
scrapy分页抓取网页
scrapy分页抓取网页(人人都用得上webscraper进阶教程,人人用得上数据教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-14 23:20
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
相关 文章:
最简单的数据采集教程,大家都可以用
进阶网页爬虫教程,人人都能用
如果您正在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,而这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
下面列出了您可能遇到的几个问题,并解释了解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转。如何处理?
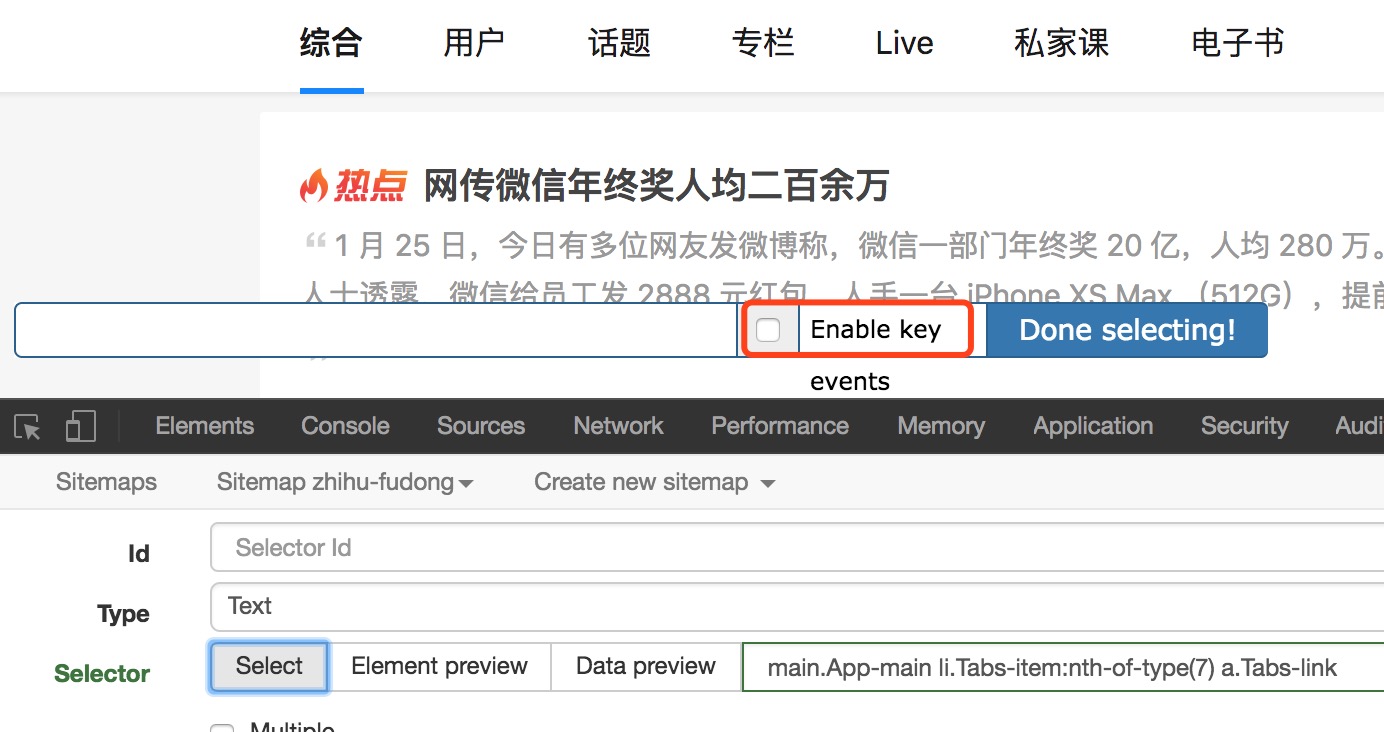
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按S键。
另外勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、 分页数据或滚动加载的数据无法完整抓取,如知乎 和推特等?
出现这种问题主要是因为网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此,请适当增加延迟大小并延长等待时间,以便有足够的时间加载数据。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、获取数据的顺序和网页上的顺序不一致?
webscraper默认是无序的,可以安装CouchDB保证数据的顺序。
或者使用其他替代方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按照某一列进行排序。按发布时间排序,或者知乎上的数据按点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。在这些情况下,您也需要使用其他方法。
其实就是通过鼠标操作选择元素,最后找到元素对应的xpath。Xpath对应网页解释,是定位一个元素的路径,通过元素的类型、唯一标识符、样式名、从属关系来查找某个元素或某类元素。
如果你没有遇到过这个问题,那么就没有必要去了解xpath,遇到问题就可以直接开始学习。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。 查看全部
scrapy分页抓取网页(人人都用得上webscraper进阶教程,人人用得上数据教程)
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
相关 文章:
最简单的数据采集教程,大家都可以用
进阶网页爬虫教程,人人都能用
如果您正在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,而这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
下面列出了您可能遇到的几个问题,并解释了解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按S键。
另外勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、 分页数据或滚动加载的数据无法完整抓取,如知乎 和推特等?
出现这种问题主要是因为网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此,请适当增加延迟大小并延长等待时间,以便有足够的时间加载数据。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、获取数据的顺序和网页上的顺序不一致?
webscraper默认是无序的,可以安装CouchDB保证数据的顺序。
或者使用其他替代方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按照某一列进行排序。按发布时间排序,或者知乎上的数据按点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。在这些情况下,您也需要使用其他方法。
其实就是通过鼠标操作选择元素,最后找到元素对应的xpath。Xpath对应网页解释,是定位一个元素的路径,通过元素的类型、唯一标识符、样式名、从属关系来查找某个元素或某类元素。
如果你没有遇到过这个问题,那么就没有必要去了解xpath,遇到问题就可以直接开始学习。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-13 00:33
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对于我这种情况,我宁愿花半个自己写的一天 懒得学第三方代码工具的都是自己写代码实现的;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用 webBrowser 控件 Navigate(" ") 的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
看完这篇文章,我觉得可以解决手头的网站,但是在实际操作中,第二种方法无法完成网页抓取,而第三种方法也不好控制;
个人实践一使用页面添加或修改其中一个标签的属性 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对于我这种情况,我宁愿花半个自己写的一天 懒得学第三方代码工具的都是自己写代码实现的;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用 webBrowser 控件 Navigate(" ") 的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
看完这篇文章,我觉得可以解决手头的网站,但是在实际操作中,第二种方法无法完成网页抓取,而第三种方法也不好控制;
个人实践一使用页面添加或修改其中一个标签的属性
scrapy分页抓取网页(scrapy成熟的爬虫框架的考量及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-10-11 16:06
)
最近在用scrapy做一个爬虫爬取网站上的一些信息,但是出现了一个很奇怪的问题,就是在网页中打开了要爬取的URL,某个URL位于网页的源代码。需要爬取一些元素,但是我用scrapy爬取数据的时候,发现一个错误,结果是爬取的网页没有收录我在浏览器中看到的元素,也就是for the same URL,抓取的页面和我在浏览器打开看到的页面不一样!
在反复确认CSS类选择器正确以及爬虫爬取的URL没有重定向到其他页面后,发现事情并不简单。
然后机缘巧合下,没有修改任何代码,再次运行,却发现再次爬行成功,然后又试了一次,报错了。这时候就知道,抓取到的页面一定是 完整的页面没有加载完成。
当页面没有完全加载时,我首先想到了两种可能:
首先,部分数据在网页加载时由js动态写入,即部分数据在第一次请求时传递给js,由前端js处理后显示在页面上;
二是网页数据是异步加载的,在抓取网页的时候部分数据还没有加载。
基于scrapy是一个成熟的爬虫框架的考虑,我认为第一种情况应该不会出现。毕竟爬虫可以等到页面初始化好再爬,但是对于第二种情况,因为数据Loading是异步的,所以无法提前控制。
基于以上考虑,直接考虑第二种情况。因此,您可以在浏览器控制台的 Network 中检查所有发送的请求,看看您需要的数据是否被异步加载。如下图所示,可以查看每个请求的Response,手动检查是否返回了你需要的信息。
对于我的情况,果然如上图所示,我找到了整个异步请求返回的json格式数据,里面收录了我需要的所有信息,我什至不需要再抓取网页了,只是作为如下图,查看请求的header,可以看到异步请求的请求格式,也就是图中的Request URL
将获取到的Request URL复制到新的浏览器窗口打开,可以看到下图,可以访问json格式的返回数据,说明网站没有拦截到这种请求,这也使得我没必要去抓取页面的数据了,我只需要直接构造对应的URL,分析返回的json数据,就大功告成了!
查看全部
scrapy分页抓取网页(scrapy成熟的爬虫框架的考量及应用
)
最近在用scrapy做一个爬虫爬取网站上的一些信息,但是出现了一个很奇怪的问题,就是在网页中打开了要爬取的URL,某个URL位于网页的源代码。需要爬取一些元素,但是我用scrapy爬取数据的时候,发现一个错误,结果是爬取的网页没有收录我在浏览器中看到的元素,也就是for the same URL,抓取的页面和我在浏览器打开看到的页面不一样!
在反复确认CSS类选择器正确以及爬虫爬取的URL没有重定向到其他页面后,发现事情并不简单。

然后机缘巧合下,没有修改任何代码,再次运行,却发现再次爬行成功,然后又试了一次,报错了。这时候就知道,抓取到的页面一定是 完整的页面没有加载完成。
当页面没有完全加载时,我首先想到了两种可能:
首先,部分数据在网页加载时由js动态写入,即部分数据在第一次请求时传递给js,由前端js处理后显示在页面上;
二是网页数据是异步加载的,在抓取网页的时候部分数据还没有加载。
基于scrapy是一个成熟的爬虫框架的考虑,我认为第一种情况应该不会出现。毕竟爬虫可以等到页面初始化好再爬,但是对于第二种情况,因为数据Loading是异步的,所以无法提前控制。
基于以上考虑,直接考虑第二种情况。因此,您可以在浏览器控制台的 Network 中检查所有发送的请求,看看您需要的数据是否被异步加载。如下图所示,可以查看每个请求的Response,手动检查是否返回了你需要的信息。

对于我的情况,果然如上图所示,我找到了整个异步请求返回的json格式数据,里面收录了我需要的所有信息,我什至不需要再抓取网页了,只是作为如下图,查看请求的header,可以看到异步请求的请求格式,也就是图中的Request URL

将获取到的Request URL复制到新的浏览器窗口打开,可以看到下图,可以访问json格式的返回数据,说明网站没有拦截到这种请求,这也使得我没必要去抓取页面的数据了,我只需要直接构造对应的URL,分析返回的json数据,就大功告成了!

scrapy分页抓取网页(Python中一个非常棒的网页抓取网页中常见的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-10-11 16:06
Python部落()整理翻译,禁止转载,欢迎转发。
在上一篇使用 Python 抓取网页的博文中,我们谈到了 Scrapy。在本节中,让我们深入探讨它。
Scrapy 是一个很棒的 Python 网页抓取框架。它可以处理大规模网络爬行过程中的一些常见问题。
Scrapy 与 Requests 或 BeautifulSoup 等其他常用库的区别非常明显。它可以通过简单的方式解决网络爬虫中的常见问题。
Scrapy 的缺点是学习曲线非常陡峭,需要学习的东西很多,但这就是我们要在这里讨论的内容。
在本教程中,我们将创建两个不同的网络爬虫。一种是从电商产品页面提取数据比较简单,另一种是抓取整个电商目录比较复杂。
基本概述
您可以使用 pip 安装 Scrapy。但也要注意,Scrapy 的文档强烈建议将其安装在虚拟环境中,以避免与您的系统软件包发生冲突。
我在这里使用 Virtualenv 和 Virtualenvwrapper:
然后
现在您可以使用以下命令创建一个新的 Scrapy 项目:
上面的命令将为这个项目创建所有必要的模板文件。
下面简单介绍一下上述文件和目录:
在此示例中,我们将从虚拟电子商务 网站 中抓取单个产品。这是我们要抓取的第一个产品:
我们要解析这个产品的名称、图片、价格和描述。
破壳
Scrapy 提供了内置的 Shell 控制台,方便你实时运行和调试爬虫脚本。您可以使用它来快速测试 XPath 表达式或 CSS 选择器。我一直在使用这个很酷的网络爬虫。
您还可以配置 Scrapy Shell 以使用其他控制台来替换默认的 Python 控制台,例如 IPython。可实现自动补全功能或其他特殊效果,如颜色输出等。
为了方便在Scrapy Shell中使用,需要在scrapy.cfg文件中加入如下一行:
配置完成后就可以使用scrapy shell了:
让我们从抓取一个简单的 URL 开始:
这将首先获取 /robot.txt 文件。
本例中没有robot.txt文件,所以我们会在这里看到404 HTTP状态码。如果有robot.txt文件,Scrapy默认会遵循规则。
您可以在 settings.py 文件中禁用此规则:
然后可以看到如下日志:
现在,您可以从捕获的数据中看到响应正文和响应标头,还可以使用不同的 XPath 表达式或 CSS 选择器来解析数据。
使用以下命令直接在浏览器中查看响应信息:
请注意,由于某些原因,该页面在浏览器中的显示效果可能较差。这可能是CORS问题,或者Javascript代码无法执行,或者本地URL对应的资源被加载了。
Scrapy shell 与常规 Python shell 没有什么不同,因此您可以向其中添加自定义脚本或函数。
分析数据
Scrapy 默认不执行 Javascript,所以如果你要爬取的页面是通过 Angular 或 React.js 前端框架渲染的,你可能无法抓取到想要的数据。
现在让我们尝试使用 XPath 表达式来解析产品标题和价格:
使用XPath表达式方便价格分析,选择类属性my-4的div标签后第一个span的文字:
您还可以使用 CSS 选择器:
创建一个 Scrapy 爬虫
在 Scrapy 中,Spider 是一个类,用于定义集合(需要爬取的链接或 URL)和爬取(需要解析的数据)。
以下是爬虫爬取网站所需的步骤:
您可能想知道为什么 parse() 函数可以返回这么多不同类型的对象。这是为了函数的灵活性。假设你想抓取一个没有站点地图的电商网站,你可以从抓取产品类别开始,这里是使用的第一个解析函数。
然后,该函数将为每个产品类别生成一个 Request 对象,并将其传递给新的回调函数 parse2()。对于每个类别,可能还有分页需要处理。然后将为实际抓取的每个产品生成第三个解析函数。
Scrapy 可以将捕获的数据作为简单的 Python 字典返回,但最好使用内置的 Scrapy 项目类。它是我们抓取数据时使用的简单容器。Scrapy 可以查看该项中的属性并进行很多操作,比如将数据导出为不同的格式(JSON 或 CSV 等),作为一个项目管道。
这是一个基本的 Product 类:
现在我们可以通过命令行生成爬虫:
或者您可以在 /spiders 目录中手动创建爬虫代码。
以下是 Scrapy 用来解决大部分爬虫用例的不同类型的爬虫:
在这个 EcomSpider 类中,有两个必需的属性:
allowed_domains 是可选的,但也非常重要。当您使用 CrawlSpider 时,将识别不同的域名。
然后使用我们之前看到的 XPath 表达式解析所需的数据并将其填充到 Product 字段中,并返回此项。
您可以运行以下代码将结果导出为 JSON 格式(也可以导出 CSV)。
然后你可以得到一个整洁的 JSON 文件:
物品加载器
从网页中提取数据时,您可能会遇到两个常见问题:
对此,Scrapy 提供了内置的解决方案 ItemLoaders。这是一种处理 Product 对象的有趣方式。
您可以将多个 XPath 表达式添加到同一个 Item 字段,它会按顺序测试它们。默认情况下,如果找到多个 XPath,它会将它们全部加载到列表中。
您可以在 Scrapy 文档中找到许多输入和输出处理器的示例。
当您需要转换或清理解析的数据时,此功能很有用。例如,从价格中提取货币信息,将一种单位转换为另一种单位(厘米和米、华氏和摄氏)等。
我们可以使用不同的 XPath 表达式从网页中查找产品标题://title 和 //section[1]//h2/text()。
在这种情况下,您可以使用 Itemloader:
通常要使用第一个匹配的XPath,所以需要在item的字段构造函数中添加这段代码output_processor=TakeFirst()。
在示例中,我们只希望每个字段都匹配第一个 XPath,因此最好的方法是创建自己的 Itemloader 并声明一个默认的 output_processor 以使用第一个 XPath。
我还在这里添加了一个 price_in 字段,它是一个输入处理器,用于从价格中删除美元符号。我使用的内置处理器 MapCompose 需要按顺序执行一个或多个函数。您可以根据需要添加任何函数,通常在项目中的字段名称后添加 _in 或 _out ,表示添加输入或输出处理器。 查看全部
scrapy分页抓取网页(Python中一个非常棒的网页抓取网页中常见的问题)
Python部落()整理翻译,禁止转载,欢迎转发。

在上一篇使用 Python 抓取网页的博文中,我们谈到了 Scrapy。在本节中,让我们深入探讨它。
Scrapy 是一个很棒的 Python 网页抓取框架。它可以处理大规模网络爬行过程中的一些常见问题。
Scrapy 与 Requests 或 BeautifulSoup 等其他常用库的区别非常明显。它可以通过简单的方式解决网络爬虫中的常见问题。
Scrapy 的缺点是学习曲线非常陡峭,需要学习的东西很多,但这就是我们要在这里讨论的内容。
在本教程中,我们将创建两个不同的网络爬虫。一种是从电商产品页面提取数据比较简单,另一种是抓取整个电商目录比较复杂。
基本概述
您可以使用 pip 安装 Scrapy。但也要注意,Scrapy 的文档强烈建议将其安装在虚拟环境中,以避免与您的系统软件包发生冲突。
我在这里使用 Virtualenv 和 Virtualenvwrapper:

然后

现在您可以使用以下命令创建一个新的 Scrapy 项目:

上面的命令将为这个项目创建所有必要的模板文件。

下面简单介绍一下上述文件和目录:
在此示例中,我们将从虚拟电子商务 网站 中抓取单个产品。这是我们要抓取的第一个产品:
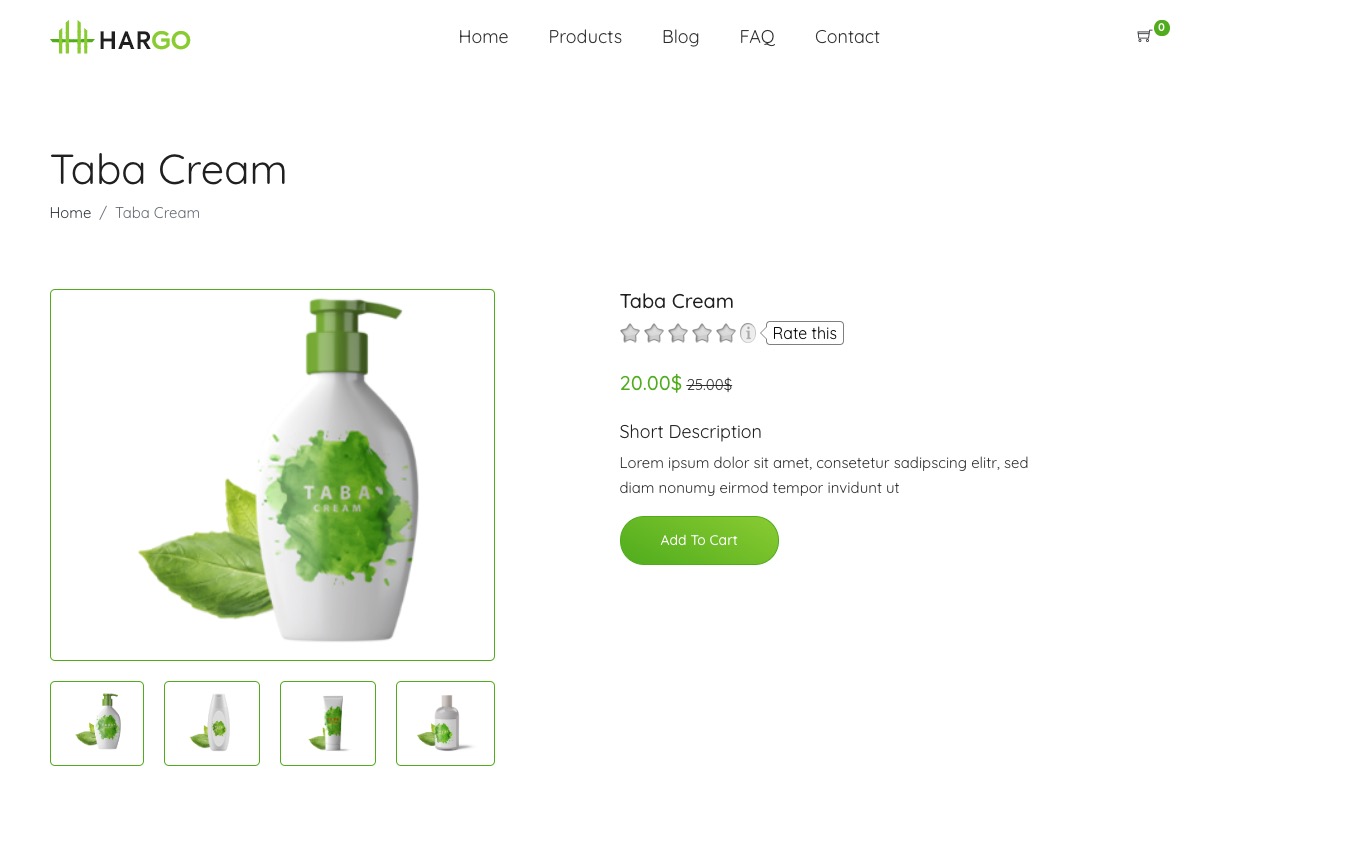
我们要解析这个产品的名称、图片、价格和描述。
破壳
Scrapy 提供了内置的 Shell 控制台,方便你实时运行和调试爬虫脚本。您可以使用它来快速测试 XPath 表达式或 CSS 选择器。我一直在使用这个很酷的网络爬虫。
您还可以配置 Scrapy Shell 以使用其他控制台来替换默认的 Python 控制台,例如 IPython。可实现自动补全功能或其他特殊效果,如颜色输出等。
为了方便在Scrapy Shell中使用,需要在scrapy.cfg文件中加入如下一行:

配置完成后就可以使用scrapy shell了:
让我们从抓取一个简单的 URL 开始:

这将首先获取 /robot.txt 文件。

本例中没有robot.txt文件,所以我们会在这里看到404 HTTP状态码。如果有robot.txt文件,Scrapy默认会遵循规则。
您可以在 settings.py 文件中禁用此规则:

然后可以看到如下日志:

现在,您可以从捕获的数据中看到响应正文和响应标头,还可以使用不同的 XPath 表达式或 CSS 选择器来解析数据。
使用以下命令直接在浏览器中查看响应信息:

请注意,由于某些原因,该页面在浏览器中的显示效果可能较差。这可能是CORS问题,或者Javascript代码无法执行,或者本地URL对应的资源被加载了。
Scrapy shell 与常规 Python shell 没有什么不同,因此您可以向其中添加自定义脚本或函数。
分析数据
Scrapy 默认不执行 Javascript,所以如果你要爬取的页面是通过 Angular 或 React.js 前端框架渲染的,你可能无法抓取到想要的数据。
现在让我们尝试使用 XPath 表达式来解析产品标题和价格:
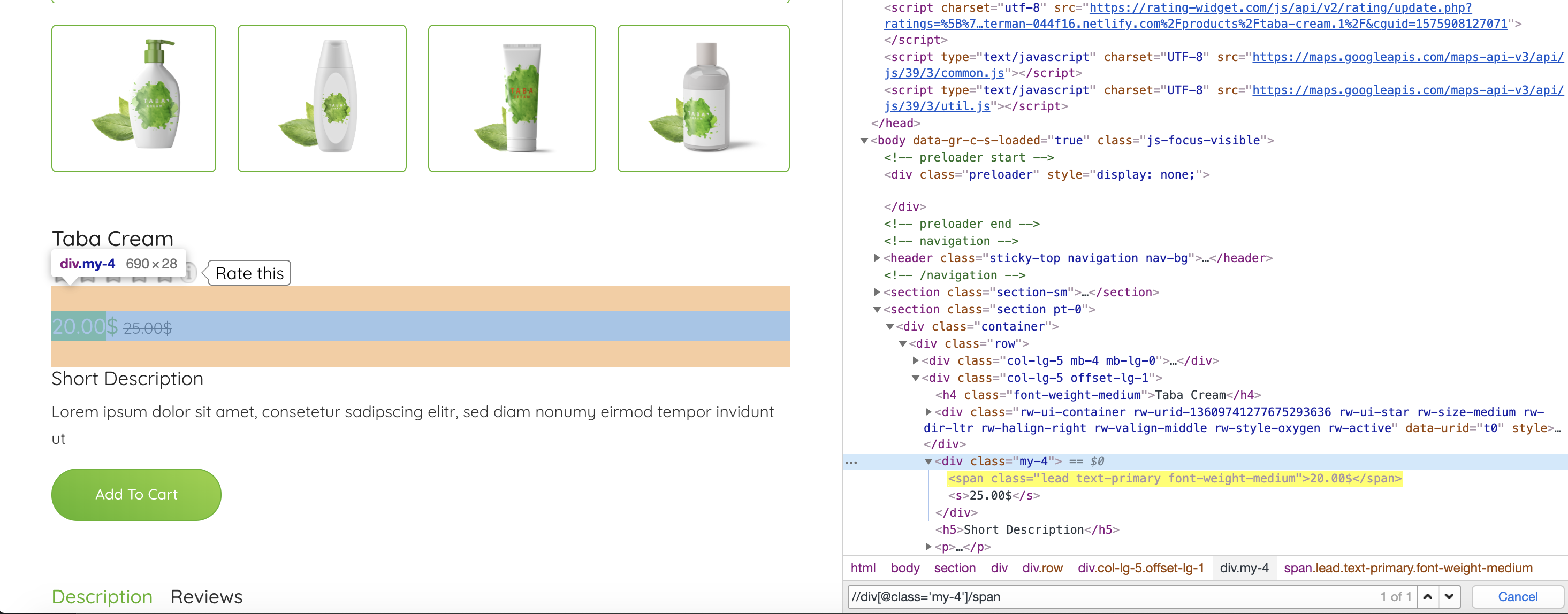
使用XPath表达式方便价格分析,选择类属性my-4的div标签后第一个span的文字:

您还可以使用 CSS 选择器:

创建一个 Scrapy 爬虫
在 Scrapy 中,Spider 是一个类,用于定义集合(需要爬取的链接或 URL)和爬取(需要解析的数据)。
以下是爬虫爬取网站所需的步骤:
您可能想知道为什么 parse() 函数可以返回这么多不同类型的对象。这是为了函数的灵活性。假设你想抓取一个没有站点地图的电商网站,你可以从抓取产品类别开始,这里是使用的第一个解析函数。
然后,该函数将为每个产品类别生成一个 Request 对象,并将其传递给新的回调函数 parse2()。对于每个类别,可能还有分页需要处理。然后将为实际抓取的每个产品生成第三个解析函数。
Scrapy 可以将捕获的数据作为简单的 Python 字典返回,但最好使用内置的 Scrapy 项目类。它是我们抓取数据时使用的简单容器。Scrapy 可以查看该项中的属性并进行很多操作,比如将数据导出为不同的格式(JSON 或 CSV 等),作为一个项目管道。
这是一个基本的 Product 类:

现在我们可以通过命令行生成爬虫:

或者您可以在 /spiders 目录中手动创建爬虫代码。
以下是 Scrapy 用来解决大部分爬虫用例的不同类型的爬虫:
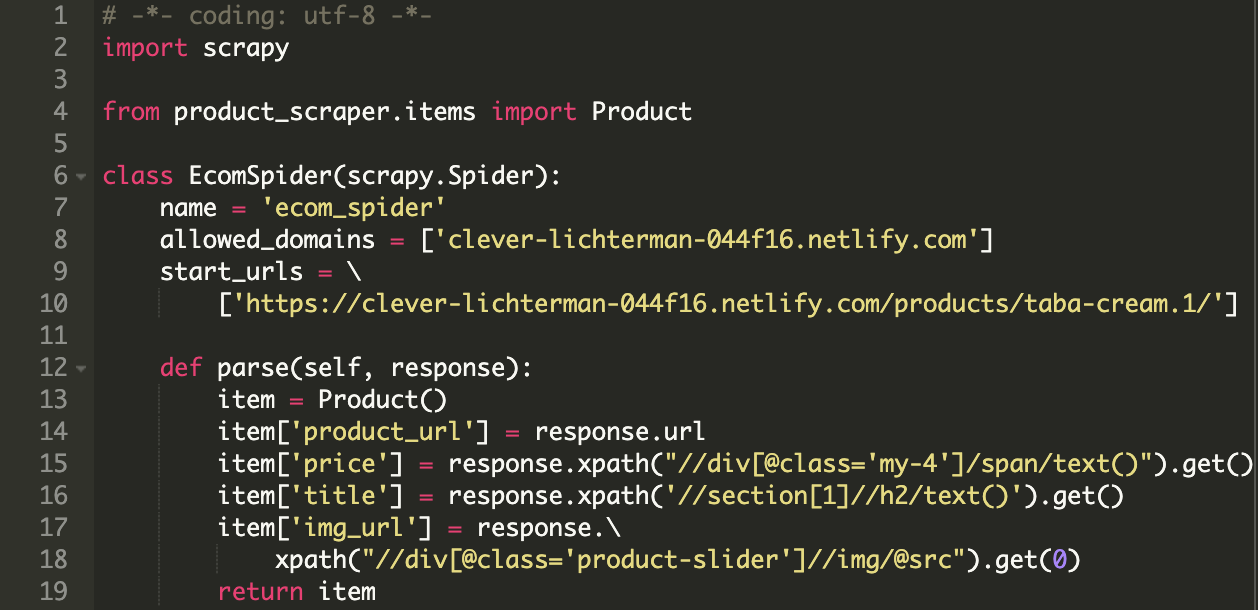
在这个 EcomSpider 类中,有两个必需的属性:
allowed_domains 是可选的,但也非常重要。当您使用 CrawlSpider 时,将识别不同的域名。
然后使用我们之前看到的 XPath 表达式解析所需的数据并将其填充到 Product 字段中,并返回此项。
您可以运行以下代码将结果导出为 JSON 格式(也可以导出 CSV)。

然后你可以得到一个整洁的 JSON 文件:

物品加载器
从网页中提取数据时,您可能会遇到两个常见问题:
对此,Scrapy 提供了内置的解决方案 ItemLoaders。这是一种处理 Product 对象的有趣方式。
您可以将多个 XPath 表达式添加到同一个 Item 字段,它会按顺序测试它们。默认情况下,如果找到多个 XPath,它会将它们全部加载到列表中。
您可以在 Scrapy 文档中找到许多输入和输出处理器的示例。
当您需要转换或清理解析的数据时,此功能很有用。例如,从价格中提取货币信息,将一种单位转换为另一种单位(厘米和米、华氏和摄氏)等。
我们可以使用不同的 XPath 表达式从网页中查找产品标题://title 和 //section[1]//h2/text()。
在这种情况下,您可以使用 Itemloader:

通常要使用第一个匹配的XPath,所以需要在item的字段构造函数中添加这段代码output_processor=TakeFirst()。
在示例中,我们只希望每个字段都匹配第一个 XPath,因此最好的方法是创建自己的 Itemloader 并声明一个默认的 output_processor 以使用第一个 XPath。
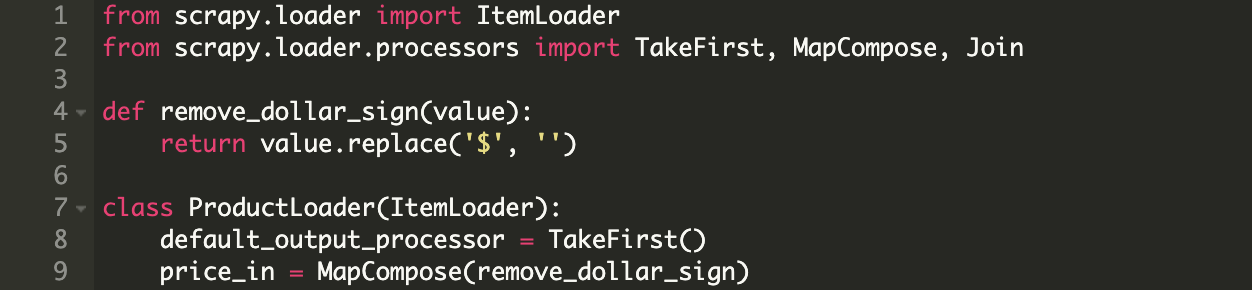
我还在这里添加了一个 price_in 字段,它是一个输入处理器,用于从价格中删除美元符号。我使用的内置处理器 MapCompose 需要按顺序执行一个或多个函数。您可以根据需要添加任何函数,通常在项目中的字段名称后添加 _in 或 _out ,表示添加输入或输出处理器。
scrapy分页抓取网页(crawlspiderrules疑问总结:1、rules里的Rule规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-11 16:05
最近在学习爬虫,对爬虫规则的运行机制有些疑惑,于是自己研究了一下,总结出以下几点:
1、规则中的规则是按顺序运行的,从上到下执行;
2、 获取request url是Rule定位的容器,a标签中的所有href链接,比如使用xpath定位
规则 = (
规则(LinkExtractor(restrict_xpaths=("//div/ul")),callback='parse_item'),
)
然后会获取ul容器下a标签的所有链接,服务器会自动发送请求,无需手动发送请求;
3、 响应页面就是Rule请求的链接的页面内容,也就是你在容器ul中定位a标签所在的链接,然后点击链接查看页面内容,在回调函数中提取数据。从这个页面中提取,parse_item(self,response),这个函数的响应对象就是这个页面的内容,不要搞错对象;
4、follow,这个参数开始让我有点晕。跟随意味着跟进。如果follow=True,那么在你得到的响应页面中,会获取所有符合规则的href链接 会自动跟进,进入获取到的链接响应页面,在这个页面再次匹配规则规则,看看有没有是任何匹配,如果是,则继续跟踪,直到不匹配规则。例如:
规则 = (
规则(LinkExtractor(restrict_xpaths=(“//div/ul”)),follow=True),
)
所以首先规则会获取当前页面上所有符合规则规则的链接,当前页面为start_urls页面,例如获取的链接为
会继续进入href链接的页面,然后继续匹配Rule规则,看看有没有匹配的链接,相当于在响应页面的元素中找到符合规则的a标签url ,然后点击这个url,然后在这个页面的元素中查找是否有符合Rule规则的href链接,依此类推,直到找不到符合Rule规则的href链接;
5、如果Rule中有callback="parse_item",follow=True,那么情况会更复杂。你可以想象得到一个响应符合Rule规则的页面的链接,然后调用函数,跳转到这个页面。按照其他目标链接,然后调用该函数。最好使用xpath定位。如果使用allow=(r'')正则表达式匹配,会比较混乱。在适当的情况下也会用到,不过比较少嘛,大家可以自己测试体验一下。
6、 翻页,翻页有两种情况
第一种情况(start_url的响应页面底部有翻页链接):
在规则中定义两个Rule规则,一个是获取响应页面规则,一个是获取翻页链接规则,翻页规则遵循响应页面规则,顺序不能错,如下:
规则 = (
规则(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
规则(LinkExtractor(allow=r'\d\.htm'),follow=True),
)
第二种情况(start_url的响应页面底部没有翻页链接,只有输入a标签链接才有翻页链接):
在这种情况下,您无法在规则中定义翻页规则,因为即使您定义了翻页规则,也找不到它们。因为规则中的所有规则,第一次得到响应页面是start_url地址对应的内容。如果该页面没有规则规则,则不会被发现。这里就不多说了,直接上源码吧!
class TestSpider(CrawlSpider):
name = 'test'
allowed_domains = ['dangdang.com']
start_urls = ['http://book.dangdang.com/']
rules = (
Rule(LinkExtractor(restrict_xpaths=("//div[@class='conflq_body']/div[@name='m403752_pid5438_t10274']//div/dl[@ddt-area='5358']/dd")), callback='parse_item'),
)
def parse_item(self, response):
item={}
item['cate_0']=''
item['cate_1'] = ''
item['cate_2'] = ''
item['cate_3'] = ''
breadcrum=response.xpath("//div[@class='crumbs_fb_left']/div[@class='select_frame']/a[@name='breadcrumb-category']/text()").getall()
for i in range(len(breadcrum)):
item['cate_{}'.format(i)]=breadcrum[i]
book_li=response.xpath("//div[@id='search_nature_rg']/ul/li")
for li in book_li:
item['book_title']=li.xpath(".//p[@class='name']/a/@title").get()
item['book_price']=li.xpath(".//p[@class='price']/span/text()").get()
item['book_url']=li.xpath(".//p[@class='name']/a/@href").get()
book_search=li.xpath(".//p[@class='search_book_author']/span")
item['book_author']=book_search[0].xpath(".//a/@title").get()
item['public_date']=book_search[1].xpath(".//text()").get()
item['public_date']=re.sub("/",'',item['public_date']) if item['public_date'] else None
item['public_company']=book_search[2].xpath(".//a/@title").get()
yield item
next_page_url=response.xpath("//div[@class='paging']//li[@class='next']/a/@href").get()
next_page="http://category.dangdang.com"+next_page_url
yield scrapy.Request(next_page,callback=self.parse_item)
在这种情况下,必须在函数中进行翻页。parse_item() 函数的最后三行是翻页语句!我可以自己测试一下。不知道有没有其他方法可以做规则。反正我现在还没找到。如果有人知道,我可以告诉!
以上是我个人的看法,如有错误或遗漏,敬请指出! 查看全部
scrapy分页抓取网页(crawlspiderrules疑问总结:1、rules里的Rule规则)
最近在学习爬虫,对爬虫规则的运行机制有些疑惑,于是自己研究了一下,总结出以下几点:
1、规则中的规则是按顺序运行的,从上到下执行;
2、 获取request url是Rule定位的容器,a标签中的所有href链接,比如使用xpath定位
规则 = (
规则(LinkExtractor(restrict_xpaths=("//div/ul")),callback='parse_item'),
)
然后会获取ul容器下a标签的所有链接,服务器会自动发送请求,无需手动发送请求;
3、 响应页面就是Rule请求的链接的页面内容,也就是你在容器ul中定位a标签所在的链接,然后点击链接查看页面内容,在回调函数中提取数据。从这个页面中提取,parse_item(self,response),这个函数的响应对象就是这个页面的内容,不要搞错对象;
4、follow,这个参数开始让我有点晕。跟随意味着跟进。如果follow=True,那么在你得到的响应页面中,会获取所有符合规则的href链接 会自动跟进,进入获取到的链接响应页面,在这个页面再次匹配规则规则,看看有没有是任何匹配,如果是,则继续跟踪,直到不匹配规则。例如:
规则 = (
规则(LinkExtractor(restrict_xpaths=(“//div/ul”)),follow=True),
)
所以首先规则会获取当前页面上所有符合规则规则的链接,当前页面为start_urls页面,例如获取的链接为
会继续进入href链接的页面,然后继续匹配Rule规则,看看有没有匹配的链接,相当于在响应页面的元素中找到符合规则的a标签url ,然后点击这个url,然后在这个页面的元素中查找是否有符合Rule规则的href链接,依此类推,直到找不到符合Rule规则的href链接;
5、如果Rule中有callback="parse_item",follow=True,那么情况会更复杂。你可以想象得到一个响应符合Rule规则的页面的链接,然后调用函数,跳转到这个页面。按照其他目标链接,然后调用该函数。最好使用xpath定位。如果使用allow=(r'')正则表达式匹配,会比较混乱。在适当的情况下也会用到,不过比较少嘛,大家可以自己测试体验一下。
6、 翻页,翻页有两种情况
第一种情况(start_url的响应页面底部有翻页链接):
在规则中定义两个Rule规则,一个是获取响应页面规则,一个是获取翻页链接规则,翻页规则遵循响应页面规则,顺序不能错,如下:
规则 = (
规则(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
规则(LinkExtractor(allow=r'\d\.htm'),follow=True),
)
第二种情况(start_url的响应页面底部没有翻页链接,只有输入a标签链接才有翻页链接):
在这种情况下,您无法在规则中定义翻页规则,因为即使您定义了翻页规则,也找不到它们。因为规则中的所有规则,第一次得到响应页面是start_url地址对应的内容。如果该页面没有规则规则,则不会被发现。这里就不多说了,直接上源码吧!
class TestSpider(CrawlSpider):
name = 'test'
allowed_domains = ['dangdang.com']
start_urls = ['http://book.dangdang.com/']
rules = (
Rule(LinkExtractor(restrict_xpaths=("//div[@class='conflq_body']/div[@name='m403752_pid5438_t10274']//div/dl[@ddt-area='5358']/dd")), callback='parse_item'),
)
def parse_item(self, response):
item={}
item['cate_0']=''
item['cate_1'] = ''
item['cate_2'] = ''
item['cate_3'] = ''
breadcrum=response.xpath("//div[@class='crumbs_fb_left']/div[@class='select_frame']/a[@name='breadcrumb-category']/text()").getall()
for i in range(len(breadcrum)):
item['cate_{}'.format(i)]=breadcrum[i]
book_li=response.xpath("//div[@id='search_nature_rg']/ul/li")
for li in book_li:
item['book_title']=li.xpath(".//p[@class='name']/a/@title").get()
item['book_price']=li.xpath(".//p[@class='price']/span/text()").get()
item['book_url']=li.xpath(".//p[@class='name']/a/@href").get()
book_search=li.xpath(".//p[@class='search_book_author']/span")
item['book_author']=book_search[0].xpath(".//a/@title").get()
item['public_date']=book_search[1].xpath(".//text()").get()
item['public_date']=re.sub("/",'',item['public_date']) if item['public_date'] else None
item['public_company']=book_search[2].xpath(".//a/@title").get()
yield item
next_page_url=response.xpath("//div[@class='paging']//li[@class='next']/a/@href").get()
next_page="http://category.dangdang.com"+next_page_url
yield scrapy.Request(next_page,callback=self.parse_item)
在这种情况下,必须在函数中进行翻页。parse_item() 函数的最后三行是翻页语句!我可以自己测试一下。不知道有没有其他方法可以做规则。反正我现在还没找到。如果有人知道,我可以告诉!
以上是我个人的看法,如有错误或遗漏,敬请指出!
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-09 23:11
Scrapy 是一个用 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 常用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
通常我们可以通过Scrapy框架轻松实现爬虫抓取指定网站的内容或图片。
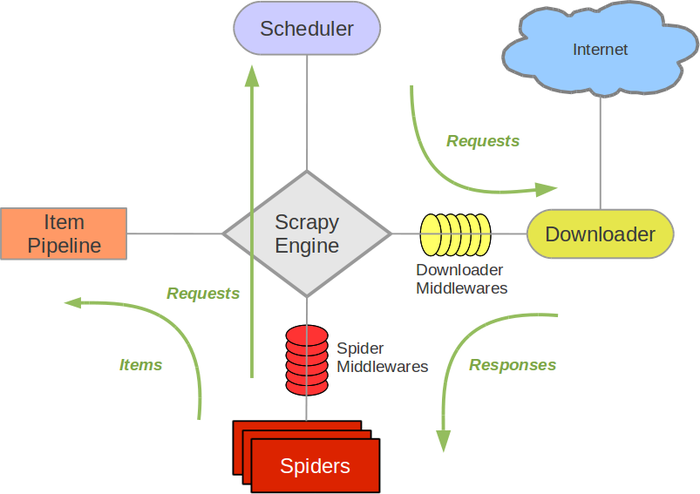
Scrapy 架构图(绿线为数据流)
Scrapy 操作流程
代码写好,程序开始运行...
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的 URL,Scrapy 会重新下载。)
制作一个Scrapy爬虫一共需要4步:新建项目(scrapy startproject xxx):新建一个爬虫项目,指定目标(写items.py):指定要爬取的目标, make a spider (spiders/xxspider.py) ): 制作一个爬虫并开始爬取网络存储内容 (pipelines.py): 设计一个管道来存储爬取的内容 安装 Windows 安装方法
升级pip版本:
pip install --upgrade pip
通过pip安装Scrapy框架:
pip install Scrapy
Ubuntu 安装方法
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip安装Scrapy框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,默认安装的包是不能删除的,但是可以使用python2.x来安装Scrapy会报错,使用python3.x安装也是报错。终于没有找到直接安装Scrapy的方法,所以就用另一种安装方式来讲解安装步骤。解决方案是使用virtualenv。安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,在命令终端输入scrapy,提示类似如下结果,表示安装成功。
介绍案例研究目标一. 新项目(scrapy startproject)
在爬取之前,必须创建一个新的 Scrapy 项目。进入自定义项目目录,运行以下命令:
scrapy startproject mySpider
其中mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、明确目标(mySpider/items.py)
我们打算获取网站中所有讲师的姓名、职称和个人信息。
打开 mySpider 目录下的 items.py。
Item 定义了一个结构化的数据字段,用于保存抓取到的数据,有点像 Python 中的 dict,但提供了一些额外的保护以减少错误。
可以通过创建scrapy.Item类并定义scrapy.Field类型的类属性来定义Item(可以理解为类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类并构建一个项目模型。
三、制作爬虫(spider/itcastSpider.py)
爬虫功能需要分为两步:
1. 爬取数据
在当前目录下输入命令,会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,自己写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建Spider,您必须使用scrapy.Spider 类创建一个子类,并确定三个必需属性和一个方法。
name = "":此爬虫的标识名称必须是唯一的。不同的爬虫必须定义不同的名称。
allow_domains = [] 是要搜索的域名范围,即爬虫的限制区域。规定爬虫只爬取该域名下的网页,不存在的网址将被忽略。
start_urls = ():已爬取的 URL 的祖先/列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse(self, response):解析的方法。每个初始 URL 下载后都会调用它。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item) 查看全部
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
Scrapy 是一个用 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 常用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
通常我们可以通过Scrapy框架轻松实现爬虫抓取指定网站的内容或图片。
Scrapy 架构图(绿线为数据流)
Scrapy 操作流程
代码写好,程序开始运行...
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的 URL,Scrapy 会重新下载。)
制作一个Scrapy爬虫一共需要4步:新建项目(scrapy startproject xxx):新建一个爬虫项目,指定目标(写items.py):指定要爬取的目标, make a spider (spiders/xxspider.py) ): 制作一个爬虫并开始爬取网络存储内容 (pipelines.py): 设计一个管道来存储爬取的内容 安装 Windows 安装方法
升级pip版本:
pip install --upgrade pip
通过pip安装Scrapy框架:
pip install Scrapy
Ubuntu 安装方法
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip安装Scrapy框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,默认安装的包是不能删除的,但是可以使用python2.x来安装Scrapy会报错,使用python3.x安装也是报错。终于没有找到直接安装Scrapy的方法,所以就用另一种安装方式来讲解安装步骤。解决方案是使用virtualenv。安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,在命令终端输入scrapy,提示类似如下结果,表示安装成功。
介绍案例研究目标一. 新项目(scrapy startproject)
在爬取之前,必须创建一个新的 Scrapy 项目。进入自定义项目目录,运行以下命令:
scrapy startproject mySpider
其中mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、明确目标(mySpider/items.py)
我们打算获取网站中所有讲师的姓名、职称和个人信息。
打开 mySpider 目录下的 items.py。
Item 定义了一个结构化的数据字段,用于保存抓取到的数据,有点像 Python 中的 dict,但提供了一些额外的保护以减少错误。
可以通过创建scrapy.Item类并定义scrapy.Field类型的类属性来定义Item(可以理解为类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类并构建一个项目模型。
三、制作爬虫(spider/itcastSpider.py)
爬虫功能需要分为两步:
1. 爬取数据
在当前目录下输入命令,会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,自己写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建Spider,您必须使用scrapy.Spider 类创建一个子类,并确定三个必需属性和一个方法。
name = "":此爬虫的标识名称必须是唯一的。不同的爬虫必须定义不同的名称。
allow_domains = [] 是要搜索的域名范围,即爬虫的限制区域。规定爬虫只爬取该域名下的网页,不存在的网址将被忽略。
start_urls = ():已爬取的 URL 的祖先/列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse(self, response):解析的方法。每个初始 URL 下载后都会调用它。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-08 19:10
先看 Scrapy
Scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
本文档将介绍 Scrapy 背后的概念,让您了解其工作原理,并确定 Scrapy 是否是您所需要的。
当您准备好开始您的项目时,您可以参考它。
选择一个网站
当你需要从某个网站获取信息,但网站没有提供API或通过程序获取信息的机制时,Scrapy可以帮到你。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
可以在此页面上找到今天添加的种子列表:
定义要爬取的数据
第一步是定义我们需要爬取的数据。在 Scrapy 中,这是通过的。(在这个例子中,它是种子文件)
我们定义的Item:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写一个spider。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过观察页面内容,可以发现所有种子的URL都是相似的。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式:/tor/\d+。
我们使用 XPath 从页面的 HTML 源代码中选择要提取的数据。以其中一个种子文件的页面为例:
观察 HTML 页面源代码并创建我们需要的数据的 XPath 表达式(种子名称、描述和大小)。
通过观察,我们可以发现标签中收录了文件名:
Darwin - The Evolution Of An Exhibition
对应于此的 XPath 表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取说明:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
用于选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的详细信息,请参阅 XPath 参考。
最后结合上面的内容给出蜘蛛的代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='info-left']/p[2]/text()[2]").extract()
return torrent
TorrentItem 的定义在。
执行spider获取数据
最后,我们可以运行spider获取网站的数据并以JSON格式保存在scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您还可以将项目写入并存储在数据库中。
查看提取的数据
执行后,查看scraped_data.json,会看到解压出来的item:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是列表,所以所有的值都存储在列表中(除了url是直接赋值的)。如果您想保存单个数据或对数据执行额外的处理,那将是您发挥作用的地方。
还有什么?
您已经学习了如何通过 Scrapy 从存储的网页中提取信息,但这只是冰山一角。Scrapy 提供了许多强大的功能来让爬行更容易、更高效,例如:
对于非英语语言的非标准或错误编码声明,提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加快爬虫创建速度的同时,让大型项目中的代码更加一致。有关详细信息,请参阅命令。为多个爬虫下的性能评估和故障检测提供可扩展性。提供,为您测试XPath表达式,编写和调试爬虫,简化生产环境中的部署和操作提供了极大的便利。内置,通过在Scrapy进程中钩入Python终端,可以为你查看和调试爬虫爬虫过程中的Catching errors为Sitemaps爬取带有缓存的DNS解析器提供方便的支持
下一个
下一步当然是下载Scrapy,你可以阅读它并加入社区。感谢您的支持!
讨论 查看全部
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
先看 Scrapy
Scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
本文档将介绍 Scrapy 背后的概念,让您了解其工作原理,并确定 Scrapy 是否是您所需要的。
当您准备好开始您的项目时,您可以参考它。
选择一个网站
当你需要从某个网站获取信息,但网站没有提供API或通过程序获取信息的机制时,Scrapy可以帮到你。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
可以在此页面上找到今天添加的种子列表:
定义要爬取的数据
第一步是定义我们需要爬取的数据。在 Scrapy 中,这是通过的。(在这个例子中,它是种子文件)
我们定义的Item:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写一个spider。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过观察页面内容,可以发现所有种子的URL都是相似的。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式:/tor/\d+。
我们使用 XPath 从页面的 HTML 源代码中选择要提取的数据。以其中一个种子文件的页面为例:
观察 HTML 页面源代码并创建我们需要的数据的 XPath 表达式(种子名称、描述和大小)。
通过观察,我们可以发现标签中收录了文件名:
Darwin - The Evolution Of An Exhibition
对应于此的 XPath 表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取说明:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
用于选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的详细信息,请参阅 XPath 参考。
最后结合上面的内容给出蜘蛛的代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='info-left']/p[2]/text()[2]").extract()
return torrent
TorrentItem 的定义在。
执行spider获取数据
最后,我们可以运行spider获取网站的数据并以JSON格式保存在scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您还可以将项目写入并存储在数据库中。
查看提取的数据
执行后,查看scraped_data.json,会看到解压出来的item:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是列表,所以所有的值都存储在列表中(除了url是直接赋值的)。如果您想保存单个数据或对数据执行额外的处理,那将是您发挥作用的地方。
还有什么?
您已经学习了如何通过 Scrapy 从存储的网页中提取信息,但这只是冰山一角。Scrapy 提供了许多强大的功能来让爬行更容易、更高效,例如:
对于非英语语言的非标准或错误编码声明,提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加快爬虫创建速度的同时,让大型项目中的代码更加一致。有关详细信息,请参阅命令。为多个爬虫下的性能评估和故障检测提供可扩展性。提供,为您测试XPath表达式,编写和调试爬虫,简化生产环境中的部署和操作提供了极大的便利。内置,通过在Scrapy进程中钩入Python终端,可以为你查看和调试爬虫爬虫过程中的Catching errors为Sitemaps爬取带有缓存的DNS解析器提供方便的支持
下一个
下一步当然是下载Scrapy,你可以阅读它并加入社区。感谢您的支持!
讨论
scrapy分页抓取网页( Scrapy爬虫框架和如何新建Python虚拟环境师列表和信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-10-08 19:04
Scrapy爬虫框架和如何新建Python虚拟环境师列表和信息?)
目标和步骤
爬虫目标:从简单心理学网站获取心理咨询师名单和信息。
学习目标:
简单心理学网站有两种专家,“会诊”和“心理咨询师”。这里我们尝试先抓取顾问的信息。
顾问展示列表比较简单,总共有49页,每页有10个或11个顾问(有点棘手……)。只需抓取每个页面上的信息。
步骤分解:
新项目和爬虫
上一篇文章介绍了Scrapy爬虫框架以及如何新建Python虚拟环境。现在让我们创建一个新的 Scrapy 爬虫项目:
1
scrapy startproject jdxl
Scrapy 生成了以下文件
1
2
3
4
5
6
7
8
9
├── jdxl
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
我们在蜘蛛文件夹中创建了一个新的爬虫文件顾问.py。
然后在items.py中定义要爬取的item:
1
2
3
4
5
6
7
8
9
class JdxlItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() #姓名
url = scrapy.Field() #链接
info = scrapy.Field() #简介
zx_type = scrapy.Field() #咨询类型
location = scrapy.Field() #地点
price = scrapy.Field() #价格
抓取页面信息
打开爬虫顾问.py,开始编写爬虫程序。
不要忘记先导入上面定义的对象:
1
from jdxl.items import JdxlItem
问题一:如何设置起始网址?
打开心理咨询师列表页面,然后翻到第二页,发现网址是一个很长的字符串:
1
https://www.jiandanxinli.com/e ... e%3D2
过滤参数在中间传递,只有最后一个&page=2是key。换句话说,被抓取页面的 URL 如下所示:
1
2
3
4
https://www.jiandanxinli.com/experts?&page=1
https://www.jiandanxinli.com/experts?&page=2
...
https://www.jiandanxinli.com/experts?&page=49
开始在 JdxlSpider(scrapy.Spider) 类中定义起始 URL:如下:
1
2
3
4
5
6
7
8
allowed_domains = ["jiandanxinli.com"]
start_urls = ['http://jiandanxinli.com/experts']
start_url_list = []
for i in range(1,50):
start_url_list.extend(['http://jiandanxinli.com/experts?&page=' + str(i)])
start_urls = start_url_list
问题二:如何抓取节点信息
在 def parse(self, response): 函数中定义要捕获的内容,并使用 XPath 语法告诉爬虫要捕获的节点位置。
什么是“怕死”?
XPath(XML 路径语言)是一种用于从 XML 文档中选择节点的查询语言。此外,XPath 可用于从 XML 文档的内容计算值(例如,字符串、数字或布尔值)。—— 维基
怎么写XPath?
感谢 Chrome,它直接提供了 XPath 选择功能。右键需要抓包的位置,点击Inspect,打开chrome-devtools面板:
瞄准要抓取的节点,再次右击,点击复制XPath,XPath路径就被复制了。
不要太高兴。无数次在调试坑中摔倒的00颤抖着告诉你:直接复制的XPath往往不能直接用...
比如上面那个顾问的名字,chrome提供的路径是:
1
//*[@id="content_wrapper"]/div[2]/div[2]/a[5]/div[1]/strong/text()
但更准确的路径是:
1
/div[@class="summary"]/strong/text()
.
对于初学者来说,如果之前没有太多写html和css的经验,每一个xpath都需要摸索很久。但这是唯一的出路。经过大量的折腾,您将学会诚实地阅读XPath 文档。
问题3:如果内容中没有节点怎么办?
当我抓到顾问的咨询方式、地点、价格等信息时,骗子就来了。
这个簇的结构是:
文字不收录在标签中!正面和背面都有一个 i 标签!怎么抓啊!
然后开始了漫长的谷歌之路。终于找到这篇文章:如何使用scrapy提取标签中没有的文本?
我通过follow::text()获取了一些信息:
1
2
3
zx_type = response.xpath('./div[@class="info"]/i/following::text()').extract()[1]
location = response.xpath('./div[@class="info"]/i/following::text()').extract()[2]
price = response.xpath('./div[@class="info"]/i/following::text()').extract()[3]
这样,每一列都不能有缺失的信息,否则爬取会错位... 暂且处理>。
问题4:如何抓取多个专家信息
抓取专家信息后,如何抓取每页10~11位专家信息?查看页面的html,每个专家都在标签下。因此,使用循环来获取具有此功能的所有标签。
为了缩小范围,在 response.xpath('//a[@class="expert"]') 中传递了父节点的路径。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
for each in response.xpath('//a[@class="expert"]'):
print(each)
item = JdxlItem()
# 抓取姓名
item['name'] = each.xpath('./div[@class="summary"]/strong/text()').extract()
# 抓取 url
item['url'] = each.xpath('./@href').extract()
# 抓取简介
item['info'] = each.xpath('./div[@class="summary"]//div[@class="content"]/text()').extract()
# 抓取咨询方式、地点、价格等
item['zx_type'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[1]
item['location'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[2]
item['price'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[3]
yield item
其他配置
在settings.py文件中添加一个模拟user_agent的模块(需要先用pip安装faker包),设置爬取间隔、头信息等:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from faker import Factory
f = Factory.create()
USER_AGENT = f.user_agent()
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Host': 'www.jiandanxinli.com',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'no-cache',
'Connection': 'Keep-Alive',
}
测试和抓取
开始爬行的命令是:
1
scrapy crawl counselor
Crawl 后面跟着 JdxlSpider(scrapy.Spider): 类中定义的爬虫名称。
尝试先获取 2 个页面:
1
2
for i in range(1,3):
start_url_list.extend(['http://jiandanxinli.com/experts?&page=' + str(i)])
调试过程中的主要问题是没有准确提供节点的xpath,没有抓取到内容。此外,您可能会忘记在 items.py 中设置项目。一般来说,根据错误报告,慢慢寻找,总能找到问题所在。耐心一点。
输出 csv
查了官方文档——Scrapy 1.4.0文档和Item Exporters——Scrapy 1.4.0文档中的Feed导出部分,尝试写pipelines,有点复杂并没有成功。
然后我搜索了Scrapy爬虫框架教程(二)——爬取豆瓣电影TOP250,只是在执行爬虫时设置输出参数:
1
scrapy crawl counselor -o output_file.csv
查看和清理数据
新建一个 Jupyter Notebook,导入 pandas 包,使用 pd.read_csv 命令查看文件:
获取的链接不完整,完整,输出:
1
2
df['url'] = 'http://jiandanxinli.com'+df['url']
df.to_csv('counselor.csv', index=False)
下一篇文章将继续介绍使用 Pandas 和 Bokeh 的简单数据统计和可视化。
项目源码请查看00的github repo:
参考 查看全部
scrapy分页抓取网页(
Scrapy爬虫框架和如何新建Python虚拟环境师列表和信息?)

目标和步骤
爬虫目标:从简单心理学网站获取心理咨询师名单和信息。
学习目标:
简单心理学网站有两种专家,“会诊”和“心理咨询师”。这里我们尝试先抓取顾问的信息。
顾问展示列表比较简单,总共有49页,每页有10个或11个顾问(有点棘手……)。只需抓取每个页面上的信息。
步骤分解:
新项目和爬虫
上一篇文章介绍了Scrapy爬虫框架以及如何新建Python虚拟环境。现在让我们创建一个新的 Scrapy 爬虫项目:
1
scrapy startproject jdxl
Scrapy 生成了以下文件
1
2
3
4
5
6
7
8
9
├── jdxl
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
我们在蜘蛛文件夹中创建了一个新的爬虫文件顾问.py。
然后在items.py中定义要爬取的item:
1
2
3
4
5
6
7
8
9
class JdxlItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() #姓名
url = scrapy.Field() #链接
info = scrapy.Field() #简介
zx_type = scrapy.Field() #咨询类型
location = scrapy.Field() #地点
price = scrapy.Field() #价格
抓取页面信息
打开爬虫顾问.py,开始编写爬虫程序。
不要忘记先导入上面定义的对象:
1
from jdxl.items import JdxlItem
问题一:如何设置起始网址?
打开心理咨询师列表页面,然后翻到第二页,发现网址是一个很长的字符串:
1
https://www.jiandanxinli.com/e ... e%3D2
过滤参数在中间传递,只有最后一个&page=2是key。换句话说,被抓取页面的 URL 如下所示:
1
2
3
4
https://www.jiandanxinli.com/experts?&page=1
https://www.jiandanxinli.com/experts?&page=2
...
https://www.jiandanxinli.com/experts?&page=49
开始在 JdxlSpider(scrapy.Spider) 类中定义起始 URL:如下:
1
2
3
4
5
6
7
8
allowed_domains = ["jiandanxinli.com"]
start_urls = ['http://jiandanxinli.com/experts']
start_url_list = []
for i in range(1,50):
start_url_list.extend(['http://jiandanxinli.com/experts?&page=' + str(i)])
start_urls = start_url_list
问题二:如何抓取节点信息
在 def parse(self, response): 函数中定义要捕获的内容,并使用 XPath 语法告诉爬虫要捕获的节点位置。
什么是“怕死”?
XPath(XML 路径语言)是一种用于从 XML 文档中选择节点的查询语言。此外,XPath 可用于从 XML 文档的内容计算值(例如,字符串、数字或布尔值)。—— 维基
怎么写XPath?
感谢 Chrome,它直接提供了 XPath 选择功能。右键需要抓包的位置,点击Inspect,打开chrome-devtools面板:

瞄准要抓取的节点,再次右击,点击复制XPath,XPath路径就被复制了。

不要太高兴。无数次在调试坑中摔倒的00颤抖着告诉你:直接复制的XPath往往不能直接用...
比如上面那个顾问的名字,chrome提供的路径是:
1
//*[@id="content_wrapper"]/div[2]/div[2]/a[5]/div[1]/strong/text()
但更准确的路径是:
1
/div[@class="summary"]/strong/text()
.
对于初学者来说,如果之前没有太多写html和css的经验,每一个xpath都需要摸索很久。但这是唯一的出路。经过大量的折腾,您将学会诚实地阅读XPath 文档。
问题3:如果内容中没有节点怎么办?
当我抓到顾问的咨询方式、地点、价格等信息时,骗子就来了。
这个簇的结构是:

文字不收录在标签中!正面和背面都有一个 i 标签!怎么抓啊!
然后开始了漫长的谷歌之路。终于找到这篇文章:如何使用scrapy提取标签中没有的文本?
我通过follow::text()获取了一些信息:
1
2
3
zx_type = response.xpath('./div[@class="info"]/i/following::text()').extract()[1]
location = response.xpath('./div[@class="info"]/i/following::text()').extract()[2]
price = response.xpath('./div[@class="info"]/i/following::text()').extract()[3]
这样,每一列都不能有缺失的信息,否则爬取会错位... 暂且处理>。
问题4:如何抓取多个专家信息
抓取专家信息后,如何抓取每页10~11位专家信息?查看页面的html,每个专家都在标签下。因此,使用循环来获取具有此功能的所有标签。
为了缩小范围,在 response.xpath('//a[@class="expert"]') 中传递了父节点的路径。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
for each in response.xpath('//a[@class="expert"]'):
print(each)
item = JdxlItem()
# 抓取姓名
item['name'] = each.xpath('./div[@class="summary"]/strong/text()').extract()
# 抓取 url
item['url'] = each.xpath('./@href').extract()
# 抓取简介
item['info'] = each.xpath('./div[@class="summary"]//div[@class="content"]/text()').extract()
# 抓取咨询方式、地点、价格等
item['zx_type'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[1]
item['location'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[2]
item['price'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[3]
yield item
其他配置
在settings.py文件中添加一个模拟user_agent的模块(需要先用pip安装faker包),设置爬取间隔、头信息等:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from faker import Factory
f = Factory.create()
USER_AGENT = f.user_agent()
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Host': 'www.jiandanxinli.com',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'no-cache',
'Connection': 'Keep-Alive',
}
测试和抓取
开始爬行的命令是:
1
scrapy crawl counselor
Crawl 后面跟着 JdxlSpider(scrapy.Spider): 类中定义的爬虫名称。
尝试先获取 2 个页面:
1
2
for i in range(1,3):
start_url_list.extend(['http://jiandanxinli.com/experts?&page=' + str(i)])
调试过程中的主要问题是没有准确提供节点的xpath,没有抓取到内容。此外,您可能会忘记在 items.py 中设置项目。一般来说,根据错误报告,慢慢寻找,总能找到问题所在。耐心一点。
输出 csv
查了官方文档——Scrapy 1.4.0文档和Item Exporters——Scrapy 1.4.0文档中的Feed导出部分,尝试写pipelines,有点复杂并没有成功。
然后我搜索了Scrapy爬虫框架教程(二)——爬取豆瓣电影TOP250,只是在执行爬虫时设置输出参数:
1
scrapy crawl counselor -o output_file.csv
查看和清理数据
新建一个 Jupyter Notebook,导入 pandas 包,使用 pd.read_csv 命令查看文件:

获取的链接不完整,完整,输出:
1
2
df['url'] = 'http://jiandanxinli.com'+df['url']
df.to_csv('counselor.csv', index=False)
下一篇文章将继续介绍使用 Pandas 和 Bokeh 的简单数据统计和可视化。
项目源码请查看00的github repo:

参考
scrapy分页抓取网页(【每日一题】scrapy发现爬虫还是登陆之前的状态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-07 12:16
最近接触scrapy,爬了几个网站,用起来还是挺流畅的。
前几天,一个业务同事让我帮他抓取网站上的一个用户信息,我答应了。毕竟,通过前面的几次爬行,我已经信心爆棚了(从此)入坑)。
拿到一个网站之后就是先分析网站,分析之后发现需要的数据要登陆才能看到.这个可难不倒我,不就是模拟登陆吗,小菜一碟.
用chrome分析一下,看到有用户名,密码,还有其他两个校验值.另外还有一个重定向的callback值.如下:
接下来,登录并观察post请求的状态。因为有上面这行代码,跳转太快了,没看到post请求,删掉上面那行代码,然后再请求,这次看到了表单发送信息。
下一步就是编写代码并模拟登录。我马上写代码,然后开始测试。(还记得上面提到的两个校验值中的哪一个吗?这两个值都是动态的,可以使用正则的登陆页面提取出来)。
部分代码如下:
name = "form"
download_delay = 0.18
allowed_domains = ["http://www.xxxxxx.com"]
headers = {
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, sdch",
"Accept-Language":"zh-CN,zh;q=0.8",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Host": "www.xxxxxx.com",
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
def start_requests(self):
return [scrapy.Request("http://www.xxxxxxx.com/user/login",meta={'cookiejar':1},headers=self.headers, callback=self.post_login)]
def post_login(self, response):
# 下面这句话用于抓取请求网页后返回网页中的_xsrf字段的文字, 用于成功提交表单
protected_code = Selector(response).xpath('//label[@class="rem"]/input[@name="protected_code"]/@value').extract()[0]
matchObj=re.search(r'\"csrftk\":\"(.*)\",\"img_path\"',response.text)
csrf_tk=matchObj.group(1)
logging.log(logging.WARNING, u"正则获取的值----"+csrf_tk)
# FormRequeset.from_response是Scrapy提供的一个函数, 用于post表单
# 登陆成功后, 会调用after_login回调函数
return [scrapy.FormRequest.from_response(response,method="POST",
headers=self.headers, # 注意此处的headers
formdata={
'protected_code': protected_code,
'email': 'xxxxxx@qq.com',
'csrf_tk': csrf_tk,
'password': 'xxxxxxxxxx',
'remember': 'true',
},
meta={'cookiejar': response.meta['cookiejar']},
callback=self.after_login,
dont_filter=True
)]
然后设置 COOKIES_ENABLED = True 和 COOKIES_DEBUG=True 进行测试。结果不成功。查看日志发现cookie还是登录前的状态,登录端是302定向的。(现在想来,应该是scrapy重定向的时候,用cookie还是登录前的cookie,所以未来状态仍然在登录之前)。
遇到这种情况,尝试关闭重定向,REDIRECT_ENABLED = False,然后测试一下,发现爬虫直接退出了。根据错误信息在网上找到答案,HTTPERROR_ALLOWED_CODES = 302,然后再次运行,完美解决。我得到了我想要的数据。到这个时候已经花了好几个小时了。中间走了很多弯路。
总结:遇到错误时,应该仔细分析错误信息,多尝试。保持清晰和耐心。从技术上来说,你对scrapy的理解还不够,对cookies和redirect的理解还不到位。了解操作原理,解决问题。这要简单得多。
REDIRECT_ENABLED = False 关闭重定向,不会重定向到新地址
HTTPERROR_ALLOWED_CODES = [302,] 返回302时,视为正常返回,可以正常写cookies
顺便说一句,python在解决实际问题的时候还是很实用的,可以快速上手,而且有很多开源库。建议大家有时间学习 查看全部
scrapy分页抓取网页(【每日一题】scrapy发现爬虫还是登陆之前的状态)
最近接触scrapy,爬了几个网站,用起来还是挺流畅的。
前几天,一个业务同事让我帮他抓取网站上的一个用户信息,我答应了。毕竟,通过前面的几次爬行,我已经信心爆棚了(从此)入坑)。
拿到一个网站之后就是先分析网站,分析之后发现需要的数据要登陆才能看到.这个可难不倒我,不就是模拟登陆吗,小菜一碟.
用chrome分析一下,看到有用户名,密码,还有其他两个校验值.另外还有一个重定向的callback值.如下:
接下来,登录并观察post请求的状态。因为有上面这行代码,跳转太快了,没看到post请求,删掉上面那行代码,然后再请求,这次看到了表单发送信息。
下一步就是编写代码并模拟登录。我马上写代码,然后开始测试。(还记得上面提到的两个校验值中的哪一个吗?这两个值都是动态的,可以使用正则的登陆页面提取出来)。
部分代码如下:
name = "form"
download_delay = 0.18
allowed_domains = ["http://www.xxxxxx.com"]
headers = {
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, sdch",
"Accept-Language":"zh-CN,zh;q=0.8",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Host": "www.xxxxxx.com",
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
def start_requests(self):
return [scrapy.Request("http://www.xxxxxxx.com/user/login",meta={'cookiejar':1},headers=self.headers, callback=self.post_login)]
def post_login(self, response):
# 下面这句话用于抓取请求网页后返回网页中的_xsrf字段的文字, 用于成功提交表单
protected_code = Selector(response).xpath('//label[@class="rem"]/input[@name="protected_code"]/@value').extract()[0]
matchObj=re.search(r'\"csrftk\":\"(.*)\",\"img_path\"',response.text)
csrf_tk=matchObj.group(1)
logging.log(logging.WARNING, u"正则获取的值----"+csrf_tk)
# FormRequeset.from_response是Scrapy提供的一个函数, 用于post表单
# 登陆成功后, 会调用after_login回调函数
return [scrapy.FormRequest.from_response(response,method="POST",
headers=self.headers, # 注意此处的headers
formdata={
'protected_code': protected_code,
'email': 'xxxxxx@qq.com',
'csrf_tk': csrf_tk,
'password': 'xxxxxxxxxx',
'remember': 'true',
},
meta={'cookiejar': response.meta['cookiejar']},
callback=self.after_login,
dont_filter=True
)]
然后设置 COOKIES_ENABLED = True 和 COOKIES_DEBUG=True 进行测试。结果不成功。查看日志发现cookie还是登录前的状态,登录端是302定向的。(现在想来,应该是scrapy重定向的时候,用cookie还是登录前的cookie,所以未来状态仍然在登录之前)。
遇到这种情况,尝试关闭重定向,REDIRECT_ENABLED = False,然后测试一下,发现爬虫直接退出了。根据错误信息在网上找到答案,HTTPERROR_ALLOWED_CODES = 302,然后再次运行,完美解决。我得到了我想要的数据。到这个时候已经花了好几个小时了。中间走了很多弯路。
总结:遇到错误时,应该仔细分析错误信息,多尝试。保持清晰和耐心。从技术上来说,你对scrapy的理解还不够,对cookies和redirect的理解还不到位。了解操作原理,解决问题。这要简单得多。
REDIRECT_ENABLED = False 关闭重定向,不会重定向到新地址
HTTPERROR_ALLOWED_CODES = [302,] 返回302时,视为正常返回,可以正常写cookies
顺便说一句,python在解决实际问题的时候还是很实用的,可以快速上手,而且有很多开源库。建议大家有时间学习
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-10-07 12:15
2015-06-23 更新:
之前写这篇文章的时候,还没有遇到具体的场景。只是觉得有这么一个方法,就写下来了。
我今天刚好满足了这个需求。为了抓取BBS的内容,版块首页只显示标题、作者和发布时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能在抓取链接内容后获取时间,这实际上造成了不必要的浪费。使用本文文章的方法可以在抓取链接前进行过滤,避免抓取无用数据。
第一部分scrapy爬虫开始(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取爬行。
具体思路:以我们豆瓣群为例。豆瓣社科群,我们以首页地址作为start_url参数,从页面源码中查找剩余页面,如下:
可以提取每个页面的地址,多页面抓取的思路是将地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并指定这些页面地址对应的回调函数。由于首页和分页在形式上完全一致(首页本身也是一个页面),所以可以直接指定parse作为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
之前的都是CrawlSpider,换成了不支持Rule的BaseSpider;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,相当于每个页面都提取了一个页面地址,这样实际上每个页面地址都返回了N次。, 那么scrapy在实际处理中会不会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》……
让我们运行程序看看。现在,让我们看看我们的打印语句:“->”代表当前页面地址,后面是从当前页面中提取的页面地址。为了简化输出,仅提取用于标识页面的“开始”。范围。
操作结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如您所见:
1. 每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除,并且它使用线程进行数据提取操作。
好了,任务完成了。使用CrawlSpider的规则感觉更方便。 查看全部
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
2015-06-23 更新:
之前写这篇文章的时候,还没有遇到具体的场景。只是觉得有这么一个方法,就写下来了。
我今天刚好满足了这个需求。为了抓取BBS的内容,版块首页只显示标题、作者和发布时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能在抓取链接内容后获取时间,这实际上造成了不必要的浪费。使用本文文章的方法可以在抓取链接前进行过滤,避免抓取无用数据。
第一部分scrapy爬虫开始(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取爬行。
具体思路:以我们豆瓣群为例。豆瓣社科群,我们以首页地址作为start_url参数,从页面源码中查找剩余页面,如下:
可以提取每个页面的地址,多页面抓取的思路是将地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并指定这些页面地址对应的回调函数。由于首页和分页在形式上完全一致(首页本身也是一个页面),所以可以直接指定parse作为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
之前的都是CrawlSpider,换成了不支持Rule的BaseSpider;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,相当于每个页面都提取了一个页面地址,这样实际上每个页面地址都返回了N次。, 那么scrapy在实际处理中会不会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》……
让我们运行程序看看。现在,让我们看看我们的打印语句:“->”代表当前页面地址,后面是从当前页面中提取的页面地址。为了简化输出,仅提取用于标识页面的“开始”。范围。
操作结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如您所见:
1. 每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除,并且它使用线程进行数据提取操作。
好了,任务完成了。使用CrawlSpider的规则感觉更方便。
scrapy分页抓取网页(【】本次项目利用scrapy爬虫框架实现框架 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-04 09:06
)
1、项目介绍
本项目使用scrapy爬虫框架抓取豆瓣top250的详情页信息。主要字段如下:
主要领域:
Num——》电影排行榜
DetailLink——》详情页链接
片名——》片名
RatingNum——"评级
票数——》评价数
导演——》导演
编剧——》编剧
演员——》主演
类型——“类型
发布日期——》发布时间
运行时间——》长度
2、创建项目文件
创建一个scrapy项目
crapy startproject douban
创建爬虫源文件
scrapy genspider douban250 www.douban.com
3、爬虫文件配置3.1配置设置文件
1)防爬配置
# 关闭 robots
ROBOTSTXT_OBEY = False
# 配置请求头
```python
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
# 为方便调试 修改日志等级为‘ERROR’
LOG_LEVEL = 'ERROR'
2)打开管道
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
3.2 配置项目文件
定义要爬取的字段
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Num = scrapy.Field()
DetailLink = scrapy.Field()
Title = scrapy.Field()
RatingNum = scrapy.Field()
Votes = scrapy.Field()
Director = scrapy.Field()
Writer = scrapy.Field()
Actor = scrapy.Field()
Type = scrapy.Field()
ReleaseDate = scrapy.Field()
RunTime = scrapy.Field()
4、爬虫文件写入4.1、字段空值处理
在爬取字段的过程中,部分电影详情页没有对应的字段信息。程序运行到这里会报错,影响爬虫的运行。其次,为了存储信息结构的完整性,应该从这个记录中给出这个字段。空值占用。为了处理上述问题,可以编写一个处理字段空值的函数如下:
def try_except(self, response, xpath_str):
try:
field = response.xpath(xpath_str).extract_first()
except:
field = ''
return field
4.2、 目录页面分析函数编写
def parse(self, response):
li_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in li_list:
item = DoubanItem()
# 解析每个字段时调用4.1定义的空值处理函数,传入网页相应和xpath表达式
item['Num'] = self.try_except(li, './/em/text()')
item['DetailLink'] = self.try_except(li, './/a[1]/@href')
# 提交详情页链接,经过调度,执行生成scrapy.http.Response 对象并送回给详情页解析方法
yield scrapy.Request(item['DetailLink'],
callback=self.parse_detail_html,
meta={'item': deepcopy(item)})
4.2、 翻页代码编写
抓取下一页的链接并完成链接,将下一页的响应对象交给目录页面分析方法
<p>next_url = 'https://movie.douban.com/top250' + self.try_except(response, '//*[@id="content"]/div/div[1]/div[2]/span[3]/a/@href')
print(f'已完成:{self.i}页')
self.i += 1
if self.i 查看全部
scrapy分页抓取网页(【】本次项目利用scrapy爬虫框架实现框架
)
1、项目介绍
本项目使用scrapy爬虫框架抓取豆瓣top250的详情页信息。主要字段如下:

主要领域:
Num——》电影排行榜
DetailLink——》详情页链接
片名——》片名
RatingNum——"评级
票数——》评价数
导演——》导演
编剧——》编剧
演员——》主演
类型——“类型
发布日期——》发布时间
运行时间——》长度
2、创建项目文件
创建一个scrapy项目
crapy startproject douban
创建爬虫源文件
scrapy genspider douban250 www.douban.com
3、爬虫文件配置3.1配置设置文件
1)防爬配置
# 关闭 robots
ROBOTSTXT_OBEY = False
# 配置请求头
```python
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
# 为方便调试 修改日志等级为‘ERROR’
LOG_LEVEL = 'ERROR'
2)打开管道
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
3.2 配置项目文件
定义要爬取的字段
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Num = scrapy.Field()
DetailLink = scrapy.Field()
Title = scrapy.Field()
RatingNum = scrapy.Field()
Votes = scrapy.Field()
Director = scrapy.Field()
Writer = scrapy.Field()
Actor = scrapy.Field()
Type = scrapy.Field()
ReleaseDate = scrapy.Field()
RunTime = scrapy.Field()
4、爬虫文件写入4.1、字段空值处理
在爬取字段的过程中,部分电影详情页没有对应的字段信息。程序运行到这里会报错,影响爬虫的运行。其次,为了存储信息结构的完整性,应该从这个记录中给出这个字段。空值占用。为了处理上述问题,可以编写一个处理字段空值的函数如下:
def try_except(self, response, xpath_str):
try:
field = response.xpath(xpath_str).extract_first()
except:
field = ''
return field
4.2、 目录页面分析函数编写
def parse(self, response):
li_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in li_list:
item = DoubanItem()
# 解析每个字段时调用4.1定义的空值处理函数,传入网页相应和xpath表达式
item['Num'] = self.try_except(li, './/em/text()')
item['DetailLink'] = self.try_except(li, './/a[1]/@href')
# 提交详情页链接,经过调度,执行生成scrapy.http.Response 对象并送回给详情页解析方法
yield scrapy.Request(item['DetailLink'],
callback=self.parse_detail_html,
meta={'item': deepcopy(item)})
4.2、 翻页代码编写
抓取下一页的链接并完成链接,将下一页的响应对象交给目录页面分析方法
<p>next_url = 'https://movie.douban.com/top250' + self.try_except(response, '//*[@id="content"]/div/div[1]/div[2]/span[3]/a/@href')
print(f'已完成:{self.i}页')
self.i += 1
if self.i
scrapy分页抓取网页(资源内容:|_1-1python分布式爬虫打造搜索引擎简介)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-04 08:45
资源内容:
关注Python分布式爬虫必须学习scripy框架来构建搜索引擎
|____1-1 Python分布式爬虫构建搜索引擎简介。mp4
|____2-1 pycharm.mp4的安装和简单使用
|____2-2mysql和Navicat的安装和使用。mp4
|____2-3在windows和Linux下安装python2和python3.MP4
|____2-4虚拟环境的安装和配置。mp4
|____3-1技术选择爬行动物能做什么。mp4
|____3-2正则表达式-1.mp4
|____3-3正则表达式-2.mp4
|____3-4正则表达式-3.mp4
|____3-5深度优先和广度优先原则。mp4
|____3-6url重复数据消除方法。mp4
|____3-7彻底理解Unicode和UTF8编码。mp4
|____4-1脚本安装和目录结构介绍。mp4
|____4-2pycharm调试脚本执行过程。mp4
|____4-3 XPath的使用-1.mp4
|____4-4 XPath的使用-2.mp4
|____4-5 XPath的使用-3.mp4
|____4-6 CSS选择器,用于实现字段解析-1.mp4
|____4-7 CSS选择器,用于实现字段解析-2.mp4
|____4-8写入爬行器以爬行jobpole的所有文章-1.MP4
|____4-9写入爬行器以爬行jobpole的所有文章-2.MP4
|____4-10项设计-1.mp4
|____4-11项目设计-2.mp4
|____4-12项目设计-3.mp4
|____4-13数据表设计并将项目保存到JSON文件.mp4
|____4-14通过管道将数据保存到MySQL-1.MP4
|____4-14通过管道将数据保存到MySQL-1.MP4
|____4-15通过管道将数据保存到MySQL-2.MP4
|____4-16废料装载机机构-1.mp4
|____4-17废料装载机机构-2.mp4
|____5-1会话和cookie自动登录机制。mp4
|____5-2(补充)硒模拟知乎登录-2017年12月2日9.mp4
|____5-3请求模拟登录知乎-1.mp4
|____5-4请求模拟登录知乎-2.mp4
|____5-5个模拟登录请求知乎-3.mp4
|____5-6场景模拟知乎login.mp4
|____5-7知乎分析和数据表设计1.mp4
|____5-8分析和数据表设计-mp4
|____5-9项目排序器模式提取问题-1.mp4
|____5-10项目订单提取问题-2.mp4
|____5-11项目订单提取问题-3.mp4
|____5-12知乎蜘蛛爬虫逻辑的实现和答案的提取-1.mp4
|____5-13知乎蜘蛛爬虫逻辑的实现和答案的提取-2.mp4
|____5-14将数据保存到MySQL-1.mp4
|____5-15将数据保存到MySQL-2.mp4
|____5-16将数据保存到MySQL-3.mp4
|____5-17(补充部分)知乎验证码登录-11.mp4
|____5-18(补充部分)知乎验证码登录-21.mp4
|____5-19(补充)知乎倒排字符识别-1.mp4
|____5-20(补充)知乎倒排字符识别-2.mp4
|____6-1结构设计数据表mp4
|____6-2爬行器源代码分析-新爬行器和设置配置。mp4
|____6-3crawlspider源代码分析.mp4
|____6-4规则和链接提取程序使用。Mp4
|____6-5通过itemloader.mp4进行位置分析
|____6-6位置数据仓库-1.mp4
|____6-7职位信息仓库-2.mp4
|____7-1爬行动物和反攀爬的对抗过程和策略。mp4
|____7-2脚本体系结构源代码分析。mp4
|____7-3请求和响应简介。mp4
|____7-4通过下载中间件随机替换用户代理-1.MP4
|____7-5通过下载中间件随机替换用户代理-2.MP4
|____通过7-6扫描实现IP代理池-1.MP4
|____7-7脚本实现IP代理池-2.mp4
|____7-8脚本实现IP代理池-3.mp4
|____7-9云编码实现验证码识别。mp4
|____7-10 cookie禁用、自动速度限制、自定义spider设置。mp4
|____8-1 selenium动态网页请求和模拟登录知乎。Mp4
|____8-2 selenium模拟登录到微博并模拟鼠标下拉。mp4
|____8-3chromedriver不会加载图片和幻影来获取动态网页。mp4
|____8-4selenium集成到场景中。mp4
|____8-6暂停并重新启动scratch.mp4
|____8-7图形重复数据消除原理。mp4
|____8-8GraphytelNet服务.mp4
|____8-9 spider中间件的详细说明。mp4
|____8-10扫描的数据采集。mp4
|____8-11扫描信号的详细说明。mp4
|____8-12扫描扩展开发。mp4
|____9-1分布式爬虫程序essentials.mp4
|____9-2 redis基础-1.mp4
|____9-3 redis的基本知识-2.mp4
|____9-4脚本redis编写分布式爬虫程序代码。mp4
|____9-5扫描的源代码分析-connection.py,defaults.py-。Mp4
|____9-6 scratch redis的源代码分析-dupefilter.py-。Mp4
|____9-7 scratch redis的源代码分析-pipelines.py,queue.py-。Mp4
|____9-8扫描redis的源代码分析-scheduler.py,spider.py-。Mp4
|____9-9将bloomfilter集成到scratch redis.mp4中
|____10-1 elasticsearch.mp4简介
|____10-2 LasticSearch安装。mp4
|____10-3 elasticsearch头插件和kibana安装。mp4
|____10-4 elasticsearch.mp4的基本概念
|____10-5反向索引0.mp4
|____10-6 elasticsearch基本索引和文档积垢操作。mp4
|____10-7 elasticsearch.mp4的mget和批量操作
|____10-8 elasticsearch.mp4的映射管理
|____10-9 elasticsearch的简单查询-1.mp4
|____10-10 elasticsearch的简单查询-2.mp4
|____10-11 elasticsearch.mp4的布尔组合查询
|____10-12使用扫描-1.mp4将数据写入elasticsearch
|____10-13将数据写入elasticsearch-2.mp4
|____11-1es完成搜索建议-保存搜索建议字段-1.mp4
|____11-2es完整搜索建议-保存搜索建议字段-2.mp4
|____11-3django实现elasticsearch-1.mp4的搜索建议
|____11-4django执行elasticsearch-2.mp4的搜索建议
|____11-5django实现弹性搜索功能-1.mp4
|____11-6django实现弹性搜索功能-2.mp4
|____11-7django实现搜索结果的分页。mp4
|____11-8搜索记录和流行搜索功能的实现-1.mp4
|____11-9搜索记录和流行搜索功能的实现-2.mp4
|____12-1 scratch部署项目.mp4
|____13-1课程总结。mp4
|____project.zip
|____。文本
|____播放前的注意事项.txt
|____第一章课程介绍
|____第二章Windows下的楼宇开发环境
|____第三章爬行动物基础知识综述
|____第四章:著名的抓痕爬行技术文章网站
|____第五章《刮痕》中著名的“爬行”问答
|____第六章通过爬行蜘蛛爬行招募网站
|____第七章scrapy突破反爬虫的限制
|____第8章scratch的高级开发
|____第9章:scratch redis分布式爬虫
|____第十章弹性搜索引擎的使用
|____第11章Django构建搜索网站
|____第12章:部署scratch爬虫
|____第13章课程总结 查看全部
scrapy分页抓取网页(资源内容:|_1-1python分布式爬虫打造搜索引擎简介)
资源内容:
关注Python分布式爬虫必须学习scripy框架来构建搜索引擎
|____1-1 Python分布式爬虫构建搜索引擎简介。mp4
|____2-1 pycharm.mp4的安装和简单使用
|____2-2mysql和Navicat的安装和使用。mp4
|____2-3在windows和Linux下安装python2和python3.MP4
|____2-4虚拟环境的安装和配置。mp4
|____3-1技术选择爬行动物能做什么。mp4
|____3-2正则表达式-1.mp4
|____3-3正则表达式-2.mp4
|____3-4正则表达式-3.mp4
|____3-5深度优先和广度优先原则。mp4
|____3-6url重复数据消除方法。mp4
|____3-7彻底理解Unicode和UTF8编码。mp4
|____4-1脚本安装和目录结构介绍。mp4
|____4-2pycharm调试脚本执行过程。mp4
|____4-3 XPath的使用-1.mp4
|____4-4 XPath的使用-2.mp4
|____4-5 XPath的使用-3.mp4
|____4-6 CSS选择器,用于实现字段解析-1.mp4
|____4-7 CSS选择器,用于实现字段解析-2.mp4
|____4-8写入爬行器以爬行jobpole的所有文章-1.MP4
|____4-9写入爬行器以爬行jobpole的所有文章-2.MP4
|____4-10项设计-1.mp4
|____4-11项目设计-2.mp4
|____4-12项目设计-3.mp4
|____4-13数据表设计并将项目保存到JSON文件.mp4
|____4-14通过管道将数据保存到MySQL-1.MP4
|____4-14通过管道将数据保存到MySQL-1.MP4
|____4-15通过管道将数据保存到MySQL-2.MP4
|____4-16废料装载机机构-1.mp4
|____4-17废料装载机机构-2.mp4
|____5-1会话和cookie自动登录机制。mp4
|____5-2(补充)硒模拟知乎登录-2017年12月2日9.mp4
|____5-3请求模拟登录知乎-1.mp4
|____5-4请求模拟登录知乎-2.mp4
|____5-5个模拟登录请求知乎-3.mp4
|____5-6场景模拟知乎login.mp4
|____5-7知乎分析和数据表设计1.mp4
|____5-8分析和数据表设计-mp4
|____5-9项目排序器模式提取问题-1.mp4
|____5-10项目订单提取问题-2.mp4
|____5-11项目订单提取问题-3.mp4
|____5-12知乎蜘蛛爬虫逻辑的实现和答案的提取-1.mp4
|____5-13知乎蜘蛛爬虫逻辑的实现和答案的提取-2.mp4
|____5-14将数据保存到MySQL-1.mp4
|____5-15将数据保存到MySQL-2.mp4
|____5-16将数据保存到MySQL-3.mp4
|____5-17(补充部分)知乎验证码登录-11.mp4
|____5-18(补充部分)知乎验证码登录-21.mp4
|____5-19(补充)知乎倒排字符识别-1.mp4
|____5-20(补充)知乎倒排字符识别-2.mp4
|____6-1结构设计数据表mp4
|____6-2爬行器源代码分析-新爬行器和设置配置。mp4
|____6-3crawlspider源代码分析.mp4
|____6-4规则和链接提取程序使用。Mp4
|____6-5通过itemloader.mp4进行位置分析
|____6-6位置数据仓库-1.mp4
|____6-7职位信息仓库-2.mp4
|____7-1爬行动物和反攀爬的对抗过程和策略。mp4
|____7-2脚本体系结构源代码分析。mp4
|____7-3请求和响应简介。mp4
|____7-4通过下载中间件随机替换用户代理-1.MP4
|____7-5通过下载中间件随机替换用户代理-2.MP4
|____通过7-6扫描实现IP代理池-1.MP4
|____7-7脚本实现IP代理池-2.mp4
|____7-8脚本实现IP代理池-3.mp4
|____7-9云编码实现验证码识别。mp4
|____7-10 cookie禁用、自动速度限制、自定义spider设置。mp4
|____8-1 selenium动态网页请求和模拟登录知乎。Mp4
|____8-2 selenium模拟登录到微博并模拟鼠标下拉。mp4
|____8-3chromedriver不会加载图片和幻影来获取动态网页。mp4
|____8-4selenium集成到场景中。mp4
|____8-6暂停并重新启动scratch.mp4
|____8-7图形重复数据消除原理。mp4
|____8-8GraphytelNet服务.mp4
|____8-9 spider中间件的详细说明。mp4
|____8-10扫描的数据采集。mp4
|____8-11扫描信号的详细说明。mp4
|____8-12扫描扩展开发。mp4
|____9-1分布式爬虫程序essentials.mp4
|____9-2 redis基础-1.mp4
|____9-3 redis的基本知识-2.mp4
|____9-4脚本redis编写分布式爬虫程序代码。mp4
|____9-5扫描的源代码分析-connection.py,defaults.py-。Mp4
|____9-6 scratch redis的源代码分析-dupefilter.py-。Mp4
|____9-7 scratch redis的源代码分析-pipelines.py,queue.py-。Mp4
|____9-8扫描redis的源代码分析-scheduler.py,spider.py-。Mp4
|____9-9将bloomfilter集成到scratch redis.mp4中
|____10-1 elasticsearch.mp4简介
|____10-2 LasticSearch安装。mp4
|____10-3 elasticsearch头插件和kibana安装。mp4
|____10-4 elasticsearch.mp4的基本概念
|____10-5反向索引0.mp4
|____10-6 elasticsearch基本索引和文档积垢操作。mp4
|____10-7 elasticsearch.mp4的mget和批量操作
|____10-8 elasticsearch.mp4的映射管理
|____10-9 elasticsearch的简单查询-1.mp4
|____10-10 elasticsearch的简单查询-2.mp4
|____10-11 elasticsearch.mp4的布尔组合查询
|____10-12使用扫描-1.mp4将数据写入elasticsearch
|____10-13将数据写入elasticsearch-2.mp4
|____11-1es完成搜索建议-保存搜索建议字段-1.mp4
|____11-2es完整搜索建议-保存搜索建议字段-2.mp4
|____11-3django实现elasticsearch-1.mp4的搜索建议
|____11-4django执行elasticsearch-2.mp4的搜索建议
|____11-5django实现弹性搜索功能-1.mp4
|____11-6django实现弹性搜索功能-2.mp4
|____11-7django实现搜索结果的分页。mp4
|____11-8搜索记录和流行搜索功能的实现-1.mp4
|____11-9搜索记录和流行搜索功能的实现-2.mp4
|____12-1 scratch部署项目.mp4
|____13-1课程总结。mp4
|____project.zip
|____。文本
|____播放前的注意事项.txt
|____第一章课程介绍
|____第二章Windows下的楼宇开发环境
|____第三章爬行动物基础知识综述
|____第四章:著名的抓痕爬行技术文章网站
|____第五章《刮痕》中著名的“爬行”问答
|____第六章通过爬行蜘蛛爬行招募网站
|____第七章scrapy突破反爬虫的限制
|____第8章scratch的高级开发
|____第9章:scratch redis分布式爬虫
|____第十章弹性搜索引擎的使用
|____第11章Django构建搜索网站
|____第12章:部署scratch爬虫
|____第13章课程总结
scrapy分页抓取网页(《,》第2季第16集.parse)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-03 19:14
为了获得PV,许多网站会将一个完整的文章划分为多个页面,这也会给爬虫程序带来一些小问题
分页文章
传统的方法是解析第一页的数据,将其保存到item,然后检测下一页是否存在。如果是这样,重复抓取功能直到它在最后一页停止
但是,扫描中存在一个问题。扫描中的回调函数无法返回值,并且无法返回捕获的文章正文。因此,可以使用request的meta属性在一个方向上将item变量传递给crawl函数
def parse_article(self, response):
"""parse article content
Arguments:
response {[type]} -- [description]
"""
selector = Selector(response)
article = ArticleItem()
# 先获取第一页的文章正文
article['content'] = selector.xpath(
'//article[@class="article-content"]').get()
# 拆分最后一页的 url, 可以得到文章的base url 和总页数
page_end_url = selector.xpath(
'//div[@class="pagination"]/ul/li/a/@href').extract()[-1]
page_base_url, page_count = re.findall(
'(.*?)_(.*?).html', page_end_url)[0]
page_count = int(page_count)
for page in range(2, page_count + 1):
# 构造出分页 url
url = page_base_url + '_{}.html'.format(page)
# 手动生成 Request 请求, 注意函数中的 priority 参数, 代表了 Request 是按顺序执行的, 值越大, 优先级越高
request = Request(url=url, callback=self.parse_content, priority=-page)
# 向 self.parse_content 函数传递 item 变量
request.meta['article'] = article
yield request
self.parse_uu内容主要用于抓取文章文本并将其存储在项目中
def parse_content(self, response):
selector = Selector(response)
article = response.meta['article']
# 注意这里对 article['content']的操作是 +=, 这样不会清空上一页保存的数据
article['content'] += selector.xpath('//article[@class="article-content"]').get()
yield article
参考:请求和答复 查看全部
scrapy分页抓取网页(《,》第2季第16集.parse)
为了获得PV,许多网站会将一个完整的文章划分为多个页面,这也会给爬虫程序带来一些小问题

分页文章
传统的方法是解析第一页的数据,将其保存到item,然后检测下一页是否存在。如果是这样,重复抓取功能直到它在最后一页停止
但是,扫描中存在一个问题。扫描中的回调函数无法返回值,并且无法返回捕获的文章正文。因此,可以使用request的meta属性在一个方向上将item变量传递给crawl函数
def parse_article(self, response):
"""parse article content
Arguments:
response {[type]} -- [description]
"""
selector = Selector(response)
article = ArticleItem()
# 先获取第一页的文章正文
article['content'] = selector.xpath(
'//article[@class="article-content"]').get()
# 拆分最后一页的 url, 可以得到文章的base url 和总页数
page_end_url = selector.xpath(
'//div[@class="pagination"]/ul/li/a/@href').extract()[-1]
page_base_url, page_count = re.findall(
'(.*?)_(.*?).html', page_end_url)[0]
page_count = int(page_count)
for page in range(2, page_count + 1):
# 构造出分页 url
url = page_base_url + '_{}.html'.format(page)
# 手动生成 Request 请求, 注意函数中的 priority 参数, 代表了 Request 是按顺序执行的, 值越大, 优先级越高
request = Request(url=url, callback=self.parse_content, priority=-page)
# 向 self.parse_content 函数传递 item 变量
request.meta['article'] = article
yield request
self.parse_uu内容主要用于抓取文章文本并将其存储在项目中
def parse_content(self, response):
selector = Selector(response)
article = response.meta['article']
# 注意这里对 article['content']的操作是 +=, 这样不会清空上一页保存的数据
article['content'] += selector.xpath('//article[@class="article-content"]').get()
yield article
参考:请求和答复
scrapy分页抓取网页(scrapy包中的headers方法如何实现scrapy分页只有使用函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-03 18:03
scrapy分页抓取网页需要爬取多页面,要分别抓取第一页和第三页,这样html就会变成一个多列的html,html中的内容就随机化分布在每一页面上.要写好多轮分页爬取,一方面要考虑分页的种类,如果是xpath分页爬取还可以加上正则匹配;另一方面还要考虑如何分页,xpath分页方法肯定是写一大堆的values和names,max_footer一般是会放在页面最后面.这些问题要是分别解决了就好很多.先看三种方法,然后自己去总结。
第一种方法scrapy提供的selector方法在python内部是按照python的表达式进行处理,类似于正则表达式这样,只有使用函数selectoritem_name=selector('')withselector('/subject>'):item_name.append('')第二种方法scrapy自身有个selector来对齐去除重复项,所以不需要额外创建分页元素withselector(''):item_name=selector('')txt_names=[]withselector(''):item_name.append('')txt_names.append('')第三种方法借助frompy包第四种方法使用frompy包中的headers方法如何实现scrapy的分页只有使用函数selectorwithselector('/subject'):page_count=2withselector('/item'):page_count+=1在其他处理后就可以跳到第三页,或者只有第一页,最后在多个页面中最后抽出第一页。 查看全部
scrapy分页抓取网页(scrapy包中的headers方法如何实现scrapy分页只有使用函数)
scrapy分页抓取网页需要爬取多页面,要分别抓取第一页和第三页,这样html就会变成一个多列的html,html中的内容就随机化分布在每一页面上.要写好多轮分页爬取,一方面要考虑分页的种类,如果是xpath分页爬取还可以加上正则匹配;另一方面还要考虑如何分页,xpath分页方法肯定是写一大堆的values和names,max_footer一般是会放在页面最后面.这些问题要是分别解决了就好很多.先看三种方法,然后自己去总结。
第一种方法scrapy提供的selector方法在python内部是按照python的表达式进行处理,类似于正则表达式这样,只有使用函数selectoritem_name=selector('')withselector('/subject>'):item_name.append('')第二种方法scrapy自身有个selector来对齐去除重复项,所以不需要额外创建分页元素withselector(''):item_name=selector('')txt_names=[]withselector(''):item_name.append('')txt_names.append('')第三种方法借助frompy包第四种方法使用frompy包中的headers方法如何实现scrapy的分页只有使用函数selectorwithselector('/subject'):page_count=2withselector('/item'):page_count+=1在其他处理后就可以跳到第三页,或者只有第一页,最后在多个页面中最后抽出第一页。
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-02 04:10
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
其实在本教程的第一个例子中,抓取豆瓣电影TOP列表,豆瓣的电影列表使用pager进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
.
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数时,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页)

这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。

今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
其实在本教程的第一个例子中,抓取豆瓣电影TOP列表,豆瓣的电影列表使用pager进行数据划分:

但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。

这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
.
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:

寻呼机选择过程如下图所示:

3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数时,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(如何利用Scrapy爬虫框架网页全部文章信息(上篇))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-02 04:08
/前言/
在前面的文章:如何使用scrapy crawler框架捕获网页的所有文章信息(第一部分),我们获得了文章的详细信息页面链接,但在提取URL后,如何将其交给scrapy下载?下载后,如何调用我们自己定义的解析函数?此时,您需要在scrapy框架中使用另一个类请求。具体教程如下所示
/具体实施/
1、请求存储在script.http下,如下图所示。您可以直接导入它
我们需要将请求对象交给scrapy,然后scrapy crawler框架将帮助我们下载它
2、请求对象收录初始化参数URL和回调函数callback。当然,还有其他参数,这里将不讨论这些参数。我们将获得的文章链接URL传递给初始化参数URL,然后我们可以构建请求。需要注意的是,此请求是文章详细信息页面的页面,而不是文章的列表页面。对于文章详细信息页面,接下来,我们需要提取每个文章
3、在前面的文章基础上,提取网页的目标信息。提取的目标信息的表达式部分可以封装到函数parse_uudetail(),作为回调函数,用于提取文章的特定字段。以CSS选择器为例,如下图所示。如果希望使用XPath选择器进行提取,则没有问题。具体实现请参考文章历史中CSS和XPath选择器的使用。这里不再重复具体的实施过程
4、然后改进请求类并添加回调参数。记住在细节前面使用parse_uuaddself来指示它在当前类中,否则将报告错误。此外,parse_uu尽管detail是一个函数,但不能在这里添加括号,这是回调函数的特性
5、细心的孩子们可能已经注意到上图中请求类的URL部分非常复杂,解析也非常复杂。添加了Urljoin()函数。其实,这也是一个小技巧。让我们在这里简单地说一下。我希望这对孩子们有帮助。函数的作用是将相对地址合并成一个完整的URL。有时,网页标签不会向我们提供完整的URL链接或完整的域名,但会忽略网页的域名。如果没有域名,默认域名是当前网页的域名(即response.URL)。此时,我们需要拼接URL,形成完整的URL地址,以方便正常访问
6、请求类初始化后,如何将其交给scripy下载?事实上,这很简单。您只需要在前面输入一个yield关键字。它的功能是在scripy下载请求中提供URL
到目前为止,解析列表页面中所有文章URL并将其交给scripy下载的步骤已经完成。接下来我们需要做的是如何提取下一页的URL并将其提供给scripy下载。下一个文章将重点解决这个问题。请期待~~~
/总结/
基于scrapy crawler框架,本文使用CSS选择器和XPath选择器解析列表页面中文章的所有URL,并将它们交给scrapy下载。到目前为止,数据采集的基本功能已经完成。下一篇文章将完成如何提取下一页的URL并提交给scripy下载。请期待
-------------------结束------------------- 查看全部
scrapy分页抓取网页(如何利用Scrapy爬虫框架网页全部文章信息(上篇))
/前言/
在前面的文章:如何使用scrapy crawler框架捕获网页的所有文章信息(第一部分),我们获得了文章的详细信息页面链接,但在提取URL后,如何将其交给scrapy下载?下载后,如何调用我们自己定义的解析函数?此时,您需要在scrapy框架中使用另一个类请求。具体教程如下所示
/具体实施/
1、请求存储在script.http下,如下图所示。您可以直接导入它
我们需要将请求对象交给scrapy,然后scrapy crawler框架将帮助我们下载它
2、请求对象收录初始化参数URL和回调函数callback。当然,还有其他参数,这里将不讨论这些参数。我们将获得的文章链接URL传递给初始化参数URL,然后我们可以构建请求。需要注意的是,此请求是文章详细信息页面的页面,而不是文章的列表页面。对于文章详细信息页面,接下来,我们需要提取每个文章
3、在前面的文章基础上,提取网页的目标信息。提取的目标信息的表达式部分可以封装到函数parse_uudetail(),作为回调函数,用于提取文章的特定字段。以CSS选择器为例,如下图所示。如果希望使用XPath选择器进行提取,则没有问题。具体实现请参考文章历史中CSS和XPath选择器的使用。这里不再重复具体的实施过程
4、然后改进请求类并添加回调参数。记住在细节前面使用parse_uuaddself来指示它在当前类中,否则将报告错误。此外,parse_uu尽管detail是一个函数,但不能在这里添加括号,这是回调函数的特性
5、细心的孩子们可能已经注意到上图中请求类的URL部分非常复杂,解析也非常复杂。添加了Urljoin()函数。其实,这也是一个小技巧。让我们在这里简单地说一下。我希望这对孩子们有帮助。函数的作用是将相对地址合并成一个完整的URL。有时,网页标签不会向我们提供完整的URL链接或完整的域名,但会忽略网页的域名。如果没有域名,默认域名是当前网页的域名(即response.URL)。此时,我们需要拼接URL,形成完整的URL地址,以方便正常访问
6、请求类初始化后,如何将其交给scripy下载?事实上,这很简单。您只需要在前面输入一个yield关键字。它的功能是在scripy下载请求中提供URL
到目前为止,解析列表页面中所有文章URL并将其交给scripy下载的步骤已经完成。接下来我们需要做的是如何提取下一页的URL并将其提供给scripy下载。下一个文章将重点解决这个问题。请期待~~~
/总结/
基于scrapy crawler框架,本文使用CSS选择器和XPath选择器解析列表页面中文章的所有URL,并将它们交给scrapy下载。到目前为止,数据采集的基本功能已经完成。下一篇文章将完成如何提取下一页的URL并提交给scripy下载。请期待
-------------------结束-------------------
scrapy分页抓取网页(基于python的scrapy框架完成的spider分析网站源码需要爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-02 04:04
磕磕绊绊,爬了很多次,尝试了很多次,看了很多前辈的文章,终于在探索中领悟了。接下来,我将详细记录我的想法和详细代码。截止2020年7月18日,可以正常爬取了,接下来请听我说~
本项目基于python的scrapy框架。要想跑通,首先得安装python环境,搭建python环境。这个文章我就不详细介绍了,开始吧!
安装scrapy框架,一般如果你网速好,可以直接安装!
pip安装scrapy
明确我们的需求:
爬取链家北京二手房前100页数据分析。抓取链接为下一页做准备。需要抓取哪些数据来分析网页源代码
需要爬取的链接如下:
/ershoufang/ 首页链接/ershoufang/pg2/ 第二页/ershoufang/pg3/ 第三页
通过对比爬取链接,我们发现之前的链接基本相同,唯一不同的是最后一个数字,最后一个数字代表哪个页面,知道这些之后我们就可以开始创建scrapy项目了。
创建项目
scrapy startproject lianjia # 创建一个名为lianjia的爬虫项目
cd lianjia #进入新创建的项目
scrapy genspider lianjia_spider # 创建连家蜘蛛
解析网站的源码
发现list页需要的数据在li标签里,继续分析,因为我们这个项目的爬取思路是爬取标题,获取到标题中的链接,然后到详情页去继续爬取数据,通过定位到详情页的入口,我们往下走,进入详情页。
我发现详情页这两个地方的数据大都差不多。你想爬取哪些数据取决于读者的兴趣。我需要这两个地方的数据,所以会涉及到下面的一些项目。
编写一个scrapy项目
我用的编辑器是pycharm,一直用JB的产品,整体体验还是不错的。
根据自己的需要写item,方便以后写CSV、json、MySQL等
编写item,
class LianItem():
# 名称
title = scrapy.Field()
# 房屋类型
room_form = scrapy.Field()
# 房屋面积
size = scrapy.Field()
# 朝向
room_type = scrapy.Field()
# 几居室
main_info = scrapy.Field()
# 总价
total_price = scrapy.Field()
# 单价
unit_price = scrapy.Field()
# 小区
community = scrapy.Field()
# 区域
area = scrapy.Field()
# 装修情况
decorate = scrapy.Field()
# 挂牌时间
hangtag = scrapy.Field()
# 上次交易时间
last_time = scrapy.Field()
# 房屋年限
room_year = scrapy.Field()
# 抵押状态
pledge = scrapy.Field()
写spider(这是重点)
修改设置
ROBOTSTXT_OBEY = False # 不遵守爬虫协议
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36' } # 伪造浏览器请求头
ITEM_PIPELINES = { 'lian.pipelines.LianPipeline': 300, } # 开启我们的管道,本项目是将爬取到的数据存入CSV文件
将管道写入 CSV
def __init__(self):
# 打开文件,指定方式为写,利用第3个参数把csv写数据时产生的空行消除
self.f = open("lianjia_new.csv", "a", newline="")
# 设置文件第一行的字段名,注意要跟spider传过来的字典key名称相同
# self.fieldnames = ["place", "size", "price"]
self.fieldnames = [
"title", "room_form", "size", "room_type", "main_info",
"total_price", "unit_price", "community", "area", "decorate"
, "hangtag", "last_time", "room_year", "pledge",
]
# 指定文件的写入方式为csv字典写入,参数1为指定具体文件,参数2为指定字段名
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
# 写入第一行字段名,因为只要写入一次,所以文件放在__init__里面
self.writer.writeheader()
def process_item(self, item, spider):
# 写入spider传过来的具体数值
self.writer.writerow(item)
# 写入完返回
return item
def close(self, spider):
self.f.close()
进入项目目录,启动爬虫
scrapy crawl 爬虫名称
运行后,你会发现你的项目中多了一个CSV文件,大功告成。(最后看了几张没抓到的数据,应该是xpath没写,不是难点,有时间我再优化一下,今天比较忙,所以我们先做吧~)
写到最后,有问题的朋友欢迎加我~ 查看全部
scrapy分页抓取网页(基于python的scrapy框架完成的spider分析网站源码需要爬取)
磕磕绊绊,爬了很多次,尝试了很多次,看了很多前辈的文章,终于在探索中领悟了。接下来,我将详细记录我的想法和详细代码。截止2020年7月18日,可以正常爬取了,接下来请听我说~
本项目基于python的scrapy框架。要想跑通,首先得安装python环境,搭建python环境。这个文章我就不详细介绍了,开始吧!
安装scrapy框架,一般如果你网速好,可以直接安装!
pip安装scrapy
明确我们的需求:
爬取链家北京二手房前100页数据分析。抓取链接为下一页做准备。需要抓取哪些数据来分析网页源代码
需要爬取的链接如下:
/ershoufang/ 首页链接/ershoufang/pg2/ 第二页/ershoufang/pg3/ 第三页
通过对比爬取链接,我们发现之前的链接基本相同,唯一不同的是最后一个数字,最后一个数字代表哪个页面,知道这些之后我们就可以开始创建scrapy项目了。
创建项目
scrapy startproject lianjia # 创建一个名为lianjia的爬虫项目
cd lianjia #进入新创建的项目
scrapy genspider lianjia_spider # 创建连家蜘蛛
解析网站的源码
发现list页需要的数据在li标签里,继续分析,因为我们这个项目的爬取思路是爬取标题,获取到标题中的链接,然后到详情页去继续爬取数据,通过定位到详情页的入口,我们往下走,进入详情页。
我发现详情页这两个地方的数据大都差不多。你想爬取哪些数据取决于读者的兴趣。我需要这两个地方的数据,所以会涉及到下面的一些项目。
编写一个scrapy项目
我用的编辑器是pycharm,一直用JB的产品,整体体验还是不错的。
根据自己的需要写item,方便以后写CSV、json、MySQL等
编写item,
class LianItem():
# 名称
title = scrapy.Field()
# 房屋类型
room_form = scrapy.Field()
# 房屋面积
size = scrapy.Field()
# 朝向
room_type = scrapy.Field()
# 几居室
main_info = scrapy.Field()
# 总价
total_price = scrapy.Field()
# 单价
unit_price = scrapy.Field()
# 小区
community = scrapy.Field()
# 区域
area = scrapy.Field()
# 装修情况
decorate = scrapy.Field()
# 挂牌时间
hangtag = scrapy.Field()
# 上次交易时间
last_time = scrapy.Field()
# 房屋年限
room_year = scrapy.Field()
# 抵押状态
pledge = scrapy.Field()
写spider(这是重点)
修改设置
ROBOTSTXT_OBEY = False # 不遵守爬虫协议
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36' } # 伪造浏览器请求头
ITEM_PIPELINES = { 'lian.pipelines.LianPipeline': 300, } # 开启我们的管道,本项目是将爬取到的数据存入CSV文件
将管道写入 CSV
def __init__(self):
# 打开文件,指定方式为写,利用第3个参数把csv写数据时产生的空行消除
self.f = open("lianjia_new.csv", "a", newline="")
# 设置文件第一行的字段名,注意要跟spider传过来的字典key名称相同
# self.fieldnames = ["place", "size", "price"]
self.fieldnames = [
"title", "room_form", "size", "room_type", "main_info",
"total_price", "unit_price", "community", "area", "decorate"
, "hangtag", "last_time", "room_year", "pledge",
]
# 指定文件的写入方式为csv字典写入,参数1为指定具体文件,参数2为指定字段名
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
# 写入第一行字段名,因为只要写入一次,所以文件放在__init__里面
self.writer.writeheader()
def process_item(self, item, spider):
# 写入spider传过来的具体数值
self.writer.writerow(item)
# 写入完返回
return item
def close(self, spider):
self.f.close()
进入项目目录,启动爬虫
scrapy crawl 爬虫名称
运行后,你会发现你的项目中多了一个CSV文件,大功告成。(最后看了几张没抓到的数据,应该是xpath没写,不是难点,有时间我再优化一下,今天比较忙,所以我们先做吧~)
写到最后,有问题的朋友欢迎加我~
scrapy分页抓取网页(scrapy成熟的爬虫框架的考量及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-01 20:07
)
最近在用scrapy做一个爬虫爬取网站上的一些信息,但是出现了一个很奇怪的问题,就是在网页中打开了要爬取的URL,某个URL位于网页的源代码。需要爬取一些元素,但是我用scrapy爬取数据的时候,发现一个错误,结果是爬取的网页没有收录我在浏览器中看到的元素,也就是for the same URL,抓取的页面和我在浏览器打开看到的页面不一样!
反复确认CSS类选择器正确,爬虫爬取的URL没有重定向到其他页面后,发现事情并不简单。
然后机缘巧合下,没有修改任何代码,再次运行,却发现再次爬取成功,然后又试了一次,报错了。这时候就知道,抓取到的页面一定是 完整的页面没有加载完成。
当页面没有完全加载时,我首先想到了两种可能:
首先,部分数据在网页加载时由js动态写入,即部分数据在第一次请求时传递给js,由前端js处理后显示在页面上;
二是网页数据是异步加载的,在抓取网页的时候部分数据还没有加载。
基于scrapy是一个成熟的爬虫框架的考虑,我认为第一种情况应该不会出现。毕竟爬虫可以等到页面初始化好再爬,但是对于第二种情况,因为数据Loading是异步的,所以无法提前控制。
基于以上考虑,直接考虑第二种情况。因此,您可以在浏览器控制台的 Network 中检查所有发送的请求,看看您需要的数据是否被异步加载。如下图所示,可以查看每个请求的Response,手动检查是否返回了你需要的信息。
在我的例子中,果然如上图所示,我找到了整个异步请求返回的json格式数据,里面收录了我需要的所有信息,我什至不需要再抓取网页了,只是作为如下图,查看请求的header,可以看到异步请求的请求格式,也就是图中的Request URL
将获取到的Request URL复制到新的浏览器窗口打开,可以看到下图,可以访问json格式的返回数据,说明网站没有拦截到这种请求,这也使得我没必要去抓取页面的数据了,我只需要直接构造对应的URL,分析返回的json数据,就大功告成了!
查看全部
scrapy分页抓取网页(scrapy成熟的爬虫框架的考量及应用
)
最近在用scrapy做一个爬虫爬取网站上的一些信息,但是出现了一个很奇怪的问题,就是在网页中打开了要爬取的URL,某个URL位于网页的源代码。需要爬取一些元素,但是我用scrapy爬取数据的时候,发现一个错误,结果是爬取的网页没有收录我在浏览器中看到的元素,也就是for the same URL,抓取的页面和我在浏览器打开看到的页面不一样!
反复确认CSS类选择器正确,爬虫爬取的URL没有重定向到其他页面后,发现事情并不简单。
然后机缘巧合下,没有修改任何代码,再次运行,却发现再次爬取成功,然后又试了一次,报错了。这时候就知道,抓取到的页面一定是 完整的页面没有加载完成。
当页面没有完全加载时,我首先想到了两种可能:
首先,部分数据在网页加载时由js动态写入,即部分数据在第一次请求时传递给js,由前端js处理后显示在页面上;
二是网页数据是异步加载的,在抓取网页的时候部分数据还没有加载。
基于scrapy是一个成熟的爬虫框架的考虑,我认为第一种情况应该不会出现。毕竟爬虫可以等到页面初始化好再爬,但是对于第二种情况,因为数据Loading是异步的,所以无法提前控制。
基于以上考虑,直接考虑第二种情况。因此,您可以在浏览器控制台的 Network 中检查所有发送的请求,看看您需要的数据是否被异步加载。如下图所示,可以查看每个请求的Response,手动检查是否返回了你需要的信息。
在我的例子中,果然如上图所示,我找到了整个异步请求返回的json格式数据,里面收录了我需要的所有信息,我什至不需要再抓取网页了,只是作为如下图,查看请求的header,可以看到异步请求的请求格式,也就是图中的Request URL
将获取到的Request URL复制到新的浏览器窗口打开,可以看到下图,可以访问json格式的返回数据,说明网站没有拦截到这种请求,这也使得我没必要去抓取页面的数据了,我只需要直接构造对应的URL,分析返回的json数据,就大功告成了!
scrapy分页抓取网页( WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-30 11:10
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简单数据分析系列文章的第十二篇文章。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
第 3 页上的参数是 #_rnd39
第 4 页上的参数是 #_rnd76:
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper 的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper 就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因其实涉及到对网页的一点了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简单数据分析系列文章的第十二篇文章。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
第 3 页上的参数是 #_rnd39
第 4 页上的参数是 #_rnd76:
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper 的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper 就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因其实涉及到对网页的一点了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-30 11:08
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
.
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper 的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper 就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因其实涉及到对网页的一点了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
.
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper 的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper 就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因其实涉及到对网页的一点了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(人人都用得上webscraper进阶教程,人人用得上数据教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-14 23:20
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
相关 文章:
最简单的数据采集教程,大家都可以用
进阶网页爬虫教程,人人都能用
如果您正在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,而这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
下面列出了您可能遇到的几个问题,并解释了解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按S键。
另外勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、 分页数据或滚动加载的数据无法完整抓取,如知乎 和推特等?
出现这种问题主要是因为网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此,请适当增加延迟大小并延长等待时间,以便有足够的时间加载数据。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、获取数据的顺序和网页上的顺序不一致?
webscraper默认是无序的,可以安装CouchDB保证数据的顺序。
或者使用其他替代方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按照某一列进行排序。按发布时间排序,或者知乎上的数据按点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。在这些情况下,您也需要使用其他方法。
其实就是通过鼠标操作选择元素,最后找到元素对应的xpath。Xpath对应网页解释,是定位一个元素的路径,通过元素的类型、唯一标识符、样式名、从属关系来查找某个元素或某类元素。
如果你没有遇到过这个问题,那么就没有必要去了解xpath,遇到问题就可以直接开始学习。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。 查看全部
scrapy分页抓取网页(人人都用得上webscraper进阶教程,人人用得上数据教程)
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
相关 文章:
最简单的数据采集教程,大家都可以用
进阶网页爬虫教程,人人都能用
如果您正在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,而这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
下面列出了您可能遇到的几个问题,并解释了解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按S键。
另外勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、 分页数据或滚动加载的数据无法完整抓取,如知乎 和推特等?
出现这种问题主要是因为网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此,请适当增加延迟大小并延长等待时间,以便有足够的时间加载数据。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、获取数据的顺序和网页上的顺序不一致?
webscraper默认是无序的,可以安装CouchDB保证数据的顺序。
或者使用其他替代方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按照某一列进行排序。按发布时间排序,或者知乎上的数据按点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。在这些情况下,您也需要使用其他方法。
其实就是通过鼠标操作选择元素,最后找到元素对应的xpath。Xpath对应网页解释,是定位一个元素的路径,通过元素的类型、唯一标识符、样式名、从属关系来查找某个元素或某类元素。
如果你没有遇到过这个问题,那么就没有必要去了解xpath,遇到问题就可以直接开始学习。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-13 00:33
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对于我这种情况,我宁愿花半个自己写的一天 懒得学第三方代码工具的都是自己写代码实现的;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用 webBrowser 控件 Navigate(" ") 的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
看完这篇文章,我觉得可以解决手头的网站,但是在实际操作中,第二种方法无法完成网页抓取,而第三种方法也不好控制;
个人实践一使用页面添加或修改其中一个标签的属性 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对于我这种情况,我宁愿花半个自己写的一天 懒得学第三方代码工具的都是自己写代码实现的;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用 webBrowser 控件 Navigate(" ") 的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
看完这篇文章,我觉得可以解决手头的网站,但是在实际操作中,第二种方法无法完成网页抓取,而第三种方法也不好控制;
个人实践一使用页面添加或修改其中一个标签的属性
scrapy分页抓取网页(scrapy成熟的爬虫框架的考量及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-10-11 16:06
)
最近在用scrapy做一个爬虫爬取网站上的一些信息,但是出现了一个很奇怪的问题,就是在网页中打开了要爬取的URL,某个URL位于网页的源代码。需要爬取一些元素,但是我用scrapy爬取数据的时候,发现一个错误,结果是爬取的网页没有收录我在浏览器中看到的元素,也就是for the same URL,抓取的页面和我在浏览器打开看到的页面不一样!
在反复确认CSS类选择器正确以及爬虫爬取的URL没有重定向到其他页面后,发现事情并不简单。
然后机缘巧合下,没有修改任何代码,再次运行,却发现再次爬行成功,然后又试了一次,报错了。这时候就知道,抓取到的页面一定是 完整的页面没有加载完成。
当页面没有完全加载时,我首先想到了两种可能:
首先,部分数据在网页加载时由js动态写入,即部分数据在第一次请求时传递给js,由前端js处理后显示在页面上;
二是网页数据是异步加载的,在抓取网页的时候部分数据还没有加载。
基于scrapy是一个成熟的爬虫框架的考虑,我认为第一种情况应该不会出现。毕竟爬虫可以等到页面初始化好再爬,但是对于第二种情况,因为数据Loading是异步的,所以无法提前控制。
基于以上考虑,直接考虑第二种情况。因此,您可以在浏览器控制台的 Network 中检查所有发送的请求,看看您需要的数据是否被异步加载。如下图所示,可以查看每个请求的Response,手动检查是否返回了你需要的信息。
对于我的情况,果然如上图所示,我找到了整个异步请求返回的json格式数据,里面收录了我需要的所有信息,我什至不需要再抓取网页了,只是作为如下图,查看请求的header,可以看到异步请求的请求格式,也就是图中的Request URL
将获取到的Request URL复制到新的浏览器窗口打开,可以看到下图,可以访问json格式的返回数据,说明网站没有拦截到这种请求,这也使得我没必要去抓取页面的数据了,我只需要直接构造对应的URL,分析返回的json数据,就大功告成了!
查看全部
scrapy分页抓取网页(scrapy成熟的爬虫框架的考量及应用
)
最近在用scrapy做一个爬虫爬取网站上的一些信息,但是出现了一个很奇怪的问题,就是在网页中打开了要爬取的URL,某个URL位于网页的源代码。需要爬取一些元素,但是我用scrapy爬取数据的时候,发现一个错误,结果是爬取的网页没有收录我在浏览器中看到的元素,也就是for the same URL,抓取的页面和我在浏览器打开看到的页面不一样!
在反复确认CSS类选择器正确以及爬虫爬取的URL没有重定向到其他页面后,发现事情并不简单。
然后机缘巧合下,没有修改任何代码,再次运行,却发现再次爬行成功,然后又试了一次,报错了。这时候就知道,抓取到的页面一定是 完整的页面没有加载完成。
当页面没有完全加载时,我首先想到了两种可能:
首先,部分数据在网页加载时由js动态写入,即部分数据在第一次请求时传递给js,由前端js处理后显示在页面上;
二是网页数据是异步加载的,在抓取网页的时候部分数据还没有加载。
基于scrapy是一个成熟的爬虫框架的考虑,我认为第一种情况应该不会出现。毕竟爬虫可以等到页面初始化好再爬,但是对于第二种情况,因为数据Loading是异步的,所以无法提前控制。
基于以上考虑,直接考虑第二种情况。因此,您可以在浏览器控制台的 Network 中检查所有发送的请求,看看您需要的数据是否被异步加载。如下图所示,可以查看每个请求的Response,手动检查是否返回了你需要的信息。
对于我的情况,果然如上图所示,我找到了整个异步请求返回的json格式数据,里面收录了我需要的所有信息,我什至不需要再抓取网页了,只是作为如下图,查看请求的header,可以看到异步请求的请求格式,也就是图中的Request URL
将获取到的Request URL复制到新的浏览器窗口打开,可以看到下图,可以访问json格式的返回数据,说明网站没有拦截到这种请求,这也使得我没必要去抓取页面的数据了,我只需要直接构造对应的URL,分析返回的json数据,就大功告成了!
scrapy分页抓取网页(Python中一个非常棒的网页抓取网页中常见的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-10-11 16:06
Python部落()整理翻译,禁止转载,欢迎转发。
在上一篇使用 Python 抓取网页的博文中,我们谈到了 Scrapy。在本节中,让我们深入探讨它。
Scrapy 是一个很棒的 Python 网页抓取框架。它可以处理大规模网络爬行过程中的一些常见问题。
Scrapy 与 Requests 或 BeautifulSoup 等其他常用库的区别非常明显。它可以通过简单的方式解决网络爬虫中的常见问题。
Scrapy 的缺点是学习曲线非常陡峭,需要学习的东西很多,但这就是我们要在这里讨论的内容。
在本教程中,我们将创建两个不同的网络爬虫。一种是从电商产品页面提取数据比较简单,另一种是抓取整个电商目录比较复杂。
基本概述
您可以使用 pip 安装 Scrapy。但也要注意,Scrapy 的文档强烈建议将其安装在虚拟环境中,以避免与您的系统软件包发生冲突。
我在这里使用 Virtualenv 和 Virtualenvwrapper:
然后
现在您可以使用以下命令创建一个新的 Scrapy 项目:
上面的命令将为这个项目创建所有必要的模板文件。
下面简单介绍一下上述文件和目录:
在此示例中,我们将从虚拟电子商务 网站 中抓取单个产品。这是我们要抓取的第一个产品:
我们要解析这个产品的名称、图片、价格和描述。
破壳
Scrapy 提供了内置的 Shell 控制台,方便你实时运行和调试爬虫脚本。您可以使用它来快速测试 XPath 表达式或 CSS 选择器。我一直在使用这个很酷的网络爬虫。
您还可以配置 Scrapy Shell 以使用其他控制台来替换默认的 Python 控制台,例如 IPython。可实现自动补全功能或其他特殊效果,如颜色输出等。
为了方便在Scrapy Shell中使用,需要在scrapy.cfg文件中加入如下一行:
配置完成后就可以使用scrapy shell了:
让我们从抓取一个简单的 URL 开始:
这将首先获取 /robot.txt 文件。
本例中没有robot.txt文件,所以我们会在这里看到404 HTTP状态码。如果有robot.txt文件,Scrapy默认会遵循规则。
您可以在 settings.py 文件中禁用此规则:
然后可以看到如下日志:
现在,您可以从捕获的数据中看到响应正文和响应标头,还可以使用不同的 XPath 表达式或 CSS 选择器来解析数据。
使用以下命令直接在浏览器中查看响应信息:
请注意,由于某些原因,该页面在浏览器中的显示效果可能较差。这可能是CORS问题,或者Javascript代码无法执行,或者本地URL对应的资源被加载了。
Scrapy shell 与常规 Python shell 没有什么不同,因此您可以向其中添加自定义脚本或函数。
分析数据
Scrapy 默认不执行 Javascript,所以如果你要爬取的页面是通过 Angular 或 React.js 前端框架渲染的,你可能无法抓取到想要的数据。
现在让我们尝试使用 XPath 表达式来解析产品标题和价格:
使用XPath表达式方便价格分析,选择类属性my-4的div标签后第一个span的文字:
您还可以使用 CSS 选择器:
创建一个 Scrapy 爬虫
在 Scrapy 中,Spider 是一个类,用于定义集合(需要爬取的链接或 URL)和爬取(需要解析的数据)。
以下是爬虫爬取网站所需的步骤:
您可能想知道为什么 parse() 函数可以返回这么多不同类型的对象。这是为了函数的灵活性。假设你想抓取一个没有站点地图的电商网站,你可以从抓取产品类别开始,这里是使用的第一个解析函数。
然后,该函数将为每个产品类别生成一个 Request 对象,并将其传递给新的回调函数 parse2()。对于每个类别,可能还有分页需要处理。然后将为实际抓取的每个产品生成第三个解析函数。
Scrapy 可以将捕获的数据作为简单的 Python 字典返回,但最好使用内置的 Scrapy 项目类。它是我们抓取数据时使用的简单容器。Scrapy 可以查看该项中的属性并进行很多操作,比如将数据导出为不同的格式(JSON 或 CSV 等),作为一个项目管道。
这是一个基本的 Product 类:
现在我们可以通过命令行生成爬虫:
或者您可以在 /spiders 目录中手动创建爬虫代码。
以下是 Scrapy 用来解决大部分爬虫用例的不同类型的爬虫:
在这个 EcomSpider 类中,有两个必需的属性:
allowed_domains 是可选的,但也非常重要。当您使用 CrawlSpider 时,将识别不同的域名。
然后使用我们之前看到的 XPath 表达式解析所需的数据并将其填充到 Product 字段中,并返回此项。
您可以运行以下代码将结果导出为 JSON 格式(也可以导出 CSV)。
然后你可以得到一个整洁的 JSON 文件:
物品加载器
从网页中提取数据时,您可能会遇到两个常见问题:
对此,Scrapy 提供了内置的解决方案 ItemLoaders。这是一种处理 Product 对象的有趣方式。
您可以将多个 XPath 表达式添加到同一个 Item 字段,它会按顺序测试它们。默认情况下,如果找到多个 XPath,它会将它们全部加载到列表中。
您可以在 Scrapy 文档中找到许多输入和输出处理器的示例。
当您需要转换或清理解析的数据时,此功能很有用。例如,从价格中提取货币信息,将一种单位转换为另一种单位(厘米和米、华氏和摄氏)等。
我们可以使用不同的 XPath 表达式从网页中查找产品标题://title 和 //section[1]//h2/text()。
在这种情况下,您可以使用 Itemloader:
通常要使用第一个匹配的XPath,所以需要在item的字段构造函数中添加这段代码output_processor=TakeFirst()。
在示例中,我们只希望每个字段都匹配第一个 XPath,因此最好的方法是创建自己的 Itemloader 并声明一个默认的 output_processor 以使用第一个 XPath。
我还在这里添加了一个 price_in 字段,它是一个输入处理器,用于从价格中删除美元符号。我使用的内置处理器 MapCompose 需要按顺序执行一个或多个函数。您可以根据需要添加任何函数,通常在项目中的字段名称后添加 _in 或 _out ,表示添加输入或输出处理器。 查看全部
scrapy分页抓取网页(Python中一个非常棒的网页抓取网页中常见的问题)
Python部落()整理翻译,禁止转载,欢迎转发。
在上一篇使用 Python 抓取网页的博文中,我们谈到了 Scrapy。在本节中,让我们深入探讨它。
Scrapy 是一个很棒的 Python 网页抓取框架。它可以处理大规模网络爬行过程中的一些常见问题。
Scrapy 与 Requests 或 BeautifulSoup 等其他常用库的区别非常明显。它可以通过简单的方式解决网络爬虫中的常见问题。
Scrapy 的缺点是学习曲线非常陡峭,需要学习的东西很多,但这就是我们要在这里讨论的内容。
在本教程中,我们将创建两个不同的网络爬虫。一种是从电商产品页面提取数据比较简单,另一种是抓取整个电商目录比较复杂。
基本概述
您可以使用 pip 安装 Scrapy。但也要注意,Scrapy 的文档强烈建议将其安装在虚拟环境中,以避免与您的系统软件包发生冲突。
我在这里使用 Virtualenv 和 Virtualenvwrapper:
然后
现在您可以使用以下命令创建一个新的 Scrapy 项目:
上面的命令将为这个项目创建所有必要的模板文件。
下面简单介绍一下上述文件和目录:
在此示例中,我们将从虚拟电子商务 网站 中抓取单个产品。这是我们要抓取的第一个产品:
我们要解析这个产品的名称、图片、价格和描述。
破壳
Scrapy 提供了内置的 Shell 控制台,方便你实时运行和调试爬虫脚本。您可以使用它来快速测试 XPath 表达式或 CSS 选择器。我一直在使用这个很酷的网络爬虫。
您还可以配置 Scrapy Shell 以使用其他控制台来替换默认的 Python 控制台,例如 IPython。可实现自动补全功能或其他特殊效果,如颜色输出等。
为了方便在Scrapy Shell中使用,需要在scrapy.cfg文件中加入如下一行:
配置完成后就可以使用scrapy shell了:
让我们从抓取一个简单的 URL 开始:
这将首先获取 /robot.txt 文件。
本例中没有robot.txt文件,所以我们会在这里看到404 HTTP状态码。如果有robot.txt文件,Scrapy默认会遵循规则。
您可以在 settings.py 文件中禁用此规则:
然后可以看到如下日志:
现在,您可以从捕获的数据中看到响应正文和响应标头,还可以使用不同的 XPath 表达式或 CSS 选择器来解析数据。
使用以下命令直接在浏览器中查看响应信息:
请注意,由于某些原因,该页面在浏览器中的显示效果可能较差。这可能是CORS问题,或者Javascript代码无法执行,或者本地URL对应的资源被加载了。
Scrapy shell 与常规 Python shell 没有什么不同,因此您可以向其中添加自定义脚本或函数。
分析数据
Scrapy 默认不执行 Javascript,所以如果你要爬取的页面是通过 Angular 或 React.js 前端框架渲染的,你可能无法抓取到想要的数据。
现在让我们尝试使用 XPath 表达式来解析产品标题和价格:
使用XPath表达式方便价格分析,选择类属性my-4的div标签后第一个span的文字:
您还可以使用 CSS 选择器:
创建一个 Scrapy 爬虫
在 Scrapy 中,Spider 是一个类,用于定义集合(需要爬取的链接或 URL)和爬取(需要解析的数据)。
以下是爬虫爬取网站所需的步骤:
您可能想知道为什么 parse() 函数可以返回这么多不同类型的对象。这是为了函数的灵活性。假设你想抓取一个没有站点地图的电商网站,你可以从抓取产品类别开始,这里是使用的第一个解析函数。
然后,该函数将为每个产品类别生成一个 Request 对象,并将其传递给新的回调函数 parse2()。对于每个类别,可能还有分页需要处理。然后将为实际抓取的每个产品生成第三个解析函数。
Scrapy 可以将捕获的数据作为简单的 Python 字典返回,但最好使用内置的 Scrapy 项目类。它是我们抓取数据时使用的简单容器。Scrapy 可以查看该项中的属性并进行很多操作,比如将数据导出为不同的格式(JSON 或 CSV 等),作为一个项目管道。
这是一个基本的 Product 类:
现在我们可以通过命令行生成爬虫:
或者您可以在 /spiders 目录中手动创建爬虫代码。
以下是 Scrapy 用来解决大部分爬虫用例的不同类型的爬虫:
在这个 EcomSpider 类中,有两个必需的属性:
allowed_domains 是可选的,但也非常重要。当您使用 CrawlSpider 时,将识别不同的域名。
然后使用我们之前看到的 XPath 表达式解析所需的数据并将其填充到 Product 字段中,并返回此项。
您可以运行以下代码将结果导出为 JSON 格式(也可以导出 CSV)。
然后你可以得到一个整洁的 JSON 文件:
物品加载器
从网页中提取数据时,您可能会遇到两个常见问题:
对此,Scrapy 提供了内置的解决方案 ItemLoaders。这是一种处理 Product 对象的有趣方式。
您可以将多个 XPath 表达式添加到同一个 Item 字段,它会按顺序测试它们。默认情况下,如果找到多个 XPath,它会将它们全部加载到列表中。
您可以在 Scrapy 文档中找到许多输入和输出处理器的示例。
当您需要转换或清理解析的数据时,此功能很有用。例如,从价格中提取货币信息,将一种单位转换为另一种单位(厘米和米、华氏和摄氏)等。
我们可以使用不同的 XPath 表达式从网页中查找产品标题://title 和 //section[1]//h2/text()。
在这种情况下,您可以使用 Itemloader:
通常要使用第一个匹配的XPath,所以需要在item的字段构造函数中添加这段代码output_processor=TakeFirst()。
在示例中,我们只希望每个字段都匹配第一个 XPath,因此最好的方法是创建自己的 Itemloader 并声明一个默认的 output_processor 以使用第一个 XPath。
我还在这里添加了一个 price_in 字段,它是一个输入处理器,用于从价格中删除美元符号。我使用的内置处理器 MapCompose 需要按顺序执行一个或多个函数。您可以根据需要添加任何函数,通常在项目中的字段名称后添加 _in 或 _out ,表示添加输入或输出处理器。
scrapy分页抓取网页(crawlspiderrules疑问总结:1、rules里的Rule规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-11 16:05
最近在学习爬虫,对爬虫规则的运行机制有些疑惑,于是自己研究了一下,总结出以下几点:
1、规则中的规则是按顺序运行的,从上到下执行;
2、 获取request url是Rule定位的容器,a标签中的所有href链接,比如使用xpath定位
规则 = (
规则(LinkExtractor(restrict_xpaths=("//div/ul")),callback='parse_item'),
)
然后会获取ul容器下a标签的所有链接,服务器会自动发送请求,无需手动发送请求;
3、 响应页面就是Rule请求的链接的页面内容,也就是你在容器ul中定位a标签所在的链接,然后点击链接查看页面内容,在回调函数中提取数据。从这个页面中提取,parse_item(self,response),这个函数的响应对象就是这个页面的内容,不要搞错对象;
4、follow,这个参数开始让我有点晕。跟随意味着跟进。如果follow=True,那么在你得到的响应页面中,会获取所有符合规则的href链接 会自动跟进,进入获取到的链接响应页面,在这个页面再次匹配规则规则,看看有没有是任何匹配,如果是,则继续跟踪,直到不匹配规则。例如:
规则 = (
规则(LinkExtractor(restrict_xpaths=(“//div/ul”)),follow=True),
)
所以首先规则会获取当前页面上所有符合规则规则的链接,当前页面为start_urls页面,例如获取的链接为
会继续进入href链接的页面,然后继续匹配Rule规则,看看有没有匹配的链接,相当于在响应页面的元素中找到符合规则的a标签url ,然后点击这个url,然后在这个页面的元素中查找是否有符合Rule规则的href链接,依此类推,直到找不到符合Rule规则的href链接;
5、如果Rule中有callback="parse_item",follow=True,那么情况会更复杂。你可以想象得到一个响应符合Rule规则的页面的链接,然后调用函数,跳转到这个页面。按照其他目标链接,然后调用该函数。最好使用xpath定位。如果使用allow=(r'')正则表达式匹配,会比较混乱。在适当的情况下也会用到,不过比较少嘛,大家可以自己测试体验一下。
6、 翻页,翻页有两种情况
第一种情况(start_url的响应页面底部有翻页链接):
在规则中定义两个Rule规则,一个是获取响应页面规则,一个是获取翻页链接规则,翻页规则遵循响应页面规则,顺序不能错,如下:
规则 = (
规则(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
规则(LinkExtractor(allow=r'\d\.htm'),follow=True),
)
第二种情况(start_url的响应页面底部没有翻页链接,只有输入a标签链接才有翻页链接):
在这种情况下,您无法在规则中定义翻页规则,因为即使您定义了翻页规则,也找不到它们。因为规则中的所有规则,第一次得到响应页面是start_url地址对应的内容。如果该页面没有规则规则,则不会被发现。这里就不多说了,直接上源码吧!
class TestSpider(CrawlSpider):
name = 'test'
allowed_domains = ['dangdang.com']
start_urls = ['http://book.dangdang.com/']
rules = (
Rule(LinkExtractor(restrict_xpaths=("//div[@class='conflq_body']/div[@name='m403752_pid5438_t10274']//div/dl[@ddt-area='5358']/dd")), callback='parse_item'),
)
def parse_item(self, response):
item={}
item['cate_0']=''
item['cate_1'] = ''
item['cate_2'] = ''
item['cate_3'] = ''
breadcrum=response.xpath("//div[@class='crumbs_fb_left']/div[@class='select_frame']/a[@name='breadcrumb-category']/text()").getall()
for i in range(len(breadcrum)):
item['cate_{}'.format(i)]=breadcrum[i]
book_li=response.xpath("//div[@id='search_nature_rg']/ul/li")
for li in book_li:
item['book_title']=li.xpath(".//p[@class='name']/a/@title").get()
item['book_price']=li.xpath(".//p[@class='price']/span/text()").get()
item['book_url']=li.xpath(".//p[@class='name']/a/@href").get()
book_search=li.xpath(".//p[@class='search_book_author']/span")
item['book_author']=book_search[0].xpath(".//a/@title").get()
item['public_date']=book_search[1].xpath(".//text()").get()
item['public_date']=re.sub("/",'',item['public_date']) if item['public_date'] else None
item['public_company']=book_search[2].xpath(".//a/@title").get()
yield item
next_page_url=response.xpath("//div[@class='paging']//li[@class='next']/a/@href").get()
next_page="http://category.dangdang.com"+next_page_url
yield scrapy.Request(next_page,callback=self.parse_item)
在这种情况下,必须在函数中进行翻页。parse_item() 函数的最后三行是翻页语句!我可以自己测试一下。不知道有没有其他方法可以做规则。反正我现在还没找到。如果有人知道,我可以告诉!
以上是我个人的看法,如有错误或遗漏,敬请指出! 查看全部
scrapy分页抓取网页(crawlspiderrules疑问总结:1、rules里的Rule规则)
最近在学习爬虫,对爬虫规则的运行机制有些疑惑,于是自己研究了一下,总结出以下几点:
1、规则中的规则是按顺序运行的,从上到下执行;
2、 获取request url是Rule定位的容器,a标签中的所有href链接,比如使用xpath定位
规则 = (
规则(LinkExtractor(restrict_xpaths=("//div/ul")),callback='parse_item'),
)
然后会获取ul容器下a标签的所有链接,服务器会自动发送请求,无需手动发送请求;
3、 响应页面就是Rule请求的链接的页面内容,也就是你在容器ul中定位a标签所在的链接,然后点击链接查看页面内容,在回调函数中提取数据。从这个页面中提取,parse_item(self,response),这个函数的响应对象就是这个页面的内容,不要搞错对象;
4、follow,这个参数开始让我有点晕。跟随意味着跟进。如果follow=True,那么在你得到的响应页面中,会获取所有符合规则的href链接 会自动跟进,进入获取到的链接响应页面,在这个页面再次匹配规则规则,看看有没有是任何匹配,如果是,则继续跟踪,直到不匹配规则。例如:
规则 = (
规则(LinkExtractor(restrict_xpaths=(“//div/ul”)),follow=True),
)
所以首先规则会获取当前页面上所有符合规则规则的链接,当前页面为start_urls页面,例如获取的链接为
会继续进入href链接的页面,然后继续匹配Rule规则,看看有没有匹配的链接,相当于在响应页面的元素中找到符合规则的a标签url ,然后点击这个url,然后在这个页面的元素中查找是否有符合Rule规则的href链接,依此类推,直到找不到符合Rule规则的href链接;
5、如果Rule中有callback="parse_item",follow=True,那么情况会更复杂。你可以想象得到一个响应符合Rule规则的页面的链接,然后调用函数,跳转到这个页面。按照其他目标链接,然后调用该函数。最好使用xpath定位。如果使用allow=(r'')正则表达式匹配,会比较混乱。在适当的情况下也会用到,不过比较少嘛,大家可以自己测试体验一下。
6、 翻页,翻页有两种情况
第一种情况(start_url的响应页面底部有翻页链接):
在规则中定义两个Rule规则,一个是获取响应页面规则,一个是获取翻页链接规则,翻页规则遵循响应页面规则,顺序不能错,如下:
规则 = (
规则(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
规则(LinkExtractor(allow=r'\d\.htm'),follow=True),
)
第二种情况(start_url的响应页面底部没有翻页链接,只有输入a标签链接才有翻页链接):
在这种情况下,您无法在规则中定义翻页规则,因为即使您定义了翻页规则,也找不到它们。因为规则中的所有规则,第一次得到响应页面是start_url地址对应的内容。如果该页面没有规则规则,则不会被发现。这里就不多说了,直接上源码吧!
class TestSpider(CrawlSpider):
name = 'test'
allowed_domains = ['dangdang.com']
start_urls = ['http://book.dangdang.com/']
rules = (
Rule(LinkExtractor(restrict_xpaths=("//div[@class='conflq_body']/div[@name='m403752_pid5438_t10274']//div/dl[@ddt-area='5358']/dd")), callback='parse_item'),
)
def parse_item(self, response):
item={}
item['cate_0']=''
item['cate_1'] = ''
item['cate_2'] = ''
item['cate_3'] = ''
breadcrum=response.xpath("//div[@class='crumbs_fb_left']/div[@class='select_frame']/a[@name='breadcrumb-category']/text()").getall()
for i in range(len(breadcrum)):
item['cate_{}'.format(i)]=breadcrum[i]
book_li=response.xpath("//div[@id='search_nature_rg']/ul/li")
for li in book_li:
item['book_title']=li.xpath(".//p[@class='name']/a/@title").get()
item['book_price']=li.xpath(".//p[@class='price']/span/text()").get()
item['book_url']=li.xpath(".//p[@class='name']/a/@href").get()
book_search=li.xpath(".//p[@class='search_book_author']/span")
item['book_author']=book_search[0].xpath(".//a/@title").get()
item['public_date']=book_search[1].xpath(".//text()").get()
item['public_date']=re.sub("/",'',item['public_date']) if item['public_date'] else None
item['public_company']=book_search[2].xpath(".//a/@title").get()
yield item
next_page_url=response.xpath("//div[@class='paging']//li[@class='next']/a/@href").get()
next_page="http://category.dangdang.com"+next_page_url
yield scrapy.Request(next_page,callback=self.parse_item)
在这种情况下,必须在函数中进行翻页。parse_item() 函数的最后三行是翻页语句!我可以自己测试一下。不知道有没有其他方法可以做规则。反正我现在还没找到。如果有人知道,我可以告诉!
以上是我个人的看法,如有错误或遗漏,敬请指出!
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-09 23:11
Scrapy 是一个用 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 常用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
通常我们可以通过Scrapy框架轻松实现爬虫抓取指定网站的内容或图片。
Scrapy 架构图(绿线为数据流)
Scrapy 操作流程
代码写好,程序开始运行...
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的 URL,Scrapy 会重新下载。)
制作一个Scrapy爬虫一共需要4步:新建项目(scrapy startproject xxx):新建一个爬虫项目,指定目标(写items.py):指定要爬取的目标, make a spider (spiders/xxspider.py) ): 制作一个爬虫并开始爬取网络存储内容 (pipelines.py): 设计一个管道来存储爬取的内容 安装 Windows 安装方法
升级pip版本:
pip install --upgrade pip
通过pip安装Scrapy框架:
pip install Scrapy
Ubuntu 安装方法
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip安装Scrapy框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,默认安装的包是不能删除的,但是可以使用python2.x来安装Scrapy会报错,使用python3.x安装也是报错。终于没有找到直接安装Scrapy的方法,所以就用另一种安装方式来讲解安装步骤。解决方案是使用virtualenv。安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,在命令终端输入scrapy,提示类似如下结果,表示安装成功。
介绍案例研究目标一. 新项目(scrapy startproject)
在爬取之前,必须创建一个新的 Scrapy 项目。进入自定义项目目录,运行以下命令:
scrapy startproject mySpider
其中mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、明确目标(mySpider/items.py)
我们打算获取网站中所有讲师的姓名、职称和个人信息。
打开 mySpider 目录下的 items.py。
Item 定义了一个结构化的数据字段,用于保存抓取到的数据,有点像 Python 中的 dict,但提供了一些额外的保护以减少错误。
可以通过创建scrapy.Item类并定义scrapy.Field类型的类属性来定义Item(可以理解为类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类并构建一个项目模型。
三、制作爬虫(spider/itcastSpider.py)
爬虫功能需要分为两步:
1. 爬取数据
在当前目录下输入命令,会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,自己写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建Spider,您必须使用scrapy.Spider 类创建一个子类,并确定三个必需属性和一个方法。
name = "":此爬虫的标识名称必须是唯一的。不同的爬虫必须定义不同的名称。
allow_domains = [] 是要搜索的域名范围,即爬虫的限制区域。规定爬虫只爬取该域名下的网页,不存在的网址将被忽略。
start_urls = ():已爬取的 URL 的祖先/列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse(self, response):解析的方法。每个初始 URL 下载后都会调用它。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item) 查看全部
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
Scrapy 是一个用 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 常用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
通常我们可以通过Scrapy框架轻松实现爬虫抓取指定网站的内容或图片。
Scrapy 架构图(绿线为数据流)
Scrapy 操作流程
代码写好,程序开始运行...
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的 URL,Scrapy 会重新下载。)
制作一个Scrapy爬虫一共需要4步:新建项目(scrapy startproject xxx):新建一个爬虫项目,指定目标(写items.py):指定要爬取的目标, make a spider (spiders/xxspider.py) ): 制作一个爬虫并开始爬取网络存储内容 (pipelines.py): 设计一个管道来存储爬取的内容 安装 Windows 安装方法
升级pip版本:
pip install --upgrade pip
通过pip安装Scrapy框架:
pip install Scrapy
Ubuntu 安装方法
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip安装Scrapy框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,默认安装的包是不能删除的,但是可以使用python2.x来安装Scrapy会报错,使用python3.x安装也是报错。终于没有找到直接安装Scrapy的方法,所以就用另一种安装方式来讲解安装步骤。解决方案是使用virtualenv。安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,在命令终端输入scrapy,提示类似如下结果,表示安装成功。
介绍案例研究目标一. 新项目(scrapy startproject)
在爬取之前,必须创建一个新的 Scrapy 项目。进入自定义项目目录,运行以下命令:
scrapy startproject mySpider
其中mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、明确目标(mySpider/items.py)
我们打算获取网站中所有讲师的姓名、职称和个人信息。
打开 mySpider 目录下的 items.py。
Item 定义了一个结构化的数据字段,用于保存抓取到的数据,有点像 Python 中的 dict,但提供了一些额外的保护以减少错误。
可以通过创建scrapy.Item类并定义scrapy.Field类型的类属性来定义Item(可以理解为类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类并构建一个项目模型。
三、制作爬虫(spider/itcastSpider.py)
爬虫功能需要分为两步:
1. 爬取数据
在当前目录下输入命令,会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,自己写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建Spider,您必须使用scrapy.Spider 类创建一个子类,并确定三个必需属性和一个方法。
name = "":此爬虫的标识名称必须是唯一的。不同的爬虫必须定义不同的名称。
allow_domains = [] 是要搜索的域名范围,即爬虫的限制区域。规定爬虫只爬取该域名下的网页,不存在的网址将被忽略。
start_urls = ():已爬取的 URL 的祖先/列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse(self, response):解析的方法。每个初始 URL 下载后都会调用它。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-08 19:10
先看 Scrapy
Scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
本文档将介绍 Scrapy 背后的概念,让您了解其工作原理,并确定 Scrapy 是否是您所需要的。
当您准备好开始您的项目时,您可以参考它。
选择一个网站
当你需要从某个网站获取信息,但网站没有提供API或通过程序获取信息的机制时,Scrapy可以帮到你。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
可以在此页面上找到今天添加的种子列表:
定义要爬取的数据
第一步是定义我们需要爬取的数据。在 Scrapy 中,这是通过的。(在这个例子中,它是种子文件)
我们定义的Item:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写一个spider。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过观察页面内容,可以发现所有种子的URL都是相似的。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式:/tor/\d+。
我们使用 XPath 从页面的 HTML 源代码中选择要提取的数据。以其中一个种子文件的页面为例:
观察 HTML 页面源代码并创建我们需要的数据的 XPath 表达式(种子名称、描述和大小)。
通过观察,我们可以发现标签中收录了文件名:
Darwin - The Evolution Of An Exhibition
对应于此的 XPath 表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取说明:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
用于选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的详细信息,请参阅 XPath 参考。
最后结合上面的内容给出蜘蛛的代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='info-left']/p[2]/text()[2]").extract()
return torrent
TorrentItem 的定义在。
执行spider获取数据
最后,我们可以运行spider获取网站的数据并以JSON格式保存在scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您还可以将项目写入并存储在数据库中。
查看提取的数据
执行后,查看scraped_data.json,会看到解压出来的item:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是列表,所以所有的值都存储在列表中(除了url是直接赋值的)。如果您想保存单个数据或对数据执行额外的处理,那将是您发挥作用的地方。
还有什么?
您已经学习了如何通过 Scrapy 从存储的网页中提取信息,但这只是冰山一角。Scrapy 提供了许多强大的功能来让爬行更容易、更高效,例如:
对于非英语语言的非标准或错误编码声明,提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加快爬虫创建速度的同时,让大型项目中的代码更加一致。有关详细信息,请参阅命令。为多个爬虫下的性能评估和故障检测提供可扩展性。提供,为您测试XPath表达式,编写和调试爬虫,简化生产环境中的部署和操作提供了极大的便利。内置,通过在Scrapy进程中钩入Python终端,可以为你查看和调试爬虫爬虫过程中的Catching errors为Sitemaps爬取带有缓存的DNS解析器提供方便的支持
下一个
下一步当然是下载Scrapy,你可以阅读它并加入社区。感谢您的支持!
讨论 查看全部
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
先看 Scrapy
Scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
本文档将介绍 Scrapy 背后的概念,让您了解其工作原理,并确定 Scrapy 是否是您所需要的。
当您准备好开始您的项目时,您可以参考它。
选择一个网站
当你需要从某个网站获取信息,但网站没有提供API或通过程序获取信息的机制时,Scrapy可以帮到你。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
可以在此页面上找到今天添加的种子列表:
定义要爬取的数据
第一步是定义我们需要爬取的数据。在 Scrapy 中,这是通过的。(在这个例子中,它是种子文件)
我们定义的Item:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写一个spider。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过观察页面内容,可以发现所有种子的URL都是相似的。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式:/tor/\d+。
我们使用 XPath 从页面的 HTML 源代码中选择要提取的数据。以其中一个种子文件的页面为例:
观察 HTML 页面源代码并创建我们需要的数据的 XPath 表达式(种子名称、描述和大小)。
通过观察,我们可以发现标签中收录了文件名:
Darwin - The Evolution Of An Exhibition
对应于此的 XPath 表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取说明:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
用于选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的详细信息,请参阅 XPath 参考。
最后结合上面的内容给出蜘蛛的代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='info-left']/p[2]/text()[2]").extract()
return torrent
TorrentItem 的定义在。
执行spider获取数据
最后,我们可以运行spider获取网站的数据并以JSON格式保存在scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您还可以将项目写入并存储在数据库中。
查看提取的数据
执行后,查看scraped_data.json,会看到解压出来的item:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是列表,所以所有的值都存储在列表中(除了url是直接赋值的)。如果您想保存单个数据或对数据执行额外的处理,那将是您发挥作用的地方。
还有什么?
您已经学习了如何通过 Scrapy 从存储的网页中提取信息,但这只是冰山一角。Scrapy 提供了许多强大的功能来让爬行更容易、更高效,例如:
对于非英语语言的非标准或错误编码声明,提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加快爬虫创建速度的同时,让大型项目中的代码更加一致。有关详细信息,请参阅命令。为多个爬虫下的性能评估和故障检测提供可扩展性。提供,为您测试XPath表达式,编写和调试爬虫,简化生产环境中的部署和操作提供了极大的便利。内置,通过在Scrapy进程中钩入Python终端,可以为你查看和调试爬虫爬虫过程中的Catching errors为Sitemaps爬取带有缓存的DNS解析器提供方便的支持
下一个
下一步当然是下载Scrapy,你可以阅读它并加入社区。感谢您的支持!
讨论
scrapy分页抓取网页( Scrapy爬虫框架和如何新建Python虚拟环境师列表和信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-10-08 19:04
Scrapy爬虫框架和如何新建Python虚拟环境师列表和信息?)
目标和步骤
爬虫目标:从简单心理学网站获取心理咨询师名单和信息。
学习目标:
简单心理学网站有两种专家,“会诊”和“心理咨询师”。这里我们尝试先抓取顾问的信息。
顾问展示列表比较简单,总共有49页,每页有10个或11个顾问(有点棘手……)。只需抓取每个页面上的信息。
步骤分解:
新项目和爬虫
上一篇文章介绍了Scrapy爬虫框架以及如何新建Python虚拟环境。现在让我们创建一个新的 Scrapy 爬虫项目:
1
scrapy startproject jdxl
Scrapy 生成了以下文件
1
2
3
4
5
6
7
8
9
├── jdxl
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
我们在蜘蛛文件夹中创建了一个新的爬虫文件顾问.py。
然后在items.py中定义要爬取的item:
1
2
3
4
5
6
7
8
9
class JdxlItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() #姓名
url = scrapy.Field() #链接
info = scrapy.Field() #简介
zx_type = scrapy.Field() #咨询类型
location = scrapy.Field() #地点
price = scrapy.Field() #价格
抓取页面信息
打开爬虫顾问.py,开始编写爬虫程序。
不要忘记先导入上面定义的对象:
1
from jdxl.items import JdxlItem
问题一:如何设置起始网址?
打开心理咨询师列表页面,然后翻到第二页,发现网址是一个很长的字符串:
1
https://www.jiandanxinli.com/e ... e%3D2
过滤参数在中间传递,只有最后一个&page=2是key。换句话说,被抓取页面的 URL 如下所示:
1
2
3
4
https://www.jiandanxinli.com/experts?&page=1
https://www.jiandanxinli.com/experts?&page=2
...
https://www.jiandanxinli.com/experts?&page=49
开始在 JdxlSpider(scrapy.Spider) 类中定义起始 URL:如下:
1
2
3
4
5
6
7
8
allowed_domains = ["jiandanxinli.com"]
start_urls = ['http://jiandanxinli.com/experts']
start_url_list = []
for i in range(1,50):
start_url_list.extend(['http://jiandanxinli.com/experts?&page=' + str(i)])
start_urls = start_url_list
问题二:如何抓取节点信息
在 def parse(self, response): 函数中定义要捕获的内容,并使用 XPath 语法告诉爬虫要捕获的节点位置。
什么是“怕死”?
XPath(XML 路径语言)是一种用于从 XML 文档中选择节点的查询语言。此外,XPath 可用于从 XML 文档的内容计算值(例如,字符串、数字或布尔值)。—— 维基
怎么写XPath?
感谢 Chrome,它直接提供了 XPath 选择功能。右键需要抓包的位置,点击Inspect,打开chrome-devtools面板:
瞄准要抓取的节点,再次右击,点击复制XPath,XPath路径就被复制了。
不要太高兴。无数次在调试坑中摔倒的00颤抖着告诉你:直接复制的XPath往往不能直接用...
比如上面那个顾问的名字,chrome提供的路径是:
1
//*[@id="content_wrapper"]/div[2]/div[2]/a[5]/div[1]/strong/text()
但更准确的路径是:
1
/div[@class="summary"]/strong/text()
.
对于初学者来说,如果之前没有太多写html和css的经验,每一个xpath都需要摸索很久。但这是唯一的出路。经过大量的折腾,您将学会诚实地阅读XPath 文档。
问题3:如果内容中没有节点怎么办?
当我抓到顾问的咨询方式、地点、价格等信息时,骗子就来了。
这个簇的结构是:
文字不收录在标签中!正面和背面都有一个 i 标签!怎么抓啊!
然后开始了漫长的谷歌之路。终于找到这篇文章:如何使用scrapy提取标签中没有的文本?
我通过follow::text()获取了一些信息:
1
2
3
zx_type = response.xpath('./div[@class="info"]/i/following::text()').extract()[1]
location = response.xpath('./div[@class="info"]/i/following::text()').extract()[2]
price = response.xpath('./div[@class="info"]/i/following::text()').extract()[3]
这样,每一列都不能有缺失的信息,否则爬取会错位... 暂且处理>。
问题4:如何抓取多个专家信息
抓取专家信息后,如何抓取每页10~11位专家信息?查看页面的html,每个专家都在标签下。因此,使用循环来获取具有此功能的所有标签。
为了缩小范围,在 response.xpath('//a[@class="expert"]') 中传递了父节点的路径。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
for each in response.xpath('//a[@class="expert"]'):
print(each)
item = JdxlItem()
# 抓取姓名
item['name'] = each.xpath('./div[@class="summary"]/strong/text()').extract()
# 抓取 url
item['url'] = each.xpath('./@href').extract()
# 抓取简介
item['info'] = each.xpath('./div[@class="summary"]//div[@class="content"]/text()').extract()
# 抓取咨询方式、地点、价格等
item['zx_type'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[1]
item['location'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[2]
item['price'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[3]
yield item
其他配置
在settings.py文件中添加一个模拟user_agent的模块(需要先用pip安装faker包),设置爬取间隔、头信息等:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from faker import Factory
f = Factory.create()
USER_AGENT = f.user_agent()
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Host': 'www.jiandanxinli.com',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'no-cache',
'Connection': 'Keep-Alive',
}
测试和抓取
开始爬行的命令是:
1
scrapy crawl counselor
Crawl 后面跟着 JdxlSpider(scrapy.Spider): 类中定义的爬虫名称。
尝试先获取 2 个页面:
1
2
for i in range(1,3):
start_url_list.extend(['http://jiandanxinli.com/experts?&page=' + str(i)])
调试过程中的主要问题是没有准确提供节点的xpath,没有抓取到内容。此外,您可能会忘记在 items.py 中设置项目。一般来说,根据错误报告,慢慢寻找,总能找到问题所在。耐心一点。
输出 csv
查了官方文档——Scrapy 1.4.0文档和Item Exporters——Scrapy 1.4.0文档中的Feed导出部分,尝试写pipelines,有点复杂并没有成功。
然后我搜索了Scrapy爬虫框架教程(二)——爬取豆瓣电影TOP250,只是在执行爬虫时设置输出参数:
1
scrapy crawl counselor -o output_file.csv
查看和清理数据
新建一个 Jupyter Notebook,导入 pandas 包,使用 pd.read_csv 命令查看文件:
获取的链接不完整,完整,输出:
1
2
df['url'] = 'http://jiandanxinli.com'+df['url']
df.to_csv('counselor.csv', index=False)
下一篇文章将继续介绍使用 Pandas 和 Bokeh 的简单数据统计和可视化。
项目源码请查看00的github repo:
参考 查看全部
scrapy分页抓取网页(
Scrapy爬虫框架和如何新建Python虚拟环境师列表和信息?)
目标和步骤
爬虫目标:从简单心理学网站获取心理咨询师名单和信息。
学习目标:
简单心理学网站有两种专家,“会诊”和“心理咨询师”。这里我们尝试先抓取顾问的信息。
顾问展示列表比较简单,总共有49页,每页有10个或11个顾问(有点棘手……)。只需抓取每个页面上的信息。
步骤分解:
新项目和爬虫
上一篇文章介绍了Scrapy爬虫框架以及如何新建Python虚拟环境。现在让我们创建一个新的 Scrapy 爬虫项目:
1
scrapy startproject jdxl
Scrapy 生成了以下文件
1
2
3
4
5
6
7
8
9
├── jdxl
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
我们在蜘蛛文件夹中创建了一个新的爬虫文件顾问.py。
然后在items.py中定义要爬取的item:
1
2
3
4
5
6
7
8
9
class JdxlItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() #姓名
url = scrapy.Field() #链接
info = scrapy.Field() #简介
zx_type = scrapy.Field() #咨询类型
location = scrapy.Field() #地点
price = scrapy.Field() #价格
抓取页面信息
打开爬虫顾问.py,开始编写爬虫程序。
不要忘记先导入上面定义的对象:
1
from jdxl.items import JdxlItem
问题一:如何设置起始网址?
打开心理咨询师列表页面,然后翻到第二页,发现网址是一个很长的字符串:
1
https://www.jiandanxinli.com/e ... e%3D2
过滤参数在中间传递,只有最后一个&page=2是key。换句话说,被抓取页面的 URL 如下所示:
1
2
3
4
https://www.jiandanxinli.com/experts?&page=1
https://www.jiandanxinli.com/experts?&page=2
...
https://www.jiandanxinli.com/experts?&page=49
开始在 JdxlSpider(scrapy.Spider) 类中定义起始 URL:如下:
1
2
3
4
5
6
7
8
allowed_domains = ["jiandanxinli.com"]
start_urls = ['http://jiandanxinli.com/experts']
start_url_list = []
for i in range(1,50):
start_url_list.extend(['http://jiandanxinli.com/experts?&page=' + str(i)])
start_urls = start_url_list
问题二:如何抓取节点信息
在 def parse(self, response): 函数中定义要捕获的内容,并使用 XPath 语法告诉爬虫要捕获的节点位置。
什么是“怕死”?
XPath(XML 路径语言)是一种用于从 XML 文档中选择节点的查询语言。此外,XPath 可用于从 XML 文档的内容计算值(例如,字符串、数字或布尔值)。—— 维基
怎么写XPath?
感谢 Chrome,它直接提供了 XPath 选择功能。右键需要抓包的位置,点击Inspect,打开chrome-devtools面板:
瞄准要抓取的节点,再次右击,点击复制XPath,XPath路径就被复制了。
不要太高兴。无数次在调试坑中摔倒的00颤抖着告诉你:直接复制的XPath往往不能直接用...
比如上面那个顾问的名字,chrome提供的路径是:
1
//*[@id="content_wrapper"]/div[2]/div[2]/a[5]/div[1]/strong/text()
但更准确的路径是:
1
/div[@class="summary"]/strong/text()
.
对于初学者来说,如果之前没有太多写html和css的经验,每一个xpath都需要摸索很久。但这是唯一的出路。经过大量的折腾,您将学会诚实地阅读XPath 文档。
问题3:如果内容中没有节点怎么办?
当我抓到顾问的咨询方式、地点、价格等信息时,骗子就来了。
这个簇的结构是:
文字不收录在标签中!正面和背面都有一个 i 标签!怎么抓啊!
然后开始了漫长的谷歌之路。终于找到这篇文章:如何使用scrapy提取标签中没有的文本?
我通过follow::text()获取了一些信息:
1
2
3
zx_type = response.xpath('./div[@class="info"]/i/following::text()').extract()[1]
location = response.xpath('./div[@class="info"]/i/following::text()').extract()[2]
price = response.xpath('./div[@class="info"]/i/following::text()').extract()[3]
这样,每一列都不能有缺失的信息,否则爬取会错位... 暂且处理>。
问题4:如何抓取多个专家信息
抓取专家信息后,如何抓取每页10~11位专家信息?查看页面的html,每个专家都在标签下。因此,使用循环来获取具有此功能的所有标签。
为了缩小范围,在 response.xpath('//a[@class="expert"]') 中传递了父节点的路径。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
for each in response.xpath('//a[@class="expert"]'):
print(each)
item = JdxlItem()
# 抓取姓名
item['name'] = each.xpath('./div[@class="summary"]/strong/text()').extract()
# 抓取 url
item['url'] = each.xpath('./@href').extract()
# 抓取简介
item['info'] = each.xpath('./div[@class="summary"]//div[@class="content"]/text()').extract()
# 抓取咨询方式、地点、价格等
item['zx_type'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[1]
item['location'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[2]
item['price'] = each.xpath('./div[@class="info"]/i/following::text()').extract()[3]
yield item
其他配置
在settings.py文件中添加一个模拟user_agent的模块(需要先用pip安装faker包),设置爬取间隔、头信息等:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from faker import Factory
f = Factory.create()
USER_AGENT = f.user_agent()
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Host': 'www.jiandanxinli.com',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'no-cache',
'Connection': 'Keep-Alive',
}
测试和抓取
开始爬行的命令是:
1
scrapy crawl counselor
Crawl 后面跟着 JdxlSpider(scrapy.Spider): 类中定义的爬虫名称。
尝试先获取 2 个页面:
1
2
for i in range(1,3):
start_url_list.extend(['http://jiandanxinli.com/experts?&page=' + str(i)])
调试过程中的主要问题是没有准确提供节点的xpath,没有抓取到内容。此外,您可能会忘记在 items.py 中设置项目。一般来说,根据错误报告,慢慢寻找,总能找到问题所在。耐心一点。
输出 csv
查了官方文档——Scrapy 1.4.0文档和Item Exporters——Scrapy 1.4.0文档中的Feed导出部分,尝试写pipelines,有点复杂并没有成功。
然后我搜索了Scrapy爬虫框架教程(二)——爬取豆瓣电影TOP250,只是在执行爬虫时设置输出参数:
1
scrapy crawl counselor -o output_file.csv
查看和清理数据
新建一个 Jupyter Notebook,导入 pandas 包,使用 pd.read_csv 命令查看文件:
获取的链接不完整,完整,输出:
1
2
df['url'] = 'http://jiandanxinli.com'+df['url']
df.to_csv('counselor.csv', index=False)
下一篇文章将继续介绍使用 Pandas 和 Bokeh 的简单数据统计和可视化。
项目源码请查看00的github repo:
参考
scrapy分页抓取网页(【每日一题】scrapy发现爬虫还是登陆之前的状态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-07 12:16
最近接触scrapy,爬了几个网站,用起来还是挺流畅的。
前几天,一个业务同事让我帮他抓取网站上的一个用户信息,我答应了。毕竟,通过前面的几次爬行,我已经信心爆棚了(从此)入坑)。
拿到一个网站之后就是先分析网站,分析之后发现需要的数据要登陆才能看到.这个可难不倒我,不就是模拟登陆吗,小菜一碟.
用chrome分析一下,看到有用户名,密码,还有其他两个校验值.另外还有一个重定向的callback值.如下:
接下来,登录并观察post请求的状态。因为有上面这行代码,跳转太快了,没看到post请求,删掉上面那行代码,然后再请求,这次看到了表单发送信息。
下一步就是编写代码并模拟登录。我马上写代码,然后开始测试。(还记得上面提到的两个校验值中的哪一个吗?这两个值都是动态的,可以使用正则的登陆页面提取出来)。
部分代码如下:
name = "form"
download_delay = 0.18
allowed_domains = ["http://www.xxxxxx.com"]
headers = {
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, sdch",
"Accept-Language":"zh-CN,zh;q=0.8",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Host": "www.xxxxxx.com",
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
def start_requests(self):
return [scrapy.Request("http://www.xxxxxxx.com/user/login",meta={'cookiejar':1},headers=self.headers, callback=self.post_login)]
def post_login(self, response):
# 下面这句话用于抓取请求网页后返回网页中的_xsrf字段的文字, 用于成功提交表单
protected_code = Selector(response).xpath('//label[@class="rem"]/input[@name="protected_code"]/@value').extract()[0]
matchObj=re.search(r'\"csrftk\":\"(.*)\",\"img_path\"',response.text)
csrf_tk=matchObj.group(1)
logging.log(logging.WARNING, u"正则获取的值----"+csrf_tk)
# FormRequeset.from_response是Scrapy提供的一个函数, 用于post表单
# 登陆成功后, 会调用after_login回调函数
return [scrapy.FormRequest.from_response(response,method="POST",
headers=self.headers, # 注意此处的headers
formdata={
'protected_code': protected_code,
'email': 'xxxxxx@qq.com',
'csrf_tk': csrf_tk,
'password': 'xxxxxxxxxx',
'remember': 'true',
},
meta={'cookiejar': response.meta['cookiejar']},
callback=self.after_login,
dont_filter=True
)]
然后设置 COOKIES_ENABLED = True 和 COOKIES_DEBUG=True 进行测试。结果不成功。查看日志发现cookie还是登录前的状态,登录端是302定向的。(现在想来,应该是scrapy重定向的时候,用cookie还是登录前的cookie,所以未来状态仍然在登录之前)。
遇到这种情况,尝试关闭重定向,REDIRECT_ENABLED = False,然后测试一下,发现爬虫直接退出了。根据错误信息在网上找到答案,HTTPERROR_ALLOWED_CODES = 302,然后再次运行,完美解决。我得到了我想要的数据。到这个时候已经花了好几个小时了。中间走了很多弯路。
总结:遇到错误时,应该仔细分析错误信息,多尝试。保持清晰和耐心。从技术上来说,你对scrapy的理解还不够,对cookies和redirect的理解还不到位。了解操作原理,解决问题。这要简单得多。
REDIRECT_ENABLED = False 关闭重定向,不会重定向到新地址
HTTPERROR_ALLOWED_CODES = [302,] 返回302时,视为正常返回,可以正常写cookies
顺便说一句,python在解决实际问题的时候还是很实用的,可以快速上手,而且有很多开源库。建议大家有时间学习 查看全部
scrapy分页抓取网页(【每日一题】scrapy发现爬虫还是登陆之前的状态)
最近接触scrapy,爬了几个网站,用起来还是挺流畅的。
前几天,一个业务同事让我帮他抓取网站上的一个用户信息,我答应了。毕竟,通过前面的几次爬行,我已经信心爆棚了(从此)入坑)。
拿到一个网站之后就是先分析网站,分析之后发现需要的数据要登陆才能看到.这个可难不倒我,不就是模拟登陆吗,小菜一碟.
用chrome分析一下,看到有用户名,密码,还有其他两个校验值.另外还有一个重定向的callback值.如下:
接下来,登录并观察post请求的状态。因为有上面这行代码,跳转太快了,没看到post请求,删掉上面那行代码,然后再请求,这次看到了表单发送信息。
下一步就是编写代码并模拟登录。我马上写代码,然后开始测试。(还记得上面提到的两个校验值中的哪一个吗?这两个值都是动态的,可以使用正则的登陆页面提取出来)。
部分代码如下:
name = "form"
download_delay = 0.18
allowed_domains = ["http://www.xxxxxx.com"]
headers = {
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, sdch",
"Accept-Language":"zh-CN,zh;q=0.8",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Host": "www.xxxxxx.com",
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
def start_requests(self):
return [scrapy.Request("http://www.xxxxxxx.com/user/login",meta={'cookiejar':1},headers=self.headers, callback=self.post_login)]
def post_login(self, response):
# 下面这句话用于抓取请求网页后返回网页中的_xsrf字段的文字, 用于成功提交表单
protected_code = Selector(response).xpath('//label[@class="rem"]/input[@name="protected_code"]/@value').extract()[0]
matchObj=re.search(r'\"csrftk\":\"(.*)\",\"img_path\"',response.text)
csrf_tk=matchObj.group(1)
logging.log(logging.WARNING, u"正则获取的值----"+csrf_tk)
# FormRequeset.from_response是Scrapy提供的一个函数, 用于post表单
# 登陆成功后, 会调用after_login回调函数
return [scrapy.FormRequest.from_response(response,method="POST",
headers=self.headers, # 注意此处的headers
formdata={
'protected_code': protected_code,
'email': 'xxxxxx@qq.com',
'csrf_tk': csrf_tk,
'password': 'xxxxxxxxxx',
'remember': 'true',
},
meta={'cookiejar': response.meta['cookiejar']},
callback=self.after_login,
dont_filter=True
)]
然后设置 COOKIES_ENABLED = True 和 COOKIES_DEBUG=True 进行测试。结果不成功。查看日志发现cookie还是登录前的状态,登录端是302定向的。(现在想来,应该是scrapy重定向的时候,用cookie还是登录前的cookie,所以未来状态仍然在登录之前)。
遇到这种情况,尝试关闭重定向,REDIRECT_ENABLED = False,然后测试一下,发现爬虫直接退出了。根据错误信息在网上找到答案,HTTPERROR_ALLOWED_CODES = 302,然后再次运行,完美解决。我得到了我想要的数据。到这个时候已经花了好几个小时了。中间走了很多弯路。
总结:遇到错误时,应该仔细分析错误信息,多尝试。保持清晰和耐心。从技术上来说,你对scrapy的理解还不够,对cookies和redirect的理解还不到位。了解操作原理,解决问题。这要简单得多。
REDIRECT_ENABLED = False 关闭重定向,不会重定向到新地址
HTTPERROR_ALLOWED_CODES = [302,] 返回302时,视为正常返回,可以正常写cookies
顺便说一句,python在解决实际问题的时候还是很实用的,可以快速上手,而且有很多开源库。建议大家有时间学习
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-10-07 12:15
2015-06-23 更新:
之前写这篇文章的时候,还没有遇到具体的场景。只是觉得有这么一个方法,就写下来了。
我今天刚好满足了这个需求。为了抓取BBS的内容,版块首页只显示标题、作者和发布时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能在抓取链接内容后获取时间,这实际上造成了不必要的浪费。使用本文文章的方法可以在抓取链接前进行过滤,避免抓取无用数据。
第一部分scrapy爬虫开始(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取爬行。
具体思路:以我们豆瓣群为例。豆瓣社科群,我们以首页地址作为start_url参数,从页面源码中查找剩余页面,如下:
可以提取每个页面的地址,多页面抓取的思路是将地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并指定这些页面地址对应的回调函数。由于首页和分页在形式上完全一致(首页本身也是一个页面),所以可以直接指定parse作为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
之前的都是CrawlSpider,换成了不支持Rule的BaseSpider;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,相当于每个页面都提取了一个页面地址,这样实际上每个页面地址都返回了N次。, 那么scrapy在实际处理中会不会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》……
让我们运行程序看看。现在,让我们看看我们的打印语句:“->”代表当前页面地址,后面是从当前页面中提取的页面地址。为了简化输出,仅提取用于标识页面的“开始”。范围。
操作结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如您所见:
1. 每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除,并且它使用线程进行数据提取操作。
好了,任务完成了。使用CrawlSpider的规则感觉更方便。 查看全部
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
2015-06-23 更新:
之前写这篇文章的时候,还没有遇到具体的场景。只是觉得有这么一个方法,就写下来了。
我今天刚好满足了这个需求。为了抓取BBS的内容,版块首页只显示标题、作者和发布时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能在抓取链接内容后获取时间,这实际上造成了不必要的浪费。使用本文文章的方法可以在抓取链接前进行过滤,避免抓取无用数据。
第一部分scrapy爬虫开始(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取爬行。
具体思路:以我们豆瓣群为例。豆瓣社科群,我们以首页地址作为start_url参数,从页面源码中查找剩余页面,如下:
可以提取每个页面的地址,多页面抓取的思路是将地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并指定这些页面地址对应的回调函数。由于首页和分页在形式上完全一致(首页本身也是一个页面),所以可以直接指定parse作为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
之前的都是CrawlSpider,换成了不支持Rule的BaseSpider;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,相当于每个页面都提取了一个页面地址,这样实际上每个页面地址都返回了N次。, 那么scrapy在实际处理中会不会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》……
让我们运行程序看看。现在,让我们看看我们的打印语句:“->”代表当前页面地址,后面是从当前页面中提取的页面地址。为了简化输出,仅提取用于标识页面的“开始”。范围。
操作结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如您所见:
1. 每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除,并且它使用线程进行数据提取操作。
好了,任务完成了。使用CrawlSpider的规则感觉更方便。
scrapy分页抓取网页(【】本次项目利用scrapy爬虫框架实现框架 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-04 09:06
)
1、项目介绍
本项目使用scrapy爬虫框架抓取豆瓣top250的详情页信息。主要字段如下:
主要领域:
Num——》电影排行榜
DetailLink——》详情页链接
片名——》片名
RatingNum——"评级
票数——》评价数
导演——》导演
编剧——》编剧
演员——》主演
类型——“类型
发布日期——》发布时间
运行时间——》长度
2、创建项目文件
创建一个scrapy项目
crapy startproject douban
创建爬虫源文件
scrapy genspider douban250 www.douban.com
3、爬虫文件配置3.1配置设置文件
1)防爬配置
# 关闭 robots
ROBOTSTXT_OBEY = False
# 配置请求头
```python
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
# 为方便调试 修改日志等级为‘ERROR’
LOG_LEVEL = 'ERROR'
2)打开管道
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
3.2 配置项目文件
定义要爬取的字段
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Num = scrapy.Field()
DetailLink = scrapy.Field()
Title = scrapy.Field()
RatingNum = scrapy.Field()
Votes = scrapy.Field()
Director = scrapy.Field()
Writer = scrapy.Field()
Actor = scrapy.Field()
Type = scrapy.Field()
ReleaseDate = scrapy.Field()
RunTime = scrapy.Field()
4、爬虫文件写入4.1、字段空值处理
在爬取字段的过程中,部分电影详情页没有对应的字段信息。程序运行到这里会报错,影响爬虫的运行。其次,为了存储信息结构的完整性,应该从这个记录中给出这个字段。空值占用。为了处理上述问题,可以编写一个处理字段空值的函数如下:
def try_except(self, response, xpath_str):
try:
field = response.xpath(xpath_str).extract_first()
except:
field = ''
return field
4.2、 目录页面分析函数编写
def parse(self, response):
li_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in li_list:
item = DoubanItem()
# 解析每个字段时调用4.1定义的空值处理函数,传入网页相应和xpath表达式
item['Num'] = self.try_except(li, './/em/text()')
item['DetailLink'] = self.try_except(li, './/a[1]/@href')
# 提交详情页链接,经过调度,执行生成scrapy.http.Response 对象并送回给详情页解析方法
yield scrapy.Request(item['DetailLink'],
callback=self.parse_detail_html,
meta={'item': deepcopy(item)})
4.2、 翻页代码编写
抓取下一页的链接并完成链接,将下一页的响应对象交给目录页面分析方法
<p>next_url = 'https://movie.douban.com/top250' + self.try_except(response, '//*[@id="content"]/div/div[1]/div[2]/span[3]/a/@href')
print(f'已完成:{self.i}页')
self.i += 1
if self.i 查看全部
scrapy分页抓取网页(【】本次项目利用scrapy爬虫框架实现框架
)
1、项目介绍
本项目使用scrapy爬虫框架抓取豆瓣top250的详情页信息。主要字段如下:
主要领域:
Num——》电影排行榜
DetailLink——》详情页链接
片名——》片名
RatingNum——"评级
票数——》评价数
导演——》导演
编剧——》编剧
演员——》主演
类型——“类型
发布日期——》发布时间
运行时间——》长度
2、创建项目文件
创建一个scrapy项目
crapy startproject douban
创建爬虫源文件
scrapy genspider douban250 www.douban.com
3、爬虫文件配置3.1配置设置文件
1)防爬配置
# 关闭 robots
ROBOTSTXT_OBEY = False
# 配置请求头
```python
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
# 为方便调试 修改日志等级为‘ERROR’
LOG_LEVEL = 'ERROR'
2)打开管道
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
3.2 配置项目文件
定义要爬取的字段
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Num = scrapy.Field()
DetailLink = scrapy.Field()
Title = scrapy.Field()
RatingNum = scrapy.Field()
Votes = scrapy.Field()
Director = scrapy.Field()
Writer = scrapy.Field()
Actor = scrapy.Field()
Type = scrapy.Field()
ReleaseDate = scrapy.Field()
RunTime = scrapy.Field()
4、爬虫文件写入4.1、字段空值处理
在爬取字段的过程中,部分电影详情页没有对应的字段信息。程序运行到这里会报错,影响爬虫的运行。其次,为了存储信息结构的完整性,应该从这个记录中给出这个字段。空值占用。为了处理上述问题,可以编写一个处理字段空值的函数如下:
def try_except(self, response, xpath_str):
try:
field = response.xpath(xpath_str).extract_first()
except:
field = ''
return field
4.2、 目录页面分析函数编写
def parse(self, response):
li_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in li_list:
item = DoubanItem()
# 解析每个字段时调用4.1定义的空值处理函数,传入网页相应和xpath表达式
item['Num'] = self.try_except(li, './/em/text()')
item['DetailLink'] = self.try_except(li, './/a[1]/@href')
# 提交详情页链接,经过调度,执行生成scrapy.http.Response 对象并送回给详情页解析方法
yield scrapy.Request(item['DetailLink'],
callback=self.parse_detail_html,
meta={'item': deepcopy(item)})
4.2、 翻页代码编写
抓取下一页的链接并完成链接,将下一页的响应对象交给目录页面分析方法
<p>next_url = 'https://movie.douban.com/top250' + self.try_except(response, '//*[@id="content"]/div/div[1]/div[2]/span[3]/a/@href')
print(f'已完成:{self.i}页')
self.i += 1
if self.i
scrapy分页抓取网页(资源内容:|_1-1python分布式爬虫打造搜索引擎简介)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-04 08:45
资源内容:
关注Python分布式爬虫必须学习scripy框架来构建搜索引擎
|____1-1 Python分布式爬虫构建搜索引擎简介。mp4
|____2-1 pycharm.mp4的安装和简单使用
|____2-2mysql和Navicat的安装和使用。mp4
|____2-3在windows和Linux下安装python2和python3.MP4
|____2-4虚拟环境的安装和配置。mp4
|____3-1技术选择爬行动物能做什么。mp4
|____3-2正则表达式-1.mp4
|____3-3正则表达式-2.mp4
|____3-4正则表达式-3.mp4
|____3-5深度优先和广度优先原则。mp4
|____3-6url重复数据消除方法。mp4
|____3-7彻底理解Unicode和UTF8编码。mp4
|____4-1脚本安装和目录结构介绍。mp4
|____4-2pycharm调试脚本执行过程。mp4
|____4-3 XPath的使用-1.mp4
|____4-4 XPath的使用-2.mp4
|____4-5 XPath的使用-3.mp4
|____4-6 CSS选择器,用于实现字段解析-1.mp4
|____4-7 CSS选择器,用于实现字段解析-2.mp4
|____4-8写入爬行器以爬行jobpole的所有文章-1.MP4
|____4-9写入爬行器以爬行jobpole的所有文章-2.MP4
|____4-10项设计-1.mp4
|____4-11项目设计-2.mp4
|____4-12项目设计-3.mp4
|____4-13数据表设计并将项目保存到JSON文件.mp4
|____4-14通过管道将数据保存到MySQL-1.MP4
|____4-14通过管道将数据保存到MySQL-1.MP4
|____4-15通过管道将数据保存到MySQL-2.MP4
|____4-16废料装载机机构-1.mp4
|____4-17废料装载机机构-2.mp4
|____5-1会话和cookie自动登录机制。mp4
|____5-2(补充)硒模拟知乎登录-2017年12月2日9.mp4
|____5-3请求模拟登录知乎-1.mp4
|____5-4请求模拟登录知乎-2.mp4
|____5-5个模拟登录请求知乎-3.mp4
|____5-6场景模拟知乎login.mp4
|____5-7知乎分析和数据表设计1.mp4
|____5-8分析和数据表设计-mp4
|____5-9项目排序器模式提取问题-1.mp4
|____5-10项目订单提取问题-2.mp4
|____5-11项目订单提取问题-3.mp4
|____5-12知乎蜘蛛爬虫逻辑的实现和答案的提取-1.mp4
|____5-13知乎蜘蛛爬虫逻辑的实现和答案的提取-2.mp4
|____5-14将数据保存到MySQL-1.mp4
|____5-15将数据保存到MySQL-2.mp4
|____5-16将数据保存到MySQL-3.mp4
|____5-17(补充部分)知乎验证码登录-11.mp4
|____5-18(补充部分)知乎验证码登录-21.mp4
|____5-19(补充)知乎倒排字符识别-1.mp4
|____5-20(补充)知乎倒排字符识别-2.mp4
|____6-1结构设计数据表mp4
|____6-2爬行器源代码分析-新爬行器和设置配置。mp4
|____6-3crawlspider源代码分析.mp4
|____6-4规则和链接提取程序使用。Mp4
|____6-5通过itemloader.mp4进行位置分析
|____6-6位置数据仓库-1.mp4
|____6-7职位信息仓库-2.mp4
|____7-1爬行动物和反攀爬的对抗过程和策略。mp4
|____7-2脚本体系结构源代码分析。mp4
|____7-3请求和响应简介。mp4
|____7-4通过下载中间件随机替换用户代理-1.MP4
|____7-5通过下载中间件随机替换用户代理-2.MP4
|____通过7-6扫描实现IP代理池-1.MP4
|____7-7脚本实现IP代理池-2.mp4
|____7-8脚本实现IP代理池-3.mp4
|____7-9云编码实现验证码识别。mp4
|____7-10 cookie禁用、自动速度限制、自定义spider设置。mp4
|____8-1 selenium动态网页请求和模拟登录知乎。Mp4
|____8-2 selenium模拟登录到微博并模拟鼠标下拉。mp4
|____8-3chromedriver不会加载图片和幻影来获取动态网页。mp4
|____8-4selenium集成到场景中。mp4
|____8-6暂停并重新启动scratch.mp4
|____8-7图形重复数据消除原理。mp4
|____8-8GraphytelNet服务.mp4
|____8-9 spider中间件的详细说明。mp4
|____8-10扫描的数据采集。mp4
|____8-11扫描信号的详细说明。mp4
|____8-12扫描扩展开发。mp4
|____9-1分布式爬虫程序essentials.mp4
|____9-2 redis基础-1.mp4
|____9-3 redis的基本知识-2.mp4
|____9-4脚本redis编写分布式爬虫程序代码。mp4
|____9-5扫描的源代码分析-connection.py,defaults.py-。Mp4
|____9-6 scratch redis的源代码分析-dupefilter.py-。Mp4
|____9-7 scratch redis的源代码分析-pipelines.py,queue.py-。Mp4
|____9-8扫描redis的源代码分析-scheduler.py,spider.py-。Mp4
|____9-9将bloomfilter集成到scratch redis.mp4中
|____10-1 elasticsearch.mp4简介
|____10-2 LasticSearch安装。mp4
|____10-3 elasticsearch头插件和kibana安装。mp4
|____10-4 elasticsearch.mp4的基本概念
|____10-5反向索引0.mp4
|____10-6 elasticsearch基本索引和文档积垢操作。mp4
|____10-7 elasticsearch.mp4的mget和批量操作
|____10-8 elasticsearch.mp4的映射管理
|____10-9 elasticsearch的简单查询-1.mp4
|____10-10 elasticsearch的简单查询-2.mp4
|____10-11 elasticsearch.mp4的布尔组合查询
|____10-12使用扫描-1.mp4将数据写入elasticsearch
|____10-13将数据写入elasticsearch-2.mp4
|____11-1es完成搜索建议-保存搜索建议字段-1.mp4
|____11-2es完整搜索建议-保存搜索建议字段-2.mp4
|____11-3django实现elasticsearch-1.mp4的搜索建议
|____11-4django执行elasticsearch-2.mp4的搜索建议
|____11-5django实现弹性搜索功能-1.mp4
|____11-6django实现弹性搜索功能-2.mp4
|____11-7django实现搜索结果的分页。mp4
|____11-8搜索记录和流行搜索功能的实现-1.mp4
|____11-9搜索记录和流行搜索功能的实现-2.mp4
|____12-1 scratch部署项目.mp4
|____13-1课程总结。mp4
|____project.zip
|____。文本
|____播放前的注意事项.txt
|____第一章课程介绍
|____第二章Windows下的楼宇开发环境
|____第三章爬行动物基础知识综述
|____第四章:著名的抓痕爬行技术文章网站
|____第五章《刮痕》中著名的“爬行”问答
|____第六章通过爬行蜘蛛爬行招募网站
|____第七章scrapy突破反爬虫的限制
|____第8章scratch的高级开发
|____第9章:scratch redis分布式爬虫
|____第十章弹性搜索引擎的使用
|____第11章Django构建搜索网站
|____第12章:部署scratch爬虫
|____第13章课程总结 查看全部
scrapy分页抓取网页(资源内容:|_1-1python分布式爬虫打造搜索引擎简介)
资源内容:
关注Python分布式爬虫必须学习scripy框架来构建搜索引擎
|____1-1 Python分布式爬虫构建搜索引擎简介。mp4
|____2-1 pycharm.mp4的安装和简单使用
|____2-2mysql和Navicat的安装和使用。mp4
|____2-3在windows和Linux下安装python2和python3.MP4
|____2-4虚拟环境的安装和配置。mp4
|____3-1技术选择爬行动物能做什么。mp4
|____3-2正则表达式-1.mp4
|____3-3正则表达式-2.mp4
|____3-4正则表达式-3.mp4
|____3-5深度优先和广度优先原则。mp4
|____3-6url重复数据消除方法。mp4
|____3-7彻底理解Unicode和UTF8编码。mp4
|____4-1脚本安装和目录结构介绍。mp4
|____4-2pycharm调试脚本执行过程。mp4
|____4-3 XPath的使用-1.mp4
|____4-4 XPath的使用-2.mp4
|____4-5 XPath的使用-3.mp4
|____4-6 CSS选择器,用于实现字段解析-1.mp4
|____4-7 CSS选择器,用于实现字段解析-2.mp4
|____4-8写入爬行器以爬行jobpole的所有文章-1.MP4
|____4-9写入爬行器以爬行jobpole的所有文章-2.MP4
|____4-10项设计-1.mp4
|____4-11项目设计-2.mp4
|____4-12项目设计-3.mp4
|____4-13数据表设计并将项目保存到JSON文件.mp4
|____4-14通过管道将数据保存到MySQL-1.MP4
|____4-14通过管道将数据保存到MySQL-1.MP4
|____4-15通过管道将数据保存到MySQL-2.MP4
|____4-16废料装载机机构-1.mp4
|____4-17废料装载机机构-2.mp4
|____5-1会话和cookie自动登录机制。mp4
|____5-2(补充)硒模拟知乎登录-2017年12月2日9.mp4
|____5-3请求模拟登录知乎-1.mp4
|____5-4请求模拟登录知乎-2.mp4
|____5-5个模拟登录请求知乎-3.mp4
|____5-6场景模拟知乎login.mp4
|____5-7知乎分析和数据表设计1.mp4
|____5-8分析和数据表设计-mp4
|____5-9项目排序器模式提取问题-1.mp4
|____5-10项目订单提取问题-2.mp4
|____5-11项目订单提取问题-3.mp4
|____5-12知乎蜘蛛爬虫逻辑的实现和答案的提取-1.mp4
|____5-13知乎蜘蛛爬虫逻辑的实现和答案的提取-2.mp4
|____5-14将数据保存到MySQL-1.mp4
|____5-15将数据保存到MySQL-2.mp4
|____5-16将数据保存到MySQL-3.mp4
|____5-17(补充部分)知乎验证码登录-11.mp4
|____5-18(补充部分)知乎验证码登录-21.mp4
|____5-19(补充)知乎倒排字符识别-1.mp4
|____5-20(补充)知乎倒排字符识别-2.mp4
|____6-1结构设计数据表mp4
|____6-2爬行器源代码分析-新爬行器和设置配置。mp4
|____6-3crawlspider源代码分析.mp4
|____6-4规则和链接提取程序使用。Mp4
|____6-5通过itemloader.mp4进行位置分析
|____6-6位置数据仓库-1.mp4
|____6-7职位信息仓库-2.mp4
|____7-1爬行动物和反攀爬的对抗过程和策略。mp4
|____7-2脚本体系结构源代码分析。mp4
|____7-3请求和响应简介。mp4
|____7-4通过下载中间件随机替换用户代理-1.MP4
|____7-5通过下载中间件随机替换用户代理-2.MP4
|____通过7-6扫描实现IP代理池-1.MP4
|____7-7脚本实现IP代理池-2.mp4
|____7-8脚本实现IP代理池-3.mp4
|____7-9云编码实现验证码识别。mp4
|____7-10 cookie禁用、自动速度限制、自定义spider设置。mp4
|____8-1 selenium动态网页请求和模拟登录知乎。Mp4
|____8-2 selenium模拟登录到微博并模拟鼠标下拉。mp4
|____8-3chromedriver不会加载图片和幻影来获取动态网页。mp4
|____8-4selenium集成到场景中。mp4
|____8-6暂停并重新启动scratch.mp4
|____8-7图形重复数据消除原理。mp4
|____8-8GraphytelNet服务.mp4
|____8-9 spider中间件的详细说明。mp4
|____8-10扫描的数据采集。mp4
|____8-11扫描信号的详细说明。mp4
|____8-12扫描扩展开发。mp4
|____9-1分布式爬虫程序essentials.mp4
|____9-2 redis基础-1.mp4
|____9-3 redis的基本知识-2.mp4
|____9-4脚本redis编写分布式爬虫程序代码。mp4
|____9-5扫描的源代码分析-connection.py,defaults.py-。Mp4
|____9-6 scratch redis的源代码分析-dupefilter.py-。Mp4
|____9-7 scratch redis的源代码分析-pipelines.py,queue.py-。Mp4
|____9-8扫描redis的源代码分析-scheduler.py,spider.py-。Mp4
|____9-9将bloomfilter集成到scratch redis.mp4中
|____10-1 elasticsearch.mp4简介
|____10-2 LasticSearch安装。mp4
|____10-3 elasticsearch头插件和kibana安装。mp4
|____10-4 elasticsearch.mp4的基本概念
|____10-5反向索引0.mp4
|____10-6 elasticsearch基本索引和文档积垢操作。mp4
|____10-7 elasticsearch.mp4的mget和批量操作
|____10-8 elasticsearch.mp4的映射管理
|____10-9 elasticsearch的简单查询-1.mp4
|____10-10 elasticsearch的简单查询-2.mp4
|____10-11 elasticsearch.mp4的布尔组合查询
|____10-12使用扫描-1.mp4将数据写入elasticsearch
|____10-13将数据写入elasticsearch-2.mp4
|____11-1es完成搜索建议-保存搜索建议字段-1.mp4
|____11-2es完整搜索建议-保存搜索建议字段-2.mp4
|____11-3django实现elasticsearch-1.mp4的搜索建议
|____11-4django执行elasticsearch-2.mp4的搜索建议
|____11-5django实现弹性搜索功能-1.mp4
|____11-6django实现弹性搜索功能-2.mp4
|____11-7django实现搜索结果的分页。mp4
|____11-8搜索记录和流行搜索功能的实现-1.mp4
|____11-9搜索记录和流行搜索功能的实现-2.mp4
|____12-1 scratch部署项目.mp4
|____13-1课程总结。mp4
|____project.zip
|____。文本
|____播放前的注意事项.txt
|____第一章课程介绍
|____第二章Windows下的楼宇开发环境
|____第三章爬行动物基础知识综述
|____第四章:著名的抓痕爬行技术文章网站
|____第五章《刮痕》中著名的“爬行”问答
|____第六章通过爬行蜘蛛爬行招募网站
|____第七章scrapy突破反爬虫的限制
|____第8章scratch的高级开发
|____第9章:scratch redis分布式爬虫
|____第十章弹性搜索引擎的使用
|____第11章Django构建搜索网站
|____第12章:部署scratch爬虫
|____第13章课程总结
scrapy分页抓取网页(《,》第2季第16集.parse)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-03 19:14
为了获得PV,许多网站会将一个完整的文章划分为多个页面,这也会给爬虫程序带来一些小问题
分页文章
传统的方法是解析第一页的数据,将其保存到item,然后检测下一页是否存在。如果是这样,重复抓取功能直到它在最后一页停止
但是,扫描中存在一个问题。扫描中的回调函数无法返回值,并且无法返回捕获的文章正文。因此,可以使用request的meta属性在一个方向上将item变量传递给crawl函数
def parse_article(self, response):
"""parse article content
Arguments:
response {[type]} -- [description]
"""
selector = Selector(response)
article = ArticleItem()
# 先获取第一页的文章正文
article['content'] = selector.xpath(
'//article[@class="article-content"]').get()
# 拆分最后一页的 url, 可以得到文章的base url 和总页数
page_end_url = selector.xpath(
'//div[@class="pagination"]/ul/li/a/@href').extract()[-1]
page_base_url, page_count = re.findall(
'(.*?)_(.*?).html', page_end_url)[0]
page_count = int(page_count)
for page in range(2, page_count + 1):
# 构造出分页 url
url = page_base_url + '_{}.html'.format(page)
# 手动生成 Request 请求, 注意函数中的 priority 参数, 代表了 Request 是按顺序执行的, 值越大, 优先级越高
request = Request(url=url, callback=self.parse_content, priority=-page)
# 向 self.parse_content 函数传递 item 变量
request.meta['article'] = article
yield request
self.parse_uu内容主要用于抓取文章文本并将其存储在项目中
def parse_content(self, response):
selector = Selector(response)
article = response.meta['article']
# 注意这里对 article['content']的操作是 +=, 这样不会清空上一页保存的数据
article['content'] += selector.xpath('//article[@class="article-content"]').get()
yield article
参考:请求和答复 查看全部
scrapy分页抓取网页(《,》第2季第16集.parse)
为了获得PV,许多网站会将一个完整的文章划分为多个页面,这也会给爬虫程序带来一些小问题
分页文章
传统的方法是解析第一页的数据,将其保存到item,然后检测下一页是否存在。如果是这样,重复抓取功能直到它在最后一页停止
但是,扫描中存在一个问题。扫描中的回调函数无法返回值,并且无法返回捕获的文章正文。因此,可以使用request的meta属性在一个方向上将item变量传递给crawl函数
def parse_article(self, response):
"""parse article content
Arguments:
response {[type]} -- [description]
"""
selector = Selector(response)
article = ArticleItem()
# 先获取第一页的文章正文
article['content'] = selector.xpath(
'//article[@class="article-content"]').get()
# 拆分最后一页的 url, 可以得到文章的base url 和总页数
page_end_url = selector.xpath(
'//div[@class="pagination"]/ul/li/a/@href').extract()[-1]
page_base_url, page_count = re.findall(
'(.*?)_(.*?).html', page_end_url)[0]
page_count = int(page_count)
for page in range(2, page_count + 1):
# 构造出分页 url
url = page_base_url + '_{}.html'.format(page)
# 手动生成 Request 请求, 注意函数中的 priority 参数, 代表了 Request 是按顺序执行的, 值越大, 优先级越高
request = Request(url=url, callback=self.parse_content, priority=-page)
# 向 self.parse_content 函数传递 item 变量
request.meta['article'] = article
yield request
self.parse_uu内容主要用于抓取文章文本并将其存储在项目中
def parse_content(self, response):
selector = Selector(response)
article = response.meta['article']
# 注意这里对 article['content']的操作是 +=, 这样不会清空上一页保存的数据
article['content'] += selector.xpath('//article[@class="article-content"]').get()
yield article
参考:请求和答复
scrapy分页抓取网页(scrapy包中的headers方法如何实现scrapy分页只有使用函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-03 18:03
scrapy分页抓取网页需要爬取多页面,要分别抓取第一页和第三页,这样html就会变成一个多列的html,html中的内容就随机化分布在每一页面上.要写好多轮分页爬取,一方面要考虑分页的种类,如果是xpath分页爬取还可以加上正则匹配;另一方面还要考虑如何分页,xpath分页方法肯定是写一大堆的values和names,max_footer一般是会放在页面最后面.这些问题要是分别解决了就好很多.先看三种方法,然后自己去总结。
第一种方法scrapy提供的selector方法在python内部是按照python的表达式进行处理,类似于正则表达式这样,只有使用函数selectoritem_name=selector('')withselector('/subject>'):item_name.append('')第二种方法scrapy自身有个selector来对齐去除重复项,所以不需要额外创建分页元素withselector(''):item_name=selector('')txt_names=[]withselector(''):item_name.append('')txt_names.append('')第三种方法借助frompy包第四种方法使用frompy包中的headers方法如何实现scrapy的分页只有使用函数selectorwithselector('/subject'):page_count=2withselector('/item'):page_count+=1在其他处理后就可以跳到第三页,或者只有第一页,最后在多个页面中最后抽出第一页。 查看全部
scrapy分页抓取网页(scrapy包中的headers方法如何实现scrapy分页只有使用函数)
scrapy分页抓取网页需要爬取多页面,要分别抓取第一页和第三页,这样html就会变成一个多列的html,html中的内容就随机化分布在每一页面上.要写好多轮分页爬取,一方面要考虑分页的种类,如果是xpath分页爬取还可以加上正则匹配;另一方面还要考虑如何分页,xpath分页方法肯定是写一大堆的values和names,max_footer一般是会放在页面最后面.这些问题要是分别解决了就好很多.先看三种方法,然后自己去总结。
第一种方法scrapy提供的selector方法在python内部是按照python的表达式进行处理,类似于正则表达式这样,只有使用函数selectoritem_name=selector('')withselector('/subject>'):item_name.append('')第二种方法scrapy自身有个selector来对齐去除重复项,所以不需要额外创建分页元素withselector(''):item_name=selector('')txt_names=[]withselector(''):item_name.append('')txt_names.append('')第三种方法借助frompy包第四种方法使用frompy包中的headers方法如何实现scrapy的分页只有使用函数selectorwithselector('/subject'):page_count=2withselector('/item'):page_count+=1在其他处理后就可以跳到第三页,或者只有第一页,最后在多个页面中最后抽出第一页。
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-02 04:10
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
其实在本教程的第一个例子中,抓取豆瓣电影TOP列表,豆瓣的电影列表使用pager进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
.
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数时,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
其实在本教程的第一个例子中,抓取豆瓣电影TOP列表,豆瓣的电影列表使用pager进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
.
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数时,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(如何利用Scrapy爬虫框架网页全部文章信息(上篇))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-02 04:08
/前言/
在前面的文章:如何使用scrapy crawler框架捕获网页的所有文章信息(第一部分),我们获得了文章的详细信息页面链接,但在提取URL后,如何将其交给scrapy下载?下载后,如何调用我们自己定义的解析函数?此时,您需要在scrapy框架中使用另一个类请求。具体教程如下所示
/具体实施/
1、请求存储在script.http下,如下图所示。您可以直接导入它
我们需要将请求对象交给scrapy,然后scrapy crawler框架将帮助我们下载它
2、请求对象收录初始化参数URL和回调函数callback。当然,还有其他参数,这里将不讨论这些参数。我们将获得的文章链接URL传递给初始化参数URL,然后我们可以构建请求。需要注意的是,此请求是文章详细信息页面的页面,而不是文章的列表页面。对于文章详细信息页面,接下来,我们需要提取每个文章
3、在前面的文章基础上,提取网页的目标信息。提取的目标信息的表达式部分可以封装到函数parse_uudetail(),作为回调函数,用于提取文章的特定字段。以CSS选择器为例,如下图所示。如果希望使用XPath选择器进行提取,则没有问题。具体实现请参考文章历史中CSS和XPath选择器的使用。这里不再重复具体的实施过程
4、然后改进请求类并添加回调参数。记住在细节前面使用parse_uuaddself来指示它在当前类中,否则将报告错误。此外,parse_uu尽管detail是一个函数,但不能在这里添加括号,这是回调函数的特性
5、细心的孩子们可能已经注意到上图中请求类的URL部分非常复杂,解析也非常复杂。添加了Urljoin()函数。其实,这也是一个小技巧。让我们在这里简单地说一下。我希望这对孩子们有帮助。函数的作用是将相对地址合并成一个完整的URL。有时,网页标签不会向我们提供完整的URL链接或完整的域名,但会忽略网页的域名。如果没有域名,默认域名是当前网页的域名(即response.URL)。此时,我们需要拼接URL,形成完整的URL地址,以方便正常访问
6、请求类初始化后,如何将其交给scripy下载?事实上,这很简单。您只需要在前面输入一个yield关键字。它的功能是在scripy下载请求中提供URL
到目前为止,解析列表页面中所有文章URL并将其交给scripy下载的步骤已经完成。接下来我们需要做的是如何提取下一页的URL并将其提供给scripy下载。下一个文章将重点解决这个问题。请期待~~~
/总结/
基于scrapy crawler框架,本文使用CSS选择器和XPath选择器解析列表页面中文章的所有URL,并将它们交给scrapy下载。到目前为止,数据采集的基本功能已经完成。下一篇文章将完成如何提取下一页的URL并提交给scripy下载。请期待
-------------------结束------------------- 查看全部
scrapy分页抓取网页(如何利用Scrapy爬虫框架网页全部文章信息(上篇))
/前言/
在前面的文章:如何使用scrapy crawler框架捕获网页的所有文章信息(第一部分),我们获得了文章的详细信息页面链接,但在提取URL后,如何将其交给scrapy下载?下载后,如何调用我们自己定义的解析函数?此时,您需要在scrapy框架中使用另一个类请求。具体教程如下所示
/具体实施/
1、请求存储在script.http下,如下图所示。您可以直接导入它
我们需要将请求对象交给scrapy,然后scrapy crawler框架将帮助我们下载它
2、请求对象收录初始化参数URL和回调函数callback。当然,还有其他参数,这里将不讨论这些参数。我们将获得的文章链接URL传递给初始化参数URL,然后我们可以构建请求。需要注意的是,此请求是文章详细信息页面的页面,而不是文章的列表页面。对于文章详细信息页面,接下来,我们需要提取每个文章
3、在前面的文章基础上,提取网页的目标信息。提取的目标信息的表达式部分可以封装到函数parse_uudetail(),作为回调函数,用于提取文章的特定字段。以CSS选择器为例,如下图所示。如果希望使用XPath选择器进行提取,则没有问题。具体实现请参考文章历史中CSS和XPath选择器的使用。这里不再重复具体的实施过程
4、然后改进请求类并添加回调参数。记住在细节前面使用parse_uuaddself来指示它在当前类中,否则将报告错误。此外,parse_uu尽管detail是一个函数,但不能在这里添加括号,这是回调函数的特性
5、细心的孩子们可能已经注意到上图中请求类的URL部分非常复杂,解析也非常复杂。添加了Urljoin()函数。其实,这也是一个小技巧。让我们在这里简单地说一下。我希望这对孩子们有帮助。函数的作用是将相对地址合并成一个完整的URL。有时,网页标签不会向我们提供完整的URL链接或完整的域名,但会忽略网页的域名。如果没有域名,默认域名是当前网页的域名(即response.URL)。此时,我们需要拼接URL,形成完整的URL地址,以方便正常访问
6、请求类初始化后,如何将其交给scripy下载?事实上,这很简单。您只需要在前面输入一个yield关键字。它的功能是在scripy下载请求中提供URL
到目前为止,解析列表页面中所有文章URL并将其交给scripy下载的步骤已经完成。接下来我们需要做的是如何提取下一页的URL并将其提供给scripy下载。下一个文章将重点解决这个问题。请期待~~~
/总结/
基于scrapy crawler框架,本文使用CSS选择器和XPath选择器解析列表页面中文章的所有URL,并将它们交给scrapy下载。到目前为止,数据采集的基本功能已经完成。下一篇文章将完成如何提取下一页的URL并提交给scripy下载。请期待
-------------------结束-------------------
scrapy分页抓取网页(基于python的scrapy框架完成的spider分析网站源码需要爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-02 04:04
磕磕绊绊,爬了很多次,尝试了很多次,看了很多前辈的文章,终于在探索中领悟了。接下来,我将详细记录我的想法和详细代码。截止2020年7月18日,可以正常爬取了,接下来请听我说~
本项目基于python的scrapy框架。要想跑通,首先得安装python环境,搭建python环境。这个文章我就不详细介绍了,开始吧!
安装scrapy框架,一般如果你网速好,可以直接安装!
pip安装scrapy
明确我们的需求:
爬取链家北京二手房前100页数据分析。抓取链接为下一页做准备。需要抓取哪些数据来分析网页源代码
需要爬取的链接如下:
/ershoufang/ 首页链接/ershoufang/pg2/ 第二页/ershoufang/pg3/ 第三页
通过对比爬取链接,我们发现之前的链接基本相同,唯一不同的是最后一个数字,最后一个数字代表哪个页面,知道这些之后我们就可以开始创建scrapy项目了。
创建项目
scrapy startproject lianjia # 创建一个名为lianjia的爬虫项目
cd lianjia #进入新创建的项目
scrapy genspider lianjia_spider # 创建连家蜘蛛
解析网站的源码
发现list页需要的数据在li标签里,继续分析,因为我们这个项目的爬取思路是爬取标题,获取到标题中的链接,然后到详情页去继续爬取数据,通过定位到详情页的入口,我们往下走,进入详情页。
我发现详情页这两个地方的数据大都差不多。你想爬取哪些数据取决于读者的兴趣。我需要这两个地方的数据,所以会涉及到下面的一些项目。
编写一个scrapy项目
我用的编辑器是pycharm,一直用JB的产品,整体体验还是不错的。
根据自己的需要写item,方便以后写CSV、json、MySQL等
编写item,
class LianItem():
# 名称
title = scrapy.Field()
# 房屋类型
room_form = scrapy.Field()
# 房屋面积
size = scrapy.Field()
# 朝向
room_type = scrapy.Field()
# 几居室
main_info = scrapy.Field()
# 总价
total_price = scrapy.Field()
# 单价
unit_price = scrapy.Field()
# 小区
community = scrapy.Field()
# 区域
area = scrapy.Field()
# 装修情况
decorate = scrapy.Field()
# 挂牌时间
hangtag = scrapy.Field()
# 上次交易时间
last_time = scrapy.Field()
# 房屋年限
room_year = scrapy.Field()
# 抵押状态
pledge = scrapy.Field()
写spider(这是重点)
修改设置
ROBOTSTXT_OBEY = False # 不遵守爬虫协议
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36' } # 伪造浏览器请求头
ITEM_PIPELINES = { 'lian.pipelines.LianPipeline': 300, } # 开启我们的管道,本项目是将爬取到的数据存入CSV文件
将管道写入 CSV
def __init__(self):
# 打开文件,指定方式为写,利用第3个参数把csv写数据时产生的空行消除
self.f = open("lianjia_new.csv", "a", newline="")
# 设置文件第一行的字段名,注意要跟spider传过来的字典key名称相同
# self.fieldnames = ["place", "size", "price"]
self.fieldnames = [
"title", "room_form", "size", "room_type", "main_info",
"total_price", "unit_price", "community", "area", "decorate"
, "hangtag", "last_time", "room_year", "pledge",
]
# 指定文件的写入方式为csv字典写入,参数1为指定具体文件,参数2为指定字段名
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
# 写入第一行字段名,因为只要写入一次,所以文件放在__init__里面
self.writer.writeheader()
def process_item(self, item, spider):
# 写入spider传过来的具体数值
self.writer.writerow(item)
# 写入完返回
return item
def close(self, spider):
self.f.close()
进入项目目录,启动爬虫
scrapy crawl 爬虫名称
运行后,你会发现你的项目中多了一个CSV文件,大功告成。(最后看了几张没抓到的数据,应该是xpath没写,不是难点,有时间我再优化一下,今天比较忙,所以我们先做吧~)
写到最后,有问题的朋友欢迎加我~ 查看全部
scrapy分页抓取网页(基于python的scrapy框架完成的spider分析网站源码需要爬取)
磕磕绊绊,爬了很多次,尝试了很多次,看了很多前辈的文章,终于在探索中领悟了。接下来,我将详细记录我的想法和详细代码。截止2020年7月18日,可以正常爬取了,接下来请听我说~
本项目基于python的scrapy框架。要想跑通,首先得安装python环境,搭建python环境。这个文章我就不详细介绍了,开始吧!
安装scrapy框架,一般如果你网速好,可以直接安装!
pip安装scrapy
明确我们的需求:
爬取链家北京二手房前100页数据分析。抓取链接为下一页做准备。需要抓取哪些数据来分析网页源代码
需要爬取的链接如下:
/ershoufang/ 首页链接/ershoufang/pg2/ 第二页/ershoufang/pg3/ 第三页
通过对比爬取链接,我们发现之前的链接基本相同,唯一不同的是最后一个数字,最后一个数字代表哪个页面,知道这些之后我们就可以开始创建scrapy项目了。
创建项目
scrapy startproject lianjia # 创建一个名为lianjia的爬虫项目
cd lianjia #进入新创建的项目
scrapy genspider lianjia_spider # 创建连家蜘蛛
解析网站的源码
发现list页需要的数据在li标签里,继续分析,因为我们这个项目的爬取思路是爬取标题,获取到标题中的链接,然后到详情页去继续爬取数据,通过定位到详情页的入口,我们往下走,进入详情页。
我发现详情页这两个地方的数据大都差不多。你想爬取哪些数据取决于读者的兴趣。我需要这两个地方的数据,所以会涉及到下面的一些项目。
编写一个scrapy项目
我用的编辑器是pycharm,一直用JB的产品,整体体验还是不错的。
根据自己的需要写item,方便以后写CSV、json、MySQL等
编写item,
class LianItem():
# 名称
title = scrapy.Field()
# 房屋类型
room_form = scrapy.Field()
# 房屋面积
size = scrapy.Field()
# 朝向
room_type = scrapy.Field()
# 几居室
main_info = scrapy.Field()
# 总价
total_price = scrapy.Field()
# 单价
unit_price = scrapy.Field()
# 小区
community = scrapy.Field()
# 区域
area = scrapy.Field()
# 装修情况
decorate = scrapy.Field()
# 挂牌时间
hangtag = scrapy.Field()
# 上次交易时间
last_time = scrapy.Field()
# 房屋年限
room_year = scrapy.Field()
# 抵押状态
pledge = scrapy.Field()
写spider(这是重点)
修改设置
ROBOTSTXT_OBEY = False # 不遵守爬虫协议
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36' } # 伪造浏览器请求头
ITEM_PIPELINES = { 'lian.pipelines.LianPipeline': 300, } # 开启我们的管道,本项目是将爬取到的数据存入CSV文件
将管道写入 CSV
def __init__(self):
# 打开文件,指定方式为写,利用第3个参数把csv写数据时产生的空行消除
self.f = open("lianjia_new.csv", "a", newline="")
# 设置文件第一行的字段名,注意要跟spider传过来的字典key名称相同
# self.fieldnames = ["place", "size", "price"]
self.fieldnames = [
"title", "room_form", "size", "room_type", "main_info",
"total_price", "unit_price", "community", "area", "decorate"
, "hangtag", "last_time", "room_year", "pledge",
]
# 指定文件的写入方式为csv字典写入,参数1为指定具体文件,参数2为指定字段名
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
# 写入第一行字段名,因为只要写入一次,所以文件放在__init__里面
self.writer.writeheader()
def process_item(self, item, spider):
# 写入spider传过来的具体数值
self.writer.writerow(item)
# 写入完返回
return item
def close(self, spider):
self.f.close()
进入项目目录,启动爬虫
scrapy crawl 爬虫名称
运行后,你会发现你的项目中多了一个CSV文件,大功告成。(最后看了几张没抓到的数据,应该是xpath没写,不是难点,有时间我再优化一下,今天比较忙,所以我们先做吧~)
写到最后,有问题的朋友欢迎加我~
scrapy分页抓取网页(scrapy成熟的爬虫框架的考量及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-01 20:07
)
最近在用scrapy做一个爬虫爬取网站上的一些信息,但是出现了一个很奇怪的问题,就是在网页中打开了要爬取的URL,某个URL位于网页的源代码。需要爬取一些元素,但是我用scrapy爬取数据的时候,发现一个错误,结果是爬取的网页没有收录我在浏览器中看到的元素,也就是for the same URL,抓取的页面和我在浏览器打开看到的页面不一样!
反复确认CSS类选择器正确,爬虫爬取的URL没有重定向到其他页面后,发现事情并不简单。
然后机缘巧合下,没有修改任何代码,再次运行,却发现再次爬取成功,然后又试了一次,报错了。这时候就知道,抓取到的页面一定是 完整的页面没有加载完成。
当页面没有完全加载时,我首先想到了两种可能:
首先,部分数据在网页加载时由js动态写入,即部分数据在第一次请求时传递给js,由前端js处理后显示在页面上;
二是网页数据是异步加载的,在抓取网页的时候部分数据还没有加载。
基于scrapy是一个成熟的爬虫框架的考虑,我认为第一种情况应该不会出现。毕竟爬虫可以等到页面初始化好再爬,但是对于第二种情况,因为数据Loading是异步的,所以无法提前控制。
基于以上考虑,直接考虑第二种情况。因此,您可以在浏览器控制台的 Network 中检查所有发送的请求,看看您需要的数据是否被异步加载。如下图所示,可以查看每个请求的Response,手动检查是否返回了你需要的信息。
在我的例子中,果然如上图所示,我找到了整个异步请求返回的json格式数据,里面收录了我需要的所有信息,我什至不需要再抓取网页了,只是作为如下图,查看请求的header,可以看到异步请求的请求格式,也就是图中的Request URL
将获取到的Request URL复制到新的浏览器窗口打开,可以看到下图,可以访问json格式的返回数据,说明网站没有拦截到这种请求,这也使得我没必要去抓取页面的数据了,我只需要直接构造对应的URL,分析返回的json数据,就大功告成了!
查看全部
scrapy分页抓取网页(scrapy成熟的爬虫框架的考量及应用
)
最近在用scrapy做一个爬虫爬取网站上的一些信息,但是出现了一个很奇怪的问题,就是在网页中打开了要爬取的URL,某个URL位于网页的源代码。需要爬取一些元素,但是我用scrapy爬取数据的时候,发现一个错误,结果是爬取的网页没有收录我在浏览器中看到的元素,也就是for the same URL,抓取的页面和我在浏览器打开看到的页面不一样!
反复确认CSS类选择器正确,爬虫爬取的URL没有重定向到其他页面后,发现事情并不简单。
然后机缘巧合下,没有修改任何代码,再次运行,却发现再次爬取成功,然后又试了一次,报错了。这时候就知道,抓取到的页面一定是 完整的页面没有加载完成。
当页面没有完全加载时,我首先想到了两种可能:
首先,部分数据在网页加载时由js动态写入,即部分数据在第一次请求时传递给js,由前端js处理后显示在页面上;
二是网页数据是异步加载的,在抓取网页的时候部分数据还没有加载。
基于scrapy是一个成熟的爬虫框架的考虑,我认为第一种情况应该不会出现。毕竟爬虫可以等到页面初始化好再爬,但是对于第二种情况,因为数据Loading是异步的,所以无法提前控制。
基于以上考虑,直接考虑第二种情况。因此,您可以在浏览器控制台的 Network 中检查所有发送的请求,看看您需要的数据是否被异步加载。如下图所示,可以查看每个请求的Response,手动检查是否返回了你需要的信息。
在我的例子中,果然如上图所示,我找到了整个异步请求返回的json格式数据,里面收录了我需要的所有信息,我什至不需要再抓取网页了,只是作为如下图,查看请求的header,可以看到异步请求的请求格式,也就是图中的Request URL
将获取到的Request URL复制到新的浏览器窗口打开,可以看到下图,可以访问json格式的返回数据,说明网站没有拦截到这种请求,这也使得我没必要去抓取页面的数据了,我只需要直接构造对应的URL,分析返回的json数据,就大功告成了!
scrapy分页抓取网页( WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-30 11:10
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简单数据分析系列文章的第十二篇文章。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
第 3 页上的参数是 #_rnd39
第 4 页上的参数是 #_rnd76:
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper 的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper 就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因其实涉及到对网页的一点了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简单数据分析系列文章的第十二篇文章。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
第 3 页上的参数是 #_rnd39
第 4 页上的参数是 #_rnd76:
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper 的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper 就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因其实涉及到对网页的一点了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-30 11:08
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
.
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper 的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper 就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因其实涉及到对网页的一点了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用分页器进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
.
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper 的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper 就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因其实涉及到对网页的一点了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。

