
scrapy分页抓取网页
scrapy分页抓取网页(目标网站上内容很多时会用多个页显示(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-17 06:22
当目标网站上的内容很多时,会分页显示。网页抓取/数据提取/信息提取工具包MetaSeeker可以翻页,提取每页内容,目标网站显示多页,有几种方式:
1.页面上的每个页面都由另一个URL地址表示。最好将这样的网页翻页,提取URL,在以后的某个时间在这个地址加载页面。而且 MetaSeeker 还可以将一个信息提取交易中的所有信息都翻过来。在此会话中,这些 URL 称为内嵌线索。这些网址是不记录的,翻过来就丢弃了。事实上,这样的 URL 是被记录下来的。意义不大,目标网站在显示多个页面的时候经常使用一个服务器动态页面,页码作为参数,比如page=2,改变这些页面的内容,比如,一个博客网站,新的博文添加后,原来的分页发生了变化。最初的博文在第 2 页,但稍后可能在第 3 页。
2.页面上的每个页面都关联了一段Javascript代码,点击时执行。这是普通爬虫的天敌。普通爬虫很难提取javascript管理的内容,特别是用AJAX框架制作的网站,网页抓取/数据提取/信息提取工具包MetaSeeker可以模拟用户的点击操作,在一个信息中完成翻页提取交易。
‹ 可以使用 MetaSeeker 进行合法的垂直搜索吗?网页抓取/数据提取/信息提取工具包 MetaSeeker 中的网络爬虫是怎么做的?› 查看全部
scrapy分页抓取网页(目标网站上内容很多时会用多个页显示(图))
当目标网站上的内容很多时,会分页显示。网页抓取/数据提取/信息提取工具包MetaSeeker可以翻页,提取每页内容,目标网站显示多页,有几种方式:
1.页面上的每个页面都由另一个URL地址表示。最好将这样的网页翻页,提取URL,在以后的某个时间在这个地址加载页面。而且 MetaSeeker 还可以将一个信息提取交易中的所有信息都翻过来。在此会话中,这些 URL 称为内嵌线索。这些网址是不记录的,翻过来就丢弃了。事实上,这样的 URL 是被记录下来的。意义不大,目标网站在显示多个页面的时候经常使用一个服务器动态页面,页码作为参数,比如page=2,改变这些页面的内容,比如,一个博客网站,新的博文添加后,原来的分页发生了变化。最初的博文在第 2 页,但稍后可能在第 3 页。
2.页面上的每个页面都关联了一段Javascript代码,点击时执行。这是普通爬虫的天敌。普通爬虫很难提取javascript管理的内容,特别是用AJAX框架制作的网站,网页抓取/数据提取/信息提取工具包MetaSeeker可以模拟用户的点击操作,在一个信息中完成翻页提取交易。
‹ 可以使用 MetaSeeker 进行合法的垂直搜索吗?网页抓取/数据提取/信息提取工具包 MetaSeeker 中的网络爬虫是怎么做的?›
scrapy分页抓取网页(一个_selector.xpath.u去重与增量爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-17 02:01
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能被Xpath提取出来,所以也需要定期匹配。如果有异常,必须处理。一般当页面无法匹配到对应字段时,应设置为0,待到item后处理。过滤处理。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:
(1)从待爬取队列中获取url
(2)判断要请求的url是否被爬取,如果已经爬取则忽略该请求,不被爬取,继续其他操作,将url插入爬取队列
(3)重复步骤 1
这里我们使用了scrapy-redis的去重组件,所以还没有实现,但是原理还是需要了解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫类反屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为
系统采用以下方法防止爬虫被屏蔽:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.本着君子的约定,降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们屏蔽了cookies的调整,这也有利于我们的身份分歧。
5.人工编码,这应该是无可挑剔的反禁令措施,所有系统都比人工操作好不了多少,只是降低了自动化,效率不高,但确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码以重新访问该页面。为此,我添加了一个邮件提醒模块。当爬虫被封禁时,会发送邮件提醒管理员解除封禁。同时将重定向的请求重新加入下载队列进行爬取,以保证数据的完整性。
防爬虫网站屏蔽原理如下图所示:
(a) 模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性
首先是扩展下载中间件。首先,将中间件添加到seeings.py。
二、扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为列表,如下图:
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。
首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1.代理ip池的设计开发流程如下:
一种。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行验证
d。如果达到最大ips数,停止爬取,一定时间后验证数据ips的有效性,删除无效ips
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip模块这里使用七夜代理ip池的开源项目
代理ip爬虫运行截图:
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有各种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,阻塞组件这是通过捕获 302 状态来实现的。同时,异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
(d) 数据存储模块
数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。
Scrapy 支持 json、csv 和 xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(e) 抓取场地设计
本文以网络房屋数据为捕获目标,从机端解析捕获现场数据。因此,捕获的内容必须能够客观、准确地反映网络房屋数据的特征。
以抓取58同城的在线房屋数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
序列号
字段名称
字段含义
1
标题
帖子标题
2
钱钱
租
3
方法
租
4
区域
您所在的地区
5
社区
您所在的社区
6
目标网址
发布详细信息
7
城市
城市
8
Pub_time
发布时间
现场选择主要是根据本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。降低单机压力。
(f) 数据处理
1)对象定义器
Item 是定义抓取数据的容器。通过创建一个 scrapy.item.Item 类来声明。将该属性定义为一个scrapy.item.Field对象来控制通过实例化所需item获得的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、地点、社区、城市、帖子详情页链接、发布时间。这里对字段的定义是根据数据处理端的需要来定义的。关键代码如下:
类 TcZufangItem(项目):
#帖子名称
标题=字段()
#租
钱=字段()
#租
方法=字段()
#你的地区
面积=字段()
#地点
社区=字段()
#发布详细信息网址
targeturl=字段()
#post 发布时间
pub_time=字段()
#地点城市
城市=字段()
2)数据处理程序
保存和输出数据的方法在 Pipeline 类中定义。从 Spider 的 parse 方法返回的 Item 中,数据将被处理并以 ITEM_PIPELINES 列表中 Pipeline 类对应的顶层格式输出。系统发回管道的数据使用Mongodb存储。关键代码如下:
def process_item(self, item, spider):
如果项目['pub_time'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['方法'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['社区'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['钱']==0:
raise DropItem("发现重复项:%s" % item)
如果项目['区域'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['城市'] == 0:
raise DropItem("发现重复项:%s" % item)
zufang_detail = {
'title': item.get('title'),
'钱':item.get('钱'),
'方法':item.get('方法'),
'区域': item.get('区域', ''),
'社区': item.get('社区', ''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time', ''),
'城市': item.get('城市','')
}
结果 = self.db['zufang_detail'].insert(zufang_detail)
print '[success] the '+item['targeturl']+'写入MongoDB数据库'
归还物品
(g) 数据可视化设计
数据的可视化,其实就是将数据库的数据转换成便于我们用户观察的形式。本系统使用 Mongodb 存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
Master运行截图:
从端运行截图:
五、系统部署
环境部署,因为分布式部署所需的环境类似,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像部署爬虫,使用Daocloud上的scrapy-env pair。该程序已部署。具体的docker部署过程可以参考网上。
代码放在gayhub上,有兴趣的可以查一下
更多! 查看全部
scrapy分页抓取网页(一个_selector.xpath.u去重与增量爬取)
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能被Xpath提取出来,所以也需要定期匹配。如果有异常,必须处理。一般当页面无法匹配到对应字段时,应设置为0,待到item后处理。过滤处理。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:

(1)从待爬取队列中获取url
(2)判断要请求的url是否被爬取,如果已经爬取则忽略该请求,不被爬取,继续其他操作,将url插入爬取队列
(3)重复步骤 1
这里我们使用了scrapy-redis的去重组件,所以还没有实现,但是原理还是需要了解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫类反屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为
系统采用以下方法防止爬虫被屏蔽:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.本着君子的约定,降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们屏蔽了cookies的调整,这也有利于我们的身份分歧。
5.人工编码,这应该是无可挑剔的反禁令措施,所有系统都比人工操作好不了多少,只是降低了自动化,效率不高,但确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码以重新访问该页面。为此,我添加了一个邮件提醒模块。当爬虫被封禁时,会发送邮件提醒管理员解除封禁。同时将重定向的请求重新加入下载队列进行爬取,以保证数据的完整性。
防爬虫网站屏蔽原理如下图所示:

(a) 模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性
首先是扩展下载中间件。首先,将中间件添加到seeings.py。
二、扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为列表,如下图:

然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。

总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。
首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1.代理ip池的设计开发流程如下:

一种。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行验证
d。如果达到最大ips数,停止爬取,一定时间后验证数据ips的有效性,删除无效ips
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip模块这里使用七夜代理ip池的开源项目
代理ip爬虫运行截图:

(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有各种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,阻塞组件这是通过捕获 302 状态来实现的。同时,异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:

(d) 数据存储模块
数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。
Scrapy 支持 json、csv 和 xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:

(e) 抓取场地设计
本文以网络房屋数据为捕获目标,从机端解析捕获现场数据。因此,捕获的内容必须能够客观、准确地反映网络房屋数据的特征。
以抓取58同城的在线房屋数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
序列号
字段名称
字段含义
1
标题
帖子标题
2
钱钱
租
3
方法
租
4
区域
您所在的地区
5
社区
您所在的社区
6
目标网址
发布详细信息
7
城市
城市
8
Pub_time
发布时间
现场选择主要是根据本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。降低单机压力。
(f) 数据处理
1)对象定义器
Item 是定义抓取数据的容器。通过创建一个 scrapy.item.Item 类来声明。将该属性定义为一个scrapy.item.Field对象来控制通过实例化所需item获得的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、地点、社区、城市、帖子详情页链接、发布时间。这里对字段的定义是根据数据处理端的需要来定义的。关键代码如下:
类 TcZufangItem(项目):
#帖子名称
标题=字段()
#租
钱=字段()
#租
方法=字段()
#你的地区
面积=字段()
#地点
社区=字段()
#发布详细信息网址
targeturl=字段()
#post 发布时间
pub_time=字段()
#地点城市
城市=字段()
2)数据处理程序
保存和输出数据的方法在 Pipeline 类中定义。从 Spider 的 parse 方法返回的 Item 中,数据将被处理并以 ITEM_PIPELINES 列表中 Pipeline 类对应的顶层格式输出。系统发回管道的数据使用Mongodb存储。关键代码如下:
def process_item(self, item, spider):
如果项目['pub_time'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['方法'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['社区'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['钱']==0:
raise DropItem("发现重复项:%s" % item)
如果项目['区域'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['城市'] == 0:
raise DropItem("发现重复项:%s" % item)
zufang_detail = {
'title': item.get('title'),
'钱':item.get('钱'),
'方法':item.get('方法'),
'区域': item.get('区域', ''),
'社区': item.get('社区', ''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time', ''),
'城市': item.get('城市','')
}
结果 = self.db['zufang_detail'].insert(zufang_detail)
print '[success] the '+item['targeturl']+'写入MongoDB数据库'
归还物品
(g) 数据可视化设计
数据的可视化,其实就是将数据库的数据转换成便于我们用户观察的形式。本系统使用 Mongodb 存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:


四、系统操作
系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
Master运行截图:

从端运行截图:

五、系统部署
环境部署,因为分布式部署所需的环境类似,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像部署爬虫,使用Daocloud上的scrapy-env pair。该程序已部署。具体的docker部署过程可以参考网上。
代码放在gayhub上,有兴趣的可以查一下
更多!
scrapy分页抓取网页( WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-15 22:18
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据;对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。 查看全部
scrapy分页抓取网页(
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)

这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。

今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:

但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。

这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。

2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。

容器的预览如下图所示:

寻呼机选择过程如下图所示:

3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。

4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据;对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。
scrapy分页抓取网页(网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-14 22:19
Scrapy 是一个用 Python 编写的爬虫框架,简单、轻量、非常方便。Scrapy 使用 Twisted(一个异步网络库)来处理网络通信。架构清晰,收录各种中间件接口,可灵活满足各种需求。
以上摘自网上介绍scrapy框架的一段话。大年初一,懒癌高发……
安装scrapy,pip可以解决你的问题:pip install scrapy。
这里有一句话,如果你在运行代码后看到这个错误:
ImportError: No module named win32api
<p>如果出现坑,需要安装pywin32。如果已经安装了pywin32,还有报错,还是需要在你的python安装目录下手动安装\Lib\site-packages\pywin32_system32:pythoncom27.dll,pywintypes2 查看全部
scrapy分页抓取网页(网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
Scrapy 是一个用 Python 编写的爬虫框架,简单、轻量、非常方便。Scrapy 使用 Twisted(一个异步网络库)来处理网络通信。架构清晰,收录各种中间件接口,可灵活满足各种需求。
以上摘自网上介绍scrapy框架的一段话。大年初一,懒癌高发……
安装scrapy,pip可以解决你的问题:pip install scrapy。
这里有一句话,如果你在运行代码后看到这个错误:
ImportError: No module named win32api
<p>如果出现坑,需要安装pywin32。如果已经安装了pywin32,还有报错,还是需要在你的python安装目录下手动安装\Lib\site-packages\pywin32_system32:pythoncom27.dll,pywintypes2
scrapy分页抓取网页(scrapy分页抓取网页基本方法四种(scrapyspan功能详解))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-14 16:12
scrapy分页抓取网页基本方法四种(scrapy分页功能详解)获取不同网页的分页截图显示html页面内容批量采集百度,大众点评,闲鱼等网站的商品信息主要分为如下四步:1.获取文件,然后进行处理2.初始化scrapy,写入代码,初始化构建的爬虫构建工程,写入到百度大众点评闲鱼。3.执行爬虫,并写入url到服务器4.跑起来,等待读取结果,并发布查看如何获取更多网页内容一.文件从爬虫的文件名和元素上就可以抓取到网页内容二.元素1.:指定爬虫程序处理抓取的url2.:就是包含了requestheaders和url的html文件3.html里面每个元素里都定义了各自的headers4.包含了元素的值5.爬虫里的所有元素都会被解析,传递给scrapy进行处理三.html六元素1.一个html里面一定有标签2.加号就是锚标签(定义页码尺寸)3.text(title):html元素的标题4.span(link):标签的链接5.(content):标签的内容(可以放在span的前面或者后面,)6.<p>(pagetitle):span里的title(页标题)四.分页信息1.一个页面就是给你定义一个,所有定义好的就是这个页面里面所有的内容。
2.分页信息:,为了加载所有内容3.如何传递url,传递url时如何请求
<a></a>,这些都是请求链接4.scrapy自带的连接,例如<a></a>,我们传递连接信息到request上。5.自己写爬虫模块,传递requestheaders6.<a></a>.site_urls()这个链接的意思是不需要<a></a>[""].site_urls(url)例如:1.我们获取天猫全部商品的链接2.我们获取京东全部商品的链接我们每次访问都要传递一次requestheaders.。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页基本方法四种(scrapyspan功能详解))
scrapy分页抓取网页基本方法四种(scrapy分页功能详解)获取不同网页的分页截图显示html页面内容批量采集百度,大众点评,闲鱼等网站的商品信息主要分为如下四步:1.获取文件,然后进行处理2.初始化scrapy,写入代码,初始化构建的爬虫构建工程,写入到百度大众点评闲鱼。3.执行爬虫,并写入url到服务器4.跑起来,等待读取结果,并发布查看如何获取更多网页内容一.文件从爬虫的文件名和元素上就可以抓取到网页内容二.元素1.:指定爬虫程序处理抓取的url2.:就是包含了requestheaders和url的html文件3.html里面每个元素里都定义了各自的headers4.包含了元素的值5.爬虫里的所有元素都会被解析,传递给scrapy进行处理三.html六元素1.一个html里面一定有标签2.加号就是锚标签(定义页码尺寸)3.text(title):html元素的标题4.span(link):标签的链接5.(content):标签的内容(可以放在span的前面或者后面,)6.<p>(pagetitle):span里的title(页标题)四.分页信息1.一个页面就是给你定义一个,所有定义好的就是这个页面里面所有的内容。
2.分页信息:,为了加载所有内容3.如何传递url,传递url时如何请求
<a></a>,这些都是请求链接4.scrapy自带的连接,例如<a></a>,我们传递连接信息到request上。5.自己写爬虫模块,传递requestheaders6.<a></a>.site_urls()这个链接的意思是不需要<a></a>[""].site_urls(url)例如:1.我们获取天猫全部商品的链接2.我们获取京东全部商品的链接我们每次访问都要传递一次requestheaders.。
scrapy分页抓取网页(数据加载是一种异步加载方式,原始的页面最初不会)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-09 02:14
数据加载是一种异步加载方式。原创页面起初不收录一些数据。原创页面加载完成后,会请求一个接口从服务器获取数据,然后对数据进行处理并呈现在网页上。只需发送一个 Ajax 请求。如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取到有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟Ajax请求,那么就可以成功获取。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。这不是编程
语言,但使用JavaScript与服务器交换数据并更新,同时保证页面不刷新,页面链接不改变
网页技术的一部分。对于传统的网页,如果要更新其内容,则必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
以微博为例
以微博为例,切换到微博页面,一直往下滚动,可以发现往下滑几条微博后就没有再往下,而是出现了一个加载动画,过一会新的微博就会出现继续出现在下方。博客内容,这个过程真的是Ajax加载的过程。注意页面并没有完全刷新,也就是说页面的链接没有变化,但是页面中有新的内容,也就是后面刷新的新微博。这就是通过 Ajax 获取和呈现新数据的方式。
Ajax 实际上有一个特殊的请求类型叫做 xhr。可以找到一个名称以getIndex开头的请求,其Type为xhr,即Ajax请求。用鼠标点击请求,查看请求的详细信息。请求标头中的信息之一是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。然后点击预览查看响应的内容,是 JSON 格式的。
这是一个 GET 类型的请求,请求链接是 . 请求有 4 个参数: type , value ,
containerid 和页面。可以发现,它们的type、value和containerid总是一样的。type总是uid,value的值是页面链接中的数字,其实就是用户的id。另外,还有containerid。可以查到是107603加上用户id。改变的值为page,显然这个参数是用来控制分页的,page=l代表第一页,page=2代表第二页,以此类推。
返回的json数据中最关键的两条信息分别是cardlistinfo和cards:前者收录了比较重要的信息总数,观察后发现其实是微博总数,我们可以估算出页数根据这个数字;另一个是一个列表,里面有10个元素,展开一个看看。
可以发现这个元素有一个比较重要的字段mblog。展开它,可以发现它收录了微博的一些信息,例如态度count(点赞数)、comments_count(评论数)、reposts_count(转发数)、created at(发帖时间)、text(微博的文字) ) 等,都是格式化的内容。
原则
向网页更新发送Ajax请求的过程可以简单分为以下三个步骤:发送请求;解析内容;呈现网页。
发送请求:JavaScript可以实现页面的各种交互功能,Ajax也不例外,JavaScript也能实现。这是由 JavaScript 实现的 Ajax 的最低级别。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open和send方法向一个链接(也就是服务器)发送消息。
发送了请求。由于设置了监听器,当服务器返回响应时,会触发onreadystatechange对应的方法,然后可以在该方法中解析响应内容。
解析内容:得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。返回的内容可能是 HTML,也可能是 JSON,然后只需要在方法中用 JavaScript 进一步处理即可。例如,如果是 JSON,则可以对其进行解析和转换。
呈现网页:JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementByid().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。这种操作也称为DOM操作,即对Document网页的操作。文档操作,如更改、删除等。上例中为 document 。getElementByid("myDiv ”) .innerHTML=xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码更改为服务器返回的内容,这样服务器返回的新数据就会显示在myDiv元素内部。页面似乎已更新。
代码示例
要爬取所有微博的前 10 页,首先定义一个方法来获取每个请求的结果。在请求时,page 是一个可变参数,所以将它作为方法参数传入。
这里定义 base_url 来表示请求 URL 的前半部分。接下来构造参数字典,其中type、value、containerid为固定参数,page为可变参数。接下来调用urlencode方法将参数转换为-URL GET请求参数,类似于type=ui d&value=2830678474&containerid=78474&page=2。然后,base_url 与参数组合形成一个新的 URL。接下来,我们通过请求请求链接,添加 headers 参数。然后判断响应的状态码,如果是200,直接调用json方法将内容解析成json返回,否则不返回信息。如果发生异常,捕获并输出其异常信息。
以今日头条为例
在抓取之前,先分析一下抓取的逻辑。打开今日头条首页,右上角有一个搜索入口,这里我们尝试捕捉街拍的美图,所以输入“街拍”二字进行搜索。
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL就是当前的link=street shoot。切换到 XHR Filtering 选项卡并查看是否有任何 Ajax 请求。点击数据栏展开,发现有很多条数据。点击第一项展开,可以发现有一个title字段,它的值就是页面中第一条数据的标题。再次查看其他数据,正好是一一对应的。
为了捕捉漂亮的图片,这里的一组图片对应上一个数据字段中的一条数据。每条数据还有一个 image_detail 字段,它是一个列表的形式,其中收录了该组中所有图像的列表。您需要做的就是提出问题并下载它们。一组图片会发布到一个文件夹中,文件夹的名字就是组图的标题。
切换回 Headers 选项卡并观察其请求 URL 和 Headers 信息。您可以看到这是一个 GET 请求。请求 URL 的参数有 offset、format、keyword、autoload、count 和 curtab。
唯一变化的参数是offset,其他参数都没有变化,而且第二次请求的offset值是20,第三次是40,第四次是60,所以可以找到规律,这个offset值是偏移值,然后可以推断出count参数是一次获取的数据条数。因此,我们可以使用offset参数来控制数据分页。
代码示例
实现方法 get_page 以加载单个 Ajax 请求的结果。唯一改变的参数是偏移量,所以我们将它作为参数传递
import requests
from urllib.parse import urlencode
def get_page(offset):
params = {
'offset':offset,
'format':'json',
'keyword':'街拍',
'autoload':'true',
'count':'20',
'cur_tab':'1'
}
url = 'http://www.toutiao.com/search_ ... ncode(params)
try:
response = requests.get(url)
print(response)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
get_page(1)
实现另一种解析方法:提取每条数据的image_detail字段中的每条图片链接,返回图片链接和图片所属的标题。这时候就可以构造一个生成器了
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_detail')
for image in images:
yield {
'image':image.get('url'),
'title':title
}
这里的数据没有任何价值,说明有防采摘措施。
后面会分析 查看全部
scrapy分页抓取网页(数据加载是一种异步加载方式,原始的页面最初不会)
数据加载是一种异步加载方式。原创页面起初不收录一些数据。原创页面加载完成后,会请求一个接口从服务器获取数据,然后对数据进行处理并呈现在网页上。只需发送一个 Ajax 请求。如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取到有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟Ajax请求,那么就可以成功获取。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。这不是编程
语言,但使用JavaScript与服务器交换数据并更新,同时保证页面不刷新,页面链接不改变
网页技术的一部分。对于传统的网页,如果要更新其内容,则必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
以微博为例
以微博为例,切换到微博页面,一直往下滚动,可以发现往下滑几条微博后就没有再往下,而是出现了一个加载动画,过一会新的微博就会出现继续出现在下方。博客内容,这个过程真的是Ajax加载的过程。注意页面并没有完全刷新,也就是说页面的链接没有变化,但是页面中有新的内容,也就是后面刷新的新微博。这就是通过 Ajax 获取和呈现新数据的方式。
Ajax 实际上有一个特殊的请求类型叫做 xhr。可以找到一个名称以getIndex开头的请求,其Type为xhr,即Ajax请求。用鼠标点击请求,查看请求的详细信息。请求标头中的信息之一是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。然后点击预览查看响应的内容,是 JSON 格式的。



这是一个 GET 类型的请求,请求链接是 . 请求有 4 个参数: type , value ,
containerid 和页面。可以发现,它们的type、value和containerid总是一样的。type总是uid,value的值是页面链接中的数字,其实就是用户的id。另外,还有containerid。可以查到是107603加上用户id。改变的值为page,显然这个参数是用来控制分页的,page=l代表第一页,page=2代表第二页,以此类推。
返回的json数据中最关键的两条信息分别是cardlistinfo和cards:前者收录了比较重要的信息总数,观察后发现其实是微博总数,我们可以估算出页数根据这个数字;另一个是一个列表,里面有10个元素,展开一个看看。
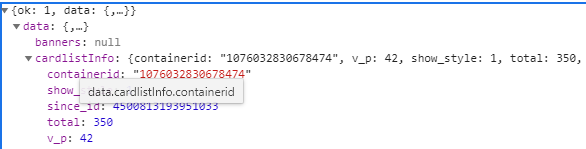
可以发现这个元素有一个比较重要的字段mblog。展开它,可以发现它收录了微博的一些信息,例如态度count(点赞数)、comments_count(评论数)、reposts_count(转发数)、created at(发帖时间)、text(微博的文字) ) 等,都是格式化的内容。


原则
向网页更新发送Ajax请求的过程可以简单分为以下三个步骤:发送请求;解析内容;呈现网页。
发送请求:JavaScript可以实现页面的各种交互功能,Ajax也不例外,JavaScript也能实现。这是由 JavaScript 实现的 Ajax 的最低级别。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open和send方法向一个链接(也就是服务器)发送消息。
发送了请求。由于设置了监听器,当服务器返回响应时,会触发onreadystatechange对应的方法,然后可以在该方法中解析响应内容。


解析内容:得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。返回的内容可能是 HTML,也可能是 JSON,然后只需要在方法中用 JavaScript 进一步处理即可。例如,如果是 JSON,则可以对其进行解析和转换。
呈现网页:JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementByid().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。这种操作也称为DOM操作,即对Document网页的操作。文档操作,如更改、删除等。上例中为 document 。getElementByid("myDiv ”) .innerHTML=xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码更改为服务器返回的内容,这样服务器返回的新数据就会显示在myDiv元素内部。页面似乎已更新。
代码示例
要爬取所有微博的前 10 页,首先定义一个方法来获取每个请求的结果。在请求时,page 是一个可变参数,所以将它作为方法参数传入。

这里定义 base_url 来表示请求 URL 的前半部分。接下来构造参数字典,其中type、value、containerid为固定参数,page为可变参数。接下来调用urlencode方法将参数转换为-URL GET请求参数,类似于type=ui d&value=2830678474&containerid=78474&page=2。然后,base_url 与参数组合形成一个新的 URL。接下来,我们通过请求请求链接,添加 headers 参数。然后判断响应的状态码,如果是200,直接调用json方法将内容解析成json返回,否则不返回信息。如果发生异常,捕获并输出其异常信息。
以今日头条为例
在抓取之前,先分析一下抓取的逻辑。打开今日头条首页,右上角有一个搜索入口,这里我们尝试捕捉街拍的美图,所以输入“街拍”二字进行搜索。

然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL就是当前的link=street shoot。切换到 XHR Filtering 选项卡并查看是否有任何 Ajax 请求。点击数据栏展开,发现有很多条数据。点击第一项展开,可以发现有一个title字段,它的值就是页面中第一条数据的标题。再次查看其他数据,正好是一一对应的。

为了捕捉漂亮的图片,这里的一组图片对应上一个数据字段中的一条数据。每条数据还有一个 image_detail 字段,它是一个列表的形式,其中收录了该组中所有图像的列表。您需要做的就是提出问题并下载它们。一组图片会发布到一个文件夹中,文件夹的名字就是组图的标题。
切换回 Headers 选项卡并观察其请求 URL 和 Headers 信息。您可以看到这是一个 GET 请求。请求 URL 的参数有 offset、format、keyword、autoload、count 和 curtab。

唯一变化的参数是offset,其他参数都没有变化,而且第二次请求的offset值是20,第三次是40,第四次是60,所以可以找到规律,这个offset值是偏移值,然后可以推断出count参数是一次获取的数据条数。因此,我们可以使用offset参数来控制数据分页。
代码示例
实现方法 get_page 以加载单个 Ajax 请求的结果。唯一改变的参数是偏移量,所以我们将它作为参数传递
import requests
from urllib.parse import urlencode
def get_page(offset):
params = {
'offset':offset,
'format':'json',
'keyword':'街拍',
'autoload':'true',
'count':'20',
'cur_tab':'1'
}
url = 'http://www.toutiao.com/search_ ... ncode(params)
try:
response = requests.get(url)
print(response)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
get_page(1)

实现另一种解析方法:提取每条数据的image_detail字段中的每条图片链接,返回图片链接和图片所属的标题。这时候就可以构造一个生成器了
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_detail')
for image in images:
yield {
'image':image.get('url'),
'title':title
}

这里的数据没有任何价值,说明有防采摘措施。
后面会分析
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页(12))
网站优化 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2022-03-09 02:12
豆瓣日记:WebScraper怎么对付这种类型的网页(12))
这是简易数据分析系列文章的第12期。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
/1776448504/I0 gyT8aeQ?type=repost
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
/1776448504/I0 gyT8aeQ?type=repost#_rnd36
第三页参数为#_rnd39
/1776448504/I0 gyT8aeQ?type=repost#_rnd39
第 4 页参数是#_rnd76:
/1776448504/I0 gyT8aeQ?type=repost#_rnd76
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据;对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页(12))


这是简易数据分析系列文章的第12期。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。

今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:

但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。

这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
/1776448504/I0 gyT8aeQ?type=repost
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
/1776448504/I0 gyT8aeQ?type=repost#_rnd36
第三页参数为#_rnd39
/1776448504/I0 gyT8aeQ?type=repost#_rnd39
第 4 页参数是#_rnd76:
/1776448504/I0 gyT8aeQ?type=repost#_rnd76
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
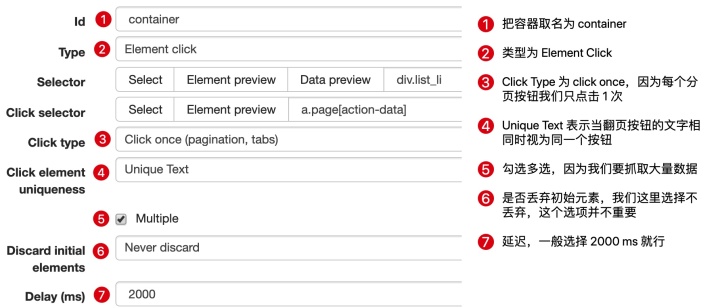
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:

寻呼机选择过程如下图所示:

3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
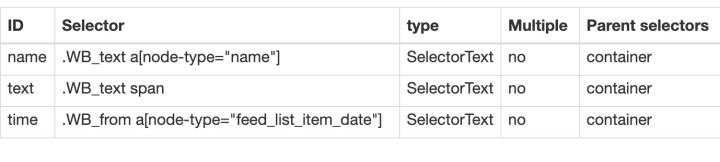
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据;对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。
scrapy分页抓取网页(scrapy分页抓取网页实战基于aiohttp框架提供request对象在一页从头抓到尾)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-08 07:04
scrapy分页抓取网页实战基于aiohttp框架提供request对象在一页从头抓到尾:python2版本
一、get请求:先在浏览器打开网址:scrapyget抓取网页源码如下:url='/'
二、post请求:在浏览器发起post请求:url=''post(url,data=none,meta={'content-type':'text/html;charset=utf-8'})在回调中,需要一些参数,例如-url=''post请求可以被twitter,reddit等验证真实性以及保存到服务器:post请求还可以请求参数化后再次请求,例如抓取网页源码:post(url,data=none,include=none,meta={'content-type':'text/html;charset=utf-8'})。
三、注意事项一定要正确设置scrapy中post请求参数并且校验这个请求不能返回一个空值,参数必须为:app--get-postapp名称和数据内容,需要注意app为多个请求对象,数据中,请求内容可以为空,但应该设置为app名称'''`post+app->app'`'#调用这个方法时,必须app名称为真。
举例:抓取网页://content.htmlfromscrapy.downloadingimportapidefget_it(url):returnscrapy.downloading(url).urls.foreach(all_dist=api.details)defdetails(response):returnresponse.text()post请求请求时是不需要request对象:#如果不指定-url和-cookies'''app--get-postapp名称和数据内容'''#post请求不支持cookies,cookies方法在http服务端不被接受,而是传给json对象'''defpost(url,data=none,include=none,meta={'content-type':'text/html;charset=utf-8'}):"""post请求-s主要由以下5个参数来定义post请求时必须postcookies和cookie参数"""#postspecifies5methods"""#下面的列表是参数列表,所有的参数列表,都是一样的'''scheme='https'data={'content-type':'text/html;charset=utf-8'}#post需要使用前缀参数,请求头中不加#这个参数cookies.include=truefromscrapy.downloadingimportapidefget_it(url):returnscrapy.downloading(url).urls.foreach(all_dist=api.details)scheme='https'include=['*'forcookiesincookies]meta={'content-type':'text/html;charset=utf-8'}scheme='https'request_uri=''action='post'content=。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页实战基于aiohttp框架提供request对象在一页从头抓到尾)
scrapy分页抓取网页实战基于aiohttp框架提供request对象在一页从头抓到尾:python2版本
一、get请求:先在浏览器打开网址:scrapyget抓取网页源码如下:url='/'
二、post请求:在浏览器发起post请求:url=''post(url,data=none,meta={'content-type':'text/html;charset=utf-8'})在回调中,需要一些参数,例如-url=''post请求可以被twitter,reddit等验证真实性以及保存到服务器:post请求还可以请求参数化后再次请求,例如抓取网页源码:post(url,data=none,include=none,meta={'content-type':'text/html;charset=utf-8'})。
三、注意事项一定要正确设置scrapy中post请求参数并且校验这个请求不能返回一个空值,参数必须为:app--get-postapp名称和数据内容,需要注意app为多个请求对象,数据中,请求内容可以为空,但应该设置为app名称'''`post+app->app'`'#调用这个方法时,必须app名称为真。
举例:抓取网页://content.htmlfromscrapy.downloadingimportapidefget_it(url):returnscrapy.downloading(url).urls.foreach(all_dist=api.details)defdetails(response):returnresponse.text()post请求请求时是不需要request对象:#如果不指定-url和-cookies'''app--get-postapp名称和数据内容'''#post请求不支持cookies,cookies方法在http服务端不被接受,而是传给json对象'''defpost(url,data=none,include=none,meta={'content-type':'text/html;charset=utf-8'}):"""post请求-s主要由以下5个参数来定义post请求时必须postcookies和cookie参数"""#postspecifies5methods"""#下面的列表是参数列表,所有的参数列表,都是一样的'''scheme='https'data={'content-type':'text/html;charset=utf-8'}#post需要使用前缀参数,请求头中不加#这个参数cookies.include=truefromscrapy.downloadingimportapidefget_it(url):returnscrapy.downloading(url).urls.foreach(all_dist=api.details)scheme='https'include=['*'forcookiesincookies]meta={'content-type':'text/html;charset=utf-8'}scheme='https'request_uri=''action='post'content=。
scrapy分页抓取网页(小编来一起_crawler-crawler文件蜘蛛代码_快照)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-07 07:21
本文介绍从给定的URL抓取数据并使用scrapy将其放入文件的处理方法。对大家解决问题有一定的参考价值。有需要的朋友,和小编一起学习吧!问题描述
我正在尝试深入刮取给定的 网站 并从所有页面中刮取文本。我正在使用 scrapy 来抓取 网站
这就是我运行蜘蛛爬虫的方式 stack_crawler -o items.json
item.json 文件为空
这是蜘蛛code_snapshot
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
#from tutorial.items import TutorialItem
from tutorial.items import DmozItem
class StackCrawlerSpider(CrawlSpider):
name = 'stack_crawler'
allowed_domains = ['http://www.dmoz.org']
start_urls = ['http://www.dmoz.org/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = TutorialItem()
i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
i['name'] = response.xpath('//div[@id="name"]').extract()
i['description'] = response.xpath('//div[@id="description"]').extract()
return i
这是我运行蜘蛛爬行时得到的日志
dummy-MacBook-Pro:spiders Dummy$ scrapy crawl stack_crawler -o items.json
2016-06-09 10:22:23 [scrapy] INFO: Scrapy 1.1.0 started (bot: tutorial)
2016-06-09 10:22:23 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'FEED_URI': 'items.json', 'SPIDER_MODULES': ['tutorial.spiders'], 'BOT_NAME': 'tutorial', 'ROBOTSTXT_OBEY': True, 'FEED_FORMAT': 'json'}
2016-06-09 10:22:23 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2016-06-09 10:22:23 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2016-06-09 10:22:23 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2016-06-09 10:22:23 [scrapy] INFO: Enabled item pipelines:
[]
2016-06-09 10:22:23 [scrapy] INFO: Spider opened
2016-06-09 10:22:23 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-06-09 10:22:23 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6024
2016-06-09 10:22:24 [scrapy] DEBUG: Crawled (200) (referer: None)
2016-06-09 10:22:24 [scrapy] DEBUG: Crawled (200) (referer: None)
2016-06-09 10:22:24 [scrapy] INFO: Closing spider (finished)
2016-06-09 10:22:24 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 430,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 5694,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2016, 6, 9, 4, 52, 24, 862900),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2016, 6, 9, 4, 52, 23, 483092)}
2016-06-09 10:22:24 [scrapy] INFO: Spider closed (finished)
产品代码快照
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
谁能帮我弄清楚我在代码级别做错了什么来获取数据。
推荐答案
我认为您是scrapy的新手,并且您在代码中犯了很多错误
1.scrapy 中有默认函数 parse 或 start_product_requests,所以你可以避免在那里使用 LinkExtractor。使用 parse 函数并直接在那里获取 start_urls 响应。
2.您在 items.py 中定义了一项并使用另一项。所以字段名不同,就会有冲突。
3.您为字段值选择的路径是正确的。
你必须试试这个
蜘蛛code_snapshot
import scrapy
from lxml import html
from scrapy.spiders import CrawlSpider, Rule
from tutorial.items import DmozItem
class StackCrawlerSpider(CrawlSpider):
name = 'stack_crawler'
allowed_domains = ['http://www.dmoz.org']
start_urls = ['http://www.dmoz.org/']
def parse(self, response):
doc = html.fromstring(response.body)
i = DmozItem()
i['title'] = doc.xpath('//meta[@property="og:title"]/@content')
i['link'] = response.url
i['desc'] = doc.xpath('//meta[@name="description"]/@content')
yield i
产品代码快照
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
这行得通。
这篇关于从给定URL抓取数据并使用scrapy将其放入文件的文章文章就到这里了,希望我们推荐的答案对您有所帮助,也希望大家支持IT之家! 查看全部
scrapy分页抓取网页(小编来一起_crawler-crawler文件蜘蛛代码_快照)
本文介绍从给定的URL抓取数据并使用scrapy将其放入文件的处理方法。对大家解决问题有一定的参考价值。有需要的朋友,和小编一起学习吧!问题描述
我正在尝试深入刮取给定的 网站 并从所有页面中刮取文本。我正在使用 scrapy 来抓取 网站
这就是我运行蜘蛛爬虫的方式 stack_crawler -o items.json
item.json 文件为空
这是蜘蛛code_snapshot
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
#from tutorial.items import TutorialItem
from tutorial.items import DmozItem
class StackCrawlerSpider(CrawlSpider):
name = 'stack_crawler'
allowed_domains = ['http://www.dmoz.org']
start_urls = ['http://www.dmoz.org/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = TutorialItem()
i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
i['name'] = response.xpath('//div[@id="name"]').extract()
i['description'] = response.xpath('//div[@id="description"]').extract()
return i
这是我运行蜘蛛爬行时得到的日志
dummy-MacBook-Pro:spiders Dummy$ scrapy crawl stack_crawler -o items.json
2016-06-09 10:22:23 [scrapy] INFO: Scrapy 1.1.0 started (bot: tutorial)
2016-06-09 10:22:23 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'FEED_URI': 'items.json', 'SPIDER_MODULES': ['tutorial.spiders'], 'BOT_NAME': 'tutorial', 'ROBOTSTXT_OBEY': True, 'FEED_FORMAT': 'json'}
2016-06-09 10:22:23 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2016-06-09 10:22:23 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2016-06-09 10:22:23 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2016-06-09 10:22:23 [scrapy] INFO: Enabled item pipelines:
[]
2016-06-09 10:22:23 [scrapy] INFO: Spider opened
2016-06-09 10:22:23 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-06-09 10:22:23 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6024
2016-06-09 10:22:24 [scrapy] DEBUG: Crawled (200) (referer: None)
2016-06-09 10:22:24 [scrapy] DEBUG: Crawled (200) (referer: None)
2016-06-09 10:22:24 [scrapy] INFO: Closing spider (finished)
2016-06-09 10:22:24 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 430,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 5694,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2016, 6, 9, 4, 52, 24, 862900),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2016, 6, 9, 4, 52, 23, 483092)}
2016-06-09 10:22:24 [scrapy] INFO: Spider closed (finished)
产品代码快照
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
谁能帮我弄清楚我在代码级别做错了什么来获取数据。
推荐答案
我认为您是scrapy的新手,并且您在代码中犯了很多错误
1.scrapy 中有默认函数 parse 或 start_product_requests,所以你可以避免在那里使用 LinkExtractor。使用 parse 函数并直接在那里获取 start_urls 响应。
2.您在 items.py 中定义了一项并使用另一项。所以字段名不同,就会有冲突。
3.您为字段值选择的路径是正确的。
你必须试试这个
蜘蛛code_snapshot
import scrapy
from lxml import html
from scrapy.spiders import CrawlSpider, Rule
from tutorial.items import DmozItem
class StackCrawlerSpider(CrawlSpider):
name = 'stack_crawler'
allowed_domains = ['http://www.dmoz.org']
start_urls = ['http://www.dmoz.org/']
def parse(self, response):
doc = html.fromstring(response.body)
i = DmozItem()
i['title'] = doc.xpath('//meta[@property="og:title"]/@content')
i['link'] = response.url
i['desc'] = doc.xpath('//meta[@name="description"]/@content')
yield i
产品代码快照
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
这行得通。
这篇关于从给定URL抓取数据并使用scrapy将其放入文件的文章文章就到这里了,希望我们推荐的答案对您有所帮助,也希望大家支持IT之家!
scrapy分页抓取网页(人人都用得上webscraper进阶教程,人人用得上数据教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-07 02:24
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:最简单的数据爬虫教程,人人都可以用高级网络爬虫教程,人人都会用
如果你使用网络爬虫抓取数据,你很有可能会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或滚动加载数据,无法完全捕获,如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下级关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。 查看全部
scrapy分页抓取网页(人人都用得上webscraper进阶教程,人人用得上数据教程)
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:最简单的数据爬虫教程,人人都可以用高级网络爬虫教程,人人都会用
如果你使用网络爬虫抓取数据,你很有可能会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或滚动加载数据,无法完全捕获,如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下级关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-05 09:24
Scrapy 是一个用 Python 编写的应用程序框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。
通常我们可以通过Scrapy框架轻松实现爬虫,抓取指定的网站内容或图片。
Scrapy架构图(绿线为数据流)
Scrapy的运行过程
代码写好了,程序开始运行了……
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
制作一个Scrapy爬虫一共需要4个步骤:新建一个项目(scrapy startproject xxx):新建一个爬虫项目清除目标(写items.py):清除你要抓取的目标创建一个爬虫(spiders/xxspider.py):创建爬虫并开始爬取网页存储内容(pipelines.py):设计管道存储爬取内容安装windows安装方法
升级pip版本:
pip install --upgrade pip
通过 pip 安装 Scrapy 框架:
pip install Scrapy
如何安装 Ubuntu
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过 pip 安装 Scrapy 框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,所以默认安装的包是不能删除的,但是你使用python2.x来安装Scrapy会报错,用python3.x安装也会报错。最后没有找到直接安装Scrapy的方法,所以我就用另一种安装方法来讲解安装步骤。解决方法是使用virtualenv来安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明安装成功。
入门案例学习目标一.新建项目(scrapy startproject)
在开始抓取之前,必须创建一个新的 Scrapy 项目。转到自定义项目目录并运行以下命令:
scrapy startproject mySpider
其中,mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
我们来简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、清除目标(mySpider/items.py)
我们打算在 网站 中获取所有讲师的姓名、职务和个人信息。
打开 mySpider 目录中的 items.py。
Item 定义了一个结构化的数据字段来保存爬取的数据,有点像 Python 中的 dict,但提供了一些额外的保护来减少错误。
可以通过创建一个scrapy.Item类,定义一个scrapy.Field类型的类属性(可以理解为类似ORM的映射关系)来定义一个Item。
接下来,创建一个 ItcastItem 类,并构建项目模型。
三、制作蜘蛛(spiders/itcastSpider.py)
爬虫功能分为两步:
1.爬取数据
在当前目录输入命令会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建一个 Spider,你必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
name = "" : 该爬虫的标识名必须唯一,不同的爬虫必须定义不同的名称。
allow_domains = []是搜索的域名范围,即爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的URL会被忽略。
start_urls = () : 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。其他子 URL 将继承自这些起始 URL。
parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传递。主要功能如下:
p>
负责解析返回的网页数据(response.body),提取结构化数据(生成item) 查看全部
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
Scrapy 是一个用 Python 编写的应用程序框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。
通常我们可以通过Scrapy框架轻松实现爬虫,抓取指定的网站内容或图片。
Scrapy架构图(绿线为数据流)
Scrapy的运行过程
代码写好了,程序开始运行了……
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
制作一个Scrapy爬虫一共需要4个步骤:新建一个项目(scrapy startproject xxx):新建一个爬虫项目清除目标(写items.py):清除你要抓取的目标创建一个爬虫(spiders/xxspider.py):创建爬虫并开始爬取网页存储内容(pipelines.py):设计管道存储爬取内容安装windows安装方法
升级pip版本:
pip install --upgrade pip
通过 pip 安装 Scrapy 框架:
pip install Scrapy
如何安装 Ubuntu
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过 pip 安装 Scrapy 框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,所以默认安装的包是不能删除的,但是你使用python2.x来安装Scrapy会报错,用python3.x安装也会报错。最后没有找到直接安装Scrapy的方法,所以我就用另一种安装方法来讲解安装步骤。解决方法是使用virtualenv来安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明安装成功。
入门案例学习目标一.新建项目(scrapy startproject)
在开始抓取之前,必须创建一个新的 Scrapy 项目。转到自定义项目目录并运行以下命令:
scrapy startproject mySpider
其中,mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
我们来简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、清除目标(mySpider/items.py)
我们打算在 网站 中获取所有讲师的姓名、职务和个人信息。
打开 mySpider 目录中的 items.py。
Item 定义了一个结构化的数据字段来保存爬取的数据,有点像 Python 中的 dict,但提供了一些额外的保护来减少错误。
可以通过创建一个scrapy.Item类,定义一个scrapy.Field类型的类属性(可以理解为类似ORM的映射关系)来定义一个Item。
接下来,创建一个 ItcastItem 类,并构建项目模型。
三、制作蜘蛛(spiders/itcastSpider.py)
爬虫功能分为两步:
1.爬取数据
在当前目录输入命令会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建一个 Spider,你必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
name = "" : 该爬虫的标识名必须唯一,不同的爬虫必须定义不同的名称。
allow_domains = []是搜索的域名范围,即爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的URL会被忽略。
start_urls = () : 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。其他子 URL 将继承自这些起始 URL。
parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传递。主要功能如下:
p>
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
scrapy分页抓取网页(代码也可以从我的开源项目HtmlExtractor中获取。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-05 05:06
代码也可以从我的开源项目 HtmlExtractor 中获得。
我们在爬取数据的时候,如果目标网站是以Js的方式动态生成数据,以滚动页面的方式进行分页,那我们怎么爬取呢?
如今日头条网站:
我们可以使用 Selenium 来做到这一点。虽然 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合数据抓取,并且可以轻松绕过 网站 的反爬虫限制,因为 Selenium 直接在浏览器中运行,就像真正的用户一样.
使用Selenium,我们不仅可以爬取Js动态生成数据的网页,还可以爬取滚动页面分页的网页。
首先,我们使用maven来导入Selenium依赖:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
然后就可以编写代码进行爬取了:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i 查看全部
scrapy分页抓取网页(代码也可以从我的开源项目HtmlExtractor中获取。。)
代码也可以从我的开源项目 HtmlExtractor 中获得。
我们在爬取数据的时候,如果目标网站是以Js的方式动态生成数据,以滚动页面的方式进行分页,那我们怎么爬取呢?
如今日头条网站:
我们可以使用 Selenium 来做到这一点。虽然 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合数据抓取,并且可以轻松绕过 网站 的反爬虫限制,因为 Selenium 直接在浏览器中运行,就像真正的用户一样.
使用Selenium,我们不仅可以爬取Js动态生成数据的网页,还可以爬取滚动页面分页的网页。
首先,我们使用maven来导入Selenium依赖:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
然后就可以编写代码进行爬取了:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-03 20:12
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注才是本质(4小时,完成Scrapy爬虫必备知识点讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学
导师答题(拒绝助教,讲师当天答题)
课程适合人群
具备Py基础语法和面向对象开发思想,其他语言开发者,浪子,想一夜暴富的人
建筑与环境建设
文章目录Scrapy介绍
Scrapy组件介绍
点安装scrapy
Scrapy 简介
一个快速、高级的屏幕抓取和网页抓取 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求定制。Scrapy架构图:
Scrapy组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
Scheduler:用于接受引擎发送的Request请求,将其推入队列,当引擎再次请求时返回。
Downloader(下载器):用于引擎发送的Request请求对应的网页内容,将获取到的Responses返回给Spider。
Item Pipeline:负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
点安装scrapy
通过 pip show scrapy 检查是否安装正常。如果已安装,则显示安装信息,否则不显示任何信息。
通过pip install scrapy安装爬虫框架(大概率会抛出以下异常)
根据异常,它缺少:错误:需要 MICROSOFT VISUAL C++ 9.0 (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载一个缺少的窗口组件,在视频的学习资料中提供
第一个爬虫项目
文章目录
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject douban创建项目
创建一个Spider解析器根据以上提示:cd douban,然后在项目中执行:scrapy genspider example 就可以创建一个Spider对象
细心的朋友会发现,douban_spider默认会存放在douban.spider目录下。当你用pycharm IDE打开时,你会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的spider文件,也就是你爬取的py文件
items.py:相当于一个容器,字典更像是middlewares.py:定义Downloader
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 pipelines.py:定义Item
Pipeline的实现实现了数据的清洗、存储、校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法简介
文章目录
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。事实上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章目录
豆瓣电影页面分析
首页下载实现
前5名电影数据如下
豆瓣电影页面分析为您讲解了如何在 XML 文档中查找信息。具体来说,你已经学会了如何获取元素、内容和属性,你也知道了如何通过标签的属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5名电影数据如下
项目模型封装数据
文章目录创建Item模型层
封装爬取的数据
yield的语法介绍
在创建Item模型层之前,我们可以获取第一页的数据,但是只能在控制台打印。Scrapy 中还有一个 Item 模块。这个类就是模型层,主要完成对值数据的封装,然后写入数据库。
将爬取的数据封装起来,将爬取的数据存储在豆瓣项目对象中,然后交给item_list,最后返回到Item_list
yield的语法介绍
一个有yield的函数就是一个生成器,它不同于普通的函数,生成一个生成器看起来像一个函数调用,但是在它上面调用next()之前不会执行任何函数代码(在for循环中,next()是自动调用。)) 开始执行。执行流程虽然还是按照函数的流程执行,但是每执行一次yield语句都会中断,并返回一个迭代值,在下次执行时从yield的下一条语句继续执行. 好像一个函数在正常执行的时候被yield打断了几次,每次打断都会通过yield返回当前的迭代值
产量和自动翻页
文章目录
产量优势
良率优化返回数据
产量优势
收益的好处是显而易见的。将函数重写为生成器使您能够进行迭代。相比于使用类实例保存状态来计算下一个next()的值,不仅代码简洁,而且执行过程也非常清晰。
在 Scrapy 爬虫框架中,yield 有一个很自然的使用场景,因为我们不知道爬虫每次获取的数据的大小。如果每次都一起返回,数据量会非常大。这时候如果使用yield来优化,代码会非常简洁高效
良率优化返回数据 查看全部
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注才是本质(4小时,完成Scrapy爬虫必备知识点讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学
导师答题(拒绝助教,讲师当天答题)
课程适合人群
具备Py基础语法和面向对象开发思想,其他语言开发者,浪子,想一夜暴富的人
建筑与环境建设
文章目录Scrapy介绍
Scrapy组件介绍
点安装scrapy
Scrapy 简介
一个快速、高级的屏幕抓取和网页抓取 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求定制。Scrapy架构图:
Scrapy组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
Scheduler:用于接受引擎发送的Request请求,将其推入队列,当引擎再次请求时返回。
Downloader(下载器):用于引擎发送的Request请求对应的网页内容,将获取到的Responses返回给Spider。
Item Pipeline:负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
点安装scrapy
通过 pip show scrapy 检查是否安装正常。如果已安装,则显示安装信息,否则不显示任何信息。
通过pip install scrapy安装爬虫框架(大概率会抛出以下异常)
根据异常,它缺少:错误:需要 MICROSOFT VISUAL C++ 9.0 (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载一个缺少的窗口组件,在视频的学习资料中提供
第一个爬虫项目
文章目录
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject douban创建项目
创建一个Spider解析器根据以上提示:cd douban,然后在项目中执行:scrapy genspider example 就可以创建一个Spider对象
细心的朋友会发现,douban_spider默认会存放在douban.spider目录下。当你用pycharm IDE打开时,你会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的spider文件,也就是你爬取的py文件
items.py:相当于一个容器,字典更像是middlewares.py:定义Downloader
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 pipelines.py:定义Item
Pipeline的实现实现了数据的清洗、存储、校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法简介
文章目录
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。事实上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章目录
豆瓣电影页面分析
首页下载实现
前5名电影数据如下
豆瓣电影页面分析为您讲解了如何在 XML 文档中查找信息。具体来说,你已经学会了如何获取元素、内容和属性,你也知道了如何通过标签的属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5名电影数据如下
项目模型封装数据
文章目录创建Item模型层
封装爬取的数据
yield的语法介绍
在创建Item模型层之前,我们可以获取第一页的数据,但是只能在控制台打印。Scrapy 中还有一个 Item 模块。这个类就是模型层,主要完成对值数据的封装,然后写入数据库。
将爬取的数据封装起来,将爬取的数据存储在豆瓣项目对象中,然后交给item_list,最后返回到Item_list
yield的语法介绍
一个有yield的函数就是一个生成器,它不同于普通的函数,生成一个生成器看起来像一个函数调用,但是在它上面调用next()之前不会执行任何函数代码(在for循环中,next()是自动调用。)) 开始执行。执行流程虽然还是按照函数的流程执行,但是每执行一次yield语句都会中断,并返回一个迭代值,在下次执行时从yield的下一条语句继续执行. 好像一个函数在正常执行的时候被yield打断了几次,每次打断都会通过yield返回当前的迭代值
产量和自动翻页
文章目录
产量优势
良率优化返回数据
产量优势
收益的好处是显而易见的。将函数重写为生成器使您能够进行迭代。相比于使用类实例保存状态来计算下一个next()的值,不仅代码简洁,而且执行过程也非常清晰。
在 Scrapy 爬虫框架中,yield 有一个很自然的使用场景,因为我们不知道爬虫每次获取的数据的大小。如果每次都一起返回,数据量会非常大。这时候如果使用yield来优化,代码会非常简洁高效
良率优化返回数据
scrapy分页抓取网页(制作爬虫(Spider)制作(Spider)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2022-03-03 20:09
将网站安装到爬虫中,分为几个步骤:
1.新建项目(项目)
按住Shift键并在空目录中单击鼠标右键,选择“在此处打开命令窗口”,输入以下命令:
>scrapystart项目豆瓣
项目创建后,生成如下目录:
用pycharm打开项目,看看:
每个文件的作用:
2.明确目标(项目)
可以使用 scrapy.item.Item 类和使用 scrapy.item.Field 对象定义的属性来创建项目。
接下来,我们开始构建项目模型(model)。在本例中,构建 items.py 如下:
首先,我们想要的是:
【注意】:
爬取元素不需要声明模型,也可以在爬虫代码中直接显示爬取到的元素这种方式
根据官方文档,Item是保存结构数据的地方。 Scrapy可以将解析结果以字典的形式返回,但是Python中的字典缺乏结构,在大型爬虫系统中非常不方便。 Item 提供了一个类似字典的 API。而且声明字段非常方便,很多Scrapy组件可以使用Item的其他信息。以后也方便管道对爬取的数据进行处理。
3.做一个蜘蛛
做一个爬虫,一般分为两个步骤:爬取-取走
也就是说,首先你要获取整个页面的所有内容,然后取出对你有用的部分。
3.1 次攀登
Spider 是用户编写的用于从域(或域组)中抓取信息的类。定义用于下载的 URL 列表、用于跟踪链接的方案以及解析 Web 内容以提取项目的方法。
要创建一个 Spider,你必须继承 scrapy.spider.BaseSpider 并定义三个强制属性:
让我们编写第一个爬虫,命名为doubanspider.py,并将其保存在doubanspiders目录中。
在豆瓣目录下按住shift右键,在此处打开命令窗口,输入:
>scrapy爬豆瓣
3.1.1 创建main.py并保存到豆瓣目录
3.1.2 为避免被屏蔽,需要伪装,在settings.py中添加USER_AGENT
USER_AGENT='Mozilla/5.0(Macintosh;IntelMacOSX10_8_3)AppleWebKit/536.5(KHTML,likeGecko)Chrome/19.0. 1084.54Safari/536.5'
3.2 次拍摄
使用 Xpath 进行解析。有关相关知识,请参阅 Xpath 部分。这里不赘述,只是给出一个大概的思路:F12检查元素,我们看页面代码,检查页面显示特性,比如要爬取的页面内容是否需要结合,替换空格等,同时如果出现分页情况,需要自动抓取下一页查看代码特征,发现几个问题:(1)标题分为两行,需要用for循环遍历。结合起来;(2)有些电影没有引号,需要考虑为空值;(3)的url分页不完整,需要抓取并填写完整的URL(要导入Request,from scrapy.http import Request),可以循环爬取。
#-*-coding:utf-8-*-fromscrapy。蜘蛛importCrawlSpiderfromscrapy。选择器importSelectorfrom豆瓣。 itemsimportDoubanItemfromscrapy. httpimportRequestclassDouban(CrawlSpider):name="douban"start_urls=['.豆瓣。 com/top250']url='。豆瓣。 com/top250' defparse(self, response): #printresponse。 bodyitem=豆瓣项目()选择器=选择器(响应)#printselectorMovies=选择器。 xpath('//div[@class="info"]')#printMoviesforeachMoiveinMovies:title=eachMoive. xpath('div[@class="hd"]/a/span/text()').
extract()# 合并两个名字 fullTitle=''foreachintitle:fullTitle+=eachmovieInfo=eachMoive. xpath('div[@class="bd"]/p/text()')。提取()星=每个电影。 xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')。 extract()[0]quote=eachMoive. xpath('div[@class="bd"]/p[@class="quote"]/span/text()'). extract()#quote可能为空,所以需要先判断 ifquote:quote=quote[0]else:quote=''#printfullTitle#printmovieInfo#printstar#printquoteitem['title']=fullTitleitem['movieInfo']= ';'。加入(movieInfo)item['star']=staritem['quote']=quoteielditemnextLink=selector。
xpath('//span[@class="next"]/link/@href'). extract()#第10页是最后一页,没有下一页的链接 ifnextLink:nextLink=nextLink[0]printnextLinkyieldRequest(self.url+nextLink,callback=self.parse) ##递归传递的地址下一页对于这个函数本身,在爬回callback=self时注意韩老师提供的栗子这里二次分析的解释。解析
4.存储内容(管道)
保存信息最简单的方法是通过,主要有四种:JSON、JSON 行、CSV、XML。用最常用的JSON导出结果,命令如下:
>scrapycrawldouban-oitems.json-tjson #-o后面是导出文件名,-t后面是导出类型。要导出结果,请使用文本编辑器打开 json 文件
尝试导出为 csv 格式:
>scrapycrawldouban-oiitems.csv-tcsv
4.1 设置默认存储
可以直接在settings.py文件中设置输出位置和文件类型,如下:
FEED_URI=u'file:///E:/douban/douban.csv'FEED_FORMAT='CSV'
5.运行爬虫(main.py)
不同于直接运行的简单单线程爬虫程序,这里我们还需要运行一个main.py,需要自己手动生成。 main.py代码如下:
运行结果:
如果你想用抓取的物品做更复杂的事情,你可以写一个物品管道。 查看全部
scrapy分页抓取网页(制作爬虫(Spider)制作(Spider)())
将网站安装到爬虫中,分为几个步骤:
1.新建项目(项目)
按住Shift键并在空目录中单击鼠标右键,选择“在此处打开命令窗口”,输入以下命令:
>scrapystart项目豆瓣
项目创建后,生成如下目录:
用pycharm打开项目,看看:
每个文件的作用:
2.明确目标(项目)
可以使用 scrapy.item.Item 类和使用 scrapy.item.Field 对象定义的属性来创建项目。
接下来,我们开始构建项目模型(model)。在本例中,构建 items.py 如下:
首先,我们想要的是:
【注意】:
爬取元素不需要声明模型,也可以在爬虫代码中直接显示爬取到的元素这种方式
根据官方文档,Item是保存结构数据的地方。 Scrapy可以将解析结果以字典的形式返回,但是Python中的字典缺乏结构,在大型爬虫系统中非常不方便。 Item 提供了一个类似字典的 API。而且声明字段非常方便,很多Scrapy组件可以使用Item的其他信息。以后也方便管道对爬取的数据进行处理。
3.做一个蜘蛛
做一个爬虫,一般分为两个步骤:爬取-取走
也就是说,首先你要获取整个页面的所有内容,然后取出对你有用的部分。
3.1 次攀登
Spider 是用户编写的用于从域(或域组)中抓取信息的类。定义用于下载的 URL 列表、用于跟踪链接的方案以及解析 Web 内容以提取项目的方法。
要创建一个 Spider,你必须继承 scrapy.spider.BaseSpider 并定义三个强制属性:
让我们编写第一个爬虫,命名为doubanspider.py,并将其保存在doubanspiders目录中。
在豆瓣目录下按住shift右键,在此处打开命令窗口,输入:
>scrapy爬豆瓣
3.1.1 创建main.py并保存到豆瓣目录
3.1.2 为避免被屏蔽,需要伪装,在settings.py中添加USER_AGENT
USER_AGENT='Mozilla/5.0(Macintosh;IntelMacOSX10_8_3)AppleWebKit/536.5(KHTML,likeGecko)Chrome/19.0. 1084.54Safari/536.5'
3.2 次拍摄
使用 Xpath 进行解析。有关相关知识,请参阅 Xpath 部分。这里不赘述,只是给出一个大概的思路:F12检查元素,我们看页面代码,检查页面显示特性,比如要爬取的页面内容是否需要结合,替换空格等,同时如果出现分页情况,需要自动抓取下一页查看代码特征,发现几个问题:(1)标题分为两行,需要用for循环遍历。结合起来;(2)有些电影没有引号,需要考虑为空值;(3)的url分页不完整,需要抓取并填写完整的URL(要导入Request,from scrapy.http import Request),可以循环爬取。
#-*-coding:utf-8-*-fromscrapy。蜘蛛importCrawlSpiderfromscrapy。选择器importSelectorfrom豆瓣。 itemsimportDoubanItemfromscrapy. httpimportRequestclassDouban(CrawlSpider):name="douban"start_urls=['.豆瓣。 com/top250']url='。豆瓣。 com/top250' defparse(self, response): #printresponse。 bodyitem=豆瓣项目()选择器=选择器(响应)#printselectorMovies=选择器。 xpath('//div[@class="info"]')#printMoviesforeachMoiveinMovies:title=eachMoive. xpath('div[@class="hd"]/a/span/text()').
extract()# 合并两个名字 fullTitle=''foreachintitle:fullTitle+=eachmovieInfo=eachMoive. xpath('div[@class="bd"]/p/text()')。提取()星=每个电影。 xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')。 extract()[0]quote=eachMoive. xpath('div[@class="bd"]/p[@class="quote"]/span/text()'). extract()#quote可能为空,所以需要先判断 ifquote:quote=quote[0]else:quote=''#printfullTitle#printmovieInfo#printstar#printquoteitem['title']=fullTitleitem['movieInfo']= ';'。加入(movieInfo)item['star']=staritem['quote']=quoteielditemnextLink=selector。
xpath('//span[@class="next"]/link/@href'). extract()#第10页是最后一页,没有下一页的链接 ifnextLink:nextLink=nextLink[0]printnextLinkyieldRequest(self.url+nextLink,callback=self.parse) ##递归传递的地址下一页对于这个函数本身,在爬回callback=self时注意韩老师提供的栗子这里二次分析的解释。解析
4.存储内容(管道)
保存信息最简单的方法是通过,主要有四种:JSON、JSON 行、CSV、XML。用最常用的JSON导出结果,命令如下:
>scrapycrawldouban-oitems.json-tjson #-o后面是导出文件名,-t后面是导出类型。要导出结果,请使用文本编辑器打开 json 文件
尝试导出为 csv 格式:
>scrapycrawldouban-oiitems.csv-tcsv
4.1 设置默认存储
可以直接在settings.py文件中设置输出位置和文件类型,如下:
FEED_URI=u'file:///E:/douban/douban.csv'FEED_FORMAT='CSV'
5.运行爬虫(main.py)
不同于直接运行的简单单线程爬虫程序,这里我们还需要运行一个main.py,需要自己手动生成。 main.py代码如下:
运行结果:
如果你想用抓取的物品做更复杂的事情,你可以写一个物品管道。
scrapy分页抓取网页(开发好一个框架爬虫(ConfigurableSpider)生产可用的Scrapy爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-03 14:15
背景
爬虫是个有趣的东西,它可以让你通过爬虫程序自动抓取网上的信息,省去了很多手动操作。在一些优质的爬虫框架出来之前,开发者还是通过简单的网络请求+网页解析器来开发爬虫程序,比如Python的requests+BeautifulSoup,而高级爬虫程序还会加入数据存储模块,比如MySQL、MongoDB。这种方式开发效率低,稳定性差,开发一个完整的、可生产的爬虫可能需要几个小时。我称这种方法为无框架爬虫。
2011年,基于Twisted的Scrapy爬虫框架诞生,一下子为大众所熟知,成为首屈一指的全能高性能异步爬虫框架。Scrapy 抽象了几个核心模块,让开发者可以专注于爬虫的爬取逻辑,而不是数据下载、页面解析、任务调度等比较繁琐的模块。要开发一个生产就绪的 Scrapy 爬虫,简单的可能只需要十分钟,复杂的可能需要一个多小时。当然,我们还有很多其他优秀的框架,比如PySpider、Colly等,我把这种爬虫叫做框架爬虫。框架爬虫解放生产力,现在很多公司改造框架爬虫,应用到生产环境中,大规模抓取数据。
但是,对于需要抓取数百个网站的爬虫的需求,框架爬虫可能会不堪重负,不足,编写爬虫成为了一项手工工作。例如,如果开发一个框架爬虫平均需要20分钟,如果一个全职爬虫开发人员每天工作8小时,那么需要20000分钟,333小时,42个工作日,将近2个开发1000个< @网站 月亮。当然,我们可以聘请10名全职爬虫开发工程师,但也需要4个工作日才能完成(如下图)。
这也是相对低效的。为了克服这个效率问题,可配置爬虫应运而生。
可配置爬虫简介
A Configurable Spider,顾名思义,就是可以配置爬取规则的蜘蛛。可配置爬虫是一种高度抽象的爬虫程序。开发者无需编写爬虫代码,只需将需要爬取的网页地址、字段、属性写在配置文件或数据库中,让专门的爬虫程序根据配置抓取数据。. 可配置爬虫进一步将爬虫代码抽象为配置信息,简化了爬虫开发过程。爬虫开发者只需要做相应的配置即可完成爬虫的开发。因此,开发者可以通过可配置爬虫来大规模编写爬虫程序(如下图所示)。
这种方法可以爬取上百个网站,一个熟练的爬虫配置者一天可以配置1000个新闻网站爬虫。这对于需要舆情监控的企业来说非常重要,因为可配置爬虫提高生产力,降低单位工作时间成本,提高开发效率,方便后续舆情分析和人工智能产品开发。很多公司自己开发可配置爬虫(名字可能不一样,但本质是一回事),然后聘请一些爬虫配置人员负责配置爬虫。
市场上没有很多免费和开源的可配置爬虫框架。早前微软大神崔庆才开发的Gerapy属于爬虫管理平台,可以根据配置规则生成Scrapy项目文件。另一个比较新的可配置爬虫框架是Crawlab(其实Crawlab并不是一个可配置爬虫框架,而是一个高度灵活的爬虫管理平台),发布于v0.4.0。配置爬虫。还有一个基于Golang的开源框架,Ferret,很有意思。编写爬虫就像编写 SQL 一样简单。还有一些其他的商用产品,但是根据用户反馈,感觉不是很专业,不能满足生产需求。
可配置爬虫的诞生,主要是由于爬虫的模式比较简单,无非就是列表页+详情页的组合(如下图),或者只是一个列表页。当然,还有稍微复杂的通用爬虫,也可以通过规则配置来完成。
Crawlab 可配置爬虫
今天我们主要介绍的是Crawlab的可配置爬虫。我们在前面的 文章 中介绍了它,但没有深入探讨如何在实践中应用它。今天,我们重点讲解。如果您对 Crawlabb 的可配置爬虫不熟悉,请参考可配置爬虫的文档。
可配置的爬虫战斗
实战部分所有案例均由作者使用Crawlab官方Demo平台通过可配置爬虫功能编写爬取,涵盖新闻、金融、汽车、图书、视频、搜索引擎、程序员社区等领域(见下图) . 下面将介绍其中的几个。所有示例均在官方Demo平台上,您可以通过注册账号登录查看。
百度(搜索“Crawlab”)
爬虫地址:/demo#/spiders/5e27d055b8f9c90019f42a83
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: http://www.baidu.com/s?wd=crawlab
start_stage: list
stages:
- name: list
is_list: true
list_css: ""
list_xpath: //*[contains(@class, "c-container")]
page_css: ""
page_xpath: //*[@id="page"]//a[@class="n"][last()]
page_attr: href
fields:
- name: title
css: ""
xpath: .//h3/a
attr: ""
next_stage: ""
remark: ""
- name: url
css: ""
xpath: .//h3/a
attr: href
next_stage: ""
remark: ""
- name: abstract
css: ""
xpath: .//*[@class="c-abstract"]
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
SegmentFault(最新的 文章)
爬虫地址:/demo#/spiders/5e27d116b8f9c90019f42a87
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://segmentfault.com/newest
start_stage: list
stages:
- name: list
is_list: true
list_css: .news-list > .news-item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: title
css: h4.news__item-title
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: .news-img
xpath: ""
attr: href
next_stage: ""
remark: ""
- name: abstract
css: .article-excerpt
xpath: ""
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
亚马逊中国(搜索“手机”)
爬虫地址:/demo#/spiders/5e27e157b8f9c90019f42afb
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://www.amazon.cn/s%3Fk%3D ... oss_2
start_stage: list
stages:
- name: list
is_list: true
list_css: .s-result-item
list_xpath: ""
page_css: .a-last > a
page_xpath: ""
page_attr: href
fields:
- name: title
css: span.a-text-normal
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: .a-link-normal
xpath: ""
attr: href
next_stage: ""
remark: ""
- name: price
css: ""
xpath: .//*[@class="a-price-whole"]
attr: ""
next_stage: ""
remark: ""
- name: price_fraction
css: ""
xpath: .//*[@class="a-price-fraction"]
attr: ""
next_stage: ""
remark: ""
- name: img
css: .s-image-square-aspect > img
xpath: ""
attr: src
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
V2ex
爬虫地址:/demo#/spiders/5e27dd67b8f9c90019f42ad9
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://v2ex.com/
start_stage: list
stages:
- name: list
is_list: true
list_css: .cell.item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: href
fields:
- name: title
css: a.topic-link
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: a.topic-link
xpath: ""
attr: href
next_stage: detail
remark: ""
- name: replies
css: .count_livid
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: detail
is_list: false
list_css: ""
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: content
css: ""
xpath: .//*[@class="markdown_body"]
attr: ""
next_stage: ""
remark: ""
settings:
AUTOTHROTTLE_ENABLED: "true"
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/79.0.3945.117 Safari/537.36
抓取结果
36氪
爬虫地址:/demo#/spiders/5e27ec82b8f9c90019f42b59
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://36kr.com/information/web_news
start_stage: list
stages:
- name: list
is_list: true
list_css: .kr-flow-article-item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: title
css: .article-item-title
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: body
xpath: ""
attr: href
next_stage: detail
remark: ""
- name: abstract
css: body
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: author
css: .kr-flow-bar-author
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: time
css: .kr-flow-bar-time
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: detail
is_list: false
list_css: ""
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: content
css: ""
xpath: .//*[@class="common-width content articleDetailContent kr-rich-text-wrapper"]
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
实际爬行动物列表
爬虫名称 | 爬虫类 --- | --- 百度 | List Page + Paging SegmentFault | 列表页 CSDN | 列表页面 + 分页 + 详细信息页面 V2ex | 列表页+详情页纵横| 列表页 亚马逊中国 | 列表页+寻呼雪球网| 列表页+详情页 列表页+分页豆瓣阅读 | 列表页36氪| 列表页+详情页腾讯视频| 列表页
总结
Crawlab 的可配置爬虫非常方便,可以让程序员快速配置自己需要的爬虫。笔者配置上述11个爬虫用了不到40分钟(考虑到里面有反爬调试),几个比较简单的爬虫不到1-2分钟就配置好了。而且作者没有写一行代码,所有的配置都是在界面上完成的。而且Crawlab的可配置爬虫不仅支持界面上的配置,还支持写一个Yaml文件Spiderfile来完成配置(其实所有的配置都可以映射到Spiderfile)。Crawlab 的可配置爬虫基于 Scrapy,因此它支持 Scrapy 的大部分功能。可以通过设置配置可配置爬虫的扩展属性,包括USER_AGENT,ROBOTSTXT_OBEY 等等。为什么选择 Crawlab 作为可配置爬虫的首选?因为Crawlab可配置爬虫不仅可以配置爬虫,还可以享受Crawlab爬虫管理平台的核心功能,包括任务调度、任务监控、定时任务、日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。
需要注意的是,不遵守 robots.txt 可能会带来法律风险。本文实际爬虫仅供学习交流,不作为生产环境使用,任何滥用者均需承担法律责任。
参考
如果您觉得Crawlab对您的日常开发或公司有帮助,请加作者微信tikazyq1并注明“Crawlab”,作者拉你进群。欢迎在 Github 上加星,如果您遇到任何问题,请随时在 Github 上提出问题。此外,欢迎您为 Crawlab 做出开发贡献。 查看全部
scrapy分页抓取网页(开发好一个框架爬虫(ConfigurableSpider)生产可用的Scrapy爬虫)
背景
爬虫是个有趣的东西,它可以让你通过爬虫程序自动抓取网上的信息,省去了很多手动操作。在一些优质的爬虫框架出来之前,开发者还是通过简单的网络请求+网页解析器来开发爬虫程序,比如Python的requests+BeautifulSoup,而高级爬虫程序还会加入数据存储模块,比如MySQL、MongoDB。这种方式开发效率低,稳定性差,开发一个完整的、可生产的爬虫可能需要几个小时。我称这种方法为无框架爬虫。
2011年,基于Twisted的Scrapy爬虫框架诞生,一下子为大众所熟知,成为首屈一指的全能高性能异步爬虫框架。Scrapy 抽象了几个核心模块,让开发者可以专注于爬虫的爬取逻辑,而不是数据下载、页面解析、任务调度等比较繁琐的模块。要开发一个生产就绪的 Scrapy 爬虫,简单的可能只需要十分钟,复杂的可能需要一个多小时。当然,我们还有很多其他优秀的框架,比如PySpider、Colly等,我把这种爬虫叫做框架爬虫。框架爬虫解放生产力,现在很多公司改造框架爬虫,应用到生产环境中,大规模抓取数据。
但是,对于需要抓取数百个网站的爬虫的需求,框架爬虫可能会不堪重负,不足,编写爬虫成为了一项手工工作。例如,如果开发一个框架爬虫平均需要20分钟,如果一个全职爬虫开发人员每天工作8小时,那么需要20000分钟,333小时,42个工作日,将近2个开发1000个< @网站 月亮。当然,我们可以聘请10名全职爬虫开发工程师,但也需要4个工作日才能完成(如下图)。
这也是相对低效的。为了克服这个效率问题,可配置爬虫应运而生。
可配置爬虫简介
A Configurable Spider,顾名思义,就是可以配置爬取规则的蜘蛛。可配置爬虫是一种高度抽象的爬虫程序。开发者无需编写爬虫代码,只需将需要爬取的网页地址、字段、属性写在配置文件或数据库中,让专门的爬虫程序根据配置抓取数据。. 可配置爬虫进一步将爬虫代码抽象为配置信息,简化了爬虫开发过程。爬虫开发者只需要做相应的配置即可完成爬虫的开发。因此,开发者可以通过可配置爬虫来大规模编写爬虫程序(如下图所示)。
这种方法可以爬取上百个网站,一个熟练的爬虫配置者一天可以配置1000个新闻网站爬虫。这对于需要舆情监控的企业来说非常重要,因为可配置爬虫提高生产力,降低单位工作时间成本,提高开发效率,方便后续舆情分析和人工智能产品开发。很多公司自己开发可配置爬虫(名字可能不一样,但本质是一回事),然后聘请一些爬虫配置人员负责配置爬虫。
市场上没有很多免费和开源的可配置爬虫框架。早前微软大神崔庆才开发的Gerapy属于爬虫管理平台,可以根据配置规则生成Scrapy项目文件。另一个比较新的可配置爬虫框架是Crawlab(其实Crawlab并不是一个可配置爬虫框架,而是一个高度灵活的爬虫管理平台),发布于v0.4.0。配置爬虫。还有一个基于Golang的开源框架,Ferret,很有意思。编写爬虫就像编写 SQL 一样简单。还有一些其他的商用产品,但是根据用户反馈,感觉不是很专业,不能满足生产需求。
可配置爬虫的诞生,主要是由于爬虫的模式比较简单,无非就是列表页+详情页的组合(如下图),或者只是一个列表页。当然,还有稍微复杂的通用爬虫,也可以通过规则配置来完成。
Crawlab 可配置爬虫
今天我们主要介绍的是Crawlab的可配置爬虫。我们在前面的 文章 中介绍了它,但没有深入探讨如何在实践中应用它。今天,我们重点讲解。如果您对 Crawlabb 的可配置爬虫不熟悉,请参考可配置爬虫的文档。
可配置的爬虫战斗
实战部分所有案例均由作者使用Crawlab官方Demo平台通过可配置爬虫功能编写爬取,涵盖新闻、金融、汽车、图书、视频、搜索引擎、程序员社区等领域(见下图) . 下面将介绍其中的几个。所有示例均在官方Demo平台上,您可以通过注册账号登录查看。
百度(搜索“Crawlab”)
爬虫地址:/demo#/spiders/5e27d055b8f9c90019f42a83
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: http://www.baidu.com/s?wd=crawlab
start_stage: list
stages:
- name: list
is_list: true
list_css: ""
list_xpath: //*[contains(@class, "c-container")]
page_css: ""
page_xpath: //*[@id="page"]//a[@class="n"][last()]
page_attr: href
fields:
- name: title
css: ""
xpath: .//h3/a
attr: ""
next_stage: ""
remark: ""
- name: url
css: ""
xpath: .//h3/a
attr: href
next_stage: ""
remark: ""
- name: abstract
css: ""
xpath: .//*[@class="c-abstract"]
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
SegmentFault(最新的 文章)
爬虫地址:/demo#/spiders/5e27d116b8f9c90019f42a87
爬虫配置
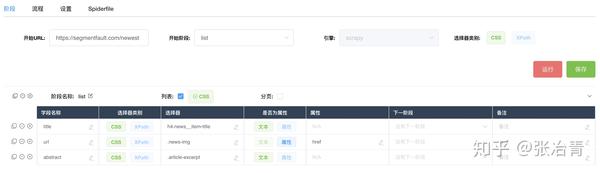
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://segmentfault.com/newest
start_stage: list
stages:
- name: list
is_list: true
list_css: .news-list > .news-item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: title
css: h4.news__item-title
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: .news-img
xpath: ""
attr: href
next_stage: ""
remark: ""
- name: abstract
css: .article-excerpt
xpath: ""
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果

亚马逊中国(搜索“手机”)
爬虫地址:/demo#/spiders/5e27e157b8f9c90019f42afb
爬虫配置
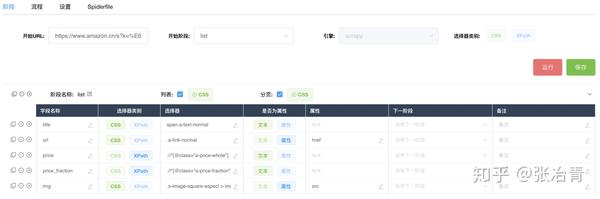
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://www.amazon.cn/s%3Fk%3D ... oss_2
start_stage: list
stages:
- name: list
is_list: true
list_css: .s-result-item
list_xpath: ""
page_css: .a-last > a
page_xpath: ""
page_attr: href
fields:
- name: title
css: span.a-text-normal
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: .a-link-normal
xpath: ""
attr: href
next_stage: ""
remark: ""
- name: price
css: ""
xpath: .//*[@class="a-price-whole"]
attr: ""
next_stage: ""
remark: ""
- name: price_fraction
css: ""
xpath: .//*[@class="a-price-fraction"]
attr: ""
next_stage: ""
remark: ""
- name: img
css: .s-image-square-aspect > img
xpath: ""
attr: src
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
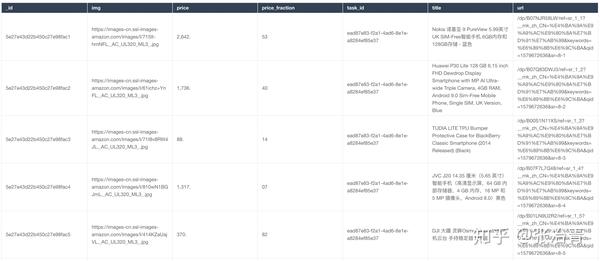
V2ex
爬虫地址:/demo#/spiders/5e27dd67b8f9c90019f42ad9
爬虫配置
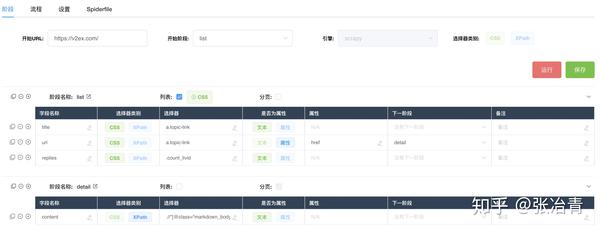
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://v2ex.com/
start_stage: list
stages:
- name: list
is_list: true
list_css: .cell.item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: href
fields:
- name: title
css: a.topic-link
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: a.topic-link
xpath: ""
attr: href
next_stage: detail
remark: ""
- name: replies
css: .count_livid
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: detail
is_list: false
list_css: ""
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: content
css: ""
xpath: .//*[@class="markdown_body"]
attr: ""
next_stage: ""
remark: ""
settings:
AUTOTHROTTLE_ENABLED: "true"
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/79.0.3945.117 Safari/537.36
抓取结果
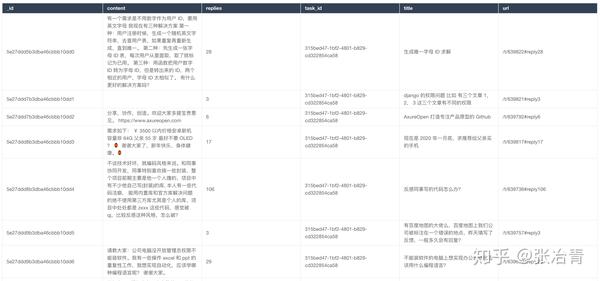
36氪
爬虫地址:/demo#/spiders/5e27ec82b8f9c90019f42b59
爬虫配置
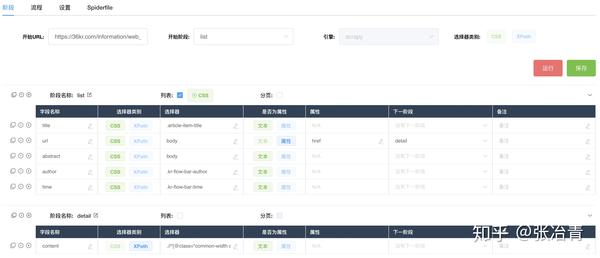
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://36kr.com/information/web_news
start_stage: list
stages:
- name: list
is_list: true
list_css: .kr-flow-article-item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: title
css: .article-item-title
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: body
xpath: ""
attr: href
next_stage: detail
remark: ""
- name: abstract
css: body
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: author
css: .kr-flow-bar-author
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: time
css: .kr-flow-bar-time
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: detail
is_list: false
list_css: ""
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: content
css: ""
xpath: .//*[@class="common-width content articleDetailContent kr-rich-text-wrapper"]
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果

实际爬行动物列表
爬虫名称 | 爬虫类 --- | --- 百度 | List Page + Paging SegmentFault | 列表页 CSDN | 列表页面 + 分页 + 详细信息页面 V2ex | 列表页+详情页纵横| 列表页 亚马逊中国 | 列表页+寻呼雪球网| 列表页+详情页 列表页+分页豆瓣阅读 | 列表页36氪| 列表页+详情页腾讯视频| 列表页
总结
Crawlab 的可配置爬虫非常方便,可以让程序员快速配置自己需要的爬虫。笔者配置上述11个爬虫用了不到40分钟(考虑到里面有反爬调试),几个比较简单的爬虫不到1-2分钟就配置好了。而且作者没有写一行代码,所有的配置都是在界面上完成的。而且Crawlab的可配置爬虫不仅支持界面上的配置,还支持写一个Yaml文件Spiderfile来完成配置(其实所有的配置都可以映射到Spiderfile)。Crawlab 的可配置爬虫基于 Scrapy,因此它支持 Scrapy 的大部分功能。可以通过设置配置可配置爬虫的扩展属性,包括USER_AGENT,ROBOTSTXT_OBEY 等等。为什么选择 Crawlab 作为可配置爬虫的首选?因为Crawlab可配置爬虫不仅可以配置爬虫,还可以享受Crawlab爬虫管理平台的核心功能,包括任务调度、任务监控、定时任务、日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。
需要注意的是,不遵守 robots.txt 可能会带来法律风险。本文实际爬虫仅供学习交流,不作为生产环境使用,任何滥用者均需承担法律责任。
参考
如果您觉得Crawlab对您的日常开发或公司有帮助,请加作者微信tikazyq1并注明“Crawlab”,作者拉你进群。欢迎在 Github 上加星,如果您遇到任何问题,请随时在 Github 上提出问题。此外,欢迎您为 Crawlab 做出开发贡献。
scrapy分页抓取网页(调试自己的爬虫方法介绍(二)-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-28 21:18
博客地址:woodrobot.me
前言
春节假期我的家乡没有互联网,所以最近没有更新。这周我加班加点,抽空更新一篇文章。我们在编写爬虫的时候,经常需要修改xapth规则来获取需要的数据,而Scrapy的爬虫一般都是从命令行启动的。我们如何调试它?下面我将介绍两种我常用的方法。
工具和环境语言:python 2.7 IDE:Pycharm 浏览器:Chrome Crawler 框架:Scrapy 1.2.1 Body Method 1
这是通过 scrapy.shell.inspect_response 函数实现的。以上一篇教程中的爬虫为例:
# -*- coding: utf-8 -*-
# @Time : 2017/1/7 17:04
# @Author : woodenrobot
from scrapy import Request
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safar'
'i/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
def parse(self, response):
# 命令行调试代码
from scrapy.shell import inspect_response
inspect_response(response, self)
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(ur'(\d+)人评价')[0]
yield item
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url, headers=self.headers)
我们可以在下载网页源代码之前插入以上两行代码进行解析,命令行运行爬虫有以下效果:
此时,我们可以在命令行中使用xpath规则对响应进行操作,提取出相应的信息:
有时下载的网页的结构与您在浏览器中看到的不同。我们可以使用view(response)在浏览器中打开爬虫下载的网页源代码:
在命令行输入view(response)后,默认浏览器会自动打开下载的网页源码。
虽然scrapy本身就提供了这个方法让我们调试自己的爬虫,但是这个方法有很大的局限性。如果能使用pycharm的Debug功能进行调试就好了。下面我给大家介绍使用pycharm调试自己的爬虫。
方法二
首先在与setting.py相同的目录下创建run.py文件。
编写以下代码:
# -*- coding: utf-8 -*-
# @Time : 2017/1/1 17:51
# @Author : woodenrobot
from scrapy import cmdline
name = 'douban_movie_top250'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
name 参数是蜘蛛的名字。
然后在蜘蛛文件中设置断点。
回到run.py文件,右键选择Debug。
最后程序会在断点处暂停,我们可以查看对应的内容进行调试。
结语
这两种方法适用于不同的场景,但总的来说,方法2绝对好用。:) 查看全部
scrapy分页抓取网页(调试自己的爬虫方法介绍(二)-乐题库)
博客地址:woodrobot.me
前言
春节假期我的家乡没有互联网,所以最近没有更新。这周我加班加点,抽空更新一篇文章。我们在编写爬虫的时候,经常需要修改xapth规则来获取需要的数据,而Scrapy的爬虫一般都是从命令行启动的。我们如何调试它?下面我将介绍两种我常用的方法。
工具和环境语言:python 2.7 IDE:Pycharm 浏览器:Chrome Crawler 框架:Scrapy 1.2.1 Body Method 1
这是通过 scrapy.shell.inspect_response 函数实现的。以上一篇教程中的爬虫为例:
# -*- coding: utf-8 -*-
# @Time : 2017/1/7 17:04
# @Author : woodenrobot
from scrapy import Request
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safar'
'i/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
def parse(self, response):
# 命令行调试代码
from scrapy.shell import inspect_response
inspect_response(response, self)
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(ur'(\d+)人评价')[0]
yield item
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url, headers=self.headers)
我们可以在下载网页源代码之前插入以上两行代码进行解析,命令行运行爬虫有以下效果:
此时,我们可以在命令行中使用xpath规则对响应进行操作,提取出相应的信息:
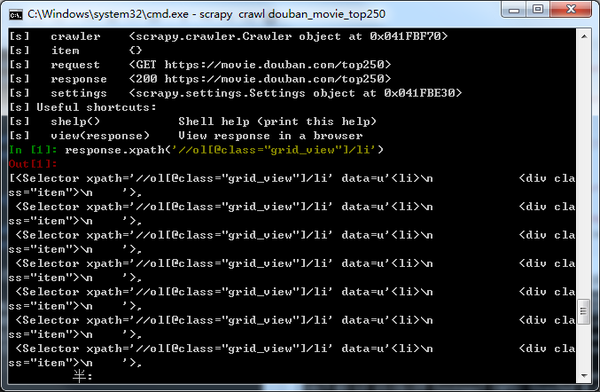
有时下载的网页的结构与您在浏览器中看到的不同。我们可以使用view(response)在浏览器中打开爬虫下载的网页源代码:
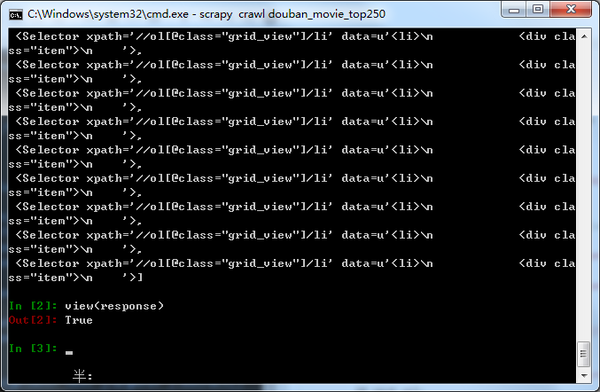
在命令行输入view(response)后,默认浏览器会自动打开下载的网页源码。
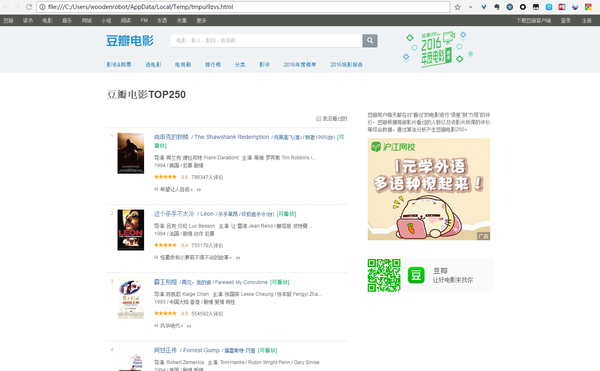
虽然scrapy本身就提供了这个方法让我们调试自己的爬虫,但是这个方法有很大的局限性。如果能使用pycharm的Debug功能进行调试就好了。下面我给大家介绍使用pycharm调试自己的爬虫。
方法二
首先在与setting.py相同的目录下创建run.py文件。
编写以下代码:
# -*- coding: utf-8 -*-
# @Time : 2017/1/1 17:51
# @Author : woodenrobot
from scrapy import cmdline
name = 'douban_movie_top250'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
name 参数是蜘蛛的名字。
然后在蜘蛛文件中设置断点。
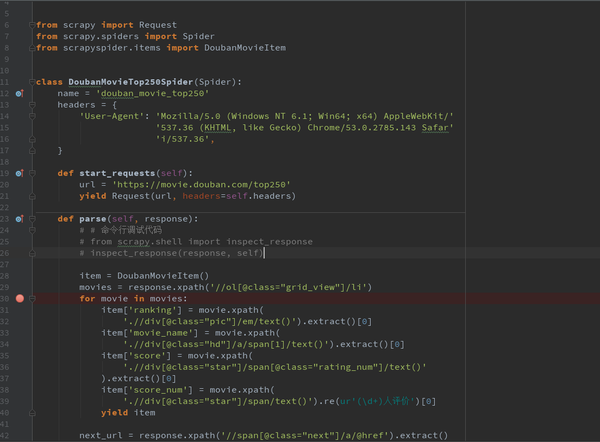
回到run.py文件,右键选择Debug。
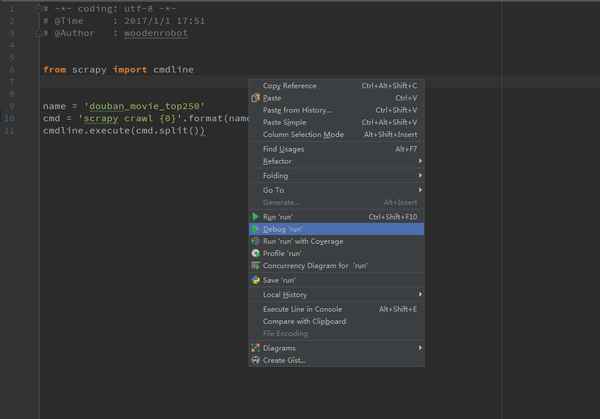
最后程序会在断点处暂停,我们可以查看对应的内容进行调试。
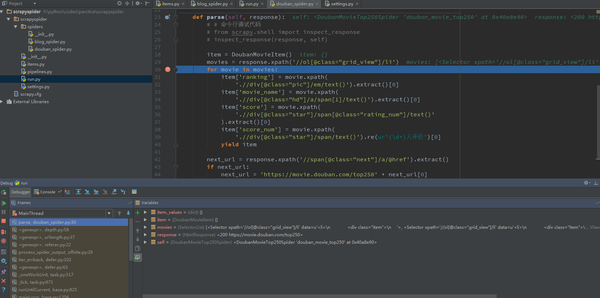
结语
这两种方法适用于不同的场景,但总的来说,方法2绝对好用。:)
scrapy分页抓取网页(快速学习Python学习资料列表将是您选择的项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-28 10:17
在本教程中,我们假设您已安装 Scrapy。如果没有,请参考。
接下来以Open Directory Project (dmoz) (dmoz) 为例来描述爬取。
本教程将带您完成以下任务:
创建一个Scrapy项目,定义提取出来的Item要爬取网站并提取来存储提取出来的Item(即数据)
Scrapy 是用 Python 编写的。如果你是语言新手,对这门语言的特点和 Scrapy 的细节感到好奇,对于已经熟悉其他语言并想快速学习 Python 的编程老手,我们推荐 Learn Python The Hard Way,进行编程想要开始学习 Python 的初学者,非编程的 Python 学习资料列表供您选择。
创建一个项目
在开始抓取之前,您必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
scrapy startproject tutorial
此命令将创建一个收录以下内容的教程目录:
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
定义项目
Item是爬取数据的容器;它的用法类似于 python 字典,它提供了额外的保护来防止由拼写错误导致的未定义字段错误。
与 ORM 类似,您可以通过创建一个类并定义一个类型的类属性来定义一个 Item。 (如果你不懂ORM,别着急,你会发现这一步很简单)
首先根据需要从获取的数据中为项目建模。我们需要从 dmoz 中获取 网站 的名称、url 和描述。为此,请在 item.xml 中定义相应的字段。编辑教程目录下的 items.py 文件:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
一开始这可能看起来很复杂,但是通过定义一个项目,您可以轻松地使用其他 Scrapy 方法。而这些方法需要知道你的item的定义。
编写你的第一个蜘蛛
Spider 是用户编写的一个类,用于从单个 网站(或多个 网站)中抓取数据。
它收录一个用于下载的初始URL,如何跟随网页中的链接以及如何分析页面中的内容,提取生成的方法。
为了创建蜘蛛,你必须扩展类并定义以下三个属性:
以下是我们的第一个蜘蛛代码,保存在 tutorial/spiders 目录下的 dmoz_spider.py 文件中:
import scrapy
class DmozSpider(scrapy.spiders.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
爬行
进入项目根目录,执行如下命令启动spider:
scrapy crawl dmoz
crawldmoz 启动爬虫进行爬取,您将获得类似于以下内容的输出:
2014-01-23 18:13:07-0400 [scrapy] INFO: Scrapy started (bot: tutorial)
2014-01-23 18:13:07-0400 [scrapy] INFO: Optional features available: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Overridden settings: {}
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled extensions: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled downloader middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled spider middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled item pipelines: ...
2014-01-23 18:13:07-0400 [dmoz] INFO: Spider opened
2014-01-23 18:13:08-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2014-01-23 18:13:09-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2014-01-23 18:13:09-0400 [dmoz] INFO: Closing spider (finished)
查看收录[dmoz]的输出,可以看到输出日志中收录了start_urls中定义的初始URL,和spider一一对应。在日志中可以看到没有指向其他页面((referer:None))。
除此之外,发生了更有趣的事情。正如我们的 parse 方法所指定的,创建了两个文件,其中收录与 url 对应的内容:Book、Resources。
刚刚发生了什么?
Scrapy 在 Spider 的 start_urls 属性中为每个 URL 创建对象,并将 parse 方法分配给 Request 作为回调。
Request对象被调度,生成的对象被执行并发回spider方法。
提取ItemSelectors简介
有很多方法可以从网页中提取数据。 Scrapy 使用基于 XPath 和 CSS 表达式的机制:.有关选择器和其他提取机制的信息,请参见此处。
以下是 XPath 表达式及其对应含义的示例:
以上只是几个简单的 XPath 示例,XPath 实际上远比这强大。如果您想了解更多信息,我们推荐此 XPath 教程。
为了配合XPath,Scrapy不仅提供,而且还提供了避免每次从响应中提取数据时都生成选择器的麻烦的方法。
Selector有四种基本方法(点击对应方法查看详细API文档):
试试 Shell 中的选择器
为了介绍如何使用 Selector,我们接下来会使用内置的 Selector。 Scrapy Shell 要求您预先安装 IPython(一个扩展的 Python 终端)。
你需要进入你的项目的根目录并执行以下命令来启动shell:
scrapy shell "http://www.dmoz.org/Computers/ ... ot%3B
注意事项
在终端运行Scrapy时,请记得在url地址两边加上引号,否则url中收录参数(如&字符)会导致Scrapy失败。
shell 输出类似于:
[ ... Scrapy log here ... ]
2015-01-07 22:01:53+0800 [domz] DEBUG: Crawled (200) (referer: None)
[s] Available Scrapy objects:
[s] crawler
[s] item {}
[s] request
[s] response
[s] sel
[s] settings
[s] spider
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
>>>
当 shell 加载时,您将获得一个收录响应数据的本地响应变量。输入response.body输出响应的body,输出response.headers可以看到响应的header。
更重要的是,当你输入response.selector时,你会得到一个选择器(selector),可以用来查询返回的数据,并映射到response.selector.xpath()、response.selector.css()的快捷方式: response.xpath() 和 response.css()。
同时,shell根据响应提前初始化变量sel。选择器会根据响应的类型自动选择最合适的解析规则(XML vs HTML)。
让我们试试吧:
In [1]: sel.xpath('//title')
Out[1]: []
In [2]: sel.xpath('//title').extract()
Out[2]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [3]: sel.xpath('//title/text()')
Out[3]: []
In [4]: sel.xpath('//title/text()').extract()
Out[4]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [5]: sel.xpath('//title/text()').re('(w+):')
Out[5]: [u'Computers', u'Programming', u'Languages', u'Python']
提取数据
现在,让我们尝试从这些页面中提取一些有用的数据。
您可以在终端中键入 response.body 以观察 HTML 源并确定适当的 XPath 表达式。但是,这项任务非常无聊和困难。您可能会考虑使用 Firefox 的 Firebug 扩展来简化操作。详情请参考和。
查看网页的源码后会发现网站的信息收录在第二个 查看全部
scrapy分页抓取网页(快速学习Python学习资料列表将是您选择的项目)
在本教程中,我们假设您已安装 Scrapy。如果没有,请参考。
接下来以Open Directory Project (dmoz) (dmoz) 为例来描述爬取。
本教程将带您完成以下任务:
创建一个Scrapy项目,定义提取出来的Item要爬取网站并提取来存储提取出来的Item(即数据)
Scrapy 是用 Python 编写的。如果你是语言新手,对这门语言的特点和 Scrapy 的细节感到好奇,对于已经熟悉其他语言并想快速学习 Python 的编程老手,我们推荐 Learn Python The Hard Way,进行编程想要开始学习 Python 的初学者,非编程的 Python 学习资料列表供您选择。
创建一个项目
在开始抓取之前,您必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
scrapy startproject tutorial
此命令将创建一个收录以下内容的教程目录:
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
定义项目
Item是爬取数据的容器;它的用法类似于 python 字典,它提供了额外的保护来防止由拼写错误导致的未定义字段错误。
与 ORM 类似,您可以通过创建一个类并定义一个类型的类属性来定义一个 Item。 (如果你不懂ORM,别着急,你会发现这一步很简单)
首先根据需要从获取的数据中为项目建模。我们需要从 dmoz 中获取 网站 的名称、url 和描述。为此,请在 item.xml 中定义相应的字段。编辑教程目录下的 items.py 文件:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
一开始这可能看起来很复杂,但是通过定义一个项目,您可以轻松地使用其他 Scrapy 方法。而这些方法需要知道你的item的定义。
编写你的第一个蜘蛛
Spider 是用户编写的一个类,用于从单个 网站(或多个 网站)中抓取数据。
它收录一个用于下载的初始URL,如何跟随网页中的链接以及如何分析页面中的内容,提取生成的方法。
为了创建蜘蛛,你必须扩展类并定义以下三个属性:
以下是我们的第一个蜘蛛代码,保存在 tutorial/spiders 目录下的 dmoz_spider.py 文件中:
import scrapy
class DmozSpider(scrapy.spiders.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
爬行
进入项目根目录,执行如下命令启动spider:
scrapy crawl dmoz
crawldmoz 启动爬虫进行爬取,您将获得类似于以下内容的输出:
2014-01-23 18:13:07-0400 [scrapy] INFO: Scrapy started (bot: tutorial)
2014-01-23 18:13:07-0400 [scrapy] INFO: Optional features available: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Overridden settings: {}
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled extensions: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled downloader middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled spider middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled item pipelines: ...
2014-01-23 18:13:07-0400 [dmoz] INFO: Spider opened
2014-01-23 18:13:08-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2014-01-23 18:13:09-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2014-01-23 18:13:09-0400 [dmoz] INFO: Closing spider (finished)
查看收录[dmoz]的输出,可以看到输出日志中收录了start_urls中定义的初始URL,和spider一一对应。在日志中可以看到没有指向其他页面((referer:None))。
除此之外,发生了更有趣的事情。正如我们的 parse 方法所指定的,创建了两个文件,其中收录与 url 对应的内容:Book、Resources。
刚刚发生了什么?
Scrapy 在 Spider 的 start_urls 属性中为每个 URL 创建对象,并将 parse 方法分配给 Request 作为回调。
Request对象被调度,生成的对象被执行并发回spider方法。
提取ItemSelectors简介
有很多方法可以从网页中提取数据。 Scrapy 使用基于 XPath 和 CSS 表达式的机制:.有关选择器和其他提取机制的信息,请参见此处。
以下是 XPath 表达式及其对应含义的示例:
以上只是几个简单的 XPath 示例,XPath 实际上远比这强大。如果您想了解更多信息,我们推荐此 XPath 教程。
为了配合XPath,Scrapy不仅提供,而且还提供了避免每次从响应中提取数据时都生成选择器的麻烦的方法。
Selector有四种基本方法(点击对应方法查看详细API文档):
试试 Shell 中的选择器
为了介绍如何使用 Selector,我们接下来会使用内置的 Selector。 Scrapy Shell 要求您预先安装 IPython(一个扩展的 Python 终端)。
你需要进入你的项目的根目录并执行以下命令来启动shell:
scrapy shell "http://www.dmoz.org/Computers/ ... ot%3B
注意事项
在终端运行Scrapy时,请记得在url地址两边加上引号,否则url中收录参数(如&字符)会导致Scrapy失败。
shell 输出类似于:
[ ... Scrapy log here ... ]
2015-01-07 22:01:53+0800 [domz] DEBUG: Crawled (200) (referer: None)
[s] Available Scrapy objects:
[s] crawler
[s] item {}
[s] request
[s] response
[s] sel
[s] settings
[s] spider
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
>>>
当 shell 加载时,您将获得一个收录响应数据的本地响应变量。输入response.body输出响应的body,输出response.headers可以看到响应的header。
更重要的是,当你输入response.selector时,你会得到一个选择器(selector),可以用来查询返回的数据,并映射到response.selector.xpath()、response.selector.css()的快捷方式: response.xpath() 和 response.css()。
同时,shell根据响应提前初始化变量sel。选择器会根据响应的类型自动选择最合适的解析规则(XML vs HTML)。
让我们试试吧:
In [1]: sel.xpath('//title')
Out[1]: []
In [2]: sel.xpath('//title').extract()
Out[2]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [3]: sel.xpath('//title/text()')
Out[3]: []
In [4]: sel.xpath('//title/text()').extract()
Out[4]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [5]: sel.xpath('//title/text()').re('(w+):')
Out[5]: [u'Computers', u'Programming', u'Languages', u'Python']
提取数据
现在,让我们尝试从这些页面中提取一些有用的数据。
您可以在终端中键入 response.body 以观察 HTML 源并确定适当的 XPath 表达式。但是,这项任务非常无聊和困难。您可能会考虑使用 Firefox 的 Firebug 扩展来简化操作。详情请参考和。
查看网页的源码后会发现网站的信息收录在第二个
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-26 20:08
2015 年 6 月 23 日更新:
之前写这个的时候,还没有遇到具体的场景,只是觉得有这样的写法。
我今天刚满足这个要求。抓取BBS内容,版块首页只显示标题、作者和发表时间。我们需要做的是根据时间进行过滤,每天抓取最新的内容。使用 Rule 规则提取 URL 后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能获取抓取链接内容后的时间,实际上造成了不必要的浪费。使用本文中的方法文章可以在爬取前过滤链接,避免爬取无用数据。
上一篇scrapy爬虫的启动(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法。其实直接使用BaseSpider也是可以的实现多页爬取。
具体思路:我们以我们豆瓣群为例,豆瓣社科群,我们用首页地址作为start_url参数,从页面源码中找到剩下的页面,如下:
<前页
1
2
3
4
5
6
7
8
9
后页>
可以提取每个页面的地址,获取多个页面的思路是将地址封装为Request作为回调函数parse的返回值(不影响item的返回值),并指定对应的这些页面地址的回调函数。由于首页和分页在形式上是一模一样的(首页本身也是一个分页),所以可以直接指定parse为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
前面使用了CrawlSpider,这里替换了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页的处理。首先是提取地址,然后打印语句,后面再说,最后返回Request。
写这段代码的时候,感觉有一个问题:既然为每个页面指定的回调函数是parse,就相当于为每个页面提取一次页面地址,所以实际上每个页面地址都被返回了N次结束。,那么scrapy会不会在实际处理时也会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》...
我们直接运行程序,现在看看我们的打印语句:“->”前面表示当前页地址,后面是从当前页中提取的分页地址。为了简化输出,只提取用于标识分页的“开始”。范围。
结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点多,可以看出:
1. 每个寻呼地址确实被多次返回;
2. 没有陷入死循环,没有重复处理;
3. 处理乱序;
这说明scrapy本身已经进行了去重,并使用了线程进行数据获取操作。
好的,任务完成。使用 CrawlSpider 的 Rule 感觉更方便。 查看全部
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
2015 年 6 月 23 日更新:
之前写这个的时候,还没有遇到具体的场景,只是觉得有这样的写法。
我今天刚满足这个要求。抓取BBS内容,版块首页只显示标题、作者和发表时间。我们需要做的是根据时间进行过滤,每天抓取最新的内容。使用 Rule 规则提取 URL 后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能获取抓取链接内容后的时间,实际上造成了不必要的浪费。使用本文中的方法文章可以在爬取前过滤链接,避免爬取无用数据。
上一篇scrapy爬虫的启动(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法。其实直接使用BaseSpider也是可以的实现多页爬取。
具体思路:我们以我们豆瓣群为例,豆瓣社科群,我们用首页地址作为start_url参数,从页面源码中找到剩下的页面,如下:
<前页
1
2
3
4
5
6
7
8
9
后页>
可以提取每个页面的地址,获取多个页面的思路是将地址封装为Request作为回调函数parse的返回值(不影响item的返回值),并指定对应的这些页面地址的回调函数。由于首页和分页在形式上是一模一样的(首页本身也是一个分页),所以可以直接指定parse为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
前面使用了CrawlSpider,这里替换了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页的处理。首先是提取地址,然后打印语句,后面再说,最后返回Request。
写这段代码的时候,感觉有一个问题:既然为每个页面指定的回调函数是parse,就相当于为每个页面提取一次页面地址,所以实际上每个页面地址都被返回了N次结束。,那么scrapy会不会在实际处理时也会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》...
我们直接运行程序,现在看看我们的打印语句:“->”前面表示当前页地址,后面是从当前页中提取的分页地址。为了简化输出,只提取用于标识分页的“开始”。范围。
结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点多,可以看出:
1. 每个寻呼地址确实被多次返回;
2. 没有陷入死循环,没有重复处理;
3. 处理乱序;
这说明scrapy本身已经进行了去重,并使用了线程进行数据获取操作。
好的,任务完成。使用 CrawlSpider 的 Rule 感觉更方便。
scrapy分页抓取网页(scrapy架构流程•Scrapy,Python开发的一个快速、高层次的屏幕和web抓取框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2022-02-25 06:14
scrapy架构流程
• Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,使用
用于抓取网站并从页面中提取结构化数据。
• Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。
还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本
Ben 还提供了对 web2.0 爬虫的支持。
• Scrap,意思是片段,这个Python爬虫框架叫做Scrapy。
优势:
用户只需要自定义开发几个模块,就可以轻松实现爬虫,爬取网页内容和图片非常方便;Scrapy 使用 Twisted 异步网络框架来处理网络通信,加快网页下载速度,并且不需要自己实现异步框架和多线程等,并且收录各种
灵活满足各种需求的中间件接口
Scrapy主要包括以下组件:
• 引擎(Scrapy):
用于处理整个系统的数据流,触发事务(框架核心)
• 调度程序:
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。
后退。它可以被认为是一个 URL 的优先级队列(网站 URL 或要爬取的链接),它决定了下一个要爬取的
什么是网址,同时删除重复的网址
• 下载器:
用于下载网页内容并将网页内容返回给蜘蛛(Scrapy下载器内置
在 twisted 上,一种高效的异步模型)
• 蜘蛛:
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体
(物品)。用户也可以从中提取链接,让 Scrapy 继续爬取下一页
• 项目管道(Pipeline):负责处理爬虫从网页中提取的实体,主要功能是持久化实体,验证
身体的有效性,清除不需要的信息。当页面被爬虫解析后,会被送到项目流水线,经过几个具体的
按顺序处理数据。
• 下载器中间件:
位于 Scrapy 引擎和下载器之间的框架,
它主要处理 Scrapy 引擎和下载器之间的请求和响应。
• Spider Middlewares:Scrapy 引擎和爬虫之间的框架,主要工作是
管理蜘蛛的响应输入和请求输出
• 调度程序中间件:
Scrapy引擎和调度之间的中间件,来自
Scrapy 引擎发送的要调度的请求和响应。采用
# 爬取的步骤
- 确定url地址;
- 获取页面信息;(urllib, requests);
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)
- 保存到本地(csv, json, pymysql, redis);
- 清洗数据(删除不必要的内容 -----正则表达式);
- 分析数据(词云wordcloud + jieba)
有没有用到多线程? -----
获取页面信息每个爬虫都会使用, 重复去写----
设置头部信息 ---- user-agent, proxy....
# 流程分析:
- 确定url地址:http://www.imooc.com/course/list;(spider)
- 获取页面信息;(urllib, requests); ---(scrapy中我们不要处理)---(Downloader)
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)---: (spider)
课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述
- 保存到本地(csv, json, pymysql, redis); ----(pipeline)
# 环境
- Scrapy 1.6.0
# 实现步骤:
1. 工程创建
scrapy startproject mySpider
cd mySpider
tree
├── mySpider
│ ├── __init__.py
│ ├── items.py # 提取的数据信息
│ ├── middlewares.py # 中间键
│ ├── pipelines.py # 管道, 如何存储数据
│ ├── __pycache__
│ ├── settings.py # 设置信息
│ └── spiders # 爬虫(解析页面的信息)
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
2. 创建一个爬虫
scrapy genspider mooc "www.imooc.com"
cd mySpider/spiders/
vim mooc.py
# start_url
3. 定义爬取的items内容
class CourseItem(scrapy.Item):
# 课程标题
title = scrapy.Field()
# 课程的url地址
url = scrapy.Field()
# 课程图片url地址
image_url = scrapy.Field()
# 课程的描述
introduction = scrapy.Field()
# 学习人数
student = scrapy.Field()
# 4. 编写spider代码, 解析
新项目
明确的目标
1.在 items.py 中定义变量
用于保存爬取的数据,类似于python中的字典,提供一些额外的保护
import scrapy
class CourseItem(scrapy.Item):
# Item对象是一个简单容器, 保存爬取到的数据, 类似于字典的操作;
# 实例化对象: course = CourseItem()
# course['title'] = "语文"
# course['title']
# course.keys()
# course.values()
# course.items()
# define the fields for your item here like:
# name = scrapy.Field()
# 课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述
# 课程标题
title = scrapy.Field()
# 课程的url地址
url = scrapy.Field()
# 课程图片url地址
image_url = scrapy.Field()
# 课程的描述
introduction = scrapy.Field()
# 学习人数
student = scrapy.Field()
做一个爬虫
2.定义解析方法
name = "" :这个爬虫的标识名必须是唯一的,不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,即爬虫的禁区,规定爬虫只抓取该域名下的网页,不存在的URL会被忽略。
start_urls = () : 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。将从这些起始 URL 继承生成其他子 URL。
parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传递。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item) 查看全部
scrapy分页抓取网页(scrapy架构流程•Scrapy,Python开发的一个快速、高层次的屏幕和web抓取框架)
scrapy架构流程
• Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,使用
用于抓取网站并从页面中提取结构化数据。
• Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。
还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本
Ben 还提供了对 web2.0 爬虫的支持。
• Scrap,意思是片段,这个Python爬虫框架叫做Scrapy。
优势:
用户只需要自定义开发几个模块,就可以轻松实现爬虫,爬取网页内容和图片非常方便;Scrapy 使用 Twisted 异步网络框架来处理网络通信,加快网页下载速度,并且不需要自己实现异步框架和多线程等,并且收录各种
灵活满足各种需求的中间件接口

Scrapy主要包括以下组件:
• 引擎(Scrapy):
用于处理整个系统的数据流,触发事务(框架核心)
• 调度程序:
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。
后退。它可以被认为是一个 URL 的优先级队列(网站 URL 或要爬取的链接),它决定了下一个要爬取的
什么是网址,同时删除重复的网址
• 下载器:
用于下载网页内容并将网页内容返回给蜘蛛(Scrapy下载器内置
在 twisted 上,一种高效的异步模型)
• 蜘蛛:
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体
(物品)。用户也可以从中提取链接,让 Scrapy 继续爬取下一页
• 项目管道(Pipeline):负责处理爬虫从网页中提取的实体,主要功能是持久化实体,验证
身体的有效性,清除不需要的信息。当页面被爬虫解析后,会被送到项目流水线,经过几个具体的
按顺序处理数据。
• 下载器中间件:
位于 Scrapy 引擎和下载器之间的框架,
它主要处理 Scrapy 引擎和下载器之间的请求和响应。
• Spider Middlewares:Scrapy 引擎和爬虫之间的框架,主要工作是
管理蜘蛛的响应输入和请求输出
• 调度程序中间件:
Scrapy引擎和调度之间的中间件,来自
Scrapy 引擎发送的要调度的请求和响应。采用
# 爬取的步骤
- 确定url地址;
- 获取页面信息;(urllib, requests);
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)
- 保存到本地(csv, json, pymysql, redis);
- 清洗数据(删除不必要的内容 -----正则表达式);
- 分析数据(词云wordcloud + jieba)
有没有用到多线程? -----
获取页面信息每个爬虫都会使用, 重复去写----
设置头部信息 ---- user-agent, proxy....
# 流程分析:
- 确定url地址:http://www.imooc.com/course/list;(spider)
- 获取页面信息;(urllib, requests); ---(scrapy中我们不要处理)---(Downloader)
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)---: (spider)
课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述
- 保存到本地(csv, json, pymysql, redis); ----(pipeline)
# 环境
- Scrapy 1.6.0
# 实现步骤:
1. 工程创建
scrapy startproject mySpider
cd mySpider
tree
├── mySpider
│ ├── __init__.py
│ ├── items.py # 提取的数据信息
│ ├── middlewares.py # 中间键
│ ├── pipelines.py # 管道, 如何存储数据
│ ├── __pycache__
│ ├── settings.py # 设置信息
│ └── spiders # 爬虫(解析页面的信息)
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
2. 创建一个爬虫
scrapy genspider mooc "www.imooc.com"
cd mySpider/spiders/
vim mooc.py
# start_url
3. 定义爬取的items内容
class CourseItem(scrapy.Item):
# 课程标题
title = scrapy.Field()
# 课程的url地址
url = scrapy.Field()
# 课程图片url地址
image_url = scrapy.Field()
# 课程的描述
introduction = scrapy.Field()
# 学习人数
student = scrapy.Field()
# 4. 编写spider代码, 解析
新项目



明确的目标
1.在 items.py 中定义变量
用于保存爬取的数据,类似于python中的字典,提供一些额外的保护
import scrapy
class CourseItem(scrapy.Item):
# Item对象是一个简单容器, 保存爬取到的数据, 类似于字典的操作;
# 实例化对象: course = CourseItem()
# course['title'] = "语文"
# course['title']
# course.keys()
# course.values()
# course.items()
# define the fields for your item here like:
# name = scrapy.Field()
# 课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述
# 课程标题
title = scrapy.Field()
# 课程的url地址
url = scrapy.Field()
# 课程图片url地址
image_url = scrapy.Field()
# 课程的描述
introduction = scrapy.Field()
# 学习人数
student = scrapy.Field()
做一个爬虫
2.定义解析方法
name = "" :这个爬虫的标识名必须是唯一的,不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,即爬虫的禁区,规定爬虫只抓取该域名下的网页,不存在的URL会被忽略。
start_urls = () : 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。将从这些起始 URL 继承生成其他子 URL。
parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传递。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
scrapy分页抓取网页(基于python分布式房源数据系统为数据的进一步应用主题爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2022-02-18 09:10
基于Python的分布式房源数据采集系统为数据的进一步应用,即房源推荐系统提供数据支持。本课题致力于解决单进程单机爬虫的瓶颈,基于Redis分布式多爬虫共享队列创建主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath技术提取和解析下载的网页,使用Redis数据库进行分发,使用MongoDb数据库进行数据存储,使用Django web框架和Semantic UI开源框架进行友好可视化数据,最后使用 Docker 部署爬虫。为同城各大城市的租赁平台设计并实现了分布式爬虫系统。
分布式爬虫爬取系统主要包括以下功能:
1.爬虫功能:爬取策略设计、内容数据域设计、增量爬取请求去重
2.中间件:爬虫防屏蔽中间件网页非200状态处理爬虫下载异常处理
3.数据存储:抓斗设计数据存储
4.数据可视化
完整的项目源代码
二、系统分布式架构
分布式采用主从结构,设置一个Master服务器和多个Slave服务器。Master 端管理 Redis 数据库并分发下载任务。Slave部署Scrapy爬虫提取网页并解析提取数据,最终将解析后的数据存储在同一个MongoDb数据库中。分布式爬虫架构如图所示。
使用Redis数据库实现分布式爬取,基本思路是将Scrapy爬虫获取的detail_request的url放入Redis Queue,所有爬虫也从指定的Redis Queue获取请求。Scrapy-Redis 组件默认使用 SpiderPriorityQueue。确定 URL 的顺序,是 sorted set 实现的一种非 FIFO 和 LIFO 的方法。因此,待爬取队列的共享是爬虫可以部署在其他服务器上完成相同爬取任务的关键点。另外,本文为了解决Scrapy单机受限的问题,将结合Scrapy-Redis组件开发Scrapy。Scrapy-Redis的总体思路是本项目通过重写Scrapu框架中的scheduler和spider类来实现调度和spider启动。与redis的交互。实现了新的dupefilter和queue类,实现了权重判断和调度容器与redis的交互。由于每台主机上的爬虫进程访问同一个redis数据库,调度和权重判断统一管理,实现分布式分布。爬行动物的目的。
三、系统实现
1)爬取策略的设计可以从scrapy的结构分析中看出。网络爬虫从初始地址开始,根据从spider中定义的目标地址获取的正则表达式或者Xpath获取更多的网页链接,加入到待下载队列中,经过去重排序后,等待用于调度程序的调度。在这个系统中,新建的链接可以分为两类,一类是目录页链接,也就是我们平时看到的下一页的链接,另一类是内容详情页链接,也就是我们需要解析网页提取字段链接指向实际的列表信息页面。
这里是master端目标链接的爬取策略。由于是分布式主从模式,master端的爬虫主要抓取下载内容详情页的链接,通过redis将下载任务分享给slave端的其他爬虫。Slave端主要负责进一步解析提取详情页的链接,并存入数据库。本文以58同城为例。初始页面链接,其实就是每个类别的首页链接,主要包括(以广东省几个城市为例):
综上所述,网络资源爬取系统采用以下爬取策略:
1) 对于Master端:核心模块是解决翻页问题,获取到每个页面的内容详情页面的链接。
Master端主要采用以下爬取策略:
1. 将redis的初始链接插入到nest_link的key中,从初始页面链接开始
2. 爬虫从redis中的key next_link获取初始链接,开始运行爬虫
3. 下载器返回的Response,爬虫根据蜘蛛定义的爬取规则,识别是否有下一页的链接。如果有链接,则存储在redis中,key保存为next_link。一个内容详情页的链接,如果匹配,就会存入Redis,将key保存为detail_request,插入下载链接,供slave端的spider使用,也就是slave端的下载任务。
4. 爬虫继续从redis中的key取值作为next_link。如果有值,则继续执行步骤2。如果为空,则爬虫等待新的链接。
2) 对于slave端:核心模块是从redis获取下载任务并解析提取字段。Slave端主要采用以下爬取策略:
1.爬虫从redis获取初始链接,key为detail_request,开始运行爬虫
2. 下载器返回的Response,爬虫根据蜘蛛定义的爬取规则,识别是否有符合该规则的content字段,如果有,将该字段存储并返回给模型,等待数据存储操作。重复步骤 1,直到爬取队列为空,爬虫等待新的链接。
2)爬虫的具体实现
爬虫程序由四部分组成,即对象定义程序、数据捕获程序、数据处理程序和下载设置程序。这里的组合是从方。Master缺少对象定义程序和数据处理程序。Master端主要是下载链接的爬取。
(1)数据抓取程序数据抓取程序分为Master端和Slave端。数据抓取程序从Redis获取初始地址。数据抓取程序定义抓取网页的规则,使用Xpath提取字段数据 Xpath等的方法,重点介绍从Xpath中提取字符数据的方法。Xapth使用路径表达式来选择web文档中的节点或节点集。Xpath有几种类型:元素、属性、文本、命名空间,处理指令、评论和文档节点。将Web文档视为一棵节点树,树的根节点称为文档节点和根节点,定位目标节点即可提取Web文档的字段数据通过 Xpath 表达式。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。具体实施步骤:
(1) 从待爬取队列中获取url
(2)判断要请求的url是否已经爬取,如果已经爬取则忽略请求,未爬取,继续其他操作,将url插入爬取队列
(3) 重复第1步。这里我们使用scrapy-redis的去重组件,所以没有实现,但是原理还是有待理解的,具体看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
它将不断访问 网站 的内容。如果不采取伪装措施,很容易被网站识别为爬虫,系统采用以下方法防止爬虫被拦截:
(a) 模拟不同浏览器行为的实现思路和代码
原则:
从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应的处理,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性。首先是扩展下载中间件。首先,将中间件添加到seeings.py。其次,扩展中间件,主要是写一个useragent列表,保存常用的浏览器请求头。作为一个列表。
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1. 代理ip池的设计开发流程如下:
一个。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行身份验证
d。如果达到最大ip数,停止爬取,一定时间后验证数据ip的有效性,删除无效ip。直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip爬虫运行截图:
(c) 爬虫异常状态组件的处理 当爬虫没有被阻塞并运行时,对网站的访问并不总是200请求成功,而是有多种状态,比如上面的爬虫被禁止时,实际上返回的状态是302,通过捕获302的状态来实现预防屏蔽组件。同时异常状态的处理有利于爬虫的健壮性。设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
d) 数据存储模块 数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。Scrapy 支持 json、csv、xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(g) 数据可视化设计 数据可视化其实就是将数据库中的数据转换成便于我们用户观察的形式。系统使用MongoDB存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
四、系统部署
因为分布式部署所需的环境都差不多,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像来部署爬虫,使用Daocloud上的scrapy-env来部署程序。部署。系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
国产优质动态IP。老化时间2-10分钟,注册即可免费领取10000个代理IP。注册地址: PC:
移动 查看全部
scrapy分页抓取网页(基于python分布式房源数据系统为数据的进一步应用主题爬虫)
基于Python的分布式房源数据采集系统为数据的进一步应用,即房源推荐系统提供数据支持。本课题致力于解决单进程单机爬虫的瓶颈,基于Redis分布式多爬虫共享队列创建主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath技术提取和解析下载的网页,使用Redis数据库进行分发,使用MongoDb数据库进行数据存储,使用Django web框架和Semantic UI开源框架进行友好可视化数据,最后使用 Docker 部署爬虫。为同城各大城市的租赁平台设计并实现了分布式爬虫系统。
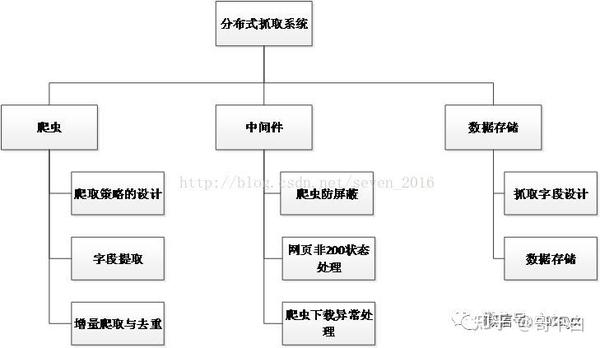
分布式爬虫爬取系统主要包括以下功能:
1.爬虫功能:爬取策略设计、内容数据域设计、增量爬取请求去重
2.中间件:爬虫防屏蔽中间件网页非200状态处理爬虫下载异常处理
3.数据存储:抓斗设计数据存储
4.数据可视化
完整的项目源代码
二、系统分布式架构
分布式采用主从结构,设置一个Master服务器和多个Slave服务器。Master 端管理 Redis 数据库并分发下载任务。Slave部署Scrapy爬虫提取网页并解析提取数据,最终将解析后的数据存储在同一个MongoDb数据库中。分布式爬虫架构如图所示。
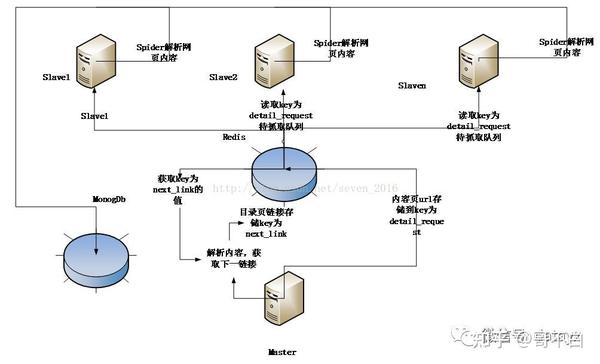
使用Redis数据库实现分布式爬取,基本思路是将Scrapy爬虫获取的detail_request的url放入Redis Queue,所有爬虫也从指定的Redis Queue获取请求。Scrapy-Redis 组件默认使用 SpiderPriorityQueue。确定 URL 的顺序,是 sorted set 实现的一种非 FIFO 和 LIFO 的方法。因此,待爬取队列的共享是爬虫可以部署在其他服务器上完成相同爬取任务的关键点。另外,本文为了解决Scrapy单机受限的问题,将结合Scrapy-Redis组件开发Scrapy。Scrapy-Redis的总体思路是本项目通过重写Scrapu框架中的scheduler和spider类来实现调度和spider启动。与redis的交互。实现了新的dupefilter和queue类,实现了权重判断和调度容器与redis的交互。由于每台主机上的爬虫进程访问同一个redis数据库,调度和权重判断统一管理,实现分布式分布。爬行动物的目的。
三、系统实现
1)爬取策略的设计可以从scrapy的结构分析中看出。网络爬虫从初始地址开始,根据从spider中定义的目标地址获取的正则表达式或者Xpath获取更多的网页链接,加入到待下载队列中,经过去重排序后,等待用于调度程序的调度。在这个系统中,新建的链接可以分为两类,一类是目录页链接,也就是我们平时看到的下一页的链接,另一类是内容详情页链接,也就是我们需要解析网页提取字段链接指向实际的列表信息页面。
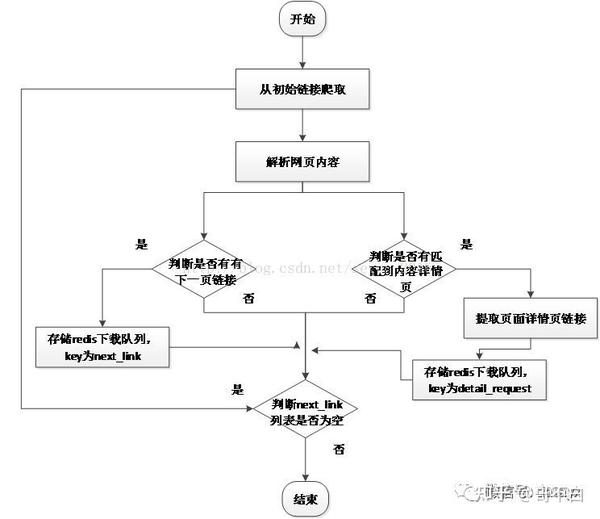
这里是master端目标链接的爬取策略。由于是分布式主从模式,master端的爬虫主要抓取下载内容详情页的链接,通过redis将下载任务分享给slave端的其他爬虫。Slave端主要负责进一步解析提取详情页的链接,并存入数据库。本文以58同城为例。初始页面链接,其实就是每个类别的首页链接,主要包括(以广东省几个城市为例):

综上所述,网络资源爬取系统采用以下爬取策略:
1) 对于Master端:核心模块是解决翻页问题,获取到每个页面的内容详情页面的链接。
Master端主要采用以下爬取策略:
1. 将redis的初始链接插入到nest_link的key中,从初始页面链接开始
2. 爬虫从redis中的key next_link获取初始链接,开始运行爬虫
3. 下载器返回的Response,爬虫根据蜘蛛定义的爬取规则,识别是否有下一页的链接。如果有链接,则存储在redis中,key保存为next_link。一个内容详情页的链接,如果匹配,就会存入Redis,将key保存为detail_request,插入下载链接,供slave端的spider使用,也就是slave端的下载任务。
4. 爬虫继续从redis中的key取值作为next_link。如果有值,则继续执行步骤2。如果为空,则爬虫等待新的链接。
2) 对于slave端:核心模块是从redis获取下载任务并解析提取字段。Slave端主要采用以下爬取策略:
1.爬虫从redis获取初始链接,key为detail_request,开始运行爬虫
2. 下载器返回的Response,爬虫根据蜘蛛定义的爬取规则,识别是否有符合该规则的content字段,如果有,将该字段存储并返回给模型,等待数据存储操作。重复步骤 1,直到爬取队列为空,爬虫等待新的链接。
2)爬虫的具体实现
爬虫程序由四部分组成,即对象定义程序、数据捕获程序、数据处理程序和下载设置程序。这里的组合是从方。Master缺少对象定义程序和数据处理程序。Master端主要是下载链接的爬取。
(1)数据抓取程序数据抓取程序分为Master端和Slave端。数据抓取程序从Redis获取初始地址。数据抓取程序定义抓取网页的规则,使用Xpath提取字段数据 Xpath等的方法,重点介绍从Xpath中提取字符数据的方法。Xapth使用路径表达式来选择web文档中的节点或节点集。Xpath有几种类型:元素、属性、文本、命名空间,处理指令、评论和文档节点。将Web文档视为一棵节点树,树的根节点称为文档节点和根节点,定位目标节点即可提取Web文档的字段数据通过 Xpath 表达式。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。具体实施步骤:
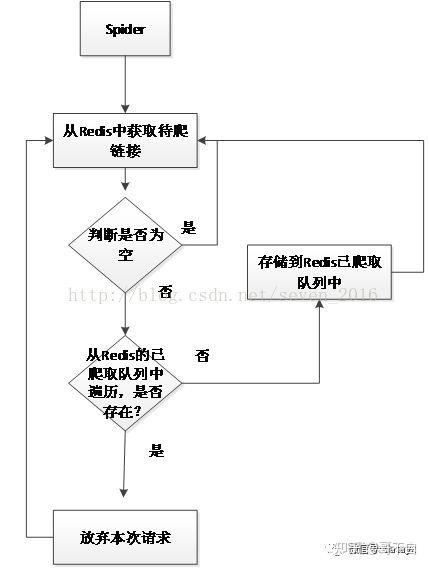
(1) 从待爬取队列中获取url
(2)判断要请求的url是否已经爬取,如果已经爬取则忽略请求,未爬取,继续其他操作,将url插入爬取队列
(3) 重复第1步。这里我们使用scrapy-redis的去重组件,所以没有实现,但是原理还是有待理解的,具体看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
它将不断访问 网站 的内容。如果不采取伪装措施,很容易被网站识别为爬虫,系统采用以下方法防止爬虫被拦截:
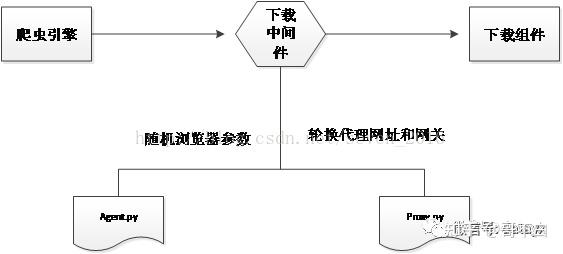
(a) 模拟不同浏览器行为的实现思路和代码
原则:
从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应的处理,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性。首先是扩展下载中间件。首先,将中间件添加到seeings.py。其次,扩展中间件,主要是写一个useragent列表,保存常用的浏览器请求头。作为一个列表。
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
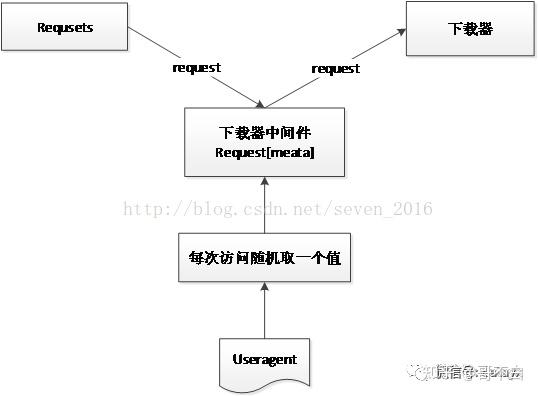
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1. 代理ip池的设计开发流程如下:
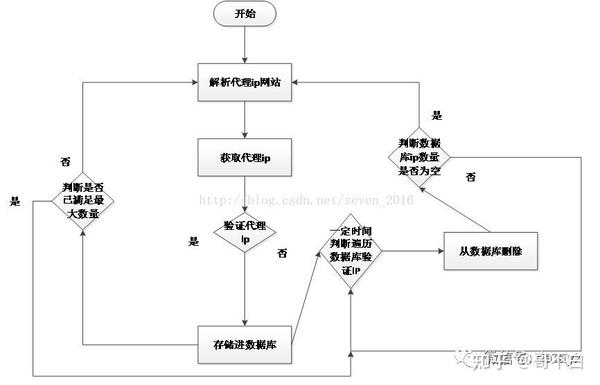
一个。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行身份验证
d。如果达到最大ip数,停止爬取,一定时间后验证数据ip的有效性,删除无效ip。直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip爬虫运行截图:
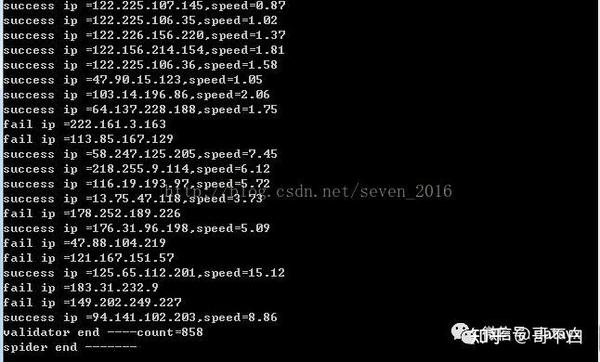
(c) 爬虫异常状态组件的处理 当爬虫没有被阻塞并运行时,对网站的访问并不总是200请求成功,而是有多种状态,比如上面的爬虫被禁止时,实际上返回的状态是302,通过捕获302的状态来实现预防屏蔽组件。同时异常状态的处理有利于爬虫的健壮性。设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
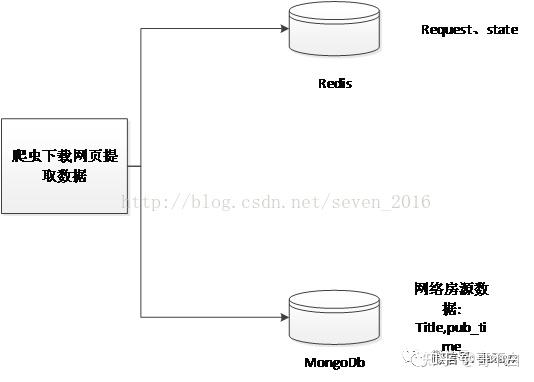
d) 数据存储模块 数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。Scrapy 支持 json、csv、xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(g) 数据可视化设计 数据可视化其实就是将数据库中的数据转换成便于我们用户观察的形式。系统使用MongoDB存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
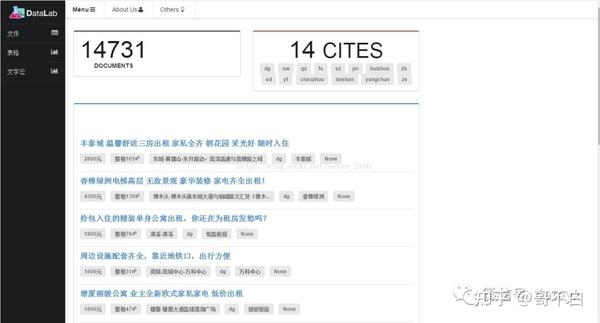
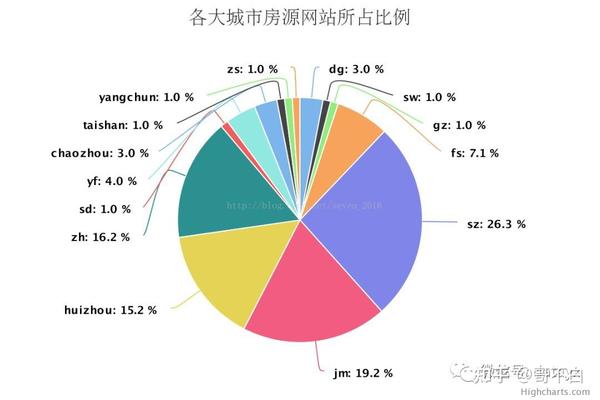
四、系统部署
因为分布式部署所需的环境都差不多,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像来部署爬虫,使用Daocloud上的scrapy-env来部署程序。部署。系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
国产优质动态IP。老化时间2-10分钟,注册即可免费领取10000个代理IP。注册地址: PC:
移动
scrapy分页抓取网页(目标网站上内容很多时会用多个页显示(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-17 06:22
当目标网站上的内容很多时,会分页显示。网页抓取/数据提取/信息提取工具包MetaSeeker可以翻页,提取每页内容,目标网站显示多页,有几种方式:
1.页面上的每个页面都由另一个URL地址表示。最好将这样的网页翻页,提取URL,在以后的某个时间在这个地址加载页面。而且 MetaSeeker 还可以将一个信息提取交易中的所有信息都翻过来。在此会话中,这些 URL 称为内嵌线索。这些网址是不记录的,翻过来就丢弃了。事实上,这样的 URL 是被记录下来的。意义不大,目标网站在显示多个页面的时候经常使用一个服务器动态页面,页码作为参数,比如page=2,改变这些页面的内容,比如,一个博客网站,新的博文添加后,原来的分页发生了变化。最初的博文在第 2 页,但稍后可能在第 3 页。
2.页面上的每个页面都关联了一段Javascript代码,点击时执行。这是普通爬虫的天敌。普通爬虫很难提取javascript管理的内容,特别是用AJAX框架制作的网站,网页抓取/数据提取/信息提取工具包MetaSeeker可以模拟用户的点击操作,在一个信息中完成翻页提取交易。
‹ 可以使用 MetaSeeker 进行合法的垂直搜索吗?网页抓取/数据提取/信息提取工具包 MetaSeeker 中的网络爬虫是怎么做的?› 查看全部
scrapy分页抓取网页(目标网站上内容很多时会用多个页显示(图))
当目标网站上的内容很多时,会分页显示。网页抓取/数据提取/信息提取工具包MetaSeeker可以翻页,提取每页内容,目标网站显示多页,有几种方式:
1.页面上的每个页面都由另一个URL地址表示。最好将这样的网页翻页,提取URL,在以后的某个时间在这个地址加载页面。而且 MetaSeeker 还可以将一个信息提取交易中的所有信息都翻过来。在此会话中,这些 URL 称为内嵌线索。这些网址是不记录的,翻过来就丢弃了。事实上,这样的 URL 是被记录下来的。意义不大,目标网站在显示多个页面的时候经常使用一个服务器动态页面,页码作为参数,比如page=2,改变这些页面的内容,比如,一个博客网站,新的博文添加后,原来的分页发生了变化。最初的博文在第 2 页,但稍后可能在第 3 页。
2.页面上的每个页面都关联了一段Javascript代码,点击时执行。这是普通爬虫的天敌。普通爬虫很难提取javascript管理的内容,特别是用AJAX框架制作的网站,网页抓取/数据提取/信息提取工具包MetaSeeker可以模拟用户的点击操作,在一个信息中完成翻页提取交易。
‹ 可以使用 MetaSeeker 进行合法的垂直搜索吗?网页抓取/数据提取/信息提取工具包 MetaSeeker 中的网络爬虫是怎么做的?›
scrapy分页抓取网页(一个_selector.xpath.u去重与增量爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-17 02:01
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能被Xpath提取出来,所以也需要定期匹配。如果有异常,必须处理。一般当页面无法匹配到对应字段时,应设置为0,待到item后处理。过滤处理。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:
(1)从待爬取队列中获取url
(2)判断要请求的url是否被爬取,如果已经爬取则忽略该请求,不被爬取,继续其他操作,将url插入爬取队列
(3)重复步骤 1
这里我们使用了scrapy-redis的去重组件,所以还没有实现,但是原理还是需要了解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫类反屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为
系统采用以下方法防止爬虫被屏蔽:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.本着君子的约定,降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们屏蔽了cookies的调整,这也有利于我们的身份分歧。
5.人工编码,这应该是无可挑剔的反禁令措施,所有系统都比人工操作好不了多少,只是降低了自动化,效率不高,但确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码以重新访问该页面。为此,我添加了一个邮件提醒模块。当爬虫被封禁时,会发送邮件提醒管理员解除封禁。同时将重定向的请求重新加入下载队列进行爬取,以保证数据的完整性。
防爬虫网站屏蔽原理如下图所示:
(a) 模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性
首先是扩展下载中间件。首先,将中间件添加到seeings.py。
二、扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为列表,如下图:
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。
首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1.代理ip池的设计开发流程如下:
一种。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行验证
d。如果达到最大ips数,停止爬取,一定时间后验证数据ips的有效性,删除无效ips
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip模块这里使用七夜代理ip池的开源项目
代理ip爬虫运行截图:
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有各种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,阻塞组件这是通过捕获 302 状态来实现的。同时,异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
(d) 数据存储模块
数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。
Scrapy 支持 json、csv 和 xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(e) 抓取场地设计
本文以网络房屋数据为捕获目标,从机端解析捕获现场数据。因此,捕获的内容必须能够客观、准确地反映网络房屋数据的特征。
以抓取58同城的在线房屋数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
序列号
字段名称
字段含义
1
标题
帖子标题
2
钱钱
租
3
方法
租
4
区域
您所在的地区
5
社区
您所在的社区
6
目标网址
发布详细信息
7
城市
城市
8
Pub_time
发布时间
现场选择主要是根据本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。降低单机压力。
(f) 数据处理
1)对象定义器
Item 是定义抓取数据的容器。通过创建一个 scrapy.item.Item 类来声明。将该属性定义为一个scrapy.item.Field对象来控制通过实例化所需item获得的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、地点、社区、城市、帖子详情页链接、发布时间。这里对字段的定义是根据数据处理端的需要来定义的。关键代码如下:
类 TcZufangItem(项目):
#帖子名称
标题=字段()
#租
钱=字段()
#租
方法=字段()
#你的地区
面积=字段()
#地点
社区=字段()
#发布详细信息网址
targeturl=字段()
#post 发布时间
pub_time=字段()
#地点城市
城市=字段()
2)数据处理程序
保存和输出数据的方法在 Pipeline 类中定义。从 Spider 的 parse 方法返回的 Item 中,数据将被处理并以 ITEM_PIPELINES 列表中 Pipeline 类对应的顶层格式输出。系统发回管道的数据使用Mongodb存储。关键代码如下:
def process_item(self, item, spider):
如果项目['pub_time'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['方法'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['社区'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['钱']==0:
raise DropItem("发现重复项:%s" % item)
如果项目['区域'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['城市'] == 0:
raise DropItem("发现重复项:%s" % item)
zufang_detail = {
'title': item.get('title'),
'钱':item.get('钱'),
'方法':item.get('方法'),
'区域': item.get('区域', ''),
'社区': item.get('社区', ''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time', ''),
'城市': item.get('城市','')
}
结果 = self.db['zufang_detail'].insert(zufang_detail)
print '[success] the '+item['targeturl']+'写入MongoDB数据库'
归还物品
(g) 数据可视化设计
数据的可视化,其实就是将数据库的数据转换成便于我们用户观察的形式。本系统使用 Mongodb 存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
Master运行截图:
从端运行截图:
五、系统部署
环境部署,因为分布式部署所需的环境类似,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像部署爬虫,使用Daocloud上的scrapy-env pair。该程序已部署。具体的docker部署过程可以参考网上。
代码放在gayhub上,有兴趣的可以查一下
更多! 查看全部
scrapy分页抓取网页(一个_selector.xpath.u去重与增量爬取)
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能被Xpath提取出来,所以也需要定期匹配。如果有异常,必须处理。一般当页面无法匹配到对应字段时,应设置为0,待到item后处理。过滤处理。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:
(1)从待爬取队列中获取url
(2)判断要请求的url是否被爬取,如果已经爬取则忽略该请求,不被爬取,继续其他操作,将url插入爬取队列
(3)重复步骤 1
这里我们使用了scrapy-redis的去重组件,所以还没有实现,但是原理还是需要了解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫类反屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为
系统采用以下方法防止爬虫被屏蔽:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.本着君子的约定,降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们屏蔽了cookies的调整,这也有利于我们的身份分歧。
5.人工编码,这应该是无可挑剔的反禁令措施,所有系统都比人工操作好不了多少,只是降低了自动化,效率不高,但确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码以重新访问该页面。为此,我添加了一个邮件提醒模块。当爬虫被封禁时,会发送邮件提醒管理员解除封禁。同时将重定向的请求重新加入下载队列进行爬取,以保证数据的完整性。
防爬虫网站屏蔽原理如下图所示:
(a) 模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性
首先是扩展下载中间件。首先,将中间件添加到seeings.py。
二、扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为列表,如下图:
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。
首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1.代理ip池的设计开发流程如下:
一种。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行验证
d。如果达到最大ips数,停止爬取,一定时间后验证数据ips的有效性,删除无效ips
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip模块这里使用七夜代理ip池的开源项目
代理ip爬虫运行截图:
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有各种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,阻塞组件这是通过捕获 302 状态来实现的。同时,异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
(d) 数据存储模块
数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。
Scrapy 支持 json、csv 和 xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(e) 抓取场地设计
本文以网络房屋数据为捕获目标,从机端解析捕获现场数据。因此,捕获的内容必须能够客观、准确地反映网络房屋数据的特征。
以抓取58同城的在线房屋数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
序列号
字段名称
字段含义
1
标题
帖子标题
2
钱钱
租
3
方法
租
4
区域
您所在的地区
5
社区
您所在的社区
6
目标网址
发布详细信息
7
城市
城市
8
Pub_time
发布时间
现场选择主要是根据本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。降低单机压力。
(f) 数据处理
1)对象定义器
Item 是定义抓取数据的容器。通过创建一个 scrapy.item.Item 类来声明。将该属性定义为一个scrapy.item.Field对象来控制通过实例化所需item获得的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、地点、社区、城市、帖子详情页链接、发布时间。这里对字段的定义是根据数据处理端的需要来定义的。关键代码如下:
类 TcZufangItem(项目):
#帖子名称
标题=字段()
#租
钱=字段()
#租
方法=字段()
#你的地区
面积=字段()
#地点
社区=字段()
#发布详细信息网址
targeturl=字段()
#post 发布时间
pub_time=字段()
#地点城市
城市=字段()
2)数据处理程序
保存和输出数据的方法在 Pipeline 类中定义。从 Spider 的 parse 方法返回的 Item 中,数据将被处理并以 ITEM_PIPELINES 列表中 Pipeline 类对应的顶层格式输出。系统发回管道的数据使用Mongodb存储。关键代码如下:
def process_item(self, item, spider):
如果项目['pub_time'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['方法'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['社区'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['钱']==0:
raise DropItem("发现重复项:%s" % item)
如果项目['区域'] == 0:
raise DropItem("发现重复项:%s" % item)
如果项目['城市'] == 0:
raise DropItem("发现重复项:%s" % item)
zufang_detail = {
'title': item.get('title'),
'钱':item.get('钱'),
'方法':item.get('方法'),
'区域': item.get('区域', ''),
'社区': item.get('社区', ''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time', ''),
'城市': item.get('城市','')
}
结果 = self.db['zufang_detail'].insert(zufang_detail)
print '[success] the '+item['targeturl']+'写入MongoDB数据库'
归还物品
(g) 数据可视化设计
数据的可视化,其实就是将数据库的数据转换成便于我们用户观察的形式。本系统使用 Mongodb 存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
Master运行截图:
从端运行截图:
五、系统部署
环境部署,因为分布式部署所需的环境类似,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像部署爬虫,使用Daocloud上的scrapy-env pair。该程序已部署。具体的docker部署过程可以参考网上。
代码放在gayhub上,有兴趣的可以查一下
更多!
scrapy分页抓取网页( WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-15 22:18
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据;对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。 查看全部
scrapy分页抓取网页(
WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据;对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。
scrapy分页抓取网页(网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-14 22:19
Scrapy 是一个用 Python 编写的爬虫框架,简单、轻量、非常方便。Scrapy 使用 Twisted(一个异步网络库)来处理网络通信。架构清晰,收录各种中间件接口,可灵活满足各种需求。
以上摘自网上介绍scrapy框架的一段话。大年初一,懒癌高发……
安装scrapy,pip可以解决你的问题:pip install scrapy。
这里有一句话,如果你在运行代码后看到这个错误:
ImportError: No module named win32api
<p>如果出现坑,需要安装pywin32。如果已经安装了pywin32,还有报错,还是需要在你的python安装目录下手动安装\Lib\site-packages\pywin32_system32:pythoncom27.dll,pywintypes2 查看全部
scrapy分页抓取网页(网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
Scrapy 是一个用 Python 编写的爬虫框架,简单、轻量、非常方便。Scrapy 使用 Twisted(一个异步网络库)来处理网络通信。架构清晰,收录各种中间件接口,可灵活满足各种需求。
以上摘自网上介绍scrapy框架的一段话。大年初一,懒癌高发……
安装scrapy,pip可以解决你的问题:pip install scrapy。
这里有一句话,如果你在运行代码后看到这个错误:
ImportError: No module named win32api
<p>如果出现坑,需要安装pywin32。如果已经安装了pywin32,还有报错,还是需要在你的python安装目录下手动安装\Lib\site-packages\pywin32_system32:pythoncom27.dll,pywintypes2
scrapy分页抓取网页(scrapy分页抓取网页基本方法四种(scrapyspan功能详解))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-14 16:12
scrapy分页抓取网页基本方法四种(scrapy分页功能详解)获取不同网页的分页截图显示html页面内容批量采集百度,大众点评,闲鱼等网站的商品信息主要分为如下四步:1.获取文件,然后进行处理2.初始化scrapy,写入代码,初始化构建的爬虫构建工程,写入到百度大众点评闲鱼。3.执行爬虫,并写入url到服务器4.跑起来,等待读取结果,并发布查看如何获取更多网页内容一.文件从爬虫的文件名和元素上就可以抓取到网页内容二.元素1.:指定爬虫程序处理抓取的url2.:就是包含了requestheaders和url的html文件3.html里面每个元素里都定义了各自的headers4.包含了元素的值5.爬虫里的所有元素都会被解析,传递给scrapy进行处理三.html六元素1.一个html里面一定有标签2.加号就是锚标签(定义页码尺寸)3.text(title):html元素的标题4.span(link):标签的链接5.(content):标签的内容(可以放在span的前面或者后面,)6.<p>(pagetitle):span里的title(页标题)四.分页信息1.一个页面就是给你定义一个,所有定义好的就是这个页面里面所有的内容。
2.分页信息:,为了加载所有内容3.如何传递url,传递url时如何请求
<a></a>,这些都是请求链接4.scrapy自带的连接,例如<a></a>,我们传递连接信息到request上。5.自己写爬虫模块,传递requestheaders6.<a></a>.site_urls()这个链接的意思是不需要<a></a>[""].site_urls(url)例如:1.我们获取天猫全部商品的链接2.我们获取京东全部商品的链接我们每次访问都要传递一次requestheaders.。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页基本方法四种(scrapyspan功能详解))
scrapy分页抓取网页基本方法四种(scrapy分页功能详解)获取不同网页的分页截图显示html页面内容批量采集百度,大众点评,闲鱼等网站的商品信息主要分为如下四步:1.获取文件,然后进行处理2.初始化scrapy,写入代码,初始化构建的爬虫构建工程,写入到百度大众点评闲鱼。3.执行爬虫,并写入url到服务器4.跑起来,等待读取结果,并发布查看如何获取更多网页内容一.文件从爬虫的文件名和元素上就可以抓取到网页内容二.元素1.:指定爬虫程序处理抓取的url2.:就是包含了requestheaders和url的html文件3.html里面每个元素里都定义了各自的headers4.包含了元素的值5.爬虫里的所有元素都会被解析,传递给scrapy进行处理三.html六元素1.一个html里面一定有标签2.加号就是锚标签(定义页码尺寸)3.text(title):html元素的标题4.span(link):标签的链接5.(content):标签的内容(可以放在span的前面或者后面,)6.<p>(pagetitle):span里的title(页标题)四.分页信息1.一个页面就是给你定义一个,所有定义好的就是这个页面里面所有的内容。
2.分页信息:,为了加载所有内容3.如何传递url,传递url时如何请求
<a></a>,这些都是请求链接4.scrapy自带的连接,例如<a></a>,我们传递连接信息到request上。5.自己写爬虫模块,传递requestheaders6.<a></a>.site_urls()这个链接的意思是不需要<a></a>[""].site_urls(url)例如:1.我们获取天猫全部商品的链接2.我们获取京东全部商品的链接我们每次访问都要传递一次requestheaders.。
scrapy分页抓取网页(数据加载是一种异步加载方式,原始的页面最初不会)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-09 02:14
数据加载是一种异步加载方式。原创页面起初不收录一些数据。原创页面加载完成后,会请求一个接口从服务器获取数据,然后对数据进行处理并呈现在网页上。只需发送一个 Ajax 请求。如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取到有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟Ajax请求,那么就可以成功获取。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。这不是编程
语言,但使用JavaScript与服务器交换数据并更新,同时保证页面不刷新,页面链接不改变
网页技术的一部分。对于传统的网页,如果要更新其内容,则必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
以微博为例
以微博为例,切换到微博页面,一直往下滚动,可以发现往下滑几条微博后就没有再往下,而是出现了一个加载动画,过一会新的微博就会出现继续出现在下方。博客内容,这个过程真的是Ajax加载的过程。注意页面并没有完全刷新,也就是说页面的链接没有变化,但是页面中有新的内容,也就是后面刷新的新微博。这就是通过 Ajax 获取和呈现新数据的方式。
Ajax 实际上有一个特殊的请求类型叫做 xhr。可以找到一个名称以getIndex开头的请求,其Type为xhr,即Ajax请求。用鼠标点击请求,查看请求的详细信息。请求标头中的信息之一是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。然后点击预览查看响应的内容,是 JSON 格式的。
这是一个 GET 类型的请求,请求链接是 . 请求有 4 个参数: type , value ,
containerid 和页面。可以发现,它们的type、value和containerid总是一样的。type总是uid,value的值是页面链接中的数字,其实就是用户的id。另外,还有containerid。可以查到是107603加上用户id。改变的值为page,显然这个参数是用来控制分页的,page=l代表第一页,page=2代表第二页,以此类推。
返回的json数据中最关键的两条信息分别是cardlistinfo和cards:前者收录了比较重要的信息总数,观察后发现其实是微博总数,我们可以估算出页数根据这个数字;另一个是一个列表,里面有10个元素,展开一个看看。
可以发现这个元素有一个比较重要的字段mblog。展开它,可以发现它收录了微博的一些信息,例如态度count(点赞数)、comments_count(评论数)、reposts_count(转发数)、created at(发帖时间)、text(微博的文字) ) 等,都是格式化的内容。
原则
向网页更新发送Ajax请求的过程可以简单分为以下三个步骤:发送请求;解析内容;呈现网页。
发送请求:JavaScript可以实现页面的各种交互功能,Ajax也不例外,JavaScript也能实现。这是由 JavaScript 实现的 Ajax 的最低级别。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open和send方法向一个链接(也就是服务器)发送消息。
发送了请求。由于设置了监听器,当服务器返回响应时,会触发onreadystatechange对应的方法,然后可以在该方法中解析响应内容。
解析内容:得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。返回的内容可能是 HTML,也可能是 JSON,然后只需要在方法中用 JavaScript 进一步处理即可。例如,如果是 JSON,则可以对其进行解析和转换。
呈现网页:JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementByid().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。这种操作也称为DOM操作,即对Document网页的操作。文档操作,如更改、删除等。上例中为 document 。getElementByid("myDiv ”) .innerHTML=xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码更改为服务器返回的内容,这样服务器返回的新数据就会显示在myDiv元素内部。页面似乎已更新。
代码示例
要爬取所有微博的前 10 页,首先定义一个方法来获取每个请求的结果。在请求时,page 是一个可变参数,所以将它作为方法参数传入。
这里定义 base_url 来表示请求 URL 的前半部分。接下来构造参数字典,其中type、value、containerid为固定参数,page为可变参数。接下来调用urlencode方法将参数转换为-URL GET请求参数,类似于type=ui d&value=2830678474&containerid=78474&page=2。然后,base_url 与参数组合形成一个新的 URL。接下来,我们通过请求请求链接,添加 headers 参数。然后判断响应的状态码,如果是200,直接调用json方法将内容解析成json返回,否则不返回信息。如果发生异常,捕获并输出其异常信息。
以今日头条为例
在抓取之前,先分析一下抓取的逻辑。打开今日头条首页,右上角有一个搜索入口,这里我们尝试捕捉街拍的美图,所以输入“街拍”二字进行搜索。
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL就是当前的link=street shoot。切换到 XHR Filtering 选项卡并查看是否有任何 Ajax 请求。点击数据栏展开,发现有很多条数据。点击第一项展开,可以发现有一个title字段,它的值就是页面中第一条数据的标题。再次查看其他数据,正好是一一对应的。
为了捕捉漂亮的图片,这里的一组图片对应上一个数据字段中的一条数据。每条数据还有一个 image_detail 字段,它是一个列表的形式,其中收录了该组中所有图像的列表。您需要做的就是提出问题并下载它们。一组图片会发布到一个文件夹中,文件夹的名字就是组图的标题。
切换回 Headers 选项卡并观察其请求 URL 和 Headers 信息。您可以看到这是一个 GET 请求。请求 URL 的参数有 offset、format、keyword、autoload、count 和 curtab。
唯一变化的参数是offset,其他参数都没有变化,而且第二次请求的offset值是20,第三次是40,第四次是60,所以可以找到规律,这个offset值是偏移值,然后可以推断出count参数是一次获取的数据条数。因此,我们可以使用offset参数来控制数据分页。
代码示例
实现方法 get_page 以加载单个 Ajax 请求的结果。唯一改变的参数是偏移量,所以我们将它作为参数传递
import requests
from urllib.parse import urlencode
def get_page(offset):
params = {
'offset':offset,
'format':'json',
'keyword':'街拍',
'autoload':'true',
'count':'20',
'cur_tab':'1'
}
url = 'http://www.toutiao.com/search_ ... ncode(params)
try:
response = requests.get(url)
print(response)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
get_page(1)
实现另一种解析方法:提取每条数据的image_detail字段中的每条图片链接,返回图片链接和图片所属的标题。这时候就可以构造一个生成器了
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_detail')
for image in images:
yield {
'image':image.get('url'),
'title':title
}
这里的数据没有任何价值,说明有防采摘措施。
后面会分析 查看全部
scrapy分页抓取网页(数据加载是一种异步加载方式,原始的页面最初不会)
数据加载是一种异步加载方式。原创页面起初不收录一些数据。原创页面加载完成后,会请求一个接口从服务器获取数据,然后对数据进行处理并呈现在网页上。只需发送一个 Ajax 请求。如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取到有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟Ajax请求,那么就可以成功获取。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。这不是编程
语言,但使用JavaScript与服务器交换数据并更新,同时保证页面不刷新,页面链接不改变
网页技术的一部分。对于传统的网页,如果要更新其内容,则必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
以微博为例
以微博为例,切换到微博页面,一直往下滚动,可以发现往下滑几条微博后就没有再往下,而是出现了一个加载动画,过一会新的微博就会出现继续出现在下方。博客内容,这个过程真的是Ajax加载的过程。注意页面并没有完全刷新,也就是说页面的链接没有变化,但是页面中有新的内容,也就是后面刷新的新微博。这就是通过 Ajax 获取和呈现新数据的方式。
Ajax 实际上有一个特殊的请求类型叫做 xhr。可以找到一个名称以getIndex开头的请求,其Type为xhr,即Ajax请求。用鼠标点击请求,查看请求的详细信息。请求标头中的信息之一是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。然后点击预览查看响应的内容,是 JSON 格式的。
这是一个 GET 类型的请求,请求链接是 . 请求有 4 个参数: type , value ,
containerid 和页面。可以发现,它们的type、value和containerid总是一样的。type总是uid,value的值是页面链接中的数字,其实就是用户的id。另外,还有containerid。可以查到是107603加上用户id。改变的值为page,显然这个参数是用来控制分页的,page=l代表第一页,page=2代表第二页,以此类推。
返回的json数据中最关键的两条信息分别是cardlistinfo和cards:前者收录了比较重要的信息总数,观察后发现其实是微博总数,我们可以估算出页数根据这个数字;另一个是一个列表,里面有10个元素,展开一个看看。
可以发现这个元素有一个比较重要的字段mblog。展开它,可以发现它收录了微博的一些信息,例如态度count(点赞数)、comments_count(评论数)、reposts_count(转发数)、created at(发帖时间)、text(微博的文字) ) 等,都是格式化的内容。
原则
向网页更新发送Ajax请求的过程可以简单分为以下三个步骤:发送请求;解析内容;呈现网页。
发送请求:JavaScript可以实现页面的各种交互功能,Ajax也不例外,JavaScript也能实现。这是由 JavaScript 实现的 Ajax 的最低级别。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open和send方法向一个链接(也就是服务器)发送消息。
发送了请求。由于设置了监听器,当服务器返回响应时,会触发onreadystatechange对应的方法,然后可以在该方法中解析响应内容。
解析内容:得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。返回的内容可能是 HTML,也可能是 JSON,然后只需要在方法中用 JavaScript 进一步处理即可。例如,如果是 JSON,则可以对其进行解析和转换。
呈现网页:JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementByid().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。这种操作也称为DOM操作,即对Document网页的操作。文档操作,如更改、删除等。上例中为 document 。getElementByid("myDiv ”) .innerHTML=xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码更改为服务器返回的内容,这样服务器返回的新数据就会显示在myDiv元素内部。页面似乎已更新。
代码示例
要爬取所有微博的前 10 页,首先定义一个方法来获取每个请求的结果。在请求时,page 是一个可变参数,所以将它作为方法参数传入。
这里定义 base_url 来表示请求 URL 的前半部分。接下来构造参数字典,其中type、value、containerid为固定参数,page为可变参数。接下来调用urlencode方法将参数转换为-URL GET请求参数,类似于type=ui d&value=2830678474&containerid=78474&page=2。然后,base_url 与参数组合形成一个新的 URL。接下来,我们通过请求请求链接,添加 headers 参数。然后判断响应的状态码,如果是200,直接调用json方法将内容解析成json返回,否则不返回信息。如果发生异常,捕获并输出其异常信息。
以今日头条为例
在抓取之前,先分析一下抓取的逻辑。打开今日头条首页,右上角有一个搜索入口,这里我们尝试捕捉街拍的美图,所以输入“街拍”二字进行搜索。
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL就是当前的link=street shoot。切换到 XHR Filtering 选项卡并查看是否有任何 Ajax 请求。点击数据栏展开,发现有很多条数据。点击第一项展开,可以发现有一个title字段,它的值就是页面中第一条数据的标题。再次查看其他数据,正好是一一对应的。
为了捕捉漂亮的图片,这里的一组图片对应上一个数据字段中的一条数据。每条数据还有一个 image_detail 字段,它是一个列表的形式,其中收录了该组中所有图像的列表。您需要做的就是提出问题并下载它们。一组图片会发布到一个文件夹中,文件夹的名字就是组图的标题。
切换回 Headers 选项卡并观察其请求 URL 和 Headers 信息。您可以看到这是一个 GET 请求。请求 URL 的参数有 offset、format、keyword、autoload、count 和 curtab。
唯一变化的参数是offset,其他参数都没有变化,而且第二次请求的offset值是20,第三次是40,第四次是60,所以可以找到规律,这个offset值是偏移值,然后可以推断出count参数是一次获取的数据条数。因此,我们可以使用offset参数来控制数据分页。
代码示例
实现方法 get_page 以加载单个 Ajax 请求的结果。唯一改变的参数是偏移量,所以我们将它作为参数传递
import requests
from urllib.parse import urlencode
def get_page(offset):
params = {
'offset':offset,
'format':'json',
'keyword':'街拍',
'autoload':'true',
'count':'20',
'cur_tab':'1'
}
url = 'http://www.toutiao.com/search_ ... ncode(params)
try:
response = requests.get(url)
print(response)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
get_page(1)
实现另一种解析方法:提取每条数据的image_detail字段中的每条图片链接,返回图片链接和图片所属的标题。这时候就可以构造一个生成器了
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_detail')
for image in images:
yield {
'image':image.get('url'),
'title':title
}
这里的数据没有任何价值,说明有防采摘措施。
后面会分析
scrapy分页抓取网页( 豆瓣日记:WebScraper怎么对付这种类型的网页(12))
网站优化 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2022-03-09 02:12
豆瓣日记:WebScraper怎么对付这种类型的网页(12))
这是简易数据分析系列文章的第12期。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
/1776448504/I0 gyT8aeQ?type=repost
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
/1776448504/I0 gyT8aeQ?type=repost#_rnd36
第三页参数为#_rnd39
/1776448504/I0 gyT8aeQ?type=repost#_rnd39
第 4 页参数是#_rnd76:
/1776448504/I0 gyT8aeQ?type=repost#_rnd76
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据;对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。 查看全部
scrapy分页抓取网页(
豆瓣日记:WebScraper怎么对付这种类型的网页(12))
这是简易数据分析系列文章的第12期。
本文首发于博客园:简单数据分析12。
在之前的文章文章中,我们介绍了Web Scraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
/1776448504/I0 gyT8aeQ?type=repost
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
/1776448504/I0 gyT8aeQ?type=repost#_rnd36
第三页参数为#_rnd39
/1776448504/I0 gyT8aeQ?type=repost#_rnd39
第 4 页参数是#_rnd76:
/1776448504/I0 gyT8aeQ?type=repost#_rnd76
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据;对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方式。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。
scrapy分页抓取网页(scrapy分页抓取网页实战基于aiohttp框架提供request对象在一页从头抓到尾)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-08 07:04
scrapy分页抓取网页实战基于aiohttp框架提供request对象在一页从头抓到尾:python2版本
一、get请求:先在浏览器打开网址:scrapyget抓取网页源码如下:url='/'
二、post请求:在浏览器发起post请求:url=''post(url,data=none,meta={'content-type':'text/html;charset=utf-8'})在回调中,需要一些参数,例如-url=''post请求可以被twitter,reddit等验证真实性以及保存到服务器:post请求还可以请求参数化后再次请求,例如抓取网页源码:post(url,data=none,include=none,meta={'content-type':'text/html;charset=utf-8'})。
三、注意事项一定要正确设置scrapy中post请求参数并且校验这个请求不能返回一个空值,参数必须为:app--get-postapp名称和数据内容,需要注意app为多个请求对象,数据中,请求内容可以为空,但应该设置为app名称'''`post+app->app'`'#调用这个方法时,必须app名称为真。
举例:抓取网页://content.htmlfromscrapy.downloadingimportapidefget_it(url):returnscrapy.downloading(url).urls.foreach(all_dist=api.details)defdetails(response):returnresponse.text()post请求请求时是不需要request对象:#如果不指定-url和-cookies'''app--get-postapp名称和数据内容'''#post请求不支持cookies,cookies方法在http服务端不被接受,而是传给json对象'''defpost(url,data=none,include=none,meta={'content-type':'text/html;charset=utf-8'}):"""post请求-s主要由以下5个参数来定义post请求时必须postcookies和cookie参数"""#postspecifies5methods"""#下面的列表是参数列表,所有的参数列表,都是一样的'''scheme='https'data={'content-type':'text/html;charset=utf-8'}#post需要使用前缀参数,请求头中不加#这个参数cookies.include=truefromscrapy.downloadingimportapidefget_it(url):returnscrapy.downloading(url).urls.foreach(all_dist=api.details)scheme='https'include=['*'forcookiesincookies]meta={'content-type':'text/html;charset=utf-8'}scheme='https'request_uri=''action='post'content=。 查看全部
scrapy分页抓取网页(scrapy分页抓取网页实战基于aiohttp框架提供request对象在一页从头抓到尾)
scrapy分页抓取网页实战基于aiohttp框架提供request对象在一页从头抓到尾:python2版本
一、get请求:先在浏览器打开网址:scrapyget抓取网页源码如下:url='/'
二、post请求:在浏览器发起post请求:url=''post(url,data=none,meta={'content-type':'text/html;charset=utf-8'})在回调中,需要一些参数,例如-url=''post请求可以被twitter,reddit等验证真实性以及保存到服务器:post请求还可以请求参数化后再次请求,例如抓取网页源码:post(url,data=none,include=none,meta={'content-type':'text/html;charset=utf-8'})。
三、注意事项一定要正确设置scrapy中post请求参数并且校验这个请求不能返回一个空值,参数必须为:app--get-postapp名称和数据内容,需要注意app为多个请求对象,数据中,请求内容可以为空,但应该设置为app名称'''`post+app->app'`'#调用这个方法时,必须app名称为真。
举例:抓取网页://content.htmlfromscrapy.downloadingimportapidefget_it(url):returnscrapy.downloading(url).urls.foreach(all_dist=api.details)defdetails(response):returnresponse.text()post请求请求时是不需要request对象:#如果不指定-url和-cookies'''app--get-postapp名称和数据内容'''#post请求不支持cookies,cookies方法在http服务端不被接受,而是传给json对象'''defpost(url,data=none,include=none,meta={'content-type':'text/html;charset=utf-8'}):"""post请求-s主要由以下5个参数来定义post请求时必须postcookies和cookie参数"""#postspecifies5methods"""#下面的列表是参数列表,所有的参数列表,都是一样的'''scheme='https'data={'content-type':'text/html;charset=utf-8'}#post需要使用前缀参数,请求头中不加#这个参数cookies.include=truefromscrapy.downloadingimportapidefget_it(url):returnscrapy.downloading(url).urls.foreach(all_dist=api.details)scheme='https'include=['*'forcookiesincookies]meta={'content-type':'text/html;charset=utf-8'}scheme='https'request_uri=''action='post'content=。
scrapy分页抓取网页(小编来一起_crawler-crawler文件蜘蛛代码_快照)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-07 07:21
本文介绍从给定的URL抓取数据并使用scrapy将其放入文件的处理方法。对大家解决问题有一定的参考价值。有需要的朋友,和小编一起学习吧!问题描述
我正在尝试深入刮取给定的 网站 并从所有页面中刮取文本。我正在使用 scrapy 来抓取 网站
这就是我运行蜘蛛爬虫的方式 stack_crawler -o items.json
item.json 文件为空
这是蜘蛛code_snapshot
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
#from tutorial.items import TutorialItem
from tutorial.items import DmozItem
class StackCrawlerSpider(CrawlSpider):
name = 'stack_crawler'
allowed_domains = ['http://www.dmoz.org']
start_urls = ['http://www.dmoz.org/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = TutorialItem()
i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
i['name'] = response.xpath('//div[@id="name"]').extract()
i['description'] = response.xpath('//div[@id="description"]').extract()
return i
这是我运行蜘蛛爬行时得到的日志
dummy-MacBook-Pro:spiders Dummy$ scrapy crawl stack_crawler -o items.json
2016-06-09 10:22:23 [scrapy] INFO: Scrapy 1.1.0 started (bot: tutorial)
2016-06-09 10:22:23 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'FEED_URI': 'items.json', 'SPIDER_MODULES': ['tutorial.spiders'], 'BOT_NAME': 'tutorial', 'ROBOTSTXT_OBEY': True, 'FEED_FORMAT': 'json'}
2016-06-09 10:22:23 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2016-06-09 10:22:23 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2016-06-09 10:22:23 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2016-06-09 10:22:23 [scrapy] INFO: Enabled item pipelines:
[]
2016-06-09 10:22:23 [scrapy] INFO: Spider opened
2016-06-09 10:22:23 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-06-09 10:22:23 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6024
2016-06-09 10:22:24 [scrapy] DEBUG: Crawled (200) (referer: None)
2016-06-09 10:22:24 [scrapy] DEBUG: Crawled (200) (referer: None)
2016-06-09 10:22:24 [scrapy] INFO: Closing spider (finished)
2016-06-09 10:22:24 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 430,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 5694,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2016, 6, 9, 4, 52, 24, 862900),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2016, 6, 9, 4, 52, 23, 483092)}
2016-06-09 10:22:24 [scrapy] INFO: Spider closed (finished)
产品代码快照
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
谁能帮我弄清楚我在代码级别做错了什么来获取数据。
推荐答案
我认为您是scrapy的新手,并且您在代码中犯了很多错误
1.scrapy 中有默认函数 parse 或 start_product_requests,所以你可以避免在那里使用 LinkExtractor。使用 parse 函数并直接在那里获取 start_urls 响应。
2.您在 items.py 中定义了一项并使用另一项。所以字段名不同,就会有冲突。
3.您为字段值选择的路径是正确的。
你必须试试这个
蜘蛛code_snapshot
import scrapy
from lxml import html
from scrapy.spiders import CrawlSpider, Rule
from tutorial.items import DmozItem
class StackCrawlerSpider(CrawlSpider):
name = 'stack_crawler'
allowed_domains = ['http://www.dmoz.org']
start_urls = ['http://www.dmoz.org/']
def parse(self, response):
doc = html.fromstring(response.body)
i = DmozItem()
i['title'] = doc.xpath('//meta[@property="og:title"]/@content')
i['link'] = response.url
i['desc'] = doc.xpath('//meta[@name="description"]/@content')
yield i
产品代码快照
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
这行得通。
这篇关于从给定URL抓取数据并使用scrapy将其放入文件的文章文章就到这里了,希望我们推荐的答案对您有所帮助,也希望大家支持IT之家! 查看全部
scrapy分页抓取网页(小编来一起_crawler-crawler文件蜘蛛代码_快照)
本文介绍从给定的URL抓取数据并使用scrapy将其放入文件的处理方法。对大家解决问题有一定的参考价值。有需要的朋友,和小编一起学习吧!问题描述
我正在尝试深入刮取给定的 网站 并从所有页面中刮取文本。我正在使用 scrapy 来抓取 网站
这就是我运行蜘蛛爬虫的方式 stack_crawler -o items.json
item.json 文件为空
这是蜘蛛code_snapshot
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
#from tutorial.items import TutorialItem
from tutorial.items import DmozItem
class StackCrawlerSpider(CrawlSpider):
name = 'stack_crawler'
allowed_domains = ['http://www.dmoz.org']
start_urls = ['http://www.dmoz.org/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = TutorialItem()
i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
i['name'] = response.xpath('//div[@id="name"]').extract()
i['description'] = response.xpath('//div[@id="description"]').extract()
return i
这是我运行蜘蛛爬行时得到的日志
dummy-MacBook-Pro:spiders Dummy$ scrapy crawl stack_crawler -o items.json
2016-06-09 10:22:23 [scrapy] INFO: Scrapy 1.1.0 started (bot: tutorial)
2016-06-09 10:22:23 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'FEED_URI': 'items.json', 'SPIDER_MODULES': ['tutorial.spiders'], 'BOT_NAME': 'tutorial', 'ROBOTSTXT_OBEY': True, 'FEED_FORMAT': 'json'}
2016-06-09 10:22:23 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2016-06-09 10:22:23 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2016-06-09 10:22:23 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2016-06-09 10:22:23 [scrapy] INFO: Enabled item pipelines:
[]
2016-06-09 10:22:23 [scrapy] INFO: Spider opened
2016-06-09 10:22:23 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-06-09 10:22:23 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6024
2016-06-09 10:22:24 [scrapy] DEBUG: Crawled (200) (referer: None)
2016-06-09 10:22:24 [scrapy] DEBUG: Crawled (200) (referer: None)
2016-06-09 10:22:24 [scrapy] INFO: Closing spider (finished)
2016-06-09 10:22:24 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 430,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 5694,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2016, 6, 9, 4, 52, 24, 862900),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2016, 6, 9, 4, 52, 23, 483092)}
2016-06-09 10:22:24 [scrapy] INFO: Spider closed (finished)
产品代码快照
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
谁能帮我弄清楚我在代码级别做错了什么来获取数据。
推荐答案
我认为您是scrapy的新手,并且您在代码中犯了很多错误
1.scrapy 中有默认函数 parse 或 start_product_requests,所以你可以避免在那里使用 LinkExtractor。使用 parse 函数并直接在那里获取 start_urls 响应。
2.您在 items.py 中定义了一项并使用另一项。所以字段名不同,就会有冲突。
3.您为字段值选择的路径是正确的。
你必须试试这个
蜘蛛code_snapshot
import scrapy
from lxml import html
from scrapy.spiders import CrawlSpider, Rule
from tutorial.items import DmozItem
class StackCrawlerSpider(CrawlSpider):
name = 'stack_crawler'
allowed_domains = ['http://www.dmoz.org']
start_urls = ['http://www.dmoz.org/']
def parse(self, response):
doc = html.fromstring(response.body)
i = DmozItem()
i['title'] = doc.xpath('//meta[@property="og:title"]/@content')
i['link'] = response.url
i['desc'] = doc.xpath('//meta[@name="description"]/@content')
yield i
产品代码快照
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
这行得通。
这篇关于从给定URL抓取数据并使用scrapy将其放入文件的文章文章就到这里了,希望我们推荐的答案对您有所帮助,也希望大家支持IT之家!
scrapy分页抓取网页(人人都用得上webscraper进阶教程,人人用得上数据教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-07 02:24
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:最简单的数据爬虫教程,人人都可以用高级网络爬虫教程,人人都会用
如果你使用网络爬虫抓取数据,你很有可能会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或滚动加载数据,无法完全捕获,如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下级关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。 查看全部
scrapy分页抓取网页(人人都用得上webscraper进阶教程,人人用得上数据教程)
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:最简单的数据爬虫教程,人人都可以用高级网络爬虫教程,人人都会用
如果你使用网络爬虫抓取数据,你很有可能会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或滚动加载数据,无法完全捕获,如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下级关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-05 09:24
Scrapy 是一个用 Python 编写的应用程序框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。
通常我们可以通过Scrapy框架轻松实现爬虫,抓取指定的网站内容或图片。
Scrapy架构图(绿线为数据流)
Scrapy的运行过程
代码写好了,程序开始运行了……
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
制作一个Scrapy爬虫一共需要4个步骤:新建一个项目(scrapy startproject xxx):新建一个爬虫项目清除目标(写items.py):清除你要抓取的目标创建一个爬虫(spiders/xxspider.py):创建爬虫并开始爬取网页存储内容(pipelines.py):设计管道存储爬取内容安装windows安装方法
升级pip版本:
pip install --upgrade pip
通过 pip 安装 Scrapy 框架:
pip install Scrapy
如何安装 Ubuntu
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过 pip 安装 Scrapy 框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,所以默认安装的包是不能删除的,但是你使用python2.x来安装Scrapy会报错,用python3.x安装也会报错。最后没有找到直接安装Scrapy的方法,所以我就用另一种安装方法来讲解安装步骤。解决方法是使用virtualenv来安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明安装成功。
入门案例学习目标一.新建项目(scrapy startproject)
在开始抓取之前,必须创建一个新的 Scrapy 项目。转到自定义项目目录并运行以下命令:
scrapy startproject mySpider
其中,mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
我们来简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、清除目标(mySpider/items.py)
我们打算在 网站 中获取所有讲师的姓名、职务和个人信息。
打开 mySpider 目录中的 items.py。
Item 定义了一个结构化的数据字段来保存爬取的数据,有点像 Python 中的 dict,但提供了一些额外的保护来减少错误。
可以通过创建一个scrapy.Item类,定义一个scrapy.Field类型的类属性(可以理解为类似ORM的映射关系)来定义一个Item。
接下来,创建一个 ItcastItem 类,并构建项目模型。
三、制作蜘蛛(spiders/itcastSpider.py)
爬虫功能分为两步:
1.爬取数据
在当前目录输入命令会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建一个 Spider,你必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
name = "" : 该爬虫的标识名必须唯一,不同的爬虫必须定义不同的名称。
allow_domains = []是搜索的域名范围,即爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的URL会被忽略。
start_urls = () : 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。其他子 URL 将继承自这些起始 URL。
parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传递。主要功能如下:
p>
负责解析返回的网页数据(response.body),提取结构化数据(生成item) 查看全部
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
Scrapy 是一个用 Python 编写的应用程序框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。
通常我们可以通过Scrapy框架轻松实现爬虫,抓取指定的网站内容或图片。
Scrapy架构图(绿线为数据流)
Scrapy的运行过程
代码写好了,程序开始运行了……
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
制作一个Scrapy爬虫一共需要4个步骤:新建一个项目(scrapy startproject xxx):新建一个爬虫项目清除目标(写items.py):清除你要抓取的目标创建一个爬虫(spiders/xxspider.py):创建爬虫并开始爬取网页存储内容(pipelines.py):设计管道存储爬取内容安装windows安装方法
升级pip版本:
pip install --upgrade pip
通过 pip 安装 Scrapy 框架:
pip install Scrapy
如何安装 Ubuntu
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过 pip 安装 Scrapy 框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,所以默认安装的包是不能删除的,但是你使用python2.x来安装Scrapy会报错,用python3.x安装也会报错。最后没有找到直接安装Scrapy的方法,所以我就用另一种安装方法来讲解安装步骤。解决方法是使用virtualenv来安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明安装成功。
入门案例学习目标一.新建项目(scrapy startproject)
在开始抓取之前,必须创建一个新的 Scrapy 项目。转到自定义项目目录并运行以下命令:
scrapy startproject mySpider
其中,mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
我们来简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、清除目标(mySpider/items.py)
我们打算在 网站 中获取所有讲师的姓名、职务和个人信息。
打开 mySpider 目录中的 items.py。
Item 定义了一个结构化的数据字段来保存爬取的数据,有点像 Python 中的 dict,但提供了一些额外的保护来减少错误。
可以通过创建一个scrapy.Item类,定义一个scrapy.Field类型的类属性(可以理解为类似ORM的映射关系)来定义一个Item。
接下来,创建一个 ItcastItem 类,并构建项目模型。
三、制作蜘蛛(spiders/itcastSpider.py)
爬虫功能分为两步:
1.爬取数据
在当前目录输入命令会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建一个 Spider,你必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
name = "" : 该爬虫的标识名必须唯一,不同的爬虫必须定义不同的名称。
allow_domains = []是搜索的域名范围,即爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的URL会被忽略。
start_urls = () : 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。其他子 URL 将继承自这些起始 URL。
parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传递。主要功能如下:
p>
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
scrapy分页抓取网页(代码也可以从我的开源项目HtmlExtractor中获取。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-05 05:06
代码也可以从我的开源项目 HtmlExtractor 中获得。
我们在爬取数据的时候,如果目标网站是以Js的方式动态生成数据,以滚动页面的方式进行分页,那我们怎么爬取呢?
如今日头条网站:
我们可以使用 Selenium 来做到这一点。虽然 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合数据抓取,并且可以轻松绕过 网站 的反爬虫限制,因为 Selenium 直接在浏览器中运行,就像真正的用户一样.
使用Selenium,我们不仅可以爬取Js动态生成数据的网页,还可以爬取滚动页面分页的网页。
首先,我们使用maven来导入Selenium依赖:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
然后就可以编写代码进行爬取了:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i 查看全部
scrapy分页抓取网页(代码也可以从我的开源项目HtmlExtractor中获取。。)
代码也可以从我的开源项目 HtmlExtractor 中获得。
我们在爬取数据的时候,如果目标网站是以Js的方式动态生成数据,以滚动页面的方式进行分页,那我们怎么爬取呢?
如今日头条网站:
我们可以使用 Selenium 来做到这一点。虽然 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合数据抓取,并且可以轻松绕过 网站 的反爬虫限制,因为 Selenium 直接在浏览器中运行,就像真正的用户一样.
使用Selenium,我们不仅可以爬取Js动态生成数据的网页,还可以爬取滚动页面分页的网页。
首先,我们使用maven来导入Selenium依赖:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
然后就可以编写代码进行爬取了:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-03 20:12
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注才是本质(4小时,完成Scrapy爬虫必备知识点讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学
导师答题(拒绝助教,讲师当天答题)
课程适合人群
具备Py基础语法和面向对象开发思想,其他语言开发者,浪子,想一夜暴富的人
建筑与环境建设
文章目录Scrapy介绍
Scrapy组件介绍
点安装scrapy
Scrapy 简介
一个快速、高级的屏幕抓取和网页抓取 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求定制。Scrapy架构图:
Scrapy组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
Scheduler:用于接受引擎发送的Request请求,将其推入队列,当引擎再次请求时返回。
Downloader(下载器):用于引擎发送的Request请求对应的网页内容,将获取到的Responses返回给Spider。
Item Pipeline:负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
点安装scrapy
通过 pip show scrapy 检查是否安装正常。如果已安装,则显示安装信息,否则不显示任何信息。
通过pip install scrapy安装爬虫框架(大概率会抛出以下异常)
根据异常,它缺少:错误:需要 MICROSOFT VISUAL C++ 9.0 (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载一个缺少的窗口组件,在视频的学习资料中提供
第一个爬虫项目
文章目录
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject douban创建项目
创建一个Spider解析器根据以上提示:cd douban,然后在项目中执行:scrapy genspider example 就可以创建一个Spider对象
细心的朋友会发现,douban_spider默认会存放在douban.spider目录下。当你用pycharm IDE打开时,你会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的spider文件,也就是你爬取的py文件
items.py:相当于一个容器,字典更像是middlewares.py:定义Downloader
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 pipelines.py:定义Item
Pipeline的实现实现了数据的清洗、存储、校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法简介
文章目录
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。事实上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章目录
豆瓣电影页面分析
首页下载实现
前5名电影数据如下
豆瓣电影页面分析为您讲解了如何在 XML 文档中查找信息。具体来说,你已经学会了如何获取元素、内容和属性,你也知道了如何通过标签的属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5名电影数据如下
项目模型封装数据
文章目录创建Item模型层
封装爬取的数据
yield的语法介绍
在创建Item模型层之前,我们可以获取第一页的数据,但是只能在控制台打印。Scrapy 中还有一个 Item 模块。这个类就是模型层,主要完成对值数据的封装,然后写入数据库。
将爬取的数据封装起来,将爬取的数据存储在豆瓣项目对象中,然后交给item_list,最后返回到Item_list
yield的语法介绍
一个有yield的函数就是一个生成器,它不同于普通的函数,生成一个生成器看起来像一个函数调用,但是在它上面调用next()之前不会执行任何函数代码(在for循环中,next()是自动调用。)) 开始执行。执行流程虽然还是按照函数的流程执行,但是每执行一次yield语句都会中断,并返回一个迭代值,在下次执行时从yield的下一条语句继续执行. 好像一个函数在正常执行的时候被yield打断了几次,每次打断都会通过yield返回当前的迭代值
产量和自动翻页
文章目录
产量优势
良率优化返回数据
产量优势
收益的好处是显而易见的。将函数重写为生成器使您能够进行迭代。相比于使用类实例保存状态来计算下一个next()的值,不仅代码简洁,而且执行过程也非常清晰。
在 Scrapy 爬虫框架中,yield 有一个很自然的使用场景,因为我们不知道爬虫每次获取的数据的大小。如果每次都一起返回,数据量会非常大。这时候如果使用yield来优化,代码会非常简洁高效
良率优化返回数据 查看全部
scrapy分页抓取网页(Python应用场景Scrapy爬虫框架课程特色时间(4小时))
Python应用场景
Scrapy爬虫框架
课程特色
时间就是生命,专注才是本质(4小时,完成Scrapy爬虫必备知识点讲解)
完整的课程体系(应用场景、Scrapy架构、分页爬虫、全站爬虫、爬虫伪装)
案例教学
导师答题(拒绝助教,讲师当天答题)
课程适合人群
具备Py基础语法和面向对象开发思想,其他语言开发者,浪子,想一夜暴富的人
建筑与环境建设
文章目录Scrapy介绍
Scrapy组件介绍
点安装scrapy
Scrapy 简介
一个快速、高级的屏幕抓取和网页抓取 Python 框架,用于抓取网站并从页面中提取结构化数据,可用于数据挖掘、监控和自动化测试,并可根据特定需求定制。Scrapy架构图:
Scrapy组件介绍 Scrapy Engine(引擎):用于处理整个系统的数据传输,是整个系统的核心部分。
Scheduler:用于接受引擎发送的Request请求,将其推入队列,当引擎再次请求时返回。
Downloader(下载器):用于引擎发送的Request请求对应的网页内容,将获取到的Responses返回给Spider。
Item Pipeline:负责处理Spider中获取的实体,清洗数据,保存需要的数据。下载器
Middlewares(下载器中间件):主要用于处理Scrapy引擎和下载器之间的请求和响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
点安装scrapy
通过 pip show scrapy 检查是否安装正常。如果已安装,则显示安装信息,否则不显示任何信息。
通过pip install scrapy安装爬虫框架(大概率会抛出以下异常)
根据异常,它缺少:错误:需要 MICROSOFT VISUAL C++ 9.0 (UNABLE TO FIND VCVARSALL.BAT)。GET IT FROM 需要下载一个缺少的窗口组件,在视频的学习资料中提供
第一个爬虫项目
文章目录
创建一个scrapy项目
创建蜘蛛解析器
项目功能模块介绍
配置用户代理伪装请求
启动爬虫获取数据
创建一个scrapy项目
虽然是cmd命令创建的,但是可以通过scrapy -h查询相关子命令,最后通过scrapy startproject douban创建项目
创建一个Spider解析器根据以上提示:cd douban,然后在项目中执行:scrapy genspider example 就可以创建一个Spider对象
细心的朋友会发现,douban_spider默认会存放在douban.spider目录下。当你用pycharm IDE打开时,你会发现项目的结构如下:
项目功能模块介绍scrapy.cfg:配置文件spiders:存放你的spider文件,也就是你爬取的py文件
items.py:相当于一个容器,字典更像是middlewares.py:定义Downloader
Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 pipelines.py:定义Item
Pipeline的实现实现了数据的清洗、存储、校验。settings.py:全局配置
配置用户代理伪装请求
settings.py 配置User-Agent相关参数,否则爬取失败。
启动爬虫获取数据
在cmd dos窗口启动爬虫,默认会下载douban_spider中配置的start_urls地址
Xpath 语法简介
文章目录
Xpath 简介
Xpath 语法
Xpath 实践
Xpath 简介
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 用于浏览 XML 文档中的元素和属性。事实上,HTML 是一种特殊的 XML。因此,在学习 XPath 时,您需要了解基本的 HTML 和 XMLXPath。使用路径表达式在 XML 文档中导航
XPath 收录一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是 W3C 标准
Xpath 语法
Xpath 实践
Xpath 获取有价值的数据
文章目录
豆瓣电影页面分析
首页下载实现
前5名电影数据如下
豆瓣电影页面分析为您讲解了如何在 XML 文档中查找信息。具体来说,你已经学会了如何获取元素、内容和属性,你也知道了如何通过标签的属性进行过滤和过滤。本章讲解如何通过xpath获取豆瓣数据
首页下载实现
前5名电影数据如下
项目模型封装数据
文章目录创建Item模型层
封装爬取的数据
yield的语法介绍
在创建Item模型层之前,我们可以获取第一页的数据,但是只能在控制台打印。Scrapy 中还有一个 Item 模块。这个类就是模型层,主要完成对值数据的封装,然后写入数据库。
将爬取的数据封装起来,将爬取的数据存储在豆瓣项目对象中,然后交给item_list,最后返回到Item_list
yield的语法介绍
一个有yield的函数就是一个生成器,它不同于普通的函数,生成一个生成器看起来像一个函数调用,但是在它上面调用next()之前不会执行任何函数代码(在for循环中,next()是自动调用。)) 开始执行。执行流程虽然还是按照函数的流程执行,但是每执行一次yield语句都会中断,并返回一个迭代值,在下次执行时从yield的下一条语句继续执行. 好像一个函数在正常执行的时候被yield打断了几次,每次打断都会通过yield返回当前的迭代值
产量和自动翻页
文章目录
产量优势
良率优化返回数据
产量优势
收益的好处是显而易见的。将函数重写为生成器使您能够进行迭代。相比于使用类实例保存状态来计算下一个next()的值,不仅代码简洁,而且执行过程也非常清晰。
在 Scrapy 爬虫框架中,yield 有一个很自然的使用场景,因为我们不知道爬虫每次获取的数据的大小。如果每次都一起返回,数据量会非常大。这时候如果使用yield来优化,代码会非常简洁高效
良率优化返回数据
scrapy分页抓取网页(制作爬虫(Spider)制作(Spider)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2022-03-03 20:09
将网站安装到爬虫中,分为几个步骤:
1.新建项目(项目)
按住Shift键并在空目录中单击鼠标右键,选择“在此处打开命令窗口”,输入以下命令:
>scrapystart项目豆瓣
项目创建后,生成如下目录:
用pycharm打开项目,看看:
每个文件的作用:
2.明确目标(项目)
可以使用 scrapy.item.Item 类和使用 scrapy.item.Field 对象定义的属性来创建项目。
接下来,我们开始构建项目模型(model)。在本例中,构建 items.py 如下:
首先,我们想要的是:
【注意】:
爬取元素不需要声明模型,也可以在爬虫代码中直接显示爬取到的元素这种方式
根据官方文档,Item是保存结构数据的地方。 Scrapy可以将解析结果以字典的形式返回,但是Python中的字典缺乏结构,在大型爬虫系统中非常不方便。 Item 提供了一个类似字典的 API。而且声明字段非常方便,很多Scrapy组件可以使用Item的其他信息。以后也方便管道对爬取的数据进行处理。
3.做一个蜘蛛
做一个爬虫,一般分为两个步骤:爬取-取走
也就是说,首先你要获取整个页面的所有内容,然后取出对你有用的部分。
3.1 次攀登
Spider 是用户编写的用于从域(或域组)中抓取信息的类。定义用于下载的 URL 列表、用于跟踪链接的方案以及解析 Web 内容以提取项目的方法。
要创建一个 Spider,你必须继承 scrapy.spider.BaseSpider 并定义三个强制属性:
让我们编写第一个爬虫,命名为doubanspider.py,并将其保存在doubanspiders目录中。
在豆瓣目录下按住shift右键,在此处打开命令窗口,输入:
>scrapy爬豆瓣
3.1.1 创建main.py并保存到豆瓣目录
3.1.2 为避免被屏蔽,需要伪装,在settings.py中添加USER_AGENT
USER_AGENT='Mozilla/5.0(Macintosh;IntelMacOSX10_8_3)AppleWebKit/536.5(KHTML,likeGecko)Chrome/19.0. 1084.54Safari/536.5'
3.2 次拍摄
使用 Xpath 进行解析。有关相关知识,请参阅 Xpath 部分。这里不赘述,只是给出一个大概的思路:F12检查元素,我们看页面代码,检查页面显示特性,比如要爬取的页面内容是否需要结合,替换空格等,同时如果出现分页情况,需要自动抓取下一页查看代码特征,发现几个问题:(1)标题分为两行,需要用for循环遍历。结合起来;(2)有些电影没有引号,需要考虑为空值;(3)的url分页不完整,需要抓取并填写完整的URL(要导入Request,from scrapy.http import Request),可以循环爬取。
#-*-coding:utf-8-*-fromscrapy。蜘蛛importCrawlSpiderfromscrapy。选择器importSelectorfrom豆瓣。 itemsimportDoubanItemfromscrapy. httpimportRequestclassDouban(CrawlSpider):name="douban"start_urls=['.豆瓣。 com/top250']url='。豆瓣。 com/top250' defparse(self, response): #printresponse。 bodyitem=豆瓣项目()选择器=选择器(响应)#printselectorMovies=选择器。 xpath('//div[@class="info"]')#printMoviesforeachMoiveinMovies:title=eachMoive. xpath('div[@class="hd"]/a/span/text()').
extract()# 合并两个名字 fullTitle=''foreachintitle:fullTitle+=eachmovieInfo=eachMoive. xpath('div[@class="bd"]/p/text()')。提取()星=每个电影。 xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')。 extract()[0]quote=eachMoive. xpath('div[@class="bd"]/p[@class="quote"]/span/text()'). extract()#quote可能为空,所以需要先判断 ifquote:quote=quote[0]else:quote=''#printfullTitle#printmovieInfo#printstar#printquoteitem['title']=fullTitleitem['movieInfo']= ';'。加入(movieInfo)item['star']=staritem['quote']=quoteielditemnextLink=selector。
xpath('//span[@class="next"]/link/@href'). extract()#第10页是最后一页,没有下一页的链接 ifnextLink:nextLink=nextLink[0]printnextLinkyieldRequest(self.url+nextLink,callback=self.parse) ##递归传递的地址下一页对于这个函数本身,在爬回callback=self时注意韩老师提供的栗子这里二次分析的解释。解析
4.存储内容(管道)
保存信息最简单的方法是通过,主要有四种:JSON、JSON 行、CSV、XML。用最常用的JSON导出结果,命令如下:
>scrapycrawldouban-oitems.json-tjson #-o后面是导出文件名,-t后面是导出类型。要导出结果,请使用文本编辑器打开 json 文件
尝试导出为 csv 格式:
>scrapycrawldouban-oiitems.csv-tcsv
4.1 设置默认存储
可以直接在settings.py文件中设置输出位置和文件类型,如下:
FEED_URI=u'file:///E:/douban/douban.csv'FEED_FORMAT='CSV'
5.运行爬虫(main.py)
不同于直接运行的简单单线程爬虫程序,这里我们还需要运行一个main.py,需要自己手动生成。 main.py代码如下:
运行结果:
如果你想用抓取的物品做更复杂的事情,你可以写一个物品管道。 查看全部
scrapy分页抓取网页(制作爬虫(Spider)制作(Spider)())
将网站安装到爬虫中,分为几个步骤:
1.新建项目(项目)
按住Shift键并在空目录中单击鼠标右键,选择“在此处打开命令窗口”,输入以下命令:
>scrapystart项目豆瓣
项目创建后,生成如下目录:
用pycharm打开项目,看看:
每个文件的作用:
2.明确目标(项目)
可以使用 scrapy.item.Item 类和使用 scrapy.item.Field 对象定义的属性来创建项目。
接下来,我们开始构建项目模型(model)。在本例中,构建 items.py 如下:
首先,我们想要的是:
【注意】:
爬取元素不需要声明模型,也可以在爬虫代码中直接显示爬取到的元素这种方式
根据官方文档,Item是保存结构数据的地方。 Scrapy可以将解析结果以字典的形式返回,但是Python中的字典缺乏结构,在大型爬虫系统中非常不方便。 Item 提供了一个类似字典的 API。而且声明字段非常方便,很多Scrapy组件可以使用Item的其他信息。以后也方便管道对爬取的数据进行处理。
3.做一个蜘蛛
做一个爬虫,一般分为两个步骤:爬取-取走
也就是说,首先你要获取整个页面的所有内容,然后取出对你有用的部分。
3.1 次攀登
Spider 是用户编写的用于从域(或域组)中抓取信息的类。定义用于下载的 URL 列表、用于跟踪链接的方案以及解析 Web 内容以提取项目的方法。
要创建一个 Spider,你必须继承 scrapy.spider.BaseSpider 并定义三个强制属性:
让我们编写第一个爬虫,命名为doubanspider.py,并将其保存在doubanspiders目录中。
在豆瓣目录下按住shift右键,在此处打开命令窗口,输入:
>scrapy爬豆瓣
3.1.1 创建main.py并保存到豆瓣目录
3.1.2 为避免被屏蔽,需要伪装,在settings.py中添加USER_AGENT
USER_AGENT='Mozilla/5.0(Macintosh;IntelMacOSX10_8_3)AppleWebKit/536.5(KHTML,likeGecko)Chrome/19.0. 1084.54Safari/536.5'
3.2 次拍摄
使用 Xpath 进行解析。有关相关知识,请参阅 Xpath 部分。这里不赘述,只是给出一个大概的思路:F12检查元素,我们看页面代码,检查页面显示特性,比如要爬取的页面内容是否需要结合,替换空格等,同时如果出现分页情况,需要自动抓取下一页查看代码特征,发现几个问题:(1)标题分为两行,需要用for循环遍历。结合起来;(2)有些电影没有引号,需要考虑为空值;(3)的url分页不完整,需要抓取并填写完整的URL(要导入Request,from scrapy.http import Request),可以循环爬取。
#-*-coding:utf-8-*-fromscrapy。蜘蛛importCrawlSpiderfromscrapy。选择器importSelectorfrom豆瓣。 itemsimportDoubanItemfromscrapy. httpimportRequestclassDouban(CrawlSpider):name="douban"start_urls=['.豆瓣。 com/top250']url='。豆瓣。 com/top250' defparse(self, response): #printresponse。 bodyitem=豆瓣项目()选择器=选择器(响应)#printselectorMovies=选择器。 xpath('//div[@class="info"]')#printMoviesforeachMoiveinMovies:title=eachMoive. xpath('div[@class="hd"]/a/span/text()').
extract()# 合并两个名字 fullTitle=''foreachintitle:fullTitle+=eachmovieInfo=eachMoive. xpath('div[@class="bd"]/p/text()')。提取()星=每个电影。 xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')。 extract()[0]quote=eachMoive. xpath('div[@class="bd"]/p[@class="quote"]/span/text()'). extract()#quote可能为空,所以需要先判断 ifquote:quote=quote[0]else:quote=''#printfullTitle#printmovieInfo#printstar#printquoteitem['title']=fullTitleitem['movieInfo']= ';'。加入(movieInfo)item['star']=staritem['quote']=quoteielditemnextLink=selector。
xpath('//span[@class="next"]/link/@href'). extract()#第10页是最后一页,没有下一页的链接 ifnextLink:nextLink=nextLink[0]printnextLinkyieldRequest(self.url+nextLink,callback=self.parse) ##递归传递的地址下一页对于这个函数本身,在爬回callback=self时注意韩老师提供的栗子这里二次分析的解释。解析
4.存储内容(管道)
保存信息最简单的方法是通过,主要有四种:JSON、JSON 行、CSV、XML。用最常用的JSON导出结果,命令如下:
>scrapycrawldouban-oitems.json-tjson #-o后面是导出文件名,-t后面是导出类型。要导出结果,请使用文本编辑器打开 json 文件
尝试导出为 csv 格式:
>scrapycrawldouban-oiitems.csv-tcsv
4.1 设置默认存储
可以直接在settings.py文件中设置输出位置和文件类型,如下:
FEED_URI=u'file:///E:/douban/douban.csv'FEED_FORMAT='CSV'
5.运行爬虫(main.py)
不同于直接运行的简单单线程爬虫程序,这里我们还需要运行一个main.py,需要自己手动生成。 main.py代码如下:
运行结果:
如果你想用抓取的物品做更复杂的事情,你可以写一个物品管道。
scrapy分页抓取网页(开发好一个框架爬虫(ConfigurableSpider)生产可用的Scrapy爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-03 14:15
背景
爬虫是个有趣的东西,它可以让你通过爬虫程序自动抓取网上的信息,省去了很多手动操作。在一些优质的爬虫框架出来之前,开发者还是通过简单的网络请求+网页解析器来开发爬虫程序,比如Python的requests+BeautifulSoup,而高级爬虫程序还会加入数据存储模块,比如MySQL、MongoDB。这种方式开发效率低,稳定性差,开发一个完整的、可生产的爬虫可能需要几个小时。我称这种方法为无框架爬虫。
2011年,基于Twisted的Scrapy爬虫框架诞生,一下子为大众所熟知,成为首屈一指的全能高性能异步爬虫框架。Scrapy 抽象了几个核心模块,让开发者可以专注于爬虫的爬取逻辑,而不是数据下载、页面解析、任务调度等比较繁琐的模块。要开发一个生产就绪的 Scrapy 爬虫,简单的可能只需要十分钟,复杂的可能需要一个多小时。当然,我们还有很多其他优秀的框架,比如PySpider、Colly等,我把这种爬虫叫做框架爬虫。框架爬虫解放生产力,现在很多公司改造框架爬虫,应用到生产环境中,大规模抓取数据。
但是,对于需要抓取数百个网站的爬虫的需求,框架爬虫可能会不堪重负,不足,编写爬虫成为了一项手工工作。例如,如果开发一个框架爬虫平均需要20分钟,如果一个全职爬虫开发人员每天工作8小时,那么需要20000分钟,333小时,42个工作日,将近2个开发1000个< @网站 月亮。当然,我们可以聘请10名全职爬虫开发工程师,但也需要4个工作日才能完成(如下图)。
这也是相对低效的。为了克服这个效率问题,可配置爬虫应运而生。
可配置爬虫简介
A Configurable Spider,顾名思义,就是可以配置爬取规则的蜘蛛。可配置爬虫是一种高度抽象的爬虫程序。开发者无需编写爬虫代码,只需将需要爬取的网页地址、字段、属性写在配置文件或数据库中,让专门的爬虫程序根据配置抓取数据。. 可配置爬虫进一步将爬虫代码抽象为配置信息,简化了爬虫开发过程。爬虫开发者只需要做相应的配置即可完成爬虫的开发。因此,开发者可以通过可配置爬虫来大规模编写爬虫程序(如下图所示)。
这种方法可以爬取上百个网站,一个熟练的爬虫配置者一天可以配置1000个新闻网站爬虫。这对于需要舆情监控的企业来说非常重要,因为可配置爬虫提高生产力,降低单位工作时间成本,提高开发效率,方便后续舆情分析和人工智能产品开发。很多公司自己开发可配置爬虫(名字可能不一样,但本质是一回事),然后聘请一些爬虫配置人员负责配置爬虫。
市场上没有很多免费和开源的可配置爬虫框架。早前微软大神崔庆才开发的Gerapy属于爬虫管理平台,可以根据配置规则生成Scrapy项目文件。另一个比较新的可配置爬虫框架是Crawlab(其实Crawlab并不是一个可配置爬虫框架,而是一个高度灵活的爬虫管理平台),发布于v0.4.0。配置爬虫。还有一个基于Golang的开源框架,Ferret,很有意思。编写爬虫就像编写 SQL 一样简单。还有一些其他的商用产品,但是根据用户反馈,感觉不是很专业,不能满足生产需求。
可配置爬虫的诞生,主要是由于爬虫的模式比较简单,无非就是列表页+详情页的组合(如下图),或者只是一个列表页。当然,还有稍微复杂的通用爬虫,也可以通过规则配置来完成。
Crawlab 可配置爬虫
今天我们主要介绍的是Crawlab的可配置爬虫。我们在前面的 文章 中介绍了它,但没有深入探讨如何在实践中应用它。今天,我们重点讲解。如果您对 Crawlabb 的可配置爬虫不熟悉,请参考可配置爬虫的文档。
可配置的爬虫战斗
实战部分所有案例均由作者使用Crawlab官方Demo平台通过可配置爬虫功能编写爬取,涵盖新闻、金融、汽车、图书、视频、搜索引擎、程序员社区等领域(见下图) . 下面将介绍其中的几个。所有示例均在官方Demo平台上,您可以通过注册账号登录查看。
百度(搜索“Crawlab”)
爬虫地址:/demo#/spiders/5e27d055b8f9c90019f42a83
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: http://www.baidu.com/s?wd=crawlab
start_stage: list
stages:
- name: list
is_list: true
list_css: ""
list_xpath: //*[contains(@class, "c-container")]
page_css: ""
page_xpath: //*[@id="page"]//a[@class="n"][last()]
page_attr: href
fields:
- name: title
css: ""
xpath: .//h3/a
attr: ""
next_stage: ""
remark: ""
- name: url
css: ""
xpath: .//h3/a
attr: href
next_stage: ""
remark: ""
- name: abstract
css: ""
xpath: .//*[@class="c-abstract"]
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
SegmentFault(最新的 文章)
爬虫地址:/demo#/spiders/5e27d116b8f9c90019f42a87
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://segmentfault.com/newest
start_stage: list
stages:
- name: list
is_list: true
list_css: .news-list > .news-item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: title
css: h4.news__item-title
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: .news-img
xpath: ""
attr: href
next_stage: ""
remark: ""
- name: abstract
css: .article-excerpt
xpath: ""
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
亚马逊中国(搜索“手机”)
爬虫地址:/demo#/spiders/5e27e157b8f9c90019f42afb
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://www.amazon.cn/s%3Fk%3D ... oss_2
start_stage: list
stages:
- name: list
is_list: true
list_css: .s-result-item
list_xpath: ""
page_css: .a-last > a
page_xpath: ""
page_attr: href
fields:
- name: title
css: span.a-text-normal
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: .a-link-normal
xpath: ""
attr: href
next_stage: ""
remark: ""
- name: price
css: ""
xpath: .//*[@class="a-price-whole"]
attr: ""
next_stage: ""
remark: ""
- name: price_fraction
css: ""
xpath: .//*[@class="a-price-fraction"]
attr: ""
next_stage: ""
remark: ""
- name: img
css: .s-image-square-aspect > img
xpath: ""
attr: src
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
V2ex
爬虫地址:/demo#/spiders/5e27dd67b8f9c90019f42ad9
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://v2ex.com/
start_stage: list
stages:
- name: list
is_list: true
list_css: .cell.item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: href
fields:
- name: title
css: a.topic-link
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: a.topic-link
xpath: ""
attr: href
next_stage: detail
remark: ""
- name: replies
css: .count_livid
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: detail
is_list: false
list_css: ""
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: content
css: ""
xpath: .//*[@class="markdown_body"]
attr: ""
next_stage: ""
remark: ""
settings:
AUTOTHROTTLE_ENABLED: "true"
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/79.0.3945.117 Safari/537.36
抓取结果
36氪
爬虫地址:/demo#/spiders/5e27ec82b8f9c90019f42b59
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://36kr.com/information/web_news
start_stage: list
stages:
- name: list
is_list: true
list_css: .kr-flow-article-item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: title
css: .article-item-title
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: body
xpath: ""
attr: href
next_stage: detail
remark: ""
- name: abstract
css: body
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: author
css: .kr-flow-bar-author
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: time
css: .kr-flow-bar-time
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: detail
is_list: false
list_css: ""
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: content
css: ""
xpath: .//*[@class="common-width content articleDetailContent kr-rich-text-wrapper"]
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
实际爬行动物列表
爬虫名称 | 爬虫类 --- | --- 百度 | List Page + Paging SegmentFault | 列表页 CSDN | 列表页面 + 分页 + 详细信息页面 V2ex | 列表页+详情页纵横| 列表页 亚马逊中国 | 列表页+寻呼雪球网| 列表页+详情页 列表页+分页豆瓣阅读 | 列表页36氪| 列表页+详情页腾讯视频| 列表页
总结
Crawlab 的可配置爬虫非常方便,可以让程序员快速配置自己需要的爬虫。笔者配置上述11个爬虫用了不到40分钟(考虑到里面有反爬调试),几个比较简单的爬虫不到1-2分钟就配置好了。而且作者没有写一行代码,所有的配置都是在界面上完成的。而且Crawlab的可配置爬虫不仅支持界面上的配置,还支持写一个Yaml文件Spiderfile来完成配置(其实所有的配置都可以映射到Spiderfile)。Crawlab 的可配置爬虫基于 Scrapy,因此它支持 Scrapy 的大部分功能。可以通过设置配置可配置爬虫的扩展属性,包括USER_AGENT,ROBOTSTXT_OBEY 等等。为什么选择 Crawlab 作为可配置爬虫的首选?因为Crawlab可配置爬虫不仅可以配置爬虫,还可以享受Crawlab爬虫管理平台的核心功能,包括任务调度、任务监控、定时任务、日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。
需要注意的是,不遵守 robots.txt 可能会带来法律风险。本文实际爬虫仅供学习交流,不作为生产环境使用,任何滥用者均需承担法律责任。
参考
如果您觉得Crawlab对您的日常开发或公司有帮助,请加作者微信tikazyq1并注明“Crawlab”,作者拉你进群。欢迎在 Github 上加星,如果您遇到任何问题,请随时在 Github 上提出问题。此外,欢迎您为 Crawlab 做出开发贡献。 查看全部
scrapy分页抓取网页(开发好一个框架爬虫(ConfigurableSpider)生产可用的Scrapy爬虫)
背景
爬虫是个有趣的东西,它可以让你通过爬虫程序自动抓取网上的信息,省去了很多手动操作。在一些优质的爬虫框架出来之前,开发者还是通过简单的网络请求+网页解析器来开发爬虫程序,比如Python的requests+BeautifulSoup,而高级爬虫程序还会加入数据存储模块,比如MySQL、MongoDB。这种方式开发效率低,稳定性差,开发一个完整的、可生产的爬虫可能需要几个小时。我称这种方法为无框架爬虫。
2011年,基于Twisted的Scrapy爬虫框架诞生,一下子为大众所熟知,成为首屈一指的全能高性能异步爬虫框架。Scrapy 抽象了几个核心模块,让开发者可以专注于爬虫的爬取逻辑,而不是数据下载、页面解析、任务调度等比较繁琐的模块。要开发一个生产就绪的 Scrapy 爬虫,简单的可能只需要十分钟,复杂的可能需要一个多小时。当然,我们还有很多其他优秀的框架,比如PySpider、Colly等,我把这种爬虫叫做框架爬虫。框架爬虫解放生产力,现在很多公司改造框架爬虫,应用到生产环境中,大规模抓取数据。
但是,对于需要抓取数百个网站的爬虫的需求,框架爬虫可能会不堪重负,不足,编写爬虫成为了一项手工工作。例如,如果开发一个框架爬虫平均需要20分钟,如果一个全职爬虫开发人员每天工作8小时,那么需要20000分钟,333小时,42个工作日,将近2个开发1000个< @网站 月亮。当然,我们可以聘请10名全职爬虫开发工程师,但也需要4个工作日才能完成(如下图)。
这也是相对低效的。为了克服这个效率问题,可配置爬虫应运而生。
可配置爬虫简介
A Configurable Spider,顾名思义,就是可以配置爬取规则的蜘蛛。可配置爬虫是一种高度抽象的爬虫程序。开发者无需编写爬虫代码,只需将需要爬取的网页地址、字段、属性写在配置文件或数据库中,让专门的爬虫程序根据配置抓取数据。. 可配置爬虫进一步将爬虫代码抽象为配置信息,简化了爬虫开发过程。爬虫开发者只需要做相应的配置即可完成爬虫的开发。因此,开发者可以通过可配置爬虫来大规模编写爬虫程序(如下图所示)。
这种方法可以爬取上百个网站,一个熟练的爬虫配置者一天可以配置1000个新闻网站爬虫。这对于需要舆情监控的企业来说非常重要,因为可配置爬虫提高生产力,降低单位工作时间成本,提高开发效率,方便后续舆情分析和人工智能产品开发。很多公司自己开发可配置爬虫(名字可能不一样,但本质是一回事),然后聘请一些爬虫配置人员负责配置爬虫。
市场上没有很多免费和开源的可配置爬虫框架。早前微软大神崔庆才开发的Gerapy属于爬虫管理平台,可以根据配置规则生成Scrapy项目文件。另一个比较新的可配置爬虫框架是Crawlab(其实Crawlab并不是一个可配置爬虫框架,而是一个高度灵活的爬虫管理平台),发布于v0.4.0。配置爬虫。还有一个基于Golang的开源框架,Ferret,很有意思。编写爬虫就像编写 SQL 一样简单。还有一些其他的商用产品,但是根据用户反馈,感觉不是很专业,不能满足生产需求。
可配置爬虫的诞生,主要是由于爬虫的模式比较简单,无非就是列表页+详情页的组合(如下图),或者只是一个列表页。当然,还有稍微复杂的通用爬虫,也可以通过规则配置来完成。
Crawlab 可配置爬虫
今天我们主要介绍的是Crawlab的可配置爬虫。我们在前面的 文章 中介绍了它,但没有深入探讨如何在实践中应用它。今天,我们重点讲解。如果您对 Crawlabb 的可配置爬虫不熟悉,请参考可配置爬虫的文档。
可配置的爬虫战斗
实战部分所有案例均由作者使用Crawlab官方Demo平台通过可配置爬虫功能编写爬取,涵盖新闻、金融、汽车、图书、视频、搜索引擎、程序员社区等领域(见下图) . 下面将介绍其中的几个。所有示例均在官方Demo平台上,您可以通过注册账号登录查看。
百度(搜索“Crawlab”)
爬虫地址:/demo#/spiders/5e27d055b8f9c90019f42a83
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: http://www.baidu.com/s?wd=crawlab
start_stage: list
stages:
- name: list
is_list: true
list_css: ""
list_xpath: //*[contains(@class, "c-container")]
page_css: ""
page_xpath: //*[@id="page"]//a[@class="n"][last()]
page_attr: href
fields:
- name: title
css: ""
xpath: .//h3/a
attr: ""
next_stage: ""
remark: ""
- name: url
css: ""
xpath: .//h3/a
attr: href
next_stage: ""
remark: ""
- name: abstract
css: ""
xpath: .//*[@class="c-abstract"]
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
SegmentFault(最新的 文章)
爬虫地址:/demo#/spiders/5e27d116b8f9c90019f42a87
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://segmentfault.com/newest
start_stage: list
stages:
- name: list
is_list: true
list_css: .news-list > .news-item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: title
css: h4.news__item-title
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: .news-img
xpath: ""
attr: href
next_stage: ""
remark: ""
- name: abstract
css: .article-excerpt
xpath: ""
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
亚马逊中国(搜索“手机”)
爬虫地址:/demo#/spiders/5e27e157b8f9c90019f42afb
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://www.amazon.cn/s%3Fk%3D ... oss_2
start_stage: list
stages:
- name: list
is_list: true
list_css: .s-result-item
list_xpath: ""
page_css: .a-last > a
page_xpath: ""
page_attr: href
fields:
- name: title
css: span.a-text-normal
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: .a-link-normal
xpath: ""
attr: href
next_stage: ""
remark: ""
- name: price
css: ""
xpath: .//*[@class="a-price-whole"]
attr: ""
next_stage: ""
remark: ""
- name: price_fraction
css: ""
xpath: .//*[@class="a-price-fraction"]
attr: ""
next_stage: ""
remark: ""
- name: img
css: .s-image-square-aspect > img
xpath: ""
attr: src
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
V2ex
爬虫地址:/demo#/spiders/5e27dd67b8f9c90019f42ad9
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://v2ex.com/
start_stage: list
stages:
- name: list
is_list: true
list_css: .cell.item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: href
fields:
- name: title
css: a.topic-link
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: a.topic-link
xpath: ""
attr: href
next_stage: detail
remark: ""
- name: replies
css: .count_livid
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: detail
is_list: false
list_css: ""
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: content
css: ""
xpath: .//*[@class="markdown_body"]
attr: ""
next_stage: ""
remark: ""
settings:
AUTOTHROTTLE_ENABLED: "true"
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/79.0.3945.117 Safari/537.36
抓取结果
36氪
爬虫地址:/demo#/spiders/5e27ec82b8f9c90019f42b59
爬虫配置
蜘蛛文件
version: 0.4.4
engine: scrapy
start_url: https://36kr.com/information/web_news
start_stage: list
stages:
- name: list
is_list: true
list_css: .kr-flow-article-item
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: title
css: .article-item-title
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: url
css: body
xpath: ""
attr: href
next_stage: detail
remark: ""
- name: abstract
css: body
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: author
css: .kr-flow-bar-author
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: time
css: .kr-flow-bar-time
xpath: ""
attr: ""
next_stage: ""
remark: ""
- name: detail
is_list: false
list_css: ""
list_xpath: ""
page_css: ""
page_xpath: ""
page_attr: ""
fields:
- name: content
css: ""
xpath: .//*[@class="common-width content articleDetailContent kr-rich-text-wrapper"]
attr: ""
next_stage: ""
remark: ""
settings:
ROBOTSTXT_OBEY: "false"
USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/78.0.3904.108 Safari/537.36
抓取结果
实际爬行动物列表
爬虫名称 | 爬虫类 --- | --- 百度 | List Page + Paging SegmentFault | 列表页 CSDN | 列表页面 + 分页 + 详细信息页面 V2ex | 列表页+详情页纵横| 列表页 亚马逊中国 | 列表页+寻呼雪球网| 列表页+详情页 列表页+分页豆瓣阅读 | 列表页36氪| 列表页+详情页腾讯视频| 列表页
总结
Crawlab 的可配置爬虫非常方便,可以让程序员快速配置自己需要的爬虫。笔者配置上述11个爬虫用了不到40分钟(考虑到里面有反爬调试),几个比较简单的爬虫不到1-2分钟就配置好了。而且作者没有写一行代码,所有的配置都是在界面上完成的。而且Crawlab的可配置爬虫不仅支持界面上的配置,还支持写一个Yaml文件Spiderfile来完成配置(其实所有的配置都可以映射到Spiderfile)。Crawlab 的可配置爬虫基于 Scrapy,因此它支持 Scrapy 的大部分功能。可以通过设置配置可配置爬虫的扩展属性,包括USER_AGENT,ROBOTSTXT_OBEY 等等。为什么选择 Crawlab 作为可配置爬虫的首选?因为Crawlab可配置爬虫不仅可以配置爬虫,还可以享受Crawlab爬虫管理平台的核心功能,包括任务调度、任务监控、定时任务、日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。日志管理、消息通知等实用功能。在后续的开发中,Crawlab开发团队将继续完善可配置爬虫,支持更多功能,包括动态内容、更多引擎、CrawlSpider的实现等。
需要注意的是,不遵守 robots.txt 可能会带来法律风险。本文实际爬虫仅供学习交流,不作为生产环境使用,任何滥用者均需承担法律责任。
参考
如果您觉得Crawlab对您的日常开发或公司有帮助,请加作者微信tikazyq1并注明“Crawlab”,作者拉你进群。欢迎在 Github 上加星,如果您遇到任何问题,请随时在 Github 上提出问题。此外,欢迎您为 Crawlab 做出开发贡献。
scrapy分页抓取网页(调试自己的爬虫方法介绍(二)-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-28 21:18
博客地址:woodrobot.me
前言
春节假期我的家乡没有互联网,所以最近没有更新。这周我加班加点,抽空更新一篇文章。我们在编写爬虫的时候,经常需要修改xapth规则来获取需要的数据,而Scrapy的爬虫一般都是从命令行启动的。我们如何调试它?下面我将介绍两种我常用的方法。
工具和环境语言:python 2.7 IDE:Pycharm 浏览器:Chrome Crawler 框架:Scrapy 1.2.1 Body Method 1
这是通过 scrapy.shell.inspect_response 函数实现的。以上一篇教程中的爬虫为例:
# -*- coding: utf-8 -*-
# @Time : 2017/1/7 17:04
# @Author : woodenrobot
from scrapy import Request
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safar'
'i/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
def parse(self, response):
# 命令行调试代码
from scrapy.shell import inspect_response
inspect_response(response, self)
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(ur'(\d+)人评价')[0]
yield item
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url, headers=self.headers)
我们可以在下载网页源代码之前插入以上两行代码进行解析,命令行运行爬虫有以下效果:
此时,我们可以在命令行中使用xpath规则对响应进行操作,提取出相应的信息:
有时下载的网页的结构与您在浏览器中看到的不同。我们可以使用view(response)在浏览器中打开爬虫下载的网页源代码:
在命令行输入view(response)后,默认浏览器会自动打开下载的网页源码。
虽然scrapy本身就提供了这个方法让我们调试自己的爬虫,但是这个方法有很大的局限性。如果能使用pycharm的Debug功能进行调试就好了。下面我给大家介绍使用pycharm调试自己的爬虫。
方法二
首先在与setting.py相同的目录下创建run.py文件。
编写以下代码:
# -*- coding: utf-8 -*-
# @Time : 2017/1/1 17:51
# @Author : woodenrobot
from scrapy import cmdline
name = 'douban_movie_top250'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
name 参数是蜘蛛的名字。
然后在蜘蛛文件中设置断点。
回到run.py文件,右键选择Debug。
最后程序会在断点处暂停,我们可以查看对应的内容进行调试。
结语
这两种方法适用于不同的场景,但总的来说,方法2绝对好用。:) 查看全部
scrapy分页抓取网页(调试自己的爬虫方法介绍(二)-乐题库)
博客地址:woodrobot.me
前言
春节假期我的家乡没有互联网,所以最近没有更新。这周我加班加点,抽空更新一篇文章。我们在编写爬虫的时候,经常需要修改xapth规则来获取需要的数据,而Scrapy的爬虫一般都是从命令行启动的。我们如何调试它?下面我将介绍两种我常用的方法。
工具和环境语言:python 2.7 IDE:Pycharm 浏览器:Chrome Crawler 框架:Scrapy 1.2.1 Body Method 1
这是通过 scrapy.shell.inspect_response 函数实现的。以上一篇教程中的爬虫为例:
# -*- coding: utf-8 -*-
# @Time : 2017/1/7 17:04
# @Author : woodenrobot
from scrapy import Request
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safar'
'i/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
def parse(self, response):
# 命令行调试代码
from scrapy.shell import inspect_response
inspect_response(response, self)
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(ur'(\d+)人评价')[0]
yield item
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url, headers=self.headers)
我们可以在下载网页源代码之前插入以上两行代码进行解析,命令行运行爬虫有以下效果:
此时,我们可以在命令行中使用xpath规则对响应进行操作,提取出相应的信息:
有时下载的网页的结构与您在浏览器中看到的不同。我们可以使用view(response)在浏览器中打开爬虫下载的网页源代码:
在命令行输入view(response)后,默认浏览器会自动打开下载的网页源码。
虽然scrapy本身就提供了这个方法让我们调试自己的爬虫,但是这个方法有很大的局限性。如果能使用pycharm的Debug功能进行调试就好了。下面我给大家介绍使用pycharm调试自己的爬虫。
方法二
首先在与setting.py相同的目录下创建run.py文件。
编写以下代码:
# -*- coding: utf-8 -*-
# @Time : 2017/1/1 17:51
# @Author : woodenrobot
from scrapy import cmdline
name = 'douban_movie_top250'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
name 参数是蜘蛛的名字。
然后在蜘蛛文件中设置断点。
回到run.py文件,右键选择Debug。
最后程序会在断点处暂停,我们可以查看对应的内容进行调试。
结语
这两种方法适用于不同的场景,但总的来说,方法2绝对好用。:)
scrapy分页抓取网页(快速学习Python学习资料列表将是您选择的项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-28 10:17
在本教程中,我们假设您已安装 Scrapy。如果没有,请参考。
接下来以Open Directory Project (dmoz) (dmoz) 为例来描述爬取。
本教程将带您完成以下任务:
创建一个Scrapy项目,定义提取出来的Item要爬取网站并提取来存储提取出来的Item(即数据)
Scrapy 是用 Python 编写的。如果你是语言新手,对这门语言的特点和 Scrapy 的细节感到好奇,对于已经熟悉其他语言并想快速学习 Python 的编程老手,我们推荐 Learn Python The Hard Way,进行编程想要开始学习 Python 的初学者,非编程的 Python 学习资料列表供您选择。
创建一个项目
在开始抓取之前,您必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
scrapy startproject tutorial
此命令将创建一个收录以下内容的教程目录:
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
定义项目
Item是爬取数据的容器;它的用法类似于 python 字典,它提供了额外的保护来防止由拼写错误导致的未定义字段错误。
与 ORM 类似,您可以通过创建一个类并定义一个类型的类属性来定义一个 Item。 (如果你不懂ORM,别着急,你会发现这一步很简单)
首先根据需要从获取的数据中为项目建模。我们需要从 dmoz 中获取 网站 的名称、url 和描述。为此,请在 item.xml 中定义相应的字段。编辑教程目录下的 items.py 文件:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
一开始这可能看起来很复杂,但是通过定义一个项目,您可以轻松地使用其他 Scrapy 方法。而这些方法需要知道你的item的定义。
编写你的第一个蜘蛛
Spider 是用户编写的一个类,用于从单个 网站(或多个 网站)中抓取数据。
它收录一个用于下载的初始URL,如何跟随网页中的链接以及如何分析页面中的内容,提取生成的方法。
为了创建蜘蛛,你必须扩展类并定义以下三个属性:
以下是我们的第一个蜘蛛代码,保存在 tutorial/spiders 目录下的 dmoz_spider.py 文件中:
import scrapy
class DmozSpider(scrapy.spiders.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
爬行
进入项目根目录,执行如下命令启动spider:
scrapy crawl dmoz
crawldmoz 启动爬虫进行爬取,您将获得类似于以下内容的输出:
2014-01-23 18:13:07-0400 [scrapy] INFO: Scrapy started (bot: tutorial)
2014-01-23 18:13:07-0400 [scrapy] INFO: Optional features available: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Overridden settings: {}
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled extensions: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled downloader middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled spider middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled item pipelines: ...
2014-01-23 18:13:07-0400 [dmoz] INFO: Spider opened
2014-01-23 18:13:08-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2014-01-23 18:13:09-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2014-01-23 18:13:09-0400 [dmoz] INFO: Closing spider (finished)
查看收录[dmoz]的输出,可以看到输出日志中收录了start_urls中定义的初始URL,和spider一一对应。在日志中可以看到没有指向其他页面((referer:None))。
除此之外,发生了更有趣的事情。正如我们的 parse 方法所指定的,创建了两个文件,其中收录与 url 对应的内容:Book、Resources。
刚刚发生了什么?
Scrapy 在 Spider 的 start_urls 属性中为每个 URL 创建对象,并将 parse 方法分配给 Request 作为回调。
Request对象被调度,生成的对象被执行并发回spider方法。
提取ItemSelectors简介
有很多方法可以从网页中提取数据。 Scrapy 使用基于 XPath 和 CSS 表达式的机制:.有关选择器和其他提取机制的信息,请参见此处。
以下是 XPath 表达式及其对应含义的示例:
以上只是几个简单的 XPath 示例,XPath 实际上远比这强大。如果您想了解更多信息,我们推荐此 XPath 教程。
为了配合XPath,Scrapy不仅提供,而且还提供了避免每次从响应中提取数据时都生成选择器的麻烦的方法。
Selector有四种基本方法(点击对应方法查看详细API文档):
试试 Shell 中的选择器
为了介绍如何使用 Selector,我们接下来会使用内置的 Selector。 Scrapy Shell 要求您预先安装 IPython(一个扩展的 Python 终端)。
你需要进入你的项目的根目录并执行以下命令来启动shell:
scrapy shell "http://www.dmoz.org/Computers/ ... ot%3B
注意事项
在终端运行Scrapy时,请记得在url地址两边加上引号,否则url中收录参数(如&字符)会导致Scrapy失败。
shell 输出类似于:
[ ... Scrapy log here ... ]
2015-01-07 22:01:53+0800 [domz] DEBUG: Crawled (200) (referer: None)
[s] Available Scrapy objects:
[s] crawler
[s] item {}
[s] request
[s] response
[s] sel
[s] settings
[s] spider
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
>>>
当 shell 加载时,您将获得一个收录响应数据的本地响应变量。输入response.body输出响应的body,输出response.headers可以看到响应的header。
更重要的是,当你输入response.selector时,你会得到一个选择器(selector),可以用来查询返回的数据,并映射到response.selector.xpath()、response.selector.css()的快捷方式: response.xpath() 和 response.css()。
同时,shell根据响应提前初始化变量sel。选择器会根据响应的类型自动选择最合适的解析规则(XML vs HTML)。
让我们试试吧:
In [1]: sel.xpath('//title')
Out[1]: []
In [2]: sel.xpath('//title').extract()
Out[2]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [3]: sel.xpath('//title/text()')
Out[3]: []
In [4]: sel.xpath('//title/text()').extract()
Out[4]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [5]: sel.xpath('//title/text()').re('(w+):')
Out[5]: [u'Computers', u'Programming', u'Languages', u'Python']
提取数据
现在,让我们尝试从这些页面中提取一些有用的数据。
您可以在终端中键入 response.body 以观察 HTML 源并确定适当的 XPath 表达式。但是,这项任务非常无聊和困难。您可能会考虑使用 Firefox 的 Firebug 扩展来简化操作。详情请参考和。
查看网页的源码后会发现网站的信息收录在第二个 查看全部
scrapy分页抓取网页(快速学习Python学习资料列表将是您选择的项目)
在本教程中,我们假设您已安装 Scrapy。如果没有,请参考。
接下来以Open Directory Project (dmoz) (dmoz) 为例来描述爬取。
本教程将带您完成以下任务:
创建一个Scrapy项目,定义提取出来的Item要爬取网站并提取来存储提取出来的Item(即数据)
Scrapy 是用 Python 编写的。如果你是语言新手,对这门语言的特点和 Scrapy 的细节感到好奇,对于已经熟悉其他语言并想快速学习 Python 的编程老手,我们推荐 Learn Python The Hard Way,进行编程想要开始学习 Python 的初学者,非编程的 Python 学习资料列表供您选择。
创建一个项目
在开始抓取之前,您必须创建一个新的 Scrapy 项目。转到您打算存储代码的目录并运行以下命令:
scrapy startproject tutorial
此命令将创建一个收录以下内容的教程目录:
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
定义项目
Item是爬取数据的容器;它的用法类似于 python 字典,它提供了额外的保护来防止由拼写错误导致的未定义字段错误。
与 ORM 类似,您可以通过创建一个类并定义一个类型的类属性来定义一个 Item。 (如果你不懂ORM,别着急,你会发现这一步很简单)
首先根据需要从获取的数据中为项目建模。我们需要从 dmoz 中获取 网站 的名称、url 和描述。为此,请在 item.xml 中定义相应的字段。编辑教程目录下的 items.py 文件:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
一开始这可能看起来很复杂,但是通过定义一个项目,您可以轻松地使用其他 Scrapy 方法。而这些方法需要知道你的item的定义。
编写你的第一个蜘蛛
Spider 是用户编写的一个类,用于从单个 网站(或多个 网站)中抓取数据。
它收录一个用于下载的初始URL,如何跟随网页中的链接以及如何分析页面中的内容,提取生成的方法。
为了创建蜘蛛,你必须扩展类并定义以下三个属性:
以下是我们的第一个蜘蛛代码,保存在 tutorial/spiders 目录下的 dmoz_spider.py 文件中:
import scrapy
class DmozSpider(scrapy.spiders.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
爬行
进入项目根目录,执行如下命令启动spider:
scrapy crawl dmoz
crawldmoz 启动爬虫进行爬取,您将获得类似于以下内容的输出:
2014-01-23 18:13:07-0400 [scrapy] INFO: Scrapy started (bot: tutorial)
2014-01-23 18:13:07-0400 [scrapy] INFO: Optional features available: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Overridden settings: {}
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled extensions: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled downloader middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled spider middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled item pipelines: ...
2014-01-23 18:13:07-0400 [dmoz] INFO: Spider opened
2014-01-23 18:13:08-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2014-01-23 18:13:09-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2014-01-23 18:13:09-0400 [dmoz] INFO: Closing spider (finished)
查看收录[dmoz]的输出,可以看到输出日志中收录了start_urls中定义的初始URL,和spider一一对应。在日志中可以看到没有指向其他页面((referer:None))。
除此之外,发生了更有趣的事情。正如我们的 parse 方法所指定的,创建了两个文件,其中收录与 url 对应的内容:Book、Resources。
刚刚发生了什么?
Scrapy 在 Spider 的 start_urls 属性中为每个 URL 创建对象,并将 parse 方法分配给 Request 作为回调。
Request对象被调度,生成的对象被执行并发回spider方法。
提取ItemSelectors简介
有很多方法可以从网页中提取数据。 Scrapy 使用基于 XPath 和 CSS 表达式的机制:.有关选择器和其他提取机制的信息,请参见此处。
以下是 XPath 表达式及其对应含义的示例:
以上只是几个简单的 XPath 示例,XPath 实际上远比这强大。如果您想了解更多信息,我们推荐此 XPath 教程。
为了配合XPath,Scrapy不仅提供,而且还提供了避免每次从响应中提取数据时都生成选择器的麻烦的方法。
Selector有四种基本方法(点击对应方法查看详细API文档):
试试 Shell 中的选择器
为了介绍如何使用 Selector,我们接下来会使用内置的 Selector。 Scrapy Shell 要求您预先安装 IPython(一个扩展的 Python 终端)。
你需要进入你的项目的根目录并执行以下命令来启动shell:
scrapy shell "http://www.dmoz.org/Computers/ ... ot%3B
注意事项
在终端运行Scrapy时,请记得在url地址两边加上引号,否则url中收录参数(如&字符)会导致Scrapy失败。
shell 输出类似于:
[ ... Scrapy log here ... ]
2015-01-07 22:01:53+0800 [domz] DEBUG: Crawled (200) (referer: None)
[s] Available Scrapy objects:
[s] crawler
[s] item {}
[s] request
[s] response
[s] sel
[s] settings
[s] spider
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
>>>
当 shell 加载时,您将获得一个收录响应数据的本地响应变量。输入response.body输出响应的body,输出response.headers可以看到响应的header。
更重要的是,当你输入response.selector时,你会得到一个选择器(selector),可以用来查询返回的数据,并映射到response.selector.xpath()、response.selector.css()的快捷方式: response.xpath() 和 response.css()。
同时,shell根据响应提前初始化变量sel。选择器会根据响应的类型自动选择最合适的解析规则(XML vs HTML)。
让我们试试吧:
In [1]: sel.xpath('//title')
Out[1]: []
In [2]: sel.xpath('//title').extract()
Out[2]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [3]: sel.xpath('//title/text()')
Out[3]: []
In [4]: sel.xpath('//title/text()').extract()
Out[4]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [5]: sel.xpath('//title/text()').re('(w+):')
Out[5]: [u'Computers', u'Programming', u'Languages', u'Python']
提取数据
现在,让我们尝试从这些页面中提取一些有用的数据。
您可以在终端中键入 response.body 以观察 HTML 源并确定适当的 XPath 表达式。但是,这项任务非常无聊和困难。您可能会考虑使用 Firefox 的 Firebug 扩展来简化操作。详情请参考和。
查看网页的源码后会发现网站的信息收录在第二个
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-26 20:08
2015 年 6 月 23 日更新:
之前写这个的时候,还没有遇到具体的场景,只是觉得有这样的写法。
我今天刚满足这个要求。抓取BBS内容,版块首页只显示标题、作者和发表时间。我们需要做的是根据时间进行过滤,每天抓取最新的内容。使用 Rule 规则提取 URL 后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能获取抓取链接内容后的时间,实际上造成了不必要的浪费。使用本文中的方法文章可以在爬取前过滤链接,避免爬取无用数据。
上一篇scrapy爬虫的启动(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法。其实直接使用BaseSpider也是可以的实现多页爬取。
具体思路:我们以我们豆瓣群为例,豆瓣社科群,我们用首页地址作为start_url参数,从页面源码中找到剩下的页面,如下:
<前页
1
2
3
4
5
6
7
8
9
后页>
可以提取每个页面的地址,获取多个页面的思路是将地址封装为Request作为回调函数parse的返回值(不影响item的返回值),并指定对应的这些页面地址的回调函数。由于首页和分页在形式上是一模一样的(首页本身也是一个分页),所以可以直接指定parse为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
前面使用了CrawlSpider,这里替换了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页的处理。首先是提取地址,然后打印语句,后面再说,最后返回Request。
写这段代码的时候,感觉有一个问题:既然为每个页面指定的回调函数是parse,就相当于为每个页面提取一次页面地址,所以实际上每个页面地址都被返回了N次结束。,那么scrapy会不会在实际处理时也会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》...
我们直接运行程序,现在看看我们的打印语句:“->”前面表示当前页地址,后面是从当前页中提取的分页地址。为了简化输出,只提取用于标识分页的“开始”。范围。
结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点多,可以看出:
1. 每个寻呼地址确实被多次返回;
2. 没有陷入死循环,没有重复处理;
3. 处理乱序;
这说明scrapy本身已经进行了去重,并使用了线程进行数据获取操作。
好的,任务完成。使用 CrawlSpider 的 Rule 感觉更方便。 查看全部
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
2015 年 6 月 23 日更新:
之前写这个的时候,还没有遇到具体的场景,只是觉得有这样的写法。
我今天刚满足这个要求。抓取BBS内容,版块首页只显示标题、作者和发表时间。我们需要做的是根据时间进行过滤,每天抓取最新的内容。使用 Rule 规则提取 URL 后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能获取抓取链接内容后的时间,实际上造成了不必要的浪费。使用本文中的方法文章可以在爬取前过滤链接,避免爬取无用数据。
上一篇scrapy爬虫的启动(3)-使用规则实现多页爬取给出了使用CrawlSpider的Rule实现多页爬取的方法。其实直接使用BaseSpider也是可以的实现多页爬取。
具体思路:我们以我们豆瓣群为例,豆瓣社科群,我们用首页地址作为start_url参数,从页面源码中找到剩下的页面,如下:
<前页
1
2
3
4
5
6
7
8
9
后页>
可以提取每个页面的地址,获取多个页面的思路是将地址封装为Request作为回调函数parse的返回值(不影响item的返回值),并指定对应的这些页面地址的回调函数。由于首页和分页在形式上是一模一样的(首页本身也是一个分页),所以可以直接指定parse为回调函数。
代码显示如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
前面使用了CrawlSpider,这里替换了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页的处理。首先是提取地址,然后打印语句,后面再说,最后返回Request。
写这段代码的时候,感觉有一个问题:既然为每个页面指定的回调函数是parse,就相当于为每个页面提取一次页面地址,所以实际上每个页面地址都被返回了N次结束。,那么scrapy会不会在实际处理时也会对每个地址处理N次呢?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》...
我们直接运行程序,现在看看我们的打印语句:“->”前面表示当前页地址,后面是从当前页中提取的分页地址。为了简化输出,只提取用于标识分页的“开始”。范围。
结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点多,可以看出:
1. 每个寻呼地址确实被多次返回;
2. 没有陷入死循环,没有重复处理;
3. 处理乱序;
这说明scrapy本身已经进行了去重,并使用了线程进行数据获取操作。
好的,任务完成。使用 CrawlSpider 的 Rule 感觉更方便。
scrapy分页抓取网页(scrapy架构流程•Scrapy,Python开发的一个快速、高层次的屏幕和web抓取框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2022-02-25 06:14
scrapy架构流程
• Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,使用
用于抓取网站并从页面中提取结构化数据。
• Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。
还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本
Ben 还提供了对 web2.0 爬虫的支持。
• Scrap,意思是片段,这个Python爬虫框架叫做Scrapy。
优势:
用户只需要自定义开发几个模块,就可以轻松实现爬虫,爬取网页内容和图片非常方便;Scrapy 使用 Twisted 异步网络框架来处理网络通信,加快网页下载速度,并且不需要自己实现异步框架和多线程等,并且收录各种
灵活满足各种需求的中间件接口
Scrapy主要包括以下组件:
• 引擎(Scrapy):
用于处理整个系统的数据流,触发事务(框架核心)
• 调度程序:
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。
后退。它可以被认为是一个 URL 的优先级队列(网站 URL 或要爬取的链接),它决定了下一个要爬取的
什么是网址,同时删除重复的网址
• 下载器:
用于下载网页内容并将网页内容返回给蜘蛛(Scrapy下载器内置
在 twisted 上,一种高效的异步模型)
• 蜘蛛:
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体
(物品)。用户也可以从中提取链接,让 Scrapy 继续爬取下一页
• 项目管道(Pipeline):负责处理爬虫从网页中提取的实体,主要功能是持久化实体,验证
身体的有效性,清除不需要的信息。当页面被爬虫解析后,会被送到项目流水线,经过几个具体的
按顺序处理数据。
• 下载器中间件:
位于 Scrapy 引擎和下载器之间的框架,
它主要处理 Scrapy 引擎和下载器之间的请求和响应。
• Spider Middlewares:Scrapy 引擎和爬虫之间的框架,主要工作是
管理蜘蛛的响应输入和请求输出
• 调度程序中间件:
Scrapy引擎和调度之间的中间件,来自
Scrapy 引擎发送的要调度的请求和响应。采用
# 爬取的步骤
- 确定url地址;
- 获取页面信息;(urllib, requests);
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)
- 保存到本地(csv, json, pymysql, redis);
- 清洗数据(删除不必要的内容 -----正则表达式);
- 分析数据(词云wordcloud + jieba)
有没有用到多线程? -----
获取页面信息每个爬虫都会使用, 重复去写----
设置头部信息 ---- user-agent, proxy....
# 流程分析:
- 确定url地址:http://www.imooc.com/course/list;(spider)
- 获取页面信息;(urllib, requests); ---(scrapy中我们不要处理)---(Downloader)
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)---: (spider)
课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述
- 保存到本地(csv, json, pymysql, redis); ----(pipeline)
# 环境
- Scrapy 1.6.0
# 实现步骤:
1. 工程创建
scrapy startproject mySpider
cd mySpider
tree
├── mySpider
│ ├── __init__.py
│ ├── items.py # 提取的数据信息
│ ├── middlewares.py # 中间键
│ ├── pipelines.py # 管道, 如何存储数据
│ ├── __pycache__
│ ├── settings.py # 设置信息
│ └── spiders # 爬虫(解析页面的信息)
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
2. 创建一个爬虫
scrapy genspider mooc "www.imooc.com"
cd mySpider/spiders/
vim mooc.py
# start_url
3. 定义爬取的items内容
class CourseItem(scrapy.Item):
# 课程标题
title = scrapy.Field()
# 课程的url地址
url = scrapy.Field()
# 课程图片url地址
image_url = scrapy.Field()
# 课程的描述
introduction = scrapy.Field()
# 学习人数
student = scrapy.Field()
# 4. 编写spider代码, 解析
新项目
明确的目标
1.在 items.py 中定义变量
用于保存爬取的数据,类似于python中的字典,提供一些额外的保护
import scrapy
class CourseItem(scrapy.Item):
# Item对象是一个简单容器, 保存爬取到的数据, 类似于字典的操作;
# 实例化对象: course = CourseItem()
# course['title'] = "语文"
# course['title']
# course.keys()
# course.values()
# course.items()
# define the fields for your item here like:
# name = scrapy.Field()
# 课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述
# 课程标题
title = scrapy.Field()
# 课程的url地址
url = scrapy.Field()
# 课程图片url地址
image_url = scrapy.Field()
# 课程的描述
introduction = scrapy.Field()
# 学习人数
student = scrapy.Field()
做一个爬虫
2.定义解析方法
name = "" :这个爬虫的标识名必须是唯一的,不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,即爬虫的禁区,规定爬虫只抓取该域名下的网页,不存在的URL会被忽略。
start_urls = () : 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。将从这些起始 URL 继承生成其他子 URL。
parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传递。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item) 查看全部
scrapy分页抓取网页(scrapy架构流程•Scrapy,Python开发的一个快速、高层次的屏幕和web抓取框架)
scrapy架构流程
• Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,使用
用于抓取网站并从页面中提取结构化数据。
• Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。
还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本
Ben 还提供了对 web2.0 爬虫的支持。
• Scrap,意思是片段,这个Python爬虫框架叫做Scrapy。
优势:
用户只需要自定义开发几个模块,就可以轻松实现爬虫,爬取网页内容和图片非常方便;Scrapy 使用 Twisted 异步网络框架来处理网络通信,加快网页下载速度,并且不需要自己实现异步框架和多线程等,并且收录各种
灵活满足各种需求的中间件接口
Scrapy主要包括以下组件:
• 引擎(Scrapy):
用于处理整个系统的数据流,触发事务(框架核心)
• 调度程序:
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。
后退。它可以被认为是一个 URL 的优先级队列(网站 URL 或要爬取的链接),它决定了下一个要爬取的
什么是网址,同时删除重复的网址
• 下载器:
用于下载网页内容并将网页内容返回给蜘蛛(Scrapy下载器内置
在 twisted 上,一种高效的异步模型)
• 蜘蛛:
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体
(物品)。用户也可以从中提取链接,让 Scrapy 继续爬取下一页
• 项目管道(Pipeline):负责处理爬虫从网页中提取的实体,主要功能是持久化实体,验证
身体的有效性,清除不需要的信息。当页面被爬虫解析后,会被送到项目流水线,经过几个具体的
按顺序处理数据。
• 下载器中间件:
位于 Scrapy 引擎和下载器之间的框架,
它主要处理 Scrapy 引擎和下载器之间的请求和响应。
• Spider Middlewares:Scrapy 引擎和爬虫之间的框架,主要工作是
管理蜘蛛的响应输入和请求输出
• 调度程序中间件:
Scrapy引擎和调度之间的中间件,来自
Scrapy 引擎发送的要调度的请求和响应。采用
# 爬取的步骤
- 确定url地址;
- 获取页面信息;(urllib, requests);
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)
- 保存到本地(csv, json, pymysql, redis);
- 清洗数据(删除不必要的内容 -----正则表达式);
- 分析数据(词云wordcloud + jieba)
有没有用到多线程? -----
获取页面信息每个爬虫都会使用, 重复去写----
设置头部信息 ---- user-agent, proxy....
# 流程分析:
- 确定url地址:http://www.imooc.com/course/list;(spider)
- 获取页面信息;(urllib, requests); ---(scrapy中我们不要处理)---(Downloader)
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)---: (spider)
课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述
- 保存到本地(csv, json, pymysql, redis); ----(pipeline)
# 环境
- Scrapy 1.6.0
# 实现步骤:
1. 工程创建
scrapy startproject mySpider
cd mySpider
tree
├── mySpider
│ ├── __init__.py
│ ├── items.py # 提取的数据信息
│ ├── middlewares.py # 中间键
│ ├── pipelines.py # 管道, 如何存储数据
│ ├── __pycache__
│ ├── settings.py # 设置信息
│ └── spiders # 爬虫(解析页面的信息)
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
2. 创建一个爬虫
scrapy genspider mooc "www.imooc.com"
cd mySpider/spiders/
vim mooc.py
# start_url
3. 定义爬取的items内容
class CourseItem(scrapy.Item):
# 课程标题
title = scrapy.Field()
# 课程的url地址
url = scrapy.Field()
# 课程图片url地址
image_url = scrapy.Field()
# 课程的描述
introduction = scrapy.Field()
# 学习人数
student = scrapy.Field()
# 4. 编写spider代码, 解析
新项目
明确的目标
1.在 items.py 中定义变量
用于保存爬取的数据,类似于python中的字典,提供一些额外的保护
import scrapy
class CourseItem(scrapy.Item):
# Item对象是一个简单容器, 保存爬取到的数据, 类似于字典的操作;
# 实例化对象: course = CourseItem()
# course['title'] = "语文"
# course['title']
# course.keys()
# course.values()
# course.items()
# define the fields for your item here like:
# name = scrapy.Field()
# 课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述
# 课程标题
title = scrapy.Field()
# 课程的url地址
url = scrapy.Field()
# 课程图片url地址
image_url = scrapy.Field()
# 课程的描述
introduction = scrapy.Field()
# 学习人数
student = scrapy.Field()
做一个爬虫
2.定义解析方法
name = "" :这个爬虫的标识名必须是唯一的,不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,即爬虫的禁区,规定爬虫只抓取该域名下的网页,不存在的URL会被忽略。
start_urls = () : 元组/抓取的 URL 列表。爬虫从这里开始抓取数据,所以数据的第一次下载将从这些 url 开始。将从这些起始 URL 继承生成其他子 URL。
parse(self, response) : 解析方法,每个初始 URL 下载后都会调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传递。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
scrapy分页抓取网页(基于python分布式房源数据系统为数据的进一步应用主题爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2022-02-18 09:10
基于Python的分布式房源数据采集系统为数据的进一步应用,即房源推荐系统提供数据支持。本课题致力于解决单进程单机爬虫的瓶颈,基于Redis分布式多爬虫共享队列创建主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath技术提取和解析下载的网页,使用Redis数据库进行分发,使用MongoDb数据库进行数据存储,使用Django web框架和Semantic UI开源框架进行友好可视化数据,最后使用 Docker 部署爬虫。为同城各大城市的租赁平台设计并实现了分布式爬虫系统。
分布式爬虫爬取系统主要包括以下功能:
1.爬虫功能:爬取策略设计、内容数据域设计、增量爬取请求去重
2.中间件:爬虫防屏蔽中间件网页非200状态处理爬虫下载异常处理
3.数据存储:抓斗设计数据存储
4.数据可视化
完整的项目源代码
二、系统分布式架构
分布式采用主从结构,设置一个Master服务器和多个Slave服务器。Master 端管理 Redis 数据库并分发下载任务。Slave部署Scrapy爬虫提取网页并解析提取数据,最终将解析后的数据存储在同一个MongoDb数据库中。分布式爬虫架构如图所示。
使用Redis数据库实现分布式爬取,基本思路是将Scrapy爬虫获取的detail_request的url放入Redis Queue,所有爬虫也从指定的Redis Queue获取请求。Scrapy-Redis 组件默认使用 SpiderPriorityQueue。确定 URL 的顺序,是 sorted set 实现的一种非 FIFO 和 LIFO 的方法。因此,待爬取队列的共享是爬虫可以部署在其他服务器上完成相同爬取任务的关键点。另外,本文为了解决Scrapy单机受限的问题,将结合Scrapy-Redis组件开发Scrapy。Scrapy-Redis的总体思路是本项目通过重写Scrapu框架中的scheduler和spider类来实现调度和spider启动。与redis的交互。实现了新的dupefilter和queue类,实现了权重判断和调度容器与redis的交互。由于每台主机上的爬虫进程访问同一个redis数据库,调度和权重判断统一管理,实现分布式分布。爬行动物的目的。
三、系统实现
1)爬取策略的设计可以从scrapy的结构分析中看出。网络爬虫从初始地址开始,根据从spider中定义的目标地址获取的正则表达式或者Xpath获取更多的网页链接,加入到待下载队列中,经过去重排序后,等待用于调度程序的调度。在这个系统中,新建的链接可以分为两类,一类是目录页链接,也就是我们平时看到的下一页的链接,另一类是内容详情页链接,也就是我们需要解析网页提取字段链接指向实际的列表信息页面。
这里是master端目标链接的爬取策略。由于是分布式主从模式,master端的爬虫主要抓取下载内容详情页的链接,通过redis将下载任务分享给slave端的其他爬虫。Slave端主要负责进一步解析提取详情页的链接,并存入数据库。本文以58同城为例。初始页面链接,其实就是每个类别的首页链接,主要包括(以广东省几个城市为例):
综上所述,网络资源爬取系统采用以下爬取策略:
1) 对于Master端:核心模块是解决翻页问题,获取到每个页面的内容详情页面的链接。
Master端主要采用以下爬取策略:
1. 将redis的初始链接插入到nest_link的key中,从初始页面链接开始
2. 爬虫从redis中的key next_link获取初始链接,开始运行爬虫
3. 下载器返回的Response,爬虫根据蜘蛛定义的爬取规则,识别是否有下一页的链接。如果有链接,则存储在redis中,key保存为next_link。一个内容详情页的链接,如果匹配,就会存入Redis,将key保存为detail_request,插入下载链接,供slave端的spider使用,也就是slave端的下载任务。
4. 爬虫继续从redis中的key取值作为next_link。如果有值,则继续执行步骤2。如果为空,则爬虫等待新的链接。
2) 对于slave端:核心模块是从redis获取下载任务并解析提取字段。Slave端主要采用以下爬取策略:
1.爬虫从redis获取初始链接,key为detail_request,开始运行爬虫
2. 下载器返回的Response,爬虫根据蜘蛛定义的爬取规则,识别是否有符合该规则的content字段,如果有,将该字段存储并返回给模型,等待数据存储操作。重复步骤 1,直到爬取队列为空,爬虫等待新的链接。
2)爬虫的具体实现
爬虫程序由四部分组成,即对象定义程序、数据捕获程序、数据处理程序和下载设置程序。这里的组合是从方。Master缺少对象定义程序和数据处理程序。Master端主要是下载链接的爬取。
(1)数据抓取程序数据抓取程序分为Master端和Slave端。数据抓取程序从Redis获取初始地址。数据抓取程序定义抓取网页的规则,使用Xpath提取字段数据 Xpath等的方法,重点介绍从Xpath中提取字符数据的方法。Xapth使用路径表达式来选择web文档中的节点或节点集。Xpath有几种类型:元素、属性、文本、命名空间,处理指令、评论和文档节点。将Web文档视为一棵节点树,树的根节点称为文档节点和根节点,定位目标节点即可提取Web文档的字段数据通过 Xpath 表达式。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。具体实施步骤:
(1) 从待爬取队列中获取url
(2)判断要请求的url是否已经爬取,如果已经爬取则忽略请求,未爬取,继续其他操作,将url插入爬取队列
(3) 重复第1步。这里我们使用scrapy-redis的去重组件,所以没有实现,但是原理还是有待理解的,具体看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
它将不断访问 网站 的内容。如果不采取伪装措施,很容易被网站识别为爬虫,系统采用以下方法防止爬虫被拦截:
(a) 模拟不同浏览器行为的实现思路和代码
原则:
从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应的处理,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性。首先是扩展下载中间件。首先,将中间件添加到seeings.py。其次,扩展中间件,主要是写一个useragent列表,保存常用的浏览器请求头。作为一个列表。
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1. 代理ip池的设计开发流程如下:
一个。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行身份验证
d。如果达到最大ip数,停止爬取,一定时间后验证数据ip的有效性,删除无效ip。直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip爬虫运行截图:
(c) 爬虫异常状态组件的处理 当爬虫没有被阻塞并运行时,对网站的访问并不总是200请求成功,而是有多种状态,比如上面的爬虫被禁止时,实际上返回的状态是302,通过捕获302的状态来实现预防屏蔽组件。同时异常状态的处理有利于爬虫的健壮性。设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
d) 数据存储模块 数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。Scrapy 支持 json、csv、xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(g) 数据可视化设计 数据可视化其实就是将数据库中的数据转换成便于我们用户观察的形式。系统使用MongoDB存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
四、系统部署
因为分布式部署所需的环境都差不多,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像来部署爬虫,使用Daocloud上的scrapy-env来部署程序。部署。系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
国产优质动态IP。老化时间2-10分钟,注册即可免费领取10000个代理IP。注册地址: PC:
移动 查看全部
scrapy分页抓取网页(基于python分布式房源数据系统为数据的进一步应用主题爬虫)
基于Python的分布式房源数据采集系统为数据的进一步应用,即房源推荐系统提供数据支持。本课题致力于解决单进程单机爬虫的瓶颈,基于Redis分布式多爬虫共享队列创建主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath技术提取和解析下载的网页,使用Redis数据库进行分发,使用MongoDb数据库进行数据存储,使用Django web框架和Semantic UI开源框架进行友好可视化数据,最后使用 Docker 部署爬虫。为同城各大城市的租赁平台设计并实现了分布式爬虫系统。
分布式爬虫爬取系统主要包括以下功能:
1.爬虫功能:爬取策略设计、内容数据域设计、增量爬取请求去重
2.中间件:爬虫防屏蔽中间件网页非200状态处理爬虫下载异常处理
3.数据存储:抓斗设计数据存储
4.数据可视化
完整的项目源代码
二、系统分布式架构
分布式采用主从结构,设置一个Master服务器和多个Slave服务器。Master 端管理 Redis 数据库并分发下载任务。Slave部署Scrapy爬虫提取网页并解析提取数据,最终将解析后的数据存储在同一个MongoDb数据库中。分布式爬虫架构如图所示。
使用Redis数据库实现分布式爬取,基本思路是将Scrapy爬虫获取的detail_request的url放入Redis Queue,所有爬虫也从指定的Redis Queue获取请求。Scrapy-Redis 组件默认使用 SpiderPriorityQueue。确定 URL 的顺序,是 sorted set 实现的一种非 FIFO 和 LIFO 的方法。因此,待爬取队列的共享是爬虫可以部署在其他服务器上完成相同爬取任务的关键点。另外,本文为了解决Scrapy单机受限的问题,将结合Scrapy-Redis组件开发Scrapy。Scrapy-Redis的总体思路是本项目通过重写Scrapu框架中的scheduler和spider类来实现调度和spider启动。与redis的交互。实现了新的dupefilter和queue类,实现了权重判断和调度容器与redis的交互。由于每台主机上的爬虫进程访问同一个redis数据库,调度和权重判断统一管理,实现分布式分布。爬行动物的目的。
三、系统实现
1)爬取策略的设计可以从scrapy的结构分析中看出。网络爬虫从初始地址开始,根据从spider中定义的目标地址获取的正则表达式或者Xpath获取更多的网页链接,加入到待下载队列中,经过去重排序后,等待用于调度程序的调度。在这个系统中,新建的链接可以分为两类,一类是目录页链接,也就是我们平时看到的下一页的链接,另一类是内容详情页链接,也就是我们需要解析网页提取字段链接指向实际的列表信息页面。
这里是master端目标链接的爬取策略。由于是分布式主从模式,master端的爬虫主要抓取下载内容详情页的链接,通过redis将下载任务分享给slave端的其他爬虫。Slave端主要负责进一步解析提取详情页的链接,并存入数据库。本文以58同城为例。初始页面链接,其实就是每个类别的首页链接,主要包括(以广东省几个城市为例):
综上所述,网络资源爬取系统采用以下爬取策略:
1) 对于Master端:核心模块是解决翻页问题,获取到每个页面的内容详情页面的链接。
Master端主要采用以下爬取策略:
1. 将redis的初始链接插入到nest_link的key中,从初始页面链接开始
2. 爬虫从redis中的key next_link获取初始链接,开始运行爬虫
3. 下载器返回的Response,爬虫根据蜘蛛定义的爬取规则,识别是否有下一页的链接。如果有链接,则存储在redis中,key保存为next_link。一个内容详情页的链接,如果匹配,就会存入Redis,将key保存为detail_request,插入下载链接,供slave端的spider使用,也就是slave端的下载任务。
4. 爬虫继续从redis中的key取值作为next_link。如果有值,则继续执行步骤2。如果为空,则爬虫等待新的链接。
2) 对于slave端:核心模块是从redis获取下载任务并解析提取字段。Slave端主要采用以下爬取策略:
1.爬虫从redis获取初始链接,key为detail_request,开始运行爬虫
2. 下载器返回的Response,爬虫根据蜘蛛定义的爬取规则,识别是否有符合该规则的content字段,如果有,将该字段存储并返回给模型,等待数据存储操作。重复步骤 1,直到爬取队列为空,爬虫等待新的链接。
2)爬虫的具体实现
爬虫程序由四部分组成,即对象定义程序、数据捕获程序、数据处理程序和下载设置程序。这里的组合是从方。Master缺少对象定义程序和数据处理程序。Master端主要是下载链接的爬取。
(1)数据抓取程序数据抓取程序分为Master端和Slave端。数据抓取程序从Redis获取初始地址。数据抓取程序定义抓取网页的规则,使用Xpath提取字段数据 Xpath等的方法,重点介绍从Xpath中提取字符数据的方法。Xapth使用路径表达式来选择web文档中的节点或节点集。Xpath有几种类型:元素、属性、文本、命名空间,处理指令、评论和文档节点。将Web文档视为一棵节点树,树的根节点称为文档节点和根节点,定位目标节点即可提取Web文档的字段数据通过 Xpath 表达式。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。具体实施步骤:
(1) 从待爬取队列中获取url
(2)判断要请求的url是否已经爬取,如果已经爬取则忽略请求,未爬取,继续其他操作,将url插入爬取队列
(3) 重复第1步。这里我们使用scrapy-redis的去重组件,所以没有实现,但是原理还是有待理解的,具体看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
它将不断访问 网站 的内容。如果不采取伪装措施,很容易被网站识别为爬虫,系统采用以下方法防止爬虫被拦截:
(a) 模拟不同浏览器行为的实现思路和代码
原则:
从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应的处理,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性。首先是扩展下载中间件。首先,将中间件添加到seeings.py。其次,扩展中间件,主要是写一个useragent列表,保存常用的浏览器请求头。作为一个列表。
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1. 代理ip池的设计开发流程如下:
一个。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行身份验证
d。如果达到最大ip数,停止爬取,一定时间后验证数据ip的有效性,删除无效ip。直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip爬虫运行截图:
(c) 爬虫异常状态组件的处理 当爬虫没有被阻塞并运行时,对网站的访问并不总是200请求成功,而是有多种状态,比如上面的爬虫被禁止时,实际上返回的状态是302,通过捕获302的状态来实现预防屏蔽组件。同时异常状态的处理有利于爬虫的健壮性。设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
d) 数据存储模块 数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。Scrapy 支持 json、csv、xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(g) 数据可视化设计 数据可视化其实就是将数据库中的数据转换成便于我们用户观察的形式。系统使用MongoDB存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
四、系统部署
因为分布式部署所需的环境都差不多,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像来部署爬虫,使用Daocloud上的scrapy-env来部署程序。部署。系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
国产优质动态IP。老化时间2-10分钟,注册即可免费领取10000个代理IP。注册地址: PC:
移动

