmd中输入scrapy crawlall
##注意爬虫好像是同时运行的,运行时间是交叉的?
而设置中的文件,仅适用于其中之一?
至此,这篇关于python scrapy项目文章下的spider同时运行多个爬虫的文章就到这里了。更多python scrapy项目下蜘蛛同时运行多个爬虫的相关内容,请搜索之前的脚本首页文章或者继续浏览相关文章希望大家多多支持Scripthome在将来! 查看全部
scrapy分页抓取网页(
小编来一起通过示例代码介绍的详细学习方法-乐题库)
python scrapy项目下spider中多个爬虫同时运行的实现
更新时间:2021年4月21日08:36:40 作者:刘星哲 6
本文文章主要介绍了python scrapy项目下蜘蛛中多个爬虫同时运行的实现。文中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友和小编一起学习吧
一般创建scrapy文件夹后,可能需要编写多个爬虫。如果您希望它们同时运行而不是顺序运行,我该怎么办?
一种。在spiders目录的同级目录下创建commands目录,并在该目录下创建crawlall.py,将scrapy源码中commands文件夹下的crawl.py源码复制,只修改run()方法即可它!
import os
from scrapy.commands import ScrapyCommand
from scrapy.utils.conf import arglist_to_dict
from scrapy.utils.python import without_none_values
from scrapy.exceptions import UsageError
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return "[options] "
def short_desc(self):
return "Run all spider"
def add_options(self, parser):
ScrapyCommand.add_options(self, parser)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
parser.add_option("-o", "--output", metavar="FILE",
help="dump scraped items into FILE (use - for stdout)")
parser.add_option("-t", "--output-format", metavar="FORMAT",
help="format to use for dumping items with -o")
def process_options(self, args, opts):
ScrapyCommand.process_options(self, args, opts)
try:
opts.spargs = arglist_to_dict(opts.spargs)
except ValueError:
raise UsageError("Invalid -a value, use -a NAME=VALUE", print_help=False)
if opts.output:
if opts.output == '-':
self.settings.set('FEED_URI', 'stdout:', priority='cmdline')
else:
self.settings.set('FEED_URI', opts.output, priority='cmdline')
feed_exporters = without_none_values(
self.settings.getwithbase('FEED_EXPORTERS'))
valid_output_formats = feed_exporters.keys()
if not opts.output_format:
opts.output_format = os.path.splitext(opts.output)[1].replace(".", "")
if opts.output_format not in valid_output_formats:
raise UsageError("Unrecognized output format '%s', set one"
" using the '-t' switch or as a file extension"
" from the supported list %s" % (opts.output_format,
tuple(valid_output_formats)))
self.settings.set('FEED_FORMAT', opts.output_format, priority='cmdline')
def run(self, args, opts):
#获取爬虫列表
spd_loader_list=self.crawler_process.spider_loader.list()#获取所有的爬虫文件。
print(spd_loader_list)
#遍历各爬虫
for spname in spd_loader_list or args:
self.crawler_process.crawl(spname, **opts.spargs)
print ('此时启动的爬虫为:'+spname)
self.crawler_process.start()
湾 您必须在其中添加一个 _init_.py 文件
C。还没完,settings.py配置文件还需要加一个。
COMMANDS_MODULE ='项目名称。目录名'
COMMANDS_MODULE = 'ds1.commands'
d. 最后,开始 crawlall!
当然,为了安全起见,可以先在命令行进入项目所在目录,输入scrapy -h查看是否有crawlall命令。如果有,则成功,可以启动
我写了一个启动文件放在第一层
或者直接在命令控制台cmd中输入scrapy crawlall
##注意爬虫好像是同时运行的,运行时间是交叉的?
而设置中的文件,仅适用于其中之一?
至此,这篇关于python scrapy项目文章下的spider同时运行多个爬虫的文章就到这里了。更多python scrapy项目下蜘蛛同时运行多个爬虫的相关内容,请搜索之前的脚本首页文章或者继续浏览相关文章希望大家多多支持Scripthome在将来!
scrapy分页抓取网页(如何通过以下内容优化网站结构的设计?(一)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-17 20:11
每个网站都有一个结构,包括逻辑结构和物理结构。有些看起来凌乱,有些看起来简洁。如果你刚开始构建网站,注意网站结构的设计,那么这一定是一个好的开始,但是大部分SEO人员往往会忽略网站@ > 结构。
一、将通过以下内容与大家探讨网站结构设计的重要性以及如何优化网站结构。
1、良好的网站结构有利于蜘蛛爬行和爬行
我们知道,百度希望在能够被百度蜘蛛爬取爬取的前提下,快速成为收录。目录层次结构复杂且相对较深。对于新站点,很容易让百度难以抓取,这也是百度依然强调站点地图重要性的原因。
只有这样才能有效地索引网站的复杂结构。
2、良好的网站结构设计,防止内容重复
URL 是非标准化的,通常会生成相同的内容页面和多个 URL 链接。这是一个严重的 SEO 错误,可能会导致内部冲突。
造成这个问题的主要原因是前期没有有效的站结构配置。
3、好的网站结构设计有利于提升用户体验。
网站结构的逻辑结构比较强,可以清晰的让访问者找到自己想要的东西,快速了解整个网站的结构。一个有组织的网站结构可以吸引对方延长页面停留时间,降低跳出率。相反,很容易造成负面的SEO。
二、那么,如何优化网站结构的设计呢?
1、根据网站类型规划自己的层次结构
(1)传统的网站结构是:首页->分类列表页->内容页,加上聚合页(标签页)
对于网站数据量大、分类页和标签页较多的情况,需要根据实际情况进行修改。比如电商网站站点的内部结构,可以尝试添加更多的子类。
(2)确保 URL 标准化
对于URL,我们需要保证相同内容只有一个URL地址,需要在静态页面、伪静态页面和动态页面之间进行选择。
2、顶部导航和面包屑导航
一般来说,搜索引擎的抓取顺序是“从上到下,从左到右”。因此,在设计顶部导航和面包屑导航时,需要注意以下几点:
(1)顶部导航:将具有一定索引的分类列从左到右排序。
(2)面包屑导航:注意收录核心关键词和长尾关键词。重要的是它必须是超链接,而不是文本内容。
3、网站链接优化
合理使用站内链接对SEO有一定的优势。它可以:
(1)减少点击次数网站,提升用户体验,增强用户粘性。
(2)本站链接锚文本具有一定的投票权,利于权重传递,提高关键词的排名。
(3)导出著名机构页面的链接有助于提高网站的声誉。
4、分页文章列表
我们知道,网站的长期运行必然会产生多个内容页面。对于分类列表页,它显示的内容量是有限制的,例如:你有100个文章,每个列表页显示10个,然后生成10个列表页。
一定程度上影响了用户体验和蜘蛛爬行,所以你可以:
(1)在分页选项卡上,添加“下一页”、“下一页”和跳转到目标页面的选项。
(2) 使用标准标签标记分类页面,避免分类页面权重分散和竞争。
5、移动友好,速度快,HTTPS配置
(1)响应式设计让页面在所有终端上都有友好的体验。
(2)避免过度使用CSS样式,合理压缩JS,提高页面访问速度。
(3)配置SSL证书,提高网站信息传输的安全等级,主动配置HTTPS链接。 查看全部
scrapy分页抓取网页(如何通过以下内容优化网站结构的设计?(一)_光明网(组图))
每个网站都有一个结构,包括逻辑结构和物理结构。有些看起来凌乱,有些看起来简洁。如果你刚开始构建网站,注意网站结构的设计,那么这一定是一个好的开始,但是大部分SEO人员往往会忽略网站@ > 结构。
一、将通过以下内容与大家探讨网站结构设计的重要性以及如何优化网站结构。
1、良好的网站结构有利于蜘蛛爬行和爬行
我们知道,百度希望在能够被百度蜘蛛爬取爬取的前提下,快速成为收录。目录层次结构复杂且相对较深。对于新站点,很容易让百度难以抓取,这也是百度依然强调站点地图重要性的原因。
只有这样才能有效地索引网站的复杂结构。
2、良好的网站结构设计,防止内容重复
URL 是非标准化的,通常会生成相同的内容页面和多个 URL 链接。这是一个严重的 SEO 错误,可能会导致内部冲突。
造成这个问题的主要原因是前期没有有效的站结构配置。
3、好的网站结构设计有利于提升用户体验。
网站结构的逻辑结构比较强,可以清晰的让访问者找到自己想要的东西,快速了解整个网站的结构。一个有组织的网站结构可以吸引对方延长页面停留时间,降低跳出率。相反,很容易造成负面的SEO。
二、那么,如何优化网站结构的设计呢?
1、根据网站类型规划自己的层次结构
(1)传统的网站结构是:首页->分类列表页->内容页,加上聚合页(标签页)
对于网站数据量大、分类页和标签页较多的情况,需要根据实际情况进行修改。比如电商网站站点的内部结构,可以尝试添加更多的子类。
(2)确保 URL 标准化
对于URL,我们需要保证相同内容只有一个URL地址,需要在静态页面、伪静态页面和动态页面之间进行选择。
2、顶部导航和面包屑导航
一般来说,搜索引擎的抓取顺序是“从上到下,从左到右”。因此,在设计顶部导航和面包屑导航时,需要注意以下几点:
(1)顶部导航:将具有一定索引的分类列从左到右排序。
(2)面包屑导航:注意收录核心关键词和长尾关键词。重要的是它必须是超链接,而不是文本内容。
3、网站链接优化
合理使用站内链接对SEO有一定的优势。它可以:
(1)减少点击次数网站,提升用户体验,增强用户粘性。
(2)本站链接锚文本具有一定的投票权,利于权重传递,提高关键词的排名。
(3)导出著名机构页面的链接有助于提高网站的声誉。
4、分页文章列表
我们知道,网站的长期运行必然会产生多个内容页面。对于分类列表页,它显示的内容量是有限制的,例如:你有100个文章,每个列表页显示10个,然后生成10个列表页。
一定程度上影响了用户体验和蜘蛛爬行,所以你可以:
(1)在分页选项卡上,添加“下一页”、“下一页”和跳转到目标页面的选项。
(2) 使用标准标签标记分类页面,避免分类页面权重分散和竞争。
5、移动友好,速度快,HTTPS配置
(1)响应式设计让页面在所有终端上都有友好的体验。
(2)避免过度使用CSS样式,合理压缩JS,提高页面访问速度。
(3)配置SSL证书,提高网站信息传输的安全等级,主动配置HTTPS链接。
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-15 04:09
2015-06-23 更新:
之前写这篇文章的时候,还没有遇到具体的场景。只是觉得有这么一个方法,就写下来了。
我今天刚刚满足了这个需求。抓取一个BBS的内容,版块首页只显示标题、作者和发表时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发帖时间)。如果要过滤,只能得到抓取链接内容后的时间,实际上造成了不必要的浪费。使用本文文章的方法可以在抓取链接前进行过滤,避免抓取无用数据。
第一部分scrapy爬虫开始(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取爬行。
具体思路:以我们豆瓣群为例。豆瓣社科组,我们以首页地址作为start_url参数,从页面源码中查找剩余页面,如下:
可以提取每个页面的地址,多页面捕获的思路是将地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并指定这些页面地址对应的回调函数。由于首页和分页在形式上完全一样(首页本身也是一个页面),所以可以直接指定parse作为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
前面是CrawlSpider,换成了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,相当于每个页面都提取了一个页面地址,这样实际上每个页面地址都返回了N次。, 那么scrapy在实际处理中会不会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》……
让我们运行程序看看。现在,让我们看看我们的打印语句:“->”代表当前页面地址,后面是从当前页面中提取的页面地址。为了简化输出,仅提取用于标识页面的“开始”。范围。
操作结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如您所见:
1. 每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除,并且它使用线程进行数据提取操作。
好了,任务完成了。使用CrawlSpider的规则感觉更方便。 查看全部
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
2015-06-23 更新:
之前写这篇文章的时候,还没有遇到具体的场景。只是觉得有这么一个方法,就写下来了。
我今天刚刚满足了这个需求。抓取一个BBS的内容,版块首页只显示标题、作者和发表时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发帖时间)。如果要过滤,只能得到抓取链接内容后的时间,实际上造成了不必要的浪费。使用本文文章的方法可以在抓取链接前进行过滤,避免抓取无用数据。
第一部分scrapy爬虫开始(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取爬行。
具体思路:以我们豆瓣群为例。豆瓣社科组,我们以首页地址作为start_url参数,从页面源码中查找剩余页面,如下:
可以提取每个页面的地址,多页面捕获的思路是将地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并指定这些页面地址对应的回调函数。由于首页和分页在形式上完全一样(首页本身也是一个页面),所以可以直接指定parse作为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
前面是CrawlSpider,换成了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,相当于每个页面都提取了一个页面地址,这样实际上每个页面地址都返回了N次。, 那么scrapy在实际处理中会不会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》……
让我们运行程序看看。现在,让我们看看我们的打印语句:“->”代表当前页面地址,后面是从当前页面中提取的页面地址。为了简化输出,仅提取用于标识页面的“开始”。范围。
操作结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如您所见:
1. 每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除,并且它使用线程进行数据提取操作。
好了,任务完成了。使用CrawlSpider的规则感觉更方便。
scrapy分页抓取网页(用Scrapy写爬虫再只要理清下面两点就能写成一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-15 04:04
)
1 简介
Scrapy模块中有4个现成的蜘蛛类,分别是:
SpiderCrawlSpiderXMLFeedSpiderCSVFeedSpider
Spider是最简单的爬虫,也是最基本的爬虫。包括自定义爬虫在内的所有其他爬虫都必须继承它。本节主要讲Scrapy编写爬虫的核心内容,从CrawlSpider类开始,开始学习如何搭建最简单的爬虫程序。
在我写的第一篇文章中,我说爬虫无非是以下几点:
请求(requests)目标站点的网页(文本);使用正则表达式、Beautiful Soup、LXML、CSS 提取数据;制定爬取规则(如“下一页”等)、爬取方式(异步爬取、设置代理等);存储数据。
至于如何存储数据,我们暂时不关心,因为在Scrapy的命令行中,可以通过参数直接将数据存储到文件中,见【命令行工具】-命令行工具。
总结我以往的经验,用Scrapy写爬虫,只要搞清楚以下两点就可以写成爬虫了:
知道要爬哪些页面,爬完这个页面后要爬哪些页面,入口点在哪里;如何从这些页面中提取数据
对于第二点,我们在最近的3次文章中已经做了详细的介绍。这里我就不多说了。学习完本节内容后,您可以进一步了解提取数据的方法:
[Easy XPath]-开始使用XPath
[RegEx]-正则表达式
【Scrapy中的选择器】-数据匹配方法
因此,本节将带您从示例中阐明编写爬虫的思路和方法。
2 需求分析
假设你目前不清楚如何用Scrapy写爬虫,那么你手头只有一个任务,就是你要爬取哪些数据网站。所以第一步就是分析需求,搞清楚爬取的顺序,其他的就别管了。
任务:
爬取->网站 热门标签下的所有引用及其作者
看看这个页面:
scrapy view http://quotes.toscrape.com/
图片右侧的红框是热门标签。让我们随机点击一个标签来签到:
http://quotes.toscrape.com/tag/love/
我们将上图定义为标签主页,上图中的红框代表我们需要提取的数据项。在数据爬取中,我们必须最大程度的保证数据的完整性,也就是说:获取所有存在于网站上的目标数据。除了标签首页的数据,剩下的数据在哪里?入口在哪里?
往下我们找到Next按钮,打开调试器查看它的地址:
http://quotes.toscrape.com/tag/love/page/2/
点击第二页,已经找不到Next按钮了,也就是love标签下的数据只存在于两个页面:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/love/page/2/
总结两个步骤:
① 获取首页右侧所有热门标签对应的地址:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/inspirational/
……
② 访问各标签首页,在各标签首页点击“下一步”获取剩余数据,直到找不到下一步按钮
最后再补充一点:
爱标签首页的数据,分析起来,是第一页。这是否意味着它相当于:
http://quotes.toscrape.com/tag/love/page/1/
我们在标签主页上找到了这个链接:
因此,可以按以下顺序获取每个标签下的数据:
http://quotes.toscrape.com/tag/love/page/1/
http://quotes.toscrape.com/tag/love/page/2/
……
这是第一点:
下面两个网站指向同一个页面:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/love/page/1/
如果我们按照上面的页数抓取数据,那么我们的数据就是重复的。我们需要在下面进一步解决这个问题。
3 CrawlSpider类使用详解
先通风一下它独特的属性和方法,然后就从刚刚完成上述任务开始,给爬虫代码,写下CrawlSpider类中各个参数用法的例子。
① parse_start_url(response)
用于处理start_urls的响应,它的用处是:如果需要模拟登录等操作,可以重写这个方法。
② Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None)
规则用于:
以指定格式提取链接(link_extractor);过滤提取的链接(process_links);为指定页面指定相应的处理方法(process_request);指定页面的处理方式(回调);为不同的提取链接方法指定后续规则(Follow);将参数 (cb_kwargs) 传递给回调函数。
避免使用 parse 作为回调函数(callback)
在 PyCharm 中创建文件如下:
env:虚拟环境
simple:爬虫文件夹
Quotes_CrawlSpider.py:爬虫
run.py:用于启动爬虫,方便调试
run.py的代码如下:
from scrapy import cmdline
cmdline.execute("scrapy runspider Quotes_CrawlSpider.py -o quotes.json".split())
解释:
相当于从命令行启动爬虫文件,-oquotes.json将爬虫产生的item保存到json文件中。
3.1 完成上述爬虫任务所需的爬虫代码
Quotes_CrawlSpider.py 的代码如下:
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'toscrape.com'
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
rules = (
Rule(LinkExtractor(allow=('/tag/\w+/$',)),
follow=True, # 如果有指定回调函数,默认不跟进
callback='parse_item',
process_links='process_links',),
Rule(LinkExtractor(allow=('/tag/\w+/page/\d+/',), deny=('/tag/\w+/page/1/',)),
callback='parse_item',
follow=True,),
)
@staticmethod
def process_links(links): # 对提取到的链接进行处理
for link in links:
link.url = link.url + 'page/1/'
yield link
@staticmethod
def parse_item(response): # 解析网页数据并返回数据字典
quote_block = response.css('div.quote')
for quote in quote_block:
text = quote.css('span.text::text').extract_first()
author = quote.xpath('span/small/text()').extract_first()
item = dict(text=text, author=author)
yield item
流程图:
详细代码:
提取规则1:(①-④)
Rule(LinkExtractor(allow=('/tag/\w+/$',)), # 从主页提取标签主页的地址,利用正则表达式
follow=True, # request标签主页得到内容,继续在该内容上上应用规则提取链接
callback='parse_item', # request标签主页得到内容,对该内容应用parse_item函数提取数据
process_links='process_links',), # 用process_links方法对提取到的链接做处理,将标签主页变成/page/1/形式
提取规则2:(⑤,⑥)
Rule(LinkExtractor(allow=('/tag/\w+/page/\d+/',), deny=('/tag/\w+/page/1/',)),
# 提取链接格式满足“/tag/英文字母/page/”数字/形式的,并拒绝第一页
callback='parse_item', # 指定parse_item作为页面的处理方法
follow=True,), # 需要在得到的页面继续搜索满足规则的链接
parse_start_url(响应)
from scrapy.spiders import CrawlSpider
class QuotesSpider(CrawlSpider):
name = "quotes"
custom_settings = {
'LOG_LEVEL': 'INFO',
}
start_urls = ['http://quotes.toscrape.com/tag/love/']
def parse_start_url(self, response):
self.logger.info('parse_start_url %s', response.url)
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
yield response.follow(next_page, self.next_parse)
def next_parse(self, response):
self.logger.info('next_pares %s', response.url)
rule的几个参数用法示例:
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'toscrape.com'
custom_settings = {
'LOG_LEVEL': 'INFO', # 设置日志级别
}
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
rules = (
Rule(LinkExtractor(allow=('/tag/\w+/$',)),
follow=False, # 为了测试几个参数的用法简单设定
callback='parse_item',
cb_kwargs={'tag': 'love'}, # 以key名tag作为变量名传给回调函数parse_item
process_links='process_links', # 对提取的链接做处理
process_request='process_req' # 对每个请求做处理),
)
@staticmethod
def process_links(links):
for link in links:
link.url = link.url + 'page/1/'
yield link
def process_req(self, req):
if 'love' in req.url: # 我们测试当链接中包含love是转给parse_love处理response
return req.replace(callback=self.parse_love)
elif 'humor' in req.url:
return req # 如果链接中包含humor则正常用回调函数parse_item处理response
def parse_love(self, response):
self.logger.info('parse_love %s' % response.url)
def parse_item(self, response, tag):
self.logger.info('parse_item %s' % response.url)
self.logger.info('not %s' % tag)
操作结果:
操作流程:
查看全部
scrapy分页抓取网页(用Scrapy写爬虫再只要理清下面两点就能写成一个
)
1 简介
Scrapy模块中有4个现成的蜘蛛类,分别是:
SpiderCrawlSpiderXMLFeedSpiderCSVFeedSpider
Spider是最简单的爬虫,也是最基本的爬虫。包括自定义爬虫在内的所有其他爬虫都必须继承它。本节主要讲Scrapy编写爬虫的核心内容,从CrawlSpider类开始,开始学习如何搭建最简单的爬虫程序。
在我写的第一篇文章中,我说爬虫无非是以下几点:
请求(requests)目标站点的网页(文本);使用正则表达式、Beautiful Soup、LXML、CSS 提取数据;制定爬取规则(如“下一页”等)、爬取方式(异步爬取、设置代理等);存储数据。
至于如何存储数据,我们暂时不关心,因为在Scrapy的命令行中,可以通过参数直接将数据存储到文件中,见【命令行工具】-命令行工具。
总结我以往的经验,用Scrapy写爬虫,只要搞清楚以下两点就可以写成爬虫了:
知道要爬哪些页面,爬完这个页面后要爬哪些页面,入口点在哪里;如何从这些页面中提取数据
对于第二点,我们在最近的3次文章中已经做了详细的介绍。这里我就不多说了。学习完本节内容后,您可以进一步了解提取数据的方法:
[Easy XPath]-开始使用XPath
[RegEx]-正则表达式
【Scrapy中的选择器】-数据匹配方法
因此,本节将带您从示例中阐明编写爬虫的思路和方法。
2 需求分析
假设你目前不清楚如何用Scrapy写爬虫,那么你手头只有一个任务,就是你要爬取哪些数据网站。所以第一步就是分析需求,搞清楚爬取的顺序,其他的就别管了。
任务:
爬取->网站 热门标签下的所有引用及其作者
看看这个页面:
scrapy view http://quotes.toscrape.com/
图片右侧的红框是热门标签。让我们随机点击一个标签来签到:
http://quotes.toscrape.com/tag/love/
我们将上图定义为标签主页,上图中的红框代表我们需要提取的数据项。在数据爬取中,我们必须最大程度的保证数据的完整性,也就是说:获取所有存在于网站上的目标数据。除了标签首页的数据,剩下的数据在哪里?入口在哪里?
往下我们找到Next按钮,打开调试器查看它的地址:
http://quotes.toscrape.com/tag/love/page/2/
点击第二页,已经找不到Next按钮了,也就是love标签下的数据只存在于两个页面:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/love/page/2/
总结两个步骤:
① 获取首页右侧所有热门标签对应的地址:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/inspirational/
……
② 访问各标签首页,在各标签首页点击“下一步”获取剩余数据,直到找不到下一步按钮
最后再补充一点:
爱标签首页的数据,分析起来,是第一页。这是否意味着它相当于:
http://quotes.toscrape.com/tag/love/page/1/
我们在标签主页上找到了这个链接:
因此,可以按以下顺序获取每个标签下的数据:
http://quotes.toscrape.com/tag/love/page/1/
http://quotes.toscrape.com/tag/love/page/2/
……
这是第一点:
下面两个网站指向同一个页面:
http://quotes.toscrape.com/tag/love/
http://quotes.toscrape.com/tag/love/page/1/
如果我们按照上面的页数抓取数据,那么我们的数据就是重复的。我们需要在下面进一步解决这个问题。
3 CrawlSpider类使用详解
先通风一下它独特的属性和方法,然后就从刚刚完成上述任务开始,给爬虫代码,写下CrawlSpider类中各个参数用法的例子。
① parse_start_url(response)
用于处理start_urls的响应,它的用处是:如果需要模拟登录等操作,可以重写这个方法。
② Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None)
规则用于:
以指定格式提取链接(link_extractor);过滤提取的链接(process_links);为指定页面指定相应的处理方法(process_request);指定页面的处理方式(回调);为不同的提取链接方法指定后续规则(Follow);将参数 (cb_kwargs) 传递给回调函数。
避免使用 parse 作为回调函数(callback)
在 PyCharm 中创建文件如下:
env:虚拟环境
simple:爬虫文件夹
Quotes_CrawlSpider.py:爬虫
run.py:用于启动爬虫,方便调试
run.py的代码如下:
from scrapy import cmdline
cmdline.execute("scrapy runspider Quotes_CrawlSpider.py -o quotes.json".split())
解释:
相当于从命令行启动爬虫文件,-oquotes.json将爬虫产生的item保存到json文件中。
3.1 完成上述爬虫任务所需的爬虫代码
Quotes_CrawlSpider.py 的代码如下:
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'toscrape.com'
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
rules = (
Rule(LinkExtractor(allow=('/tag/\w+/$',)),
follow=True, # 如果有指定回调函数,默认不跟进
callback='parse_item',
process_links='process_links',),
Rule(LinkExtractor(allow=('/tag/\w+/page/\d+/',), deny=('/tag/\w+/page/1/',)),
callback='parse_item',
follow=True,),
)
@staticmethod
def process_links(links): # 对提取到的链接进行处理
for link in links:
link.url = link.url + 'page/1/'
yield link
@staticmethod
def parse_item(response): # 解析网页数据并返回数据字典
quote_block = response.css('div.quote')
for quote in quote_block:
text = quote.css('span.text::text').extract_first()
author = quote.xpath('span/small/text()').extract_first()
item = dict(text=text, author=author)
yield item
流程图:
详细代码:
提取规则1:(①-④)
Rule(LinkExtractor(allow=('/tag/\w+/$',)), # 从主页提取标签主页的地址,利用正则表达式
follow=True, # request标签主页得到内容,继续在该内容上上应用规则提取链接
callback='parse_item', # request标签主页得到内容,对该内容应用parse_item函数提取数据
process_links='process_links',), # 用process_links方法对提取到的链接做处理,将标签主页变成/page/1/形式
提取规则2:(⑤,⑥)
Rule(LinkExtractor(allow=('/tag/\w+/page/\d+/',), deny=('/tag/\w+/page/1/',)),
# 提取链接格式满足“/tag/英文字母/page/”数字/形式的,并拒绝第一页
callback='parse_item', # 指定parse_item作为页面的处理方法
follow=True,), # 需要在得到的页面继续搜索满足规则的链接
parse_start_url(响应)
from scrapy.spiders import CrawlSpider
class QuotesSpider(CrawlSpider):
name = "quotes"
custom_settings = {
'LOG_LEVEL': 'INFO',
}
start_urls = ['http://quotes.toscrape.com/tag/love/']
def parse_start_url(self, response):
self.logger.info('parse_start_url %s', response.url)
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
yield response.follow(next_page, self.next_parse)
def next_parse(self, response):
self.logger.info('next_pares %s', response.url)
rule的几个参数用法示例:
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'toscrape.com'
custom_settings = {
'LOG_LEVEL': 'INFO', # 设置日志级别
}
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
rules = (
Rule(LinkExtractor(allow=('/tag/\w+/$',)),
follow=False, # 为了测试几个参数的用法简单设定
callback='parse_item',
cb_kwargs={'tag': 'love'}, # 以key名tag作为变量名传给回调函数parse_item
process_links='process_links', # 对提取的链接做处理
process_request='process_req' # 对每个请求做处理),
)
@staticmethod
def process_links(links):
for link in links:
link.url = link.url + 'page/1/'
yield link
def process_req(self, req):
if 'love' in req.url: # 我们测试当链接中包含love是转给parse_love处理response
return req.replace(callback=self.parse_love)
elif 'humor' in req.url:
return req # 如果链接中包含humor则正常用回调函数parse_item处理response
def parse_love(self, response):
self.logger.info('parse_love %s' % response.url)
def parse_item(self, response, tag):
self.logger.info('parse_item %s' % response.url)
self.logger.info('not %s' % tag)
操作结果:
操作流程:
scrapy分页抓取网页(WebScraper的扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-14 06:15
本文内容
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少,虽然可以自己写代码来实现,但这很荒谬。大锤?
市面上已经有一些成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装后需要重启Chrome一次,然后F12就可以看到工具了
2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图了
选择器
直译,它是一个选择器。要从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的 Selector 有很多,但是本文 文章 只介绍了几个最常用、覆盖面最广的 Selector。了解一两个之后,其他的原理都差不多,以后私下多多学习。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有网站的下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的 CSDN 博客文章并将其拉到底部以查看评论区。
如果你的文章很火,当有很多同学评论的时候,CSDN会分页显示,但是不管评论在哪个页面,都属于同一篇文章文章@ >、浏览时无需刷新任何页面评论区的博文,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"clickElementSelector":"li.js-page-next","clickElementUniquenessType":"uniqueText","clickType":"clickMore","delay":2000,"discardInitialElements":"do-not-discard","id":"next_page","multiple":true,"parentSelectors":["_root","next_page"],"selector":"div.comment-list-container","type":"SelectorElementClick"},{"delay":0,"id":"comment","multiple":true,"parentSelectors":["_root","next_page"],"selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","type":"SelectorElement"},{"delay":0,"id":"content","multiple":false,"parentSelectors":["comment"],"regex":"","selector":"_parent_","type":"SelectorText"}]}
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"comment","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","multiple":true,"delay":0},{"id":"content","parentSelectors":["comment"],"type":"SelectorText","selector":"_parent_","multiple":false,"delay":0,"regex":""}]}
要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种寻呼机,Element Click无能为力,读者可以自行验证,只能爬到一个页面后关闭。
并且作为分页的Pagination选择器,自然适用
爬取的拓扑和上面一样,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习
{"_id":"mycsdn","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"article","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"div.article-item-box","multiple":true,"delay":0},{"id":"title","parentSelectors":["article"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":"[0-9]+"},{"id":"comments","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""},{"id":"publish_time","parentSelectors":["article"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""}]}
4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果您想获得更多信息,如博文正文、点赞数、采集数、评论区内容等,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果你想抓取博文更详细的信息,你必须打开一个新页面才能获取,而网络爬虫的链接选择器恰好可以做到这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap配置如下,可以直接导入使用
{"_id":"csdn_detail","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"container","parentSelectors":["_root"],"type":"SelectorElement","selector":"[data-articleid='111936614']","multiple":false,"delay":0},{"id":"article_detail_link","parentSelectors":["container"],"type":"SelectorLink","selector":"h4 a","multiple":false,"delay":0},{"id":"detail","parentSelectors":["article_detail_link"],"type":"SelectorText","selector":"article","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["container"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"time","parentSelectors":["container"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":""},{"id":"comments","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""}]}
5. 写在最后
上面整理了分页和二级页面的爬取方案,主要是:pager爬取和二级页面爬取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。 查看全部
scrapy分页抓取网页(WebScraper的扩展插件,安装后你可以直接在F12调试工具里使用)
本文内容
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少,虽然可以自己写代码来实现,但这很荒谬。大锤?
市面上已经有一些成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装后需要重启Chrome一次,然后F12就可以看到工具了
2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图了
选择器
直译,它是一个选择器。要从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的 Selector 有很多,但是本文 文章 只介绍了几个最常用、覆盖面最广的 Selector。了解一两个之后,其他的原理都差不多,以后私下多多学习。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有网站的下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的 CSDN 博客文章并将其拉到底部以查看评论区。
如果你的文章很火,当有很多同学评论的时候,CSDN会分页显示,但是不管评论在哪个页面,都属于同一篇文章文章@ >、浏览时无需刷新任何页面评论区的博文,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"clickElementSelector":"li.js-page-next","clickElementUniquenessType":"uniqueText","clickType":"clickMore","delay":2000,"discardInitialElements":"do-not-discard","id":"next_page","multiple":true,"parentSelectors":["_root","next_page"],"selector":"div.comment-list-container","type":"SelectorElementClick"},{"delay":0,"id":"comment","multiple":true,"parentSelectors":["_root","next_page"],"selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","type":"SelectorElement"},{"delay":0,"id":"content","multiple":false,"parentSelectors":["comment"],"regex":"","selector":"_parent_","type":"SelectorText"}]}
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"comment","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","multiple":true,"delay":0},{"id":"content","parentSelectors":["comment"],"type":"SelectorText","selector":"_parent_","multiple":false,"delay":0,"regex":""}]}
要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种寻呼机,Element Click无能为力,读者可以自行验证,只能爬到一个页面后关闭。
并且作为分页的Pagination选择器,自然适用
爬取的拓扑和上面一样,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习
{"_id":"mycsdn","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"article","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"div.article-item-box","multiple":true,"delay":0},{"id":"title","parentSelectors":["article"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":"[0-9]+"},{"id":"comments","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""},{"id":"publish_time","parentSelectors":["article"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""}]}
4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果您想获得更多信息,如博文正文、点赞数、采集数、评论区内容等,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果你想抓取博文更详细的信息,你必须打开一个新页面才能获取,而网络爬虫的链接选择器恰好可以做到这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap配置如下,可以直接导入使用
{"_id":"csdn_detail","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"container","parentSelectors":["_root"],"type":"SelectorElement","selector":"[data-articleid='111936614']","multiple":false,"delay":0},{"id":"article_detail_link","parentSelectors":["container"],"type":"SelectorLink","selector":"h4 a","multiple":false,"delay":0},{"id":"detail","parentSelectors":["article_detail_link"],"type":"SelectorText","selector":"article","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["container"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"time","parentSelectors":["container"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":""},{"id":"comments","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""}]}
5. 写在最后
上面整理了分页和二级页面的爬取方案,主要是:pager爬取和二级页面爬取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。
scrapy分页抓取网页(目标网站是以滚动页面的方式动态生成数据的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-13 03:01
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
类似于今日头条网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合用于数据捕获。由于Selenium直接在浏览器中运行,因此可以轻松绕过网站的反爬虫限制。 , 就像真正的用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动页面分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码进行捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
scrapy分页抓取网页(目标网站是以滚动页面的方式动态生成数据的网页)
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
类似于今日头条网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合用于数据捕获。由于Selenium直接在浏览器中运行,因此可以轻松绕过网站的反爬虫限制。 , 就像真正的用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动页面分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码进行捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
scrapy分页抓取网页(:RSS阅读器分页信息分页分页(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-11 17:19
专利名称:Rss信息分页抓取系统及方法
技术领域:
本发明涉及互联网技术领域,尤其涉及一种RSS信息的分页抓取系统及方法。
背景技术:
RSS(Simple Information Syndication,也称为聚合内容)是一种用于描述和同步网站内容的格式。RSS 可以是以下三种解释之一: 真正简单的联合;RDF(资源描述框架)站点摘要;丰富的网站摘要。实际上,这三种解释指的是同一种 Syndication 技术。RSS 目前广泛用于在线新闻频道、博客和维基。主要版本有0.91、I.0、2.O。使用RSS订阅,获取信息更快。网站提供RSS输出,有利于用户获取网站内容的最新更新。网络用户可以使用客户端的RSS聚合工具软件阅读支持RSS输出的网站内容,无需打开网站 内容页。其中,RSS订阅是站点与其他站点共享内容的一种简单方式。面对迎面而来的新闻,你不需要花大量时间从新闻网站上冲浪和下载,只需通过RSS阅读器就可以阅读大量信息。目前,RSS订阅主要有两种类型。第一个是用户通过RSS阅读器从RSS源站提取信息。这种方式需要用户主动添加RSS源。信息来源单一,RSS内容完全由源站决定。RSS源只推送信息摘要。如需查看详细信息,必须到原网页查看;二是用户订阅了一些第三方网站,第三方订阅站点预先从一些高质量的RSS源中提取信息,并进行一定的处理,返回给用户的是聚合后的信息。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。
发明内容
本发明要解决的技术问题是如何提供一种RSS信息的分页抓取系统及方法,以保证在从RSS源中提取信息时能够识别分页并提取全文。为解决上述技术问题,本发明提供了一种RSS信息寻呼抓取系统,包括列表创建单元,用于采集带有寻呼的RSS频道,建立寻呼频道列表。列表分析单元,用于分析寻呼信道列表,获取每个RSS信道对应的寻呼标签;代码获取单元,用于在从RSS源页面代码中抓取信息时,如果当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的信息。标签查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。适配在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。适配在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。
标签对应模块,用于分析分页网页的页面代码,找到其中的分页标签作为对应的RSS频道。其中,代码获取单元还包括信息抓取模块,用于从RSS源抓取信息。判断模块,用于判断当前信息源的目标RSS频道是否属于分页频道列表;代码获取模块,用于当作为当前信息源的目标RSS频道属于寻呼频道列表时,获取当前信息对应的寻呼代码。其中,分页组合单元还包括URL获取模块,用于根据找到的分页标签获取每个页面的URL。提取每一页的文字;页面组合模块适用于对每个页面的文本进行组合以获得完整的RSS信息。其中,该系统还包括推送单元,用于向用户推送完整的RSS信息。本发明还提供了一种获取RSS信息的寻呼方法,包括:采集带有寻呼的RSS频道,建立寻呼频道列表。分析寻呼频道列表,得到每个RSS频道对应的寻呼标签;当从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码;在页面代码中查找目标RSS频道对应的页面代码;根据搜索你得到的分页标签可以得到每个分页对应的页面,将每个分页对应的页面组合起来就可以得到完整的RSS信息。其中,分析寻呼频道列表,得到每个RSS频道对应的寻呼标签,具体包括依次取出寻呼频道列表中的每个RSS频道,在RSS频道中找到有寻呼的网页。分析所述带有分页的网页的页面代码,找到其中的分页标签作为对应RSS频道对应的分页标签。其中,当从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,然后获取当前信息的页面代码具体包括从RSS源抓取信息,判断当前信息源的目标RSS频道是否属于寻呼频道列表,如果是,则获取当前对应的页面代码信息; 否则,认为当前信息对应的网页没有分页,流程结束。其中,所述根据找到的标签获取各个标签对应的页面,并结合各个标签对应的页面获取完整的RSS信息具体包括:根据找到的标签获取各个标签的URL。根据每个标签的URL获取每个标签的URL 分页的页面代码从页面代码中提取每个页面的文本;
其中,获取完整的RSS信息后,还包括向用户推送完整的RSS信息的步骤。本发明还提供了一种服务器,包括RSS信息分页抓取系统。本发明的RSS信息寻呼抓取系统及方法根据常用的RSS频道建立寻呼频道列表,获取每个RSS频道对应的寻呼标签,然后在对应的页面代码中查找对应的页面代码。从RSS源分页标签中抓取信息,根据分页标签获取每个页面的内容,从而获取完整的RSS信息,保证推送给用户的RSS信息的完整性,提高用户的阅读效率。
无花果。附图说明图1为本发明实施例一的RSS信息分页抓取系统的模块结构示意图;
图2a b为页面标签对应的页面显示效果图;图3为列表分析单元模块结构示意图;图4为代码获取单元模块结构示意图;图5为页面组合单元模块结构示意图;无花果。图6为本发明实施例二的RSS信息分页抓取系统的模块结构示意图;无花果。图7为本发明实施例三提供的RSS信息分页抓取方法的流程图。
具体实施方式以下结合附图和实施例,对本发明的具体实施方式进行说明。
欲知详情。以下实施例用于说明本发明,但不用于限制本发明的范围。无花果。图1为本发明实施例一的RSS信息分页抓取系统的模块结构示意图。如图所示。RSS频道一般指按内容类型划分的新闻频道、娱乐频道、生活休闲频道、阅读频道、下载频道、体育频道、游戏频道、音乐频道、视频频道、汽车频道、房地产等。频道和其他部分。由于网站的不同,这些频道的名称可能不同,频道之间的层次关系也可能不同。例如,在某些 网站 中,游戏频道可以作为娱乐频道的子频道出现。为方便起见,上述收录子频道的频道称为父频道。由于同一个网站中每个父频道下的网页采用相同的分页格式,因此本应用中的RSS频道可以对应父频道。一层不对应子信道向下。寻呼频道列表包括所有常见的带有寻呼功能的RSS频道,如新浪汽车频道、网易数字频道、搜狐军事频道等。列表分析单元200,用于对寻呼信道列表进行分析,得到每个RSS信道对应的寻呼标签。每个 RSS 频道对应一个分页标签。例如,图2a为新浪汽车频道分页标签对应的页面展示效果图。表Ia是分页标签对应的源代码。分页标签可以概括为类属性。是Pb的div标签;图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。
表 Ia 新浪自动频道分页标签
权限请求
1. RSS信息的寻呼抓取系统,包括列表构建单元,适用于采集寻呼RSS频道,建立寻呼频道列表;列表分析单元,用于分析寻呼信道列表,得到RSS信道对应的A寻呼标签;代码获取单元,用于在从RSS源检索信息时,如果当前信息的源目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码;查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面合并单元,用于根据找到的页面标签获取每个页面对应的页面,
2.如权利要求1所述的系统,其特征在于,所述列表分析单元还包括网页提取模块,用于依次提取分页后的频道列表中的各个RSS频道,并找到该RSS频道一个带有分页标签的网页对应模块,用于分析分页网页的页面代码,找到其中的分页标签作为对应的RSS频道。
3.如权利要求1所述的系统,其特征在于,所述代码获取单元还包括信息抓取模块,用于抓取来自RSS源的信息;判断模块,用于判断当前信息的来源目标RSS频道是否属于寻呼频道列表;代码获取模块,用于当作为当前信息源的目标RSS频道属于寻呼频道列表时,获取当前信息对应的寻呼代码。
4.如权利要求1所述的系统,其特征在于,所述分页组合单元还包括URL获取模块,用于根据找到的分页标签获取每个页面的URL;正文获取模块,用于根据每个页面的URL获取URL,获取每个页面的页面代码,并从页面代码中提取出每个页面的文本;页面组合模块适用于对每个页面的文本进行组合以获得完整的RSS信息。
5.如权利要求1所述的系统,其特征在于,所述系统还包括推送单元,用于向用户推送完整的RSS信息。
6. 一种RSS信息的寻呼方法,包括采集带有寻呼的RSS频道和建立寻呼频道列表的步骤;分析寻呼频道列表,得到每个RSS频道对应的寻呼标签;获取信息时,如果当前信息来源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面编码;在页面代码中找到目标RSS频道对应的分页标签;根据找到的分页标签获取每个分页对应的页面,将每个分页对应的页面组合起来得到完整的RSS信息。
7.如权利要求6所述的方法,其特征在于,所述分析寻呼频道列表,得到各个RSS频道对应的寻呼标签,具体包括依次提取寻呼频道列表Channel中的各个RSS频道,在RSS频道中找到带有分页的网页; 分析带有分页的网页的页面代码,找到分页标签作为对应的RSS频道。
8.如权利要求6所述的方法,其特征在于,当从RSS源捕获信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则当前信息的页面代码具体为包括从RSS源抓取信息,判断作为当前信息源的目标RSS频道是否属于寻呼频道列表,如果是,则获取当前信息对应的页面代码。否则,认为当前信息对应的网页没有分页,流程结束。
9.如权利要求6所述的方法,其特征在于,所述根据找到的页面标签获取各页面对应的页面,并组合各页面对应的页面以获取完整的RSS信息具体包括以下步骤: 获取URL每个页面根据每个页面的URL;根据每个页面的URL获取每个页面的页面代码,从页面代码中提取每个页面的文本;结合每一页的文字,得到完整的RSS信息。
10.如权利要求6所述的方法,其特征在于,在获取完整RSS信息后,还包括向用户推送完整RSS信息的步骤。
11. 一种服务器,包括如权利要求1至5中任一项所述的RSS信息分页爬取系统。
全文摘要
本发明公开了一种RSS信息的页面抓取系统及方法。该系统包括列表创建单元,用于采集带有寻呼的RSS频道,建立寻呼频道列表;列表分析单元,用于分析寻呼信道列表,得到每个RSS信道对应的寻呼标签;代码获取单元,适用于在从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码。标签查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面合并单元用于根据找到的页面标签获取每个页面对应的页面,并将每个页面对应的页面组合起来,得到完整的RSS信息。本发明保证推送给用户的RSS信息的完整性,提高用户的阅读效率。
文件编号 G06F17/30GK102819613SQ20121031166
公布日期 2012 年 12 月 12 日 申请日期 2012 年 8 月 28 日 优先权日期 2012 年 8 月 28 日
发明人郑伟、赵刚申请人:、 查看全部
scrapy分页抓取网页(:RSS阅读器分页信息分页分页(图))
专利名称:Rss信息分页抓取系统及方法
技术领域:
本发明涉及互联网技术领域,尤其涉及一种RSS信息的分页抓取系统及方法。
背景技术:
RSS(Simple Information Syndication,也称为聚合内容)是一种用于描述和同步网站内容的格式。RSS 可以是以下三种解释之一: 真正简单的联合;RDF(资源描述框架)站点摘要;丰富的网站摘要。实际上,这三种解释指的是同一种 Syndication 技术。RSS 目前广泛用于在线新闻频道、博客和维基。主要版本有0.91、I.0、2.O。使用RSS订阅,获取信息更快。网站提供RSS输出,有利于用户获取网站内容的最新更新。网络用户可以使用客户端的RSS聚合工具软件阅读支持RSS输出的网站内容,无需打开网站 内容页。其中,RSS订阅是站点与其他站点共享内容的一种简单方式。面对迎面而来的新闻,你不需要花大量时间从新闻网站上冲浪和下载,只需通过RSS阅读器就可以阅读大量信息。目前,RSS订阅主要有两种类型。第一个是用户通过RSS阅读器从RSS源站提取信息。这种方式需要用户主动添加RSS源。信息来源单一,RSS内容完全由源站决定。RSS源只推送信息摘要。如需查看详细信息,必须到原网页查看;二是用户订阅了一些第三方网站,第三方订阅站点预先从一些高质量的RSS源中提取信息,并进行一定的处理,返回给用户的是聚合后的信息。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。第二种订阅方式显然更能满足用户的阅读需求,但也存在问题。第三方订阅站点从RSS提要中提取信息时,假设提取的信息是文章的摘要,则从原文中提取。从链接中提取全文,但如果对原文内容进行分页,则只能提取第一页。
发明内容
本发明要解决的技术问题是如何提供一种RSS信息的分页抓取系统及方法,以保证在从RSS源中提取信息时能够识别分页并提取全文。为解决上述技术问题,本发明提供了一种RSS信息寻呼抓取系统,包括列表创建单元,用于采集带有寻呼的RSS频道,建立寻呼频道列表。列表分析单元,用于分析寻呼信道列表,获取每个RSS信道对应的寻呼标签;代码获取单元,用于在从RSS源页面代码中抓取信息时,如果当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的信息。标签查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。适配在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。适配在页面代码中查找目标RSS频道对应的页面标签;页面组合单元,用于根据找到的页面标签获取每个页面对应的页面,并组合每个页面Page对应的页面,得到完整的RSS信息。其中,列表分析单元还包括网页提取模块,用于依次取出被分页频道列表中的各个RSS频道,在RSS频道中找到被分页的网页。
标签对应模块,用于分析分页网页的页面代码,找到其中的分页标签作为对应的RSS频道。其中,代码获取单元还包括信息抓取模块,用于从RSS源抓取信息。判断模块,用于判断当前信息源的目标RSS频道是否属于分页频道列表;代码获取模块,用于当作为当前信息源的目标RSS频道属于寻呼频道列表时,获取当前信息对应的寻呼代码。其中,分页组合单元还包括URL获取模块,用于根据找到的分页标签获取每个页面的URL。提取每一页的文字;页面组合模块适用于对每个页面的文本进行组合以获得完整的RSS信息。其中,该系统还包括推送单元,用于向用户推送完整的RSS信息。本发明还提供了一种获取RSS信息的寻呼方法,包括:采集带有寻呼的RSS频道,建立寻呼频道列表。分析寻呼频道列表,得到每个RSS频道对应的寻呼标签;当从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码;在页面代码中查找目标RSS频道对应的页面代码;根据搜索你得到的分页标签可以得到每个分页对应的页面,将每个分页对应的页面组合起来就可以得到完整的RSS信息。其中,分析寻呼频道列表,得到每个RSS频道对应的寻呼标签,具体包括依次取出寻呼频道列表中的每个RSS频道,在RSS频道中找到有寻呼的网页。分析所述带有分页的网页的页面代码,找到其中的分页标签作为对应RSS频道对应的分页标签。其中,当从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,然后获取当前信息的页面代码具体包括从RSS源抓取信息,判断当前信息源的目标RSS频道是否属于寻呼频道列表,如果是,则获取当前对应的页面代码信息; 否则,认为当前信息对应的网页没有分页,流程结束。其中,所述根据找到的标签获取各个标签对应的页面,并结合各个标签对应的页面获取完整的RSS信息具体包括:根据找到的标签获取各个标签的URL。根据每个标签的URL获取每个标签的URL 分页的页面代码从页面代码中提取每个页面的文本;
其中,获取完整的RSS信息后,还包括向用户推送完整的RSS信息的步骤。本发明还提供了一种服务器,包括RSS信息分页抓取系统。本发明的RSS信息寻呼抓取系统及方法根据常用的RSS频道建立寻呼频道列表,获取每个RSS频道对应的寻呼标签,然后在对应的页面代码中查找对应的页面代码。从RSS源分页标签中抓取信息,根据分页标签获取每个页面的内容,从而获取完整的RSS信息,保证推送给用户的RSS信息的完整性,提高用户的阅读效率。
无花果。附图说明图1为本发明实施例一的RSS信息分页抓取系统的模块结构示意图;
图2a b为页面标签对应的页面显示效果图;图3为列表分析单元模块结构示意图;图4为代码获取单元模块结构示意图;图5为页面组合单元模块结构示意图;无花果。图6为本发明实施例二的RSS信息分页抓取系统的模块结构示意图;无花果。图7为本发明实施例三提供的RSS信息分页抓取方法的流程图。
具体实施方式以下结合附图和实施例,对本发明的具体实施方式进行说明。
欲知详情。以下实施例用于说明本发明,但不用于限制本发明的范围。无花果。图1为本发明实施例一的RSS信息分页抓取系统的模块结构示意图。如图所示。RSS频道一般指按内容类型划分的新闻频道、娱乐频道、生活休闲频道、阅读频道、下载频道、体育频道、游戏频道、音乐频道、视频频道、汽车频道、房地产等。频道和其他部分。由于网站的不同,这些频道的名称可能不同,频道之间的层次关系也可能不同。例如,在某些 网站 中,游戏频道可以作为娱乐频道的子频道出现。为方便起见,上述收录子频道的频道称为父频道。由于同一个网站中每个父频道下的网页采用相同的分页格式,因此本应用中的RSS频道可以对应父频道。一层不对应子信道向下。寻呼频道列表包括所有常见的带有寻呼功能的RSS频道,如新浪汽车频道、网易数字频道、搜狐军事频道等。列表分析单元200,用于对寻呼信道列表进行分析,得到每个RSS信道对应的寻呼标签。每个 RSS 频道对应一个分页标签。例如,图2a为新浪汽车频道分页标签对应的页面展示效果图。表Ia是分页标签对应的源代码。分页标签可以概括为类属性。是Pb的div标签;图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。图2b为网易数字频道分页标签对应的页面显示效果图。表Ib是分页标签对应的源代码。分页标签可以概括为具有endPageNum的class属性的div标签。一般来说,一个RSS频道的所有网页信息,如果有分页,都会使用同一个标签。根据这种情况,可以建立一个RSS频道和标签的对应表。
表 Ia 新浪自动频道分页标签
权限请求
1. RSS信息的寻呼抓取系统,包括列表构建单元,适用于采集寻呼RSS频道,建立寻呼频道列表;列表分析单元,用于分析寻呼信道列表,得到RSS信道对应的A寻呼标签;代码获取单元,用于在从RSS源检索信息时,如果当前信息的源目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码;查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面合并单元,用于根据找到的页面标签获取每个页面对应的页面,
2.如权利要求1所述的系统,其特征在于,所述列表分析单元还包括网页提取模块,用于依次提取分页后的频道列表中的各个RSS频道,并找到该RSS频道一个带有分页标签的网页对应模块,用于分析分页网页的页面代码,找到其中的分页标签作为对应的RSS频道。
3.如权利要求1所述的系统,其特征在于,所述代码获取单元还包括信息抓取模块,用于抓取来自RSS源的信息;判断模块,用于判断当前信息的来源目标RSS频道是否属于寻呼频道列表;代码获取模块,用于当作为当前信息源的目标RSS频道属于寻呼频道列表时,获取当前信息对应的寻呼代码。
4.如权利要求1所述的系统,其特征在于,所述分页组合单元还包括URL获取模块,用于根据找到的分页标签获取每个页面的URL;正文获取模块,用于根据每个页面的URL获取URL,获取每个页面的页面代码,并从页面代码中提取出每个页面的文本;页面组合模块适用于对每个页面的文本进行组合以获得完整的RSS信息。
5.如权利要求1所述的系统,其特征在于,所述系统还包括推送单元,用于向用户推送完整的RSS信息。
6. 一种RSS信息的寻呼方法,包括采集带有寻呼的RSS频道和建立寻呼频道列表的步骤;分析寻呼频道列表,得到每个RSS频道对应的寻呼标签;获取信息时,如果当前信息来源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面编码;在页面代码中找到目标RSS频道对应的分页标签;根据找到的分页标签获取每个分页对应的页面,将每个分页对应的页面组合起来得到完整的RSS信息。
7.如权利要求6所述的方法,其特征在于,所述分析寻呼频道列表,得到各个RSS频道对应的寻呼标签,具体包括依次提取寻呼频道列表Channel中的各个RSS频道,在RSS频道中找到带有分页的网页; 分析带有分页的网页的页面代码,找到分页标签作为对应的RSS频道。
8.如权利要求6所述的方法,其特征在于,当从RSS源捕获信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则当前信息的页面代码具体为包括从RSS源抓取信息,判断作为当前信息源的目标RSS频道是否属于寻呼频道列表,如果是,则获取当前信息对应的页面代码。否则,认为当前信息对应的网页没有分页,流程结束。
9.如权利要求6所述的方法,其特征在于,所述根据找到的页面标签获取各页面对应的页面,并组合各页面对应的页面以获取完整的RSS信息具体包括以下步骤: 获取URL每个页面根据每个页面的URL;根据每个页面的URL获取每个页面的页面代码,从页面代码中提取每个页面的文本;结合每一页的文字,得到完整的RSS信息。
10.如权利要求6所述的方法,其特征在于,在获取完整RSS信息后,还包括向用户推送完整RSS信息的步骤。
11. 一种服务器,包括如权利要求1至5中任一项所述的RSS信息分页爬取系统。
全文摘要
本发明公开了一种RSS信息的页面抓取系统及方法。该系统包括列表创建单元,用于采集带有寻呼的RSS频道,建立寻呼频道列表;列表分析单元,用于分析寻呼信道列表,得到每个RSS信道对应的寻呼标签;代码获取单元,适用于在从RSS源抓取信息时,如果作为当前信息源的目标RSS频道属于寻呼频道列表,则获取当前信息对应的页面代码。标签查找单元,用于在页面代码中查找目标RSS频道对应的页面标签;页面合并单元用于根据找到的页面标签获取每个页面对应的页面,并将每个页面对应的页面组合起来,得到完整的RSS信息。本发明保证推送给用户的RSS信息的完整性,提高用户的阅读效率。
文件编号 G06F17/30GK102819613SQ20121031166
公布日期 2012 年 12 月 12 日 申请日期 2012 年 8 月 28 日 优先权日期 2012 年 8 月 28 日
发明人郑伟、赵刚申请人:、
scrapy分页抓取网页(我有一个3级站点,我想抓取并解析2级的链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-11 10:11
我有一个 3 级站点,我想抓取和解析 2 级和 3 级链接。问题是在第 2 级,有一个 javascript 选项卡可以为每个页面提供不同的链接(总共 5 个页面)。
示例:
Level 1:主菜单(我使用 SgmlLinkExtractor catid = 22767 提取类别的链接)
Level 2:有一些链接我想解析,但也有JavaScript分页,我需要提取其余的链接(即catid = 22767 & page1 = 2)
级别 3:对于上述步骤中的每个链接,我都想解析响应。
网站is()
级别 2 是 (summary.asp? catid = 22768)
Level3是我要分析的文章页面(article.asp?catid = 22768&subid = 2&pubid = 63929343)
问题是:对于从第一级提取的每个链接,我如何创建一个循环并构造所有5个链接,然后在第二级使用SgmlLinkExtractor跟踪这些链接?
有两个答案:
通常,网站 提供其 网站 的可搜索版本,或者您可以实现站点地图。
您可以使用 selenium 之类的东西在浏览器中呈现页面,从而启用 JavaScript,并且您可以像用户一样使用它,并且仍然可以抓取它。
确保以合乎道德的方式爬行以避免网站超载:) 查看全部
scrapy分页抓取网页(我有一个3级站点,我想抓取并解析2级的链接)
我有一个 3 级站点,我想抓取和解析 2 级和 3 级链接。问题是在第 2 级,有一个 javascript 选项卡可以为每个页面提供不同的链接(总共 5 个页面)。
示例:
Level 1:主菜单(我使用 SgmlLinkExtractor catid = 22767 提取类别的链接)
Level 2:有一些链接我想解析,但也有JavaScript分页,我需要提取其余的链接(即catid = 22767 & page1 = 2)
级别 3:对于上述步骤中的每个链接,我都想解析响应。
网站is()
级别 2 是 (summary.asp? catid = 22768)
Level3是我要分析的文章页面(article.asp?catid = 22768&subid = 2&pubid = 63929343)
问题是:对于从第一级提取的每个链接,我如何创建一个循环并构造所有5个链接,然后在第二级使用SgmlLinkExtractor跟踪这些链接?
有两个答案:
通常,网站 提供其 网站 的可搜索版本,或者您可以实现站点地图。
您可以使用 selenium 之类的东西在浏览器中呈现页面,从而启用 JavaScript,并且您可以像用户一样使用它,并且仍然可以抓取它。
确保以合乎道德的方式爬行以避免网站超载:)
scrapy分页抓取网页(怎么去爬取这些数据?一个站点:“”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-10 14:12
微博关键词爬虫;超详细的爬虫教程;整个爬虫编写过程和思路;Xpath 表达式编写;数据存储和处理
我们都知道,一般来说,要爬取微博的相关信息,不如爬取本站的一些内容。但是这个网站没有关键词搜索,所以无法根据我们要搜索的关键词抓取到我们想要的内容。然而,博主发现微博有一个站点:“”。这是一个专门用于检索基于关键词的相关微博的站点。下面,我将使用scrapy抓取本站相关微博,为大家详细讲解过程。
可以爬取的字段
先展示那些可以爬取的字段:
如何分析数据是你自己的事情。下面我们详细介绍一下如何抓取这些数据。
一、网页分析
首先我们进入,输入我们要搜索的内容,F12怎么按,观察网页格式。
为了从网页中提取我们想要的内容,我们选择使用xpath来获取。在scrapy中还有一个.xpath()方法,方便我们写爬虫。这里教大家一个小技巧,我们可以右击我们想要的标签,如何选择复制xpath,可以复制标签的xpath表达式,如何按住Ctrl+F,把复制的表达式放到搜索框中,那么我们后面就可以直接修改表达式,提取出标签下或者与标签同级的标签下的对应内容。这一步很重要,可以提高我们后面写代码的效率。
比如我们这里复制了页面第一个内容的xpath表达式,然后我修改了表达式来提取相似的标签。
如您所见,这种类型有 22 个标签。我数了数。这个页面下只有22条微博。然后,我们只需要在这个 xpath 表达式后面添加内容就可以进一步提取我们想要的字段。. 我们以微博的文字内容为例。
首先,我们先选择中微博的文字内容:
然后检查标签
此时,我们只需要提取 p 标签的文本即可。首先,我们需要定位到p标签,在刚才的xpath表达式后面加上:“//p[@node-type="feed_list_content"”,所以我们选择这个页面下所有微博的文字内容是现在。其他领域也是如此。我们把所有字段的xpath表达式搞清楚,后面爬的时候具体处理一下。
二、爬虫部分
对于爬虫部分,我们使用scrapy框架来编写。这个框架的安装以及如何创建项目我就不详细介绍了。您可以自行查找信息。
创建项目并制作蜘蛛后,我们首先编写item.py,在item中定义我们要爬取的字段。
from scrapy import Item, Field
class KeywordItem(Item):
"""
关键词微博
"""
keyword = Field()
weibo_url = Field()
content = Field()
weibo_id = Field()
crawl_time = Field()
created_at = Field()
tool = Field()
repost_num = Field()
comment_num = Field()
like_num = Field()
user_url = Field()
user_id = Field()
然后编写pipeline.py 将爬虫存储在本地数据库中。
import pymongo
from pymongo.errors import DuplicateKeyError
from settings import MONGO_HOST, MONGO_PORT
class MongoDBPipeline(object):
def __init__(self):
client = pymongo.MongoClient(MONGO_HOST, MONGO_PORT)
db = client['edg']
self.Keyword = db["Keyword"]
def process_item(self, item, spider):
self.insert_item(self.Keyword, item)
@staticmethod
def insert_item(collection, item):
try:
collection.insert(dict(item))
except DuplicateKeyError:
pass
首先是初始化函数,定义了数据库的端口、名称和表名;然后 process_item 函数将所有项目字段插入到表 Keyword 中。item是scrapy的一大特色,类似于字典的数据结构,爬虫部分将爬取到的数据存储在item中,提交到pipeline进行存储。
然后我们开始写爬虫部分,在spider文件夹下创建keyword.py,在start_requests中定义要爬取的网页和headers。
def start_requests(self):
headers = {
'Host': 's.weibo.com',
'Cookie': ''
}
keywords = ['edg']
url = 'https://s.weibo.com/weibo?q={}&Refer=index&page=1'
那么我们一定要抓取数据,不能只抓取一页的数据。根据网站的URL我们可以发现有一个page参数。我们只需要构造这个参数的值就可以为不同的页面生成URL。,我把他放到一个URL列表中,迭代访问。
urls = []
for keyword in keywords:
urls.append(url.format(keyword))
for url in urls:
yield Request(url, callback=self.parse,headers=headers)
然后我们编写爬虫处理函数parse。
def parse(self, response):
if response.url.endswith('page=1'):
page = 50
for page_num in range(2, page+1):
page_url = response.url.replace('page=1', 'page={}'.format(page_num))
yield Request(page_url, self.parse, dont_filter=True, meta=response.meta)
if response.status == 200:
html_result = response.text
data = etree.HTML(html_result)
nodes = data.xpath('//div[@class="card"]')
首先是判断url的最后一个page参数是否为1,如果是,那么我们把页面复制到50(因为网站最多可以显示50页的微博内容),然后使用format 方法构造 50 个 URL,每个都提交给 parse 方法进行处理。
如果访问成功,所有“//div[@class="card"]”将被提取并分配给节点。这是我们上面的网络分析提取的所有收录微博内容的 xpath 表达式。然后它提取节点循环中的所有文本内容。
这里我们仅以提取微博文本内容为例
你只需要将提取的微博文本内容的xpath表达式提取到"//div[@class="card"]"之后添加到内容中,处理后放入keyword_item中(我刚才说的类似字典结构,用法同字典)。如何处理它提取所有文本?这需要不断的实验。例如,在我意识到我使用的是 .xpath('string(.)') 之前,我尝试了很多次。最后别忘了提交给项目。
extract_weibo_content() 是处理和提取文本中多余的表情符号、符号和 URL 的函数。代码显示如下:
def extract_weibo_content(weibo_html):
s = weibo_html
if 'class="ctt">' in s:
s = s.split('class="ctt">', maxsplit=1)[1]
s = emoji_re.sub('', s)
s = url_re.sub('', s)
s = div_re.sub('', s)
s = image_re.sub('', s)
if '' in s:
s = s.split('')[0]
splits = s.split('赞[')
if len(splits) == 2:
s = splits[0]
if len(splits) == 3:
origin_text = splits[0]
retweet_text = splits[1].split('转发理由:')[1]
s = origin_text + '转发理由:' + retweet_text
s = white_space_re.sub(' ', s)
s = keyword_re.sub('', s)
s = s.replace('\xa0', '')
s = s.strip(':')
s = s.strip()
return s
三、数据抓取与处理
然后我们就可以开始运行爬虫了。
可以看出爬虫运行没有问题。我用一个ip和一个账号来爬取。经测试,速度约为每小时10000次爬行。
最后查看我们在mongodb中爬取的数据,我也爬取了微博上的评论
这里的数据量有点小,主要是我过了一会儿就停了。如果你想爬得更多,你可以自己尝试一下。
有了数据,接下来我们要怎么分析,至少我们还有饭要煮。微博和评论的词云在这里产生
我也是爬虫爱好者,希望写这篇文章可以帮助到一些刚入门的人。欢迎大家交流批评指正。 查看全部
scrapy分页抓取网页(怎么去爬取这些数据?一个站点:“”)
微博关键词爬虫;超详细的爬虫教程;整个爬虫编写过程和思路;Xpath 表达式编写;数据存储和处理
我们都知道,一般来说,要爬取微博的相关信息,不如爬取本站的一些内容。但是这个网站没有关键词搜索,所以无法根据我们要搜索的关键词抓取到我们想要的内容。然而,博主发现微博有一个站点:“”。这是一个专门用于检索基于关键词的相关微博的站点。下面,我将使用scrapy抓取本站相关微博,为大家详细讲解过程。
可以爬取的字段
先展示那些可以爬取的字段:
如何分析数据是你自己的事情。下面我们详细介绍一下如何抓取这些数据。
一、网页分析
首先我们进入,输入我们要搜索的内容,F12怎么按,观察网页格式。
为了从网页中提取我们想要的内容,我们选择使用xpath来获取。在scrapy中还有一个.xpath()方法,方便我们写爬虫。这里教大家一个小技巧,我们可以右击我们想要的标签,如何选择复制xpath,可以复制标签的xpath表达式,如何按住Ctrl+F,把复制的表达式放到搜索框中,那么我们后面就可以直接修改表达式,提取出标签下或者与标签同级的标签下的对应内容。这一步很重要,可以提高我们后面写代码的效率。
比如我们这里复制了页面第一个内容的xpath表达式,然后我修改了表达式来提取相似的标签。
如您所见,这种类型有 22 个标签。我数了数。这个页面下只有22条微博。然后,我们只需要在这个 xpath 表达式后面添加内容就可以进一步提取我们想要的字段。. 我们以微博的文字内容为例。
首先,我们先选择中微博的文字内容:
然后检查标签
此时,我们只需要提取 p 标签的文本即可。首先,我们需要定位到p标签,在刚才的xpath表达式后面加上:“//p[@node-type="feed_list_content"”,所以我们选择这个页面下所有微博的文字内容是现在。其他领域也是如此。我们把所有字段的xpath表达式搞清楚,后面爬的时候具体处理一下。
二、爬虫部分
对于爬虫部分,我们使用scrapy框架来编写。这个框架的安装以及如何创建项目我就不详细介绍了。您可以自行查找信息。
创建项目并制作蜘蛛后,我们首先编写item.py,在item中定义我们要爬取的字段。
from scrapy import Item, Field
class KeywordItem(Item):
"""
关键词微博
"""
keyword = Field()
weibo_url = Field()
content = Field()
weibo_id = Field()
crawl_time = Field()
created_at = Field()
tool = Field()
repost_num = Field()
comment_num = Field()
like_num = Field()
user_url = Field()
user_id = Field()
然后编写pipeline.py 将爬虫存储在本地数据库中。
import pymongo
from pymongo.errors import DuplicateKeyError
from settings import MONGO_HOST, MONGO_PORT
class MongoDBPipeline(object):
def __init__(self):
client = pymongo.MongoClient(MONGO_HOST, MONGO_PORT)
db = client['edg']
self.Keyword = db["Keyword"]
def process_item(self, item, spider):
self.insert_item(self.Keyword, item)
@staticmethod
def insert_item(collection, item):
try:
collection.insert(dict(item))
except DuplicateKeyError:
pass
首先是初始化函数,定义了数据库的端口、名称和表名;然后 process_item 函数将所有项目字段插入到表 Keyword 中。item是scrapy的一大特色,类似于字典的数据结构,爬虫部分将爬取到的数据存储在item中,提交到pipeline进行存储。
然后我们开始写爬虫部分,在spider文件夹下创建keyword.py,在start_requests中定义要爬取的网页和headers。
def start_requests(self):
headers = {
'Host': 's.weibo.com',
'Cookie': ''
}
keywords = ['edg']
url = 'https://s.weibo.com/weibo?q={}&Refer=index&page=1'
那么我们一定要抓取数据,不能只抓取一页的数据。根据网站的URL我们可以发现有一个page参数。我们只需要构造这个参数的值就可以为不同的页面生成URL。,我把他放到一个URL列表中,迭代访问。
urls = []
for keyword in keywords:
urls.append(url.format(keyword))
for url in urls:
yield Request(url, callback=self.parse,headers=headers)
然后我们编写爬虫处理函数parse。
def parse(self, response):
if response.url.endswith('page=1'):
page = 50
for page_num in range(2, page+1):
page_url = response.url.replace('page=1', 'page={}'.format(page_num))
yield Request(page_url, self.parse, dont_filter=True, meta=response.meta)
if response.status == 200:
html_result = response.text
data = etree.HTML(html_result)
nodes = data.xpath('//div[@class="card"]')
首先是判断url的最后一个page参数是否为1,如果是,那么我们把页面复制到50(因为网站最多可以显示50页的微博内容),然后使用format 方法构造 50 个 URL,每个都提交给 parse 方法进行处理。
如果访问成功,所有“//div[@class="card"]”将被提取并分配给节点。这是我们上面的网络分析提取的所有收录微博内容的 xpath 表达式。然后它提取节点循环中的所有文本内容。
这里我们仅以提取微博文本内容为例
你只需要将提取的微博文本内容的xpath表达式提取到"//div[@class="card"]"之后添加到内容中,处理后放入keyword_item中(我刚才说的类似字典结构,用法同字典)。如何处理它提取所有文本?这需要不断的实验。例如,在我意识到我使用的是 .xpath('string(.)') 之前,我尝试了很多次。最后别忘了提交给项目。
extract_weibo_content() 是处理和提取文本中多余的表情符号、符号和 URL 的函数。代码显示如下:
def extract_weibo_content(weibo_html):
s = weibo_html
if 'class="ctt">' in s:
s = s.split('class="ctt">', maxsplit=1)[1]
s = emoji_re.sub('', s)
s = url_re.sub('', s)
s = div_re.sub('', s)
s = image_re.sub('', s)
if '' in s:
s = s.split('')[0]
splits = s.split('赞[')
if len(splits) == 2:
s = splits[0]
if len(splits) == 3:
origin_text = splits[0]
retweet_text = splits[1].split('转发理由:')[1]
s = origin_text + '转发理由:' + retweet_text
s = white_space_re.sub(' ', s)
s = keyword_re.sub('', s)
s = s.replace('\xa0', '')
s = s.strip(':')
s = s.strip()
return s
三、数据抓取与处理
然后我们就可以开始运行爬虫了。
可以看出爬虫运行没有问题。我用一个ip和一个账号来爬取。经测试,速度约为每小时10000次爬行。
最后查看我们在mongodb中爬取的数据,我也爬取了微博上的评论
这里的数据量有点小,主要是我过了一会儿就停了。如果你想爬得更多,你可以自己尝试一下。
有了数据,接下来我们要怎么分析,至少我们还有饭要煮。微博和评论的词云在这里产生
我也是爬虫爱好者,希望写这篇文章可以帮助到一些刚入门的人。欢迎大家交流批评指正。
scrapy分页抓取网页(scrapy分页抓取网页数据教程和scrapy一起抓取数据(scrapy中文文档))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-07 14:01
scrapy分页抓取网页数据教程requests和scrapy一起抓取网页数据(scrapy中文文档)jsonorxml
我之前做过一个爬虫,调用知乎api的,
scrapy比较火scrapy的多线程抓取
python2requestsgetpostplsurllib3urllib2都有对应框架
scrapy有python库,对scrapy比较熟悉,
要想知道哪些问题需要学习scrapy,基本上可以从python类库上开始看,例如scrapy等。是不是需要学习scrapy框架的源码等问题。两者都是轻量级的爬虫框架,但是因为学习的目的不同,scrapy必须不停的对接不同的文件对接等操作。建议学习时先对scrapy框架有个了解,做一些有趣有意义的项目,多用scrapy来抓取数据,然后再去了解scrapy源码。
scrapy都是基于scrapy框架,只有以后有更多的文章要写了,才会更详细的把scrapy技术演变过程拿出来。我就是在文章中详细讲解了scrapy技术详细历史,还有最核心的组件,如何使用scrapy爬取网站内容的。希望对你有所帮助。总结起来,自scrapy开始,到scrapyforpython,再到scrapyforjava,然后到现在的scrapyforjavascript。
反爬虫,基于xpath请求,利用cookie记录所有的数据,比如评论数、粉丝数,他们数据需要存储。如果感兴趣, 查看全部
scrapy分页抓取网页(scrapy分页抓取网页数据教程和scrapy一起抓取数据(scrapy中文文档))
scrapy分页抓取网页数据教程requests和scrapy一起抓取网页数据(scrapy中文文档)jsonorxml
我之前做过一个爬虫,调用知乎api的,
scrapy比较火scrapy的多线程抓取
python2requestsgetpostplsurllib3urllib2都有对应框架
scrapy有python库,对scrapy比较熟悉,
要想知道哪些问题需要学习scrapy,基本上可以从python类库上开始看,例如scrapy等。是不是需要学习scrapy框架的源码等问题。两者都是轻量级的爬虫框架,但是因为学习的目的不同,scrapy必须不停的对接不同的文件对接等操作。建议学习时先对scrapy框架有个了解,做一些有趣有意义的项目,多用scrapy来抓取数据,然后再去了解scrapy源码。
scrapy都是基于scrapy框架,只有以后有更多的文章要写了,才会更详细的把scrapy技术演变过程拿出来。我就是在文章中详细讲解了scrapy技术详细历史,还有最核心的组件,如何使用scrapy爬取网站内容的。希望对你有所帮助。总结起来,自scrapy开始,到scrapyforpython,再到scrapyforjava,然后到现在的scrapyforjavascript。
反爬虫,基于xpath请求,利用cookie记录所有的数据,比如评论数、粉丝数,他们数据需要存储。如果感兴趣,
scrapy分页抓取网页( WebScraper怎么对付这种类型的网页?翻页链接不规律)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-07 05:22
WebScraper怎么对付这种类型的网页?翻页链接不规律)
【这是简单数据分析系列的第12篇文章】
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则页面链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进来增加坤坤的阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,会发现这个转发的网页网址不规则,只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬虫系统(比如突然弹出验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
WebScraper怎么对付这种类型的网页?翻页链接不规律)
【这是简单数据分析系列的第12篇文章】
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则页面链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进来增加坤坤的阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,会发现这个转发的网页网址不规则,只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬虫系统(比如突然弹出验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(抓取慕课网课程信息展示之scrapy框架数据的过程介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-07 00:14
)
本例主要通过抓取Mukenet的课程信息来演示scrapy框架爬取数据的过程。
1、抢夺网站 简介
爬网网站:
截取内容:截取内容为所有课程名称、课程介绍、课程网址、课程图片网址、课程编号(由于动态渲染)
网站图片:
2、创建项目
以命令行方式创建项目
scrapy startprojectscrapy_course
建立完成后,用pycharm打开,目录如下:
scrapy.cfg:项目配置文件
scrapytest/:项目的python模块。稍后您将在此处添加代码。
scrapytest/items.py:项目中的item文件。
scrapytest/pipelines.py:项目中的管道文件。
scrapytest/settings.py:项目的设置文件。
scrapytest/spiders/:蜘蛛代码放置的目录。
3、创建爬虫
下面的步骤解释了如何编写一个简单的爬虫。
我们要写一个爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
该文件收录一个 MySpider 类,该类必须继承 scrapy.Spider 类。
同时它必须定义三个属性:
-name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。
-start_urls:收录Spider启动时会爬取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。
-parse() 是蜘蛛的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
MySpider.py创建后的代码如下
定义爬虫项目
创建好Spider文件后,先别急着写爬虫代码
我们首先定义一个容器来存放要爬取的数据。
所以我们使用Item
为了定义常用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬取的数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
我们可以在项目目录中看到一个项目文件,我们可以更改这个文件或创建一个新文件来定义我们的项目。
在这里,我们在同一层上创建一个新的项目文件 CourseItems.py
根据上面的代码,我们创建了一个名为courseItem的容器来存储和抓取信息。
title->课程名称,url->课程url,image_url->课程标题图片,介绍->课程描述,学生->学号
创建项目文件后,我们可以使用类似字典的 API 和简单的语法来声明可用字段。
常用方法如下
4、编写Spider代码
定义好item后,我们就可以开始爬取部分的工作了。
为简单起见,我们首先抓取页面上的信息。
首先我们编写爬取代码
正如我们上面所说,爬取部分是在 MySpider 类的 parse() 方法中执行的。
parse() 方法负责处理响应并返回处理后的数据和/或 URL 以供后续处理。
此方法和其他 Request 回调函数必须返回一个收录 Request 和/或 Item 的可迭代对象。
我们在之前创建的 MySpider.py 中编写以下代码。
注意上面与 MySpider.py 的区别
# -*- coding:utf8-*-
import scrapy
import sys
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from scrapy_course.items import CourseItem
from scrapy.selector import Selector
sys.stdout = open(\'output.txt\', \'w\')
pageIndex = 0
class MySpider(scrapy.Spider):
#用于区别Spider
name = "MySpider"
#允许访问的域
allowed_domains = [\'imooc.com\']
#爬取的地址
start_urls = ["http://www.imooc.com/course/list"]
#爬取方法
def parse(self, response):
# 实例一个容器保存爬取的信息
item = CourseItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个课程的div
sel = Selector(response)
title = sel.xpath(\'/html/head/title/text()\').extract() # 标题
print title[0]
# sels = sel.xpath(\'//div[@class="course-card-content"]\')
sels = sel.xpath(\'//a[@class="course-card"]\')
pictures = sel.xpath(\'//div[@class="course-card-bk"]\')
index = 0
global pageIndex
pageIndex += 1
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
print \'第\' + str(pageIndex)+ \'页 \'
print \'----------------------------------------------\'
for box in sels:
print \' \'
# 获取div中的课程标题
item[\'title\'] = box.xpath(\'.//h3[@class="course-card-name"]/text()\').extract()[0].strip()
print \'标题:\' + item[\'title\']
# 获取div中的课程简介
item[\'introduction\'] = box.xpath(\'.//p/text()\').extract()[0].strip()
print \'简介:\' + item[\'introduction\']
# 获取每个div中的课程路径
item[\'url\'] = \'http://www.imooc.com\' + box.xpath(\'.//@href\').extract()[0]
print \'路径:\' +item[\'url\']
# 获取div中的学生人数
item[\'student\'] = box.xpath(\'.//div[@class="course-card-info"]/text()\').extract()[0].strip()
print item[\'student\']
# 获取div中的标题图片地址
item[\'image_url\'] = pictures[index].xpath(\'.//img/@src\').extract()[0]
print \'图片地址:\' + item[\'image_url\']
index += 1
yield item
time.sleep(1)
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
# next =u\'下一页\'
# url = response.xpath("//a[contains(text(),\'" + next + "\')]/@href").extract()
# if url:
# # 将信息组合成下一页的url
# page = \'http://www.imooc.com\' + url[0]
# # 返回url
# yield scrapy.Request(page, callback=self.parse)
使用 Pipeline 处理数据
在我们成功获取信息后,我们需要对信息进行验证和存储。这里我们以存储为例。
当 Item 在 Spider 中被采集到时,它会被传递到 Pipeline,一些组件会按照一定的顺序执行 Item 的处理。
流水线经常执行以下操作:
清理 HTML 数据
验证爬取的数据(检查项目是否收录某些字段)
重复检查(并丢弃)
目前,抓取结果暂时保存在文本中
这里只进行简单的将数据存储在json文件中的操作。
pipelines.py 代码如下
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
import codecs
import json
class ScrapyCoursePipeline(object):
def __init__(self):
# self.file = open(\'data.json\', \'wb\')
# self.file = codecs.open(
# \'spider.txt\', \'w\', encoding=\'utf-8\')
self.file = codecs.open(
\'spider.json\', \'w\', encoding=\'utf-8\')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
要使用Pipeline,您必须先注册Pipeline
找到settings.py文件,这个文件就是爬虫的配置文件
添加进去
ITEM_PIPELINES = {
\'scrapy_course.pipelines.ScrapyCoursePipeline\':300
}
上面的代码是用来注册Pipeline的,其中scrapy_course.pipelines.ScrapyCoursePipeline是你要注册的类,右边的'300'是Pipeline的优先级,范围从1到1000。管道越小,越早执行。
经过以上操作,我们最基本的爬取操作之一就完成了
然后我们运行
5、运行
在命令行下运行scrapy crawl MySpider
如何将数据存储在文本文件中,在代码前添加如下代码,
sys.stdout = open(\'output.txt\', \'w\'),这会将数据保存到当前项目路径下的output.txt文件中
如下:
查看全部
scrapy分页抓取网页(抓取慕课网课程信息展示之scrapy框架数据的过程介绍
)
本例主要通过抓取Mukenet的课程信息来演示scrapy框架爬取数据的过程。
1、抢夺网站 简介
爬网网站:
截取内容:截取内容为所有课程名称、课程介绍、课程网址、课程图片网址、课程编号(由于动态渲染)
网站图片:
2、创建项目
以命令行方式创建项目
scrapy startprojectscrapy_course
建立完成后,用pycharm打开,目录如下:
scrapy.cfg:项目配置文件
scrapytest/:项目的python模块。稍后您将在此处添加代码。
scrapytest/items.py:项目中的item文件。
scrapytest/pipelines.py:项目中的管道文件。
scrapytest/settings.py:项目的设置文件。
scrapytest/spiders/:蜘蛛代码放置的目录。
3、创建爬虫
下面的步骤解释了如何编写一个简单的爬虫。
我们要写一个爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
该文件收录一个 MySpider 类,该类必须继承 scrapy.Spider 类。
同时它必须定义三个属性:
-name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。
-start_urls:收录Spider启动时会爬取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。
-parse() 是蜘蛛的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
MySpider.py创建后的代码如下
定义爬虫项目
创建好Spider文件后,先别急着写爬虫代码
我们首先定义一个容器来存放要爬取的数据。
所以我们使用Item
为了定义常用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬取的数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
我们可以在项目目录中看到一个项目文件,我们可以更改这个文件或创建一个新文件来定义我们的项目。
在这里,我们在同一层上创建一个新的项目文件 CourseItems.py
根据上面的代码,我们创建了一个名为courseItem的容器来存储和抓取信息。
title->课程名称,url->课程url,image_url->课程标题图片,介绍->课程描述,学生->学号
创建项目文件后,我们可以使用类似字典的 API 和简单的语法来声明可用字段。
常用方法如下
4、编写Spider代码
定义好item后,我们就可以开始爬取部分的工作了。
为简单起见,我们首先抓取页面上的信息。
首先我们编写爬取代码
正如我们上面所说,爬取部分是在 MySpider 类的 parse() 方法中执行的。
parse() 方法负责处理响应并返回处理后的数据和/或 URL 以供后续处理。
此方法和其他 Request 回调函数必须返回一个收录 Request 和/或 Item 的可迭代对象。
我们在之前创建的 MySpider.py 中编写以下代码。
注意上面与 MySpider.py 的区别
# -*- coding:utf8-*-
import scrapy
import sys
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from scrapy_course.items import CourseItem
from scrapy.selector import Selector
sys.stdout = open(\'output.txt\', \'w\')
pageIndex = 0
class MySpider(scrapy.Spider):
#用于区别Spider
name = "MySpider"
#允许访问的域
allowed_domains = [\'imooc.com\']
#爬取的地址
start_urls = ["http://www.imooc.com/course/list"]
#爬取方法
def parse(self, response):
# 实例一个容器保存爬取的信息
item = CourseItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个课程的div
sel = Selector(response)
title = sel.xpath(\'/html/head/title/text()\').extract() # 标题
print title[0]
# sels = sel.xpath(\'//div[@class="course-card-content"]\')
sels = sel.xpath(\'//a[@class="course-card"]\')
pictures = sel.xpath(\'//div[@class="course-card-bk"]\')
index = 0
global pageIndex
pageIndex += 1
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
print \'第\' + str(pageIndex)+ \'页 \'
print \'----------------------------------------------\'
for box in sels:
print \' \'
# 获取div中的课程标题
item[\'title\'] = box.xpath(\'.//h3[@class="course-card-name"]/text()\').extract()[0].strip()
print \'标题:\' + item[\'title\']
# 获取div中的课程简介
item[\'introduction\'] = box.xpath(\'.//p/text()\').extract()[0].strip()
print \'简介:\' + item[\'introduction\']
# 获取每个div中的课程路径
item[\'url\'] = \'http://www.imooc.com\' + box.xpath(\'.//@href\').extract()[0]
print \'路径:\' +item[\'url\']
# 获取div中的学生人数
item[\'student\'] = box.xpath(\'.//div[@class="course-card-info"]/text()\').extract()[0].strip()
print item[\'student\']
# 获取div中的标题图片地址
item[\'image_url\'] = pictures[index].xpath(\'.//img/@src\').extract()[0]
print \'图片地址:\' + item[\'image_url\']
index += 1
yield item
time.sleep(1)
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
# next =u\'下一页\'
# url = response.xpath("//a[contains(text(),\'" + next + "\')]/@href").extract()
# if url:
# # 将信息组合成下一页的url
# page = \'http://www.imooc.com\' + url[0]
# # 返回url
# yield scrapy.Request(page, callback=self.parse)
使用 Pipeline 处理数据
在我们成功获取信息后,我们需要对信息进行验证和存储。这里我们以存储为例。
当 Item 在 Spider 中被采集到时,它会被传递到 Pipeline,一些组件会按照一定的顺序执行 Item 的处理。
流水线经常执行以下操作:
清理 HTML 数据
验证爬取的数据(检查项目是否收录某些字段)
重复检查(并丢弃)
目前,抓取结果暂时保存在文本中
这里只进行简单的将数据存储在json文件中的操作。
pipelines.py 代码如下
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
import codecs
import json
class ScrapyCoursePipeline(object):
def __init__(self):
# self.file = open(\'data.json\', \'wb\')
# self.file = codecs.open(
# \'spider.txt\', \'w\', encoding=\'utf-8\')
self.file = codecs.open(
\'spider.json\', \'w\', encoding=\'utf-8\')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
要使用Pipeline,您必须先注册Pipeline
找到settings.py文件,这个文件就是爬虫的配置文件
添加进去
ITEM_PIPELINES = {
\'scrapy_course.pipelines.ScrapyCoursePipeline\':300
}
上面的代码是用来注册Pipeline的,其中scrapy_course.pipelines.ScrapyCoursePipeline是你要注册的类,右边的'300'是Pipeline的优先级,范围从1到1000。管道越小,越早执行。
经过以上操作,我们最基本的爬取操作之一就完成了
然后我们运行
5、运行
在命令行下运行scrapy crawl MySpider
如何将数据存储在文本文件中,在代码前添加如下代码,
sys.stdout = open(\'output.txt\', \'w\'),这会将数据保存到当前项目路径下的output.txt文件中
如下:
scrapy分页抓取网页(scrapy分页抓取网页进行分析(一)_抓取程序前端代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-06 01:01
scrapy分页抓取网页进行分析。可以修改需要抓取网页的源代码,(源代码可以自己存,但只能提取上一页到底的信息)将源代码重新赋值到指定网页地址。用scrapy还可以实现抓取第二页,第三页等等。
抓取抓取程序前端代码在python中可以用scrapy,但是建议由抓爬最后再调整。抓到后先在request中找到所有页面的连接,由于ie浏览器不支持scrapy,所以只有extract("page1.txt")这个函数。
1)importscrapy
2)pip3installscrapylist_txt=scrapy.list_txt()
3)txt=pd.read_table(list_txt)
4)scrapy.cookies.updater(user_agent)
5)list_txt=txt。strip()out=scrapy。formspider(callback=scrapy。spider。request。output_mode,check_cookies=scrapy。cookies)#第一次请求(登录页)out[:3]=list_txt。contentout[:3]=""forpageinout:page=page。
replace("//","/\w+/\w+/\w+/\w+")print("第%s页,"%page)out[:3]=pageout[:3]="/\w+/\w+"ifisinstance(out,request):forpageinout:content=""print("username="+username)out[:3]=contentout[:3]="/\w+/\w+/\w+"ifout!=none:elifout。
is_error:scrapy。error("accessmissing:",isinstance(out,request))。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页进行分析(一)_抓取程序前端代码)
scrapy分页抓取网页进行分析。可以修改需要抓取网页的源代码,(源代码可以自己存,但只能提取上一页到底的信息)将源代码重新赋值到指定网页地址。用scrapy还可以实现抓取第二页,第三页等等。
抓取抓取程序前端代码在python中可以用scrapy,但是建议由抓爬最后再调整。抓到后先在request中找到所有页面的连接,由于ie浏览器不支持scrapy,所以只有extract("page1.txt")这个函数。
1)importscrapy
2)pip3installscrapylist_txt=scrapy.list_txt()
3)txt=pd.read_table(list_txt)
4)scrapy.cookies.updater(user_agent)
5)list_txt=txt。strip()out=scrapy。formspider(callback=scrapy。spider。request。output_mode,check_cookies=scrapy。cookies)#第一次请求(登录页)out[:3]=list_txt。contentout[:3]=""forpageinout:page=page。
replace("//","/\w+/\w+/\w+/\w+")print("第%s页,"%page)out[:3]=pageout[:3]="/\w+/\w+"ifisinstance(out,request):forpageinout:content=""print("username="+username)out[:3]=contentout[:3]="/\w+/\w+/\w+"ifout!=none:elifout。
is_error:scrapy。error("accessmissing:",isinstance(out,request))。
scrapy分页抓取网页(Crawlab的可配置爬虫只需要爬虫工程师配置一些必要的CSS/XPath提取规则 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-01 05:14
)
前言
开发爬虫是一件很有趣的事情。编写一个程序,向感兴趣的目标网站发起HTTP请求,获取HTML,解析HTML,提取数据,将数据保存到数据库或CSV、JSON等格式,然后使用你熟悉的语言如作为 Python 对这些数据进行分析以生成很酷的图表。这个过程是不是很刺激?
然而,开发爬虫并不是一件简单的事情。通常,开发一个简单的爬虫往往需要几个模块:下载器、解析器、提取规则和保存模块。用Python实现这个简单的爬虫,至少需要写10-20行代码,如果考虑并发和调度,通常需要写50多行代码。比较麻烦的是,如果要管理多个爬虫实现爬虫工程,需要从每个爬虫代码中提取通用模块和参数。这个过程需要相当的工程经验和时间的积累。其实大体上,主要网站的结构是类似的,只是提取规则需要改变。很多爬虫工程师在大型项目中要写上百条抽取规则,
可配置爬虫
幸运的是,Crawlab 在 v0.2.1 版本中添加了一个新的特性可配置爬虫,让工程师从这些重复性工作中解放出来。Crawlab的可配置爬虫只需要爬虫工程师配置一些必要的CSS/XPath提取规则就可以完成常规的爬虫开发。根据作者的实验,对于稍微熟悉 CSS 选择器或 XPath 的工程师来说,使用可配置的爬虫开发一个五脏俱全的常规爬虫只需要 1-3 分钟。
Crawlab 的可配置爬虫是基于 Scrapy 的,所以天生就是支持并发的。而且,可配置爬虫完全支持Crawlab自定义爬虫的通用功能,因此也支持任务调度、任务监控、日志监控、数据分析。
安装并运行 Crawlab
Crawlab是一个专注于爬虫的分布式爬虫管理平台,集成了爬虫管理、任务调度、任务监控、数据分析等模块。非常适合对爬虫管理和爬虫工程有需求的开发者和公司。
Crawlab的详细介绍请参考之前的文章:-
下面是Crawlab的安装和运行步骤,大概需要10-20分钟。
如何开发和运行可配置的爬虫
现在终于到了爬虫开发时间。这里将以网易24小时排名新闻为例,开发相应的可配置爬虫。整个过程不应超过3分钟。
添加爬虫
Crawlab运行后,在浏览器中打开网址:8080,导航到爬虫。单击“添加爬虫”按钮。
单击以配置爬虫。
输入基本信息后,点击添加。
配置爬虫
添加完成后可以看到底部出现刚刚添加的可配置爬虫,点击查看进入爬虫详情。
单击配置选项卡,进入配置页面。接下来,我们需要配置爬虫规则。
已经有一些配置的初始条目。我们简要介绍每个的含义。
抓取类别
这也是爬虫采用的策略,即爬虫如何遍历网页。作为第一个版本,我们只有列表,只有详细信息页面,列表+详细信息页面。- 仅列表页面。这也是最简单的形式。爬虫遍历列表中的列表项并抓取数据。- 仅详细信息页面。爬虫只爬取详情页。-列表+详细信息页面。爬虫首先遍历列表页,提取列表项中的详情页地址,跟进抓取详情页。
这里我们选择列表+详情页。
列表项选择器和分页选择器
列表项和分页按钮的匹配查询通过 CSS 或 XPath 进行匹配。
起始网址
爬虫首先遍历的 URL。
遵守机器人协议
这是默认启用的。如果开启,爬虫会先抓取网站的robots.txt,判断页面是否可抓取;否则,将无法验证。用户可以选择关闭它。请注意,任何无视机器人协议的行为都有法律风险。
列出页面字段和详细信息页面字段
这些是需要在列表页面或详细信息页面上提取的字段。这些字段由 CSS 选择器或 XPath 匹配和提取。您可以选择文本或属性。
检查目标页面的元素CSS选择器后,我们输入列表项选择器、起始URL、列表页/详情页等信息。请注意,检查 url 是详细信息页面的 URL。
单击保存、预览以查看预览内容。
OK,现在配置完成,终于可以开始运行爬虫了!
运行爬虫
您唯一需要做的就是单击运行按钮并确认。点击Overview选项卡,可以看到任务已经开始运行了。
点击创建时间链接,导航到任务详情,点击结果选项卡,可以看到抓取的结果已经保存。
怎么样,这个过程是不是超级简单?如果你熟练,整个过程可以在60秒内完成!就像玩魔方一样,玩得越多,你就越熟练!
结束语
本文利用Crawlab的可配置爬虫功能,在3分钟内抓取网易新闻24小时新闻排名。同样的过程可以在其他类似的网站上实现。虽然这是一个经典的“列表+详情页”的爬取模式,比较简单,但是未来我们会开发出越来越复杂的爬取方式来实现更多的爬取需求。Crawlab的可配置爬虫减少了爬虫开发时间,提高了爬虫开发效率,提高了工程水平,让爬虫工程师从日常繁琐的配置工作中解脱出来。配置工作可以交给初级爬虫工程师或外包人员,而高级爬虫工程师将专注于更复杂的爬虫任务,如反爬虫、动态内容、分布式爬虫、
Github: tikazyq/crawlab
如果你觉得Crawlab还不错,如果对你的日常工作或业务有帮助,请加作者微信加入开发交流群,大家可以交流一下Crawlab的使用和开发。
查看全部
scrapy分页抓取网页(Crawlab的可配置爬虫只需要爬虫工程师配置一些必要的CSS/XPath提取规则
)
前言
开发爬虫是一件很有趣的事情。编写一个程序,向感兴趣的目标网站发起HTTP请求,获取HTML,解析HTML,提取数据,将数据保存到数据库或CSV、JSON等格式,然后使用你熟悉的语言如作为 Python 对这些数据进行分析以生成很酷的图表。这个过程是不是很刺激?
然而,开发爬虫并不是一件简单的事情。通常,开发一个简单的爬虫往往需要几个模块:下载器、解析器、提取规则和保存模块。用Python实现这个简单的爬虫,至少需要写10-20行代码,如果考虑并发和调度,通常需要写50多行代码。比较麻烦的是,如果要管理多个爬虫实现爬虫工程,需要从每个爬虫代码中提取通用模块和参数。这个过程需要相当的工程经验和时间的积累。其实大体上,主要网站的结构是类似的,只是提取规则需要改变。很多爬虫工程师在大型项目中要写上百条抽取规则,
可配置爬虫
幸运的是,Crawlab 在 v0.2.1 版本中添加了一个新的特性可配置爬虫,让工程师从这些重复性工作中解放出来。Crawlab的可配置爬虫只需要爬虫工程师配置一些必要的CSS/XPath提取规则就可以完成常规的爬虫开发。根据作者的实验,对于稍微熟悉 CSS 选择器或 XPath 的工程师来说,使用可配置的爬虫开发一个五脏俱全的常规爬虫只需要 1-3 分钟。
Crawlab 的可配置爬虫是基于 Scrapy 的,所以天生就是支持并发的。而且,可配置爬虫完全支持Crawlab自定义爬虫的通用功能,因此也支持任务调度、任务监控、日志监控、数据分析。
安装并运行 Crawlab
Crawlab是一个专注于爬虫的分布式爬虫管理平台,集成了爬虫管理、任务调度、任务监控、数据分析等模块。非常适合对爬虫管理和爬虫工程有需求的开发者和公司。
Crawlab的详细介绍请参考之前的文章:-
下面是Crawlab的安装和运行步骤,大概需要10-20分钟。
如何开发和运行可配置的爬虫
现在终于到了爬虫开发时间。这里将以网易24小时排名新闻为例,开发相应的可配置爬虫。整个过程不应超过3分钟。
添加爬虫
Crawlab运行后,在浏览器中打开网址:8080,导航到爬虫。单击“添加爬虫”按钮。
单击以配置爬虫。
输入基本信息后,点击添加。
配置爬虫
添加完成后可以看到底部出现刚刚添加的可配置爬虫,点击查看进入爬虫详情。
单击配置选项卡,进入配置页面。接下来,我们需要配置爬虫规则。
已经有一些配置的初始条目。我们简要介绍每个的含义。
抓取类别
这也是爬虫采用的策略,即爬虫如何遍历网页。作为第一个版本,我们只有列表,只有详细信息页面,列表+详细信息页面。- 仅列表页面。这也是最简单的形式。爬虫遍历列表中的列表项并抓取数据。- 仅详细信息页面。爬虫只爬取详情页。-列表+详细信息页面。爬虫首先遍历列表页,提取列表项中的详情页地址,跟进抓取详情页。
这里我们选择列表+详情页。
列表项选择器和分页选择器
列表项和分页按钮的匹配查询通过 CSS 或 XPath 进行匹配。
起始网址
爬虫首先遍历的 URL。
遵守机器人协议
这是默认启用的。如果开启,爬虫会先抓取网站的robots.txt,判断页面是否可抓取;否则,将无法验证。用户可以选择关闭它。请注意,任何无视机器人协议的行为都有法律风险。
列出页面字段和详细信息页面字段
这些是需要在列表页面或详细信息页面上提取的字段。这些字段由 CSS 选择器或 XPath 匹配和提取。您可以选择文本或属性。
检查目标页面的元素CSS选择器后,我们输入列表项选择器、起始URL、列表页/详情页等信息。请注意,检查 url 是详细信息页面的 URL。
单击保存、预览以查看预览内容。
OK,现在配置完成,终于可以开始运行爬虫了!
运行爬虫
您唯一需要做的就是单击运行按钮并确认。点击Overview选项卡,可以看到任务已经开始运行了。
点击创建时间链接,导航到任务详情,点击结果选项卡,可以看到抓取的结果已经保存。
怎么样,这个过程是不是超级简单?如果你熟练,整个过程可以在60秒内完成!就像玩魔方一样,玩得越多,你就越熟练!
结束语
本文利用Crawlab的可配置爬虫功能,在3分钟内抓取网易新闻24小时新闻排名。同样的过程可以在其他类似的网站上实现。虽然这是一个经典的“列表+详情页”的爬取模式,比较简单,但是未来我们会开发出越来越复杂的爬取方式来实现更多的爬取需求。Crawlab的可配置爬虫减少了爬虫开发时间,提高了爬虫开发效率,提高了工程水平,让爬虫工程师从日常繁琐的配置工作中解脱出来。配置工作可以交给初级爬虫工程师或外包人员,而高级爬虫工程师将专注于更复杂的爬虫任务,如反爬虫、动态内容、分布式爬虫、
Github: tikazyq/crawlab
如果你觉得Crawlab还不错,如果对你的日常工作或业务有帮助,请加作者微信加入开发交流群,大家可以交流一下Crawlab的使用和开发。
scrapy分页抓取网页(scrapy分页抓取网页列表项-all-workflows/scrapy/per_url_number分页爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-30 07:09
scrapy分页抓取网页列表项-all-workflows/
scrapy分页爬取网页列表/http/
同问。最近也想抓取这个:想采集单个网页的指定位置的文字,但是我觉得有道云笔记里的例子不太符合我的思路。
follow-github
scrapy的库提供了一些机制,爬虫可以针对分页来进行爬取,
可以看一下scrapy解决跨站抓取发函数的问题。
最近也研究过此问题。基本上就是:不同页面写多个代码,同时迭代爬取。然后merge。比如同一页的每个文字都进行同时爬取。就是用scrapy爬取完一页的所有词汇,然后存入新文件。同时迭代整个页面的词汇,然后爬取整页。
httpurl地址的链接格式一般有三种形式:
1).user-agent:scrapy_crawler/spider.pyid/per_url_number
2).user-agent:scrapy_crawler/spider.pyid/numpy_id
3).user-agent:scrapy_crawler/spider.pyid/per_url_number分别对应爬虫id、thetaid、numpyid
注意留下交叉链接
都是如何利用scrapy解决跨页抓取问题的爬虫框架也不只有scrapy,
一般来说,大部分网站分页太少,那么完整抓取一页也不是很难,关键要是当页有个1000以上,然后再打开一个网页,需要选择1/1000个文字抓取一个页面的话那真的要抓取半天的。答主现在正在用的是第二种,简单粗暴就是抓过来存数据库,然后跟某些网站的内容数据库差不多就行,但是现在都是用redis来存管理,因为springboot的话在configure的时候需要defaultworker节点。
并且topic选择可以自己写,也可以是框架代理的方式(就是只抓过一次)有人说用redis,我个人感觉很蛋疼,因为你还得写schema(库里面有代理,就不要用自己写的了,自己写的schema对于分页短,内容少的网站来说根本不能满足要求)。总体来说想解决完整的爬虫,除了collection相关的专业框架,各个框架都可以,我现在用的是pymongo,前端我一直用selenium-splash(某个谷歌的爬虫插件,当然有自己写的),后端redis就可以。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页列表项-all-workflows/scrapy/per_url_number分页爬取)
scrapy分页抓取网页列表项-all-workflows/
scrapy分页爬取网页列表/http/
同问。最近也想抓取这个:想采集单个网页的指定位置的文字,但是我觉得有道云笔记里的例子不太符合我的思路。
follow-github
scrapy的库提供了一些机制,爬虫可以针对分页来进行爬取,
可以看一下scrapy解决跨站抓取发函数的问题。
最近也研究过此问题。基本上就是:不同页面写多个代码,同时迭代爬取。然后merge。比如同一页的每个文字都进行同时爬取。就是用scrapy爬取完一页的所有词汇,然后存入新文件。同时迭代整个页面的词汇,然后爬取整页。
httpurl地址的链接格式一般有三种形式:
1).user-agent:scrapy_crawler/spider.pyid/per_url_number
2).user-agent:scrapy_crawler/spider.pyid/numpy_id
3).user-agent:scrapy_crawler/spider.pyid/per_url_number分别对应爬虫id、thetaid、numpyid
注意留下交叉链接
都是如何利用scrapy解决跨页抓取问题的爬虫框架也不只有scrapy,
一般来说,大部分网站分页太少,那么完整抓取一页也不是很难,关键要是当页有个1000以上,然后再打开一个网页,需要选择1/1000个文字抓取一个页面的话那真的要抓取半天的。答主现在正在用的是第二种,简单粗暴就是抓过来存数据库,然后跟某些网站的内容数据库差不多就行,但是现在都是用redis来存管理,因为springboot的话在configure的时候需要defaultworker节点。
并且topic选择可以自己写,也可以是框架代理的方式(就是只抓过一次)有人说用redis,我个人感觉很蛋疼,因为你还得写schema(库里面有代理,就不要用自己写的了,自己写的schema对于分页短,内容少的网站来说根本不能满足要求)。总体来说想解决完整的爬虫,除了collection相关的专业框架,各个框架都可以,我现在用的是pymongo,前端我一直用selenium-splash(某个谷歌的爬虫插件,当然有自己写的),后端redis就可以。

