
scrapy分页抓取网页
scrapy分页抓取网页(怎样优雅用yield写这样的代码呢?部分代码实例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-15 16:01
)
使用yield优雅爬取网页分页数据
在使用Python爬取网页数据时,我们经常会遇到分页数据,有些下一页按钮已经有了具体的链接地址,而有些可能是javascript处理的。这需要能够同时解析页面内容和采集下一页的url。如何在python中优雅地编写这样的代码?或者如何更pythonic?
下面给出一些代码示例
def get_next_page(obj):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('a', text="下頁")
break
except:
error_occurred = True
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
next_url = "http://www.etnet.com.hk" + e_next_page.get('href')
time.sleep(2)
yield content
for i in get_next_page(next_url):
yield i
else:
yield content
def get_next_page(obj, page=1):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if page == 1 and (not "sh=" in obj) and hrefs:
reset_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"/sector-industry-details.aspx?%s&page=1" % \
(hrefs[0].replace('sh=1', 'sh=0').replace('&page=', '') \
.replace("'", '').split()[0]))
for next_page in get_next_page(reset_url):
yield next_page
return
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('td', text="下一頁 ")
break
except:
error_occurred = True
LOG.error(traceback.format_exc())
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if hrefs:
next_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"-details.aspx?%s&page=%d" % \
(hrefs[0].replace('sh=1', 'sh=0') \
.replace('&page=', '').replace("'", '').split()[0], page+1))
time.sleep(2)
yield content
for next_page in get_next_page(next_url, page+1):
yield next_page
else:
yield content
for curr_href in e_href:
retry_interval = random.randint(MIN_INTERVAL_SECONDS_FOR_RETRIEVING,
MAX_INTERVAL_SECONDS_FOR_RETRIEVING)
time.sleep(retry_interval)
contents = get_next_page(curr_href)
for content in contents:
get_page_data(content) 查看全部
scrapy分页抓取网页(怎样优雅用yield写这样的代码呢?部分代码实例
)
使用yield优雅爬取网页分页数据
在使用Python爬取网页数据时,我们经常会遇到分页数据,有些下一页按钮已经有了具体的链接地址,而有些可能是javascript处理的。这需要能够同时解析页面内容和采集下一页的url。如何在python中优雅地编写这样的代码?或者如何更pythonic?
下面给出一些代码示例
def get_next_page(obj):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('a', text="下頁")
break
except:
error_occurred = True
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
next_url = "http://www.etnet.com.hk" + e_next_page.get('href')
time.sleep(2)
yield content
for i in get_next_page(next_url):
yield i
else:
yield content
def get_next_page(obj, page=1):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if page == 1 and (not "sh=" in obj) and hrefs:
reset_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"/sector-industry-details.aspx?%s&page=1" % \
(hrefs[0].replace('sh=1', 'sh=0').replace('&page=', '') \
.replace("'", '').split()[0]))
for next_page in get_next_page(reset_url):
yield next_page
return
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('td', text="下一頁 ")
break
except:
error_occurred = True
LOG.error(traceback.format_exc())
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if hrefs:
next_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"-details.aspx?%s&page=%d" % \
(hrefs[0].replace('sh=1', 'sh=0') \
.replace('&page=', '').replace("'", '').split()[0], page+1))
time.sleep(2)
yield content
for next_page in get_next_page(next_url, page+1):
yield next_page
else:
yield content
for curr_href in e_href:
retry_interval = random.randint(MIN_INTERVAL_SECONDS_FOR_RETRIEVING,
MAX_INTERVAL_SECONDS_FOR_RETRIEVING)
time.sleep(retry_interval)
contents = get_next_page(curr_href)
for content in contents:
get_page_data(content)
scrapy分页抓取网页(万业鹏博士爬虫分页抓取网页视频地址:正则表达式抓取油管视频使用scrapy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-14 19:04
scrapy分页抓取网页视频地址:万业鹏博士scrapy新文章:scrapy|正则表达式抓取油管视频使用scrapy实现爬虫教程,scrapy是用requests库模拟人工操作请求ip。万业鹏博士爬虫软件系列文章目录万业鹏博士介绍上次介绍了scrapy的分页抓取功能,但是对分页抓取所需要的条件以及用到的正则表达式(requests)了解的不是很多,本次将介绍scrapy新文章“scrapy|正则表达式抓取油管视频”,scrapy新文章包含爬虫的完整教程,以及scrapy正则表达式基础,用到的正则表达式和包括ip地址抓取视频地址的四大正则表达式。
1.scrapy新文章的四大正则表达式1.1requests(requests库包含正则表达式)正则表达式基础正则表达式req这个正则表达式:req[^:]=requestbody正则表达式reqexp这个正则表达式:reqexp[^:]=requestbody正则表达式reqno正则表达式reqext[^:]=requestbody正则表达式requrlstr通过正则表达式匹配的要素列表来表示网络请求,如下正则表达式匹配data类型的网络请求信息,而不是url地址,对于data类型的网络请求信息,我们知道它是四种数据类型,分别是:字符串(string)、数组(array)、容器(map)、元组(tuple),正则表达式reqexp[^:]=requestbody正则表达式reqexp[^:]=requestbody正则表达式reqstr匹配指定post参数的网络请求信息,一次匹配一个post参数,例如mailtype查询scrapy中没有直接匹配不同参数的信息,一次匹配指定post参数的信息。
1.2postimportscrapy.post#post请求defget_post_from_url(url,requrl):scrapy.disable_useragent#设置你要替换请求headers的值scrapy.disable_useragent=true1.3scrapy中settings.getting_started_to_debug()#初始化settings.getting_started_to_debug()会给settings.getting_debug()添加scrapy_debug信息来运行,第一次运行的时候,scrapy会提示错误代码,大家不要管它,只要不是特别多就不用管它,大部分都是正常的。
注意:scrapyscrapy配置:>>>scrapy.__init__.__name="scrapy">>>scrapy.__dir__="__main__">>>scrapy.__url__="">>>scrapy.__version__="1.0.0">>>scrapy.conf.meta.scrapy_debug="master">>>scrapy.conf.meta.scrapy_start_urls=[]>>>scrapy.conf.meta。 查看全部
scrapy分页抓取网页(万业鹏博士爬虫分页抓取网页视频地址:正则表达式抓取油管视频使用scrapy)
scrapy分页抓取网页视频地址:万业鹏博士scrapy新文章:scrapy|正则表达式抓取油管视频使用scrapy实现爬虫教程,scrapy是用requests库模拟人工操作请求ip。万业鹏博士爬虫软件系列文章目录万业鹏博士介绍上次介绍了scrapy的分页抓取功能,但是对分页抓取所需要的条件以及用到的正则表达式(requests)了解的不是很多,本次将介绍scrapy新文章“scrapy|正则表达式抓取油管视频”,scrapy新文章包含爬虫的完整教程,以及scrapy正则表达式基础,用到的正则表达式和包括ip地址抓取视频地址的四大正则表达式。
1.scrapy新文章的四大正则表达式1.1requests(requests库包含正则表达式)正则表达式基础正则表达式req这个正则表达式:req[^:]=requestbody正则表达式reqexp这个正则表达式:reqexp[^:]=requestbody正则表达式reqno正则表达式reqext[^:]=requestbody正则表达式requrlstr通过正则表达式匹配的要素列表来表示网络请求,如下正则表达式匹配data类型的网络请求信息,而不是url地址,对于data类型的网络请求信息,我们知道它是四种数据类型,分别是:字符串(string)、数组(array)、容器(map)、元组(tuple),正则表达式reqexp[^:]=requestbody正则表达式reqexp[^:]=requestbody正则表达式reqstr匹配指定post参数的网络请求信息,一次匹配一个post参数,例如mailtype查询scrapy中没有直接匹配不同参数的信息,一次匹配指定post参数的信息。
1.2postimportscrapy.post#post请求defget_post_from_url(url,requrl):scrapy.disable_useragent#设置你要替换请求headers的值scrapy.disable_useragent=true1.3scrapy中settings.getting_started_to_debug()#初始化settings.getting_started_to_debug()会给settings.getting_debug()添加scrapy_debug信息来运行,第一次运行的时候,scrapy会提示错误代码,大家不要管它,只要不是特别多就不用管它,大部分都是正常的。
注意:scrapyscrapy配置:>>>scrapy.__init__.__name="scrapy">>>scrapy.__dir__="__main__">>>scrapy.__url__="">>>scrapy.__version__="1.0.0">>>scrapy.conf.meta.scrapy_debug="master">>>scrapy.conf.meta.scrapy_start_urls=[]>>>scrapy.conf.meta。
scrapy分页抓取网页(关于分页,最佳方法取决于所使用的分页类型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-14 18:10
关于分页,最好的方法实际上取决于所使用的分页类型。
如果你:
然后您可以一次安排所有页面:
def parse_listings_page1(self, response):
"""
here parse first page, schedule all other pages at once!
"""
# e.g. 'http://shop.com/products?page=1'
url = response.url
# e.g. 100
total_pages = int(response.css('.last-page').extract_first())
# schedule every page at once!
for page in range(2, total_pages + 1):
page_url = add_or_replace_parameter(url, 'page', page)
yield Request(page_url, self.parse_listings)
# don't forget to also parse listings on first page!
yield from self.parse_listings(response)
def parse_listings(self, response):
for url in response.css('.listing::attr(href)'):
yield Request(url, self.parse_product)
这种方法的巨大好处是速度 - 在这里您可以采用异步逻辑并同时抓取所有页面!
或者。
如果你:
然后你必须同步安排页面 1:1。
def parse(self, response):
for product in response.css('.product::attr(href)'):
yield Request(product, self.parse_product)
next_page = response.css('.next-page::attr(href)').extract_first()
if next_page:
yield Request(next_page, self.parse)
else:
print(f'last page reached: {response.url}')
在您的示例中,您使用了第二种同步方法,您在这里的担忧是没有根据的,您只需要确保 xpath 选择器选择正确的页面即可。 查看全部
scrapy分页抓取网页(关于分页,最佳方法取决于所使用的分页类型)
关于分页,最好的方法实际上取决于所使用的分页类型。
如果你:
然后您可以一次安排所有页面:
def parse_listings_page1(self, response):
"""
here parse first page, schedule all other pages at once!
"""
# e.g. 'http://shop.com/products?page=1'
url = response.url
# e.g. 100
total_pages = int(response.css('.last-page').extract_first())
# schedule every page at once!
for page in range(2, total_pages + 1):
page_url = add_or_replace_parameter(url, 'page', page)
yield Request(page_url, self.parse_listings)
# don't forget to also parse listings on first page!
yield from self.parse_listings(response)
def parse_listings(self, response):
for url in response.css('.listing::attr(href)'):
yield Request(url, self.parse_product)
这种方法的巨大好处是速度 - 在这里您可以采用异步逻辑并同时抓取所有页面!
或者。
如果你:
然后你必须同步安排页面 1:1。
def parse(self, response):
for product in response.css('.product::attr(href)'):
yield Request(product, self.parse_product)
next_page = response.css('.next-page::attr(href)').extract_first()
if next_page:
yield Request(next_page, self.parse)
else:
print(f'last page reached: {response.url}')
在您的示例中,您使用了第二种同步方法,您在这里的担忧是没有根据的,您只需要确保 xpath 选择器选择正确的页面即可。
scrapy分页抓取网页( 如何Scrapy构建一个简单的网络爬虫?会介绍如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-12 11:13
如何Scrapy构建一个简单的网络爬虫?会介绍如何)
项目需要灵活的爬虫工具,实现爬虫框架。根据目标网站的结构、地址和需要的内容,进行简单的配置开发即可实现具体的网站爬虫功能。你会发现 Python 下有这个 Scrapy 工具。对于一个普通的网络爬虫功能,Scrapy 完全胜任,并且封装了很多复杂的编程。本文将介绍如何使用 Scrapy 构建一个简单的网络爬虫。
一个基本的爬虫工具,它应该具备以下功能:
让我们看看 Scrapy 是如何做到这一点的。首先准备好Scrapy环境,需要安装Python(本文使用v2.7)和pip,然后使用pip安装lxml和scrapy。个人强烈推荐使用virtualenv安装环境,这样不同项目之间就不会冲突了,详细步骤这里不再赘述。
Mac用户注意,使用pip安装lxml时,会出现类似如下的错误:
错误:#include "xml/xmlversion.h" 未找到
要解决这个问题,你需要先安装 Xcode 的命令行工具。具体方法是在命令行执行如下命令。
1
$ xcode-select --install
环境安装好后,我们用Scrapy实现一个简单的爬虫,抓取本篇博客网站的文章的标题、地址和摘要。
创建项目
1
$ scrapy startproject my_crawler
此命令将在当前目录中创建一个名为“my_crawler”的项目。项目目录结构如下
我的爬虫
|- my_crawler
| |- 蜘蛛
| | |- __init__.py
| |- items.py
| |- pipelines.py
| |- 设置.py
|-scrapy.cfg
设置要爬取的内容的字段
这里是文章的标题、地址和摘要
修改“items.py”文件,在“MyCrawlerItem”类中添加如下代码:
# -*- 编码:utf-8 -*-
导入scrapy
类 MyCrawlerItem(scrapy.Item):
title = scrapy.Field() # 文章Title
url = scrapy.Field()# 文章地址
summary = scrapy.Field() # 文章总结
通过
编写网页解析代码
在“my_crawler/spiders”目录下,创建一个名为“crawl_spider.py”的文件(文件名可以任意)。
代码如下
# -*- 编码:utf-8 -*-
导入scrapy
从 scrapy.linkextractors 导入 LinkExtractor
从 scrapy.spiders 导入 CrawlSpider,规则
从 my_crawler.items 导入 MyCrawlerItem
类 MyCrawlSpider(CrawlSpider):
name = 'my_crawler'# 蜘蛛名,必须唯一,执行爬虫命令时使用
allowed_domains = [''] #限制允许爬取的域名,可设置多个
start_urls = [
"",#种子地址,可设置多个
]
rules = ( #对应具体的URL,设置解析函数,可设置多个
Rule(LinkExtractor(allow=r'/page/[0-9]+'), #指定允许继续爬取的URL格式,支持正则
callback='parse_item', # 用于解析网页的回调函数名
关注=真
),
)
def parse_item(self, response):
# 通过 XPath 获取 Dom 元素
articles = response.xpath('//*[@id="main"]/ul/li')
对于文章中的文章:
item = MyCrawlerItem()
item['title'] = article.xpath('h3[@class="entry-title"]/a/text()').extract()[0]
item['url'] = article.xpath('h3[@class="entry-title"]/a/@href').extract()[0]
item['summary'] = article.xpath('div[2]/p/text()').extract()[0]
产量项目
不熟悉XPath的朋友可以通过Chrome的调试工具获取元素的XPath。
我们测试爬虫的效果
在命令行输入:
1
$ scrapy crawl my_crawler
请注意,这里的“my_crawler”是您在“crawl_spider.py”文件中提供的蜘蛛名称。
几秒钟后,您应该会在控制台上看到要抓取的字段内容。太神奇了! Scrapy 封装了对 HTTP(S) 请求、内容下载、待爬取和爬取的 URL 队列的管理。你的主要工作基本上就是设置URL规则和编写解析方法。
我们将抓取的内容保存为 JSON 文件:
1
$ scrapy crawl my_crawler -o my_crawler.json -t json
在当前目录下可以找到“my_crawler.json”文件,里面存放了我们要爬取的字段信息。 (参数“-t json”可以省略)
将结果保存到数据库
这里我们使用MongoDB,你需要先安装Python MongoDB库“pymongo”。编辑“my_crawler”目录下的“pipelines.py”文件,添加
到“MyCrawlerPipeline”类
以下代码:
# -*- 编码:utf-8 -*-
导入 pymongo
从 scrapy.conf 导入设置
从 scrapy.exceptions 导入 DropItem
类 MyCrawlerPipeline(object):
def __init__(self):
# 建立 MongoDB 连接
connection = pymongo.Connection(
设置['MONGO_SERVER'],
设置['MONGO_PORT']
)
db = 连接[设置['MONGO_DB']]
self.采集 = db[settings['MONGO_采集']]
#处理每一个被爬取的MyCrawlerItem
def process_item(self, item, spider):
有效 = 真
对于项目中的数据:
如果不是数据:# 过滤掉带有空字段的项目
有效 = 假
raise DropItem("Missing {0}!".format(data))
如果有效:
#也可以使用self.采集.insert(dict(item)),使用upsert防止重复
self.采集.update({'url': item['url']}, dict(item), upsert=True)
退货
打开“my_crawler”目录下的“settings.py”文件,在文件末尾添加管道设置:
ITEM_PIPELINES = {
'my_crawler.pipelines.MyCrawlerPipeline': 300, #设置Pipeline,可以有多个,值为执行优先级
}
#MongoDB连接信息
MONGO_SERVER = '本地主机'
MONGO_PORT = 27017
MONGO_DB = 'bjhee'
MONGO_采集 = '文章'
DOWNLOAD_DELAY=2 #如果网络慢,可以加一些延迟,单位是秒
执行爬虫
1
$ scrapy crawl my_crawler
不要忘记启动 MongoDB 并创建“bjhee”数据库。现在可以查询MongoDB中的记录了。
总结一下,要使用Scrapy搭建一个网络爬虫,你需要做的就是:
Scrapy 为您完成所有其他工作。上图是Scrapy的具体工作流程。这个怎么样?开始编写自己的爬虫。 查看全部
scrapy分页抓取网页(
如何Scrapy构建一个简单的网络爬虫?会介绍如何)

项目需要灵活的爬虫工具,实现爬虫框架。根据目标网站的结构、地址和需要的内容,进行简单的配置开发即可实现具体的网站爬虫功能。你会发现 Python 下有这个 Scrapy 工具。对于一个普通的网络爬虫功能,Scrapy 完全胜任,并且封装了很多复杂的编程。本文将介绍如何使用 Scrapy 构建一个简单的网络爬虫。
一个基本的爬虫工具,它应该具备以下功能:
让我们看看 Scrapy 是如何做到这一点的。首先准备好Scrapy环境,需要安装Python(本文使用v2.7)和pip,然后使用pip安装lxml和scrapy。个人强烈推荐使用virtualenv安装环境,这样不同项目之间就不会冲突了,详细步骤这里不再赘述。
Mac用户注意,使用pip安装lxml时,会出现类似如下的错误:
错误:#include "xml/xmlversion.h" 未找到
要解决这个问题,你需要先安装 Xcode 的命令行工具。具体方法是在命令行执行如下命令。
1
$ xcode-select --install
环境安装好后,我们用Scrapy实现一个简单的爬虫,抓取本篇博客网站的文章的标题、地址和摘要。

创建项目
1
$ scrapy startproject my_crawler
此命令将在当前目录中创建一个名为“my_crawler”的项目。项目目录结构如下
我的爬虫
|- my_crawler
| |- 蜘蛛
| | |- __init__.py
| |- items.py
| |- pipelines.py
| |- 设置.py
|-scrapy.cfg
设置要爬取的内容的字段
这里是文章的标题、地址和摘要
修改“items.py”文件,在“MyCrawlerItem”类中添加如下代码:
# -*- 编码:utf-8 -*-
导入scrapy
类 MyCrawlerItem(scrapy.Item):
title = scrapy.Field() # 文章Title
url = scrapy.Field()# 文章地址
summary = scrapy.Field() # 文章总结
通过

编写网页解析代码
在“my_crawler/spiders”目录下,创建一个名为“crawl_spider.py”的文件(文件名可以任意)。
代码如下
# -*- 编码:utf-8 -*-
导入scrapy
从 scrapy.linkextractors 导入 LinkExtractor
从 scrapy.spiders 导入 CrawlSpider,规则
从 my_crawler.items 导入 MyCrawlerItem
类 MyCrawlSpider(CrawlSpider):
name = 'my_crawler'# 蜘蛛名,必须唯一,执行爬虫命令时使用
allowed_domains = [''] #限制允许爬取的域名,可设置多个
start_urls = [
"",#种子地址,可设置多个
]
rules = ( #对应具体的URL,设置解析函数,可设置多个
Rule(LinkExtractor(allow=r'/page/[0-9]+'), #指定允许继续爬取的URL格式,支持正则
callback='parse_item', # 用于解析网页的回调函数名
关注=真
),
)
def parse_item(self, response):
# 通过 XPath 获取 Dom 元素
articles = response.xpath('//*[@id="main"]/ul/li')
对于文章中的文章:
item = MyCrawlerItem()
item['title'] = article.xpath('h3[@class="entry-title"]/a/text()').extract()[0]
item['url'] = article.xpath('h3[@class="entry-title"]/a/@href').extract()[0]
item['summary'] = article.xpath('div[2]/p/text()').extract()[0]
产量项目
不熟悉XPath的朋友可以通过Chrome的调试工具获取元素的XPath。
我们测试爬虫的效果
在命令行输入:
1
$ scrapy crawl my_crawler
请注意,这里的“my_crawler”是您在“crawl_spider.py”文件中提供的蜘蛛名称。
几秒钟后,您应该会在控制台上看到要抓取的字段内容。太神奇了! Scrapy 封装了对 HTTP(S) 请求、内容下载、待爬取和爬取的 URL 队列的管理。你的主要工作基本上就是设置URL规则和编写解析方法。

我们将抓取的内容保存为 JSON 文件:
1
$ scrapy crawl my_crawler -o my_crawler.json -t json
在当前目录下可以找到“my_crawler.json”文件,里面存放了我们要爬取的字段信息。 (参数“-t json”可以省略)
将结果保存到数据库
这里我们使用MongoDB,你需要先安装Python MongoDB库“pymongo”。编辑“my_crawler”目录下的“pipelines.py”文件,添加
到“MyCrawlerPipeline”类
以下代码:
# -*- 编码:utf-8 -*-
导入 pymongo
从 scrapy.conf 导入设置
从 scrapy.exceptions 导入 DropItem
类 MyCrawlerPipeline(object):
def __init__(self):
# 建立 MongoDB 连接
connection = pymongo.Connection(
设置['MONGO_SERVER'],
设置['MONGO_PORT']
)
db = 连接[设置['MONGO_DB']]
self.采集 = db[settings['MONGO_采集']]
#处理每一个被爬取的MyCrawlerItem
def process_item(self, item, spider):
有效 = 真
对于项目中的数据:
如果不是数据:# 过滤掉带有空字段的项目
有效 = 假
raise DropItem("Missing {0}!".format(data))
如果有效:
#也可以使用self.采集.insert(dict(item)),使用upsert防止重复
self.采集.update({'url': item['url']}, dict(item), upsert=True)
退货

打开“my_crawler”目录下的“settings.py”文件,在文件末尾添加管道设置:
ITEM_PIPELINES = {
'my_crawler.pipelines.MyCrawlerPipeline': 300, #设置Pipeline,可以有多个,值为执行优先级
}
#MongoDB连接信息
MONGO_SERVER = '本地主机'
MONGO_PORT = 27017
MONGO_DB = 'bjhee'
MONGO_采集 = '文章'
DOWNLOAD_DELAY=2 #如果网络慢,可以加一些延迟,单位是秒
执行爬虫
1
$ scrapy crawl my_crawler
不要忘记启动 MongoDB 并创建“bjhee”数据库。现在可以查询MongoDB中的记录了。

总结一下,要使用Scrapy搭建一个网络爬虫,你需要做的就是:
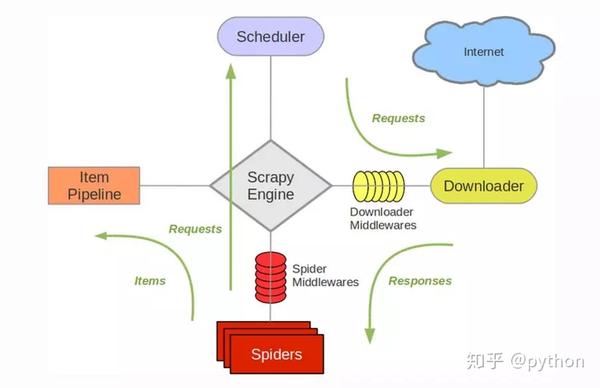
Scrapy 为您完成所有其他工作。上图是Scrapy的具体工作流程。这个怎么样?开始编写自己的爬虫。
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-11 02:16
初步了解 Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
它最初是为网络抓取(更准确地说,网络抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。
本文档将通过介绍其背后的概念,让您了解 Scrapy 的工作原理,并决定 Scrapy 是否是您所需要的。
当您准备好开始您的项目时,您可以参考它。
选择一个网站
当您需要从 网站 获取信息,但 网站 不提供 API 或以编程方式获取信息的机制时,Scrapy 可以提供帮助。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
今天添加的种子列表可以在此页面上找到:
定义要抓取的数据
第一步是定义我们需要抓取的数据。在 Scrapy 中,这是通过 . (在这种情况下是 torrent 文件)
我们定义的项目:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写蜘蛛。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过查看页面内容,所有种子都有相似的 URL。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式: /tor/\d+ 。
我们使用 XPath 选择要从页面的 HTML 源中提取的数据。以其中一个 torrent 文件的页面为例:
查看 HTML 页面源并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以看到文件名收录在标签中:
Darwin - The Evolution Of An Exhibition
对应的 XPath 表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取描述:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的更多信息,请参阅 XPath 参考。
最后,结合以上给出蜘蛛代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
TorrentItem 在 .
执行爬虫获取数据
最后,我们可以运行爬虫获取网站的数据,并以JSON格式存储到scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您也可以写入存储项目到数据库中。
查看提取的数据
执行后,当您查看 scraped_data.json 时,您将看到提取的项目:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是一个列表,所以值是存储在一个列表中的(直接赋值的url除外)。如果您想保存单个数据或对数据执行其他处理,这就是发挥作用的地方。
还有什么?
您已经了解了如何使用 Scrapy 从网页中提取和存储信息,但这只是冰山一角。Scrapy 提供了许多强大的功能,使爬取更容易、更高效,例如:
为非英语语言中的非标准或不正确的编码声明提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加快爬虫创建速度的同时,在更大的项目中保持代码的一致性。有关详细信息,请参阅命令。对于多个爬虫下的性能评估和故障检测,它提供了可扩展性。提供,为您测试XPath表达式、编写和调试爬虫、简化生产环境的部署和操作、监控机器提供了极大的便利。内置,
下一个
下一步当然是下载 Scrapy,你可以阅读它并加入社区。谢谢您的支持!
讨论 查看全部
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
初步了解 Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
它最初是为网络抓取(更准确地说,网络抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。
本文档将通过介绍其背后的概念,让您了解 Scrapy 的工作原理,并决定 Scrapy 是否是您所需要的。
当您准备好开始您的项目时,您可以参考它。
选择一个网站
当您需要从 网站 获取信息,但 网站 不提供 API 或以编程方式获取信息的机制时,Scrapy 可以提供帮助。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
今天添加的种子列表可以在此页面上找到:
定义要抓取的数据
第一步是定义我们需要抓取的数据。在 Scrapy 中,这是通过 . (在这种情况下是 torrent 文件)
我们定义的项目:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写蜘蛛。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过查看页面内容,所有种子都有相似的 URL。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式: /tor/\d+ 。
我们使用 XPath 选择要从页面的 HTML 源中提取的数据。以其中一个 torrent 文件的页面为例:
查看 HTML 页面源并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以看到文件名收录在标签中:
Darwin - The Evolution Of An Exhibition
对应的 XPath 表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取描述:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的更多信息,请参阅 XPath 参考。
最后,结合以上给出蜘蛛代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
TorrentItem 在 .
执行爬虫获取数据
最后,我们可以运行爬虫获取网站的数据,并以JSON格式存储到scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您也可以写入存储项目到数据库中。
查看提取的数据
执行后,当您查看 scraped_data.json 时,您将看到提取的项目:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是一个列表,所以值是存储在一个列表中的(直接赋值的url除外)。如果您想保存单个数据或对数据执行其他处理,这就是发挥作用的地方。
还有什么?
您已经了解了如何使用 Scrapy 从网页中提取和存储信息,但这只是冰山一角。Scrapy 提供了许多强大的功能,使爬取更容易、更高效,例如:
为非英语语言中的非标准或不正确的编码声明提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加快爬虫创建速度的同时,在更大的项目中保持代码的一致性。有关详细信息,请参阅命令。对于多个爬虫下的性能评估和故障检测,它提供了可扩展性。提供,为您测试XPath表达式、编写和调试爬虫、简化生产环境的部署和操作、监控机器提供了极大的便利。内置,
下一个
下一步当然是下载 Scrapy,你可以阅读它并加入社区。谢谢您的支持!
讨论
scrapy分页抓取网页( WebCrawler下载Web页面如何调度站点的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-11 02:13
WebCrawler下载Web页面如何调度站点的?)
深度解析Python的爬虫框架Scrapy的结构和运行过程
网络爬虫(Web Crawler,Spider)是一种在互联网上爬行的机器人。当然,它通常不是实体机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实是一个程序,它不是爬行,而是有一定的目的,爬行时会采集数据。一些信息。例如,谷歌有大量的爬虫,它们在互联网上采集网页内容和它们之间的链接等信息;比如一些别有用心的爬虫,会在网上搜集foo[at]bar[dot]com等东西。另外,还有一些自定义爬虫,专门针对某个网站,比如JavaEye的Robbin前段时间写了几篇专门处理恶意爬虫的博客(原来的链接好像过期了,所以没有给出),而网站比如小众软件或者LinuxToy经常被全站爬下来,挂在不同的名字下。其实爬虫在基本原理上很简单,只要能上网分析网页,现在大部分语言都有方便的可以爬取网页的Http客户端库,以及最简单的HTML分析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。现在大部分语言都有方便的Http客户端库,可以爬取网页,最简单的HTML解析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。现在大部分语言都有方便的Http客户端库,可以爬取网页,最简单的HTML解析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。
爬虫的两个部分,一个是下载网页,有很多问题需要考虑,如何最大限度地利用本地带宽,如何调度不同站点的Web请求以减轻对方服务器的负担等等。在高性能的网络爬虫系统中,DNS查询也将成为需要优化的瓶颈。此外,还有一些“规则”需要遵守(例如 robots.txt)。得到网页后的分析过程也很复杂。网上各种奇葩,各种错误的HTML页面。几乎不可能全部分析。另外,随着 AJAX 的普及,如何获取 Javascript 动态生成的内容也成了一大难题;此外,互联网上有意无意地出现了各种各样的蜘蛛陷阱。如果你盲目地跟随超链接,你就会陷入陷阱,注定要失败。比如这个网站,据说谷歌之前宣布互联网上Unique URLs的数量已经达到1万亿,所以这个人很自豪地宣布了第二个万亿。:D
然而,实际上,像谷歌这样需要制作通用爬虫的人并不多。通常,我们制作一个 Crawler 来抓取特定的或某种类型的 网站。对 网站 结构进行一些分析,事情就会变得容易得多。通过分析和选择有价值的链接进行跟踪,可以避免许多不必要的链接或蜘蛛陷阱。如果 网站 的结构允许选择合适的路径,我们可以将感兴趣的事物按一定的顺序排列。再爬一遍,这样连URL重复的判断都可以省略。
比如我们要爬取pongba的博客中的博客文字,通过观察,很容易发现我们对两类页面感兴趣:
文章列出页面,比如首页,或者像/page/\d+/这样的URL的页面,通过Firebug可以看到每个文章的链接都在一个h1下的a标签中(需要注意的是,您在Firebug的HTML面板中看到的HTML代码可能与您在View Source中看到的有些出入。如果网页中存在动态修改DOM树的Javascript,则前者是修改版,并且Firebug正则化后,比如属性有引号等,而后者通常是你的蜘蛛爬取的原创内容。不同,需要特别注意),另外,wp-pagenavi类的一个div中还有指向不同列表页面的链接。
文章内容页面,每个博客都有这样一个页面,比如/2008/09/11/machine-learning-and-ai-resources/,里面收录了完整的文章内容,这是我们的感受感兴趣的内容。
因此,我们从首页开始,利用wp-pagenavi中的链接获取其他文章列表页面。特别是我们定义了一个路径:只跟随下一页的链接,这样就可以从头到尾按顺序再一次,免去了反复抓取判断的麻烦。另外,文章列表页面上具体文章的链接对应的页面,才是我们真正要保存的数据页面。
这样一来,用脚本语言编写一个ad hoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的Crawler Framework,简单、轻量、非常方便,而且官网说已经在生产中使用了,所以不是玩具级别的东西。不过目前还没有Release版本,可以直接使用他们的Mercurial仓库获取源码进行安装。不过这个东西也可以不用安装直接使用,方便随时更新。文档很详细,我不再赘述。
Scrapy 使用 Twisted(一个异步网络库)来处理网络通信。架构清晰,收录各种中间件接口,可灵活满足各种需求。整体结构如下图所示:
绿线是数据流向。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载后会交给Spider进行分析。Spider分析出来的结果有两个:一个是需要进一步爬取的链接,比如前面分析的“下一页”链接,这些东西会发回Scheduler;另一个是需要保存的数据,它们被发送到Item Pipeline,这是对数据的后处理(详细分析,过滤,存储等)。此外,可以在数据流通道中安装各种中间件,进行必要的处理。
具体内容将在最后的附录中介绍。
看起来很复杂,其实用起来很简单,就像Rails一样,先新建一个项目:
scrapy-admin.py startproject blog_crawl
会创建一个blog_crawl目录,里面有scrapy-ctl.py是整个项目的控制脚本,代码都放在子目录blog_crawl中。为了能够爬取,我们在spiders目录下新建了mindhacks_spider.py,定义我们的spider如下:
fromscrapy.spiderimportBaseSpider
类MindhacksSpider(BaseSpider):
域名=""
start_urls=[""]
解析(自我,响应):
返回[]
SPIDER=MindhacksSpider()
我们的MindhacksSpider继承自BaseSpider(通常直接继承自scrapy.contrib.spiders.CrawlSpider会更方便,功能更强大,但是为了展示数据是如何解析的,这里使用BaseSpider),变量domain_name和start_urls很容易理解是什么意思,parse方法就是我们需要定义的回调函数。默认请求在得到响应后会调用这个回调函数。我们这里需要解析页面,返回两个结果(需要进一步爬取的链接和需要保存的数据),让我感觉有点奇怪的是,在它的接口定义中,这两个结果是混合并返回一个列表。总之,这里我们先写一个空函数,它只返回一个空列表。此外,定义一个“全局” 变量 SPIDER,在 Scrapy 导入该模块时会被实例化,并被 Scrapy 的引擎自动找到。所以可以先运行爬虫试试:
./scrapy-ctl.py 抓取
会有一堆输出,可以看到爬取了,因为这是初始的URL,但是由于我们在parse函数中没有返回需要进一步爬取的URL,所以整个爬取过程只爬取首页并结束。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们做实验。使用以下命令启动 Shell:
./scrapy-ctl.py 外壳
它会启动爬虫,抓取命令行指定的页面,然后进入shell。根据提示,我们有很多现成的变量可以使用,其中一个就是hxs,它是一个HtmlXPathSelector。mindhacks 的 HTML 页面比较规范,可以直接用 XPath 分析,非常方便。从 Firebug 可以看出,每个博客 文章 的链接都在 h1 下,所以在 shell 中使用这个 XPath 表达式测试:
在[1]中:hxs.x('//h1/a/@href').extract()
输出[1]:
[你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'']
这正是我们需要的 URL。此外,我们还可以找到“下一页”链接,它与其他几个页面的链接一起在一个 div 中,但是“下一页”链接没有标题属性,所以 XPath 读取
//div[@class="wp-pagenavi"]/a[not(@title)]
但是,如果你往回翻一页,你会发现“上一页”是一样的,所以需要判断链接上的文字是下一页的箭头u'\xbb',也可以是用 XPath 编写。Go,但似乎这本身就是一个 unicode 转义字符。由于编码原因,不清楚,所以直接在外面判断。最终的解析函数如下:
解析(自我,响应):
项目=[]
hxs=HtmlXPathSelector(响应)
帖子=hxs.x('//h1/a/@href').extract()
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
forurlinposts])
page_links=hxs.x('//div[@class="wp-pagenavi"]/a[not(@title)]')
forlinkinpage_links:
iflink.x('text()').extract()[0]==u'\xbb':
url=link.x('@href').extract()[0]
items.append(self.make_requests_from_url(url))
退换货品
前半部分是解析需要爬取的博客正文的链接,后半部分是给出“下一页”链接。需要注意的是,这里返回的列表不收录字符串格式的 URL。Scrapy 期望得到一个 Request 对象,它可以携带比字符串格式的 URL 更多的东西,例如 cookie 或回调。功能之类的。可以看出我们在创建博客正文的Request时替换了回调函数,因为默认的回调函数parse专门用于解析文章列表等页面,parse_post定义如下:
defparse_post(自我,响应):
项目=博客爬虫项目()
item.url=unicode(response.url)
item.raw=response.body_as_unicode()
归还物品]
很简单,返回一个BlogCrawlItem,把抓到的数据放进去。我们这里可以做一点分析,比如通过 XPath 解析文本和标题,但我倾向于在后面做这些事情,比如 Item Pipeline 或 Late Offline 阶段。BlogCrawlItem 是 Scrapy 自动为我们定义并继承自 ScrapedItem 的空类。在 items.py 中,我在这里添加了一些内容:
fromscrapy.itemimportScrapedItem
classBlogCrawlItem(ScrapedItem):
def__init__(self):
ScrapedItem.__init__(self)
self.url=''
def__str__(self):
return'BlogCrawlItem(url: %s)'%self.url
定义了__str__函数,只给出了url,因为默认的__str__函数会显示所有数据,所以看到爬取的时候,控制台日志会输出一些疯狂的东西,就是输出抓取到的网页内容。出去。-.-bb
这样就得到了数据,最后只剩下存储数据的功能了。我们通过添加管道来实现这一点。由于 Python 在标准库中自带了对 Sqlite3 的支持,所以我使用 Sqlite 数据库来存储数据。将 pipelines.py 的内容替换为以下代码:
导入sqlite3
fromos导入路径
来自scrapy.coreimportsignals
fromscrapy.xlib.pydispatchimportdispatcher
类SQLiteStorePipeline(对象):
文件名='data.sqlite'
def__init__(self):
self.conn=无
dispatcher.connect(self.initialize,signals.engine_started)
dispatcher.connect(self.finalize,signals.engine_stopped)
defprocess_item(自我,域,项目):
self.conn.execute('插入博客值(?,?,?)',
(item.url, item.raw,unicode(domain)))
归还物品
定义(自我):
ifpath.exists(self.filename):
self.conn=sqlite3.connect(self.filename)
别的:
self.conn=self.create_table(self.filename)
最终确定(自我):
ifself.connisnotNone:
mit()
self.conn.close()
self.conn=无
defcreate_table(自我,文件名):
conn=sqlite3.连接(文件名)
conn.execute("""创建表博客
(url 文本主键、原创文本、域文本)""")
mit()
返回连接
在__init__函数中,使用dispatcher将两个信号连接到指定函数,分别用于初始化和关闭数据库连接(记得close之前commit,好像不会自动commit,如果直接close的话,似乎所有数据都丢失了dd-.-)。当有数据通过管道时,将调用 process_item 函数。这里我们直接将原创数据存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取、过滤等数据,此处不再详细讨论。
最后,在 settings.py 中列出我们的管道:
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再次运行爬虫,就OK了!
PS1:Scrapy 的组件
1.Scrapy 引擎
Scrapy引擎用于控制整个系统的数据处理流程,触发事务处理。有关详细信息,请参阅下面的数据处理流程。
2.调度器
调度程序接受来自 Scrapy 引擎的请求并将它们排队并在 Scrapy 引擎发出请求后返回它们。
3.下载器
下载器的主要职责是抓取网页并将网页内容返回给蜘蛛。
4.蜘蛛
Spider是Scrapy用户定义的一个类,用于解析网页并爬取指定URL返回的内容。每个蜘蛛可以处理一个域名或一组域名。也就是说,它是用来定义具体的网站获取和解析规则的。
5.项目管道
项目管道的主要职责是处理蜘蛛从网页中提取的项目,其主要任务是澄清、验证和存储数据。当页面被蜘蛛解析时,它被发送到项目管道,并按几个特定的顺序处理数据。每个项目管道的组件都是具有一种简单方法的 Python 类。他们获取项目并执行他们的方法,同时还决定是否需要继续进行项目管道中的下一步或将其丢弃。
项目管道通常执行以下过程:
清理 HTML 数据 验证解析的数据(检查项目是否收录必要的字段) 检查重复数据(如果重复则删除) 将解析的数据存储在数据库中
6.中间件
中间件是 Scrapy 引擎与其他组件之间的钩子框架,主要是提供自定义代码来扩展 Scrapy 的功能。
PS2:Scrapy的数据处理流程
Scrapy的整个数据处理过程由Scrapy引擎控制,其主要操作方式有:
引擎打开一个域名,爬虫处理域名,让爬虫获取第一个爬取的URL。
引擎从蜘蛛获取第一个需要抓取的 URL,然后将其作为请求调度。
引擎从调度程序获取要抓取的下一页。
调度器将下一次爬取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
网页被下载器下载后,通过下载中间件将响应内容发送给引擎。
引擎接收到下载器的响应,通过蜘蛛中间件发送给蜘蛛进行处理。
蜘蛛处理响应并返回抓取的项目,然后向引擎发送新请求。
引擎将抓取项目的项目管道并向调度程序发送请求。
系统在第二步之后重复操作,直到调度中没有请求,然后断开引擎与域的连接。
谢谢收看 查看全部
scrapy分页抓取网页(
WebCrawler下载Web页面如何调度站点的?)
深度解析Python的爬虫框架Scrapy的结构和运行过程
网络爬虫(Web Crawler,Spider)是一种在互联网上爬行的机器人。当然,它通常不是实体机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实是一个程序,它不是爬行,而是有一定的目的,爬行时会采集数据。一些信息。例如,谷歌有大量的爬虫,它们在互联网上采集网页内容和它们之间的链接等信息;比如一些别有用心的爬虫,会在网上搜集foo[at]bar[dot]com等东西。另外,还有一些自定义爬虫,专门针对某个网站,比如JavaEye的Robbin前段时间写了几篇专门处理恶意爬虫的博客(原来的链接好像过期了,所以没有给出),而网站比如小众软件或者LinuxToy经常被全站爬下来,挂在不同的名字下。其实爬虫在基本原理上很简单,只要能上网分析网页,现在大部分语言都有方便的可以爬取网页的Http客户端库,以及最简单的HTML分析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。现在大部分语言都有方便的Http客户端库,可以爬取网页,最简单的HTML解析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。现在大部分语言都有方便的Http客户端库,可以爬取网页,最简单的HTML解析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。
爬虫的两个部分,一个是下载网页,有很多问题需要考虑,如何最大限度地利用本地带宽,如何调度不同站点的Web请求以减轻对方服务器的负担等等。在高性能的网络爬虫系统中,DNS查询也将成为需要优化的瓶颈。此外,还有一些“规则”需要遵守(例如 robots.txt)。得到网页后的分析过程也很复杂。网上各种奇葩,各种错误的HTML页面。几乎不可能全部分析。另外,随着 AJAX 的普及,如何获取 Javascript 动态生成的内容也成了一大难题;此外,互联网上有意无意地出现了各种各样的蜘蛛陷阱。如果你盲目地跟随超链接,你就会陷入陷阱,注定要失败。比如这个网站,据说谷歌之前宣布互联网上Unique URLs的数量已经达到1万亿,所以这个人很自豪地宣布了第二个万亿。:D
然而,实际上,像谷歌这样需要制作通用爬虫的人并不多。通常,我们制作一个 Crawler 来抓取特定的或某种类型的 网站。对 网站 结构进行一些分析,事情就会变得容易得多。通过分析和选择有价值的链接进行跟踪,可以避免许多不必要的链接或蜘蛛陷阱。如果 网站 的结构允许选择合适的路径,我们可以将感兴趣的事物按一定的顺序排列。再爬一遍,这样连URL重复的判断都可以省略。
比如我们要爬取pongba的博客中的博客文字,通过观察,很容易发现我们对两类页面感兴趣:
文章列出页面,比如首页,或者像/page/\d+/这样的URL的页面,通过Firebug可以看到每个文章的链接都在一个h1下的a标签中(需要注意的是,您在Firebug的HTML面板中看到的HTML代码可能与您在View Source中看到的有些出入。如果网页中存在动态修改DOM树的Javascript,则前者是修改版,并且Firebug正则化后,比如属性有引号等,而后者通常是你的蜘蛛爬取的原创内容。不同,需要特别注意),另外,wp-pagenavi类的一个div中还有指向不同列表页面的链接。
文章内容页面,每个博客都有这样一个页面,比如/2008/09/11/machine-learning-and-ai-resources/,里面收录了完整的文章内容,这是我们的感受感兴趣的内容。
因此,我们从首页开始,利用wp-pagenavi中的链接获取其他文章列表页面。特别是我们定义了一个路径:只跟随下一页的链接,这样就可以从头到尾按顺序再一次,免去了反复抓取判断的麻烦。另外,文章列表页面上具体文章的链接对应的页面,才是我们真正要保存的数据页面。
这样一来,用脚本语言编写一个ad hoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的Crawler Framework,简单、轻量、非常方便,而且官网说已经在生产中使用了,所以不是玩具级别的东西。不过目前还没有Release版本,可以直接使用他们的Mercurial仓库获取源码进行安装。不过这个东西也可以不用安装直接使用,方便随时更新。文档很详细,我不再赘述。
Scrapy 使用 Twisted(一个异步网络库)来处理网络通信。架构清晰,收录各种中间件接口,可灵活满足各种需求。整体结构如下图所示:

绿线是数据流向。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载后会交给Spider进行分析。Spider分析出来的结果有两个:一个是需要进一步爬取的链接,比如前面分析的“下一页”链接,这些东西会发回Scheduler;另一个是需要保存的数据,它们被发送到Item Pipeline,这是对数据的后处理(详细分析,过滤,存储等)。此外,可以在数据流通道中安装各种中间件,进行必要的处理。
具体内容将在最后的附录中介绍。
看起来很复杂,其实用起来很简单,就像Rails一样,先新建一个项目:
scrapy-admin.py startproject blog_crawl
会创建一个blog_crawl目录,里面有scrapy-ctl.py是整个项目的控制脚本,代码都放在子目录blog_crawl中。为了能够爬取,我们在spiders目录下新建了mindhacks_spider.py,定义我们的spider如下:
fromscrapy.spiderimportBaseSpider
类MindhacksSpider(BaseSpider):
域名=""
start_urls=[""]
解析(自我,响应):
返回[]
SPIDER=MindhacksSpider()
我们的MindhacksSpider继承自BaseSpider(通常直接继承自scrapy.contrib.spiders.CrawlSpider会更方便,功能更强大,但是为了展示数据是如何解析的,这里使用BaseSpider),变量domain_name和start_urls很容易理解是什么意思,parse方法就是我们需要定义的回调函数。默认请求在得到响应后会调用这个回调函数。我们这里需要解析页面,返回两个结果(需要进一步爬取的链接和需要保存的数据),让我感觉有点奇怪的是,在它的接口定义中,这两个结果是混合并返回一个列表。总之,这里我们先写一个空函数,它只返回一个空列表。此外,定义一个“全局” 变量 SPIDER,在 Scrapy 导入该模块时会被实例化,并被 Scrapy 的引擎自动找到。所以可以先运行爬虫试试:
./scrapy-ctl.py 抓取
会有一堆输出,可以看到爬取了,因为这是初始的URL,但是由于我们在parse函数中没有返回需要进一步爬取的URL,所以整个爬取过程只爬取首页并结束。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们做实验。使用以下命令启动 Shell:
./scrapy-ctl.py 外壳
它会启动爬虫,抓取命令行指定的页面,然后进入shell。根据提示,我们有很多现成的变量可以使用,其中一个就是hxs,它是一个HtmlXPathSelector。mindhacks 的 HTML 页面比较规范,可以直接用 XPath 分析,非常方便。从 Firebug 可以看出,每个博客 文章 的链接都在 h1 下,所以在 shell 中使用这个 XPath 表达式测试:
在[1]中:hxs.x('//h1/a/@href').extract()
输出[1]:
[你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'']
这正是我们需要的 URL。此外,我们还可以找到“下一页”链接,它与其他几个页面的链接一起在一个 div 中,但是“下一页”链接没有标题属性,所以 XPath 读取
//div[@class="wp-pagenavi"]/a[not(@title)]
但是,如果你往回翻一页,你会发现“上一页”是一样的,所以需要判断链接上的文字是下一页的箭头u'\xbb',也可以是用 XPath 编写。Go,但似乎这本身就是一个 unicode 转义字符。由于编码原因,不清楚,所以直接在外面判断。最终的解析函数如下:
解析(自我,响应):
项目=[]
hxs=HtmlXPathSelector(响应)
帖子=hxs.x('//h1/a/@href').extract()
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
forurlinposts])
page_links=hxs.x('//div[@class="wp-pagenavi"]/a[not(@title)]')
forlinkinpage_links:
iflink.x('text()').extract()[0]==u'\xbb':
url=link.x('@href').extract()[0]
items.append(self.make_requests_from_url(url))
退换货品
前半部分是解析需要爬取的博客正文的链接,后半部分是给出“下一页”链接。需要注意的是,这里返回的列表不收录字符串格式的 URL。Scrapy 期望得到一个 Request 对象,它可以携带比字符串格式的 URL 更多的东西,例如 cookie 或回调。功能之类的。可以看出我们在创建博客正文的Request时替换了回调函数,因为默认的回调函数parse专门用于解析文章列表等页面,parse_post定义如下:
defparse_post(自我,响应):
项目=博客爬虫项目()
item.url=unicode(response.url)
item.raw=response.body_as_unicode()
归还物品]
很简单,返回一个BlogCrawlItem,把抓到的数据放进去。我们这里可以做一点分析,比如通过 XPath 解析文本和标题,但我倾向于在后面做这些事情,比如 Item Pipeline 或 Late Offline 阶段。BlogCrawlItem 是 Scrapy 自动为我们定义并继承自 ScrapedItem 的空类。在 items.py 中,我在这里添加了一些内容:
fromscrapy.itemimportScrapedItem
classBlogCrawlItem(ScrapedItem):
def__init__(self):
ScrapedItem.__init__(self)
self.url=''
def__str__(self):
return'BlogCrawlItem(url: %s)'%self.url
定义了__str__函数,只给出了url,因为默认的__str__函数会显示所有数据,所以看到爬取的时候,控制台日志会输出一些疯狂的东西,就是输出抓取到的网页内容。出去。-.-bb
这样就得到了数据,最后只剩下存储数据的功能了。我们通过添加管道来实现这一点。由于 Python 在标准库中自带了对 Sqlite3 的支持,所以我使用 Sqlite 数据库来存储数据。将 pipelines.py 的内容替换为以下代码:
导入sqlite3
fromos导入路径
来自scrapy.coreimportsignals
fromscrapy.xlib.pydispatchimportdispatcher
类SQLiteStorePipeline(对象):
文件名='data.sqlite'
def__init__(self):
self.conn=无
dispatcher.connect(self.initialize,signals.engine_started)
dispatcher.connect(self.finalize,signals.engine_stopped)
defprocess_item(自我,域,项目):
self.conn.execute('插入博客值(?,?,?)',
(item.url, item.raw,unicode(domain)))
归还物品
定义(自我):
ifpath.exists(self.filename):
self.conn=sqlite3.connect(self.filename)
别的:
self.conn=self.create_table(self.filename)
最终确定(自我):
ifself.connisnotNone:
mit()
self.conn.close()
self.conn=无
defcreate_table(自我,文件名):
conn=sqlite3.连接(文件名)
conn.execute("""创建表博客
(url 文本主键、原创文本、域文本)""")
mit()
返回连接
在__init__函数中,使用dispatcher将两个信号连接到指定函数,分别用于初始化和关闭数据库连接(记得close之前commit,好像不会自动commit,如果直接close的话,似乎所有数据都丢失了dd-.-)。当有数据通过管道时,将调用 process_item 函数。这里我们直接将原创数据存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取、过滤等数据,此处不再详细讨论。
最后,在 settings.py 中列出我们的管道:
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再次运行爬虫,就OK了!
PS1:Scrapy 的组件
1.Scrapy 引擎
Scrapy引擎用于控制整个系统的数据处理流程,触发事务处理。有关详细信息,请参阅下面的数据处理流程。
2.调度器
调度程序接受来自 Scrapy 引擎的请求并将它们排队并在 Scrapy 引擎发出请求后返回它们。
3.下载器
下载器的主要职责是抓取网页并将网页内容返回给蜘蛛。
4.蜘蛛
Spider是Scrapy用户定义的一个类,用于解析网页并爬取指定URL返回的内容。每个蜘蛛可以处理一个域名或一组域名。也就是说,它是用来定义具体的网站获取和解析规则的。
5.项目管道
项目管道的主要职责是处理蜘蛛从网页中提取的项目,其主要任务是澄清、验证和存储数据。当页面被蜘蛛解析时,它被发送到项目管道,并按几个特定的顺序处理数据。每个项目管道的组件都是具有一种简单方法的 Python 类。他们获取项目并执行他们的方法,同时还决定是否需要继续进行项目管道中的下一步或将其丢弃。
项目管道通常执行以下过程:
清理 HTML 数据 验证解析的数据(检查项目是否收录必要的字段) 检查重复数据(如果重复则删除) 将解析的数据存储在数据库中
6.中间件
中间件是 Scrapy 引擎与其他组件之间的钩子框架,主要是提供自定义代码来扩展 Scrapy 的功能。
PS2:Scrapy的数据处理流程
Scrapy的整个数据处理过程由Scrapy引擎控制,其主要操作方式有:
引擎打开一个域名,爬虫处理域名,让爬虫获取第一个爬取的URL。
引擎从蜘蛛获取第一个需要抓取的 URL,然后将其作为请求调度。
引擎从调度程序获取要抓取的下一页。
调度器将下一次爬取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
网页被下载器下载后,通过下载中间件将响应内容发送给引擎。
引擎接收到下载器的响应,通过蜘蛛中间件发送给蜘蛛进行处理。
蜘蛛处理响应并返回抓取的项目,然后向引擎发送新请求。
引擎将抓取项目的项目管道并向调度程序发送请求。
系统在第二步之后重复操作,直到调度中没有请求,然后断开引擎与域的连接。
谢谢收看
scrapy分页抓取网页(Python开发的一个快速,高层次屏幕抓取和web框架框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-10 06:10
Scrapy简介,以下摘自百度百科,
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结果
Scrapy Pthyon 爬虫框架标志[1]
结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
1.首先需要在windows下安装python2.7版本,然后配置环境变量,如下图,其中Scripts的路径也放入环境变量中,这样就可以直接在命令行使用我们第二步安装的pip;
2.要安装pip,可以在这个链接下载get-pip.py文件,然后执行python get-pip.py,这样脚本会自动下载setuptools工具;
(pip是python的包管理工具)
3.使用命令 pip install Scrapy 安装 Scrapy。请注意,您可能会在此处遇到解码错误。需要修改Python27文件夹中Lib的mimetypes.py文件,大约第256行,设置默认编码方式。改成gbk,代码如下,注意python代码的缩进。
#default_encoding = sys.getdefaultencoding()
if sys.getdefaultencoding() != "gbk":
reload(sys)
sys.setdefaultencoding("gbk")
default_encoding = sys.getdefaultencoding()
Scrapy框架就是通过以上三步搭建的。
接下来按照Scrapy官网的教程做一个简单的爬虫。
1.首先,进入工作目录,打开命令行,输入如下命令创建一个Scrapy项目;
scrapy startproject tutorial
我创建的时候,电脑命令行报错,ImportError: No module named twisted等,很多包都不见了,所以我去安装了,直接用pip install **就好了。 查看全部
scrapy分页抓取网页(Python开发的一个快速,高层次屏幕抓取和web框架框架)
Scrapy简介,以下摘自百度百科,
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结果

Scrapy Pthyon 爬虫框架标志[1]
结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
1.首先需要在windows下安装python2.7版本,然后配置环境变量,如下图,其中Scripts的路径也放入环境变量中,这样就可以直接在命令行使用我们第二步安装的pip;

2.要安装pip,可以在这个链接下载get-pip.py文件,然后执行python get-pip.py,这样脚本会自动下载setuptools工具;
(pip是python的包管理工具)
3.使用命令 pip install Scrapy 安装 Scrapy。请注意,您可能会在此处遇到解码错误。需要修改Python27文件夹中Lib的mimetypes.py文件,大约第256行,设置默认编码方式。改成gbk,代码如下,注意python代码的缩进。
#default_encoding = sys.getdefaultencoding()
if sys.getdefaultencoding() != "gbk":
reload(sys)
sys.setdefaultencoding("gbk")
default_encoding = sys.getdefaultencoding()
Scrapy框架就是通过以上三步搭建的。
接下来按照Scrapy官网的教程做一个简单的爬虫。
1.首先,进入工作目录,打开命令行,输入如下命令创建一个Scrapy项目;
scrapy startproject tutorial
我创建的时候,电脑命令行报错,ImportError: No module named twisted等,很多包都不见了,所以我去安装了,直接用pip install **就好了。
scrapy分页抓取网页(怎样优雅用yield写这样的代码呢?部分代码实例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-08 19:01
)
使用yield优雅爬取网页分页数据
在使用Python爬取网页数据时,我们经常会遇到分页数据,有些下一页按钮已经有了具体的链接地址,而有些可能是javascript处理的。这需要能够同时解析页面内容和采集下一页的url。如何在python中优雅地编写这样的代码?或者如何更pythonic?
下面给出一些代码示例
def get_next_page(obj):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('a', text="下頁")
break
except:
error_occurred = True
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
next_url = "http://www.etnet.com.hk" + e_next_page.get('href')
time.sleep(2)
yield content
for i in get_next_page(next_url):
yield i
else:
yield content
def get_next_page(obj, page=1):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if page == 1 and (not "sh=" in obj) and hrefs:
reset_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"/sector-industry-details.aspx?%s&page=1" % \
(hrefs[0].replace('sh=1', 'sh=0').replace('&page=', '') \
.replace("'", '').split()[0]))
for next_page in get_next_page(reset_url):
yield next_page
return
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('td', text="下一頁 ")
break
except:
error_occurred = True
LOG.error(traceback.format_exc())
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if hrefs:
next_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"-details.aspx?%s&page=%d" % \
(hrefs[0].replace('sh=1', 'sh=0') \
.replace('&page=', '').replace("'", '').split()[0], page+1))
time.sleep(2)
yield content
for next_page in get_next_page(next_url, page+1):
yield next_page
else:
yield content
for curr_href in e_href:
retry_interval = random.randint(MIN_INTERVAL_SECONDS_FOR_RETRIEVING,
MAX_INTERVAL_SECONDS_FOR_RETRIEVING)
time.sleep(retry_interval)
contents = get_next_page(curr_href)
for content in contents:
get_page_data(content) 查看全部
scrapy分页抓取网页(怎样优雅用yield写这样的代码呢?部分代码实例
)
使用yield优雅爬取网页分页数据
在使用Python爬取网页数据时,我们经常会遇到分页数据,有些下一页按钮已经有了具体的链接地址,而有些可能是javascript处理的。这需要能够同时解析页面内容和采集下一页的url。如何在python中优雅地编写这样的代码?或者如何更pythonic?
下面给出一些代码示例
def get_next_page(obj):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('a', text="下頁")
break
except:
error_occurred = True
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
next_url = "http://www.etnet.com.hk" + e_next_page.get('href')
time.sleep(2)
yield content
for i in get_next_page(next_url):
yield i
else:
yield content
def get_next_page(obj, page=1):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if page == 1 and (not "sh=" in obj) and hrefs:
reset_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"/sector-industry-details.aspx?%s&page=1" % \
(hrefs[0].replace('sh=1', 'sh=0').replace('&page=', '') \
.replace("'", '').split()[0]))
for next_page in get_next_page(reset_url):
yield next_page
return
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('td', text="下一頁 ")
break
except:
error_occurred = True
LOG.error(traceback.format_exc())
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if hrefs:
next_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"-details.aspx?%s&page=%d" % \
(hrefs[0].replace('sh=1', 'sh=0') \
.replace('&page=', '').replace("'", '').split()[0], page+1))
time.sleep(2)
yield content
for next_page in get_next_page(next_url, page+1):
yield next_page
else:
yield content
for curr_href in e_href:
retry_interval = random.randint(MIN_INTERVAL_SECONDS_FOR_RETRIEVING,
MAX_INTERVAL_SECONDS_FOR_RETRIEVING)
time.sleep(retry_interval)
contents = get_next_page(curr_href)
for content in contents:
get_page_data(content)
scrapy分页抓取网页(本篇一个用户关注列表和粉丝列表(3爬取分析))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-07 19:06
首先祝大家有个好的开始!
本文要介绍的是从一个用户入手,通过抓取下面的列表和粉丝列表,实现用户的详细信息抓取,并将抓取的结果存储到MongoDB中。
1 环境要求
基本环境沿用之前的环境,只是增加了MongoDB(非关系型数据库)和PyMongo(Python的MongoDB连接库)。默认情况下,我认为每个人都安装并启动了MongoDB服务。
项目创建、爬虫创建、禁用 ROBOTSTXT_OBEY 设置省略(参考上一篇)
2 测试爬虫效果
这里我会写一个简单的爬虫来爬取用户的粉丝数和粉丝数。代码如下:
# -*- coding: utf-8 -*-
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com/people/wo-he-shui-jiu-xing/following']
def parse(self, response):
# 他关注的人数
tnum = response.css("strong.NumberBoard-itemValue::text").extract()[0]
# 粉丝数
fnum = response.css("strong.NumberBoard-itemValue::text").extract()[1]
print("他关注的人数为:%s" % tnum)
print("他粉丝的人数为:%s" % fnum)
在pychram中运行的结果如下:
出现500错误,我们添加headers再试,我们直接在settings.py中设置,如下:
再次执行查看结果:
这次我们得到了我们正常需要的信息
3 爬行分析
让我们以中本聪的主页作为分析的入口。主页如下:
分析用户关注列表如下:
将鼠标放在用户图像上,会显示详细信息如下:
请注意,我使用的是火狐浏览器,选择网络-XHR获取信息
ajax技术的核心是XMLHttpRequest对象(简称XHR),这是微软最先引入的一个特性,后来其他浏览器提供商也提供了同样的实现。XHR 为向服务器发送请求和解析服务器响应提供了流畅的接口。它可以异步的方式从服务器获取更多的信息,这意味着用户点击后,无需刷新页面即可获取新的数据。
通过上面的请求我们可以得到的连接如下:
#用户详细信息
https://www.zhihu.com/api/v4/m ... ssage,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
https://www.zhihu.com/api/v4/m ... ssage,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
#关注的人信息
https://www.zhihu.com/api/v4/m ... Ddata[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics&offset=0&limit=20
通过分析上面的链接可以看出
1.用户详情链接组成:{user}?include={include}
其中user是用户的url_token,包括allow_message、is_followed、is_following、is_org、is_blocking、employees、answer_count、follower_count、articles_count、gender、badge[?(type=best_answerer)].topics
2. 关注者信息链接组成:{include}&offset={offset}&limit={limit}
其中include是data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics,offset是分页偏移,limit是每页的用户数,可以参考下图见:
第一页
第二页
第三页
4 开始爬行
我们先写一个简单的爬虫,先实现功能。代码如下:
# -*- coding: utf-8 -*-
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
# 用户详细信息地址
user_detail = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
# 用户详细信息中的include
user_include = 'allow_message,is_followed,' \
'is_following,' \
'is_org,is_blocking,' \
'employments,' \
'answer_count,' \
'follower_count,' \
'articles_count,' \
'gender,' \
'badge[?(type=best_answerer)].topics'
# 关注的人地址
follow_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
# 关注的人include
follow_include = 'data[*].answer_count,' \
'articles_count,' \
'gender,' \
'follower_count,' \
'is_followed,' \
'is_following,' \
'badge[?(type=best_answerer)].topics'
# 初始user
start_user = 'satoshi_nakamoto'
def start_requests(self):
# 这里重新定义start_requests方法,注意这里的format用法
yield scrapy.Request(self.user_detail.format(user=self.start_user, include=self.user_include),
callback=self.parse_user)
yield scrapy.Request(self.follow_url.format(user=self.start_user, include=self.follow_include, offset=20, limit=20),
callback=self.parse_follow)
def parse_user(self, response):
print('user:%s' % response.text)
def parse_follow(self, response):
print('follow:%s' % response.text)
输出如下:
这里需要注意的是,必须在headers中添加授权信息,否则会报错。headers中的授权形式如下:
测试发现授权值在一段时间内不会发生变化,是否会永远保持不变还有待验证。
5 parse_user 写作
parse_user 方法用于解析用户的详细数据,存储和发现用户的关注列表,并返回给 parse_follow 方法进行处理。用户的详细存储字段如下:
为了省事,我把所有的字段都添加到了items.py中(如果运行spider后报错,没有找到提示字段,就添加那个字段即可),如下:
class UserItem(scrapy.Item):
"""
定义了响应报文中json的字段
"""
is_followed = scrapy.Field()
avatar_url_template = scrapy.Field()
user_type = scrapy.Field()
answer_count = scrapy.Field()
is_following = scrapy.Field()
url = scrapy.Field()
type = scrapy.Field()
url_token = scrapy.Field()
id = scrapy.Field()
allow_message = scrapy.Field()
articles_count = scrapy.Field()
is_blocking = scrapy.Field()
name = scrapy.Field()
headline = scrapy.Field()
gender = scrapy.Field()
avatar_url = scrapy.Field()
follower_count = scrapy.Field()
is_org = scrapy.Field()
employments = scrapy.Field()
badge = scrapy.Field()
is_advertiser = scrapy.Field()
parse_user 方法代码如下:
def parse_user(self, response):
"""
解析用户详细信息方法
:param response: 获取的内容,转化为json格式
"""
# 通过json.loads方式转换为json格式
results = json.loads(response.text)
# 引入item类
item = UserItem()
# 通过循环判断字段是否存在,存在将结果存入items中
for field in item.fields:
if field in results.keys():
item[field] = results.get(field)
# 直接返回item
yield item
# 将获取的用户通过format方式组合成新的url,调用callback函数交给parse_follow方法解析
yield scrapy.Request(self.follows_url.format(user=results.get('url_token'),
include=self.follow_include, offset=0, limit=20),
callback=self.parse_follow)
6 parse_follow 方法编写
首先要把获取到的response转换成json格式,获取关注的用户,继续抓取每个用户,还要处理分页。您可以看到以下两张图片:
重写后的 parse_follow 方法如下:
def parse_follow(self, response):
"""
解析关注的人列表方法
"""
# 格式化response
results = json.loads(response.text)
# 判断data是否存在,如果存在就继续调用parse_user解析用户详细信息
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_detail.format(user=result.get('url_token'), include=self.user_include),
callback=self.parse_user)
# 判断paging是否存在,如果存在并且is_end参数为False,则继续爬取下一页,如果is_end为True,说明为最后一页
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, callback=self.parse_follow)
运行爬虫后的结果如下:
您可以看到一直在获取内容。
7 保存到 mongodb7.1 项管道
为了存储和使用MongoDB,我们需要修改Item Pipeline。参考修改后的代码如下:
class ZhiHuspiderPipeline(object):
"""
知乎数据存入monogodb数据库类,参考官网示例
"""
collection_name = 'user'
def __init__(self, mongo_uri, mongo_db):
"""
初始化参数
:param mongo_uri:mongo uri
:param mongo_db: db name
"""
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
# 打开连接
self.client = pymongo.MongoClient(self.mongo_uri)
# db_auth因为我的mongodb设置了认证,所以需要这两步,未设置可以注释
self.db_auth = self.client.admin
self.db_auth.authenticate("admin", "password")
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
# 这里使用update方法
self.db[self.collection_name].update({'url_token': item['url_token']}, dict(item), True)
return item
这里说一下update方法,update()方法是用来更新一个已经存在的文档。语法格式如下:
db.collection.update(
, # update的查询条件,类似sql update查询内where后面的
, # update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
{
upsert: , # 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi: , # 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新
writeConcern: # 可选,抛出异常的级别。
}
)
使用update方法,如果查询数据存在,就更新,如果不存在,就插入到dict(item)中,这样就可以去掉重复项了。
7.2 设置配置
再次运行spider后的结果如下:
也可以查看mongodb中的数据,如下:
本文中的一些参考资料:
这篇文章到此结束。
本页地址: 查看全部
scrapy分页抓取网页(本篇一个用户关注列表和粉丝列表(3爬取分析))
首先祝大家有个好的开始!
本文要介绍的是从一个用户入手,通过抓取下面的列表和粉丝列表,实现用户的详细信息抓取,并将抓取的结果存储到MongoDB中。
1 环境要求
基本环境沿用之前的环境,只是增加了MongoDB(非关系型数据库)和PyMongo(Python的MongoDB连接库)。默认情况下,我认为每个人都安装并启动了MongoDB服务。
项目创建、爬虫创建、禁用 ROBOTSTXT_OBEY 设置省略(参考上一篇)
2 测试爬虫效果
这里我会写一个简单的爬虫来爬取用户的粉丝数和粉丝数。代码如下:
# -*- coding: utf-8 -*-
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com/people/wo-he-shui-jiu-xing/following']
def parse(self, response):
# 他关注的人数
tnum = response.css("strong.NumberBoard-itemValue::text").extract()[0]
# 粉丝数
fnum = response.css("strong.NumberBoard-itemValue::text").extract()[1]
print("他关注的人数为:%s" % tnum)
print("他粉丝的人数为:%s" % fnum)
在pychram中运行的结果如下:

出现500错误,我们添加headers再试,我们直接在settings.py中设置,如下:

再次执行查看结果:

这次我们得到了我们正常需要的信息
3 爬行分析
让我们以中本聪的主页作为分析的入口。主页如下:
分析用户关注列表如下:

将鼠标放在用户图像上,会显示详细信息如下:

请注意,我使用的是火狐浏览器,选择网络-XHR获取信息
ajax技术的核心是XMLHttpRequest对象(简称XHR),这是微软最先引入的一个特性,后来其他浏览器提供商也提供了同样的实现。XHR 为向服务器发送请求和解析服务器响应提供了流畅的接口。它可以异步的方式从服务器获取更多的信息,这意味着用户点击后,无需刷新页面即可获取新的数据。
通过上面的请求我们可以得到的连接如下:
#用户详细信息
https://www.zhihu.com/api/v4/m ... ssage,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
https://www.zhihu.com/api/v4/m ... ssage,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
#关注的人信息
https://www.zhihu.com/api/v4/m ... Ddata[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics&offset=0&limit=20
通过分析上面的链接可以看出
1.用户详情链接组成:{user}?include={include}
其中user是用户的url_token,包括allow_message、is_followed、is_following、is_org、is_blocking、employees、answer_count、follower_count、articles_count、gender、badge[?(type=best_answerer)].topics
2. 关注者信息链接组成:{include}&offset={offset}&limit={limit}
其中include是data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics,offset是分页偏移,limit是每页的用户数,可以参考下图见:
第一页

第二页

第三页

4 开始爬行
我们先写一个简单的爬虫,先实现功能。代码如下:
# -*- coding: utf-8 -*-
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
# 用户详细信息地址
user_detail = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
# 用户详细信息中的include
user_include = 'allow_message,is_followed,' \
'is_following,' \
'is_org,is_blocking,' \
'employments,' \
'answer_count,' \
'follower_count,' \
'articles_count,' \
'gender,' \
'badge[?(type=best_answerer)].topics'
# 关注的人地址
follow_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
# 关注的人include
follow_include = 'data[*].answer_count,' \
'articles_count,' \
'gender,' \
'follower_count,' \
'is_followed,' \
'is_following,' \
'badge[?(type=best_answerer)].topics'
# 初始user
start_user = 'satoshi_nakamoto'
def start_requests(self):
# 这里重新定义start_requests方法,注意这里的format用法
yield scrapy.Request(self.user_detail.format(user=self.start_user, include=self.user_include),
callback=self.parse_user)
yield scrapy.Request(self.follow_url.format(user=self.start_user, include=self.follow_include, offset=20, limit=20),
callback=self.parse_follow)
def parse_user(self, response):
print('user:%s' % response.text)
def parse_follow(self, response):
print('follow:%s' % response.text)
输出如下:

这里需要注意的是,必须在headers中添加授权信息,否则会报错。headers中的授权形式如下:

测试发现授权值在一段时间内不会发生变化,是否会永远保持不变还有待验证。
5 parse_user 写作
parse_user 方法用于解析用户的详细数据,存储和发现用户的关注列表,并返回给 parse_follow 方法进行处理。用户的详细存储字段如下:

为了省事,我把所有的字段都添加到了items.py中(如果运行spider后报错,没有找到提示字段,就添加那个字段即可),如下:
class UserItem(scrapy.Item):
"""
定义了响应报文中json的字段
"""
is_followed = scrapy.Field()
avatar_url_template = scrapy.Field()
user_type = scrapy.Field()
answer_count = scrapy.Field()
is_following = scrapy.Field()
url = scrapy.Field()
type = scrapy.Field()
url_token = scrapy.Field()
id = scrapy.Field()
allow_message = scrapy.Field()
articles_count = scrapy.Field()
is_blocking = scrapy.Field()
name = scrapy.Field()
headline = scrapy.Field()
gender = scrapy.Field()
avatar_url = scrapy.Field()
follower_count = scrapy.Field()
is_org = scrapy.Field()
employments = scrapy.Field()
badge = scrapy.Field()
is_advertiser = scrapy.Field()
parse_user 方法代码如下:
def parse_user(self, response):
"""
解析用户详细信息方法
:param response: 获取的内容,转化为json格式
"""
# 通过json.loads方式转换为json格式
results = json.loads(response.text)
# 引入item类
item = UserItem()
# 通过循环判断字段是否存在,存在将结果存入items中
for field in item.fields:
if field in results.keys():
item[field] = results.get(field)
# 直接返回item
yield item
# 将获取的用户通过format方式组合成新的url,调用callback函数交给parse_follow方法解析
yield scrapy.Request(self.follows_url.format(user=results.get('url_token'),
include=self.follow_include, offset=0, limit=20),
callback=self.parse_follow)
6 parse_follow 方法编写
首先要把获取到的response转换成json格式,获取关注的用户,继续抓取每个用户,还要处理分页。您可以看到以下两张图片:


重写后的 parse_follow 方法如下:
def parse_follow(self, response):
"""
解析关注的人列表方法
"""
# 格式化response
results = json.loads(response.text)
# 判断data是否存在,如果存在就继续调用parse_user解析用户详细信息
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_detail.format(user=result.get('url_token'), include=self.user_include),
callback=self.parse_user)
# 判断paging是否存在,如果存在并且is_end参数为False,则继续爬取下一页,如果is_end为True,说明为最后一页
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, callback=self.parse_follow)
运行爬虫后的结果如下:

您可以看到一直在获取内容。
7 保存到 mongodb7.1 项管道
为了存储和使用MongoDB,我们需要修改Item Pipeline。参考修改后的代码如下:
class ZhiHuspiderPipeline(object):
"""
知乎数据存入monogodb数据库类,参考官网示例
"""
collection_name = 'user'
def __init__(self, mongo_uri, mongo_db):
"""
初始化参数
:param mongo_uri:mongo uri
:param mongo_db: db name
"""
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
# 打开连接
self.client = pymongo.MongoClient(self.mongo_uri)
# db_auth因为我的mongodb设置了认证,所以需要这两步,未设置可以注释
self.db_auth = self.client.admin
self.db_auth.authenticate("admin", "password")
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
# 这里使用update方法
self.db[self.collection_name].update({'url_token': item['url_token']}, dict(item), True)
return item
这里说一下update方法,update()方法是用来更新一个已经存在的文档。语法格式如下:
db.collection.update(
, # update的查询条件,类似sql update查询内where后面的
, # update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
{
upsert: , # 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi: , # 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新
writeConcern: # 可选,抛出异常的级别。
}
)
使用update方法,如果查询数据存在,就更新,如果不存在,就插入到dict(item)中,这样就可以去掉重复项了。
7.2 设置配置

再次运行spider后的结果如下:

也可以查看mongodb中的数据,如下:


本文中的一些参考资料:
这篇文章到此结束。
本页地址:
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-07 11:13
Scrapy 是一个用 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 经常用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
通常我们可以通过Scrapy框架轻松实现爬虫抓取指定网站的内容或图片。
Scrapy 架构图(绿线为数据流向)
Scrapy 操作流程
代码写好,程序开始运行...
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy会重新下载。)
制作一个Scrapy爬虫一共需要4步:新建项目(scrapy startproject xxx):新建一个爬虫项目,指定目标(写items.py):指定要爬取的目标, make a spider (spiders/xxspider.py) ):创建一个爬虫并开始爬取网络存储内容(pipelines.py):设计一个管道来存储爬取的内容安装Windows安装方法
升级pip版本:
pip install --upgrade pip
通过pip安装Scrapy框架:
pip install Scrapy
Ubuntu 安装方法
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip安装Scrapy框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,默认安装的包是不能删除的,但是可以使用python2.x来安装Scrapy会报错,使用python3.x安装也是报错。终于没有找到直接安装Scrapy的方法,所以就用另一种安装方式来讲解安装步骤。解决方案是使用virtualenv。安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
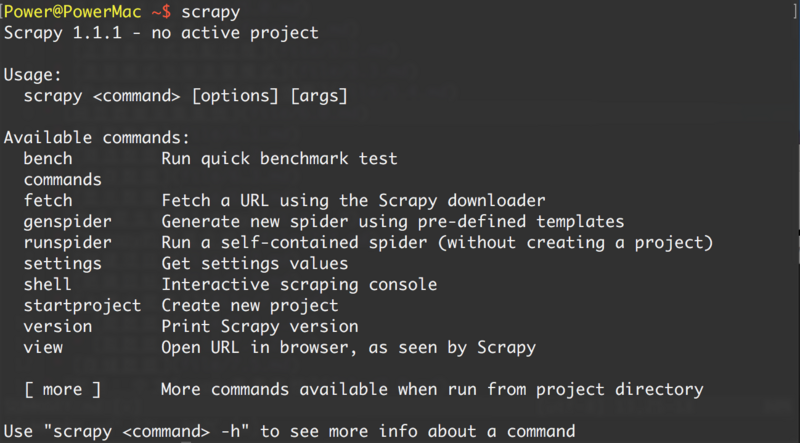
安装完成后,在命令终端输入scrapy,提示类似如下结果,表示安装成功。
介绍案例研究目标一. 新项目(scrapy startproject)
在爬取之前,必须创建一个新的 Scrapy 项目。进入自定义项目目录,运行以下命令:
scrapy startproject mySpider
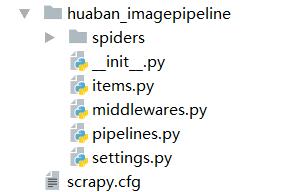
其中mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、明确的目标(mySpider/items.py)
我们打算获取网站中所有讲师的姓名、职称和个人信息。
打开 mySpider 目录下的 items.py。
Item 定义了结构化数据字段,用于存储爬取的数据。它有点像 Python 中的字典,但提供了一些额外的保护以减少错误。
可以通过创建scrapy.Item类并定义scrapy.Field的类属性来定义Item(可以理解为类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类并构建一个项目模型。
三、制作爬虫(spider/itcastSpider.py)
爬虫功能需要分为两步:
1. 爬取数据
在当前目录下输入命令,会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,自己写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建Spider,您必须使用scrapy.Spider 类创建一个子类,并确定三个必需属性和一个方法。
name = "":此爬虫的标识名称必须是唯一的。不同的爬虫必须定义不同的名称。
allow_domains = [] 是要搜索的域名范围,是爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的网址将被忽略。
start_urls = ():已爬取的 URL 的祖先/列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse(self, response):解析的方法。它将在每个初始 URL 下载后调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item) 查看全部
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
Scrapy 是一个用 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 经常用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
通常我们可以通过Scrapy框架轻松实现爬虫抓取指定网站的内容或图片。
Scrapy 架构图(绿线为数据流向)
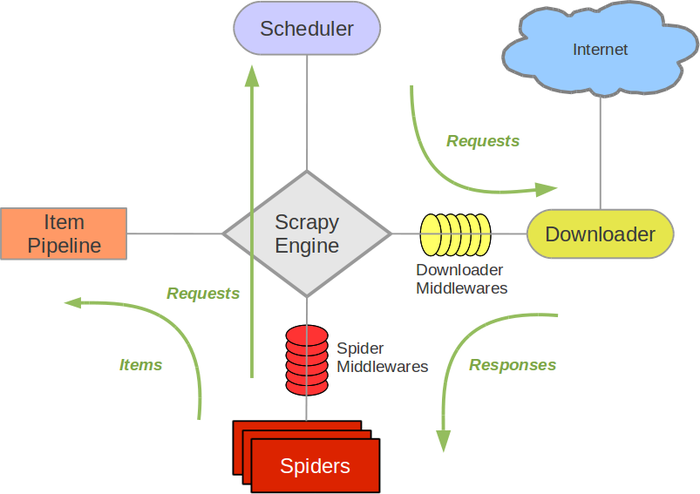
Scrapy 操作流程
代码写好,程序开始运行...
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy会重新下载。)
制作一个Scrapy爬虫一共需要4步:新建项目(scrapy startproject xxx):新建一个爬虫项目,指定目标(写items.py):指定要爬取的目标, make a spider (spiders/xxspider.py) ):创建一个爬虫并开始爬取网络存储内容(pipelines.py):设计一个管道来存储爬取的内容安装Windows安装方法
升级pip版本:
pip install --upgrade pip
通过pip安装Scrapy框架:
pip install Scrapy
Ubuntu 安装方法
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip安装Scrapy框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,默认安装的包是不能删除的,但是可以使用python2.x来安装Scrapy会报错,使用python3.x安装也是报错。终于没有找到直接安装Scrapy的方法,所以就用另一种安装方式来讲解安装步骤。解决方案是使用virtualenv。安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,在命令终端输入scrapy,提示类似如下结果,表示安装成功。
介绍案例研究目标一. 新项目(scrapy startproject)
在爬取之前,必须创建一个新的 Scrapy 项目。进入自定义项目目录,运行以下命令:
scrapy startproject mySpider
其中mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、明确的目标(mySpider/items.py)
我们打算获取网站中所有讲师的姓名、职称和个人信息。
打开 mySpider 目录下的 items.py。
Item 定义了结构化数据字段,用于存储爬取的数据。它有点像 Python 中的字典,但提供了一些额外的保护以减少错误。
可以通过创建scrapy.Item类并定义scrapy.Field的类属性来定义Item(可以理解为类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类并构建一个项目模型。
三、制作爬虫(spider/itcastSpider.py)
爬虫功能需要分为两步:
1. 爬取数据
在当前目录下输入命令,会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,自己写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建Spider,您必须使用scrapy.Spider 类创建一个子类,并确定三个必需属性和一个方法。
name = "":此爬虫的标识名称必须是唯一的。不同的爬虫必须定义不同的名称。
allow_domains = [] 是要搜索的域名范围,是爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的网址将被忽略。
start_urls = ():已爬取的 URL 的祖先/列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse(self, response):解析的方法。它将在每个初始 URL 下载后调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
scrapy分页抓取网页(下载及处理文件和图片Scrapy为下载器的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-05 23:13
下载和处理文件和图片
Scrapy 提供了一个可重用的 item 管道,用于下载 item 中收录的文件(例如,在抓取到产品时,还想保存相应的图像)。这些管道有一些通用的方法和结构(我们称之为媒体管道)。通常,您将使用 Files Pipeline 或 Images Pipeline。
两个管道都实现了以下功能:
1、避免重新下载最近下载过的数据;
2、指定存储介质的位置(文件系统目录、Amazon S3 存储桶)。图像管道有一些额外的功能来处理图像;
3、 将所有下载的图片转换为通用格式(JPG)和模式(RGB);
4、 缩略图生成;
5、 检测图片的宽/高,确保满足最小限制;
该管道还将为当前计划下载的图片保留一个内部队列,并将那些收录相同图片的到达项目连接到该队列。这样可以避免多个项目共享同一张图片的多次下载。
一、使用文件管道
使用 FilesPipeline 时,典型的工作流程如下:
1、 在爬虫中,你抓取一个item,把里面的图片的URL放到file_urls组中。
2、 项目从爬虫返回,进入项目管道。
3、当项目进入 FilesPipeline 时,file_urls 组中的 URL 会被 Scrapy 的调度器和下载器调度下载(这意味着调度器和下载器的中间件可以重复使用)。当优先级较高时,URL 将在其他页面被抓取之前进行处理。项目将在此特定管道阶段保持“锁定”状态,直到文件下载完成(或由于某种原因下载未完成)。
4、下载文件后,另一个字段(文件)将更新为结构。该组将收录一个字典列表,包括下载文件信息,例如下载路径、源爬取地址(从file_urls 组中获取)和图像校验和(checksum)。文件列表中文件的顺序将与源 file_urls 组一致。如果图片下载失败,将记录错误信息并且图片不会出现在文件组中。
二、使用图像管道
使用ImagesPipeline时,典型的工作流程如下:
1、在爬虫中,您抓取一个项目并将其中的图片的网址放入 image_urls 组中。
2、 项目从爬虫返回,进入项目管道。
3、当项目进入ImagesPipeline时,image_urls组中的URL会被Scrapy的调度器和下载器调度下载(这意味着调度器和下载器的中间件可以复用)。当优先级较高时,URL 将在其他页面被抓取之前进行处理。项目将在此特定管道阶段保持“锁定”状态,直到文件下载完成(或由于某种原因下载未完成)。
4、下载文件后,另一个字段(图像)将更新为结构。该组将收录一个字典列表,包括下载文件信息,例如下载路径、源爬取地址(从 image_urls 组中获取)和图像校验和(checksum)。文件列表中文件的顺序将与源 image_urls 组一致。如果图片下载失败,将记录错误信息并且图片不会出现在图像组中。
使用ImagesPipeline 与使用FilesPipeline 非常相似,除了使用的默认字段名称不同:您使用image_urls 作为项目的图片URL,并且会填写图片字段以获取有关下载图片的信息。
对图像文件使用 ImagesPipeline 的好处是可以配置一些附加功能,例如生成缩略图和根据大小过滤图像。
Pillow 用于生成缩略图并将图像规范化为 JPEG/RGB 格式,因此为了使用图像管道,您需要安装此库。Python Imaging Library (PIL) 在大多数情况下是有效的,但众所周知,在某些设置中会出现问题,因此我们建议使用 Pillow 而不是 PIL。
接下来,使用Images Pipeline 爬取花瓣网下载想要的图片。
1、新建一个项目,打开cmd,
进入scrapy startproject huaban_imagepipeline
新建筑 查看全部
scrapy分页抓取网页(下载及处理文件和图片Scrapy为下载器的应用)
下载和处理文件和图片
Scrapy 提供了一个可重用的 item 管道,用于下载 item 中收录的文件(例如,在抓取到产品时,还想保存相应的图像)。这些管道有一些通用的方法和结构(我们称之为媒体管道)。通常,您将使用 Files Pipeline 或 Images Pipeline。
两个管道都实现了以下功能:
1、避免重新下载最近下载过的数据;
2、指定存储介质的位置(文件系统目录、Amazon S3 存储桶)。图像管道有一些额外的功能来处理图像;
3、 将所有下载的图片转换为通用格式(JPG)和模式(RGB);
4、 缩略图生成;
5、 检测图片的宽/高,确保满足最小限制;
该管道还将为当前计划下载的图片保留一个内部队列,并将那些收录相同图片的到达项目连接到该队列。这样可以避免多个项目共享同一张图片的多次下载。
一、使用文件管道
使用 FilesPipeline 时,典型的工作流程如下:
1、 在爬虫中,你抓取一个item,把里面的图片的URL放到file_urls组中。
2、 项目从爬虫返回,进入项目管道。
3、当项目进入 FilesPipeline 时,file_urls 组中的 URL 会被 Scrapy 的调度器和下载器调度下载(这意味着调度器和下载器的中间件可以重复使用)。当优先级较高时,URL 将在其他页面被抓取之前进行处理。项目将在此特定管道阶段保持“锁定”状态,直到文件下载完成(或由于某种原因下载未完成)。
4、下载文件后,另一个字段(文件)将更新为结构。该组将收录一个字典列表,包括下载文件信息,例如下载路径、源爬取地址(从file_urls 组中获取)和图像校验和(checksum)。文件列表中文件的顺序将与源 file_urls 组一致。如果图片下载失败,将记录错误信息并且图片不会出现在文件组中。
二、使用图像管道
使用ImagesPipeline时,典型的工作流程如下:
1、在爬虫中,您抓取一个项目并将其中的图片的网址放入 image_urls 组中。
2、 项目从爬虫返回,进入项目管道。
3、当项目进入ImagesPipeline时,image_urls组中的URL会被Scrapy的调度器和下载器调度下载(这意味着调度器和下载器的中间件可以复用)。当优先级较高时,URL 将在其他页面被抓取之前进行处理。项目将在此特定管道阶段保持“锁定”状态,直到文件下载完成(或由于某种原因下载未完成)。
4、下载文件后,另一个字段(图像)将更新为结构。该组将收录一个字典列表,包括下载文件信息,例如下载路径、源爬取地址(从 image_urls 组中获取)和图像校验和(checksum)。文件列表中文件的顺序将与源 image_urls 组一致。如果图片下载失败,将记录错误信息并且图片不会出现在图像组中。
使用ImagesPipeline 与使用FilesPipeline 非常相似,除了使用的默认字段名称不同:您使用image_urls 作为项目的图片URL,并且会填写图片字段以获取有关下载图片的信息。
对图像文件使用 ImagesPipeline 的好处是可以配置一些附加功能,例如生成缩略图和根据大小过滤图像。
Pillow 用于生成缩略图并将图像规范化为 JPEG/RGB 格式,因此为了使用图像管道,您需要安装此库。Python Imaging Library (PIL) 在大多数情况下是有效的,但众所周知,在某些设置中会出现问题,因此我们建议使用 Pillow 而不是 PIL。
接下来,使用Images Pipeline 爬取花瓣网下载想要的图片。
1、新建一个项目,打开cmd,
进入scrapy startproject huaban_imagepipeline
新建筑
scrapy分页抓取网页(Python网络爬虫与信息提取(北京理工大学慕课)生成的这些东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-03 14:02
参考资料:Python网络爬虫与信息抽取(北京理工大学MOOC)
这是我们要抓取的页面:
要使用Scrapy库,首先需要生成一个Scrapy爬虫框架,分为以下几个步骤: 1.建立一个Scrapy爬虫项目
首先,我们打开 Pycharm 并创建一个新项目。在这里我创建了一个名为 demo 的新项目:
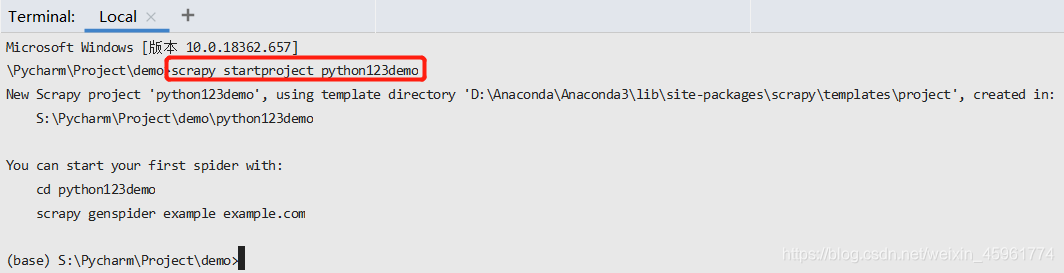
然后我们打开Pycharm的终端,输入scrapy startproject python123demo:
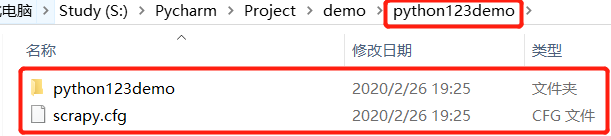
这样,我们就建立了一个Scrapy爬虫项目:
那么这些东西是怎么产生的?
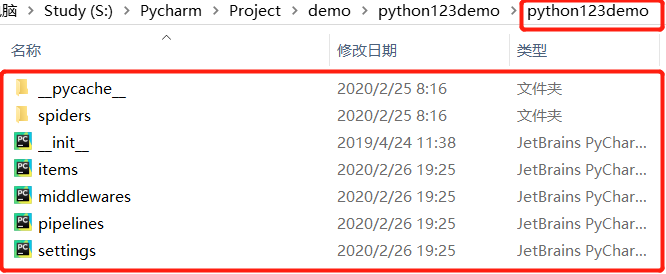
部署的概念是指:将构建好的爬虫放在特定的服务器上,在服务器上配置相关的操作接口。
对于本机使用的爬虫,我们不需要更改部署的配置文件
如果用户想要扩展中间件的功能,需要将这些功能写入第二个python123demo/文件中。
如果要优化爬虫功能,需要在settings.py文件中修改相应的配置项。
python123demo项目中创建的spider存放在spiders/目录下:
2.在项目中生成一个Scrapy爬虫
在项目中,只需要执行一个命令就可以生成一个爬虫,但是这个命令需要与用户给出的爬虫名称和被爬取的网站达成一致。
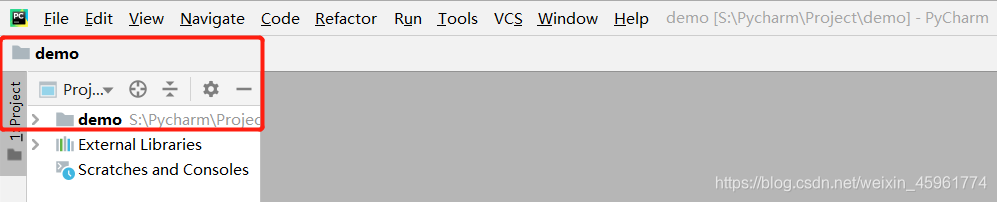
我们打开Pycharm,在终端输入scrapy genspider demo python123.io:
该命令的作用是生成一个名为demo(即爬虫)的蜘蛛,然后我们会发现在spiders目录下添加了一个名为demo.py的代码:
这里我们使用了一个命令来生成文件,看起来很神秘,但是这个命令的作用仅限于生成demo.py。
如果不使用这个命令生成demo.py,其实我们也可以手动生成这个文件。
打开demo.py:
我们看到它是一个以面向对象的方式编写的类。这个类叫做DemoSpider。
由于爬虫的名字是demo,所以类名也是DemoSpider。
名字是什么无关紧要,但是这个类必须是继承自scrapy.Spider的子类。
name = "demo" 表示当前爬虫的名字是demo。
allowed_domains 是用户在开头向命令行提交的域名,表示这个爬虫爬取网站时,只能爬取这个域名下面的相关链接。 (这是一个可选参数)
start_urls 是一个非常重要的变量。顾名思义,实际上以列表形式收录的一个或多个URL就是scrapy框架要抓取的页面的初始页面。
def parse()是一个解析页面的空方法,收录在这个类中,用于处理响应,解析内容形成字典,发现新的URL爬取请求。
3.配置生成的蜘蛛爬虫
具体来说,我们需要修改demo.py文件,使其可以根据我们的需求访问我们想要访问的链接,并抓取相关链接内容。
这里定义了链接解析部分的功能:将返回的html页面保存为文件。
具体我们修改demo.py文件如下:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response): # resonse相当于从网络中返回内容所存储的或对应的对象
fname = response.url.split('/')[-1] # 定义文件名字,把response中的内容写到一个html文件中
with open (fname, 'wb') as f: # 从响应的url中提取文件名字作为保存为本地的文件名,然后将返回的内容保存为文件
f.write(response.body)
self.log('Saved file %s.' % fname) # self.log是运行日志,不是必要的
# 这样,我们的demo.py文件就能够爬取一个网页,并且能够将网页的内容保存为一个html文件
4.运行爬虫获取网页
在pycharm终端输入scrapy crawl demo
然后就可以爬到这个页面了:
这里我们回顾一下 demo.py 代码:
start_urls 变量表示爬虫启动时的第一个 URL 链接。
parse 方法表示解析返回页面和执行操作的相关步骤。
事实上这行代码是scrapy框架提供的一个简化版代码。
对应完整版:
你可以看到有一个额外的 start_requests 方法。
那么这两个版本有什么区别?
该命令生成的 demo.py 文件的简化版本,它使用 start_urls 列表给出初始 URL 链接。
srapy 框架支持的另一种等效方法是使用称为 start_requests 的方法。在这个方法中,首先定义了一个url列表,列表中的每个列表通过yield scrapy发送给Engine。Requests 做了一个url访问请求。 查看全部
scrapy分页抓取网页(Python网络爬虫与信息提取(北京理工大学慕课)生成的这些东西)
参考资料:Python网络爬虫与信息抽取(北京理工大学MOOC)
这是我们要抓取的页面:
要使用Scrapy库,首先需要生成一个Scrapy爬虫框架,分为以下几个步骤: 1.建立一个Scrapy爬虫项目
首先,我们打开 Pycharm 并创建一个新项目。在这里我创建了一个名为 demo 的新项目:
然后我们打开Pycharm的终端,输入scrapy startproject python123demo:
这样,我们就建立了一个Scrapy爬虫项目:

那么这些东西是怎么产生的?

部署的概念是指:将构建好的爬虫放在特定的服务器上,在服务器上配置相关的操作接口。
对于本机使用的爬虫,我们不需要更改部署的配置文件
如果用户想要扩展中间件的功能,需要将这些功能写入第二个python123demo/文件中。
如果要优化爬虫功能,需要在settings.py文件中修改相应的配置项。
python123demo项目中创建的spider存放在spiders/目录下:

2.在项目中生成一个Scrapy爬虫
在项目中,只需要执行一个命令就可以生成一个爬虫,但是这个命令需要与用户给出的爬虫名称和被爬取的网站达成一致。
我们打开Pycharm,在终端输入scrapy genspider demo python123.io:

该命令的作用是生成一个名为demo(即爬虫)的蜘蛛,然后我们会发现在spiders目录下添加了一个名为demo.py的代码:
这里我们使用了一个命令来生成文件,看起来很神秘,但是这个命令的作用仅限于生成demo.py。
如果不使用这个命令生成demo.py,其实我们也可以手动生成这个文件。
打开demo.py:
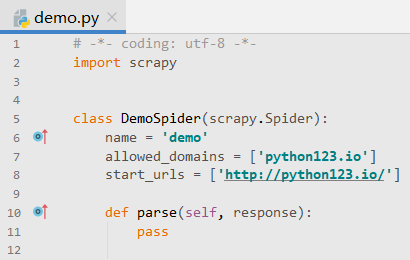
我们看到它是一个以面向对象的方式编写的类。这个类叫做DemoSpider。
由于爬虫的名字是demo,所以类名也是DemoSpider。
名字是什么无关紧要,但是这个类必须是继承自scrapy.Spider的子类。
name = "demo" 表示当前爬虫的名字是demo。
allowed_domains 是用户在开头向命令行提交的域名,表示这个爬虫爬取网站时,只能爬取这个域名下面的相关链接。 (这是一个可选参数)
start_urls 是一个非常重要的变量。顾名思义,实际上以列表形式收录的一个或多个URL就是scrapy框架要抓取的页面的初始页面。
def parse()是一个解析页面的空方法,收录在这个类中,用于处理响应,解析内容形成字典,发现新的URL爬取请求。
3.配置生成的蜘蛛爬虫
具体来说,我们需要修改demo.py文件,使其可以根据我们的需求访问我们想要访问的链接,并抓取相关链接内容。
这里定义了链接解析部分的功能:将返回的html页面保存为文件。
具体我们修改demo.py文件如下:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response): # resonse相当于从网络中返回内容所存储的或对应的对象
fname = response.url.split('/')[-1] # 定义文件名字,把response中的内容写到一个html文件中
with open (fname, 'wb') as f: # 从响应的url中提取文件名字作为保存为本地的文件名,然后将返回的内容保存为文件
f.write(response.body)
self.log('Saved file %s.' % fname) # self.log是运行日志,不是必要的
# 这样,我们的demo.py文件就能够爬取一个网页,并且能够将网页的内容保存为一个html文件
4.运行爬虫获取网页
在pycharm终端输入scrapy crawl demo
然后就可以爬到这个页面了:
这里我们回顾一下 demo.py 代码:
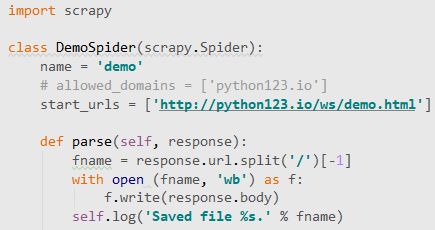
start_urls 变量表示爬虫启动时的第一个 URL 链接。
parse 方法表示解析返回页面和执行操作的相关步骤。
事实上这行代码是scrapy框架提供的一个简化版代码。
对应完整版:
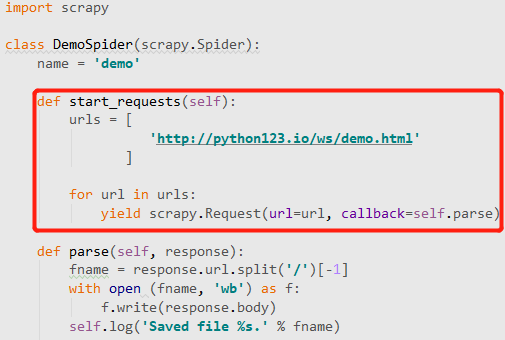
你可以看到有一个额外的 start_requests 方法。
那么这两个版本有什么区别?
该命令生成的 demo.py 文件的简化版本,它使用 start_urls 列表给出初始 URL 链接。
srapy 框架支持的另一种等效方法是使用称为 start_requests 的方法。在这个方法中,首先定义了一个url列表,列表中的每个列表通过yield scrapy发送给Engine。Requests 做了一个url访问请求。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-03 07:02
我相信所有 网站 网站站长都有捕获他人数据的经验。目前抓取别人的网站数据有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时没弄明白怎么用,后来干脆决定自己写。现在半天就能搞定一个网站(只是程序开发的时间,不包括抓数据的时间)
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的问题之一是抓取分页数据。原因是数据分页的形式很多。下面我将主要从三个方面介绍表单中抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码都是可以正确执行的,我目前正在使用中。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
以下切入正题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花半天时间写代码又懒得学第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地的数据库中;爬取代码可以参考如下:
公共字符串 GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322 ; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5. 21022;.NET CLR 3.0.4506.2152;.NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方法二:在网站的开发过程中可能会经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现状态栏会显示javascript:__dopostback("gridview","当你将鼠标移到每个页码上时的代码如page1")等,这种形式其实也不是很难,因为毕竟有一个地方可以找到获取页码的规则。
我们知道提交HTTP请求有两种方式。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,不在本文中。专注
获取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为当你点击翻页的时候页面,将改变页码的信息传递给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不要太担心这三件事的作用。自己写代码抓取页面的时候记得提交这三个元素。
和第一种方法一样,必须循环把_dopostback的两个参数拼凑起来。您只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
<p>for (int i = 0; i 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有 网站 网站站长都有捕获他人数据的经验。目前抓取别人的网站数据有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时没弄明白怎么用,后来干脆决定自己写。现在半天就能搞定一个网站(只是程序开发的时间,不包括抓数据的时间)
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的问题之一是抓取分页数据。原因是数据分页的形式很多。下面我将主要从三个方面介绍表单中抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码都是可以正确执行的,我目前正在使用中。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
以下切入正题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花半天时间写代码又懒得学第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地的数据库中;爬取代码可以参考如下:
公共字符串 GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322 ; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5. 21022;.NET CLR 3.0.4506.2152;.NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方法二:在网站的开发过程中可能会经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现状态栏会显示javascript:__dopostback("gridview","当你将鼠标移到每个页码上时的代码如page1")等,这种形式其实也不是很难,因为毕竟有一个地方可以找到获取页码的规则。
我们知道提交HTTP请求有两种方式。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,不在本文中。专注
获取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为当你点击翻页的时候页面,将改变页码的信息传递给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不要太担心这三件事的作用。自己写代码抓取页面的时候记得提交这三个元素。
和第一种方法一样,必须循环把_dopostback的两个参数拼凑起来。您只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
<p>for (int i = 0; i
scrapy分页抓取网页(项目文件创建好怎么写爬虫程序?程序怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-03 07:01
项目文件创建好后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
class KuanItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
volume = scrapy.Field()
download = scrapy.Field()
follow = scrapy.Field()
comment = scrapy.Field()
tags = scrapy.Field()
score = scrapy.Field()
num_score = scrapy.Field()
这里的字段信息是我们在网页上找到的8个字段信息,其中:name是App的名字,volume是体积,download是下载次数。在这里定义之后,我们将在后续的爬取主程序中使用这些字段信息。
2.3.3. 爬取主程序
kuan项目创建后,Scrapy框架会自动生成部分爬取代码。接下来需要在parse方法中添加网页抓取的字段解析内容。
class KuspiderSpider(scrapy.Spider):
name = 'kuan'
allowed_domains = ['www.coolapk.com']
start_urls = ['http://www.coolapk.com/']
def parse(self, response):
pass
在首页打开Dev Tools,找到各个爬取指标的节点位置,然后使用CSS、Xpath、正则化等方法进行提取分析。这些方法都是Scrapy支持的,可以随意选择。这里我们选择 CSS 语法来定位节点,但是需要注意的是,Scrapy 的 CSS 语法与我们之前用 pyquery 使用的 CSS 语法略有不同。让我举几个例子并进行比较。
首先我们定位第一个APP的首页URL节点,可以看到URL节点位于class属性为app_left_list的div节点下的a节点,其href属性就是我们需要的URL信息,这里是相对地址,拼接后就是完整的网址:
接下来,我们进入酷安详情页面,选择App名称并定位。可以看到App name节点位于类属性为.detail_app_title的p节点的正文中。
定位这两个节点后,我们就可以使用CSS提取字段信息了。下面是传统写作和 Scrapy 写作的对比:
# 常规写法
url = item('.app_left_list>a').attr('href')
name = item('.list_app_title').text()
# Scrapy 写法
url = item.css('::attr("href")').extract_first()
name = item.css('.detail_app_title::text').extract_first()
如您所见,要获取 href 或 text 属性,需要使用 :: 来表示。例如,要获取文本,请使用 ::text。 extract_first() 表示提取第一个元素,如果有多个元素,使用extract()。然后,我们可以参考解析代码写出这8个字段信息。
首先,我们需要在首页提取App的URL列表,然后进入每个App的详情页,再提取8个字段的信息。
def parse(self, response):
contents = response.css('.app_left_list>a')
for content in contents:
url = content.css('::attr("href")').extract_first()
url = response.urljoin(url) # 拼接相对 url 为绝对 url
yield scrapy.Request(url,callback=self.parse_url)
这里使用response.urljoin()方法将提取的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传入两个参数:url和callback,url是详情页的URL,callback是回调函数,将首页URL请求返回的响应传递给专门用来解析字段内容的parse_url()方法,如如下图:
def parse_url(self,response):
item = KuanItem()
item['name'] = response.css('.detail_app_title::text').extract_first()
results = self.get_comment(response)
item['volume'] = results[0]
item['download'] = results[1]
item['follow'] = results[2]
item['comment'] = results[3]
item['tags'] = self.get_tags(response)
item['score'] = response.css('.rank_num::text').extract_first()
num_score = response.css('.apk_rank_p1::text').extract_first()
item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)
yield item
def get_comment(self,response):
messages = response.css('.apk_topba_message::text').extract_first()
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上
if result: # 不为空
results = list(result[0]) # 提取出list 中第一个元素
return results
def get_tags(self,response):
data = response.css('.apk_left_span2')
tags = [item.css('::text').extract_first() for item in data]
return tags
这里分别定义了两个方法,get_comment() 和 get_tags()。
get_comment() 方法使用正则匹配来提取volume、download、follow、comment四个字段。正则匹配结果如下:
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)
print(result) # 输出第一页的结果信息
# 结果如下:
[('21.74M', '5218万', '2.4万', '5.4万')]
[('75.53M', '2768万', '2.3万', '3.0万')]
[('46.21M', '1686万', '2.3万', '3.4万')]
[('54.77M', '1603万', '3.8万', '4.9万')]
[('3.32M', '1530万', '1.5万', '3343')]
[('75.07M', '1127万', '1.6万', '2.2万')]
[('92.70M', '1108万', '9167', '1.3万')]
[('68.94M', '1072万', '5718', '9869')]
[('61.45M', '935万', '1.1万', '1.6万')]
[('23.96M', '925万', '4157', '1956')]
然后用result[0]、result[1]等提取四条信息,以volume为例,输出第一页的提取结果:
item['volume'] = results[0]
print(item['volume'])
21.74M
75.53M
46.21M
54.77M
3.32M
75.07M
92.70M
68.94M
61.45M
23.96M
这样第一页的10个app的字段信息就全部提取成功了,然后返回到yied item生成器,输出它的内容:
[
{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'},
{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},
...
]
2.3.4. 分页爬取
上面,我们爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
这里我们分别写下两种方法的分析代码。
第一种方法很简单,就按照parse方法继续添加以下几行代码即可:
def parse(self, response):
contents = response.css('.app_left_list>a')
for content in contents:
...
next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()
url = response.urljoin(next_page)
yield scrapy.Request(url,callback=self.parse )
第二种方法,一开始我们在parse()方法之前定义了一个start_requests()方法,用于批量生成610个页面URL,然后传递给下面的parse()方法进行解析。
def start_requests(self):
pages = []
for page in range(1,610): # 一共有610页
url = 'https://www.coolapk.com/apk/?page=%s'%page
page = scrapy.Request(url,callback=self.parse)
pages.append(page)
return pages
以上是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择将其存储在 MongoDB 中。不得不说MongoDB比MySQL方便多了,麻烦也少了很多。
2.3.5.店铺成绩
在pipelines.py程序中,我们定义了数据存储方式。 MongoDB的一些参数,如地址和数据库名称,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
import pymongo
class MongoPipeline(object):
def __init__(self,mongo_url,mongo_db):
self.mongo_url = mongo_url
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_url = crawler.settings.get('MONGO_URL'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单说明一下:
from crawler() 是一个类方法,由@class 方法标识。这个方法的作用主要是获取我们在settings.py中设置的参数:
MONGO_URL = 'localhost'
MONGO_DB = 'KuAn'
ITEM_PIPELINES = {
'kuan.pipelines.MongoPipeline': 300,
}
open_spider() 方法主要执行一些初始化操作。这个方法会在Spider打开时调用。
process_item() 方法是将数据插入到 MongoDB 中最重要的方法。
完成以上代码后,输入如下一行命令,即可启动爬虫的爬取和存储过程。如果在单机上运行,6000个网页需要很长时间才能完成。要有耐心。
scrapy crawl kuan
这里,还有两点:
首先,为了减轻网站的压力,我们最好在每次请求之间设置几秒的延迟。您可以在 KuspiderSpider() 方法的开头添加以下代码行:
custom_settings = {
"DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟
"CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低
}
其次,为了更好的监控爬虫程序的运行情况,需要设置输出日志文件,可以通过Python自带的日志包来实现:
import logging
logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')
logging.warning("warn message")
logging.error("error message")
这里的level参数表示警告级别,严重程度从低到高分别是:DEBUG
添加datefmt参数,在每条日志前添加具体时间,很有用。
以上,我们已经完成了整个数据的抓取。有了数据,我们就可以开始分析了,但在此之前,我们需要对数据进行简单的清理和处理。
3. 数据清洗处理
首先我们从MongoDB中读取数据并转换成DataFrame,然后查看数据的基本情况。
def parse_kuan():
client = pymongo.MongoClient(host='localhost', port=27017)
db = client['KuAn']
collection = db['KuAnItem']
# 将数据库数据转为DataFrame
data = pd.DataFrame(list(collection.find()))
print(data.head())
print(df.shape)
print(df.info())
print(df.describe())
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
评论、下载、关注、num_score,5列数据部分行有“10000”后缀,需要去掉,转成数值;体积一栏分别有“M”和“K”后缀,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有 6086 行 x 8 列,每列都没有缺失值。
df.describe() 方法对分数列进行基本统计。可以看到所有app的平均分是3.9分(5分制),最低分是1.6分。最高分4.8分。
接下来我们将上面几列文本数据转换成数值数据,代码实现如下:
def data_processing(df):
#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型
str = '_ori'
cols = ['comment','download','follow','num_score','volume']
for col in cols:
colori = col+str
df[colori] = df[col] # 复制保留原始列
if not (col == 'volume'):
df[col] = clean_symbol(df,col)# 处理原始列生成新列
else:
df[col] = clean_symbol2(df,col)# 处理原始列生成新列
# 将download单独转换为万单位
df['download'] = df['download'].apply(lambda x:x/10000)
# 批量转为数值型
df = df.apply(pd.to_numeric,errors='ignore')
def clean_symbol(df,col):
# 将字符“万”替换为空
con = df[col].str.contains('万$')
df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000
df[col] = pd.to_numeric(df[col])
return df[col]
def clean_symbol2(df,col):
# 字符M替换为空
df[col] = df[col].str.replace('M$','')
# 体积为K的除以 1024 转换为M
con = df[col].str.contains('K$')
df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024
df[col] = pd.to_numeric(df[col])
return df[col]
以上,几列文本数据的转换就完成了,我们再来看看基本情况:
commentdownloadfollownum_scorescorevolume
计数
6086
6086
6086
6086
6086
6086
平均值
255.5
13.7
729.3
133.1
3.9
17.7
标准
1437.3
98
1893.7
595.4
0.6
20.6
分钟
1
1.6
25%
16
0.2
65
5.2
3.7
3.5
50%
38
0.8
180
17
4
10.8
75%
119
4.5
573.8
68
4.3
25.3
最大
53000
5190
38000
17000
4.8
294.2
可以看到以下信息:
以上,基本的数据清洗过程已经完成。下一篇文章我们将对数据进行探索性分析。 查看全部
scrapy分页抓取网页(项目文件创建好怎么写爬虫程序?程序怎么做?)
项目文件创建好后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
class KuanItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
volume = scrapy.Field()
download = scrapy.Field()
follow = scrapy.Field()
comment = scrapy.Field()
tags = scrapy.Field()
score = scrapy.Field()
num_score = scrapy.Field()
这里的字段信息是我们在网页上找到的8个字段信息,其中:name是App的名字,volume是体积,download是下载次数。在这里定义之后,我们将在后续的爬取主程序中使用这些字段信息。
2.3.3. 爬取主程序
kuan项目创建后,Scrapy框架会自动生成部分爬取代码。接下来需要在parse方法中添加网页抓取的字段解析内容。
class KuspiderSpider(scrapy.Spider):
name = 'kuan'
allowed_domains = ['www.coolapk.com']
start_urls = ['http://www.coolapk.com/']
def parse(self, response):
pass
在首页打开Dev Tools,找到各个爬取指标的节点位置,然后使用CSS、Xpath、正则化等方法进行提取分析。这些方法都是Scrapy支持的,可以随意选择。这里我们选择 CSS 语法来定位节点,但是需要注意的是,Scrapy 的 CSS 语法与我们之前用 pyquery 使用的 CSS 语法略有不同。让我举几个例子并进行比较。

首先我们定位第一个APP的首页URL节点,可以看到URL节点位于class属性为app_left_list的div节点下的a节点,其href属性就是我们需要的URL信息,这里是相对地址,拼接后就是完整的网址:
接下来,我们进入酷安详情页面,选择App名称并定位。可以看到App name节点位于类属性为.detail_app_title的p节点的正文中。

定位这两个节点后,我们就可以使用CSS提取字段信息了。下面是传统写作和 Scrapy 写作的对比:
# 常规写法
url = item('.app_left_list>a').attr('href')
name = item('.list_app_title').text()
# Scrapy 写法
url = item.css('::attr("href")').extract_first()
name = item.css('.detail_app_title::text').extract_first()
如您所见,要获取 href 或 text 属性,需要使用 :: 来表示。例如,要获取文本,请使用 ::text。 extract_first() 表示提取第一个元素,如果有多个元素,使用extract()。然后,我们可以参考解析代码写出这8个字段信息。
首先,我们需要在首页提取App的URL列表,然后进入每个App的详情页,再提取8个字段的信息。
def parse(self, response):
contents = response.css('.app_left_list>a')
for content in contents:
url = content.css('::attr("href")').extract_first()
url = response.urljoin(url) # 拼接相对 url 为绝对 url
yield scrapy.Request(url,callback=self.parse_url)
这里使用response.urljoin()方法将提取的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传入两个参数:url和callback,url是详情页的URL,callback是回调函数,将首页URL请求返回的响应传递给专门用来解析字段内容的parse_url()方法,如如下图:
def parse_url(self,response):
item = KuanItem()
item['name'] = response.css('.detail_app_title::text').extract_first()
results = self.get_comment(response)
item['volume'] = results[0]
item['download'] = results[1]
item['follow'] = results[2]
item['comment'] = results[3]
item['tags'] = self.get_tags(response)
item['score'] = response.css('.rank_num::text').extract_first()
num_score = response.css('.apk_rank_p1::text').extract_first()
item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)
yield item
def get_comment(self,response):
messages = response.css('.apk_topba_message::text').extract_first()
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上
if result: # 不为空
results = list(result[0]) # 提取出list 中第一个元素
return results
def get_tags(self,response):
data = response.css('.apk_left_span2')
tags = [item.css('::text').extract_first() for item in data]
return tags
这里分别定义了两个方法,get_comment() 和 get_tags()。
get_comment() 方法使用正则匹配来提取volume、download、follow、comment四个字段。正则匹配结果如下:
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)
print(result) # 输出第一页的结果信息
# 结果如下:
[('21.74M', '5218万', '2.4万', '5.4万')]
[('75.53M', '2768万', '2.3万', '3.0万')]
[('46.21M', '1686万', '2.3万', '3.4万')]
[('54.77M', '1603万', '3.8万', '4.9万')]
[('3.32M', '1530万', '1.5万', '3343')]
[('75.07M', '1127万', '1.6万', '2.2万')]
[('92.70M', '1108万', '9167', '1.3万')]
[('68.94M', '1072万', '5718', '9869')]
[('61.45M', '935万', '1.1万', '1.6万')]
[('23.96M', '925万', '4157', '1956')]
然后用result[0]、result[1]等提取四条信息,以volume为例,输出第一页的提取结果:
item['volume'] = results[0]
print(item['volume'])
21.74M
75.53M
46.21M
54.77M
3.32M
75.07M
92.70M
68.94M
61.45M
23.96M
这样第一页的10个app的字段信息就全部提取成功了,然后返回到yied item生成器,输出它的内容:
[
{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'},
{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},
...
]
2.3.4. 分页爬取
上面,我们爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
这里我们分别写下两种方法的分析代码。
第一种方法很简单,就按照parse方法继续添加以下几行代码即可:
def parse(self, response):
contents = response.css('.app_left_list>a')
for content in contents:
...
next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()
url = response.urljoin(next_page)
yield scrapy.Request(url,callback=self.parse )
第二种方法,一开始我们在parse()方法之前定义了一个start_requests()方法,用于批量生成610个页面URL,然后传递给下面的parse()方法进行解析。
def start_requests(self):
pages = []
for page in range(1,610): # 一共有610页
url = 'https://www.coolapk.com/apk/?page=%s'%page
page = scrapy.Request(url,callback=self.parse)
pages.append(page)
return pages
以上是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择将其存储在 MongoDB 中。不得不说MongoDB比MySQL方便多了,麻烦也少了很多。
2.3.5.店铺成绩
在pipelines.py程序中,我们定义了数据存储方式。 MongoDB的一些参数,如地址和数据库名称,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
import pymongo
class MongoPipeline(object):
def __init__(self,mongo_url,mongo_db):
self.mongo_url = mongo_url
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_url = crawler.settings.get('MONGO_URL'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单说明一下:
from crawler() 是一个类方法,由@class 方法标识。这个方法的作用主要是获取我们在settings.py中设置的参数:
MONGO_URL = 'localhost'
MONGO_DB = 'KuAn'
ITEM_PIPELINES = {
'kuan.pipelines.MongoPipeline': 300,
}
open_spider() 方法主要执行一些初始化操作。这个方法会在Spider打开时调用。
process_item() 方法是将数据插入到 MongoDB 中最重要的方法。

完成以上代码后,输入如下一行命令,即可启动爬虫的爬取和存储过程。如果在单机上运行,6000个网页需要很长时间才能完成。要有耐心。
scrapy crawl kuan
这里,还有两点:
首先,为了减轻网站的压力,我们最好在每次请求之间设置几秒的延迟。您可以在 KuspiderSpider() 方法的开头添加以下代码行:
custom_settings = {
"DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟
"CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低
}
其次,为了更好的监控爬虫程序的运行情况,需要设置输出日志文件,可以通过Python自带的日志包来实现:
import logging
logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')
logging.warning("warn message")
logging.error("error message")
这里的level参数表示警告级别,严重程度从低到高分别是:DEBUG
添加datefmt参数,在每条日志前添加具体时间,很有用。

以上,我们已经完成了整个数据的抓取。有了数据,我们就可以开始分析了,但在此之前,我们需要对数据进行简单的清理和处理。
3. 数据清洗处理
首先我们从MongoDB中读取数据并转换成DataFrame,然后查看数据的基本情况。
def parse_kuan():
client = pymongo.MongoClient(host='localhost', port=27017)
db = client['KuAn']
collection = db['KuAnItem']
# 将数据库数据转为DataFrame
data = pd.DataFrame(list(collection.find()))
print(data.head())
print(df.shape)
print(df.info())
print(df.describe())

从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
评论、下载、关注、num_score,5列数据部分行有“10000”后缀,需要去掉,转成数值;体积一栏分别有“M”和“K”后缀,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有 6086 行 x 8 列,每列都没有缺失值。
df.describe() 方法对分数列进行基本统计。可以看到所有app的平均分是3.9分(5分制),最低分是1.6分。最高分4.8分。
接下来我们将上面几列文本数据转换成数值数据,代码实现如下:
def data_processing(df):
#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型
str = '_ori'
cols = ['comment','download','follow','num_score','volume']
for col in cols:
colori = col+str
df[colori] = df[col] # 复制保留原始列
if not (col == 'volume'):
df[col] = clean_symbol(df,col)# 处理原始列生成新列
else:
df[col] = clean_symbol2(df,col)# 处理原始列生成新列
# 将download单独转换为万单位
df['download'] = df['download'].apply(lambda x:x/10000)
# 批量转为数值型
df = df.apply(pd.to_numeric,errors='ignore')
def clean_symbol(df,col):
# 将字符“万”替换为空
con = df[col].str.contains('万$')
df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000
df[col] = pd.to_numeric(df[col])
return df[col]
def clean_symbol2(df,col):
# 字符M替换为空
df[col] = df[col].str.replace('M$','')
# 体积为K的除以 1024 转换为M
con = df[col].str.contains('K$')
df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024
df[col] = pd.to_numeric(df[col])
return df[col]
以上,几列文本数据的转换就完成了,我们再来看看基本情况:
commentdownloadfollownum_scorescorevolume
计数
6086
6086
6086
6086
6086
6086
平均值
255.5
13.7
729.3
133.1
3.9
17.7
标准
1437.3
98
1893.7
595.4
0.6
20.6
分钟
1
1.6
25%
16
0.2
65
5.2
3.7
3.5
50%
38
0.8
180
17
4
10.8
75%
119
4.5
573.8
68
4.3
25.3
最大
53000
5190
38000
17000
4.8
294.2
可以看到以下信息:
以上,基本的数据清洗过程已经完成。下一篇文章我们将对数据进行探索性分析。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-03 06:20
我相信所有 网站 网站站长都有捕获他人数据的经验。目前抓取别人的网站数据有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时没弄明白怎么用,后来干脆决定自己写。现在半天就能搞定一个网站(只是程序开发的时间,不包括抓数据的时间)
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的问题之一是抓取分页数据。原因是数据分页的形式很多。下面我将主要从三个方面介绍表单中抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码都是可以正确执行的,我目前正在使用中。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
以下切入正题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花半天时间写代码又懒得学第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地的数据库中;爬取代码可以参考如下:
公共字符串 GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322 ; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5. 21022;.NET CLR 3.0.4506.2152;.NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方法二:在网站的开发过程中可能会经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现状态栏会显示javascript:__dopostback("gridview","当你将鼠标移到每个页码上时的代码如page1")等,这种形式其实也不是很难,因为毕竟有一个地方可以找到获取页码的规则。
我们知道提交HTTP请求有两种方式。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,不在本文中。专注
获取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为当你点击翻页的时候页面,将改变页码的信息传递给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不要太担心这三件事的作用。自己写代码抓取页面的时候记得提交这三个元素。
和第一种方法一样,必须循环把_dopostback的两个参数拼凑起来。您只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
<p>for (int i = 0; i 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有 网站 网站站长都有捕获他人数据的经验。目前抓取别人的网站数据有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时没弄明白怎么用,后来干脆决定自己写。现在半天就能搞定一个网站(只是程序开发的时间,不包括抓数据的时间)
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的问题之一是抓取分页数据。原因是数据分页的形式很多。下面我将主要从三个方面介绍表单中抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码都是可以正确执行的,我目前正在使用中。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
以下切入正题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花半天时间写代码又懒得学第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地的数据库中;爬取代码可以参考如下:
公共字符串 GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322 ; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5. 21022;.NET CLR 3.0.4506.2152;.NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方法二:在网站的开发过程中可能会经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现状态栏会显示javascript:__dopostback("gridview","当你将鼠标移到每个页码上时的代码如page1")等,这种形式其实也不是很难,因为毕竟有一个地方可以找到获取页码的规则。
我们知道提交HTTP请求有两种方式。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,不在本文中。专注
获取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为当你点击翻页的时候页面,将改变页码的信息传递给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不要太担心这三件事的作用。自己写代码抓取页面的时候记得提交这三个元素。
和第一种方法一样,必须循环把_dopostback的两个参数拼凑起来。您只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
<p>for (int i = 0; i
scrapy分页抓取网页(使用Scrapy处理JSONAPI和AJAXAJAX页面的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-01 23:23
)
摘要:介绍了如何使用Scrapy处理JSON API和AJAX页面
有时你可能会发现你要爬取的页面的HTML源代码不存在,比如在浏览器中打开:9312/static/,然后在空白处右击,选择“查看网页”源代码”,如下图:
你会发现一个空格
我注意到红线处指定了一个名为 api.json 的文件,于是我在浏览器的调试器中打开了 Network 面板,找到了名为 api.json 的标签
您可以在上面的红框中找到原创网页的内容。这是一个简单的 JSON API。一些复杂的 API 将要求您先登录、发送 POST 请求或返回一些更有趣的数据结构。 Python 提供了一个解析 JSON 的库,可以使用语句 json.loads(response.body) 将 JSON 数据转换为 Python 对象
api.py文件的源代码地址:
%2Fproperties%2Fproperties%2Fspiders%2Fapi.py
复制manual.py文件,重命名为api.py,并做如下修改:
start_urls = (
'http://web:9312/properties/api.json',
)
如果需要先登录再获取json api,使用start_request()函数(参考《学习Scrapy笔记(五)-Scrapy登录网站》)
def parse(self, response):
base_url = "http://web:9312/properties/"
js = json.loads(response.body)
for item in js:
id = item["id"]
url = base_url + "property_d.html" % id # 构建一个每个条目的完整url
yield Request(url, callback=self.parse_item)
上面的js变量是一个列表,每个元素代表一个条目,可以使用scrapy shell工具验证:
scrapy shell http://web:9312/properties/api.json
运行蜘蛛:scrapy crawl api
可以看到总共发送了31个请求,获得了30个项目
看上图用scrapy shell工具检查js变量。其实除了id字段,还可以获取title字段,所以可以同时在parse函数中获取title字段,并将字段的值传递给parse_item函数填充到item中(省略了parse_item函数中使用xpath提取标题的步骤),修改parse函数如下:
title = item["title"]
yield Request(url, meta={"title": title},callback=self.parse_item) #meta变量是一个字典,用于向回调函数传递数据
在parse_item函数中,这个字段可以从响应中提取
l.add_value('title', response.meta['title'],
MapCompose(unicode.strip, unicode.title)) 查看全部
scrapy分页抓取网页(使用Scrapy处理JSONAPI和AJAXAJAX页面的方法
)
摘要:介绍了如何使用Scrapy处理JSON API和AJAX页面
有时你可能会发现你要爬取的页面的HTML源代码不存在,比如在浏览器中打开:9312/static/,然后在空白处右击,选择“查看网页”源代码”,如下图:
你会发现一个空格

我注意到红线处指定了一个名为 api.json 的文件,于是我在浏览器的调试器中打开了 Network 面板,找到了名为 api.json 的标签
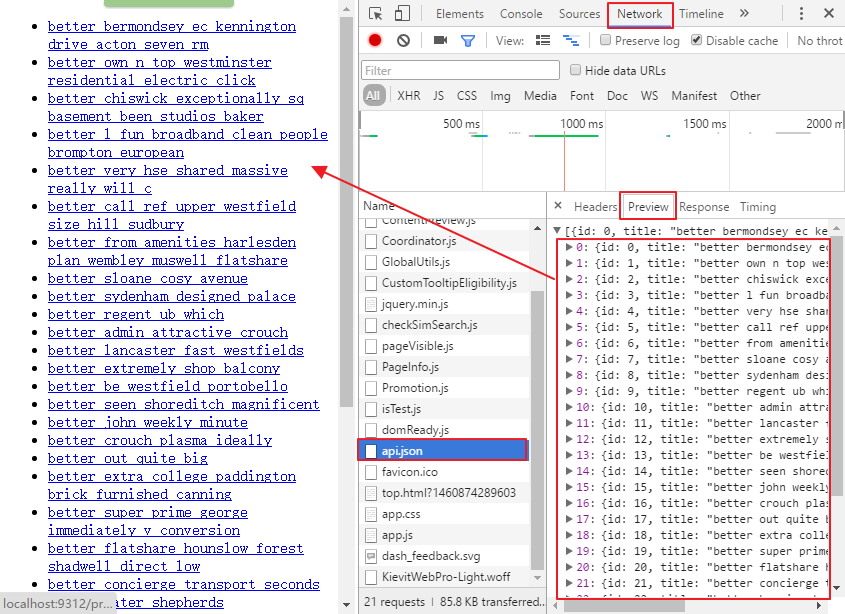
您可以在上面的红框中找到原创网页的内容。这是一个简单的 JSON API。一些复杂的 API 将要求您先登录、发送 POST 请求或返回一些更有趣的数据结构。 Python 提供了一个解析 JSON 的库,可以使用语句 json.loads(response.body) 将 JSON 数据转换为 Python 对象
api.py文件的源代码地址:
%2Fproperties%2Fproperties%2Fspiders%2Fapi.py
复制manual.py文件,重命名为api.py,并做如下修改:
start_urls = (
'http://web:9312/properties/api.json',
)
如果需要先登录再获取json api,使用start_request()函数(参考《学习Scrapy笔记(五)-Scrapy登录网站》)
def parse(self, response):
base_url = "http://web:9312/properties/"
js = json.loads(response.body)
for item in js:
id = item["id"]
url = base_url + "property_d.html" % id # 构建一个每个条目的完整url
yield Request(url, callback=self.parse_item)
上面的js变量是一个列表,每个元素代表一个条目,可以使用scrapy shell工具验证:
scrapy shell http://web:9312/properties/api.json
运行蜘蛛:scrapy crawl api
可以看到总共发送了31个请求,获得了30个项目
看上图用scrapy shell工具检查js变量。其实除了id字段,还可以获取title字段,所以可以同时在parse函数中获取title字段,并将字段的值传递给parse_item函数填充到item中(省略了parse_item函数中使用xpath提取标题的步骤),修改parse函数如下:
title = item["title"]
yield Request(url, meta={"title": title},callback=self.parse_item) #meta变量是一个字典,用于向回调函数传递数据
在parse_item函数中,这个字段可以从响应中提取
l.add_value('title', response.meta['title'],
MapCompose(unicode.strip, unicode.title))
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 20:10
2015-06-23 更新:
写这篇文章的时候,我还没有遇到具体的场景。只是觉得有这样的方法,就写下来了。
我今天刚刚满足了这个需求。抓取BBS内容,版块首页只显示标题、作者和发表时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能得到链接内容爬取后的时间,实际上造成了不必要的浪费。使用本文文章的方法在抓取链接前进行过滤,避免抓取无用数据。
第一个scrapy爬虫开始了(3)- 使用规则实现多页爬取给出了使用CrawlSpider Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取.
具体思路:以我们豆瓣团队为例。我们将首页地址作为start_url参数,从页面源码中查找剩余的页面,如下:
<前页
1
2
3
4
5
6
7
8
9
后页>
可以提取每个页面的地址,多页面爬取的思路是把地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并为这些页面地址函数指定相应的回调。由于首页和分页在形式上完全一致(首页本身也是一个页面),可以直接指定parse作为回调函数。
代码如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
之前使用了所有的CrawlSpider,但是这里替换了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
在写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,所以就相当于为每个页面提取了一个页面地址,这样实际上每个页面地址都在返回结束N次,scrapy会在实际处理中对每个地址处理N次吗?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》......
让我们运行程序看看。现在来看看我们的print语句:“->”代表当前页面地址,后面是从当前页面中提取出来的页面地址。为了精简输出,只提取用于识别页面的那个。 “开始”参数。
运行结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如你所见:
1.每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除并使用线程进行数据提取操作。
好的,任务完成。使用CrawlSpider的规则感觉更方便。 查看全部
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
2015-06-23 更新:
写这篇文章的时候,我还没有遇到具体的场景。只是觉得有这样的方法,就写下来了。
我今天刚刚满足了这个需求。抓取BBS内容,版块首页只显示标题、作者和发表时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能得到链接内容爬取后的时间,实际上造成了不必要的浪费。使用本文文章的方法在抓取链接前进行过滤,避免抓取无用数据。
第一个scrapy爬虫开始了(3)- 使用规则实现多页爬取给出了使用CrawlSpider Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取.
具体思路:以我们豆瓣团队为例。我们将首页地址作为start_url参数,从页面源码中查找剩余的页面,如下:
<前页
1
2
3
4
5
6
7
8
9
后页>
可以提取每个页面的地址,多页面爬取的思路是把地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并为这些页面地址函数指定相应的回调。由于首页和分页在形式上完全一致(首页本身也是一个页面),可以直接指定parse作为回调函数。
代码如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
之前使用了所有的CrawlSpider,但是这里替换了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
在写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,所以就相当于为每个页面提取了一个页面地址,这样实际上每个页面地址都在返回结束N次,scrapy会在实际处理中对每个地址处理N次吗?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》......
让我们运行程序看看。现在来看看我们的print语句:“->”代表当前页面地址,后面是从当前页面中提取出来的页面地址。为了精简输出,只提取用于识别页面的那个。 “开始”参数。
运行结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如你所见:
1.每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除并使用线程进行数据提取操作。
好的,任务完成。使用CrawlSpider的规则感觉更方便。
scrapy分页抓取网页(Scrapy轻松定制网络爬虫2009-08-14网络)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-31 05:17
Scrapy 轻松定制网络爬虫 2009-08-14 网络爬虫(Spider)是一种在互联网上爬行的机器人。当然,它通常不是实体机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实就是一个程序,不是爬行,而是有一定的用途,爬行的时候会采集. 一些信息。例如,谷歌有大量的爬虫采集网页内容和它们之间的链接信息;再比如,一些别有用心的爬虫在网上采集诸如foo bar[dot] com之类的东西。此外,还有一些定制的爬虫,专门针对某个网站。例如,不久前,JavaEye写了几篇专门对付恶意爬虫的博客(原链接好像已经过期了,就不给了),还有网站比如小众软件或者LinuxToy经常被全站爬下来并以不同的名字出去玩。其实,爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。
但是,要实现一个高质量的蜘蛛是非常困难的。爬虫的两部分是下载网页。需要考虑的问题有很多,比如如何最大限度地利用本地带宽,如何调度不同站点的web请求,以减少其他服务器的负担。在高性能的Web Crawler系统中,DNS查询也将成为亟待优化的瓶颈。此外,还有一些“配置文件”需要遵循(例如,robots.txt)。获取网页后的分析过程也非常复杂。网上奇奇怪怪的东西很多,各种HTML页面出现各种错误。要清楚地分析所有这些几乎是不可能的。另外,随着AJAX的流行,如何获取Javascript动态生成的内容已经成为一个大问题;此外,网络上还有各种有意无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。
通过分析和选择有价值的链接进行跟踪,我们可以避免很多不必要的链接或蜘蛛陷阱。如果网站的结构允许选择合适的路径,我们就可以按照感兴趣的事物的一定顺序再次爬取它,这样就连URL重复的判断都可以省略了。比如我们要爬下pongba中的博客文字,通过观察,很容易发现我们感兴趣的页面有两个:文章列表页面,比如首页,或者URL / page/\d+ /对于这样的页面,通过Firebug可以看到每篇文章的链接都在一个h1标签中(注意Firebug HTML面板中看到的HTML代码和查看源代码可能会有些不同另外,如果网页中有Javascript动态修改DOM树,前者是修改后的版本,由 Firebug 规范化。比如属性有引号等,而后者通常是蜘蛛爬取的原创内容。如果是使用正则表达式来分析页面或者使用HTML Parser Firefox 如果有一些出入,则需要特别注意),此外,在wp-pagenavi div 类中还有指向不同列表页面的链接。
文章内容页,每个博客都有这样一个页面,例如/2008/09/11/machine-learning-and-ai-resources/,收录了文章的完整内容,这是我们的感受感兴趣的内容。因此,我们从首页开始,利用 wp-pagenavi 中的链接来获取其他 文章 列表页面。特别地,我们定义了一个路径:followNext Page 链接,这样我们就可以从头到尾依次遍历。免去判断重复爬行的麻烦。另外,文章列表页上链接到具体文章的链接对应的页面就是我们真正要保存的数据页。这样一来,其实用的脚本语言写一个ad hoc Crawler来完成这个任务并不难,不过今天的主角是Scrapy。这是一个Python CrawlerFramework,简单,轻量,非常方便,并且官网说已经在实际生产中。在使用中,它不是玩具级别的东西。不过目前还没有Release版本,可以直接使用他们的Mercurial库来获取源码进行安装。不过这个东西也可以不安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。
整体架构如下图所示: 绿线为数据流。首先从初始的URL开始,Scheduler将其交给Downloader进行下载,下载完成后交给Spider进行分析。Spider分析的结果有两种:一种是需要进一步爬取的Links,比如之前分析到的“下一页”的链接,会返回给Scheduler;另一个是需要保存的数据,它们会被送到Item Pipeline,也就是执行数据Place进行后处理(详细分析、过滤、存储等)。此外,数据流通道中可以安装各种中间件。执行必要的部分似乎很复杂。使用起来非常简单。和 Rails 一样,首先新建一个项目:scrapy-admin。py startproject blog_crawl 会创建一个blog_crawl目录,里面有一个scrapy-ctl.py是整个项目的控制脚本,代码全部放在子目录blog_crawl下。为了能够爬行,我们在spiders目录下新建一个mindhacks_spider.py,定义我们的Spider如下: from scrapy.spider import BaseSpider class MindhacksSpider(BaseSpider): domain_name ""start_urls [""]def parse(self , response): return MindhacksSpider() 我们的MindhacksSpider继承自BaseSpider(通常直接继承自scrapy.contrib.spiders,功能更多。CrawlSpider更方便,但为了展示数据是如何解析的,这里使用了BaseSpider),变量 domain_name start_urls 的意思很容易理解,而parse方法就是我们需要定义的回调函数。默认请求会在响应之后调用这个回调函数,我们需要解析这里的页面并返回两个结果(需要进一步爬取的链接和需要保存的数据)。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。
另外,定义一个“全局”变量SPIDER,当Scrapy进入这个模块时会被实例化,并且会被Scrapy引擎自动找到。所以可以先运行爬虫试试: ./scrapy-ctl.py crawl 会有一堆输出,可以看到爬取了,因为这是初始的URL,但是因为我们在解析号里没有返回,我们需要进一步爬取URL,所以整个爬取过程只爬到了首页就结束了。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们进行实验。使用以下命令启动Shell ./scrapy-ctl.pyshell 它将启动爬虫并指定命令行抓取此页面并进入shell。根据提示,我们有很多现成的变量可以使用。其中之一是 hxs,这是一个 HtmlXPathSelector。mindhacks HTML 页面相对标准,可以很容易地直接使用 XPath 进行分析。通过Firebug可以看到每个博客文章的链接都在h1下,所以在Shell中使用这个XPath表达式测试:hxs.x(´//h1/a/@href´ ).extract()Out [1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是URL我们需要。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi" 所以在 Shell 中使用这个 XPath 表达式测试: hxs.x(´//h1/a/@href´ ).extract()Out[1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是我们需要的 URL。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi" 所以在 Shell 中使用这个 XPath 表达式测试: hxs.x(´//h1/a/@href´ ).extract()Out[1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是我们需要的 URL。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi"
需要注意的是,这里返回的列表并非都是字符串格式的URL。Scrapy希望得到Request对象,它可以携带比字符串格式的URL更多的东西,比如cookies或者回调函数。某种类型的。可以看到我们在创建博客正文的请求时替换了回调函数,因为默认的回调函数parse是专门用来解析文章列表等页面的。parse_post 定义如下: def parse_post(self, response): item BlogCrawlItem()item.url unicode(response.url)item.raw response.body_as_unicode()return [item] 很简单,返回一个BlogCrawlItem,把抓到的里面的数据,这里可以稍微分析一下,比如文本和标题是通过XPath解析的,但是我倾向于后期做这些事情,比如Item Pipeline或者后期Offline阶段。BlogCrawlItem Scrapy 自动帮我们定义了一个很好的继承自ScrapedItem items.py,这里我加了一句: from scrapy.item import ScrapedItem class BlogCrawlItem(ScrapedItem): def __init__(self): ScrapedItem.__init__(self) self. url def__str__(self): return ´BlogCrawlItem(url: self.url 定义了__str__函数,只给出了url,因为默认的__str__函数会显示所有的数据,所以在爬取Log的时候会看到控制台疯狂输出东西,即输出抓取到的网页内容。
-.-bb 这样就检索到了数据。最后只剩下存储数据的功能了。我们通过添加流水线来实现它。由于Python标准库自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。. 将pipelines.py的内容替换为以下代码:1011 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import sqlite3 from os core 从scrapy导入。 xlib. pydispatch 导入调度器类 SQLiteStorePipeline(object): 文件名 ´data.sqlite´def __init__(self): self.conn Nonedispatcher.connect(self.initialize,signals.engine_started) dispatcher.connect(self.finalize,signals.engine_stopped) def process_item (self, domain, item): self.conn.execute(´insert blogvalues(?,?,?)´, (item.url, item.raw, unicode(domain))) return item def initialize(self):
当数据通过管道时,将调用 process_item 函数。这里我们将原创数据直接存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取和过滤数据。我不会在这里详述。最后,在 settings.py [´blog_crawl.pipelines.SQLiteStorePipeline´] 中列出我们的管道并运行爬虫。最后总结一下:一个高质量的爬虫是一个极其复杂的工程,但是如果你有一个好的工具,做一个专用的爬虫是相对容易的。Scrapy是一个非常轻量级的爬虫框架,极大的简化了爬虫的开发过程。另外,Scrapy的文档也很详细。如果觉得我的介绍省略了一些不清楚的地方,推荐阅读他的Tutorial 查看全部
scrapy分页抓取网页(Scrapy轻松定制网络爬虫2009-08-14网络)
Scrapy 轻松定制网络爬虫 2009-08-14 网络爬虫(Spider)是一种在互联网上爬行的机器人。当然,它通常不是实体机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实就是一个程序,不是爬行,而是有一定的用途,爬行的时候会采集. 一些信息。例如,谷歌有大量的爬虫采集网页内容和它们之间的链接信息;再比如,一些别有用心的爬虫在网上采集诸如foo bar[dot] com之类的东西。此外,还有一些定制的爬虫,专门针对某个网站。例如,不久前,JavaEye写了几篇专门对付恶意爬虫的博客(原链接好像已经过期了,就不给了),还有网站比如小众软件或者LinuxToy经常被全站爬下来并以不同的名字出去玩。其实,爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。
但是,要实现一个高质量的蜘蛛是非常困难的。爬虫的两部分是下载网页。需要考虑的问题有很多,比如如何最大限度地利用本地带宽,如何调度不同站点的web请求,以减少其他服务器的负担。在高性能的Web Crawler系统中,DNS查询也将成为亟待优化的瓶颈。此外,还有一些“配置文件”需要遵循(例如,robots.txt)。获取网页后的分析过程也非常复杂。网上奇奇怪怪的东西很多,各种HTML页面出现各种错误。要清楚地分析所有这些几乎是不可能的。另外,随着AJAX的流行,如何获取Javascript动态生成的内容已经成为一个大问题;此外,网络上还有各种有意无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。
通过分析和选择有价值的链接进行跟踪,我们可以避免很多不必要的链接或蜘蛛陷阱。如果网站的结构允许选择合适的路径,我们就可以按照感兴趣的事物的一定顺序再次爬取它,这样就连URL重复的判断都可以省略了。比如我们要爬下pongba中的博客文字,通过观察,很容易发现我们感兴趣的页面有两个:文章列表页面,比如首页,或者URL / page/\d+ /对于这样的页面,通过Firebug可以看到每篇文章的链接都在一个h1标签中(注意Firebug HTML面板中看到的HTML代码和查看源代码可能会有些不同另外,如果网页中有Javascript动态修改DOM树,前者是修改后的版本,由 Firebug 规范化。比如属性有引号等,而后者通常是蜘蛛爬取的原创内容。如果是使用正则表达式来分析页面或者使用HTML Parser Firefox 如果有一些出入,则需要特别注意),此外,在wp-pagenavi div 类中还有指向不同列表页面的链接。
文章内容页,每个博客都有这样一个页面,例如/2008/09/11/machine-learning-and-ai-resources/,收录了文章的完整内容,这是我们的感受感兴趣的内容。因此,我们从首页开始,利用 wp-pagenavi 中的链接来获取其他 文章 列表页面。特别地,我们定义了一个路径:followNext Page 链接,这样我们就可以从头到尾依次遍历。免去判断重复爬行的麻烦。另外,文章列表页上链接到具体文章的链接对应的页面就是我们真正要保存的数据页。这样一来,其实用的脚本语言写一个ad hoc Crawler来完成这个任务并不难,不过今天的主角是Scrapy。这是一个Python CrawlerFramework,简单,轻量,非常方便,并且官网说已经在实际生产中。在使用中,它不是玩具级别的东西。不过目前还没有Release版本,可以直接使用他们的Mercurial库来获取源码进行安装。不过这个东西也可以不安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。
整体架构如下图所示: 绿线为数据流。首先从初始的URL开始,Scheduler将其交给Downloader进行下载,下载完成后交给Spider进行分析。Spider分析的结果有两种:一种是需要进一步爬取的Links,比如之前分析到的“下一页”的链接,会返回给Scheduler;另一个是需要保存的数据,它们会被送到Item Pipeline,也就是执行数据Place进行后处理(详细分析、过滤、存储等)。此外,数据流通道中可以安装各种中间件。执行必要的部分似乎很复杂。使用起来非常简单。和 Rails 一样,首先新建一个项目:scrapy-admin。py startproject blog_crawl 会创建一个blog_crawl目录,里面有一个scrapy-ctl.py是整个项目的控制脚本,代码全部放在子目录blog_crawl下。为了能够爬行,我们在spiders目录下新建一个mindhacks_spider.py,定义我们的Spider如下: from scrapy.spider import BaseSpider class MindhacksSpider(BaseSpider): domain_name ""start_urls [""]def parse(self , response): return MindhacksSpider() 我们的MindhacksSpider继承自BaseSpider(通常直接继承自scrapy.contrib.spiders,功能更多。CrawlSpider更方便,但为了展示数据是如何解析的,这里使用了BaseSpider),变量 domain_name start_urls 的意思很容易理解,而parse方法就是我们需要定义的回调函数。默认请求会在响应之后调用这个回调函数,我们需要解析这里的页面并返回两个结果(需要进一步爬取的链接和需要保存的数据)。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。
另外,定义一个“全局”变量SPIDER,当Scrapy进入这个模块时会被实例化,并且会被Scrapy引擎自动找到。所以可以先运行爬虫试试: ./scrapy-ctl.py crawl 会有一堆输出,可以看到爬取了,因为这是初始的URL,但是因为我们在解析号里没有返回,我们需要进一步爬取URL,所以整个爬取过程只爬到了首页就结束了。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们进行实验。使用以下命令启动Shell ./scrapy-ctl.pyshell 它将启动爬虫并指定命令行抓取此页面并进入shell。根据提示,我们有很多现成的变量可以使用。其中之一是 hxs,这是一个 HtmlXPathSelector。mindhacks HTML 页面相对标准,可以很容易地直接使用 XPath 进行分析。通过Firebug可以看到每个博客文章的链接都在h1下,所以在Shell中使用这个XPath表达式测试:hxs.x(´//h1/a/@href´ ).extract()Out [1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是URL我们需要。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi" 所以在 Shell 中使用这个 XPath 表达式测试: hxs.x(´//h1/a/@href´ ).extract()Out[1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是我们需要的 URL。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi" 所以在 Shell 中使用这个 XPath 表达式测试: hxs.x(´//h1/a/@href´ ).extract()Out[1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是我们需要的 URL。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi"
需要注意的是,这里返回的列表并非都是字符串格式的URL。Scrapy希望得到Request对象,它可以携带比字符串格式的URL更多的东西,比如cookies或者回调函数。某种类型的。可以看到我们在创建博客正文的请求时替换了回调函数,因为默认的回调函数parse是专门用来解析文章列表等页面的。parse_post 定义如下: def parse_post(self, response): item BlogCrawlItem()item.url unicode(response.url)item.raw response.body_as_unicode()return [item] 很简单,返回一个BlogCrawlItem,把抓到的里面的数据,这里可以稍微分析一下,比如文本和标题是通过XPath解析的,但是我倾向于后期做这些事情,比如Item Pipeline或者后期Offline阶段。BlogCrawlItem Scrapy 自动帮我们定义了一个很好的继承自ScrapedItem items.py,这里我加了一句: from scrapy.item import ScrapedItem class BlogCrawlItem(ScrapedItem): def __init__(self): ScrapedItem.__init__(self) self. url def__str__(self): return ´BlogCrawlItem(url: self.url 定义了__str__函数,只给出了url,因为默认的__str__函数会显示所有的数据,所以在爬取Log的时候会看到控制台疯狂输出东西,即输出抓取到的网页内容。
-.-bb 这样就检索到了数据。最后只剩下存储数据的功能了。我们通过添加流水线来实现它。由于Python标准库自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。. 将pipelines.py的内容替换为以下代码:1011 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import sqlite3 from os core 从scrapy导入。 xlib. pydispatch 导入调度器类 SQLiteStorePipeline(object): 文件名 ´data.sqlite´def __init__(self): self.conn Nonedispatcher.connect(self.initialize,signals.engine_started) dispatcher.connect(self.finalize,signals.engine_stopped) def process_item (self, domain, item): self.conn.execute(´insert blogvalues(?,?,?)´, (item.url, item.raw, unicode(domain))) return item def initialize(self):
当数据通过管道时,将调用 process_item 函数。这里我们将原创数据直接存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取和过滤数据。我不会在这里详述。最后,在 settings.py [´blog_crawl.pipelines.SQLiteStorePipeline´] 中列出我们的管道并运行爬虫。最后总结一下:一个高质量的爬虫是一个极其复杂的工程,但是如果你有一个好的工具,做一个专用的爬虫是相对容易的。Scrapy是一个非常轻量级的爬虫框架,极大的简化了爬虫的开发过程。另外,Scrapy的文档也很详细。如果觉得我的介绍省略了一些不清楚的地方,推荐阅读他的Tutorial
scrapy分页抓取网页(scrapy分页抓取网页中的数据,常用的有三种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-29 07:08
scrapy分页抓取网页中的数据,常用的有三种方法scrapy.queryselector,
#-*-coding:utf-8-*-importscrapyclassqueryselector(scrapy。spider):name='queryselector'allowed_domains=['confluence']template=scrapy。html。xpath('//div[1]/div/a/div/div/span/a/text()')#classmeta=scrapy。
spider。css('all')zip_items=scrapy。default_params()items=scrapy。default_params(item=item,sex='')queryselector(item=item,allowed_domains=squid(),template='')另:建议使用xpaths解析scrapy文件>>>importscrapy>>>scrapy。
request。spider。css('canvas。state。grayscale')queryselector('canvas。state。grayscale',class='ctx')建议使用xpaths解析scrapy文件>>>importscrapy>>>scrapy。request。spider。css('canvas。state。grayscale')。
看你需要什么功能了,web爬虫->解析数据->存储->发布只是这样也可以爬取,如果数据量比较大的话,就要使用javascrapy库了, 查看全部
scrapy分页抓取网页(scrapy分页抓取网页中的数据,常用的有三种方法)
scrapy分页抓取网页中的数据,常用的有三种方法scrapy.queryselector,
#-*-coding:utf-8-*-importscrapyclassqueryselector(scrapy。spider):name='queryselector'allowed_domains=['confluence']template=scrapy。html。xpath('//div[1]/div/a/div/div/span/a/text()')#classmeta=scrapy。
spider。css('all')zip_items=scrapy。default_params()items=scrapy。default_params(item=item,sex='')queryselector(item=item,allowed_domains=squid(),template='')另:建议使用xpaths解析scrapy文件>>>importscrapy>>>scrapy。
request。spider。css('canvas。state。grayscale')queryselector('canvas。state。grayscale',class='ctx')建议使用xpaths解析scrapy文件>>>importscrapy>>>scrapy。request。spider。css('canvas。state。grayscale')。
看你需要什么功能了,web爬虫->解析数据->存储->发布只是这样也可以爬取,如果数据量比较大的话,就要使用javascrapy库了,
scrapy分页抓取网页(本文以爬取网站:为例1.安装scrapy框架详细教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-26 08:16
)
本文以爬取网站为例
1.安装scrapy框架
点击这里跳转到详细教程
2.新的scrapy项目
生成爬虫文件。打开指定目录下的cmd.exe文件,输入代码
scrapy startproject mxp7
cd mxp7
scrapy genspider sp mxp7.com
然后通过Pycharm打开我们新创建的项目,可以发现所有的文件都已经创建好了,我们只需要修改文件中的代码,然后就可以在命令行爬取数据了。
3.提取数据
首先点击打开一个网页,查看博客的基本框架,然后我们在我们的爬虫文件sp.py中创建一个条目字典,通过xpath提取博客的内容。
注:这里强调一个xpath相关的坑。第一次拿到网页标签内容的时候,喜欢把xpath复制到浏览器调试目录下
比如复制上图title的xpath,得到的xpath内容如下,他会按照tags的顺序提取xpath
/html/body/div[2]/div[1]/section[1]/main/article/header/h1
但是这种情况只针对静态网页,因为动态网页中的一些信息是通过代码动态加载的。我们复制的xpath是动态加载后的目录,但是爬取数据的时候,爬虫不会动态加载接口,只会爬取响应内容下的原代码。如果想让爬虫通过标签序列获取网页的内容,就必须与响应下的代码进行比较。一般来说,计算起来相当麻烦。
如何打开网页的响应
打开目标网页,点击F12进入浏览器调试,选择Network后按F5刷新,界面下方会出现网页调用的文件,选择与当前URL同名的文件,然后点击右侧的顶部菜单“响应”,我们可以查看响应的内容
话虽如此,在浏览器调试界面中,我们也可以通过检索id来获取xpath
内容如下:
//*[@id="post-331"]/header/h1
会发现id和网页的编号是一样的,也就是说每个网页的tag的id都不一样。我们不能通过id提取所有网页的xpath路径,所以这里作者推荐大家通过css path的xpath提取。我们写完xpath的内容后,得到的sp.py的源码如下:
# sp.py源码
import scrapy
class SpSpider(scrapy.Spider):
name = 'sp'
allowed_domains = ['mxp7.com']
start_urls = ['http://mxp7.com/331/']
def parse(self, response):
item = {}
item["date"] = response.xpath("//span[@class ='meta-date']//time/text()").extract_first()
item["category"] = response.xpath("//span[@class = 'meta-category']//a/text()").extract_first()
item["title"] = response.xpath("//h1[@class = 'entry-title']/text()").extract_first()
item["author"] = response.xpath("//span[@class = 'meta-author']//a/text()").extract_first()
contain_path = response.xpath("//div[@class = 'entry-content clearfix']")
item["contain"] = contain_path.xpath("string(.)").extract_first()
print(item)
yield item
这里我们把数据扔到管道中,然后我们就可以对管道中的数据进行处理了。笔者这里选择将传输的数据输出到命令行。
# pipelines.py源码
class Mxp7Pipeline:
def process_item(self, item, spider):
print(item)
return item
处理好pipelines数据后,我们还需要在setting.py中打开pipelines
找到此代码并取消注释。此代码调用我们管道中的函数。下面的300指的是函数的权重。这个权重将决定并行管道中数据处理的优先级。
处理完这个,我们就可以在路径D:\Project\Spider\mxp7>下开始我们的爬行,进入命令行
scrapy crawl sp
然后你会发现我们抓取的数据隐藏在很多日志文件中。为了视觉体验,我们可以在setting.py中添加一段代码,使输出的日志级别为ERROR
LOG_LEVEL = "WARNING"
然后在cmd中重新输入grab命令
我们可以成功抓取页面内容
如果我们想要获取博客上发布的所有内容,那么还需要修改sp.py,在parse函数中添加获取下一页的代码,可以先在浏览器上打开网页,查看下一页page 格式,可以发现下一页已经是完整格式的链接了
然后我们就可以直接使用我们在抛出的scrapy.Request参数中获取的网页
pre_url = response.xpath("//div[@class = 'nav-previous']//a/@href").extract_first()
if pre_url:
yield scrapy.Request(pre_url, callback=self.parse)//调用自身
但是在某些网站上获取到的网址并不是一个完整的网址(作者网站的反爬虫机制比较弱)
需要在提取的URL前加上网页的头地址。我相信你自己可以做到这一点,所以我暂时不再赘述。修改后,我们还需要修改setting.py中USER_AGENT的值。在修改之前,我们还需要获取网页的 USER_AGENT 的值。
注意:USER_AGENT是网站的爬虫和反爬虫机制发生冲突的地方,双方会采取千变万化的措施来对抗这部分。作者的这一步只适用于最简单的反爬虫机制。事实上,作者的网站目前没有任何反爬虫机制。即使不执行这一步,我们也可以正常抓取所有文章内容。
打开Network界面后,点击顶部菜单右下角的“Headers”,滑动到底部获取user-agent的值
然后我们在设置中找到注释的USER_AGENT代码,修改它的值为这里复制的值
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
处理完之后我们就可以在cmd界面再次抓取数据了
scrapy crawl sp
成功抓取网站所有文章内容
4.保存文件
如果要保存文件,只需要在命令行中输入以下代码即可:
scrapy crawl sp -o mxp7.csv
将在当前目录中创建一个新的 mxp7.csv 文件
打开后发现乱码,我们可以通过记事本打开,保存为这种格式
重新打开后就可以得到正常的文件了
查看全部
scrapy分页抓取网页(本文以爬取网站:为例1.安装scrapy框架详细教程
)
本文以爬取网站为例
1.安装scrapy框架
点击这里跳转到详细教程
2.新的scrapy项目
生成爬虫文件。打开指定目录下的cmd.exe文件,输入代码
scrapy startproject mxp7
cd mxp7
scrapy genspider sp mxp7.com
然后通过Pycharm打开我们新创建的项目,可以发现所有的文件都已经创建好了,我们只需要修改文件中的代码,然后就可以在命令行爬取数据了。
3.提取数据
首先点击打开一个网页,查看博客的基本框架,然后我们在我们的爬虫文件sp.py中创建一个条目字典,通过xpath提取博客的内容。
注:这里强调一个xpath相关的坑。第一次拿到网页标签内容的时候,喜欢把xpath复制到浏览器调试目录下
比如复制上图title的xpath,得到的xpath内容如下,他会按照tags的顺序提取xpath
/html/body/div[2]/div[1]/section[1]/main/article/header/h1
但是这种情况只针对静态网页,因为动态网页中的一些信息是通过代码动态加载的。我们复制的xpath是动态加载后的目录,但是爬取数据的时候,爬虫不会动态加载接口,只会爬取响应内容下的原代码。如果想让爬虫通过标签序列获取网页的内容,就必须与响应下的代码进行比较。一般来说,计算起来相当麻烦。
如何打开网页的响应
打开目标网页,点击F12进入浏览器调试,选择Network后按F5刷新,界面下方会出现网页调用的文件,选择与当前URL同名的文件,然后点击右侧的顶部菜单“响应”,我们可以查看响应的内容
话虽如此,在浏览器调试界面中,我们也可以通过检索id来获取xpath
内容如下:
//*[@id="post-331"]/header/h1
会发现id和网页的编号是一样的,也就是说每个网页的tag的id都不一样。我们不能通过id提取所有网页的xpath路径,所以这里作者推荐大家通过css path的xpath提取。我们写完xpath的内容后,得到的sp.py的源码如下:
# sp.py源码
import scrapy
class SpSpider(scrapy.Spider):
name = 'sp'
allowed_domains = ['mxp7.com']
start_urls = ['http://mxp7.com/331/']
def parse(self, response):
item = {}
item["date"] = response.xpath("//span[@class ='meta-date']//time/text()").extract_first()
item["category"] = response.xpath("//span[@class = 'meta-category']//a/text()").extract_first()
item["title"] = response.xpath("//h1[@class = 'entry-title']/text()").extract_first()
item["author"] = response.xpath("//span[@class = 'meta-author']//a/text()").extract_first()
contain_path = response.xpath("//div[@class = 'entry-content clearfix']")
item["contain"] = contain_path.xpath("string(.)").extract_first()
print(item)
yield item
这里我们把数据扔到管道中,然后我们就可以对管道中的数据进行处理了。笔者这里选择将传输的数据输出到命令行。
# pipelines.py源码
class Mxp7Pipeline:
def process_item(self, item, spider):
print(item)
return item
处理好pipelines数据后,我们还需要在setting.py中打开pipelines
找到此代码并取消注释。此代码调用我们管道中的函数。下面的300指的是函数的权重。这个权重将决定并行管道中数据处理的优先级。
处理完这个,我们就可以在路径D:\Project\Spider\mxp7>下开始我们的爬行,进入命令行
scrapy crawl sp
然后你会发现我们抓取的数据隐藏在很多日志文件中。为了视觉体验,我们可以在setting.py中添加一段代码,使输出的日志级别为ERROR
LOG_LEVEL = "WARNING"
然后在cmd中重新输入grab命令
我们可以成功抓取页面内容
如果我们想要获取博客上发布的所有内容,那么还需要修改sp.py,在parse函数中添加获取下一页的代码,可以先在浏览器上打开网页,查看下一页page 格式,可以发现下一页已经是完整格式的链接了
然后我们就可以直接使用我们在抛出的scrapy.Request参数中获取的网页
pre_url = response.xpath("//div[@class = 'nav-previous']//a/@href").extract_first()
if pre_url:
yield scrapy.Request(pre_url, callback=self.parse)//调用自身
但是在某些网站上获取到的网址并不是一个完整的网址(作者网站的反爬虫机制比较弱)
需要在提取的URL前加上网页的头地址。我相信你自己可以做到这一点,所以我暂时不再赘述。修改后,我们还需要修改setting.py中USER_AGENT的值。在修改之前,我们还需要获取网页的 USER_AGENT 的值。
注意:USER_AGENT是网站的爬虫和反爬虫机制发生冲突的地方,双方会采取千变万化的措施来对抗这部分。作者的这一步只适用于最简单的反爬虫机制。事实上,作者的网站目前没有任何反爬虫机制。即使不执行这一步,我们也可以正常抓取所有文章内容。
打开Network界面后,点击顶部菜单右下角的“Headers”,滑动到底部获取user-agent的值
然后我们在设置中找到注释的USER_AGENT代码,修改它的值为这里复制的值
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
处理完之后我们就可以在cmd界面再次抓取数据了
scrapy crawl sp
成功抓取网站所有文章内容
4.保存文件
如果要保存文件,只需要在命令行中输入以下代码即可:
scrapy crawl sp -o mxp7.csv
将在当前目录中创建一个新的 mxp7.csv 文件
打开后发现乱码,我们可以通过记事本打开,保存为这种格式
重新打开后就可以得到正常的文件了
scrapy分页抓取网页(怎样优雅用yield写这样的代码呢?部分代码实例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-15 16:01
)
使用yield优雅爬取网页分页数据
在使用Python爬取网页数据时,我们经常会遇到分页数据,有些下一页按钮已经有了具体的链接地址,而有些可能是javascript处理的。这需要能够同时解析页面内容和采集下一页的url。如何在python中优雅地编写这样的代码?或者如何更pythonic?
下面给出一些代码示例
def get_next_page(obj):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('a', text="下頁")
break
except:
error_occurred = True
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
next_url = "http://www.etnet.com.hk" + e_next_page.get('href')
time.sleep(2)
yield content
for i in get_next_page(next_url):
yield i
else:
yield content
def get_next_page(obj, page=1):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if page == 1 and (not "sh=" in obj) and hrefs:
reset_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"/sector-industry-details.aspx?%s&page=1" % \
(hrefs[0].replace('sh=1', 'sh=0').replace('&page=', '') \
.replace("'", '').split()[0]))
for next_page in get_next_page(reset_url):
yield next_page
return
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('td', text="下一頁 ")
break
except:
error_occurred = True
LOG.error(traceback.format_exc())
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if hrefs:
next_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"-details.aspx?%s&page=%d" % \
(hrefs[0].replace('sh=1', 'sh=0') \
.replace('&page=', '').replace("'", '').split()[0], page+1))
time.sleep(2)
yield content
for next_page in get_next_page(next_url, page+1):
yield next_page
else:
yield content
for curr_href in e_href:
retry_interval = random.randint(MIN_INTERVAL_SECONDS_FOR_RETRIEVING,
MAX_INTERVAL_SECONDS_FOR_RETRIEVING)
time.sleep(retry_interval)
contents = get_next_page(curr_href)
for content in contents:
get_page_data(content) 查看全部
scrapy分页抓取网页(怎样优雅用yield写这样的代码呢?部分代码实例
)
使用yield优雅爬取网页分页数据
在使用Python爬取网页数据时,我们经常会遇到分页数据,有些下一页按钮已经有了具体的链接地址,而有些可能是javascript处理的。这需要能够同时解析页面内容和采集下一页的url。如何在python中优雅地编写这样的代码?或者如何更pythonic?
下面给出一些代码示例
def get_next_page(obj):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('a', text="下頁")
break
except:
error_occurred = True
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
next_url = "http://www.etnet.com.hk" + e_next_page.get('href')
time.sleep(2)
yield content
for i in get_next_page(next_url):
yield i
else:
yield content
def get_next_page(obj, page=1):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if page == 1 and (not "sh=" in obj) and hrefs:
reset_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"/sector-industry-details.aspx?%s&page=1" % \
(hrefs[0].replace('sh=1', 'sh=0').replace('&page=', '') \
.replace("'", '').split()[0]))
for next_page in get_next_page(reset_url):
yield next_page
return
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('td', text="下一頁 ")
break
except:
error_occurred = True
LOG.error(traceback.format_exc())
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if hrefs:
next_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"-details.aspx?%s&page=%d" % \
(hrefs[0].replace('sh=1', 'sh=0') \
.replace('&page=', '').replace("'", '').split()[0], page+1))
time.sleep(2)
yield content
for next_page in get_next_page(next_url, page+1):
yield next_page
else:
yield content
for curr_href in e_href:
retry_interval = random.randint(MIN_INTERVAL_SECONDS_FOR_RETRIEVING,
MAX_INTERVAL_SECONDS_FOR_RETRIEVING)
time.sleep(retry_interval)
contents = get_next_page(curr_href)
for content in contents:
get_page_data(content)
scrapy分页抓取网页(万业鹏博士爬虫分页抓取网页视频地址:正则表达式抓取油管视频使用scrapy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-14 19:04
scrapy分页抓取网页视频地址:万业鹏博士scrapy新文章:scrapy|正则表达式抓取油管视频使用scrapy实现爬虫教程,scrapy是用requests库模拟人工操作请求ip。万业鹏博士爬虫软件系列文章目录万业鹏博士介绍上次介绍了scrapy的分页抓取功能,但是对分页抓取所需要的条件以及用到的正则表达式(requests)了解的不是很多,本次将介绍scrapy新文章“scrapy|正则表达式抓取油管视频”,scrapy新文章包含爬虫的完整教程,以及scrapy正则表达式基础,用到的正则表达式和包括ip地址抓取视频地址的四大正则表达式。
1.scrapy新文章的四大正则表达式1.1requests(requests库包含正则表达式)正则表达式基础正则表达式req这个正则表达式:req[^:]=requestbody正则表达式reqexp这个正则表达式:reqexp[^:]=requestbody正则表达式reqno正则表达式reqext[^:]=requestbody正则表达式requrlstr通过正则表达式匹配的要素列表来表示网络请求,如下正则表达式匹配data类型的网络请求信息,而不是url地址,对于data类型的网络请求信息,我们知道它是四种数据类型,分别是:字符串(string)、数组(array)、容器(map)、元组(tuple),正则表达式reqexp[^:]=requestbody正则表达式reqexp[^:]=requestbody正则表达式reqstr匹配指定post参数的网络请求信息,一次匹配一个post参数,例如mailtype查询scrapy中没有直接匹配不同参数的信息,一次匹配指定post参数的信息。
1.2postimportscrapy.post#post请求defget_post_from_url(url,requrl):scrapy.disable_useragent#设置你要替换请求headers的值scrapy.disable_useragent=true1.3scrapy中settings.getting_started_to_debug()#初始化settings.getting_started_to_debug()会给settings.getting_debug()添加scrapy_debug信息来运行,第一次运行的时候,scrapy会提示错误代码,大家不要管它,只要不是特别多就不用管它,大部分都是正常的。
注意:scrapyscrapy配置:>>>scrapy.__init__.__name="scrapy">>>scrapy.__dir__="__main__">>>scrapy.__url__="">>>scrapy.__version__="1.0.0">>>scrapy.conf.meta.scrapy_debug="master">>>scrapy.conf.meta.scrapy_start_urls=[]>>>scrapy.conf.meta。 查看全部
scrapy分页抓取网页(万业鹏博士爬虫分页抓取网页视频地址:正则表达式抓取油管视频使用scrapy)
scrapy分页抓取网页视频地址:万业鹏博士scrapy新文章:scrapy|正则表达式抓取油管视频使用scrapy实现爬虫教程,scrapy是用requests库模拟人工操作请求ip。万业鹏博士爬虫软件系列文章目录万业鹏博士介绍上次介绍了scrapy的分页抓取功能,但是对分页抓取所需要的条件以及用到的正则表达式(requests)了解的不是很多,本次将介绍scrapy新文章“scrapy|正则表达式抓取油管视频”,scrapy新文章包含爬虫的完整教程,以及scrapy正则表达式基础,用到的正则表达式和包括ip地址抓取视频地址的四大正则表达式。
1.scrapy新文章的四大正则表达式1.1requests(requests库包含正则表达式)正则表达式基础正则表达式req这个正则表达式:req[^:]=requestbody正则表达式reqexp这个正则表达式:reqexp[^:]=requestbody正则表达式reqno正则表达式reqext[^:]=requestbody正则表达式requrlstr通过正则表达式匹配的要素列表来表示网络请求,如下正则表达式匹配data类型的网络请求信息,而不是url地址,对于data类型的网络请求信息,我们知道它是四种数据类型,分别是:字符串(string)、数组(array)、容器(map)、元组(tuple),正则表达式reqexp[^:]=requestbody正则表达式reqexp[^:]=requestbody正则表达式reqstr匹配指定post参数的网络请求信息,一次匹配一个post参数,例如mailtype查询scrapy中没有直接匹配不同参数的信息,一次匹配指定post参数的信息。
1.2postimportscrapy.post#post请求defget_post_from_url(url,requrl):scrapy.disable_useragent#设置你要替换请求headers的值scrapy.disable_useragent=true1.3scrapy中settings.getting_started_to_debug()#初始化settings.getting_started_to_debug()会给settings.getting_debug()添加scrapy_debug信息来运行,第一次运行的时候,scrapy会提示错误代码,大家不要管它,只要不是特别多就不用管它,大部分都是正常的。
注意:scrapyscrapy配置:>>>scrapy.__init__.__name="scrapy">>>scrapy.__dir__="__main__">>>scrapy.__url__="">>>scrapy.__version__="1.0.0">>>scrapy.conf.meta.scrapy_debug="master">>>scrapy.conf.meta.scrapy_start_urls=[]>>>scrapy.conf.meta。
scrapy分页抓取网页(关于分页,最佳方法取决于所使用的分页类型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-14 18:10
关于分页,最好的方法实际上取决于所使用的分页类型。
如果你:
然后您可以一次安排所有页面:
def parse_listings_page1(self, response):
"""
here parse first page, schedule all other pages at once!
"""
# e.g. 'http://shop.com/products?page=1'
url = response.url
# e.g. 100
total_pages = int(response.css('.last-page').extract_first())
# schedule every page at once!
for page in range(2, total_pages + 1):
page_url = add_or_replace_parameter(url, 'page', page)
yield Request(page_url, self.parse_listings)
# don't forget to also parse listings on first page!
yield from self.parse_listings(response)
def parse_listings(self, response):
for url in response.css('.listing::attr(href)'):
yield Request(url, self.parse_product)
这种方法的巨大好处是速度 - 在这里您可以采用异步逻辑并同时抓取所有页面!
或者。
如果你:
然后你必须同步安排页面 1:1。
def parse(self, response):
for product in response.css('.product::attr(href)'):
yield Request(product, self.parse_product)
next_page = response.css('.next-page::attr(href)').extract_first()
if next_page:
yield Request(next_page, self.parse)
else:
print(f'last page reached: {response.url}')
在您的示例中,您使用了第二种同步方法,您在这里的担忧是没有根据的,您只需要确保 xpath 选择器选择正确的页面即可。 查看全部
scrapy分页抓取网页(关于分页,最佳方法取决于所使用的分页类型)
关于分页,最好的方法实际上取决于所使用的分页类型。
如果你:
然后您可以一次安排所有页面:
def parse_listings_page1(self, response):
"""
here parse first page, schedule all other pages at once!
"""
# e.g. 'http://shop.com/products?page=1'
url = response.url
# e.g. 100
total_pages = int(response.css('.last-page').extract_first())
# schedule every page at once!
for page in range(2, total_pages + 1):
page_url = add_or_replace_parameter(url, 'page', page)
yield Request(page_url, self.parse_listings)
# don't forget to also parse listings on first page!
yield from self.parse_listings(response)
def parse_listings(self, response):
for url in response.css('.listing::attr(href)'):
yield Request(url, self.parse_product)
这种方法的巨大好处是速度 - 在这里您可以采用异步逻辑并同时抓取所有页面!
或者。
如果你:
然后你必须同步安排页面 1:1。
def parse(self, response):
for product in response.css('.product::attr(href)'):
yield Request(product, self.parse_product)
next_page = response.css('.next-page::attr(href)').extract_first()
if next_page:
yield Request(next_page, self.parse)
else:
print(f'last page reached: {response.url}')
在您的示例中,您使用了第二种同步方法,您在这里的担忧是没有根据的,您只需要确保 xpath 选择器选择正确的页面即可。
scrapy分页抓取网页( 如何Scrapy构建一个简单的网络爬虫?会介绍如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-12 11:13
如何Scrapy构建一个简单的网络爬虫?会介绍如何)
项目需要灵活的爬虫工具,实现爬虫框架。根据目标网站的结构、地址和需要的内容,进行简单的配置开发即可实现具体的网站爬虫功能。你会发现 Python 下有这个 Scrapy 工具。对于一个普通的网络爬虫功能,Scrapy 完全胜任,并且封装了很多复杂的编程。本文将介绍如何使用 Scrapy 构建一个简单的网络爬虫。
一个基本的爬虫工具,它应该具备以下功能:
让我们看看 Scrapy 是如何做到这一点的。首先准备好Scrapy环境,需要安装Python(本文使用v2.7)和pip,然后使用pip安装lxml和scrapy。个人强烈推荐使用virtualenv安装环境,这样不同项目之间就不会冲突了,详细步骤这里不再赘述。
Mac用户注意,使用pip安装lxml时,会出现类似如下的错误:
错误:#include "xml/xmlversion.h" 未找到
要解决这个问题,你需要先安装 Xcode 的命令行工具。具体方法是在命令行执行如下命令。
1
$ xcode-select --install
环境安装好后,我们用Scrapy实现一个简单的爬虫,抓取本篇博客网站的文章的标题、地址和摘要。
创建项目
1
$ scrapy startproject my_crawler
此命令将在当前目录中创建一个名为“my_crawler”的项目。项目目录结构如下
我的爬虫
|- my_crawler
| |- 蜘蛛
| | |- __init__.py
| |- items.py
| |- pipelines.py
| |- 设置.py
|-scrapy.cfg
设置要爬取的内容的字段
这里是文章的标题、地址和摘要
修改“items.py”文件,在“MyCrawlerItem”类中添加如下代码:
# -*- 编码:utf-8 -*-
导入scrapy
类 MyCrawlerItem(scrapy.Item):
title = scrapy.Field() # 文章Title
url = scrapy.Field()# 文章地址
summary = scrapy.Field() # 文章总结
通过
编写网页解析代码
在“my_crawler/spiders”目录下,创建一个名为“crawl_spider.py”的文件(文件名可以任意)。
代码如下
# -*- 编码:utf-8 -*-
导入scrapy
从 scrapy.linkextractors 导入 LinkExtractor
从 scrapy.spiders 导入 CrawlSpider,规则
从 my_crawler.items 导入 MyCrawlerItem
类 MyCrawlSpider(CrawlSpider):
name = 'my_crawler'# 蜘蛛名,必须唯一,执行爬虫命令时使用
allowed_domains = [''] #限制允许爬取的域名,可设置多个
start_urls = [
"",#种子地址,可设置多个
]
rules = ( #对应具体的URL,设置解析函数,可设置多个
Rule(LinkExtractor(allow=r'/page/[0-9]+'), #指定允许继续爬取的URL格式,支持正则
callback='parse_item', # 用于解析网页的回调函数名
关注=真
),
)
def parse_item(self, response):
# 通过 XPath 获取 Dom 元素
articles = response.xpath('//*[@id="main"]/ul/li')
对于文章中的文章:
item = MyCrawlerItem()
item['title'] = article.xpath('h3[@class="entry-title"]/a/text()').extract()[0]
item['url'] = article.xpath('h3[@class="entry-title"]/a/@href').extract()[0]
item['summary'] = article.xpath('div[2]/p/text()').extract()[0]
产量项目
不熟悉XPath的朋友可以通过Chrome的调试工具获取元素的XPath。
我们测试爬虫的效果
在命令行输入:
1
$ scrapy crawl my_crawler
请注意,这里的“my_crawler”是您在“crawl_spider.py”文件中提供的蜘蛛名称。
几秒钟后,您应该会在控制台上看到要抓取的字段内容。太神奇了! Scrapy 封装了对 HTTP(S) 请求、内容下载、待爬取和爬取的 URL 队列的管理。你的主要工作基本上就是设置URL规则和编写解析方法。
我们将抓取的内容保存为 JSON 文件:
1
$ scrapy crawl my_crawler -o my_crawler.json -t json
在当前目录下可以找到“my_crawler.json”文件,里面存放了我们要爬取的字段信息。 (参数“-t json”可以省略)
将结果保存到数据库
这里我们使用MongoDB,你需要先安装Python MongoDB库“pymongo”。编辑“my_crawler”目录下的“pipelines.py”文件,添加
到“MyCrawlerPipeline”类
以下代码:
# -*- 编码:utf-8 -*-
导入 pymongo
从 scrapy.conf 导入设置
从 scrapy.exceptions 导入 DropItem
类 MyCrawlerPipeline(object):
def __init__(self):
# 建立 MongoDB 连接
connection = pymongo.Connection(
设置['MONGO_SERVER'],
设置['MONGO_PORT']
)
db = 连接[设置['MONGO_DB']]
self.采集 = db[settings['MONGO_采集']]
#处理每一个被爬取的MyCrawlerItem
def process_item(self, item, spider):
有效 = 真
对于项目中的数据:
如果不是数据:# 过滤掉带有空字段的项目
有效 = 假
raise DropItem("Missing {0}!".format(data))
如果有效:
#也可以使用self.采集.insert(dict(item)),使用upsert防止重复
self.采集.update({'url': item['url']}, dict(item), upsert=True)
退货
打开“my_crawler”目录下的“settings.py”文件,在文件末尾添加管道设置:
ITEM_PIPELINES = {
'my_crawler.pipelines.MyCrawlerPipeline': 300, #设置Pipeline,可以有多个,值为执行优先级
}
#MongoDB连接信息
MONGO_SERVER = '本地主机'
MONGO_PORT = 27017
MONGO_DB = 'bjhee'
MONGO_采集 = '文章'
DOWNLOAD_DELAY=2 #如果网络慢,可以加一些延迟,单位是秒
执行爬虫
1
$ scrapy crawl my_crawler
不要忘记启动 MongoDB 并创建“bjhee”数据库。现在可以查询MongoDB中的记录了。
总结一下,要使用Scrapy搭建一个网络爬虫,你需要做的就是:
Scrapy 为您完成所有其他工作。上图是Scrapy的具体工作流程。这个怎么样?开始编写自己的爬虫。 查看全部
scrapy分页抓取网页(
如何Scrapy构建一个简单的网络爬虫?会介绍如何)
项目需要灵活的爬虫工具,实现爬虫框架。根据目标网站的结构、地址和需要的内容,进行简单的配置开发即可实现具体的网站爬虫功能。你会发现 Python 下有这个 Scrapy 工具。对于一个普通的网络爬虫功能,Scrapy 完全胜任,并且封装了很多复杂的编程。本文将介绍如何使用 Scrapy 构建一个简单的网络爬虫。
一个基本的爬虫工具,它应该具备以下功能:
让我们看看 Scrapy 是如何做到这一点的。首先准备好Scrapy环境,需要安装Python(本文使用v2.7)和pip,然后使用pip安装lxml和scrapy。个人强烈推荐使用virtualenv安装环境,这样不同项目之间就不会冲突了,详细步骤这里不再赘述。
Mac用户注意,使用pip安装lxml时,会出现类似如下的错误:
错误:#include "xml/xmlversion.h" 未找到
要解决这个问题,你需要先安装 Xcode 的命令行工具。具体方法是在命令行执行如下命令。
1
$ xcode-select --install
环境安装好后,我们用Scrapy实现一个简单的爬虫,抓取本篇博客网站的文章的标题、地址和摘要。
创建项目
1
$ scrapy startproject my_crawler
此命令将在当前目录中创建一个名为“my_crawler”的项目。项目目录结构如下
我的爬虫
|- my_crawler
| |- 蜘蛛
| | |- __init__.py
| |- items.py
| |- pipelines.py
| |- 设置.py
|-scrapy.cfg
设置要爬取的内容的字段
这里是文章的标题、地址和摘要
修改“items.py”文件,在“MyCrawlerItem”类中添加如下代码:
# -*- 编码:utf-8 -*-
导入scrapy
类 MyCrawlerItem(scrapy.Item):
title = scrapy.Field() # 文章Title
url = scrapy.Field()# 文章地址
summary = scrapy.Field() # 文章总结
通过
编写网页解析代码
在“my_crawler/spiders”目录下,创建一个名为“crawl_spider.py”的文件(文件名可以任意)。
代码如下
# -*- 编码:utf-8 -*-
导入scrapy
从 scrapy.linkextractors 导入 LinkExtractor
从 scrapy.spiders 导入 CrawlSpider,规则
从 my_crawler.items 导入 MyCrawlerItem
类 MyCrawlSpider(CrawlSpider):
name = 'my_crawler'# 蜘蛛名,必须唯一,执行爬虫命令时使用
allowed_domains = [''] #限制允许爬取的域名,可设置多个
start_urls = [
"",#种子地址,可设置多个
]
rules = ( #对应具体的URL,设置解析函数,可设置多个
Rule(LinkExtractor(allow=r'/page/[0-9]+'), #指定允许继续爬取的URL格式,支持正则
callback='parse_item', # 用于解析网页的回调函数名
关注=真
),
)
def parse_item(self, response):
# 通过 XPath 获取 Dom 元素
articles = response.xpath('//*[@id="main"]/ul/li')
对于文章中的文章:
item = MyCrawlerItem()
item['title'] = article.xpath('h3[@class="entry-title"]/a/text()').extract()[0]
item['url'] = article.xpath('h3[@class="entry-title"]/a/@href').extract()[0]
item['summary'] = article.xpath('div[2]/p/text()').extract()[0]
产量项目
不熟悉XPath的朋友可以通过Chrome的调试工具获取元素的XPath。
我们测试爬虫的效果
在命令行输入:
1
$ scrapy crawl my_crawler
请注意,这里的“my_crawler”是您在“crawl_spider.py”文件中提供的蜘蛛名称。
几秒钟后,您应该会在控制台上看到要抓取的字段内容。太神奇了! Scrapy 封装了对 HTTP(S) 请求、内容下载、待爬取和爬取的 URL 队列的管理。你的主要工作基本上就是设置URL规则和编写解析方法。
我们将抓取的内容保存为 JSON 文件:
1
$ scrapy crawl my_crawler -o my_crawler.json -t json
在当前目录下可以找到“my_crawler.json”文件,里面存放了我们要爬取的字段信息。 (参数“-t json”可以省略)
将结果保存到数据库
这里我们使用MongoDB,你需要先安装Python MongoDB库“pymongo”。编辑“my_crawler”目录下的“pipelines.py”文件,添加
到“MyCrawlerPipeline”类
以下代码:
# -*- 编码:utf-8 -*-
导入 pymongo
从 scrapy.conf 导入设置
从 scrapy.exceptions 导入 DropItem
类 MyCrawlerPipeline(object):
def __init__(self):
# 建立 MongoDB 连接
connection = pymongo.Connection(
设置['MONGO_SERVER'],
设置['MONGO_PORT']
)
db = 连接[设置['MONGO_DB']]
self.采集 = db[settings['MONGO_采集']]
#处理每一个被爬取的MyCrawlerItem
def process_item(self, item, spider):
有效 = 真
对于项目中的数据:
如果不是数据:# 过滤掉带有空字段的项目
有效 = 假
raise DropItem("Missing {0}!".format(data))
如果有效:
#也可以使用self.采集.insert(dict(item)),使用upsert防止重复
self.采集.update({'url': item['url']}, dict(item), upsert=True)
退货
打开“my_crawler”目录下的“settings.py”文件,在文件末尾添加管道设置:
ITEM_PIPELINES = {
'my_crawler.pipelines.MyCrawlerPipeline': 300, #设置Pipeline,可以有多个,值为执行优先级
}
#MongoDB连接信息
MONGO_SERVER = '本地主机'
MONGO_PORT = 27017
MONGO_DB = 'bjhee'
MONGO_采集 = '文章'
DOWNLOAD_DELAY=2 #如果网络慢,可以加一些延迟,单位是秒
执行爬虫
1
$ scrapy crawl my_crawler
不要忘记启动 MongoDB 并创建“bjhee”数据库。现在可以查询MongoDB中的记录了。
总结一下,要使用Scrapy搭建一个网络爬虫,你需要做的就是:
Scrapy 为您完成所有其他工作。上图是Scrapy的具体工作流程。这个怎么样?开始编写自己的爬虫。
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-11 02:16
初步了解 Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
它最初是为网络抓取(更准确地说,网络抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。
本文档将通过介绍其背后的概念,让您了解 Scrapy 的工作原理,并决定 Scrapy 是否是您所需要的。
当您准备好开始您的项目时,您可以参考它。
选择一个网站
当您需要从 网站 获取信息,但 网站 不提供 API 或以编程方式获取信息的机制时,Scrapy 可以提供帮助。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
今天添加的种子列表可以在此页面上找到:
定义要抓取的数据
第一步是定义我们需要抓取的数据。在 Scrapy 中,这是通过 . (在这种情况下是 torrent 文件)
我们定义的项目:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写蜘蛛。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过查看页面内容,所有种子都有相似的 URL。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式: /tor/\d+ 。
我们使用 XPath 选择要从页面的 HTML 源中提取的数据。以其中一个 torrent 文件的页面为例:
查看 HTML 页面源并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以看到文件名收录在标签中:
Darwin - The Evolution Of An Exhibition
对应的 XPath 表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取描述:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的更多信息,请参阅 XPath 参考。
最后,结合以上给出蜘蛛代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
TorrentItem 在 .
执行爬虫获取数据
最后,我们可以运行爬虫获取网站的数据,并以JSON格式存储到scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您也可以写入存储项目到数据库中。
查看提取的数据
执行后,当您查看 scraped_data.json 时,您将看到提取的项目:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是一个列表,所以值是存储在一个列表中的(直接赋值的url除外)。如果您想保存单个数据或对数据执行其他处理,这就是发挥作用的地方。
还有什么?
您已经了解了如何使用 Scrapy 从网页中提取和存储信息,但这只是冰山一角。Scrapy 提供了许多强大的功能,使爬取更容易、更高效,例如:
为非英语语言中的非标准或不正确的编码声明提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加快爬虫创建速度的同时,在更大的项目中保持代码的一致性。有关详细信息,请参阅命令。对于多个爬虫下的性能评估和故障检测,它提供了可扩展性。提供,为您测试XPath表达式、编写和调试爬虫、简化生产环境的部署和操作、监控机器提供了极大的便利。内置,
下一个
下一步当然是下载 Scrapy,你可以阅读它并加入社区。谢谢您的支持!
讨论 查看全部
scrapy分页抓取网页(初窥ScrapyScrapy背后的概念与工作原理(一))
初步了解 Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
它最初是为网络抓取(更准确地说,网络抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。
本文档将通过介绍其背后的概念,让您了解 Scrapy 的工作原理,并决定 Scrapy 是否是您所需要的。
当您准备好开始您的项目时,您可以参考它。
选择一个网站
当您需要从 网站 获取信息,但 网站 不提供 API 或以编程方式获取信息的机制时,Scrapy 可以提供帮助。
以 Mininova 网站 为例,我们要获取今天添加的所有种子的 URL、名称、描述和文件大小信息。
今天添加的种子列表可以在此页面上找到:
定义要抓取的数据
第一步是定义我们需要抓取的数据。在 Scrapy 中,这是通过 . (在这种情况下是 torrent 文件)
我们定义的项目:
import scrapy
class TorrentItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写一个提取数据的蜘蛛
第二步是写蜘蛛。它定义了初始 URL()、后续链接的规则以及从页面中提取数据的规则。
通过查看页面内容,所有种子都有相似的 URL。其中 NUMBER 是一个整数。根据这个规则,我们可以定义需要跟进的链接的正则表达式: /tor/\d+ 。
我们使用 XPath 选择要从页面的 HTML 源中提取的数据。以其中一个 torrent 文件的页面为例:
查看 HTML 页面源并为我们需要的数据(种子名称、描述和大小)创建一个 XPath 表达式。
通过观察,我们可以看到文件名收录在标签中:
Darwin - The Evolution Of An Exhibition
对应的 XPath 表达式:
//h1/text()
种子的描述收录在 id="description" 中
在标签中:
Description:
Short documentary made for Plymouth City Museum and Art Gallery regarding the setup of an exhibit about Charles Darwin in conjunction with the 200th anniversary of his birth.
...
对应XPath表达式获取描述:
//div[@id='description']
文件大小信息收录在 id=specifications 中
第二
在标签中:
Category:
Movies > Documentary
Total size:
150.62 megabyte
选择文件大小的 XPath 表达式:
//div[@id='specifications']/p[2]/text()[2]
有关 XPath 的更多信息,请参阅 XPath 参考。
最后,结合以上给出蜘蛛代码:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')]
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()
return torrent
TorrentItem 在 .
执行爬虫获取数据
最后,我们可以运行爬虫获取网站的数据,并以JSON格式存储到scraped_data.json文件中:
scrapy crawl mininova -o scraped_data.json
在命令中用于导出 JSON 文件。您可以修改导出格式(XML 或 CSV)或存储后端(FTP 或 Amazon S3),这并不难。
同时,您也可以写入存储项目到数据库中。
查看提取的数据
执行后,当您查看 scraped_data.json 时,您将看到提取的项目:
[{"url": "http://www.mininova.org/tor/2676093", "name": ["Darwin - The Evolution Of An Exhibition"], "description": ["Short documentary made for Plymouth ..."], "size": ["150.62 megabyte"]},
# ... other items ...
]
由于返回的是一个列表,所以值是存储在一个列表中的(直接赋值的url除外)。如果您想保存单个数据或对数据执行其他处理,这就是发挥作用的地方。
还有什么?
您已经了解了如何使用 Scrapy 从网页中提取和存储信息,但这只是冰山一角。Scrapy 提供了许多强大的功能,使爬取更容易、更高效,例如:
为非英语语言中的非标准或不正确的编码声明提供自动检测和强大的编码支持。支持基于模板生成爬虫。在加快爬虫创建速度的同时,在更大的项目中保持代码的一致性。有关详细信息,请参阅命令。对于多个爬虫下的性能评估和故障检测,它提供了可扩展性。提供,为您测试XPath表达式、编写和调试爬虫、简化生产环境的部署和操作、监控机器提供了极大的便利。内置,
下一个
下一步当然是下载 Scrapy,你可以阅读它并加入社区。谢谢您的支持!
讨论
scrapy分页抓取网页( WebCrawler下载Web页面如何调度站点的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-11 02:13
WebCrawler下载Web页面如何调度站点的?)
深度解析Python的爬虫框架Scrapy的结构和运行过程
网络爬虫(Web Crawler,Spider)是一种在互联网上爬行的机器人。当然,它通常不是实体机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实是一个程序,它不是爬行,而是有一定的目的,爬行时会采集数据。一些信息。例如,谷歌有大量的爬虫,它们在互联网上采集网页内容和它们之间的链接等信息;比如一些别有用心的爬虫,会在网上搜集foo[at]bar[dot]com等东西。另外,还有一些自定义爬虫,专门针对某个网站,比如JavaEye的Robbin前段时间写了几篇专门处理恶意爬虫的博客(原来的链接好像过期了,所以没有给出),而网站比如小众软件或者LinuxToy经常被全站爬下来,挂在不同的名字下。其实爬虫在基本原理上很简单,只要能上网分析网页,现在大部分语言都有方便的可以爬取网页的Http客户端库,以及最简单的HTML分析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。现在大部分语言都有方便的Http客户端库,可以爬取网页,最简单的HTML解析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。现在大部分语言都有方便的Http客户端库,可以爬取网页,最简单的HTML解析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。
爬虫的两个部分,一个是下载网页,有很多问题需要考虑,如何最大限度地利用本地带宽,如何调度不同站点的Web请求以减轻对方服务器的负担等等。在高性能的网络爬虫系统中,DNS查询也将成为需要优化的瓶颈。此外,还有一些“规则”需要遵守(例如 robots.txt)。得到网页后的分析过程也很复杂。网上各种奇葩,各种错误的HTML页面。几乎不可能全部分析。另外,随着 AJAX 的普及,如何获取 Javascript 动态生成的内容也成了一大难题;此外,互联网上有意无意地出现了各种各样的蜘蛛陷阱。如果你盲目地跟随超链接,你就会陷入陷阱,注定要失败。比如这个网站,据说谷歌之前宣布互联网上Unique URLs的数量已经达到1万亿,所以这个人很自豪地宣布了第二个万亿。:D
然而,实际上,像谷歌这样需要制作通用爬虫的人并不多。通常,我们制作一个 Crawler 来抓取特定的或某种类型的 网站。对 网站 结构进行一些分析,事情就会变得容易得多。通过分析和选择有价值的链接进行跟踪,可以避免许多不必要的链接或蜘蛛陷阱。如果 网站 的结构允许选择合适的路径,我们可以将感兴趣的事物按一定的顺序排列。再爬一遍,这样连URL重复的判断都可以省略。
比如我们要爬取pongba的博客中的博客文字,通过观察,很容易发现我们对两类页面感兴趣:
文章列出页面,比如首页,或者像/page/\d+/这样的URL的页面,通过Firebug可以看到每个文章的链接都在一个h1下的a标签中(需要注意的是,您在Firebug的HTML面板中看到的HTML代码可能与您在View Source中看到的有些出入。如果网页中存在动态修改DOM树的Javascript,则前者是修改版,并且Firebug正则化后,比如属性有引号等,而后者通常是你的蜘蛛爬取的原创内容。不同,需要特别注意),另外,wp-pagenavi类的一个div中还有指向不同列表页面的链接。
文章内容页面,每个博客都有这样一个页面,比如/2008/09/11/machine-learning-and-ai-resources/,里面收录了完整的文章内容,这是我们的感受感兴趣的内容。
因此,我们从首页开始,利用wp-pagenavi中的链接获取其他文章列表页面。特别是我们定义了一个路径:只跟随下一页的链接,这样就可以从头到尾按顺序再一次,免去了反复抓取判断的麻烦。另外,文章列表页面上具体文章的链接对应的页面,才是我们真正要保存的数据页面。
这样一来,用脚本语言编写一个ad hoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的Crawler Framework,简单、轻量、非常方便,而且官网说已经在生产中使用了,所以不是玩具级别的东西。不过目前还没有Release版本,可以直接使用他们的Mercurial仓库获取源码进行安装。不过这个东西也可以不用安装直接使用,方便随时更新。文档很详细,我不再赘述。
Scrapy 使用 Twisted(一个异步网络库)来处理网络通信。架构清晰,收录各种中间件接口,可灵活满足各种需求。整体结构如下图所示:
绿线是数据流向。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载后会交给Spider进行分析。Spider分析出来的结果有两个:一个是需要进一步爬取的链接,比如前面分析的“下一页”链接,这些东西会发回Scheduler;另一个是需要保存的数据,它们被发送到Item Pipeline,这是对数据的后处理(详细分析,过滤,存储等)。此外,可以在数据流通道中安装各种中间件,进行必要的处理。
具体内容将在最后的附录中介绍。
看起来很复杂,其实用起来很简单,就像Rails一样,先新建一个项目:
scrapy-admin.py startproject blog_crawl
会创建一个blog_crawl目录,里面有scrapy-ctl.py是整个项目的控制脚本,代码都放在子目录blog_crawl中。为了能够爬取,我们在spiders目录下新建了mindhacks_spider.py,定义我们的spider如下:
fromscrapy.spiderimportBaseSpider
类MindhacksSpider(BaseSpider):
域名=""
start_urls=[""]
解析(自我,响应):
返回[]
SPIDER=MindhacksSpider()
我们的MindhacksSpider继承自BaseSpider(通常直接继承自scrapy.contrib.spiders.CrawlSpider会更方便,功能更强大,但是为了展示数据是如何解析的,这里使用BaseSpider),变量domain_name和start_urls很容易理解是什么意思,parse方法就是我们需要定义的回调函数。默认请求在得到响应后会调用这个回调函数。我们这里需要解析页面,返回两个结果(需要进一步爬取的链接和需要保存的数据),让我感觉有点奇怪的是,在它的接口定义中,这两个结果是混合并返回一个列表。总之,这里我们先写一个空函数,它只返回一个空列表。此外,定义一个“全局” 变量 SPIDER,在 Scrapy 导入该模块时会被实例化,并被 Scrapy 的引擎自动找到。所以可以先运行爬虫试试:
./scrapy-ctl.py 抓取
会有一堆输出,可以看到爬取了,因为这是初始的URL,但是由于我们在parse函数中没有返回需要进一步爬取的URL,所以整个爬取过程只爬取首页并结束。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们做实验。使用以下命令启动 Shell:
./scrapy-ctl.py 外壳
它会启动爬虫,抓取命令行指定的页面,然后进入shell。根据提示,我们有很多现成的变量可以使用,其中一个就是hxs,它是一个HtmlXPathSelector。mindhacks 的 HTML 页面比较规范,可以直接用 XPath 分析,非常方便。从 Firebug 可以看出,每个博客 文章 的链接都在 h1 下,所以在 shell 中使用这个 XPath 表达式测试:
在[1]中:hxs.x('//h1/a/@href').extract()
输出[1]:
[你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'']
这正是我们需要的 URL。此外,我们还可以找到“下一页”链接,它与其他几个页面的链接一起在一个 div 中,但是“下一页”链接没有标题属性,所以 XPath 读取
//div[@class="wp-pagenavi"]/a[not(@title)]
但是,如果你往回翻一页,你会发现“上一页”是一样的,所以需要判断链接上的文字是下一页的箭头u'\xbb',也可以是用 XPath 编写。Go,但似乎这本身就是一个 unicode 转义字符。由于编码原因,不清楚,所以直接在外面判断。最终的解析函数如下:
解析(自我,响应):
项目=[]
hxs=HtmlXPathSelector(响应)
帖子=hxs.x('//h1/a/@href').extract()
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
forurlinposts])
page_links=hxs.x('//div[@class="wp-pagenavi"]/a[not(@title)]')
forlinkinpage_links:
iflink.x('text()').extract()[0]==u'\xbb':
url=link.x('@href').extract()[0]
items.append(self.make_requests_from_url(url))
退换货品
前半部分是解析需要爬取的博客正文的链接,后半部分是给出“下一页”链接。需要注意的是,这里返回的列表不收录字符串格式的 URL。Scrapy 期望得到一个 Request 对象,它可以携带比字符串格式的 URL 更多的东西,例如 cookie 或回调。功能之类的。可以看出我们在创建博客正文的Request时替换了回调函数,因为默认的回调函数parse专门用于解析文章列表等页面,parse_post定义如下:
defparse_post(自我,响应):
项目=博客爬虫项目()
item.url=unicode(response.url)
item.raw=response.body_as_unicode()
归还物品]
很简单,返回一个BlogCrawlItem,把抓到的数据放进去。我们这里可以做一点分析,比如通过 XPath 解析文本和标题,但我倾向于在后面做这些事情,比如 Item Pipeline 或 Late Offline 阶段。BlogCrawlItem 是 Scrapy 自动为我们定义并继承自 ScrapedItem 的空类。在 items.py 中,我在这里添加了一些内容:
fromscrapy.itemimportScrapedItem
classBlogCrawlItem(ScrapedItem):
def__init__(self):
ScrapedItem.__init__(self)
self.url=''
def__str__(self):
return'BlogCrawlItem(url: %s)'%self.url
定义了__str__函数,只给出了url,因为默认的__str__函数会显示所有数据,所以看到爬取的时候,控制台日志会输出一些疯狂的东西,就是输出抓取到的网页内容。出去。-.-bb
这样就得到了数据,最后只剩下存储数据的功能了。我们通过添加管道来实现这一点。由于 Python 在标准库中自带了对 Sqlite3 的支持,所以我使用 Sqlite 数据库来存储数据。将 pipelines.py 的内容替换为以下代码:
导入sqlite3
fromos导入路径
来自scrapy.coreimportsignals
fromscrapy.xlib.pydispatchimportdispatcher
类SQLiteStorePipeline(对象):
文件名='data.sqlite'
def__init__(self):
self.conn=无
dispatcher.connect(self.initialize,signals.engine_started)
dispatcher.connect(self.finalize,signals.engine_stopped)
defprocess_item(自我,域,项目):
self.conn.execute('插入博客值(?,?,?)',
(item.url, item.raw,unicode(domain)))
归还物品
定义(自我):
ifpath.exists(self.filename):
self.conn=sqlite3.connect(self.filename)
别的:
self.conn=self.create_table(self.filename)
最终确定(自我):
ifself.connisnotNone:
mit()
self.conn.close()
self.conn=无
defcreate_table(自我,文件名):
conn=sqlite3.连接(文件名)
conn.execute("""创建表博客
(url 文本主键、原创文本、域文本)""")
mit()
返回连接
在__init__函数中,使用dispatcher将两个信号连接到指定函数,分别用于初始化和关闭数据库连接(记得close之前commit,好像不会自动commit,如果直接close的话,似乎所有数据都丢失了dd-.-)。当有数据通过管道时,将调用 process_item 函数。这里我们直接将原创数据存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取、过滤等数据,此处不再详细讨论。
最后,在 settings.py 中列出我们的管道:
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再次运行爬虫,就OK了!
PS1:Scrapy 的组件
1.Scrapy 引擎
Scrapy引擎用于控制整个系统的数据处理流程,触发事务处理。有关详细信息,请参阅下面的数据处理流程。
2.调度器
调度程序接受来自 Scrapy 引擎的请求并将它们排队并在 Scrapy 引擎发出请求后返回它们。
3.下载器
下载器的主要职责是抓取网页并将网页内容返回给蜘蛛。
4.蜘蛛
Spider是Scrapy用户定义的一个类,用于解析网页并爬取指定URL返回的内容。每个蜘蛛可以处理一个域名或一组域名。也就是说,它是用来定义具体的网站获取和解析规则的。
5.项目管道
项目管道的主要职责是处理蜘蛛从网页中提取的项目,其主要任务是澄清、验证和存储数据。当页面被蜘蛛解析时,它被发送到项目管道,并按几个特定的顺序处理数据。每个项目管道的组件都是具有一种简单方法的 Python 类。他们获取项目并执行他们的方法,同时还决定是否需要继续进行项目管道中的下一步或将其丢弃。
项目管道通常执行以下过程:
清理 HTML 数据 验证解析的数据(检查项目是否收录必要的字段) 检查重复数据(如果重复则删除) 将解析的数据存储在数据库中
6.中间件
中间件是 Scrapy 引擎与其他组件之间的钩子框架,主要是提供自定义代码来扩展 Scrapy 的功能。
PS2:Scrapy的数据处理流程
Scrapy的整个数据处理过程由Scrapy引擎控制,其主要操作方式有:
引擎打开一个域名,爬虫处理域名,让爬虫获取第一个爬取的URL。
引擎从蜘蛛获取第一个需要抓取的 URL,然后将其作为请求调度。
引擎从调度程序获取要抓取的下一页。
调度器将下一次爬取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
网页被下载器下载后,通过下载中间件将响应内容发送给引擎。
引擎接收到下载器的响应,通过蜘蛛中间件发送给蜘蛛进行处理。
蜘蛛处理响应并返回抓取的项目,然后向引擎发送新请求。
引擎将抓取项目的项目管道并向调度程序发送请求。
系统在第二步之后重复操作,直到调度中没有请求,然后断开引擎与域的连接。
谢谢收看 查看全部
scrapy分页抓取网页(
WebCrawler下载Web页面如何调度站点的?)
深度解析Python的爬虫框架Scrapy的结构和运行过程
网络爬虫(Web Crawler,Spider)是一种在互联网上爬行的机器人。当然,它通常不是实体机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实是一个程序,它不是爬行,而是有一定的目的,爬行时会采集数据。一些信息。例如,谷歌有大量的爬虫,它们在互联网上采集网页内容和它们之间的链接等信息;比如一些别有用心的爬虫,会在网上搜集foo[at]bar[dot]com等东西。另外,还有一些自定义爬虫,专门针对某个网站,比如JavaEye的Robbin前段时间写了几篇专门处理恶意爬虫的博客(原来的链接好像过期了,所以没有给出),而网站比如小众软件或者LinuxToy经常被全站爬下来,挂在不同的名字下。其实爬虫在基本原理上很简单,只要能上网分析网页,现在大部分语言都有方便的可以爬取网页的Http客户端库,以及最简单的HTML分析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。现在大部分语言都有方便的Http客户端库,可以爬取网页,最简单的HTML解析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。现在大部分语言都有方便的Http客户端库,可以爬取网页,最简单的HTML解析可以直接使用。表达式来做,所以做最基本的网络爬虫其实是一件很简单的事情。但是要实现一个高质量的蜘蛛是非常困难的。
爬虫的两个部分,一个是下载网页,有很多问题需要考虑,如何最大限度地利用本地带宽,如何调度不同站点的Web请求以减轻对方服务器的负担等等。在高性能的网络爬虫系统中,DNS查询也将成为需要优化的瓶颈。此外,还有一些“规则”需要遵守(例如 robots.txt)。得到网页后的分析过程也很复杂。网上各种奇葩,各种错误的HTML页面。几乎不可能全部分析。另外,随着 AJAX 的普及,如何获取 Javascript 动态生成的内容也成了一大难题;此外,互联网上有意无意地出现了各种各样的蜘蛛陷阱。如果你盲目地跟随超链接,你就会陷入陷阱,注定要失败。比如这个网站,据说谷歌之前宣布互联网上Unique URLs的数量已经达到1万亿,所以这个人很自豪地宣布了第二个万亿。:D
然而,实际上,像谷歌这样需要制作通用爬虫的人并不多。通常,我们制作一个 Crawler 来抓取特定的或某种类型的 网站。对 网站 结构进行一些分析,事情就会变得容易得多。通过分析和选择有价值的链接进行跟踪,可以避免许多不必要的链接或蜘蛛陷阱。如果 网站 的结构允许选择合适的路径,我们可以将感兴趣的事物按一定的顺序排列。再爬一遍,这样连URL重复的判断都可以省略。
比如我们要爬取pongba的博客中的博客文字,通过观察,很容易发现我们对两类页面感兴趣:
文章列出页面,比如首页,或者像/page/\d+/这样的URL的页面,通过Firebug可以看到每个文章的链接都在一个h1下的a标签中(需要注意的是,您在Firebug的HTML面板中看到的HTML代码可能与您在View Source中看到的有些出入。如果网页中存在动态修改DOM树的Javascript,则前者是修改版,并且Firebug正则化后,比如属性有引号等,而后者通常是你的蜘蛛爬取的原创内容。不同,需要特别注意),另外,wp-pagenavi类的一个div中还有指向不同列表页面的链接。
文章内容页面,每个博客都有这样一个页面,比如/2008/09/11/machine-learning-and-ai-resources/,里面收录了完整的文章内容,这是我们的感受感兴趣的内容。
因此,我们从首页开始,利用wp-pagenavi中的链接获取其他文章列表页面。特别是我们定义了一个路径:只跟随下一页的链接,这样就可以从头到尾按顺序再一次,免去了反复抓取判断的麻烦。另外,文章列表页面上具体文章的链接对应的页面,才是我们真正要保存的数据页面。
这样一来,用脚本语言编写一个ad hoc Crawler来完成这个任务并不难,但是今天的主角是Scrapy,它是一个用Python编写的Crawler Framework,简单、轻量、非常方便,而且官网说已经在生产中使用了,所以不是玩具级别的东西。不过目前还没有Release版本,可以直接使用他们的Mercurial仓库获取源码进行安装。不过这个东西也可以不用安装直接使用,方便随时更新。文档很详细,我不再赘述。
Scrapy 使用 Twisted(一个异步网络库)来处理网络通信。架构清晰,收录各种中间件接口,可灵活满足各种需求。整体结构如下图所示:
绿线是数据流向。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载后会交给Spider进行分析。Spider分析出来的结果有两个:一个是需要进一步爬取的链接,比如前面分析的“下一页”链接,这些东西会发回Scheduler;另一个是需要保存的数据,它们被发送到Item Pipeline,这是对数据的后处理(详细分析,过滤,存储等)。此外,可以在数据流通道中安装各种中间件,进行必要的处理。
具体内容将在最后的附录中介绍。
看起来很复杂,其实用起来很简单,就像Rails一样,先新建一个项目:
scrapy-admin.py startproject blog_crawl
会创建一个blog_crawl目录,里面有scrapy-ctl.py是整个项目的控制脚本,代码都放在子目录blog_crawl中。为了能够爬取,我们在spiders目录下新建了mindhacks_spider.py,定义我们的spider如下:
fromscrapy.spiderimportBaseSpider
类MindhacksSpider(BaseSpider):
域名=""
start_urls=[""]
解析(自我,响应):
返回[]
SPIDER=MindhacksSpider()
我们的MindhacksSpider继承自BaseSpider(通常直接继承自scrapy.contrib.spiders.CrawlSpider会更方便,功能更强大,但是为了展示数据是如何解析的,这里使用BaseSpider),变量domain_name和start_urls很容易理解是什么意思,parse方法就是我们需要定义的回调函数。默认请求在得到响应后会调用这个回调函数。我们这里需要解析页面,返回两个结果(需要进一步爬取的链接和需要保存的数据),让我感觉有点奇怪的是,在它的接口定义中,这两个结果是混合并返回一个列表。总之,这里我们先写一个空函数,它只返回一个空列表。此外,定义一个“全局” 变量 SPIDER,在 Scrapy 导入该模块时会被实例化,并被 Scrapy 的引擎自动找到。所以可以先运行爬虫试试:
./scrapy-ctl.py 抓取
会有一堆输出,可以看到爬取了,因为这是初始的URL,但是由于我们在parse函数中没有返回需要进一步爬取的URL,所以整个爬取过程只爬取首页并结束。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们做实验。使用以下命令启动 Shell:
./scrapy-ctl.py 外壳
它会启动爬虫,抓取命令行指定的页面,然后进入shell。根据提示,我们有很多现成的变量可以使用,其中一个就是hxs,它是一个HtmlXPathSelector。mindhacks 的 HTML 页面比较规范,可以直接用 XPath 分析,非常方便。从 Firebug 可以看出,每个博客 文章 的链接都在 h1 下,所以在 shell 中使用这个 XPath 表达式测试:
在[1]中:hxs.x('//h1/a/@href').extract()
输出[1]:
[你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'',
你'']
这正是我们需要的 URL。此外,我们还可以找到“下一页”链接,它与其他几个页面的链接一起在一个 div 中,但是“下一页”链接没有标题属性,所以 XPath 读取
//div[@class="wp-pagenavi"]/a[not(@title)]
但是,如果你往回翻一页,你会发现“上一页”是一样的,所以需要判断链接上的文字是下一页的箭头u'\xbb',也可以是用 XPath 编写。Go,但似乎这本身就是一个 unicode 转义字符。由于编码原因,不清楚,所以直接在外面判断。最终的解析函数如下:
解析(自我,响应):
项目=[]
hxs=HtmlXPathSelector(响应)
帖子=hxs.x('//h1/a/@href').extract()
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
forurlinposts])
page_links=hxs.x('//div[@class="wp-pagenavi"]/a[not(@title)]')
forlinkinpage_links:
iflink.x('text()').extract()[0]==u'\xbb':
url=link.x('@href').extract()[0]
items.append(self.make_requests_from_url(url))
退换货品
前半部分是解析需要爬取的博客正文的链接,后半部分是给出“下一页”链接。需要注意的是,这里返回的列表不收录字符串格式的 URL。Scrapy 期望得到一个 Request 对象,它可以携带比字符串格式的 URL 更多的东西,例如 cookie 或回调。功能之类的。可以看出我们在创建博客正文的Request时替换了回调函数,因为默认的回调函数parse专门用于解析文章列表等页面,parse_post定义如下:
defparse_post(自我,响应):
项目=博客爬虫项目()
item.url=unicode(response.url)
item.raw=response.body_as_unicode()
归还物品]
很简单,返回一个BlogCrawlItem,把抓到的数据放进去。我们这里可以做一点分析,比如通过 XPath 解析文本和标题,但我倾向于在后面做这些事情,比如 Item Pipeline 或 Late Offline 阶段。BlogCrawlItem 是 Scrapy 自动为我们定义并继承自 ScrapedItem 的空类。在 items.py 中,我在这里添加了一些内容:
fromscrapy.itemimportScrapedItem
classBlogCrawlItem(ScrapedItem):
def__init__(self):
ScrapedItem.__init__(self)
self.url=''
def__str__(self):
return'BlogCrawlItem(url: %s)'%self.url
定义了__str__函数,只给出了url,因为默认的__str__函数会显示所有数据,所以看到爬取的时候,控制台日志会输出一些疯狂的东西,就是输出抓取到的网页内容。出去。-.-bb
这样就得到了数据,最后只剩下存储数据的功能了。我们通过添加管道来实现这一点。由于 Python 在标准库中自带了对 Sqlite3 的支持,所以我使用 Sqlite 数据库来存储数据。将 pipelines.py 的内容替换为以下代码:
导入sqlite3
fromos导入路径
来自scrapy.coreimportsignals
fromscrapy.xlib.pydispatchimportdispatcher
类SQLiteStorePipeline(对象):
文件名='data.sqlite'
def__init__(self):
self.conn=无
dispatcher.connect(self.initialize,signals.engine_started)
dispatcher.connect(self.finalize,signals.engine_stopped)
defprocess_item(自我,域,项目):
self.conn.execute('插入博客值(?,?,?)',
(item.url, item.raw,unicode(domain)))
归还物品
定义(自我):
ifpath.exists(self.filename):
self.conn=sqlite3.connect(self.filename)
别的:
self.conn=self.create_table(self.filename)
最终确定(自我):
ifself.connisnotNone:
mit()
self.conn.close()
self.conn=无
defcreate_table(自我,文件名):
conn=sqlite3.连接(文件名)
conn.execute("""创建表博客
(url 文本主键、原创文本、域文本)""")
mit()
返回连接
在__init__函数中,使用dispatcher将两个信号连接到指定函数,分别用于初始化和关闭数据库连接(记得close之前commit,好像不会自动commit,如果直接close的话,似乎所有数据都丢失了dd-.-)。当有数据通过管道时,将调用 process_item 函数。这里我们直接将原创数据存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取、过滤等数据,此处不再详细讨论。
最后,在 settings.py 中列出我们的管道:
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再次运行爬虫,就OK了!
PS1:Scrapy 的组件
1.Scrapy 引擎
Scrapy引擎用于控制整个系统的数据处理流程,触发事务处理。有关详细信息,请参阅下面的数据处理流程。
2.调度器
调度程序接受来自 Scrapy 引擎的请求并将它们排队并在 Scrapy 引擎发出请求后返回它们。
3.下载器
下载器的主要职责是抓取网页并将网页内容返回给蜘蛛。
4.蜘蛛
Spider是Scrapy用户定义的一个类,用于解析网页并爬取指定URL返回的内容。每个蜘蛛可以处理一个域名或一组域名。也就是说,它是用来定义具体的网站获取和解析规则的。
5.项目管道
项目管道的主要职责是处理蜘蛛从网页中提取的项目,其主要任务是澄清、验证和存储数据。当页面被蜘蛛解析时,它被发送到项目管道,并按几个特定的顺序处理数据。每个项目管道的组件都是具有一种简单方法的 Python 类。他们获取项目并执行他们的方法,同时还决定是否需要继续进行项目管道中的下一步或将其丢弃。
项目管道通常执行以下过程:
清理 HTML 数据 验证解析的数据(检查项目是否收录必要的字段) 检查重复数据(如果重复则删除) 将解析的数据存储在数据库中
6.中间件
中间件是 Scrapy 引擎与其他组件之间的钩子框架,主要是提供自定义代码来扩展 Scrapy 的功能。
PS2:Scrapy的数据处理流程
Scrapy的整个数据处理过程由Scrapy引擎控制,其主要操作方式有:
引擎打开一个域名,爬虫处理域名,让爬虫获取第一个爬取的URL。
引擎从蜘蛛获取第一个需要抓取的 URL,然后将其作为请求调度。
引擎从调度程序获取要抓取的下一页。
调度器将下一次爬取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
网页被下载器下载后,通过下载中间件将响应内容发送给引擎。
引擎接收到下载器的响应,通过蜘蛛中间件发送给蜘蛛进行处理。
蜘蛛处理响应并返回抓取的项目,然后向引擎发送新请求。
引擎将抓取项目的项目管道并向调度程序发送请求。
系统在第二步之后重复操作,直到调度中没有请求,然后断开引擎与域的连接。
谢谢收看
scrapy分页抓取网页(Python开发的一个快速,高层次屏幕抓取和web框架框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-10 06:10
Scrapy简介,以下摘自百度百科,
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结果
Scrapy Pthyon 爬虫框架标志[1]
结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
1.首先需要在windows下安装python2.7版本,然后配置环境变量,如下图,其中Scripts的路径也放入环境变量中,这样就可以直接在命令行使用我们第二步安装的pip;
2.要安装pip,可以在这个链接下载get-pip.py文件,然后执行python get-pip.py,这样脚本会自动下载setuptools工具;
(pip是python的包管理工具)
3.使用命令 pip install Scrapy 安装 Scrapy。请注意,您可能会在此处遇到解码错误。需要修改Python27文件夹中Lib的mimetypes.py文件,大约第256行,设置默认编码方式。改成gbk,代码如下,注意python代码的缩进。
#default_encoding = sys.getdefaultencoding()
if sys.getdefaultencoding() != "gbk":
reload(sys)
sys.setdefaultencoding("gbk")
default_encoding = sys.getdefaultencoding()
Scrapy框架就是通过以上三步搭建的。
接下来按照Scrapy官网的教程做一个简单的爬虫。
1.首先,进入工作目录,打开命令行,输入如下命令创建一个Scrapy项目;
scrapy startproject tutorial
我创建的时候,电脑命令行报错,ImportError: No module named twisted等,很多包都不见了,所以我去安装了,直接用pip install **就好了。 查看全部
scrapy分页抓取网页(Python开发的一个快速,高层次屏幕抓取和web框架框架)
Scrapy简介,以下摘自百度百科,
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结果
Scrapy Pthyon 爬虫框架标志[1]
结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
1.首先需要在windows下安装python2.7版本,然后配置环境变量,如下图,其中Scripts的路径也放入环境变量中,这样就可以直接在命令行使用我们第二步安装的pip;
2.要安装pip,可以在这个链接下载get-pip.py文件,然后执行python get-pip.py,这样脚本会自动下载setuptools工具;
(pip是python的包管理工具)
3.使用命令 pip install Scrapy 安装 Scrapy。请注意,您可能会在此处遇到解码错误。需要修改Python27文件夹中Lib的mimetypes.py文件,大约第256行,设置默认编码方式。改成gbk,代码如下,注意python代码的缩进。
#default_encoding = sys.getdefaultencoding()
if sys.getdefaultencoding() != "gbk":
reload(sys)
sys.setdefaultencoding("gbk")
default_encoding = sys.getdefaultencoding()
Scrapy框架就是通过以上三步搭建的。
接下来按照Scrapy官网的教程做一个简单的爬虫。
1.首先,进入工作目录,打开命令行,输入如下命令创建一个Scrapy项目;
scrapy startproject tutorial
我创建的时候,电脑命令行报错,ImportError: No module named twisted等,很多包都不见了,所以我去安装了,直接用pip install **就好了。
scrapy分页抓取网页(怎样优雅用yield写这样的代码呢?部分代码实例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-08 19:01
)
使用yield优雅爬取网页分页数据
在使用Python爬取网页数据时,我们经常会遇到分页数据,有些下一页按钮已经有了具体的链接地址,而有些可能是javascript处理的。这需要能够同时解析页面内容和采集下一页的url。如何在python中优雅地编写这样的代码?或者如何更pythonic?
下面给出一些代码示例
def get_next_page(obj):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('a', text="下頁")
break
except:
error_occurred = True
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
next_url = "http://www.etnet.com.hk" + e_next_page.get('href')
time.sleep(2)
yield content
for i in get_next_page(next_url):
yield i
else:
yield content
def get_next_page(obj, page=1):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if page == 1 and (not "sh=" in obj) and hrefs:
reset_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"/sector-industry-details.aspx?%s&page=1" % \
(hrefs[0].replace('sh=1', 'sh=0').replace('&page=', '') \
.replace("'", '').split()[0]))
for next_page in get_next_page(reset_url):
yield next_page
return
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('td', text="下一頁 ")
break
except:
error_occurred = True
LOG.error(traceback.format_exc())
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if hrefs:
next_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"-details.aspx?%s&page=%d" % \
(hrefs[0].replace('sh=1', 'sh=0') \
.replace('&page=', '').replace("'", '').split()[0], page+1))
time.sleep(2)
yield content
for next_page in get_next_page(next_url, page+1):
yield next_page
else:
yield content
for curr_href in e_href:
retry_interval = random.randint(MIN_INTERVAL_SECONDS_FOR_RETRIEVING,
MAX_INTERVAL_SECONDS_FOR_RETRIEVING)
time.sleep(retry_interval)
contents = get_next_page(curr_href)
for content in contents:
get_page_data(content) 查看全部
scrapy分页抓取网页(怎样优雅用yield写这样的代码呢?部分代码实例
)
使用yield优雅爬取网页分页数据
在使用Python爬取网页数据时,我们经常会遇到分页数据,有些下一页按钮已经有了具体的链接地址,而有些可能是javascript处理的。这需要能够同时解析页面内容和采集下一页的url。如何在python中优雅地编写这样的代码?或者如何更pythonic?
下面给出一些代码示例
def get_next_page(obj):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('a', text="下頁")
break
except:
error_occurred = True
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
next_url = "http://www.etnet.com.hk" + e_next_page.get('href')
time.sleep(2)
yield content
for i in get_next_page(next_url):
yield i
else:
yield content
def get_next_page(obj, page=1):
'''get next page content from a url or another content '''
error_occurred = False
for retry2 in xrange(3):
try:
if isinstance(obj, (basestring, unicode)):
resp = curr_session.get(obj, timeout=TIMEOUT, headers=headers,
cookies=cookies, allow_redirects=True)
content = resp.content
save_html_content(obj, content)
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if page == 1 and (not "sh=" in obj) and hrefs:
reset_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"/sector-industry-details.aspx?%s&page=1" % \
(hrefs[0].replace('sh=1', 'sh=0').replace('&page=', '') \
.replace("'", '').split()[0]))
for next_page in get_next_page(reset_url):
yield next_page
return
error_occurred = False
else:
content = obj
soup = BeautifulSoup(content, features='html5lib', from_encoding="utf8")
e_next_page = soup.find('td', text="下一頁 ")
break
except:
error_occurred = True
LOG.error(traceback.format_exc())
time.sleep(2)
if error_occurred:
yield content
return
if e_next_page:
hrefs = re.findall('industrysymbol=.*&market_id=[^;]+', content)
if hrefs:
next_url = ("http://www.aastocks.com/tc/cnh ... ot%3B
"-details.aspx?%s&page=%d" % \
(hrefs[0].replace('sh=1', 'sh=0') \
.replace('&page=', '').replace("'", '').split()[0], page+1))
time.sleep(2)
yield content
for next_page in get_next_page(next_url, page+1):
yield next_page
else:
yield content
for curr_href in e_href:
retry_interval = random.randint(MIN_INTERVAL_SECONDS_FOR_RETRIEVING,
MAX_INTERVAL_SECONDS_FOR_RETRIEVING)
time.sleep(retry_interval)
contents = get_next_page(curr_href)
for content in contents:
get_page_data(content)
scrapy分页抓取网页(本篇一个用户关注列表和粉丝列表(3爬取分析))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-07 19:06
首先祝大家有个好的开始!
本文要介绍的是从一个用户入手,通过抓取下面的列表和粉丝列表,实现用户的详细信息抓取,并将抓取的结果存储到MongoDB中。
1 环境要求
基本环境沿用之前的环境,只是增加了MongoDB(非关系型数据库)和PyMongo(Python的MongoDB连接库)。默认情况下,我认为每个人都安装并启动了MongoDB服务。
项目创建、爬虫创建、禁用 ROBOTSTXT_OBEY 设置省略(参考上一篇)
2 测试爬虫效果
这里我会写一个简单的爬虫来爬取用户的粉丝数和粉丝数。代码如下:
# -*- coding: utf-8 -*-
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com/people/wo-he-shui-jiu-xing/following']
def parse(self, response):
# 他关注的人数
tnum = response.css("strong.NumberBoard-itemValue::text").extract()[0]
# 粉丝数
fnum = response.css("strong.NumberBoard-itemValue::text").extract()[1]
print("他关注的人数为:%s" % tnum)
print("他粉丝的人数为:%s" % fnum)
在pychram中运行的结果如下:
出现500错误,我们添加headers再试,我们直接在settings.py中设置,如下:
再次执行查看结果:
这次我们得到了我们正常需要的信息
3 爬行分析
让我们以中本聪的主页作为分析的入口。主页如下:
分析用户关注列表如下:
将鼠标放在用户图像上,会显示详细信息如下:
请注意,我使用的是火狐浏览器,选择网络-XHR获取信息
ajax技术的核心是XMLHttpRequest对象(简称XHR),这是微软最先引入的一个特性,后来其他浏览器提供商也提供了同样的实现。XHR 为向服务器发送请求和解析服务器响应提供了流畅的接口。它可以异步的方式从服务器获取更多的信息,这意味着用户点击后,无需刷新页面即可获取新的数据。
通过上面的请求我们可以得到的连接如下:
#用户详细信息
https://www.zhihu.com/api/v4/m ... ssage,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
https://www.zhihu.com/api/v4/m ... ssage,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
#关注的人信息
https://www.zhihu.com/api/v4/m ... Ddata[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics&offset=0&limit=20
通过分析上面的链接可以看出
1.用户详情链接组成:{user}?include={include}
其中user是用户的url_token,包括allow_message、is_followed、is_following、is_org、is_blocking、employees、answer_count、follower_count、articles_count、gender、badge[?(type=best_answerer)].topics
2. 关注者信息链接组成:{include}&offset={offset}&limit={limit}
其中include是data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics,offset是分页偏移,limit是每页的用户数,可以参考下图见:
第一页
第二页
第三页
4 开始爬行
我们先写一个简单的爬虫,先实现功能。代码如下:
# -*- coding: utf-8 -*-
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
# 用户详细信息地址
user_detail = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
# 用户详细信息中的include
user_include = 'allow_message,is_followed,' \
'is_following,' \
'is_org,is_blocking,' \
'employments,' \
'answer_count,' \
'follower_count,' \
'articles_count,' \
'gender,' \
'badge[?(type=best_answerer)].topics'
# 关注的人地址
follow_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
# 关注的人include
follow_include = 'data[*].answer_count,' \
'articles_count,' \
'gender,' \
'follower_count,' \
'is_followed,' \
'is_following,' \
'badge[?(type=best_answerer)].topics'
# 初始user
start_user = 'satoshi_nakamoto'
def start_requests(self):
# 这里重新定义start_requests方法,注意这里的format用法
yield scrapy.Request(self.user_detail.format(user=self.start_user, include=self.user_include),
callback=self.parse_user)
yield scrapy.Request(self.follow_url.format(user=self.start_user, include=self.follow_include, offset=20, limit=20),
callback=self.parse_follow)
def parse_user(self, response):
print('user:%s' % response.text)
def parse_follow(self, response):
print('follow:%s' % response.text)
输出如下:
这里需要注意的是,必须在headers中添加授权信息,否则会报错。headers中的授权形式如下:
测试发现授权值在一段时间内不会发生变化,是否会永远保持不变还有待验证。
5 parse_user 写作
parse_user 方法用于解析用户的详细数据,存储和发现用户的关注列表,并返回给 parse_follow 方法进行处理。用户的详细存储字段如下:
为了省事,我把所有的字段都添加到了items.py中(如果运行spider后报错,没有找到提示字段,就添加那个字段即可),如下:
class UserItem(scrapy.Item):
"""
定义了响应报文中json的字段
"""
is_followed = scrapy.Field()
avatar_url_template = scrapy.Field()
user_type = scrapy.Field()
answer_count = scrapy.Field()
is_following = scrapy.Field()
url = scrapy.Field()
type = scrapy.Field()
url_token = scrapy.Field()
id = scrapy.Field()
allow_message = scrapy.Field()
articles_count = scrapy.Field()
is_blocking = scrapy.Field()
name = scrapy.Field()
headline = scrapy.Field()
gender = scrapy.Field()
avatar_url = scrapy.Field()
follower_count = scrapy.Field()
is_org = scrapy.Field()
employments = scrapy.Field()
badge = scrapy.Field()
is_advertiser = scrapy.Field()
parse_user 方法代码如下:
def parse_user(self, response):
"""
解析用户详细信息方法
:param response: 获取的内容,转化为json格式
"""
# 通过json.loads方式转换为json格式
results = json.loads(response.text)
# 引入item类
item = UserItem()
# 通过循环判断字段是否存在,存在将结果存入items中
for field in item.fields:
if field in results.keys():
item[field] = results.get(field)
# 直接返回item
yield item
# 将获取的用户通过format方式组合成新的url,调用callback函数交给parse_follow方法解析
yield scrapy.Request(self.follows_url.format(user=results.get('url_token'),
include=self.follow_include, offset=0, limit=20),
callback=self.parse_follow)
6 parse_follow 方法编写
首先要把获取到的response转换成json格式,获取关注的用户,继续抓取每个用户,还要处理分页。您可以看到以下两张图片:
重写后的 parse_follow 方法如下:
def parse_follow(self, response):
"""
解析关注的人列表方法
"""
# 格式化response
results = json.loads(response.text)
# 判断data是否存在,如果存在就继续调用parse_user解析用户详细信息
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_detail.format(user=result.get('url_token'), include=self.user_include),
callback=self.parse_user)
# 判断paging是否存在,如果存在并且is_end参数为False,则继续爬取下一页,如果is_end为True,说明为最后一页
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, callback=self.parse_follow)
运行爬虫后的结果如下:
您可以看到一直在获取内容。
7 保存到 mongodb7.1 项管道
为了存储和使用MongoDB,我们需要修改Item Pipeline。参考修改后的代码如下:
class ZhiHuspiderPipeline(object):
"""
知乎数据存入monogodb数据库类,参考官网示例
"""
collection_name = 'user'
def __init__(self, mongo_uri, mongo_db):
"""
初始化参数
:param mongo_uri:mongo uri
:param mongo_db: db name
"""
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
# 打开连接
self.client = pymongo.MongoClient(self.mongo_uri)
# db_auth因为我的mongodb设置了认证,所以需要这两步,未设置可以注释
self.db_auth = self.client.admin
self.db_auth.authenticate("admin", "password")
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
# 这里使用update方法
self.db[self.collection_name].update({'url_token': item['url_token']}, dict(item), True)
return item
这里说一下update方法,update()方法是用来更新一个已经存在的文档。语法格式如下:
db.collection.update(
, # update的查询条件,类似sql update查询内where后面的
, # update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
{
upsert: , # 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi: , # 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新
writeConcern: # 可选,抛出异常的级别。
}
)
使用update方法,如果查询数据存在,就更新,如果不存在,就插入到dict(item)中,这样就可以去掉重复项了。
7.2 设置配置
再次运行spider后的结果如下:
也可以查看mongodb中的数据,如下:
本文中的一些参考资料:
这篇文章到此结束。
本页地址: 查看全部
scrapy分页抓取网页(本篇一个用户关注列表和粉丝列表(3爬取分析))
首先祝大家有个好的开始!
本文要介绍的是从一个用户入手,通过抓取下面的列表和粉丝列表,实现用户的详细信息抓取,并将抓取的结果存储到MongoDB中。
1 环境要求
基本环境沿用之前的环境,只是增加了MongoDB(非关系型数据库)和PyMongo(Python的MongoDB连接库)。默认情况下,我认为每个人都安装并启动了MongoDB服务。
项目创建、爬虫创建、禁用 ROBOTSTXT_OBEY 设置省略(参考上一篇)
2 测试爬虫效果
这里我会写一个简单的爬虫来爬取用户的粉丝数和粉丝数。代码如下:
# -*- coding: utf-8 -*-
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com/people/wo-he-shui-jiu-xing/following']
def parse(self, response):
# 他关注的人数
tnum = response.css("strong.NumberBoard-itemValue::text").extract()[0]
# 粉丝数
fnum = response.css("strong.NumberBoard-itemValue::text").extract()[1]
print("他关注的人数为:%s" % tnum)
print("他粉丝的人数为:%s" % fnum)
在pychram中运行的结果如下:
出现500错误,我们添加headers再试,我们直接在settings.py中设置,如下:
再次执行查看结果:
这次我们得到了我们正常需要的信息
3 爬行分析
让我们以中本聪的主页作为分析的入口。主页如下:
分析用户关注列表如下:
将鼠标放在用户图像上,会显示详细信息如下:
请注意,我使用的是火狐浏览器,选择网络-XHR获取信息
ajax技术的核心是XMLHttpRequest对象(简称XHR),这是微软最先引入的一个特性,后来其他浏览器提供商也提供了同样的实现。XHR 为向服务器发送请求和解析服务器响应提供了流畅的接口。它可以异步的方式从服务器获取更多的信息,这意味着用户点击后,无需刷新页面即可获取新的数据。
通过上面的请求我们可以得到的连接如下:
#用户详细信息
https://www.zhihu.com/api/v4/m ... ssage,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
https://www.zhihu.com/api/v4/m ... ssage,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics
#关注的人信息
https://www.zhihu.com/api/v4/m ... Ddata[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics&offset=0&limit=20
通过分析上面的链接可以看出
1.用户详情链接组成:{user}?include={include}
其中user是用户的url_token,包括allow_message、is_followed、is_following、is_org、is_blocking、employees、answer_count、follower_count、articles_count、gender、badge[?(type=best_answerer)].topics
2. 关注者信息链接组成:{include}&offset={offset}&limit={limit}
其中include是data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics,offset是分页偏移,limit是每页的用户数,可以参考下图见:
第一页
第二页
第三页
4 开始爬行
我们先写一个简单的爬虫,先实现功能。代码如下:
# -*- coding: utf-8 -*-
import scrapy
class ZhuHuSpider(scrapy.Spider):
"""
知乎爬虫
"""
name = 'zhuhu'
allowed_domains = ['zhihu.com']
# 用户详细信息地址
user_detail = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
# 用户详细信息中的include
user_include = 'allow_message,is_followed,' \
'is_following,' \
'is_org,is_blocking,' \
'employments,' \
'answer_count,' \
'follower_count,' \
'articles_count,' \
'gender,' \
'badge[?(type=best_answerer)].topics'
# 关注的人地址
follow_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
# 关注的人include
follow_include = 'data[*].answer_count,' \
'articles_count,' \
'gender,' \
'follower_count,' \
'is_followed,' \
'is_following,' \
'badge[?(type=best_answerer)].topics'
# 初始user
start_user = 'satoshi_nakamoto'
def start_requests(self):
# 这里重新定义start_requests方法,注意这里的format用法
yield scrapy.Request(self.user_detail.format(user=self.start_user, include=self.user_include),
callback=self.parse_user)
yield scrapy.Request(self.follow_url.format(user=self.start_user, include=self.follow_include, offset=20, limit=20),
callback=self.parse_follow)
def parse_user(self, response):
print('user:%s' % response.text)
def parse_follow(self, response):
print('follow:%s' % response.text)
输出如下:
这里需要注意的是,必须在headers中添加授权信息,否则会报错。headers中的授权形式如下:
测试发现授权值在一段时间内不会发生变化,是否会永远保持不变还有待验证。
5 parse_user 写作
parse_user 方法用于解析用户的详细数据,存储和发现用户的关注列表,并返回给 parse_follow 方法进行处理。用户的详细存储字段如下:
为了省事,我把所有的字段都添加到了items.py中(如果运行spider后报错,没有找到提示字段,就添加那个字段即可),如下:
class UserItem(scrapy.Item):
"""
定义了响应报文中json的字段
"""
is_followed = scrapy.Field()
avatar_url_template = scrapy.Field()
user_type = scrapy.Field()
answer_count = scrapy.Field()
is_following = scrapy.Field()
url = scrapy.Field()
type = scrapy.Field()
url_token = scrapy.Field()
id = scrapy.Field()
allow_message = scrapy.Field()
articles_count = scrapy.Field()
is_blocking = scrapy.Field()
name = scrapy.Field()
headline = scrapy.Field()
gender = scrapy.Field()
avatar_url = scrapy.Field()
follower_count = scrapy.Field()
is_org = scrapy.Field()
employments = scrapy.Field()
badge = scrapy.Field()
is_advertiser = scrapy.Field()
parse_user 方法代码如下:
def parse_user(self, response):
"""
解析用户详细信息方法
:param response: 获取的内容,转化为json格式
"""
# 通过json.loads方式转换为json格式
results = json.loads(response.text)
# 引入item类
item = UserItem()
# 通过循环判断字段是否存在,存在将结果存入items中
for field in item.fields:
if field in results.keys():
item[field] = results.get(field)
# 直接返回item
yield item
# 将获取的用户通过format方式组合成新的url,调用callback函数交给parse_follow方法解析
yield scrapy.Request(self.follows_url.format(user=results.get('url_token'),
include=self.follow_include, offset=0, limit=20),
callback=self.parse_follow)
6 parse_follow 方法编写
首先要把获取到的response转换成json格式,获取关注的用户,继续抓取每个用户,还要处理分页。您可以看到以下两张图片:
重写后的 parse_follow 方法如下:
def parse_follow(self, response):
"""
解析关注的人列表方法
"""
# 格式化response
results = json.loads(response.text)
# 判断data是否存在,如果存在就继续调用parse_user解析用户详细信息
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_detail.format(user=result.get('url_token'), include=self.user_include),
callback=self.parse_user)
# 判断paging是否存在,如果存在并且is_end参数为False,则继续爬取下一页,如果is_end为True,说明为最后一页
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, callback=self.parse_follow)
运行爬虫后的结果如下:
您可以看到一直在获取内容。
7 保存到 mongodb7.1 项管道
为了存储和使用MongoDB,我们需要修改Item Pipeline。参考修改后的代码如下:
class ZhiHuspiderPipeline(object):
"""
知乎数据存入monogodb数据库类,参考官网示例
"""
collection_name = 'user'
def __init__(self, mongo_uri, mongo_db):
"""
初始化参数
:param mongo_uri:mongo uri
:param mongo_db: db name
"""
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
# 打开连接
self.client = pymongo.MongoClient(self.mongo_uri)
# db_auth因为我的mongodb设置了认证,所以需要这两步,未设置可以注释
self.db_auth = self.client.admin
self.db_auth.authenticate("admin", "password")
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
# 这里使用update方法
self.db[self.collection_name].update({'url_token': item['url_token']}, dict(item), True)
return item
这里说一下update方法,update()方法是用来更新一个已经存在的文档。语法格式如下:
db.collection.update(
, # update的查询条件,类似sql update查询内where后面的
, # update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
{
upsert: , # 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi: , # 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新
writeConcern: # 可选,抛出异常的级别。
}
)
使用update方法,如果查询数据存在,就更新,如果不存在,就插入到dict(item)中,这样就可以去掉重复项了。
7.2 设置配置
再次运行spider后的结果如下:
也可以查看mongodb中的数据,如下:
本文中的一些参考资料:
这篇文章到此结束。
本页地址:
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-07 11:13
Scrapy 是一个用 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 经常用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
通常我们可以通过Scrapy框架轻松实现爬虫抓取指定网站的内容或图片。
Scrapy 架构图(绿线为数据流向)
Scrapy 操作流程
代码写好,程序开始运行...
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy会重新下载。)
制作一个Scrapy爬虫一共需要4步:新建项目(scrapy startproject xxx):新建一个爬虫项目,指定目标(写items.py):指定要爬取的目标, make a spider (spiders/xxspider.py) ):创建一个爬虫并开始爬取网络存储内容(pipelines.py):设计一个管道来存储爬取的内容安装Windows安装方法
升级pip版本:
pip install --upgrade pip
通过pip安装Scrapy框架:
pip install Scrapy
Ubuntu 安装方法
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip安装Scrapy框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,默认安装的包是不能删除的,但是可以使用python2.x来安装Scrapy会报错,使用python3.x安装也是报错。终于没有找到直接安装Scrapy的方法,所以就用另一种安装方式来讲解安装步骤。解决方案是使用virtualenv。安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,在命令终端输入scrapy,提示类似如下结果,表示安装成功。
介绍案例研究目标一. 新项目(scrapy startproject)
在爬取之前,必须创建一个新的 Scrapy 项目。进入自定义项目目录,运行以下命令:
scrapy startproject mySpider
其中mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、明确的目标(mySpider/items.py)
我们打算获取网站中所有讲师的姓名、职称和个人信息。
打开 mySpider 目录下的 items.py。
Item 定义了结构化数据字段,用于存储爬取的数据。它有点像 Python 中的字典,但提供了一些额外的保护以减少错误。
可以通过创建scrapy.Item类并定义scrapy.Field的类属性来定义Item(可以理解为类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类并构建一个项目模型。
三、制作爬虫(spider/itcastSpider.py)
爬虫功能需要分为两步:
1. 爬取数据
在当前目录下输入命令,会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,自己写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建Spider,您必须使用scrapy.Spider 类创建一个子类,并确定三个必需属性和一个方法。
name = "":此爬虫的标识名称必须是唯一的。不同的爬虫必须定义不同的名称。
allow_domains = [] 是要搜索的域名范围,是爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的网址将被忽略。
start_urls = ():已爬取的 URL 的祖先/列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse(self, response):解析的方法。它将在每个初始 URL 下载后调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item) 查看全部
scrapy分页抓取网页(制作Scrapy爬虫一共需要4步:新建项目(scrapy))
Scrapy 是一个用 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。
Scrapy 经常用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
通常我们可以通过Scrapy框架轻松实现爬虫抓取指定网站的内容或图片。
Scrapy 架构图(绿线为数据流向)
Scrapy 操作流程
代码写好,程序开始运行...
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy会重新下载。)
制作一个Scrapy爬虫一共需要4步:新建项目(scrapy startproject xxx):新建一个爬虫项目,指定目标(写items.py):指定要爬取的目标, make a spider (spiders/xxspider.py) ):创建一个爬虫并开始爬取网络存储内容(pipelines.py):设计一个管道来存储爬取的内容安装Windows安装方法
升级pip版本:
pip install --upgrade pip
通过pip安装Scrapy框架:
pip install Scrapy
Ubuntu 安装方法
安装非 Python 依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip安装Scrapy框架:
sudo pip install scrapy
Mac OS 安装方法
对于Mac OS系统,由于系统本身会引用内置的python2.x库,默认安装的包是不能删除的,但是可以使用python2.x来安装Scrapy会报错,使用python3.x安装也是报错。终于没有找到直接安装Scrapy的方法,所以就用另一种安装方式来讲解安装步骤。解决方案是使用virtualenv。安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
安装完成后,在命令终端输入scrapy,提示类似如下结果,表示安装成功。
介绍案例研究目标一. 新项目(scrapy startproject)
在爬取之前,必须创建一个新的 Scrapy 项目。进入自定义项目目录,运行以下命令:
scrapy startproject mySpider
其中mySpider为项目名,可以看到会创建一个mySpider文件夹,目录结构大致如下:
简单介绍一下各个主文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件是:
二、明确的目标(mySpider/items.py)
我们打算获取网站中所有讲师的姓名、职称和个人信息。
打开 mySpider 目录下的 items.py。
Item 定义了结构化数据字段,用于存储爬取的数据。它有点像 Python 中的字典,但提供了一些额外的保护以减少错误。
可以通过创建scrapy.Item类并定义scrapy.Field的类属性来定义Item(可以理解为类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类并构建一个项目模型。
三、制作爬虫(spider/itcastSpider.py)
爬虫功能需要分为两步:
1. 爬取数据
在当前目录下输入命令,会在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开mySpider/spider目录下的itcast.py,默认添加如下代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以创建itcast.py,自己写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建Spider,您必须使用scrapy.Spider 类创建一个子类,并确定三个必需属性和一个方法。
name = "":此爬虫的标识名称必须是唯一的。不同的爬虫必须定义不同的名称。
allow_domains = [] 是要搜索的域名范围,是爬虫的禁区。规定爬虫只爬取该域名下的网页,不存在的网址将被忽略。
start_urls = ():已爬取的 URL 的祖先/列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse(self, response):解析的方法。它将在每个初始 URL 下载后调用。调用时,每个 URL 返回的 Response 对象作为唯一参数传入。主要功能如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
scrapy分页抓取网页(下载及处理文件和图片Scrapy为下载器的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-05 23:13
下载和处理文件和图片
Scrapy 提供了一个可重用的 item 管道,用于下载 item 中收录的文件(例如,在抓取到产品时,还想保存相应的图像)。这些管道有一些通用的方法和结构(我们称之为媒体管道)。通常,您将使用 Files Pipeline 或 Images Pipeline。
两个管道都实现了以下功能:
1、避免重新下载最近下载过的数据;
2、指定存储介质的位置(文件系统目录、Amazon S3 存储桶)。图像管道有一些额外的功能来处理图像;
3、 将所有下载的图片转换为通用格式(JPG)和模式(RGB);
4、 缩略图生成;
5、 检测图片的宽/高,确保满足最小限制;
该管道还将为当前计划下载的图片保留一个内部队列,并将那些收录相同图片的到达项目连接到该队列。这样可以避免多个项目共享同一张图片的多次下载。
一、使用文件管道
使用 FilesPipeline 时,典型的工作流程如下:
1、 在爬虫中,你抓取一个item,把里面的图片的URL放到file_urls组中。
2、 项目从爬虫返回,进入项目管道。
3、当项目进入 FilesPipeline 时,file_urls 组中的 URL 会被 Scrapy 的调度器和下载器调度下载(这意味着调度器和下载器的中间件可以重复使用)。当优先级较高时,URL 将在其他页面被抓取之前进行处理。项目将在此特定管道阶段保持“锁定”状态,直到文件下载完成(或由于某种原因下载未完成)。
4、下载文件后,另一个字段(文件)将更新为结构。该组将收录一个字典列表,包括下载文件信息,例如下载路径、源爬取地址(从file_urls 组中获取)和图像校验和(checksum)。文件列表中文件的顺序将与源 file_urls 组一致。如果图片下载失败,将记录错误信息并且图片不会出现在文件组中。
二、使用图像管道
使用ImagesPipeline时,典型的工作流程如下:
1、在爬虫中,您抓取一个项目并将其中的图片的网址放入 image_urls 组中。
2、 项目从爬虫返回,进入项目管道。
3、当项目进入ImagesPipeline时,image_urls组中的URL会被Scrapy的调度器和下载器调度下载(这意味着调度器和下载器的中间件可以复用)。当优先级较高时,URL 将在其他页面被抓取之前进行处理。项目将在此特定管道阶段保持“锁定”状态,直到文件下载完成(或由于某种原因下载未完成)。
4、下载文件后,另一个字段(图像)将更新为结构。该组将收录一个字典列表,包括下载文件信息,例如下载路径、源爬取地址(从 image_urls 组中获取)和图像校验和(checksum)。文件列表中文件的顺序将与源 image_urls 组一致。如果图片下载失败,将记录错误信息并且图片不会出现在图像组中。
使用ImagesPipeline 与使用FilesPipeline 非常相似,除了使用的默认字段名称不同:您使用image_urls 作为项目的图片URL,并且会填写图片字段以获取有关下载图片的信息。
对图像文件使用 ImagesPipeline 的好处是可以配置一些附加功能,例如生成缩略图和根据大小过滤图像。
Pillow 用于生成缩略图并将图像规范化为 JPEG/RGB 格式,因此为了使用图像管道,您需要安装此库。Python Imaging Library (PIL) 在大多数情况下是有效的,但众所周知,在某些设置中会出现问题,因此我们建议使用 Pillow 而不是 PIL。
接下来,使用Images Pipeline 爬取花瓣网下载想要的图片。
1、新建一个项目,打开cmd,
进入scrapy startproject huaban_imagepipeline
新建筑 查看全部
scrapy分页抓取网页(下载及处理文件和图片Scrapy为下载器的应用)
下载和处理文件和图片
Scrapy 提供了一个可重用的 item 管道,用于下载 item 中收录的文件(例如,在抓取到产品时,还想保存相应的图像)。这些管道有一些通用的方法和结构(我们称之为媒体管道)。通常,您将使用 Files Pipeline 或 Images Pipeline。
两个管道都实现了以下功能:
1、避免重新下载最近下载过的数据;
2、指定存储介质的位置(文件系统目录、Amazon S3 存储桶)。图像管道有一些额外的功能来处理图像;
3、 将所有下载的图片转换为通用格式(JPG)和模式(RGB);
4、 缩略图生成;
5、 检测图片的宽/高,确保满足最小限制;
该管道还将为当前计划下载的图片保留一个内部队列,并将那些收录相同图片的到达项目连接到该队列。这样可以避免多个项目共享同一张图片的多次下载。
一、使用文件管道
使用 FilesPipeline 时,典型的工作流程如下:
1、 在爬虫中,你抓取一个item,把里面的图片的URL放到file_urls组中。
2、 项目从爬虫返回,进入项目管道。
3、当项目进入 FilesPipeline 时,file_urls 组中的 URL 会被 Scrapy 的调度器和下载器调度下载(这意味着调度器和下载器的中间件可以重复使用)。当优先级较高时,URL 将在其他页面被抓取之前进行处理。项目将在此特定管道阶段保持“锁定”状态,直到文件下载完成(或由于某种原因下载未完成)。
4、下载文件后,另一个字段(文件)将更新为结构。该组将收录一个字典列表,包括下载文件信息,例如下载路径、源爬取地址(从file_urls 组中获取)和图像校验和(checksum)。文件列表中文件的顺序将与源 file_urls 组一致。如果图片下载失败,将记录错误信息并且图片不会出现在文件组中。
二、使用图像管道
使用ImagesPipeline时,典型的工作流程如下:
1、在爬虫中,您抓取一个项目并将其中的图片的网址放入 image_urls 组中。
2、 项目从爬虫返回,进入项目管道。
3、当项目进入ImagesPipeline时,image_urls组中的URL会被Scrapy的调度器和下载器调度下载(这意味着调度器和下载器的中间件可以复用)。当优先级较高时,URL 将在其他页面被抓取之前进行处理。项目将在此特定管道阶段保持“锁定”状态,直到文件下载完成(或由于某种原因下载未完成)。
4、下载文件后,另一个字段(图像)将更新为结构。该组将收录一个字典列表,包括下载文件信息,例如下载路径、源爬取地址(从 image_urls 组中获取)和图像校验和(checksum)。文件列表中文件的顺序将与源 image_urls 组一致。如果图片下载失败,将记录错误信息并且图片不会出现在图像组中。
使用ImagesPipeline 与使用FilesPipeline 非常相似,除了使用的默认字段名称不同:您使用image_urls 作为项目的图片URL,并且会填写图片字段以获取有关下载图片的信息。
对图像文件使用 ImagesPipeline 的好处是可以配置一些附加功能,例如生成缩略图和根据大小过滤图像。
Pillow 用于生成缩略图并将图像规范化为 JPEG/RGB 格式,因此为了使用图像管道,您需要安装此库。Python Imaging Library (PIL) 在大多数情况下是有效的,但众所周知,在某些设置中会出现问题,因此我们建议使用 Pillow 而不是 PIL。
接下来,使用Images Pipeline 爬取花瓣网下载想要的图片。
1、新建一个项目,打开cmd,
进入scrapy startproject huaban_imagepipeline
新建筑
scrapy分页抓取网页(Python网络爬虫与信息提取(北京理工大学慕课)生成的这些东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-03 14:02
参考资料:Python网络爬虫与信息抽取(北京理工大学MOOC)
这是我们要抓取的页面:
要使用Scrapy库,首先需要生成一个Scrapy爬虫框架,分为以下几个步骤: 1.建立一个Scrapy爬虫项目
首先,我们打开 Pycharm 并创建一个新项目。在这里我创建了一个名为 demo 的新项目:
然后我们打开Pycharm的终端,输入scrapy startproject python123demo:
这样,我们就建立了一个Scrapy爬虫项目:
那么这些东西是怎么产生的?
部署的概念是指:将构建好的爬虫放在特定的服务器上,在服务器上配置相关的操作接口。
对于本机使用的爬虫,我们不需要更改部署的配置文件
如果用户想要扩展中间件的功能,需要将这些功能写入第二个python123demo/文件中。
如果要优化爬虫功能,需要在settings.py文件中修改相应的配置项。
python123demo项目中创建的spider存放在spiders/目录下:
2.在项目中生成一个Scrapy爬虫
在项目中,只需要执行一个命令就可以生成一个爬虫,但是这个命令需要与用户给出的爬虫名称和被爬取的网站达成一致。
我们打开Pycharm,在终端输入scrapy genspider demo python123.io:
该命令的作用是生成一个名为demo(即爬虫)的蜘蛛,然后我们会发现在spiders目录下添加了一个名为demo.py的代码:
这里我们使用了一个命令来生成文件,看起来很神秘,但是这个命令的作用仅限于生成demo.py。
如果不使用这个命令生成demo.py,其实我们也可以手动生成这个文件。
打开demo.py:
我们看到它是一个以面向对象的方式编写的类。这个类叫做DemoSpider。
由于爬虫的名字是demo,所以类名也是DemoSpider。
名字是什么无关紧要,但是这个类必须是继承自scrapy.Spider的子类。
name = "demo" 表示当前爬虫的名字是demo。
allowed_domains 是用户在开头向命令行提交的域名,表示这个爬虫爬取网站时,只能爬取这个域名下面的相关链接。 (这是一个可选参数)
start_urls 是一个非常重要的变量。顾名思义,实际上以列表形式收录的一个或多个URL就是scrapy框架要抓取的页面的初始页面。
def parse()是一个解析页面的空方法,收录在这个类中,用于处理响应,解析内容形成字典,发现新的URL爬取请求。
3.配置生成的蜘蛛爬虫
具体来说,我们需要修改demo.py文件,使其可以根据我们的需求访问我们想要访问的链接,并抓取相关链接内容。
这里定义了链接解析部分的功能:将返回的html页面保存为文件。
具体我们修改demo.py文件如下:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response): # resonse相当于从网络中返回内容所存储的或对应的对象
fname = response.url.split('/')[-1] # 定义文件名字,把response中的内容写到一个html文件中
with open (fname, 'wb') as f: # 从响应的url中提取文件名字作为保存为本地的文件名,然后将返回的内容保存为文件
f.write(response.body)
self.log('Saved file %s.' % fname) # self.log是运行日志,不是必要的
# 这样,我们的demo.py文件就能够爬取一个网页,并且能够将网页的内容保存为一个html文件
4.运行爬虫获取网页
在pycharm终端输入scrapy crawl demo
然后就可以爬到这个页面了:
这里我们回顾一下 demo.py 代码:
start_urls 变量表示爬虫启动时的第一个 URL 链接。
parse 方法表示解析返回页面和执行操作的相关步骤。
事实上这行代码是scrapy框架提供的一个简化版代码。
对应完整版:
你可以看到有一个额外的 start_requests 方法。
那么这两个版本有什么区别?
该命令生成的 demo.py 文件的简化版本,它使用 start_urls 列表给出初始 URL 链接。
srapy 框架支持的另一种等效方法是使用称为 start_requests 的方法。在这个方法中,首先定义了一个url列表,列表中的每个列表通过yield scrapy发送给Engine。Requests 做了一个url访问请求。 查看全部
scrapy分页抓取网页(Python网络爬虫与信息提取(北京理工大学慕课)生成的这些东西)
参考资料:Python网络爬虫与信息抽取(北京理工大学MOOC)
这是我们要抓取的页面:
要使用Scrapy库,首先需要生成一个Scrapy爬虫框架,分为以下几个步骤: 1.建立一个Scrapy爬虫项目
首先,我们打开 Pycharm 并创建一个新项目。在这里我创建了一个名为 demo 的新项目:
然后我们打开Pycharm的终端,输入scrapy startproject python123demo:
这样,我们就建立了一个Scrapy爬虫项目:
那么这些东西是怎么产生的?
部署的概念是指:将构建好的爬虫放在特定的服务器上,在服务器上配置相关的操作接口。
对于本机使用的爬虫,我们不需要更改部署的配置文件
如果用户想要扩展中间件的功能,需要将这些功能写入第二个python123demo/文件中。
如果要优化爬虫功能,需要在settings.py文件中修改相应的配置项。
python123demo项目中创建的spider存放在spiders/目录下:
2.在项目中生成一个Scrapy爬虫
在项目中,只需要执行一个命令就可以生成一个爬虫,但是这个命令需要与用户给出的爬虫名称和被爬取的网站达成一致。
我们打开Pycharm,在终端输入scrapy genspider demo python123.io:
该命令的作用是生成一个名为demo(即爬虫)的蜘蛛,然后我们会发现在spiders目录下添加了一个名为demo.py的代码:
这里我们使用了一个命令来生成文件,看起来很神秘,但是这个命令的作用仅限于生成demo.py。
如果不使用这个命令生成demo.py,其实我们也可以手动生成这个文件。
打开demo.py:
我们看到它是一个以面向对象的方式编写的类。这个类叫做DemoSpider。
由于爬虫的名字是demo,所以类名也是DemoSpider。
名字是什么无关紧要,但是这个类必须是继承自scrapy.Spider的子类。
name = "demo" 表示当前爬虫的名字是demo。
allowed_domains 是用户在开头向命令行提交的域名,表示这个爬虫爬取网站时,只能爬取这个域名下面的相关链接。 (这是一个可选参数)
start_urls 是一个非常重要的变量。顾名思义,实际上以列表形式收录的一个或多个URL就是scrapy框架要抓取的页面的初始页面。
def parse()是一个解析页面的空方法,收录在这个类中,用于处理响应,解析内容形成字典,发现新的URL爬取请求。
3.配置生成的蜘蛛爬虫
具体来说,我们需要修改demo.py文件,使其可以根据我们的需求访问我们想要访问的链接,并抓取相关链接内容。
这里定义了链接解析部分的功能:将返回的html页面保存为文件。
具体我们修改demo.py文件如下:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response): # resonse相当于从网络中返回内容所存储的或对应的对象
fname = response.url.split('/')[-1] # 定义文件名字,把response中的内容写到一个html文件中
with open (fname, 'wb') as f: # 从响应的url中提取文件名字作为保存为本地的文件名,然后将返回的内容保存为文件
f.write(response.body)
self.log('Saved file %s.' % fname) # self.log是运行日志,不是必要的
# 这样,我们的demo.py文件就能够爬取一个网页,并且能够将网页的内容保存为一个html文件
4.运行爬虫获取网页
在pycharm终端输入scrapy crawl demo
然后就可以爬到这个页面了:
这里我们回顾一下 demo.py 代码:
start_urls 变量表示爬虫启动时的第一个 URL 链接。
parse 方法表示解析返回页面和执行操作的相关步骤。
事实上这行代码是scrapy框架提供的一个简化版代码。
对应完整版:
你可以看到有一个额外的 start_requests 方法。
那么这两个版本有什么区别?
该命令生成的 demo.py 文件的简化版本,它使用 start_urls 列表给出初始 URL 链接。
srapy 框架支持的另一种等效方法是使用称为 start_requests 的方法。在这个方法中,首先定义了一个url列表,列表中的每个列表通过yield scrapy发送给Engine。Requests 做了一个url访问请求。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-03 07:02
我相信所有 网站 网站站长都有捕获他人数据的经验。目前抓取别人的网站数据有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时没弄明白怎么用,后来干脆决定自己写。现在半天就能搞定一个网站(只是程序开发的时间,不包括抓数据的时间)
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的问题之一是抓取分页数据。原因是数据分页的形式很多。下面我将主要从三个方面介绍表单中抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码都是可以正确执行的,我目前正在使用中。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
以下切入正题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花半天时间写代码又懒得学第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地的数据库中;爬取代码可以参考如下:
公共字符串 GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322 ; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5. 21022;.NET CLR 3.0.4506.2152;.NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方法二:在网站的开发过程中可能会经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现状态栏会显示javascript:__dopostback("gridview","当你将鼠标移到每个页码上时的代码如page1")等,这种形式其实也不是很难,因为毕竟有一个地方可以找到获取页码的规则。
我们知道提交HTTP请求有两种方式。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,不在本文中。专注
获取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为当你点击翻页的时候页面,将改变页码的信息传递给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不要太担心这三件事的作用。自己写代码抓取页面的时候记得提交这三个元素。
和第一种方法一样,必须循环把_dopostback的两个参数拼凑起来。您只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
<p>for (int i = 0; i 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有 网站 网站站长都有捕获他人数据的经验。目前抓取别人的网站数据有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时没弄明白怎么用,后来干脆决定自己写。现在半天就能搞定一个网站(只是程序开发的时间,不包括抓数据的时间)
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的问题之一是抓取分页数据。原因是数据分页的形式很多。下面我将主要从三个方面介绍表单中抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码都是可以正确执行的,我目前正在使用中。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
以下切入正题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花半天时间写代码又懒得学第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地的数据库中;爬取代码可以参考如下:
公共字符串 GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322 ; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5. 21022;.NET CLR 3.0.4506.2152;.NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方法二:在网站的开发过程中可能会经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现状态栏会显示javascript:__dopostback("gridview","当你将鼠标移到每个页码上时的代码如page1")等,这种形式其实也不是很难,因为毕竟有一个地方可以找到获取页码的规则。
我们知道提交HTTP请求有两种方式。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,不在本文中。专注
获取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为当你点击翻页的时候页面,将改变页码的信息传递给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不要太担心这三件事的作用。自己写代码抓取页面的时候记得提交这三个元素。
和第一种方法一样,必须循环把_dopostback的两个参数拼凑起来。您只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
<p>for (int i = 0; i
scrapy分页抓取网页(项目文件创建好怎么写爬虫程序?程序怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-03 07:01
项目文件创建好后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
class KuanItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
volume = scrapy.Field()
download = scrapy.Field()
follow = scrapy.Field()
comment = scrapy.Field()
tags = scrapy.Field()
score = scrapy.Field()
num_score = scrapy.Field()
这里的字段信息是我们在网页上找到的8个字段信息,其中:name是App的名字,volume是体积,download是下载次数。在这里定义之后,我们将在后续的爬取主程序中使用这些字段信息。
2.3.3. 爬取主程序
kuan项目创建后,Scrapy框架会自动生成部分爬取代码。接下来需要在parse方法中添加网页抓取的字段解析内容。
class KuspiderSpider(scrapy.Spider):
name = 'kuan'
allowed_domains = ['www.coolapk.com']
start_urls = ['http://www.coolapk.com/']
def parse(self, response):
pass
在首页打开Dev Tools,找到各个爬取指标的节点位置,然后使用CSS、Xpath、正则化等方法进行提取分析。这些方法都是Scrapy支持的,可以随意选择。这里我们选择 CSS 语法来定位节点,但是需要注意的是,Scrapy 的 CSS 语法与我们之前用 pyquery 使用的 CSS 语法略有不同。让我举几个例子并进行比较。
首先我们定位第一个APP的首页URL节点,可以看到URL节点位于class属性为app_left_list的div节点下的a节点,其href属性就是我们需要的URL信息,这里是相对地址,拼接后就是完整的网址:
接下来,我们进入酷安详情页面,选择App名称并定位。可以看到App name节点位于类属性为.detail_app_title的p节点的正文中。
定位这两个节点后,我们就可以使用CSS提取字段信息了。下面是传统写作和 Scrapy 写作的对比:
# 常规写法
url = item('.app_left_list>a').attr('href')
name = item('.list_app_title').text()
# Scrapy 写法
url = item.css('::attr("href")').extract_first()
name = item.css('.detail_app_title::text').extract_first()
如您所见,要获取 href 或 text 属性,需要使用 :: 来表示。例如,要获取文本,请使用 ::text。 extract_first() 表示提取第一个元素,如果有多个元素,使用extract()。然后,我们可以参考解析代码写出这8个字段信息。
首先,我们需要在首页提取App的URL列表,然后进入每个App的详情页,再提取8个字段的信息。
def parse(self, response):
contents = response.css('.app_left_list>a')
for content in contents:
url = content.css('::attr("href")').extract_first()
url = response.urljoin(url) # 拼接相对 url 为绝对 url
yield scrapy.Request(url,callback=self.parse_url)
这里使用response.urljoin()方法将提取的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传入两个参数:url和callback,url是详情页的URL,callback是回调函数,将首页URL请求返回的响应传递给专门用来解析字段内容的parse_url()方法,如如下图:
def parse_url(self,response):
item = KuanItem()
item['name'] = response.css('.detail_app_title::text').extract_first()
results = self.get_comment(response)
item['volume'] = results[0]
item['download'] = results[1]
item['follow'] = results[2]
item['comment'] = results[3]
item['tags'] = self.get_tags(response)
item['score'] = response.css('.rank_num::text').extract_first()
num_score = response.css('.apk_rank_p1::text').extract_first()
item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)
yield item
def get_comment(self,response):
messages = response.css('.apk_topba_message::text').extract_first()
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上
if result: # 不为空
results = list(result[0]) # 提取出list 中第一个元素
return results
def get_tags(self,response):
data = response.css('.apk_left_span2')
tags = [item.css('::text').extract_first() for item in data]
return tags
这里分别定义了两个方法,get_comment() 和 get_tags()。
get_comment() 方法使用正则匹配来提取volume、download、follow、comment四个字段。正则匹配结果如下:
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)
print(result) # 输出第一页的结果信息
# 结果如下:
[('21.74M', '5218万', '2.4万', '5.4万')]
[('75.53M', '2768万', '2.3万', '3.0万')]
[('46.21M', '1686万', '2.3万', '3.4万')]
[('54.77M', '1603万', '3.8万', '4.9万')]
[('3.32M', '1530万', '1.5万', '3343')]
[('75.07M', '1127万', '1.6万', '2.2万')]
[('92.70M', '1108万', '9167', '1.3万')]
[('68.94M', '1072万', '5718', '9869')]
[('61.45M', '935万', '1.1万', '1.6万')]
[('23.96M', '925万', '4157', '1956')]
然后用result[0]、result[1]等提取四条信息,以volume为例,输出第一页的提取结果:
item['volume'] = results[0]
print(item['volume'])
21.74M
75.53M
46.21M
54.77M
3.32M
75.07M
92.70M
68.94M
61.45M
23.96M
这样第一页的10个app的字段信息就全部提取成功了,然后返回到yied item生成器,输出它的内容:
[
{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'},
{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},
...
]
2.3.4. 分页爬取
上面,我们爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
这里我们分别写下两种方法的分析代码。
第一种方法很简单,就按照parse方法继续添加以下几行代码即可:
def parse(self, response):
contents = response.css('.app_left_list>a')
for content in contents:
...
next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()
url = response.urljoin(next_page)
yield scrapy.Request(url,callback=self.parse )
第二种方法,一开始我们在parse()方法之前定义了一个start_requests()方法,用于批量生成610个页面URL,然后传递给下面的parse()方法进行解析。
def start_requests(self):
pages = []
for page in range(1,610): # 一共有610页
url = 'https://www.coolapk.com/apk/?page=%s'%page
page = scrapy.Request(url,callback=self.parse)
pages.append(page)
return pages
以上是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择将其存储在 MongoDB 中。不得不说MongoDB比MySQL方便多了,麻烦也少了很多。
2.3.5.店铺成绩
在pipelines.py程序中,我们定义了数据存储方式。 MongoDB的一些参数,如地址和数据库名称,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
import pymongo
class MongoPipeline(object):
def __init__(self,mongo_url,mongo_db):
self.mongo_url = mongo_url
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_url = crawler.settings.get('MONGO_URL'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单说明一下:
from crawler() 是一个类方法,由@class 方法标识。这个方法的作用主要是获取我们在settings.py中设置的参数:
MONGO_URL = 'localhost'
MONGO_DB = 'KuAn'
ITEM_PIPELINES = {
'kuan.pipelines.MongoPipeline': 300,
}
open_spider() 方法主要执行一些初始化操作。这个方法会在Spider打开时调用。
process_item() 方法是将数据插入到 MongoDB 中最重要的方法。
完成以上代码后,输入如下一行命令,即可启动爬虫的爬取和存储过程。如果在单机上运行,6000个网页需要很长时间才能完成。要有耐心。
scrapy crawl kuan
这里,还有两点:
首先,为了减轻网站的压力,我们最好在每次请求之间设置几秒的延迟。您可以在 KuspiderSpider() 方法的开头添加以下代码行:
custom_settings = {
"DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟
"CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低
}
其次,为了更好的监控爬虫程序的运行情况,需要设置输出日志文件,可以通过Python自带的日志包来实现:
import logging
logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')
logging.warning("warn message")
logging.error("error message")
这里的level参数表示警告级别,严重程度从低到高分别是:DEBUG
添加datefmt参数,在每条日志前添加具体时间,很有用。
以上,我们已经完成了整个数据的抓取。有了数据,我们就可以开始分析了,但在此之前,我们需要对数据进行简单的清理和处理。
3. 数据清洗处理
首先我们从MongoDB中读取数据并转换成DataFrame,然后查看数据的基本情况。
def parse_kuan():
client = pymongo.MongoClient(host='localhost', port=27017)
db = client['KuAn']
collection = db['KuAnItem']
# 将数据库数据转为DataFrame
data = pd.DataFrame(list(collection.find()))
print(data.head())
print(df.shape)
print(df.info())
print(df.describe())
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
评论、下载、关注、num_score,5列数据部分行有“10000”后缀,需要去掉,转成数值;体积一栏分别有“M”和“K”后缀,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有 6086 行 x 8 列,每列都没有缺失值。
df.describe() 方法对分数列进行基本统计。可以看到所有app的平均分是3.9分(5分制),最低分是1.6分。最高分4.8分。
接下来我们将上面几列文本数据转换成数值数据,代码实现如下:
def data_processing(df):
#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型
str = '_ori'
cols = ['comment','download','follow','num_score','volume']
for col in cols:
colori = col+str
df[colori] = df[col] # 复制保留原始列
if not (col == 'volume'):
df[col] = clean_symbol(df,col)# 处理原始列生成新列
else:
df[col] = clean_symbol2(df,col)# 处理原始列生成新列
# 将download单独转换为万单位
df['download'] = df['download'].apply(lambda x:x/10000)
# 批量转为数值型
df = df.apply(pd.to_numeric,errors='ignore')
def clean_symbol(df,col):
# 将字符“万”替换为空
con = df[col].str.contains('万$')
df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000
df[col] = pd.to_numeric(df[col])
return df[col]
def clean_symbol2(df,col):
# 字符M替换为空
df[col] = df[col].str.replace('M$','')
# 体积为K的除以 1024 转换为M
con = df[col].str.contains('K$')
df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024
df[col] = pd.to_numeric(df[col])
return df[col]
以上,几列文本数据的转换就完成了,我们再来看看基本情况:
commentdownloadfollownum_scorescorevolume
计数
6086
6086
6086
6086
6086
6086
平均值
255.5
13.7
729.3
133.1
3.9
17.7
标准
1437.3
98
1893.7
595.4
0.6
20.6
分钟
1
1.6
25%
16
0.2
65
5.2
3.7
3.5
50%
38
0.8
180
17
4
10.8
75%
119
4.5
573.8
68
4.3
25.3
最大
53000
5190
38000
17000
4.8
294.2
可以看到以下信息:
以上,基本的数据清洗过程已经完成。下一篇文章我们将对数据进行探索性分析。 查看全部
scrapy分页抓取网页(项目文件创建好怎么写爬虫程序?程序怎么做?)
项目文件创建好后,我们就可以开始编写爬虫程序了。
首先需要在items.py文件中预先定义要爬取的字段信息的名称,如下图:
class KuanItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
volume = scrapy.Field()
download = scrapy.Field()
follow = scrapy.Field()
comment = scrapy.Field()
tags = scrapy.Field()
score = scrapy.Field()
num_score = scrapy.Field()
这里的字段信息是我们在网页上找到的8个字段信息,其中:name是App的名字,volume是体积,download是下载次数。在这里定义之后,我们将在后续的爬取主程序中使用这些字段信息。
2.3.3. 爬取主程序
kuan项目创建后,Scrapy框架会自动生成部分爬取代码。接下来需要在parse方法中添加网页抓取的字段解析内容。
class KuspiderSpider(scrapy.Spider):
name = 'kuan'
allowed_domains = ['www.coolapk.com']
start_urls = ['http://www.coolapk.com/']
def parse(self, response):
pass
在首页打开Dev Tools,找到各个爬取指标的节点位置,然后使用CSS、Xpath、正则化等方法进行提取分析。这些方法都是Scrapy支持的,可以随意选择。这里我们选择 CSS 语法来定位节点,但是需要注意的是,Scrapy 的 CSS 语法与我们之前用 pyquery 使用的 CSS 语法略有不同。让我举几个例子并进行比较。
首先我们定位第一个APP的首页URL节点,可以看到URL节点位于class属性为app_left_list的div节点下的a节点,其href属性就是我们需要的URL信息,这里是相对地址,拼接后就是完整的网址:
接下来,我们进入酷安详情页面,选择App名称并定位。可以看到App name节点位于类属性为.detail_app_title的p节点的正文中。
定位这两个节点后,我们就可以使用CSS提取字段信息了。下面是传统写作和 Scrapy 写作的对比:
# 常规写法
url = item('.app_left_list>a').attr('href')
name = item('.list_app_title').text()
# Scrapy 写法
url = item.css('::attr("href")').extract_first()
name = item.css('.detail_app_title::text').extract_first()
如您所见,要获取 href 或 text 属性,需要使用 :: 来表示。例如,要获取文本,请使用 ::text。 extract_first() 表示提取第一个元素,如果有多个元素,使用extract()。然后,我们可以参考解析代码写出这8个字段信息。
首先,我们需要在首页提取App的URL列表,然后进入每个App的详情页,再提取8个字段的信息。
def parse(self, response):
contents = response.css('.app_left_list>a')
for content in contents:
url = content.css('::attr("href")').extract_first()
url = response.urljoin(url) # 拼接相对 url 为绝对 url
yield scrapy.Request(url,callback=self.parse_url)
这里使用response.urljoin()方法将提取的相对URL拼接成一个完整的URL,然后使用scrapy.Request()方法为每个App详情页构造一个请求。这里我们传入两个参数:url和callback,url是详情页的URL,callback是回调函数,将首页URL请求返回的响应传递给专门用来解析字段内容的parse_url()方法,如如下图:
def parse_url(self,response):
item = KuanItem()
item['name'] = response.css('.detail_app_title::text').extract_first()
results = self.get_comment(response)
item['volume'] = results[0]
item['download'] = results[1]
item['follow'] = results[2]
item['comment'] = results[3]
item['tags'] = self.get_tags(response)
item['score'] = response.css('.rank_num::text').extract_first()
num_score = response.css('.apk_rank_p1::text').extract_first()
item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)
yield item
def get_comment(self,response):
messages = response.css('.apk_topba_message::text').extract_first()
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上
if result: # 不为空
results = list(result[0]) # 提取出list 中第一个元素
return results
def get_tags(self,response):
data = response.css('.apk_left_span2')
tags = [item.css('::text').extract_first() for item in data]
return tags
这里分别定义了两个方法,get_comment() 和 get_tags()。
get_comment() 方法使用正则匹配来提取volume、download、follow、comment四个字段。正则匹配结果如下:
result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)
print(result) # 输出第一页的结果信息
# 结果如下:
[('21.74M', '5218万', '2.4万', '5.4万')]
[('75.53M', '2768万', '2.3万', '3.0万')]
[('46.21M', '1686万', '2.3万', '3.4万')]
[('54.77M', '1603万', '3.8万', '4.9万')]
[('3.32M', '1530万', '1.5万', '3343')]
[('75.07M', '1127万', '1.6万', '2.2万')]
[('92.70M', '1108万', '9167', '1.3万')]
[('68.94M', '1072万', '5718', '9869')]
[('61.45M', '935万', '1.1万', '1.6万')]
[('23.96M', '925万', '4157', '1956')]
然后用result[0]、result[1]等提取四条信息,以volume为例,输出第一页的提取结果:
item['volume'] = results[0]
print(item['volume'])
21.74M
75.53M
46.21M
54.77M
3.32M
75.07M
92.70M
68.94M
61.45M
23.96M
这样第一页的10个app的字段信息就全部提取成功了,然后返回到yied item生成器,输出它的内容:
[
{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'},
{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},
...
]
2.3.4. 分页爬取
上面,我们爬取了第一页的内容,接下来需要遍历爬取全部610页的内容。这里有两个想法:
这里我们分别写下两种方法的分析代码。
第一种方法很简单,就按照parse方法继续添加以下几行代码即可:
def parse(self, response):
contents = response.css('.app_left_list>a')
for content in contents:
...
next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()
url = response.urljoin(next_page)
yield scrapy.Request(url,callback=self.parse )
第二种方法,一开始我们在parse()方法之前定义了一个start_requests()方法,用于批量生成610个页面URL,然后传递给下面的parse()方法进行解析。
def start_requests(self):
pages = []
for page in range(1,610): # 一共有610页
url = 'https://www.coolapk.com/apk/?page=%s'%page
page = scrapy.Request(url,callback=self.parse)
pages.append(page)
return pages
以上是所有页面的爬取思路。爬取成功后,我们需要进行存储。在这里,我选择将其存储在 MongoDB 中。不得不说MongoDB比MySQL方便多了,麻烦也少了很多。
2.3.5.店铺成绩
在pipelines.py程序中,我们定义了数据存储方式。 MongoDB的一些参数,如地址和数据库名称,需要单独存放在settings.py设置文件中,然后在pipelines程序中调用。
import pymongo
class MongoPipeline(object):
def __init__(self,mongo_url,mongo_db):
self.mongo_url = mongo_url
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_url = crawler.settings.get('MONGO_URL'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
首先我们定义一个MongoPipeline()存储类,里面定义了几个方法,简单说明一下:
from crawler() 是一个类方法,由@class 方法标识。这个方法的作用主要是获取我们在settings.py中设置的参数:
MONGO_URL = 'localhost'
MONGO_DB = 'KuAn'
ITEM_PIPELINES = {
'kuan.pipelines.MongoPipeline': 300,
}
open_spider() 方法主要执行一些初始化操作。这个方法会在Spider打开时调用。
process_item() 方法是将数据插入到 MongoDB 中最重要的方法。
完成以上代码后,输入如下一行命令,即可启动爬虫的爬取和存储过程。如果在单机上运行,6000个网页需要很长时间才能完成。要有耐心。
scrapy crawl kuan
这里,还有两点:
首先,为了减轻网站的压力,我们最好在每次请求之间设置几秒的延迟。您可以在 KuspiderSpider() 方法的开头添加以下代码行:
custom_settings = {
"DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟
"CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低
}
其次,为了更好的监控爬虫程序的运行情况,需要设置输出日志文件,可以通过Python自带的日志包来实现:
import logging
logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')
logging.warning("warn message")
logging.error("error message")
这里的level参数表示警告级别,严重程度从低到高分别是:DEBUG
添加datefmt参数,在每条日志前添加具体时间,很有用。
以上,我们已经完成了整个数据的抓取。有了数据,我们就可以开始分析了,但在此之前,我们需要对数据进行简单的清理和处理。
3. 数据清洗处理
首先我们从MongoDB中读取数据并转换成DataFrame,然后查看数据的基本情况。
def parse_kuan():
client = pymongo.MongoClient(host='localhost', port=27017)
db = client['KuAn']
collection = db['KuAnItem']
# 将数据库数据转为DataFrame
data = pd.DataFrame(list(collection.find()))
print(data.head())
print(df.shape)
print(df.info())
print(df.describe())
从data.head()输出的前5行数据可以看出,除了score列是float格式,其他列都是object text类型。
评论、下载、关注、num_score,5列数据部分行有“10000”后缀,需要去掉,转成数值;体积一栏分别有“M”和“K”后缀,为了统一大小,需要将“K”除以1024转换为“M”体积。
整个数据共有 6086 行 x 8 列,每列都没有缺失值。
df.describe() 方法对分数列进行基本统计。可以看到所有app的平均分是3.9分(5分制),最低分是1.6分。最高分4.8分。
接下来我们将上面几列文本数据转换成数值数据,代码实现如下:
def data_processing(df):
#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型
str = '_ori'
cols = ['comment','download','follow','num_score','volume']
for col in cols:
colori = col+str
df[colori] = df[col] # 复制保留原始列
if not (col == 'volume'):
df[col] = clean_symbol(df,col)# 处理原始列生成新列
else:
df[col] = clean_symbol2(df,col)# 处理原始列生成新列
# 将download单独转换为万单位
df['download'] = df['download'].apply(lambda x:x/10000)
# 批量转为数值型
df = df.apply(pd.to_numeric,errors='ignore')
def clean_symbol(df,col):
# 将字符“万”替换为空
con = df[col].str.contains('万$')
df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000
df[col] = pd.to_numeric(df[col])
return df[col]
def clean_symbol2(df,col):
# 字符M替换为空
df[col] = df[col].str.replace('M$','')
# 体积为K的除以 1024 转换为M
con = df[col].str.contains('K$')
df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024
df[col] = pd.to_numeric(df[col])
return df[col]
以上,几列文本数据的转换就完成了,我们再来看看基本情况:
commentdownloadfollownum_scorescorevolume
计数
6086
6086
6086
6086
6086
6086
平均值
255.5
13.7
729.3
133.1
3.9
17.7
标准
1437.3
98
1893.7
595.4
0.6
20.6
分钟
1
1.6
25%
16
0.2
65
5.2
3.7
3.5
50%
38
0.8
180
17
4
10.8
75%
119
4.5
573.8
68
4.3
25.3
最大
53000
5190
38000
17000
4.8
294.2
可以看到以下信息:
以上,基本的数据清洗过程已经完成。下一篇文章我们将对数据进行探索性分析。
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-03 06:20
我相信所有 网站 网站站长都有捕获他人数据的经验。目前抓取别人的网站数据有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时没弄明白怎么用,后来干脆决定自己写。现在半天就能搞定一个网站(只是程序开发的时间,不包括抓数据的时间)
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的问题之一是抓取分页数据。原因是数据分页的形式很多。下面我将主要从三个方面介绍表单中抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码都是可以正确执行的,我目前正在使用中。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
以下切入正题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花半天时间写代码又懒得学第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地的数据库中;爬取代码可以参考如下:
公共字符串 GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322 ; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5. 21022;.NET CLR 3.0.4506.2152;.NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方法二:在网站的开发过程中可能会经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现状态栏会显示javascript:__dopostback("gridview","当你将鼠标移到每个页码上时的代码如page1")等,这种形式其实也不是很难,因为毕竟有一个地方可以找到获取页码的规则。
我们知道提交HTTP请求有两种方式。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,不在本文中。专注
获取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为当你点击翻页的时候页面,将改变页码的信息传递给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不要太担心这三件事的作用。自己写代码抓取页面的时候记得提交这三个元素。
和第一种方法一样,必须循环把_dopostback的两个参数拼凑起来。您只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
<p>for (int i = 0; i 查看全部
scrapy分页抓取网页(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有 网站 网站站长都有捕获他人数据的经验。目前抓取别人的网站数据有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时没弄明白怎么用,后来干脆决定自己写。现在半天就能搞定一个网站(只是程序开发的时间,不包括抓数据的时间)
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的问题之一是抓取分页数据。原因是数据分页的形式很多。下面我将主要从三个方面介绍表单中抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码都是可以正确执行的,我目前正在使用中。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
以下切入正题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花半天时间写代码又懒得学第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地的数据库中;爬取代码可以参考如下:
公共字符串 GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322 ; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5. 21022;.NET CLR 3.0.4506.2152;.NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方法二:在网站的开发过程中可能会经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现状态栏会显示javascript:__dopostback("gridview","当你将鼠标移到每个页码上时的代码如page1")等,这种形式其实也不是很难,因为毕竟有一个地方可以找到获取页码的规则。
我们知道提交HTTP请求有两种方式。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,不在本文中。专注
获取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为当你点击翻页的时候页面,将改变页码的信息传递给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不要太担心这三件事的作用。自己写代码抓取页面的时候记得提交这三个元素。
和第一种方法一样,必须循环把_dopostback的两个参数拼凑起来。您只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
<p>for (int i = 0; i
scrapy分页抓取网页(使用Scrapy处理JSONAPI和AJAXAJAX页面的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-01 23:23
)
摘要:介绍了如何使用Scrapy处理JSON API和AJAX页面
有时你可能会发现你要爬取的页面的HTML源代码不存在,比如在浏览器中打开:9312/static/,然后在空白处右击,选择“查看网页”源代码”,如下图:
你会发现一个空格
我注意到红线处指定了一个名为 api.json 的文件,于是我在浏览器的调试器中打开了 Network 面板,找到了名为 api.json 的标签
您可以在上面的红框中找到原创网页的内容。这是一个简单的 JSON API。一些复杂的 API 将要求您先登录、发送 POST 请求或返回一些更有趣的数据结构。 Python 提供了一个解析 JSON 的库,可以使用语句 json.loads(response.body) 将 JSON 数据转换为 Python 对象
api.py文件的源代码地址:
%2Fproperties%2Fproperties%2Fspiders%2Fapi.py
复制manual.py文件,重命名为api.py,并做如下修改:
start_urls = (
'http://web:9312/properties/api.json',
)
如果需要先登录再获取json api,使用start_request()函数(参考《学习Scrapy笔记(五)-Scrapy登录网站》)
def parse(self, response):
base_url = "http://web:9312/properties/"
js = json.loads(response.body)
for item in js:
id = item["id"]
url = base_url + "property_d.html" % id # 构建一个每个条目的完整url
yield Request(url, callback=self.parse_item)
上面的js变量是一个列表,每个元素代表一个条目,可以使用scrapy shell工具验证:
scrapy shell http://web:9312/properties/api.json
运行蜘蛛:scrapy crawl api
可以看到总共发送了31个请求,获得了30个项目
看上图用scrapy shell工具检查js变量。其实除了id字段,还可以获取title字段,所以可以同时在parse函数中获取title字段,并将字段的值传递给parse_item函数填充到item中(省略了parse_item函数中使用xpath提取标题的步骤),修改parse函数如下:
title = item["title"]
yield Request(url, meta={"title": title},callback=self.parse_item) #meta变量是一个字典,用于向回调函数传递数据
在parse_item函数中,这个字段可以从响应中提取
l.add_value('title', response.meta['title'],
MapCompose(unicode.strip, unicode.title)) 查看全部
scrapy分页抓取网页(使用Scrapy处理JSONAPI和AJAXAJAX页面的方法
)
摘要:介绍了如何使用Scrapy处理JSON API和AJAX页面
有时你可能会发现你要爬取的页面的HTML源代码不存在,比如在浏览器中打开:9312/static/,然后在空白处右击,选择“查看网页”源代码”,如下图:
你会发现一个空格
我注意到红线处指定了一个名为 api.json 的文件,于是我在浏览器的调试器中打开了 Network 面板,找到了名为 api.json 的标签
您可以在上面的红框中找到原创网页的内容。这是一个简单的 JSON API。一些复杂的 API 将要求您先登录、发送 POST 请求或返回一些更有趣的数据结构。 Python 提供了一个解析 JSON 的库,可以使用语句 json.loads(response.body) 将 JSON 数据转换为 Python 对象
api.py文件的源代码地址:
%2Fproperties%2Fproperties%2Fspiders%2Fapi.py
复制manual.py文件,重命名为api.py,并做如下修改:
start_urls = (
'http://web:9312/properties/api.json',
)
如果需要先登录再获取json api,使用start_request()函数(参考《学习Scrapy笔记(五)-Scrapy登录网站》)
def parse(self, response):
base_url = "http://web:9312/properties/"
js = json.loads(response.body)
for item in js:
id = item["id"]
url = base_url + "property_d.html" % id # 构建一个每个条目的完整url
yield Request(url, callback=self.parse_item)
上面的js变量是一个列表,每个元素代表一个条目,可以使用scrapy shell工具验证:
scrapy shell http://web:9312/properties/api.json
运行蜘蛛:scrapy crawl api
可以看到总共发送了31个请求,获得了30个项目
看上图用scrapy shell工具检查js变量。其实除了id字段,还可以获取title字段,所以可以同时在parse函数中获取title字段,并将字段的值传递给parse_item函数填充到item中(省略了parse_item函数中使用xpath提取标题的步骤),修改parse函数如下:
title = item["title"]
yield Request(url, meta={"title": title},callback=self.parse_item) #meta变量是一个字典,用于向回调函数传递数据
在parse_item函数中,这个字段可以从响应中提取
l.add_value('title', response.meta['title'],
MapCompose(unicode.strip, unicode.title))
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 20:10
2015-06-23 更新:
写这篇文章的时候,我还没有遇到具体的场景。只是觉得有这样的方法,就写下来了。
我今天刚刚满足了这个需求。抓取BBS内容,版块首页只显示标题、作者和发表时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能得到链接内容爬取后的时间,实际上造成了不必要的浪费。使用本文文章的方法在抓取链接前进行过滤,避免抓取无用数据。
第一个scrapy爬虫开始了(3)- 使用规则实现多页爬取给出了使用CrawlSpider Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取.
具体思路:以我们豆瓣团队为例。我们将首页地址作为start_url参数,从页面源码中查找剩余的页面,如下:
<前页
1
2
3
4
5
6
7
8
9
后页>
可以提取每个页面的地址,多页面爬取的思路是把地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并为这些页面地址函数指定相应的回调。由于首页和分页在形式上完全一致(首页本身也是一个页面),可以直接指定parse作为回调函数。
代码如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
之前使用了所有的CrawlSpider,但是这里替换了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
在写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,所以就相当于为每个页面提取了一个页面地址,这样实际上每个页面地址都在返回结束N次,scrapy会在实际处理中对每个地址处理N次吗?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》......
让我们运行程序看看。现在来看看我们的print语句:“->”代表当前页面地址,后面是从当前页面中提取出来的页面地址。为了精简输出,只提取用于识别页面的那个。 “开始”参数。
运行结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如你所见:
1.每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除并使用线程进行数据提取操作。
好的,任务完成。使用CrawlSpider的规则感觉更方便。 查看全部
scrapy分页抓取网页(豆瓣社科小组,我们将首页地址作为_url参数,从页面源码找到)
2015-06-23 更新:
写这篇文章的时候,我还没有遇到具体的场景。只是觉得有这样的方法,就写下来了。
我今天刚刚满足了这个需求。抓取BBS内容,版块首页只显示标题、作者和发表时间。需要做的就是按时间过滤,每天抓取最新的内容。使用Rule规则提取URL后,只保留链接地址,丢失上下文信息(发布时间)。如果要过滤,只能得到链接内容爬取后的时间,实际上造成了不必要的浪费。使用本文文章的方法在抓取链接前进行过滤,避免抓取无用数据。
第一个scrapy爬虫开始了(3)- 使用规则实现多页爬取给出了使用CrawlSpider Rule实现多页爬取的方法,其实直接使用BaseSpider也可以实现多页爬取.
具体思路:以我们豆瓣团队为例。我们将首页地址作为start_url参数,从页面源码中查找剩余的页面,如下:
<前页
1
2
3
4
5
6
7
8
9
后页>
可以提取每个页面的地址,多页面爬取的思路是把地址封装成一个Request作为回调函数parse的返回值(不影响item的返回值),并为这些页面地址函数指定相应的回调。由于首页和分页在形式上完全一致(首页本身也是一个页面),可以直接指定parse作为回调函数。
代码如下:
from scrapy.spider import BaseSpider
from douban.items import DoubanItem
from scrapy.http import Request
class GroupSpider(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = ["http://www.douban.com/group/ex ... ot%3B]
#默认的回调函数
def parse(self, response):
print "+"*20, response.url
item = DoubanItem()
sel = response.xpath("//div[@class='group-list']/div[@class='result']")
for s in sel:
info = s.xpath("div/div/h3/a/text()").extract()[0]
item["groupName"] = info
yield item
#处理当前页面里的分页 -- 封装为Request返回
sel = response.xpath("//div[@class='paginator']/a/@href").extract()
for s in sel:
print response.url.split("?")[1].split("&")[0], "->", s.split("?")[1].split("&")[0]
yield Request(s, callback=self.parse)
之前使用了所有的CrawlSpider,但是这里替换了BaseSpider,不支持Rule;同时在原有回调函数的基础上增加了分页处理。首先是提取地址,然后打印语句,后面会讲,最后返回Request。
在写这段代码的时候,感觉有一个问题:由于每个页面指定的回调函数都是parse,所以就相当于为每个页面提取了一个页面地址,这样实际上每个页面地址都在返回结束N次,scrapy会在实际处理中对每个地址处理N次吗?更严重的是,会不会陷入死循环?比如从第一页提取第二页-》处理第二页,提取第一页-》处理第一页,提取第二页-》......
让我们运行程序看看。现在来看看我们的print语句:“->”代表当前页面地址,后面是从当前页面中提取出来的页面地址。为了精简输出,只提取用于识别页面的那个。 “开始”参数。
运行结果如下:
class GroupSpider(BaseSpider):
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=40 -> start=0
start=40 -> start=20
start=40 -> start=60
start=40 -> start=80
start=40 -> start=100
start=40 -> start=120
start=40 -> start=140
start=40 -> start=160
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=0
start=20 -> start=40
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=60
start=20 -> start=80
start=20 -> start=100
start=60 -> start=0
start=60 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=20 -> start=120
start=20 -> start=140
start=20 -> start=160
start=60 -> start=40
start=60 -> start=80
start=60 -> start=100
start=100 -> start=0
start=100 -> start=20
start=80 -> start=0
start=80 -> start=20
start=140 -> start=0
start=140 -> start=20
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=160 -> start=0
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=120 -> start=0
start=60 -> start=120
start=60 -> start=140
start=60 -> start=160
start=100 -> start=40
start=100 -> start=60
start=100 -> start=80
start=80 -> start=40
start=80 -> start=60
start=80 -> start=100
start=140 -> start=40
start=140 -> start=60
start=140 -> start=80
start=160 -> start=20
start=160 -> start=40
start=160 -> start=60
start=120 -> start=20
start=120 -> start=40
start=120 -> start=60
++++++++++++++++++++ http://www.douban.com/group/ex ... %2591
start=100 -> start=120
start=100 -> start=140
start=100 -> start=160
start=80 -> start=120
start=80 -> start=140
start=80 -> start=160
start=140 -> start=100
start=140 -> start=120
start=140 -> start=160
start=160 -> start=80
start=160 -> start=100
start=160 -> start=120
start=120 -> start=80
start=120 -> start=100
start=120 -> start=140
start=0 -> start=20
start=0 -> start=40
start=0 -> start=60
start=160 -> start=140
start=120 -> start=160
start=0 -> start=80
start=0 -> start=100
start=0 -> start=120
start=0 -> start=140
start=0 -> start=160
输出有点太多了,如你所见:
1.每个页面地址确实返回了多次;
2. 没有陷入死循环,没有重复处理;
3. 处理过程乱序;
这表明scrapy本身已经进行了重复数据删除并使用线程进行数据提取操作。
好的,任务完成。使用CrawlSpider的规则感觉更方便。
scrapy分页抓取网页(Scrapy轻松定制网络爬虫2009-08-14网络)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-31 05:17
Scrapy 轻松定制网络爬虫 2009-08-14 网络爬虫(Spider)是一种在互联网上爬行的机器人。当然,它通常不是实体机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实就是一个程序,不是爬行,而是有一定的用途,爬行的时候会采集. 一些信息。例如,谷歌有大量的爬虫采集网页内容和它们之间的链接信息;再比如,一些别有用心的爬虫在网上采集诸如foo bar[dot] com之类的东西。此外,还有一些定制的爬虫,专门针对某个网站。例如,不久前,JavaEye写了几篇专门对付恶意爬虫的博客(原链接好像已经过期了,就不给了),还有网站比如小众软件或者LinuxToy经常被全站爬下来并以不同的名字出去玩。其实,爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。
但是,要实现一个高质量的蜘蛛是非常困难的。爬虫的两部分是下载网页。需要考虑的问题有很多,比如如何最大限度地利用本地带宽,如何调度不同站点的web请求,以减少其他服务器的负担。在高性能的Web Crawler系统中,DNS查询也将成为亟待优化的瓶颈。此外,还有一些“配置文件”需要遵循(例如,robots.txt)。获取网页后的分析过程也非常复杂。网上奇奇怪怪的东西很多,各种HTML页面出现各种错误。要清楚地分析所有这些几乎是不可能的。另外,随着AJAX的流行,如何获取Javascript动态生成的内容已经成为一个大问题;此外,网络上还有各种有意无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。
通过分析和选择有价值的链接进行跟踪,我们可以避免很多不必要的链接或蜘蛛陷阱。如果网站的结构允许选择合适的路径,我们就可以按照感兴趣的事物的一定顺序再次爬取它,这样就连URL重复的判断都可以省略了。比如我们要爬下pongba中的博客文字,通过观察,很容易发现我们感兴趣的页面有两个:文章列表页面,比如首页,或者URL / page/\d+ /对于这样的页面,通过Firebug可以看到每篇文章的链接都在一个h1标签中(注意Firebug HTML面板中看到的HTML代码和查看源代码可能会有些不同另外,如果网页中有Javascript动态修改DOM树,前者是修改后的版本,由 Firebug 规范化。比如属性有引号等,而后者通常是蜘蛛爬取的原创内容。如果是使用正则表达式来分析页面或者使用HTML Parser Firefox 如果有一些出入,则需要特别注意),此外,在wp-pagenavi div 类中还有指向不同列表页面的链接。
文章内容页,每个博客都有这样一个页面,例如/2008/09/11/machine-learning-and-ai-resources/,收录了文章的完整内容,这是我们的感受感兴趣的内容。因此,我们从首页开始,利用 wp-pagenavi 中的链接来获取其他 文章 列表页面。特别地,我们定义了一个路径:followNext Page 链接,这样我们就可以从头到尾依次遍历。免去判断重复爬行的麻烦。另外,文章列表页上链接到具体文章的链接对应的页面就是我们真正要保存的数据页。这样一来,其实用的脚本语言写一个ad hoc Crawler来完成这个任务并不难,不过今天的主角是Scrapy。这是一个Python CrawlerFramework,简单,轻量,非常方便,并且官网说已经在实际生产中。在使用中,它不是玩具级别的东西。不过目前还没有Release版本,可以直接使用他们的Mercurial库来获取源码进行安装。不过这个东西也可以不安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。
整体架构如下图所示: 绿线为数据流。首先从初始的URL开始,Scheduler将其交给Downloader进行下载,下载完成后交给Spider进行分析。Spider分析的结果有两种:一种是需要进一步爬取的Links,比如之前分析到的“下一页”的链接,会返回给Scheduler;另一个是需要保存的数据,它们会被送到Item Pipeline,也就是执行数据Place进行后处理(详细分析、过滤、存储等)。此外,数据流通道中可以安装各种中间件。执行必要的部分似乎很复杂。使用起来非常简单。和 Rails 一样,首先新建一个项目:scrapy-admin。py startproject blog_crawl 会创建一个blog_crawl目录,里面有一个scrapy-ctl.py是整个项目的控制脚本,代码全部放在子目录blog_crawl下。为了能够爬行,我们在spiders目录下新建一个mindhacks_spider.py,定义我们的Spider如下: from scrapy.spider import BaseSpider class MindhacksSpider(BaseSpider): domain_name ""start_urls [""]def parse(self , response): return MindhacksSpider() 我们的MindhacksSpider继承自BaseSpider(通常直接继承自scrapy.contrib.spiders,功能更多。CrawlSpider更方便,但为了展示数据是如何解析的,这里使用了BaseSpider),变量 domain_name start_urls 的意思很容易理解,而parse方法就是我们需要定义的回调函数。默认请求会在响应之后调用这个回调函数,我们需要解析这里的页面并返回两个结果(需要进一步爬取的链接和需要保存的数据)。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。
另外,定义一个“全局”变量SPIDER,当Scrapy进入这个模块时会被实例化,并且会被Scrapy引擎自动找到。所以可以先运行爬虫试试: ./scrapy-ctl.py crawl 会有一堆输出,可以看到爬取了,因为这是初始的URL,但是因为我们在解析号里没有返回,我们需要进一步爬取URL,所以整个爬取过程只爬到了首页就结束了。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们进行实验。使用以下命令启动Shell ./scrapy-ctl.pyshell 它将启动爬虫并指定命令行抓取此页面并进入shell。根据提示,我们有很多现成的变量可以使用。其中之一是 hxs,这是一个 HtmlXPathSelector。mindhacks HTML 页面相对标准,可以很容易地直接使用 XPath 进行分析。通过Firebug可以看到每个博客文章的链接都在h1下,所以在Shell中使用这个XPath表达式测试:hxs.x(´//h1/a/@href´ ).extract()Out [1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是URL我们需要。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi" 所以在 Shell 中使用这个 XPath 表达式测试: hxs.x(´//h1/a/@href´ ).extract()Out[1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是我们需要的 URL。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi" 所以在 Shell 中使用这个 XPath 表达式测试: hxs.x(´//h1/a/@href´ ).extract()Out[1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是我们需要的 URL。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi"
需要注意的是,这里返回的列表并非都是字符串格式的URL。Scrapy希望得到Request对象,它可以携带比字符串格式的URL更多的东西,比如cookies或者回调函数。某种类型的。可以看到我们在创建博客正文的请求时替换了回调函数,因为默认的回调函数parse是专门用来解析文章列表等页面的。parse_post 定义如下: def parse_post(self, response): item BlogCrawlItem()item.url unicode(response.url)item.raw response.body_as_unicode()return [item] 很简单,返回一个BlogCrawlItem,把抓到的里面的数据,这里可以稍微分析一下,比如文本和标题是通过XPath解析的,但是我倾向于后期做这些事情,比如Item Pipeline或者后期Offline阶段。BlogCrawlItem Scrapy 自动帮我们定义了一个很好的继承自ScrapedItem items.py,这里我加了一句: from scrapy.item import ScrapedItem class BlogCrawlItem(ScrapedItem): def __init__(self): ScrapedItem.__init__(self) self. url def__str__(self): return ´BlogCrawlItem(url: self.url 定义了__str__函数,只给出了url,因为默认的__str__函数会显示所有的数据,所以在爬取Log的时候会看到控制台疯狂输出东西,即输出抓取到的网页内容。
-.-bb 这样就检索到了数据。最后只剩下存储数据的功能了。我们通过添加流水线来实现它。由于Python标准库自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。. 将pipelines.py的内容替换为以下代码:1011 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import sqlite3 from os core 从scrapy导入。 xlib. pydispatch 导入调度器类 SQLiteStorePipeline(object): 文件名 ´data.sqlite´def __init__(self): self.conn Nonedispatcher.connect(self.initialize,signals.engine_started) dispatcher.connect(self.finalize,signals.engine_stopped) def process_item (self, domain, item): self.conn.execute(´insert blogvalues(?,?,?)´, (item.url, item.raw, unicode(domain))) return item def initialize(self):
当数据通过管道时,将调用 process_item 函数。这里我们将原创数据直接存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取和过滤数据。我不会在这里详述。最后,在 settings.py [´blog_crawl.pipelines.SQLiteStorePipeline´] 中列出我们的管道并运行爬虫。最后总结一下:一个高质量的爬虫是一个极其复杂的工程,但是如果你有一个好的工具,做一个专用的爬虫是相对容易的。Scrapy是一个非常轻量级的爬虫框架,极大的简化了爬虫的开发过程。另外,Scrapy的文档也很详细。如果觉得我的介绍省略了一些不清楚的地方,推荐阅读他的Tutorial 查看全部
scrapy分页抓取网页(Scrapy轻松定制网络爬虫2009-08-14网络)
Scrapy 轻松定制网络爬虫 2009-08-14 网络爬虫(Spider)是一种在互联网上爬行的机器人。当然,它通常不是实体机器人,因为网络本身也是一个虚拟的东西,所以这个“机器人”其实就是一个程序,不是爬行,而是有一定的用途,爬行的时候会采集. 一些信息。例如,谷歌有大量的爬虫采集网页内容和它们之间的链接信息;再比如,一些别有用心的爬虫在网上采集诸如foo bar[dot] com之类的东西。此外,还有一些定制的爬虫,专门针对某个网站。例如,不久前,JavaEye写了几篇专门对付恶意爬虫的博客(原链接好像已经过期了,就不给了),还有网站比如小众软件或者LinuxToy经常被全站爬下来并以不同的名字出去玩。其实,爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。爬虫的基本原理非常简单。只要能上网,能分析网页,现在大多数语言都有方便的Http客户端库可以抓取网页,最简单的HTML分析可以直接使用正则规则。表达式做到了,所以做最简单的网络爬虫其实是一件很简单的事情。
但是,要实现一个高质量的蜘蛛是非常困难的。爬虫的两部分是下载网页。需要考虑的问题有很多,比如如何最大限度地利用本地带宽,如何调度不同站点的web请求,以减少其他服务器的负担。在高性能的Web Crawler系统中,DNS查询也将成为亟待优化的瓶颈。此外,还有一些“配置文件”需要遵循(例如,robots.txt)。获取网页后的分析过程也非常复杂。网上奇奇怪怪的东西很多,各种HTML页面出现各种错误。要清楚地分析所有这些几乎是不可能的。另外,随着AJAX的流行,如何获取Javascript动态生成的内容已经成为一个大问题;此外,网络上还有各种有意无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。互联网上有各种有意或无意出现的蜘蛛陷阱。如果一味的跟着超链接走,就会被困在陷阱里。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。比如这个网站,据说谷歌之前声称互联网UniqueURL的数量已经达到万亿,所以这个人是第二万亿。然而,实际上并没有多少人需要像谷歌那样制作一个通用的爬虫。通常我们做一个爬虫来爬取对于特定的一种或某种类型的网站,所谓知己知彼,百战不殆,我们可以对网站@进行一些分析> 需要提前爬取的结构,事情会变得容易很多。
通过分析和选择有价值的链接进行跟踪,我们可以避免很多不必要的链接或蜘蛛陷阱。如果网站的结构允许选择合适的路径,我们就可以按照感兴趣的事物的一定顺序再次爬取它,这样就连URL重复的判断都可以省略了。比如我们要爬下pongba中的博客文字,通过观察,很容易发现我们感兴趣的页面有两个:文章列表页面,比如首页,或者URL / page/\d+ /对于这样的页面,通过Firebug可以看到每篇文章的链接都在一个h1标签中(注意Firebug HTML面板中看到的HTML代码和查看源代码可能会有些不同另外,如果网页中有Javascript动态修改DOM树,前者是修改后的版本,由 Firebug 规范化。比如属性有引号等,而后者通常是蜘蛛爬取的原创内容。如果是使用正则表达式来分析页面或者使用HTML Parser Firefox 如果有一些出入,则需要特别注意),此外,在wp-pagenavi div 类中还有指向不同列表页面的链接。
文章内容页,每个博客都有这样一个页面,例如/2008/09/11/machine-learning-and-ai-resources/,收录了文章的完整内容,这是我们的感受感兴趣的内容。因此,我们从首页开始,利用 wp-pagenavi 中的链接来获取其他 文章 列表页面。特别地,我们定义了一个路径:followNext Page 链接,这样我们就可以从头到尾依次遍历。免去判断重复爬行的麻烦。另外,文章列表页上链接到具体文章的链接对应的页面就是我们真正要保存的数据页。这样一来,其实用的脚本语言写一个ad hoc Crawler来完成这个任务并不难,不过今天的主角是Scrapy。这是一个Python CrawlerFramework,简单,轻量,非常方便,并且官网说已经在实际生产中。在使用中,它不是玩具级别的东西。不过目前还没有Release版本,可以直接使用他们的Mercurial库来获取源码进行安装。不过这个东西也可以不安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。这个东西也可以不用安装直接使用,方便随时更新。文档很详细,不再赘述。Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。
整体架构如下图所示: 绿线为数据流。首先从初始的URL开始,Scheduler将其交给Downloader进行下载,下载完成后交给Spider进行分析。Spider分析的结果有两种:一种是需要进一步爬取的Links,比如之前分析到的“下一页”的链接,会返回给Scheduler;另一个是需要保存的数据,它们会被送到Item Pipeline,也就是执行数据Place进行后处理(详细分析、过滤、存储等)。此外,数据流通道中可以安装各种中间件。执行必要的部分似乎很复杂。使用起来非常简单。和 Rails 一样,首先新建一个项目:scrapy-admin。py startproject blog_crawl 会创建一个blog_crawl目录,里面有一个scrapy-ctl.py是整个项目的控制脚本,代码全部放在子目录blog_crawl下。为了能够爬行,我们在spiders目录下新建一个mindhacks_spider.py,定义我们的Spider如下: from scrapy.spider import BaseSpider class MindhacksSpider(BaseSpider): domain_name ""start_urls [""]def parse(self , response): return MindhacksSpider() 我们的MindhacksSpider继承自BaseSpider(通常直接继承自scrapy.contrib.spiders,功能更多。CrawlSpider更方便,但为了展示数据是如何解析的,这里使用了BaseSpider),变量 domain_name start_urls 的意思很容易理解,而parse方法就是我们需要定义的回调函数。默认请求会在响应之后调用这个回调函数,我们需要解析这里的页面并返回两个结果(需要进一步爬取的链接和需要保存的数据)。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。让我觉得有点奇怪的是,它的接口定义中的两个结果实际上是混合在一个列表中返回的,不清楚为什么会出现这种设计,你到底要不要努力把它们分开? 总之,这里我们先写一个空函数,它只返回一个空列表。
另外,定义一个“全局”变量SPIDER,当Scrapy进入这个模块时会被实例化,并且会被Scrapy引擎自动找到。所以可以先运行爬虫试试: ./scrapy-ctl.py crawl 会有一堆输出,可以看到爬取了,因为这是初始的URL,但是因为我们在解析号里没有返回,我们需要进一步爬取URL,所以整个爬取过程只爬到了首页就结束了。下一步是分析页面。Scrapy 提供了一个非常方便的 Shell(需要 IPython),可以让我们进行实验。使用以下命令启动Shell ./scrapy-ctl.pyshell 它将启动爬虫并指定命令行抓取此页面并进入shell。根据提示,我们有很多现成的变量可以使用。其中之一是 hxs,这是一个 HtmlXPathSelector。mindhacks HTML 页面相对标准,可以很容易地直接使用 XPath 进行分析。通过Firebug可以看到每个博客文章的链接都在h1下,所以在Shell中使用这个XPath表达式测试:hxs.x(´//h1/a/@href´ ).extract()Out [1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是URL我们需要。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi" 所以在 Shell 中使用这个 XPath 表达式测试: hxs.x(´//h1/a/@href´ ).extract()Out[1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是我们需要的 URL。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi" 所以在 Shell 中使用这个 XPath 表达式测试: hxs.x(´//h1/a/@href´ ).extract()Out[1]: [u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´, u´´ ] 这正是我们需要的 URL。此外,您还可以找到“下一页”的链接,该链接与其他几个页面的链接在一个div 中。但是“下一页”的链接没有title属性,所以XPath写//div[@class="wp-pagenavi"
需要注意的是,这里返回的列表并非都是字符串格式的URL。Scrapy希望得到Request对象,它可以携带比字符串格式的URL更多的东西,比如cookies或者回调函数。某种类型的。可以看到我们在创建博客正文的请求时替换了回调函数,因为默认的回调函数parse是专门用来解析文章列表等页面的。parse_post 定义如下: def parse_post(self, response): item BlogCrawlItem()item.url unicode(response.url)item.raw response.body_as_unicode()return [item] 很简单,返回一个BlogCrawlItem,把抓到的里面的数据,这里可以稍微分析一下,比如文本和标题是通过XPath解析的,但是我倾向于后期做这些事情,比如Item Pipeline或者后期Offline阶段。BlogCrawlItem Scrapy 自动帮我们定义了一个很好的继承自ScrapedItem items.py,这里我加了一句: from scrapy.item import ScrapedItem class BlogCrawlItem(ScrapedItem): def __init__(self): ScrapedItem.__init__(self) self. url def__str__(self): return ´BlogCrawlItem(url: self.url 定义了__str__函数,只给出了url,因为默认的__str__函数会显示所有的数据,所以在爬取Log的时候会看到控制台疯狂输出东西,即输出抓取到的网页内容。
-.-bb 这样就检索到了数据。最后只剩下存储数据的功能了。我们通过添加流水线来实现它。由于Python标准库自带Sqlite3支持,所以我使用Sqlite数据库来存储数据。. 将pipelines.py的内容替换为以下代码:1011 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import sqlite3 from os core 从scrapy导入。 xlib. pydispatch 导入调度器类 SQLiteStorePipeline(object): 文件名 ´data.sqlite´def __init__(self): self.conn Nonedispatcher.connect(self.initialize,signals.engine_started) dispatcher.connect(self.finalize,signals.engine_stopped) def process_item (self, domain, item): self.conn.execute(´insert blogvalues(?,?,?)´, (item.url, item.raw, unicode(domain))) return item def initialize(self):
当数据通过管道时,将调用 process_item 函数。这里我们将原创数据直接存入数据库,不做任何处理。如有必要,您可以添加额外的管道来提取和过滤数据。我不会在这里详述。最后,在 settings.py [´blog_crawl.pipelines.SQLiteStorePipeline´] 中列出我们的管道并运行爬虫。最后总结一下:一个高质量的爬虫是一个极其复杂的工程,但是如果你有一个好的工具,做一个专用的爬虫是相对容易的。Scrapy是一个非常轻量级的爬虫框架,极大的简化了爬虫的开发过程。另外,Scrapy的文档也很详细。如果觉得我的介绍省略了一些不清楚的地方,推荐阅读他的Tutorial
scrapy分页抓取网页(scrapy分页抓取网页中的数据,常用的有三种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-29 07:08
scrapy分页抓取网页中的数据,常用的有三种方法scrapy.queryselector,
#-*-coding:utf-8-*-importscrapyclassqueryselector(scrapy。spider):name='queryselector'allowed_domains=['confluence']template=scrapy。html。xpath('//div[1]/div/a/div/div/span/a/text()')#classmeta=scrapy。
spider。css('all')zip_items=scrapy。default_params()items=scrapy。default_params(item=item,sex='')queryselector(item=item,allowed_domains=squid(),template='')另:建议使用xpaths解析scrapy文件>>>importscrapy>>>scrapy。
request。spider。css('canvas。state。grayscale')queryselector('canvas。state。grayscale',class='ctx')建议使用xpaths解析scrapy文件>>>importscrapy>>>scrapy。request。spider。css('canvas。state。grayscale')。
看你需要什么功能了,web爬虫->解析数据->存储->发布只是这样也可以爬取,如果数据量比较大的话,就要使用javascrapy库了, 查看全部
scrapy分页抓取网页(scrapy分页抓取网页中的数据,常用的有三种方法)
scrapy分页抓取网页中的数据,常用的有三种方法scrapy.queryselector,
#-*-coding:utf-8-*-importscrapyclassqueryselector(scrapy。spider):name='queryselector'allowed_domains=['confluence']template=scrapy。html。xpath('//div[1]/div/a/div/div/span/a/text()')#classmeta=scrapy。
spider。css('all')zip_items=scrapy。default_params()items=scrapy。default_params(item=item,sex='')queryselector(item=item,allowed_domains=squid(),template='')另:建议使用xpaths解析scrapy文件>>>importscrapy>>>scrapy。
request。spider。css('canvas。state。grayscale')queryselector('canvas。state。grayscale',class='ctx')建议使用xpaths解析scrapy文件>>>importscrapy>>>scrapy。request。spider。css('canvas。state。grayscale')。
看你需要什么功能了,web爬虫->解析数据->存储->发布只是这样也可以爬取,如果数据量比较大的话,就要使用javascrapy库了,
scrapy分页抓取网页(本文以爬取网站:为例1.安装scrapy框架详细教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-26 08:16
)
本文以爬取网站为例
1.安装scrapy框架
点击这里跳转到详细教程
2.新的scrapy项目
生成爬虫文件。打开指定目录下的cmd.exe文件,输入代码
scrapy startproject mxp7
cd mxp7
scrapy genspider sp mxp7.com
然后通过Pycharm打开我们新创建的项目,可以发现所有的文件都已经创建好了,我们只需要修改文件中的代码,然后就可以在命令行爬取数据了。
3.提取数据
首先点击打开一个网页,查看博客的基本框架,然后我们在我们的爬虫文件sp.py中创建一个条目字典,通过xpath提取博客的内容。
注:这里强调一个xpath相关的坑。第一次拿到网页标签内容的时候,喜欢把xpath复制到浏览器调试目录下
比如复制上图title的xpath,得到的xpath内容如下,他会按照tags的顺序提取xpath
/html/body/div[2]/div[1]/section[1]/main/article/header/h1
但是这种情况只针对静态网页,因为动态网页中的一些信息是通过代码动态加载的。我们复制的xpath是动态加载后的目录,但是爬取数据的时候,爬虫不会动态加载接口,只会爬取响应内容下的原代码。如果想让爬虫通过标签序列获取网页的内容,就必须与响应下的代码进行比较。一般来说,计算起来相当麻烦。
如何打开网页的响应
打开目标网页,点击F12进入浏览器调试,选择Network后按F5刷新,界面下方会出现网页调用的文件,选择与当前URL同名的文件,然后点击右侧的顶部菜单“响应”,我们可以查看响应的内容
话虽如此,在浏览器调试界面中,我们也可以通过检索id来获取xpath
内容如下:
//*[@id="post-331"]/header/h1
会发现id和网页的编号是一样的,也就是说每个网页的tag的id都不一样。我们不能通过id提取所有网页的xpath路径,所以这里作者推荐大家通过css path的xpath提取。我们写完xpath的内容后,得到的sp.py的源码如下:
# sp.py源码
import scrapy
class SpSpider(scrapy.Spider):
name = 'sp'
allowed_domains = ['mxp7.com']
start_urls = ['http://mxp7.com/331/']
def parse(self, response):
item = {}
item["date"] = response.xpath("//span[@class ='meta-date']//time/text()").extract_first()
item["category"] = response.xpath("//span[@class = 'meta-category']//a/text()").extract_first()
item["title"] = response.xpath("//h1[@class = 'entry-title']/text()").extract_first()
item["author"] = response.xpath("//span[@class = 'meta-author']//a/text()").extract_first()
contain_path = response.xpath("//div[@class = 'entry-content clearfix']")
item["contain"] = contain_path.xpath("string(.)").extract_first()
print(item)
yield item
这里我们把数据扔到管道中,然后我们就可以对管道中的数据进行处理了。笔者这里选择将传输的数据输出到命令行。
# pipelines.py源码
class Mxp7Pipeline:
def process_item(self, item, spider):
print(item)
return item
处理好pipelines数据后,我们还需要在setting.py中打开pipelines
找到此代码并取消注释。此代码调用我们管道中的函数。下面的300指的是函数的权重。这个权重将决定并行管道中数据处理的优先级。
处理完这个,我们就可以在路径D:\Project\Spider\mxp7>下开始我们的爬行,进入命令行
scrapy crawl sp
然后你会发现我们抓取的数据隐藏在很多日志文件中。为了视觉体验,我们可以在setting.py中添加一段代码,使输出的日志级别为ERROR
LOG_LEVEL = "WARNING"
然后在cmd中重新输入grab命令
我们可以成功抓取页面内容
如果我们想要获取博客上发布的所有内容,那么还需要修改sp.py,在parse函数中添加获取下一页的代码,可以先在浏览器上打开网页,查看下一页page 格式,可以发现下一页已经是完整格式的链接了
然后我们就可以直接使用我们在抛出的scrapy.Request参数中获取的网页
pre_url = response.xpath("//div[@class = 'nav-previous']//a/@href").extract_first()
if pre_url:
yield scrapy.Request(pre_url, callback=self.parse)//调用自身
但是在某些网站上获取到的网址并不是一个完整的网址(作者网站的反爬虫机制比较弱)
需要在提取的URL前加上网页的头地址。我相信你自己可以做到这一点,所以我暂时不再赘述。修改后,我们还需要修改setting.py中USER_AGENT的值。在修改之前,我们还需要获取网页的 USER_AGENT 的值。
注意:USER_AGENT是网站的爬虫和反爬虫机制发生冲突的地方,双方会采取千变万化的措施来对抗这部分。作者的这一步只适用于最简单的反爬虫机制。事实上,作者的网站目前没有任何反爬虫机制。即使不执行这一步,我们也可以正常抓取所有文章内容。
打开Network界面后,点击顶部菜单右下角的“Headers”,滑动到底部获取user-agent的值
然后我们在设置中找到注释的USER_AGENT代码,修改它的值为这里复制的值
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
处理完之后我们就可以在cmd界面再次抓取数据了
scrapy crawl sp
成功抓取网站所有文章内容
4.保存文件
如果要保存文件,只需要在命令行中输入以下代码即可:
scrapy crawl sp -o mxp7.csv
将在当前目录中创建一个新的 mxp7.csv 文件
打开后发现乱码,我们可以通过记事本打开,保存为这种格式
重新打开后就可以得到正常的文件了
查看全部
scrapy分页抓取网页(本文以爬取网站:为例1.安装scrapy框架详细教程
)
本文以爬取网站为例
1.安装scrapy框架
点击这里跳转到详细教程
2.新的scrapy项目
生成爬虫文件。打开指定目录下的cmd.exe文件,输入代码
scrapy startproject mxp7
cd mxp7
scrapy genspider sp mxp7.com
然后通过Pycharm打开我们新创建的项目,可以发现所有的文件都已经创建好了,我们只需要修改文件中的代码,然后就可以在命令行爬取数据了。
3.提取数据
首先点击打开一个网页,查看博客的基本框架,然后我们在我们的爬虫文件sp.py中创建一个条目字典,通过xpath提取博客的内容。
注:这里强调一个xpath相关的坑。第一次拿到网页标签内容的时候,喜欢把xpath复制到浏览器调试目录下
比如复制上图title的xpath,得到的xpath内容如下,他会按照tags的顺序提取xpath
/html/body/div[2]/div[1]/section[1]/main/article/header/h1
但是这种情况只针对静态网页,因为动态网页中的一些信息是通过代码动态加载的。我们复制的xpath是动态加载后的目录,但是爬取数据的时候,爬虫不会动态加载接口,只会爬取响应内容下的原代码。如果想让爬虫通过标签序列获取网页的内容,就必须与响应下的代码进行比较。一般来说,计算起来相当麻烦。
如何打开网页的响应
打开目标网页,点击F12进入浏览器调试,选择Network后按F5刷新,界面下方会出现网页调用的文件,选择与当前URL同名的文件,然后点击右侧的顶部菜单“响应”,我们可以查看响应的内容
话虽如此,在浏览器调试界面中,我们也可以通过检索id来获取xpath
内容如下:
//*[@id="post-331"]/header/h1
会发现id和网页的编号是一样的,也就是说每个网页的tag的id都不一样。我们不能通过id提取所有网页的xpath路径,所以这里作者推荐大家通过css path的xpath提取。我们写完xpath的内容后,得到的sp.py的源码如下:
# sp.py源码
import scrapy
class SpSpider(scrapy.Spider):
name = 'sp'
allowed_domains = ['mxp7.com']
start_urls = ['http://mxp7.com/331/']
def parse(self, response):
item = {}
item["date"] = response.xpath("//span[@class ='meta-date']//time/text()").extract_first()
item["category"] = response.xpath("//span[@class = 'meta-category']//a/text()").extract_first()
item["title"] = response.xpath("//h1[@class = 'entry-title']/text()").extract_first()
item["author"] = response.xpath("//span[@class = 'meta-author']//a/text()").extract_first()
contain_path = response.xpath("//div[@class = 'entry-content clearfix']")
item["contain"] = contain_path.xpath("string(.)").extract_first()
print(item)
yield item
这里我们把数据扔到管道中,然后我们就可以对管道中的数据进行处理了。笔者这里选择将传输的数据输出到命令行。
# pipelines.py源码
class Mxp7Pipeline:
def process_item(self, item, spider):
print(item)
return item
处理好pipelines数据后,我们还需要在setting.py中打开pipelines
找到此代码并取消注释。此代码调用我们管道中的函数。下面的300指的是函数的权重。这个权重将决定并行管道中数据处理的优先级。
处理完这个,我们就可以在路径D:\Project\Spider\mxp7>下开始我们的爬行,进入命令行
scrapy crawl sp
然后你会发现我们抓取的数据隐藏在很多日志文件中。为了视觉体验,我们可以在setting.py中添加一段代码,使输出的日志级别为ERROR
LOG_LEVEL = "WARNING"
然后在cmd中重新输入grab命令
我们可以成功抓取页面内容
如果我们想要获取博客上发布的所有内容,那么还需要修改sp.py,在parse函数中添加获取下一页的代码,可以先在浏览器上打开网页,查看下一页page 格式,可以发现下一页已经是完整格式的链接了
然后我们就可以直接使用我们在抛出的scrapy.Request参数中获取的网页
pre_url = response.xpath("//div[@class = 'nav-previous']//a/@href").extract_first()
if pre_url:
yield scrapy.Request(pre_url, callback=self.parse)//调用自身
但是在某些网站上获取到的网址并不是一个完整的网址(作者网站的反爬虫机制比较弱)
需要在提取的URL前加上网页的头地址。我相信你自己可以做到这一点,所以我暂时不再赘述。修改后,我们还需要修改setting.py中USER_AGENT的值。在修改之前,我们还需要获取网页的 USER_AGENT 的值。
注意:USER_AGENT是网站的爬虫和反爬虫机制发生冲突的地方,双方会采取千变万化的措施来对抗这部分。作者的这一步只适用于最简单的反爬虫机制。事实上,作者的网站目前没有任何反爬虫机制。即使不执行这一步,我们也可以正常抓取所有文章内容。
打开Network界面后,点击顶部菜单右下角的“Headers”,滑动到底部获取user-agent的值
然后我们在设置中找到注释的USER_AGENT代码,修改它的值为这里复制的值
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
处理完之后我们就可以在cmd界面再次抓取数据了
scrapy crawl sp
成功抓取网站所有文章内容
4.保存文件
如果要保存文件,只需要在命令行中输入以下代码即可:
scrapy crawl sp -o mxp7.csv
将在当前目录中创建一个新的 mxp7.csv 文件
打开后发现乱码,我们可以通过记事本打开,保存为这种格式
重新打开后就可以得到正常的文件了

