
scrapy分页抓取网页
scrapy分页抓取网页( page=4那么我们是不是可以通过,改变页码去完成呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-25 17:27
page=4那么我们是不是可以通过,改变页码去完成呢?)
页=4
那么我们可以改变页码(page)来完成分页吗?因为首页和7天热点类似,我用了7天热点的爬取思路来爬取(蜘蛛——Scrapy),但是很明显网址抓不到首页的信息。除了尝试所有参数之外别无他法。首先我们看一下seen_snote_ids[]的参数,除了page的参数外,应该在那里找到。
第一页
我们看到第一页没有参数,我们看第二页的请求信息
第二页请求信息
ID有很多,那么我们应该在哪里找到它们呢?我们先来看看第一页的源代码。
第一页的来源信息
看到这些数字,是不是和第二页的参数有关?经过对比,确实和第二页的参数id一致。有了线索,我们再看第三页(进一步确定携带的参数)
第三页参数
经过分析,我们发现第三页的参数是40,第二页是20,第一页是0,第二页的id参数,我们可以在第一页的源码中得到。可以在第二页上看到第三页吗?,我们看一下第二页的源码
可能有身份证
因为网页是直接加载的,所以我们大致确定第二页的位置,然后比较第三页的一些参数信息。
第三页部分参数
仔细对比可以发现,第三页的参数确实收录
了第一页和第二页的id信息。
现在差不多我们对这个页面的加载方式和分页方式有了更好的了解,即除了后续每个页面的page参数变化外,携带的seen_snote_ids[]都是前一个(几个)的id参数页,那么这个有多少页?我真的一直点击加载。最终,page参数停留在了15页(seen_snote_ids[]的数量非常多),“read more”字样没有出现。让我们来看看。
第十五页
我们可以看到请求的URL的长度,并且参数一直在增加,所以暂时我认为i是15页。下面是获取 id 和分页 URL 的示例代码:
1.获取id
html = requests.get(url,headers = self.headers,cookies = self.cookies).text
response = etree.HTML(html)
ids = response.xpath('//*[@id="list-container"]/ul/li')
for one in ids:
one = 'seen_snote_ids[]=' + one.xpath('@data-note-id')[0]
2.构造页码
def totalPage(self):
for i in range(1,16):
data = '&'.join(self.params)
url = 'http://www.jianshu.com/?' + data + '&page={}'.format(i)
self.getData(url)
遇到的问题+示例源码
1.遇到的问题
以前是按照我7号的小本子的流行思路写的,最后得到了重复数据,加上id后,也是重复数据。罗罗盘在跑到合适的boss之前给我看了首页分析的文章,看和我对比后,感觉差不多,就是拿不到数据。之后,你们说参数可能不够。LEONYao大哥也说可以把所有参数都放进去,弹到满状态,往右边跑。之后说带cookies是可行的,但是经过测试确实可行(小cookie困扰了很久,没想到带cookies)
2.示例代码
# -*- coding:utf-8 -*-
from lxml import etree
import requests
import re
from Class.store_csv import CSV
class Spider(object):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
cookies = {
'UM_distinctid': '15ac11bdff316-0ce09a4511f531-67f1a39-100200-15ac11bdff447d',
'CNZZDATA1258679142': '1034687255-1492307094-%7C1493259066',
'remember_user_token': 'W1s1MjA4MDY0XSwiJDJhJDEwJFVWVjUwbXBsS1hldkc1d0l3UG5DSmUiLCIxNDk0ODkyNTg0LjczNDM2ODgiXQ%3D%3D--f04b34c274980b45e5f7ee17c2686aeb4b567197',
'_gat': '1',
'_session_id': 'N0tvclN3V09wZ25UNFloZ0NrRTBVT3ZYQUR5VkRlV1c2Tno1bnNZc3dmQm9kQ3hmOGY4a0dFUlVLMDdPYWZJdCsydGJMaENZVU1XSHdZMHozblNhUERqaldYTHNWYXVPd2tISHVCeWJtbUFwMjJxQ3lyU2NZaTNoVUZsblV4Si94N2hRRC94MkJkUjhGNkNCYm1zVmM0R0ZqR2hFSFltZnhEcXVLbG54SlNSQU5lR0dtZ2MxOWlyYWVBMVl1a1lMVkFTYS8yQVF3bGFiR2hMblcweTU5cnR5ZTluTGlZdnFKbUdFWUYzcm9sZFZLOGduWFdnUU9yN3I0OTNZbWMxQ2UvbU5aQnByQmVoMFNjR1NmaDJJSXF6WHBYQXpPQnBVRVJnaVZVQ2xUR1p4MXNUaDhQSE80N1paLzg0amlBdjRxMU15a0JORlB1YXJ4V2g0b3hYZXpjR1NkSHVVdnA2RkgvVkJmdkJzdTg5ODhnUVRCSnN2cnlwRVJvWWc4N0lZMWhCMWNSMktMMWNERktycE0wcHFhTnYyK3ZoSWFSUFQzbkVyMDlXd2d5bz0tLThrdXQ2cFdRTTNaYXFRZm5RNWtYZUE9PQ%3D%3D--bc52e90a4f1d720f4766a5894866b3764c0482dd',
'_ga': 'GA1.2.1781682389.1492310343',
'_gid': 'GA1.2.163793537.1495583991',
'Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1495360310,1495416048,1495516194,1495583956',
'Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1495583991'
}
params = []
def __init__(self):
field = ['标题', '作者', '发表时间', '阅读量', '评论数', '点赞数', '打赏数', '所投专题']
self.write = CSV('main.csv', field)
def totalPage(self):
for i in range(1,16):
data = '&'.join(self.params)
url = 'http://www.jianshu.com/?' + data + '&page={}'.format(i)
self.getData(url)
def getData(self,url):
print url
html = requests.get(url,headers = self.headers,cookies = self.cookies).text
response = etree.HTML(html)
ids = response.xpath('//*[@id="list-container"]/ul/li')
for one in ids:
one = 'seen_snote_ids[]=' + one.xpath('@data-note-id')[0]
self.params.append(one)
item = {}
flag = 0
read = re.findall(r'ic-list-read"> (\d+)', html)
comment = re.findall(r'ic-list-comments"> (\d+)', html)
result = response.xpath('//*[@id="list-container"]/ul/li/div')
for one in result:
item[1] = one.xpath('a/text()')[0]
item[2] = one.xpath('div[1]/div/a/text()')[0]
item[3] = one.xpath('div[1]/div/span/@data-shared-at')[0]
item[4] = read[flag]
try:
item[5] = comment[flag]
except:
item[5] = u''
item[6] = one.xpath('div[2]/span/text()')[0].strip()
try:
item[7] = one.xpath('div[2]/span[2]/text()')[0].strip()
except:
item[7] = u'0'
try:
item[8] = one.xpath('div[2]/a[1]/text()')[0]
except:
item[8] = u''
flag += 1
row = [item[i] for i in range(1, 9)]
self.write.writeRow(row)
if __name__ == "__main__":
jian = Spider()
jian.totalPage()
结果截图
信息详情
总结
现在想一想,在抓取网站的时候,我们可以携带尽可能多的参数(俗话说,很多人不怪它),以免遇到我的错误。目前正在编写scrapy版本。有兴趣的可以参考私聊源码。 查看全部
scrapy分页抓取网页(
page=4那么我们是不是可以通过,改变页码去完成呢?)

页=4
那么我们可以改变页码(page)来完成分页吗?因为首页和7天热点类似,我用了7天热点的爬取思路来爬取(蜘蛛——Scrapy),但是很明显网址抓不到首页的信息。除了尝试所有参数之外别无他法。首先我们看一下seen_snote_ids[]的参数,除了page的参数外,应该在那里找到。
第一页
我们看到第一页没有参数,我们看第二页的请求信息
第二页请求信息
ID有很多,那么我们应该在哪里找到它们呢?我们先来看看第一页的源代码。
第一页的来源信息
看到这些数字,是不是和第二页的参数有关?经过对比,确实和第二页的参数id一致。有了线索,我们再看第三页(进一步确定携带的参数)
第三页参数
经过分析,我们发现第三页的参数是40,第二页是20,第一页是0,第二页的id参数,我们可以在第一页的源码中得到。可以在第二页上看到第三页吗?,我们看一下第二页的源码
可能有身份证
因为网页是直接加载的,所以我们大致确定第二页的位置,然后比较第三页的一些参数信息。
第三页部分参数
仔细对比可以发现,第三页的参数确实收录
了第一页和第二页的id信息。
现在差不多我们对这个页面的加载方式和分页方式有了更好的了解,即除了后续每个页面的page参数变化外,携带的seen_snote_ids[]都是前一个(几个)的id参数页,那么这个有多少页?我真的一直点击加载。最终,page参数停留在了15页(seen_snote_ids[]的数量非常多),“read more”字样没有出现。让我们来看看。
第十五页
我们可以看到请求的URL的长度,并且参数一直在增加,所以暂时我认为i是15页。下面是获取 id 和分页 URL 的示例代码:
1.获取id
html = requests.get(url,headers = self.headers,cookies = self.cookies).text
response = etree.HTML(html)
ids = response.xpath('//*[@id="list-container"]/ul/li')
for one in ids:
one = 'seen_snote_ids[]=' + one.xpath('@data-note-id')[0]
2.构造页码
def totalPage(self):
for i in range(1,16):
data = '&'.join(self.params)
url = 'http://www.jianshu.com/?' + data + '&page={}'.format(i)
self.getData(url)
遇到的问题+示例源码
1.遇到的问题
以前是按照我7号的小本子的流行思路写的,最后得到了重复数据,加上id后,也是重复数据。罗罗盘在跑到合适的boss之前给我看了首页分析的文章,看和我对比后,感觉差不多,就是拿不到数据。之后,你们说参数可能不够。LEONYao大哥也说可以把所有参数都放进去,弹到满状态,往右边跑。之后说带cookies是可行的,但是经过测试确实可行(小cookie困扰了很久,没想到带cookies)
2.示例代码
# -*- coding:utf-8 -*-
from lxml import etree
import requests
import re
from Class.store_csv import CSV
class Spider(object):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
cookies = {
'UM_distinctid': '15ac11bdff316-0ce09a4511f531-67f1a39-100200-15ac11bdff447d',
'CNZZDATA1258679142': '1034687255-1492307094-%7C1493259066',
'remember_user_token': 'W1s1MjA4MDY0XSwiJDJhJDEwJFVWVjUwbXBsS1hldkc1d0l3UG5DSmUiLCIxNDk0ODkyNTg0LjczNDM2ODgiXQ%3D%3D--f04b34c274980b45e5f7ee17c2686aeb4b567197',
'_gat': '1',
'_session_id': 'N0tvclN3V09wZ25UNFloZ0NrRTBVT3ZYQUR5VkRlV1c2Tno1bnNZc3dmQm9kQ3hmOGY4a0dFUlVLMDdPYWZJdCsydGJMaENZVU1XSHdZMHozblNhUERqaldYTHNWYXVPd2tISHVCeWJtbUFwMjJxQ3lyU2NZaTNoVUZsblV4Si94N2hRRC94MkJkUjhGNkNCYm1zVmM0R0ZqR2hFSFltZnhEcXVLbG54SlNSQU5lR0dtZ2MxOWlyYWVBMVl1a1lMVkFTYS8yQVF3bGFiR2hMblcweTU5cnR5ZTluTGlZdnFKbUdFWUYzcm9sZFZLOGduWFdnUU9yN3I0OTNZbWMxQ2UvbU5aQnByQmVoMFNjR1NmaDJJSXF6WHBYQXpPQnBVRVJnaVZVQ2xUR1p4MXNUaDhQSE80N1paLzg0amlBdjRxMU15a0JORlB1YXJ4V2g0b3hYZXpjR1NkSHVVdnA2RkgvVkJmdkJzdTg5ODhnUVRCSnN2cnlwRVJvWWc4N0lZMWhCMWNSMktMMWNERktycE0wcHFhTnYyK3ZoSWFSUFQzbkVyMDlXd2d5bz0tLThrdXQ2cFdRTTNaYXFRZm5RNWtYZUE9PQ%3D%3D--bc52e90a4f1d720f4766a5894866b3764c0482dd',
'_ga': 'GA1.2.1781682389.1492310343',
'_gid': 'GA1.2.163793537.1495583991',
'Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1495360310,1495416048,1495516194,1495583956',
'Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1495583991'
}
params = []
def __init__(self):
field = ['标题', '作者', '发表时间', '阅读量', '评论数', '点赞数', '打赏数', '所投专题']
self.write = CSV('main.csv', field)
def totalPage(self):
for i in range(1,16):
data = '&'.join(self.params)
url = 'http://www.jianshu.com/?' + data + '&page={}'.format(i)
self.getData(url)
def getData(self,url):
print url
html = requests.get(url,headers = self.headers,cookies = self.cookies).text
response = etree.HTML(html)
ids = response.xpath('//*[@id="list-container"]/ul/li')
for one in ids:
one = 'seen_snote_ids[]=' + one.xpath('@data-note-id')[0]
self.params.append(one)
item = {}
flag = 0
read = re.findall(r'ic-list-read"> (\d+)', html)
comment = re.findall(r'ic-list-comments"> (\d+)', html)
result = response.xpath('//*[@id="list-container"]/ul/li/div')
for one in result:
item[1] = one.xpath('a/text()')[0]
item[2] = one.xpath('div[1]/div/a/text()')[0]
item[3] = one.xpath('div[1]/div/span/@data-shared-at')[0]
item[4] = read[flag]
try:
item[5] = comment[flag]
except:
item[5] = u''
item[6] = one.xpath('div[2]/span/text()')[0].strip()
try:
item[7] = one.xpath('div[2]/span[2]/text()')[0].strip()
except:
item[7] = u'0'
try:
item[8] = one.xpath('div[2]/a[1]/text()')[0]
except:
item[8] = u''
flag += 1
row = [item[i] for i in range(1, 9)]
self.write.writeRow(row)
if __name__ == "__main__":
jian = Spider()
jian.totalPage()
结果截图
信息详情
总结
现在想一想,在抓取网站的时候,我们可以携带尽可能多的参数(俗话说,很多人不怪它),以免遇到我的错误。目前正在编写scrapy版本。有兴趣的可以参考私聊源码。
scrapy分页抓取网页(使用Scrapy分页–使用Python进行网页抓取原文:.. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-25 13:12
)
使用 Python 使用 Scrapy-Web 爬行进行分页
原来的:。极客们。org/paging-use-scrapy-web-scratch-with-python/
使用剪贴簿分页。网页抓取是一种从网站获取信息的技术。Scrapy 用作 Web 抓取的 Python 框架。从普通网站获取数据更容易。你只需要拉取网站的HTMl,通过过滤标签获取数据即可。但是,如果您尝试获取的数据中存在分页,例如 - 亚马逊产品可以有多个页面。要成功丢弃所有产品,您需要分页的概念。
**分页: **分页,又称分页,是将一个文档分成离散的页面的过程,即将不同的页面上的数据进行捆绑。这些不同的网页都有自己的 URL。所以我们需要一一抓取这些网址和页面。但要记住的是什么时候停止分页。一般来说,页面有一个下一步按钮。这个下一步按钮没问题。当页面完成时,它被禁用。此方法用于获取网页的 URL,直到下一页按钮能够使用,当它被禁用时,没有页面可供抓取。
使用scrapy应用程序分页的项目
从亚马逊网站获取移动详细信息并在以下项目中应用分页。爬取的详细信息包括手机的名称和价格以及分页爬取下面搜索到的所有结果的网址
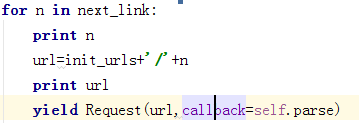
**分页背后的逻辑:**这里 next_page 变量仅在下一页可用时获取下一页的 url,但如果没有剩余页面,则此条件为 false。
next_page = response.xpath("//div/div/ul/li[@class='alast']/a/@href").get()
if next_page:
abs_url = f"https://www.amazon.in{next_page}"
yield scrapy.Request(
url=abs_url,
callback=self.parse
)
笔记:
abs_url = f"https://www.amazon.in{next_page}"
因为next_page是/page2,所以需要在这里取。这是不完整的,完整的网址是
刮刮结果:
查看全部
scrapy分页抓取网页(使用Scrapy分页–使用Python进行网页抓取原文:..
)
使用 Python 使用 Scrapy-Web 爬行进行分页
原来的:。极客们。org/paging-use-scrapy-web-scratch-with-python/
使用剪贴簿分页。网页抓取是一种从网站获取信息的技术。Scrapy 用作 Web 抓取的 Python 框架。从普通网站获取数据更容易。你只需要拉取网站的HTMl,通过过滤标签获取数据即可。但是,如果您尝试获取的数据中存在分页,例如 - 亚马逊产品可以有多个页面。要成功丢弃所有产品,您需要分页的概念。
**分页: **分页,又称分页,是将一个文档分成离散的页面的过程,即将不同的页面上的数据进行捆绑。这些不同的网页都有自己的 URL。所以我们需要一一抓取这些网址和页面。但要记住的是什么时候停止分页。一般来说,页面有一个下一步按钮。这个下一步按钮没问题。当页面完成时,它被禁用。此方法用于获取网页的 URL,直到下一页按钮能够使用,当它被禁用时,没有页面可供抓取。
使用scrapy应用程序分页的项目
从亚马逊网站获取移动详细信息并在以下项目中应用分页。爬取的详细信息包括手机的名称和价格以及分页爬取下面搜索到的所有结果的网址
**分页背后的逻辑:**这里 next_page 变量仅在下一页可用时获取下一页的 url,但如果没有剩余页面,则此条件为 false。
next_page = response.xpath("//div/div/ul/li[@class='alast']/a/@href").get()
if next_page:
abs_url = f"https://www.amazon.in{next_page}"
yield scrapy.Request(
url=abs_url,
callback=self.parse
)
笔记:
abs_url = f"https://www.amazon.in{next_page}"
因为next_page是/page2,所以需要在这里取。这是不完整的,完整的网址是
刮刮结果:

scrapy分页抓取网页(抓取慕课网课程信息展示之scrapy框架数据的过程介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-24 22:23
)
本例主要通过抓取的课程信息来演示scrapy框架爬取数据的过程。
1、抓取网站 简介
爬网网站:
截取内容:截取内容为所有课程名称、课程介绍、课程地址、课程图片地址、课程编号(由于动态渲染)
网站图片:
2、创建项目
以命令行方式创建项目
scrapy startprojectscrapy_course
建立完成后,用pycharm打开,目录如下:
scrapy.cfg:项目配置文件
scrapytest/:项目的python模块。稍后您将在此处添加代码。
scrapytest/items.py:项目中的item文件。
scrapytest/pipelines.py:项目中的管道文件。
scrapytest/settings.py:项目的设置文件。
scrapytest/spiders/:放置蜘蛛代码的目录。
3、创建爬虫
下面的步骤解释了如何编写一个简单的爬虫。
我们要写爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
该文件收录一个MySpider 类,该类必须继承scrapy.Spider 类。
同时它必须定义三个属性:
-name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。
-start_urls:收录Spider启动时会爬取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获取的数据中提取后续 URL。
-parse() 是蜘蛛的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
MySpider.py创建后的代码如下
定义爬虫项目
创建好Spider文件后,先别急着写爬虫代码
我们首先定义一个容器来存放要爬取的数据。
所以我们使用Item
为了定义常用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬取的数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
我们可以在项目目录中看到一个items文件,我们可以改变这个文件或者创建一个新文件来定义我们的items。
在这里,我们在同一层上创建一个新的项目文件 CourseItems.py
根据上面的代码,我们创建了一个名为courseItem的容器来存储和抓取信息。
title->课程名称,url->课程url,image_url->课程标题图片,介绍->课程描述,学生->学号
创建项目文件后,我们可以使用类似字典的 API 和简单的语法来声明可用字段。
常用方法如下
4、编写Spider代码
定义好item后,我们就可以开始爬取部分的工作了。
为简单起见,我们首先抓取页面上的信息。
首先我们编写爬取代码
上面我们说过,爬取部分是在MySpider类的parse()方法中进行的。
parse() 方法负责处理响应并返回处理后的数据和/或 URL 以供后续处理。
此方法和其他 Request 回调函数必须返回一个收录 Request 和/或 Item 的可迭代对象。
我们在之前创建的 MySpider.py 中编写以下代码。
注意上面与 MySpider.py 的区别
# -*- coding:utf8-*-
import scrapy
import sys
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from scrapy_course.items import CourseItem
from scrapy.selector import Selector
sys.stdout = open(\'output.txt\', \'w\')
pageIndex = 0
class MySpider(scrapy.Spider):
#用于区别Spider
name = "MySpider"
#允许访问的域
allowed_domains = [\'imooc.com\']
#爬取的地址
start_urls = ["http://www.imooc.com/course/list"]
#爬取方法
def parse(self, response):
# 实例一个容器保存爬取的信息
item = CourseItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个课程的div
sel = Selector(response)
title = sel.xpath(\'/html/head/title/text()\').extract() # 标题
print title[0]
# sels = sel.xpath(\'//div[@class="course-card-content"]\')
sels = sel.xpath(\'//a[@class="course-card"]\')
pictures = sel.xpath(\'//div[@class="course-card-bk"]\')
index = 0
global pageIndex
pageIndex += 1
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
print \'第\' + str(pageIndex)+ \'页 \'
print \'----------------------------------------------\'
for box in sels:
print \' \'
# 获取div中的课程标题
item[\'title\'] = box.xpath(\'.//h3[@class="course-card-name"]/text()\').extract()[0].strip()
print \'标题:\' + item[\'title\']
# 获取div中的课程简介
item[\'introduction\'] = box.xpath(\'.//p/text()\').extract()[0].strip()
print \'简介:\' + item[\'introduction\']
# 获取每个div中的课程路径
item[\'url\'] = \'http://www.imooc.com\' + box.xpath(\'.//@href\').extract()[0]
print \'路径:\' +item[\'url\']
# 获取div中的学生人数
item[\'student\'] = box.xpath(\'.//div[@class="course-card-info"]/text()\').extract()[0].strip()
print item[\'student\']
# 获取div中的标题图片地址
item[\'image_url\'] = pictures[index].xpath(\'.//img/@src\').extract()[0]
print \'图片地址:\' + item[\'image_url\']
index += 1
yield item
time.sleep(1)
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
# next =u\'下一页\'
# url = response.xpath("//a[contains(text(),\'" + next + "\')]/@href").extract()
# if url:
# # 将信息组合成下一页的url
# page = \'http://www.imooc.com\' + url[0]
# # 返回url
# yield scrapy.Request(page, callback=self.parse)
使用 Pipeline 处理数据
在我们成功获取信息后,我们需要对信息进行验证和存储。这里我们以存储为例。
在Spider中采集到Item后,会传递给Pipeline,一些组件会按照一定的顺序执行Item的处理。
流水线经常执行以下操作:
清理 HTML 数据
验证爬取的数据(检查该项目是否收录某些字段)
重复检查(并丢弃)
目前暂时将爬取结果保存到文本中
这里只进行简单的将数据存储在json文件中的操作。
pipelines.py代码如下
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
import codecs
import json
class ScrapyCoursePipeline(object):
def __init__(self):
# self.file = open(\'data.json\', \'wb\')
# self.file = codecs.open(
# \'spider.txt\', \'w\', encoding=\'utf-8\')
self.file = codecs.open(
\'spider.json\', \'w\', encoding=\'utf-8\')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
要使用Pipeline,必须先注册Pipeline
找到settings.py文件,这个文件就是爬虫的配置文件
添加进去
ITEM_PIPELINES = {
\'scrapy_course.pipelines.ScrapyCoursePipeline\':300
}
以上代码用于注册Pipeline,其中scrapy_course.pipelines.ScrapyCoursePipeline是你要注册的类,右边的'300'是Pipeline的优先级,范围从1到1000。管道越小,第一个执行。
执行完以上操作,我们最基本的爬取操作之一就完成了
然后我们运行
5、运行
在命令行下运行scrapy crawl MySpider
如何将数据存储在文本文件中,在代码前添加如下代码,
sys.stdout = open(\'output.txt\', \'w\'),这会将数据保存到当前项目路径下的output.txt文件中
如下:
查看全部
scrapy分页抓取网页(抓取慕课网课程信息展示之scrapy框架数据的过程介绍
)
本例主要通过抓取的课程信息来演示scrapy框架爬取数据的过程。
1、抓取网站 简介
爬网网站:
截取内容:截取内容为所有课程名称、课程介绍、课程地址、课程图片地址、课程编号(由于动态渲染)
网站图片:
2、创建项目
以命令行方式创建项目
scrapy startprojectscrapy_course
建立完成后,用pycharm打开,目录如下:
scrapy.cfg:项目配置文件
scrapytest/:项目的python模块。稍后您将在此处添加代码。
scrapytest/items.py:项目中的item文件。
scrapytest/pipelines.py:项目中的管道文件。
scrapytest/settings.py:项目的设置文件。
scrapytest/spiders/:放置蜘蛛代码的目录。
3、创建爬虫
下面的步骤解释了如何编写一个简单的爬虫。
我们要写爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
该文件收录一个MySpider 类,该类必须继承scrapy.Spider 类。
同时它必须定义三个属性:
-name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。
-start_urls:收录Spider启动时会爬取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获取的数据中提取后续 URL。
-parse() 是蜘蛛的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
MySpider.py创建后的代码如下
定义爬虫项目
创建好Spider文件后,先别急着写爬虫代码
我们首先定义一个容器来存放要爬取的数据。
所以我们使用Item
为了定义常用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬取的数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
我们可以在项目目录中看到一个items文件,我们可以改变这个文件或者创建一个新文件来定义我们的items。
在这里,我们在同一层上创建一个新的项目文件 CourseItems.py
根据上面的代码,我们创建了一个名为courseItem的容器来存储和抓取信息。
title->课程名称,url->课程url,image_url->课程标题图片,介绍->课程描述,学生->学号
创建项目文件后,我们可以使用类似字典的 API 和简单的语法来声明可用字段。
常用方法如下
4、编写Spider代码
定义好item后,我们就可以开始爬取部分的工作了。
为简单起见,我们首先抓取页面上的信息。
首先我们编写爬取代码
上面我们说过,爬取部分是在MySpider类的parse()方法中进行的。
parse() 方法负责处理响应并返回处理后的数据和/或 URL 以供后续处理。
此方法和其他 Request 回调函数必须返回一个收录 Request 和/或 Item 的可迭代对象。
我们在之前创建的 MySpider.py 中编写以下代码。
注意上面与 MySpider.py 的区别
# -*- coding:utf8-*-
import scrapy
import sys
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from scrapy_course.items import CourseItem
from scrapy.selector import Selector
sys.stdout = open(\'output.txt\', \'w\')
pageIndex = 0
class MySpider(scrapy.Spider):
#用于区别Spider
name = "MySpider"
#允许访问的域
allowed_domains = [\'imooc.com\']
#爬取的地址
start_urls = ["http://www.imooc.com/course/list"]
#爬取方法
def parse(self, response):
# 实例一个容器保存爬取的信息
item = CourseItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个课程的div
sel = Selector(response)
title = sel.xpath(\'/html/head/title/text()\').extract() # 标题
print title[0]
# sels = sel.xpath(\'//div[@class="course-card-content"]\')
sels = sel.xpath(\'//a[@class="course-card"]\')
pictures = sel.xpath(\'//div[@class="course-card-bk"]\')
index = 0
global pageIndex
pageIndex += 1
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
print \'第\' + str(pageIndex)+ \'页 \'
print \'----------------------------------------------\'
for box in sels:
print \' \'
# 获取div中的课程标题
item[\'title\'] = box.xpath(\'.//h3[@class="course-card-name"]/text()\').extract()[0].strip()
print \'标题:\' + item[\'title\']
# 获取div中的课程简介
item[\'introduction\'] = box.xpath(\'.//p/text()\').extract()[0].strip()
print \'简介:\' + item[\'introduction\']
# 获取每个div中的课程路径
item[\'url\'] = \'http://www.imooc.com\' + box.xpath(\'.//@href\').extract()[0]
print \'路径:\' +item[\'url\']
# 获取div中的学生人数
item[\'student\'] = box.xpath(\'.//div[@class="course-card-info"]/text()\').extract()[0].strip()
print item[\'student\']
# 获取div中的标题图片地址
item[\'image_url\'] = pictures[index].xpath(\'.//img/@src\').extract()[0]
print \'图片地址:\' + item[\'image_url\']
index += 1
yield item
time.sleep(1)
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
# next =u\'下一页\'
# url = response.xpath("//a[contains(text(),\'" + next + "\')]/@href").extract()
# if url:
# # 将信息组合成下一页的url
# page = \'http://www.imooc.com\' + url[0]
# # 返回url
# yield scrapy.Request(page, callback=self.parse)
使用 Pipeline 处理数据
在我们成功获取信息后,我们需要对信息进行验证和存储。这里我们以存储为例。
在Spider中采集到Item后,会传递给Pipeline,一些组件会按照一定的顺序执行Item的处理。
流水线经常执行以下操作:
清理 HTML 数据
验证爬取的数据(检查该项目是否收录某些字段)
重复检查(并丢弃)
目前暂时将爬取结果保存到文本中
这里只进行简单的将数据存储在json文件中的操作。
pipelines.py代码如下
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
import codecs
import json
class ScrapyCoursePipeline(object):
def __init__(self):
# self.file = open(\'data.json\', \'wb\')
# self.file = codecs.open(
# \'spider.txt\', \'w\', encoding=\'utf-8\')
self.file = codecs.open(
\'spider.json\', \'w\', encoding=\'utf-8\')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
要使用Pipeline,必须先注册Pipeline
找到settings.py文件,这个文件就是爬虫的配置文件
添加进去
ITEM_PIPELINES = {
\'scrapy_course.pipelines.ScrapyCoursePipeline\':300
}
以上代码用于注册Pipeline,其中scrapy_course.pipelines.ScrapyCoursePipeline是你要注册的类,右边的'300'是Pipeline的优先级,范围从1到1000。管道越小,第一个执行。
执行完以上操作,我们最基本的爬取操作之一就完成了
然后我们运行
5、运行
在命令行下运行scrapy crawl MySpider
如何将数据存储在文本文件中,在代码前添加如下代码,
sys.stdout = open(\'output.txt\', \'w\'),这会将数据保存到当前项目路径下的output.txt文件中
如下:
scrapy分页抓取网页( 什么是Scrapy二.准备环境三.大体设置数据存储模板)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-24 22:21
什么是Scrapy二.准备环境三.大体设置数据存储模板)
Python爬虫学习的scrapy框架(一)爬取豆瓣书单
文章内容
html
Python爬虫学习的scrapy框架(一)爬取豆瓣书单
资源连接
一.什么是Scrapy
二.准备环境
三.一般流程
四.使用框架python
1.创建项目mysql
2.各部分正则表达式介绍
3.创建爬虫sql
4.设置数据存储模板数据库
5.分析网页,编写爬虫应用
6.数据处理框架
7.设置dom的一部分
8.执行scrapy
一.什么是Scrapy
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。写Python爬虫程序也不是不行,但是有框架可以用,何乐而不为呢?我相信Scrapy可以事半功倍。与请求相比,scrapy 更侧重于爬虫框架而不是页面下载。
二.准备环境
Scrapy爬虫需要库pypiwin32、lxml、twisted、scrapy、Microsoft Visual C++ 14.0以上编译环境
数据库链接模块pymysql,以上库我都是用pip安装的,我把清华大学的镜像源放在这里/simple
三.一般流程
首先,引擎从调度程序获取连接(URL)以进行下一次抓取
1. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
2. 然后,爬虫解析响应。
3.如果实体(Item)被解析,就会交给实体管道做进一步处理。
4.如果解析出来的是连接(URL),那么这个URL就会交给Scheduler等待爬取。
四.使用框架1.创建项目
使用命令scrapy startproject projectname
PS D:\pythonpractice> scrapy startproject douban
New Scrapy project 'douban', using template directory 'D:\python38install\Lib\site-packages\scrapy\templates\project', created in:
D:\pythonpractice\douban
You can start your first spider with:
cd douban
scrapy genspider example example.com
我用的是vscode,我用ctrl和·调用终端,输入命令,我要去爬豆瓣的一些页面,所以我把它命名为豆瓣,可以看到在你打开的文件夹下出现了一个新文件夹。名字是我做的
以后用cd豆瓣命令进入项目所在的文件夹
PS D:\pythonpractice> cd douban
PS D:\pythonpractice\douban>
2.各部分介绍
在项目文件夹中,可以看到还有一个和项目同名的文件夹,里面有一些文件,
1.items.py 负责创建数据模型,为结构化数据设置数据存储模板,如:Django Model
2.middlewares.py 是自己定义的中间件
3.pipelines.py 负责处理蜘蛛返回的数据,比如数据持久化
4.settings.py 负责整个爬虫的配置
5. spiders目录负责存放从scrapy继承而来的爬虫
6.scrapy.cfg 是scrapy的基本配置
3.构建爬虫
使用scrapy genspider [options] 构建自己的爬虫,
我输入了scrapy genspider来创建一个名为book的爬虫。域名部分是爬虫的范围,被爬取的网页不能超过这个域名。
4.设置数据存储模板
修改以下item.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
img_src = scrapy.Field()
score = scrapy.Field()
publish_house = scrapy.Field()
publish_detail = scrapy.Field()
slogan = scrapy.Field()
detail_addr = scrapy.Field()
comment_people = scrapy.Field()
5.分析网页,编写爬虫
打开网站链接:豆瓣阅读250强(/top250)
F12打开网页源代码,
能看结构就很清楚了,我需要的是这本书的资料,下面写book.py,
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['douban.com']
start_urls = ['https://book.douban.com/top250?start=0']
url_sets = set()
def parse(self, response):
if response.url.startswith('https://book.douban.com'):
seclectors = response.xpath('//div[@class="indent"]/table')
for seclector in seclectors:
item = DoubanItem()
item['title'] = seclector.xpath("./tr/td[2]/div/a/@title").extract()[0]
item['img_src'] = seclector.xpath("./tr/td[1]/a/img/@src").extract()[0]
item['publish_detail'] = seclector.xpath("./tr/td[2]/p[@class='pl']/text()").extract()[0]
item['score'] = seclector.xpath("./tr/td[2]/div[@class='star clearfix']/span[@class='rating_nums']/text()").extract()[0]
item['detail_addr'] = seclector.xpath("./tr/td[2]/div[@class='pl2']/a/@href").extract()[0]
#标语爬取
item['slogan'] = seclector.xpath("./tr/td[2]/p[@class='quote']/span/text()").get()
if item['slogan']:
pass
else:
item['slogan'] = '暂无信息'
#评论人数爬取
item['comment_people'] = seclector.xpath("./tr/td[2]/div[@class='star clearfix']/span[@class='pl']/text()").extract()[0]
comment = str(item['comment_people'])
rex = '[0-9]+'
num = re.findall(rex, comment)
if num:
item['comment_people'] = num[0]
else:
item['comment_people'] = '暂无信息'
#出版社爬取
t = str(item['publish_detail'])
s = t.encode() #进行字符串转义
temp = s.decode('utf-8')
pattern="[\u4e00-\u9fa5]*\u51fa\u7248[\u4e00-\u9fa5]*|[\u4e00-\u9fa5]*\u4E66\u5E97[\u4e00-\u9fa5]*" #中文 unicode编码出版 正则表达式
results = re.findall(pattern, temp) #匹配
if results:
item['publish_house'] = results[0]
else:
item['publish_house'] = '暂无信息'
yield item
#分页处理
urls = response.xpath("//div[@class='paginator']/span[@class='next']/a/@href").extract()
for url in urls:
if url.startswith('https://book.douban.com'):
if url in self.url_sets:
pass
else:
self.url_sets.add(url)
yield self.make_requests_from_url(url)
else:
pass
(1) 其中start_urls为起始页,后续页面从网页的pager中获取,但是如果网站使用js进行分页,则没有办法。
(2) 提取网页内容的方法有很多,比如beautifulsoup和lxml,但是scrapy中默认使用selector。相对来说,最好用xpath来分析页面。你可以找来了解一下xpath 自己动手吧,单纯为爬虫做网页分析感觉不难。
(3)书的封面图片,获取地址后,可以选择保存在本地,但是因为我觉得不喜欢把图片上传到我PC上的mysql,总觉得那个不是很靠谱,就爬取它的地址,如果你写了网站,想使用这些图片,应该可以直接使用地址。
(4)出版商信息爬取部分,因为这是作者/出版商/日期/价格组成,我用正则表达式将收录“出版商”、“书店”等关键字的字符串提取出来,方便数据持久化后的数据分析。
6.数据处理
编写以下pipline.py
from itemadapter import ItemAdapter
import urllib.request
import os
import pymysql
class DoubanPipeline:
def process_item(self, item, spider):
#保存图片
# url = item['img_addr']
# req = urllib.request.Request(url)
# with urllib.request.urlopen(req) as pic:
# data = pic.read()
# file_name = os.path.join(r'D:\bookpic',item['name'] + '.jpg')
# with open(file_name, 'wb') as fp:
# fp.write(data)
#保存到数据库
info = [item['title'], item['score'], item['publish_detail'], item['slogan'], item['publish_house'], item['img_src'], item['detail_addr'], item['comment_people']]
connection = pymysql.connect(host='localhost', user='root', password='', database='', charset='utf8')
try:
with connection.cursor() as cursor:
sql = 'insert into app_book (title, score, publish_detail, slogan, publish_house, img_src, detail_addr, comment_people) values (%s, %s, %s, %s, %s, %s, %s, %s)'
affectedcount = cursor.execute(sql, info)
print('成功修改{0}条数据'.format(affectedcount))
connection.commit()
except pymysql.DatabaseError:
connection.rollback()
finally:
connection.close()
return item
7.设置部分
settings.py 增长以下内容
(1)设置处理返回数据的类和执行优先级
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 100,
}
(2)添加用户代理
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) G ecko/20100101 Firefox/52.0'
}
8.执行爬虫
输入命令scrapy crawl book,爬虫开始执行 查看全部
scrapy分页抓取网页(
什么是Scrapy二.准备环境三.大体设置数据存储模板)
Python爬虫学习的scrapy框架(一)爬取豆瓣书单
文章内容
html
Python爬虫学习的scrapy框架(一)爬取豆瓣书单
资源连接
一.什么是Scrapy
二.准备环境
三.一般流程
四.使用框架python
1.创建项目mysql
2.各部分正则表达式介绍
3.创建爬虫sql
4.设置数据存储模板数据库
5.分析网页,编写爬虫应用
6.数据处理框架
7.设置dom的一部分
8.执行scrapy
一.什么是Scrapy
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。写Python爬虫程序也不是不行,但是有框架可以用,何乐而不为呢?我相信Scrapy可以事半功倍。与请求相比,scrapy 更侧重于爬虫框架而不是页面下载。
二.准备环境
Scrapy爬虫需要库pypiwin32、lxml、twisted、scrapy、Microsoft Visual C++ 14.0以上编译环境
数据库链接模块pymysql,以上库我都是用pip安装的,我把清华大学的镜像源放在这里/simple
三.一般流程
首先,引擎从调度程序获取连接(URL)以进行下一次抓取
1. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
2. 然后,爬虫解析响应。
3.如果实体(Item)被解析,就会交给实体管道做进一步处理。
4.如果解析出来的是连接(URL),那么这个URL就会交给Scheduler等待爬取。
四.使用框架1.创建项目
使用命令scrapy startproject projectname
PS D:\pythonpractice> scrapy startproject douban
New Scrapy project 'douban', using template directory 'D:\python38install\Lib\site-packages\scrapy\templates\project', created in:
D:\pythonpractice\douban
You can start your first spider with:
cd douban
scrapy genspider example example.com
我用的是vscode,我用ctrl和·调用终端,输入命令,我要去爬豆瓣的一些页面,所以我把它命名为豆瓣,可以看到在你打开的文件夹下出现了一个新文件夹。名字是我做的
以后用cd豆瓣命令进入项目所在的文件夹
PS D:\pythonpractice> cd douban
PS D:\pythonpractice\douban>
2.各部分介绍
在项目文件夹中,可以看到还有一个和项目同名的文件夹,里面有一些文件,
1.items.py 负责创建数据模型,为结构化数据设置数据存储模板,如:Django Model
2.middlewares.py 是自己定义的中间件
3.pipelines.py 负责处理蜘蛛返回的数据,比如数据持久化
4.settings.py 负责整个爬虫的配置
5. spiders目录负责存放从scrapy继承而来的爬虫
6.scrapy.cfg 是scrapy的基本配置
3.构建爬虫
使用scrapy genspider [options] 构建自己的爬虫,
我输入了scrapy genspider来创建一个名为book的爬虫。域名部分是爬虫的范围,被爬取的网页不能超过这个域名。
4.设置数据存储模板
修改以下item.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
img_src = scrapy.Field()
score = scrapy.Field()
publish_house = scrapy.Field()
publish_detail = scrapy.Field()
slogan = scrapy.Field()
detail_addr = scrapy.Field()
comment_people = scrapy.Field()
5.分析网页,编写爬虫
打开网站链接:豆瓣阅读250强(/top250)

F12打开网页源代码,


能看结构就很清楚了,我需要的是这本书的资料,下面写book.py,
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['douban.com']
start_urls = ['https://book.douban.com/top250?start=0']
url_sets = set()
def parse(self, response):
if response.url.startswith('https://book.douban.com'):
seclectors = response.xpath('//div[@class="indent"]/table')
for seclector in seclectors:
item = DoubanItem()
item['title'] = seclector.xpath("./tr/td[2]/div/a/@title").extract()[0]
item['img_src'] = seclector.xpath("./tr/td[1]/a/img/@src").extract()[0]
item['publish_detail'] = seclector.xpath("./tr/td[2]/p[@class='pl']/text()").extract()[0]
item['score'] = seclector.xpath("./tr/td[2]/div[@class='star clearfix']/span[@class='rating_nums']/text()").extract()[0]
item['detail_addr'] = seclector.xpath("./tr/td[2]/div[@class='pl2']/a/@href").extract()[0]
#标语爬取
item['slogan'] = seclector.xpath("./tr/td[2]/p[@class='quote']/span/text()").get()
if item['slogan']:
pass
else:
item['slogan'] = '暂无信息'
#评论人数爬取
item['comment_people'] = seclector.xpath("./tr/td[2]/div[@class='star clearfix']/span[@class='pl']/text()").extract()[0]
comment = str(item['comment_people'])
rex = '[0-9]+'
num = re.findall(rex, comment)
if num:
item['comment_people'] = num[0]
else:
item['comment_people'] = '暂无信息'
#出版社爬取
t = str(item['publish_detail'])
s = t.encode() #进行字符串转义
temp = s.decode('utf-8')
pattern="[\u4e00-\u9fa5]*\u51fa\u7248[\u4e00-\u9fa5]*|[\u4e00-\u9fa5]*\u4E66\u5E97[\u4e00-\u9fa5]*" #中文 unicode编码出版 正则表达式
results = re.findall(pattern, temp) #匹配
if results:
item['publish_house'] = results[0]
else:
item['publish_house'] = '暂无信息'
yield item
#分页处理
urls = response.xpath("//div[@class='paginator']/span[@class='next']/a/@href").extract()
for url in urls:
if url.startswith('https://book.douban.com'):
if url in self.url_sets:
pass
else:
self.url_sets.add(url)
yield self.make_requests_from_url(url)
else:
pass
(1) 其中start_urls为起始页,后续页面从网页的pager中获取,但是如果网站使用js进行分页,则没有办法。
(2) 提取网页内容的方法有很多,比如beautifulsoup和lxml,但是scrapy中默认使用selector。相对来说,最好用xpath来分析页面。你可以找来了解一下xpath 自己动手吧,单纯为爬虫做网页分析感觉不难。
(3)书的封面图片,获取地址后,可以选择保存在本地,但是因为我觉得不喜欢把图片上传到我PC上的mysql,总觉得那个不是很靠谱,就爬取它的地址,如果你写了网站,想使用这些图片,应该可以直接使用地址。
(4)出版商信息爬取部分,因为这是作者/出版商/日期/价格组成,我用正则表达式将收录“出版商”、“书店”等关键字的字符串提取出来,方便数据持久化后的数据分析。
6.数据处理

编写以下pipline.py
from itemadapter import ItemAdapter
import urllib.request
import os
import pymysql
class DoubanPipeline:
def process_item(self, item, spider):
#保存图片
# url = item['img_addr']
# req = urllib.request.Request(url)
# with urllib.request.urlopen(req) as pic:
# data = pic.read()
# file_name = os.path.join(r'D:\bookpic',item['name'] + '.jpg')
# with open(file_name, 'wb') as fp:
# fp.write(data)
#保存到数据库
info = [item['title'], item['score'], item['publish_detail'], item['slogan'], item['publish_house'], item['img_src'], item['detail_addr'], item['comment_people']]
connection = pymysql.connect(host='localhost', user='root', password='', database='', charset='utf8')
try:
with connection.cursor() as cursor:
sql = 'insert into app_book (title, score, publish_detail, slogan, publish_house, img_src, detail_addr, comment_people) values (%s, %s, %s, %s, %s, %s, %s, %s)'
affectedcount = cursor.execute(sql, info)
print('成功修改{0}条数据'.format(affectedcount))
connection.commit()
except pymysql.DatabaseError:
connection.rollback()
finally:
connection.close()
return item
7.设置部分
settings.py 增长以下内容
(1)设置处理返回数据的类和执行优先级
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 100,
}
(2)添加用户代理
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) G ecko/20100101 Firefox/52.0'
}
8.执行爬虫
输入命令scrapy crawl book,爬虫开始执行
scrapy分页抓取网页(scrapy,分析源码结构分析页面html结构下载器流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-24 17:06
Scrapy内部提供了FilesPipeline来下载文件,我们可以把它看成一个特殊的下载器,只要传入要下载的文件的url,下载器就会自动将文件下载到本地
流程简单
我们用伪代码来说明下载过程,假设我们要下载如下页面的文件
GEM专辑
下载《偶尔》
下载《一路逆风》
下载《来自天堂的魔鬼》
下载上述mp3文件的步骤如下:
在settings.py中打开FilesPipeline并指定下载路径
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}
FILES_STORE = '/music_downloads'
FilesPipeline 应该放在其他 Item Pipeline 之前
Spider解析页面,提取要下载的url并赋值给item的file_urls字段
伪代码如下:
class DownloadMusicSpider(scrapy.Spider):
# ...
def parse(response):
item = {}
# 提取 url 组装成列表,并赋给 item 的 file_urls 字段
for url in response.xpath('//a/@href').extract():
download_url = response.urljoin(url)
item['file_urls'].append(download_url)
yield item
项目实际需求分析
是一个著名的python绘图库,每个例子都有对应的源码下载,如:
下载源代码
我们的需求是抓取matplotlib的示例代码,下载保存到本地
写代码前,使用scrapy shell分析源码结构
$ scrapy shell http://matplotlib.org/examples/index.html
# ...
In [1]: view(response) # 将页面下载到本地,分析其 html 结构
Out[1]: True
分析页面html结构
分析显示所有示例链接都在
在以下每个
在scrapy shell中提取链接
In [2]: from scrapy.linkextractors import LinkExtractor
In [3]: le = LinkExtractor(restrict_css='div.toctree-wrapper.compound li.toctree-l2')
In [4]: links = le.extract_links(response)
In [5]: [link.url for link in links]
Out[5]:
['https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
# ...
]
然后分析具体示例页面,提取下载源代码的url
In [6]: fetch('https://matplotlib.org/example ... 23x27;)
2019-07-21 22:15:22 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
In [7]: view(response)
Out[7]: True
下载页面html结构
分析显示下载url是在元素中获取的
In [8]: href = response.css('a.reference.external::attr(href)').extract_first()
In [9]: href
Out[9]: 'animate_decay.py'
In [10]: response.urljoin(href) # 组装成绝对地址
Out[10]: 'https://matplotlib.org/example ... 27%3B
实现项目创建的具体编码
本文参与腾讯云自媒体分享计划,欢迎您加入,与正在阅读的您分享。 查看全部
scrapy分页抓取网页(scrapy,分析源码结构分析页面html结构下载器流程)
Scrapy内部提供了FilesPipeline来下载文件,我们可以把它看成一个特殊的下载器,只要传入要下载的文件的url,下载器就会自动将文件下载到本地
流程简单
我们用伪代码来说明下载过程,假设我们要下载如下页面的文件
GEM专辑
下载《偶尔》
下载《一路逆风》
下载《来自天堂的魔鬼》
下载上述mp3文件的步骤如下:
在settings.py中打开FilesPipeline并指定下载路径
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}
FILES_STORE = '/music_downloads'
FilesPipeline 应该放在其他 Item Pipeline 之前
Spider解析页面,提取要下载的url并赋值给item的file_urls字段
伪代码如下:
class DownloadMusicSpider(scrapy.Spider):
# ...
def parse(response):
item = {}
# 提取 url 组装成列表,并赋给 item 的 file_urls 字段
for url in response.xpath('//a/@href').extract():
download_url = response.urljoin(url)
item['file_urls'].append(download_url)
yield item
项目实际需求分析
是一个著名的python绘图库,每个例子都有对应的源码下载,如:
下载源代码
我们的需求是抓取matplotlib的示例代码,下载保存到本地
写代码前,使用scrapy shell分析源码结构
$ scrapy shell http://matplotlib.org/examples/index.html
# ...
In [1]: view(response) # 将页面下载到本地,分析其 html 结构
Out[1]: True
分析页面html结构
分析显示所有示例链接都在
在以下每个
在scrapy shell中提取链接
In [2]: from scrapy.linkextractors import LinkExtractor
In [3]: le = LinkExtractor(restrict_css='div.toctree-wrapper.compound li.toctree-l2')
In [4]: links = le.extract_links(response)
In [5]: [link.url for link in links]
Out[5]:
['https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
# ...
]
然后分析具体示例页面,提取下载源代码的url
In [6]: fetch('https://matplotlib.org/example ... 23x27;)
2019-07-21 22:15:22 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
In [7]: view(response)
Out[7]: True
下载页面html结构
分析显示下载url是在元素中获取的
In [8]: href = response.css('a.reference.external::attr(href)').extract_first()
In [9]: href
Out[9]: 'animate_decay.py'
In [10]: response.urljoin(href) # 组装成绝对地址
Out[10]: 'https://matplotlib.org/example ... 27%3B
实现项目创建的具体编码
本文参与腾讯云自媒体分享计划,欢迎您加入,与正在阅读的您分享。
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-21 08:15
豆瓣日记:WebScraper怎么对付这种类型的网页(组图))
图片
这是简单数据分析系列文章的第12篇。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据. 今天我们讲的是一种比较常见的翻页机。
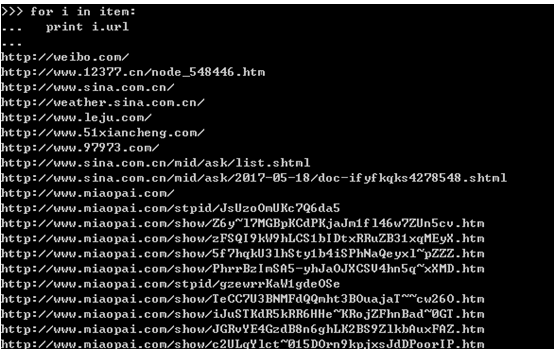
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
图片
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
图片
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
图片
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,让我们看一下第1页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发页面的URL是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
图片
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
图片
容器的预览如下图所示:
图片
寻呼机选择的过程如下图所示:
图片
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
图片
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。URL的反爬虫系统(比如突然弹出验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第二页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
寻呼机是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页(组图))
图片
这是简单数据分析系列文章的第12篇。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据. 今天我们讲的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。

图片
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
图片
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
图片
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,让我们看一下第1页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发页面的URL是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
图片
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
图片
容器的预览如下图所示:
图片
寻呼机选择的过程如下图所示:

图片
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
图片
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。URL的反爬虫系统(比如突然弹出验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第二页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
寻呼机是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(PythonScrapy爬虫框架很久了,、Pycharm框架详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-18 09:00
想长期学习Python Scrapy爬虫框架。最近通过在线课程对Scrapy有了初步的了解。使用的工具主要是Anaconda3、Pycharm。现在我分享以下内容:
顾名思义,爬虫是一种自动抓取互联网信息的程序。通过此程序后,您可以使用互联网数据来分析和开发产品。
URL管理模块:对计划爬取或已经爬取的URL进行管理。网页下载模块:访问和下载URL管理模块中指定的URL。网页分析模块:解析网页下载模块中的URL,处理或保存数据。如果解析URL继续爬取,则返回URL管理模块继续循环。一个开源的 Python 爬虫框架,用于爬取网站并从页面中提取结果。快速而强大,只需编写少量代码即可完成抓取任务。安装: conda install -c conda-forge scrapy。检查是否安装成功:scrapy bench通用开发及编写步骤(1)创建项目:scrapy startproject教程(自定义名称)(2)define Item,Construct crawled objects(1)
项目介绍:通过Python Scrapy框架抓取pm25.in上全国各大城市的空气质量数据,下载到本地CSV文件中。
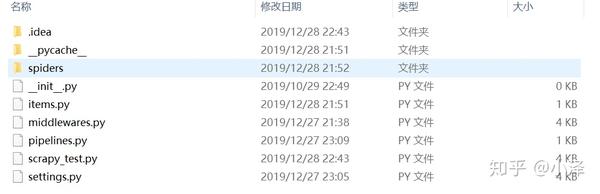
项目第一步:创建项目。在项目文件夹的DOS命令行输入scrapy startproject教程,目录下会生成如下文件,包括蜘蛛、项目、管道、设置等基本重要文件:
创建项目教程
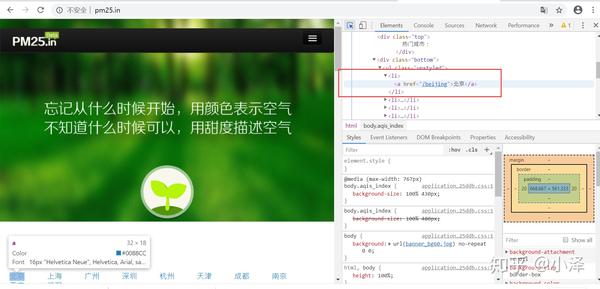
项目第二步:通过对网站的查看和初步分析,找到感兴趣的数据字段,定义ITEM,根据项目需要获取的数据字段定义Item,即定义类城市项目。
使用浏览器工具对网页和字段进行初步分析
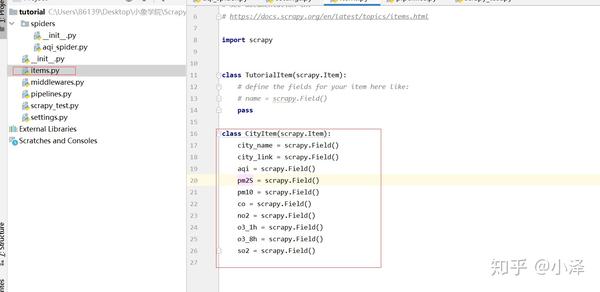
编写items.py程序
项目第三步:创建一个Spider。在命令行界面下输入scrapy genspider aqispider pm25.in,框架会根据这个命令根据基础模板生成aqi_spider
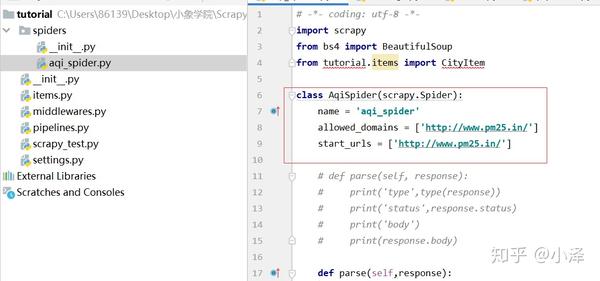
项目第四步:编写AqiSpider的主程序,即网页下载和网页分析。
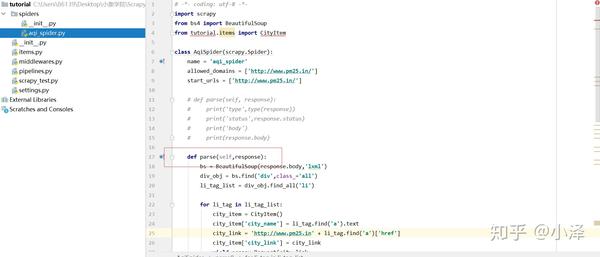
编写主程序最重要的解析函数
def parse(self,response):
bs = BeautifulSoup(response.body,'lxml') #通过BeautifulSoup函数解析网页内容
div_obj = bs.find('div',class_='all') #获取目标对象的div
li_tag_list = div_obj.find_all('li') #获取包含城市名称和链接的div
for li_tag in li_tag_list:
city_item = CityItem() #定义一个CityItem对象
city_item['city_name'] = li_tag.find('a').text #获取城市名
city_link = 'http://www.pm25.in' + li_tag.find('a')['href'] #由于该网页中href对应的是一个部分二级链接地址,因此需要拼接完整地址
city_item['city_link'] = city_link #保存链接到链接字段
yield scrapy.Request(city_link, #通过该语句跳转至二级链接的解析
meta={'item':city_item}, #利用meta来传递CityItem对象
callback = self.parse_city_link, #通过callback调用二级网址解析函数parse_city_link
dont_filter = True)
def parse_city_link(self,response):
city_item = response.meta['item']
bs = BeautifulSoup(response.body,'lxml')
print('正在爬取',city_item['city_name'])
data_div_tag = bs.find('div',class_='span12 data')
value_div_tag_list = data_div_tag.find_all('div',class_='value')
city_item['aqi'] = float(value_div_tag_list[0].text)
city_item['pm2S'] = float(value_div_tag_list[1].text)
city_item['pm10'] = float(value_div_tag_list[2].text)
city_item['co'] = float(value_div_tag_list[3].text)
city_item['no2'] = float(value_div_tag_list[4].text)
city_item['o3_1h'] = float(value_div_tag_list[5].text)
city_item['o3_8h'] = float(value_div_tag_list[6].text)
city_item['so2'] = float(value_div_tag_list[7].text)
yield city_item #利用yield爬取出各项数据。
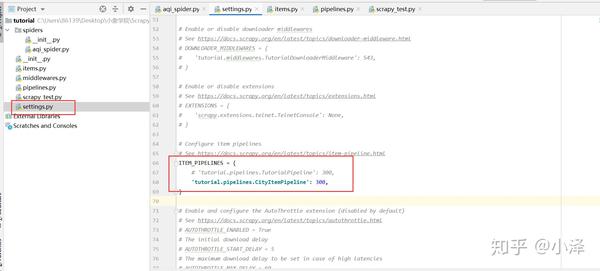
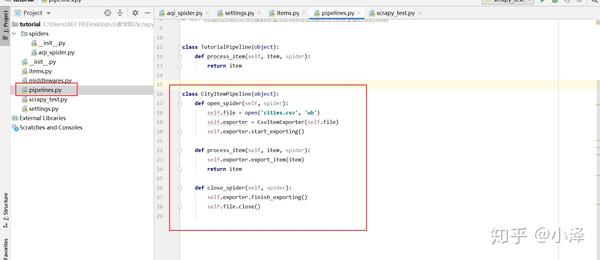
项目第五步:如果要将爬取到的数据导出为csv文件,需要编写并配置一个Pipeline。必须先在设置文件中进行配置,注意设置语句中有一个“300”。这是指多个管道的优先级。数字越小,优先级越高。然后编写管道函数。基本上scrapy的pipeline功能写的差不多,可以复制重复使用。
项目最后:在命令行输入scrapy crawl aqi_spider执行爬虫,可以打开导出的csv文件,发现是乱码。那是因为csv的编码格式与utf-8不同,所以如果出现中文乱码,只需在弹出的“数据”--“从Text/csv导入”文本框中选择编码为utf即可Excel软件导航-8就可以解决了,到此为止,通过scrapy框架已经弯曲了一个简单的数据爬虫。
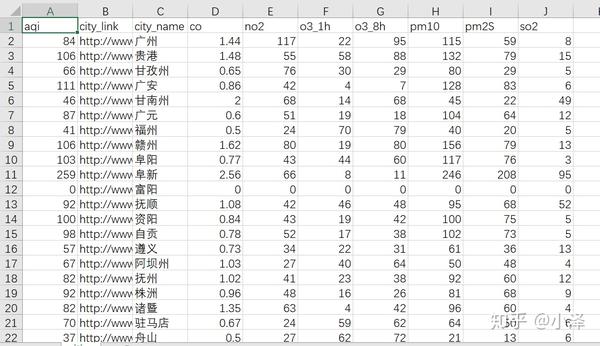
愉快充实的学习经历,期待更深入的爬虫之旅~! 查看全部
scrapy分页抓取网页(PythonScrapy爬虫框架很久了,、Pycharm框架详解)
想长期学习Python Scrapy爬虫框架。最近通过在线课程对Scrapy有了初步的了解。使用的工具主要是Anaconda3、Pycharm。现在我分享以下内容:
顾名思义,爬虫是一种自动抓取互联网信息的程序。通过此程序后,您可以使用互联网数据来分析和开发产品。
URL管理模块:对计划爬取或已经爬取的URL进行管理。网页下载模块:访问和下载URL管理模块中指定的URL。网页分析模块:解析网页下载模块中的URL,处理或保存数据。如果解析URL继续爬取,则返回URL管理模块继续循环。一个开源的 Python 爬虫框架,用于爬取网站并从页面中提取结果。快速而强大,只需编写少量代码即可完成抓取任务。安装: conda install -c conda-forge scrapy。检查是否安装成功:scrapy bench通用开发及编写步骤(1)创建项目:scrapy startproject教程(自定义名称)(2)define Item,Construct crawled objects(1)
项目介绍:通过Python Scrapy框架抓取pm25.in上全国各大城市的空气质量数据,下载到本地CSV文件中。
项目第一步:创建项目。在项目文件夹的DOS命令行输入scrapy startproject教程,目录下会生成如下文件,包括蜘蛛、项目、管道、设置等基本重要文件:
创建项目教程
项目第二步:通过对网站的查看和初步分析,找到感兴趣的数据字段,定义ITEM,根据项目需要获取的数据字段定义Item,即定义类城市项目。
使用浏览器工具对网页和字段进行初步分析
编写items.py程序
项目第三步:创建一个Spider。在命令行界面下输入scrapy genspider aqispider pm25.in,框架会根据这个命令根据基础模板生成aqi_spider
项目第四步:编写AqiSpider的主程序,即网页下载和网页分析。
编写主程序最重要的解析函数
def parse(self,response):
bs = BeautifulSoup(response.body,'lxml') #通过BeautifulSoup函数解析网页内容
div_obj = bs.find('div',class_='all') #获取目标对象的div
li_tag_list = div_obj.find_all('li') #获取包含城市名称和链接的div
for li_tag in li_tag_list:
city_item = CityItem() #定义一个CityItem对象
city_item['city_name'] = li_tag.find('a').text #获取城市名
city_link = 'http://www.pm25.in' + li_tag.find('a')['href'] #由于该网页中href对应的是一个部分二级链接地址,因此需要拼接完整地址
city_item['city_link'] = city_link #保存链接到链接字段
yield scrapy.Request(city_link, #通过该语句跳转至二级链接的解析
meta={'item':city_item}, #利用meta来传递CityItem对象
callback = self.parse_city_link, #通过callback调用二级网址解析函数parse_city_link
dont_filter = True)
def parse_city_link(self,response):
city_item = response.meta['item']
bs = BeautifulSoup(response.body,'lxml')
print('正在爬取',city_item['city_name'])
data_div_tag = bs.find('div',class_='span12 data')
value_div_tag_list = data_div_tag.find_all('div',class_='value')
city_item['aqi'] = float(value_div_tag_list[0].text)
city_item['pm2S'] = float(value_div_tag_list[1].text)
city_item['pm10'] = float(value_div_tag_list[2].text)
city_item['co'] = float(value_div_tag_list[3].text)
city_item['no2'] = float(value_div_tag_list[4].text)
city_item['o3_1h'] = float(value_div_tag_list[5].text)
city_item['o3_8h'] = float(value_div_tag_list[6].text)
city_item['so2'] = float(value_div_tag_list[7].text)
yield city_item #利用yield爬取出各项数据。
项目第五步:如果要将爬取到的数据导出为csv文件,需要编写并配置一个Pipeline。必须先在设置文件中进行配置,注意设置语句中有一个“300”。这是指多个管道的优先级。数字越小,优先级越高。然后编写管道函数。基本上scrapy的pipeline功能写的差不多,可以复制重复使用。
项目最后:在命令行输入scrapy crawl aqi_spider执行爬虫,可以打开导出的csv文件,发现是乱码。那是因为csv的编码格式与utf-8不同,所以如果出现中文乱码,只需在弹出的“数据”--“从Text/csv导入”文本框中选择编码为utf即可Excel软件导航-8就可以解决了,到此为止,通过scrapy框架已经弯曲了一个简单的数据爬虫。
愉快充实的学习经历,期待更深入的爬虫之旅~!
scrapy分页抓取网页( 自动爬取网页存储代码如下:.py:属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-12-17 08:28
自动爬取网页存储代码如下:.py:属性)
最后得到生成的网页链接。并致电请求重新申请此网页的数据
所以在管道中。我们还需要修改存储的代码。具体如下。您可以看到这里没有使用JSON,直接打开txt文件进行存储
class Test1Pipeline(object):
def __init__(self):
self.file=''
def process_item(self, item, spider):
self.file=open(r'E:\scrapy_project\xiaoshuo.txt','wb')
self.file.write(item['content'])
self.file.close()
return item
完整的代码如下:这里需要注意两次yield的用法。在第一次屈服后,它将自动转到test1pipeline进行数据存储,然后在存储后获得下一个网页。然后通过请求获取下一个网页的内容
class testSpider(Spider):
name="test1"
allowd_domains=['http://www.xunsee.com']
start_urls=["http://www.xunread.com/article ... ot%3B]
def parse(self, response):
init_urls="http://www.xunread.com/article ... ot%3B
sel=Selector(response)
context=''
content=sel.xpath('//div[@id="content_1"]/text()').extract()
for c in content:
context=context+c.encode('utf-8')
items=Test1Item()
items['content']=context
count = len(sel.xpath('//div[@id="nav_1"]/a').extract())
if count > 2:
next_link=sel.xpath('//div[@id="nav_1"]/a')[2].xpath('@href').extract()
else:
next_link=sel.xpath('//div[@id="nav_1"]/a')[1].xpath('@href').extract()
yield items
for n in next_link:
url=init_urls+'/'+n
print url
yield Request(url,callback=self.parse)
有一种更方便的自动抓取网页的方法:crawlespider
前面描述的爬行器只能在URL中的开始网页上进行解析。虽然自动爬行的规则也在前一章中实现。但有点负责任。爬行爬行器可用于自动抓取划痕中的网页
爬行规则的原型如下:
上流社会的。contrib。蜘蛛。规则(link\u提取器,callback=None,cb\u kwargs=None,follow=None,process\u links=None,process\u request=None)
链接抽取器:它的功能是定义如何从已爬网的页面中提取链接
Callback指的是一个调用函数,每当从linkextractor获取链接时,都会调用该函数进行处理。回调函数接受响应作为第一个参数。注意:使用crawlespider时,不允许将parse作为回调函数。因为crawlspider使用parse方法来实现逻辑,所以使用parse函数将导致调用失败
Follow是一个判断值,指示是否需要跟踪从响应中提取的链接
以scratch shell中的提取为例
LinkedExtractor中的Allow仅适用于href属性:
例如,以下链接仅提取href属性的正则表达式
结构如下:您可以获得各种链接
您可以使用restrict\uxpath对每个链接进行如下限制:
示例2:以前面的xunread网络为例
提取网页中下一节的地址:
网址: 查看全部
scrapy分页抓取网页(
自动爬取网页存储代码如下:.py:属性)

最后得到生成的网页链接。并致电请求重新申请此网页的数据
所以在管道中。我们还需要修改存储的代码。具体如下。您可以看到这里没有使用JSON,直接打开txt文件进行存储
class Test1Pipeline(object):
def __init__(self):
self.file=''
def process_item(self, item, spider):
self.file=open(r'E:\scrapy_project\xiaoshuo.txt','wb')
self.file.write(item['content'])
self.file.close()
return item
完整的代码如下:这里需要注意两次yield的用法。在第一次屈服后,它将自动转到test1pipeline进行数据存储,然后在存储后获得下一个网页。然后通过请求获取下一个网页的内容
class testSpider(Spider):
name="test1"
allowd_domains=['http://www.xunsee.com']
start_urls=["http://www.xunread.com/article ... ot%3B]
def parse(self, response):
init_urls="http://www.xunread.com/article ... ot%3B
sel=Selector(response)
context=''
content=sel.xpath('//div[@id="content_1"]/text()').extract()
for c in content:
context=context+c.encode('utf-8')
items=Test1Item()
items['content']=context
count = len(sel.xpath('//div[@id="nav_1"]/a').extract())
if count > 2:
next_link=sel.xpath('//div[@id="nav_1"]/a')[2].xpath('@href').extract()
else:
next_link=sel.xpath('//div[@id="nav_1"]/a')[1].xpath('@href').extract()
yield items
for n in next_link:
url=init_urls+'/'+n
print url
yield Request(url,callback=self.parse)
有一种更方便的自动抓取网页的方法:crawlespider
前面描述的爬行器只能在URL中的开始网页上进行解析。虽然自动爬行的规则也在前一章中实现。但有点负责任。爬行爬行器可用于自动抓取划痕中的网页
爬行规则的原型如下:
上流社会的。contrib。蜘蛛。规则(link\u提取器,callback=None,cb\u kwargs=None,follow=None,process\u links=None,process\u request=None)
链接抽取器:它的功能是定义如何从已爬网的页面中提取链接
Callback指的是一个调用函数,每当从linkextractor获取链接时,都会调用该函数进行处理。回调函数接受响应作为第一个参数。注意:使用crawlespider时,不允许将parse作为回调函数。因为crawlspider使用parse方法来实现逻辑,所以使用parse函数将导致调用失败
Follow是一个判断值,指示是否需要跟踪从响应中提取的链接
以scratch shell中的提取为例

LinkedExtractor中的Allow仅适用于href属性:
例如,以下链接仅提取href属性的正则表达式
结构如下:您可以获得各种链接
您可以使用restrict\uxpath对每个链接进行如下限制:

示例2:以前面的xunread网络为例
提取网页中下一节的地址:
网址:
scrapy分页抓取网页(1-4-104.10模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-17 01:26
1-4-5 4.5_Construct 请求对象
1-4-6 4.6_URL 编码转换
1-4-7 4.7_Processing GET 请求
1-4-8 4.8_处理POST请求
1-4-9 4.9_添加特定的Headers——请求伪装
1-4-10 4.10_简单的自定义开瓶器
1-4-11 4.11_设置代理服务器
1-4-12 4.12_timeout 设置
1-4-13 4.13_URLError 异常及捕获
1-4-14 4.14_HttpError 异常和捕获
1-4-15 4.15_请求库是什么
1-4-16 4.16_requests 库发送请求
1-4-17 4.17_requests 库返回响应
1-5 数据分析
1-5-1 5.1_网页数据格式
1-5-2 5.2_查看页面结构
1-5-3 5.3_数据分析技术
1-5-4 5.4_正则表达式备份
1-5-5 5.5_什么是Xpath备份
1-5-6 5.6_XPath 开发工具
1-5-7 5.7_XPath 语法
1-5-8 5.8_什么是lxml库
1-5-9 5.9_lxml 的基本使用
1-5-10 5.10_什么是BeautifulSoup
1-5-11 5.11_构建一个 BeautifulSoup 对象
1-5-12 5.12_按操作方法检索
1-5-13 5.13_通过 CSS 选择器搜索
1-5-14 5.14_什么是JSON0
1-5-15 5.15_JSON 与 XML 语言对比
1-5-16 5.16_json 模块介绍
1-5-17 5.17_json 模块的基本使用
1-5-18 5.18_jsonpath 介绍
1-5-19 5.19_JSONPath 和 XPath 语法对比
1-6 并发下载
1-6-1 6.1_多线程爬虫进程分析
1-6-2 6.2_queue(队列)模块介绍
1-6-3 6.3_Queue类介绍
1-6-4 6.4_协程爬虫的进程解析
1-6-5 6.5_第三方库gevent
1-7 获取动态内容
1-7-1 7.1_动态网页介绍
1-7-2 7.2_selenium 和 PhantomJS 概述
1-7-3 7.3_selenium_PhantomJS 安装配置
1-7-4 7.4_开始使用
1-7-5 7.5_定位页面元素
1-7-6 7.6_鼠标动作链
1-7-7 7.7_填写表格
1-7-8 7.8_pop-up 处理
1-7-9 7.9_pop-up 处理
1-7-10 7.10_向前和向后翻页
1-7-11 7.11_获取页面 Cookie
1-7-12 7.12_page 等待
1-8 图像识别与文字处理
1-8-1 8.1_OCR 技术介绍
1-8-2 8.2_tesseract 下载安装
1-8-3 8.3_tesseract 下载安装
1-8-4 8.4_PIL 库介绍
1-8-5 8.5_读取图片中的格式化文本
1-8-6 8.6_对图像进行阈值滤波和降噪处理
1-8-7 8.7_识别图片中的汉字
1-8-8 8.8_验证码分类
1-8-9 8.9_简易识别图文验证码
1-9 存储爬虫数据
1-9-1 9.1_数据存储介绍
1-9-2 9.2_什么是MongoDB
1-9-3 9.3_在Windows平台上安装MongoDB数据库
1-9-4 9.4_MongoDB 和 MySQL 的术语比较
1-9-5 9.5_什么是 PyMongo
1-9-6 9.6_PyMongo 基本操作
8 P1 c; n,`" Y/ v#@
1-10 初识爬虫框架Scrapy
1-10-1 10.1_常见爬虫框架介绍
1-10-2 10.2_Scrapy 框架架构
1-10-3 10.3_Scrapy框架运行流程
1-10-4 10.4_安装 Scrapy 框架
1-10-5 10.5_新建一个 Scrapy 项目
1-10-6 10.6_清除抓取目标
1-10-7 10.7_让蜘蛛抓取网页
1-10-8 10.8_永久存储数据
1-11 Scrapy 终端及核心组件
1-11-1 11.1_Enable Scrapy shell
1-11-2 11.2_使用 Scrapy shell
1-11-3 11.3_Spiders——抓取和提取结构化数据
1-11-4 11.4_自定义项目管道
1-11-5 11.5_Downloader Middlewares——防止反爬虫
1-11-6 11.6_Settings——自定义 Scrapy 组件
1-12个自动抓取网页的CrawlSpider
1-12-1 12.1_第一次认识CrawlSpider
1-12-2 12.2_CrawlSpider 类的工作原理
1-12-3 12.3_通过Rule类确定爬取规则
1-12-4 12.4_通过LinkExtractor类提取链接
1-13 Scrapy-Redis 分布式爬虫
1-13-1 13.1_Scrapy-Redis 介绍
1-13-2 13.2_Scrapy-Redis 完整架构
1-13-3 13.3_Scrapy-Redis 操作流程
1-13-4 13.4_Scrapy-Redis 的主要组成部分
1-13-5 13.5_安装 Scrapy-Redis
1-13-6 13.6_安装并启动Redis数据库
1-13-7 13.7_修改配置文件redis.conf
1-13-8 13.8_分布式策略
1-13-9 13.9_测试slave端远程连接Master端
1-13-10 13.10_创建一个Scrapy项目并设置Scrapy-Redis组件
1-13-11 13.11_清除抓取目标
1-13-12 13.12_make 蜘蛛抓取网页
1-13-13 13.13_执行分布式爬虫
1-13-14 13.14_使用多管道存储
1-13-15 13.15_处理Redis数据库中的数据 查看全部
scrapy分页抓取网页(1-4-104.10模块)
1-4-5 4.5_Construct 请求对象
1-4-6 4.6_URL 编码转换
1-4-7 4.7_Processing GET 请求
1-4-8 4.8_处理POST请求
1-4-9 4.9_添加特定的Headers——请求伪装
1-4-10 4.10_简单的自定义开瓶器
1-4-11 4.11_设置代理服务器
1-4-12 4.12_timeout 设置
1-4-13 4.13_URLError 异常及捕获
1-4-14 4.14_HttpError 异常和捕获
1-4-15 4.15_请求库是什么
1-4-16 4.16_requests 库发送请求
1-4-17 4.17_requests 库返回响应
1-5 数据分析
1-5-1 5.1_网页数据格式
1-5-2 5.2_查看页面结构
1-5-3 5.3_数据分析技术
1-5-4 5.4_正则表达式备份
1-5-5 5.5_什么是Xpath备份
1-5-6 5.6_XPath 开发工具
1-5-7 5.7_XPath 语法
1-5-8 5.8_什么是lxml库
1-5-9 5.9_lxml 的基本使用
1-5-10 5.10_什么是BeautifulSoup
1-5-11 5.11_构建一个 BeautifulSoup 对象
1-5-12 5.12_按操作方法检索
1-5-13 5.13_通过 CSS 选择器搜索
1-5-14 5.14_什么是JSON0
1-5-15 5.15_JSON 与 XML 语言对比
1-5-16 5.16_json 模块介绍
1-5-17 5.17_json 模块的基本使用
1-5-18 5.18_jsonpath 介绍
1-5-19 5.19_JSONPath 和 XPath 语法对比
1-6 并发下载
1-6-1 6.1_多线程爬虫进程分析
1-6-2 6.2_queue(队列)模块介绍
1-6-3 6.3_Queue类介绍
1-6-4 6.4_协程爬虫的进程解析
1-6-5 6.5_第三方库gevent
1-7 获取动态内容
1-7-1 7.1_动态网页介绍
1-7-2 7.2_selenium 和 PhantomJS 概述
1-7-3 7.3_selenium_PhantomJS 安装配置
1-7-4 7.4_开始使用
1-7-5 7.5_定位页面元素
1-7-6 7.6_鼠标动作链
1-7-7 7.7_填写表格
1-7-8 7.8_pop-up 处理
1-7-9 7.9_pop-up 处理
1-7-10 7.10_向前和向后翻页
1-7-11 7.11_获取页面 Cookie
1-7-12 7.12_page 等待
1-8 图像识别与文字处理
1-8-1 8.1_OCR 技术介绍
1-8-2 8.2_tesseract 下载安装
1-8-3 8.3_tesseract 下载安装
1-8-4 8.4_PIL 库介绍
1-8-5 8.5_读取图片中的格式化文本
1-8-6 8.6_对图像进行阈值滤波和降噪处理
1-8-7 8.7_识别图片中的汉字
1-8-8 8.8_验证码分类
1-8-9 8.9_简易识别图文验证码
1-9 存储爬虫数据
1-9-1 9.1_数据存储介绍
1-9-2 9.2_什么是MongoDB
1-9-3 9.3_在Windows平台上安装MongoDB数据库
1-9-4 9.4_MongoDB 和 MySQL 的术语比较
1-9-5 9.5_什么是 PyMongo
1-9-6 9.6_PyMongo 基本操作
8 P1 c; n,`" Y/ v#@
1-10 初识爬虫框架Scrapy
1-10-1 10.1_常见爬虫框架介绍
1-10-2 10.2_Scrapy 框架架构
1-10-3 10.3_Scrapy框架运行流程
1-10-4 10.4_安装 Scrapy 框架
1-10-5 10.5_新建一个 Scrapy 项目
1-10-6 10.6_清除抓取目标
1-10-7 10.7_让蜘蛛抓取网页
1-10-8 10.8_永久存储数据
1-11 Scrapy 终端及核心组件
1-11-1 11.1_Enable Scrapy shell
1-11-2 11.2_使用 Scrapy shell
1-11-3 11.3_Spiders——抓取和提取结构化数据
1-11-4 11.4_自定义项目管道
1-11-5 11.5_Downloader Middlewares——防止反爬虫
1-11-6 11.6_Settings——自定义 Scrapy 组件
1-12个自动抓取网页的CrawlSpider
1-12-1 12.1_第一次认识CrawlSpider
1-12-2 12.2_CrawlSpider 类的工作原理
1-12-3 12.3_通过Rule类确定爬取规则
1-12-4 12.4_通过LinkExtractor类提取链接
1-13 Scrapy-Redis 分布式爬虫
1-13-1 13.1_Scrapy-Redis 介绍
1-13-2 13.2_Scrapy-Redis 完整架构
1-13-3 13.3_Scrapy-Redis 操作流程
1-13-4 13.4_Scrapy-Redis 的主要组成部分
1-13-5 13.5_安装 Scrapy-Redis
1-13-6 13.6_安装并启动Redis数据库
1-13-7 13.7_修改配置文件redis.conf
1-13-8 13.8_分布式策略
1-13-9 13.9_测试slave端远程连接Master端
1-13-10 13.10_创建一个Scrapy项目并设置Scrapy-Redis组件
1-13-11 13.11_清除抓取目标
1-13-12 13.12_make 蜘蛛抓取网页
1-13-13 13.13_执行分布式爬虫
1-13-14 13.14_使用多管道存储
1-13-15 13.15_处理Redis数据库中的数据
scrapy分页抓取网页(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-14 12:06
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview自带的分页功能,点击页面时分页号的时候,你会发现url地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")。等等,这种形式的代码其实也不是很难,因为毕竟找页码的规则是有地方的。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个javascript自动生成页面的方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,再逐页翻页。爬行的。 查看全部
scrapy分页抓取网页(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview自带的分页功能,点击页面时分页号的时候,你会发现url地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")。等等,这种形式的代码其实也不是很难,因为毕竟找页码的规则是有地方的。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个javascript自动生成页面的方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,再逐页翻页。爬行的。
scrapy分页抓取网页(第三方工具使用工具的方法和内容的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-14 12:05
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方法:通过asp.NET开发的网站可能经常遇到。它的分页控件通过post向后端代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页页码时,你会发现URL地址没有变,而是页码变了,页面内容也变了。仔细看会发现,当鼠标移到每个页码上时,状态栏会显示:__dopostback("gridview","page1")等等。这种形式的代码其实也不是很难,因为毕竟是有找页码规则的地方的。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
抓取这种页面需要注意asp.Net页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个javascript自动生成页面的方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,您可以使用WebBroser 控件来实现您可以在IE 中操作网页的任何功能,因此当然可以单击翻页按钮。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。呵呵 查看全部
scrapy分页抓取网页(第三方工具使用工具的方法和内容的区别)
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方法:通过asp.NET开发的网站可能经常遇到。它的分页控件通过post向后端代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页页码时,你会发现URL地址没有变,而是页码变了,页面内容也变了。仔细看会发现,当鼠标移到每个页码上时,状态栏会显示:__dopostback("gridview","page1")等等。这种形式的代码其实也不是很难,因为毕竟是有找页码规则的地方的。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
抓取这种页面需要注意asp.Net页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个javascript自动生成页面的方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,您可以使用WebBroser 控件来实现您可以在IE 中操作网页的任何功能,因此当然可以单击翻页按钮。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。呵呵
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-13 10:29
先看Scrapy
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
本文档将介绍 Scrapy 背后的概念,让您了解其工作原理,并确定 Scrapy 是否是您所需要的。
当你准备好开始你的项目时,你可以参考它。
选择一个网站
当你需要从某个网站获取信息,但是网站没有提供API或者通过程序获取信息的机制,Scrapy可以帮到你。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
可以在此页面上找到今天添加的种子列表:
定义要爬取的数据
第一步是定义我们需要爬取的数据。在 Scrapy 中,这是通过的。(在这个例子中,它是种子文件)
我们定义的Item:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写蜘蛛。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过观察页面的内容,可以发现所有种子的URL都是相似的。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式:/tor/\d+。
我们使用 XPath 从页面的 HTML 源代码中选择要提取的数据。以其中一个种子文件的页面为例:
观察 HTML 页面源代码并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以发现标签中收录了文件名:
Darwin - The Evolution Of An Exhibition
对应于此的XPath表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取描述:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
用于选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的详细信息,请参阅 XPath 参考。
最后结合上面的内容给出spider的代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
TorrentItem 的定义在。
执行spider获取数据
最后,我们可以运行spider获取网站的数据,并以JSON格式保存在scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您还可以将项目写入并存储在数据库中。
查看提取的数据
执行后,查看scraped_data.json,会看到解压出来的item:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是列表,所以所有的值都存储在列表中(除了url是直接赋值的)。如果您想保存单个数据或对数据执行其他处理,这就是它发挥作用的地方。
还有什么?
您已经学习了如何通过 Scrapy 从存储的网页中提取信息,但这只是冰山一角。Scrapy 提供了很多强大的功能,让爬取更容易、更高效,例如:
对于非英语语言的非标准或错误编码声明,提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加速爬虫创建的同时,让大型项目中的代码更加一致。有关详细信息,请参阅命令。为多个爬虫下的性能评估和故障检测提供可扩展性。提供,为您测试XPath表达式,编写和调试爬虫,简化生产环境中的部署和操作提供了极大的便利。内置,以便您可以监控和控制您的机器。内置,通过在 Scrapy 进程中钩入 Python 终端,可以查看和调试爬虫。方便您在抓取过程中捕捉错误。支持站点地图。使用缓存抓取 DNS 解析器
下一个
下一步当然是下载Scrapy,你可以阅读它并加入社区。谢谢您的支持!
讨论 查看全部
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
先看Scrapy
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
本文档将介绍 Scrapy 背后的概念,让您了解其工作原理,并确定 Scrapy 是否是您所需要的。
当你准备好开始你的项目时,你可以参考它。
选择一个网站
当你需要从某个网站获取信息,但是网站没有提供API或者通过程序获取信息的机制,Scrapy可以帮到你。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
可以在此页面上找到今天添加的种子列表:
定义要爬取的数据
第一步是定义我们需要爬取的数据。在 Scrapy 中,这是通过的。(在这个例子中,它是种子文件)
我们定义的Item:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写蜘蛛。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过观察页面的内容,可以发现所有种子的URL都是相似的。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式:/tor/\d+。
我们使用 XPath 从页面的 HTML 源代码中选择要提取的数据。以其中一个种子文件的页面为例:
观察 HTML 页面源代码并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以发现标签中收录了文件名:
Darwin - The Evolution Of An Exhibition
对应于此的XPath表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取描述:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
用于选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的详细信息,请参阅 XPath 参考。
最后结合上面的内容给出spider的代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
TorrentItem 的定义在。
执行spider获取数据
最后,我们可以运行spider获取网站的数据,并以JSON格式保存在scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您还可以将项目写入并存储在数据库中。
查看提取的数据
执行后,查看scraped_data.json,会看到解压出来的item:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是列表,所以所有的值都存储在列表中(除了url是直接赋值的)。如果您想保存单个数据或对数据执行其他处理,这就是它发挥作用的地方。
还有什么?
您已经学习了如何通过 Scrapy 从存储的网页中提取信息,但这只是冰山一角。Scrapy 提供了很多强大的功能,让爬取更容易、更高效,例如:
对于非英语语言的非标准或错误编码声明,提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加速爬虫创建的同时,让大型项目中的代码更加一致。有关详细信息,请参阅命令。为多个爬虫下的性能评估和故障检测提供可扩展性。提供,为您测试XPath表达式,编写和调试爬虫,简化生产环境中的部署和操作提供了极大的便利。内置,以便您可以监控和控制您的机器。内置,通过在 Scrapy 进程中钩入 Python 终端,可以查看和调试爬虫。方便您在抓取过程中捕捉错误。支持站点地图。使用缓存抓取 DNS 解析器
下一个
下一步当然是下载Scrapy,你可以阅读它并加入社区。谢谢您的支持!
讨论
scrapy分页抓取网页(python脚本获取指定用户的所有图像.body)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-10 13:03
作为练习,我决定编写一个python脚本来获取指定用户的所有图像。我对 Scrapy 有点熟悉,这也是我选择它作为爬虫的原因。目前,该脚本只能从第一页(最多 12 个)下载图像。
据我所知,instagram 页面是由 javascript 生成的。 Scrapy 的 response.body(类似于从 Chrome 查看的源代码)不像 Chrome 的 Inspector 那样显示 html 结构。在Chrome中,在12张图片后,底部有一个带有下一页链接的按钮。
例如,/instagram。第 2 页上的链接是 /instagram/?max_id=51632610。在第 2 页上,有一个指向第 3 页的链接,地址为 max_id=57754444 。
我如何在 Scrapy 中获得这个数字,以便我可以将我的蜘蛛发送到那里? response.body 甚至不收录该数字。有没有其他方法可以进入下一页?
我知道 Instagram API 会提供一些好处,但我认为它可以在没有所有这些令牌的情况下完成。 查看全部
scrapy分页抓取网页(python脚本获取指定用户的所有图像.body)
作为练习,我决定编写一个python脚本来获取指定用户的所有图像。我对 Scrapy 有点熟悉,这也是我选择它作为爬虫的原因。目前,该脚本只能从第一页(最多 12 个)下载图像。
据我所知,instagram 页面是由 javascript 生成的。 Scrapy 的 response.body(类似于从 Chrome 查看的源代码)不像 Chrome 的 Inspector 那样显示 html 结构。在Chrome中,在12张图片后,底部有一个带有下一页链接的按钮。
例如,/instagram。第 2 页上的链接是 /instagram/?max_id=51632610。在第 2 页上,有一个指向第 3 页的链接,地址为 max_id=57754444 。
我如何在 Scrapy 中获得这个数字,以便我可以将我的蜘蛛发送到那里? response.body 甚至不收录该数字。有没有其他方法可以进入下一页?
我知道 Instagram API 会提供一些好处,但我认为它可以在没有所有这些令牌的情况下完成。
scrapy分页抓取网页(Scrapy框架介绍架构图安装Scrapy使用爬虫使用使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-07 04:26
scrapy框架简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
Scrapy框架:用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了Twisted(其主要对手是Tornado)多线程异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
粗糙结构图
Scrapy主要包括了以下组件:
Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):
它负责接受`引擎`发送过来的Request请求,并按照一定的方式进行整理排列,入队,当`引擎`需要时,交还给`引擎`。
Downloader(下载器):
负责下载`Scrapy Engine(引擎)`发送的所有Requests请求,并将其获取到的Responses交还给`Scrapy Engine(引擎)`,由`引擎`交给`Spider`来处理,
Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给`引擎`,再次进入`Scheduler(调度器)`,
Item Pipeline(管道):
它负责处理`Spider`中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):
你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):
你可以理解为是一个可以自定扩展和操作`引擎`和`Spider`中间`通信`的功能组件(比如进入`Spider`的Responses和从`Spider`出去的Requests)
安装刮板
Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs. ... .html
安装方式:
pip install scrapy
如果安装出现错误,可以按照下面的顺序先安装依赖包:
1、安装wheel
pip install wheel
2、安装lxml
pip install lxml
3、安装pyopenssl
pip install pyopenssl
4、安装Twisted
需要我们自己下载Twisted,然后安装。这里有Python的各种依赖包。选择适合自己Python以及系统的Twisted版本:https://www.lfd.uci.edu/~gohlk ... isted
# 3.6版本(cp后是python版本)
pip install Twisted-18.9.0-cp36-cp36m-win_amd64.whl
5、安装pywin32
pip install pywin32
6、安装scrapy
pip install scrapy
安装后,只要在命令终端输入scrapy来检测是否安装成功
可以按照以下步骤将爬虫程序与scrape一起使用:创建一个scrape项,定义提取的项,将爬行器写入爬网网站,提取项,写入项管道以存储提取的项(即数据)1.创建一个新的scrape项以对数据进行爬网,并使用以下命令:
scrapy startproject meiju
创建爬虫
cd meiju
scrapy genspider meijuSpider meijutt.tv
其中:
meijuSpider为爬虫文件名
meijutt.com为爬取网址的域名
在创建一个碎片项目后,将自动创建多个文件。下面简要介绍每个主文件的功能:
scrapy.cfg:
项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py:
设置数据存储模板,用于结构化数据,如:Django的Model
pipelines:
数据处理行为,如:一般结构化的数据持久化
settings.py:
配置文件,如:递归的层数、并发数,延迟下载等
spiders:
爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2.定义项目
项是用于存储爬网数据的容器;其使用方法类似于Python字典。虽然我们可以在scripy中直接使用dict,但item提供了额外的保护机制,以避免拼写错误导致的未定义字段错误
与ORM中的模型定义字段类似,我们可以定义要在场景中爬网的字段。项目类别
import scrapy
class MeijuItem(scrapy.Item):
name = scrapy.Field()
3.写入爬虫程序
# -*- coding: utf-8 -*-
import scrapy
from lxml import etree
from meiju.items import MeijuItem
class MeijuspiderSpider(scrapy.Spider):
# 爬虫名
name = 'meijuSpider'
# 被允许的域名
allowed_domains = ['meijutt.tv']
# 起始爬取的url
start_urls = ['http://www.meijutt.tv/new100.html']
# 数据处理
def parse(self, response):
# response响应对象
# xpath
mytree = etree.HTML(response.text)
movie_list = mytree.xpath('//ul[@class="top-list fn-clear"]/li')
for movie in movie_list:
name = movie.xpath('./h5/a/text()')
# 创建item(类字典对象)
item = MeijuItem()
item['name'] = name
yield item
启用项目管道组件
为了启用项目管道组件,必须将其类添加到settings.py文件item\管道配置修改settings.py并设置优先级。分配给每个类的整数值决定了它们的运行顺序。项目按从低到高的顺序排列。通过管道,这些数字通常定义在0-1000范围内(0-1000可以任意设置,值越低,组件的优先级越高)
ITEM_PIPELINES = {
'meiju.pipelines.MeijuPipeline': 300,
}
设置UA
在代理的setting.py_uu值中设置用户
4.编写一个管道来存储提取的项目(即数据)
class SomethingPipeline(object):
def init(self):
# 可选实现,做参数初始化等
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
运行爬虫程序:
scrapy crawl meijuSpider
# nolog模式
scrapy crawl meijuSpider --nolog
在草稿中保存信息的最简单方法如下,-o以指定格式输出文件:
scrapy crawl meijuSpider -o meiju.json
scrapy crawl meijuSpider -o meiju.csv
scrapy crawl meijuSpider -o meiju.xml
练习:scripy将新浪新闻爬行到数据库中 查看全部
scrapy分页抓取网页(Scrapy框架介绍架构图安装Scrapy使用爬虫使用使用)
scrapy框架简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
Scrapy框架:用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了Twisted(其主要对手是Tornado)多线程异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
粗糙结构图
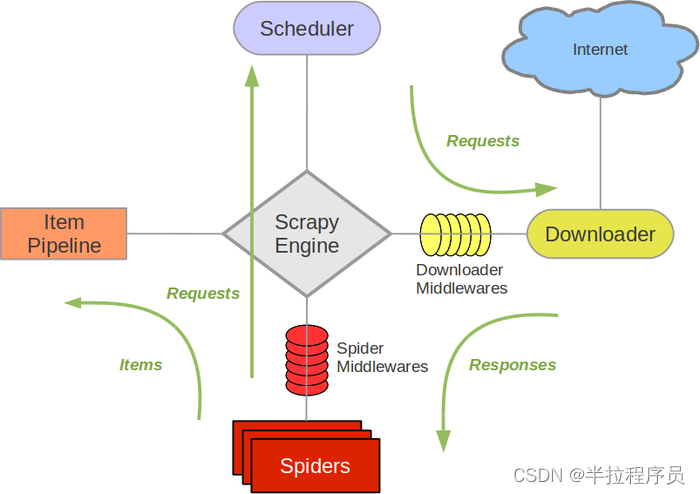
Scrapy主要包括了以下组件:
Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):
它负责接受`引擎`发送过来的Request请求,并按照一定的方式进行整理排列,入队,当`引擎`需要时,交还给`引擎`。
Downloader(下载器):
负责下载`Scrapy Engine(引擎)`发送的所有Requests请求,并将其获取到的Responses交还给`Scrapy Engine(引擎)`,由`引擎`交给`Spider`来处理,
Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给`引擎`,再次进入`Scheduler(调度器)`,
Item Pipeline(管道):
它负责处理`Spider`中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):
你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):
你可以理解为是一个可以自定扩展和操作`引擎`和`Spider`中间`通信`的功能组件(比如进入`Spider`的Responses和从`Spider`出去的Requests)
安装刮板
Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs. ... .html
安装方式:
pip install scrapy
如果安装出现错误,可以按照下面的顺序先安装依赖包:
1、安装wheel
pip install wheel
2、安装lxml
pip install lxml
3、安装pyopenssl
pip install pyopenssl
4、安装Twisted
需要我们自己下载Twisted,然后安装。这里有Python的各种依赖包。选择适合自己Python以及系统的Twisted版本:https://www.lfd.uci.edu/~gohlk ... isted
# 3.6版本(cp后是python版本)
pip install Twisted-18.9.0-cp36-cp36m-win_amd64.whl
5、安装pywin32
pip install pywin32
6、安装scrapy
pip install scrapy
安装后,只要在命令终端输入scrapy来检测是否安装成功
可以按照以下步骤将爬虫程序与scrape一起使用:创建一个scrape项,定义提取的项,将爬行器写入爬网网站,提取项,写入项管道以存储提取的项(即数据)1.创建一个新的scrape项以对数据进行爬网,并使用以下命令:
scrapy startproject meiju
创建爬虫
cd meiju
scrapy genspider meijuSpider meijutt.tv
其中:
meijuSpider为爬虫文件名
meijutt.com为爬取网址的域名
在创建一个碎片项目后,将自动创建多个文件。下面简要介绍每个主文件的功能:
scrapy.cfg:
项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py:
设置数据存储模板,用于结构化数据,如:Django的Model
pipelines:
数据处理行为,如:一般结构化的数据持久化
settings.py:
配置文件,如:递归的层数、并发数,延迟下载等
spiders:
爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2.定义项目
项是用于存储爬网数据的容器;其使用方法类似于Python字典。虽然我们可以在scripy中直接使用dict,但item提供了额外的保护机制,以避免拼写错误导致的未定义字段错误
与ORM中的模型定义字段类似,我们可以定义要在场景中爬网的字段。项目类别
import scrapy
class MeijuItem(scrapy.Item):
name = scrapy.Field()
3.写入爬虫程序
# -*- coding: utf-8 -*-
import scrapy
from lxml import etree
from meiju.items import MeijuItem
class MeijuspiderSpider(scrapy.Spider):
# 爬虫名
name = 'meijuSpider'
# 被允许的域名
allowed_domains = ['meijutt.tv']
# 起始爬取的url
start_urls = ['http://www.meijutt.tv/new100.html']
# 数据处理
def parse(self, response):
# response响应对象
# xpath
mytree = etree.HTML(response.text)
movie_list = mytree.xpath('//ul[@class="top-list fn-clear"]/li')
for movie in movie_list:
name = movie.xpath('./h5/a/text()')
# 创建item(类字典对象)
item = MeijuItem()
item['name'] = name
yield item
启用项目管道组件
为了启用项目管道组件,必须将其类添加到settings.py文件item\管道配置修改settings.py并设置优先级。分配给每个类的整数值决定了它们的运行顺序。项目按从低到高的顺序排列。通过管道,这些数字通常定义在0-1000范围内(0-1000可以任意设置,值越低,组件的优先级越高)
ITEM_PIPELINES = {
'meiju.pipelines.MeijuPipeline': 300,
}
设置UA
在代理的setting.py_uu值中设置用户
4.编写一个管道来存储提取的项目(即数据)
class SomethingPipeline(object):
def init(self):
# 可选实现,做参数初始化等
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
运行爬虫程序:
scrapy crawl meijuSpider
# nolog模式
scrapy crawl meijuSpider --nolog
在草稿中保存信息的最简单方法如下,-o以指定格式输出文件:
scrapy crawl meijuSpider -o meiju.json
scrapy crawl meijuSpider -o meiju.csv
scrapy crawl meijuSpider -o meiju.xml
练习:scripy将新浪新闻爬行到数据库中
scrapy分页抓取网页( WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-04 09:16
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简单数据分析系列文章的第12篇。
在之前的文章文章中,我们介绍了Web Scraper针对各种翻页方案的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,让我们看一下第1页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
第 3 页上的参数是 #_rnd39
第 4 页上的参数是 #_rnd76:
多看几个链接,会发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper是无能为力的)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器一重置,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)

这是简单数据分析系列文章的第12篇。
在之前的文章文章中,我们介绍了Web Scraper针对各种翻页方案的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。

今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:

但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。

这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,让我们看一下第1页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
第 3 页上的参数是 #_rnd39
第 4 页上的参数是 #_rnd76:
多看几个链接,会发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
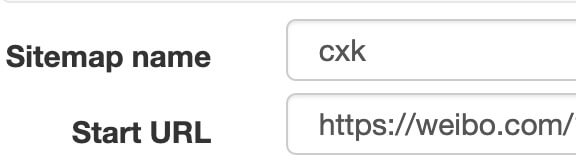
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
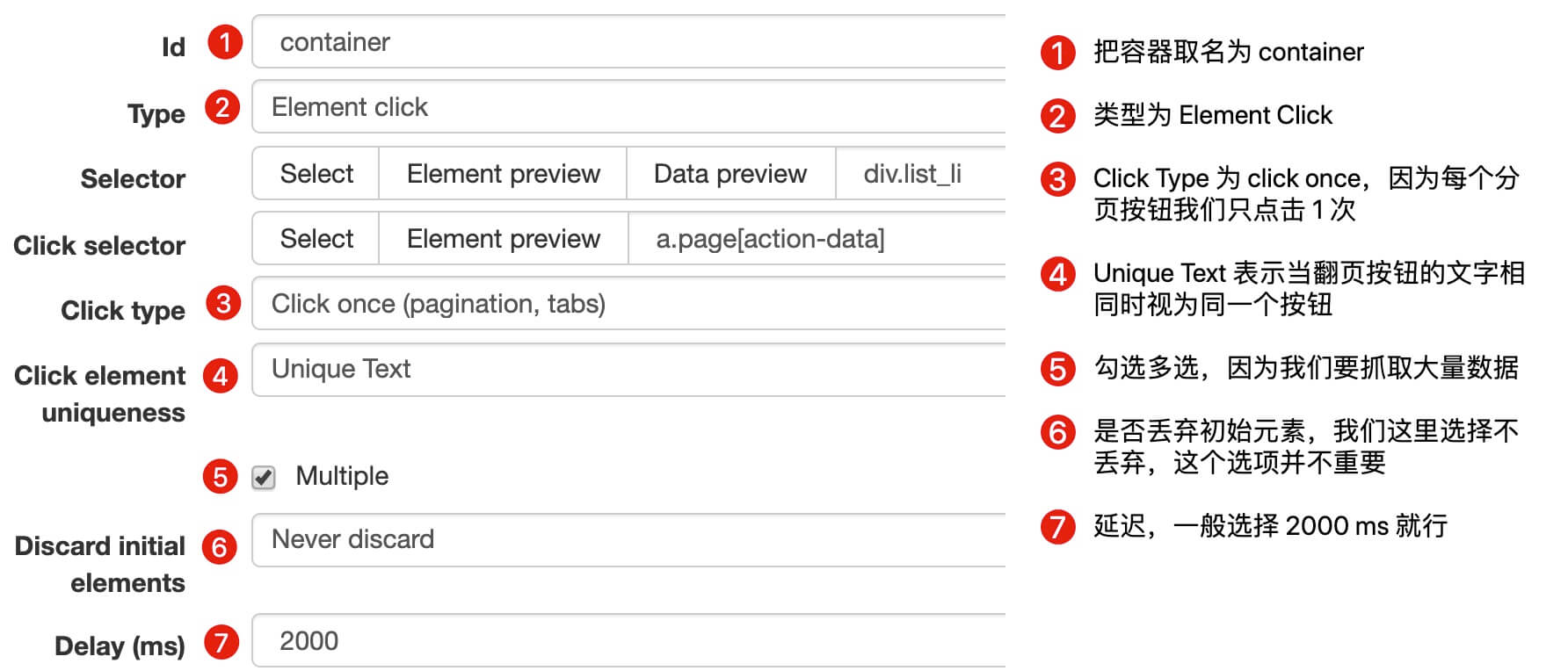
容器的预览如下图所示:

寻呼机选择过程如下图所示:

3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper是无能为力的)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器一重置,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(支持列表页的自动翻页抓取,支持图片、文件的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-03 12:01
网络爬虫5.1可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。 分析抓取的页面内容,获取新闻标题等结构化信息、作者、出处、正文等,支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。用户指定要爬取的网站、要爬取的页面类型(固定页面、分页页面等),并配置如何解析数据项(如新闻标题、作者、来源、正文)等),系统可以根据配置信息,实时自动抓取数据,并且开始抓拍的时间也可以通过配置来设置,真正做到了“按需抓拍,一次配置,永久抓拍”。捕获的数据可以保存到数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等,该工具可以完全替代传统的编辑手工信息处理模式。能够实时、准确、24*60全天为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。该工具的主要特点如下: *适用范围广,可以抓取任何网页(包括登录后可以访问的网页) *处理速度快,如果网络畅通,可以抓取和解析10,1小时000个网页 *采用独特的重复数据过滤技术,支持增量数据抓取,可实时抓取数据,如:股票交易信息、天气预报等。 *抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性 *支持断点续抓,崩溃或异常情况后,可以恢复抓包,继续后续抓包工作,提高系统抓取效率 *针对列表页,支持页面转动,就可以抓取所有列表页面中的数据。对于文本页面,可以自动合并页面中显示的内容;*支持页面深度爬取,页面可逐层爬取。比如通过列表页面抓取body页面的URL,然后抓取正文页面。各级页面可以单独存放在库中;*WEB操作界面,一次安装,随处使用 *一步一步分析,一步一步存储 查看全部
scrapy分页抓取网页(支持列表页的自动翻页抓取,支持图片、文件的抓取)
网络爬虫5.1可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。 分析抓取的页面内容,获取新闻标题等结构化信息、作者、出处、正文等,支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。用户指定要爬取的网站、要爬取的页面类型(固定页面、分页页面等),并配置如何解析数据项(如新闻标题、作者、来源、正文)等),系统可以根据配置信息,实时自动抓取数据,并且开始抓拍的时间也可以通过配置来设置,真正做到了“按需抓拍,一次配置,永久抓拍”。捕获的数据可以保存到数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等,该工具可以完全替代传统的编辑手工信息处理模式。能够实时、准确、24*60全天为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。该工具的主要特点如下: *适用范围广,可以抓取任何网页(包括登录后可以访问的网页) *处理速度快,如果网络畅通,可以抓取和解析10,1小时000个网页 *采用独特的重复数据过滤技术,支持增量数据抓取,可实时抓取数据,如:股票交易信息、天气预报等。 *抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性 *支持断点续抓,崩溃或异常情况后,可以恢复抓包,继续后续抓包工作,提高系统抓取效率 *针对列表页,支持页面转动,就可以抓取所有列表页面中的数据。对于文本页面,可以自动合并页面中显示的内容;*支持页面深度爬取,页面可逐层爬取。比如通过列表页面抓取body页面的URL,然后抓取正文页面。各级页面可以单独存放在库中;*WEB操作界面,一次安装,随处使用 *一步一步分析,一步一步存储
scrapy分页抓取网页(scrapy爬虫分页抓取网页资源的方法:requests+xpath)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-02 11:05
scrapy分页抓取网页所以我们首先得准备爬虫所需的工具python3.5以上版本,matplotlib库(最好用)然后搭建一个python爬虫学习路线的话,把几本经典的python爬虫入门书籍看一遍(比如《利用python进行数据分析》等),再把一些经典的python爬虫案例实战做一下就差不多了。关于怎么把网站抓下来,这个可以看看那些爬虫论坛,比如itemitage之类的。
然后你就可以把爬虫用python写出来了。爬虫主要还是采集网页中各个链接的信息,所以网页数据来源是关键,可以看我简单总结的2种获取网页资源的方法:requests+xpath。最后编写一个ajax模块,处理多个网页中某一个部分的信息。
你这个东西的前端感觉有点简单,chrome能帮你做。但是直接一个cookie效率太低了,一直认为这么做是个坑。而且你以前肯定有把内容备份过。所以可以用flaskweb框架,然后自己写爬虫代码。直接tagurls就可以了,注意要redirect。抓到链接之后,直接requests拿到这个链接,另存为就可以了。
或者用requests之后再转mysql.selectxml,用pymysql,会快点。但是如果是爬取一个静态内容的话,还是能写出来但是不太高效。
我没有这个架构,也没这个经验,所以给不了太有用的答案。这个问题很好,借此机会先抛砖引玉,求不喷。先回答怎么拿到网页,再针对这个网页的内容做什么。抓取网页,其实不难。我们当然能直接拿到某个bbs首页,这对一个bbs简直是不要太简单。问题是从bbs首页爬取,有些什么问题,导致相关爬虫的兼容性问题,我们也能直接拿到但是不方便。
比如,某个用户有发表内容,你这个时候在同一个页面发送的连接直接抓,可能有些不方便查看。怎么获取首页,我们第一步是要获取title标题。所以我们首先要实现title的获取。推荐用requests库,可以直接返回网页内容,接下来只需要将其与第三方库(github,selenium等)的接口进行接入,就能获取gif图片的title。
至于配置方法,不用我说你也知道。然后我们可以获取某条评论的title标题,接下来我们要获取某个用户的title评论。因为这个时候用户不可能同时有评论,而最常见的评论格式就是“某人点了赞”,那么利用while(1)来tag这个评论的title,我们就可以爬取第二条评论的title。这样一个tag就完成了。
如果需要跳转评论,那么我们就tag评论的首行,就可以跳转到对应评论。这样也不需要我们重复tag第二条评论的title,不过要记得,我们需要将第一条评论的title作为返回值。实现这样的功能需要用到requests、while、github、selen。 查看全部
scrapy分页抓取网页(scrapy爬虫分页抓取网页资源的方法:requests+xpath)
scrapy分页抓取网页所以我们首先得准备爬虫所需的工具python3.5以上版本,matplotlib库(最好用)然后搭建一个python爬虫学习路线的话,把几本经典的python爬虫入门书籍看一遍(比如《利用python进行数据分析》等),再把一些经典的python爬虫案例实战做一下就差不多了。关于怎么把网站抓下来,这个可以看看那些爬虫论坛,比如itemitage之类的。
然后你就可以把爬虫用python写出来了。爬虫主要还是采集网页中各个链接的信息,所以网页数据来源是关键,可以看我简单总结的2种获取网页资源的方法:requests+xpath。最后编写一个ajax模块,处理多个网页中某一个部分的信息。
你这个东西的前端感觉有点简单,chrome能帮你做。但是直接一个cookie效率太低了,一直认为这么做是个坑。而且你以前肯定有把内容备份过。所以可以用flaskweb框架,然后自己写爬虫代码。直接tagurls就可以了,注意要redirect。抓到链接之后,直接requests拿到这个链接,另存为就可以了。
或者用requests之后再转mysql.selectxml,用pymysql,会快点。但是如果是爬取一个静态内容的话,还是能写出来但是不太高效。
我没有这个架构,也没这个经验,所以给不了太有用的答案。这个问题很好,借此机会先抛砖引玉,求不喷。先回答怎么拿到网页,再针对这个网页的内容做什么。抓取网页,其实不难。我们当然能直接拿到某个bbs首页,这对一个bbs简直是不要太简单。问题是从bbs首页爬取,有些什么问题,导致相关爬虫的兼容性问题,我们也能直接拿到但是不方便。
比如,某个用户有发表内容,你这个时候在同一个页面发送的连接直接抓,可能有些不方便查看。怎么获取首页,我们第一步是要获取title标题。所以我们首先要实现title的获取。推荐用requests库,可以直接返回网页内容,接下来只需要将其与第三方库(github,selenium等)的接口进行接入,就能获取gif图片的title。
至于配置方法,不用我说你也知道。然后我们可以获取某条评论的title标题,接下来我们要获取某个用户的title评论。因为这个时候用户不可能同时有评论,而最常见的评论格式就是“某人点了赞”,那么利用while(1)来tag这个评论的title,我们就可以爬取第二条评论的title。这样一个tag就完成了。
如果需要跳转评论,那么我们就tag评论的首行,就可以跳转到对应评论。这样也不需要我们重复tag第二条评论的title,不过要记得,我们需要将第一条评论的title作为返回值。实现这样的功能需要用到requests、while、github、selen。
scrapy分页抓取网页( 如何查看二级页面(详情页)的三连数据?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-02 05:12
如何查看二级页面(详情页)的三连数据?(一))
这样做的话,其实可以抓取所有已知的列表数据,但是本文的重点是:如何抓取二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper本质上是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要抓取一个链接时,我们需要创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了一张动图,注意我鼠标突出显示的导航路线部分,可以很清楚的看到这几个选择器的层次关系:
4.创建详情页子选择器
当您点击该链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如喜欢的数量、硬币的数量、采集的数量和分享的数量。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们要开始爬取数据了。但是我们需要在爬行之前将等待时间调整得更长一些。默认时间为 2000 毫秒。我在这里将其更改为 5000 毫秒。
你为什么这么做?看下图就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察诸如要捕获的喜欢数量之类的数据。页面刚加载时,其值为“--”,过一会就变成一个数字。
所以我们直接等了5000ms,等页面和数据加载完成后,我们统一取了。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明此方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在生产过程中遇到问题,可以参考我的配置。我已经详细解释了 SiteMap 导入的功能。你可以一起服用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为套路都是一样的:先创建Link选择器,然后抓取Link选择器指向的下一页数据,我就不一一演示了。
今天我们也来聊聊Web Scraper的翻页技巧。
本次更新的灵感来自一位读者,他想使用 Web 爬虫爬取被寻呼机分页的页面,但发现我之前介绍的方法不起作用。我研究了一下,发现我错过了一个非常常见的翻页场景。
在文章中,我们讲了如何使用Element Click选择器来模拟鼠标点击分页器翻页,不过把同样的方法放在最上面,翻到第二页时抓取窗口会自动退出. , 无法捕获一条数据。
其实最主要的原因是我没有明确说明这个方法的适用边界。
Element Click 翻页仅适用于不刷新网页的情况。在文章文章中,我引用了蔡徐坤微博评论的一个例子。翻页时网页没有刷新:
仔细看下图,链接变了,但是刷新按钮没变,说明网页没有刷新,但是内容变了
在豆瓣TOP 250网页上,每次翻页都会重新加载网页:
仔细看下图,网页在链接变化时刷新,并且有明显的加载圆圈动画
其实这个原理从技术规范中已经很好的解释了:
-当URL链接为#字符且数据发生变化时,网页不会刷新;
-当链接的其他部分发生变化时,页面会刷新。
当然,这只是随便提一下,有兴趣的同学可以去这个链接学习,不感兴趣的可以跳过。
1.创建站点地图
本文文章将讲解如何使用Web Scraper抓取翻页时会刷新页面的pager网站。
对于这个网页,我们选择网站-豆瓣电影TOP250,他练习了爬虫:
像这种网站,我们需要使用Link选择器来帮助我们翻页。我们引入了Link标签,我们可以使用这个标签跳转到一个网页并从另一个网页抓取数据。这里我们使用Link标签跳转到下一页分页网站。
首先我们使用Link选择器选择下一页按钮,具体配置如下图所示:
这里有一个特殊的地方:Parent Selectors——父选择器。
我们以前从未接触过这个选择框的内容。这次 Next_page 将有两个父节点——_root 和 next_page。您可以通过按键盘上的 shift 然后单击鼠标来选择多个。先按我说的做,以后再做。解释这样做的原因。
保存next_page选择器后,在同层级下创建一个容器节点来抓取电影数据:
这里注意:页面选择器节点next_page和数据选择器节点容器在同一层级,两个节点都有两个父节点:_root和next_page:
因为重点是webscraper翻页技巧,我就简单的抓取一下我抓取到的数据的标题和排名:
然后我们点击Selector图查看我们写的爬虫结构:
可以清晰的看到这个爬虫的结构,可以无限嵌套:
点击Scrape,尝试爬取,你会发现所有的数据都爬下来了:
2.分析原理
按照上面的过程,你可能还是会一头雾水。数据被捕获,但为什么可以这样做呢?为什么 next_page 和 container 处于同一级别?为什么他们同时选择两个父节点:_root 和 next_page?
麻烦的原因是我们在倒推,从结果中推断步骤;下面我们就从正面思考来一步步讲解。
首先我们要知道我们爬取的数据是一个树状结构。_root 代表根节点,也就是我们抓取的第一个网页。我们应该在这个网页上选择什么?
1.一个是下一页的节点,本例中是Link选择器选择的next_page
2. 一个是数据节点,在这个例子中是元素选择器选择的容器
因为next_page节点会跳转,所以会跳转到第二页。除数据不同外,第二页与第一页结构相同。为了继续跳转,我们必须选择下一页。为了抓取数据,我们必须选择数据节点:
如果我们逆向箭头,就会发现真相就在眼前。next_page 的父节点不就是_root 和next_page 吗?容器的父节点也是_root和next_page!
道理到这里基本就讲清楚了,不明白的同学可以多看几遍。和 next_page 一样,我调用我自己的表单。编程中有一个术语-递归,在计算机领域也是一个比较抽象的概念。有兴趣的同学可以自行搜索。 查看全部
scrapy分页抓取网页(
如何查看二级页面(详情页)的三连数据?(一))


这样做的话,其实可以抓取所有已知的列表数据,但是本文的重点是:如何抓取二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper本质上是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:

Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:

当我们想要抓取一个链接时,我们需要创建另一个选择器。选中的元素是一样的,但是Type是Link:

创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了一张动图,注意我鼠标突出显示的导航路线部分,可以很清楚的看到这几个选择器的层次关系:
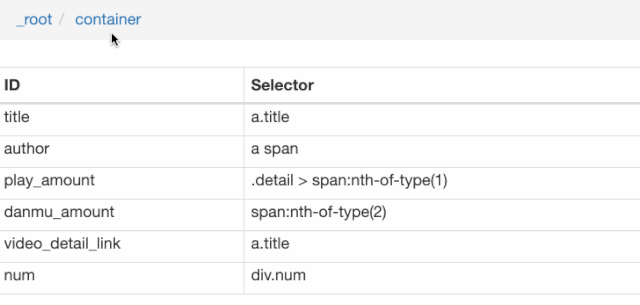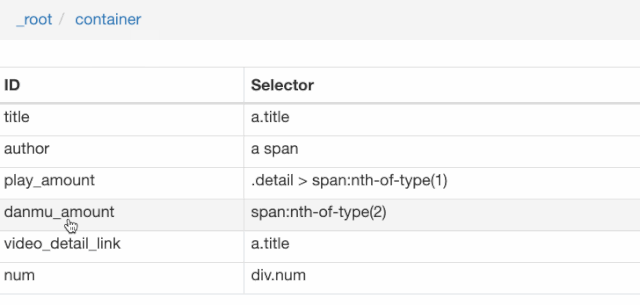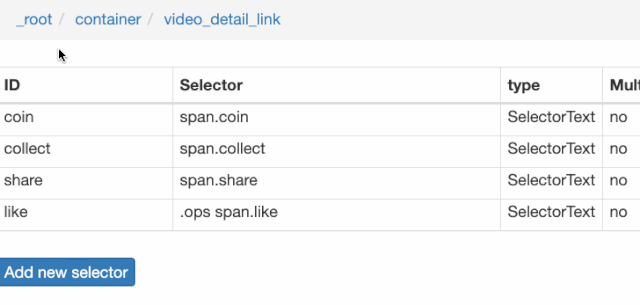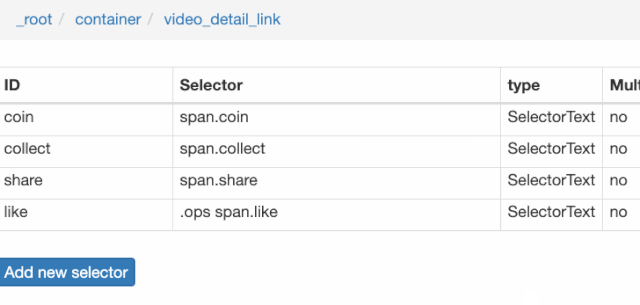
4.创建详情页子选择器
当您点击该链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
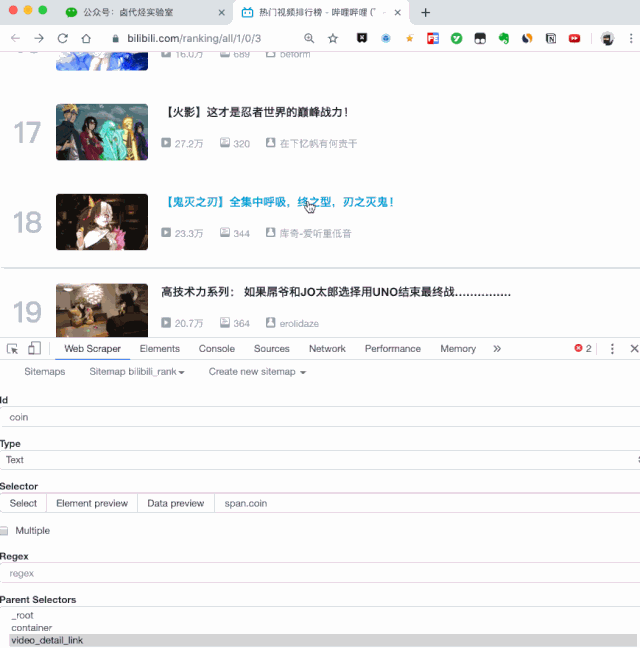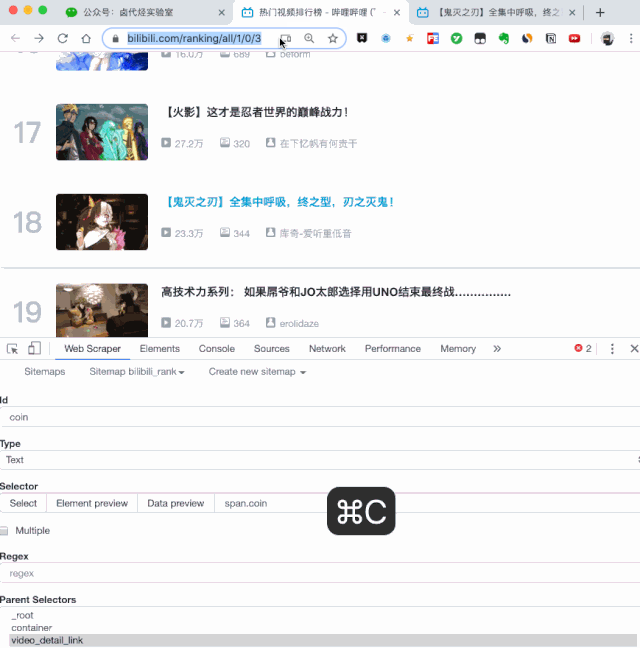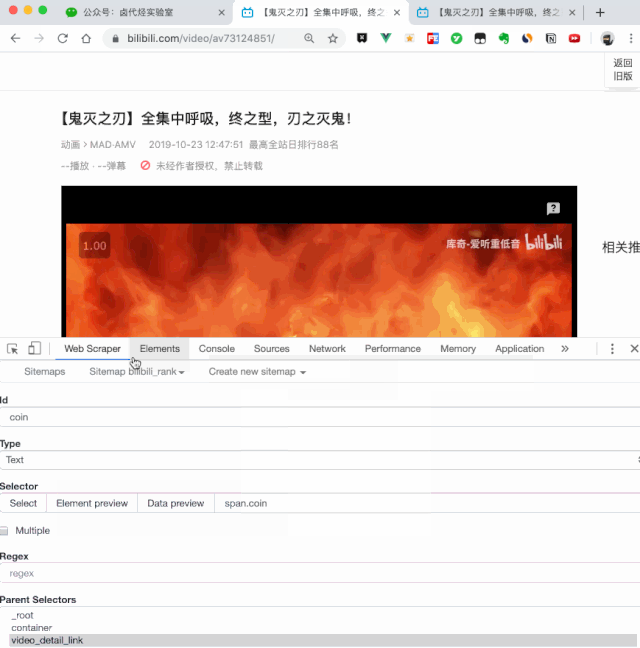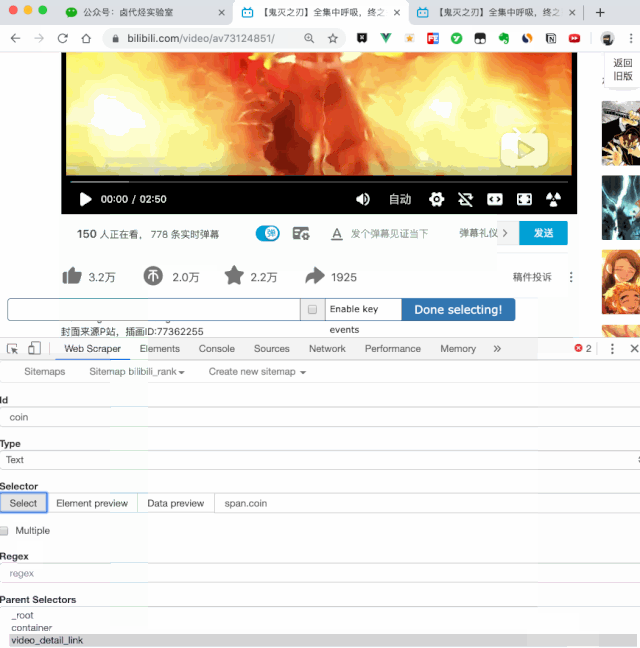
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如喜欢的数量、硬币的数量、采集的数量和分享的数量。这个操作也很简单,这里就不赘述了。

所有选择器的结构图如下:
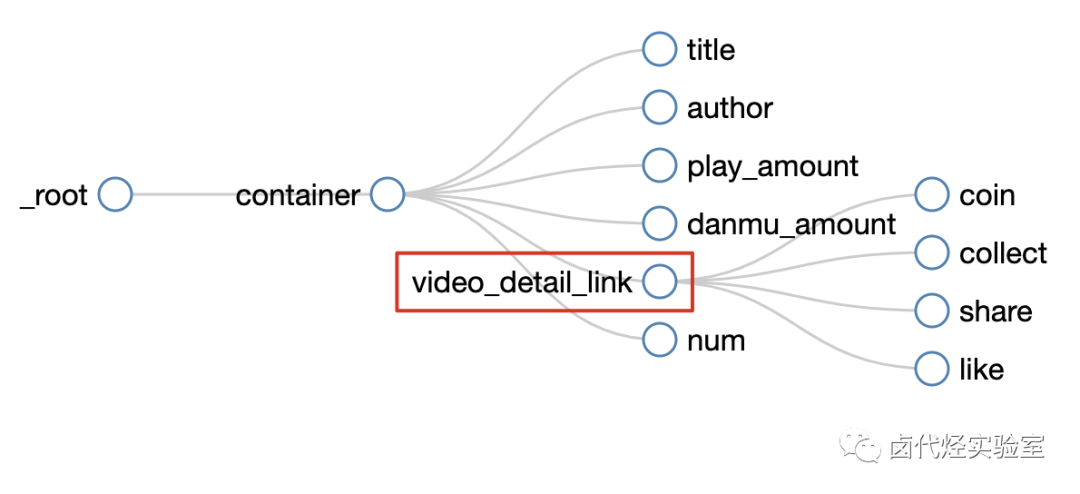
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们要开始爬取数据了。但是我们需要在爬行之前将等待时间调整得更长一些。默认时间为 2000 毫秒。我在这里将其更改为 5000 毫秒。

你为什么这么做?看下图就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察诸如要捕获的喜欢数量之类的数据。页面刚加载时,其值为“--”,过一会就变成一个数字。
所以我们直接等了5000ms,等页面和数据加载完成后,我们统一取了。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明此方法有用:
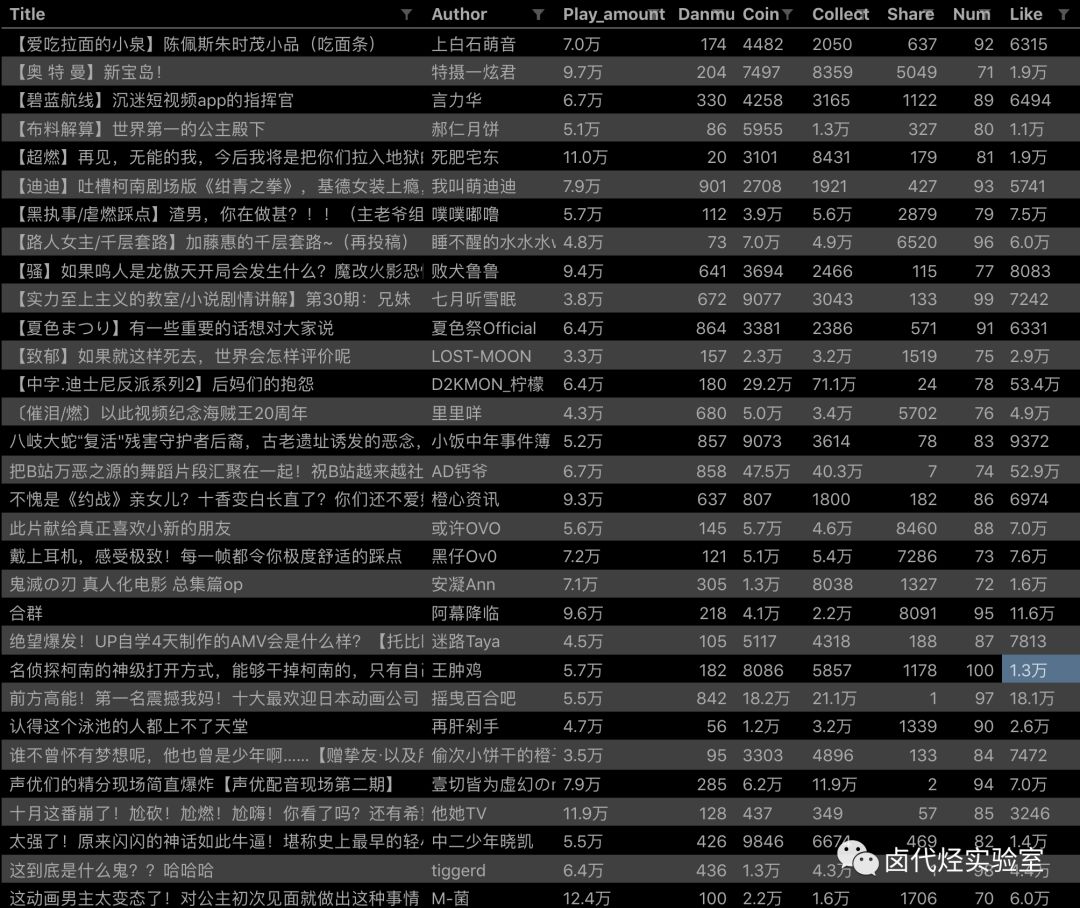
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在生产过程中遇到问题,可以参考我的配置。我已经详细解释了 SiteMap 导入的功能。你可以一起服用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为套路都是一样的:先创建Link选择器,然后抓取Link选择器指向的下一页数据,我就不一一演示了。

今天我们也来聊聊Web Scraper的翻页技巧。
本次更新的灵感来自一位读者,他想使用 Web 爬虫爬取被寻呼机分页的页面,但发现我之前介绍的方法不起作用。我研究了一下,发现我错过了一个非常常见的翻页场景。
在文章中,我们讲了如何使用Element Click选择器来模拟鼠标点击分页器翻页,不过把同样的方法放在最上面,翻到第二页时抓取窗口会自动退出. , 无法捕获一条数据。
其实最主要的原因是我没有明确说明这个方法的适用边界。
Element Click 翻页仅适用于不刷新网页的情况。在文章文章中,我引用了蔡徐坤微博评论的一个例子。翻页时网页没有刷新:
仔细看下图,链接变了,但是刷新按钮没变,说明网页没有刷新,但是内容变了

在豆瓣TOP 250网页上,每次翻页都会重新加载网页:
仔细看下图,网页在链接变化时刷新,并且有明显的加载圆圈动画

其实这个原理从技术规范中已经很好的解释了:
-当URL链接为#字符且数据发生变化时,网页不会刷新;
-当链接的其他部分发生变化时,页面会刷新。
当然,这只是随便提一下,有兴趣的同学可以去这个链接学习,不感兴趣的可以跳过。
1.创建站点地图
本文文章将讲解如何使用Web Scraper抓取翻页时会刷新页面的pager网站。
对于这个网页,我们选择网站-豆瓣电影TOP250,他练习了爬虫:
像这种网站,我们需要使用Link选择器来帮助我们翻页。我们引入了Link标签,我们可以使用这个标签跳转到一个网页并从另一个网页抓取数据。这里我们使用Link标签跳转到下一页分页网站。
首先我们使用Link选择器选择下一页按钮,具体配置如下图所示:
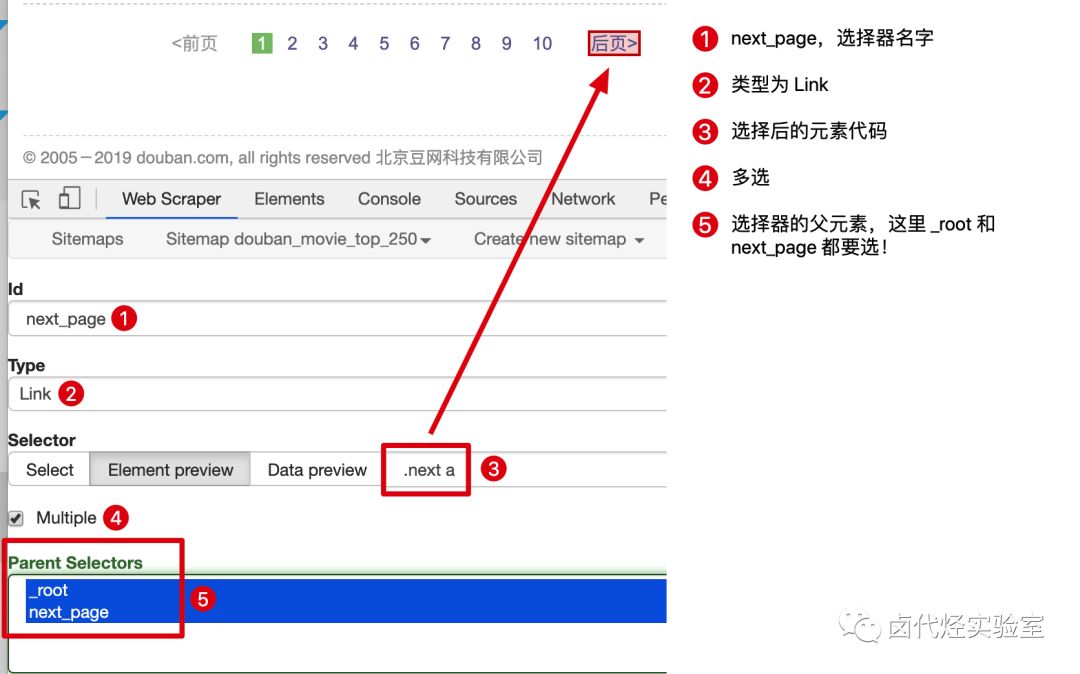
这里有一个特殊的地方:Parent Selectors——父选择器。
我们以前从未接触过这个选择框的内容。这次 Next_page 将有两个父节点——_root 和 next_page。您可以通过按键盘上的 shift 然后单击鼠标来选择多个。先按我说的做,以后再做。解释这样做的原因。
保存next_page选择器后,在同层级下创建一个容器节点来抓取电影数据:
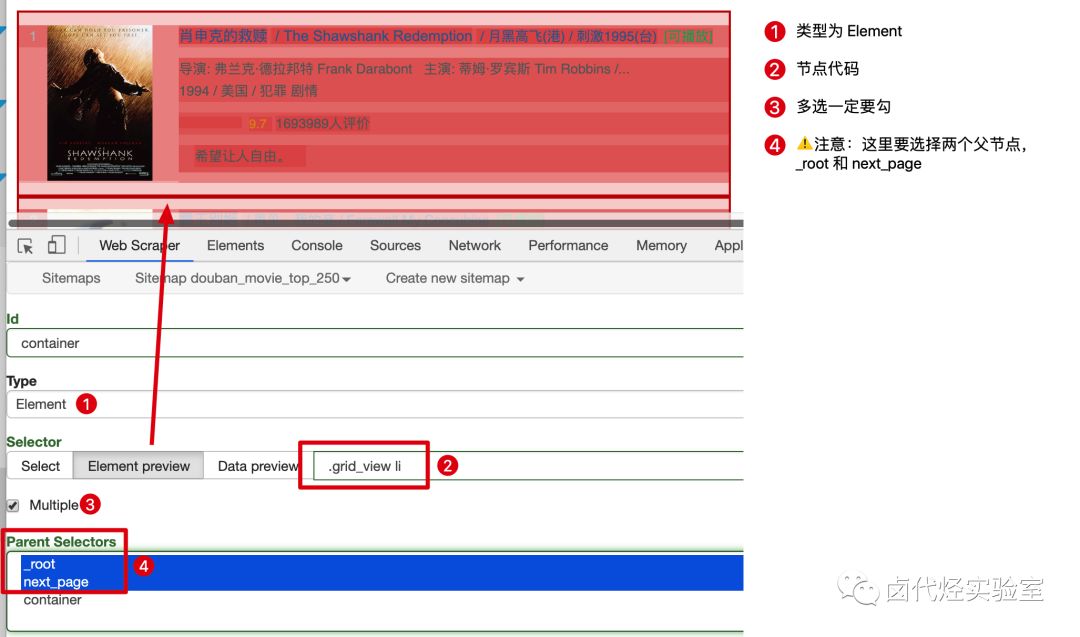
这里注意:页面选择器节点next_page和数据选择器节点容器在同一层级,两个节点都有两个父节点:_root和next_page:

因为重点是webscraper翻页技巧,我就简单的抓取一下我抓取到的数据的标题和排名:
然后我们点击Selector图查看我们写的爬虫结构:
可以清晰的看到这个爬虫的结构,可以无限嵌套:
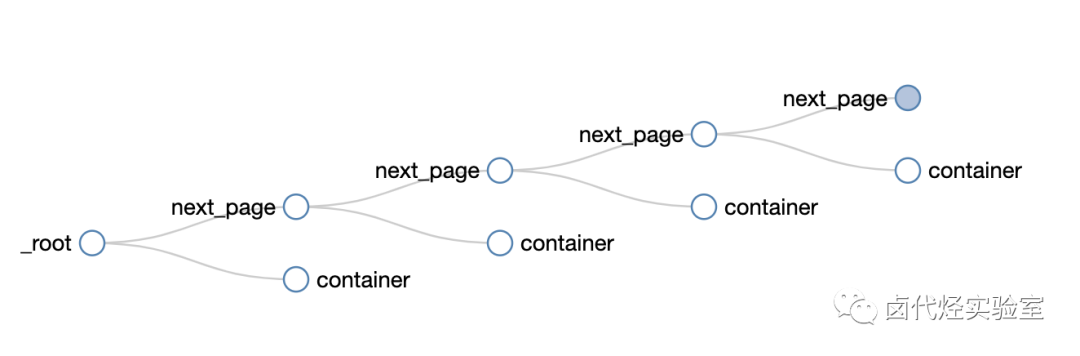
点击Scrape,尝试爬取,你会发现所有的数据都爬下来了:
2.分析原理
按照上面的过程,你可能还是会一头雾水。数据被捕获,但为什么可以这样做呢?为什么 next_page 和 container 处于同一级别?为什么他们同时选择两个父节点:_root 和 next_page?
麻烦的原因是我们在倒推,从结果中推断步骤;下面我们就从正面思考来一步步讲解。
首先我们要知道我们爬取的数据是一个树状结构。_root 代表根节点,也就是我们抓取的第一个网页。我们应该在这个网页上选择什么?
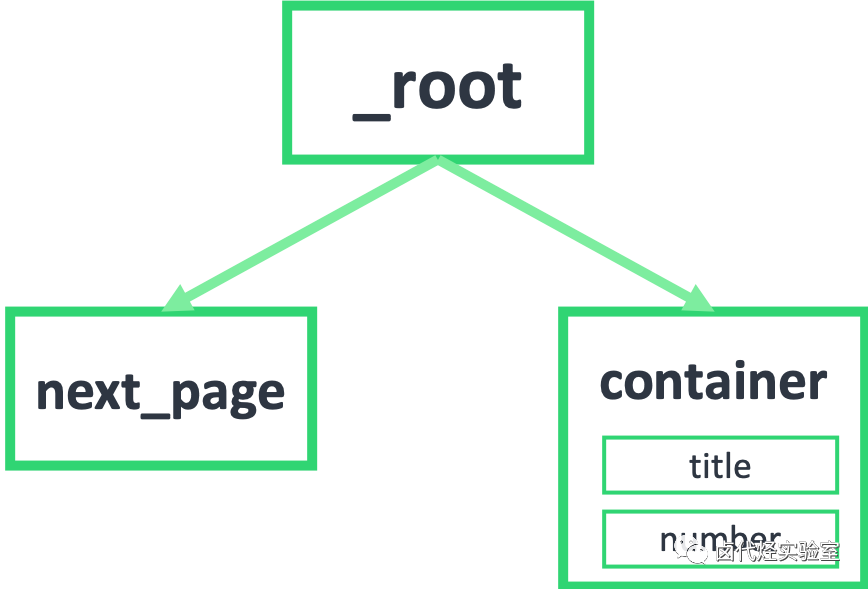
1.一个是下一页的节点,本例中是Link选择器选择的next_page
2. 一个是数据节点,在这个例子中是元素选择器选择的容器
因为next_page节点会跳转,所以会跳转到第二页。除数据不同外,第二页与第一页结构相同。为了继续跳转,我们必须选择下一页。为了抓取数据,我们必须选择数据节点:
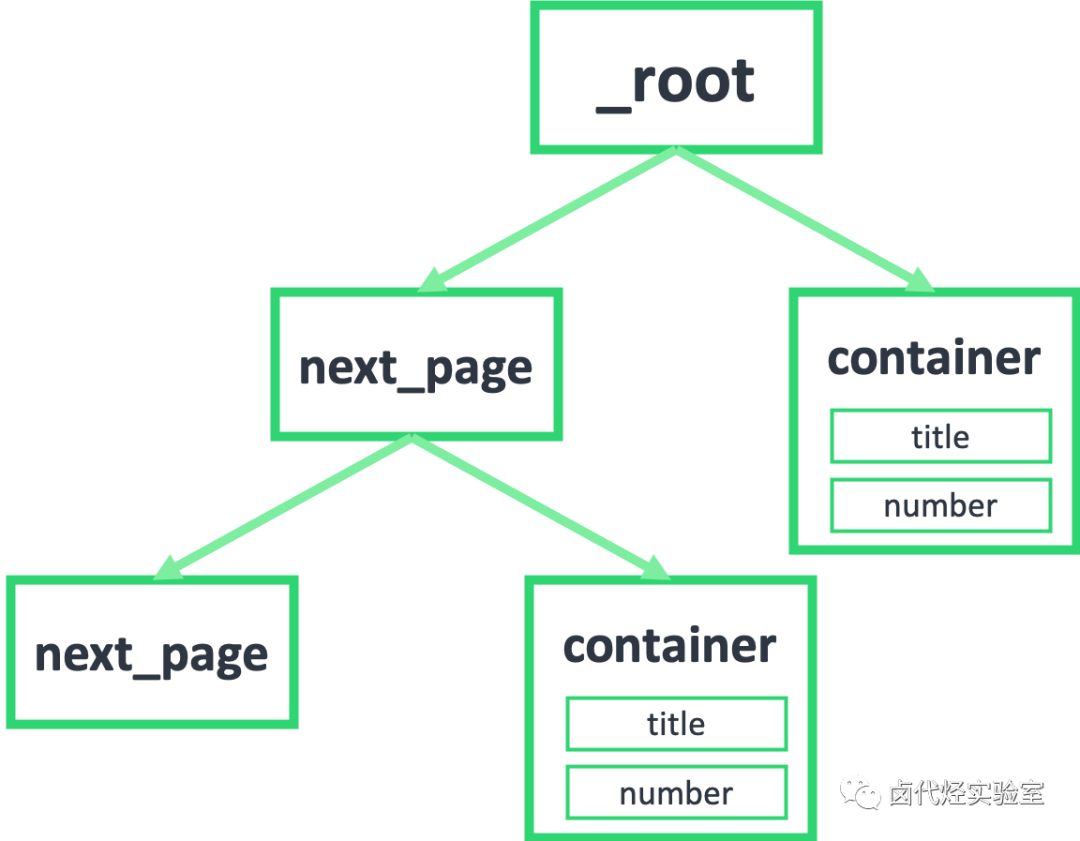
如果我们逆向箭头,就会发现真相就在眼前。next_page 的父节点不就是_root 和next_page 吗?容器的父节点也是_root和next_page!
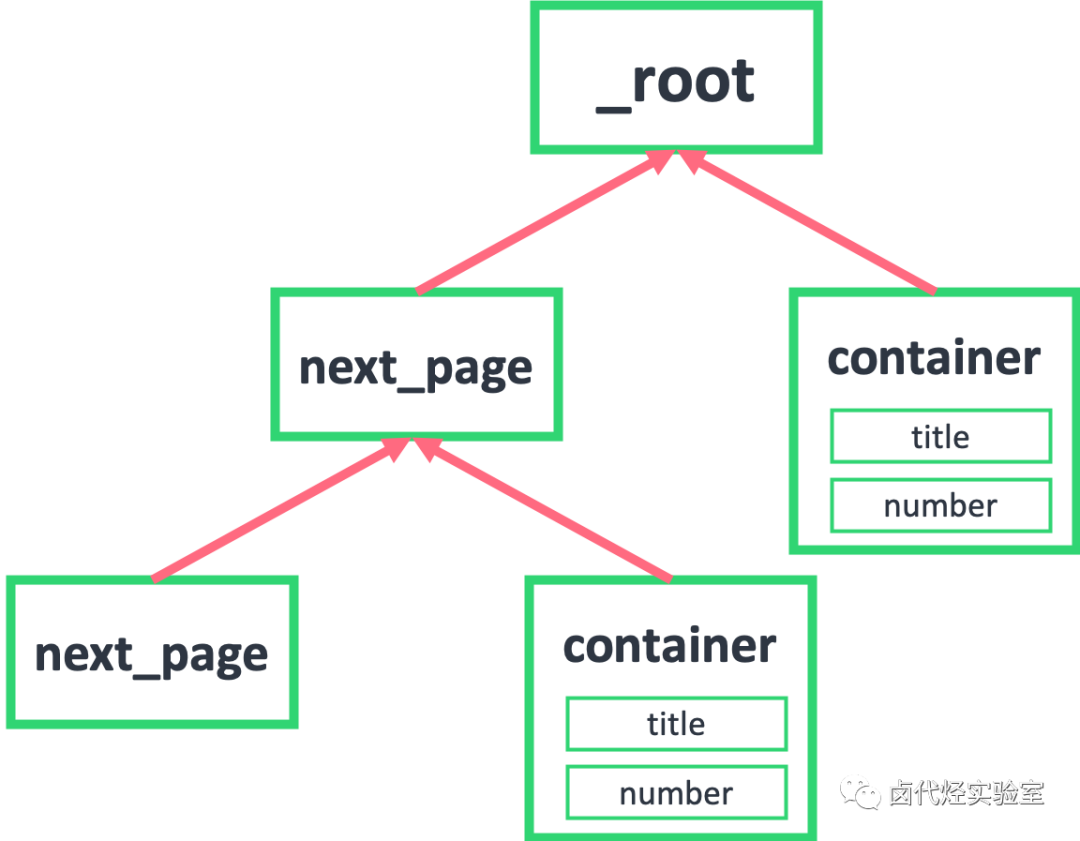
道理到这里基本就讲清楚了,不明白的同学可以多看几遍。和 next_page 一样,我调用我自己的表单。编程中有一个术语-递归,在计算机领域也是一个比较抽象的概念。有兴趣的同学可以自行搜索。
scrapy分页抓取网页(10w+新闻数据,新闻信息以json文件格式保存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-25 04:21
一、选择主题
工程搜索类型:
针对采集 3-4个新闻网站,实现对这些网站信息的提取、索引和检索。网页数量不少于100,000。可以按照相关性、时间、流行度等属性进行排序(需要自己定义),可以实现相似新闻的自动聚类。
需求:相关搜索推荐、片段生成、结果预览(鼠标移至相关结果,可预览)功能
二、开发工具三、设计方案3.1总体思路
在新闻信息检索系统的实现中,首先进行信息采集。信息采集结束后,使用Lucene提供的api构建索引库,前端使用jsp接收用户查询,后台servlet使用servlet对用户查询进行分段。处理后,在索引库中进行文档匹配,最后将查询结果集反馈给用户并展示在前端页面上。
3.2 信息采集
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。我们采集有10w+条新闻数据,新闻信息以json文件格式保存。scrapy 采集 流程:
采集 新闻资料至:
新闻格式:
3.3倒排索引构建
在索引构建模块中,主要包括以下三个关键步骤:数据预处理、新闻内容切分和倒排索引构建。
**数据预处理:**Gson 是 Google 提供的 Java 类库,用于在 Java 对象和 JSON 数据之间进行映射。您可以将 JSON 字符串转换为 Java 对象,反之亦然。我们使用 Gson 将 json 文件转换为 News 对象
**中文分词:**IK Analyzer是一款基于java语言开发的开源、轻量级的中文分词工具包。IK 已经发展成为 Java 的公共分词组件,独立于 Lucene 项目,并为 Lucene 提供了一个默认值。优化实施。IK分词采用独有的“前向迭代最细粒度分词算法”,支持细粒度和智能分词两种分词模式,采用多子处理器分析模式,支持英文字母、数字、中文词汇等分词处理,兼容韩日字符。
**构建倒排索引:**Lucene 提供了一种构建倒排索引的方法。步骤如下图所示:
Luke是Lucene搜索引擎的第三方工具,方便开发和诊断。它可以访问
现有的 Lucene 索引。使用luke打开索引目录,可以看到索引库中存储了新闻信息。
3.4 索引查询
创建索引后,查询可以分为以下几个步骤:
1. 设置查询索引的目录(这里是上面创建索引的目录)。
2. 创建 indexSearcher。
3. 设置查询的分词方式
4. 设置查询字段,例如查询字段是新闻标题,然后到新闻标题字段进行比较 5. 设置查询字符串,即要查询的关键词 .
6. 返回的结果是文档的集合,放在TopDocs中,通过循环TopDocs数组输出查询结果。用户一般只看前几页的数据。为了加快前端数据的显示速度,将前1000条数据返回给前端。
3.5关键字高亮
搜索结果的高亮对用户的体验和友好度非常重要,可以快速标记用户搜索的关键词。Lucene 的 Highlighter 类可以通过在关键字前面添加 css 片段来返回文档中的关键字高亮。
3.6用户界面
使用jsp编写用户界面,服务器为Tomcat 7.0,用户输入关键词然后提交表单,然后
该站使用servlet接收用户查询,然后以查询字符串作为搜索关键字在索引库中搜索文档。检索效果:
3.7 按时间和页面结果排序
按时间排序:所有新闻结果存储在一个列表集合中,集合中的每个元素都是一个新闻对象。通过重写Comparator类中的compare方法,实现了集合中每个新闻元素的时间排序。
结果分页:定义一个Page类来记录当前页数、总页数、每页数据条数、数据总数、每页起始数、每页结束数、是否有下一页,是否有上一页。
四、参考资料
可以参考以下材料:
1. lucene全文搜索基础
2. lucene 创建索引
3. Lucene 查询索引
4. Lucene 查询结果高亮显示
5. Lucene 查询(Query)子类
6. java操作json
7. java 集合
8. Servlet 基础知识
五、总结
开源工具的使用已经显着提高了开发效率,但是从头开始构建仍然需要大量学习和不断积累。
欢迎批评和指正。 查看全部
scrapy分页抓取网页(10w+新闻数据,新闻信息以json文件格式保存)
一、选择主题
工程搜索类型:
针对采集 3-4个新闻网站,实现对这些网站信息的提取、索引和检索。网页数量不少于100,000。可以按照相关性、时间、流行度等属性进行排序(需要自己定义),可以实现相似新闻的自动聚类。
需求:相关搜索推荐、片段生成、结果预览(鼠标移至相关结果,可预览)功能
二、开发工具三、设计方案3.1总体思路
在新闻信息检索系统的实现中,首先进行信息采集。信息采集结束后,使用Lucene提供的api构建索引库,前端使用jsp接收用户查询,后台servlet使用servlet对用户查询进行分段。处理后,在索引库中进行文档匹配,最后将查询结果集反馈给用户并展示在前端页面上。
3.2 信息采集
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。我们采集有10w+条新闻数据,新闻信息以json文件格式保存。scrapy 采集 流程:
采集 新闻资料至:
新闻格式:
3.3倒排索引构建
在索引构建模块中,主要包括以下三个关键步骤:数据预处理、新闻内容切分和倒排索引构建。
**数据预处理:**Gson 是 Google 提供的 Java 类库,用于在 Java 对象和 JSON 数据之间进行映射。您可以将 JSON 字符串转换为 Java 对象,反之亦然。我们使用 Gson 将 json 文件转换为 News 对象
**中文分词:**IK Analyzer是一款基于java语言开发的开源、轻量级的中文分词工具包。IK 已经发展成为 Java 的公共分词组件,独立于 Lucene 项目,并为 Lucene 提供了一个默认值。优化实施。IK分词采用独有的“前向迭代最细粒度分词算法”,支持细粒度和智能分词两种分词模式,采用多子处理器分析模式,支持英文字母、数字、中文词汇等分词处理,兼容韩日字符。
**构建倒排索引:**Lucene 提供了一种构建倒排索引的方法。步骤如下图所示:
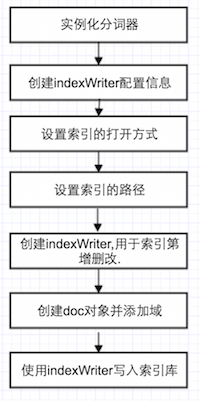
Luke是Lucene搜索引擎的第三方工具,方便开发和诊断。它可以访问
现有的 Lucene 索引。使用luke打开索引目录,可以看到索引库中存储了新闻信息。
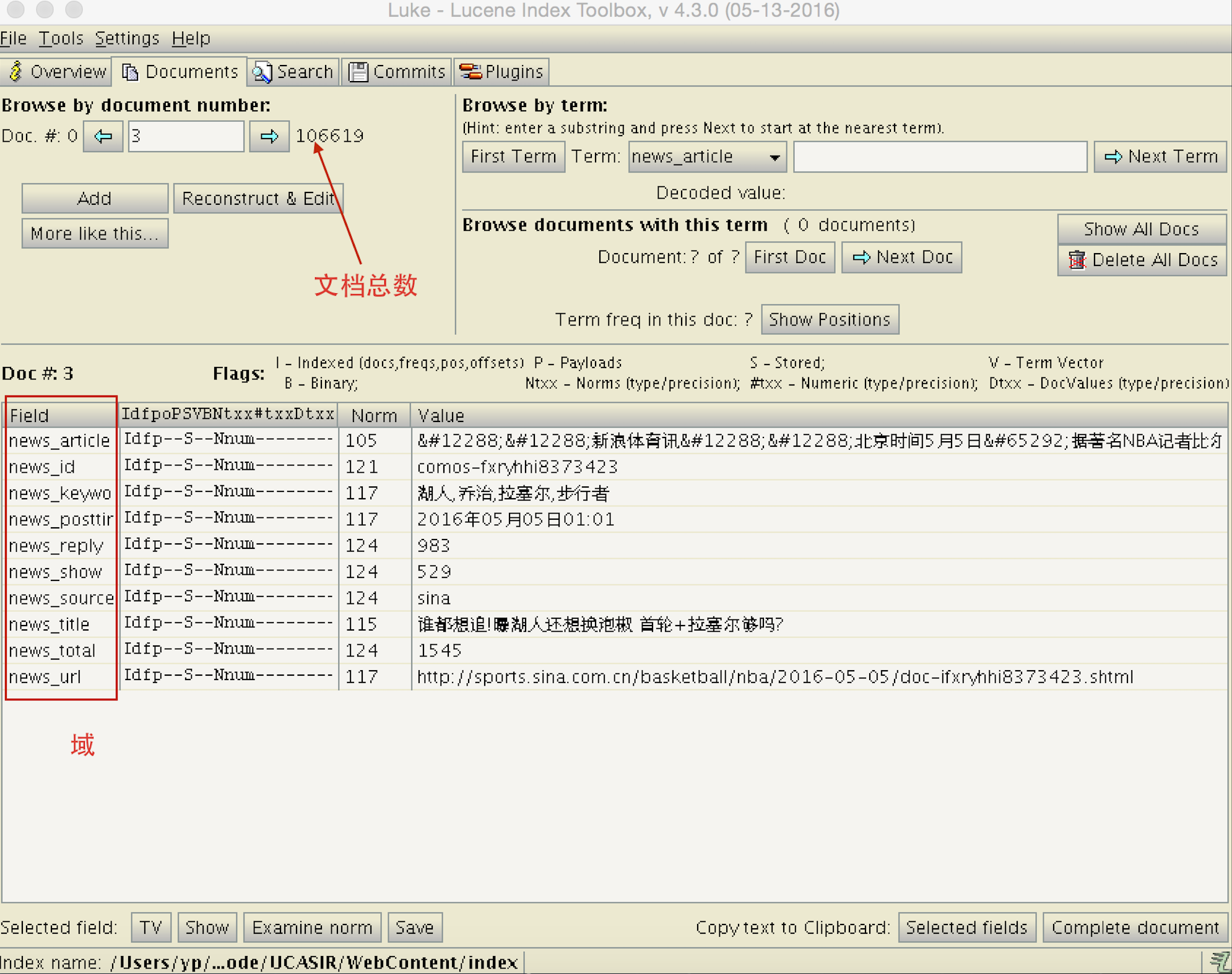
3.4 索引查询
创建索引后,查询可以分为以下几个步骤:
1. 设置查询索引的目录(这里是上面创建索引的目录)。
2. 创建 indexSearcher。
3. 设置查询的分词方式
4. 设置查询字段,例如查询字段是新闻标题,然后到新闻标题字段进行比较 5. 设置查询字符串,即要查询的关键词 .
6. 返回的结果是文档的集合,放在TopDocs中,通过循环TopDocs数组输出查询结果。用户一般只看前几页的数据。为了加快前端数据的显示速度,将前1000条数据返回给前端。
3.5关键字高亮
搜索结果的高亮对用户的体验和友好度非常重要,可以快速标记用户搜索的关键词。Lucene 的 Highlighter 类可以通过在关键字前面添加 css 片段来返回文档中的关键字高亮。
3.6用户界面
使用jsp编写用户界面,服务器为Tomcat 7.0,用户输入关键词然后提交表单,然后
该站使用servlet接收用户查询,然后以查询字符串作为搜索关键字在索引库中搜索文档。检索效果:
3.7 按时间和页面结果排序
按时间排序:所有新闻结果存储在一个列表集合中,集合中的每个元素都是一个新闻对象。通过重写Comparator类中的compare方法,实现了集合中每个新闻元素的时间排序。
结果分页:定义一个Page类来记录当前页数、总页数、每页数据条数、数据总数、每页起始数、每页结束数、是否有下一页,是否有上一页。
四、参考资料
可以参考以下材料:
1. lucene全文搜索基础
2. lucene 创建索引
3. Lucene 查询索引
4. Lucene 查询结果高亮显示
5. Lucene 查询(Query)子类
6. java操作json
7. java 集合
8. Servlet 基础知识
五、总结
开源工具的使用已经显着提高了开发效率,但是从头开始构建仍然需要大量学习和不断积累。
欢迎批评和指正。
scrapy分页抓取网页(分布式网络新闻抓取系统设计与实现的项目介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-11-25 04:21
1 项目介绍
本项目的主要内容是分布式网络新闻采集系统的设计与实现。主要有以下几个部分介绍:
(1)深入分析网络新闻爬虫的特点,设计分布式网络新闻爬虫系统爬取策略、爬取字段、**页面爬取方法、分布式结构、系统监控和数据存储六大关键功能。
(2)结合程序代码的分解,讲解分布式网络新闻爬虫系统的实现过程。包括爬虫编写、爬虫规避、**页面数据爬取、分布式爬虫部署、系统监控,一共六项内容,结合实际定向抓取腾讯新闻数据,通过测试测试系统性能。
(3) 规划设计一个数据处理模块,包括数据清洗、代码转换、数据分类、对象添加等功能。
分布式网络新闻抓取系统的设计
2.1 整体系统架构设计
系统采用分布式主从结构,设置1台Master服务器和多台Slave服务器。Master管理Redis数据库,分发下载任务。Slave 部署 Scrapy 来抓取网页并解析提取项目数据。服务器基础环境为Ubuntu操作系统,Master服务器安装Redis数据库服务器和Graphite,Slave安装Scrapy和Redis客户端。系统按功能可分为两大模块,一是数据采集模块,二是数据处理模块。数据抓取模块包括浏览器调用、网页下载、字段提取、爬虫规避、数据存储和系统监控六大功能;数据处理模块包括数据清洗、对象添加、
2.2 爬取策略的设计
本项目的网络爬虫采用深度优先的爬取策略,根据设置下载网页数据。网页链接处理流程如下:
1.手动设置初始下载地址,一般是网站导航地址。
2、爬虫开始运行,从初始地址抓取第一批网页链接。
3、爬虫根据正则表达式识别新链接中的目录页面地址和新闻内容页面地址,将识别出的新地址加入到下载队列中等待爬取。无法识别的网页地址被定义为无用链接并丢失。
4、爬虫从等待队列中依次取出网页链接进行数据下载和提取。
5.下载队列为空,爬虫停止爬行。
新闻网站的导航页数是有限的。这个规则决定了新闻导航页面的URL在一定的人工参与下可以很容易的获取,并作为爬虫系统的初始URL。
2.3 爬取字段的设计
本项目旨在捕捉网络新闻数据,因此内容必须能够客观准确地反映网络新闻的特点。
本文以抓取腾讯在线新闻数据为例,通过对网页结构的分析,确定了一个两步抓取的过程。第一步,抓取新闻内容页面,获取新闻标题、新闻来源、新闻内容、发布时间、评论数、评论地址、相关搜索、用户还喜欢的新闻、点赞数。第二步在获取评论地址后,抓取评论页面,获取评论者ID、评论者昵称、评论者性别、评论者所在位置、评论时间、评论内容、单条评论支持人数、评论回复数单条评论。
2.4 **页面爬取方法设计
腾讯新闻网页使用Java Script生成**页面内容。一些由JS事件触发的页面在打开的时候内容会发生变化,有的页面没有JS支持根本无法运行。一般爬虫根本无法从这些网页中获取数据。解决JavaScript **页面爬虫问题有四种方法:
1.编写代码模拟相关JS逻辑。
2. 调用一个带接口的浏览器,类似于各种广泛用于测试的,比如Selenium等。
3、使用无界面浏览器,各种基于Webkit的,如Casperjs、Phantomjs等。
4、结合JS执行引擎,实现轻量级浏览器。
由于本项目是基于Python为主要语言编写的,所以使用Selenium来处理JS动态新闻页面。其优点是简单易行。使用Python代码模拟用户在浏览器上的操作。首先将网页加载到浏览器中并打开,然后从浏览器缓存中获取网页数据,传递给蜘蛛进行分析提取,最后将目标数据传递给项目通道。
2.5 Crawler 分布式设计
Redis数据库用于实现分布式爬取。基本思路是将Scrapy爬虫获取到的url(请求)放在一个Redis Queue中,所有爬虫也从指定的Redis Queue中获取请求(url)。Scrapy-Redis 默认使用 Spider Priority Queue 来确定 URL 的顺序。这是一种由有序集合实现的非 FIFO、LIFO 方法。
Redis 存储了 Scrapy 项目的请求和统计信息。根据这些信息可以掌握任务状态和爬虫状态,在分配任务时平衡系统负载,有助于克服爬虫的性能瓶颈。同时,利用Redis的高性能和易扩展的特性,可以轻松实现高效下载。当Redis存储或访问速度遇到问题时,可以通过增加Redis集群和爬虫集群的数量来提高。Scrapy-Redis分布式解决方案很好的解决了爬行中断和重复数据删除的问题。爬虫重启后,会针对Redis队列中的URL进行爬取,爬取到的URL会被自动过滤掉。
2.6 基于Graphite系统的监控组件设计
使用Graphite监控系统的运行状态,实现了分布式系统的statscollector,将系统的stats信息以图表的形式动态实时展示,即实时监控。Graphite监控的信息包括:系统下载信息、日志信息、文件计数、调度信息、爬虫运行信息、爬虫异常信息、文件数、获取的item数、最大请求深度、收到响应数等。
2.7 数据存储模块设计
Scrapy支持json、csv、xml等文本格式的数据存储。用户可以在运行爬虫时进行设置,例如:scrapy crawlspider -o items.json -t json,也可以在Scrapy项目文件的Item Pipeline文件中定义。此外,Scrapy 提供了多种数据库 API 来支持数据库存储。如Mongo DB、Redis等。 数据存储分为两部分,一是网页链接的存储,二是项目数据的存储。网页链接存储在Redis数据库中,用于实现分布式爬虫的下载管理;项目数据包括新闻数据和评论数据,以JSON格式保存为文本文件,方便处理。存储评论数据时,以评论url中收录的评论ID命名。通过这种方式,
3 项目总结
以上就是分布式网络新闻爬取系统的系统设计部分。分布式设计是因为单个爬虫的爬行量和爬行速度的限制。整体设计部分如上图所示。 查看全部
scrapy分页抓取网页(分布式网络新闻抓取系统设计与实现的项目介绍(一))
1 项目介绍
本项目的主要内容是分布式网络新闻采集系统的设计与实现。主要有以下几个部分介绍:
(1)深入分析网络新闻爬虫的特点,设计分布式网络新闻爬虫系统爬取策略、爬取字段、**页面爬取方法、分布式结构、系统监控和数据存储六大关键功能。
(2)结合程序代码的分解,讲解分布式网络新闻爬虫系统的实现过程。包括爬虫编写、爬虫规避、**页面数据爬取、分布式爬虫部署、系统监控,一共六项内容,结合实际定向抓取腾讯新闻数据,通过测试测试系统性能。
(3) 规划设计一个数据处理模块,包括数据清洗、代码转换、数据分类、对象添加等功能。
分布式网络新闻抓取系统的设计
2.1 整体系统架构设计
系统采用分布式主从结构,设置1台Master服务器和多台Slave服务器。Master管理Redis数据库,分发下载任务。Slave 部署 Scrapy 来抓取网页并解析提取项目数据。服务器基础环境为Ubuntu操作系统,Master服务器安装Redis数据库服务器和Graphite,Slave安装Scrapy和Redis客户端。系统按功能可分为两大模块,一是数据采集模块,二是数据处理模块。数据抓取模块包括浏览器调用、网页下载、字段提取、爬虫规避、数据存储和系统监控六大功能;数据处理模块包括数据清洗、对象添加、
2.2 爬取策略的设计
本项目的网络爬虫采用深度优先的爬取策略,根据设置下载网页数据。网页链接处理流程如下:
1.手动设置初始下载地址,一般是网站导航地址。
2、爬虫开始运行,从初始地址抓取第一批网页链接。
3、爬虫根据正则表达式识别新链接中的目录页面地址和新闻内容页面地址,将识别出的新地址加入到下载队列中等待爬取。无法识别的网页地址被定义为无用链接并丢失。
4、爬虫从等待队列中依次取出网页链接进行数据下载和提取。
5.下载队列为空,爬虫停止爬行。
新闻网站的导航页数是有限的。这个规则决定了新闻导航页面的URL在一定的人工参与下可以很容易的获取,并作为爬虫系统的初始URL。
2.3 爬取字段的设计
本项目旨在捕捉网络新闻数据,因此内容必须能够客观准确地反映网络新闻的特点。
本文以抓取腾讯在线新闻数据为例,通过对网页结构的分析,确定了一个两步抓取的过程。第一步,抓取新闻内容页面,获取新闻标题、新闻来源、新闻内容、发布时间、评论数、评论地址、相关搜索、用户还喜欢的新闻、点赞数。第二步在获取评论地址后,抓取评论页面,获取评论者ID、评论者昵称、评论者性别、评论者所在位置、评论时间、评论内容、单条评论支持人数、评论回复数单条评论。
2.4 **页面爬取方法设计
腾讯新闻网页使用Java Script生成**页面内容。一些由JS事件触发的页面在打开的时候内容会发生变化,有的页面没有JS支持根本无法运行。一般爬虫根本无法从这些网页中获取数据。解决JavaScript **页面爬虫问题有四种方法:
1.编写代码模拟相关JS逻辑。
2. 调用一个带接口的浏览器,类似于各种广泛用于测试的,比如Selenium等。
3、使用无界面浏览器,各种基于Webkit的,如Casperjs、Phantomjs等。
4、结合JS执行引擎,实现轻量级浏览器。
由于本项目是基于Python为主要语言编写的,所以使用Selenium来处理JS动态新闻页面。其优点是简单易行。使用Python代码模拟用户在浏览器上的操作。首先将网页加载到浏览器中并打开,然后从浏览器缓存中获取网页数据,传递给蜘蛛进行分析提取,最后将目标数据传递给项目通道。
2.5 Crawler 分布式设计
Redis数据库用于实现分布式爬取。基本思路是将Scrapy爬虫获取到的url(请求)放在一个Redis Queue中,所有爬虫也从指定的Redis Queue中获取请求(url)。Scrapy-Redis 默认使用 Spider Priority Queue 来确定 URL 的顺序。这是一种由有序集合实现的非 FIFO、LIFO 方法。
Redis 存储了 Scrapy 项目的请求和统计信息。根据这些信息可以掌握任务状态和爬虫状态,在分配任务时平衡系统负载,有助于克服爬虫的性能瓶颈。同时,利用Redis的高性能和易扩展的特性,可以轻松实现高效下载。当Redis存储或访问速度遇到问题时,可以通过增加Redis集群和爬虫集群的数量来提高。Scrapy-Redis分布式解决方案很好的解决了爬行中断和重复数据删除的问题。爬虫重启后,会针对Redis队列中的URL进行爬取,爬取到的URL会被自动过滤掉。
2.6 基于Graphite系统的监控组件设计
使用Graphite监控系统的运行状态,实现了分布式系统的statscollector,将系统的stats信息以图表的形式动态实时展示,即实时监控。Graphite监控的信息包括:系统下载信息、日志信息、文件计数、调度信息、爬虫运行信息、爬虫异常信息、文件数、获取的item数、最大请求深度、收到响应数等。
2.7 数据存储模块设计
Scrapy支持json、csv、xml等文本格式的数据存储。用户可以在运行爬虫时进行设置,例如:scrapy crawlspider -o items.json -t json,也可以在Scrapy项目文件的Item Pipeline文件中定义。此外,Scrapy 提供了多种数据库 API 来支持数据库存储。如Mongo DB、Redis等。 数据存储分为两部分,一是网页链接的存储,二是项目数据的存储。网页链接存储在Redis数据库中,用于实现分布式爬虫的下载管理;项目数据包括新闻数据和评论数据,以JSON格式保存为文本文件,方便处理。存储评论数据时,以评论url中收录的评论ID命名。通过这种方式,
3 项目总结
以上就是分布式网络新闻爬取系统的系统设计部分。分布式设计是因为单个爬虫的爬行量和爬行速度的限制。整体设计部分如上图所示。
scrapy分页抓取网页( page=4那么我们是不是可以通过,改变页码去完成呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-25 17:27
page=4那么我们是不是可以通过,改变页码去完成呢?)
页=4
那么我们可以改变页码(page)来完成分页吗?因为首页和7天热点类似,我用了7天热点的爬取思路来爬取(蜘蛛——Scrapy),但是很明显网址抓不到首页的信息。除了尝试所有参数之外别无他法。首先我们看一下seen_snote_ids[]的参数,除了page的参数外,应该在那里找到。
第一页
我们看到第一页没有参数,我们看第二页的请求信息
第二页请求信息
ID有很多,那么我们应该在哪里找到它们呢?我们先来看看第一页的源代码。
第一页的来源信息
看到这些数字,是不是和第二页的参数有关?经过对比,确实和第二页的参数id一致。有了线索,我们再看第三页(进一步确定携带的参数)
第三页参数
经过分析,我们发现第三页的参数是40,第二页是20,第一页是0,第二页的id参数,我们可以在第一页的源码中得到。可以在第二页上看到第三页吗?,我们看一下第二页的源码
可能有身份证
因为网页是直接加载的,所以我们大致确定第二页的位置,然后比较第三页的一些参数信息。
第三页部分参数
仔细对比可以发现,第三页的参数确实收录
了第一页和第二页的id信息。
现在差不多我们对这个页面的加载方式和分页方式有了更好的了解,即除了后续每个页面的page参数变化外,携带的seen_snote_ids[]都是前一个(几个)的id参数页,那么这个有多少页?我真的一直点击加载。最终,page参数停留在了15页(seen_snote_ids[]的数量非常多),“read more”字样没有出现。让我们来看看。
第十五页
我们可以看到请求的URL的长度,并且参数一直在增加,所以暂时我认为i是15页。下面是获取 id 和分页 URL 的示例代码:
1.获取id
html = requests.get(url,headers = self.headers,cookies = self.cookies).text
response = etree.HTML(html)
ids = response.xpath('//*[@id="list-container"]/ul/li')
for one in ids:
one = 'seen_snote_ids[]=' + one.xpath('@data-note-id')[0]
2.构造页码
def totalPage(self):
for i in range(1,16):
data = '&'.join(self.params)
url = 'http://www.jianshu.com/?' + data + '&page={}'.format(i)
self.getData(url)
遇到的问题+示例源码
1.遇到的问题
以前是按照我7号的小本子的流行思路写的,最后得到了重复数据,加上id后,也是重复数据。罗罗盘在跑到合适的boss之前给我看了首页分析的文章,看和我对比后,感觉差不多,就是拿不到数据。之后,你们说参数可能不够。LEONYao大哥也说可以把所有参数都放进去,弹到满状态,往右边跑。之后说带cookies是可行的,但是经过测试确实可行(小cookie困扰了很久,没想到带cookies)
2.示例代码
# -*- coding:utf-8 -*-
from lxml import etree
import requests
import re
from Class.store_csv import CSV
class Spider(object):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
cookies = {
'UM_distinctid': '15ac11bdff316-0ce09a4511f531-67f1a39-100200-15ac11bdff447d',
'CNZZDATA1258679142': '1034687255-1492307094-%7C1493259066',
'remember_user_token': 'W1s1MjA4MDY0XSwiJDJhJDEwJFVWVjUwbXBsS1hldkc1d0l3UG5DSmUiLCIxNDk0ODkyNTg0LjczNDM2ODgiXQ%3D%3D--f04b34c274980b45e5f7ee17c2686aeb4b567197',
'_gat': '1',
'_session_id': 'N0tvclN3V09wZ25UNFloZ0NrRTBVT3ZYQUR5VkRlV1c2Tno1bnNZc3dmQm9kQ3hmOGY4a0dFUlVLMDdPYWZJdCsydGJMaENZVU1XSHdZMHozblNhUERqaldYTHNWYXVPd2tISHVCeWJtbUFwMjJxQ3lyU2NZaTNoVUZsblV4Si94N2hRRC94MkJkUjhGNkNCYm1zVmM0R0ZqR2hFSFltZnhEcXVLbG54SlNSQU5lR0dtZ2MxOWlyYWVBMVl1a1lMVkFTYS8yQVF3bGFiR2hMblcweTU5cnR5ZTluTGlZdnFKbUdFWUYzcm9sZFZLOGduWFdnUU9yN3I0OTNZbWMxQ2UvbU5aQnByQmVoMFNjR1NmaDJJSXF6WHBYQXpPQnBVRVJnaVZVQ2xUR1p4MXNUaDhQSE80N1paLzg0amlBdjRxMU15a0JORlB1YXJ4V2g0b3hYZXpjR1NkSHVVdnA2RkgvVkJmdkJzdTg5ODhnUVRCSnN2cnlwRVJvWWc4N0lZMWhCMWNSMktMMWNERktycE0wcHFhTnYyK3ZoSWFSUFQzbkVyMDlXd2d5bz0tLThrdXQ2cFdRTTNaYXFRZm5RNWtYZUE9PQ%3D%3D--bc52e90a4f1d720f4766a5894866b3764c0482dd',
'_ga': 'GA1.2.1781682389.1492310343',
'_gid': 'GA1.2.163793537.1495583991',
'Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1495360310,1495416048,1495516194,1495583956',
'Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1495583991'
}
params = []
def __init__(self):
field = ['标题', '作者', '发表时间', '阅读量', '评论数', '点赞数', '打赏数', '所投专题']
self.write = CSV('main.csv', field)
def totalPage(self):
for i in range(1,16):
data = '&'.join(self.params)
url = 'http://www.jianshu.com/?' + data + '&page={}'.format(i)
self.getData(url)
def getData(self,url):
print url
html = requests.get(url,headers = self.headers,cookies = self.cookies).text
response = etree.HTML(html)
ids = response.xpath('//*[@id="list-container"]/ul/li')
for one in ids:
one = 'seen_snote_ids[]=' + one.xpath('@data-note-id')[0]
self.params.append(one)
item = {}
flag = 0
read = re.findall(r'ic-list-read"> (\d+)', html)
comment = re.findall(r'ic-list-comments"> (\d+)', html)
result = response.xpath('//*[@id="list-container"]/ul/li/div')
for one in result:
item[1] = one.xpath('a/text()')[0]
item[2] = one.xpath('div[1]/div/a/text()')[0]
item[3] = one.xpath('div[1]/div/span/@data-shared-at')[0]
item[4] = read[flag]
try:
item[5] = comment[flag]
except:
item[5] = u''
item[6] = one.xpath('div[2]/span/text()')[0].strip()
try:
item[7] = one.xpath('div[2]/span[2]/text()')[0].strip()
except:
item[7] = u'0'
try:
item[8] = one.xpath('div[2]/a[1]/text()')[0]
except:
item[8] = u''
flag += 1
row = [item[i] for i in range(1, 9)]
self.write.writeRow(row)
if __name__ == "__main__":
jian = Spider()
jian.totalPage()
结果截图
信息详情
总结
现在想一想,在抓取网站的时候,我们可以携带尽可能多的参数(俗话说,很多人不怪它),以免遇到我的错误。目前正在编写scrapy版本。有兴趣的可以参考私聊源码。 查看全部
scrapy分页抓取网页(
page=4那么我们是不是可以通过,改变页码去完成呢?)
页=4
那么我们可以改变页码(page)来完成分页吗?因为首页和7天热点类似,我用了7天热点的爬取思路来爬取(蜘蛛——Scrapy),但是很明显网址抓不到首页的信息。除了尝试所有参数之外别无他法。首先我们看一下seen_snote_ids[]的参数,除了page的参数外,应该在那里找到。
第一页
我们看到第一页没有参数,我们看第二页的请求信息
第二页请求信息
ID有很多,那么我们应该在哪里找到它们呢?我们先来看看第一页的源代码。
第一页的来源信息
看到这些数字,是不是和第二页的参数有关?经过对比,确实和第二页的参数id一致。有了线索,我们再看第三页(进一步确定携带的参数)
第三页参数
经过分析,我们发现第三页的参数是40,第二页是20,第一页是0,第二页的id参数,我们可以在第一页的源码中得到。可以在第二页上看到第三页吗?,我们看一下第二页的源码
可能有身份证
因为网页是直接加载的,所以我们大致确定第二页的位置,然后比较第三页的一些参数信息。
第三页部分参数
仔细对比可以发现,第三页的参数确实收录
了第一页和第二页的id信息。
现在差不多我们对这个页面的加载方式和分页方式有了更好的了解,即除了后续每个页面的page参数变化外,携带的seen_snote_ids[]都是前一个(几个)的id参数页,那么这个有多少页?我真的一直点击加载。最终,page参数停留在了15页(seen_snote_ids[]的数量非常多),“read more”字样没有出现。让我们来看看。
第十五页
我们可以看到请求的URL的长度,并且参数一直在增加,所以暂时我认为i是15页。下面是获取 id 和分页 URL 的示例代码:
1.获取id
html = requests.get(url,headers = self.headers,cookies = self.cookies).text
response = etree.HTML(html)
ids = response.xpath('//*[@id="list-container"]/ul/li')
for one in ids:
one = 'seen_snote_ids[]=' + one.xpath('@data-note-id')[0]
2.构造页码
def totalPage(self):
for i in range(1,16):
data = '&'.join(self.params)
url = 'http://www.jianshu.com/?' + data + '&page={}'.format(i)
self.getData(url)
遇到的问题+示例源码
1.遇到的问题
以前是按照我7号的小本子的流行思路写的,最后得到了重复数据,加上id后,也是重复数据。罗罗盘在跑到合适的boss之前给我看了首页分析的文章,看和我对比后,感觉差不多,就是拿不到数据。之后,你们说参数可能不够。LEONYao大哥也说可以把所有参数都放进去,弹到满状态,往右边跑。之后说带cookies是可行的,但是经过测试确实可行(小cookie困扰了很久,没想到带cookies)
2.示例代码
# -*- coding:utf-8 -*-
from lxml import etree
import requests
import re
from Class.store_csv import CSV
class Spider(object):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
cookies = {
'UM_distinctid': '15ac11bdff316-0ce09a4511f531-67f1a39-100200-15ac11bdff447d',
'CNZZDATA1258679142': '1034687255-1492307094-%7C1493259066',
'remember_user_token': 'W1s1MjA4MDY0XSwiJDJhJDEwJFVWVjUwbXBsS1hldkc1d0l3UG5DSmUiLCIxNDk0ODkyNTg0LjczNDM2ODgiXQ%3D%3D--f04b34c274980b45e5f7ee17c2686aeb4b567197',
'_gat': '1',
'_session_id': 'N0tvclN3V09wZ25UNFloZ0NrRTBVT3ZYQUR5VkRlV1c2Tno1bnNZc3dmQm9kQ3hmOGY4a0dFUlVLMDdPYWZJdCsydGJMaENZVU1XSHdZMHozblNhUERqaldYTHNWYXVPd2tISHVCeWJtbUFwMjJxQ3lyU2NZaTNoVUZsblV4Si94N2hRRC94MkJkUjhGNkNCYm1zVmM0R0ZqR2hFSFltZnhEcXVLbG54SlNSQU5lR0dtZ2MxOWlyYWVBMVl1a1lMVkFTYS8yQVF3bGFiR2hMblcweTU5cnR5ZTluTGlZdnFKbUdFWUYzcm9sZFZLOGduWFdnUU9yN3I0OTNZbWMxQ2UvbU5aQnByQmVoMFNjR1NmaDJJSXF6WHBYQXpPQnBVRVJnaVZVQ2xUR1p4MXNUaDhQSE80N1paLzg0amlBdjRxMU15a0JORlB1YXJ4V2g0b3hYZXpjR1NkSHVVdnA2RkgvVkJmdkJzdTg5ODhnUVRCSnN2cnlwRVJvWWc4N0lZMWhCMWNSMktMMWNERktycE0wcHFhTnYyK3ZoSWFSUFQzbkVyMDlXd2d5bz0tLThrdXQ2cFdRTTNaYXFRZm5RNWtYZUE9PQ%3D%3D--bc52e90a4f1d720f4766a5894866b3764c0482dd',
'_ga': 'GA1.2.1781682389.1492310343',
'_gid': 'GA1.2.163793537.1495583991',
'Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1495360310,1495416048,1495516194,1495583956',
'Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1495583991'
}
params = []
def __init__(self):
field = ['标题', '作者', '发表时间', '阅读量', '评论数', '点赞数', '打赏数', '所投专题']
self.write = CSV('main.csv', field)
def totalPage(self):
for i in range(1,16):
data = '&'.join(self.params)
url = 'http://www.jianshu.com/?' + data + '&page={}'.format(i)
self.getData(url)
def getData(self,url):
print url
html = requests.get(url,headers = self.headers,cookies = self.cookies).text
response = etree.HTML(html)
ids = response.xpath('//*[@id="list-container"]/ul/li')
for one in ids:
one = 'seen_snote_ids[]=' + one.xpath('@data-note-id')[0]
self.params.append(one)
item = {}
flag = 0
read = re.findall(r'ic-list-read"> (\d+)', html)
comment = re.findall(r'ic-list-comments"> (\d+)', html)
result = response.xpath('//*[@id="list-container"]/ul/li/div')
for one in result:
item[1] = one.xpath('a/text()')[0]
item[2] = one.xpath('div[1]/div/a/text()')[0]
item[3] = one.xpath('div[1]/div/span/@data-shared-at')[0]
item[4] = read[flag]
try:
item[5] = comment[flag]
except:
item[5] = u''
item[6] = one.xpath('div[2]/span/text()')[0].strip()
try:
item[7] = one.xpath('div[2]/span[2]/text()')[0].strip()
except:
item[7] = u'0'
try:
item[8] = one.xpath('div[2]/a[1]/text()')[0]
except:
item[8] = u''
flag += 1
row = [item[i] for i in range(1, 9)]
self.write.writeRow(row)
if __name__ == "__main__":
jian = Spider()
jian.totalPage()
结果截图
信息详情
总结
现在想一想,在抓取网站的时候,我们可以携带尽可能多的参数(俗话说,很多人不怪它),以免遇到我的错误。目前正在编写scrapy版本。有兴趣的可以参考私聊源码。
scrapy分页抓取网页(使用Scrapy分页–使用Python进行网页抓取原文:.. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-25 13:12
)
使用 Python 使用 Scrapy-Web 爬行进行分页
原来的:。极客们。org/paging-use-scrapy-web-scratch-with-python/
使用剪贴簿分页。网页抓取是一种从网站获取信息的技术。Scrapy 用作 Web 抓取的 Python 框架。从普通网站获取数据更容易。你只需要拉取网站的HTMl,通过过滤标签获取数据即可。但是,如果您尝试获取的数据中存在分页,例如 - 亚马逊产品可以有多个页面。要成功丢弃所有产品,您需要分页的概念。
**分页: **分页,又称分页,是将一个文档分成离散的页面的过程,即将不同的页面上的数据进行捆绑。这些不同的网页都有自己的 URL。所以我们需要一一抓取这些网址和页面。但要记住的是什么时候停止分页。一般来说,页面有一个下一步按钮。这个下一步按钮没问题。当页面完成时,它被禁用。此方法用于获取网页的 URL,直到下一页按钮能够使用,当它被禁用时,没有页面可供抓取。
使用scrapy应用程序分页的项目
从亚马逊网站获取移动详细信息并在以下项目中应用分页。爬取的详细信息包括手机的名称和价格以及分页爬取下面搜索到的所有结果的网址
**分页背后的逻辑:**这里 next_page 变量仅在下一页可用时获取下一页的 url,但如果没有剩余页面,则此条件为 false。
next_page = response.xpath("//div/div/ul/li[@class='alast']/a/@href").get()
if next_page:
abs_url = f"https://www.amazon.in{next_page}"
yield scrapy.Request(
url=abs_url,
callback=self.parse
)
笔记:
abs_url = f"https://www.amazon.in{next_page}"
因为next_page是/page2,所以需要在这里取。这是不完整的,完整的网址是
刮刮结果:
查看全部
scrapy分页抓取网页(使用Scrapy分页–使用Python进行网页抓取原文:..
)
使用 Python 使用 Scrapy-Web 爬行进行分页
原来的:。极客们。org/paging-use-scrapy-web-scratch-with-python/
使用剪贴簿分页。网页抓取是一种从网站获取信息的技术。Scrapy 用作 Web 抓取的 Python 框架。从普通网站获取数据更容易。你只需要拉取网站的HTMl,通过过滤标签获取数据即可。但是,如果您尝试获取的数据中存在分页,例如 - 亚马逊产品可以有多个页面。要成功丢弃所有产品,您需要分页的概念。
**分页: **分页,又称分页,是将一个文档分成离散的页面的过程,即将不同的页面上的数据进行捆绑。这些不同的网页都有自己的 URL。所以我们需要一一抓取这些网址和页面。但要记住的是什么时候停止分页。一般来说,页面有一个下一步按钮。这个下一步按钮没问题。当页面完成时,它被禁用。此方法用于获取网页的 URL,直到下一页按钮能够使用,当它被禁用时,没有页面可供抓取。
使用scrapy应用程序分页的项目
从亚马逊网站获取移动详细信息并在以下项目中应用分页。爬取的详细信息包括手机的名称和价格以及分页爬取下面搜索到的所有结果的网址
**分页背后的逻辑:**这里 next_page 变量仅在下一页可用时获取下一页的 url,但如果没有剩余页面,则此条件为 false。
next_page = response.xpath("//div/div/ul/li[@class='alast']/a/@href").get()
if next_page:
abs_url = f"https://www.amazon.in{next_page}"
yield scrapy.Request(
url=abs_url,
callback=self.parse
)
笔记:
abs_url = f"https://www.amazon.in{next_page}"
因为next_page是/page2,所以需要在这里取。这是不完整的,完整的网址是
刮刮结果:
scrapy分页抓取网页(抓取慕课网课程信息展示之scrapy框架数据的过程介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-24 22:23
)
本例主要通过抓取的课程信息来演示scrapy框架爬取数据的过程。
1、抓取网站 简介
爬网网站:
截取内容:截取内容为所有课程名称、课程介绍、课程地址、课程图片地址、课程编号(由于动态渲染)
网站图片:
2、创建项目
以命令行方式创建项目
scrapy startprojectscrapy_course
建立完成后,用pycharm打开,目录如下:
scrapy.cfg:项目配置文件
scrapytest/:项目的python模块。稍后您将在此处添加代码。
scrapytest/items.py:项目中的item文件。
scrapytest/pipelines.py:项目中的管道文件。
scrapytest/settings.py:项目的设置文件。
scrapytest/spiders/:放置蜘蛛代码的目录。
3、创建爬虫
下面的步骤解释了如何编写一个简单的爬虫。
我们要写爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
该文件收录一个MySpider 类,该类必须继承scrapy.Spider 类。
同时它必须定义三个属性:
-name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。
-start_urls:收录Spider启动时会爬取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获取的数据中提取后续 URL。
-parse() 是蜘蛛的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
MySpider.py创建后的代码如下
定义爬虫项目
创建好Spider文件后,先别急着写爬虫代码
我们首先定义一个容器来存放要爬取的数据。
所以我们使用Item
为了定义常用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬取的数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
我们可以在项目目录中看到一个items文件,我们可以改变这个文件或者创建一个新文件来定义我们的items。
在这里,我们在同一层上创建一个新的项目文件 CourseItems.py
根据上面的代码,我们创建了一个名为courseItem的容器来存储和抓取信息。
title->课程名称,url->课程url,image_url->课程标题图片,介绍->课程描述,学生->学号
创建项目文件后,我们可以使用类似字典的 API 和简单的语法来声明可用字段。
常用方法如下
4、编写Spider代码
定义好item后,我们就可以开始爬取部分的工作了。
为简单起见,我们首先抓取页面上的信息。
首先我们编写爬取代码
上面我们说过,爬取部分是在MySpider类的parse()方法中进行的。
parse() 方法负责处理响应并返回处理后的数据和/或 URL 以供后续处理。
此方法和其他 Request 回调函数必须返回一个收录 Request 和/或 Item 的可迭代对象。
我们在之前创建的 MySpider.py 中编写以下代码。
注意上面与 MySpider.py 的区别
# -*- coding:utf8-*-
import scrapy
import sys
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from scrapy_course.items import CourseItem
from scrapy.selector import Selector
sys.stdout = open(\'output.txt\', \'w\')
pageIndex = 0
class MySpider(scrapy.Spider):
#用于区别Spider
name = "MySpider"
#允许访问的域
allowed_domains = [\'imooc.com\']
#爬取的地址
start_urls = ["http://www.imooc.com/course/list"]
#爬取方法
def parse(self, response):
# 实例一个容器保存爬取的信息
item = CourseItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个课程的div
sel = Selector(response)
title = sel.xpath(\'/html/head/title/text()\').extract() # 标题
print title[0]
# sels = sel.xpath(\'//div[@class="course-card-content"]\')
sels = sel.xpath(\'//a[@class="course-card"]\')
pictures = sel.xpath(\'//div[@class="course-card-bk"]\')
index = 0
global pageIndex
pageIndex += 1
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
print \'第\' + str(pageIndex)+ \'页 \'
print \'----------------------------------------------\'
for box in sels:
print \' \'
# 获取div中的课程标题
item[\'title\'] = box.xpath(\'.//h3[@class="course-card-name"]/text()\').extract()[0].strip()
print \'标题:\' + item[\'title\']
# 获取div中的课程简介
item[\'introduction\'] = box.xpath(\'.//p/text()\').extract()[0].strip()
print \'简介:\' + item[\'introduction\']
# 获取每个div中的课程路径
item[\'url\'] = \'http://www.imooc.com\' + box.xpath(\'.//@href\').extract()[0]
print \'路径:\' +item[\'url\']
# 获取div中的学生人数
item[\'student\'] = box.xpath(\'.//div[@class="course-card-info"]/text()\').extract()[0].strip()
print item[\'student\']
# 获取div中的标题图片地址
item[\'image_url\'] = pictures[index].xpath(\'.//img/@src\').extract()[0]
print \'图片地址:\' + item[\'image_url\']
index += 1
yield item
time.sleep(1)
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
# next =u\'下一页\'
# url = response.xpath("//a[contains(text(),\'" + next + "\')]/@href").extract()
# if url:
# # 将信息组合成下一页的url
# page = \'http://www.imooc.com\' + url[0]
# # 返回url
# yield scrapy.Request(page, callback=self.parse)
使用 Pipeline 处理数据
在我们成功获取信息后,我们需要对信息进行验证和存储。这里我们以存储为例。
在Spider中采集到Item后,会传递给Pipeline,一些组件会按照一定的顺序执行Item的处理。
流水线经常执行以下操作:
清理 HTML 数据
验证爬取的数据(检查该项目是否收录某些字段)
重复检查(并丢弃)
目前暂时将爬取结果保存到文本中
这里只进行简单的将数据存储在json文件中的操作。
pipelines.py代码如下
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
import codecs
import json
class ScrapyCoursePipeline(object):
def __init__(self):
# self.file = open(\'data.json\', \'wb\')
# self.file = codecs.open(
# \'spider.txt\', \'w\', encoding=\'utf-8\')
self.file = codecs.open(
\'spider.json\', \'w\', encoding=\'utf-8\')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
要使用Pipeline,必须先注册Pipeline
找到settings.py文件,这个文件就是爬虫的配置文件
添加进去
ITEM_PIPELINES = {
\'scrapy_course.pipelines.ScrapyCoursePipeline\':300
}
以上代码用于注册Pipeline,其中scrapy_course.pipelines.ScrapyCoursePipeline是你要注册的类,右边的'300'是Pipeline的优先级,范围从1到1000。管道越小,第一个执行。
执行完以上操作,我们最基本的爬取操作之一就完成了
然后我们运行
5、运行
在命令行下运行scrapy crawl MySpider
如何将数据存储在文本文件中,在代码前添加如下代码,
sys.stdout = open(\'output.txt\', \'w\'),这会将数据保存到当前项目路径下的output.txt文件中
如下:
查看全部
scrapy分页抓取网页(抓取慕课网课程信息展示之scrapy框架数据的过程介绍
)
本例主要通过抓取的课程信息来演示scrapy框架爬取数据的过程。
1、抓取网站 简介
爬网网站:
截取内容:截取内容为所有课程名称、课程介绍、课程地址、课程图片地址、课程编号(由于动态渲染)
网站图片:
2、创建项目
以命令行方式创建项目
scrapy startprojectscrapy_course
建立完成后,用pycharm打开,目录如下:
scrapy.cfg:项目配置文件
scrapytest/:项目的python模块。稍后您将在此处添加代码。
scrapytest/items.py:项目中的item文件。
scrapytest/pipelines.py:项目中的管道文件。
scrapytest/settings.py:项目的设置文件。
scrapytest/spiders/:放置蜘蛛代码的目录。
3、创建爬虫
下面的步骤解释了如何编写一个简单的爬虫。
我们要写爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
该文件收录一个MySpider 类,该类必须继承scrapy.Spider 类。
同时它必须定义三个属性:
-name:用于区分Spider。名称必须唯一,不能为不同的蜘蛛设置相同的名称。
-start_urls:收录Spider启动时会爬取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获取的数据中提取后续 URL。
-parse() 是蜘蛛的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
MySpider.py创建后的代码如下
定义爬虫项目
创建好Spider文件后,先别急着写爬虫代码
我们首先定义一个容器来存放要爬取的数据。
所以我们使用Item
为了定义常用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬取的数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
我们可以在项目目录中看到一个items文件,我们可以改变这个文件或者创建一个新文件来定义我们的items。
在这里,我们在同一层上创建一个新的项目文件 CourseItems.py
根据上面的代码,我们创建了一个名为courseItem的容器来存储和抓取信息。
title->课程名称,url->课程url,image_url->课程标题图片,介绍->课程描述,学生->学号
创建项目文件后,我们可以使用类似字典的 API 和简单的语法来声明可用字段。
常用方法如下
4、编写Spider代码
定义好item后,我们就可以开始爬取部分的工作了。
为简单起见,我们首先抓取页面上的信息。
首先我们编写爬取代码
上面我们说过,爬取部分是在MySpider类的parse()方法中进行的。
parse() 方法负责处理响应并返回处理后的数据和/或 URL 以供后续处理。
此方法和其他 Request 回调函数必须返回一个收录 Request 和/或 Item 的可迭代对象。
我们在之前创建的 MySpider.py 中编写以下代码。
注意上面与 MySpider.py 的区别
# -*- coding:utf8-*-
import scrapy
import sys
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from scrapy_course.items import CourseItem
from scrapy.selector import Selector
sys.stdout = open(\'output.txt\', \'w\')
pageIndex = 0
class MySpider(scrapy.Spider):
#用于区别Spider
name = "MySpider"
#允许访问的域
allowed_domains = [\'imooc.com\']
#爬取的地址
start_urls = ["http://www.imooc.com/course/list"]
#爬取方法
def parse(self, response):
# 实例一个容器保存爬取的信息
item = CourseItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个课程的div
sel = Selector(response)
title = sel.xpath(\'/html/head/title/text()\').extract() # 标题
print title[0]
# sels = sel.xpath(\'//div[@class="course-card-content"]\')
sels = sel.xpath(\'//a[@class="course-card"]\')
pictures = sel.xpath(\'//div[@class="course-card-bk"]\')
index = 0
global pageIndex
pageIndex += 1
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
print \'第\' + str(pageIndex)+ \'页 \'
print \'----------------------------------------------\'
for box in sels:
print \' \'
# 获取div中的课程标题
item[\'title\'] = box.xpath(\'.//h3[@class="course-card-name"]/text()\').extract()[0].strip()
print \'标题:\' + item[\'title\']
# 获取div中的课程简介
item[\'introduction\'] = box.xpath(\'.//p/text()\').extract()[0].strip()
print \'简介:\' + item[\'introduction\']
# 获取每个div中的课程路径
item[\'url\'] = \'http://www.imooc.com\' + box.xpath(\'.//@href\').extract()[0]
print \'路径:\' +item[\'url\']
# 获取div中的学生人数
item[\'student\'] = box.xpath(\'.//div[@class="course-card-info"]/text()\').extract()[0].strip()
print item[\'student\']
# 获取div中的标题图片地址
item[\'image_url\'] = pictures[index].xpath(\'.//img/@src\').extract()[0]
print \'图片地址:\' + item[\'image_url\']
index += 1
yield item
time.sleep(1)
print u\'%s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'))
# next =u\'下一页\'
# url = response.xpath("//a[contains(text(),\'" + next + "\')]/@href").extract()
# if url:
# # 将信息组合成下一页的url
# page = \'http://www.imooc.com\' + url[0]
# # 返回url
# yield scrapy.Request(page, callback=self.parse)
使用 Pipeline 处理数据
在我们成功获取信息后,我们需要对信息进行验证和存储。这里我们以存储为例。
在Spider中采集到Item后,会传递给Pipeline,一些组件会按照一定的顺序执行Item的处理。
流水线经常执行以下操作:
清理 HTML 数据
验证爬取的数据(检查该项目是否收录某些字段)
重复检查(并丢弃)
目前暂时将爬取结果保存到文本中
这里只进行简单的将数据存储在json文件中的操作。
pipelines.py代码如下
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don\'t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
import codecs
import json
class ScrapyCoursePipeline(object):
def __init__(self):
# self.file = open(\'data.json\', \'wb\')
# self.file = codecs.open(
# \'spider.txt\', \'w\', encoding=\'utf-8\')
self.file = codecs.open(
\'spider.json\', \'w\', encoding=\'utf-8\')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
要使用Pipeline,必须先注册Pipeline
找到settings.py文件,这个文件就是爬虫的配置文件
添加进去
ITEM_PIPELINES = {
\'scrapy_course.pipelines.ScrapyCoursePipeline\':300
}
以上代码用于注册Pipeline,其中scrapy_course.pipelines.ScrapyCoursePipeline是你要注册的类,右边的'300'是Pipeline的优先级,范围从1到1000。管道越小,第一个执行。
执行完以上操作,我们最基本的爬取操作之一就完成了
然后我们运行
5、运行
在命令行下运行scrapy crawl MySpider
如何将数据存储在文本文件中,在代码前添加如下代码,
sys.stdout = open(\'output.txt\', \'w\'),这会将数据保存到当前项目路径下的output.txt文件中
如下:
scrapy分页抓取网页( 什么是Scrapy二.准备环境三.大体设置数据存储模板)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-24 22:21
什么是Scrapy二.准备环境三.大体设置数据存储模板)
Python爬虫学习的scrapy框架(一)爬取豆瓣书单
文章内容
html
Python爬虫学习的scrapy框架(一)爬取豆瓣书单
资源连接
一.什么是Scrapy
二.准备环境
三.一般流程
四.使用框架python
1.创建项目mysql
2.各部分正则表达式介绍
3.创建爬虫sql
4.设置数据存储模板数据库
5.分析网页,编写爬虫应用
6.数据处理框架
7.设置dom的一部分
8.执行scrapy
一.什么是Scrapy
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。写Python爬虫程序也不是不行,但是有框架可以用,何乐而不为呢?我相信Scrapy可以事半功倍。与请求相比,scrapy 更侧重于爬虫框架而不是页面下载。
二.准备环境
Scrapy爬虫需要库pypiwin32、lxml、twisted、scrapy、Microsoft Visual C++ 14.0以上编译环境
数据库链接模块pymysql,以上库我都是用pip安装的,我把清华大学的镜像源放在这里/simple
三.一般流程
首先,引擎从调度程序获取连接(URL)以进行下一次抓取
1. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
2. 然后,爬虫解析响应。
3.如果实体(Item)被解析,就会交给实体管道做进一步处理。
4.如果解析出来的是连接(URL),那么这个URL就会交给Scheduler等待爬取。
四.使用框架1.创建项目
使用命令scrapy startproject projectname
PS D:\pythonpractice> scrapy startproject douban
New Scrapy project 'douban', using template directory 'D:\python38install\Lib\site-packages\scrapy\templates\project', created in:
D:\pythonpractice\douban
You can start your first spider with:
cd douban
scrapy genspider example example.com
我用的是vscode,我用ctrl和·调用终端,输入命令,我要去爬豆瓣的一些页面,所以我把它命名为豆瓣,可以看到在你打开的文件夹下出现了一个新文件夹。名字是我做的
以后用cd豆瓣命令进入项目所在的文件夹
PS D:\pythonpractice> cd douban
PS D:\pythonpractice\douban>
2.各部分介绍
在项目文件夹中,可以看到还有一个和项目同名的文件夹,里面有一些文件,
1.items.py 负责创建数据模型,为结构化数据设置数据存储模板,如:Django Model
2.middlewares.py 是自己定义的中间件
3.pipelines.py 负责处理蜘蛛返回的数据,比如数据持久化
4.settings.py 负责整个爬虫的配置
5. spiders目录负责存放从scrapy继承而来的爬虫
6.scrapy.cfg 是scrapy的基本配置
3.构建爬虫
使用scrapy genspider [options] 构建自己的爬虫,
我输入了scrapy genspider来创建一个名为book的爬虫。域名部分是爬虫的范围,被爬取的网页不能超过这个域名。
4.设置数据存储模板
修改以下item.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
img_src = scrapy.Field()
score = scrapy.Field()
publish_house = scrapy.Field()
publish_detail = scrapy.Field()
slogan = scrapy.Field()
detail_addr = scrapy.Field()
comment_people = scrapy.Field()
5.分析网页,编写爬虫
打开网站链接:豆瓣阅读250强(/top250)
F12打开网页源代码,
能看结构就很清楚了,我需要的是这本书的资料,下面写book.py,
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['douban.com']
start_urls = ['https://book.douban.com/top250?start=0']
url_sets = set()
def parse(self, response):
if response.url.startswith('https://book.douban.com'):
seclectors = response.xpath('//div[@class="indent"]/table')
for seclector in seclectors:
item = DoubanItem()
item['title'] = seclector.xpath("./tr/td[2]/div/a/@title").extract()[0]
item['img_src'] = seclector.xpath("./tr/td[1]/a/img/@src").extract()[0]
item['publish_detail'] = seclector.xpath("./tr/td[2]/p[@class='pl']/text()").extract()[0]
item['score'] = seclector.xpath("./tr/td[2]/div[@class='star clearfix']/span[@class='rating_nums']/text()").extract()[0]
item['detail_addr'] = seclector.xpath("./tr/td[2]/div[@class='pl2']/a/@href").extract()[0]
#标语爬取
item['slogan'] = seclector.xpath("./tr/td[2]/p[@class='quote']/span/text()").get()
if item['slogan']:
pass
else:
item['slogan'] = '暂无信息'
#评论人数爬取
item['comment_people'] = seclector.xpath("./tr/td[2]/div[@class='star clearfix']/span[@class='pl']/text()").extract()[0]
comment = str(item['comment_people'])
rex = '[0-9]+'
num = re.findall(rex, comment)
if num:
item['comment_people'] = num[0]
else:
item['comment_people'] = '暂无信息'
#出版社爬取
t = str(item['publish_detail'])
s = t.encode() #进行字符串转义
temp = s.decode('utf-8')
pattern="[\u4e00-\u9fa5]*\u51fa\u7248[\u4e00-\u9fa5]*|[\u4e00-\u9fa5]*\u4E66\u5E97[\u4e00-\u9fa5]*" #中文 unicode编码出版 正则表达式
results = re.findall(pattern, temp) #匹配
if results:
item['publish_house'] = results[0]
else:
item['publish_house'] = '暂无信息'
yield item
#分页处理
urls = response.xpath("//div[@class='paginator']/span[@class='next']/a/@href").extract()
for url in urls:
if url.startswith('https://book.douban.com'):
if url in self.url_sets:
pass
else:
self.url_sets.add(url)
yield self.make_requests_from_url(url)
else:
pass
(1) 其中start_urls为起始页,后续页面从网页的pager中获取,但是如果网站使用js进行分页,则没有办法。
(2) 提取网页内容的方法有很多,比如beautifulsoup和lxml,但是scrapy中默认使用selector。相对来说,最好用xpath来分析页面。你可以找来了解一下xpath 自己动手吧,单纯为爬虫做网页分析感觉不难。
(3)书的封面图片,获取地址后,可以选择保存在本地,但是因为我觉得不喜欢把图片上传到我PC上的mysql,总觉得那个不是很靠谱,就爬取它的地址,如果你写了网站,想使用这些图片,应该可以直接使用地址。
(4)出版商信息爬取部分,因为这是作者/出版商/日期/价格组成,我用正则表达式将收录“出版商”、“书店”等关键字的字符串提取出来,方便数据持久化后的数据分析。
6.数据处理
编写以下pipline.py
from itemadapter import ItemAdapter
import urllib.request
import os
import pymysql
class DoubanPipeline:
def process_item(self, item, spider):
#保存图片
# url = item['img_addr']
# req = urllib.request.Request(url)
# with urllib.request.urlopen(req) as pic:
# data = pic.read()
# file_name = os.path.join(r'D:\bookpic',item['name'] + '.jpg')
# with open(file_name, 'wb') as fp:
# fp.write(data)
#保存到数据库
info = [item['title'], item['score'], item['publish_detail'], item['slogan'], item['publish_house'], item['img_src'], item['detail_addr'], item['comment_people']]
connection = pymysql.connect(host='localhost', user='root', password='', database='', charset='utf8')
try:
with connection.cursor() as cursor:
sql = 'insert into app_book (title, score, publish_detail, slogan, publish_house, img_src, detail_addr, comment_people) values (%s, %s, %s, %s, %s, %s, %s, %s)'
affectedcount = cursor.execute(sql, info)
print('成功修改{0}条数据'.format(affectedcount))
connection.commit()
except pymysql.DatabaseError:
connection.rollback()
finally:
connection.close()
return item
7.设置部分
settings.py 增长以下内容
(1)设置处理返回数据的类和执行优先级
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 100,
}
(2)添加用户代理
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) G ecko/20100101 Firefox/52.0'
}
8.执行爬虫
输入命令scrapy crawl book,爬虫开始执行 查看全部
scrapy分页抓取网页(
什么是Scrapy二.准备环境三.大体设置数据存储模板)
Python爬虫学习的scrapy框架(一)爬取豆瓣书单
文章内容
html
Python爬虫学习的scrapy框架(一)爬取豆瓣书单
资源连接
一.什么是Scrapy
二.准备环境
三.一般流程
四.使用框架python
1.创建项目mysql
2.各部分正则表达式介绍
3.创建爬虫sql
4.设置数据存储模板数据库
5.分析网页,编写爬虫应用
6.数据处理框架
7.设置dom的一部分
8.执行scrapy
一.什么是Scrapy
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。写Python爬虫程序也不是不行,但是有框架可以用,何乐而不为呢?我相信Scrapy可以事半功倍。与请求相比,scrapy 更侧重于爬虫框架而不是页面下载。
二.准备环境
Scrapy爬虫需要库pypiwin32、lxml、twisted、scrapy、Microsoft Visual C++ 14.0以上编译环境
数据库链接模块pymysql,以上库我都是用pip安装的,我把清华大学的镜像源放在这里/simple
三.一般流程
首先,引擎从调度程序获取连接(URL)以进行下一次抓取
1. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
2. 然后,爬虫解析响应。
3.如果实体(Item)被解析,就会交给实体管道做进一步处理。
4.如果解析出来的是连接(URL),那么这个URL就会交给Scheduler等待爬取。
四.使用框架1.创建项目
使用命令scrapy startproject projectname
PS D:\pythonpractice> scrapy startproject douban
New Scrapy project 'douban', using template directory 'D:\python38install\Lib\site-packages\scrapy\templates\project', created in:
D:\pythonpractice\douban
You can start your first spider with:
cd douban
scrapy genspider example example.com
我用的是vscode,我用ctrl和·调用终端,输入命令,我要去爬豆瓣的一些页面,所以我把它命名为豆瓣,可以看到在你打开的文件夹下出现了一个新文件夹。名字是我做的
以后用cd豆瓣命令进入项目所在的文件夹
PS D:\pythonpractice> cd douban
PS D:\pythonpractice\douban>
2.各部分介绍
在项目文件夹中,可以看到还有一个和项目同名的文件夹,里面有一些文件,
1.items.py 负责创建数据模型,为结构化数据设置数据存储模板,如:Django Model
2.middlewares.py 是自己定义的中间件
3.pipelines.py 负责处理蜘蛛返回的数据,比如数据持久化
4.settings.py 负责整个爬虫的配置
5. spiders目录负责存放从scrapy继承而来的爬虫
6.scrapy.cfg 是scrapy的基本配置
3.构建爬虫
使用scrapy genspider [options] 构建自己的爬虫,
我输入了scrapy genspider来创建一个名为book的爬虫。域名部分是爬虫的范围,被爬取的网页不能超过这个域名。
4.设置数据存储模板
修改以下item.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
img_src = scrapy.Field()
score = scrapy.Field()
publish_house = scrapy.Field()
publish_detail = scrapy.Field()
slogan = scrapy.Field()
detail_addr = scrapy.Field()
comment_people = scrapy.Field()
5.分析网页,编写爬虫
打开网站链接:豆瓣阅读250强(/top250)
F12打开网页源代码,
能看结构就很清楚了,我需要的是这本书的资料,下面写book.py,
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['douban.com']
start_urls = ['https://book.douban.com/top250?start=0']
url_sets = set()
def parse(self, response):
if response.url.startswith('https://book.douban.com'):
seclectors = response.xpath('//div[@class="indent"]/table')
for seclector in seclectors:
item = DoubanItem()
item['title'] = seclector.xpath("./tr/td[2]/div/a/@title").extract()[0]
item['img_src'] = seclector.xpath("./tr/td[1]/a/img/@src").extract()[0]
item['publish_detail'] = seclector.xpath("./tr/td[2]/p[@class='pl']/text()").extract()[0]
item['score'] = seclector.xpath("./tr/td[2]/div[@class='star clearfix']/span[@class='rating_nums']/text()").extract()[0]
item['detail_addr'] = seclector.xpath("./tr/td[2]/div[@class='pl2']/a/@href").extract()[0]
#标语爬取
item['slogan'] = seclector.xpath("./tr/td[2]/p[@class='quote']/span/text()").get()
if item['slogan']:
pass
else:
item['slogan'] = '暂无信息'
#评论人数爬取
item['comment_people'] = seclector.xpath("./tr/td[2]/div[@class='star clearfix']/span[@class='pl']/text()").extract()[0]
comment = str(item['comment_people'])
rex = '[0-9]+'
num = re.findall(rex, comment)
if num:
item['comment_people'] = num[0]
else:
item['comment_people'] = '暂无信息'
#出版社爬取
t = str(item['publish_detail'])
s = t.encode() #进行字符串转义
temp = s.decode('utf-8')
pattern="[\u4e00-\u9fa5]*\u51fa\u7248[\u4e00-\u9fa5]*|[\u4e00-\u9fa5]*\u4E66\u5E97[\u4e00-\u9fa5]*" #中文 unicode编码出版 正则表达式
results = re.findall(pattern, temp) #匹配
if results:
item['publish_house'] = results[0]
else:
item['publish_house'] = '暂无信息'
yield item
#分页处理
urls = response.xpath("//div[@class='paginator']/span[@class='next']/a/@href").extract()
for url in urls:
if url.startswith('https://book.douban.com'):
if url in self.url_sets:
pass
else:
self.url_sets.add(url)
yield self.make_requests_from_url(url)
else:
pass
(1) 其中start_urls为起始页,后续页面从网页的pager中获取,但是如果网站使用js进行分页,则没有办法。
(2) 提取网页内容的方法有很多,比如beautifulsoup和lxml,但是scrapy中默认使用selector。相对来说,最好用xpath来分析页面。你可以找来了解一下xpath 自己动手吧,单纯为爬虫做网页分析感觉不难。
(3)书的封面图片,获取地址后,可以选择保存在本地,但是因为我觉得不喜欢把图片上传到我PC上的mysql,总觉得那个不是很靠谱,就爬取它的地址,如果你写了网站,想使用这些图片,应该可以直接使用地址。
(4)出版商信息爬取部分,因为这是作者/出版商/日期/价格组成,我用正则表达式将收录“出版商”、“书店”等关键字的字符串提取出来,方便数据持久化后的数据分析。
6.数据处理
编写以下pipline.py
from itemadapter import ItemAdapter
import urllib.request
import os
import pymysql
class DoubanPipeline:
def process_item(self, item, spider):
#保存图片
# url = item['img_addr']
# req = urllib.request.Request(url)
# with urllib.request.urlopen(req) as pic:
# data = pic.read()
# file_name = os.path.join(r'D:\bookpic',item['name'] + '.jpg')
# with open(file_name, 'wb') as fp:
# fp.write(data)
#保存到数据库
info = [item['title'], item['score'], item['publish_detail'], item['slogan'], item['publish_house'], item['img_src'], item['detail_addr'], item['comment_people']]
connection = pymysql.connect(host='localhost', user='root', password='', database='', charset='utf8')
try:
with connection.cursor() as cursor:
sql = 'insert into app_book (title, score, publish_detail, slogan, publish_house, img_src, detail_addr, comment_people) values (%s, %s, %s, %s, %s, %s, %s, %s)'
affectedcount = cursor.execute(sql, info)
print('成功修改{0}条数据'.format(affectedcount))
connection.commit()
except pymysql.DatabaseError:
connection.rollback()
finally:
connection.close()
return item
7.设置部分
settings.py 增长以下内容
(1)设置处理返回数据的类和执行优先级
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 100,
}
(2)添加用户代理
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) G ecko/20100101 Firefox/52.0'
}
8.执行爬虫
输入命令scrapy crawl book,爬虫开始执行
scrapy分页抓取网页(scrapy,分析源码结构分析页面html结构下载器流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-24 17:06
Scrapy内部提供了FilesPipeline来下载文件,我们可以把它看成一个特殊的下载器,只要传入要下载的文件的url,下载器就会自动将文件下载到本地
流程简单
我们用伪代码来说明下载过程,假设我们要下载如下页面的文件
GEM专辑
下载《偶尔》
下载《一路逆风》
下载《来自天堂的魔鬼》
下载上述mp3文件的步骤如下:
在settings.py中打开FilesPipeline并指定下载路径
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}
FILES_STORE = '/music_downloads'
FilesPipeline 应该放在其他 Item Pipeline 之前
Spider解析页面,提取要下载的url并赋值给item的file_urls字段
伪代码如下:
class DownloadMusicSpider(scrapy.Spider):
# ...
def parse(response):
item = {}
# 提取 url 组装成列表,并赋给 item 的 file_urls 字段
for url in response.xpath('//a/@href').extract():
download_url = response.urljoin(url)
item['file_urls'].append(download_url)
yield item
项目实际需求分析
是一个著名的python绘图库,每个例子都有对应的源码下载,如:
下载源代码
我们的需求是抓取matplotlib的示例代码,下载保存到本地
写代码前,使用scrapy shell分析源码结构
$ scrapy shell http://matplotlib.org/examples/index.html
# ...
In [1]: view(response) # 将页面下载到本地,分析其 html 结构
Out[1]: True
分析页面html结构
分析显示所有示例链接都在
在以下每个
在scrapy shell中提取链接
In [2]: from scrapy.linkextractors import LinkExtractor
In [3]: le = LinkExtractor(restrict_css='div.toctree-wrapper.compound li.toctree-l2')
In [4]: links = le.extract_links(response)
In [5]: [link.url for link in links]
Out[5]:
['https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
# ...
]
然后分析具体示例页面,提取下载源代码的url
In [6]: fetch('https://matplotlib.org/example ... 23x27;)
2019-07-21 22:15:22 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
In [7]: view(response)
Out[7]: True
下载页面html结构
分析显示下载url是在元素中获取的
In [8]: href = response.css('a.reference.external::attr(href)').extract_first()
In [9]: href
Out[9]: 'animate_decay.py'
In [10]: response.urljoin(href) # 组装成绝对地址
Out[10]: 'https://matplotlib.org/example ... 27%3B
实现项目创建的具体编码
本文参与腾讯云自媒体分享计划,欢迎您加入,与正在阅读的您分享。 查看全部
scrapy分页抓取网页(scrapy,分析源码结构分析页面html结构下载器流程)
Scrapy内部提供了FilesPipeline来下载文件,我们可以把它看成一个特殊的下载器,只要传入要下载的文件的url,下载器就会自动将文件下载到本地
流程简单
我们用伪代码来说明下载过程,假设我们要下载如下页面的文件
GEM专辑
下载《偶尔》
下载《一路逆风》
下载《来自天堂的魔鬼》
下载上述mp3文件的步骤如下:
在settings.py中打开FilesPipeline并指定下载路径
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}
FILES_STORE = '/music_downloads'
FilesPipeline 应该放在其他 Item Pipeline 之前
Spider解析页面,提取要下载的url并赋值给item的file_urls字段
伪代码如下:
class DownloadMusicSpider(scrapy.Spider):
# ...
def parse(response):
item = {}
# 提取 url 组装成列表,并赋给 item 的 file_urls 字段
for url in response.xpath('//a/@href').extract():
download_url = response.urljoin(url)
item['file_urls'].append(download_url)
yield item
项目实际需求分析
是一个著名的python绘图库,每个例子都有对应的源码下载,如:
下载源代码
我们的需求是抓取matplotlib的示例代码,下载保存到本地
写代码前,使用scrapy shell分析源码结构
$ scrapy shell http://matplotlib.org/examples/index.html
# ...
In [1]: view(response) # 将页面下载到本地,分析其 html 结构
Out[1]: True
分析页面html结构
分析显示所有示例链接都在
在以下每个
在scrapy shell中提取链接
In [2]: from scrapy.linkextractors import LinkExtractor
In [3]: le = LinkExtractor(restrict_css='div.toctree-wrapper.compound li.toctree-l2')
In [4]: links = le.extract_links(response)
In [5]: [link.url for link in links]
Out[5]:
['https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
'https://matplotlib.org/example ... 27%3B,
# ...
]
然后分析具体示例页面,提取下载源代码的url
In [6]: fetch('https://matplotlib.org/example ... 23x27;)
2019-07-21 22:15:22 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
In [7]: view(response)
Out[7]: True
下载页面html结构
分析显示下载url是在元素中获取的
In [8]: href = response.css('a.reference.external::attr(href)').extract_first()
In [9]: href
Out[9]: 'animate_decay.py'
In [10]: response.urljoin(href) # 组装成绝对地址
Out[10]: 'https://matplotlib.org/example ... 27%3B
实现项目创建的具体编码
本文参与腾讯云自媒体分享计划,欢迎您加入,与正在阅读的您分享。
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-21 08:15
豆瓣日记:WebScraper怎么对付这种类型的网页(组图))
图片
这是简单数据分析系列文章的第12篇。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据. 今天我们讲的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
图片
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
图片
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
图片
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,让我们看一下第1页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发页面的URL是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
图片
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
图片
容器的预览如下图所示:
图片
寻呼机选择的过程如下图所示:
图片
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
图片
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。URL的反爬虫系统(比如突然弹出验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第二页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
寻呼机是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页(组图))
图片
这是简单数据分析系列文章的第12篇。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据. 今天我们讲的是一种比较常见的翻页机。
我想解释什么叫做寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
图片
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
图片
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
图片
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,让我们看一下第1页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
#_rnd36
第 3 页上的参数是 #_rnd39
#_rnd39
第 4 页上的参数是 #_rnd76:
#_rnd76
多看几个链接,可以发现这个转发页面的URL是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
图片
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
图片
容器的预览如下图所示:
图片
寻呼机选择的过程如下图所示:
图片
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
图片
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。URL的反爬虫系统(比如突然弹出验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后,当翻页时,设置一个新的计数器,第二页结束。一条数据还是980,翻页计数器复位,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
寻呼机是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(PythonScrapy爬虫框架很久了,、Pycharm框架详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-18 09:00
想长期学习Python Scrapy爬虫框架。最近通过在线课程对Scrapy有了初步的了解。使用的工具主要是Anaconda3、Pycharm。现在我分享以下内容:
顾名思义,爬虫是一种自动抓取互联网信息的程序。通过此程序后,您可以使用互联网数据来分析和开发产品。
URL管理模块:对计划爬取或已经爬取的URL进行管理。网页下载模块:访问和下载URL管理模块中指定的URL。网页分析模块:解析网页下载模块中的URL,处理或保存数据。如果解析URL继续爬取,则返回URL管理模块继续循环。一个开源的 Python 爬虫框架,用于爬取网站并从页面中提取结果。快速而强大,只需编写少量代码即可完成抓取任务。安装: conda install -c conda-forge scrapy。检查是否安装成功:scrapy bench通用开发及编写步骤(1)创建项目:scrapy startproject教程(自定义名称)(2)define Item,Construct crawled objects(1)
项目介绍:通过Python Scrapy框架抓取pm25.in上全国各大城市的空气质量数据,下载到本地CSV文件中。
项目第一步:创建项目。在项目文件夹的DOS命令行输入scrapy startproject教程,目录下会生成如下文件,包括蜘蛛、项目、管道、设置等基本重要文件:
创建项目教程
项目第二步:通过对网站的查看和初步分析,找到感兴趣的数据字段,定义ITEM,根据项目需要获取的数据字段定义Item,即定义类城市项目。
使用浏览器工具对网页和字段进行初步分析
编写items.py程序
项目第三步:创建一个Spider。在命令行界面下输入scrapy genspider aqispider pm25.in,框架会根据这个命令根据基础模板生成aqi_spider
项目第四步:编写AqiSpider的主程序,即网页下载和网页分析。
编写主程序最重要的解析函数
def parse(self,response):
bs = BeautifulSoup(response.body,'lxml') #通过BeautifulSoup函数解析网页内容
div_obj = bs.find('div',class_='all') #获取目标对象的div
li_tag_list = div_obj.find_all('li') #获取包含城市名称和链接的div
for li_tag in li_tag_list:
city_item = CityItem() #定义一个CityItem对象
city_item['city_name'] = li_tag.find('a').text #获取城市名
city_link = 'http://www.pm25.in' + li_tag.find('a')['href'] #由于该网页中href对应的是一个部分二级链接地址,因此需要拼接完整地址
city_item['city_link'] = city_link #保存链接到链接字段
yield scrapy.Request(city_link, #通过该语句跳转至二级链接的解析
meta={'item':city_item}, #利用meta来传递CityItem对象
callback = self.parse_city_link, #通过callback调用二级网址解析函数parse_city_link
dont_filter = True)
def parse_city_link(self,response):
city_item = response.meta['item']
bs = BeautifulSoup(response.body,'lxml')
print('正在爬取',city_item['city_name'])
data_div_tag = bs.find('div',class_='span12 data')
value_div_tag_list = data_div_tag.find_all('div',class_='value')
city_item['aqi'] = float(value_div_tag_list[0].text)
city_item['pm2S'] = float(value_div_tag_list[1].text)
city_item['pm10'] = float(value_div_tag_list[2].text)
city_item['co'] = float(value_div_tag_list[3].text)
city_item['no2'] = float(value_div_tag_list[4].text)
city_item['o3_1h'] = float(value_div_tag_list[5].text)
city_item['o3_8h'] = float(value_div_tag_list[6].text)
city_item['so2'] = float(value_div_tag_list[7].text)
yield city_item #利用yield爬取出各项数据。
项目第五步:如果要将爬取到的数据导出为csv文件,需要编写并配置一个Pipeline。必须先在设置文件中进行配置,注意设置语句中有一个“300”。这是指多个管道的优先级。数字越小,优先级越高。然后编写管道函数。基本上scrapy的pipeline功能写的差不多,可以复制重复使用。
项目最后:在命令行输入scrapy crawl aqi_spider执行爬虫,可以打开导出的csv文件,发现是乱码。那是因为csv的编码格式与utf-8不同,所以如果出现中文乱码,只需在弹出的“数据”--“从Text/csv导入”文本框中选择编码为utf即可Excel软件导航-8就可以解决了,到此为止,通过scrapy框架已经弯曲了一个简单的数据爬虫。
愉快充实的学习经历,期待更深入的爬虫之旅~! 查看全部
scrapy分页抓取网页(PythonScrapy爬虫框架很久了,、Pycharm框架详解)
想长期学习Python Scrapy爬虫框架。最近通过在线课程对Scrapy有了初步的了解。使用的工具主要是Anaconda3、Pycharm。现在我分享以下内容:
顾名思义,爬虫是一种自动抓取互联网信息的程序。通过此程序后,您可以使用互联网数据来分析和开发产品。
URL管理模块:对计划爬取或已经爬取的URL进行管理。网页下载模块:访问和下载URL管理模块中指定的URL。网页分析模块:解析网页下载模块中的URL,处理或保存数据。如果解析URL继续爬取,则返回URL管理模块继续循环。一个开源的 Python 爬虫框架,用于爬取网站并从页面中提取结果。快速而强大,只需编写少量代码即可完成抓取任务。安装: conda install -c conda-forge scrapy。检查是否安装成功:scrapy bench通用开发及编写步骤(1)创建项目:scrapy startproject教程(自定义名称)(2)define Item,Construct crawled objects(1)
项目介绍:通过Python Scrapy框架抓取pm25.in上全国各大城市的空气质量数据,下载到本地CSV文件中。
项目第一步:创建项目。在项目文件夹的DOS命令行输入scrapy startproject教程,目录下会生成如下文件,包括蜘蛛、项目、管道、设置等基本重要文件:
创建项目教程
项目第二步:通过对网站的查看和初步分析,找到感兴趣的数据字段,定义ITEM,根据项目需要获取的数据字段定义Item,即定义类城市项目。
使用浏览器工具对网页和字段进行初步分析
编写items.py程序
项目第三步:创建一个Spider。在命令行界面下输入scrapy genspider aqispider pm25.in,框架会根据这个命令根据基础模板生成aqi_spider
项目第四步:编写AqiSpider的主程序,即网页下载和网页分析。
编写主程序最重要的解析函数
def parse(self,response):
bs = BeautifulSoup(response.body,'lxml') #通过BeautifulSoup函数解析网页内容
div_obj = bs.find('div',class_='all') #获取目标对象的div
li_tag_list = div_obj.find_all('li') #获取包含城市名称和链接的div
for li_tag in li_tag_list:
city_item = CityItem() #定义一个CityItem对象
city_item['city_name'] = li_tag.find('a').text #获取城市名
city_link = 'http://www.pm25.in' + li_tag.find('a')['href'] #由于该网页中href对应的是一个部分二级链接地址,因此需要拼接完整地址
city_item['city_link'] = city_link #保存链接到链接字段
yield scrapy.Request(city_link, #通过该语句跳转至二级链接的解析
meta={'item':city_item}, #利用meta来传递CityItem对象
callback = self.parse_city_link, #通过callback调用二级网址解析函数parse_city_link
dont_filter = True)
def parse_city_link(self,response):
city_item = response.meta['item']
bs = BeautifulSoup(response.body,'lxml')
print('正在爬取',city_item['city_name'])
data_div_tag = bs.find('div',class_='span12 data')
value_div_tag_list = data_div_tag.find_all('div',class_='value')
city_item['aqi'] = float(value_div_tag_list[0].text)
city_item['pm2S'] = float(value_div_tag_list[1].text)
city_item['pm10'] = float(value_div_tag_list[2].text)
city_item['co'] = float(value_div_tag_list[3].text)
city_item['no2'] = float(value_div_tag_list[4].text)
city_item['o3_1h'] = float(value_div_tag_list[5].text)
city_item['o3_8h'] = float(value_div_tag_list[6].text)
city_item['so2'] = float(value_div_tag_list[7].text)
yield city_item #利用yield爬取出各项数据。
项目第五步:如果要将爬取到的数据导出为csv文件,需要编写并配置一个Pipeline。必须先在设置文件中进行配置,注意设置语句中有一个“300”。这是指多个管道的优先级。数字越小,优先级越高。然后编写管道函数。基本上scrapy的pipeline功能写的差不多,可以复制重复使用。
项目最后:在命令行输入scrapy crawl aqi_spider执行爬虫,可以打开导出的csv文件,发现是乱码。那是因为csv的编码格式与utf-8不同,所以如果出现中文乱码,只需在弹出的“数据”--“从Text/csv导入”文本框中选择编码为utf即可Excel软件导航-8就可以解决了,到此为止,通过scrapy框架已经弯曲了一个简单的数据爬虫。
愉快充实的学习经历,期待更深入的爬虫之旅~!
scrapy分页抓取网页( 自动爬取网页存储代码如下:.py:属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-12-17 08:28
自动爬取网页存储代码如下:.py:属性)
最后得到生成的网页链接。并致电请求重新申请此网页的数据
所以在管道中。我们还需要修改存储的代码。具体如下。您可以看到这里没有使用JSON,直接打开txt文件进行存储
class Test1Pipeline(object):
def __init__(self):
self.file=''
def process_item(self, item, spider):
self.file=open(r'E:\scrapy_project\xiaoshuo.txt','wb')
self.file.write(item['content'])
self.file.close()
return item
完整的代码如下:这里需要注意两次yield的用法。在第一次屈服后,它将自动转到test1pipeline进行数据存储,然后在存储后获得下一个网页。然后通过请求获取下一个网页的内容
class testSpider(Spider):
name="test1"
allowd_domains=['http://www.xunsee.com']
start_urls=["http://www.xunread.com/article ... ot%3B]
def parse(self, response):
init_urls="http://www.xunread.com/article ... ot%3B
sel=Selector(response)
context=''
content=sel.xpath('//div[@id="content_1"]/text()').extract()
for c in content:
context=context+c.encode('utf-8')
items=Test1Item()
items['content']=context
count = len(sel.xpath('//div[@id="nav_1"]/a').extract())
if count > 2:
next_link=sel.xpath('//div[@id="nav_1"]/a')[2].xpath('@href').extract()
else:
next_link=sel.xpath('//div[@id="nav_1"]/a')[1].xpath('@href').extract()
yield items
for n in next_link:
url=init_urls+'/'+n
print url
yield Request(url,callback=self.parse)
有一种更方便的自动抓取网页的方法:crawlespider
前面描述的爬行器只能在URL中的开始网页上进行解析。虽然自动爬行的规则也在前一章中实现。但有点负责任。爬行爬行器可用于自动抓取划痕中的网页
爬行规则的原型如下:
上流社会的。contrib。蜘蛛。规则(link\u提取器,callback=None,cb\u kwargs=None,follow=None,process\u links=None,process\u request=None)
链接抽取器:它的功能是定义如何从已爬网的页面中提取链接
Callback指的是一个调用函数,每当从linkextractor获取链接时,都会调用该函数进行处理。回调函数接受响应作为第一个参数。注意:使用crawlespider时,不允许将parse作为回调函数。因为crawlspider使用parse方法来实现逻辑,所以使用parse函数将导致调用失败
Follow是一个判断值,指示是否需要跟踪从响应中提取的链接
以scratch shell中的提取为例
LinkedExtractor中的Allow仅适用于href属性:
例如,以下链接仅提取href属性的正则表达式
结构如下:您可以获得各种链接
您可以使用restrict\uxpath对每个链接进行如下限制:
示例2:以前面的xunread网络为例
提取网页中下一节的地址:
网址: 查看全部
scrapy分页抓取网页(
自动爬取网页存储代码如下:.py:属性)
最后得到生成的网页链接。并致电请求重新申请此网页的数据
所以在管道中。我们还需要修改存储的代码。具体如下。您可以看到这里没有使用JSON,直接打开txt文件进行存储
class Test1Pipeline(object):
def __init__(self):
self.file=''
def process_item(self, item, spider):
self.file=open(r'E:\scrapy_project\xiaoshuo.txt','wb')
self.file.write(item['content'])
self.file.close()
return item
完整的代码如下:这里需要注意两次yield的用法。在第一次屈服后,它将自动转到test1pipeline进行数据存储,然后在存储后获得下一个网页。然后通过请求获取下一个网页的内容
class testSpider(Spider):
name="test1"
allowd_domains=['http://www.xunsee.com']
start_urls=["http://www.xunread.com/article ... ot%3B]
def parse(self, response):
init_urls="http://www.xunread.com/article ... ot%3B
sel=Selector(response)
context=''
content=sel.xpath('//div[@id="content_1"]/text()').extract()
for c in content:
context=context+c.encode('utf-8')
items=Test1Item()
items['content']=context
count = len(sel.xpath('//div[@id="nav_1"]/a').extract())
if count > 2:
next_link=sel.xpath('//div[@id="nav_1"]/a')[2].xpath('@href').extract()
else:
next_link=sel.xpath('//div[@id="nav_1"]/a')[1].xpath('@href').extract()
yield items
for n in next_link:
url=init_urls+'/'+n
print url
yield Request(url,callback=self.parse)
有一种更方便的自动抓取网页的方法:crawlespider
前面描述的爬行器只能在URL中的开始网页上进行解析。虽然自动爬行的规则也在前一章中实现。但有点负责任。爬行爬行器可用于自动抓取划痕中的网页
爬行规则的原型如下:
上流社会的。contrib。蜘蛛。规则(link\u提取器,callback=None,cb\u kwargs=None,follow=None,process\u links=None,process\u request=None)
链接抽取器:它的功能是定义如何从已爬网的页面中提取链接
Callback指的是一个调用函数,每当从linkextractor获取链接时,都会调用该函数进行处理。回调函数接受响应作为第一个参数。注意:使用crawlespider时,不允许将parse作为回调函数。因为crawlspider使用parse方法来实现逻辑,所以使用parse函数将导致调用失败
Follow是一个判断值,指示是否需要跟踪从响应中提取的链接
以scratch shell中的提取为例
LinkedExtractor中的Allow仅适用于href属性:
例如,以下链接仅提取href属性的正则表达式
结构如下:您可以获得各种链接
您可以使用restrict\uxpath对每个链接进行如下限制:
示例2:以前面的xunread网络为例
提取网页中下一节的地址:
网址:
scrapy分页抓取网页(1-4-104.10模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-17 01:26
1-4-5 4.5_Construct 请求对象
1-4-6 4.6_URL 编码转换
1-4-7 4.7_Processing GET 请求
1-4-8 4.8_处理POST请求
1-4-9 4.9_添加特定的Headers——请求伪装
1-4-10 4.10_简单的自定义开瓶器
1-4-11 4.11_设置代理服务器
1-4-12 4.12_timeout 设置
1-4-13 4.13_URLError 异常及捕获
1-4-14 4.14_HttpError 异常和捕获
1-4-15 4.15_请求库是什么
1-4-16 4.16_requests 库发送请求
1-4-17 4.17_requests 库返回响应
1-5 数据分析
1-5-1 5.1_网页数据格式
1-5-2 5.2_查看页面结构
1-5-3 5.3_数据分析技术
1-5-4 5.4_正则表达式备份
1-5-5 5.5_什么是Xpath备份
1-5-6 5.6_XPath 开发工具
1-5-7 5.7_XPath 语法
1-5-8 5.8_什么是lxml库
1-5-9 5.9_lxml 的基本使用
1-5-10 5.10_什么是BeautifulSoup
1-5-11 5.11_构建一个 BeautifulSoup 对象
1-5-12 5.12_按操作方法检索
1-5-13 5.13_通过 CSS 选择器搜索
1-5-14 5.14_什么是JSON0
1-5-15 5.15_JSON 与 XML 语言对比
1-5-16 5.16_json 模块介绍
1-5-17 5.17_json 模块的基本使用
1-5-18 5.18_jsonpath 介绍
1-5-19 5.19_JSONPath 和 XPath 语法对比
1-6 并发下载
1-6-1 6.1_多线程爬虫进程分析
1-6-2 6.2_queue(队列)模块介绍
1-6-3 6.3_Queue类介绍
1-6-4 6.4_协程爬虫的进程解析
1-6-5 6.5_第三方库gevent
1-7 获取动态内容
1-7-1 7.1_动态网页介绍
1-7-2 7.2_selenium 和 PhantomJS 概述
1-7-3 7.3_selenium_PhantomJS 安装配置
1-7-4 7.4_开始使用
1-7-5 7.5_定位页面元素
1-7-6 7.6_鼠标动作链
1-7-7 7.7_填写表格
1-7-8 7.8_pop-up 处理
1-7-9 7.9_pop-up 处理
1-7-10 7.10_向前和向后翻页
1-7-11 7.11_获取页面 Cookie
1-7-12 7.12_page 等待
1-8 图像识别与文字处理
1-8-1 8.1_OCR 技术介绍
1-8-2 8.2_tesseract 下载安装
1-8-3 8.3_tesseract 下载安装
1-8-4 8.4_PIL 库介绍
1-8-5 8.5_读取图片中的格式化文本
1-8-6 8.6_对图像进行阈值滤波和降噪处理
1-8-7 8.7_识别图片中的汉字
1-8-8 8.8_验证码分类
1-8-9 8.9_简易识别图文验证码
1-9 存储爬虫数据
1-9-1 9.1_数据存储介绍
1-9-2 9.2_什么是MongoDB
1-9-3 9.3_在Windows平台上安装MongoDB数据库
1-9-4 9.4_MongoDB 和 MySQL 的术语比较
1-9-5 9.5_什么是 PyMongo
1-9-6 9.6_PyMongo 基本操作
8 P1 c; n,`" Y/ v#@
1-10 初识爬虫框架Scrapy
1-10-1 10.1_常见爬虫框架介绍
1-10-2 10.2_Scrapy 框架架构
1-10-3 10.3_Scrapy框架运行流程
1-10-4 10.4_安装 Scrapy 框架
1-10-5 10.5_新建一个 Scrapy 项目
1-10-6 10.6_清除抓取目标
1-10-7 10.7_让蜘蛛抓取网页
1-10-8 10.8_永久存储数据
1-11 Scrapy 终端及核心组件
1-11-1 11.1_Enable Scrapy shell
1-11-2 11.2_使用 Scrapy shell
1-11-3 11.3_Spiders——抓取和提取结构化数据
1-11-4 11.4_自定义项目管道
1-11-5 11.5_Downloader Middlewares——防止反爬虫
1-11-6 11.6_Settings——自定义 Scrapy 组件
1-12个自动抓取网页的CrawlSpider
1-12-1 12.1_第一次认识CrawlSpider
1-12-2 12.2_CrawlSpider 类的工作原理
1-12-3 12.3_通过Rule类确定爬取规则
1-12-4 12.4_通过LinkExtractor类提取链接
1-13 Scrapy-Redis 分布式爬虫
1-13-1 13.1_Scrapy-Redis 介绍
1-13-2 13.2_Scrapy-Redis 完整架构
1-13-3 13.3_Scrapy-Redis 操作流程
1-13-4 13.4_Scrapy-Redis 的主要组成部分
1-13-5 13.5_安装 Scrapy-Redis
1-13-6 13.6_安装并启动Redis数据库
1-13-7 13.7_修改配置文件redis.conf
1-13-8 13.8_分布式策略
1-13-9 13.9_测试slave端远程连接Master端
1-13-10 13.10_创建一个Scrapy项目并设置Scrapy-Redis组件
1-13-11 13.11_清除抓取目标
1-13-12 13.12_make 蜘蛛抓取网页
1-13-13 13.13_执行分布式爬虫
1-13-14 13.14_使用多管道存储
1-13-15 13.15_处理Redis数据库中的数据 查看全部
scrapy分页抓取网页(1-4-104.10模块)
1-4-5 4.5_Construct 请求对象
1-4-6 4.6_URL 编码转换
1-4-7 4.7_Processing GET 请求
1-4-8 4.8_处理POST请求
1-4-9 4.9_添加特定的Headers——请求伪装
1-4-10 4.10_简单的自定义开瓶器
1-4-11 4.11_设置代理服务器
1-4-12 4.12_timeout 设置
1-4-13 4.13_URLError 异常及捕获
1-4-14 4.14_HttpError 异常和捕获
1-4-15 4.15_请求库是什么
1-4-16 4.16_requests 库发送请求
1-4-17 4.17_requests 库返回响应
1-5 数据分析
1-5-1 5.1_网页数据格式
1-5-2 5.2_查看页面结构
1-5-3 5.3_数据分析技术
1-5-4 5.4_正则表达式备份
1-5-5 5.5_什么是Xpath备份
1-5-6 5.6_XPath 开发工具
1-5-7 5.7_XPath 语法
1-5-8 5.8_什么是lxml库
1-5-9 5.9_lxml 的基本使用
1-5-10 5.10_什么是BeautifulSoup
1-5-11 5.11_构建一个 BeautifulSoup 对象
1-5-12 5.12_按操作方法检索
1-5-13 5.13_通过 CSS 选择器搜索
1-5-14 5.14_什么是JSON0
1-5-15 5.15_JSON 与 XML 语言对比
1-5-16 5.16_json 模块介绍
1-5-17 5.17_json 模块的基本使用
1-5-18 5.18_jsonpath 介绍
1-5-19 5.19_JSONPath 和 XPath 语法对比
1-6 并发下载
1-6-1 6.1_多线程爬虫进程分析
1-6-2 6.2_queue(队列)模块介绍
1-6-3 6.3_Queue类介绍
1-6-4 6.4_协程爬虫的进程解析
1-6-5 6.5_第三方库gevent
1-7 获取动态内容
1-7-1 7.1_动态网页介绍
1-7-2 7.2_selenium 和 PhantomJS 概述
1-7-3 7.3_selenium_PhantomJS 安装配置
1-7-4 7.4_开始使用
1-7-5 7.5_定位页面元素
1-7-6 7.6_鼠标动作链
1-7-7 7.7_填写表格
1-7-8 7.8_pop-up 处理
1-7-9 7.9_pop-up 处理
1-7-10 7.10_向前和向后翻页
1-7-11 7.11_获取页面 Cookie
1-7-12 7.12_page 等待
1-8 图像识别与文字处理
1-8-1 8.1_OCR 技术介绍
1-8-2 8.2_tesseract 下载安装
1-8-3 8.3_tesseract 下载安装
1-8-4 8.4_PIL 库介绍
1-8-5 8.5_读取图片中的格式化文本
1-8-6 8.6_对图像进行阈值滤波和降噪处理
1-8-7 8.7_识别图片中的汉字
1-8-8 8.8_验证码分类
1-8-9 8.9_简易识别图文验证码
1-9 存储爬虫数据
1-9-1 9.1_数据存储介绍
1-9-2 9.2_什么是MongoDB
1-9-3 9.3_在Windows平台上安装MongoDB数据库
1-9-4 9.4_MongoDB 和 MySQL 的术语比较
1-9-5 9.5_什么是 PyMongo
1-9-6 9.6_PyMongo 基本操作
8 P1 c; n,`" Y/ v#@
1-10 初识爬虫框架Scrapy
1-10-1 10.1_常见爬虫框架介绍
1-10-2 10.2_Scrapy 框架架构
1-10-3 10.3_Scrapy框架运行流程
1-10-4 10.4_安装 Scrapy 框架
1-10-5 10.5_新建一个 Scrapy 项目
1-10-6 10.6_清除抓取目标
1-10-7 10.7_让蜘蛛抓取网页
1-10-8 10.8_永久存储数据
1-11 Scrapy 终端及核心组件
1-11-1 11.1_Enable Scrapy shell
1-11-2 11.2_使用 Scrapy shell
1-11-3 11.3_Spiders——抓取和提取结构化数据
1-11-4 11.4_自定义项目管道
1-11-5 11.5_Downloader Middlewares——防止反爬虫
1-11-6 11.6_Settings——自定义 Scrapy 组件
1-12个自动抓取网页的CrawlSpider
1-12-1 12.1_第一次认识CrawlSpider
1-12-2 12.2_CrawlSpider 类的工作原理
1-12-3 12.3_通过Rule类确定爬取规则
1-12-4 12.4_通过LinkExtractor类提取链接
1-13 Scrapy-Redis 分布式爬虫
1-13-1 13.1_Scrapy-Redis 介绍
1-13-2 13.2_Scrapy-Redis 完整架构
1-13-3 13.3_Scrapy-Redis 操作流程
1-13-4 13.4_Scrapy-Redis 的主要组成部分
1-13-5 13.5_安装 Scrapy-Redis
1-13-6 13.6_安装并启动Redis数据库
1-13-7 13.7_修改配置文件redis.conf
1-13-8 13.8_分布式策略
1-13-9 13.9_测试slave端远程连接Master端
1-13-10 13.10_创建一个Scrapy项目并设置Scrapy-Redis组件
1-13-11 13.11_清除抓取目标
1-13-12 13.12_make 蜘蛛抓取网页
1-13-13 13.13_执行分布式爬虫
1-13-14 13.14_使用多管道存储
1-13-15 13.15_处理Redis数据库中的数据
scrapy分页抓取网页(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-14 12:06
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview自带的分页功能,点击页面时分页号的时候,你会发现url地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")。等等,这种形式的代码其实也不是很难,因为毕竟找页码的规则是有地方的。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个javascript自动生成页面的方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,再逐页翻页。爬行的。 查看全部
scrapy分页抓取网页(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview自带的分页功能,点击页面时分页号的时候,你会发现url地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")。等等,这种形式的代码其实也不是很难,因为毕竟找页码的规则是有地方的。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个javascript自动生成页面的方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,再逐页翻页。爬行的。
scrapy分页抓取网页(第三方工具使用工具的方法和内容的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-14 12:05
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方法:通过asp.NET开发的网站可能经常遇到。它的分页控件通过post向后端代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页页码时,你会发现URL地址没有变,而是页码变了,页面内容也变了。仔细看会发现,当鼠标移到每个页码上时,状态栏会显示:__dopostback("gridview","page1")等等。这种形式的代码其实也不是很难,因为毕竟是有找页码规则的地方的。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
抓取这种页面需要注意asp.Net页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个javascript自动生成页面的方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,您可以使用WebBroser 控件来实现您可以在IE 中操作网页的任何功能,因此当然可以单击翻页按钮。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。呵呵 查看全部
scrapy分页抓取网页(第三方工具使用工具的方法和内容的区别)
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方法:通过asp.NET开发的网站可能经常遇到。它的分页控件通过post向后端代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页页码时,你会发现URL地址没有变,而是页码变了,页面内容也变了。仔细看会发现,当鼠标移到每个页码上时,状态栏会显示:__dopostback("gridview","page1")等等。这种形式的代码其实也不是很难,因为毕竟是有找页码规则的地方的。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
抓取这种页面需要注意asp.Net页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个javascript自动生成页面的方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,您可以使用WebBroser 控件来实现您可以在IE 中操作网页的任何功能,因此当然可以单击翻页按钮。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。呵呵
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-13 10:29
先看Scrapy
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
本文档将介绍 Scrapy 背后的概念,让您了解其工作原理,并确定 Scrapy 是否是您所需要的。
当你准备好开始你的项目时,你可以参考它。
选择一个网站
当你需要从某个网站获取信息,但是网站没有提供API或者通过程序获取信息的机制,Scrapy可以帮到你。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
可以在此页面上找到今天添加的种子列表:
定义要爬取的数据
第一步是定义我们需要爬取的数据。在 Scrapy 中,这是通过的。(在这个例子中,它是种子文件)
我们定义的Item:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写蜘蛛。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过观察页面的内容,可以发现所有种子的URL都是相似的。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式:/tor/\d+。
我们使用 XPath 从页面的 HTML 源代码中选择要提取的数据。以其中一个种子文件的页面为例:
观察 HTML 页面源代码并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以发现标签中收录了文件名:
Darwin - The Evolution Of An Exhibition
对应于此的XPath表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取描述:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
用于选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的详细信息,请参阅 XPath 参考。
最后结合上面的内容给出spider的代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
TorrentItem 的定义在。
执行spider获取数据
最后,我们可以运行spider获取网站的数据,并以JSON格式保存在scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您还可以将项目写入并存储在数据库中。
查看提取的数据
执行后,查看scraped_data.json,会看到解压出来的item:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是列表,所以所有的值都存储在列表中(除了url是直接赋值的)。如果您想保存单个数据或对数据执行其他处理,这就是它发挥作用的地方。
还有什么?
您已经学习了如何通过 Scrapy 从存储的网页中提取信息,但这只是冰山一角。Scrapy 提供了很多强大的功能,让爬取更容易、更高效,例如:
对于非英语语言的非标准或错误编码声明,提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加速爬虫创建的同时,让大型项目中的代码更加一致。有关详细信息,请参阅命令。为多个爬虫下的性能评估和故障检测提供可扩展性。提供,为您测试XPath表达式,编写和调试爬虫,简化生产环境中的部署和操作提供了极大的便利。内置,以便您可以监控和控制您的机器。内置,通过在 Scrapy 进程中钩入 Python 终端,可以查看和调试爬虫。方便您在抓取过程中捕捉错误。支持站点地图。使用缓存抓取 DNS 解析器
下一个
下一步当然是下载Scrapy,你可以阅读它并加入社区。谢谢您的支持!
讨论 查看全部
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
先看Scrapy
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。
它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
本文档将介绍 Scrapy 背后的概念,让您了解其工作原理,并确定 Scrapy 是否是您所需要的。
当你准备好开始你的项目时,你可以参考它。
选择一个网站
当你需要从某个网站获取信息,但是网站没有提供API或者通过程序获取信息的机制,Scrapy可以帮到你。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
可以在此页面上找到今天添加的种子列表:
定义要爬取的数据
第一步是定义我们需要爬取的数据。在 Scrapy 中,这是通过的。(在这个例子中,它是种子文件)
我们定义的Item:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写蜘蛛。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过观察页面的内容,可以发现所有种子的URL都是相似的。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式:/tor/\d+。
我们使用 XPath 从页面的 HTML 源代码中选择要提取的数据。以其中一个种子文件的页面为例:
观察 HTML 页面源代码并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以发现标签中收录了文件名:
Darwin - The Evolution Of An Exhibition
对应于此的XPath表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取描述:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
用于选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的详细信息,请参阅 XPath 参考。
最后结合上面的内容给出spider的代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
TorrentItem 的定义在。
执行spider获取数据
最后,我们可以运行spider获取网站的数据,并以JSON格式保存在scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您还可以将项目写入并存储在数据库中。
查看提取的数据
执行后,查看scraped_data.json,会看到解压出来的item:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是列表,所以所有的值都存储在列表中(除了url是直接赋值的)。如果您想保存单个数据或对数据执行其他处理,这就是它发挥作用的地方。
还有什么?
您已经学习了如何通过 Scrapy 从存储的网页中提取信息,但这只是冰山一角。Scrapy 提供了很多强大的功能,让爬取更容易、更高效,例如:
对于非英语语言的非标准或错误编码声明,提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加速爬虫创建的同时,让大型项目中的代码更加一致。有关详细信息,请参阅命令。为多个爬虫下的性能评估和故障检测提供可扩展性。提供,为您测试XPath表达式,编写和调试爬虫,简化生产环境中的部署和操作提供了极大的便利。内置,以便您可以监控和控制您的机器。内置,通过在 Scrapy 进程中钩入 Python 终端,可以查看和调试爬虫。方便您在抓取过程中捕捉错误。支持站点地图。使用缓存抓取 DNS 解析器
下一个
下一步当然是下载Scrapy,你可以阅读它并加入社区。谢谢您的支持!
讨论
scrapy分页抓取网页(python脚本获取指定用户的所有图像.body)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-10 13:03
作为练习,我决定编写一个python脚本来获取指定用户的所有图像。我对 Scrapy 有点熟悉,这也是我选择它作为爬虫的原因。目前,该脚本只能从第一页(最多 12 个)下载图像。
据我所知,instagram 页面是由 javascript 生成的。 Scrapy 的 response.body(类似于从 Chrome 查看的源代码)不像 Chrome 的 Inspector 那样显示 html 结构。在Chrome中,在12张图片后,底部有一个带有下一页链接的按钮。
例如,/instagram。第 2 页上的链接是 /instagram/?max_id=51632610。在第 2 页上,有一个指向第 3 页的链接,地址为 max_id=57754444 。
我如何在 Scrapy 中获得这个数字,以便我可以将我的蜘蛛发送到那里? response.body 甚至不收录该数字。有没有其他方法可以进入下一页?
我知道 Instagram API 会提供一些好处,但我认为它可以在没有所有这些令牌的情况下完成。 查看全部
scrapy分页抓取网页(python脚本获取指定用户的所有图像.body)
作为练习,我决定编写一个python脚本来获取指定用户的所有图像。我对 Scrapy 有点熟悉,这也是我选择它作为爬虫的原因。目前,该脚本只能从第一页(最多 12 个)下载图像。
据我所知,instagram 页面是由 javascript 生成的。 Scrapy 的 response.body(类似于从 Chrome 查看的源代码)不像 Chrome 的 Inspector 那样显示 html 结构。在Chrome中,在12张图片后,底部有一个带有下一页链接的按钮。
例如,/instagram。第 2 页上的链接是 /instagram/?max_id=51632610。在第 2 页上,有一个指向第 3 页的链接,地址为 max_id=57754444 。
我如何在 Scrapy 中获得这个数字,以便我可以将我的蜘蛛发送到那里? response.body 甚至不收录该数字。有没有其他方法可以进入下一页?
我知道 Instagram API 会提供一些好处,但我认为它可以在没有所有这些令牌的情况下完成。
scrapy分页抓取网页(Scrapy框架介绍架构图安装Scrapy使用爬虫使用使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-07 04:26
scrapy框架简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
Scrapy框架:用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了Twisted(其主要对手是Tornado)多线程异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
粗糙结构图
Scrapy主要包括了以下组件:
Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):
它负责接受`引擎`发送过来的Request请求,并按照一定的方式进行整理排列,入队,当`引擎`需要时,交还给`引擎`。
Downloader(下载器):
负责下载`Scrapy Engine(引擎)`发送的所有Requests请求,并将其获取到的Responses交还给`Scrapy Engine(引擎)`,由`引擎`交给`Spider`来处理,
Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给`引擎`,再次进入`Scheduler(调度器)`,
Item Pipeline(管道):
它负责处理`Spider`中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):
你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):
你可以理解为是一个可以自定扩展和操作`引擎`和`Spider`中间`通信`的功能组件(比如进入`Spider`的Responses和从`Spider`出去的Requests)
安装刮板
Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs. ... .html
安装方式:
pip install scrapy
如果安装出现错误,可以按照下面的顺序先安装依赖包:
1、安装wheel
pip install wheel
2、安装lxml
pip install lxml
3、安装pyopenssl
pip install pyopenssl
4、安装Twisted
需要我们自己下载Twisted,然后安装。这里有Python的各种依赖包。选择适合自己Python以及系统的Twisted版本:https://www.lfd.uci.edu/~gohlk ... isted
# 3.6版本(cp后是python版本)
pip install Twisted-18.9.0-cp36-cp36m-win_amd64.whl
5、安装pywin32
pip install pywin32
6、安装scrapy
pip install scrapy
安装后,只要在命令终端输入scrapy来检测是否安装成功
可以按照以下步骤将爬虫程序与scrape一起使用:创建一个scrape项,定义提取的项,将爬行器写入爬网网站,提取项,写入项管道以存储提取的项(即数据)1.创建一个新的scrape项以对数据进行爬网,并使用以下命令:
scrapy startproject meiju
创建爬虫
cd meiju
scrapy genspider meijuSpider meijutt.tv
其中:
meijuSpider为爬虫文件名
meijutt.com为爬取网址的域名
在创建一个碎片项目后,将自动创建多个文件。下面简要介绍每个主文件的功能:
scrapy.cfg:
项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py:
设置数据存储模板,用于结构化数据,如:Django的Model
pipelines:
数据处理行为,如:一般结构化的数据持久化
settings.py:
配置文件,如:递归的层数、并发数,延迟下载等
spiders:
爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2.定义项目
项是用于存储爬网数据的容器;其使用方法类似于Python字典。虽然我们可以在scripy中直接使用dict,但item提供了额外的保护机制,以避免拼写错误导致的未定义字段错误
与ORM中的模型定义字段类似,我们可以定义要在场景中爬网的字段。项目类别
import scrapy
class MeijuItem(scrapy.Item):
name = scrapy.Field()
3.写入爬虫程序
# -*- coding: utf-8 -*-
import scrapy
from lxml import etree
from meiju.items import MeijuItem
class MeijuspiderSpider(scrapy.Spider):
# 爬虫名
name = 'meijuSpider'
# 被允许的域名
allowed_domains = ['meijutt.tv']
# 起始爬取的url
start_urls = ['http://www.meijutt.tv/new100.html']
# 数据处理
def parse(self, response):
# response响应对象
# xpath
mytree = etree.HTML(response.text)
movie_list = mytree.xpath('//ul[@class="top-list fn-clear"]/li')
for movie in movie_list:
name = movie.xpath('./h5/a/text()')
# 创建item(类字典对象)
item = MeijuItem()
item['name'] = name
yield item
启用项目管道组件
为了启用项目管道组件,必须将其类添加到settings.py文件item\管道配置修改settings.py并设置优先级。分配给每个类的整数值决定了它们的运行顺序。项目按从低到高的顺序排列。通过管道,这些数字通常定义在0-1000范围内(0-1000可以任意设置,值越低,组件的优先级越高)
ITEM_PIPELINES = {
'meiju.pipelines.MeijuPipeline': 300,
}
设置UA
在代理的setting.py_uu值中设置用户
4.编写一个管道来存储提取的项目(即数据)
class SomethingPipeline(object):
def init(self):
# 可选实现,做参数初始化等
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
运行爬虫程序:
scrapy crawl meijuSpider
# nolog模式
scrapy crawl meijuSpider --nolog
在草稿中保存信息的最简单方法如下,-o以指定格式输出文件:
scrapy crawl meijuSpider -o meiju.json
scrapy crawl meijuSpider -o meiju.csv
scrapy crawl meijuSpider -o meiju.xml
练习:scripy将新浪新闻爬行到数据库中 查看全部
scrapy分页抓取网页(Scrapy框架介绍架构图安装Scrapy使用爬虫使用使用)
scrapy框架简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
Scrapy框架:用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了Twisted(其主要对手是Tornado)多线程异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
粗糙结构图
Scrapy主要包括了以下组件:
Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):
它负责接受`引擎`发送过来的Request请求,并按照一定的方式进行整理排列,入队,当`引擎`需要时,交还给`引擎`。
Downloader(下载器):
负责下载`Scrapy Engine(引擎)`发送的所有Requests请求,并将其获取到的Responses交还给`Scrapy Engine(引擎)`,由`引擎`交给`Spider`来处理,
Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给`引擎`,再次进入`Scheduler(调度器)`,
Item Pipeline(管道):
它负责处理`Spider`中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):
你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):
你可以理解为是一个可以自定扩展和操作`引擎`和`Spider`中间`通信`的功能组件(比如进入`Spider`的Responses和从`Spider`出去的Requests)
安装刮板
Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs. ... .html
安装方式:
pip install scrapy
如果安装出现错误,可以按照下面的顺序先安装依赖包:
1、安装wheel
pip install wheel
2、安装lxml
pip install lxml
3、安装pyopenssl
pip install pyopenssl
4、安装Twisted
需要我们自己下载Twisted,然后安装。这里有Python的各种依赖包。选择适合自己Python以及系统的Twisted版本:https://www.lfd.uci.edu/~gohlk ... isted
# 3.6版本(cp后是python版本)
pip install Twisted-18.9.0-cp36-cp36m-win_amd64.whl
5、安装pywin32
pip install pywin32
6、安装scrapy
pip install scrapy
安装后,只要在命令终端输入scrapy来检测是否安装成功
可以按照以下步骤将爬虫程序与scrape一起使用:创建一个scrape项,定义提取的项,将爬行器写入爬网网站,提取项,写入项管道以存储提取的项(即数据)1.创建一个新的scrape项以对数据进行爬网,并使用以下命令:
scrapy startproject meiju
创建爬虫
cd meiju
scrapy genspider meijuSpider meijutt.tv
其中:
meijuSpider为爬虫文件名
meijutt.com为爬取网址的域名
在创建一个碎片项目后,将自动创建多个文件。下面简要介绍每个主文件的功能:
scrapy.cfg:
项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py:
设置数据存储模板,用于结构化数据,如:Django的Model
pipelines:
数据处理行为,如:一般结构化的数据持久化
settings.py:
配置文件,如:递归的层数、并发数,延迟下载等
spiders:
爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2.定义项目
项是用于存储爬网数据的容器;其使用方法类似于Python字典。虽然我们可以在scripy中直接使用dict,但item提供了额外的保护机制,以避免拼写错误导致的未定义字段错误
与ORM中的模型定义字段类似,我们可以定义要在场景中爬网的字段。项目类别
import scrapy
class MeijuItem(scrapy.Item):
name = scrapy.Field()
3.写入爬虫程序
# -*- coding: utf-8 -*-
import scrapy
from lxml import etree
from meiju.items import MeijuItem
class MeijuspiderSpider(scrapy.Spider):
# 爬虫名
name = 'meijuSpider'
# 被允许的域名
allowed_domains = ['meijutt.tv']
# 起始爬取的url
start_urls = ['http://www.meijutt.tv/new100.html']
# 数据处理
def parse(self, response):
# response响应对象
# xpath
mytree = etree.HTML(response.text)
movie_list = mytree.xpath('//ul[@class="top-list fn-clear"]/li')
for movie in movie_list:
name = movie.xpath('./h5/a/text()')
# 创建item(类字典对象)
item = MeijuItem()
item['name'] = name
yield item
启用项目管道组件
为了启用项目管道组件,必须将其类添加到settings.py文件item\管道配置修改settings.py并设置优先级。分配给每个类的整数值决定了它们的运行顺序。项目按从低到高的顺序排列。通过管道,这些数字通常定义在0-1000范围内(0-1000可以任意设置,值越低,组件的优先级越高)
ITEM_PIPELINES = {
'meiju.pipelines.MeijuPipeline': 300,
}
设置UA
在代理的setting.py_uu值中设置用户
4.编写一个管道来存储提取的项目(即数据)
class SomethingPipeline(object):
def init(self):
# 可选实现,做参数初始化等
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
运行爬虫程序:
scrapy crawl meijuSpider
# nolog模式
scrapy crawl meijuSpider --nolog
在草稿中保存信息的最简单方法如下,-o以指定格式输出文件:
scrapy crawl meijuSpider -o meiju.json
scrapy crawl meijuSpider -o meiju.csv
scrapy crawl meijuSpider -o meiju.xml
练习:scripy将新浪新闻爬行到数据库中
scrapy分页抓取网页( WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-04 09:16
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简单数据分析系列文章的第12篇。
在之前的文章文章中,我们介绍了Web Scraper针对各种翻页方案的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,让我们看一下第1页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
第 3 页上的参数是 #_rnd39
第 4 页上的参数是 #_rnd76:
多看几个链接,会发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper是无能为力的)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器一重置,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。 查看全部
scrapy分页抓取网页(
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简单数据分析系列文章的第12篇。
在之前的文章文章中,我们介绍了Web Scraper针对各种翻页方案的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
首先,让我们看一下第1页的转发链接,它看起来像这样:
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
第 3 页上的参数是 #_rnd39
第 4 页上的参数是 #_rnd76:
多看几个链接,会发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper是无能为力的)。
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器一重置,又变成1000了……所以这种控制数字的方法是无效的。
所以结论是,如果你想早点结束pager类网页的抓取,只有这种断网的方法。当然,如果你有更好的计划,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种很常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束抓取。
scrapy分页抓取网页(支持列表页的自动翻页抓取,支持图片、文件的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-03 12:01
网络爬虫5.1可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。 分析抓取的页面内容,获取新闻标题等结构化信息、作者、出处、正文等,支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。用户指定要爬取的网站、要爬取的页面类型(固定页面、分页页面等),并配置如何解析数据项(如新闻标题、作者、来源、正文)等),系统可以根据配置信息,实时自动抓取数据,并且开始抓拍的时间也可以通过配置来设置,真正做到了“按需抓拍,一次配置,永久抓拍”。捕获的数据可以保存到数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等,该工具可以完全替代传统的编辑手工信息处理模式。能够实时、准确、24*60全天为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。该工具的主要特点如下: *适用范围广,可以抓取任何网页(包括登录后可以访问的网页) *处理速度快,如果网络畅通,可以抓取和解析10,1小时000个网页 *采用独特的重复数据过滤技术,支持增量数据抓取,可实时抓取数据,如:股票交易信息、天气预报等。 *抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性 *支持断点续抓,崩溃或异常情况后,可以恢复抓包,继续后续抓包工作,提高系统抓取效率 *针对列表页,支持页面转动,就可以抓取所有列表页面中的数据。对于文本页面,可以自动合并页面中显示的内容;*支持页面深度爬取,页面可逐层爬取。比如通过列表页面抓取body页面的URL,然后抓取正文页面。各级页面可以单独存放在库中;*WEB操作界面,一次安装,随处使用 *一步一步分析,一步一步存储 查看全部
scrapy分页抓取网页(支持列表页的自动翻页抓取,支持图片、文件的抓取)
网络爬虫5.1可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。 分析抓取的页面内容,获取新闻标题等结构化信息、作者、出处、正文等,支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。用户指定要爬取的网站、要爬取的页面类型(固定页面、分页页面等),并配置如何解析数据项(如新闻标题、作者、来源、正文)等),系统可以根据配置信息,实时自动抓取数据,并且开始抓拍的时间也可以通过配置来设置,真正做到了“按需抓拍,一次配置,永久抓拍”。捕获的数据可以保存到数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等,该工具可以完全替代传统的编辑手工信息处理模式。能够实时、准确、24*60全天为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。该工具的主要特点如下: *适用范围广,可以抓取任何网页(包括登录后可以访问的网页) *处理速度快,如果网络畅通,可以抓取和解析10,1小时000个网页 *采用独特的重复数据过滤技术,支持增量数据抓取,可实时抓取数据,如:股票交易信息、天气预报等。 *抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性 *支持断点续抓,崩溃或异常情况后,可以恢复抓包,继续后续抓包工作,提高系统抓取效率 *针对列表页,支持页面转动,就可以抓取所有列表页面中的数据。对于文本页面,可以自动合并页面中显示的内容;*支持页面深度爬取,页面可逐层爬取。比如通过列表页面抓取body页面的URL,然后抓取正文页面。各级页面可以单独存放在库中;*WEB操作界面,一次安装,随处使用 *一步一步分析,一步一步存储
scrapy分页抓取网页(scrapy爬虫分页抓取网页资源的方法:requests+xpath)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-02 11:05
scrapy分页抓取网页所以我们首先得准备爬虫所需的工具python3.5以上版本,matplotlib库(最好用)然后搭建一个python爬虫学习路线的话,把几本经典的python爬虫入门书籍看一遍(比如《利用python进行数据分析》等),再把一些经典的python爬虫案例实战做一下就差不多了。关于怎么把网站抓下来,这个可以看看那些爬虫论坛,比如itemitage之类的。
然后你就可以把爬虫用python写出来了。爬虫主要还是采集网页中各个链接的信息,所以网页数据来源是关键,可以看我简单总结的2种获取网页资源的方法:requests+xpath。最后编写一个ajax模块,处理多个网页中某一个部分的信息。
你这个东西的前端感觉有点简单,chrome能帮你做。但是直接一个cookie效率太低了,一直认为这么做是个坑。而且你以前肯定有把内容备份过。所以可以用flaskweb框架,然后自己写爬虫代码。直接tagurls就可以了,注意要redirect。抓到链接之后,直接requests拿到这个链接,另存为就可以了。
或者用requests之后再转mysql.selectxml,用pymysql,会快点。但是如果是爬取一个静态内容的话,还是能写出来但是不太高效。
我没有这个架构,也没这个经验,所以给不了太有用的答案。这个问题很好,借此机会先抛砖引玉,求不喷。先回答怎么拿到网页,再针对这个网页的内容做什么。抓取网页,其实不难。我们当然能直接拿到某个bbs首页,这对一个bbs简直是不要太简单。问题是从bbs首页爬取,有些什么问题,导致相关爬虫的兼容性问题,我们也能直接拿到但是不方便。
比如,某个用户有发表内容,你这个时候在同一个页面发送的连接直接抓,可能有些不方便查看。怎么获取首页,我们第一步是要获取title标题。所以我们首先要实现title的获取。推荐用requests库,可以直接返回网页内容,接下来只需要将其与第三方库(github,selenium等)的接口进行接入,就能获取gif图片的title。
至于配置方法,不用我说你也知道。然后我们可以获取某条评论的title标题,接下来我们要获取某个用户的title评论。因为这个时候用户不可能同时有评论,而最常见的评论格式就是“某人点了赞”,那么利用while(1)来tag这个评论的title,我们就可以爬取第二条评论的title。这样一个tag就完成了。
如果需要跳转评论,那么我们就tag评论的首行,就可以跳转到对应评论。这样也不需要我们重复tag第二条评论的title,不过要记得,我们需要将第一条评论的title作为返回值。实现这样的功能需要用到requests、while、github、selen。 查看全部
scrapy分页抓取网页(scrapy爬虫分页抓取网页资源的方法:requests+xpath)
scrapy分页抓取网页所以我们首先得准备爬虫所需的工具python3.5以上版本,matplotlib库(最好用)然后搭建一个python爬虫学习路线的话,把几本经典的python爬虫入门书籍看一遍(比如《利用python进行数据分析》等),再把一些经典的python爬虫案例实战做一下就差不多了。关于怎么把网站抓下来,这个可以看看那些爬虫论坛,比如itemitage之类的。
然后你就可以把爬虫用python写出来了。爬虫主要还是采集网页中各个链接的信息,所以网页数据来源是关键,可以看我简单总结的2种获取网页资源的方法:requests+xpath。最后编写一个ajax模块,处理多个网页中某一个部分的信息。
你这个东西的前端感觉有点简单,chrome能帮你做。但是直接一个cookie效率太低了,一直认为这么做是个坑。而且你以前肯定有把内容备份过。所以可以用flaskweb框架,然后自己写爬虫代码。直接tagurls就可以了,注意要redirect。抓到链接之后,直接requests拿到这个链接,另存为就可以了。
或者用requests之后再转mysql.selectxml,用pymysql,会快点。但是如果是爬取一个静态内容的话,还是能写出来但是不太高效。
我没有这个架构,也没这个经验,所以给不了太有用的答案。这个问题很好,借此机会先抛砖引玉,求不喷。先回答怎么拿到网页,再针对这个网页的内容做什么。抓取网页,其实不难。我们当然能直接拿到某个bbs首页,这对一个bbs简直是不要太简单。问题是从bbs首页爬取,有些什么问题,导致相关爬虫的兼容性问题,我们也能直接拿到但是不方便。
比如,某个用户有发表内容,你这个时候在同一个页面发送的连接直接抓,可能有些不方便查看。怎么获取首页,我们第一步是要获取title标题。所以我们首先要实现title的获取。推荐用requests库,可以直接返回网页内容,接下来只需要将其与第三方库(github,selenium等)的接口进行接入,就能获取gif图片的title。
至于配置方法,不用我说你也知道。然后我们可以获取某条评论的title标题,接下来我们要获取某个用户的title评论。因为这个时候用户不可能同时有评论,而最常见的评论格式就是“某人点了赞”,那么利用while(1)来tag这个评论的title,我们就可以爬取第二条评论的title。这样一个tag就完成了。
如果需要跳转评论,那么我们就tag评论的首行,就可以跳转到对应评论。这样也不需要我们重复tag第二条评论的title,不过要记得,我们需要将第一条评论的title作为返回值。实现这样的功能需要用到requests、while、github、selen。
scrapy分页抓取网页( 如何查看二级页面(详情页)的三连数据?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-02 05:12
如何查看二级页面(详情页)的三连数据?(一))
这样做的话,其实可以抓取所有已知的列表数据,但是本文的重点是:如何抓取二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper本质上是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要抓取一个链接时,我们需要创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了一张动图,注意我鼠标突出显示的导航路线部分,可以很清楚的看到这几个选择器的层次关系:
4.创建详情页子选择器
当您点击该链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如喜欢的数量、硬币的数量、采集的数量和分享的数量。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们要开始爬取数据了。但是我们需要在爬行之前将等待时间调整得更长一些。默认时间为 2000 毫秒。我在这里将其更改为 5000 毫秒。
你为什么这么做?看下图就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察诸如要捕获的喜欢数量之类的数据。页面刚加载时,其值为“--”,过一会就变成一个数字。
所以我们直接等了5000ms,等页面和数据加载完成后,我们统一取了。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明此方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在生产过程中遇到问题,可以参考我的配置。我已经详细解释了 SiteMap 导入的功能。你可以一起服用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为套路都是一样的:先创建Link选择器,然后抓取Link选择器指向的下一页数据,我就不一一演示了。
今天我们也来聊聊Web Scraper的翻页技巧。
本次更新的灵感来自一位读者,他想使用 Web 爬虫爬取被寻呼机分页的页面,但发现我之前介绍的方法不起作用。我研究了一下,发现我错过了一个非常常见的翻页场景。
在文章中,我们讲了如何使用Element Click选择器来模拟鼠标点击分页器翻页,不过把同样的方法放在最上面,翻到第二页时抓取窗口会自动退出. , 无法捕获一条数据。
其实最主要的原因是我没有明确说明这个方法的适用边界。
Element Click 翻页仅适用于不刷新网页的情况。在文章文章中,我引用了蔡徐坤微博评论的一个例子。翻页时网页没有刷新:
仔细看下图,链接变了,但是刷新按钮没变,说明网页没有刷新,但是内容变了
在豆瓣TOP 250网页上,每次翻页都会重新加载网页:
仔细看下图,网页在链接变化时刷新,并且有明显的加载圆圈动画
其实这个原理从技术规范中已经很好的解释了:
-当URL链接为#字符且数据发生变化时,网页不会刷新;
-当链接的其他部分发生变化时,页面会刷新。
当然,这只是随便提一下,有兴趣的同学可以去这个链接学习,不感兴趣的可以跳过。
1.创建站点地图
本文文章将讲解如何使用Web Scraper抓取翻页时会刷新页面的pager网站。
对于这个网页,我们选择网站-豆瓣电影TOP250,他练习了爬虫:
像这种网站,我们需要使用Link选择器来帮助我们翻页。我们引入了Link标签,我们可以使用这个标签跳转到一个网页并从另一个网页抓取数据。这里我们使用Link标签跳转到下一页分页网站。
首先我们使用Link选择器选择下一页按钮,具体配置如下图所示:
这里有一个特殊的地方:Parent Selectors——父选择器。
我们以前从未接触过这个选择框的内容。这次 Next_page 将有两个父节点——_root 和 next_page。您可以通过按键盘上的 shift 然后单击鼠标来选择多个。先按我说的做,以后再做。解释这样做的原因。
保存next_page选择器后,在同层级下创建一个容器节点来抓取电影数据:
这里注意:页面选择器节点next_page和数据选择器节点容器在同一层级,两个节点都有两个父节点:_root和next_page:
因为重点是webscraper翻页技巧,我就简单的抓取一下我抓取到的数据的标题和排名:
然后我们点击Selector图查看我们写的爬虫结构:
可以清晰的看到这个爬虫的结构,可以无限嵌套:
点击Scrape,尝试爬取,你会发现所有的数据都爬下来了:
2.分析原理
按照上面的过程,你可能还是会一头雾水。数据被捕获,但为什么可以这样做呢?为什么 next_page 和 container 处于同一级别?为什么他们同时选择两个父节点:_root 和 next_page?
麻烦的原因是我们在倒推,从结果中推断步骤;下面我们就从正面思考来一步步讲解。
首先我们要知道我们爬取的数据是一个树状结构。_root 代表根节点,也就是我们抓取的第一个网页。我们应该在这个网页上选择什么?
1.一个是下一页的节点,本例中是Link选择器选择的next_page
2. 一个是数据节点,在这个例子中是元素选择器选择的容器
因为next_page节点会跳转,所以会跳转到第二页。除数据不同外,第二页与第一页结构相同。为了继续跳转,我们必须选择下一页。为了抓取数据,我们必须选择数据节点:
如果我们逆向箭头,就会发现真相就在眼前。next_page 的父节点不就是_root 和next_page 吗?容器的父节点也是_root和next_page!
道理到这里基本就讲清楚了,不明白的同学可以多看几遍。和 next_page 一样,我调用我自己的表单。编程中有一个术语-递归,在计算机领域也是一个比较抽象的概念。有兴趣的同学可以自行搜索。 查看全部
scrapy分页抓取网页(
如何查看二级页面(详情页)的三连数据?(一))
这样做的话,其实可以抓取所有已知的列表数据,但是本文的重点是:如何抓取二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper本质上是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要抓取一个链接时,我们需要创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了一张动图,注意我鼠标突出显示的导航路线部分,可以很清楚的看到这几个选择器的层次关系:
4.创建详情页子选择器
当您点击该链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如喜欢的数量、硬币的数量、采集的数量和分享的数量。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们要开始爬取数据了。但是我们需要在爬行之前将等待时间调整得更长一些。默认时间为 2000 毫秒。我在这里将其更改为 5000 毫秒。
你为什么这么做?看下图就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察诸如要捕获的喜欢数量之类的数据。页面刚加载时,其值为“--”,过一会就变成一个数字。
所以我们直接等了5000ms,等页面和数据加载完成后,我们统一取了。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明此方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在生产过程中遇到问题,可以参考我的配置。我已经详细解释了 SiteMap 导入的功能。你可以一起服用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为套路都是一样的:先创建Link选择器,然后抓取Link选择器指向的下一页数据,我就不一一演示了。
今天我们也来聊聊Web Scraper的翻页技巧。
本次更新的灵感来自一位读者,他想使用 Web 爬虫爬取被寻呼机分页的页面,但发现我之前介绍的方法不起作用。我研究了一下,发现我错过了一个非常常见的翻页场景。
在文章中,我们讲了如何使用Element Click选择器来模拟鼠标点击分页器翻页,不过把同样的方法放在最上面,翻到第二页时抓取窗口会自动退出. , 无法捕获一条数据。
其实最主要的原因是我没有明确说明这个方法的适用边界。
Element Click 翻页仅适用于不刷新网页的情况。在文章文章中,我引用了蔡徐坤微博评论的一个例子。翻页时网页没有刷新:
仔细看下图,链接变了,但是刷新按钮没变,说明网页没有刷新,但是内容变了
在豆瓣TOP 250网页上,每次翻页都会重新加载网页:
仔细看下图,网页在链接变化时刷新,并且有明显的加载圆圈动画
其实这个原理从技术规范中已经很好的解释了:
-当URL链接为#字符且数据发生变化时,网页不会刷新;
-当链接的其他部分发生变化时,页面会刷新。
当然,这只是随便提一下,有兴趣的同学可以去这个链接学习,不感兴趣的可以跳过。
1.创建站点地图
本文文章将讲解如何使用Web Scraper抓取翻页时会刷新页面的pager网站。
对于这个网页,我们选择网站-豆瓣电影TOP250,他练习了爬虫:
像这种网站,我们需要使用Link选择器来帮助我们翻页。我们引入了Link标签,我们可以使用这个标签跳转到一个网页并从另一个网页抓取数据。这里我们使用Link标签跳转到下一页分页网站。
首先我们使用Link选择器选择下一页按钮,具体配置如下图所示:
这里有一个特殊的地方:Parent Selectors——父选择器。
我们以前从未接触过这个选择框的内容。这次 Next_page 将有两个父节点——_root 和 next_page。您可以通过按键盘上的 shift 然后单击鼠标来选择多个。先按我说的做,以后再做。解释这样做的原因。
保存next_page选择器后,在同层级下创建一个容器节点来抓取电影数据:
这里注意:页面选择器节点next_page和数据选择器节点容器在同一层级,两个节点都有两个父节点:_root和next_page:
因为重点是webscraper翻页技巧,我就简单的抓取一下我抓取到的数据的标题和排名:
然后我们点击Selector图查看我们写的爬虫结构:
可以清晰的看到这个爬虫的结构,可以无限嵌套:
点击Scrape,尝试爬取,你会发现所有的数据都爬下来了:
2.分析原理
按照上面的过程,你可能还是会一头雾水。数据被捕获,但为什么可以这样做呢?为什么 next_page 和 container 处于同一级别?为什么他们同时选择两个父节点:_root 和 next_page?
麻烦的原因是我们在倒推,从结果中推断步骤;下面我们就从正面思考来一步步讲解。
首先我们要知道我们爬取的数据是一个树状结构。_root 代表根节点,也就是我们抓取的第一个网页。我们应该在这个网页上选择什么?
1.一个是下一页的节点,本例中是Link选择器选择的next_page
2. 一个是数据节点,在这个例子中是元素选择器选择的容器
因为next_page节点会跳转,所以会跳转到第二页。除数据不同外,第二页与第一页结构相同。为了继续跳转,我们必须选择下一页。为了抓取数据,我们必须选择数据节点:
如果我们逆向箭头,就会发现真相就在眼前。next_page 的父节点不就是_root 和next_page 吗?容器的父节点也是_root和next_page!
道理到这里基本就讲清楚了,不明白的同学可以多看几遍。和 next_page 一样,我调用我自己的表单。编程中有一个术语-递归,在计算机领域也是一个比较抽象的概念。有兴趣的同学可以自行搜索。
scrapy分页抓取网页(10w+新闻数据,新闻信息以json文件格式保存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-25 04:21
一、选择主题
工程搜索类型:
针对采集 3-4个新闻网站,实现对这些网站信息的提取、索引和检索。网页数量不少于100,000。可以按照相关性、时间、流行度等属性进行排序(需要自己定义),可以实现相似新闻的自动聚类。
需求:相关搜索推荐、片段生成、结果预览(鼠标移至相关结果,可预览)功能
二、开发工具三、设计方案3.1总体思路
在新闻信息检索系统的实现中,首先进行信息采集。信息采集结束后,使用Lucene提供的api构建索引库,前端使用jsp接收用户查询,后台servlet使用servlet对用户查询进行分段。处理后,在索引库中进行文档匹配,最后将查询结果集反馈给用户并展示在前端页面上。
3.2 信息采集
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。我们采集有10w+条新闻数据,新闻信息以json文件格式保存。scrapy 采集 流程:
采集 新闻资料至:
新闻格式:
3.3倒排索引构建
在索引构建模块中,主要包括以下三个关键步骤:数据预处理、新闻内容切分和倒排索引构建。
**数据预处理:**Gson 是 Google 提供的 Java 类库,用于在 Java 对象和 JSON 数据之间进行映射。您可以将 JSON 字符串转换为 Java 对象,反之亦然。我们使用 Gson 将 json 文件转换为 News 对象
**中文分词:**IK Analyzer是一款基于java语言开发的开源、轻量级的中文分词工具包。IK 已经发展成为 Java 的公共分词组件,独立于 Lucene 项目,并为 Lucene 提供了一个默认值。优化实施。IK分词采用独有的“前向迭代最细粒度分词算法”,支持细粒度和智能分词两种分词模式,采用多子处理器分析模式,支持英文字母、数字、中文词汇等分词处理,兼容韩日字符。
**构建倒排索引:**Lucene 提供了一种构建倒排索引的方法。步骤如下图所示:
Luke是Lucene搜索引擎的第三方工具,方便开发和诊断。它可以访问
现有的 Lucene 索引。使用luke打开索引目录,可以看到索引库中存储了新闻信息。
3.4 索引查询
创建索引后,查询可以分为以下几个步骤:
1. 设置查询索引的目录(这里是上面创建索引的目录)。
2. 创建 indexSearcher。
3. 设置查询的分词方式
4. 设置查询字段,例如查询字段是新闻标题,然后到新闻标题字段进行比较 5. 设置查询字符串,即要查询的关键词 .
6. 返回的结果是文档的集合,放在TopDocs中,通过循环TopDocs数组输出查询结果。用户一般只看前几页的数据。为了加快前端数据的显示速度,将前1000条数据返回给前端。
3.5关键字高亮
搜索结果的高亮对用户的体验和友好度非常重要,可以快速标记用户搜索的关键词。Lucene 的 Highlighter 类可以通过在关键字前面添加 css 片段来返回文档中的关键字高亮。
3.6用户界面
使用jsp编写用户界面,服务器为Tomcat 7.0,用户输入关键词然后提交表单,然后
该站使用servlet接收用户查询,然后以查询字符串作为搜索关键字在索引库中搜索文档。检索效果:
3.7 按时间和页面结果排序
按时间排序:所有新闻结果存储在一个列表集合中,集合中的每个元素都是一个新闻对象。通过重写Comparator类中的compare方法,实现了集合中每个新闻元素的时间排序。
结果分页:定义一个Page类来记录当前页数、总页数、每页数据条数、数据总数、每页起始数、每页结束数、是否有下一页,是否有上一页。
四、参考资料
可以参考以下材料:
1. lucene全文搜索基础
2. lucene 创建索引
3. Lucene 查询索引
4. Lucene 查询结果高亮显示
5. Lucene 查询(Query)子类
6. java操作json
7. java 集合
8. Servlet 基础知识
五、总结
开源工具的使用已经显着提高了开发效率,但是从头开始构建仍然需要大量学习和不断积累。
欢迎批评和指正。 查看全部
scrapy分页抓取网页(10w+新闻数据,新闻信息以json文件格式保存)
一、选择主题
工程搜索类型:
针对采集 3-4个新闻网站,实现对这些网站信息的提取、索引和检索。网页数量不少于100,000。可以按照相关性、时间、流行度等属性进行排序(需要自己定义),可以实现相似新闻的自动聚类。
需求:相关搜索推荐、片段生成、结果预览(鼠标移至相关结果,可预览)功能
二、开发工具三、设计方案3.1总体思路
在新闻信息检索系统的实现中,首先进行信息采集。信息采集结束后,使用Lucene提供的api构建索引库,前端使用jsp接收用户查询,后台servlet使用servlet对用户查询进行分段。处理后,在索引库中进行文档匹配,最后将查询结果集反馈给用户并展示在前端页面上。
3.2 信息采集
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。我们采集有10w+条新闻数据,新闻信息以json文件格式保存。scrapy 采集 流程:
采集 新闻资料至:
新闻格式:
3.3倒排索引构建
在索引构建模块中,主要包括以下三个关键步骤:数据预处理、新闻内容切分和倒排索引构建。
**数据预处理:**Gson 是 Google 提供的 Java 类库,用于在 Java 对象和 JSON 数据之间进行映射。您可以将 JSON 字符串转换为 Java 对象,反之亦然。我们使用 Gson 将 json 文件转换为 News 对象
**中文分词:**IK Analyzer是一款基于java语言开发的开源、轻量级的中文分词工具包。IK 已经发展成为 Java 的公共分词组件,独立于 Lucene 项目,并为 Lucene 提供了一个默认值。优化实施。IK分词采用独有的“前向迭代最细粒度分词算法”,支持细粒度和智能分词两种分词模式,采用多子处理器分析模式,支持英文字母、数字、中文词汇等分词处理,兼容韩日字符。
**构建倒排索引:**Lucene 提供了一种构建倒排索引的方法。步骤如下图所示:
Luke是Lucene搜索引擎的第三方工具,方便开发和诊断。它可以访问
现有的 Lucene 索引。使用luke打开索引目录,可以看到索引库中存储了新闻信息。
3.4 索引查询
创建索引后,查询可以分为以下几个步骤:
1. 设置查询索引的目录(这里是上面创建索引的目录)。
2. 创建 indexSearcher。
3. 设置查询的分词方式
4. 设置查询字段,例如查询字段是新闻标题,然后到新闻标题字段进行比较 5. 设置查询字符串,即要查询的关键词 .
6. 返回的结果是文档的集合,放在TopDocs中,通过循环TopDocs数组输出查询结果。用户一般只看前几页的数据。为了加快前端数据的显示速度,将前1000条数据返回给前端。
3.5关键字高亮
搜索结果的高亮对用户的体验和友好度非常重要,可以快速标记用户搜索的关键词。Lucene 的 Highlighter 类可以通过在关键字前面添加 css 片段来返回文档中的关键字高亮。
3.6用户界面
使用jsp编写用户界面,服务器为Tomcat 7.0,用户输入关键词然后提交表单,然后
该站使用servlet接收用户查询,然后以查询字符串作为搜索关键字在索引库中搜索文档。检索效果:
3.7 按时间和页面结果排序
按时间排序:所有新闻结果存储在一个列表集合中,集合中的每个元素都是一个新闻对象。通过重写Comparator类中的compare方法,实现了集合中每个新闻元素的时间排序。
结果分页:定义一个Page类来记录当前页数、总页数、每页数据条数、数据总数、每页起始数、每页结束数、是否有下一页,是否有上一页。
四、参考资料
可以参考以下材料:
1. lucene全文搜索基础
2. lucene 创建索引
3. Lucene 查询索引
4. Lucene 查询结果高亮显示
5. Lucene 查询(Query)子类
6. java操作json
7. java 集合
8. Servlet 基础知识
五、总结
开源工具的使用已经显着提高了开发效率,但是从头开始构建仍然需要大量学习和不断积累。
欢迎批评和指正。
scrapy分页抓取网页(分布式网络新闻抓取系统设计与实现的项目介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-11-25 04:21
1 项目介绍
本项目的主要内容是分布式网络新闻采集系统的设计与实现。主要有以下几个部分介绍:
(1)深入分析网络新闻爬虫的特点,设计分布式网络新闻爬虫系统爬取策略、爬取字段、**页面爬取方法、分布式结构、系统监控和数据存储六大关键功能。
(2)结合程序代码的分解,讲解分布式网络新闻爬虫系统的实现过程。包括爬虫编写、爬虫规避、**页面数据爬取、分布式爬虫部署、系统监控,一共六项内容,结合实际定向抓取腾讯新闻数据,通过测试测试系统性能。
(3) 规划设计一个数据处理模块,包括数据清洗、代码转换、数据分类、对象添加等功能。
分布式网络新闻抓取系统的设计
2.1 整体系统架构设计
系统采用分布式主从结构,设置1台Master服务器和多台Slave服务器。Master管理Redis数据库,分发下载任务。Slave 部署 Scrapy 来抓取网页并解析提取项目数据。服务器基础环境为Ubuntu操作系统,Master服务器安装Redis数据库服务器和Graphite,Slave安装Scrapy和Redis客户端。系统按功能可分为两大模块,一是数据采集模块,二是数据处理模块。数据抓取模块包括浏览器调用、网页下载、字段提取、爬虫规避、数据存储和系统监控六大功能;数据处理模块包括数据清洗、对象添加、
2.2 爬取策略的设计
本项目的网络爬虫采用深度优先的爬取策略,根据设置下载网页数据。网页链接处理流程如下:
1.手动设置初始下载地址,一般是网站导航地址。
2、爬虫开始运行,从初始地址抓取第一批网页链接。
3、爬虫根据正则表达式识别新链接中的目录页面地址和新闻内容页面地址,将识别出的新地址加入到下载队列中等待爬取。无法识别的网页地址被定义为无用链接并丢失。
4、爬虫从等待队列中依次取出网页链接进行数据下载和提取。
5.下载队列为空,爬虫停止爬行。
新闻网站的导航页数是有限的。这个规则决定了新闻导航页面的URL在一定的人工参与下可以很容易的获取,并作为爬虫系统的初始URL。
2.3 爬取字段的设计
本项目旨在捕捉网络新闻数据,因此内容必须能够客观准确地反映网络新闻的特点。
本文以抓取腾讯在线新闻数据为例,通过对网页结构的分析,确定了一个两步抓取的过程。第一步,抓取新闻内容页面,获取新闻标题、新闻来源、新闻内容、发布时间、评论数、评论地址、相关搜索、用户还喜欢的新闻、点赞数。第二步在获取评论地址后,抓取评论页面,获取评论者ID、评论者昵称、评论者性别、评论者所在位置、评论时间、评论内容、单条评论支持人数、评论回复数单条评论。
2.4 **页面爬取方法设计
腾讯新闻网页使用Java Script生成**页面内容。一些由JS事件触发的页面在打开的时候内容会发生变化,有的页面没有JS支持根本无法运行。一般爬虫根本无法从这些网页中获取数据。解决JavaScript **页面爬虫问题有四种方法:
1.编写代码模拟相关JS逻辑。
2. 调用一个带接口的浏览器,类似于各种广泛用于测试的,比如Selenium等。
3、使用无界面浏览器,各种基于Webkit的,如Casperjs、Phantomjs等。
4、结合JS执行引擎,实现轻量级浏览器。
由于本项目是基于Python为主要语言编写的,所以使用Selenium来处理JS动态新闻页面。其优点是简单易行。使用Python代码模拟用户在浏览器上的操作。首先将网页加载到浏览器中并打开,然后从浏览器缓存中获取网页数据,传递给蜘蛛进行分析提取,最后将目标数据传递给项目通道。
2.5 Crawler 分布式设计
Redis数据库用于实现分布式爬取。基本思路是将Scrapy爬虫获取到的url(请求)放在一个Redis Queue中,所有爬虫也从指定的Redis Queue中获取请求(url)。Scrapy-Redis 默认使用 Spider Priority Queue 来确定 URL 的顺序。这是一种由有序集合实现的非 FIFO、LIFO 方法。
Redis 存储了 Scrapy 项目的请求和统计信息。根据这些信息可以掌握任务状态和爬虫状态,在分配任务时平衡系统负载,有助于克服爬虫的性能瓶颈。同时,利用Redis的高性能和易扩展的特性,可以轻松实现高效下载。当Redis存储或访问速度遇到问题时,可以通过增加Redis集群和爬虫集群的数量来提高。Scrapy-Redis分布式解决方案很好的解决了爬行中断和重复数据删除的问题。爬虫重启后,会针对Redis队列中的URL进行爬取,爬取到的URL会被自动过滤掉。
2.6 基于Graphite系统的监控组件设计
使用Graphite监控系统的运行状态,实现了分布式系统的statscollector,将系统的stats信息以图表的形式动态实时展示,即实时监控。Graphite监控的信息包括:系统下载信息、日志信息、文件计数、调度信息、爬虫运行信息、爬虫异常信息、文件数、获取的item数、最大请求深度、收到响应数等。
2.7 数据存储模块设计
Scrapy支持json、csv、xml等文本格式的数据存储。用户可以在运行爬虫时进行设置,例如:scrapy crawlspider -o items.json -t json,也可以在Scrapy项目文件的Item Pipeline文件中定义。此外,Scrapy 提供了多种数据库 API 来支持数据库存储。如Mongo DB、Redis等。 数据存储分为两部分,一是网页链接的存储,二是项目数据的存储。网页链接存储在Redis数据库中,用于实现分布式爬虫的下载管理;项目数据包括新闻数据和评论数据,以JSON格式保存为文本文件,方便处理。存储评论数据时,以评论url中收录的评论ID命名。通过这种方式,
3 项目总结
以上就是分布式网络新闻爬取系统的系统设计部分。分布式设计是因为单个爬虫的爬行量和爬行速度的限制。整体设计部分如上图所示。 查看全部
scrapy分页抓取网页(分布式网络新闻抓取系统设计与实现的项目介绍(一))
1 项目介绍
本项目的主要内容是分布式网络新闻采集系统的设计与实现。主要有以下几个部分介绍:
(1)深入分析网络新闻爬虫的特点,设计分布式网络新闻爬虫系统爬取策略、爬取字段、**页面爬取方法、分布式结构、系统监控和数据存储六大关键功能。
(2)结合程序代码的分解,讲解分布式网络新闻爬虫系统的实现过程。包括爬虫编写、爬虫规避、**页面数据爬取、分布式爬虫部署、系统监控,一共六项内容,结合实际定向抓取腾讯新闻数据,通过测试测试系统性能。
(3) 规划设计一个数据处理模块,包括数据清洗、代码转换、数据分类、对象添加等功能。
分布式网络新闻抓取系统的设计
2.1 整体系统架构设计
系统采用分布式主从结构,设置1台Master服务器和多台Slave服务器。Master管理Redis数据库,分发下载任务。Slave 部署 Scrapy 来抓取网页并解析提取项目数据。服务器基础环境为Ubuntu操作系统,Master服务器安装Redis数据库服务器和Graphite,Slave安装Scrapy和Redis客户端。系统按功能可分为两大模块,一是数据采集模块,二是数据处理模块。数据抓取模块包括浏览器调用、网页下载、字段提取、爬虫规避、数据存储和系统监控六大功能;数据处理模块包括数据清洗、对象添加、
2.2 爬取策略的设计
本项目的网络爬虫采用深度优先的爬取策略,根据设置下载网页数据。网页链接处理流程如下:
1.手动设置初始下载地址,一般是网站导航地址。
2、爬虫开始运行,从初始地址抓取第一批网页链接。
3、爬虫根据正则表达式识别新链接中的目录页面地址和新闻内容页面地址,将识别出的新地址加入到下载队列中等待爬取。无法识别的网页地址被定义为无用链接并丢失。
4、爬虫从等待队列中依次取出网页链接进行数据下载和提取。
5.下载队列为空,爬虫停止爬行。
新闻网站的导航页数是有限的。这个规则决定了新闻导航页面的URL在一定的人工参与下可以很容易的获取,并作为爬虫系统的初始URL。
2.3 爬取字段的设计
本项目旨在捕捉网络新闻数据,因此内容必须能够客观准确地反映网络新闻的特点。
本文以抓取腾讯在线新闻数据为例,通过对网页结构的分析,确定了一个两步抓取的过程。第一步,抓取新闻内容页面,获取新闻标题、新闻来源、新闻内容、发布时间、评论数、评论地址、相关搜索、用户还喜欢的新闻、点赞数。第二步在获取评论地址后,抓取评论页面,获取评论者ID、评论者昵称、评论者性别、评论者所在位置、评论时间、评论内容、单条评论支持人数、评论回复数单条评论。
2.4 **页面爬取方法设计
腾讯新闻网页使用Java Script生成**页面内容。一些由JS事件触发的页面在打开的时候内容会发生变化,有的页面没有JS支持根本无法运行。一般爬虫根本无法从这些网页中获取数据。解决JavaScript **页面爬虫问题有四种方法:
1.编写代码模拟相关JS逻辑。
2. 调用一个带接口的浏览器,类似于各种广泛用于测试的,比如Selenium等。
3、使用无界面浏览器,各种基于Webkit的,如Casperjs、Phantomjs等。
4、结合JS执行引擎,实现轻量级浏览器。
由于本项目是基于Python为主要语言编写的,所以使用Selenium来处理JS动态新闻页面。其优点是简单易行。使用Python代码模拟用户在浏览器上的操作。首先将网页加载到浏览器中并打开,然后从浏览器缓存中获取网页数据,传递给蜘蛛进行分析提取,最后将目标数据传递给项目通道。
2.5 Crawler 分布式设计
Redis数据库用于实现分布式爬取。基本思路是将Scrapy爬虫获取到的url(请求)放在一个Redis Queue中,所有爬虫也从指定的Redis Queue中获取请求(url)。Scrapy-Redis 默认使用 Spider Priority Queue 来确定 URL 的顺序。这是一种由有序集合实现的非 FIFO、LIFO 方法。
Redis 存储了 Scrapy 项目的请求和统计信息。根据这些信息可以掌握任务状态和爬虫状态,在分配任务时平衡系统负载,有助于克服爬虫的性能瓶颈。同时,利用Redis的高性能和易扩展的特性,可以轻松实现高效下载。当Redis存储或访问速度遇到问题时,可以通过增加Redis集群和爬虫集群的数量来提高。Scrapy-Redis分布式解决方案很好的解决了爬行中断和重复数据删除的问题。爬虫重启后,会针对Redis队列中的URL进行爬取,爬取到的URL会被自动过滤掉。
2.6 基于Graphite系统的监控组件设计
使用Graphite监控系统的运行状态,实现了分布式系统的statscollector,将系统的stats信息以图表的形式动态实时展示,即实时监控。Graphite监控的信息包括:系统下载信息、日志信息、文件计数、调度信息、爬虫运行信息、爬虫异常信息、文件数、获取的item数、最大请求深度、收到响应数等。
2.7 数据存储模块设计
Scrapy支持json、csv、xml等文本格式的数据存储。用户可以在运行爬虫时进行设置,例如:scrapy crawlspider -o items.json -t json,也可以在Scrapy项目文件的Item Pipeline文件中定义。此外,Scrapy 提供了多种数据库 API 来支持数据库存储。如Mongo DB、Redis等。 数据存储分为两部分,一是网页链接的存储,二是项目数据的存储。网页链接存储在Redis数据库中,用于实现分布式爬虫的下载管理;项目数据包括新闻数据和评论数据,以JSON格式保存为文本文件,方便处理。存储评论数据时,以评论url中收录的评论ID命名。通过这种方式,
3 项目总结
以上就是分布式网络新闻爬取系统的系统设计部分。分布式设计是因为单个爬虫的爬行量和爬行速度的限制。整体设计部分如上图所示。

