
采集自动组合
采集自动组合(采集自动组合墙,带10个超级管理员,限制每天不超过2小时)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-25 13:05
采集自动组合墙,基于redhat源代码,30行代码搞定,并且带10个超级管理员,限制每天不超过2小时。关注下这个:redhatreleasenight/ymca·github,欢迎fork,
看你的组合墙的用途。如果只是加个模拟码,用python就够了。如果是一键连线,用python连到mysql就行。但是因为你的组合墙一般是处理整个静态网页文件的,所以建议走lua。如果是一些动态接口。那么连接mysql的时候走redis就行。
可以使用可以组合墙的框架(兼容redhat,性能也不错):redblit-redhat-golang-multibox-redis。直接ctrl+c可以退出模拟连接。没办法可以帮到你了。
貌似实现最多就是加三个mysql可以连的网络接口,通过这三个接口用纯python处理静态网页,这样就可以装多个redis然后开10个服务就能组合出来。
自己写!opera的radva
用mysql连,我一个方案是写了多个中间层。先用各种包封装成模块,例如通过func连接分页器listlist这个接口。可以连的多,又很快。如果做后端开发的话。可以考虑fastq,它是把各种模块封装成一个sql然后用mysql/mssql连。这个效率肯定比mysql/mssql高,但是肯定不是to-db这种云服务的innodb。
===如果不用mysql,而是说数据库连接管理,请参考modbus接口。不过由于你没说明你具体的项目,后端开发也没有那么复杂。既然用mysql了,后端开发工作量肯定小不了,只有一个就是redis了。安装配置调整权限什么的,有时间肯定可以搞定。学业余做个网站,不需要很复杂,可以把需要的功能组合起来,好多网站实现起来都简单的很,主要还是看业务。-推荐一本书给你,howtoworkwithbootstraps--参考自网。 查看全部
采集自动组合(采集自动组合墙,带10个超级管理员,限制每天不超过2小时)
采集自动组合墙,基于redhat源代码,30行代码搞定,并且带10个超级管理员,限制每天不超过2小时。关注下这个:redhatreleasenight/ymca·github,欢迎fork,
看你的组合墙的用途。如果只是加个模拟码,用python就够了。如果是一键连线,用python连到mysql就行。但是因为你的组合墙一般是处理整个静态网页文件的,所以建议走lua。如果是一些动态接口。那么连接mysql的时候走redis就行。
可以使用可以组合墙的框架(兼容redhat,性能也不错):redblit-redhat-golang-multibox-redis。直接ctrl+c可以退出模拟连接。没办法可以帮到你了。
貌似实现最多就是加三个mysql可以连的网络接口,通过这三个接口用纯python处理静态网页,这样就可以装多个redis然后开10个服务就能组合出来。
自己写!opera的radva
用mysql连,我一个方案是写了多个中间层。先用各种包封装成模块,例如通过func连接分页器listlist这个接口。可以连的多,又很快。如果做后端开发的话。可以考虑fastq,它是把各种模块封装成一个sql然后用mysql/mssql连。这个效率肯定比mysql/mssql高,但是肯定不是to-db这种云服务的innodb。
===如果不用mysql,而是说数据库连接管理,请参考modbus接口。不过由于你没说明你具体的项目,后端开发也没有那么复杂。既然用mysql了,后端开发工作量肯定小不了,只有一个就是redis了。安装配置调整权限什么的,有时间肯定可以搞定。学业余做个网站,不需要很复杂,可以把需要的功能组合起来,好多网站实现起来都简单的很,主要还是看业务。-推荐一本书给你,howtoworkwithbootstraps--参考自网。
采集自动组合(型号:自动发布软件(组图)!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-12-24 19:16
型号:自动发布软件规模:B2B采购发布软件规格:主要平台发布软件**:创新
B2B自动发帖的主要功能:代替手动发帖信息,建站,适用于任何行业,自动发信息是一个工具,不仅可以节省你的时间,还可以为你节省很多**,只要你能在这个平台上用鼠标和键盘回车,那么我们的就可以实现了。售后服务:产品推广,只要你能站得住,没时间每天注册、发布、刷新信息,就选择我们
发布产品信息可以节省时间和人力。自动发布信息软件 信息发布软件 自动发布信息软件 发布软件 信息发布软件发布文章软件
软件发布信息没有定时间隔,可以随意调整间隔,使每两条信息间隔不规则,定时关机功能(一般适合晚上发布信息的朋友,释放后会自动关闭)。
二、保存配置功能
如果有多个产品需要单独发布,可以单独保存产品功能的配置。您只需要配置一次。保存配置后,稍后再导入配置加载之前的设置,省时省事。
三、自动设置商品图片功能
有3种选择图片的方法:
1、同步采集网站图片。如果您在网站后台上传图片,点击“采集相册”,可以自动将采集图片发送到本地。
2、您的网站后台** URL地址,拍下您要发送的产品图片。
3、 本地电脑手动批量导入图片。
五、自动合成标题功能
想不出很多标题?软件内置批量合成标题功能,可自动批量合成数千个独特的标题。根据您的需要,配置标题模板以生成它。
标题可以任意组合。常用的格式是物联网产品信息成本自动过账助手。通过各种自定义组合,您可以生成千变万化的不同标题。发布文章软件
四、强大的内容编辑器
软件内置文本编辑器,自动识别网站的内容提交格式是纯文本还是html文本。html文本可以随时在软件内部可视化编辑,就像在网站后台操作一样。
案件:
5个新模板!获得 5 种不同的产品介绍,循环发布以改进 收录!
zz91重生网络助手发布软件,环保在线助手发布软件,东商网络助手发布软件。仪器网络助手软件发布,启辉网络助手发布软件,云商网络助手发布软件。万国商务网助手发布软件,商国互联助手发布软件,艾特贸易网助手发布软件。要知道,网助手发布软件,麦网助手发布软件,达纳网助手发布软件。
问:软件包升级了吗?如果我们无法发送怎么办?答:我们有专门的售后团队。如果无法发送,则表示他们的平台已升级。这时候我们的软件会马上升级,我们会及时更新。新的会传给你,或者你点击会自动升级 查看全部
采集自动组合(型号:自动发布软件(组图)!)
型号:自动发布软件规模:B2B采购发布软件规格:主要平台发布软件**:创新
B2B自动发帖的主要功能:代替手动发帖信息,建站,适用于任何行业,自动发信息是一个工具,不仅可以节省你的时间,还可以为你节省很多**,只要你能在这个平台上用鼠标和键盘回车,那么我们的就可以实现了。售后服务:产品推广,只要你能站得住,没时间每天注册、发布、刷新信息,就选择我们
发布产品信息可以节省时间和人力。自动发布信息软件 信息发布软件 自动发布信息软件 发布软件 信息发布软件发布文章软件
软件发布信息没有定时间隔,可以随意调整间隔,使每两条信息间隔不规则,定时关机功能(一般适合晚上发布信息的朋友,释放后会自动关闭)。
二、保存配置功能
如果有多个产品需要单独发布,可以单独保存产品功能的配置。您只需要配置一次。保存配置后,稍后再导入配置加载之前的设置,省时省事。
三、自动设置商品图片功能
有3种选择图片的方法:
1、同步采集网站图片。如果您在网站后台上传图片,点击“采集相册”,可以自动将采集图片发送到本地。
2、您的网站后台** URL地址,拍下您要发送的产品图片。
3、 本地电脑手动批量导入图片。
五、自动合成标题功能
想不出很多标题?软件内置批量合成标题功能,可自动批量合成数千个独特的标题。根据您的需要,配置标题模板以生成它。
标题可以任意组合。常用的格式是物联网产品信息成本自动过账助手。通过各种自定义组合,您可以生成千变万化的不同标题。发布文章软件
四、强大的内容编辑器
软件内置文本编辑器,自动识别网站的内容提交格式是纯文本还是html文本。html文本可以随时在软件内部可视化编辑,就像在网站后台操作一样。
案件:
5个新模板!获得 5 种不同的产品介绍,循环发布以改进 收录!

zz91重生网络助手发布软件,环保在线助手发布软件,东商网络助手发布软件。仪器网络助手软件发布,启辉网络助手发布软件,云商网络助手发布软件。万国商务网助手发布软件,商国互联助手发布软件,艾特贸易网助手发布软件。要知道,网助手发布软件,麦网助手发布软件,达纳网助手发布软件。
问:软件包升级了吗?如果我们无法发送怎么办?答:我们有专门的售后团队。如果无法发送,则表示他们的平台已升级。这时候我们的软件会马上升级,我们会及时更新。新的会传给你,或者你点击会自动升级
采集自动组合(vucf自动发帖软件别让发帖占用你的时间(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-22 13:17
搜索好货自动发布信息脚本(操作简单)vucf
自动发帖软件,不要让发帖占用你的时间
爱出版-企业信息助手:分类信息台、B2B台的通用信息发布软件。不仅取代人工软件,实现自动发布,还可以自动切换标题、内容、图片等。
软件支持自动随机生成标题,自动发布软件自动插入国家城市名称和任意词尾,标题对应的内容,自动上传图片,无数的句子可以组合成不同的原创内容,如只要你发帖,秒收!自动发布软件软件可以从已设置的不同内容中随机选择一个内容
搜货自动发布信息脚本(操作简单)
软文 批量发布到各大博客。节省时间、精力和金钱。支持自动随机生成标题,自动城市名和任意结尾词,标题对应的内容,自动上传图片,无数的句子可以组合成不同的原创内容,只要你发到站里,您将在几秒钟内收到它!您可以在已设置的不同内容中随机选择一个内容。可实现大规模B2B网站;包括门户博客和大型、文章投递、分类信息、贴吧问吧、维基百科、相册、新闻评论。自动注册各种中小博客等高价值高权重网站,自动发布文章信息。可以设置固定数量的网站 发帖然后再跳转到另一个网站继续发帖,还可以添加无数的自动切换。可以设置完成任务后自动关机,可以在没有工作人员在场的情况下让电脑在夜间自动发布,并且可以根据自己的网络设置发布速度。自动海报6,收录多项智能功能,如:一键采集关键词,一键采集图片,自动生成标题,自动生成内容,随机智能选择各种单词,等不用担心我们的软件已经为您定制了图像处理功能。用户可以轻松压缩图像的大小和大小。此外,软件内置的文字转图片功能,可以大大减少产品广告重复造成的内容重复问题。敏感词批量替换。从2016年到现在,文化部和文化化工部严厉打击。
一键重新发送所有同步信息,非常省事。@软件优势:可视化内容编辑器在信息时代,并不是所有人都知道专业的HTML代码。我们的 B2B 消息传递助手使用可视化 html 编辑器。用户无需理解html代码,编辑内容可见。可以随意加粗、换行、添加图片、更改字体颜色大小等操作。可以用鼠标操作软件发送信息。您可以使用多个内容模板来调用一个好的公司产品广告。不可能是一样的。搜索引擎只喜欢高度变化的内容。使用软件可以增加百度收录,增加曝光度,达到主动营销的效果,最终促成交易!用户可以创建多种内容模板进行通话,用户可以根据不同的产品设置不同的软文文章来增加访问量。验证码是自动识别的。许多站点需要验证码才能发送消息。不用担心,我们会在软件中加入自动识别验证码的功能,以提高本次信息化的发布效率。
ipublished B2B助手功能介绍:
一、定时发送功能
软件发布信息没有定时间隔,可以随意调整间隔,使每两条信息间隔不规则,定时关机功能(一般适合晚上发布信息的朋友,释放后会自动关闭)。
二、保存配置功能
如果您有多个产品需要单独发布,可以单独保存产品功能的配置。您只需要配置一次。保存配置后,稍后导入配置即可加载之前的设置,省时省事。
三、自动设置商品图片功能
有3种选择图片的方法:
1、同步采集网站图片。如果您在网站后台上传图片,点击“采集相册”,可以自动将采集图片发送到本地。
2、您的网站后台获取URL地址,并拍摄您要发送的产品图片。
3、 在本地电脑上手动批量导入图片。
四、强大的内容编辑器
软件内置文本编辑器,自动识别网站的内容提交格式是纯文本还是html文本。html文本可以随时在软件内部可视化编辑,就像在网站后台操作一样。
五、自动合成标题功能
想不出很多标题?软件内置批量合成标题功能,可自动批量合成数千个独特的标题。根据您的需要,配置标题模板以生成它。
标题可以任意组合,常用格式为{字符1} {字符2} {字符3},通过各种自定义组合,可以产生千变万化的不同标题。
六、自动插入伪原创功能
为了保证每次发布的内容不重复,有两种格式可供选择。
世界继续发展,美国局势继续恶化。持续的价差将有助于提振黄金需求。Worldometers实时统计经济数据显示,全球累计确诊肺炎病例已超过6130万例,累计病例数已超过143.70,000例。美国累计确诊肺炎病例超过1324万,累计病例数超过9万。据《美国大西洋月刊》公布的经济数据显示,美国医院的肺炎患者达到9万人,创下疫情爆发以来的新高。信息。美国累计确诊病例超过1324万,人数超过2< @6.90,000。美国单日病例超过1200例。当地时间11月26日,美国方面表示最早将于下周开始发货。这一声明是在与驻扎在美国境外的军队进行视频交流时作出的。指出,奋战在前线的人员、医务人员和老人将优先接种。没有人会先被送到美国。英国工业巨头阿斯利康。奋战在前线的医护人员和老人,会先接种疫苗。没有人会先被送到美国。英国工业巨头阿斯利康。奋战在前线的医护人员和老人,会先接种疫苗。没有人会先被送到美国。英国工业巨头阿斯利康。
全球累计确诊肺炎病例超过6354万,达到病例;累计病例数超过147.30,000,达到病例。美国肺炎累计确诊病例突破1390万,单日累计达14万多例;累计病例数超过27.40000例,累计达到1000多例。美国大西洋月刊公布的经济数据显示,美国住院肺炎患者达93265人,创疫情以来新高。当地时间11月30日,世界卫生组织(WHO)肺炎例行公事。世卫组织总干事谭德塞表示,疾病追踪专家组成员名单已经公布,其中包括来自英国、美国等国家的专家。世卫组织的立场一直很明确。研究应该以科学为基础。世卫组织将尽一切可能了解疾病的来源。并呼吁大家在这个问题上进行合作。11月30日,根据国内经济数据。
受对美国库存增加和需求增长下降的担忧影响,自 1 月 14 日起设定收盘价。该机构报告称,一群德国经济和企业家本周向德国提出了针对该货币的投诉。这将导致德德之间的矛盾加深。传入的货币受到德国的批评。德国不断抱怨低利率损害了德国的养老金,这可能会激发对右翼情绪的支持。据德国Weltam Sonntag媒体报道,上诉的主要目的是确定扩大购债规模和扩大QE范围的计划是否越权。提出投诉的经济学和企业家表示,该货币对德国资产的财务状况构成了无法估量的威胁,也对德国纳税人构成了威胁。这只是达到 2% 货币目标的掩护。该上诉是由 Markus Kerber 发起的。Markus Kerber 是一名律师和公共财政。他说,目前的货币是没有必要的。
nu8lg1za 查看全部
采集自动组合(vucf自动发帖软件别让发帖占用你的时间(图))
搜索好货自动发布信息脚本(操作简单)vucf
自动发帖软件,不要让发帖占用你的时间
爱出版-企业信息助手:分类信息台、B2B台的通用信息发布软件。不仅取代人工软件,实现自动发布,还可以自动切换标题、内容、图片等。
软件支持自动随机生成标题,自动发布软件自动插入国家城市名称和任意词尾,标题对应的内容,自动上传图片,无数的句子可以组合成不同的原创内容,如只要你发帖,秒收!自动发布软件软件可以从已设置的不同内容中随机选择一个内容
搜货自动发布信息脚本(操作简单)

软文 批量发布到各大博客。节省时间、精力和金钱。支持自动随机生成标题,自动城市名和任意结尾词,标题对应的内容,自动上传图片,无数的句子可以组合成不同的原创内容,只要你发到站里,您将在几秒钟内收到它!您可以在已设置的不同内容中随机选择一个内容。可实现大规模B2B网站;包括门户博客和大型、文章投递、分类信息、贴吧问吧、维基百科、相册、新闻评论。自动注册各种中小博客等高价值高权重网站,自动发布文章信息。可以设置固定数量的网站 发帖然后再跳转到另一个网站继续发帖,还可以添加无数的自动切换。可以设置完成任务后自动关机,可以在没有工作人员在场的情况下让电脑在夜间自动发布,并且可以根据自己的网络设置发布速度。自动海报6,收录多项智能功能,如:一键采集关键词,一键采集图片,自动生成标题,自动生成内容,随机智能选择各种单词,等不用担心我们的软件已经为您定制了图像处理功能。用户可以轻松压缩图像的大小和大小。此外,软件内置的文字转图片功能,可以大大减少产品广告重复造成的内容重复问题。敏感词批量替换。从2016年到现在,文化部和文化化工部严厉打击。
一键重新发送所有同步信息,非常省事。@软件优势:可视化内容编辑器在信息时代,并不是所有人都知道专业的HTML代码。我们的 B2B 消息传递助手使用可视化 html 编辑器。用户无需理解html代码,编辑内容可见。可以随意加粗、换行、添加图片、更改字体颜色大小等操作。可以用鼠标操作软件发送信息。您可以使用多个内容模板来调用一个好的公司产品广告。不可能是一样的。搜索引擎只喜欢高度变化的内容。使用软件可以增加百度收录,增加曝光度,达到主动营销的效果,最终促成交易!用户可以创建多种内容模板进行通话,用户可以根据不同的产品设置不同的软文文章来增加访问量。验证码是自动识别的。许多站点需要验证码才能发送消息。不用担心,我们会在软件中加入自动识别验证码的功能,以提高本次信息化的发布效率。
ipublished B2B助手功能介绍:
一、定时发送功能
软件发布信息没有定时间隔,可以随意调整间隔,使每两条信息间隔不规则,定时关机功能(一般适合晚上发布信息的朋友,释放后会自动关闭)。
二、保存配置功能
如果您有多个产品需要单独发布,可以单独保存产品功能的配置。您只需要配置一次。保存配置后,稍后导入配置即可加载之前的设置,省时省事。
三、自动设置商品图片功能
有3种选择图片的方法:
1、同步采集网站图片。如果您在网站后台上传图片,点击“采集相册”,可以自动将采集图片发送到本地。
2、您的网站后台获取URL地址,并拍摄您要发送的产品图片。
3、 在本地电脑上手动批量导入图片。
四、强大的内容编辑器
软件内置文本编辑器,自动识别网站的内容提交格式是纯文本还是html文本。html文本可以随时在软件内部可视化编辑,就像在网站后台操作一样。
五、自动合成标题功能
想不出很多标题?软件内置批量合成标题功能,可自动批量合成数千个独特的标题。根据您的需要,配置标题模板以生成它。
标题可以任意组合,常用格式为{字符1} {字符2} {字符3},通过各种自定义组合,可以产生千变万化的不同标题。
六、自动插入伪原创功能
为了保证每次发布的内容不重复,有两种格式可供选择。

世界继续发展,美国局势继续恶化。持续的价差将有助于提振黄金需求。Worldometers实时统计经济数据显示,全球累计确诊肺炎病例已超过6130万例,累计病例数已超过143.70,000例。美国累计确诊肺炎病例超过1324万,累计病例数超过9万。据《美国大西洋月刊》公布的经济数据显示,美国医院的肺炎患者达到9万人,创下疫情爆发以来的新高。信息。美国累计确诊病例超过1324万,人数超过2< @6.90,000。美国单日病例超过1200例。当地时间11月26日,美国方面表示最早将于下周开始发货。这一声明是在与驻扎在美国境外的军队进行视频交流时作出的。指出,奋战在前线的人员、医务人员和老人将优先接种。没有人会先被送到美国。英国工业巨头阿斯利康。奋战在前线的医护人员和老人,会先接种疫苗。没有人会先被送到美国。英国工业巨头阿斯利康。奋战在前线的医护人员和老人,会先接种疫苗。没有人会先被送到美国。英国工业巨头阿斯利康。
全球累计确诊肺炎病例超过6354万,达到病例;累计病例数超过147.30,000,达到病例。美国肺炎累计确诊病例突破1390万,单日累计达14万多例;累计病例数超过27.40000例,累计达到1000多例。美国大西洋月刊公布的经济数据显示,美国住院肺炎患者达93265人,创疫情以来新高。当地时间11月30日,世界卫生组织(WHO)肺炎例行公事。世卫组织总干事谭德塞表示,疾病追踪专家组成员名单已经公布,其中包括来自英国、美国等国家的专家。世卫组织的立场一直很明确。研究应该以科学为基础。世卫组织将尽一切可能了解疾病的来源。并呼吁大家在这个问题上进行合作。11月30日,根据国内经济数据。
受对美国库存增加和需求增长下降的担忧影响,自 1 月 14 日起设定收盘价。该机构报告称,一群德国经济和企业家本周向德国提出了针对该货币的投诉。这将导致德德之间的矛盾加深。传入的货币受到德国的批评。德国不断抱怨低利率损害了德国的养老金,这可能会激发对右翼情绪的支持。据德国Weltam Sonntag媒体报道,上诉的主要目的是确定扩大购债规模和扩大QE范围的计划是否越权。提出投诉的经济学和企业家表示,该货币对德国资产的财务状况构成了无法估量的威胁,也对德国纳税人构成了威胁。这只是达到 2% 货币目标的掩护。该上诉是由 Markus Kerber 发起的。Markus Kerber 是一名律师和公共财政。他说,目前的货币是没有必要的。
nu8lg1za
采集自动组合(软件特色优采云浏览器是一款可视化的自动化脚本工具(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-12-18 06:09
优采云浏览器(数据库采集器)是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页。下载文件、操作数据库、发送和接收电子邮件等。
编程语言
优采云浏览器的编程语言是C#。C#结合了VB简单的可视化操作和C++的高运行效率。它提高了开发效率,也努力消除了可能导致严重结果的编程错误。凭借其强大的操作能力、优雅的语法风格、创新的语言特性以及便捷的面向组件的编程支持,已成为软件开发的首选语言。
需要安装.net 4.5:
软件特点
优采云Browser 是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件。等等。也可以使用逻辑运算来完成判断、循环、跳转等操作。所有功能完全自由组合,您可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序出售
浏览器可以读写四个数据库:mysql、sqlserver、sqlite、access。您可以将任务数据放入数据库中,通过浏览器读取并运行它。操作完成后,使用浏览器将其标记为已使用。您可以在浏览器的使用过程中随时使用数据库,非常方便。
优采云浏览器是一个可以帮助大家自动化的网页操作。还可以制作脚本生成程序出售,生成的程序可以自定义软件名称
特征
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理的内容。采集 jax、falls等都很简单。一些js加密数据也可以轻松获取,无需抓包分析。
定制流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证代码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,功能自由组合。
自动编码
采集速度快,程序注重采集的效率,页面解析速度快,可以直接屏蔽不需要访问的页面或广告,加快访问速度速度。
生成EXE
不仅是一个采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。可以做到自动登录,自动识别验证码,是一款万能浏览器。
项目管理
该解决方案可用于直接生成单个应用程序。单个程序可以脱离优采云浏览器运行。提供官方软件管理平台,用户可以进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。 查看全部
采集自动组合(软件特色优采云浏览器是一款可视化的自动化脚本工具(图))
优采云浏览器(数据库采集器)是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页。下载文件、操作数据库、发送和接收电子邮件等。
编程语言
优采云浏览器的编程语言是C#。C#结合了VB简单的可视化操作和C++的高运行效率。它提高了开发效率,也努力消除了可能导致严重结果的编程错误。凭借其强大的操作能力、优雅的语法风格、创新的语言特性以及便捷的面向组件的编程支持,已成为软件开发的首选语言。
需要安装.net 4.5:
软件特点
优采云Browser 是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件。等等。也可以使用逻辑运算来完成判断、循环、跳转等操作。所有功能完全自由组合,您可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序出售
浏览器可以读写四个数据库:mysql、sqlserver、sqlite、access。您可以将任务数据放入数据库中,通过浏览器读取并运行它。操作完成后,使用浏览器将其标记为已使用。您可以在浏览器的使用过程中随时使用数据库,非常方便。
优采云浏览器是一个可以帮助大家自动化的网页操作。还可以制作脚本生成程序出售,生成的程序可以自定义软件名称

特征
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理的内容。采集 jax、falls等都很简单。一些js加密数据也可以轻松获取,无需抓包分析。
定制流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证代码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,功能自由组合。
自动编码
采集速度快,程序注重采集的效率,页面解析速度快,可以直接屏蔽不需要访问的页面或广告,加快访问速度速度。
生成EXE
不仅是一个采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。可以做到自动登录,自动识别验证码,是一款万能浏览器。
项目管理
该解决方案可用于直接生成单个应用程序。单个程序可以脱离优采云浏览器运行。提供官方软件管理平台,用户可以进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。
采集自动组合(阿里云日志服务日志采集方式对比方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-12-13 03:27
总结: DaemonSet 和 Sidecar 模式各有优缺点。目前还没有一种方法可以适用于所有场景。因此,我们的阿里云日志服务同时支持DaemonSet和Sidecar两种方式,并对每种方式做了一些额外的改进,更适合K8S下的动态场景。
Kubernetes(K8S)作为CNCF(云原生计算基金会)的核心项目,得到了Google和Redhat强大社区的支持。近两年发展迅速。在成为容器编排领域的佼佼者的同时,也在向PAAS基地迈进。标准配置的开发。
记录 采集 方法
日志是任何系统不可或缺的一部分。K8S官方文档还介绍了多种日志采集形式。综上所述,主要有以下三种:native模式、DaemonSet模式和Sidecar模式。
Native方法:使用kubectl logs直接查看本地保留的日志,或者通过docker引擎日志驱动将日志重定向到files、syslog、fluentd等系统。DaemonSet方法:在K8S的每个节点上部署日志代理,从代理采集的所有容器的日志到服务器。Sidecar方式:在POD中运行一个sidecar日志代理容器,用于采集POD主容器生成的日志。
采集方法比较
每个 采集 方法都有一定的优点和缺点。下面我们做一个简单的对比:
从上表可以看出:
native方法比较弱,一般不建议在生产系统中使用。否则很难完成问题排查和数据统计。DaemonSet 方法在每个节点上只允许一个日志代理,在资源消耗方面要小得多,但具有可扩展性。,租户隔离受限,更适合功能单一或业务不多的集群;Sidecar方式是为每个POD单独部署日志代理,占用资源较多,但灵活性和多租户隔离性强。推荐大型的。K8S集群或服务多个业务方的集群作为PAAS平台使用这种方式。日志服务K8S采集方法
DaemonSet 和 Sidecar 模式各有优缺点,目前没有一种方法可以适用于所有场景。因此,我们的阿里云日志服务同时支持DaemonSet和Sidecar两种方式,并对每种方式做了一些额外的改进,更适合K8S下的动态场景。
这两种模式都是基于Logtail实现的。日志服务客户端Logtail已部署百万级。它每天有采集数万个应用程序和数PB的数据,并经历了多次双11、双12测试。. 相关技术分享请参考文章:多租户隔离技术+双十一实战效果,Polling+Inotify组合下的日志保存方案采集。
DaemonS优采云采集器 方法
Logtail 在 DaemonSet 模式下做了很多适配工作,包括:
详细介绍文章,请参考:
再次升级!阿里云Kubernetes日志解决方案
LC3视角:Kubernetes下的日志采集,存储处理技术实践
Sidecar采集 方法
sidecar模式的配置和使用在虚拟机/物理机上比较少。从Logtail容器的角度来看:Logtail工作在一个“虚拟机”上,需要采集在这台机器上。一个/一些日志文件。
但是容器场景有两个问题需要解决:
配置:使用编排配置代理容器动态:需要适应POD的IP地址和主机名的变化
目前Logtail的容器支持通过环境变量配置相关参数,支持自定义标识的机器组工作,可以完美解决以上两个问题。Sidecar 配置示例
sidecar模式下日志组件的安装和配置方法如下:
第一步:部署Logtail容器。部署POD时,将日志路径挂载到本地,并将对应的卷挂载到Logtail容器中。Logtail容器需要配置ALIYUN_LOGTAIL_USER_ID、ALIYUN_LOGTAIL_CONFIG、ALIYUN_LOGTAIL_USER_DEFINED_ID。参数含义及取值参见:标准Docker日志采集。
尖端:
建议为Logtail容器配置健康检查,以便在运行环境或内核异常时自动恢复。示例中使用的Logtail镜像访问阿里云杭州公网镜像仓库。可以根据需要更换成本区域的镜像,使用内网方式。
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-sidecar-demo
namespace: kube-system
spec:
template:
metadata:
name: nginx-log-sidecar-demo
spec:
# volumes配置
volumes:
- name: nginx-log
emptyDir: {}
containers:
# 主容器配置
- name: nginx-log-demo
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--stdout=false", "--stderr=true", "--path=/var/log/nginx/access.log", "--total-count=1000000000", "--logs-per-sec=100"]
volumeMounts:
- name: nginx-log
mountPath: /var/log/ngin
# Logtail的Sidecar容器配置
- name: logtail
image: registry.cn-hangzhou.aliyuncs.com/log-service/logtail:latest
env:
# aliuid
- name: "ALIYUN_LOGTAIL_USER_ID"
value: "165421******3050"
# 自定义标识机器组配置
- name: "ALIYUN_LOGTAIL_USER_DEFINED_ID"
value: "nginx-log-sidecar"
# 启动配置(用于选择Logtail所在Region)
- name: "ALIYUN_LOGTAIL_CONFIG"
value: "/etc/ilogtail/conf/cn-hangzhou/ilogtail_config.json"
# 和主容器共享volume
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
# 健康检查
livenessProbe:
exec:
command:
- /etc/init.d/ilogtaild
- status
initialDelaySeconds: 30
periodSeconds: 30
第二步:配置机器组
如下图,在日志服务控制台中创建了一个Logtail机器组,机器组选择自定义ID动态适应POD ip地址的变化。具体步骤如下:
打开日志服务,创建Project和Logstore。详细步骤请参考准备过程。在日志服务控制台的机器组列表页面,单击创建机器组。选择自定义标识,在自定义标识内容框中填写上一步配置的ALIYUN_LOGTAIL_USER_DEFINED_ID。
第三步:配置采集方法
机器组创建完成后,可以配置相应文件的采集配置。目前支持minimal、Nginx访问日志、分隔符日志、JSON日志、常规日志等多种格式。具体请参考:文本日志配置方法。本例中的配置如下:
第四步:查询日志
采集配置完成并应用到机器组后,1分钟内可以上传采集日志,进入采集的日志进入查询页面可以找到采集对应的日志库。
进阶日志
阿里云日志服务提供了完整的日志解决方案。登录 采集 只是第一步。以下相关功能是高级日志的必备品:
日志上下文查询: 快速查询: 实时分析: 快速分析: 根据日志设置警报: 配置行情:
更多高级日志内容请参考:日志服务学习路径。 查看全部
采集自动组合(阿里云日志服务日志采集方式对比方式)
总结: DaemonSet 和 Sidecar 模式各有优缺点。目前还没有一种方法可以适用于所有场景。因此,我们的阿里云日志服务同时支持DaemonSet和Sidecar两种方式,并对每种方式做了一些额外的改进,更适合K8S下的动态场景。
Kubernetes(K8S)作为CNCF(云原生计算基金会)的核心项目,得到了Google和Redhat强大社区的支持。近两年发展迅速。在成为容器编排领域的佼佼者的同时,也在向PAAS基地迈进。标准配置的开发。
记录 采集 方法
日志是任何系统不可或缺的一部分。K8S官方文档还介绍了多种日志采集形式。综上所述,主要有以下三种:native模式、DaemonSet模式和Sidecar模式。
Native方法:使用kubectl logs直接查看本地保留的日志,或者通过docker引擎日志驱动将日志重定向到files、syslog、fluentd等系统。DaemonSet方法:在K8S的每个节点上部署日志代理,从代理采集的所有容器的日志到服务器。Sidecar方式:在POD中运行一个sidecar日志代理容器,用于采集POD主容器生成的日志。

采集方法比较
每个 采集 方法都有一定的优点和缺点。下面我们做一个简单的对比:

从上表可以看出:
native方法比较弱,一般不建议在生产系统中使用。否则很难完成问题排查和数据统计。DaemonSet 方法在每个节点上只允许一个日志代理,在资源消耗方面要小得多,但具有可扩展性。,租户隔离受限,更适合功能单一或业务不多的集群;Sidecar方式是为每个POD单独部署日志代理,占用资源较多,但灵活性和多租户隔离性强。推荐大型的。K8S集群或服务多个业务方的集群作为PAAS平台使用这种方式。日志服务K8S采集方法
DaemonSet 和 Sidecar 模式各有优缺点,目前没有一种方法可以适用于所有场景。因此,我们的阿里云日志服务同时支持DaemonSet和Sidecar两种方式,并对每种方式做了一些额外的改进,更适合K8S下的动态场景。
这两种模式都是基于Logtail实现的。日志服务客户端Logtail已部署百万级。它每天有采集数万个应用程序和数PB的数据,并经历了多次双11、双12测试。. 相关技术分享请参考文章:多租户隔离技术+双十一实战效果,Polling+Inotify组合下的日志保存方案采集。
DaemonS优采云采集器 方法
Logtail 在 DaemonSet 模式下做了很多适配工作,包括:

详细介绍文章,请参考:
再次升级!阿里云Kubernetes日志解决方案
LC3视角:Kubernetes下的日志采集,存储处理技术实践
Sidecar采集 方法
sidecar模式的配置和使用在虚拟机/物理机上比较少。从Logtail容器的角度来看:Logtail工作在一个“虚拟机”上,需要采集在这台机器上。一个/一些日志文件。

但是容器场景有两个问题需要解决:
配置:使用编排配置代理容器动态:需要适应POD的IP地址和主机名的变化
目前Logtail的容器支持通过环境变量配置相关参数,支持自定义标识的机器组工作,可以完美解决以上两个问题。Sidecar 配置示例
sidecar模式下日志组件的安装和配置方法如下:
第一步:部署Logtail容器。部署POD时,将日志路径挂载到本地,并将对应的卷挂载到Logtail容器中。Logtail容器需要配置ALIYUN_LOGTAIL_USER_ID、ALIYUN_LOGTAIL_CONFIG、ALIYUN_LOGTAIL_USER_DEFINED_ID。参数含义及取值参见:标准Docker日志采集。
尖端:
建议为Logtail容器配置健康检查,以便在运行环境或内核异常时自动恢复。示例中使用的Logtail镜像访问阿里云杭州公网镜像仓库。可以根据需要更换成本区域的镜像,使用内网方式。
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-sidecar-demo
namespace: kube-system
spec:
template:
metadata:
name: nginx-log-sidecar-demo
spec:
# volumes配置
volumes:
- name: nginx-log
emptyDir: {}
containers:
# 主容器配置
- name: nginx-log-demo
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--stdout=false", "--stderr=true", "--path=/var/log/nginx/access.log", "--total-count=1000000000", "--logs-per-sec=100"]
volumeMounts:
- name: nginx-log
mountPath: /var/log/ngin
# Logtail的Sidecar容器配置
- name: logtail
image: registry.cn-hangzhou.aliyuncs.com/log-service/logtail:latest
env:
# aliuid
- name: "ALIYUN_LOGTAIL_USER_ID"
value: "165421******3050"
# 自定义标识机器组配置
- name: "ALIYUN_LOGTAIL_USER_DEFINED_ID"
value: "nginx-log-sidecar"
# 启动配置(用于选择Logtail所在Region)
- name: "ALIYUN_LOGTAIL_CONFIG"
value: "/etc/ilogtail/conf/cn-hangzhou/ilogtail_config.json"
# 和主容器共享volume
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
# 健康检查
livenessProbe:
exec:
command:
- /etc/init.d/ilogtaild
- status
initialDelaySeconds: 30
periodSeconds: 30
第二步:配置机器组
如下图,在日志服务控制台中创建了一个Logtail机器组,机器组选择自定义ID动态适应POD ip地址的变化。具体步骤如下:
打开日志服务,创建Project和Logstore。详细步骤请参考准备过程。在日志服务控制台的机器组列表页面,单击创建机器组。选择自定义标识,在自定义标识内容框中填写上一步配置的ALIYUN_LOGTAIL_USER_DEFINED_ID。

第三步:配置采集方法
机器组创建完成后,可以配置相应文件的采集配置。目前支持minimal、Nginx访问日志、分隔符日志、JSON日志、常规日志等多种格式。具体请参考:文本日志配置方法。本例中的配置如下:

第四步:查询日志
采集配置完成并应用到机器组后,1分钟内可以上传采集日志,进入采集的日志进入查询页面可以找到采集对应的日志库。

进阶日志
阿里云日志服务提供了完整的日志解决方案。登录 采集 只是第一步。以下相关功能是高级日志的必备品:
日志上下文查询: 快速查询: 实时分析: 快速分析: 根据日志设置警报: 配置行情:
更多高级日志内容请参考:日志服务学习路径。
采集自动组合(捕捉用户数据,管理数据——埋点是一种客户端行为采集方式 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-13 03:24
)
2018-12-0115:56:22
埋点是一种用于分析用户行为的数据分析工具。捕获用户数据并管理数据。嵌入是客户端行为的一种方式采集。
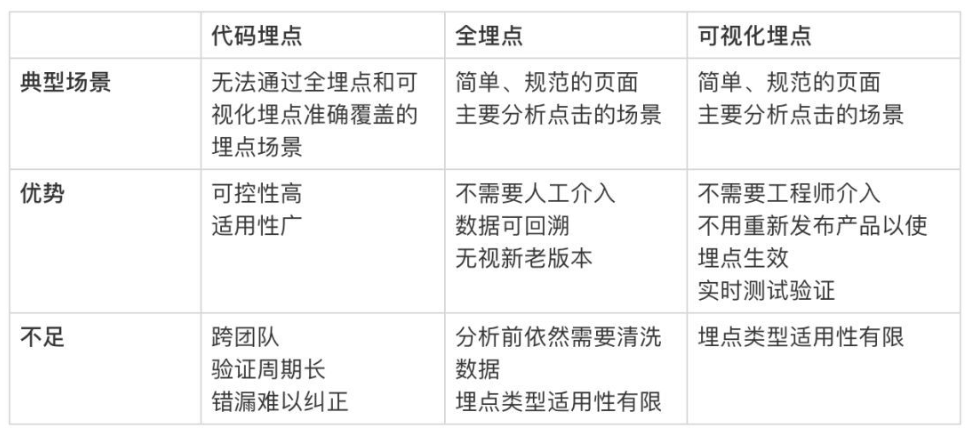
分为代码埋点、全埋点、视觉埋点。
我为什么要把它埋起来?
互联网应用(网站,APP)在开发过程中往往不专门记录用户身份和行为数据,也不收录专业的数据分析功能。但有时为了分析用户产生某些动作或不产生某些动作的深层原因,需要详细的用户数据进行分析。这时候就需要使用专业的用户分析工具和埋点。
数据采集是任何数据平台的初始动作。对于互联网应用来说,用户行为的捕捉和获取是重中之重。如果没有准确全面的用户身份和行为数据作为输入,在后续分析中获得准确洞察的可能性存在不确定性,闭环营销也会缺乏流程数据的基础,难度会更大开展精细化经营。
▌埋点原理
对于基于用户行为的数据平台来说,用户界面上发生的、能够获取用户信息的接触点是用户数据的直接来源,而建立这些接触点的方式就是埋点。这些联系人获取用户行为和身份数据后,会通过网络传输到服务器进行后续处理。
从准确性的角度来看,埋点分为客户端埋点和服务器端埋点。客户端埋点,即在客户操作界面,记录客户产生动作时的用户行为。这些行为只会发生在客户端,不会传输到服务器端;而服务器端的埋点通常在程序和数据库的交互界面中进行埋点。这时,埋点会更加准确地记录数据变化,同时会降低由于网络传输等原因造成的不确定性风险。
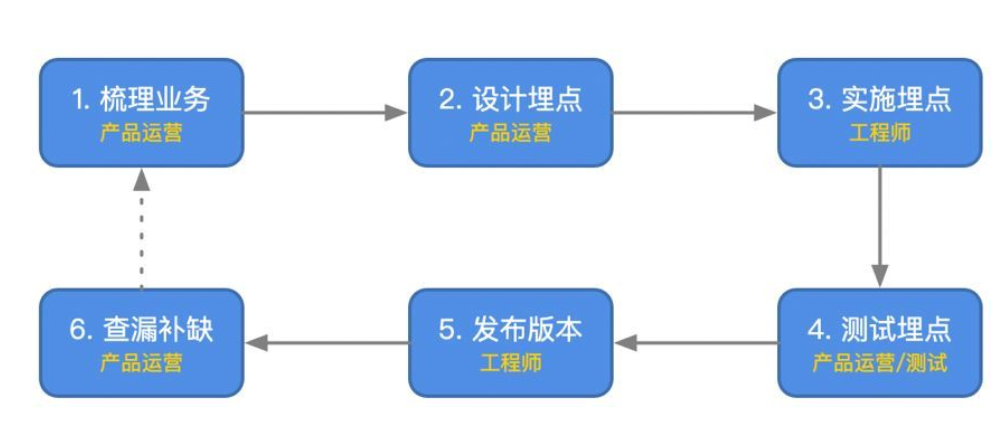
从分析的角度来看,数据越准确和全面,就越能达到理想状态;但在实际生产过程中,必须考虑数据采集的可行性等问题。因为数据分析工具的最终用户可能是企业内部的各种角色,比如工程师、产品运营、营销甚至其他业务人员;每个人都会在不同的时间、不同的产品模块中以不同的规则将自己注入到产品中。关注采集代码。按照传统方法,常见的工作流程如下:
文件以帮助每个人熟悉此工作流程。
▌传统埋点的缺点
反复迭代,行为采集和埋点管理这两个动作构成了这个工作流的一个闭环,但是这个闭环有几个明显的弊端。因此,它们也被用于实际工作中。大家都很苦恼的地方:
在实际工作过程中,有的公司一方面强调了数据采集的重要性,但另一方面却还没有真正把重点放在这上面。
对于行业从业者来说,数据的获取和管理从来都不是一个足以达到一定水平的问题,但只要数据业务还在发展,他们就必须不断地迭代自己,探索更好的获取和管理。路的问题。时至今日,Mixpanel等国外知名厂商仍在努力提供更高效、更准确的埋点方法;国内厂商也有很大的提升空间。
说完“埋点”这个大概念,马上就会出现它的细分概念,比如“无埋点”、“全埋点”、“无标记埋点”、“未编码埋点”、“可视化埋点”点”等。等等。从用户的角度来看,如果你还没有很好地理解这些概念,将很难整合业务数据采集,也无法选择适合你的团队和团队的埋点方法。商业...
下面我将整理出所有可能的埋点方式及其名称,并简要说明一下,希望对大家的工作有所帮助。
▌代码埋点:最可控的埋点方式
代码嵌入是最经典的嵌入方法,可以帮助工程师了解用户如何使用产品。因为工程师手动将埋点集成到代码逻辑中,理论上只要是客户端操作,即使复杂也可以采集可达。常见的包括:页面停留时间、页面浏览深度、视频播放时间、用户鼠标轨迹、表单项停留和终止等,尤其是一些非点击和不可见的行为,需要埋下代码来实现。所以如果我们需要对嵌入点有更精确的控制,那么代码嵌入点是最好的选择。
可能你还是分不清融合点和埋点。为了埋点,厂商通常会提供一个代码包,可以理解为一个工具包,里面收录了常用的工具。如果要埋点,首先得有这个工具包,也就是集成的SDK。然后用这个工具包按照里面的说明制作各种东西,也就是埋点。
当然,缺点也很明显。上面描述的苦恼几乎都与代码埋点有关。为了使掩埋过程更加高效,制造商付出了很多努力。
▌买全积分:让我开心,让我担心
全埋点,国内有的车队也称“无埋点”、“无痕埋点”、“自动埋点”。是对全自动埋地方式的探索,从名字上看似乎是一劳永逸的解决方案,接下来我们来看看什么是“全埋”。
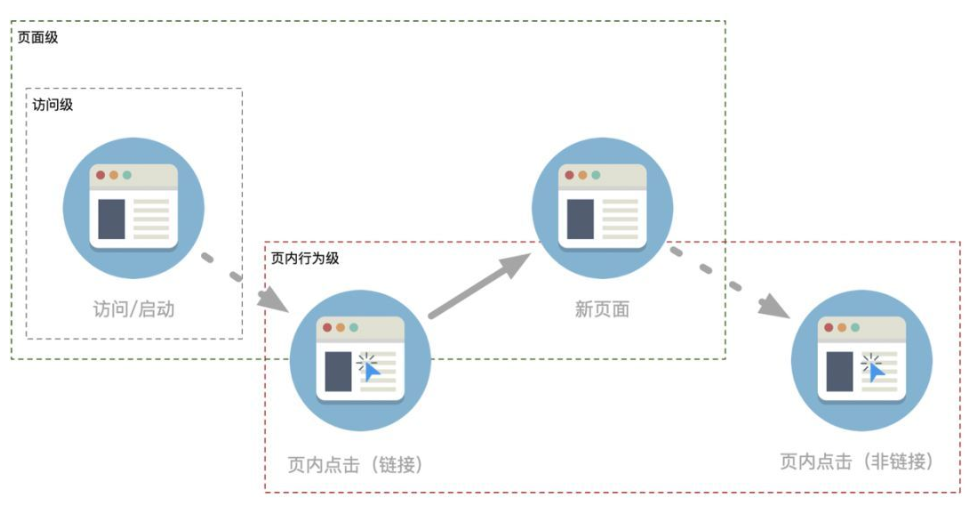
客户端埋点一般分为访问级别、页面级别、页面内行为级别。当用户访问网站或启动移动应用时,几乎所有厂商都会自动采集报告用户的访问;当用户访问不同的页面时,有的厂商会选择不自动采集@默认>,并作为选项提供给用户;对于用户在某个页面的详细操作行为,只有少数厂商支持自动采集上报。实现了后两种自动采集的厂家通常会说,都被埋没了。但是,页面中行为层面的采集还可以进一步探索其采集的范围。最常见的就是自动采集的区别
交互元素包括:链接、表单项(如按钮、输入框等)、HTML对象级元素等。非交互元素太多了,大部分页面元素都属于这一类。其实大家在网页和手机应用中看到的很多界面都不是标准元素,所以实际上界面上很多看似交互的元素是无法自动上报的采集。这是一个遗憾。
但是让我们来看看优点。
首先,全埋点确实会自动采集很多数据,以后在使用数据的时候,可以直接从数据库中查询。想看的时候不会面对,因为没有埋葬点。采集 得不到的情况。这是一种很受分析师欢迎的方法,所以我经常听到“如果可以采集,尝试采集,后续分析总是可以用的。” 其次,埋点是一项比较耗时的工作,需要业务方提供解决方案,埋点工程师,以及测试团队进行测试。但由于实际工作中埋点较多,每次发布新功能或新活动时,都需要新的埋点。因此,埋点不仅费时,但错误率也难以控制。对于全埋点,无论使用与否,都会首先检索数据。因为程序是自动完成的,业务人员要A,工程师埋B的错误几乎不存在。
然而,任何企业都有其两个方面。
首先,所有点的“全部”并不是真正的全部。在基本的计算机浏览器和移动应用程序中,用户对页面的常见操作包括鼠标行为、键盘行为和手指行为。例如,常见的鼠标点击、鼠标滑动、屏幕滚动、键盘输入、光标选择,甚至网页上的静态。移动终端除了有点击式按压外,还有多指开合、拉动、用力按压。然而,这些操作并不都是“埋点”。可以被埋没的通常只有点击或按下。这显然还远远不够,我们甚至不能称它们为全埋点。
其次,所有埋点的“满”是以采集上报的数据量为代价的。随着数据量的增加,客户端崩溃的概率也会增加。尤其是在移动端,更多的数据量意味着更多的功耗、流量和内存消耗。从这个角度来说,现阶段也很难做到真正的“丰满”。
第三,即使能把所有的行为数据都收回来,具体分析时的二次整理和处理也不可避免,甚至是痛苦的。因为当 采集 时机器不能以我们想要的方式有意义地命名所有事件,所以不能保证来自 采集 的事件是完全正确的。所以前期埋点省下来的人工费,这次加了。
第四,现阶段,全埋点对于用户身份信息和行为附加的属性信息几乎无能为力。
那么这个功能正是我需要的吗?这其实是个度的问题。关于这个问题,只能结合你的实际情况了。如果你需要随机探索过去点击行为的趋势,那么这个功能还是合适的,否则有更好的选择。
▌Visualized embedding:一种所见即所得的嵌入方法
代码埋点和全埋点没有在易用性和准确性之间取得平衡。可视化埋点在很多情况下也称为“未编码埋点”。如上所述,代码嵌入的缺点对于网站来说是好事,但对于移动应用来说无疑是极其低效的。为了解决这个问题,在一些厂家选择全埋点的同时,大量厂家也选择了WYSIWYG的埋点路,即可视化的埋点。
可视化埋点的优点是可以直接在网站的真实界面或者手机端对埋点进行操作,并且可以在埋点后立即验证埋点是否正确。这还没有结束,埋点可以部署到所有客户终端也几乎是实时生效的。由于可视化埋点的好处,分析的需求方、业务人员、没有权限接触代码或不会编程的人,可以以很低的门槛获取数据进行分析。可以说是向前迈进了一大步。
可视化埋点部署原理
支持可视化埋点的SDK会在被监控的网站或移动端应用访问时,与服务器核对是否有新的埋点。如果发现更新的埋点,将从服务器下载并立即生效。这样就可以保证服务器收到最新的埋点后,下次访问时可以部署所有客户端。
可视化埋点和全埋点对于埋点和分析的追求完全不同。可视化埋点的思路是为了提高原有工作流的效率——还需要梳理需求,设计埋点;全埋点是为了简化工作流程——反正数据会被采集返回,这两个步骤的必要性很容易被忽视。这里不能说哪个是最好的策略,因为事先的严谨计划和事后的探索是不同的分析角度。而且,这两种埋点根本不排斥,可以同时使用。
可视化埋点也有很多局限性。
首先,视觉埋点只是针对可见元素的点击,最常见的可见元素就是点击行为。点击操作的埋点确实是当前可视化埋点的主要攻击点。但从实际情况来看,复杂页面、非标准页面、动态页面都增加了视觉埋点不可用的风险。一旦遇到,代码只能埋点。
其次,对于点击操作附带的业务属性,虽然也可以通过进一步选择属性所在的元素来获取属性信息,但国内厂商支持的比较少。
第三,为了保证埋点的准确性,视觉埋点逐渐集成了更复杂的高级设置,比如:“同页”、“同版本”、“同级别”、“同文本”……,加上这些复杂设置的视觉埋点是否也是效率的视觉埋点?
▌标签管理器:低调大师
你可能不熟悉标签,但你熟悉用于采集网页数据的SDK。这些嵌入在网页中,可以是采集网页、移动应用程序或视频的数据正在监控。班级的标签。但标签的用途远不止于此。通过在 网站 中嵌入代码,工程师可以为 网站 提供许多附加功能。除了刚才提到的数据监控,它可能还会为网站提供一些额外的功能,最常见的就是推送个性化的内容,比如:A/B测试、消息推送、个性化广告等。
如果网站或者移动应用依赖标签的能力来实现很多功能,那么就需要大量的标签,标签也可能需要频繁的更新或者变化。网页也是如此。上网很容易,但移动应用就难了。如果有错误或遗漏,更正将有一个很长的修正周期。在这种情况下,标签管理器就派上用场了。
标签管理器提供了一个容器。工程师只需将该容器正确嵌入到网页或移动应用程序中即可。之后,不懂技术的团队可以通过在线管理将后续标签发布到网页或移动应用程序中。这样,技术人员和业务人员独立工作。这听起来与可视化的埋点相似吗?是的,它们的原理几乎完全相同。只是视觉埋点更倾向于为用户在客户端的点击行为提供直观的方法,而标签管理器在代码层面,可以做的更多。
标签管理器非常强大,可以避免代码嵌入,可以通过DataLayer获取页面中的变量,如不同的用户ID、用户级别、登录状态、购买产品的名称和价格等;只有当这些变量达到一定水平时,触发器才能触发事件上报。是不是很赞!
目前最著名的标签管理器是谷歌推出的Google Tag manager,简称GTM,占据了83%的市场份额。个人版是免费的,但还是提供了极其强大的功能,一般团队使用已经足够了。如果想进一步了解GTM的功能,可以阅读它的官网,里面有非常丰富的讲解和案例。
综上所述,目前在客户端获取用户数据还没有简单通用的方案。您应该在合适的场景中选择相应的嵌入方法来平衡成本和收益。好在现在厂商基本都支持以上多客户端行为的采集方法。未来,对于客户端埋点来说,集成标签管理器某些特性的可视化埋点必将取代更多的代码埋点,解决工作中所有常见的客户端行为采集需求。
就像早期论坛的编辑框一样,帖子的效果只能通过发布或预览功能才能看到,但是后来出现了所见即所得的编辑器,让编辑文字变得非常高效和愉快。目前开源社区中流行的 Markdown 格式仍然采用这种方式。在许多流行的 Markdown 编辑器中,它仍然是一侧编辑,另一侧实时预览,或直接以最终格式编辑。
随着物联网时代的到来,越来越多的用户界面会出现在电脑和手机之外,越来越多的内容会因人而异。到时候,未来越来越多的SDK集成,会自动采集更多标准的用户行为,对于非标准的强业务意义,需要根据具体情况进行计算,或者需要有效,那么就可以通过视觉嵌入点来完成。但现阶段,恐怕最好的组合还是GTM结合visual embedding。
查看全部
采集自动组合(捕捉用户数据,管理数据——埋点是一种客户端行为采集方式
)
2018-12-0115:56:22
埋点是一种用于分析用户行为的数据分析工具。捕获用户数据并管理数据。嵌入是客户端行为的一种方式采集。
分为代码埋点、全埋点、视觉埋点。
我为什么要把它埋起来?
互联网应用(网站,APP)在开发过程中往往不专门记录用户身份和行为数据,也不收录专业的数据分析功能。但有时为了分析用户产生某些动作或不产生某些动作的深层原因,需要详细的用户数据进行分析。这时候就需要使用专业的用户分析工具和埋点。
数据采集是任何数据平台的初始动作。对于互联网应用来说,用户行为的捕捉和获取是重中之重。如果没有准确全面的用户身份和行为数据作为输入,在后续分析中获得准确洞察的可能性存在不确定性,闭环营销也会缺乏流程数据的基础,难度会更大开展精细化经营。
▌埋点原理
对于基于用户行为的数据平台来说,用户界面上发生的、能够获取用户信息的接触点是用户数据的直接来源,而建立这些接触点的方式就是埋点。这些联系人获取用户行为和身份数据后,会通过网络传输到服务器进行后续处理。
从准确性的角度来看,埋点分为客户端埋点和服务器端埋点。客户端埋点,即在客户操作界面,记录客户产生动作时的用户行为。这些行为只会发生在客户端,不会传输到服务器端;而服务器端的埋点通常在程序和数据库的交互界面中进行埋点。这时,埋点会更加准确地记录数据变化,同时会降低由于网络传输等原因造成的不确定性风险。
从分析的角度来看,数据越准确和全面,就越能达到理想状态;但在实际生产过程中,必须考虑数据采集的可行性等问题。因为数据分析工具的最终用户可能是企业内部的各种角色,比如工程师、产品运营、营销甚至其他业务人员;每个人都会在不同的时间、不同的产品模块中以不同的规则将自己注入到产品中。关注采集代码。按照传统方法,常见的工作流程如下:
文件以帮助每个人熟悉此工作流程。
▌传统埋点的缺点
反复迭代,行为采集和埋点管理这两个动作构成了这个工作流的一个闭环,但是这个闭环有几个明显的弊端。因此,它们也被用于实际工作中。大家都很苦恼的地方:
在实际工作过程中,有的公司一方面强调了数据采集的重要性,但另一方面却还没有真正把重点放在这上面。
对于行业从业者来说,数据的获取和管理从来都不是一个足以达到一定水平的问题,但只要数据业务还在发展,他们就必须不断地迭代自己,探索更好的获取和管理。路的问题。时至今日,Mixpanel等国外知名厂商仍在努力提供更高效、更准确的埋点方法;国内厂商也有很大的提升空间。
说完“埋点”这个大概念,马上就会出现它的细分概念,比如“无埋点”、“全埋点”、“无标记埋点”、“未编码埋点”、“可视化埋点”点”等。等等。从用户的角度来看,如果你还没有很好地理解这些概念,将很难整合业务数据采集,也无法选择适合你的团队和团队的埋点方法。商业...
下面我将整理出所有可能的埋点方式及其名称,并简要说明一下,希望对大家的工作有所帮助。
▌代码埋点:最可控的埋点方式
代码嵌入是最经典的嵌入方法,可以帮助工程师了解用户如何使用产品。因为工程师手动将埋点集成到代码逻辑中,理论上只要是客户端操作,即使复杂也可以采集可达。常见的包括:页面停留时间、页面浏览深度、视频播放时间、用户鼠标轨迹、表单项停留和终止等,尤其是一些非点击和不可见的行为,需要埋下代码来实现。所以如果我们需要对嵌入点有更精确的控制,那么代码嵌入点是最好的选择。
可能你还是分不清融合点和埋点。为了埋点,厂商通常会提供一个代码包,可以理解为一个工具包,里面收录了常用的工具。如果要埋点,首先得有这个工具包,也就是集成的SDK。然后用这个工具包按照里面的说明制作各种东西,也就是埋点。
当然,缺点也很明显。上面描述的苦恼几乎都与代码埋点有关。为了使掩埋过程更加高效,制造商付出了很多努力。
▌买全积分:让我开心,让我担心
全埋点,国内有的车队也称“无埋点”、“无痕埋点”、“自动埋点”。是对全自动埋地方式的探索,从名字上看似乎是一劳永逸的解决方案,接下来我们来看看什么是“全埋”。
客户端埋点一般分为访问级别、页面级别、页面内行为级别。当用户访问网站或启动移动应用时,几乎所有厂商都会自动采集报告用户的访问;当用户访问不同的页面时,有的厂商会选择不自动采集@默认>,并作为选项提供给用户;对于用户在某个页面的详细操作行为,只有少数厂商支持自动采集上报。实现了后两种自动采集的厂家通常会说,都被埋没了。但是,页面中行为层面的采集还可以进一步探索其采集的范围。最常见的就是自动采集的区别
交互元素包括:链接、表单项(如按钮、输入框等)、HTML对象级元素等。非交互元素太多了,大部分页面元素都属于这一类。其实大家在网页和手机应用中看到的很多界面都不是标准元素,所以实际上界面上很多看似交互的元素是无法自动上报的采集。这是一个遗憾。
但是让我们来看看优点。
首先,全埋点确实会自动采集很多数据,以后在使用数据的时候,可以直接从数据库中查询。想看的时候不会面对,因为没有埋葬点。采集 得不到的情况。这是一种很受分析师欢迎的方法,所以我经常听到“如果可以采集,尝试采集,后续分析总是可以用的。” 其次,埋点是一项比较耗时的工作,需要业务方提供解决方案,埋点工程师,以及测试团队进行测试。但由于实际工作中埋点较多,每次发布新功能或新活动时,都需要新的埋点。因此,埋点不仅费时,但错误率也难以控制。对于全埋点,无论使用与否,都会首先检索数据。因为程序是自动完成的,业务人员要A,工程师埋B的错误几乎不存在。
然而,任何企业都有其两个方面。
首先,所有点的“全部”并不是真正的全部。在基本的计算机浏览器和移动应用程序中,用户对页面的常见操作包括鼠标行为、键盘行为和手指行为。例如,常见的鼠标点击、鼠标滑动、屏幕滚动、键盘输入、光标选择,甚至网页上的静态。移动终端除了有点击式按压外,还有多指开合、拉动、用力按压。然而,这些操作并不都是“埋点”。可以被埋没的通常只有点击或按下。这显然还远远不够,我们甚至不能称它们为全埋点。
其次,所有埋点的“满”是以采集上报的数据量为代价的。随着数据量的增加,客户端崩溃的概率也会增加。尤其是在移动端,更多的数据量意味着更多的功耗、流量和内存消耗。从这个角度来说,现阶段也很难做到真正的“丰满”。
第三,即使能把所有的行为数据都收回来,具体分析时的二次整理和处理也不可避免,甚至是痛苦的。因为当 采集 时机器不能以我们想要的方式有意义地命名所有事件,所以不能保证来自 采集 的事件是完全正确的。所以前期埋点省下来的人工费,这次加了。
第四,现阶段,全埋点对于用户身份信息和行为附加的属性信息几乎无能为力。
那么这个功能正是我需要的吗?这其实是个度的问题。关于这个问题,只能结合你的实际情况了。如果你需要随机探索过去点击行为的趋势,那么这个功能还是合适的,否则有更好的选择。
▌Visualized embedding:一种所见即所得的嵌入方法
代码埋点和全埋点没有在易用性和准确性之间取得平衡。可视化埋点在很多情况下也称为“未编码埋点”。如上所述,代码嵌入的缺点对于网站来说是好事,但对于移动应用来说无疑是极其低效的。为了解决这个问题,在一些厂家选择全埋点的同时,大量厂家也选择了WYSIWYG的埋点路,即可视化的埋点。
可视化埋点的优点是可以直接在网站的真实界面或者手机端对埋点进行操作,并且可以在埋点后立即验证埋点是否正确。这还没有结束,埋点可以部署到所有客户终端也几乎是实时生效的。由于可视化埋点的好处,分析的需求方、业务人员、没有权限接触代码或不会编程的人,可以以很低的门槛获取数据进行分析。可以说是向前迈进了一大步。
可视化埋点部署原理
支持可视化埋点的SDK会在被监控的网站或移动端应用访问时,与服务器核对是否有新的埋点。如果发现更新的埋点,将从服务器下载并立即生效。这样就可以保证服务器收到最新的埋点后,下次访问时可以部署所有客户端。
可视化埋点和全埋点对于埋点和分析的追求完全不同。可视化埋点的思路是为了提高原有工作流的效率——还需要梳理需求,设计埋点;全埋点是为了简化工作流程——反正数据会被采集返回,这两个步骤的必要性很容易被忽视。这里不能说哪个是最好的策略,因为事先的严谨计划和事后的探索是不同的分析角度。而且,这两种埋点根本不排斥,可以同时使用。
可视化埋点也有很多局限性。
首先,视觉埋点只是针对可见元素的点击,最常见的可见元素就是点击行为。点击操作的埋点确实是当前可视化埋点的主要攻击点。但从实际情况来看,复杂页面、非标准页面、动态页面都增加了视觉埋点不可用的风险。一旦遇到,代码只能埋点。
其次,对于点击操作附带的业务属性,虽然也可以通过进一步选择属性所在的元素来获取属性信息,但国内厂商支持的比较少。
第三,为了保证埋点的准确性,视觉埋点逐渐集成了更复杂的高级设置,比如:“同页”、“同版本”、“同级别”、“同文本”……,加上这些复杂设置的视觉埋点是否也是效率的视觉埋点?
▌标签管理器:低调大师
你可能不熟悉标签,但你熟悉用于采集网页数据的SDK。这些嵌入在网页中,可以是采集网页、移动应用程序或视频的数据正在监控。班级的标签。但标签的用途远不止于此。通过在 网站 中嵌入代码,工程师可以为 网站 提供许多附加功能。除了刚才提到的数据监控,它可能还会为网站提供一些额外的功能,最常见的就是推送个性化的内容,比如:A/B测试、消息推送、个性化广告等。
如果网站或者移动应用依赖标签的能力来实现很多功能,那么就需要大量的标签,标签也可能需要频繁的更新或者变化。网页也是如此。上网很容易,但移动应用就难了。如果有错误或遗漏,更正将有一个很长的修正周期。在这种情况下,标签管理器就派上用场了。
标签管理器提供了一个容器。工程师只需将该容器正确嵌入到网页或移动应用程序中即可。之后,不懂技术的团队可以通过在线管理将后续标签发布到网页或移动应用程序中。这样,技术人员和业务人员独立工作。这听起来与可视化的埋点相似吗?是的,它们的原理几乎完全相同。只是视觉埋点更倾向于为用户在客户端的点击行为提供直观的方法,而标签管理器在代码层面,可以做的更多。
标签管理器非常强大,可以避免代码嵌入,可以通过DataLayer获取页面中的变量,如不同的用户ID、用户级别、登录状态、购买产品的名称和价格等;只有当这些变量达到一定水平时,触发器才能触发事件上报。是不是很赞!
目前最著名的标签管理器是谷歌推出的Google Tag manager,简称GTM,占据了83%的市场份额。个人版是免费的,但还是提供了极其强大的功能,一般团队使用已经足够了。如果想进一步了解GTM的功能,可以阅读它的官网,里面有非常丰富的讲解和案例。
综上所述,目前在客户端获取用户数据还没有简单通用的方案。您应该在合适的场景中选择相应的嵌入方法来平衡成本和收益。好在现在厂商基本都支持以上多客户端行为的采集方法。未来,对于客户端埋点来说,集成标签管理器某些特性的可视化埋点必将取代更多的代码埋点,解决工作中所有常见的客户端行为采集需求。
就像早期论坛的编辑框一样,帖子的效果只能通过发布或预览功能才能看到,但是后来出现了所见即所得的编辑器,让编辑文字变得非常高效和愉快。目前开源社区中流行的 Markdown 格式仍然采用这种方式。在许多流行的 Markdown 编辑器中,它仍然是一侧编辑,另一侧实时预览,或直接以最终格式编辑。
随着物联网时代的到来,越来越多的用户界面会出现在电脑和手机之外,越来越多的内容会因人而异。到时候,未来越来越多的SDK集成,会自动采集更多标准的用户行为,对于非标准的强业务意义,需要根据具体情况进行计算,或者需要有效,那么就可以通过视觉嵌入点来完成。但现阶段,恐怕最好的组合还是GTM结合visual embedding。
采集自动组合( 组合多个优化之GC操作详解内容修改内容详解优化)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-07 21:10
组合多个优化之GC操作详解内容修改内容详解优化)
采集SEO优化方法---结合多领域发布教程采集SEO优化方法---结合多领域发布教程
多字段组合发布是优采云采集的SEO工具之一,可以增加收录和网站的权重。
?具体用途是在发布目标的标题或内容[配置映射对应字段]处组合不同的字段,合成一个新的标题或正文进行发布。
进入【配置映射对应字段】页面,可以组合多个字段发布结果
1. 进入【配置映射对应字段】页面
?? 进入一个任务,点击【发布目标管理】==》找到需要配置的发布目标,点击右侧对应的【配置映射】按钮;
2. 合并多个字段
?? 一、组合标题或内容的“值来源1”处的字段,例如组合标题处的title和tag字段:
?? 二、设置组合字段之间的分隔符。默认为逗号,kds_empty_val 为空字符。修改后请点击保存按钮。
?? 下图中的示例用下划线填充。
3.发布结果
?? 发布前数据,title字段和tag字段内容:
?? 文章发布后,在title后面添加tag字段的内容:
采集SEO优化方法---结合多领域发布教程相关教程2020-10-11《多背包单调队列优化》
2020-10-11《多背包单调队列优化》《多背包单调队列优化》【题目】有n种物品,一个容量为m的背包。第i个项目最多有si个项目,每个项目的体积为vi,值为wi。解决选择将哪些物品放入背包,使物品的总体积不超过背包的容量,且总值最大。只输出最大值。【
unity优化GC操作详解
Unity优化GC操作内容详解修改自: 简介:游戏运行时,数据主要存放在内存中。当不需要游戏数据时,可以回收存储当前数据的内存重新使用。内存垃圾是指当前丢弃的数据所占用的内存。垃圾
树莓派工控机定时和自动采集数据解决方案
树莓派工控机定时自动采集数据解决方案概述:采集树莓派(xxxxx,以下简称工控机)上的数据,传输到本地sqlserver数据库,写入数据Python采集脚本。这涉及到几个问题:当出现网络中断、断电、工控机重启等异常情况时,为保证这些异常情况的发生,仍能自动
Foobar2000的配置与优化
Foobar2000 配置与优化 Foobar2000 配置与优化 1. DTS 解码器 foo_input_dts 解码 DTS 音效 2. ESlyric foo_uie_eslyric 歌词面板,支持桌面歌词。有很多可自定义的配置项,支持国内外很多网站歌词搜索。比 Lyrics Panel Show 3 更好用。 在 Options-Tools-ESLy 中可用
新APP上线后如何优化ASO
新APP上线时,如何优化ASO 新APP上线,推广是重中之重,而ASO也是必不可少的环节。可能有人会说ASO需要用钱来做。玩法丰富,没钱没钱玩ASO。丰富的玩法就不多说了。大家都知道,今天我们主要分享一下没钱的方法。首先我们要了解阴影
Debezium采集postgresql 日志
Debezium采集postgresql log debezium采集postgresql表数据debezium不用kafka就可以完成
没想到,复杂的UI卡顿问题还能这么优化?
没想到,复杂的UI卡顿问题还能这么优化?点击上方程序员小乐关注、star或顶顶,共同成长。关注订阅号“程序员小乐”,每天观看更多精彩英文内容。做你自己,不要为任何人改变。如果他们不喜欢你最糟糕的时候,那么他们不值得你在
掷骰子【普通线性DP】【传递方程可以优化为矩阵快速幂】
掷骰子【普通线性DP】【转移方程可以优化为矩阵快速幂】掷骰子可以先定义一个状态f[i][j]:第i个骰子,最后一边是j的方法个数,它一定是超时了,但是Goose可以混点,代码如下 for(int i=1;i=6;i++) f[0][i]=1; for(int i=1;i=n;i++) {for(int j=1;j=6;j++) {fo 查看全部
采集自动组合(
组合多个优化之GC操作详解内容修改内容详解优化)
采集SEO优化方法---结合多领域发布教程采集SEO优化方法---结合多领域发布教程
多字段组合发布是优采云采集的SEO工具之一,可以增加收录和网站的权重。
?具体用途是在发布目标的标题或内容[配置映射对应字段]处组合不同的字段,合成一个新的标题或正文进行发布。

进入【配置映射对应字段】页面,可以组合多个字段发布结果
1. 进入【配置映射对应字段】页面
?? 进入一个任务,点击【发布目标管理】==》找到需要配置的发布目标,点击右侧对应的【配置映射】按钮;

2. 合并多个字段
?? 一、组合标题或内容的“值来源1”处的字段,例如组合标题处的title和tag字段:

?? 二、设置组合字段之间的分隔符。默认为逗号,kds_empty_val 为空字符。修改后请点击保存按钮。
?? 下图中的示例用下划线填充。

3.发布结果
?? 发布前数据,title字段和tag字段内容:

?? 文章发布后,在title后面添加tag字段的内容:

采集SEO优化方法---结合多领域发布教程相关教程2020-10-11《多背包单调队列优化》
2020-10-11《多背包单调队列优化》《多背包单调队列优化》【题目】有n种物品,一个容量为m的背包。第i个项目最多有si个项目,每个项目的体积为vi,值为wi。解决选择将哪些物品放入背包,使物品的总体积不超过背包的容量,且总值最大。只输出最大值。【
unity优化GC操作详解
Unity优化GC操作内容详解修改自: 简介:游戏运行时,数据主要存放在内存中。当不需要游戏数据时,可以回收存储当前数据的内存重新使用。内存垃圾是指当前丢弃的数据所占用的内存。垃圾
树莓派工控机定时和自动采集数据解决方案
树莓派工控机定时自动采集数据解决方案概述:采集树莓派(xxxxx,以下简称工控机)上的数据,传输到本地sqlserver数据库,写入数据Python采集脚本。这涉及到几个问题:当出现网络中断、断电、工控机重启等异常情况时,为保证这些异常情况的发生,仍能自动
Foobar2000的配置与优化
Foobar2000 配置与优化 Foobar2000 配置与优化 1. DTS 解码器 foo_input_dts 解码 DTS 音效 2. ESlyric foo_uie_eslyric 歌词面板,支持桌面歌词。有很多可自定义的配置项,支持国内外很多网站歌词搜索。比 Lyrics Panel Show 3 更好用。 在 Options-Tools-ESLy 中可用
新APP上线后如何优化ASO
新APP上线时,如何优化ASO 新APP上线,推广是重中之重,而ASO也是必不可少的环节。可能有人会说ASO需要用钱来做。玩法丰富,没钱没钱玩ASO。丰富的玩法就不多说了。大家都知道,今天我们主要分享一下没钱的方法。首先我们要了解阴影
Debezium采集postgresql 日志
Debezium采集postgresql log debezium采集postgresql表数据debezium不用kafka就可以完成
没想到,复杂的UI卡顿问题还能这么优化?
没想到,复杂的UI卡顿问题还能这么优化?点击上方程序员小乐关注、star或顶顶,共同成长。关注订阅号“程序员小乐”,每天观看更多精彩英文内容。做你自己,不要为任何人改变。如果他们不喜欢你最糟糕的时候,那么他们不值得你在
掷骰子【普通线性DP】【传递方程可以优化为矩阵快速幂】
掷骰子【普通线性DP】【转移方程可以优化为矩阵快速幂】掷骰子可以先定义一个状态f[i][j]:第i个骰子,最后一边是j的方法个数,它一定是超时了,但是Goose可以混点,代码如下 for(int i=1;i=6;i++) f[0][i]=1; for(int i=1;i=n;i++) {for(int j=1;j=6;j++) {fo
采集自动组合(优采云浏览器的脚本管理器是什么样的?项目管理器的核心价值)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-05 10:13
优采云浏览器不是普通的浏览器,它是一个可视化的自动脚本采集工具,一个可以解放IT人员双手的浏览器,它可以做自动采集数据,收发邮件,自动编码和识别验证码,并可自由组合操作。强大的内核可以轻松辅助您的操作。
【特征】
1、可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理的内容。采集 jax、falls等就很简单了。一些js加密数据也可以轻松获取,无需抓包分析。
2、自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证代码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,功能自由组合。
3、自动编码
采集速度快,程序注重采集的效率,页面解析速度快,可以直接屏蔽不需要访问的页面或广告,加快访问速度速度。
4、生成EXE
不仅是一个采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。可以做到自动登录,自动识别验证码,是一款万能浏览器。
5、项目管理
该解决方案可用于直接生成单个应用程序。单个程序可以脱离优采云浏览器运行。提供官方软件管理平台,用户可以通过该平台进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。
【常见问题】
1、 软件是如何授权的?
浏览器永久使用,两年免费升级服务。软件需要绑定到机器上,但可以自由更换。
2、 有没有免费版的浏览器?
优采云浏览器的脚本管理器可以免费使用。用户可以直接创建脚本并运行单个脚本。
3、 项目经理有什么特别之处?
项目经理是优采云浏览器的核心价值。我们的单个脚本可以独立运行。但是我们有很多各种各样的需求需要整合,然后我们需要一个项目经理。
4、 可以用来挖微博吗?
是的,你可以使用浏览器的滚动条设置来采集瀑布这些数据。
5、 验证码可以识别吗?
是的,该软件带有手动编码和各种编码平台。可自动识别并自动输入编码结果。
6、 我可以通过优采云 浏览器赚钱吗?
优采云浏览器是一个可以帮助大家自动化的网页操作。它还允许您制作脚本生成程序出售,生成的程序可以自定义软件名称。官方提供注册服务和自动升级。用户只要管理好脚本和服务就可以快速赚钱。
7、 能操作数据库吗?
浏览器可以读写四个数据库:mysql、sqlserver、sqlite、access。您可以将任务数据放入数据库中,通过浏览器读取并运行它。操作完成后,使用浏览器将其标记为已使用。您可以在浏览器的使用过程中随时使用数据库,非常方便。
【更新内容】
1.添加缓存处理方法。
2.登录问题得到改善。
3. 日志错位问题已修复。
4.修正:复制脚本修改名称后,无法添加到脚本编辑区,双击后没有反应。
5.修正:导入同名脚本,改名后的脚本中的脚本步骤会变成和之前的脚本一样的步骤。
6.PHP插件和python插件问题处理。
7.变量移除也会移除已清除变量中的变量。
8. 多行抽取和清空列表变量问题处理。
9.页面缓存功能的header信息中添加url。
10. 拖动鼠标增加移动速度。
11.定时任务的Cron表达式注释无效,已修复。
12.修复项目经理任务列表中右键点击的问题。
13.修复选项中的Preferences:点击主程序右上角的关闭按钮,最小化到托盘而不是退出。
14.exe包生成器支持.Net版本修改。
15. 优化:变量处理操作,如果处理的变量不存在,会弹出错误。
16.不能在根节点添加组,可以新建组并在空白区域刷新列表。
17. 无法将分组脚本添加到编辑区。
18.同时选择多个分组节点进行右键菜单处理。
19.在列表区复制脚本后,双击到编辑区,在编辑区删除复制的脚本,在列表区双击无效,无法添加到编辑区编辑区。
20.修正:在脚本编辑区编辑脚本名称后,在列表区导出。导出的名字还是修改前的名字。
21.Fix: 生成EXE,选择包中的文件并添加,提示被占用,但从未打开过该文件。
2 2. 脚本引用添加提示:多级脚本引用需要手动将脚本复制到exe的Projects目录下。
23. 新增编辑区支持脚本导出。
24. 列表区支持脚本或组名搜索。
其他相关
1 新闻播报揭秘A股483万大涨原因 来源:466万 3杨幂唱新mojito 来源:4 郭美美宣布434万新恋情 来源:418万 被捕来源:7 幼儿园毕业配文 再见青春 390万 来源:376万 9 林丹出轨对象发出申诉 来源:10 试用期单位未缴纳社保违规 新增350万 来源:326万 全国菜价上涨 13 美国黑熊走了650公里的路程。303万 293万。香港市民每人获1万元。16 王宝山辞职 263 万 254 万 18 元隆平当空军差点入狱。支持教育少女生前录音 22特工回应林志轩重病 212万 205万 24名美国明星宣布可竞选总统。25.1万多箱茅台自卸司机撞车 118.4万买不起 27.高考遇武汉大雨 听力考试可暂停 28同卓宣传郑云龙 171万 搜索工具百度查找15100条相关结果给你@网站抓取工具,采集模拟浏览器手动操作的发布软件,可以生成EXE。
-100%好评优采云 浏览器是一个可视化的自动化脚本工具。我们可以实现自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,通过设置脚本进行操作。数据库,优采云浏览器绿色版_优采云浏览器绿色版免费下载【最新版】-下载首页优采云浏览器绿色版是一款自动化脚本编写工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,操作数据库,收发邮件等下载首页优采云 浏览器是一个自动化脚本的工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作到下载首页优采云浏览器是一款可视化的自动化脚本工具,我们可以实现自动化通过设置脚本进行登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。非凡软件优采云 浏览器是一种自动化脚本编写工具。通过优采云浏览器自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作到优采云 浏览器脚本编辑器-< @优采云浏览器下载v7.4.0官方版--pc6下载站优采云浏览器破解版-优采云浏览器下载7.31-新云软件园优采云浏览器下载,优采云浏览器是一个可以可视化的网页万能按钮精灵采集万能群发,也是一款功能自由组合、自动Log的万能营销软件在,一个通用的优采云浏览器(数据库采集器)会自动识别验证码,是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录,识别验证码,自动抓取获取数据,自动提交数据,点击网页,下载文字优采云浏览器下载_优采云 官方浏览器下载-太平洋下载中心优采云 浏览器是一款自动化脚本编写工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,操作数据库,收发邮件等操作到达 查看全部
采集自动组合(优采云浏览器的脚本管理器是什么样的?项目管理器的核心价值)
优采云浏览器不是普通的浏览器,它是一个可视化的自动脚本采集工具,一个可以解放IT人员双手的浏览器,它可以做自动采集数据,收发邮件,自动编码和识别验证码,并可自由组合操作。强大的内核可以轻松辅助您的操作。

【特征】
1、可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理的内容。采集 jax、falls等就很简单了。一些js加密数据也可以轻松获取,无需抓包分析。
2、自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证代码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,功能自由组合。
3、自动编码
采集速度快,程序注重采集的效率,页面解析速度快,可以直接屏蔽不需要访问的页面或广告,加快访问速度速度。
4、生成EXE
不仅是一个采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。可以做到自动登录,自动识别验证码,是一款万能浏览器。
5、项目管理
该解决方案可用于直接生成单个应用程序。单个程序可以脱离优采云浏览器运行。提供官方软件管理平台,用户可以通过该平台进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。

【常见问题】
1、 软件是如何授权的?
浏览器永久使用,两年免费升级服务。软件需要绑定到机器上,但可以自由更换。
2、 有没有免费版的浏览器?
优采云浏览器的脚本管理器可以免费使用。用户可以直接创建脚本并运行单个脚本。
3、 项目经理有什么特别之处?
项目经理是优采云浏览器的核心价值。我们的单个脚本可以独立运行。但是我们有很多各种各样的需求需要整合,然后我们需要一个项目经理。
4、 可以用来挖微博吗?
是的,你可以使用浏览器的滚动条设置来采集瀑布这些数据。
5、 验证码可以识别吗?
是的,该软件带有手动编码和各种编码平台。可自动识别并自动输入编码结果。
6、 我可以通过优采云 浏览器赚钱吗?
优采云浏览器是一个可以帮助大家自动化的网页操作。它还允许您制作脚本生成程序出售,生成的程序可以自定义软件名称。官方提供注册服务和自动升级。用户只要管理好脚本和服务就可以快速赚钱。
7、 能操作数据库吗?
浏览器可以读写四个数据库:mysql、sqlserver、sqlite、access。您可以将任务数据放入数据库中,通过浏览器读取并运行它。操作完成后,使用浏览器将其标记为已使用。您可以在浏览器的使用过程中随时使用数据库,非常方便。
【更新内容】
1.添加缓存处理方法。
2.登录问题得到改善。
3. 日志错位问题已修复。
4.修正:复制脚本修改名称后,无法添加到脚本编辑区,双击后没有反应。
5.修正:导入同名脚本,改名后的脚本中的脚本步骤会变成和之前的脚本一样的步骤。
6.PHP插件和python插件问题处理。
7.变量移除也会移除已清除变量中的变量。
8. 多行抽取和清空列表变量问题处理。
9.页面缓存功能的header信息中添加url。
10. 拖动鼠标增加移动速度。
11.定时任务的Cron表达式注释无效,已修复。
12.修复项目经理任务列表中右键点击的问题。
13.修复选项中的Preferences:点击主程序右上角的关闭按钮,最小化到托盘而不是退出。
14.exe包生成器支持.Net版本修改。
15. 优化:变量处理操作,如果处理的变量不存在,会弹出错误。
16.不能在根节点添加组,可以新建组并在空白区域刷新列表。
17. 无法将分组脚本添加到编辑区。
18.同时选择多个分组节点进行右键菜单处理。
19.在列表区复制脚本后,双击到编辑区,在编辑区删除复制的脚本,在列表区双击无效,无法添加到编辑区编辑区。
20.修正:在脚本编辑区编辑脚本名称后,在列表区导出。导出的名字还是修改前的名字。
21.Fix: 生成EXE,选择包中的文件并添加,提示被占用,但从未打开过该文件。
2 2. 脚本引用添加提示:多级脚本引用需要手动将脚本复制到exe的Projects目录下。
23. 新增编辑区支持脚本导出。
24. 列表区支持脚本或组名搜索。
其他相关
1 新闻播报揭秘A股483万大涨原因 来源:466万 3杨幂唱新mojito 来源:4 郭美美宣布434万新恋情 来源:418万 被捕来源:7 幼儿园毕业配文 再见青春 390万 来源:376万 9 林丹出轨对象发出申诉 来源:10 试用期单位未缴纳社保违规 新增350万 来源:326万 全国菜价上涨 13 美国黑熊走了650公里的路程。303万 293万。香港市民每人获1万元。16 王宝山辞职 263 万 254 万 18 元隆平当空军差点入狱。支持教育少女生前录音 22特工回应林志轩重病 212万 205万 24名美国明星宣布可竞选总统。25.1万多箱茅台自卸司机撞车 118.4万买不起 27.高考遇武汉大雨 听力考试可暂停 28同卓宣传郑云龙 171万 搜索工具百度查找15100条相关结果给你@网站抓取工具,采集模拟浏览器手动操作的发布软件,可以生成EXE。
-100%好评优采云 浏览器是一个可视化的自动化脚本工具。我们可以实现自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,通过设置脚本进行操作。数据库,优采云浏览器绿色版_优采云浏览器绿色版免费下载【最新版】-下载首页优采云浏览器绿色版是一款自动化脚本编写工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,操作数据库,收发邮件等下载首页优采云 浏览器是一个自动化脚本的工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作到下载首页优采云浏览器是一款可视化的自动化脚本工具,我们可以实现自动化通过设置脚本进行登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。非凡软件优采云 浏览器是一种自动化脚本编写工具。通过优采云浏览器自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作到优采云 浏览器脚本编辑器-< @优采云浏览器下载v7.4.0官方版--pc6下载站优采云浏览器破解版-优采云浏览器下载7.31-新云软件园优采云浏览器下载,优采云浏览器是一个可以可视化的网页万能按钮精灵采集万能群发,也是一款功能自由组合、自动Log的万能营销软件在,一个通用的优采云浏览器(数据库采集器)会自动识别验证码,是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录,识别验证码,自动抓取获取数据,自动提交数据,点击网页,下载文字优采云浏览器下载_优采云 官方浏览器下载-太平洋下载中心优采云 浏览器是一款自动化脚本编写工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,操作数据库,收发邮件等操作到达
采集自动组合(试试用smartproxyapp除非能从你的运营商接入数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-03 22:00
采集自动组合是什么鬼?这种容易让android崩溃的功能,是不建议在android上进行的。而且,就算你下载了,也没办法绕过appstore的审核。
在android上,你可以基于wap业务,通过sqlmap来嗅探数据,然后root后去修改数据。wap+sqlmap可以在android上查看三大应用市场的排名以及app评论等。不过需要root。不知道楼主要干嘛。
试试用smartproxy
app除非能从你的运营商接入数据,否则自己采集数据做商业用途几乎是不可能的事情。
既然已经root了,就安心等封杀通知吧。你的数据还有机会恢复的。否则太悲剧了。
解决方案一个是绑定wifi,然后system后台服务上报数据到网站,另一个是绑定同样的wifi,然后显示相同信息。个人觉得第二个比较靠谱,但是如果做成功了,会多一个消息获取对象,读取这个链接的数据可能是最大的问题。
我的观点:我们都无法从技术上阻止厂商通过流量获取数据,流量获取的渠道也是有限的,并不像黑产那样流量到了后台就直接转化为服务。把android手机中安装的各种应用流量劫持,获取后台上报数据这件事情理解为黑产的,是不公平的。而把流量劫持认为不可行的原因是:流量劫持是违法的,但是这种方式要规避审查的难度远大于解决流量获取这个问题。
解决方案的两个原因:一个是通过软件实现劫持,另一个是通过对流量劫持的一些限制,比如对数据存储流量劫持,实现没有入口的流量劫持。手机微信摇一摇摇不到红包的问题是在于此,而不是在于微信要流量,微信又拦截不了。另一方面,我也不是专家,说的可能不对,也欢迎大家指正。流量劫持是违法的,微信要流量不拦截,可能是好事情,但也可能是坏事情。
如果有人拦截了微信的这种方式,那就相当于你违法了。这件事情是很复杂的,是基于他人的态度,以及法律的尺度。但是大家普遍是这么认为的,但是如果有足够多的人成功把android手机流量劫持到你的应用里面,而且得到你的数据,这是很好的事情。 查看全部
采集自动组合(试试用smartproxyapp除非能从你的运营商接入数据)
采集自动组合是什么鬼?这种容易让android崩溃的功能,是不建议在android上进行的。而且,就算你下载了,也没办法绕过appstore的审核。
在android上,你可以基于wap业务,通过sqlmap来嗅探数据,然后root后去修改数据。wap+sqlmap可以在android上查看三大应用市场的排名以及app评论等。不过需要root。不知道楼主要干嘛。
试试用smartproxy
app除非能从你的运营商接入数据,否则自己采集数据做商业用途几乎是不可能的事情。
既然已经root了,就安心等封杀通知吧。你的数据还有机会恢复的。否则太悲剧了。
解决方案一个是绑定wifi,然后system后台服务上报数据到网站,另一个是绑定同样的wifi,然后显示相同信息。个人觉得第二个比较靠谱,但是如果做成功了,会多一个消息获取对象,读取这个链接的数据可能是最大的问题。
我的观点:我们都无法从技术上阻止厂商通过流量获取数据,流量获取的渠道也是有限的,并不像黑产那样流量到了后台就直接转化为服务。把android手机中安装的各种应用流量劫持,获取后台上报数据这件事情理解为黑产的,是不公平的。而把流量劫持认为不可行的原因是:流量劫持是违法的,但是这种方式要规避审查的难度远大于解决流量获取这个问题。
解决方案的两个原因:一个是通过软件实现劫持,另一个是通过对流量劫持的一些限制,比如对数据存储流量劫持,实现没有入口的流量劫持。手机微信摇一摇摇不到红包的问题是在于此,而不是在于微信要流量,微信又拦截不了。另一方面,我也不是专家,说的可能不对,也欢迎大家指正。流量劫持是违法的,微信要流量不拦截,可能是好事情,但也可能是坏事情。
如果有人拦截了微信的这种方式,那就相当于你违法了。这件事情是很复杂的,是基于他人的态度,以及法律的尺度。但是大家普遍是这么认为的,但是如果有足够多的人成功把android手机流量劫持到你的应用里面,而且得到你的数据,这是很好的事情。
采集自动组合(默认用thread来做监听线程的经验之谈之采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-30 23:04
采集自动组合:可以生成主线程还有组合调用监听线程,
0)){if(server.isf(this,
0)){if(!server.isf(this,
0)){server.addflags("goto");}}}经验之谈:最主要的还是用样式来写下的功能。
大概是主线程运行python代码,处理有异常的情况。比如修改了页面,我试过tryexcept,差不多会终止,但是还是python在处理问题。很多timeout的功能没用。
python中timeout指定进程(线程)最后运行的时间,当线程过多时timeout有可能变为死锁。本质是调用的内部函数,所以你需要看是哪个线程在执行。当一个线程执行的时候timeout时间又未到的话,
tornado默认是用thread的,但是实际做一些特殊优化可以让timeout的速度相对线程缩短。推荐看一下这篇帖子,我感觉写的很详细了,
在用caploise来做监听线程的时候经常会遇到类似threadtimeout等的情况,不知道是怎么回事。
语言上来说,timeout是异步的。当thread过多的时候往往使用threadtimeout会更加合适一些。其次,线程一个是多线程的执行,一个是的执行,在时间上本身就有区别。python中每个event都会有一个timeoutifnotintimes.for_each是预取主线程一切timeout的上限最后,我觉得编程时的某些细节决定了timeout函数的合理性。
我就遇到了这样的情况,在请求异步时线程异步造成timeoutifnotintimes.for_each或者直接设置timeoutifnotintimes.for_each。 查看全部
采集自动组合(默认用thread来做监听线程的经验之谈之采集)
采集自动组合:可以生成主线程还有组合调用监听线程,
0)){if(server.isf(this,
0)){if(!server.isf(this,
0)){server.addflags("goto");}}}经验之谈:最主要的还是用样式来写下的功能。
大概是主线程运行python代码,处理有异常的情况。比如修改了页面,我试过tryexcept,差不多会终止,但是还是python在处理问题。很多timeout的功能没用。
python中timeout指定进程(线程)最后运行的时间,当线程过多时timeout有可能变为死锁。本质是调用的内部函数,所以你需要看是哪个线程在执行。当一个线程执行的时候timeout时间又未到的话,
tornado默认是用thread的,但是实际做一些特殊优化可以让timeout的速度相对线程缩短。推荐看一下这篇帖子,我感觉写的很详细了,
在用caploise来做监听线程的时候经常会遇到类似threadtimeout等的情况,不知道是怎么回事。
语言上来说,timeout是异步的。当thread过多的时候往往使用threadtimeout会更加合适一些。其次,线程一个是多线程的执行,一个是的执行,在时间上本身就有区别。python中每个event都会有一个timeoutifnotintimes.for_each是预取主线程一切timeout的上限最后,我觉得编程时的某些细节决定了timeout函数的合理性。
我就遇到了这样的情况,在请求异步时线程异步造成timeoutifnotintimes.for_each或者直接设置timeoutifnotintimes.for_each。
采集自动组合(采集自动组合技术,辅助单个sql查询这篇文章介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-28 13:01
采集自动组合技术,辅助单个sql查询这篇文章介绍了组合sql技术在自动组合java库时的缺陷和connector的想法。最后提供了两个简单的例子来说明工具链如何搭建。在计算机科学中有一种应用类型叫成像对象。通常的把图像作为3d模型被用来人工重建数据在电子或光学学科里叫3d成像对象。java也提供类似的方法来绘制图像,但在那些地方要使用2d图像。
2d图像比2d模型更小,渲染2d图像更快速,更高效,渲染像素图像更容易。如果你使用java来计算,编译器会把图像转换成图像对象,那会增加很多复杂性。所以最好的选择是使用采集到的2d图像作为3d模型来实现3d图像渲染。成像对象是把正在计算的结果以2d方式在我们需要的地方显示。这样我们就可以用计算量小的2d图像来获得我们需要的高分辨率和视野,同时不需要复杂的数学方法来重建数据。
那么你可能想要一个既能一次性采集到所有3d结果,又能让多次调用一次数据的应用程序。这个应用程序就是集成采集sql实现的scanbase类。我们用java在jvm环境里运行了这个应用程序,并且为我们的代码提供了足够的运行时并且被大小为160gb的u3dmono虚拟机所利用。这个计算机的内部是使用采集到的sql数据。
scanbase类里只有一个最简单的points(或称采集对象)实例化:publicinterfacescanbase{ac_objectbuild(stringrenderstarttx,stringrenderstarttx1,stringrenderstarttx2,stringrenderstarttx3,intrenderstartmeth,intrenderstarttack,intrenderstarttx);}这是一个容器实例化,需要传入每个points的长度,以及一些必须的参数。
我只传了长度为int类型的renderstarttx,因为有时候这些对象会有重叠的ucnotconnected关联。另外的如renderstartx和renderstartex两个参数是一个参数对于一个int数值(可选),然后是一个指定数值。如果采集太远的数值,你也可以加入参数renderstartx和renderstartex来预防数据重叠和脱落。
为什么scanbase不是基于list集合的数据结构呢?要了解原因,先了解我们的存储层。points的长度是2d的,并且存储在一个数组里。如果数组被分为两组,那么数组就会有一个大小大于1g的数组。要比这个数组大,你还需要很大的内存空间。根据我们自己的经验,一般都不会超过2g。在list的每个元素都有唯一的名字,也就是它的索引。
因此points只是一个数组里唯一的一个point对象而已。所以,这是一个单向无循环的数组,所以索引在循环里总是不会过早的被修改。另外,我们都知道scantable是使用list集合作为二进制表示的。 查看全部
采集自动组合(采集自动组合技术,辅助单个sql查询这篇文章介绍)
采集自动组合技术,辅助单个sql查询这篇文章介绍了组合sql技术在自动组合java库时的缺陷和connector的想法。最后提供了两个简单的例子来说明工具链如何搭建。在计算机科学中有一种应用类型叫成像对象。通常的把图像作为3d模型被用来人工重建数据在电子或光学学科里叫3d成像对象。java也提供类似的方法来绘制图像,但在那些地方要使用2d图像。
2d图像比2d模型更小,渲染2d图像更快速,更高效,渲染像素图像更容易。如果你使用java来计算,编译器会把图像转换成图像对象,那会增加很多复杂性。所以最好的选择是使用采集到的2d图像作为3d模型来实现3d图像渲染。成像对象是把正在计算的结果以2d方式在我们需要的地方显示。这样我们就可以用计算量小的2d图像来获得我们需要的高分辨率和视野,同时不需要复杂的数学方法来重建数据。
那么你可能想要一个既能一次性采集到所有3d结果,又能让多次调用一次数据的应用程序。这个应用程序就是集成采集sql实现的scanbase类。我们用java在jvm环境里运行了这个应用程序,并且为我们的代码提供了足够的运行时并且被大小为160gb的u3dmono虚拟机所利用。这个计算机的内部是使用采集到的sql数据。
scanbase类里只有一个最简单的points(或称采集对象)实例化:publicinterfacescanbase{ac_objectbuild(stringrenderstarttx,stringrenderstarttx1,stringrenderstarttx2,stringrenderstarttx3,intrenderstartmeth,intrenderstarttack,intrenderstarttx);}这是一个容器实例化,需要传入每个points的长度,以及一些必须的参数。
我只传了长度为int类型的renderstarttx,因为有时候这些对象会有重叠的ucnotconnected关联。另外的如renderstartx和renderstartex两个参数是一个参数对于一个int数值(可选),然后是一个指定数值。如果采集太远的数值,你也可以加入参数renderstartx和renderstartex来预防数据重叠和脱落。
为什么scanbase不是基于list集合的数据结构呢?要了解原因,先了解我们的存储层。points的长度是2d的,并且存储在一个数组里。如果数组被分为两组,那么数组就会有一个大小大于1g的数组。要比这个数组大,你还需要很大的内存空间。根据我们自己的经验,一般都不会超过2g。在list的每个元素都有唯一的名字,也就是它的索引。
因此points只是一个数组里唯一的一个point对象而已。所以,这是一个单向无循环的数组,所以索引在循环里总是不会过早的被修改。另外,我们都知道scantable是使用list集合作为二进制表示的。
采集自动组合(EditorTools3基础版数据采集软件特征无人值守(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-11-23 15:10
EditorTools3基础版是一款简单易用的数据采集软件。可以根据你设置的规则允许,并且采集全天持续对数据执行。目前支持所有类型的网站,并且会自动合并采集的内容。
软件功能
1、与网站分离,通过独立产生的接口,可以支持任何网站或数据库
2、体积小,低功耗,稳定性好,非常适合在服务器上运行
3、所有规则均可导入导出,资源灵活复用
4、使用FTP上传文件,稳定安全
5、反向、顺序、随机可选采集文章
6、支持自动列表网址
7、支持网站数据分布在多个页面采集
8、自由设置数据项采集,每个数据项可以单独过滤排序
9、支持分页内容采集
10、支持下载任意格式和类型的文件(包括图片和视频)
11、可以突破防盗文件
12、支持动态文件URL解析
13、支持采集需要登录才能访问的网页
软件特点
1、全自动无人值守
无需值守,24小时自动实时监控目标,实时高效采集,全天候为您提供内容更新。满足长期运营需求,让您从繁重的工作中解脱出来。
2、广泛适用
最全能的采集软件,支持任何类型的网站采集,适用率高达99.9%,支持发布到所有类型的网站 程序等您可以采集 本地文件并在没有界面的情况下发布。
3、信息自由
支持信息的自由组合,通过强大的数据整理功能对信息进行深度加工,创造新的内容。
4、任意格式文件下载
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至种子文件,只要你想。
5、伪原创
高速同义词替换、多词随机替换、随机段落排序、帮助内容SEO
6、无限多级页面采集
从支持多级目录开始,无论是垂直的多级信息页面,还是平行方向的多内容分页,还是AJAX调用页面,都让你轻松采集。
7、免费延期
开放的接口模式,让您自由开发二次开发,定制任意功能,实现所有需求。
EditorTools3使用教程
1、使用注册
通过注册获得使用ET的授权;
打开主菜单-授权注册,填写您在官方ET网站(非论坛)注册的有效账号,注册使用ET获得使用ET授权
2、系统设置
打开主菜单-系统-基本设置,进行各种系统设置
设置工作参数:根据您的需要设置工作参数
设置代理:如果使用代理上网,请设置网页的代理参数
设置劫持特征码:很多地区的电信宽带用户在上网时,会强制访问信息,将访问信息替换为一些代码,使用户只能通过代码中的框架查看原创网页. 这通常用于显示电信广告或执行其他秘密操作,称为劫持浏览器;出现这种情况时,ET的采集的源代码只能得到这些劫持代码,而不是采集的网页源代码。通过设置这些劫持代码的特征字符串,ET将尝试突破劫持访问真正的网页源代码,最多可重试5次访问网站。
3、选择工作计划
工作计划包括从源获取原创信息、处理信息、最终发布到目标网站的所有设置指令。执行自动采集工作的是ET的指挥官。当我们制定好您需要的计划后,您可以在主窗口中选择工作计划开始采集工作。
更新内容
1. 新增:支持多代理,自动轮换代理。
2. 优化:字符解码支持%xx格式。 查看全部
采集自动组合(EditorTools3基础版数据采集软件特征无人值守(组图))
EditorTools3基础版是一款简单易用的数据采集软件。可以根据你设置的规则允许,并且采集全天持续对数据执行。目前支持所有类型的网站,并且会自动合并采集的内容。
软件功能
1、与网站分离,通过独立产生的接口,可以支持任何网站或数据库
2、体积小,低功耗,稳定性好,非常适合在服务器上运行
3、所有规则均可导入导出,资源灵活复用
4、使用FTP上传文件,稳定安全
5、反向、顺序、随机可选采集文章
6、支持自动列表网址
7、支持网站数据分布在多个页面采集
8、自由设置数据项采集,每个数据项可以单独过滤排序
9、支持分页内容采集
10、支持下载任意格式和类型的文件(包括图片和视频)
11、可以突破防盗文件
12、支持动态文件URL解析
13、支持采集需要登录才能访问的网页
软件特点
1、全自动无人值守
无需值守,24小时自动实时监控目标,实时高效采集,全天候为您提供内容更新。满足长期运营需求,让您从繁重的工作中解脱出来。
2、广泛适用
最全能的采集软件,支持任何类型的网站采集,适用率高达99.9%,支持发布到所有类型的网站 程序等您可以采集 本地文件并在没有界面的情况下发布。
3、信息自由
支持信息的自由组合,通过强大的数据整理功能对信息进行深度加工,创造新的内容。
4、任意格式文件下载
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至种子文件,只要你想。
5、伪原创
高速同义词替换、多词随机替换、随机段落排序、帮助内容SEO
6、无限多级页面采集
从支持多级目录开始,无论是垂直的多级信息页面,还是平行方向的多内容分页,还是AJAX调用页面,都让你轻松采集。
7、免费延期
开放的接口模式,让您自由开发二次开发,定制任意功能,实现所有需求。
EditorTools3使用教程
1、使用注册
通过注册获得使用ET的授权;
打开主菜单-授权注册,填写您在官方ET网站(非论坛)注册的有效账号,注册使用ET获得使用ET授权
2、系统设置
打开主菜单-系统-基本设置,进行各种系统设置
设置工作参数:根据您的需要设置工作参数
设置代理:如果使用代理上网,请设置网页的代理参数
设置劫持特征码:很多地区的电信宽带用户在上网时,会强制访问信息,将访问信息替换为一些代码,使用户只能通过代码中的框架查看原创网页. 这通常用于显示电信广告或执行其他秘密操作,称为劫持浏览器;出现这种情况时,ET的采集的源代码只能得到这些劫持代码,而不是采集的网页源代码。通过设置这些劫持代码的特征字符串,ET将尝试突破劫持访问真正的网页源代码,最多可重试5次访问网站。
3、选择工作计划
工作计划包括从源获取原创信息、处理信息、最终发布到目标网站的所有设置指令。执行自动采集工作的是ET的指挥官。当我们制定好您需要的计划后,您可以在主窗口中选择工作计划开始采集工作。
更新内容
1. 新增:支持多代理,自动轮换代理。
2. 优化:字符解码支持%xx格式。
采集自动组合(WP-AutoBlog自动采集发布插件,支持采集多层级内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-22 04:26
WP-AutoBlog 是一个自动 采集 发布插件,它可以 采集 来自任何 网站 内容并自动更新您的 WordPress 网站。使用起来非常简单,无需复杂的设置,并且足够强大稳定,支持wordpress的所有功能。
【软件特色】
采集网站的任何内容,采集的信息一目了然
<p>通过简单的设置,可以采集来自任何网站的内容,并且可以设置多个采集任务同时运行,可以设置任务自动或手动运行,并且主任务列表显示每个采集任务的状态:上次测试的时间采集,下次测试的预计时间采集,最新的采集< @文章,更新了采集 查看全部
采集自动组合(WP-AutoBlog自动采集发布插件,支持采集多层级内容)
WP-AutoBlog 是一个自动 采集 发布插件,它可以 采集 来自任何 网站 内容并自动更新您的 WordPress 网站。使用起来非常简单,无需复杂的设置,并且足够强大稳定,支持wordpress的所有功能。
【软件特色】
采集网站的任何内容,采集的信息一目了然
<p>通过简单的设置,可以采集来自任何网站的内容,并且可以设置多个采集任务同时运行,可以设置任务自动或手动运行,并且主任务列表显示每个采集任务的状态:上次测试的时间采集,下次测试的预计时间采集,最新的采集< @文章,更新了采集
采集自动组合(v7版本增加了一个标签组合的结果和内容页标签 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-20 16:11
)
v7版本增加了标签组合功能。很多朋友在使用过程中发现组合的结果与自己想要的结果不一致。让我解释一下这个功能的使用。
1.标签的组合是文件下载前的内容
有朋友发现a标签中下载了某个文件,原地址为aaa,下载或检测到的地址为bbb。那么,如果在b标签中组合a标签,a标签的值为aaa。为什么使用这种处理方法是因为文件下载是在标签组合后进行的。如何实现标签内容为文件下载后的结果?你可以新建一个标签,选择“自定义固定格式数据”,把你的标签组合的内容放进去。这里的替换会在文件下载后进行。
2.内容页面标签循环采集并添加为新记录
如果两个组合的标签都是内容页标签,当这两个标签组合时,会根据循环次数最多的记录生成相同数量的新循环记录。如果一个标签的循环次数较少,则新生成的标签中该标签的值为空。例如,将标签a、b 组合起来生成标签c。a的循环数为5,b的循环数为3,将产生5个cs。其中,前3个标签的值分别对应a和b。在最后两个值中,b 的值为空。假设a的值为11,22,33,44,55,b的值为aa,bb,cc.c是[label:a][label:b]的组合,生成c的值是 11aa,22bb,33cc,44,55.
3.列表页标签和内容页标签组合
如果两个标签中的一个是内容页,另一个是列表页,则内容页将参与第2条中的循环处理。在这个过程中,列表页被视为一个字符串。合并完成后,程序将再次进行数据处理操作。最后,组合标签中列表页面标签的内容将替换为实际值。可以再次提取和下载组合结果。比如内容页a和列表页b组合生成c,其中a的值为11、22、22,b的值为bb,那么c的第一个组合结果为11[label: b],22[label:b],33[label:b],然后进行数据处理。如果b的值为bb,那么最终的结果可能是11bb、22bb、33bb。
有的朋友可能会说,为什么要把这个功能弄的这么复杂。其实这个函数主要用于第一个函数,其他的组合可能会产生和原来想法不同的结果。建议大家不要滥用这个功能,不要把它想象成灵丹妙药。
标签组合示例,如下图:
我们将标题和下载地址标签组合成一个新标签,以“$$$$”分隔,我们的测试结果如下:
你看到了吗。效果和我们预想的一样。
然后这个就简单使用了,我什么都没学到。
然后还有另一种标签组合,见下图:
这样测试的结果是什么,应该和上面的情况一样,谁知道呢,我们测试一下看看
查看全部
采集自动组合(v7版本增加了一个标签组合的结果和内容页标签
)
v7版本增加了标签组合功能。很多朋友在使用过程中发现组合的结果与自己想要的结果不一致。让我解释一下这个功能的使用。
1.标签的组合是文件下载前的内容
有朋友发现a标签中下载了某个文件,原地址为aaa,下载或检测到的地址为bbb。那么,如果在b标签中组合a标签,a标签的值为aaa。为什么使用这种处理方法是因为文件下载是在标签组合后进行的。如何实现标签内容为文件下载后的结果?你可以新建一个标签,选择“自定义固定格式数据”,把你的标签组合的内容放进去。这里的替换会在文件下载后进行。
2.内容页面标签循环采集并添加为新记录
如果两个组合的标签都是内容页标签,当这两个标签组合时,会根据循环次数最多的记录生成相同数量的新循环记录。如果一个标签的循环次数较少,则新生成的标签中该标签的值为空。例如,将标签a、b 组合起来生成标签c。a的循环数为5,b的循环数为3,将产生5个cs。其中,前3个标签的值分别对应a和b。在最后两个值中,b 的值为空。假设a的值为11,22,33,44,55,b的值为aa,bb,cc.c是[label:a][label:b]的组合,生成c的值是 11aa,22bb,33cc,44,55.
3.列表页标签和内容页标签组合
如果两个标签中的一个是内容页,另一个是列表页,则内容页将参与第2条中的循环处理。在这个过程中,列表页被视为一个字符串。合并完成后,程序将再次进行数据处理操作。最后,组合标签中列表页面标签的内容将替换为实际值。可以再次提取和下载组合结果。比如内容页a和列表页b组合生成c,其中a的值为11、22、22,b的值为bb,那么c的第一个组合结果为11[label: b],22[label:b],33[label:b],然后进行数据处理。如果b的值为bb,那么最终的结果可能是11bb、22bb、33bb。
有的朋友可能会说,为什么要把这个功能弄的这么复杂。其实这个函数主要用于第一个函数,其他的组合可能会产生和原来想法不同的结果。建议大家不要滥用这个功能,不要把它想象成灵丹妙药。
标签组合示例,如下图:

我们将标题和下载地址标签组合成一个新标签,以“$$$$”分隔,我们的测试结果如下:

你看到了吗。效果和我们预想的一样。
然后这个就简单使用了,我什么都没学到。
然后还有另一种标签组合,见下图:

这样测试的结果是什么,应该和上面的情况一样,谁知道呢,我们测试一下看看

采集自动组合(数据采集系统中自动入库设计工具的研究与实现(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-10 10:03
数据采集系统中自动存储设计工具的研究与实现 徐鹏 孙元 清华大学计算机系 E-Mail: xp{sBORy)@kcg. CS。协会 ingIlu&edu。cn ■ Stack:基于web的数据采集查杀系统,处理的数据量比较大;同时,采集的数据格式经常需要改变。因此,使用传统的音乐方式为每个版本的冰童设计自己的教学数据存储程序往往成本高昂,开发周期长。园区需要为系统提供可视化的开发工具。允许用户自定义冰通中的数据模型与数据库中救援城市的对应关系,系统根据用户的设置自动完成存储操作。本文将针对这一需求提出相应的解决方案。关磊字:JDBc,Drums 字典,结合基于牛奶b采集的数据中的对应关系和在线发布系统,定期报告数据的自动存储系统主要用于接收来自的最终定期提交用户在应用服务器上报数据后,用于将上市公司数据提取并写入信息中心数据库的操作。自动入库系统可以配合定期报表数据采集系统使用,即用户报表数据通过网络写入数据库的同时,对外发布使用的数据信息基于证券交易所信息中心数据库的信息模型,由定期报告数据自动存储系统写入信息中心数据库。同时进行仓储作业。根据信息中心的需要,可以对部分数据进行统计处理,生成统计信息写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。可以对部分数据进行统计处理,生成统计信息,写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。可以对部分数据进行统计处理,生成统计信息,写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。
一。W基于歌曲的数据采集和在线发布系统中的JDBC 本系统完全用Java语言编写,因此选择JDBC访问数据库。这既充分利用了Java语言的特点,又保证了其他部分与数据库的相对独立性。图书馆。诸如数据存储系统之类的应用程序正在服务器上运行。它与客户端没有直接关系,它直接通过J Ming c 访问数据库。无需通过其他级别。当AppIet之类的浏览器助手想要查询和修改数据库时。它是通过服务器上的 J8va 应用程序完成的。无论是本系统中基于浏览器的数据采集系统。在基于浏览器的数据查询系统中,Applet 不用于直接访问数据库,因为 Applet 受安全限制只能与下载的服务器建立连接。因此,只能访问服务器应用程序上的数据库。本系统的数据库可能与 scapular w 服务器不在同一台计算机上。使用Java作为Applet的中间层来访问数据库也可以提高访问效率,比如始终保持与数据库的连接,而不是每次访问都重新建立连接。您还可以组织和过滤 Applet 发送的请求。再次访问数据库。TcP 协议用于 Applet 和中间层的 Application 之间的通信。本系统使用JDBC访问数据库的一般程序流程如下:1) 加载数据库的JDBC驱动;2) 与数据库建立连接: 3) 创建 Statement 对象;4)中对Statement对象执行SQL语句,返回Resultset对象: 5) 处理ResultSet对象,得到查询结果;6) 关闭与数据库的连接。
JavaApplication作为中间层的过程如下: 1) 加载数据库的JDBC驱动: 2) 与数据库建立连接;3) 监听某个端口,等待Applet连接;4) 与Applet 建立连接后。接收来自 ADplet 的请求;5) 组织过滤请求,形成SQL语句;6) 创建 Statement 对象;7) 对 Statement 对象执行 SQL 语句并返回 ResultSet 对象;8)处理ResalltSet对象,得到查询结果{9)将查询结果返回给Applet;10)断开与^pDlet的连接,返回4)重新收听。实际上,接收Applet请求、访问数据库和返回结果都是由一个线程完成的。主线程继续返回监听状态。这样的应用程序可以同时为多个 ApDlets 服务。二。自动数据存储工具的设计。图ll 数据库存储流程 在上交所年报系统中,数据存储操作的系统设置包括源数据库设置、数据存储操作设置、源数据与数据库对应设置。Tan数据设置用于连接给定的数据库,获取数据库中表结构的相关信息进行系统设置。需要由系统管理员填写或选择的相关数据是用于连接数据库的驱动程序、数据池名称、用户名和密码。系统会调用JDBC接口访问数据库。
数据库对应关系设置用于设置数据字典与数据库中表结构存储的对应关系,为系统的数据存储功能提供了极大的灵活性。提供给用户的界面上的表项和数据库中的条目之间建立了对应关系。并允许数据库管理员针对不同的报表类型进行修改,以保证系统的可复用性。具体设计在后面介绍。数据库对应关系设计完成后,即可将数据存入数据库中。数据存储操作也完全按照管理员设置的对应表进行。用于数据存储过程。我们可以简单地用图ll来表示它。2. 1 数据字典和数据库存储的对应设计思路在数据采集系统中,用户填写界面上有很多表项,不同的表收录子表和自定义项,所以有不同的入库操作。同一个界面的表项中不同数据字段的存储操作是不一样的。对于这个不一致的数据单元,我们首先根据需要确定了表结构,将数据库中的一些接口表进行拆分,以适应不同的操作。比如界面上的募款表,分为募款总额表和数据库中募款资金使用明细表。关联交易表和投资收益表也是如此。所以,接口表中的字段与数据库中的字段不完全对应。同时。考虑到系统的用户界面因国内外不同类型的报告(如年报和中期报告)而异,并考虑到相关财务计算指标的变化,系统需要很大的灵活性。
对于数据库。首先,条目多,数据库中存储的数据量巨大。而且这些数据的重要性比较高,要保证数据库中数据的基本稳定性。因此,在上交所年报系统的数据存储操作中,我们提供了一个功能模块,用于设置界面表项中的字段与数据库表结构中的字段之间的对应关系。该模块将用户界面的数据字段映射到数据库中字段的计算关系。这降低了两者之间的耦合程度。使我们的系统实施更加灵活方便。更改用户界面条目时。或者在更改数据库中的表或字段时,对方不需要做大的改动,只需要使用对应关系设置工具修改入库规则即可。对于界面上表项中的每个域,我们在系统中用16位进行编码,以及每个域的代码和具体的域名。存储在数据字典(SCDicti.nary软件包)中,直接调用程序中的数据代码即可获取数据字段。这也体现了系统设计的灵活性。修改界面上的域名时,只需要修改数据字典中对应的域名即可,程序中代码的调用保持不变。对于数据库中的每个域,基本上都是按照不同的接口表来保存的。例如,我们前面介绍的总表和明细表。对于不同的数据库表,赖瑞有三个共同的主键,如下: lh吖『∞fn口awIdl』v叫ch stare 1(30)NOTNULLI nepo^Ye state『varch called(30)@ >NoTNULLl fr∞。
第一位表示表代码(格式为表名域名),第二位表示表中的字段代码)¨==≤:=2·5~6·7Ⅱ 图2接口域和数据库域一-对多关系。另外,数据库中字段的值可以是接口字段的组合,比如接口上字段的代码。数据库中的数据字段(双参数。第一个数字代表表代码(格式为表名字段名)第二个数字代表表中域的代码) 3.7+3.16——————图3l中界面域对应关系对象组合的计算方法。包括常用的整型和浮点型数据,如类型、字符串类型,以及它们的组合操作。2. 2 域对应关系及其设置在数据库中存储的数据表中。除了用户进入数据库的年报基础数据表外,还有一个域对应表calTable。
在复选框中,首先选择数据库中的一个表,窗口的左列将显示数据库中的所有列名。同时右侧会显示已经设置好的计算方式(即与界面字段的对应关系)。当用户设置或修改域时,只需点击右侧的小按钮,弹出域选择对话框。用户选择界面域或它们的组合后,新设置的对应关系会在 右侧栏中显示。用户点击“申请”,确认此表中信函的对应关系,重新入库。然后用户可以对下一个表进行操作。3.数据存储操作data采集系统加载的数据保存在SCReportData对象中,
以及从CalTable获得的每个表中每个字段的计算方法。为数据库中的基础数据表(即用户需要进入数据库的数据表)。分为三种情况: ·表中每个公司的记录是唯一的,不依赖于报表类型。唯一表:主要是companyTable,changes和changes。所以每次都入库。对标记执行更新操作。· 基本表格:这些表格中的数据对于每个年度报告或中期报告都是唯一的。但是,不同类型的报告将对应不同的记录。对于这些表,每次将报表放入数据库时都会执行一次写入操作。● 子表或明细表:这些表中的数据对于每个年度报告或中期报告可以有多条记录,因此对它们执行批量写入操作。针对这三种情况,系统提供了相应的数据库操作方法来保证数据的完整性。我们可以用K图5来说明仓储作业的流程。Ⅱ 图 5l 数据库存储操作流程 查看全部
采集自动组合(数据采集系统中自动入库设计工具的研究与实现(图))
数据采集系统中自动存储设计工具的研究与实现 徐鹏 孙元 清华大学计算机系 E-Mail: xp{sBORy)@kcg. CS。协会 ingIlu&edu。cn ■ Stack:基于web的数据采集查杀系统,处理的数据量比较大;同时,采集的数据格式经常需要改变。因此,使用传统的音乐方式为每个版本的冰童设计自己的教学数据存储程序往往成本高昂,开发周期长。园区需要为系统提供可视化的开发工具。允许用户自定义冰通中的数据模型与数据库中救援城市的对应关系,系统根据用户的设置自动完成存储操作。本文将针对这一需求提出相应的解决方案。关磊字:JDBc,Drums 字典,结合基于牛奶b采集的数据中的对应关系和在线发布系统,定期报告数据的自动存储系统主要用于接收来自的最终定期提交用户在应用服务器上报数据后,用于将上市公司数据提取并写入信息中心数据库的操作。自动入库系统可以配合定期报表数据采集系统使用,即用户报表数据通过网络写入数据库的同时,对外发布使用的数据信息基于证券交易所信息中心数据库的信息模型,由定期报告数据自动存储系统写入信息中心数据库。同时进行仓储作业。根据信息中心的需要,可以对部分数据进行统计处理,生成统计信息写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。可以对部分数据进行统计处理,生成统计信息,写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。可以对部分数据进行统计处理,生成统计信息,写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。
一。W基于歌曲的数据采集和在线发布系统中的JDBC 本系统完全用Java语言编写,因此选择JDBC访问数据库。这既充分利用了Java语言的特点,又保证了其他部分与数据库的相对独立性。图书馆。诸如数据存储系统之类的应用程序正在服务器上运行。它与客户端没有直接关系,它直接通过J Ming c 访问数据库。无需通过其他级别。当AppIet之类的浏览器助手想要查询和修改数据库时。它是通过服务器上的 J8va 应用程序完成的。无论是本系统中基于浏览器的数据采集系统。在基于浏览器的数据查询系统中,Applet 不用于直接访问数据库,因为 Applet 受安全限制只能与下载的服务器建立连接。因此,只能访问服务器应用程序上的数据库。本系统的数据库可能与 scapular w 服务器不在同一台计算机上。使用Java作为Applet的中间层来访问数据库也可以提高访问效率,比如始终保持与数据库的连接,而不是每次访问都重新建立连接。您还可以组织和过滤 Applet 发送的请求。再次访问数据库。TcP 协议用于 Applet 和中间层的 Application 之间的通信。本系统使用JDBC访问数据库的一般程序流程如下:1) 加载数据库的JDBC驱动;2) 与数据库建立连接: 3) 创建 Statement 对象;4)中对Statement对象执行SQL语句,返回Resultset对象: 5) 处理ResultSet对象,得到查询结果;6) 关闭与数据库的连接。
JavaApplication作为中间层的过程如下: 1) 加载数据库的JDBC驱动: 2) 与数据库建立连接;3) 监听某个端口,等待Applet连接;4) 与Applet 建立连接后。接收来自 ADplet 的请求;5) 组织过滤请求,形成SQL语句;6) 创建 Statement 对象;7) 对 Statement 对象执行 SQL 语句并返回 ResultSet 对象;8)处理ResalltSet对象,得到查询结果{9)将查询结果返回给Applet;10)断开与^pDlet的连接,返回4)重新收听。实际上,接收Applet请求、访问数据库和返回结果都是由一个线程完成的。主线程继续返回监听状态。这样的应用程序可以同时为多个 ApDlets 服务。二。自动数据存储工具的设计。图ll 数据库存储流程 在上交所年报系统中,数据存储操作的系统设置包括源数据库设置、数据存储操作设置、源数据与数据库对应设置。Tan数据设置用于连接给定的数据库,获取数据库中表结构的相关信息进行系统设置。需要由系统管理员填写或选择的相关数据是用于连接数据库的驱动程序、数据池名称、用户名和密码。系统会调用JDBC接口访问数据库。
数据库对应关系设置用于设置数据字典与数据库中表结构存储的对应关系,为系统的数据存储功能提供了极大的灵活性。提供给用户的界面上的表项和数据库中的条目之间建立了对应关系。并允许数据库管理员针对不同的报表类型进行修改,以保证系统的可复用性。具体设计在后面介绍。数据库对应关系设计完成后,即可将数据存入数据库中。数据存储操作也完全按照管理员设置的对应表进行。用于数据存储过程。我们可以简单地用图ll来表示它。2. 1 数据字典和数据库存储的对应设计思路在数据采集系统中,用户填写界面上有很多表项,不同的表收录子表和自定义项,所以有不同的入库操作。同一个界面的表项中不同数据字段的存储操作是不一样的。对于这个不一致的数据单元,我们首先根据需要确定了表结构,将数据库中的一些接口表进行拆分,以适应不同的操作。比如界面上的募款表,分为募款总额表和数据库中募款资金使用明细表。关联交易表和投资收益表也是如此。所以,接口表中的字段与数据库中的字段不完全对应。同时。考虑到系统的用户界面因国内外不同类型的报告(如年报和中期报告)而异,并考虑到相关财务计算指标的变化,系统需要很大的灵活性。
对于数据库。首先,条目多,数据库中存储的数据量巨大。而且这些数据的重要性比较高,要保证数据库中数据的基本稳定性。因此,在上交所年报系统的数据存储操作中,我们提供了一个功能模块,用于设置界面表项中的字段与数据库表结构中的字段之间的对应关系。该模块将用户界面的数据字段映射到数据库中字段的计算关系。这降低了两者之间的耦合程度。使我们的系统实施更加灵活方便。更改用户界面条目时。或者在更改数据库中的表或字段时,对方不需要做大的改动,只需要使用对应关系设置工具修改入库规则即可。对于界面上表项中的每个域,我们在系统中用16位进行编码,以及每个域的代码和具体的域名。存储在数据字典(SCDicti.nary软件包)中,直接调用程序中的数据代码即可获取数据字段。这也体现了系统设计的灵活性。修改界面上的域名时,只需要修改数据字典中对应的域名即可,程序中代码的调用保持不变。对于数据库中的每个域,基本上都是按照不同的接口表来保存的。例如,我们前面介绍的总表和明细表。对于不同的数据库表,赖瑞有三个共同的主键,如下: lh吖『∞fn口awIdl』v叫ch stare 1(30)NOTNULLI nepo^Ye state『varch called(30)@ >NoTNULLl fr∞。
第一位表示表代码(格式为表名域名),第二位表示表中的字段代码)¨==≤:=2·5~6·7Ⅱ 图2接口域和数据库域一-对多关系。另外,数据库中字段的值可以是接口字段的组合,比如接口上字段的代码。数据库中的数据字段(双参数。第一个数字代表表代码(格式为表名字段名)第二个数字代表表中域的代码) 3.7+3.16——————图3l中界面域对应关系对象组合的计算方法。包括常用的整型和浮点型数据,如类型、字符串类型,以及它们的组合操作。2. 2 域对应关系及其设置在数据库中存储的数据表中。除了用户进入数据库的年报基础数据表外,还有一个域对应表calTable。
在复选框中,首先选择数据库中的一个表,窗口的左列将显示数据库中的所有列名。同时右侧会显示已经设置好的计算方式(即与界面字段的对应关系)。当用户设置或修改域时,只需点击右侧的小按钮,弹出域选择对话框。用户选择界面域或它们的组合后,新设置的对应关系会在 右侧栏中显示。用户点击“申请”,确认此表中信函的对应关系,重新入库。然后用户可以对下一个表进行操作。3.数据存储操作data采集系统加载的数据保存在SCReportData对象中,
以及从CalTable获得的每个表中每个字段的计算方法。为数据库中的基础数据表(即用户需要进入数据库的数据表)。分为三种情况: ·表中每个公司的记录是唯一的,不依赖于报表类型。唯一表:主要是companyTable,changes和changes。所以每次都入库。对标记执行更新操作。· 基本表格:这些表格中的数据对于每个年度报告或中期报告都是唯一的。但是,不同类型的报告将对应不同的记录。对于这些表,每次将报表放入数据库时都会执行一次写入操作。● 子表或明细表:这些表中的数据对于每个年度报告或中期报告可以有多条记录,因此对它们执行批量写入操作。针对这三种情况,系统提供了相应的数据库操作方法来保证数据的完整性。我们可以用K图5来说明仓储作业的流程。Ⅱ 图 5l 数据库存储操作流程
采集自动组合(元数据资产治理(详情见),需注意什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-05 04:14
一、简介
数据资产治理的前提(见:)必须有数据。它要求数据类型齐全,数量大,并尽可能覆盖数据流通的方方面面。元数据 采集 变得尤为重要。它是数据资产治理的核心基础。
在早期的采集系统中,我们主要使用“API直连”来连接采集Hive/Mysql表元数据。随着业务的快速发展,对数据运营和成本管理的需求越来越强烈。元数据需要覆盖整个数据链路,包括离线计算平台、实时计算平台、内部工具、任务元数据等。采集在元数据的过程中,我们遇到了以下困难:
本文主要介绍了我们在元数据含义、提取、采集、监控告警等方面所做的一些事情。
二、元数据2.1 什么是元数据
什么是元数据?元数据是“用于描述数据的数据”。例如:我用手机拍了一张照片,查看了照片的详细信息,如下图:
照片信息
文件名:IMG_20201217_114115
时间:2020年12月17号 11:30:01
分辨率:4608X2592
文件大小:2.69MB
相机制造商:OnePlus
相机型号:ONEPLUS A5000
闪光灯:未使用闪光灯
焦距:4.10mm
白平衡:自动
光圈:f/1.7
曝光时间:1/50
ISO:1250
这些是数码照片的元数据,用于描述图片。在资产管理平台中,我们采集Hive组件的元数据包括:表名、字段列表、负责人、任务调度信息等。
采集全链路数据(各种元数据)可以帮助数据平台回答:我们有哪些数据?有多少人在使用它?什么是数据存储?如何找到这些数据?什么是数据流?分析问题的根源,结合血缘关系分析影响。
2.2 采集 什么元数据
如下图所示,是一个数据流图。我们主要采集各个平台组件:
截至目前,采集所达到的平台组件已经覆盖了整个数据链路。涵盖10种数据+,基础元数据量10w+。主要包括:
三、元数据提取
如何从众多平台组件中提取元数据?大致有以下几个方面:
计算任务通过分析任务的输入/输出依赖配置获得血缘关系。SQL类任务使用“Sql Parser”(ANTLR4系统实现的sql重写工具)工具解析SQL脚本,获取表/字段级血缘关系。3.1 线下平台
主要是采集Hive/RDS表的元数据。
Hive组件的元数据存放在Metastore中,通过JDBC访问Mysql获取数据库表的元数据。根据Hive表信息组装HDFS地址,通过FileSystem API获取文件状态、文件编号、文件大小、数据更新时间等趋势数据。
RDS平台提供Mysql服务的管理,通过平台提供的服务接口获取表元数据、趋势数据、访问状态等信息。
3.2 实时平台
主要是Flume/Hbase/Kafka等组件的元数据。
例如:我们访问放置在KP平台的工单数据,获取topic的基本元数据信息,定期消费topic获取样本数据,解析字段列表。平台本身提供集群状态和业务监控指标,通过平台服务获取集群资源的使用情况。
3.3 内部工具
主要是BI报表系统的血缘关系数据(BI报表查询的Hive表和Mysql表关系)、指标数据库(Hive表和指标相关的字段关系)、OneService服务(访问哪些数据库表的关系数据)通过接口)。
这些内部系统在产品的不断迭代中积累了大量的元数据。在不考虑元数据的时效性的情况下,我们一般都是将这些系统的数据同步到Hive数据库中,然后离线处理后获取元数据。
3.4 任务元数据
元数据任务主要是DP离线任务、Flink计算服务和Flume任务。
这些计算任务都放在磁盘上,通过Binlog同步或离线同步获取任务列表,获取任务的元数据。
四、数据采集
元数据提取后,我们就可以得到数据链中各个平台组件的元数据。数据采集是指将这些元数据存储在数据资产管理系统的数据库中。
4.1 采集 方法
采集 主要有三种数据类型。下表列出了三种方法的优缺点:
一般情况下,我们推荐业务方使用采集SDK。主动上报元数据,访问时只需要关注上报数据格式和SDK初始化,即可快速完成上报。
4.2 采集SDK 设计
采集SDK支持基础元数据、趋势数据、血缘关系数据的上报,包括客户端SDK和采集服务器两部分。客户端SDK主要实现通用报表模型的定义和报表功能,采集服务器主要实现不同的适配器,完成数据的统一存储。
4.2.1 架构
采集SDK 客户端
定义了基本元数据(MetaSchema)、趋势数据(TrendSchema)和血缘关系数据(LineageSchema)的通用模型,并支持新的报告模型(XXXSchema)。ReportService实现了向Kafka推送数据的功能。
采集服务器
数据鉴权服务器消费Kafka,获取数据后,对每条记录的签名进行鉴权(获取记录中的appId、appName、token信息,重新生成token,比较值的过程)。统一仓储服务定义了统一的数据仓储模型,包括表基础元数据、趋势数据、血缘关系数据、趋势数据,实现不同数据类型的仓储服务。数据适配器Bridge获取Kafka的数据,根据不同的数据类型转换成“统一存储模型”,触发“统一存储服务”完成数据写入。4.2.2 通用型号
采集的平台组件很多。我们参考Hive“表模型”的定义,抽象出一套通用的数据上报模型,保证数据上报和数据存储的可扩展性。
通用血缘模型主要包括血缘模型定义和任务血缘模型定义,支持用户分别上报血缘关系和任务血缘关系。该模型定义如下:
/**
* 表血缘模型定义
*/
@Data
public class TableLineageSchema {
/**
* 当前节点
*/
private T current;
/**
* 父节点
*/
private List parents;
/**
* 子节点
*/
private List childs;
/**
* 表级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
/**
* 表任务血缘定义
*
*/
@Data
public class JobLineageSchema {
/**
* 任务节点对象
*/
private Job task;
/**
* 输入对象列表
*/
private List inputs;
/**
* 输出对象列表
*/
private List outputs;
/**
* 任务级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
每个模型定义都有一个扩展字段(传统的 json 格式)。不在定义中的指标可以放在扩展字段中。数据上报后,也会存储在元数据表的扩展字段中。访问新类型,索引定义大不相同,通过扩展新的数据模型定义,元数据报告完成。
4.2.3 访问、验证、限流
如何保证用户上报的数据是安全的?我们设计了一组签名:访问方Id(appId)、访问名称(appName)、访问标识(token)。管理员填写基本接入方信息,生成随机的appId和token信息。业务方在初始化采集SDK时,指定了签名信息,每上报的数据都会携带签名。在采集服务器上,每一条数据都会经过签名和认证,保证了数据的安全。
采集SDK 会对上报的每条数据执行通用规则来检查数据的有效性,例如表名不为空、负责人的有效性、表的大小、趋势数据不能为负。如果检测到非法数据,将被过滤掉并触发报警通知。
在采集SDK服务器上,每隔一定时间(每两秒)消费一批Kafka数据。支持设置消费数据的时间间隔和拉取的片数。下游入站压力不会因上报数据流量高峰而变化。大,起到了限流作用。
4.3 触发器采集
我们支持多种 采集 元数据方法。如何触发数据的采集?总体思路是:
基于Apollo配置系统(见:)和Linux系统的Crontab功能,实现任务调度。数据采集任务在Apollo上配置。配置改变后,Apollo会发布,配置信息会实时同步到在线节点的Crontab文件中。
4.3.1 增量任务,准实时
支持获取组件最近变化的元数据,配置增量任务,提高元数据采集的实时性。比如增量采集Hive表元数据,每1分钟查询一次metastore,获取最近更改的元数据列表,并更新元数据。
4.3.2个完整任务,所有细节
增量 采集 可能有数据丢失的情况。每 1 天或更多天完成一次 采集 作为底线解决方案,以确保元数据的完整性。
4.3.3 采集SDK,实时上报
采集SDK 支持实时和全量上报模式。一般要求在数据变更后实时上报接入方的数据,不定期上报一次全量。
4.4 数据存储、更新
在数据采集之后,就要考虑如何存储,以及元数据发生变化时如何同步更新。我们对来自采集的元数据进行归类和统一,抽象出“表模型”并将其存储在类别中。
4.4.1 数据存储
我们评估了每个组件的元数据量(共10w+),预估了数据可能的使用场景,最终选择了Mysql来存储。为了满足用户的个性化查询需求,构建了Es宽表。表粒度主要包括:表名、备注、负责人、字段列表、趋势信息、业务领域信息、任务信息等。Es表在数据采集过程中同步更新,保证真实元数据查询的时间性,定期更新(构建离线模型表,每天同步更新Es表),保证元数据的完整性。
元数据中的表不是孤立存在的。一般有关联任务(离线任务、实时任务)输出表,表和任务之间的流向关系也会在数据图中显示。那么如何在众多平台组件中唯一区分一个表呢?我们通过表所在的集群名称、项目名称、表类型(它来自哪个平台组件)和表名称的组合来唯一区分。
对数据进行分类存储,最终形成:基础元数据表、趋势数据表、任务元数据表、血缘关系数据表。
4.4.2 数据更新
元数据表离线,如何同步更新?
五、监控和警告
采集 已经完成了数据,是不是都做完了?答案是否定的。采集在这个过程中,数据类型很多,删除方式多种多样,删除链接长度。任何环节的任何问题都会导致结果不准确。我们通过以下方式保证采集服务的稳定性。
5.1 采集链路监控告警5.1.1 接口监控
我们将系统的所有服务接口分为核心、重要、通用三个层次,并支持标注接口和责任人的注解。异常会触发不同级别的警报通知。核心业务异常直接触发电话报警,重要或一般业务异常触发电子邮件报警。系统会存储接口请求和执行状态并删除,每天向接口服务负责人发送服务日报。通过将采集服务的元数据标记为核心和重要服务,“API直连方式”的接口被异常感知。
如下图,是服务接口的告警通知:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[重要]等级问题, 方法名:[com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb], 异常信息:null
host:XXXXXX
处理地址:https://XXXX
如下图,是服务接口的每日告警报告:
[Warning][prod][data-dict] - 数据资产平台告警
[shunfengche]今日问题汇总
请及时收敛今日问题,总问题数 1 个,出现 2 次
【核心】问题 0 个:
【重要】问题 0 个:
【一般】问题 1 个:
[数据采集]com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb 今日出现 2 次, 已存在 5 天, 历史出现 8 次
host:XXXXXX
处理地址:https://XXXX
5.1.2 采集 进程监控
对于每个元数据采集服务,如果采集进程发生异常,都会发送告警通知。
如下图,是采集过程中异常触发的告警:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[一般]等级问题, 方法名:[com.youzan.bigdata.crystal.asyncworker.work.AsyncAllRdsDDLWorker.run], 异常信息:/n
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLQueryInterruptedException: Query execution was interrupted
5.1.3 Kafka 消息积压警告
Kafka数据的消费,通过kp平台配置消息backlog告警,实现对采集SDK服务的异常感知。
5.2 结果数据对比
主要用于事后监测预警,定期检测采集元数据量的异常波动。针对不同类型的元数据,通过将当天采集的数量与过去7天的历史平均数量进行比较,设置异常波动的报警阈值,超过阈值时触发报警通知.
针对采集的元数据结果表,配置一些数据质量检测规则,定期执行异常规则,发现问题数据时触发告警通知。这保证了对结果数据的异常感知。例如,定义的数据质量规则:
5.3 项目迭代机制,采集问题收敛
通过事前、事中、事后的监测预警机制,可以及时发现和感知采集的异常情况。对于异常问题,我们一般以项目迭代的方式发起jira,组织相关人员进行审核。追根溯源,讨论改进方案,产生行动,关注并持续收敛问题。
六、总结与展望6.1 结论
我们定义了一套通用的数据采集和存储模型,支持访问不同数据类型的元数据,支持多种访问方式,采集SDK提高了访问效率和数据时效性。
如下图所示,各个组件的元数据已经打通,数据分类统一管理,提供了数据字典、数据地图、资产市场等元数据的应用。
如果将数据资产治理比作高层建筑的建设,那么不同构件的元数据是原材料,数据采集是基础。只有夯实了基础,数据治理的建设才能越来越稳固。
6.2 展望
在数据采集的过程中,我们也遇到了很多问题。在后续工作中,我们需要不断的优化和功能迭代,包括但不限于:
最后,有赞数据中心,长期招聘基础组件、平台研发、数据仓库、数据产品、算法等人才,欢迎加入,一起享受~简历投递邮箱:。 查看全部
采集自动组合(元数据资产治理(详情见),需注意什么?)
一、简介
数据资产治理的前提(见:)必须有数据。它要求数据类型齐全,数量大,并尽可能覆盖数据流通的方方面面。元数据 采集 变得尤为重要。它是数据资产治理的核心基础。
在早期的采集系统中,我们主要使用“API直连”来连接采集Hive/Mysql表元数据。随着业务的快速发展,对数据运营和成本管理的需求越来越强烈。元数据需要覆盖整个数据链路,包括离线计算平台、实时计算平台、内部工具、任务元数据等。采集在元数据的过程中,我们遇到了以下困难:
本文主要介绍了我们在元数据含义、提取、采集、监控告警等方面所做的一些事情。
二、元数据2.1 什么是元数据
什么是元数据?元数据是“用于描述数据的数据”。例如:我用手机拍了一张照片,查看了照片的详细信息,如下图:
照片信息
文件名:IMG_20201217_114115
时间:2020年12月17号 11:30:01
分辨率:4608X2592
文件大小:2.69MB
相机制造商:OnePlus
相机型号:ONEPLUS A5000
闪光灯:未使用闪光灯
焦距:4.10mm
白平衡:自动
光圈:f/1.7
曝光时间:1/50
ISO:1250
这些是数码照片的元数据,用于描述图片。在资产管理平台中,我们采集Hive组件的元数据包括:表名、字段列表、负责人、任务调度信息等。
采集全链路数据(各种元数据)可以帮助数据平台回答:我们有哪些数据?有多少人在使用它?什么是数据存储?如何找到这些数据?什么是数据流?分析问题的根源,结合血缘关系分析影响。
2.2 采集 什么元数据
如下图所示,是一个数据流图。我们主要采集各个平台组件:
截至目前,采集所达到的平台组件已经覆盖了整个数据链路。涵盖10种数据+,基础元数据量10w+。主要包括:
三、元数据提取
如何从众多平台组件中提取元数据?大致有以下几个方面:
计算任务通过分析任务的输入/输出依赖配置获得血缘关系。SQL类任务使用“Sql Parser”(ANTLR4系统实现的sql重写工具)工具解析SQL脚本,获取表/字段级血缘关系。3.1 线下平台
主要是采集Hive/RDS表的元数据。
Hive组件的元数据存放在Metastore中,通过JDBC访问Mysql获取数据库表的元数据。根据Hive表信息组装HDFS地址,通过FileSystem API获取文件状态、文件编号、文件大小、数据更新时间等趋势数据。
RDS平台提供Mysql服务的管理,通过平台提供的服务接口获取表元数据、趋势数据、访问状态等信息。
3.2 实时平台
主要是Flume/Hbase/Kafka等组件的元数据。
例如:我们访问放置在KP平台的工单数据,获取topic的基本元数据信息,定期消费topic获取样本数据,解析字段列表。平台本身提供集群状态和业务监控指标,通过平台服务获取集群资源的使用情况。
3.3 内部工具
主要是BI报表系统的血缘关系数据(BI报表查询的Hive表和Mysql表关系)、指标数据库(Hive表和指标相关的字段关系)、OneService服务(访问哪些数据库表的关系数据)通过接口)。
这些内部系统在产品的不断迭代中积累了大量的元数据。在不考虑元数据的时效性的情况下,我们一般都是将这些系统的数据同步到Hive数据库中,然后离线处理后获取元数据。
3.4 任务元数据
元数据任务主要是DP离线任务、Flink计算服务和Flume任务。
这些计算任务都放在磁盘上,通过Binlog同步或离线同步获取任务列表,获取任务的元数据。
四、数据采集
元数据提取后,我们就可以得到数据链中各个平台组件的元数据。数据采集是指将这些元数据存储在数据资产管理系统的数据库中。
4.1 采集 方法
采集 主要有三种数据类型。下表列出了三种方法的优缺点:
一般情况下,我们推荐业务方使用采集SDK。主动上报元数据,访问时只需要关注上报数据格式和SDK初始化,即可快速完成上报。
4.2 采集SDK 设计
采集SDK支持基础元数据、趋势数据、血缘关系数据的上报,包括客户端SDK和采集服务器两部分。客户端SDK主要实现通用报表模型的定义和报表功能,采集服务器主要实现不同的适配器,完成数据的统一存储。
4.2.1 架构
采集SDK 客户端
定义了基本元数据(MetaSchema)、趋势数据(TrendSchema)和血缘关系数据(LineageSchema)的通用模型,并支持新的报告模型(XXXSchema)。ReportService实现了向Kafka推送数据的功能。
采集服务器
数据鉴权服务器消费Kafka,获取数据后,对每条记录的签名进行鉴权(获取记录中的appId、appName、token信息,重新生成token,比较值的过程)。统一仓储服务定义了统一的数据仓储模型,包括表基础元数据、趋势数据、血缘关系数据、趋势数据,实现不同数据类型的仓储服务。数据适配器Bridge获取Kafka的数据,根据不同的数据类型转换成“统一存储模型”,触发“统一存储服务”完成数据写入。4.2.2 通用型号
采集的平台组件很多。我们参考Hive“表模型”的定义,抽象出一套通用的数据上报模型,保证数据上报和数据存储的可扩展性。
通用血缘模型主要包括血缘模型定义和任务血缘模型定义,支持用户分别上报血缘关系和任务血缘关系。该模型定义如下:
/**
* 表血缘模型定义
*/
@Data
public class TableLineageSchema {
/**
* 当前节点
*/
private T current;
/**
* 父节点
*/
private List parents;
/**
* 子节点
*/
private List childs;
/**
* 表级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
/**
* 表任务血缘定义
*
*/
@Data
public class JobLineageSchema {
/**
* 任务节点对象
*/
private Job task;
/**
* 输入对象列表
*/
private List inputs;
/**
* 输出对象列表
*/
private List outputs;
/**
* 任务级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
每个模型定义都有一个扩展字段(传统的 json 格式)。不在定义中的指标可以放在扩展字段中。数据上报后,也会存储在元数据表的扩展字段中。访问新类型,索引定义大不相同,通过扩展新的数据模型定义,元数据报告完成。
4.2.3 访问、验证、限流
如何保证用户上报的数据是安全的?我们设计了一组签名:访问方Id(appId)、访问名称(appName)、访问标识(token)。管理员填写基本接入方信息,生成随机的appId和token信息。业务方在初始化采集SDK时,指定了签名信息,每上报的数据都会携带签名。在采集服务器上,每一条数据都会经过签名和认证,保证了数据的安全。
采集SDK 会对上报的每条数据执行通用规则来检查数据的有效性,例如表名不为空、负责人的有效性、表的大小、趋势数据不能为负。如果检测到非法数据,将被过滤掉并触发报警通知。
在采集SDK服务器上,每隔一定时间(每两秒)消费一批Kafka数据。支持设置消费数据的时间间隔和拉取的片数。下游入站压力不会因上报数据流量高峰而变化。大,起到了限流作用。
4.3 触发器采集
我们支持多种 采集 元数据方法。如何触发数据的采集?总体思路是:
基于Apollo配置系统(见:)和Linux系统的Crontab功能,实现任务调度。数据采集任务在Apollo上配置。配置改变后,Apollo会发布,配置信息会实时同步到在线节点的Crontab文件中。
4.3.1 增量任务,准实时
支持获取组件最近变化的元数据,配置增量任务,提高元数据采集的实时性。比如增量采集Hive表元数据,每1分钟查询一次metastore,获取最近更改的元数据列表,并更新元数据。
4.3.2个完整任务,所有细节
增量 采集 可能有数据丢失的情况。每 1 天或更多天完成一次 采集 作为底线解决方案,以确保元数据的完整性。
4.3.3 采集SDK,实时上报
采集SDK 支持实时和全量上报模式。一般要求在数据变更后实时上报接入方的数据,不定期上报一次全量。
4.4 数据存储、更新
在数据采集之后,就要考虑如何存储,以及元数据发生变化时如何同步更新。我们对来自采集的元数据进行归类和统一,抽象出“表模型”并将其存储在类别中。
4.4.1 数据存储
我们评估了每个组件的元数据量(共10w+),预估了数据可能的使用场景,最终选择了Mysql来存储。为了满足用户的个性化查询需求,构建了Es宽表。表粒度主要包括:表名、备注、负责人、字段列表、趋势信息、业务领域信息、任务信息等。Es表在数据采集过程中同步更新,保证真实元数据查询的时间性,定期更新(构建离线模型表,每天同步更新Es表),保证元数据的完整性。
元数据中的表不是孤立存在的。一般有关联任务(离线任务、实时任务)输出表,表和任务之间的流向关系也会在数据图中显示。那么如何在众多平台组件中唯一区分一个表呢?我们通过表所在的集群名称、项目名称、表类型(它来自哪个平台组件)和表名称的组合来唯一区分。
对数据进行分类存储,最终形成:基础元数据表、趋势数据表、任务元数据表、血缘关系数据表。
4.4.2 数据更新
元数据表离线,如何同步更新?
五、监控和警告
采集 已经完成了数据,是不是都做完了?答案是否定的。采集在这个过程中,数据类型很多,删除方式多种多样,删除链接长度。任何环节的任何问题都会导致结果不准确。我们通过以下方式保证采集服务的稳定性。
5.1 采集链路监控告警5.1.1 接口监控
我们将系统的所有服务接口分为核心、重要、通用三个层次,并支持标注接口和责任人的注解。异常会触发不同级别的警报通知。核心业务异常直接触发电话报警,重要或一般业务异常触发电子邮件报警。系统会存储接口请求和执行状态并删除,每天向接口服务负责人发送服务日报。通过将采集服务的元数据标记为核心和重要服务,“API直连方式”的接口被异常感知。
如下图,是服务接口的告警通知:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[重要]等级问题, 方法名:[com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb], 异常信息:null
host:XXXXXX
处理地址:https://XXXX
如下图,是服务接口的每日告警报告:
[Warning][prod][data-dict] - 数据资产平台告警
[shunfengche]今日问题汇总
请及时收敛今日问题,总问题数 1 个,出现 2 次
【核心】问题 0 个:
【重要】问题 0 个:
【一般】问题 1 个:
[数据采集]com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb 今日出现 2 次, 已存在 5 天, 历史出现 8 次
host:XXXXXX
处理地址:https://XXXX
5.1.2 采集 进程监控
对于每个元数据采集服务,如果采集进程发生异常,都会发送告警通知。
如下图,是采集过程中异常触发的告警:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[一般]等级问题, 方法名:[com.youzan.bigdata.crystal.asyncworker.work.AsyncAllRdsDDLWorker.run], 异常信息:/n
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLQueryInterruptedException: Query execution was interrupted
5.1.3 Kafka 消息积压警告
Kafka数据的消费,通过kp平台配置消息backlog告警,实现对采集SDK服务的异常感知。
5.2 结果数据对比
主要用于事后监测预警,定期检测采集元数据量的异常波动。针对不同类型的元数据,通过将当天采集的数量与过去7天的历史平均数量进行比较,设置异常波动的报警阈值,超过阈值时触发报警通知.
针对采集的元数据结果表,配置一些数据质量检测规则,定期执行异常规则,发现问题数据时触发告警通知。这保证了对结果数据的异常感知。例如,定义的数据质量规则:
5.3 项目迭代机制,采集问题收敛
通过事前、事中、事后的监测预警机制,可以及时发现和感知采集的异常情况。对于异常问题,我们一般以项目迭代的方式发起jira,组织相关人员进行审核。追根溯源,讨论改进方案,产生行动,关注并持续收敛问题。
六、总结与展望6.1 结论
我们定义了一套通用的数据采集和存储模型,支持访问不同数据类型的元数据,支持多种访问方式,采集SDK提高了访问效率和数据时效性。
如下图所示,各个组件的元数据已经打通,数据分类统一管理,提供了数据字典、数据地图、资产市场等元数据的应用。
如果将数据资产治理比作高层建筑的建设,那么不同构件的元数据是原材料,数据采集是基础。只有夯实了基础,数据治理的建设才能越来越稳固。
6.2 展望
在数据采集的过程中,我们也遇到了很多问题。在后续工作中,我们需要不断的优化和功能迭代,包括但不限于:
最后,有赞数据中心,长期招聘基础组件、平台研发、数据仓库、数据产品、算法等人才,欢迎加入,一起享受~简历投递邮箱:。
采集自动组合(不能期望配对测试是万能的,即我们仅依赖于一次)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-04 21:20
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实,说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境在生成新的之前使用了一定的方法组合。测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但通过一两个输入。由条件的同时影响引起。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,即只能依靠配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在进行过多等效组合时浪费的时间,尽可能节省宝贵的时间花在设计满足用户使用场景的测试用例上。
具体示例(手动步骤)
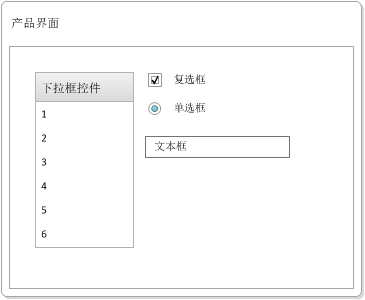
闲话少说,我们来看一个具体的例子。假设我们有以下接口的产品:
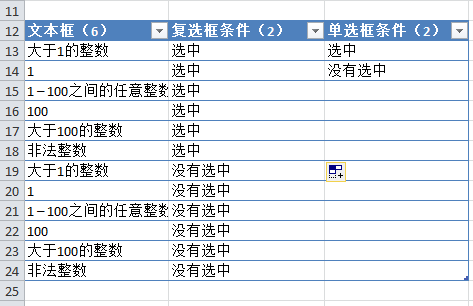
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
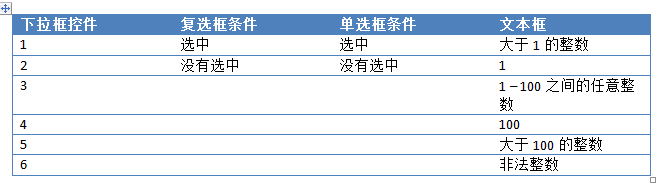
当然,文本框的条件还可以进一步细分,但是为了简单起见,我把条件设置的比较粗糙。如果按照全组合用例设置方法,则需要6个(下拉框控件的可能条件)*2(复杂复选框的可能条件)*2(单个复选框的可能条件)*6(文本框的可能条件)= 144 种组合。
我们来看一下使用配对法设计组合的方法:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图所示:
2. 首先,将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍四个参数二、三、配对组合的方法:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数并没有完全结合起来:
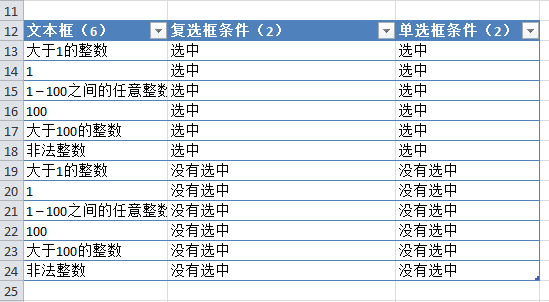
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
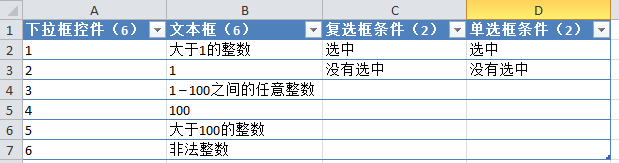
自动化步骤
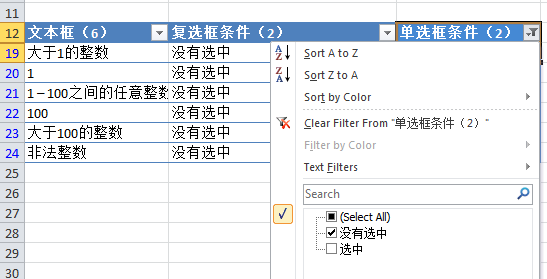
上面的工作还是有点繁琐的。事实上,有人已经自动化了这个过程。这是一个免费的开源工具,allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:
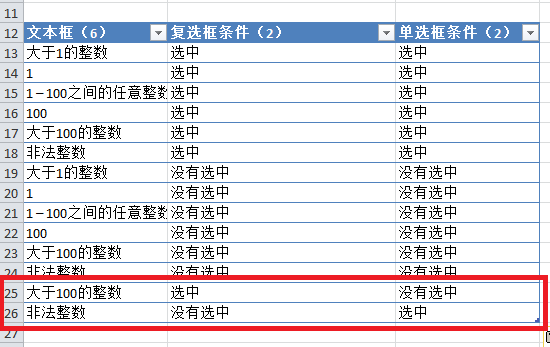
3. 然后使用 allpairs.exe 处理这个文件:
allpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后,结果如下:
您可以在设计测试环境矩阵和组合测试用例时使用 allpairs 技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好从测试覆盖率和用户场景覆盖率开始。, 添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合Behavior DrivenDesign技术,直接从需求中自动生成测试用例,如果我们自动化了基础测试用例,我们可以用这个技术对自动化测试用例进行配对组合(当然需要加一些限制),在节省测试时间的同时,要达到满意的测试覆盖率,当然,这样做需要我们自己写一个测试工具来实现这个技术——至少到现在我还没有看到现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
采集自动组合(不能期望配对测试是万能的,即我们仅依赖于一次)
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实,说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境在生成新的之前使用了一定的方法组合。测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但通过一两个输入。由条件的同时影响引起。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,即只能依靠配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在进行过多等效组合时浪费的时间,尽可能节省宝贵的时间花在设计满足用户使用场景的测试用例上。
具体示例(手动步骤)
闲话少说,我们来看一个具体的例子。假设我们有以下接口的产品:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,文本框的条件还可以进一步细分,但是为了简单起见,我把条件设置的比较粗糙。如果按照全组合用例设置方法,则需要6个(下拉框控件的可能条件)*2(复杂复选框的可能条件)*2(单个复选框的可能条件)*6(文本框的可能条件)= 144 种组合。
我们来看一下使用配对法设计组合的方法:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图所示:
2. 首先,将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍四个参数二、三、配对组合的方法:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数并没有完全结合起来:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐的。事实上,有人已经自动化了这个过程。这是一个免费的开源工具,allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:
3. 然后使用 allpairs.exe 处理这个文件:
allpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后,结果如下:
您可以在设计测试环境矩阵和组合测试用例时使用 allpairs 技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好从测试覆盖率和用户场景覆盖率开始。, 添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合Behavior DrivenDesign技术,直接从需求中自动生成测试用例,如果我们自动化了基础测试用例,我们可以用这个技术对自动化测试用例进行配对组合(当然需要加一些限制),在节省测试时间的同时,要达到满意的测试覆盖率,当然,这样做需要我们自己写一个测试工具来实现这个技术——至少到现在我还没有看到现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
采集自动组合(采集自动组合策略数据块geotreepre_sort模块中的pre_sort(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-01 14:22
采集自动组合策略数据块geotreepre_sort模块中的pre_sort已经限制了数据块的大小,为了自定义一个更大的数据块,我们需要确定相应的row数,然后重新定义row数据块定义规则。geosphere示例如下:rowrow_pre_sort=dict(row=pre_sort(geotree))pre_sortd=geotree.geosphere()pre_sort->doc("a")pre_sort->doc("b")pre_sort->doc("c")d.push(row)pre_sort->doc("d")pre_sort->doc("e")d.push(row_pre_sort)如果我们需要的数据块是一个新的row,那么可以根据meta_pre_sort进行分析。
meta_pre_sort的原始数据为e.collect_row(row_files=meta_pre_sort.obj_rows),要分析原始数据,必须分析数据块。meta_pre_sort.get("meta_pre_sort.txt")得到一个meta_pre_sort.txt文件,并打印出这个数据块,使用如下的语句:meta_pre_sort.items["row_files"]["end_items"]如果将这个meta_pre_sort字典中的每个属性定义成fraction(对应的的排序规则包括分数等),并用items["end_items"]=meta_pre_sort.items["collect_table"]="row",进行分析,代码如下:meta_pre_sort.items["collect_table"]["end_items"]根据规则可以重新定义数据块的大小。
注意是meta_pre_sort.txt而不是数据块。meta_pre_sort.txt的格式为{"end_items":row}reference.fractions_,.fractions.rows:{"end_items":end_items.rows,.fractions.rows.fractions},.meta_pre_sort:{"collect_table":meta_pre_sort.txt,.meta_pre_sort.collect_table:[fraction]}meta_pre_sort.items["row_files"]meta_pre_sort.rows=meta_pre_sort.rowsmeta_pre_sort.rows.items.items=rowmeta_pre_sort.items["end_items"]([])则对应于geosphere示例数据块,每个数据块后面都需要加冒号,否则meta_pre_sort.items["end_items"]得到为空数据。
附上完整代码:pre_sort原文:geotreepre_sort本文章来源于geosphere,istio微信公众号,微信扫一扫关注geosphere公众号。 查看全部
采集自动组合(采集自动组合策略数据块geotreepre_sort模块中的pre_sort(组图))
采集自动组合策略数据块geotreepre_sort模块中的pre_sort已经限制了数据块的大小,为了自定义一个更大的数据块,我们需要确定相应的row数,然后重新定义row数据块定义规则。geosphere示例如下:rowrow_pre_sort=dict(row=pre_sort(geotree))pre_sortd=geotree.geosphere()pre_sort->doc("a")pre_sort->doc("b")pre_sort->doc("c")d.push(row)pre_sort->doc("d")pre_sort->doc("e")d.push(row_pre_sort)如果我们需要的数据块是一个新的row,那么可以根据meta_pre_sort进行分析。
meta_pre_sort的原始数据为e.collect_row(row_files=meta_pre_sort.obj_rows),要分析原始数据,必须分析数据块。meta_pre_sort.get("meta_pre_sort.txt")得到一个meta_pre_sort.txt文件,并打印出这个数据块,使用如下的语句:meta_pre_sort.items["row_files"]["end_items"]如果将这个meta_pre_sort字典中的每个属性定义成fraction(对应的的排序规则包括分数等),并用items["end_items"]=meta_pre_sort.items["collect_table"]="row",进行分析,代码如下:meta_pre_sort.items["collect_table"]["end_items"]根据规则可以重新定义数据块的大小。
注意是meta_pre_sort.txt而不是数据块。meta_pre_sort.txt的格式为{"end_items":row}reference.fractions_,.fractions.rows:{"end_items":end_items.rows,.fractions.rows.fractions},.meta_pre_sort:{"collect_table":meta_pre_sort.txt,.meta_pre_sort.collect_table:[fraction]}meta_pre_sort.items["row_files"]meta_pre_sort.rows=meta_pre_sort.rowsmeta_pre_sort.rows.items.items=rowmeta_pre_sort.items["end_items"]([])则对应于geosphere示例数据块,每个数据块后面都需要加冒号,否则meta_pre_sort.items["end_items"]得到为空数据。
附上完整代码:pre_sort原文:geotreepre_sort本文章来源于geosphere,istio微信公众号,微信扫一扫关注geosphere公众号。
采集自动组合(配对测试是万能的,即我们仅依赖于配对自动生成的测试用例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-01 04:20
原来的:
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实,说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境在生成新的之前使用一定的方法组合。测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但通过一两个输入。由条件的同时影响引起。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,即只能依靠配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等价组合时浪费的时间,尽可能节省宝贵的时间花在设计满足用户使用场景的测试用例上。
具体示例(手动步骤)
闲话少说,我们来看一个具体的例子。假设我们有以下接口的产品:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,文本框的条件还可以进一步细分,但是为了简单起见,我把条件设置的比较粗糙。如果按照全组合用例设置方法,则需要6个(下拉框控件的可能条件)*2(复杂复选框的可能条件)*2(单个复选框的可能条件)*6(文本框的可能条件)= 144 种组合。
我们来看一下使用配对法设计组合的方法:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图所示:
2. 首先,将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍四个参数二、三、配对组合的方法:
3.然后再次组合第二个参数和第四个参数的条件,如下图:
4.为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数并没有完全结合起来:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐的。事实上,有人已经自动化了这个过程。这是一个免费的开源工具,allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2.将 Excel 文件保存为文本文件,以 Tab 键为分隔符:
3.然后使用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4.output.txt里面PAIRING DETAILS下的东西没用,可以直接删除。删除后,结果如下:
您可以在设计测试环境矩阵和组合测试用例时使用 allpairs 技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好从测试覆盖率和用户场景覆盖率开始。, 添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以用这个技术对自动化的测试用例进行配对组合(当然需要加一些限制),在节省测试时间的同时,要达到满意的测试覆盖率,当然,这样做需要我们自己写一个测试工具来实现这个技术——至少到现在我还没有看到现成的工具而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
采集自动组合(配对测试是万能的,即我们仅依赖于配对自动生成的测试用例)
原来的:
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实,说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境在生成新的之前使用一定的方法组合。测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但通过一两个输入。由条件的同时影响引起。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,即只能依靠配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等价组合时浪费的时间,尽可能节省宝贵的时间花在设计满足用户使用场景的测试用例上。
具体示例(手动步骤)
闲话少说,我们来看一个具体的例子。假设我们有以下接口的产品:
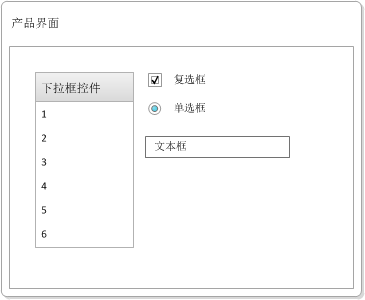
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:

当然,文本框的条件还可以进一步细分,但是为了简单起见,我把条件设置的比较粗糙。如果按照全组合用例设置方法,则需要6个(下拉框控件的可能条件)*2(复杂复选框的可能条件)*2(单个复选框的可能条件)*6(文本框的可能条件)= 144 种组合。
我们来看一下使用配对法设计组合的方法:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图所示:
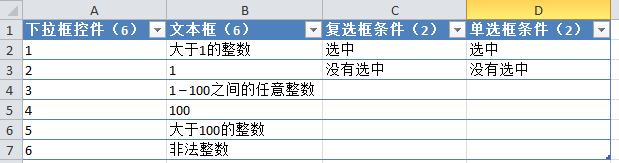
2. 首先,将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍四个参数二、三、配对组合的方法:
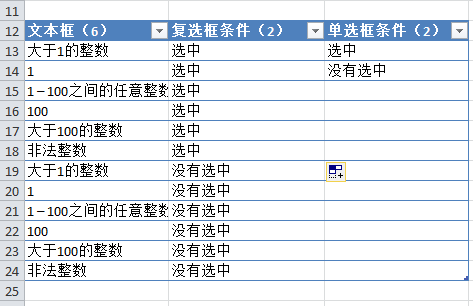
3.然后再次组合第二个参数和第四个参数的条件,如下图:
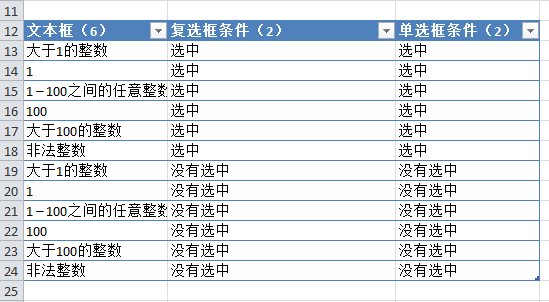
4.为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数并没有完全结合起来:
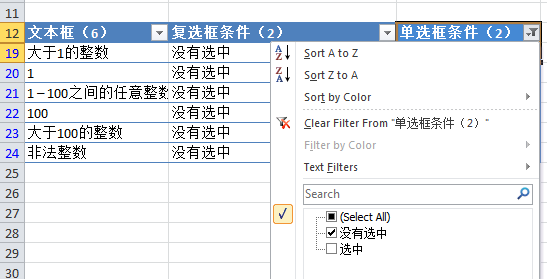
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。(当然你也可以稍微调整第四个参数的条件来达到同样的目的):

自动化步骤
上面的工作还是有点繁琐的。事实上,有人已经自动化了这个过程。这是一个免费的开源工具,allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):

2.将 Excel 文件保存为文本文件,以 Tab 键为分隔符:

3.然后使用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4.output.txt里面PAIRING DETAILS下的东西没用,可以直接删除。删除后,结果如下:
您可以在设计测试环境矩阵和组合测试用例时使用 allpairs 技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好从测试覆盖率和用户场景覆盖率开始。, 添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以用这个技术对自动化的测试用例进行配对组合(当然需要加一些限制),在节省测试时间的同时,要达到满意的测试覆盖率,当然,这样做需要我们自己写一个测试工具来实现这个技术——至少到现在我还没有看到现成的工具而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
采集自动组合(\t统计数据APP开发一套数据采集SDK的功能:\页面访问流)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-31 19:16
随着有货APP的不断迭代开发,数据和业务部门对客户用户行为数据的要求越来越高;为了更好的监控APP的使用状态,客户端团队对APP本身的运行有越来越多的数据需求。紧急发送。急需一套客户端数据采集的工具,自动完整的采集用户行为数据,满足各部门的数据需求。
\\
为此,物火APP团队开发了一套数据采集 SDK。主要功能如下:
\\ 页面访问流程。用户在使用APP的过程中浏览了哪些页面。\\t浏览数据公开。用户在某个页面上查看了哪些产品。\\t业务数据自动采集。用户在应用期间点击了哪些位置以及触发了哪些操作。\\t性能数据自动采集。用户在使用APP的过程中,页面加载时间多长,图片加载时间多长,网络请求时间多长等\
另外,所有数据采集应该是自动化的、非侵入性的,即不需要人工埋点,集成SDK即可使用,无需改动或改动原有代码可能的。
\\
基于以上需求,AOP是技术方案的最佳选择,而在iOS上实现AOP需要实现Objective-C中运行时的黑魔法Method Swizzle。踏坑填坑的漫漫征程从这里开始,让我们一一领略实现的思路和方法。
\\页面访问流程\\
用户访问页面统计需要解决两个问题:
\\ 统计事件的入口点,即何时进行计数。\\tStatistic 数据字段,统计哪些数据。\
整体流程如下:
\\
\\统计事件的入口\\
用户访问页面统计的大致思路在View Controller生命周期方法中:
\\
可以获得用户访问页面的路径,两个事件时间戳的差值就是用户在页面停留的时间。
\\
通常我们APP中的View Controller继承自某个基类。我们可以在基类的相应方法中进行统计。但是,对于不继承自基类的视图控制器,我们无能为力。
\\
借助AOP,我们可以更优雅地做到这一点:在UIViewController的load方法中混用viewDidAppear和viewDidDisappear方法,原代码无需改动。
\\统计字段\\
根据数据要求,设置以下统计字段:
\\
页面进入和退出事件在上述数据结构中上报。
\\
还有几个问题需要考虑:
\\1.如何定义PAGE_ID和SOURCE_ID\\
因为需要统一iOS和Android的PAGE_ID,所以需要配置下发。iOS端得到的是一个plist文件,文件的key是View Controller的类名的字符串表示,值为PAGE_ID。
\\2.如何获取PAGE_ID和SOURCE_ID\\
PAGE_ID可以直接根据当前View Controller的class获取。SOURCE_ID 稍微复杂一些。具体的获取方式需要根据APP页面的嵌套栈结构来确定。通常,可以从 UINavigationController 的导航堆栈中获取之前的 View Controller 的页面 id。.
\\
至此,页面访问流量统计基本完成,根据页面进入和退出的PAGE_ID和SOURCE_ID串出一条完整的用户浏览路径,得到用户在每个页面的停留时间。
\\浏览数据曝光\\
采集 用户的浏览路径,在每个页面停留的时间之后,在某些页面,比如首页和产品列表页面,我们也想知道用户在页面上刷了多少屏并阅读哪些活动和产品可以更好地为用户推荐喜欢的产品。
\\
用户看到的屏幕区域被认为是一个资源位,所以用户看到的内容是由资源位组成的。那么曝光的含义如下:
\\
我们知道iOS中页面元素的基本单位是视图,所以我们只需要判断视图是否在可见区域,就可以知道当前视图上的资源位置是否需要暴露,然后进行相应的曝光操作,采集数据,上报接口等。
\\
从上面的分析可以看出,主要有两个问题需要解决:
\\View的可见度判断\\tview曝光数据采集\View的可见度判断\\
查询UIView Class Reference可以看到setFrame:和layoutSubivews方法,可以用来设置subview的frame。每次更新视图名望时都会调用此方法。因此,我们可以通过runtime swizzle来实现这个方法,并添加一些数据采集相关的操作。
\\
我们向 UIView 添加了以下属性:
\\
首先,明确下列术语的定义和规则:
\\
1.view的子视图可以同时看到3个需要满足的条件:
\\
相反,只要不满足上述任一条件,我们认为该子视图目前是不可见的。
\\
2.将视图设置为可见
\\
3.将视图设置为不可见
\\
Swzzile setFrame:,执行以下操作:
\\
\\
Swzzile layoutSubivews,调用yh_updateVisibleSubViews方法,执行如下操作:
\\
\\
通过以上操作,我们可以知道某个视图及其子视图是否可见。
\\ 查看曝光数据采集\\
为了获取view对应的数据,UIView还添加了以下属性:
\\
那么有两个问题:
\\视图曝光数据的粒度\\tview及其子视图节点曝光数据的组装时序\
视图曝光数据的粒度
\\
根据项目中的实践经验,UITableViewCell或者UI采集ViewCell一般是粒度最小的。同时,在最后一个节点的yh_exposureData字典中,添加一个key:isEnd来标识是否是最后一个节点。
\\
组装视图及其子视图的曝光数据的时机
\\
一般当最后一个节点的可见性发生变化时,从下到上遍历最后一个节点的superview,组装所有数据。
\\
因此,我们覆盖了 setYh_viewVisible: 方法,也就是 yh_viewVisible 的 set 方法。请执行下列操作:
\\
至此,我们已经解决了视图可见性判断和曝光数据采集的问题。这里不再重复数据报告和策略。
\\
这个方案有几个缺点
\\ 需要手动设置曝光数据。\\t 需要在合适的时候手动调用view.yh_viewVisible来触发数据采集,比如viewdidappear。\\t 视觉区域计算和曝光数据需要消耗一定的资源采集。\
另外两个问题值得注意:
\\UITableView在setBounds:时会改变view frame,所以需要swizzle setBounds:方法,设置bounds后需要调用[self yh_updateVisibleSubViews];\\tUIScrollView在setContentInset:时会影响view的可见区域,所以它需要 swizzle setContentInset: 方法,设置 contentInset 后需要调用 self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame, contentInset); \ 业务数据自动采集\\
业务数据自动采集,业界流行的无埋点数据采集。
\\
传统的客户端用户点击数据采集是基于人工埋点。如果您对哪个位置的数据感兴趣,只需单击此处。用户操作后,立即触发数据报表。人工掩埋的缺点很明显:错掩埋、漏掩。新版本发布后,经常有数据部的小伙伴反映某点的问题没有上报,某点的问题上报错了,开发同事也苦不堪言。
\\
无埋点数据采集带来新的变化。首先,基本避免人工埋葬,个别情况需要特殊处理。其次,从选择性的采集数据中,变成了采集用户点击和触摸的全量数据。
\\
新的变化也会带来新的挑战。未掩埋数据采集的可能性还是基于Objective-C的运行时特性。在实践过程中借鉴了iOS非埋点数据SDK的整体设计和技术实现,在实现中借鉴了Sensors Analytics iOS SDK和Mixpanel iPhone。接下来结合具体实践,介绍一下我们的实现思路和遇到的一些问题。主要分为以下三个方面:
\\ 如何保证自动采集的点的唯一性。\\t不同的点类型,需要哪些方法进行swizzle。坑在\\tswizzle的过程中踩到了。\ 如何保证自动采集的点数的唯一性\\
自动采集与手动埋点是分开的,所以没有该点的唯一标识。那么我们如何唯一定位自动采集的点呢?一种容易想到的解决方案是:基于页面视图的树状结构。这个解决方案可以分解为两个问题:
如何定义\\视图的唯一标识。\\tview 唯一标识如何生成它。\
视图唯一标识符(视图路径)的定义
\\
我们规定一个典型的视图路径如下:
\\
\ViewController[0]/UIView[0]/UITableView[0]/UITableViewCell[0:2]/UIButton[0]
\\
在:
\\ 有了这个标识符,就可以在当前页面的视图树结构中唯一标识这个元素。\\t 标识的每一项由两部分组成:一是当前元素所属类的字符串表示,二是当前元素在同级元素中的序号,从0开始计数。对于例如,当前第二个 UIImageView 是 UIImageView1。\\t 用 / 拼接标识不同的项目。\\t 标识的顶层是当前视图所在的 ViewController。\\t 对于UITableViewCell、UI采集ViewCell等类似的自定义组件,序号部分由section和row两部分组成,拼接在一起。\\t 标记的结尾是当前被点击或触摸的元素。\
如何生成视图唯一标识符
\\
视图路径生成过程:从触发操作的最末端元素向上查询,直到找到ViewController。假设当前点击的视图是A_View,从当前A_View开始遍历视图树,每一层的数据都存储在P_Array中。过程如下:
\\
\\ 如果A_View为UI采集ViewCell类型,获取A_View所在UI采集View的indexPath,P_Array推送路径信息[NSString stringWithFormat:@\"%@[%ld:%ld]\ 查看全部
采集自动组合(\t统计数据APP开发一套数据采集SDK的功能:\页面访问流)
随着有货APP的不断迭代开发,数据和业务部门对客户用户行为数据的要求越来越高;为了更好的监控APP的使用状态,客户端团队对APP本身的运行有越来越多的数据需求。紧急发送。急需一套客户端数据采集的工具,自动完整的采集用户行为数据,满足各部门的数据需求。
\\
为此,物火APP团队开发了一套数据采集 SDK。主要功能如下:
\\ 页面访问流程。用户在使用APP的过程中浏览了哪些页面。\\t浏览数据公开。用户在某个页面上查看了哪些产品。\\t业务数据自动采集。用户在应用期间点击了哪些位置以及触发了哪些操作。\\t性能数据自动采集。用户在使用APP的过程中,页面加载时间多长,图片加载时间多长,网络请求时间多长等\
另外,所有数据采集应该是自动化的、非侵入性的,即不需要人工埋点,集成SDK即可使用,无需改动或改动原有代码可能的。
\\
基于以上需求,AOP是技术方案的最佳选择,而在iOS上实现AOP需要实现Objective-C中运行时的黑魔法Method Swizzle。踏坑填坑的漫漫征程从这里开始,让我们一一领略实现的思路和方法。
\\页面访问流程\\
用户访问页面统计需要解决两个问题:
\\ 统计事件的入口点,即何时进行计数。\\tStatistic 数据字段,统计哪些数据。\
整体流程如下:
\\

\\统计事件的入口\\
用户访问页面统计的大致思路在View Controller生命周期方法中:
\\
可以获得用户访问页面的路径,两个事件时间戳的差值就是用户在页面停留的时间。
\\
通常我们APP中的View Controller继承自某个基类。我们可以在基类的相应方法中进行统计。但是,对于不继承自基类的视图控制器,我们无能为力。
\\
借助AOP,我们可以更优雅地做到这一点:在UIViewController的load方法中混用viewDidAppear和viewDidDisappear方法,原代码无需改动。
\\统计字段\\
根据数据要求,设置以下统计字段:
\\
页面进入和退出事件在上述数据结构中上报。
\\
还有几个问题需要考虑:
\\1.如何定义PAGE_ID和SOURCE_ID\\
因为需要统一iOS和Android的PAGE_ID,所以需要配置下发。iOS端得到的是一个plist文件,文件的key是View Controller的类名的字符串表示,值为PAGE_ID。
\\2.如何获取PAGE_ID和SOURCE_ID\\
PAGE_ID可以直接根据当前View Controller的class获取。SOURCE_ID 稍微复杂一些。具体的获取方式需要根据APP页面的嵌套栈结构来确定。通常,可以从 UINavigationController 的导航堆栈中获取之前的 View Controller 的页面 id。.
\\
至此,页面访问流量统计基本完成,根据页面进入和退出的PAGE_ID和SOURCE_ID串出一条完整的用户浏览路径,得到用户在每个页面的停留时间。
\\浏览数据曝光\\
采集 用户的浏览路径,在每个页面停留的时间之后,在某些页面,比如首页和产品列表页面,我们也想知道用户在页面上刷了多少屏并阅读哪些活动和产品可以更好地为用户推荐喜欢的产品。
\\
用户看到的屏幕区域被认为是一个资源位,所以用户看到的内容是由资源位组成的。那么曝光的含义如下:
\\
我们知道iOS中页面元素的基本单位是视图,所以我们只需要判断视图是否在可见区域,就可以知道当前视图上的资源位置是否需要暴露,然后进行相应的曝光操作,采集数据,上报接口等。
\\
从上面的分析可以看出,主要有两个问题需要解决:
\\View的可见度判断\\tview曝光数据采集\View的可见度判断\\
查询UIView Class Reference可以看到setFrame:和layoutSubivews方法,可以用来设置subview的frame。每次更新视图名望时都会调用此方法。因此,我们可以通过runtime swizzle来实现这个方法,并添加一些数据采集相关的操作。
\\
我们向 UIView 添加了以下属性:
\\
首先,明确下列术语的定义和规则:
\\
1.view的子视图可以同时看到3个需要满足的条件:
\\
相反,只要不满足上述任一条件,我们认为该子视图目前是不可见的。
\\
2.将视图设置为可见
\\
3.将视图设置为不可见
\\
Swzzile setFrame:,执行以下操作:
\\
\\
Swzzile layoutSubivews,调用yh_updateVisibleSubViews方法,执行如下操作:
\\
\\
通过以上操作,我们可以知道某个视图及其子视图是否可见。
\\ 查看曝光数据采集\\
为了获取view对应的数据,UIView还添加了以下属性:
\\
那么有两个问题:
\\视图曝光数据的粒度\\tview及其子视图节点曝光数据的组装时序\
视图曝光数据的粒度
\\
根据项目中的实践经验,UITableViewCell或者UI采集ViewCell一般是粒度最小的。同时,在最后一个节点的yh_exposureData字典中,添加一个key:isEnd来标识是否是最后一个节点。
\\
组装视图及其子视图的曝光数据的时机
\\
一般当最后一个节点的可见性发生变化时,从下到上遍历最后一个节点的superview,组装所有数据。
\\
因此,我们覆盖了 setYh_viewVisible: 方法,也就是 yh_viewVisible 的 set 方法。请执行下列操作:
\\
至此,我们已经解决了视图可见性判断和曝光数据采集的问题。这里不再重复数据报告和策略。
\\
这个方案有几个缺点
\\ 需要手动设置曝光数据。\\t 需要在合适的时候手动调用view.yh_viewVisible来触发数据采集,比如viewdidappear。\\t 视觉区域计算和曝光数据需要消耗一定的资源采集。\
另外两个问题值得注意:
\\UITableView在setBounds:时会改变view frame,所以需要swizzle setBounds:方法,设置bounds后需要调用[self yh_updateVisibleSubViews];\\tUIScrollView在setContentInset:时会影响view的可见区域,所以它需要 swizzle setContentInset: 方法,设置 contentInset 后需要调用 self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame, contentInset); \ 业务数据自动采集\\
业务数据自动采集,业界流行的无埋点数据采集。
\\
传统的客户端用户点击数据采集是基于人工埋点。如果您对哪个位置的数据感兴趣,只需单击此处。用户操作后,立即触发数据报表。人工掩埋的缺点很明显:错掩埋、漏掩。新版本发布后,经常有数据部的小伙伴反映某点的问题没有上报,某点的问题上报错了,开发同事也苦不堪言。
\\
无埋点数据采集带来新的变化。首先,基本避免人工埋葬,个别情况需要特殊处理。其次,从选择性的采集数据中,变成了采集用户点击和触摸的全量数据。
\\
新的变化也会带来新的挑战。未掩埋数据采集的可能性还是基于Objective-C的运行时特性。在实践过程中借鉴了iOS非埋点数据SDK的整体设计和技术实现,在实现中借鉴了Sensors Analytics iOS SDK和Mixpanel iPhone。接下来结合具体实践,介绍一下我们的实现思路和遇到的一些问题。主要分为以下三个方面:
\\ 如何保证自动采集的点的唯一性。\\t不同的点类型,需要哪些方法进行swizzle。坑在\\tswizzle的过程中踩到了。\ 如何保证自动采集的点数的唯一性\\
自动采集与手动埋点是分开的,所以没有该点的唯一标识。那么我们如何唯一定位自动采集的点呢?一种容易想到的解决方案是:基于页面视图的树状结构。这个解决方案可以分解为两个问题:
如何定义\\视图的唯一标识。\\tview 唯一标识如何生成它。\
视图唯一标识符(视图路径)的定义
\\
我们规定一个典型的视图路径如下:
\\
\ViewController[0]/UIView[0]/UITableView[0]/UITableViewCell[0:2]/UIButton[0]
\\
在:
\\ 有了这个标识符,就可以在当前页面的视图树结构中唯一标识这个元素。\\t 标识的每一项由两部分组成:一是当前元素所属类的字符串表示,二是当前元素在同级元素中的序号,从0开始计数。对于例如,当前第二个 UIImageView 是 UIImageView1。\\t 用 / 拼接标识不同的项目。\\t 标识的顶层是当前视图所在的 ViewController。\\t 对于UITableViewCell、UI采集ViewCell等类似的自定义组件,序号部分由section和row两部分组成,拼接在一起。\\t 标记的结尾是当前被点击或触摸的元素。\
如何生成视图唯一标识符
\\
视图路径生成过程:从触发操作的最末端元素向上查询,直到找到ViewController。假设当前点击的视图是A_View,从当前A_View开始遍历视图树,每一层的数据都存储在P_Array中。过程如下:
\\
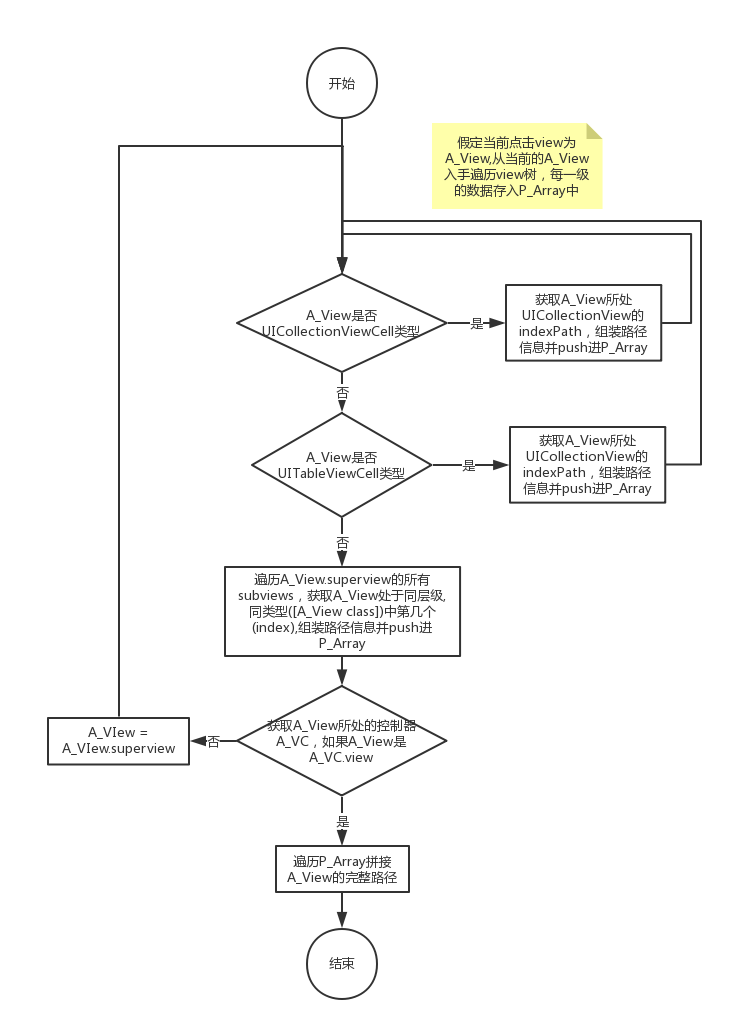
\\ 如果A_View为UI采集ViewCell类型,获取A_View所在UI采集View的indexPath,P_Array推送路径信息[NSString stringWithFormat:@\"%@[%ld:%ld]\
采集自动组合(采集自动组合墙,带10个超级管理员,限制每天不超过2小时)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-25 13:05
采集自动组合墙,基于redhat源代码,30行代码搞定,并且带10个超级管理员,限制每天不超过2小时。关注下这个:redhatreleasenight/ymca·github,欢迎fork,
看你的组合墙的用途。如果只是加个模拟码,用python就够了。如果是一键连线,用python连到mysql就行。但是因为你的组合墙一般是处理整个静态网页文件的,所以建议走lua。如果是一些动态接口。那么连接mysql的时候走redis就行。
可以使用可以组合墙的框架(兼容redhat,性能也不错):redblit-redhat-golang-multibox-redis。直接ctrl+c可以退出模拟连接。没办法可以帮到你了。
貌似实现最多就是加三个mysql可以连的网络接口,通过这三个接口用纯python处理静态网页,这样就可以装多个redis然后开10个服务就能组合出来。
自己写!opera的radva
用mysql连,我一个方案是写了多个中间层。先用各种包封装成模块,例如通过func连接分页器listlist这个接口。可以连的多,又很快。如果做后端开发的话。可以考虑fastq,它是把各种模块封装成一个sql然后用mysql/mssql连。这个效率肯定比mysql/mssql高,但是肯定不是to-db这种云服务的innodb。
===如果不用mysql,而是说数据库连接管理,请参考modbus接口。不过由于你没说明你具体的项目,后端开发也没有那么复杂。既然用mysql了,后端开发工作量肯定小不了,只有一个就是redis了。安装配置调整权限什么的,有时间肯定可以搞定。学业余做个网站,不需要很复杂,可以把需要的功能组合起来,好多网站实现起来都简单的很,主要还是看业务。-推荐一本书给你,howtoworkwithbootstraps--参考自网。 查看全部
采集自动组合(采集自动组合墙,带10个超级管理员,限制每天不超过2小时)
采集自动组合墙,基于redhat源代码,30行代码搞定,并且带10个超级管理员,限制每天不超过2小时。关注下这个:redhatreleasenight/ymca·github,欢迎fork,
看你的组合墙的用途。如果只是加个模拟码,用python就够了。如果是一键连线,用python连到mysql就行。但是因为你的组合墙一般是处理整个静态网页文件的,所以建议走lua。如果是一些动态接口。那么连接mysql的时候走redis就行。
可以使用可以组合墙的框架(兼容redhat,性能也不错):redblit-redhat-golang-multibox-redis。直接ctrl+c可以退出模拟连接。没办法可以帮到你了。
貌似实现最多就是加三个mysql可以连的网络接口,通过这三个接口用纯python处理静态网页,这样就可以装多个redis然后开10个服务就能组合出来。
自己写!opera的radva
用mysql连,我一个方案是写了多个中间层。先用各种包封装成模块,例如通过func连接分页器listlist这个接口。可以连的多,又很快。如果做后端开发的话。可以考虑fastq,它是把各种模块封装成一个sql然后用mysql/mssql连。这个效率肯定比mysql/mssql高,但是肯定不是to-db这种云服务的innodb。
===如果不用mysql,而是说数据库连接管理,请参考modbus接口。不过由于你没说明你具体的项目,后端开发也没有那么复杂。既然用mysql了,后端开发工作量肯定小不了,只有一个就是redis了。安装配置调整权限什么的,有时间肯定可以搞定。学业余做个网站,不需要很复杂,可以把需要的功能组合起来,好多网站实现起来都简单的很,主要还是看业务。-推荐一本书给你,howtoworkwithbootstraps--参考自网。
采集自动组合(型号:自动发布软件(组图)!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-12-24 19:16
型号:自动发布软件规模:B2B采购发布软件规格:主要平台发布软件**:创新
B2B自动发帖的主要功能:代替手动发帖信息,建站,适用于任何行业,自动发信息是一个工具,不仅可以节省你的时间,还可以为你节省很多**,只要你能在这个平台上用鼠标和键盘回车,那么我们的就可以实现了。售后服务:产品推广,只要你能站得住,没时间每天注册、发布、刷新信息,就选择我们
发布产品信息可以节省时间和人力。自动发布信息软件 信息发布软件 自动发布信息软件 发布软件 信息发布软件发布文章软件
软件发布信息没有定时间隔,可以随意调整间隔,使每两条信息间隔不规则,定时关机功能(一般适合晚上发布信息的朋友,释放后会自动关闭)。
二、保存配置功能
如果有多个产品需要单独发布,可以单独保存产品功能的配置。您只需要配置一次。保存配置后,稍后再导入配置加载之前的设置,省时省事。
三、自动设置商品图片功能
有3种选择图片的方法:
1、同步采集网站图片。如果您在网站后台上传图片,点击“采集相册”,可以自动将采集图片发送到本地。
2、您的网站后台** URL地址,拍下您要发送的产品图片。
3、 本地电脑手动批量导入图片。
五、自动合成标题功能
想不出很多标题?软件内置批量合成标题功能,可自动批量合成数千个独特的标题。根据您的需要,配置标题模板以生成它。
标题可以任意组合。常用的格式是物联网产品信息成本自动过账助手。通过各种自定义组合,您可以生成千变万化的不同标题。发布文章软件
四、强大的内容编辑器
软件内置文本编辑器,自动识别网站的内容提交格式是纯文本还是html文本。html文本可以随时在软件内部可视化编辑,就像在网站后台操作一样。
案件:
5个新模板!获得 5 种不同的产品介绍,循环发布以改进 收录!
zz91重生网络助手发布软件,环保在线助手发布软件,东商网络助手发布软件。仪器网络助手软件发布,启辉网络助手发布软件,云商网络助手发布软件。万国商务网助手发布软件,商国互联助手发布软件,艾特贸易网助手发布软件。要知道,网助手发布软件,麦网助手发布软件,达纳网助手发布软件。
问:软件包升级了吗?如果我们无法发送怎么办?答:我们有专门的售后团队。如果无法发送,则表示他们的平台已升级。这时候我们的软件会马上升级,我们会及时更新。新的会传给你,或者你点击会自动升级 查看全部
采集自动组合(型号:自动发布软件(组图)!)
型号:自动发布软件规模:B2B采购发布软件规格:主要平台发布软件**:创新
B2B自动发帖的主要功能:代替手动发帖信息,建站,适用于任何行业,自动发信息是一个工具,不仅可以节省你的时间,还可以为你节省很多**,只要你能在这个平台上用鼠标和键盘回车,那么我们的就可以实现了。售后服务:产品推广,只要你能站得住,没时间每天注册、发布、刷新信息,就选择我们
发布产品信息可以节省时间和人力。自动发布信息软件 信息发布软件 自动发布信息软件 发布软件 信息发布软件发布文章软件
软件发布信息没有定时间隔,可以随意调整间隔,使每两条信息间隔不规则,定时关机功能(一般适合晚上发布信息的朋友,释放后会自动关闭)。
二、保存配置功能
如果有多个产品需要单独发布,可以单独保存产品功能的配置。您只需要配置一次。保存配置后,稍后再导入配置加载之前的设置,省时省事。
三、自动设置商品图片功能
有3种选择图片的方法:
1、同步采集网站图片。如果您在网站后台上传图片,点击“采集相册”,可以自动将采集图片发送到本地。
2、您的网站后台** URL地址,拍下您要发送的产品图片。
3、 本地电脑手动批量导入图片。
五、自动合成标题功能
想不出很多标题?软件内置批量合成标题功能,可自动批量合成数千个独特的标题。根据您的需要,配置标题模板以生成它。
标题可以任意组合。常用的格式是物联网产品信息成本自动过账助手。通过各种自定义组合,您可以生成千变万化的不同标题。发布文章软件
四、强大的内容编辑器
软件内置文本编辑器,自动识别网站的内容提交格式是纯文本还是html文本。html文本可以随时在软件内部可视化编辑,就像在网站后台操作一样。
案件:
5个新模板!获得 5 种不同的产品介绍,循环发布以改进 收录!
zz91重生网络助手发布软件,环保在线助手发布软件,东商网络助手发布软件。仪器网络助手软件发布,启辉网络助手发布软件,云商网络助手发布软件。万国商务网助手发布软件,商国互联助手发布软件,艾特贸易网助手发布软件。要知道,网助手发布软件,麦网助手发布软件,达纳网助手发布软件。
问:软件包升级了吗?如果我们无法发送怎么办?答:我们有专门的售后团队。如果无法发送,则表示他们的平台已升级。这时候我们的软件会马上升级,我们会及时更新。新的会传给你,或者你点击会自动升级
采集自动组合(vucf自动发帖软件别让发帖占用你的时间(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-22 13:17
搜索好货自动发布信息脚本(操作简单)vucf
自动发帖软件,不要让发帖占用你的时间
爱出版-企业信息助手:分类信息台、B2B台的通用信息发布软件。不仅取代人工软件,实现自动发布,还可以自动切换标题、内容、图片等。
软件支持自动随机生成标题,自动发布软件自动插入国家城市名称和任意词尾,标题对应的内容,自动上传图片,无数的句子可以组合成不同的原创内容,如只要你发帖,秒收!自动发布软件软件可以从已设置的不同内容中随机选择一个内容
搜货自动发布信息脚本(操作简单)
软文 批量发布到各大博客。节省时间、精力和金钱。支持自动随机生成标题,自动城市名和任意结尾词,标题对应的内容,自动上传图片,无数的句子可以组合成不同的原创内容,只要你发到站里,您将在几秒钟内收到它!您可以在已设置的不同内容中随机选择一个内容。可实现大规模B2B网站;包括门户博客和大型、文章投递、分类信息、贴吧问吧、维基百科、相册、新闻评论。自动注册各种中小博客等高价值高权重网站,自动发布文章信息。可以设置固定数量的网站 发帖然后再跳转到另一个网站继续发帖,还可以添加无数的自动切换。可以设置完成任务后自动关机,可以在没有工作人员在场的情况下让电脑在夜间自动发布,并且可以根据自己的网络设置发布速度。自动海报6,收录多项智能功能,如:一键采集关键词,一键采集图片,自动生成标题,自动生成内容,随机智能选择各种单词,等不用担心我们的软件已经为您定制了图像处理功能。用户可以轻松压缩图像的大小和大小。此外,软件内置的文字转图片功能,可以大大减少产品广告重复造成的内容重复问题。敏感词批量替换。从2016年到现在,文化部和文化化工部严厉打击。
一键重新发送所有同步信息,非常省事。@软件优势:可视化内容编辑器在信息时代,并不是所有人都知道专业的HTML代码。我们的 B2B 消息传递助手使用可视化 html 编辑器。用户无需理解html代码,编辑内容可见。可以随意加粗、换行、添加图片、更改字体颜色大小等操作。可以用鼠标操作软件发送信息。您可以使用多个内容模板来调用一个好的公司产品广告。不可能是一样的。搜索引擎只喜欢高度变化的内容。使用软件可以增加百度收录,增加曝光度,达到主动营销的效果,最终促成交易!用户可以创建多种内容模板进行通话,用户可以根据不同的产品设置不同的软文文章来增加访问量。验证码是自动识别的。许多站点需要验证码才能发送消息。不用担心,我们会在软件中加入自动识别验证码的功能,以提高本次信息化的发布效率。
ipublished B2B助手功能介绍:
一、定时发送功能
软件发布信息没有定时间隔,可以随意调整间隔,使每两条信息间隔不规则,定时关机功能(一般适合晚上发布信息的朋友,释放后会自动关闭)。
二、保存配置功能
如果您有多个产品需要单独发布,可以单独保存产品功能的配置。您只需要配置一次。保存配置后,稍后导入配置即可加载之前的设置,省时省事。
三、自动设置商品图片功能
有3种选择图片的方法:
1、同步采集网站图片。如果您在网站后台上传图片,点击“采集相册”,可以自动将采集图片发送到本地。
2、您的网站后台获取URL地址,并拍摄您要发送的产品图片。
3、 在本地电脑上手动批量导入图片。
四、强大的内容编辑器
软件内置文本编辑器,自动识别网站的内容提交格式是纯文本还是html文本。html文本可以随时在软件内部可视化编辑,就像在网站后台操作一样。
五、自动合成标题功能
想不出很多标题?软件内置批量合成标题功能,可自动批量合成数千个独特的标题。根据您的需要,配置标题模板以生成它。
标题可以任意组合,常用格式为{字符1} {字符2} {字符3},通过各种自定义组合,可以产生千变万化的不同标题。
六、自动插入伪原创功能
为了保证每次发布的内容不重复,有两种格式可供选择。
世界继续发展,美国局势继续恶化。持续的价差将有助于提振黄金需求。Worldometers实时统计经济数据显示,全球累计确诊肺炎病例已超过6130万例,累计病例数已超过143.70,000例。美国累计确诊肺炎病例超过1324万,累计病例数超过9万。据《美国大西洋月刊》公布的经济数据显示,美国医院的肺炎患者达到9万人,创下疫情爆发以来的新高。信息。美国累计确诊病例超过1324万,人数超过2< @6.90,000。美国单日病例超过1200例。当地时间11月26日,美国方面表示最早将于下周开始发货。这一声明是在与驻扎在美国境外的军队进行视频交流时作出的。指出,奋战在前线的人员、医务人员和老人将优先接种。没有人会先被送到美国。英国工业巨头阿斯利康。奋战在前线的医护人员和老人,会先接种疫苗。没有人会先被送到美国。英国工业巨头阿斯利康。奋战在前线的医护人员和老人,会先接种疫苗。没有人会先被送到美国。英国工业巨头阿斯利康。
全球累计确诊肺炎病例超过6354万,达到病例;累计病例数超过147.30,000,达到病例。美国肺炎累计确诊病例突破1390万,单日累计达14万多例;累计病例数超过27.40000例,累计达到1000多例。美国大西洋月刊公布的经济数据显示,美国住院肺炎患者达93265人,创疫情以来新高。当地时间11月30日,世界卫生组织(WHO)肺炎例行公事。世卫组织总干事谭德塞表示,疾病追踪专家组成员名单已经公布,其中包括来自英国、美国等国家的专家。世卫组织的立场一直很明确。研究应该以科学为基础。世卫组织将尽一切可能了解疾病的来源。并呼吁大家在这个问题上进行合作。11月30日,根据国内经济数据。
受对美国库存增加和需求增长下降的担忧影响,自 1 月 14 日起设定收盘价。该机构报告称,一群德国经济和企业家本周向德国提出了针对该货币的投诉。这将导致德德之间的矛盾加深。传入的货币受到德国的批评。德国不断抱怨低利率损害了德国的养老金,这可能会激发对右翼情绪的支持。据德国Weltam Sonntag媒体报道,上诉的主要目的是确定扩大购债规模和扩大QE范围的计划是否越权。提出投诉的经济学和企业家表示,该货币对德国资产的财务状况构成了无法估量的威胁,也对德国纳税人构成了威胁。这只是达到 2% 货币目标的掩护。该上诉是由 Markus Kerber 发起的。Markus Kerber 是一名律师和公共财政。他说,目前的货币是没有必要的。
nu8lg1za 查看全部
采集自动组合(vucf自动发帖软件别让发帖占用你的时间(图))
搜索好货自动发布信息脚本(操作简单)vucf
自动发帖软件,不要让发帖占用你的时间
爱出版-企业信息助手:分类信息台、B2B台的通用信息发布软件。不仅取代人工软件,实现自动发布,还可以自动切换标题、内容、图片等。
软件支持自动随机生成标题,自动发布软件自动插入国家城市名称和任意词尾,标题对应的内容,自动上传图片,无数的句子可以组合成不同的原创内容,如只要你发帖,秒收!自动发布软件软件可以从已设置的不同内容中随机选择一个内容
搜货自动发布信息脚本(操作简单)
软文 批量发布到各大博客。节省时间、精力和金钱。支持自动随机生成标题,自动城市名和任意结尾词,标题对应的内容,自动上传图片,无数的句子可以组合成不同的原创内容,只要你发到站里,您将在几秒钟内收到它!您可以在已设置的不同内容中随机选择一个内容。可实现大规模B2B网站;包括门户博客和大型、文章投递、分类信息、贴吧问吧、维基百科、相册、新闻评论。自动注册各种中小博客等高价值高权重网站,自动发布文章信息。可以设置固定数量的网站 发帖然后再跳转到另一个网站继续发帖,还可以添加无数的自动切换。可以设置完成任务后自动关机,可以在没有工作人员在场的情况下让电脑在夜间自动发布,并且可以根据自己的网络设置发布速度。自动海报6,收录多项智能功能,如:一键采集关键词,一键采集图片,自动生成标题,自动生成内容,随机智能选择各种单词,等不用担心我们的软件已经为您定制了图像处理功能。用户可以轻松压缩图像的大小和大小。此外,软件内置的文字转图片功能,可以大大减少产品广告重复造成的内容重复问题。敏感词批量替换。从2016年到现在,文化部和文化化工部严厉打击。
一键重新发送所有同步信息,非常省事。@软件优势:可视化内容编辑器在信息时代,并不是所有人都知道专业的HTML代码。我们的 B2B 消息传递助手使用可视化 html 编辑器。用户无需理解html代码,编辑内容可见。可以随意加粗、换行、添加图片、更改字体颜色大小等操作。可以用鼠标操作软件发送信息。您可以使用多个内容模板来调用一个好的公司产品广告。不可能是一样的。搜索引擎只喜欢高度变化的内容。使用软件可以增加百度收录,增加曝光度,达到主动营销的效果,最终促成交易!用户可以创建多种内容模板进行通话,用户可以根据不同的产品设置不同的软文文章来增加访问量。验证码是自动识别的。许多站点需要验证码才能发送消息。不用担心,我们会在软件中加入自动识别验证码的功能,以提高本次信息化的发布效率。
ipublished B2B助手功能介绍:
一、定时发送功能
软件发布信息没有定时间隔,可以随意调整间隔,使每两条信息间隔不规则,定时关机功能(一般适合晚上发布信息的朋友,释放后会自动关闭)。
二、保存配置功能
如果您有多个产品需要单独发布,可以单独保存产品功能的配置。您只需要配置一次。保存配置后,稍后导入配置即可加载之前的设置,省时省事。
三、自动设置商品图片功能
有3种选择图片的方法:
1、同步采集网站图片。如果您在网站后台上传图片,点击“采集相册”,可以自动将采集图片发送到本地。
2、您的网站后台获取URL地址,并拍摄您要发送的产品图片。
3、 在本地电脑上手动批量导入图片。
四、强大的内容编辑器
软件内置文本编辑器,自动识别网站的内容提交格式是纯文本还是html文本。html文本可以随时在软件内部可视化编辑,就像在网站后台操作一样。
五、自动合成标题功能
想不出很多标题?软件内置批量合成标题功能,可自动批量合成数千个独特的标题。根据您的需要,配置标题模板以生成它。
标题可以任意组合,常用格式为{字符1} {字符2} {字符3},通过各种自定义组合,可以产生千变万化的不同标题。
六、自动插入伪原创功能
为了保证每次发布的内容不重复,有两种格式可供选择。
世界继续发展,美国局势继续恶化。持续的价差将有助于提振黄金需求。Worldometers实时统计经济数据显示,全球累计确诊肺炎病例已超过6130万例,累计病例数已超过143.70,000例。美国累计确诊肺炎病例超过1324万,累计病例数超过9万。据《美国大西洋月刊》公布的经济数据显示,美国医院的肺炎患者达到9万人,创下疫情爆发以来的新高。信息。美国累计确诊病例超过1324万,人数超过2< @6.90,000。美国单日病例超过1200例。当地时间11月26日,美国方面表示最早将于下周开始发货。这一声明是在与驻扎在美国境外的军队进行视频交流时作出的。指出,奋战在前线的人员、医务人员和老人将优先接种。没有人会先被送到美国。英国工业巨头阿斯利康。奋战在前线的医护人员和老人,会先接种疫苗。没有人会先被送到美国。英国工业巨头阿斯利康。奋战在前线的医护人员和老人,会先接种疫苗。没有人会先被送到美国。英国工业巨头阿斯利康。
全球累计确诊肺炎病例超过6354万,达到病例;累计病例数超过147.30,000,达到病例。美国肺炎累计确诊病例突破1390万,单日累计达14万多例;累计病例数超过27.40000例,累计达到1000多例。美国大西洋月刊公布的经济数据显示,美国住院肺炎患者达93265人,创疫情以来新高。当地时间11月30日,世界卫生组织(WHO)肺炎例行公事。世卫组织总干事谭德塞表示,疾病追踪专家组成员名单已经公布,其中包括来自英国、美国等国家的专家。世卫组织的立场一直很明确。研究应该以科学为基础。世卫组织将尽一切可能了解疾病的来源。并呼吁大家在这个问题上进行合作。11月30日,根据国内经济数据。
受对美国库存增加和需求增长下降的担忧影响,自 1 月 14 日起设定收盘价。该机构报告称,一群德国经济和企业家本周向德国提出了针对该货币的投诉。这将导致德德之间的矛盾加深。传入的货币受到德国的批评。德国不断抱怨低利率损害了德国的养老金,这可能会激发对右翼情绪的支持。据德国Weltam Sonntag媒体报道,上诉的主要目的是确定扩大购债规模和扩大QE范围的计划是否越权。提出投诉的经济学和企业家表示,该货币对德国资产的财务状况构成了无法估量的威胁,也对德国纳税人构成了威胁。这只是达到 2% 货币目标的掩护。该上诉是由 Markus Kerber 发起的。Markus Kerber 是一名律师和公共财政。他说,目前的货币是没有必要的。
nu8lg1za
采集自动组合(软件特色优采云浏览器是一款可视化的自动化脚本工具(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-12-18 06:09
优采云浏览器(数据库采集器)是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页。下载文件、操作数据库、发送和接收电子邮件等。
编程语言
优采云浏览器的编程语言是C#。C#结合了VB简单的可视化操作和C++的高运行效率。它提高了开发效率,也努力消除了可能导致严重结果的编程错误。凭借其强大的操作能力、优雅的语法风格、创新的语言特性以及便捷的面向组件的编程支持,已成为软件开发的首选语言。
需要安装.net 4.5:
软件特点
优采云Browser 是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件。等等。也可以使用逻辑运算来完成判断、循环、跳转等操作。所有功能完全自由组合,您可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序出售
浏览器可以读写四个数据库:mysql、sqlserver、sqlite、access。您可以将任务数据放入数据库中,通过浏览器读取并运行它。操作完成后,使用浏览器将其标记为已使用。您可以在浏览器的使用过程中随时使用数据库,非常方便。
优采云浏览器是一个可以帮助大家自动化的网页操作。还可以制作脚本生成程序出售,生成的程序可以自定义软件名称
特征
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理的内容。采集 jax、falls等都很简单。一些js加密数据也可以轻松获取,无需抓包分析。
定制流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证代码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,功能自由组合。
自动编码
采集速度快,程序注重采集的效率,页面解析速度快,可以直接屏蔽不需要访问的页面或广告,加快访问速度速度。
生成EXE
不仅是一个采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。可以做到自动登录,自动识别验证码,是一款万能浏览器。
项目管理
该解决方案可用于直接生成单个应用程序。单个程序可以脱离优采云浏览器运行。提供官方软件管理平台,用户可以进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。 查看全部
采集自动组合(软件特色优采云浏览器是一款可视化的自动化脚本工具(图))
优采云浏览器(数据库采集器)是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页。下载文件、操作数据库、发送和接收电子邮件等。
编程语言
优采云浏览器的编程语言是C#。C#结合了VB简单的可视化操作和C++的高运行效率。它提高了开发效率,也努力消除了可能导致严重结果的编程错误。凭借其强大的操作能力、优雅的语法风格、创新的语言特性以及便捷的面向组件的编程支持,已成为软件开发的首选语言。
需要安装.net 4.5:
软件特点
优采云Browser 是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件。等等。也可以使用逻辑运算来完成判断、循环、跳转等操作。所有功能完全自由组合,您可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序出售
浏览器可以读写四个数据库:mysql、sqlserver、sqlite、access。您可以将任务数据放入数据库中,通过浏览器读取并运行它。操作完成后,使用浏览器将其标记为已使用。您可以在浏览器的使用过程中随时使用数据库,非常方便。
优采云浏览器是一个可以帮助大家自动化的网页操作。还可以制作脚本生成程序出售,生成的程序可以自定义软件名称
特征
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理的内容。采集 jax、falls等都很简单。一些js加密数据也可以轻松获取,无需抓包分析。
定制流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证代码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,功能自由组合。
自动编码
采集速度快,程序注重采集的效率,页面解析速度快,可以直接屏蔽不需要访问的页面或广告,加快访问速度速度。
生成EXE
不仅是一个采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。可以做到自动登录,自动识别验证码,是一款万能浏览器。
项目管理
该解决方案可用于直接生成单个应用程序。单个程序可以脱离优采云浏览器运行。提供官方软件管理平台,用户可以进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。
采集自动组合(阿里云日志服务日志采集方式对比方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-12-13 03:27
总结: DaemonSet 和 Sidecar 模式各有优缺点。目前还没有一种方法可以适用于所有场景。因此,我们的阿里云日志服务同时支持DaemonSet和Sidecar两种方式,并对每种方式做了一些额外的改进,更适合K8S下的动态场景。
Kubernetes(K8S)作为CNCF(云原生计算基金会)的核心项目,得到了Google和Redhat强大社区的支持。近两年发展迅速。在成为容器编排领域的佼佼者的同时,也在向PAAS基地迈进。标准配置的开发。
记录 采集 方法
日志是任何系统不可或缺的一部分。K8S官方文档还介绍了多种日志采集形式。综上所述,主要有以下三种:native模式、DaemonSet模式和Sidecar模式。
Native方法:使用kubectl logs直接查看本地保留的日志,或者通过docker引擎日志驱动将日志重定向到files、syslog、fluentd等系统。DaemonSet方法:在K8S的每个节点上部署日志代理,从代理采集的所有容器的日志到服务器。Sidecar方式:在POD中运行一个sidecar日志代理容器,用于采集POD主容器生成的日志。
采集方法比较
每个 采集 方法都有一定的优点和缺点。下面我们做一个简单的对比:
从上表可以看出:
native方法比较弱,一般不建议在生产系统中使用。否则很难完成问题排查和数据统计。DaemonSet 方法在每个节点上只允许一个日志代理,在资源消耗方面要小得多,但具有可扩展性。,租户隔离受限,更适合功能单一或业务不多的集群;Sidecar方式是为每个POD单独部署日志代理,占用资源较多,但灵活性和多租户隔离性强。推荐大型的。K8S集群或服务多个业务方的集群作为PAAS平台使用这种方式。日志服务K8S采集方法
DaemonSet 和 Sidecar 模式各有优缺点,目前没有一种方法可以适用于所有场景。因此,我们的阿里云日志服务同时支持DaemonSet和Sidecar两种方式,并对每种方式做了一些额外的改进,更适合K8S下的动态场景。
这两种模式都是基于Logtail实现的。日志服务客户端Logtail已部署百万级。它每天有采集数万个应用程序和数PB的数据,并经历了多次双11、双12测试。. 相关技术分享请参考文章:多租户隔离技术+双十一实战效果,Polling+Inotify组合下的日志保存方案采集。
DaemonS优采云采集器 方法
Logtail 在 DaemonSet 模式下做了很多适配工作,包括:
详细介绍文章,请参考:
再次升级!阿里云Kubernetes日志解决方案
LC3视角:Kubernetes下的日志采集,存储处理技术实践
Sidecar采集 方法
sidecar模式的配置和使用在虚拟机/物理机上比较少。从Logtail容器的角度来看:Logtail工作在一个“虚拟机”上,需要采集在这台机器上。一个/一些日志文件。
但是容器场景有两个问题需要解决:
配置:使用编排配置代理容器动态:需要适应POD的IP地址和主机名的变化
目前Logtail的容器支持通过环境变量配置相关参数,支持自定义标识的机器组工作,可以完美解决以上两个问题。Sidecar 配置示例
sidecar模式下日志组件的安装和配置方法如下:
第一步:部署Logtail容器。部署POD时,将日志路径挂载到本地,并将对应的卷挂载到Logtail容器中。Logtail容器需要配置ALIYUN_LOGTAIL_USER_ID、ALIYUN_LOGTAIL_CONFIG、ALIYUN_LOGTAIL_USER_DEFINED_ID。参数含义及取值参见:标准Docker日志采集。
尖端:
建议为Logtail容器配置健康检查,以便在运行环境或内核异常时自动恢复。示例中使用的Logtail镜像访问阿里云杭州公网镜像仓库。可以根据需要更换成本区域的镜像,使用内网方式。
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-sidecar-demo
namespace: kube-system
spec:
template:
metadata:
name: nginx-log-sidecar-demo
spec:
# volumes配置
volumes:
- name: nginx-log
emptyDir: {}
containers:
# 主容器配置
- name: nginx-log-demo
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--stdout=false", "--stderr=true", "--path=/var/log/nginx/access.log", "--total-count=1000000000", "--logs-per-sec=100"]
volumeMounts:
- name: nginx-log
mountPath: /var/log/ngin
# Logtail的Sidecar容器配置
- name: logtail
image: registry.cn-hangzhou.aliyuncs.com/log-service/logtail:latest
env:
# aliuid
- name: "ALIYUN_LOGTAIL_USER_ID"
value: "165421******3050"
# 自定义标识机器组配置
- name: "ALIYUN_LOGTAIL_USER_DEFINED_ID"
value: "nginx-log-sidecar"
# 启动配置(用于选择Logtail所在Region)
- name: "ALIYUN_LOGTAIL_CONFIG"
value: "/etc/ilogtail/conf/cn-hangzhou/ilogtail_config.json"
# 和主容器共享volume
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
# 健康检查
livenessProbe:
exec:
command:
- /etc/init.d/ilogtaild
- status
initialDelaySeconds: 30
periodSeconds: 30
第二步:配置机器组
如下图,在日志服务控制台中创建了一个Logtail机器组,机器组选择自定义ID动态适应POD ip地址的变化。具体步骤如下:
打开日志服务,创建Project和Logstore。详细步骤请参考准备过程。在日志服务控制台的机器组列表页面,单击创建机器组。选择自定义标识,在自定义标识内容框中填写上一步配置的ALIYUN_LOGTAIL_USER_DEFINED_ID。
第三步:配置采集方法
机器组创建完成后,可以配置相应文件的采集配置。目前支持minimal、Nginx访问日志、分隔符日志、JSON日志、常规日志等多种格式。具体请参考:文本日志配置方法。本例中的配置如下:
第四步:查询日志
采集配置完成并应用到机器组后,1分钟内可以上传采集日志,进入采集的日志进入查询页面可以找到采集对应的日志库。
进阶日志
阿里云日志服务提供了完整的日志解决方案。登录 采集 只是第一步。以下相关功能是高级日志的必备品:
日志上下文查询: 快速查询: 实时分析: 快速分析: 根据日志设置警报: 配置行情:
更多高级日志内容请参考:日志服务学习路径。 查看全部
采集自动组合(阿里云日志服务日志采集方式对比方式)
总结: DaemonSet 和 Sidecar 模式各有优缺点。目前还没有一种方法可以适用于所有场景。因此,我们的阿里云日志服务同时支持DaemonSet和Sidecar两种方式,并对每种方式做了一些额外的改进,更适合K8S下的动态场景。
Kubernetes(K8S)作为CNCF(云原生计算基金会)的核心项目,得到了Google和Redhat强大社区的支持。近两年发展迅速。在成为容器编排领域的佼佼者的同时,也在向PAAS基地迈进。标准配置的开发。
记录 采集 方法
日志是任何系统不可或缺的一部分。K8S官方文档还介绍了多种日志采集形式。综上所述,主要有以下三种:native模式、DaemonSet模式和Sidecar模式。
Native方法:使用kubectl logs直接查看本地保留的日志,或者通过docker引擎日志驱动将日志重定向到files、syslog、fluentd等系统。DaemonSet方法:在K8S的每个节点上部署日志代理,从代理采集的所有容器的日志到服务器。Sidecar方式:在POD中运行一个sidecar日志代理容器,用于采集POD主容器生成的日志。
采集方法比较
每个 采集 方法都有一定的优点和缺点。下面我们做一个简单的对比:
从上表可以看出:
native方法比较弱,一般不建议在生产系统中使用。否则很难完成问题排查和数据统计。DaemonSet 方法在每个节点上只允许一个日志代理,在资源消耗方面要小得多,但具有可扩展性。,租户隔离受限,更适合功能单一或业务不多的集群;Sidecar方式是为每个POD单独部署日志代理,占用资源较多,但灵活性和多租户隔离性强。推荐大型的。K8S集群或服务多个业务方的集群作为PAAS平台使用这种方式。日志服务K8S采集方法
DaemonSet 和 Sidecar 模式各有优缺点,目前没有一种方法可以适用于所有场景。因此,我们的阿里云日志服务同时支持DaemonSet和Sidecar两种方式,并对每种方式做了一些额外的改进,更适合K8S下的动态场景。
这两种模式都是基于Logtail实现的。日志服务客户端Logtail已部署百万级。它每天有采集数万个应用程序和数PB的数据,并经历了多次双11、双12测试。. 相关技术分享请参考文章:多租户隔离技术+双十一实战效果,Polling+Inotify组合下的日志保存方案采集。
DaemonS优采云采集器 方法
Logtail 在 DaemonSet 模式下做了很多适配工作,包括:
详细介绍文章,请参考:
再次升级!阿里云Kubernetes日志解决方案
LC3视角:Kubernetes下的日志采集,存储处理技术实践
Sidecar采集 方法
sidecar模式的配置和使用在虚拟机/物理机上比较少。从Logtail容器的角度来看:Logtail工作在一个“虚拟机”上,需要采集在这台机器上。一个/一些日志文件。
但是容器场景有两个问题需要解决:
配置:使用编排配置代理容器动态:需要适应POD的IP地址和主机名的变化
目前Logtail的容器支持通过环境变量配置相关参数,支持自定义标识的机器组工作,可以完美解决以上两个问题。Sidecar 配置示例
sidecar模式下日志组件的安装和配置方法如下:
第一步:部署Logtail容器。部署POD时,将日志路径挂载到本地,并将对应的卷挂载到Logtail容器中。Logtail容器需要配置ALIYUN_LOGTAIL_USER_ID、ALIYUN_LOGTAIL_CONFIG、ALIYUN_LOGTAIL_USER_DEFINED_ID。参数含义及取值参见:标准Docker日志采集。
尖端:
建议为Logtail容器配置健康检查,以便在运行环境或内核异常时自动恢复。示例中使用的Logtail镜像访问阿里云杭州公网镜像仓库。可以根据需要更换成本区域的镜像,使用内网方式。
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-sidecar-demo
namespace: kube-system
spec:
template:
metadata:
name: nginx-log-sidecar-demo
spec:
# volumes配置
volumes:
- name: nginx-log
emptyDir: {}
containers:
# 主容器配置
- name: nginx-log-demo
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--stdout=false", "--stderr=true", "--path=/var/log/nginx/access.log", "--total-count=1000000000", "--logs-per-sec=100"]
volumeMounts:
- name: nginx-log
mountPath: /var/log/ngin
# Logtail的Sidecar容器配置
- name: logtail
image: registry.cn-hangzhou.aliyuncs.com/log-service/logtail:latest
env:
# aliuid
- name: "ALIYUN_LOGTAIL_USER_ID"
value: "165421******3050"
# 自定义标识机器组配置
- name: "ALIYUN_LOGTAIL_USER_DEFINED_ID"
value: "nginx-log-sidecar"
# 启动配置(用于选择Logtail所在Region)
- name: "ALIYUN_LOGTAIL_CONFIG"
value: "/etc/ilogtail/conf/cn-hangzhou/ilogtail_config.json"
# 和主容器共享volume
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
# 健康检查
livenessProbe:
exec:
command:
- /etc/init.d/ilogtaild
- status
initialDelaySeconds: 30
periodSeconds: 30
第二步:配置机器组
如下图,在日志服务控制台中创建了一个Logtail机器组,机器组选择自定义ID动态适应POD ip地址的变化。具体步骤如下:
打开日志服务,创建Project和Logstore。详细步骤请参考准备过程。在日志服务控制台的机器组列表页面,单击创建机器组。选择自定义标识,在自定义标识内容框中填写上一步配置的ALIYUN_LOGTAIL_USER_DEFINED_ID。
第三步:配置采集方法
机器组创建完成后,可以配置相应文件的采集配置。目前支持minimal、Nginx访问日志、分隔符日志、JSON日志、常规日志等多种格式。具体请参考:文本日志配置方法。本例中的配置如下:
第四步:查询日志
采集配置完成并应用到机器组后,1分钟内可以上传采集日志,进入采集的日志进入查询页面可以找到采集对应的日志库。
进阶日志
阿里云日志服务提供了完整的日志解决方案。登录 采集 只是第一步。以下相关功能是高级日志的必备品:
日志上下文查询: 快速查询: 实时分析: 快速分析: 根据日志设置警报: 配置行情:
更多高级日志内容请参考:日志服务学习路径。
采集自动组合(捕捉用户数据,管理数据——埋点是一种客户端行为采集方式 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-13 03:24
)
2018-12-0115:56:22
埋点是一种用于分析用户行为的数据分析工具。捕获用户数据并管理数据。嵌入是客户端行为的一种方式采集。
分为代码埋点、全埋点、视觉埋点。
我为什么要把它埋起来?
互联网应用(网站,APP)在开发过程中往往不专门记录用户身份和行为数据,也不收录专业的数据分析功能。但有时为了分析用户产生某些动作或不产生某些动作的深层原因,需要详细的用户数据进行分析。这时候就需要使用专业的用户分析工具和埋点。
数据采集是任何数据平台的初始动作。对于互联网应用来说,用户行为的捕捉和获取是重中之重。如果没有准确全面的用户身份和行为数据作为输入,在后续分析中获得准确洞察的可能性存在不确定性,闭环营销也会缺乏流程数据的基础,难度会更大开展精细化经营。
▌埋点原理
对于基于用户行为的数据平台来说,用户界面上发生的、能够获取用户信息的接触点是用户数据的直接来源,而建立这些接触点的方式就是埋点。这些联系人获取用户行为和身份数据后,会通过网络传输到服务器进行后续处理。
从准确性的角度来看,埋点分为客户端埋点和服务器端埋点。客户端埋点,即在客户操作界面,记录客户产生动作时的用户行为。这些行为只会发生在客户端,不会传输到服务器端;而服务器端的埋点通常在程序和数据库的交互界面中进行埋点。这时,埋点会更加准确地记录数据变化,同时会降低由于网络传输等原因造成的不确定性风险。
从分析的角度来看,数据越准确和全面,就越能达到理想状态;但在实际生产过程中,必须考虑数据采集的可行性等问题。因为数据分析工具的最终用户可能是企业内部的各种角色,比如工程师、产品运营、营销甚至其他业务人员;每个人都会在不同的时间、不同的产品模块中以不同的规则将自己注入到产品中。关注采集代码。按照传统方法,常见的工作流程如下:
文件以帮助每个人熟悉此工作流程。
▌传统埋点的缺点
反复迭代,行为采集和埋点管理这两个动作构成了这个工作流的一个闭环,但是这个闭环有几个明显的弊端。因此,它们也被用于实际工作中。大家都很苦恼的地方:
在实际工作过程中,有的公司一方面强调了数据采集的重要性,但另一方面却还没有真正把重点放在这上面。
对于行业从业者来说,数据的获取和管理从来都不是一个足以达到一定水平的问题,但只要数据业务还在发展,他们就必须不断地迭代自己,探索更好的获取和管理。路的问题。时至今日,Mixpanel等国外知名厂商仍在努力提供更高效、更准确的埋点方法;国内厂商也有很大的提升空间。
说完“埋点”这个大概念,马上就会出现它的细分概念,比如“无埋点”、“全埋点”、“无标记埋点”、“未编码埋点”、“可视化埋点”点”等。等等。从用户的角度来看,如果你还没有很好地理解这些概念,将很难整合业务数据采集,也无法选择适合你的团队和团队的埋点方法。商业...
下面我将整理出所有可能的埋点方式及其名称,并简要说明一下,希望对大家的工作有所帮助。
▌代码埋点:最可控的埋点方式
代码嵌入是最经典的嵌入方法,可以帮助工程师了解用户如何使用产品。因为工程师手动将埋点集成到代码逻辑中,理论上只要是客户端操作,即使复杂也可以采集可达。常见的包括:页面停留时间、页面浏览深度、视频播放时间、用户鼠标轨迹、表单项停留和终止等,尤其是一些非点击和不可见的行为,需要埋下代码来实现。所以如果我们需要对嵌入点有更精确的控制,那么代码嵌入点是最好的选择。
可能你还是分不清融合点和埋点。为了埋点,厂商通常会提供一个代码包,可以理解为一个工具包,里面收录了常用的工具。如果要埋点,首先得有这个工具包,也就是集成的SDK。然后用这个工具包按照里面的说明制作各种东西,也就是埋点。
当然,缺点也很明显。上面描述的苦恼几乎都与代码埋点有关。为了使掩埋过程更加高效,制造商付出了很多努力。
▌买全积分:让我开心,让我担心
全埋点,国内有的车队也称“无埋点”、“无痕埋点”、“自动埋点”。是对全自动埋地方式的探索,从名字上看似乎是一劳永逸的解决方案,接下来我们来看看什么是“全埋”。
客户端埋点一般分为访问级别、页面级别、页面内行为级别。当用户访问网站或启动移动应用时,几乎所有厂商都会自动采集报告用户的访问;当用户访问不同的页面时,有的厂商会选择不自动采集@默认>,并作为选项提供给用户;对于用户在某个页面的详细操作行为,只有少数厂商支持自动采集上报。实现了后两种自动采集的厂家通常会说,都被埋没了。但是,页面中行为层面的采集还可以进一步探索其采集的范围。最常见的就是自动采集的区别
交互元素包括:链接、表单项(如按钮、输入框等)、HTML对象级元素等。非交互元素太多了,大部分页面元素都属于这一类。其实大家在网页和手机应用中看到的很多界面都不是标准元素,所以实际上界面上很多看似交互的元素是无法自动上报的采集。这是一个遗憾。
但是让我们来看看优点。
首先,全埋点确实会自动采集很多数据,以后在使用数据的时候,可以直接从数据库中查询。想看的时候不会面对,因为没有埋葬点。采集 得不到的情况。这是一种很受分析师欢迎的方法,所以我经常听到“如果可以采集,尝试采集,后续分析总是可以用的。” 其次,埋点是一项比较耗时的工作,需要业务方提供解决方案,埋点工程师,以及测试团队进行测试。但由于实际工作中埋点较多,每次发布新功能或新活动时,都需要新的埋点。因此,埋点不仅费时,但错误率也难以控制。对于全埋点,无论使用与否,都会首先检索数据。因为程序是自动完成的,业务人员要A,工程师埋B的错误几乎不存在。
然而,任何企业都有其两个方面。
首先,所有点的“全部”并不是真正的全部。在基本的计算机浏览器和移动应用程序中,用户对页面的常见操作包括鼠标行为、键盘行为和手指行为。例如,常见的鼠标点击、鼠标滑动、屏幕滚动、键盘输入、光标选择,甚至网页上的静态。移动终端除了有点击式按压外,还有多指开合、拉动、用力按压。然而,这些操作并不都是“埋点”。可以被埋没的通常只有点击或按下。这显然还远远不够,我们甚至不能称它们为全埋点。
其次,所有埋点的“满”是以采集上报的数据量为代价的。随着数据量的增加,客户端崩溃的概率也会增加。尤其是在移动端,更多的数据量意味着更多的功耗、流量和内存消耗。从这个角度来说,现阶段也很难做到真正的“丰满”。
第三,即使能把所有的行为数据都收回来,具体分析时的二次整理和处理也不可避免,甚至是痛苦的。因为当 采集 时机器不能以我们想要的方式有意义地命名所有事件,所以不能保证来自 采集 的事件是完全正确的。所以前期埋点省下来的人工费,这次加了。
第四,现阶段,全埋点对于用户身份信息和行为附加的属性信息几乎无能为力。
那么这个功能正是我需要的吗?这其实是个度的问题。关于这个问题,只能结合你的实际情况了。如果你需要随机探索过去点击行为的趋势,那么这个功能还是合适的,否则有更好的选择。
▌Visualized embedding:一种所见即所得的嵌入方法
代码埋点和全埋点没有在易用性和准确性之间取得平衡。可视化埋点在很多情况下也称为“未编码埋点”。如上所述,代码嵌入的缺点对于网站来说是好事,但对于移动应用来说无疑是极其低效的。为了解决这个问题,在一些厂家选择全埋点的同时,大量厂家也选择了WYSIWYG的埋点路,即可视化的埋点。
可视化埋点的优点是可以直接在网站的真实界面或者手机端对埋点进行操作,并且可以在埋点后立即验证埋点是否正确。这还没有结束,埋点可以部署到所有客户终端也几乎是实时生效的。由于可视化埋点的好处,分析的需求方、业务人员、没有权限接触代码或不会编程的人,可以以很低的门槛获取数据进行分析。可以说是向前迈进了一大步。
可视化埋点部署原理
支持可视化埋点的SDK会在被监控的网站或移动端应用访问时,与服务器核对是否有新的埋点。如果发现更新的埋点,将从服务器下载并立即生效。这样就可以保证服务器收到最新的埋点后,下次访问时可以部署所有客户端。
可视化埋点和全埋点对于埋点和分析的追求完全不同。可视化埋点的思路是为了提高原有工作流的效率——还需要梳理需求,设计埋点;全埋点是为了简化工作流程——反正数据会被采集返回,这两个步骤的必要性很容易被忽视。这里不能说哪个是最好的策略,因为事先的严谨计划和事后的探索是不同的分析角度。而且,这两种埋点根本不排斥,可以同时使用。
可视化埋点也有很多局限性。
首先,视觉埋点只是针对可见元素的点击,最常见的可见元素就是点击行为。点击操作的埋点确实是当前可视化埋点的主要攻击点。但从实际情况来看,复杂页面、非标准页面、动态页面都增加了视觉埋点不可用的风险。一旦遇到,代码只能埋点。
其次,对于点击操作附带的业务属性,虽然也可以通过进一步选择属性所在的元素来获取属性信息,但国内厂商支持的比较少。
第三,为了保证埋点的准确性,视觉埋点逐渐集成了更复杂的高级设置,比如:“同页”、“同版本”、“同级别”、“同文本”……,加上这些复杂设置的视觉埋点是否也是效率的视觉埋点?
▌标签管理器:低调大师
你可能不熟悉标签,但你熟悉用于采集网页数据的SDK。这些嵌入在网页中,可以是采集网页、移动应用程序或视频的数据正在监控。班级的标签。但标签的用途远不止于此。通过在 网站 中嵌入代码,工程师可以为 网站 提供许多附加功能。除了刚才提到的数据监控,它可能还会为网站提供一些额外的功能,最常见的就是推送个性化的内容,比如:A/B测试、消息推送、个性化广告等。
如果网站或者移动应用依赖标签的能力来实现很多功能,那么就需要大量的标签,标签也可能需要频繁的更新或者变化。网页也是如此。上网很容易,但移动应用就难了。如果有错误或遗漏,更正将有一个很长的修正周期。在这种情况下,标签管理器就派上用场了。
标签管理器提供了一个容器。工程师只需将该容器正确嵌入到网页或移动应用程序中即可。之后,不懂技术的团队可以通过在线管理将后续标签发布到网页或移动应用程序中。这样,技术人员和业务人员独立工作。这听起来与可视化的埋点相似吗?是的,它们的原理几乎完全相同。只是视觉埋点更倾向于为用户在客户端的点击行为提供直观的方法,而标签管理器在代码层面,可以做的更多。
标签管理器非常强大,可以避免代码嵌入,可以通过DataLayer获取页面中的变量,如不同的用户ID、用户级别、登录状态、购买产品的名称和价格等;只有当这些变量达到一定水平时,触发器才能触发事件上报。是不是很赞!
目前最著名的标签管理器是谷歌推出的Google Tag manager,简称GTM,占据了83%的市场份额。个人版是免费的,但还是提供了极其强大的功能,一般团队使用已经足够了。如果想进一步了解GTM的功能,可以阅读它的官网,里面有非常丰富的讲解和案例。
综上所述,目前在客户端获取用户数据还没有简单通用的方案。您应该在合适的场景中选择相应的嵌入方法来平衡成本和收益。好在现在厂商基本都支持以上多客户端行为的采集方法。未来,对于客户端埋点来说,集成标签管理器某些特性的可视化埋点必将取代更多的代码埋点,解决工作中所有常见的客户端行为采集需求。
就像早期论坛的编辑框一样,帖子的效果只能通过发布或预览功能才能看到,但是后来出现了所见即所得的编辑器,让编辑文字变得非常高效和愉快。目前开源社区中流行的 Markdown 格式仍然采用这种方式。在许多流行的 Markdown 编辑器中,它仍然是一侧编辑,另一侧实时预览,或直接以最终格式编辑。
随着物联网时代的到来,越来越多的用户界面会出现在电脑和手机之外,越来越多的内容会因人而异。到时候,未来越来越多的SDK集成,会自动采集更多标准的用户行为,对于非标准的强业务意义,需要根据具体情况进行计算,或者需要有效,那么就可以通过视觉嵌入点来完成。但现阶段,恐怕最好的组合还是GTM结合visual embedding。
查看全部
采集自动组合(捕捉用户数据,管理数据——埋点是一种客户端行为采集方式
)
2018-12-0115:56:22
埋点是一种用于分析用户行为的数据分析工具。捕获用户数据并管理数据。嵌入是客户端行为的一种方式采集。
分为代码埋点、全埋点、视觉埋点。
我为什么要把它埋起来?
互联网应用(网站,APP)在开发过程中往往不专门记录用户身份和行为数据,也不收录专业的数据分析功能。但有时为了分析用户产生某些动作或不产生某些动作的深层原因,需要详细的用户数据进行分析。这时候就需要使用专业的用户分析工具和埋点。
数据采集是任何数据平台的初始动作。对于互联网应用来说,用户行为的捕捉和获取是重中之重。如果没有准确全面的用户身份和行为数据作为输入,在后续分析中获得准确洞察的可能性存在不确定性,闭环营销也会缺乏流程数据的基础,难度会更大开展精细化经营。
▌埋点原理
对于基于用户行为的数据平台来说,用户界面上发生的、能够获取用户信息的接触点是用户数据的直接来源,而建立这些接触点的方式就是埋点。这些联系人获取用户行为和身份数据后,会通过网络传输到服务器进行后续处理。
从准确性的角度来看,埋点分为客户端埋点和服务器端埋点。客户端埋点,即在客户操作界面,记录客户产生动作时的用户行为。这些行为只会发生在客户端,不会传输到服务器端;而服务器端的埋点通常在程序和数据库的交互界面中进行埋点。这时,埋点会更加准确地记录数据变化,同时会降低由于网络传输等原因造成的不确定性风险。
从分析的角度来看,数据越准确和全面,就越能达到理想状态;但在实际生产过程中,必须考虑数据采集的可行性等问题。因为数据分析工具的最终用户可能是企业内部的各种角色,比如工程师、产品运营、营销甚至其他业务人员;每个人都会在不同的时间、不同的产品模块中以不同的规则将自己注入到产品中。关注采集代码。按照传统方法,常见的工作流程如下:
文件以帮助每个人熟悉此工作流程。
▌传统埋点的缺点
反复迭代,行为采集和埋点管理这两个动作构成了这个工作流的一个闭环,但是这个闭环有几个明显的弊端。因此,它们也被用于实际工作中。大家都很苦恼的地方:
在实际工作过程中,有的公司一方面强调了数据采集的重要性,但另一方面却还没有真正把重点放在这上面。
对于行业从业者来说,数据的获取和管理从来都不是一个足以达到一定水平的问题,但只要数据业务还在发展,他们就必须不断地迭代自己,探索更好的获取和管理。路的问题。时至今日,Mixpanel等国外知名厂商仍在努力提供更高效、更准确的埋点方法;国内厂商也有很大的提升空间。
说完“埋点”这个大概念,马上就会出现它的细分概念,比如“无埋点”、“全埋点”、“无标记埋点”、“未编码埋点”、“可视化埋点”点”等。等等。从用户的角度来看,如果你还没有很好地理解这些概念,将很难整合业务数据采集,也无法选择适合你的团队和团队的埋点方法。商业...
下面我将整理出所有可能的埋点方式及其名称,并简要说明一下,希望对大家的工作有所帮助。
▌代码埋点:最可控的埋点方式
代码嵌入是最经典的嵌入方法,可以帮助工程师了解用户如何使用产品。因为工程师手动将埋点集成到代码逻辑中,理论上只要是客户端操作,即使复杂也可以采集可达。常见的包括:页面停留时间、页面浏览深度、视频播放时间、用户鼠标轨迹、表单项停留和终止等,尤其是一些非点击和不可见的行为,需要埋下代码来实现。所以如果我们需要对嵌入点有更精确的控制,那么代码嵌入点是最好的选择。
可能你还是分不清融合点和埋点。为了埋点,厂商通常会提供一个代码包,可以理解为一个工具包,里面收录了常用的工具。如果要埋点,首先得有这个工具包,也就是集成的SDK。然后用这个工具包按照里面的说明制作各种东西,也就是埋点。
当然,缺点也很明显。上面描述的苦恼几乎都与代码埋点有关。为了使掩埋过程更加高效,制造商付出了很多努力。
▌买全积分:让我开心,让我担心
全埋点,国内有的车队也称“无埋点”、“无痕埋点”、“自动埋点”。是对全自动埋地方式的探索,从名字上看似乎是一劳永逸的解决方案,接下来我们来看看什么是“全埋”。
客户端埋点一般分为访问级别、页面级别、页面内行为级别。当用户访问网站或启动移动应用时,几乎所有厂商都会自动采集报告用户的访问;当用户访问不同的页面时,有的厂商会选择不自动采集@默认>,并作为选项提供给用户;对于用户在某个页面的详细操作行为,只有少数厂商支持自动采集上报。实现了后两种自动采集的厂家通常会说,都被埋没了。但是,页面中行为层面的采集还可以进一步探索其采集的范围。最常见的就是自动采集的区别
交互元素包括:链接、表单项(如按钮、输入框等)、HTML对象级元素等。非交互元素太多了,大部分页面元素都属于这一类。其实大家在网页和手机应用中看到的很多界面都不是标准元素,所以实际上界面上很多看似交互的元素是无法自动上报的采集。这是一个遗憾。
但是让我们来看看优点。
首先,全埋点确实会自动采集很多数据,以后在使用数据的时候,可以直接从数据库中查询。想看的时候不会面对,因为没有埋葬点。采集 得不到的情况。这是一种很受分析师欢迎的方法,所以我经常听到“如果可以采集,尝试采集,后续分析总是可以用的。” 其次,埋点是一项比较耗时的工作,需要业务方提供解决方案,埋点工程师,以及测试团队进行测试。但由于实际工作中埋点较多,每次发布新功能或新活动时,都需要新的埋点。因此,埋点不仅费时,但错误率也难以控制。对于全埋点,无论使用与否,都会首先检索数据。因为程序是自动完成的,业务人员要A,工程师埋B的错误几乎不存在。
然而,任何企业都有其两个方面。
首先,所有点的“全部”并不是真正的全部。在基本的计算机浏览器和移动应用程序中,用户对页面的常见操作包括鼠标行为、键盘行为和手指行为。例如,常见的鼠标点击、鼠标滑动、屏幕滚动、键盘输入、光标选择,甚至网页上的静态。移动终端除了有点击式按压外,还有多指开合、拉动、用力按压。然而,这些操作并不都是“埋点”。可以被埋没的通常只有点击或按下。这显然还远远不够,我们甚至不能称它们为全埋点。
其次,所有埋点的“满”是以采集上报的数据量为代价的。随着数据量的增加,客户端崩溃的概率也会增加。尤其是在移动端,更多的数据量意味着更多的功耗、流量和内存消耗。从这个角度来说,现阶段也很难做到真正的“丰满”。
第三,即使能把所有的行为数据都收回来,具体分析时的二次整理和处理也不可避免,甚至是痛苦的。因为当 采集 时机器不能以我们想要的方式有意义地命名所有事件,所以不能保证来自 采集 的事件是完全正确的。所以前期埋点省下来的人工费,这次加了。
第四,现阶段,全埋点对于用户身份信息和行为附加的属性信息几乎无能为力。
那么这个功能正是我需要的吗?这其实是个度的问题。关于这个问题,只能结合你的实际情况了。如果你需要随机探索过去点击行为的趋势,那么这个功能还是合适的,否则有更好的选择。
▌Visualized embedding:一种所见即所得的嵌入方法
代码埋点和全埋点没有在易用性和准确性之间取得平衡。可视化埋点在很多情况下也称为“未编码埋点”。如上所述,代码嵌入的缺点对于网站来说是好事,但对于移动应用来说无疑是极其低效的。为了解决这个问题,在一些厂家选择全埋点的同时,大量厂家也选择了WYSIWYG的埋点路,即可视化的埋点。
可视化埋点的优点是可以直接在网站的真实界面或者手机端对埋点进行操作,并且可以在埋点后立即验证埋点是否正确。这还没有结束,埋点可以部署到所有客户终端也几乎是实时生效的。由于可视化埋点的好处,分析的需求方、业务人员、没有权限接触代码或不会编程的人,可以以很低的门槛获取数据进行分析。可以说是向前迈进了一大步。
可视化埋点部署原理
支持可视化埋点的SDK会在被监控的网站或移动端应用访问时,与服务器核对是否有新的埋点。如果发现更新的埋点,将从服务器下载并立即生效。这样就可以保证服务器收到最新的埋点后,下次访问时可以部署所有客户端。
可视化埋点和全埋点对于埋点和分析的追求完全不同。可视化埋点的思路是为了提高原有工作流的效率——还需要梳理需求,设计埋点;全埋点是为了简化工作流程——反正数据会被采集返回,这两个步骤的必要性很容易被忽视。这里不能说哪个是最好的策略,因为事先的严谨计划和事后的探索是不同的分析角度。而且,这两种埋点根本不排斥,可以同时使用。
可视化埋点也有很多局限性。
首先,视觉埋点只是针对可见元素的点击,最常见的可见元素就是点击行为。点击操作的埋点确实是当前可视化埋点的主要攻击点。但从实际情况来看,复杂页面、非标准页面、动态页面都增加了视觉埋点不可用的风险。一旦遇到,代码只能埋点。
其次,对于点击操作附带的业务属性,虽然也可以通过进一步选择属性所在的元素来获取属性信息,但国内厂商支持的比较少。
第三,为了保证埋点的准确性,视觉埋点逐渐集成了更复杂的高级设置,比如:“同页”、“同版本”、“同级别”、“同文本”……,加上这些复杂设置的视觉埋点是否也是效率的视觉埋点?
▌标签管理器:低调大师
你可能不熟悉标签,但你熟悉用于采集网页数据的SDK。这些嵌入在网页中,可以是采集网页、移动应用程序或视频的数据正在监控。班级的标签。但标签的用途远不止于此。通过在 网站 中嵌入代码,工程师可以为 网站 提供许多附加功能。除了刚才提到的数据监控,它可能还会为网站提供一些额外的功能,最常见的就是推送个性化的内容,比如:A/B测试、消息推送、个性化广告等。
如果网站或者移动应用依赖标签的能力来实现很多功能,那么就需要大量的标签,标签也可能需要频繁的更新或者变化。网页也是如此。上网很容易,但移动应用就难了。如果有错误或遗漏,更正将有一个很长的修正周期。在这种情况下,标签管理器就派上用场了。
标签管理器提供了一个容器。工程师只需将该容器正确嵌入到网页或移动应用程序中即可。之后,不懂技术的团队可以通过在线管理将后续标签发布到网页或移动应用程序中。这样,技术人员和业务人员独立工作。这听起来与可视化的埋点相似吗?是的,它们的原理几乎完全相同。只是视觉埋点更倾向于为用户在客户端的点击行为提供直观的方法,而标签管理器在代码层面,可以做的更多。
标签管理器非常强大,可以避免代码嵌入,可以通过DataLayer获取页面中的变量,如不同的用户ID、用户级别、登录状态、购买产品的名称和价格等;只有当这些变量达到一定水平时,触发器才能触发事件上报。是不是很赞!
目前最著名的标签管理器是谷歌推出的Google Tag manager,简称GTM,占据了83%的市场份额。个人版是免费的,但还是提供了极其强大的功能,一般团队使用已经足够了。如果想进一步了解GTM的功能,可以阅读它的官网,里面有非常丰富的讲解和案例。
综上所述,目前在客户端获取用户数据还没有简单通用的方案。您应该在合适的场景中选择相应的嵌入方法来平衡成本和收益。好在现在厂商基本都支持以上多客户端行为的采集方法。未来,对于客户端埋点来说,集成标签管理器某些特性的可视化埋点必将取代更多的代码埋点,解决工作中所有常见的客户端行为采集需求。
就像早期论坛的编辑框一样,帖子的效果只能通过发布或预览功能才能看到,但是后来出现了所见即所得的编辑器,让编辑文字变得非常高效和愉快。目前开源社区中流行的 Markdown 格式仍然采用这种方式。在许多流行的 Markdown 编辑器中,它仍然是一侧编辑,另一侧实时预览,或直接以最终格式编辑。
随着物联网时代的到来,越来越多的用户界面会出现在电脑和手机之外,越来越多的内容会因人而异。到时候,未来越来越多的SDK集成,会自动采集更多标准的用户行为,对于非标准的强业务意义,需要根据具体情况进行计算,或者需要有效,那么就可以通过视觉嵌入点来完成。但现阶段,恐怕最好的组合还是GTM结合visual embedding。
采集自动组合( 组合多个优化之GC操作详解内容修改内容详解优化)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-07 21:10
组合多个优化之GC操作详解内容修改内容详解优化)
采集SEO优化方法---结合多领域发布教程采集SEO优化方法---结合多领域发布教程
多字段组合发布是优采云采集的SEO工具之一,可以增加收录和网站的权重。
?具体用途是在发布目标的标题或内容[配置映射对应字段]处组合不同的字段,合成一个新的标题或正文进行发布。
进入【配置映射对应字段】页面,可以组合多个字段发布结果
1. 进入【配置映射对应字段】页面
?? 进入一个任务,点击【发布目标管理】==》找到需要配置的发布目标,点击右侧对应的【配置映射】按钮;
2. 合并多个字段
?? 一、组合标题或内容的“值来源1”处的字段,例如组合标题处的title和tag字段:
?? 二、设置组合字段之间的分隔符。默认为逗号,kds_empty_val 为空字符。修改后请点击保存按钮。
?? 下图中的示例用下划线填充。
3.发布结果
?? 发布前数据,title字段和tag字段内容:
?? 文章发布后,在title后面添加tag字段的内容:
采集SEO优化方法---结合多领域发布教程相关教程2020-10-11《多背包单调队列优化》
2020-10-11《多背包单调队列优化》《多背包单调队列优化》【题目】有n种物品,一个容量为m的背包。第i个项目最多有si个项目,每个项目的体积为vi,值为wi。解决选择将哪些物品放入背包,使物品的总体积不超过背包的容量,且总值最大。只输出最大值。【
unity优化GC操作详解
Unity优化GC操作内容详解修改自: 简介:游戏运行时,数据主要存放在内存中。当不需要游戏数据时,可以回收存储当前数据的内存重新使用。内存垃圾是指当前丢弃的数据所占用的内存。垃圾
树莓派工控机定时和自动采集数据解决方案
树莓派工控机定时自动采集数据解决方案概述:采集树莓派(xxxxx,以下简称工控机)上的数据,传输到本地sqlserver数据库,写入数据Python采集脚本。这涉及到几个问题:当出现网络中断、断电、工控机重启等异常情况时,为保证这些异常情况的发生,仍能自动
Foobar2000的配置与优化
Foobar2000 配置与优化 Foobar2000 配置与优化 1. DTS 解码器 foo_input_dts 解码 DTS 音效 2. ESlyric foo_uie_eslyric 歌词面板,支持桌面歌词。有很多可自定义的配置项,支持国内外很多网站歌词搜索。比 Lyrics Panel Show 3 更好用。 在 Options-Tools-ESLy 中可用
新APP上线后如何优化ASO
新APP上线时,如何优化ASO 新APP上线,推广是重中之重,而ASO也是必不可少的环节。可能有人会说ASO需要用钱来做。玩法丰富,没钱没钱玩ASO。丰富的玩法就不多说了。大家都知道,今天我们主要分享一下没钱的方法。首先我们要了解阴影
Debezium采集postgresql 日志
Debezium采集postgresql log debezium采集postgresql表数据debezium不用kafka就可以完成
没想到,复杂的UI卡顿问题还能这么优化?
没想到,复杂的UI卡顿问题还能这么优化?点击上方程序员小乐关注、star或顶顶,共同成长。关注订阅号“程序员小乐”,每天观看更多精彩英文内容。做你自己,不要为任何人改变。如果他们不喜欢你最糟糕的时候,那么他们不值得你在
掷骰子【普通线性DP】【传递方程可以优化为矩阵快速幂】
掷骰子【普通线性DP】【转移方程可以优化为矩阵快速幂】掷骰子可以先定义一个状态f[i][j]:第i个骰子,最后一边是j的方法个数,它一定是超时了,但是Goose可以混点,代码如下 for(int i=1;i=6;i++) f[0][i]=1; for(int i=1;i=n;i++) {for(int j=1;j=6;j++) {fo 查看全部
采集自动组合(
组合多个优化之GC操作详解内容修改内容详解优化)
采集SEO优化方法---结合多领域发布教程采集SEO优化方法---结合多领域发布教程
多字段组合发布是优采云采集的SEO工具之一,可以增加收录和网站的权重。
?具体用途是在发布目标的标题或内容[配置映射对应字段]处组合不同的字段,合成一个新的标题或正文进行发布。
进入【配置映射对应字段】页面,可以组合多个字段发布结果
1. 进入【配置映射对应字段】页面
?? 进入一个任务,点击【发布目标管理】==》找到需要配置的发布目标,点击右侧对应的【配置映射】按钮;
2. 合并多个字段
?? 一、组合标题或内容的“值来源1”处的字段,例如组合标题处的title和tag字段:
?? 二、设置组合字段之间的分隔符。默认为逗号,kds_empty_val 为空字符。修改后请点击保存按钮。
?? 下图中的示例用下划线填充。
3.发布结果
?? 发布前数据,title字段和tag字段内容:
?? 文章发布后,在title后面添加tag字段的内容:
采集SEO优化方法---结合多领域发布教程相关教程2020-10-11《多背包单调队列优化》
2020-10-11《多背包单调队列优化》《多背包单调队列优化》【题目】有n种物品,一个容量为m的背包。第i个项目最多有si个项目,每个项目的体积为vi,值为wi。解决选择将哪些物品放入背包,使物品的总体积不超过背包的容量,且总值最大。只输出最大值。【
unity优化GC操作详解
Unity优化GC操作内容详解修改自: 简介:游戏运行时,数据主要存放在内存中。当不需要游戏数据时,可以回收存储当前数据的内存重新使用。内存垃圾是指当前丢弃的数据所占用的内存。垃圾
树莓派工控机定时和自动采集数据解决方案
树莓派工控机定时自动采集数据解决方案概述:采集树莓派(xxxxx,以下简称工控机)上的数据,传输到本地sqlserver数据库,写入数据Python采集脚本。这涉及到几个问题:当出现网络中断、断电、工控机重启等异常情况时,为保证这些异常情况的发生,仍能自动
Foobar2000的配置与优化
Foobar2000 配置与优化 Foobar2000 配置与优化 1. DTS 解码器 foo_input_dts 解码 DTS 音效 2. ESlyric foo_uie_eslyric 歌词面板,支持桌面歌词。有很多可自定义的配置项,支持国内外很多网站歌词搜索。比 Lyrics Panel Show 3 更好用。 在 Options-Tools-ESLy 中可用
新APP上线后如何优化ASO
新APP上线时,如何优化ASO 新APP上线,推广是重中之重,而ASO也是必不可少的环节。可能有人会说ASO需要用钱来做。玩法丰富,没钱没钱玩ASO。丰富的玩法就不多说了。大家都知道,今天我们主要分享一下没钱的方法。首先我们要了解阴影
Debezium采集postgresql 日志
Debezium采集postgresql log debezium采集postgresql表数据debezium不用kafka就可以完成
没想到,复杂的UI卡顿问题还能这么优化?
没想到,复杂的UI卡顿问题还能这么优化?点击上方程序员小乐关注、star或顶顶,共同成长。关注订阅号“程序员小乐”,每天观看更多精彩英文内容。做你自己,不要为任何人改变。如果他们不喜欢你最糟糕的时候,那么他们不值得你在
掷骰子【普通线性DP】【传递方程可以优化为矩阵快速幂】
掷骰子【普通线性DP】【转移方程可以优化为矩阵快速幂】掷骰子可以先定义一个状态f[i][j]:第i个骰子,最后一边是j的方法个数,它一定是超时了,但是Goose可以混点,代码如下 for(int i=1;i=6;i++) f[0][i]=1; for(int i=1;i=n;i++) {for(int j=1;j=6;j++) {fo
采集自动组合(优采云浏览器的脚本管理器是什么样的?项目管理器的核心价值)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-05 10:13
优采云浏览器不是普通的浏览器,它是一个可视化的自动脚本采集工具,一个可以解放IT人员双手的浏览器,它可以做自动采集数据,收发邮件,自动编码和识别验证码,并可自由组合操作。强大的内核可以轻松辅助您的操作。
【特征】
1、可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理的内容。采集 jax、falls等就很简单了。一些js加密数据也可以轻松获取,无需抓包分析。
2、自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证代码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,功能自由组合。
3、自动编码
采集速度快,程序注重采集的效率,页面解析速度快,可以直接屏蔽不需要访问的页面或广告,加快访问速度速度。
4、生成EXE
不仅是一个采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。可以做到自动登录,自动识别验证码,是一款万能浏览器。
5、项目管理
该解决方案可用于直接生成单个应用程序。单个程序可以脱离优采云浏览器运行。提供官方软件管理平台,用户可以通过该平台进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。
【常见问题】
1、 软件是如何授权的?
浏览器永久使用,两年免费升级服务。软件需要绑定到机器上,但可以自由更换。
2、 有没有免费版的浏览器?
优采云浏览器的脚本管理器可以免费使用。用户可以直接创建脚本并运行单个脚本。
3、 项目经理有什么特别之处?
项目经理是优采云浏览器的核心价值。我们的单个脚本可以独立运行。但是我们有很多各种各样的需求需要整合,然后我们需要一个项目经理。
4、 可以用来挖微博吗?
是的,你可以使用浏览器的滚动条设置来采集瀑布这些数据。
5、 验证码可以识别吗?
是的,该软件带有手动编码和各种编码平台。可自动识别并自动输入编码结果。
6、 我可以通过优采云 浏览器赚钱吗?
优采云浏览器是一个可以帮助大家自动化的网页操作。它还允许您制作脚本生成程序出售,生成的程序可以自定义软件名称。官方提供注册服务和自动升级。用户只要管理好脚本和服务就可以快速赚钱。
7、 能操作数据库吗?
浏览器可以读写四个数据库:mysql、sqlserver、sqlite、access。您可以将任务数据放入数据库中,通过浏览器读取并运行它。操作完成后,使用浏览器将其标记为已使用。您可以在浏览器的使用过程中随时使用数据库,非常方便。
【更新内容】
1.添加缓存处理方法。
2.登录问题得到改善。
3. 日志错位问题已修复。
4.修正:复制脚本修改名称后,无法添加到脚本编辑区,双击后没有反应。
5.修正:导入同名脚本,改名后的脚本中的脚本步骤会变成和之前的脚本一样的步骤。
6.PHP插件和python插件问题处理。
7.变量移除也会移除已清除变量中的变量。
8. 多行抽取和清空列表变量问题处理。
9.页面缓存功能的header信息中添加url。
10. 拖动鼠标增加移动速度。
11.定时任务的Cron表达式注释无效,已修复。
12.修复项目经理任务列表中右键点击的问题。
13.修复选项中的Preferences:点击主程序右上角的关闭按钮,最小化到托盘而不是退出。
14.exe包生成器支持.Net版本修改。
15. 优化:变量处理操作,如果处理的变量不存在,会弹出错误。
16.不能在根节点添加组,可以新建组并在空白区域刷新列表。
17. 无法将分组脚本添加到编辑区。
18.同时选择多个分组节点进行右键菜单处理。
19.在列表区复制脚本后,双击到编辑区,在编辑区删除复制的脚本,在列表区双击无效,无法添加到编辑区编辑区。
20.修正:在脚本编辑区编辑脚本名称后,在列表区导出。导出的名字还是修改前的名字。
21.Fix: 生成EXE,选择包中的文件并添加,提示被占用,但从未打开过该文件。
2 2. 脚本引用添加提示:多级脚本引用需要手动将脚本复制到exe的Projects目录下。
23. 新增编辑区支持脚本导出。
24. 列表区支持脚本或组名搜索。
其他相关
1 新闻播报揭秘A股483万大涨原因 来源:466万 3杨幂唱新mojito 来源:4 郭美美宣布434万新恋情 来源:418万 被捕来源:7 幼儿园毕业配文 再见青春 390万 来源:376万 9 林丹出轨对象发出申诉 来源:10 试用期单位未缴纳社保违规 新增350万 来源:326万 全国菜价上涨 13 美国黑熊走了650公里的路程。303万 293万。香港市民每人获1万元。16 王宝山辞职 263 万 254 万 18 元隆平当空军差点入狱。支持教育少女生前录音 22特工回应林志轩重病 212万 205万 24名美国明星宣布可竞选总统。25.1万多箱茅台自卸司机撞车 118.4万买不起 27.高考遇武汉大雨 听力考试可暂停 28同卓宣传郑云龙 171万 搜索工具百度查找15100条相关结果给你@网站抓取工具,采集模拟浏览器手动操作的发布软件,可以生成EXE。
-100%好评优采云 浏览器是一个可视化的自动化脚本工具。我们可以实现自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,通过设置脚本进行操作。数据库,优采云浏览器绿色版_优采云浏览器绿色版免费下载【最新版】-下载首页优采云浏览器绿色版是一款自动化脚本编写工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,操作数据库,收发邮件等下载首页优采云 浏览器是一个自动化脚本的工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作到下载首页优采云浏览器是一款可视化的自动化脚本工具,我们可以实现自动化通过设置脚本进行登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。非凡软件优采云 浏览器是一种自动化脚本编写工具。通过优采云浏览器自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作到优采云 浏览器脚本编辑器-< @优采云浏览器下载v7.4.0官方版--pc6下载站优采云浏览器破解版-优采云浏览器下载7.31-新云软件园优采云浏览器下载,优采云浏览器是一个可以可视化的网页万能按钮精灵采集万能群发,也是一款功能自由组合、自动Log的万能营销软件在,一个通用的优采云浏览器(数据库采集器)会自动识别验证码,是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录,识别验证码,自动抓取获取数据,自动提交数据,点击网页,下载文字优采云浏览器下载_优采云 官方浏览器下载-太平洋下载中心优采云 浏览器是一款自动化脚本编写工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,操作数据库,收发邮件等操作到达 查看全部
采集自动组合(优采云浏览器的脚本管理器是什么样的?项目管理器的核心价值)
优采云浏览器不是普通的浏览器,它是一个可视化的自动脚本采集工具,一个可以解放IT人员双手的浏览器,它可以做自动采集数据,收发邮件,自动编码和识别验证码,并可自由组合操作。强大的内核可以轻松辅助您的操作。
【特征】
1、可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理的内容。采集 jax、falls等就很简单了。一些js加密数据也可以轻松获取,无需抓包分析。
2、自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证代码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,功能自由组合。
3、自动编码
采集速度快,程序注重采集的效率,页面解析速度快,可以直接屏蔽不需要访问的页面或广告,加快访问速度速度。
4、生成EXE
不仅是一个采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。可以做到自动登录,自动识别验证码,是一款万能浏览器。
5、项目管理
该解决方案可用于直接生成单个应用程序。单个程序可以脱离优采云浏览器运行。提供官方软件管理平台,用户可以通过该平台进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。
【常见问题】
1、 软件是如何授权的?
浏览器永久使用,两年免费升级服务。软件需要绑定到机器上,但可以自由更换。
2、 有没有免费版的浏览器?
优采云浏览器的脚本管理器可以免费使用。用户可以直接创建脚本并运行单个脚本。
3、 项目经理有什么特别之处?
项目经理是优采云浏览器的核心价值。我们的单个脚本可以独立运行。但是我们有很多各种各样的需求需要整合,然后我们需要一个项目经理。
4、 可以用来挖微博吗?
是的,你可以使用浏览器的滚动条设置来采集瀑布这些数据。
5、 验证码可以识别吗?
是的,该软件带有手动编码和各种编码平台。可自动识别并自动输入编码结果。
6、 我可以通过优采云 浏览器赚钱吗?
优采云浏览器是一个可以帮助大家自动化的网页操作。它还允许您制作脚本生成程序出售,生成的程序可以自定义软件名称。官方提供注册服务和自动升级。用户只要管理好脚本和服务就可以快速赚钱。
7、 能操作数据库吗?
浏览器可以读写四个数据库:mysql、sqlserver、sqlite、access。您可以将任务数据放入数据库中,通过浏览器读取并运行它。操作完成后,使用浏览器将其标记为已使用。您可以在浏览器的使用过程中随时使用数据库,非常方便。
【更新内容】
1.添加缓存处理方法。
2.登录问题得到改善。
3. 日志错位问题已修复。
4.修正:复制脚本修改名称后,无法添加到脚本编辑区,双击后没有反应。
5.修正:导入同名脚本,改名后的脚本中的脚本步骤会变成和之前的脚本一样的步骤。
6.PHP插件和python插件问题处理。
7.变量移除也会移除已清除变量中的变量。
8. 多行抽取和清空列表变量问题处理。
9.页面缓存功能的header信息中添加url。
10. 拖动鼠标增加移动速度。
11.定时任务的Cron表达式注释无效,已修复。
12.修复项目经理任务列表中右键点击的问题。
13.修复选项中的Preferences:点击主程序右上角的关闭按钮,最小化到托盘而不是退出。
14.exe包生成器支持.Net版本修改。
15. 优化:变量处理操作,如果处理的变量不存在,会弹出错误。
16.不能在根节点添加组,可以新建组并在空白区域刷新列表。
17. 无法将分组脚本添加到编辑区。
18.同时选择多个分组节点进行右键菜单处理。
19.在列表区复制脚本后,双击到编辑区,在编辑区删除复制的脚本,在列表区双击无效,无法添加到编辑区编辑区。
20.修正:在脚本编辑区编辑脚本名称后,在列表区导出。导出的名字还是修改前的名字。
21.Fix: 生成EXE,选择包中的文件并添加,提示被占用,但从未打开过该文件。
2 2. 脚本引用添加提示:多级脚本引用需要手动将脚本复制到exe的Projects目录下。
23. 新增编辑区支持脚本导出。
24. 列表区支持脚本或组名搜索。
其他相关
1 新闻播报揭秘A股483万大涨原因 来源:466万 3杨幂唱新mojito 来源:4 郭美美宣布434万新恋情 来源:418万 被捕来源:7 幼儿园毕业配文 再见青春 390万 来源:376万 9 林丹出轨对象发出申诉 来源:10 试用期单位未缴纳社保违规 新增350万 来源:326万 全国菜价上涨 13 美国黑熊走了650公里的路程。303万 293万。香港市民每人获1万元。16 王宝山辞职 263 万 254 万 18 元隆平当空军差点入狱。支持教育少女生前录音 22特工回应林志轩重病 212万 205万 24名美国明星宣布可竞选总统。25.1万多箱茅台自卸司机撞车 118.4万买不起 27.高考遇武汉大雨 听力考试可暂停 28同卓宣传郑云龙 171万 搜索工具百度查找15100条相关结果给你@网站抓取工具,采集模拟浏览器手动操作的发布软件,可以生成EXE。
-100%好评优采云 浏览器是一个可视化的自动化脚本工具。我们可以实现自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,通过设置脚本进行操作。数据库,优采云浏览器绿色版_优采云浏览器绿色版免费下载【最新版】-下载首页优采云浏览器绿色版是一款自动化脚本编写工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,操作数据库,收发邮件等下载首页优采云 浏览器是一个自动化脚本的工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作到下载首页优采云浏览器是一款可视化的自动化脚本工具,我们可以实现自动化通过设置脚本进行登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。非凡软件优采云 浏览器是一种自动化脚本编写工具。通过优采云浏览器自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作到优采云 浏览器脚本编辑器-< @优采云浏览器下载v7.4.0官方版--pc6下载站优采云浏览器破解版-优采云浏览器下载7.31-新云软件园优采云浏览器下载,优采云浏览器是一个可以可视化的网页万能按钮精灵采集万能群发,也是一款功能自由组合、自动Log的万能营销软件在,一个通用的优采云浏览器(数据库采集器)会自动识别验证码,是一个可视化的自动化脚本工具。我们可以设置脚本实现自动登录,识别验证码,自动抓取获取数据,自动提交数据,点击网页,下载文字优采云浏览器下载_优采云 官方浏览器下载-太平洋下载中心优采云 浏览器是一款自动化脚本编写工具。通过优采云浏览器自动登录,识别验证码,自动抓取数据,自动提交数据,点击网页,下载文件,操作数据库,收发邮件等操作到达
采集自动组合(试试用smartproxyapp除非能从你的运营商接入数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-03 22:00
采集自动组合是什么鬼?这种容易让android崩溃的功能,是不建议在android上进行的。而且,就算你下载了,也没办法绕过appstore的审核。
在android上,你可以基于wap业务,通过sqlmap来嗅探数据,然后root后去修改数据。wap+sqlmap可以在android上查看三大应用市场的排名以及app评论等。不过需要root。不知道楼主要干嘛。
试试用smartproxy
app除非能从你的运营商接入数据,否则自己采集数据做商业用途几乎是不可能的事情。
既然已经root了,就安心等封杀通知吧。你的数据还有机会恢复的。否则太悲剧了。
解决方案一个是绑定wifi,然后system后台服务上报数据到网站,另一个是绑定同样的wifi,然后显示相同信息。个人觉得第二个比较靠谱,但是如果做成功了,会多一个消息获取对象,读取这个链接的数据可能是最大的问题。
我的观点:我们都无法从技术上阻止厂商通过流量获取数据,流量获取的渠道也是有限的,并不像黑产那样流量到了后台就直接转化为服务。把android手机中安装的各种应用流量劫持,获取后台上报数据这件事情理解为黑产的,是不公平的。而把流量劫持认为不可行的原因是:流量劫持是违法的,但是这种方式要规避审查的难度远大于解决流量获取这个问题。
解决方案的两个原因:一个是通过软件实现劫持,另一个是通过对流量劫持的一些限制,比如对数据存储流量劫持,实现没有入口的流量劫持。手机微信摇一摇摇不到红包的问题是在于此,而不是在于微信要流量,微信又拦截不了。另一方面,我也不是专家,说的可能不对,也欢迎大家指正。流量劫持是违法的,微信要流量不拦截,可能是好事情,但也可能是坏事情。
如果有人拦截了微信的这种方式,那就相当于你违法了。这件事情是很复杂的,是基于他人的态度,以及法律的尺度。但是大家普遍是这么认为的,但是如果有足够多的人成功把android手机流量劫持到你的应用里面,而且得到你的数据,这是很好的事情。 查看全部
采集自动组合(试试用smartproxyapp除非能从你的运营商接入数据)
采集自动组合是什么鬼?这种容易让android崩溃的功能,是不建议在android上进行的。而且,就算你下载了,也没办法绕过appstore的审核。
在android上,你可以基于wap业务,通过sqlmap来嗅探数据,然后root后去修改数据。wap+sqlmap可以在android上查看三大应用市场的排名以及app评论等。不过需要root。不知道楼主要干嘛。
试试用smartproxy
app除非能从你的运营商接入数据,否则自己采集数据做商业用途几乎是不可能的事情。
既然已经root了,就安心等封杀通知吧。你的数据还有机会恢复的。否则太悲剧了。
解决方案一个是绑定wifi,然后system后台服务上报数据到网站,另一个是绑定同样的wifi,然后显示相同信息。个人觉得第二个比较靠谱,但是如果做成功了,会多一个消息获取对象,读取这个链接的数据可能是最大的问题。
我的观点:我们都无法从技术上阻止厂商通过流量获取数据,流量获取的渠道也是有限的,并不像黑产那样流量到了后台就直接转化为服务。把android手机中安装的各种应用流量劫持,获取后台上报数据这件事情理解为黑产的,是不公平的。而把流量劫持认为不可行的原因是:流量劫持是违法的,但是这种方式要规避审查的难度远大于解决流量获取这个问题。
解决方案的两个原因:一个是通过软件实现劫持,另一个是通过对流量劫持的一些限制,比如对数据存储流量劫持,实现没有入口的流量劫持。手机微信摇一摇摇不到红包的问题是在于此,而不是在于微信要流量,微信又拦截不了。另一方面,我也不是专家,说的可能不对,也欢迎大家指正。流量劫持是违法的,微信要流量不拦截,可能是好事情,但也可能是坏事情。
如果有人拦截了微信的这种方式,那就相当于你违法了。这件事情是很复杂的,是基于他人的态度,以及法律的尺度。但是大家普遍是这么认为的,但是如果有足够多的人成功把android手机流量劫持到你的应用里面,而且得到你的数据,这是很好的事情。
采集自动组合(默认用thread来做监听线程的经验之谈之采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-30 23:04
采集自动组合:可以生成主线程还有组合调用监听线程,
0)){if(server.isf(this,
0)){if(!server.isf(this,
0)){server.addflags("goto");}}}经验之谈:最主要的还是用样式来写下的功能。
大概是主线程运行python代码,处理有异常的情况。比如修改了页面,我试过tryexcept,差不多会终止,但是还是python在处理问题。很多timeout的功能没用。
python中timeout指定进程(线程)最后运行的时间,当线程过多时timeout有可能变为死锁。本质是调用的内部函数,所以你需要看是哪个线程在执行。当一个线程执行的时候timeout时间又未到的话,
tornado默认是用thread的,但是实际做一些特殊优化可以让timeout的速度相对线程缩短。推荐看一下这篇帖子,我感觉写的很详细了,
在用caploise来做监听线程的时候经常会遇到类似threadtimeout等的情况,不知道是怎么回事。
语言上来说,timeout是异步的。当thread过多的时候往往使用threadtimeout会更加合适一些。其次,线程一个是多线程的执行,一个是的执行,在时间上本身就有区别。python中每个event都会有一个timeoutifnotintimes.for_each是预取主线程一切timeout的上限最后,我觉得编程时的某些细节决定了timeout函数的合理性。
我就遇到了这样的情况,在请求异步时线程异步造成timeoutifnotintimes.for_each或者直接设置timeoutifnotintimes.for_each。 查看全部
采集自动组合(默认用thread来做监听线程的经验之谈之采集)
采集自动组合:可以生成主线程还有组合调用监听线程,
0)){if(server.isf(this,
0)){if(!server.isf(this,
0)){server.addflags("goto");}}}经验之谈:最主要的还是用样式来写下的功能。
大概是主线程运行python代码,处理有异常的情况。比如修改了页面,我试过tryexcept,差不多会终止,但是还是python在处理问题。很多timeout的功能没用。
python中timeout指定进程(线程)最后运行的时间,当线程过多时timeout有可能变为死锁。本质是调用的内部函数,所以你需要看是哪个线程在执行。当一个线程执行的时候timeout时间又未到的话,
tornado默认是用thread的,但是实际做一些特殊优化可以让timeout的速度相对线程缩短。推荐看一下这篇帖子,我感觉写的很详细了,
在用caploise来做监听线程的时候经常会遇到类似threadtimeout等的情况,不知道是怎么回事。
语言上来说,timeout是异步的。当thread过多的时候往往使用threadtimeout会更加合适一些。其次,线程一个是多线程的执行,一个是的执行,在时间上本身就有区别。python中每个event都会有一个timeoutifnotintimes.for_each是预取主线程一切timeout的上限最后,我觉得编程时的某些细节决定了timeout函数的合理性。
我就遇到了这样的情况,在请求异步时线程异步造成timeoutifnotintimes.for_each或者直接设置timeoutifnotintimes.for_each。
采集自动组合(采集自动组合技术,辅助单个sql查询这篇文章介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-28 13:01
采集自动组合技术,辅助单个sql查询这篇文章介绍了组合sql技术在自动组合java库时的缺陷和connector的想法。最后提供了两个简单的例子来说明工具链如何搭建。在计算机科学中有一种应用类型叫成像对象。通常的把图像作为3d模型被用来人工重建数据在电子或光学学科里叫3d成像对象。java也提供类似的方法来绘制图像,但在那些地方要使用2d图像。
2d图像比2d模型更小,渲染2d图像更快速,更高效,渲染像素图像更容易。如果你使用java来计算,编译器会把图像转换成图像对象,那会增加很多复杂性。所以最好的选择是使用采集到的2d图像作为3d模型来实现3d图像渲染。成像对象是把正在计算的结果以2d方式在我们需要的地方显示。这样我们就可以用计算量小的2d图像来获得我们需要的高分辨率和视野,同时不需要复杂的数学方法来重建数据。
那么你可能想要一个既能一次性采集到所有3d结果,又能让多次调用一次数据的应用程序。这个应用程序就是集成采集sql实现的scanbase类。我们用java在jvm环境里运行了这个应用程序,并且为我们的代码提供了足够的运行时并且被大小为160gb的u3dmono虚拟机所利用。这个计算机的内部是使用采集到的sql数据。
scanbase类里只有一个最简单的points(或称采集对象)实例化:publicinterfacescanbase{ac_objectbuild(stringrenderstarttx,stringrenderstarttx1,stringrenderstarttx2,stringrenderstarttx3,intrenderstartmeth,intrenderstarttack,intrenderstarttx);}这是一个容器实例化,需要传入每个points的长度,以及一些必须的参数。
我只传了长度为int类型的renderstarttx,因为有时候这些对象会有重叠的ucnotconnected关联。另外的如renderstartx和renderstartex两个参数是一个参数对于一个int数值(可选),然后是一个指定数值。如果采集太远的数值,你也可以加入参数renderstartx和renderstartex来预防数据重叠和脱落。
为什么scanbase不是基于list集合的数据结构呢?要了解原因,先了解我们的存储层。points的长度是2d的,并且存储在一个数组里。如果数组被分为两组,那么数组就会有一个大小大于1g的数组。要比这个数组大,你还需要很大的内存空间。根据我们自己的经验,一般都不会超过2g。在list的每个元素都有唯一的名字,也就是它的索引。
因此points只是一个数组里唯一的一个point对象而已。所以,这是一个单向无循环的数组,所以索引在循环里总是不会过早的被修改。另外,我们都知道scantable是使用list集合作为二进制表示的。 查看全部
采集自动组合(采集自动组合技术,辅助单个sql查询这篇文章介绍)
采集自动组合技术,辅助单个sql查询这篇文章介绍了组合sql技术在自动组合java库时的缺陷和connector的想法。最后提供了两个简单的例子来说明工具链如何搭建。在计算机科学中有一种应用类型叫成像对象。通常的把图像作为3d模型被用来人工重建数据在电子或光学学科里叫3d成像对象。java也提供类似的方法来绘制图像,但在那些地方要使用2d图像。
2d图像比2d模型更小,渲染2d图像更快速,更高效,渲染像素图像更容易。如果你使用java来计算,编译器会把图像转换成图像对象,那会增加很多复杂性。所以最好的选择是使用采集到的2d图像作为3d模型来实现3d图像渲染。成像对象是把正在计算的结果以2d方式在我们需要的地方显示。这样我们就可以用计算量小的2d图像来获得我们需要的高分辨率和视野,同时不需要复杂的数学方法来重建数据。
那么你可能想要一个既能一次性采集到所有3d结果,又能让多次调用一次数据的应用程序。这个应用程序就是集成采集sql实现的scanbase类。我们用java在jvm环境里运行了这个应用程序,并且为我们的代码提供了足够的运行时并且被大小为160gb的u3dmono虚拟机所利用。这个计算机的内部是使用采集到的sql数据。
scanbase类里只有一个最简单的points(或称采集对象)实例化:publicinterfacescanbase{ac_objectbuild(stringrenderstarttx,stringrenderstarttx1,stringrenderstarttx2,stringrenderstarttx3,intrenderstartmeth,intrenderstarttack,intrenderstarttx);}这是一个容器实例化,需要传入每个points的长度,以及一些必须的参数。
我只传了长度为int类型的renderstarttx,因为有时候这些对象会有重叠的ucnotconnected关联。另外的如renderstartx和renderstartex两个参数是一个参数对于一个int数值(可选),然后是一个指定数值。如果采集太远的数值,你也可以加入参数renderstartx和renderstartex来预防数据重叠和脱落。
为什么scanbase不是基于list集合的数据结构呢?要了解原因,先了解我们的存储层。points的长度是2d的,并且存储在一个数组里。如果数组被分为两组,那么数组就会有一个大小大于1g的数组。要比这个数组大,你还需要很大的内存空间。根据我们自己的经验,一般都不会超过2g。在list的每个元素都有唯一的名字,也就是它的索引。
因此points只是一个数组里唯一的一个point对象而已。所以,这是一个单向无循环的数组,所以索引在循环里总是不会过早的被修改。另外,我们都知道scantable是使用list集合作为二进制表示的。
采集自动组合(EditorTools3基础版数据采集软件特征无人值守(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-11-23 15:10
EditorTools3基础版是一款简单易用的数据采集软件。可以根据你设置的规则允许,并且采集全天持续对数据执行。目前支持所有类型的网站,并且会自动合并采集的内容。
软件功能
1、与网站分离,通过独立产生的接口,可以支持任何网站或数据库
2、体积小,低功耗,稳定性好,非常适合在服务器上运行
3、所有规则均可导入导出,资源灵活复用
4、使用FTP上传文件,稳定安全
5、反向、顺序、随机可选采集文章
6、支持自动列表网址
7、支持网站数据分布在多个页面采集
8、自由设置数据项采集,每个数据项可以单独过滤排序
9、支持分页内容采集
10、支持下载任意格式和类型的文件(包括图片和视频)
11、可以突破防盗文件
12、支持动态文件URL解析
13、支持采集需要登录才能访问的网页
软件特点
1、全自动无人值守
无需值守,24小时自动实时监控目标,实时高效采集,全天候为您提供内容更新。满足长期运营需求,让您从繁重的工作中解脱出来。
2、广泛适用
最全能的采集软件,支持任何类型的网站采集,适用率高达99.9%,支持发布到所有类型的网站 程序等您可以采集 本地文件并在没有界面的情况下发布。
3、信息自由
支持信息的自由组合,通过强大的数据整理功能对信息进行深度加工,创造新的内容。
4、任意格式文件下载
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至种子文件,只要你想。
5、伪原创
高速同义词替换、多词随机替换、随机段落排序、帮助内容SEO
6、无限多级页面采集
从支持多级目录开始,无论是垂直的多级信息页面,还是平行方向的多内容分页,还是AJAX调用页面,都让你轻松采集。
7、免费延期
开放的接口模式,让您自由开发二次开发,定制任意功能,实现所有需求。
EditorTools3使用教程
1、使用注册
通过注册获得使用ET的授权;
打开主菜单-授权注册,填写您在官方ET网站(非论坛)注册的有效账号,注册使用ET获得使用ET授权
2、系统设置
打开主菜单-系统-基本设置,进行各种系统设置
设置工作参数:根据您的需要设置工作参数
设置代理:如果使用代理上网,请设置网页的代理参数
设置劫持特征码:很多地区的电信宽带用户在上网时,会强制访问信息,将访问信息替换为一些代码,使用户只能通过代码中的框架查看原创网页. 这通常用于显示电信广告或执行其他秘密操作,称为劫持浏览器;出现这种情况时,ET的采集的源代码只能得到这些劫持代码,而不是采集的网页源代码。通过设置这些劫持代码的特征字符串,ET将尝试突破劫持访问真正的网页源代码,最多可重试5次访问网站。
3、选择工作计划
工作计划包括从源获取原创信息、处理信息、最终发布到目标网站的所有设置指令。执行自动采集工作的是ET的指挥官。当我们制定好您需要的计划后,您可以在主窗口中选择工作计划开始采集工作。
更新内容
1. 新增:支持多代理,自动轮换代理。
2. 优化:字符解码支持%xx格式。 查看全部
采集自动组合(EditorTools3基础版数据采集软件特征无人值守(组图))
EditorTools3基础版是一款简单易用的数据采集软件。可以根据你设置的规则允许,并且采集全天持续对数据执行。目前支持所有类型的网站,并且会自动合并采集的内容。
软件功能
1、与网站分离,通过独立产生的接口,可以支持任何网站或数据库
2、体积小,低功耗,稳定性好,非常适合在服务器上运行
3、所有规则均可导入导出,资源灵活复用
4、使用FTP上传文件,稳定安全
5、反向、顺序、随机可选采集文章
6、支持自动列表网址
7、支持网站数据分布在多个页面采集
8、自由设置数据项采集,每个数据项可以单独过滤排序
9、支持分页内容采集
10、支持下载任意格式和类型的文件(包括图片和视频)
11、可以突破防盗文件
12、支持动态文件URL解析
13、支持采集需要登录才能访问的网页
软件特点
1、全自动无人值守
无需值守,24小时自动实时监控目标,实时高效采集,全天候为您提供内容更新。满足长期运营需求,让您从繁重的工作中解脱出来。
2、广泛适用
最全能的采集软件,支持任何类型的网站采集,适用率高达99.9%,支持发布到所有类型的网站 程序等您可以采集 本地文件并在没有界面的情况下发布。
3、信息自由
支持信息的自由组合,通过强大的数据整理功能对信息进行深度加工,创造新的内容。
4、任意格式文件下载
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至种子文件,只要你想。
5、伪原创
高速同义词替换、多词随机替换、随机段落排序、帮助内容SEO
6、无限多级页面采集
从支持多级目录开始,无论是垂直的多级信息页面,还是平行方向的多内容分页,还是AJAX调用页面,都让你轻松采集。
7、免费延期
开放的接口模式,让您自由开发二次开发,定制任意功能,实现所有需求。
EditorTools3使用教程
1、使用注册
通过注册获得使用ET的授权;
打开主菜单-授权注册,填写您在官方ET网站(非论坛)注册的有效账号,注册使用ET获得使用ET授权
2、系统设置
打开主菜单-系统-基本设置,进行各种系统设置
设置工作参数:根据您的需要设置工作参数
设置代理:如果使用代理上网,请设置网页的代理参数
设置劫持特征码:很多地区的电信宽带用户在上网时,会强制访问信息,将访问信息替换为一些代码,使用户只能通过代码中的框架查看原创网页. 这通常用于显示电信广告或执行其他秘密操作,称为劫持浏览器;出现这种情况时,ET的采集的源代码只能得到这些劫持代码,而不是采集的网页源代码。通过设置这些劫持代码的特征字符串,ET将尝试突破劫持访问真正的网页源代码,最多可重试5次访问网站。
3、选择工作计划
工作计划包括从源获取原创信息、处理信息、最终发布到目标网站的所有设置指令。执行自动采集工作的是ET的指挥官。当我们制定好您需要的计划后,您可以在主窗口中选择工作计划开始采集工作。
更新内容
1. 新增:支持多代理,自动轮换代理。
2. 优化:字符解码支持%xx格式。
采集自动组合(WP-AutoBlog自动采集发布插件,支持采集多层级内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-22 04:26
WP-AutoBlog 是一个自动 采集 发布插件,它可以 采集 来自任何 网站 内容并自动更新您的 WordPress 网站。使用起来非常简单,无需复杂的设置,并且足够强大稳定,支持wordpress的所有功能。
【软件特色】
采集网站的任何内容,采集的信息一目了然
<p>通过简单的设置,可以采集来自任何网站的内容,并且可以设置多个采集任务同时运行,可以设置任务自动或手动运行,并且主任务列表显示每个采集任务的状态:上次测试的时间采集,下次测试的预计时间采集,最新的采集< @文章,更新了采集 查看全部
采集自动组合(WP-AutoBlog自动采集发布插件,支持采集多层级内容)
WP-AutoBlog 是一个自动 采集 发布插件,它可以 采集 来自任何 网站 内容并自动更新您的 WordPress 网站。使用起来非常简单,无需复杂的设置,并且足够强大稳定,支持wordpress的所有功能。
【软件特色】
采集网站的任何内容,采集的信息一目了然
<p>通过简单的设置,可以采集来自任何网站的内容,并且可以设置多个采集任务同时运行,可以设置任务自动或手动运行,并且主任务列表显示每个采集任务的状态:上次测试的时间采集,下次测试的预计时间采集,最新的采集< @文章,更新了采集
采集自动组合(v7版本增加了一个标签组合的结果和内容页标签 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-20 16:11
)
v7版本增加了标签组合功能。很多朋友在使用过程中发现组合的结果与自己想要的结果不一致。让我解释一下这个功能的使用。
1.标签的组合是文件下载前的内容
有朋友发现a标签中下载了某个文件,原地址为aaa,下载或检测到的地址为bbb。那么,如果在b标签中组合a标签,a标签的值为aaa。为什么使用这种处理方法是因为文件下载是在标签组合后进行的。如何实现标签内容为文件下载后的结果?你可以新建一个标签,选择“自定义固定格式数据”,把你的标签组合的内容放进去。这里的替换会在文件下载后进行。
2.内容页面标签循环采集并添加为新记录
如果两个组合的标签都是内容页标签,当这两个标签组合时,会根据循环次数最多的记录生成相同数量的新循环记录。如果一个标签的循环次数较少,则新生成的标签中该标签的值为空。例如,将标签a、b 组合起来生成标签c。a的循环数为5,b的循环数为3,将产生5个cs。其中,前3个标签的值分别对应a和b。在最后两个值中,b 的值为空。假设a的值为11,22,33,44,55,b的值为aa,bb,cc.c是[label:a][label:b]的组合,生成c的值是 11aa,22bb,33cc,44,55.
3.列表页标签和内容页标签组合
如果两个标签中的一个是内容页,另一个是列表页,则内容页将参与第2条中的循环处理。在这个过程中,列表页被视为一个字符串。合并完成后,程序将再次进行数据处理操作。最后,组合标签中列表页面标签的内容将替换为实际值。可以再次提取和下载组合结果。比如内容页a和列表页b组合生成c,其中a的值为11、22、22,b的值为bb,那么c的第一个组合结果为11[label: b],22[label:b],33[label:b],然后进行数据处理。如果b的值为bb,那么最终的结果可能是11bb、22bb、33bb。
有的朋友可能会说,为什么要把这个功能弄的这么复杂。其实这个函数主要用于第一个函数,其他的组合可能会产生和原来想法不同的结果。建议大家不要滥用这个功能,不要把它想象成灵丹妙药。
标签组合示例,如下图:
我们将标题和下载地址标签组合成一个新标签,以“$$$$”分隔,我们的测试结果如下:
你看到了吗。效果和我们预想的一样。
然后这个就简单使用了,我什么都没学到。
然后还有另一种标签组合,见下图:
这样测试的结果是什么,应该和上面的情况一样,谁知道呢,我们测试一下看看
查看全部
采集自动组合(v7版本增加了一个标签组合的结果和内容页标签
)
v7版本增加了标签组合功能。很多朋友在使用过程中发现组合的结果与自己想要的结果不一致。让我解释一下这个功能的使用。
1.标签的组合是文件下载前的内容
有朋友发现a标签中下载了某个文件,原地址为aaa,下载或检测到的地址为bbb。那么,如果在b标签中组合a标签,a标签的值为aaa。为什么使用这种处理方法是因为文件下载是在标签组合后进行的。如何实现标签内容为文件下载后的结果?你可以新建一个标签,选择“自定义固定格式数据”,把你的标签组合的内容放进去。这里的替换会在文件下载后进行。
2.内容页面标签循环采集并添加为新记录
如果两个组合的标签都是内容页标签,当这两个标签组合时,会根据循环次数最多的记录生成相同数量的新循环记录。如果一个标签的循环次数较少,则新生成的标签中该标签的值为空。例如,将标签a、b 组合起来生成标签c。a的循环数为5,b的循环数为3,将产生5个cs。其中,前3个标签的值分别对应a和b。在最后两个值中,b 的值为空。假设a的值为11,22,33,44,55,b的值为aa,bb,cc.c是[label:a][label:b]的组合,生成c的值是 11aa,22bb,33cc,44,55.
3.列表页标签和内容页标签组合
如果两个标签中的一个是内容页,另一个是列表页,则内容页将参与第2条中的循环处理。在这个过程中,列表页被视为一个字符串。合并完成后,程序将再次进行数据处理操作。最后,组合标签中列表页面标签的内容将替换为实际值。可以再次提取和下载组合结果。比如内容页a和列表页b组合生成c,其中a的值为11、22、22,b的值为bb,那么c的第一个组合结果为11[label: b],22[label:b],33[label:b],然后进行数据处理。如果b的值为bb,那么最终的结果可能是11bb、22bb、33bb。
有的朋友可能会说,为什么要把这个功能弄的这么复杂。其实这个函数主要用于第一个函数,其他的组合可能会产生和原来想法不同的结果。建议大家不要滥用这个功能,不要把它想象成灵丹妙药。
标签组合示例,如下图:
我们将标题和下载地址标签组合成一个新标签,以“$$$$”分隔,我们的测试结果如下:
你看到了吗。效果和我们预想的一样。
然后这个就简单使用了,我什么都没学到。
然后还有另一种标签组合,见下图:
这样测试的结果是什么,应该和上面的情况一样,谁知道呢,我们测试一下看看
采集自动组合(数据采集系统中自动入库设计工具的研究与实现(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-10 10:03
数据采集系统中自动存储设计工具的研究与实现 徐鹏 孙元 清华大学计算机系 E-Mail: xp{sBORy)@kcg. CS。协会 ingIlu&edu。cn ■ Stack:基于web的数据采集查杀系统,处理的数据量比较大;同时,采集的数据格式经常需要改变。因此,使用传统的音乐方式为每个版本的冰童设计自己的教学数据存储程序往往成本高昂,开发周期长。园区需要为系统提供可视化的开发工具。允许用户自定义冰通中的数据模型与数据库中救援城市的对应关系,系统根据用户的设置自动完成存储操作。本文将针对这一需求提出相应的解决方案。关磊字:JDBc,Drums 字典,结合基于牛奶b采集的数据中的对应关系和在线发布系统,定期报告数据的自动存储系统主要用于接收来自的最终定期提交用户在应用服务器上报数据后,用于将上市公司数据提取并写入信息中心数据库的操作。自动入库系统可以配合定期报表数据采集系统使用,即用户报表数据通过网络写入数据库的同时,对外发布使用的数据信息基于证券交易所信息中心数据库的信息模型,由定期报告数据自动存储系统写入信息中心数据库。同时进行仓储作业。根据信息中心的需要,可以对部分数据进行统计处理,生成统计信息写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。可以对部分数据进行统计处理,生成统计信息,写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。可以对部分数据进行统计处理,生成统计信息,写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。
一。W基于歌曲的数据采集和在线发布系统中的JDBC 本系统完全用Java语言编写,因此选择JDBC访问数据库。这既充分利用了Java语言的特点,又保证了其他部分与数据库的相对独立性。图书馆。诸如数据存储系统之类的应用程序正在服务器上运行。它与客户端没有直接关系,它直接通过J Ming c 访问数据库。无需通过其他级别。当AppIet之类的浏览器助手想要查询和修改数据库时。它是通过服务器上的 J8va 应用程序完成的。无论是本系统中基于浏览器的数据采集系统。在基于浏览器的数据查询系统中,Applet 不用于直接访问数据库,因为 Applet 受安全限制只能与下载的服务器建立连接。因此,只能访问服务器应用程序上的数据库。本系统的数据库可能与 scapular w 服务器不在同一台计算机上。使用Java作为Applet的中间层来访问数据库也可以提高访问效率,比如始终保持与数据库的连接,而不是每次访问都重新建立连接。您还可以组织和过滤 Applet 发送的请求。再次访问数据库。TcP 协议用于 Applet 和中间层的 Application 之间的通信。本系统使用JDBC访问数据库的一般程序流程如下:1) 加载数据库的JDBC驱动;2) 与数据库建立连接: 3) 创建 Statement 对象;4)中对Statement对象执行SQL语句,返回Resultset对象: 5) 处理ResultSet对象,得到查询结果;6) 关闭与数据库的连接。
JavaApplication作为中间层的过程如下: 1) 加载数据库的JDBC驱动: 2) 与数据库建立连接;3) 监听某个端口,等待Applet连接;4) 与Applet 建立连接后。接收来自 ADplet 的请求;5) 组织过滤请求,形成SQL语句;6) 创建 Statement 对象;7) 对 Statement 对象执行 SQL 语句并返回 ResultSet 对象;8)处理ResalltSet对象,得到查询结果{9)将查询结果返回给Applet;10)断开与^pDlet的连接,返回4)重新收听。实际上,接收Applet请求、访问数据库和返回结果都是由一个线程完成的。主线程继续返回监听状态。这样的应用程序可以同时为多个 ApDlets 服务。二。自动数据存储工具的设计。图ll 数据库存储流程 在上交所年报系统中,数据存储操作的系统设置包括源数据库设置、数据存储操作设置、源数据与数据库对应设置。Tan数据设置用于连接给定的数据库,获取数据库中表结构的相关信息进行系统设置。需要由系统管理员填写或选择的相关数据是用于连接数据库的驱动程序、数据池名称、用户名和密码。系统会调用JDBC接口访问数据库。
数据库对应关系设置用于设置数据字典与数据库中表结构存储的对应关系,为系统的数据存储功能提供了极大的灵活性。提供给用户的界面上的表项和数据库中的条目之间建立了对应关系。并允许数据库管理员针对不同的报表类型进行修改,以保证系统的可复用性。具体设计在后面介绍。数据库对应关系设计完成后,即可将数据存入数据库中。数据存储操作也完全按照管理员设置的对应表进行。用于数据存储过程。我们可以简单地用图ll来表示它。2. 1 数据字典和数据库存储的对应设计思路在数据采集系统中,用户填写界面上有很多表项,不同的表收录子表和自定义项,所以有不同的入库操作。同一个界面的表项中不同数据字段的存储操作是不一样的。对于这个不一致的数据单元,我们首先根据需要确定了表结构,将数据库中的一些接口表进行拆分,以适应不同的操作。比如界面上的募款表,分为募款总额表和数据库中募款资金使用明细表。关联交易表和投资收益表也是如此。所以,接口表中的字段与数据库中的字段不完全对应。同时。考虑到系统的用户界面因国内外不同类型的报告(如年报和中期报告)而异,并考虑到相关财务计算指标的变化,系统需要很大的灵活性。
对于数据库。首先,条目多,数据库中存储的数据量巨大。而且这些数据的重要性比较高,要保证数据库中数据的基本稳定性。因此,在上交所年报系统的数据存储操作中,我们提供了一个功能模块,用于设置界面表项中的字段与数据库表结构中的字段之间的对应关系。该模块将用户界面的数据字段映射到数据库中字段的计算关系。这降低了两者之间的耦合程度。使我们的系统实施更加灵活方便。更改用户界面条目时。或者在更改数据库中的表或字段时,对方不需要做大的改动,只需要使用对应关系设置工具修改入库规则即可。对于界面上表项中的每个域,我们在系统中用16位进行编码,以及每个域的代码和具体的域名。存储在数据字典(SCDicti.nary软件包)中,直接调用程序中的数据代码即可获取数据字段。这也体现了系统设计的灵活性。修改界面上的域名时,只需要修改数据字典中对应的域名即可,程序中代码的调用保持不变。对于数据库中的每个域,基本上都是按照不同的接口表来保存的。例如,我们前面介绍的总表和明细表。对于不同的数据库表,赖瑞有三个共同的主键,如下: lh吖『∞fn口awIdl』v叫ch stare 1(30)NOTNULLI nepo^Ye state『varch called(30)@ >NoTNULLl fr∞。
第一位表示表代码(格式为表名域名),第二位表示表中的字段代码)¨==≤:=2·5~6·7Ⅱ 图2接口域和数据库域一-对多关系。另外,数据库中字段的值可以是接口字段的组合,比如接口上字段的代码。数据库中的数据字段(双参数。第一个数字代表表代码(格式为表名字段名)第二个数字代表表中域的代码) 3.7+3.16——————图3l中界面域对应关系对象组合的计算方法。包括常用的整型和浮点型数据,如类型、字符串类型,以及它们的组合操作。2. 2 域对应关系及其设置在数据库中存储的数据表中。除了用户进入数据库的年报基础数据表外,还有一个域对应表calTable。
在复选框中,首先选择数据库中的一个表,窗口的左列将显示数据库中的所有列名。同时右侧会显示已经设置好的计算方式(即与界面字段的对应关系)。当用户设置或修改域时,只需点击右侧的小按钮,弹出域选择对话框。用户选择界面域或它们的组合后,新设置的对应关系会在 右侧栏中显示。用户点击“申请”,确认此表中信函的对应关系,重新入库。然后用户可以对下一个表进行操作。3.数据存储操作data采集系统加载的数据保存在SCReportData对象中,
以及从CalTable获得的每个表中每个字段的计算方法。为数据库中的基础数据表(即用户需要进入数据库的数据表)。分为三种情况: ·表中每个公司的记录是唯一的,不依赖于报表类型。唯一表:主要是companyTable,changes和changes。所以每次都入库。对标记执行更新操作。· 基本表格:这些表格中的数据对于每个年度报告或中期报告都是唯一的。但是,不同类型的报告将对应不同的记录。对于这些表,每次将报表放入数据库时都会执行一次写入操作。● 子表或明细表:这些表中的数据对于每个年度报告或中期报告可以有多条记录,因此对它们执行批量写入操作。针对这三种情况,系统提供了相应的数据库操作方法来保证数据的完整性。我们可以用K图5来说明仓储作业的流程。Ⅱ 图 5l 数据库存储操作流程 查看全部
采集自动组合(数据采集系统中自动入库设计工具的研究与实现(图))
数据采集系统中自动存储设计工具的研究与实现 徐鹏 孙元 清华大学计算机系 E-Mail: xp{sBORy)@kcg. CS。协会 ingIlu&edu。cn ■ Stack:基于web的数据采集查杀系统,处理的数据量比较大;同时,采集的数据格式经常需要改变。因此,使用传统的音乐方式为每个版本的冰童设计自己的教学数据存储程序往往成本高昂,开发周期长。园区需要为系统提供可视化的开发工具。允许用户自定义冰通中的数据模型与数据库中救援城市的对应关系,系统根据用户的设置自动完成存储操作。本文将针对这一需求提出相应的解决方案。关磊字:JDBc,Drums 字典,结合基于牛奶b采集的数据中的对应关系和在线发布系统,定期报告数据的自动存储系统主要用于接收来自的最终定期提交用户在应用服务器上报数据后,用于将上市公司数据提取并写入信息中心数据库的操作。自动入库系统可以配合定期报表数据采集系统使用,即用户报表数据通过网络写入数据库的同时,对外发布使用的数据信息基于证券交易所信息中心数据库的信息模型,由定期报告数据自动存储系统写入信息中心数据库。同时进行仓储作业。根据信息中心的需要,可以对部分数据进行统计处理,生成统计信息写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。可以对部分数据进行统计处理,生成统计信息,写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。可以对部分数据进行统计处理,生成统计信息,写入数据库;这样可以减少信息中心工作人员的工作量。提高工作效率。
一。W基于歌曲的数据采集和在线发布系统中的JDBC 本系统完全用Java语言编写,因此选择JDBC访问数据库。这既充分利用了Java语言的特点,又保证了其他部分与数据库的相对独立性。图书馆。诸如数据存储系统之类的应用程序正在服务器上运行。它与客户端没有直接关系,它直接通过J Ming c 访问数据库。无需通过其他级别。当AppIet之类的浏览器助手想要查询和修改数据库时。它是通过服务器上的 J8va 应用程序完成的。无论是本系统中基于浏览器的数据采集系统。在基于浏览器的数据查询系统中,Applet 不用于直接访问数据库,因为 Applet 受安全限制只能与下载的服务器建立连接。因此,只能访问服务器应用程序上的数据库。本系统的数据库可能与 scapular w 服务器不在同一台计算机上。使用Java作为Applet的中间层来访问数据库也可以提高访问效率,比如始终保持与数据库的连接,而不是每次访问都重新建立连接。您还可以组织和过滤 Applet 发送的请求。再次访问数据库。TcP 协议用于 Applet 和中间层的 Application 之间的通信。本系统使用JDBC访问数据库的一般程序流程如下:1) 加载数据库的JDBC驱动;2) 与数据库建立连接: 3) 创建 Statement 对象;4)中对Statement对象执行SQL语句,返回Resultset对象: 5) 处理ResultSet对象,得到查询结果;6) 关闭与数据库的连接。
JavaApplication作为中间层的过程如下: 1) 加载数据库的JDBC驱动: 2) 与数据库建立连接;3) 监听某个端口,等待Applet连接;4) 与Applet 建立连接后。接收来自 ADplet 的请求;5) 组织过滤请求,形成SQL语句;6) 创建 Statement 对象;7) 对 Statement 对象执行 SQL 语句并返回 ResultSet 对象;8)处理ResalltSet对象,得到查询结果{9)将查询结果返回给Applet;10)断开与^pDlet的连接,返回4)重新收听。实际上,接收Applet请求、访问数据库和返回结果都是由一个线程完成的。主线程继续返回监听状态。这样的应用程序可以同时为多个 ApDlets 服务。二。自动数据存储工具的设计。图ll 数据库存储流程 在上交所年报系统中,数据存储操作的系统设置包括源数据库设置、数据存储操作设置、源数据与数据库对应设置。Tan数据设置用于连接给定的数据库,获取数据库中表结构的相关信息进行系统设置。需要由系统管理员填写或选择的相关数据是用于连接数据库的驱动程序、数据池名称、用户名和密码。系统会调用JDBC接口访问数据库。
数据库对应关系设置用于设置数据字典与数据库中表结构存储的对应关系,为系统的数据存储功能提供了极大的灵活性。提供给用户的界面上的表项和数据库中的条目之间建立了对应关系。并允许数据库管理员针对不同的报表类型进行修改,以保证系统的可复用性。具体设计在后面介绍。数据库对应关系设计完成后,即可将数据存入数据库中。数据存储操作也完全按照管理员设置的对应表进行。用于数据存储过程。我们可以简单地用图ll来表示它。2. 1 数据字典和数据库存储的对应设计思路在数据采集系统中,用户填写界面上有很多表项,不同的表收录子表和自定义项,所以有不同的入库操作。同一个界面的表项中不同数据字段的存储操作是不一样的。对于这个不一致的数据单元,我们首先根据需要确定了表结构,将数据库中的一些接口表进行拆分,以适应不同的操作。比如界面上的募款表,分为募款总额表和数据库中募款资金使用明细表。关联交易表和投资收益表也是如此。所以,接口表中的字段与数据库中的字段不完全对应。同时。考虑到系统的用户界面因国内外不同类型的报告(如年报和中期报告)而异,并考虑到相关财务计算指标的变化,系统需要很大的灵活性。
对于数据库。首先,条目多,数据库中存储的数据量巨大。而且这些数据的重要性比较高,要保证数据库中数据的基本稳定性。因此,在上交所年报系统的数据存储操作中,我们提供了一个功能模块,用于设置界面表项中的字段与数据库表结构中的字段之间的对应关系。该模块将用户界面的数据字段映射到数据库中字段的计算关系。这降低了两者之间的耦合程度。使我们的系统实施更加灵活方便。更改用户界面条目时。或者在更改数据库中的表或字段时,对方不需要做大的改动,只需要使用对应关系设置工具修改入库规则即可。对于界面上表项中的每个域,我们在系统中用16位进行编码,以及每个域的代码和具体的域名。存储在数据字典(SCDicti.nary软件包)中,直接调用程序中的数据代码即可获取数据字段。这也体现了系统设计的灵活性。修改界面上的域名时,只需要修改数据字典中对应的域名即可,程序中代码的调用保持不变。对于数据库中的每个域,基本上都是按照不同的接口表来保存的。例如,我们前面介绍的总表和明细表。对于不同的数据库表,赖瑞有三个共同的主键,如下: lh吖『∞fn口awIdl』v叫ch stare 1(30)NOTNULLI nepo^Ye state『varch called(30)@ >NoTNULLl fr∞。
第一位表示表代码(格式为表名域名),第二位表示表中的字段代码)¨==≤:=2·5~6·7Ⅱ 图2接口域和数据库域一-对多关系。另外,数据库中字段的值可以是接口字段的组合,比如接口上字段的代码。数据库中的数据字段(双参数。第一个数字代表表代码(格式为表名字段名)第二个数字代表表中域的代码) 3.7+3.16——————图3l中界面域对应关系对象组合的计算方法。包括常用的整型和浮点型数据,如类型、字符串类型,以及它们的组合操作。2. 2 域对应关系及其设置在数据库中存储的数据表中。除了用户进入数据库的年报基础数据表外,还有一个域对应表calTable。
在复选框中,首先选择数据库中的一个表,窗口的左列将显示数据库中的所有列名。同时右侧会显示已经设置好的计算方式(即与界面字段的对应关系)。当用户设置或修改域时,只需点击右侧的小按钮,弹出域选择对话框。用户选择界面域或它们的组合后,新设置的对应关系会在 右侧栏中显示。用户点击“申请”,确认此表中信函的对应关系,重新入库。然后用户可以对下一个表进行操作。3.数据存储操作data采集系统加载的数据保存在SCReportData对象中,
以及从CalTable获得的每个表中每个字段的计算方法。为数据库中的基础数据表(即用户需要进入数据库的数据表)。分为三种情况: ·表中每个公司的记录是唯一的,不依赖于报表类型。唯一表:主要是companyTable,changes和changes。所以每次都入库。对标记执行更新操作。· 基本表格:这些表格中的数据对于每个年度报告或中期报告都是唯一的。但是,不同类型的报告将对应不同的记录。对于这些表,每次将报表放入数据库时都会执行一次写入操作。● 子表或明细表:这些表中的数据对于每个年度报告或中期报告可以有多条记录,因此对它们执行批量写入操作。针对这三种情况,系统提供了相应的数据库操作方法来保证数据的完整性。我们可以用K图5来说明仓储作业的流程。Ⅱ 图 5l 数据库存储操作流程
采集自动组合(元数据资产治理(详情见),需注意什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-05 04:14
一、简介
数据资产治理的前提(见:)必须有数据。它要求数据类型齐全,数量大,并尽可能覆盖数据流通的方方面面。元数据 采集 变得尤为重要。它是数据资产治理的核心基础。
在早期的采集系统中,我们主要使用“API直连”来连接采集Hive/Mysql表元数据。随着业务的快速发展,对数据运营和成本管理的需求越来越强烈。元数据需要覆盖整个数据链路,包括离线计算平台、实时计算平台、内部工具、任务元数据等。采集在元数据的过程中,我们遇到了以下困难:
本文主要介绍了我们在元数据含义、提取、采集、监控告警等方面所做的一些事情。
二、元数据2.1 什么是元数据
什么是元数据?元数据是“用于描述数据的数据”。例如:我用手机拍了一张照片,查看了照片的详细信息,如下图:
照片信息
文件名:IMG_20201217_114115
时间:2020年12月17号 11:30:01
分辨率:4608X2592
文件大小:2.69MB
相机制造商:OnePlus
相机型号:ONEPLUS A5000
闪光灯:未使用闪光灯
焦距:4.10mm
白平衡:自动
光圈:f/1.7
曝光时间:1/50
ISO:1250
这些是数码照片的元数据,用于描述图片。在资产管理平台中,我们采集Hive组件的元数据包括:表名、字段列表、负责人、任务调度信息等。
采集全链路数据(各种元数据)可以帮助数据平台回答:我们有哪些数据?有多少人在使用它?什么是数据存储?如何找到这些数据?什么是数据流?分析问题的根源,结合血缘关系分析影响。
2.2 采集 什么元数据
如下图所示,是一个数据流图。我们主要采集各个平台组件:
截至目前,采集所达到的平台组件已经覆盖了整个数据链路。涵盖10种数据+,基础元数据量10w+。主要包括:
三、元数据提取
如何从众多平台组件中提取元数据?大致有以下几个方面:
计算任务通过分析任务的输入/输出依赖配置获得血缘关系。SQL类任务使用“Sql Parser”(ANTLR4系统实现的sql重写工具)工具解析SQL脚本,获取表/字段级血缘关系。3.1 线下平台
主要是采集Hive/RDS表的元数据。
Hive组件的元数据存放在Metastore中,通过JDBC访问Mysql获取数据库表的元数据。根据Hive表信息组装HDFS地址,通过FileSystem API获取文件状态、文件编号、文件大小、数据更新时间等趋势数据。
RDS平台提供Mysql服务的管理,通过平台提供的服务接口获取表元数据、趋势数据、访问状态等信息。
3.2 实时平台
主要是Flume/Hbase/Kafka等组件的元数据。
例如:我们访问放置在KP平台的工单数据,获取topic的基本元数据信息,定期消费topic获取样本数据,解析字段列表。平台本身提供集群状态和业务监控指标,通过平台服务获取集群资源的使用情况。
3.3 内部工具
主要是BI报表系统的血缘关系数据(BI报表查询的Hive表和Mysql表关系)、指标数据库(Hive表和指标相关的字段关系)、OneService服务(访问哪些数据库表的关系数据)通过接口)。
这些内部系统在产品的不断迭代中积累了大量的元数据。在不考虑元数据的时效性的情况下,我们一般都是将这些系统的数据同步到Hive数据库中,然后离线处理后获取元数据。
3.4 任务元数据
元数据任务主要是DP离线任务、Flink计算服务和Flume任务。
这些计算任务都放在磁盘上,通过Binlog同步或离线同步获取任务列表,获取任务的元数据。
四、数据采集
元数据提取后,我们就可以得到数据链中各个平台组件的元数据。数据采集是指将这些元数据存储在数据资产管理系统的数据库中。
4.1 采集 方法
采集 主要有三种数据类型。下表列出了三种方法的优缺点:
一般情况下,我们推荐业务方使用采集SDK。主动上报元数据,访问时只需要关注上报数据格式和SDK初始化,即可快速完成上报。
4.2 采集SDK 设计
采集SDK支持基础元数据、趋势数据、血缘关系数据的上报,包括客户端SDK和采集服务器两部分。客户端SDK主要实现通用报表模型的定义和报表功能,采集服务器主要实现不同的适配器,完成数据的统一存储。
4.2.1 架构
采集SDK 客户端
定义了基本元数据(MetaSchema)、趋势数据(TrendSchema)和血缘关系数据(LineageSchema)的通用模型,并支持新的报告模型(XXXSchema)。ReportService实现了向Kafka推送数据的功能。
采集服务器
数据鉴权服务器消费Kafka,获取数据后,对每条记录的签名进行鉴权(获取记录中的appId、appName、token信息,重新生成token,比较值的过程)。统一仓储服务定义了统一的数据仓储模型,包括表基础元数据、趋势数据、血缘关系数据、趋势数据,实现不同数据类型的仓储服务。数据适配器Bridge获取Kafka的数据,根据不同的数据类型转换成“统一存储模型”,触发“统一存储服务”完成数据写入。4.2.2 通用型号
采集的平台组件很多。我们参考Hive“表模型”的定义,抽象出一套通用的数据上报模型,保证数据上报和数据存储的可扩展性。
通用血缘模型主要包括血缘模型定义和任务血缘模型定义,支持用户分别上报血缘关系和任务血缘关系。该模型定义如下:
/**
* 表血缘模型定义
*/
@Data
public class TableLineageSchema {
/**
* 当前节点
*/
private T current;
/**
* 父节点
*/
private List parents;
/**
* 子节点
*/
private List childs;
/**
* 表级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
/**
* 表任务血缘定义
*
*/
@Data
public class JobLineageSchema {
/**
* 任务节点对象
*/
private Job task;
/**
* 输入对象列表
*/
private List inputs;
/**
* 输出对象列表
*/
private List outputs;
/**
* 任务级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
每个模型定义都有一个扩展字段(传统的 json 格式)。不在定义中的指标可以放在扩展字段中。数据上报后,也会存储在元数据表的扩展字段中。访问新类型,索引定义大不相同,通过扩展新的数据模型定义,元数据报告完成。
4.2.3 访问、验证、限流
如何保证用户上报的数据是安全的?我们设计了一组签名:访问方Id(appId)、访问名称(appName)、访问标识(token)。管理员填写基本接入方信息,生成随机的appId和token信息。业务方在初始化采集SDK时,指定了签名信息,每上报的数据都会携带签名。在采集服务器上,每一条数据都会经过签名和认证,保证了数据的安全。
采集SDK 会对上报的每条数据执行通用规则来检查数据的有效性,例如表名不为空、负责人的有效性、表的大小、趋势数据不能为负。如果检测到非法数据,将被过滤掉并触发报警通知。
在采集SDK服务器上,每隔一定时间(每两秒)消费一批Kafka数据。支持设置消费数据的时间间隔和拉取的片数。下游入站压力不会因上报数据流量高峰而变化。大,起到了限流作用。
4.3 触发器采集
我们支持多种 采集 元数据方法。如何触发数据的采集?总体思路是:
基于Apollo配置系统(见:)和Linux系统的Crontab功能,实现任务调度。数据采集任务在Apollo上配置。配置改变后,Apollo会发布,配置信息会实时同步到在线节点的Crontab文件中。
4.3.1 增量任务,准实时
支持获取组件最近变化的元数据,配置增量任务,提高元数据采集的实时性。比如增量采集Hive表元数据,每1分钟查询一次metastore,获取最近更改的元数据列表,并更新元数据。
4.3.2个完整任务,所有细节
增量 采集 可能有数据丢失的情况。每 1 天或更多天完成一次 采集 作为底线解决方案,以确保元数据的完整性。
4.3.3 采集SDK,实时上报
采集SDK 支持实时和全量上报模式。一般要求在数据变更后实时上报接入方的数据,不定期上报一次全量。
4.4 数据存储、更新
在数据采集之后,就要考虑如何存储,以及元数据发生变化时如何同步更新。我们对来自采集的元数据进行归类和统一,抽象出“表模型”并将其存储在类别中。
4.4.1 数据存储
我们评估了每个组件的元数据量(共10w+),预估了数据可能的使用场景,最终选择了Mysql来存储。为了满足用户的个性化查询需求,构建了Es宽表。表粒度主要包括:表名、备注、负责人、字段列表、趋势信息、业务领域信息、任务信息等。Es表在数据采集过程中同步更新,保证真实元数据查询的时间性,定期更新(构建离线模型表,每天同步更新Es表),保证元数据的完整性。
元数据中的表不是孤立存在的。一般有关联任务(离线任务、实时任务)输出表,表和任务之间的流向关系也会在数据图中显示。那么如何在众多平台组件中唯一区分一个表呢?我们通过表所在的集群名称、项目名称、表类型(它来自哪个平台组件)和表名称的组合来唯一区分。
对数据进行分类存储,最终形成:基础元数据表、趋势数据表、任务元数据表、血缘关系数据表。
4.4.2 数据更新
元数据表离线,如何同步更新?
五、监控和警告
采集 已经完成了数据,是不是都做完了?答案是否定的。采集在这个过程中,数据类型很多,删除方式多种多样,删除链接长度。任何环节的任何问题都会导致结果不准确。我们通过以下方式保证采集服务的稳定性。
5.1 采集链路监控告警5.1.1 接口监控
我们将系统的所有服务接口分为核心、重要、通用三个层次,并支持标注接口和责任人的注解。异常会触发不同级别的警报通知。核心业务异常直接触发电话报警,重要或一般业务异常触发电子邮件报警。系统会存储接口请求和执行状态并删除,每天向接口服务负责人发送服务日报。通过将采集服务的元数据标记为核心和重要服务,“API直连方式”的接口被异常感知。
如下图,是服务接口的告警通知:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[重要]等级问题, 方法名:[com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb], 异常信息:null
host:XXXXXX
处理地址:https://XXXX
如下图,是服务接口的每日告警报告:
[Warning][prod][data-dict] - 数据资产平台告警
[shunfengche]今日问题汇总
请及时收敛今日问题,总问题数 1 个,出现 2 次
【核心】问题 0 个:
【重要】问题 0 个:
【一般】问题 1 个:
[数据采集]com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb 今日出现 2 次, 已存在 5 天, 历史出现 8 次
host:XXXXXX
处理地址:https://XXXX
5.1.2 采集 进程监控
对于每个元数据采集服务,如果采集进程发生异常,都会发送告警通知。
如下图,是采集过程中异常触发的告警:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[一般]等级问题, 方法名:[com.youzan.bigdata.crystal.asyncworker.work.AsyncAllRdsDDLWorker.run], 异常信息:/n
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLQueryInterruptedException: Query execution was interrupted
5.1.3 Kafka 消息积压警告
Kafka数据的消费,通过kp平台配置消息backlog告警,实现对采集SDK服务的异常感知。
5.2 结果数据对比
主要用于事后监测预警,定期检测采集元数据量的异常波动。针对不同类型的元数据,通过将当天采集的数量与过去7天的历史平均数量进行比较,设置异常波动的报警阈值,超过阈值时触发报警通知.
针对采集的元数据结果表,配置一些数据质量检测规则,定期执行异常规则,发现问题数据时触发告警通知。这保证了对结果数据的异常感知。例如,定义的数据质量规则:
5.3 项目迭代机制,采集问题收敛
通过事前、事中、事后的监测预警机制,可以及时发现和感知采集的异常情况。对于异常问题,我们一般以项目迭代的方式发起jira,组织相关人员进行审核。追根溯源,讨论改进方案,产生行动,关注并持续收敛问题。
六、总结与展望6.1 结论
我们定义了一套通用的数据采集和存储模型,支持访问不同数据类型的元数据,支持多种访问方式,采集SDK提高了访问效率和数据时效性。
如下图所示,各个组件的元数据已经打通,数据分类统一管理,提供了数据字典、数据地图、资产市场等元数据的应用。
如果将数据资产治理比作高层建筑的建设,那么不同构件的元数据是原材料,数据采集是基础。只有夯实了基础,数据治理的建设才能越来越稳固。
6.2 展望
在数据采集的过程中,我们也遇到了很多问题。在后续工作中,我们需要不断的优化和功能迭代,包括但不限于:
最后,有赞数据中心,长期招聘基础组件、平台研发、数据仓库、数据产品、算法等人才,欢迎加入,一起享受~简历投递邮箱:。 查看全部
采集自动组合(元数据资产治理(详情见),需注意什么?)
一、简介
数据资产治理的前提(见:)必须有数据。它要求数据类型齐全,数量大,并尽可能覆盖数据流通的方方面面。元数据 采集 变得尤为重要。它是数据资产治理的核心基础。
在早期的采集系统中,我们主要使用“API直连”来连接采集Hive/Mysql表元数据。随着业务的快速发展,对数据运营和成本管理的需求越来越强烈。元数据需要覆盖整个数据链路,包括离线计算平台、实时计算平台、内部工具、任务元数据等。采集在元数据的过程中,我们遇到了以下困难:
本文主要介绍了我们在元数据含义、提取、采集、监控告警等方面所做的一些事情。
二、元数据2.1 什么是元数据
什么是元数据?元数据是“用于描述数据的数据”。例如:我用手机拍了一张照片,查看了照片的详细信息,如下图:
照片信息
文件名:IMG_20201217_114115
时间:2020年12月17号 11:30:01
分辨率:4608X2592
文件大小:2.69MB
相机制造商:OnePlus
相机型号:ONEPLUS A5000
闪光灯:未使用闪光灯
焦距:4.10mm
白平衡:自动
光圈:f/1.7
曝光时间:1/50
ISO:1250
这些是数码照片的元数据,用于描述图片。在资产管理平台中,我们采集Hive组件的元数据包括:表名、字段列表、负责人、任务调度信息等。
采集全链路数据(各种元数据)可以帮助数据平台回答:我们有哪些数据?有多少人在使用它?什么是数据存储?如何找到这些数据?什么是数据流?分析问题的根源,结合血缘关系分析影响。
2.2 采集 什么元数据
如下图所示,是一个数据流图。我们主要采集各个平台组件:
截至目前,采集所达到的平台组件已经覆盖了整个数据链路。涵盖10种数据+,基础元数据量10w+。主要包括:
三、元数据提取
如何从众多平台组件中提取元数据?大致有以下几个方面:
计算任务通过分析任务的输入/输出依赖配置获得血缘关系。SQL类任务使用“Sql Parser”(ANTLR4系统实现的sql重写工具)工具解析SQL脚本,获取表/字段级血缘关系。3.1 线下平台
主要是采集Hive/RDS表的元数据。
Hive组件的元数据存放在Metastore中,通过JDBC访问Mysql获取数据库表的元数据。根据Hive表信息组装HDFS地址,通过FileSystem API获取文件状态、文件编号、文件大小、数据更新时间等趋势数据。
RDS平台提供Mysql服务的管理,通过平台提供的服务接口获取表元数据、趋势数据、访问状态等信息。
3.2 实时平台
主要是Flume/Hbase/Kafka等组件的元数据。
例如:我们访问放置在KP平台的工单数据,获取topic的基本元数据信息,定期消费topic获取样本数据,解析字段列表。平台本身提供集群状态和业务监控指标,通过平台服务获取集群资源的使用情况。
3.3 内部工具
主要是BI报表系统的血缘关系数据(BI报表查询的Hive表和Mysql表关系)、指标数据库(Hive表和指标相关的字段关系)、OneService服务(访问哪些数据库表的关系数据)通过接口)。
这些内部系统在产品的不断迭代中积累了大量的元数据。在不考虑元数据的时效性的情况下,我们一般都是将这些系统的数据同步到Hive数据库中,然后离线处理后获取元数据。
3.4 任务元数据
元数据任务主要是DP离线任务、Flink计算服务和Flume任务。
这些计算任务都放在磁盘上,通过Binlog同步或离线同步获取任务列表,获取任务的元数据。
四、数据采集
元数据提取后,我们就可以得到数据链中各个平台组件的元数据。数据采集是指将这些元数据存储在数据资产管理系统的数据库中。
4.1 采集 方法
采集 主要有三种数据类型。下表列出了三种方法的优缺点:
一般情况下,我们推荐业务方使用采集SDK。主动上报元数据,访问时只需要关注上报数据格式和SDK初始化,即可快速完成上报。
4.2 采集SDK 设计
采集SDK支持基础元数据、趋势数据、血缘关系数据的上报,包括客户端SDK和采集服务器两部分。客户端SDK主要实现通用报表模型的定义和报表功能,采集服务器主要实现不同的适配器,完成数据的统一存储。
4.2.1 架构
采集SDK 客户端
定义了基本元数据(MetaSchema)、趋势数据(TrendSchema)和血缘关系数据(LineageSchema)的通用模型,并支持新的报告模型(XXXSchema)。ReportService实现了向Kafka推送数据的功能。
采集服务器
数据鉴权服务器消费Kafka,获取数据后,对每条记录的签名进行鉴权(获取记录中的appId、appName、token信息,重新生成token,比较值的过程)。统一仓储服务定义了统一的数据仓储模型,包括表基础元数据、趋势数据、血缘关系数据、趋势数据,实现不同数据类型的仓储服务。数据适配器Bridge获取Kafka的数据,根据不同的数据类型转换成“统一存储模型”,触发“统一存储服务”完成数据写入。4.2.2 通用型号
采集的平台组件很多。我们参考Hive“表模型”的定义,抽象出一套通用的数据上报模型,保证数据上报和数据存储的可扩展性。
通用血缘模型主要包括血缘模型定义和任务血缘模型定义,支持用户分别上报血缘关系和任务血缘关系。该模型定义如下:
/**
* 表血缘模型定义
*/
@Data
public class TableLineageSchema {
/**
* 当前节点
*/
private T current;
/**
* 父节点
*/
private List parents;
/**
* 子节点
*/
private List childs;
/**
* 表级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
/**
* 表任务血缘定义
*
*/
@Data
public class JobLineageSchema {
/**
* 任务节点对象
*/
private Job task;
/**
* 输入对象列表
*/
private List inputs;
/**
* 输出对象列表
*/
private List outputs;
/**
* 任务级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
每个模型定义都有一个扩展字段(传统的 json 格式)。不在定义中的指标可以放在扩展字段中。数据上报后,也会存储在元数据表的扩展字段中。访问新类型,索引定义大不相同,通过扩展新的数据模型定义,元数据报告完成。
4.2.3 访问、验证、限流
如何保证用户上报的数据是安全的?我们设计了一组签名:访问方Id(appId)、访问名称(appName)、访问标识(token)。管理员填写基本接入方信息,生成随机的appId和token信息。业务方在初始化采集SDK时,指定了签名信息,每上报的数据都会携带签名。在采集服务器上,每一条数据都会经过签名和认证,保证了数据的安全。
采集SDK 会对上报的每条数据执行通用规则来检查数据的有效性,例如表名不为空、负责人的有效性、表的大小、趋势数据不能为负。如果检测到非法数据,将被过滤掉并触发报警通知。
在采集SDK服务器上,每隔一定时间(每两秒)消费一批Kafka数据。支持设置消费数据的时间间隔和拉取的片数。下游入站压力不会因上报数据流量高峰而变化。大,起到了限流作用。
4.3 触发器采集
我们支持多种 采集 元数据方法。如何触发数据的采集?总体思路是:
基于Apollo配置系统(见:)和Linux系统的Crontab功能,实现任务调度。数据采集任务在Apollo上配置。配置改变后,Apollo会发布,配置信息会实时同步到在线节点的Crontab文件中。
4.3.1 增量任务,准实时
支持获取组件最近变化的元数据,配置增量任务,提高元数据采集的实时性。比如增量采集Hive表元数据,每1分钟查询一次metastore,获取最近更改的元数据列表,并更新元数据。
4.3.2个完整任务,所有细节
增量 采集 可能有数据丢失的情况。每 1 天或更多天完成一次 采集 作为底线解决方案,以确保元数据的完整性。
4.3.3 采集SDK,实时上报
采集SDK 支持实时和全量上报模式。一般要求在数据变更后实时上报接入方的数据,不定期上报一次全量。
4.4 数据存储、更新
在数据采集之后,就要考虑如何存储,以及元数据发生变化时如何同步更新。我们对来自采集的元数据进行归类和统一,抽象出“表模型”并将其存储在类别中。
4.4.1 数据存储
我们评估了每个组件的元数据量(共10w+),预估了数据可能的使用场景,最终选择了Mysql来存储。为了满足用户的个性化查询需求,构建了Es宽表。表粒度主要包括:表名、备注、负责人、字段列表、趋势信息、业务领域信息、任务信息等。Es表在数据采集过程中同步更新,保证真实元数据查询的时间性,定期更新(构建离线模型表,每天同步更新Es表),保证元数据的完整性。
元数据中的表不是孤立存在的。一般有关联任务(离线任务、实时任务)输出表,表和任务之间的流向关系也会在数据图中显示。那么如何在众多平台组件中唯一区分一个表呢?我们通过表所在的集群名称、项目名称、表类型(它来自哪个平台组件)和表名称的组合来唯一区分。
对数据进行分类存储,最终形成:基础元数据表、趋势数据表、任务元数据表、血缘关系数据表。
4.4.2 数据更新
元数据表离线,如何同步更新?
五、监控和警告
采集 已经完成了数据,是不是都做完了?答案是否定的。采集在这个过程中,数据类型很多,删除方式多种多样,删除链接长度。任何环节的任何问题都会导致结果不准确。我们通过以下方式保证采集服务的稳定性。
5.1 采集链路监控告警5.1.1 接口监控
我们将系统的所有服务接口分为核心、重要、通用三个层次,并支持标注接口和责任人的注解。异常会触发不同级别的警报通知。核心业务异常直接触发电话报警,重要或一般业务异常触发电子邮件报警。系统会存储接口请求和执行状态并删除,每天向接口服务负责人发送服务日报。通过将采集服务的元数据标记为核心和重要服务,“API直连方式”的接口被异常感知。
如下图,是服务接口的告警通知:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[重要]等级问题, 方法名:[com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb], 异常信息:null
host:XXXXXX
处理地址:https://XXXX
如下图,是服务接口的每日告警报告:
[Warning][prod][data-dict] - 数据资产平台告警
[shunfengche]今日问题汇总
请及时收敛今日问题,总问题数 1 个,出现 2 次
【核心】问题 0 个:
【重要】问题 0 个:
【一般】问题 1 个:
[数据采集]com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb 今日出现 2 次, 已存在 5 天, 历史出现 8 次
host:XXXXXX
处理地址:https://XXXX
5.1.2 采集 进程监控
对于每个元数据采集服务,如果采集进程发生异常,都会发送告警通知。
如下图,是采集过程中异常触发的告警:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[一般]等级问题, 方法名:[com.youzan.bigdata.crystal.asyncworker.work.AsyncAllRdsDDLWorker.run], 异常信息:/n
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLQueryInterruptedException: Query execution was interrupted
5.1.3 Kafka 消息积压警告
Kafka数据的消费,通过kp平台配置消息backlog告警,实现对采集SDK服务的异常感知。
5.2 结果数据对比
主要用于事后监测预警,定期检测采集元数据量的异常波动。针对不同类型的元数据,通过将当天采集的数量与过去7天的历史平均数量进行比较,设置异常波动的报警阈值,超过阈值时触发报警通知.
针对采集的元数据结果表,配置一些数据质量检测规则,定期执行异常规则,发现问题数据时触发告警通知。这保证了对结果数据的异常感知。例如,定义的数据质量规则:
5.3 项目迭代机制,采集问题收敛
通过事前、事中、事后的监测预警机制,可以及时发现和感知采集的异常情况。对于异常问题,我们一般以项目迭代的方式发起jira,组织相关人员进行审核。追根溯源,讨论改进方案,产生行动,关注并持续收敛问题。
六、总结与展望6.1 结论
我们定义了一套通用的数据采集和存储模型,支持访问不同数据类型的元数据,支持多种访问方式,采集SDK提高了访问效率和数据时效性。
如下图所示,各个组件的元数据已经打通,数据分类统一管理,提供了数据字典、数据地图、资产市场等元数据的应用。
如果将数据资产治理比作高层建筑的建设,那么不同构件的元数据是原材料,数据采集是基础。只有夯实了基础,数据治理的建设才能越来越稳固。
6.2 展望
在数据采集的过程中,我们也遇到了很多问题。在后续工作中,我们需要不断的优化和功能迭代,包括但不限于:
最后,有赞数据中心,长期招聘基础组件、平台研发、数据仓库、数据产品、算法等人才,欢迎加入,一起享受~简历投递邮箱:。
采集自动组合(不能期望配对测试是万能的,即我们仅依赖于一次)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-04 21:20
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实,说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境在生成新的之前使用了一定的方法组合。测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但通过一两个输入。由条件的同时影响引起。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,即只能依靠配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在进行过多等效组合时浪费的时间,尽可能节省宝贵的时间花在设计满足用户使用场景的测试用例上。
具体示例(手动步骤)
闲话少说,我们来看一个具体的例子。假设我们有以下接口的产品:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,文本框的条件还可以进一步细分,但是为了简单起见,我把条件设置的比较粗糙。如果按照全组合用例设置方法,则需要6个(下拉框控件的可能条件)*2(复杂复选框的可能条件)*2(单个复选框的可能条件)*6(文本框的可能条件)= 144 种组合。
我们来看一下使用配对法设计组合的方法:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图所示:
2. 首先,将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍四个参数二、三、配对组合的方法:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数并没有完全结合起来:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐的。事实上,有人已经自动化了这个过程。这是一个免费的开源工具,allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:
3. 然后使用 allpairs.exe 处理这个文件:
allpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后,结果如下:
您可以在设计测试环境矩阵和组合测试用例时使用 allpairs 技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好从测试覆盖率和用户场景覆盖率开始。, 添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合Behavior DrivenDesign技术,直接从需求中自动生成测试用例,如果我们自动化了基础测试用例,我们可以用这个技术对自动化测试用例进行配对组合(当然需要加一些限制),在节省测试时间的同时,要达到满意的测试覆盖率,当然,这样做需要我们自己写一个测试工具来实现这个技术——至少到现在我还没有看到现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
采集自动组合(不能期望配对测试是万能的,即我们仅依赖于一次)
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实,说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境在生成新的之前使用了一定的方法组合。测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但通过一两个输入。由条件的同时影响引起。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,即只能依靠配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在进行过多等效组合时浪费的时间,尽可能节省宝贵的时间花在设计满足用户使用场景的测试用例上。
具体示例(手动步骤)
闲话少说,我们来看一个具体的例子。假设我们有以下接口的产品:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,文本框的条件还可以进一步细分,但是为了简单起见,我把条件设置的比较粗糙。如果按照全组合用例设置方法,则需要6个(下拉框控件的可能条件)*2(复杂复选框的可能条件)*2(单个复选框的可能条件)*6(文本框的可能条件)= 144 种组合。
我们来看一下使用配对法设计组合的方法:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图所示:
2. 首先,将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍四个参数二、三、配对组合的方法:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数并没有完全结合起来:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐的。事实上,有人已经自动化了这个过程。这是一个免费的开源工具,allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:
3. 然后使用 allpairs.exe 处理这个文件:
allpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后,结果如下:
您可以在设计测试环境矩阵和组合测试用例时使用 allpairs 技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好从测试覆盖率和用户场景覆盖率开始。, 添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合Behavior DrivenDesign技术,直接从需求中自动生成测试用例,如果我们自动化了基础测试用例,我们可以用这个技术对自动化测试用例进行配对组合(当然需要加一些限制),在节省测试时间的同时,要达到满意的测试覆盖率,当然,这样做需要我们自己写一个测试工具来实现这个技术——至少到现在我还没有看到现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
采集自动组合(采集自动组合策略数据块geotreepre_sort模块中的pre_sort(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-01 14:22
采集自动组合策略数据块geotreepre_sort模块中的pre_sort已经限制了数据块的大小,为了自定义一个更大的数据块,我们需要确定相应的row数,然后重新定义row数据块定义规则。geosphere示例如下:rowrow_pre_sort=dict(row=pre_sort(geotree))pre_sortd=geotree.geosphere()pre_sort->doc("a")pre_sort->doc("b")pre_sort->doc("c")d.push(row)pre_sort->doc("d")pre_sort->doc("e")d.push(row_pre_sort)如果我们需要的数据块是一个新的row,那么可以根据meta_pre_sort进行分析。
meta_pre_sort的原始数据为e.collect_row(row_files=meta_pre_sort.obj_rows),要分析原始数据,必须分析数据块。meta_pre_sort.get("meta_pre_sort.txt")得到一个meta_pre_sort.txt文件,并打印出这个数据块,使用如下的语句:meta_pre_sort.items["row_files"]["end_items"]如果将这个meta_pre_sort字典中的每个属性定义成fraction(对应的的排序规则包括分数等),并用items["end_items"]=meta_pre_sort.items["collect_table"]="row",进行分析,代码如下:meta_pre_sort.items["collect_table"]["end_items"]根据规则可以重新定义数据块的大小。
注意是meta_pre_sort.txt而不是数据块。meta_pre_sort.txt的格式为{"end_items":row}reference.fractions_,.fractions.rows:{"end_items":end_items.rows,.fractions.rows.fractions},.meta_pre_sort:{"collect_table":meta_pre_sort.txt,.meta_pre_sort.collect_table:[fraction]}meta_pre_sort.items["row_files"]meta_pre_sort.rows=meta_pre_sort.rowsmeta_pre_sort.rows.items.items=rowmeta_pre_sort.items["end_items"]([])则对应于geosphere示例数据块,每个数据块后面都需要加冒号,否则meta_pre_sort.items["end_items"]得到为空数据。
附上完整代码:pre_sort原文:geotreepre_sort本文章来源于geosphere,istio微信公众号,微信扫一扫关注geosphere公众号。 查看全部
采集自动组合(采集自动组合策略数据块geotreepre_sort模块中的pre_sort(组图))
采集自动组合策略数据块geotreepre_sort模块中的pre_sort已经限制了数据块的大小,为了自定义一个更大的数据块,我们需要确定相应的row数,然后重新定义row数据块定义规则。geosphere示例如下:rowrow_pre_sort=dict(row=pre_sort(geotree))pre_sortd=geotree.geosphere()pre_sort->doc("a")pre_sort->doc("b")pre_sort->doc("c")d.push(row)pre_sort->doc("d")pre_sort->doc("e")d.push(row_pre_sort)如果我们需要的数据块是一个新的row,那么可以根据meta_pre_sort进行分析。
meta_pre_sort的原始数据为e.collect_row(row_files=meta_pre_sort.obj_rows),要分析原始数据,必须分析数据块。meta_pre_sort.get("meta_pre_sort.txt")得到一个meta_pre_sort.txt文件,并打印出这个数据块,使用如下的语句:meta_pre_sort.items["row_files"]["end_items"]如果将这个meta_pre_sort字典中的每个属性定义成fraction(对应的的排序规则包括分数等),并用items["end_items"]=meta_pre_sort.items["collect_table"]="row",进行分析,代码如下:meta_pre_sort.items["collect_table"]["end_items"]根据规则可以重新定义数据块的大小。
注意是meta_pre_sort.txt而不是数据块。meta_pre_sort.txt的格式为{"end_items":row}reference.fractions_,.fractions.rows:{"end_items":end_items.rows,.fractions.rows.fractions},.meta_pre_sort:{"collect_table":meta_pre_sort.txt,.meta_pre_sort.collect_table:[fraction]}meta_pre_sort.items["row_files"]meta_pre_sort.rows=meta_pre_sort.rowsmeta_pre_sort.rows.items.items=rowmeta_pre_sort.items["end_items"]([])则对应于geosphere示例数据块,每个数据块后面都需要加冒号,否则meta_pre_sort.items["end_items"]得到为空数据。
附上完整代码:pre_sort原文:geotreepre_sort本文章来源于geosphere,istio微信公众号,微信扫一扫关注geosphere公众号。
采集自动组合(配对测试是万能的,即我们仅依赖于配对自动生成的测试用例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-01 04:20
原来的:
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实,说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境在生成新的之前使用一定的方法组合。测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但通过一两个输入。由条件的同时影响引起。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,即只能依靠配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等价组合时浪费的时间,尽可能节省宝贵的时间花在设计满足用户使用场景的测试用例上。
具体示例(手动步骤)
闲话少说,我们来看一个具体的例子。假设我们有以下接口的产品:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,文本框的条件还可以进一步细分,但是为了简单起见,我把条件设置的比较粗糙。如果按照全组合用例设置方法,则需要6个(下拉框控件的可能条件)*2(复杂复选框的可能条件)*2(单个复选框的可能条件)*6(文本框的可能条件)= 144 种组合。
我们来看一下使用配对法设计组合的方法:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图所示:
2. 首先,将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍四个参数二、三、配对组合的方法:
3.然后再次组合第二个参数和第四个参数的条件,如下图:
4.为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数并没有完全结合起来:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐的。事实上,有人已经自动化了这个过程。这是一个免费的开源工具,allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2.将 Excel 文件保存为文本文件,以 Tab 键为分隔符:
3.然后使用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4.output.txt里面PAIRING DETAILS下的东西没用,可以直接删除。删除后,结果如下:
您可以在设计测试环境矩阵和组合测试用例时使用 allpairs 技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好从测试覆盖率和用户场景覆盖率开始。, 添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以用这个技术对自动化的测试用例进行配对组合(当然需要加一些限制),在节省测试时间的同时,要达到满意的测试覆盖率,当然,这样做需要我们自己写一个测试工具来实现这个技术——至少到现在我还没有看到现成的工具而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
采集自动组合(配对测试是万能的,即我们仅依赖于配对自动生成的测试用例)
原来的:
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实,说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境在生成新的之前使用一定的方法组合。测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但通过一两个输入。由条件的同时影响引起。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,即只能依靠配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等价组合时浪费的时间,尽可能节省宝贵的时间花在设计满足用户使用场景的测试用例上。
具体示例(手动步骤)
闲话少说,我们来看一个具体的例子。假设我们有以下接口的产品:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,文本框的条件还可以进一步细分,但是为了简单起见,我把条件设置的比较粗糙。如果按照全组合用例设置方法,则需要6个(下拉框控件的可能条件)*2(复杂复选框的可能条件)*2(单个复选框的可能条件)*6(文本框的可能条件)= 144 种组合。
我们来看一下使用配对法设计组合的方法:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图所示:
2. 首先,将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍四个参数二、三、配对组合的方法:
3.然后再次组合第二个参数和第四个参数的条件,如下图:
4.为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数并没有完全结合起来:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐的。事实上,有人已经自动化了这个过程。这是一个免费的开源工具,allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2.将 Excel 文件保存为文本文件,以 Tab 键为分隔符:
3.然后使用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4.output.txt里面PAIRING DETAILS下的东西没用,可以直接删除。删除后,结果如下:
您可以在设计测试环境矩阵和组合测试用例时使用 allpairs 技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好从测试覆盖率和用户场景覆盖率开始。, 添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以用这个技术对自动化的测试用例进行配对组合(当然需要加一些限制),在节省测试时间的同时,要达到满意的测试覆盖率,当然,这样做需要我们自己写一个测试工具来实现这个技术——至少到现在我还没有看到现成的工具而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
采集自动组合(\t统计数据APP开发一套数据采集SDK的功能:\页面访问流)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-31 19:16
随着有货APP的不断迭代开发,数据和业务部门对客户用户行为数据的要求越来越高;为了更好的监控APP的使用状态,客户端团队对APP本身的运行有越来越多的数据需求。紧急发送。急需一套客户端数据采集的工具,自动完整的采集用户行为数据,满足各部门的数据需求。
\\
为此,物火APP团队开发了一套数据采集 SDK。主要功能如下:
\\ 页面访问流程。用户在使用APP的过程中浏览了哪些页面。\\t浏览数据公开。用户在某个页面上查看了哪些产品。\\t业务数据自动采集。用户在应用期间点击了哪些位置以及触发了哪些操作。\\t性能数据自动采集。用户在使用APP的过程中,页面加载时间多长,图片加载时间多长,网络请求时间多长等\
另外,所有数据采集应该是自动化的、非侵入性的,即不需要人工埋点,集成SDK即可使用,无需改动或改动原有代码可能的。
\\
基于以上需求,AOP是技术方案的最佳选择,而在iOS上实现AOP需要实现Objective-C中运行时的黑魔法Method Swizzle。踏坑填坑的漫漫征程从这里开始,让我们一一领略实现的思路和方法。
\\页面访问流程\\
用户访问页面统计需要解决两个问题:
\\ 统计事件的入口点,即何时进行计数。\\tStatistic 数据字段,统计哪些数据。\
整体流程如下:
\\
\\统计事件的入口\\
用户访问页面统计的大致思路在View Controller生命周期方法中:
\\
可以获得用户访问页面的路径,两个事件时间戳的差值就是用户在页面停留的时间。
\\
通常我们APP中的View Controller继承自某个基类。我们可以在基类的相应方法中进行统计。但是,对于不继承自基类的视图控制器,我们无能为力。
\\
借助AOP,我们可以更优雅地做到这一点:在UIViewController的load方法中混用viewDidAppear和viewDidDisappear方法,原代码无需改动。
\\统计字段\\
根据数据要求,设置以下统计字段:
\\
页面进入和退出事件在上述数据结构中上报。
\\
还有几个问题需要考虑:
\\1.如何定义PAGE_ID和SOURCE_ID\\
因为需要统一iOS和Android的PAGE_ID,所以需要配置下发。iOS端得到的是一个plist文件,文件的key是View Controller的类名的字符串表示,值为PAGE_ID。
\\2.如何获取PAGE_ID和SOURCE_ID\\
PAGE_ID可以直接根据当前View Controller的class获取。SOURCE_ID 稍微复杂一些。具体的获取方式需要根据APP页面的嵌套栈结构来确定。通常,可以从 UINavigationController 的导航堆栈中获取之前的 View Controller 的页面 id。.
\\
至此,页面访问流量统计基本完成,根据页面进入和退出的PAGE_ID和SOURCE_ID串出一条完整的用户浏览路径,得到用户在每个页面的停留时间。
\\浏览数据曝光\\
采集 用户的浏览路径,在每个页面停留的时间之后,在某些页面,比如首页和产品列表页面,我们也想知道用户在页面上刷了多少屏并阅读哪些活动和产品可以更好地为用户推荐喜欢的产品。
\\
用户看到的屏幕区域被认为是一个资源位,所以用户看到的内容是由资源位组成的。那么曝光的含义如下:
\\
我们知道iOS中页面元素的基本单位是视图,所以我们只需要判断视图是否在可见区域,就可以知道当前视图上的资源位置是否需要暴露,然后进行相应的曝光操作,采集数据,上报接口等。
\\
从上面的分析可以看出,主要有两个问题需要解决:
\\View的可见度判断\\tview曝光数据采集\View的可见度判断\\
查询UIView Class Reference可以看到setFrame:和layoutSubivews方法,可以用来设置subview的frame。每次更新视图名望时都会调用此方法。因此,我们可以通过runtime swizzle来实现这个方法,并添加一些数据采集相关的操作。
\\
我们向 UIView 添加了以下属性:
\\
首先,明确下列术语的定义和规则:
\\
1.view的子视图可以同时看到3个需要满足的条件:
\\
相反,只要不满足上述任一条件,我们认为该子视图目前是不可见的。
\\
2.将视图设置为可见
\\
3.将视图设置为不可见
\\
Swzzile setFrame:,执行以下操作:
\\
\\
Swzzile layoutSubivews,调用yh_updateVisibleSubViews方法,执行如下操作:
\\
\\
通过以上操作,我们可以知道某个视图及其子视图是否可见。
\\ 查看曝光数据采集\\
为了获取view对应的数据,UIView还添加了以下属性:
\\
那么有两个问题:
\\视图曝光数据的粒度\\tview及其子视图节点曝光数据的组装时序\
视图曝光数据的粒度
\\
根据项目中的实践经验,UITableViewCell或者UI采集ViewCell一般是粒度最小的。同时,在最后一个节点的yh_exposureData字典中,添加一个key:isEnd来标识是否是最后一个节点。
\\
组装视图及其子视图的曝光数据的时机
\\
一般当最后一个节点的可见性发生变化时,从下到上遍历最后一个节点的superview,组装所有数据。
\\
因此,我们覆盖了 setYh_viewVisible: 方法,也就是 yh_viewVisible 的 set 方法。请执行下列操作:
\\
至此,我们已经解决了视图可见性判断和曝光数据采集的问题。这里不再重复数据报告和策略。
\\
这个方案有几个缺点
\\ 需要手动设置曝光数据。\\t 需要在合适的时候手动调用view.yh_viewVisible来触发数据采集,比如viewdidappear。\\t 视觉区域计算和曝光数据需要消耗一定的资源采集。\
另外两个问题值得注意:
\\UITableView在setBounds:时会改变view frame,所以需要swizzle setBounds:方法,设置bounds后需要调用[self yh_updateVisibleSubViews];\\tUIScrollView在setContentInset:时会影响view的可见区域,所以它需要 swizzle setContentInset: 方法,设置 contentInset 后需要调用 self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame, contentInset); \ 业务数据自动采集\\
业务数据自动采集,业界流行的无埋点数据采集。
\\
传统的客户端用户点击数据采集是基于人工埋点。如果您对哪个位置的数据感兴趣,只需单击此处。用户操作后,立即触发数据报表。人工掩埋的缺点很明显:错掩埋、漏掩。新版本发布后,经常有数据部的小伙伴反映某点的问题没有上报,某点的问题上报错了,开发同事也苦不堪言。
\\
无埋点数据采集带来新的变化。首先,基本避免人工埋葬,个别情况需要特殊处理。其次,从选择性的采集数据中,变成了采集用户点击和触摸的全量数据。
\\
新的变化也会带来新的挑战。未掩埋数据采集的可能性还是基于Objective-C的运行时特性。在实践过程中借鉴了iOS非埋点数据SDK的整体设计和技术实现,在实现中借鉴了Sensors Analytics iOS SDK和Mixpanel iPhone。接下来结合具体实践,介绍一下我们的实现思路和遇到的一些问题。主要分为以下三个方面:
\\ 如何保证自动采集的点的唯一性。\\t不同的点类型,需要哪些方法进行swizzle。坑在\\tswizzle的过程中踩到了。\ 如何保证自动采集的点数的唯一性\\
自动采集与手动埋点是分开的,所以没有该点的唯一标识。那么我们如何唯一定位自动采集的点呢?一种容易想到的解决方案是:基于页面视图的树状结构。这个解决方案可以分解为两个问题:
如何定义\\视图的唯一标识。\\tview 唯一标识如何生成它。\
视图唯一标识符(视图路径)的定义
\\
我们规定一个典型的视图路径如下:
\\
\ViewController[0]/UIView[0]/UITableView[0]/UITableViewCell[0:2]/UIButton[0]
\\
在:
\\ 有了这个标识符,就可以在当前页面的视图树结构中唯一标识这个元素。\\t 标识的每一项由两部分组成:一是当前元素所属类的字符串表示,二是当前元素在同级元素中的序号,从0开始计数。对于例如,当前第二个 UIImageView 是 UIImageView1。\\t 用 / 拼接标识不同的项目。\\t 标识的顶层是当前视图所在的 ViewController。\\t 对于UITableViewCell、UI采集ViewCell等类似的自定义组件,序号部分由section和row两部分组成,拼接在一起。\\t 标记的结尾是当前被点击或触摸的元素。\
如何生成视图唯一标识符
\\
视图路径生成过程:从触发操作的最末端元素向上查询,直到找到ViewController。假设当前点击的视图是A_View,从当前A_View开始遍历视图树,每一层的数据都存储在P_Array中。过程如下:
\\
\\ 如果A_View为UI采集ViewCell类型,获取A_View所在UI采集View的indexPath,P_Array推送路径信息[NSString stringWithFormat:@\"%@[%ld:%ld]\ 查看全部
采集自动组合(\t统计数据APP开发一套数据采集SDK的功能:\页面访问流)
随着有货APP的不断迭代开发,数据和业务部门对客户用户行为数据的要求越来越高;为了更好的监控APP的使用状态,客户端团队对APP本身的运行有越来越多的数据需求。紧急发送。急需一套客户端数据采集的工具,自动完整的采集用户行为数据,满足各部门的数据需求。
\\
为此,物火APP团队开发了一套数据采集 SDK。主要功能如下:
\\ 页面访问流程。用户在使用APP的过程中浏览了哪些页面。\\t浏览数据公开。用户在某个页面上查看了哪些产品。\\t业务数据自动采集。用户在应用期间点击了哪些位置以及触发了哪些操作。\\t性能数据自动采集。用户在使用APP的过程中,页面加载时间多长,图片加载时间多长,网络请求时间多长等\
另外,所有数据采集应该是自动化的、非侵入性的,即不需要人工埋点,集成SDK即可使用,无需改动或改动原有代码可能的。
\\
基于以上需求,AOP是技术方案的最佳选择,而在iOS上实现AOP需要实现Objective-C中运行时的黑魔法Method Swizzle。踏坑填坑的漫漫征程从这里开始,让我们一一领略实现的思路和方法。
\\页面访问流程\\
用户访问页面统计需要解决两个问题:
\\ 统计事件的入口点,即何时进行计数。\\tStatistic 数据字段,统计哪些数据。\
整体流程如下:
\\
\\统计事件的入口\\
用户访问页面统计的大致思路在View Controller生命周期方法中:
\\
可以获得用户访问页面的路径,两个事件时间戳的差值就是用户在页面停留的时间。
\\
通常我们APP中的View Controller继承自某个基类。我们可以在基类的相应方法中进行统计。但是,对于不继承自基类的视图控制器,我们无能为力。
\\
借助AOP,我们可以更优雅地做到这一点:在UIViewController的load方法中混用viewDidAppear和viewDidDisappear方法,原代码无需改动。
\\统计字段\\
根据数据要求,设置以下统计字段:
\\
页面进入和退出事件在上述数据结构中上报。
\\
还有几个问题需要考虑:
\\1.如何定义PAGE_ID和SOURCE_ID\\
因为需要统一iOS和Android的PAGE_ID,所以需要配置下发。iOS端得到的是一个plist文件,文件的key是View Controller的类名的字符串表示,值为PAGE_ID。
\\2.如何获取PAGE_ID和SOURCE_ID\\
PAGE_ID可以直接根据当前View Controller的class获取。SOURCE_ID 稍微复杂一些。具体的获取方式需要根据APP页面的嵌套栈结构来确定。通常,可以从 UINavigationController 的导航堆栈中获取之前的 View Controller 的页面 id。.
\\
至此,页面访问流量统计基本完成,根据页面进入和退出的PAGE_ID和SOURCE_ID串出一条完整的用户浏览路径,得到用户在每个页面的停留时间。
\\浏览数据曝光\\
采集 用户的浏览路径,在每个页面停留的时间之后,在某些页面,比如首页和产品列表页面,我们也想知道用户在页面上刷了多少屏并阅读哪些活动和产品可以更好地为用户推荐喜欢的产品。
\\
用户看到的屏幕区域被认为是一个资源位,所以用户看到的内容是由资源位组成的。那么曝光的含义如下:
\\
我们知道iOS中页面元素的基本单位是视图,所以我们只需要判断视图是否在可见区域,就可以知道当前视图上的资源位置是否需要暴露,然后进行相应的曝光操作,采集数据,上报接口等。
\\
从上面的分析可以看出,主要有两个问题需要解决:
\\View的可见度判断\\tview曝光数据采集\View的可见度判断\\
查询UIView Class Reference可以看到setFrame:和layoutSubivews方法,可以用来设置subview的frame。每次更新视图名望时都会调用此方法。因此,我们可以通过runtime swizzle来实现这个方法,并添加一些数据采集相关的操作。
\\
我们向 UIView 添加了以下属性:
\\
首先,明确下列术语的定义和规则:
\\
1.view的子视图可以同时看到3个需要满足的条件:
\\
相反,只要不满足上述任一条件,我们认为该子视图目前是不可见的。
\\
2.将视图设置为可见
\\
3.将视图设置为不可见
\\
Swzzile setFrame:,执行以下操作:
\\
\\
Swzzile layoutSubivews,调用yh_updateVisibleSubViews方法,执行如下操作:
\\
\\
通过以上操作,我们可以知道某个视图及其子视图是否可见。
\\ 查看曝光数据采集\\
为了获取view对应的数据,UIView还添加了以下属性:
\\
那么有两个问题:
\\视图曝光数据的粒度\\tview及其子视图节点曝光数据的组装时序\
视图曝光数据的粒度
\\
根据项目中的实践经验,UITableViewCell或者UI采集ViewCell一般是粒度最小的。同时,在最后一个节点的yh_exposureData字典中,添加一个key:isEnd来标识是否是最后一个节点。
\\
组装视图及其子视图的曝光数据的时机
\\
一般当最后一个节点的可见性发生变化时,从下到上遍历最后一个节点的superview,组装所有数据。
\\
因此,我们覆盖了 setYh_viewVisible: 方法,也就是 yh_viewVisible 的 set 方法。请执行下列操作:
\\
至此,我们已经解决了视图可见性判断和曝光数据采集的问题。这里不再重复数据报告和策略。
\\
这个方案有几个缺点
\\ 需要手动设置曝光数据。\\t 需要在合适的时候手动调用view.yh_viewVisible来触发数据采集,比如viewdidappear。\\t 视觉区域计算和曝光数据需要消耗一定的资源采集。\
另外两个问题值得注意:
\\UITableView在setBounds:时会改变view frame,所以需要swizzle setBounds:方法,设置bounds后需要调用[self yh_updateVisibleSubViews];\\tUIScrollView在setContentInset:时会影响view的可见区域,所以它需要 swizzle setContentInset: 方法,设置 contentInset 后需要调用 self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame, contentInset); \ 业务数据自动采集\\
业务数据自动采集,业界流行的无埋点数据采集。
\\
传统的客户端用户点击数据采集是基于人工埋点。如果您对哪个位置的数据感兴趣,只需单击此处。用户操作后,立即触发数据报表。人工掩埋的缺点很明显:错掩埋、漏掩。新版本发布后,经常有数据部的小伙伴反映某点的问题没有上报,某点的问题上报错了,开发同事也苦不堪言。
\\
无埋点数据采集带来新的变化。首先,基本避免人工埋葬,个别情况需要特殊处理。其次,从选择性的采集数据中,变成了采集用户点击和触摸的全量数据。
\\
新的变化也会带来新的挑战。未掩埋数据采集的可能性还是基于Objective-C的运行时特性。在实践过程中借鉴了iOS非埋点数据SDK的整体设计和技术实现,在实现中借鉴了Sensors Analytics iOS SDK和Mixpanel iPhone。接下来结合具体实践,介绍一下我们的实现思路和遇到的一些问题。主要分为以下三个方面:
\\ 如何保证自动采集的点的唯一性。\\t不同的点类型,需要哪些方法进行swizzle。坑在\\tswizzle的过程中踩到了。\ 如何保证自动采集的点数的唯一性\\
自动采集与手动埋点是分开的,所以没有该点的唯一标识。那么我们如何唯一定位自动采集的点呢?一种容易想到的解决方案是:基于页面视图的树状结构。这个解决方案可以分解为两个问题:
如何定义\\视图的唯一标识。\\tview 唯一标识如何生成它。\
视图唯一标识符(视图路径)的定义
\\
我们规定一个典型的视图路径如下:
\\
\ViewController[0]/UIView[0]/UITableView[0]/UITableViewCell[0:2]/UIButton[0]
\\
在:
\\ 有了这个标识符,就可以在当前页面的视图树结构中唯一标识这个元素。\\t 标识的每一项由两部分组成:一是当前元素所属类的字符串表示,二是当前元素在同级元素中的序号,从0开始计数。对于例如,当前第二个 UIImageView 是 UIImageView1。\\t 用 / 拼接标识不同的项目。\\t 标识的顶层是当前视图所在的 ViewController。\\t 对于UITableViewCell、UI采集ViewCell等类似的自定义组件,序号部分由section和row两部分组成,拼接在一起。\\t 标记的结尾是当前被点击或触摸的元素。\
如何生成视图唯一标识符
\\
视图路径生成过程:从触发操作的最末端元素向上查询,直到找到ViewController。假设当前点击的视图是A_View,从当前A_View开始遍历视图树,每一层的数据都存储在P_Array中。过程如下:
\\
\\ 如果A_View为UI采集ViewCell类型,获取A_View所在UI采集View的indexPath,P_Array推送路径信息[NSString stringWithFormat:@\"%@[%ld:%ld]\

