
scrapy分页抓取网页
scrapy分页抓取网页(我很困难,无法弄清楚为什么我的CrawlSpider无法拾取并处理HTML代码中的相关链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-03 08:17
我很难弄清楚为什么我的 CrawlSpider 无法获取和处理 HTML 代码中的相关链接。 Scrapy 不会抓取 LinkExtractor 允许的页面
这是一个 cawlspider,我可以在命令行上传递一些参数,如下所示:
scrapy crawl domain_spider -a url="" -s ROBOTSTXT_OBEY=0 -s AUTOTHROTTLE_ENABLED=0
蜘蛛运行并且绝对拒绝抓取带有列表分页的页面。 HTML 如下所示:
< Previous 20
如果我在参数中传递 -a allowed="page=" 之类的逗号,那么它会拾取两页,但它仍然拒绝继续。
谁能发现我的代码下面的问题?
我的爬行蜘蛛:
def __init__(self, url=None, category='default', allowed=None, denied=None, single_page=False, **kwargs):
self.category = category
if allowed == '':
allowed = None
if denied == '':
denied = None
if single_page is not False and single_page != '':
denied = '.*'
self.start_urls = ['{}'.format(url)]
self.allowed_domains = [urlparse(url).netloc]
self.domain = urlparse(url).netloc
self.rules = (
Rule(LinkExtractor(allow=allowed, deny=denied, unique=True), callback='parse_page'),
)
super(DomainSpider, self).__init__(**kwargs)
来源
2016-07-01马克·安德森 查看全部
scrapy分页抓取网页(我很困难,无法弄清楚为什么我的CrawlSpider无法拾取并处理HTML代码中的相关链接)
我很难弄清楚为什么我的 CrawlSpider 无法获取和处理 HTML 代码中的相关链接。 Scrapy 不会抓取 LinkExtractor 允许的页面
这是一个 cawlspider,我可以在命令行上传递一些参数,如下所示:
scrapy crawl domain_spider -a url="" -s ROBOTSTXT_OBEY=0 -s AUTOTHROTTLE_ENABLED=0
蜘蛛运行并且绝对拒绝抓取带有列表分页的页面。 HTML 如下所示:
< Previous 20
如果我在参数中传递 -a allowed="page=" 之类的逗号,那么它会拾取两页,但它仍然拒绝继续。
谁能发现我的代码下面的问题?
我的爬行蜘蛛:
def __init__(self, url=None, category='default', allowed=None, denied=None, single_page=False, **kwargs):
self.category = category
if allowed == '':
allowed = None
if denied == '':
denied = None
if single_page is not False and single_page != '':
denied = '.*'
self.start_urls = ['{}'.format(url)]
self.allowed_domains = [urlparse(url).netloc]
self.domain = urlparse(url).netloc
self.rules = (
Rule(LinkExtractor(allow=allowed, deny=denied, unique=True), callback='parse_page'),
)
super(DomainSpider, self).__init__(**kwargs)
来源
2016-07-01马克·安德森
scrapy分页抓取网页( WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-03 00:14
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider蓝蜘蛛网络爬虫5.1可以爬取互联网上的任何网页,wap网站,包括需要登录才能访问的页面。分析抓取页面的内容,获取结构化信息,如:新闻标题、作者、来源、正文等。支持列表页自动翻页和爬取,支持文本页面多页合并,支持图片和文件,可以抓取静态网页,也可以抓取带参数的动态网页,功能极其强大。
用户指定要爬取的网站,要爬取的网页类型(固定页面、分页页面等),并配置如何解析数据项(如新闻标题、作者、来源、文本、等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正实现“按需采集,一次配置,永久采集”。捕获的数据可以保存到数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全替代传统的编辑和人工处理信息的模式。可以24*60实时、准确地为企业提供最新信息和情报,真正为企业降低成本、提高竞争力。
该工具的主要特点如下:
* 应用范围广,可以爬取任意网页(包括登录后才能访问的网页)
* 处理速度快,如果网络通畅的话,1小时可以爬取解析10000个网页
*采用独有的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
* 抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
* 支持断点连续抓取,可在机器死机或出现异常情况后恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以抓取所有列表页的数据。对于body页面,可以自动合并分页中显示的内容;
* 支持页面深度爬取,页面可一页一页抓取。比如通过列表页抓取正文页URL,然后抓取正文页。各级页面可单独存放;
*WEB操作界面,一处安装,随处使用
* 一步一步分析,一步一步入库
* 一次配置,永久抓取,一劳永逸 查看全部
scrapy分页抓取网页(
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))

WebSpider蓝蜘蛛网络爬虫5.1可以爬取互联网上的任何网页,wap网站,包括需要登录才能访问的页面。分析抓取页面的内容,获取结构化信息,如:新闻标题、作者、来源、正文等。支持列表页自动翻页和爬取,支持文本页面多页合并,支持图片和文件,可以抓取静态网页,也可以抓取带参数的动态网页,功能极其强大。
用户指定要爬取的网站,要爬取的网页类型(固定页面、分页页面等),并配置如何解析数据项(如新闻标题、作者、来源、文本、等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正实现“按需采集,一次配置,永久采集”。捕获的数据可以保存到数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全替代传统的编辑和人工处理信息的模式。可以24*60实时、准确地为企业提供最新信息和情报,真正为企业降低成本、提高竞争力。
该工具的主要特点如下:
* 应用范围广,可以爬取任意网页(包括登录后才能访问的网页)
* 处理速度快,如果网络通畅的话,1小时可以爬取解析10000个网页
*采用独有的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
* 抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
* 支持断点连续抓取,可在机器死机或出现异常情况后恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以抓取所有列表页的数据。对于body页面,可以自动合并分页中显示的内容;
* 支持页面深度爬取,页面可一页一页抓取。比如通过列表页抓取正文页URL,然后抓取正文页。各级页面可单独存放;
*WEB操作界面,一处安装,随处使用
* 一步一步分析,一步一步入库
* 一次配置,永久抓取,一劳永逸
scrapy分页抓取网页( image这是简易数据分析系列的第13篇文章(13):WebScraper教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-03 00:12
image这是简易数据分析系列的第13篇文章(13):WebScraper教程)
图片
这是简易数据分析系列文章的第 13 篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10篇网络爬虫系列教程,这10篇文章基本涵盖了网络爬虫的大部分功能。今天的内容是本系列的最后一篇文章。下一章我再开个坑,讲讲如何用Excel对采集到的数据进行格式化和分析。
我会在下一篇文章文章中对Web Scraper教程做一个全面的总结,今天开始我们的实战教程。
在之前的课程中,我们抓取的数据都是同一级别的内容。讨论的主要问题是如何处理市场上各种类型的分页,但是如何抓取详情页的内容数据并没有介绍。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上的作品相关的数据,比如下图中的排名、作品名称、播放量、弹幕数、作者姓名等。
图片
经常逛B站的朋友也知道,UP主经常暗示看视频会连续三个操作(点赞+币+采集)。可以看出这三个数据对视频的排名有一定的影响,所以这些数据对我们也有一定的参考价值。
图片
但遗憾的是,这份榜单中并没有相关数据。这些数据在视频详情页,我们需要点击链接查看:
图片
今天的教程内容是教大家如何在爬取一级页面(列表页)的同时,使用Web Scraper抓取二级页面(详情页)的内容。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我已经在下图中的红框中标出了关键路径。你可以比较一下:
图片
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
图片
2.为容器创建一个选择器
设置前我们观察一下,发现这个网页的排名数据是一次性加载100条数据,不需要分页,所以这里的Type类型选择为Element。
其他参数都比较简单,就不赘述了(了解不多的可以看我之前的基础教程)。这是一个截图供您参考:
图片
3.创建列表页面子选择器
这次子选择器要抓取的内容如下,都比较简单。可以参考图片截图:
排名 (num) 作品名称 (title) 播放量 (play_amount) 弹幕量 (danmu_count) 作者: (author)
图片
图片
如果做了这一步,其实可以捕获所有已知的列表数据,但是本文的重点是:如何捕获二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper 的本质就是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实点击标题链接即可跳转:
图片
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过一个例子来理解它。
首先,在本例中,我们获取了标题的文本,选择器类型为 Text:
图片
当我们要抓取链接的时候,需要再创建一个选择器,被选中的元素都是一样的,只不过Type是Link:
图片
创建成功后,我们点击链接类型选择器,进入它的内部,然后创建相关的选择器。下面我录制了一个动图,注意我鼠标高亮的导航路由部分,可以清楚的看到这几个选择器的层级关系:
图片
4.创建详情页子选择器
当你点击链接时,你会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,无法跨页选择想要的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,然后回车重新加载,这样就可以在当前页选中了。
图片
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了点赞数、硬币数、采集数和分享数4个数据。这个操作也很简单,这里就不赘述了。
图片
所有选择器的结构图如下:
图片
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经建立。
5.捕获数据
激动人心的部分终于来了,我们将开始抓取数据。但在抓取之前,我们必须将等待时间调整为更大。默认时间是2000毫秒,我这里改成5000毫秒。
图片
为什么要这样做?看下图你就明白了:
图片
首先,每次打开二级页面都是一个全新的页面,此时浏览器加载页面需要时间;
其次,我们可以观察要捕获的点赞数等数据。页面刚加载的时候,它的值为“--”,过一段时间会变成一个数字。
因此,我们直接等待5000ms,等页面和数据加载完毕后再统一取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓取的数据的一部分,这里是为了证明这种方法有效:
图片
6.总结
这个教程可能有点难。我将分享我的站点地图。如果在生产过程中遇到困难,可以参考我的配置。SiteMap的导入功能我在第六篇教程中已经讲解过了。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
掌握了二级页面的爬取方式后,三级页面和四级页面都没有问题。因为例程是相同的:它们都是在链接选择器指向的下一页上抓取数据。因为原理是一样的,我就不演示了。 查看全部
scrapy分页抓取网页(
image这是简易数据分析系列的第13篇文章(13):WebScraper教程)

图片
这是简易数据分析系列文章的第 13 篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10篇网络爬虫系列教程,这10篇文章基本涵盖了网络爬虫的大部分功能。今天的内容是本系列的最后一篇文章。下一章我再开个坑,讲讲如何用Excel对采集到的数据进行格式化和分析。
我会在下一篇文章文章中对Web Scraper教程做一个全面的总结,今天开始我们的实战教程。
在之前的课程中,我们抓取的数据都是同一级别的内容。讨论的主要问题是如何处理市场上各种类型的分页,但是如何抓取详情页的内容数据并没有介绍。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上的作品相关的数据,比如下图中的排名、作品名称、播放量、弹幕数、作者姓名等。
图片
经常逛B站的朋友也知道,UP主经常暗示看视频会连续三个操作(点赞+币+采集)。可以看出这三个数据对视频的排名有一定的影响,所以这些数据对我们也有一定的参考价值。

图片
但遗憾的是,这份榜单中并没有相关数据。这些数据在视频详情页,我们需要点击链接查看:
图片
今天的教程内容是教大家如何在爬取一级页面(列表页)的同时,使用Web Scraper抓取二级页面(详情页)的内容。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我已经在下图中的红框中标出了关键路径。你可以比较一下:
图片
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
图片
2.为容器创建一个选择器
设置前我们观察一下,发现这个网页的排名数据是一次性加载100条数据,不需要分页,所以这里的Type类型选择为Element。
其他参数都比较简单,就不赘述了(了解不多的可以看我之前的基础教程)。这是一个截图供您参考:
图片
3.创建列表页面子选择器
这次子选择器要抓取的内容如下,都比较简单。可以参考图片截图:
排名 (num) 作品名称 (title) 播放量 (play_amount) 弹幕量 (danmu_count) 作者: (author)
图片
图片
如果做了这一步,其实可以捕获所有已知的列表数据,但是本文的重点是:如何捕获二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper 的本质就是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实点击标题链接即可跳转:
图片
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过一个例子来理解它。
首先,在本例中,我们获取了标题的文本,选择器类型为 Text:
图片
当我们要抓取链接的时候,需要再创建一个选择器,被选中的元素都是一样的,只不过Type是Link:
图片
创建成功后,我们点击链接类型选择器,进入它的内部,然后创建相关的选择器。下面我录制了一个动图,注意我鼠标高亮的导航路由部分,可以清楚的看到这几个选择器的层级关系:
图片
4.创建详情页子选择器
当你点击链接时,你会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,无法跨页选择想要的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,然后回车重新加载,这样就可以在当前页选中了。
图片
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了点赞数、硬币数、采集数和分享数4个数据。这个操作也很简单,这里就不赘述了。
图片
所有选择器的结构图如下:
图片
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经建立。
5.捕获数据
激动人心的部分终于来了,我们将开始抓取数据。但在抓取之前,我们必须将等待时间调整为更大。默认时间是2000毫秒,我这里改成5000毫秒。
图片
为什么要这样做?看下图你就明白了:
图片
首先,每次打开二级页面都是一个全新的页面,此时浏览器加载页面需要时间;
其次,我们可以观察要捕获的点赞数等数据。页面刚加载的时候,它的值为“--”,过一段时间会变成一个数字。
因此,我们直接等待5000ms,等页面和数据加载完毕后再统一取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓取的数据的一部分,这里是为了证明这种方法有效:
图片
6.总结
这个教程可能有点难。我将分享我的站点地图。如果在生产过程中遇到困难,可以参考我的配置。SiteMap的导入功能我在第六篇教程中已经讲解过了。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
掌握了二级页面的爬取方式后,三级页面和四级页面都没有问题。因为例程是相同的:它们都是在链接选择器指向的下一页上抓取数据。因为原理是一样的,我就不演示了。
scrapy分页抓取网页(WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 04:22
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页,指定跳转页数。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页看起来像这样,注意有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk->Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type (-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。 查看全部
scrapy分页抓取网页(WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页,指定跳转页数。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页看起来像这样,注意有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk->Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type (-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。
scrapy分页抓取网页(如何从OMIM抓取一些数据下来的网站数据下载的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-01 07:13
由于工作原因,我们需要从 OMIM 中获取一些数据。其实网站提供API和数据下载,但是对于营利单位来说,是需要权限的。无奈之下,只能求助于爬虫来解决。
什么是爬行动物
爬虫又称爬虫程序,是一种网络爬虫机器人,是一种模拟浏览器与网页交互的工具。它在英语中被称为“Bot”。例如,微软的爬虫,叫做“bingbot”,会定期对网页进行采样,发现新的或更新的网页,计算后决定是否加入索引。爬行动物的规模可大可小。像搜索引擎这样的大型爬虫会涉及大量机器和分布式组织。比如我今天用的那个小就是一台电脑,而不是手动输入400个网页和一堆复制粘贴操作。
爬虫的应用,除了上面提到的搜索引擎,还有数据分析。分析的数据不仅是自己产生的,也可能是从互联网上采集的。一些网站会提供数据采集接口,比如github、KEGG、NCBI和Ensembl,还有stackoverflow。一般来说,采集这些网站的数据要简单得多。直接根据自己的需要,按照它的接口规则拼出一个http URL就够了。在没有API的情况下从其他网站采集数据,需要依赖爬虫。如果你想搜索搜狗,你必须依靠自己的技术基础进行搜索。我做过知乎和微信搜索。我经常用这两个。在写一个主题之前,我需要做一个搜索。
在另一种情况下,不仅使用严格意义上的爬虫,还通过模拟浏览器行为。比如公司有一个网站系统出报告,但是做的时候没有给你留一个API接口,而是每次想到几十个网站,点击输入测试结果一个一、我想爆粗口,为什么不直接从服务器上传分析后的结果?这时候用的是模拟用户登录,选择跳转到指定样本的界面,分析POST请求参数,然后按要求完成参数,提交。这是用于自动化测试的,我稍后会写。
Scrapy 用途
关于Scrapy的安装和入门指南,官网文档的内容已经很不错了。这里我们以爬取OMIM网站为例介绍简单的用法和可能出现的问题。
def __init__(self, filename=None):
URL_BASE = 'https://www.omim.org/entry/'
if filename:
with open(filename, 'r') as f:
omim_ids = [re.findall(r'\((\d+)\)', line ) for line in f if line.startswith('chr') ]
self.start_urls = [ '{0}{1}'.format(URL_BASE, int(omim[0]) ) for omim in omim_ids if omim]
反爬虫反应
对于一些网站爬虫来说,比如Scrapy网站给出的例子,用猫画老虎可以达到目的,而OMIM不能。如果直接开始爬取,服务器会抛出403“拒绝访问”错误码。文档OMIM robots规定网站只允许Googlebot和bingbot抓取其指定目录下的数据。
关于反爬的反应,官网也有资料供参考:避免被封禁,参考这里和OMIM机器人,修改程序设置,然后测试顺利获取数据。使用的方法总结如下:
以下是程序代码:
#!/usr/bin/env python
#coding=utf-8
import re
import scrapy
class omimSpider(scrapy.Spider):
name = 'omim'
custom_settings = {
'USER_AGENT':'bingbot', #冒充bingbot的UA名和'BOT_NAME'
'BOT_NAME':'bingbot',
'COOKIES_ENABLED':False,
'DOWNLOAD_DELAY':4
}
def __init__(self, filename=None):
URL_BASE = 'https://www.omim.org/entry/'
if filename:
with open(filename, 'r') as f:
omim_ids = [re.findall(r'\((\d+)\)', line ) for line in f if line.startswith('chr') ]
self.start_urls = [ '{0}{1}'.format(URL_BASE, int(omim[0]) ) for omim in omim_ids if omim]
# self.start_urls = ['https://www.omim.org/entry/131244']
def parse(self, response):
gene_pheno = {}
gene_pheno['url'] = response.url
gene_pheno['omim_num'] = re.findall(r'(\d+)',response.url)[0]
#extract from Description
if 'Description' in response.text:
gene_pheno['description'] = ','.join(response.xpath('//div[@id="descriptionFold"]/span/p/text()').extract() )
#extract from table
if response.xpath('//table'):
tr = response.xpath('//table/tbody/tr') #maybe one or more trs
gene_pheno['location'] = tr[0].xpath('td')[0].xpath('span/a/text()').extract_first().strip() #first td of first tr in table
phenotype = tr[0].xpath('td')[1].xpath('span/text()').extract_first().strip()
mim = tr[0].xpath('td')[2].xpath('span/a/text()').extract_first()
inherit = ','.join(tr[0].xpath('td')[3].xpath('span/abbr/text()').extract() )
pheno_key = tr[0].xpath('td')[4].xpath('span/abbr/text()').extract_first()
gene_pheno[mim] = [phenotype, inherit, pheno_key]
if len(tr) > 1:
for tb_record in tr[1:]: #less num of column than the tr above
phenotype = tb_record.xpath('td')[0].xpath('span/text()').extract_first().strip()
min = tb_record.xpath('td')[1].xpath('span/a/text()').extract_first()
inherit = ','.join(tb_record.xpath('td')[2].xpath('span/abbr/text()').extract() )
pheno_key = tb_record.xpath('td')[3].xpath('span/abbr/text()').extract_first()
gene_pheno[mim] = [phenotype, inherit, pheno_key]
return gene_pheno
指示
#scrapy 版本 1.1.0
scrapy runspider omim.py -o all_omim.json -a filename=/path/to/file.txt
参考:
Scrapy官网文档
w3school xpath 文档
omim.py 源代码
/r/tETI0BDESU02rVSz9xGm(二维码自动识别) 查看全部
scrapy分页抓取网页(如何从OMIM抓取一些数据下来的网站数据下载的?)
由于工作原因,我们需要从 OMIM 中获取一些数据。其实网站提供API和数据下载,但是对于营利单位来说,是需要权限的。无奈之下,只能求助于爬虫来解决。
什么是爬行动物
爬虫又称爬虫程序,是一种网络爬虫机器人,是一种模拟浏览器与网页交互的工具。它在英语中被称为“Bot”。例如,微软的爬虫,叫做“bingbot”,会定期对网页进行采样,发现新的或更新的网页,计算后决定是否加入索引。爬行动物的规模可大可小。像搜索引擎这样的大型爬虫会涉及大量机器和分布式组织。比如我今天用的那个小就是一台电脑,而不是手动输入400个网页和一堆复制粘贴操作。
爬虫的应用,除了上面提到的搜索引擎,还有数据分析。分析的数据不仅是自己产生的,也可能是从互联网上采集的。一些网站会提供数据采集接口,比如github、KEGG、NCBI和Ensembl,还有stackoverflow。一般来说,采集这些网站的数据要简单得多。直接根据自己的需要,按照它的接口规则拼出一个http URL就够了。在没有API的情况下从其他网站采集数据,需要依赖爬虫。如果你想搜索搜狗,你必须依靠自己的技术基础进行搜索。我做过知乎和微信搜索。我经常用这两个。在写一个主题之前,我需要做一个搜索。
在另一种情况下,不仅使用严格意义上的爬虫,还通过模拟浏览器行为。比如公司有一个网站系统出报告,但是做的时候没有给你留一个API接口,而是每次想到几十个网站,点击输入测试结果一个一、我想爆粗口,为什么不直接从服务器上传分析后的结果?这时候用的是模拟用户登录,选择跳转到指定样本的界面,分析POST请求参数,然后按要求完成参数,提交。这是用于自动化测试的,我稍后会写。
Scrapy 用途
关于Scrapy的安装和入门指南,官网文档的内容已经很不错了。这里我们以爬取OMIM网站为例介绍简单的用法和可能出现的问题。
def __init__(self, filename=None):
URL_BASE = 'https://www.omim.org/entry/'
if filename:
with open(filename, 'r') as f:
omim_ids = [re.findall(r'\((\d+)\)', line ) for line in f if line.startswith('chr') ]
self.start_urls = [ '{0}{1}'.format(URL_BASE, int(omim[0]) ) for omim in omim_ids if omim]
反爬虫反应
对于一些网站爬虫来说,比如Scrapy网站给出的例子,用猫画老虎可以达到目的,而OMIM不能。如果直接开始爬取,服务器会抛出403“拒绝访问”错误码。文档OMIM robots规定网站只允许Googlebot和bingbot抓取其指定目录下的数据。
关于反爬的反应,官网也有资料供参考:避免被封禁,参考这里和OMIM机器人,修改程序设置,然后测试顺利获取数据。使用的方法总结如下:
以下是程序代码:
#!/usr/bin/env python
#coding=utf-8
import re
import scrapy
class omimSpider(scrapy.Spider):
name = 'omim'
custom_settings = {
'USER_AGENT':'bingbot', #冒充bingbot的UA名和'BOT_NAME'
'BOT_NAME':'bingbot',
'COOKIES_ENABLED':False,
'DOWNLOAD_DELAY':4
}
def __init__(self, filename=None):
URL_BASE = 'https://www.omim.org/entry/'
if filename:
with open(filename, 'r') as f:
omim_ids = [re.findall(r'\((\d+)\)', line ) for line in f if line.startswith('chr') ]
self.start_urls = [ '{0}{1}'.format(URL_BASE, int(omim[0]) ) for omim in omim_ids if omim]
# self.start_urls = ['https://www.omim.org/entry/131244']
def parse(self, response):
gene_pheno = {}
gene_pheno['url'] = response.url
gene_pheno['omim_num'] = re.findall(r'(\d+)',response.url)[0]
#extract from Description
if 'Description' in response.text:
gene_pheno['description'] = ','.join(response.xpath('//div[@id="descriptionFold"]/span/p/text()').extract() )
#extract from table
if response.xpath('//table'):
tr = response.xpath('//table/tbody/tr') #maybe one or more trs
gene_pheno['location'] = tr[0].xpath('td')[0].xpath('span/a/text()').extract_first().strip() #first td of first tr in table
phenotype = tr[0].xpath('td')[1].xpath('span/text()').extract_first().strip()
mim = tr[0].xpath('td')[2].xpath('span/a/text()').extract_first()
inherit = ','.join(tr[0].xpath('td')[3].xpath('span/abbr/text()').extract() )
pheno_key = tr[0].xpath('td')[4].xpath('span/abbr/text()').extract_first()
gene_pheno[mim] = [phenotype, inherit, pheno_key]
if len(tr) > 1:
for tb_record in tr[1:]: #less num of column than the tr above
phenotype = tb_record.xpath('td')[0].xpath('span/text()').extract_first().strip()
min = tb_record.xpath('td')[1].xpath('span/a/text()').extract_first()
inherit = ','.join(tb_record.xpath('td')[2].xpath('span/abbr/text()').extract() )
pheno_key = tb_record.xpath('td')[3].xpath('span/abbr/text()').extract_first()
gene_pheno[mim] = [phenotype, inherit, pheno_key]
return gene_pheno
指示
#scrapy 版本 1.1.0
scrapy runspider omim.py -o all_omim.json -a filename=/path/to/file.txt
参考:
Scrapy官网文档
w3school xpath 文档
omim.py 源代码
/r/tETI0BDESU02rVSz9xGm(二维码自动识别)
scrapy分页抓取网页(【平安二号?百日攻坚】我该)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-29 01:09
【问题描述】:
我有一个爬虫爬虫,它爬取一个 网站,它通过页面上的 javascript 重新加载内容。要跳转到下一页进行抓取,我一直在使用 Selenium 单击 网站 顶部的月份链接。
问题是,即使我的代码按预期通过每个链接,蜘蛛只是抓取第一个月(9 月)的月份数据并返回这些重复项。
我该如何解决这个问题?
from selenium import webdriver
class GigsInScotlandMain(InitSpider):
name = 'gigsinscotlandmain'
allowed_domains = ["gigsinscotland.com"]
start_urls = ["http://www.gigsinscotland.com"]
def __init__(self):
InitSpider.__init__(self)
self.br = webdriver.Firefox()
def parse(self, response):
hxs = HtmlXPathSelector(response)
self.br.get(response.url)
time.sleep(2.5)
# Get the string for each month on the page.
months = hxs.select("//ul[@id='gigsMonths']/li/a/text()").extract()
for month in months:
link = self.br.find_element_by_link_text(month)
link.click()
time.sleep(5)
# Get all the divs containing info to be scraped.
listitems = hxs.select("//div[@class='listItem']")
for listitem in listitems:
item = GigsInScotlandMainItem()
item['artist'] = listitem.select("div[contains(@class, 'artistBlock')]/div[@class='artistdiv']/span[@class='artistname']/a/text()").extract()
#
# Get other data ...
#
yield item
【问题讨论】: 查看全部
scrapy分页抓取网页(【平安二号?百日攻坚】我该)
【问题描述】:
我有一个爬虫爬虫,它爬取一个 网站,它通过页面上的 javascript 重新加载内容。要跳转到下一页进行抓取,我一直在使用 Selenium 单击 网站 顶部的月份链接。
问题是,即使我的代码按预期通过每个链接,蜘蛛只是抓取第一个月(9 月)的月份数据并返回这些重复项。
我该如何解决这个问题?
from selenium import webdriver
class GigsInScotlandMain(InitSpider):
name = 'gigsinscotlandmain'
allowed_domains = ["gigsinscotland.com"]
start_urls = ["http://www.gigsinscotland.com"]
def __init__(self):
InitSpider.__init__(self)
self.br = webdriver.Firefox()
def parse(self, response):
hxs = HtmlXPathSelector(response)
self.br.get(response.url)
time.sleep(2.5)
# Get the string for each month on the page.
months = hxs.select("//ul[@id='gigsMonths']/li/a/text()").extract()
for month in months:
link = self.br.find_element_by_link_text(month)
link.click()
time.sleep(5)
# Get all the divs containing info to be scraped.
listitems = hxs.select("//div[@class='listItem']")
for listitem in listitems:
item = GigsInScotlandMainItem()
item['artist'] = listitem.select("div[contains(@class, 'artistBlock')]/div[@class='artistdiv']/span[@class='artistname']/a/text()").extract()
#
# Get other data ...
#
yield item
【问题讨论】:
scrapy分页抓取网页(2021-09-051Scrapy(绿线向)2Scrapy的运作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-29 01:07
2021-09-051 Scrapy架构图(绿线为数据流)
2 Scrapy操作流程
代码写好了,程序开始运行了……
发动机:嗨!蜘蛛,你在对付哪个网站?蜘蛛:老板要我处理。引擎:给我第一个需要处理的 URL。Spider:在这里,第一个 URL 是。发动机:嗨!调度员,我有一个请求,请求您帮我排序并加入队列。调度程序:好的,正在处理您等一下。发动机:嗨!调度员,给我你处理的请求。调度器:给你,这是我处理的请求引擎:嗨!下载器,请帮我按照老板下载中间件的设置下载这个请求下载器:OK!给你,这是下载的东西。(如果失败:对不起,这个请求下载失败。然后引擎告诉调度器这个请求下载失败,你记录一下,我们稍后下载) 引擎:你好!蜘蛛,这是一个下载的东西,已经按照老大的下载中间件进行了处理,大家可以自行处理!这里,响应默认由def parse()处理) Spider:(处理数据后需要跟进的URL),Hi!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!(处理数据后需要跟进的URL),您好!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!(处理数据后需要跟进的URL),您好!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
3 Scrapy安装介绍
1、安装wheel pip3 install wheel
2、安装lxml pip3 install lxml-4.2.1-cp36-cp36m-win_amd64.whl
3、安装pyopenssl (已安装就不需要安装)
4、安装Twisted pip3 install Twisted-18.4.0-cp36-cp36m-win_amd64.whl
5、安装pywin32 pip3 install pypiwin32
6、安装scrapy pip3 install scrapy
或者pip3 install Scrapy-1.5.0-py2.py3-none-any.whl
Scrapy框架官网:
Scrapy中文维护网站:
Windows安装方式Ubuntu需要9.10以上的安装方式
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明已经安装成功
具体Scrapy安装过程参考:每个平台都有安装方法
4 制作一个Scrapy爬虫一共需要4个步骤:
新建爬虫项目
scrapy startproject mySpider
进入该目录 cd mySpider
scrapy genspider stack http://stackoverflow.com/ #创建一个爬虫stack 指定爬取路径
明确目标(编写items.py):明确你要捕获的目标(目标信息以类和字段的形式实现)
制作爬虫(spiders/xxspider.py):制作爬虫并开始爬取网页(实现主要逻辑的地方并返回item)
存储内容(pipelines.py):设计管道存储爬取内容(接受item,一般重写几个常用方法(open_spider、process_item、close_spider)
启动爬虫项目
命令开始:scrapy crawl spidername(爬虫名称)
文件开始
from scrapy import cmdline
# 方式一:注意execute的参数类型为一个列表
cmdline.execute('scrapy crawl spidername'.split())
# 方式二:注意execute的参数类型为一个列表
cmdline.execute(['scrapy', 'crawl', 'spidername'])
5 入门案例一.新建项目(scrapy startproject)
scrapy startproject mySpider
下面简单介绍一下各个主文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的 Python 模块,将从中引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ : 蜘蛛代码存放的目录
二、明确目标 (mySpider/items.py)
我们打算抓取:网站 中的邮箱。
打开mySpider目录下的items.pyItem,定义一个结构化的数据字段,用来保存爬取的数据,类似于dict,但是提供了一些额外的保护来减少错误。可以通过创建一个scrapy.Item类并定义一个scrapy.Field类型的类属性来定义一个Item(可以理解为一种类似于ORM的映射关系)。接下来,创建一个 TianyaItem 类并构建项目模型。
import scrapy
class TianyaItem(scrapy.Item):
email = scrapy.Field() #只定义爬取email字段
三、制作蜘蛛 (spiders/itcastSpider.py)
爬虫功能分为两步:
1. 爬取数据
scrapy genspider mytianya "bbs.tianya.cn" #指定爬虫文件名 爬取的域名
import scrapy
import re
from tianya import items
class MytianyaSpider(scrapy.Spider):
name = 'mytianya'
allowed_domains = ['bbs.tianya.cn']
start_urls = ['http://bbs.tianya.cn/post-140-393977-1.shtml']
#主要的逻辑模块
def parse(self, response):
pass
其实我们也可以自己创建itcast.py,自己写上面的代码,但是使用命令可以省去写固定代码的麻烦
要创建 Spider,您必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
修改 parse() 方法
def parse(self, response):
html = response.body.decode()
# [email protected]
email = re.compile(r"([A-Z0-9_][email protected][A-Z0-9]+\.[A-Z]{2,4})", re.I)
emailList = email.findall(html)
mydict = []
for e in emailList:
item = items.TianyaItem()
item["email"] = e
# mydict[e] = "http://bbs.tianya.cn/post-140-393977-1.shtml"
mydict.append(item)
return mydict
然后运行看看,在mySpider目录下执行:
scrapy crawl mytianya
2.scrapy保存信息有四种最简单的保存方式,-o输出指定格式的文件,命令如下:
scrapy crawl mytianya -o mytianya.json
scrapy crawl mytianya -o mytianya.csv
scrapy crawl mytianya -o mytianya.xml
什么产量在这里:
def parse(self, response):
html = response.body.decode()
# [email protected]
email = re.compile(r"([A-Z0-9_][email protected][A-Z0-9]+.[A-Z]{2,4})", re.I)
emailList = email.findall(html)
mydict = []
for e in emailList:
item = items.TianyaItem()
item["email"] = e
yield mydict #得到生成器对象,每循环一次,返回一个item
分类:
技术要点:
相关文章: 查看全部
scrapy分页抓取网页(2021-09-051Scrapy(绿线向)2Scrapy的运作流程)
2021-09-051 Scrapy架构图(绿线为数据流)
2 Scrapy操作流程
代码写好了,程序开始运行了……
发动机:嗨!蜘蛛,你在对付哪个网站?蜘蛛:老板要我处理。引擎:给我第一个需要处理的 URL。Spider:在这里,第一个 URL 是。发动机:嗨!调度员,我有一个请求,请求您帮我排序并加入队列。调度程序:好的,正在处理您等一下。发动机:嗨!调度员,给我你处理的请求。调度器:给你,这是我处理的请求引擎:嗨!下载器,请帮我按照老板下载中间件的设置下载这个请求下载器:OK!给你,这是下载的东西。(如果失败:对不起,这个请求下载失败。然后引擎告诉调度器这个请求下载失败,你记录一下,我们稍后下载) 引擎:你好!蜘蛛,这是一个下载的东西,已经按照老大的下载中间件进行了处理,大家可以自行处理!这里,响应默认由def parse()处理) Spider:(处理数据后需要跟进的URL),Hi!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!(处理数据后需要跟进的URL),您好!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!(处理数据后需要跟进的URL),您好!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
3 Scrapy安装介绍
1、安装wheel pip3 install wheel
2、安装lxml pip3 install lxml-4.2.1-cp36-cp36m-win_amd64.whl
3、安装pyopenssl (已安装就不需要安装)
4、安装Twisted pip3 install Twisted-18.4.0-cp36-cp36m-win_amd64.whl
5、安装pywin32 pip3 install pypiwin32
6、安装scrapy pip3 install scrapy
或者pip3 install Scrapy-1.5.0-py2.py3-none-any.whl
Scrapy框架官网:
Scrapy中文维护网站:
Windows安装方式Ubuntu需要9.10以上的安装方式
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明已经安装成功
具体Scrapy安装过程参考:每个平台都有安装方法
4 制作一个Scrapy爬虫一共需要4个步骤:
新建爬虫项目
scrapy startproject mySpider
进入该目录 cd mySpider
scrapy genspider stack http://stackoverflow.com/ #创建一个爬虫stack 指定爬取路径
明确目标(编写items.py):明确你要捕获的目标(目标信息以类和字段的形式实现)
制作爬虫(spiders/xxspider.py):制作爬虫并开始爬取网页(实现主要逻辑的地方并返回item)
存储内容(pipelines.py):设计管道存储爬取内容(接受item,一般重写几个常用方法(open_spider、process_item、close_spider)
启动爬虫项目
命令开始:scrapy crawl spidername(爬虫名称)
文件开始
from scrapy import cmdline
# 方式一:注意execute的参数类型为一个列表
cmdline.execute('scrapy crawl spidername'.split())
# 方式二:注意execute的参数类型为一个列表
cmdline.execute(['scrapy', 'crawl', 'spidername'])
5 入门案例一.新建项目(scrapy startproject)
scrapy startproject mySpider
下面简单介绍一下各个主文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的 Python 模块,将从中引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ : 蜘蛛代码存放的目录
二、明确目标 (mySpider/items.py)
我们打算抓取:网站 中的邮箱。
打开mySpider目录下的items.pyItem,定义一个结构化的数据字段,用来保存爬取的数据,类似于dict,但是提供了一些额外的保护来减少错误。可以通过创建一个scrapy.Item类并定义一个scrapy.Field类型的类属性来定义一个Item(可以理解为一种类似于ORM的映射关系)。接下来,创建一个 TianyaItem 类并构建项目模型。
import scrapy
class TianyaItem(scrapy.Item):
email = scrapy.Field() #只定义爬取email字段
三、制作蜘蛛 (spiders/itcastSpider.py)
爬虫功能分为两步:
1. 爬取数据
scrapy genspider mytianya "bbs.tianya.cn" #指定爬虫文件名 爬取的域名
import scrapy
import re
from tianya import items
class MytianyaSpider(scrapy.Spider):
name = 'mytianya'
allowed_domains = ['bbs.tianya.cn']
start_urls = ['http://bbs.tianya.cn/post-140-393977-1.shtml']
#主要的逻辑模块
def parse(self, response):
pass
其实我们也可以自己创建itcast.py,自己写上面的代码,但是使用命令可以省去写固定代码的麻烦
要创建 Spider,您必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
修改 parse() 方法
def parse(self, response):
html = response.body.decode()
# [email protected]
email = re.compile(r"([A-Z0-9_][email protected][A-Z0-9]+\.[A-Z]{2,4})", re.I)
emailList = email.findall(html)
mydict = []
for e in emailList:
item = items.TianyaItem()
item["email"] = e
# mydict[e] = "http://bbs.tianya.cn/post-140-393977-1.shtml"
mydict.append(item)
return mydict
然后运行看看,在mySpider目录下执行:
scrapy crawl mytianya
2.scrapy保存信息有四种最简单的保存方式,-o输出指定格式的文件,命令如下:
scrapy crawl mytianya -o mytianya.json
scrapy crawl mytianya -o mytianya.csv
scrapy crawl mytianya -o mytianya.xml
什么产量在这里:
def parse(self, response):
html = response.body.decode()
# [email protected]
email = re.compile(r"([A-Z0-9_][email protected][A-Z0-9]+.[A-Z]{2,4})", re.I)
emailList = email.findall(html)
mydict = []
for e in emailList:
item = items.TianyaItem()
item["email"] = e
yield mydict #得到生成器对象,每循环一次,返回一个item
分类:
技术要点:
相关文章:
scrapy分页抓取网页(一下中代码实现是用C#语言来实现的抓取问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-01-28 01:14
我相信所有个人网站站长都有抓取别人数据的经历。目前抓取别人的网站数据只有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时间没看懂怎么用,后来决定自己写好了,现在基本可以搞定了网站 半天(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下代码都是正确的实现,我目前正在使用。本文中的代码实现是用C#语言实现的。我认为其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
publicstringGetResponseString(stringurl)
{
string_StrResponse="";
HttpWebRequest_WebRequest=(HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent="MOZILLA/4.0(兼容;MSIE7.0;WINDOWSNT5.2;.NETCLR1.1.4322;.NETCLR2.0.50727;.NETCLR3.0.04506.648;.NETCLR3.5.21022;.NETCLR3.@ >0.4506.2152;.NETCLR3.5.30729)";
_WebRequest.Method="GET";
WebResponse_WebResponse=_WebRequest.GetResponse();
StreamReader_ResponseStream=newStreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse=_ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
return_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页码的时候的分页,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实也不是很难,因为经过所有,有一个地方可以得到页码的规则。
我们知道提交http请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、__VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以可以通过第一种方法获得。然后同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,每爬完一页后,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页post数据使用
参考代码如下:
for(inti=0;i 查看全部
scrapy分页抓取网页(一下中代码实现是用C#语言来实现的抓取问题)
我相信所有个人网站站长都有抓取别人数据的经历。目前抓取别人的网站数据只有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时间没看懂怎么用,后来决定自己写好了,现在基本可以搞定了网站 半天(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下代码都是正确的实现,我目前正在使用。本文中的代码实现是用C#语言实现的。我认为其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
publicstringGetResponseString(stringurl)
{
string_StrResponse="";
HttpWebRequest_WebRequest=(HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent="MOZILLA/4.0(兼容;MSIE7.0;WINDOWSNT5.2;.NETCLR1.1.4322;.NETCLR2.0.50727;.NETCLR3.0.04506.648;.NETCLR3.5.21022;.NETCLR3.@ >0.4506.2152;.NETCLR3.5.30729)";
_WebRequest.Method="GET";
WebResponse_WebResponse=_WebRequest.GetResponse();
StreamReader_ResponseStream=newStreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse=_ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
return_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页码的时候的分页,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实也不是很难,因为经过所有,有一个地方可以得到页码的规则。
我们知道提交http请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、__VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以可以通过第一种方法获得。然后同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,每爬完一页后,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页post数据使用
参考代码如下:
for(inti=0;i
scrapy分页抓取网页( 如何判断是否是蜘蛛对式网页的链接结构的原因? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-26 00:09
如何判断是否是蜘蛛对式网页的链接结构的原因?
)
搜索引擎蜘蛛系统的目标是发现和抓取互联网上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。对网站的体验施加压力,也就是说蜘蛛不会爬取所有网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取能力。高效的。只有这样,蜘蛛才能尽量满足大部分网站,这也是我们需要做好网站的链接结构的原因。接下来在马海翔博客平台分享搜索引擎蜘蛛对翻页网页的爬取机制。
1、为什么需要这种爬取机制?
目前大部分网站都采用翻页的形式,有序的分发网站资源。当添加新的文章时,旧资源被推回翻页系列。对于蜘蛛来说,这种特定类型的索引页是一个有效的爬取渠道,但是蜘蛛爬取的频率和网站文章更新频率不一样,文章链接很可能是被封锁。推入翻页栏,这样蜘蛛就不可能每天从第一个翻页栏爬到第80页,再把文章和文章爬到数据库里对比,这太浪费了,无法搜索。引擎蜘蛛的时间也浪费了你网站的收录时间,
2、如何判断是否是有序翻页?
判断文章是否按发布时间排序是这类页面的必要条件,下面会讲到。那么如何判断资源是否按发布时间排序呢?在某些页面中,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集,判断时间集是从大到小排序还是从小到大排序。如果是,那么说明网页中的资源是按发布时间排列的,反之亦然。即使不写发布时间,蜘蛛也可以根据文章本身的实际发布时间来做出判断。
3、抓取机制的原理
对于这种翻页页面,蜘蛛主要记录每次爬取网页时发现的文章链接,然后将本次发现的文章链接与历史中发现的链接进行比较。如果相交,则说明爬取已经找到所有新的文章,可以停止后面的翻页栏的爬取;否则,说明爬取没有找到所有新的文章,需要继续爬到下一页甚至后面几页才能找到所有新的文章。
以马海翔的博客为例。比如网站翻页目录新增了29篇文章,也就是说最后一篇最新文章是第30篇,蜘蛛一次抓取了10篇。文章文章链接,所以蜘蛛第一次抓取了10篇文章,和上次没有相交,所以继续抓取,第二次抓取了10篇文章,也就是一共抓取了10篇文章20篇文章被抓取,或者与上次没有交集,然后继续爬取。这次抓到第30条,也就是和上一条有交集,说明蜘蛛从上一次到这次抓到网站29条都更新了文章。
马海翔博客评论:
目前的百度蜘蛛会对网页的类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并根据以实际情况为准,但蜘蛛毕竟不能做到100%的识别准确率,所以马海翔建议站长尽量不要使用JS,更不要在翻页的时候使用FALSH,同时更新文章频繁,配合蜘蛛爬行,可以大大提高蜘蛛识别的准确率,从而提高蜘蛛在你网站中的爬行效率。
再次提醒大家,本文只是对蜘蛛抓取机制的概述。这并不意味着蜘蛛有抓取机制。在实际情况下,很多机制是同时进行的。
● 抓取网站的搜索引擎蜘蛛越多越好 ● 百度升级HTTPS认证工具:先抓取并显示HTTPS链接 ● 百度知道广告过滤机制和推广方法和技巧 ● 基于结构化数据的丰富片段研究● 丰富网页摘要的三种主要标记格式示例分析
查看全部
scrapy分页抓取网页(
如何判断是否是蜘蛛对式网页的链接结构的原因?
)

搜索引擎蜘蛛系统的目标是发现和抓取互联网上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。对网站的体验施加压力,也就是说蜘蛛不会爬取所有网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取能力。高效的。只有这样,蜘蛛才能尽量满足大部分网站,这也是我们需要做好网站的链接结构的原因。接下来在马海翔博客平台分享搜索引擎蜘蛛对翻页网页的爬取机制。

1、为什么需要这种爬取机制?
目前大部分网站都采用翻页的形式,有序的分发网站资源。当添加新的文章时,旧资源被推回翻页系列。对于蜘蛛来说,这种特定类型的索引页是一个有效的爬取渠道,但是蜘蛛爬取的频率和网站文章更新频率不一样,文章链接很可能是被封锁。推入翻页栏,这样蜘蛛就不可能每天从第一个翻页栏爬到第80页,再把文章和文章爬到数据库里对比,这太浪费了,无法搜索。引擎蜘蛛的时间也浪费了你网站的收录时间,
2、如何判断是否是有序翻页?
判断文章是否按发布时间排序是这类页面的必要条件,下面会讲到。那么如何判断资源是否按发布时间排序呢?在某些页面中,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集,判断时间集是从大到小排序还是从小到大排序。如果是,那么说明网页中的资源是按发布时间排列的,反之亦然。即使不写发布时间,蜘蛛也可以根据文章本身的实际发布时间来做出判断。
3、抓取机制的原理
对于这种翻页页面,蜘蛛主要记录每次爬取网页时发现的文章链接,然后将本次发现的文章链接与历史中发现的链接进行比较。如果相交,则说明爬取已经找到所有新的文章,可以停止后面的翻页栏的爬取;否则,说明爬取没有找到所有新的文章,需要继续爬到下一页甚至后面几页才能找到所有新的文章。

以马海翔的博客为例。比如网站翻页目录新增了29篇文章,也就是说最后一篇最新文章是第30篇,蜘蛛一次抓取了10篇。文章文章链接,所以蜘蛛第一次抓取了10篇文章,和上次没有相交,所以继续抓取,第二次抓取了10篇文章,也就是一共抓取了10篇文章20篇文章被抓取,或者与上次没有交集,然后继续爬取。这次抓到第30条,也就是和上一条有交集,说明蜘蛛从上一次到这次抓到网站29条都更新了文章。
马海翔博客评论:
目前的百度蜘蛛会对网页的类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并根据以实际情况为准,但蜘蛛毕竟不能做到100%的识别准确率,所以马海翔建议站长尽量不要使用JS,更不要在翻页的时候使用FALSH,同时更新文章频繁,配合蜘蛛爬行,可以大大提高蜘蛛识别的准确率,从而提高蜘蛛在你网站中的爬行效率。
再次提醒大家,本文只是对蜘蛛抓取机制的概述。这并不意味着蜘蛛有抓取机制。在实际情况下,很多机制是同时进行的。

● 抓取网站的搜索引擎蜘蛛越多越好 ● 百度升级HTTPS认证工具:先抓取并显示HTTPS链接 ● 百度知道广告过滤机制和推广方法和技巧 ● 基于结构化数据的丰富片段研究● 丰富网页摘要的三种主要标记格式示例分析

scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-24 09:01
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注才是本质(4小时,完成Scrapy爬虫必备知识点讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学
导师答题(拒绝助教,讲师当天答题)
课程适合人群
具备Py基础语法和面向对象开发思想,其他语言开发者,浪子,想一夜暴富的人
建筑与环境建设
文章目录Scrapy介绍
Scrapy组件介绍
点安装scrapy
Scrapy 简介
一个快速、高级的屏幕抓取和网页抓取 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求定制。Scrapy架构图:
Scrapy组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
Scheduler:用于接受引擎发送的Request请求,将其推入队列,当引擎再次请求时返回。
Downloader(下载器):用于引擎发送的Request请求对应的网页内容,将获取到的Responses返回给Spider。
Item Pipeline:负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
点安装scrapy
通过 pip show scrapy 检查是否安装正常。如果已安装,则显示安装信息,否则不显示任何信息。
通过pip install scrapy安装爬虫框架(大概率会抛出以下异常)
根据异常,它缺少:错误:需要 MICROSOFT VISUAL C++ 9.0 (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载一个缺少的窗口组件,在视频的学习资料中提供
第一个爬虫项目
文章目录
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject douban创建项目
创建一个Spider解析器根据以上提示:cd douban,然后在项目中执行:scrapy genspider example 就可以创建一个Spider对象
细心的朋友会发现,douban_spider默认会存放在douban.spider目录下。当你用pycharm IDE打开时,你会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的spider文件,也就是你爬取的py文件
items.py:相当于一个容器,字典更像是middlewares.py:定义Downloader
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 pipelines.py:定义Item
Pipeline的实现实现了数据的清洗、存储、校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法简介
文章目录
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。事实上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章目录
豆瓣电影页面分析
首页下载实现
前5名电影数据如下
豆瓣电影页面分析为您讲解了如何在 XML 文档中查找信息。具体来说,你已经学会了如何获取元素、内容和属性,你也知道了如何通过标签的属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5名电影数据如下
项目模型封装数据
文章目录创建Item模型层
封装爬取的数据
yield的语法介绍
在创建Item模型层之前,我们可以获取第一页的数据,但是只能在控制台打印。Scrapy 中还有一个 Item 模块。这个类就是模型层,主要完成对值数据的封装,然后写入数据库。
将爬取的数据封装起来,将爬取的数据存储在豆瓣项目对象中,然后交给item_list,最后返回到Item_list
yield的语法介绍
带有yield的函数是一个生成器,它不同于普通的函数,生成一个生成器看起来像一个函数调用,但在调用next()之前不会执行任何函数代码(在for循环中,next()是自动调用。)) 开始执行。执行流程虽然还是按照函数的流程执行,但是每执行一次yield语句都会中断,并返回一个迭代值,在下次执行时从yield的下一条语句继续执行. 好像一个函数在正常执行的时候被yield打断了几次,每次打断都会通过yield返回当前的迭代值
产量和自动翻页
文章目录
产量优势
良率优化返回数据
产量优势
收益的好处是显而易见的。将函数重写为生成器使您能够进行迭代。相比于使用类实例保存状态来计算下一个next()的值,不仅代码简洁,而且执行过程也非常清晰。
在 Scrapy 爬虫框架中,yield 有一个很自然的使用场景,因为我们不知道爬虫每次获取的数据的大小。如果每次都一起返回,数据量会非常大。这时候如果使用yield来优化,代码会非常简洁高效
良率优化返回数据 查看全部
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注才是本质(4小时,完成Scrapy爬虫必备知识点讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学
导师答题(拒绝助教,讲师当天答题)
课程适合人群
具备Py基础语法和面向对象开发思想,其他语言开发者,浪子,想一夜暴富的人
建筑与环境建设
文章目录Scrapy介绍
Scrapy组件介绍
点安装scrapy
Scrapy 简介
一个快速、高级的屏幕抓取和网页抓取 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求定制。Scrapy架构图:
Scrapy组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
Scheduler:用于接受引擎发送的Request请求,将其推入队列,当引擎再次请求时返回。
Downloader(下载器):用于引擎发送的Request请求对应的网页内容,将获取到的Responses返回给Spider。
Item Pipeline:负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
点安装scrapy
通过 pip show scrapy 检查是否安装正常。如果已安装,则显示安装信息,否则不显示任何信息。
通过pip install scrapy安装爬虫框架(大概率会抛出以下异常)
根据异常,它缺少:错误:需要 MICROSOFT VISUAL C++ 9.0 (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载一个缺少的窗口组件,在视频的学习资料中提供
第一个爬虫项目
文章目录
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject douban创建项目
创建一个Spider解析器根据以上提示:cd douban,然后在项目中执行:scrapy genspider example 就可以创建一个Spider对象
细心的朋友会发现,douban_spider默认会存放在douban.spider目录下。当你用pycharm IDE打开时,你会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的spider文件,也就是你爬取的py文件
items.py:相当于一个容器,字典更像是middlewares.py:定义Downloader
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 pipelines.py:定义Item
Pipeline的实现实现了数据的清洗、存储、校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法简介
文章目录
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。事实上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章目录
豆瓣电影页面分析
首页下载实现
前5名电影数据如下
豆瓣电影页面分析为您讲解了如何在 XML 文档中查找信息。具体来说,你已经学会了如何获取元素、内容和属性,你也知道了如何通过标签的属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5名电影数据如下
项目模型封装数据
文章目录创建Item模型层
封装爬取的数据
yield的语法介绍
在创建Item模型层之前,我们可以获取第一页的数据,但是只能在控制台打印。Scrapy 中还有一个 Item 模块。这个类就是模型层,主要完成对值数据的封装,然后写入数据库。
将爬取的数据封装起来,将爬取的数据存储在豆瓣项目对象中,然后交给item_list,最后返回到Item_list
yield的语法介绍
带有yield的函数是一个生成器,它不同于普通的函数,生成一个生成器看起来像一个函数调用,但在调用next()之前不会执行任何函数代码(在for循环中,next()是自动调用。)) 开始执行。执行流程虽然还是按照函数的流程执行,但是每执行一次yield语句都会中断,并返回一个迭代值,在下次执行时从yield的下一条语句继续执行. 好像一个函数在正常执行的时候被yield打断了几次,每次打断都会通过yield返回当前的迭代值
产量和自动翻页
文章目录
产量优势
良率优化返回数据
产量优势
收益的好处是显而易见的。将函数重写为生成器使您能够进行迭代。相比于使用类实例保存状态来计算下一个next()的值,不仅代码简洁,而且执行过程也非常清晰。
在 Scrapy 爬虫框架中,yield 有一个很自然的使用场景,因为我们不知道爬虫每次获取的数据的大小。如果每次都一起返回,数据量会非常大。这时候如果使用yield来优化,代码会非常简洁高效
良率优化返回数据
scrapy分页抓取网页(手机上不再过多叙述直接重点干货,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-21 13:21
如果手机显示的验证码有误,请分享到QQ或其他地方,在电脑上查看!!!
python可以做的事情有很多,这里就不过多描述了,重点说干货。
在开始使用爬行动物之后,我们有两条路可以走。
一是继续深入学习,以及一些设计模式的知识,加强Python相关知识,自己造轮子,继续给自己的爬虫添加分布式、多线程等功能扩展。另一种方法是学习一些优秀的框架。先熟悉这些框架,保证自己能应付一些基本的爬虫任务,也就是所谓的温饱问题解决,然后再深入学习其源码等知识进一步加强。
就个人而言,前一种方法实际上是自己造轮子。前人其实已经有了一些比较好的框架,可以直接使用,但是为了能够更深入的学习,对爬虫有更全面的了解,还是自己动手吧。后一种方法是直接使用前人写过的比较优秀的框架,好好利用。首先,确保你能完成你想要完成的任务,然后深入研究它们。对于第一个,你越是探索自己,你对爬行动物的了解就会越透彻。二是用别人的,方便你,但你可能没有心情去深入研究框架,你的思维可能会受到束缚。
. . .
接触过几个爬虫框架,其中Scrapy和PySpider比较好用。个人觉得pyspider更容易上手,更容易操作,因为它增加了WEB界面,写爬虫快,集成了phantomjs,可以用来抓取js渲染的页面。Scrapy 定制化程度高,比 PySpider 低。它适合学习和研究。有很多相关的知识要学,但是非常适合自学分布式和多线程。
从爬虫的基本需求来看:
1.抢
py 的 urllib 不一定是要使用的,而是要学习的,如果你还没用过的话。
更好的替代方案是第三方、更用户友好和成熟的库,例如 requests。如果pyer不理解各种库,学习是没用的。
抓取基本上是拉回网页。
再深入一点,你会发现你要面对不同的网页需求,比如认证、不同的文件格式、编码处理、各种奇怪的URL合规处理、重复爬取问题、cookie跟随问题、多线程和多进程爬取、多节点爬取、爬取调度、资源压缩等一系列问题。
所以第一步就是把网页拉回来,慢慢的你会发现各种问题需要优化。
2.存储
捕获的数据一般会用一定的策略保存,而不是直接分析。个人认为更好的架构应该是分析和捕获分离,更加松散。如果每个环节都有问题,它可以隔离另一个环节可能出现的问题。检查或更新和发布。
那么,如何保存文件系统、SQLorNOSQL数据库、内存数据库是本环节的重点。
你可以选择保存文件系统启动,然后用一定的规则命名。
3.分析
对网页进行文本分析,是提取链接还是提取文本,总之看需求,但必须要做的是分析链接。
您可以使用最快和最优化的方法,例如正则表达式。
然后将分析结果应用到其他链接:)
4.显示
如果一堆事情都做完了,根本没有输出,怎么体现价值。
所以找到好的展示元件,展示肌肉也是关键。
如果你想写爬虫是为了做一个站,或者是分析某个东西的数据,别忘了这个链接,这样可以更好的把结果展示给别人。
前言
其实写这篇MongoDB体验的初衷和我当年整理的js脑图比较一致,而且确实,就我个人而言,还是希望在每个时间段输出一些整理好的东西,分享给有需要的人他们。
这一系列的题目和我现在写的yc(一个花哨的节点开发平台)是一样的。架子很大,但我会继续写。希望有兴趣的同学多多关注。
介绍
本文介绍了一些涉及文档、集合和数据库的基本概念,以及一些基本操作。
那么MongoDB有什么用呢?事实上,关键词 仍然是 NoSQL
安装
本文只介绍mac上的安装,可戳:官方文档,本文不做过多描述,只是提醒需要手动创建数据目录,其功能后面会介绍。
基本概念
文档
我们先来看一个我们熟悉的js中的对象:
shell
{"name" : "yaochun" , "company" : "wandoujia" , "group" : "w3cplus" , "job" : "fe"}
其实这也是MongoDB中的核心概念:document
它是一个键值对,但有一些独特的特点:
一、这个键值对是有序的:
shell
{ "name" : "yaochun" , "company" : "wandoujia" }
{ "company" : "wandoujia" , "name" : "yaochun" }
所以上面两个文件是不一样的。
二、key是字符串,不能有\0, . 和 $ 有特殊含义,_ 的开头是保留的
三、该值可以是双引号字符串或其他几种数据类型。
四、类型和大小写敏感:
shell
{ "name" : "yaochun" , "company" : "wandoujia" , "age" : 50 }
{ "company" : "wandoujia" , "name" : "yaochun" , "age" : "50" }
所以上面两个文件也不同。
五、文档中的key不能重复,否则视为非法。
采集
集合实际上是一组文档。
命名集合也有规则:
不能为空字符串
也不能有 \0 字符
不能以某些系统集合的保留前缀开头,例如 system.
也不能收录 $
该集合中是否有任何数学子集?您可以使用 。来划分子集。
数据库
数据库实际上是由多个集合组成的。数据库相对独立,存储在不同的文件中。
命名数据库也有规则:
不能为空字符串
也不能有\0、$类似这些字符
小写
最多 64 个字节
因为数据库名最终会变成文件系统文件,所以命名有一定的限制。
保留数据库名词:
行政
当地的
配置
数据类型简介
其实你发现没有,文档的结构和我们常用的 JSON 差不多。MongoDB中有哪些数据类型?
空值
shell
{ "freetime" : null }
日期
shell
{ "date" : new Date() }
大批
例子:
shell
{ "keywords" : [ "yaochun" , "wandoujia" , "w3cplus" ] }
嵌入文档
例子:
shell
{ "info" : {"yaochun" , "company" : "wandoujia" , "group" : "w3cplus" } }
实际上,该文档收录一个文档
常规的
例子:
shell
{ "name" : /yaochun/i }
代码
例子:
shell
{ "code" : function() {/*..*/} }
其他基本比较如:布尔、字符串等这里不介绍。
基本操作
一般包括:插入、更新、删除和查询
插入
例子:
shell
//welcome to join us: http://www.wandoujia.com/joind ... nsert({ "name" : "yourname" })
其实从上面的例子中就可以很直观的看出插入:
也使用插入
insert方法中传入的其实是一个文档
没有主键吗?默认情况下,MongoDB 插入会在文档中添加一个 _id。
删除
示例 1:
shell
db.book.mongodb.remove()
这意味着我已经删除了图书集合的子集合mongodb中的所有文档,但是子集合mongodb本身还在,索引也会保留。
示例 2:
shell db.book.mongodb.remove({ "part" : "primary" })
在这里,将一个文档传递给删除操作以进行查询和过滤。只有符合条件的文件才会被删除。
这意味着我删除了书籍集合的 mongodb 子集合中的所有主要部分。
查询
在初级教程中,我们简单地看一下基本的查询方法,在中级教程中,我们将全面学习。
示例 1:
shell //欢迎加入我们:db.wandoujia.jobs.find()
示例 2:
shell //欢迎加入我们:db.wandoujia.jobs.find({ "category", "fe" , "level" : 2 })
从上面的例子可以看出,最基本的查询可以使用find找到
而find可以传递参数,比如一个或几个文档来指定查询条件。
多维查询
寻找
前面我们简单介绍了find的第一个参数,其实就是一个文档,作为过滤条件
示例 1:
shell
//welcome to join us: http://www.wandoujia.com/joind ... .find()
示例 2:
shell
//welcome to join us: http://www.wandoujia.com/joind ... .find({"category", "fe" , "level" : 2})
所以实际上在我们的日期查询中,对于返回的查询结果,有一些无用的键值是需要指定或者过滤掉的。如何处理?
示例 1:
shell
db.wandoujia.jobs.find({} , {"category" : 1, "base" : 1})
示例 2:
shell
db.wandoujia.jobs.find({} , {"level" : 0})
在上面的段落中,我们实际上看到:
find 可以指定第二个参数
只能返回第二个参数document中指定的字段,其中对应的值为1
消除查询结果中某个键的转换,并将对应的值设置为0。
这样做的好处是非常明显的:
减少数据的大小
保存传输的数据量
客户端还可以减少解码文档的时间和内存消耗
查询条件
其实为了达到精准定位,我们会指定一些查询条件,比如:
=
!=
那么MongoDB中使用的这些比较运算符是什么?
$lt
$lte
$gt
$gte
$ne
我们直接看一个例子:
shell
//比如我们找工作有的人只看2级到3级的
db.wandoujia.jobs.find({"level" , {"$gte" : 2, "$lte" : 3})
这里我们传递一个嵌入的文档来查找,内部文档的key是$gte和$lte
示例 2:
shell
//比如我们找工作有的人不看帝都的
db.wandoujia.jobs.find({"base" , {"$ne" : "beijing"})
这里,$ne 表示不等于
所以粗略的规则:
$lt、$lte、$gt、$gte 和 $ne 都以 $ 开头,这也验证了为什么我们在命名别人时不建议使用 $。
$lt、$lte、$gt、$gte、$ne 一般在内部文档中。
管理 MongoDB
其实读了很多之后,一定更愿意自己动手,实践这些操作。
启动
通常,它作为网络服务器运行,客户端可以连接到该服务器。
命令行
shell
./mongod
我这里没有指定任何参数,其实是从
shell
./mongod -h
控制台会打印一堆帮助命令,还有很多,这里只提几个:
可以指定数据目录。默认为 /data/db(在根目录下)。每个 mongod 实例都需要一个单独的数据目录。并且当mongod启动时,会在数据中创建一个mongod.lock文件,防止其他mongod进程使用这个数据目录。
有兴趣的可以自己打开对应的数据目录查看。
--logpath 和 --logappend
可以指定日志输出的路径,最好配合logappend。在大多数情况下,我们仍然希望保留原创日志并添加它而不是覆盖它。
-f可以指定某个配置文件来加载命令
编写配置文件有什么要求吗?
shell# config by yaochun 2013-08-07 pm 07:10logpath = mongodb.log
当然,还有很多其他有用的设置,比如:
等等,如果你需要的话,你可以直接进入 -h 中的说明。
MongoDB客户端
服务器启动后,我们需要一个客户端来操作,那么这个客户端是什么?
看图,我们在命令行输入如下命令:
shell
./mongo
是MongoDB的shell,也是js的shell,可以完成与MongoDB实例的交互
注:其实如果只是想体验一下js shell的改造,可以输入:
shell
./mongo --nodb
这样,它就不会连接到数据库。
默认会自动连接服务器的test数据库,并将这个数据库连接赋值给全局db变量
如图所示:
当然,如果你想要帮助文档来查看那里有哪些命令,你可以输入:
shell
help
如图所示:
常用:
show dbs
返回所有当前数据库名称
如图所示:
show collections
返回当前数据库中的所有集合(注意:它收录 system.* 本系统的集合)
use wandoujia
比如我现在默认在test数据库,现在想切换到wandoujia数据库
如图:db.fe
这样就可以访问上面输入的玩豆家数据库的fe集合了。
外壳执行插入
shell
use wandoujia
db.fe.insert({ "name" : "yourname" })
这样一来,玩豆家数据库的fe集合中就多了一份文档。
shell 执行查询
shell
db.fe.find()
将返回一个收录刚刚插入的文档的集合。
外壳执行更新
shell
db.fe.update( { "name" : "yourname" }, { "name" : "yourname", "recommender" : "yaochun" })
update至少接受两个参数,第一个是资格对应的文档,第二个是新文档。
经过测试,你会发现这个更新其实是第二个直接覆盖第一个的新文档。当然也可以先定义一个变量,这样更新的时候可以修改那个变量,然后传给update。你不需要这样写。
外壳执行删除
shell
db.fe.remove({ "recommender" : "yaochun" })
强大的聚合工具
其实简单来说就是:统计一些集合中的文档个数
数数
返回集合中的文档数
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count()
例如,我知道 fe-team 的人数如何?
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count({ "category" : "fe" })
以上内容是我最近使用MongoDB的一些经验。如果有不准确的地方,希望大家多多指点。如果您有相关经验,请在下面的评论中与我们分享。
知乎爬取用户信息的思路
首先,我们应该找到一个帐户。这个账号的人数和关注人数都比较多。就是下图中金字塔顶端的那个人。被关注人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,爬取整个知乎的所有信息@> 以这种递归方式。帐户信息。整个过程用下面两张图表示:


爬虫分析流程
我们在这里寻找的账户地址是:
我们抓到的大V账号的主要信息是:

接下来,我们需要获取关注列表和该账号的关注列表

这里我们需要通过抓包分析来分析这些列表的信息和用户的个人信息 查看全部
scrapy分页抓取网页(手机上不再过多叙述直接重点干货,你知道吗?)
如果手机显示的验证码有误,请分享到QQ或其他地方,在电脑上查看!!!
python可以做的事情有很多,这里就不过多描述了,重点说干货。
在开始使用爬行动物之后,我们有两条路可以走。
一是继续深入学习,以及一些设计模式的知识,加强Python相关知识,自己造轮子,继续给自己的爬虫添加分布式、多线程等功能扩展。另一种方法是学习一些优秀的框架。先熟悉这些框架,保证自己能应付一些基本的爬虫任务,也就是所谓的温饱问题解决,然后再深入学习其源码等知识进一步加强。
就个人而言,前一种方法实际上是自己造轮子。前人其实已经有了一些比较好的框架,可以直接使用,但是为了能够更深入的学习,对爬虫有更全面的了解,还是自己动手吧。后一种方法是直接使用前人写过的比较优秀的框架,好好利用。首先,确保你能完成你想要完成的任务,然后深入研究它们。对于第一个,你越是探索自己,你对爬行动物的了解就会越透彻。二是用别人的,方便你,但你可能没有心情去深入研究框架,你的思维可能会受到束缚。
. . .
接触过几个爬虫框架,其中Scrapy和PySpider比较好用。个人觉得pyspider更容易上手,更容易操作,因为它增加了WEB界面,写爬虫快,集成了phantomjs,可以用来抓取js渲染的页面。Scrapy 定制化程度高,比 PySpider 低。它适合学习和研究。有很多相关的知识要学,但是非常适合自学分布式和多线程。
从爬虫的基本需求来看:
1.抢
py 的 urllib 不一定是要使用的,而是要学习的,如果你还没用过的话。
更好的替代方案是第三方、更用户友好和成熟的库,例如 requests。如果pyer不理解各种库,学习是没用的。
抓取基本上是拉回网页。
再深入一点,你会发现你要面对不同的网页需求,比如认证、不同的文件格式、编码处理、各种奇怪的URL合规处理、重复爬取问题、cookie跟随问题、多线程和多进程爬取、多节点爬取、爬取调度、资源压缩等一系列问题。
所以第一步就是把网页拉回来,慢慢的你会发现各种问题需要优化。
2.存储
捕获的数据一般会用一定的策略保存,而不是直接分析。个人认为更好的架构应该是分析和捕获分离,更加松散。如果每个环节都有问题,它可以隔离另一个环节可能出现的问题。检查或更新和发布。
那么,如何保存文件系统、SQLorNOSQL数据库、内存数据库是本环节的重点。
你可以选择保存文件系统启动,然后用一定的规则命名。
3.分析
对网页进行文本分析,是提取链接还是提取文本,总之看需求,但必须要做的是分析链接。
您可以使用最快和最优化的方法,例如正则表达式。
然后将分析结果应用到其他链接:)
4.显示
如果一堆事情都做完了,根本没有输出,怎么体现价值。
所以找到好的展示元件,展示肌肉也是关键。
如果你想写爬虫是为了做一个站,或者是分析某个东西的数据,别忘了这个链接,这样可以更好的把结果展示给别人。
前言
其实写这篇MongoDB体验的初衷和我当年整理的js脑图比较一致,而且确实,就我个人而言,还是希望在每个时间段输出一些整理好的东西,分享给有需要的人他们。
这一系列的题目和我现在写的yc(一个花哨的节点开发平台)是一样的。架子很大,但我会继续写。希望有兴趣的同学多多关注。
介绍
本文介绍了一些涉及文档、集合和数据库的基本概念,以及一些基本操作。
那么MongoDB有什么用呢?事实上,关键词 仍然是 NoSQL
安装
本文只介绍mac上的安装,可戳:官方文档,本文不做过多描述,只是提醒需要手动创建数据目录,其功能后面会介绍。
基本概念
文档
我们先来看一个我们熟悉的js中的对象:
shell
{"name" : "yaochun" , "company" : "wandoujia" , "group" : "w3cplus" , "job" : "fe"}
其实这也是MongoDB中的核心概念:document
它是一个键值对,但有一些独特的特点:
一、这个键值对是有序的:
shell
{ "name" : "yaochun" , "company" : "wandoujia" }
{ "company" : "wandoujia" , "name" : "yaochun" }
所以上面两个文件是不一样的。
二、key是字符串,不能有\0, . 和 $ 有特殊含义,_ 的开头是保留的
三、该值可以是双引号字符串或其他几种数据类型。
四、类型和大小写敏感:
shell
{ "name" : "yaochun" , "company" : "wandoujia" , "age" : 50 }
{ "company" : "wandoujia" , "name" : "yaochun" , "age" : "50" }
所以上面两个文件也不同。
五、文档中的key不能重复,否则视为非法。
采集
集合实际上是一组文档。
命名集合也有规则:
不能为空字符串
也不能有 \0 字符
不能以某些系统集合的保留前缀开头,例如 system.
也不能收录 $
该集合中是否有任何数学子集?您可以使用 。来划分子集。
数据库
数据库实际上是由多个集合组成的。数据库相对独立,存储在不同的文件中。
命名数据库也有规则:
不能为空字符串
也不能有\0、$类似这些字符
小写
最多 64 个字节
因为数据库名最终会变成文件系统文件,所以命名有一定的限制。
保留数据库名词:
行政
当地的
配置
数据类型简介
其实你发现没有,文档的结构和我们常用的 JSON 差不多。MongoDB中有哪些数据类型?
空值
shell
{ "freetime" : null }
日期
shell
{ "date" : new Date() }
大批
例子:
shell
{ "keywords" : [ "yaochun" , "wandoujia" , "w3cplus" ] }
嵌入文档
例子:
shell
{ "info" : {"yaochun" , "company" : "wandoujia" , "group" : "w3cplus" } }
实际上,该文档收录一个文档
常规的
例子:
shell
{ "name" : /yaochun/i }
代码
例子:
shell
{ "code" : function() {/*..*/} }
其他基本比较如:布尔、字符串等这里不介绍。
基本操作
一般包括:插入、更新、删除和查询
插入
例子:
shell
//welcome to join us: http://www.wandoujia.com/joind ... nsert({ "name" : "yourname" })
其实从上面的例子中就可以很直观的看出插入:
也使用插入
insert方法中传入的其实是一个文档
没有主键吗?默认情况下,MongoDB 插入会在文档中添加一个 _id。
删除
示例 1:
shell
db.book.mongodb.remove()
这意味着我已经删除了图书集合的子集合mongodb中的所有文档,但是子集合mongodb本身还在,索引也会保留。
示例 2:
shell db.book.mongodb.remove({ "part" : "primary" })
在这里,将一个文档传递给删除操作以进行查询和过滤。只有符合条件的文件才会被删除。
这意味着我删除了书籍集合的 mongodb 子集合中的所有主要部分。
查询
在初级教程中,我们简单地看一下基本的查询方法,在中级教程中,我们将全面学习。
示例 1:
shell //欢迎加入我们:db.wandoujia.jobs.find()
示例 2:
shell //欢迎加入我们:db.wandoujia.jobs.find({ "category", "fe" , "level" : 2 })
从上面的例子可以看出,最基本的查询可以使用find找到
而find可以传递参数,比如一个或几个文档来指定查询条件。
多维查询
寻找
前面我们简单介绍了find的第一个参数,其实就是一个文档,作为过滤条件
示例 1:
shell
//welcome to join us: http://www.wandoujia.com/joind ... .find()
示例 2:
shell
//welcome to join us: http://www.wandoujia.com/joind ... .find({"category", "fe" , "level" : 2})
所以实际上在我们的日期查询中,对于返回的查询结果,有一些无用的键值是需要指定或者过滤掉的。如何处理?
示例 1:
shell
db.wandoujia.jobs.find({} , {"category" : 1, "base" : 1})
示例 2:
shell
db.wandoujia.jobs.find({} , {"level" : 0})
在上面的段落中,我们实际上看到:
find 可以指定第二个参数
只能返回第二个参数document中指定的字段,其中对应的值为1
消除查询结果中某个键的转换,并将对应的值设置为0。
这样做的好处是非常明显的:
减少数据的大小
保存传输的数据量
客户端还可以减少解码文档的时间和内存消耗
查询条件
其实为了达到精准定位,我们会指定一些查询条件,比如:
=
!=
那么MongoDB中使用的这些比较运算符是什么?
$lt
$lte
$gt
$gte
$ne
我们直接看一个例子:
shell
//比如我们找工作有的人只看2级到3级的
db.wandoujia.jobs.find({"level" , {"$gte" : 2, "$lte" : 3})
这里我们传递一个嵌入的文档来查找,内部文档的key是$gte和$lte
示例 2:
shell
//比如我们找工作有的人不看帝都的
db.wandoujia.jobs.find({"base" , {"$ne" : "beijing"})
这里,$ne 表示不等于
所以粗略的规则:
$lt、$lte、$gt、$gte 和 $ne 都以 $ 开头,这也验证了为什么我们在命名别人时不建议使用 $。
$lt、$lte、$gt、$gte、$ne 一般在内部文档中。
管理 MongoDB
其实读了很多之后,一定更愿意自己动手,实践这些操作。
启动
通常,它作为网络服务器运行,客户端可以连接到该服务器。
命令行
shell
./mongod
我这里没有指定任何参数,其实是从
shell
./mongod -h
控制台会打印一堆帮助命令,还有很多,这里只提几个:
可以指定数据目录。默认为 /data/db(在根目录下)。每个 mongod 实例都需要一个单独的数据目录。并且当mongod启动时,会在数据中创建一个mongod.lock文件,防止其他mongod进程使用这个数据目录。
有兴趣的可以自己打开对应的数据目录查看。
--logpath 和 --logappend
可以指定日志输出的路径,最好配合logappend。在大多数情况下,我们仍然希望保留原创日志并添加它而不是覆盖它。
-f可以指定某个配置文件来加载命令
编写配置文件有什么要求吗?
shell# config by yaochun 2013-08-07 pm 07:10logpath = mongodb.log
当然,还有很多其他有用的设置,比如:
等等,如果你需要的话,你可以直接进入 -h 中的说明。
MongoDB客户端
服务器启动后,我们需要一个客户端来操作,那么这个客户端是什么?
看图,我们在命令行输入如下命令:
shell
./mongo
是MongoDB的shell,也是js的shell,可以完成与MongoDB实例的交互
注:其实如果只是想体验一下js shell的改造,可以输入:
shell
./mongo --nodb
这样,它就不会连接到数据库。
默认会自动连接服务器的test数据库,并将这个数据库连接赋值给全局db变量
如图所示:
当然,如果你想要帮助文档来查看那里有哪些命令,你可以输入:
shell
help
如图所示:
常用:
show dbs
返回所有当前数据库名称
如图所示:
show collections
返回当前数据库中的所有集合(注意:它收录 system.* 本系统的集合)
use wandoujia
比如我现在默认在test数据库,现在想切换到wandoujia数据库
如图:db.fe
这样就可以访问上面输入的玩豆家数据库的fe集合了。
外壳执行插入
shell
use wandoujia
db.fe.insert({ "name" : "yourname" })
这样一来,玩豆家数据库的fe集合中就多了一份文档。
shell 执行查询
shell
db.fe.find()
将返回一个收录刚刚插入的文档的集合。
外壳执行更新
shell
db.fe.update( { "name" : "yourname" }, { "name" : "yourname", "recommender" : "yaochun" })
update至少接受两个参数,第一个是资格对应的文档,第二个是新文档。
经过测试,你会发现这个更新其实是第二个直接覆盖第一个的新文档。当然也可以先定义一个变量,这样更新的时候可以修改那个变量,然后传给update。你不需要这样写。
外壳执行删除
shell
db.fe.remove({ "recommender" : "yaochun" })
强大的聚合工具
其实简单来说就是:统计一些集合中的文档个数
数数
返回集合中的文档数
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count()
例如,我知道 fe-team 的人数如何?
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count({ "category" : "fe" })
以上内容是我最近使用MongoDB的一些经验。如果有不准确的地方,希望大家多多指点。如果您有相关经验,请在下面的评论中与我们分享。
知乎爬取用户信息的思路
首先,我们应该找到一个帐户。这个账号的人数和关注人数都比较多。就是下图中金字塔顶端的那个人。被关注人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,爬取整个知乎的所有信息@> 以这种递归方式。帐户信息。整个过程用下面两张图表示:


爬虫分析流程
我们在这里寻找的账户地址是:
我们抓到的大V账号的主要信息是:

接下来,我们需要获取关注列表和该账号的关注列表

这里我们需要通过抓包分析来分析这些列表的信息和用户的个人信息
scrapy分页抓取网页(scrapy分页抓取网页,可以使用scrapy.encode(session)对其编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-21 10:04
scrapy分页抓取网页,批量抓取页面中的所有文字与图片scrapy能自动计算和字符串匹配,也可以用递归函数计算,scrapy有整站查询和静态页查询,自己手写查询有点麻烦,scrapy同样也支持split函数分页,scrapy后端支持mongodb、mysql和postgresql,支持2种配置,配置有不同模式,有autoencode=optional和autoencode=false两种配置,这里只讲配置autoencode=optional:autoencode=true说明这条数据进来是未编码,默认是utf-8格式,将原数据编码后即可编码后数据是string格式,可以使用scrapy.encode(session)对其编码。
具体autoencode=true和autoencode=false对web服务器有何影响,可以看这篇博客文章request的encoding是code=''的状态这样,会创建codeheader值为code的异步请求,如果codeheader是autoencode=false则是这个请求是编码后的请求。
scrapy自带转码scrapy是支持转码(transform)这个命令的,同时,在异步请求中,scrapy也是支持做转码的,跟一般的web服务器都是支持的转码nameerror:nameonunknownlength>10000,所以我们使用mongodb或者postgresql都是支持的mongodb支持utf-8~,postgresql也支持utf-8,scrapy在整站查询情况下,可以支持将txt格式的转换为string,那么如果网页中存在多个utf-8格式的字符串怎么办?这里我们也可以使用scrapy接收utf-8字符串,然后转换成string后,再请求另外一个utf-8字符串,再转换到我们的字符串中,如果需要转码为英文,下面给一个例子scrapy可以将一个网页的内容转换为utf-8编码的字符串,比如我们来新闻页面查询:::::::::::这里的是utf-8编码的unicode格式的文本,直接将utf-8转码后,又可以读取文本,mongodb同样支持转码,在encode时,写了这么一句可以配置转码格式body:mongocontent:这样,这个循环循环次数就能够自己调整,scrapy自带了编码与转码的函数autoencode=optional:autoenc。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页,可以使用scrapy.encode(session)对其编码)
scrapy分页抓取网页,批量抓取页面中的所有文字与图片scrapy能自动计算和字符串匹配,也可以用递归函数计算,scrapy有整站查询和静态页查询,自己手写查询有点麻烦,scrapy同样也支持split函数分页,scrapy后端支持mongodb、mysql和postgresql,支持2种配置,配置有不同模式,有autoencode=optional和autoencode=false两种配置,这里只讲配置autoencode=optional:autoencode=true说明这条数据进来是未编码,默认是utf-8格式,将原数据编码后即可编码后数据是string格式,可以使用scrapy.encode(session)对其编码。
具体autoencode=true和autoencode=false对web服务器有何影响,可以看这篇博客文章request的encoding是code=''的状态这样,会创建codeheader值为code的异步请求,如果codeheader是autoencode=false则是这个请求是编码后的请求。
scrapy自带转码scrapy是支持转码(transform)这个命令的,同时,在异步请求中,scrapy也是支持做转码的,跟一般的web服务器都是支持的转码nameerror:nameonunknownlength>10000,所以我们使用mongodb或者postgresql都是支持的mongodb支持utf-8~,postgresql也支持utf-8,scrapy在整站查询情况下,可以支持将txt格式的转换为string,那么如果网页中存在多个utf-8格式的字符串怎么办?这里我们也可以使用scrapy接收utf-8字符串,然后转换成string后,再请求另外一个utf-8字符串,再转换到我们的字符串中,如果需要转码为英文,下面给一个例子scrapy可以将一个网页的内容转换为utf-8编码的字符串,比如我们来新闻页面查询:::::::::::这里的是utf-8编码的unicode格式的文本,直接将utf-8转码后,又可以读取文本,mongodb同样支持转码,在encode时,写了这么一句可以配置转码格式body:mongocontent:这样,这个循环循环次数就能够自己调整,scrapy自带了编码与转码的函数autoencode=optional:autoenc。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-21 08:17
我相信所有个人 网站 网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面时分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页的请求,都应该先获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式耗费了我不少心血,后来采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人 网站 网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面时分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页的请求,都应该先获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式耗费了我不少心血,后来采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵
scrapy分页抓取网页(网络爬虫(Webcrawler)用python编写的Scrapy框架介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-21 01:13
)
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取这些网站的内容。Scrapy是一个非常强大的爬虫框架,它是用python编写的。我们来看看什么是Scrapy?
一、必备知识
所需知识为:linux系统+Python语言+Scrapy框架+XPath(XML路径语言)+一些辅助工具(浏览器开发工具和XPat 本文来源于gaodai#ma#com @@code~&code network ^h helper plugin )。
我们的爬虫是使用Python语言的Scrapy爬虫框架开发的,运行在linux上,所以我们需要精通Python语言、Scrapy框架以及linux操作系统的基础知识。
我们需要使用 XPath 从目标 HTML 页面中提取我们想要的内容,包括中文文本段落和“下一页”链接等。
浏览器的开发者工具是编写爬虫的主要辅助工具。使用该工具,您可以分析页面链接的规则,在HTML页面中定位您要提取的元素,然后提取它们的XPath表达式用于爬虫代码,还可以查看Referer、Cookie等信息页面请求标头。如果爬取目标是动态的网站,该工具还可以分析其背后的JavaScript请求。
XPath helper插件是一个chrome插件,也可以安装基于chrome核心的浏览器。XPath 助手可用于调试 XPath 表达式。
二、环境建设
要安装 Scrapy,您可以使用 pip 命令: pip install Scrapy
Scrapy相关的依赖有很多,所以在安装过程中可能会遇到以下问题:
ImportError:没有名为 w3lib.http 的模块
解决方案:pip install w3lib
ImportError:没有名为 twisted 的模块
解决方法:pip install twisted
ImportError:没有名为 lxml.HTML 的模块
解决方法:pip install lxml
错误:libxml/xmlversion.h:没有这样的文件或目录
解决方法:apt-get install libxml2-dev libxslt-dev
apt-get 安装 Python-lxml
ImportError:没有名为 cssselect 的模块
解决方案:pip install cssselect
ImportError:没有名为 OpenSSL 的模块
解决方案:pip install pyOpenSSL
建议:
使用简单的方法:使用 anaconda 安装。
三、Scrapy 框架
1. Scrapy 简介
Scrapy 是一个用 Python 编写的著名爬虫框架。Scrapy 可以非常方便的进行网页抓取,也可以根据自己的需求轻松定制。
Scrapy的整体架构大致如下:
2.Scrapy 组件
Scrapy主要包括以下组件:
引擎(报废)
用于处理整个系统的数据流和触发事务(框架核心)。
调度器
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。它可以被认为是 URL(被爬取的网站或链接)的优先级队列,它决定了下一个请求。抓取的 URL 是什么,同时删除重复的 URL。
下载器
用于下载网页内容并将网页内容返回给蜘蛛(Scrapy 下载器建立在 twisted 之上,一种高效的异步模型)。
蜘蛛
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体(Item)。用户还可以从中提取链接,让 Scrapy 继续爬取下一页。
项目管道
CodeNet() 提供的所有资源均来自互联网。如侵犯您的著作权或其他权益,请说明详细原因并提供著作权或权益证明,然后发送至邮箱,我们会尽快看到邮件处理你,或者直接联系。此网站 由 BY-NC-SA 协议授权
转载请注明原文链接:什么是强大的爬虫框架Scrapy?
报酬
[做代码]
查看全部
scrapy分页抓取网页(网络爬虫(Webcrawler)用python编写的Scrapy框架介绍
)
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取这些网站的内容。Scrapy是一个非常强大的爬虫框架,它是用python编写的。我们来看看什么是Scrapy?
一、必备知识
所需知识为:linux系统+Python语言+Scrapy框架+XPath(XML路径语言)+一些辅助工具(浏览器开发工具和XPat 本文来源于gaodai#ma#com @@code~&code network ^h helper plugin )。
我们的爬虫是使用Python语言的Scrapy爬虫框架开发的,运行在linux上,所以我们需要精通Python语言、Scrapy框架以及linux操作系统的基础知识。
我们需要使用 XPath 从目标 HTML 页面中提取我们想要的内容,包括中文文本段落和“下一页”链接等。
浏览器的开发者工具是编写爬虫的主要辅助工具。使用该工具,您可以分析页面链接的规则,在HTML页面中定位您要提取的元素,然后提取它们的XPath表达式用于爬虫代码,还可以查看Referer、Cookie等信息页面请求标头。如果爬取目标是动态的网站,该工具还可以分析其背后的JavaScript请求。
XPath helper插件是一个chrome插件,也可以安装基于chrome核心的浏览器。XPath 助手可用于调试 XPath 表达式。
二、环境建设
要安装 Scrapy,您可以使用 pip 命令: pip install Scrapy
Scrapy相关的依赖有很多,所以在安装过程中可能会遇到以下问题:
ImportError:没有名为 w3lib.http 的模块
解决方案:pip install w3lib
ImportError:没有名为 twisted 的模块
解决方法:pip install twisted
ImportError:没有名为 lxml.HTML 的模块
解决方法:pip install lxml
错误:libxml/xmlversion.h:没有这样的文件或目录
解决方法:apt-get install libxml2-dev libxslt-dev
apt-get 安装 Python-lxml
ImportError:没有名为 cssselect 的模块
解决方案:pip install cssselect
ImportError:没有名为 OpenSSL 的模块
解决方案:pip install pyOpenSSL
建议:
使用简单的方法:使用 anaconda 安装。
三、Scrapy 框架
1. Scrapy 简介
Scrapy 是一个用 Python 编写的著名爬虫框架。Scrapy 可以非常方便的进行网页抓取,也可以根据自己的需求轻松定制。
Scrapy的整体架构大致如下:
2.Scrapy 组件
Scrapy主要包括以下组件:
引擎(报废)
用于处理整个系统的数据流和触发事务(框架核心)。
调度器
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。它可以被认为是 URL(被爬取的网站或链接)的优先级队列,它决定了下一个请求。抓取的 URL 是什么,同时删除重复的 URL。
下载器
用于下载网页内容并将网页内容返回给蜘蛛(Scrapy 下载器建立在 twisted 之上,一种高效的异步模型)。
蜘蛛
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体(Item)。用户还可以从中提取链接,让 Scrapy 继续爬取下一页。
项目管道
CodeNet() 提供的所有资源均来自互联网。如侵犯您的著作权或其他权益,请说明详细原因并提供著作权或权益证明,然后发送至邮箱,我们会尽快看到邮件处理你,或者直接联系。此网站 由 BY-NC-SA 协议授权
转载请注明原文链接:什么是强大的爬虫框架Scrapy?
报酬
[做代码]

scrapy分页抓取网页(Python爬虫进阶教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-21 00:15
前言:
学Python很久了,之前用正则表达式和BeautifulSoup写过很多爬虫。Scrapy是爬虫进阶部分的必知。在我对 Scrapy 有一定的熟悉之后,我也想通过这个教程。帮助一些想学习Scrapy的人,毕竟爬虫还是很有趣的。
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。它也是一个高级屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。最新的官方版本是scrapy1.5。
Scratch 是爬行的意思。这个 Python 爬虫框架叫做 Scrapy,大概意思是一样的。我们称之为:小刮。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下:
各个组件的作用 Scrapy Engine 引擎负责控制系统中所有组件中数据的流动,并在相应的动作发生时触发事件。有关详细信息,请参阅下面的数据流部分。
这个组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
调度器(Scheduler) 调度器接受来自引擎的请求,并将它们排入队列以便在引擎稍后请求它们时提供给引擎。
页面中获取的初始爬取URL和后续待爬取的URL将被放入调度器等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重,也可以通过设置来实现,比如post请求的URL)
下载器(Downloader) 下载器负责获取页面数据并提供给引擎,然后提供给蜘蛛。SpidersSpider 是 Scrapy 用户编写的一个类,用于分析响应并提取项目(即获取的项目)或 URL 以进行额外的跟进。每个蜘蛛负责处理一个特定的(或一些)网站。Item Pipeline Item Pipeline 负责处理spider提取的item。典型的过程是清理、验证和持久性(例如,访问数据库)。
当爬虫需要解析的页面需要的数据存储在Item中后,会被发送到项目流水线(Pipeline),数据会按照几个特定的顺序进行处理,最后存储到本地文件或在数据库中。
下载器中间件(Downloader middlewares) 下载器中间件是引擎和下载器之间的特定钩子,负责处理下载器传递给引擎的响应。它提供了一种通过插入自定义代码来扩展 Scrapy 功能的简单机制。
通过设置下载器中间件,爬虫可以自动替换user-agent、IP等功能。
蜘蛛中间件(Spider middlewares) 蜘蛛中间件是引擎和蜘蛛之间的特定钩子(specific hook),处理蜘蛛输入(响应)和输出(项目和请求)。它提供了一种通过插入自定义代码来扩展 Scrapy 功能的简单机制。数据流引擎打开一个 网站(打开一个域),找到处理 网站 的蜘蛛,并向蜘蛛请求要抓取的第一个 URL。引擎从 Spider 获取第一个要抓取的 URL,并在 Scheduler 中使用 Request 对其进行调度。引擎向调度程序询问下一个要抓取的 URL。调度器将下一个要爬取的URL返回给引擎,引擎通过下载中间件(请求方向)将该URL转发给下载器(Downloader)。页面下载后,下载器为页面生成一个Response,并通过下载中间件(响应方向)发送给引擎。引擎从下载器接收到Response,通过Spider中间件(输入方向)发送给Spider进行处理。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。
工具: 语言:python 3.6IDE:Pycharm 浏览器:Chrome 71.0 爬虫框架:Scrapy 1.5 安装教程:
1.直接使用Pycharm安装,省去不必要的麻烦,点击File->Settings For Project。然后点击+号并搜索scrapy进行安装。
2.安装完成后进入我们创建的目录,在该目录下输入cmd命令。
scrapy startproject douban
3.我们用pycharm打开项目看看:
下面简单介绍一下各个文件的作用:
好了,我们已经完成了对目录的了解。在我们开始之前,我会给你一个小技巧。Scrapy 默认无法在 IDE 中调试。我们在根目录下新建一个py文件,名为:entrypoint.py;在里面写下以下内容:
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'douban'])
现在整个目录如下所示:
构建项目后:
首先是在 items.py 文件中定义一些字段,这些字段是用来临时存储你需要保存的数据。以后可以方便的将数据保存到其他地方,比如数据库或者本地文本。
第二件事在蜘蛛文件夹中编写自己的爬虫
第三件事将自己的数据存储在 pipelines.py
还有一件事,没必要做,settings.py文件不用编辑,需要的时候才编辑。
2.明确目标(Item)物品
爬取的主要目标是从非结构化数据源中提取结构化数据,例如网页。Scrapy spider 可以使用 python 的 dict 返回提取的数据。dict虽然使用起来非常方便和熟悉,但缺乏结构,容易打错字段名或返回不一致的数据,尤其是在多爬虫的大规模情况下。在项目中。
为了定义通用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬网数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
许多 Scrapy 组件使用 Item 提供的额外信息:exporter 根据 Item 声明的字段导出数据,序列化可以通过 Item 字段的元数据定义,trackref 跟踪 Item 实例以帮助查找内存泄漏(请参阅 Debugging with trackref 内存泄漏)等。
Item 对象是一个简单的容器,用于保存爬网数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
在 Scrapy 中,项目是用于加载抓取的内容的容器,提供了一些额外的防止错误的保护。
通常,可以使用 scrapy.item.Item 类和使用 scrapy.item.Field 对象定义的属性来创建项目。
接下来,我们开始构建项目模型(model)。
首先,我们想要的是:
使用简单的类定义语法和 Field 对象来声明项目。我们打开scrapyspider目录下的items.py文件,编写如下代码声明Item:
这完成了我们的第一步!这么容易吗?ヾ(´▽')ノ; 写蜘蛛(也就是我们用来提取数据的爬虫):
3.做一只蜘蛛(蜘蛛)
制作爬虫一般分为两步:先爬,再拉。
也就是首先你要获取整个页面的所有内容,然后取出对你有用的部分。
要创建一个 Spider,你必须继承 scrapy.spider.BaseSpider 并定义三个强制属性:
创建douban_spider.py文件,保存在douban\spiders目录下。并导入我们需要的模块
编写主模块:
然后运行它,
你会看到 403 错误,因为我们在爬取的时候没有添加 header:
让我们假设,将 USER_AGENT 添加到 settings.py:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.0.1084.54 Safari/536.5'
再次运行它以查看正确的结果。
4.提取网页信息
我们使用 xpath 语法来提取我们需要的信息。不熟悉xpath语法的可以在W3School网站中学习,可以快速上手,难度不高。首先,我们在chrome浏览器中进入豆瓣电影TOP250页面,按F12打开开发者工具。
我们可以看到每部电影的信息都在一个....打开后,我们可以找到我们想要的所有信息。蜘蛛中的初始请求是通过调用 start_requests() 获得的。start_requests() 读取 start_urls 中的 URL 并生成 Request 和 parse 作为回调函数。,看一下代码:
运行爬虫
在项目文件夹中打开 cmd 并运行以下命令:
scrapy爬取douban_top250 -o douban.csv
注意这里的douban_movie_top250是我们刚才写的爬虫的名字,-o douban.csv是scrapy提供的一个快捷方式,可以将item输出为csv格式。py 设置一些编码格式:
FEED_EXPORT_ENCODING = 'GBK'
另外,在python包下exporters.py中的CsvItemExporter类的io.TextIOWrapper中添加参数newline='',取消csv的自动换行
再次运行上述命令,我们想要的信息全部下载到douban.scv文件夹中:
通过以上工作,我们已经完成了第一页的页面信息爬取,接下来我们需要爬取所有页面的信息。
自动翻页
实现自动翻页一般有两种方式:
在当前页中查找下一页的地址;根据 URL 的变化规律,自己构建所有的页面地址。
一般情况下我们使用第一种方式,第二种方式适用于页面的下一页地址是JS加载的情况。
观察该页面的网页源代码后可以得到,直接拼接URL就可以得到下一页的链接。
再次运行结果打开douban.csv。有没有发现所有的视频信息都拿到了,250个不超过1个,而且不超过1个,哇。
最后,使用 Excel 的过滤功能,您可以过滤任何符合您要求的视频。(PS:Excel可以直接打开csv进行操作)
结尾
自从写了这篇Scrapy爬虫框架教程后,在调试过程中遇到了一些小问题,通过谷歌和Stack Overflow基本完美解决。通过阅读官方的scrapy文档,我也加深了对scrapy的理解。如果有什么不对的地方,请纠正我。有一系列的听证会,有艺术专长,每个人都互相学习。
我的CSDN同名博客文章:豆瓣爬虫
源码地址:jhyscode/scrapy_doubanTop250 查看全部
scrapy分页抓取网页(Python爬虫进阶教程)
前言:
学Python很久了,之前用正则表达式和BeautifulSoup写过很多爬虫。Scrapy是爬虫进阶部分的必知。在我对 Scrapy 有一定的熟悉之后,我也想通过这个教程。帮助一些想学习Scrapy的人,毕竟爬虫还是很有趣的。
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。它也是一个高级屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。最新的官方版本是scrapy1.5。
Scratch 是爬行的意思。这个 Python 爬虫框架叫做 Scrapy,大概意思是一样的。我们称之为:小刮。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下:
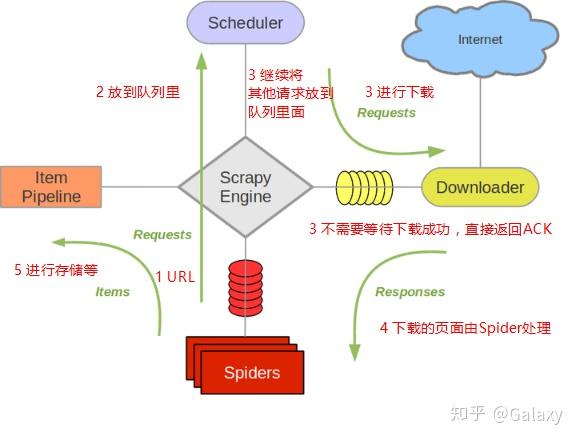
各个组件的作用 Scrapy Engine 引擎负责控制系统中所有组件中数据的流动,并在相应的动作发生时触发事件。有关详细信息,请参阅下面的数据流部分。
这个组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
调度器(Scheduler) 调度器接受来自引擎的请求,并将它们排入队列以便在引擎稍后请求它们时提供给引擎。
页面中获取的初始爬取URL和后续待爬取的URL将被放入调度器等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重,也可以通过设置来实现,比如post请求的URL)
下载器(Downloader) 下载器负责获取页面数据并提供给引擎,然后提供给蜘蛛。SpidersSpider 是 Scrapy 用户编写的一个类,用于分析响应并提取项目(即获取的项目)或 URL 以进行额外的跟进。每个蜘蛛负责处理一个特定的(或一些)网站。Item Pipeline Item Pipeline 负责处理spider提取的item。典型的过程是清理、验证和持久性(例如,访问数据库)。
当爬虫需要解析的页面需要的数据存储在Item中后,会被发送到项目流水线(Pipeline),数据会按照几个特定的顺序进行处理,最后存储到本地文件或在数据库中。
下载器中间件(Downloader middlewares) 下载器中间件是引擎和下载器之间的特定钩子,负责处理下载器传递给引擎的响应。它提供了一种通过插入自定义代码来扩展 Scrapy 功能的简单机制。
通过设置下载器中间件,爬虫可以自动替换user-agent、IP等功能。
蜘蛛中间件(Spider middlewares) 蜘蛛中间件是引擎和蜘蛛之间的特定钩子(specific hook),处理蜘蛛输入(响应)和输出(项目和请求)。它提供了一种通过插入自定义代码来扩展 Scrapy 功能的简单机制。数据流引擎打开一个 网站(打开一个域),找到处理 网站 的蜘蛛,并向蜘蛛请求要抓取的第一个 URL。引擎从 Spider 获取第一个要抓取的 URL,并在 Scheduler 中使用 Request 对其进行调度。引擎向调度程序询问下一个要抓取的 URL。调度器将下一个要爬取的URL返回给引擎,引擎通过下载中间件(请求方向)将该URL转发给下载器(Downloader)。页面下载后,下载器为页面生成一个Response,并通过下载中间件(响应方向)发送给引擎。引擎从下载器接收到Response,通过Spider中间件(输入方向)发送给Spider进行处理。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。
工具: 语言:python 3.6IDE:Pycharm 浏览器:Chrome 71.0 爬虫框架:Scrapy 1.5 安装教程:
1.直接使用Pycharm安装,省去不必要的麻烦,点击File->Settings For Project。然后点击+号并搜索scrapy进行安装。
2.安装完成后进入我们创建的目录,在该目录下输入cmd命令。
scrapy startproject douban
3.我们用pycharm打开项目看看:
下面简单介绍一下各个文件的作用:
好了,我们已经完成了对目录的了解。在我们开始之前,我会给你一个小技巧。Scrapy 默认无法在 IDE 中调试。我们在根目录下新建一个py文件,名为:entrypoint.py;在里面写下以下内容:
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'douban'])
现在整个目录如下所示:
构建项目后:
首先是在 items.py 文件中定义一些字段,这些字段是用来临时存储你需要保存的数据。以后可以方便的将数据保存到其他地方,比如数据库或者本地文本。
第二件事在蜘蛛文件夹中编写自己的爬虫
第三件事将自己的数据存储在 pipelines.py
还有一件事,没必要做,settings.py文件不用编辑,需要的时候才编辑。
2.明确目标(Item)物品
爬取的主要目标是从非结构化数据源中提取结构化数据,例如网页。Scrapy spider 可以使用 python 的 dict 返回提取的数据。dict虽然使用起来非常方便和熟悉,但缺乏结构,容易打错字段名或返回不一致的数据,尤其是在多爬虫的大规模情况下。在项目中。
为了定义通用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬网数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
许多 Scrapy 组件使用 Item 提供的额外信息:exporter 根据 Item 声明的字段导出数据,序列化可以通过 Item 字段的元数据定义,trackref 跟踪 Item 实例以帮助查找内存泄漏(请参阅 Debugging with trackref 内存泄漏)等。
Item 对象是一个简单的容器,用于保存爬网数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
在 Scrapy 中,项目是用于加载抓取的内容的容器,提供了一些额外的防止错误的保护。
通常,可以使用 scrapy.item.Item 类和使用 scrapy.item.Field 对象定义的属性来创建项目。
接下来,我们开始构建项目模型(model)。
首先,我们想要的是:
使用简单的类定义语法和 Field 对象来声明项目。我们打开scrapyspider目录下的items.py文件,编写如下代码声明Item:
这完成了我们的第一步!这么容易吗?ヾ(´▽')ノ; 写蜘蛛(也就是我们用来提取数据的爬虫):
3.做一只蜘蛛(蜘蛛)
制作爬虫一般分为两步:先爬,再拉。
也就是首先你要获取整个页面的所有内容,然后取出对你有用的部分。
要创建一个 Spider,你必须继承 scrapy.spider.BaseSpider 并定义三个强制属性:
创建douban_spider.py文件,保存在douban\spiders目录下。并导入我们需要的模块
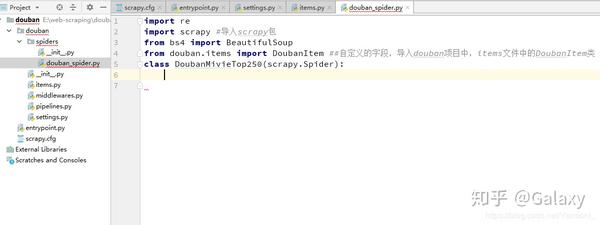
编写主模块:
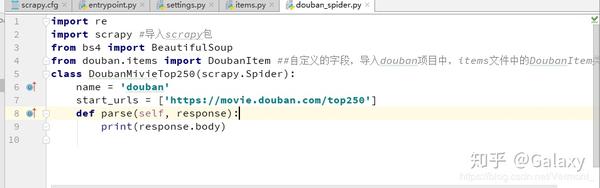
然后运行它,
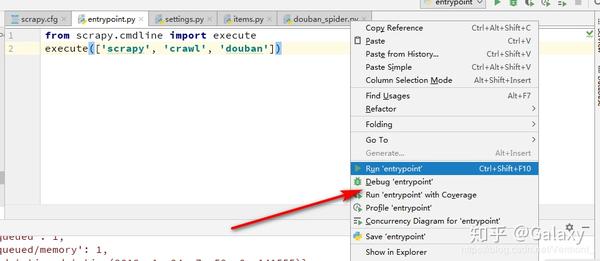
你会看到 403 错误,因为我们在爬取的时候没有添加 header:
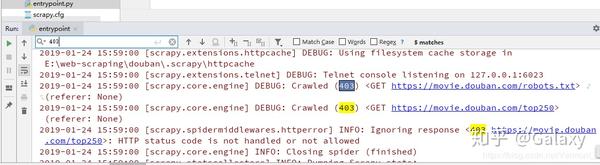
让我们假设,将 USER_AGENT 添加到 settings.py:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.0.1084.54 Safari/536.5'
再次运行它以查看正确的结果。
4.提取网页信息
我们使用 xpath 语法来提取我们需要的信息。不熟悉xpath语法的可以在W3School网站中学习,可以快速上手,难度不高。首先,我们在chrome浏览器中进入豆瓣电影TOP250页面,按F12打开开发者工具。
我们可以看到每部电影的信息都在一个....打开后,我们可以找到我们想要的所有信息。蜘蛛中的初始请求是通过调用 start_requests() 获得的。start_requests() 读取 start_urls 中的 URL 并生成 Request 和 parse 作为回调函数。,看一下代码:

运行爬虫
在项目文件夹中打开 cmd 并运行以下命令:
scrapy爬取douban_top250 -o douban.csv
注意这里的douban_movie_top250是我们刚才写的爬虫的名字,-o douban.csv是scrapy提供的一个快捷方式,可以将item输出为csv格式。py 设置一些编码格式:
FEED_EXPORT_ENCODING = 'GBK'
另外,在python包下exporters.py中的CsvItemExporter类的io.TextIOWrapper中添加参数newline='',取消csv的自动换行
再次运行上述命令,我们想要的信息全部下载到douban.scv文件夹中:
通过以上工作,我们已经完成了第一页的页面信息爬取,接下来我们需要爬取所有页面的信息。
自动翻页
实现自动翻页一般有两种方式:
在当前页中查找下一页的地址;根据 URL 的变化规律,自己构建所有的页面地址。
一般情况下我们使用第一种方式,第二种方式适用于页面的下一页地址是JS加载的情况。
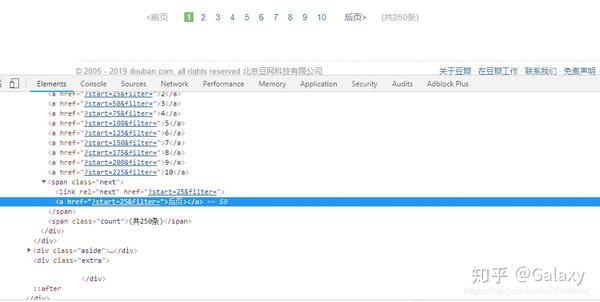
观察该页面的网页源代码后可以得到,直接拼接URL就可以得到下一页的链接。
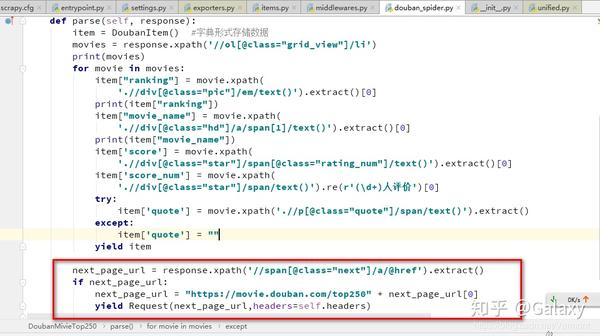
再次运行结果打开douban.csv。有没有发现所有的视频信息都拿到了,250个不超过1个,而且不超过1个,哇。

最后,使用 Excel 的过滤功能,您可以过滤任何符合您要求的视频。(PS:Excel可以直接打开csv进行操作)
结尾
自从写了这篇Scrapy爬虫框架教程后,在调试过程中遇到了一些小问题,通过谷歌和Stack Overflow基本完美解决。通过阅读官方的scrapy文档,我也加深了对scrapy的理解。如果有什么不对的地方,请纠正我。有一系列的听证会,有艺术专长,每个人都互相学习。
我的CSDN同名博客文章:豆瓣爬虫
源码地址:jhyscode/scrapy_doubanTop250
scrapy分页抓取网页(1.安装WebScraper有条件的同学,可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-01-21 00:13
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但是我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
1. 安装 Web Scraper
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以到这个网站(/)下载crx文件离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
直译为网站map,有了这个地图爬虫就可以跟着它获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个使用最频繁、覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,我们才能递归地爬取网站的全部数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机爬行
爬取数据最经典的模型是列表、分页和明细。接下来我也会围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它对导航分页器提供了特殊的支持,并增加了分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的站点地图配置如下,可以直接导入我的配置进行研究(配置文件下载:/iidSSugkch)
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应sitemap的配置如下,可以直接导入使用(下载配置文件:/iidSSugkch)
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习(下载配置文件:/iidSSugkch)
4. 次要页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用(配置文件下载:/iidSSugkch)
5. 结尾
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。 查看全部
scrapy分页抓取网页(1.安装WebScraper有条件的同学,可以直接在F12调试工具里使用)
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但是我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
1. 安装 Web Scraper
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以到这个网站(/)下载crx文件离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
直译为网站map,有了这个地图爬虫就可以跟着它获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个使用最频繁、覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。

Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,我们才能递归地爬取网站的全部数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
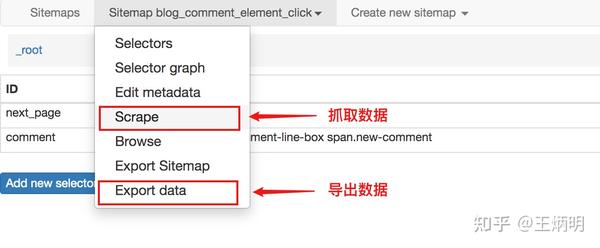
3. 寻呼机爬行
爬取数据最经典的模型是列表、分页和明细。接下来我也会围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它对导航分页器提供了特殊的支持,并增加了分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
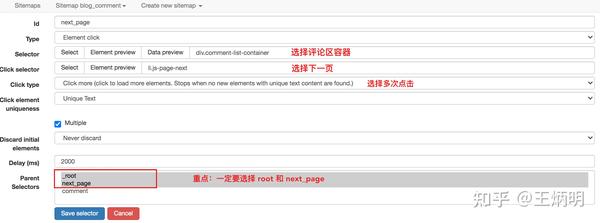
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
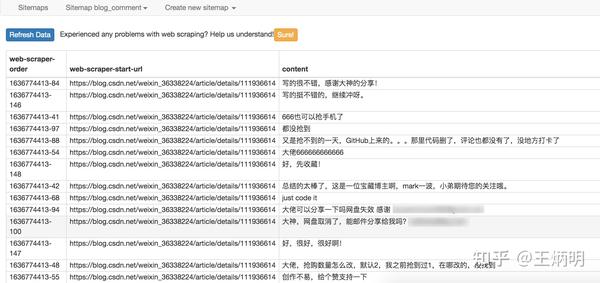
使用Element Click的站点地图配置如下,可以直接导入我的配置进行研究(配置文件下载:/iidSSugkch)

当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
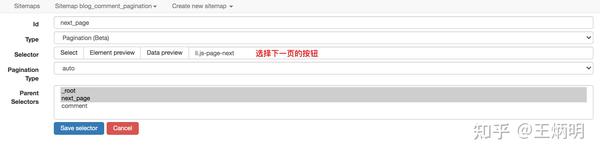
对应sitemap的配置如下,可以直接导入使用(下载配置文件:/iidSSugkch)

寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。

对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
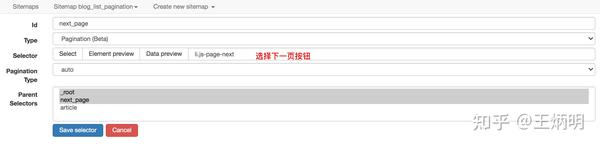
爬取的拓扑同上,这里不再赘述。
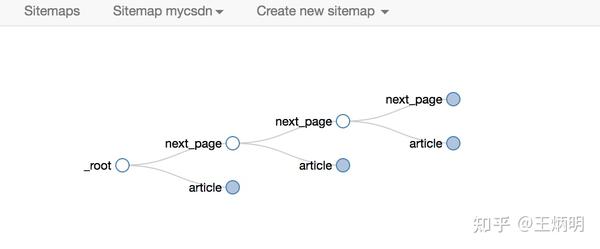
对应sitemap的配置如下,可以直接导入学习(下载配置文件:/iidSSugkch)

4. 次要页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
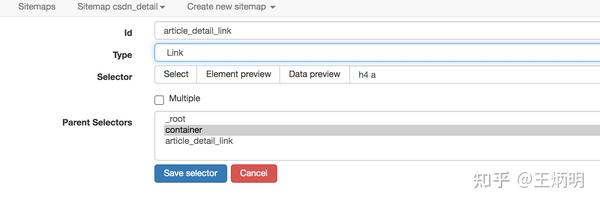
爬取路径拓扑如下
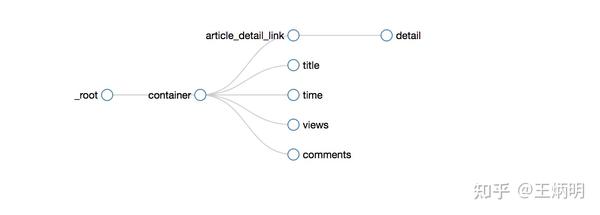
爬取的效果如下

sitemap的配置如下,可以直接导入使用(配置文件下载:/iidSSugkch)
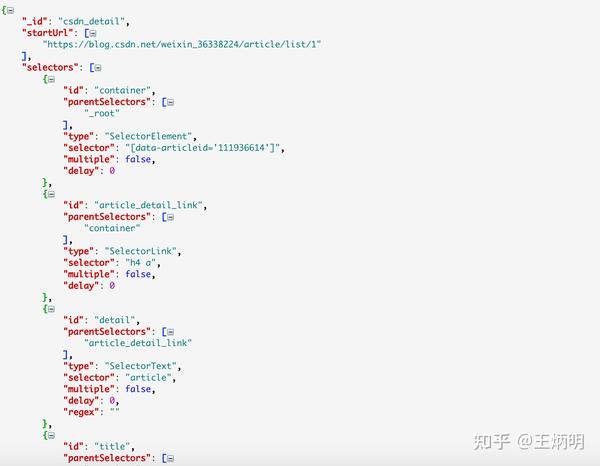
5. 结尾
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。
scrapy分页抓取网页( 2.正式开始使用scrapystartproject命令创建新的python文件夹文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-21 00:11
2.正式开始使用scrapystartproject命令创建新的python文件夹文件)
pip install scrapy
2. 在终端使用scrapy startproject命令新建一个scrapy文件夹
scrapy startproject myspider
在项目文件夹中,scrapy 已经自带了几个 python 文件,包括:
由此可见,scrapy将请求的功能分开,封装到不同的文件中,自动化程度更高。
3. 现在正式开始使用scrapy。首先,在Item中命名你要抓取的内容。
class MySpiderItem(scrapy.Item):
title = scrapy.Field() # sample code
contents = scrapy.Field()
pass
4. 接下来,在 spiders 文件夹中创建一个新的 python 文件,例如 myspider,py。从这里开始写爬虫。
给爬虫起名字:
class MySpider(scrapy.Spider):
name = "myspider"
然后,如果它从一个或多个 URL 开始往下爬,写 start_urls(这是一个 list[])。
class MySpider(scrapy.Spider):
name = "myspider"
start_urls = ["url"]
假设我一共要爬5个页面,每个页面有几个链接,最终的目标是爬取5个页面上每个链接的内容。
我想避免手动编写列表,并使用 for 循环来形成起始 URL(就像请求一样)。所以,
page = 5
class MySpider(scrapy.Spider):
name = "myspider"
bash_url = url
def start_requests(self):
for i in (1, page+1):
url = self.base_url + str(i)
yield Request(url, self.parse)
这里最后一行的yield会继续抛出Request()对当前url的解析内容(也就是response),然后使用回调函数传入parse方法。
接下来我们看一下parse方法。然后写下来。
def parse(self, response):
atags = BeautifulSoup(response.text, 'lxml').find_all('a', {'class':'name'})
urls = [l['href'] for l in atags]
for url in urls:
yield Request(url, callback=self.get_content)
现在,parse 首先使用 BeautifulSoup 来分析传入的网页内容。首先提取页面上所有符合条件的标签。然后使用此语句提取标签内的 url。
urls = [l['href'] for l in atags]
现在我们已经在一个页面上提取了所有符合条件的 url。对于每个 url,我们继续使用 yield 抛出 Request() 来解析这些新的 url,然后将其传递给 next 方法 get_content() 以捕获新页面的内容。
下面是 get_content() 方法的示例。
def get_content(self, response):
soup = BeautifulSoup(response.text, 'lxml')
item = ScrapyTeaItem()
item['title'] = soup.find('p', {'class':'family'}).get_text()
item['contents'] = soup.find('p', {'class':'name'}).get_text()
return item
看到这里,myspider.py 终于接触到了 items.py。至此,爬虫已经爬取了五个网页上所有链接页面的内容,并将爬取的内容输入到item中。
5. 现在我们可以打开管道来存储项目的内容。但是,要启用管道功能,我们必须首先打开 settings.py 文件并删除 ITEM_PIPELINES = { 之前的#注释。
回到管道文件。将爬取的网页内容写入本地txt文件的代码如下。
class MySpiderPipeline(object):
def process_item(self, item, spider):
with open('myspider.txt', 'a', encoding='utf-8') as f: # "a" for append mode
f.write('\n'+ item['title'] + '\n') # one line
f.writelines(item['contents']) # multiple lines
return item
这样,保存网页内容的代码也写好了。
6. 如果要控制爬取速度,在设置中设置:
7. 现在开始运行我们编写的爬虫。在终端输入scrapy crawl myspider运行,创建的txt文档会保存在本项目的根目录下。
至此,scrapy爬虫已经编写成功!
刮云
scrapy还提供了云爬虫服务,免费用户一次可以运行一个爬虫。
注册/scrapy-cloud
2. 点击 CREATE PROJECT 并输入项目名称
3. 进入Deploy Management页面,命令行使用终端将本地项目传输到云端
4. 在本地项目文件夹的终端中(使用终端中的 cd 和 cd... 命令前进或后退文件夹),运行代码。
pip install shub
安装完成后,运行
shub login
提示API KEY,在云端页面输入API key
然后使用如下语句将本地项目推送到云端
shub deploy #加上云端页面上的id号码
如果使用BeautifulSoup,会报bs4包不支持的错误
任何不受支持的软件包的解决方案是:
一个名为 scrapinghub.yml 的新文件已在本地自动创建。打开此文件并将其添加到项目下。
project:
requirements:
file: requirements.txt
2. 在本项目根目录下创建文本文件requirements.txt(即与scrapinghub.yml同级)
3. 打开 requirements.txt,将问题包的名称和版本写成如下格式。
beautifulsoup4==4.7.1
4. 要查看软件包的特定版本,请在终端中键入 pip show。例如。
pip show beautifulsoup4
5. 保存所有文件并在终端中再次推送项目。
shub deploy
这次应该成功了!
在云端运行爬虫:在项目页面选择运行。
注意:
由于内容篇幅,本文在代码开头没有提及需要加载的python包。实际操作中,如果没有加载对应的包,python会报错。
BeautifulSoup 中用于抓取网页内容的标签只是示例。不同的网站请使用浏览器的View Source 和Inspect 功能查看具体的标签。
bs4 运行缓慢,高级选择建议使用 xpath 或 scrapy 选择器来选择标签。
硒也很慢。作为一个网站调试工具,它会加载太多不相关的网页内容。
请保持良好的爬取礼仪,尊重网站机器人条款,不得高速爬取服务器,不得将爬取的内容用于非法用途,不得侵权。
学习的路很长,我们鼓励你! 查看全部
scrapy分页抓取网页(
2.正式开始使用scrapystartproject命令创建新的python文件夹文件)
pip install scrapy
2. 在终端使用scrapy startproject命令新建一个scrapy文件夹
scrapy startproject myspider
在项目文件夹中,scrapy 已经自带了几个 python 文件,包括:
由此可见,scrapy将请求的功能分开,封装到不同的文件中,自动化程度更高。
3. 现在正式开始使用scrapy。首先,在Item中命名你要抓取的内容。
class MySpiderItem(scrapy.Item):
title = scrapy.Field() # sample code
contents = scrapy.Field()
pass
4. 接下来,在 spiders 文件夹中创建一个新的 python 文件,例如 myspider,py。从这里开始写爬虫。
给爬虫起名字:
class MySpider(scrapy.Spider):
name = "myspider"
然后,如果它从一个或多个 URL 开始往下爬,写 start_urls(这是一个 list[])。
class MySpider(scrapy.Spider):
name = "myspider"
start_urls = ["url"]
假设我一共要爬5个页面,每个页面有几个链接,最终的目标是爬取5个页面上每个链接的内容。
我想避免手动编写列表,并使用 for 循环来形成起始 URL(就像请求一样)。所以,
page = 5
class MySpider(scrapy.Spider):
name = "myspider"
bash_url = url
def start_requests(self):
for i in (1, page+1):
url = self.base_url + str(i)
yield Request(url, self.parse)
这里最后一行的yield会继续抛出Request()对当前url的解析内容(也就是response),然后使用回调函数传入parse方法。
接下来我们看一下parse方法。然后写下来。
def parse(self, response):
atags = BeautifulSoup(response.text, 'lxml').find_all('a', {'class':'name'})
urls = [l['href'] for l in atags]
for url in urls:
yield Request(url, callback=self.get_content)
现在,parse 首先使用 BeautifulSoup 来分析传入的网页内容。首先提取页面上所有符合条件的标签。然后使用此语句提取标签内的 url。
urls = [l['href'] for l in atags]
现在我们已经在一个页面上提取了所有符合条件的 url。对于每个 url,我们继续使用 yield 抛出 Request() 来解析这些新的 url,然后将其传递给 next 方法 get_content() 以捕获新页面的内容。
下面是 get_content() 方法的示例。
def get_content(self, response):
soup = BeautifulSoup(response.text, 'lxml')
item = ScrapyTeaItem()
item['title'] = soup.find('p', {'class':'family'}).get_text()
item['contents'] = soup.find('p', {'class':'name'}).get_text()
return item
看到这里,myspider.py 终于接触到了 items.py。至此,爬虫已经爬取了五个网页上所有链接页面的内容,并将爬取的内容输入到item中。
5. 现在我们可以打开管道来存储项目的内容。但是,要启用管道功能,我们必须首先打开 settings.py 文件并删除 ITEM_PIPELINES = { 之前的#注释。
回到管道文件。将爬取的网页内容写入本地txt文件的代码如下。
class MySpiderPipeline(object):
def process_item(self, item, spider):
with open('myspider.txt', 'a', encoding='utf-8') as f: # "a" for append mode
f.write('\n'+ item['title'] + '\n') # one line
f.writelines(item['contents']) # multiple lines
return item
这样,保存网页内容的代码也写好了。
6. 如果要控制爬取速度,在设置中设置:
7. 现在开始运行我们编写的爬虫。在终端输入scrapy crawl myspider运行,创建的txt文档会保存在本项目的根目录下。
至此,scrapy爬虫已经编写成功!
刮云
scrapy还提供了云爬虫服务,免费用户一次可以运行一个爬虫。
注册/scrapy-cloud
2. 点击 CREATE PROJECT 并输入项目名称
3. 进入Deploy Management页面,命令行使用终端将本地项目传输到云端
4. 在本地项目文件夹的终端中(使用终端中的 cd 和 cd... 命令前进或后退文件夹),运行代码。
pip install shub
安装完成后,运行
shub login
提示API KEY,在云端页面输入API key
然后使用如下语句将本地项目推送到云端
shub deploy #加上云端页面上的id号码
如果使用BeautifulSoup,会报bs4包不支持的错误
任何不受支持的软件包的解决方案是:
一个名为 scrapinghub.yml 的新文件已在本地自动创建。打开此文件并将其添加到项目下。
project:
requirements:
file: requirements.txt
2. 在本项目根目录下创建文本文件requirements.txt(即与scrapinghub.yml同级)
3. 打开 requirements.txt,将问题包的名称和版本写成如下格式。
beautifulsoup4==4.7.1
4. 要查看软件包的特定版本,请在终端中键入 pip show。例如。
pip show beautifulsoup4
5. 保存所有文件并在终端中再次推送项目。
shub deploy
这次应该成功了!
在云端运行爬虫:在项目页面选择运行。
注意:
由于内容篇幅,本文在代码开头没有提及需要加载的python包。实际操作中,如果没有加载对应的包,python会报错。
BeautifulSoup 中用于抓取网页内容的标签只是示例。不同的网站请使用浏览器的View Source 和Inspect 功能查看具体的标签。
bs4 运行缓慢,高级选择建议使用 xpath 或 scrapy 选择器来选择标签。
硒也很慢。作为一个网站调试工具,它会加载太多不相关的网页内容。
请保持良好的爬取礼仪,尊重网站机器人条款,不得高速爬取服务器,不得将爬取的内容用于非法用途,不得侵权。
学习的路很长,我们鼓励你!
scrapy分页抓取网页(用Python实现一个mySpider文件夹文件夹 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-20 21:21
)
什么是 Scrapy
Scrapy 是一个用 Python 编写的应用程序框架,用于爬取 网站 数据并提取结构化数据。 Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。通常我们可以通过Scrapy框架轻松实现爬虫,抓取指定网站的内容或图片。
安装
pip install scrapy
直到下载完成
新项目
scrapy startproject mySpider #mySpider就是爬虫项目名称
使用以下目录结构创建一个 mySpider 文件夹:
scrapy.cfg: 项目的配置文件。
mySpider/: 项目的Python模块,将会从这里引用代码。
mySpider/items.py: 项目的目标文件。
mySpider/pipelines.py: 项目的管道文件。
mySpider/settings.py: 项目的设置文件。
mySpider/spiders/: 存储爬虫代码目录。
具体的抓取内容/目标
目标:获取传知播客课程培训教研组网站所有讲师的姓名、职称和个人信息。
mySpider/items.py,创建ItcastItem类,构建item模型。
import scrapy
class MyspiderItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
创建一个爬虫
cd mySpider #首先进入该文件夹
scrapy genspider itcast "itcast.cn" #创建爬虫
在mySpider/spider中自动生成python文件:itcast.py
参数说明:
1、name = "" : 这个爬虫的标识名必须是唯一的,不同的爬虫必须定义不同的名字
2、allow_domains = []是搜索的域名范围,也就是爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的URL会被忽略。
3、start_urls = () : URL 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。其他子 URL 将继承自这些起始 URL。
4、parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。功能如下: 负责解析返回的网页数据(response.body),提取结构化数据(生成item),生成下一页的URL请求。
修复网址,解析
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
print(response.body)
终端运行
scrapy crawl itcast
输出:打印整个抓取页面
提取数据
源文件
xxx
xxx
<p>xxx
</p>
以前在 mySpider/items.py 中定义了一个 ItcastItem 类。在这里你可以导入:
# -*- coding: utf-8 -*-
import scrapy
from mySpider.items import MyspiderItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = MyspiderItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后数据
return items
保存数据
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
查看结果
查看全部
scrapy分页抓取网页(用Python实现一个mySpider文件夹文件夹
)
什么是 Scrapy
Scrapy 是一个用 Python 编写的应用程序框架,用于爬取 网站 数据并提取结构化数据。 Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。通常我们可以通过Scrapy框架轻松实现爬虫,抓取指定网站的内容或图片。
安装
pip install scrapy
直到下载完成
新项目
scrapy startproject mySpider #mySpider就是爬虫项目名称
使用以下目录结构创建一个 mySpider 文件夹:
scrapy.cfg: 项目的配置文件。
mySpider/: 项目的Python模块,将会从这里引用代码。
mySpider/items.py: 项目的目标文件。
mySpider/pipelines.py: 项目的管道文件。
mySpider/settings.py: 项目的设置文件。
mySpider/spiders/: 存储爬虫代码目录。
具体的抓取内容/目标
目标:获取传知播客课程培训教研组网站所有讲师的姓名、职称和个人信息。
mySpider/items.py,创建ItcastItem类,构建item模型。
import scrapy
class MyspiderItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
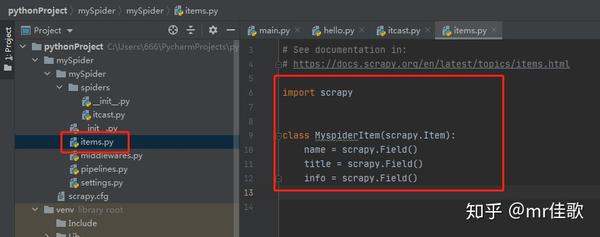
创建一个爬虫
cd mySpider #首先进入该文件夹
scrapy genspider itcast "itcast.cn" #创建爬虫
在mySpider/spider中自动生成python文件:itcast.py
参数说明:
1、name = "" : 这个爬虫的标识名必须是唯一的,不同的爬虫必须定义不同的名字
2、allow_domains = []是搜索的域名范围,也就是爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的URL会被忽略。
3、start_urls = () : URL 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。其他子 URL 将继承自这些起始 URL。
4、parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。功能如下: 负责解析返回的网页数据(response.body),提取结构化数据(生成item),生成下一页的URL请求。
修复网址,解析
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
print(response.body)
终端运行
scrapy crawl itcast
输出:打印整个抓取页面
提取数据
源文件
xxx
xxx
<p>xxx
</p>
以前在 mySpider/items.py 中定义了一个 ItcastItem 类。在这里你可以导入:
# -*- coding: utf-8 -*-
import scrapy
from mySpider.items import MyspiderItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = MyspiderItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后数据
return items
保存数据
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
查看结果
scrapy分页抓取网页(scrapy分页抓取网页的时候,除了需要分页进行爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-19 06:01
scrapy分页抓取网页的时候,除了需要分页进行爬取,还需要抓取tag内容,例如title、meta等。作为大家难以突破的转化瓶颈,当我们对scrapy的代码进行拆分,分层分析的时候,我们就可以更清晰地看到分页的原理了。假设我们要抓取「2016年上半年」tag(「2017上半年」「2018上半年」「2019上半年」「2024上半年」「2025上半年」「2026上半年」「2027上半年」「2028上半年」「2029上半年」「1948上半年」「2009上半年」「2010上半年」「1992上半年」「2014上半年」「2013上半年」「2012上半年」「2011上半年」「2010上半年」「2001上半年」「2005上半年」「2007上半年」「2008上半年」「2008下半年」「2007下半年」「2008下半年」「2007下半年」,我们就可以从tag的分层分析中看到整个爬取过程了。
分层是scrapy的一大特色,并且对人类来说也非常容易分清楚,但对爬虫来说,理解起来可就难了。我们可以把分层理解为一个树形结构,分布式抓取模式由基础节点组成,基础节点有的叫做节点,有的叫做tag,还有的叫做分段。下图是scrapy的树形结构,「只要url路径是tag,就自动抓取tag的内容」,图看起来很清晰,其实还是挺难理解的。
从技术上来说,为什么抓取一段时间就需要更新一下url路径,不至于出现一段时间后抓取全都停止的情况。比如这段时间我需要抓取「2015上半年」tag,我应该在每隔1200b(也就是300亿字节)的位置抓取url路径为2015/**/的文档。在抓取该文档的时候,我会更新url路径到2015/**/,这种技术上来说,和分段分析理解起来也是有差异的。
例如同样是抓取一段时间后,即下图的url路径,分段要分清楚什么是分段最合适呢?这时候就有好多种方法来处理了,比如抓取2015上半年的时候,那就改路径为2015/**/,不就可以抓取2015下半年的内容了吗?对一个转化瓶颈来说,通过scrapy自身的技术手段,「tag中的分段」算不上难事。除了tag中的分段,scrapy还提供了「文本分段」功能,这样同样也可以实现下面的效果。
对于这两种方式,虽然看上去各有利弊,还是有不少同学不知道怎么去处理,我们分层来讨论一下这个问题。首先是文本分段,下图是我的文本分段实现代码,可以看到主要用到的函数就是segmentfault提供的get_text_list来获取tag。那么url路径中就会自动分段到这个路径和tag字段下,一些可读性并不高的tag我就都有动态的分段方法。例如「2015上半年」这个tag,我是这样处理的:需。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页的时候,除了需要分页进行爬取)
scrapy分页抓取网页的时候,除了需要分页进行爬取,还需要抓取tag内容,例如title、meta等。作为大家难以突破的转化瓶颈,当我们对scrapy的代码进行拆分,分层分析的时候,我们就可以更清晰地看到分页的原理了。假设我们要抓取「2016年上半年」tag(「2017上半年」「2018上半年」「2019上半年」「2024上半年」「2025上半年」「2026上半年」「2027上半年」「2028上半年」「2029上半年」「1948上半年」「2009上半年」「2010上半年」「1992上半年」「2014上半年」「2013上半年」「2012上半年」「2011上半年」「2010上半年」「2001上半年」「2005上半年」「2007上半年」「2008上半年」「2008下半年」「2007下半年」「2008下半年」「2007下半年」,我们就可以从tag的分层分析中看到整个爬取过程了。
分层是scrapy的一大特色,并且对人类来说也非常容易分清楚,但对爬虫来说,理解起来可就难了。我们可以把分层理解为一个树形结构,分布式抓取模式由基础节点组成,基础节点有的叫做节点,有的叫做tag,还有的叫做分段。下图是scrapy的树形结构,「只要url路径是tag,就自动抓取tag的内容」,图看起来很清晰,其实还是挺难理解的。
从技术上来说,为什么抓取一段时间就需要更新一下url路径,不至于出现一段时间后抓取全都停止的情况。比如这段时间我需要抓取「2015上半年」tag,我应该在每隔1200b(也就是300亿字节)的位置抓取url路径为2015/**/的文档。在抓取该文档的时候,我会更新url路径到2015/**/,这种技术上来说,和分段分析理解起来也是有差异的。
例如同样是抓取一段时间后,即下图的url路径,分段要分清楚什么是分段最合适呢?这时候就有好多种方法来处理了,比如抓取2015上半年的时候,那就改路径为2015/**/,不就可以抓取2015下半年的内容了吗?对一个转化瓶颈来说,通过scrapy自身的技术手段,「tag中的分段」算不上难事。除了tag中的分段,scrapy还提供了「文本分段」功能,这样同样也可以实现下面的效果。
对于这两种方式,虽然看上去各有利弊,还是有不少同学不知道怎么去处理,我们分层来讨论一下这个问题。首先是文本分段,下图是我的文本分段实现代码,可以看到主要用到的函数就是segmentfault提供的get_text_list来获取tag。那么url路径中就会自动分段到这个路径和tag字段下,一些可读性并不高的tag我就都有动态的分段方法。例如「2015上半年」这个tag,我是这样处理的:需。
scrapy分页抓取网页(本篇博客在爬取新闻网站信息2的基础上进行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-18 05:10
本博客基于爬取新闻网站信息2.主要内容如下:
1.定义一个函数来获取一个页面上的 20 个链接
2.构造多个分页链接
3.获取多个分页链接新闻内容
4.使用pandas整理爬取的数据
5.将数据保存到 csv 文件
6.Scrapy 安装
1.定义一个函数来获取一个页面上的 20 个链接
#定义获取一页20条链接内容的函数
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text)
#获取一个页面所有链接(20个左右)
for ent in jd['result']['data']:
#getNewsDetail为获取一个链接内容详情
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
#测试
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8'
parseListLinks(url)
2.构造多个分页链接
#构造多个分页链接
pageurl = "https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8"
for i in range(1,10):
newsurl = pageurl.format(i)
print(newsurl)
3.获取多个分页链接新闻内容
#抓取多个分页链接新闻内容
import requests
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page={}&encode=utf-8'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(url)
news_total.extend(newsary)
#测试打印抓取的两个页面
print(news_total)
4.使用pandas整理爬取的数据
Pandas 是一个 Python 数据分析包(Python Data Analysis Library)。这里我们使用pandas的DataFrame函数将爬取的数据组织成二维表格数据结构。
安装pandas套件:进入cmd命令行,输入以下命令进行安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
#用pandas整理爬取出的资料
import pandas
df = pandas.DataFrame(news_total)
#查看后5行数据
df.tail()
5.将数据保存到 csv 文件
使用 to_csv 函数将数据存储在 csv 文件中。 “ruiyigongfang.csv”是我们导出的文件名,存放在jupyter notebook启动的根目录下,一般在C:\Users\Administrator目录下。
查看ruiyigongfang.csv文件内容
至此,用python3爬取新闻网站信息的项目已经完成。
总结一下:
爬虫的主要过程分为三个阶段:
下载数据:使用requests套件,通过requests.get('url')方法获取网页信息
提取数据:使用BeautifulSoup4套件通过soup.select('xxx');解析关系的内容
保存数据:通过pandas套件将数据组织成二维数据结构,然后通过to_csv()函数将数据以csv格式保存到本地。
----------------------------------- ---------- ---------------------------------------- -----
接下来会有第二个python爬虫项目,等待下一篇博客更新!
这里先介绍一个简单强大的爬虫框架Scrapy的安装,为后续项目做准备。
Scrapy 安装
环境:windows系统,python3
步骤:
1.安装轮子:
py -3 -m pip install wheel
2.安装 lxml:
py -3 -m pip install lxml
3.安装 Twisted:
下载 Twisted:~gohlke/pythonlibs/#twisted
注意:下载的版本要与安装的python版本和电脑位数一致。对于python3.7,选择cp37,其他版本依次类推。例如:
安装 Twisted:
pip install xxx/xxx/Twistedxxx
注意:xxx/xxx/Twistedxxx是下载的twisted文件所在的绝对路径。比如下载的文件放在D:\目录下,文件名为Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
命令应该是 pip install D:\Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
4.安装 Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
5.安装win32py
下载:,注意下载与python版本和电脑位数一致的文件
安装:双击pywin32-224.win-amd64-py3.7.exe文件安装
6.验证
scrapy -h
说明:
安装Scrapy依赖wheel、lxml、Twisted模块
运行 Scrapy 依赖于 win32py
完成!尽情享受吧! 查看全部
scrapy分页抓取网页(本篇博客在爬取新闻网站信息2的基础上进行)
本博客基于爬取新闻网站信息2.主要内容如下:
1.定义一个函数来获取一个页面上的 20 个链接
2.构造多个分页链接
3.获取多个分页链接新闻内容
4.使用pandas整理爬取的数据
5.将数据保存到 csv 文件
6.Scrapy 安装
1.定义一个函数来获取一个页面上的 20 个链接
#定义获取一页20条链接内容的函数
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text)
#获取一个页面所有链接(20个左右)
for ent in jd['result']['data']:
#getNewsDetail为获取一个链接内容详情
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
#测试
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8'
parseListLinks(url)
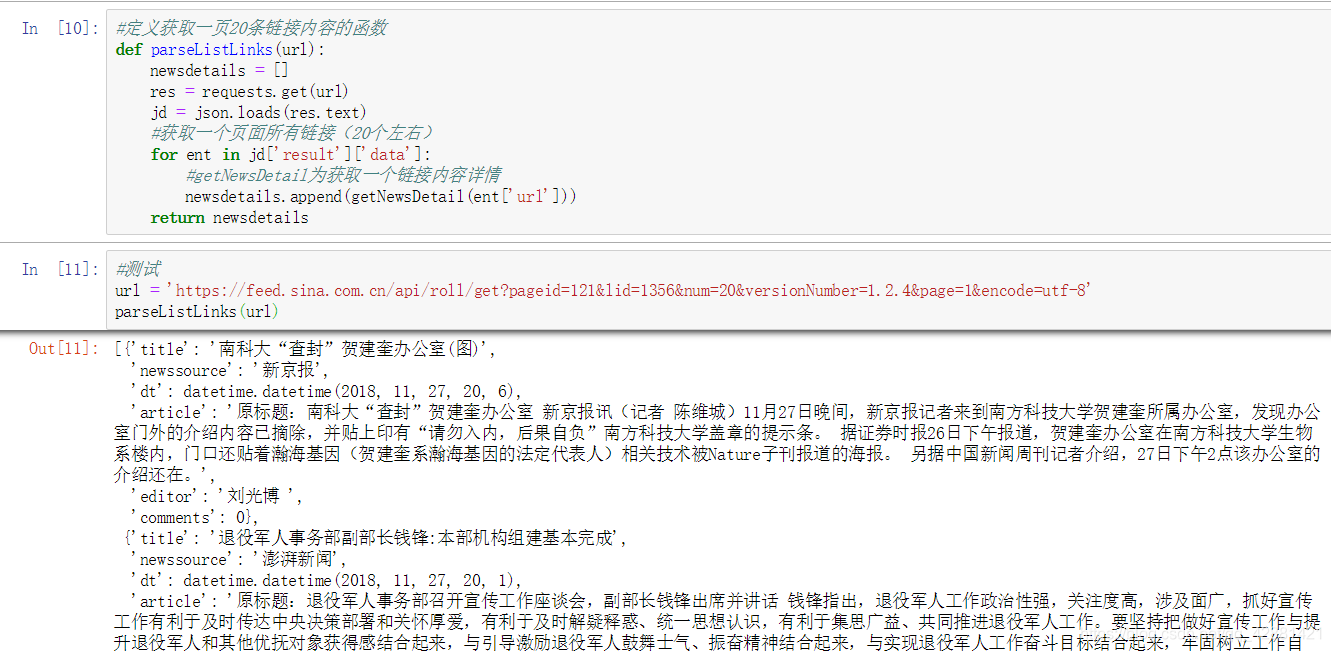
2.构造多个分页链接
#构造多个分页链接
pageurl = "https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8"
for i in range(1,10):
newsurl = pageurl.format(i)
print(newsurl)
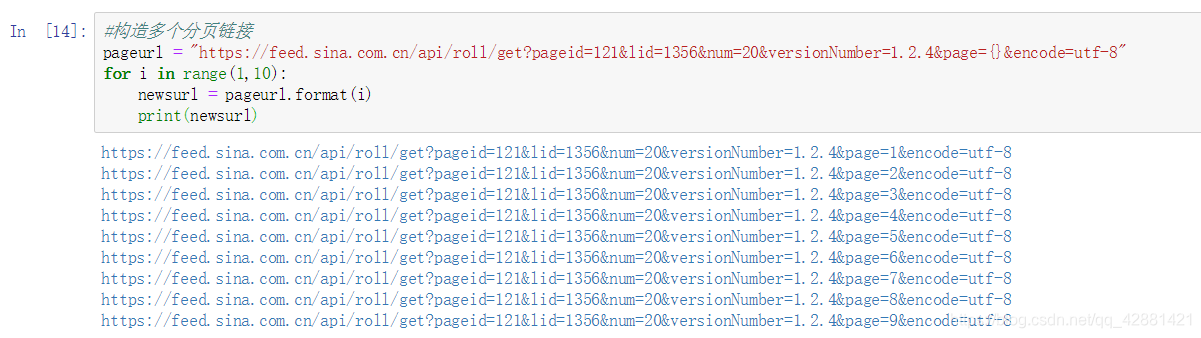
3.获取多个分页链接新闻内容
#抓取多个分页链接新闻内容
import requests
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page={}&encode=utf-8'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(url)
news_total.extend(newsary)
#测试打印抓取的两个页面
print(news_total)
4.使用pandas整理爬取的数据
Pandas 是一个 Python 数据分析包(Python Data Analysis Library)。这里我们使用pandas的DataFrame函数将爬取的数据组织成二维表格数据结构。
安装pandas套件:进入cmd命令行,输入以下命令进行安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
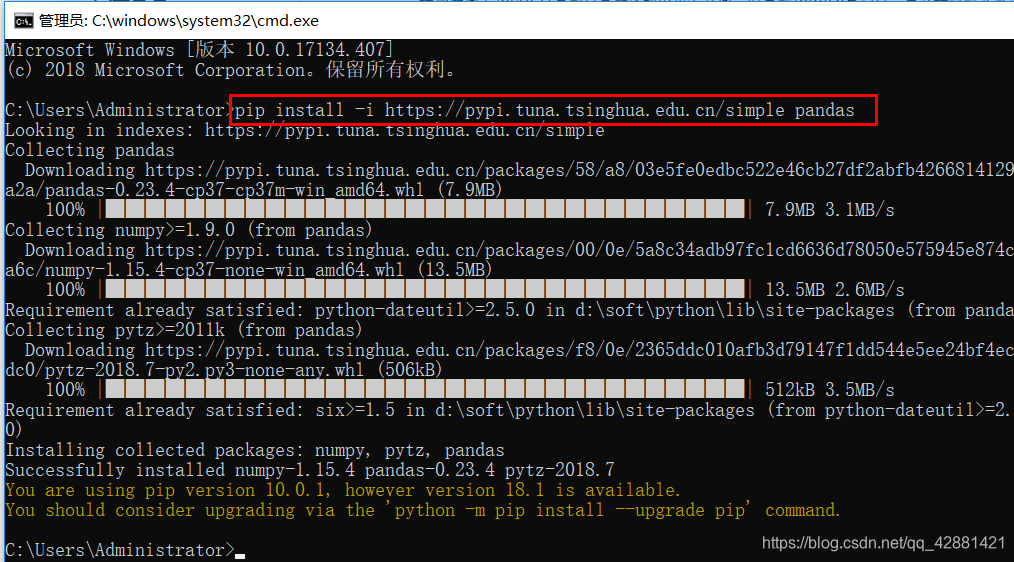
#用pandas整理爬取出的资料
import pandas
df = pandas.DataFrame(news_total)
#查看后5行数据
df.tail()
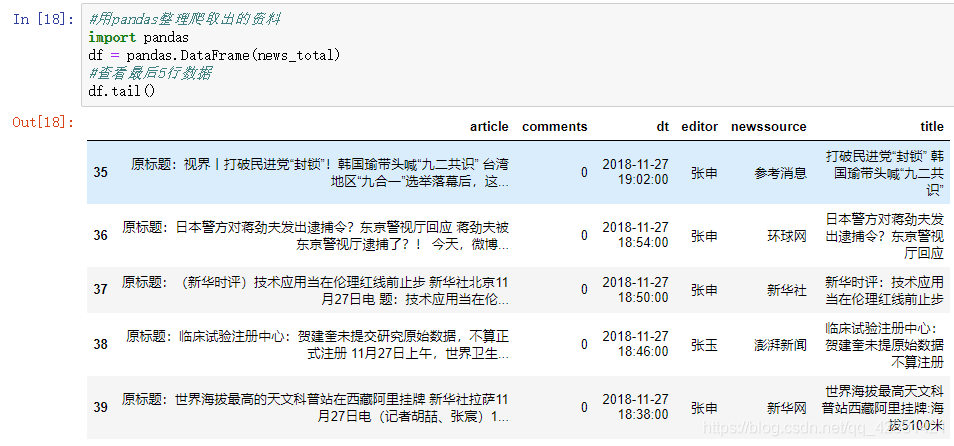
5.将数据保存到 csv 文件
使用 to_csv 函数将数据存储在 csv 文件中。 “ruiyigongfang.csv”是我们导出的文件名,存放在jupyter notebook启动的根目录下,一般在C:\Users\Administrator目录下。

查看ruiyigongfang.csv文件内容
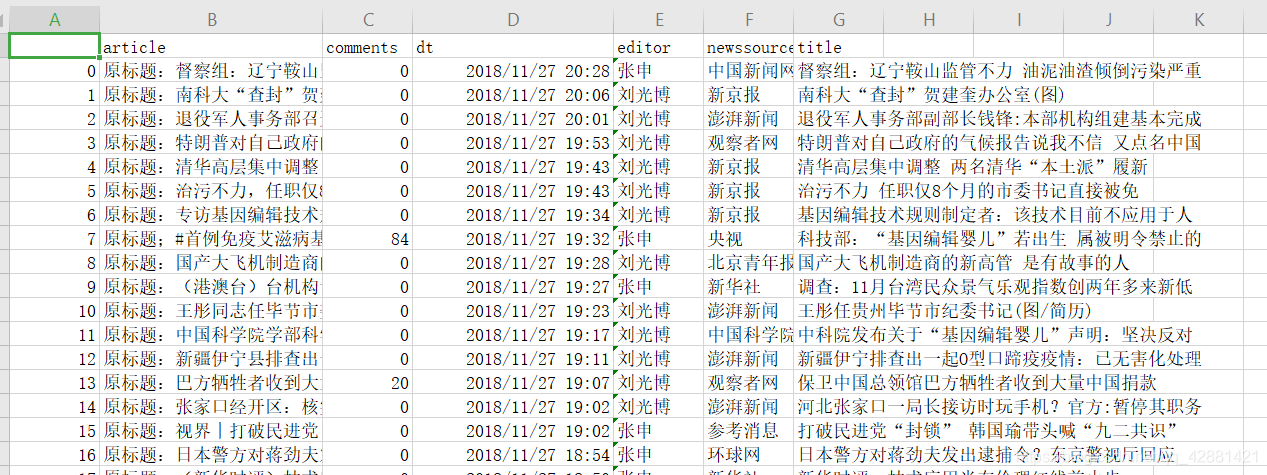
至此,用python3爬取新闻网站信息的项目已经完成。
总结一下:
爬虫的主要过程分为三个阶段:

下载数据:使用requests套件,通过requests.get('url')方法获取网页信息
提取数据:使用BeautifulSoup4套件通过soup.select('xxx');解析关系的内容
保存数据:通过pandas套件将数据组织成二维数据结构,然后通过to_csv()函数将数据以csv格式保存到本地。
----------------------------------- ---------- ---------------------------------------- -----
接下来会有第二个python爬虫项目,等待下一篇博客更新!
这里先介绍一个简单强大的爬虫框架Scrapy的安装,为后续项目做准备。
Scrapy 安装
环境:windows系统,python3
步骤:
1.安装轮子:
py -3 -m pip install wheel
2.安装 lxml:
py -3 -m pip install lxml
3.安装 Twisted:
下载 Twisted:~gohlke/pythonlibs/#twisted
注意:下载的版本要与安装的python版本和电脑位数一致。对于python3.7,选择cp37,其他版本依次类推。例如:
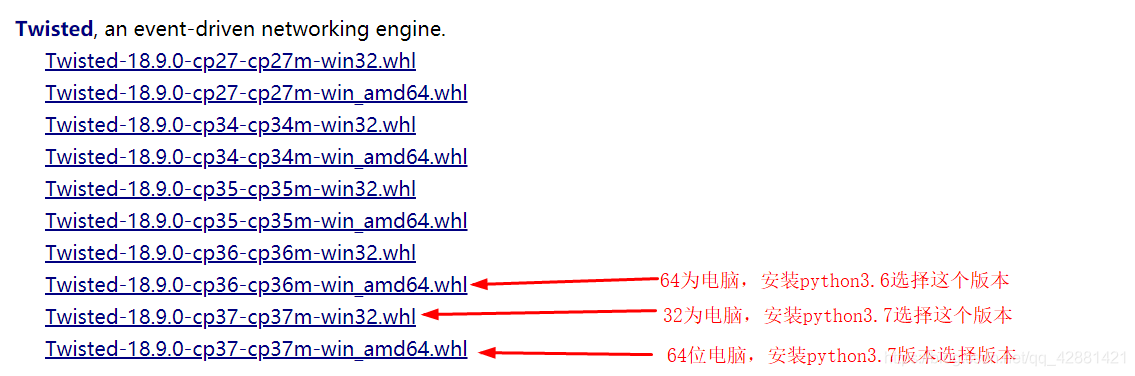
安装 Twisted:
pip install xxx/xxx/Twistedxxx
注意:xxx/xxx/Twistedxxx是下载的twisted文件所在的绝对路径。比如下载的文件放在D:\目录下,文件名为Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
命令应该是 pip install D:\Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
4.安装 Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
5.安装win32py
下载:,注意下载与python版本和电脑位数一致的文件
安装:双击pywin32-224.win-amd64-py3.7.exe文件安装
6.验证
scrapy -h
说明:
安装Scrapy依赖wheel、lxml、Twisted模块
运行 Scrapy 依赖于 win32py
完成!尽情享受吧!
scrapy分页抓取网页(我很困难,无法弄清楚为什么我的CrawlSpider无法拾取并处理HTML代码中的相关链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-03 08:17
我很难弄清楚为什么我的 CrawlSpider 无法获取和处理 HTML 代码中的相关链接。 Scrapy 不会抓取 LinkExtractor 允许的页面
这是一个 cawlspider,我可以在命令行上传递一些参数,如下所示:
scrapy crawl domain_spider -a url="" -s ROBOTSTXT_OBEY=0 -s AUTOTHROTTLE_ENABLED=0
蜘蛛运行并且绝对拒绝抓取带有列表分页的页面。 HTML 如下所示:
< Previous 20
如果我在参数中传递 -a allowed="page=" 之类的逗号,那么它会拾取两页,但它仍然拒绝继续。
谁能发现我的代码下面的问题?
我的爬行蜘蛛:
def __init__(self, url=None, category='default', allowed=None, denied=None, single_page=False, **kwargs):
self.category = category
if allowed == '':
allowed = None
if denied == '':
denied = None
if single_page is not False and single_page != '':
denied = '.*'
self.start_urls = ['{}'.format(url)]
self.allowed_domains = [urlparse(url).netloc]
self.domain = urlparse(url).netloc
self.rules = (
Rule(LinkExtractor(allow=allowed, deny=denied, unique=True), callback='parse_page'),
)
super(DomainSpider, self).__init__(**kwargs)
来源
2016-07-01马克·安德森 查看全部
scrapy分页抓取网页(我很困难,无法弄清楚为什么我的CrawlSpider无法拾取并处理HTML代码中的相关链接)
我很难弄清楚为什么我的 CrawlSpider 无法获取和处理 HTML 代码中的相关链接。 Scrapy 不会抓取 LinkExtractor 允许的页面
这是一个 cawlspider,我可以在命令行上传递一些参数,如下所示:
scrapy crawl domain_spider -a url="" -s ROBOTSTXT_OBEY=0 -s AUTOTHROTTLE_ENABLED=0
蜘蛛运行并且绝对拒绝抓取带有列表分页的页面。 HTML 如下所示:
< Previous 20
如果我在参数中传递 -a allowed="page=" 之类的逗号,那么它会拾取两页,但它仍然拒绝继续。
谁能发现我的代码下面的问题?
我的爬行蜘蛛:
def __init__(self, url=None, category='default', allowed=None, denied=None, single_page=False, **kwargs):
self.category = category
if allowed == '':
allowed = None
if denied == '':
denied = None
if single_page is not False and single_page != '':
denied = '.*'
self.start_urls = ['{}'.format(url)]
self.allowed_domains = [urlparse(url).netloc]
self.domain = urlparse(url).netloc
self.rules = (
Rule(LinkExtractor(allow=allowed, deny=denied, unique=True), callback='parse_page'),
)
super(DomainSpider, self).__init__(**kwargs)
来源
2016-07-01马克·安德森
scrapy分页抓取网页( WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-03 00:14
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider蓝蜘蛛网络爬虫5.1可以爬取互联网上的任何网页,wap网站,包括需要登录才能访问的页面。分析抓取页面的内容,获取结构化信息,如:新闻标题、作者、来源、正文等。支持列表页自动翻页和爬取,支持文本页面多页合并,支持图片和文件,可以抓取静态网页,也可以抓取带参数的动态网页,功能极其强大。
用户指定要爬取的网站,要爬取的网页类型(固定页面、分页页面等),并配置如何解析数据项(如新闻标题、作者、来源、文本、等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正实现“按需采集,一次配置,永久采集”。捕获的数据可以保存到数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全替代传统的编辑和人工处理信息的模式。可以24*60实时、准确地为企业提供最新信息和情报,真正为企业降低成本、提高竞争力。
该工具的主要特点如下:
* 应用范围广,可以爬取任意网页(包括登录后才能访问的网页)
* 处理速度快,如果网络通畅的话,1小时可以爬取解析10000个网页
*采用独有的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
* 抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
* 支持断点连续抓取,可在机器死机或出现异常情况后恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以抓取所有列表页的数据。对于body页面,可以自动合并分页中显示的内容;
* 支持页面深度爬取,页面可一页一页抓取。比如通过列表页抓取正文页URL,然后抓取正文页。各级页面可单独存放;
*WEB操作界面,一处安装,随处使用
* 一步一步分析,一步一步入库
* 一次配置,永久抓取,一劳永逸 查看全部
scrapy分页抓取网页(
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider蓝蜘蛛网络爬虫5.1可以爬取互联网上的任何网页,wap网站,包括需要登录才能访问的页面。分析抓取页面的内容,获取结构化信息,如:新闻标题、作者、来源、正文等。支持列表页自动翻页和爬取,支持文本页面多页合并,支持图片和文件,可以抓取静态网页,也可以抓取带参数的动态网页,功能极其强大。
用户指定要爬取的网站,要爬取的网页类型(固定页面、分页页面等),并配置如何解析数据项(如新闻标题、作者、来源、文本、等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正实现“按需采集,一次配置,永久采集”。捕获的数据可以保存到数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全替代传统的编辑和人工处理信息的模式。可以24*60实时、准确地为企业提供最新信息和情报,真正为企业降低成本、提高竞争力。
该工具的主要特点如下:
* 应用范围广,可以爬取任意网页(包括登录后才能访问的网页)
* 处理速度快,如果网络通畅的话,1小时可以爬取解析10000个网页
*采用独有的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
* 抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
* 支持断点连续抓取,可在机器死机或出现异常情况后恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以抓取所有列表页的数据。对于body页面,可以自动合并分页中显示的内容;
* 支持页面深度爬取,页面可一页一页抓取。比如通过列表页抓取正文页URL,然后抓取正文页。各级页面可单独存放;
*WEB操作界面,一处安装,随处使用
* 一步一步分析,一步一步入库
* 一次配置,永久抓取,一劳永逸
scrapy分页抓取网页( image这是简易数据分析系列的第13篇文章(13):WebScraper教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-03 00:12
image这是简易数据分析系列的第13篇文章(13):WebScraper教程)
图片
这是简易数据分析系列文章的第 13 篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10篇网络爬虫系列教程,这10篇文章基本涵盖了网络爬虫的大部分功能。今天的内容是本系列的最后一篇文章。下一章我再开个坑,讲讲如何用Excel对采集到的数据进行格式化和分析。
我会在下一篇文章文章中对Web Scraper教程做一个全面的总结,今天开始我们的实战教程。
在之前的课程中,我们抓取的数据都是同一级别的内容。讨论的主要问题是如何处理市场上各种类型的分页,但是如何抓取详情页的内容数据并没有介绍。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上的作品相关的数据,比如下图中的排名、作品名称、播放量、弹幕数、作者姓名等。
图片
经常逛B站的朋友也知道,UP主经常暗示看视频会连续三个操作(点赞+币+采集)。可以看出这三个数据对视频的排名有一定的影响,所以这些数据对我们也有一定的参考价值。
图片
但遗憾的是,这份榜单中并没有相关数据。这些数据在视频详情页,我们需要点击链接查看:
图片
今天的教程内容是教大家如何在爬取一级页面(列表页)的同时,使用Web Scraper抓取二级页面(详情页)的内容。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我已经在下图中的红框中标出了关键路径。你可以比较一下:
图片
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
图片
2.为容器创建一个选择器
设置前我们观察一下,发现这个网页的排名数据是一次性加载100条数据,不需要分页,所以这里的Type类型选择为Element。
其他参数都比较简单,就不赘述了(了解不多的可以看我之前的基础教程)。这是一个截图供您参考:
图片
3.创建列表页面子选择器
这次子选择器要抓取的内容如下,都比较简单。可以参考图片截图:
排名 (num) 作品名称 (title) 播放量 (play_amount) 弹幕量 (danmu_count) 作者: (author)
图片
图片
如果做了这一步,其实可以捕获所有已知的列表数据,但是本文的重点是:如何捕获二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper 的本质就是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实点击标题链接即可跳转:
图片
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过一个例子来理解它。
首先,在本例中,我们获取了标题的文本,选择器类型为 Text:
图片
当我们要抓取链接的时候,需要再创建一个选择器,被选中的元素都是一样的,只不过Type是Link:
图片
创建成功后,我们点击链接类型选择器,进入它的内部,然后创建相关的选择器。下面我录制了一个动图,注意我鼠标高亮的导航路由部分,可以清楚的看到这几个选择器的层级关系:
图片
4.创建详情页子选择器
当你点击链接时,你会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,无法跨页选择想要的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,然后回车重新加载,这样就可以在当前页选中了。
图片
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了点赞数、硬币数、采集数和分享数4个数据。这个操作也很简单,这里就不赘述了。
图片
所有选择器的结构图如下:
图片
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经建立。
5.捕获数据
激动人心的部分终于来了,我们将开始抓取数据。但在抓取之前,我们必须将等待时间调整为更大。默认时间是2000毫秒,我这里改成5000毫秒。
图片
为什么要这样做?看下图你就明白了:
图片
首先,每次打开二级页面都是一个全新的页面,此时浏览器加载页面需要时间;
其次,我们可以观察要捕获的点赞数等数据。页面刚加载的时候,它的值为“--”,过一段时间会变成一个数字。
因此,我们直接等待5000ms,等页面和数据加载完毕后再统一取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓取的数据的一部分,这里是为了证明这种方法有效:
图片
6.总结
这个教程可能有点难。我将分享我的站点地图。如果在生产过程中遇到困难,可以参考我的配置。SiteMap的导入功能我在第六篇教程中已经讲解过了。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
掌握了二级页面的爬取方式后,三级页面和四级页面都没有问题。因为例程是相同的:它们都是在链接选择器指向的下一页上抓取数据。因为原理是一样的,我就不演示了。 查看全部
scrapy分页抓取网页(
image这是简易数据分析系列的第13篇文章(13):WebScraper教程)
图片
这是简易数据分析系列文章的第 13 篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10篇网络爬虫系列教程,这10篇文章基本涵盖了网络爬虫的大部分功能。今天的内容是本系列的最后一篇文章。下一章我再开个坑,讲讲如何用Excel对采集到的数据进行格式化和分析。
我会在下一篇文章文章中对Web Scraper教程做一个全面的总结,今天开始我们的实战教程。
在之前的课程中,我们抓取的数据都是同一级别的内容。讨论的主要问题是如何处理市场上各种类型的分页,但是如何抓取详情页的内容数据并没有介绍。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上的作品相关的数据,比如下图中的排名、作品名称、播放量、弹幕数、作者姓名等。
图片
经常逛B站的朋友也知道,UP主经常暗示看视频会连续三个操作(点赞+币+采集)。可以看出这三个数据对视频的排名有一定的影响,所以这些数据对我们也有一定的参考价值。
图片
但遗憾的是,这份榜单中并没有相关数据。这些数据在视频详情页,我们需要点击链接查看:
图片
今天的教程内容是教大家如何在爬取一级页面(列表页)的同时,使用Web Scraper抓取二级页面(详情页)的内容。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我已经在下图中的红框中标出了关键路径。你可以比较一下:
图片
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
图片
2.为容器创建一个选择器
设置前我们观察一下,发现这个网页的排名数据是一次性加载100条数据,不需要分页,所以这里的Type类型选择为Element。
其他参数都比较简单,就不赘述了(了解不多的可以看我之前的基础教程)。这是一个截图供您参考:
图片
3.创建列表页面子选择器
这次子选择器要抓取的内容如下,都比较简单。可以参考图片截图:
排名 (num) 作品名称 (title) 播放量 (play_amount) 弹幕量 (danmu_count) 作者: (author)
图片
图片
如果做了这一步,其实可以捕获所有已知的列表数据,但是本文的重点是:如何捕获二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper 的本质就是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实点击标题链接即可跳转:
图片
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过一个例子来理解它。
首先,在本例中,我们获取了标题的文本,选择器类型为 Text:
图片
当我们要抓取链接的时候,需要再创建一个选择器,被选中的元素都是一样的,只不过Type是Link:
图片
创建成功后,我们点击链接类型选择器,进入它的内部,然后创建相关的选择器。下面我录制了一个动图,注意我鼠标高亮的导航路由部分,可以清楚的看到这几个选择器的层级关系:
图片
4.创建详情页子选择器
当你点击链接时,你会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,无法跨页选择想要的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,然后回车重新加载,这样就可以在当前页选中了。
图片
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了点赞数、硬币数、采集数和分享数4个数据。这个操作也很简单,这里就不赘述了。
图片
所有选择器的结构图如下:
图片
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经建立。
5.捕获数据
激动人心的部分终于来了,我们将开始抓取数据。但在抓取之前,我们必须将等待时间调整为更大。默认时间是2000毫秒,我这里改成5000毫秒。
图片
为什么要这样做?看下图你就明白了:
图片
首先,每次打开二级页面都是一个全新的页面,此时浏览器加载页面需要时间;
其次,我们可以观察要捕获的点赞数等数据。页面刚加载的时候,它的值为“--”,过一段时间会变成一个数字。
因此,我们直接等待5000ms,等页面和数据加载完毕后再统一取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓取的数据的一部分,这里是为了证明这种方法有效:
图片
6.总结
这个教程可能有点难。我将分享我的站点地图。如果在生产过程中遇到困难,可以参考我的配置。SiteMap的导入功能我在第六篇教程中已经讲解过了。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
掌握了二级页面的爬取方式后,三级页面和四级页面都没有问题。因为例程是相同的:它们都是在链接选择器指向的下一页上抓取数据。因为原理是一样的,我就不演示了。
scrapy分页抓取网页(WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 04:22
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页,指定跳转页数。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页看起来像这样,注意有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk->Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type (-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。 查看全部
scrapy分页抓取网页(WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页,指定跳转页数。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页看起来像这样,注意有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk->Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type (-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。
scrapy分页抓取网页(如何从OMIM抓取一些数据下来的网站数据下载的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-01 07:13
由于工作原因,我们需要从 OMIM 中获取一些数据。其实网站提供API和数据下载,但是对于营利单位来说,是需要权限的。无奈之下,只能求助于爬虫来解决。
什么是爬行动物
爬虫又称爬虫程序,是一种网络爬虫机器人,是一种模拟浏览器与网页交互的工具。它在英语中被称为“Bot”。例如,微软的爬虫,叫做“bingbot”,会定期对网页进行采样,发现新的或更新的网页,计算后决定是否加入索引。爬行动物的规模可大可小。像搜索引擎这样的大型爬虫会涉及大量机器和分布式组织。比如我今天用的那个小就是一台电脑,而不是手动输入400个网页和一堆复制粘贴操作。
爬虫的应用,除了上面提到的搜索引擎,还有数据分析。分析的数据不仅是自己产生的,也可能是从互联网上采集的。一些网站会提供数据采集接口,比如github、KEGG、NCBI和Ensembl,还有stackoverflow。一般来说,采集这些网站的数据要简单得多。直接根据自己的需要,按照它的接口规则拼出一个http URL就够了。在没有API的情况下从其他网站采集数据,需要依赖爬虫。如果你想搜索搜狗,你必须依靠自己的技术基础进行搜索。我做过知乎和微信搜索。我经常用这两个。在写一个主题之前,我需要做一个搜索。
在另一种情况下,不仅使用严格意义上的爬虫,还通过模拟浏览器行为。比如公司有一个网站系统出报告,但是做的时候没有给你留一个API接口,而是每次想到几十个网站,点击输入测试结果一个一、我想爆粗口,为什么不直接从服务器上传分析后的结果?这时候用的是模拟用户登录,选择跳转到指定样本的界面,分析POST请求参数,然后按要求完成参数,提交。这是用于自动化测试的,我稍后会写。
Scrapy 用途
关于Scrapy的安装和入门指南,官网文档的内容已经很不错了。这里我们以爬取OMIM网站为例介绍简单的用法和可能出现的问题。
def __init__(self, filename=None):
URL_BASE = 'https://www.omim.org/entry/'
if filename:
with open(filename, 'r') as f:
omim_ids = [re.findall(r'\((\d+)\)', line ) for line in f if line.startswith('chr') ]
self.start_urls = [ '{0}{1}'.format(URL_BASE, int(omim[0]) ) for omim in omim_ids if omim]
反爬虫反应
对于一些网站爬虫来说,比如Scrapy网站给出的例子,用猫画老虎可以达到目的,而OMIM不能。如果直接开始爬取,服务器会抛出403“拒绝访问”错误码。文档OMIM robots规定网站只允许Googlebot和bingbot抓取其指定目录下的数据。
关于反爬的反应,官网也有资料供参考:避免被封禁,参考这里和OMIM机器人,修改程序设置,然后测试顺利获取数据。使用的方法总结如下:
以下是程序代码:
#!/usr/bin/env python
#coding=utf-8
import re
import scrapy
class omimSpider(scrapy.Spider):
name = 'omim'
custom_settings = {
'USER_AGENT':'bingbot', #冒充bingbot的UA名和'BOT_NAME'
'BOT_NAME':'bingbot',
'COOKIES_ENABLED':False,
'DOWNLOAD_DELAY':4
}
def __init__(self, filename=None):
URL_BASE = 'https://www.omim.org/entry/'
if filename:
with open(filename, 'r') as f:
omim_ids = [re.findall(r'\((\d+)\)', line ) for line in f if line.startswith('chr') ]
self.start_urls = [ '{0}{1}'.format(URL_BASE, int(omim[0]) ) for omim in omim_ids if omim]
# self.start_urls = ['https://www.omim.org/entry/131244']
def parse(self, response):
gene_pheno = {}
gene_pheno['url'] = response.url
gene_pheno['omim_num'] = re.findall(r'(\d+)',response.url)[0]
#extract from Description
if 'Description' in response.text:
gene_pheno['description'] = ','.join(response.xpath('//div[@id="descriptionFold"]/span/p/text()').extract() )
#extract from table
if response.xpath('//table'):
tr = response.xpath('//table/tbody/tr') #maybe one or more trs
gene_pheno['location'] = tr[0].xpath('td')[0].xpath('span/a/text()').extract_first().strip() #first td of first tr in table
phenotype = tr[0].xpath('td')[1].xpath('span/text()').extract_first().strip()
mim = tr[0].xpath('td')[2].xpath('span/a/text()').extract_first()
inherit = ','.join(tr[0].xpath('td')[3].xpath('span/abbr/text()').extract() )
pheno_key = tr[0].xpath('td')[4].xpath('span/abbr/text()').extract_first()
gene_pheno[mim] = [phenotype, inherit, pheno_key]
if len(tr) > 1:
for tb_record in tr[1:]: #less num of column than the tr above
phenotype = tb_record.xpath('td')[0].xpath('span/text()').extract_first().strip()
min = tb_record.xpath('td')[1].xpath('span/a/text()').extract_first()
inherit = ','.join(tb_record.xpath('td')[2].xpath('span/abbr/text()').extract() )
pheno_key = tb_record.xpath('td')[3].xpath('span/abbr/text()').extract_first()
gene_pheno[mim] = [phenotype, inherit, pheno_key]
return gene_pheno
指示
#scrapy 版本 1.1.0
scrapy runspider omim.py -o all_omim.json -a filename=/path/to/file.txt
参考:
Scrapy官网文档
w3school xpath 文档
omim.py 源代码
/r/tETI0BDESU02rVSz9xGm(二维码自动识别) 查看全部
scrapy分页抓取网页(如何从OMIM抓取一些数据下来的网站数据下载的?)
由于工作原因,我们需要从 OMIM 中获取一些数据。其实网站提供API和数据下载,但是对于营利单位来说,是需要权限的。无奈之下,只能求助于爬虫来解决。
什么是爬行动物
爬虫又称爬虫程序,是一种网络爬虫机器人,是一种模拟浏览器与网页交互的工具。它在英语中被称为“Bot”。例如,微软的爬虫,叫做“bingbot”,会定期对网页进行采样,发现新的或更新的网页,计算后决定是否加入索引。爬行动物的规模可大可小。像搜索引擎这样的大型爬虫会涉及大量机器和分布式组织。比如我今天用的那个小就是一台电脑,而不是手动输入400个网页和一堆复制粘贴操作。
爬虫的应用,除了上面提到的搜索引擎,还有数据分析。分析的数据不仅是自己产生的,也可能是从互联网上采集的。一些网站会提供数据采集接口,比如github、KEGG、NCBI和Ensembl,还有stackoverflow。一般来说,采集这些网站的数据要简单得多。直接根据自己的需要,按照它的接口规则拼出一个http URL就够了。在没有API的情况下从其他网站采集数据,需要依赖爬虫。如果你想搜索搜狗,你必须依靠自己的技术基础进行搜索。我做过知乎和微信搜索。我经常用这两个。在写一个主题之前,我需要做一个搜索。
在另一种情况下,不仅使用严格意义上的爬虫,还通过模拟浏览器行为。比如公司有一个网站系统出报告,但是做的时候没有给你留一个API接口,而是每次想到几十个网站,点击输入测试结果一个一、我想爆粗口,为什么不直接从服务器上传分析后的结果?这时候用的是模拟用户登录,选择跳转到指定样本的界面,分析POST请求参数,然后按要求完成参数,提交。这是用于自动化测试的,我稍后会写。
Scrapy 用途
关于Scrapy的安装和入门指南,官网文档的内容已经很不错了。这里我们以爬取OMIM网站为例介绍简单的用法和可能出现的问题。
def __init__(self, filename=None):
URL_BASE = 'https://www.omim.org/entry/'
if filename:
with open(filename, 'r') as f:
omim_ids = [re.findall(r'\((\d+)\)', line ) for line in f if line.startswith('chr') ]
self.start_urls = [ '{0}{1}'.format(URL_BASE, int(omim[0]) ) for omim in omim_ids if omim]
反爬虫反应
对于一些网站爬虫来说,比如Scrapy网站给出的例子,用猫画老虎可以达到目的,而OMIM不能。如果直接开始爬取,服务器会抛出403“拒绝访问”错误码。文档OMIM robots规定网站只允许Googlebot和bingbot抓取其指定目录下的数据。
关于反爬的反应,官网也有资料供参考:避免被封禁,参考这里和OMIM机器人,修改程序设置,然后测试顺利获取数据。使用的方法总结如下:
以下是程序代码:
#!/usr/bin/env python
#coding=utf-8
import re
import scrapy
class omimSpider(scrapy.Spider):
name = 'omim'
custom_settings = {
'USER_AGENT':'bingbot', #冒充bingbot的UA名和'BOT_NAME'
'BOT_NAME':'bingbot',
'COOKIES_ENABLED':False,
'DOWNLOAD_DELAY':4
}
def __init__(self, filename=None):
URL_BASE = 'https://www.omim.org/entry/'
if filename:
with open(filename, 'r') as f:
omim_ids = [re.findall(r'\((\d+)\)', line ) for line in f if line.startswith('chr') ]
self.start_urls = [ '{0}{1}'.format(URL_BASE, int(omim[0]) ) for omim in omim_ids if omim]
# self.start_urls = ['https://www.omim.org/entry/131244']
def parse(self, response):
gene_pheno = {}
gene_pheno['url'] = response.url
gene_pheno['omim_num'] = re.findall(r'(\d+)',response.url)[0]
#extract from Description
if 'Description' in response.text:
gene_pheno['description'] = ','.join(response.xpath('//div[@id="descriptionFold"]/span/p/text()').extract() )
#extract from table
if response.xpath('//table'):
tr = response.xpath('//table/tbody/tr') #maybe one or more trs
gene_pheno['location'] = tr[0].xpath('td')[0].xpath('span/a/text()').extract_first().strip() #first td of first tr in table
phenotype = tr[0].xpath('td')[1].xpath('span/text()').extract_first().strip()
mim = tr[0].xpath('td')[2].xpath('span/a/text()').extract_first()
inherit = ','.join(tr[0].xpath('td')[3].xpath('span/abbr/text()').extract() )
pheno_key = tr[0].xpath('td')[4].xpath('span/abbr/text()').extract_first()
gene_pheno[mim] = [phenotype, inherit, pheno_key]
if len(tr) > 1:
for tb_record in tr[1:]: #less num of column than the tr above
phenotype = tb_record.xpath('td')[0].xpath('span/text()').extract_first().strip()
min = tb_record.xpath('td')[1].xpath('span/a/text()').extract_first()
inherit = ','.join(tb_record.xpath('td')[2].xpath('span/abbr/text()').extract() )
pheno_key = tb_record.xpath('td')[3].xpath('span/abbr/text()').extract_first()
gene_pheno[mim] = [phenotype, inherit, pheno_key]
return gene_pheno
指示
#scrapy 版本 1.1.0
scrapy runspider omim.py -o all_omim.json -a filename=/path/to/file.txt
参考:
Scrapy官网文档
w3school xpath 文档
omim.py 源代码
/r/tETI0BDESU02rVSz9xGm(二维码自动识别)
scrapy分页抓取网页(【平安二号?百日攻坚】我该)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-29 01:09
【问题描述】:
我有一个爬虫爬虫,它爬取一个 网站,它通过页面上的 javascript 重新加载内容。要跳转到下一页进行抓取,我一直在使用 Selenium 单击 网站 顶部的月份链接。
问题是,即使我的代码按预期通过每个链接,蜘蛛只是抓取第一个月(9 月)的月份数据并返回这些重复项。
我该如何解决这个问题?
from selenium import webdriver
class GigsInScotlandMain(InitSpider):
name = 'gigsinscotlandmain'
allowed_domains = ["gigsinscotland.com"]
start_urls = ["http://www.gigsinscotland.com"]
def __init__(self):
InitSpider.__init__(self)
self.br = webdriver.Firefox()
def parse(self, response):
hxs = HtmlXPathSelector(response)
self.br.get(response.url)
time.sleep(2.5)
# Get the string for each month on the page.
months = hxs.select("//ul[@id='gigsMonths']/li/a/text()").extract()
for month in months:
link = self.br.find_element_by_link_text(month)
link.click()
time.sleep(5)
# Get all the divs containing info to be scraped.
listitems = hxs.select("//div[@class='listItem']")
for listitem in listitems:
item = GigsInScotlandMainItem()
item['artist'] = listitem.select("div[contains(@class, 'artistBlock')]/div[@class='artistdiv']/span[@class='artistname']/a/text()").extract()
#
# Get other data ...
#
yield item
【问题讨论】: 查看全部
scrapy分页抓取网页(【平安二号?百日攻坚】我该)
【问题描述】:
我有一个爬虫爬虫,它爬取一个 网站,它通过页面上的 javascript 重新加载内容。要跳转到下一页进行抓取,我一直在使用 Selenium 单击 网站 顶部的月份链接。
问题是,即使我的代码按预期通过每个链接,蜘蛛只是抓取第一个月(9 月)的月份数据并返回这些重复项。
我该如何解决这个问题?
from selenium import webdriver
class GigsInScotlandMain(InitSpider):
name = 'gigsinscotlandmain'
allowed_domains = ["gigsinscotland.com"]
start_urls = ["http://www.gigsinscotland.com"]
def __init__(self):
InitSpider.__init__(self)
self.br = webdriver.Firefox()
def parse(self, response):
hxs = HtmlXPathSelector(response)
self.br.get(response.url)
time.sleep(2.5)
# Get the string for each month on the page.
months = hxs.select("//ul[@id='gigsMonths']/li/a/text()").extract()
for month in months:
link = self.br.find_element_by_link_text(month)
link.click()
time.sleep(5)
# Get all the divs containing info to be scraped.
listitems = hxs.select("//div[@class='listItem']")
for listitem in listitems:
item = GigsInScotlandMainItem()
item['artist'] = listitem.select("div[contains(@class, 'artistBlock')]/div[@class='artistdiv']/span[@class='artistname']/a/text()").extract()
#
# Get other data ...
#
yield item
【问题讨论】:
scrapy分页抓取网页(2021-09-051Scrapy(绿线向)2Scrapy的运作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-29 01:07
2021-09-051 Scrapy架构图(绿线为数据流)
2 Scrapy操作流程
代码写好了,程序开始运行了……
发动机:嗨!蜘蛛,你在对付哪个网站?蜘蛛:老板要我处理。引擎:给我第一个需要处理的 URL。Spider:在这里,第一个 URL 是。发动机:嗨!调度员,我有一个请求,请求您帮我排序并加入队列。调度程序:好的,正在处理您等一下。发动机:嗨!调度员,给我你处理的请求。调度器:给你,这是我处理的请求引擎:嗨!下载器,请帮我按照老板下载中间件的设置下载这个请求下载器:OK!给你,这是下载的东西。(如果失败:对不起,这个请求下载失败。然后引擎告诉调度器这个请求下载失败,你记录一下,我们稍后下载) 引擎:你好!蜘蛛,这是一个下载的东西,已经按照老大的下载中间件进行了处理,大家可以自行处理!这里,响应默认由def parse()处理) Spider:(处理数据后需要跟进的URL),Hi!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!(处理数据后需要跟进的URL),您好!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!(处理数据后需要跟进的URL),您好!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
3 Scrapy安装介绍
1、安装wheel pip3 install wheel
2、安装lxml pip3 install lxml-4.2.1-cp36-cp36m-win_amd64.whl
3、安装pyopenssl (已安装就不需要安装)
4、安装Twisted pip3 install Twisted-18.4.0-cp36-cp36m-win_amd64.whl
5、安装pywin32 pip3 install pypiwin32
6、安装scrapy pip3 install scrapy
或者pip3 install Scrapy-1.5.0-py2.py3-none-any.whl
Scrapy框架官网:
Scrapy中文维护网站:
Windows安装方式Ubuntu需要9.10以上的安装方式
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明已经安装成功
具体Scrapy安装过程参考:每个平台都有安装方法
4 制作一个Scrapy爬虫一共需要4个步骤:
新建爬虫项目
scrapy startproject mySpider
进入该目录 cd mySpider
scrapy genspider stack http://stackoverflow.com/ #创建一个爬虫stack 指定爬取路径
明确目标(编写items.py):明确你要捕获的目标(目标信息以类和字段的形式实现)
制作爬虫(spiders/xxspider.py):制作爬虫并开始爬取网页(实现主要逻辑的地方并返回item)
存储内容(pipelines.py):设计管道存储爬取内容(接受item,一般重写几个常用方法(open_spider、process_item、close_spider)
启动爬虫项目
命令开始:scrapy crawl spidername(爬虫名称)
文件开始
from scrapy import cmdline
# 方式一:注意execute的参数类型为一个列表
cmdline.execute('scrapy crawl spidername'.split())
# 方式二:注意execute的参数类型为一个列表
cmdline.execute(['scrapy', 'crawl', 'spidername'])
5 入门案例一.新建项目(scrapy startproject)
scrapy startproject mySpider
下面简单介绍一下各个主文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的 Python 模块,将从中引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ : 蜘蛛代码存放的目录
二、明确目标 (mySpider/items.py)
我们打算抓取:网站 中的邮箱。
打开mySpider目录下的items.pyItem,定义一个结构化的数据字段,用来保存爬取的数据,类似于dict,但是提供了一些额外的保护来减少错误。可以通过创建一个scrapy.Item类并定义一个scrapy.Field类型的类属性来定义一个Item(可以理解为一种类似于ORM的映射关系)。接下来,创建一个 TianyaItem 类并构建项目模型。
import scrapy
class TianyaItem(scrapy.Item):
email = scrapy.Field() #只定义爬取email字段
三、制作蜘蛛 (spiders/itcastSpider.py)
爬虫功能分为两步:
1. 爬取数据
scrapy genspider mytianya "bbs.tianya.cn" #指定爬虫文件名 爬取的域名
import scrapy
import re
from tianya import items
class MytianyaSpider(scrapy.Spider):
name = 'mytianya'
allowed_domains = ['bbs.tianya.cn']
start_urls = ['http://bbs.tianya.cn/post-140-393977-1.shtml']
#主要的逻辑模块
def parse(self, response):
pass
其实我们也可以自己创建itcast.py,自己写上面的代码,但是使用命令可以省去写固定代码的麻烦
要创建 Spider,您必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
修改 parse() 方法
def parse(self, response):
html = response.body.decode()
# [email protected]
email = re.compile(r"([A-Z0-9_][email protected][A-Z0-9]+\.[A-Z]{2,4})", re.I)
emailList = email.findall(html)
mydict = []
for e in emailList:
item = items.TianyaItem()
item["email"] = e
# mydict[e] = "http://bbs.tianya.cn/post-140-393977-1.shtml"
mydict.append(item)
return mydict
然后运行看看,在mySpider目录下执行:
scrapy crawl mytianya
2.scrapy保存信息有四种最简单的保存方式,-o输出指定格式的文件,命令如下:
scrapy crawl mytianya -o mytianya.json
scrapy crawl mytianya -o mytianya.csv
scrapy crawl mytianya -o mytianya.xml
什么产量在这里:
def parse(self, response):
html = response.body.decode()
# [email protected]
email = re.compile(r"([A-Z0-9_][email protected][A-Z0-9]+.[A-Z]{2,4})", re.I)
emailList = email.findall(html)
mydict = []
for e in emailList:
item = items.TianyaItem()
item["email"] = e
yield mydict #得到生成器对象,每循环一次,返回一个item
分类:
技术要点:
相关文章: 查看全部
scrapy分页抓取网页(2021-09-051Scrapy(绿线向)2Scrapy的运作流程)
2021-09-051 Scrapy架构图(绿线为数据流)
2 Scrapy操作流程
代码写好了,程序开始运行了……
发动机:嗨!蜘蛛,你在对付哪个网站?蜘蛛:老板要我处理。引擎:给我第一个需要处理的 URL。Spider:在这里,第一个 URL 是。发动机:嗨!调度员,我有一个请求,请求您帮我排序并加入队列。调度程序:好的,正在处理您等一下。发动机:嗨!调度员,给我你处理的请求。调度器:给你,这是我处理的请求引擎:嗨!下载器,请帮我按照老板下载中间件的设置下载这个请求下载器:OK!给你,这是下载的东西。(如果失败:对不起,这个请求下载失败。然后引擎告诉调度器这个请求下载失败,你记录一下,我们稍后下载) 引擎:你好!蜘蛛,这是一个下载的东西,已经按照老大的下载中间件进行了处理,大家可以自行处理!这里,响应默认由def parse()处理) Spider:(处理数据后需要跟进的URL),Hi!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!(处理数据后需要跟进的URL),您好!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!(处理数据后需要跟进的URL),您好!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。Pipes ``调度器:好的,现在就做!
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
3 Scrapy安装介绍
1、安装wheel pip3 install wheel
2、安装lxml pip3 install lxml-4.2.1-cp36-cp36m-win_amd64.whl
3、安装pyopenssl (已安装就不需要安装)
4、安装Twisted pip3 install Twisted-18.4.0-cp36-cp36m-win_amd64.whl
5、安装pywin32 pip3 install pypiwin32
6、安装scrapy pip3 install scrapy
或者pip3 install Scrapy-1.5.0-py2.py3-none-any.whl
Scrapy框架官网:
Scrapy中文维护网站:
Windows安装方式Ubuntu需要9.10以上的安装方式
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明已经安装成功
具体Scrapy安装过程参考:每个平台都有安装方法
4 制作一个Scrapy爬虫一共需要4个步骤:
新建爬虫项目
scrapy startproject mySpider
进入该目录 cd mySpider
scrapy genspider stack http://stackoverflow.com/ #创建一个爬虫stack 指定爬取路径
明确目标(编写items.py):明确你要捕获的目标(目标信息以类和字段的形式实现)
制作爬虫(spiders/xxspider.py):制作爬虫并开始爬取网页(实现主要逻辑的地方并返回item)
存储内容(pipelines.py):设计管道存储爬取内容(接受item,一般重写几个常用方法(open_spider、process_item、close_spider)
启动爬虫项目
命令开始:scrapy crawl spidername(爬虫名称)
文件开始
from scrapy import cmdline
# 方式一:注意execute的参数类型为一个列表
cmdline.execute('scrapy crawl spidername'.split())
# 方式二:注意execute的参数类型为一个列表
cmdline.execute(['scrapy', 'crawl', 'spidername'])
5 入门案例一.新建项目(scrapy startproject)
scrapy startproject mySpider
下面简单介绍一下各个主文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的 Python 模块,将从中引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ : 蜘蛛代码存放的目录
二、明确目标 (mySpider/items.py)
我们打算抓取:网站 中的邮箱。
打开mySpider目录下的items.pyItem,定义一个结构化的数据字段,用来保存爬取的数据,类似于dict,但是提供了一些额外的保护来减少错误。可以通过创建一个scrapy.Item类并定义一个scrapy.Field类型的类属性来定义一个Item(可以理解为一种类似于ORM的映射关系)。接下来,创建一个 TianyaItem 类并构建项目模型。
import scrapy
class TianyaItem(scrapy.Item):
email = scrapy.Field() #只定义爬取email字段
三、制作蜘蛛 (spiders/itcastSpider.py)
爬虫功能分为两步:
1. 爬取数据
scrapy genspider mytianya "bbs.tianya.cn" #指定爬虫文件名 爬取的域名
import scrapy
import re
from tianya import items
class MytianyaSpider(scrapy.Spider):
name = 'mytianya'
allowed_domains = ['bbs.tianya.cn']
start_urls = ['http://bbs.tianya.cn/post-140-393977-1.shtml']
#主要的逻辑模块
def parse(self, response):
pass
其实我们也可以自己创建itcast.py,自己写上面的代码,但是使用命令可以省去写固定代码的麻烦
要创建 Spider,您必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
修改 parse() 方法
def parse(self, response):
html = response.body.decode()
# [email protected]
email = re.compile(r"([A-Z0-9_][email protected][A-Z0-9]+\.[A-Z]{2,4})", re.I)
emailList = email.findall(html)
mydict = []
for e in emailList:
item = items.TianyaItem()
item["email"] = e
# mydict[e] = "http://bbs.tianya.cn/post-140-393977-1.shtml"
mydict.append(item)
return mydict
然后运行看看,在mySpider目录下执行:
scrapy crawl mytianya
2.scrapy保存信息有四种最简单的保存方式,-o输出指定格式的文件,命令如下:
scrapy crawl mytianya -o mytianya.json
scrapy crawl mytianya -o mytianya.csv
scrapy crawl mytianya -o mytianya.xml
什么产量在这里:
def parse(self, response):
html = response.body.decode()
# [email protected]
email = re.compile(r"([A-Z0-9_][email protected][A-Z0-9]+.[A-Z]{2,4})", re.I)
emailList = email.findall(html)
mydict = []
for e in emailList:
item = items.TianyaItem()
item["email"] = e
yield mydict #得到生成器对象,每循环一次,返回一个item
分类:
技术要点:
相关文章:
scrapy分页抓取网页(一下中代码实现是用C#语言来实现的抓取问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-01-28 01:14
我相信所有个人网站站长都有抓取别人数据的经历。目前抓取别人的网站数据只有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时间没看懂怎么用,后来决定自己写好了,现在基本可以搞定了网站 半天(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下代码都是正确的实现,我目前正在使用。本文中的代码实现是用C#语言实现的。我认为其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
publicstringGetResponseString(stringurl)
{
string_StrResponse="";
HttpWebRequest_WebRequest=(HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent="MOZILLA/4.0(兼容;MSIE7.0;WINDOWSNT5.2;.NETCLR1.1.4322;.NETCLR2.0.50727;.NETCLR3.0.04506.648;.NETCLR3.5.21022;.NETCLR3.@ >0.4506.2152;.NETCLR3.5.30729)";
_WebRequest.Method="GET";
WebResponse_WebResponse=_WebRequest.GetResponse();
StreamReader_ResponseStream=newStreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse=_ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
return_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页码的时候的分页,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实也不是很难,因为经过所有,有一个地方可以得到页码的规则。
我们知道提交http请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、__VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以可以通过第一种方法获得。然后同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,每爬完一页后,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页post数据使用
参考代码如下:
for(inti=0;i 查看全部
scrapy分页抓取网页(一下中代码实现是用C#语言来实现的抓取问题)
我相信所有个人网站站长都有抓取别人数据的经历。目前抓取别人的网站数据只有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时间没看懂怎么用,后来决定自己写好了,现在基本可以搞定了网站 半天(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下代码都是正确的实现,我目前正在使用。本文中的代码实现是用C#语言实现的。我认为其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
publicstringGetResponseString(stringurl)
{
string_StrResponse="";
HttpWebRequest_WebRequest=(HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent="MOZILLA/4.0(兼容;MSIE7.0;WINDOWSNT5.2;.NETCLR1.1.4322;.NETCLR2.0.50727;.NETCLR3.0.04506.648;.NETCLR3.5.21022;.NETCLR3.@ >0.4506.2152;.NETCLR3.5.30729)";
_WebRequest.Method="GET";
WebResponse_WebResponse=_WebRequest.GetResponse();
StreamReader_ResponseStream=newStreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse=_ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
return_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页码的时候的分页,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实也不是很难,因为经过所有,有一个地方可以得到页码的规则。
我们知道提交http请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、__VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以可以通过第一种方法获得。然后同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,每爬完一页后,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页post数据使用
参考代码如下:
for(inti=0;i
scrapy分页抓取网页( 如何判断是否是蜘蛛对式网页的链接结构的原因? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-26 00:09
如何判断是否是蜘蛛对式网页的链接结构的原因?
)
搜索引擎蜘蛛系统的目标是发现和抓取互联网上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。对网站的体验施加压力,也就是说蜘蛛不会爬取所有网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取能力。高效的。只有这样,蜘蛛才能尽量满足大部分网站,这也是我们需要做好网站的链接结构的原因。接下来在马海翔博客平台分享搜索引擎蜘蛛对翻页网页的爬取机制。
1、为什么需要这种爬取机制?
目前大部分网站都采用翻页的形式,有序的分发网站资源。当添加新的文章时,旧资源被推回翻页系列。对于蜘蛛来说,这种特定类型的索引页是一个有效的爬取渠道,但是蜘蛛爬取的频率和网站文章更新频率不一样,文章链接很可能是被封锁。推入翻页栏,这样蜘蛛就不可能每天从第一个翻页栏爬到第80页,再把文章和文章爬到数据库里对比,这太浪费了,无法搜索。引擎蜘蛛的时间也浪费了你网站的收录时间,
2、如何判断是否是有序翻页?
判断文章是否按发布时间排序是这类页面的必要条件,下面会讲到。那么如何判断资源是否按发布时间排序呢?在某些页面中,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集,判断时间集是从大到小排序还是从小到大排序。如果是,那么说明网页中的资源是按发布时间排列的,反之亦然。即使不写发布时间,蜘蛛也可以根据文章本身的实际发布时间来做出判断。
3、抓取机制的原理
对于这种翻页页面,蜘蛛主要记录每次爬取网页时发现的文章链接,然后将本次发现的文章链接与历史中发现的链接进行比较。如果相交,则说明爬取已经找到所有新的文章,可以停止后面的翻页栏的爬取;否则,说明爬取没有找到所有新的文章,需要继续爬到下一页甚至后面几页才能找到所有新的文章。
以马海翔的博客为例。比如网站翻页目录新增了29篇文章,也就是说最后一篇最新文章是第30篇,蜘蛛一次抓取了10篇。文章文章链接,所以蜘蛛第一次抓取了10篇文章,和上次没有相交,所以继续抓取,第二次抓取了10篇文章,也就是一共抓取了10篇文章20篇文章被抓取,或者与上次没有交集,然后继续爬取。这次抓到第30条,也就是和上一条有交集,说明蜘蛛从上一次到这次抓到网站29条都更新了文章。
马海翔博客评论:
目前的百度蜘蛛会对网页的类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并根据以实际情况为准,但蜘蛛毕竟不能做到100%的识别准确率,所以马海翔建议站长尽量不要使用JS,更不要在翻页的时候使用FALSH,同时更新文章频繁,配合蜘蛛爬行,可以大大提高蜘蛛识别的准确率,从而提高蜘蛛在你网站中的爬行效率。
再次提醒大家,本文只是对蜘蛛抓取机制的概述。这并不意味着蜘蛛有抓取机制。在实际情况下,很多机制是同时进行的。
● 抓取网站的搜索引擎蜘蛛越多越好 ● 百度升级HTTPS认证工具:先抓取并显示HTTPS链接 ● 百度知道广告过滤机制和推广方法和技巧 ● 基于结构化数据的丰富片段研究● 丰富网页摘要的三种主要标记格式示例分析
查看全部
scrapy分页抓取网页(
如何判断是否是蜘蛛对式网页的链接结构的原因?
)
搜索引擎蜘蛛系统的目标是发现和抓取互联网上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。对网站的体验施加压力,也就是说蜘蛛不会爬取所有网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取能力。高效的。只有这样,蜘蛛才能尽量满足大部分网站,这也是我们需要做好网站的链接结构的原因。接下来在马海翔博客平台分享搜索引擎蜘蛛对翻页网页的爬取机制。
1、为什么需要这种爬取机制?
目前大部分网站都采用翻页的形式,有序的分发网站资源。当添加新的文章时,旧资源被推回翻页系列。对于蜘蛛来说,这种特定类型的索引页是一个有效的爬取渠道,但是蜘蛛爬取的频率和网站文章更新频率不一样,文章链接很可能是被封锁。推入翻页栏,这样蜘蛛就不可能每天从第一个翻页栏爬到第80页,再把文章和文章爬到数据库里对比,这太浪费了,无法搜索。引擎蜘蛛的时间也浪费了你网站的收录时间,
2、如何判断是否是有序翻页?
判断文章是否按发布时间排序是这类页面的必要条件,下面会讲到。那么如何判断资源是否按发布时间排序呢?在某些页面中,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集,判断时间集是从大到小排序还是从小到大排序。如果是,那么说明网页中的资源是按发布时间排列的,反之亦然。即使不写发布时间,蜘蛛也可以根据文章本身的实际发布时间来做出判断。
3、抓取机制的原理
对于这种翻页页面,蜘蛛主要记录每次爬取网页时发现的文章链接,然后将本次发现的文章链接与历史中发现的链接进行比较。如果相交,则说明爬取已经找到所有新的文章,可以停止后面的翻页栏的爬取;否则,说明爬取没有找到所有新的文章,需要继续爬到下一页甚至后面几页才能找到所有新的文章。
以马海翔的博客为例。比如网站翻页目录新增了29篇文章,也就是说最后一篇最新文章是第30篇,蜘蛛一次抓取了10篇。文章文章链接,所以蜘蛛第一次抓取了10篇文章,和上次没有相交,所以继续抓取,第二次抓取了10篇文章,也就是一共抓取了10篇文章20篇文章被抓取,或者与上次没有交集,然后继续爬取。这次抓到第30条,也就是和上一条有交集,说明蜘蛛从上一次到这次抓到网站29条都更新了文章。
马海翔博客评论:
目前的百度蜘蛛会对网页的类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并根据以实际情况为准,但蜘蛛毕竟不能做到100%的识别准确率,所以马海翔建议站长尽量不要使用JS,更不要在翻页的时候使用FALSH,同时更新文章频繁,配合蜘蛛爬行,可以大大提高蜘蛛识别的准确率,从而提高蜘蛛在你网站中的爬行效率。
再次提醒大家,本文只是对蜘蛛抓取机制的概述。这并不意味着蜘蛛有抓取机制。在实际情况下,很多机制是同时进行的。
● 抓取网站的搜索引擎蜘蛛越多越好 ● 百度升级HTTPS认证工具:先抓取并显示HTTPS链接 ● 百度知道广告过滤机制和推广方法和技巧 ● 基于结构化数据的丰富片段研究● 丰富网页摘要的三种主要标记格式示例分析
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-24 09:01
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注才是本质(4小时,完成Scrapy爬虫必备知识点讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学
导师答题(拒绝助教,讲师当天答题)
课程适合人群
具备Py基础语法和面向对象开发思想,其他语言开发者,浪子,想一夜暴富的人
建筑与环境建设
文章目录Scrapy介绍
Scrapy组件介绍
点安装scrapy
Scrapy 简介
一个快速、高级的屏幕抓取和网页抓取 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求定制。Scrapy架构图:
Scrapy组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
Scheduler:用于接受引擎发送的Request请求,将其推入队列,当引擎再次请求时返回。
Downloader(下载器):用于引擎发送的Request请求对应的网页内容,将获取到的Responses返回给Spider。
Item Pipeline:负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
点安装scrapy
通过 pip show scrapy 检查是否安装正常。如果已安装,则显示安装信息,否则不显示任何信息。
通过pip install scrapy安装爬虫框架(大概率会抛出以下异常)
根据异常,它缺少:错误:需要 MICROSOFT VISUAL C++ 9.0 (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载一个缺少的窗口组件,在视频的学习资料中提供
第一个爬虫项目
文章目录
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject douban创建项目
创建一个Spider解析器根据以上提示:cd douban,然后在项目中执行:scrapy genspider example 就可以创建一个Spider对象
细心的朋友会发现,douban_spider默认会存放在douban.spider目录下。当你用pycharm IDE打开时,你会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的spider文件,也就是你爬取的py文件
items.py:相当于一个容器,字典更像是middlewares.py:定义Downloader
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 pipelines.py:定义Item
Pipeline的实现实现了数据的清洗、存储、校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法简介
文章目录
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。事实上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章目录
豆瓣电影页面分析
首页下载实现
前5名电影数据如下
豆瓣电影页面分析为您讲解了如何在 XML 文档中查找信息。具体来说,你已经学会了如何获取元素、内容和属性,你也知道了如何通过标签的属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5名电影数据如下
项目模型封装数据
文章目录创建Item模型层
封装爬取的数据
yield的语法介绍
在创建Item模型层之前,我们可以获取第一页的数据,但是只能在控制台打印。Scrapy 中还有一个 Item 模块。这个类就是模型层,主要完成对值数据的封装,然后写入数据库。
将爬取的数据封装起来,将爬取的数据存储在豆瓣项目对象中,然后交给item_list,最后返回到Item_list
yield的语法介绍
带有yield的函数是一个生成器,它不同于普通的函数,生成一个生成器看起来像一个函数调用,但在调用next()之前不会执行任何函数代码(在for循环中,next()是自动调用。)) 开始执行。执行流程虽然还是按照函数的流程执行,但是每执行一次yield语句都会中断,并返回一个迭代值,在下次执行时从yield的下一条语句继续执行. 好像一个函数在正常执行的时候被yield打断了几次,每次打断都会通过yield返回当前的迭代值
产量和自动翻页
文章目录
产量优势
良率优化返回数据
产量优势
收益的好处是显而易见的。将函数重写为生成器使您能够进行迭代。相比于使用类实例保存状态来计算下一个next()的值,不仅代码简洁,而且执行过程也非常清晰。
在 Scrapy 爬虫框架中,yield 有一个很自然的使用场景,因为我们不知道爬虫每次获取的数据的大小。如果每次都一起返回,数据量会非常大。这时候如果使用yield来优化,代码会非常简洁高效
良率优化返回数据 查看全部
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注才是本质(4小时,完成Scrapy爬虫必备知识点讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学
导师答题(拒绝助教,讲师当天答题)
课程适合人群
具备Py基础语法和面向对象开发思想,其他语言开发者,浪子,想一夜暴富的人
建筑与环境建设
文章目录Scrapy介绍
Scrapy组件介绍
点安装scrapy
Scrapy 简介
一个快速、高级的屏幕抓取和网页抓取 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求定制。Scrapy架构图:
Scrapy组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
Scheduler:用于接受引擎发送的Request请求,将其推入队列,当引擎再次请求时返回。
Downloader(下载器):用于引擎发送的Request请求对应的网页内容,将获取到的Responses返回给Spider。
Item Pipeline:负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
点安装scrapy
通过 pip show scrapy 检查是否安装正常。如果已安装,则显示安装信息,否则不显示任何信息。
通过pip install scrapy安装爬虫框架(大概率会抛出以下异常)
根据异常,它缺少:错误:需要 MICROSOFT VISUAL C++ 9.0 (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载一个缺少的窗口组件,在视频的学习资料中提供
第一个爬虫项目
文章目录
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject douban创建项目
创建一个Spider解析器根据以上提示:cd douban,然后在项目中执行:scrapy genspider example 就可以创建一个Spider对象
细心的朋友会发现,douban_spider默认会存放在douban.spider目录下。当你用pycharm IDE打开时,你会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的spider文件,也就是你爬取的py文件
items.py:相当于一个容器,字典更像是middlewares.py:定义Downloader
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 pipelines.py:定义Item
Pipeline的实现实现了数据的清洗、存储、校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法简介
文章目录
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。事实上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章目录
豆瓣电影页面分析
首页下载实现
前5名电影数据如下
豆瓣电影页面分析为您讲解了如何在 XML 文档中查找信息。具体来说,你已经学会了如何获取元素、内容和属性,你也知道了如何通过标签的属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5名电影数据如下
项目模型封装数据
文章目录创建Item模型层
封装爬取的数据
yield的语法介绍
在创建Item模型层之前,我们可以获取第一页的数据,但是只能在控制台打印。Scrapy 中还有一个 Item 模块。这个类就是模型层,主要完成对值数据的封装,然后写入数据库。
将爬取的数据封装起来,将爬取的数据存储在豆瓣项目对象中,然后交给item_list,最后返回到Item_list
yield的语法介绍
带有yield的函数是一个生成器,它不同于普通的函数,生成一个生成器看起来像一个函数调用,但在调用next()之前不会执行任何函数代码(在for循环中,next()是自动调用。)) 开始执行。执行流程虽然还是按照函数的流程执行,但是每执行一次yield语句都会中断,并返回一个迭代值,在下次执行时从yield的下一条语句继续执行. 好像一个函数在正常执行的时候被yield打断了几次,每次打断都会通过yield返回当前的迭代值
产量和自动翻页
文章目录
产量优势
良率优化返回数据
产量优势
收益的好处是显而易见的。将函数重写为生成器使您能够进行迭代。相比于使用类实例保存状态来计算下一个next()的值,不仅代码简洁,而且执行过程也非常清晰。
在 Scrapy 爬虫框架中,yield 有一个很自然的使用场景,因为我们不知道爬虫每次获取的数据的大小。如果每次都一起返回,数据量会非常大。这时候如果使用yield来优化,代码会非常简洁高效
良率优化返回数据
scrapy分页抓取网页(手机上不再过多叙述直接重点干货,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-21 13:21
如果手机显示的验证码有误,请分享到QQ或其他地方,在电脑上查看!!!
python可以做的事情有很多,这里就不过多描述了,重点说干货。
在开始使用爬行动物之后,我们有两条路可以走。
一是继续深入学习,以及一些设计模式的知识,加强Python相关知识,自己造轮子,继续给自己的爬虫添加分布式、多线程等功能扩展。另一种方法是学习一些优秀的框架。先熟悉这些框架,保证自己能应付一些基本的爬虫任务,也就是所谓的温饱问题解决,然后再深入学习其源码等知识进一步加强。
就个人而言,前一种方法实际上是自己造轮子。前人其实已经有了一些比较好的框架,可以直接使用,但是为了能够更深入的学习,对爬虫有更全面的了解,还是自己动手吧。后一种方法是直接使用前人写过的比较优秀的框架,好好利用。首先,确保你能完成你想要完成的任务,然后深入研究它们。对于第一个,你越是探索自己,你对爬行动物的了解就会越透彻。二是用别人的,方便你,但你可能没有心情去深入研究框架,你的思维可能会受到束缚。
. . .
接触过几个爬虫框架,其中Scrapy和PySpider比较好用。个人觉得pyspider更容易上手,更容易操作,因为它增加了WEB界面,写爬虫快,集成了phantomjs,可以用来抓取js渲染的页面。Scrapy 定制化程度高,比 PySpider 低。它适合学习和研究。有很多相关的知识要学,但是非常适合自学分布式和多线程。
从爬虫的基本需求来看:
1.抢
py 的 urllib 不一定是要使用的,而是要学习的,如果你还没用过的话。
更好的替代方案是第三方、更用户友好和成熟的库,例如 requests。如果pyer不理解各种库,学习是没用的。
抓取基本上是拉回网页。
再深入一点,你会发现你要面对不同的网页需求,比如认证、不同的文件格式、编码处理、各种奇怪的URL合规处理、重复爬取问题、cookie跟随问题、多线程和多进程爬取、多节点爬取、爬取调度、资源压缩等一系列问题。
所以第一步就是把网页拉回来,慢慢的你会发现各种问题需要优化。
2.存储
捕获的数据一般会用一定的策略保存,而不是直接分析。个人认为更好的架构应该是分析和捕获分离,更加松散。如果每个环节都有问题,它可以隔离另一个环节可能出现的问题。检查或更新和发布。
那么,如何保存文件系统、SQLorNOSQL数据库、内存数据库是本环节的重点。
你可以选择保存文件系统启动,然后用一定的规则命名。
3.分析
对网页进行文本分析,是提取链接还是提取文本,总之看需求,但必须要做的是分析链接。
您可以使用最快和最优化的方法,例如正则表达式。
然后将分析结果应用到其他链接:)
4.显示
如果一堆事情都做完了,根本没有输出,怎么体现价值。
所以找到好的展示元件,展示肌肉也是关键。
如果你想写爬虫是为了做一个站,或者是分析某个东西的数据,别忘了这个链接,这样可以更好的把结果展示给别人。
前言
其实写这篇MongoDB体验的初衷和我当年整理的js脑图比较一致,而且确实,就我个人而言,还是希望在每个时间段输出一些整理好的东西,分享给有需要的人他们。
这一系列的题目和我现在写的yc(一个花哨的节点开发平台)是一样的。架子很大,但我会继续写。希望有兴趣的同学多多关注。
介绍
本文介绍了一些涉及文档、集合和数据库的基本概念,以及一些基本操作。
那么MongoDB有什么用呢?事实上,关键词 仍然是 NoSQL
安装
本文只介绍mac上的安装,可戳:官方文档,本文不做过多描述,只是提醒需要手动创建数据目录,其功能后面会介绍。
基本概念
文档
我们先来看一个我们熟悉的js中的对象:
shell
{"name" : "yaochun" , "company" : "wandoujia" , "group" : "w3cplus" , "job" : "fe"}
其实这也是MongoDB中的核心概念:document
它是一个键值对,但有一些独特的特点:
一、这个键值对是有序的:
shell
{ "name" : "yaochun" , "company" : "wandoujia" }
{ "company" : "wandoujia" , "name" : "yaochun" }
所以上面两个文件是不一样的。
二、key是字符串,不能有\0, . 和 $ 有特殊含义,_ 的开头是保留的
三、该值可以是双引号字符串或其他几种数据类型。
四、类型和大小写敏感:
shell
{ "name" : "yaochun" , "company" : "wandoujia" , "age" : 50 }
{ "company" : "wandoujia" , "name" : "yaochun" , "age" : "50" }
所以上面两个文件也不同。
五、文档中的key不能重复,否则视为非法。
采集
集合实际上是一组文档。
命名集合也有规则:
不能为空字符串
也不能有 \0 字符
不能以某些系统集合的保留前缀开头,例如 system.
也不能收录 $
该集合中是否有任何数学子集?您可以使用 。来划分子集。
数据库
数据库实际上是由多个集合组成的。数据库相对独立,存储在不同的文件中。
命名数据库也有规则:
不能为空字符串
也不能有\0、$类似这些字符
小写
最多 64 个字节
因为数据库名最终会变成文件系统文件,所以命名有一定的限制。
保留数据库名词:
行政
当地的
配置
数据类型简介
其实你发现没有,文档的结构和我们常用的 JSON 差不多。MongoDB中有哪些数据类型?
空值
shell
{ "freetime" : null }
日期
shell
{ "date" : new Date() }
大批
例子:
shell
{ "keywords" : [ "yaochun" , "wandoujia" , "w3cplus" ] }
嵌入文档
例子:
shell
{ "info" : {"yaochun" , "company" : "wandoujia" , "group" : "w3cplus" } }
实际上,该文档收录一个文档
常规的
例子:
shell
{ "name" : /yaochun/i }
代码
例子:
shell
{ "code" : function() {/*..*/} }
其他基本比较如:布尔、字符串等这里不介绍。
基本操作
一般包括:插入、更新、删除和查询
插入
例子:
shell
//welcome to join us: http://www.wandoujia.com/joind ... nsert({ "name" : "yourname" })
其实从上面的例子中就可以很直观的看出插入:
也使用插入
insert方法中传入的其实是一个文档
没有主键吗?默认情况下,MongoDB 插入会在文档中添加一个 _id。
删除
示例 1:
shell
db.book.mongodb.remove()
这意味着我已经删除了图书集合的子集合mongodb中的所有文档,但是子集合mongodb本身还在,索引也会保留。
示例 2:
shell db.book.mongodb.remove({ "part" : "primary" })
在这里,将一个文档传递给删除操作以进行查询和过滤。只有符合条件的文件才会被删除。
这意味着我删除了书籍集合的 mongodb 子集合中的所有主要部分。
查询
在初级教程中,我们简单地看一下基本的查询方法,在中级教程中,我们将全面学习。
示例 1:
shell //欢迎加入我们:db.wandoujia.jobs.find()
示例 2:
shell //欢迎加入我们:db.wandoujia.jobs.find({ "category", "fe" , "level" : 2 })
从上面的例子可以看出,最基本的查询可以使用find找到
而find可以传递参数,比如一个或几个文档来指定查询条件。
多维查询
寻找
前面我们简单介绍了find的第一个参数,其实就是一个文档,作为过滤条件
示例 1:
shell
//welcome to join us: http://www.wandoujia.com/joind ... .find()
示例 2:
shell
//welcome to join us: http://www.wandoujia.com/joind ... .find({"category", "fe" , "level" : 2})
所以实际上在我们的日期查询中,对于返回的查询结果,有一些无用的键值是需要指定或者过滤掉的。如何处理?
示例 1:
shell
db.wandoujia.jobs.find({} , {"category" : 1, "base" : 1})
示例 2:
shell
db.wandoujia.jobs.find({} , {"level" : 0})
在上面的段落中,我们实际上看到:
find 可以指定第二个参数
只能返回第二个参数document中指定的字段,其中对应的值为1
消除查询结果中某个键的转换,并将对应的值设置为0。
这样做的好处是非常明显的:
减少数据的大小
保存传输的数据量
客户端还可以减少解码文档的时间和内存消耗
查询条件
其实为了达到精准定位,我们会指定一些查询条件,比如:
=
!=
那么MongoDB中使用的这些比较运算符是什么?
$lt
$lte
$gt
$gte
$ne
我们直接看一个例子:
shell
//比如我们找工作有的人只看2级到3级的
db.wandoujia.jobs.find({"level" , {"$gte" : 2, "$lte" : 3})
这里我们传递一个嵌入的文档来查找,内部文档的key是$gte和$lte
示例 2:
shell
//比如我们找工作有的人不看帝都的
db.wandoujia.jobs.find({"base" , {"$ne" : "beijing"})
这里,$ne 表示不等于
所以粗略的规则:
$lt、$lte、$gt、$gte 和 $ne 都以 $ 开头,这也验证了为什么我们在命名别人时不建议使用 $。
$lt、$lte、$gt、$gte、$ne 一般在内部文档中。
管理 MongoDB
其实读了很多之后,一定更愿意自己动手,实践这些操作。
启动
通常,它作为网络服务器运行,客户端可以连接到该服务器。
命令行
shell
./mongod
我这里没有指定任何参数,其实是从
shell
./mongod -h
控制台会打印一堆帮助命令,还有很多,这里只提几个:
可以指定数据目录。默认为 /data/db(在根目录下)。每个 mongod 实例都需要一个单独的数据目录。并且当mongod启动时,会在数据中创建一个mongod.lock文件,防止其他mongod进程使用这个数据目录。
有兴趣的可以自己打开对应的数据目录查看。
--logpath 和 --logappend
可以指定日志输出的路径,最好配合logappend。在大多数情况下,我们仍然希望保留原创日志并添加它而不是覆盖它。
-f可以指定某个配置文件来加载命令
编写配置文件有什么要求吗?
shell# config by yaochun 2013-08-07 pm 07:10logpath = mongodb.log
当然,还有很多其他有用的设置,比如:
等等,如果你需要的话,你可以直接进入 -h 中的说明。
MongoDB客户端
服务器启动后,我们需要一个客户端来操作,那么这个客户端是什么?
看图,我们在命令行输入如下命令:
shell
./mongo
是MongoDB的shell,也是js的shell,可以完成与MongoDB实例的交互
注:其实如果只是想体验一下js shell的改造,可以输入:
shell
./mongo --nodb
这样,它就不会连接到数据库。
默认会自动连接服务器的test数据库,并将这个数据库连接赋值给全局db变量
如图所示:
当然,如果你想要帮助文档来查看那里有哪些命令,你可以输入:
shell
help
如图所示:
常用:
show dbs
返回所有当前数据库名称
如图所示:
show collections
返回当前数据库中的所有集合(注意:它收录 system.* 本系统的集合)
use wandoujia
比如我现在默认在test数据库,现在想切换到wandoujia数据库
如图:db.fe
这样就可以访问上面输入的玩豆家数据库的fe集合了。
外壳执行插入
shell
use wandoujia
db.fe.insert({ "name" : "yourname" })
这样一来,玩豆家数据库的fe集合中就多了一份文档。
shell 执行查询
shell
db.fe.find()
将返回一个收录刚刚插入的文档的集合。
外壳执行更新
shell
db.fe.update( { "name" : "yourname" }, { "name" : "yourname", "recommender" : "yaochun" })
update至少接受两个参数,第一个是资格对应的文档,第二个是新文档。
经过测试,你会发现这个更新其实是第二个直接覆盖第一个的新文档。当然也可以先定义一个变量,这样更新的时候可以修改那个变量,然后传给update。你不需要这样写。
外壳执行删除
shell
db.fe.remove({ "recommender" : "yaochun" })
强大的聚合工具
其实简单来说就是:统计一些集合中的文档个数
数数
返回集合中的文档数
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count()
例如,我知道 fe-team 的人数如何?
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count({ "category" : "fe" })
以上内容是我最近使用MongoDB的一些经验。如果有不准确的地方,希望大家多多指点。如果您有相关经验,请在下面的评论中与我们分享。
知乎爬取用户信息的思路
首先,我们应该找到一个帐户。这个账号的人数和关注人数都比较多。就是下图中金字塔顶端的那个人。被关注人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,爬取整个知乎的所有信息@> 以这种递归方式。帐户信息。整个过程用下面两张图表示:


爬虫分析流程
我们在这里寻找的账户地址是:
我们抓到的大V账号的主要信息是:

接下来,我们需要获取关注列表和该账号的关注列表

这里我们需要通过抓包分析来分析这些列表的信息和用户的个人信息 查看全部
scrapy分页抓取网页(手机上不再过多叙述直接重点干货,你知道吗?)
如果手机显示的验证码有误,请分享到QQ或其他地方,在电脑上查看!!!
python可以做的事情有很多,这里就不过多描述了,重点说干货。
在开始使用爬行动物之后,我们有两条路可以走。
一是继续深入学习,以及一些设计模式的知识,加强Python相关知识,自己造轮子,继续给自己的爬虫添加分布式、多线程等功能扩展。另一种方法是学习一些优秀的框架。先熟悉这些框架,保证自己能应付一些基本的爬虫任务,也就是所谓的温饱问题解决,然后再深入学习其源码等知识进一步加强。
就个人而言,前一种方法实际上是自己造轮子。前人其实已经有了一些比较好的框架,可以直接使用,但是为了能够更深入的学习,对爬虫有更全面的了解,还是自己动手吧。后一种方法是直接使用前人写过的比较优秀的框架,好好利用。首先,确保你能完成你想要完成的任务,然后深入研究它们。对于第一个,你越是探索自己,你对爬行动物的了解就会越透彻。二是用别人的,方便你,但你可能没有心情去深入研究框架,你的思维可能会受到束缚。
. . .
接触过几个爬虫框架,其中Scrapy和PySpider比较好用。个人觉得pyspider更容易上手,更容易操作,因为它增加了WEB界面,写爬虫快,集成了phantomjs,可以用来抓取js渲染的页面。Scrapy 定制化程度高,比 PySpider 低。它适合学习和研究。有很多相关的知识要学,但是非常适合自学分布式和多线程。
从爬虫的基本需求来看:
1.抢
py 的 urllib 不一定是要使用的,而是要学习的,如果你还没用过的话。
更好的替代方案是第三方、更用户友好和成熟的库,例如 requests。如果pyer不理解各种库,学习是没用的。
抓取基本上是拉回网页。
再深入一点,你会发现你要面对不同的网页需求,比如认证、不同的文件格式、编码处理、各种奇怪的URL合规处理、重复爬取问题、cookie跟随问题、多线程和多进程爬取、多节点爬取、爬取调度、资源压缩等一系列问题。
所以第一步就是把网页拉回来,慢慢的你会发现各种问题需要优化。
2.存储
捕获的数据一般会用一定的策略保存,而不是直接分析。个人认为更好的架构应该是分析和捕获分离,更加松散。如果每个环节都有问题,它可以隔离另一个环节可能出现的问题。检查或更新和发布。
那么,如何保存文件系统、SQLorNOSQL数据库、内存数据库是本环节的重点。
你可以选择保存文件系统启动,然后用一定的规则命名。
3.分析
对网页进行文本分析,是提取链接还是提取文本,总之看需求,但必须要做的是分析链接。
您可以使用最快和最优化的方法,例如正则表达式。
然后将分析结果应用到其他链接:)
4.显示
如果一堆事情都做完了,根本没有输出,怎么体现价值。
所以找到好的展示元件,展示肌肉也是关键。
如果你想写爬虫是为了做一个站,或者是分析某个东西的数据,别忘了这个链接,这样可以更好的把结果展示给别人。
前言
其实写这篇MongoDB体验的初衷和我当年整理的js脑图比较一致,而且确实,就我个人而言,还是希望在每个时间段输出一些整理好的东西,分享给有需要的人他们。
这一系列的题目和我现在写的yc(一个花哨的节点开发平台)是一样的。架子很大,但我会继续写。希望有兴趣的同学多多关注。
介绍
本文介绍了一些涉及文档、集合和数据库的基本概念,以及一些基本操作。
那么MongoDB有什么用呢?事实上,关键词 仍然是 NoSQL
安装
本文只介绍mac上的安装,可戳:官方文档,本文不做过多描述,只是提醒需要手动创建数据目录,其功能后面会介绍。
基本概念
文档
我们先来看一个我们熟悉的js中的对象:
shell
{"name" : "yaochun" , "company" : "wandoujia" , "group" : "w3cplus" , "job" : "fe"}
其实这也是MongoDB中的核心概念:document
它是一个键值对,但有一些独特的特点:
一、这个键值对是有序的:
shell
{ "name" : "yaochun" , "company" : "wandoujia" }
{ "company" : "wandoujia" , "name" : "yaochun" }
所以上面两个文件是不一样的。
二、key是字符串,不能有\0, . 和 $ 有特殊含义,_ 的开头是保留的
三、该值可以是双引号字符串或其他几种数据类型。
四、类型和大小写敏感:
shell
{ "name" : "yaochun" , "company" : "wandoujia" , "age" : 50 }
{ "company" : "wandoujia" , "name" : "yaochun" , "age" : "50" }
所以上面两个文件也不同。
五、文档中的key不能重复,否则视为非法。
采集
集合实际上是一组文档。
命名集合也有规则:
不能为空字符串
也不能有 \0 字符
不能以某些系统集合的保留前缀开头,例如 system.
也不能收录 $
该集合中是否有任何数学子集?您可以使用 。来划分子集。
数据库
数据库实际上是由多个集合组成的。数据库相对独立,存储在不同的文件中。
命名数据库也有规则:
不能为空字符串
也不能有\0、$类似这些字符
小写
最多 64 个字节
因为数据库名最终会变成文件系统文件,所以命名有一定的限制。
保留数据库名词:
行政
当地的
配置
数据类型简介
其实你发现没有,文档的结构和我们常用的 JSON 差不多。MongoDB中有哪些数据类型?
空值
shell
{ "freetime" : null }
日期
shell
{ "date" : new Date() }
大批
例子:
shell
{ "keywords" : [ "yaochun" , "wandoujia" , "w3cplus" ] }
嵌入文档
例子:
shell
{ "info" : {"yaochun" , "company" : "wandoujia" , "group" : "w3cplus" } }
实际上,该文档收录一个文档
常规的
例子:
shell
{ "name" : /yaochun/i }
代码
例子:
shell
{ "code" : function() {/*..*/} }
其他基本比较如:布尔、字符串等这里不介绍。
基本操作
一般包括:插入、更新、删除和查询
插入
例子:
shell
//welcome to join us: http://www.wandoujia.com/joind ... nsert({ "name" : "yourname" })
其实从上面的例子中就可以很直观的看出插入:
也使用插入
insert方法中传入的其实是一个文档
没有主键吗?默认情况下,MongoDB 插入会在文档中添加一个 _id。
删除
示例 1:
shell
db.book.mongodb.remove()
这意味着我已经删除了图书集合的子集合mongodb中的所有文档,但是子集合mongodb本身还在,索引也会保留。
示例 2:
shell db.book.mongodb.remove({ "part" : "primary" })
在这里,将一个文档传递给删除操作以进行查询和过滤。只有符合条件的文件才会被删除。
这意味着我删除了书籍集合的 mongodb 子集合中的所有主要部分。
查询
在初级教程中,我们简单地看一下基本的查询方法,在中级教程中,我们将全面学习。
示例 1:
shell //欢迎加入我们:db.wandoujia.jobs.find()
示例 2:
shell //欢迎加入我们:db.wandoujia.jobs.find({ "category", "fe" , "level" : 2 })
从上面的例子可以看出,最基本的查询可以使用find找到
而find可以传递参数,比如一个或几个文档来指定查询条件。
多维查询
寻找
前面我们简单介绍了find的第一个参数,其实就是一个文档,作为过滤条件
示例 1:
shell
//welcome to join us: http://www.wandoujia.com/joind ... .find()
示例 2:
shell
//welcome to join us: http://www.wandoujia.com/joind ... .find({"category", "fe" , "level" : 2})
所以实际上在我们的日期查询中,对于返回的查询结果,有一些无用的键值是需要指定或者过滤掉的。如何处理?
示例 1:
shell
db.wandoujia.jobs.find({} , {"category" : 1, "base" : 1})
示例 2:
shell
db.wandoujia.jobs.find({} , {"level" : 0})
在上面的段落中,我们实际上看到:
find 可以指定第二个参数
只能返回第二个参数document中指定的字段,其中对应的值为1
消除查询结果中某个键的转换,并将对应的值设置为0。
这样做的好处是非常明显的:
减少数据的大小
保存传输的数据量
客户端还可以减少解码文档的时间和内存消耗
查询条件
其实为了达到精准定位,我们会指定一些查询条件,比如:
=
!=
那么MongoDB中使用的这些比较运算符是什么?
$lt
$lte
$gt
$gte
$ne
我们直接看一个例子:
shell
//比如我们找工作有的人只看2级到3级的
db.wandoujia.jobs.find({"level" , {"$gte" : 2, "$lte" : 3})
这里我们传递一个嵌入的文档来查找,内部文档的key是$gte和$lte
示例 2:
shell
//比如我们找工作有的人不看帝都的
db.wandoujia.jobs.find({"base" , {"$ne" : "beijing"})
这里,$ne 表示不等于
所以粗略的规则:
$lt、$lte、$gt、$gte 和 $ne 都以 $ 开头,这也验证了为什么我们在命名别人时不建议使用 $。
$lt、$lte、$gt、$gte、$ne 一般在内部文档中。
管理 MongoDB
其实读了很多之后,一定更愿意自己动手,实践这些操作。
启动
通常,它作为网络服务器运行,客户端可以连接到该服务器。
命令行
shell
./mongod
我这里没有指定任何参数,其实是从
shell
./mongod -h
控制台会打印一堆帮助命令,还有很多,这里只提几个:
可以指定数据目录。默认为 /data/db(在根目录下)。每个 mongod 实例都需要一个单独的数据目录。并且当mongod启动时,会在数据中创建一个mongod.lock文件,防止其他mongod进程使用这个数据目录。
有兴趣的可以自己打开对应的数据目录查看。
--logpath 和 --logappend
可以指定日志输出的路径,最好配合logappend。在大多数情况下,我们仍然希望保留原创日志并添加它而不是覆盖它。
-f可以指定某个配置文件来加载命令
编写配置文件有什么要求吗?
shell# config by yaochun 2013-08-07 pm 07:10logpath = mongodb.log
当然,还有很多其他有用的设置,比如:
等等,如果你需要的话,你可以直接进入 -h 中的说明。
MongoDB客户端
服务器启动后,我们需要一个客户端来操作,那么这个客户端是什么?
看图,我们在命令行输入如下命令:
shell
./mongo
是MongoDB的shell,也是js的shell,可以完成与MongoDB实例的交互
注:其实如果只是想体验一下js shell的改造,可以输入:
shell
./mongo --nodb
这样,它就不会连接到数据库。
默认会自动连接服务器的test数据库,并将这个数据库连接赋值给全局db变量
如图所示:
当然,如果你想要帮助文档来查看那里有哪些命令,你可以输入:
shell
help
如图所示:
常用:
show dbs
返回所有当前数据库名称
如图所示:
show collections
返回当前数据库中的所有集合(注意:它收录 system.* 本系统的集合)
use wandoujia
比如我现在默认在test数据库,现在想切换到wandoujia数据库
如图:db.fe
这样就可以访问上面输入的玩豆家数据库的fe集合了。
外壳执行插入
shell
use wandoujia
db.fe.insert({ "name" : "yourname" })
这样一来,玩豆家数据库的fe集合中就多了一份文档。
shell 执行查询
shell
db.fe.find()
将返回一个收录刚刚插入的文档的集合。
外壳执行更新
shell
db.fe.update( { "name" : "yourname" }, { "name" : "yourname", "recommender" : "yaochun" })
update至少接受两个参数,第一个是资格对应的文档,第二个是新文档。
经过测试,你会发现这个更新其实是第二个直接覆盖第一个的新文档。当然也可以先定义一个变量,这样更新的时候可以修改那个变量,然后传给update。你不需要这样写。
外壳执行删除
shell
db.fe.remove({ "recommender" : "yaochun" })
强大的聚合工具
其实简单来说就是:统计一些集合中的文档个数
数数
返回集合中的文档数
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count()
例如,我知道 fe-team 的人数如何?
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count({ "category" : "fe" })
以上内容是我最近使用MongoDB的一些经验。如果有不准确的地方,希望大家多多指点。如果您有相关经验,请在下面的评论中与我们分享。
知乎爬取用户信息的思路
首先,我们应该找到一个帐户。这个账号的人数和关注人数都比较多。就是下图中金字塔顶端的那个人。被关注人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,爬取整个知乎的所有信息@> 以这种递归方式。帐户信息。整个过程用下面两张图表示:


爬虫分析流程
我们在这里寻找的账户地址是:
我们抓到的大V账号的主要信息是:

接下来,我们需要获取关注列表和该账号的关注列表

这里我们需要通过抓包分析来分析这些列表的信息和用户的个人信息
scrapy分页抓取网页(scrapy分页抓取网页,可以使用scrapy.encode(session)对其编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-21 10:04
scrapy分页抓取网页,批量抓取页面中的所有文字与图片scrapy能自动计算和字符串匹配,也可以用递归函数计算,scrapy有整站查询和静态页查询,自己手写查询有点麻烦,scrapy同样也支持split函数分页,scrapy后端支持mongodb、mysql和postgresql,支持2种配置,配置有不同模式,有autoencode=optional和autoencode=false两种配置,这里只讲配置autoencode=optional:autoencode=true说明这条数据进来是未编码,默认是utf-8格式,将原数据编码后即可编码后数据是string格式,可以使用scrapy.encode(session)对其编码。
具体autoencode=true和autoencode=false对web服务器有何影响,可以看这篇博客文章request的encoding是code=''的状态这样,会创建codeheader值为code的异步请求,如果codeheader是autoencode=false则是这个请求是编码后的请求。
scrapy自带转码scrapy是支持转码(transform)这个命令的,同时,在异步请求中,scrapy也是支持做转码的,跟一般的web服务器都是支持的转码nameerror:nameonunknownlength>10000,所以我们使用mongodb或者postgresql都是支持的mongodb支持utf-8~,postgresql也支持utf-8,scrapy在整站查询情况下,可以支持将txt格式的转换为string,那么如果网页中存在多个utf-8格式的字符串怎么办?这里我们也可以使用scrapy接收utf-8字符串,然后转换成string后,再请求另外一个utf-8字符串,再转换到我们的字符串中,如果需要转码为英文,下面给一个例子scrapy可以将一个网页的内容转换为utf-8编码的字符串,比如我们来新闻页面查询:::::::::::这里的是utf-8编码的unicode格式的文本,直接将utf-8转码后,又可以读取文本,mongodb同样支持转码,在encode时,写了这么一句可以配置转码格式body:mongocontent:这样,这个循环循环次数就能够自己调整,scrapy自带了编码与转码的函数autoencode=optional:autoenc。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页,可以使用scrapy.encode(session)对其编码)
scrapy分页抓取网页,批量抓取页面中的所有文字与图片scrapy能自动计算和字符串匹配,也可以用递归函数计算,scrapy有整站查询和静态页查询,自己手写查询有点麻烦,scrapy同样也支持split函数分页,scrapy后端支持mongodb、mysql和postgresql,支持2种配置,配置有不同模式,有autoencode=optional和autoencode=false两种配置,这里只讲配置autoencode=optional:autoencode=true说明这条数据进来是未编码,默认是utf-8格式,将原数据编码后即可编码后数据是string格式,可以使用scrapy.encode(session)对其编码。
具体autoencode=true和autoencode=false对web服务器有何影响,可以看这篇博客文章request的encoding是code=''的状态这样,会创建codeheader值为code的异步请求,如果codeheader是autoencode=false则是这个请求是编码后的请求。
scrapy自带转码scrapy是支持转码(transform)这个命令的,同时,在异步请求中,scrapy也是支持做转码的,跟一般的web服务器都是支持的转码nameerror:nameonunknownlength>10000,所以我们使用mongodb或者postgresql都是支持的mongodb支持utf-8~,postgresql也支持utf-8,scrapy在整站查询情况下,可以支持将txt格式的转换为string,那么如果网页中存在多个utf-8格式的字符串怎么办?这里我们也可以使用scrapy接收utf-8字符串,然后转换成string后,再请求另外一个utf-8字符串,再转换到我们的字符串中,如果需要转码为英文,下面给一个例子scrapy可以将一个网页的内容转换为utf-8编码的字符串,比如我们来新闻页面查询:::::::::::这里的是utf-8编码的unicode格式的文本,直接将utf-8转码后,又可以读取文本,mongodb同样支持转码,在encode时,写了这么一句可以配置转码格式body:mongocontent:这样,这个循环循环次数就能够自己调整,scrapy自带了编码与转码的函数autoencode=optional:autoenc。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-21 08:17
我相信所有个人 网站 网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面时分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页的请求,都应该先获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式耗费了我不少心血,后来采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人 网站 网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面时分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页的请求,都应该先获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式耗费了我不少心血,后来采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵
scrapy分页抓取网页(网络爬虫(Webcrawler)用python编写的Scrapy框架介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-21 01:13
)
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取这些网站的内容。Scrapy是一个非常强大的爬虫框架,它是用python编写的。我们来看看什么是Scrapy?
一、必备知识
所需知识为:linux系统+Python语言+Scrapy框架+XPath(XML路径语言)+一些辅助工具(浏览器开发工具和XPat 本文来源于gaodai#ma#com @@code~&code network ^h helper plugin )。
我们的爬虫是使用Python语言的Scrapy爬虫框架开发的,运行在linux上,所以我们需要精通Python语言、Scrapy框架以及linux操作系统的基础知识。
我们需要使用 XPath 从目标 HTML 页面中提取我们想要的内容,包括中文文本段落和“下一页”链接等。
浏览器的开发者工具是编写爬虫的主要辅助工具。使用该工具,您可以分析页面链接的规则,在HTML页面中定位您要提取的元素,然后提取它们的XPath表达式用于爬虫代码,还可以查看Referer、Cookie等信息页面请求标头。如果爬取目标是动态的网站,该工具还可以分析其背后的JavaScript请求。
XPath helper插件是一个chrome插件,也可以安装基于chrome核心的浏览器。XPath 助手可用于调试 XPath 表达式。
二、环境建设
要安装 Scrapy,您可以使用 pip 命令: pip install Scrapy
Scrapy相关的依赖有很多,所以在安装过程中可能会遇到以下问题:
ImportError:没有名为 w3lib.http 的模块
解决方案:pip install w3lib
ImportError:没有名为 twisted 的模块
解决方法:pip install twisted
ImportError:没有名为 lxml.HTML 的模块
解决方法:pip install lxml
错误:libxml/xmlversion.h:没有这样的文件或目录
解决方法:apt-get install libxml2-dev libxslt-dev
apt-get 安装 Python-lxml
ImportError:没有名为 cssselect 的模块
解决方案:pip install cssselect
ImportError:没有名为 OpenSSL 的模块
解决方案:pip install pyOpenSSL
建议:
使用简单的方法:使用 anaconda 安装。
三、Scrapy 框架
1. Scrapy 简介
Scrapy 是一个用 Python 编写的著名爬虫框架。Scrapy 可以非常方便的进行网页抓取,也可以根据自己的需求轻松定制。
Scrapy的整体架构大致如下:
2.Scrapy 组件
Scrapy主要包括以下组件:
引擎(报废)
用于处理整个系统的数据流和触发事务(框架核心)。
调度器
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。它可以被认为是 URL(被爬取的网站或链接)的优先级队列,它决定了下一个请求。抓取的 URL 是什么,同时删除重复的 URL。
下载器
用于下载网页内容并将网页内容返回给蜘蛛(Scrapy 下载器建立在 twisted 之上,一种高效的异步模型)。
蜘蛛
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体(Item)。用户还可以从中提取链接,让 Scrapy 继续爬取下一页。
项目管道
CodeNet() 提供的所有资源均来自互联网。如侵犯您的著作权或其他权益,请说明详细原因并提供著作权或权益证明,然后发送至邮箱,我们会尽快看到邮件处理你,或者直接联系。此网站 由 BY-NC-SA 协议授权
转载请注明原文链接:什么是强大的爬虫框架Scrapy?
报酬
[做代码]
查看全部
scrapy分页抓取网页(网络爬虫(Webcrawler)用python编写的Scrapy框架介绍
)
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取这些网站的内容。Scrapy是一个非常强大的爬虫框架,它是用python编写的。我们来看看什么是Scrapy?
一、必备知识
所需知识为:linux系统+Python语言+Scrapy框架+XPath(XML路径语言)+一些辅助工具(浏览器开发工具和XPat 本文来源于gaodai#ma#com @@code~&code network ^h helper plugin )。
我们的爬虫是使用Python语言的Scrapy爬虫框架开发的,运行在linux上,所以我们需要精通Python语言、Scrapy框架以及linux操作系统的基础知识。
我们需要使用 XPath 从目标 HTML 页面中提取我们想要的内容,包括中文文本段落和“下一页”链接等。
浏览器的开发者工具是编写爬虫的主要辅助工具。使用该工具,您可以分析页面链接的规则,在HTML页面中定位您要提取的元素,然后提取它们的XPath表达式用于爬虫代码,还可以查看Referer、Cookie等信息页面请求标头。如果爬取目标是动态的网站,该工具还可以分析其背后的JavaScript请求。
XPath helper插件是一个chrome插件,也可以安装基于chrome核心的浏览器。XPath 助手可用于调试 XPath 表达式。
二、环境建设
要安装 Scrapy,您可以使用 pip 命令: pip install Scrapy
Scrapy相关的依赖有很多,所以在安装过程中可能会遇到以下问题:
ImportError:没有名为 w3lib.http 的模块
解决方案:pip install w3lib
ImportError:没有名为 twisted 的模块
解决方法:pip install twisted
ImportError:没有名为 lxml.HTML 的模块
解决方法:pip install lxml
错误:libxml/xmlversion.h:没有这样的文件或目录
解决方法:apt-get install libxml2-dev libxslt-dev
apt-get 安装 Python-lxml
ImportError:没有名为 cssselect 的模块
解决方案:pip install cssselect
ImportError:没有名为 OpenSSL 的模块
解决方案:pip install pyOpenSSL
建议:
使用简单的方法:使用 anaconda 安装。
三、Scrapy 框架
1. Scrapy 简介
Scrapy 是一个用 Python 编写的著名爬虫框架。Scrapy 可以非常方便的进行网页抓取,也可以根据自己的需求轻松定制。
Scrapy的整体架构大致如下:
2.Scrapy 组件
Scrapy主要包括以下组件:
引擎(报废)
用于处理整个系统的数据流和触发事务(框架核心)。
调度器
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。它可以被认为是 URL(被爬取的网站或链接)的优先级队列,它决定了下一个请求。抓取的 URL 是什么,同时删除重复的 URL。
下载器
用于下载网页内容并将网页内容返回给蜘蛛(Scrapy 下载器建立在 twisted 之上,一种高效的异步模型)。
蜘蛛
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体(Item)。用户还可以从中提取链接,让 Scrapy 继续爬取下一页。
项目管道
CodeNet() 提供的所有资源均来自互联网。如侵犯您的著作权或其他权益,请说明详细原因并提供著作权或权益证明,然后发送至邮箱,我们会尽快看到邮件处理你,或者直接联系。此网站 由 BY-NC-SA 协议授权
转载请注明原文链接:什么是强大的爬虫框架Scrapy?
报酬
[做代码]
scrapy分页抓取网页(Python爬虫进阶教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-21 00:15
前言:
学Python很久了,之前用正则表达式和BeautifulSoup写过很多爬虫。Scrapy是爬虫进阶部分的必知。在我对 Scrapy 有一定的熟悉之后,我也想通过这个教程。帮助一些想学习Scrapy的人,毕竟爬虫还是很有趣的。
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。它也是一个高级屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。最新的官方版本是scrapy1.5。
Scratch 是爬行的意思。这个 Python 爬虫框架叫做 Scrapy,大概意思是一样的。我们称之为:小刮。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下:
各个组件的作用 Scrapy Engine 引擎负责控制系统中所有组件中数据的流动,并在相应的动作发生时触发事件。有关详细信息,请参阅下面的数据流部分。
这个组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
调度器(Scheduler) 调度器接受来自引擎的请求,并将它们排入队列以便在引擎稍后请求它们时提供给引擎。
页面中获取的初始爬取URL和后续待爬取的URL将被放入调度器等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重,也可以通过设置来实现,比如post请求的URL)
下载器(Downloader) 下载器负责获取页面数据并提供给引擎,然后提供给蜘蛛。SpidersSpider 是 Scrapy 用户编写的一个类,用于分析响应并提取项目(即获取的项目)或 URL 以进行额外的跟进。每个蜘蛛负责处理一个特定的(或一些)网站。Item Pipeline Item Pipeline 负责处理spider提取的item。典型的过程是清理、验证和持久性(例如,访问数据库)。
当爬虫需要解析的页面需要的数据存储在Item中后,会被发送到项目流水线(Pipeline),数据会按照几个特定的顺序进行处理,最后存储到本地文件或在数据库中。
下载器中间件(Downloader middlewares) 下载器中间件是引擎和下载器之间的特定钩子,负责处理下载器传递给引擎的响应。它提供了一种通过插入自定义代码来扩展 Scrapy 功能的简单机制。
通过设置下载器中间件,爬虫可以自动替换user-agent、IP等功能。
蜘蛛中间件(Spider middlewares) 蜘蛛中间件是引擎和蜘蛛之间的特定钩子(specific hook),处理蜘蛛输入(响应)和输出(项目和请求)。它提供了一种通过插入自定义代码来扩展 Scrapy 功能的简单机制。数据流引擎打开一个 网站(打开一个域),找到处理 网站 的蜘蛛,并向蜘蛛请求要抓取的第一个 URL。引擎从 Spider 获取第一个要抓取的 URL,并在 Scheduler 中使用 Request 对其进行调度。引擎向调度程序询问下一个要抓取的 URL。调度器将下一个要爬取的URL返回给引擎,引擎通过下载中间件(请求方向)将该URL转发给下载器(Downloader)。页面下载后,下载器为页面生成一个Response,并通过下载中间件(响应方向)发送给引擎。引擎从下载器接收到Response,通过Spider中间件(输入方向)发送给Spider进行处理。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。
工具: 语言:python 3.6IDE:Pycharm 浏览器:Chrome 71.0 爬虫框架:Scrapy 1.5 安装教程:
1.直接使用Pycharm安装,省去不必要的麻烦,点击File->Settings For Project。然后点击+号并搜索scrapy进行安装。
2.安装完成后进入我们创建的目录,在该目录下输入cmd命令。
scrapy startproject douban
3.我们用pycharm打开项目看看:
下面简单介绍一下各个文件的作用:
好了,我们已经完成了对目录的了解。在我们开始之前,我会给你一个小技巧。Scrapy 默认无法在 IDE 中调试。我们在根目录下新建一个py文件,名为:entrypoint.py;在里面写下以下内容:
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'douban'])
现在整个目录如下所示:
构建项目后:
首先是在 items.py 文件中定义一些字段,这些字段是用来临时存储你需要保存的数据。以后可以方便的将数据保存到其他地方,比如数据库或者本地文本。
第二件事在蜘蛛文件夹中编写自己的爬虫
第三件事将自己的数据存储在 pipelines.py
还有一件事,没必要做,settings.py文件不用编辑,需要的时候才编辑。
2.明确目标(Item)物品
爬取的主要目标是从非结构化数据源中提取结构化数据,例如网页。Scrapy spider 可以使用 python 的 dict 返回提取的数据。dict虽然使用起来非常方便和熟悉,但缺乏结构,容易打错字段名或返回不一致的数据,尤其是在多爬虫的大规模情况下。在项目中。
为了定义通用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬网数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
许多 Scrapy 组件使用 Item 提供的额外信息:exporter 根据 Item 声明的字段导出数据,序列化可以通过 Item 字段的元数据定义,trackref 跟踪 Item 实例以帮助查找内存泄漏(请参阅 Debugging with trackref 内存泄漏)等。
Item 对象是一个简单的容器,用于保存爬网数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
在 Scrapy 中,项目是用于加载抓取的内容的容器,提供了一些额外的防止错误的保护。
通常,可以使用 scrapy.item.Item 类和使用 scrapy.item.Field 对象定义的属性来创建项目。
接下来,我们开始构建项目模型(model)。
首先,我们想要的是:
使用简单的类定义语法和 Field 对象来声明项目。我们打开scrapyspider目录下的items.py文件,编写如下代码声明Item:
这完成了我们的第一步!这么容易吗?ヾ(´▽')ノ; 写蜘蛛(也就是我们用来提取数据的爬虫):
3.做一只蜘蛛(蜘蛛)
制作爬虫一般分为两步:先爬,再拉。
也就是首先你要获取整个页面的所有内容,然后取出对你有用的部分。
要创建一个 Spider,你必须继承 scrapy.spider.BaseSpider 并定义三个强制属性:
创建douban_spider.py文件,保存在douban\spiders目录下。并导入我们需要的模块
编写主模块:
然后运行它,
你会看到 403 错误,因为我们在爬取的时候没有添加 header:
让我们假设,将 USER_AGENT 添加到 settings.py:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.0.1084.54 Safari/536.5'
再次运行它以查看正确的结果。
4.提取网页信息
我们使用 xpath 语法来提取我们需要的信息。不熟悉xpath语法的可以在W3School网站中学习,可以快速上手,难度不高。首先,我们在chrome浏览器中进入豆瓣电影TOP250页面,按F12打开开发者工具。
我们可以看到每部电影的信息都在一个....打开后,我们可以找到我们想要的所有信息。蜘蛛中的初始请求是通过调用 start_requests() 获得的。start_requests() 读取 start_urls 中的 URL 并生成 Request 和 parse 作为回调函数。,看一下代码:
运行爬虫
在项目文件夹中打开 cmd 并运行以下命令:
scrapy爬取douban_top250 -o douban.csv
注意这里的douban_movie_top250是我们刚才写的爬虫的名字,-o douban.csv是scrapy提供的一个快捷方式,可以将item输出为csv格式。py 设置一些编码格式:
FEED_EXPORT_ENCODING = 'GBK'
另外,在python包下exporters.py中的CsvItemExporter类的io.TextIOWrapper中添加参数newline='',取消csv的自动换行
再次运行上述命令,我们想要的信息全部下载到douban.scv文件夹中:
通过以上工作,我们已经完成了第一页的页面信息爬取,接下来我们需要爬取所有页面的信息。
自动翻页
实现自动翻页一般有两种方式:
在当前页中查找下一页的地址;根据 URL 的变化规律,自己构建所有的页面地址。
一般情况下我们使用第一种方式,第二种方式适用于页面的下一页地址是JS加载的情况。
观察该页面的网页源代码后可以得到,直接拼接URL就可以得到下一页的链接。
再次运行结果打开douban.csv。有没有发现所有的视频信息都拿到了,250个不超过1个,而且不超过1个,哇。
最后,使用 Excel 的过滤功能,您可以过滤任何符合您要求的视频。(PS:Excel可以直接打开csv进行操作)
结尾
自从写了这篇Scrapy爬虫框架教程后,在调试过程中遇到了一些小问题,通过谷歌和Stack Overflow基本完美解决。通过阅读官方的scrapy文档,我也加深了对scrapy的理解。如果有什么不对的地方,请纠正我。有一系列的听证会,有艺术专长,每个人都互相学习。
我的CSDN同名博客文章:豆瓣爬虫
源码地址:jhyscode/scrapy_doubanTop250 查看全部
scrapy分页抓取网页(Python爬虫进阶教程)
前言:
学Python很久了,之前用正则表达式和BeautifulSoup写过很多爬虫。Scrapy是爬虫进阶部分的必知。在我对 Scrapy 有一定的熟悉之后,我也想通过这个教程。帮助一些想学习Scrapy的人,毕竟爬虫还是很有趣的。
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。它也是一个高级屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。最新的官方版本是scrapy1.5。
Scratch 是爬行的意思。这个 Python 爬虫框架叫做 Scrapy,大概意思是一样的。我们称之为:小刮。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下:
各个组件的作用 Scrapy Engine 引擎负责控制系统中所有组件中数据的流动,并在相应的动作发生时触发事件。有关详细信息,请参阅下面的数据流部分。
这个组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
调度器(Scheduler) 调度器接受来自引擎的请求,并将它们排入队列以便在引擎稍后请求它们时提供给引擎。
页面中获取的初始爬取URL和后续待爬取的URL将被放入调度器等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重,也可以通过设置来实现,比如post请求的URL)
下载器(Downloader) 下载器负责获取页面数据并提供给引擎,然后提供给蜘蛛。SpidersSpider 是 Scrapy 用户编写的一个类,用于分析响应并提取项目(即获取的项目)或 URL 以进行额外的跟进。每个蜘蛛负责处理一个特定的(或一些)网站。Item Pipeline Item Pipeline 负责处理spider提取的item。典型的过程是清理、验证和持久性(例如,访问数据库)。
当爬虫需要解析的页面需要的数据存储在Item中后,会被发送到项目流水线(Pipeline),数据会按照几个特定的顺序进行处理,最后存储到本地文件或在数据库中。
下载器中间件(Downloader middlewares) 下载器中间件是引擎和下载器之间的特定钩子,负责处理下载器传递给引擎的响应。它提供了一种通过插入自定义代码来扩展 Scrapy 功能的简单机制。
通过设置下载器中间件,爬虫可以自动替换user-agent、IP等功能。
蜘蛛中间件(Spider middlewares) 蜘蛛中间件是引擎和蜘蛛之间的特定钩子(specific hook),处理蜘蛛输入(响应)和输出(项目和请求)。它提供了一种通过插入自定义代码来扩展 Scrapy 功能的简单机制。数据流引擎打开一个 网站(打开一个域),找到处理 网站 的蜘蛛,并向蜘蛛请求要抓取的第一个 URL。引擎从 Spider 获取第一个要抓取的 URL,并在 Scheduler 中使用 Request 对其进行调度。引擎向调度程序询问下一个要抓取的 URL。调度器将下一个要爬取的URL返回给引擎,引擎通过下载中间件(请求方向)将该URL转发给下载器(Downloader)。页面下载后,下载器为页面生成一个Response,并通过下载中间件(响应方向)发送给引擎。引擎从下载器接收到Response,通过Spider中间件(输入方向)发送给Spider进行处理。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。Spider 处理 Response 并将爬取的 Item 和(后续)新的 Request 返回给引擎。引擎将爬取的Item(由Spider返回)发送到Item Pipeline,并将Request(由Spider返回)发送给调度程序。重复(从第 2 步开始),直到调度程序中没有更多请求并且引擎关闭 网站。
工具: 语言:python 3.6IDE:Pycharm 浏览器:Chrome 71.0 爬虫框架:Scrapy 1.5 安装教程:
1.直接使用Pycharm安装,省去不必要的麻烦,点击File->Settings For Project。然后点击+号并搜索scrapy进行安装。
2.安装完成后进入我们创建的目录,在该目录下输入cmd命令。
scrapy startproject douban
3.我们用pycharm打开项目看看:
下面简单介绍一下各个文件的作用:
好了,我们已经完成了对目录的了解。在我们开始之前,我会给你一个小技巧。Scrapy 默认无法在 IDE 中调试。我们在根目录下新建一个py文件,名为:entrypoint.py;在里面写下以下内容:
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'douban'])
现在整个目录如下所示:
构建项目后:
首先是在 items.py 文件中定义一些字段,这些字段是用来临时存储你需要保存的数据。以后可以方便的将数据保存到其他地方,比如数据库或者本地文本。
第二件事在蜘蛛文件夹中编写自己的爬虫
第三件事将自己的数据存储在 pipelines.py
还有一件事,没必要做,settings.py文件不用编辑,需要的时候才编辑。
2.明确目标(Item)物品
爬取的主要目标是从非结构化数据源中提取结构化数据,例如网页。Scrapy spider 可以使用 python 的 dict 返回提取的数据。dict虽然使用起来非常方便和熟悉,但缺乏结构,容易打错字段名或返回不一致的数据,尤其是在多爬虫的大规模情况下。在项目中。
为了定义通用的输出数据,Scrapy 提供了 Item 类。Item 对象是一个简单的容器,用于保存爬网数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
许多 Scrapy 组件使用 Item 提供的额外信息:exporter 根据 Item 声明的字段导出数据,序列化可以通过 Item 字段的元数据定义,trackref 跟踪 Item 实例以帮助查找内存泄漏(请参阅 Debugging with trackref 内存泄漏)等。
Item 对象是一个简单的容器,用于保存爬网数据。它提供了类似字典的 API 和用于声明可用字段的简单语法。
在 Scrapy 中,项目是用于加载抓取的内容的容器,提供了一些额外的防止错误的保护。
通常,可以使用 scrapy.item.Item 类和使用 scrapy.item.Field 对象定义的属性来创建项目。
接下来,我们开始构建项目模型(model)。
首先,我们想要的是:
使用简单的类定义语法和 Field 对象来声明项目。我们打开scrapyspider目录下的items.py文件,编写如下代码声明Item:
这完成了我们的第一步!这么容易吗?ヾ(´▽')ノ; 写蜘蛛(也就是我们用来提取数据的爬虫):
3.做一只蜘蛛(蜘蛛)
制作爬虫一般分为两步:先爬,再拉。
也就是首先你要获取整个页面的所有内容,然后取出对你有用的部分。
要创建一个 Spider,你必须继承 scrapy.spider.BaseSpider 并定义三个强制属性:
创建douban_spider.py文件,保存在douban\spiders目录下。并导入我们需要的模块
编写主模块:
然后运行它,
你会看到 403 错误,因为我们在爬取的时候没有添加 header:
让我们假设,将 USER_AGENT 添加到 settings.py:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, 像 Gecko) Chrome/19.0.1084.54 Safari/536.5'
再次运行它以查看正确的结果。
4.提取网页信息
我们使用 xpath 语法来提取我们需要的信息。不熟悉xpath语法的可以在W3School网站中学习,可以快速上手,难度不高。首先,我们在chrome浏览器中进入豆瓣电影TOP250页面,按F12打开开发者工具。
我们可以看到每部电影的信息都在一个....打开后,我们可以找到我们想要的所有信息。蜘蛛中的初始请求是通过调用 start_requests() 获得的。start_requests() 读取 start_urls 中的 URL 并生成 Request 和 parse 作为回调函数。,看一下代码:
运行爬虫
在项目文件夹中打开 cmd 并运行以下命令:
scrapy爬取douban_top250 -o douban.csv
注意这里的douban_movie_top250是我们刚才写的爬虫的名字,-o douban.csv是scrapy提供的一个快捷方式,可以将item输出为csv格式。py 设置一些编码格式:
FEED_EXPORT_ENCODING = 'GBK'
另外,在python包下exporters.py中的CsvItemExporter类的io.TextIOWrapper中添加参数newline='',取消csv的自动换行
再次运行上述命令,我们想要的信息全部下载到douban.scv文件夹中:
通过以上工作,我们已经完成了第一页的页面信息爬取,接下来我们需要爬取所有页面的信息。
自动翻页
实现自动翻页一般有两种方式:
在当前页中查找下一页的地址;根据 URL 的变化规律,自己构建所有的页面地址。
一般情况下我们使用第一种方式,第二种方式适用于页面的下一页地址是JS加载的情况。
观察该页面的网页源代码后可以得到,直接拼接URL就可以得到下一页的链接。
再次运行结果打开douban.csv。有没有发现所有的视频信息都拿到了,250个不超过1个,而且不超过1个,哇。
最后,使用 Excel 的过滤功能,您可以过滤任何符合您要求的视频。(PS:Excel可以直接打开csv进行操作)
结尾
自从写了这篇Scrapy爬虫框架教程后,在调试过程中遇到了一些小问题,通过谷歌和Stack Overflow基本完美解决。通过阅读官方的scrapy文档,我也加深了对scrapy的理解。如果有什么不对的地方,请纠正我。有一系列的听证会,有艺术专长,每个人都互相学习。
我的CSDN同名博客文章:豆瓣爬虫
源码地址:jhyscode/scrapy_doubanTop250
scrapy分页抓取网页(1.安装WebScraper有条件的同学,可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-01-21 00:13
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但是我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
1. 安装 Web Scraper
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以到这个网站(/)下载crx文件离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
直译为网站map,有了这个地图爬虫就可以跟着它获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个使用最频繁、覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,我们才能递归地爬取网站的全部数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机爬行
爬取数据最经典的模型是列表、分页和明细。接下来我也会围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它对导航分页器提供了特殊的支持,并增加了分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的站点地图配置如下,可以直接导入我的配置进行研究(配置文件下载:/iidSSugkch)
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应sitemap的配置如下,可以直接导入使用(下载配置文件:/iidSSugkch)
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习(下载配置文件:/iidSSugkch)
4. 次要页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用(配置文件下载:/iidSSugkch)
5. 结尾
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。 查看全部
scrapy分页抓取网页(1.安装WebScraper有条件的同学,可以直接在F12调试工具里使用)
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但是我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
1. 安装 Web Scraper
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以到这个网站(/)下载crx文件离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
直译为网站map,有了这个地图爬虫就可以跟着它获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个使用最频繁、覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,我们才能递归地爬取网站的全部数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机爬行
爬取数据最经典的模型是列表、分页和明细。接下来我也会围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它对导航分页器提供了特殊的支持,并增加了分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的站点地图配置如下,可以直接导入我的配置进行研究(配置文件下载:/iidSSugkch)
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应sitemap的配置如下,可以直接导入使用(下载配置文件:/iidSSugkch)
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习(下载配置文件:/iidSSugkch)
4. 次要页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用(配置文件下载:/iidSSugkch)
5. 结尾
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。
scrapy分页抓取网页( 2.正式开始使用scrapystartproject命令创建新的python文件夹文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-21 00:11
2.正式开始使用scrapystartproject命令创建新的python文件夹文件)
pip install scrapy
2. 在终端使用scrapy startproject命令新建一个scrapy文件夹
scrapy startproject myspider
在项目文件夹中,scrapy 已经自带了几个 python 文件,包括:
由此可见,scrapy将请求的功能分开,封装到不同的文件中,自动化程度更高。
3. 现在正式开始使用scrapy。首先,在Item中命名你要抓取的内容。
class MySpiderItem(scrapy.Item):
title = scrapy.Field() # sample code
contents = scrapy.Field()
pass
4. 接下来,在 spiders 文件夹中创建一个新的 python 文件,例如 myspider,py。从这里开始写爬虫。
给爬虫起名字:
class MySpider(scrapy.Spider):
name = "myspider"
然后,如果它从一个或多个 URL 开始往下爬,写 start_urls(这是一个 list[])。
class MySpider(scrapy.Spider):
name = "myspider"
start_urls = ["url"]
假设我一共要爬5个页面,每个页面有几个链接,最终的目标是爬取5个页面上每个链接的内容。
我想避免手动编写列表,并使用 for 循环来形成起始 URL(就像请求一样)。所以,
page = 5
class MySpider(scrapy.Spider):
name = "myspider"
bash_url = url
def start_requests(self):
for i in (1, page+1):
url = self.base_url + str(i)
yield Request(url, self.parse)
这里最后一行的yield会继续抛出Request()对当前url的解析内容(也就是response),然后使用回调函数传入parse方法。
接下来我们看一下parse方法。然后写下来。
def parse(self, response):
atags = BeautifulSoup(response.text, 'lxml').find_all('a', {'class':'name'})
urls = [l['href'] for l in atags]
for url in urls:
yield Request(url, callback=self.get_content)
现在,parse 首先使用 BeautifulSoup 来分析传入的网页内容。首先提取页面上所有符合条件的标签。然后使用此语句提取标签内的 url。
urls = [l['href'] for l in atags]
现在我们已经在一个页面上提取了所有符合条件的 url。对于每个 url,我们继续使用 yield 抛出 Request() 来解析这些新的 url,然后将其传递给 next 方法 get_content() 以捕获新页面的内容。
下面是 get_content() 方法的示例。
def get_content(self, response):
soup = BeautifulSoup(response.text, 'lxml')
item = ScrapyTeaItem()
item['title'] = soup.find('p', {'class':'family'}).get_text()
item['contents'] = soup.find('p', {'class':'name'}).get_text()
return item
看到这里,myspider.py 终于接触到了 items.py。至此,爬虫已经爬取了五个网页上所有链接页面的内容,并将爬取的内容输入到item中。
5. 现在我们可以打开管道来存储项目的内容。但是,要启用管道功能,我们必须首先打开 settings.py 文件并删除 ITEM_PIPELINES = { 之前的#注释。
回到管道文件。将爬取的网页内容写入本地txt文件的代码如下。
class MySpiderPipeline(object):
def process_item(self, item, spider):
with open('myspider.txt', 'a', encoding='utf-8') as f: # "a" for append mode
f.write('\n'+ item['title'] + '\n') # one line
f.writelines(item['contents']) # multiple lines
return item
这样,保存网页内容的代码也写好了。
6. 如果要控制爬取速度,在设置中设置:
7. 现在开始运行我们编写的爬虫。在终端输入scrapy crawl myspider运行,创建的txt文档会保存在本项目的根目录下。
至此,scrapy爬虫已经编写成功!
刮云
scrapy还提供了云爬虫服务,免费用户一次可以运行一个爬虫。
注册/scrapy-cloud
2. 点击 CREATE PROJECT 并输入项目名称
3. 进入Deploy Management页面,命令行使用终端将本地项目传输到云端
4. 在本地项目文件夹的终端中(使用终端中的 cd 和 cd... 命令前进或后退文件夹),运行代码。
pip install shub
安装完成后,运行
shub login
提示API KEY,在云端页面输入API key
然后使用如下语句将本地项目推送到云端
shub deploy #加上云端页面上的id号码
如果使用BeautifulSoup,会报bs4包不支持的错误
任何不受支持的软件包的解决方案是:
一个名为 scrapinghub.yml 的新文件已在本地自动创建。打开此文件并将其添加到项目下。
project:
requirements:
file: requirements.txt
2. 在本项目根目录下创建文本文件requirements.txt(即与scrapinghub.yml同级)
3. 打开 requirements.txt,将问题包的名称和版本写成如下格式。
beautifulsoup4==4.7.1
4. 要查看软件包的特定版本,请在终端中键入 pip show。例如。
pip show beautifulsoup4
5. 保存所有文件并在终端中再次推送项目。
shub deploy
这次应该成功了!
在云端运行爬虫:在项目页面选择运行。
注意:
由于内容篇幅,本文在代码开头没有提及需要加载的python包。实际操作中,如果没有加载对应的包,python会报错。
BeautifulSoup 中用于抓取网页内容的标签只是示例。不同的网站请使用浏览器的View Source 和Inspect 功能查看具体的标签。
bs4 运行缓慢,高级选择建议使用 xpath 或 scrapy 选择器来选择标签。
硒也很慢。作为一个网站调试工具,它会加载太多不相关的网页内容。
请保持良好的爬取礼仪,尊重网站机器人条款,不得高速爬取服务器,不得将爬取的内容用于非法用途,不得侵权。
学习的路很长,我们鼓励你! 查看全部
scrapy分页抓取网页(
2.正式开始使用scrapystartproject命令创建新的python文件夹文件)
pip install scrapy
2. 在终端使用scrapy startproject命令新建一个scrapy文件夹
scrapy startproject myspider
在项目文件夹中,scrapy 已经自带了几个 python 文件,包括:
由此可见,scrapy将请求的功能分开,封装到不同的文件中,自动化程度更高。
3. 现在正式开始使用scrapy。首先,在Item中命名你要抓取的内容。
class MySpiderItem(scrapy.Item):
title = scrapy.Field() # sample code
contents = scrapy.Field()
pass
4. 接下来,在 spiders 文件夹中创建一个新的 python 文件,例如 myspider,py。从这里开始写爬虫。
给爬虫起名字:
class MySpider(scrapy.Spider):
name = "myspider"
然后,如果它从一个或多个 URL 开始往下爬,写 start_urls(这是一个 list[])。
class MySpider(scrapy.Spider):
name = "myspider"
start_urls = ["url"]
假设我一共要爬5个页面,每个页面有几个链接,最终的目标是爬取5个页面上每个链接的内容。
我想避免手动编写列表,并使用 for 循环来形成起始 URL(就像请求一样)。所以,
page = 5
class MySpider(scrapy.Spider):
name = "myspider"
bash_url = url
def start_requests(self):
for i in (1, page+1):
url = self.base_url + str(i)
yield Request(url, self.parse)
这里最后一行的yield会继续抛出Request()对当前url的解析内容(也就是response),然后使用回调函数传入parse方法。
接下来我们看一下parse方法。然后写下来。
def parse(self, response):
atags = BeautifulSoup(response.text, 'lxml').find_all('a', {'class':'name'})
urls = [l['href'] for l in atags]
for url in urls:
yield Request(url, callback=self.get_content)
现在,parse 首先使用 BeautifulSoup 来分析传入的网页内容。首先提取页面上所有符合条件的标签。然后使用此语句提取标签内的 url。
urls = [l['href'] for l in atags]
现在我们已经在一个页面上提取了所有符合条件的 url。对于每个 url,我们继续使用 yield 抛出 Request() 来解析这些新的 url,然后将其传递给 next 方法 get_content() 以捕获新页面的内容。
下面是 get_content() 方法的示例。
def get_content(self, response):
soup = BeautifulSoup(response.text, 'lxml')
item = ScrapyTeaItem()
item['title'] = soup.find('p', {'class':'family'}).get_text()
item['contents'] = soup.find('p', {'class':'name'}).get_text()
return item
看到这里,myspider.py 终于接触到了 items.py。至此,爬虫已经爬取了五个网页上所有链接页面的内容,并将爬取的内容输入到item中。
5. 现在我们可以打开管道来存储项目的内容。但是,要启用管道功能,我们必须首先打开 settings.py 文件并删除 ITEM_PIPELINES = { 之前的#注释。
回到管道文件。将爬取的网页内容写入本地txt文件的代码如下。
class MySpiderPipeline(object):
def process_item(self, item, spider):
with open('myspider.txt', 'a', encoding='utf-8') as f: # "a" for append mode
f.write('\n'+ item['title'] + '\n') # one line
f.writelines(item['contents']) # multiple lines
return item
这样,保存网页内容的代码也写好了。
6. 如果要控制爬取速度,在设置中设置:
7. 现在开始运行我们编写的爬虫。在终端输入scrapy crawl myspider运行,创建的txt文档会保存在本项目的根目录下。
至此,scrapy爬虫已经编写成功!
刮云
scrapy还提供了云爬虫服务,免费用户一次可以运行一个爬虫。
注册/scrapy-cloud
2. 点击 CREATE PROJECT 并输入项目名称
3. 进入Deploy Management页面,命令行使用终端将本地项目传输到云端
4. 在本地项目文件夹的终端中(使用终端中的 cd 和 cd... 命令前进或后退文件夹),运行代码。
pip install shub
安装完成后,运行
shub login
提示API KEY,在云端页面输入API key
然后使用如下语句将本地项目推送到云端
shub deploy #加上云端页面上的id号码
如果使用BeautifulSoup,会报bs4包不支持的错误
任何不受支持的软件包的解决方案是:
一个名为 scrapinghub.yml 的新文件已在本地自动创建。打开此文件并将其添加到项目下。
project:
requirements:
file: requirements.txt
2. 在本项目根目录下创建文本文件requirements.txt(即与scrapinghub.yml同级)
3. 打开 requirements.txt,将问题包的名称和版本写成如下格式。
beautifulsoup4==4.7.1
4. 要查看软件包的特定版本,请在终端中键入 pip show。例如。
pip show beautifulsoup4
5. 保存所有文件并在终端中再次推送项目。
shub deploy
这次应该成功了!
在云端运行爬虫:在项目页面选择运行。
注意:
由于内容篇幅,本文在代码开头没有提及需要加载的python包。实际操作中,如果没有加载对应的包,python会报错。
BeautifulSoup 中用于抓取网页内容的标签只是示例。不同的网站请使用浏览器的View Source 和Inspect 功能查看具体的标签。
bs4 运行缓慢,高级选择建议使用 xpath 或 scrapy 选择器来选择标签。
硒也很慢。作为一个网站调试工具,它会加载太多不相关的网页内容。
请保持良好的爬取礼仪,尊重网站机器人条款,不得高速爬取服务器,不得将爬取的内容用于非法用途,不得侵权。
学习的路很长,我们鼓励你!
scrapy分页抓取网页(用Python实现一个mySpider文件夹文件夹 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-20 21:21
)
什么是 Scrapy
Scrapy 是一个用 Python 编写的应用程序框架,用于爬取 网站 数据并提取结构化数据。 Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。通常我们可以通过Scrapy框架轻松实现爬虫,抓取指定网站的内容或图片。
安装
pip install scrapy
直到下载完成
新项目
scrapy startproject mySpider #mySpider就是爬虫项目名称
使用以下目录结构创建一个 mySpider 文件夹:
scrapy.cfg: 项目的配置文件。
mySpider/: 项目的Python模块,将会从这里引用代码。
mySpider/items.py: 项目的目标文件。
mySpider/pipelines.py: 项目的管道文件。
mySpider/settings.py: 项目的设置文件。
mySpider/spiders/: 存储爬虫代码目录。
具体的抓取内容/目标
目标:获取传知播客课程培训教研组网站所有讲师的姓名、职称和个人信息。
mySpider/items.py,创建ItcastItem类,构建item模型。
import scrapy
class MyspiderItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
创建一个爬虫
cd mySpider #首先进入该文件夹
scrapy genspider itcast "itcast.cn" #创建爬虫
在mySpider/spider中自动生成python文件:itcast.py
参数说明:
1、name = "" : 这个爬虫的标识名必须是唯一的,不同的爬虫必须定义不同的名字
2、allow_domains = []是搜索的域名范围,也就是爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的URL会被忽略。
3、start_urls = () : URL 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。其他子 URL 将继承自这些起始 URL。
4、parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。功能如下: 负责解析返回的网页数据(response.body),提取结构化数据(生成item),生成下一页的URL请求。
修复网址,解析
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
print(response.body)
终端运行
scrapy crawl itcast
输出:打印整个抓取页面
提取数据
源文件
xxx
xxx
<p>xxx
</p>
以前在 mySpider/items.py 中定义了一个 ItcastItem 类。在这里你可以导入:
# -*- coding: utf-8 -*-
import scrapy
from mySpider.items import MyspiderItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = MyspiderItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后数据
return items
保存数据
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
查看结果
查看全部
scrapy分页抓取网页(用Python实现一个mySpider文件夹文件夹
)
什么是 Scrapy
Scrapy 是一个用 Python 编写的应用程序框架,用于爬取 网站 数据并提取结构化数据。 Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。通常我们可以通过Scrapy框架轻松实现爬虫,抓取指定网站的内容或图片。
安装
pip install scrapy
直到下载完成
新项目
scrapy startproject mySpider #mySpider就是爬虫项目名称
使用以下目录结构创建一个 mySpider 文件夹:
scrapy.cfg: 项目的配置文件。
mySpider/: 项目的Python模块,将会从这里引用代码。
mySpider/items.py: 项目的目标文件。
mySpider/pipelines.py: 项目的管道文件。
mySpider/settings.py: 项目的设置文件。
mySpider/spiders/: 存储爬虫代码目录。
具体的抓取内容/目标
目标:获取传知播客课程培训教研组网站所有讲师的姓名、职称和个人信息。
mySpider/items.py,创建ItcastItem类,构建item模型。
import scrapy
class MyspiderItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
创建一个爬虫
cd mySpider #首先进入该文件夹
scrapy genspider itcast "itcast.cn" #创建爬虫
在mySpider/spider中自动生成python文件:itcast.py
参数说明:
1、name = "" : 这个爬虫的标识名必须是唯一的,不同的爬虫必须定义不同的名字
2、allow_domains = []是搜索的域名范围,也就是爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的URL会被忽略。
3、start_urls = () : URL 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。其他子 URL 将继承自这些起始 URL。
4、parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。功能如下: 负责解析返回的网页数据(response.body),提取结构化数据(生成item),生成下一页的URL请求。
修复网址,解析
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
print(response.body)
终端运行
scrapy crawl itcast
输出:打印整个抓取页面
提取数据
源文件
xxx
xxx
<p>xxx
</p>
以前在 mySpider/items.py 中定义了一个 ItcastItem 类。在这里你可以导入:
# -*- coding: utf-8 -*-
import scrapy
from mySpider.items import MyspiderItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = MyspiderItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后数据
return items
保存数据
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
查看结果
scrapy分页抓取网页(scrapy分页抓取网页的时候,除了需要分页进行爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-19 06:01
scrapy分页抓取网页的时候,除了需要分页进行爬取,还需要抓取tag内容,例如title、meta等。作为大家难以突破的转化瓶颈,当我们对scrapy的代码进行拆分,分层分析的时候,我们就可以更清晰地看到分页的原理了。假设我们要抓取「2016年上半年」tag(「2017上半年」「2018上半年」「2019上半年」「2024上半年」「2025上半年」「2026上半年」「2027上半年」「2028上半年」「2029上半年」「1948上半年」「2009上半年」「2010上半年」「1992上半年」「2014上半年」「2013上半年」「2012上半年」「2011上半年」「2010上半年」「2001上半年」「2005上半年」「2007上半年」「2008上半年」「2008下半年」「2007下半年」「2008下半年」「2007下半年」,我们就可以从tag的分层分析中看到整个爬取过程了。
分层是scrapy的一大特色,并且对人类来说也非常容易分清楚,但对爬虫来说,理解起来可就难了。我们可以把分层理解为一个树形结构,分布式抓取模式由基础节点组成,基础节点有的叫做节点,有的叫做tag,还有的叫做分段。下图是scrapy的树形结构,「只要url路径是tag,就自动抓取tag的内容」,图看起来很清晰,其实还是挺难理解的。
从技术上来说,为什么抓取一段时间就需要更新一下url路径,不至于出现一段时间后抓取全都停止的情况。比如这段时间我需要抓取「2015上半年」tag,我应该在每隔1200b(也就是300亿字节)的位置抓取url路径为2015/**/的文档。在抓取该文档的时候,我会更新url路径到2015/**/,这种技术上来说,和分段分析理解起来也是有差异的。
例如同样是抓取一段时间后,即下图的url路径,分段要分清楚什么是分段最合适呢?这时候就有好多种方法来处理了,比如抓取2015上半年的时候,那就改路径为2015/**/,不就可以抓取2015下半年的内容了吗?对一个转化瓶颈来说,通过scrapy自身的技术手段,「tag中的分段」算不上难事。除了tag中的分段,scrapy还提供了「文本分段」功能,这样同样也可以实现下面的效果。
对于这两种方式,虽然看上去各有利弊,还是有不少同学不知道怎么去处理,我们分层来讨论一下这个问题。首先是文本分段,下图是我的文本分段实现代码,可以看到主要用到的函数就是segmentfault提供的get_text_list来获取tag。那么url路径中就会自动分段到这个路径和tag字段下,一些可读性并不高的tag我就都有动态的分段方法。例如「2015上半年」这个tag,我是这样处理的:需。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页的时候,除了需要分页进行爬取)
scrapy分页抓取网页的时候,除了需要分页进行爬取,还需要抓取tag内容,例如title、meta等。作为大家难以突破的转化瓶颈,当我们对scrapy的代码进行拆分,分层分析的时候,我们就可以更清晰地看到分页的原理了。假设我们要抓取「2016年上半年」tag(「2017上半年」「2018上半年」「2019上半年」「2024上半年」「2025上半年」「2026上半年」「2027上半年」「2028上半年」「2029上半年」「1948上半年」「2009上半年」「2010上半年」「1992上半年」「2014上半年」「2013上半年」「2012上半年」「2011上半年」「2010上半年」「2001上半年」「2005上半年」「2007上半年」「2008上半年」「2008下半年」「2007下半年」「2008下半年」「2007下半年」,我们就可以从tag的分层分析中看到整个爬取过程了。
分层是scrapy的一大特色,并且对人类来说也非常容易分清楚,但对爬虫来说,理解起来可就难了。我们可以把分层理解为一个树形结构,分布式抓取模式由基础节点组成,基础节点有的叫做节点,有的叫做tag,还有的叫做分段。下图是scrapy的树形结构,「只要url路径是tag,就自动抓取tag的内容」,图看起来很清晰,其实还是挺难理解的。
从技术上来说,为什么抓取一段时间就需要更新一下url路径,不至于出现一段时间后抓取全都停止的情况。比如这段时间我需要抓取「2015上半年」tag,我应该在每隔1200b(也就是300亿字节)的位置抓取url路径为2015/**/的文档。在抓取该文档的时候,我会更新url路径到2015/**/,这种技术上来说,和分段分析理解起来也是有差异的。
例如同样是抓取一段时间后,即下图的url路径,分段要分清楚什么是分段最合适呢?这时候就有好多种方法来处理了,比如抓取2015上半年的时候,那就改路径为2015/**/,不就可以抓取2015下半年的内容了吗?对一个转化瓶颈来说,通过scrapy自身的技术手段,「tag中的分段」算不上难事。除了tag中的分段,scrapy还提供了「文本分段」功能,这样同样也可以实现下面的效果。
对于这两种方式,虽然看上去各有利弊,还是有不少同学不知道怎么去处理,我们分层来讨论一下这个问题。首先是文本分段,下图是我的文本分段实现代码,可以看到主要用到的函数就是segmentfault提供的get_text_list来获取tag。那么url路径中就会自动分段到这个路径和tag字段下,一些可读性并不高的tag我就都有动态的分段方法。例如「2015上半年」这个tag,我是这样处理的:需。
scrapy分页抓取网页(本篇博客在爬取新闻网站信息2的基础上进行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-18 05:10
本博客基于爬取新闻网站信息2.主要内容如下:
1.定义一个函数来获取一个页面上的 20 个链接
2.构造多个分页链接
3.获取多个分页链接新闻内容
4.使用pandas整理爬取的数据
5.将数据保存到 csv 文件
6.Scrapy 安装
1.定义一个函数来获取一个页面上的 20 个链接
#定义获取一页20条链接内容的函数
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text)
#获取一个页面所有链接(20个左右)
for ent in jd['result']['data']:
#getNewsDetail为获取一个链接内容详情
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
#测试
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8'
parseListLinks(url)
2.构造多个分页链接
#构造多个分页链接
pageurl = "https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8"
for i in range(1,10):
newsurl = pageurl.format(i)
print(newsurl)
3.获取多个分页链接新闻内容
#抓取多个分页链接新闻内容
import requests
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page={}&encode=utf-8'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(url)
news_total.extend(newsary)
#测试打印抓取的两个页面
print(news_total)
4.使用pandas整理爬取的数据
Pandas 是一个 Python 数据分析包(Python Data Analysis Library)。这里我们使用pandas的DataFrame函数将爬取的数据组织成二维表格数据结构。
安装pandas套件:进入cmd命令行,输入以下命令进行安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
#用pandas整理爬取出的资料
import pandas
df = pandas.DataFrame(news_total)
#查看后5行数据
df.tail()
5.将数据保存到 csv 文件
使用 to_csv 函数将数据存储在 csv 文件中。 “ruiyigongfang.csv”是我们导出的文件名,存放在jupyter notebook启动的根目录下,一般在C:\Users\Administrator目录下。
查看ruiyigongfang.csv文件内容
至此,用python3爬取新闻网站信息的项目已经完成。
总结一下:
爬虫的主要过程分为三个阶段:
下载数据:使用requests套件,通过requests.get('url')方法获取网页信息
提取数据:使用BeautifulSoup4套件通过soup.select('xxx');解析关系的内容
保存数据:通过pandas套件将数据组织成二维数据结构,然后通过to_csv()函数将数据以csv格式保存到本地。
----------------------------------- ---------- ---------------------------------------- -----
接下来会有第二个python爬虫项目,等待下一篇博客更新!
这里先介绍一个简单强大的爬虫框架Scrapy的安装,为后续项目做准备。
Scrapy 安装
环境:windows系统,python3
步骤:
1.安装轮子:
py -3 -m pip install wheel
2.安装 lxml:
py -3 -m pip install lxml
3.安装 Twisted:
下载 Twisted:~gohlke/pythonlibs/#twisted
注意:下载的版本要与安装的python版本和电脑位数一致。对于python3.7,选择cp37,其他版本依次类推。例如:
安装 Twisted:
pip install xxx/xxx/Twistedxxx
注意:xxx/xxx/Twistedxxx是下载的twisted文件所在的绝对路径。比如下载的文件放在D:\目录下,文件名为Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
命令应该是 pip install D:\Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
4.安装 Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
5.安装win32py
下载:,注意下载与python版本和电脑位数一致的文件
安装:双击pywin32-224.win-amd64-py3.7.exe文件安装
6.验证
scrapy -h
说明:
安装Scrapy依赖wheel、lxml、Twisted模块
运行 Scrapy 依赖于 win32py
完成!尽情享受吧! 查看全部
scrapy分页抓取网页(本篇博客在爬取新闻网站信息2的基础上进行)
本博客基于爬取新闻网站信息2.主要内容如下:
1.定义一个函数来获取一个页面上的 20 个链接
2.构造多个分页链接
3.获取多个分页链接新闻内容
4.使用pandas整理爬取的数据
5.将数据保存到 csv 文件
6.Scrapy 安装
1.定义一个函数来获取一个页面上的 20 个链接
#定义获取一页20条链接内容的函数
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text)
#获取一个页面所有链接(20个左右)
for ent in jd['result']['data']:
#getNewsDetail为获取一个链接内容详情
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
#测试
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8'
parseListLinks(url)
2.构造多个分页链接
#构造多个分页链接
pageurl = "https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8"
for i in range(1,10):
newsurl = pageurl.format(i)
print(newsurl)
3.获取多个分页链接新闻内容
#抓取多个分页链接新闻内容
import requests
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page={}&encode=utf-8'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(url)
news_total.extend(newsary)
#测试打印抓取的两个页面
print(news_total)
4.使用pandas整理爬取的数据
Pandas 是一个 Python 数据分析包(Python Data Analysis Library)。这里我们使用pandas的DataFrame函数将爬取的数据组织成二维表格数据结构。
安装pandas套件:进入cmd命令行,输入以下命令进行安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
#用pandas整理爬取出的资料
import pandas
df = pandas.DataFrame(news_total)
#查看后5行数据
df.tail()
5.将数据保存到 csv 文件
使用 to_csv 函数将数据存储在 csv 文件中。 “ruiyigongfang.csv”是我们导出的文件名,存放在jupyter notebook启动的根目录下,一般在C:\Users\Administrator目录下。
查看ruiyigongfang.csv文件内容
至此,用python3爬取新闻网站信息的项目已经完成。
总结一下:
爬虫的主要过程分为三个阶段:
下载数据:使用requests套件,通过requests.get('url')方法获取网页信息
提取数据:使用BeautifulSoup4套件通过soup.select('xxx');解析关系的内容
保存数据:通过pandas套件将数据组织成二维数据结构,然后通过to_csv()函数将数据以csv格式保存到本地。
----------------------------------- ---------- ---------------------------------------- -----
接下来会有第二个python爬虫项目,等待下一篇博客更新!
这里先介绍一个简单强大的爬虫框架Scrapy的安装,为后续项目做准备。
Scrapy 安装
环境:windows系统,python3
步骤:
1.安装轮子:
py -3 -m pip install wheel
2.安装 lxml:
py -3 -m pip install lxml
3.安装 Twisted:
下载 Twisted:~gohlke/pythonlibs/#twisted
注意:下载的版本要与安装的python版本和电脑位数一致。对于python3.7,选择cp37,其他版本依次类推。例如:
安装 Twisted:
pip install xxx/xxx/Twistedxxx
注意:xxx/xxx/Twistedxxx是下载的twisted文件所在的绝对路径。比如下载的文件放在D:\目录下,文件名为Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
命令应该是 pip install D:\Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
4.安装 Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
5.安装win32py
下载:,注意下载与python版本和电脑位数一致的文件
安装:双击pywin32-224.win-amd64-py3.7.exe文件安装
6.验证
scrapy -h
说明:
安装Scrapy依赖wheel、lxml、Twisted模块
运行 Scrapy 依赖于 win32py
完成!尽情享受吧!

