
scrapy分页抓取网页
scrapy分页抓取网页( Java开发之scrapy框架(一):日期,热度和ID)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-26 07:11
Java开发之scrapy框架(一):日期,热度和ID)
4、日期、人气和ID
5、程序运行图
三、具体开发
1、任务要求
1.爬取文章及网易、搜狐、凤凰、澎湃的评论网站及评论
2.新闻页数不低于10万页
3.每个新闻页面及其评论可在1天内更新
2、功能设计
1. 设计一个可以抓取指定网站的所有页面的网络爬虫,并提取文章和评论内容
2. 定期运行网络爬虫,每天更新数据
3、系统架构
先简单介绍下scrapy框架,它是一个爬虫框架
绿线是数据流向,
(1)首先从初始URL开始,Scheduler会交给Downloader下载,
(2)下载后交给Spider分析,这里的Spider是爬虫的核心功能代码
(3)Spider对结果的分析有两种方式:一种是需要进一步爬取的链接,通过中间件返回给Scheduler;另一种是需要保存的数据,发送到ItemPipeline,处理和存储
(4)最后输出所有数据并保存为文件
4、实际项目
(1)项目结构
可以看到,NewsSpider-master是一个完整的项目文件夹,下面存放着每个网站对应的爬虫启动脚本debug_xx.py。 scrapyspider文件夹存放scrapy框架需要的相关文件,spiders文件夹存放实际爬虫代码
(2)爬虫引擎
以网易新闻的爬虫news_163.py为例,简单说明部分核心代码:
①定义爬虫类:
class news163_Spider(CrawlSpider):
# 网易新闻爬虫名称
name = "163news"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
#网易全网
allowed_domains = [
"163.com"
]
#新闻版
start_urls = [
'http://news.163.com/'
]
#正则表达式表示可以继续访问的url规则,http://news.163.com/\d\d\d\d\d(/([\w\._+-])*)*$
rules = [
Rule(LinkExtractor(
allow=(
('http://news\.163\.com/.*$')
),
deny = ('http://.*.163.com/photo.*$')
),
callback="parse_item",
follow=True)
]
②网页内容分析模块
根据不同内容的Xpath路径从页面中提取内容。由于网站不同时期的页面结构不同,根据不同的页面布局分为几个if判断语句块;
def parse_item(self, response):
# response是当前url的响应
article = Selector(response)
article_url = response.url
global count
# 分析网页类型
# 比较新的网易新闻 http://news.163.com/05-17/
if get_category(article) == 1:
articleXpath = '//*[@id="epContentLeft"]'
if article.xpath(articleXpath):
titleXpath = '//*[@id="epContentLeft"]/h1/text()'
dateXpath = '//*[@id="epContentLeft"]/div[1]/text()'
contentXpath = '//*[@id="endText"]'
news_infoXpath ='//*[@id="post_comment_area"]/script[3]/text()'
# 标题
if article.xpath(titleXpath):
news_item = newsItem()
news_item['url'] = article_url
get_title(article, titleXpath, news_item)
# 日期
if article.xpath(dateXpath):
get_date(article, dateXpath, news_item)
# 内容
if article.xpath(contentXpath):
get_content(article, contentXpath, news_item)
count = count + 1
news_item['id'] = count
# 评论
try:
comment_url = get_comment_url(article, news_infoXpath)
# 评论处理
comments = get_comment(comment_url, news_item)[1]
news_item['comments'] = comments
except:
news_item['comments'] = ' '
news_item['heat'] = 0
yield news_item
根据正则表达式匹配页面内容中的日期信息:
'''通用日期处理函数'''
def get_date(article, dateXpath, news_item):
# 时间
try:
article_date = article.xpath(dateXpath).extract()[0]
pattern = re.compile("(\d.*\d)") # 正则匹配新闻时间
article_datetime = pattern.findall(article_date)[0]
#article_datetime = datetime.datetime.strptime(article_datetime, "%Y-%m-%d %H:%M:%S")
news_item['date'] = article_datetime
except:
news_item['date'] = '2010-10-01 17:00:00'
其他功能:
'''网站分类函数'''
def get_category(article):
'''字符过滤函数'''
def str_replace(content):
'''通用正文处理函数'''
def get_content(article, contentXpath, news_item):
'''评论信息提取函数'''
def get_comment_url(article, news_infoXpath):
'''评论处理函数'''
def get_comment(comment_url, news_item):
(3)运行爬虫并格式化存储
①在settings.py中配置
import sys
# 这里改成爬虫项目的绝对路径,防止出现路径搜索的bug
sys.path.append('E:\Python\以前的项目\\NewsSpider-master\scrapyspider')
# 爬虫名称
BOT_NAME = 'scrapyspider'
# 设置是否服从网站的爬虫规则
ROBOTSTXT_OBEY = True
# 同时并发请求数,越大则爬取越快同时负载也大
CONCURRENT_REQUESTS = 32
#禁止cookies,防止被ban
COOKIES_ENABLED = False
# 输出的编码格式,由于Excel默认是ANSI编码,所以这里保持一致
# 如果有其他编码需求如utf-8等可自行更改
FEED_EXPORT_ENCODING = 'ANSI'
# 增加爬取延迟,降低被爬网站服务器压力
DOWNLOAD_DELAY = 0.01
# 爬取的新闻条数上限
CLOSESPIDER_ITEMCOUNT = 500
# 下载超时设定,超过10秒没响应则放弃当前URL
DOWNLOAD_TIMEOUT = 100
ITEM_PIPELINES = {
'scrapyspider.pipelines.ScrapyspiderPipeline': 300,# pipeline中的类名
}
②运行爬虫,保存新闻内容
抓取到的新闻内容和评论需要进行格式化和存储。如果在IDE中运行调试脚本,效果如下:
抓取后会保存为.csv文件,用Excel打开即可查看:
③如果需要单独提取评论,可以使用csv_process.py,效果如下:
四、其他补充
目前不可用 查看全部
scrapy分页抓取网页(
Java开发之scrapy框架(一):日期,热度和ID)
4、日期、人气和ID
5、程序运行图
三、具体开发
1、任务要求
1.爬取文章及网易、搜狐、凤凰、澎湃的评论网站及评论
2.新闻页数不低于10万页
3.每个新闻页面及其评论可在1天内更新
2、功能设计
1. 设计一个可以抓取指定网站的所有页面的网络爬虫,并提取文章和评论内容
2. 定期运行网络爬虫,每天更新数据
3、系统架构
先简单介绍下scrapy框架,它是一个爬虫框架
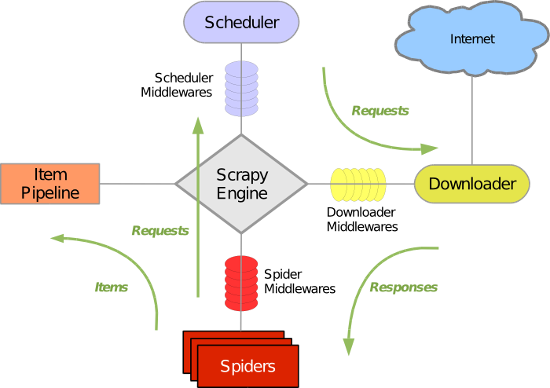
绿线是数据流向,
(1)首先从初始URL开始,Scheduler会交给Downloader下载,
(2)下载后交给Spider分析,这里的Spider是爬虫的核心功能代码
(3)Spider对结果的分析有两种方式:一种是需要进一步爬取的链接,通过中间件返回给Scheduler;另一种是需要保存的数据,发送到ItemPipeline,处理和存储
(4)最后输出所有数据并保存为文件
4、实际项目
(1)项目结构
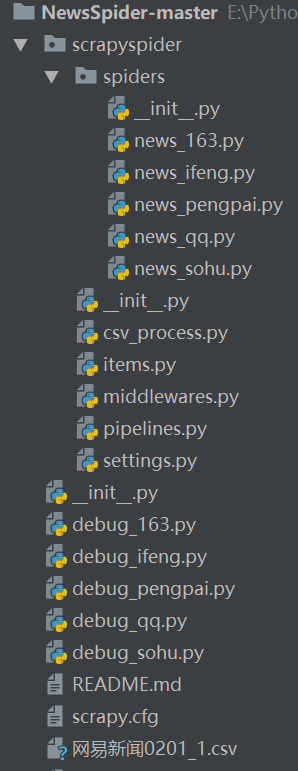
可以看到,NewsSpider-master是一个完整的项目文件夹,下面存放着每个网站对应的爬虫启动脚本debug_xx.py。 scrapyspider文件夹存放scrapy框架需要的相关文件,spiders文件夹存放实际爬虫代码
(2)爬虫引擎
以网易新闻的爬虫news_163.py为例,简单说明部分核心代码:
①定义爬虫类:
class news163_Spider(CrawlSpider):
# 网易新闻爬虫名称
name = "163news"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
#网易全网
allowed_domains = [
"163.com"
]
#新闻版
start_urls = [
'http://news.163.com/'
]
#正则表达式表示可以继续访问的url规则,http://news.163.com/\d\d\d\d\d(/([\w\._+-])*)*$
rules = [
Rule(LinkExtractor(
allow=(
('http://news\.163\.com/.*$')
),
deny = ('http://.*.163.com/photo.*$')
),
callback="parse_item",
follow=True)
]
②网页内容分析模块
根据不同内容的Xpath路径从页面中提取内容。由于网站不同时期的页面结构不同,根据不同的页面布局分为几个if判断语句块;
def parse_item(self, response):
# response是当前url的响应
article = Selector(response)
article_url = response.url
global count
# 分析网页类型
# 比较新的网易新闻 http://news.163.com/05-17/
if get_category(article) == 1:
articleXpath = '//*[@id="epContentLeft"]'
if article.xpath(articleXpath):
titleXpath = '//*[@id="epContentLeft"]/h1/text()'
dateXpath = '//*[@id="epContentLeft"]/div[1]/text()'
contentXpath = '//*[@id="endText"]'
news_infoXpath ='//*[@id="post_comment_area"]/script[3]/text()'
# 标题
if article.xpath(titleXpath):
news_item = newsItem()
news_item['url'] = article_url
get_title(article, titleXpath, news_item)
# 日期
if article.xpath(dateXpath):
get_date(article, dateXpath, news_item)
# 内容
if article.xpath(contentXpath):
get_content(article, contentXpath, news_item)
count = count + 1
news_item['id'] = count
# 评论
try:
comment_url = get_comment_url(article, news_infoXpath)
# 评论处理
comments = get_comment(comment_url, news_item)[1]
news_item['comments'] = comments
except:
news_item['comments'] = ' '
news_item['heat'] = 0
yield news_item
根据正则表达式匹配页面内容中的日期信息:
'''通用日期处理函数'''
def get_date(article, dateXpath, news_item):
# 时间
try:
article_date = article.xpath(dateXpath).extract()[0]
pattern = re.compile("(\d.*\d)") # 正则匹配新闻时间
article_datetime = pattern.findall(article_date)[0]
#article_datetime = datetime.datetime.strptime(article_datetime, "%Y-%m-%d %H:%M:%S")
news_item['date'] = article_datetime
except:
news_item['date'] = '2010-10-01 17:00:00'
其他功能:
'''网站分类函数'''
def get_category(article):
'''字符过滤函数'''
def str_replace(content):
'''通用正文处理函数'''
def get_content(article, contentXpath, news_item):
'''评论信息提取函数'''
def get_comment_url(article, news_infoXpath):
'''评论处理函数'''
def get_comment(comment_url, news_item):
(3)运行爬虫并格式化存储
①在settings.py中配置
import sys
# 这里改成爬虫项目的绝对路径,防止出现路径搜索的bug
sys.path.append('E:\Python\以前的项目\\NewsSpider-master\scrapyspider')
# 爬虫名称
BOT_NAME = 'scrapyspider'
# 设置是否服从网站的爬虫规则
ROBOTSTXT_OBEY = True
# 同时并发请求数,越大则爬取越快同时负载也大
CONCURRENT_REQUESTS = 32
#禁止cookies,防止被ban
COOKIES_ENABLED = False
# 输出的编码格式,由于Excel默认是ANSI编码,所以这里保持一致
# 如果有其他编码需求如utf-8等可自行更改
FEED_EXPORT_ENCODING = 'ANSI'
# 增加爬取延迟,降低被爬网站服务器压力
DOWNLOAD_DELAY = 0.01
# 爬取的新闻条数上限
CLOSESPIDER_ITEMCOUNT = 500
# 下载超时设定,超过10秒没响应则放弃当前URL
DOWNLOAD_TIMEOUT = 100
ITEM_PIPELINES = {
'scrapyspider.pipelines.ScrapyspiderPipeline': 300,# pipeline中的类名
}
②运行爬虫,保存新闻内容
抓取到的新闻内容和评论需要进行格式化和存储。如果在IDE中运行调试脚本,效果如下:
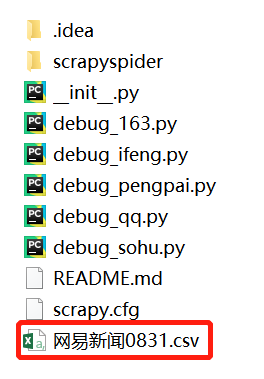
抓取后会保存为.csv文件,用Excel打开即可查看:
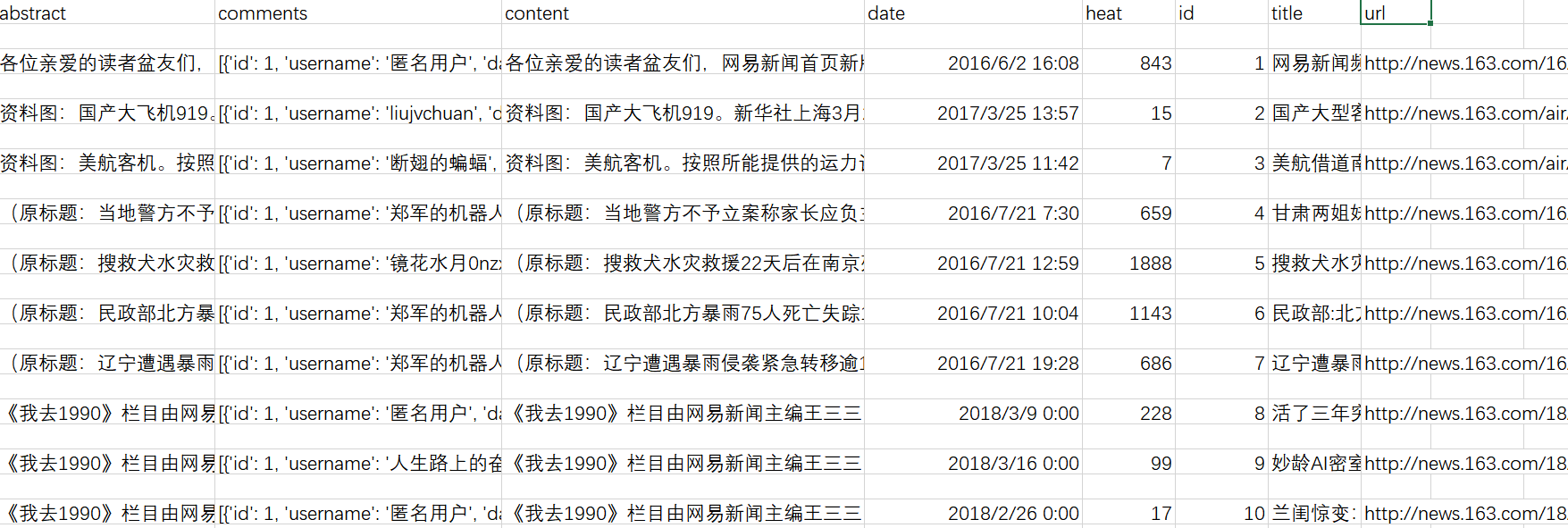
③如果需要单独提取评论,可以使用csv_process.py,效果如下:
四、其他补充
目前不可用
scrapy分页抓取网页(Scrapy跳转到倒数第二页(基于示例地址地址)吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-25 18:10
我有 Scrapy 的分页问题。
我通常成功使用以下代码
next_page = response.xpath("//div//div[4]//ul[1]//li[10]//a[1]//@href").extract_first()
if next_page is not None:
yield scrapy.Request(url = response.urljoin(next_page), callback=self.parse)
事实证明,在这次尝试中,我遇到了一个使用 5 个页面块的 网站。见下文。
因此,在捕获前 5 页后,Scrapy 跳转到倒数第二页(526).
分页结构遵循以下逻辑:
它在数量上增加。
任何人都可以帮助我进行此分页增量查询(基于示例地址)?
最佳答案
当谈到分页时,最好的方法实际上取决于所使用的分页类型。
如果你:
了解url页面格式
比如url参数page表示你所在的页面知道总页数
然后您可以一次安排所有页面:
def parse_listings_page1(self, response):
"""
here parse first page, schedule all other pages at once!
"""
# e.g. 'http://shop.com/products?page=1'
url = response.url
# e.g. 100
total_pages = int(response.css('.last-page').extract_first())
# schedule every page at once!
for page in range(2, total_pages + 1):
page_url = add_or_replace_parameter(url, 'page', page)
yield Request(page_url, self.parse_listings)
# don't forget to also parse listings on first page!
yield from self.parse_listings(response)
def parse_listings(self, response):
for url in response.css('.listing::attr(href)'):
yield Request(url, self.parse_product)
这种方式最大的好处就是速度——在这里你可以采用异步逻辑,同时抓取所有页面!
或者。
如果你: 查看全部
scrapy分页抓取网页(Scrapy跳转到倒数第二页(基于示例地址地址)吗?)
我有 Scrapy 的分页问题。
我通常成功使用以下代码
next_page = response.xpath("//div//div[4]//ul[1]//li[10]//a[1]//@href").extract_first()
if next_page is not None:
yield scrapy.Request(url = response.urljoin(next_page), callback=self.parse)
事实证明,在这次尝试中,我遇到了一个使用 5 个页面块的 网站。见下文。

因此,在捕获前 5 页后,Scrapy 跳转到倒数第二页(526).
分页结构遵循以下逻辑:
它在数量上增加。
任何人都可以帮助我进行此分页增量查询(基于示例地址)?
最佳答案
当谈到分页时,最好的方法实际上取决于所使用的分页类型。
如果你:
了解url页面格式
比如url参数page表示你所在的页面知道总页数
然后您可以一次安排所有页面:
def parse_listings_page1(self, response):
"""
here parse first page, schedule all other pages at once!
"""
# e.g. 'http://shop.com/products?page=1'
url = response.url
# e.g. 100
total_pages = int(response.css('.last-page').extract_first())
# schedule every page at once!
for page in range(2, total_pages + 1):
page_url = add_or_replace_parameter(url, 'page', page)
yield Request(page_url, self.parse_listings)
# don't forget to also parse listings on first page!
yield from self.parse_listings(response)
def parse_listings(self, response):
for url in response.css('.listing::attr(href)'):
yield Request(url, self.parse_product)
这种方式最大的好处就是速度——在这里你可以采用异步逻辑,同时抓取所有页面!
或者。
如果你:
scrapy分页抓取网页(接下来分析如何要闻页签下的所有新闻标题和链接(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-25 18:08
本文的目的是捕获所有在腾讯新闻首页新闻主页上签名的新闻标题和链接。
如图:
地址:
新闻标签中通常有几个标签:
因此,要抓取所有新闻标题和新闻下的链接,需要一一抓取。让我们开始编写代码。
首先获取腾讯新闻页面的内容,编写一个接口获取页面。
首先导入本次爬网所需的库
# -*- coding:utf-8 -*-
#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#随机数生成
import random
#gzip
import gzip
from StringIO import StringIO
构建请求头、请求页面
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
请求一个腾讯新闻页面,返回的页面数据有时会被gzip压缩,如果直接读取会出现二进制代码,所以在处理返回的页面时需要做gizp解压
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
整理代码段,最后封装成页面请求接口
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):
try:
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
html = None
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
return html
#如果请求异常
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
elif hasattr(e, "reason"):
print e.reason
return None
#其他异常
except Exception,e:
return None
页面请求接口写好后,接下来就是分析如何上报新闻页面下的所有数据。新闻页面下有几个选项卡。当我们请求分页时,可以看到腾讯新闻页面的请求是通过ajax实现的。打开谷歌在浏览器的网络中,可以看到请求分页时的信息。如图:
分析请求地址会发现每一个分页请求都是一个地址后面跟着一个随机数,地址中会有这个请求的索引。
这样我们就可以构造出页面的请求地址,获取到每个页面的信息。但在此之前,我们不知道腾讯新闻会有多少页。
分析腾讯新闻的页面,我们最终会发现首页的一段js表示腾讯新闻有多少个页面。
所以我们先抓取腾讯新闻页面的内容,获取新闻中有多少个页面,构造页面请求,最后取出页面信息中的所有新闻
标题和原创链接就好了。代码显示如下:
<p>def tencentStart():
#腾讯新闻地址
INDEX_URL = 'http://news.qq.com/top_index.shtml#hotnews'
#腾讯要闻请求地址
SUB_URL = "http://news.qq.com/c/2013ywList_{0}.htm"
#页面数获取正则
PAGE_PATTERNS = 'getString.pageCount.*?=.*?(\d+);'
#标题和链接获取正则
NEWS_PATTERNS = ' 查看全部
scrapy分页抓取网页(接下来分析如何要闻页签下的所有新闻标题和链接(图))
本文的目的是捕获所有在腾讯新闻首页新闻主页上签名的新闻标题和链接。
如图:

地址:
新闻标签中通常有几个标签:

因此,要抓取所有新闻标题和新闻下的链接,需要一一抓取。让我们开始编写代码。
首先获取腾讯新闻页面的内容,编写一个接口获取页面。
首先导入本次爬网所需的库
# -*- coding:utf-8 -*-
#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#随机数生成
import random
#gzip
import gzip
from StringIO import StringIO
构建请求头、请求页面
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
请求一个腾讯新闻页面,返回的页面数据有时会被gzip压缩,如果直接读取会出现二进制代码,所以在处理返回的页面时需要做gizp解压
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
整理代码段,最后封装成页面请求接口
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):
try:
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
html = None
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
return html
#如果请求异常
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
elif hasattr(e, "reason"):
print e.reason
return None
#其他异常
except Exception,e:
return None
页面请求接口写好后,接下来就是分析如何上报新闻页面下的所有数据。新闻页面下有几个选项卡。当我们请求分页时,可以看到腾讯新闻页面的请求是通过ajax实现的。打开谷歌在浏览器的网络中,可以看到请求分页时的信息。如图:
分析请求地址会发现每一个分页请求都是一个地址后面跟着一个随机数,地址中会有这个请求的索引。
这样我们就可以构造出页面的请求地址,获取到每个页面的信息。但在此之前,我们不知道腾讯新闻会有多少页。
分析腾讯新闻的页面,我们最终会发现首页的一段js表示腾讯新闻有多少个页面。

所以我们先抓取腾讯新闻页面的内容,获取新闻中有多少个页面,构造页面请求,最后取出页面信息中的所有新闻
标题和原创链接就好了。代码显示如下:
<p>def tencentStart():
#腾讯新闻地址
INDEX_URL = 'http://news.qq.com/top_index.shtml#hotnews'
#腾讯要闻请求地址
SUB_URL = "http://news.qq.com/c/2013ywList_{0}.htm"
#页面数获取正则
PAGE_PATTERNS = 'getString.pageCount.*?=.*?(\d+);'
#标题和链接获取正则
NEWS_PATTERNS = '
scrapy分页抓取网页( 基于Twisted异步网络库来处理网络通讯的整体架构大致Scrapy )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-24 07:10
基于Twisted异步网络库来处理网络通讯的整体架构大致Scrapy
)
1. Scrapy 简介
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如,Amazon Associates Web Services)或一般网络抓取工具返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试
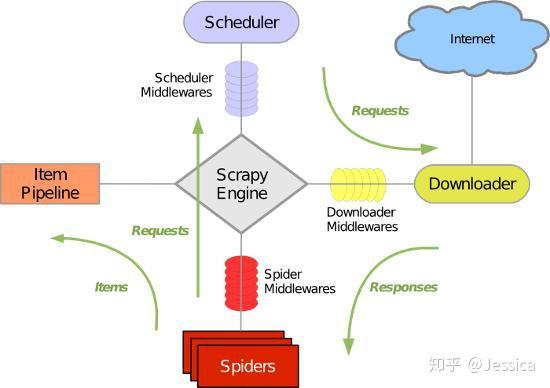
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
刮痧
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
首先,引擎从调度器中获取一个链接(URL),供下一个爬虫引擎使用,将URL封装成请求(Request)传递给下载器,下载器下载资源并封装成响应包(Response ) 然后,如果爬虫解析Response解析出一个实体(Item),就会交给实体管道做进一步处理。如果是解析的链接(URL),则将该URL交给Scheduler等待爬取
2. 安装 Scrapy
使用以下命令:
更多虚拟环境操作请查看我的博文
3. Scrapy 教程
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
该命令会在当前目录下新建一个目录tutorial,其结构如下:
这些文件主要是:
3.1. 定义项
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
通过创建一个scrapy.Item 类并定义一个scrapy.Field 类型的类属性来声明一个Item。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。编辑教程目录下的 items.py 文件
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的强制性属性:
在 /tutorial/tutorial/spiders 目录下创建 dmoz_spider.py
3.3. 爬行
当前项目结构
进入项目根目录,运行命令:
操作结果:
3.4. 提取项目
3.4.1. 介绍选择器
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 或 CSS 的表达机制:Scrapy Selectors
XPath 表达式示例及对应含义:
更强大的功能请查看XPath教程
为了方便XPaths的使用,Scrapy提供了Selector类,它有四个方法:
3.4.2. 获取数据
首先使用谷歌浏览器开发者工具,查看网站的源码,看到需要取出的数据表格(这个方法比较麻烦),比较简单的方法就是在你要的东西上右击有兴趣查看元素,可以直接查看网站源码
查看网站的源码后,网站的信息在第二个
编写自己的项目管道非常简单。每个item管道组件都是一个独立的Python类,必须同时实现以下方法:
为 JSON 文件编写一个项目
在settings.py中设置ITEM_PIPELINES来激活item管道,默认为[]
3.6. 存储数据
使用以下命令存储为json文件格式
4. Scarpy 优化豆瓣爬虫爬取
主要是对之前写过的豆瓣爬虫的重构:
豆瓣具有抗爬虫机制。只成功一次后,被ban后会显示403。先说爬虫结构。
完整的豆瓣爬虫代码链接
4.1. 物品
4.2. Spider 主程序
4.3. 未来需要解决的问题
豆瓣抓了一阵子,还没来得及兴奋就被禁了。
禁止
最后为大家准备了一些python学习教程,希望对大家有所帮助。
查看全部
scrapy分页抓取网页(
基于Twisted异步网络库来处理网络通讯的整体架构大致Scrapy
)

1. Scrapy 简介
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如,Amazon Associates Web Services)或一般网络抓取工具返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
刮痧
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
首先,引擎从调度器中获取一个链接(URL),供下一个爬虫引擎使用,将URL封装成请求(Request)传递给下载器,下载器下载资源并封装成响应包(Response ) 然后,如果爬虫解析Response解析出一个实体(Item),就会交给实体管道做进一步处理。如果是解析的链接(URL),则将该URL交给Scheduler等待爬取
2. 安装 Scrapy
使用以下命令:
更多虚拟环境操作请查看我的博文
3. Scrapy 教程
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
该命令会在当前目录下新建一个目录tutorial,其结构如下:
这些文件主要是:
3.1. 定义项
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
通过创建一个scrapy.Item 类并定义一个scrapy.Field 类型的类属性来声明一个Item。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。编辑教程目录下的 items.py 文件
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的强制性属性:
在 /tutorial/tutorial/spiders 目录下创建 dmoz_spider.py
3.3. 爬行
当前项目结构
进入项目根目录,运行命令:
操作结果:
3.4. 提取项目
3.4.1. 介绍选择器
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 或 CSS 的表达机制:Scrapy Selectors
XPath 表达式示例及对应含义:
更强大的功能请查看XPath教程
为了方便XPaths的使用,Scrapy提供了Selector类,它有四个方法:
3.4.2. 获取数据
首先使用谷歌浏览器开发者工具,查看网站的源码,看到需要取出的数据表格(这个方法比较麻烦),比较简单的方法就是在你要的东西上右击有兴趣查看元素,可以直接查看网站源码
查看网站的源码后,网站的信息在第二个
编写自己的项目管道非常简单。每个item管道组件都是一个独立的Python类,必须同时实现以下方法:
为 JSON 文件编写一个项目
在settings.py中设置ITEM_PIPELINES来激活item管道,默认为[]
3.6. 存储数据
使用以下命令存储为json文件格式
4. Scarpy 优化豆瓣爬虫爬取
主要是对之前写过的豆瓣爬虫的重构:
豆瓣具有抗爬虫机制。只成功一次后,被ban后会显示403。先说爬虫结构。
完整的豆瓣爬虫代码链接
4.1. 物品
4.2. Spider 主程序
4.3. 未来需要解决的问题
豆瓣抓了一阵子,还没来得及兴奋就被禁了。
禁止
最后为大家准备了一些python学习教程,希望对大家有所帮助。

scrapy分页抓取网页(WebCrawler如何调度针对不同站点的网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-23 17:18
网络爬虫(Spider)是一种在互联网上爬行的机器人。当然,它通常不是物理机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实就是一个程序,不是爬行,而是有一定的用途,爬行的时候会采集. 一些信息。例如,谷歌有很多爬虫采集网页内容和它们之间的链接信息;另一个例子是别有用心的爬虫在互联网上采集诸如foo [at] bar [dot] com之类的东西。此外,还有一些定制的爬虫,专门针对某个网站。比如JavaEye的Robbin前段时间写了几篇专门对付恶意爬虫的博客(原链接好像已经过期了,所以不行),还有网站 小众软件、LinuxToy、酷琴网等经常被整个站点爬下来,挂在另一个名字下。其实,爬虫的基本原理非常简单。只要能上网,能分析网页,现在大部分语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。
爬虫的两部分是下载网页。有很多问题需要考虑,比如如何最大限度地利用本地带宽,如何调度不同站点的Web请求以减少其他服务器的负担。在高性能的Web Crawler系统中,DNS查询也将成为亟待优化的瓶颈。此外,还有一些“配置文件”需要遵循(例如,robots.txt)。获取网页后的分析过程也很复杂。网上奇奇怪怪的东西很多,各种HTML页面也有各种错误。几乎不可能清楚地分析所有这些。另外,随着AJAX的普及,如何获取Javascript动态生成的内容成为了一个大问题;此外,互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。例如,这个网站据说是谷歌之前宣布互联网上Unique URL的数量已经达到1万亿,所以这个人很自豪地宣布第二万亿。
然而,实际上并没有多少人需要像谷歌这样的通用爬虫。通常我们构建一个爬虫来爬取某个特定的或者某类网站,所谓知己知彼,百战不死,我们可以提前爬取对网站做一些分析网站 结构,事情变得容易多了。通过分析和选择有价值的链接进行跟踪,我们可以避免很多不必要的链接或蜘蛛陷阱。如果网站的结构允许选择合适的路径,我们可以把感兴趣的东西按照一定的顺序重新爬上去,这样就连URL重复的判断都可以省略了。
比如我们要爬下pongba博客中的博客文字,通过观察,很容易发现我们对其中的两个页面感兴趣:
文章列表页面,比如首页,或者URL为/page/\d+/的页面,通过Firebug可以看到每个文章链接都在h1下的一个标签中(应该是注意到Firebug的HTML面板中看到的HTML代码可能与View Source中看到的有些不同,如果网页中有动态修改DOM树的Javascript,则前者是修改后的版本,Firebug是正则化的,对于比如属性有引号等等,后者通常是你的蜘蛛爬取的原创内容,如果用正则表达式分析页面或者使用的HTML Parser和Firefox有些不同,(需要特别注意)。另外,一个div里面有指向不同列表页的链接,类是wp-pagenavi 文章 内容页,每个博客都有这样一个页面,比如/2008/09/11/machine-learning-and-ai-resources/,收录了文章的完整内容,这是我们感觉感兴趣的内容。
因此,我们从首页开始,利用 wp-pagenavi 中的链接来获取其他 文章 列表页面。特别是我们定义了一个路径:只跟随Next Page的链接,这样我们就可以从头到尾按顺序走一遍,免去了判断和重复爬行的麻烦。另外,文章列表页上链接到具体文章的链接对应的页面就是我们真正要保存的数据页。
这样,它实用的脚本语言写一个ad hoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的Crawler Framework,简单轻量,非常方便,官网说已经在实际生产中使用过,所以不是玩具级别的东西。不过目前还没有Release版本,你可以直接使用他们的Mercurial仓库获取安装源码。不过这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。
Scrapy 使用异步网络库 Twisted 来处理网络通信。它结构清晰,收录各种中间件接口,可以灵活满足各种需求。整体架构如下图所示:
绿线是数据流。首先从初始URL开始,Scheduler将其交给Downloader下载,下载完成后交给Spider进行分析。Spider分析的结果有两种:一种是需要进一步爬取的链接。比如之前分析过的“下一页”的链接,这些东西会被发回给Scheduler;另一个是需要保存的数据,发送到Item Pipeline,就是数据的后处理(详细分析、过滤、存储等)。此外,可以在数据流通道中安装各种中间件来进行必要的处理。
它看起来很复杂,但使用起来非常简单。就像Rails一样,首先新建一个项目:
scrapy-admin.py startproject blog_crawl
会创建一个blog_crawl目录,里面有一个scrapy-ctl.py是整个项目的控制脚本,代码全部放在子目录blog_crawl下。为了能够爬取,我们在spiders目录下新建了一个mindhacks_spider.py,定义我们的Spider如下:
from scrapy.spider import BaseSpider
class MindhacksSpider(BaseSpider):
domain_name = "mindhacks.cn"
start_urls = ["http://mindhacks.cn/"]
def parse(self, response):
return []
SPIDER = MindhacksSpider()
我们的MindhacksSpider继承自BaseSpider(通常是直接继承自scrapy.contrib.spiders.CrawlSpider,它更通用,更方便,但为了展示数据是如何解析的,这里使用了BaseSpider),变量domain_name和start_urls很容易理解是什么意思,parse方法就是我们需要定义的回调函数。默认请求在得到响应后会调用这个回调函数。我们这里需要解析页面,返回两个结果(需要进一步爬取链接,需要保存Data),让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是在一个混合列表中返回的。目前尚不清楚为什么会出现这种设计。最后不是要分开吗?总之,这里我们先写一个空函数,它只返回一个空列表。另外,定义一个“全局”变量 SPIDER,当 Scrapy 导入这个模块时会实例化,并且会被 Scrapy 引擎自动找到。所以你可以先运行爬虫试试:
./scrapy-ctl.py crawl mindhacks.cn
会有一堆输出,可以看到爬取了,因为这是初始的URL,但是因为我们在parse函数中没有返回需要进一步爬取的URL,所以整个爬取过程只爬到了首页就结束了. 下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们进行实验。使用以下命令启动 Shell:
./scrapy-ctl.py shell http://mindhacks.cn
它会启动爬虫,抓取命令行指定的页面,然后进入shell。根据提示,我们有很多现成的变量可以使用。其中之一是 hxs,它是一个 HtmlXPathSelector。mindhacks 的 HTML 页面更加标准化。直接用XPath分析非常方便。通过Firebug可以看到每个博客文章的链接都在h1下,所以在Shell中使用这个XPath表达式测试:
In [1]: hxs.x('//h1/a/@href').extract()
Out[1]:
[u'http://mindhacks.cn/2009/07/06/why-you-should-do-it-yourself/',
u'http://mindhacks.cn/2009/05/17/seven-years-in-nju/',
u'http://mindhacks.cn/2009/03/28/effective-learning-and-memorization/',
u'http://mindhacks.cn/2009/03/15/preconception-explained/',
u'http://mindhacks.cn/2009/03/09/first-principles-of-programming/',
u'http://mindhacks.cn/2009/02/15/why-you-should-start-blogging-now/',
u'http://mindhacks.cn/2009/02/09/writing-is-better-thinking/',
u'http://mindhacks.cn/2009/02/07/better-explained-conflicts-in-intimate-relationship/',
u'http://mindhacks.cn/2009/02/07/independence-day/',
u'http://mindhacks.cn/2009/01/18/escape-from-your-shawshank-part1/']
这正是我们需要的 URL。另外可以找到“下一页”的链接,和其他几个页面的链接放在一个div里,但是“下一页”的链接没有title属性,所以写XPath
//div[@class="wp-pagenavi"]/a[not(@title)]
但是,如果你往回翻一页,你会发现“上一页”其实是一样的,所以你需要确定链接上的文字是下一页的箭头u'\xbb',这可能有是用 XPath 写的。去,不过好像这本身就是一个unicode转义字符,由于编码原因不清楚,直接在外面判断,最终解析函数如下:
def parse(self, response):
items = []
hxs = HtmlXPathSelector(response)
posts = hxs.x('//h1/a/@href').extract()
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
for url in posts])
page_links = hxs.x('//div[@class="wp-pagenavi"]/a[not(@title)]')
for link in page_links:
if link.x('text()').extract()[0] == u'\xbb':
url = link.x('@href').extract()[0]
items.append(self.make_requests_from_url(url))
return items
前半部分是解析需要爬取的博客正文的链接,后半部分是给出“下一页”的链接。需要注意的是,这里返回的列表并非都是字符串格式的URL。Scrapy希望得到Request对象,它可以携带比字符串格式的URL更多的东西,比如cookies或者回调。功能等。可以看到我们在创建博客正文的请求时替换了回调函数,因为默认的回调函数parse是专门用来解析文章列表等页面的,parse_post定义如下:
def parse_post(self, response):
item = BlogCrawlItem()
item.url = unicode(response.url)
item.raw = response.body_as_unicode()
return [item]
这很简单。返回一个 BlogCrawlItem 并将捕获的数据放入其中。你可以在这里做一些分析。比如可以通过XPath解析文本和标题,但是我倾向于后期做这些事情,比如Item Pipeline或者Later Offline stage。BlogCrawlItem 是 Scrapy 自动为我们定义的一个空类,继承自 ScrapedItem。在 items.py 中,我在这里添加了一些内容:
from scrapy.item import ScrapedItem
class BlogCrawlItem(ScrapedItem):
def __init__(self):
ScrapedItem.__init__(self)
self.url = ''
def __str__(self):
return 'BlogCrawlItem(url: %s)' % self.url
定义了__str__函数,只给出了URL,因为默认的__str__函数会显示所有的数据,所以看到爬取的时候,控制台日志会输出一些东西,就是把爬取到的网页的内容输出出来。-.-bb
这样,数据就被取出来了,最后只剩下存储数据的功能了。我们通过添加流水线来实现它。由于Python在标准库中自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。将 pipelines.py 的内容替换为以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import sqlite3
from os import path
from scrapy.core import signals
from scrapy.xlib.pydispatch import dispatcher
class SQLiteStorePipeline(object):
filename = 'data.sqlite'
def __init__(self):
self.conn = None
dispatcher.connect(self.initialize, signals.engine_started)
dispatcher.connect(self.finalize, signals.engine_stopped)
def process_item(self, domain, item):
self.conn.execute('insert into blog values(?,?,?)',
(item.url, item.raw, unicode(domain)))
return item
def initialize(self):
if path.exists(self.filename):
self.conn = sqlite3.connect(self.filename)
else:
self.conn = self.create_table(self.filename)
def finalize(self):
if self.conn is not None:
self.conn.commit()
self.conn.close()
self.conn = None
def create_table(self, filename):
conn = sqlite3.connect(filename)
conn.execute("""create table blog
(url text primary key, raw text, domain text)""")
conn.commit()
return conn
在__init__函数中,使用dispatcher将两个信号连接到指定函数,用于初始化和关闭数据库连接。Dd-.-) 丢失。当数据通过管道时,将调用 process_item 函数。这里我们将原创数据直接存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取和过滤数据,但我不会在这里详细介绍。
最后,在 settings.py 中列出我们的管道:
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再次运行爬虫就OK了!最后总结一下:一个高质量的爬虫是一个极其复杂的项目,但是如果你有一个好的工具,做一个专用的爬虫是相对容易的。Scrapy是一个非常轻量级的爬虫框架,极大的简化了爬虫的开发过程。另外,Scrapy的文档也很详细。如果觉得我的介绍省略了一些不清楚的地方,推荐阅读他的Tutorial。
本文来自: 查看全部
scrapy分页抓取网页(WebCrawler如何调度针对不同站点的网络爬虫)
网络爬虫(Spider)是一种在互联网上爬行的机器人。当然,它通常不是物理机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实就是一个程序,不是爬行,而是有一定的用途,爬行的时候会采集. 一些信息。例如,谷歌有很多爬虫采集网页内容和它们之间的链接信息;另一个例子是别有用心的爬虫在互联网上采集诸如foo [at] bar [dot] com之类的东西。此外,还有一些定制的爬虫,专门针对某个网站。比如JavaEye的Robbin前段时间写了几篇专门对付恶意爬虫的博客(原链接好像已经过期了,所以不行),还有网站 小众软件、LinuxToy、酷琴网等经常被整个站点爬下来,挂在另一个名字下。其实,爬虫的基本原理非常简单。只要能上网,能分析网页,现在大部分语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。
爬虫的两部分是下载网页。有很多问题需要考虑,比如如何最大限度地利用本地带宽,如何调度不同站点的Web请求以减少其他服务器的负担。在高性能的Web Crawler系统中,DNS查询也将成为亟待优化的瓶颈。此外,还有一些“配置文件”需要遵循(例如,robots.txt)。获取网页后的分析过程也很复杂。网上奇奇怪怪的东西很多,各种HTML页面也有各种错误。几乎不可能清楚地分析所有这些。另外,随着AJAX的普及,如何获取Javascript动态生成的内容成为了一个大问题;此外,互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。例如,这个网站据说是谷歌之前宣布互联网上Unique URL的数量已经达到1万亿,所以这个人很自豪地宣布第二万亿。
然而,实际上并没有多少人需要像谷歌这样的通用爬虫。通常我们构建一个爬虫来爬取某个特定的或者某类网站,所谓知己知彼,百战不死,我们可以提前爬取对网站做一些分析网站 结构,事情变得容易多了。通过分析和选择有价值的链接进行跟踪,我们可以避免很多不必要的链接或蜘蛛陷阱。如果网站的结构允许选择合适的路径,我们可以把感兴趣的东西按照一定的顺序重新爬上去,这样就连URL重复的判断都可以省略了。
比如我们要爬下pongba博客中的博客文字,通过观察,很容易发现我们对其中的两个页面感兴趣:
文章列表页面,比如首页,或者URL为/page/\d+/的页面,通过Firebug可以看到每个文章链接都在h1下的一个标签中(应该是注意到Firebug的HTML面板中看到的HTML代码可能与View Source中看到的有些不同,如果网页中有动态修改DOM树的Javascript,则前者是修改后的版本,Firebug是正则化的,对于比如属性有引号等等,后者通常是你的蜘蛛爬取的原创内容,如果用正则表达式分析页面或者使用的HTML Parser和Firefox有些不同,(需要特别注意)。另外,一个div里面有指向不同列表页的链接,类是wp-pagenavi 文章 内容页,每个博客都有这样一个页面,比如/2008/09/11/machine-learning-and-ai-resources/,收录了文章的完整内容,这是我们感觉感兴趣的内容。
因此,我们从首页开始,利用 wp-pagenavi 中的链接来获取其他 文章 列表页面。特别是我们定义了一个路径:只跟随Next Page的链接,这样我们就可以从头到尾按顺序走一遍,免去了判断和重复爬行的麻烦。另外,文章列表页上链接到具体文章的链接对应的页面就是我们真正要保存的数据页。
这样,它实用的脚本语言写一个ad hoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的Crawler Framework,简单轻量,非常方便,官网说已经在实际生产中使用过,所以不是玩具级别的东西。不过目前还没有Release版本,你可以直接使用他们的Mercurial仓库获取安装源码。不过这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。
Scrapy 使用异步网络库 Twisted 来处理网络通信。它结构清晰,收录各种中间件接口,可以灵活满足各种需求。整体架构如下图所示:

绿线是数据流。首先从初始URL开始,Scheduler将其交给Downloader下载,下载完成后交给Spider进行分析。Spider分析的结果有两种:一种是需要进一步爬取的链接。比如之前分析过的“下一页”的链接,这些东西会被发回给Scheduler;另一个是需要保存的数据,发送到Item Pipeline,就是数据的后处理(详细分析、过滤、存储等)。此外,可以在数据流通道中安装各种中间件来进行必要的处理。
它看起来很复杂,但使用起来非常简单。就像Rails一样,首先新建一个项目:
scrapy-admin.py startproject blog_crawl
会创建一个blog_crawl目录,里面有一个scrapy-ctl.py是整个项目的控制脚本,代码全部放在子目录blog_crawl下。为了能够爬取,我们在spiders目录下新建了一个mindhacks_spider.py,定义我们的Spider如下:
from scrapy.spider import BaseSpider
class MindhacksSpider(BaseSpider):
domain_name = "mindhacks.cn"
start_urls = ["http://mindhacks.cn/"]
def parse(self, response):
return []
SPIDER = MindhacksSpider()
我们的MindhacksSpider继承自BaseSpider(通常是直接继承自scrapy.contrib.spiders.CrawlSpider,它更通用,更方便,但为了展示数据是如何解析的,这里使用了BaseSpider),变量domain_name和start_urls很容易理解是什么意思,parse方法就是我们需要定义的回调函数。默认请求在得到响应后会调用这个回调函数。我们这里需要解析页面,返回两个结果(需要进一步爬取链接,需要保存Data),让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是在一个混合列表中返回的。目前尚不清楚为什么会出现这种设计。最后不是要分开吗?总之,这里我们先写一个空函数,它只返回一个空列表。另外,定义一个“全局”变量 SPIDER,当 Scrapy 导入这个模块时会实例化,并且会被 Scrapy 引擎自动找到。所以你可以先运行爬虫试试:
./scrapy-ctl.py crawl mindhacks.cn
会有一堆输出,可以看到爬取了,因为这是初始的URL,但是因为我们在parse函数中没有返回需要进一步爬取的URL,所以整个爬取过程只爬到了首页就结束了. 下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们进行实验。使用以下命令启动 Shell:
./scrapy-ctl.py shell http://mindhacks.cn
它会启动爬虫,抓取命令行指定的页面,然后进入shell。根据提示,我们有很多现成的变量可以使用。其中之一是 hxs,它是一个 HtmlXPathSelector。mindhacks 的 HTML 页面更加标准化。直接用XPath分析非常方便。通过Firebug可以看到每个博客文章的链接都在h1下,所以在Shell中使用这个XPath表达式测试:
In [1]: hxs.x('//h1/a/@href').extract()
Out[1]:
[u'http://mindhacks.cn/2009/07/06/why-you-should-do-it-yourself/',
u'http://mindhacks.cn/2009/05/17/seven-years-in-nju/',
u'http://mindhacks.cn/2009/03/28/effective-learning-and-memorization/',
u'http://mindhacks.cn/2009/03/15/preconception-explained/',
u'http://mindhacks.cn/2009/03/09/first-principles-of-programming/',
u'http://mindhacks.cn/2009/02/15/why-you-should-start-blogging-now/',
u'http://mindhacks.cn/2009/02/09/writing-is-better-thinking/',
u'http://mindhacks.cn/2009/02/07/better-explained-conflicts-in-intimate-relationship/',
u'http://mindhacks.cn/2009/02/07/independence-day/',
u'http://mindhacks.cn/2009/01/18/escape-from-your-shawshank-part1/']
这正是我们需要的 URL。另外可以找到“下一页”的链接,和其他几个页面的链接放在一个div里,但是“下一页”的链接没有title属性,所以写XPath
//div[@class="wp-pagenavi"]/a[not(@title)]
但是,如果你往回翻一页,你会发现“上一页”其实是一样的,所以你需要确定链接上的文字是下一页的箭头u'\xbb',这可能有是用 XPath 写的。去,不过好像这本身就是一个unicode转义字符,由于编码原因不清楚,直接在外面判断,最终解析函数如下:
def parse(self, response):
items = []
hxs = HtmlXPathSelector(response)
posts = hxs.x('//h1/a/@href').extract()
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
for url in posts])
page_links = hxs.x('//div[@class="wp-pagenavi"]/a[not(@title)]')
for link in page_links:
if link.x('text()').extract()[0] == u'\xbb':
url = link.x('@href').extract()[0]
items.append(self.make_requests_from_url(url))
return items
前半部分是解析需要爬取的博客正文的链接,后半部分是给出“下一页”的链接。需要注意的是,这里返回的列表并非都是字符串格式的URL。Scrapy希望得到Request对象,它可以携带比字符串格式的URL更多的东西,比如cookies或者回调。功能等。可以看到我们在创建博客正文的请求时替换了回调函数,因为默认的回调函数parse是专门用来解析文章列表等页面的,parse_post定义如下:
def parse_post(self, response):
item = BlogCrawlItem()
item.url = unicode(response.url)
item.raw = response.body_as_unicode()
return [item]
这很简单。返回一个 BlogCrawlItem 并将捕获的数据放入其中。你可以在这里做一些分析。比如可以通过XPath解析文本和标题,但是我倾向于后期做这些事情,比如Item Pipeline或者Later Offline stage。BlogCrawlItem 是 Scrapy 自动为我们定义的一个空类,继承自 ScrapedItem。在 items.py 中,我在这里添加了一些内容:
from scrapy.item import ScrapedItem
class BlogCrawlItem(ScrapedItem):
def __init__(self):
ScrapedItem.__init__(self)
self.url = ''
def __str__(self):
return 'BlogCrawlItem(url: %s)' % self.url
定义了__str__函数,只给出了URL,因为默认的__str__函数会显示所有的数据,所以看到爬取的时候,控制台日志会输出一些东西,就是把爬取到的网页的内容输出出来。-.-bb
这样,数据就被取出来了,最后只剩下存储数据的功能了。我们通过添加流水线来实现它。由于Python在标准库中自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。将 pipelines.py 的内容替换为以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import sqlite3
from os import path
from scrapy.core import signals
from scrapy.xlib.pydispatch import dispatcher
class SQLiteStorePipeline(object):
filename = 'data.sqlite'
def __init__(self):
self.conn = None
dispatcher.connect(self.initialize, signals.engine_started)
dispatcher.connect(self.finalize, signals.engine_stopped)
def process_item(self, domain, item):
self.conn.execute('insert into blog values(?,?,?)',
(item.url, item.raw, unicode(domain)))
return item
def initialize(self):
if path.exists(self.filename):
self.conn = sqlite3.connect(self.filename)
else:
self.conn = self.create_table(self.filename)
def finalize(self):
if self.conn is not None:
self.conn.commit()
self.conn.close()
self.conn = None
def create_table(self, filename):
conn = sqlite3.connect(filename)
conn.execute("""create table blog
(url text primary key, raw text, domain text)""")
conn.commit()
return conn
在__init__函数中,使用dispatcher将两个信号连接到指定函数,用于初始化和关闭数据库连接。Dd-.-) 丢失。当数据通过管道时,将调用 process_item 函数。这里我们将原创数据直接存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取和过滤数据,但我不会在这里详细介绍。
最后,在 settings.py 中列出我们的管道:
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再次运行爬虫就OK了!最后总结一下:一个高质量的爬虫是一个极其复杂的项目,但是如果你有一个好的工具,做一个专用的爬虫是相对容易的。Scrapy是一个非常轻量级的爬虫框架,极大的简化了爬虫的开发过程。另外,Scrapy的文档也很详细。如果觉得我的介绍省略了一些不清楚的地方,推荐阅读他的Tutorial。
本文来自:
scrapy分页抓取网页(接下来分析如何要闻页签下的所有新闻标题和链接(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-23 07:11
本文的目的是捕获所有在腾讯新闻首页新闻主页上签名的新闻标题和链接。
如图:
地址:
新闻标签中通常有几个标签:
因此,要抓取所有新闻标题和新闻下的链接,需要一一抓取。让我们开始编写代码。
首先获取腾讯新闻页面的内容,编写一个接口获取页面。
首先导入本次爬网所需的库
# -*- coding:utf-8 -*-
#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#随机数生成
import random
#gzip
import gzip
from StringIO import StringIO
构建请求头、请求页面
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
请求一个腾讯新闻页面,返回的页面数据有时会被gzip压缩,如果直接读取会出现二进制代码,所以在处理返回的页面时需要做gizp解压
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
整理代码段,最后封装成页面请求接口
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):
try:
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
html = None
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
return html
#如果请求异常
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
elif hasattr(e, "reason"):
print e.reason
return None
#其他异常
except Exception,e:
return None
页面请求接口写好后,接下来就是分析如何上报新闻页面下的所有数据。新闻页面下有几个选项卡。当我们请求分页时,可以看到腾讯新闻页面的请求是通过ajax实现的。打开谷歌在浏览器的网络中,可以看到请求分页时的信息。如图:
分析请求地址会发现每一个分页请求都是一个地址后面跟着一个随机数,地址中会有这个请求的索引。
这样我们就可以构造出页面的请求地址,获取到每个页面的信息。但在此之前,我们不知道腾讯新闻会有多少页。
分析腾讯新闻的页面,我们最终会发现首页的一段js表示腾讯新闻有多少页面。
所以我们先抓取腾讯新闻页面的内容,获取新闻中有多少个页面,构造页面请求,最后取出页面信息中的所有新闻
标题和原创链接就好了。代码显示如下:
<p>def tencentStart():
#腾讯新闻地址
INDEX_URL = 'http://news.qq.com/top_index.shtml#hotnews'
#腾讯要闻请求地址
SUB_URL = "http://news.qq.com/c/2013ywList_{0}.htm"
#页面数获取正则
PAGE_PATTERNS = 'getString.pageCount.*?=.*?(\d+);'
#标题和链接获取正则
NEWS_PATTERNS = ' 查看全部
scrapy分页抓取网页(接下来分析如何要闻页签下的所有新闻标题和链接(图))
本文的目的是捕获所有在腾讯新闻首页新闻主页上签名的新闻标题和链接。
如图:
地址:
新闻标签中通常有几个标签:
因此,要抓取所有新闻标题和新闻下的链接,需要一一抓取。让我们开始编写代码。
首先获取腾讯新闻页面的内容,编写一个接口获取页面。
首先导入本次爬网所需的库
# -*- coding:utf-8 -*-
#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#随机数生成
import random
#gzip
import gzip
from StringIO import StringIO
构建请求头、请求页面
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
请求一个腾讯新闻页面,返回的页面数据有时会被gzip压缩,如果直接读取会出现二进制代码,所以在处理返回的页面时需要做gizp解压
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
整理代码段,最后封装成页面请求接口
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):
try:
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
html = None
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
return html
#如果请求异常
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
elif hasattr(e, "reason"):
print e.reason
return None
#其他异常
except Exception,e:
return None
页面请求接口写好后,接下来就是分析如何上报新闻页面下的所有数据。新闻页面下有几个选项卡。当我们请求分页时,可以看到腾讯新闻页面的请求是通过ajax实现的。打开谷歌在浏览器的网络中,可以看到请求分页时的信息。如图:
分析请求地址会发现每一个分页请求都是一个地址后面跟着一个随机数,地址中会有这个请求的索引。
这样我们就可以构造出页面的请求地址,获取到每个页面的信息。但在此之前,我们不知道腾讯新闻会有多少页。
分析腾讯新闻的页面,我们最终会发现首页的一段js表示腾讯新闻有多少页面。
所以我们先抓取腾讯新闻页面的内容,获取新闻中有多少个页面,构造页面请求,最后取出页面信息中的所有新闻
标题和原创链接就好了。代码显示如下:
<p>def tencentStart():
#腾讯新闻地址
INDEX_URL = 'http://news.qq.com/top_index.shtml#hotnews'
#腾讯要闻请求地址
SUB_URL = "http://news.qq.com/c/2013ywList_{0}.htm"
#页面数获取正则
PAGE_PATTERNS = 'getString.pageCount.*?=.*?(\d+);'
#标题和链接获取正则
NEWS_PATTERNS = '
scrapy分页抓取网页(scrapy爬虫框架的熟悉(一)——scrapy需爬取框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-23 07:09
熟悉scrapy爬虫框架
最近在学习scrapy爬虫框架,通过爬取Sunshine平台的内容可以进一步了解和熟悉这个框架。为了以后快速回顾一下这个爬虫框架,在此做个记录。
首先,明确抓取目标。
这是要爬取的平台,爬取的数据有标题和日期
不仅如此,我们还需要抓取详细的内容。我们随机点击一个链接,我们知道需要抓取详细的内容,如下图所示。

就我个人而言,一开始我倾向于在 xpath 方法中爬行。毕竟这个方法对我比较友好,所以我开始比较元素和网络的内容是否可以一一对应。
对比上面两张图,发现两列的内容差不多,都有表格,对应的tr/td内容也比较规整,所以初步判断可以用xpath的方法
但是,在使用 xpath 方法时要特别注意这个 tbody 字符串。它存在于元素但不存在于网络中(如下图所示)
这点在写程序时要特别注意
最后,开始创建scrapy项目并生成爬虫
创建步骤不再一一赘述。
创建后如下图所示:
下面我们直接开始编写主程序部分:
先爬取基本信息
from yangguang.items import YangguangItem
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first() # 爬取进入详情页面的链接
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first() # 爬取主题
item["date"] = li.xpath("./td[5]/text()").extract_first() # 爬取日期
yield item
分析:
因为是xpath方式,首页url链接可以直接是url名:
xpath节点的内容需要通过XPath Helper插件尝试后输入到代码中。我不确定,有没有人可以指点一下?)
class YangguangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
link = scrapy.Field()
title = scrapy.Field()
date = scrapy.Field()
detail_content = scrapy.Field()
分析:
这里的代码是echo上一个类的调用
item = YangguangItem()
class YangguangPipeline(object):
def process_item(self, item, spider):
print(item)
return item
LOG_LEVEL = "WARNING"
ITEM_PIPELINES = {
'yangguang.pipelines.YangguangPipeline': 300,
}
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
添加第一个内容可以使输出内容更加简洁,只输出警告级别以上的日志内容
第二个内容作为注释出现在文件本身中,我们可以清除它的注释
第三个内容:加上模拟浏览器行为所需的用户代理
这样我们就初步生成了一个可用的爬虫,我们运行一下看看结果
爬取结果中有日期、链接和主题。看来这个新生的爬行者还是比较健康的。
接下来我们必须种植它
爬取链接中的详细内容
前面说过,阳光平台的详细内容才是我们真正需要的,详细内容是通过链接进一步提取出来的,所以我们需要对程序进行进一步的扩展。
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first()
item["date"] = li.xpath("./td[5]/text()").extract_first()
# yield item
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
def parse_detail(self, response): # 详情页面处理
item = response.meta["item"]
item["detail_content"] = response.xpath("//div[@class='wzy1']//tr[1]/td[@class='txt16_3']//text()").extract() # 输出详情投诉内容
yield item
将之前获取到的link链接合并到生成器中,定义另一种方法来处理详情页。
这里主要是添加一个内容提取detail_content
我们启动爬虫后,发现内容已经展开,增加了detail_content的内容,但是内容中含有其他杂质。这时候我们就可以使用正则表达式来提取我们真正需要的内容了。
import re
class YangguangPipeline(object):
def process_item(self, item, spider):
item["detail_content"] = self.process_content(item["detail_content"])
print(item)
return item
def process_content(self, content):
"""对详情内容进行(正则)处理"""
content = [re.sub("\xa0|\s", "", i) for i in content] # 将指定字符替换为空字符
content = [i for i in content if len(i) > 0] # 去除空字符
return content
再次启动爬虫
至此,我们发现detail_content的内容变得简洁明了,不再有其他不相关的字符串干扰我们的视觉。
至此,我们的爬虫已经能够爬取一整页需要的信息了。然而,我们的爬行动物可以进一步生长,可以捕捉更多信息,而不仅仅是一页猎物。
接下来我们继续扩展爬虫来爬取多页内容。
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first()
item["date"] = li.xpath("./td[5]/text()").extract_first()
# yield item
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
# 处理下一页
next_url = response.xpath("//a[text()='>']/@href").extract_first()
print("*" * 50)
print(next_url)
if next_url is not None:
yield scrapy.Request(
next_url,
callback=self.parse
)
最后启动爬虫,效果如下
最后,我们完成了整个爬虫,但是这个爬虫不是太健康。毕竟我们没有考虑处理所谓的反爬虫机制的策略。这个爬虫可能对服务器不太友好,毕竟会增加对方服务器的压力。当然,我们的小爬虫还没有到其他人可以使用爬虫机制的地步。毕竟,它真的很小。. .
总结:
其实仔细想想,这整个爬虫的生成过程很简单,描述也只是一点点泼,因为它只说怎么做,不说为什么要做,也就是所谓知其然,不知其所以然。
比如下面的代码中,为什么后面添加了extract_first()方法?
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
再举个例子,下面代码的原理机制
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
以后需要慢慢补充。毕竟,要成为专家,您必须知道正在发生的事情以及原因。
为了记录我的学习过程,我做了我的第一个原创博客。请不要不喜欢。 查看全部
scrapy分页抓取网页(scrapy爬虫框架的熟悉(一)——scrapy需爬取框架)
熟悉scrapy爬虫框架
最近在学习scrapy爬虫框架,通过爬取Sunshine平台的内容可以进一步了解和熟悉这个框架。为了以后快速回顾一下这个爬虫框架,在此做个记录。
首先,明确抓取目标。

这是要爬取的平台,爬取的数据有标题和日期
不仅如此,我们还需要抓取详细的内容。我们随机点击一个链接,我们知道需要抓取详细的内容,如下图所示。

就我个人而言,一开始我倾向于在 xpath 方法中爬行。毕竟这个方法对我比较友好,所以我开始比较元素和网络的内容是否可以一一对应。


对比上面两张图,发现两列的内容差不多,都有表格,对应的tr/td内容也比较规整,所以初步判断可以用xpath的方法

但是,在使用 xpath 方法时要特别注意这个 tbody 字符串。它存在于元素但不存在于网络中(如下图所示)

这点在写程序时要特别注意
最后,开始创建scrapy项目并生成爬虫
创建步骤不再一一赘述。
创建后如下图所示:

下面我们直接开始编写主程序部分:
先爬取基本信息
from yangguang.items import YangguangItem
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first() # 爬取进入详情页面的链接
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first() # 爬取主题
item["date"] = li.xpath("./td[5]/text()").extract_first() # 爬取日期
yield item
分析:
因为是xpath方式,首页url链接可以直接是url名:
xpath节点的内容需要通过XPath Helper插件尝试后输入到代码中。我不确定,有没有人可以指点一下?)
class YangguangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
link = scrapy.Field()
title = scrapy.Field()
date = scrapy.Field()
detail_content = scrapy.Field()
分析:
这里的代码是echo上一个类的调用
item = YangguangItem()
class YangguangPipeline(object):
def process_item(self, item, spider):
print(item)
return item
LOG_LEVEL = "WARNING"
ITEM_PIPELINES = {
'yangguang.pipelines.YangguangPipeline': 300,
}
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
添加第一个内容可以使输出内容更加简洁,只输出警告级别以上的日志内容
第二个内容作为注释出现在文件本身中,我们可以清除它的注释
第三个内容:加上模拟浏览器行为所需的用户代理
这样我们就初步生成了一个可用的爬虫,我们运行一下看看结果

爬取结果中有日期、链接和主题。看来这个新生的爬行者还是比较健康的。
接下来我们必须种植它
爬取链接中的详细内容
前面说过,阳光平台的详细内容才是我们真正需要的,详细内容是通过链接进一步提取出来的,所以我们需要对程序进行进一步的扩展。
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first()
item["date"] = li.xpath("./td[5]/text()").extract_first()
# yield item
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
def parse_detail(self, response): # 详情页面处理
item = response.meta["item"]
item["detail_content"] = response.xpath("//div[@class='wzy1']//tr[1]/td[@class='txt16_3']//text()").extract() # 输出详情投诉内容
yield item
将之前获取到的link链接合并到生成器中,定义另一种方法来处理详情页。
这里主要是添加一个内容提取detail_content

我们启动爬虫后,发现内容已经展开,增加了detail_content的内容,但是内容中含有其他杂质。这时候我们就可以使用正则表达式来提取我们真正需要的内容了。
import re
class YangguangPipeline(object):
def process_item(self, item, spider):
item["detail_content"] = self.process_content(item["detail_content"])
print(item)
return item
def process_content(self, content):
"""对详情内容进行(正则)处理"""
content = [re.sub("\xa0|\s", "", i) for i in content] # 将指定字符替换为空字符
content = [i for i in content if len(i) > 0] # 去除空字符
return content
再次启动爬虫

至此,我们发现detail_content的内容变得简洁明了,不再有其他不相关的字符串干扰我们的视觉。
至此,我们的爬虫已经能够爬取一整页需要的信息了。然而,我们的爬行动物可以进一步生长,可以捕捉更多信息,而不仅仅是一页猎物。
接下来我们继续扩展爬虫来爬取多页内容。
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first()
item["date"] = li.xpath("./td[5]/text()").extract_first()
# yield item
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
# 处理下一页
next_url = response.xpath("//a[text()='>']/@href").extract_first()
print("*" * 50)
print(next_url)
if next_url is not None:
yield scrapy.Request(
next_url,
callback=self.parse
)
最后启动爬虫,效果如下

最后,我们完成了整个爬虫,但是这个爬虫不是太健康。毕竟我们没有考虑处理所谓的反爬虫机制的策略。这个爬虫可能对服务器不太友好,毕竟会增加对方服务器的压力。当然,我们的小爬虫还没有到其他人可以使用爬虫机制的地步。毕竟,它真的很小。. .
总结:
其实仔细想想,这整个爬虫的生成过程很简单,描述也只是一点点泼,因为它只说怎么做,不说为什么要做,也就是所谓知其然,不知其所以然。
比如下面的代码中,为什么后面添加了extract_first()方法?
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
再举个例子,下面代码的原理机制
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
以后需要慢慢补充。毕竟,要成为专家,您必须知道正在发生的事情以及原因。
为了记录我的学习过程,我做了我的第一个原创博客。请不要不喜欢。
scrapy分页抓取网页( Scrapy从基本原理上来讲很简单的可以直接用正则表入党积极分子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-23 02:19
Scrapy从基本原理上来讲很简单的可以直接用正则表入党积极分子)
Scrapy轻松定制网络爬虫随机爬取有一定目的,爬取时采集一些信息。例如,谷歌有很多爬虫采集互联网上的信息以及它们之间的链接。例如,一些别有用心的爬虫会在互联网上采集信息。foobarcom 或者 foo[at]bar[dot]com 之类的东西,除了一些专门针对某个网站的自定义爬虫,比如前段时间JavaEye的Robbin写了几篇专门对付恶意的文章 原文链接爬虫的博客好像过期了,不会给了。还有诸如小众软件或者LinuxToy网站经常被整个站点爬下来改名挂掉。其实,爬虫的基本原理非常简单。只要能访问网络和分析网页,现在大多数语言都有方便的Http客户端库,可以抓取网页和HTML。最简单的分析可以直接用正则表、党内积极分子数、条目数和毫米对照表、教师职称等级表、员工考核得分表、普通年金现值系数表达式,所以做一个最简单的网络爬虫其实是一件很简单的事情,但是要实现一个高质量的蜘蛛却是非常困难的。爬虫的两个部分。首先是下载网页。有很多问题。乘法。口头算术。100个问题。七年级。有理数。混合操作。应用问题 真心话大冒险刺激问题。您需要考虑如何最大限度地利用本地带宽。如何调度不同站点的Web请求,以减轻其他服务器的负担。高性能 WebCrawler 系统中的 DNS 查询也将成为需要优化的瓶颈。有一些规则需要遵守,比如robotstxt,获取网页后的分析过程也很复杂。互联网上有很多奇怪的事情。有各种带有各种错误的 HTML 页面。分析所有这些几乎是不可能的。另外,随着AJAX的流行,如何获取Javascript动态生成的内容也成为了一个大问题。此外,互联网上还有各种有意或无意出现的SpiderTraps。如果一味的跟着超链接走,就会掉入陷阱。比如这个网站,据说谷歌之前宣称互联网上UniqueURL的数量已经达到1万亿,所以这个人很自豪的宣布第二万亿。但实际上,像谷歌这样需要成为通用爬虫的人并不多。通常我们构建一个爬虫来爬取某个特定的或者某个像网站 所谓知己知彼,我们可以对需要爬取的网站结构提前做一些分析,它变得容易多了。通过分析和选择有价值的链接进行跟踪,我们可以避免许多不必要的链接。或者SpiderTrap if 网站如果结构允许选择合适的路径,我们就可以按照一定的顺序爬取感兴趣的东西。这样,连URL重复的判断都可以省略。例如,如果我们想通过观察爬下 Pongba 的 blogmindhackscn 中的博客文字,很容易发现我们对其中两个页面感兴趣。1 文章 列表页面,如首页或URL被分页的页面。通过Firebug可以看到文章的每一个链接都在一个h1下。需要注意的是,Firebug 的 HTML 面板中看到的 HTML 代码可能与 ViewSource 中看到的有些不同。如果网页中的 DOM 树是通过 Javascript 动态修改的,则前者是修改后的版本,已经通过了 Firebug。规则、素材编码规则、三大议事规则、文件编号规则、乒乓球比赛规则、不规则动词,例如属性有引号等,后者通常是你的蜘蛛爬取的原创内容。如果您使用正则表达式分析页面或者使用的 HTMLParser 和 Firefox 之间是否存在一些差异,则需要特别注意。另外,在一个带有 wp-pagenavi 类的 div 中还有指向不同列表页面的链接。2文章内容页面每个博客都有这样一个页面,比如20080911machine-learning-and-ai-resources收录了完整的文章内容。这就是我们感兴趣的。所以我们从首页开始,利用wp-pagenavi中的链接获取其他文章列表页面,特别是我们定义了一个只链接到followNextPage的路径,这样我们就可以通过它是为了从头到尾避免判断重复爬行的麻烦。另外,列表页面上那些到具体文章链接对应的页面,就是我们真正要保存的数据页面。用它实用的脚本语言写一个adhoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的CrawlerFramework,简单轻量而且非常方便,官网说已经实际生产中使用,所以不是玩具级别的东西。但是,目前还没有 Release 版本。可以直接使用他们的 Mercurial 仓库抓取源码进行安装。不过这个东西也可以直接安装。使用它随时更新文档也很方便。我不会重复。Scrapy 使用 Twisted,一个异步网络库来处理网络通信。架构清晰,收录各种中间件接口,可以灵活完成各种需求。整体架构如下图所示。绿线是数据流向。首先,调度器会将其交给下载器进行下载,并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 调度程序会将其交给下载程序进行下载并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 调度程序会将其交给下载程序进行下载并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很
很简单实用,就像Rails一样。首先新建一个项目scrapy-adminpystart项目blog_crawl会创建一个blog_crawl目录,整个项目有scrapy-ctlpy控制脚本,代码全部放在子目录blog_crawl下,以便能够爬取mindhackscn。在spiders目录下新建一个mindhacks_spiderpy来定义我们的spider如下 fromscrapyspiderimportBaseSpiderclassMindhacksSpiderBaseSpiderdomain_name"mindhackscn"start_urls["httpmindhackscn"]defparseselfresponsereturn[]SPIDERMindhacksSpider 我们的MindhacksSpider继承自BaseSpider,通常直接继承自BaseSpider的特性,通常是直接从more-trichSpiderscrapids继承 这样更方便。但是为了展示数据是如何解析的,这里使用了BaseSpider。变量 domain_name 和 start_urls 很容易理解它们的含义和解析方法 二重积分的计算方法 84 消毒液的配比方法 愚人节 全人法 现金流量表编制方法 求和的七种方法序号是我们需要定义的回调函数,默认请求在得到响应后会调用这个回调函数。我们需要解析这里的页面返回两个结果。需要进一步爬取的链接和需要保存的数据让我觉得有点奇怪,它的接口定义中的两个结果居然混在了一个列表中。不清楚为什么在这里。到底是不是要努力把他们分开?简而言之,让我们写一个空函数,只返回一个空列表。另外,我们定义了一个全局变量 SPIDER,在 Scrapy 导入这个模块的时候会实例化,并且会被 Scrapy 引擎自动找到。可以先运行爬虫,试试scrapy-ctlpycrawlmindhackscn。会有一堆输出。可以看到爬取了httpmindhackscn,因为这是初始URL,但是因为我们在parse函数中没有返回需要进一步爬取的URL,所以只爬取了整个爬取过程。主页结束了。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell。需要 IPython 才能让我们做实验。使用以下命令启动 Shellscrapy-ctlpyshell httpmindhackscn。它将启动爬虫并抓取命令行指定的页面。进入shell并按照提示操作。我们有很多现成的变量可以使用。其中之一是 hxs,它是 HtmlXPathSelectormindhacks 的 HTML 页面。是比较规范的波形梁钢护栏护理文件编写规范。操作流程规范。建筑工程验收规范。医疗文件书写规范可以非常方便和直接。使用 XPath 进行分析。通过Firebug可以看到每个博客文章的链接都在h1下,所以用这样的XPath表达式壳牌测试在文献[1] hxsxh1ahrefextractOut [1] [uhttpmindhackscn20090706why任您应该-DO-IT-yourselfuhttpmindhackscn20090517seven年合njuuhttpmindhackscn20090328effective学习和-memorizationuhttpmindhackscn20090315preconception-explaineduhttpmindhackscn20090309first原理-OF-programminguhttpmindhackscn20090215why-你,应该启动 - 博客 - nowuhttpmindhackscn20090209writing就是更好-thinkinguhttpmindhackscn20090207better解释的 - 冲突 - 在亲密-relationshipuhttpmindhackscn20090207independence-dayuhttpmindhackscn20090118escape从 - 您-肖申克的,第一部分]这正是我们所需要的URL。另外,我们可以在一个div中找到下一页的链接和其他几个页面的链接,但是下一页的链接没有title属性所以XPath写成div[class" 但看起来这是一个unicodeescape字符,因为编码原因不清楚。最终解析函数判断如下: defparseselfresponseitems[]hxsHtmlXPathSelectorresponsepostshxsxh1ahrefextractitemsextend[selfmake_requests_from_urlreplacecallbackselfparse_postforurlinposts]page_avilink"xsxdiv[class] 但看起来这是一个unicodeescape字符,因为编码原因不清楚。最终解析函数判断如下: defparseselfresponseitems[]hxsHtmlXPathSelectorresponsepostshxsxh1ahrefextractitemsextend[selfmake_requests_from_urlreplacecallbackselfparse_postforurlinposts]page_avilink"xsxdiv[class]
npage_linksiflinkxtextextract[0]uxbburllinkxhrefextract[0]itemsappendselfmake_requests_from_urlurlreturnitems 前半部分是解析需要爬取的博客正文的链接。后半部分是给出下一页的链接。需要注意的是,这里返回的列表不是字符串格式。网址结束。Scrapy希望得到的是Request对象,它可以承载比字符串格式的URL更多的东西,比如cookies或者回调函数。可以看到我们在创建博客正文的Request时替换了回调函数。因为默认的回调函数parse是专门用来解析文章对于列表这样的页面的,所以parse_post定义如下:defparse_postselfresponseitemBlogCrawlItemitemurlunicoderesponseurlitemrawresponsebody_as_unicodereturn[item] 返回一个BlogCrawlItem并将捕获的数据放入其中非常简单。在这里我可以做一些分析,比如通过XPath解析文本和标题,但我倾向于稍后再做。这些东西,例如 ItemPipeline 或以后的 Offline 阶段。BlogCrawlItem 是 Scrapy 自动为我们定义的一个空类,继承自 ScrapedItem。在itemspy中,我添加了一些fromscrapyitemimportScrapedItemclassBlogCrawlItemScrapedItemdef__init__selfScrapedItem_self_self_self_returnBlog url_self_self_self_self_self_returnBlog_url_def__str__self_self_self_return_self_self_self_return_Blog def__str_returnself_self_str 函数,所以当你看到所有的数据时,会显示__str_returnself_self_self_str函数,控制台日志会疯狂地输出内容。即输出爬取的网页内容-bb,让数据取到最后,只留下 存储数据的功能,通过添加Pipeline来实现。由于Python在标准库中自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。更换pipelinespy的用下面的代码内容:622324252627282930313233selfinitializesignalsengine_starteddispatcherconnectselffinalizesignalsengine_stoppeddefprocess_itemselfdomainitemselfconnexecuteinsertintoblogvaluesitemurlitemrawunicodedomainreturnitemdefinitializeselfifpathexistsselffilenameselfconnsqlite3connectselffilenameelseselfconnselfcreate_tableselffilenamedeffinalizeselfifselfconnisnotNoneselfconncommitselfconncloseselfconnNonedefcreate_tableselffilenameconnsqlite3connectfilename34353637connexecute“ 总结一下,一个高质量的爬虫是一个极其复杂的项目,但是如果你有一个好的工具,做一个专用的爬虫就容易多了。Scrapy 非常容易。轻量级的爬虫框架大大简化了爬虫开发的流程。另外,Scrapy的文档也很详细。如果你觉得我的介绍不够清楚,推荐阅读他的教程。 查看全部
scrapy分页抓取网页(
Scrapy从基本原理上来讲很简单的可以直接用正则表入党积极分子)

Scrapy轻松定制网络爬虫随机爬取有一定目的,爬取时采集一些信息。例如,谷歌有很多爬虫采集互联网上的信息以及它们之间的链接。例如,一些别有用心的爬虫会在互联网上采集信息。foobarcom 或者 foo[at]bar[dot]com 之类的东西,除了一些专门针对某个网站的自定义爬虫,比如前段时间JavaEye的Robbin写了几篇专门对付恶意的文章 原文链接爬虫的博客好像过期了,不会给了。还有诸如小众软件或者LinuxToy网站经常被整个站点爬下来改名挂掉。其实,爬虫的基本原理非常简单。只要能访问网络和分析网页,现在大多数语言都有方便的Http客户端库,可以抓取网页和HTML。最简单的分析可以直接用正则表、党内积极分子数、条目数和毫米对照表、教师职称等级表、员工考核得分表、普通年金现值系数表达式,所以做一个最简单的网络爬虫其实是一件很简单的事情,但是要实现一个高质量的蜘蛛却是非常困难的。爬虫的两个部分。首先是下载网页。有很多问题。乘法。口头算术。100个问题。七年级。有理数。混合操作。应用问题 真心话大冒险刺激问题。您需要考虑如何最大限度地利用本地带宽。如何调度不同站点的Web请求,以减轻其他服务器的负担。高性能 WebCrawler 系统中的 DNS 查询也将成为需要优化的瓶颈。有一些规则需要遵守,比如robotstxt,获取网页后的分析过程也很复杂。互联网上有很多奇怪的事情。有各种带有各种错误的 HTML 页面。分析所有这些几乎是不可能的。另外,随着AJAX的流行,如何获取Javascript动态生成的内容也成为了一个大问题。此外,互联网上还有各种有意或无意出现的SpiderTraps。如果一味的跟着超链接走,就会掉入陷阱。比如这个网站,据说谷歌之前宣称互联网上UniqueURL的数量已经达到1万亿,所以这个人很自豪的宣布第二万亿。但实际上,像谷歌这样需要成为通用爬虫的人并不多。通常我们构建一个爬虫来爬取某个特定的或者某个像网站 所谓知己知彼,我们可以对需要爬取的网站结构提前做一些分析,它变得容易多了。通过分析和选择有价值的链接进行跟踪,我们可以避免许多不必要的链接。或者SpiderTrap if 网站如果结构允许选择合适的路径,我们就可以按照一定的顺序爬取感兴趣的东西。这样,连URL重复的判断都可以省略。例如,如果我们想通过观察爬下 Pongba 的 blogmindhackscn 中的博客文字,很容易发现我们对其中两个页面感兴趣。1 文章 列表页面,如首页或URL被分页的页面。通过Firebug可以看到文章的每一个链接都在一个h1下。需要注意的是,Firebug 的 HTML 面板中看到的 HTML 代码可能与 ViewSource 中看到的有些不同。如果网页中的 DOM 树是通过 Javascript 动态修改的,则前者是修改后的版本,已经通过了 Firebug。规则、素材编码规则、三大议事规则、文件编号规则、乒乓球比赛规则、不规则动词,例如属性有引号等,后者通常是你的蜘蛛爬取的原创内容。如果您使用正则表达式分析页面或者使用的 HTMLParser 和 Firefox 之间是否存在一些差异,则需要特别注意。另外,在一个带有 wp-pagenavi 类的 div 中还有指向不同列表页面的链接。2文章内容页面每个博客都有这样一个页面,比如20080911machine-learning-and-ai-resources收录了完整的文章内容。这就是我们感兴趣的。所以我们从首页开始,利用wp-pagenavi中的链接获取其他文章列表页面,特别是我们定义了一个只链接到followNextPage的路径,这样我们就可以通过它是为了从头到尾避免判断重复爬行的麻烦。另外,列表页面上那些到具体文章链接对应的页面,就是我们真正要保存的数据页面。用它实用的脚本语言写一个adhoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的CrawlerFramework,简单轻量而且非常方便,官网说已经实际生产中使用,所以不是玩具级别的东西。但是,目前还没有 Release 版本。可以直接使用他们的 Mercurial 仓库抓取源码进行安装。不过这个东西也可以直接安装。使用它随时更新文档也很方便。我不会重复。Scrapy 使用 Twisted,一个异步网络库来处理网络通信。架构清晰,收录各种中间件接口,可以灵活完成各种需求。整体架构如下图所示。绿线是数据流向。首先,调度器会将其交给下载器进行下载,并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 调度程序会将其交给下载程序进行下载并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 调度程序会将其交给下载程序进行下载并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很

很简单实用,就像Rails一样。首先新建一个项目scrapy-adminpystart项目blog_crawl会创建一个blog_crawl目录,整个项目有scrapy-ctlpy控制脚本,代码全部放在子目录blog_crawl下,以便能够爬取mindhackscn。在spiders目录下新建一个mindhacks_spiderpy来定义我们的spider如下 fromscrapyspiderimportBaseSpiderclassMindhacksSpiderBaseSpiderdomain_name"mindhackscn"start_urls["httpmindhackscn"]defparseselfresponsereturn[]SPIDERMindhacksSpider 我们的MindhacksSpider继承自BaseSpider,通常直接继承自BaseSpider的特性,通常是直接从more-trichSpiderscrapids继承 这样更方便。但是为了展示数据是如何解析的,这里使用了BaseSpider。变量 domain_name 和 start_urls 很容易理解它们的含义和解析方法 二重积分的计算方法 84 消毒液的配比方法 愚人节 全人法 现金流量表编制方法 求和的七种方法序号是我们需要定义的回调函数,默认请求在得到响应后会调用这个回调函数。我们需要解析这里的页面返回两个结果。需要进一步爬取的链接和需要保存的数据让我觉得有点奇怪,它的接口定义中的两个结果居然混在了一个列表中。不清楚为什么在这里。到底是不是要努力把他们分开?简而言之,让我们写一个空函数,只返回一个空列表。另外,我们定义了一个全局变量 SPIDER,在 Scrapy 导入这个模块的时候会实例化,并且会被 Scrapy 引擎自动找到。可以先运行爬虫,试试scrapy-ctlpycrawlmindhackscn。会有一堆输出。可以看到爬取了httpmindhackscn,因为这是初始URL,但是因为我们在parse函数中没有返回需要进一步爬取的URL,所以只爬取了整个爬取过程。主页结束了。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell。需要 IPython 才能让我们做实验。使用以下命令启动 Shellscrapy-ctlpyshell httpmindhackscn。它将启动爬虫并抓取命令行指定的页面。进入shell并按照提示操作。我们有很多现成的变量可以使用。其中之一是 hxs,它是 HtmlXPathSelectormindhacks 的 HTML 页面。是比较规范的波形梁钢护栏护理文件编写规范。操作流程规范。建筑工程验收规范。医疗文件书写规范可以非常方便和直接。使用 XPath 进行分析。通过Firebug可以看到每个博客文章的链接都在h1下,所以用这样的XPath表达式壳牌测试在文献[1] hxsxh1ahrefextractOut [1] [uhttpmindhackscn20090706why任您应该-DO-IT-yourselfuhttpmindhackscn20090517seven年合njuuhttpmindhackscn20090328effective学习和-memorizationuhttpmindhackscn20090315preconception-explaineduhttpmindhackscn20090309first原理-OF-programminguhttpmindhackscn20090215why-你,应该启动 - 博客 - nowuhttpmindhackscn20090209writing就是更好-thinkinguhttpmindhackscn20090207better解释的 - 冲突 - 在亲密-relationshipuhttpmindhackscn20090207independence-dayuhttpmindhackscn20090118escape从 - 您-肖申克的,第一部分]这正是我们所需要的URL。另外,我们可以在一个div中找到下一页的链接和其他几个页面的链接,但是下一页的链接没有title属性所以XPath写成div[class" 但看起来这是一个unicodeescape字符,因为编码原因不清楚。最终解析函数判断如下: defparseselfresponseitems[]hxsHtmlXPathSelectorresponsepostshxsxh1ahrefextractitemsextend[selfmake_requests_from_urlreplacecallbackselfparse_postforurlinposts]page_avilink"xsxdiv[class] 但看起来这是一个unicodeescape字符,因为编码原因不清楚。最终解析函数判断如下: defparseselfresponseitems[]hxsHtmlXPathSelectorresponsepostshxsxh1ahrefextractitemsextend[selfmake_requests_from_urlreplacecallbackselfparse_postforurlinposts]page_avilink"xsxdiv[class]

npage_linksiflinkxtextextract[0]uxbburllinkxhrefextract[0]itemsappendselfmake_requests_from_urlurlreturnitems 前半部分是解析需要爬取的博客正文的链接。后半部分是给出下一页的链接。需要注意的是,这里返回的列表不是字符串格式。网址结束。Scrapy希望得到的是Request对象,它可以承载比字符串格式的URL更多的东西,比如cookies或者回调函数。可以看到我们在创建博客正文的Request时替换了回调函数。因为默认的回调函数parse是专门用来解析文章对于列表这样的页面的,所以parse_post定义如下:defparse_postselfresponseitemBlogCrawlItemitemurlunicoderesponseurlitemrawresponsebody_as_unicodereturn[item] 返回一个BlogCrawlItem并将捕获的数据放入其中非常简单。在这里我可以做一些分析,比如通过XPath解析文本和标题,但我倾向于稍后再做。这些东西,例如 ItemPipeline 或以后的 Offline 阶段。BlogCrawlItem 是 Scrapy 自动为我们定义的一个空类,继承自 ScrapedItem。在itemspy中,我添加了一些fromscrapyitemimportScrapedItemclassBlogCrawlItemScrapedItemdef__init__selfScrapedItem_self_self_self_returnBlog url_self_self_self_self_self_returnBlog_url_def__str__self_self_self_return_self_self_self_return_Blog def__str_returnself_self_str 函数,所以当你看到所有的数据时,会显示__str_returnself_self_self_str函数,控制台日志会疯狂地输出内容。即输出爬取的网页内容-bb,让数据取到最后,只留下 存储数据的功能,通过添加Pipeline来实现。由于Python在标准库中自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。更换pipelinespy的用下面的代码内容:622324252627282930313233selfinitializesignalsengine_starteddispatcherconnectselffinalizesignalsengine_stoppeddefprocess_itemselfdomainitemselfconnexecuteinsertintoblogvaluesitemurlitemrawunicodedomainreturnitemdefinitializeselfifpathexistsselffilenameselfconnsqlite3connectselffilenameelseselfconnselfcreate_tableselffilenamedeffinalizeselfifselfconnisnotNoneselfconncommitselfconncloseselfconnNonedefcreate_tableselffilenameconnsqlite3connectfilename34353637connexecute“ 总结一下,一个高质量的爬虫是一个极其复杂的项目,但是如果你有一个好的工具,做一个专用的爬虫就容易多了。Scrapy 非常容易。轻量级的爬虫框架大大简化了爬虫开发的流程。另外,Scrapy的文档也很详细。如果你觉得我的介绍不够清楚,推荐阅读他的教程。
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-21 04:03
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注就是本质(4小时,完成了Scrapy爬虫必备知识点的讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学(深入浅出,以案例为导向,学以致用)
讲师问答(拒绝助教,讲师当天解答)
课程适合人群
拥有Py的基本语法和面向对象开发的思想,其他语言的开发者,回归浪子的人,想一夜暴富的人
建筑与环境建设
文章Scrapy 简介
Scrapy 组件介绍
pip安装scrapy
Scrapy 简介
用于屏幕抓取和网页抓取的快速、高级 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求进行个性化定制. Scrapy架构图:
Scrapy 组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
调度器(Scheduler):用于接受引擎发送的Request请求,将其压入队列,当引擎再次请求时返回。
Downloader(下载器):用于请求引擎发送的Request对应的网页内容,并将获取到的Responses返回给Spider。
Item Pipeline(管道):负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider Responses和Requests
pip安装scrapy
正常情况下通过pip show scrapy查看是否安装,如果安装则显示安装信息,否则不显示任何信息
通过pip install scrapy安装爬虫框架(可能会抛出以下异常)
根据异常提示:ERROR: MICROSOFT VISUAL C++ 9.0 IS REQUIRED (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载缺失的window组件,视频学习资料中提供
第一个爬虫项目
文章内容
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject豆瓣就可以创建项目了
按照上面的提示创建Spider解析器:cd豆瓣,然后在项目中执行:scrapy genspider example就可以创建Spider对象了
细心的朋友会发现douban_spider默认会存放在douban.spider目录下。用pycharm IDE打开,会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的Spider文件,也就是你爬取的py文件
items.py:相当于一个容器,更像是一个字典 middlewares.py:定义下载器
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现pipelines.py:Define Item
Pipeline的实现实现了数据的清洗、存储和校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法介绍
文章内容
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。实际上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航。
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章内容
豆瓣电影页面分析
首页下载实现
前5部电影的数据如下
豆瓣电影页面分析为大家讲解了如何在XML文档中查找信息,具体来说,您已经学会了如何获取元素、内容、属性,以及如何通过标签属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5部电影的数据如下
物品模型包数据
文章在目录中创建Item模型层
封装爬取的数据
yield 的语法介绍
在创建Item模型层之前,我们可以拿到第一页的数据,但是只能在控制台打印出来。Scrapy中还有一个Item模块,就是模型层,主要完成值数据的封装,然后写入数据库
对抓取到的数据进行封装,将抓取到的数据存放在豆瓣Item对象中,然后交给item_list,最后返回Item_list
yield 的语法介绍
具有 yield 的函数是生成器。它不同于普通的功能。生成生成器看起来像一个函数调用,但在调用 next() 之前不会执行任何函数代码(在 for 循环中,next() 将被自动调用。))开始执行。虽然执行流程还是按照函数的流程执行,但是每次执行yield语句都会被中断,并且会返回一个迭代值。下一次执行将从下一个 yield 语句开始。好像一个函数在正常执行过程中被yield多次中断,每次中断都会通过yield返回当前的迭代值。
产量和自动翻页
文章内容
收益优势
收益优化回报数据
收益优势
收益的好处是显而易见的。将函数重写为生成器可以获得迭代能力。与使用类实例保存状态来计算下一个next()值相比,不仅代码简洁,执行流程也非常清晰。
在Scrapy爬虫框架中,yield有一个自然的使用场景,因为我们不知道爬虫每次获取数据的大小。如果爬虫每次都返回,数据量会非常大。这时候如果用yield来优化代码,代码会非常简洁高效
收益优化回报数据 查看全部
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注就是本质(4小时,完成了Scrapy爬虫必备知识点的讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学(深入浅出,以案例为导向,学以致用)
讲师问答(拒绝助教,讲师当天解答)
课程适合人群
拥有Py的基本语法和面向对象开发的思想,其他语言的开发者,回归浪子的人,想一夜暴富的人
建筑与环境建设
文章Scrapy 简介
Scrapy 组件介绍
pip安装scrapy
Scrapy 简介
用于屏幕抓取和网页抓取的快速、高级 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求进行个性化定制. Scrapy架构图:
Scrapy 组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
调度器(Scheduler):用于接受引擎发送的Request请求,将其压入队列,当引擎再次请求时返回。
Downloader(下载器):用于请求引擎发送的Request对应的网页内容,并将获取到的Responses返回给Spider。
Item Pipeline(管道):负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider Responses和Requests
pip安装scrapy
正常情况下通过pip show scrapy查看是否安装,如果安装则显示安装信息,否则不显示任何信息
通过pip install scrapy安装爬虫框架(可能会抛出以下异常)
根据异常提示:ERROR: MICROSOFT VISUAL C++ 9.0 IS REQUIRED (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载缺失的window组件,视频学习资料中提供
第一个爬虫项目
文章内容
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject豆瓣就可以创建项目了
按照上面的提示创建Spider解析器:cd豆瓣,然后在项目中执行:scrapy genspider example就可以创建Spider对象了
细心的朋友会发现douban_spider默认会存放在douban.spider目录下。用pycharm IDE打开,会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的Spider文件,也就是你爬取的py文件
items.py:相当于一个容器,更像是一个字典 middlewares.py:定义下载器
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现pipelines.py:Define Item
Pipeline的实现实现了数据的清洗、存储和校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法介绍
文章内容
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。实际上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航。
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章内容
豆瓣电影页面分析
首页下载实现
前5部电影的数据如下
豆瓣电影页面分析为大家讲解了如何在XML文档中查找信息,具体来说,您已经学会了如何获取元素、内容、属性,以及如何通过标签属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5部电影的数据如下
物品模型包数据
文章在目录中创建Item模型层
封装爬取的数据
yield 的语法介绍
在创建Item模型层之前,我们可以拿到第一页的数据,但是只能在控制台打印出来。Scrapy中还有一个Item模块,就是模型层,主要完成值数据的封装,然后写入数据库
对抓取到的数据进行封装,将抓取到的数据存放在豆瓣Item对象中,然后交给item_list,最后返回Item_list
yield 的语法介绍
具有 yield 的函数是生成器。它不同于普通的功能。生成生成器看起来像一个函数调用,但在调用 next() 之前不会执行任何函数代码(在 for 循环中,next() 将被自动调用。))开始执行。虽然执行流程还是按照函数的流程执行,但是每次执行yield语句都会被中断,并且会返回一个迭代值。下一次执行将从下一个 yield 语句开始。好像一个函数在正常执行过程中被yield多次中断,每次中断都会通过yield返回当前的迭代值。
产量和自动翻页
文章内容
收益优势
收益优化回报数据
收益优势
收益的好处是显而易见的。将函数重写为生成器可以获得迭代能力。与使用类实例保存状态来计算下一个next()值相比,不仅代码简洁,执行流程也非常清晰。
在Scrapy爬虫框架中,yield有一个自然的使用场景,因为我们不知道爬虫每次获取数据的大小。如果爬虫每次都返回,数据量会非常大。这时候如果用yield来优化代码,代码会非常简洁高效
收益优化回报数据
scrapy分页抓取网页( 2017年12月01日Python框架Scrapy爬虫入门之页面提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-21 01:11
2017年12月01日Python框架Scrapy爬虫入门之页面提取)
Python爬虫框架Scrapy爬虫入门:页面提取
更新时间:2017-12-01 12:02:34 作者:大虫
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。下面文章文章主要介绍了提取Python爬虫框架Scrapy爬虫入口页面的相关信息,文章中通过示例代码的介绍非常详细,有需要的朋友可以参考。
前言
Scrapy 是一个非常好的抓取框架。它不仅提供了一些开箱即用的基本组件,还可以根据自己的需求进行强大的定制。本文主要为大家介绍Python爬虫框架Scrapy页面提取的相关内容,分享出来供大家参考。和小编一起学习吧。
在开始之前,可以参考这个文章关于scrapy框架的介绍:
我们以土冲网为例,创建一个抓取图片的爬虫项目。
一、内容分析
打开土冲,最上面的菜单“发现”和“标签”是各种图片的分类,点击一个标签,比如“美女”,网页的链接是:美女/,我们以此为爬虫入口分析一下这一页 :
打开页面后,会出现一张图集,点击图集可以全屏浏览图片,向下滚动页面会出现更多的图集,没有设置页码。在Chrome中右键“检查元素”,打开开发者工具,查看页面源码,内容如下:
<p> 查看全部
scrapy分页抓取网页(
2017年12月01日Python框架Scrapy爬虫入门之页面提取)
Python爬虫框架Scrapy爬虫入门:页面提取
更新时间:2017-12-01 12:02:34 作者:大虫
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。下面文章文章主要介绍了提取Python爬虫框架Scrapy爬虫入口页面的相关信息,文章中通过示例代码的介绍非常详细,有需要的朋友可以参考。
前言
Scrapy 是一个非常好的抓取框架。它不仅提供了一些开箱即用的基本组件,还可以根据自己的需求进行强大的定制。本文主要为大家介绍Python爬虫框架Scrapy页面提取的相关内容,分享出来供大家参考。和小编一起学习吧。
在开始之前,可以参考这个文章关于scrapy框架的介绍:
我们以土冲网为例,创建一个抓取图片的爬虫项目。
一、内容分析
打开土冲,最上面的菜单“发现”和“标签”是各种图片的分类,点击一个标签,比如“美女”,网页的链接是:美女/,我们以此为爬虫入口分析一下这一页 :
打开页面后,会出现一张图集,点击图集可以全屏浏览图片,向下滚动页面会出现更多的图集,没有设置页码。在Chrome中右键“检查元素”,打开开发者工具,查看页面源码,内容如下:
<p>
scrapy分页抓取网页(C#编写的多线程异步抓取网页的网络爬虫控制台程序功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-21 01:08
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个互联网网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序可以捕获所有链接,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件,“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不是后缀。犯了一个错误。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不是后缀。犯了一个错误。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。 查看全部
scrapy分页抓取网页(C#编写的多线程异步抓取网页的网络爬虫控制台程序功能)
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个互联网网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序可以捕获所有链接,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件,“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不是后缀。犯了一个错误。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不是后缀。犯了一个错误。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-20 07:18
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现翻阅一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
其实在本教程的第一个例子中,抓取豆瓣电影TOP列表,豆瓣的电影列表使用pager进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝们给了坤坤一份300W转发。微博的转发数据碰巧被传呼机分割了。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现翻阅一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
其实在本教程的第一个例子中,抓取豆瓣电影TOP列表,豆瓣的电影列表使用pager进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝们给了坤坤一份300W转发。微博的转发数据碰巧被传呼机分割了。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(《》爬取第2讲:爬取网站抓取策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-10-20 07:15
显式爬取网站:
爬取策略:关注所有文章页面,逐页爬取。
具体策略一:改变页码值
缺点:当总页数发生变化时,需要修改源代码
具体策略二:一步一步提取下一页,不需要随着页面变化而修改源代码
下面是策略二。
准备好工作了:
创建一个新的虚拟环境:
C:\Users\wex>mkvirtualenv article
Using base prefix 'c:\\users\\wex\\appdata\\local\\programs\\python\\python35'
New python executable in C:\Users\wex\Envs\article\Scripts\python.exe
Installing setuptools, pip, wheel...done.
创建项目:
I:\python项目>scrapy startproject ArticleSpider
New Scrapy project 'ArticleSpider', using template directory 'c:\\users\\wex\\appdata\\local\\programs\\python\\python35\\lib\\site-packages\\scrapy\\templates\\project', created in:
I:\python项目\ArticleSpider
You can start your first spider with:
cd ArticleSpider
scrapy genspider example example.com
根据默认模板创建爬虫文件:
I:\python项目\ArticleSpider>scrapy genspider jobbole blog.jobbole.com
Created spider 'jobbole' using template 'basic' in module:
ArticleSpider.spiders.jobbole
Scrapy 启动一个蜘蛛方法(名字就是蜘蛛中的名字):
scrapy crawl jobbole
当报错时:
ImportError: No module named 'win32api'
根据错误安装:
I:\python项目\ArticleSpider>pip install pypiwin32
Collecting pypiwin32
Downloading pypiwin32-219-cp35-none-win_amd64.whl (8.6MB)
100% |████████████████████████████████| 8.6MB 88kB/s
Installing collected packages: pypiwin32
Successfully installed pypiwin32-219
这时候重启是不会报错的。
在 Pycharm 中新建一个 main.py 文件来运行蜘蛛文件。
#调用这个函数可以执行scrapy文件
from scrapy.cmdline import execute
import sys
import os
#设置ArticleSpider工程目录
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
#调用execute函数运行spider
execute(["scrapy","crawl","jobbole"])
请注意,在设置文件中:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
防止不符合协议的 URL 被过滤掉。
关于 xpath:介绍、术语、语法
1. XPath 使用多路径表达式在 xml 和 html 中导航
2. xpath 收录标准函数库
3. XPath 是 w3c 标准
xpath 节点关系
1、父节点
2. 子节点
3. 兄弟节点
4. 高级节点
5. 后代节点
语法:选择节点
表达式 说明
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
article 选取所有article元素的所有子节点
/article 选取根元素article
article/a 选取所有属于article的子元素的a元素
//div 选取所有div元素(不论出现在文档任何地方)
//@class 选取所有名为class的属性
谓词
谓词用于查找特定节点或收录指定值的节点。
谓词嵌入在方括号中
/article/div[1] 选取属于article子元素的第一个div元素
/article/div[last()] 选取属于article子元素的最后一个div元素
/article/div[last()-1] 选取属于article子元素的倒数第二个div元素
/article/div[last()35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
选择未知节点
* 匹配任何元素节点
@* 匹配任何属性节点
node() 匹配任何类型的节点
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
/div/* 选取属于div元素的所有子节点
//* 选取所有元素
//div[@*] 获取所有有带属性的div元素
/div/a | /div/p 获取所有div元素的a和p元素
//span | //ul 选取文档中的span和ul元素
article/div/p | //span 选取所有属于article元素的div元素的p元素 以及文档中所有的span元素
有一点需要注意:查看F12得到的包括加载js和css,可能与查看源码得到的不一致。
我们提取网页内容: 查看全部
scrapy分页抓取网页(《》爬取第2讲:爬取网站抓取策略)
显式爬取网站:
爬取策略:关注所有文章页面,逐页爬取。
具体策略一:改变页码值
缺点:当总页数发生变化时,需要修改源代码
具体策略二:一步一步提取下一页,不需要随着页面变化而修改源代码
下面是策略二。
准备好工作了:
创建一个新的虚拟环境:
C:\Users\wex>mkvirtualenv article
Using base prefix 'c:\\users\\wex\\appdata\\local\\programs\\python\\python35'
New python executable in C:\Users\wex\Envs\article\Scripts\python.exe
Installing setuptools, pip, wheel...done.
创建项目:
I:\python项目>scrapy startproject ArticleSpider
New Scrapy project 'ArticleSpider', using template directory 'c:\\users\\wex\\appdata\\local\\programs\\python\\python35\\lib\\site-packages\\scrapy\\templates\\project', created in:
I:\python项目\ArticleSpider
You can start your first spider with:
cd ArticleSpider
scrapy genspider example example.com
根据默认模板创建爬虫文件:
I:\python项目\ArticleSpider>scrapy genspider jobbole blog.jobbole.com
Created spider 'jobbole' using template 'basic' in module:
ArticleSpider.spiders.jobbole
Scrapy 启动一个蜘蛛方法(名字就是蜘蛛中的名字):
scrapy crawl jobbole
当报错时:
ImportError: No module named 'win32api'
根据错误安装:
I:\python项目\ArticleSpider>pip install pypiwin32
Collecting pypiwin32
Downloading pypiwin32-219-cp35-none-win_amd64.whl (8.6MB)
100% |████████████████████████████████| 8.6MB 88kB/s
Installing collected packages: pypiwin32
Successfully installed pypiwin32-219
这时候重启是不会报错的。
在 Pycharm 中新建一个 main.py 文件来运行蜘蛛文件。
#调用这个函数可以执行scrapy文件
from scrapy.cmdline import execute
import sys
import os
#设置ArticleSpider工程目录
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
#调用execute函数运行spider
execute(["scrapy","crawl","jobbole"])
请注意,在设置文件中:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
防止不符合协议的 URL 被过滤掉。
关于 xpath:介绍、术语、语法
1. XPath 使用多路径表达式在 xml 和 html 中导航
2. xpath 收录标准函数库
3. XPath 是 w3c 标准
xpath 节点关系
1、父节点
2. 子节点
3. 兄弟节点
4. 高级节点
5. 后代节点
语法:选择节点
表达式 说明
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
article 选取所有article元素的所有子节点
/article 选取根元素article
article/a 选取所有属于article的子元素的a元素
//div 选取所有div元素(不论出现在文档任何地方)
//@class 选取所有名为class的属性
谓词
谓词用于查找特定节点或收录指定值的节点。
谓词嵌入在方括号中
/article/div[1] 选取属于article子元素的第一个div元素
/article/div[last()] 选取属于article子元素的最后一个div元素
/article/div[last()-1] 选取属于article子元素的倒数第二个div元素
/article/div[last()35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
选择未知节点
* 匹配任何元素节点
@* 匹配任何属性节点
node() 匹配任何类型的节点
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
/div/* 选取属于div元素的所有子节点
//* 选取所有元素
//div[@*] 获取所有有带属性的div元素
/div/a | /div/p 获取所有div元素的a和p元素
//span | //ul 选取文档中的span和ul元素
article/div/p | //span 选取所有属于article元素的div元素的p元素 以及文档中所有的span元素
有一点需要注意:查看F12得到的包括加载js和css,可能与查看源码得到的不一致。
我们提取网页内容:
scrapy分页抓取网页(Python大火,为了跟上时代,试着自学了下某位作者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-20 07:14
Python 近来大受欢迎。为了跟上时代的步伐,我尝试着自学。Scrapy 是一个高级的 Python 爬虫框架。不仅收录爬虫的特性,还可以方便的将爬虫数据保存为csv、json等文件。
今天我们尝试用Scrapy爬取某某某作者的所有文章。
在本教程中,我们假设您已经安装了 Scrapy。如果没有,请参考。
1.创建项目
在开始爬取之前,我们必须创建一个新的 Scrapy 项目,这里我将其命名为 jianshu_article。打开Mac终端,cd到你打算存放代码的目录,运行以下命令:
//Mac终端运行如下命令:
scrapy startproject jianshu_article
2.创建爬虫
//cd到上面创建的文件目录
cd jianshu_article
//创建爬虫程序
scrapy genspider jianshu jianshu.com
/*
文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模型,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:USER_AGENT(模拟浏览器,应对网站反爬),递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
*/
为了方便编写程序,我们使用Pycharm打开项目。执行上述命令后,程序会自动创建目录和文件。生成了一个名为 jianshu.py 的文件,后面我们的主要逻辑会写在这个文件中。
简书.py
3.设置数据模型
双击 items.py 文件。
找到你要爬取的短书作者的主页,比如我自己的主页,用谷歌浏览器打开,空白处右击,点击“勾选”,进入控制台开发者模式:
打开控制台.png
通过分析网页的源代码,我们大概需要这些内容:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JianshuArticalItem(scrapy.Item):
avatar = scrapy.Field() #头像
nickname = scrapy.Field() #昵称
time = scrapy.Field() #发表时间
wrap_img = scrapy.Field() #封面(缺省值)
title = scrapy.Field() #标题
abstract = scrapy.Field() #正文部分显示
read = scrapy.Field() #查看人数
comments = scrapy.Field() #评论数
like = scrapy.Field() #喜欢(点赞)
detail = scrapy.Field() #文章详情url
pass
这样,数据模型就创建好了。后面运行爬虫的时候,得到的数据会存储在模型对应的位置。
4.分析网页源码,写爬虫
因为我比较懒,很少写文章,而且文章的数量也比较少。为了展示分页的效果,我选择了一个作者CC老师_MissCC的主页在短书中进行爬取。
我们可以通过分析 URL 发现一些特征:
作者的 URL 是: + 作者 ID:
作者主页 URL.png
文章 的 URL 是: + 文章ID:
文章网址.png
虽然我们直接在浏览器中打开作者的网址,但是用鼠标滚轮向下滚动会动态加载下一页,直到最后一篇文章文章网址保持不变。但是作为一个Scrapy爬虫,好像只能拿到第一页,那怎么办呢?以我多年的开发经验,尝试拼接一个“page”参数和url后面的页数。正如预期的那样,可以请求不同的数据。
拼接参数页获取分页数据.png
找到这些规则,我们就可以通过分析HTML源代码得到我们想要的数据了。
首先,我们回到 jianshu.py 文件并导入模型:
//从项目名 jianshu_article的文件items.py导入JianshuArticleItem类
from jianshu_article.items import JianshuArticleItem
设置必要的参数以启动第一个请求:
# -*- coding: utf-8 -*-
import scrapy
from jianshu_article.items import JianshuArticleItem
class JianshuSpider(scrapy.Spider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
user_id = "1b4c832fb2ca"
url = "https://www.jianshu.com/u/{0}?page=1".format(user_id)
start_urls = [
url,
]
def parse(self, response):
#用户头像
c = response.xpath('//div[@class="main-top"]/a[@class="avatar"]/img/@src').extract_first()
print(c)
pass
此时终端运行命令scrapy crawl jianshu,理论上可以打印网页内容。事实上,情况并非如此。如果没有请求数据,终端会打印一些日志信息:
日志.png
不难发现,报了403问题和HTTP状态码未处理或不允许问题,导致“Closing spider(finished)”爬虫终止。通过万能百度知道网站已经采取了一些相应的反爬虫措施。要对症下药,我们只需要在settings.py中做一些相应的修改:
```
User_Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的
操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
通俗点讲,我们配置这个字段的目的就是为了伪装成浏览器打开网页,达到骗过目标网站的监测。
```
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
CONCURRENT_REQUESTS = 1 #并发数
DOWNLOAD_DELAY = 5 #为了防止IP被封,我们5秒请求一次
HTTPERROR_ALLOWED_CODES = [403] #上面报的是403,就把403加入
#默认为True,就是要遵守robots.txt 的规则,这里我们改为False
ROBOTSTXT_OBEY = False
进行相应的修改后,我们再次执行爬虫命令:scrapy crawl jianshu,查看日志打印获取头像。
获取头像.png
既然可以成功抓取网页数据,接下来我们要做的就是分析网页的源代码,下面我们就不一一分析了。当然在此之前你需要对xpath有一定的了解。
以下引用Scrapy中文官网的介绍:
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 和 CSS: 的表达机制。请参阅有关选择器和其他提取机制的信息。
以下是 XPath 表达式及其对应含义的示例:
以上只是几个简单的XPath例子,XPath其实比这个强大很多。如果您想了解更多,我们推荐这个 XPath 教程。
通过上面的介绍,相信你可以做好接下来的爬虫工作,把jianshu.py的所有代码贴在下面供参考:
# -*- coding: utf-8 -*-
import scrapy
from jianshu_article.items import JianshuArticleItem
class JianshuSpider(scrapy.Spider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
user_id = "1b4c832fb2ca" #替换此用户ID可获取你需要的数据,或者放开下一行的注释
#user_id = input('请输入作者id:\n')
url = "https://www.jianshu.com/u/{0}?page=1".format(user_id)
start_urls = [
url,
]
def parse(self, response):
# [关注,粉丝,文章]
a = response.xpath('//div[@class="main-top"]/div[@class="info"]/ul/li/div/a/p/text()').extract()
print(a)
# [字数,收获喜欢]
b = response.xpath('//div[@class="main-top"]/div[@class="info"]/ul/li/div/p/text()').extract()
print(b)
# 大头像
c = response.xpath('//div[@class="main-top"]/a[@class="avatar"]/img/@src').extract_first()
print(c)
# 用户名
d = response.xpath('//div[@class="main-top"]/div[@class="title"]/a/text()').extract_first()
print(d)
# 性别
e = response.xpath('//div[@class="main-top"]/div[@class="title"]/i/@class').extract_first()
print(e)
# 获取文章总数,计算页数。(简书网站默认每页是9组数据)
temp = int(a[2])
if (temp % 9 > 0):
count = temp // 9 + 1
else:
count = temp // 9
print("总共" + str(count) + "页")
base_url = "https://www.jianshu.com/u/{0}?page={1}"
for i in range(1, count + 1):
i = count + 1 - i #理论上正序1~count就是按顺序获取的,但是获取的数据是倒置的,所以我们获取count~1的数据,得到的数组就是按照网页形式1~count页码排序的了
yield scrapy.Request(base_url.format(self.user_id, i), dont_filter=True, callback=self.parse_page)
#迭代返回每页的内容
def parse_page(self, response):
for sel in response.xpath('//div[@id="list-container"]/ul/li'):
item = JianshuArticleItem()
item['wrap_img'] = sel.xpath('a/img/@src').extract_first()
item['avatar'] = sel.xpath('div//a[@class="avatar"]/img/@src').extract_first()
item['nickname'] = sel.xpath('div//a[@class="nickname"]/text()').extract_first()
item['time'] = sel.xpath('div//span[@class="time"]/@data-shared-at').extract_first()
item['title'] = sel.xpath('div/a[@class="title"]/text()').extract_first()
item['abstract'] = sel.xpath('div/p[@class="abstract"]/text()').extract_first()
item['read'] = sel.xpath('div/div[@class="meta"]/a[1]/text()').extract()[1]
item['comments'] = sel.xpath('div/div[@class="meta"]/a[2]/text()').extract()[1]
item['like'] = sel.xpath('div/div[@class="meta"]/span/text()').extract_first()
item['detail'] = sel.xpath('div/a[@class="title"]/@href').extract_first()
yield item
至此,爬虫代码已经编写完毕。如果要保存获取的数据,可以在终端执行以下命令:
/*
此命令用于把爬取的数据保存为json文件格式,当然你也可以保存为别的文件格式。
Scrapy官方列出的文件格式有如下几种:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')。
温馨提示:如果要再次爬取,最好换一个文件名或者清空数据再爬取,因为第二还是写入上一个文件,数据不会覆盖,
会堆积在上次获取的下面,造成json文件格式报错。
*/
scrapy crawl jianshu -o data.json
程序执行完后,我们可以在文件目录下看到新生成的data.json文件,双击可以看到我们要获取的所有数据:
执行 crawler.png 得到的数据
json解析出来的数据和网站.png上的完全一样
github地址: 查看全部
scrapy分页抓取网页(Python大火,为了跟上时代,试着自学了下某位作者)
Python 近来大受欢迎。为了跟上时代的步伐,我尝试着自学。Scrapy 是一个高级的 Python 爬虫框架。不仅收录爬虫的特性,还可以方便的将爬虫数据保存为csv、json等文件。
今天我们尝试用Scrapy爬取某某某作者的所有文章。
在本教程中,我们假设您已经安装了 Scrapy。如果没有,请参考。
1.创建项目
在开始爬取之前,我们必须创建一个新的 Scrapy 项目,这里我将其命名为 jianshu_article。打开Mac终端,cd到你打算存放代码的目录,运行以下命令:
//Mac终端运行如下命令:
scrapy startproject jianshu_article
2.创建爬虫
//cd到上面创建的文件目录
cd jianshu_article
//创建爬虫程序
scrapy genspider jianshu jianshu.com
/*
文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模型,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:USER_AGENT(模拟浏览器,应对网站反爬),递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
*/
为了方便编写程序,我们使用Pycharm打开项目。执行上述命令后,程序会自动创建目录和文件。生成了一个名为 jianshu.py 的文件,后面我们的主要逻辑会写在这个文件中。

简书.py
3.设置数据模型
双击 items.py 文件。
找到你要爬取的短书作者的主页,比如我自己的主页,用谷歌浏览器打开,空白处右击,点击“勾选”,进入控制台开发者模式:

打开控制台.png
通过分析网页的源代码,我们大概需要这些内容:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JianshuArticalItem(scrapy.Item):
avatar = scrapy.Field() #头像
nickname = scrapy.Field() #昵称
time = scrapy.Field() #发表时间
wrap_img = scrapy.Field() #封面(缺省值)
title = scrapy.Field() #标题
abstract = scrapy.Field() #正文部分显示
read = scrapy.Field() #查看人数
comments = scrapy.Field() #评论数
like = scrapy.Field() #喜欢(点赞)
detail = scrapy.Field() #文章详情url
pass
这样,数据模型就创建好了。后面运行爬虫的时候,得到的数据会存储在模型对应的位置。
4.分析网页源码,写爬虫
因为我比较懒,很少写文章,而且文章的数量也比较少。为了展示分页的效果,我选择了一个作者CC老师_MissCC的主页在短书中进行爬取。
我们可以通过分析 URL 发现一些特征:
作者的 URL 是: + 作者 ID:

作者主页 URL.png
文章 的 URL 是: + 文章ID:

文章网址.png
虽然我们直接在浏览器中打开作者的网址,但是用鼠标滚轮向下滚动会动态加载下一页,直到最后一篇文章文章网址保持不变。但是作为一个Scrapy爬虫,好像只能拿到第一页,那怎么办呢?以我多年的开发经验,尝试拼接一个“page”参数和url后面的页数。正如预期的那样,可以请求不同的数据。

拼接参数页获取分页数据.png
找到这些规则,我们就可以通过分析HTML源代码得到我们想要的数据了。
首先,我们回到 jianshu.py 文件并导入模型:
//从项目名 jianshu_article的文件items.py导入JianshuArticleItem类
from jianshu_article.items import JianshuArticleItem
设置必要的参数以启动第一个请求:
# -*- coding: utf-8 -*-
import scrapy
from jianshu_article.items import JianshuArticleItem
class JianshuSpider(scrapy.Spider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
user_id = "1b4c832fb2ca"
url = "https://www.jianshu.com/u/{0}?page=1".format(user_id)
start_urls = [
url,
]
def parse(self, response):
#用户头像
c = response.xpath('//div[@class="main-top"]/a[@class="avatar"]/img/@src').extract_first()
print(c)
pass
此时终端运行命令scrapy crawl jianshu,理论上可以打印网页内容。事实上,情况并非如此。如果没有请求数据,终端会打印一些日志信息:

日志.png
不难发现,报了403问题和HTTP状态码未处理或不允许问题,导致“Closing spider(finished)”爬虫终止。通过万能百度知道网站已经采取了一些相应的反爬虫措施。要对症下药,我们只需要在settings.py中做一些相应的修改:
```
User_Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的
操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
通俗点讲,我们配置这个字段的目的就是为了伪装成浏览器打开网页,达到骗过目标网站的监测。
```
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
CONCURRENT_REQUESTS = 1 #并发数
DOWNLOAD_DELAY = 5 #为了防止IP被封,我们5秒请求一次
HTTPERROR_ALLOWED_CODES = [403] #上面报的是403,就把403加入
#默认为True,就是要遵守robots.txt 的规则,这里我们改为False
ROBOTSTXT_OBEY = False
进行相应的修改后,我们再次执行爬虫命令:scrapy crawl jianshu,查看日志打印获取头像。

获取头像.png
既然可以成功抓取网页数据,接下来我们要做的就是分析网页的源代码,下面我们就不一一分析了。当然在此之前你需要对xpath有一定的了解。
以下引用Scrapy中文官网的介绍:
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 和 CSS: 的表达机制。请参阅有关选择器和其他提取机制的信息。
以下是 XPath 表达式及其对应含义的示例:
以上只是几个简单的XPath例子,XPath其实比这个强大很多。如果您想了解更多,我们推荐这个 XPath 教程。
通过上面的介绍,相信你可以做好接下来的爬虫工作,把jianshu.py的所有代码贴在下面供参考:
# -*- coding: utf-8 -*-
import scrapy
from jianshu_article.items import JianshuArticleItem
class JianshuSpider(scrapy.Spider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
user_id = "1b4c832fb2ca" #替换此用户ID可获取你需要的数据,或者放开下一行的注释
#user_id = input('请输入作者id:\n')
url = "https://www.jianshu.com/u/{0}?page=1".format(user_id)
start_urls = [
url,
]
def parse(self, response):
# [关注,粉丝,文章]
a = response.xpath('//div[@class="main-top"]/div[@class="info"]/ul/li/div/a/p/text()').extract()
print(a)
# [字数,收获喜欢]
b = response.xpath('//div[@class="main-top"]/div[@class="info"]/ul/li/div/p/text()').extract()
print(b)
# 大头像
c = response.xpath('//div[@class="main-top"]/a[@class="avatar"]/img/@src').extract_first()
print(c)
# 用户名
d = response.xpath('//div[@class="main-top"]/div[@class="title"]/a/text()').extract_first()
print(d)
# 性别
e = response.xpath('//div[@class="main-top"]/div[@class="title"]/i/@class').extract_first()
print(e)
# 获取文章总数,计算页数。(简书网站默认每页是9组数据)
temp = int(a[2])
if (temp % 9 > 0):
count = temp // 9 + 1
else:
count = temp // 9
print("总共" + str(count) + "页")
base_url = "https://www.jianshu.com/u/{0}?page={1}"
for i in range(1, count + 1):
i = count + 1 - i #理论上正序1~count就是按顺序获取的,但是获取的数据是倒置的,所以我们获取count~1的数据,得到的数组就是按照网页形式1~count页码排序的了
yield scrapy.Request(base_url.format(self.user_id, i), dont_filter=True, callback=self.parse_page)
#迭代返回每页的内容
def parse_page(self, response):
for sel in response.xpath('//div[@id="list-container"]/ul/li'):
item = JianshuArticleItem()
item['wrap_img'] = sel.xpath('a/img/@src').extract_first()
item['avatar'] = sel.xpath('div//a[@class="avatar"]/img/@src').extract_first()
item['nickname'] = sel.xpath('div//a[@class="nickname"]/text()').extract_first()
item['time'] = sel.xpath('div//span[@class="time"]/@data-shared-at').extract_first()
item['title'] = sel.xpath('div/a[@class="title"]/text()').extract_first()
item['abstract'] = sel.xpath('div/p[@class="abstract"]/text()').extract_first()
item['read'] = sel.xpath('div/div[@class="meta"]/a[1]/text()').extract()[1]
item['comments'] = sel.xpath('div/div[@class="meta"]/a[2]/text()').extract()[1]
item['like'] = sel.xpath('div/div[@class="meta"]/span/text()').extract_first()
item['detail'] = sel.xpath('div/a[@class="title"]/@href').extract_first()
yield item
至此,爬虫代码已经编写完毕。如果要保存获取的数据,可以在终端执行以下命令:
/*
此命令用于把爬取的数据保存为json文件格式,当然你也可以保存为别的文件格式。
Scrapy官方列出的文件格式有如下几种:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')。
温馨提示:如果要再次爬取,最好换一个文件名或者清空数据再爬取,因为第二还是写入上一个文件,数据不会覆盖,
会堆积在上次获取的下面,造成json文件格式报错。
*/
scrapy crawl jianshu -o data.json
程序执行完后,我们可以在文件目录下看到新生成的data.json文件,双击可以看到我们要获取的所有数据:

执行 crawler.png 得到的数据

json解析出来的数据和网站.png上的完全一样
github地址:
scrapy分页抓取网页(crawlspiderrules有点疑问总结:1、rules里的Rule规则运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-19 17:01
最近在学习爬虫,对爬虫规则的运行机制有些疑惑,于是自己研究了一下,总结出以下几点:
1、规则中的规则是按顺序运行的,从上到下执行;
2、 获取request url是Rule定位的容器,a标签中的所有href链接,比如使用xpath定位
规则 = (
规则(LinkExtractor(restrict_xpaths=("//div/ul")),callback='parse_item'),
)
然后会获取ul容器下a标签的所有链接,服务器会自动发送请求,无需手动发送请求;
3、 响应页面就是Rule请求的链接的页面内容,也就是你在容器ul中定位a标签所在的链接,然后点击链接查看页面内容,在回调函数中提取数据。从这个页面中提取,parse_item(self,response),这个函数的响应对象就是这个页面的内容,不要搞错对象;
4、follow,这个参数开始让我有点晕。跟随意味着跟进。如果follow=True,那么在你得到的响应页面中,会获取所有符合规则的href链接 会自动跟进,进入获取的链接响应页面,在这个页面再次匹配规则规则,看是否有是任何匹配,如果匹配,则继续跟踪,直到匹配规则失败。例如:
规则 = (
规则(LinkExtractor(restrict_xpaths=(“//div/ul”)),follow=True),
)
所以首先规则会获取当前页面上所有符合规则规则的链接,当前页面为start_urls页面,例如获取的链接为
教科书
会继续进入href链接的页面,然后继续匹配Rule规则,看看有没有匹配的链接,相当于在响应页面的元素中找到符合规则的a标签url ,然后点击这个url,然后在这个页面的元素中查找是否有符合Rule规则的href链接,依此类推,直到找不到符合Rule规则的href链接;
5、如果Rule中有callback="parse_item",follow=True,那么情况会更复杂。你可以想象得到一个响应符合Rule规则的页面的链接,然后调用函数,跳转到这个页面。按照其他目标链接,然后调用该函数。最好使用xpath定位。如果使用allow=(r'')正则表达式匹配,会比较混乱。在适当的情况下也会用到,不过比较少嘛,大家可以自己测试体验一下。
6、 翻页,翻页有两种情况
第一种情况(start_url的响应页面底部有翻页链接):
在规则中定义两个Rule规则,一个是获取响应页面规则,一个是获取翻页链接规则,翻页规则遵循响应页面规则,顺序不能错,如下:
规则 = (
规则(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
规则(LinkExtractor(allow=r'\d\.htm'),follow=True),
)
第二种情况(start_url的响应页面底部没有翻页链接,只有输入a标签链接才有翻页链接):
在这种情况下,您无法在规则中定义翻页规则,因为即使您定义了翻页规则,也找不到它们。因为规则中的所有规则,第一次得到响应页面是start_url地址对应的内容。如果该页面没有规则规则,则不会被发现。这里就不多说了,直接上源码吧!
class TestSpider(CrawlSpider):
name = 'test'
allowed_domains = ['dangdang.com']
start_urls = ['http://book.dangdang.com/']
rules = (
Rule(LinkExtractor(restrict_xpaths=("//div[@class='conflq_body']/div[@name='m403752_pid5438_t10274']//div/dl[@ddt-area='5358']/dd")), callback='parse_item'),
)
def parse_item(self, response):
item={}
item['cate_0']=''
item['cate_1'] = ''
item['cate_2'] = ''
item['cate_3'] = ''
breadcrum=response.xpath("//div[@class='crumbs_fb_left']/div[@class='select_frame']/a[@name='breadcrumb-category']/text()").getall()
for i in range(len(breadcrum)):
item['cate_{}'.format(i)]=breadcrum[i]
book_li=response.xpath("//div[@id='search_nature_rg']/ul/li")
for li in book_li:
item['book_title']=li.xpath(".//p[@class='name']/a/@title").get()
item['book_price']=li.xpath(".//p[@class='price']/span/text()").get()
item['book_url']=li.xpath(".//p[@class='name']/a/@href").get()
book_search=li.xpath(".//p[@class='search_book_author']/span")
item['book_author']=book_search[0].xpath(".//a/@title").get()
item['public_date']=book_search[1].xpath(".//text()").get()
item['public_date']=re.sub("/",'',item['public_date']) if item['public_date'] else None
item['public_company']=book_search[2].xpath(".//a/@title").get()
yield item
next_page_url=response.xpath("//div[@class='paging']//li[@class='next']/a/@href").get()
next_page="http://category.dangdang.com"+next_page_url
yield scrapy.Request(next_page,callback=self.parse_item)
在这种情况下,必须在函数中进行翻页。parse_item() 函数的最后三行是翻页语句!我可以自己测试一下。不知道有没有其他方法可以做规则。反正我现在还没找到。如果有人知道,我可以告诉!
以上是我个人的看法,如有错误或遗漏,敬请指出! 查看全部
scrapy分页抓取网页(crawlspiderrules有点疑问总结:1、rules里的Rule规则运行)
最近在学习爬虫,对爬虫规则的运行机制有些疑惑,于是自己研究了一下,总结出以下几点:
1、规则中的规则是按顺序运行的,从上到下执行;
2、 获取request url是Rule定位的容器,a标签中的所有href链接,比如使用xpath定位
规则 = (
规则(LinkExtractor(restrict_xpaths=("//div/ul")),callback='parse_item'),
)
然后会获取ul容器下a标签的所有链接,服务器会自动发送请求,无需手动发送请求;
3、 响应页面就是Rule请求的链接的页面内容,也就是你在容器ul中定位a标签所在的链接,然后点击链接查看页面内容,在回调函数中提取数据。从这个页面中提取,parse_item(self,response),这个函数的响应对象就是这个页面的内容,不要搞错对象;
4、follow,这个参数开始让我有点晕。跟随意味着跟进。如果follow=True,那么在你得到的响应页面中,会获取所有符合规则的href链接 会自动跟进,进入获取的链接响应页面,在这个页面再次匹配规则规则,看是否有是任何匹配,如果匹配,则继续跟踪,直到匹配规则失败。例如:
规则 = (
规则(LinkExtractor(restrict_xpaths=(“//div/ul”)),follow=True),
)
所以首先规则会获取当前页面上所有符合规则规则的链接,当前页面为start_urls页面,例如获取的链接为
教科书
会继续进入href链接的页面,然后继续匹配Rule规则,看看有没有匹配的链接,相当于在响应页面的元素中找到符合规则的a标签url ,然后点击这个url,然后在这个页面的元素中查找是否有符合Rule规则的href链接,依此类推,直到找不到符合Rule规则的href链接;
5、如果Rule中有callback="parse_item",follow=True,那么情况会更复杂。你可以想象得到一个响应符合Rule规则的页面的链接,然后调用函数,跳转到这个页面。按照其他目标链接,然后调用该函数。最好使用xpath定位。如果使用allow=(r'')正则表达式匹配,会比较混乱。在适当的情况下也会用到,不过比较少嘛,大家可以自己测试体验一下。
6、 翻页,翻页有两种情况
第一种情况(start_url的响应页面底部有翻页链接):
在规则中定义两个Rule规则,一个是获取响应页面规则,一个是获取翻页链接规则,翻页规则遵循响应页面规则,顺序不能错,如下:
规则 = (
规则(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
规则(LinkExtractor(allow=r'\d\.htm'),follow=True),
)
第二种情况(start_url的响应页面底部没有翻页链接,只有输入a标签链接才有翻页链接):
在这种情况下,您无法在规则中定义翻页规则,因为即使您定义了翻页规则,也找不到它们。因为规则中的所有规则,第一次得到响应页面是start_url地址对应的内容。如果该页面没有规则规则,则不会被发现。这里就不多说了,直接上源码吧!
class TestSpider(CrawlSpider):
name = 'test'
allowed_domains = ['dangdang.com']
start_urls = ['http://book.dangdang.com/']
rules = (
Rule(LinkExtractor(restrict_xpaths=("//div[@class='conflq_body']/div[@name='m403752_pid5438_t10274']//div/dl[@ddt-area='5358']/dd")), callback='parse_item'),
)
def parse_item(self, response):
item={}
item['cate_0']=''
item['cate_1'] = ''
item['cate_2'] = ''
item['cate_3'] = ''
breadcrum=response.xpath("//div[@class='crumbs_fb_left']/div[@class='select_frame']/a[@name='breadcrumb-category']/text()").getall()
for i in range(len(breadcrum)):
item['cate_{}'.format(i)]=breadcrum[i]
book_li=response.xpath("//div[@id='search_nature_rg']/ul/li")
for li in book_li:
item['book_title']=li.xpath(".//p[@class='name']/a/@title").get()
item['book_price']=li.xpath(".//p[@class='price']/span/text()").get()
item['book_url']=li.xpath(".//p[@class='name']/a/@href").get()
book_search=li.xpath(".//p[@class='search_book_author']/span")
item['book_author']=book_search[0].xpath(".//a/@title").get()
item['public_date']=book_search[1].xpath(".//text()").get()
item['public_date']=re.sub("/",'',item['public_date']) if item['public_date'] else None
item['public_company']=book_search[2].xpath(".//a/@title").get()
yield item
next_page_url=response.xpath("//div[@class='paging']//li[@class='next']/a/@href").get()
next_page="http://category.dangdang.com"+next_page_url
yield scrapy.Request(next_page,callback=self.parse_item)
在这种情况下,必须在函数中进行翻页。parse_item() 函数的最后三行是翻页语句!我可以自己测试一下。不知道有没有其他方法可以做规则。反正我现在还没找到。如果有人知道,我可以告诉!
以上是我个人的看法,如有错误或遗漏,敬请指出!
scrapy分页抓取网页( Python中一个非常棒的网页抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-18 11:06
Python中一个非常棒的网页抓取工具)
在上一篇使用 Python 抓取网页的博文中,我们谈到了 Scrapy。在本节中,让我们深入探讨它。
Scrapy 是一个很棒的 Python 网页抓取框架。它可以处理大规模网络爬行过程中的一些常见问题。
Scrapy 与 Requests 或 BeautifulSoup 等其他常用库的区别非常明显。它可以通过简单的方式解决网络爬虫中的常见问题。
Scrapy 的缺点是学习曲线非常陡峭,需要学习的东西很多,但这就是我们要在这里讨论的内容。
在本教程中,我们将创建两个不同的网络爬虫。一种是从电商产品页面提取数据比较简单,另一种是抓取整个电商目录比较复杂。
基本概述
您可以使用 pip 安装 Scrapy。但也要注意,Scrapy 的文档强烈建议将其安装在虚拟环境中,以避免与您的系统软件包发生冲突。
我在这里使用 Virtualenv 和 Virtualenvwrapper:
然后
现在您可以使用以下命令创建一个新的 Scrapy 项目:
上面的命令将为这个项目创建所有必要的模板文件。
下面简单介绍一下上述文件和目录:
在此示例中,我们将从虚拟电子商务 网站 中抓取单个产品。这是我们要抓取的第一个产品:
我们要解析这个产品的名称、图片、价格和描述。
破壳
Scrapy 提供了内置的 Shell 控制台,方便你实时运行和调试爬虫脚本。您可以使用它来快速测试 XPath 表达式或 CSS 选择器。我一直在使用这个很酷的网络爬虫。
您还可以配置 Scrapy Shell 以使用其他控制台来替换默认的 Python 控制台,例如 IPython。可实现自动补全功能或其他特殊效果,如颜色输出等。
为了方便在Scrapy Shell中使用,需要在scrapy.cfg文件中加入如下一行:
配置完成后就可以使用scrapy shell了:
让我们从抓取一个简单的 URL 开始:
这将首先获取 /robot.txt 文件。
本例中没有robot.txt文件,所以我们会在这里看到404 HTTP状态码。如果有robot.txt文件,Scrapy默认会遵循规则。
您可以在 settings.py 文件中禁用此规则:
然后可以看到如下日志:
现在,您可以从捕获的数据中看到响应正文和响应标头,还可以使用不同的 XPath 表达式或 CSS 选择器来解析数据。
使用以下命令直接在浏览器中查看响应信息:
请注意,由于某些原因,该页面在浏览器中的显示效果可能较差。这可能是CORS问题,或者Javascript代码无法执行,或者本地URL对应的资源被加载了。
Scrapy shell 与常规 Python shell 没有什么不同,因此您可以向其中添加自定义脚本或函数。
分析数据
Scrapy 默认不执行 Javascript,所以如果你要爬取的页面是通过 Angular 或 React.js 前端框架渲染的,你可能无法抓取到想要的数据。
现在让我们尝试使用 XPath 表达式来解析产品标题和价格:
使用XPath表达式方便价格分析,选择类属性my-4的div标签后第一个span的文字:
您还可以使用 CSS 选择器:
创建一个 Scrapy 爬虫
在 Scrapy 中,Spider 是一个类,用于定义集合(需要爬取的链接或 URL)和爬取(需要解析的数据)。
以下是爬虫爬取网站所需的步骤:
您可能想知道为什么 parse() 函数可以返回这么多不同类型的对象。这是为了函数的灵活性。假设你想抓取一个没有站点地图的电商网站,你可以从抓取产品类别开始,这里是使用的第一个解析函数。
然后,该函数将为每个产品类别生成一个 Request 对象,并将其传递给新的回调函数 parse2()。对于每个类别,可能还有分页需要处理。然后将为实际抓取的每个产品生成第三个解析函数。
Scrapy 可以将捕获的数据作为简单的 Python 字典返回,但最好使用内置的 Scrapy 项目类。它是我们抓取数据时使用的一个简单容器。Scrapy 可以查看该项中的属性并进行很多操作,比如将数据导出为不同的格式(JSON 或 CSV 等),作为一个项目管道。
这是一个基本的 Product 类:
现在我们可以通过命令行生成爬虫:
或者您可以在 /spiders 目录中手动创建爬虫代码。
以下是 Scrapy 用来解决大部分爬虫用例的不同类型的爬虫:
在这个 EcomSpider 类中,有两个必需的属性:
allowed_domains 是可选的,但也非常重要。当您使用 CrawlSpider 时,将识别不同的域名。
然后使用我们之前看到的 XPath 表达式解析所需的数据并将其填充到 Product 字段中,并返回此项。
您可以运行以下代码将结果导出为 JSON 格式(也可以导出 CSV)。
然后你可以得到一个整洁的 JSON 文件:
物品加载器
从网页中提取数据时,您可能会遇到两个常见问题:
对此,Scrapy 提供了内置的解决方案 ItemLoaders。这是一种处理 Product 对象的有趣方式。
您可以将多个 XPath 表达式添加到同一个 Item 字段,它会按顺序测试它们。默认情况下,如果找到多个 XPath,它会将它们全部加载到列表中。
您可以在 Scrapy 文档中找到许多输入和输出处理器的示例。
当您需要转换或清理解析的数据时,此功能很有用。例如,从价格中提取货币信息,将一种单位转换为另一种单位(厘米和米、华氏和摄氏)等。
我们可以使用不同的 XPath 表达式从网页中查找产品标题://title 和 //section[1]//h2/text()。
在这种情况下,您可以使用 Itemloader:
通常要使用第一个匹配的XPath,所以需要在item的字段构造函数中添加这段代码output_processor=TakeFirst()。
在示例中,我们只希望每个字段都匹配第一个 XPath,因此最好的方法是创建自己的 Itemloader 并声明一个默认的 output_processor 以使用第一个 XPath。
我还在这里添加了一个 price_in 字段,它是一个输入处理器,用于从价格中删除美元符号。我使用的内置处理器 MapCompose 需要按顺序执行一个或多个函数。您可以根据需要添加任何函数,通常是在项目中的字段名称后添加 _in 或 _out ,这意味着添加输入或输出处理器。 查看全部
scrapy分页抓取网页(
Python中一个非常棒的网页抓取工具)

在上一篇使用 Python 抓取网页的博文中,我们谈到了 Scrapy。在本节中,让我们深入探讨它。
Scrapy 是一个很棒的 Python 网页抓取框架。它可以处理大规模网络爬行过程中的一些常见问题。
Scrapy 与 Requests 或 BeautifulSoup 等其他常用库的区别非常明显。它可以通过简单的方式解决网络爬虫中的常见问题。
Scrapy 的缺点是学习曲线非常陡峭,需要学习的东西很多,但这就是我们要在这里讨论的内容。
在本教程中,我们将创建两个不同的网络爬虫。一种是从电商产品页面提取数据比较简单,另一种是抓取整个电商目录比较复杂。
基本概述
您可以使用 pip 安装 Scrapy。但也要注意,Scrapy 的文档强烈建议将其安装在虚拟环境中,以避免与您的系统软件包发生冲突。
我在这里使用 Virtualenv 和 Virtualenvwrapper:

然后

现在您可以使用以下命令创建一个新的 Scrapy 项目:

上面的命令将为这个项目创建所有必要的模板文件。

下面简单介绍一下上述文件和目录:
在此示例中,我们将从虚拟电子商务 网站 中抓取单个产品。这是我们要抓取的第一个产品:
我们要解析这个产品的名称、图片、价格和描述。
破壳
Scrapy 提供了内置的 Shell 控制台,方便你实时运行和调试爬虫脚本。您可以使用它来快速测试 XPath 表达式或 CSS 选择器。我一直在使用这个很酷的网络爬虫。
您还可以配置 Scrapy Shell 以使用其他控制台来替换默认的 Python 控制台,例如 IPython。可实现自动补全功能或其他特殊效果,如颜色输出等。
为了方便在Scrapy Shell中使用,需要在scrapy.cfg文件中加入如下一行:

配置完成后就可以使用scrapy shell了:
让我们从抓取一个简单的 URL 开始:

这将首先获取 /robot.txt 文件。

本例中没有robot.txt文件,所以我们会在这里看到404 HTTP状态码。如果有robot.txt文件,Scrapy默认会遵循规则。
您可以在 settings.py 文件中禁用此规则:

然后可以看到如下日志:

现在,您可以从捕获的数据中看到响应正文和响应标头,还可以使用不同的 XPath 表达式或 CSS 选择器来解析数据。
使用以下命令直接在浏览器中查看响应信息:

请注意,由于某些原因,该页面在浏览器中的显示效果可能较差。这可能是CORS问题,或者Javascript代码无法执行,或者本地URL对应的资源被加载了。
Scrapy shell 与常规 Python shell 没有什么不同,因此您可以向其中添加自定义脚本或函数。
分析数据
Scrapy 默认不执行 Javascript,所以如果你要爬取的页面是通过 Angular 或 React.js 前端框架渲染的,你可能无法抓取到想要的数据。
现在让我们尝试使用 XPath 表达式来解析产品标题和价格:
使用XPath表达式方便价格分析,选择类属性my-4的div标签后第一个span的文字:

您还可以使用 CSS 选择器:

创建一个 Scrapy 爬虫
在 Scrapy 中,Spider 是一个类,用于定义集合(需要爬取的链接或 URL)和爬取(需要解析的数据)。
以下是爬虫爬取网站所需的步骤:
您可能想知道为什么 parse() 函数可以返回这么多不同类型的对象。这是为了函数的灵活性。假设你想抓取一个没有站点地图的电商网站,你可以从抓取产品类别开始,这里是使用的第一个解析函数。
然后,该函数将为每个产品类别生成一个 Request 对象,并将其传递给新的回调函数 parse2()。对于每个类别,可能还有分页需要处理。然后将为实际抓取的每个产品生成第三个解析函数。
Scrapy 可以将捕获的数据作为简单的 Python 字典返回,但最好使用内置的 Scrapy 项目类。它是我们抓取数据时使用的一个简单容器。Scrapy 可以查看该项中的属性并进行很多操作,比如将数据导出为不同的格式(JSON 或 CSV 等),作为一个项目管道。
这是一个基本的 Product 类:

现在我们可以通过命令行生成爬虫:

或者您可以在 /spiders 目录中手动创建爬虫代码。
以下是 Scrapy 用来解决大部分爬虫用例的不同类型的爬虫:
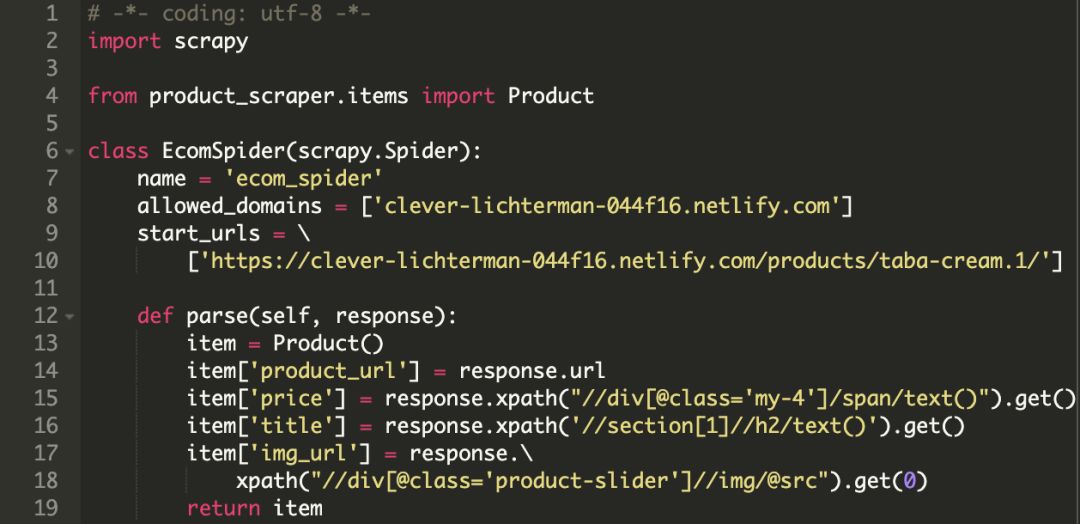
在这个 EcomSpider 类中,有两个必需的属性:
allowed_domains 是可选的,但也非常重要。当您使用 CrawlSpider 时,将识别不同的域名。
然后使用我们之前看到的 XPath 表达式解析所需的数据并将其填充到 Product 字段中,并返回此项。
您可以运行以下代码将结果导出为 JSON 格式(也可以导出 CSV)。

然后你可以得到一个整洁的 JSON 文件:
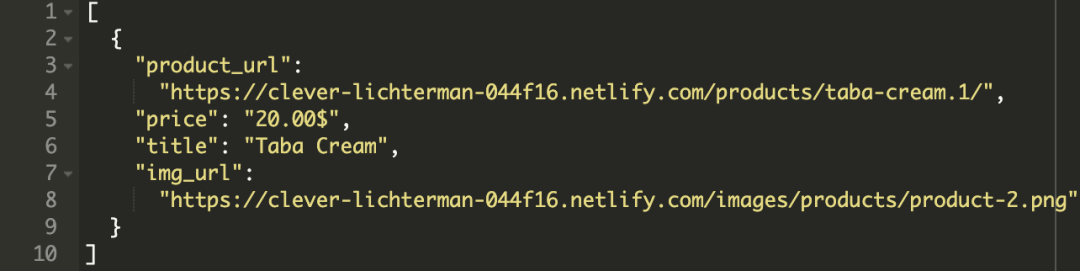
物品加载器
从网页中提取数据时,您可能会遇到两个常见问题:
对此,Scrapy 提供了内置的解决方案 ItemLoaders。这是一种处理 Product 对象的有趣方式。
您可以将多个 XPath 表达式添加到同一个 Item 字段,它会按顺序测试它们。默认情况下,如果找到多个 XPath,它会将它们全部加载到列表中。
您可以在 Scrapy 文档中找到许多输入和输出处理器的示例。
当您需要转换或清理解析的数据时,此功能很有用。例如,从价格中提取货币信息,将一种单位转换为另一种单位(厘米和米、华氏和摄氏)等。
我们可以使用不同的 XPath 表达式从网页中查找产品标题://title 和 //section[1]//h2/text()。
在这种情况下,您可以使用 Itemloader:

通常要使用第一个匹配的XPath,所以需要在item的字段构造函数中添加这段代码output_processor=TakeFirst()。
在示例中,我们只希望每个字段都匹配第一个 XPath,因此最好的方法是创建自己的 Itemloader 并声明一个默认的 output_processor 以使用第一个 XPath。
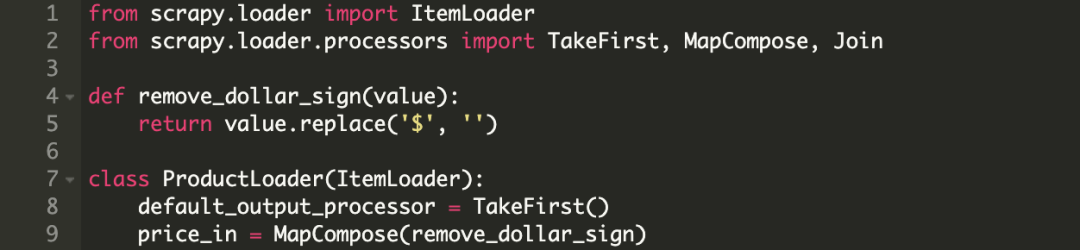
我还在这里添加了一个 price_in 字段,它是一个输入处理器,用于从价格中删除美元符号。我使用的内置处理器 MapCompose 需要按顺序执行一个或多个函数。您可以根据需要添加任何函数,通常是在项目中的字段名称后添加 _in 或 _out ,这意味着添加输入或输出处理器。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-18 11:05
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对于我这种情况,我宁愿花半个自己写的一天 懒得学第三方代码工具的都是自己写代码实现的;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用 webBrowser 控件 Navigate(" ") 的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出某个论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
看完这篇文章,我觉得可以解决手头的网站,但是在实际操作中,第二种方法无法完成网页抓取,而第三种方法也不好控制;
个人实践一使用页面添加或修改其中一个标签的属性 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对于我这种情况,我宁愿花半个自己写的一天 懒得学第三方代码工具的都是自己写代码实现的;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用 webBrowser 控件 Navigate(" ") 的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出某个论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
看完这篇文章,我觉得可以解决手头的网站,但是在实际操作中,第二种方法无法完成网页抓取,而第三种方法也不好控制;
个人实践一使用页面添加或修改其中一个标签的属性
scrapy分页抓取网页(讲讲如何抓取网页表格里的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-16 12:23
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的。您只需要添加一个空格和一个标点符号。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,你可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是真品,所以自然不是。认可。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如,和。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,豆瓣的这个电影列表使用分页器来拆分数据:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝们给了坤坤一份300W转发。微博的转发数据碰巧被传呼机分割了。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进来增加坤坤的阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们已经详细解释过了,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你再看一遍之前的教程,你可能想用:nth-of-type(-n+N)来控制N条数据的获取。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
正如我之前提到的,他们新加载的数据被添加到当前页面上。您不断向下滚动,数据不断加载。同时网页的滚动条会越来越短,这意味着所有的数据都在同一个页面上。.
当我们使用:nth-of-type(-n+N)来控制加载次数时,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
● 简易数据分析(六):Web Scraper 翻页——抓取「滚动加载」类型网页● 简易数据分析(二):Web Scraper 初尝鲜,抓取豆瓣高分电影● 简易数据分析 (一):源起、了解 Web Scraper 与浏览器技巧
·结尾· 查看全部
scrapy分页抓取网页(讲讲如何抓取网页表格里的数据?(图))
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的。您只需要添加一个空格和一个标点符号。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,你可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是真品,所以自然不是。认可。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如,和。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,豆瓣的这个电影列表使用分页器来拆分数据:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝们给了坤坤一份300W转发。微博的转发数据碰巧被传呼机分割了。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进来增加坤坤的阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们已经详细解释过了,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你再看一遍之前的教程,你可能想用:nth-of-type(-n+N)来控制N条数据的获取。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
正如我之前提到的,他们新加载的数据被添加到当前页面上。您不断向下滚动,数据不断加载。同时网页的滚动条会越来越短,这意味着所有的数据都在同一个页面上。.
当我们使用:nth-of-type(-n+N)来控制加载次数时,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
● 简易数据分析(六):Web Scraper 翻页——抓取「滚动加载」类型网页● 简易数据分析(二):Web Scraper 初尝鲜,抓取豆瓣高分电影● 简易数据分析 (一):源起、了解 Web Scraper 与浏览器技巧
·结尾·
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-16 12:19
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是页面自动生成的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方法对我来说花费了很多精力。更狠的方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是页面自动生成的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方法对我来说花费了很多精力。更狠的方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
scrapy分页抓取网页(scrapy分页抓取网页(.cfg)中文路径_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-15 18:01
scrapy分页抓取网页一、准备工作首先准备以下三个文件::#scrapy.cfg中文路径:/root/scrapy/site_scrapy/#site_scrapy中文路径:/root/scrapy/site_scrapy/#scrapy.sh中文路径:/root/scrapy/site_scrapy/.bash_profile从上图可知scrapy.sh并不在scrapy文件夹下,而是直接保存在scrapy目录中的目录文件中,所以之前我们直接使用scrapy.sh在scrapy目录下的conf.py中写代码的时候,会报错:>>>importscrapy>>>scrapy.headers.user-agentscrapy.startproject("scrapy",project_name="scrapy_inspector")首先,我们要把把false改成true。
这样就直接能把scrapy.startproject("scrapy",project_name="scrapy_inspector")执行成功。二、webpack与promise.jswebpack环境搭建已经写过,在这里就不再赘述。总之,在此处,webpack会把所有plugins文件打包到scrapy.cfg中,修改scrapy.cfg文件就能让webpack将下面的plugins子节点打包进去。
下面来看下webpack打包进去之后,剩下的东西。1.下载工具集webpack-generator,下载地址:webpack-generator-1.5.0-snapshot-env.zip下载后解压到venv/lib/webpack.cfg文件中。再修改webpack.cfg文件如下:webpack.cfg{entry:"./common.js",directory:["local/src/common.js"],loaders:["style-loader","text-loader","less","sass","scss","sass-loader","style-loader","style-scheme","outline-prettier","webpack-dev-server","scss-loader","less","sass-loader","style-scheme","transform-sass","transform-scss","sass-loader","babel-loader","multiple-sources","sass-plugin","style-loader","jsx","css-selector","less","style-loader","esm","less-loader","xml-selector","xslt","sass-loader","babel-jsx","babel-loader","jstl","jstl-script","test-script","commonjs","less","sass-loader","less-loader","babel-loader","esm","babel-loader","less-loader","less-loader","eslint","tslint","t。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页(.cfg)中文路径_光明网)
scrapy分页抓取网页一、准备工作首先准备以下三个文件::#scrapy.cfg中文路径:/root/scrapy/site_scrapy/#site_scrapy中文路径:/root/scrapy/site_scrapy/#scrapy.sh中文路径:/root/scrapy/site_scrapy/.bash_profile从上图可知scrapy.sh并不在scrapy文件夹下,而是直接保存在scrapy目录中的目录文件中,所以之前我们直接使用scrapy.sh在scrapy目录下的conf.py中写代码的时候,会报错:>>>importscrapy>>>scrapy.headers.user-agentscrapy.startproject("scrapy",project_name="scrapy_inspector")首先,我们要把把false改成true。
这样就直接能把scrapy.startproject("scrapy",project_name="scrapy_inspector")执行成功。二、webpack与promise.jswebpack环境搭建已经写过,在这里就不再赘述。总之,在此处,webpack会把所有plugins文件打包到scrapy.cfg中,修改scrapy.cfg文件就能让webpack将下面的plugins子节点打包进去。
下面来看下webpack打包进去之后,剩下的东西。1.下载工具集webpack-generator,下载地址:webpack-generator-1.5.0-snapshot-env.zip下载后解压到venv/lib/webpack.cfg文件中。再修改webpack.cfg文件如下:webpack.cfg{entry:"./common.js",directory:["local/src/common.js"],loaders:["style-loader","text-loader","less","sass","scss","sass-loader","style-loader","style-scheme","outline-prettier","webpack-dev-server","scss-loader","less","sass-loader","style-scheme","transform-sass","transform-scss","sass-loader","babel-loader","multiple-sources","sass-plugin","style-loader","jsx","css-selector","less","style-loader","esm","less-loader","xml-selector","xslt","sass-loader","babel-jsx","babel-loader","jstl","jstl-script","test-script","commonjs","less","sass-loader","less-loader","babel-loader","esm","babel-loader","less-loader","less-loader","eslint","tslint","t。
scrapy分页抓取网页( Java开发之scrapy框架(一):日期,热度和ID)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-26 07:11
Java开发之scrapy框架(一):日期,热度和ID)
4、日期、人气和ID
5、程序运行图
三、具体开发
1、任务要求
1.爬取文章及网易、搜狐、凤凰、澎湃的评论网站及评论
2.新闻页数不低于10万页
3.每个新闻页面及其评论可在1天内更新
2、功能设计
1. 设计一个可以抓取指定网站的所有页面的网络爬虫,并提取文章和评论内容
2. 定期运行网络爬虫,每天更新数据
3、系统架构
先简单介绍下scrapy框架,它是一个爬虫框架
绿线是数据流向,
(1)首先从初始URL开始,Scheduler会交给Downloader下载,
(2)下载后交给Spider分析,这里的Spider是爬虫的核心功能代码
(3)Spider对结果的分析有两种方式:一种是需要进一步爬取的链接,通过中间件返回给Scheduler;另一种是需要保存的数据,发送到ItemPipeline,处理和存储
(4)最后输出所有数据并保存为文件
4、实际项目
(1)项目结构
可以看到,NewsSpider-master是一个完整的项目文件夹,下面存放着每个网站对应的爬虫启动脚本debug_xx.py。 scrapyspider文件夹存放scrapy框架需要的相关文件,spiders文件夹存放实际爬虫代码
(2)爬虫引擎
以网易新闻的爬虫news_163.py为例,简单说明部分核心代码:
①定义爬虫类:
class news163_Spider(CrawlSpider):
# 网易新闻爬虫名称
name = "163news"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
#网易全网
allowed_domains = [
"163.com"
]
#新闻版
start_urls = [
'http://news.163.com/'
]
#正则表达式表示可以继续访问的url规则,http://news.163.com/\d\d\d\d\d(/([\w\._+-])*)*$
rules = [
Rule(LinkExtractor(
allow=(
('http://news\.163\.com/.*$')
),
deny = ('http://.*.163.com/photo.*$')
),
callback="parse_item",
follow=True)
]
②网页内容分析模块
根据不同内容的Xpath路径从页面中提取内容。由于网站不同时期的页面结构不同,根据不同的页面布局分为几个if判断语句块;
def parse_item(self, response):
# response是当前url的响应
article = Selector(response)
article_url = response.url
global count
# 分析网页类型
# 比较新的网易新闻 http://news.163.com/05-17/
if get_category(article) == 1:
articleXpath = '//*[@id="epContentLeft"]'
if article.xpath(articleXpath):
titleXpath = '//*[@id="epContentLeft"]/h1/text()'
dateXpath = '//*[@id="epContentLeft"]/div[1]/text()'
contentXpath = '//*[@id="endText"]'
news_infoXpath ='//*[@id="post_comment_area"]/script[3]/text()'
# 标题
if article.xpath(titleXpath):
news_item = newsItem()
news_item['url'] = article_url
get_title(article, titleXpath, news_item)
# 日期
if article.xpath(dateXpath):
get_date(article, dateXpath, news_item)
# 内容
if article.xpath(contentXpath):
get_content(article, contentXpath, news_item)
count = count + 1
news_item['id'] = count
# 评论
try:
comment_url = get_comment_url(article, news_infoXpath)
# 评论处理
comments = get_comment(comment_url, news_item)[1]
news_item['comments'] = comments
except:
news_item['comments'] = ' '
news_item['heat'] = 0
yield news_item
根据正则表达式匹配页面内容中的日期信息:
'''通用日期处理函数'''
def get_date(article, dateXpath, news_item):
# 时间
try:
article_date = article.xpath(dateXpath).extract()[0]
pattern = re.compile("(\d.*\d)") # 正则匹配新闻时间
article_datetime = pattern.findall(article_date)[0]
#article_datetime = datetime.datetime.strptime(article_datetime, "%Y-%m-%d %H:%M:%S")
news_item['date'] = article_datetime
except:
news_item['date'] = '2010-10-01 17:00:00'
其他功能:
'''网站分类函数'''
def get_category(article):
'''字符过滤函数'''
def str_replace(content):
'''通用正文处理函数'''
def get_content(article, contentXpath, news_item):
'''评论信息提取函数'''
def get_comment_url(article, news_infoXpath):
'''评论处理函数'''
def get_comment(comment_url, news_item):
(3)运行爬虫并格式化存储
①在settings.py中配置
import sys
# 这里改成爬虫项目的绝对路径,防止出现路径搜索的bug
sys.path.append('E:\Python\以前的项目\\NewsSpider-master\scrapyspider')
# 爬虫名称
BOT_NAME = 'scrapyspider'
# 设置是否服从网站的爬虫规则
ROBOTSTXT_OBEY = True
# 同时并发请求数,越大则爬取越快同时负载也大
CONCURRENT_REQUESTS = 32
#禁止cookies,防止被ban
COOKIES_ENABLED = False
# 输出的编码格式,由于Excel默认是ANSI编码,所以这里保持一致
# 如果有其他编码需求如utf-8等可自行更改
FEED_EXPORT_ENCODING = 'ANSI'
# 增加爬取延迟,降低被爬网站服务器压力
DOWNLOAD_DELAY = 0.01
# 爬取的新闻条数上限
CLOSESPIDER_ITEMCOUNT = 500
# 下载超时设定,超过10秒没响应则放弃当前URL
DOWNLOAD_TIMEOUT = 100
ITEM_PIPELINES = {
'scrapyspider.pipelines.ScrapyspiderPipeline': 300,# pipeline中的类名
}
②运行爬虫,保存新闻内容
抓取到的新闻内容和评论需要进行格式化和存储。如果在IDE中运行调试脚本,效果如下:
抓取后会保存为.csv文件,用Excel打开即可查看:
③如果需要单独提取评论,可以使用csv_process.py,效果如下:
四、其他补充
目前不可用 查看全部
scrapy分页抓取网页(
Java开发之scrapy框架(一):日期,热度和ID)
4、日期、人气和ID
5、程序运行图
三、具体开发
1、任务要求
1.爬取文章及网易、搜狐、凤凰、澎湃的评论网站及评论
2.新闻页数不低于10万页
3.每个新闻页面及其评论可在1天内更新
2、功能设计
1. 设计一个可以抓取指定网站的所有页面的网络爬虫,并提取文章和评论内容
2. 定期运行网络爬虫,每天更新数据
3、系统架构
先简单介绍下scrapy框架,它是一个爬虫框架
绿线是数据流向,
(1)首先从初始URL开始,Scheduler会交给Downloader下载,
(2)下载后交给Spider分析,这里的Spider是爬虫的核心功能代码
(3)Spider对结果的分析有两种方式:一种是需要进一步爬取的链接,通过中间件返回给Scheduler;另一种是需要保存的数据,发送到ItemPipeline,处理和存储
(4)最后输出所有数据并保存为文件
4、实际项目
(1)项目结构
可以看到,NewsSpider-master是一个完整的项目文件夹,下面存放着每个网站对应的爬虫启动脚本debug_xx.py。 scrapyspider文件夹存放scrapy框架需要的相关文件,spiders文件夹存放实际爬虫代码
(2)爬虫引擎
以网易新闻的爬虫news_163.py为例,简单说明部分核心代码:
①定义爬虫类:
class news163_Spider(CrawlSpider):
# 网易新闻爬虫名称
name = "163news"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
#网易全网
allowed_domains = [
"163.com"
]
#新闻版
start_urls = [
'http://news.163.com/'
]
#正则表达式表示可以继续访问的url规则,http://news.163.com/\d\d\d\d\d(/([\w\._+-])*)*$
rules = [
Rule(LinkExtractor(
allow=(
('http://news\.163\.com/.*$')
),
deny = ('http://.*.163.com/photo.*$')
),
callback="parse_item",
follow=True)
]
②网页内容分析模块
根据不同内容的Xpath路径从页面中提取内容。由于网站不同时期的页面结构不同,根据不同的页面布局分为几个if判断语句块;
def parse_item(self, response):
# response是当前url的响应
article = Selector(response)
article_url = response.url
global count
# 分析网页类型
# 比较新的网易新闻 http://news.163.com/05-17/
if get_category(article) == 1:
articleXpath = '//*[@id="epContentLeft"]'
if article.xpath(articleXpath):
titleXpath = '//*[@id="epContentLeft"]/h1/text()'
dateXpath = '//*[@id="epContentLeft"]/div[1]/text()'
contentXpath = '//*[@id="endText"]'
news_infoXpath ='//*[@id="post_comment_area"]/script[3]/text()'
# 标题
if article.xpath(titleXpath):
news_item = newsItem()
news_item['url'] = article_url
get_title(article, titleXpath, news_item)
# 日期
if article.xpath(dateXpath):
get_date(article, dateXpath, news_item)
# 内容
if article.xpath(contentXpath):
get_content(article, contentXpath, news_item)
count = count + 1
news_item['id'] = count
# 评论
try:
comment_url = get_comment_url(article, news_infoXpath)
# 评论处理
comments = get_comment(comment_url, news_item)[1]
news_item['comments'] = comments
except:
news_item['comments'] = ' '
news_item['heat'] = 0
yield news_item
根据正则表达式匹配页面内容中的日期信息:
'''通用日期处理函数'''
def get_date(article, dateXpath, news_item):
# 时间
try:
article_date = article.xpath(dateXpath).extract()[0]
pattern = re.compile("(\d.*\d)") # 正则匹配新闻时间
article_datetime = pattern.findall(article_date)[0]
#article_datetime = datetime.datetime.strptime(article_datetime, "%Y-%m-%d %H:%M:%S")
news_item['date'] = article_datetime
except:
news_item['date'] = '2010-10-01 17:00:00'
其他功能:
'''网站分类函数'''
def get_category(article):
'''字符过滤函数'''
def str_replace(content):
'''通用正文处理函数'''
def get_content(article, contentXpath, news_item):
'''评论信息提取函数'''
def get_comment_url(article, news_infoXpath):
'''评论处理函数'''
def get_comment(comment_url, news_item):
(3)运行爬虫并格式化存储
①在settings.py中配置
import sys
# 这里改成爬虫项目的绝对路径,防止出现路径搜索的bug
sys.path.append('E:\Python\以前的项目\\NewsSpider-master\scrapyspider')
# 爬虫名称
BOT_NAME = 'scrapyspider'
# 设置是否服从网站的爬虫规则
ROBOTSTXT_OBEY = True
# 同时并发请求数,越大则爬取越快同时负载也大
CONCURRENT_REQUESTS = 32
#禁止cookies,防止被ban
COOKIES_ENABLED = False
# 输出的编码格式,由于Excel默认是ANSI编码,所以这里保持一致
# 如果有其他编码需求如utf-8等可自行更改
FEED_EXPORT_ENCODING = 'ANSI'
# 增加爬取延迟,降低被爬网站服务器压力
DOWNLOAD_DELAY = 0.01
# 爬取的新闻条数上限
CLOSESPIDER_ITEMCOUNT = 500
# 下载超时设定,超过10秒没响应则放弃当前URL
DOWNLOAD_TIMEOUT = 100
ITEM_PIPELINES = {
'scrapyspider.pipelines.ScrapyspiderPipeline': 300,# pipeline中的类名
}
②运行爬虫,保存新闻内容
抓取到的新闻内容和评论需要进行格式化和存储。如果在IDE中运行调试脚本,效果如下:
抓取后会保存为.csv文件,用Excel打开即可查看:
③如果需要单独提取评论,可以使用csv_process.py,效果如下:
四、其他补充
目前不可用
scrapy分页抓取网页(Scrapy跳转到倒数第二页(基于示例地址地址)吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-25 18:10
我有 Scrapy 的分页问题。
我通常成功使用以下代码
next_page = response.xpath("//div//div[4]//ul[1]//li[10]//a[1]//@href").extract_first()
if next_page is not None:
yield scrapy.Request(url = response.urljoin(next_page), callback=self.parse)
事实证明,在这次尝试中,我遇到了一个使用 5 个页面块的 网站。见下文。
因此,在捕获前 5 页后,Scrapy 跳转到倒数第二页(526).
分页结构遵循以下逻辑:
它在数量上增加。
任何人都可以帮助我进行此分页增量查询(基于示例地址)?
最佳答案
当谈到分页时,最好的方法实际上取决于所使用的分页类型。
如果你:
了解url页面格式
比如url参数page表示你所在的页面知道总页数
然后您可以一次安排所有页面:
def parse_listings_page1(self, response):
"""
here parse first page, schedule all other pages at once!
"""
# e.g. 'http://shop.com/products?page=1'
url = response.url
# e.g. 100
total_pages = int(response.css('.last-page').extract_first())
# schedule every page at once!
for page in range(2, total_pages + 1):
page_url = add_or_replace_parameter(url, 'page', page)
yield Request(page_url, self.parse_listings)
# don't forget to also parse listings on first page!
yield from self.parse_listings(response)
def parse_listings(self, response):
for url in response.css('.listing::attr(href)'):
yield Request(url, self.parse_product)
这种方式最大的好处就是速度——在这里你可以采用异步逻辑,同时抓取所有页面!
或者。
如果你: 查看全部
scrapy分页抓取网页(Scrapy跳转到倒数第二页(基于示例地址地址)吗?)
我有 Scrapy 的分页问题。
我通常成功使用以下代码
next_page = response.xpath("//div//div[4]//ul[1]//li[10]//a[1]//@href").extract_first()
if next_page is not None:
yield scrapy.Request(url = response.urljoin(next_page), callback=self.parse)
事实证明,在这次尝试中,我遇到了一个使用 5 个页面块的 网站。见下文。
因此,在捕获前 5 页后,Scrapy 跳转到倒数第二页(526).
分页结构遵循以下逻辑:
它在数量上增加。
任何人都可以帮助我进行此分页增量查询(基于示例地址)?
最佳答案
当谈到分页时,最好的方法实际上取决于所使用的分页类型。
如果你:
了解url页面格式
比如url参数page表示你所在的页面知道总页数
然后您可以一次安排所有页面:
def parse_listings_page1(self, response):
"""
here parse first page, schedule all other pages at once!
"""
# e.g. 'http://shop.com/products?page=1'
url = response.url
# e.g. 100
total_pages = int(response.css('.last-page').extract_first())
# schedule every page at once!
for page in range(2, total_pages + 1):
page_url = add_or_replace_parameter(url, 'page', page)
yield Request(page_url, self.parse_listings)
# don't forget to also parse listings on first page!
yield from self.parse_listings(response)
def parse_listings(self, response):
for url in response.css('.listing::attr(href)'):
yield Request(url, self.parse_product)
这种方式最大的好处就是速度——在这里你可以采用异步逻辑,同时抓取所有页面!
或者。
如果你:
scrapy分页抓取网页(接下来分析如何要闻页签下的所有新闻标题和链接(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-25 18:08
本文的目的是捕获所有在腾讯新闻首页新闻主页上签名的新闻标题和链接。
如图:
地址:
新闻标签中通常有几个标签:
因此,要抓取所有新闻标题和新闻下的链接,需要一一抓取。让我们开始编写代码。
首先获取腾讯新闻页面的内容,编写一个接口获取页面。
首先导入本次爬网所需的库
# -*- coding:utf-8 -*-
#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#随机数生成
import random
#gzip
import gzip
from StringIO import StringIO
构建请求头、请求页面
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
请求一个腾讯新闻页面,返回的页面数据有时会被gzip压缩,如果直接读取会出现二进制代码,所以在处理返回的页面时需要做gizp解压
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
整理代码段,最后封装成页面请求接口
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):
try:
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
html = None
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
return html
#如果请求异常
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
elif hasattr(e, "reason"):
print e.reason
return None
#其他异常
except Exception,e:
return None
页面请求接口写好后,接下来就是分析如何上报新闻页面下的所有数据。新闻页面下有几个选项卡。当我们请求分页时,可以看到腾讯新闻页面的请求是通过ajax实现的。打开谷歌在浏览器的网络中,可以看到请求分页时的信息。如图:
分析请求地址会发现每一个分页请求都是一个地址后面跟着一个随机数,地址中会有这个请求的索引。
这样我们就可以构造出页面的请求地址,获取到每个页面的信息。但在此之前,我们不知道腾讯新闻会有多少页。
分析腾讯新闻的页面,我们最终会发现首页的一段js表示腾讯新闻有多少个页面。
所以我们先抓取腾讯新闻页面的内容,获取新闻中有多少个页面,构造页面请求,最后取出页面信息中的所有新闻
标题和原创链接就好了。代码显示如下:
<p>def tencentStart():
#腾讯新闻地址
INDEX_URL = 'http://news.qq.com/top_index.shtml#hotnews'
#腾讯要闻请求地址
SUB_URL = "http://news.qq.com/c/2013ywList_{0}.htm"
#页面数获取正则
PAGE_PATTERNS = 'getString.pageCount.*?=.*?(\d+);'
#标题和链接获取正则
NEWS_PATTERNS = ' 查看全部
scrapy分页抓取网页(接下来分析如何要闻页签下的所有新闻标题和链接(图))
本文的目的是捕获所有在腾讯新闻首页新闻主页上签名的新闻标题和链接。
如图:
地址:
新闻标签中通常有几个标签:
因此,要抓取所有新闻标题和新闻下的链接,需要一一抓取。让我们开始编写代码。
首先获取腾讯新闻页面的内容,编写一个接口获取页面。
首先导入本次爬网所需的库
# -*- coding:utf-8 -*-
#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#随机数生成
import random
#gzip
import gzip
from StringIO import StringIO
构建请求头、请求页面
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
请求一个腾讯新闻页面,返回的页面数据有时会被gzip压缩,如果直接读取会出现二进制代码,所以在处理返回的页面时需要做gizp解压
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
整理代码段,最后封装成页面请求接口
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):
try:
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
html = None
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
return html
#如果请求异常
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
elif hasattr(e, "reason"):
print e.reason
return None
#其他异常
except Exception,e:
return None
页面请求接口写好后,接下来就是分析如何上报新闻页面下的所有数据。新闻页面下有几个选项卡。当我们请求分页时,可以看到腾讯新闻页面的请求是通过ajax实现的。打开谷歌在浏览器的网络中,可以看到请求分页时的信息。如图:
分析请求地址会发现每一个分页请求都是一个地址后面跟着一个随机数,地址中会有这个请求的索引。
这样我们就可以构造出页面的请求地址,获取到每个页面的信息。但在此之前,我们不知道腾讯新闻会有多少页。
分析腾讯新闻的页面,我们最终会发现首页的一段js表示腾讯新闻有多少个页面。
所以我们先抓取腾讯新闻页面的内容,获取新闻中有多少个页面,构造页面请求,最后取出页面信息中的所有新闻
标题和原创链接就好了。代码显示如下:
<p>def tencentStart():
#腾讯新闻地址
INDEX_URL = 'http://news.qq.com/top_index.shtml#hotnews'
#腾讯要闻请求地址
SUB_URL = "http://news.qq.com/c/2013ywList_{0}.htm"
#页面数获取正则
PAGE_PATTERNS = 'getString.pageCount.*?=.*?(\d+);'
#标题和链接获取正则
NEWS_PATTERNS = '
scrapy分页抓取网页( 基于Twisted异步网络库来处理网络通讯的整体架构大致Scrapy )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-24 07:10
基于Twisted异步网络库来处理网络通讯的整体架构大致Scrapy
)
1. Scrapy 简介
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如,Amazon Associates Web Services)或一般网络抓取工具返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
刮痧
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
首先,引擎从调度器中获取一个链接(URL),供下一个爬虫引擎使用,将URL封装成请求(Request)传递给下载器,下载器下载资源并封装成响应包(Response ) 然后,如果爬虫解析Response解析出一个实体(Item),就会交给实体管道做进一步处理。如果是解析的链接(URL),则将该URL交给Scheduler等待爬取
2. 安装 Scrapy
使用以下命令:
更多虚拟环境操作请查看我的博文
3. Scrapy 教程
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
该命令会在当前目录下新建一个目录tutorial,其结构如下:
这些文件主要是:
3.1. 定义项
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
通过创建一个scrapy.Item 类并定义一个scrapy.Field 类型的类属性来声明一个Item。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。编辑教程目录下的 items.py 文件
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的强制性属性:
在 /tutorial/tutorial/spiders 目录下创建 dmoz_spider.py
3.3. 爬行
当前项目结构
进入项目根目录,运行命令:
操作结果:
3.4. 提取项目
3.4.1. 介绍选择器
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 或 CSS 的表达机制:Scrapy Selectors
XPath 表达式示例及对应含义:
更强大的功能请查看XPath教程
为了方便XPaths的使用,Scrapy提供了Selector类,它有四个方法:
3.4.2. 获取数据
首先使用谷歌浏览器开发者工具,查看网站的源码,看到需要取出的数据表格(这个方法比较麻烦),比较简单的方法就是在你要的东西上右击有兴趣查看元素,可以直接查看网站源码
查看网站的源码后,网站的信息在第二个
编写自己的项目管道非常简单。每个item管道组件都是一个独立的Python类,必须同时实现以下方法:
为 JSON 文件编写一个项目
在settings.py中设置ITEM_PIPELINES来激活item管道,默认为[]
3.6. 存储数据
使用以下命令存储为json文件格式
4. Scarpy 优化豆瓣爬虫爬取
主要是对之前写过的豆瓣爬虫的重构:
豆瓣具有抗爬虫机制。只成功一次后,被ban后会显示403。先说爬虫结构。
完整的豆瓣爬虫代码链接
4.1. 物品
4.2. Spider 主程序
4.3. 未来需要解决的问题
豆瓣抓了一阵子,还没来得及兴奋就被禁了。
禁止
最后为大家准备了一些python学习教程,希望对大家有所帮助。
查看全部
scrapy分页抓取网页(
基于Twisted异步网络库来处理网络通讯的整体架构大致Scrapy
)
1. Scrapy 简介
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如,Amazon Associates Web Services)或一般网络抓取工具返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
刮痧
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
首先,引擎从调度器中获取一个链接(URL),供下一个爬虫引擎使用,将URL封装成请求(Request)传递给下载器,下载器下载资源并封装成响应包(Response ) 然后,如果爬虫解析Response解析出一个实体(Item),就会交给实体管道做进一步处理。如果是解析的链接(URL),则将该URL交给Scheduler等待爬取
2. 安装 Scrapy
使用以下命令:
更多虚拟环境操作请查看我的博文
3. Scrapy 教程
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
该命令会在当前目录下新建一个目录tutorial,其结构如下:
这些文件主要是:
3.1. 定义项
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
通过创建一个scrapy.Item 类并定义一个scrapy.Field 类型的类属性来声明一个Item。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。编辑教程目录下的 items.py 文件
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的强制性属性:
在 /tutorial/tutorial/spiders 目录下创建 dmoz_spider.py
3.3. 爬行
当前项目结构
进入项目根目录,运行命令:
操作结果:
3.4. 提取项目
3.4.1. 介绍选择器
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 或 CSS 的表达机制:Scrapy Selectors
XPath 表达式示例及对应含义:
更强大的功能请查看XPath教程
为了方便XPaths的使用,Scrapy提供了Selector类,它有四个方法:
3.4.2. 获取数据
首先使用谷歌浏览器开发者工具,查看网站的源码,看到需要取出的数据表格(这个方法比较麻烦),比较简单的方法就是在你要的东西上右击有兴趣查看元素,可以直接查看网站源码
查看网站的源码后,网站的信息在第二个
编写自己的项目管道非常简单。每个item管道组件都是一个独立的Python类,必须同时实现以下方法:
为 JSON 文件编写一个项目
在settings.py中设置ITEM_PIPELINES来激活item管道,默认为[]
3.6. 存储数据
使用以下命令存储为json文件格式
4. Scarpy 优化豆瓣爬虫爬取
主要是对之前写过的豆瓣爬虫的重构:
豆瓣具有抗爬虫机制。只成功一次后,被ban后会显示403。先说爬虫结构。
完整的豆瓣爬虫代码链接
4.1. 物品
4.2. Spider 主程序
4.3. 未来需要解决的问题
豆瓣抓了一阵子,还没来得及兴奋就被禁了。
禁止
最后为大家准备了一些python学习教程,希望对大家有所帮助。
scrapy分页抓取网页(WebCrawler如何调度针对不同站点的网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-23 17:18
网络爬虫(Spider)是一种在互联网上爬行的机器人。当然,它通常不是物理机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实就是一个程序,不是爬行,而是有一定的用途,爬行的时候会采集. 一些信息。例如,谷歌有很多爬虫采集网页内容和它们之间的链接信息;另一个例子是别有用心的爬虫在互联网上采集诸如foo [at] bar [dot] com之类的东西。此外,还有一些定制的爬虫,专门针对某个网站。比如JavaEye的Robbin前段时间写了几篇专门对付恶意爬虫的博客(原链接好像已经过期了,所以不行),还有网站 小众软件、LinuxToy、酷琴网等经常被整个站点爬下来,挂在另一个名字下。其实,爬虫的基本原理非常简单。只要能上网,能分析网页,现在大部分语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。
爬虫的两部分是下载网页。有很多问题需要考虑,比如如何最大限度地利用本地带宽,如何调度不同站点的Web请求以减少其他服务器的负担。在高性能的Web Crawler系统中,DNS查询也将成为亟待优化的瓶颈。此外,还有一些“配置文件”需要遵循(例如,robots.txt)。获取网页后的分析过程也很复杂。网上奇奇怪怪的东西很多,各种HTML页面也有各种错误。几乎不可能清楚地分析所有这些。另外,随着AJAX的普及,如何获取Javascript动态生成的内容成为了一个大问题;此外,互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。例如,这个网站据说是谷歌之前宣布互联网上Unique URL的数量已经达到1万亿,所以这个人很自豪地宣布第二万亿。
然而,实际上并没有多少人需要像谷歌这样的通用爬虫。通常我们构建一个爬虫来爬取某个特定的或者某类网站,所谓知己知彼,百战不死,我们可以提前爬取对网站做一些分析网站 结构,事情变得容易多了。通过分析和选择有价值的链接进行跟踪,我们可以避免很多不必要的链接或蜘蛛陷阱。如果网站的结构允许选择合适的路径,我们可以把感兴趣的东西按照一定的顺序重新爬上去,这样就连URL重复的判断都可以省略了。
比如我们要爬下pongba博客中的博客文字,通过观察,很容易发现我们对其中的两个页面感兴趣:
文章列表页面,比如首页,或者URL为/page/\d+/的页面,通过Firebug可以看到每个文章链接都在h1下的一个标签中(应该是注意到Firebug的HTML面板中看到的HTML代码可能与View Source中看到的有些不同,如果网页中有动态修改DOM树的Javascript,则前者是修改后的版本,Firebug是正则化的,对于比如属性有引号等等,后者通常是你的蜘蛛爬取的原创内容,如果用正则表达式分析页面或者使用的HTML Parser和Firefox有些不同,(需要特别注意)。另外,一个div里面有指向不同列表页的链接,类是wp-pagenavi 文章 内容页,每个博客都有这样一个页面,比如/2008/09/11/machine-learning-and-ai-resources/,收录了文章的完整内容,这是我们感觉感兴趣的内容。
因此,我们从首页开始,利用 wp-pagenavi 中的链接来获取其他 文章 列表页面。特别是我们定义了一个路径:只跟随Next Page的链接,这样我们就可以从头到尾按顺序走一遍,免去了判断和重复爬行的麻烦。另外,文章列表页上链接到具体文章的链接对应的页面就是我们真正要保存的数据页。
这样,它实用的脚本语言写一个ad hoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的Crawler Framework,简单轻量,非常方便,官网说已经在实际生产中使用过,所以不是玩具级别的东西。不过目前还没有Release版本,你可以直接使用他们的Mercurial仓库获取安装源码。不过这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。
Scrapy 使用异步网络库 Twisted 来处理网络通信。它结构清晰,收录各种中间件接口,可以灵活满足各种需求。整体架构如下图所示:
绿线是数据流。首先从初始URL开始,Scheduler将其交给Downloader下载,下载完成后交给Spider进行分析。Spider分析的结果有两种:一种是需要进一步爬取的链接。比如之前分析过的“下一页”的链接,这些东西会被发回给Scheduler;另一个是需要保存的数据,发送到Item Pipeline,就是数据的后处理(详细分析、过滤、存储等)。此外,可以在数据流通道中安装各种中间件来进行必要的处理。
它看起来很复杂,但使用起来非常简单。就像Rails一样,首先新建一个项目:
scrapy-admin.py startproject blog_crawl
会创建一个blog_crawl目录,里面有一个scrapy-ctl.py是整个项目的控制脚本,代码全部放在子目录blog_crawl下。为了能够爬取,我们在spiders目录下新建了一个mindhacks_spider.py,定义我们的Spider如下:
from scrapy.spider import BaseSpider
class MindhacksSpider(BaseSpider):
domain_name = "mindhacks.cn"
start_urls = ["http://mindhacks.cn/"]
def parse(self, response):
return []
SPIDER = MindhacksSpider()
我们的MindhacksSpider继承自BaseSpider(通常是直接继承自scrapy.contrib.spiders.CrawlSpider,它更通用,更方便,但为了展示数据是如何解析的,这里使用了BaseSpider),变量domain_name和start_urls很容易理解是什么意思,parse方法就是我们需要定义的回调函数。默认请求在得到响应后会调用这个回调函数。我们这里需要解析页面,返回两个结果(需要进一步爬取链接,需要保存Data),让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是在一个混合列表中返回的。目前尚不清楚为什么会出现这种设计。最后不是要分开吗?总之,这里我们先写一个空函数,它只返回一个空列表。另外,定义一个“全局”变量 SPIDER,当 Scrapy 导入这个模块时会实例化,并且会被 Scrapy 引擎自动找到。所以你可以先运行爬虫试试:
./scrapy-ctl.py crawl mindhacks.cn
会有一堆输出,可以看到爬取了,因为这是初始的URL,但是因为我们在parse函数中没有返回需要进一步爬取的URL,所以整个爬取过程只爬到了首页就结束了. 下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们进行实验。使用以下命令启动 Shell:
./scrapy-ctl.py shell http://mindhacks.cn
它会启动爬虫,抓取命令行指定的页面,然后进入shell。根据提示,我们有很多现成的变量可以使用。其中之一是 hxs,它是一个 HtmlXPathSelector。mindhacks 的 HTML 页面更加标准化。直接用XPath分析非常方便。通过Firebug可以看到每个博客文章的链接都在h1下,所以在Shell中使用这个XPath表达式测试:
In [1]: hxs.x('//h1/a/@href').extract()
Out[1]:
[u'http://mindhacks.cn/2009/07/06/why-you-should-do-it-yourself/',
u'http://mindhacks.cn/2009/05/17/seven-years-in-nju/',
u'http://mindhacks.cn/2009/03/28/effective-learning-and-memorization/',
u'http://mindhacks.cn/2009/03/15/preconception-explained/',
u'http://mindhacks.cn/2009/03/09/first-principles-of-programming/',
u'http://mindhacks.cn/2009/02/15/why-you-should-start-blogging-now/',
u'http://mindhacks.cn/2009/02/09/writing-is-better-thinking/',
u'http://mindhacks.cn/2009/02/07/better-explained-conflicts-in-intimate-relationship/',
u'http://mindhacks.cn/2009/02/07/independence-day/',
u'http://mindhacks.cn/2009/01/18/escape-from-your-shawshank-part1/']
这正是我们需要的 URL。另外可以找到“下一页”的链接,和其他几个页面的链接放在一个div里,但是“下一页”的链接没有title属性,所以写XPath
//div[@class="wp-pagenavi"]/a[not(@title)]
但是,如果你往回翻一页,你会发现“上一页”其实是一样的,所以你需要确定链接上的文字是下一页的箭头u'\xbb',这可能有是用 XPath 写的。去,不过好像这本身就是一个unicode转义字符,由于编码原因不清楚,直接在外面判断,最终解析函数如下:
def parse(self, response):
items = []
hxs = HtmlXPathSelector(response)
posts = hxs.x('//h1/a/@href').extract()
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
for url in posts])
page_links = hxs.x('//div[@class="wp-pagenavi"]/a[not(@title)]')
for link in page_links:
if link.x('text()').extract()[0] == u'\xbb':
url = link.x('@href').extract()[0]
items.append(self.make_requests_from_url(url))
return items
前半部分是解析需要爬取的博客正文的链接,后半部分是给出“下一页”的链接。需要注意的是,这里返回的列表并非都是字符串格式的URL。Scrapy希望得到Request对象,它可以携带比字符串格式的URL更多的东西,比如cookies或者回调。功能等。可以看到我们在创建博客正文的请求时替换了回调函数,因为默认的回调函数parse是专门用来解析文章列表等页面的,parse_post定义如下:
def parse_post(self, response):
item = BlogCrawlItem()
item.url = unicode(response.url)
item.raw = response.body_as_unicode()
return [item]
这很简单。返回一个 BlogCrawlItem 并将捕获的数据放入其中。你可以在这里做一些分析。比如可以通过XPath解析文本和标题,但是我倾向于后期做这些事情,比如Item Pipeline或者Later Offline stage。BlogCrawlItem 是 Scrapy 自动为我们定义的一个空类,继承自 ScrapedItem。在 items.py 中,我在这里添加了一些内容:
from scrapy.item import ScrapedItem
class BlogCrawlItem(ScrapedItem):
def __init__(self):
ScrapedItem.__init__(self)
self.url = ''
def __str__(self):
return 'BlogCrawlItem(url: %s)' % self.url
定义了__str__函数,只给出了URL,因为默认的__str__函数会显示所有的数据,所以看到爬取的时候,控制台日志会输出一些东西,就是把爬取到的网页的内容输出出来。-.-bb
这样,数据就被取出来了,最后只剩下存储数据的功能了。我们通过添加流水线来实现它。由于Python在标准库中自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。将 pipelines.py 的内容替换为以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import sqlite3
from os import path
from scrapy.core import signals
from scrapy.xlib.pydispatch import dispatcher
class SQLiteStorePipeline(object):
filename = 'data.sqlite'
def __init__(self):
self.conn = None
dispatcher.connect(self.initialize, signals.engine_started)
dispatcher.connect(self.finalize, signals.engine_stopped)
def process_item(self, domain, item):
self.conn.execute('insert into blog values(?,?,?)',
(item.url, item.raw, unicode(domain)))
return item
def initialize(self):
if path.exists(self.filename):
self.conn = sqlite3.connect(self.filename)
else:
self.conn = self.create_table(self.filename)
def finalize(self):
if self.conn is not None:
self.conn.commit()
self.conn.close()
self.conn = None
def create_table(self, filename):
conn = sqlite3.connect(filename)
conn.execute("""create table blog
(url text primary key, raw text, domain text)""")
conn.commit()
return conn
在__init__函数中,使用dispatcher将两个信号连接到指定函数,用于初始化和关闭数据库连接。Dd-.-) 丢失。当数据通过管道时,将调用 process_item 函数。这里我们将原创数据直接存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取和过滤数据,但我不会在这里详细介绍。
最后,在 settings.py 中列出我们的管道:
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再次运行爬虫就OK了!最后总结一下:一个高质量的爬虫是一个极其复杂的项目,但是如果你有一个好的工具,做一个专用的爬虫是相对容易的。Scrapy是一个非常轻量级的爬虫框架,极大的简化了爬虫的开发过程。另外,Scrapy的文档也很详细。如果觉得我的介绍省略了一些不清楚的地方,推荐阅读他的Tutorial。
本文来自: 查看全部
scrapy分页抓取网页(WebCrawler如何调度针对不同站点的网络爬虫)
网络爬虫(Spider)是一种在互联网上爬行的机器人。当然,它通常不是物理机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实就是一个程序,不是爬行,而是有一定的用途,爬行的时候会采集. 一些信息。例如,谷歌有很多爬虫采集网页内容和它们之间的链接信息;另一个例子是别有用心的爬虫在互联网上采集诸如foo [at] bar [dot] com之类的东西。此外,还有一些定制的爬虫,专门针对某个网站。比如JavaEye的Robbin前段时间写了几篇专门对付恶意爬虫的博客(原链接好像已经过期了,所以不行),还有网站 小众软件、LinuxToy、酷琴网等经常被整个站点爬下来,挂在另一个名字下。其实,爬虫的基本原理非常简单。只要能上网,能分析网页,现在大部分语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式来做,所以做一个最简单的网络爬虫其实是一件很简单的事情。但是,实现一个高质量的蜘蛛是非常困难的。
爬虫的两部分是下载网页。有很多问题需要考虑,比如如何最大限度地利用本地带宽,如何调度不同站点的Web请求以减少其他服务器的负担。在高性能的Web Crawler系统中,DNS查询也将成为亟待优化的瓶颈。此外,还有一些“配置文件”需要遵循(例如,robots.txt)。获取网页后的分析过程也很复杂。网上奇奇怪怪的东西很多,各种HTML页面也有各种错误。几乎不可能清楚地分析所有这些。另外,随着AJAX的普及,如何获取Javascript动态生成的内容成为了一个大问题;此外,互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。例如,这个网站据说是谷歌之前宣布互联网上Unique URL的数量已经达到1万亿,所以这个人很自豪地宣布第二万亿。
然而,实际上并没有多少人需要像谷歌这样的通用爬虫。通常我们构建一个爬虫来爬取某个特定的或者某类网站,所谓知己知彼,百战不死,我们可以提前爬取对网站做一些分析网站 结构,事情变得容易多了。通过分析和选择有价值的链接进行跟踪,我们可以避免很多不必要的链接或蜘蛛陷阱。如果网站的结构允许选择合适的路径,我们可以把感兴趣的东西按照一定的顺序重新爬上去,这样就连URL重复的判断都可以省略了。
比如我们要爬下pongba博客中的博客文字,通过观察,很容易发现我们对其中的两个页面感兴趣:
文章列表页面,比如首页,或者URL为/page/\d+/的页面,通过Firebug可以看到每个文章链接都在h1下的一个标签中(应该是注意到Firebug的HTML面板中看到的HTML代码可能与View Source中看到的有些不同,如果网页中有动态修改DOM树的Javascript,则前者是修改后的版本,Firebug是正则化的,对于比如属性有引号等等,后者通常是你的蜘蛛爬取的原创内容,如果用正则表达式分析页面或者使用的HTML Parser和Firefox有些不同,(需要特别注意)。另外,一个div里面有指向不同列表页的链接,类是wp-pagenavi 文章 内容页,每个博客都有这样一个页面,比如/2008/09/11/machine-learning-and-ai-resources/,收录了文章的完整内容,这是我们感觉感兴趣的内容。
因此,我们从首页开始,利用 wp-pagenavi 中的链接来获取其他 文章 列表页面。特别是我们定义了一个路径:只跟随Next Page的链接,这样我们就可以从头到尾按顺序走一遍,免去了判断和重复爬行的麻烦。另外,文章列表页上链接到具体文章的链接对应的页面就是我们真正要保存的数据页。
这样,它实用的脚本语言写一个ad hoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的Crawler Framework,简单轻量,非常方便,官网说已经在实际生产中使用过,所以不是玩具级别的东西。不过目前还没有Release版本,你可以直接使用他们的Mercurial仓库获取安装源码。不过这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。
Scrapy 使用异步网络库 Twisted 来处理网络通信。它结构清晰,收录各种中间件接口,可以灵活满足各种需求。整体架构如下图所示:
绿线是数据流。首先从初始URL开始,Scheduler将其交给Downloader下载,下载完成后交给Spider进行分析。Spider分析的结果有两种:一种是需要进一步爬取的链接。比如之前分析过的“下一页”的链接,这些东西会被发回给Scheduler;另一个是需要保存的数据,发送到Item Pipeline,就是数据的后处理(详细分析、过滤、存储等)。此外,可以在数据流通道中安装各种中间件来进行必要的处理。
它看起来很复杂,但使用起来非常简单。就像Rails一样,首先新建一个项目:
scrapy-admin.py startproject blog_crawl
会创建一个blog_crawl目录,里面有一个scrapy-ctl.py是整个项目的控制脚本,代码全部放在子目录blog_crawl下。为了能够爬取,我们在spiders目录下新建了一个mindhacks_spider.py,定义我们的Spider如下:
from scrapy.spider import BaseSpider
class MindhacksSpider(BaseSpider):
domain_name = "mindhacks.cn"
start_urls = ["http://mindhacks.cn/"]
def parse(self, response):
return []
SPIDER = MindhacksSpider()
我们的MindhacksSpider继承自BaseSpider(通常是直接继承自scrapy.contrib.spiders.CrawlSpider,它更通用,更方便,但为了展示数据是如何解析的,这里使用了BaseSpider),变量domain_name和start_urls很容易理解是什么意思,parse方法就是我们需要定义的回调函数。默认请求在得到响应后会调用这个回调函数。我们这里需要解析页面,返回两个结果(需要进一步爬取链接,需要保存Data),让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是在一个混合列表中返回的。目前尚不清楚为什么会出现这种设计。最后不是要分开吗?总之,这里我们先写一个空函数,它只返回一个空列表。另外,定义一个“全局”变量 SPIDER,当 Scrapy 导入这个模块时会实例化,并且会被 Scrapy 引擎自动找到。所以你可以先运行爬虫试试:
./scrapy-ctl.py crawl mindhacks.cn
会有一堆输出,可以看到爬取了,因为这是初始的URL,但是因为我们在parse函数中没有返回需要进一步爬取的URL,所以整个爬取过程只爬到了首页就结束了. 下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们进行实验。使用以下命令启动 Shell:
./scrapy-ctl.py shell http://mindhacks.cn
它会启动爬虫,抓取命令行指定的页面,然后进入shell。根据提示,我们有很多现成的变量可以使用。其中之一是 hxs,它是一个 HtmlXPathSelector。mindhacks 的 HTML 页面更加标准化。直接用XPath分析非常方便。通过Firebug可以看到每个博客文章的链接都在h1下,所以在Shell中使用这个XPath表达式测试:
In [1]: hxs.x('//h1/a/@href').extract()
Out[1]:
[u'http://mindhacks.cn/2009/07/06/why-you-should-do-it-yourself/',
u'http://mindhacks.cn/2009/05/17/seven-years-in-nju/',
u'http://mindhacks.cn/2009/03/28/effective-learning-and-memorization/',
u'http://mindhacks.cn/2009/03/15/preconception-explained/',
u'http://mindhacks.cn/2009/03/09/first-principles-of-programming/',
u'http://mindhacks.cn/2009/02/15/why-you-should-start-blogging-now/',
u'http://mindhacks.cn/2009/02/09/writing-is-better-thinking/',
u'http://mindhacks.cn/2009/02/07/better-explained-conflicts-in-intimate-relationship/',
u'http://mindhacks.cn/2009/02/07/independence-day/',
u'http://mindhacks.cn/2009/01/18/escape-from-your-shawshank-part1/']
这正是我们需要的 URL。另外可以找到“下一页”的链接,和其他几个页面的链接放在一个div里,但是“下一页”的链接没有title属性,所以写XPath
//div[@class="wp-pagenavi"]/a[not(@title)]
但是,如果你往回翻一页,你会发现“上一页”其实是一样的,所以你需要确定链接上的文字是下一页的箭头u'\xbb',这可能有是用 XPath 写的。去,不过好像这本身就是一个unicode转义字符,由于编码原因不清楚,直接在外面判断,最终解析函数如下:
def parse(self, response):
items = []
hxs = HtmlXPathSelector(response)
posts = hxs.x('//h1/a/@href').extract()
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
for url in posts])
page_links = hxs.x('//div[@class="wp-pagenavi"]/a[not(@title)]')
for link in page_links:
if link.x('text()').extract()[0] == u'\xbb':
url = link.x('@href').extract()[0]
items.append(self.make_requests_from_url(url))
return items
前半部分是解析需要爬取的博客正文的链接,后半部分是给出“下一页”的链接。需要注意的是,这里返回的列表并非都是字符串格式的URL。Scrapy希望得到Request对象,它可以携带比字符串格式的URL更多的东西,比如cookies或者回调。功能等。可以看到我们在创建博客正文的请求时替换了回调函数,因为默认的回调函数parse是专门用来解析文章列表等页面的,parse_post定义如下:
def parse_post(self, response):
item = BlogCrawlItem()
item.url = unicode(response.url)
item.raw = response.body_as_unicode()
return [item]
这很简单。返回一个 BlogCrawlItem 并将捕获的数据放入其中。你可以在这里做一些分析。比如可以通过XPath解析文本和标题,但是我倾向于后期做这些事情,比如Item Pipeline或者Later Offline stage。BlogCrawlItem 是 Scrapy 自动为我们定义的一个空类,继承自 ScrapedItem。在 items.py 中,我在这里添加了一些内容:
from scrapy.item import ScrapedItem
class BlogCrawlItem(ScrapedItem):
def __init__(self):
ScrapedItem.__init__(self)
self.url = ''
def __str__(self):
return 'BlogCrawlItem(url: %s)' % self.url
定义了__str__函数,只给出了URL,因为默认的__str__函数会显示所有的数据,所以看到爬取的时候,控制台日志会输出一些东西,就是把爬取到的网页的内容输出出来。-.-bb
这样,数据就被取出来了,最后只剩下存储数据的功能了。我们通过添加流水线来实现它。由于Python在标准库中自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。将 pipelines.py 的内容替换为以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import sqlite3
from os import path
from scrapy.core import signals
from scrapy.xlib.pydispatch import dispatcher
class SQLiteStorePipeline(object):
filename = 'data.sqlite'
def __init__(self):
self.conn = None
dispatcher.connect(self.initialize, signals.engine_started)
dispatcher.connect(self.finalize, signals.engine_stopped)
def process_item(self, domain, item):
self.conn.execute('insert into blog values(?,?,?)',
(item.url, item.raw, unicode(domain)))
return item
def initialize(self):
if path.exists(self.filename):
self.conn = sqlite3.connect(self.filename)
else:
self.conn = self.create_table(self.filename)
def finalize(self):
if self.conn is not None:
self.conn.commit()
self.conn.close()
self.conn = None
def create_table(self, filename):
conn = sqlite3.connect(filename)
conn.execute("""create table blog
(url text primary key, raw text, domain text)""")
conn.commit()
return conn
在__init__函数中,使用dispatcher将两个信号连接到指定函数,用于初始化和关闭数据库连接。Dd-.-) 丢失。当数据通过管道时,将调用 process_item 函数。这里我们将原创数据直接存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取和过滤数据,但我不会在这里详细介绍。
最后,在 settings.py 中列出我们的管道:
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再次运行爬虫就OK了!最后总结一下:一个高质量的爬虫是一个极其复杂的项目,但是如果你有一个好的工具,做一个专用的爬虫是相对容易的。Scrapy是一个非常轻量级的爬虫框架,极大的简化了爬虫的开发过程。另外,Scrapy的文档也很详细。如果觉得我的介绍省略了一些不清楚的地方,推荐阅读他的Tutorial。
本文来自:
scrapy分页抓取网页(接下来分析如何要闻页签下的所有新闻标题和链接(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-23 07:11
本文的目的是捕获所有在腾讯新闻首页新闻主页上签名的新闻标题和链接。
如图:
地址:
新闻标签中通常有几个标签:
因此,要抓取所有新闻标题和新闻下的链接,需要一一抓取。让我们开始编写代码。
首先获取腾讯新闻页面的内容,编写一个接口获取页面。
首先导入本次爬网所需的库
# -*- coding:utf-8 -*-
#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#随机数生成
import random
#gzip
import gzip
from StringIO import StringIO
构建请求头、请求页面
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
请求一个腾讯新闻页面,返回的页面数据有时会被gzip压缩,如果直接读取会出现二进制代码,所以在处理返回的页面时需要做gizp解压
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
整理代码段,最后封装成页面请求接口
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):
try:
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
html = None
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
return html
#如果请求异常
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
elif hasattr(e, "reason"):
print e.reason
return None
#其他异常
except Exception,e:
return None
页面请求接口写好后,接下来就是分析如何上报新闻页面下的所有数据。新闻页面下有几个选项卡。当我们请求分页时,可以看到腾讯新闻页面的请求是通过ajax实现的。打开谷歌在浏览器的网络中,可以看到请求分页时的信息。如图:
分析请求地址会发现每一个分页请求都是一个地址后面跟着一个随机数,地址中会有这个请求的索引。
这样我们就可以构造出页面的请求地址,获取到每个页面的信息。但在此之前,我们不知道腾讯新闻会有多少页。
分析腾讯新闻的页面,我们最终会发现首页的一段js表示腾讯新闻有多少页面。
所以我们先抓取腾讯新闻页面的内容,获取新闻中有多少个页面,构造页面请求,最后取出页面信息中的所有新闻
标题和原创链接就好了。代码显示如下:
<p>def tencentStart():
#腾讯新闻地址
INDEX_URL = 'http://news.qq.com/top_index.shtml#hotnews'
#腾讯要闻请求地址
SUB_URL = "http://news.qq.com/c/2013ywList_{0}.htm"
#页面数获取正则
PAGE_PATTERNS = 'getString.pageCount.*?=.*?(\d+);'
#标题和链接获取正则
NEWS_PATTERNS = ' 查看全部
scrapy分页抓取网页(接下来分析如何要闻页签下的所有新闻标题和链接(图))
本文的目的是捕获所有在腾讯新闻首页新闻主页上签名的新闻标题和链接。
如图:
地址:
新闻标签中通常有几个标签:
因此,要抓取所有新闻标题和新闻下的链接,需要一一抓取。让我们开始编写代码。
首先获取腾讯新闻页面的内容,编写一个接口获取页面。
首先导入本次爬网所需的库
# -*- coding:utf-8 -*-
#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#随机数生成
import random
#gzip
import gzip
from StringIO import StringIO
构建请求头、请求页面
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
请求一个腾讯新闻页面,返回的页面数据有时会被gzip压缩,如果直接读取会出现二进制代码,所以在处理返回的页面时需要做gizp解压
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
整理代码段,最后封装成页面请求接口
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):
try:
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
response = urllib2.urlopen(request, timeout = 45)
html = None
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
else:
html = response.read()
return html
#如果请求异常
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
elif hasattr(e, "reason"):
print e.reason
return None
#其他异常
except Exception,e:
return None
页面请求接口写好后,接下来就是分析如何上报新闻页面下的所有数据。新闻页面下有几个选项卡。当我们请求分页时,可以看到腾讯新闻页面的请求是通过ajax实现的。打开谷歌在浏览器的网络中,可以看到请求分页时的信息。如图:
分析请求地址会发现每一个分页请求都是一个地址后面跟着一个随机数,地址中会有这个请求的索引。
这样我们就可以构造出页面的请求地址,获取到每个页面的信息。但在此之前,我们不知道腾讯新闻会有多少页。
分析腾讯新闻的页面,我们最终会发现首页的一段js表示腾讯新闻有多少页面。
所以我们先抓取腾讯新闻页面的内容,获取新闻中有多少个页面,构造页面请求,最后取出页面信息中的所有新闻
标题和原创链接就好了。代码显示如下:
<p>def tencentStart():
#腾讯新闻地址
INDEX_URL = 'http://news.qq.com/top_index.shtml#hotnews'
#腾讯要闻请求地址
SUB_URL = "http://news.qq.com/c/2013ywList_{0}.htm"
#页面数获取正则
PAGE_PATTERNS = 'getString.pageCount.*?=.*?(\d+);'
#标题和链接获取正则
NEWS_PATTERNS = '
scrapy分页抓取网页(scrapy爬虫框架的熟悉(一)——scrapy需爬取框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-23 07:09
熟悉scrapy爬虫框架
最近在学习scrapy爬虫框架,通过爬取Sunshine平台的内容可以进一步了解和熟悉这个框架。为了以后快速回顾一下这个爬虫框架,在此做个记录。
首先,明确抓取目标。
这是要爬取的平台,爬取的数据有标题和日期
不仅如此,我们还需要抓取详细的内容。我们随机点击一个链接,我们知道需要抓取详细的内容,如下图所示。

就我个人而言,一开始我倾向于在 xpath 方法中爬行。毕竟这个方法对我比较友好,所以我开始比较元素和网络的内容是否可以一一对应。
对比上面两张图,发现两列的内容差不多,都有表格,对应的tr/td内容也比较规整,所以初步判断可以用xpath的方法
但是,在使用 xpath 方法时要特别注意这个 tbody 字符串。它存在于元素但不存在于网络中(如下图所示)
这点在写程序时要特别注意
最后,开始创建scrapy项目并生成爬虫
创建步骤不再一一赘述。
创建后如下图所示:
下面我们直接开始编写主程序部分:
先爬取基本信息
from yangguang.items import YangguangItem
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first() # 爬取进入详情页面的链接
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first() # 爬取主题
item["date"] = li.xpath("./td[5]/text()").extract_first() # 爬取日期
yield item
分析:
因为是xpath方式,首页url链接可以直接是url名:
xpath节点的内容需要通过XPath Helper插件尝试后输入到代码中。我不确定,有没有人可以指点一下?)
class YangguangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
link = scrapy.Field()
title = scrapy.Field()
date = scrapy.Field()
detail_content = scrapy.Field()
分析:
这里的代码是echo上一个类的调用
item = YangguangItem()
class YangguangPipeline(object):
def process_item(self, item, spider):
print(item)
return item
LOG_LEVEL = "WARNING"
ITEM_PIPELINES = {
'yangguang.pipelines.YangguangPipeline': 300,
}
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
添加第一个内容可以使输出内容更加简洁,只输出警告级别以上的日志内容
第二个内容作为注释出现在文件本身中,我们可以清除它的注释
第三个内容:加上模拟浏览器行为所需的用户代理
这样我们就初步生成了一个可用的爬虫,我们运行一下看看结果
爬取结果中有日期、链接和主题。看来这个新生的爬行者还是比较健康的。
接下来我们必须种植它
爬取链接中的详细内容
前面说过,阳光平台的详细内容才是我们真正需要的,详细内容是通过链接进一步提取出来的,所以我们需要对程序进行进一步的扩展。
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first()
item["date"] = li.xpath("./td[5]/text()").extract_first()
# yield item
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
def parse_detail(self, response): # 详情页面处理
item = response.meta["item"]
item["detail_content"] = response.xpath("//div[@class='wzy1']//tr[1]/td[@class='txt16_3']//text()").extract() # 输出详情投诉内容
yield item
将之前获取到的link链接合并到生成器中,定义另一种方法来处理详情页。
这里主要是添加一个内容提取detail_content
我们启动爬虫后,发现内容已经展开,增加了detail_content的内容,但是内容中含有其他杂质。这时候我们就可以使用正则表达式来提取我们真正需要的内容了。
import re
class YangguangPipeline(object):
def process_item(self, item, spider):
item["detail_content"] = self.process_content(item["detail_content"])
print(item)
return item
def process_content(self, content):
"""对详情内容进行(正则)处理"""
content = [re.sub("\xa0|\s", "", i) for i in content] # 将指定字符替换为空字符
content = [i for i in content if len(i) > 0] # 去除空字符
return content
再次启动爬虫
至此,我们发现detail_content的内容变得简洁明了,不再有其他不相关的字符串干扰我们的视觉。
至此,我们的爬虫已经能够爬取一整页需要的信息了。然而,我们的爬行动物可以进一步生长,可以捕捉更多信息,而不仅仅是一页猎物。
接下来我们继续扩展爬虫来爬取多页内容。
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first()
item["date"] = li.xpath("./td[5]/text()").extract_first()
# yield item
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
# 处理下一页
next_url = response.xpath("//a[text()='>']/@href").extract_first()
print("*" * 50)
print(next_url)
if next_url is not None:
yield scrapy.Request(
next_url,
callback=self.parse
)
最后启动爬虫,效果如下
最后,我们完成了整个爬虫,但是这个爬虫不是太健康。毕竟我们没有考虑处理所谓的反爬虫机制的策略。这个爬虫可能对服务器不太友好,毕竟会增加对方服务器的压力。当然,我们的小爬虫还没有到其他人可以使用爬虫机制的地步。毕竟,它真的很小。. .
总结:
其实仔细想想,这整个爬虫的生成过程很简单,描述也只是一点点泼,因为它只说怎么做,不说为什么要做,也就是所谓知其然,不知其所以然。
比如下面的代码中,为什么后面添加了extract_first()方法?
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
再举个例子,下面代码的原理机制
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
以后需要慢慢补充。毕竟,要成为专家,您必须知道正在发生的事情以及原因。
为了记录我的学习过程,我做了我的第一个原创博客。请不要不喜欢。 查看全部
scrapy分页抓取网页(scrapy爬虫框架的熟悉(一)——scrapy需爬取框架)
熟悉scrapy爬虫框架
最近在学习scrapy爬虫框架,通过爬取Sunshine平台的内容可以进一步了解和熟悉这个框架。为了以后快速回顾一下这个爬虫框架,在此做个记录。
首先,明确抓取目标。
这是要爬取的平台,爬取的数据有标题和日期
不仅如此,我们还需要抓取详细的内容。我们随机点击一个链接,我们知道需要抓取详细的内容,如下图所示。

就我个人而言,一开始我倾向于在 xpath 方法中爬行。毕竟这个方法对我比较友好,所以我开始比较元素和网络的内容是否可以一一对应。
对比上面两张图,发现两列的内容差不多,都有表格,对应的tr/td内容也比较规整,所以初步判断可以用xpath的方法
但是,在使用 xpath 方法时要特别注意这个 tbody 字符串。它存在于元素但不存在于网络中(如下图所示)
这点在写程序时要特别注意
最后,开始创建scrapy项目并生成爬虫
创建步骤不再一一赘述。
创建后如下图所示:
下面我们直接开始编写主程序部分:
先爬取基本信息
from yangguang.items import YangguangItem
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first() # 爬取进入详情页面的链接
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first() # 爬取主题
item["date"] = li.xpath("./td[5]/text()").extract_first() # 爬取日期
yield item
分析:
因为是xpath方式,首页url链接可以直接是url名:
xpath节点的内容需要通过XPath Helper插件尝试后输入到代码中。我不确定,有没有人可以指点一下?)
class YangguangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
link = scrapy.Field()
title = scrapy.Field()
date = scrapy.Field()
detail_content = scrapy.Field()
分析:
这里的代码是echo上一个类的调用
item = YangguangItem()
class YangguangPipeline(object):
def process_item(self, item, spider):
print(item)
return item
LOG_LEVEL = "WARNING"
ITEM_PIPELINES = {
'yangguang.pipelines.YangguangPipeline': 300,
}
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
添加第一个内容可以使输出内容更加简洁,只输出警告级别以上的日志内容
第二个内容作为注释出现在文件本身中,我们可以清除它的注释
第三个内容:加上模拟浏览器行为所需的用户代理
这样我们就初步生成了一个可用的爬虫,我们运行一下看看结果
爬取结果中有日期、链接和主题。看来这个新生的爬行者还是比较健康的。
接下来我们必须种植它
爬取链接中的详细内容
前面说过,阳光平台的详细内容才是我们真正需要的,详细内容是通过链接进一步提取出来的,所以我们需要对程序进行进一步的扩展。
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first()
item["date"] = li.xpath("./td[5]/text()").extract_first()
# yield item
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
def parse_detail(self, response): # 详情页面处理
item = response.meta["item"]
item["detail_content"] = response.xpath("//div[@class='wzy1']//tr[1]/td[@class='txt16_3']//text()").extract() # 输出详情投诉内容
yield item
将之前获取到的link链接合并到生成器中,定义另一种方法来处理详情页。
这里主要是添加一个内容提取detail_content
我们启动爬虫后,发现内容已经展开,增加了detail_content的内容,但是内容中含有其他杂质。这时候我们就可以使用正则表达式来提取我们真正需要的内容了。
import re
class YangguangPipeline(object):
def process_item(self, item, spider):
item["detail_content"] = self.process_content(item["detail_content"])
print(item)
return item
def process_content(self, content):
"""对详情内容进行(正则)处理"""
content = [re.sub("\xa0|\s", "", i) for i in content] # 将指定字符替换为空字符
content = [i for i in content if len(i) > 0] # 去除空字符
return content
再次启动爬虫
至此,我们发现detail_content的内容变得简洁明了,不再有其他不相关的字符串干扰我们的视觉。
至此,我们的爬虫已经能够爬取一整页需要的信息了。然而,我们的爬行动物可以进一步生长,可以捕捉更多信息,而不仅仅是一页猎物。
接下来我们继续扩展爬虫来爬取多页内容。
def parse(self, response):
li_list = response.xpath("//div[@class='greyframe']/table[2]//tr")[1:]
for li in li_list:
item = YangguangItem()
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
item["title"] = li.xpath("./td[2]/a[2]/@title").extract_first()
item["date"] = li.xpath("./td[5]/text()").extract_first()
# yield item
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
# 处理下一页
next_url = response.xpath("//a[text()='>']/@href").extract_first()
print("*" * 50)
print(next_url)
if next_url is not None:
yield scrapy.Request(
next_url,
callback=self.parse
)
最后启动爬虫,效果如下
最后,我们完成了整个爬虫,但是这个爬虫不是太健康。毕竟我们没有考虑处理所谓的反爬虫机制的策略。这个爬虫可能对服务器不太友好,毕竟会增加对方服务器的压力。当然,我们的小爬虫还没有到其他人可以使用爬虫机制的地步。毕竟,它真的很小。. .
总结:
其实仔细想想,这整个爬虫的生成过程很简单,描述也只是一点点泼,因为它只说怎么做,不说为什么要做,也就是所谓知其然,不知其所以然。
比如下面的代码中,为什么后面添加了extract_first()方法?
item["link"] = li.xpath("./td[2]/a[2]/@href").extract_first()
再举个例子,下面代码的原理机制
yield scrapy.Request(
item["link"],
callback=self.parse_detail,
meta={"item": item}
)
以后需要慢慢补充。毕竟,要成为专家,您必须知道正在发生的事情以及原因。
为了记录我的学习过程,我做了我的第一个原创博客。请不要不喜欢。
scrapy分页抓取网页( Scrapy从基本原理上来讲很简单的可以直接用正则表入党积极分子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-23 02:19
Scrapy从基本原理上来讲很简单的可以直接用正则表入党积极分子)
Scrapy轻松定制网络爬虫随机爬取有一定目的,爬取时采集一些信息。例如,谷歌有很多爬虫采集互联网上的信息以及它们之间的链接。例如,一些别有用心的爬虫会在互联网上采集信息。foobarcom 或者 foo[at]bar[dot]com 之类的东西,除了一些专门针对某个网站的自定义爬虫,比如前段时间JavaEye的Robbin写了几篇专门对付恶意的文章 原文链接爬虫的博客好像过期了,不会给了。还有诸如小众软件或者LinuxToy网站经常被整个站点爬下来改名挂掉。其实,爬虫的基本原理非常简单。只要能访问网络和分析网页,现在大多数语言都有方便的Http客户端库,可以抓取网页和HTML。最简单的分析可以直接用正则表、党内积极分子数、条目数和毫米对照表、教师职称等级表、员工考核得分表、普通年金现值系数表达式,所以做一个最简单的网络爬虫其实是一件很简单的事情,但是要实现一个高质量的蜘蛛却是非常困难的。爬虫的两个部分。首先是下载网页。有很多问题。乘法。口头算术。100个问题。七年级。有理数。混合操作。应用问题 真心话大冒险刺激问题。您需要考虑如何最大限度地利用本地带宽。如何调度不同站点的Web请求,以减轻其他服务器的负担。高性能 WebCrawler 系统中的 DNS 查询也将成为需要优化的瓶颈。有一些规则需要遵守,比如robotstxt,获取网页后的分析过程也很复杂。互联网上有很多奇怪的事情。有各种带有各种错误的 HTML 页面。分析所有这些几乎是不可能的。另外,随着AJAX的流行,如何获取Javascript动态生成的内容也成为了一个大问题。此外,互联网上还有各种有意或无意出现的SpiderTraps。如果一味的跟着超链接走,就会掉入陷阱。比如这个网站,据说谷歌之前宣称互联网上UniqueURL的数量已经达到1万亿,所以这个人很自豪的宣布第二万亿。但实际上,像谷歌这样需要成为通用爬虫的人并不多。通常我们构建一个爬虫来爬取某个特定的或者某个像网站 所谓知己知彼,我们可以对需要爬取的网站结构提前做一些分析,它变得容易多了。通过分析和选择有价值的链接进行跟踪,我们可以避免许多不必要的链接。或者SpiderTrap if 网站如果结构允许选择合适的路径,我们就可以按照一定的顺序爬取感兴趣的东西。这样,连URL重复的判断都可以省略。例如,如果我们想通过观察爬下 Pongba 的 blogmindhackscn 中的博客文字,很容易发现我们对其中两个页面感兴趣。1 文章 列表页面,如首页或URL被分页的页面。通过Firebug可以看到文章的每一个链接都在一个h1下。需要注意的是,Firebug 的 HTML 面板中看到的 HTML 代码可能与 ViewSource 中看到的有些不同。如果网页中的 DOM 树是通过 Javascript 动态修改的,则前者是修改后的版本,已经通过了 Firebug。规则、素材编码规则、三大议事规则、文件编号规则、乒乓球比赛规则、不规则动词,例如属性有引号等,后者通常是你的蜘蛛爬取的原创内容。如果您使用正则表达式分析页面或者使用的 HTMLParser 和 Firefox 之间是否存在一些差异,则需要特别注意。另外,在一个带有 wp-pagenavi 类的 div 中还有指向不同列表页面的链接。2文章内容页面每个博客都有这样一个页面,比如20080911machine-learning-and-ai-resources收录了完整的文章内容。这就是我们感兴趣的。所以我们从首页开始,利用wp-pagenavi中的链接获取其他文章列表页面,特别是我们定义了一个只链接到followNextPage的路径,这样我们就可以通过它是为了从头到尾避免判断重复爬行的麻烦。另外,列表页面上那些到具体文章链接对应的页面,就是我们真正要保存的数据页面。用它实用的脚本语言写一个adhoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的CrawlerFramework,简单轻量而且非常方便,官网说已经实际生产中使用,所以不是玩具级别的东西。但是,目前还没有 Release 版本。可以直接使用他们的 Mercurial 仓库抓取源码进行安装。不过这个东西也可以直接安装。使用它随时更新文档也很方便。我不会重复。Scrapy 使用 Twisted,一个异步网络库来处理网络通信。架构清晰,收录各种中间件接口,可以灵活完成各种需求。整体架构如下图所示。绿线是数据流向。首先,调度器会将其交给下载器进行下载,并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 调度程序会将其交给下载程序进行下载并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 调度程序会将其交给下载程序进行下载并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很
很简单实用,就像Rails一样。首先新建一个项目scrapy-adminpystart项目blog_crawl会创建一个blog_crawl目录,整个项目有scrapy-ctlpy控制脚本,代码全部放在子目录blog_crawl下,以便能够爬取mindhackscn。在spiders目录下新建一个mindhacks_spiderpy来定义我们的spider如下 fromscrapyspiderimportBaseSpiderclassMindhacksSpiderBaseSpiderdomain_name"mindhackscn"start_urls["httpmindhackscn"]defparseselfresponsereturn[]SPIDERMindhacksSpider 我们的MindhacksSpider继承自BaseSpider,通常直接继承自BaseSpider的特性,通常是直接从more-trichSpiderscrapids继承 这样更方便。但是为了展示数据是如何解析的,这里使用了BaseSpider。变量 domain_name 和 start_urls 很容易理解它们的含义和解析方法 二重积分的计算方法 84 消毒液的配比方法 愚人节 全人法 现金流量表编制方法 求和的七种方法序号是我们需要定义的回调函数,默认请求在得到响应后会调用这个回调函数。我们需要解析这里的页面返回两个结果。需要进一步爬取的链接和需要保存的数据让我觉得有点奇怪,它的接口定义中的两个结果居然混在了一个列表中。不清楚为什么在这里。到底是不是要努力把他们分开?简而言之,让我们写一个空函数,只返回一个空列表。另外,我们定义了一个全局变量 SPIDER,在 Scrapy 导入这个模块的时候会实例化,并且会被 Scrapy 引擎自动找到。可以先运行爬虫,试试scrapy-ctlpycrawlmindhackscn。会有一堆输出。可以看到爬取了httpmindhackscn,因为这是初始URL,但是因为我们在parse函数中没有返回需要进一步爬取的URL,所以只爬取了整个爬取过程。主页结束了。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell。需要 IPython 才能让我们做实验。使用以下命令启动 Shellscrapy-ctlpyshell httpmindhackscn。它将启动爬虫并抓取命令行指定的页面。进入shell并按照提示操作。我们有很多现成的变量可以使用。其中之一是 hxs,它是 HtmlXPathSelectormindhacks 的 HTML 页面。是比较规范的波形梁钢护栏护理文件编写规范。操作流程规范。建筑工程验收规范。医疗文件书写规范可以非常方便和直接。使用 XPath 进行分析。通过Firebug可以看到每个博客文章的链接都在h1下,所以用这样的XPath表达式壳牌测试在文献[1] hxsxh1ahrefextractOut [1] [uhttpmindhackscn20090706why任您应该-DO-IT-yourselfuhttpmindhackscn20090517seven年合njuuhttpmindhackscn20090328effective学习和-memorizationuhttpmindhackscn20090315preconception-explaineduhttpmindhackscn20090309first原理-OF-programminguhttpmindhackscn20090215why-你,应该启动 - 博客 - nowuhttpmindhackscn20090209writing就是更好-thinkinguhttpmindhackscn20090207better解释的 - 冲突 - 在亲密-relationshipuhttpmindhackscn20090207independence-dayuhttpmindhackscn20090118escape从 - 您-肖申克的,第一部分]这正是我们所需要的URL。另外,我们可以在一个div中找到下一页的链接和其他几个页面的链接,但是下一页的链接没有title属性所以XPath写成div[class" 但看起来这是一个unicodeescape字符,因为编码原因不清楚。最终解析函数判断如下: defparseselfresponseitems[]hxsHtmlXPathSelectorresponsepostshxsxh1ahrefextractitemsextend[selfmake_requests_from_urlreplacecallbackselfparse_postforurlinposts]page_avilink"xsxdiv[class] 但看起来这是一个unicodeescape字符,因为编码原因不清楚。最终解析函数判断如下: defparseselfresponseitems[]hxsHtmlXPathSelectorresponsepostshxsxh1ahrefextractitemsextend[selfmake_requests_from_urlreplacecallbackselfparse_postforurlinposts]page_avilink"xsxdiv[class]
npage_linksiflinkxtextextract[0]uxbburllinkxhrefextract[0]itemsappendselfmake_requests_from_urlurlreturnitems 前半部分是解析需要爬取的博客正文的链接。后半部分是给出下一页的链接。需要注意的是,这里返回的列表不是字符串格式。网址结束。Scrapy希望得到的是Request对象,它可以承载比字符串格式的URL更多的东西,比如cookies或者回调函数。可以看到我们在创建博客正文的Request时替换了回调函数。因为默认的回调函数parse是专门用来解析文章对于列表这样的页面的,所以parse_post定义如下:defparse_postselfresponseitemBlogCrawlItemitemurlunicoderesponseurlitemrawresponsebody_as_unicodereturn[item] 返回一个BlogCrawlItem并将捕获的数据放入其中非常简单。在这里我可以做一些分析,比如通过XPath解析文本和标题,但我倾向于稍后再做。这些东西,例如 ItemPipeline 或以后的 Offline 阶段。BlogCrawlItem 是 Scrapy 自动为我们定义的一个空类,继承自 ScrapedItem。在itemspy中,我添加了一些fromscrapyitemimportScrapedItemclassBlogCrawlItemScrapedItemdef__init__selfScrapedItem_self_self_self_returnBlog url_self_self_self_self_self_returnBlog_url_def__str__self_self_self_return_self_self_self_return_Blog def__str_returnself_self_str 函数,所以当你看到所有的数据时,会显示__str_returnself_self_self_str函数,控制台日志会疯狂地输出内容。即输出爬取的网页内容-bb,让数据取到最后,只留下 存储数据的功能,通过添加Pipeline来实现。由于Python在标准库中自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。更换pipelinespy的用下面的代码内容:622324252627282930313233selfinitializesignalsengine_starteddispatcherconnectselffinalizesignalsengine_stoppeddefprocess_itemselfdomainitemselfconnexecuteinsertintoblogvaluesitemurlitemrawunicodedomainreturnitemdefinitializeselfifpathexistsselffilenameselfconnsqlite3connectselffilenameelseselfconnselfcreate_tableselffilenamedeffinalizeselfifselfconnisnotNoneselfconncommitselfconncloseselfconnNonedefcreate_tableselffilenameconnsqlite3connectfilename34353637connexecute“ 总结一下,一个高质量的爬虫是一个极其复杂的项目,但是如果你有一个好的工具,做一个专用的爬虫就容易多了。Scrapy 非常容易。轻量级的爬虫框架大大简化了爬虫开发的流程。另外,Scrapy的文档也很详细。如果你觉得我的介绍不够清楚,推荐阅读他的教程。 查看全部
scrapy分页抓取网页(
Scrapy从基本原理上来讲很简单的可以直接用正则表入党积极分子)
Scrapy轻松定制网络爬虫随机爬取有一定目的,爬取时采集一些信息。例如,谷歌有很多爬虫采集互联网上的信息以及它们之间的链接。例如,一些别有用心的爬虫会在互联网上采集信息。foobarcom 或者 foo[at]bar[dot]com 之类的东西,除了一些专门针对某个网站的自定义爬虫,比如前段时间JavaEye的Robbin写了几篇专门对付恶意的文章 原文链接爬虫的博客好像过期了,不会给了。还有诸如小众软件或者LinuxToy网站经常被整个站点爬下来改名挂掉。其实,爬虫的基本原理非常简单。只要能访问网络和分析网页,现在大多数语言都有方便的Http客户端库,可以抓取网页和HTML。最简单的分析可以直接用正则表、党内积极分子数、条目数和毫米对照表、教师职称等级表、员工考核得分表、普通年金现值系数表达式,所以做一个最简单的网络爬虫其实是一件很简单的事情,但是要实现一个高质量的蜘蛛却是非常困难的。爬虫的两个部分。首先是下载网页。有很多问题。乘法。口头算术。100个问题。七年级。有理数。混合操作。应用问题 真心话大冒险刺激问题。您需要考虑如何最大限度地利用本地带宽。如何调度不同站点的Web请求,以减轻其他服务器的负担。高性能 WebCrawler 系统中的 DNS 查询也将成为需要优化的瓶颈。有一些规则需要遵守,比如robotstxt,获取网页后的分析过程也很复杂。互联网上有很多奇怪的事情。有各种带有各种错误的 HTML 页面。分析所有这些几乎是不可能的。另外,随着AJAX的流行,如何获取Javascript动态生成的内容也成为了一个大问题。此外,互联网上还有各种有意或无意出现的SpiderTraps。如果一味的跟着超链接走,就会掉入陷阱。比如这个网站,据说谷歌之前宣称互联网上UniqueURL的数量已经达到1万亿,所以这个人很自豪的宣布第二万亿。但实际上,像谷歌这样需要成为通用爬虫的人并不多。通常我们构建一个爬虫来爬取某个特定的或者某个像网站 所谓知己知彼,我们可以对需要爬取的网站结构提前做一些分析,它变得容易多了。通过分析和选择有价值的链接进行跟踪,我们可以避免许多不必要的链接。或者SpiderTrap if 网站如果结构允许选择合适的路径,我们就可以按照一定的顺序爬取感兴趣的东西。这样,连URL重复的判断都可以省略。例如,如果我们想通过观察爬下 Pongba 的 blogmindhackscn 中的博客文字,很容易发现我们对其中两个页面感兴趣。1 文章 列表页面,如首页或URL被分页的页面。通过Firebug可以看到文章的每一个链接都在一个h1下。需要注意的是,Firebug 的 HTML 面板中看到的 HTML 代码可能与 ViewSource 中看到的有些不同。如果网页中的 DOM 树是通过 Javascript 动态修改的,则前者是修改后的版本,已经通过了 Firebug。规则、素材编码规则、三大议事规则、文件编号规则、乒乓球比赛规则、不规则动词,例如属性有引号等,后者通常是你的蜘蛛爬取的原创内容。如果您使用正则表达式分析页面或者使用的 HTMLParser 和 Firefox 之间是否存在一些差异,则需要特别注意。另外,在一个带有 wp-pagenavi 类的 div 中还有指向不同列表页面的链接。2文章内容页面每个博客都有这样一个页面,比如20080911machine-learning-and-ai-resources收录了完整的文章内容。这就是我们感兴趣的。所以我们从首页开始,利用wp-pagenavi中的链接获取其他文章列表页面,特别是我们定义了一个只链接到followNextPage的路径,这样我们就可以通过它是为了从头到尾避免判断重复爬行的麻烦。另外,列表页面上那些到具体文章链接对应的页面,就是我们真正要保存的数据页面。用它实用的脚本语言写一个adhoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的CrawlerFramework,简单轻量而且非常方便,官网说已经实际生产中使用,所以不是玩具级别的东西。但是,目前还没有 Release 版本。可以直接使用他们的 Mercurial 仓库抓取源码进行安装。不过这个东西也可以直接安装。使用它随时更新文档也很方便。我不会重复。Scrapy 使用 Twisted,一个异步网络库来处理网络通信。架构清晰,收录各种中间件接口,可以灵活完成各种需求。整体架构如下图所示。绿线是数据流向。首先,调度器会将其交给下载器进行下载,并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 调度程序会将其交给下载程序进行下载并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 调度程序会将其交给下载程序进行下载并从初始 URL 下载。然后,将其交给Spider进行分析。Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 Spider分析的结果有两种。一是需要进一步爬取的链接。一个页面链接,这些东西会被发回Scheduler,另外一个是需要保存的数据,它们被发送到ItemPipeline,这是对数据进行后处理,详细分析,过滤,存储,等。此外,它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很 它可以安装在数据流通道中。各种中间件的必要处理好像很处理好像很处理好像很
很简单实用,就像Rails一样。首先新建一个项目scrapy-adminpystart项目blog_crawl会创建一个blog_crawl目录,整个项目有scrapy-ctlpy控制脚本,代码全部放在子目录blog_crawl下,以便能够爬取mindhackscn。在spiders目录下新建一个mindhacks_spiderpy来定义我们的spider如下 fromscrapyspiderimportBaseSpiderclassMindhacksSpiderBaseSpiderdomain_name"mindhackscn"start_urls["httpmindhackscn"]defparseselfresponsereturn[]SPIDERMindhacksSpider 我们的MindhacksSpider继承自BaseSpider,通常直接继承自BaseSpider的特性,通常是直接从more-trichSpiderscrapids继承 这样更方便。但是为了展示数据是如何解析的,这里使用了BaseSpider。变量 domain_name 和 start_urls 很容易理解它们的含义和解析方法 二重积分的计算方法 84 消毒液的配比方法 愚人节 全人法 现金流量表编制方法 求和的七种方法序号是我们需要定义的回调函数,默认请求在得到响应后会调用这个回调函数。我们需要解析这里的页面返回两个结果。需要进一步爬取的链接和需要保存的数据让我觉得有点奇怪,它的接口定义中的两个结果居然混在了一个列表中。不清楚为什么在这里。到底是不是要努力把他们分开?简而言之,让我们写一个空函数,只返回一个空列表。另外,我们定义了一个全局变量 SPIDER,在 Scrapy 导入这个模块的时候会实例化,并且会被 Scrapy 引擎自动找到。可以先运行爬虫,试试scrapy-ctlpycrawlmindhackscn。会有一堆输出。可以看到爬取了httpmindhackscn,因为这是初始URL,但是因为我们在parse函数中没有返回需要进一步爬取的URL,所以只爬取了整个爬取过程。主页结束了。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell。需要 IPython 才能让我们做实验。使用以下命令启动 Shellscrapy-ctlpyshell httpmindhackscn。它将启动爬虫并抓取命令行指定的页面。进入shell并按照提示操作。我们有很多现成的变量可以使用。其中之一是 hxs,它是 HtmlXPathSelectormindhacks 的 HTML 页面。是比较规范的波形梁钢护栏护理文件编写规范。操作流程规范。建筑工程验收规范。医疗文件书写规范可以非常方便和直接。使用 XPath 进行分析。通过Firebug可以看到每个博客文章的链接都在h1下,所以用这样的XPath表达式壳牌测试在文献[1] hxsxh1ahrefextractOut [1] [uhttpmindhackscn20090706why任您应该-DO-IT-yourselfuhttpmindhackscn20090517seven年合njuuhttpmindhackscn20090328effective学习和-memorizationuhttpmindhackscn20090315preconception-explaineduhttpmindhackscn20090309first原理-OF-programminguhttpmindhackscn20090215why-你,应该启动 - 博客 - nowuhttpmindhackscn20090209writing就是更好-thinkinguhttpmindhackscn20090207better解释的 - 冲突 - 在亲密-relationshipuhttpmindhackscn20090207independence-dayuhttpmindhackscn20090118escape从 - 您-肖申克的,第一部分]这正是我们所需要的URL。另外,我们可以在一个div中找到下一页的链接和其他几个页面的链接,但是下一页的链接没有title属性所以XPath写成div[class" 但看起来这是一个unicodeescape字符,因为编码原因不清楚。最终解析函数判断如下: defparseselfresponseitems[]hxsHtmlXPathSelectorresponsepostshxsxh1ahrefextractitemsextend[selfmake_requests_from_urlreplacecallbackselfparse_postforurlinposts]page_avilink"xsxdiv[class] 但看起来这是一个unicodeescape字符,因为编码原因不清楚。最终解析函数判断如下: defparseselfresponseitems[]hxsHtmlXPathSelectorresponsepostshxsxh1ahrefextractitemsextend[selfmake_requests_from_urlreplacecallbackselfparse_postforurlinposts]page_avilink"xsxdiv[class]
npage_linksiflinkxtextextract[0]uxbburllinkxhrefextract[0]itemsappendselfmake_requests_from_urlurlreturnitems 前半部分是解析需要爬取的博客正文的链接。后半部分是给出下一页的链接。需要注意的是,这里返回的列表不是字符串格式。网址结束。Scrapy希望得到的是Request对象,它可以承载比字符串格式的URL更多的东西,比如cookies或者回调函数。可以看到我们在创建博客正文的Request时替换了回调函数。因为默认的回调函数parse是专门用来解析文章对于列表这样的页面的,所以parse_post定义如下:defparse_postselfresponseitemBlogCrawlItemitemurlunicoderesponseurlitemrawresponsebody_as_unicodereturn[item] 返回一个BlogCrawlItem并将捕获的数据放入其中非常简单。在这里我可以做一些分析,比如通过XPath解析文本和标题,但我倾向于稍后再做。这些东西,例如 ItemPipeline 或以后的 Offline 阶段。BlogCrawlItem 是 Scrapy 自动为我们定义的一个空类,继承自 ScrapedItem。在itemspy中,我添加了一些fromscrapyitemimportScrapedItemclassBlogCrawlItemScrapedItemdef__init__selfScrapedItem_self_self_self_returnBlog url_self_self_self_self_self_returnBlog_url_def__str__self_self_self_return_self_self_self_return_Blog def__str_returnself_self_str 函数,所以当你看到所有的数据时,会显示__str_returnself_self_self_str函数,控制台日志会疯狂地输出内容。即输出爬取的网页内容-bb,让数据取到最后,只留下 存储数据的功能,通过添加Pipeline来实现。由于Python在标准库中自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。更换pipelinespy的用下面的代码内容:622324252627282930313233selfinitializesignalsengine_starteddispatcherconnectselffinalizesignalsengine_stoppeddefprocess_itemselfdomainitemselfconnexecuteinsertintoblogvaluesitemurlitemrawunicodedomainreturnitemdefinitializeselfifpathexistsselffilenameselfconnsqlite3connectselffilenameelseselfconnselfcreate_tableselffilenamedeffinalizeselfifselfconnisnotNoneselfconncommitselfconncloseselfconnNonedefcreate_tableselffilenameconnsqlite3connectfilename34353637connexecute“ 总结一下,一个高质量的爬虫是一个极其复杂的项目,但是如果你有一个好的工具,做一个专用的爬虫就容易多了。Scrapy 非常容易。轻量级的爬虫框架大大简化了爬虫开发的流程。另外,Scrapy的文档也很详细。如果你觉得我的介绍不够清楚,推荐阅读他的教程。
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-21 04:03
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注就是本质(4小时,完成了Scrapy爬虫必备知识点的讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学(深入浅出,以案例为导向,学以致用)
讲师问答(拒绝助教,讲师当天解答)
课程适合人群
拥有Py的基本语法和面向对象开发的思想,其他语言的开发者,回归浪子的人,想一夜暴富的人
建筑与环境建设
文章Scrapy 简介
Scrapy 组件介绍
pip安装scrapy
Scrapy 简介
用于屏幕抓取和网页抓取的快速、高级 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求进行个性化定制. Scrapy架构图:
Scrapy 组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
调度器(Scheduler):用于接受引擎发送的Request请求,将其压入队列,当引擎再次请求时返回。
Downloader(下载器):用于请求引擎发送的Request对应的网页内容,并将获取到的Responses返回给Spider。
Item Pipeline(管道):负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider Responses和Requests
pip安装scrapy
正常情况下通过pip show scrapy查看是否安装,如果安装则显示安装信息,否则不显示任何信息
通过pip install scrapy安装爬虫框架(可能会抛出以下异常)
根据异常提示:ERROR: MICROSOFT VISUAL C++ 9.0 IS REQUIRED (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载缺失的window组件,视频学习资料中提供
第一个爬虫项目
文章内容
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject豆瓣就可以创建项目了
按照上面的提示创建Spider解析器:cd豆瓣,然后在项目中执行:scrapy genspider example就可以创建Spider对象了
细心的朋友会发现douban_spider默认会存放在douban.spider目录下。用pycharm IDE打开,会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的Spider文件,也就是你爬取的py文件
items.py:相当于一个容器,更像是一个字典 middlewares.py:定义下载器
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现pipelines.py:Define Item
Pipeline的实现实现了数据的清洗、存储和校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法介绍
文章内容
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。实际上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航。
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章内容
豆瓣电影页面分析
首页下载实现
前5部电影的数据如下
豆瓣电影页面分析为大家讲解了如何在XML文档中查找信息,具体来说,您已经学会了如何获取元素、内容、属性,以及如何通过标签属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5部电影的数据如下
物品模型包数据
文章在目录中创建Item模型层
封装爬取的数据
yield 的语法介绍
在创建Item模型层之前,我们可以拿到第一页的数据,但是只能在控制台打印出来。Scrapy中还有一个Item模块,就是模型层,主要完成值数据的封装,然后写入数据库
对抓取到的数据进行封装,将抓取到的数据存放在豆瓣Item对象中,然后交给item_list,最后返回Item_list
yield 的语法介绍
具有 yield 的函数是生成器。它不同于普通的功能。生成生成器看起来像一个函数调用,但在调用 next() 之前不会执行任何函数代码(在 for 循环中,next() 将被自动调用。))开始执行。虽然执行流程还是按照函数的流程执行,但是每次执行yield语句都会被中断,并且会返回一个迭代值。下一次执行将从下一个 yield 语句开始。好像一个函数在正常执行过程中被yield多次中断,每次中断都会通过yield返回当前的迭代值。
产量和自动翻页
文章内容
收益优势
收益优化回报数据
收益优势
收益的好处是显而易见的。将函数重写为生成器可以获得迭代能力。与使用类实例保存状态来计算下一个next()值相比,不仅代码简洁,执行流程也非常清晰。
在Scrapy爬虫框架中,yield有一个自然的使用场景,因为我们不知道爬虫每次获取数据的大小。如果爬虫每次都返回,数据量会非常大。这时候如果用yield来优化代码,代码会非常简洁高效
收益优化回报数据 查看全部
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注就是本质(4小时,完成了Scrapy爬虫必备知识点的讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学(深入浅出,以案例为导向,学以致用)
讲师问答(拒绝助教,讲师当天解答)
课程适合人群
拥有Py的基本语法和面向对象开发的思想,其他语言的开发者,回归浪子的人,想一夜暴富的人
建筑与环境建设
文章Scrapy 简介
Scrapy 组件介绍
pip安装scrapy
Scrapy 简介
用于屏幕抓取和网页抓取的快速、高级 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求进行个性化定制. Scrapy架构图:
Scrapy 组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
调度器(Scheduler):用于接受引擎发送的Request请求,将其压入队列,当引擎再次请求时返回。
Downloader(下载器):用于请求引擎发送的Request对应的网页内容,并将获取到的Responses返回给Spider。
Item Pipeline(管道):负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider Responses和Requests
pip安装scrapy
正常情况下通过pip show scrapy查看是否安装,如果安装则显示安装信息,否则不显示任何信息
通过pip install scrapy安装爬虫框架(可能会抛出以下异常)
根据异常提示:ERROR: MICROSOFT VISUAL C++ 9.0 IS REQUIRED (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载缺失的window组件,视频学习资料中提供
第一个爬虫项目
文章内容
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject豆瓣就可以创建项目了
按照上面的提示创建Spider解析器:cd豆瓣,然后在项目中执行:scrapy genspider example就可以创建Spider对象了
细心的朋友会发现douban_spider默认会存放在douban.spider目录下。用pycharm IDE打开,会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的Spider文件,也就是你爬取的py文件
items.py:相当于一个容器,更像是一个字典 middlewares.py:定义下载器
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现pipelines.py:Define Item
Pipeline的实现实现了数据的清洗、存储和校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法介绍
文章内容
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。实际上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航。
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章内容
豆瓣电影页面分析
首页下载实现
前5部电影的数据如下
豆瓣电影页面分析为大家讲解了如何在XML文档中查找信息,具体来说,您已经学会了如何获取元素、内容、属性,以及如何通过标签属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5部电影的数据如下
物品模型包数据
文章在目录中创建Item模型层
封装爬取的数据
yield 的语法介绍
在创建Item模型层之前,我们可以拿到第一页的数据,但是只能在控制台打印出来。Scrapy中还有一个Item模块,就是模型层,主要完成值数据的封装,然后写入数据库
对抓取到的数据进行封装,将抓取到的数据存放在豆瓣Item对象中,然后交给item_list,最后返回Item_list
yield 的语法介绍
具有 yield 的函数是生成器。它不同于普通的功能。生成生成器看起来像一个函数调用,但在调用 next() 之前不会执行任何函数代码(在 for 循环中,next() 将被自动调用。))开始执行。虽然执行流程还是按照函数的流程执行,但是每次执行yield语句都会被中断,并且会返回一个迭代值。下一次执行将从下一个 yield 语句开始。好像一个函数在正常执行过程中被yield多次中断,每次中断都会通过yield返回当前的迭代值。
产量和自动翻页
文章内容
收益优势
收益优化回报数据
收益优势
收益的好处是显而易见的。将函数重写为生成器可以获得迭代能力。与使用类实例保存状态来计算下一个next()值相比,不仅代码简洁,执行流程也非常清晰。
在Scrapy爬虫框架中,yield有一个自然的使用场景,因为我们不知道爬虫每次获取数据的大小。如果爬虫每次都返回,数据量会非常大。这时候如果用yield来优化代码,代码会非常简洁高效
收益优化回报数据
scrapy分页抓取网页( 2017年12月01日Python框架Scrapy爬虫入门之页面提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-21 01:11
2017年12月01日Python框架Scrapy爬虫入门之页面提取)
Python爬虫框架Scrapy爬虫入门:页面提取
更新时间:2017-12-01 12:02:34 作者:大虫
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。下面文章文章主要介绍了提取Python爬虫框架Scrapy爬虫入口页面的相关信息,文章中通过示例代码的介绍非常详细,有需要的朋友可以参考。
前言
Scrapy 是一个非常好的抓取框架。它不仅提供了一些开箱即用的基本组件,还可以根据自己的需求进行强大的定制。本文主要为大家介绍Python爬虫框架Scrapy页面提取的相关内容,分享出来供大家参考。和小编一起学习吧。
在开始之前,可以参考这个文章关于scrapy框架的介绍:
我们以土冲网为例,创建一个抓取图片的爬虫项目。
一、内容分析
打开土冲,最上面的菜单“发现”和“标签”是各种图片的分类,点击一个标签,比如“美女”,网页的链接是:美女/,我们以此为爬虫入口分析一下这一页 :
打开页面后,会出现一张图集,点击图集可以全屏浏览图片,向下滚动页面会出现更多的图集,没有设置页码。在Chrome中右键“检查元素”,打开开发者工具,查看页面源码,内容如下:
<p> 查看全部
scrapy分页抓取网页(
2017年12月01日Python框架Scrapy爬虫入门之页面提取)
Python爬虫框架Scrapy爬虫入门:页面提取
更新时间:2017-12-01 12:02:34 作者:大虫
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。下面文章文章主要介绍了提取Python爬虫框架Scrapy爬虫入口页面的相关信息,文章中通过示例代码的介绍非常详细,有需要的朋友可以参考。
前言
Scrapy 是一个非常好的抓取框架。它不仅提供了一些开箱即用的基本组件,还可以根据自己的需求进行强大的定制。本文主要为大家介绍Python爬虫框架Scrapy页面提取的相关内容,分享出来供大家参考。和小编一起学习吧。
在开始之前,可以参考这个文章关于scrapy框架的介绍:
我们以土冲网为例,创建一个抓取图片的爬虫项目。
一、内容分析
打开土冲,最上面的菜单“发现”和“标签”是各种图片的分类,点击一个标签,比如“美女”,网页的链接是:美女/,我们以此为爬虫入口分析一下这一页 :
打开页面后,会出现一张图集,点击图集可以全屏浏览图片,向下滚动页面会出现更多的图集,没有设置页码。在Chrome中右键“检查元素”,打开开发者工具,查看页面源码,内容如下:
<p>
scrapy分页抓取网页(C#编写的多线程异步抓取网页的网络爬虫控制台程序功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-21 01:08
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个互联网网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序可以捕获所有链接,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件,“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不是后缀。犯了一个错误。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不是后缀。犯了一个错误。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。 查看全部
scrapy分页抓取网页(C#编写的多线程异步抓取网页的网络爬虫控制台程序功能)
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个互联网网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序可以捕获所有链接,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件,“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不是后缀。犯了一个错误。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不是后缀。犯了一个错误。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-20 07:18
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现翻阅一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
其实在本教程的第一个例子中,抓取豆瓣电影TOP列表,豆瓣的电影列表使用pager进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝们给了坤坤一份300W转发。微博的转发数据碰巧被传呼机分割了。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页)
这是简单数据分析系列文章的第十二篇文章。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现翻阅一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
其实在本教程的第一个例子中,抓取豆瓣电影TOP列表,豆瓣的电影列表使用pager进行数据划分:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝们给了坤坤一份300W转发。微博的转发数据碰巧被传呼机分割了。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时,网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(《》爬取第2讲:爬取网站抓取策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-10-20 07:15
显式爬取网站:
爬取策略:关注所有文章页面,逐页爬取。
具体策略一:改变页码值
缺点:当总页数发生变化时,需要修改源代码
具体策略二:一步一步提取下一页,不需要随着页面变化而修改源代码
下面是策略二。
准备好工作了:
创建一个新的虚拟环境:
C:\Users\wex>mkvirtualenv article
Using base prefix 'c:\\users\\wex\\appdata\\local\\programs\\python\\python35'
New python executable in C:\Users\wex\Envs\article\Scripts\python.exe
Installing setuptools, pip, wheel...done.
创建项目:
I:\python项目>scrapy startproject ArticleSpider
New Scrapy project 'ArticleSpider', using template directory 'c:\\users\\wex\\appdata\\local\\programs\\python\\python35\\lib\\site-packages\\scrapy\\templates\\project', created in:
I:\python项目\ArticleSpider
You can start your first spider with:
cd ArticleSpider
scrapy genspider example example.com
根据默认模板创建爬虫文件:
I:\python项目\ArticleSpider>scrapy genspider jobbole blog.jobbole.com
Created spider 'jobbole' using template 'basic' in module:
ArticleSpider.spiders.jobbole
Scrapy 启动一个蜘蛛方法(名字就是蜘蛛中的名字):
scrapy crawl jobbole
当报错时:
ImportError: No module named 'win32api'
根据错误安装:
I:\python项目\ArticleSpider>pip install pypiwin32
Collecting pypiwin32
Downloading pypiwin32-219-cp35-none-win_amd64.whl (8.6MB)
100% |████████████████████████████████| 8.6MB 88kB/s
Installing collected packages: pypiwin32
Successfully installed pypiwin32-219
这时候重启是不会报错的。
在 Pycharm 中新建一个 main.py 文件来运行蜘蛛文件。
#调用这个函数可以执行scrapy文件
from scrapy.cmdline import execute
import sys
import os
#设置ArticleSpider工程目录
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
#调用execute函数运行spider
execute(["scrapy","crawl","jobbole"])
请注意,在设置文件中:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
防止不符合协议的 URL 被过滤掉。
关于 xpath:介绍、术语、语法
1. XPath 使用多路径表达式在 xml 和 html 中导航
2. xpath 收录标准函数库
3. XPath 是 w3c 标准
xpath 节点关系
1、父节点
2. 子节点
3. 兄弟节点
4. 高级节点
5. 后代节点
语法:选择节点
表达式 说明
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
article 选取所有article元素的所有子节点
/article 选取根元素article
article/a 选取所有属于article的子元素的a元素
//div 选取所有div元素(不论出现在文档任何地方)
//@class 选取所有名为class的属性
谓词
谓词用于查找特定节点或收录指定值的节点。
谓词嵌入在方括号中
/article/div[1] 选取属于article子元素的第一个div元素
/article/div[last()] 选取属于article子元素的最后一个div元素
/article/div[last()-1] 选取属于article子元素的倒数第二个div元素
/article/div[last()35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
选择未知节点
* 匹配任何元素节点
@* 匹配任何属性节点
node() 匹配任何类型的节点
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
/div/* 选取属于div元素的所有子节点
//* 选取所有元素
//div[@*] 获取所有有带属性的div元素
/div/a | /div/p 获取所有div元素的a和p元素
//span | //ul 选取文档中的span和ul元素
article/div/p | //span 选取所有属于article元素的div元素的p元素 以及文档中所有的span元素
有一点需要注意:查看F12得到的包括加载js和css,可能与查看源码得到的不一致。
我们提取网页内容: 查看全部
scrapy分页抓取网页(《》爬取第2讲:爬取网站抓取策略)
显式爬取网站:
爬取策略:关注所有文章页面,逐页爬取。
具体策略一:改变页码值
缺点:当总页数发生变化时,需要修改源代码
具体策略二:一步一步提取下一页,不需要随着页面变化而修改源代码
下面是策略二。
准备好工作了:
创建一个新的虚拟环境:
C:\Users\wex>mkvirtualenv article
Using base prefix 'c:\\users\\wex\\appdata\\local\\programs\\python\\python35'
New python executable in C:\Users\wex\Envs\article\Scripts\python.exe
Installing setuptools, pip, wheel...done.
创建项目:
I:\python项目>scrapy startproject ArticleSpider
New Scrapy project 'ArticleSpider', using template directory 'c:\\users\\wex\\appdata\\local\\programs\\python\\python35\\lib\\site-packages\\scrapy\\templates\\project', created in:
I:\python项目\ArticleSpider
You can start your first spider with:
cd ArticleSpider
scrapy genspider example example.com
根据默认模板创建爬虫文件:
I:\python项目\ArticleSpider>scrapy genspider jobbole blog.jobbole.com
Created spider 'jobbole' using template 'basic' in module:
ArticleSpider.spiders.jobbole
Scrapy 启动一个蜘蛛方法(名字就是蜘蛛中的名字):
scrapy crawl jobbole
当报错时:
ImportError: No module named 'win32api'
根据错误安装:
I:\python项目\ArticleSpider>pip install pypiwin32
Collecting pypiwin32
Downloading pypiwin32-219-cp35-none-win_amd64.whl (8.6MB)
100% |████████████████████████████████| 8.6MB 88kB/s
Installing collected packages: pypiwin32
Successfully installed pypiwin32-219
这时候重启是不会报错的。
在 Pycharm 中新建一个 main.py 文件来运行蜘蛛文件。
#调用这个函数可以执行scrapy文件
from scrapy.cmdline import execute
import sys
import os
#设置ArticleSpider工程目录
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
#调用execute函数运行spider
execute(["scrapy","crawl","jobbole"])
请注意,在设置文件中:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
防止不符合协议的 URL 被过滤掉。
关于 xpath:介绍、术语、语法
1. XPath 使用多路径表达式在 xml 和 html 中导航
2. xpath 收录标准函数库
3. XPath 是 w3c 标准
xpath 节点关系
1、父节点
2. 子节点
3. 兄弟节点
4. 高级节点
5. 后代节点
语法:选择节点
表达式 说明
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
article 选取所有article元素的所有子节点
/article 选取根元素article
article/a 选取所有属于article的子元素的a元素
//div 选取所有div元素(不论出现在文档任何地方)
//@class 选取所有名为class的属性
谓词
谓词用于查找特定节点或收录指定值的节点。
谓词嵌入在方括号中
/article/div[1] 选取属于article子元素的第一个div元素
/article/div[last()] 选取属于article子元素的最后一个div元素
/article/div[last()-1] 选取属于article子元素的倒数第二个div元素
/article/div[last()35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
选择未知节点
* 匹配任何元素节点
@* 匹配任何属性节点
node() 匹配任何类型的节点
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
/div/* 选取属于div元素的所有子节点
//* 选取所有元素
//div[@*] 获取所有有带属性的div元素
/div/a | /div/p 获取所有div元素的a和p元素
//span | //ul 选取文档中的span和ul元素
article/div/p | //span 选取所有属于article元素的div元素的p元素 以及文档中所有的span元素
有一点需要注意:查看F12得到的包括加载js和css,可能与查看源码得到的不一致。
我们提取网页内容:
scrapy分页抓取网页(Python大火,为了跟上时代,试着自学了下某位作者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-20 07:14
Python 近来大受欢迎。为了跟上时代的步伐,我尝试着自学。Scrapy 是一个高级的 Python 爬虫框架。不仅收录爬虫的特性,还可以方便的将爬虫数据保存为csv、json等文件。
今天我们尝试用Scrapy爬取某某某作者的所有文章。
在本教程中,我们假设您已经安装了 Scrapy。如果没有,请参考。
1.创建项目
在开始爬取之前,我们必须创建一个新的 Scrapy 项目,这里我将其命名为 jianshu_article。打开Mac终端,cd到你打算存放代码的目录,运行以下命令:
//Mac终端运行如下命令:
scrapy startproject jianshu_article
2.创建爬虫
//cd到上面创建的文件目录
cd jianshu_article
//创建爬虫程序
scrapy genspider jianshu jianshu.com
/*
文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模型,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:USER_AGENT(模拟浏览器,应对网站反爬),递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
*/
为了方便编写程序,我们使用Pycharm打开项目。执行上述命令后,程序会自动创建目录和文件。生成了一个名为 jianshu.py 的文件,后面我们的主要逻辑会写在这个文件中。
简书.py
3.设置数据模型
双击 items.py 文件。
找到你要爬取的短书作者的主页,比如我自己的主页,用谷歌浏览器打开,空白处右击,点击“勾选”,进入控制台开发者模式:
打开控制台.png
通过分析网页的源代码,我们大概需要这些内容:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JianshuArticalItem(scrapy.Item):
avatar = scrapy.Field() #头像
nickname = scrapy.Field() #昵称
time = scrapy.Field() #发表时间
wrap_img = scrapy.Field() #封面(缺省值)
title = scrapy.Field() #标题
abstract = scrapy.Field() #正文部分显示
read = scrapy.Field() #查看人数
comments = scrapy.Field() #评论数
like = scrapy.Field() #喜欢(点赞)
detail = scrapy.Field() #文章详情url
pass
这样,数据模型就创建好了。后面运行爬虫的时候,得到的数据会存储在模型对应的位置。
4.分析网页源码,写爬虫
因为我比较懒,很少写文章,而且文章的数量也比较少。为了展示分页的效果,我选择了一个作者CC老师_MissCC的主页在短书中进行爬取。
我们可以通过分析 URL 发现一些特征:
作者的 URL 是: + 作者 ID:
作者主页 URL.png
文章 的 URL 是: + 文章ID:
文章网址.png
虽然我们直接在浏览器中打开作者的网址,但是用鼠标滚轮向下滚动会动态加载下一页,直到最后一篇文章文章网址保持不变。但是作为一个Scrapy爬虫,好像只能拿到第一页,那怎么办呢?以我多年的开发经验,尝试拼接一个“page”参数和url后面的页数。正如预期的那样,可以请求不同的数据。
拼接参数页获取分页数据.png
找到这些规则,我们就可以通过分析HTML源代码得到我们想要的数据了。
首先,我们回到 jianshu.py 文件并导入模型:
//从项目名 jianshu_article的文件items.py导入JianshuArticleItem类
from jianshu_article.items import JianshuArticleItem
设置必要的参数以启动第一个请求:
# -*- coding: utf-8 -*-
import scrapy
from jianshu_article.items import JianshuArticleItem
class JianshuSpider(scrapy.Spider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
user_id = "1b4c832fb2ca"
url = "https://www.jianshu.com/u/{0}?page=1".format(user_id)
start_urls = [
url,
]
def parse(self, response):
#用户头像
c = response.xpath('//div[@class="main-top"]/a[@class="avatar"]/img/@src').extract_first()
print(c)
pass
此时终端运行命令scrapy crawl jianshu,理论上可以打印网页内容。事实上,情况并非如此。如果没有请求数据,终端会打印一些日志信息:
日志.png
不难发现,报了403问题和HTTP状态码未处理或不允许问题,导致“Closing spider(finished)”爬虫终止。通过万能百度知道网站已经采取了一些相应的反爬虫措施。要对症下药,我们只需要在settings.py中做一些相应的修改:
```
User_Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的
操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
通俗点讲,我们配置这个字段的目的就是为了伪装成浏览器打开网页,达到骗过目标网站的监测。
```
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
CONCURRENT_REQUESTS = 1 #并发数
DOWNLOAD_DELAY = 5 #为了防止IP被封,我们5秒请求一次
HTTPERROR_ALLOWED_CODES = [403] #上面报的是403,就把403加入
#默认为True,就是要遵守robots.txt 的规则,这里我们改为False
ROBOTSTXT_OBEY = False
进行相应的修改后,我们再次执行爬虫命令:scrapy crawl jianshu,查看日志打印获取头像。
获取头像.png
既然可以成功抓取网页数据,接下来我们要做的就是分析网页的源代码,下面我们就不一一分析了。当然在此之前你需要对xpath有一定的了解。
以下引用Scrapy中文官网的介绍:
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 和 CSS: 的表达机制。请参阅有关选择器和其他提取机制的信息。
以下是 XPath 表达式及其对应含义的示例:
以上只是几个简单的XPath例子,XPath其实比这个强大很多。如果您想了解更多,我们推荐这个 XPath 教程。
通过上面的介绍,相信你可以做好接下来的爬虫工作,把jianshu.py的所有代码贴在下面供参考:
# -*- coding: utf-8 -*-
import scrapy
from jianshu_article.items import JianshuArticleItem
class JianshuSpider(scrapy.Spider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
user_id = "1b4c832fb2ca" #替换此用户ID可获取你需要的数据,或者放开下一行的注释
#user_id = input('请输入作者id:\n')
url = "https://www.jianshu.com/u/{0}?page=1".format(user_id)
start_urls = [
url,
]
def parse(self, response):
# [关注,粉丝,文章]
a = response.xpath('//div[@class="main-top"]/div[@class="info"]/ul/li/div/a/p/text()').extract()
print(a)
# [字数,收获喜欢]
b = response.xpath('//div[@class="main-top"]/div[@class="info"]/ul/li/div/p/text()').extract()
print(b)
# 大头像
c = response.xpath('//div[@class="main-top"]/a[@class="avatar"]/img/@src').extract_first()
print(c)
# 用户名
d = response.xpath('//div[@class="main-top"]/div[@class="title"]/a/text()').extract_first()
print(d)
# 性别
e = response.xpath('//div[@class="main-top"]/div[@class="title"]/i/@class').extract_first()
print(e)
# 获取文章总数,计算页数。(简书网站默认每页是9组数据)
temp = int(a[2])
if (temp % 9 > 0):
count = temp // 9 + 1
else:
count = temp // 9
print("总共" + str(count) + "页")
base_url = "https://www.jianshu.com/u/{0}?page={1}"
for i in range(1, count + 1):
i = count + 1 - i #理论上正序1~count就是按顺序获取的,但是获取的数据是倒置的,所以我们获取count~1的数据,得到的数组就是按照网页形式1~count页码排序的了
yield scrapy.Request(base_url.format(self.user_id, i), dont_filter=True, callback=self.parse_page)
#迭代返回每页的内容
def parse_page(self, response):
for sel in response.xpath('//div[@id="list-container"]/ul/li'):
item = JianshuArticleItem()
item['wrap_img'] = sel.xpath('a/img/@src').extract_first()
item['avatar'] = sel.xpath('div//a[@class="avatar"]/img/@src').extract_first()
item['nickname'] = sel.xpath('div//a[@class="nickname"]/text()').extract_first()
item['time'] = sel.xpath('div//span[@class="time"]/@data-shared-at').extract_first()
item['title'] = sel.xpath('div/a[@class="title"]/text()').extract_first()
item['abstract'] = sel.xpath('div/p[@class="abstract"]/text()').extract_first()
item['read'] = sel.xpath('div/div[@class="meta"]/a[1]/text()').extract()[1]
item['comments'] = sel.xpath('div/div[@class="meta"]/a[2]/text()').extract()[1]
item['like'] = sel.xpath('div/div[@class="meta"]/span/text()').extract_first()
item['detail'] = sel.xpath('div/a[@class="title"]/@href').extract_first()
yield item
至此,爬虫代码已经编写完毕。如果要保存获取的数据,可以在终端执行以下命令:
/*
此命令用于把爬取的数据保存为json文件格式,当然你也可以保存为别的文件格式。
Scrapy官方列出的文件格式有如下几种:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')。
温馨提示:如果要再次爬取,最好换一个文件名或者清空数据再爬取,因为第二还是写入上一个文件,数据不会覆盖,
会堆积在上次获取的下面,造成json文件格式报错。
*/
scrapy crawl jianshu -o data.json
程序执行完后,我们可以在文件目录下看到新生成的data.json文件,双击可以看到我们要获取的所有数据:
执行 crawler.png 得到的数据
json解析出来的数据和网站.png上的完全一样
github地址: 查看全部
scrapy分页抓取网页(Python大火,为了跟上时代,试着自学了下某位作者)
Python 近来大受欢迎。为了跟上时代的步伐,我尝试着自学。Scrapy 是一个高级的 Python 爬虫框架。不仅收录爬虫的特性,还可以方便的将爬虫数据保存为csv、json等文件。
今天我们尝试用Scrapy爬取某某某作者的所有文章。
在本教程中,我们假设您已经安装了 Scrapy。如果没有,请参考。
1.创建项目
在开始爬取之前,我们必须创建一个新的 Scrapy 项目,这里我将其命名为 jianshu_article。打开Mac终端,cd到你打算存放代码的目录,运行以下命令:
//Mac终端运行如下命令:
scrapy startproject jianshu_article
2.创建爬虫
//cd到上面创建的文件目录
cd jianshu_article
//创建爬虫程序
scrapy genspider jianshu jianshu.com
/*
文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模型,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:USER_AGENT(模拟浏览器,应对网站反爬),递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
*/
为了方便编写程序,我们使用Pycharm打开项目。执行上述命令后,程序会自动创建目录和文件。生成了一个名为 jianshu.py 的文件,后面我们的主要逻辑会写在这个文件中。
简书.py
3.设置数据模型
双击 items.py 文件。
找到你要爬取的短书作者的主页,比如我自己的主页,用谷歌浏览器打开,空白处右击,点击“勾选”,进入控制台开发者模式:
打开控制台.png
通过分析网页的源代码,我们大概需要这些内容:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JianshuArticalItem(scrapy.Item):
avatar = scrapy.Field() #头像
nickname = scrapy.Field() #昵称
time = scrapy.Field() #发表时间
wrap_img = scrapy.Field() #封面(缺省值)
title = scrapy.Field() #标题
abstract = scrapy.Field() #正文部分显示
read = scrapy.Field() #查看人数
comments = scrapy.Field() #评论数
like = scrapy.Field() #喜欢(点赞)
detail = scrapy.Field() #文章详情url
pass
这样,数据模型就创建好了。后面运行爬虫的时候,得到的数据会存储在模型对应的位置。
4.分析网页源码,写爬虫
因为我比较懒,很少写文章,而且文章的数量也比较少。为了展示分页的效果,我选择了一个作者CC老师_MissCC的主页在短书中进行爬取。
我们可以通过分析 URL 发现一些特征:
作者的 URL 是: + 作者 ID:
作者主页 URL.png
文章 的 URL 是: + 文章ID:
文章网址.png
虽然我们直接在浏览器中打开作者的网址,但是用鼠标滚轮向下滚动会动态加载下一页,直到最后一篇文章文章网址保持不变。但是作为一个Scrapy爬虫,好像只能拿到第一页,那怎么办呢?以我多年的开发经验,尝试拼接一个“page”参数和url后面的页数。正如预期的那样,可以请求不同的数据。
拼接参数页获取分页数据.png
找到这些规则,我们就可以通过分析HTML源代码得到我们想要的数据了。
首先,我们回到 jianshu.py 文件并导入模型:
//从项目名 jianshu_article的文件items.py导入JianshuArticleItem类
from jianshu_article.items import JianshuArticleItem
设置必要的参数以启动第一个请求:
# -*- coding: utf-8 -*-
import scrapy
from jianshu_article.items import JianshuArticleItem
class JianshuSpider(scrapy.Spider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
user_id = "1b4c832fb2ca"
url = "https://www.jianshu.com/u/{0}?page=1".format(user_id)
start_urls = [
url,
]
def parse(self, response):
#用户头像
c = response.xpath('//div[@class="main-top"]/a[@class="avatar"]/img/@src').extract_first()
print(c)
pass
此时终端运行命令scrapy crawl jianshu,理论上可以打印网页内容。事实上,情况并非如此。如果没有请求数据,终端会打印一些日志信息:
日志.png
不难发现,报了403问题和HTTP状态码未处理或不允许问题,导致“Closing spider(finished)”爬虫终止。通过万能百度知道网站已经采取了一些相应的反爬虫措施。要对症下药,我们只需要在settings.py中做一些相应的修改:
```
User_Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的
操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
通俗点讲,我们配置这个字段的目的就是为了伪装成浏览器打开网页,达到骗过目标网站的监测。
```
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
CONCURRENT_REQUESTS = 1 #并发数
DOWNLOAD_DELAY = 5 #为了防止IP被封,我们5秒请求一次
HTTPERROR_ALLOWED_CODES = [403] #上面报的是403,就把403加入
#默认为True,就是要遵守robots.txt 的规则,这里我们改为False
ROBOTSTXT_OBEY = False
进行相应的修改后,我们再次执行爬虫命令:scrapy crawl jianshu,查看日志打印获取头像。
获取头像.png
既然可以成功抓取网页数据,接下来我们要做的就是分析网页的源代码,下面我们就不一一分析了。当然在此之前你需要对xpath有一定的了解。
以下引用Scrapy中文官网的介绍:
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 和 CSS: 的表达机制。请参阅有关选择器和其他提取机制的信息。
以下是 XPath 表达式及其对应含义的示例:
以上只是几个简单的XPath例子,XPath其实比这个强大很多。如果您想了解更多,我们推荐这个 XPath 教程。
通过上面的介绍,相信你可以做好接下来的爬虫工作,把jianshu.py的所有代码贴在下面供参考:
# -*- coding: utf-8 -*-
import scrapy
from jianshu_article.items import JianshuArticleItem
class JianshuSpider(scrapy.Spider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
user_id = "1b4c832fb2ca" #替换此用户ID可获取你需要的数据,或者放开下一行的注释
#user_id = input('请输入作者id:\n')
url = "https://www.jianshu.com/u/{0}?page=1".format(user_id)
start_urls = [
url,
]
def parse(self, response):
# [关注,粉丝,文章]
a = response.xpath('//div[@class="main-top"]/div[@class="info"]/ul/li/div/a/p/text()').extract()
print(a)
# [字数,收获喜欢]
b = response.xpath('//div[@class="main-top"]/div[@class="info"]/ul/li/div/p/text()').extract()
print(b)
# 大头像
c = response.xpath('//div[@class="main-top"]/a[@class="avatar"]/img/@src').extract_first()
print(c)
# 用户名
d = response.xpath('//div[@class="main-top"]/div[@class="title"]/a/text()').extract_first()
print(d)
# 性别
e = response.xpath('//div[@class="main-top"]/div[@class="title"]/i/@class').extract_first()
print(e)
# 获取文章总数,计算页数。(简书网站默认每页是9组数据)
temp = int(a[2])
if (temp % 9 > 0):
count = temp // 9 + 1
else:
count = temp // 9
print("总共" + str(count) + "页")
base_url = "https://www.jianshu.com/u/{0}?page={1}"
for i in range(1, count + 1):
i = count + 1 - i #理论上正序1~count就是按顺序获取的,但是获取的数据是倒置的,所以我们获取count~1的数据,得到的数组就是按照网页形式1~count页码排序的了
yield scrapy.Request(base_url.format(self.user_id, i), dont_filter=True, callback=self.parse_page)
#迭代返回每页的内容
def parse_page(self, response):
for sel in response.xpath('//div[@id="list-container"]/ul/li'):
item = JianshuArticleItem()
item['wrap_img'] = sel.xpath('a/img/@src').extract_first()
item['avatar'] = sel.xpath('div//a[@class="avatar"]/img/@src').extract_first()
item['nickname'] = sel.xpath('div//a[@class="nickname"]/text()').extract_first()
item['time'] = sel.xpath('div//span[@class="time"]/@data-shared-at').extract_first()
item['title'] = sel.xpath('div/a[@class="title"]/text()').extract_first()
item['abstract'] = sel.xpath('div/p[@class="abstract"]/text()').extract_first()
item['read'] = sel.xpath('div/div[@class="meta"]/a[1]/text()').extract()[1]
item['comments'] = sel.xpath('div/div[@class="meta"]/a[2]/text()').extract()[1]
item['like'] = sel.xpath('div/div[@class="meta"]/span/text()').extract_first()
item['detail'] = sel.xpath('div/a[@class="title"]/@href').extract_first()
yield item
至此,爬虫代码已经编写完毕。如果要保存获取的数据,可以在终端执行以下命令:
/*
此命令用于把爬取的数据保存为json文件格式,当然你也可以保存为别的文件格式。
Scrapy官方列出的文件格式有如下几种:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')。
温馨提示:如果要再次爬取,最好换一个文件名或者清空数据再爬取,因为第二还是写入上一个文件,数据不会覆盖,
会堆积在上次获取的下面,造成json文件格式报错。
*/
scrapy crawl jianshu -o data.json
程序执行完后,我们可以在文件目录下看到新生成的data.json文件,双击可以看到我们要获取的所有数据:
执行 crawler.png 得到的数据
json解析出来的数据和网站.png上的完全一样
github地址:
scrapy分页抓取网页(crawlspiderrules有点疑问总结:1、rules里的Rule规则运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-19 17:01
最近在学习爬虫,对爬虫规则的运行机制有些疑惑,于是自己研究了一下,总结出以下几点:
1、规则中的规则是按顺序运行的,从上到下执行;
2、 获取request url是Rule定位的容器,a标签中的所有href链接,比如使用xpath定位
规则 = (
规则(LinkExtractor(restrict_xpaths=("//div/ul")),callback='parse_item'),
)
然后会获取ul容器下a标签的所有链接,服务器会自动发送请求,无需手动发送请求;
3、 响应页面就是Rule请求的链接的页面内容,也就是你在容器ul中定位a标签所在的链接,然后点击链接查看页面内容,在回调函数中提取数据。从这个页面中提取,parse_item(self,response),这个函数的响应对象就是这个页面的内容,不要搞错对象;
4、follow,这个参数开始让我有点晕。跟随意味着跟进。如果follow=True,那么在你得到的响应页面中,会获取所有符合规则的href链接 会自动跟进,进入获取的链接响应页面,在这个页面再次匹配规则规则,看是否有是任何匹配,如果匹配,则继续跟踪,直到匹配规则失败。例如:
规则 = (
规则(LinkExtractor(restrict_xpaths=(“//div/ul”)),follow=True),
)
所以首先规则会获取当前页面上所有符合规则规则的链接,当前页面为start_urls页面,例如获取的链接为
教科书
会继续进入href链接的页面,然后继续匹配Rule规则,看看有没有匹配的链接,相当于在响应页面的元素中找到符合规则的a标签url ,然后点击这个url,然后在这个页面的元素中查找是否有符合Rule规则的href链接,依此类推,直到找不到符合Rule规则的href链接;
5、如果Rule中有callback="parse_item",follow=True,那么情况会更复杂。你可以想象得到一个响应符合Rule规则的页面的链接,然后调用函数,跳转到这个页面。按照其他目标链接,然后调用该函数。最好使用xpath定位。如果使用allow=(r'')正则表达式匹配,会比较混乱。在适当的情况下也会用到,不过比较少嘛,大家可以自己测试体验一下。
6、 翻页,翻页有两种情况
第一种情况(start_url的响应页面底部有翻页链接):
在规则中定义两个Rule规则,一个是获取响应页面规则,一个是获取翻页链接规则,翻页规则遵循响应页面规则,顺序不能错,如下:
规则 = (
规则(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
规则(LinkExtractor(allow=r'\d\.htm'),follow=True),
)
第二种情况(start_url的响应页面底部没有翻页链接,只有输入a标签链接才有翻页链接):
在这种情况下,您无法在规则中定义翻页规则,因为即使您定义了翻页规则,也找不到它们。因为规则中的所有规则,第一次得到响应页面是start_url地址对应的内容。如果该页面没有规则规则,则不会被发现。这里就不多说了,直接上源码吧!
class TestSpider(CrawlSpider):
name = 'test'
allowed_domains = ['dangdang.com']
start_urls = ['http://book.dangdang.com/']
rules = (
Rule(LinkExtractor(restrict_xpaths=("//div[@class='conflq_body']/div[@name='m403752_pid5438_t10274']//div/dl[@ddt-area='5358']/dd")), callback='parse_item'),
)
def parse_item(self, response):
item={}
item['cate_0']=''
item['cate_1'] = ''
item['cate_2'] = ''
item['cate_3'] = ''
breadcrum=response.xpath("//div[@class='crumbs_fb_left']/div[@class='select_frame']/a[@name='breadcrumb-category']/text()").getall()
for i in range(len(breadcrum)):
item['cate_{}'.format(i)]=breadcrum[i]
book_li=response.xpath("//div[@id='search_nature_rg']/ul/li")
for li in book_li:
item['book_title']=li.xpath(".//p[@class='name']/a/@title").get()
item['book_price']=li.xpath(".//p[@class='price']/span/text()").get()
item['book_url']=li.xpath(".//p[@class='name']/a/@href").get()
book_search=li.xpath(".//p[@class='search_book_author']/span")
item['book_author']=book_search[0].xpath(".//a/@title").get()
item['public_date']=book_search[1].xpath(".//text()").get()
item['public_date']=re.sub("/",'',item['public_date']) if item['public_date'] else None
item['public_company']=book_search[2].xpath(".//a/@title").get()
yield item
next_page_url=response.xpath("//div[@class='paging']//li[@class='next']/a/@href").get()
next_page="http://category.dangdang.com"+next_page_url
yield scrapy.Request(next_page,callback=self.parse_item)
在这种情况下,必须在函数中进行翻页。parse_item() 函数的最后三行是翻页语句!我可以自己测试一下。不知道有没有其他方法可以做规则。反正我现在还没找到。如果有人知道,我可以告诉!
以上是我个人的看法,如有错误或遗漏,敬请指出! 查看全部
scrapy分页抓取网页(crawlspiderrules有点疑问总结:1、rules里的Rule规则运行)
最近在学习爬虫,对爬虫规则的运行机制有些疑惑,于是自己研究了一下,总结出以下几点:
1、规则中的规则是按顺序运行的,从上到下执行;
2、 获取request url是Rule定位的容器,a标签中的所有href链接,比如使用xpath定位
规则 = (
规则(LinkExtractor(restrict_xpaths=("//div/ul")),callback='parse_item'),
)
然后会获取ul容器下a标签的所有链接,服务器会自动发送请求,无需手动发送请求;
3、 响应页面就是Rule请求的链接的页面内容,也就是你在容器ul中定位a标签所在的链接,然后点击链接查看页面内容,在回调函数中提取数据。从这个页面中提取,parse_item(self,response),这个函数的响应对象就是这个页面的内容,不要搞错对象;
4、follow,这个参数开始让我有点晕。跟随意味着跟进。如果follow=True,那么在你得到的响应页面中,会获取所有符合规则的href链接 会自动跟进,进入获取的链接响应页面,在这个页面再次匹配规则规则,看是否有是任何匹配,如果匹配,则继续跟踪,直到匹配规则失败。例如:
规则 = (
规则(LinkExtractor(restrict_xpaths=(“//div/ul”)),follow=True),
)
所以首先规则会获取当前页面上所有符合规则规则的链接,当前页面为start_urls页面,例如获取的链接为
教科书
会继续进入href链接的页面,然后继续匹配Rule规则,看看有没有匹配的链接,相当于在响应页面的元素中找到符合规则的a标签url ,然后点击这个url,然后在这个页面的元素中查找是否有符合Rule规则的href链接,依此类推,直到找不到符合Rule规则的href链接;
5、如果Rule中有callback="parse_item",follow=True,那么情况会更复杂。你可以想象得到一个响应符合Rule规则的页面的链接,然后调用函数,跳转到这个页面。按照其他目标链接,然后调用该函数。最好使用xpath定位。如果使用allow=(r'')正则表达式匹配,会比较混乱。在适当的情况下也会用到,不过比较少嘛,大家可以自己测试体验一下。
6、 翻页,翻页有两种情况
第一种情况(start_url的响应页面底部有翻页链接):
在规则中定义两个Rule规则,一个是获取响应页面规则,一个是获取翻页链接规则,翻页规则遵循响应页面规则,顺序不能错,如下:
规则 = (
规则(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
规则(LinkExtractor(allow=r'\d\.htm'),follow=True),
)
第二种情况(start_url的响应页面底部没有翻页链接,只有输入a标签链接才有翻页链接):
在这种情况下,您无法在规则中定义翻页规则,因为即使您定义了翻页规则,也找不到它们。因为规则中的所有规则,第一次得到响应页面是start_url地址对应的内容。如果该页面没有规则规则,则不会被发现。这里就不多说了,直接上源码吧!
class TestSpider(CrawlSpider):
name = 'test'
allowed_domains = ['dangdang.com']
start_urls = ['http://book.dangdang.com/']
rules = (
Rule(LinkExtractor(restrict_xpaths=("//div[@class='conflq_body']/div[@name='m403752_pid5438_t10274']//div/dl[@ddt-area='5358']/dd")), callback='parse_item'),
)
def parse_item(self, response):
item={}
item['cate_0']=''
item['cate_1'] = ''
item['cate_2'] = ''
item['cate_3'] = ''
breadcrum=response.xpath("//div[@class='crumbs_fb_left']/div[@class='select_frame']/a[@name='breadcrumb-category']/text()").getall()
for i in range(len(breadcrum)):
item['cate_{}'.format(i)]=breadcrum[i]
book_li=response.xpath("//div[@id='search_nature_rg']/ul/li")
for li in book_li:
item['book_title']=li.xpath(".//p[@class='name']/a/@title").get()
item['book_price']=li.xpath(".//p[@class='price']/span/text()").get()
item['book_url']=li.xpath(".//p[@class='name']/a/@href").get()
book_search=li.xpath(".//p[@class='search_book_author']/span")
item['book_author']=book_search[0].xpath(".//a/@title").get()
item['public_date']=book_search[1].xpath(".//text()").get()
item['public_date']=re.sub("/",'',item['public_date']) if item['public_date'] else None
item['public_company']=book_search[2].xpath(".//a/@title").get()
yield item
next_page_url=response.xpath("//div[@class='paging']//li[@class='next']/a/@href").get()
next_page="http://category.dangdang.com"+next_page_url
yield scrapy.Request(next_page,callback=self.parse_item)
在这种情况下,必须在函数中进行翻页。parse_item() 函数的最后三行是翻页语句!我可以自己测试一下。不知道有没有其他方法可以做规则。反正我现在还没找到。如果有人知道,我可以告诉!
以上是我个人的看法,如有错误或遗漏,敬请指出!
scrapy分页抓取网页( Python中一个非常棒的网页抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-18 11:06
Python中一个非常棒的网页抓取工具)
在上一篇使用 Python 抓取网页的博文中,我们谈到了 Scrapy。在本节中,让我们深入探讨它。
Scrapy 是一个很棒的 Python 网页抓取框架。它可以处理大规模网络爬行过程中的一些常见问题。
Scrapy 与 Requests 或 BeautifulSoup 等其他常用库的区别非常明显。它可以通过简单的方式解决网络爬虫中的常见问题。
Scrapy 的缺点是学习曲线非常陡峭,需要学习的东西很多,但这就是我们要在这里讨论的内容。
在本教程中,我们将创建两个不同的网络爬虫。一种是从电商产品页面提取数据比较简单,另一种是抓取整个电商目录比较复杂。
基本概述
您可以使用 pip 安装 Scrapy。但也要注意,Scrapy 的文档强烈建议将其安装在虚拟环境中,以避免与您的系统软件包发生冲突。
我在这里使用 Virtualenv 和 Virtualenvwrapper:
然后
现在您可以使用以下命令创建一个新的 Scrapy 项目:
上面的命令将为这个项目创建所有必要的模板文件。
下面简单介绍一下上述文件和目录:
在此示例中,我们将从虚拟电子商务 网站 中抓取单个产品。这是我们要抓取的第一个产品:
我们要解析这个产品的名称、图片、价格和描述。
破壳
Scrapy 提供了内置的 Shell 控制台,方便你实时运行和调试爬虫脚本。您可以使用它来快速测试 XPath 表达式或 CSS 选择器。我一直在使用这个很酷的网络爬虫。
您还可以配置 Scrapy Shell 以使用其他控制台来替换默认的 Python 控制台,例如 IPython。可实现自动补全功能或其他特殊效果,如颜色输出等。
为了方便在Scrapy Shell中使用,需要在scrapy.cfg文件中加入如下一行:
配置完成后就可以使用scrapy shell了:
让我们从抓取一个简单的 URL 开始:
这将首先获取 /robot.txt 文件。
本例中没有robot.txt文件,所以我们会在这里看到404 HTTP状态码。如果有robot.txt文件,Scrapy默认会遵循规则。
您可以在 settings.py 文件中禁用此规则:
然后可以看到如下日志:
现在,您可以从捕获的数据中看到响应正文和响应标头,还可以使用不同的 XPath 表达式或 CSS 选择器来解析数据。
使用以下命令直接在浏览器中查看响应信息:
请注意,由于某些原因,该页面在浏览器中的显示效果可能较差。这可能是CORS问题,或者Javascript代码无法执行,或者本地URL对应的资源被加载了。
Scrapy shell 与常规 Python shell 没有什么不同,因此您可以向其中添加自定义脚本或函数。
分析数据
Scrapy 默认不执行 Javascript,所以如果你要爬取的页面是通过 Angular 或 React.js 前端框架渲染的,你可能无法抓取到想要的数据。
现在让我们尝试使用 XPath 表达式来解析产品标题和价格:
使用XPath表达式方便价格分析,选择类属性my-4的div标签后第一个span的文字:
您还可以使用 CSS 选择器:
创建一个 Scrapy 爬虫
在 Scrapy 中,Spider 是一个类,用于定义集合(需要爬取的链接或 URL)和爬取(需要解析的数据)。
以下是爬虫爬取网站所需的步骤:
您可能想知道为什么 parse() 函数可以返回这么多不同类型的对象。这是为了函数的灵活性。假设你想抓取一个没有站点地图的电商网站,你可以从抓取产品类别开始,这里是使用的第一个解析函数。
然后,该函数将为每个产品类别生成一个 Request 对象,并将其传递给新的回调函数 parse2()。对于每个类别,可能还有分页需要处理。然后将为实际抓取的每个产品生成第三个解析函数。
Scrapy 可以将捕获的数据作为简单的 Python 字典返回,但最好使用内置的 Scrapy 项目类。它是我们抓取数据时使用的一个简单容器。Scrapy 可以查看该项中的属性并进行很多操作,比如将数据导出为不同的格式(JSON 或 CSV 等),作为一个项目管道。
这是一个基本的 Product 类:
现在我们可以通过命令行生成爬虫:
或者您可以在 /spiders 目录中手动创建爬虫代码。
以下是 Scrapy 用来解决大部分爬虫用例的不同类型的爬虫:
在这个 EcomSpider 类中,有两个必需的属性:
allowed_domains 是可选的,但也非常重要。当您使用 CrawlSpider 时,将识别不同的域名。
然后使用我们之前看到的 XPath 表达式解析所需的数据并将其填充到 Product 字段中,并返回此项。
您可以运行以下代码将结果导出为 JSON 格式(也可以导出 CSV)。
然后你可以得到一个整洁的 JSON 文件:
物品加载器
从网页中提取数据时,您可能会遇到两个常见问题:
对此,Scrapy 提供了内置的解决方案 ItemLoaders。这是一种处理 Product 对象的有趣方式。
您可以将多个 XPath 表达式添加到同一个 Item 字段,它会按顺序测试它们。默认情况下,如果找到多个 XPath,它会将它们全部加载到列表中。
您可以在 Scrapy 文档中找到许多输入和输出处理器的示例。
当您需要转换或清理解析的数据时,此功能很有用。例如,从价格中提取货币信息,将一种单位转换为另一种单位(厘米和米、华氏和摄氏)等。
我们可以使用不同的 XPath 表达式从网页中查找产品标题://title 和 //section[1]//h2/text()。
在这种情况下,您可以使用 Itemloader:
通常要使用第一个匹配的XPath,所以需要在item的字段构造函数中添加这段代码output_processor=TakeFirst()。
在示例中,我们只希望每个字段都匹配第一个 XPath,因此最好的方法是创建自己的 Itemloader 并声明一个默认的 output_processor 以使用第一个 XPath。
我还在这里添加了一个 price_in 字段,它是一个输入处理器,用于从价格中删除美元符号。我使用的内置处理器 MapCompose 需要按顺序执行一个或多个函数。您可以根据需要添加任何函数,通常是在项目中的字段名称后添加 _in 或 _out ,这意味着添加输入或输出处理器。 查看全部
scrapy分页抓取网页(
Python中一个非常棒的网页抓取工具)
在上一篇使用 Python 抓取网页的博文中,我们谈到了 Scrapy。在本节中,让我们深入探讨它。
Scrapy 是一个很棒的 Python 网页抓取框架。它可以处理大规模网络爬行过程中的一些常见问题。
Scrapy 与 Requests 或 BeautifulSoup 等其他常用库的区别非常明显。它可以通过简单的方式解决网络爬虫中的常见问题。
Scrapy 的缺点是学习曲线非常陡峭,需要学习的东西很多,但这就是我们要在这里讨论的内容。
在本教程中,我们将创建两个不同的网络爬虫。一种是从电商产品页面提取数据比较简单,另一种是抓取整个电商目录比较复杂。
基本概述
您可以使用 pip 安装 Scrapy。但也要注意,Scrapy 的文档强烈建议将其安装在虚拟环境中,以避免与您的系统软件包发生冲突。
我在这里使用 Virtualenv 和 Virtualenvwrapper:
然后
现在您可以使用以下命令创建一个新的 Scrapy 项目:
上面的命令将为这个项目创建所有必要的模板文件。
下面简单介绍一下上述文件和目录:
在此示例中,我们将从虚拟电子商务 网站 中抓取单个产品。这是我们要抓取的第一个产品:
我们要解析这个产品的名称、图片、价格和描述。
破壳
Scrapy 提供了内置的 Shell 控制台,方便你实时运行和调试爬虫脚本。您可以使用它来快速测试 XPath 表达式或 CSS 选择器。我一直在使用这个很酷的网络爬虫。
您还可以配置 Scrapy Shell 以使用其他控制台来替换默认的 Python 控制台,例如 IPython。可实现自动补全功能或其他特殊效果,如颜色输出等。
为了方便在Scrapy Shell中使用,需要在scrapy.cfg文件中加入如下一行:
配置完成后就可以使用scrapy shell了:
让我们从抓取一个简单的 URL 开始:
这将首先获取 /robot.txt 文件。
本例中没有robot.txt文件,所以我们会在这里看到404 HTTP状态码。如果有robot.txt文件,Scrapy默认会遵循规则。
您可以在 settings.py 文件中禁用此规则:
然后可以看到如下日志:
现在,您可以从捕获的数据中看到响应正文和响应标头,还可以使用不同的 XPath 表达式或 CSS 选择器来解析数据。
使用以下命令直接在浏览器中查看响应信息:
请注意,由于某些原因,该页面在浏览器中的显示效果可能较差。这可能是CORS问题,或者Javascript代码无法执行,或者本地URL对应的资源被加载了。
Scrapy shell 与常规 Python shell 没有什么不同,因此您可以向其中添加自定义脚本或函数。
分析数据
Scrapy 默认不执行 Javascript,所以如果你要爬取的页面是通过 Angular 或 React.js 前端框架渲染的,你可能无法抓取到想要的数据。
现在让我们尝试使用 XPath 表达式来解析产品标题和价格:
使用XPath表达式方便价格分析,选择类属性my-4的div标签后第一个span的文字:
您还可以使用 CSS 选择器:
创建一个 Scrapy 爬虫
在 Scrapy 中,Spider 是一个类,用于定义集合(需要爬取的链接或 URL)和爬取(需要解析的数据)。
以下是爬虫爬取网站所需的步骤:
您可能想知道为什么 parse() 函数可以返回这么多不同类型的对象。这是为了函数的灵活性。假设你想抓取一个没有站点地图的电商网站,你可以从抓取产品类别开始,这里是使用的第一个解析函数。
然后,该函数将为每个产品类别生成一个 Request 对象,并将其传递给新的回调函数 parse2()。对于每个类别,可能还有分页需要处理。然后将为实际抓取的每个产品生成第三个解析函数。
Scrapy 可以将捕获的数据作为简单的 Python 字典返回,但最好使用内置的 Scrapy 项目类。它是我们抓取数据时使用的一个简单容器。Scrapy 可以查看该项中的属性并进行很多操作,比如将数据导出为不同的格式(JSON 或 CSV 等),作为一个项目管道。
这是一个基本的 Product 类:
现在我们可以通过命令行生成爬虫:
或者您可以在 /spiders 目录中手动创建爬虫代码。
以下是 Scrapy 用来解决大部分爬虫用例的不同类型的爬虫:
在这个 EcomSpider 类中,有两个必需的属性:
allowed_domains 是可选的,但也非常重要。当您使用 CrawlSpider 时,将识别不同的域名。
然后使用我们之前看到的 XPath 表达式解析所需的数据并将其填充到 Product 字段中,并返回此项。
您可以运行以下代码将结果导出为 JSON 格式(也可以导出 CSV)。
然后你可以得到一个整洁的 JSON 文件:
物品加载器
从网页中提取数据时,您可能会遇到两个常见问题:
对此,Scrapy 提供了内置的解决方案 ItemLoaders。这是一种处理 Product 对象的有趣方式。
您可以将多个 XPath 表达式添加到同一个 Item 字段,它会按顺序测试它们。默认情况下,如果找到多个 XPath,它会将它们全部加载到列表中。
您可以在 Scrapy 文档中找到许多输入和输出处理器的示例。
当您需要转换或清理解析的数据时,此功能很有用。例如,从价格中提取货币信息,将一种单位转换为另一种单位(厘米和米、华氏和摄氏)等。
我们可以使用不同的 XPath 表达式从网页中查找产品标题://title 和 //section[1]//h2/text()。
在这种情况下,您可以使用 Itemloader:
通常要使用第一个匹配的XPath,所以需要在item的字段构造函数中添加这段代码output_processor=TakeFirst()。
在示例中,我们只希望每个字段都匹配第一个 XPath,因此最好的方法是创建自己的 Itemloader 并声明一个默认的 output_processor 以使用第一个 XPath。
我还在这里添加了一个 price_in 字段,它是一个输入处理器,用于从价格中删除美元符号。我使用的内置处理器 MapCompose 需要按顺序执行一个或多个函数。您可以根据需要添加任何函数,通常是在项目中的字段名称后添加 _in 或 _out ,这意味着添加输入或输出处理器。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-18 11:05
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对于我这种情况,我宁愿花半个自己写的一天 懒得学第三方代码工具的都是自己写代码实现的;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用 webBrowser 控件 Navigate(" ") 的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出某个论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
看完这篇文章,我觉得可以解决手头的网站,但是在实际操作中,第二种方法无法完成网页抓取,而第三种方法也不好控制;
个人实践一使用页面添加或修改其中一个标签的属性 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对于我这种情况,我宁愿花半个自己写的一天 懒得学第三方代码工具的都是自己写代码实现的;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用 webBrowser 控件 Navigate(" ") 的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出某个论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
看完这篇文章,我觉得可以解决手头的网站,但是在实际操作中,第二种方法无法完成网页抓取,而第三种方法也不好控制;
个人实践一使用页面添加或修改其中一个标签的属性
scrapy分页抓取网页(讲讲如何抓取网页表格里的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-16 12:23
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的。您只需要添加一个空格和一个标点符号。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,你可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是真品,所以自然不是。认可。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如,和。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,豆瓣的这个电影列表使用分页器来拆分数据:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝们给了坤坤一份300W转发。微博的转发数据碰巧被传呼机分割了。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进来增加坤坤的阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们已经详细解释过了,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你再看一遍之前的教程,你可能想用:nth-of-type(-n+N)来控制N条数据的获取。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
正如我之前提到的,他们新加载的数据被添加到当前页面上。您不断向下滚动,数据不断加载。同时网页的滚动条会越来越短,这意味着所有的数据都在同一个页面上。.
当我们使用:nth-of-type(-n+N)来控制加载次数时,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
● 简易数据分析(六):Web Scraper 翻页——抓取「滚动加载」类型网页● 简易数据分析(二):Web Scraper 初尝鲜,抓取豆瓣高分电影● 简易数据分析 (一):源起、了解 Web Scraper 与浏览器技巧
·结尾· 查看全部
scrapy分页抓取网页(讲讲如何抓取网页表格里的数据?(图))
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的。您只需要添加一个空格和一个标点符号。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,你可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是真品,所以自然不是。认可。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如,和。今天我们说的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页下一页,指定页码跳转。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,豆瓣的这个电影列表使用分页器来拆分数据:
但当时,我们正在寻找定期抓取的网络链接,我们没有使用寻呼机来抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取的代价是最低的;如果网页可以翻,但链接变化不规律,就得去翻页了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝们给了坤坤一份300W转发。微博的转发数据碰巧被传呼机分割了。我们来分析一下微博的转发。信息页,看看这类数据是如何用 Web Scraper 爬取的。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进来增加坤坤的阅读量。
首先,我们来看看第 1 页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。下面开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们已经详细解释过了,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我能把它全部爬下来吗?
听起来不切实际。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如突然弹出验证码,这个Web Scraper就无能为力了)。
考虑到这个问题,如果你再看一遍之前的教程,你可能想用:nth-of-type(-n+N)来控制N条数据的获取。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
正如我之前提到的,他们新加载的数据被添加到当前页面上。您不断向下滚动,数据不断加载。同时网页的滚动条会越来越短,这意味着所有的数据都在同一个页面上。.
当我们使用:nth-of-type(-n+N)来控制加载次数时,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是对于使用翻页设备的网页来说,每次翻页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你想抓取1000条数据,但是页面第一页只有20条数据,抓到最后一条,还有980条数据;然后当翻页时,设置一个新的计数器,并抓取第 2 页的最后一个。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束对pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
● 简易数据分析(六):Web Scraper 翻页——抓取「滚动加载」类型网页● 简易数据分析(二):Web Scraper 初尝鲜,抓取豆瓣高分电影● 简易数据分析 (一):源起、了解 Web Scraper 与浏览器技巧
·结尾·
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-16 12:19
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是页面自动生成的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方法对我来说花费了很多精力。更狠的方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是页面自动生成的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方法对我来说花费了很多精力。更狠的方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然这个不推荐。哈哈
scrapy分页抓取网页(scrapy分页抓取网页(.cfg)中文路径_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-15 18:01
scrapy分页抓取网页一、准备工作首先准备以下三个文件::#scrapy.cfg中文路径:/root/scrapy/site_scrapy/#site_scrapy中文路径:/root/scrapy/site_scrapy/#scrapy.sh中文路径:/root/scrapy/site_scrapy/.bash_profile从上图可知scrapy.sh并不在scrapy文件夹下,而是直接保存在scrapy目录中的目录文件中,所以之前我们直接使用scrapy.sh在scrapy目录下的conf.py中写代码的时候,会报错:>>>importscrapy>>>scrapy.headers.user-agentscrapy.startproject("scrapy",project_name="scrapy_inspector")首先,我们要把把false改成true。
这样就直接能把scrapy.startproject("scrapy",project_name="scrapy_inspector")执行成功。二、webpack与promise.jswebpack环境搭建已经写过,在这里就不再赘述。总之,在此处,webpack会把所有plugins文件打包到scrapy.cfg中,修改scrapy.cfg文件就能让webpack将下面的plugins子节点打包进去。
下面来看下webpack打包进去之后,剩下的东西。1.下载工具集webpack-generator,下载地址:webpack-generator-1.5.0-snapshot-env.zip下载后解压到venv/lib/webpack.cfg文件中。再修改webpack.cfg文件如下:webpack.cfg{entry:"./common.js",directory:["local/src/common.js"],loaders:["style-loader","text-loader","less","sass","scss","sass-loader","style-loader","style-scheme","outline-prettier","webpack-dev-server","scss-loader","less","sass-loader","style-scheme","transform-sass","transform-scss","sass-loader","babel-loader","multiple-sources","sass-plugin","style-loader","jsx","css-selector","less","style-loader","esm","less-loader","xml-selector","xslt","sass-loader","babel-jsx","babel-loader","jstl","jstl-script","test-script","commonjs","less","sass-loader","less-loader","babel-loader","esm","babel-loader","less-loader","less-loader","eslint","tslint","t。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页(.cfg)中文路径_光明网)
scrapy分页抓取网页一、准备工作首先准备以下三个文件::#scrapy.cfg中文路径:/root/scrapy/site_scrapy/#site_scrapy中文路径:/root/scrapy/site_scrapy/#scrapy.sh中文路径:/root/scrapy/site_scrapy/.bash_profile从上图可知scrapy.sh并不在scrapy文件夹下,而是直接保存在scrapy目录中的目录文件中,所以之前我们直接使用scrapy.sh在scrapy目录下的conf.py中写代码的时候,会报错:>>>importscrapy>>>scrapy.headers.user-agentscrapy.startproject("scrapy",project_name="scrapy_inspector")首先,我们要把把false改成true。
这样就直接能把scrapy.startproject("scrapy",project_name="scrapy_inspector")执行成功。二、webpack与promise.jswebpack环境搭建已经写过,在这里就不再赘述。总之,在此处,webpack会把所有plugins文件打包到scrapy.cfg中,修改scrapy.cfg文件就能让webpack将下面的plugins子节点打包进去。
下面来看下webpack打包进去之后,剩下的东西。1.下载工具集webpack-generator,下载地址:webpack-generator-1.5.0-snapshot-env.zip下载后解压到venv/lib/webpack.cfg文件中。再修改webpack.cfg文件如下:webpack.cfg{entry:"./common.js",directory:["local/src/common.js"],loaders:["style-loader","text-loader","less","sass","scss","sass-loader","style-loader","style-scheme","outline-prettier","webpack-dev-server","scss-loader","less","sass-loader","style-scheme","transform-sass","transform-scss","sass-loader","babel-loader","multiple-sources","sass-plugin","style-loader","jsx","css-selector","less","style-loader","esm","less-loader","xml-selector","xslt","sass-loader","babel-jsx","babel-loader","jstl","jstl-script","test-script","commonjs","less","sass-loader","less-loader","babel-loader","esm","babel-loader","less-loader","less-loader","eslint","tslint","t。

