scrapy分页抓取网页(项目文件创建好以后可以写爬虫程序了,怎么办?)
优采云 发布时间: 2022-03-22 21:18scrapy分页抓取网页(项目文件创建好以后可以写爬虫程序了,怎么办?)
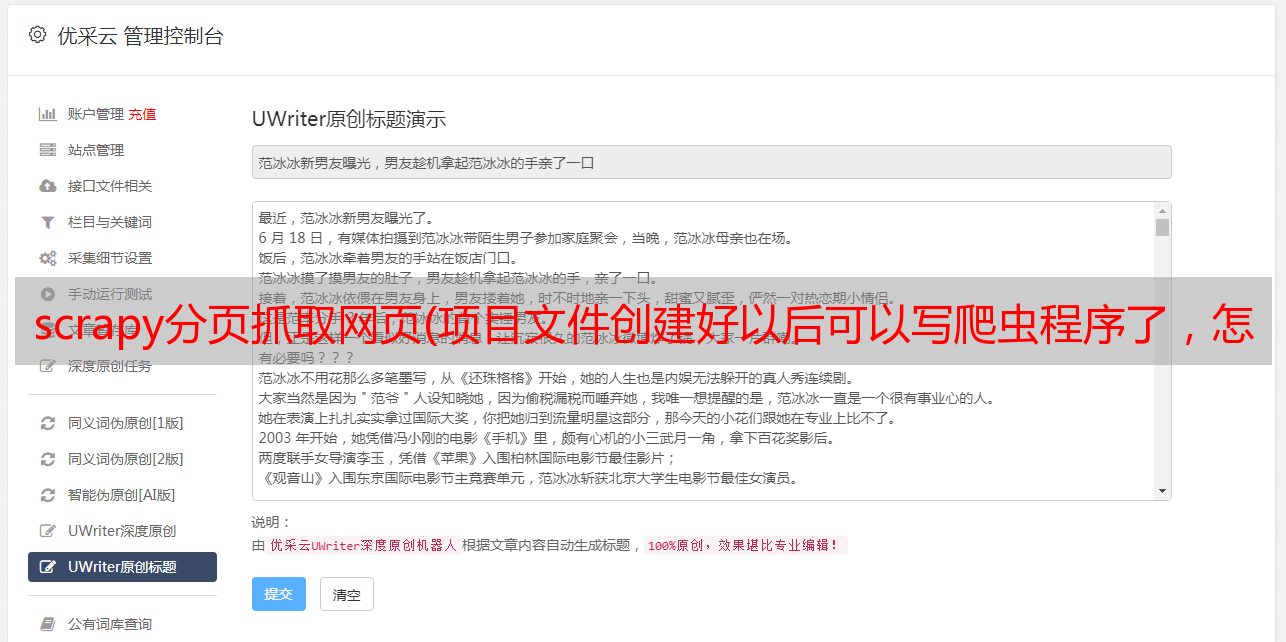
项目文件创建完成后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
这里的字段信息就是我们之前在网页中定位的8个字段信息,包括:name代表app名称,volume代表音量,download代表下载次数。在这里定义好之后,我们会在后续的爬取主程序中用到这些字段信息。
2.3.3. 爬取主程序
kuan项目创建后,Scrapy框架会自动生成一些爬虫的代码。接下来,我们需要在 parse 方法中添加网页抓取的字段解析内容。
在首页打开Dev Tools,找到每个抓取索引的节点位置,然后使用CSS、Xpath、正则化等方法提取解析。这些方法都是 Scrapy 支持的,可以随意选择。这里我们使用 CSS 语法来定位节点,但是需要注意的是,Scrapy 的 CSS 语法与我们之前用 pyquery 使用的 CSS 语法略有不同。让我们举几个例子并进行比较。

首先,我们定位到第一个APP的首页URL节点。我们可以看到URL节点位于class属性为app_left_list的div节点下的a节点中。它的 href 属性就是我们需要的 URL 信息。这是相对地址。拼接后就是完整的URL。
然后我们进入Kuan详情页面,选择app名称并定位。可以看到app名称节点位于类属性为.detail_app_title的p节点的文本中。
定位到这两个节点后,我们就可以使用 CSS 来提取字段信息了。下面是常规写法和Scrapy中写法的对比:
如您所见,要获取 href 或 text 属性,您需要使用 :: 来表示它。例如,要获取文本,请使用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,使用extract()。然后,我们可以参考解析代码写出8个字段信息。
首先,我们需要在首页提取App的URL列表,然后进入各个App的详情页面,进一步提取8个字段的信息。
这里使用response.urljoin()方法将提取出来的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传递两个参数:url和callback,url为详情页URL,callback为回调函数,将首页URL请求返回的响应传递给专门用于解析字段内容的parse_url()方法,如下图:
这里,get_comment() 和 get_tags() 方法是分开定义的。
get_comment() 方法通过正则匹配提取音量、下载、关注、评论四个字段信息。正则匹配结果如下:
然后使用result[0]、result[1]等提取4条信息,以volume为例,输出第一页的提取结果:
这样,第一页的10个app的字段信息全部提取成功,然后返回到yield item generator,我们输出它的内容:
2.3.4. 分页爬取
以上,我们已经爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
在这里,我们分别编写这两种方法的解析代码。第一种方法非常简单。只需按照 parse 方法继续添加以下代码行:
在第二种方法中,我们在第一个parse()方法之前定义了一个start_requests()方法来批量生成610个页面url,然后通过scrapy.Request()方法中的回调参数传递给后面的parse()方法用于解析。
以上就是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择存储在 MongoDB 中。不得不说 MongoDB 比 MySQL 方便多了,而且省事多了。
2.3.5. 存储结果
在 pipelines.py 程序中,我们定义了数据存储方式。MongoDB的一些参数,比如地址和数据库名,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单解释一下:
from crawler() 是一个类方法,由@class 方法标识。该方法的作用是获取我们在settings.py中设置的参数:
open_spider() 方法主要执行一些初始化操作。这个方法会在 Spider 打开时被调用。
process_item() 方法是向 MongoDB 插入数据最重要的方法。

完成上述代码后,输入以下命令,启动整个爬虫的爬取和存储过程。如果在单机上运行,完成6000个网页需要大量时间,请耐心等待。
在这里,还有两个额外的点:
首先,为了减轻网站的压力,我们最好在每个请求之间设置几秒的延迟。您可以在 KuanSpider() 方法的开头添加以下代码行:
二、为了更好的监控爬虫的运行情况,需要设置输出日志文件,可以通过Python自带的日志包实现:
这里的level参数代表警告级别,严重程度从低到高:DEBUG
添加 datefmt 参数以将特定时间添加到每个日志中,这很有用。

以上,我们就完成了整个数据的抓取。有了数据,我们可以开始分析它,但在此之前,我们需要简单地清理和处理数据。
3. 数据清洗过程
首先,我们从 MongoDB 中读取数据并将其转换为 DataFrame,然后查看数据的基础知识。
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
在comment、download、follow、num_score这五列中,有些行加了“million”字尾,需要去掉,转成数值类型;体积列分别有“M”和“K”后缀,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有6086行x 8列,每列没有缺失值。
df.describe() 方法对 score 列进行基本统计。可以看出所有app的平均分3.9分(5分制),最低分1.6分,最高分1.@k36@ >8 分。
接下来,我们将以上列文本数据转换为数值数据。代码实现如下:
以上,几列文本数据的转换就完成了。先来看看基本情况:
下载被列为应用程序下载的数量。下载次数最多的app有5190万次,最少的是0(极少),平均下载次数是14万次。可以看到以下信息:
至此,基本的数据清洗流程就完成了,下面将对数据进行探索性分析。
4. 数据分析
我们主要从整体和分类两个维度分析App下载量、评分、量等指标。
4.1.整体状态4.1.1.下载排名
首先,我们来看看应用程序的下载量。很多时候我们下载一个应用,下载量是一个非常重要的参考指标。由于大部分app的下载量都比较小,直方图看不出趋势,所以我们选择将数据分段离散化成直方图,绘图工具是Pyecharts。
可以看到,多达 5,517 个(占总数的 84%)应用下载量低于 10 万,只有 20 个应用下载量超过 500 万。要开发一个盈利的应用程序,用户下载尤为重要。由此看来,大部分app都处于尴尬的境地,至少在宽平台上是这样。
代码实现如下:
接下来,我们来看看下载次数最多的20款应用分别是:

可以看到,这里的“酷安”App以5000万+的下载量遥遥领先,几乎是第二名微信2700万下载量的两倍。如此巨大的优势不难理解。毕竟是自己的App。如果你的手机上没有“酷安”,就说明你不是真正的“机器爱好者”。从图片中,我们还可以看到以下信息:
为了比较,让我们看看下载量最少的 20 个应用程序。

可以看出,这些与上面下载量最多的app相比相形见绌,而下载量最少的《广州限行证》只有63次下载。
这并不奇怪。可能是该应用程序没有被宣传,或者它可能刚刚开发。这么少的下载量分数还不错,还能继续更新。我喜欢这些开发者。
事实上,这类应用程序并不尴尬。真正尴尬的应该是那些下载量大、评分低的应用。给人的感觉是:“太爱了,有本事就别用了。” .
限于篇幅,文章截取了部分内容。其实爬虫加数据分析很有意思!许多学生正在寻找爬行动物的职位。其实纯爬虫的职位并不多,尤其是二线城市!如果你同时具备爬虫和数据分析能力,那么找工作会容易得多。
近 150 家公司的 210 位 Python 合作伙伴
都在 Python 工作圈

