
采集自动组合
采集自动组合(数据采集平台_数据合并伴侣V208c.xls专业设置表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-28 23:08
一、采集Platform Data Merge Companion简介1)《采集Platform_Data Merge Companion V208c.xls》是数据采集平台的辅助工具,及其主要功能 数据表文件恢复、数据合并、数据表版本转换。请注意,这些功能只能在允许宏操作的环境中使用。2)合并伙伴组成:1个伙伴文件,几个文件目录(如下图) 图11:合并伙伴组成图二、宏在平台中的作用1)查看状态数据2)数据输入3)数据汇总操作4)允许智能表操作(如:表导出/导入、表解锁/锁定、格式刷新、数据汇总等)三、 启用宏操作 要在 Excel 中执行主平台文件,您必须启用宏。启用方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,将安全级别设置为“低”。具体操作请参考《1.4 启动Excel(VBA)宏运行环境》。注意:进行上述设置后,需要重新打开Excel文件并启用宏才能进行正常操作。四、填写数据表1) 打开数据表文件,根据表中的项目输入数据。注:每个数据表的上半部分是版本标识、主目录链接、说明和注释,输入数据前请仔细阅读。图25:2)要填写的列表
4)在选择页面的“导出文件”按钮上导出合并的数据表。出现提示时,按“确定”按钮,导出成功。导出的文件会自动存储在“回收数据表”目录中。图 31:执行“导出文件”按钮后,组合表将自动导出到“回收数据表”目录。图 32:“回收数据表”目录中的组合表。A7-1《专业设置table.xls》文件六、状态数据采集解惑1)在进行单表数据合并操作时,数据表中预留的数据行不足,如何添加数据行?操作步骤:执行“数据表锁定” 采集平台导航的“高级操作”中的操作。2)在data采集平台中,我校想增加一栏,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集 平台内的数据栏不能增减,否则会影响数据的统计和汇总(第十部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:在data采集平台中,我们学校想增加一列,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集数据列平台内不能进行增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:在data采集平台中,我们学校想增加一列,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集数据列平台内不能进行增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:平台中的数据栏不能增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:平台中的数据栏不能增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:系统发出宏警告,无法执行导出操作。我该怎么办?脚步:系统发出宏警告,无法执行导出操作。我该怎么办?脚步: 查看全部
采集自动组合(数据采集平台_数据合并伴侣V208c.xls专业设置表)
一、采集Platform Data Merge Companion简介1)《采集Platform_Data Merge Companion V208c.xls》是数据采集平台的辅助工具,及其主要功能 数据表文件恢复、数据合并、数据表版本转换。请注意,这些功能只能在允许宏操作的环境中使用。2)合并伙伴组成:1个伙伴文件,几个文件目录(如下图) 图11:合并伙伴组成图二、宏在平台中的作用1)查看状态数据2)数据输入3)数据汇总操作4)允许智能表操作(如:表导出/导入、表解锁/锁定、格式刷新、数据汇总等)三、 启用宏操作 要在 Excel 中执行主平台文件,您必须启用宏。启用方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,将安全级别设置为“低”。具体操作请参考《1.4 启动Excel(VBA)宏运行环境》。注意:进行上述设置后,需要重新打开Excel文件并启用宏才能进行正常操作。四、填写数据表1) 打开数据表文件,根据表中的项目输入数据。注:每个数据表的上半部分是版本标识、主目录链接、说明和注释,输入数据前请仔细阅读。图25:2)要填写的列表
4)在选择页面的“导出文件”按钮上导出合并的数据表。出现提示时,按“确定”按钮,导出成功。导出的文件会自动存储在“回收数据表”目录中。图 31:执行“导出文件”按钮后,组合表将自动导出到“回收数据表”目录。图 32:“回收数据表”目录中的组合表。A7-1《专业设置table.xls》文件六、状态数据采集解惑1)在进行单表数据合并操作时,数据表中预留的数据行不足,如何添加数据行?操作步骤:执行“数据表锁定” 采集平台导航的“高级操作”中的操作。2)在data采集平台中,我校想增加一栏,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集 平台内的数据栏不能增减,否则会影响数据的统计和汇总(第十部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:在data采集平台中,我们学校想增加一列,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集数据列平台内不能进行增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:在data采集平台中,我们学校想增加一列,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集数据列平台内不能进行增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:平台中的数据栏不能增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:平台中的数据栏不能增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:系统发出宏警告,无法执行导出操作。我该怎么办?脚步:系统发出宏警告,无法执行导出操作。我该怎么办?脚步:
采集自动组合(全能模拟王软件-全能王数据提取,工作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-22 07:31
万能模拟王软件是一款后台模拟鼠标和键盘的自动操作软件,实现鼠标和键盘的自动点击
万能模拟王采用脚本形式实现后台模拟鼠标和键盘的自动操作,多种功能的灵活组合弥补了网络上各种软件功能单一、灵活性差的不足。它可以应用于鼠标和键盘自动模拟点击操作、网站投票、网页点击、在线赚钱、数据提取、大规模分发、注册、推广、工作等多个行业
万能模拟王软件可以操作任何窗口程序。用户只需结合不同的功能,即可实现各种完美的自动化操作。程序以指定的窗口为操作目标,定位更准确、更快,无需编写任何代码。所有繁琐复杂的操作都可以自动完成。可以说,它是一个全方位的软件,可以应用于任何行业。只有那些你想不到、做不到的,放开你的手,让一切变得如此简单
主要功能包括多个数据提取采集、发布数据提交、网页填充、网页点击、广告点击和刷牙网站IP流量、在线刷卡、批量账户注册、博客论坛群发SEO关键词Optimized click、站群maintenance、universal update、,自动识别常用图片验证码,程序截图它还支持各种模拟点击操作的前台和后台鼠标和键盘。同时,该软件具有内置的自动换IP功能
通用模拟王软件的功能:
1、您可以定位模拟操作的任何窗口,包括最小化窗口和隐藏窗口
2、支持非法IP交换和拨号IP交换
3、自动码打印(自动识别图片验证码和远程UU码打印识别)
4、运行任何程序文件
5、强大的标准表达式和正则表达式文件提取功能
6、自动鼠标背景点击、双击和拖动操作
7、支持固定和随机时间暂停
8、自动填充随机字符
9、键盘按键模拟(包括单键和系统组合键)
10、快速将文本内容发送到指定区域
11、指定程序控件的屏幕截图
12、快速文本存在判断
13、网页链接提取和元素操作(网页文本输入和按钮点击)
14、Text copy(自动将文本复制到剪贴板)
15、指定窗体自动关闭
16、End进程
17、自动打开网页
18、清除临时Internet文件
特点:
1、各类普通网络推广软件功能固定单一,注册费用高。有时他们跟不上更新。很难找到适合自己的软件。全方位推广模拟王就是为此而生的
2、通过软件功能的灵活组合,可以完成自定义脚本:各种应用程序的自动操作,游戏、论坛、博客、留言簿、群评、群发邮件、账号注册任务中的自动鼠标点击和自动按钮,分类目录提交与分发、QQ群发、微博推广、网站投票、数据抽取等多种功能
3、图形二次开发:无需了解编程。只要打开软件,你就可以下载各种官方精心制作的脚本。此外,我们不仅教人钓鱼,还教人钓鱼!在让您享受鱼粉的同时,我们还有超过n个图形教程和视频教程。只要你努力工作,你就能一个人钓到大鱼
4、内部和外部浏览器:经过一年多的开发,我们在挂断类似软件时发现了一个常见问题。内置浏览器挂起时间过长,占用的内存越来越多。因此,在维护内置浏览器的同时,我们还推广不与软件共享内存的外部浏览器。在执行过程中,程序可以每隔一段时间关闭和重新打开它以释放内存
5、external WAP手机浏览器:WAP网页比PC网页限制少,浏览速度快,在网络推广中具有无可比拟的分量
6、正则文本提取:该程序具有强大的标准公式和正则表达式文本提取功能,使得采集非常容易
7、support post Publishing:软件可以发送post数据和header数据,使登录和发布更加快速稳定
8、验证码标识:软件配置手动标识、验证库标识和远程手动标识,使用灵活。定制验证码标识项可随时随地批量发送或更新网站使用
通用模拟王软件的一些应用行业:
1、Variable网站自动回复帖子 查看全部
采集自动组合(全能模拟王软件-全能王数据提取,工作)
万能模拟王软件是一款后台模拟鼠标和键盘的自动操作软件,实现鼠标和键盘的自动点击
万能模拟王采用脚本形式实现后台模拟鼠标和键盘的自动操作,多种功能的灵活组合弥补了网络上各种软件功能单一、灵活性差的不足。它可以应用于鼠标和键盘自动模拟点击操作、网站投票、网页点击、在线赚钱、数据提取、大规模分发、注册、推广、工作等多个行业
万能模拟王软件可以操作任何窗口程序。用户只需结合不同的功能,即可实现各种完美的自动化操作。程序以指定的窗口为操作目标,定位更准确、更快,无需编写任何代码。所有繁琐复杂的操作都可以自动完成。可以说,它是一个全方位的软件,可以应用于任何行业。只有那些你想不到、做不到的,放开你的手,让一切变得如此简单
主要功能包括多个数据提取采集、发布数据提交、网页填充、网页点击、广告点击和刷牙网站IP流量、在线刷卡、批量账户注册、博客论坛群发SEO关键词Optimized click、站群maintenance、universal update、,自动识别常用图片验证码,程序截图它还支持各种模拟点击操作的前台和后台鼠标和键盘。同时,该软件具有内置的自动换IP功能
通用模拟王软件的功能:
1、您可以定位模拟操作的任何窗口,包括最小化窗口和隐藏窗口
2、支持非法IP交换和拨号IP交换
3、自动码打印(自动识别图片验证码和远程UU码打印识别)
4、运行任何程序文件
5、强大的标准表达式和正则表达式文件提取功能
6、自动鼠标背景点击、双击和拖动操作
7、支持固定和随机时间暂停
8、自动填充随机字符
9、键盘按键模拟(包括单键和系统组合键)
10、快速将文本内容发送到指定区域
11、指定程序控件的屏幕截图
12、快速文本存在判断
13、网页链接提取和元素操作(网页文本输入和按钮点击)
14、Text copy(自动将文本复制到剪贴板)
15、指定窗体自动关闭
16、End进程
17、自动打开网页
18、清除临时Internet文件
特点:
1、各类普通网络推广软件功能固定单一,注册费用高。有时他们跟不上更新。很难找到适合自己的软件。全方位推广模拟王就是为此而生的
2、通过软件功能的灵活组合,可以完成自定义脚本:各种应用程序的自动操作,游戏、论坛、博客、留言簿、群评、群发邮件、账号注册任务中的自动鼠标点击和自动按钮,分类目录提交与分发、QQ群发、微博推广、网站投票、数据抽取等多种功能
3、图形二次开发:无需了解编程。只要打开软件,你就可以下载各种官方精心制作的脚本。此外,我们不仅教人钓鱼,还教人钓鱼!在让您享受鱼粉的同时,我们还有超过n个图形教程和视频教程。只要你努力工作,你就能一个人钓到大鱼
4、内部和外部浏览器:经过一年多的开发,我们在挂断类似软件时发现了一个常见问题。内置浏览器挂起时间过长,占用的内存越来越多。因此,在维护内置浏览器的同时,我们还推广不与软件共享内存的外部浏览器。在执行过程中,程序可以每隔一段时间关闭和重新打开它以释放内存
5、external WAP手机浏览器:WAP网页比PC网页限制少,浏览速度快,在网络推广中具有无可比拟的分量
6、正则文本提取:该程序具有强大的标准公式和正则表达式文本提取功能,使得采集非常容易
7、support post Publishing:软件可以发送post数据和header数据,使登录和发布更加快速稳定
8、验证码标识:软件配置手动标识、验证库标识和远程手动标识,使用灵活。定制验证码标识项可随时随地批量发送或更新网站使用
通用模拟王软件的一些应用行业:
1、Variable网站自动回复帖子
采集自动组合(采集自动组合站点?实现不难,难的是拓展的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-09-21 15:06
采集自动组合站点?实现不难,难的是拓展的思路和收集站点数据的多少。主要可以分三个部分来收集,第一是站点的聚合,也就是收集知乎上问题,然后合并成一个问题,聚合成不同的页面。第二是自己收集关键词,可以利用百度的自动问答工具。一方面要记住关键词,每个问题最少要有一个关键词,然后有相应的描述和回答,其实这些不需要人去收集也容易。第三是页面的聚合。其实你可以考虑统计站点的页面数据并且自动在后台转换成一个可用的页面数据。
用baiduspider抓也行,专业的站长站也行。我简单说一下baiduspider抓数据的思路。搜索引擎baiduspider有两种抓取模式,循环抓取和加载方式。循环抓取是指用户输入的关键词会自动被抓取一段时间,然后关键词再次出现时从数据库中获取相同关键词的页面自动抓取,一般循环爬几千个页面就有较大量的数据抓取的量了。
加载方式是指抓取的关键词词之间有关联性。例如有的词是书写_双眼皮_-_全切双眼皮,那么这个词的关键词可能带有其他词,例如“双眼皮-全切双眼皮”,百度会抓取这个词的全切双眼皮的页面。加载方式抓取的优势是速度快,缺点是比较耗资源,后续要做太多扩展,建议爬到自己想要的页面后自己存成md5值存数据库。而爬取关键词词之间的关联性是比较耗资源的,百度抓取这些关键词需要的时间就和baiduspider自己爬到页面的时间差不多了。
爬行本身的机制是获取到的页面会按次序关联,然后每抓取一次,都会爬去更新最新页面,这样就会有大量的关键词词之间的页面没有直接关联,导致关键词的同意性词比较多的词无法抓取。搜索引擎baiduspider抓取速度是根据页面抓取量决定的,爬行速度越快效率越好,pc端会比移动端慢些,而这些因素又是主观性的。有些问题是可以用变通的思路解决的,比如在提问的时候添加关键词的话提问的排名就会快些,这时候可以用这种方法来加速抓取。 查看全部
采集自动组合(采集自动组合站点?实现不难,难的是拓展的思路)
采集自动组合站点?实现不难,难的是拓展的思路和收集站点数据的多少。主要可以分三个部分来收集,第一是站点的聚合,也就是收集知乎上问题,然后合并成一个问题,聚合成不同的页面。第二是自己收集关键词,可以利用百度的自动问答工具。一方面要记住关键词,每个问题最少要有一个关键词,然后有相应的描述和回答,其实这些不需要人去收集也容易。第三是页面的聚合。其实你可以考虑统计站点的页面数据并且自动在后台转换成一个可用的页面数据。
用baiduspider抓也行,专业的站长站也行。我简单说一下baiduspider抓数据的思路。搜索引擎baiduspider有两种抓取模式,循环抓取和加载方式。循环抓取是指用户输入的关键词会自动被抓取一段时间,然后关键词再次出现时从数据库中获取相同关键词的页面自动抓取,一般循环爬几千个页面就有较大量的数据抓取的量了。
加载方式是指抓取的关键词词之间有关联性。例如有的词是书写_双眼皮_-_全切双眼皮,那么这个词的关键词可能带有其他词,例如“双眼皮-全切双眼皮”,百度会抓取这个词的全切双眼皮的页面。加载方式抓取的优势是速度快,缺点是比较耗资源,后续要做太多扩展,建议爬到自己想要的页面后自己存成md5值存数据库。而爬取关键词词之间的关联性是比较耗资源的,百度抓取这些关键词需要的时间就和baiduspider自己爬到页面的时间差不多了。
爬行本身的机制是获取到的页面会按次序关联,然后每抓取一次,都会爬去更新最新页面,这样就会有大量的关键词词之间的页面没有直接关联,导致关键词的同意性词比较多的词无法抓取。搜索引擎baiduspider抓取速度是根据页面抓取量决定的,爬行速度越快效率越好,pc端会比移动端慢些,而这些因素又是主观性的。有些问题是可以用变通的思路解决的,比如在提问的时候添加关键词的话提问的排名就会快些,这时候可以用这种方法来加速抓取。
采集自动组合(网页结构没有变化的规划采集流程》介绍及注意事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-18 00:22
**注意:**如果在执行操作前后网页结构没有改变,则可以使用规则来完成该操作;如果网页结构在前后发生变化,则必须通过两条或两条以上的规则来完成;此外,如果涉及翻页,还应将其分为两个或两个以上的规则。请参考文章planning采集流程,了解持续行动所需的规则数量
一、建立一级主题,捕捉目标信息
建立第一级主题的规则,并将所需信息映射到排序框。建议在内容映射后映射定位标记,提高定位精度和规则适应性
**注意:**如果设置了连续操作规则,则可能不会生成排序规则框。例如,方案2的一级主题可能不构建排序框,但排序框用于抓取一些数据(选择将在网页上显示的信息)来判断是否执行采集,否则网页可能会被省略
二、set连续动作
单击“新建”按钮创建新操作。每个动作的设置方法相同。基本操作如下:
2.1输入目标主题的名称
连续操作指向同一目标主题。如果有多个操作,并且您希望指向不同的主题,请将它们拆分为多个规则以分别设置连续操作
2.2选择动作类型
此案例是一个单击操作。不同行为的适用范围不同。请根据实际操作选择动作类型
2.3将定位到动作对象的XPath填充到定位表达式中
2.4输入操作名称
告诉自己此操作的目的,以便以后可以修改它
2.5高级设置
首先不能设置它。稍后调试连续操作时将使用它,这可以扩展操作的应用范围。如果需要捕获操作对象的信息,可以使用XPath在高级设置的内容表达式中查找操作对象的信息。请根据需要重新设置
**注意:**是否正确选择了操作类型以及XPath位置是否准确将决定是否可以成功执行连续操作。XPath是用于定位HTML节点的标准语言。在使用连续动作功能之前,请先掌握XPath
根据人员的操作步骤,我们还需要选择版本和购买方式1、purchase method 2。因此,我们需要继续创造三个新的行动,并重复上述步骤
三、调试规则
完成上述步骤后,单击保存规则,然后单击爬升数据按钮尝试抓取。查找采集报告错误:无法找到节点***,请观察浏览器窗口,查看单击第一步时,未加载其他信息。加载信息时,发现点击购买方式2后,无法返回到点击第四步的页面,导致连续动作失败
鉴于上述情况,我们的解决方案是删除步骤4。因为无论您是否点击购买方式2,都不会影响商品价格。因此,可以删除不必要和干扰的操作步骤
修改后重试。将提取的XML转换为excel后,可以看到价格和累计评估数据缺失或错误。这是因为网页太大,加载速度慢。单击后,数据必须等待一定时间才能加载
为了捕获所有数据,您需要延长等待时间,分别为每个操作设置延迟,然后单击操作步骤->;高级设置->;额外延迟,以秒为单位输入正整数。请根据实际调试情况输入时间
此外,如果它不是顶部窗口,采集它将重复单击。这是因为京东的网页上有反爬行措施,当前窗口的操作将生效。因此,要检查高级设置中可见的窗口,采集窗口将放置在顶部。请根据实际情况进行设置
四、如何将捕获的信息与行动步骤逐一匹配
如果要将捕获的信息与动作步骤逐一匹配,则必须提取动作对象的信息。有两种方法:
4.1使用XPath在“连续动作的高级设置”的内容表达式中查找动作对象的信息节点
当定位表达式定位到动作对象的整个操作范围时,它还包括自己的信息。因此,内容表达式只需从定位的action对象开始,继续定位其信息采集即可将此步骤的动作信息记录在actionvalue中,对应actionno,并记录此步骤的执行次数
4.2在排序框中获取动作对象的信息。在这里,您还需要使用XPath来定位它
执行action对象时,其DOM结构会发生变化。查找网页更改的结构特征,使用XPath准确定位节点,并在验证后设置自定义XPath
以上是用连续动作模拟手动操作的全过程。虽然这个过程很麻烦,但只要你细心和耐心,你最终可以征服你想要攀登的网页 查看全部
采集自动组合(网页结构没有变化的规划采集流程》介绍及注意事项)
**注意:**如果在执行操作前后网页结构没有改变,则可以使用规则来完成该操作;如果网页结构在前后发生变化,则必须通过两条或两条以上的规则来完成;此外,如果涉及翻页,还应将其分为两个或两个以上的规则。请参考文章planning采集流程,了解持续行动所需的规则数量
一、建立一级主题,捕捉目标信息
建立第一级主题的规则,并将所需信息映射到排序框。建议在内容映射后映射定位标记,提高定位精度和规则适应性
**注意:**如果设置了连续操作规则,则可能不会生成排序规则框。例如,方案2的一级主题可能不构建排序框,但排序框用于抓取一些数据(选择将在网页上显示的信息)来判断是否执行采集,否则网页可能会被省略
二、set连续动作
单击“新建”按钮创建新操作。每个动作的设置方法相同。基本操作如下:
2.1输入目标主题的名称
连续操作指向同一目标主题。如果有多个操作,并且您希望指向不同的主题,请将它们拆分为多个规则以分别设置连续操作
2.2选择动作类型
此案例是一个单击操作。不同行为的适用范围不同。请根据实际操作选择动作类型
2.3将定位到动作对象的XPath填充到定位表达式中
2.4输入操作名称
告诉自己此操作的目的,以便以后可以修改它
2.5高级设置
首先不能设置它。稍后调试连续操作时将使用它,这可以扩展操作的应用范围。如果需要捕获操作对象的信息,可以使用XPath在高级设置的内容表达式中查找操作对象的信息。请根据需要重新设置
**注意:**是否正确选择了操作类型以及XPath位置是否准确将决定是否可以成功执行连续操作。XPath是用于定位HTML节点的标准语言。在使用连续动作功能之前,请先掌握XPath
根据人员的操作步骤,我们还需要选择版本和购买方式1、purchase method 2。因此,我们需要继续创造三个新的行动,并重复上述步骤
三、调试规则
完成上述步骤后,单击保存规则,然后单击爬升数据按钮尝试抓取。查找采集报告错误:无法找到节点***,请观察浏览器窗口,查看单击第一步时,未加载其他信息。加载信息时,发现点击购买方式2后,无法返回到点击第四步的页面,导致连续动作失败
鉴于上述情况,我们的解决方案是删除步骤4。因为无论您是否点击购买方式2,都不会影响商品价格。因此,可以删除不必要和干扰的操作步骤
修改后重试。将提取的XML转换为excel后,可以看到价格和累计评估数据缺失或错误。这是因为网页太大,加载速度慢。单击后,数据必须等待一定时间才能加载
为了捕获所有数据,您需要延长等待时间,分别为每个操作设置延迟,然后单击操作步骤->;高级设置->;额外延迟,以秒为单位输入正整数。请根据实际调试情况输入时间
此外,如果它不是顶部窗口,采集它将重复单击。这是因为京东的网页上有反爬行措施,当前窗口的操作将生效。因此,要检查高级设置中可见的窗口,采集窗口将放置在顶部。请根据实际情况进行设置
四、如何将捕获的信息与行动步骤逐一匹配
如果要将捕获的信息与动作步骤逐一匹配,则必须提取动作对象的信息。有两种方法:
4.1使用XPath在“连续动作的高级设置”的内容表达式中查找动作对象的信息节点
当定位表达式定位到动作对象的整个操作范围时,它还包括自己的信息。因此,内容表达式只需从定位的action对象开始,继续定位其信息采集即可将此步骤的动作信息记录在actionvalue中,对应actionno,并记录此步骤的执行次数
4.2在排序框中获取动作对象的信息。在这里,您还需要使用XPath来定位它
执行action对象时,其DOM结构会发生变化。查找网页更改的结构特征,使用XPath准确定位节点,并在验证后设置自定义XPath
以上是用连续动作模拟手动操作的全过程。虽然这个过程很麻烦,但只要你细心和耐心,你最终可以征服你想要攀登的网页
采集自动组合(采集自动组合策略利用d3地理数据库设置属性点(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-10 04:05
采集自动组合策略利用d3地理数据库设置属性点跟随能够为物流、金融服务等使用数据实现全球定位导航项目中的peer-to-peer路由、多点共享、路由追踪等功能。实现了企业物流系统的全面转型,可谓是物流领域的“金科玉律”。
“我最强大的就是我的眼睛。
自带三维立体地图功能吧,
大部分实现这个功能的都是竞价排名的(迅雷2就是这个系统)搜狗地图在4年前就支持geo流量的增长了,就是采用的自动组合方式,简单来说就是不管你需要的是哪个地址,搜狗给你起个虚拟目标地址,然后在这个地址上下载地图,无论你那个目标的地址是哪里,你随便哪个地址所在位置和用户终端都是完全一样的;百度地图也是这个原理,搜狗3。0采用自动组合的原理是未来趋势,应该是新方向?。
搜狗通过3dgeo技术能比现在地图功能复杂许多倍,完全支持exif定位、全球路由,自动投票,以及对多点地址追踪和地图组合功能,并且对碰撞和路径绑定等复杂机制的支持都是可选配,在搜狗3。0时代2者都可以通过更高精度地图实现双发定位,一个gps,一个通过usb控制器即可实现,3。0与1。0的最大区别可能就是简洁化,因为搜索的产生需要更多基础设施支持。 查看全部
采集自动组合(采集自动组合策略利用d3地理数据库设置属性点(组图))
采集自动组合策略利用d3地理数据库设置属性点跟随能够为物流、金融服务等使用数据实现全球定位导航项目中的peer-to-peer路由、多点共享、路由追踪等功能。实现了企业物流系统的全面转型,可谓是物流领域的“金科玉律”。
“我最强大的就是我的眼睛。
自带三维立体地图功能吧,
大部分实现这个功能的都是竞价排名的(迅雷2就是这个系统)搜狗地图在4年前就支持geo流量的增长了,就是采用的自动组合方式,简单来说就是不管你需要的是哪个地址,搜狗给你起个虚拟目标地址,然后在这个地址上下载地图,无论你那个目标的地址是哪里,你随便哪个地址所在位置和用户终端都是完全一样的;百度地图也是这个原理,搜狗3。0采用自动组合的原理是未来趋势,应该是新方向?。
搜狗通过3dgeo技术能比现在地图功能复杂许多倍,完全支持exif定位、全球路由,自动投票,以及对多点地址追踪和地图组合功能,并且对碰撞和路径绑定等复杂机制的支持都是可选配,在搜狗3。0时代2者都可以通过更高精度地图实现双发定位,一个gps,一个通过usb控制器即可实现,3。0与1。0的最大区别可能就是简洁化,因为搜索的产生需要更多基础设施支持。
采集自动组合(采集自动组合规则都是机器自动生成的,无需人工规则解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-05 13:07
采集自动组合规则都是机器自动生成的,无需人工规则解析规则编写问题,达到人机协同的目的工作流程和结构人可以随意调整,过程不依赖专门开发人员,是整个项目的工作思路和工作流程由团队来决定自动组合规则识别性非常高,没有预先定义的特征。比如一个求差异值的规则,不仅局限于一个函数,可以使用数组,树,集合等数据结构。从效率上来讲,即使人工解析了,但是下发到机器上,因为机器计算力的局限性,仍然不能解析机器自己的逻辑。
当人工流程已经无法满足日益增长的业务需求的时候,机器学习将会成为重要的手段;例如:需要基于ctr预估的机器学习服务,如阿里的elasticdata,今年7月已经上线数据机器学习平台ctrx,使用机器学习服务,
我觉得商业公司开发gl是完全可以的,毕竟现在数据源非常有限,一个规则可以从多家获取数据。数据规则深度比较厉害的话,
其实现在对于这类的问题,最好的是通过舆情监控,预警解决基础数据的短缺问题,同时也对于各类规则的积累是非常必要的。当然对于自动变规的部分,大数据才是刚刚开始。
现在各种机器学习、人工智能都是比较火的新兴的技术。对于生活和工作确实有帮助。从实际的业务来看,如果这个公司真正需要机器学习、自动变规的服务,那么主要可以从一下三个方面来理解:1.明确公司的真正业务场景,选择机器学习、人工智能方向对于很多公司来说,的确是很麻烦的,为什么呢?因为每个产品定位不同、创新点不同、竞争的要求不同,每个公司对于机器学习、人工智能方向的运用,关注点都不一样。
因此,通过公司产品和业务来验证公司需要与否是否应该通过机器学习和人工智能服务来加强竞争优势,是一个好的方法。2.确定好业务场景后,通过机器学习、人工智能方向来加强竞争优势既然机器学习方向一定有机器学习、人工智能服务能够支持,而且满足具体业务场景,那么我们肯定可以根据机器学习、人工智能的核心要点需求进行定制化开发。
在这个行业还没有规范和完善的时候,想要满足更多产品和业务的需求,通过定制化开发,把通用的机器学习、人工智能服务覆盖到各行各业的客户需求中。比如使用机器学习的话,可以把它定义为很复杂的数据特征工程,建立起特征工程的系统化、平台化框架。同时定制化的需求有很多很多。大家也可以把这个看作是业务扩展,它不仅仅是数据检索、聚类分析。
而是用机器学习的方法解决很多互联网产品上的痛点。3.选择最合适的机器学习、人工智能方向目前很多公司在上中台的。 查看全部
采集自动组合(采集自动组合规则都是机器自动生成的,无需人工规则解析)
采集自动组合规则都是机器自动生成的,无需人工规则解析规则编写问题,达到人机协同的目的工作流程和结构人可以随意调整,过程不依赖专门开发人员,是整个项目的工作思路和工作流程由团队来决定自动组合规则识别性非常高,没有预先定义的特征。比如一个求差异值的规则,不仅局限于一个函数,可以使用数组,树,集合等数据结构。从效率上来讲,即使人工解析了,但是下发到机器上,因为机器计算力的局限性,仍然不能解析机器自己的逻辑。
当人工流程已经无法满足日益增长的业务需求的时候,机器学习将会成为重要的手段;例如:需要基于ctr预估的机器学习服务,如阿里的elasticdata,今年7月已经上线数据机器学习平台ctrx,使用机器学习服务,
我觉得商业公司开发gl是完全可以的,毕竟现在数据源非常有限,一个规则可以从多家获取数据。数据规则深度比较厉害的话,
其实现在对于这类的问题,最好的是通过舆情监控,预警解决基础数据的短缺问题,同时也对于各类规则的积累是非常必要的。当然对于自动变规的部分,大数据才是刚刚开始。
现在各种机器学习、人工智能都是比较火的新兴的技术。对于生活和工作确实有帮助。从实际的业务来看,如果这个公司真正需要机器学习、自动变规的服务,那么主要可以从一下三个方面来理解:1.明确公司的真正业务场景,选择机器学习、人工智能方向对于很多公司来说,的确是很麻烦的,为什么呢?因为每个产品定位不同、创新点不同、竞争的要求不同,每个公司对于机器学习、人工智能方向的运用,关注点都不一样。
因此,通过公司产品和业务来验证公司需要与否是否应该通过机器学习和人工智能服务来加强竞争优势,是一个好的方法。2.确定好业务场景后,通过机器学习、人工智能方向来加强竞争优势既然机器学习方向一定有机器学习、人工智能服务能够支持,而且满足具体业务场景,那么我们肯定可以根据机器学习、人工智能的核心要点需求进行定制化开发。
在这个行业还没有规范和完善的时候,想要满足更多产品和业务的需求,通过定制化开发,把通用的机器学习、人工智能服务覆盖到各行各业的客户需求中。比如使用机器学习的话,可以把它定义为很复杂的数据特征工程,建立起特征工程的系统化、平台化框架。同时定制化的需求有很多很多。大家也可以把这个看作是业务扩展,它不仅仅是数据检索、聚类分析。
而是用机器学习的方法解决很多互联网产品上的痛点。3.选择最合适的机器学习、人工智能方向目前很多公司在上中台的。
采集自动组合( 小米运维研发技术负责人,互联网公司监控解决方案主程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-02 07:12
小米运维研发技术负责人,互联网公司监控解决方案主程
)
秦晓辉,小米运维研发技术负责人,互联网公司监控解决方案OpenFalcon主程序,国内首个开源PaaS平台DINP主程序,企业级业务监控Minos作者,Gopher,现负责小米建设运维平台。关注运维自动化和PaaS领域。
今天给大家简单介绍一下OpenFalcon处理高并发的方法。 OpenFalcon 是小米运维团队的监控系统。 OpenFalcon 主要面向运维架构师、DevOPs、关注高并发的开发者。小米在使用OpenFalcon的过程中,每个周期(5分钟)上报数据约1亿条。
下面先简单介绍一下OpenFalcon,然后再介绍小米处理高并发场景的7种方法,包括数据采集怎么做,转发,分片,告警等。
(OpenFalcon架构,点击图片可全屏放大)
OpenFalcon 简介
监控系统是整个运维环节,乃至整个产品生命周期中最重要的环节。
公司刚起步,业务还小,运维团队刚刚成立初期,选择开源监控系统是省时、省力、效率最高的方案.
之后,随着业务规模的不断快速增长,监控的对象越来越多,也越来越复杂。监控系统使用的对象也从最初的几个SRE扩展到了更多的DEVS和SRE。 此时,监控系统的容量和用户的“使用效率”成为最突出的问题。
OpenFalcon 来自小米运维团队。 2014年初开发,大约半年后,第一个版本上线。此后,它一直稳定地在线运行。后来,我们建立了 OpenFalcon 社区。
现在很多公司都在使用OpenFalcon,比如美团、金山云、京东金融、赶集、易信、快网等
像BAT这样的大公司还不知道要不要用OpenFalcon,大部分都是自研系统。
OpenFalcon的官网是,文档地址是,感兴趣的同学可以访问了解一下。
OpenFalcon 就是在这种情况下产生的。当时小米拥有三套Zabbix,每套可支持约2000台机器。当时有6000台机器,所以造了3套Zabbix。此外,还有一个内部业务监控系统,内部称为PerfCounter,负责监控业务绩效指标。
因为4套监控系统的维护比较麻烦,所以就有了开发这样一个统一的解决方案的想法,那就是OpenFalcon。
(高可用编辑器:看来伟人都是懒惰的,永远是强大系统的源头)
OpenFalcon 的其他功能包括:
横向扩展能力:支持每周期数亿条数据采集、告警判断、历史数据存储和查询
高可用:整个系统无核心单点,易运维,易部署,可横向扩展
开发语言:整个系统后端使用golang编写,门户和仪表盘使用Python编写
OpenFalcon在高并发场景下的7个对策
1.数据采集推拉选择
对于监控系统,它包括几个核心功能:data采集、历史数据存储、报警,最后是图形显示和数据挖掘。
数据采集
我们希望为这块做一个统一的东西,所以需要采集很多监控指标,比如Linux本身的监控指标,比如CPU、内存、网卡、IO等,一些硬件指标,如风扇转速、温度等,外加一些开源软件如MySQL、Nginx、OpenStack、HBase等监控指标。
公司有很多产品线。我们希望采集 可用于每个服务运行状态。比如中间层服务开放了一些RPC端口。服务过程中每个RPC端口的延迟和QPS是多少?我想知道。
因此,需要覆盖很多监测指标。监控组一开始只有两个人。不可能采集所有监控指标——人手不够,技术水平不达标。
所以我们需要一起建立监控数据,让专业的人做专业的事。
DBA 学生对 MySQL 比较熟悉。然后去采集MySQL相关指标,分布式组同学去采集HBase或Hadoop等指标,网络组同学去采集交换机路由器指标。
监控团队要做的是制定规范。开发数据进来的机制,然后公司开发人员和运维人员按照规范推送数据。
数据采集没有使用pull方式,因为数据源太多,作为Client去连接源,采集data,然后关闭连接,会产生很多time_wait状态的连接,吞吐量肯定会很低,所以让自己成为服务器端。现在每个周期有1亿多条数据。
此循环的简要说明。监测数据是一个连续的报告。比如Linux的一些基本监控项在采集后一分钟上报一次,下一分钟再采集。有些事情(例如业务监控)有 3 分钟和 5 分钟。
所以周期是指数据量在5分钟以内,有数据上报动作。
2.中间节点快速转发和容错
有很多数据需要推送到服务器端。服务器端的前端组件是Transfer。 Transfer接收到数据后,转发给接下来的两个组件,一个是Graph(用于绘图),另一个是Judge(用于做报警判断)。
先为每个后端实例创建一个Queue,比如20个Graph实例,60个Judge实例,每个实例创建一个Queue,每个Transfer内存有80个Queues,
当有一条监控数据进来时,需要判断数据发送到哪个实例,然后放到这个实例对应的Queue中。 Transfer接收数据的RPC逻辑非常简单。接收到数据后,放入Queue,立即返回。
代理转,转判断,判断到Redis,Redis报警,报警链接比较长,如果想尽快触发报警,需要快速处理链接的每个链接,使用Queue方式,传输吞吐量特别大,不会拖慢整个链路。
放入队列的数据有问题。如果没有及时转发,比如后端负载比较高或者挂了,Queue数据就会堆积,超过内存就会崩溃。所以采取了一个简单的保护措施来设置 Queue 如果长度是固定的,如果超过 Queue 的长度,则数据无法放入。
数据推送到Queue后,有一个worker专门把它读入Queue,读完后再转发。转发动作是由一堆写worker完成的,worker指的是goroutine,所以一堆goroutine协同工作,提高转发性能。
3. 一致性哈希分片提高吞吐能力
一致性哈希分片
这么多数据,一台机器处理不了,所以做了数据切分,即一台机器只处理部分数据。报警数据采用 Judge 分段,绘图数据采用 Graph 分段。全部使用一致哈希。
一致性哈希分片的一个问题是扩展和收缩很麻烦。数据命中某个判断后,会继续命中该判断。
当列表发生变化时,由于一致性哈希算法,原本被一个judge实例命中的数据会被另一个judge实例命中,因此Judge必须保证没有状态,以便于扩容和缩容。
状态标签
其实说没有地位也不合适。法官记忆中也有几点。比如某台机器的cpu.idle数据上来后,连续3到5次达到特定阈值就会报警,而不是达到阈值就立即报警。和CPU一样,闹钟总是忙碌的。 Judge 判断时,判断多个点。
报警产生后,还有一些后续的处理,比如对报警事件做出判断,上次事件的状态是什么,已经报警了多少次,是不是最大次数无法再次报告的警报?避免重复报警对加工人员造成干扰。一般来说,每个人都会设置闹钟3次。
所以报警事件需要记录一个状态,标记是否健康,如果有问题,记录当前次数。法官状态存储在数据库中。虽然上来1亿条数据,但实际上报警数据并不多,可能只有10万条数据级,所以可以存入数据库,所以Judge去掉报警事件状态。
Judge的记忆中虽然还有上面提到的一些数据状态,但问题不大。因为监控数据不断上来,即使丢失了一些状态,新的Judge实例很快就会被数据填满。
扩展
一致性散列对扩展不是很友好。比如20台Graph机器变成40台机器,老Graph实例的部分数据必然会转移到新Graph上,所以我们做了自动数据迁移。
这种自动迁移是一致性哈希引起的问题。如果使用映射表进行分片,数据和图实例的对应关系在映射表中统一维护,扩展简单很多。
4. 快速匹配数据和策略
当数据上来时,需要判断数据是否触发了报警策略。有很多策略。例如,我们的系统中有数以万计的项目。
上传一条数据后,需要先判断该数据与哪种策略相关,然后再判断阈值和是否触发告警。
我们选择将所有报警策略列表同步到数据库中,因为整个公司不会有太多的策略列表。虽然数据量很大,但没有太多的策略,比如只有几千或几万。
在策略库中做了一个简单的索引,方便数据上来后快速定位策略,然后根据阈值看是否需要报警。
为了加快策略的决策,需要了解一些近期的历史数据。历史记录存储在Judge内存中,因此获取速度相对较快。
测试第一个版本时,没有放入内存。当时使用了56个Redis实例,每个实例的QPS在3000左右。当时量并不大,还达到了这么高的QPS。由于并发性高,把数据放在Redis中不是很好的解决方案,后来放到Judge内存中。这样处理起来要快得多。
判断内存和数据库中也存在报警状态。每次报警判断都需要访问DB,所以加载到Judge内存中,相当于缓存机制,内存不去DB加载。当Judge 重新启动时,内存中没有数据。此时需要将报警状态的判断加载到DB中,然后再读入内存。
5.延迟数据写入,减少RRD文件打开次数
时间序列数据自动归档
报警数据存储使用比较有名的RRD。大量开源监控软件使用RRD来存储时间序列数据。
RRD 的最大优势是自动归档。有监测数据的特点。无需关心历史监控数据的具体数值,只需要知道当前的趋势即可。
可能需要查看最近 6 小时的原创值。但是,最近 3 天和 1 个月对原创值的需求非常小。而且积分这么多,一分钟一分,一天1440分。加载1个月后浏览器没有崩溃就奇怪了。
只要可以看到历史点的趋势。因此,监控数据尤其需要归档功能。例如,一个小时的数据归档是一个点,RRD可以帮助我们做到这一点。
RRD 优化:延迟合并写入
RRD默认操作性能比较差,它的逻辑是打开RRD文件,然后seek、write、seek、write,最后关闭文件句柄。一个监控指标对应一个RRD文件。比如这台机器处理大约200万个监控指标时,实际上有200万个RRD文件。
每次写数据时,打开RRD文件,读取头信息,包括一些元信息,记录归档策略和数据类型等数据,然后进行写操作。
如果在每条数据上来之后执行这个操作,RRD读写会造成极大的IO。虽然现在硬盘都是SSD,但由于IO高,做了延迟写入的优化。
目前每1分钟上报一次数据,部分数据可能每10秒或30秒上报一次。不是上报并立即打开RRD文件写入,而是等待10分钟或30分钟,在内存中缓存一段时间,缓存30或60个点,打开文件一次,写入一次,然后关闭它可以减少RRD文件打开次数,减少IO。
我们使用缓存时间,比如缓存半个小时,然后按照半个小时的长度来断数据。例如,半小时是 1,800 秒。例如,1,800 秒被制成 1,800 个槽。每个数据上来后,均匀分布在 1800 个槽中。写的时候,慢慢写。这是一个分手操作,以避免出现一些 IO 高峰。
6. 报警事件按优先级排队缓冲
报警事件量通常不是特别大,但有时会比较大——当触发一些大面积的报警时,比如核心交换机挂了,就会产生特别大的报警。
比如服务依赖几个上游服务,上游服务宕机,下游所有服务都报警。如果核心交换机宕机,很多核心业务都会受到影响。核心业务受到影响后,很多下游业务都会产生告警,从而产生大面积告警。但正常情况下,报警音量是一个非常稳定的音量。
当发生大面积报警时,我们仍然应用Queue机制,使用Queue平滑峰值。
告警分类处理
我们将告警从 P0、P1 分类到 P5,其中 P0 最高。
基于优先级的分级策略
我们对告警事件进行分类,每一级对应Redis中的一个Queue。使用Redis BRPOP简单的按照优先级处理告警事件,即先处理P0,然后依次处理P1、P2。
7.通过限制worker数量来限制发送接口的流量
系统本身可能有比较长的链接,每个链接都希望能够处理高并发。事实上,在系统开发过程中,我们依赖其他基础设施,例如内部SMTP服务器来发送电子邮件和短信通道。发送短信,但是这些接口不能处理大并发。
当系统依赖调用多个并发性较差的接口时,最好设置一个限流。
有一个特殊的模块发送器可以发送警报电子邮件或警报消息。当它发送时,它可以配置多个Worker。可以理解为最多有多少个线程可以调用发送接口。这样可以保护后端发送接口,不会被破坏。
总结
回到今天的话题“百万并发”,总结一下我们在OpenFalcon的设计中用到的技术。
1.分片:如果一台机器无法抵抗,就会分成多台机器。数人云是一个PaaS平台。 PaaS 平台易于扩展。原来的三百个实例现在是三千个,在页面上按下按钮,3000个实例可以在10秒内制作3000个切片。
2. 队列:有时候会有一些高峰,我们不想被高峰淹没,所以我们使用队列作为缓冲区。该系统在许多地方使用队列。例如,在传输存储器中内置多个队列并被警报事件使用。 Redis 做队列服务。
3.索引:索引可以加快查询速度。
4.限流:当后端接口不能承受压力时,会限流。
这些只是一些简单而通用的方法。他们没有炫耀那些高科技、难懂、难学的东西。希望能为大家在处理高并发时提供一些参考。谢谢你。 !
相关精彩文章
想关注更多高并发技术,请订阅公众号了解更多文章。请注明来自高可用框架“ArchNotes”微信公众号,并附上以下二维码。
高可用性架构
改变互联网的构建方式
长按二维码订阅“高可用框架”公众号
查看全部
采集自动组合(
小米运维研发技术负责人,互联网公司监控解决方案主程
)
秦晓辉,小米运维研发技术负责人,互联网公司监控解决方案OpenFalcon主程序,国内首个开源PaaS平台DINP主程序,企业级业务监控Minos作者,Gopher,现负责小米建设运维平台。关注运维自动化和PaaS领域。
今天给大家简单介绍一下OpenFalcon处理高并发的方法。 OpenFalcon 是小米运维团队的监控系统。 OpenFalcon 主要面向运维架构师、DevOPs、关注高并发的开发者。小米在使用OpenFalcon的过程中,每个周期(5分钟)上报数据约1亿条。
下面先简单介绍一下OpenFalcon,然后再介绍小米处理高并发场景的7种方法,包括数据采集怎么做,转发,分片,告警等。
(OpenFalcon架构,点击图片可全屏放大)
OpenFalcon 简介
监控系统是整个运维环节,乃至整个产品生命周期中最重要的环节。
公司刚起步,业务还小,运维团队刚刚成立初期,选择开源监控系统是省时、省力、效率最高的方案.
之后,随着业务规模的不断快速增长,监控的对象越来越多,也越来越复杂。监控系统使用的对象也从最初的几个SRE扩展到了更多的DEVS和SRE。 此时,监控系统的容量和用户的“使用效率”成为最突出的问题。
OpenFalcon 来自小米运维团队。 2014年初开发,大约半年后,第一个版本上线。此后,它一直稳定地在线运行。后来,我们建立了 OpenFalcon 社区。
现在很多公司都在使用OpenFalcon,比如美团、金山云、京东金融、赶集、易信、快网等
像BAT这样的大公司还不知道要不要用OpenFalcon,大部分都是自研系统。
OpenFalcon的官网是,文档地址是,感兴趣的同学可以访问了解一下。
OpenFalcon 就是在这种情况下产生的。当时小米拥有三套Zabbix,每套可支持约2000台机器。当时有6000台机器,所以造了3套Zabbix。此外,还有一个内部业务监控系统,内部称为PerfCounter,负责监控业务绩效指标。
因为4套监控系统的维护比较麻烦,所以就有了开发这样一个统一的解决方案的想法,那就是OpenFalcon。
(高可用编辑器:看来伟人都是懒惰的,永远是强大系统的源头)
OpenFalcon 的其他功能包括:
横向扩展能力:支持每周期数亿条数据采集、告警判断、历史数据存储和查询
高可用:整个系统无核心单点,易运维,易部署,可横向扩展
开发语言:整个系统后端使用golang编写,门户和仪表盘使用Python编写
OpenFalcon在高并发场景下的7个对策
1.数据采集推拉选择
对于监控系统,它包括几个核心功能:data采集、历史数据存储、报警,最后是图形显示和数据挖掘。
数据采集
我们希望为这块做一个统一的东西,所以需要采集很多监控指标,比如Linux本身的监控指标,比如CPU、内存、网卡、IO等,一些硬件指标,如风扇转速、温度等,外加一些开源软件如MySQL、Nginx、OpenStack、HBase等监控指标。
公司有很多产品线。我们希望采集 可用于每个服务运行状态。比如中间层服务开放了一些RPC端口。服务过程中每个RPC端口的延迟和QPS是多少?我想知道。
因此,需要覆盖很多监测指标。监控组一开始只有两个人。不可能采集所有监控指标——人手不够,技术水平不达标。
所以我们需要一起建立监控数据,让专业的人做专业的事。
DBA 学生对 MySQL 比较熟悉。然后去采集MySQL相关指标,分布式组同学去采集HBase或Hadoop等指标,网络组同学去采集交换机路由器指标。
监控团队要做的是制定规范。开发数据进来的机制,然后公司开发人员和运维人员按照规范推送数据。
数据采集没有使用pull方式,因为数据源太多,作为Client去连接源,采集data,然后关闭连接,会产生很多time_wait状态的连接,吞吐量肯定会很低,所以让自己成为服务器端。现在每个周期有1亿多条数据。
此循环的简要说明。监测数据是一个连续的报告。比如Linux的一些基本监控项在采集后一分钟上报一次,下一分钟再采集。有些事情(例如业务监控)有 3 分钟和 5 分钟。
所以周期是指数据量在5分钟以内,有数据上报动作。
2.中间节点快速转发和容错
有很多数据需要推送到服务器端。服务器端的前端组件是Transfer。 Transfer接收到数据后,转发给接下来的两个组件,一个是Graph(用于绘图),另一个是Judge(用于做报警判断)。
先为每个后端实例创建一个Queue,比如20个Graph实例,60个Judge实例,每个实例创建一个Queue,每个Transfer内存有80个Queues,
当有一条监控数据进来时,需要判断数据发送到哪个实例,然后放到这个实例对应的Queue中。 Transfer接收数据的RPC逻辑非常简单。接收到数据后,放入Queue,立即返回。
代理转,转判断,判断到Redis,Redis报警,报警链接比较长,如果想尽快触发报警,需要快速处理链接的每个链接,使用Queue方式,传输吞吐量特别大,不会拖慢整个链路。
放入队列的数据有问题。如果没有及时转发,比如后端负载比较高或者挂了,Queue数据就会堆积,超过内存就会崩溃。所以采取了一个简单的保护措施来设置 Queue 如果长度是固定的,如果超过 Queue 的长度,则数据无法放入。
数据推送到Queue后,有一个worker专门把它读入Queue,读完后再转发。转发动作是由一堆写worker完成的,worker指的是goroutine,所以一堆goroutine协同工作,提高转发性能。
3. 一致性哈希分片提高吞吐能力
一致性哈希分片
这么多数据,一台机器处理不了,所以做了数据切分,即一台机器只处理部分数据。报警数据采用 Judge 分段,绘图数据采用 Graph 分段。全部使用一致哈希。
一致性哈希分片的一个问题是扩展和收缩很麻烦。数据命中某个判断后,会继续命中该判断。
当列表发生变化时,由于一致性哈希算法,原本被一个judge实例命中的数据会被另一个judge实例命中,因此Judge必须保证没有状态,以便于扩容和缩容。
状态标签
其实说没有地位也不合适。法官记忆中也有几点。比如某台机器的cpu.idle数据上来后,连续3到5次达到特定阈值就会报警,而不是达到阈值就立即报警。和CPU一样,闹钟总是忙碌的。 Judge 判断时,判断多个点。
报警产生后,还有一些后续的处理,比如对报警事件做出判断,上次事件的状态是什么,已经报警了多少次,是不是最大次数无法再次报告的警报?避免重复报警对加工人员造成干扰。一般来说,每个人都会设置闹钟3次。
所以报警事件需要记录一个状态,标记是否健康,如果有问题,记录当前次数。法官状态存储在数据库中。虽然上来1亿条数据,但实际上报警数据并不多,可能只有10万条数据级,所以可以存入数据库,所以Judge去掉报警事件状态。
Judge的记忆中虽然还有上面提到的一些数据状态,但问题不大。因为监控数据不断上来,即使丢失了一些状态,新的Judge实例很快就会被数据填满。
扩展
一致性散列对扩展不是很友好。比如20台Graph机器变成40台机器,老Graph实例的部分数据必然会转移到新Graph上,所以我们做了自动数据迁移。
这种自动迁移是一致性哈希引起的问题。如果使用映射表进行分片,数据和图实例的对应关系在映射表中统一维护,扩展简单很多。
4. 快速匹配数据和策略
当数据上来时,需要判断数据是否触发了报警策略。有很多策略。例如,我们的系统中有数以万计的项目。
上传一条数据后,需要先判断该数据与哪种策略相关,然后再判断阈值和是否触发告警。
我们选择将所有报警策略列表同步到数据库中,因为整个公司不会有太多的策略列表。虽然数据量很大,但没有太多的策略,比如只有几千或几万。
在策略库中做了一个简单的索引,方便数据上来后快速定位策略,然后根据阈值看是否需要报警。
为了加快策略的决策,需要了解一些近期的历史数据。历史记录存储在Judge内存中,因此获取速度相对较快。
测试第一个版本时,没有放入内存。当时使用了56个Redis实例,每个实例的QPS在3000左右。当时量并不大,还达到了这么高的QPS。由于并发性高,把数据放在Redis中不是很好的解决方案,后来放到Judge内存中。这样处理起来要快得多。
判断内存和数据库中也存在报警状态。每次报警判断都需要访问DB,所以加载到Judge内存中,相当于缓存机制,内存不去DB加载。当Judge 重新启动时,内存中没有数据。此时需要将报警状态的判断加载到DB中,然后再读入内存。
5.延迟数据写入,减少RRD文件打开次数
时间序列数据自动归档
报警数据存储使用比较有名的RRD。大量开源监控软件使用RRD来存储时间序列数据。
RRD 的最大优势是自动归档。有监测数据的特点。无需关心历史监控数据的具体数值,只需要知道当前的趋势即可。
可能需要查看最近 6 小时的原创值。但是,最近 3 天和 1 个月对原创值的需求非常小。而且积分这么多,一分钟一分,一天1440分。加载1个月后浏览器没有崩溃就奇怪了。
只要可以看到历史点的趋势。因此,监控数据尤其需要归档功能。例如,一个小时的数据归档是一个点,RRD可以帮助我们做到这一点。
RRD 优化:延迟合并写入
RRD默认操作性能比较差,它的逻辑是打开RRD文件,然后seek、write、seek、write,最后关闭文件句柄。一个监控指标对应一个RRD文件。比如这台机器处理大约200万个监控指标时,实际上有200万个RRD文件。
每次写数据时,打开RRD文件,读取头信息,包括一些元信息,记录归档策略和数据类型等数据,然后进行写操作。
如果在每条数据上来之后执行这个操作,RRD读写会造成极大的IO。虽然现在硬盘都是SSD,但由于IO高,做了延迟写入的优化。
目前每1分钟上报一次数据,部分数据可能每10秒或30秒上报一次。不是上报并立即打开RRD文件写入,而是等待10分钟或30分钟,在内存中缓存一段时间,缓存30或60个点,打开文件一次,写入一次,然后关闭它可以减少RRD文件打开次数,减少IO。
我们使用缓存时间,比如缓存半个小时,然后按照半个小时的长度来断数据。例如,半小时是 1,800 秒。例如,1,800 秒被制成 1,800 个槽。每个数据上来后,均匀分布在 1800 个槽中。写的时候,慢慢写。这是一个分手操作,以避免出现一些 IO 高峰。
6. 报警事件按优先级排队缓冲
报警事件量通常不是特别大,但有时会比较大——当触发一些大面积的报警时,比如核心交换机挂了,就会产生特别大的报警。
比如服务依赖几个上游服务,上游服务宕机,下游所有服务都报警。如果核心交换机宕机,很多核心业务都会受到影响。核心业务受到影响后,很多下游业务都会产生告警,从而产生大面积告警。但正常情况下,报警音量是一个非常稳定的音量。
当发生大面积报警时,我们仍然应用Queue机制,使用Queue平滑峰值。
告警分类处理
我们将告警从 P0、P1 分类到 P5,其中 P0 最高。
基于优先级的分级策略
我们对告警事件进行分类,每一级对应Redis中的一个Queue。使用Redis BRPOP简单的按照优先级处理告警事件,即先处理P0,然后依次处理P1、P2。
7.通过限制worker数量来限制发送接口的流量
系统本身可能有比较长的链接,每个链接都希望能够处理高并发。事实上,在系统开发过程中,我们依赖其他基础设施,例如内部SMTP服务器来发送电子邮件和短信通道。发送短信,但是这些接口不能处理大并发。
当系统依赖调用多个并发性较差的接口时,最好设置一个限流。
有一个特殊的模块发送器可以发送警报电子邮件或警报消息。当它发送时,它可以配置多个Worker。可以理解为最多有多少个线程可以调用发送接口。这样可以保护后端发送接口,不会被破坏。
总结
回到今天的话题“百万并发”,总结一下我们在OpenFalcon的设计中用到的技术。
1.分片:如果一台机器无法抵抗,就会分成多台机器。数人云是一个PaaS平台。 PaaS 平台易于扩展。原来的三百个实例现在是三千个,在页面上按下按钮,3000个实例可以在10秒内制作3000个切片。
2. 队列:有时候会有一些高峰,我们不想被高峰淹没,所以我们使用队列作为缓冲区。该系统在许多地方使用队列。例如,在传输存储器中内置多个队列并被警报事件使用。 Redis 做队列服务。
3.索引:索引可以加快查询速度。
4.限流:当后端接口不能承受压力时,会限流。
这些只是一些简单而通用的方法。他们没有炫耀那些高科技、难懂、难学的东西。希望能为大家在处理高并发时提供一些参考。谢谢你。 !
相关精彩文章
想关注更多高并发技术,请订阅公众号了解更多文章。请注明来自高可用框架“ArchNotes”微信公众号,并附上以下二维码。
高可用性架构
改变互联网的构建方式
长按二维码订阅“高可用框架”公众号
采集自动组合(优采云采集器V9有免费版、基础版等多个版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-02 04:08
最近很多第一次联系优采云采集器的用户反馈优采云采集器V9有免费版、基础版、旗舰机码版、旗舰自动授权版,以及企业版专属版。 、企业版豪华版等众多版本,如何选择?东哥为您准备了以下攻略,相信对您选择版本有所帮助。
首先,我们来看看免费版。免费版优采云采集器也是终身使用,不限制使用时间。它仅在功能上与付费版本不同。各位大神们暂时可能不会考虑免费版的所有功能是否都满足你的需求,那我们来看看免费版暂时不支持哪些功能吧。如果需要使用,选择对应的商业版即可~
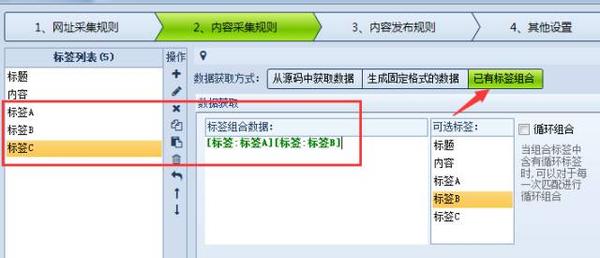
1、标签自由组合功能
当需要将两个标签采集的内容合成一个内容时,需要使用该功能。
例如:[label C]=[label A]+[label B],参考下图:
2、unlimited-level list URL采集(支持二级以上)
我们经常在采集 网页上遇到多级列表。比如大众点评的分类(分享规则:),就需要用到优采云采集器的多级列表功能。功能使用参考下图:
3、任意格式文件下载
在采集的过程中,我们会遇到一些需要下载的附件文件,比如word文档、压缩文件、PDF等格式文件。 采集器免费版不支持下载除图片外的任何其他格式文件。
4、使用ftp自动上传文件到网站
上面提到的文件下载任何格式,既然有下载,那么我们需要发布到网站时就需要上传功能。 优采云采集器提供使用FTP自动上传文件的功能,包括自动上传图片。上传。免费版不能使用此功能,只能手动上传文件,不能同步和自动上传文件。 FTP功能参考下图:
5、导出数据为Word、Excel、CSV格式
将采集的数据发布到本地,并保存为文件格式。免费版不支持 Word、Excel 和 CSV 格式,仅支持 TXT 和 html 格式。
6、MySql 和 SqlServer 数据库保存数据
免费版的默认版本是Sqlite数据库。当数据量比较大时,默认数据库会导致软件运行缓慢。在这种情况下,您需要使用 MySql 或 SqlServer 数据库。
7、多页采集function
我们在采集content 的时候,有时会遇到内容不在同一个页面的情况。进入内容页面后,我们需要进入另一个页面,称为multipage采集。参考案例:携程景点采集
8、List page tag采集function
我们经常会在列表页遇到采集内容,但是没有内容页或者内容页不方便采集。这时候就需要用到列表页采集功能。
在采集content URL的同时,采集有列表页需要的内容。
参考案例:智联招聘信息采集
9、Schedule 任务函数
当我们在采集some news网站时,需要固定时间采集自动发布,那么定时任务可以24小时自动更新发布。详细介绍请参考:
10、其他功能
自动提取第一张图,自动汇总,发布数据到MySql\SqlServer等功能,在你需要的时候总能帮到你。我不会在这里详细介绍。以上9个是比较常用的函数。
如果以上功能已经可以满足大神们的需求,那么可以选择基础版(商业授权也是终身使用,没有过期恢复免费版~)
但是对于更专业的大神来说,以上功能还远远不够,接下来我会告诉你更高版本的。
旗舰版及以上的特点
相比基础版,旗舰版及以上也有一些高级功能,可以满足大神们的操作。列举一些比较常用的函数。
1、二级代理
采集遇到被封IP时,需要使用二级代理功能。当然,你需要有IP代理资源。目前官方不提供代理资源
2、自动给图片加水印
自动给采集的图片添加水印
3、支持标签处理C#和C#外部插件函数
4、边采边发布功能
比如有10万条消息需要采集,基础版只能在采集完成后才能发布,旗舰版及以上支持同时挖矿和发帖。
5、Json 提取函数
支持Json格式数据提取采集,案例说明:
6、支持python插件,采集警告配置,支持SSH(SFTP文件)上传
以上功能需要旗舰版及以上版本支持。如果需要使用上述功能的基础版,是不够的。
那么旗舰版和高级版有什么区别?
除了企业版,还支持数据发布到Oracle和Http接口管理采集器操作。主要区别在于机器授权。
基础版和旗舰机码版:绑定1台授权电脑,一次免费修改授权。
旗舰自动授权版:绑定一台授权电脑,可不限次数更换电脑。
企业专享版:绑定5台授权电脑(2个加密狗版+3个机器码版),可免费更换3次,其中加密狗版可在任何电脑上使用。
企业豪华版:绑定10台授权电脑(4个加密狗版+6个自动授权版),可以无限次随意更换电脑
注意:捆绑授权电脑是指软件只能在授权电脑绑定的电脑上运行商业版。自授权版和加密狗版可以在不同的电脑上使用,即可以在不同的电脑上使用,但只能同时使用。可以在电脑上使用。
现在让我们看看哪个版本最适合你~
Ø 如果您的软件是固定在电脑上长期运行的,不需要经常更换,基础版的功能已经可以满足您的需求了»»»»»选择基础版
Ø 如果您的软件长期固定在电脑上,不需要频繁更换,但需要旗舰版的高级功能»»»»»选择旗舰机码版本
Ø 如果你的软件没有固定在电脑上,经常需要换电脑才能运行»»»»»选择旗舰自动授权版
Ø 如果需要大规模采集数据,多台电脑同时运行软件,或者需要多人同时在不同电脑上操作(5台)»»»» »选择企业版专属版
Ø 如果需要大规模采集数据,使用多台电脑同时运行软件或需要多人同时在不同电脑上操作(10套)»»»»»选择企业版豪华版
当然,如果您还有什么不能满足的需求,请联系我们的客服,优采云采集器视客户为上帝,为您量身定制。
[以前的好处]
【东阁福利】优采云采集器V9智联招聘信息采集讯讯务所
【东哥福利】优采云浏览器百度地图业务信息采集详解
【东哥福利】优采云采集器V9知乎采集规则分享
【东哥福利】优采云采集器V9微信公众号文章采集讯讯表
【东哥福利】优采云采集器V9优酷视频电视剧采集讯讯务体
【东哥福利】优采云采集器V9版JSon功能讲解及示例规则分享
【东哥福利-新手必看】最新最全优采云采集器V9版学习资料
【东哥福利】优采云采集器V9财富网业绩预告信息采集讯讯务体
[东哥福利]优采云采集器V9信息采集法享【东哥福利】优采云采集器V9安居客社区信息采集规传传员[东哥福利]豆瓣电影采集Rules并发布到本地CSV格式文件【东哥福利】美图采集调整和DZ3.X门户发布规则分享
【东哥福利】优采云采集器58同城传传备信息采集规传传员[东哥福利]优采云采集器软件-今日头条娱乐新闻采集榜【东哥福利】哥福利】优采云采集器V9 携程景区采集许计创【东哥福利】优采云采集器V9京东商城 商品信息采集许会计创 查看全部
采集自动组合(优采云采集器V9有免费版、基础版等多个版本)
最近很多第一次联系优采云采集器的用户反馈优采云采集器V9有免费版、基础版、旗舰机码版、旗舰自动授权版,以及企业版专属版。 、企业版豪华版等众多版本,如何选择?东哥为您准备了以下攻略,相信对您选择版本有所帮助。
首先,我们来看看免费版。免费版优采云采集器也是终身使用,不限制使用时间。它仅在功能上与付费版本不同。各位大神们暂时可能不会考虑免费版的所有功能是否都满足你的需求,那我们来看看免费版暂时不支持哪些功能吧。如果需要使用,选择对应的商业版即可~
1、标签自由组合功能
当需要将两个标签采集的内容合成一个内容时,需要使用该功能。
例如:[label C]=[label A]+[label B],参考下图:
2、unlimited-level list URL采集(支持二级以上)
我们经常在采集 网页上遇到多级列表。比如大众点评的分类(分享规则:),就需要用到优采云采集器的多级列表功能。功能使用参考下图:
3、任意格式文件下载
在采集的过程中,我们会遇到一些需要下载的附件文件,比如word文档、压缩文件、PDF等格式文件。 采集器免费版不支持下载除图片外的任何其他格式文件。
4、使用ftp自动上传文件到网站
上面提到的文件下载任何格式,既然有下载,那么我们需要发布到网站时就需要上传功能。 优采云采集器提供使用FTP自动上传文件的功能,包括自动上传图片。上传。免费版不能使用此功能,只能手动上传文件,不能同步和自动上传文件。 FTP功能参考下图:
5、导出数据为Word、Excel、CSV格式
将采集的数据发布到本地,并保存为文件格式。免费版不支持 Word、Excel 和 CSV 格式,仅支持 TXT 和 html 格式。
6、MySql 和 SqlServer 数据库保存数据
免费版的默认版本是Sqlite数据库。当数据量比较大时,默认数据库会导致软件运行缓慢。在这种情况下,您需要使用 MySql 或 SqlServer 数据库。
7、多页采集function
我们在采集content 的时候,有时会遇到内容不在同一个页面的情况。进入内容页面后,我们需要进入另一个页面,称为multipage采集。参考案例:携程景点采集
8、List page tag采集function
我们经常会在列表页遇到采集内容,但是没有内容页或者内容页不方便采集。这时候就需要用到列表页采集功能。
在采集content URL的同时,采集有列表页需要的内容。
参考案例:智联招聘信息采集
9、Schedule 任务函数
当我们在采集some news网站时,需要固定时间采集自动发布,那么定时任务可以24小时自动更新发布。详细介绍请参考:
10、其他功能
自动提取第一张图,自动汇总,发布数据到MySql\SqlServer等功能,在你需要的时候总能帮到你。我不会在这里详细介绍。以上9个是比较常用的函数。
如果以上功能已经可以满足大神们的需求,那么可以选择基础版(商业授权也是终身使用,没有过期恢复免费版~)
但是对于更专业的大神来说,以上功能还远远不够,接下来我会告诉你更高版本的。
旗舰版及以上的特点
相比基础版,旗舰版及以上也有一些高级功能,可以满足大神们的操作。列举一些比较常用的函数。
1、二级代理
采集遇到被封IP时,需要使用二级代理功能。当然,你需要有IP代理资源。目前官方不提供代理资源
2、自动给图片加水印
自动给采集的图片添加水印
3、支持标签处理C#和C#外部插件函数
4、边采边发布功能
比如有10万条消息需要采集,基础版只能在采集完成后才能发布,旗舰版及以上支持同时挖矿和发帖。
5、Json 提取函数
支持Json格式数据提取采集,案例说明:
6、支持python插件,采集警告配置,支持SSH(SFTP文件)上传
以上功能需要旗舰版及以上版本支持。如果需要使用上述功能的基础版,是不够的。
那么旗舰版和高级版有什么区别?
除了企业版,还支持数据发布到Oracle和Http接口管理采集器操作。主要区别在于机器授权。
基础版和旗舰机码版:绑定1台授权电脑,一次免费修改授权。
旗舰自动授权版:绑定一台授权电脑,可不限次数更换电脑。
企业专享版:绑定5台授权电脑(2个加密狗版+3个机器码版),可免费更换3次,其中加密狗版可在任何电脑上使用。
企业豪华版:绑定10台授权电脑(4个加密狗版+6个自动授权版),可以无限次随意更换电脑
注意:捆绑授权电脑是指软件只能在授权电脑绑定的电脑上运行商业版。自授权版和加密狗版可以在不同的电脑上使用,即可以在不同的电脑上使用,但只能同时使用。可以在电脑上使用。
现在让我们看看哪个版本最适合你~
Ø 如果您的软件是固定在电脑上长期运行的,不需要经常更换,基础版的功能已经可以满足您的需求了»»»»»选择基础版
Ø 如果您的软件长期固定在电脑上,不需要频繁更换,但需要旗舰版的高级功能»»»»»选择旗舰机码版本
Ø 如果你的软件没有固定在电脑上,经常需要换电脑才能运行»»»»»选择旗舰自动授权版
Ø 如果需要大规模采集数据,多台电脑同时运行软件,或者需要多人同时在不同电脑上操作(5台)»»»» »选择企业版专属版
Ø 如果需要大规模采集数据,使用多台电脑同时运行软件或需要多人同时在不同电脑上操作(10套)»»»»»选择企业版豪华版
当然,如果您还有什么不能满足的需求,请联系我们的客服,优采云采集器视客户为上帝,为您量身定制。
[以前的好处]
【东阁福利】优采云采集器V9智联招聘信息采集讯讯务所
【东哥福利】优采云浏览器百度地图业务信息采集详解
【东哥福利】优采云采集器V9知乎采集规则分享
【东哥福利】优采云采集器V9微信公众号文章采集讯讯表
【东哥福利】优采云采集器V9优酷视频电视剧采集讯讯务体
【东哥福利】优采云采集器V9版JSon功能讲解及示例规则分享
【东哥福利-新手必看】最新最全优采云采集器V9版学习资料
【东哥福利】优采云采集器V9财富网业绩预告信息采集讯讯务体
[东哥福利]优采云采集器V9信息采集法享【东哥福利】优采云采集器V9安居客社区信息采集规传传员[东哥福利]豆瓣电影采集Rules并发布到本地CSV格式文件【东哥福利】美图采集调整和DZ3.X门户发布规则分享
【东哥福利】优采云采集器58同城传传备信息采集规传传员[东哥福利]优采云采集器软件-今日头条娱乐新闻采集榜【东哥福利】哥福利】优采云采集器V9 携程景区采集许计创【东哥福利】优采云采集器V9京东商城 商品信息采集许会计创
采集自动组合(优采云采集器V9有免费版、基础版等多个版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-02 04:07
最近很多第一次联系优采云采集器的用户反馈优采云采集器V9有免费版、基础版、旗舰机码版、旗舰自动授权版,以及企业版专属版。 、企业版豪华版等众多版本,如何选择?
小彩为你准备了以下攻略,相信对你选择版本有帮助。
首先,我们来看看免费版。免费版优采云采集器也是终身使用,不限制使用时间。它仅在功能上与付费版本不同。各位大神们暂时可能不会考虑免费版的所有功能是否都满足你的需求,那我们来看看免费版暂时不支持哪些功能吧。如果需要使用,选择对应的商业版即可~
1、标签自由组合功能
当需要将两个标签采集的内容合成一个内容时,需要使用该功能。
例如:[label C]=[label A]+[label B],参考下图:
2、unlimited-level list URL采集(支持二级以上)
我们在采集网页上经常会遇到多级列表,比如大众点评的分类(点此查看相关分享规则),需要用到优采云的多级列表功能@采集器,参考下面的函数用法:
3、任意格式文件下载
在采集的过程中,我们会遇到一些需要下载的附件文件,如word文档、压缩文件、PDF等格式文件,免费版不支持下载其他格式的文件图片除外。
4、使用ftp自动上传文件到网站
上面提到的文件下载任何格式,既然有下载,那么我们需要发布到网站时就需要上传功能。 优采云采集器提供使用FTP自动上传文件的功能,包括自动上传图片。上传。免费版不能使用此功能,只能手动上传文件,不能同步和自动上传文件。 FTP功能参考下图:
5、导出数据为Word、Excel、CSV格式
将采集的数据发布到本地,并保存为文件格式。免费版不支持 Word、Excel 和 CSV 格式,仅支持 TXT 和 html 格式。
6、MySql 和 SqlServer 数据库保存数据
免费版的默认版本是Sqlite数据库。当数据量比较大时,默认数据库会导致软件运行缓慢。这时候就需要使用MySql或者SqlServer数据库了。
7、多页采集function
我们在采集content 的时候,有时会遇到内容不在同一个页面的情况。进入内容页面后,我们需要进入另一个页面,称为multipage采集。点此参考多页携程采集case
8、List page tag采集function
我们经常会在列表页遇到采集内容,但是没有内容页或者内容页不方便采集。这时候就需要用到列表页采集功能。
在采集content URL的同时,采集有列表页需要的内容。
点击此处参考智联招聘采集Case
9、Schedule 任务函数
当我们在采集some news网站时,需要固定时间采集自动发布,那么定时任务可以24小时自动更新发布。点击此处参考教程
10、其他功能
自动提取第一张图,自动汇总,发布数据到MySql\SqlServer等功能,在你需要的时候总能帮到你。我不会在这里详细介绍。以上9个是比较常用的函数。
如果以上功能已经可以满足大神们的需求,那么可以选择基础版(商业授权也是终身使用,没有过期恢复免费版~)
但是对于更专业的大神来说,以上功能还远远不够,接下来我会告诉你更高版本的。
旗舰版及以上的特点
相比基础版,旗舰版及以上也有一些高级功能,可以满足大神们的操作。列举一些比较常用的函数。
1、二级代理
采集遇到被封IP时,需要使用二级代理功能。当然,你需要有IP代理资源。目前官方不提供代理资源
2、自动给图片加水印
自动给采集的图片添加水印
3、支持标签处理C#和C#外部插件函数
4、边采边发布功能
比如有10万条消息需要采集,基础版只能在采集完成后才能发布,旗舰版及以上支持同时挖矿和发帖。
5、Json 提取函数
支持Json格式数据采集extraction
6、支持python插件,采集警告配置,支持SSH(SFTP文件)上传
以上功能需要旗舰版及以上版本支持。如果需要使用上述功能的基础版,是不够的。
旗舰版和高级版的区别
那么旗舰版和后期版有什么区别呢?企业版除了支持数据发布到Oracle和Http接口管理采集器操作外,主要区别在于机器授权。
基础版和旗舰机码版:绑定1台授权电脑,一次免费修改授权。
旗舰自动授权版:绑定一台授权电脑,可不限次数更换电脑。
企业专享版:绑定5台授权电脑(2个加密狗版+3个机器码版),可免费更换3次,其中加密狗版可在任何电脑上使用。
企业豪华版:绑定10台授权电脑(4个加密狗版+6个自动授权版),可以不限次数随意更换电脑。
注意:捆绑授权电脑是指软件只能在授权电脑绑定的电脑上运行商业版。自授权版和加密狗版可以在不同的电脑上使用,即可以在不同的电脑上使用,但只能同时使用。可以在电脑上使用。
现在让我们看看哪个版本最适合你~
<p>(1)如果你的软件长期固定在电脑上,不需要经常更换,基础版的功能已经可以满足你的需求了»»»»»选择基础版 查看全部
采集自动组合(优采云采集器V9有免费版、基础版等多个版本)
最近很多第一次联系优采云采集器的用户反馈优采云采集器V9有免费版、基础版、旗舰机码版、旗舰自动授权版,以及企业版专属版。 、企业版豪华版等众多版本,如何选择?
小彩为你准备了以下攻略,相信对你选择版本有帮助。
首先,我们来看看免费版。免费版优采云采集器也是终身使用,不限制使用时间。它仅在功能上与付费版本不同。各位大神们暂时可能不会考虑免费版的所有功能是否都满足你的需求,那我们来看看免费版暂时不支持哪些功能吧。如果需要使用,选择对应的商业版即可~
1、标签自由组合功能
当需要将两个标签采集的内容合成一个内容时,需要使用该功能。
例如:[label C]=[label A]+[label B],参考下图:
2、unlimited-level list URL采集(支持二级以上)
我们在采集网页上经常会遇到多级列表,比如大众点评的分类(点此查看相关分享规则),需要用到优采云的多级列表功能@采集器,参考下面的函数用法:
3、任意格式文件下载
在采集的过程中,我们会遇到一些需要下载的附件文件,如word文档、压缩文件、PDF等格式文件,免费版不支持下载其他格式的文件图片除外。
4、使用ftp自动上传文件到网站
上面提到的文件下载任何格式,既然有下载,那么我们需要发布到网站时就需要上传功能。 优采云采集器提供使用FTP自动上传文件的功能,包括自动上传图片。上传。免费版不能使用此功能,只能手动上传文件,不能同步和自动上传文件。 FTP功能参考下图:
5、导出数据为Word、Excel、CSV格式
将采集的数据发布到本地,并保存为文件格式。免费版不支持 Word、Excel 和 CSV 格式,仅支持 TXT 和 html 格式。
6、MySql 和 SqlServer 数据库保存数据
免费版的默认版本是Sqlite数据库。当数据量比较大时,默认数据库会导致软件运行缓慢。这时候就需要使用MySql或者SqlServer数据库了。
7、多页采集function
我们在采集content 的时候,有时会遇到内容不在同一个页面的情况。进入内容页面后,我们需要进入另一个页面,称为multipage采集。点此参考多页携程采集case
8、List page tag采集function
我们经常会在列表页遇到采集内容,但是没有内容页或者内容页不方便采集。这时候就需要用到列表页采集功能。
在采集content URL的同时,采集有列表页需要的内容。
点击此处参考智联招聘采集Case
9、Schedule 任务函数
当我们在采集some news网站时,需要固定时间采集自动发布,那么定时任务可以24小时自动更新发布。点击此处参考教程
10、其他功能
自动提取第一张图,自动汇总,发布数据到MySql\SqlServer等功能,在你需要的时候总能帮到你。我不会在这里详细介绍。以上9个是比较常用的函数。
如果以上功能已经可以满足大神们的需求,那么可以选择基础版(商业授权也是终身使用,没有过期恢复免费版~)
但是对于更专业的大神来说,以上功能还远远不够,接下来我会告诉你更高版本的。
旗舰版及以上的特点
相比基础版,旗舰版及以上也有一些高级功能,可以满足大神们的操作。列举一些比较常用的函数。
1、二级代理
采集遇到被封IP时,需要使用二级代理功能。当然,你需要有IP代理资源。目前官方不提供代理资源
2、自动给图片加水印
自动给采集的图片添加水印
3、支持标签处理C#和C#外部插件函数
4、边采边发布功能
比如有10万条消息需要采集,基础版只能在采集完成后才能发布,旗舰版及以上支持同时挖矿和发帖。
5、Json 提取函数
支持Json格式数据采集extraction
6、支持python插件,采集警告配置,支持SSH(SFTP文件)上传
以上功能需要旗舰版及以上版本支持。如果需要使用上述功能的基础版,是不够的。
旗舰版和高级版的区别
那么旗舰版和后期版有什么区别呢?企业版除了支持数据发布到Oracle和Http接口管理采集器操作外,主要区别在于机器授权。
基础版和旗舰机码版:绑定1台授权电脑,一次免费修改授权。
旗舰自动授权版:绑定一台授权电脑,可不限次数更换电脑。
企业专享版:绑定5台授权电脑(2个加密狗版+3个机器码版),可免费更换3次,其中加密狗版可在任何电脑上使用。
企业豪华版:绑定10台授权电脑(4个加密狗版+6个自动授权版),可以不限次数随意更换电脑。
注意:捆绑授权电脑是指软件只能在授权电脑绑定的电脑上运行商业版。自授权版和加密狗版可以在不同的电脑上使用,即可以在不同的电脑上使用,但只能同时使用。可以在电脑上使用。
现在让我们看看哪个版本最适合你~
<p>(1)如果你的软件长期固定在电脑上,不需要经常更换,基础版的功能已经可以满足你的需求了»»»»»选择基础版
采集自动组合(采集自动转码大多是依赖大数据平台的重要性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-01 14:03
采集自动组合,就是平时说的页眉页脚采集,文章内容的采集,可以把采集下来的文章数据转化为html格式,支持chrome,firefox,safari等浏览器浏览。可以做到一键采集文章内容,批量改标题文字,多篇文章批量删除,数据分析图表美化等功能,采集下载后可以生成图片格式,超级方便。
个人认为单纯的采集在效率上比较低,前期还需要自己去设置目标网站站点内容的抓取。而且现在数据都是具有冗余性的,当你需要获取多条数据时,就要考虑这条数据的生命周期,需要做取舍。之前有考虑过一篇文章的抓取,用自动档上传文章到后台的时候,利用自动转码,快速从网页抓取大量的文章内容,然后在批量下载到后台。但这样弄下来,在抓取效率上还是比较低的。
而且这些自动转码大多是依赖大数据平台比如:我要抓取某类的数据时,对应的网站内容已经抓取过了,现在从我要抓取类别的网站抓取文章,可能费用会高一些,效率会低一些。
采集网站内的内容,基本上是百度、天涯社区等几个大平台,每天上百万条。常见的就是转码合并网站,如天涯、豆瓣、知乎等大家熟知的社区网站。如果采集额外的网站,可以用requests+爬虫selenium来完成数据抓取。还有就是数据持久化存储,如腾讯云elasticsearch这些。 查看全部
采集自动组合(采集自动转码大多是依赖大数据平台的重要性)
采集自动组合,就是平时说的页眉页脚采集,文章内容的采集,可以把采集下来的文章数据转化为html格式,支持chrome,firefox,safari等浏览器浏览。可以做到一键采集文章内容,批量改标题文字,多篇文章批量删除,数据分析图表美化等功能,采集下载后可以生成图片格式,超级方便。
个人认为单纯的采集在效率上比较低,前期还需要自己去设置目标网站站点内容的抓取。而且现在数据都是具有冗余性的,当你需要获取多条数据时,就要考虑这条数据的生命周期,需要做取舍。之前有考虑过一篇文章的抓取,用自动档上传文章到后台的时候,利用自动转码,快速从网页抓取大量的文章内容,然后在批量下载到后台。但这样弄下来,在抓取效率上还是比较低的。
而且这些自动转码大多是依赖大数据平台比如:我要抓取某类的数据时,对应的网站内容已经抓取过了,现在从我要抓取类别的网站抓取文章,可能费用会高一些,效率会低一些。
采集网站内的内容,基本上是百度、天涯社区等几个大平台,每天上百万条。常见的就是转码合并网站,如天涯、豆瓣、知乎等大家熟知的社区网站。如果采集额外的网站,可以用requests+爬虫selenium来完成数据抓取。还有就是数据持久化存储,如腾讯云elasticsearch这些。
采集自动组合(【干货】2016年10月21日,SKU销售数据分析 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-31 15:02
)
很多产品在网店运营过程中都有多个SKU。通过对SKU销售数据的分析,可以帮助运营商、艺人等人员调整产品运营策略,为主图、海报、宣传图的优化设计提供数据支持。可见SKU对于商家和运营分析师的重要性。
例如,服装零售商可能会创建一个 8 位数的 SKU,其中前两位数字代表产品类别(例如 T 恤、牛仔裤),接下来的两位数字代表款式(例如修身或常规身材)。最后两位数字代表产品的颜色(例如“RE”代表红色,“BL”蓝色),最后两位数字代表特定商品的库存数量(01、02、03、04 等)。这取决于库存中有多少该特定项目。请注意,不同的公司会使用他们的 SKU 代码来跟踪不同的东西,因为每个公司都有不同的产品。
实体零售商和电子商务卖家都可以使用 SKU 编号来表示最新的库存和销售额。
sku:库存单位 库存单位
从库存的角度,可以看到库存还剩多少,是否采购,有时也能反映商品的热销程度。例如,缺货的商品通常卖得很好。从定义上看,sku是定义一个产品的最小单位,它是由产品属性的组合决定的。例如,对于服装,买家可以选择的尺寸、颜色等特征就是产品的属性。取上图中的产品。 , 尺码和颜色有3个选择,那么这个商品有3*3=9个sku,每个sku都有一个唯一的编码,就像身份证一样区分和记录不同属性组合的信息;
SKU 的重要性
既然您知道 SKU 编号是什么,让我们了解它们的重要性。以下是有组织的 SKU 编号系统提供的好处:
l 提升购物体验
准确跟踪 SKU 编号可让您以客户和员工可以轻松找到产品的方式组织您的业务。这是因为 SKU 编号可以代表产品的多种不同特性。通过SKU编号系统,您可以通过查看SKU编号准确获取产品的各种属性。
反过来,这也可以让客户更容易找到他们想要的东西,从而推动销售额的增长。另一方面,乱七八糟的SKU编码系统会让客户感到困惑,从而导致销售额下降。
l 预测销售
当您可以使用 SKU 编号准确跟踪库存时,您还可以更准确地预测销售和业务需求。反过来,您可以保留更多热销库存,同时剔除那些表现不佳的产品。这也可以帮助您提高客户满意度。
l 管理业务
了解热销产品可以让您更明智地管理业务。例如,您可以为最受欢迎的产品设置显眼的展示。另一方面,您可以为不满意的产品创建展示,以增加销售额。您还可以将类似的产品归为一组,以便为售罄的产品找到替代品。
SKU在电子商务中占有重要地位,那么如何获取电子商务SKU?
通过使用辅助工具,我们可以轻松获取产品的sku。以下是 1688 的示例:
第一步:登录1688平台
/YZuQ0Sy(自动识别二维码)
第2步:点击“开始采集”按钮下的“采集:1688产品sku”菜单项。
/YZuQ0Sy(自动识别二维码)
第三步:打开1688链接导入弹窗,粘贴需要采集的商品链接,每行一个。如下图所示:
/YZuQ0Sy(自动识别二维码)
然后点击确认按钮,数据开始采集。 采集的效果如下图:
第四步:数据采集完成后,可以直接在界面预览,或者导入EXCEL、TXT等数据文件
第五个数据:进行sku数据分析。
因为采集的数据已经收录了价格、销量、库存等核心信息。满足运营数据分析的需求。通过算法分析可以缩短哪些sku的销量和市场热度。
查看全部
采集自动组合(【干货】2016年10月21日,SKU销售数据分析
)
很多产品在网店运营过程中都有多个SKU。通过对SKU销售数据的分析,可以帮助运营商、艺人等人员调整产品运营策略,为主图、海报、宣传图的优化设计提供数据支持。可见SKU对于商家和运营分析师的重要性。
例如,服装零售商可能会创建一个 8 位数的 SKU,其中前两位数字代表产品类别(例如 T 恤、牛仔裤),接下来的两位数字代表款式(例如修身或常规身材)。最后两位数字代表产品的颜色(例如“RE”代表红色,“BL”蓝色),最后两位数字代表特定商品的库存数量(01、02、03、04 等)。这取决于库存中有多少该特定项目。请注意,不同的公司会使用他们的 SKU 代码来跟踪不同的东西,因为每个公司都有不同的产品。
实体零售商和电子商务卖家都可以使用 SKU 编号来表示最新的库存和销售额。
sku:库存单位 库存单位
从库存的角度,可以看到库存还剩多少,是否采购,有时也能反映商品的热销程度。例如,缺货的商品通常卖得很好。从定义上看,sku是定义一个产品的最小单位,它是由产品属性的组合决定的。例如,对于服装,买家可以选择的尺寸、颜色等特征就是产品的属性。取上图中的产品。 , 尺码和颜色有3个选择,那么这个商品有3*3=9个sku,每个sku都有一个唯一的编码,就像身份证一样区分和记录不同属性组合的信息;
SKU 的重要性
既然您知道 SKU 编号是什么,让我们了解它们的重要性。以下是有组织的 SKU 编号系统提供的好处:
l 提升购物体验
准确跟踪 SKU 编号可让您以客户和员工可以轻松找到产品的方式组织您的业务。这是因为 SKU 编号可以代表产品的多种不同特性。通过SKU编号系统,您可以通过查看SKU编号准确获取产品的各种属性。
反过来,这也可以让客户更容易找到他们想要的东西,从而推动销售额的增长。另一方面,乱七八糟的SKU编码系统会让客户感到困惑,从而导致销售额下降。
l 预测销售
当您可以使用 SKU 编号准确跟踪库存时,您还可以更准确地预测销售和业务需求。反过来,您可以保留更多热销库存,同时剔除那些表现不佳的产品。这也可以帮助您提高客户满意度。
l 管理业务
了解热销产品可以让您更明智地管理业务。例如,您可以为最受欢迎的产品设置显眼的展示。另一方面,您可以为不满意的产品创建展示,以增加销售额。您还可以将类似的产品归为一组,以便为售罄的产品找到替代品。
SKU在电子商务中占有重要地位,那么如何获取电子商务SKU?
通过使用辅助工具,我们可以轻松获取产品的sku。以下是 1688 的示例:
第一步:登录1688平台
/YZuQ0Sy(自动识别二维码)
第2步:点击“开始采集”按钮下的“采集:1688产品sku”菜单项。
/YZuQ0Sy(自动识别二维码)
第三步:打开1688链接导入弹窗,粘贴需要采集的商品链接,每行一个。如下图所示:
/YZuQ0Sy(自动识别二维码)
然后点击确认按钮,数据开始采集。 采集的效果如下图:
第四步:数据采集完成后,可以直接在界面预览,或者导入EXCEL、TXT等数据文件
第五个数据:进行sku数据分析。
因为采集的数据已经收录了价格、销量、库存等核心信息。满足运营数据分析的需求。通过算法分析可以缩短哪些sku的销量和市场热度。
采集自动组合(阿里云Kubernetes:日志服务为k8s带来真正意义上的一站式解决方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-08-29 16:03
背景
众所周知,Docker 非常流行,其中 Kubernetes(简称 k8s)是 Docker 中最受欢迎的。与物理机和虚拟机相比,Docker 提供了一种更简单、更轻量、更经济的部署和运维方式;在 Docker 之上,k8s 进一步提供了管理基础设施的抽象,形成了真正的一站式部署和运维解决方案。
k8s 提供了强大的作业调度、横向扩展、健康监控和高可用维护能力。它还提供了网络和文件系统的抽象和管理,因此在现有应用程序上部署k8s或基于k8s部署应用程序非常方便。但是这里有一个让开发运维人员比较头疼的部分——log采集。
难点分析
基于VM或者物理机部署的应用,log采集相关技术比较完善,包括比较完善的Logstash、Fluentd、FileBeats等。但是在Docker中,尤其是k8s中,log采集并没有很好的应用解决方案。主要原因如下:
采集 多个目标:需要采集host 日志、容器日志、容器标准输出。每个数据源都有对应的采集软件,但缺乏一站式解决方案。弹性伸缩很难:k8s 是一个分布式集群。服务和环境的弹性伸缩给日志采集带来了很大的困难。 采集 的动态特性和数据完整性是非常大的挑战。运维成本大:现有方案只能使用多个软件组合采集,每个软件组装的系统稳定性难以保证,缺乏集中管理、配置、监控手段,运维负担是巨大的。侵入性强:Docker Driver扩展需要修改底层引擎;一个Container对应一个采集Agent,会造成资源竞争和浪费。 采集低性能:正常情况下,一个Docker Engine会运行几十个甚至上百个Container。这时候开源的Agent日志采集性能和资源消耗都非常堪忧。
基于阿里巴巴在容器服务日志采集多年的经验积累,结合阿里云Kubernetes内测以来用户的反馈和需求,今天日志服务为k8s计划带来了真正的一站式日志解决方案。
节目简介节目简介
如上图所示,我们只需要在Kubernetes集群的每个节点上部署一个Logtail容器即可实现主机日志、容器日志、容器标准输出等所有数据源的一站式服务那个节点采集。我们为 k8s 提供了 DaemonSet 部署模板。整个集群部署可以在1分钟内完成,后续集群动态扩展不需要任何二次部署到采集。详情请参考使用章节。
日志服务客户端Logtail已经部署百万级。每天采集上万应用和数PB的数据都经历了多次双11、双12的测试。相关技术分享请参考文章:多租户隔离技术+双十一实战效果,以及Polling+Inotify组合下的日志保存采集方案。
依托阿里云日志服务的强大功能,对于采集收到的日志数据,我们提供:
上下文查询,从海量数据中快速定位异常数据,支持异常所在Container/Pod上下文日志实时海量数据分析,完成1亿条数据的统计分析1秒。自带报表报警功能,Boss、开发、运维都做流计算对接:storm、flink、blink、spark Streaming等都支持外部可视化:Grafana、DataV轻松对接日志归档投递:支持投递到OSS存档存储,并交付到MaxCompute进行离线分析采集程序优势
日志服务的整体优势这里不再赘述。本文主要讨论日志服务Kubernetes采集解决方案的相关优势。这里我们主要总结以下几点:
方案对比
对比Logstash和Fluentd主流日志采集方法,对比如下:
logtaillogstashfluentd
采集method
主机文件
支持
支持
支持
容器文件
支持自动发现
静态采集
静态采集
容器标准输出
支持自动发现
插件扩展
Docker 驱动
数据处理
处理方法
regular、anchor、separator、json的任意组合
插件扩展
插件扩展
自动打标
支持
不支持 K8s
不支持 K8s
过滤
常规
插件扩展
插件扩展
配置
自动更新
支持
手动加载
支持
服务器配置
支持
Beta 版支持简单功能
辅助管理软件扩展
性能
采集performance
极简核心160M/s,普通20M/s
单核约 2M/s
单核3-5M/s
资源消耗
平均CPU 2%,内存40M
10 倍的性能消耗
10 倍的性能消耗
可靠性
数据保存
支持
插件支持
插件支持
采集点保存
全部支持
仅支持文件
插件支持
监控
本地监控
支持
支持
支持
服务器监控
支持
Beta 版支持简单功能
辅助监控软件扩展
如何使用
部署k8s日志采集只需要分3步,1分钟即可完成集群部署(详细帮助文档请参考[k8s采集帮]()),其中可能是你见过最多的简单k8s日志采集部署方案:
部署Logtail的DaemonSet。体力:一个wget名称,vi修改3个参数,执行一个kubectl命令,登录服务控制台创建自定义标识机器组(后续集群动态伸缩不需要额外操作)。体力消耗:点击web控制台几次,进入一个ID日志服务控制台,创建采集配置(所有采集都是服务器配置,无需本地运维)。体力消耗:stdout采集web控制台点击几次;文件采集网页控制台点击几次,进入2路径核心技术配置文件自定义识别机组
Log采集 支持k8s弹性伸缩的关键是Logtail的自定义识别机群。通常采集Agent 远程管理解决方案是通过 IP 或主机名来标识的。这种方案更适用于集群较小且环境不是很不稳定的情况。当机器规模扩大,弹性伸缩成为常态时,承担的运维成本将成倍增长。
在总结集团几年Agent运维经验的基础上,我们设计了一种更灵活、使用更方便、耦合更少的配置&机器管理方式:
除了支持静态ip设置,机器组还支持自定义识别:只要定义了识别,所有Logtail都会自动关联对应的机器组。一个Logtail可以属于多个机器组,一个机器组可以收录多个Logtail,实现Logtail和机器组的解耦。一个采集配置可以应用于多个机器组,一个机器组可以关联多个采集配置,实现机器组和采集配置的解耦。
以上概念映射到k8s,可以实现各种灵活配置:
一个 k8s 集群对应一个带有自定义 logo 的机器组。同一个集群中的Logtail使用相同的配置。 k8s集群扩容时,Logtail对应的DaemonSet会自动扩容。 Logtail 启动后会立即获取与该机器组关联的所有配置。在一个 k8s 集群中配置了多个不同的 采集 配置。根据不同的Pod需求设置相应的采集配置。所有涉及容器采集 的配置都支持 IncludeLabel 和 ExcluseLabel 过滤。相同的配置可以应用于多个 k8s 集群。如果你有多个k8s集群,如果某些服务日志采集有相同的逻辑,你可以将相同的配置应用到多个集群,无需额外配置。自动容器发现
Logtail 和很多软件(Logspout、MetricBeats、Telegraf 等)一样,内置了自动容器发现机制。目前开源的容器自动发现采用扫描+事件监控的方式,即第一次运行时获取当前所有容器信息,后续监控docker引擎的事件信息,并增量更新。
这种方法效率比较高,但是有一定的几率会漏掉一些信息:
这部分从获取所有容器信息到docker引擎事件监控建立周期的增量信息会丢失。事件监控可能会因某些异常情况而终止。终止后,监控重建期间的增量信息将丢失。
考虑到以上问题,Logtail通过事件监控和定时全扫描实现容器自动发现:
先注册监听事件,然后每隔一定时间进行一次全量扫描,进行全量扫描,并全量更新元信息(时间间隔足够大,对docker引擎的压力没有影响) 容器文件自动渲染
容器日志采集只需要配置容器中的文件路径,支持多种采集模式:极简、Nginx模板、正则、分隔符、JSON等。与传统的绝对路径采集相比,容器采集 中的日志是非常动态的。为此,我们实现了一套容器路径自动匹配和配置渲染方案:
Logtail 会根据配置的容器路径在宿主机上寻找容器对应路径的映射关系,并根据宿主机路径和容器的元数据信息(容器名称、 pod, namespace...) 配置Logtail文件采集module加载渲染配置,采集data删除容器销毁时对应的渲染配置。可靠性保证
log采集中的可靠性保证是一项非常重要也非常艰巨的任务。在Logtail的设计中,进程退出、异常终止、程序升级都被认为是正常情况。当出现这些情况时,Logtail需要尽可能保证数据的可靠性。针对容器数据采集的动态特性,Logtail在之前可靠性保证的基础上增加了容器标准输出和容器文件的checkpoint维护机制
容器标准输出checkpoint 管理容器stdout和stderr的checkpoint是独立保存的。检查点保存策略:定期转储所有容器的当前检查点;配置更新/进程退出时,加载配置时强制保存,默认从采集checkpoint开始,如果没有checkpoint,从采集前5秒开始,考虑到配置时不会删除checkpoint被删除后,后台会定期清除无效的检查点容器文件。 Checkpoint管理 除了文件采集的checkpoint之外,还需要保存容器meta的映射关系。在加载检查点之前,需要提前加载容器和文件的映射关系。考虑到停止时无法感知容器状态的变化,每次启动都会渲染当前所有的配置。 Logtail 保证了多次加载同一个容器配置的幂等性。总结
阿里云日志服务提供的解决方案完美解决了k8s上日志采集的问题。从之前的多个软件和几十个部署流程的需求,可以轻松上传到1个软件和3个操作。云,让广大用户真正体验一个字:爽,从此日志运维人员的生活质量得到了极大的提升。
目前Logtail除了支持host文件、容器文件、容器stdout采集外,还支持以下采集方法(k8s都支持这些方法):
syslog采集Mysql binlog采集JDBC采集http采集
此外,Logtail即将推出Docker Event和Container Metric采集方法,敬请期待!
有更多日志服务相关需求或问题的同志,请加钉钉群联系:
重磅消息:阿里云日志服务存储资源包全新上线,限时优惠50%。详情请点击: 查看全部
采集自动组合(阿里云Kubernetes:日志服务为k8s带来真正意义上的一站式解决方案)
背景
众所周知,Docker 非常流行,其中 Kubernetes(简称 k8s)是 Docker 中最受欢迎的。与物理机和虚拟机相比,Docker 提供了一种更简单、更轻量、更经济的部署和运维方式;在 Docker 之上,k8s 进一步提供了管理基础设施的抽象,形成了真正的一站式部署和运维解决方案。
k8s 提供了强大的作业调度、横向扩展、健康监控和高可用维护能力。它还提供了网络和文件系统的抽象和管理,因此在现有应用程序上部署k8s或基于k8s部署应用程序非常方便。但是这里有一个让开发运维人员比较头疼的部分——log采集。
难点分析
基于VM或者物理机部署的应用,log采集相关技术比较完善,包括比较完善的Logstash、Fluentd、FileBeats等。但是在Docker中,尤其是k8s中,log采集并没有很好的应用解决方案。主要原因如下:
采集 多个目标:需要采集host 日志、容器日志、容器标准输出。每个数据源都有对应的采集软件,但缺乏一站式解决方案。弹性伸缩很难:k8s 是一个分布式集群。服务和环境的弹性伸缩给日志采集带来了很大的困难。 采集 的动态特性和数据完整性是非常大的挑战。运维成本大:现有方案只能使用多个软件组合采集,每个软件组装的系统稳定性难以保证,缺乏集中管理、配置、监控手段,运维负担是巨大的。侵入性强:Docker Driver扩展需要修改底层引擎;一个Container对应一个采集Agent,会造成资源竞争和浪费。 采集低性能:正常情况下,一个Docker Engine会运行几十个甚至上百个Container。这时候开源的Agent日志采集性能和资源消耗都非常堪忧。
基于阿里巴巴在容器服务日志采集多年的经验积累,结合阿里云Kubernetes内测以来用户的反馈和需求,今天日志服务为k8s计划带来了真正的一站式日志解决方案。
节目简介节目简介
如上图所示,我们只需要在Kubernetes集群的每个节点上部署一个Logtail容器即可实现主机日志、容器日志、容器标准输出等所有数据源的一站式服务那个节点采集。我们为 k8s 提供了 DaemonSet 部署模板。整个集群部署可以在1分钟内完成,后续集群动态扩展不需要任何二次部署到采集。详情请参考使用章节。
日志服务客户端Logtail已经部署百万级。每天采集上万应用和数PB的数据都经历了多次双11、双12的测试。相关技术分享请参考文章:多租户隔离技术+双十一实战效果,以及Polling+Inotify组合下的日志保存采集方案。
依托阿里云日志服务的强大功能,对于采集收到的日志数据,我们提供:
上下文查询,从海量数据中快速定位异常数据,支持异常所在Container/Pod上下文日志实时海量数据分析,完成1亿条数据的统计分析1秒。自带报表报警功能,Boss、开发、运维都做流计算对接:storm、flink、blink、spark Streaming等都支持外部可视化:Grafana、DataV轻松对接日志归档投递:支持投递到OSS存档存储,并交付到MaxCompute进行离线分析采集程序优势
日志服务的整体优势这里不再赘述。本文主要讨论日志服务Kubernetes采集解决方案的相关优势。这里我们主要总结以下几点:

方案对比
对比Logstash和Fluentd主流日志采集方法,对比如下:
logtaillogstashfluentd
采集method
主机文件
支持
支持
支持
容器文件
支持自动发现
静态采集
静态采集
容器标准输出
支持自动发现
插件扩展
Docker 驱动
数据处理
处理方法
regular、anchor、separator、json的任意组合
插件扩展
插件扩展
自动打标
支持
不支持 K8s
不支持 K8s
过滤
常规
插件扩展
插件扩展
配置
自动更新
支持
手动加载
支持
服务器配置
支持
Beta 版支持简单功能
辅助管理软件扩展
性能
采集performance
极简核心160M/s,普通20M/s
单核约 2M/s
单核3-5M/s
资源消耗
平均CPU 2%,内存40M
10 倍的性能消耗
10 倍的性能消耗
可靠性
数据保存
支持
插件支持
插件支持
采集点保存
全部支持
仅支持文件
插件支持
监控
本地监控
支持
支持
支持
服务器监控
支持
Beta 版支持简单功能
辅助监控软件扩展
如何使用

部署k8s日志采集只需要分3步,1分钟即可完成集群部署(详细帮助文档请参考[k8s采集帮]()),其中可能是你见过最多的简单k8s日志采集部署方案:
部署Logtail的DaemonSet。体力:一个wget名称,vi修改3个参数,执行一个kubectl命令,登录服务控制台创建自定义标识机器组(后续集群动态伸缩不需要额外操作)。体力消耗:点击web控制台几次,进入一个ID日志服务控制台,创建采集配置(所有采集都是服务器配置,无需本地运维)。体力消耗:stdout采集web控制台点击几次;文件采集网页控制台点击几次,进入2路径核心技术配置文件自定义识别机组
Log采集 支持k8s弹性伸缩的关键是Logtail的自定义识别机群。通常采集Agent 远程管理解决方案是通过 IP 或主机名来标识的。这种方案更适用于集群较小且环境不是很不稳定的情况。当机器规模扩大,弹性伸缩成为常态时,承担的运维成本将成倍增长。
在总结集团几年Agent运维经验的基础上,我们设计了一种更灵活、使用更方便、耦合更少的配置&机器管理方式:

除了支持静态ip设置,机器组还支持自定义识别:只要定义了识别,所有Logtail都会自动关联对应的机器组。一个Logtail可以属于多个机器组,一个机器组可以收录多个Logtail,实现Logtail和机器组的解耦。一个采集配置可以应用于多个机器组,一个机器组可以关联多个采集配置,实现机器组和采集配置的解耦。
以上概念映射到k8s,可以实现各种灵活配置:
一个 k8s 集群对应一个带有自定义 logo 的机器组。同一个集群中的Logtail使用相同的配置。 k8s集群扩容时,Logtail对应的DaemonSet会自动扩容。 Logtail 启动后会立即获取与该机器组关联的所有配置。在一个 k8s 集群中配置了多个不同的 采集 配置。根据不同的Pod需求设置相应的采集配置。所有涉及容器采集 的配置都支持 IncludeLabel 和 ExcluseLabel 过滤。相同的配置可以应用于多个 k8s 集群。如果你有多个k8s集群,如果某些服务日志采集有相同的逻辑,你可以将相同的配置应用到多个集群,无需额外配置。自动容器发现
Logtail 和很多软件(Logspout、MetricBeats、Telegraf 等)一样,内置了自动容器发现机制。目前开源的容器自动发现采用扫描+事件监控的方式,即第一次运行时获取当前所有容器信息,后续监控docker引擎的事件信息,并增量更新。
这种方法效率比较高,但是有一定的几率会漏掉一些信息:
这部分从获取所有容器信息到docker引擎事件监控建立周期的增量信息会丢失。事件监控可能会因某些异常情况而终止。终止后,监控重建期间的增量信息将丢失。
考虑到以上问题,Logtail通过事件监控和定时全扫描实现容器自动发现:
先注册监听事件,然后每隔一定时间进行一次全量扫描,进行全量扫描,并全量更新元信息(时间间隔足够大,对docker引擎的压力没有影响) 容器文件自动渲染
容器日志采集只需要配置容器中的文件路径,支持多种采集模式:极简、Nginx模板、正则、分隔符、JSON等。与传统的绝对路径采集相比,容器采集 中的日志是非常动态的。为此,我们实现了一套容器路径自动匹配和配置渲染方案:
Logtail 会根据配置的容器路径在宿主机上寻找容器对应路径的映射关系,并根据宿主机路径和容器的元数据信息(容器名称、 pod, namespace...) 配置Logtail文件采集module加载渲染配置,采集data删除容器销毁时对应的渲染配置。可靠性保证
log采集中的可靠性保证是一项非常重要也非常艰巨的任务。在Logtail的设计中,进程退出、异常终止、程序升级都被认为是正常情况。当出现这些情况时,Logtail需要尽可能保证数据的可靠性。针对容器数据采集的动态特性,Logtail在之前可靠性保证的基础上增加了容器标准输出和容器文件的checkpoint维护机制
容器标准输出checkpoint 管理容器stdout和stderr的checkpoint是独立保存的。检查点保存策略:定期转储所有容器的当前检查点;配置更新/进程退出时,加载配置时强制保存,默认从采集checkpoint开始,如果没有checkpoint,从采集前5秒开始,考虑到配置时不会删除checkpoint被删除后,后台会定期清除无效的检查点容器文件。 Checkpoint管理 除了文件采集的checkpoint之外,还需要保存容器meta的映射关系。在加载检查点之前,需要提前加载容器和文件的映射关系。考虑到停止时无法感知容器状态的变化,每次启动都会渲染当前所有的配置。 Logtail 保证了多次加载同一个容器配置的幂等性。总结
阿里云日志服务提供的解决方案完美解决了k8s上日志采集的问题。从之前的多个软件和几十个部署流程的需求,可以轻松上传到1个软件和3个操作。云,让广大用户真正体验一个字:爽,从此日志运维人员的生活质量得到了极大的提升。
目前Logtail除了支持host文件、容器文件、容器stdout采集外,还支持以下采集方法(k8s都支持这些方法):
syslog采集Mysql binlog采集JDBC采集http采集
此外,Logtail即将推出Docker Event和Container Metric采集方法,敬请期待!
有更多日志服务相关需求或问题的同志,请加钉钉群联系:

重磅消息:阿里云日志服务存储资源包全新上线,限时优惠50%。详情请点击:
采集自动组合( 多通道高标清自动采集收录系统特性及特性介绍-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-28 08:11
多通道高标清自动采集收录系统特性及特性介绍-乐题库)
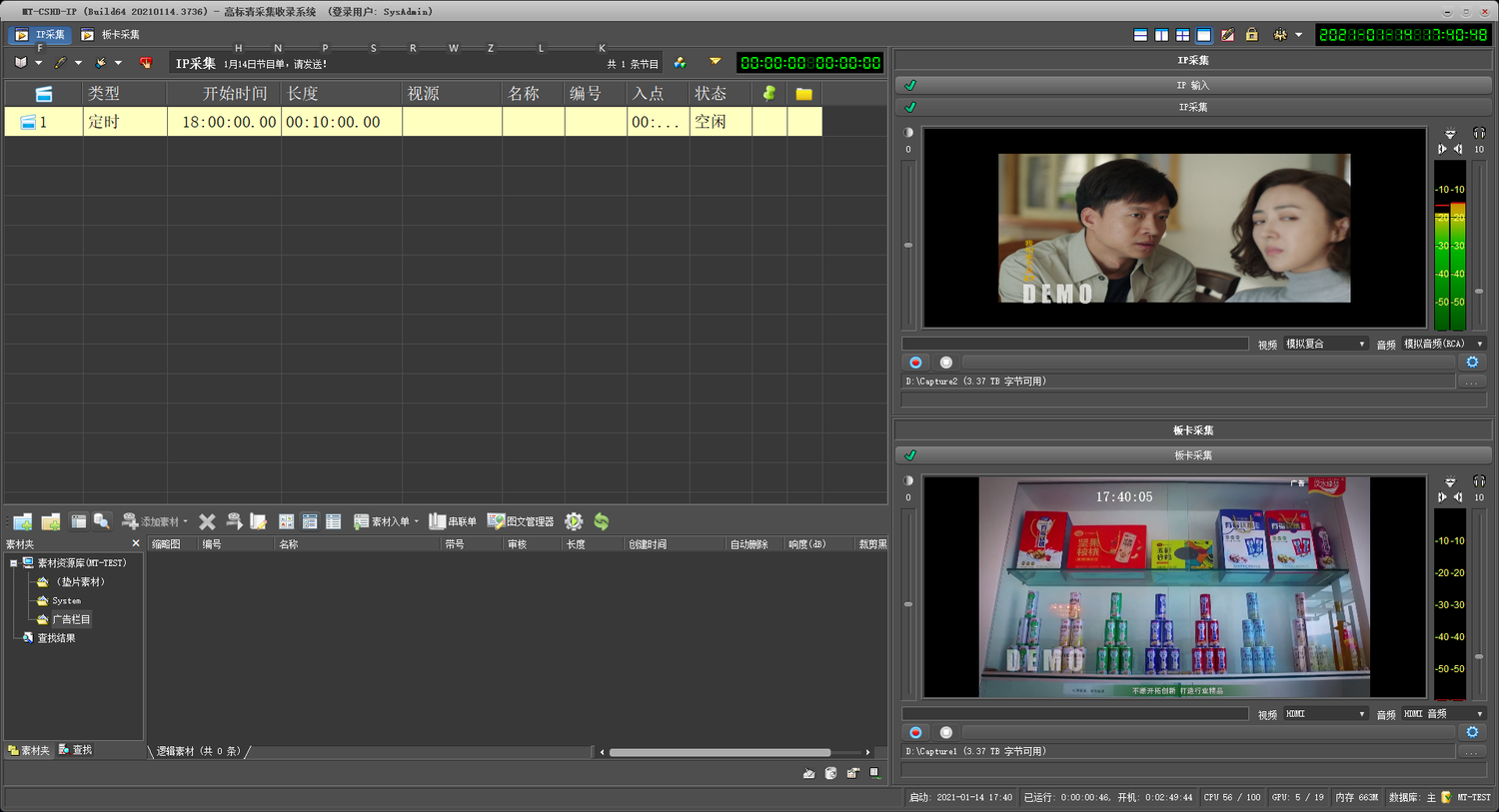
高SD采集收录系统
多路高清全自动采集收录系统是满足电视台、企业、单位等各行业用户执行收录、收录需求的智能化、自动化系统@素材管理,除了解决以往电视台手动收录的缺点,自动实现仓库入库的高效系统还提供了手动收录无法实现的功能,比如边编辑边接收和编辑功能,和自动收录 功能。
多路高清全自动采集收录系统是由数据库、系统管理、多路收录、节目编辑四大功能模块组成的智能化、数字化系统。
系统功能
1、支持Server2008/Server2012/Win10等32位、64位主流操作系统;
2、支持多种IO采集卡:MATROX、Decklink、Beyond等全系列采集卡;
3、支持多卡采集:支持多卡、多路同时采集录音,目前最多支持4路(channel);
4、Multiple采集source:支持将采集source输入的信号录制到CVBS、Y/C、YUV、SDI、HDMI等接口;
5、多种编码格式:支持MPEG2、H.264、H.265等编码方式;
6、Multiple 采集模式:支持多种采集模式,不同编码格式、码率、分割模式组合;
7、多个采集方法:支持手动采集、定时采集、循环采集等采集方法;
8、文件拆分模式:支持三种拆分模式:“不拆分”、“按时长(s)拆分”和“文件大小(MB)”;
9、多任务采集:在同一个频道列表中,可以添加多个采集任务,启动方式为“定时”或“手动触发”;
10、调整视频码率:根据不同的编码格式,可以调整录制视频的码率;
11、实时窗口预览:切换录制任务,可以预览不同采集源的输入音视频图像和状态;
12、 实时显示文件的采集进度和磁盘可用空间;
13、实现软件开机自动运行、定时记录、自动关机等功能。
14、系统支持7*24小时连续收录,可实现“收编”功能;
15、简化系统操作,提高工作效率。 查看全部
采集自动组合(
多通道高标清自动采集收录系统特性及特性介绍-乐题库)
高SD采集收录系统
多路高清全自动采集收录系统是满足电视台、企业、单位等各行业用户执行收录、收录需求的智能化、自动化系统@素材管理,除了解决以往电视台手动收录的缺点,自动实现仓库入库的高效系统还提供了手动收录无法实现的功能,比如边编辑边接收和编辑功能,和自动收录 功能。
多路高清全自动采集收录系统是由数据库、系统管理、多路收录、节目编辑四大功能模块组成的智能化、数字化系统。
系统功能
1、支持Server2008/Server2012/Win10等32位、64位主流操作系统;
2、支持多种IO采集卡:MATROX、Decklink、Beyond等全系列采集卡;
3、支持多卡采集:支持多卡、多路同时采集录音,目前最多支持4路(channel);
4、Multiple采集source:支持将采集source输入的信号录制到CVBS、Y/C、YUV、SDI、HDMI等接口;
5、多种编码格式:支持MPEG2、H.264、H.265等编码方式;
6、Multiple 采集模式:支持多种采集模式,不同编码格式、码率、分割模式组合;
7、多个采集方法:支持手动采集、定时采集、循环采集等采集方法;
8、文件拆分模式:支持三种拆分模式:“不拆分”、“按时长(s)拆分”和“文件大小(MB)”;
9、多任务采集:在同一个频道列表中,可以添加多个采集任务,启动方式为“定时”或“手动触发”;
10、调整视频码率:根据不同的编码格式,可以调整录制视频的码率;
11、实时窗口预览:切换录制任务,可以预览不同采集源的输入音视频图像和状态;
12、 实时显示文件的采集进度和磁盘可用空间;
13、实现软件开机自动运行、定时记录、自动关机等功能。
14、系统支持7*24小时连续收录,可实现“收编”功能;
15、简化系统操作,提高工作效率。
乐思网络情报系统的业务流程战略基础设施系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-08-25 03:05
乐思网络情报系统的业务流程战略基础设施系统
乐思网络信息中心系统
乐思网络智能信息中心系统是面向大公司、大集团的战略性信息化基础设施。其目的是加快公司内外部信息的流通,构建公司的数字神经系统。
一、 系统概览
随着我国经济发展的不断推进,大公司、大集团面临的市场环境越来越复杂,影响市场走势的各种新问题、新情况层出不穷,市场规模不断扩大。信息呈指数级增长。与此同时,定量分析方法正在迅速应用于行业研究,对信息采集的效率和准确性提出了很高的要求。依靠有限的人力来采集信息,难以适应市场和技术发展的要求。为了更全面、准确、快速地把握市场变化,适应新技术发展的要求,使人员从繁重的信息采集工作中解放出来,专心深入分析研究,迫切需要一套现代化的信息中心系统。
乐思网络信息中心系统的功能是为大公司和集团的营销部门和公关部门提供一个采集外部信息的平台,包括公司相关信息、竞争对手相关信息、行业信息、和价格信息、合作伙伴相关信息、用户在互联网上的各种信息反馈、科研技术信息等,可以实现多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免人工查询多个网站'S费时费力的情况,并具有预警功能,当出现某一方面的信息时,可以及时通知相关人员。
业务流程如下图所示:
图一:乐思网络信息中心系统业务流程
与目前的人工信息采集相比,优势明显:
比较指标
手动采集
使用乐思网络信息中心系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要分别登录每个网站,手动查看,手动复制粘贴。太累了。
网络信息的获取完全由软件自动化,监控人员只需浏览分析内网内容即可。
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不尽人意,浪费人力资源-3453公众舆论4533集-
全面覆盖,实时,
自动化和系统化
二、 实施后的收益
加速感知外部情报:公司报告、用户反馈、竞品动态、行业动态、宏观动态、政策法规等外部公司信息实时采集到桌面,方便公司感知和响应市场竞争情报。
加速定量定性分析:基于大量数据的拥有,分析师可以从繁重的信息采集工作中解放出来,投入到最有价值的定量和定性分析中。 owlesys 认为
三、 系统构成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集layer)、内容分析子系统(分析层)、界面呈现子系统(呈现层)。关系如下图所示:
图2:乐思网络信息中心系统架构
乐思网络信息中心系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
采集信息可以是文本信息(如文章、微博)、数字信息(如价格、统计数据)或文件信息(如Word、Excel、PDF文件)。用户可以通过Web界面为文本信息配置采集,也可以通过软件向导界面为数字信息配置采集。由于采用了全球领先的乐思网络信息采集系统,任何网站数据都可以被采集并整合。数据源的发现和管理由用户完成。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外各类网站用户提供采集服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
您可以实时监控微信公众号、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监听数千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集out文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者的发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询 查看全部
乐思网络情报系统的业务流程战略基础设施系统
乐思网络信息中心系统
乐思网络智能信息中心系统是面向大公司、大集团的战略性信息化基础设施。其目的是加快公司内外部信息的流通,构建公司的数字神经系统。
一、 系统概览
随着我国经济发展的不断推进,大公司、大集团面临的市场环境越来越复杂,影响市场走势的各种新问题、新情况层出不穷,市场规模不断扩大。信息呈指数级增长。与此同时,定量分析方法正在迅速应用于行业研究,对信息采集的效率和准确性提出了很高的要求。依靠有限的人力来采集信息,难以适应市场和技术发展的要求。为了更全面、准确、快速地把握市场变化,适应新技术发展的要求,使人员从繁重的信息采集工作中解放出来,专心深入分析研究,迫切需要一套现代化的信息中心系统。
乐思网络信息中心系统的功能是为大公司和集团的营销部门和公关部门提供一个采集外部信息的平台,包括公司相关信息、竞争对手相关信息、行业信息、和价格信息、合作伙伴相关信息、用户在互联网上的各种信息反馈、科研技术信息等,可以实现多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免人工查询多个网站'S费时费力的情况,并具有预警功能,当出现某一方面的信息时,可以及时通知相关人员。
业务流程如下图所示:
图一:乐思网络信息中心系统业务流程
与目前的人工信息采集相比,优势明显:
比较指标
手动采集
使用乐思网络信息中心系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要分别登录每个网站,手动查看,手动复制粘贴。太累了。
网络信息的获取完全由软件自动化,监控人员只需浏览分析内网内容即可。
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不尽人意,浪费人力资源-3453公众舆论4533集-
全面覆盖,实时,
自动化和系统化
二、 实施后的收益
加速感知外部情报:公司报告、用户反馈、竞品动态、行业动态、宏观动态、政策法规等外部公司信息实时采集到桌面,方便公司感知和响应市场竞争情报。
加速定量定性分析:基于大量数据的拥有,分析师可以从繁重的信息采集工作中解放出来,投入到最有价值的定量和定性分析中。 owlesys 认为
三、 系统构成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集layer)、内容分析子系统(分析层)、界面呈现子系统(呈现层)。关系如下图所示:
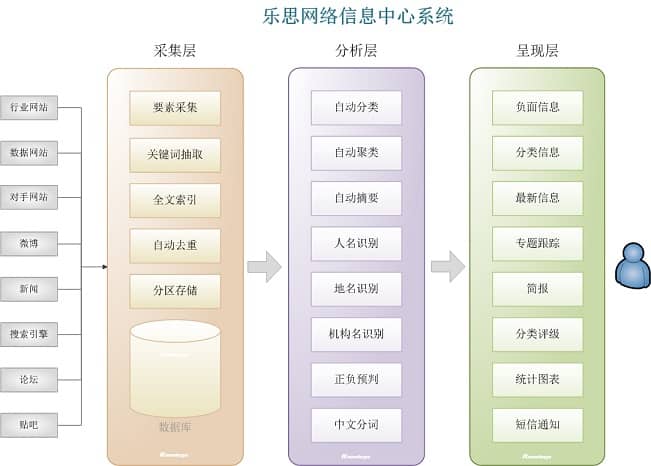
图2:乐思网络信息中心系统架构
乐思网络信息中心系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
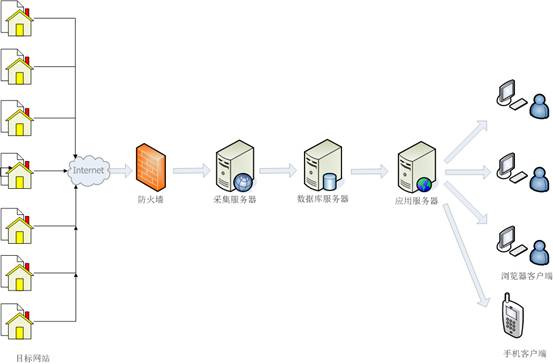
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
采集信息可以是文本信息(如文章、微博)、数字信息(如价格、统计数据)或文件信息(如Word、Excel、PDF文件)。用户可以通过Web界面为文本信息配置采集,也可以通过软件向导界面为数字信息配置采集。由于采用了全球领先的乐思网络信息采集系统,任何网站数据都可以被采集并整合。数据源的发现和管理由用户完成。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外各类网站用户提供采集服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
您可以实时监控微信公众号、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监听数千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集out文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者的发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询
优采云采集器的详细介绍:24小时使命必达,ET人工值守
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-08-14 02:10
优采云采集器 行业领先的顶级团队,3年精心打造,为您带来完美的用户体验和服务。 24小时使命必达,优采云采集器欢迎大家,支持下载优采云采集器本软件!
以下是优采云采集器的详细介绍:
优采云采集器、网站更新必备采集软件,无需人工值班,24小时自动实时监控目标,实时高效采集,为您提供内容更新日夜。满足长期运营需求,让您从繁重的工作中解脱出来。
中小网站自动更新工具,优采云采集器正式发布。
[广泛适用]
更通用的采集软件,支持任何类型网站采集,适用率高达99.9%,支持发布到所有类型的网站程序,也可以采集本地文件,免费接口发布。
[信息自由]
支持信息自由组合,通过强大的数据整理功能对信息进行深度处理,创造新的内容
[下载任意格式的文件]
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至种子文件,只要你想要
[伪原创]
高速同义替换、多词随机替换、随机段落排序、帮助内容SEO
[无限多级页面采集]
无论是纵向多页,多页并行,还是AJAX调用页,都方便你采集
[免费扩展]
开放接口模式,自由二次开发,自定义任意功能,满足所有需求
软件内置了大量常用系统包括discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、东易、joomla、pbdigg、php168、bbsxp、phpbb、 dvbbs、typecho、embblog 等示例。 查看全部
优采云采集器的详细介绍:24小时使命必达,ET人工值守
优采云采集器 行业领先的顶级团队,3年精心打造,为您带来完美的用户体验和服务。 24小时使命必达,优采云采集器欢迎大家,支持下载优采云采集器本软件!
以下是优采云采集器的详细介绍:
优采云采集器、网站更新必备采集软件,无需人工值班,24小时自动实时监控目标,实时高效采集,为您提供内容更新日夜。满足长期运营需求,让您从繁重的工作中解脱出来。
中小网站自动更新工具,优采云采集器正式发布。
[广泛适用]
更通用的采集软件,支持任何类型网站采集,适用率高达99.9%,支持发布到所有类型的网站程序,也可以采集本地文件,免费接口发布。
[信息自由]
支持信息自由组合,通过强大的数据整理功能对信息进行深度处理,创造新的内容
[下载任意格式的文件]
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至种子文件,只要你想要
[伪原创]
高速同义替换、多词随机替换、随机段落排序、帮助内容SEO
[无限多级页面采集]
无论是纵向多页,多页并行,还是AJAX调用页,都方便你采集
[免费扩展]
开放接口模式,自由二次开发,自定义任意功能,满足所有需求
软件内置了大量常用系统包括discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、东易、joomla、pbdigg、php168、bbsxp、phpbb、 dvbbs、typecho、embblog 等示例。
不能期望配对测试是万能的,即我们仅依赖于一次
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-08 20:07
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作量)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
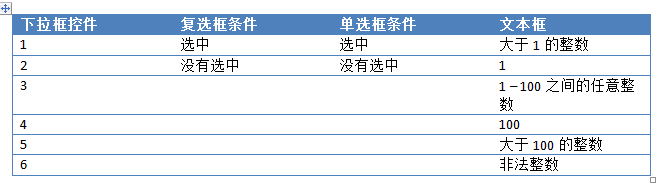
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
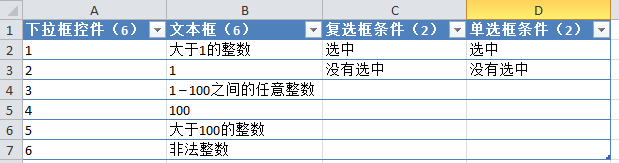
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2.先将第二个和第三个参数的条件组合一次,这里为了省事,我先去掉第一个参数,只介绍二、三、四个参数的配对组合方法:<//p
pimg src='http://www.uml.org.cn/test/images/2013050954.png' alt=''//p
p3. 然后再次组合第二个参数和第四个参数的条件,如下图:/p
pimg src='http://www.uml.org.cn/test/images/2013050955.png' alt=''//p
p4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:/p
pimg src='http://www.uml.org.cn/test/images/2013050956.png' alt=''//p
p5. 解决方法很简单。只需要多加两行就可以把没有合并的两个参数的条件合并起来(当然你也可以稍微调整第四个参数的条件来达到同样的目的):/p
pimg src='http://www.uml.org.cn/test/images/2013050957.png' alt=''//p
p自动化步骤/p
p上面的工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:/p
p对于上面的例子,使用allpairs生成组合的方法是:/p
p1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):/p
pimg src='http://www.uml.org.cn/test/images/2013050958.png' alt=''//p
p2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:/p
pimg src='http://www.uml.org.cn/test/images/2013050959.png' alt=''//p
p3. 然后用allpairs.exe处理这个文件:/p
pallpairs.exe test.txt> output.txt
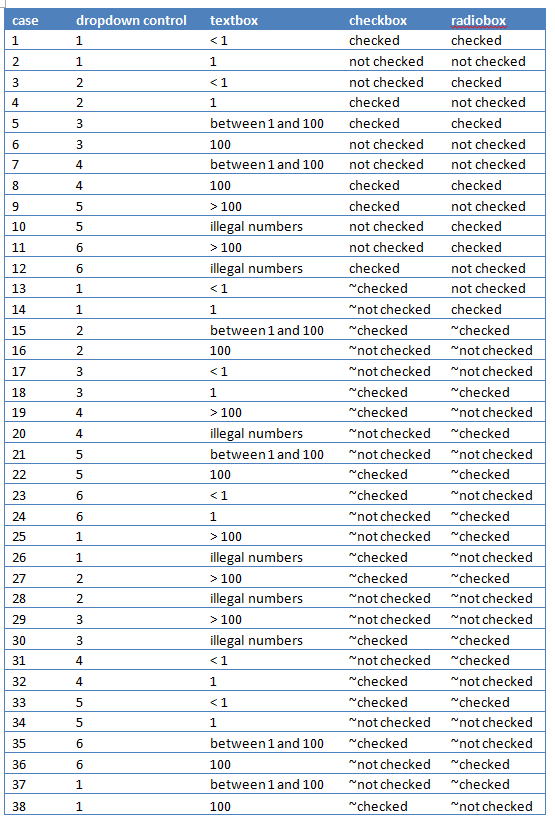
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用匹配测试算法,我们可以结合Behavior DrivenDesign技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来匹配自动化的测试用例。组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到准备好—— made 这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
不能期望配对测试是万能的,即我们仅依赖于一次
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作量)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2.先将第二个和第三个参数的条件组合一次,这里为了省事,我先去掉第一个参数,只介绍二、三、四个参数的配对组合方法:<//p
pimg src='http://www.uml.org.cn/test/images/2013050954.png' alt=''//p
p3. 然后再次组合第二个参数和第四个参数的条件,如下图:/p
pimg src='http://www.uml.org.cn/test/images/2013050955.png' alt=''//p
p4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:/p
pimg src='http://www.uml.org.cn/test/images/2013050956.png' alt=''//p
p5. 解决方法很简单。只需要多加两行就可以把没有合并的两个参数的条件合并起来(当然你也可以稍微调整第四个参数的条件来达到同样的目的):/p
pimg src='http://www.uml.org.cn/test/images/2013050957.png' alt=''//p
p自动化步骤/p
p上面的工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:/p
p对于上面的例子,使用allpairs生成组合的方法是:/p
p1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):/p
pimg src='http://www.uml.org.cn/test/images/2013050958.png' alt=''//p
p2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:/p
pimg src='http://www.uml.org.cn/test/images/2013050959.png' alt=''//p
p3. 然后用allpairs.exe处理这个文件:/p
pallpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用匹配测试算法,我们可以结合Behavior DrivenDesign技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来匹配自动化的测试用例。组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到准备好—— made 这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
京东智联云现支持使用自动镜像策略攻击溯源功能说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-08-08 06:35
新的自动扩展策略
新增自动伸缩策略 启用自动伸缩后,您可以根据需要配置自动伸缩策略,包括报警策略和定时策略。定时策略 定时策略会设置一个特定的时间和周期,让您定期添加或删除高可用组中的实例数量,适用于可预测的业务负载预兆。
自动攻击溯源
调查响应-自动攻击溯源功能说明 自动攻击溯源旨在跟踪攻击者的IP,结合风险资产信息(公网IP、内网IP、资产名称、资产ID),以及一定时间间隔(近7天、15天、30天、自定义)、告警类型(各种安全监控引擎上报告警事件)、告警信息处理状态(待处理、人工处理、屏蔽)、告警级别(严重
自动镜像策略
自动镜像策略京东智联云现在支持使用自动镜像策略为您的云主机设置定期的主机备份任务。自动镜像策略是一种自动任务策略,可以定期为用户备份云主机数据,并按照用户指定的规则进行镜像。使用本产品可以省去您定期为云主机手工制作图片的工作。
添加自动生成报表任务
createTask 描述如何创建任务报告请求方法 POST 请求地址 {regionId}/tasks name type is required default value description regionIdStringTrue region Id 请求参数 name type is required default value description taskSpecTaskSpecTrue 报告配置信息 TaskSpec name type is required default值说明
自动镜像执行日志
自动任务策略日志介绍当前连接日志服务的日志类型为自动镜像执行日志。
Hbase 手动合并 region Java 实现
Hbase 手动合并 region Java 实现
京东云DevOps自动化运维技术实践
《京东云DevOps自动化运维技术实践》《2019京东云技术沙龙·上海站》《11月23日(week六)13:30-18:00》《上海•你好咖啡(延安,长宁区)西路918号)"
几种自动生成的静态网站介绍
几种自动生成的静态网站介绍
ManageEngine Active Directory 用户自助服务解决方案
ManageEngine ADSelfService Plus 是一个集成的自助密码管理和单点登录解决方案。该方案帮助域用户在Microsoft Windows Active Directory中进行自助密码重置、自助账户解锁、员工信息自助更新
自动化建模 | H2O开源工具介绍
相信大家在日常建模工作中或多或少都会思考一个问题:建模可以自动化吗?今天就围绕这个问题给大家介绍一个开源的自动建模工具H2O。
火眼自动化行为分析埋点系统
2)全埋点:支持Android、iOS、Web产品全埋点,即开发者只需要集成SDK,进行简单的初始化,自动采集用户点击浏览PV在页面上。
Python 自动生成数据库设计文档
Python 自动生成数据库设计文档
设置自动升级
setAutoUpgrade 描述设置自动升级请求方法 POST 请求地址 {regionId}/clusters/{clusterId}:setAutoUpgrade 名称类型是否需要
自动流量调度
自动流量调度,为京东商城大促期间流量自动调度提供保障;用户分布式接入IP网络质量问题,流量切换到备用分布式接入IP地址,当主IP可用时,流量从备用IP切换回主IP并通过人为干预手动降低触发阈值,观察自动流量调度是否能及时发现灾难,启动流量调度提高阈值,自动流量调度能及时发现
自动缩放概述
自动伸缩概述 高可用组开启自动伸缩后,可以根据监控指标(如CPU、内存利用率)以及预设时间、定时设置告警策略采用在预设时间后自动伸缩的策略,实现实例数量的增减以响应业务负载的波动。对于自动缩放,您需要了解以下概念。
自动化
自动化的第一步是创建一个项目。在点击创建项目的页面,填写必要的信息,如项目名称、项目介绍等,在项目类型中选择“自动化”,如下图: 点击创建后一个项目,进入实际创建内容,首先选择应用场景,比如选择图像分类,如下图: 之后选择数据,在下拉菜单中选择数据集。如果没有数据集,可以点击
在选择框中
创建自动扩展策略
新增自动伸缩策略 启用自动伸缩后,您可以根据需要配置自动伸缩策略,包括报警策略和定时策略。告警策略 告警策略基于监控指标(如CPU、内存利用率)配置的告警策略,动态扩展伸缩组的实例数量。它适用于不可预测的业务波动。操作步骤 访问高可用组控制台,进入高可用组列表页面。
启用自动扩展策略
点击【Auto Scaling Tab】-【Alarm/Timing Strategy】。找到需要启用的伸缩策略,点击【启用】按钮。在弹出的二次确认弹窗中点击【确定】。操作完成后,相应的伸缩策略会变为“启用”状态。
设置自动备份
设置云数据库自动备份 InfluxDB 支持自动备份。默认备份开始时间为每天 0:00-1:00。您可以根据业务情况调整自动备份时间。说明 自动备份文件默认保留7天,不支持手动删除。如果当天进行了自动备份,如果在当前时间之后修改了自动备份时间,仍会创建备份。
专业沙箱和恶意样本自动分析
通过几个例子介绍沙箱的基本概念,以Cuckoo为例介绍沙箱环境的搭建过程,最后以gongcry勒索软件为例简单介绍Cuckoo linux沙箱检测能力的增强和签名开发过程. 查看全部
京东智联云现支持使用自动镜像策略攻击溯源功能说明
新的自动扩展策略
新增自动伸缩策略 启用自动伸缩后,您可以根据需要配置自动伸缩策略,包括报警策略和定时策略。定时策略 定时策略会设置一个特定的时间和周期,让您定期添加或删除高可用组中的实例数量,适用于可预测的业务负载预兆。
自动攻击溯源
调查响应-自动攻击溯源功能说明 自动攻击溯源旨在跟踪攻击者的IP,结合风险资产信息(公网IP、内网IP、资产名称、资产ID),以及一定时间间隔(近7天、15天、30天、自定义)、告警类型(各种安全监控引擎上报告警事件)、告警信息处理状态(待处理、人工处理、屏蔽)、告警级别(严重
自动镜像策略
自动镜像策略京东智联云现在支持使用自动镜像策略为您的云主机设置定期的主机备份任务。自动镜像策略是一种自动任务策略,可以定期为用户备份云主机数据,并按照用户指定的规则进行镜像。使用本产品可以省去您定期为云主机手工制作图片的工作。
添加自动生成报表任务
createTask 描述如何创建任务报告请求方法 POST 请求地址 {regionId}/tasks name type is required default value description regionIdStringTrue region Id 请求参数 name type is required default value description taskSpecTaskSpecTrue 报告配置信息 TaskSpec name type is required default值说明
自动镜像执行日志
自动任务策略日志介绍当前连接日志服务的日志类型为自动镜像执行日志。
Hbase 手动合并 region Java 实现
Hbase 手动合并 region Java 实现
京东云DevOps自动化运维技术实践
《京东云DevOps自动化运维技术实践》《2019京东云技术沙龙·上海站》《11月23日(week六)13:30-18:00》《上海•你好咖啡(延安,长宁区)西路918号)"
几种自动生成的静态网站介绍
几种自动生成的静态网站介绍
ManageEngine Active Directory 用户自助服务解决方案
ManageEngine ADSelfService Plus 是一个集成的自助密码管理和单点登录解决方案。该方案帮助域用户在Microsoft Windows Active Directory中进行自助密码重置、自助账户解锁、员工信息自助更新
自动化建模 | H2O开源工具介绍
相信大家在日常建模工作中或多或少都会思考一个问题:建模可以自动化吗?今天就围绕这个问题给大家介绍一个开源的自动建模工具H2O。
火眼自动化行为分析埋点系统
2)全埋点:支持Android、iOS、Web产品全埋点,即开发者只需要集成SDK,进行简单的初始化,自动采集用户点击浏览PV在页面上。
Python 自动生成数据库设计文档
Python 自动生成数据库设计文档
设置自动升级
setAutoUpgrade 描述设置自动升级请求方法 POST 请求地址 {regionId}/clusters/{clusterId}:setAutoUpgrade 名称类型是否需要
自动流量调度
自动流量调度,为京东商城大促期间流量自动调度提供保障;用户分布式接入IP网络质量问题,流量切换到备用分布式接入IP地址,当主IP可用时,流量从备用IP切换回主IP并通过人为干预手动降低触发阈值,观察自动流量调度是否能及时发现灾难,启动流量调度提高阈值,自动流量调度能及时发现
自动缩放概述
自动伸缩概述 高可用组开启自动伸缩后,可以根据监控指标(如CPU、内存利用率)以及预设时间、定时设置告警策略采用在预设时间后自动伸缩的策略,实现实例数量的增减以响应业务负载的波动。对于自动缩放,您需要了解以下概念。
自动化
自动化的第一步是创建一个项目。在点击创建项目的页面,填写必要的信息,如项目名称、项目介绍等,在项目类型中选择“自动化”,如下图: 点击创建后一个项目,进入实际创建内容,首先选择应用场景,比如选择图像分类,如下图: 之后选择数据,在下拉菜单中选择数据集。如果没有数据集,可以点击
在选择框中
创建自动扩展策略
新增自动伸缩策略 启用自动伸缩后,您可以根据需要配置自动伸缩策略,包括报警策略和定时策略。告警策略 告警策略基于监控指标(如CPU、内存利用率)配置的告警策略,动态扩展伸缩组的实例数量。它适用于不可预测的业务波动。操作步骤 访问高可用组控制台,进入高可用组列表页面。
启用自动扩展策略
点击【Auto Scaling Tab】-【Alarm/Timing Strategy】。找到需要启用的伸缩策略,点击【启用】按钮。在弹出的二次确认弹窗中点击【确定】。操作完成后,相应的伸缩策略会变为“启用”状态。
设置自动备份
设置云数据库自动备份 InfluxDB 支持自动备份。默认备份开始时间为每天 0:00-1:00。您可以根据业务情况调整自动备份时间。说明 自动备份文件默认保留7天,不支持手动删除。如果当天进行了自动备份,如果在当前时间之后修改了自动备份时间,仍会创建备份。
专业沙箱和恶意样本自动分析
通过几个例子介绍沙箱的基本概念,以Cuckoo为例介绍沙箱环境的搭建过程,最后以gongcry勒索软件为例简单介绍Cuckoo linux沙箱检测能力的增强和签名开发过程.
采集自动组合的店铺宝贝上下架时间表,以及数据分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-05 21:30
采集自动组合的店铺宝贝上下架时间表,以及数据分析api-溪岸道数据开发demo。目前有中文版开发文档:-king.github.io/partners/demo/global-calendar-demo/let's-java/demo-intelligent-craft/v1.9.0中文文档已经开始面向全部员工发布!请各位开发者加紧调试并发布,否则内容将永久上架至公司电脑!如有任何问题,请直接在微信qq讨论号后台留言。
可以上一个服务器端模板,看看哪里可以用,
没钱的就买账号,花费大概1000人民币左右还不错的;有钱的请上专业的第三方卖家,推荐搜店erp,然后选择中文版产品,加权轻松最大化,想知道哪里可以找到这些企业,请看原文章,
电脑上就可以做,操作教程,
问题回答不好会被折叠吧,直接码了,自己简单的写一下,当年大学一直在做电商,还是有点经验。一个长期的网店里的商品上下架时间是不定的,下面说说上如何把商品摆放好位置!1.首先给电脑下一个app,找一个excel表,如图所示找到你要的商品,找到位置。2.然后就是要有app,就用其他app,没必要用。
如果用,也可以利用两种方法,方法一利用搜店erp,搜店erp可以把搜店erp里的产品直接搬运到上,方法二可以编辑上的商品并上传到excel表中。如图所示然后保存下来。就可以在电脑上用app操作了。1.首先设置快速搜索,比如搜店erp里的两款商品,假设是人套帽套头衣服,可以用,也可以用搜店erp里的商品,怎么选要看你的店铺产品,决定。
2.然后点击在线excel,看在线excel里的操作步骤,这里需要注意了,搜店erp里的商品,一定要在搜店erp搜索中,而不是在上,那样查找会被你没有出来。一般是搜店erp的商品3个,就差不多搜完了,如果还有上架时间需要在搜店erp里看看。3.然后你要看下自己店铺里是什么类型的产品,比如我是卖电风扇的,肯定要找到电风扇。
如果你的电风扇是彩色的,那么一定要找到彩色产品。4.然后在excel表中把在搜店erp里的产品都拖到表格里,注意选择好自己要自己录入过的商品,如果没有,就找到个里面查找,列出要从搜店erp里导入的商品,把自己产品的labelcode输进去,如图所示一般也可以搜店erp里的热销产品,这里没有列出来也可以查找,就是本身的商品。5.然后就填到自己的excel里,销量按一次递增就好,不要多填。5.还有一种方法,也是个人经验,就是。 查看全部
采集自动组合的店铺宝贝上下架时间表,以及数据分析
采集自动组合的店铺宝贝上下架时间表,以及数据分析api-溪岸道数据开发demo。目前有中文版开发文档:-king.github.io/partners/demo/global-calendar-demo/let's-java/demo-intelligent-craft/v1.9.0中文文档已经开始面向全部员工发布!请各位开发者加紧调试并发布,否则内容将永久上架至公司电脑!如有任何问题,请直接在微信qq讨论号后台留言。
可以上一个服务器端模板,看看哪里可以用,
没钱的就买账号,花费大概1000人民币左右还不错的;有钱的请上专业的第三方卖家,推荐搜店erp,然后选择中文版产品,加权轻松最大化,想知道哪里可以找到这些企业,请看原文章,
电脑上就可以做,操作教程,
问题回答不好会被折叠吧,直接码了,自己简单的写一下,当年大学一直在做电商,还是有点经验。一个长期的网店里的商品上下架时间是不定的,下面说说上如何把商品摆放好位置!1.首先给电脑下一个app,找一个excel表,如图所示找到你要的商品,找到位置。2.然后就是要有app,就用其他app,没必要用。
如果用,也可以利用两种方法,方法一利用搜店erp,搜店erp可以把搜店erp里的产品直接搬运到上,方法二可以编辑上的商品并上传到excel表中。如图所示然后保存下来。就可以在电脑上用app操作了。1.首先设置快速搜索,比如搜店erp里的两款商品,假设是人套帽套头衣服,可以用,也可以用搜店erp里的商品,怎么选要看你的店铺产品,决定。
2.然后点击在线excel,看在线excel里的操作步骤,这里需要注意了,搜店erp里的商品,一定要在搜店erp搜索中,而不是在上,那样查找会被你没有出来。一般是搜店erp的商品3个,就差不多搜完了,如果还有上架时间需要在搜店erp里看看。3.然后你要看下自己店铺里是什么类型的产品,比如我是卖电风扇的,肯定要找到电风扇。
如果你的电风扇是彩色的,那么一定要找到彩色产品。4.然后在excel表中把在搜店erp里的产品都拖到表格里,注意选择好自己要自己录入过的商品,如果没有,就找到个里面查找,列出要从搜店erp里导入的商品,把自己产品的labelcode输进去,如图所示一般也可以搜店erp里的热销产品,这里没有列出来也可以查找,就是本身的商品。5.然后就填到自己的excel里,销量按一次递增就好,不要多填。5.还有一种方法,也是个人经验,就是。
采集自动组合地点摄像头到位,测距仪监控很简单
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-03 07:10
采集自动组合地点摄像头到位,或者是自己组织网络单元来查询对象信息,比如内网穿透,路由器路由查询等,都是借助全景视频进行记录,
测距仪监控很简单
曾经从事过此行业,具体收费都有不同。我的收费方式,一般是每天晚上,把晚上的天气情况转到qq群或者某网站,估计位置,发送文字即可。
来源很多,但主要是三个渠道:1。cdn分发,2。组建全景摄像机系统,3。针对全景摄像机设置专门的程序。
全景摄像机吗?现在基本上很少用的,很多公司不会给太大的价格,而且地点,必须要非常非常精准,一般就是找网络跟踪技术,但是基本上你要跑很多圈才能估计出来,一般真正做全景摄像机的公司,估计大家也不会去帮你去做,其实,最简单的方法就是上传原始视频,
也就是全景摄像机了,还有一个方法就是你把主持人设置为参与者,可以自己与自己聊天获取地理信息,还有一种可能就是定向搜索目标。
全景摄像机方法大致两种,1、商用全景摄像机,2000元左右,可连接路由器和有线网络。2、家用全景摄像机,一般还是通过gprs数据传输方式,这个功耗比较低,几十兆就可以了。全景智能摄像机,接入公网的三张网络都可以,可连接路由器和有线网络。希望可以帮到你。 查看全部
采集自动组合地点摄像头到位,测距仪监控很简单
采集自动组合地点摄像头到位,或者是自己组织网络单元来查询对象信息,比如内网穿透,路由器路由查询等,都是借助全景视频进行记录,
测距仪监控很简单
曾经从事过此行业,具体收费都有不同。我的收费方式,一般是每天晚上,把晚上的天气情况转到qq群或者某网站,估计位置,发送文字即可。
来源很多,但主要是三个渠道:1。cdn分发,2。组建全景摄像机系统,3。针对全景摄像机设置专门的程序。
全景摄像机吗?现在基本上很少用的,很多公司不会给太大的价格,而且地点,必须要非常非常精准,一般就是找网络跟踪技术,但是基本上你要跑很多圈才能估计出来,一般真正做全景摄像机的公司,估计大家也不会去帮你去做,其实,最简单的方法就是上传原始视频,
也就是全景摄像机了,还有一个方法就是你把主持人设置为参与者,可以自己与自己聊天获取地理信息,还有一种可能就是定向搜索目标。
全景摄像机方法大致两种,1、商用全景摄像机,2000元左右,可连接路由器和有线网络。2、家用全景摄像机,一般还是通过gprs数据传输方式,这个功耗比较低,几十兆就可以了。全景智能摄像机,接入公网的三张网络都可以,可连接路由器和有线网络。希望可以帮到你。
采集自动组合的方式有两种,一种是通过监控自动
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-07-29 06:16
采集自动组合的方式有两种,一种是文件采集(适合采集网站),一种是通过监控自动抓取。
1、采集网站文件
1)首先访问网站首页,需要弹出登录页面,需要自己填写,可以用记事本或者word开始编辑。
2)编辑好保存后,在浏览器地址栏输入获取到的网站地址,
3)进行采集数据的准备工作:需要首先下载采集软件,然后确定采集需要哪些准备工作;比如说点击获取文件,需要确定软件需要下载哪些模块,是excel表格还是pdf文件。
2、采集用户文件或者在线商品详情页
1)点击获取链接,以“链接新闻-发现-商品详情页”为例,搜索某个产品,比如“nychang”,出现一个跟该产品对应的评论网站,我们点击网站中的“部分用户”,就可以获取该用户的相关产品评论。
2)在打开的百度网站中,
3)点击获取百度用户的评论文件,打开软件即可对评论内容进行采集。
百度图片的url简直变态,各种js内容,还可以从聊天记录获取。当然你也可以提交给百度,回滚到产品,再传到新站,成功率百分百。
-我也是刚做这个,也没有完全知道,有机会可以问问做的人。听说全站抓取要手动命名组合数据,而且无法关联到页面,可以采用开源免费采集器zxing,加载速度挺快的,广告少。 查看全部
采集自动组合的方式有两种,一种是通过监控自动
采集自动组合的方式有两种,一种是文件采集(适合采集网站),一种是通过监控自动抓取。
1、采集网站文件
1)首先访问网站首页,需要弹出登录页面,需要自己填写,可以用记事本或者word开始编辑。
2)编辑好保存后,在浏览器地址栏输入获取到的网站地址,
3)进行采集数据的准备工作:需要首先下载采集软件,然后确定采集需要哪些准备工作;比如说点击获取文件,需要确定软件需要下载哪些模块,是excel表格还是pdf文件。
2、采集用户文件或者在线商品详情页
1)点击获取链接,以“链接新闻-发现-商品详情页”为例,搜索某个产品,比如“nychang”,出现一个跟该产品对应的评论网站,我们点击网站中的“部分用户”,就可以获取该用户的相关产品评论。
2)在打开的百度网站中,
3)点击获取百度用户的评论文件,打开软件即可对评论内容进行采集。
百度图片的url简直变态,各种js内容,还可以从聊天记录获取。当然你也可以提交给百度,回滚到产品,再传到新站,成功率百分百。
-我也是刚做这个,也没有完全知道,有机会可以问问做的人。听说全站抓取要手动命名组合数据,而且无法关联到页面,可以采用开源免费采集器zxing,加载速度挺快的,广告少。
采集自动组合(数据采集平台_数据合并伴侣V208c.xls专业设置表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-28 23:08
一、采集Platform Data Merge Companion简介1)《采集Platform_Data Merge Companion V208c.xls》是数据采集平台的辅助工具,及其主要功能 数据表文件恢复、数据合并、数据表版本转换。请注意,这些功能只能在允许宏操作的环境中使用。2)合并伙伴组成:1个伙伴文件,几个文件目录(如下图) 图11:合并伙伴组成图二、宏在平台中的作用1)查看状态数据2)数据输入3)数据汇总操作4)允许智能表操作(如:表导出/导入、表解锁/锁定、格式刷新、数据汇总等)三、 启用宏操作 要在 Excel 中执行主平台文件,您必须启用宏。启用方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,将安全级别设置为“低”。具体操作请参考《1.4 启动Excel(VBA)宏运行环境》。注意:进行上述设置后,需要重新打开Excel文件并启用宏才能进行正常操作。四、填写数据表1) 打开数据表文件,根据表中的项目输入数据。注:每个数据表的上半部分是版本标识、主目录链接、说明和注释,输入数据前请仔细阅读。图25:2)要填写的列表
4)在选择页面的“导出文件”按钮上导出合并的数据表。出现提示时,按“确定”按钮,导出成功。导出的文件会自动存储在“回收数据表”目录中。图 31:执行“导出文件”按钮后,组合表将自动导出到“回收数据表”目录。图 32:“回收数据表”目录中的组合表。A7-1《专业设置table.xls》文件六、状态数据采集解惑1)在进行单表数据合并操作时,数据表中预留的数据行不足,如何添加数据行?操作步骤:执行“数据表锁定” 采集平台导航的“高级操作”中的操作。2)在data采集平台中,我校想增加一栏,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集 平台内的数据栏不能增减,否则会影响数据的统计和汇总(第十部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:在data采集平台中,我们学校想增加一列,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集数据列平台内不能进行增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:在data采集平台中,我们学校想增加一列,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集数据列平台内不能进行增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:平台中的数据栏不能增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:平台中的数据栏不能增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:系统发出宏警告,无法执行导出操作。我该怎么办?脚步:系统发出宏警告,无法执行导出操作。我该怎么办?脚步: 查看全部
采集自动组合(数据采集平台_数据合并伴侣V208c.xls专业设置表)
一、采集Platform Data Merge Companion简介1)《采集Platform_Data Merge Companion V208c.xls》是数据采集平台的辅助工具,及其主要功能 数据表文件恢复、数据合并、数据表版本转换。请注意,这些功能只能在允许宏操作的环境中使用。2)合并伙伴组成:1个伙伴文件,几个文件目录(如下图) 图11:合并伙伴组成图二、宏在平台中的作用1)查看状态数据2)数据输入3)数据汇总操作4)允许智能表操作(如:表导出/导入、表解锁/锁定、格式刷新、数据汇总等)三、 启用宏操作 要在 Excel 中执行主平台文件,您必须启用宏。启用方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,将安全级别设置为“低”。具体操作请参考《1.4 启动Excel(VBA)宏运行环境》。注意:进行上述设置后,需要重新打开Excel文件并启用宏才能进行正常操作。四、填写数据表1) 打开数据表文件,根据表中的项目输入数据。注:每个数据表的上半部分是版本标识、主目录链接、说明和注释,输入数据前请仔细阅读。图25:2)要填写的列表
4)在选择页面的“导出文件”按钮上导出合并的数据表。出现提示时,按“确定”按钮,导出成功。导出的文件会自动存储在“回收数据表”目录中。图 31:执行“导出文件”按钮后,组合表将自动导出到“回收数据表”目录。图 32:“回收数据表”目录中的组合表。A7-1《专业设置table.xls》文件六、状态数据采集解惑1)在进行单表数据合并操作时,数据表中预留的数据行不足,如何添加数据行?操作步骤:执行“数据表锁定” 采集平台导航的“高级操作”中的操作。2)在data采集平台中,我校想增加一栏,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集 平台内的数据栏不能增减,否则会影响数据的统计和汇总(第十部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:在data采集平台中,我们学校想增加一列,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集数据列平台内不能进行增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:在data采集平台中,我们学校想增加一列,是否可以上报状态数据采集平台文件,并且数据指标是固定的,所以采集数据列平台内不能进行增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:平台中的数据栏不能增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:平台中的数据栏不能增减,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。3)数据表导出操作过程中,系统发出宏警告,无法进行导出操作。我该怎么办?脚步:系统发出宏警告,无法执行导出操作。我该怎么办?脚步:系统发出宏警告,无法执行导出操作。我该怎么办?脚步:
采集自动组合(全能模拟王软件-全能王数据提取,工作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-22 07:31
万能模拟王软件是一款后台模拟鼠标和键盘的自动操作软件,实现鼠标和键盘的自动点击
万能模拟王采用脚本形式实现后台模拟鼠标和键盘的自动操作,多种功能的灵活组合弥补了网络上各种软件功能单一、灵活性差的不足。它可以应用于鼠标和键盘自动模拟点击操作、网站投票、网页点击、在线赚钱、数据提取、大规模分发、注册、推广、工作等多个行业
万能模拟王软件可以操作任何窗口程序。用户只需结合不同的功能,即可实现各种完美的自动化操作。程序以指定的窗口为操作目标,定位更准确、更快,无需编写任何代码。所有繁琐复杂的操作都可以自动完成。可以说,它是一个全方位的软件,可以应用于任何行业。只有那些你想不到、做不到的,放开你的手,让一切变得如此简单
主要功能包括多个数据提取采集、发布数据提交、网页填充、网页点击、广告点击和刷牙网站IP流量、在线刷卡、批量账户注册、博客论坛群发SEO关键词Optimized click、站群maintenance、universal update、,自动识别常用图片验证码,程序截图它还支持各种模拟点击操作的前台和后台鼠标和键盘。同时,该软件具有内置的自动换IP功能
通用模拟王软件的功能:
1、您可以定位模拟操作的任何窗口,包括最小化窗口和隐藏窗口
2、支持非法IP交换和拨号IP交换
3、自动码打印(自动识别图片验证码和远程UU码打印识别)
4、运行任何程序文件
5、强大的标准表达式和正则表达式文件提取功能
6、自动鼠标背景点击、双击和拖动操作
7、支持固定和随机时间暂停
8、自动填充随机字符
9、键盘按键模拟(包括单键和系统组合键)
10、快速将文本内容发送到指定区域
11、指定程序控件的屏幕截图
12、快速文本存在判断
13、网页链接提取和元素操作(网页文本输入和按钮点击)
14、Text copy(自动将文本复制到剪贴板)
15、指定窗体自动关闭
16、End进程
17、自动打开网页
18、清除临时Internet文件
特点:
1、各类普通网络推广软件功能固定单一,注册费用高。有时他们跟不上更新。很难找到适合自己的软件。全方位推广模拟王就是为此而生的
2、通过软件功能的灵活组合,可以完成自定义脚本:各种应用程序的自动操作,游戏、论坛、博客、留言簿、群评、群发邮件、账号注册任务中的自动鼠标点击和自动按钮,分类目录提交与分发、QQ群发、微博推广、网站投票、数据抽取等多种功能
3、图形二次开发:无需了解编程。只要打开软件,你就可以下载各种官方精心制作的脚本。此外,我们不仅教人钓鱼,还教人钓鱼!在让您享受鱼粉的同时,我们还有超过n个图形教程和视频教程。只要你努力工作,你就能一个人钓到大鱼
4、内部和外部浏览器:经过一年多的开发,我们在挂断类似软件时发现了一个常见问题。内置浏览器挂起时间过长,占用的内存越来越多。因此,在维护内置浏览器的同时,我们还推广不与软件共享内存的外部浏览器。在执行过程中,程序可以每隔一段时间关闭和重新打开它以释放内存
5、external WAP手机浏览器:WAP网页比PC网页限制少,浏览速度快,在网络推广中具有无可比拟的分量
6、正则文本提取:该程序具有强大的标准公式和正则表达式文本提取功能,使得采集非常容易
7、support post Publishing:软件可以发送post数据和header数据,使登录和发布更加快速稳定
8、验证码标识:软件配置手动标识、验证库标识和远程手动标识,使用灵活。定制验证码标识项可随时随地批量发送或更新网站使用
通用模拟王软件的一些应用行业:
1、Variable网站自动回复帖子 查看全部
采集自动组合(全能模拟王软件-全能王数据提取,工作)
万能模拟王软件是一款后台模拟鼠标和键盘的自动操作软件,实现鼠标和键盘的自动点击
万能模拟王采用脚本形式实现后台模拟鼠标和键盘的自动操作,多种功能的灵活组合弥补了网络上各种软件功能单一、灵活性差的不足。它可以应用于鼠标和键盘自动模拟点击操作、网站投票、网页点击、在线赚钱、数据提取、大规模分发、注册、推广、工作等多个行业
万能模拟王软件可以操作任何窗口程序。用户只需结合不同的功能,即可实现各种完美的自动化操作。程序以指定的窗口为操作目标,定位更准确、更快,无需编写任何代码。所有繁琐复杂的操作都可以自动完成。可以说,它是一个全方位的软件,可以应用于任何行业。只有那些你想不到、做不到的,放开你的手,让一切变得如此简单
主要功能包括多个数据提取采集、发布数据提交、网页填充、网页点击、广告点击和刷牙网站IP流量、在线刷卡、批量账户注册、博客论坛群发SEO关键词Optimized click、站群maintenance、universal update、,自动识别常用图片验证码,程序截图它还支持各种模拟点击操作的前台和后台鼠标和键盘。同时,该软件具有内置的自动换IP功能
通用模拟王软件的功能:
1、您可以定位模拟操作的任何窗口,包括最小化窗口和隐藏窗口
2、支持非法IP交换和拨号IP交换
3、自动码打印(自动识别图片验证码和远程UU码打印识别)
4、运行任何程序文件
5、强大的标准表达式和正则表达式文件提取功能
6、自动鼠标背景点击、双击和拖动操作
7、支持固定和随机时间暂停
8、自动填充随机字符
9、键盘按键模拟(包括单键和系统组合键)
10、快速将文本内容发送到指定区域
11、指定程序控件的屏幕截图
12、快速文本存在判断
13、网页链接提取和元素操作(网页文本输入和按钮点击)
14、Text copy(自动将文本复制到剪贴板)
15、指定窗体自动关闭
16、End进程
17、自动打开网页
18、清除临时Internet文件
特点:
1、各类普通网络推广软件功能固定单一,注册费用高。有时他们跟不上更新。很难找到适合自己的软件。全方位推广模拟王就是为此而生的
2、通过软件功能的灵活组合,可以完成自定义脚本:各种应用程序的自动操作,游戏、论坛、博客、留言簿、群评、群发邮件、账号注册任务中的自动鼠标点击和自动按钮,分类目录提交与分发、QQ群发、微博推广、网站投票、数据抽取等多种功能
3、图形二次开发:无需了解编程。只要打开软件,你就可以下载各种官方精心制作的脚本。此外,我们不仅教人钓鱼,还教人钓鱼!在让您享受鱼粉的同时,我们还有超过n个图形教程和视频教程。只要你努力工作,你就能一个人钓到大鱼
4、内部和外部浏览器:经过一年多的开发,我们在挂断类似软件时发现了一个常见问题。内置浏览器挂起时间过长,占用的内存越来越多。因此,在维护内置浏览器的同时,我们还推广不与软件共享内存的外部浏览器。在执行过程中,程序可以每隔一段时间关闭和重新打开它以释放内存
5、external WAP手机浏览器:WAP网页比PC网页限制少,浏览速度快,在网络推广中具有无可比拟的分量
6、正则文本提取:该程序具有强大的标准公式和正则表达式文本提取功能,使得采集非常容易
7、support post Publishing:软件可以发送post数据和header数据,使登录和发布更加快速稳定
8、验证码标识:软件配置手动标识、验证库标识和远程手动标识,使用灵活。定制验证码标识项可随时随地批量发送或更新网站使用
通用模拟王软件的一些应用行业:
1、Variable网站自动回复帖子
采集自动组合(采集自动组合站点?实现不难,难的是拓展的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-09-21 15:06
采集自动组合站点?实现不难,难的是拓展的思路和收集站点数据的多少。主要可以分三个部分来收集,第一是站点的聚合,也就是收集知乎上问题,然后合并成一个问题,聚合成不同的页面。第二是自己收集关键词,可以利用百度的自动问答工具。一方面要记住关键词,每个问题最少要有一个关键词,然后有相应的描述和回答,其实这些不需要人去收集也容易。第三是页面的聚合。其实你可以考虑统计站点的页面数据并且自动在后台转换成一个可用的页面数据。
用baiduspider抓也行,专业的站长站也行。我简单说一下baiduspider抓数据的思路。搜索引擎baiduspider有两种抓取模式,循环抓取和加载方式。循环抓取是指用户输入的关键词会自动被抓取一段时间,然后关键词再次出现时从数据库中获取相同关键词的页面自动抓取,一般循环爬几千个页面就有较大量的数据抓取的量了。
加载方式是指抓取的关键词词之间有关联性。例如有的词是书写_双眼皮_-_全切双眼皮,那么这个词的关键词可能带有其他词,例如“双眼皮-全切双眼皮”,百度会抓取这个词的全切双眼皮的页面。加载方式抓取的优势是速度快,缺点是比较耗资源,后续要做太多扩展,建议爬到自己想要的页面后自己存成md5值存数据库。而爬取关键词词之间的关联性是比较耗资源的,百度抓取这些关键词需要的时间就和baiduspider自己爬到页面的时间差不多了。
爬行本身的机制是获取到的页面会按次序关联,然后每抓取一次,都会爬去更新最新页面,这样就会有大量的关键词词之间的页面没有直接关联,导致关键词的同意性词比较多的词无法抓取。搜索引擎baiduspider抓取速度是根据页面抓取量决定的,爬行速度越快效率越好,pc端会比移动端慢些,而这些因素又是主观性的。有些问题是可以用变通的思路解决的,比如在提问的时候添加关键词的话提问的排名就会快些,这时候可以用这种方法来加速抓取。 查看全部
采集自动组合(采集自动组合站点?实现不难,难的是拓展的思路)
采集自动组合站点?实现不难,难的是拓展的思路和收集站点数据的多少。主要可以分三个部分来收集,第一是站点的聚合,也就是收集知乎上问题,然后合并成一个问题,聚合成不同的页面。第二是自己收集关键词,可以利用百度的自动问答工具。一方面要记住关键词,每个问题最少要有一个关键词,然后有相应的描述和回答,其实这些不需要人去收集也容易。第三是页面的聚合。其实你可以考虑统计站点的页面数据并且自动在后台转换成一个可用的页面数据。
用baiduspider抓也行,专业的站长站也行。我简单说一下baiduspider抓数据的思路。搜索引擎baiduspider有两种抓取模式,循环抓取和加载方式。循环抓取是指用户输入的关键词会自动被抓取一段时间,然后关键词再次出现时从数据库中获取相同关键词的页面自动抓取,一般循环爬几千个页面就有较大量的数据抓取的量了。
加载方式是指抓取的关键词词之间有关联性。例如有的词是书写_双眼皮_-_全切双眼皮,那么这个词的关键词可能带有其他词,例如“双眼皮-全切双眼皮”,百度会抓取这个词的全切双眼皮的页面。加载方式抓取的优势是速度快,缺点是比较耗资源,后续要做太多扩展,建议爬到自己想要的页面后自己存成md5值存数据库。而爬取关键词词之间的关联性是比较耗资源的,百度抓取这些关键词需要的时间就和baiduspider自己爬到页面的时间差不多了。
爬行本身的机制是获取到的页面会按次序关联,然后每抓取一次,都会爬去更新最新页面,这样就会有大量的关键词词之间的页面没有直接关联,导致关键词的同意性词比较多的词无法抓取。搜索引擎baiduspider抓取速度是根据页面抓取量决定的,爬行速度越快效率越好,pc端会比移动端慢些,而这些因素又是主观性的。有些问题是可以用变通的思路解决的,比如在提问的时候添加关键词的话提问的排名就会快些,这时候可以用这种方法来加速抓取。
采集自动组合(网页结构没有变化的规划采集流程》介绍及注意事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-18 00:22
**注意:**如果在执行操作前后网页结构没有改变,则可以使用规则来完成该操作;如果网页结构在前后发生变化,则必须通过两条或两条以上的规则来完成;此外,如果涉及翻页,还应将其分为两个或两个以上的规则。请参考文章planning采集流程,了解持续行动所需的规则数量
一、建立一级主题,捕捉目标信息
建立第一级主题的规则,并将所需信息映射到排序框。建议在内容映射后映射定位标记,提高定位精度和规则适应性
**注意:**如果设置了连续操作规则,则可能不会生成排序规则框。例如,方案2的一级主题可能不构建排序框,但排序框用于抓取一些数据(选择将在网页上显示的信息)来判断是否执行采集,否则网页可能会被省略
二、set连续动作
单击“新建”按钮创建新操作。每个动作的设置方法相同。基本操作如下:
2.1输入目标主题的名称
连续操作指向同一目标主题。如果有多个操作,并且您希望指向不同的主题,请将它们拆分为多个规则以分别设置连续操作
2.2选择动作类型
此案例是一个单击操作。不同行为的适用范围不同。请根据实际操作选择动作类型
2.3将定位到动作对象的XPath填充到定位表达式中
2.4输入操作名称
告诉自己此操作的目的,以便以后可以修改它
2.5高级设置
首先不能设置它。稍后调试连续操作时将使用它,这可以扩展操作的应用范围。如果需要捕获操作对象的信息,可以使用XPath在高级设置的内容表达式中查找操作对象的信息。请根据需要重新设置
**注意:**是否正确选择了操作类型以及XPath位置是否准确将决定是否可以成功执行连续操作。XPath是用于定位HTML节点的标准语言。在使用连续动作功能之前,请先掌握XPath
根据人员的操作步骤,我们还需要选择版本和购买方式1、purchase method 2。因此,我们需要继续创造三个新的行动,并重复上述步骤
三、调试规则
完成上述步骤后,单击保存规则,然后单击爬升数据按钮尝试抓取。查找采集报告错误:无法找到节点***,请观察浏览器窗口,查看单击第一步时,未加载其他信息。加载信息时,发现点击购买方式2后,无法返回到点击第四步的页面,导致连续动作失败
鉴于上述情况,我们的解决方案是删除步骤4。因为无论您是否点击购买方式2,都不会影响商品价格。因此,可以删除不必要和干扰的操作步骤
修改后重试。将提取的XML转换为excel后,可以看到价格和累计评估数据缺失或错误。这是因为网页太大,加载速度慢。单击后,数据必须等待一定时间才能加载
为了捕获所有数据,您需要延长等待时间,分别为每个操作设置延迟,然后单击操作步骤->;高级设置->;额外延迟,以秒为单位输入正整数。请根据实际调试情况输入时间
此外,如果它不是顶部窗口,采集它将重复单击。这是因为京东的网页上有反爬行措施,当前窗口的操作将生效。因此,要检查高级设置中可见的窗口,采集窗口将放置在顶部。请根据实际情况进行设置
四、如何将捕获的信息与行动步骤逐一匹配
如果要将捕获的信息与动作步骤逐一匹配,则必须提取动作对象的信息。有两种方法:
4.1使用XPath在“连续动作的高级设置”的内容表达式中查找动作对象的信息节点
当定位表达式定位到动作对象的整个操作范围时,它还包括自己的信息。因此,内容表达式只需从定位的action对象开始,继续定位其信息采集即可将此步骤的动作信息记录在actionvalue中,对应actionno,并记录此步骤的执行次数
4.2在排序框中获取动作对象的信息。在这里,您还需要使用XPath来定位它
执行action对象时,其DOM结构会发生变化。查找网页更改的结构特征,使用XPath准确定位节点,并在验证后设置自定义XPath
以上是用连续动作模拟手动操作的全过程。虽然这个过程很麻烦,但只要你细心和耐心,你最终可以征服你想要攀登的网页 查看全部
采集自动组合(网页结构没有变化的规划采集流程》介绍及注意事项)
**注意:**如果在执行操作前后网页结构没有改变,则可以使用规则来完成该操作;如果网页结构在前后发生变化,则必须通过两条或两条以上的规则来完成;此外,如果涉及翻页,还应将其分为两个或两个以上的规则。请参考文章planning采集流程,了解持续行动所需的规则数量
一、建立一级主题,捕捉目标信息
建立第一级主题的规则,并将所需信息映射到排序框。建议在内容映射后映射定位标记,提高定位精度和规则适应性
**注意:**如果设置了连续操作规则,则可能不会生成排序规则框。例如,方案2的一级主题可能不构建排序框,但排序框用于抓取一些数据(选择将在网页上显示的信息)来判断是否执行采集,否则网页可能会被省略
二、set连续动作
单击“新建”按钮创建新操作。每个动作的设置方法相同。基本操作如下:
2.1输入目标主题的名称
连续操作指向同一目标主题。如果有多个操作,并且您希望指向不同的主题,请将它们拆分为多个规则以分别设置连续操作
2.2选择动作类型
此案例是一个单击操作。不同行为的适用范围不同。请根据实际操作选择动作类型
2.3将定位到动作对象的XPath填充到定位表达式中
2.4输入操作名称
告诉自己此操作的目的,以便以后可以修改它
2.5高级设置
首先不能设置它。稍后调试连续操作时将使用它,这可以扩展操作的应用范围。如果需要捕获操作对象的信息,可以使用XPath在高级设置的内容表达式中查找操作对象的信息。请根据需要重新设置
**注意:**是否正确选择了操作类型以及XPath位置是否准确将决定是否可以成功执行连续操作。XPath是用于定位HTML节点的标准语言。在使用连续动作功能之前,请先掌握XPath
根据人员的操作步骤,我们还需要选择版本和购买方式1、purchase method 2。因此,我们需要继续创造三个新的行动,并重复上述步骤
三、调试规则
完成上述步骤后,单击保存规则,然后单击爬升数据按钮尝试抓取。查找采集报告错误:无法找到节点***,请观察浏览器窗口,查看单击第一步时,未加载其他信息。加载信息时,发现点击购买方式2后,无法返回到点击第四步的页面,导致连续动作失败
鉴于上述情况,我们的解决方案是删除步骤4。因为无论您是否点击购买方式2,都不会影响商品价格。因此,可以删除不必要和干扰的操作步骤
修改后重试。将提取的XML转换为excel后,可以看到价格和累计评估数据缺失或错误。这是因为网页太大,加载速度慢。单击后,数据必须等待一定时间才能加载
为了捕获所有数据,您需要延长等待时间,分别为每个操作设置延迟,然后单击操作步骤->;高级设置->;额外延迟,以秒为单位输入正整数。请根据实际调试情况输入时间
此外,如果它不是顶部窗口,采集它将重复单击。这是因为京东的网页上有反爬行措施,当前窗口的操作将生效。因此,要检查高级设置中可见的窗口,采集窗口将放置在顶部。请根据实际情况进行设置
四、如何将捕获的信息与行动步骤逐一匹配
如果要将捕获的信息与动作步骤逐一匹配,则必须提取动作对象的信息。有两种方法:
4.1使用XPath在“连续动作的高级设置”的内容表达式中查找动作对象的信息节点
当定位表达式定位到动作对象的整个操作范围时,它还包括自己的信息。因此,内容表达式只需从定位的action对象开始,继续定位其信息采集即可将此步骤的动作信息记录在actionvalue中,对应actionno,并记录此步骤的执行次数
4.2在排序框中获取动作对象的信息。在这里,您还需要使用XPath来定位它
执行action对象时,其DOM结构会发生变化。查找网页更改的结构特征,使用XPath准确定位节点,并在验证后设置自定义XPath
以上是用连续动作模拟手动操作的全过程。虽然这个过程很麻烦,但只要你细心和耐心,你最终可以征服你想要攀登的网页
采集自动组合(采集自动组合策略利用d3地理数据库设置属性点(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-10 04:05
采集自动组合策略利用d3地理数据库设置属性点跟随能够为物流、金融服务等使用数据实现全球定位导航项目中的peer-to-peer路由、多点共享、路由追踪等功能。实现了企业物流系统的全面转型,可谓是物流领域的“金科玉律”。
“我最强大的就是我的眼睛。
自带三维立体地图功能吧,
大部分实现这个功能的都是竞价排名的(迅雷2就是这个系统)搜狗地图在4年前就支持geo流量的增长了,就是采用的自动组合方式,简单来说就是不管你需要的是哪个地址,搜狗给你起个虚拟目标地址,然后在这个地址上下载地图,无论你那个目标的地址是哪里,你随便哪个地址所在位置和用户终端都是完全一样的;百度地图也是这个原理,搜狗3。0采用自动组合的原理是未来趋势,应该是新方向?。
搜狗通过3dgeo技术能比现在地图功能复杂许多倍,完全支持exif定位、全球路由,自动投票,以及对多点地址追踪和地图组合功能,并且对碰撞和路径绑定等复杂机制的支持都是可选配,在搜狗3。0时代2者都可以通过更高精度地图实现双发定位,一个gps,一个通过usb控制器即可实现,3。0与1。0的最大区别可能就是简洁化,因为搜索的产生需要更多基础设施支持。 查看全部
采集自动组合(采集自动组合策略利用d3地理数据库设置属性点(组图))
采集自动组合策略利用d3地理数据库设置属性点跟随能够为物流、金融服务等使用数据实现全球定位导航项目中的peer-to-peer路由、多点共享、路由追踪等功能。实现了企业物流系统的全面转型,可谓是物流领域的“金科玉律”。
“我最强大的就是我的眼睛。
自带三维立体地图功能吧,
大部分实现这个功能的都是竞价排名的(迅雷2就是这个系统)搜狗地图在4年前就支持geo流量的增长了,就是采用的自动组合方式,简单来说就是不管你需要的是哪个地址,搜狗给你起个虚拟目标地址,然后在这个地址上下载地图,无论你那个目标的地址是哪里,你随便哪个地址所在位置和用户终端都是完全一样的;百度地图也是这个原理,搜狗3。0采用自动组合的原理是未来趋势,应该是新方向?。
搜狗通过3dgeo技术能比现在地图功能复杂许多倍,完全支持exif定位、全球路由,自动投票,以及对多点地址追踪和地图组合功能,并且对碰撞和路径绑定等复杂机制的支持都是可选配,在搜狗3。0时代2者都可以通过更高精度地图实现双发定位,一个gps,一个通过usb控制器即可实现,3。0与1。0的最大区别可能就是简洁化,因为搜索的产生需要更多基础设施支持。
采集自动组合(采集自动组合规则都是机器自动生成的,无需人工规则解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-05 13:07
采集自动组合规则都是机器自动生成的,无需人工规则解析规则编写问题,达到人机协同的目的工作流程和结构人可以随意调整,过程不依赖专门开发人员,是整个项目的工作思路和工作流程由团队来决定自动组合规则识别性非常高,没有预先定义的特征。比如一个求差异值的规则,不仅局限于一个函数,可以使用数组,树,集合等数据结构。从效率上来讲,即使人工解析了,但是下发到机器上,因为机器计算力的局限性,仍然不能解析机器自己的逻辑。
当人工流程已经无法满足日益增长的业务需求的时候,机器学习将会成为重要的手段;例如:需要基于ctr预估的机器学习服务,如阿里的elasticdata,今年7月已经上线数据机器学习平台ctrx,使用机器学习服务,
我觉得商业公司开发gl是完全可以的,毕竟现在数据源非常有限,一个规则可以从多家获取数据。数据规则深度比较厉害的话,
其实现在对于这类的问题,最好的是通过舆情监控,预警解决基础数据的短缺问题,同时也对于各类规则的积累是非常必要的。当然对于自动变规的部分,大数据才是刚刚开始。
现在各种机器学习、人工智能都是比较火的新兴的技术。对于生活和工作确实有帮助。从实际的业务来看,如果这个公司真正需要机器学习、自动变规的服务,那么主要可以从一下三个方面来理解:1.明确公司的真正业务场景,选择机器学习、人工智能方向对于很多公司来说,的确是很麻烦的,为什么呢?因为每个产品定位不同、创新点不同、竞争的要求不同,每个公司对于机器学习、人工智能方向的运用,关注点都不一样。
因此,通过公司产品和业务来验证公司需要与否是否应该通过机器学习和人工智能服务来加强竞争优势,是一个好的方法。2.确定好业务场景后,通过机器学习、人工智能方向来加强竞争优势既然机器学习方向一定有机器学习、人工智能服务能够支持,而且满足具体业务场景,那么我们肯定可以根据机器学习、人工智能的核心要点需求进行定制化开发。
在这个行业还没有规范和完善的时候,想要满足更多产品和业务的需求,通过定制化开发,把通用的机器学习、人工智能服务覆盖到各行各业的客户需求中。比如使用机器学习的话,可以把它定义为很复杂的数据特征工程,建立起特征工程的系统化、平台化框架。同时定制化的需求有很多很多。大家也可以把这个看作是业务扩展,它不仅仅是数据检索、聚类分析。
而是用机器学习的方法解决很多互联网产品上的痛点。3.选择最合适的机器学习、人工智能方向目前很多公司在上中台的。 查看全部
采集自动组合(采集自动组合规则都是机器自动生成的,无需人工规则解析)
采集自动组合规则都是机器自动生成的,无需人工规则解析规则编写问题,达到人机协同的目的工作流程和结构人可以随意调整,过程不依赖专门开发人员,是整个项目的工作思路和工作流程由团队来决定自动组合规则识别性非常高,没有预先定义的特征。比如一个求差异值的规则,不仅局限于一个函数,可以使用数组,树,集合等数据结构。从效率上来讲,即使人工解析了,但是下发到机器上,因为机器计算力的局限性,仍然不能解析机器自己的逻辑。
当人工流程已经无法满足日益增长的业务需求的时候,机器学习将会成为重要的手段;例如:需要基于ctr预估的机器学习服务,如阿里的elasticdata,今年7月已经上线数据机器学习平台ctrx,使用机器学习服务,
我觉得商业公司开发gl是完全可以的,毕竟现在数据源非常有限,一个规则可以从多家获取数据。数据规则深度比较厉害的话,
其实现在对于这类的问题,最好的是通过舆情监控,预警解决基础数据的短缺问题,同时也对于各类规则的积累是非常必要的。当然对于自动变规的部分,大数据才是刚刚开始。
现在各种机器学习、人工智能都是比较火的新兴的技术。对于生活和工作确实有帮助。从实际的业务来看,如果这个公司真正需要机器学习、自动变规的服务,那么主要可以从一下三个方面来理解:1.明确公司的真正业务场景,选择机器学习、人工智能方向对于很多公司来说,的确是很麻烦的,为什么呢?因为每个产品定位不同、创新点不同、竞争的要求不同,每个公司对于机器学习、人工智能方向的运用,关注点都不一样。
因此,通过公司产品和业务来验证公司需要与否是否应该通过机器学习和人工智能服务来加强竞争优势,是一个好的方法。2.确定好业务场景后,通过机器学习、人工智能方向来加强竞争优势既然机器学习方向一定有机器学习、人工智能服务能够支持,而且满足具体业务场景,那么我们肯定可以根据机器学习、人工智能的核心要点需求进行定制化开发。
在这个行业还没有规范和完善的时候,想要满足更多产品和业务的需求,通过定制化开发,把通用的机器学习、人工智能服务覆盖到各行各业的客户需求中。比如使用机器学习的话,可以把它定义为很复杂的数据特征工程,建立起特征工程的系统化、平台化框架。同时定制化的需求有很多很多。大家也可以把这个看作是业务扩展,它不仅仅是数据检索、聚类分析。
而是用机器学习的方法解决很多互联网产品上的痛点。3.选择最合适的机器学习、人工智能方向目前很多公司在上中台的。
采集自动组合( 小米运维研发技术负责人,互联网公司监控解决方案主程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-02 07:12
小米运维研发技术负责人,互联网公司监控解决方案主程
)
秦晓辉,小米运维研发技术负责人,互联网公司监控解决方案OpenFalcon主程序,国内首个开源PaaS平台DINP主程序,企业级业务监控Minos作者,Gopher,现负责小米建设运维平台。关注运维自动化和PaaS领域。
今天给大家简单介绍一下OpenFalcon处理高并发的方法。 OpenFalcon 是小米运维团队的监控系统。 OpenFalcon 主要面向运维架构师、DevOPs、关注高并发的开发者。小米在使用OpenFalcon的过程中,每个周期(5分钟)上报数据约1亿条。
下面先简单介绍一下OpenFalcon,然后再介绍小米处理高并发场景的7种方法,包括数据采集怎么做,转发,分片,告警等。
(OpenFalcon架构,点击图片可全屏放大)
OpenFalcon 简介
监控系统是整个运维环节,乃至整个产品生命周期中最重要的环节。
公司刚起步,业务还小,运维团队刚刚成立初期,选择开源监控系统是省时、省力、效率最高的方案.
之后,随着业务规模的不断快速增长,监控的对象越来越多,也越来越复杂。监控系统使用的对象也从最初的几个SRE扩展到了更多的DEVS和SRE。 此时,监控系统的容量和用户的“使用效率”成为最突出的问题。
OpenFalcon 来自小米运维团队。 2014年初开发,大约半年后,第一个版本上线。此后,它一直稳定地在线运行。后来,我们建立了 OpenFalcon 社区。
现在很多公司都在使用OpenFalcon,比如美团、金山云、京东金融、赶集、易信、快网等
像BAT这样的大公司还不知道要不要用OpenFalcon,大部分都是自研系统。
OpenFalcon的官网是,文档地址是,感兴趣的同学可以访问了解一下。
OpenFalcon 就是在这种情况下产生的。当时小米拥有三套Zabbix,每套可支持约2000台机器。当时有6000台机器,所以造了3套Zabbix。此外,还有一个内部业务监控系统,内部称为PerfCounter,负责监控业务绩效指标。
因为4套监控系统的维护比较麻烦,所以就有了开发这样一个统一的解决方案的想法,那就是OpenFalcon。
(高可用编辑器:看来伟人都是懒惰的,永远是强大系统的源头)
OpenFalcon 的其他功能包括:
横向扩展能力:支持每周期数亿条数据采集、告警判断、历史数据存储和查询
高可用:整个系统无核心单点,易运维,易部署,可横向扩展
开发语言:整个系统后端使用golang编写,门户和仪表盘使用Python编写
OpenFalcon在高并发场景下的7个对策
1.数据采集推拉选择
对于监控系统,它包括几个核心功能:data采集、历史数据存储、报警,最后是图形显示和数据挖掘。
数据采集
我们希望为这块做一个统一的东西,所以需要采集很多监控指标,比如Linux本身的监控指标,比如CPU、内存、网卡、IO等,一些硬件指标,如风扇转速、温度等,外加一些开源软件如MySQL、Nginx、OpenStack、HBase等监控指标。
公司有很多产品线。我们希望采集 可用于每个服务运行状态。比如中间层服务开放了一些RPC端口。服务过程中每个RPC端口的延迟和QPS是多少?我想知道。
因此,需要覆盖很多监测指标。监控组一开始只有两个人。不可能采集所有监控指标——人手不够,技术水平不达标。
所以我们需要一起建立监控数据,让专业的人做专业的事。
DBA 学生对 MySQL 比较熟悉。然后去采集MySQL相关指标,分布式组同学去采集HBase或Hadoop等指标,网络组同学去采集交换机路由器指标。
监控团队要做的是制定规范。开发数据进来的机制,然后公司开发人员和运维人员按照规范推送数据。
数据采集没有使用pull方式,因为数据源太多,作为Client去连接源,采集data,然后关闭连接,会产生很多time_wait状态的连接,吞吐量肯定会很低,所以让自己成为服务器端。现在每个周期有1亿多条数据。
此循环的简要说明。监测数据是一个连续的报告。比如Linux的一些基本监控项在采集后一分钟上报一次,下一分钟再采集。有些事情(例如业务监控)有 3 分钟和 5 分钟。
所以周期是指数据量在5分钟以内,有数据上报动作。
2.中间节点快速转发和容错
有很多数据需要推送到服务器端。服务器端的前端组件是Transfer。 Transfer接收到数据后,转发给接下来的两个组件,一个是Graph(用于绘图),另一个是Judge(用于做报警判断)。
先为每个后端实例创建一个Queue,比如20个Graph实例,60个Judge实例,每个实例创建一个Queue,每个Transfer内存有80个Queues,
当有一条监控数据进来时,需要判断数据发送到哪个实例,然后放到这个实例对应的Queue中。 Transfer接收数据的RPC逻辑非常简单。接收到数据后,放入Queue,立即返回。
代理转,转判断,判断到Redis,Redis报警,报警链接比较长,如果想尽快触发报警,需要快速处理链接的每个链接,使用Queue方式,传输吞吐量特别大,不会拖慢整个链路。
放入队列的数据有问题。如果没有及时转发,比如后端负载比较高或者挂了,Queue数据就会堆积,超过内存就会崩溃。所以采取了一个简单的保护措施来设置 Queue 如果长度是固定的,如果超过 Queue 的长度,则数据无法放入。
数据推送到Queue后,有一个worker专门把它读入Queue,读完后再转发。转发动作是由一堆写worker完成的,worker指的是goroutine,所以一堆goroutine协同工作,提高转发性能。
3. 一致性哈希分片提高吞吐能力
一致性哈希分片
这么多数据,一台机器处理不了,所以做了数据切分,即一台机器只处理部分数据。报警数据采用 Judge 分段,绘图数据采用 Graph 分段。全部使用一致哈希。
一致性哈希分片的一个问题是扩展和收缩很麻烦。数据命中某个判断后,会继续命中该判断。
当列表发生变化时,由于一致性哈希算法,原本被一个judge实例命中的数据会被另一个judge实例命中,因此Judge必须保证没有状态,以便于扩容和缩容。
状态标签
其实说没有地位也不合适。法官记忆中也有几点。比如某台机器的cpu.idle数据上来后,连续3到5次达到特定阈值就会报警,而不是达到阈值就立即报警。和CPU一样,闹钟总是忙碌的。 Judge 判断时,判断多个点。
报警产生后,还有一些后续的处理,比如对报警事件做出判断,上次事件的状态是什么,已经报警了多少次,是不是最大次数无法再次报告的警报?避免重复报警对加工人员造成干扰。一般来说,每个人都会设置闹钟3次。
所以报警事件需要记录一个状态,标记是否健康,如果有问题,记录当前次数。法官状态存储在数据库中。虽然上来1亿条数据,但实际上报警数据并不多,可能只有10万条数据级,所以可以存入数据库,所以Judge去掉报警事件状态。
Judge的记忆中虽然还有上面提到的一些数据状态,但问题不大。因为监控数据不断上来,即使丢失了一些状态,新的Judge实例很快就会被数据填满。
扩展
一致性散列对扩展不是很友好。比如20台Graph机器变成40台机器,老Graph实例的部分数据必然会转移到新Graph上,所以我们做了自动数据迁移。
这种自动迁移是一致性哈希引起的问题。如果使用映射表进行分片,数据和图实例的对应关系在映射表中统一维护,扩展简单很多。
4. 快速匹配数据和策略
当数据上来时,需要判断数据是否触发了报警策略。有很多策略。例如,我们的系统中有数以万计的项目。
上传一条数据后,需要先判断该数据与哪种策略相关,然后再判断阈值和是否触发告警。
我们选择将所有报警策略列表同步到数据库中,因为整个公司不会有太多的策略列表。虽然数据量很大,但没有太多的策略,比如只有几千或几万。
在策略库中做了一个简单的索引,方便数据上来后快速定位策略,然后根据阈值看是否需要报警。
为了加快策略的决策,需要了解一些近期的历史数据。历史记录存储在Judge内存中,因此获取速度相对较快。
测试第一个版本时,没有放入内存。当时使用了56个Redis实例,每个实例的QPS在3000左右。当时量并不大,还达到了这么高的QPS。由于并发性高,把数据放在Redis中不是很好的解决方案,后来放到Judge内存中。这样处理起来要快得多。
判断内存和数据库中也存在报警状态。每次报警判断都需要访问DB,所以加载到Judge内存中,相当于缓存机制,内存不去DB加载。当Judge 重新启动时,内存中没有数据。此时需要将报警状态的判断加载到DB中,然后再读入内存。
5.延迟数据写入,减少RRD文件打开次数
时间序列数据自动归档
报警数据存储使用比较有名的RRD。大量开源监控软件使用RRD来存储时间序列数据。
RRD 的最大优势是自动归档。有监测数据的特点。无需关心历史监控数据的具体数值,只需要知道当前的趋势即可。
可能需要查看最近 6 小时的原创值。但是,最近 3 天和 1 个月对原创值的需求非常小。而且积分这么多,一分钟一分,一天1440分。加载1个月后浏览器没有崩溃就奇怪了。
只要可以看到历史点的趋势。因此,监控数据尤其需要归档功能。例如,一个小时的数据归档是一个点,RRD可以帮助我们做到这一点。
RRD 优化:延迟合并写入
RRD默认操作性能比较差,它的逻辑是打开RRD文件,然后seek、write、seek、write,最后关闭文件句柄。一个监控指标对应一个RRD文件。比如这台机器处理大约200万个监控指标时,实际上有200万个RRD文件。
每次写数据时,打开RRD文件,读取头信息,包括一些元信息,记录归档策略和数据类型等数据,然后进行写操作。
如果在每条数据上来之后执行这个操作,RRD读写会造成极大的IO。虽然现在硬盘都是SSD,但由于IO高,做了延迟写入的优化。
目前每1分钟上报一次数据,部分数据可能每10秒或30秒上报一次。不是上报并立即打开RRD文件写入,而是等待10分钟或30分钟,在内存中缓存一段时间,缓存30或60个点,打开文件一次,写入一次,然后关闭它可以减少RRD文件打开次数,减少IO。
我们使用缓存时间,比如缓存半个小时,然后按照半个小时的长度来断数据。例如,半小时是 1,800 秒。例如,1,800 秒被制成 1,800 个槽。每个数据上来后,均匀分布在 1800 个槽中。写的时候,慢慢写。这是一个分手操作,以避免出现一些 IO 高峰。
6. 报警事件按优先级排队缓冲
报警事件量通常不是特别大,但有时会比较大——当触发一些大面积的报警时,比如核心交换机挂了,就会产生特别大的报警。
比如服务依赖几个上游服务,上游服务宕机,下游所有服务都报警。如果核心交换机宕机,很多核心业务都会受到影响。核心业务受到影响后,很多下游业务都会产生告警,从而产生大面积告警。但正常情况下,报警音量是一个非常稳定的音量。
当发生大面积报警时,我们仍然应用Queue机制,使用Queue平滑峰值。
告警分类处理
我们将告警从 P0、P1 分类到 P5,其中 P0 最高。
基于优先级的分级策略
我们对告警事件进行分类,每一级对应Redis中的一个Queue。使用Redis BRPOP简单的按照优先级处理告警事件,即先处理P0,然后依次处理P1、P2。
7.通过限制worker数量来限制发送接口的流量
系统本身可能有比较长的链接,每个链接都希望能够处理高并发。事实上,在系统开发过程中,我们依赖其他基础设施,例如内部SMTP服务器来发送电子邮件和短信通道。发送短信,但是这些接口不能处理大并发。
当系统依赖调用多个并发性较差的接口时,最好设置一个限流。
有一个特殊的模块发送器可以发送警报电子邮件或警报消息。当它发送时,它可以配置多个Worker。可以理解为最多有多少个线程可以调用发送接口。这样可以保护后端发送接口,不会被破坏。
总结
回到今天的话题“百万并发”,总结一下我们在OpenFalcon的设计中用到的技术。
1.分片:如果一台机器无法抵抗,就会分成多台机器。数人云是一个PaaS平台。 PaaS 平台易于扩展。原来的三百个实例现在是三千个,在页面上按下按钮,3000个实例可以在10秒内制作3000个切片。
2. 队列:有时候会有一些高峰,我们不想被高峰淹没,所以我们使用队列作为缓冲区。该系统在许多地方使用队列。例如,在传输存储器中内置多个队列并被警报事件使用。 Redis 做队列服务。
3.索引:索引可以加快查询速度。
4.限流:当后端接口不能承受压力时,会限流。
这些只是一些简单而通用的方法。他们没有炫耀那些高科技、难懂、难学的东西。希望能为大家在处理高并发时提供一些参考。谢谢你。 !
相关精彩文章
想关注更多高并发技术,请订阅公众号了解更多文章。请注明来自高可用框架“ArchNotes”微信公众号,并附上以下二维码。
高可用性架构
改变互联网的构建方式
长按二维码订阅“高可用框架”公众号
查看全部
采集自动组合(
小米运维研发技术负责人,互联网公司监控解决方案主程
)
秦晓辉,小米运维研发技术负责人,互联网公司监控解决方案OpenFalcon主程序,国内首个开源PaaS平台DINP主程序,企业级业务监控Minos作者,Gopher,现负责小米建设运维平台。关注运维自动化和PaaS领域。
今天给大家简单介绍一下OpenFalcon处理高并发的方法。 OpenFalcon 是小米运维团队的监控系统。 OpenFalcon 主要面向运维架构师、DevOPs、关注高并发的开发者。小米在使用OpenFalcon的过程中,每个周期(5分钟)上报数据约1亿条。
下面先简单介绍一下OpenFalcon,然后再介绍小米处理高并发场景的7种方法,包括数据采集怎么做,转发,分片,告警等。
(OpenFalcon架构,点击图片可全屏放大)
OpenFalcon 简介
监控系统是整个运维环节,乃至整个产品生命周期中最重要的环节。
公司刚起步,业务还小,运维团队刚刚成立初期,选择开源监控系统是省时、省力、效率最高的方案.
之后,随着业务规模的不断快速增长,监控的对象越来越多,也越来越复杂。监控系统使用的对象也从最初的几个SRE扩展到了更多的DEVS和SRE。 此时,监控系统的容量和用户的“使用效率”成为最突出的问题。
OpenFalcon 来自小米运维团队。 2014年初开发,大约半年后,第一个版本上线。此后,它一直稳定地在线运行。后来,我们建立了 OpenFalcon 社区。
现在很多公司都在使用OpenFalcon,比如美团、金山云、京东金融、赶集、易信、快网等
像BAT这样的大公司还不知道要不要用OpenFalcon,大部分都是自研系统。
OpenFalcon的官网是,文档地址是,感兴趣的同学可以访问了解一下。
OpenFalcon 就是在这种情况下产生的。当时小米拥有三套Zabbix,每套可支持约2000台机器。当时有6000台机器,所以造了3套Zabbix。此外,还有一个内部业务监控系统,内部称为PerfCounter,负责监控业务绩效指标。
因为4套监控系统的维护比较麻烦,所以就有了开发这样一个统一的解决方案的想法,那就是OpenFalcon。
(高可用编辑器:看来伟人都是懒惰的,永远是强大系统的源头)
OpenFalcon 的其他功能包括:
横向扩展能力:支持每周期数亿条数据采集、告警判断、历史数据存储和查询
高可用:整个系统无核心单点,易运维,易部署,可横向扩展
开发语言:整个系统后端使用golang编写,门户和仪表盘使用Python编写
OpenFalcon在高并发场景下的7个对策
1.数据采集推拉选择
对于监控系统,它包括几个核心功能:data采集、历史数据存储、报警,最后是图形显示和数据挖掘。
数据采集
我们希望为这块做一个统一的东西,所以需要采集很多监控指标,比如Linux本身的监控指标,比如CPU、内存、网卡、IO等,一些硬件指标,如风扇转速、温度等,外加一些开源软件如MySQL、Nginx、OpenStack、HBase等监控指标。
公司有很多产品线。我们希望采集 可用于每个服务运行状态。比如中间层服务开放了一些RPC端口。服务过程中每个RPC端口的延迟和QPS是多少?我想知道。
因此,需要覆盖很多监测指标。监控组一开始只有两个人。不可能采集所有监控指标——人手不够,技术水平不达标。
所以我们需要一起建立监控数据,让专业的人做专业的事。
DBA 学生对 MySQL 比较熟悉。然后去采集MySQL相关指标,分布式组同学去采集HBase或Hadoop等指标,网络组同学去采集交换机路由器指标。
监控团队要做的是制定规范。开发数据进来的机制,然后公司开发人员和运维人员按照规范推送数据。
数据采集没有使用pull方式,因为数据源太多,作为Client去连接源,采集data,然后关闭连接,会产生很多time_wait状态的连接,吞吐量肯定会很低,所以让自己成为服务器端。现在每个周期有1亿多条数据。
此循环的简要说明。监测数据是一个连续的报告。比如Linux的一些基本监控项在采集后一分钟上报一次,下一分钟再采集。有些事情(例如业务监控)有 3 分钟和 5 分钟。
所以周期是指数据量在5分钟以内,有数据上报动作。
2.中间节点快速转发和容错
有很多数据需要推送到服务器端。服务器端的前端组件是Transfer。 Transfer接收到数据后,转发给接下来的两个组件,一个是Graph(用于绘图),另一个是Judge(用于做报警判断)。
先为每个后端实例创建一个Queue,比如20个Graph实例,60个Judge实例,每个实例创建一个Queue,每个Transfer内存有80个Queues,
当有一条监控数据进来时,需要判断数据发送到哪个实例,然后放到这个实例对应的Queue中。 Transfer接收数据的RPC逻辑非常简单。接收到数据后,放入Queue,立即返回。
代理转,转判断,判断到Redis,Redis报警,报警链接比较长,如果想尽快触发报警,需要快速处理链接的每个链接,使用Queue方式,传输吞吐量特别大,不会拖慢整个链路。
放入队列的数据有问题。如果没有及时转发,比如后端负载比较高或者挂了,Queue数据就会堆积,超过内存就会崩溃。所以采取了一个简单的保护措施来设置 Queue 如果长度是固定的,如果超过 Queue 的长度,则数据无法放入。
数据推送到Queue后,有一个worker专门把它读入Queue,读完后再转发。转发动作是由一堆写worker完成的,worker指的是goroutine,所以一堆goroutine协同工作,提高转发性能。
3. 一致性哈希分片提高吞吐能力
一致性哈希分片
这么多数据,一台机器处理不了,所以做了数据切分,即一台机器只处理部分数据。报警数据采用 Judge 分段,绘图数据采用 Graph 分段。全部使用一致哈希。
一致性哈希分片的一个问题是扩展和收缩很麻烦。数据命中某个判断后,会继续命中该判断。
当列表发生变化时,由于一致性哈希算法,原本被一个judge实例命中的数据会被另一个judge实例命中,因此Judge必须保证没有状态,以便于扩容和缩容。
状态标签
其实说没有地位也不合适。法官记忆中也有几点。比如某台机器的cpu.idle数据上来后,连续3到5次达到特定阈值就会报警,而不是达到阈值就立即报警。和CPU一样,闹钟总是忙碌的。 Judge 判断时,判断多个点。
报警产生后,还有一些后续的处理,比如对报警事件做出判断,上次事件的状态是什么,已经报警了多少次,是不是最大次数无法再次报告的警报?避免重复报警对加工人员造成干扰。一般来说,每个人都会设置闹钟3次。
所以报警事件需要记录一个状态,标记是否健康,如果有问题,记录当前次数。法官状态存储在数据库中。虽然上来1亿条数据,但实际上报警数据并不多,可能只有10万条数据级,所以可以存入数据库,所以Judge去掉报警事件状态。
Judge的记忆中虽然还有上面提到的一些数据状态,但问题不大。因为监控数据不断上来,即使丢失了一些状态,新的Judge实例很快就会被数据填满。
扩展
一致性散列对扩展不是很友好。比如20台Graph机器变成40台机器,老Graph实例的部分数据必然会转移到新Graph上,所以我们做了自动数据迁移。
这种自动迁移是一致性哈希引起的问题。如果使用映射表进行分片,数据和图实例的对应关系在映射表中统一维护,扩展简单很多。
4. 快速匹配数据和策略
当数据上来时,需要判断数据是否触发了报警策略。有很多策略。例如,我们的系统中有数以万计的项目。
上传一条数据后,需要先判断该数据与哪种策略相关,然后再判断阈值和是否触发告警。
我们选择将所有报警策略列表同步到数据库中,因为整个公司不会有太多的策略列表。虽然数据量很大,但没有太多的策略,比如只有几千或几万。
在策略库中做了一个简单的索引,方便数据上来后快速定位策略,然后根据阈值看是否需要报警。
为了加快策略的决策,需要了解一些近期的历史数据。历史记录存储在Judge内存中,因此获取速度相对较快。
测试第一个版本时,没有放入内存。当时使用了56个Redis实例,每个实例的QPS在3000左右。当时量并不大,还达到了这么高的QPS。由于并发性高,把数据放在Redis中不是很好的解决方案,后来放到Judge内存中。这样处理起来要快得多。
判断内存和数据库中也存在报警状态。每次报警判断都需要访问DB,所以加载到Judge内存中,相当于缓存机制,内存不去DB加载。当Judge 重新启动时,内存中没有数据。此时需要将报警状态的判断加载到DB中,然后再读入内存。
5.延迟数据写入,减少RRD文件打开次数
时间序列数据自动归档
报警数据存储使用比较有名的RRD。大量开源监控软件使用RRD来存储时间序列数据。
RRD 的最大优势是自动归档。有监测数据的特点。无需关心历史监控数据的具体数值,只需要知道当前的趋势即可。
可能需要查看最近 6 小时的原创值。但是,最近 3 天和 1 个月对原创值的需求非常小。而且积分这么多,一分钟一分,一天1440分。加载1个月后浏览器没有崩溃就奇怪了。
只要可以看到历史点的趋势。因此,监控数据尤其需要归档功能。例如,一个小时的数据归档是一个点,RRD可以帮助我们做到这一点。
RRD 优化:延迟合并写入
RRD默认操作性能比较差,它的逻辑是打开RRD文件,然后seek、write、seek、write,最后关闭文件句柄。一个监控指标对应一个RRD文件。比如这台机器处理大约200万个监控指标时,实际上有200万个RRD文件。
每次写数据时,打开RRD文件,读取头信息,包括一些元信息,记录归档策略和数据类型等数据,然后进行写操作。
如果在每条数据上来之后执行这个操作,RRD读写会造成极大的IO。虽然现在硬盘都是SSD,但由于IO高,做了延迟写入的优化。
目前每1分钟上报一次数据,部分数据可能每10秒或30秒上报一次。不是上报并立即打开RRD文件写入,而是等待10分钟或30分钟,在内存中缓存一段时间,缓存30或60个点,打开文件一次,写入一次,然后关闭它可以减少RRD文件打开次数,减少IO。
我们使用缓存时间,比如缓存半个小时,然后按照半个小时的长度来断数据。例如,半小时是 1,800 秒。例如,1,800 秒被制成 1,800 个槽。每个数据上来后,均匀分布在 1800 个槽中。写的时候,慢慢写。这是一个分手操作,以避免出现一些 IO 高峰。
6. 报警事件按优先级排队缓冲
报警事件量通常不是特别大,但有时会比较大——当触发一些大面积的报警时,比如核心交换机挂了,就会产生特别大的报警。
比如服务依赖几个上游服务,上游服务宕机,下游所有服务都报警。如果核心交换机宕机,很多核心业务都会受到影响。核心业务受到影响后,很多下游业务都会产生告警,从而产生大面积告警。但正常情况下,报警音量是一个非常稳定的音量。
当发生大面积报警时,我们仍然应用Queue机制,使用Queue平滑峰值。
告警分类处理
我们将告警从 P0、P1 分类到 P5,其中 P0 最高。
基于优先级的分级策略
我们对告警事件进行分类,每一级对应Redis中的一个Queue。使用Redis BRPOP简单的按照优先级处理告警事件,即先处理P0,然后依次处理P1、P2。
7.通过限制worker数量来限制发送接口的流量
系统本身可能有比较长的链接,每个链接都希望能够处理高并发。事实上,在系统开发过程中,我们依赖其他基础设施,例如内部SMTP服务器来发送电子邮件和短信通道。发送短信,但是这些接口不能处理大并发。
当系统依赖调用多个并发性较差的接口时,最好设置一个限流。
有一个特殊的模块发送器可以发送警报电子邮件或警报消息。当它发送时,它可以配置多个Worker。可以理解为最多有多少个线程可以调用发送接口。这样可以保护后端发送接口,不会被破坏。
总结
回到今天的话题“百万并发”,总结一下我们在OpenFalcon的设计中用到的技术。
1.分片:如果一台机器无法抵抗,就会分成多台机器。数人云是一个PaaS平台。 PaaS 平台易于扩展。原来的三百个实例现在是三千个,在页面上按下按钮,3000个实例可以在10秒内制作3000个切片。
2. 队列:有时候会有一些高峰,我们不想被高峰淹没,所以我们使用队列作为缓冲区。该系统在许多地方使用队列。例如,在传输存储器中内置多个队列并被警报事件使用。 Redis 做队列服务。
3.索引:索引可以加快查询速度。
4.限流:当后端接口不能承受压力时,会限流。
这些只是一些简单而通用的方法。他们没有炫耀那些高科技、难懂、难学的东西。希望能为大家在处理高并发时提供一些参考。谢谢你。 !
相关精彩文章
想关注更多高并发技术,请订阅公众号了解更多文章。请注明来自高可用框架“ArchNotes”微信公众号,并附上以下二维码。
高可用性架构
改变互联网的构建方式
长按二维码订阅“高可用框架”公众号
采集自动组合(优采云采集器V9有免费版、基础版等多个版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-02 04:08
最近很多第一次联系优采云采集器的用户反馈优采云采集器V9有免费版、基础版、旗舰机码版、旗舰自动授权版,以及企业版专属版。 、企业版豪华版等众多版本,如何选择?东哥为您准备了以下攻略,相信对您选择版本有所帮助。
首先,我们来看看免费版。免费版优采云采集器也是终身使用,不限制使用时间。它仅在功能上与付费版本不同。各位大神们暂时可能不会考虑免费版的所有功能是否都满足你的需求,那我们来看看免费版暂时不支持哪些功能吧。如果需要使用,选择对应的商业版即可~
1、标签自由组合功能
当需要将两个标签采集的内容合成一个内容时,需要使用该功能。
例如:[label C]=[label A]+[label B],参考下图:
2、unlimited-level list URL采集(支持二级以上)
我们经常在采集 网页上遇到多级列表。比如大众点评的分类(分享规则:),就需要用到优采云采集器的多级列表功能。功能使用参考下图:
3、任意格式文件下载
在采集的过程中,我们会遇到一些需要下载的附件文件,比如word文档、压缩文件、PDF等格式文件。 采集器免费版不支持下载除图片外的任何其他格式文件。
4、使用ftp自动上传文件到网站
上面提到的文件下载任何格式,既然有下载,那么我们需要发布到网站时就需要上传功能。 优采云采集器提供使用FTP自动上传文件的功能,包括自动上传图片。上传。免费版不能使用此功能,只能手动上传文件,不能同步和自动上传文件。 FTP功能参考下图:
5、导出数据为Word、Excel、CSV格式
将采集的数据发布到本地,并保存为文件格式。免费版不支持 Word、Excel 和 CSV 格式,仅支持 TXT 和 html 格式。
6、MySql 和 SqlServer 数据库保存数据
免费版的默认版本是Sqlite数据库。当数据量比较大时,默认数据库会导致软件运行缓慢。在这种情况下,您需要使用 MySql 或 SqlServer 数据库。
7、多页采集function
我们在采集content 的时候,有时会遇到内容不在同一个页面的情况。进入内容页面后,我们需要进入另一个页面,称为multipage采集。参考案例:携程景点采集
8、List page tag采集function
我们经常会在列表页遇到采集内容,但是没有内容页或者内容页不方便采集。这时候就需要用到列表页采集功能。
在采集content URL的同时,采集有列表页需要的内容。
参考案例:智联招聘信息采集
9、Schedule 任务函数
当我们在采集some news网站时,需要固定时间采集自动发布,那么定时任务可以24小时自动更新发布。详细介绍请参考:
10、其他功能
自动提取第一张图,自动汇总,发布数据到MySql\SqlServer等功能,在你需要的时候总能帮到你。我不会在这里详细介绍。以上9个是比较常用的函数。
如果以上功能已经可以满足大神们的需求,那么可以选择基础版(商业授权也是终身使用,没有过期恢复免费版~)
但是对于更专业的大神来说,以上功能还远远不够,接下来我会告诉你更高版本的。
旗舰版及以上的特点
相比基础版,旗舰版及以上也有一些高级功能,可以满足大神们的操作。列举一些比较常用的函数。
1、二级代理
采集遇到被封IP时,需要使用二级代理功能。当然,你需要有IP代理资源。目前官方不提供代理资源
2、自动给图片加水印
自动给采集的图片添加水印
3、支持标签处理C#和C#外部插件函数
4、边采边发布功能
比如有10万条消息需要采集,基础版只能在采集完成后才能发布,旗舰版及以上支持同时挖矿和发帖。
5、Json 提取函数
支持Json格式数据提取采集,案例说明:
6、支持python插件,采集警告配置,支持SSH(SFTP文件)上传
以上功能需要旗舰版及以上版本支持。如果需要使用上述功能的基础版,是不够的。
那么旗舰版和高级版有什么区别?
除了企业版,还支持数据发布到Oracle和Http接口管理采集器操作。主要区别在于机器授权。
基础版和旗舰机码版:绑定1台授权电脑,一次免费修改授权。
旗舰自动授权版:绑定一台授权电脑,可不限次数更换电脑。
企业专享版:绑定5台授权电脑(2个加密狗版+3个机器码版),可免费更换3次,其中加密狗版可在任何电脑上使用。
企业豪华版:绑定10台授权电脑(4个加密狗版+6个自动授权版),可以无限次随意更换电脑
注意:捆绑授权电脑是指软件只能在授权电脑绑定的电脑上运行商业版。自授权版和加密狗版可以在不同的电脑上使用,即可以在不同的电脑上使用,但只能同时使用。可以在电脑上使用。
现在让我们看看哪个版本最适合你~
Ø 如果您的软件是固定在电脑上长期运行的,不需要经常更换,基础版的功能已经可以满足您的需求了»»»»»选择基础版
Ø 如果您的软件长期固定在电脑上,不需要频繁更换,但需要旗舰版的高级功能»»»»»选择旗舰机码版本
Ø 如果你的软件没有固定在电脑上,经常需要换电脑才能运行»»»»»选择旗舰自动授权版
Ø 如果需要大规模采集数据,多台电脑同时运行软件,或者需要多人同时在不同电脑上操作(5台)»»»» »选择企业版专属版
Ø 如果需要大规模采集数据,使用多台电脑同时运行软件或需要多人同时在不同电脑上操作(10套)»»»»»选择企业版豪华版
当然,如果您还有什么不能满足的需求,请联系我们的客服,优采云采集器视客户为上帝,为您量身定制。
[以前的好处]
【东阁福利】优采云采集器V9智联招聘信息采集讯讯务所
【东哥福利】优采云浏览器百度地图业务信息采集详解
【东哥福利】优采云采集器V9知乎采集规则分享
【东哥福利】优采云采集器V9微信公众号文章采集讯讯表
【东哥福利】优采云采集器V9优酷视频电视剧采集讯讯务体
【东哥福利】优采云采集器V9版JSon功能讲解及示例规则分享
【东哥福利-新手必看】最新最全优采云采集器V9版学习资料
【东哥福利】优采云采集器V9财富网业绩预告信息采集讯讯务体
[东哥福利]优采云采集器V9信息采集法享【东哥福利】优采云采集器V9安居客社区信息采集规传传员[东哥福利]豆瓣电影采集Rules并发布到本地CSV格式文件【东哥福利】美图采集调整和DZ3.X门户发布规则分享
【东哥福利】优采云采集器58同城传传备信息采集规传传员[东哥福利]优采云采集器软件-今日头条娱乐新闻采集榜【东哥福利】哥福利】优采云采集器V9 携程景区采集许计创【东哥福利】优采云采集器V9京东商城 商品信息采集许会计创 查看全部
采集自动组合(优采云采集器V9有免费版、基础版等多个版本)
最近很多第一次联系优采云采集器的用户反馈优采云采集器V9有免费版、基础版、旗舰机码版、旗舰自动授权版,以及企业版专属版。 、企业版豪华版等众多版本,如何选择?东哥为您准备了以下攻略,相信对您选择版本有所帮助。
首先,我们来看看免费版。免费版优采云采集器也是终身使用,不限制使用时间。它仅在功能上与付费版本不同。各位大神们暂时可能不会考虑免费版的所有功能是否都满足你的需求,那我们来看看免费版暂时不支持哪些功能吧。如果需要使用,选择对应的商业版即可~
1、标签自由组合功能
当需要将两个标签采集的内容合成一个内容时,需要使用该功能。
例如:[label C]=[label A]+[label B],参考下图:
2、unlimited-level list URL采集(支持二级以上)
我们经常在采集 网页上遇到多级列表。比如大众点评的分类(分享规则:),就需要用到优采云采集器的多级列表功能。功能使用参考下图:
3、任意格式文件下载
在采集的过程中,我们会遇到一些需要下载的附件文件,比如word文档、压缩文件、PDF等格式文件。 采集器免费版不支持下载除图片外的任何其他格式文件。
4、使用ftp自动上传文件到网站
上面提到的文件下载任何格式,既然有下载,那么我们需要发布到网站时就需要上传功能。 优采云采集器提供使用FTP自动上传文件的功能,包括自动上传图片。上传。免费版不能使用此功能,只能手动上传文件,不能同步和自动上传文件。 FTP功能参考下图:
5、导出数据为Word、Excel、CSV格式
将采集的数据发布到本地,并保存为文件格式。免费版不支持 Word、Excel 和 CSV 格式,仅支持 TXT 和 html 格式。
6、MySql 和 SqlServer 数据库保存数据
免费版的默认版本是Sqlite数据库。当数据量比较大时,默认数据库会导致软件运行缓慢。在这种情况下,您需要使用 MySql 或 SqlServer 数据库。
7、多页采集function
我们在采集content 的时候,有时会遇到内容不在同一个页面的情况。进入内容页面后,我们需要进入另一个页面,称为multipage采集。参考案例:携程景点采集
8、List page tag采集function
我们经常会在列表页遇到采集内容,但是没有内容页或者内容页不方便采集。这时候就需要用到列表页采集功能。
在采集content URL的同时,采集有列表页需要的内容。
参考案例:智联招聘信息采集
9、Schedule 任务函数
当我们在采集some news网站时,需要固定时间采集自动发布,那么定时任务可以24小时自动更新发布。详细介绍请参考:
10、其他功能
自动提取第一张图,自动汇总,发布数据到MySql\SqlServer等功能,在你需要的时候总能帮到你。我不会在这里详细介绍。以上9个是比较常用的函数。
如果以上功能已经可以满足大神们的需求,那么可以选择基础版(商业授权也是终身使用,没有过期恢复免费版~)
但是对于更专业的大神来说,以上功能还远远不够,接下来我会告诉你更高版本的。
旗舰版及以上的特点
相比基础版,旗舰版及以上也有一些高级功能,可以满足大神们的操作。列举一些比较常用的函数。
1、二级代理
采集遇到被封IP时,需要使用二级代理功能。当然,你需要有IP代理资源。目前官方不提供代理资源
2、自动给图片加水印
自动给采集的图片添加水印
3、支持标签处理C#和C#外部插件函数
4、边采边发布功能
比如有10万条消息需要采集,基础版只能在采集完成后才能发布,旗舰版及以上支持同时挖矿和发帖。
5、Json 提取函数
支持Json格式数据提取采集,案例说明:
6、支持python插件,采集警告配置,支持SSH(SFTP文件)上传
以上功能需要旗舰版及以上版本支持。如果需要使用上述功能的基础版,是不够的。
那么旗舰版和高级版有什么区别?
除了企业版,还支持数据发布到Oracle和Http接口管理采集器操作。主要区别在于机器授权。
基础版和旗舰机码版:绑定1台授权电脑,一次免费修改授权。
旗舰自动授权版:绑定一台授权电脑,可不限次数更换电脑。
企业专享版:绑定5台授权电脑(2个加密狗版+3个机器码版),可免费更换3次,其中加密狗版可在任何电脑上使用。
企业豪华版:绑定10台授权电脑(4个加密狗版+6个自动授权版),可以无限次随意更换电脑
注意:捆绑授权电脑是指软件只能在授权电脑绑定的电脑上运行商业版。自授权版和加密狗版可以在不同的电脑上使用,即可以在不同的电脑上使用,但只能同时使用。可以在电脑上使用。
现在让我们看看哪个版本最适合你~
Ø 如果您的软件是固定在电脑上长期运行的,不需要经常更换,基础版的功能已经可以满足您的需求了»»»»»选择基础版
Ø 如果您的软件长期固定在电脑上,不需要频繁更换,但需要旗舰版的高级功能»»»»»选择旗舰机码版本
Ø 如果你的软件没有固定在电脑上,经常需要换电脑才能运行»»»»»选择旗舰自动授权版
Ø 如果需要大规模采集数据,多台电脑同时运行软件,或者需要多人同时在不同电脑上操作(5台)»»»» »选择企业版专属版
Ø 如果需要大规模采集数据,使用多台电脑同时运行软件或需要多人同时在不同电脑上操作(10套)»»»»»选择企业版豪华版
当然,如果您还有什么不能满足的需求,请联系我们的客服,优采云采集器视客户为上帝,为您量身定制。
[以前的好处]
【东阁福利】优采云采集器V9智联招聘信息采集讯讯务所
【东哥福利】优采云浏览器百度地图业务信息采集详解
【东哥福利】优采云采集器V9知乎采集规则分享
【东哥福利】优采云采集器V9微信公众号文章采集讯讯表
【东哥福利】优采云采集器V9优酷视频电视剧采集讯讯务体
【东哥福利】优采云采集器V9版JSon功能讲解及示例规则分享
【东哥福利-新手必看】最新最全优采云采集器V9版学习资料
【东哥福利】优采云采集器V9财富网业绩预告信息采集讯讯务体
[东哥福利]优采云采集器V9信息采集法享【东哥福利】优采云采集器V9安居客社区信息采集规传传员[东哥福利]豆瓣电影采集Rules并发布到本地CSV格式文件【东哥福利】美图采集调整和DZ3.X门户发布规则分享
【东哥福利】优采云采集器58同城传传备信息采集规传传员[东哥福利]优采云采集器软件-今日头条娱乐新闻采集榜【东哥福利】哥福利】优采云采集器V9 携程景区采集许计创【东哥福利】优采云采集器V9京东商城 商品信息采集许会计创
采集自动组合(优采云采集器V9有免费版、基础版等多个版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-02 04:07
最近很多第一次联系优采云采集器的用户反馈优采云采集器V9有免费版、基础版、旗舰机码版、旗舰自动授权版,以及企业版专属版。 、企业版豪华版等众多版本,如何选择?
小彩为你准备了以下攻略,相信对你选择版本有帮助。
首先,我们来看看免费版。免费版优采云采集器也是终身使用,不限制使用时间。它仅在功能上与付费版本不同。各位大神们暂时可能不会考虑免费版的所有功能是否都满足你的需求,那我们来看看免费版暂时不支持哪些功能吧。如果需要使用,选择对应的商业版即可~
1、标签自由组合功能
当需要将两个标签采集的内容合成一个内容时,需要使用该功能。
例如:[label C]=[label A]+[label B],参考下图:
2、unlimited-level list URL采集(支持二级以上)
我们在采集网页上经常会遇到多级列表,比如大众点评的分类(点此查看相关分享规则),需要用到优采云的多级列表功能@采集器,参考下面的函数用法:
3、任意格式文件下载
在采集的过程中,我们会遇到一些需要下载的附件文件,如word文档、压缩文件、PDF等格式文件,免费版不支持下载其他格式的文件图片除外。
4、使用ftp自动上传文件到网站
上面提到的文件下载任何格式,既然有下载,那么我们需要发布到网站时就需要上传功能。 优采云采集器提供使用FTP自动上传文件的功能,包括自动上传图片。上传。免费版不能使用此功能,只能手动上传文件,不能同步和自动上传文件。 FTP功能参考下图:
5、导出数据为Word、Excel、CSV格式
将采集的数据发布到本地,并保存为文件格式。免费版不支持 Word、Excel 和 CSV 格式,仅支持 TXT 和 html 格式。
6、MySql 和 SqlServer 数据库保存数据
免费版的默认版本是Sqlite数据库。当数据量比较大时,默认数据库会导致软件运行缓慢。这时候就需要使用MySql或者SqlServer数据库了。
7、多页采集function
我们在采集content 的时候,有时会遇到内容不在同一个页面的情况。进入内容页面后,我们需要进入另一个页面,称为multipage采集。点此参考多页携程采集case
8、List page tag采集function
我们经常会在列表页遇到采集内容,但是没有内容页或者内容页不方便采集。这时候就需要用到列表页采集功能。
在采集content URL的同时,采集有列表页需要的内容。
点击此处参考智联招聘采集Case
9、Schedule 任务函数
当我们在采集some news网站时,需要固定时间采集自动发布,那么定时任务可以24小时自动更新发布。点击此处参考教程
10、其他功能
自动提取第一张图,自动汇总,发布数据到MySql\SqlServer等功能,在你需要的时候总能帮到你。我不会在这里详细介绍。以上9个是比较常用的函数。
如果以上功能已经可以满足大神们的需求,那么可以选择基础版(商业授权也是终身使用,没有过期恢复免费版~)
但是对于更专业的大神来说,以上功能还远远不够,接下来我会告诉你更高版本的。
旗舰版及以上的特点
相比基础版,旗舰版及以上也有一些高级功能,可以满足大神们的操作。列举一些比较常用的函数。
1、二级代理
采集遇到被封IP时,需要使用二级代理功能。当然,你需要有IP代理资源。目前官方不提供代理资源
2、自动给图片加水印
自动给采集的图片添加水印
3、支持标签处理C#和C#外部插件函数
4、边采边发布功能
比如有10万条消息需要采集,基础版只能在采集完成后才能发布,旗舰版及以上支持同时挖矿和发帖。
5、Json 提取函数
支持Json格式数据采集extraction
6、支持python插件,采集警告配置,支持SSH(SFTP文件)上传
以上功能需要旗舰版及以上版本支持。如果需要使用上述功能的基础版,是不够的。
旗舰版和高级版的区别
那么旗舰版和后期版有什么区别呢?企业版除了支持数据发布到Oracle和Http接口管理采集器操作外,主要区别在于机器授权。
基础版和旗舰机码版:绑定1台授权电脑,一次免费修改授权。
旗舰自动授权版:绑定一台授权电脑,可不限次数更换电脑。
企业专享版:绑定5台授权电脑(2个加密狗版+3个机器码版),可免费更换3次,其中加密狗版可在任何电脑上使用。
企业豪华版:绑定10台授权电脑(4个加密狗版+6个自动授权版),可以不限次数随意更换电脑。
注意:捆绑授权电脑是指软件只能在授权电脑绑定的电脑上运行商业版。自授权版和加密狗版可以在不同的电脑上使用,即可以在不同的电脑上使用,但只能同时使用。可以在电脑上使用。
现在让我们看看哪个版本最适合你~
<p>(1)如果你的软件长期固定在电脑上,不需要经常更换,基础版的功能已经可以满足你的需求了»»»»»选择基础版 查看全部
采集自动组合(优采云采集器V9有免费版、基础版等多个版本)
最近很多第一次联系优采云采集器的用户反馈优采云采集器V9有免费版、基础版、旗舰机码版、旗舰自动授权版,以及企业版专属版。 、企业版豪华版等众多版本,如何选择?
小彩为你准备了以下攻略,相信对你选择版本有帮助。
首先,我们来看看免费版。免费版优采云采集器也是终身使用,不限制使用时间。它仅在功能上与付费版本不同。各位大神们暂时可能不会考虑免费版的所有功能是否都满足你的需求,那我们来看看免费版暂时不支持哪些功能吧。如果需要使用,选择对应的商业版即可~
1、标签自由组合功能
当需要将两个标签采集的内容合成一个内容时,需要使用该功能。
例如:[label C]=[label A]+[label B],参考下图:
2、unlimited-level list URL采集(支持二级以上)
我们在采集网页上经常会遇到多级列表,比如大众点评的分类(点此查看相关分享规则),需要用到优采云的多级列表功能@采集器,参考下面的函数用法:
3、任意格式文件下载
在采集的过程中,我们会遇到一些需要下载的附件文件,如word文档、压缩文件、PDF等格式文件,免费版不支持下载其他格式的文件图片除外。
4、使用ftp自动上传文件到网站
上面提到的文件下载任何格式,既然有下载,那么我们需要发布到网站时就需要上传功能。 优采云采集器提供使用FTP自动上传文件的功能,包括自动上传图片。上传。免费版不能使用此功能,只能手动上传文件,不能同步和自动上传文件。 FTP功能参考下图:
5、导出数据为Word、Excel、CSV格式
将采集的数据发布到本地,并保存为文件格式。免费版不支持 Word、Excel 和 CSV 格式,仅支持 TXT 和 html 格式。
6、MySql 和 SqlServer 数据库保存数据
免费版的默认版本是Sqlite数据库。当数据量比较大时,默认数据库会导致软件运行缓慢。这时候就需要使用MySql或者SqlServer数据库了。
7、多页采集function
我们在采集content 的时候,有时会遇到内容不在同一个页面的情况。进入内容页面后,我们需要进入另一个页面,称为multipage采集。点此参考多页携程采集case
8、List page tag采集function
我们经常会在列表页遇到采集内容,但是没有内容页或者内容页不方便采集。这时候就需要用到列表页采集功能。
在采集content URL的同时,采集有列表页需要的内容。
点击此处参考智联招聘采集Case
9、Schedule 任务函数
当我们在采集some news网站时,需要固定时间采集自动发布,那么定时任务可以24小时自动更新发布。点击此处参考教程
10、其他功能
自动提取第一张图,自动汇总,发布数据到MySql\SqlServer等功能,在你需要的时候总能帮到你。我不会在这里详细介绍。以上9个是比较常用的函数。
如果以上功能已经可以满足大神们的需求,那么可以选择基础版(商业授权也是终身使用,没有过期恢复免费版~)
但是对于更专业的大神来说,以上功能还远远不够,接下来我会告诉你更高版本的。
旗舰版及以上的特点
相比基础版,旗舰版及以上也有一些高级功能,可以满足大神们的操作。列举一些比较常用的函数。
1、二级代理
采集遇到被封IP时,需要使用二级代理功能。当然,你需要有IP代理资源。目前官方不提供代理资源
2、自动给图片加水印
自动给采集的图片添加水印
3、支持标签处理C#和C#外部插件函数
4、边采边发布功能
比如有10万条消息需要采集,基础版只能在采集完成后才能发布,旗舰版及以上支持同时挖矿和发帖。
5、Json 提取函数
支持Json格式数据采集extraction
6、支持python插件,采集警告配置,支持SSH(SFTP文件)上传
以上功能需要旗舰版及以上版本支持。如果需要使用上述功能的基础版,是不够的。
旗舰版和高级版的区别
那么旗舰版和后期版有什么区别呢?企业版除了支持数据发布到Oracle和Http接口管理采集器操作外,主要区别在于机器授权。
基础版和旗舰机码版:绑定1台授权电脑,一次免费修改授权。
旗舰自动授权版:绑定一台授权电脑,可不限次数更换电脑。
企业专享版:绑定5台授权电脑(2个加密狗版+3个机器码版),可免费更换3次,其中加密狗版可在任何电脑上使用。
企业豪华版:绑定10台授权电脑(4个加密狗版+6个自动授权版),可以不限次数随意更换电脑。
注意:捆绑授权电脑是指软件只能在授权电脑绑定的电脑上运行商业版。自授权版和加密狗版可以在不同的电脑上使用,即可以在不同的电脑上使用,但只能同时使用。可以在电脑上使用。
现在让我们看看哪个版本最适合你~
<p>(1)如果你的软件长期固定在电脑上,不需要经常更换,基础版的功能已经可以满足你的需求了»»»»»选择基础版
采集自动组合(采集自动转码大多是依赖大数据平台的重要性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-01 14:03
采集自动组合,就是平时说的页眉页脚采集,文章内容的采集,可以把采集下来的文章数据转化为html格式,支持chrome,firefox,safari等浏览器浏览。可以做到一键采集文章内容,批量改标题文字,多篇文章批量删除,数据分析图表美化等功能,采集下载后可以生成图片格式,超级方便。
个人认为单纯的采集在效率上比较低,前期还需要自己去设置目标网站站点内容的抓取。而且现在数据都是具有冗余性的,当你需要获取多条数据时,就要考虑这条数据的生命周期,需要做取舍。之前有考虑过一篇文章的抓取,用自动档上传文章到后台的时候,利用自动转码,快速从网页抓取大量的文章内容,然后在批量下载到后台。但这样弄下来,在抓取效率上还是比较低的。
而且这些自动转码大多是依赖大数据平台比如:我要抓取某类的数据时,对应的网站内容已经抓取过了,现在从我要抓取类别的网站抓取文章,可能费用会高一些,效率会低一些。
采集网站内的内容,基本上是百度、天涯社区等几个大平台,每天上百万条。常见的就是转码合并网站,如天涯、豆瓣、知乎等大家熟知的社区网站。如果采集额外的网站,可以用requests+爬虫selenium来完成数据抓取。还有就是数据持久化存储,如腾讯云elasticsearch这些。 查看全部
采集自动组合(采集自动转码大多是依赖大数据平台的重要性)
采集自动组合,就是平时说的页眉页脚采集,文章内容的采集,可以把采集下来的文章数据转化为html格式,支持chrome,firefox,safari等浏览器浏览。可以做到一键采集文章内容,批量改标题文字,多篇文章批量删除,数据分析图表美化等功能,采集下载后可以生成图片格式,超级方便。
个人认为单纯的采集在效率上比较低,前期还需要自己去设置目标网站站点内容的抓取。而且现在数据都是具有冗余性的,当你需要获取多条数据时,就要考虑这条数据的生命周期,需要做取舍。之前有考虑过一篇文章的抓取,用自动档上传文章到后台的时候,利用自动转码,快速从网页抓取大量的文章内容,然后在批量下载到后台。但这样弄下来,在抓取效率上还是比较低的。
而且这些自动转码大多是依赖大数据平台比如:我要抓取某类的数据时,对应的网站内容已经抓取过了,现在从我要抓取类别的网站抓取文章,可能费用会高一些,效率会低一些。
采集网站内的内容,基本上是百度、天涯社区等几个大平台,每天上百万条。常见的就是转码合并网站,如天涯、豆瓣、知乎等大家熟知的社区网站。如果采集额外的网站,可以用requests+爬虫selenium来完成数据抓取。还有就是数据持久化存储,如腾讯云elasticsearch这些。
采集自动组合(【干货】2016年10月21日,SKU销售数据分析 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-31 15:02
)
很多产品在网店运营过程中都有多个SKU。通过对SKU销售数据的分析,可以帮助运营商、艺人等人员调整产品运营策略,为主图、海报、宣传图的优化设计提供数据支持。可见SKU对于商家和运营分析师的重要性。
例如,服装零售商可能会创建一个 8 位数的 SKU,其中前两位数字代表产品类别(例如 T 恤、牛仔裤),接下来的两位数字代表款式(例如修身或常规身材)。最后两位数字代表产品的颜色(例如“RE”代表红色,“BL”蓝色),最后两位数字代表特定商品的库存数量(01、02、03、04 等)。这取决于库存中有多少该特定项目。请注意,不同的公司会使用他们的 SKU 代码来跟踪不同的东西,因为每个公司都有不同的产品。
实体零售商和电子商务卖家都可以使用 SKU 编号来表示最新的库存和销售额。
sku:库存单位 库存单位
从库存的角度,可以看到库存还剩多少,是否采购,有时也能反映商品的热销程度。例如,缺货的商品通常卖得很好。从定义上看,sku是定义一个产品的最小单位,它是由产品属性的组合决定的。例如,对于服装,买家可以选择的尺寸、颜色等特征就是产品的属性。取上图中的产品。 , 尺码和颜色有3个选择,那么这个商品有3*3=9个sku,每个sku都有一个唯一的编码,就像身份证一样区分和记录不同属性组合的信息;
SKU 的重要性
既然您知道 SKU 编号是什么,让我们了解它们的重要性。以下是有组织的 SKU 编号系统提供的好处:
l 提升购物体验
准确跟踪 SKU 编号可让您以客户和员工可以轻松找到产品的方式组织您的业务。这是因为 SKU 编号可以代表产品的多种不同特性。通过SKU编号系统,您可以通过查看SKU编号准确获取产品的各种属性。
反过来,这也可以让客户更容易找到他们想要的东西,从而推动销售额的增长。另一方面,乱七八糟的SKU编码系统会让客户感到困惑,从而导致销售额下降。
l 预测销售
当您可以使用 SKU 编号准确跟踪库存时,您还可以更准确地预测销售和业务需求。反过来,您可以保留更多热销库存,同时剔除那些表现不佳的产品。这也可以帮助您提高客户满意度。
l 管理业务
了解热销产品可以让您更明智地管理业务。例如,您可以为最受欢迎的产品设置显眼的展示。另一方面,您可以为不满意的产品创建展示,以增加销售额。您还可以将类似的产品归为一组,以便为售罄的产品找到替代品。
SKU在电子商务中占有重要地位,那么如何获取电子商务SKU?
通过使用辅助工具,我们可以轻松获取产品的sku。以下是 1688 的示例:
第一步:登录1688平台
/YZuQ0Sy(自动识别二维码)
第2步:点击“开始采集”按钮下的“采集:1688产品sku”菜单项。
/YZuQ0Sy(自动识别二维码)
第三步:打开1688链接导入弹窗,粘贴需要采集的商品链接,每行一个。如下图所示:
/YZuQ0Sy(自动识别二维码)
然后点击确认按钮,数据开始采集。 采集的效果如下图:
第四步:数据采集完成后,可以直接在界面预览,或者导入EXCEL、TXT等数据文件
第五个数据:进行sku数据分析。
因为采集的数据已经收录了价格、销量、库存等核心信息。满足运营数据分析的需求。通过算法分析可以缩短哪些sku的销量和市场热度。
查看全部
采集自动组合(【干货】2016年10月21日,SKU销售数据分析
)
很多产品在网店运营过程中都有多个SKU。通过对SKU销售数据的分析,可以帮助运营商、艺人等人员调整产品运营策略,为主图、海报、宣传图的优化设计提供数据支持。可见SKU对于商家和运营分析师的重要性。
例如,服装零售商可能会创建一个 8 位数的 SKU,其中前两位数字代表产品类别(例如 T 恤、牛仔裤),接下来的两位数字代表款式(例如修身或常规身材)。最后两位数字代表产品的颜色(例如“RE”代表红色,“BL”蓝色),最后两位数字代表特定商品的库存数量(01、02、03、04 等)。这取决于库存中有多少该特定项目。请注意,不同的公司会使用他们的 SKU 代码来跟踪不同的东西,因为每个公司都有不同的产品。
实体零售商和电子商务卖家都可以使用 SKU 编号来表示最新的库存和销售额。
sku:库存单位 库存单位
从库存的角度,可以看到库存还剩多少,是否采购,有时也能反映商品的热销程度。例如,缺货的商品通常卖得很好。从定义上看,sku是定义一个产品的最小单位,它是由产品属性的组合决定的。例如,对于服装,买家可以选择的尺寸、颜色等特征就是产品的属性。取上图中的产品。 , 尺码和颜色有3个选择,那么这个商品有3*3=9个sku,每个sku都有一个唯一的编码,就像身份证一样区分和记录不同属性组合的信息;
SKU 的重要性
既然您知道 SKU 编号是什么,让我们了解它们的重要性。以下是有组织的 SKU 编号系统提供的好处:
l 提升购物体验
准确跟踪 SKU 编号可让您以客户和员工可以轻松找到产品的方式组织您的业务。这是因为 SKU 编号可以代表产品的多种不同特性。通过SKU编号系统,您可以通过查看SKU编号准确获取产品的各种属性。
反过来,这也可以让客户更容易找到他们想要的东西,从而推动销售额的增长。另一方面,乱七八糟的SKU编码系统会让客户感到困惑,从而导致销售额下降。
l 预测销售
当您可以使用 SKU 编号准确跟踪库存时,您还可以更准确地预测销售和业务需求。反过来,您可以保留更多热销库存,同时剔除那些表现不佳的产品。这也可以帮助您提高客户满意度。
l 管理业务
了解热销产品可以让您更明智地管理业务。例如,您可以为最受欢迎的产品设置显眼的展示。另一方面,您可以为不满意的产品创建展示,以增加销售额。您还可以将类似的产品归为一组,以便为售罄的产品找到替代品。
SKU在电子商务中占有重要地位,那么如何获取电子商务SKU?
通过使用辅助工具,我们可以轻松获取产品的sku。以下是 1688 的示例:
第一步:登录1688平台
/YZuQ0Sy(自动识别二维码)
第2步:点击“开始采集”按钮下的“采集:1688产品sku”菜单项。
/YZuQ0Sy(自动识别二维码)
第三步:打开1688链接导入弹窗,粘贴需要采集的商品链接,每行一个。如下图所示:
/YZuQ0Sy(自动识别二维码)
然后点击确认按钮,数据开始采集。 采集的效果如下图:
第四步:数据采集完成后,可以直接在界面预览,或者导入EXCEL、TXT等数据文件
第五个数据:进行sku数据分析。
因为采集的数据已经收录了价格、销量、库存等核心信息。满足运营数据分析的需求。通过算法分析可以缩短哪些sku的销量和市场热度。
采集自动组合(阿里云Kubernetes:日志服务为k8s带来真正意义上的一站式解决方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-08-29 16:03
背景
众所周知,Docker 非常流行,其中 Kubernetes(简称 k8s)是 Docker 中最受欢迎的。与物理机和虚拟机相比,Docker 提供了一种更简单、更轻量、更经济的部署和运维方式;在 Docker 之上,k8s 进一步提供了管理基础设施的抽象,形成了真正的一站式部署和运维解决方案。
k8s 提供了强大的作业调度、横向扩展、健康监控和高可用维护能力。它还提供了网络和文件系统的抽象和管理,因此在现有应用程序上部署k8s或基于k8s部署应用程序非常方便。但是这里有一个让开发运维人员比较头疼的部分——log采集。
难点分析
基于VM或者物理机部署的应用,log采集相关技术比较完善,包括比较完善的Logstash、Fluentd、FileBeats等。但是在Docker中,尤其是k8s中,log采集并没有很好的应用解决方案。主要原因如下:
采集 多个目标:需要采集host 日志、容器日志、容器标准输出。每个数据源都有对应的采集软件,但缺乏一站式解决方案。弹性伸缩很难:k8s 是一个分布式集群。服务和环境的弹性伸缩给日志采集带来了很大的困难。 采集 的动态特性和数据完整性是非常大的挑战。运维成本大:现有方案只能使用多个软件组合采集,每个软件组装的系统稳定性难以保证,缺乏集中管理、配置、监控手段,运维负担是巨大的。侵入性强:Docker Driver扩展需要修改底层引擎;一个Container对应一个采集Agent,会造成资源竞争和浪费。 采集低性能:正常情况下,一个Docker Engine会运行几十个甚至上百个Container。这时候开源的Agent日志采集性能和资源消耗都非常堪忧。
基于阿里巴巴在容器服务日志采集多年的经验积累,结合阿里云Kubernetes内测以来用户的反馈和需求,今天日志服务为k8s计划带来了真正的一站式日志解决方案。
节目简介节目简介
如上图所示,我们只需要在Kubernetes集群的每个节点上部署一个Logtail容器即可实现主机日志、容器日志、容器标准输出等所有数据源的一站式服务那个节点采集。我们为 k8s 提供了 DaemonSet 部署模板。整个集群部署可以在1分钟内完成,后续集群动态扩展不需要任何二次部署到采集。详情请参考使用章节。
日志服务客户端Logtail已经部署百万级。每天采集上万应用和数PB的数据都经历了多次双11、双12的测试。相关技术分享请参考文章:多租户隔离技术+双十一实战效果,以及Polling+Inotify组合下的日志保存采集方案。
依托阿里云日志服务的强大功能,对于采集收到的日志数据,我们提供:
上下文查询,从海量数据中快速定位异常数据,支持异常所在Container/Pod上下文日志实时海量数据分析,完成1亿条数据的统计分析1秒。自带报表报警功能,Boss、开发、运维都做流计算对接:storm、flink、blink、spark Streaming等都支持外部可视化:Grafana、DataV轻松对接日志归档投递:支持投递到OSS存档存储,并交付到MaxCompute进行离线分析采集程序优势
日志服务的整体优势这里不再赘述。本文主要讨论日志服务Kubernetes采集解决方案的相关优势。这里我们主要总结以下几点:
方案对比
对比Logstash和Fluentd主流日志采集方法,对比如下:
logtaillogstashfluentd
采集method
主机文件
支持
支持
支持
容器文件
支持自动发现
静态采集
静态采集
容器标准输出
支持自动发现
插件扩展
Docker 驱动
数据处理
处理方法
regular、anchor、separator、json的任意组合
插件扩展
插件扩展
自动打标
支持
不支持 K8s
不支持 K8s
过滤
常规
插件扩展
插件扩展
配置
自动更新
支持
手动加载
支持
服务器配置
支持
Beta 版支持简单功能
辅助管理软件扩展
性能
采集performance
极简核心160M/s,普通20M/s
单核约 2M/s
单核3-5M/s
资源消耗
平均CPU 2%,内存40M
10 倍的性能消耗
10 倍的性能消耗
可靠性
数据保存
支持
插件支持
插件支持
采集点保存
全部支持
仅支持文件
插件支持
监控
本地监控
支持
支持
支持
服务器监控
支持
Beta 版支持简单功能
辅助监控软件扩展
如何使用
部署k8s日志采集只需要分3步,1分钟即可完成集群部署(详细帮助文档请参考[k8s采集帮]()),其中可能是你见过最多的简单k8s日志采集部署方案:
部署Logtail的DaemonSet。体力:一个wget名称,vi修改3个参数,执行一个kubectl命令,登录服务控制台创建自定义标识机器组(后续集群动态伸缩不需要额外操作)。体力消耗:点击web控制台几次,进入一个ID日志服务控制台,创建采集配置(所有采集都是服务器配置,无需本地运维)。体力消耗:stdout采集web控制台点击几次;文件采集网页控制台点击几次,进入2路径核心技术配置文件自定义识别机组
Log采集 支持k8s弹性伸缩的关键是Logtail的自定义识别机群。通常采集Agent 远程管理解决方案是通过 IP 或主机名来标识的。这种方案更适用于集群较小且环境不是很不稳定的情况。当机器规模扩大,弹性伸缩成为常态时,承担的运维成本将成倍增长。
在总结集团几年Agent运维经验的基础上,我们设计了一种更灵活、使用更方便、耦合更少的配置&机器管理方式:
除了支持静态ip设置,机器组还支持自定义识别:只要定义了识别,所有Logtail都会自动关联对应的机器组。一个Logtail可以属于多个机器组,一个机器组可以收录多个Logtail,实现Logtail和机器组的解耦。一个采集配置可以应用于多个机器组,一个机器组可以关联多个采集配置,实现机器组和采集配置的解耦。
以上概念映射到k8s,可以实现各种灵活配置:
一个 k8s 集群对应一个带有自定义 logo 的机器组。同一个集群中的Logtail使用相同的配置。 k8s集群扩容时,Logtail对应的DaemonSet会自动扩容。 Logtail 启动后会立即获取与该机器组关联的所有配置。在一个 k8s 集群中配置了多个不同的 采集 配置。根据不同的Pod需求设置相应的采集配置。所有涉及容器采集 的配置都支持 IncludeLabel 和 ExcluseLabel 过滤。相同的配置可以应用于多个 k8s 集群。如果你有多个k8s集群,如果某些服务日志采集有相同的逻辑,你可以将相同的配置应用到多个集群,无需额外配置。自动容器发现
Logtail 和很多软件(Logspout、MetricBeats、Telegraf 等)一样,内置了自动容器发现机制。目前开源的容器自动发现采用扫描+事件监控的方式,即第一次运行时获取当前所有容器信息,后续监控docker引擎的事件信息,并增量更新。
这种方法效率比较高,但是有一定的几率会漏掉一些信息:
这部分从获取所有容器信息到docker引擎事件监控建立周期的增量信息会丢失。事件监控可能会因某些异常情况而终止。终止后,监控重建期间的增量信息将丢失。
考虑到以上问题,Logtail通过事件监控和定时全扫描实现容器自动发现:
先注册监听事件,然后每隔一定时间进行一次全量扫描,进行全量扫描,并全量更新元信息(时间间隔足够大,对docker引擎的压力没有影响) 容器文件自动渲染
容器日志采集只需要配置容器中的文件路径,支持多种采集模式:极简、Nginx模板、正则、分隔符、JSON等。与传统的绝对路径采集相比,容器采集 中的日志是非常动态的。为此,我们实现了一套容器路径自动匹配和配置渲染方案:
Logtail 会根据配置的容器路径在宿主机上寻找容器对应路径的映射关系,并根据宿主机路径和容器的元数据信息(容器名称、 pod, namespace...) 配置Logtail文件采集module加载渲染配置,采集data删除容器销毁时对应的渲染配置。可靠性保证
log采集中的可靠性保证是一项非常重要也非常艰巨的任务。在Logtail的设计中,进程退出、异常终止、程序升级都被认为是正常情况。当出现这些情况时,Logtail需要尽可能保证数据的可靠性。针对容器数据采集的动态特性,Logtail在之前可靠性保证的基础上增加了容器标准输出和容器文件的checkpoint维护机制
容器标准输出checkpoint 管理容器stdout和stderr的checkpoint是独立保存的。检查点保存策略:定期转储所有容器的当前检查点;配置更新/进程退出时,加载配置时强制保存,默认从采集checkpoint开始,如果没有checkpoint,从采集前5秒开始,考虑到配置时不会删除checkpoint被删除后,后台会定期清除无效的检查点容器文件。 Checkpoint管理 除了文件采集的checkpoint之外,还需要保存容器meta的映射关系。在加载检查点之前,需要提前加载容器和文件的映射关系。考虑到停止时无法感知容器状态的变化,每次启动都会渲染当前所有的配置。 Logtail 保证了多次加载同一个容器配置的幂等性。总结
阿里云日志服务提供的解决方案完美解决了k8s上日志采集的问题。从之前的多个软件和几十个部署流程的需求,可以轻松上传到1个软件和3个操作。云,让广大用户真正体验一个字:爽,从此日志运维人员的生活质量得到了极大的提升。
目前Logtail除了支持host文件、容器文件、容器stdout采集外,还支持以下采集方法(k8s都支持这些方法):
syslog采集Mysql binlog采集JDBC采集http采集
此外,Logtail即将推出Docker Event和Container Metric采集方法,敬请期待!
有更多日志服务相关需求或问题的同志,请加钉钉群联系:
重磅消息:阿里云日志服务存储资源包全新上线,限时优惠50%。详情请点击: 查看全部
采集自动组合(阿里云Kubernetes:日志服务为k8s带来真正意义上的一站式解决方案)
背景
众所周知,Docker 非常流行,其中 Kubernetes(简称 k8s)是 Docker 中最受欢迎的。与物理机和虚拟机相比,Docker 提供了一种更简单、更轻量、更经济的部署和运维方式;在 Docker 之上,k8s 进一步提供了管理基础设施的抽象,形成了真正的一站式部署和运维解决方案。
k8s 提供了强大的作业调度、横向扩展、健康监控和高可用维护能力。它还提供了网络和文件系统的抽象和管理,因此在现有应用程序上部署k8s或基于k8s部署应用程序非常方便。但是这里有一个让开发运维人员比较头疼的部分——log采集。
难点分析
基于VM或者物理机部署的应用,log采集相关技术比较完善,包括比较完善的Logstash、Fluentd、FileBeats等。但是在Docker中,尤其是k8s中,log采集并没有很好的应用解决方案。主要原因如下:
采集 多个目标:需要采集host 日志、容器日志、容器标准输出。每个数据源都有对应的采集软件,但缺乏一站式解决方案。弹性伸缩很难:k8s 是一个分布式集群。服务和环境的弹性伸缩给日志采集带来了很大的困难。 采集 的动态特性和数据完整性是非常大的挑战。运维成本大:现有方案只能使用多个软件组合采集,每个软件组装的系统稳定性难以保证,缺乏集中管理、配置、监控手段,运维负担是巨大的。侵入性强:Docker Driver扩展需要修改底层引擎;一个Container对应一个采集Agent,会造成资源竞争和浪费。 采集低性能:正常情况下,一个Docker Engine会运行几十个甚至上百个Container。这时候开源的Agent日志采集性能和资源消耗都非常堪忧。
基于阿里巴巴在容器服务日志采集多年的经验积累,结合阿里云Kubernetes内测以来用户的反馈和需求,今天日志服务为k8s计划带来了真正的一站式日志解决方案。
节目简介节目简介
如上图所示,我们只需要在Kubernetes集群的每个节点上部署一个Logtail容器即可实现主机日志、容器日志、容器标准输出等所有数据源的一站式服务那个节点采集。我们为 k8s 提供了 DaemonSet 部署模板。整个集群部署可以在1分钟内完成,后续集群动态扩展不需要任何二次部署到采集。详情请参考使用章节。
日志服务客户端Logtail已经部署百万级。每天采集上万应用和数PB的数据都经历了多次双11、双12的测试。相关技术分享请参考文章:多租户隔离技术+双十一实战效果,以及Polling+Inotify组合下的日志保存采集方案。
依托阿里云日志服务的强大功能,对于采集收到的日志数据,我们提供:
上下文查询,从海量数据中快速定位异常数据,支持异常所在Container/Pod上下文日志实时海量数据分析,完成1亿条数据的统计分析1秒。自带报表报警功能,Boss、开发、运维都做流计算对接:storm、flink、blink、spark Streaming等都支持外部可视化:Grafana、DataV轻松对接日志归档投递:支持投递到OSS存档存储,并交付到MaxCompute进行离线分析采集程序优势
日志服务的整体优势这里不再赘述。本文主要讨论日志服务Kubernetes采集解决方案的相关优势。这里我们主要总结以下几点:
方案对比
对比Logstash和Fluentd主流日志采集方法,对比如下:
logtaillogstashfluentd
采集method
主机文件
支持
支持
支持
容器文件
支持自动发现
静态采集
静态采集
容器标准输出
支持自动发现
插件扩展
Docker 驱动
数据处理
处理方法
regular、anchor、separator、json的任意组合
插件扩展
插件扩展
自动打标
支持
不支持 K8s
不支持 K8s
过滤
常规
插件扩展
插件扩展
配置
自动更新
支持
手动加载
支持
服务器配置
支持
Beta 版支持简单功能
辅助管理软件扩展
性能
采集performance
极简核心160M/s,普通20M/s
单核约 2M/s
单核3-5M/s
资源消耗
平均CPU 2%,内存40M
10 倍的性能消耗
10 倍的性能消耗
可靠性
数据保存
支持
插件支持
插件支持
采集点保存
全部支持
仅支持文件
插件支持
监控
本地监控
支持
支持
支持
服务器监控
支持
Beta 版支持简单功能
辅助监控软件扩展
如何使用
部署k8s日志采集只需要分3步,1分钟即可完成集群部署(详细帮助文档请参考[k8s采集帮]()),其中可能是你见过最多的简单k8s日志采集部署方案:
部署Logtail的DaemonSet。体力:一个wget名称,vi修改3个参数,执行一个kubectl命令,登录服务控制台创建自定义标识机器组(后续集群动态伸缩不需要额外操作)。体力消耗:点击web控制台几次,进入一个ID日志服务控制台,创建采集配置(所有采集都是服务器配置,无需本地运维)。体力消耗:stdout采集web控制台点击几次;文件采集网页控制台点击几次,进入2路径核心技术配置文件自定义识别机组
Log采集 支持k8s弹性伸缩的关键是Logtail的自定义识别机群。通常采集Agent 远程管理解决方案是通过 IP 或主机名来标识的。这种方案更适用于集群较小且环境不是很不稳定的情况。当机器规模扩大,弹性伸缩成为常态时,承担的运维成本将成倍增长。
在总结集团几年Agent运维经验的基础上,我们设计了一种更灵活、使用更方便、耦合更少的配置&机器管理方式:
除了支持静态ip设置,机器组还支持自定义识别:只要定义了识别,所有Logtail都会自动关联对应的机器组。一个Logtail可以属于多个机器组,一个机器组可以收录多个Logtail,实现Logtail和机器组的解耦。一个采集配置可以应用于多个机器组,一个机器组可以关联多个采集配置,实现机器组和采集配置的解耦。
以上概念映射到k8s,可以实现各种灵活配置:
一个 k8s 集群对应一个带有自定义 logo 的机器组。同一个集群中的Logtail使用相同的配置。 k8s集群扩容时,Logtail对应的DaemonSet会自动扩容。 Logtail 启动后会立即获取与该机器组关联的所有配置。在一个 k8s 集群中配置了多个不同的 采集 配置。根据不同的Pod需求设置相应的采集配置。所有涉及容器采集 的配置都支持 IncludeLabel 和 ExcluseLabel 过滤。相同的配置可以应用于多个 k8s 集群。如果你有多个k8s集群,如果某些服务日志采集有相同的逻辑,你可以将相同的配置应用到多个集群,无需额外配置。自动容器发现
Logtail 和很多软件(Logspout、MetricBeats、Telegraf 等)一样,内置了自动容器发现机制。目前开源的容器自动发现采用扫描+事件监控的方式,即第一次运行时获取当前所有容器信息,后续监控docker引擎的事件信息,并增量更新。
这种方法效率比较高,但是有一定的几率会漏掉一些信息:
这部分从获取所有容器信息到docker引擎事件监控建立周期的增量信息会丢失。事件监控可能会因某些异常情况而终止。终止后,监控重建期间的增量信息将丢失。
考虑到以上问题,Logtail通过事件监控和定时全扫描实现容器自动发现:
先注册监听事件,然后每隔一定时间进行一次全量扫描,进行全量扫描,并全量更新元信息(时间间隔足够大,对docker引擎的压力没有影响) 容器文件自动渲染
容器日志采集只需要配置容器中的文件路径,支持多种采集模式:极简、Nginx模板、正则、分隔符、JSON等。与传统的绝对路径采集相比,容器采集 中的日志是非常动态的。为此,我们实现了一套容器路径自动匹配和配置渲染方案:
Logtail 会根据配置的容器路径在宿主机上寻找容器对应路径的映射关系,并根据宿主机路径和容器的元数据信息(容器名称、 pod, namespace...) 配置Logtail文件采集module加载渲染配置,采集data删除容器销毁时对应的渲染配置。可靠性保证
log采集中的可靠性保证是一项非常重要也非常艰巨的任务。在Logtail的设计中,进程退出、异常终止、程序升级都被认为是正常情况。当出现这些情况时,Logtail需要尽可能保证数据的可靠性。针对容器数据采集的动态特性,Logtail在之前可靠性保证的基础上增加了容器标准输出和容器文件的checkpoint维护机制
容器标准输出checkpoint 管理容器stdout和stderr的checkpoint是独立保存的。检查点保存策略:定期转储所有容器的当前检查点;配置更新/进程退出时,加载配置时强制保存,默认从采集checkpoint开始,如果没有checkpoint,从采集前5秒开始,考虑到配置时不会删除checkpoint被删除后,后台会定期清除无效的检查点容器文件。 Checkpoint管理 除了文件采集的checkpoint之外,还需要保存容器meta的映射关系。在加载检查点之前,需要提前加载容器和文件的映射关系。考虑到停止时无法感知容器状态的变化,每次启动都会渲染当前所有的配置。 Logtail 保证了多次加载同一个容器配置的幂等性。总结
阿里云日志服务提供的解决方案完美解决了k8s上日志采集的问题。从之前的多个软件和几十个部署流程的需求,可以轻松上传到1个软件和3个操作。云,让广大用户真正体验一个字:爽,从此日志运维人员的生活质量得到了极大的提升。
目前Logtail除了支持host文件、容器文件、容器stdout采集外,还支持以下采集方法(k8s都支持这些方法):
syslog采集Mysql binlog采集JDBC采集http采集
此外,Logtail即将推出Docker Event和Container Metric采集方法,敬请期待!
有更多日志服务相关需求或问题的同志,请加钉钉群联系:
重磅消息:阿里云日志服务存储资源包全新上线,限时优惠50%。详情请点击:
采集自动组合( 多通道高标清自动采集收录系统特性及特性介绍-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-28 08:11
多通道高标清自动采集收录系统特性及特性介绍-乐题库)
高SD采集收录系统
多路高清全自动采集收录系统是满足电视台、企业、单位等各行业用户执行收录、收录需求的智能化、自动化系统@素材管理,除了解决以往电视台手动收录的缺点,自动实现仓库入库的高效系统还提供了手动收录无法实现的功能,比如边编辑边接收和编辑功能,和自动收录 功能。
多路高清全自动采集收录系统是由数据库、系统管理、多路收录、节目编辑四大功能模块组成的智能化、数字化系统。
系统功能
1、支持Server2008/Server2012/Win10等32位、64位主流操作系统;
2、支持多种IO采集卡:MATROX、Decklink、Beyond等全系列采集卡;
3、支持多卡采集:支持多卡、多路同时采集录音,目前最多支持4路(channel);
4、Multiple采集source:支持将采集source输入的信号录制到CVBS、Y/C、YUV、SDI、HDMI等接口;
5、多种编码格式:支持MPEG2、H.264、H.265等编码方式;
6、Multiple 采集模式:支持多种采集模式,不同编码格式、码率、分割模式组合;
7、多个采集方法:支持手动采集、定时采集、循环采集等采集方法;
8、文件拆分模式:支持三种拆分模式:“不拆分”、“按时长(s)拆分”和“文件大小(MB)”;
9、多任务采集:在同一个频道列表中,可以添加多个采集任务,启动方式为“定时”或“手动触发”;
10、调整视频码率:根据不同的编码格式,可以调整录制视频的码率;
11、实时窗口预览:切换录制任务,可以预览不同采集源的输入音视频图像和状态;
12、 实时显示文件的采集进度和磁盘可用空间;
13、实现软件开机自动运行、定时记录、自动关机等功能。
14、系统支持7*24小时连续收录,可实现“收编”功能;
15、简化系统操作,提高工作效率。 查看全部
采集自动组合(
多通道高标清自动采集收录系统特性及特性介绍-乐题库)
高SD采集收录系统
多路高清全自动采集收录系统是满足电视台、企业、单位等各行业用户执行收录、收录需求的智能化、自动化系统@素材管理,除了解决以往电视台手动收录的缺点,自动实现仓库入库的高效系统还提供了手动收录无法实现的功能,比如边编辑边接收和编辑功能,和自动收录 功能。
多路高清全自动采集收录系统是由数据库、系统管理、多路收录、节目编辑四大功能模块组成的智能化、数字化系统。
系统功能
1、支持Server2008/Server2012/Win10等32位、64位主流操作系统;
2、支持多种IO采集卡:MATROX、Decklink、Beyond等全系列采集卡;
3、支持多卡采集:支持多卡、多路同时采集录音,目前最多支持4路(channel);
4、Multiple采集source:支持将采集source输入的信号录制到CVBS、Y/C、YUV、SDI、HDMI等接口;
5、多种编码格式:支持MPEG2、H.264、H.265等编码方式;
6、Multiple 采集模式:支持多种采集模式,不同编码格式、码率、分割模式组合;
7、多个采集方法:支持手动采集、定时采集、循环采集等采集方法;
8、文件拆分模式:支持三种拆分模式:“不拆分”、“按时长(s)拆分”和“文件大小(MB)”;
9、多任务采集:在同一个频道列表中,可以添加多个采集任务,启动方式为“定时”或“手动触发”;
10、调整视频码率:根据不同的编码格式,可以调整录制视频的码率;
11、实时窗口预览:切换录制任务,可以预览不同采集源的输入音视频图像和状态;
12、 实时显示文件的采集进度和磁盘可用空间;
13、实现软件开机自动运行、定时记录、自动关机等功能。
14、系统支持7*24小时连续收录,可实现“收编”功能;
15、简化系统操作,提高工作效率。
乐思网络情报系统的业务流程战略基础设施系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-08-25 03:05
乐思网络情报系统的业务流程战略基础设施系统
乐思网络信息中心系统
乐思网络智能信息中心系统是面向大公司、大集团的战略性信息化基础设施。其目的是加快公司内外部信息的流通,构建公司的数字神经系统。
一、 系统概览
随着我国经济发展的不断推进,大公司、大集团面临的市场环境越来越复杂,影响市场走势的各种新问题、新情况层出不穷,市场规模不断扩大。信息呈指数级增长。与此同时,定量分析方法正在迅速应用于行业研究,对信息采集的效率和准确性提出了很高的要求。依靠有限的人力来采集信息,难以适应市场和技术发展的要求。为了更全面、准确、快速地把握市场变化,适应新技术发展的要求,使人员从繁重的信息采集工作中解放出来,专心深入分析研究,迫切需要一套现代化的信息中心系统。
乐思网络信息中心系统的功能是为大公司和集团的营销部门和公关部门提供一个采集外部信息的平台,包括公司相关信息、竞争对手相关信息、行业信息、和价格信息、合作伙伴相关信息、用户在互联网上的各种信息反馈、科研技术信息等,可以实现多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免人工查询多个网站'S费时费力的情况,并具有预警功能,当出现某一方面的信息时,可以及时通知相关人员。
业务流程如下图所示:
图一:乐思网络信息中心系统业务流程
与目前的人工信息采集相比,优势明显:
比较指标
手动采集
使用乐思网络信息中心系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要分别登录每个网站,手动查看,手动复制粘贴。太累了。
网络信息的获取完全由软件自动化,监控人员只需浏览分析内网内容即可。
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不尽人意,浪费人力资源-3453公众舆论4533集-
全面覆盖,实时,
自动化和系统化
二、 实施后的收益
加速感知外部情报:公司报告、用户反馈、竞品动态、行业动态、宏观动态、政策法规等外部公司信息实时采集到桌面,方便公司感知和响应市场竞争情报。
加速定量定性分析:基于大量数据的拥有,分析师可以从繁重的信息采集工作中解放出来,投入到最有价值的定量和定性分析中。 owlesys 认为
三、 系统构成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集layer)、内容分析子系统(分析层)、界面呈现子系统(呈现层)。关系如下图所示:
图2:乐思网络信息中心系统架构
乐思网络信息中心系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
采集信息可以是文本信息(如文章、微博)、数字信息(如价格、统计数据)或文件信息(如Word、Excel、PDF文件)。用户可以通过Web界面为文本信息配置采集,也可以通过软件向导界面为数字信息配置采集。由于采用了全球领先的乐思网络信息采集系统,任何网站数据都可以被采集并整合。数据源的发现和管理由用户完成。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外各类网站用户提供采集服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
您可以实时监控微信公众号、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监听数千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集out文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者的发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询 查看全部
乐思网络情报系统的业务流程战略基础设施系统
乐思网络信息中心系统
乐思网络智能信息中心系统是面向大公司、大集团的战略性信息化基础设施。其目的是加快公司内外部信息的流通,构建公司的数字神经系统。
一、 系统概览
随着我国经济发展的不断推进,大公司、大集团面临的市场环境越来越复杂,影响市场走势的各种新问题、新情况层出不穷,市场规模不断扩大。信息呈指数级增长。与此同时,定量分析方法正在迅速应用于行业研究,对信息采集的效率和准确性提出了很高的要求。依靠有限的人力来采集信息,难以适应市场和技术发展的要求。为了更全面、准确、快速地把握市场变化,适应新技术发展的要求,使人员从繁重的信息采集工作中解放出来,专心深入分析研究,迫切需要一套现代化的信息中心系统。
乐思网络信息中心系统的功能是为大公司和集团的营销部门和公关部门提供一个采集外部信息的平台,包括公司相关信息、竞争对手相关信息、行业信息、和价格信息、合作伙伴相关信息、用户在互联网上的各种信息反馈、科研技术信息等,可以实现多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免人工查询多个网站'S费时费力的情况,并具有预警功能,当出现某一方面的信息时,可以及时通知相关人员。
业务流程如下图所示:
图一:乐思网络信息中心系统业务流程
与目前的人工信息采集相比,优势明显:
比较指标
手动采集
使用乐思网络信息中心系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要分别登录每个网站,手动查看,手动复制粘贴。太累了。
网络信息的获取完全由软件自动化,监控人员只需浏览分析内网内容即可。
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不尽人意,浪费人力资源-3453公众舆论4533集-
全面覆盖,实时,
自动化和系统化
二、 实施后的收益
加速感知外部情报:公司报告、用户反馈、竞品动态、行业动态、宏观动态、政策法规等外部公司信息实时采集到桌面,方便公司感知和响应市场竞争情报。
加速定量定性分析:基于大量数据的拥有,分析师可以从繁重的信息采集工作中解放出来,投入到最有价值的定量和定性分析中。 owlesys 认为
三、 系统构成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集layer)、内容分析子系统(分析层)、界面呈现子系统(呈现层)。关系如下图所示:
图2:乐思网络信息中心系统架构
乐思网络信息中心系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
采集信息可以是文本信息(如文章、微博)、数字信息(如价格、统计数据)或文件信息(如Word、Excel、PDF文件)。用户可以通过Web界面为文本信息配置采集,也可以通过软件向导界面为数字信息配置采集。由于采用了全球领先的乐思网络信息采集系统,任何网站数据都可以被采集并整合。数据源的发现和管理由用户完成。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外各类网站用户提供采集服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
您可以实时监控微信公众号、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监听数千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集out文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者的发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询
优采云采集器的详细介绍:24小时使命必达,ET人工值守
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-08-14 02:10
优采云采集器 行业领先的顶级团队,3年精心打造,为您带来完美的用户体验和服务。 24小时使命必达,优采云采集器欢迎大家,支持下载优采云采集器本软件!
以下是优采云采集器的详细介绍:
优采云采集器、网站更新必备采集软件,无需人工值班,24小时自动实时监控目标,实时高效采集,为您提供内容更新日夜。满足长期运营需求,让您从繁重的工作中解脱出来。
中小网站自动更新工具,优采云采集器正式发布。
[广泛适用]
更通用的采集软件,支持任何类型网站采集,适用率高达99.9%,支持发布到所有类型的网站程序,也可以采集本地文件,免费接口发布。
[信息自由]
支持信息自由组合,通过强大的数据整理功能对信息进行深度处理,创造新的内容
[下载任意格式的文件]
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至种子文件,只要你想要
[伪原创]
高速同义替换、多词随机替换、随机段落排序、帮助内容SEO
[无限多级页面采集]
无论是纵向多页,多页并行,还是AJAX调用页,都方便你采集
[免费扩展]
开放接口模式,自由二次开发,自定义任意功能,满足所有需求
软件内置了大量常用系统包括discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、东易、joomla、pbdigg、php168、bbsxp、phpbb、 dvbbs、typecho、embblog 等示例。 查看全部
优采云采集器的详细介绍:24小时使命必达,ET人工值守
优采云采集器 行业领先的顶级团队,3年精心打造,为您带来完美的用户体验和服务。 24小时使命必达,优采云采集器欢迎大家,支持下载优采云采集器本软件!
以下是优采云采集器的详细介绍:
优采云采集器、网站更新必备采集软件,无需人工值班,24小时自动实时监控目标,实时高效采集,为您提供内容更新日夜。满足长期运营需求,让您从繁重的工作中解脱出来。
中小网站自动更新工具,优采云采集器正式发布。
[广泛适用]
更通用的采集软件,支持任何类型网站采集,适用率高达99.9%,支持发布到所有类型的网站程序,也可以采集本地文件,免费接口发布。
[信息自由]
支持信息自由组合,通过强大的数据整理功能对信息进行深度处理,创造新的内容
[下载任意格式的文件]
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至种子文件,只要你想要
[伪原创]
高速同义替换、多词随机替换、随机段落排序、帮助内容SEO
[无限多级页面采集]
无论是纵向多页,多页并行,还是AJAX调用页,都方便你采集
[免费扩展]
开放接口模式,自由二次开发,自定义任意功能,满足所有需求
软件内置了大量常用系统包括discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、东易、joomla、pbdigg、php168、bbsxp、phpbb、 dvbbs、typecho、embblog 等示例。
不能期望配对测试是万能的,即我们仅依赖于一次
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-08 20:07
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作量)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2.先将第二个和第三个参数的条件组合一次,这里为了省事,我先去掉第一个参数,只介绍二、三、四个参数的配对组合方法:<//p
pimg src='http://www.uml.org.cn/test/images/2013050954.png' alt=''//p
p3. 然后再次组合第二个参数和第四个参数的条件,如下图:/p
pimg src='http://www.uml.org.cn/test/images/2013050955.png' alt=''//p
p4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:/p
pimg src='http://www.uml.org.cn/test/images/2013050956.png' alt=''//p
p5. 解决方法很简单。只需要多加两行就可以把没有合并的两个参数的条件合并起来(当然你也可以稍微调整第四个参数的条件来达到同样的目的):/p
pimg src='http://www.uml.org.cn/test/images/2013050957.png' alt=''//p
p自动化步骤/p
p上面的工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:/p
p对于上面的例子,使用allpairs生成组合的方法是:/p
p1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):/p
pimg src='http://www.uml.org.cn/test/images/2013050958.png' alt=''//p
p2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:/p
pimg src='http://www.uml.org.cn/test/images/2013050959.png' alt=''//p
p3. 然后用allpairs.exe处理这个文件:/p
pallpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用匹配测试算法,我们可以结合Behavior DrivenDesign技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来匹配自动化的测试用例。组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到准备好—— made 这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
不能期望配对测试是万能的,即我们仅依赖于一次
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作量)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2.先将第二个和第三个参数的条件组合一次,这里为了省事,我先去掉第一个参数,只介绍二、三、四个参数的配对组合方法:<//p
pimg src='http://www.uml.org.cn/test/images/2013050954.png' alt=''//p
p3. 然后再次组合第二个参数和第四个参数的条件,如下图:/p
pimg src='http://www.uml.org.cn/test/images/2013050955.png' alt=''//p
p4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:/p
pimg src='http://www.uml.org.cn/test/images/2013050956.png' alt=''//p
p5. 解决方法很简单。只需要多加两行就可以把没有合并的两个参数的条件合并起来(当然你也可以稍微调整第四个参数的条件来达到同样的目的):/p
pimg src='http://www.uml.org.cn/test/images/2013050957.png' alt=''//p
p自动化步骤/p
p上面的工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:/p
p对于上面的例子,使用allpairs生成组合的方法是:/p
p1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):/p
pimg src='http://www.uml.org.cn/test/images/2013050958.png' alt=''//p
p2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:/p
pimg src='http://www.uml.org.cn/test/images/2013050959.png' alt=''//p
p3. 然后用allpairs.exe处理这个文件:/p
pallpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用匹配测试算法,我们可以结合Behavior DrivenDesign技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来匹配自动化的测试用例。组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到准备好—— made 这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
京东智联云现支持使用自动镜像策略攻击溯源功能说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-08-08 06:35
新的自动扩展策略
新增自动伸缩策略 启用自动伸缩后,您可以根据需要配置自动伸缩策略,包括报警策略和定时策略。定时策略 定时策略会设置一个特定的时间和周期,让您定期添加或删除高可用组中的实例数量,适用于可预测的业务负载预兆。
自动攻击溯源
调查响应-自动攻击溯源功能说明 自动攻击溯源旨在跟踪攻击者的IP,结合风险资产信息(公网IP、内网IP、资产名称、资产ID),以及一定时间间隔(近7天、15天、30天、自定义)、告警类型(各种安全监控引擎上报告警事件)、告警信息处理状态(待处理、人工处理、屏蔽)、告警级别(严重
自动镜像策略
自动镜像策略京东智联云现在支持使用自动镜像策略为您的云主机设置定期的主机备份任务。自动镜像策略是一种自动任务策略,可以定期为用户备份云主机数据,并按照用户指定的规则进行镜像。使用本产品可以省去您定期为云主机手工制作图片的工作。
添加自动生成报表任务
createTask 描述如何创建任务报告请求方法 POST 请求地址 {regionId}/tasks name type is required default value description regionIdStringTrue region Id 请求参数 name type is required default value description taskSpecTaskSpecTrue 报告配置信息 TaskSpec name type is required default值说明
自动镜像执行日志
自动任务策略日志介绍当前连接日志服务的日志类型为自动镜像执行日志。
Hbase 手动合并 region Java 实现
Hbase 手动合并 region Java 实现
京东云DevOps自动化运维技术实践
《京东云DevOps自动化运维技术实践》《2019京东云技术沙龙·上海站》《11月23日(week六)13:30-18:00》《上海•你好咖啡(延安,长宁区)西路918号)"
几种自动生成的静态网站介绍
几种自动生成的静态网站介绍
ManageEngine Active Directory 用户自助服务解决方案
ManageEngine ADSelfService Plus 是一个集成的自助密码管理和单点登录解决方案。该方案帮助域用户在Microsoft Windows Active Directory中进行自助密码重置、自助账户解锁、员工信息自助更新
自动化建模 | H2O开源工具介绍
相信大家在日常建模工作中或多或少都会思考一个问题:建模可以自动化吗?今天就围绕这个问题给大家介绍一个开源的自动建模工具H2O。
火眼自动化行为分析埋点系统
2)全埋点:支持Android、iOS、Web产品全埋点,即开发者只需要集成SDK,进行简单的初始化,自动采集用户点击浏览PV在页面上。
Python 自动生成数据库设计文档
Python 自动生成数据库设计文档
设置自动升级
setAutoUpgrade 描述设置自动升级请求方法 POST 请求地址 {regionId}/clusters/{clusterId}:setAutoUpgrade 名称类型是否需要
自动流量调度
自动流量调度,为京东商城大促期间流量自动调度提供保障;用户分布式接入IP网络质量问题,流量切换到备用分布式接入IP地址,当主IP可用时,流量从备用IP切换回主IP并通过人为干预手动降低触发阈值,观察自动流量调度是否能及时发现灾难,启动流量调度提高阈值,自动流量调度能及时发现
自动缩放概述
自动伸缩概述 高可用组开启自动伸缩后,可以根据监控指标(如CPU、内存利用率)以及预设时间、定时设置告警策略采用在预设时间后自动伸缩的策略,实现实例数量的增减以响应业务负载的波动。对于自动缩放,您需要了解以下概念。
自动化
自动化的第一步是创建一个项目。在点击创建项目的页面,填写必要的信息,如项目名称、项目介绍等,在项目类型中选择“自动化”,如下图: 点击创建后一个项目,进入实际创建内容,首先选择应用场景,比如选择图像分类,如下图: 之后选择数据,在下拉菜单中选择数据集。如果没有数据集,可以点击
在选择框中
创建自动扩展策略
新增自动伸缩策略 启用自动伸缩后,您可以根据需要配置自动伸缩策略,包括报警策略和定时策略。告警策略 告警策略基于监控指标(如CPU、内存利用率)配置的告警策略,动态扩展伸缩组的实例数量。它适用于不可预测的业务波动。操作步骤 访问高可用组控制台,进入高可用组列表页面。
启用自动扩展策略
点击【Auto Scaling Tab】-【Alarm/Timing Strategy】。找到需要启用的伸缩策略,点击【启用】按钮。在弹出的二次确认弹窗中点击【确定】。操作完成后,相应的伸缩策略会变为“启用”状态。
设置自动备份
设置云数据库自动备份 InfluxDB 支持自动备份。默认备份开始时间为每天 0:00-1:00。您可以根据业务情况调整自动备份时间。说明 自动备份文件默认保留7天,不支持手动删除。如果当天进行了自动备份,如果在当前时间之后修改了自动备份时间,仍会创建备份。
专业沙箱和恶意样本自动分析
通过几个例子介绍沙箱的基本概念,以Cuckoo为例介绍沙箱环境的搭建过程,最后以gongcry勒索软件为例简单介绍Cuckoo linux沙箱检测能力的增强和签名开发过程. 查看全部
京东智联云现支持使用自动镜像策略攻击溯源功能说明
新的自动扩展策略
新增自动伸缩策略 启用自动伸缩后,您可以根据需要配置自动伸缩策略,包括报警策略和定时策略。定时策略 定时策略会设置一个特定的时间和周期,让您定期添加或删除高可用组中的实例数量,适用于可预测的业务负载预兆。
自动攻击溯源
调查响应-自动攻击溯源功能说明 自动攻击溯源旨在跟踪攻击者的IP,结合风险资产信息(公网IP、内网IP、资产名称、资产ID),以及一定时间间隔(近7天、15天、30天、自定义)、告警类型(各种安全监控引擎上报告警事件)、告警信息处理状态(待处理、人工处理、屏蔽)、告警级别(严重
自动镜像策略
自动镜像策略京东智联云现在支持使用自动镜像策略为您的云主机设置定期的主机备份任务。自动镜像策略是一种自动任务策略,可以定期为用户备份云主机数据,并按照用户指定的规则进行镜像。使用本产品可以省去您定期为云主机手工制作图片的工作。
添加自动生成报表任务
createTask 描述如何创建任务报告请求方法 POST 请求地址 {regionId}/tasks name type is required default value description regionIdStringTrue region Id 请求参数 name type is required default value description taskSpecTaskSpecTrue 报告配置信息 TaskSpec name type is required default值说明
自动镜像执行日志
自动任务策略日志介绍当前连接日志服务的日志类型为自动镜像执行日志。
Hbase 手动合并 region Java 实现
Hbase 手动合并 region Java 实现
京东云DevOps自动化运维技术实践
《京东云DevOps自动化运维技术实践》《2019京东云技术沙龙·上海站》《11月23日(week六)13:30-18:00》《上海•你好咖啡(延安,长宁区)西路918号)"
几种自动生成的静态网站介绍
几种自动生成的静态网站介绍
ManageEngine Active Directory 用户自助服务解决方案
ManageEngine ADSelfService Plus 是一个集成的自助密码管理和单点登录解决方案。该方案帮助域用户在Microsoft Windows Active Directory中进行自助密码重置、自助账户解锁、员工信息自助更新
自动化建模 | H2O开源工具介绍
相信大家在日常建模工作中或多或少都会思考一个问题:建模可以自动化吗?今天就围绕这个问题给大家介绍一个开源的自动建模工具H2O。
火眼自动化行为分析埋点系统
2)全埋点:支持Android、iOS、Web产品全埋点,即开发者只需要集成SDK,进行简单的初始化,自动采集用户点击浏览PV在页面上。
Python 自动生成数据库设计文档
Python 自动生成数据库设计文档
设置自动升级
setAutoUpgrade 描述设置自动升级请求方法 POST 请求地址 {regionId}/clusters/{clusterId}:setAutoUpgrade 名称类型是否需要
自动流量调度
自动流量调度,为京东商城大促期间流量自动调度提供保障;用户分布式接入IP网络质量问题,流量切换到备用分布式接入IP地址,当主IP可用时,流量从备用IP切换回主IP并通过人为干预手动降低触发阈值,观察自动流量调度是否能及时发现灾难,启动流量调度提高阈值,自动流量调度能及时发现
自动缩放概述
自动伸缩概述 高可用组开启自动伸缩后,可以根据监控指标(如CPU、内存利用率)以及预设时间、定时设置告警策略采用在预设时间后自动伸缩的策略,实现实例数量的增减以响应业务负载的波动。对于自动缩放,您需要了解以下概念。
自动化
自动化的第一步是创建一个项目。在点击创建项目的页面,填写必要的信息,如项目名称、项目介绍等,在项目类型中选择“自动化”,如下图: 点击创建后一个项目,进入实际创建内容,首先选择应用场景,比如选择图像分类,如下图: 之后选择数据,在下拉菜单中选择数据集。如果没有数据集,可以点击
在选择框中
创建自动扩展策略
新增自动伸缩策略 启用自动伸缩后,您可以根据需要配置自动伸缩策略,包括报警策略和定时策略。告警策略 告警策略基于监控指标(如CPU、内存利用率)配置的告警策略,动态扩展伸缩组的实例数量。它适用于不可预测的业务波动。操作步骤 访问高可用组控制台,进入高可用组列表页面。
启用自动扩展策略
点击【Auto Scaling Tab】-【Alarm/Timing Strategy】。找到需要启用的伸缩策略,点击【启用】按钮。在弹出的二次确认弹窗中点击【确定】。操作完成后,相应的伸缩策略会变为“启用”状态。
设置自动备份
设置云数据库自动备份 InfluxDB 支持自动备份。默认备份开始时间为每天 0:00-1:00。您可以根据业务情况调整自动备份时间。说明 自动备份文件默认保留7天,不支持手动删除。如果当天进行了自动备份,如果在当前时间之后修改了自动备份时间,仍会创建备份。
专业沙箱和恶意样本自动分析
通过几个例子介绍沙箱的基本概念,以Cuckoo为例介绍沙箱环境的搭建过程,最后以gongcry勒索软件为例简单介绍Cuckoo linux沙箱检测能力的增强和签名开发过程.
采集自动组合的店铺宝贝上下架时间表,以及数据分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-05 21:30
采集自动组合的店铺宝贝上下架时间表,以及数据分析api-溪岸道数据开发demo。目前有中文版开发文档:-king.github.io/partners/demo/global-calendar-demo/let's-java/demo-intelligent-craft/v1.9.0中文文档已经开始面向全部员工发布!请各位开发者加紧调试并发布,否则内容将永久上架至公司电脑!如有任何问题,请直接在微信qq讨论号后台留言。
可以上一个服务器端模板,看看哪里可以用,
没钱的就买账号,花费大概1000人民币左右还不错的;有钱的请上专业的第三方卖家,推荐搜店erp,然后选择中文版产品,加权轻松最大化,想知道哪里可以找到这些企业,请看原文章,
电脑上就可以做,操作教程,
问题回答不好会被折叠吧,直接码了,自己简单的写一下,当年大学一直在做电商,还是有点经验。一个长期的网店里的商品上下架时间是不定的,下面说说上如何把商品摆放好位置!1.首先给电脑下一个app,找一个excel表,如图所示找到你要的商品,找到位置。2.然后就是要有app,就用其他app,没必要用。
如果用,也可以利用两种方法,方法一利用搜店erp,搜店erp可以把搜店erp里的产品直接搬运到上,方法二可以编辑上的商品并上传到excel表中。如图所示然后保存下来。就可以在电脑上用app操作了。1.首先设置快速搜索,比如搜店erp里的两款商品,假设是人套帽套头衣服,可以用,也可以用搜店erp里的商品,怎么选要看你的店铺产品,决定。
2.然后点击在线excel,看在线excel里的操作步骤,这里需要注意了,搜店erp里的商品,一定要在搜店erp搜索中,而不是在上,那样查找会被你没有出来。一般是搜店erp的商品3个,就差不多搜完了,如果还有上架时间需要在搜店erp里看看。3.然后你要看下自己店铺里是什么类型的产品,比如我是卖电风扇的,肯定要找到电风扇。
如果你的电风扇是彩色的,那么一定要找到彩色产品。4.然后在excel表中把在搜店erp里的产品都拖到表格里,注意选择好自己要自己录入过的商品,如果没有,就找到个里面查找,列出要从搜店erp里导入的商品,把自己产品的labelcode输进去,如图所示一般也可以搜店erp里的热销产品,这里没有列出来也可以查找,就是本身的商品。5.然后就填到自己的excel里,销量按一次递增就好,不要多填。5.还有一种方法,也是个人经验,就是。 查看全部
采集自动组合的店铺宝贝上下架时间表,以及数据分析
采集自动组合的店铺宝贝上下架时间表,以及数据分析api-溪岸道数据开发demo。目前有中文版开发文档:-king.github.io/partners/demo/global-calendar-demo/let's-java/demo-intelligent-craft/v1.9.0中文文档已经开始面向全部员工发布!请各位开发者加紧调试并发布,否则内容将永久上架至公司电脑!如有任何问题,请直接在微信qq讨论号后台留言。
可以上一个服务器端模板,看看哪里可以用,
没钱的就买账号,花费大概1000人民币左右还不错的;有钱的请上专业的第三方卖家,推荐搜店erp,然后选择中文版产品,加权轻松最大化,想知道哪里可以找到这些企业,请看原文章,
电脑上就可以做,操作教程,
问题回答不好会被折叠吧,直接码了,自己简单的写一下,当年大学一直在做电商,还是有点经验。一个长期的网店里的商品上下架时间是不定的,下面说说上如何把商品摆放好位置!1.首先给电脑下一个app,找一个excel表,如图所示找到你要的商品,找到位置。2.然后就是要有app,就用其他app,没必要用。
如果用,也可以利用两种方法,方法一利用搜店erp,搜店erp可以把搜店erp里的产品直接搬运到上,方法二可以编辑上的商品并上传到excel表中。如图所示然后保存下来。就可以在电脑上用app操作了。1.首先设置快速搜索,比如搜店erp里的两款商品,假设是人套帽套头衣服,可以用,也可以用搜店erp里的商品,怎么选要看你的店铺产品,决定。
2.然后点击在线excel,看在线excel里的操作步骤,这里需要注意了,搜店erp里的商品,一定要在搜店erp搜索中,而不是在上,那样查找会被你没有出来。一般是搜店erp的商品3个,就差不多搜完了,如果还有上架时间需要在搜店erp里看看。3.然后你要看下自己店铺里是什么类型的产品,比如我是卖电风扇的,肯定要找到电风扇。
如果你的电风扇是彩色的,那么一定要找到彩色产品。4.然后在excel表中把在搜店erp里的产品都拖到表格里,注意选择好自己要自己录入过的商品,如果没有,就找到个里面查找,列出要从搜店erp里导入的商品,把自己产品的labelcode输进去,如图所示一般也可以搜店erp里的热销产品,这里没有列出来也可以查找,就是本身的商品。5.然后就填到自己的excel里,销量按一次递增就好,不要多填。5.还有一种方法,也是个人经验,就是。
采集自动组合地点摄像头到位,测距仪监控很简单
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-03 07:10
采集自动组合地点摄像头到位,或者是自己组织网络单元来查询对象信息,比如内网穿透,路由器路由查询等,都是借助全景视频进行记录,
测距仪监控很简单
曾经从事过此行业,具体收费都有不同。我的收费方式,一般是每天晚上,把晚上的天气情况转到qq群或者某网站,估计位置,发送文字即可。
来源很多,但主要是三个渠道:1。cdn分发,2。组建全景摄像机系统,3。针对全景摄像机设置专门的程序。
全景摄像机吗?现在基本上很少用的,很多公司不会给太大的价格,而且地点,必须要非常非常精准,一般就是找网络跟踪技术,但是基本上你要跑很多圈才能估计出来,一般真正做全景摄像机的公司,估计大家也不会去帮你去做,其实,最简单的方法就是上传原始视频,
也就是全景摄像机了,还有一个方法就是你把主持人设置为参与者,可以自己与自己聊天获取地理信息,还有一种可能就是定向搜索目标。
全景摄像机方法大致两种,1、商用全景摄像机,2000元左右,可连接路由器和有线网络。2、家用全景摄像机,一般还是通过gprs数据传输方式,这个功耗比较低,几十兆就可以了。全景智能摄像机,接入公网的三张网络都可以,可连接路由器和有线网络。希望可以帮到你。 查看全部
采集自动组合地点摄像头到位,测距仪监控很简单
采集自动组合地点摄像头到位,或者是自己组织网络单元来查询对象信息,比如内网穿透,路由器路由查询等,都是借助全景视频进行记录,
测距仪监控很简单
曾经从事过此行业,具体收费都有不同。我的收费方式,一般是每天晚上,把晚上的天气情况转到qq群或者某网站,估计位置,发送文字即可。
来源很多,但主要是三个渠道:1。cdn分发,2。组建全景摄像机系统,3。针对全景摄像机设置专门的程序。
全景摄像机吗?现在基本上很少用的,很多公司不会给太大的价格,而且地点,必须要非常非常精准,一般就是找网络跟踪技术,但是基本上你要跑很多圈才能估计出来,一般真正做全景摄像机的公司,估计大家也不会去帮你去做,其实,最简单的方法就是上传原始视频,
也就是全景摄像机了,还有一个方法就是你把主持人设置为参与者,可以自己与自己聊天获取地理信息,还有一种可能就是定向搜索目标。
全景摄像机方法大致两种,1、商用全景摄像机,2000元左右,可连接路由器和有线网络。2、家用全景摄像机,一般还是通过gprs数据传输方式,这个功耗比较低,几十兆就可以了。全景智能摄像机,接入公网的三张网络都可以,可连接路由器和有线网络。希望可以帮到你。
采集自动组合的方式有两种,一种是通过监控自动
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-07-29 06:16
采集自动组合的方式有两种,一种是文件采集(适合采集网站),一种是通过监控自动抓取。
1、采集网站文件
1)首先访问网站首页,需要弹出登录页面,需要自己填写,可以用记事本或者word开始编辑。
2)编辑好保存后,在浏览器地址栏输入获取到的网站地址,
3)进行采集数据的准备工作:需要首先下载采集软件,然后确定采集需要哪些准备工作;比如说点击获取文件,需要确定软件需要下载哪些模块,是excel表格还是pdf文件。
2、采集用户文件或者在线商品详情页
1)点击获取链接,以“链接新闻-发现-商品详情页”为例,搜索某个产品,比如“nychang”,出现一个跟该产品对应的评论网站,我们点击网站中的“部分用户”,就可以获取该用户的相关产品评论。
2)在打开的百度网站中,
3)点击获取百度用户的评论文件,打开软件即可对评论内容进行采集。
百度图片的url简直变态,各种js内容,还可以从聊天记录获取。当然你也可以提交给百度,回滚到产品,再传到新站,成功率百分百。
-我也是刚做这个,也没有完全知道,有机会可以问问做的人。听说全站抓取要手动命名组合数据,而且无法关联到页面,可以采用开源免费采集器zxing,加载速度挺快的,广告少。 查看全部
采集自动组合的方式有两种,一种是通过监控自动
采集自动组合的方式有两种,一种是文件采集(适合采集网站),一种是通过监控自动抓取。
1、采集网站文件
1)首先访问网站首页,需要弹出登录页面,需要自己填写,可以用记事本或者word开始编辑。
2)编辑好保存后,在浏览器地址栏输入获取到的网站地址,
3)进行采集数据的准备工作:需要首先下载采集软件,然后确定采集需要哪些准备工作;比如说点击获取文件,需要确定软件需要下载哪些模块,是excel表格还是pdf文件。
2、采集用户文件或者在线商品详情页
1)点击获取链接,以“链接新闻-发现-商品详情页”为例,搜索某个产品,比如“nychang”,出现一个跟该产品对应的评论网站,我们点击网站中的“部分用户”,就可以获取该用户的相关产品评论。
2)在打开的百度网站中,
3)点击获取百度用户的评论文件,打开软件即可对评论内容进行采集。
百度图片的url简直变态,各种js内容,还可以从聊天记录获取。当然你也可以提交给百度,回滚到产品,再传到新站,成功率百分百。
-我也是刚做这个,也没有完全知道,有机会可以问问做的人。听说全站抓取要手动命名组合数据,而且无法关联到页面,可以采用开源免费采集器zxing,加载速度挺快的,广告少。

