
scrapy分页抓取网页
谈谈对Python爬虫的理解
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-05-08 00:00
爬虫也可以称为Python爬虫
不知从何时起,Python这门语言和爬虫就像一对恋人,二者如胶似漆 ,形影不离,你中有我、我中有你
一提起爬虫,就会想到Python,一说起Python,就会想到人工智能……和爬虫
所以,一般说爬虫的时候,大部分程序员潜意识里都会联想为Python爬虫,为什么会这样,我觉得有两个原因:
任何一个学习Python的程序员,应该都或多或少地见过甚至研究过爬虫,我当时写Python的目的就非常纯粹——为了写爬虫
所以本文的目的很简单,就是说说我个人对Python爬虫的理解与实践,作为一名程序员,我觉得了解一下爬虫的相关知识对你只有好处,所以读完这篇文章后,如果能对你有帮助,那便再好不过
什么是爬虫
爬虫是一个程序,这个程序的目的就是为了抓取万维网信息资源,比如你日常使用的谷歌等搜索引擎,搜索结果就全都依赖爬虫来定时获取
看上述搜索结果,除了wiki相关介绍外,爬虫有关的搜索结果全都带上了Python,前人说Python爬虫,现在看来果然诚不欺我~
爬虫的目标对象也很丰富,不论是文字、图片、视频,任何结构化非结构化的数据爬虫都可以爬取,爬虫经过发展,也衍生出了各种爬虫类型:
不想说这些大方向的概念,让我们以一个获取网页内容为例,从爬虫技术本身出发,来说说网页爬虫,步骤如下:
什么是爬虫,这就是爬虫:
<p>"""让我们根据上面说的步骤来完成一个简单的爬虫程序"""
import requests
<br />
from bs4 import BeautifulSoup
<br />
target_url = 'http://www.baidu.com/s?wd=爬虫'
<br />
# 第一步 发起一个GET请求
res = requests.get(target_url)
<br />
# 第二步 提取HTML并解析想获取的数据 比如获取 title
soup = BeautifulSoup(res.text, "lxml")
# 输出 soup.title.text
title = soup.title.text
<br />
# 第三步 持久化 比如保存到本地
with open('title.txt', 'w') as fp:
fp.write(title)</p>
加上注释不到20行代码,你就完成了一个爬虫,简单吧
怎么写爬虫
网页世界多姿多彩、亿万网页资源供你选择,面对不同的页面,怎么使自己编写的爬虫程序够稳健、持久,这是一个值得讨论的问题
俗话说,磨刀不误砍柴工,在开始编写爬虫之前,很有必要掌握一些基本知识:
这两句描述体现了一名爬虫开发人员需要掌握的基本知识,不过一名基本的后端或者前端工程师都会这些哈哈,这也说明了爬虫的入门难度极低,从这两句话,你能思考出哪些爬虫必备的知识点呢?
有了这些知识储备,接下来就可以选择一门语言,开始编写自己的爬虫程序了,还是按照上一节说的三个步骤,然后以Python为例,说一说要在编程语言方面做那些准备:
掌握了上面这些,你大可放开手脚大干一场,万维网就是你的名利场,去吧~
我觉得对于一个目标网站的网页,可以分下面四个类型:
具体是什么意思呢,可能看起来有点绕,但明白这些,你之后写爬虫,只要在脑子里面过一遍着网页对应什么类型,然后套上对应类型的程序(写多了都应该有一套自己的常用代码库),那写爬虫的速度,自然不会慢
单页面单目标
通俗来说,就是在这个网页里面,我们的目标就只有一个,假设我们的需求是抓取这部电影-肖申克的救赎的名称,首先打开网页右键审查元素,找到电影名称对应的元素位置,如下图所示:
在某个单一页面内,看目标是不是只有一个,一眼就能看出标题的CSS Selector规则为:#content > h1 > span:nth-child(1),然后用我自己写的常用库,我用不到十行代码就能写完抓取这个页面电影名称的爬虫:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
title = TextField(css_select='#content > h1 > span:nth-child(1)')
<br />
async_func = DoubanItem.get_item(url="https://movie.douban.com/subject/1292052/")
item = asyncio.get_event_loop().run_until_complete(async_func)
print(item.title)</p>
多页面多目标就是此情况下多个url的衍生情况
单页面多目标
假设现在的需求是抓取豆瓣电影250第一页中的所有电影名称,你需要提取25个电影名称,因为这个目标页的目标数据是多个item的,因此目标需要循环获取,这就是所谓的单页面多目标了:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
async_func = DoubanItem.get_items(url="https://movie.douban.com/top250")
items = asyncio.get_event_loop().run_until_complete(async_func)
for item in items:
print(item)</p>
多页面多目标
多页面多目标是上述单页面多目标情况的衍生,在这个问题上来看,此时就是获取所有分页的电影名称
<p>from ruia import TextField, Item, Request, Spider
<br />
<br />
class DoubanItem(Item):
"""
定义爬虫的目标字段
"""
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
class DoubanSpider(Spider):
start_urls = ['https://movie.douban.com/top250']
concurrency = 10
<br />
async def parse(self, res):
etree = res.html_etree
pages = ['?start=0&filter='] + [i.get('href') for i in etree.cssselect('.paginator>a')]
<br />
for index, page in enumerate(pages):
url = self.start_urls[0] + page
yield Request(
url,
callback=self.parse_item,
metadata={'index': index},
request_config=self.request_config
)
<br />
async def parse_item(self, res):
items_data = await DoubanItem.get_items(html=res.html)
res_list = []
for item in items_data:
res_list.append(item.title)
return res_list
<br />
<br />
if __name__ == '__main__':
DoubanSpider.start()</p>
如果网络没问题的话,会得到如下输出:
注意爬虫运行时间,1s不到,这就是异步的魅力
用Python写爬虫,就是这么简单优雅,诸位,看着网页就思考下:
一个爬虫程序就成型了,顺便一提,爬虫这东西,可以说是防君子不防小人,robots.txt大部分网站都有(它的目的是告诉爬虫什么可以爬取什么不可以爬取,比如:),各位想怎么爬取,自己衡量
如何进阶
不要以为写好一个爬虫程序就可以出师了,此时还有更多的问题在前面等着你,你要含情脉脉地看着你的爬虫程序,问自己三个问题:
前两个关于人性的问题在此不做过多叙述,因此跳过,但你们如果作为爬虫工程师的话,切不可跳过
会被反爬虫干掉么?
最后关于反爬虫的问题才是你爬虫程序强壮与否的关键因素,什么是反爬虫?
当越来越多的爬虫在互联网上横冲直撞后,网页资源维护者为了防止自身数据被抓取,开始进行一系列的措施来使得自身数据不易被别的程序爬取,这些措施就是反爬虫
比如检测IP访问频率、资源访问速度、链接是否带有关键参数、验证码检测机器人、ajax混淆、js加密等等
对于目前市场上的反爬虫,爬虫工程师常有的反反爬虫方案是下面这样的:
爬虫工程师的进阶之路其实就是不断反反爬虫,可谓艰辛,但换个角度想也是乐趣所在
关于框架
爬虫有自己的编写流程和标准,有了标准,自然就有了框架,像Python这种生态强大的语言,框架自然是多不胜数,目前世面上用的比较多的有:
这里不过多介绍,框架只是工具,是一种提升效率的方式,看你选择
说明
任何事物都有两面性,爬虫自然也不例外,因此我送诸位一张图,关键时刻好好想想
往期推荐:
查看全部
谈谈对Python爬虫的理解
爬虫也可以称为Python爬虫
不知从何时起,Python这门语言和爬虫就像一对恋人,二者如胶似漆 ,形影不离,你中有我、我中有你
一提起爬虫,就会想到Python,一说起Python,就会想到人工智能……和爬虫
所以,一般说爬虫的时候,大部分程序员潜意识里都会联想为Python爬虫,为什么会这样,我觉得有两个原因:
任何一个学习Python的程序员,应该都或多或少地见过甚至研究过爬虫,我当时写Python的目的就非常纯粹——为了写爬虫
所以本文的目的很简单,就是说说我个人对Python爬虫的理解与实践,作为一名程序员,我觉得了解一下爬虫的相关知识对你只有好处,所以读完这篇文章后,如果能对你有帮助,那便再好不过
什么是爬虫
爬虫是一个程序,这个程序的目的就是为了抓取万维网信息资源,比如你日常使用的谷歌等搜索引擎,搜索结果就全都依赖爬虫来定时获取
看上述搜索结果,除了wiki相关介绍外,爬虫有关的搜索结果全都带上了Python,前人说Python爬虫,现在看来果然诚不欺我~
爬虫的目标对象也很丰富,不论是文字、图片、视频,任何结构化非结构化的数据爬虫都可以爬取,爬虫经过发展,也衍生出了各种爬虫类型:
不想说这些大方向的概念,让我们以一个获取网页内容为例,从爬虫技术本身出发,来说说网页爬虫,步骤如下:
什么是爬虫,这就是爬虫:
<p>"""让我们根据上面说的步骤来完成一个简单的爬虫程序"""
import requests
<br />
from bs4 import BeautifulSoup
<br />
target_url = 'http://www.baidu.com/s?wd=爬虫'
<br />
# 第一步 发起一个GET请求
res = requests.get(target_url)
<br />
# 第二步 提取HTML并解析想获取的数据 比如获取 title
soup = BeautifulSoup(res.text, "lxml")
# 输出 soup.title.text
title = soup.title.text
<br />
# 第三步 持久化 比如保存到本地
with open('title.txt', 'w') as fp:
fp.write(title)</p>
加上注释不到20行代码,你就完成了一个爬虫,简单吧
怎么写爬虫
网页世界多姿多彩、亿万网页资源供你选择,面对不同的页面,怎么使自己编写的爬虫程序够稳健、持久,这是一个值得讨论的问题
俗话说,磨刀不误砍柴工,在开始编写爬虫之前,很有必要掌握一些基本知识:
这两句描述体现了一名爬虫开发人员需要掌握的基本知识,不过一名基本的后端或者前端工程师都会这些哈哈,这也说明了爬虫的入门难度极低,从这两句话,你能思考出哪些爬虫必备的知识点呢?
有了这些知识储备,接下来就可以选择一门语言,开始编写自己的爬虫程序了,还是按照上一节说的三个步骤,然后以Python为例,说一说要在编程语言方面做那些准备:
掌握了上面这些,你大可放开手脚大干一场,万维网就是你的名利场,去吧~
我觉得对于一个目标网站的网页,可以分下面四个类型:
具体是什么意思呢,可能看起来有点绕,但明白这些,你之后写爬虫,只要在脑子里面过一遍着网页对应什么类型,然后套上对应类型的程序(写多了都应该有一套自己的常用代码库),那写爬虫的速度,自然不会慢
单页面单目标
通俗来说,就是在这个网页里面,我们的目标就只有一个,假设我们的需求是抓取这部电影-肖申克的救赎的名称,首先打开网页右键审查元素,找到电影名称对应的元素位置,如下图所示:
在某个单一页面内,看目标是不是只有一个,一眼就能看出标题的CSS Selector规则为:#content > h1 > span:nth-child(1),然后用我自己写的常用库,我用不到十行代码就能写完抓取这个页面电影名称的爬虫:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
title = TextField(css_select='#content > h1 > span:nth-child(1)')
<br />
async_func = DoubanItem.get_item(url="https://movie.douban.com/subject/1292052/";)
item = asyncio.get_event_loop().run_until_complete(async_func)
print(item.title)</p>
多页面多目标就是此情况下多个url的衍生情况
单页面多目标
假设现在的需求是抓取豆瓣电影250第一页中的所有电影名称,你需要提取25个电影名称,因为这个目标页的目标数据是多个item的,因此目标需要循环获取,这就是所谓的单页面多目标了:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
async_func = DoubanItem.get_items(url="https://movie.douban.com/top250";)
items = asyncio.get_event_loop().run_until_complete(async_func)
for item in items:
print(item)</p>
多页面多目标
多页面多目标是上述单页面多目标情况的衍生,在这个问题上来看,此时就是获取所有分页的电影名称
<p>from ruia import TextField, Item, Request, Spider
<br />
<br />
class DoubanItem(Item):
"""
定义爬虫的目标字段
"""
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
class DoubanSpider(Spider):
start_urls = ['https://movie.douban.com/top250']
concurrency = 10
<br />
async def parse(self, res):
etree = res.html_etree
pages = ['?start=0&filter='] + [i.get('href') for i in etree.cssselect('.paginator>a')]
<br />
for index, page in enumerate(pages):
url = self.start_urls[0] + page
yield Request(
url,
callback=self.parse_item,
metadata={'index': index},
request_config=self.request_config
)
<br />
async def parse_item(self, res):
items_data = await DoubanItem.get_items(html=res.html)
res_list = []
for item in items_data:
res_list.append(item.title)
return res_list
<br />
<br />
if __name__ == '__main__':
DoubanSpider.start()</p>
如果网络没问题的话,会得到如下输出:
注意爬虫运行时间,1s不到,这就是异步的魅力
用Python写爬虫,就是这么简单优雅,诸位,看着网页就思考下:
一个爬虫程序就成型了,顺便一提,爬虫这东西,可以说是防君子不防小人,robots.txt大部分网站都有(它的目的是告诉爬虫什么可以爬取什么不可以爬取,比如:),各位想怎么爬取,自己衡量
如何进阶
不要以为写好一个爬虫程序就可以出师了,此时还有更多的问题在前面等着你,你要含情脉脉地看着你的爬虫程序,问自己三个问题:
前两个关于人性的问题在此不做过多叙述,因此跳过,但你们如果作为爬虫工程师的话,切不可跳过
会被反爬虫干掉么?
最后关于反爬虫的问题才是你爬虫程序强壮与否的关键因素,什么是反爬虫?
当越来越多的爬虫在互联网上横冲直撞后,网页资源维护者为了防止自身数据被抓取,开始进行一系列的措施来使得自身数据不易被别的程序爬取,这些措施就是反爬虫
比如检测IP访问频率、资源访问速度、链接是否带有关键参数、验证码检测机器人、ajax混淆、js加密等等
对于目前市场上的反爬虫,爬虫工程师常有的反反爬虫方案是下面这样的:
爬虫工程师的进阶之路其实就是不断反反爬虫,可谓艰辛,但换个角度想也是乐趣所在
关于框架
爬虫有自己的编写流程和标准,有了标准,自然就有了框架,像Python这种生态强大的语言,框架自然是多不胜数,目前世面上用的比较多的有:
这里不过多介绍,框架只是工具,是一种提升效率的方式,看你选择
说明
任何事物都有两面性,爬虫自然也不例外,因此我送诸位一张图,关键时刻好好想想
往期推荐:
scrapy分页抓取网页 6000 多款 App,看我如何搞定她们并将其洗白白~
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-05-06 04:09
项目文件创建好以后,我们就可以开始写爬虫程序了。
首先,需要在 items.py 文件中,预先定义好要爬取的字段信息名称,如下所示:
1class KuanItem(scrapy.Item):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2# define the fields for your item here like:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3name = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4volume = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5download = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6follow = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7comment = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8tags = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9score = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10num_score = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里的字段信息就是我们前面在网页中定位的 8 个字段信息,包括:name 表示 App 名称、volume 表示体积、download 表示下载数量。在这里定义好之后,我们在后续的爬取主程序中会利用到这些字段信息。
2.3.3. 爬取主程序
创建好 kuan 项目后,Scrapy 框架会自动生成爬取的部分代码,我们接下来就需要在 parse 方法中增加网页抓取的字段解析内容。
1class KuanspiderSpider(scrapy.Spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 name = 'kuan'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 allowed_domains = ['www.coolapk.com']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 start_urls = ['http://www.coolapk.com/']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 pass<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
打开主页 Dev Tools,找到每项抓取指标的节点位置,然后可以采用 CSS、Xpath、正则等方法进行提取解析,这些方法 Scrapy 都支持,可随意选择,这里我们选用 CSS 语法来定位节点,不过需要注意的是,Scrapy 的 CSS 语法和之前我们利用 pyquery 使用的 CSS 语法稍有不同,举几个例子,对比说明一下。
首先,我们定位到第一个 APP 的主页 URL 节点,可以看到 URL 节点位于 class 属性为app_left_list的 div 节点下的 a 节点中,其 href 属性就是我们需要的 URL 信息,这里是相对地址,拼接后就是完整的 URL。
接着我们进入酷安详情页,选择 App 名称并进行定位,可以看到 App 名称节点位于 class 属性为.detail_app_title的 p 节点的文本中。
定位到这两个节点之后,我们就可以使用 CSS 提取字段信息了,这里对比一下常规写法和 Scrapy 中的写法:
1# 常规写法<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2url = item('.app_left_list>a').attr('href')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3name = item('.list_app_title').text()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4# Scrapy 写法<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5url = item.css('::attr("href")').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6name = item.css('.detail_app_title::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
可以看到,要获取 href 或者 text 属性,需要用 :: 表示,比如获取 text,则用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,则用 extract() 。接着,我们就可以参照写出 8 个字段信息的解析代码。
首先,我们需要在主页提取 App 的 URL 列表,然后再进入每个 App 的详情页进一步提取 8 个字段信息。
1def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 contents = response.css('.app_left_list>a')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for content in contents:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 url = content.css('::attr("href")').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5 url = response.urljoin(url) # 拼接相对 url 为绝对 url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 yield scrapy.Request(url,callback=self.parse_url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,利用 response.urljoin() 方法将提取出的相对 URL 拼接为完整的 URL,然后利用 scrapy.Request() 方法构造每个 App 详情页的请求,这里我们传递两个参数:url 和 callback,url 为详情页 URL,callback 是回调函数,它将主页 URL 请求返回的响应 response 传给专门用来解析字段内容的 parse_url() 方法,如下所示:
1def parse_url(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2 item = KuanItem()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 item['name'] = response.css('.detail_app_title::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 results = self.get_comment(response)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 item['volume'] = results[0]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 item['download'] = results[1]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 item['follow'] = results[2]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 item['comment'] = results[3]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 item['tags'] = self.get_tags(response)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 item['score'] = response.css('.rank_num::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 num_score = response.css('.apk_rank_p1::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12 item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 yield item<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15def get_comment(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 messages = response.css('.apk_topba_message::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17 result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18 if result: # 不为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 results = list(result[0]) # 提取出list 中第一个元素<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 return results<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />21<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />22def get_tags(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />23 data = response.css('.apk_left_span2')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />24 tags = [item.css('::text').extract_first() for item in data]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />25 return tags<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,单独定义了 get_comment() 和 get_tags() 两个方法.
get_comment() 方法通过正则匹配提取 volume、download、follow、comment 四个字段信息,正则匹配结果如下:
1result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2print(result) # 输出第一页的结果信息<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3# 结果如下:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4[('21.74M', '5218万', '2.4万', '5.4万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5[('75.53M', '2768万', '2.3万', '3.0万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6[('46.21M', '1686万', '2.3万', '3.4万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7[('54.77M', '1603万', '3.8万', '4.9万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8[('3.32M', '1530万', '1.5万', '3343')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9[('75.07M', '1127万', '1.6万', '2.2万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10[('92.70M', '1108万', '9167', '1.3万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11[('68.94M', '1072万', '5718', '9869')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12[('61.45M', '935万', '1.1万', '1.6万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13[('23.96M', '925万', '4157', '1956')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
然后利用 result[0]、result[1] 等分别提取出四项信息,以 volume 为例,输出第一页的提取结果:
1item['volume'] = results[0]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2print(item['volume'])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 321.74M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 475.53M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 546.21M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 654.77M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 73.32M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 875.07M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 992.70M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1068.94M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1161.45M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1223.96M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这样一来,第一页 10 款 App 的所有字段信息都被成功提取出来,然后返回到 yied item 生成器中,我们输出一下它的内容:
1[<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'}, <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4...<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
2.3.4. 分页爬取
以上,我们爬取了第一页内容,接下去需要遍历爬取全部 610 页的内容,这里有两种思路:
这里,我们分别写出两种方法的解析代码,第一种方法很简单,直接接着 parse 方法继续添加以下几行代码即可:
1def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 contents = response.css('.app_left_list>a')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for content in contents:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 ...<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 url = response.urljoin(next_page)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />8 yield scrapy.Request(url,callback=self.parse )<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
第二种方法,我们在最开头的 parse() 方法前,定义一个 start_requests() 方法,用来批量生成 610 页的 URL,然后通过 scrapy.Request() 方法中的 callback 参数,传递给下面的 parse() 方法进行解析。
1def start_requests(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 pages = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for page in range(1,610): # 一共有610页<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 url = 'https://www.coolapk.com/apk/?page=%s'%page<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5 page = scrapy.Request(url,callback=self.parse)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 pages.append(page)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 return pages<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
以上就是全部页面的爬取思路,爬取成功后,我们需要存储下来。这里,我面选择存储到 MongoDB 中,不得不说,相比 MySQL,MongoDB 要方便省事很多。
2.3.5. 存储结果
我们在 pipelines.py 程序中,定义数据存储方法,MongoDB 的一些参数,比如地址和数据库名称,需单独存放在 settings.py 设置文件中去,然后在 pipelines 程序中进行调用即可。
1import pymongo<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2class MongoPipeline(object):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 def __init__(self,mongo_url,mongo_db):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 self.mongo_url = mongo_url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 self.mongo_db = mongo_db<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 @classmethod<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 def from_crawler(cls,crawler):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 return cls(<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 mongo_url = crawler.settings.get('MONGO_URL'),<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 mongo_db = crawler.settings.get('MONGO_DB')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 )<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12 def open_spider(self,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 self.client = pymongo.MongoClient(self.mongo_url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14 self.db = self.client[self.mongo_db]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15 def process_item(self,item,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 name = item.__class__.__name__<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17 self.db[name].insert(dict(item))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18 return item<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 def close_spider(self,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 self.client.close()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
首先,我们定义一个 MongoPipeline()存储类,里面定义了几个方法,简单进行一下说明:
from crawler() 是一个类方法,用 @class method 标识,这个方法的作用主要是用来获取我们在 settings.py 中设置的这几项参数:
1MONGO_URL = 'localhost'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2MONGO_DB = 'KuAn'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3ITEM_PIPELINES = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 'kuan.pipelines.MongoPipeline': 300,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5}<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
open_spider() 方法主要进行一些初始化操作 ,在 Spider 开启时,这个方法就会被调用 。
process_item() 方法是最重要的方法,实现插入数据到 MongoDB 中。
完成上述代码以后,输入下面一行命令就可以开始整个爬虫的抓取和存储过程了,单机跑的话,6000 个网页需要不少时间才能完成,保持耐心。
1scrapy crawl kuan<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,还有两点补充:
第一,为了减轻网站压力,我们最好在每个请求之间设置几秒延时,可以在 KuanSpider() 方法开头出,加入以下几行代码:
1custom_settings = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 "DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 "CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 }<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
第二,为了更好监控爬虫程序运行,有必要设置输出日志文件,可以通过 Python 自带的 logging 包实现:
1import logging<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4logging.warning("warn message")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5logging.error("error message")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里的 level 参数表示警告级别,严重程度从低到高分别是:DEBUG < INFO < WARNING < ERROR < CRITICAL,如果想日志文件不要记录太多内容,可以设置高一点的级别,这里设置为 WARNING,意味着只有 WARNING 级别以上的信息才会输出到日志中去。
添加 datefmt 参数是为了在每条日志前面加具体的时间,这点很有用处。
以上,我们就完成了整个数据的抓取,有了数据我们就可以着手进行分析,不过这之前还需简单地对数据做一下清洗和处理。
3. 数据清洗处理
首先,我们从 MongoDB 中读取数据并转化为 DataFrame,然后查看一下数据的基本情况。
1def parse_kuan():<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2 client = pymongo.MongoClient(host='localhost', port=27017)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 db = client['KuAn']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 collection = db['KuAnItem']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 # 将数据库数据转为DataFrame<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 data = pd.DataFrame(list(collection.find()))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 print(data.head())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 print(df.shape)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 print(df.info())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 print(df.describe())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
从 data.head() 输出的前 5 行数据中可以看到,除了 score 列是 float 格式以外,其他列都是 object 文本类型。
comment、download、follow、num_score 这 5 列数据中部分行带有「万」字后缀,需要将字符去掉再转换为数值型;volume 体积列,则分别带有「M」和「K」后缀,为了统一大小,则需将「K」除以 1024,转换为 「M」体积。
整个数据一共有 6086 行 x 8 列,每列均没有缺失值。
df.describe() 方法对 score 列做了基本统计,可以看到,所有 App 的平均得分是 3.9 分(5 分制),最低得分 1.6 分,最高得分 4.8 分。
下面,我们将以上几列文本型数据转换为数值型数据,代码实现如下:
1def data_processing(df):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 str = '_ori'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 cols = ['comment','download','follow','num_score','volume']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 for col in cols:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 colori = col+str<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 df[colori] = df[col] # 复制保留原始列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 if not (col == 'volume'):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 df[col] = clean_symbol(df,col)# 处理原始列生成新列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 df[col] = clean_symbol2(df,col)# 处理原始列生成新列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 # 将download单独转换为万单位<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14 df['download'] = df['download'].apply(lambda x:x/10000)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15 # 批量转为数值型<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 df = df.apply(pd.to_numeric,errors='ignore')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18def clean_symbol(df,col):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 # 将字符“万”替换为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 con = df[col].str.contains('万$')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />21 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />22 df[col] = pd.to_numeric(df[col])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />23 return df[col]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />24<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />25def clean_symbol2(df,col):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />26 # 字符M替换为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />27 df[col] = df[col].str.replace('M$','')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />28 # 体积为K的除以 1024 转换为M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />29 con = df[col].str.contains('K$')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />30 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />31 df[col] = pd.to_numeric(df[col])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />32 return df[col]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
以上,就完成了几列文本型数据的转换,我们再来查看一下基本情况:
download 列为 App 下载数量,下载量最多的 App 有 5190 万次,最少的为 0 (很少很少),平均下载次数为 14 万次;从中可以看出以下几点信息:
以上,就完成了基本的数据清洗处理过程,下一期将对这6000多款App进行探索性分析,看看有多少佳软神器你没有使用过哦。 查看全部
scrapy分页抓取网页 6000 多款 App,看我如何搞定她们并将其洗白白~
项目文件创建好以后,我们就可以开始写爬虫程序了。
首先,需要在 items.py 文件中,预先定义好要爬取的字段信息名称,如下所示:
1class KuanItem(scrapy.Item):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2# define the fields for your item here like:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3name = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4volume = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5download = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6follow = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7comment = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8tags = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9score = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10num_score = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里的字段信息就是我们前面在网页中定位的 8 个字段信息,包括:name 表示 App 名称、volume 表示体积、download 表示下载数量。在这里定义好之后,我们在后续的爬取主程序中会利用到这些字段信息。
2.3.3. 爬取主程序
创建好 kuan 项目后,Scrapy 框架会自动生成爬取的部分代码,我们接下来就需要在 parse 方法中增加网页抓取的字段解析内容。
1class KuanspiderSpider(scrapy.Spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 name = 'kuan'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 allowed_domains = ['www.coolapk.com']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 start_urls = ['http://www.coolapk.com/']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 pass<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
打开主页 Dev Tools,找到每项抓取指标的节点位置,然后可以采用 CSS、Xpath、正则等方法进行提取解析,这些方法 Scrapy 都支持,可随意选择,这里我们选用 CSS 语法来定位节点,不过需要注意的是,Scrapy 的 CSS 语法和之前我们利用 pyquery 使用的 CSS 语法稍有不同,举几个例子,对比说明一下。
首先,我们定位到第一个 APP 的主页 URL 节点,可以看到 URL 节点位于 class 属性为app_left_list的 div 节点下的 a 节点中,其 href 属性就是我们需要的 URL 信息,这里是相对地址,拼接后就是完整的 URL。
接着我们进入酷安详情页,选择 App 名称并进行定位,可以看到 App 名称节点位于 class 属性为.detail_app_title的 p 节点的文本中。
定位到这两个节点之后,我们就可以使用 CSS 提取字段信息了,这里对比一下常规写法和 Scrapy 中的写法:
1# 常规写法<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2url = item('.app_left_list>a').attr('href')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3name = item('.list_app_title').text()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4# Scrapy 写法<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5url = item.css('::attr("href")').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6name = item.css('.detail_app_title::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
可以看到,要获取 href 或者 text 属性,需要用 :: 表示,比如获取 text,则用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,则用 extract() 。接着,我们就可以参照写出 8 个字段信息的解析代码。
首先,我们需要在主页提取 App 的 URL 列表,然后再进入每个 App 的详情页进一步提取 8 个字段信息。
1def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 contents = response.css('.app_left_list>a')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for content in contents:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 url = content.css('::attr("href")').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5 url = response.urljoin(url) # 拼接相对 url 为绝对 url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 yield scrapy.Request(url,callback=self.parse_url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,利用 response.urljoin() 方法将提取出的相对 URL 拼接为完整的 URL,然后利用 scrapy.Request() 方法构造每个 App 详情页的请求,这里我们传递两个参数:url 和 callback,url 为详情页 URL,callback 是回调函数,它将主页 URL 请求返回的响应 response 传给专门用来解析字段内容的 parse_url() 方法,如下所示:
1def parse_url(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2 item = KuanItem()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 item['name'] = response.css('.detail_app_title::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 results = self.get_comment(response)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 item['volume'] = results[0]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 item['download'] = results[1]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 item['follow'] = results[2]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 item['comment'] = results[3]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 item['tags'] = self.get_tags(response)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 item['score'] = response.css('.rank_num::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 num_score = response.css('.apk_rank_p1::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12 item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 yield item<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15def get_comment(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 messages = response.css('.apk_topba_message::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17 result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18 if result: # 不为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 results = list(result[0]) # 提取出list 中第一个元素<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 return results<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />21<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />22def get_tags(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />23 data = response.css('.apk_left_span2')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />24 tags = [item.css('::text').extract_first() for item in data]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />25 return tags<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,单独定义了 get_comment() 和 get_tags() 两个方法.
get_comment() 方法通过正则匹配提取 volume、download、follow、comment 四个字段信息,正则匹配结果如下:
1result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2print(result) # 输出第一页的结果信息<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3# 结果如下:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4[('21.74M', '5218万', '2.4万', '5.4万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5[('75.53M', '2768万', '2.3万', '3.0万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6[('46.21M', '1686万', '2.3万', '3.4万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7[('54.77M', '1603万', '3.8万', '4.9万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8[('3.32M', '1530万', '1.5万', '3343')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9[('75.07M', '1127万', '1.6万', '2.2万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10[('92.70M', '1108万', '9167', '1.3万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11[('68.94M', '1072万', '5718', '9869')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12[('61.45M', '935万', '1.1万', '1.6万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13[('23.96M', '925万', '4157', '1956')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
然后利用 result[0]、result[1] 等分别提取出四项信息,以 volume 为例,输出第一页的提取结果:
1item['volume'] = results[0]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2print(item['volume'])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 321.74M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 475.53M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 546.21M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 654.77M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 73.32M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 875.07M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 992.70M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1068.94M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1161.45M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1223.96M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这样一来,第一页 10 款 App 的所有字段信息都被成功提取出来,然后返回到 yied item 生成器中,我们输出一下它的内容:
1[<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'}, <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4...<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
2.3.4. 分页爬取
以上,我们爬取了第一页内容,接下去需要遍历爬取全部 610 页的内容,这里有两种思路:
这里,我们分别写出两种方法的解析代码,第一种方法很简单,直接接着 parse 方法继续添加以下几行代码即可:
1def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 contents = response.css('.app_left_list>a')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for content in contents:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 ...<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 url = response.urljoin(next_page)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />8 yield scrapy.Request(url,callback=self.parse )<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
第二种方法,我们在最开头的 parse() 方法前,定义一个 start_requests() 方法,用来批量生成 610 页的 URL,然后通过 scrapy.Request() 方法中的 callback 参数,传递给下面的 parse() 方法进行解析。
1def start_requests(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 pages = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for page in range(1,610): # 一共有610页<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 url = 'https://www.coolapk.com/apk/?page=%s'%page<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5 page = scrapy.Request(url,callback=self.parse)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 pages.append(page)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 return pages<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
以上就是全部页面的爬取思路,爬取成功后,我们需要存储下来。这里,我面选择存储到 MongoDB 中,不得不说,相比 MySQL,MongoDB 要方便省事很多。
2.3.5. 存储结果
我们在 pipelines.py 程序中,定义数据存储方法,MongoDB 的一些参数,比如地址和数据库名称,需单独存放在 settings.py 设置文件中去,然后在 pipelines 程序中进行调用即可。
1import pymongo<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2class MongoPipeline(object):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 def __init__(self,mongo_url,mongo_db):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 self.mongo_url = mongo_url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 self.mongo_db = mongo_db<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 @classmethod<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 def from_crawler(cls,crawler):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 return cls(<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 mongo_url = crawler.settings.get('MONGO_URL'),<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 mongo_db = crawler.settings.get('MONGO_DB')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 )<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12 def open_spider(self,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 self.client = pymongo.MongoClient(self.mongo_url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14 self.db = self.client[self.mongo_db]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15 def process_item(self,item,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 name = item.__class__.__name__<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17 self.db[name].insert(dict(item))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18 return item<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 def close_spider(self,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 self.client.close()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
首先,我们定义一个 MongoPipeline()存储类,里面定义了几个方法,简单进行一下说明:
from crawler() 是一个类方法,用 @class method 标识,这个方法的作用主要是用来获取我们在 settings.py 中设置的这几项参数:
1MONGO_URL = 'localhost'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2MONGO_DB = 'KuAn'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3ITEM_PIPELINES = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 'kuan.pipelines.MongoPipeline': 300,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5}<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
open_spider() 方法主要进行一些初始化操作 ,在 Spider 开启时,这个方法就会被调用 。
process_item() 方法是最重要的方法,实现插入数据到 MongoDB 中。
完成上述代码以后,输入下面一行命令就可以开始整个爬虫的抓取和存储过程了,单机跑的话,6000 个网页需要不少时间才能完成,保持耐心。
1scrapy crawl kuan<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,还有两点补充:
第一,为了减轻网站压力,我们最好在每个请求之间设置几秒延时,可以在 KuanSpider() 方法开头出,加入以下几行代码:
1custom_settings = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 "DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 "CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 }<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
第二,为了更好监控爬虫程序运行,有必要设置输出日志文件,可以通过 Python 自带的 logging 包实现:
1import logging<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4logging.warning("warn message")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5logging.error("error message")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里的 level 参数表示警告级别,严重程度从低到高分别是:DEBUG < INFO < WARNING < ERROR < CRITICAL,如果想日志文件不要记录太多内容,可以设置高一点的级别,这里设置为 WARNING,意味着只有 WARNING 级别以上的信息才会输出到日志中去。
添加 datefmt 参数是为了在每条日志前面加具体的时间,这点很有用处。
以上,我们就完成了整个数据的抓取,有了数据我们就可以着手进行分析,不过这之前还需简单地对数据做一下清洗和处理。
3. 数据清洗处理
首先,我们从 MongoDB 中读取数据并转化为 DataFrame,然后查看一下数据的基本情况。
1def parse_kuan():<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2 client = pymongo.MongoClient(host='localhost', port=27017)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 db = client['KuAn']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 collection = db['KuAnItem']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 # 将数据库数据转为DataFrame<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 data = pd.DataFrame(list(collection.find()))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 print(data.head())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 print(df.shape)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 print(df.info())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 print(df.describe())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
从 data.head() 输出的前 5 行数据中可以看到,除了 score 列是 float 格式以外,其他列都是 object 文本类型。
comment、download、follow、num_score 这 5 列数据中部分行带有「万」字后缀,需要将字符去掉再转换为数值型;volume 体积列,则分别带有「M」和「K」后缀,为了统一大小,则需将「K」除以 1024,转换为 「M」体积。
整个数据一共有 6086 行 x 8 列,每列均没有缺失值。
df.describe() 方法对 score 列做了基本统计,可以看到,所有 App 的平均得分是 3.9 分(5 分制),最低得分 1.6 分,最高得分 4.8 分。
下面,我们将以上几列文本型数据转换为数值型数据,代码实现如下:
1def data_processing(df):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 str = '_ori'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 cols = ['comment','download','follow','num_score','volume']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 for col in cols:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 colori = col+str<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 df[colori] = df[col] # 复制保留原始列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 if not (col == 'volume'):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 df[col] = clean_symbol(df,col)# 处理原始列生成新列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 df[col] = clean_symbol2(df,col)# 处理原始列生成新列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 # 将download单独转换为万单位<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14 df['download'] = df['download'].apply(lambda x:x/10000)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15 # 批量转为数值型<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 df = df.apply(pd.to_numeric,errors='ignore')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18def clean_symbol(df,col):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 # 将字符“万”替换为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 con = df[col].str.contains('万$')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />21 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />22 df[col] = pd.to_numeric(df[col])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />23 return df[col]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />24<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />25def clean_symbol2(df,col):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />26 # 字符M替换为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />27 df[col] = df[col].str.replace('M$','')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />28 # 体积为K的除以 1024 转换为M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />29 con = df[col].str.contains('K$')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />30 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />31 df[col] = pd.to_numeric(df[col])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />32 return df[col]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
以上,就完成了几列文本型数据的转换,我们再来查看一下基本情况:
download 列为 App 下载数量,下载量最多的 App 有 5190 万次,最少的为 0 (很少很少),平均下载次数为 14 万次;从中可以看出以下几点信息:
以上,就完成了基本的数据清洗处理过程,下一期将对这6000多款App进行探索性分析,看看有多少佳软神器你没有使用过哦。
scrapy分页抓取网页(不重载页面的页面器爬取点入(1)_社会万象_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-20 13:36
一种是:点击下一页,只会重新渲染当前页面的一部分
在早期版本的 web-scraper 中,两种抓取方式是不同的。
需要重新加载的页面需要链接选择器
如果不需要重新加载页面,可以使用元素点击选择器
对于某些 网站 可以,但有很大的限制。
经过我的实验,使用Link选择器的第一个原理是取出下一页的a标签的超链接,然后去访问,但是并不是所有的网站的下一页都通过一个标签实现。
如果你使用js监听事件并像下面这样跳转,就不能使用Link选择器了。
新版网络爬虫特别支持导航分页器,并增加了分页选择器,可以完全适用于两种场景。下面我分别演示一下。
无需重新加载页面的分页器抓取
点击具体的CSDN博文,拉到底部查看评论区。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面,评论都属于同一篇文章文章,当您浏览任何页面的评论部分时,无需刷新博文,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点要注意root和next_page的选择,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的站点地图配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器,更精简,效果最好
对应sitemap的配置如下,可以直接导入使用,下载配置文件:
寻呼机抓取以重新加载页面
CSDN博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click什么都做不了,读者可以自行验证,最多爬一页后就关闭了。
而作为分页选择器的分页自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习,下载配置文件:
4.二级页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看它
网络爬虫的操作逻辑与人类似。如果你想抓取更详细的博文信息,你必须打开一个新页面来获取它,而网络爬虫的链接选择器就是这样做的。
爬取路径的拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用,下载配置文件:
5.写在最后
以上整理了分页和二级页面的爬取方案,主要是:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。 查看全部
scrapy分页抓取网页(不重载页面的页面器爬取点入(1)_社会万象_光明网(组图))
一种是:点击下一页,只会重新渲染当前页面的一部分
在早期版本的 web-scraper 中,两种抓取方式是不同的。
需要重新加载的页面需要链接选择器
如果不需要重新加载页面,可以使用元素点击选择器
对于某些 网站 可以,但有很大的限制。
经过我的实验,使用Link选择器的第一个原理是取出下一页的a标签的超链接,然后去访问,但是并不是所有的网站的下一页都通过一个标签实现。
如果你使用js监听事件并像下面这样跳转,就不能使用Link选择器了。

新版网络爬虫特别支持导航分页器,并增加了分页选择器,可以完全适用于两种场景。下面我分别演示一下。
无需重新加载页面的分页器抓取
点击具体的CSDN博文,拉到底部查看评论区。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面,评论都属于同一篇文章文章,当您浏览任何页面的评论部分时,无需刷新博文,因为这种分页不会重新加载页面。

对于这种不需要重新加载页面的点击,可以使用Element Click来解决。

最后一点要注意root和next_page的选择,只有这样才能递归爬取

最终爬取效果如下

使用Element Click的站点地图配置如下,可以直接导入我的配置进行研究,下载配置文件:

当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器,更精简,效果最好

对应sitemap的配置如下,可以直接导入使用,下载配置文件:

寻呼机抓取以重新加载页面
CSDN博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。

对于这种分页器,Element Click什么都做不了,读者可以自行验证,最多爬一页后就关闭了。
而作为分页选择器的分页自然适用

爬取的拓扑同上,这里不再赘述。

对应sitemap的配置如下,可以直接导入学习,下载配置文件:

4.二级页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看它

网络爬虫的操作逻辑与人类似。如果你想抓取更详细的博文信息,你必须打开一个新页面来获取它,而网络爬虫的链接选择器就是这样做的。
爬取路径的拓扑如下

爬取的效果如下

sitemap的配置如下,可以直接导入使用,下载配置文件:

5.写在最后
以上整理了分页和二级页面的爬取方案,主要是:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。
scrapy分页抓取网页(-2.png页面抓取一条数据较为简单(图)信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-04-20 02:27
)
Scrapy 在页面上抓取一条数据相对简单。如果您在一个页面上抓取多条数据,则有一个技巧可以确定循环点的位置。
以简书首页为例。比如抢热门文章,一条信息包括:作者、文章标题、浏览量、评论数、点赞数、打赏数。一页上有多条数据。
-2.png
其实就是把页面上的数据提取出来封装成一个object item,但是最后没有放到采集里面。
物品定义
class JsuserItem(Item):
author = Field()
url = Field()
title = Field()
reads = Field()
comments = Field()
likes = Field()
rewards = Field()
提取数据的循环点应以收录一条信息和多条数据的标签开头,分析页面代码为div>li
-0.png
第一次提取的是一整块内容:(即多个数据块的内容)
infos = selector.xpath('//li/div')
第二次提取该节点下整个区块中的数据字段:
author = info.xpath('p/a/text()').extract()
title = info.xpath('h4/a/text()').extract()
-1.png
完整代码:
def parse(self, response):
selector = Selector(response)
infos = selector.xpath('//li/div')
for info in infos:
item = JsuserItem()
author = info.xpath('p/a/text()').extract()
title = info.xpath('h4/a/text()').extract()
url = info.xpath('h4/a/@href').extract()
reads = info.xpath('div/a[1]/text()').extract()
comments = info.xpath('div/a[2]/text()').extract()
likes = info.xpath('div/span[1]/text()').extract()
#注意有些文章是没有打赏的
rewards = info.xpath('div/span[2]/text()')
if len(rewards)==1 :
rds = info.xpath('div/span[2]/text()').extract()
rds = int(filter(str.isdigit,str(rds[0])))
else:
rds = 0
item['author']=author
item['title']=title
item['url']='http://www.jianshu.com'+url[0]
item['reads']=int(filter(str.isdigit,str(reads[0])))
item['comments']=int(filter(str.isdigit,str(comments[0])))
item['likes']=int(filter(str.isdigit,str(likes[0])))
item['rewards']=rds 查看全部
scrapy分页抓取网页(-2.png页面抓取一条数据较为简单(图)信息
)
Scrapy 在页面上抓取一条数据相对简单。如果您在一个页面上抓取多条数据,则有一个技巧可以确定循环点的位置。
以简书首页为例。比如抢热门文章,一条信息包括:作者、文章标题、浏览量、评论数、点赞数、打赏数。一页上有多条数据。

-2.png
其实就是把页面上的数据提取出来封装成一个object item,但是最后没有放到采集里面。
物品定义
class JsuserItem(Item):
author = Field()
url = Field()
title = Field()
reads = Field()
comments = Field()
likes = Field()
rewards = Field()
提取数据的循环点应以收录一条信息和多条数据的标签开头,分析页面代码为div>li
-0.png
第一次提取的是一整块内容:(即多个数据块的内容)
infos = selector.xpath('//li/div')
第二次提取该节点下整个区块中的数据字段:
author = info.xpath('p/a/text()').extract()
title = info.xpath('h4/a/text()').extract()
-1.png
完整代码:
def parse(self, response):
selector = Selector(response)
infos = selector.xpath('//li/div')
for info in infos:
item = JsuserItem()
author = info.xpath('p/a/text()').extract()
title = info.xpath('h4/a/text()').extract()
url = info.xpath('h4/a/@href').extract()
reads = info.xpath('div/a[1]/text()').extract()
comments = info.xpath('div/a[2]/text()').extract()
likes = info.xpath('div/span[1]/text()').extract()
#注意有些文章是没有打赏的
rewards = info.xpath('div/span[2]/text()')
if len(rewards)==1 :
rds = info.xpath('div/span[2]/text()').extract()
rds = int(filter(str.isdigit,str(rds[0])))
else:
rds = 0
item['author']=author
item['title']=title
item['url']='http://www.jianshu.com'+url[0]
item['reads']=int(filter(str.isdigit,str(reads[0])))
item['comments']=int(filter(str.isdigit,str(comments[0])))
item['likes']=int(filter(str.isdigit,str(likes[0])))
item['rewards']=rds
scrapy分页抓取网页(牛津小马哥web前端工程师陈小妹妹(之前)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-19 16:44
)
原创:陈晓梅,Oxford Pony Brothers Web 前端工程师。
在本文中,我将编写一个网络爬虫,从 OLX 的电子和电器项目中抓取数据。但在我进入代码之前,这里先简要介绍一下 Scrapy 本身。
什么是刮痧?
Scrapy(发音为 Scrapy)是一个用 Python 编写的开源网络爬虫框架。最初是为网页抓取而设计的。目前由 Scrapinghub 维护。
>>>>
创建一个项目。
Scrapy的一个设计思路是一个项目可以收录多个爬虫。这种设计很有用,尤其是在为站点或子域的不同部分编写多个机器人时。所以首先创建项目:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ scrapy startproject olxNew
Scrapy project 'olx', using template directory '//anaconda/lib/python2.7/site-packages/scrapy/templates/project', created in:
/Development/PetProjects/ScrapyCrawlers/olx
You can start your first spider with:
cd olx
scrapy genspider example example.com
>>>>
创建爬虫
我运行了命令 scrapy startproject olx,它将创建一个名为 olx 的项目。接下来,进入新创建的文件夹,执行命令生成第一个爬虫,并带有要爬取的站点的名称和域:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ cd olx/
Adnans-MBP:olx AdnanAhmad$ scrapy genspider electronics www.olx.com.pk
Created spider 'electronics' using template 'basic' in module:
olx.spiders.electronics
下面是 OLX 的“电子”文件部分,最终的项目结构将类似于以下示例:
如您所见,这个新创建的爬虫有一个单独的文件夹。您可以将多个爬虫添加到一个项目中。让我们打开爬虫文件electronics.py。当您打开它时,您将看到以下内容:
# -*- coding: utf-8 -*-
import scrapy
class ElectronicsSpider(scrapy.Spider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = ['http://www.olx.com.pk/']
def parse(self, response):
pass
如您所见,ElectronicsSpider 是 scrapy.Spider 的子类。name 属性其实就是蜘蛛的名字,在spider中指定。allowed_domains 属性告诉我们这个爬虫可以访问哪些域,start_urls 位置是需要首先访问初始 URL 的位置。
parse 顾名思义,这个方法会解析被访问页面的内容。由于我想写一个爬虫到多个页面,我会做一些改变。
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class ElectronicsSpider(CrawlSpider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = [
'https://www.olx.com.pk/compute ... 39%3B,
'https://www.olx.com.pk/tv-video-audio/',
'https://www.olx.com.pk/games-e ... 39%3B
]
rules = (
Rule(LinkExtractor(allow=(), restrict_css=('.pageNextPrev',)),
callback="parse_item",
follow=True),)
def parse_item(self, response):
print('Processing..' + response.url)
为了让爬虫导航到多个页面,我从 scrapy.Spider 子类化为 CrawlSpider。这个类可以更容易地抓取 网站 的许多页面。您可以对生成的代码执行类似的操作,但您需要小心递归以导航下一页。
下一步是设置规则变量。在这里可以设置浏览网站的规则。在 LinkExtractor 中设置一些导航限制。这里我使用restrict_css参数来设置NEXT页面的类。如果您转到此页面并检查元素,您可以找到以下内容:
pageNextPrev 是用于获取下一页链接的类。call_back 参数告诉使用哪种方法来访问页面元素。
请记住,您需要将方法的名称从 parse() 更改为 parse_item() 或其他名称,以避免覆盖基类,否则即使您设置 follow=True ,您的规则也将不起作用。
到现在为止还挺好; 让我们测试一下到目前为止我们制作的爬虫。转到终端,在项目目录中输入:
scrapy crawl electronics
第三个参数其实是蜘蛛的名字,ElectronicsSpiders,之前在类名属性中设置的。在终端中,您会发现许多有助于调试的有用信息。如果不想看到调试信息,可以禁用调试器。此命令类似于 --nologswitch。
scrapy crawl --nolog electronics
如果现在运行,它将显示以下内容:
Adnans-MBP:olx AdnanAhmad$ scrapy crawl --nolog electronics
Processing..https://www.olx.com.pk/compute ... e%3D2
Processing..https://www.olx.com.pk/tv-video-audio/?page=2
Processing..https://www.olx.com.pk/games-entertainment/?page=2
Processing..https://www.olx.com.pk/computers-accessories/
Processing..https://www.olx.com.pk/tv-video-audio/
Processing..https://www.olx.com.pk/games-entertainment/
Processing..https://www.olx.com.pk/compute ... e%3D3
Processing..https://www.olx.com.pk/tv-video-audio/?page=3
Processing..https://www.olx.com.pk/games-entertainment/?page=3
Processing..https://www.olx.com.pk/compute ... e%3D4
Processing..https://www.olx.com.pk/tv-video-audio/?page=4
Processing..https://www.olx.com.pk/games-entertainment/?page=4
Processing..https://www.olx.com.pk/compute ... e%3D5
Processing..https://www.olx.com.pk/tv-video-audio/?page=5
Processing..https://www.olx.com.pk/games-entertainment/?page=5
Processing..https://www.olx.com.pk/compute ... e%3D6
Processing..https://www.olx.com.pk/tv-video-audio/?page=6
Processing..https://www.olx.com.pk/games-entertainment/?page=6
Processing..https://www.olx.com.pk/compute ... e%3D7
Processing..https://www.olx.com.pk/tv-video-audio/?page=7
Processing..https://www.olx.com.pk/games-entertainment/?page=7
由于我设置了follow=True,爬虫会检查NEXT页面的规则,并继续导航,直到到达不满足规则的页面,通常是列表的最后一页。
Scrapy 解除了编写爬虫的所有任务,让我可以专注于主要逻辑,通过编写爬虫来提取信息。
现在,我将继续编写代码以从列表页面获取单个项目链接。我将在 parse_item 方法中对其进行修改。
item_links = response.css('.large > .detailsLink::attr(href)').extract()
for a in item_links:
yield scrapy.Request(a, callback=self.parse_detail_page)
在这里,我使用 .css 响应方法获取链接。您也可以使用 xpath,这取决于您。在这种情况下,它非常简单:
锚链接有一个类 detailsLink。如果您只使用 response.css('.detailsLink'),由于 img 和 h3 标签中的重复链接,它将为单个条目选择重复链接。我还提到了用于唯一链接的大型父类。我之前提取的 href 部分 ::attr(href) 是链接本身。然后,我使用 extract() 方法。
使用此方法的原因是 .css 和 .xpath 返回 SelectorList 对象,而 extract() 有助于返回实际的 DOM 以供进一步处理。最后,我在 scrapy.Request 回调中收录了 yield 链接。我没有检查 Scrapy 的内部代码,但很可能他们使用的是 yield 而不是 A, return 因为你可以生产多个项目。由于爬虫需要同时处理多个链接,因此 yield 是这里的最佳选择。
parse_detail_page 顾名思义,这个方法会解析详情页中的个体信息。所以实际发生的是:
您将获得 parse_item 中的项目列表。
您将它们传递给回调方法以进行进一步处理。
由于它只是一个两层遍历,我可以借助两种方法到达最低层。如果要从OLX主页开始爬,这里要写三个方法:前两个获取子类及其条目,最后一个解析实际信息。知道了?
最后,我将解析实际信息,这些信息可以在与此类似的项目中找到。
解析此页面中的信息没有什么不同,但需要一些操作来存储解析的信息。我们需要为数据定义一个模型。这意味着我们需要告诉 Scrapy 我们想要存储哪些信息以供以后使用。让我们编辑之前由 Scrapy 生成的 item.py 文件。
import scrapy
class OlxItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
OlxItem 我将设置所需字段以保存信息的类。我将为模型类定义三个字段。
class OlxItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
price = scrapy.Field()
url = scrapy.Field()
我将存储帖子的标题、价格和 URL 本身。
让我们回到爬虫类,修改parse_detail_page。
现在,一种方法是开始编写代码,通过运行整个爬虫来测试它,看看你是否走在正确的轨道上,但是 Scrapy 提供了另一个很棒的工具。
>>>>
废壳
Scrapy Shell 是一个命令行工具,允许您在不运行整个爬虫的情况下测试解析代码。与访问所有链接的爬虫不同,Scrapy Shell 保存单个页面的 DOM 以进行数据提取。就我而言,我做了以下事情:
Adnans-MBP:olx AdnanAhmad$ scrapy shell https://www.olx.com.pk/item/as ... 29891
现在我可以轻松地测试代码,而不必一次又一次地访问相同的 URL。我这样做是为了获得标题:
In [8]: response.css('h1::text').extract()[0].strip()
Out[8]: u"Asus Eee PC Atom Dual-Core 4CPU's Beautiful Laptops fresh Stock"
您可以在 response.css 中找到熟悉的内容。由于整个 DOM 都可用,因此您可以使用它。
我通过这样做得到价格:
In [11]: response.css('.pricelabel > strong::text').extract()[0]
Out[11]: u'Rs 10,500'
由于 response.url 返回的是当前访问的 URL,所以不需要做任何事情来获取 url。
现在已经检查了所有代码,是时候将其合并到 parse_detail_page 中了:
title = response.css('h1::text').extract()[0].strip()
price = response.css('.pricelabel > strong::text').extract()[0]
item = OlxItem()
item['title'] = title
item['price'] = price
item['url'] = response.url
yield item
解析所需信息后,OlxItem 将创建实例并设置属性。现在是时候运行爬虫并存储信息了,对命令进行了一些修改:
scrapy crawl electronics -o data.csv -t csv
我正在传递文件名和文件格式来保存数据。运行后,它将为您生成 CSV。很简单,不是吗?与您自己编写的爬虫不同,您必须编写自己的例程来保存数据。
可是等等!它并不止于此,您甚至可以获取 JSON 格式的数据。您所要做的就是使用 -t 开关传递 json。
Scrapy 为您提供了另一个功能。在实际情况下,传递一个固定的文件名没有任何意义。如何生成唯一的文件名?好吧,为此,您需要修改 settings.py 文件并添加以下两个条目:
FEED_URI = 'data/%(name)s/%(time)s.json'
FEED_FORMAT = 'json'
这里我给出文件的模式,%(name)% 是爬虫本身的名字和时间戳。你可以在这里了解更多。现在,当我运行 scrapy crawl --nolog electronics 或 scrapy crawl electronics 时,它会在 data 文件夹中生成一个 JSON 文件,如下所示:
[
{"url": "https://www.olx.com.pk/item/ac ... ot%3B, "price": "Rs 42,000", "title": "Acer Ultra Slim Gaming Laptop with AMD FX Processor 3GB Dedicated"},
{"url": "https://www.olx.com.pk/item/sa ... ot%3B, "price": "Rs 80,000", "title": "Saw Machine"},
{"url": "https://www.olx.com.pk/item/la ... ot%3B, "price": "Rs 22,000", "title": "Laptop HP Probook 6570b Core i 5 3rd Gen"},
{"url": "https://www.olx.com.pk/item/zo ... ot%3B, "price": "Rs 4,000", "title": "Zong 4g could mifi anlock all Sim supported"},
...
] 查看全部
scrapy分页抓取网页(牛津小马哥web前端工程师陈小妹妹(之前)(图)
)
原创:陈晓梅,Oxford Pony Brothers Web 前端工程师。

在本文中,我将编写一个网络爬虫,从 OLX 的电子和电器项目中抓取数据。但在我进入代码之前,这里先简要介绍一下 Scrapy 本身。
什么是刮痧?
Scrapy(发音为 Scrapy)是一个用 Python 编写的开源网络爬虫框架。最初是为网页抓取而设计的。目前由 Scrapinghub 维护。
>>>>
创建一个项目。
Scrapy的一个设计思路是一个项目可以收录多个爬虫。这种设计很有用,尤其是在为站点或子域的不同部分编写多个机器人时。所以首先创建项目:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ scrapy startproject olxNew
Scrapy project 'olx', using template directory '//anaconda/lib/python2.7/site-packages/scrapy/templates/project', created in:
/Development/PetProjects/ScrapyCrawlers/olx
You can start your first spider with:
cd olx
scrapy genspider example example.com
>>>>
创建爬虫
我运行了命令 scrapy startproject olx,它将创建一个名为 olx 的项目。接下来,进入新创建的文件夹,执行命令生成第一个爬虫,并带有要爬取的站点的名称和域:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ cd olx/
Adnans-MBP:olx AdnanAhmad$ scrapy genspider electronics www.olx.com.pk
Created spider 'electronics' using template 'basic' in module:
olx.spiders.electronics
下面是 OLX 的“电子”文件部分,最终的项目结构将类似于以下示例:
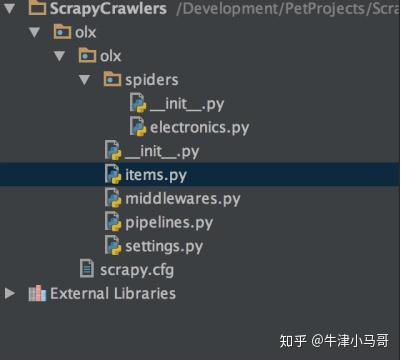
如您所见,这个新创建的爬虫有一个单独的文件夹。您可以将多个爬虫添加到一个项目中。让我们打开爬虫文件electronics.py。当您打开它时,您将看到以下内容:
# -*- coding: utf-8 -*-
import scrapy
class ElectronicsSpider(scrapy.Spider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = ['http://www.olx.com.pk/']
def parse(self, response):
pass
如您所见,ElectronicsSpider 是 scrapy.Spider 的子类。name 属性其实就是蜘蛛的名字,在spider中指定。allowed_domains 属性告诉我们这个爬虫可以访问哪些域,start_urls 位置是需要首先访问初始 URL 的位置。
parse 顾名思义,这个方法会解析被访问页面的内容。由于我想写一个爬虫到多个页面,我会做一些改变。
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class ElectronicsSpider(CrawlSpider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = [
'https://www.olx.com.pk/compute ... 39%3B,
'https://www.olx.com.pk/tv-video-audio/',
'https://www.olx.com.pk/games-e ... 39%3B
]
rules = (
Rule(LinkExtractor(allow=(), restrict_css=('.pageNextPrev',)),
callback="parse_item",
follow=True),)
def parse_item(self, response):
print('Processing..' + response.url)
为了让爬虫导航到多个页面,我从 scrapy.Spider 子类化为 CrawlSpider。这个类可以更容易地抓取 网站 的许多页面。您可以对生成的代码执行类似的操作,但您需要小心递归以导航下一页。
下一步是设置规则变量。在这里可以设置浏览网站的规则。在 LinkExtractor 中设置一些导航限制。这里我使用restrict_css参数来设置NEXT页面的类。如果您转到此页面并检查元素,您可以找到以下内容:
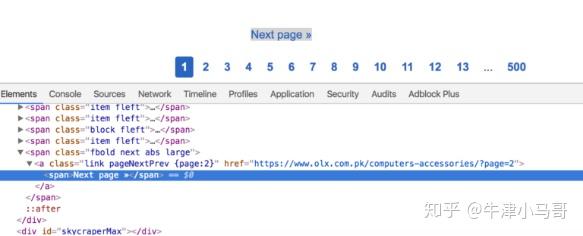
pageNextPrev 是用于获取下一页链接的类。call_back 参数告诉使用哪种方法来访问页面元素。
请记住,您需要将方法的名称从 parse() 更改为 parse_item() 或其他名称,以避免覆盖基类,否则即使您设置 follow=True ,您的规则也将不起作用。
到现在为止还挺好; 让我们测试一下到目前为止我们制作的爬虫。转到终端,在项目目录中输入:
scrapy crawl electronics
第三个参数其实是蜘蛛的名字,ElectronicsSpiders,之前在类名属性中设置的。在终端中,您会发现许多有助于调试的有用信息。如果不想看到调试信息,可以禁用调试器。此命令类似于 --nologswitch。
scrapy crawl --nolog electronics
如果现在运行,它将显示以下内容:
Adnans-MBP:olx AdnanAhmad$ scrapy crawl --nolog electronics
Processing..https://www.olx.com.pk/compute ... e%3D2
Processing..https://www.olx.com.pk/tv-video-audio/?page=2
Processing..https://www.olx.com.pk/games-entertainment/?page=2
Processing..https://www.olx.com.pk/computers-accessories/
Processing..https://www.olx.com.pk/tv-video-audio/
Processing..https://www.olx.com.pk/games-entertainment/
Processing..https://www.olx.com.pk/compute ... e%3D3
Processing..https://www.olx.com.pk/tv-video-audio/?page=3
Processing..https://www.olx.com.pk/games-entertainment/?page=3
Processing..https://www.olx.com.pk/compute ... e%3D4
Processing..https://www.olx.com.pk/tv-video-audio/?page=4
Processing..https://www.olx.com.pk/games-entertainment/?page=4
Processing..https://www.olx.com.pk/compute ... e%3D5
Processing..https://www.olx.com.pk/tv-video-audio/?page=5
Processing..https://www.olx.com.pk/games-entertainment/?page=5
Processing..https://www.olx.com.pk/compute ... e%3D6
Processing..https://www.olx.com.pk/tv-video-audio/?page=6
Processing..https://www.olx.com.pk/games-entertainment/?page=6
Processing..https://www.olx.com.pk/compute ... e%3D7
Processing..https://www.olx.com.pk/tv-video-audio/?page=7
Processing..https://www.olx.com.pk/games-entertainment/?page=7
由于我设置了follow=True,爬虫会检查NEXT页面的规则,并继续导航,直到到达不满足规则的页面,通常是列表的最后一页。
Scrapy 解除了编写爬虫的所有任务,让我可以专注于主要逻辑,通过编写爬虫来提取信息。
现在,我将继续编写代码以从列表页面获取单个项目链接。我将在 parse_item 方法中对其进行修改。
item_links = response.css('.large > .detailsLink::attr(href)').extract()
for a in item_links:
yield scrapy.Request(a, callback=self.parse_detail_page)
在这里,我使用 .css 响应方法获取链接。您也可以使用 xpath,这取决于您。在这种情况下,它非常简单:

锚链接有一个类 detailsLink。如果您只使用 response.css('.detailsLink'),由于 img 和 h3 标签中的重复链接,它将为单个条目选择重复链接。我还提到了用于唯一链接的大型父类。我之前提取的 href 部分 ::attr(href) 是链接本身。然后,我使用 extract() 方法。
使用此方法的原因是 .css 和 .xpath 返回 SelectorList 对象,而 extract() 有助于返回实际的 DOM 以供进一步处理。最后,我在 scrapy.Request 回调中收录了 yield 链接。我没有检查 Scrapy 的内部代码,但很可能他们使用的是 yield 而不是 A, return 因为你可以生产多个项目。由于爬虫需要同时处理多个链接,因此 yield 是这里的最佳选择。
parse_detail_page 顾名思义,这个方法会解析详情页中的个体信息。所以实际发生的是:
您将获得 parse_item 中的项目列表。
您将它们传递给回调方法以进行进一步处理。
由于它只是一个两层遍历,我可以借助两种方法到达最低层。如果要从OLX主页开始爬,这里要写三个方法:前两个获取子类及其条目,最后一个解析实际信息。知道了?
最后,我将解析实际信息,这些信息可以在与此类似的项目中找到。
解析此页面中的信息没有什么不同,但需要一些操作来存储解析的信息。我们需要为数据定义一个模型。这意味着我们需要告诉 Scrapy 我们想要存储哪些信息以供以后使用。让我们编辑之前由 Scrapy 生成的 item.py 文件。
import scrapy
class OlxItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
OlxItem 我将设置所需字段以保存信息的类。我将为模型类定义三个字段。
class OlxItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
price = scrapy.Field()
url = scrapy.Field()
我将存储帖子的标题、价格和 URL 本身。
让我们回到爬虫类,修改parse_detail_page。
现在,一种方法是开始编写代码,通过运行整个爬虫来测试它,看看你是否走在正确的轨道上,但是 Scrapy 提供了另一个很棒的工具。
>>>>
废壳
Scrapy Shell 是一个命令行工具,允许您在不运行整个爬虫的情况下测试解析代码。与访问所有链接的爬虫不同,Scrapy Shell 保存单个页面的 DOM 以进行数据提取。就我而言,我做了以下事情:
Adnans-MBP:olx AdnanAhmad$ scrapy shell https://www.olx.com.pk/item/as ... 29891
现在我可以轻松地测试代码,而不必一次又一次地访问相同的 URL。我这样做是为了获得标题:
In [8]: response.css('h1::text').extract()[0].strip()
Out[8]: u"Asus Eee PC Atom Dual-Core 4CPU's Beautiful Laptops fresh Stock"
您可以在 response.css 中找到熟悉的内容。由于整个 DOM 都可用,因此您可以使用它。
我通过这样做得到价格:
In [11]: response.css('.pricelabel > strong::text').extract()[0]
Out[11]: u'Rs 10,500'
由于 response.url 返回的是当前访问的 URL,所以不需要做任何事情来获取 url。
现在已经检查了所有代码,是时候将其合并到 parse_detail_page 中了:
title = response.css('h1::text').extract()[0].strip()
price = response.css('.pricelabel > strong::text').extract()[0]
item = OlxItem()
item['title'] = title
item['price'] = price
item['url'] = response.url
yield item
解析所需信息后,OlxItem 将创建实例并设置属性。现在是时候运行爬虫并存储信息了,对命令进行了一些修改:
scrapy crawl electronics -o data.csv -t csv
我正在传递文件名和文件格式来保存数据。运行后,它将为您生成 CSV。很简单,不是吗?与您自己编写的爬虫不同,您必须编写自己的例程来保存数据。
可是等等!它并不止于此,您甚至可以获取 JSON 格式的数据。您所要做的就是使用 -t 开关传递 json。
Scrapy 为您提供了另一个功能。在实际情况下,传递一个固定的文件名没有任何意义。如何生成唯一的文件名?好吧,为此,您需要修改 settings.py 文件并添加以下两个条目:
FEED_URI = 'data/%(name)s/%(time)s.json'
FEED_FORMAT = 'json'
这里我给出文件的模式,%(name)% 是爬虫本身的名字和时间戳。你可以在这里了解更多。现在,当我运行 scrapy crawl --nolog electronics 或 scrapy crawl electronics 时,它会在 data 文件夹中生成一个 JSON 文件,如下所示:
[
{"url": "https://www.olx.com.pk/item/ac ... ot%3B, "price": "Rs 42,000", "title": "Acer Ultra Slim Gaming Laptop with AMD FX Processor 3GB Dedicated"},
{"url": "https://www.olx.com.pk/item/sa ... ot%3B, "price": "Rs 80,000", "title": "Saw Machine"},
{"url": "https://www.olx.com.pk/item/la ... ot%3B, "price": "Rs 22,000", "title": "Laptop HP Probook 6570b Core i 5 3rd Gen"},
{"url": "https://www.olx.com.pk/item/zo ... ot%3B, "price": "Rs 4,000", "title": "Zong 4g could mifi anlock all Sim supported"},
...
]
scrapy分页抓取网页(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-18 12:34
"
阅读这篇文章大约需要 7 分钟。
"
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但是我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以来这个网站()下载crx文件,然后离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
# 2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
直译为网站map,有了这个地图爬虫就可以跟着它获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个使用最频繁、覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,我们才能递归地爬取网站的全部数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机爬取
爬取数据最经典的模型是列表、分页和明细。接下来我就围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它提供了对导航分页器的特殊支持,并增加了一个分页选择器,可以完全适用于两种场景,我将在下面进行演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应sitemap的配置如下,可以直接导入使用,下载配置文件:
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习,下载配置文件:
# 4. 次要页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用,下载配置文件:
# 5. 最后
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。 查看全部
scrapy分页抓取网页(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
"
阅读这篇文章大约需要 7 分钟。
"
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但是我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以来这个网站()下载crx文件,然后离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
# 2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
直译为网站map,有了这个地图爬虫就可以跟着它获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个使用最频繁、覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。

Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,我们才能递归地爬取网站的全部数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
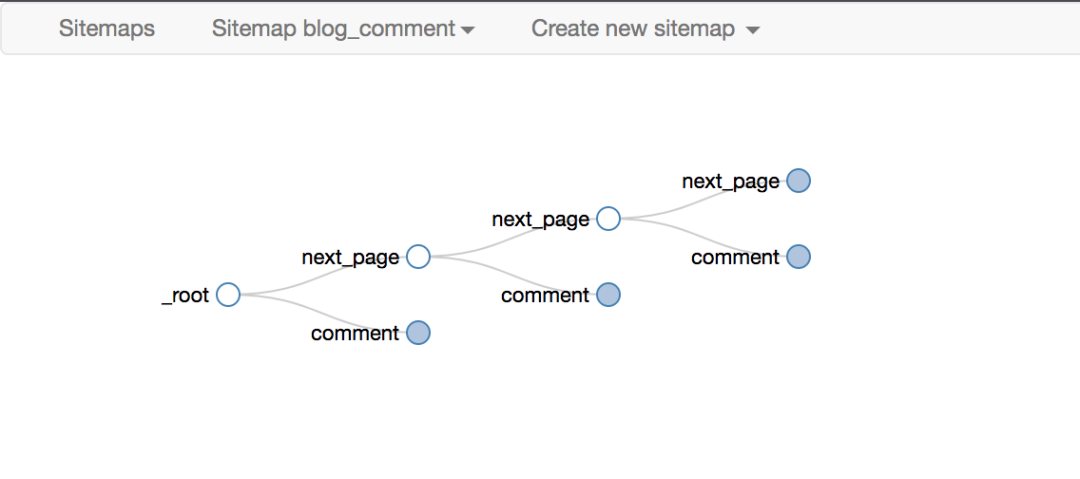
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
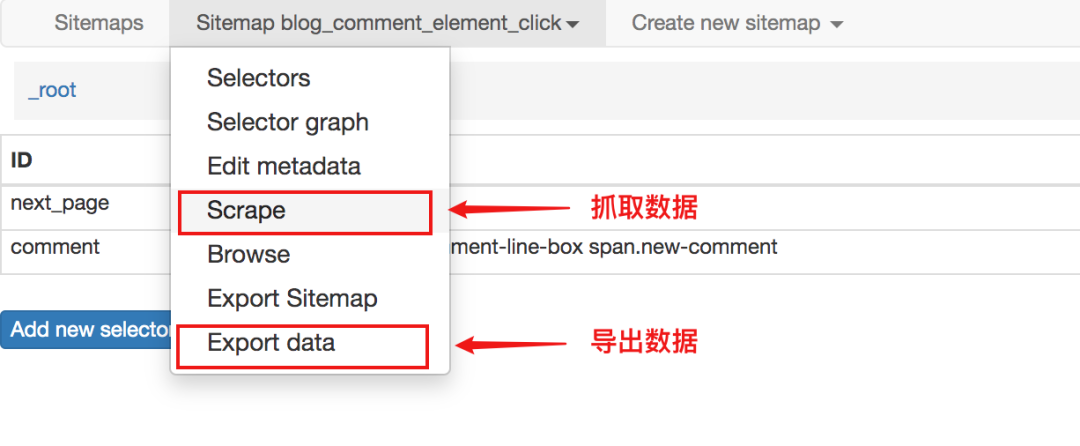
# 3. 寻呼机爬取
爬取数据最经典的模型是列表、分页和明细。接下来我就围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
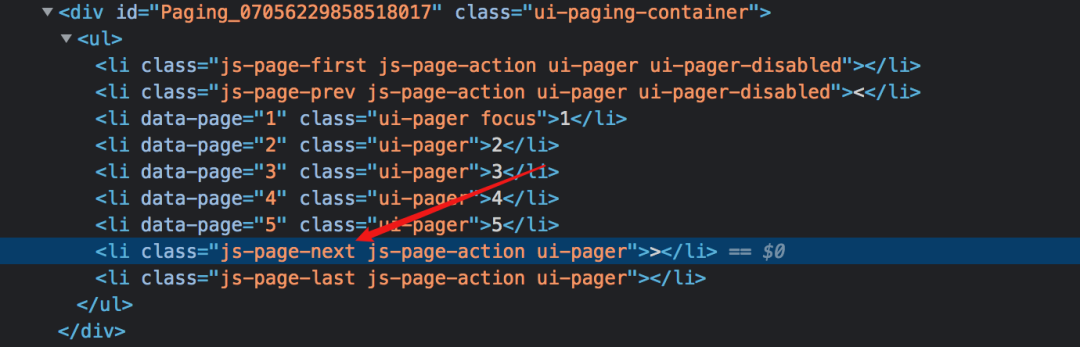
在新版本的网络爬虫中,它提供了对导航分页器的特殊支持,并增加了一个分页选择器,可以完全适用于两种场景,我将在下面进行演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
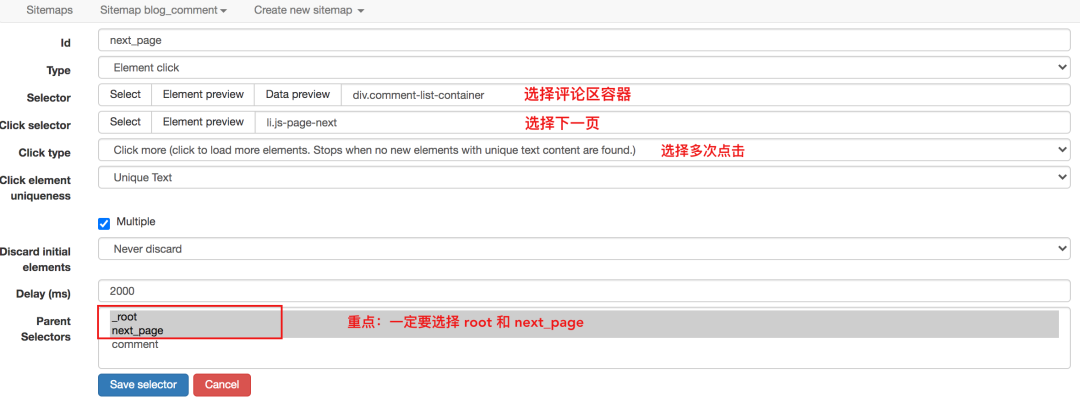
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
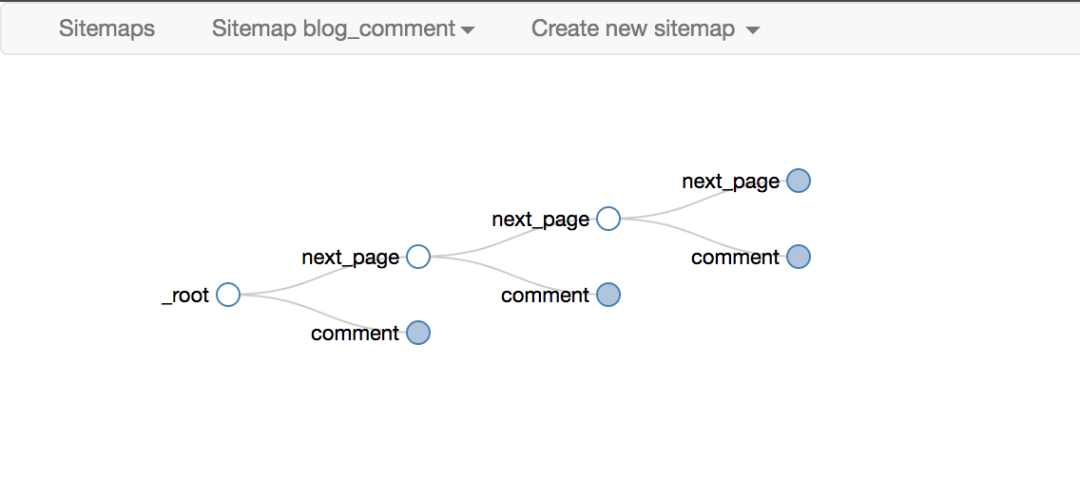
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:

当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
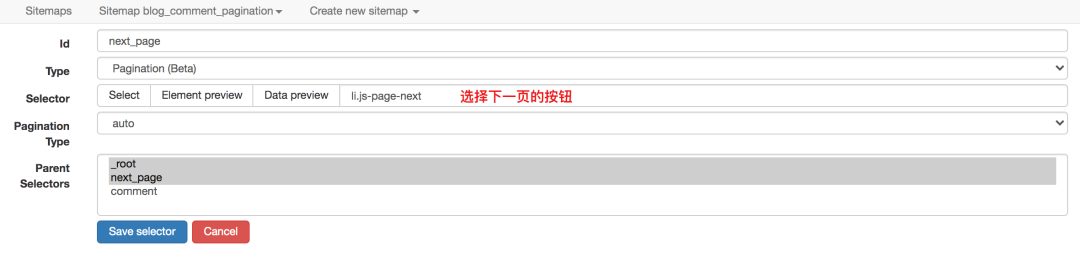
对应sitemap的配置如下,可以直接导入使用,下载配置文件:

寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。

对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
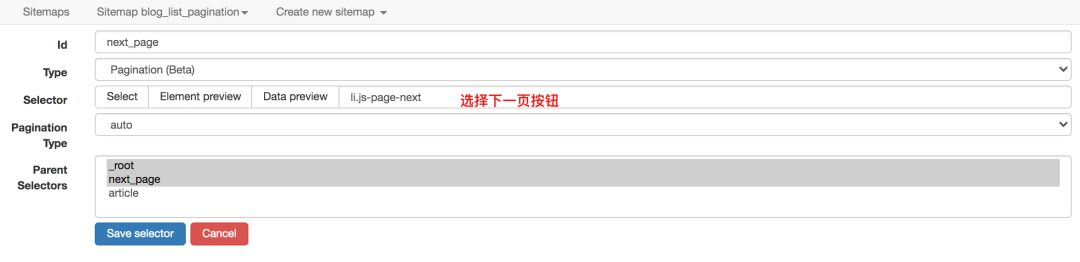
爬取的拓扑同上,这里不再赘述。
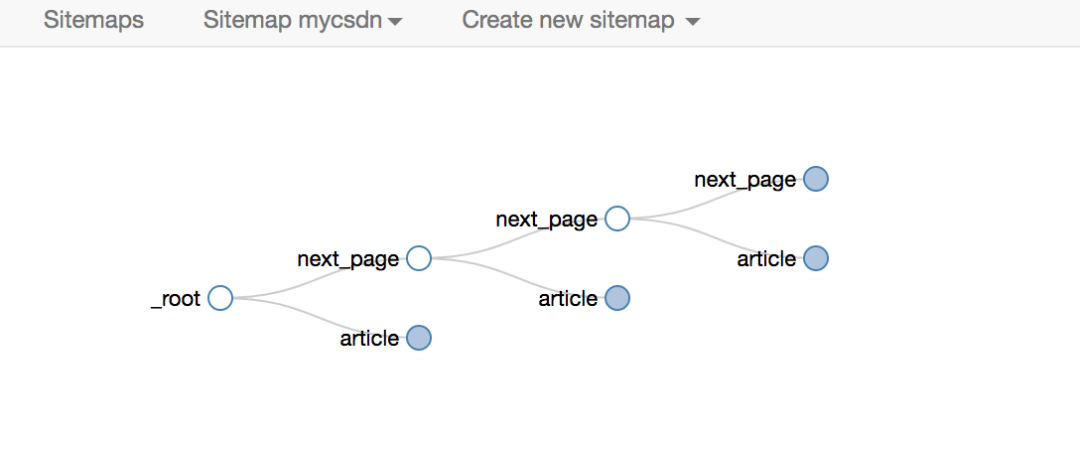
对应sitemap的配置如下,可以直接导入学习,下载配置文件:

# 4. 次要页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
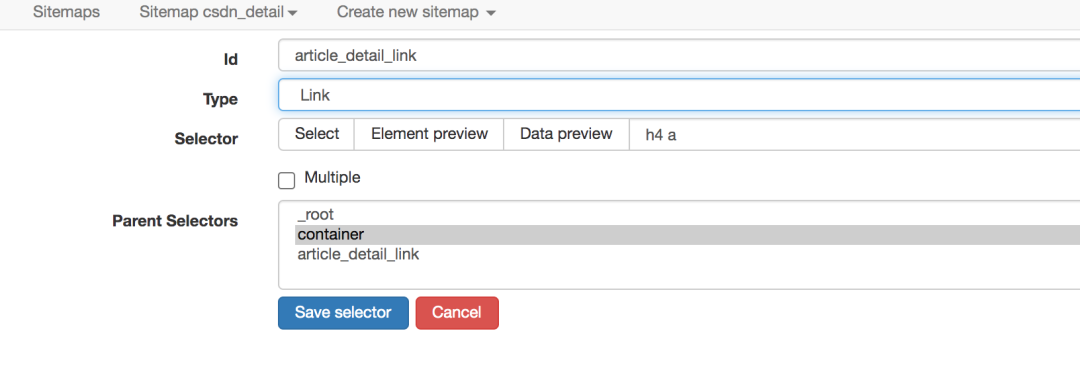
爬取路径拓扑如下
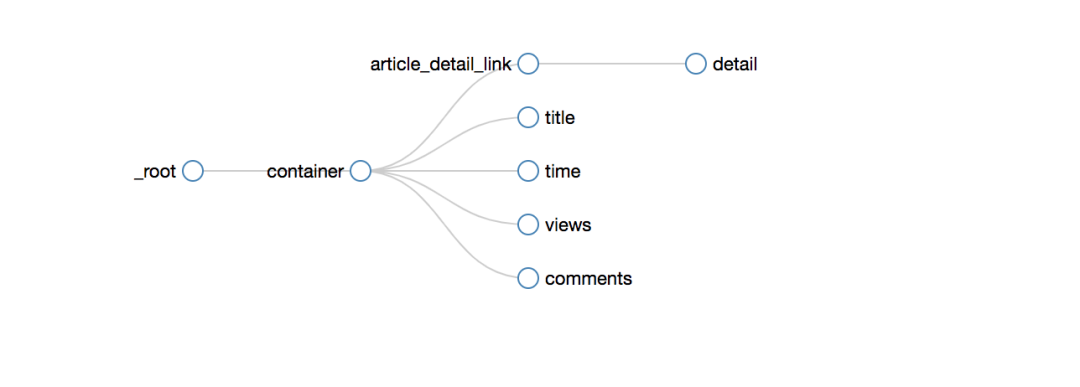
爬取的效果如下
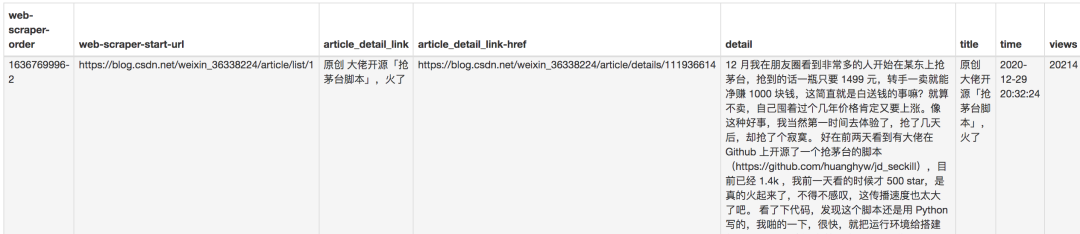
sitemap的配置如下,可以直接导入使用,下载配置文件:
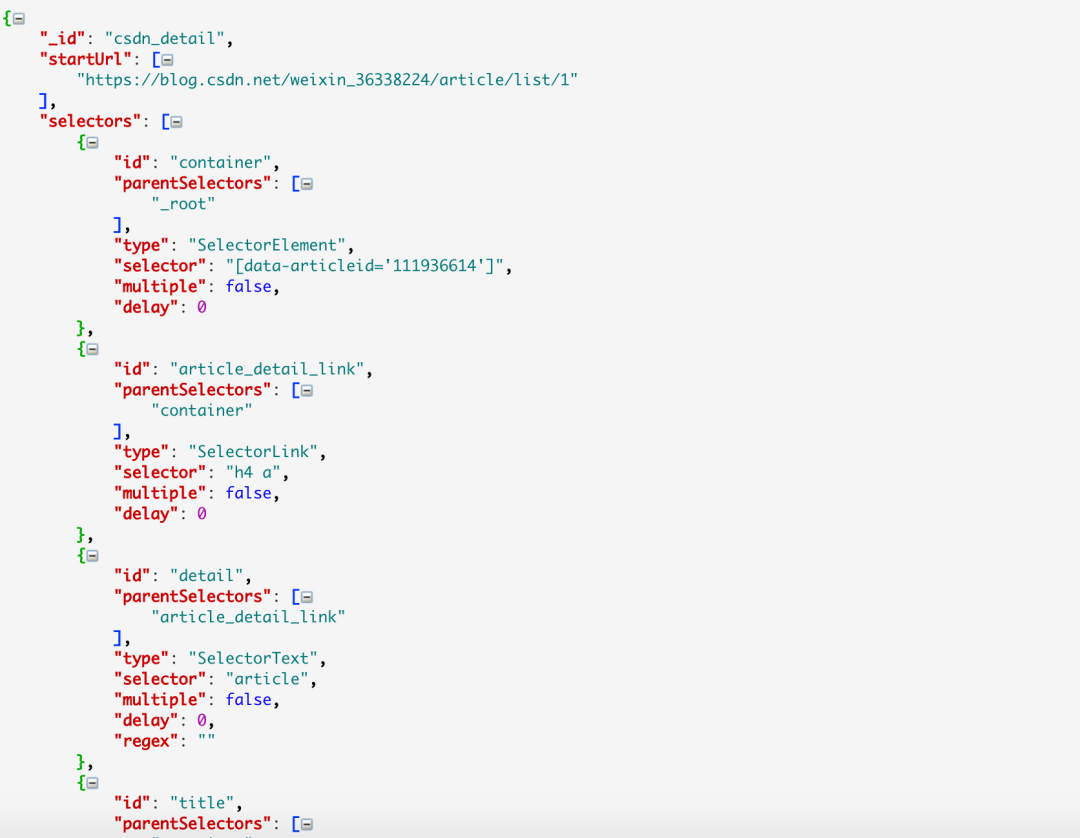
# 5. 最后
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。
scrapy分页抓取网页( ByShinChanPublished92014atglance)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-13 20:32
ByShinChanPublished92014atglance)
Scrapy爬虫爬取网站数据
由ShinChan
2014 年 11 月 9 日出版
内容
一目了然
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下:
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据的采集工作,它为我们做了很多工作,无需自己开发。
Scrapy 教程
在本文中,假设您已经安装了 Scrapy。如果没有,请参考。
下面以爬取饮用水源BBS数据为例说明爬取过程。详情请参考 bbsdmoz 代码。
本教程将带您完成以下任务:
1. 创建一个Scrapy项目
2. 定义提取的Item
3. 编写爬取网站的 spider 并提取 Item
4. 编写 Item Pipeline 来存储提取到的Item(即数据)
Scrapy 是用 Python 编写的。如果你是语言新手,对这门语言的特点和 Scrapy 的细节感到好奇,对于已经熟悉其他语言并想快速学习 Python 的编程老手,我们推荐 Learn Python The Hard Way,进行编程想要开始学习 Python 的初学者,非编程的 Python 学习资料列表供您选择。
创建项目
在开始抓取之前,您必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
1
scrapy startproject bbsdmoz
此命令将创建具有以下内容的 bbsDmoz 目录:
bbsDmoz/
scrapy.cfg
bbsDmoz/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
定义我们的项目
item是爬取数据的容器;它的用法类似于 python 字典,它提供了额外的保护来防止由拼写错误导致的未定义字段错误。
与您在 ORM 中所做的类似,您可以通过创建一个 scrapy.Item 类并定义一个类型为 scrapy.Field 的类属性来定义一个 Item。(如果你不懂ORM,别担心,你会发现这一步很简单)
首先根据从bbs网站获取的数据对item进行建模。我们需要从中获取 url、post board、poster 和 post 的内容。为此,请在 item.xml 中定义相应的字段。编辑 bbsDmoz 目录中的 items.py 文件:
123456789101112
# -*- coding: utf-8 -*-# Define here the models for your scraped items# See documentation in:# http://doc.scrapy.org/en/lates ... lfrom scrapy.item import Item, Fieldclass BbsDmozItem(Item): # define the fields for your item here like: # name = scrapy.Field() url = Field() forum = Field() poster = Field() content = Field()
起初这可能看起来很复杂,但是通过定义一个项目,您可以轻松地使用其他 Scrapy 方法。而这些方法需要知道你的item的定义。
我们的第一只蜘蛛
蜘蛛是用户编写的类,用于从单个 网站(或某些 网站)中抓取数据。
它包括一个用于下载的初始URL,如何跟踪网页中的链接以及如何分析页面中的内容,以及提取生成项目的方法。
创建蜘蛛
为了创建一个存储在 bbsDmoz/spiders 中的 Spider,您必须扩展 scrapy.Spider 类并定义以下三个属性:
选择器选择器
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 和 CSS 表达式的机制:. 有关选择器和其他提取机制的信息,请参见此处。
我们使用 XPath 选择要从页面的 HTML 源中提取的数据。以下是 XPath 表达式及其对应含义的示例:
以饮水思源论坛首页为例:
查看 HTML 页面源并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以发现poster是收录在pre/a标签中的,这里是userid=jasperstream:
123
...[回复本文][原帖] 发信人: jasperstream
所以可以提取jasperstream的XPath表达式为:
1
'//pre/a/text()'
同理,我可以提取其他内容的XPath,提取后最好验证其正确性。以上只是几个简单的 XPath 示例,XPath 实际上远比这强大。如果您想了解更多信息,我们推荐此 XPath 教程。
为了配合XPath,除了提供Selector之外,Scrapy还提供了避免每次从response中提取数据都生成selector的麻烦的方法。
Selector 有四种基本方法(点击对应方法查看详细 API 文档):
比如提取上面的poster数据:
1
sel.xpath('//pre/a/text()').extract()
使用物品
项目对象是自定义 python 字典。您可以使用标准字典语法来获取其每个字段的值(该字段是我们之前用 Field 分配的属性)。一般来说,爬虫会将爬取的数据作为Item对象返回。
蜘蛛代码
以下是我们的第一个蜘蛛代码,保存在 bbsDmoz/spiders 目录下的 forumSpider.py 文件中:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950
#-*- coding: utf-8 -*-'''bbsSpider, Created on Oct, 2014#version: 1.0#author: chenqx @http://chenqx.github.comSee more: http://doc.scrapy.org/en/latest/index.html'''from scrapy.selector import Selectorfrom scrapy.http import Requestfrom scrapy.contrib.spiders import CrawlSpiderfrom scrapy.contrib.loader import ItemLoaderfrom scrapy.contrib.linkextractors.sgml import SgmlLinkExtractorfrom bbs.items import BbsItemclass forumSpider(CrawlSpider): # name of spiders name = 'bbsSpider' allow_domain = ['bbs.sjtu.edu.cn'] start_urls = [ 'https://bbs.sjtu.edu.cn/bbsall' ] link_extractor = { 'page': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+\.html$'), 'page_down': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+,page,\d+\.html$'), 'content': SgmlLinkExtractor(allow = '/bbscon,board,\w+,file,M\.\d+\.A\.html$'), } _x_query = { 'page_content': '//pre/text()[2]', 'poster' : '//pre/a/text()', 'forum' : '//center/text()[2]', } def parse(self, response): for link in self.link_extractor['page'].extract_links(response): yield Request(url = link.url, callback=self.parse_page) def parse_page(self, response): for link in self.link_extractor['page_down'].extract_links(response): yield Request(url = link.url, callback=self.parse_page) for link in self.link_extractor['content'].extract_links(response): yield Request(url = link.url, callback=self.parse_content) def parse_content(self, response): bbsItem_loader = ItemLoader(item=BbsItem(), response = response) url = str(response.url) bbsItem_loader.add_value('url', url) bbsItem_loader.add_xpath('forum', self._x_query['forum']) bbsItem_loader.add_xpath('poster', self._x_query['poster']) bbsItem_loader.add_xpath('content', self._x_query['page_content']) return bbsItem_loader.load_item()
定义项目管道
在Spider中采集到Item后,会传递给Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个项目管道组件(有时称为“项目管道”)都是一个实现简单方法的 Python 类。他们接收项目并对其执行一些操作,并且还决定该项目是继续通过管道还是被丢弃而不进行进一步处理。
以下是item pipeline的一些典型应用:
编写项目管道
编写自己的项目管道很简单,每个项目管道组件都是一个单独的 Python 类,并且必须实现以下方法:
process_item(item, spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。
参数:item (Item object) – 由 parse 方法返回的 Item 对象
spider (Spider object) – 抓取到这个 Item 对象对应的爬虫对象
此外,他们还可以实现以下方法:
open_spider(spider)
当spider被开启时,这个方法被调用。
参数: spider (Spider object) – 被开启的spider
close_spider(spider)
当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。
参数: spider (Spider object) – 被关闭的spider
本文爬虫的item pipeline如下,保存为xml文件:
12345678910111213141516171819202122232425262728293031
# -*- coding: utf-8 -*-# Define your item pipelines here# Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: http://doc.scrapy.org/en/lates ... lfrom scrapy import signalsfrom scrapy import logfrom bbsDmoz.items import BbsDmozItemfrom twisted.enterprise import adbapifrom scrapy.contrib.exporter import XmlItemExporterfrom dataProcess import dataProcessclass XmlWritePipeline(object): def __init__(self): pass @classmethod def from_crawler(cls, crawler): pipeline = cls() crawler.signals.connect(pipeline.spider_opened, signals.spider_opened) crawler.signals.connect(pipeline.spider_closed, signals.spider_closed) return pipeline def spider_opened(self, spider): self.file = open('bbsData.xml', 'wb') self.expoter = XmlItemExporter(self.file) self.expoter.start_exporting() def spider_closed(self, spider): self.expoter.finish_exporting() self.file.close() # process the crawled data, define and call dataProcess function # dataProcess('bbsData.xml', 'text.txt') def process_item(self, item, spider): self.expoter.export_item(item) return item
启用和设置项目管道
为了启用 Item Pipeline 组件,您必须将其类添加到 ITEM_PIPELINES,如下例所示:
123
ITEM_PIPELINES = { 'bbsDmoz.pipelines.XmlWritePipeline': 1000,}
分配给每个类的整数值决定了它们运行的顺序,项目按数字顺序从低到高,通过管道,这些数字通常定义在 0-1000 范围内。
设置
Scrapy 设置(settings)提供了一种自定义 Scrapy 组件的方法。您可以控制包括核心、扩展、管道和蜘蛛在内的组件。
这些设置为代码提供了一个全局命名空间,可以从中提取键值映射配置值。可以通过下面描述的各种机制来设置设置。
设置也是一种选择当前活动的 Scrapy 项目(如果你有多个)的方法。
在设置配置文件中,可以指定抓拍的速率,是否在桌面显示抓拍进程信息等,具体请参考。
该爬虫的设置配置如下:
12345678910111213141516
# -*- coding: utf-8 -*-# Scrapy settings for bbs project# For simplicity, this file contains only the most important settings by# default. All the other settings are documented here:# http://doc.scrapy.org/en/lates ... _NAME = 'bbsDomz'CONCURRENT_REQUESTS = 200LOG_LEVEL = 'INFO'COOKIES_ENABLED = TrueRETRY_ENABLED = TrueSPIDER_MODULES = ['bbsDomz.spiders']NEWSPIDER_MODULE = 'bbsDomz.spiders'# JOBDIR = 'jobdir'ITEM_PIPELINES = { 'bbsDomz.pipelines.XmlWritePipeline': 1000,}
爬行
爬虫程序写好后,我们就可以运行程序来抓取数据了。进入项目 bbsDomz/ 的根目录,执行以下命令启动蜘蛛:
1
scrapy crawl bbsSpider
这样您就可以等到程序完成运行。
进一步阅读 查看全部
scrapy分页抓取网页(
ByShinChanPublished92014atglance)
Scrapy爬虫爬取网站数据
由ShinChan
2014 年 11 月 9 日出版
内容
一目了然
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下:

Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据的采集工作,它为我们做了很多工作,无需自己开发。
Scrapy 教程
在本文中,假设您已经安装了 Scrapy。如果没有,请参考。
下面以爬取饮用水源BBS数据为例说明爬取过程。详情请参考 bbsdmoz 代码。
本教程将带您完成以下任务:
1. 创建一个Scrapy项目
2. 定义提取的Item
3. 编写爬取网站的 spider 并提取 Item
4. 编写 Item Pipeline 来存储提取到的Item(即数据)
Scrapy 是用 Python 编写的。如果你是语言新手,对这门语言的特点和 Scrapy 的细节感到好奇,对于已经熟悉其他语言并想快速学习 Python 的编程老手,我们推荐 Learn Python The Hard Way,进行编程想要开始学习 Python 的初学者,非编程的 Python 学习资料列表供您选择。
创建项目
在开始抓取之前,您必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
1
scrapy startproject bbsdmoz
此命令将创建具有以下内容的 bbsDmoz 目录:
bbsDmoz/
scrapy.cfg
bbsDmoz/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
定义我们的项目
item是爬取数据的容器;它的用法类似于 python 字典,它提供了额外的保护来防止由拼写错误导致的未定义字段错误。
与您在 ORM 中所做的类似,您可以通过创建一个 scrapy.Item 类并定义一个类型为 scrapy.Field 的类属性来定义一个 Item。(如果你不懂ORM,别担心,你会发现这一步很简单)
首先根据从bbs网站获取的数据对item进行建模。我们需要从中获取 url、post board、poster 和 post 的内容。为此,请在 item.xml 中定义相应的字段。编辑 bbsDmoz 目录中的 items.py 文件:
123456789101112
# -*- coding: utf-8 -*-# Define here the models for your scraped items# See documentation in:# http://doc.scrapy.org/en/lates ... lfrom scrapy.item import Item, Fieldclass BbsDmozItem(Item): # define the fields for your item here like: # name = scrapy.Field() url = Field() forum = Field() poster = Field() content = Field()
起初这可能看起来很复杂,但是通过定义一个项目,您可以轻松地使用其他 Scrapy 方法。而这些方法需要知道你的item的定义。
我们的第一只蜘蛛
蜘蛛是用户编写的类,用于从单个 网站(或某些 网站)中抓取数据。
它包括一个用于下载的初始URL,如何跟踪网页中的链接以及如何分析页面中的内容,以及提取生成项目的方法。
创建蜘蛛
为了创建一个存储在 bbsDmoz/spiders 中的 Spider,您必须扩展 scrapy.Spider 类并定义以下三个属性:
选择器选择器
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 和 CSS 表达式的机制:. 有关选择器和其他提取机制的信息,请参见此处。
我们使用 XPath 选择要从页面的 HTML 源中提取的数据。以下是 XPath 表达式及其对应含义的示例:
以饮水思源论坛首页为例:
查看 HTML 页面源并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以发现poster是收录在pre/a标签中的,这里是userid=jasperstream:
123
...[回复本文][原帖] 发信人: jasperstream
所以可以提取jasperstream的XPath表达式为:
1
'//pre/a/text()'
同理,我可以提取其他内容的XPath,提取后最好验证其正确性。以上只是几个简单的 XPath 示例,XPath 实际上远比这强大。如果您想了解更多信息,我们推荐此 XPath 教程。
为了配合XPath,除了提供Selector之外,Scrapy还提供了避免每次从response中提取数据都生成selector的麻烦的方法。
Selector 有四种基本方法(点击对应方法查看详细 API 文档):
比如提取上面的poster数据:
1
sel.xpath('//pre/a/text()').extract()
使用物品
项目对象是自定义 python 字典。您可以使用标准字典语法来获取其每个字段的值(该字段是我们之前用 Field 分配的属性)。一般来说,爬虫会将爬取的数据作为Item对象返回。
蜘蛛代码
以下是我们的第一个蜘蛛代码,保存在 bbsDmoz/spiders 目录下的 forumSpider.py 文件中:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950
#-*- coding: utf-8 -*-'''bbsSpider, Created on Oct, 2014#version: 1.0#author: chenqx @http://chenqx.github.comSee more: http://doc.scrapy.org/en/latest/index.html'''from scrapy.selector import Selectorfrom scrapy.http import Requestfrom scrapy.contrib.spiders import CrawlSpiderfrom scrapy.contrib.loader import ItemLoaderfrom scrapy.contrib.linkextractors.sgml import SgmlLinkExtractorfrom bbs.items import BbsItemclass forumSpider(CrawlSpider): # name of spiders name = 'bbsSpider' allow_domain = ['bbs.sjtu.edu.cn'] start_urls = [ 'https://bbs.sjtu.edu.cn/bbsall' ] link_extractor = { 'page': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+\.html$'), 'page_down': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+,page,\d+\.html$'), 'content': SgmlLinkExtractor(allow = '/bbscon,board,\w+,file,M\.\d+\.A\.html$'), } _x_query = { 'page_content': '//pre/text()[2]', 'poster' : '//pre/a/text()', 'forum' : '//center/text()[2]', } def parse(self, response): for link in self.link_extractor['page'].extract_links(response): yield Request(url = link.url, callback=self.parse_page) def parse_page(self, response): for link in self.link_extractor['page_down'].extract_links(response): yield Request(url = link.url, callback=self.parse_page) for link in self.link_extractor['content'].extract_links(response): yield Request(url = link.url, callback=self.parse_content) def parse_content(self, response): bbsItem_loader = ItemLoader(item=BbsItem(), response = response) url = str(response.url) bbsItem_loader.add_value('url', url) bbsItem_loader.add_xpath('forum', self._x_query['forum']) bbsItem_loader.add_xpath('poster', self._x_query['poster']) bbsItem_loader.add_xpath('content', self._x_query['page_content']) return bbsItem_loader.load_item()
定义项目管道
在Spider中采集到Item后,会传递给Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个项目管道组件(有时称为“项目管道”)都是一个实现简单方法的 Python 类。他们接收项目并对其执行一些操作,并且还决定该项目是继续通过管道还是被丢弃而不进行进一步处理。
以下是item pipeline的一些典型应用:
编写项目管道
编写自己的项目管道很简单,每个项目管道组件都是一个单独的 Python 类,并且必须实现以下方法:
process_item(item, spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。
参数:item (Item object) – 由 parse 方法返回的 Item 对象
spider (Spider object) – 抓取到这个 Item 对象对应的爬虫对象
此外,他们还可以实现以下方法:
open_spider(spider)
当spider被开启时,这个方法被调用。
参数: spider (Spider object) – 被开启的spider
close_spider(spider)
当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。
参数: spider (Spider object) – 被关闭的spider
本文爬虫的item pipeline如下,保存为xml文件:
12345678910111213141516171819202122232425262728293031
# -*- coding: utf-8 -*-# Define your item pipelines here# Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: http://doc.scrapy.org/en/lates ... lfrom scrapy import signalsfrom scrapy import logfrom bbsDmoz.items import BbsDmozItemfrom twisted.enterprise import adbapifrom scrapy.contrib.exporter import XmlItemExporterfrom dataProcess import dataProcessclass XmlWritePipeline(object): def __init__(self): pass @classmethod def from_crawler(cls, crawler): pipeline = cls() crawler.signals.connect(pipeline.spider_opened, signals.spider_opened) crawler.signals.connect(pipeline.spider_closed, signals.spider_closed) return pipeline def spider_opened(self, spider): self.file = open('bbsData.xml', 'wb') self.expoter = XmlItemExporter(self.file) self.expoter.start_exporting() def spider_closed(self, spider): self.expoter.finish_exporting() self.file.close() # process the crawled data, define and call dataProcess function # dataProcess('bbsData.xml', 'text.txt') def process_item(self, item, spider): self.expoter.export_item(item) return item
启用和设置项目管道
为了启用 Item Pipeline 组件,您必须将其类添加到 ITEM_PIPELINES,如下例所示:
123
ITEM_PIPELINES = { 'bbsDmoz.pipelines.XmlWritePipeline': 1000,}
分配给每个类的整数值决定了它们运行的顺序,项目按数字顺序从低到高,通过管道,这些数字通常定义在 0-1000 范围内。
设置
Scrapy 设置(settings)提供了一种自定义 Scrapy 组件的方法。您可以控制包括核心、扩展、管道和蜘蛛在内的组件。
这些设置为代码提供了一个全局命名空间,可以从中提取键值映射配置值。可以通过下面描述的各种机制来设置设置。
设置也是一种选择当前活动的 Scrapy 项目(如果你有多个)的方法。
在设置配置文件中,可以指定抓拍的速率,是否在桌面显示抓拍进程信息等,具体请参考。
该爬虫的设置配置如下:
12345678910111213141516
# -*- coding: utf-8 -*-# Scrapy settings for bbs project# For simplicity, this file contains only the most important settings by# default. All the other settings are documented here:# http://doc.scrapy.org/en/lates ... _NAME = 'bbsDomz'CONCURRENT_REQUESTS = 200LOG_LEVEL = 'INFO'COOKIES_ENABLED = TrueRETRY_ENABLED = TrueSPIDER_MODULES = ['bbsDomz.spiders']NEWSPIDER_MODULE = 'bbsDomz.spiders'# JOBDIR = 'jobdir'ITEM_PIPELINES = { 'bbsDomz.pipelines.XmlWritePipeline': 1000,}
爬行
爬虫程序写好后,我们就可以运行程序来抓取数据了。进入项目 bbsDomz/ 的根目录,执行以下命令启动蜘蛛:
1
scrapy crawl bbsSpider
这样您就可以等到程序完成运行。
进一步阅读
scrapy分页抓取网页(项目文件创建好怎么写爬虫程序?程序怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-11 20:00
项目文件创建完成后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
class KuanItem(scrapy.Item):<br /># define the fields for your item here like:<br />name = scrapy.Field()<br />volume = scrapy.Field()<br />download = scrapy.Field()<br />follow = scrapy.Field()<br />comment = scrapy.Field()<br />tags = scrapy.Field()<br />score = scrapy.Field()<br />num_score = scrapy.Field()<br />
这里的字段信息是我们之前在网页中定位的8个字段信息,包括:name代表app的名称,volume代表音量,download代表下载次数。在这里定义好之后,我们会在后续的爬取主程序中用到这些字段信息。
2.3.3.爬取主程序
创建kuan项目后,Scrapy框架会自动生成一些爬取的代码。接下来,我们需要在parse方法中添加网页抓取的字段解析内容。
class KuspiderSpider(scrapy.Spider):<br /> name = 'kuan'<br /> allowed_domains = ['www.coolapk.com']<br /> start_urls = ['http://www.coolapk.com/']<br /><br /> def parse(self, response):<br /> pass<br />
在首页打开Dev Tools,找到每个抓取索引的节点位置,然后使用CSS、Xpath、regular等方法提取解析。这些方法都是 Scrapy 支持的,可以随意选择。这里我们使用 CSS 语法来定位节点,但需要注意的是,Scrapy 的 CSS 语法与我们之前使用 pyquery 的 CSS 语法略有不同。让我们举几个例子来比较一下。
首先,我们定位到第一个APP的首页URL节点。可以看到URL节点位于class属性为app_left_list的div节点下的a节点中,其href属性就是我们需要的URL信息,这里是相对地址,拼接后就是完整的URL:。
然后我们进入Kuan详情页面,选择app名称并定位。可以看到app name节点位于class属性为.detail_app_title的p节点的文本中。
定位到这两个节点后,我们就可以使用CSS来提取字段信息了。下面是常规写法和Scrapy中写法的对比:
# 常规写法<br />url = item('.app_left_list>a').attr('href')<br />name = item('.list_app_title').text()<br /># Scrapy 写法<br />url = item.css('::attr("href")').extract_first()<br />name = item.css('.detail_app_title::text').extract_first()<br />
如您所见,要获取 href 或 text 属性,您需要使用 :: 来表示它。例如,要获取文本,请使用 ::text。 extract_first() 表示提取第一个元素,如果有多个元素,使用 extract() 。然后,我们可以参考解析代码写出8个字段的信息。
首先,我们需要在首页提取应用的URL列表,然后进入每个应用的详情页,进一步提取8个字段的信息。
def parse(self, response):<br /> contents = response.css('.app_left_list>a')<br /> for content in contents:<br /> url = content.css('::attr("href")').extract_first()<br /> url = response.urljoin(url) # 拼接相对 url 为绝对 url<br /> yield scrapy.Request(url,callback=self.parse_url)<br />
这里使用response.urljoin()方法将提取出来的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传递两个参数:url和callback,url是详情页的URL,callback是回调函数,它将首页URL请求返回的响应传递给专门用于解析字段内容的parse_url()方法,如如下图:
def parse_url(self,response):<br /> item = KuanItem()<br /> item['name'] = response.css('.detail_app_title::text').extract_first()<br /> results = self.get_comment(response)<br /> item['volume'] = results[0]<br /> item['download'] = results[1]<br /> item['follow'] = results[2]<br /> item['comment'] = results[3]<br /> item['tags'] = self.get_tags(response)<br /> item['score'] = response.css('.rank_num::text').extract_first()<br /> num_score = response.css('.apk_rank_p1::text').extract_first()<br /> item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)<br /> yield item<br /> <br />def get_comment(self,response):<br /> messages = response.css('.apk_topba_message::text').extract_first()<br /> result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上<br /> if result: # 不为空<br /> results = list(result[0]) # 提取出list 中第一个元素<br /> return results<br /><br />def get_tags(self,response):<br /> data = response.css('.apk_left_span2')<br /> tags = [item.css('::text').extract_first() for item in data]<br /> return tags<br />
这里,get_comment() 和 get_tags() 方法是分开定义的。
get_comment()方法通过正则匹配提取出volume、download、follow、comment这四个字段。正则匹配结果如下:
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)<br />print(result) # 输出第一页的结果信息<br /># 结果如下:<br />[('21.74M', '5218万', '2.4万', '5.4万')]<br />[('75.53M', '2768万', '2.3万', '3.0万')]<br />[('46.21M', '1686万', '2.3万', '3.4万')]<br />[('54.77M', '1603万', '3.8万', '4.9万')]<br />[('3.32M', '1530万', '1.5万', '3343')]<br />[('75.07M', '1127万', '1.6万', '2.2万')]<br />[('92.70M', '1108万', '9167', '1.3万')]<br />[('68.94M', '1072万', '5718', '9869')]<br />[('61.45M', '935万', '1.1万', '1.6万')]<br />[('23.96M', '925万', '4157', '1956')]<br />
然后使用result[0]、result[1]等提取4条信息,以volume为例,输出第一页的提取结果:
item['volume'] = results[0]<br />print(item['volume'])<br />21.74M<br />75.53M<br />46.21M<br />54.77M<br />3.32M<br />75.07M<br />92.70M<br />68.94M<br />61.45M<br />23.96M<br />
这样,第一页10个app的字段信息全部提取成功,然后返回到yield item generator,我们输出它的内容:
[<br />{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'}, <br />{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},<br />...<br />]<br />
2.3.4.分页爬取
以上,我们已经爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
这里,我们分别编写这两个方法的解析代码。
第一种方法很简单,直接在parse方法后面继续添加下面几行代码即可:
def parse(self, response):<br /> contents = response.css('.app_left_list>a')<br /> for content in contents:<br /> ...<br /> <br /> next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()<br /> url = response.urljoin(next_page)<br /> yield scrapy.Request(url,callback=self.parse )<br />
第二种方法,我们在第一个parse()方法之前定义一个start_requests()方法,批量生成610个页面url,然后传给scrapy.Request()方法中的回调参数。下面的 parse() 方法进行解析。
def start_requests(self):<br /> pages = []<br /> for page in range(1,610): # 一共有610页<br /> url = 'https://www.coolapk.com/apk/%3 ... %3Bbr /> page = scrapy.Request(url,callback=self.parse)<br /> pages.append(page)<br /> return pages<br />
以上是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择存储在 MongoDB 中。不得不说MongoDB比MySQL方便多了。
2.3.5. 存储结果
在 pipelines.py 程序中,我们定义了数据的存储方式。 MongoDB的一些参数,比如地址和数据库名,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
import pymongo<br />class MongoPipeline(object):<br /> def __init__(self,mongo_url,mongo_db):<br /> self.mongo_url = mongo_url<br /> self.mongo_db = mongo_db<br /> @classmethod<br /> def from_crawler(cls,crawler):<br /> return cls(<br /> mongo_url = crawler.settings.get('MONGO_URL'),<br /> mongo_db = crawler.settings.get('MONGO_DB')<br /> )<br /> def open_spider(self,spider):<br /> self.client = pymongo.MongoClient(self.mongo_url)<br /> self.db = self.client[self.mongo_db]<br /> def process_item(self,item,spider):<br /> name = item.__class__.__name__<br /> self.db[name].insert(dict(item))<br /> return item<br /> def close_spider(self,spider):<br /> self.client.close()<br />
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单解释一下:
from crawler()是一个类方法,用@class方法标识,这个方法的作用就是获取我们在settings.py中设置的这些参数:
MONGO_URL = 'localhost'<br />MONGO_DB = 'KuAn'<br />ITEM_PIPELINES = {<br /> 'kuan.pipelines.MongoPipeline': 300,<br />}<br />
open_spider() 方法主要执行一些初始化操作。该方法会在 Spider 打开时调用。
process_item() 方法是向 MongoDB 插入数据最重要的方法。
完成以上代码后,输入以下命令,启动整个爬虫的爬取和存储过程。如果在单机上运行,完成6000个网页需要大量时间,请耐心等待。
scrapy crawl kuan<br />
这里还有两点:
首先,为了减轻网站的压力,我们最好在每个请求之间设置几秒的延迟。您可以在 KuspiderSpider() 方法的开头添加以下代码行:
custom_settings = {<br /> "DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟<br /> "CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低<br /> }<br />
其次,为了更好的监控爬虫的运行,需要设置输出日志文件,可以通过Python自带的日志包实现:
import logging<br /><br />logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')<br />logging.warning("warn message")<br />logging.error("error message")<br />
这里的level参数表示警告级别,严重程度从低到高依次为:DEBUG
添加 datefmt 参数对于在每个日志的前面添加特定时间很有用。
以上,我们已经完成了整个数据的采集。有了数据,我们就可以开始分析了,但在此之前,我们需要简单地清理和处理数据。
3.数据清洗
首先,我们从MongoDB中读取数据并将其转换为DataFrame,然后看一下数据的基础知识。
def parse_kuan():<br /> client = pymongo.MongoClient(host='localhost', port=27017)<br /> db = client['KuAn']<br /> collection = db['KuAnItem']<br /> # 将数据库数据转为DataFrame<br /> data = pd.DataFrame(list(collection.find()))<br /> print(data.head())<br /> print(df.shape)<br /> print(df.info())<br /> print(df.describe())<br />
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
comment、download、follow、num_score,五列数据中的部分行带有“百万”字尾,需要去掉,转为数值类型;体积列的后缀分别为“M”和“K”,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有6086行x 8列,每列没有缺失值。
df.describe() 方法对 score 列进行基本统计。可以看出,所有app的平均分3.9分(5分制),最低分1.6分。最高分 4.8 分。
接下来,我们将以上列文本数据转换为数值数据。代码实现如下:
def data_processing(df):<br />#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型<br /> str = '_ori'<br /> cols = ['comment','download','follow','num_score','volume']<br /> for col in cols:<br /> colori = col+str<br /> df[colori] = df[col] # 复制保留原始列<br /> if not (col == 'volume'):<br /> df[col] = clean_symbol(df,col)# 处理原始列生成新列<br /> else:<br /> df[col] = clean_symbol2(df,col)# 处理原始列生成新列<br /><br /> # 将download单独转换为万单位<br /> df['download'] = df['download'].apply(lambda x:x/10000)<br /> # 批量转为数值型<br /> df = df.apply(pd.to_numeric,errors='ignore')<br /> <br />def clean_symbol(df,col):<br /> # 将字符“万”替换为空<br /> con = df[col].str.contains('万$')<br /> df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000<br /> df[col] = pd.to_numeric(df[col])<br /> return df[col]<br /><br />def clean_symbol2(df,col):<br /> # 字符M替换为空<br /> df[col] = df[col].str.replace('M$','')<br /> # 体积为K的除以 1024 转换为M<br /> con = df[col].str.contains('K$')<br /> df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024<br /> df[col] = pd.to_numeric(df[col])<br /> return df[col]<br />
至此,几列文本数据的转换就完成了。先来看看基本情况:
commentdownloadfollownum_scorescorevolume
计数
6086
6086
6086
6086
6086
6086
意思
255.5
13.7
729.3
133.1
3.9
17.7
标准
1437.3
98
1893.7
595.4
0.6
20.6
分钟
1
1.6
25%
16
0.2
65
5.2
3.7
3.5
50%
38
0.8
180
17
4
10.8
75%
119
4.5
573.8
68
4.3
25.3
最大
53000
5190
38000
17000
4.8
294.2
由此可以看出以下信息:
至此,基本的数据清洗流程已经完成。在下一篇文章中文章我们将对数据进行探索性分析。
转载于: 查看全部
scrapy分页抓取网页(项目文件创建好怎么写爬虫程序?程序怎么做?)
项目文件创建完成后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
class KuanItem(scrapy.Item):<br /># define the fields for your item here like:<br />name = scrapy.Field()<br />volume = scrapy.Field()<br />download = scrapy.Field()<br />follow = scrapy.Field()<br />comment = scrapy.Field()<br />tags = scrapy.Field()<br />score = scrapy.Field()<br />num_score = scrapy.Field()<br />
这里的字段信息是我们之前在网页中定位的8个字段信息,包括:name代表app的名称,volume代表音量,download代表下载次数。在这里定义好之后,我们会在后续的爬取主程序中用到这些字段信息。
2.3.3.爬取主程序
创建kuan项目后,Scrapy框架会自动生成一些爬取的代码。接下来,我们需要在parse方法中添加网页抓取的字段解析内容。
class KuspiderSpider(scrapy.Spider):<br /> name = 'kuan'<br /> allowed_domains = ['www.coolapk.com']<br /> start_urls = ['http://www.coolapk.com/']<br /><br /> def parse(self, response):<br /> pass<br />
在首页打开Dev Tools,找到每个抓取索引的节点位置,然后使用CSS、Xpath、regular等方法提取解析。这些方法都是 Scrapy 支持的,可以随意选择。这里我们使用 CSS 语法来定位节点,但需要注意的是,Scrapy 的 CSS 语法与我们之前使用 pyquery 的 CSS 语法略有不同。让我们举几个例子来比较一下。

首先,我们定位到第一个APP的首页URL节点。可以看到URL节点位于class属性为app_left_list的div节点下的a节点中,其href属性就是我们需要的URL信息,这里是相对地址,拼接后就是完整的URL:。
然后我们进入Kuan详情页面,选择app名称并定位。可以看到app name节点位于class属性为.detail_app_title的p节点的文本中。

定位到这两个节点后,我们就可以使用CSS来提取字段信息了。下面是常规写法和Scrapy中写法的对比:
# 常规写法<br />url = item('.app_left_list>a').attr('href')<br />name = item('.list_app_title').text()<br /># Scrapy 写法<br />url = item.css('::attr("href")').extract_first()<br />name = item.css('.detail_app_title::text').extract_first()<br />
如您所见,要获取 href 或 text 属性,您需要使用 :: 来表示它。例如,要获取文本,请使用 ::text。 extract_first() 表示提取第一个元素,如果有多个元素,使用 extract() 。然后,我们可以参考解析代码写出8个字段的信息。
首先,我们需要在首页提取应用的URL列表,然后进入每个应用的详情页,进一步提取8个字段的信息。
def parse(self, response):<br /> contents = response.css('.app_left_list>a')<br /> for content in contents:<br /> url = content.css('::attr("href")').extract_first()<br /> url = response.urljoin(url) # 拼接相对 url 为绝对 url<br /> yield scrapy.Request(url,callback=self.parse_url)<br />
这里使用response.urljoin()方法将提取出来的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传递两个参数:url和callback,url是详情页的URL,callback是回调函数,它将首页URL请求返回的响应传递给专门用于解析字段内容的parse_url()方法,如如下图:
def parse_url(self,response):<br /> item = KuanItem()<br /> item['name'] = response.css('.detail_app_title::text').extract_first()<br /> results = self.get_comment(response)<br /> item['volume'] = results[0]<br /> item['download'] = results[1]<br /> item['follow'] = results[2]<br /> item['comment'] = results[3]<br /> item['tags'] = self.get_tags(response)<br /> item['score'] = response.css('.rank_num::text').extract_first()<br /> num_score = response.css('.apk_rank_p1::text').extract_first()<br /> item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)<br /> yield item<br /> <br />def get_comment(self,response):<br /> messages = response.css('.apk_topba_message::text').extract_first()<br /> result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上<br /> if result: # 不为空<br /> results = list(result[0]) # 提取出list 中第一个元素<br /> return results<br /><br />def get_tags(self,response):<br /> data = response.css('.apk_left_span2')<br /> tags = [item.css('::text').extract_first() for item in data]<br /> return tags<br />
这里,get_comment() 和 get_tags() 方法是分开定义的。
get_comment()方法通过正则匹配提取出volume、download、follow、comment这四个字段。正则匹配结果如下:
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)<br />print(result) # 输出第一页的结果信息<br /># 结果如下:<br />[('21.74M', '5218万', '2.4万', '5.4万')]<br />[('75.53M', '2768万', '2.3万', '3.0万')]<br />[('46.21M', '1686万', '2.3万', '3.4万')]<br />[('54.77M', '1603万', '3.8万', '4.9万')]<br />[('3.32M', '1530万', '1.5万', '3343')]<br />[('75.07M', '1127万', '1.6万', '2.2万')]<br />[('92.70M', '1108万', '9167', '1.3万')]<br />[('68.94M', '1072万', '5718', '9869')]<br />[('61.45M', '935万', '1.1万', '1.6万')]<br />[('23.96M', '925万', '4157', '1956')]<br />
然后使用result[0]、result[1]等提取4条信息,以volume为例,输出第一页的提取结果:
item['volume'] = results[0]<br />print(item['volume'])<br />21.74M<br />75.53M<br />46.21M<br />54.77M<br />3.32M<br />75.07M<br />92.70M<br />68.94M<br />61.45M<br />23.96M<br />
这样,第一页10个app的字段信息全部提取成功,然后返回到yield item generator,我们输出它的内容:
[<br />{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'}, <br />{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},<br />...<br />]<br />
2.3.4.分页爬取
以上,我们已经爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
这里,我们分别编写这两个方法的解析代码。
第一种方法很简单,直接在parse方法后面继续添加下面几行代码即可:
def parse(self, response):<br /> contents = response.css('.app_left_list>a')<br /> for content in contents:<br /> ...<br /> <br /> next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()<br /> url = response.urljoin(next_page)<br /> yield scrapy.Request(url,callback=self.parse )<br />
第二种方法,我们在第一个parse()方法之前定义一个start_requests()方法,批量生成610个页面url,然后传给scrapy.Request()方法中的回调参数。下面的 parse() 方法进行解析。
def start_requests(self):<br /> pages = []<br /> for page in range(1,610): # 一共有610页<br /> url = 'https://www.coolapk.com/apk/%3 ... %3Bbr /> page = scrapy.Request(url,callback=self.parse)<br /> pages.append(page)<br /> return pages<br />
以上是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择存储在 MongoDB 中。不得不说MongoDB比MySQL方便多了。
2.3.5. 存储结果
在 pipelines.py 程序中,我们定义了数据的存储方式。 MongoDB的一些参数,比如地址和数据库名,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
import pymongo<br />class MongoPipeline(object):<br /> def __init__(self,mongo_url,mongo_db):<br /> self.mongo_url = mongo_url<br /> self.mongo_db = mongo_db<br /> @classmethod<br /> def from_crawler(cls,crawler):<br /> return cls(<br /> mongo_url = crawler.settings.get('MONGO_URL'),<br /> mongo_db = crawler.settings.get('MONGO_DB')<br /> )<br /> def open_spider(self,spider):<br /> self.client = pymongo.MongoClient(self.mongo_url)<br /> self.db = self.client[self.mongo_db]<br /> def process_item(self,item,spider):<br /> name = item.__class__.__name__<br /> self.db[name].insert(dict(item))<br /> return item<br /> def close_spider(self,spider):<br /> self.client.close()<br />
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单解释一下:
from crawler()是一个类方法,用@class方法标识,这个方法的作用就是获取我们在settings.py中设置的这些参数:
MONGO_URL = 'localhost'<br />MONGO_DB = 'KuAn'<br />ITEM_PIPELINES = {<br /> 'kuan.pipelines.MongoPipeline': 300,<br />}<br />
open_spider() 方法主要执行一些初始化操作。该方法会在 Spider 打开时调用。
process_item() 方法是向 MongoDB 插入数据最重要的方法。

完成以上代码后,输入以下命令,启动整个爬虫的爬取和存储过程。如果在单机上运行,完成6000个网页需要大量时间,请耐心等待。
scrapy crawl kuan<br />
这里还有两点:
首先,为了减轻网站的压力,我们最好在每个请求之间设置几秒的延迟。您可以在 KuspiderSpider() 方法的开头添加以下代码行:
custom_settings = {<br /> "DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟<br /> "CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低<br /> }<br />
其次,为了更好的监控爬虫的运行,需要设置输出日志文件,可以通过Python自带的日志包实现:
import logging<br /><br />logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')<br />logging.warning("warn message")<br />logging.error("error message")<br />
这里的level参数表示警告级别,严重程度从低到高依次为:DEBUG
添加 datefmt 参数对于在每个日志的前面添加特定时间很有用。

以上,我们已经完成了整个数据的采集。有了数据,我们就可以开始分析了,但在此之前,我们需要简单地清理和处理数据。
3.数据清洗
首先,我们从MongoDB中读取数据并将其转换为DataFrame,然后看一下数据的基础知识。
def parse_kuan():<br /> client = pymongo.MongoClient(host='localhost', port=27017)<br /> db = client['KuAn']<br /> collection = db['KuAnItem']<br /> # 将数据库数据转为DataFrame<br /> data = pd.DataFrame(list(collection.find()))<br /> print(data.head())<br /> print(df.shape)<br /> print(df.info())<br /> print(df.describe())<br />

从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
comment、download、follow、num_score,五列数据中的部分行带有“百万”字尾,需要去掉,转为数值类型;体积列的后缀分别为“M”和“K”,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有6086行x 8列,每列没有缺失值。
df.describe() 方法对 score 列进行基本统计。可以看出,所有app的平均分3.9分(5分制),最低分1.6分。最高分 4.8 分。
接下来,我们将以上列文本数据转换为数值数据。代码实现如下:
def data_processing(df):<br />#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型<br /> str = '_ori'<br /> cols = ['comment','download','follow','num_score','volume']<br /> for col in cols:<br /> colori = col+str<br /> df[colori] = df[col] # 复制保留原始列<br /> if not (col == 'volume'):<br /> df[col] = clean_symbol(df,col)# 处理原始列生成新列<br /> else:<br /> df[col] = clean_symbol2(df,col)# 处理原始列生成新列<br /><br /> # 将download单独转换为万单位<br /> df['download'] = df['download'].apply(lambda x:x/10000)<br /> # 批量转为数值型<br /> df = df.apply(pd.to_numeric,errors='ignore')<br /> <br />def clean_symbol(df,col):<br /> # 将字符“万”替换为空<br /> con = df[col].str.contains('万$')<br /> df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000<br /> df[col] = pd.to_numeric(df[col])<br /> return df[col]<br /><br />def clean_symbol2(df,col):<br /> # 字符M替换为空<br /> df[col] = df[col].str.replace('M$','')<br /> # 体积为K的除以 1024 转换为M<br /> con = df[col].str.contains('K$')<br /> df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024<br /> df[col] = pd.to_numeric(df[col])<br /> return df[col]<br />
至此,几列文本数据的转换就完成了。先来看看基本情况:
commentdownloadfollownum_scorescorevolume
计数
6086
6086
6086
6086
6086
6086
意思
255.5
13.7
729.3
133.1
3.9
17.7
标准
1437.3
98
1893.7
595.4
0.6
20.6
分钟
1
1.6
25%
16
0.2
65
5.2
3.7
3.5
50%
38
0.8
180
17
4
10.8
75%
119
4.5
573.8
68
4.3
25.3
最大
53000
5190
38000
17000
4.8
294.2
由此可以看出以下信息:
至此,基本的数据清洗流程已经完成。在下一篇文章中文章我们将对数据进行探索性分析。
转载于:
scrapy分页抓取网页(【干货】scrapy-redis框架抓取网页网页(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-11 18:34
1. 介绍scrapy-redis 框架
scrapy-redis
一个基于redis的三方分布式爬虫框架,配合scrapy使用,使爬虫具备分布式爬虫的功能。
github地址:/darkrho/scrapy-redis
2. 分布式原理
scrapy-redis实现分布式,其实原理上很简单,这里为了描述方便,我们把我们的核心服务器叫做master,用来运行爬虫程序的机器叫做slave
我们知道要使用scrapy框架爬取一个网页,我们需要先给它一些start_urls。爬虫首先访问start_urls中的url,然后根据我们的具体逻辑,对里面的元素,或者其他二级三级页面进行操作。抓。要实现分布式,我们只需要在这个starts_urls中做文章
我们在master上建一个redis数据库(注意这个数据库只用于url存储),为每一种需要爬取的网站打开一个单独的列表字段。通过在slave上设置scrapy-redis来获取url的地址作为master地址。结果是虽然有多个slave,但是大家获取url的地方只有一个,那就是服务器master上的redis数据库
而且由于scrapy-redis自带的队列机制,slave获取的链接不会相互冲突。这样,每个slave完成爬取任务后,将得到的结果汇总到服务器。
益处
程序可移植性强,只要处理好路径问题,将slave上的程序移植到另一台机器上运行基本上就是复制粘贴的问题
3.分布式爬虫的实现使用了三台机器,一台是win10,一台是centos6,两台机器上部署了scrapy进行分布式爬虫。一个 网站
win10的IP地址为192.168.31.245,作为redis的master,centos的机器作为slave
master的爬虫在运行时会将提取的url封装成request放入redis中的数据库:“dmoz:requests”,从数据库中提取请求下载网页,然后存储“dmoz:items”中另一个redis数据库中的网页
slave从master的redis中取出要爬取的请求,下载网页后将网页的内容发回master的redis
重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,然后将master的redis中的“dmoz:items”数据库写入mongodb
在master中的reids中还有一个数据“dmoz:dupefilter”,用于存储抓取到的url的指纹(使用hash函数对url进行操作的结果),用于防止重复爬取。
4. 安装scrapy-redis框架
pip install scrapy-redis
5. 部署scrapy-redis5.1 在slave端Windows的settings.py文件末尾添加下面一行
REDIS_HOST = 'localhost' #master IP
REDIS_PORT = 6379
配置远程redis地址后,启动两个爬虫(启动爬虫没有顺序限制)
6 为爬虫添加配置信息
7 运行程序7.1 运行从机
scrapy runspider 文件名.py
无序打开
7.2 运行主机
lpush (redis_key) url #括号不用写
说明-这个命令在redis-cli中运行-redis_key是spider.py文件中redis_key的值-url开始爬取地址不带双引号
8 将数据导入mongodb
爬虫完成后,如果要将数据存储在mongodb中,需要修改master端的process_items.py文件,如下
9 将数据导入 MySQL
爬虫完成后,如果要将数据存储在mongodb中,需要修改master端的process_items.py文件,如下
推荐视频教程: 查看全部
scrapy分页抓取网页(【干货】scrapy-redis框架抓取网页网页(一))
1. 介绍scrapy-redis 框架
scrapy-redis
一个基于redis的三方分布式爬虫框架,配合scrapy使用,使爬虫具备分布式爬虫的功能。
github地址:/darkrho/scrapy-redis
2. 分布式原理
scrapy-redis实现分布式,其实原理上很简单,这里为了描述方便,我们把我们的核心服务器叫做master,用来运行爬虫程序的机器叫做slave
我们知道要使用scrapy框架爬取一个网页,我们需要先给它一些start_urls。爬虫首先访问start_urls中的url,然后根据我们的具体逻辑,对里面的元素,或者其他二级三级页面进行操作。抓。要实现分布式,我们只需要在这个starts_urls中做文章
我们在master上建一个redis数据库(注意这个数据库只用于url存储),为每一种需要爬取的网站打开一个单独的列表字段。通过在slave上设置scrapy-redis来获取url的地址作为master地址。结果是虽然有多个slave,但是大家获取url的地方只有一个,那就是服务器master上的redis数据库
而且由于scrapy-redis自带的队列机制,slave获取的链接不会相互冲突。这样,每个slave完成爬取任务后,将得到的结果汇总到服务器。
益处
程序可移植性强,只要处理好路径问题,将slave上的程序移植到另一台机器上运行基本上就是复制粘贴的问题
3.分布式爬虫的实现使用了三台机器,一台是win10,一台是centos6,两台机器上部署了scrapy进行分布式爬虫。一个 网站
win10的IP地址为192.168.31.245,作为redis的master,centos的机器作为slave
master的爬虫在运行时会将提取的url封装成request放入redis中的数据库:“dmoz:requests”,从数据库中提取请求下载网页,然后存储“dmoz:items”中另一个redis数据库中的网页
slave从master的redis中取出要爬取的请求,下载网页后将网页的内容发回master的redis
重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,然后将master的redis中的“dmoz:items”数据库写入mongodb
在master中的reids中还有一个数据“dmoz:dupefilter”,用于存储抓取到的url的指纹(使用hash函数对url进行操作的结果),用于防止重复爬取。
4. 安装scrapy-redis框架
pip install scrapy-redis
5. 部署scrapy-redis5.1 在slave端Windows的settings.py文件末尾添加下面一行
REDIS_HOST = 'localhost' #master IP
REDIS_PORT = 6379
配置远程redis地址后,启动两个爬虫(启动爬虫没有顺序限制)
6 为爬虫添加配置信息
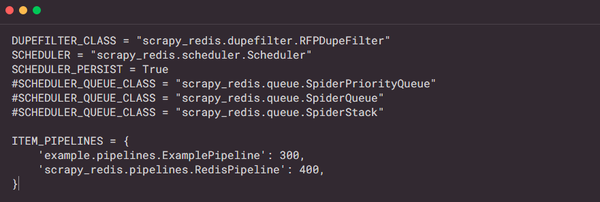
7 运行程序7.1 运行从机
scrapy runspider 文件名.py
无序打开
7.2 运行主机
lpush (redis_key) url #括号不用写
说明-这个命令在redis-cli中运行-redis_key是spider.py文件中redis_key的值-url开始爬取地址不带双引号
8 将数据导入mongodb
爬虫完成后,如果要将数据存储在mongodb中,需要修改master端的process_items.py文件,如下
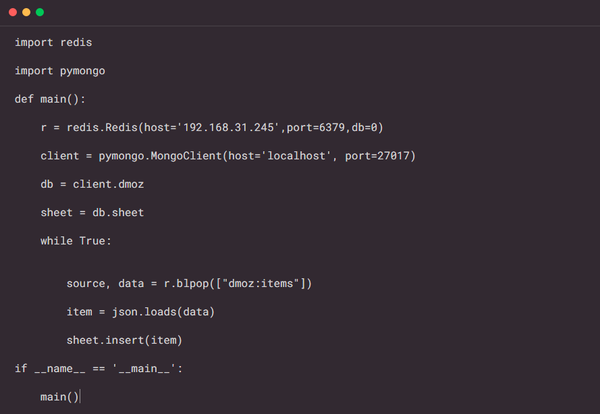
9 将数据导入 MySQL
爬虫完成后,如果要将数据存储在mongodb中,需要修改master端的process_items.py文件,如下
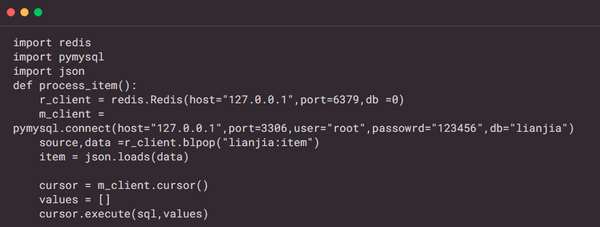
推荐视频教程:
scrapy分页抓取网页(我抓取的网页内容是时时在变的如何实现, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-04-07 00:01
)
爬取网页,如何在分页中显示内容我爬取的网页内容时常变化,如何在页面中显示,例如分段策略以连接数为标志。通常,5个链接设置为一个段落。怎么实现,关键是idea,能不能录入数据库?----------Programming Q&A-------- ------------ - 一个段落的 5 个链接
==========================>>>>>>
首先抓取所有连接的库,
然后在抓取内容时。每5次读出grab>>loop>>end--------编程问答--------------- ------楼上,我要的数据时常变化。如果我将它写入数据库,我应该不时更换它吗?
-------------------- 编程问题和答案-------- 已知连接?未知连接?
只爬取内容,自己的连接
抢内容,先连接?--------编程问答------ 抢先连接,再点击连接显示内容--------编程问答------ --- ---用PHP更容易实现--------编程问答--------------- ---- - 先抓取连接,然后点击连接显示内容
========================================>>>
然后先写表达式,抓取连接
然后下载连接的源码,然后写表达式获取内容--------编程问答------ ------ ---- 分2部分,第一步是抓取网页的显示部分
在抓取内容部分,然后划分内容,将内容添加到刚才的网页中是拉--------编程问答--- ------ ------------- 如果不存储在数据库中,那么只能在内存中分页。
补充:.NET技术 , C# 查看全部
scrapy分页抓取网页(我抓取的网页内容是时时在变的如何实现,
)
爬取网页,如何在分页中显示内容我爬取的网页内容时常变化,如何在页面中显示,例如分段策略以连接数为标志。通常,5个链接设置为一个段落。怎么实现,关键是idea,能不能录入数据库?----------Programming Q&A-------- ------------ - 一个段落的 5 个链接
==========================>>>>>>
首先抓取所有连接的库,
然后在抓取内容时。每5次读出grab>>loop>>end--------编程问答--------------- ------楼上,我要的数据时常变化。如果我将它写入数据库,我应该不时更换它吗?
-------------------- 编程问题和答案-------- 已知连接?未知连接?
只爬取内容,自己的连接
抢内容,先连接?--------编程问答------ 抢先连接,再点击连接显示内容--------编程问答------ --- ---用PHP更容易实现--------编程问答--------------- ---- - 先抓取连接,然后点击连接显示内容
========================================>>>
然后先写表达式,抓取连接
然后下载连接的源码,然后写表达式获取内容--------编程问答------ ------ ---- 分2部分,第一步是抓取网页的显示部分
在抓取内容部分,然后划分内容,将内容添加到刚才的网页中是拉--------编程问答--- ------ ------------- 如果不存储在数据库中,那么只能在内存中分页。
补充:.NET技术 , C#
scrapy分页抓取网页(如何构建自定义的爬虫站点和监控程序第一步开发项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-06 23:27
电商主和管理者可能需要自己爬取网站来监控网页、跟踪网站流量、寻找优化机会等。
对于其中的每一个,都可以使用离散工具、网络爬虫和服务来帮助监控网站。只需相对较少的开发工作,您就可以创建自己的站点爬虫和站点监控系统。
要构建自定义爬虫站点并进行监控,第一步是简单地获取 网站 上所有页面的列表。本文将向您展示如何使用 Python 编程语言和一个名为 Scrapy 的简洁网络爬虫框架轻松生成这些页面的列表。
你需要一个服务器、Python 和 Scrapy
这是一个开发项目。需要安装了 Python 和 Scrapy 的服务器。还需要通过终端应用程序或 SSH 客户端对服务器进行命令行访问。有关安装 Python 的信息也可从 . Scrapy网站 也有很好的安装文档。请确认您的服务器已准备好安装 Python 和 Scrapy。
创建一个 Scrapy 项目
使用 SSH 客户端(如 Windows 的 Putty)或 Mac、Linux 计算机上的终端应用程序,导航到要保存 Scrapy 项目的目录。使用内置的 Scrapy 命令 startproject,我们可以快速生成所需的基础文件。
本文将抓取一个名为《Business Idea Daily》的网站,因此得名“bid”。
生成一个新的 Scrapy Web Spider
为方便起见,Scrapy 还有另一个命令行工具,可以自动生成新的网络蜘蛛。
scrapy genspider -t crawl getbid businessideadaily.com
第一个术语,scrapy,指的是 Scrapy 框架。接下来,有 genspider 命令告诉 Scrapy 我们想要一个新的网络蜘蛛,或者,如果你愿意,一个新的网络爬虫。
-t 告诉 Scrapy 我们要选择一个特定的模板。genspider 命令可以生成四种通用网络蜘蛛模板中的任何一种:basic、crawl、csvfeed 和 xmlfeed。在 -t 之后,我们立即指定所需的模板。在本例中,我们将通过 Scrapy 创建一个名为 CrawlSpider 的模板。“getbid”这个词是蜘蛛的名字。
该命令的最后一部分告诉 Scrapy 我们要抓取哪个 网站。框架将使用它来填充一些新的蜘蛛参数。
定义项目
在 Scrapy 中,Items 是一种组织蜘蛛在抓取特定 网站 时采集东西的方式/模型。虽然我们可以轻松实现我们的目标 - 获取特定 网站 上所有页面的列表 - 不使用 Items,如果我们以后想要扩展我们的爬虫,不使用 Items 可能会限制我们。
要定义一个项目,只需打开我们生成项目时创建的 Scrapy 的 items.py 文件。在其中,将有一个名为 BidItem 的类。类名是基于我们给项目命名的。
class BidItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
将 pass 替换为名为 url 的新字段的定义。
url = scrapy.Field()
保存完成的文档
构建一个网络蜘蛛
接下来打开项目中的spider目录,寻找生成的新Spider Scrapy。在这个例子中,蜘蛛被称为 getbid,所以文件是 getbid.py。
当您在编辑器中打开此文件时,您应该会看到类似以下内容。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from bid.items import BidItem
class GetbidSpider(CrawlSpider):
name = 'getbid'
allowed_domains = ['businessideadaily.com']
start_urls = ['http://www.businessideadaily.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = BidItem()
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
我们需要对 Scrapy 为我们生成的代码做一些小的改动。首先,我们需要在规则下修改LinkExtractor的参数。删除括号中的所有内容。
规则(LinkExtractor(),回调='parse_item',follow=True),
通过这次更新,我们的蜘蛛将找到起始页(主页)上的每个链接,将单个链接传递给 parse_item 方法,并跟随链接到 网站 下一页以确保我们获得每个链接的页面。
接下来,我们需要更新 parse_item 方法。删除所有注释行。这些行只是 Scrapy 给我们的例子。
def parse_item(self, response):
i = BidItem()
return i
我喜欢使用有意义的变量名。所以我要把i改成href,这是HTML链接中属性的名称,如果有的话,它会保存目标链接的地址。
def parse_item(自我,响应):
href = 投标项目()
返回href
现在神奇的事情发生了,我们将页面 URL 捕获为 Items。
def parse_item(self, response):
href = BidItem()
href['url'] = response.url
return href
现在是对的。新的 Spider 已准备好爬行。
抓取 网站,获取数据
从命令行,我们想要导航到我们的项目目录。一旦进入该目录,我们将运行一个简单的命令来发送我们的新蜘蛛并获取页面列表。
scrapy爬取getbid -o 012916.csv
这个命令有几个部分。首先,我们参考 Scrapy 框架。我们告诉 Scrapy 我们想要爬行。我们指定使用 getbid 蜘蛛。
-o 告诉 Scrapy 输出结果。该命令的 012916.csv 部分告诉 Scrapy 将结果放入具有该名称的逗号分隔值(.csv)文件中。
在示例中,Scrapy 将返回三个页面地址。我为这个例子选择这个 网站 的原因之一是它只有几页长。如果您在具有数千页的 网站 上定位类似的蜘蛛,则运行需要一些时间,但它会返回类似的响应。
网址
只需几行代码,您就可以为自己的站点监控应用程序奠定基础。
本文由数据银河原创赞助 查看全部
scrapy分页抓取网页(如何构建自定义的爬虫站点和监控程序第一步开发项目)
电商主和管理者可能需要自己爬取网站来监控网页、跟踪网站流量、寻找优化机会等。
对于其中的每一个,都可以使用离散工具、网络爬虫和服务来帮助监控网站。只需相对较少的开发工作,您就可以创建自己的站点爬虫和站点监控系统。
要构建自定义爬虫站点并进行监控,第一步是简单地获取 网站 上所有页面的列表。本文将向您展示如何使用 Python 编程语言和一个名为 Scrapy 的简洁网络爬虫框架轻松生成这些页面的列表。

你需要一个服务器、Python 和 Scrapy
这是一个开发项目。需要安装了 Python 和 Scrapy 的服务器。还需要通过终端应用程序或 SSH 客户端对服务器进行命令行访问。有关安装 Python 的信息也可从 . Scrapy网站 也有很好的安装文档。请确认您的服务器已准备好安装 Python 和 Scrapy。
创建一个 Scrapy 项目
使用 SSH 客户端(如 Windows 的 Putty)或 Mac、Linux 计算机上的终端应用程序,导航到要保存 Scrapy 项目的目录。使用内置的 Scrapy 命令 startproject,我们可以快速生成所需的基础文件。
本文将抓取一个名为《Business Idea Daily》的网站,因此得名“bid”。
生成一个新的 Scrapy Web Spider
为方便起见,Scrapy 还有另一个命令行工具,可以自动生成新的网络蜘蛛。
scrapy genspider -t crawl getbid businessideadaily.com
第一个术语,scrapy,指的是 Scrapy 框架。接下来,有 genspider 命令告诉 Scrapy 我们想要一个新的网络蜘蛛,或者,如果你愿意,一个新的网络爬虫。
-t 告诉 Scrapy 我们要选择一个特定的模板。genspider 命令可以生成四种通用网络蜘蛛模板中的任何一种:basic、crawl、csvfeed 和 xmlfeed。在 -t 之后,我们立即指定所需的模板。在本例中,我们将通过 Scrapy 创建一个名为 CrawlSpider 的模板。“getbid”这个词是蜘蛛的名字。
该命令的最后一部分告诉 Scrapy 我们要抓取哪个 网站。框架将使用它来填充一些新的蜘蛛参数。
定义项目
在 Scrapy 中,Items 是一种组织蜘蛛在抓取特定 网站 时采集东西的方式/模型。虽然我们可以轻松实现我们的目标 - 获取特定 网站 上所有页面的列表 - 不使用 Items,如果我们以后想要扩展我们的爬虫,不使用 Items 可能会限制我们。
要定义一个项目,只需打开我们生成项目时创建的 Scrapy 的 items.py 文件。在其中,将有一个名为 BidItem 的类。类名是基于我们给项目命名的。
class BidItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
将 pass 替换为名为 url 的新字段的定义。
url = scrapy.Field()
保存完成的文档
构建一个网络蜘蛛
接下来打开项目中的spider目录,寻找生成的新Spider Scrapy。在这个例子中,蜘蛛被称为 getbid,所以文件是 getbid.py。
当您在编辑器中打开此文件时,您应该会看到类似以下内容。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from bid.items import BidItem
class GetbidSpider(CrawlSpider):
name = 'getbid'
allowed_domains = ['businessideadaily.com']
start_urls = ['http://www.businessideadaily.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = BidItem()
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
我们需要对 Scrapy 为我们生成的代码做一些小的改动。首先,我们需要在规则下修改LinkExtractor的参数。删除括号中的所有内容。
规则(LinkExtractor(),回调='parse_item',follow=True),
通过这次更新,我们的蜘蛛将找到起始页(主页)上的每个链接,将单个链接传递给 parse_item 方法,并跟随链接到 网站 下一页以确保我们获得每个链接的页面。
接下来,我们需要更新 parse_item 方法。删除所有注释行。这些行只是 Scrapy 给我们的例子。
def parse_item(self, response):
i = BidItem()
return i
我喜欢使用有意义的变量名。所以我要把i改成href,这是HTML链接中属性的名称,如果有的话,它会保存目标链接的地址。
def parse_item(自我,响应):
href = 投标项目()
返回href
现在神奇的事情发生了,我们将页面 URL 捕获为 Items。
def parse_item(self, response):
href = BidItem()
href['url'] = response.url
return href
现在是对的。新的 Spider 已准备好爬行。
抓取 网站,获取数据
从命令行,我们想要导航到我们的项目目录。一旦进入该目录,我们将运行一个简单的命令来发送我们的新蜘蛛并获取页面列表。
scrapy爬取getbid -o 012916.csv
这个命令有几个部分。首先,我们参考 Scrapy 框架。我们告诉 Scrapy 我们想要爬行。我们指定使用 getbid 蜘蛛。
-o 告诉 Scrapy 输出结果。该命令的 012916.csv 部分告诉 Scrapy 将结果放入具有该名称的逗号分隔值(.csv)文件中。
在示例中,Scrapy 将返回三个页面地址。我为这个例子选择这个 网站 的原因之一是它只有几页长。如果您在具有数千页的 网站 上定位类似的蜘蛛,则运行需要一些时间,但它会返回类似的响应。
网址
只需几行代码,您就可以为自己的站点监控应用程序奠定基础。
本文由数据银河原创赞助
scrapy分页抓取网页(这篇教程比Scrapy官方教程构建网页爬虫的内部工作机制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-06 23:22
当我刚开始在这个行业工作时,我首先意识到的一件事是,有时您需要自己采集、组织和清理数据。在本教程中,我们将从众筹的 网站FundRazr 采集数据。和很多网站一样,这个网站有自己的结构、形式和大量有用的数据,但是它没有结构化的API,所以获取数据并不容易。在本教程中,我们将抓取 网站 数据并将其组织成有序的形式来创建我们自己的数据集。
我们将使用 Scrapy,一个用于构建网络爬虫的框架。Scrapy 可以帮助我们创建和维护网络爬虫。它使我们能够专注于使用 CSS 选择器和 XPath 表达式提取数据,而不是关注爬虫的内部工作。本教程比官方的 Scrapy 教程更深入一些。希望大家看完本教程后,在需要抓取数据有一定难度的时候,也能自己完成。好吧,让我们开始吧。
准备
如果您已经安装了 anaconda 和 google chrome(或 firefox),则可以跳过此部分。
安装蟒蛇。可以从官网下载anaconda自行安装,也可以参考我之前写的anaconda安装教程(Mac、Windows、Ubuntu、环境管理)。
安装 Scrapy。其实Anaconda已经自带了Scrapy,但是如果遇到问题,也可以自己安装:
conda install -c conda-forge scrapy
确保您安装了 chrome 或 firefox。在本教程中,我将使用 chrome。
创建新的 Scrapy 项目
可以使用 startproject 命令创建一个新项目:
此命令将创建一个 fundrazr 目录:
基金/
scrapy.cfg # 部署配置文件
fundrazr/ # 项目的 Python 模块
__init__.py
items.py # 物品物品定义
pipelines.py # 项目管道文件
settings.py # 项目设置文件
spiders/ # 蜘蛛目录
__init__.py
scrapy startprojectfundrazr
使用 chrome(或 firefox)的开发者工具查找初始 url
在爬虫框架中,start_urls是爬虫开始爬取的url列表。我们将为 start_urls 列表中的每个元素获得一个指向单个项目页面的链接。
下图显示初始 url 因所选类别而异。黑框高亮部分是要抓取的类别。
在本教程中,start_urls 列表中的第一项是:
接下来,我们将看到如何访问下一页并将相应的 url 添加到 start_urls 中。
第二个网址是:
下面是创建 start_urls 列表的代码。其中,npages 指定要翻的页数。
start_urls = [“”]
npages = 2
对于范围内的 i (2, npages + 2 ):
start_urls.append(";page="+str(i)+"")
使用 Srapy shell 查找单个项目页面
使用 Scrapy shell 是学习如何基于 Scrapy 提取数据的最佳方式。我们将使用 XPaths,它可用于选择 HTML 文档中的元素。
我们首先需要尝试获取单个项目页面链接的 XPath。我们将使用浏览器的检查元素。
我们将使用 XPath 提取下图中红色框内的部分。
我们首先启动 Scrapy shell:
刮痧壳 '#39;
在 Scrapy shell 中输入以下代码:
response.xpath("//h2[contains(@class, 'title header-font')]/a[contains(@class, 'campaign-link')]//@href").extract()
使用 exit() 退出 Scrapy shell。
单品页面
之前我们介绍了如何提取单个项目页面链接。现在我们将介绍如何在单个项目页面上提取信息。
首先我们进入将被抓取的单品页面(链接如下)。
使用上一节中提到的方法,检查页面的标题。
现在我们将再次使用 Scrapy shell,只是这次来自单个项目页面。
刮壳“手臂”
提取标题的代码是:
response.xpath("//div[contains(@id, 'campaign-title')]/descendant::text()").extract()[0]
页面的其他部分也是如此:
# 筹款总额
response.xpath("//span[contains(@class,'stat')]/span[contains(@class, 'amount-raised')]/descendant::text()").extract()
#筹款目标
response.xpath("//div[contains(@class, 'stats-primary with-goal')]//span[contains(@class, 'stats-label hidden-phone')]/text()"). 提炼()
# 货币
response.xpath("//div[contains(@class, 'stats-primary with-goal')]/@title").extract()
# 最后期限
response.xpath("//div[contains(@id, 'campaign-stats')]//span[contains(@class,'stats-label hidden-phone')]/span[@class='nowrap'] /text()").extract()
# 参与
response.xpath("//div[contains(@class, 'stats-secondary with-goal')]//span[contains(@class, 'donation-count stat')]/text()").extract( )
# 故事
response.xpath("//div[contains(@id, 'full-story')]/descendant::text()").extract()
# 网址
response.xpath("//meta[@property='og:url']/@content").extract()
项目
网页抓取的主要目标是从非结构化来源中提取结构化信息。Scrapy 爬虫以 Python 字典的形式返回提取的数据。Python 字典虽然方便熟悉,但仍然不是很结构化:字段名容易出现拼写错误,返回的信息不一致,尤其是在有多个爬虫的大型项目中。因此,我们定义 Item 类来存储数据(在输出数据之前)。
导入scrapy
classFundrazrItem(scrapy.Item):
活动标题 = scrapy.Field()
amountRaised = scrapy.Field()
目标 = scrapy.Field()
货币类型 = scrapy.Field()
endDate = scrapy.Field()
numberContributors = scrapy.Field()
故事 = scrapy.Field()
url = scrapy.Field()
将其保存在 fundrazr/fundrazr 目录中(覆盖原来的 items.py 文件)。
爬虫
我们定义了一个爬虫类,供 Scrapy 用来抓取 网站(或一组 网站)信息。
# 继承scrapy.Spider类
classFundrazr(scrapy.Spider):
# 指定爬虫名称,运行爬虫时需要
名称 = “我的刮刀”
# 定义 start_urls, npages
# 具体定义见上文
def 解析(自我,响应):
for href in response.xpath("//h2[contains(@class, 'title header-font')]/a[contains(@class, 'campaign-link')]//@href"):
# 添加协议名称 查看全部
scrapy分页抓取网页(这篇教程比Scrapy官方教程构建网页爬虫的内部工作机制)
当我刚开始在这个行业工作时,我首先意识到的一件事是,有时您需要自己采集、组织和清理数据。在本教程中,我们将从众筹的 网站FundRazr 采集数据。和很多网站一样,这个网站有自己的结构、形式和大量有用的数据,但是它没有结构化的API,所以获取数据并不容易。在本教程中,我们将抓取 网站 数据并将其组织成有序的形式来创建我们自己的数据集。
我们将使用 Scrapy,一个用于构建网络爬虫的框架。Scrapy 可以帮助我们创建和维护网络爬虫。它使我们能够专注于使用 CSS 选择器和 XPath 表达式提取数据,而不是关注爬虫的内部工作。本教程比官方的 Scrapy 教程更深入一些。希望大家看完本教程后,在需要抓取数据有一定难度的时候,也能自己完成。好吧,让我们开始吧。
准备
如果您已经安装了 anaconda 和 google chrome(或 firefox),则可以跳过此部分。
安装蟒蛇。可以从官网下载anaconda自行安装,也可以参考我之前写的anaconda安装教程(Mac、Windows、Ubuntu、环境管理)。
安装 Scrapy。其实Anaconda已经自带了Scrapy,但是如果遇到问题,也可以自己安装:
conda install -c conda-forge scrapy
确保您安装了 chrome 或 firefox。在本教程中,我将使用 chrome。
创建新的 Scrapy 项目
可以使用 startproject 命令创建一个新项目:
此命令将创建一个 fundrazr 目录:
基金/
scrapy.cfg # 部署配置文件
fundrazr/ # 项目的 Python 模块
__init__.py
items.py # 物品物品定义
pipelines.py # 项目管道文件
settings.py # 项目设置文件
spiders/ # 蜘蛛目录
__init__.py
scrapy startprojectfundrazr
使用 chrome(或 firefox)的开发者工具查找初始 url
在爬虫框架中,start_urls是爬虫开始爬取的url列表。我们将为 start_urls 列表中的每个元素获得一个指向单个项目页面的链接。
下图显示初始 url 因所选类别而异。黑框高亮部分是要抓取的类别。
在本教程中,start_urls 列表中的第一项是:
接下来,我们将看到如何访问下一页并将相应的 url 添加到 start_urls 中。
第二个网址是:
下面是创建 start_urls 列表的代码。其中,npages 指定要翻的页数。
start_urls = [“”]
npages = 2
对于范围内的 i (2, npages + 2 ):
start_urls.append(";page="+str(i)+"")
使用 Srapy shell 查找单个项目页面
使用 Scrapy shell 是学习如何基于 Scrapy 提取数据的最佳方式。我们将使用 XPaths,它可用于选择 HTML 文档中的元素。
我们首先需要尝试获取单个项目页面链接的 XPath。我们将使用浏览器的检查元素。
我们将使用 XPath 提取下图中红色框内的部分。

我们首先启动 Scrapy shell:
刮痧壳 '#39;
在 Scrapy shell 中输入以下代码:
response.xpath("//h2[contains(@class, 'title header-font')]/a[contains(@class, 'campaign-link')]//@href").extract()

使用 exit() 退出 Scrapy shell。
单品页面
之前我们介绍了如何提取单个项目页面链接。现在我们将介绍如何在单个项目页面上提取信息。
首先我们进入将被抓取的单品页面(链接如下)。
使用上一节中提到的方法,检查页面的标题。
现在我们将再次使用 Scrapy shell,只是这次来自单个项目页面。
刮壳“手臂”
提取标题的代码是:
response.xpath("//div[contains(@id, 'campaign-title')]/descendant::text()").extract()[0]
页面的其他部分也是如此:
# 筹款总额
response.xpath("//span[contains(@class,'stat')]/span[contains(@class, 'amount-raised')]/descendant::text()").extract()
#筹款目标
response.xpath("//div[contains(@class, 'stats-primary with-goal')]//span[contains(@class, 'stats-label hidden-phone')]/text()"). 提炼()
# 货币
response.xpath("//div[contains(@class, 'stats-primary with-goal')]/@title").extract()
# 最后期限
response.xpath("//div[contains(@id, 'campaign-stats')]//span[contains(@class,'stats-label hidden-phone')]/span[@class='nowrap'] /text()").extract()
# 参与
response.xpath("//div[contains(@class, 'stats-secondary with-goal')]//span[contains(@class, 'donation-count stat')]/text()").extract( )
# 故事
response.xpath("//div[contains(@id, 'full-story')]/descendant::text()").extract()
# 网址
response.xpath("//meta[@property='og:url']/@content").extract()
项目
网页抓取的主要目标是从非结构化来源中提取结构化信息。Scrapy 爬虫以 Python 字典的形式返回提取的数据。Python 字典虽然方便熟悉,但仍然不是很结构化:字段名容易出现拼写错误,返回的信息不一致,尤其是在有多个爬虫的大型项目中。因此,我们定义 Item 类来存储数据(在输出数据之前)。
导入scrapy
classFundrazrItem(scrapy.Item):
活动标题 = scrapy.Field()
amountRaised = scrapy.Field()
目标 = scrapy.Field()
货币类型 = scrapy.Field()
endDate = scrapy.Field()
numberContributors = scrapy.Field()
故事 = scrapy.Field()
url = scrapy.Field()
将其保存在 fundrazr/fundrazr 目录中(覆盖原来的 items.py 文件)。
爬虫
我们定义了一个爬虫类,供 Scrapy 用来抓取 网站(或一组 网站)信息。
# 继承scrapy.Spider类
classFundrazr(scrapy.Spider):
# 指定爬虫名称,运行爬虫时需要
名称 = “我的刮刀”
# 定义 start_urls, npages
# 具体定义见上文
def 解析(自我,响应):
for href in response.xpath("//h2[contains(@class, 'title header-font')]/a[contains(@class, 'campaign-link')]//@href"):
# 添加协议名称
scrapy分页抓取网页(蜘蛛代码中如何使用Scrapy跟踪链接和回调的机制?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-06 23:19
(可选)为了从站点中提取数据,Scrapy 使用“表达式”。这些扫描所有可用数据并仅选择我们需要的信息。您可以将这些表达式视为一组定义我们需要的数据的规则。我们可以选择使用 CSS 选择器或 XPath 在 Scrapy 中创建这些表达式。在决定实际选择一个之前,您应该尝试两者。只需在蜘蛛代码中提供您所在城市的 URL。如前所述,网站允许抓取数据,前提是抓取延迟不少于 10 秒,即您必须等待至少 10 秒才能向其请求另一个 URL。这可以在 网站 的 robots.txt 中找到。. 在 Scrapy 中,制作了一个在 网站 上滑动并帮助获取信息的蜘蛛,因此要制作一个,移动到蜘蛛文件夹并在那里制作一个 python 文档。第一种是通过为蜘蛛指定一个命名变量来命名它,然后给出蜘蛛应该开始爬行的起始 URL。默认情况下,Scrapy 会过滤掉对已经访问过的 URL 的重复请求,避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。希望现在您对如何使用 Scrapy 跟踪链接和回调的机制有了很好的理解。. 避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。希望现在您对如何使用 Scrapy 跟踪链接和回调的机制有了很好的理解。. 避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。 查看全部
scrapy分页抓取网页(蜘蛛代码中如何使用Scrapy跟踪链接和回调的机制?)
(可选)为了从站点中提取数据,Scrapy 使用“表达式”。这些扫描所有可用数据并仅选择我们需要的信息。您可以将这些表达式视为一组定义我们需要的数据的规则。我们可以选择使用 CSS 选择器或 XPath 在 Scrapy 中创建这些表达式。在决定实际选择一个之前,您应该尝试两者。只需在蜘蛛代码中提供您所在城市的 URL。如前所述,网站允许抓取数据,前提是抓取延迟不少于 10 秒,即您必须等待至少 10 秒才能向其请求另一个 URL。这可以在 网站 的 robots.txt 中找到。. 在 Scrapy 中,制作了一个在 网站 上滑动并帮助获取信息的蜘蛛,因此要制作一个,移动到蜘蛛文件夹并在那里制作一个 python 文档。第一种是通过为蜘蛛指定一个命名变量来命名它,然后给出蜘蛛应该开始爬行的起始 URL。默认情况下,Scrapy 会过滤掉对已经访问过的 URL 的重复请求,避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。希望现在您对如何使用 Scrapy 跟踪链接和回调的机制有了很好的理解。. 避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。希望现在您对如何使用 Scrapy 跟踪链接和回调的机制有了很好的理解。. 避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。
scrapy分页抓取网页(一个分享到此结束框架教程目录及参考网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-05 05:03
Scrapy作为爬虫工具,是一个非常不错的Python爬虫框架,现在支持Python3。具体安装过程可以参考:. srapy的具体介绍可以参考网站:
本文将介绍一个非常简单的例子,帮助读者快速进入scrapy的世界,并会持续更新进一步深入研究。本文scrapy版本为1.0.3-1,python版本为2.7.12.
我们要爬取的页面是菜鸟教程的Git教程目录,如下图:
首先我们在当前目录新建一个scrapy项目:scrapy_git,在终端输入如下命令:
scrapy startproject scrapy_git
输入tree scrapy_git查看文件的树形结构:
然后切换到spider目录,新建文件:git_jc.py,代码如下:
import scrapy
class ToScrapeCSSSpider(scrapy.Spider):
name = "toscrape-css"
start_urls = ['http://www.runoob.com/git/git-tutorial.html',]
def parse(self,response):
with open('/home/vagrant/python.txt', 'w') as f:
for i in range(1,12):
text = response.xpath('//*[@id="leftcolumn"]/a[%d]/text()'%i).extract()[0].encode("utf-8").strip('\n').strip('\t')
f.write(text+'\n')
其中,toscrape-css是爬虫的名字,非常重要。 start_urls 是被抓取网页的 URL。定义parse()函数,将爬取的目录写入/home/vagrant/python.txt。在这段代码中,使用xpath来定位网页元素,当然也可以使用css来定位。
使用xpath定位网页元素的具体方法是:选择需要的元素,右键,选择勾号(N),在弹出的网页源代码中,右键,选择复制,然后选择复制 XPath,然后粘贴即可。
使用scrapy list查看可用爬虫的名称:
最后输入如下命令运行爬虫:(先创建一个python.txt文件)
运行后查看python.txt文件,内容如下:
Bingo,我们的scrapy爬虫运行成功!
在这个爬虫中,我们并没有移动其他文件,只是新建了一个git_jc.py文件,可见scrapy的简单和高效!期待下次分享^_^...
本次分享到此结束,欢迎大家批评交流~~ 查看全部
scrapy分页抓取网页(一个分享到此结束框架教程目录及参考网址)
Scrapy作为爬虫工具,是一个非常不错的Python爬虫框架,现在支持Python3。具体安装过程可以参考:. srapy的具体介绍可以参考网站:
本文将介绍一个非常简单的例子,帮助读者快速进入scrapy的世界,并会持续更新进一步深入研究。本文scrapy版本为1.0.3-1,python版本为2.7.12.
我们要爬取的页面是菜鸟教程的Git教程目录,如下图:

首先我们在当前目录新建一个scrapy项目:scrapy_git,在终端输入如下命令:
scrapy startproject scrapy_git
输入tree scrapy_git查看文件的树形结构:
然后切换到spider目录,新建文件:git_jc.py,代码如下:
import scrapy
class ToScrapeCSSSpider(scrapy.Spider):
name = "toscrape-css"
start_urls = ['http://www.runoob.com/git/git-tutorial.html',]
def parse(self,response):
with open('/home/vagrant/python.txt', 'w') as f:
for i in range(1,12):
text = response.xpath('//*[@id="leftcolumn"]/a[%d]/text()'%i).extract()[0].encode("utf-8").strip('\n').strip('\t')
f.write(text+'\n')
其中,toscrape-css是爬虫的名字,非常重要。 start_urls 是被抓取网页的 URL。定义parse()函数,将爬取的目录写入/home/vagrant/python.txt。在这段代码中,使用xpath来定位网页元素,当然也可以使用css来定位。
使用xpath定位网页元素的具体方法是:选择需要的元素,右键,选择勾号(N),在弹出的网页源代码中,右键,选择复制,然后选择复制 XPath,然后粘贴即可。
使用scrapy list查看可用爬虫的名称:
最后输入如下命令运行爬虫:(先创建一个python.txt文件)
运行后查看python.txt文件,内容如下:
Bingo,我们的scrapy爬虫运行成功!
在这个爬虫中,我们并没有移动其他文件,只是新建了一个git_jc.py文件,可见scrapy的简单和高效!期待下次分享^_^...
本次分享到此结束,欢迎大家批评交流~~
scrapy分页抓取网页(ASP.js代码怎么封装,不如直接抓包看看传递什么参数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-31 04:13
)
以上文章介绍了scrapy爬取的一般架构,本文文章解释了一些技术问题。
一、如何处理 ASP.NET 分页
我们以深圳房地产信息系统为例。
因为之前一直在写ASP.NET,所以很多.NET控件都是通过拖拽来实现的。很多代码可以省去编写过程,自动生成。这里的下一页操作是通过自动生成的js代码,scrapy框架无法执行js代码。但是我们知道他执行了_doPostBack函数,我们来看看_doPostBack是怎么定义的。
function __doPostBack(eventTarget, eventArgument) {
if (!theForm.onsubmit || (theForm.onsubmit() != false)) {
theForm.__EVENTTARGET.value = eventTarget;
theForm.__EVENTARGUMENT.value = eventArgument;
theForm.submit();
}
}
看看form1是怎么定义的
里面有很多隐藏的控件,里面有很多值,都是自动生成的。我不知道这意味着什么。
但是我们知道他的原理是再次向这个页面发送一个POST请求进行分页。所以URL地址没有变化。既然有POST操作,那传入什么参数。一闪而过,与其研究如何封装JS代码,不如直接抓包看看传了什么参数。
这里使用常用的wireshark,简单易上手,一目了然。
当我们点击next时,我们可以看到发送了一个HTTP请求并执行了POST方法。
进一步展开。所有参数都一一列出。传递参数也隐藏在页面上。
回去看看我为递归查询编写的分页代码。
def parse(self, response):
context = response.xpath('//tr[@bgcolor="#F5F9FC"]/td[3]')
dbhelp=RishomePipeline()
for item in context:
title=item.xpath('a/text()').extract_first()
idstr=item.xpath('a/@href').extract_first()
idstr=idstr[idstr.find('=')+1:]
if dbhelp.ispropertyexits(idstr):
return
request=scrapy.Request(url='http://ris.szpl.gov.cn/bol/pro ... idstr, method='GET',callback=self.showdetailpage)
yield request
'''以下是分页代码,组合post_data结构体,
POST请求要使用 yield scrapy.FormRequest(url=response.url,formdata =post_data,callback=self.parse,dont_filter=True)函数。
'''
next_page = response.xpath('//*[@id="AspNetPager1"]/div[2]/a[3]/@href')
pnum=next_page.extract_first().split(',')[1].replace("'","").replace(")","")
post_data = {
"__EVENTTARGET" : "AspNetPager1",
"__EVENTARGUMENT" :pnum,
"__VIEWSTATEENCRYPTED" : "",
"tep_name" : "",
"organ_name" : "",
"site_address" : "",
"AspNetPager1_input" : "1"}
a = response.xpath('//*[@id="__VIEWSTATE"]/@value')
post_data['__VIEWSTATE']=a.extract_first()
b=response.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')
post_data['__VIEWSTATEGENERATOR']=b.extract_first()
c = response.xpath('//*[@id="__EVENTVALIDATION"]/@value')
post_data['__EVENTVALIDATION'] = c.extract_first()
'''分页到最后一页,‘下一页’的按钮就不是链接了,页面没有href参数了,此时判断分页结束,即 递归结束'''
if pnum is not None and pnum!="":
yield scrapy.FormRequest(url=response.url,formdata =post_data,callback=self.parse,dont_filter=True)
二、如何在请求和响应之间传递参数
有时需要将两个页面的内容合并为一项。这时候就需要在产生scrapy.Request的同时传递一些参数到下一页。此时您可以执行此操作。
request=scrapy.Request(houseurl,method='GET',callback=self.showhousedetail)
request.meta['biid']=biid
yield request
def showhousedetail(self,response):
house=HouseItem()
house['bulidingid']=response.meta['biid']
三、管道区分传入的Item
每个页面都会封装item并传递给管道进行处理,管道只接收一个条目:
def process_item(self, item, spider)函数
用于区分项目的方法。
def process_item(self, item, spider):
if str(type(item))=="":
self.saverishome(item)
if str(type(item))=="":
self.savebuliding(item)
if str(type(item))=="":
self.savehouse(item)
return item # 必须实现返回 查看全部
scrapy分页抓取网页(ASP.js代码怎么封装,不如直接抓包看看传递什么参数
)
以上文章介绍了scrapy爬取的一般架构,本文文章解释了一些技术问题。
一、如何处理 ASP.NET 分页
我们以深圳房地产信息系统为例。

因为之前一直在写ASP.NET,所以很多.NET控件都是通过拖拽来实现的。很多代码可以省去编写过程,自动生成。这里的下一页操作是通过自动生成的js代码,scrapy框架无法执行js代码。但是我们知道他执行了_doPostBack函数,我们来看看_doPostBack是怎么定义的。
function __doPostBack(eventTarget, eventArgument) {
if (!theForm.onsubmit || (theForm.onsubmit() != false)) {
theForm.__EVENTTARGET.value = eventTarget;
theForm.__EVENTARGUMENT.value = eventArgument;
theForm.submit();
}
}
看看form1是怎么定义的
里面有很多隐藏的控件,里面有很多值,都是自动生成的。我不知道这意味着什么。
但是我们知道他的原理是再次向这个页面发送一个POST请求进行分页。所以URL地址没有变化。既然有POST操作,那传入什么参数。一闪而过,与其研究如何封装JS代码,不如直接抓包看看传了什么参数。
这里使用常用的wireshark,简单易上手,一目了然。
当我们点击next时,我们可以看到发送了一个HTTP请求并执行了POST方法。

进一步展开。所有参数都一一列出。传递参数也隐藏在页面上。
回去看看我为递归查询编写的分页代码。
def parse(self, response):
context = response.xpath('//tr[@bgcolor="#F5F9FC"]/td[3]')
dbhelp=RishomePipeline()
for item in context:
title=item.xpath('a/text()').extract_first()
idstr=item.xpath('a/@href').extract_first()
idstr=idstr[idstr.find('=')+1:]
if dbhelp.ispropertyexits(idstr):
return
request=scrapy.Request(url='http://ris.szpl.gov.cn/bol/pro ... idstr, method='GET',callback=self.showdetailpage)
yield request
'''以下是分页代码,组合post_data结构体,
POST请求要使用 yield scrapy.FormRequest(url=response.url,formdata =post_data,callback=self.parse,dont_filter=True)函数。
'''
next_page = response.xpath('//*[@id="AspNetPager1"]/div[2]/a[3]/@href')
pnum=next_page.extract_first().split(',')[1].replace("'","").replace(")","")
post_data = {
"__EVENTTARGET" : "AspNetPager1",
"__EVENTARGUMENT" :pnum,
"__VIEWSTATEENCRYPTED" : "",
"tep_name" : "",
"organ_name" : "",
"site_address" : "",
"AspNetPager1_input" : "1"}
a = response.xpath('//*[@id="__VIEWSTATE"]/@value')
post_data['__VIEWSTATE']=a.extract_first()
b=response.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')
post_data['__VIEWSTATEGENERATOR']=b.extract_first()
c = response.xpath('//*[@id="__EVENTVALIDATION"]/@value')
post_data['__EVENTVALIDATION'] = c.extract_first()
'''分页到最后一页,‘下一页’的按钮就不是链接了,页面没有href参数了,此时判断分页结束,即 递归结束'''
if pnum is not None and pnum!="":
yield scrapy.FormRequest(url=response.url,formdata =post_data,callback=self.parse,dont_filter=True)
二、如何在请求和响应之间传递参数
有时需要将两个页面的内容合并为一项。这时候就需要在产生scrapy.Request的同时传递一些参数到下一页。此时您可以执行此操作。
request=scrapy.Request(houseurl,method='GET',callback=self.showhousedetail)
request.meta['biid']=biid
yield request
def showhousedetail(self,response):
house=HouseItem()
house['bulidingid']=response.meta['biid']
三、管道区分传入的Item
每个页面都会封装item并传递给管道进行处理,管道只接收一个条目:
def process_item(self, item, spider)函数
用于区分项目的方法。
def process_item(self, item, spider):
if str(type(item))=="":
self.saverishome(item)
if str(type(item))=="":
self.savebuliding(item)
if str(type(item))=="":
self.savehouse(item)
return item # 必须实现返回
scrapy分页抓取网页( 爬虫案例代码地址这里我是使用的Scrapy框架进行爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-28 11:19
爬虫案例代码地址这里我是使用的Scrapy框架进行爬虫
)
由于互联网的飞速发展,目前所有的信息都处于海量积累的状态。我们不仅需要从外界获取大量数据,还要从大量数据中过滤掉无用的数据。对于我们的有益数据,我们需要指定爬取,所以出现了目前的爬虫技术,通过它我们可以快速获取我们需要的数据。但是在这个爬取过程中,信息拥有者会对爬虫进行反爬处理,我们需要一一攻破这些难点。
前段时间刚做了一些爬虫相关的工作,所以这里有一些相关的经验。
本文案例代码地址
这里我使用的是Scrapy框架进行爬取,开发环境的相关版本号:
Scrapy : 1.5.1
lxml : 4.2.5.0
libxml2 : 2.9.8
cssselect : 1.0.3
parsel : 1.5.1
w3lib : 1.20.0
Twisted : 18.9.0
Python : 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)]
pyOpenSSL : 18.0.0 (OpenSSL 1.1.1a 20 Nov 2018)
cryptography : 2.4.2
Platform : Windows-10-10.0.15063-SP0
对于本地开发环境,建议使用Anaconda安装相关环境,否则可能会出现各种依赖冲突。本文主要使用Xpath提取页面数据,所以在进行本文案例操作之前,先了解一下Xpath的基本使用。
创建一个 Scrapy 项目
用scrapy创建项目非常简单,一个命令就可以搞定。接下来,我们创建一个 ytaoCrawl 项目:
scrapy startproject ytaoCrawl
请注意,项目名称必须以字母开头,并且只能收录字母、数字和下划线。创建成功后,界面显示:
初始化项目的文件是:
每个文件的用途:
了解了几个默认生成的文件后,再看下面的scrapy结构示意图,还是比较容易理解的。
这样,我们的一个scrapy爬虫项目就创建好了。
创建蜘蛛
我们首先创建一个python文件ytaoSpider,它必须继承scrapy.Spider类。接下来,我们以北京58租房信息的爬取为例进行分析。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
#
# @Author : YangTao
# @blog : https://ytao.top
#
import scrapy
class YtaoSpider(scrapy.Spider):
# 定义爬虫名称
name = "crawldemo"
# 允许爬取的域名,但不包含 start_urls 中的链接
allowed_domains = ["58.com"]
# 起始爬取链接
start_urls = [
"https://bj.58.com/chuzu/%3FPGT ... ot%3B
]
def download(self, response, fName):
with open(fName + ".html", 'wb') as f:
f.write(response.body)
# response 是返回抓取后的对象
def parse(self, response):
# 下载北京租房页面到本地,便于分析
self.download(response, "北京租房")
通过执行命令启动爬虫,指定爬虫名称:
scrapy crawl crawldemo
当我们有多个爬虫时,我们可以通过scrapy list获取所有爬虫名称。
当然,你也可以在开发过程中使用mian函数在编辑器中启动:
if __name__ == '__main__':
name = YtaoSpider.name
cmd = 'scrapy crawl {0} '.format(name)
cmdline.execute(cmd.split())
这时候我们爬取的页面就会在我们启动的目录下下载生成。
翻页
上面我们只爬了第一页,但是在实际爬取数据的过程中,肯定会涉及到分页,所以我们观察到网站的分页是为了显示最后一页(最多58只在显示前)七十页数据),如图所示。
从下图中观察分页代码的 html 部分。
接下来通过Xpath和正则匹配得到最后一页的页码。
<p>def pageNum(self, response):
# 获取分页的 html 代码块
page_ele = response.xpath("//li[@id='pager_wrap']/div[@class='pager']")
# 通过正则获取含有页码数字的文本
num_eles = re.findall(r">\d+", "").replace(" 查看全部
scrapy分页抓取网页(
爬虫案例代码地址这里我是使用的Scrapy框架进行爬虫
)
由于互联网的飞速发展,目前所有的信息都处于海量积累的状态。我们不仅需要从外界获取大量数据,还要从大量数据中过滤掉无用的数据。对于我们的有益数据,我们需要指定爬取,所以出现了目前的爬虫技术,通过它我们可以快速获取我们需要的数据。但是在这个爬取过程中,信息拥有者会对爬虫进行反爬处理,我们需要一一攻破这些难点。
前段时间刚做了一些爬虫相关的工作,所以这里有一些相关的经验。
本文案例代码地址
这里我使用的是Scrapy框架进行爬取,开发环境的相关版本号:
Scrapy : 1.5.1
lxml : 4.2.5.0
libxml2 : 2.9.8
cssselect : 1.0.3
parsel : 1.5.1
w3lib : 1.20.0
Twisted : 18.9.0
Python : 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)]
pyOpenSSL : 18.0.0 (OpenSSL 1.1.1a 20 Nov 2018)
cryptography : 2.4.2
Platform : Windows-10-10.0.15063-SP0
对于本地开发环境,建议使用Anaconda安装相关环境,否则可能会出现各种依赖冲突。本文主要使用Xpath提取页面数据,所以在进行本文案例操作之前,先了解一下Xpath的基本使用。
创建一个 Scrapy 项目
用scrapy创建项目非常简单,一个命令就可以搞定。接下来,我们创建一个 ytaoCrawl 项目:
scrapy startproject ytaoCrawl
请注意,项目名称必须以字母开头,并且只能收录字母、数字和下划线。创建成功后,界面显示:
初始化项目的文件是:
每个文件的用途:
了解了几个默认生成的文件后,再看下面的scrapy结构示意图,还是比较容易理解的。
这样,我们的一个scrapy爬虫项目就创建好了。
创建蜘蛛
我们首先创建一个python文件ytaoSpider,它必须继承scrapy.Spider类。接下来,我们以北京58租房信息的爬取为例进行分析。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
#
# @Author : YangTao
# @blog : https://ytao.top
#
import scrapy
class YtaoSpider(scrapy.Spider):
# 定义爬虫名称
name = "crawldemo"
# 允许爬取的域名,但不包含 start_urls 中的链接
allowed_domains = ["58.com"]
# 起始爬取链接
start_urls = [
"https://bj.58.com/chuzu/%3FPGT ... ot%3B
]
def download(self, response, fName):
with open(fName + ".html", 'wb') as f:
f.write(response.body)
# response 是返回抓取后的对象
def parse(self, response):
# 下载北京租房页面到本地,便于分析
self.download(response, "北京租房")
通过执行命令启动爬虫,指定爬虫名称:
scrapy crawl crawldemo
当我们有多个爬虫时,我们可以通过scrapy list获取所有爬虫名称。
当然,你也可以在开发过程中使用mian函数在编辑器中启动:
if __name__ == '__main__':
name = YtaoSpider.name
cmd = 'scrapy crawl {0} '.format(name)
cmdline.execute(cmd.split())
这时候我们爬取的页面就会在我们启动的目录下下载生成。
翻页
上面我们只爬了第一页,但是在实际爬取数据的过程中,肯定会涉及到分页,所以我们观察到网站的分页是为了显示最后一页(最多58只在显示前)七十页数据),如图所示。
从下图中观察分页代码的 html 部分。
接下来通过Xpath和正则匹配得到最后一页的页码。
<p>def pageNum(self, response):
# 获取分页的 html 代码块
page_ele = response.xpath("//li[@id='pager_wrap']/div[@class='pager']")
# 通过正则获取含有页码数字的文本
num_eles = re.findall(r">\d+", "").replace("
scrapy分页抓取网页( Python编写的快速开源网络爬虫框架用于网页中提取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-22 21:19
Python编写的快速开源网络爬虫框架用于网页中提取数据)
Scrapy 教程
Scrapy 是一个用 Python 编写的快速开源网络爬虫框架,用于借助基于 XPath 的选择器从网页中提取数据。
Scrapy 于 2008 年 6 月 26 日首次发布,采用 BSD 许可,2015 年 6 月发布里程碑1.0。
为什么要使用 Scrapy?构建和扩展大型爬行项目更容易。它有一个名为 Selectors 的内置机制,用于从 网站 中提取数据。它异步处理请求并且速度很快。它使用自动节流机制。确保开发人员可访问性。 Scrapy 的特点 Scrapy 是一个开源和免费使用的网络抓取框架。 Scrapy 以 JSON、CSV 和 XML 等格式生成提要导出。 Scrapy 内置支持通过 XPath 或 CSS 表达式从源中选择和提取数据。基于爬虫的 Scrapy,允许从网页中自动提取数据。优点 Scrapy 易于扩展、快速且强大。它是一个跨平台的应用程序框架(Windows、Linux、Mac OS 和 BSD)。 Scrapy 请求是异步调度和处理的。 Scrapy 带有一个名为 Scrapyd 的内置服务,它允许使用 JSON Web 服务上传项目和控制爬虫。任何 网站 都可以被弃用,尽管 网站 没有用于访问原创数据的 API。缺点 Scrapy 仅适用于 Python 2.7、 + 不同的操作系统安装方式不同。 查看全部
scrapy分页抓取网页(
Python编写的快速开源网络爬虫框架用于网页中提取数据)
Scrapy 教程
Scrapy 是一个用 Python 编写的快速开源网络爬虫框架,用于借助基于 XPath 的选择器从网页中提取数据。
Scrapy 于 2008 年 6 月 26 日首次发布,采用 BSD 许可,2015 年 6 月发布里程碑1.0。
为什么要使用 Scrapy?构建和扩展大型爬行项目更容易。它有一个名为 Selectors 的内置机制,用于从 网站 中提取数据。它异步处理请求并且速度很快。它使用自动节流机制。确保开发人员可访问性。 Scrapy 的特点 Scrapy 是一个开源和免费使用的网络抓取框架。 Scrapy 以 JSON、CSV 和 XML 等格式生成提要导出。 Scrapy 内置支持通过 XPath 或 CSS 表达式从源中选择和提取数据。基于爬虫的 Scrapy,允许从网页中自动提取数据。优点 Scrapy 易于扩展、快速且强大。它是一个跨平台的应用程序框架(Windows、Linux、Mac OS 和 BSD)。 Scrapy 请求是异步调度和处理的。 Scrapy 带有一个名为 Scrapyd 的内置服务,它允许使用 JSON Web 服务上传项目和控制爬虫。任何 网站 都可以被弃用,尽管 网站 没有用于访问原创数据的 API。缺点 Scrapy 仅适用于 Python 2.7、 + 不同的操作系统安装方式不同。
scrapy分页抓取网页(项目文件创建好以后可以写爬虫程序了,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-22 21:18
项目文件创建完成后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
这里的字段信息就是我们之前在网页中定位的8个字段信息,包括:name代表app名称,volume代表音量,download代表下载次数。在这里定义好之后,我们会在后续的爬取主程序中用到这些字段信息。
2.3.3. 爬取主程序
kuan项目创建后,Scrapy框架会自动生成一些爬虫的代码。接下来,我们需要在 parse 方法中添加网页抓取的字段解析内容。
在首页打开Dev Tools,找到每个抓取索引的节点位置,然后使用CSS、Xpath、正则化等方法提取解析。这些方法都是 Scrapy 支持的,可以随意选择。这里我们使用 CSS 语法来定位节点,但是需要注意的是,Scrapy 的 CSS 语法与我们之前用 pyquery 使用的 CSS 语法略有不同。让我们举几个例子并进行比较。
首先,我们定位到第一个APP的首页URL节点。我们可以看到URL节点位于class属性为app_left_list的div节点下的a节点中。它的 href 属性就是我们需要的 URL 信息。这是相对地址。拼接后就是完整的URL。
然后我们进入Kuan详情页面,选择app名称并定位。可以看到app名称节点位于类属性为.detail_app_title的p节点的文本中。
定位到这两个节点后,我们就可以使用 CSS 来提取字段信息了。下面是常规写法和Scrapy中写法的对比:
如您所见,要获取 href 或 text 属性,您需要使用 :: 来表示它。例如,要获取文本,请使用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,使用extract()。然后,我们可以参考解析代码写出8个字段信息。
首先,我们需要在首页提取App的URL列表,然后进入各个App的详情页面,进一步提取8个字段的信息。
这里使用response.urljoin()方法将提取出来的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传递两个参数:url和callback,url为详情页URL,callback为回调函数,将首页URL请求返回的响应传递给专门用于解析字段内容的parse_url()方法,如下图:
这里,get_comment() 和 get_tags() 方法是分开定义的。
get_comment() 方法通过正则匹配提取音量、下载、关注、评论四个字段信息。正则匹配结果如下:
然后使用result[0]、result[1]等提取4条信息,以volume为例,输出第一页的提取结果:
这样,第一页的10个app的字段信息全部提取成功,然后返回到yield item generator,我们输出它的内容:
2.3.4. 分页爬取
以上,我们已经爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
在这里,我们分别编写这两种方法的解析代码。第一种方法非常简单。只需按照 parse 方法继续添加以下代码行:
在第二种方法中,我们在第一个parse()方法之前定义了一个start_requests()方法来批量生成610个页面url,然后通过scrapy.Request()方法中的回调参数传递给后面的parse()方法用于解析。
以上就是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择存储在 MongoDB 中。不得不说 MongoDB 比 MySQL 方便多了,而且省事多了。
2.3.5. 存储结果
在 pipelines.py 程序中,我们定义了数据存储方式。MongoDB的一些参数,比如地址和数据库名,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单解释一下:
from crawler() 是一个类方法,由@class 方法标识。该方法的作用是获取我们在settings.py中设置的参数:
open_spider() 方法主要执行一些初始化操作。这个方法会在 Spider 打开时被调用。
process_item() 方法是向 MongoDB 插入数据最重要的方法。
完成上述代码后,输入以下命令,启动整个爬虫的爬取和存储过程。如果在单机上运行,完成6000个网页需要大量时间,请耐心等待。
在这里,还有两个额外的点:
首先,为了减轻网站的压力,我们最好在每个请求之间设置几秒的延迟。您可以在 KuanSpider() 方法的开头添加以下代码行:
二、为了更好的监控爬虫的运行情况,需要设置输出日志文件,可以通过Python自带的日志包实现:
这里的level参数代表警告级别,严重程度从低到高:DEBUG
添加 datefmt 参数以将特定时间添加到每个日志中,这很有用。
以上,我们就完成了整个数据的抓取。有了数据,我们可以开始分析它,但在此之前,我们需要简单地清理和处理数据。
3. 数据清洗过程
首先,我们从 MongoDB 中读取数据并将其转换为 DataFrame,然后查看数据的基础知识。
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
在comment、download、follow、num_score这五列中,有些行加了“million”字尾,需要去掉,转成数值类型;体积列分别有“M”和“K”后缀,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有6086行x 8列,每列没有缺失值。
df.describe() 方法对 score 列进行基本统计。可以看出所有app的平均分3.9分(5分制),最低分1.6分,最高分1.@k36@ >8 分。
接下来,我们将以上列文本数据转换为数值数据。代码实现如下:
以上,几列文本数据的转换就完成了。先来看看基本情况:
下载被列为应用程序下载的数量。下载次数最多的app有5190万次,最少的是0(极少),平均下载次数是14万次。可以看到以下信息:
至此,基本的数据清洗流程就完成了,下面将对数据进行探索性分析。
4. 数据分析
我们主要从整体和分类两个维度分析App下载量、评分、量等指标。
4.1.整体状态4.1.1.下载排名
首先,我们来看看应用程序的下载量。很多时候我们下载一个应用,下载量是一个非常重要的参考指标。由于大部分app的下载量都比较小,直方图看不出趋势,所以我们选择将数据分段离散化成直方图,绘图工具是Pyecharts。
可以看到,多达 5,517 个(占总数的 84%)应用下载量低于 10 万,只有 20 个应用下载量超过 500 万。要开发一个盈利的应用程序,用户下载尤为重要。由此看来,大部分app都处于尴尬的境地,至少在宽平台上是这样。
代码实现如下:
接下来,我们来看看下载次数最多的20款应用分别是:
可以看到,这里的“酷安”App以5000万+的下载量遥遥领先,几乎是第二名微信2700万下载量的两倍。如此巨大的优势不难理解。毕竟是自己的App。如果你的手机上没有“酷安”,就说明你不是真正的“机器爱好者”。从图片中,我们还可以看到以下信息:
为了比较,让我们看看下载量最少的 20 个应用程序。
可以看出,这些与上面下载量最多的app相比相形见绌,而下载量最少的《广州限行证》只有63次下载。
这并不奇怪。可能是该应用程序没有被宣传,或者它可能刚刚开发。这么少的下载量分数还不错,还能继续更新。我喜欢这些开发者。
事实上,这类应用程序并不尴尬。真正尴尬的应该是那些下载量大、评分低的应用。给人的感觉是:“太爱了,有本事就别用了。” .
限于篇幅,文章截取了部分内容。其实爬虫加数据分析很有意思!许多学生正在寻找爬行动物的职位。其实纯爬虫的职位并不多,尤其是二线城市!如果你同时具备爬虫和数据分析能力,那么找工作会容易得多。
近 150 家公司的 210 位 Python 合作伙伴
都在 Python 工作圈 查看全部
scrapy分页抓取网页(项目文件创建好以后可以写爬虫程序了,怎么办?)
项目文件创建完成后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
这里的字段信息就是我们之前在网页中定位的8个字段信息,包括:name代表app名称,volume代表音量,download代表下载次数。在这里定义好之后,我们会在后续的爬取主程序中用到这些字段信息。
2.3.3. 爬取主程序
kuan项目创建后,Scrapy框架会自动生成一些爬虫的代码。接下来,我们需要在 parse 方法中添加网页抓取的字段解析内容。
在首页打开Dev Tools,找到每个抓取索引的节点位置,然后使用CSS、Xpath、正则化等方法提取解析。这些方法都是 Scrapy 支持的,可以随意选择。这里我们使用 CSS 语法来定位节点,但是需要注意的是,Scrapy 的 CSS 语法与我们之前用 pyquery 使用的 CSS 语法略有不同。让我们举几个例子并进行比较。

首先,我们定位到第一个APP的首页URL节点。我们可以看到URL节点位于class属性为app_left_list的div节点下的a节点中。它的 href 属性就是我们需要的 URL 信息。这是相对地址。拼接后就是完整的URL。
然后我们进入Kuan详情页面,选择app名称并定位。可以看到app名称节点位于类属性为.detail_app_title的p节点的文本中。

定位到这两个节点后,我们就可以使用 CSS 来提取字段信息了。下面是常规写法和Scrapy中写法的对比:
如您所见,要获取 href 或 text 属性,您需要使用 :: 来表示它。例如,要获取文本,请使用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,使用extract()。然后,我们可以参考解析代码写出8个字段信息。
首先,我们需要在首页提取App的URL列表,然后进入各个App的详情页面,进一步提取8个字段的信息。
这里使用response.urljoin()方法将提取出来的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传递两个参数:url和callback,url为详情页URL,callback为回调函数,将首页URL请求返回的响应传递给专门用于解析字段内容的parse_url()方法,如下图:
这里,get_comment() 和 get_tags() 方法是分开定义的。
get_comment() 方法通过正则匹配提取音量、下载、关注、评论四个字段信息。正则匹配结果如下:
然后使用result[0]、result[1]等提取4条信息,以volume为例,输出第一页的提取结果:
这样,第一页的10个app的字段信息全部提取成功,然后返回到yield item generator,我们输出它的内容:
2.3.4. 分页爬取
以上,我们已经爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
在这里,我们分别编写这两种方法的解析代码。第一种方法非常简单。只需按照 parse 方法继续添加以下代码行:
在第二种方法中,我们在第一个parse()方法之前定义了一个start_requests()方法来批量生成610个页面url,然后通过scrapy.Request()方法中的回调参数传递给后面的parse()方法用于解析。
以上就是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择存储在 MongoDB 中。不得不说 MongoDB 比 MySQL 方便多了,而且省事多了。
2.3.5. 存储结果
在 pipelines.py 程序中,我们定义了数据存储方式。MongoDB的一些参数,比如地址和数据库名,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单解释一下:
from crawler() 是一个类方法,由@class 方法标识。该方法的作用是获取我们在settings.py中设置的参数:
open_spider() 方法主要执行一些初始化操作。这个方法会在 Spider 打开时被调用。
process_item() 方法是向 MongoDB 插入数据最重要的方法。

完成上述代码后,输入以下命令,启动整个爬虫的爬取和存储过程。如果在单机上运行,完成6000个网页需要大量时间,请耐心等待。
在这里,还有两个额外的点:
首先,为了减轻网站的压力,我们最好在每个请求之间设置几秒的延迟。您可以在 KuanSpider() 方法的开头添加以下代码行:
二、为了更好的监控爬虫的运行情况,需要设置输出日志文件,可以通过Python自带的日志包实现:
这里的level参数代表警告级别,严重程度从低到高:DEBUG
添加 datefmt 参数以将特定时间添加到每个日志中,这很有用。

以上,我们就完成了整个数据的抓取。有了数据,我们可以开始分析它,但在此之前,我们需要简单地清理和处理数据。
3. 数据清洗过程
首先,我们从 MongoDB 中读取数据并将其转换为 DataFrame,然后查看数据的基础知识。

从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
在comment、download、follow、num_score这五列中,有些行加了“million”字尾,需要去掉,转成数值类型;体积列分别有“M”和“K”后缀,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有6086行x 8列,每列没有缺失值。
df.describe() 方法对 score 列进行基本统计。可以看出所有app的平均分3.9分(5分制),最低分1.6分,最高分1.@k36@ >8 分。
接下来,我们将以上列文本数据转换为数值数据。代码实现如下:
以上,几列文本数据的转换就完成了。先来看看基本情况:

下载被列为应用程序下载的数量。下载次数最多的app有5190万次,最少的是0(极少),平均下载次数是14万次。可以看到以下信息:
至此,基本的数据清洗流程就完成了,下面将对数据进行探索性分析。
4. 数据分析
我们主要从整体和分类两个维度分析App下载量、评分、量等指标。
4.1.整体状态4.1.1.下载排名
首先,我们来看看应用程序的下载量。很多时候我们下载一个应用,下载量是一个非常重要的参考指标。由于大部分app的下载量都比较小,直方图看不出趋势,所以我们选择将数据分段离散化成直方图,绘图工具是Pyecharts。

可以看到,多达 5,517 个(占总数的 84%)应用下载量低于 10 万,只有 20 个应用下载量超过 500 万。要开发一个盈利的应用程序,用户下载尤为重要。由此看来,大部分app都处于尴尬的境地,至少在宽平台上是这样。
代码实现如下:
接下来,我们来看看下载次数最多的20款应用分别是:

可以看到,这里的“酷安”App以5000万+的下载量遥遥领先,几乎是第二名微信2700万下载量的两倍。如此巨大的优势不难理解。毕竟是自己的App。如果你的手机上没有“酷安”,就说明你不是真正的“机器爱好者”。从图片中,我们还可以看到以下信息:
为了比较,让我们看看下载量最少的 20 个应用程序。

可以看出,这些与上面下载量最多的app相比相形见绌,而下载量最少的《广州限行证》只有63次下载。
这并不奇怪。可能是该应用程序没有被宣传,或者它可能刚刚开发。这么少的下载量分数还不错,还能继续更新。我喜欢这些开发者。
事实上,这类应用程序并不尴尬。真正尴尬的应该是那些下载量大、评分低的应用。给人的感觉是:“太爱了,有本事就别用了。” .

限于篇幅,文章截取了部分内容。其实爬虫加数据分析很有意思!许多学生正在寻找爬行动物的职位。其实纯爬虫的职位并不多,尤其是二线城市!如果你同时具备爬虫和数据分析能力,那么找工作会容易得多。
近 150 家公司的 210 位 Python 合作伙伴
都在 Python 工作圈
scrapy分页抓取网页(爬取的思路如下图(站点分析)的应用思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-20 08:20
2021-05-16介绍
知乎用户信息量很大,本文为scrapy实战:如何抓取所有知乎用户信息。
爬取的思路如下图所示:
现场分析
本文以Brother Wheel为根节点(根节点可随意选择),打开Brother Wheel的关注列表,翻页查看关注列表:
翻页是一个 AJAX 请求,每页有 20 个关注用户和一些简短的用户信息
其中之一是 url-token,用于识别用户。在上面的截图中,用户的主页 url 是:
其中有url-token
项目实战
创建项目
思想分析
获取用户信息
首先,您需要获取用户的基本信息。可以通过请求类似以下的 url 来获取这些基本信息:
{url_token}/以下
而url_token可以在用户的关注列表中获取,上面url的页面是这样的
此外,还有赞数、采集数、感谢权
从上面的url获取到用户的基本信息后,下一步就是获取当前用户的关注列表:
获取用户关注列表
此列表具有翻页功能。经分析可知,关注列表的翻页是通过AJAX请求实现的。获取页面关注列表的url如下:
[*].answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge[%3F(type%3Dbest_answerer)].topics&offset=0&limit=20
提取规则:
{url-token}/followees?include={include}&offset={offset}&limit=2{limit}
其中包括:
数据[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics
上面的url返回一个json,里面收录20个follower,响应数据如下图所示:
对于一个follower,我们只需要得到用户的url-token*,然后我们就可以通过url-token拼接出用户的主页,还可以得到用户的基本信息和follower列表。
获取到url-token后,我们需要判断是否有下一页,如果有则翻页,上图后半部分还有一个字段:
翻到当前最后一页,字段如下图:
因此,根据is_end字段可以判断是否关注了下一页的follower,利用next字段的值可以得到下一页的follower列表。
构思安排
所以呢?在解析用户基本信息的同时,我们可以得到用户的url_token,进而可以得到用户的follower列表。通过这种方式爬取,我们基本上可以得到所有知乎用户的所有基本信息。
源码和一些爬取的数据:
部分爬取的知乎用户数据
源代码
文章中已经引入了爬取知乎用户的思路。思路理清后,实现比较块。
主要是源码有点长,这里就不一一贴了。需要源码的同学可以通过文末获取
扫描下方二维码发送关键词“知乎”即可获取本文完整源码和详细程序评论
关注公众号:互联网求职面试、java、python、爬虫、大数据等技术,海量数据分享:在公众号后台回复“csdn库下载”即可领取【csdn】和【百度库】 ] 免费下载服务;公众号后台回复“数据”:可以获得5T优质学习资料、java面试考点和java面授总结,还有几十个java和大数据项目,资料很丰富完成,你几乎可以找到你想要的一切
分类:
技术要点:
相关文章: 查看全部
scrapy分页抓取网页(爬取的思路如下图(站点分析)的应用思路)
2021-05-16介绍
知乎用户信息量很大,本文为scrapy实战:如何抓取所有知乎用户信息。
爬取的思路如下图所示:
现场分析
本文以Brother Wheel为根节点(根节点可随意选择),打开Brother Wheel的关注列表,翻页查看关注列表:
翻页是一个 AJAX 请求,每页有 20 个关注用户和一些简短的用户信息
其中之一是 url-token,用于识别用户。在上面的截图中,用户的主页 url 是:
其中有url-token
项目实战
创建项目
思想分析
获取用户信息
首先,您需要获取用户的基本信息。可以通过请求类似以下的 url 来获取这些基本信息:
{url_token}/以下
而url_token可以在用户的关注列表中获取,上面url的页面是这样的
此外,还有赞数、采集数、感谢权
从上面的url获取到用户的基本信息后,下一步就是获取当前用户的关注列表:
获取用户关注列表
此列表具有翻页功能。经分析可知,关注列表的翻页是通过AJAX请求实现的。获取页面关注列表的url如下:
[*].answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge[%3F(type%3Dbest_answerer)].topics&offset=0&limit=20
提取规则:
{url-token}/followees?include={include}&offset={offset}&limit=2{limit}
其中包括:
数据[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics
上面的url返回一个json,里面收录20个follower,响应数据如下图所示:
对于一个follower,我们只需要得到用户的url-token*,然后我们就可以通过url-token拼接出用户的主页,还可以得到用户的基本信息和follower列表。
获取到url-token后,我们需要判断是否有下一页,如果有则翻页,上图后半部分还有一个字段:
翻到当前最后一页,字段如下图:
因此,根据is_end字段可以判断是否关注了下一页的follower,利用next字段的值可以得到下一页的follower列表。
构思安排
所以呢?在解析用户基本信息的同时,我们可以得到用户的url_token,进而可以得到用户的follower列表。通过这种方式爬取,我们基本上可以得到所有知乎用户的所有基本信息。
源码和一些爬取的数据:
部分爬取的知乎用户数据
源代码
文章中已经引入了爬取知乎用户的思路。思路理清后,实现比较块。
主要是源码有点长,这里就不一一贴了。需要源码的同学可以通过文末获取
扫描下方二维码发送关键词“知乎”即可获取本文完整源码和详细程序评论
关注公众号:互联网求职面试、java、python、爬虫、大数据等技术,海量数据分享:在公众号后台回复“csdn库下载”即可领取【csdn】和【百度库】 ] 免费下载服务;公众号后台回复“数据”:可以获得5T优质学习资料、java面试考点和java面授总结,还有几十个java和大数据项目,资料很丰富完成,你几乎可以找到你想要的一切
分类:
技术要点:
相关文章:
scrapy分页抓取网页(【干货】selenium下载中间件常用函数_response下载详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-19 15:19
1、需补充知识1.下载中间件常用函数process_response(self, request, spider):2.scrapy与selenium对接
scrapy 通过在 setting.py 文件中设置 DOWNLOADER_MIDDLEWARES 添加自己的下载中间件。通常使用的selenium相关的内容都写在这个下载中间件里面,后面会有代码说明。
关于 selenium 的基本使用,请参见:
3.常用设置的内置设置
参考链接:
2、案例研究
分析:
一共需要抓取三页。首先,抓取第一页上的所有城市名称和相应的链接。地址是:
然后抓取每个城市和每个月的具体信息(即年月),地址:%E5%AE%89%E5%BA%B7,这里只是其中一个城市
最后,抓取每个月的每一天的数据,示例地址:%E5%AE%89%E5%BA%B7&month=2015-01
其中,首页为静态页面,可直接抓取上面的城市信息;第二页和第三页是动态页面,是selenium结合Phantomjs爬取的(也可以用谷歌浏览器)
1. 创建一个项目
scrapy startproject ChinaAir
2.指定需要抓取的字段
在 items.py 文件中定义要抓取的字段,并编写相关代码。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ChinaairItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
"""
首先明确抓取目标,包括城市,日期,指标的值
"""
# 城市
city = scrapy.Field()
# 日期
date = scrapy.Field()
# 空气质量指数
AQI = scrapy.Field()
# 空气质量等级
level = scrapy.Field()
# pm2.5的值
PM2_5 = scrapy.Field()
# pm10
PM10 = scrapy.Field()
# 二氧化硫
SO2 = scrapy.Field()
# 一氧化碳
CO = scrapy.Field()
# 二氧化氮
NO2 = scrapy.Field()
# 臭氧浓度
O3_8h = scrapy.Field()
# 数据源(数据来源)
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
3.生成爬虫文件
创建一个名为airChina的爬虫,并给出一个初始地址。
scrapy genspider airChina https://www.aqistudy.cn/historydata/
进入爬虫文件,开始编写爬虫部分的代码。
4.写一个爬虫
# -*- coding: utf-8 -*-
import scrapy
from ChinaAir.items import ChinaairItem
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
pass
yield之后,来到下载中间件文件。由于每个请求都要经过下载中间件,所以当请求从第一页解析的url时,可以在下载中间件中进行某些操作,例如使用selenium进行请求。
进入middlerwares.py文件,把已经写的全部删掉,改写我们需要的。
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
# 导入User-Agent列表
from ChinaAir.settings import USER_AGENT as ua_list
# class UserAgentMiddlerware(object):
# """
# 定义一个中间件,给每一个请求随机选择USER_AGENT
# 注意,不要忘了在setting文件中打开DOWNLOADER_MIDDLERWARE的注释
# """
# def process_request(self, request, spider):
#
# # 从ua_list中随机选择一个User-Agent
# user_agent = random.choice(ua_list)
# # 给请求添加头信息
# request.headers['User-Agent'] = user_agent
# # 当然,也可以添加代理ip,方式如下,此处不用代理,仅说明代理使用方法
# # request.meta['proxy'] = "..."
# print(request.headers['User-Agent'])
import time
import scrapy
from selenium import webdriver
class SeleniumMiddlerware(object):
"""
利用selenium,获取动态页面数据
"""
def process_request(self, request, spider):
# 判断请求是否来自第二个页面,只在第二个页面调用浏览器
if not request.url == "https://www.aqistudy.cn/historydata/":
# 实例化。selenium结合谷歌浏览器,
self.driver = webdriver.PhantomJS() # 实在受不了每次测试都打开浏览器界面,所以换成无界面的了
# 请求
self.driver.get(request.url)
time.sleep(2)
# 获取请求后得到的源码
html = self.driver.page_source
# 关闭浏览器
self.driver.quit()
# 构造一个请求的结果,将谷歌浏览器访问得到的结果构造成response,并返回给引擎
response = scrapy.http.HtmlResponse(url=request.url, body=html, request=request, encoding='utf-8')
return response
其中,注释部分是下载中间件为每个请求分配一个随机的User-Agent和代理IP。当然,这里没有用到,所以不用担心。
由于每次生成请求请求,都必须经过下载中间件。因此,在编写判断条件时,使用 selenium 只从第二页开始执行请求。
在代码的最后一行,下载中间件将 selenium 请求的结果构造成响应,返回给引擎,继续后续处理。注意下载中间件的注释要在settings.py文件中开启。
得到第二页返回的响应后,继续爬虫文件,解析响应并提取第三页需要的url,代码如下:
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[:1]
# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[:1]
# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
"""
拿到每个城市的,每个月份的数据
此页面为动态页面,这里利用selenium结合浏览器获取动态数据
因此在下载中间件中添加中间件代码
:param response:
:return:
"""
# 获取城市每个月份的链接
url_list = response.xpath('//tr/td/a/@href').extract()[:1]
for url in url_list:
url = self.base_url + url # 构造该url
yield scrapy.Request(url=url, meta={'city': response.meta['city']}, callback=self.parse_day)
拿到第二页的数据后,解析第三页请求的url,回调并提取要抓取的数据,爬虫部分的代码就完成了。因此,整个爬虫文件的代码如下:
# -*- coding: utf-8 -*-
import scrapy
from ChinaAir.items import ChinaairItem
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[:1]
# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[:1]
# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
"""
拿到每个城市的,每个月份的数据
此页面为动态页面,这里利用selenium结合浏览器获取动态数据
因此在下载中间件中添加中间件代码
:param response:
:return:
"""
# 获取城市每个月份的链接
url_list = response.xpath('//tr/td/a/@href').extract()[:1]
for url in url_list:
url = self.base_url + url # 构造该url
yield scrapy.Request(url=url, meta={'city': response.meta['city']}, callback=self.parse_day)
def parse_day(self, response):
"""
获取每一天的数据
:param response:
:return:
"""
node_list = response.xpath('//tr')
node_list.pop(0)
for node in node_list:
# 解析目标数据
item = ChinaairItem()
item['city'] = response.meta['city']
item['date'] = node.xpath('./td[1]/text()').extract_first()
item['AQI'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['PM2_5'] = node.xpath('./td[4]/text()').extract_first()
item['PM10'] = node.xpath('./td[5]/text()').extract_first()
item['SO2'] = node.xpath('./td[6]/text()').extract_first()
item['CO'] = node.xpath('./td[7]/text()').extract_first()
item['NO2'] = node.xpath('./td[8]/text()').extract_first()
item['O3_8h'] = node.xpath('./td[9]/text()').extract_first()
yield item
5.写管道文件
抓取数据后,就可以开始编写保存数据的逻辑了。在这里,只有数据以json格式写入。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
import json
from datetime import datetime
class ChinaAirPipeline(object):
def process_item(self, item, spider):
item["source"] = spider.name
item['utc_time'] = str(datetime.utcnow())
return item
class ChinaAirJsonPipeline(object):
def open_spider(self, spider):
self.file = open('air.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(content)
def close_spider(self, spider):
self.file.close()
ChinaAirPipeline接收到pipeline抛出的item后,继续添加两个自读,捕获时间和数据源,添加完后,继续通过pipeline抛到下面的ChinaAirJsonPipelines文件中保存。
其中,别忘了在settings.py文件中注册管道信息。
6.运行爬虫,抓取数据
scrapy crawl airChina
3、完整代码
也可以看看: 查看全部
scrapy分页抓取网页(【干货】selenium下载中间件常用函数_response下载详解)
1、需补充知识1.下载中间件常用函数process_response(self, request, spider):2.scrapy与selenium对接
scrapy 通过在 setting.py 文件中设置 DOWNLOADER_MIDDLEWARES 添加自己的下载中间件。通常使用的selenium相关的内容都写在这个下载中间件里面,后面会有代码说明。
关于 selenium 的基本使用,请参见:
3.常用设置的内置设置
参考链接:
2、案例研究
分析:
一共需要抓取三页。首先,抓取第一页上的所有城市名称和相应的链接。地址是:
然后抓取每个城市和每个月的具体信息(即年月),地址:%E5%AE%89%E5%BA%B7,这里只是其中一个城市
最后,抓取每个月的每一天的数据,示例地址:%E5%AE%89%E5%BA%B7&month=2015-01
其中,首页为静态页面,可直接抓取上面的城市信息;第二页和第三页是动态页面,是selenium结合Phantomjs爬取的(也可以用谷歌浏览器)
1. 创建一个项目
scrapy startproject ChinaAir
2.指定需要抓取的字段
在 items.py 文件中定义要抓取的字段,并编写相关代码。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ChinaairItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
"""
首先明确抓取目标,包括城市,日期,指标的值
"""
# 城市
city = scrapy.Field()
# 日期
date = scrapy.Field()
# 空气质量指数
AQI = scrapy.Field()
# 空气质量等级
level = scrapy.Field()
# pm2.5的值
PM2_5 = scrapy.Field()
# pm10
PM10 = scrapy.Field()
# 二氧化硫
SO2 = scrapy.Field()
# 一氧化碳
CO = scrapy.Field()
# 二氧化氮
NO2 = scrapy.Field()
# 臭氧浓度
O3_8h = scrapy.Field()
# 数据源(数据来源)
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
3.生成爬虫文件
创建一个名为airChina的爬虫,并给出一个初始地址。
scrapy genspider airChina https://www.aqistudy.cn/historydata/
进入爬虫文件,开始编写爬虫部分的代码。
4.写一个爬虫
# -*- coding: utf-8 -*-
import scrapy
from ChinaAir.items import ChinaairItem
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
pass
yield之后,来到下载中间件文件。由于每个请求都要经过下载中间件,所以当请求从第一页解析的url时,可以在下载中间件中进行某些操作,例如使用selenium进行请求。
进入middlerwares.py文件,把已经写的全部删掉,改写我们需要的。
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
# 导入User-Agent列表
from ChinaAir.settings import USER_AGENT as ua_list
# class UserAgentMiddlerware(object):
# """
# 定义一个中间件,给每一个请求随机选择USER_AGENT
# 注意,不要忘了在setting文件中打开DOWNLOADER_MIDDLERWARE的注释
# """
# def process_request(self, request, spider):
#
# # 从ua_list中随机选择一个User-Agent
# user_agent = random.choice(ua_list)
# # 给请求添加头信息
# request.headers['User-Agent'] = user_agent
# # 当然,也可以添加代理ip,方式如下,此处不用代理,仅说明代理使用方法
# # request.meta['proxy'] = "..."
# print(request.headers['User-Agent'])
import time
import scrapy
from selenium import webdriver
class SeleniumMiddlerware(object):
"""
利用selenium,获取动态页面数据
"""
def process_request(self, request, spider):
# 判断请求是否来自第二个页面,只在第二个页面调用浏览器
if not request.url == "https://www.aqistudy.cn/historydata/":
# 实例化。selenium结合谷歌浏览器,
self.driver = webdriver.PhantomJS() # 实在受不了每次测试都打开浏览器界面,所以换成无界面的了
# 请求
self.driver.get(request.url)
time.sleep(2)
# 获取请求后得到的源码
html = self.driver.page_source
# 关闭浏览器
self.driver.quit()
# 构造一个请求的结果,将谷歌浏览器访问得到的结果构造成response,并返回给引擎
response = scrapy.http.HtmlResponse(url=request.url, body=html, request=request, encoding='utf-8')
return response
其中,注释部分是下载中间件为每个请求分配一个随机的User-Agent和代理IP。当然,这里没有用到,所以不用担心。
由于每次生成请求请求,都必须经过下载中间件。因此,在编写判断条件时,使用 selenium 只从第二页开始执行请求。
在代码的最后一行,下载中间件将 selenium 请求的结果构造成响应,返回给引擎,继续后续处理。注意下载中间件的注释要在settings.py文件中开启。

得到第二页返回的响应后,继续爬虫文件,解析响应并提取第三页需要的url,代码如下:
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[:1]
# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[:1]
# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
"""
拿到每个城市的,每个月份的数据
此页面为动态页面,这里利用selenium结合浏览器获取动态数据
因此在下载中间件中添加中间件代码
:param response:
:return:
"""
# 获取城市每个月份的链接
url_list = response.xpath('//tr/td/a/@href').extract()[:1]
for url in url_list:
url = self.base_url + url # 构造该url
yield scrapy.Request(url=url, meta={'city': response.meta['city']}, callback=self.parse_day)
拿到第二页的数据后,解析第三页请求的url,回调并提取要抓取的数据,爬虫部分的代码就完成了。因此,整个爬虫文件的代码如下:
# -*- coding: utf-8 -*-
import scrapy
from ChinaAir.items import ChinaairItem
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[:1]
# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[:1]
# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
"""
拿到每个城市的,每个月份的数据
此页面为动态页面,这里利用selenium结合浏览器获取动态数据
因此在下载中间件中添加中间件代码
:param response:
:return:
"""
# 获取城市每个月份的链接
url_list = response.xpath('//tr/td/a/@href').extract()[:1]
for url in url_list:
url = self.base_url + url # 构造该url
yield scrapy.Request(url=url, meta={'city': response.meta['city']}, callback=self.parse_day)
def parse_day(self, response):
"""
获取每一天的数据
:param response:
:return:
"""
node_list = response.xpath('//tr')
node_list.pop(0)
for node in node_list:
# 解析目标数据
item = ChinaairItem()
item['city'] = response.meta['city']
item['date'] = node.xpath('./td[1]/text()').extract_first()
item['AQI'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['PM2_5'] = node.xpath('./td[4]/text()').extract_first()
item['PM10'] = node.xpath('./td[5]/text()').extract_first()
item['SO2'] = node.xpath('./td[6]/text()').extract_first()
item['CO'] = node.xpath('./td[7]/text()').extract_first()
item['NO2'] = node.xpath('./td[8]/text()').extract_first()
item['O3_8h'] = node.xpath('./td[9]/text()').extract_first()
yield item
5.写管道文件
抓取数据后,就可以开始编写保存数据的逻辑了。在这里,只有数据以json格式写入。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
import json
from datetime import datetime
class ChinaAirPipeline(object):
def process_item(self, item, spider):
item["source"] = spider.name
item['utc_time'] = str(datetime.utcnow())
return item
class ChinaAirJsonPipeline(object):
def open_spider(self, spider):
self.file = open('air.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(content)
def close_spider(self, spider):
self.file.close()
ChinaAirPipeline接收到pipeline抛出的item后,继续添加两个自读,捕获时间和数据源,添加完后,继续通过pipeline抛到下面的ChinaAirJsonPipelines文件中保存。
其中,别忘了在settings.py文件中注册管道信息。
6.运行爬虫,抓取数据
scrapy crawl airChina
3、完整代码
也可以看看:
谈谈对Python爬虫的理解
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-05-08 00:00
爬虫也可以称为Python爬虫
不知从何时起,Python这门语言和爬虫就像一对恋人,二者如胶似漆 ,形影不离,你中有我、我中有你
一提起爬虫,就会想到Python,一说起Python,就会想到人工智能……和爬虫
所以,一般说爬虫的时候,大部分程序员潜意识里都会联想为Python爬虫,为什么会这样,我觉得有两个原因:
任何一个学习Python的程序员,应该都或多或少地见过甚至研究过爬虫,我当时写Python的目的就非常纯粹——为了写爬虫
所以本文的目的很简单,就是说说我个人对Python爬虫的理解与实践,作为一名程序员,我觉得了解一下爬虫的相关知识对你只有好处,所以读完这篇文章后,如果能对你有帮助,那便再好不过
什么是爬虫
爬虫是一个程序,这个程序的目的就是为了抓取万维网信息资源,比如你日常使用的谷歌等搜索引擎,搜索结果就全都依赖爬虫来定时获取
看上述搜索结果,除了wiki相关介绍外,爬虫有关的搜索结果全都带上了Python,前人说Python爬虫,现在看来果然诚不欺我~
爬虫的目标对象也很丰富,不论是文字、图片、视频,任何结构化非结构化的数据爬虫都可以爬取,爬虫经过发展,也衍生出了各种爬虫类型:
不想说这些大方向的概念,让我们以一个获取网页内容为例,从爬虫技术本身出发,来说说网页爬虫,步骤如下:
什么是爬虫,这就是爬虫:
<p>"""让我们根据上面说的步骤来完成一个简单的爬虫程序"""
import requests
<br />
from bs4 import BeautifulSoup
<br />
target_url = 'http://www.baidu.com/s?wd=爬虫'
<br />
# 第一步 发起一个GET请求
res = requests.get(target_url)
<br />
# 第二步 提取HTML并解析想获取的数据 比如获取 title
soup = BeautifulSoup(res.text, "lxml")
# 输出 soup.title.text
title = soup.title.text
<br />
# 第三步 持久化 比如保存到本地
with open('title.txt', 'w') as fp:
fp.write(title)</p>
加上注释不到20行代码,你就完成了一个爬虫,简单吧
怎么写爬虫
网页世界多姿多彩、亿万网页资源供你选择,面对不同的页面,怎么使自己编写的爬虫程序够稳健、持久,这是一个值得讨论的问题
俗话说,磨刀不误砍柴工,在开始编写爬虫之前,很有必要掌握一些基本知识:
这两句描述体现了一名爬虫开发人员需要掌握的基本知识,不过一名基本的后端或者前端工程师都会这些哈哈,这也说明了爬虫的入门难度极低,从这两句话,你能思考出哪些爬虫必备的知识点呢?
有了这些知识储备,接下来就可以选择一门语言,开始编写自己的爬虫程序了,还是按照上一节说的三个步骤,然后以Python为例,说一说要在编程语言方面做那些准备:
掌握了上面这些,你大可放开手脚大干一场,万维网就是你的名利场,去吧~
我觉得对于一个目标网站的网页,可以分下面四个类型:
具体是什么意思呢,可能看起来有点绕,但明白这些,你之后写爬虫,只要在脑子里面过一遍着网页对应什么类型,然后套上对应类型的程序(写多了都应该有一套自己的常用代码库),那写爬虫的速度,自然不会慢
单页面单目标
通俗来说,就是在这个网页里面,我们的目标就只有一个,假设我们的需求是抓取这部电影-肖申克的救赎的名称,首先打开网页右键审查元素,找到电影名称对应的元素位置,如下图所示:
在某个单一页面内,看目标是不是只有一个,一眼就能看出标题的CSS Selector规则为:#content > h1 > span:nth-child(1),然后用我自己写的常用库,我用不到十行代码就能写完抓取这个页面电影名称的爬虫:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
title = TextField(css_select='#content > h1 > span:nth-child(1)')
<br />
async_func = DoubanItem.get_item(url="https://movie.douban.com/subject/1292052/")
item = asyncio.get_event_loop().run_until_complete(async_func)
print(item.title)</p>
多页面多目标就是此情况下多个url的衍生情况
单页面多目标
假设现在的需求是抓取豆瓣电影250第一页中的所有电影名称,你需要提取25个电影名称,因为这个目标页的目标数据是多个item的,因此目标需要循环获取,这就是所谓的单页面多目标了:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
async_func = DoubanItem.get_items(url="https://movie.douban.com/top250")
items = asyncio.get_event_loop().run_until_complete(async_func)
for item in items:
print(item)</p>
多页面多目标
多页面多目标是上述单页面多目标情况的衍生,在这个问题上来看,此时就是获取所有分页的电影名称
<p>from ruia import TextField, Item, Request, Spider
<br />
<br />
class DoubanItem(Item):
"""
定义爬虫的目标字段
"""
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
class DoubanSpider(Spider):
start_urls = ['https://movie.douban.com/top250']
concurrency = 10
<br />
async def parse(self, res):
etree = res.html_etree
pages = ['?start=0&filter='] + [i.get('href') for i in etree.cssselect('.paginator>a')]
<br />
for index, page in enumerate(pages):
url = self.start_urls[0] + page
yield Request(
url,
callback=self.parse_item,
metadata={'index': index},
request_config=self.request_config
)
<br />
async def parse_item(self, res):
items_data = await DoubanItem.get_items(html=res.html)
res_list = []
for item in items_data:
res_list.append(item.title)
return res_list
<br />
<br />
if __name__ == '__main__':
DoubanSpider.start()</p>
如果网络没问题的话,会得到如下输出:
注意爬虫运行时间,1s不到,这就是异步的魅力
用Python写爬虫,就是这么简单优雅,诸位,看着网页就思考下:
一个爬虫程序就成型了,顺便一提,爬虫这东西,可以说是防君子不防小人,robots.txt大部分网站都有(它的目的是告诉爬虫什么可以爬取什么不可以爬取,比如:),各位想怎么爬取,自己衡量
如何进阶
不要以为写好一个爬虫程序就可以出师了,此时还有更多的问题在前面等着你,你要含情脉脉地看着你的爬虫程序,问自己三个问题:
前两个关于人性的问题在此不做过多叙述,因此跳过,但你们如果作为爬虫工程师的话,切不可跳过
会被反爬虫干掉么?
最后关于反爬虫的问题才是你爬虫程序强壮与否的关键因素,什么是反爬虫?
当越来越多的爬虫在互联网上横冲直撞后,网页资源维护者为了防止自身数据被抓取,开始进行一系列的措施来使得自身数据不易被别的程序爬取,这些措施就是反爬虫
比如检测IP访问频率、资源访问速度、链接是否带有关键参数、验证码检测机器人、ajax混淆、js加密等等
对于目前市场上的反爬虫,爬虫工程师常有的反反爬虫方案是下面这样的:
爬虫工程师的进阶之路其实就是不断反反爬虫,可谓艰辛,但换个角度想也是乐趣所在
关于框架
爬虫有自己的编写流程和标准,有了标准,自然就有了框架,像Python这种生态强大的语言,框架自然是多不胜数,目前世面上用的比较多的有:
这里不过多介绍,框架只是工具,是一种提升效率的方式,看你选择
说明
任何事物都有两面性,爬虫自然也不例外,因此我送诸位一张图,关键时刻好好想想
往期推荐:
查看全部
谈谈对Python爬虫的理解
爬虫也可以称为Python爬虫
不知从何时起,Python这门语言和爬虫就像一对恋人,二者如胶似漆 ,形影不离,你中有我、我中有你
一提起爬虫,就会想到Python,一说起Python,就会想到人工智能……和爬虫
所以,一般说爬虫的时候,大部分程序员潜意识里都会联想为Python爬虫,为什么会这样,我觉得有两个原因:
任何一个学习Python的程序员,应该都或多或少地见过甚至研究过爬虫,我当时写Python的目的就非常纯粹——为了写爬虫
所以本文的目的很简单,就是说说我个人对Python爬虫的理解与实践,作为一名程序员,我觉得了解一下爬虫的相关知识对你只有好处,所以读完这篇文章后,如果能对你有帮助,那便再好不过
什么是爬虫
爬虫是一个程序,这个程序的目的就是为了抓取万维网信息资源,比如你日常使用的谷歌等搜索引擎,搜索结果就全都依赖爬虫来定时获取
看上述搜索结果,除了wiki相关介绍外,爬虫有关的搜索结果全都带上了Python,前人说Python爬虫,现在看来果然诚不欺我~
爬虫的目标对象也很丰富,不论是文字、图片、视频,任何结构化非结构化的数据爬虫都可以爬取,爬虫经过发展,也衍生出了各种爬虫类型:
不想说这些大方向的概念,让我们以一个获取网页内容为例,从爬虫技术本身出发,来说说网页爬虫,步骤如下:
什么是爬虫,这就是爬虫:
<p>"""让我们根据上面说的步骤来完成一个简单的爬虫程序"""
import requests
<br />
from bs4 import BeautifulSoup
<br />
target_url = 'http://www.baidu.com/s?wd=爬虫'
<br />
# 第一步 发起一个GET请求
res = requests.get(target_url)
<br />
# 第二步 提取HTML并解析想获取的数据 比如获取 title
soup = BeautifulSoup(res.text, "lxml")
# 输出 soup.title.text
title = soup.title.text
<br />
# 第三步 持久化 比如保存到本地
with open('title.txt', 'w') as fp:
fp.write(title)</p>
加上注释不到20行代码,你就完成了一个爬虫,简单吧
怎么写爬虫
网页世界多姿多彩、亿万网页资源供你选择,面对不同的页面,怎么使自己编写的爬虫程序够稳健、持久,这是一个值得讨论的问题
俗话说,磨刀不误砍柴工,在开始编写爬虫之前,很有必要掌握一些基本知识:
这两句描述体现了一名爬虫开发人员需要掌握的基本知识,不过一名基本的后端或者前端工程师都会这些哈哈,这也说明了爬虫的入门难度极低,从这两句话,你能思考出哪些爬虫必备的知识点呢?
有了这些知识储备,接下来就可以选择一门语言,开始编写自己的爬虫程序了,还是按照上一节说的三个步骤,然后以Python为例,说一说要在编程语言方面做那些准备:
掌握了上面这些,你大可放开手脚大干一场,万维网就是你的名利场,去吧~
我觉得对于一个目标网站的网页,可以分下面四个类型:
具体是什么意思呢,可能看起来有点绕,但明白这些,你之后写爬虫,只要在脑子里面过一遍着网页对应什么类型,然后套上对应类型的程序(写多了都应该有一套自己的常用代码库),那写爬虫的速度,自然不会慢
单页面单目标
通俗来说,就是在这个网页里面,我们的目标就只有一个,假设我们的需求是抓取这部电影-肖申克的救赎的名称,首先打开网页右键审查元素,找到电影名称对应的元素位置,如下图所示:
在某个单一页面内,看目标是不是只有一个,一眼就能看出标题的CSS Selector规则为:#content > h1 > span:nth-child(1),然后用我自己写的常用库,我用不到十行代码就能写完抓取这个页面电影名称的爬虫:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
title = TextField(css_select='#content > h1 > span:nth-child(1)')
<br />
async_func = DoubanItem.get_item(url="https://movie.douban.com/subject/1292052/";)
item = asyncio.get_event_loop().run_until_complete(async_func)
print(item.title)</p>
多页面多目标就是此情况下多个url的衍生情况
单页面多目标
假设现在的需求是抓取豆瓣电影250第一页中的所有电影名称,你需要提取25个电影名称,因为这个目标页的目标数据是多个item的,因此目标需要循环获取,这就是所谓的单页面多目标了:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
async_func = DoubanItem.get_items(url="https://movie.douban.com/top250";)
items = asyncio.get_event_loop().run_until_complete(async_func)
for item in items:
print(item)</p>
多页面多目标
多页面多目标是上述单页面多目标情况的衍生,在这个问题上来看,此时就是获取所有分页的电影名称
<p>from ruia import TextField, Item, Request, Spider
<br />
<br />
class DoubanItem(Item):
"""
定义爬虫的目标字段
"""
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
class DoubanSpider(Spider):
start_urls = ['https://movie.douban.com/top250']
concurrency = 10
<br />
async def parse(self, res):
etree = res.html_etree
pages = ['?start=0&filter='] + [i.get('href') for i in etree.cssselect('.paginator>a')]
<br />
for index, page in enumerate(pages):
url = self.start_urls[0] + page
yield Request(
url,
callback=self.parse_item,
metadata={'index': index},
request_config=self.request_config
)
<br />
async def parse_item(self, res):
items_data = await DoubanItem.get_items(html=res.html)
res_list = []
for item in items_data:
res_list.append(item.title)
return res_list
<br />
<br />
if __name__ == '__main__':
DoubanSpider.start()</p>
如果网络没问题的话,会得到如下输出:
注意爬虫运行时间,1s不到,这就是异步的魅力
用Python写爬虫,就是这么简单优雅,诸位,看着网页就思考下:
一个爬虫程序就成型了,顺便一提,爬虫这东西,可以说是防君子不防小人,robots.txt大部分网站都有(它的目的是告诉爬虫什么可以爬取什么不可以爬取,比如:),各位想怎么爬取,自己衡量
如何进阶
不要以为写好一个爬虫程序就可以出师了,此时还有更多的问题在前面等着你,你要含情脉脉地看着你的爬虫程序,问自己三个问题:
前两个关于人性的问题在此不做过多叙述,因此跳过,但你们如果作为爬虫工程师的话,切不可跳过
会被反爬虫干掉么?
最后关于反爬虫的问题才是你爬虫程序强壮与否的关键因素,什么是反爬虫?
当越来越多的爬虫在互联网上横冲直撞后,网页资源维护者为了防止自身数据被抓取,开始进行一系列的措施来使得自身数据不易被别的程序爬取,这些措施就是反爬虫
比如检测IP访问频率、资源访问速度、链接是否带有关键参数、验证码检测机器人、ajax混淆、js加密等等
对于目前市场上的反爬虫,爬虫工程师常有的反反爬虫方案是下面这样的:
爬虫工程师的进阶之路其实就是不断反反爬虫,可谓艰辛,但换个角度想也是乐趣所在
关于框架
爬虫有自己的编写流程和标准,有了标准,自然就有了框架,像Python这种生态强大的语言,框架自然是多不胜数,目前世面上用的比较多的有:
这里不过多介绍,框架只是工具,是一种提升效率的方式,看你选择
说明
任何事物都有两面性,爬虫自然也不例外,因此我送诸位一张图,关键时刻好好想想
往期推荐:
scrapy分页抓取网页 6000 多款 App,看我如何搞定她们并将其洗白白~
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-05-06 04:09
项目文件创建好以后,我们就可以开始写爬虫程序了。
首先,需要在 items.py 文件中,预先定义好要爬取的字段信息名称,如下所示:
1class KuanItem(scrapy.Item):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2# define the fields for your item here like:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3name = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4volume = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5download = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6follow = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7comment = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8tags = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9score = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10num_score = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里的字段信息就是我们前面在网页中定位的 8 个字段信息,包括:name 表示 App 名称、volume 表示体积、download 表示下载数量。在这里定义好之后,我们在后续的爬取主程序中会利用到这些字段信息。
2.3.3. 爬取主程序
创建好 kuan 项目后,Scrapy 框架会自动生成爬取的部分代码,我们接下来就需要在 parse 方法中增加网页抓取的字段解析内容。
1class KuanspiderSpider(scrapy.Spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 name = 'kuan'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 allowed_domains = ['www.coolapk.com']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 start_urls = ['http://www.coolapk.com/']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 pass<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
打开主页 Dev Tools,找到每项抓取指标的节点位置,然后可以采用 CSS、Xpath、正则等方法进行提取解析,这些方法 Scrapy 都支持,可随意选择,这里我们选用 CSS 语法来定位节点,不过需要注意的是,Scrapy 的 CSS 语法和之前我们利用 pyquery 使用的 CSS 语法稍有不同,举几个例子,对比说明一下。
首先,我们定位到第一个 APP 的主页 URL 节点,可以看到 URL 节点位于 class 属性为app_left_list的 div 节点下的 a 节点中,其 href 属性就是我们需要的 URL 信息,这里是相对地址,拼接后就是完整的 URL。
接着我们进入酷安详情页,选择 App 名称并进行定位,可以看到 App 名称节点位于 class 属性为.detail_app_title的 p 节点的文本中。
定位到这两个节点之后,我们就可以使用 CSS 提取字段信息了,这里对比一下常规写法和 Scrapy 中的写法:
1# 常规写法<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2url = item('.app_left_list>a').attr('href')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3name = item('.list_app_title').text()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4# Scrapy 写法<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5url = item.css('::attr("href")').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6name = item.css('.detail_app_title::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
可以看到,要获取 href 或者 text 属性,需要用 :: 表示,比如获取 text,则用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,则用 extract() 。接着,我们就可以参照写出 8 个字段信息的解析代码。
首先,我们需要在主页提取 App 的 URL 列表,然后再进入每个 App 的详情页进一步提取 8 个字段信息。
1def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 contents = response.css('.app_left_list>a')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for content in contents:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 url = content.css('::attr("href")').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5 url = response.urljoin(url) # 拼接相对 url 为绝对 url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 yield scrapy.Request(url,callback=self.parse_url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,利用 response.urljoin() 方法将提取出的相对 URL 拼接为完整的 URL,然后利用 scrapy.Request() 方法构造每个 App 详情页的请求,这里我们传递两个参数:url 和 callback,url 为详情页 URL,callback 是回调函数,它将主页 URL 请求返回的响应 response 传给专门用来解析字段内容的 parse_url() 方法,如下所示:
1def parse_url(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2 item = KuanItem()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 item['name'] = response.css('.detail_app_title::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 results = self.get_comment(response)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 item['volume'] = results[0]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 item['download'] = results[1]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 item['follow'] = results[2]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 item['comment'] = results[3]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 item['tags'] = self.get_tags(response)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 item['score'] = response.css('.rank_num::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 num_score = response.css('.apk_rank_p1::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12 item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 yield item<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15def get_comment(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 messages = response.css('.apk_topba_message::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17 result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18 if result: # 不为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 results = list(result[0]) # 提取出list 中第一个元素<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 return results<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />21<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />22def get_tags(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />23 data = response.css('.apk_left_span2')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />24 tags = [item.css('::text').extract_first() for item in data]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />25 return tags<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,单独定义了 get_comment() 和 get_tags() 两个方法.
get_comment() 方法通过正则匹配提取 volume、download、follow、comment 四个字段信息,正则匹配结果如下:
1result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2print(result) # 输出第一页的结果信息<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3# 结果如下:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4[('21.74M', '5218万', '2.4万', '5.4万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5[('75.53M', '2768万', '2.3万', '3.0万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6[('46.21M', '1686万', '2.3万', '3.4万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7[('54.77M', '1603万', '3.8万', '4.9万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8[('3.32M', '1530万', '1.5万', '3343')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9[('75.07M', '1127万', '1.6万', '2.2万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10[('92.70M', '1108万', '9167', '1.3万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11[('68.94M', '1072万', '5718', '9869')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12[('61.45M', '935万', '1.1万', '1.6万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13[('23.96M', '925万', '4157', '1956')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
然后利用 result[0]、result[1] 等分别提取出四项信息,以 volume 为例,输出第一页的提取结果:
1item['volume'] = results[0]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2print(item['volume'])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 321.74M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 475.53M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 546.21M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 654.77M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 73.32M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 875.07M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 992.70M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1068.94M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1161.45M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1223.96M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这样一来,第一页 10 款 App 的所有字段信息都被成功提取出来,然后返回到 yied item 生成器中,我们输出一下它的内容:
1[<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'}, <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4...<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
2.3.4. 分页爬取
以上,我们爬取了第一页内容,接下去需要遍历爬取全部 610 页的内容,这里有两种思路:
这里,我们分别写出两种方法的解析代码,第一种方法很简单,直接接着 parse 方法继续添加以下几行代码即可:
1def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 contents = response.css('.app_left_list>a')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for content in contents:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 ...<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 url = response.urljoin(next_page)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />8 yield scrapy.Request(url,callback=self.parse )<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
第二种方法,我们在最开头的 parse() 方法前,定义一个 start_requests() 方法,用来批量生成 610 页的 URL,然后通过 scrapy.Request() 方法中的 callback 参数,传递给下面的 parse() 方法进行解析。
1def start_requests(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 pages = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for page in range(1,610): # 一共有610页<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 url = 'https://www.coolapk.com/apk/?page=%s'%page<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5 page = scrapy.Request(url,callback=self.parse)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 pages.append(page)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 return pages<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
以上就是全部页面的爬取思路,爬取成功后,我们需要存储下来。这里,我面选择存储到 MongoDB 中,不得不说,相比 MySQL,MongoDB 要方便省事很多。
2.3.5. 存储结果
我们在 pipelines.py 程序中,定义数据存储方法,MongoDB 的一些参数,比如地址和数据库名称,需单独存放在 settings.py 设置文件中去,然后在 pipelines 程序中进行调用即可。
1import pymongo<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2class MongoPipeline(object):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 def __init__(self,mongo_url,mongo_db):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 self.mongo_url = mongo_url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 self.mongo_db = mongo_db<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 @classmethod<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 def from_crawler(cls,crawler):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 return cls(<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 mongo_url = crawler.settings.get('MONGO_URL'),<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 mongo_db = crawler.settings.get('MONGO_DB')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 )<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12 def open_spider(self,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 self.client = pymongo.MongoClient(self.mongo_url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14 self.db = self.client[self.mongo_db]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15 def process_item(self,item,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 name = item.__class__.__name__<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17 self.db[name].insert(dict(item))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18 return item<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 def close_spider(self,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 self.client.close()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
首先,我们定义一个 MongoPipeline()存储类,里面定义了几个方法,简单进行一下说明:
from crawler() 是一个类方法,用 @class method 标识,这个方法的作用主要是用来获取我们在 settings.py 中设置的这几项参数:
1MONGO_URL = 'localhost'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2MONGO_DB = 'KuAn'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3ITEM_PIPELINES = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 'kuan.pipelines.MongoPipeline': 300,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5}<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
open_spider() 方法主要进行一些初始化操作 ,在 Spider 开启时,这个方法就会被调用 。
process_item() 方法是最重要的方法,实现插入数据到 MongoDB 中。
完成上述代码以后,输入下面一行命令就可以开始整个爬虫的抓取和存储过程了,单机跑的话,6000 个网页需要不少时间才能完成,保持耐心。
1scrapy crawl kuan<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,还有两点补充:
第一,为了减轻网站压力,我们最好在每个请求之间设置几秒延时,可以在 KuanSpider() 方法开头出,加入以下几行代码:
1custom_settings = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 "DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 "CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 }<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
第二,为了更好监控爬虫程序运行,有必要设置输出日志文件,可以通过 Python 自带的 logging 包实现:
1import logging<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4logging.warning("warn message")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5logging.error("error message")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里的 level 参数表示警告级别,严重程度从低到高分别是:DEBUG < INFO < WARNING < ERROR < CRITICAL,如果想日志文件不要记录太多内容,可以设置高一点的级别,这里设置为 WARNING,意味着只有 WARNING 级别以上的信息才会输出到日志中去。
添加 datefmt 参数是为了在每条日志前面加具体的时间,这点很有用处。
以上,我们就完成了整个数据的抓取,有了数据我们就可以着手进行分析,不过这之前还需简单地对数据做一下清洗和处理。
3. 数据清洗处理
首先,我们从 MongoDB 中读取数据并转化为 DataFrame,然后查看一下数据的基本情况。
1def parse_kuan():<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2 client = pymongo.MongoClient(host='localhost', port=27017)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 db = client['KuAn']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 collection = db['KuAnItem']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 # 将数据库数据转为DataFrame<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 data = pd.DataFrame(list(collection.find()))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 print(data.head())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 print(df.shape)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 print(df.info())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 print(df.describe())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
从 data.head() 输出的前 5 行数据中可以看到,除了 score 列是 float 格式以外,其他列都是 object 文本类型。
comment、download、follow、num_score 这 5 列数据中部分行带有「万」字后缀,需要将字符去掉再转换为数值型;volume 体积列,则分别带有「M」和「K」后缀,为了统一大小,则需将「K」除以 1024,转换为 「M」体积。
整个数据一共有 6086 行 x 8 列,每列均没有缺失值。
df.describe() 方法对 score 列做了基本统计,可以看到,所有 App 的平均得分是 3.9 分(5 分制),最低得分 1.6 分,最高得分 4.8 分。
下面,我们将以上几列文本型数据转换为数值型数据,代码实现如下:
1def data_processing(df):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 str = '_ori'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 cols = ['comment','download','follow','num_score','volume']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 for col in cols:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 colori = col+str<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 df[colori] = df[col] # 复制保留原始列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 if not (col == 'volume'):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 df[col] = clean_symbol(df,col)# 处理原始列生成新列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 df[col] = clean_symbol2(df,col)# 处理原始列生成新列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 # 将download单独转换为万单位<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14 df['download'] = df['download'].apply(lambda x:x/10000)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15 # 批量转为数值型<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 df = df.apply(pd.to_numeric,errors='ignore')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18def clean_symbol(df,col):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 # 将字符“万”替换为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 con = df[col].str.contains('万$')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />21 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />22 df[col] = pd.to_numeric(df[col])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />23 return df[col]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />24<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />25def clean_symbol2(df,col):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />26 # 字符M替换为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />27 df[col] = df[col].str.replace('M$','')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />28 # 体积为K的除以 1024 转换为M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />29 con = df[col].str.contains('K$')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />30 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />31 df[col] = pd.to_numeric(df[col])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />32 return df[col]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
以上,就完成了几列文本型数据的转换,我们再来查看一下基本情况:
download 列为 App 下载数量,下载量最多的 App 有 5190 万次,最少的为 0 (很少很少),平均下载次数为 14 万次;从中可以看出以下几点信息:
以上,就完成了基本的数据清洗处理过程,下一期将对这6000多款App进行探索性分析,看看有多少佳软神器你没有使用过哦。 查看全部
scrapy分页抓取网页 6000 多款 App,看我如何搞定她们并将其洗白白~
项目文件创建好以后,我们就可以开始写爬虫程序了。
首先,需要在 items.py 文件中,预先定义好要爬取的字段信息名称,如下所示:
1class KuanItem(scrapy.Item):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2# define the fields for your item here like:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3name = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4volume = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5download = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6follow = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7comment = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8tags = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9score = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10num_score = scrapy.Field()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里的字段信息就是我们前面在网页中定位的 8 个字段信息,包括:name 表示 App 名称、volume 表示体积、download 表示下载数量。在这里定义好之后,我们在后续的爬取主程序中会利用到这些字段信息。
2.3.3. 爬取主程序
创建好 kuan 项目后,Scrapy 框架会自动生成爬取的部分代码,我们接下来就需要在 parse 方法中增加网页抓取的字段解析内容。
1class KuanspiderSpider(scrapy.Spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 name = 'kuan'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 allowed_domains = ['www.coolapk.com']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 start_urls = ['http://www.coolapk.com/']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 pass<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
打开主页 Dev Tools,找到每项抓取指标的节点位置,然后可以采用 CSS、Xpath、正则等方法进行提取解析,这些方法 Scrapy 都支持,可随意选择,这里我们选用 CSS 语法来定位节点,不过需要注意的是,Scrapy 的 CSS 语法和之前我们利用 pyquery 使用的 CSS 语法稍有不同,举几个例子,对比说明一下。
首先,我们定位到第一个 APP 的主页 URL 节点,可以看到 URL 节点位于 class 属性为app_left_list的 div 节点下的 a 节点中,其 href 属性就是我们需要的 URL 信息,这里是相对地址,拼接后就是完整的 URL。
接着我们进入酷安详情页,选择 App 名称并进行定位,可以看到 App 名称节点位于 class 属性为.detail_app_title的 p 节点的文本中。
定位到这两个节点之后,我们就可以使用 CSS 提取字段信息了,这里对比一下常规写法和 Scrapy 中的写法:
1# 常规写法<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2url = item('.app_left_list>a').attr('href')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3name = item('.list_app_title').text()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4# Scrapy 写法<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5url = item.css('::attr("href")').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6name = item.css('.detail_app_title::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
可以看到,要获取 href 或者 text 属性,需要用 :: 表示,比如获取 text,则用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,则用 extract() 。接着,我们就可以参照写出 8 个字段信息的解析代码。
首先,我们需要在主页提取 App 的 URL 列表,然后再进入每个 App 的详情页进一步提取 8 个字段信息。
1def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 contents = response.css('.app_left_list>a')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for content in contents:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 url = content.css('::attr("href")').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5 url = response.urljoin(url) # 拼接相对 url 为绝对 url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 yield scrapy.Request(url,callback=self.parse_url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,利用 response.urljoin() 方法将提取出的相对 URL 拼接为完整的 URL,然后利用 scrapy.Request() 方法构造每个 App 详情页的请求,这里我们传递两个参数:url 和 callback,url 为详情页 URL,callback 是回调函数,它将主页 URL 请求返回的响应 response 传给专门用来解析字段内容的 parse_url() 方法,如下所示:
1def parse_url(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2 item = KuanItem()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 item['name'] = response.css('.detail_app_title::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 results = self.get_comment(response)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 item['volume'] = results[0]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 item['download'] = results[1]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 item['follow'] = results[2]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 item['comment'] = results[3]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 item['tags'] = self.get_tags(response)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 item['score'] = response.css('.rank_num::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 num_score = response.css('.apk_rank_p1::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12 item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 yield item<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15def get_comment(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 messages = response.css('.apk_topba_message::text').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17 result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18 if result: # 不为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 results = list(result[0]) # 提取出list 中第一个元素<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 return results<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />21<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />22def get_tags(self,response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />23 data = response.css('.apk_left_span2')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />24 tags = [item.css('::text').extract_first() for item in data]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />25 return tags<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,单独定义了 get_comment() 和 get_tags() 两个方法.
get_comment() 方法通过正则匹配提取 volume、download、follow、comment 四个字段信息,正则匹配结果如下:
1result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2print(result) # 输出第一页的结果信息<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3# 结果如下:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4[('21.74M', '5218万', '2.4万', '5.4万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5[('75.53M', '2768万', '2.3万', '3.0万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6[('46.21M', '1686万', '2.3万', '3.4万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7[('54.77M', '1603万', '3.8万', '4.9万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8[('3.32M', '1530万', '1.5万', '3343')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9[('75.07M', '1127万', '1.6万', '2.2万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10[('92.70M', '1108万', '9167', '1.3万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11[('68.94M', '1072万', '5718', '9869')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12[('61.45M', '935万', '1.1万', '1.6万')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13[('23.96M', '925万', '4157', '1956')]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
然后利用 result[0]、result[1] 等分别提取出四项信息,以 volume 为例,输出第一页的提取结果:
1item['volume'] = results[0]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2print(item['volume'])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 321.74M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 475.53M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 546.21M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 654.77M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 73.32M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 875.07M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 992.70M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1068.94M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1161.45M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />1223.96M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这样一来,第一页 10 款 App 的所有字段信息都被成功提取出来,然后返回到 yied item 生成器中,我们输出一下它的内容:
1[<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'}, <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4...<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
2.3.4. 分页爬取
以上,我们爬取了第一页内容,接下去需要遍历爬取全部 610 页的内容,这里有两种思路:
这里,我们分别写出两种方法的解析代码,第一种方法很简单,直接接着 parse 方法继续添加以下几行代码即可:
1def parse(self, response):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 contents = response.css('.app_left_list>a')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for content in contents:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 ...<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 url = response.urljoin(next_page)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />8 yield scrapy.Request(url,callback=self.parse )<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
第二种方法,我们在最开头的 parse() 方法前,定义一个 start_requests() 方法,用来批量生成 610 页的 URL,然后通过 scrapy.Request() 方法中的 callback 参数,传递给下面的 parse() 方法进行解析。
1def start_requests(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 pages = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 for page in range(1,610): # 一共有610页<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 url = 'https://www.coolapk.com/apk/?page=%s'%page<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5 page = scrapy.Request(url,callback=self.parse)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />6 pages.append(page)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />7 return pages<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
以上就是全部页面的爬取思路,爬取成功后,我们需要存储下来。这里,我面选择存储到 MongoDB 中,不得不说,相比 MySQL,MongoDB 要方便省事很多。
2.3.5. 存储结果
我们在 pipelines.py 程序中,定义数据存储方法,MongoDB 的一些参数,比如地址和数据库名称,需单独存放在 settings.py 设置文件中去,然后在 pipelines 程序中进行调用即可。
1import pymongo<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2class MongoPipeline(object):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 def __init__(self,mongo_url,mongo_db):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 self.mongo_url = mongo_url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 self.mongo_db = mongo_db<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 @classmethod<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 def from_crawler(cls,crawler):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 return cls(<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 mongo_url = crawler.settings.get('MONGO_URL'),<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 mongo_db = crawler.settings.get('MONGO_DB')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 )<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12 def open_spider(self,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 self.client = pymongo.MongoClient(self.mongo_url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14 self.db = self.client[self.mongo_db]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15 def process_item(self,item,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 name = item.__class__.__name__<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17 self.db[name].insert(dict(item))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18 return item<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 def close_spider(self,spider):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 self.client.close()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
首先,我们定义一个 MongoPipeline()存储类,里面定义了几个方法,简单进行一下说明:
from crawler() 是一个类方法,用 @class method 标识,这个方法的作用主要是用来获取我们在 settings.py 中设置的这几项参数:
1MONGO_URL = 'localhost'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2MONGO_DB = 'KuAn'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3ITEM_PIPELINES = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 'kuan.pipelines.MongoPipeline': 300,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5}<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
open_spider() 方法主要进行一些初始化操作 ,在 Spider 开启时,这个方法就会被调用 。
process_item() 方法是最重要的方法,实现插入数据到 MongoDB 中。
完成上述代码以后,输入下面一行命令就可以开始整个爬虫的抓取和存储过程了,单机跑的话,6000 个网页需要不少时间才能完成,保持耐心。
1scrapy crawl kuan<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里,还有两点补充:
第一,为了减轻网站压力,我们最好在每个请求之间设置几秒延时,可以在 KuanSpider() 方法开头出,加入以下几行代码:
1custom_settings = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2 "DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3 "CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4 }<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
第二,为了更好监控爬虫程序运行,有必要设置输出日志文件,可以通过 Python 自带的 logging 包实现:
1import logging<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />2<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />3logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />4logging.warning("warn message")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />5logging.error("error message")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
这里的 level 参数表示警告级别,严重程度从低到高分别是:DEBUG < INFO < WARNING < ERROR < CRITICAL,如果想日志文件不要记录太多内容,可以设置高一点的级别,这里设置为 WARNING,意味着只有 WARNING 级别以上的信息才会输出到日志中去。
添加 datefmt 参数是为了在每条日志前面加具体的时间,这点很有用处。
以上,我们就完成了整个数据的抓取,有了数据我们就可以着手进行分析,不过这之前还需简单地对数据做一下清洗和处理。
3. 数据清洗处理
首先,我们从 MongoDB 中读取数据并转化为 DataFrame,然后查看一下数据的基本情况。
1def parse_kuan():<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2 client = pymongo.MongoClient(host='localhost', port=27017)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 db = client['KuAn']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 collection = db['KuAnItem']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 # 将数据库数据转为DataFrame<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 data = pd.DataFrame(list(collection.find()))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 print(data.head())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 print(df.shape)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 print(df.info())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 print(df.describe())<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
从 data.head() 输出的前 5 行数据中可以看到,除了 score 列是 float 格式以外,其他列都是 object 文本类型。
comment、download、follow、num_score 这 5 列数据中部分行带有「万」字后缀,需要将字符去掉再转换为数值型;volume 体积列,则分别带有「M」和「K」后缀,为了统一大小,则需将「K」除以 1024,转换为 「M」体积。
整个数据一共有 6086 行 x 8 列,每列均没有缺失值。
df.describe() 方法对 score 列做了基本统计,可以看到,所有 App 的平均得分是 3.9 分(5 分制),最低得分 1.6 分,最高得分 4.8 分。
下面,我们将以上几列文本型数据转换为数值型数据,代码实现如下:
1def data_processing(df):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 2#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 3 str = '_ori'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 4 cols = ['comment','download','follow','num_score','volume']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 5 for col in cols:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 6 colori = col+str<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 7 df[colori] = df[col] # 复制保留原始列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 8 if not (col == 'volume'):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 9 df[col] = clean_symbol(df,col)# 处理原始列生成新列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />10 else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />11 df[col] = clean_symbol2(df,col)# 处理原始列生成新列<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />12<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />13 # 将download单独转换为万单位<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />14 df['download'] = df['download'].apply(lambda x:x/10000)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />15 # 批量转为数值型<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />16 df = df.apply(pd.to_numeric,errors='ignore')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />17<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />18def clean_symbol(df,col):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />19 # 将字符“万”替换为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />20 con = df[col].str.contains('万$')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />21 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />22 df[col] = pd.to_numeric(df[col])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />23 return df[col]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />24<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />25def clean_symbol2(df,col):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />26 # 字符M替换为空<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />27 df[col] = df[col].str.replace('M$','')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />28 # 体积为K的除以 1024 转换为M<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />29 con = df[col].str.contains('K$')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />30 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />31 df[col] = pd.to_numeric(df[col])<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />32 return df[col]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
以上,就完成了几列文本型数据的转换,我们再来查看一下基本情况:
download 列为 App 下载数量,下载量最多的 App 有 5190 万次,最少的为 0 (很少很少),平均下载次数为 14 万次;从中可以看出以下几点信息:
以上,就完成了基本的数据清洗处理过程,下一期将对这6000多款App进行探索性分析,看看有多少佳软神器你没有使用过哦。
scrapy分页抓取网页(不重载页面的页面器爬取点入(1)_社会万象_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-20 13:36
一种是:点击下一页,只会重新渲染当前页面的一部分
在早期版本的 web-scraper 中,两种抓取方式是不同的。
需要重新加载的页面需要链接选择器
如果不需要重新加载页面,可以使用元素点击选择器
对于某些 网站 可以,但有很大的限制。
经过我的实验,使用Link选择器的第一个原理是取出下一页的a标签的超链接,然后去访问,但是并不是所有的网站的下一页都通过一个标签实现。
如果你使用js监听事件并像下面这样跳转,就不能使用Link选择器了。
新版网络爬虫特别支持导航分页器,并增加了分页选择器,可以完全适用于两种场景。下面我分别演示一下。
无需重新加载页面的分页器抓取
点击具体的CSDN博文,拉到底部查看评论区。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面,评论都属于同一篇文章文章,当您浏览任何页面的评论部分时,无需刷新博文,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点要注意root和next_page的选择,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的站点地图配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器,更精简,效果最好
对应sitemap的配置如下,可以直接导入使用,下载配置文件:
寻呼机抓取以重新加载页面
CSDN博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click什么都做不了,读者可以自行验证,最多爬一页后就关闭了。
而作为分页选择器的分页自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习,下载配置文件:
4.二级页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看它
网络爬虫的操作逻辑与人类似。如果你想抓取更详细的博文信息,你必须打开一个新页面来获取它,而网络爬虫的链接选择器就是这样做的。
爬取路径的拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用,下载配置文件:
5.写在最后
以上整理了分页和二级页面的爬取方案,主要是:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。 查看全部
scrapy分页抓取网页(不重载页面的页面器爬取点入(1)_社会万象_光明网(组图))
一种是:点击下一页,只会重新渲染当前页面的一部分
在早期版本的 web-scraper 中,两种抓取方式是不同的。
需要重新加载的页面需要链接选择器
如果不需要重新加载页面,可以使用元素点击选择器
对于某些 网站 可以,但有很大的限制。
经过我的实验,使用Link选择器的第一个原理是取出下一页的a标签的超链接,然后去访问,但是并不是所有的网站的下一页都通过一个标签实现。
如果你使用js监听事件并像下面这样跳转,就不能使用Link选择器了。
新版网络爬虫特别支持导航分页器,并增加了分页选择器,可以完全适用于两种场景。下面我分别演示一下。
无需重新加载页面的分页器抓取
点击具体的CSDN博文,拉到底部查看评论区。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面,评论都属于同一篇文章文章,当您浏览任何页面的评论部分时,无需刷新博文,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点要注意root和next_page的选择,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的站点地图配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器,更精简,效果最好
对应sitemap的配置如下,可以直接导入使用,下载配置文件:
寻呼机抓取以重新加载页面
CSDN博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click什么都做不了,读者可以自行验证,最多爬一页后就关闭了。
而作为分页选择器的分页自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习,下载配置文件:
4.二级页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看它
网络爬虫的操作逻辑与人类似。如果你想抓取更详细的博文信息,你必须打开一个新页面来获取它,而网络爬虫的链接选择器就是这样做的。
爬取路径的拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用,下载配置文件:
5.写在最后
以上整理了分页和二级页面的爬取方案,主要是:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。
scrapy分页抓取网页(-2.png页面抓取一条数据较为简单(图)信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-04-20 02:27
)
Scrapy 在页面上抓取一条数据相对简单。如果您在一个页面上抓取多条数据,则有一个技巧可以确定循环点的位置。
以简书首页为例。比如抢热门文章,一条信息包括:作者、文章标题、浏览量、评论数、点赞数、打赏数。一页上有多条数据。
-2.png
其实就是把页面上的数据提取出来封装成一个object item,但是最后没有放到采集里面。
物品定义
class JsuserItem(Item):
author = Field()
url = Field()
title = Field()
reads = Field()
comments = Field()
likes = Field()
rewards = Field()
提取数据的循环点应以收录一条信息和多条数据的标签开头,分析页面代码为div>li
-0.png
第一次提取的是一整块内容:(即多个数据块的内容)
infos = selector.xpath('//li/div')
第二次提取该节点下整个区块中的数据字段:
author = info.xpath('p/a/text()').extract()
title = info.xpath('h4/a/text()').extract()
-1.png
完整代码:
def parse(self, response):
selector = Selector(response)
infos = selector.xpath('//li/div')
for info in infos:
item = JsuserItem()
author = info.xpath('p/a/text()').extract()
title = info.xpath('h4/a/text()').extract()
url = info.xpath('h4/a/@href').extract()
reads = info.xpath('div/a[1]/text()').extract()
comments = info.xpath('div/a[2]/text()').extract()
likes = info.xpath('div/span[1]/text()').extract()
#注意有些文章是没有打赏的
rewards = info.xpath('div/span[2]/text()')
if len(rewards)==1 :
rds = info.xpath('div/span[2]/text()').extract()
rds = int(filter(str.isdigit,str(rds[0])))
else:
rds = 0
item['author']=author
item['title']=title
item['url']='http://www.jianshu.com'+url[0]
item['reads']=int(filter(str.isdigit,str(reads[0])))
item['comments']=int(filter(str.isdigit,str(comments[0])))
item['likes']=int(filter(str.isdigit,str(likes[0])))
item['rewards']=rds 查看全部
scrapy分页抓取网页(-2.png页面抓取一条数据较为简单(图)信息
)
Scrapy 在页面上抓取一条数据相对简单。如果您在一个页面上抓取多条数据,则有一个技巧可以确定循环点的位置。
以简书首页为例。比如抢热门文章,一条信息包括:作者、文章标题、浏览量、评论数、点赞数、打赏数。一页上有多条数据。
-2.png
其实就是把页面上的数据提取出来封装成一个object item,但是最后没有放到采集里面。
物品定义
class JsuserItem(Item):
author = Field()
url = Field()
title = Field()
reads = Field()
comments = Field()
likes = Field()
rewards = Field()
提取数据的循环点应以收录一条信息和多条数据的标签开头,分析页面代码为div>li
-0.png
第一次提取的是一整块内容:(即多个数据块的内容)
infos = selector.xpath('//li/div')
第二次提取该节点下整个区块中的数据字段:
author = info.xpath('p/a/text()').extract()
title = info.xpath('h4/a/text()').extract()
-1.png
完整代码:
def parse(self, response):
selector = Selector(response)
infos = selector.xpath('//li/div')
for info in infos:
item = JsuserItem()
author = info.xpath('p/a/text()').extract()
title = info.xpath('h4/a/text()').extract()
url = info.xpath('h4/a/@href').extract()
reads = info.xpath('div/a[1]/text()').extract()
comments = info.xpath('div/a[2]/text()').extract()
likes = info.xpath('div/span[1]/text()').extract()
#注意有些文章是没有打赏的
rewards = info.xpath('div/span[2]/text()')
if len(rewards)==1 :
rds = info.xpath('div/span[2]/text()').extract()
rds = int(filter(str.isdigit,str(rds[0])))
else:
rds = 0
item['author']=author
item['title']=title
item['url']='http://www.jianshu.com'+url[0]
item['reads']=int(filter(str.isdigit,str(reads[0])))
item['comments']=int(filter(str.isdigit,str(comments[0])))
item['likes']=int(filter(str.isdigit,str(likes[0])))
item['rewards']=rds
scrapy分页抓取网页(牛津小马哥web前端工程师陈小妹妹(之前)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-19 16:44
)
原创:陈晓梅,Oxford Pony Brothers Web 前端工程师。
在本文中,我将编写一个网络爬虫,从 OLX 的电子和电器项目中抓取数据。但在我进入代码之前,这里先简要介绍一下 Scrapy 本身。
什么是刮痧?
Scrapy(发音为 Scrapy)是一个用 Python 编写的开源网络爬虫框架。最初是为网页抓取而设计的。目前由 Scrapinghub 维护。
>>>>
创建一个项目。
Scrapy的一个设计思路是一个项目可以收录多个爬虫。这种设计很有用,尤其是在为站点或子域的不同部分编写多个机器人时。所以首先创建项目:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ scrapy startproject olxNew
Scrapy project 'olx', using template directory '//anaconda/lib/python2.7/site-packages/scrapy/templates/project', created in:
/Development/PetProjects/ScrapyCrawlers/olx
You can start your first spider with:
cd olx
scrapy genspider example example.com
>>>>
创建爬虫
我运行了命令 scrapy startproject olx,它将创建一个名为 olx 的项目。接下来,进入新创建的文件夹,执行命令生成第一个爬虫,并带有要爬取的站点的名称和域:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ cd olx/
Adnans-MBP:olx AdnanAhmad$ scrapy genspider electronics www.olx.com.pk
Created spider 'electronics' using template 'basic' in module:
olx.spiders.electronics
下面是 OLX 的“电子”文件部分,最终的项目结构将类似于以下示例:
如您所见,这个新创建的爬虫有一个单独的文件夹。您可以将多个爬虫添加到一个项目中。让我们打开爬虫文件electronics.py。当您打开它时,您将看到以下内容:
# -*- coding: utf-8 -*-
import scrapy
class ElectronicsSpider(scrapy.Spider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = ['http://www.olx.com.pk/']
def parse(self, response):
pass
如您所见,ElectronicsSpider 是 scrapy.Spider 的子类。name 属性其实就是蜘蛛的名字,在spider中指定。allowed_domains 属性告诉我们这个爬虫可以访问哪些域,start_urls 位置是需要首先访问初始 URL 的位置。
parse 顾名思义,这个方法会解析被访问页面的内容。由于我想写一个爬虫到多个页面,我会做一些改变。
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class ElectronicsSpider(CrawlSpider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = [
'https://www.olx.com.pk/compute ... 39%3B,
'https://www.olx.com.pk/tv-video-audio/',
'https://www.olx.com.pk/games-e ... 39%3B
]
rules = (
Rule(LinkExtractor(allow=(), restrict_css=('.pageNextPrev',)),
callback="parse_item",
follow=True),)
def parse_item(self, response):
print('Processing..' + response.url)
为了让爬虫导航到多个页面,我从 scrapy.Spider 子类化为 CrawlSpider。这个类可以更容易地抓取 网站 的许多页面。您可以对生成的代码执行类似的操作,但您需要小心递归以导航下一页。
下一步是设置规则变量。在这里可以设置浏览网站的规则。在 LinkExtractor 中设置一些导航限制。这里我使用restrict_css参数来设置NEXT页面的类。如果您转到此页面并检查元素,您可以找到以下内容:
pageNextPrev 是用于获取下一页链接的类。call_back 参数告诉使用哪种方法来访问页面元素。
请记住,您需要将方法的名称从 parse() 更改为 parse_item() 或其他名称,以避免覆盖基类,否则即使您设置 follow=True ,您的规则也将不起作用。
到现在为止还挺好; 让我们测试一下到目前为止我们制作的爬虫。转到终端,在项目目录中输入:
scrapy crawl electronics
第三个参数其实是蜘蛛的名字,ElectronicsSpiders,之前在类名属性中设置的。在终端中,您会发现许多有助于调试的有用信息。如果不想看到调试信息,可以禁用调试器。此命令类似于 --nologswitch。
scrapy crawl --nolog electronics
如果现在运行,它将显示以下内容:
Adnans-MBP:olx AdnanAhmad$ scrapy crawl --nolog electronics
Processing..https://www.olx.com.pk/compute ... e%3D2
Processing..https://www.olx.com.pk/tv-video-audio/?page=2
Processing..https://www.olx.com.pk/games-entertainment/?page=2
Processing..https://www.olx.com.pk/computers-accessories/
Processing..https://www.olx.com.pk/tv-video-audio/
Processing..https://www.olx.com.pk/games-entertainment/
Processing..https://www.olx.com.pk/compute ... e%3D3
Processing..https://www.olx.com.pk/tv-video-audio/?page=3
Processing..https://www.olx.com.pk/games-entertainment/?page=3
Processing..https://www.olx.com.pk/compute ... e%3D4
Processing..https://www.olx.com.pk/tv-video-audio/?page=4
Processing..https://www.olx.com.pk/games-entertainment/?page=4
Processing..https://www.olx.com.pk/compute ... e%3D5
Processing..https://www.olx.com.pk/tv-video-audio/?page=5
Processing..https://www.olx.com.pk/games-entertainment/?page=5
Processing..https://www.olx.com.pk/compute ... e%3D6
Processing..https://www.olx.com.pk/tv-video-audio/?page=6
Processing..https://www.olx.com.pk/games-entertainment/?page=6
Processing..https://www.olx.com.pk/compute ... e%3D7
Processing..https://www.olx.com.pk/tv-video-audio/?page=7
Processing..https://www.olx.com.pk/games-entertainment/?page=7
由于我设置了follow=True,爬虫会检查NEXT页面的规则,并继续导航,直到到达不满足规则的页面,通常是列表的最后一页。
Scrapy 解除了编写爬虫的所有任务,让我可以专注于主要逻辑,通过编写爬虫来提取信息。
现在,我将继续编写代码以从列表页面获取单个项目链接。我将在 parse_item 方法中对其进行修改。
item_links = response.css('.large > .detailsLink::attr(href)').extract()
for a in item_links:
yield scrapy.Request(a, callback=self.parse_detail_page)
在这里,我使用 .css 响应方法获取链接。您也可以使用 xpath,这取决于您。在这种情况下,它非常简单:
锚链接有一个类 detailsLink。如果您只使用 response.css('.detailsLink'),由于 img 和 h3 标签中的重复链接,它将为单个条目选择重复链接。我还提到了用于唯一链接的大型父类。我之前提取的 href 部分 ::attr(href) 是链接本身。然后,我使用 extract() 方法。
使用此方法的原因是 .css 和 .xpath 返回 SelectorList 对象,而 extract() 有助于返回实际的 DOM 以供进一步处理。最后,我在 scrapy.Request 回调中收录了 yield 链接。我没有检查 Scrapy 的内部代码,但很可能他们使用的是 yield 而不是 A, return 因为你可以生产多个项目。由于爬虫需要同时处理多个链接,因此 yield 是这里的最佳选择。
parse_detail_page 顾名思义,这个方法会解析详情页中的个体信息。所以实际发生的是:
您将获得 parse_item 中的项目列表。
您将它们传递给回调方法以进行进一步处理。
由于它只是一个两层遍历,我可以借助两种方法到达最低层。如果要从OLX主页开始爬,这里要写三个方法:前两个获取子类及其条目,最后一个解析实际信息。知道了?
最后,我将解析实际信息,这些信息可以在与此类似的项目中找到。
解析此页面中的信息没有什么不同,但需要一些操作来存储解析的信息。我们需要为数据定义一个模型。这意味着我们需要告诉 Scrapy 我们想要存储哪些信息以供以后使用。让我们编辑之前由 Scrapy 生成的 item.py 文件。
import scrapy
class OlxItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
OlxItem 我将设置所需字段以保存信息的类。我将为模型类定义三个字段。
class OlxItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
price = scrapy.Field()
url = scrapy.Field()
我将存储帖子的标题、价格和 URL 本身。
让我们回到爬虫类,修改parse_detail_page。
现在,一种方法是开始编写代码,通过运行整个爬虫来测试它,看看你是否走在正确的轨道上,但是 Scrapy 提供了另一个很棒的工具。
>>>>
废壳
Scrapy Shell 是一个命令行工具,允许您在不运行整个爬虫的情况下测试解析代码。与访问所有链接的爬虫不同,Scrapy Shell 保存单个页面的 DOM 以进行数据提取。就我而言,我做了以下事情:
Adnans-MBP:olx AdnanAhmad$ scrapy shell https://www.olx.com.pk/item/as ... 29891
现在我可以轻松地测试代码,而不必一次又一次地访问相同的 URL。我这样做是为了获得标题:
In [8]: response.css('h1::text').extract()[0].strip()
Out[8]: u"Asus Eee PC Atom Dual-Core 4CPU's Beautiful Laptops fresh Stock"
您可以在 response.css 中找到熟悉的内容。由于整个 DOM 都可用,因此您可以使用它。
我通过这样做得到价格:
In [11]: response.css('.pricelabel > strong::text').extract()[0]
Out[11]: u'Rs 10,500'
由于 response.url 返回的是当前访问的 URL,所以不需要做任何事情来获取 url。
现在已经检查了所有代码,是时候将其合并到 parse_detail_page 中了:
title = response.css('h1::text').extract()[0].strip()
price = response.css('.pricelabel > strong::text').extract()[0]
item = OlxItem()
item['title'] = title
item['price'] = price
item['url'] = response.url
yield item
解析所需信息后,OlxItem 将创建实例并设置属性。现在是时候运行爬虫并存储信息了,对命令进行了一些修改:
scrapy crawl electronics -o data.csv -t csv
我正在传递文件名和文件格式来保存数据。运行后,它将为您生成 CSV。很简单,不是吗?与您自己编写的爬虫不同,您必须编写自己的例程来保存数据。
可是等等!它并不止于此,您甚至可以获取 JSON 格式的数据。您所要做的就是使用 -t 开关传递 json。
Scrapy 为您提供了另一个功能。在实际情况下,传递一个固定的文件名没有任何意义。如何生成唯一的文件名?好吧,为此,您需要修改 settings.py 文件并添加以下两个条目:
FEED_URI = 'data/%(name)s/%(time)s.json'
FEED_FORMAT = 'json'
这里我给出文件的模式,%(name)% 是爬虫本身的名字和时间戳。你可以在这里了解更多。现在,当我运行 scrapy crawl --nolog electronics 或 scrapy crawl electronics 时,它会在 data 文件夹中生成一个 JSON 文件,如下所示:
[
{"url": "https://www.olx.com.pk/item/ac ... ot%3B, "price": "Rs 42,000", "title": "Acer Ultra Slim Gaming Laptop with AMD FX Processor 3GB Dedicated"},
{"url": "https://www.olx.com.pk/item/sa ... ot%3B, "price": "Rs 80,000", "title": "Saw Machine"},
{"url": "https://www.olx.com.pk/item/la ... ot%3B, "price": "Rs 22,000", "title": "Laptop HP Probook 6570b Core i 5 3rd Gen"},
{"url": "https://www.olx.com.pk/item/zo ... ot%3B, "price": "Rs 4,000", "title": "Zong 4g could mifi anlock all Sim supported"},
...
] 查看全部
scrapy分页抓取网页(牛津小马哥web前端工程师陈小妹妹(之前)(图)
)
原创:陈晓梅,Oxford Pony Brothers Web 前端工程师。
在本文中,我将编写一个网络爬虫,从 OLX 的电子和电器项目中抓取数据。但在我进入代码之前,这里先简要介绍一下 Scrapy 本身。
什么是刮痧?
Scrapy(发音为 Scrapy)是一个用 Python 编写的开源网络爬虫框架。最初是为网页抓取而设计的。目前由 Scrapinghub 维护。
>>>>
创建一个项目。
Scrapy的一个设计思路是一个项目可以收录多个爬虫。这种设计很有用,尤其是在为站点或子域的不同部分编写多个机器人时。所以首先创建项目:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ scrapy startproject olxNew
Scrapy project 'olx', using template directory '//anaconda/lib/python2.7/site-packages/scrapy/templates/project', created in:
/Development/PetProjects/ScrapyCrawlers/olx
You can start your first spider with:
cd olx
scrapy genspider example example.com
>>>>
创建爬虫
我运行了命令 scrapy startproject olx,它将创建一个名为 olx 的项目。接下来,进入新创建的文件夹,执行命令生成第一个爬虫,并带有要爬取的站点的名称和域:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ cd olx/
Adnans-MBP:olx AdnanAhmad$ scrapy genspider electronics www.olx.com.pk
Created spider 'electronics' using template 'basic' in module:
olx.spiders.electronics
下面是 OLX 的“电子”文件部分,最终的项目结构将类似于以下示例:
如您所见,这个新创建的爬虫有一个单独的文件夹。您可以将多个爬虫添加到一个项目中。让我们打开爬虫文件electronics.py。当您打开它时,您将看到以下内容:
# -*- coding: utf-8 -*-
import scrapy
class ElectronicsSpider(scrapy.Spider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = ['http://www.olx.com.pk/']
def parse(self, response):
pass
如您所见,ElectronicsSpider 是 scrapy.Spider 的子类。name 属性其实就是蜘蛛的名字,在spider中指定。allowed_domains 属性告诉我们这个爬虫可以访问哪些域,start_urls 位置是需要首先访问初始 URL 的位置。
parse 顾名思义,这个方法会解析被访问页面的内容。由于我想写一个爬虫到多个页面,我会做一些改变。
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class ElectronicsSpider(CrawlSpider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = [
'https://www.olx.com.pk/compute ... 39%3B,
'https://www.olx.com.pk/tv-video-audio/',
'https://www.olx.com.pk/games-e ... 39%3B
]
rules = (
Rule(LinkExtractor(allow=(), restrict_css=('.pageNextPrev',)),
callback="parse_item",
follow=True),)
def parse_item(self, response):
print('Processing..' + response.url)
为了让爬虫导航到多个页面,我从 scrapy.Spider 子类化为 CrawlSpider。这个类可以更容易地抓取 网站 的许多页面。您可以对生成的代码执行类似的操作,但您需要小心递归以导航下一页。
下一步是设置规则变量。在这里可以设置浏览网站的规则。在 LinkExtractor 中设置一些导航限制。这里我使用restrict_css参数来设置NEXT页面的类。如果您转到此页面并检查元素,您可以找到以下内容:
pageNextPrev 是用于获取下一页链接的类。call_back 参数告诉使用哪种方法来访问页面元素。
请记住,您需要将方法的名称从 parse() 更改为 parse_item() 或其他名称,以避免覆盖基类,否则即使您设置 follow=True ,您的规则也将不起作用。
到现在为止还挺好; 让我们测试一下到目前为止我们制作的爬虫。转到终端,在项目目录中输入:
scrapy crawl electronics
第三个参数其实是蜘蛛的名字,ElectronicsSpiders,之前在类名属性中设置的。在终端中,您会发现许多有助于调试的有用信息。如果不想看到调试信息,可以禁用调试器。此命令类似于 --nologswitch。
scrapy crawl --nolog electronics
如果现在运行,它将显示以下内容:
Adnans-MBP:olx AdnanAhmad$ scrapy crawl --nolog electronics
Processing..https://www.olx.com.pk/compute ... e%3D2
Processing..https://www.olx.com.pk/tv-video-audio/?page=2
Processing..https://www.olx.com.pk/games-entertainment/?page=2
Processing..https://www.olx.com.pk/computers-accessories/
Processing..https://www.olx.com.pk/tv-video-audio/
Processing..https://www.olx.com.pk/games-entertainment/
Processing..https://www.olx.com.pk/compute ... e%3D3
Processing..https://www.olx.com.pk/tv-video-audio/?page=3
Processing..https://www.olx.com.pk/games-entertainment/?page=3
Processing..https://www.olx.com.pk/compute ... e%3D4
Processing..https://www.olx.com.pk/tv-video-audio/?page=4
Processing..https://www.olx.com.pk/games-entertainment/?page=4
Processing..https://www.olx.com.pk/compute ... e%3D5
Processing..https://www.olx.com.pk/tv-video-audio/?page=5
Processing..https://www.olx.com.pk/games-entertainment/?page=5
Processing..https://www.olx.com.pk/compute ... e%3D6
Processing..https://www.olx.com.pk/tv-video-audio/?page=6
Processing..https://www.olx.com.pk/games-entertainment/?page=6
Processing..https://www.olx.com.pk/compute ... e%3D7
Processing..https://www.olx.com.pk/tv-video-audio/?page=7
Processing..https://www.olx.com.pk/games-entertainment/?page=7
由于我设置了follow=True,爬虫会检查NEXT页面的规则,并继续导航,直到到达不满足规则的页面,通常是列表的最后一页。
Scrapy 解除了编写爬虫的所有任务,让我可以专注于主要逻辑,通过编写爬虫来提取信息。
现在,我将继续编写代码以从列表页面获取单个项目链接。我将在 parse_item 方法中对其进行修改。
item_links = response.css('.large > .detailsLink::attr(href)').extract()
for a in item_links:
yield scrapy.Request(a, callback=self.parse_detail_page)
在这里,我使用 .css 响应方法获取链接。您也可以使用 xpath,这取决于您。在这种情况下,它非常简单:
锚链接有一个类 detailsLink。如果您只使用 response.css('.detailsLink'),由于 img 和 h3 标签中的重复链接,它将为单个条目选择重复链接。我还提到了用于唯一链接的大型父类。我之前提取的 href 部分 ::attr(href) 是链接本身。然后,我使用 extract() 方法。
使用此方法的原因是 .css 和 .xpath 返回 SelectorList 对象,而 extract() 有助于返回实际的 DOM 以供进一步处理。最后,我在 scrapy.Request 回调中收录了 yield 链接。我没有检查 Scrapy 的内部代码,但很可能他们使用的是 yield 而不是 A, return 因为你可以生产多个项目。由于爬虫需要同时处理多个链接,因此 yield 是这里的最佳选择。
parse_detail_page 顾名思义,这个方法会解析详情页中的个体信息。所以实际发生的是:
您将获得 parse_item 中的项目列表。
您将它们传递给回调方法以进行进一步处理。
由于它只是一个两层遍历,我可以借助两种方法到达最低层。如果要从OLX主页开始爬,这里要写三个方法:前两个获取子类及其条目,最后一个解析实际信息。知道了?
最后,我将解析实际信息,这些信息可以在与此类似的项目中找到。
解析此页面中的信息没有什么不同,但需要一些操作来存储解析的信息。我们需要为数据定义一个模型。这意味着我们需要告诉 Scrapy 我们想要存储哪些信息以供以后使用。让我们编辑之前由 Scrapy 生成的 item.py 文件。
import scrapy
class OlxItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
OlxItem 我将设置所需字段以保存信息的类。我将为模型类定义三个字段。
class OlxItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
price = scrapy.Field()
url = scrapy.Field()
我将存储帖子的标题、价格和 URL 本身。
让我们回到爬虫类,修改parse_detail_page。
现在,一种方法是开始编写代码,通过运行整个爬虫来测试它,看看你是否走在正确的轨道上,但是 Scrapy 提供了另一个很棒的工具。
>>>>
废壳
Scrapy Shell 是一个命令行工具,允许您在不运行整个爬虫的情况下测试解析代码。与访问所有链接的爬虫不同,Scrapy Shell 保存单个页面的 DOM 以进行数据提取。就我而言,我做了以下事情:
Adnans-MBP:olx AdnanAhmad$ scrapy shell https://www.olx.com.pk/item/as ... 29891
现在我可以轻松地测试代码,而不必一次又一次地访问相同的 URL。我这样做是为了获得标题:
In [8]: response.css('h1::text').extract()[0].strip()
Out[8]: u"Asus Eee PC Atom Dual-Core 4CPU's Beautiful Laptops fresh Stock"
您可以在 response.css 中找到熟悉的内容。由于整个 DOM 都可用,因此您可以使用它。
我通过这样做得到价格:
In [11]: response.css('.pricelabel > strong::text').extract()[0]
Out[11]: u'Rs 10,500'
由于 response.url 返回的是当前访问的 URL,所以不需要做任何事情来获取 url。
现在已经检查了所有代码,是时候将其合并到 parse_detail_page 中了:
title = response.css('h1::text').extract()[0].strip()
price = response.css('.pricelabel > strong::text').extract()[0]
item = OlxItem()
item['title'] = title
item['price'] = price
item['url'] = response.url
yield item
解析所需信息后,OlxItem 将创建实例并设置属性。现在是时候运行爬虫并存储信息了,对命令进行了一些修改:
scrapy crawl electronics -o data.csv -t csv
我正在传递文件名和文件格式来保存数据。运行后,它将为您生成 CSV。很简单,不是吗?与您自己编写的爬虫不同,您必须编写自己的例程来保存数据。
可是等等!它并不止于此,您甚至可以获取 JSON 格式的数据。您所要做的就是使用 -t 开关传递 json。
Scrapy 为您提供了另一个功能。在实际情况下,传递一个固定的文件名没有任何意义。如何生成唯一的文件名?好吧,为此,您需要修改 settings.py 文件并添加以下两个条目:
FEED_URI = 'data/%(name)s/%(time)s.json'
FEED_FORMAT = 'json'
这里我给出文件的模式,%(name)% 是爬虫本身的名字和时间戳。你可以在这里了解更多。现在,当我运行 scrapy crawl --nolog electronics 或 scrapy crawl electronics 时,它会在 data 文件夹中生成一个 JSON 文件,如下所示:
[
{"url": "https://www.olx.com.pk/item/ac ... ot%3B, "price": "Rs 42,000", "title": "Acer Ultra Slim Gaming Laptop with AMD FX Processor 3GB Dedicated"},
{"url": "https://www.olx.com.pk/item/sa ... ot%3B, "price": "Rs 80,000", "title": "Saw Machine"},
{"url": "https://www.olx.com.pk/item/la ... ot%3B, "price": "Rs 22,000", "title": "Laptop HP Probook 6570b Core i 5 3rd Gen"},
{"url": "https://www.olx.com.pk/item/zo ... ot%3B, "price": "Rs 4,000", "title": "Zong 4g could mifi anlock all Sim supported"},
...
]
scrapy分页抓取网页(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-18 12:34
"
阅读这篇文章大约需要 7 分钟。
"
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但是我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以来这个网站()下载crx文件,然后离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
# 2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
直译为网站map,有了这个地图爬虫就可以跟着它获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个使用最频繁、覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,我们才能递归地爬取网站的全部数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机爬取
爬取数据最经典的模型是列表、分页和明细。接下来我就围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它提供了对导航分页器的特殊支持,并增加了一个分页选择器,可以完全适用于两种场景,我将在下面进行演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应sitemap的配置如下,可以直接导入使用,下载配置文件:
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习,下载配置文件:
# 4. 次要页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用,下载配置文件:
# 5. 最后
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。 查看全部
scrapy分页抓取网页(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
"
阅读这篇文章大约需要 7 分钟。
"
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但是我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以来这个网站()下载crx文件,然后离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
# 2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
直译为网站map,有了这个地图爬虫就可以跟着它获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个使用最频繁、覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,我们才能递归地爬取网站的全部数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机爬取
爬取数据最经典的模型是列表、分页和明细。接下来我就围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它提供了对导航分页器的特殊支持,并增加了一个分页选择器,可以完全适用于两种场景,我将在下面进行演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应sitemap的配置如下,可以直接导入使用,下载配置文件:
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习,下载配置文件:
# 4. 次要页面的爬取
CSDN的博客列表列表页,显示的信息比较粗略,只有标题,发表时间,阅读量,评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用,下载配置文件:
# 5. 最后
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。
scrapy分页抓取网页( ByShinChanPublished92014atglance)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-13 20:32
ByShinChanPublished92014atglance)
Scrapy爬虫爬取网站数据
由ShinChan
2014 年 11 月 9 日出版
内容
一目了然
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下:
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据的采集工作,它为我们做了很多工作,无需自己开发。
Scrapy 教程
在本文中,假设您已经安装了 Scrapy。如果没有,请参考。
下面以爬取饮用水源BBS数据为例说明爬取过程。详情请参考 bbsdmoz 代码。
本教程将带您完成以下任务:
1. 创建一个Scrapy项目
2. 定义提取的Item
3. 编写爬取网站的 spider 并提取 Item
4. 编写 Item Pipeline 来存储提取到的Item(即数据)
Scrapy 是用 Python 编写的。如果你是语言新手,对这门语言的特点和 Scrapy 的细节感到好奇,对于已经熟悉其他语言并想快速学习 Python 的编程老手,我们推荐 Learn Python The Hard Way,进行编程想要开始学习 Python 的初学者,非编程的 Python 学习资料列表供您选择。
创建项目
在开始抓取之前,您必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
1
scrapy startproject bbsdmoz
此命令将创建具有以下内容的 bbsDmoz 目录:
bbsDmoz/
scrapy.cfg
bbsDmoz/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
定义我们的项目
item是爬取数据的容器;它的用法类似于 python 字典,它提供了额外的保护来防止由拼写错误导致的未定义字段错误。
与您在 ORM 中所做的类似,您可以通过创建一个 scrapy.Item 类并定义一个类型为 scrapy.Field 的类属性来定义一个 Item。(如果你不懂ORM,别担心,你会发现这一步很简单)
首先根据从bbs网站获取的数据对item进行建模。我们需要从中获取 url、post board、poster 和 post 的内容。为此,请在 item.xml 中定义相应的字段。编辑 bbsDmoz 目录中的 items.py 文件:
123456789101112
# -*- coding: utf-8 -*-# Define here the models for your scraped items# See documentation in:# http://doc.scrapy.org/en/lates ... lfrom scrapy.item import Item, Fieldclass BbsDmozItem(Item): # define the fields for your item here like: # name = scrapy.Field() url = Field() forum = Field() poster = Field() content = Field()
起初这可能看起来很复杂,但是通过定义一个项目,您可以轻松地使用其他 Scrapy 方法。而这些方法需要知道你的item的定义。
我们的第一只蜘蛛
蜘蛛是用户编写的类,用于从单个 网站(或某些 网站)中抓取数据。
它包括一个用于下载的初始URL,如何跟踪网页中的链接以及如何分析页面中的内容,以及提取生成项目的方法。
创建蜘蛛
为了创建一个存储在 bbsDmoz/spiders 中的 Spider,您必须扩展 scrapy.Spider 类并定义以下三个属性:
选择器选择器
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 和 CSS 表达式的机制:. 有关选择器和其他提取机制的信息,请参见此处。
我们使用 XPath 选择要从页面的 HTML 源中提取的数据。以下是 XPath 表达式及其对应含义的示例:
以饮水思源论坛首页为例:
查看 HTML 页面源并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以发现poster是收录在pre/a标签中的,这里是userid=jasperstream:
123
...[回复本文][原帖] 发信人: jasperstream
所以可以提取jasperstream的XPath表达式为:
1
'//pre/a/text()'
同理,我可以提取其他内容的XPath,提取后最好验证其正确性。以上只是几个简单的 XPath 示例,XPath 实际上远比这强大。如果您想了解更多信息,我们推荐此 XPath 教程。
为了配合XPath,除了提供Selector之外,Scrapy还提供了避免每次从response中提取数据都生成selector的麻烦的方法。
Selector 有四种基本方法(点击对应方法查看详细 API 文档):
比如提取上面的poster数据:
1
sel.xpath('//pre/a/text()').extract()
使用物品
项目对象是自定义 python 字典。您可以使用标准字典语法来获取其每个字段的值(该字段是我们之前用 Field 分配的属性)。一般来说,爬虫会将爬取的数据作为Item对象返回。
蜘蛛代码
以下是我们的第一个蜘蛛代码,保存在 bbsDmoz/spiders 目录下的 forumSpider.py 文件中:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950
#-*- coding: utf-8 -*-'''bbsSpider, Created on Oct, 2014#version: 1.0#author: chenqx @http://chenqx.github.comSee more: http://doc.scrapy.org/en/latest/index.html'''from scrapy.selector import Selectorfrom scrapy.http import Requestfrom scrapy.contrib.spiders import CrawlSpiderfrom scrapy.contrib.loader import ItemLoaderfrom scrapy.contrib.linkextractors.sgml import SgmlLinkExtractorfrom bbs.items import BbsItemclass forumSpider(CrawlSpider): # name of spiders name = 'bbsSpider' allow_domain = ['bbs.sjtu.edu.cn'] start_urls = [ 'https://bbs.sjtu.edu.cn/bbsall' ] link_extractor = { 'page': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+\.html$'), 'page_down': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+,page,\d+\.html$'), 'content': SgmlLinkExtractor(allow = '/bbscon,board,\w+,file,M\.\d+\.A\.html$'), } _x_query = { 'page_content': '//pre/text()[2]', 'poster' : '//pre/a/text()', 'forum' : '//center/text()[2]', } def parse(self, response): for link in self.link_extractor['page'].extract_links(response): yield Request(url = link.url, callback=self.parse_page) def parse_page(self, response): for link in self.link_extractor['page_down'].extract_links(response): yield Request(url = link.url, callback=self.parse_page) for link in self.link_extractor['content'].extract_links(response): yield Request(url = link.url, callback=self.parse_content) def parse_content(self, response): bbsItem_loader = ItemLoader(item=BbsItem(), response = response) url = str(response.url) bbsItem_loader.add_value('url', url) bbsItem_loader.add_xpath('forum', self._x_query['forum']) bbsItem_loader.add_xpath('poster', self._x_query['poster']) bbsItem_loader.add_xpath('content', self._x_query['page_content']) return bbsItem_loader.load_item()
定义项目管道
在Spider中采集到Item后,会传递给Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个项目管道组件(有时称为“项目管道”)都是一个实现简单方法的 Python 类。他们接收项目并对其执行一些操作,并且还决定该项目是继续通过管道还是被丢弃而不进行进一步处理。
以下是item pipeline的一些典型应用:
编写项目管道
编写自己的项目管道很简单,每个项目管道组件都是一个单独的 Python 类,并且必须实现以下方法:
process_item(item, spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。
参数:item (Item object) – 由 parse 方法返回的 Item 对象
spider (Spider object) – 抓取到这个 Item 对象对应的爬虫对象
此外,他们还可以实现以下方法:
open_spider(spider)
当spider被开启时,这个方法被调用。
参数: spider (Spider object) – 被开启的spider
close_spider(spider)
当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。
参数: spider (Spider object) – 被关闭的spider
本文爬虫的item pipeline如下,保存为xml文件:
12345678910111213141516171819202122232425262728293031
# -*- coding: utf-8 -*-# Define your item pipelines here# Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: http://doc.scrapy.org/en/lates ... lfrom scrapy import signalsfrom scrapy import logfrom bbsDmoz.items import BbsDmozItemfrom twisted.enterprise import adbapifrom scrapy.contrib.exporter import XmlItemExporterfrom dataProcess import dataProcessclass XmlWritePipeline(object): def __init__(self): pass @classmethod def from_crawler(cls, crawler): pipeline = cls() crawler.signals.connect(pipeline.spider_opened, signals.spider_opened) crawler.signals.connect(pipeline.spider_closed, signals.spider_closed) return pipeline def spider_opened(self, spider): self.file = open('bbsData.xml', 'wb') self.expoter = XmlItemExporter(self.file) self.expoter.start_exporting() def spider_closed(self, spider): self.expoter.finish_exporting() self.file.close() # process the crawled data, define and call dataProcess function # dataProcess('bbsData.xml', 'text.txt') def process_item(self, item, spider): self.expoter.export_item(item) return item
启用和设置项目管道
为了启用 Item Pipeline 组件,您必须将其类添加到 ITEM_PIPELINES,如下例所示:
123
ITEM_PIPELINES = { 'bbsDmoz.pipelines.XmlWritePipeline': 1000,}
分配给每个类的整数值决定了它们运行的顺序,项目按数字顺序从低到高,通过管道,这些数字通常定义在 0-1000 范围内。
设置
Scrapy 设置(settings)提供了一种自定义 Scrapy 组件的方法。您可以控制包括核心、扩展、管道和蜘蛛在内的组件。
这些设置为代码提供了一个全局命名空间,可以从中提取键值映射配置值。可以通过下面描述的各种机制来设置设置。
设置也是一种选择当前活动的 Scrapy 项目(如果你有多个)的方法。
在设置配置文件中,可以指定抓拍的速率,是否在桌面显示抓拍进程信息等,具体请参考。
该爬虫的设置配置如下:
12345678910111213141516
# -*- coding: utf-8 -*-# Scrapy settings for bbs project# For simplicity, this file contains only the most important settings by# default. All the other settings are documented here:# http://doc.scrapy.org/en/lates ... _NAME = 'bbsDomz'CONCURRENT_REQUESTS = 200LOG_LEVEL = 'INFO'COOKIES_ENABLED = TrueRETRY_ENABLED = TrueSPIDER_MODULES = ['bbsDomz.spiders']NEWSPIDER_MODULE = 'bbsDomz.spiders'# JOBDIR = 'jobdir'ITEM_PIPELINES = { 'bbsDomz.pipelines.XmlWritePipeline': 1000,}
爬行
爬虫程序写好后,我们就可以运行程序来抓取数据了。进入项目 bbsDomz/ 的根目录,执行以下命令启动蜘蛛:
1
scrapy crawl bbsSpider
这样您就可以等到程序完成运行。
进一步阅读 查看全部
scrapy分页抓取网页(
ByShinChanPublished92014atglance)
Scrapy爬虫爬取网站数据
由ShinChan
2014 年 11 月 9 日出版
内容
一目了然
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下:
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据的采集工作,它为我们做了很多工作,无需自己开发。
Scrapy 教程
在本文中,假设您已经安装了 Scrapy。如果没有,请参考。
下面以爬取饮用水源BBS数据为例说明爬取过程。详情请参考 bbsdmoz 代码。
本教程将带您完成以下任务:
1. 创建一个Scrapy项目
2. 定义提取的Item
3. 编写爬取网站的 spider 并提取 Item
4. 编写 Item Pipeline 来存储提取到的Item(即数据)
Scrapy 是用 Python 编写的。如果你是语言新手,对这门语言的特点和 Scrapy 的细节感到好奇,对于已经熟悉其他语言并想快速学习 Python 的编程老手,我们推荐 Learn Python The Hard Way,进行编程想要开始学习 Python 的初学者,非编程的 Python 学习资料列表供您选择。
创建项目
在开始抓取之前,您必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
1
scrapy startproject bbsdmoz
此命令将创建具有以下内容的 bbsDmoz 目录:
bbsDmoz/
scrapy.cfg
bbsDmoz/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
定义我们的项目
item是爬取数据的容器;它的用法类似于 python 字典,它提供了额外的保护来防止由拼写错误导致的未定义字段错误。
与您在 ORM 中所做的类似,您可以通过创建一个 scrapy.Item 类并定义一个类型为 scrapy.Field 的类属性来定义一个 Item。(如果你不懂ORM,别担心,你会发现这一步很简单)
首先根据从bbs网站获取的数据对item进行建模。我们需要从中获取 url、post board、poster 和 post 的内容。为此,请在 item.xml 中定义相应的字段。编辑 bbsDmoz 目录中的 items.py 文件:
123456789101112
# -*- coding: utf-8 -*-# Define here the models for your scraped items# See documentation in:# http://doc.scrapy.org/en/lates ... lfrom scrapy.item import Item, Fieldclass BbsDmozItem(Item): # define the fields for your item here like: # name = scrapy.Field() url = Field() forum = Field() poster = Field() content = Field()
起初这可能看起来很复杂,但是通过定义一个项目,您可以轻松地使用其他 Scrapy 方法。而这些方法需要知道你的item的定义。
我们的第一只蜘蛛
蜘蛛是用户编写的类,用于从单个 网站(或某些 网站)中抓取数据。
它包括一个用于下载的初始URL,如何跟踪网页中的链接以及如何分析页面中的内容,以及提取生成项目的方法。
创建蜘蛛
为了创建一个存储在 bbsDmoz/spiders 中的 Spider,您必须扩展 scrapy.Spider 类并定义以下三个属性:
选择器选择器
有很多方法可以从网页中提取数据。Scrapy 使用基于 XPath 和 CSS 表达式的机制:. 有关选择器和其他提取机制的信息,请参见此处。
我们使用 XPath 选择要从页面的 HTML 源中提取的数据。以下是 XPath 表达式及其对应含义的示例:
以饮水思源论坛首页为例:
查看 HTML 页面源并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以发现poster是收录在pre/a标签中的,这里是userid=jasperstream:
123
...[回复本文][原帖] 发信人: jasperstream
所以可以提取jasperstream的XPath表达式为:
1
'//pre/a/text()'
同理,我可以提取其他内容的XPath,提取后最好验证其正确性。以上只是几个简单的 XPath 示例,XPath 实际上远比这强大。如果您想了解更多信息,我们推荐此 XPath 教程。
为了配合XPath,除了提供Selector之外,Scrapy还提供了避免每次从response中提取数据都生成selector的麻烦的方法。
Selector 有四种基本方法(点击对应方法查看详细 API 文档):
比如提取上面的poster数据:
1
sel.xpath('//pre/a/text()').extract()
使用物品
项目对象是自定义 python 字典。您可以使用标准字典语法来获取其每个字段的值(该字段是我们之前用 Field 分配的属性)。一般来说,爬虫会将爬取的数据作为Item对象返回。
蜘蛛代码
以下是我们的第一个蜘蛛代码,保存在 bbsDmoz/spiders 目录下的 forumSpider.py 文件中:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950
#-*- coding: utf-8 -*-'''bbsSpider, Created on Oct, 2014#version: 1.0#author: chenqx @http://chenqx.github.comSee more: http://doc.scrapy.org/en/latest/index.html'''from scrapy.selector import Selectorfrom scrapy.http import Requestfrom scrapy.contrib.spiders import CrawlSpiderfrom scrapy.contrib.loader import ItemLoaderfrom scrapy.contrib.linkextractors.sgml import SgmlLinkExtractorfrom bbs.items import BbsItemclass forumSpider(CrawlSpider): # name of spiders name = 'bbsSpider' allow_domain = ['bbs.sjtu.edu.cn'] start_urls = [ 'https://bbs.sjtu.edu.cn/bbsall' ] link_extractor = { 'page': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+\.html$'), 'page_down': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+,page,\d+\.html$'), 'content': SgmlLinkExtractor(allow = '/bbscon,board,\w+,file,M\.\d+\.A\.html$'), } _x_query = { 'page_content': '//pre/text()[2]', 'poster' : '//pre/a/text()', 'forum' : '//center/text()[2]', } def parse(self, response): for link in self.link_extractor['page'].extract_links(response): yield Request(url = link.url, callback=self.parse_page) def parse_page(self, response): for link in self.link_extractor['page_down'].extract_links(response): yield Request(url = link.url, callback=self.parse_page) for link in self.link_extractor['content'].extract_links(response): yield Request(url = link.url, callback=self.parse_content) def parse_content(self, response): bbsItem_loader = ItemLoader(item=BbsItem(), response = response) url = str(response.url) bbsItem_loader.add_value('url', url) bbsItem_loader.add_xpath('forum', self._x_query['forum']) bbsItem_loader.add_xpath('poster', self._x_query['poster']) bbsItem_loader.add_xpath('content', self._x_query['page_content']) return bbsItem_loader.load_item()
定义项目管道
在Spider中采集到Item后,会传递给Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个项目管道组件(有时称为“项目管道”)都是一个实现简单方法的 Python 类。他们接收项目并对其执行一些操作,并且还决定该项目是继续通过管道还是被丢弃而不进行进一步处理。
以下是item pipeline的一些典型应用:
编写项目管道
编写自己的项目管道很简单,每个项目管道组件都是一个单独的 Python 类,并且必须实现以下方法:
process_item(item, spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。
参数:item (Item object) – 由 parse 方法返回的 Item 对象
spider (Spider object) – 抓取到这个 Item 对象对应的爬虫对象
此外,他们还可以实现以下方法:
open_spider(spider)
当spider被开启时,这个方法被调用。
参数: spider (Spider object) – 被开启的spider
close_spider(spider)
当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。
参数: spider (Spider object) – 被关闭的spider
本文爬虫的item pipeline如下,保存为xml文件:
12345678910111213141516171819202122232425262728293031
# -*- coding: utf-8 -*-# Define your item pipelines here# Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: http://doc.scrapy.org/en/lates ... lfrom scrapy import signalsfrom scrapy import logfrom bbsDmoz.items import BbsDmozItemfrom twisted.enterprise import adbapifrom scrapy.contrib.exporter import XmlItemExporterfrom dataProcess import dataProcessclass XmlWritePipeline(object): def __init__(self): pass @classmethod def from_crawler(cls, crawler): pipeline = cls() crawler.signals.connect(pipeline.spider_opened, signals.spider_opened) crawler.signals.connect(pipeline.spider_closed, signals.spider_closed) return pipeline def spider_opened(self, spider): self.file = open('bbsData.xml', 'wb') self.expoter = XmlItemExporter(self.file) self.expoter.start_exporting() def spider_closed(self, spider): self.expoter.finish_exporting() self.file.close() # process the crawled data, define and call dataProcess function # dataProcess('bbsData.xml', 'text.txt') def process_item(self, item, spider): self.expoter.export_item(item) return item
启用和设置项目管道
为了启用 Item Pipeline 组件,您必须将其类添加到 ITEM_PIPELINES,如下例所示:
123
ITEM_PIPELINES = { 'bbsDmoz.pipelines.XmlWritePipeline': 1000,}
分配给每个类的整数值决定了它们运行的顺序,项目按数字顺序从低到高,通过管道,这些数字通常定义在 0-1000 范围内。
设置
Scrapy 设置(settings)提供了一种自定义 Scrapy 组件的方法。您可以控制包括核心、扩展、管道和蜘蛛在内的组件。
这些设置为代码提供了一个全局命名空间,可以从中提取键值映射配置值。可以通过下面描述的各种机制来设置设置。
设置也是一种选择当前活动的 Scrapy 项目(如果你有多个)的方法。
在设置配置文件中,可以指定抓拍的速率,是否在桌面显示抓拍进程信息等,具体请参考。
该爬虫的设置配置如下:
12345678910111213141516
# -*- coding: utf-8 -*-# Scrapy settings for bbs project# For simplicity, this file contains only the most important settings by# default. All the other settings are documented here:# http://doc.scrapy.org/en/lates ... _NAME = 'bbsDomz'CONCURRENT_REQUESTS = 200LOG_LEVEL = 'INFO'COOKIES_ENABLED = TrueRETRY_ENABLED = TrueSPIDER_MODULES = ['bbsDomz.spiders']NEWSPIDER_MODULE = 'bbsDomz.spiders'# JOBDIR = 'jobdir'ITEM_PIPELINES = { 'bbsDomz.pipelines.XmlWritePipeline': 1000,}
爬行
爬虫程序写好后,我们就可以运行程序来抓取数据了。进入项目 bbsDomz/ 的根目录,执行以下命令启动蜘蛛:
1
scrapy crawl bbsSpider
这样您就可以等到程序完成运行。
进一步阅读
scrapy分页抓取网页(项目文件创建好怎么写爬虫程序?程序怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-11 20:00
项目文件创建完成后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
class KuanItem(scrapy.Item):<br /># define the fields for your item here like:<br />name = scrapy.Field()<br />volume = scrapy.Field()<br />download = scrapy.Field()<br />follow = scrapy.Field()<br />comment = scrapy.Field()<br />tags = scrapy.Field()<br />score = scrapy.Field()<br />num_score = scrapy.Field()<br />
这里的字段信息是我们之前在网页中定位的8个字段信息,包括:name代表app的名称,volume代表音量,download代表下载次数。在这里定义好之后,我们会在后续的爬取主程序中用到这些字段信息。
2.3.3.爬取主程序
创建kuan项目后,Scrapy框架会自动生成一些爬取的代码。接下来,我们需要在parse方法中添加网页抓取的字段解析内容。
class KuspiderSpider(scrapy.Spider):<br /> name = 'kuan'<br /> allowed_domains = ['www.coolapk.com']<br /> start_urls = ['http://www.coolapk.com/']<br /><br /> def parse(self, response):<br /> pass<br />
在首页打开Dev Tools,找到每个抓取索引的节点位置,然后使用CSS、Xpath、regular等方法提取解析。这些方法都是 Scrapy 支持的,可以随意选择。这里我们使用 CSS 语法来定位节点,但需要注意的是,Scrapy 的 CSS 语法与我们之前使用 pyquery 的 CSS 语法略有不同。让我们举几个例子来比较一下。
首先,我们定位到第一个APP的首页URL节点。可以看到URL节点位于class属性为app_left_list的div节点下的a节点中,其href属性就是我们需要的URL信息,这里是相对地址,拼接后就是完整的URL:。
然后我们进入Kuan详情页面,选择app名称并定位。可以看到app name节点位于class属性为.detail_app_title的p节点的文本中。
定位到这两个节点后,我们就可以使用CSS来提取字段信息了。下面是常规写法和Scrapy中写法的对比:
# 常规写法<br />url = item('.app_left_list>a').attr('href')<br />name = item('.list_app_title').text()<br /># Scrapy 写法<br />url = item.css('::attr("href")').extract_first()<br />name = item.css('.detail_app_title::text').extract_first()<br />
如您所见,要获取 href 或 text 属性,您需要使用 :: 来表示它。例如,要获取文本,请使用 ::text。 extract_first() 表示提取第一个元素,如果有多个元素,使用 extract() 。然后,我们可以参考解析代码写出8个字段的信息。
首先,我们需要在首页提取应用的URL列表,然后进入每个应用的详情页,进一步提取8个字段的信息。
def parse(self, response):<br /> contents = response.css('.app_left_list>a')<br /> for content in contents:<br /> url = content.css('::attr("href")').extract_first()<br /> url = response.urljoin(url) # 拼接相对 url 为绝对 url<br /> yield scrapy.Request(url,callback=self.parse_url)<br />
这里使用response.urljoin()方法将提取出来的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传递两个参数:url和callback,url是详情页的URL,callback是回调函数,它将首页URL请求返回的响应传递给专门用于解析字段内容的parse_url()方法,如如下图:
def parse_url(self,response):<br /> item = KuanItem()<br /> item['name'] = response.css('.detail_app_title::text').extract_first()<br /> results = self.get_comment(response)<br /> item['volume'] = results[0]<br /> item['download'] = results[1]<br /> item['follow'] = results[2]<br /> item['comment'] = results[3]<br /> item['tags'] = self.get_tags(response)<br /> item['score'] = response.css('.rank_num::text').extract_first()<br /> num_score = response.css('.apk_rank_p1::text').extract_first()<br /> item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)<br /> yield item<br /> <br />def get_comment(self,response):<br /> messages = response.css('.apk_topba_message::text').extract_first()<br /> result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上<br /> if result: # 不为空<br /> results = list(result[0]) # 提取出list 中第一个元素<br /> return results<br /><br />def get_tags(self,response):<br /> data = response.css('.apk_left_span2')<br /> tags = [item.css('::text').extract_first() for item in data]<br /> return tags<br />
这里,get_comment() 和 get_tags() 方法是分开定义的。
get_comment()方法通过正则匹配提取出volume、download、follow、comment这四个字段。正则匹配结果如下:
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)<br />print(result) # 输出第一页的结果信息<br /># 结果如下:<br />[('21.74M', '5218万', '2.4万', '5.4万')]<br />[('75.53M', '2768万', '2.3万', '3.0万')]<br />[('46.21M', '1686万', '2.3万', '3.4万')]<br />[('54.77M', '1603万', '3.8万', '4.9万')]<br />[('3.32M', '1530万', '1.5万', '3343')]<br />[('75.07M', '1127万', '1.6万', '2.2万')]<br />[('92.70M', '1108万', '9167', '1.3万')]<br />[('68.94M', '1072万', '5718', '9869')]<br />[('61.45M', '935万', '1.1万', '1.6万')]<br />[('23.96M', '925万', '4157', '1956')]<br />
然后使用result[0]、result[1]等提取4条信息,以volume为例,输出第一页的提取结果:
item['volume'] = results[0]<br />print(item['volume'])<br />21.74M<br />75.53M<br />46.21M<br />54.77M<br />3.32M<br />75.07M<br />92.70M<br />68.94M<br />61.45M<br />23.96M<br />
这样,第一页10个app的字段信息全部提取成功,然后返回到yield item generator,我们输出它的内容:
[<br />{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'}, <br />{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},<br />...<br />]<br />
2.3.4.分页爬取
以上,我们已经爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
这里,我们分别编写这两个方法的解析代码。
第一种方法很简单,直接在parse方法后面继续添加下面几行代码即可:
def parse(self, response):<br /> contents = response.css('.app_left_list>a')<br /> for content in contents:<br /> ...<br /> <br /> next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()<br /> url = response.urljoin(next_page)<br /> yield scrapy.Request(url,callback=self.parse )<br />
第二种方法,我们在第一个parse()方法之前定义一个start_requests()方法,批量生成610个页面url,然后传给scrapy.Request()方法中的回调参数。下面的 parse() 方法进行解析。
def start_requests(self):<br /> pages = []<br /> for page in range(1,610): # 一共有610页<br /> url = 'https://www.coolapk.com/apk/%3 ... %3Bbr /> page = scrapy.Request(url,callback=self.parse)<br /> pages.append(page)<br /> return pages<br />
以上是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择存储在 MongoDB 中。不得不说MongoDB比MySQL方便多了。
2.3.5. 存储结果
在 pipelines.py 程序中,我们定义了数据的存储方式。 MongoDB的一些参数,比如地址和数据库名,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
import pymongo<br />class MongoPipeline(object):<br /> def __init__(self,mongo_url,mongo_db):<br /> self.mongo_url = mongo_url<br /> self.mongo_db = mongo_db<br /> @classmethod<br /> def from_crawler(cls,crawler):<br /> return cls(<br /> mongo_url = crawler.settings.get('MONGO_URL'),<br /> mongo_db = crawler.settings.get('MONGO_DB')<br /> )<br /> def open_spider(self,spider):<br /> self.client = pymongo.MongoClient(self.mongo_url)<br /> self.db = self.client[self.mongo_db]<br /> def process_item(self,item,spider):<br /> name = item.__class__.__name__<br /> self.db[name].insert(dict(item))<br /> return item<br /> def close_spider(self,spider):<br /> self.client.close()<br />
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单解释一下:
from crawler()是一个类方法,用@class方法标识,这个方法的作用就是获取我们在settings.py中设置的这些参数:
MONGO_URL = 'localhost'<br />MONGO_DB = 'KuAn'<br />ITEM_PIPELINES = {<br /> 'kuan.pipelines.MongoPipeline': 300,<br />}<br />
open_spider() 方法主要执行一些初始化操作。该方法会在 Spider 打开时调用。
process_item() 方法是向 MongoDB 插入数据最重要的方法。
完成以上代码后,输入以下命令,启动整个爬虫的爬取和存储过程。如果在单机上运行,完成6000个网页需要大量时间,请耐心等待。
scrapy crawl kuan<br />
这里还有两点:
首先,为了减轻网站的压力,我们最好在每个请求之间设置几秒的延迟。您可以在 KuspiderSpider() 方法的开头添加以下代码行:
custom_settings = {<br /> "DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟<br /> "CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低<br /> }<br />
其次,为了更好的监控爬虫的运行,需要设置输出日志文件,可以通过Python自带的日志包实现:
import logging<br /><br />logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')<br />logging.warning("warn message")<br />logging.error("error message")<br />
这里的level参数表示警告级别,严重程度从低到高依次为:DEBUG
添加 datefmt 参数对于在每个日志的前面添加特定时间很有用。
以上,我们已经完成了整个数据的采集。有了数据,我们就可以开始分析了,但在此之前,我们需要简单地清理和处理数据。
3.数据清洗
首先,我们从MongoDB中读取数据并将其转换为DataFrame,然后看一下数据的基础知识。
def parse_kuan():<br /> client = pymongo.MongoClient(host='localhost', port=27017)<br /> db = client['KuAn']<br /> collection = db['KuAnItem']<br /> # 将数据库数据转为DataFrame<br /> data = pd.DataFrame(list(collection.find()))<br /> print(data.head())<br /> print(df.shape)<br /> print(df.info())<br /> print(df.describe())<br />
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
comment、download、follow、num_score,五列数据中的部分行带有“百万”字尾,需要去掉,转为数值类型;体积列的后缀分别为“M”和“K”,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有6086行x 8列,每列没有缺失值。
df.describe() 方法对 score 列进行基本统计。可以看出,所有app的平均分3.9分(5分制),最低分1.6分。最高分 4.8 分。
接下来,我们将以上列文本数据转换为数值数据。代码实现如下:
def data_processing(df):<br />#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型<br /> str = '_ori'<br /> cols = ['comment','download','follow','num_score','volume']<br /> for col in cols:<br /> colori = col+str<br /> df[colori] = df[col] # 复制保留原始列<br /> if not (col == 'volume'):<br /> df[col] = clean_symbol(df,col)# 处理原始列生成新列<br /> else:<br /> df[col] = clean_symbol2(df,col)# 处理原始列生成新列<br /><br /> # 将download单独转换为万单位<br /> df['download'] = df['download'].apply(lambda x:x/10000)<br /> # 批量转为数值型<br /> df = df.apply(pd.to_numeric,errors='ignore')<br /> <br />def clean_symbol(df,col):<br /> # 将字符“万”替换为空<br /> con = df[col].str.contains('万$')<br /> df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000<br /> df[col] = pd.to_numeric(df[col])<br /> return df[col]<br /><br />def clean_symbol2(df,col):<br /> # 字符M替换为空<br /> df[col] = df[col].str.replace('M$','')<br /> # 体积为K的除以 1024 转换为M<br /> con = df[col].str.contains('K$')<br /> df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024<br /> df[col] = pd.to_numeric(df[col])<br /> return df[col]<br />
至此,几列文本数据的转换就完成了。先来看看基本情况:
commentdownloadfollownum_scorescorevolume
计数
6086
6086
6086
6086
6086
6086
意思
255.5
13.7
729.3
133.1
3.9
17.7
标准
1437.3
98
1893.7
595.4
0.6
20.6
分钟
1
1.6
25%
16
0.2
65
5.2
3.7
3.5
50%
38
0.8
180
17
4
10.8
75%
119
4.5
573.8
68
4.3
25.3
最大
53000
5190
38000
17000
4.8
294.2
由此可以看出以下信息:
至此,基本的数据清洗流程已经完成。在下一篇文章中文章我们将对数据进行探索性分析。
转载于: 查看全部
scrapy分页抓取网页(项目文件创建好怎么写爬虫程序?程序怎么做?)
项目文件创建完成后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
class KuanItem(scrapy.Item):<br /># define the fields for your item here like:<br />name = scrapy.Field()<br />volume = scrapy.Field()<br />download = scrapy.Field()<br />follow = scrapy.Field()<br />comment = scrapy.Field()<br />tags = scrapy.Field()<br />score = scrapy.Field()<br />num_score = scrapy.Field()<br />
这里的字段信息是我们之前在网页中定位的8个字段信息,包括:name代表app的名称,volume代表音量,download代表下载次数。在这里定义好之后,我们会在后续的爬取主程序中用到这些字段信息。
2.3.3.爬取主程序
创建kuan项目后,Scrapy框架会自动生成一些爬取的代码。接下来,我们需要在parse方法中添加网页抓取的字段解析内容。
class KuspiderSpider(scrapy.Spider):<br /> name = 'kuan'<br /> allowed_domains = ['www.coolapk.com']<br /> start_urls = ['http://www.coolapk.com/']<br /><br /> def parse(self, response):<br /> pass<br />
在首页打开Dev Tools,找到每个抓取索引的节点位置,然后使用CSS、Xpath、regular等方法提取解析。这些方法都是 Scrapy 支持的,可以随意选择。这里我们使用 CSS 语法来定位节点,但需要注意的是,Scrapy 的 CSS 语法与我们之前使用 pyquery 的 CSS 语法略有不同。让我们举几个例子来比较一下。
首先,我们定位到第一个APP的首页URL节点。可以看到URL节点位于class属性为app_left_list的div节点下的a节点中,其href属性就是我们需要的URL信息,这里是相对地址,拼接后就是完整的URL:。
然后我们进入Kuan详情页面,选择app名称并定位。可以看到app name节点位于class属性为.detail_app_title的p节点的文本中。
定位到这两个节点后,我们就可以使用CSS来提取字段信息了。下面是常规写法和Scrapy中写法的对比:
# 常规写法<br />url = item('.app_left_list>a').attr('href')<br />name = item('.list_app_title').text()<br /># Scrapy 写法<br />url = item.css('::attr("href")').extract_first()<br />name = item.css('.detail_app_title::text').extract_first()<br />
如您所见,要获取 href 或 text 属性,您需要使用 :: 来表示它。例如,要获取文本,请使用 ::text。 extract_first() 表示提取第一个元素,如果有多个元素,使用 extract() 。然后,我们可以参考解析代码写出8个字段的信息。
首先,我们需要在首页提取应用的URL列表,然后进入每个应用的详情页,进一步提取8个字段的信息。
def parse(self, response):<br /> contents = response.css('.app_left_list>a')<br /> for content in contents:<br /> url = content.css('::attr("href")').extract_first()<br /> url = response.urljoin(url) # 拼接相对 url 为绝对 url<br /> yield scrapy.Request(url,callback=self.parse_url)<br />
这里使用response.urljoin()方法将提取出来的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传递两个参数:url和callback,url是详情页的URL,callback是回调函数,它将首页URL请求返回的响应传递给专门用于解析字段内容的parse_url()方法,如如下图:
def parse_url(self,response):<br /> item = KuanItem()<br /> item['name'] = response.css('.detail_app_title::text').extract_first()<br /> results = self.get_comment(response)<br /> item['volume'] = results[0]<br /> item['download'] = results[1]<br /> item['follow'] = results[2]<br /> item['comment'] = results[3]<br /> item['tags'] = self.get_tags(response)<br /> item['score'] = response.css('.rank_num::text').extract_first()<br /> num_score = response.css('.apk_rank_p1::text').extract_first()<br /> item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)<br /> yield item<br /> <br />def get_comment(self,response):<br /> messages = response.css('.apk_topba_message::text').extract_first()<br /> result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上<br /> if result: # 不为空<br /> results = list(result[0]) # 提取出list 中第一个元素<br /> return results<br /><br />def get_tags(self,response):<br /> data = response.css('.apk_left_span2')<br /> tags = [item.css('::text').extract_first() for item in data]<br /> return tags<br />
这里,get_comment() 和 get_tags() 方法是分开定义的。
get_comment()方法通过正则匹配提取出volume、download、follow、comment这四个字段。正则匹配结果如下:
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)<br />print(result) # 输出第一页的结果信息<br /># 结果如下:<br />[('21.74M', '5218万', '2.4万', '5.4万')]<br />[('75.53M', '2768万', '2.3万', '3.0万')]<br />[('46.21M', '1686万', '2.3万', '3.4万')]<br />[('54.77M', '1603万', '3.8万', '4.9万')]<br />[('3.32M', '1530万', '1.5万', '3343')]<br />[('75.07M', '1127万', '1.6万', '2.2万')]<br />[('92.70M', '1108万', '9167', '1.3万')]<br />[('68.94M', '1072万', '5718', '9869')]<br />[('61.45M', '935万', '1.1万', '1.6万')]<br />[('23.96M', '925万', '4157', '1956')]<br />
然后使用result[0]、result[1]等提取4条信息,以volume为例,输出第一页的提取结果:
item['volume'] = results[0]<br />print(item['volume'])<br />21.74M<br />75.53M<br />46.21M<br />54.77M<br />3.32M<br />75.07M<br />92.70M<br />68.94M<br />61.45M<br />23.96M<br />
这样,第一页10个app的字段信息全部提取成功,然后返回到yield item generator,我们输出它的内容:
[<br />{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'}, <br />{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},<br />...<br />]<br />
2.3.4.分页爬取
以上,我们已经爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
这里,我们分别编写这两个方法的解析代码。
第一种方法很简单,直接在parse方法后面继续添加下面几行代码即可:
def parse(self, response):<br /> contents = response.css('.app_left_list>a')<br /> for content in contents:<br /> ...<br /> <br /> next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()<br /> url = response.urljoin(next_page)<br /> yield scrapy.Request(url,callback=self.parse )<br />
第二种方法,我们在第一个parse()方法之前定义一个start_requests()方法,批量生成610个页面url,然后传给scrapy.Request()方法中的回调参数。下面的 parse() 方法进行解析。
def start_requests(self):<br /> pages = []<br /> for page in range(1,610): # 一共有610页<br /> url = 'https://www.coolapk.com/apk/%3 ... %3Bbr /> page = scrapy.Request(url,callback=self.parse)<br /> pages.append(page)<br /> return pages<br />
以上是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择存储在 MongoDB 中。不得不说MongoDB比MySQL方便多了。
2.3.5. 存储结果
在 pipelines.py 程序中,我们定义了数据的存储方式。 MongoDB的一些参数,比如地址和数据库名,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
import pymongo<br />class MongoPipeline(object):<br /> def __init__(self,mongo_url,mongo_db):<br /> self.mongo_url = mongo_url<br /> self.mongo_db = mongo_db<br /> @classmethod<br /> def from_crawler(cls,crawler):<br /> return cls(<br /> mongo_url = crawler.settings.get('MONGO_URL'),<br /> mongo_db = crawler.settings.get('MONGO_DB')<br /> )<br /> def open_spider(self,spider):<br /> self.client = pymongo.MongoClient(self.mongo_url)<br /> self.db = self.client[self.mongo_db]<br /> def process_item(self,item,spider):<br /> name = item.__class__.__name__<br /> self.db[name].insert(dict(item))<br /> return item<br /> def close_spider(self,spider):<br /> self.client.close()<br />
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单解释一下:
from crawler()是一个类方法,用@class方法标识,这个方法的作用就是获取我们在settings.py中设置的这些参数:
MONGO_URL = 'localhost'<br />MONGO_DB = 'KuAn'<br />ITEM_PIPELINES = {<br /> 'kuan.pipelines.MongoPipeline': 300,<br />}<br />
open_spider() 方法主要执行一些初始化操作。该方法会在 Spider 打开时调用。
process_item() 方法是向 MongoDB 插入数据最重要的方法。
完成以上代码后,输入以下命令,启动整个爬虫的爬取和存储过程。如果在单机上运行,完成6000个网页需要大量时间,请耐心等待。
scrapy crawl kuan<br />
这里还有两点:
首先,为了减轻网站的压力,我们最好在每个请求之间设置几秒的延迟。您可以在 KuspiderSpider() 方法的开头添加以下代码行:
custom_settings = {<br /> "DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟<br /> "CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低<br /> }<br />
其次,为了更好的监控爬虫的运行,需要设置输出日志文件,可以通过Python自带的日志包实现:
import logging<br /><br />logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')<br />logging.warning("warn message")<br />logging.error("error message")<br />
这里的level参数表示警告级别,严重程度从低到高依次为:DEBUG
添加 datefmt 参数对于在每个日志的前面添加特定时间很有用。
以上,我们已经完成了整个数据的采集。有了数据,我们就可以开始分析了,但在此之前,我们需要简单地清理和处理数据。
3.数据清洗
首先,我们从MongoDB中读取数据并将其转换为DataFrame,然后看一下数据的基础知识。
def parse_kuan():<br /> client = pymongo.MongoClient(host='localhost', port=27017)<br /> db = client['KuAn']<br /> collection = db['KuAnItem']<br /> # 将数据库数据转为DataFrame<br /> data = pd.DataFrame(list(collection.find()))<br /> print(data.head())<br /> print(df.shape)<br /> print(df.info())<br /> print(df.describe())<br />
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
comment、download、follow、num_score,五列数据中的部分行带有“百万”字尾,需要去掉,转为数值类型;体积列的后缀分别为“M”和“K”,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有6086行x 8列,每列没有缺失值。
df.describe() 方法对 score 列进行基本统计。可以看出,所有app的平均分3.9分(5分制),最低分1.6分。最高分 4.8 分。
接下来,我们将以上列文本数据转换为数值数据。代码实现如下:
def data_processing(df):<br />#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型<br /> str = '_ori'<br /> cols = ['comment','download','follow','num_score','volume']<br /> for col in cols:<br /> colori = col+str<br /> df[colori] = df[col] # 复制保留原始列<br /> if not (col == 'volume'):<br /> df[col] = clean_symbol(df,col)# 处理原始列生成新列<br /> else:<br /> df[col] = clean_symbol2(df,col)# 处理原始列生成新列<br /><br /> # 将download单独转换为万单位<br /> df['download'] = df['download'].apply(lambda x:x/10000)<br /> # 批量转为数值型<br /> df = df.apply(pd.to_numeric,errors='ignore')<br /> <br />def clean_symbol(df,col):<br /> # 将字符“万”替换为空<br /> con = df[col].str.contains('万$')<br /> df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000<br /> df[col] = pd.to_numeric(df[col])<br /> return df[col]<br /><br />def clean_symbol2(df,col):<br /> # 字符M替换为空<br /> df[col] = df[col].str.replace('M$','')<br /> # 体积为K的除以 1024 转换为M<br /> con = df[col].str.contains('K$')<br /> df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024<br /> df[col] = pd.to_numeric(df[col])<br /> return df[col]<br />
至此,几列文本数据的转换就完成了。先来看看基本情况:
commentdownloadfollownum_scorescorevolume
计数
6086
6086
6086
6086
6086
6086
意思
255.5
13.7
729.3
133.1
3.9
17.7
标准
1437.3
98
1893.7
595.4
0.6
20.6
分钟
1
1.6
25%
16
0.2
65
5.2
3.7
3.5
50%
38
0.8
180
17
4
10.8
75%
119
4.5
573.8
68
4.3
25.3
最大
53000
5190
38000
17000
4.8
294.2
由此可以看出以下信息:
至此,基本的数据清洗流程已经完成。在下一篇文章中文章我们将对数据进行探索性分析。
转载于:
scrapy分页抓取网页(【干货】scrapy-redis框架抓取网页网页(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-11 18:34
1. 介绍scrapy-redis 框架
scrapy-redis
一个基于redis的三方分布式爬虫框架,配合scrapy使用,使爬虫具备分布式爬虫的功能。
github地址:/darkrho/scrapy-redis
2. 分布式原理
scrapy-redis实现分布式,其实原理上很简单,这里为了描述方便,我们把我们的核心服务器叫做master,用来运行爬虫程序的机器叫做slave
我们知道要使用scrapy框架爬取一个网页,我们需要先给它一些start_urls。爬虫首先访问start_urls中的url,然后根据我们的具体逻辑,对里面的元素,或者其他二级三级页面进行操作。抓。要实现分布式,我们只需要在这个starts_urls中做文章
我们在master上建一个redis数据库(注意这个数据库只用于url存储),为每一种需要爬取的网站打开一个单独的列表字段。通过在slave上设置scrapy-redis来获取url的地址作为master地址。结果是虽然有多个slave,但是大家获取url的地方只有一个,那就是服务器master上的redis数据库
而且由于scrapy-redis自带的队列机制,slave获取的链接不会相互冲突。这样,每个slave完成爬取任务后,将得到的结果汇总到服务器。
益处
程序可移植性强,只要处理好路径问题,将slave上的程序移植到另一台机器上运行基本上就是复制粘贴的问题
3.分布式爬虫的实现使用了三台机器,一台是win10,一台是centos6,两台机器上部署了scrapy进行分布式爬虫。一个 网站
win10的IP地址为192.168.31.245,作为redis的master,centos的机器作为slave
master的爬虫在运行时会将提取的url封装成request放入redis中的数据库:“dmoz:requests”,从数据库中提取请求下载网页,然后存储“dmoz:items”中另一个redis数据库中的网页
slave从master的redis中取出要爬取的请求,下载网页后将网页的内容发回master的redis
重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,然后将master的redis中的“dmoz:items”数据库写入mongodb
在master中的reids中还有一个数据“dmoz:dupefilter”,用于存储抓取到的url的指纹(使用hash函数对url进行操作的结果),用于防止重复爬取。
4. 安装scrapy-redis框架
pip install scrapy-redis
5. 部署scrapy-redis5.1 在slave端Windows的settings.py文件末尾添加下面一行
REDIS_HOST = 'localhost' #master IP
REDIS_PORT = 6379
配置远程redis地址后,启动两个爬虫(启动爬虫没有顺序限制)
6 为爬虫添加配置信息
7 运行程序7.1 运行从机
scrapy runspider 文件名.py
无序打开
7.2 运行主机
lpush (redis_key) url #括号不用写
说明-这个命令在redis-cli中运行-redis_key是spider.py文件中redis_key的值-url开始爬取地址不带双引号
8 将数据导入mongodb
爬虫完成后,如果要将数据存储在mongodb中,需要修改master端的process_items.py文件,如下
9 将数据导入 MySQL
爬虫完成后,如果要将数据存储在mongodb中,需要修改master端的process_items.py文件,如下
推荐视频教程: 查看全部
scrapy分页抓取网页(【干货】scrapy-redis框架抓取网页网页(一))
1. 介绍scrapy-redis 框架
scrapy-redis
一个基于redis的三方分布式爬虫框架,配合scrapy使用,使爬虫具备分布式爬虫的功能。
github地址:/darkrho/scrapy-redis
2. 分布式原理
scrapy-redis实现分布式,其实原理上很简单,这里为了描述方便,我们把我们的核心服务器叫做master,用来运行爬虫程序的机器叫做slave
我们知道要使用scrapy框架爬取一个网页,我们需要先给它一些start_urls。爬虫首先访问start_urls中的url,然后根据我们的具体逻辑,对里面的元素,或者其他二级三级页面进行操作。抓。要实现分布式,我们只需要在这个starts_urls中做文章
我们在master上建一个redis数据库(注意这个数据库只用于url存储),为每一种需要爬取的网站打开一个单独的列表字段。通过在slave上设置scrapy-redis来获取url的地址作为master地址。结果是虽然有多个slave,但是大家获取url的地方只有一个,那就是服务器master上的redis数据库
而且由于scrapy-redis自带的队列机制,slave获取的链接不会相互冲突。这样,每个slave完成爬取任务后,将得到的结果汇总到服务器。
益处
程序可移植性强,只要处理好路径问题,将slave上的程序移植到另一台机器上运行基本上就是复制粘贴的问题
3.分布式爬虫的实现使用了三台机器,一台是win10,一台是centos6,两台机器上部署了scrapy进行分布式爬虫。一个 网站
win10的IP地址为192.168.31.245,作为redis的master,centos的机器作为slave
master的爬虫在运行时会将提取的url封装成request放入redis中的数据库:“dmoz:requests”,从数据库中提取请求下载网页,然后存储“dmoz:items”中另一个redis数据库中的网页
slave从master的redis中取出要爬取的请求,下载网页后将网页的内容发回master的redis
重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,然后将master的redis中的“dmoz:items”数据库写入mongodb
在master中的reids中还有一个数据“dmoz:dupefilter”,用于存储抓取到的url的指纹(使用hash函数对url进行操作的结果),用于防止重复爬取。
4. 安装scrapy-redis框架
pip install scrapy-redis
5. 部署scrapy-redis5.1 在slave端Windows的settings.py文件末尾添加下面一行
REDIS_HOST = 'localhost' #master IP
REDIS_PORT = 6379
配置远程redis地址后,启动两个爬虫(启动爬虫没有顺序限制)
6 为爬虫添加配置信息
7 运行程序7.1 运行从机
scrapy runspider 文件名.py
无序打开
7.2 运行主机
lpush (redis_key) url #括号不用写
说明-这个命令在redis-cli中运行-redis_key是spider.py文件中redis_key的值-url开始爬取地址不带双引号
8 将数据导入mongodb
爬虫完成后,如果要将数据存储在mongodb中,需要修改master端的process_items.py文件,如下
9 将数据导入 MySQL
爬虫完成后,如果要将数据存储在mongodb中,需要修改master端的process_items.py文件,如下
推荐视频教程:
scrapy分页抓取网页(我抓取的网页内容是时时在变的如何实现, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-04-07 00:01
)
爬取网页,如何在分页中显示内容我爬取的网页内容时常变化,如何在页面中显示,例如分段策略以连接数为标志。通常,5个链接设置为一个段落。怎么实现,关键是idea,能不能录入数据库?----------Programming Q&A-------- ------------ - 一个段落的 5 个链接
==========================>>>>>>
首先抓取所有连接的库,
然后在抓取内容时。每5次读出grab>>loop>>end--------编程问答--------------- ------楼上,我要的数据时常变化。如果我将它写入数据库,我应该不时更换它吗?
-------------------- 编程问题和答案-------- 已知连接?未知连接?
只爬取内容,自己的连接
抢内容,先连接?--------编程问答------ 抢先连接,再点击连接显示内容--------编程问答------ --- ---用PHP更容易实现--------编程问答--------------- ---- - 先抓取连接,然后点击连接显示内容
========================================>>>
然后先写表达式,抓取连接
然后下载连接的源码,然后写表达式获取内容--------编程问答------ ------ ---- 分2部分,第一步是抓取网页的显示部分
在抓取内容部分,然后划分内容,将内容添加到刚才的网页中是拉--------编程问答--- ------ ------------- 如果不存储在数据库中,那么只能在内存中分页。
补充:.NET技术 , C# 查看全部
scrapy分页抓取网页(我抓取的网页内容是时时在变的如何实现,
)
爬取网页,如何在分页中显示内容我爬取的网页内容时常变化,如何在页面中显示,例如分段策略以连接数为标志。通常,5个链接设置为一个段落。怎么实现,关键是idea,能不能录入数据库?----------Programming Q&A-------- ------------ - 一个段落的 5 个链接
==========================>>>>>>
首先抓取所有连接的库,
然后在抓取内容时。每5次读出grab>>loop>>end--------编程问答--------------- ------楼上,我要的数据时常变化。如果我将它写入数据库,我应该不时更换它吗?
-------------------- 编程问题和答案-------- 已知连接?未知连接?
只爬取内容,自己的连接
抢内容,先连接?--------编程问答------ 抢先连接,再点击连接显示内容--------编程问答------ --- ---用PHP更容易实现--------编程问答--------------- ---- - 先抓取连接,然后点击连接显示内容
========================================>>>
然后先写表达式,抓取连接
然后下载连接的源码,然后写表达式获取内容--------编程问答------ ------ ---- 分2部分,第一步是抓取网页的显示部分
在抓取内容部分,然后划分内容,将内容添加到刚才的网页中是拉--------编程问答--- ------ ------------- 如果不存储在数据库中,那么只能在内存中分页。
补充:.NET技术 , C#
scrapy分页抓取网页(如何构建自定义的爬虫站点和监控程序第一步开发项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-06 23:27
电商主和管理者可能需要自己爬取网站来监控网页、跟踪网站流量、寻找优化机会等。
对于其中的每一个,都可以使用离散工具、网络爬虫和服务来帮助监控网站。只需相对较少的开发工作,您就可以创建自己的站点爬虫和站点监控系统。
要构建自定义爬虫站点并进行监控,第一步是简单地获取 网站 上所有页面的列表。本文将向您展示如何使用 Python 编程语言和一个名为 Scrapy 的简洁网络爬虫框架轻松生成这些页面的列表。
你需要一个服务器、Python 和 Scrapy
这是一个开发项目。需要安装了 Python 和 Scrapy 的服务器。还需要通过终端应用程序或 SSH 客户端对服务器进行命令行访问。有关安装 Python 的信息也可从 . Scrapy网站 也有很好的安装文档。请确认您的服务器已准备好安装 Python 和 Scrapy。
创建一个 Scrapy 项目
使用 SSH 客户端(如 Windows 的 Putty)或 Mac、Linux 计算机上的终端应用程序,导航到要保存 Scrapy 项目的目录。使用内置的 Scrapy 命令 startproject,我们可以快速生成所需的基础文件。
本文将抓取一个名为《Business Idea Daily》的网站,因此得名“bid”。
生成一个新的 Scrapy Web Spider
为方便起见,Scrapy 还有另一个命令行工具,可以自动生成新的网络蜘蛛。
scrapy genspider -t crawl getbid businessideadaily.com
第一个术语,scrapy,指的是 Scrapy 框架。接下来,有 genspider 命令告诉 Scrapy 我们想要一个新的网络蜘蛛,或者,如果你愿意,一个新的网络爬虫。
-t 告诉 Scrapy 我们要选择一个特定的模板。genspider 命令可以生成四种通用网络蜘蛛模板中的任何一种:basic、crawl、csvfeed 和 xmlfeed。在 -t 之后,我们立即指定所需的模板。在本例中,我们将通过 Scrapy 创建一个名为 CrawlSpider 的模板。“getbid”这个词是蜘蛛的名字。
该命令的最后一部分告诉 Scrapy 我们要抓取哪个 网站。框架将使用它来填充一些新的蜘蛛参数。
定义项目
在 Scrapy 中,Items 是一种组织蜘蛛在抓取特定 网站 时采集东西的方式/模型。虽然我们可以轻松实现我们的目标 - 获取特定 网站 上所有页面的列表 - 不使用 Items,如果我们以后想要扩展我们的爬虫,不使用 Items 可能会限制我们。
要定义一个项目,只需打开我们生成项目时创建的 Scrapy 的 items.py 文件。在其中,将有一个名为 BidItem 的类。类名是基于我们给项目命名的。
class BidItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
将 pass 替换为名为 url 的新字段的定义。
url = scrapy.Field()
保存完成的文档
构建一个网络蜘蛛
接下来打开项目中的spider目录,寻找生成的新Spider Scrapy。在这个例子中,蜘蛛被称为 getbid,所以文件是 getbid.py。
当您在编辑器中打开此文件时,您应该会看到类似以下内容。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from bid.items import BidItem
class GetbidSpider(CrawlSpider):
name = 'getbid'
allowed_domains = ['businessideadaily.com']
start_urls = ['http://www.businessideadaily.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = BidItem()
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
我们需要对 Scrapy 为我们生成的代码做一些小的改动。首先,我们需要在规则下修改LinkExtractor的参数。删除括号中的所有内容。
规则(LinkExtractor(),回调='parse_item',follow=True),
通过这次更新,我们的蜘蛛将找到起始页(主页)上的每个链接,将单个链接传递给 parse_item 方法,并跟随链接到 网站 下一页以确保我们获得每个链接的页面。
接下来,我们需要更新 parse_item 方法。删除所有注释行。这些行只是 Scrapy 给我们的例子。
def parse_item(self, response):
i = BidItem()
return i
我喜欢使用有意义的变量名。所以我要把i改成href,这是HTML链接中属性的名称,如果有的话,它会保存目标链接的地址。
def parse_item(自我,响应):
href = 投标项目()
返回href
现在神奇的事情发生了,我们将页面 URL 捕获为 Items。
def parse_item(self, response):
href = BidItem()
href['url'] = response.url
return href
现在是对的。新的 Spider 已准备好爬行。
抓取 网站,获取数据
从命令行,我们想要导航到我们的项目目录。一旦进入该目录,我们将运行一个简单的命令来发送我们的新蜘蛛并获取页面列表。
scrapy爬取getbid -o 012916.csv
这个命令有几个部分。首先,我们参考 Scrapy 框架。我们告诉 Scrapy 我们想要爬行。我们指定使用 getbid 蜘蛛。
-o 告诉 Scrapy 输出结果。该命令的 012916.csv 部分告诉 Scrapy 将结果放入具有该名称的逗号分隔值(.csv)文件中。
在示例中,Scrapy 将返回三个页面地址。我为这个例子选择这个 网站 的原因之一是它只有几页长。如果您在具有数千页的 网站 上定位类似的蜘蛛,则运行需要一些时间,但它会返回类似的响应。
网址
只需几行代码,您就可以为自己的站点监控应用程序奠定基础。
本文由数据银河原创赞助 查看全部
scrapy分页抓取网页(如何构建自定义的爬虫站点和监控程序第一步开发项目)
电商主和管理者可能需要自己爬取网站来监控网页、跟踪网站流量、寻找优化机会等。
对于其中的每一个,都可以使用离散工具、网络爬虫和服务来帮助监控网站。只需相对较少的开发工作,您就可以创建自己的站点爬虫和站点监控系统。
要构建自定义爬虫站点并进行监控,第一步是简单地获取 网站 上所有页面的列表。本文将向您展示如何使用 Python 编程语言和一个名为 Scrapy 的简洁网络爬虫框架轻松生成这些页面的列表。
你需要一个服务器、Python 和 Scrapy
这是一个开发项目。需要安装了 Python 和 Scrapy 的服务器。还需要通过终端应用程序或 SSH 客户端对服务器进行命令行访问。有关安装 Python 的信息也可从 . Scrapy网站 也有很好的安装文档。请确认您的服务器已准备好安装 Python 和 Scrapy。
创建一个 Scrapy 项目
使用 SSH 客户端(如 Windows 的 Putty)或 Mac、Linux 计算机上的终端应用程序,导航到要保存 Scrapy 项目的目录。使用内置的 Scrapy 命令 startproject,我们可以快速生成所需的基础文件。
本文将抓取一个名为《Business Idea Daily》的网站,因此得名“bid”。
生成一个新的 Scrapy Web Spider
为方便起见,Scrapy 还有另一个命令行工具,可以自动生成新的网络蜘蛛。
scrapy genspider -t crawl getbid businessideadaily.com
第一个术语,scrapy,指的是 Scrapy 框架。接下来,有 genspider 命令告诉 Scrapy 我们想要一个新的网络蜘蛛,或者,如果你愿意,一个新的网络爬虫。
-t 告诉 Scrapy 我们要选择一个特定的模板。genspider 命令可以生成四种通用网络蜘蛛模板中的任何一种:basic、crawl、csvfeed 和 xmlfeed。在 -t 之后,我们立即指定所需的模板。在本例中,我们将通过 Scrapy 创建一个名为 CrawlSpider 的模板。“getbid”这个词是蜘蛛的名字。
该命令的最后一部分告诉 Scrapy 我们要抓取哪个 网站。框架将使用它来填充一些新的蜘蛛参数。
定义项目
在 Scrapy 中,Items 是一种组织蜘蛛在抓取特定 网站 时采集东西的方式/模型。虽然我们可以轻松实现我们的目标 - 获取特定 网站 上所有页面的列表 - 不使用 Items,如果我们以后想要扩展我们的爬虫,不使用 Items 可能会限制我们。
要定义一个项目,只需打开我们生成项目时创建的 Scrapy 的 items.py 文件。在其中,将有一个名为 BidItem 的类。类名是基于我们给项目命名的。
class BidItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
将 pass 替换为名为 url 的新字段的定义。
url = scrapy.Field()
保存完成的文档
构建一个网络蜘蛛
接下来打开项目中的spider目录,寻找生成的新Spider Scrapy。在这个例子中,蜘蛛被称为 getbid,所以文件是 getbid.py。
当您在编辑器中打开此文件时,您应该会看到类似以下内容。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from bid.items import BidItem
class GetbidSpider(CrawlSpider):
name = 'getbid'
allowed_domains = ['businessideadaily.com']
start_urls = ['http://www.businessideadaily.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = BidItem()
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
我们需要对 Scrapy 为我们生成的代码做一些小的改动。首先,我们需要在规则下修改LinkExtractor的参数。删除括号中的所有内容。
规则(LinkExtractor(),回调='parse_item',follow=True),
通过这次更新,我们的蜘蛛将找到起始页(主页)上的每个链接,将单个链接传递给 parse_item 方法,并跟随链接到 网站 下一页以确保我们获得每个链接的页面。
接下来,我们需要更新 parse_item 方法。删除所有注释行。这些行只是 Scrapy 给我们的例子。
def parse_item(self, response):
i = BidItem()
return i
我喜欢使用有意义的变量名。所以我要把i改成href,这是HTML链接中属性的名称,如果有的话,它会保存目标链接的地址。
def parse_item(自我,响应):
href = 投标项目()
返回href
现在神奇的事情发生了,我们将页面 URL 捕获为 Items。
def parse_item(self, response):
href = BidItem()
href['url'] = response.url
return href
现在是对的。新的 Spider 已准备好爬行。
抓取 网站,获取数据
从命令行,我们想要导航到我们的项目目录。一旦进入该目录,我们将运行一个简单的命令来发送我们的新蜘蛛并获取页面列表。
scrapy爬取getbid -o 012916.csv
这个命令有几个部分。首先,我们参考 Scrapy 框架。我们告诉 Scrapy 我们想要爬行。我们指定使用 getbid 蜘蛛。
-o 告诉 Scrapy 输出结果。该命令的 012916.csv 部分告诉 Scrapy 将结果放入具有该名称的逗号分隔值(.csv)文件中。
在示例中,Scrapy 将返回三个页面地址。我为这个例子选择这个 网站 的原因之一是它只有几页长。如果您在具有数千页的 网站 上定位类似的蜘蛛,则运行需要一些时间,但它会返回类似的响应。
网址
只需几行代码,您就可以为自己的站点监控应用程序奠定基础。
本文由数据银河原创赞助
scrapy分页抓取网页(这篇教程比Scrapy官方教程构建网页爬虫的内部工作机制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-06 23:22
当我刚开始在这个行业工作时,我首先意识到的一件事是,有时您需要自己采集、组织和清理数据。在本教程中,我们将从众筹的 网站FundRazr 采集数据。和很多网站一样,这个网站有自己的结构、形式和大量有用的数据,但是它没有结构化的API,所以获取数据并不容易。在本教程中,我们将抓取 网站 数据并将其组织成有序的形式来创建我们自己的数据集。
我们将使用 Scrapy,一个用于构建网络爬虫的框架。Scrapy 可以帮助我们创建和维护网络爬虫。它使我们能够专注于使用 CSS 选择器和 XPath 表达式提取数据,而不是关注爬虫的内部工作。本教程比官方的 Scrapy 教程更深入一些。希望大家看完本教程后,在需要抓取数据有一定难度的时候,也能自己完成。好吧,让我们开始吧。
准备
如果您已经安装了 anaconda 和 google chrome(或 firefox),则可以跳过此部分。
安装蟒蛇。可以从官网下载anaconda自行安装,也可以参考我之前写的anaconda安装教程(Mac、Windows、Ubuntu、环境管理)。
安装 Scrapy。其实Anaconda已经自带了Scrapy,但是如果遇到问题,也可以自己安装:
conda install -c conda-forge scrapy
确保您安装了 chrome 或 firefox。在本教程中,我将使用 chrome。
创建新的 Scrapy 项目
可以使用 startproject 命令创建一个新项目:
此命令将创建一个 fundrazr 目录:
基金/
scrapy.cfg # 部署配置文件
fundrazr/ # 项目的 Python 模块
__init__.py
items.py # 物品物品定义
pipelines.py # 项目管道文件
settings.py # 项目设置文件
spiders/ # 蜘蛛目录
__init__.py
scrapy startprojectfundrazr
使用 chrome(或 firefox)的开发者工具查找初始 url
在爬虫框架中,start_urls是爬虫开始爬取的url列表。我们将为 start_urls 列表中的每个元素获得一个指向单个项目页面的链接。
下图显示初始 url 因所选类别而异。黑框高亮部分是要抓取的类别。
在本教程中,start_urls 列表中的第一项是:
接下来,我们将看到如何访问下一页并将相应的 url 添加到 start_urls 中。
第二个网址是:
下面是创建 start_urls 列表的代码。其中,npages 指定要翻的页数。
start_urls = [“”]
npages = 2
对于范围内的 i (2, npages + 2 ):
start_urls.append(";page="+str(i)+"")
使用 Srapy shell 查找单个项目页面
使用 Scrapy shell 是学习如何基于 Scrapy 提取数据的最佳方式。我们将使用 XPaths,它可用于选择 HTML 文档中的元素。
我们首先需要尝试获取单个项目页面链接的 XPath。我们将使用浏览器的检查元素。
我们将使用 XPath 提取下图中红色框内的部分。
我们首先启动 Scrapy shell:
刮痧壳 '#39;
在 Scrapy shell 中输入以下代码:
response.xpath("//h2[contains(@class, 'title header-font')]/a[contains(@class, 'campaign-link')]//@href").extract()
使用 exit() 退出 Scrapy shell。
单品页面
之前我们介绍了如何提取单个项目页面链接。现在我们将介绍如何在单个项目页面上提取信息。
首先我们进入将被抓取的单品页面(链接如下)。
使用上一节中提到的方法,检查页面的标题。
现在我们将再次使用 Scrapy shell,只是这次来自单个项目页面。
刮壳“手臂”
提取标题的代码是:
response.xpath("//div[contains(@id, 'campaign-title')]/descendant::text()").extract()[0]
页面的其他部分也是如此:
# 筹款总额
response.xpath("//span[contains(@class,'stat')]/span[contains(@class, 'amount-raised')]/descendant::text()").extract()
#筹款目标
response.xpath("//div[contains(@class, 'stats-primary with-goal')]//span[contains(@class, 'stats-label hidden-phone')]/text()"). 提炼()
# 货币
response.xpath("//div[contains(@class, 'stats-primary with-goal')]/@title").extract()
# 最后期限
response.xpath("//div[contains(@id, 'campaign-stats')]//span[contains(@class,'stats-label hidden-phone')]/span[@class='nowrap'] /text()").extract()
# 参与
response.xpath("//div[contains(@class, 'stats-secondary with-goal')]//span[contains(@class, 'donation-count stat')]/text()").extract( )
# 故事
response.xpath("//div[contains(@id, 'full-story')]/descendant::text()").extract()
# 网址
response.xpath("//meta[@property='og:url']/@content").extract()
项目
网页抓取的主要目标是从非结构化来源中提取结构化信息。Scrapy 爬虫以 Python 字典的形式返回提取的数据。Python 字典虽然方便熟悉,但仍然不是很结构化:字段名容易出现拼写错误,返回的信息不一致,尤其是在有多个爬虫的大型项目中。因此,我们定义 Item 类来存储数据(在输出数据之前)。
导入scrapy
classFundrazrItem(scrapy.Item):
活动标题 = scrapy.Field()
amountRaised = scrapy.Field()
目标 = scrapy.Field()
货币类型 = scrapy.Field()
endDate = scrapy.Field()
numberContributors = scrapy.Field()
故事 = scrapy.Field()
url = scrapy.Field()
将其保存在 fundrazr/fundrazr 目录中(覆盖原来的 items.py 文件)。
爬虫
我们定义了一个爬虫类,供 Scrapy 用来抓取 网站(或一组 网站)信息。
# 继承scrapy.Spider类
classFundrazr(scrapy.Spider):
# 指定爬虫名称,运行爬虫时需要
名称 = “我的刮刀”
# 定义 start_urls, npages
# 具体定义见上文
def 解析(自我,响应):
for href in response.xpath("//h2[contains(@class, 'title header-font')]/a[contains(@class, 'campaign-link')]//@href"):
# 添加协议名称 查看全部
scrapy分页抓取网页(这篇教程比Scrapy官方教程构建网页爬虫的内部工作机制)
当我刚开始在这个行业工作时,我首先意识到的一件事是,有时您需要自己采集、组织和清理数据。在本教程中,我们将从众筹的 网站FundRazr 采集数据。和很多网站一样,这个网站有自己的结构、形式和大量有用的数据,但是它没有结构化的API,所以获取数据并不容易。在本教程中,我们将抓取 网站 数据并将其组织成有序的形式来创建我们自己的数据集。
我们将使用 Scrapy,一个用于构建网络爬虫的框架。Scrapy 可以帮助我们创建和维护网络爬虫。它使我们能够专注于使用 CSS 选择器和 XPath 表达式提取数据,而不是关注爬虫的内部工作。本教程比官方的 Scrapy 教程更深入一些。希望大家看完本教程后,在需要抓取数据有一定难度的时候,也能自己完成。好吧,让我们开始吧。
准备
如果您已经安装了 anaconda 和 google chrome(或 firefox),则可以跳过此部分。
安装蟒蛇。可以从官网下载anaconda自行安装,也可以参考我之前写的anaconda安装教程(Mac、Windows、Ubuntu、环境管理)。
安装 Scrapy。其实Anaconda已经自带了Scrapy,但是如果遇到问题,也可以自己安装:
conda install -c conda-forge scrapy
确保您安装了 chrome 或 firefox。在本教程中,我将使用 chrome。
创建新的 Scrapy 项目
可以使用 startproject 命令创建一个新项目:
此命令将创建一个 fundrazr 目录:
基金/
scrapy.cfg # 部署配置文件
fundrazr/ # 项目的 Python 模块
__init__.py
items.py # 物品物品定义
pipelines.py # 项目管道文件
settings.py # 项目设置文件
spiders/ # 蜘蛛目录
__init__.py
scrapy startprojectfundrazr
使用 chrome(或 firefox)的开发者工具查找初始 url
在爬虫框架中,start_urls是爬虫开始爬取的url列表。我们将为 start_urls 列表中的每个元素获得一个指向单个项目页面的链接。
下图显示初始 url 因所选类别而异。黑框高亮部分是要抓取的类别。
在本教程中,start_urls 列表中的第一项是:
接下来,我们将看到如何访问下一页并将相应的 url 添加到 start_urls 中。
第二个网址是:
下面是创建 start_urls 列表的代码。其中,npages 指定要翻的页数。
start_urls = [“”]
npages = 2
对于范围内的 i (2, npages + 2 ):
start_urls.append(";page="+str(i)+"")
使用 Srapy shell 查找单个项目页面
使用 Scrapy shell 是学习如何基于 Scrapy 提取数据的最佳方式。我们将使用 XPaths,它可用于选择 HTML 文档中的元素。
我们首先需要尝试获取单个项目页面链接的 XPath。我们将使用浏览器的检查元素。
我们将使用 XPath 提取下图中红色框内的部分。
我们首先启动 Scrapy shell:
刮痧壳 '#39;
在 Scrapy shell 中输入以下代码:
response.xpath("//h2[contains(@class, 'title header-font')]/a[contains(@class, 'campaign-link')]//@href").extract()
使用 exit() 退出 Scrapy shell。
单品页面
之前我们介绍了如何提取单个项目页面链接。现在我们将介绍如何在单个项目页面上提取信息。
首先我们进入将被抓取的单品页面(链接如下)。
使用上一节中提到的方法,检查页面的标题。
现在我们将再次使用 Scrapy shell,只是这次来自单个项目页面。
刮壳“手臂”
提取标题的代码是:
response.xpath("//div[contains(@id, 'campaign-title')]/descendant::text()").extract()[0]
页面的其他部分也是如此:
# 筹款总额
response.xpath("//span[contains(@class,'stat')]/span[contains(@class, 'amount-raised')]/descendant::text()").extract()
#筹款目标
response.xpath("//div[contains(@class, 'stats-primary with-goal')]//span[contains(@class, 'stats-label hidden-phone')]/text()"). 提炼()
# 货币
response.xpath("//div[contains(@class, 'stats-primary with-goal')]/@title").extract()
# 最后期限
response.xpath("//div[contains(@id, 'campaign-stats')]//span[contains(@class,'stats-label hidden-phone')]/span[@class='nowrap'] /text()").extract()
# 参与
response.xpath("//div[contains(@class, 'stats-secondary with-goal')]//span[contains(@class, 'donation-count stat')]/text()").extract( )
# 故事
response.xpath("//div[contains(@id, 'full-story')]/descendant::text()").extract()
# 网址
response.xpath("//meta[@property='og:url']/@content").extract()
项目
网页抓取的主要目标是从非结构化来源中提取结构化信息。Scrapy 爬虫以 Python 字典的形式返回提取的数据。Python 字典虽然方便熟悉,但仍然不是很结构化:字段名容易出现拼写错误,返回的信息不一致,尤其是在有多个爬虫的大型项目中。因此,我们定义 Item 类来存储数据(在输出数据之前)。
导入scrapy
classFundrazrItem(scrapy.Item):
活动标题 = scrapy.Field()
amountRaised = scrapy.Field()
目标 = scrapy.Field()
货币类型 = scrapy.Field()
endDate = scrapy.Field()
numberContributors = scrapy.Field()
故事 = scrapy.Field()
url = scrapy.Field()
将其保存在 fundrazr/fundrazr 目录中(覆盖原来的 items.py 文件)。
爬虫
我们定义了一个爬虫类,供 Scrapy 用来抓取 网站(或一组 网站)信息。
# 继承scrapy.Spider类
classFundrazr(scrapy.Spider):
# 指定爬虫名称,运行爬虫时需要
名称 = “我的刮刀”
# 定义 start_urls, npages
# 具体定义见上文
def 解析(自我,响应):
for href in response.xpath("//h2[contains(@class, 'title header-font')]/a[contains(@class, 'campaign-link')]//@href"):
# 添加协议名称
scrapy分页抓取网页(蜘蛛代码中如何使用Scrapy跟踪链接和回调的机制?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-06 23:19
(可选)为了从站点中提取数据,Scrapy 使用“表达式”。这些扫描所有可用数据并仅选择我们需要的信息。您可以将这些表达式视为一组定义我们需要的数据的规则。我们可以选择使用 CSS 选择器或 XPath 在 Scrapy 中创建这些表达式。在决定实际选择一个之前,您应该尝试两者。只需在蜘蛛代码中提供您所在城市的 URL。如前所述,网站允许抓取数据,前提是抓取延迟不少于 10 秒,即您必须等待至少 10 秒才能向其请求另一个 URL。这可以在 网站 的 robots.txt 中找到。. 在 Scrapy 中,制作了一个在 网站 上滑动并帮助获取信息的蜘蛛,因此要制作一个,移动到蜘蛛文件夹并在那里制作一个 python 文档。第一种是通过为蜘蛛指定一个命名变量来命名它,然后给出蜘蛛应该开始爬行的起始 URL。默认情况下,Scrapy 会过滤掉对已经访问过的 URL 的重复请求,避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。希望现在您对如何使用 Scrapy 跟踪链接和回调的机制有了很好的理解。. 避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。希望现在您对如何使用 Scrapy 跟踪链接和回调的机制有了很好的理解。. 避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。 查看全部
scrapy分页抓取网页(蜘蛛代码中如何使用Scrapy跟踪链接和回调的机制?)
(可选)为了从站点中提取数据,Scrapy 使用“表达式”。这些扫描所有可用数据并仅选择我们需要的信息。您可以将这些表达式视为一组定义我们需要的数据的规则。我们可以选择使用 CSS 选择器或 XPath 在 Scrapy 中创建这些表达式。在决定实际选择一个之前,您应该尝试两者。只需在蜘蛛代码中提供您所在城市的 URL。如前所述,网站允许抓取数据,前提是抓取延迟不少于 10 秒,即您必须等待至少 10 秒才能向其请求另一个 URL。这可以在 网站 的 robots.txt 中找到。. 在 Scrapy 中,制作了一个在 网站 上滑动并帮助获取信息的蜘蛛,因此要制作一个,移动到蜘蛛文件夹并在那里制作一个 python 文档。第一种是通过为蜘蛛指定一个命名变量来命名它,然后给出蜘蛛应该开始爬行的起始 URL。默认情况下,Scrapy 会过滤掉对已经访问过的 URL 的重复请求,避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。希望现在您对如何使用 Scrapy 跟踪链接和回调的机制有了很好的理解。. 避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。希望现在您对如何使用 Scrapy 跟踪链接和回调的机制有了很好的理解。. 避免因编程错误导致服务器访问过多的问题。这可以通过设置 DUPEFILTER_CLASS 来配置。
scrapy分页抓取网页(一个分享到此结束框架教程目录及参考网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-05 05:03
Scrapy作为爬虫工具,是一个非常不错的Python爬虫框架,现在支持Python3。具体安装过程可以参考:. srapy的具体介绍可以参考网站:
本文将介绍一个非常简单的例子,帮助读者快速进入scrapy的世界,并会持续更新进一步深入研究。本文scrapy版本为1.0.3-1,python版本为2.7.12.
我们要爬取的页面是菜鸟教程的Git教程目录,如下图:
首先我们在当前目录新建一个scrapy项目:scrapy_git,在终端输入如下命令:
scrapy startproject scrapy_git
输入tree scrapy_git查看文件的树形结构:
然后切换到spider目录,新建文件:git_jc.py,代码如下:
import scrapy
class ToScrapeCSSSpider(scrapy.Spider):
name = "toscrape-css"
start_urls = ['http://www.runoob.com/git/git-tutorial.html',]
def parse(self,response):
with open('/home/vagrant/python.txt', 'w') as f:
for i in range(1,12):
text = response.xpath('//*[@id="leftcolumn"]/a[%d]/text()'%i).extract()[0].encode("utf-8").strip('\n').strip('\t')
f.write(text+'\n')
其中,toscrape-css是爬虫的名字,非常重要。 start_urls 是被抓取网页的 URL。定义parse()函数,将爬取的目录写入/home/vagrant/python.txt。在这段代码中,使用xpath来定位网页元素,当然也可以使用css来定位。
使用xpath定位网页元素的具体方法是:选择需要的元素,右键,选择勾号(N),在弹出的网页源代码中,右键,选择复制,然后选择复制 XPath,然后粘贴即可。
使用scrapy list查看可用爬虫的名称:
最后输入如下命令运行爬虫:(先创建一个python.txt文件)
运行后查看python.txt文件,内容如下:
Bingo,我们的scrapy爬虫运行成功!
在这个爬虫中,我们并没有移动其他文件,只是新建了一个git_jc.py文件,可见scrapy的简单和高效!期待下次分享^_^...
本次分享到此结束,欢迎大家批评交流~~ 查看全部
scrapy分页抓取网页(一个分享到此结束框架教程目录及参考网址)
Scrapy作为爬虫工具,是一个非常不错的Python爬虫框架,现在支持Python3。具体安装过程可以参考:. srapy的具体介绍可以参考网站:
本文将介绍一个非常简单的例子,帮助读者快速进入scrapy的世界,并会持续更新进一步深入研究。本文scrapy版本为1.0.3-1,python版本为2.7.12.
我们要爬取的页面是菜鸟教程的Git教程目录,如下图:
首先我们在当前目录新建一个scrapy项目:scrapy_git,在终端输入如下命令:
scrapy startproject scrapy_git
输入tree scrapy_git查看文件的树形结构:
然后切换到spider目录,新建文件:git_jc.py,代码如下:
import scrapy
class ToScrapeCSSSpider(scrapy.Spider):
name = "toscrape-css"
start_urls = ['http://www.runoob.com/git/git-tutorial.html',]
def parse(self,response):
with open('/home/vagrant/python.txt', 'w') as f:
for i in range(1,12):
text = response.xpath('//*[@id="leftcolumn"]/a[%d]/text()'%i).extract()[0].encode("utf-8").strip('\n').strip('\t')
f.write(text+'\n')
其中,toscrape-css是爬虫的名字,非常重要。 start_urls 是被抓取网页的 URL。定义parse()函数,将爬取的目录写入/home/vagrant/python.txt。在这段代码中,使用xpath来定位网页元素,当然也可以使用css来定位。
使用xpath定位网页元素的具体方法是:选择需要的元素,右键,选择勾号(N),在弹出的网页源代码中,右键,选择复制,然后选择复制 XPath,然后粘贴即可。
使用scrapy list查看可用爬虫的名称:
最后输入如下命令运行爬虫:(先创建一个python.txt文件)
运行后查看python.txt文件,内容如下:
Bingo,我们的scrapy爬虫运行成功!
在这个爬虫中,我们并没有移动其他文件,只是新建了一个git_jc.py文件,可见scrapy的简单和高效!期待下次分享^_^...
本次分享到此结束,欢迎大家批评交流~~
scrapy分页抓取网页(ASP.js代码怎么封装,不如直接抓包看看传递什么参数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-31 04:13
)
以上文章介绍了scrapy爬取的一般架构,本文文章解释了一些技术问题。
一、如何处理 ASP.NET 分页
我们以深圳房地产信息系统为例。
因为之前一直在写ASP.NET,所以很多.NET控件都是通过拖拽来实现的。很多代码可以省去编写过程,自动生成。这里的下一页操作是通过自动生成的js代码,scrapy框架无法执行js代码。但是我们知道他执行了_doPostBack函数,我们来看看_doPostBack是怎么定义的。
function __doPostBack(eventTarget, eventArgument) {
if (!theForm.onsubmit || (theForm.onsubmit() != false)) {
theForm.__EVENTTARGET.value = eventTarget;
theForm.__EVENTARGUMENT.value = eventArgument;
theForm.submit();
}
}
看看form1是怎么定义的
里面有很多隐藏的控件,里面有很多值,都是自动生成的。我不知道这意味着什么。
但是我们知道他的原理是再次向这个页面发送一个POST请求进行分页。所以URL地址没有变化。既然有POST操作,那传入什么参数。一闪而过,与其研究如何封装JS代码,不如直接抓包看看传了什么参数。
这里使用常用的wireshark,简单易上手,一目了然。
当我们点击next时,我们可以看到发送了一个HTTP请求并执行了POST方法。
进一步展开。所有参数都一一列出。传递参数也隐藏在页面上。
回去看看我为递归查询编写的分页代码。
def parse(self, response):
context = response.xpath('//tr[@bgcolor="#F5F9FC"]/td[3]')
dbhelp=RishomePipeline()
for item in context:
title=item.xpath('a/text()').extract_first()
idstr=item.xpath('a/@href').extract_first()
idstr=idstr[idstr.find('=')+1:]
if dbhelp.ispropertyexits(idstr):
return
request=scrapy.Request(url='http://ris.szpl.gov.cn/bol/pro ... idstr, method='GET',callback=self.showdetailpage)
yield request
'''以下是分页代码,组合post_data结构体,
POST请求要使用 yield scrapy.FormRequest(url=response.url,formdata =post_data,callback=self.parse,dont_filter=True)函数。
'''
next_page = response.xpath('//*[@id="AspNetPager1"]/div[2]/a[3]/@href')
pnum=next_page.extract_first().split(',')[1].replace("'","").replace(")","")
post_data = {
"__EVENTTARGET" : "AspNetPager1",
"__EVENTARGUMENT" :pnum,
"__VIEWSTATEENCRYPTED" : "",
"tep_name" : "",
"organ_name" : "",
"site_address" : "",
"AspNetPager1_input" : "1"}
a = response.xpath('//*[@id="__VIEWSTATE"]/@value')
post_data['__VIEWSTATE']=a.extract_first()
b=response.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')
post_data['__VIEWSTATEGENERATOR']=b.extract_first()
c = response.xpath('//*[@id="__EVENTVALIDATION"]/@value')
post_data['__EVENTVALIDATION'] = c.extract_first()
'''分页到最后一页,‘下一页’的按钮就不是链接了,页面没有href参数了,此时判断分页结束,即 递归结束'''
if pnum is not None and pnum!="":
yield scrapy.FormRequest(url=response.url,formdata =post_data,callback=self.parse,dont_filter=True)
二、如何在请求和响应之间传递参数
有时需要将两个页面的内容合并为一项。这时候就需要在产生scrapy.Request的同时传递一些参数到下一页。此时您可以执行此操作。
request=scrapy.Request(houseurl,method='GET',callback=self.showhousedetail)
request.meta['biid']=biid
yield request
def showhousedetail(self,response):
house=HouseItem()
house['bulidingid']=response.meta['biid']
三、管道区分传入的Item
每个页面都会封装item并传递给管道进行处理,管道只接收一个条目:
def process_item(self, item, spider)函数
用于区分项目的方法。
def process_item(self, item, spider):
if str(type(item))=="":
self.saverishome(item)
if str(type(item))=="":
self.savebuliding(item)
if str(type(item))=="":
self.savehouse(item)
return item # 必须实现返回 查看全部
scrapy分页抓取网页(ASP.js代码怎么封装,不如直接抓包看看传递什么参数
)
以上文章介绍了scrapy爬取的一般架构,本文文章解释了一些技术问题。
一、如何处理 ASP.NET 分页
我们以深圳房地产信息系统为例。
因为之前一直在写ASP.NET,所以很多.NET控件都是通过拖拽来实现的。很多代码可以省去编写过程,自动生成。这里的下一页操作是通过自动生成的js代码,scrapy框架无法执行js代码。但是我们知道他执行了_doPostBack函数,我们来看看_doPostBack是怎么定义的。
function __doPostBack(eventTarget, eventArgument) {
if (!theForm.onsubmit || (theForm.onsubmit() != false)) {
theForm.__EVENTTARGET.value = eventTarget;
theForm.__EVENTARGUMENT.value = eventArgument;
theForm.submit();
}
}
看看form1是怎么定义的
里面有很多隐藏的控件,里面有很多值,都是自动生成的。我不知道这意味着什么。
但是我们知道他的原理是再次向这个页面发送一个POST请求进行分页。所以URL地址没有变化。既然有POST操作,那传入什么参数。一闪而过,与其研究如何封装JS代码,不如直接抓包看看传了什么参数。
这里使用常用的wireshark,简单易上手,一目了然。
当我们点击next时,我们可以看到发送了一个HTTP请求并执行了POST方法。
进一步展开。所有参数都一一列出。传递参数也隐藏在页面上。
回去看看我为递归查询编写的分页代码。
def parse(self, response):
context = response.xpath('//tr[@bgcolor="#F5F9FC"]/td[3]')
dbhelp=RishomePipeline()
for item in context:
title=item.xpath('a/text()').extract_first()
idstr=item.xpath('a/@href').extract_first()
idstr=idstr[idstr.find('=')+1:]
if dbhelp.ispropertyexits(idstr):
return
request=scrapy.Request(url='http://ris.szpl.gov.cn/bol/pro ... idstr, method='GET',callback=self.showdetailpage)
yield request
'''以下是分页代码,组合post_data结构体,
POST请求要使用 yield scrapy.FormRequest(url=response.url,formdata =post_data,callback=self.parse,dont_filter=True)函数。
'''
next_page = response.xpath('//*[@id="AspNetPager1"]/div[2]/a[3]/@href')
pnum=next_page.extract_first().split(',')[1].replace("'","").replace(")","")
post_data = {
"__EVENTTARGET" : "AspNetPager1",
"__EVENTARGUMENT" :pnum,
"__VIEWSTATEENCRYPTED" : "",
"tep_name" : "",
"organ_name" : "",
"site_address" : "",
"AspNetPager1_input" : "1"}
a = response.xpath('//*[@id="__VIEWSTATE"]/@value')
post_data['__VIEWSTATE']=a.extract_first()
b=response.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')
post_data['__VIEWSTATEGENERATOR']=b.extract_first()
c = response.xpath('//*[@id="__EVENTVALIDATION"]/@value')
post_data['__EVENTVALIDATION'] = c.extract_first()
'''分页到最后一页,‘下一页’的按钮就不是链接了,页面没有href参数了,此时判断分页结束,即 递归结束'''
if pnum is not None and pnum!="":
yield scrapy.FormRequest(url=response.url,formdata =post_data,callback=self.parse,dont_filter=True)
二、如何在请求和响应之间传递参数
有时需要将两个页面的内容合并为一项。这时候就需要在产生scrapy.Request的同时传递一些参数到下一页。此时您可以执行此操作。
request=scrapy.Request(houseurl,method='GET',callback=self.showhousedetail)
request.meta['biid']=biid
yield request
def showhousedetail(self,response):
house=HouseItem()
house['bulidingid']=response.meta['biid']
三、管道区分传入的Item
每个页面都会封装item并传递给管道进行处理,管道只接收一个条目:
def process_item(self, item, spider)函数
用于区分项目的方法。
def process_item(self, item, spider):
if str(type(item))=="":
self.saverishome(item)
if str(type(item))=="":
self.savebuliding(item)
if str(type(item))=="":
self.savehouse(item)
return item # 必须实现返回
scrapy分页抓取网页( 爬虫案例代码地址这里我是使用的Scrapy框架进行爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-28 11:19
爬虫案例代码地址这里我是使用的Scrapy框架进行爬虫
)
由于互联网的飞速发展,目前所有的信息都处于海量积累的状态。我们不仅需要从外界获取大量数据,还要从大量数据中过滤掉无用的数据。对于我们的有益数据,我们需要指定爬取,所以出现了目前的爬虫技术,通过它我们可以快速获取我们需要的数据。但是在这个爬取过程中,信息拥有者会对爬虫进行反爬处理,我们需要一一攻破这些难点。
前段时间刚做了一些爬虫相关的工作,所以这里有一些相关的经验。
本文案例代码地址
这里我使用的是Scrapy框架进行爬取,开发环境的相关版本号:
Scrapy : 1.5.1
lxml : 4.2.5.0
libxml2 : 2.9.8
cssselect : 1.0.3
parsel : 1.5.1
w3lib : 1.20.0
Twisted : 18.9.0
Python : 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)]
pyOpenSSL : 18.0.0 (OpenSSL 1.1.1a 20 Nov 2018)
cryptography : 2.4.2
Platform : Windows-10-10.0.15063-SP0
对于本地开发环境,建议使用Anaconda安装相关环境,否则可能会出现各种依赖冲突。本文主要使用Xpath提取页面数据,所以在进行本文案例操作之前,先了解一下Xpath的基本使用。
创建一个 Scrapy 项目
用scrapy创建项目非常简单,一个命令就可以搞定。接下来,我们创建一个 ytaoCrawl 项目:
scrapy startproject ytaoCrawl
请注意,项目名称必须以字母开头,并且只能收录字母、数字和下划线。创建成功后,界面显示:
初始化项目的文件是:
每个文件的用途:
了解了几个默认生成的文件后,再看下面的scrapy结构示意图,还是比较容易理解的。
这样,我们的一个scrapy爬虫项目就创建好了。
创建蜘蛛
我们首先创建一个python文件ytaoSpider,它必须继承scrapy.Spider类。接下来,我们以北京58租房信息的爬取为例进行分析。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
#
# @Author : YangTao
# @blog : https://ytao.top
#
import scrapy
class YtaoSpider(scrapy.Spider):
# 定义爬虫名称
name = "crawldemo"
# 允许爬取的域名,但不包含 start_urls 中的链接
allowed_domains = ["58.com"]
# 起始爬取链接
start_urls = [
"https://bj.58.com/chuzu/%3FPGT ... ot%3B
]
def download(self, response, fName):
with open(fName + ".html", 'wb') as f:
f.write(response.body)
# response 是返回抓取后的对象
def parse(self, response):
# 下载北京租房页面到本地,便于分析
self.download(response, "北京租房")
通过执行命令启动爬虫,指定爬虫名称:
scrapy crawl crawldemo
当我们有多个爬虫时,我们可以通过scrapy list获取所有爬虫名称。
当然,你也可以在开发过程中使用mian函数在编辑器中启动:
if __name__ == '__main__':
name = YtaoSpider.name
cmd = 'scrapy crawl {0} '.format(name)
cmdline.execute(cmd.split())
这时候我们爬取的页面就会在我们启动的目录下下载生成。
翻页
上面我们只爬了第一页,但是在实际爬取数据的过程中,肯定会涉及到分页,所以我们观察到网站的分页是为了显示最后一页(最多58只在显示前)七十页数据),如图所示。
从下图中观察分页代码的 html 部分。
接下来通过Xpath和正则匹配得到最后一页的页码。
<p>def pageNum(self, response):
# 获取分页的 html 代码块
page_ele = response.xpath("//li[@id='pager_wrap']/div[@class='pager']")
# 通过正则获取含有页码数字的文本
num_eles = re.findall(r">\d+", "").replace(" 查看全部
scrapy分页抓取网页(
爬虫案例代码地址这里我是使用的Scrapy框架进行爬虫
)
由于互联网的飞速发展,目前所有的信息都处于海量积累的状态。我们不仅需要从外界获取大量数据,还要从大量数据中过滤掉无用的数据。对于我们的有益数据,我们需要指定爬取,所以出现了目前的爬虫技术,通过它我们可以快速获取我们需要的数据。但是在这个爬取过程中,信息拥有者会对爬虫进行反爬处理,我们需要一一攻破这些难点。
前段时间刚做了一些爬虫相关的工作,所以这里有一些相关的经验。
本文案例代码地址
这里我使用的是Scrapy框架进行爬取,开发环境的相关版本号:
Scrapy : 1.5.1
lxml : 4.2.5.0
libxml2 : 2.9.8
cssselect : 1.0.3
parsel : 1.5.1
w3lib : 1.20.0
Twisted : 18.9.0
Python : 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)]
pyOpenSSL : 18.0.0 (OpenSSL 1.1.1a 20 Nov 2018)
cryptography : 2.4.2
Platform : Windows-10-10.0.15063-SP0
对于本地开发环境,建议使用Anaconda安装相关环境,否则可能会出现各种依赖冲突。本文主要使用Xpath提取页面数据,所以在进行本文案例操作之前,先了解一下Xpath的基本使用。
创建一个 Scrapy 项目
用scrapy创建项目非常简单,一个命令就可以搞定。接下来,我们创建一个 ytaoCrawl 项目:
scrapy startproject ytaoCrawl
请注意,项目名称必须以字母开头,并且只能收录字母、数字和下划线。创建成功后,界面显示:
初始化项目的文件是:
每个文件的用途:
了解了几个默认生成的文件后,再看下面的scrapy结构示意图,还是比较容易理解的。
这样,我们的一个scrapy爬虫项目就创建好了。
创建蜘蛛
我们首先创建一个python文件ytaoSpider,它必须继承scrapy.Spider类。接下来,我们以北京58租房信息的爬取为例进行分析。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
#
# @Author : YangTao
# @blog : https://ytao.top
#
import scrapy
class YtaoSpider(scrapy.Spider):
# 定义爬虫名称
name = "crawldemo"
# 允许爬取的域名,但不包含 start_urls 中的链接
allowed_domains = ["58.com"]
# 起始爬取链接
start_urls = [
"https://bj.58.com/chuzu/%3FPGT ... ot%3B
]
def download(self, response, fName):
with open(fName + ".html", 'wb') as f:
f.write(response.body)
# response 是返回抓取后的对象
def parse(self, response):
# 下载北京租房页面到本地,便于分析
self.download(response, "北京租房")
通过执行命令启动爬虫,指定爬虫名称:
scrapy crawl crawldemo
当我们有多个爬虫时,我们可以通过scrapy list获取所有爬虫名称。
当然,你也可以在开发过程中使用mian函数在编辑器中启动:
if __name__ == '__main__':
name = YtaoSpider.name
cmd = 'scrapy crawl {0} '.format(name)
cmdline.execute(cmd.split())
这时候我们爬取的页面就会在我们启动的目录下下载生成。
翻页
上面我们只爬了第一页,但是在实际爬取数据的过程中,肯定会涉及到分页,所以我们观察到网站的分页是为了显示最后一页(最多58只在显示前)七十页数据),如图所示。
从下图中观察分页代码的 html 部分。
接下来通过Xpath和正则匹配得到最后一页的页码。
<p>def pageNum(self, response):
# 获取分页的 html 代码块
page_ele = response.xpath("//li[@id='pager_wrap']/div[@class='pager']")
# 通过正则获取含有页码数字的文本
num_eles = re.findall(r">\d+", "").replace("
scrapy分页抓取网页( Python编写的快速开源网络爬虫框架用于网页中提取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-22 21:19
Python编写的快速开源网络爬虫框架用于网页中提取数据)
Scrapy 教程
Scrapy 是一个用 Python 编写的快速开源网络爬虫框架,用于借助基于 XPath 的选择器从网页中提取数据。
Scrapy 于 2008 年 6 月 26 日首次发布,采用 BSD 许可,2015 年 6 月发布里程碑1.0。
为什么要使用 Scrapy?构建和扩展大型爬行项目更容易。它有一个名为 Selectors 的内置机制,用于从 网站 中提取数据。它异步处理请求并且速度很快。它使用自动节流机制。确保开发人员可访问性。 Scrapy 的特点 Scrapy 是一个开源和免费使用的网络抓取框架。 Scrapy 以 JSON、CSV 和 XML 等格式生成提要导出。 Scrapy 内置支持通过 XPath 或 CSS 表达式从源中选择和提取数据。基于爬虫的 Scrapy,允许从网页中自动提取数据。优点 Scrapy 易于扩展、快速且强大。它是一个跨平台的应用程序框架(Windows、Linux、Mac OS 和 BSD)。 Scrapy 请求是异步调度和处理的。 Scrapy 带有一个名为 Scrapyd 的内置服务,它允许使用 JSON Web 服务上传项目和控制爬虫。任何 网站 都可以被弃用,尽管 网站 没有用于访问原创数据的 API。缺点 Scrapy 仅适用于 Python 2.7、 + 不同的操作系统安装方式不同。 查看全部
scrapy分页抓取网页(
Python编写的快速开源网络爬虫框架用于网页中提取数据)
Scrapy 教程
Scrapy 是一个用 Python 编写的快速开源网络爬虫框架,用于借助基于 XPath 的选择器从网页中提取数据。
Scrapy 于 2008 年 6 月 26 日首次发布,采用 BSD 许可,2015 年 6 月发布里程碑1.0。
为什么要使用 Scrapy?构建和扩展大型爬行项目更容易。它有一个名为 Selectors 的内置机制,用于从 网站 中提取数据。它异步处理请求并且速度很快。它使用自动节流机制。确保开发人员可访问性。 Scrapy 的特点 Scrapy 是一个开源和免费使用的网络抓取框架。 Scrapy 以 JSON、CSV 和 XML 等格式生成提要导出。 Scrapy 内置支持通过 XPath 或 CSS 表达式从源中选择和提取数据。基于爬虫的 Scrapy,允许从网页中自动提取数据。优点 Scrapy 易于扩展、快速且强大。它是一个跨平台的应用程序框架(Windows、Linux、Mac OS 和 BSD)。 Scrapy 请求是异步调度和处理的。 Scrapy 带有一个名为 Scrapyd 的内置服务,它允许使用 JSON Web 服务上传项目和控制爬虫。任何 网站 都可以被弃用,尽管 网站 没有用于访问原创数据的 API。缺点 Scrapy 仅适用于 Python 2.7、 + 不同的操作系统安装方式不同。
scrapy分页抓取网页(项目文件创建好以后可以写爬虫程序了,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-22 21:18
项目文件创建完成后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
这里的字段信息就是我们之前在网页中定位的8个字段信息,包括:name代表app名称,volume代表音量,download代表下载次数。在这里定义好之后,我们会在后续的爬取主程序中用到这些字段信息。
2.3.3. 爬取主程序
kuan项目创建后,Scrapy框架会自动生成一些爬虫的代码。接下来,我们需要在 parse 方法中添加网页抓取的字段解析内容。
在首页打开Dev Tools,找到每个抓取索引的节点位置,然后使用CSS、Xpath、正则化等方法提取解析。这些方法都是 Scrapy 支持的,可以随意选择。这里我们使用 CSS 语法来定位节点,但是需要注意的是,Scrapy 的 CSS 语法与我们之前用 pyquery 使用的 CSS 语法略有不同。让我们举几个例子并进行比较。
首先,我们定位到第一个APP的首页URL节点。我们可以看到URL节点位于class属性为app_left_list的div节点下的a节点中。它的 href 属性就是我们需要的 URL 信息。这是相对地址。拼接后就是完整的URL。
然后我们进入Kuan详情页面,选择app名称并定位。可以看到app名称节点位于类属性为.detail_app_title的p节点的文本中。
定位到这两个节点后,我们就可以使用 CSS 来提取字段信息了。下面是常规写法和Scrapy中写法的对比:
如您所见,要获取 href 或 text 属性,您需要使用 :: 来表示它。例如,要获取文本,请使用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,使用extract()。然后,我们可以参考解析代码写出8个字段信息。
首先,我们需要在首页提取App的URL列表,然后进入各个App的详情页面,进一步提取8个字段的信息。
这里使用response.urljoin()方法将提取出来的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传递两个参数:url和callback,url为详情页URL,callback为回调函数,将首页URL请求返回的响应传递给专门用于解析字段内容的parse_url()方法,如下图:
这里,get_comment() 和 get_tags() 方法是分开定义的。
get_comment() 方法通过正则匹配提取音量、下载、关注、评论四个字段信息。正则匹配结果如下:
然后使用result[0]、result[1]等提取4条信息,以volume为例,输出第一页的提取结果:
这样,第一页的10个app的字段信息全部提取成功,然后返回到yield item generator,我们输出它的内容:
2.3.4. 分页爬取
以上,我们已经爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
在这里,我们分别编写这两种方法的解析代码。第一种方法非常简单。只需按照 parse 方法继续添加以下代码行:
在第二种方法中,我们在第一个parse()方法之前定义了一个start_requests()方法来批量生成610个页面url,然后通过scrapy.Request()方法中的回调参数传递给后面的parse()方法用于解析。
以上就是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择存储在 MongoDB 中。不得不说 MongoDB 比 MySQL 方便多了,而且省事多了。
2.3.5. 存储结果
在 pipelines.py 程序中,我们定义了数据存储方式。MongoDB的一些参数,比如地址和数据库名,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单解释一下:
from crawler() 是一个类方法,由@class 方法标识。该方法的作用是获取我们在settings.py中设置的参数:
open_spider() 方法主要执行一些初始化操作。这个方法会在 Spider 打开时被调用。
process_item() 方法是向 MongoDB 插入数据最重要的方法。
完成上述代码后,输入以下命令,启动整个爬虫的爬取和存储过程。如果在单机上运行,完成6000个网页需要大量时间,请耐心等待。
在这里,还有两个额外的点:
首先,为了减轻网站的压力,我们最好在每个请求之间设置几秒的延迟。您可以在 KuanSpider() 方法的开头添加以下代码行:
二、为了更好的监控爬虫的运行情况,需要设置输出日志文件,可以通过Python自带的日志包实现:
这里的level参数代表警告级别,严重程度从低到高:DEBUG
添加 datefmt 参数以将特定时间添加到每个日志中,这很有用。
以上,我们就完成了整个数据的抓取。有了数据,我们可以开始分析它,但在此之前,我们需要简单地清理和处理数据。
3. 数据清洗过程
首先,我们从 MongoDB 中读取数据并将其转换为 DataFrame,然后查看数据的基础知识。
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
在comment、download、follow、num_score这五列中,有些行加了“million”字尾,需要去掉,转成数值类型;体积列分别有“M”和“K”后缀,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有6086行x 8列,每列没有缺失值。
df.describe() 方法对 score 列进行基本统计。可以看出所有app的平均分3.9分(5分制),最低分1.6分,最高分1.@k36@ >8 分。
接下来,我们将以上列文本数据转换为数值数据。代码实现如下:
以上,几列文本数据的转换就完成了。先来看看基本情况:
下载被列为应用程序下载的数量。下载次数最多的app有5190万次,最少的是0(极少),平均下载次数是14万次。可以看到以下信息:
至此,基本的数据清洗流程就完成了,下面将对数据进行探索性分析。
4. 数据分析
我们主要从整体和分类两个维度分析App下载量、评分、量等指标。
4.1.整体状态4.1.1.下载排名
首先,我们来看看应用程序的下载量。很多时候我们下载一个应用,下载量是一个非常重要的参考指标。由于大部分app的下载量都比较小,直方图看不出趋势,所以我们选择将数据分段离散化成直方图,绘图工具是Pyecharts。
可以看到,多达 5,517 个(占总数的 84%)应用下载量低于 10 万,只有 20 个应用下载量超过 500 万。要开发一个盈利的应用程序,用户下载尤为重要。由此看来,大部分app都处于尴尬的境地,至少在宽平台上是这样。
代码实现如下:
接下来,我们来看看下载次数最多的20款应用分别是:
可以看到,这里的“酷安”App以5000万+的下载量遥遥领先,几乎是第二名微信2700万下载量的两倍。如此巨大的优势不难理解。毕竟是自己的App。如果你的手机上没有“酷安”,就说明你不是真正的“机器爱好者”。从图片中,我们还可以看到以下信息:
为了比较,让我们看看下载量最少的 20 个应用程序。
可以看出,这些与上面下载量最多的app相比相形见绌,而下载量最少的《广州限行证》只有63次下载。
这并不奇怪。可能是该应用程序没有被宣传,或者它可能刚刚开发。这么少的下载量分数还不错,还能继续更新。我喜欢这些开发者。
事实上,这类应用程序并不尴尬。真正尴尬的应该是那些下载量大、评分低的应用。给人的感觉是:“太爱了,有本事就别用了。” .
限于篇幅,文章截取了部分内容。其实爬虫加数据分析很有意思!许多学生正在寻找爬行动物的职位。其实纯爬虫的职位并不多,尤其是二线城市!如果你同时具备爬虫和数据分析能力,那么找工作会容易得多。
近 150 家公司的 210 位 Python 合作伙伴
都在 Python 工作圈 查看全部
scrapy分页抓取网页(项目文件创建好以后可以写爬虫程序了,怎么办?)
项目文件创建完成后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
这里的字段信息就是我们之前在网页中定位的8个字段信息,包括:name代表app名称,volume代表音量,download代表下载次数。在这里定义好之后,我们会在后续的爬取主程序中用到这些字段信息。
2.3.3. 爬取主程序
kuan项目创建后,Scrapy框架会自动生成一些爬虫的代码。接下来,我们需要在 parse 方法中添加网页抓取的字段解析内容。
在首页打开Dev Tools,找到每个抓取索引的节点位置,然后使用CSS、Xpath、正则化等方法提取解析。这些方法都是 Scrapy 支持的,可以随意选择。这里我们使用 CSS 语法来定位节点,但是需要注意的是,Scrapy 的 CSS 语法与我们之前用 pyquery 使用的 CSS 语法略有不同。让我们举几个例子并进行比较。
首先,我们定位到第一个APP的首页URL节点。我们可以看到URL节点位于class属性为app_left_list的div节点下的a节点中。它的 href 属性就是我们需要的 URL 信息。这是相对地址。拼接后就是完整的URL。
然后我们进入Kuan详情页面,选择app名称并定位。可以看到app名称节点位于类属性为.detail_app_title的p节点的文本中。
定位到这两个节点后,我们就可以使用 CSS 来提取字段信息了。下面是常规写法和Scrapy中写法的对比:
如您所见,要获取 href 或 text 属性,您需要使用 :: 来表示它。例如,要获取文本,请使用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,使用extract()。然后,我们可以参考解析代码写出8个字段信息。
首先,我们需要在首页提取App的URL列表,然后进入各个App的详情页面,进一步提取8个字段的信息。
这里使用response.urljoin()方法将提取出来的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传递两个参数:url和callback,url为详情页URL,callback为回调函数,将首页URL请求返回的响应传递给专门用于解析字段内容的parse_url()方法,如下图:
这里,get_comment() 和 get_tags() 方法是分开定义的。
get_comment() 方法通过正则匹配提取音量、下载、关注、评论四个字段信息。正则匹配结果如下:
然后使用result[0]、result[1]等提取4条信息,以volume为例,输出第一页的提取结果:
这样,第一页的10个app的字段信息全部提取成功,然后返回到yield item generator,我们输出它的内容:
2.3.4. 分页爬取
以上,我们已经爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
在这里,我们分别编写这两种方法的解析代码。第一种方法非常简单。只需按照 parse 方法继续添加以下代码行:
在第二种方法中,我们在第一个parse()方法之前定义了一个start_requests()方法来批量生成610个页面url,然后通过scrapy.Request()方法中的回调参数传递给后面的parse()方法用于解析。
以上就是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择存储在 MongoDB 中。不得不说 MongoDB 比 MySQL 方便多了,而且省事多了。
2.3.5. 存储结果
在 pipelines.py 程序中,我们定义了数据存储方式。MongoDB的一些参数,比如地址和数据库名,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单解释一下:
from crawler() 是一个类方法,由@class 方法标识。该方法的作用是获取我们在settings.py中设置的参数:
open_spider() 方法主要执行一些初始化操作。这个方法会在 Spider 打开时被调用。
process_item() 方法是向 MongoDB 插入数据最重要的方法。
完成上述代码后,输入以下命令,启动整个爬虫的爬取和存储过程。如果在单机上运行,完成6000个网页需要大量时间,请耐心等待。
在这里,还有两个额外的点:
首先,为了减轻网站的压力,我们最好在每个请求之间设置几秒的延迟。您可以在 KuanSpider() 方法的开头添加以下代码行:
二、为了更好的监控爬虫的运行情况,需要设置输出日志文件,可以通过Python自带的日志包实现:
这里的level参数代表警告级别,严重程度从低到高:DEBUG
添加 datefmt 参数以将特定时间添加到每个日志中,这很有用。
以上,我们就完成了整个数据的抓取。有了数据,我们可以开始分析它,但在此之前,我们需要简单地清理和处理数据。
3. 数据清洗过程
首先,我们从 MongoDB 中读取数据并将其转换为 DataFrame,然后查看数据的基础知识。
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
在comment、download、follow、num_score这五列中,有些行加了“million”字尾,需要去掉,转成数值类型;体积列分别有“M”和“K”后缀,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有6086行x 8列,每列没有缺失值。
df.describe() 方法对 score 列进行基本统计。可以看出所有app的平均分3.9分(5分制),最低分1.6分,最高分1.@k36@ >8 分。
接下来,我们将以上列文本数据转换为数值数据。代码实现如下:
以上,几列文本数据的转换就完成了。先来看看基本情况:
下载被列为应用程序下载的数量。下载次数最多的app有5190万次,最少的是0(极少),平均下载次数是14万次。可以看到以下信息:
至此,基本的数据清洗流程就完成了,下面将对数据进行探索性分析。
4. 数据分析
我们主要从整体和分类两个维度分析App下载量、评分、量等指标。
4.1.整体状态4.1.1.下载排名
首先,我们来看看应用程序的下载量。很多时候我们下载一个应用,下载量是一个非常重要的参考指标。由于大部分app的下载量都比较小,直方图看不出趋势,所以我们选择将数据分段离散化成直方图,绘图工具是Pyecharts。
可以看到,多达 5,517 个(占总数的 84%)应用下载量低于 10 万,只有 20 个应用下载量超过 500 万。要开发一个盈利的应用程序,用户下载尤为重要。由此看来,大部分app都处于尴尬的境地,至少在宽平台上是这样。
代码实现如下:
接下来,我们来看看下载次数最多的20款应用分别是:
可以看到,这里的“酷安”App以5000万+的下载量遥遥领先,几乎是第二名微信2700万下载量的两倍。如此巨大的优势不难理解。毕竟是自己的App。如果你的手机上没有“酷安”,就说明你不是真正的“机器爱好者”。从图片中,我们还可以看到以下信息:
为了比较,让我们看看下载量最少的 20 个应用程序。
可以看出,这些与上面下载量最多的app相比相形见绌,而下载量最少的《广州限行证》只有63次下载。
这并不奇怪。可能是该应用程序没有被宣传,或者它可能刚刚开发。这么少的下载量分数还不错,还能继续更新。我喜欢这些开发者。
事实上,这类应用程序并不尴尬。真正尴尬的应该是那些下载量大、评分低的应用。给人的感觉是:“太爱了,有本事就别用了。” .
限于篇幅,文章截取了部分内容。其实爬虫加数据分析很有意思!许多学生正在寻找爬行动物的职位。其实纯爬虫的职位并不多,尤其是二线城市!如果你同时具备爬虫和数据分析能力,那么找工作会容易得多。
近 150 家公司的 210 位 Python 合作伙伴
都在 Python 工作圈
scrapy分页抓取网页(爬取的思路如下图(站点分析)的应用思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-20 08:20
2021-05-16介绍
知乎用户信息量很大,本文为scrapy实战:如何抓取所有知乎用户信息。
爬取的思路如下图所示:
现场分析
本文以Brother Wheel为根节点(根节点可随意选择),打开Brother Wheel的关注列表,翻页查看关注列表:
翻页是一个 AJAX 请求,每页有 20 个关注用户和一些简短的用户信息
其中之一是 url-token,用于识别用户。在上面的截图中,用户的主页 url 是:
其中有url-token
项目实战
创建项目
思想分析
获取用户信息
首先,您需要获取用户的基本信息。可以通过请求类似以下的 url 来获取这些基本信息:
{url_token}/以下
而url_token可以在用户的关注列表中获取,上面url的页面是这样的
此外,还有赞数、采集数、感谢权
从上面的url获取到用户的基本信息后,下一步就是获取当前用户的关注列表:
获取用户关注列表
此列表具有翻页功能。经分析可知,关注列表的翻页是通过AJAX请求实现的。获取页面关注列表的url如下:
[*].answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge[%3F(type%3Dbest_answerer)].topics&offset=0&limit=20
提取规则:
{url-token}/followees?include={include}&offset={offset}&limit=2{limit}
其中包括:
数据[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics
上面的url返回一个json,里面收录20个follower,响应数据如下图所示:
对于一个follower,我们只需要得到用户的url-token*,然后我们就可以通过url-token拼接出用户的主页,还可以得到用户的基本信息和follower列表。
获取到url-token后,我们需要判断是否有下一页,如果有则翻页,上图后半部分还有一个字段:
翻到当前最后一页,字段如下图:
因此,根据is_end字段可以判断是否关注了下一页的follower,利用next字段的值可以得到下一页的follower列表。
构思安排
所以呢?在解析用户基本信息的同时,我们可以得到用户的url_token,进而可以得到用户的follower列表。通过这种方式爬取,我们基本上可以得到所有知乎用户的所有基本信息。
源码和一些爬取的数据:
部分爬取的知乎用户数据
源代码
文章中已经引入了爬取知乎用户的思路。思路理清后,实现比较块。
主要是源码有点长,这里就不一一贴了。需要源码的同学可以通过文末获取
扫描下方二维码发送关键词“知乎”即可获取本文完整源码和详细程序评论
关注公众号:互联网求职面试、java、python、爬虫、大数据等技术,海量数据分享:在公众号后台回复“csdn库下载”即可领取【csdn】和【百度库】 ] 免费下载服务;公众号后台回复“数据”:可以获得5T优质学习资料、java面试考点和java面授总结,还有几十个java和大数据项目,资料很丰富完成,你几乎可以找到你想要的一切
分类:
技术要点:
相关文章: 查看全部
scrapy分页抓取网页(爬取的思路如下图(站点分析)的应用思路)
2021-05-16介绍
知乎用户信息量很大,本文为scrapy实战:如何抓取所有知乎用户信息。
爬取的思路如下图所示:
现场分析
本文以Brother Wheel为根节点(根节点可随意选择),打开Brother Wheel的关注列表,翻页查看关注列表:
翻页是一个 AJAX 请求,每页有 20 个关注用户和一些简短的用户信息
其中之一是 url-token,用于识别用户。在上面的截图中,用户的主页 url 是:
其中有url-token
项目实战
创建项目
思想分析
获取用户信息
首先,您需要获取用户的基本信息。可以通过请求类似以下的 url 来获取这些基本信息:
{url_token}/以下
而url_token可以在用户的关注列表中获取,上面url的页面是这样的
此外,还有赞数、采集数、感谢权
从上面的url获取到用户的基本信息后,下一步就是获取当前用户的关注列表:
获取用户关注列表
此列表具有翻页功能。经分析可知,关注列表的翻页是通过AJAX请求实现的。获取页面关注列表的url如下:
[*].answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge[%3F(type%3Dbest_answerer)].topics&offset=0&limit=20
提取规则:
{url-token}/followees?include={include}&offset={offset}&limit=2{limit}
其中包括:
数据[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics
上面的url返回一个json,里面收录20个follower,响应数据如下图所示:
对于一个follower,我们只需要得到用户的url-token*,然后我们就可以通过url-token拼接出用户的主页,还可以得到用户的基本信息和follower列表。
获取到url-token后,我们需要判断是否有下一页,如果有则翻页,上图后半部分还有一个字段:
翻到当前最后一页,字段如下图:
因此,根据is_end字段可以判断是否关注了下一页的follower,利用next字段的值可以得到下一页的follower列表。
构思安排
所以呢?在解析用户基本信息的同时,我们可以得到用户的url_token,进而可以得到用户的follower列表。通过这种方式爬取,我们基本上可以得到所有知乎用户的所有基本信息。
源码和一些爬取的数据:
部分爬取的知乎用户数据
源代码
文章中已经引入了爬取知乎用户的思路。思路理清后,实现比较块。
主要是源码有点长,这里就不一一贴了。需要源码的同学可以通过文末获取
扫描下方二维码发送关键词“知乎”即可获取本文完整源码和详细程序评论
关注公众号:互联网求职面试、java、python、爬虫、大数据等技术,海量数据分享:在公众号后台回复“csdn库下载”即可领取【csdn】和【百度库】 ] 免费下载服务;公众号后台回复“数据”:可以获得5T优质学习资料、java面试考点和java面授总结,还有几十个java和大数据项目,资料很丰富完成,你几乎可以找到你想要的一切
分类:
技术要点:
相关文章:
scrapy分页抓取网页(【干货】selenium下载中间件常用函数_response下载详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-19 15:19
1、需补充知识1.下载中间件常用函数process_response(self, request, spider):2.scrapy与selenium对接
scrapy 通过在 setting.py 文件中设置 DOWNLOADER_MIDDLEWARES 添加自己的下载中间件。通常使用的selenium相关的内容都写在这个下载中间件里面,后面会有代码说明。
关于 selenium 的基本使用,请参见:
3.常用设置的内置设置
参考链接:
2、案例研究
分析:
一共需要抓取三页。首先,抓取第一页上的所有城市名称和相应的链接。地址是:
然后抓取每个城市和每个月的具体信息(即年月),地址:%E5%AE%89%E5%BA%B7,这里只是其中一个城市
最后,抓取每个月的每一天的数据,示例地址:%E5%AE%89%E5%BA%B7&month=2015-01
其中,首页为静态页面,可直接抓取上面的城市信息;第二页和第三页是动态页面,是selenium结合Phantomjs爬取的(也可以用谷歌浏览器)
1. 创建一个项目
scrapy startproject ChinaAir
2.指定需要抓取的字段
在 items.py 文件中定义要抓取的字段,并编写相关代码。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ChinaairItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
"""
首先明确抓取目标,包括城市,日期,指标的值
"""
# 城市
city = scrapy.Field()
# 日期
date = scrapy.Field()
# 空气质量指数
AQI = scrapy.Field()
# 空气质量等级
level = scrapy.Field()
# pm2.5的值
PM2_5 = scrapy.Field()
# pm10
PM10 = scrapy.Field()
# 二氧化硫
SO2 = scrapy.Field()
# 一氧化碳
CO = scrapy.Field()
# 二氧化氮
NO2 = scrapy.Field()
# 臭氧浓度
O3_8h = scrapy.Field()
# 数据源(数据来源)
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
3.生成爬虫文件
创建一个名为airChina的爬虫,并给出一个初始地址。
scrapy genspider airChina https://www.aqistudy.cn/historydata/
进入爬虫文件,开始编写爬虫部分的代码。
4.写一个爬虫
# -*- coding: utf-8 -*-
import scrapy
from ChinaAir.items import ChinaairItem
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
pass
yield之后,来到下载中间件文件。由于每个请求都要经过下载中间件,所以当请求从第一页解析的url时,可以在下载中间件中进行某些操作,例如使用selenium进行请求。
进入middlerwares.py文件,把已经写的全部删掉,改写我们需要的。
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
# 导入User-Agent列表
from ChinaAir.settings import USER_AGENT as ua_list
# class UserAgentMiddlerware(object):
# """
# 定义一个中间件,给每一个请求随机选择USER_AGENT
# 注意,不要忘了在setting文件中打开DOWNLOADER_MIDDLERWARE的注释
# """
# def process_request(self, request, spider):
#
# # 从ua_list中随机选择一个User-Agent
# user_agent = random.choice(ua_list)
# # 给请求添加头信息
# request.headers['User-Agent'] = user_agent
# # 当然,也可以添加代理ip,方式如下,此处不用代理,仅说明代理使用方法
# # request.meta['proxy'] = "..."
# print(request.headers['User-Agent'])
import time
import scrapy
from selenium import webdriver
class SeleniumMiddlerware(object):
"""
利用selenium,获取动态页面数据
"""
def process_request(self, request, spider):
# 判断请求是否来自第二个页面,只在第二个页面调用浏览器
if not request.url == "https://www.aqistudy.cn/historydata/":
# 实例化。selenium结合谷歌浏览器,
self.driver = webdriver.PhantomJS() # 实在受不了每次测试都打开浏览器界面,所以换成无界面的了
# 请求
self.driver.get(request.url)
time.sleep(2)
# 获取请求后得到的源码
html = self.driver.page_source
# 关闭浏览器
self.driver.quit()
# 构造一个请求的结果,将谷歌浏览器访问得到的结果构造成response,并返回给引擎
response = scrapy.http.HtmlResponse(url=request.url, body=html, request=request, encoding='utf-8')
return response
其中,注释部分是下载中间件为每个请求分配一个随机的User-Agent和代理IP。当然,这里没有用到,所以不用担心。
由于每次生成请求请求,都必须经过下载中间件。因此,在编写判断条件时,使用 selenium 只从第二页开始执行请求。
在代码的最后一行,下载中间件将 selenium 请求的结果构造成响应,返回给引擎,继续后续处理。注意下载中间件的注释要在settings.py文件中开启。
得到第二页返回的响应后,继续爬虫文件,解析响应并提取第三页需要的url,代码如下:
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[:1]
# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[:1]
# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
"""
拿到每个城市的,每个月份的数据
此页面为动态页面,这里利用selenium结合浏览器获取动态数据
因此在下载中间件中添加中间件代码
:param response:
:return:
"""
# 获取城市每个月份的链接
url_list = response.xpath('//tr/td/a/@href').extract()[:1]
for url in url_list:
url = self.base_url + url # 构造该url
yield scrapy.Request(url=url, meta={'city': response.meta['city']}, callback=self.parse_day)
拿到第二页的数据后,解析第三页请求的url,回调并提取要抓取的数据,爬虫部分的代码就完成了。因此,整个爬虫文件的代码如下:
# -*- coding: utf-8 -*-
import scrapy
from ChinaAir.items import ChinaairItem
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[:1]
# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[:1]
# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
"""
拿到每个城市的,每个月份的数据
此页面为动态页面,这里利用selenium结合浏览器获取动态数据
因此在下载中间件中添加中间件代码
:param response:
:return:
"""
# 获取城市每个月份的链接
url_list = response.xpath('//tr/td/a/@href').extract()[:1]
for url in url_list:
url = self.base_url + url # 构造该url
yield scrapy.Request(url=url, meta={'city': response.meta['city']}, callback=self.parse_day)
def parse_day(self, response):
"""
获取每一天的数据
:param response:
:return:
"""
node_list = response.xpath('//tr')
node_list.pop(0)
for node in node_list:
# 解析目标数据
item = ChinaairItem()
item['city'] = response.meta['city']
item['date'] = node.xpath('./td[1]/text()').extract_first()
item['AQI'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['PM2_5'] = node.xpath('./td[4]/text()').extract_first()
item['PM10'] = node.xpath('./td[5]/text()').extract_first()
item['SO2'] = node.xpath('./td[6]/text()').extract_first()
item['CO'] = node.xpath('./td[7]/text()').extract_first()
item['NO2'] = node.xpath('./td[8]/text()').extract_first()
item['O3_8h'] = node.xpath('./td[9]/text()').extract_first()
yield item
5.写管道文件
抓取数据后,就可以开始编写保存数据的逻辑了。在这里,只有数据以json格式写入。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
import json
from datetime import datetime
class ChinaAirPipeline(object):
def process_item(self, item, spider):
item["source"] = spider.name
item['utc_time'] = str(datetime.utcnow())
return item
class ChinaAirJsonPipeline(object):
def open_spider(self, spider):
self.file = open('air.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(content)
def close_spider(self, spider):
self.file.close()
ChinaAirPipeline接收到pipeline抛出的item后,继续添加两个自读,捕获时间和数据源,添加完后,继续通过pipeline抛到下面的ChinaAirJsonPipelines文件中保存。
其中,别忘了在settings.py文件中注册管道信息。
6.运行爬虫,抓取数据
scrapy crawl airChina
3、完整代码
也可以看看: 查看全部
scrapy分页抓取网页(【干货】selenium下载中间件常用函数_response下载详解)
1、需补充知识1.下载中间件常用函数process_response(self, request, spider):2.scrapy与selenium对接
scrapy 通过在 setting.py 文件中设置 DOWNLOADER_MIDDLEWARES 添加自己的下载中间件。通常使用的selenium相关的内容都写在这个下载中间件里面,后面会有代码说明。
关于 selenium 的基本使用,请参见:
3.常用设置的内置设置
参考链接:
2、案例研究
分析:
一共需要抓取三页。首先,抓取第一页上的所有城市名称和相应的链接。地址是:
然后抓取每个城市和每个月的具体信息(即年月),地址:%E5%AE%89%E5%BA%B7,这里只是其中一个城市
最后,抓取每个月的每一天的数据,示例地址:%E5%AE%89%E5%BA%B7&month=2015-01
其中,首页为静态页面,可直接抓取上面的城市信息;第二页和第三页是动态页面,是selenium结合Phantomjs爬取的(也可以用谷歌浏览器)
1. 创建一个项目
scrapy startproject ChinaAir
2.指定需要抓取的字段
在 items.py 文件中定义要抓取的字段,并编写相关代码。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ChinaairItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
"""
首先明确抓取目标,包括城市,日期,指标的值
"""
# 城市
city = scrapy.Field()
# 日期
date = scrapy.Field()
# 空气质量指数
AQI = scrapy.Field()
# 空气质量等级
level = scrapy.Field()
# pm2.5的值
PM2_5 = scrapy.Field()
# pm10
PM10 = scrapy.Field()
# 二氧化硫
SO2 = scrapy.Field()
# 一氧化碳
CO = scrapy.Field()
# 二氧化氮
NO2 = scrapy.Field()
# 臭氧浓度
O3_8h = scrapy.Field()
# 数据源(数据来源)
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
3.生成爬虫文件
创建一个名为airChina的爬虫,并给出一个初始地址。
scrapy genspider airChina https://www.aqistudy.cn/historydata/
进入爬虫文件,开始编写爬虫部分的代码。
4.写一个爬虫
# -*- coding: utf-8 -*-
import scrapy
from ChinaAir.items import ChinaairItem
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
pass
yield之后,来到下载中间件文件。由于每个请求都要经过下载中间件,所以当请求从第一页解析的url时,可以在下载中间件中进行某些操作,例如使用selenium进行请求。
进入middlerwares.py文件,把已经写的全部删掉,改写我们需要的。
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
# 导入User-Agent列表
from ChinaAir.settings import USER_AGENT as ua_list
# class UserAgentMiddlerware(object):
# """
# 定义一个中间件,给每一个请求随机选择USER_AGENT
# 注意,不要忘了在setting文件中打开DOWNLOADER_MIDDLERWARE的注释
# """
# def process_request(self, request, spider):
#
# # 从ua_list中随机选择一个User-Agent
# user_agent = random.choice(ua_list)
# # 给请求添加头信息
# request.headers['User-Agent'] = user_agent
# # 当然,也可以添加代理ip,方式如下,此处不用代理,仅说明代理使用方法
# # request.meta['proxy'] = "..."
# print(request.headers['User-Agent'])
import time
import scrapy
from selenium import webdriver
class SeleniumMiddlerware(object):
"""
利用selenium,获取动态页面数据
"""
def process_request(self, request, spider):
# 判断请求是否来自第二个页面,只在第二个页面调用浏览器
if not request.url == "https://www.aqistudy.cn/historydata/":
# 实例化。selenium结合谷歌浏览器,
self.driver = webdriver.PhantomJS() # 实在受不了每次测试都打开浏览器界面,所以换成无界面的了
# 请求
self.driver.get(request.url)
time.sleep(2)
# 获取请求后得到的源码
html = self.driver.page_source
# 关闭浏览器
self.driver.quit()
# 构造一个请求的结果,将谷歌浏览器访问得到的结果构造成response,并返回给引擎
response = scrapy.http.HtmlResponse(url=request.url, body=html, request=request, encoding='utf-8')
return response
其中,注释部分是下载中间件为每个请求分配一个随机的User-Agent和代理IP。当然,这里没有用到,所以不用担心。
由于每次生成请求请求,都必须经过下载中间件。因此,在编写判断条件时,使用 selenium 只从第二页开始执行请求。
在代码的最后一行,下载中间件将 selenium 请求的结果构造成响应,返回给引擎,继续后续处理。注意下载中间件的注释要在settings.py文件中开启。
得到第二页返回的响应后,继续爬虫文件,解析响应并提取第三页需要的url,代码如下:
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[:1]
# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[:1]
# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
"""
拿到每个城市的,每个月份的数据
此页面为动态页面,这里利用selenium结合浏览器获取动态数据
因此在下载中间件中添加中间件代码
:param response:
:return:
"""
# 获取城市每个月份的链接
url_list = response.xpath('//tr/td/a/@href').extract()[:1]
for url in url_list:
url = self.base_url + url # 构造该url
yield scrapy.Request(url=url, meta={'city': response.meta['city']}, callback=self.parse_day)
拿到第二页的数据后,解析第三页请求的url,回调并提取要抓取的数据,爬虫部分的代码就完成了。因此,整个爬虫文件的代码如下:
# -*- coding: utf-8 -*-
import scrapy
from ChinaAir.items import ChinaairItem
class AirchinaSpider(scrapy.Spider):
name = 'airChina'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
# 抓取首页
start_urls = [base_url]
def parse(self, response):
# 拿到页面的所有城市名称链接
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[:1]
# 拿到页面的所有城市名
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[:1]
# 将城市名及其对应的链接,进行一一对应
for city, url in zip(city_list, url_list):
# 拼接该城市的链接
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city": city})
def parse_month(self, response):
"""
拿到每个城市的,每个月份的数据
此页面为动态页面,这里利用selenium结合浏览器获取动态数据
因此在下载中间件中添加中间件代码
:param response:
:return:
"""
# 获取城市每个月份的链接
url_list = response.xpath('//tr/td/a/@href').extract()[:1]
for url in url_list:
url = self.base_url + url # 构造该url
yield scrapy.Request(url=url, meta={'city': response.meta['city']}, callback=self.parse_day)
def parse_day(self, response):
"""
获取每一天的数据
:param response:
:return:
"""
node_list = response.xpath('//tr')
node_list.pop(0)
for node in node_list:
# 解析目标数据
item = ChinaairItem()
item['city'] = response.meta['city']
item['date'] = node.xpath('./td[1]/text()').extract_first()
item['AQI'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['PM2_5'] = node.xpath('./td[4]/text()').extract_first()
item['PM10'] = node.xpath('./td[5]/text()').extract_first()
item['SO2'] = node.xpath('./td[6]/text()').extract_first()
item['CO'] = node.xpath('./td[7]/text()').extract_first()
item['NO2'] = node.xpath('./td[8]/text()').extract_first()
item['O3_8h'] = node.xpath('./td[9]/text()').extract_first()
yield item
5.写管道文件
抓取数据后,就可以开始编写保存数据的逻辑了。在这里,只有数据以json格式写入。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
import json
from datetime import datetime
class ChinaAirPipeline(object):
def process_item(self, item, spider):
item["source"] = spider.name
item['utc_time'] = str(datetime.utcnow())
return item
class ChinaAirJsonPipeline(object):
def open_spider(self, spider):
self.file = open('air.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(content)
def close_spider(self, spider):
self.file.close()
ChinaAirPipeline接收到pipeline抛出的item后,继续添加两个自读,捕获时间和数据源,添加完后,继续通过pipeline抛到下面的ChinaAirJsonPipelines文件中保存。
其中,别忘了在settings.py文件中注册管道信息。
6.运行爬虫,抓取数据
scrapy crawl airChina
3、完整代码
也可以看看:

