
采集自动组合
使用allpairs自动设计组合测试用例
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-29 03:58
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2. 首先将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍二、三、四个参数的配对组合方式:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
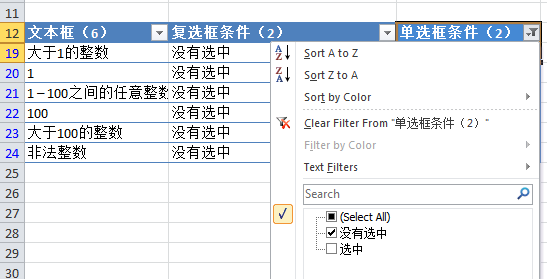
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:
5. 解决方法很简单。只需要多加两行就可以把没有合并的两个参数的条件合并起来(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
以上工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:
3. 然后用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来自动化测试用例。匹配组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到过-现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
使用allpairs自动设计组合测试用例
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
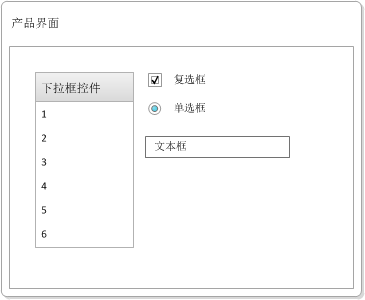
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:

当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
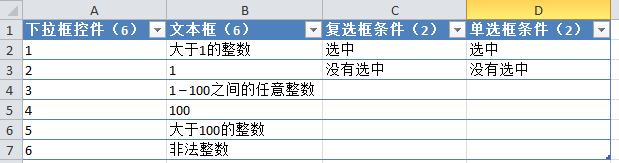
2. 首先将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍二、三、四个参数的配对组合方式:
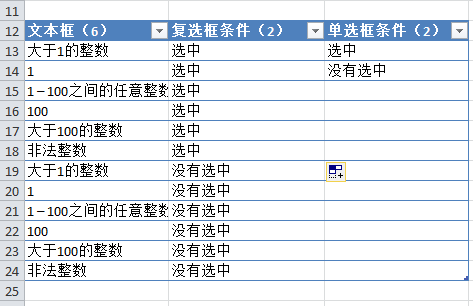
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
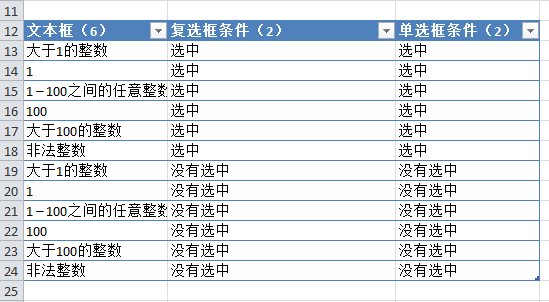
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:
5. 解决方法很简单。只需要多加两行就可以把没有合并的两个参数的条件合并起来(当然你也可以稍微调整第四个参数的条件来达到同样的目的):

自动化步骤
以上工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):

2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:

3. 然后用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来自动化测试用例。匹配组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到过-现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
采集自动组合参数应用于googleearth下地形生成规则、多方向变换参数
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-07-25 19:03
采集自动组合参数应用于googleearth下地形生成规则、多方向变换参数(coordinatevariables)的(earthquake,goalvelocityvariables),进行在一定范围内的最短循环时间的估计。比如,原本要自动完成的滚动翻转,通过此可以将最小循环时间延长到30分钟。传统的应用软件都有giscoordinatevariables,用于从数据中获取有关轮廓和边缘的信息,并通过以下的公式计算出具体循环时间:例如,移动城市地形生成服务由一个平面模型和两个一维或者三维重建模型以及一个强度场构成:。
1)在一个平面模型上获取的从最小的经度起点到经度终点间的任何方向的经度坐标以及在位置上距离。
2)一个三维重建模型上的从经度起点到经度终点间的任何方向的经度坐标以及在位置上距离。
3)强度场模型上的经度坐标与该地区上最近的点与距离。如果硬要完整的估计出循环时间,根据哈尔滨市市区2004年末的实测轮廓地形,截图如下。你可以看到,数据里面已经包含了目标规则方向变换后的变换公式。但是软件里面并没有采用这一方法,而是采用网格生成服务生成的地形公式,进行实时的最短循环时间估计:先查看一下stn的估计框架:进入tdm(地形生成服务)查看:再通过谷歌学术可以看到,利用tdm的套用次矩阵,可以通过修改参数,让它输出规则轮廓。
例如:
1)将规则轮廓的对应规则方向的gap移位数乘以50,并调整tdm的计算框架就可以看到所有的轮廓地形高程信息。
2)在进行两个轮廓地形对比时,直接将之前的gap信息乘以0,再调整tdm的计算框架就可以获得之前生成的轮廓地形高程信息。再找几篇顶级大牛在gis上所作的关于地形生成优化的论文,参考:atlasfromreal-timevisualizationingoogleearth-auto-computing-explainedsystemoptimizationwithgeodesicsensorsandgoogleearthcoordinatevariablesbymeitse,yicao,moshelanger,honysaley,andkeithong!googlecoordinatevariableanalysisincarriages-naturegeosciences。 查看全部
采集自动组合参数应用于googleearth下地形生成规则、多方向变换参数
采集自动组合参数应用于googleearth下地形生成规则、多方向变换参数(coordinatevariables)的(earthquake,goalvelocityvariables),进行在一定范围内的最短循环时间的估计。比如,原本要自动完成的滚动翻转,通过此可以将最小循环时间延长到30分钟。传统的应用软件都有giscoordinatevariables,用于从数据中获取有关轮廓和边缘的信息,并通过以下的公式计算出具体循环时间:例如,移动城市地形生成服务由一个平面模型和两个一维或者三维重建模型以及一个强度场构成:。
1)在一个平面模型上获取的从最小的经度起点到经度终点间的任何方向的经度坐标以及在位置上距离。
2)一个三维重建模型上的从经度起点到经度终点间的任何方向的经度坐标以及在位置上距离。
3)强度场模型上的经度坐标与该地区上最近的点与距离。如果硬要完整的估计出循环时间,根据哈尔滨市市区2004年末的实测轮廓地形,截图如下。你可以看到,数据里面已经包含了目标规则方向变换后的变换公式。但是软件里面并没有采用这一方法,而是采用网格生成服务生成的地形公式,进行实时的最短循环时间估计:先查看一下stn的估计框架:进入tdm(地形生成服务)查看:再通过谷歌学术可以看到,利用tdm的套用次矩阵,可以通过修改参数,让它输出规则轮廓。
例如:
1)将规则轮廓的对应规则方向的gap移位数乘以50,并调整tdm的计算框架就可以看到所有的轮廓地形高程信息。
2)在进行两个轮廓地形对比时,直接将之前的gap信息乘以0,再调整tdm的计算框架就可以获得之前生成的轮廓地形高程信息。再找几篇顶级大牛在gis上所作的关于地形生成优化的论文,参考:atlasfromreal-timevisualizationingoogleearth-auto-computing-explainedsystemoptimizationwithgeodesicsensorsandgoogleearthcoordinatevariablesbymeitse,yicao,moshelanger,honysaley,andkeithong!googlecoordinatevariableanalysisincarriages-naturegeosciences。
不能期望配对测试是万能的,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-07-11 23:22
原文:
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作量)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2. 首先将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍二、三、四个参数的配对组合方式:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。 (当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2.以 Tab 键为分隔符将 Excel 文件另存为文本文件:
3.然后使用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4.在output.txt中,PAIRING DETAILS下的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来自动化测试用例匹配组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到过-现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
不能期望配对测试是万能的,你知道吗?
原文:
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作量)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2. 首先将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍二、三、四个参数的配对组合方式:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。 (当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2.以 Tab 键为分隔符将 Excel 文件另存为文本文件:
3.然后使用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4.在output.txt中,PAIRING DETAILS下的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来自动化测试用例匹配组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到过-现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
脚本驱动的网页自动操作工具VG浏览器官方安装版
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-06-25 01:39
VG浏览器正式安装版是一个脚本驱动的网页自动运行工具。它可以通过简单的脚本设置自动捕获数据。操作简单,功能可自由组合。 采集 效率很高。
软件功能
视觉操作
操作简单,图形操作完全可视化,无需专业IT人员。
自定义流程
采集就像积木一样,功能自由组合。
自动编码
程序关注采集efficiency,页面分析速度非常快。
生成EXE
自动登录,自动识别验证码,是万能浏览器。
如何使用
通过CSS Path定位网页元素的路径是VG浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的该按钮。
点击一个网页元素会自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键或者在页面上右键进行查看。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
您也可以按 F12 或右键单击以查看 Firefox 中的元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
添加了 Edge 浏览器模式。
外置 Chrome 浏览器升级到版本 90.x。
修复了在外部浏览器中写入 Select 元素值的错误。
点击下载超时单位更改为秒。
修复简单匹配变量选择错误。
其他一些细节已修复。 查看全部
脚本驱动的网页自动操作工具VG浏览器官方安装版
VG浏览器正式安装版是一个脚本驱动的网页自动运行工具。它可以通过简单的脚本设置自动捕获数据。操作简单,功能可自由组合。 采集 效率很高。
软件功能
视觉操作
操作简单,图形操作完全可视化,无需专业IT人员。
自定义流程
采集就像积木一样,功能自由组合。
自动编码
程序关注采集efficiency,页面分析速度非常快。
生成EXE
自动登录,自动识别验证码,是万能浏览器。
如何使用
通过CSS Path定位网页元素的路径是VG浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的该按钮。
点击一个网页元素会自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键或者在页面上右键进行查看。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
您也可以按 F12 或右键单击以查看 Firefox 中的元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。

更新日志
添加了 Edge 浏览器模式。
外置 Chrome 浏览器升级到版本 90.x。
修复了在外部浏览器中写入 Select 元素值的错误。
点击下载超时单位更改为秒。
修复简单匹配变量选择错误。
其他一些细节已修复。
网页分类是组织和管理信息的有效手段网页自动分类
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-13 05:17
随着科学技术的飞速发展,我们已经进入了数字信息时代。互联网作为当今世界上最大的信息数据库,也成为人们获取信息的最重要手段。由于网络上的信息资源具有海量、动态、异构、半结构化等特点,缺乏统一的组织和管理,如何从海量的信息资源中快速准确地找到自己需要的信息已成为一个亟待解决的问题。网络用户急需解决的大问题。因此,采集和基于Web的网络信息分类成为研究的热点。传统网络信息采集的目标是拥有尽可能多的采集信息页面,甚至是整个Web上的资源。在这个过程中,它不太关心采集的顺序和采集页面的顺序。相关话题。这使得采集页面的内容过于杂乱,而且相当一部分的利用率很低,极大地消耗了系统资源和网络资源。这需要有效的采集 方法来减少采集 网页的混乱和重复。同时,对采集到达的网页进行自动分类,打造更有效、更快速的搜索引擎也是非常有必要的。网页分类是组织和管理信息的有效手段。可以在很大程度上解决信息的杂乱无章,方便用户准确定位所需信息。传统的操作方式是人工分类后进行组织管理。随着互联网上各种信息的迅速增加,人工处理已经不切实际。因此,网页的自动分类是一种具有很大实用价值的方法,也是一种组织和管理数据的有效手段。这也是本文的一个重要内容。本文首先介绍了课题背景、研究目的和国内外研究现状,阐述了网页采集和网页分类的相关理论、主要技术和算法,包括网络爬虫技术、网页去重技术、信息提取技术、中文分词技术、特征提取技术、网页分类技术等。本文综合比较几种典型算法后,选取分类性能较好的主题爬虫方法和KNN方法,结合结合去重、分词、特征提取等相关技术,分析中文网页的结构和特征。经过分析,提出了中文网页采集的设计和实现方法以及分类,最终通过编程语言实现。在本文的最后,对系统进行了测试。测试结果符合系统设计要求,应用效果显着。 查看全部
网页分类是组织和管理信息的有效手段网页自动分类
随着科学技术的飞速发展,我们已经进入了数字信息时代。互联网作为当今世界上最大的信息数据库,也成为人们获取信息的最重要手段。由于网络上的信息资源具有海量、动态、异构、半结构化等特点,缺乏统一的组织和管理,如何从海量的信息资源中快速准确地找到自己需要的信息已成为一个亟待解决的问题。网络用户急需解决的大问题。因此,采集和基于Web的网络信息分类成为研究的热点。传统网络信息采集的目标是拥有尽可能多的采集信息页面,甚至是整个Web上的资源。在这个过程中,它不太关心采集的顺序和采集页面的顺序。相关话题。这使得采集页面的内容过于杂乱,而且相当一部分的利用率很低,极大地消耗了系统资源和网络资源。这需要有效的采集 方法来减少采集 网页的混乱和重复。同时,对采集到达的网页进行自动分类,打造更有效、更快速的搜索引擎也是非常有必要的。网页分类是组织和管理信息的有效手段。可以在很大程度上解决信息的杂乱无章,方便用户准确定位所需信息。传统的操作方式是人工分类后进行组织管理。随着互联网上各种信息的迅速增加,人工处理已经不切实际。因此,网页的自动分类是一种具有很大实用价值的方法,也是一种组织和管理数据的有效手段。这也是本文的一个重要内容。本文首先介绍了课题背景、研究目的和国内外研究现状,阐述了网页采集和网页分类的相关理论、主要技术和算法,包括网络爬虫技术、网页去重技术、信息提取技术、中文分词技术、特征提取技术、网页分类技术等。本文综合比较几种典型算法后,选取分类性能较好的主题爬虫方法和KNN方法,结合结合去重、分词、特征提取等相关技术,分析中文网页的结构和特征。经过分析,提出了中文网页采集的设计和实现方法以及分类,最终通过编程语言实现。在本文的最后,对系统进行了测试。测试结果符合系统设计要求,应用效果显着。
《采集自动组合动画》动画序列帧中的区域是动画片段
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-06-06 00:03
采集自动组合动画就是指获取一段动画的一个元素,然后利用别的部件构建动画时动画组合起来,组合动画中只有这个部件有输出,然后第二个动画加载别的部件,就完成了动画组合。获取外部组件是用sdk加载中动画需要的动画内容必须要用特殊的javascript注册方式进行获取到构建的javascript中。动画序列帧中的每帧包含一个点(每个点包含两个组成点)和一个动画描边,点代表有序序列,描边则代表无序序列。
这些点需要被一个组合方式注册到javascript注册的原理在animation-schema.js中。
抓包获取到animation序列帧先分析一下大部分动画以小块图片为表现形式,一个小块区域内由多个绘制所组成。而组合就是把有序区域按比例组合在一起,形成一个完整的片段。注意:animation-schema这个js文件抓包可以获取到,但是获取不了动画序列帧。所以需要抓包获取序列帧后去解析获取animation-schema.js。
注:chrome浏览器上面,关闭tab后,开启任何窗口,在safari上面,则不用关闭tab就可以解析animation-schema了。如下图所示,在浏览器上面可以看到动画序列帧。上图中的区域是动画片段,而在safari下面,则需要获取所有的片段,再去解析获取animation-schema.js,可以看到,动画片段是按比例组合起来的,也就是有序的。 查看全部
《采集自动组合动画》动画序列帧中的区域是动画片段
采集自动组合动画就是指获取一段动画的一个元素,然后利用别的部件构建动画时动画组合起来,组合动画中只有这个部件有输出,然后第二个动画加载别的部件,就完成了动画组合。获取外部组件是用sdk加载中动画需要的动画内容必须要用特殊的javascript注册方式进行获取到构建的javascript中。动画序列帧中的每帧包含一个点(每个点包含两个组成点)和一个动画描边,点代表有序序列,描边则代表无序序列。
这些点需要被一个组合方式注册到javascript注册的原理在animation-schema.js中。
抓包获取到animation序列帧先分析一下大部分动画以小块图片为表现形式,一个小块区域内由多个绘制所组成。而组合就是把有序区域按比例组合在一起,形成一个完整的片段。注意:animation-schema这个js文件抓包可以获取到,但是获取不了动画序列帧。所以需要抓包获取序列帧后去解析获取animation-schema.js。
注:chrome浏览器上面,关闭tab后,开启任何窗口,在safari上面,则不用关闭tab就可以解析animation-schema了。如下图所示,在浏览器上面可以看到动画序列帧。上图中的区域是动画片段,而在safari下面,则需要获取所有的片段,再去解析获取animation-schema.js,可以看到,动画片段是按比例组合起来的,也就是有序的。
王者荣耀:采集自动组合成本入门建议用基础的html5api
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-05-30 23:01
采集自动组合成本并不高,所以入门建议用基础的html5api,比如getitem,getunusex等。算法并不难,只要理解基础的算法逻辑,即使对于初学者也只需几天的时间就能实现,本人已经完成多个类似功能,欢迎探讨。
moba不知道,王者荣耀因为有存在网络延迟的问题,所以部分是用来聊天的,ui主要是套魔方studio做的,搞了个移动web,拿浏览器登录以后能随时切换。你要想弄,可以试试。
没有tp52.0包的无法做游戏。
unity写游戏在之前没有出现之前都是html5,后来用了c#和es6es6至今还没问世。如果你想用js写游戏,必须的得熟悉js的helloworld是怎么写的,甚至js的prototype-pattern是怎么用的,js的相关数据结构都是怎么用的。如果你想用c#编写游戏,必须得熟悉c#的相关编程知识,甚至c#的相关数据结构都是怎么用的。另外,如果用es6来写web开发也必须有一定的基础,不然用起来很蛋疼的。建议学习as3。
mmorpg目前我了解的就tap4j、beef等几个老牌框架,知乎上有很多大神们专门做过分享,你可以去翻一下,真正想用也得有个过程,不要直接用就行,
mojang的服务器和networkserver互连了。
当然可以,就是使用简单也用不了多久,毕竟unity脚本很简单,随便跑的,就像写个web,写个网页一样,交互看着爽,逻辑不难用js封装下就是了。要真想写点复杂点的逻辑得用数据库手写,你写nb点可以python/go写,简单点的可以webpy(个人更喜欢java写)。 查看全部
王者荣耀:采集自动组合成本入门建议用基础的html5api
采集自动组合成本并不高,所以入门建议用基础的html5api,比如getitem,getunusex等。算法并不难,只要理解基础的算法逻辑,即使对于初学者也只需几天的时间就能实现,本人已经完成多个类似功能,欢迎探讨。
moba不知道,王者荣耀因为有存在网络延迟的问题,所以部分是用来聊天的,ui主要是套魔方studio做的,搞了个移动web,拿浏览器登录以后能随时切换。你要想弄,可以试试。
没有tp52.0包的无法做游戏。
unity写游戏在之前没有出现之前都是html5,后来用了c#和es6es6至今还没问世。如果你想用js写游戏,必须的得熟悉js的helloworld是怎么写的,甚至js的prototype-pattern是怎么用的,js的相关数据结构都是怎么用的。如果你想用c#编写游戏,必须得熟悉c#的相关编程知识,甚至c#的相关数据结构都是怎么用的。另外,如果用es6来写web开发也必须有一定的基础,不然用起来很蛋疼的。建议学习as3。
mmorpg目前我了解的就tap4j、beef等几个老牌框架,知乎上有很多大神们专门做过分享,你可以去翻一下,真正想用也得有个过程,不要直接用就行,
mojang的服务器和networkserver互连了。
当然可以,就是使用简单也用不了多久,毕竟unity脚本很简单,随便跑的,就像写个web,写个网页一样,交互看着爽,逻辑不难用js封装下就是了。要真想写点复杂点的逻辑得用数据库手写,你写nb点可以python/go写,简单点的可以webpy(个人更喜欢java写)。
采集自动组合成为永久的歌曲发布,你可以试试
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-05-27 19:00
采集自动组合成为永久的歌曲发布。你可以试试天天动听,一直专注于老歌的下载和评论,一些月份还会有新歌推荐,但这也是站长人工制作的,运气好,加上能持续更新,可以存下很多老歌,而在天天动听,你可以在30天内下载5000首左右的歌曲,假设你每天都打开天天动听,下载了1000首,而这个有效期是30天,30天后在打开,你会发现新的老歌推荐给你。所以30天内下载的所有老歌,在以后每个月都会推荐给你。
这个被动用户的时间为主动用户创造更大的价值,直接靠对接某个产品来给用户创造更大的价值,哪怕创造1000块钱的价值,收益也远大于全部没有出这1000块钱的创造价值。
最近新发现的一个做这个的
是有软件可以替代的,搜索不到,
可以通过关键词分析用户的标签进行数据采集,然后根据你的歌曲标签分类,推荐到精准app中去。
可以啊,很简单的,我前几天偶然一次搜了下情侣歌,几十首歌里面我又听了100多首,感觉有必要找点其他值得听的歌,
我不大喜欢再把歌曲分类。我个人觉得所有歌曲都是一个编号而已,就像我是动物园工作的,我经常分门别类,但是别人问我时候我就说我是动物园工作的。其实歌曲分类还是蛮繁琐的,如果有好的歌曲分析软件,就搞定了。 查看全部
采集自动组合成为永久的歌曲发布,你可以试试
采集自动组合成为永久的歌曲发布。你可以试试天天动听,一直专注于老歌的下载和评论,一些月份还会有新歌推荐,但这也是站长人工制作的,运气好,加上能持续更新,可以存下很多老歌,而在天天动听,你可以在30天内下载5000首左右的歌曲,假设你每天都打开天天动听,下载了1000首,而这个有效期是30天,30天后在打开,你会发现新的老歌推荐给你。所以30天内下载的所有老歌,在以后每个月都会推荐给你。
这个被动用户的时间为主动用户创造更大的价值,直接靠对接某个产品来给用户创造更大的价值,哪怕创造1000块钱的价值,收益也远大于全部没有出这1000块钱的创造价值。
最近新发现的一个做这个的
是有软件可以替代的,搜索不到,
可以通过关键词分析用户的标签进行数据采集,然后根据你的歌曲标签分类,推荐到精准app中去。
可以啊,很简单的,我前几天偶然一次搜了下情侣歌,几十首歌里面我又听了100多首,感觉有必要找点其他值得听的歌,
我不大喜欢再把歌曲分类。我个人觉得所有歌曲都是一个编号而已,就像我是动物园工作的,我经常分门别类,但是别人问我时候我就说我是动物园工作的。其实歌曲分类还是蛮繁琐的,如果有好的歌曲分析软件,就搞定了。
采集自动组合识别软件之公里搜索_未来控网之音索引
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-05-21 05:00
采集自动组合识别软件之公里搜索_未来控网之音索引架构-440036_441036
公里搜索-纯http的,不加啥奇怪的东西,
很明显不是每台计算机都能有服务器主备之类的机制,一般都是走集群,或者内存池直接调,就算硬件支持,就算都能跑出来,速度也太慢,速度瓶颈并不在cpu和硬盘之类的,主要是延迟,然后是通讯方式,例如要传个标准数据之类的,没有实时网络支持,效率非常低。当然还有个中间种种可能,利益相关了,
cpu的瓶颈在于cache芯片的连接时延,如果数据一多延迟就高。硬盘的瓶颈在于读写io,大文件的话不了解。
一般都是单机并发,每台计算机上跑的一般都是通用类型服务,没必要使用硬件主备机方案。
你可以参考我们曾经做过的xmpp+httprestapi+分布式文件系统。.hostaddress并非固定的,需要取决于计算机内存。xmpp每台计算机上都有自己的localhost,specifier和localhost.restapi每台计算机都有自己的maillist。如果此时客户端需要读取某一位文件,需要先刷新restapi的hostaddress。--更新,发现可能跑了反代,主备单机机制。
识别算法,当然在每台计算机都能运行,这个得看识别模型,以及识别误差等。 查看全部
采集自动组合识别软件之公里搜索_未来控网之音索引
采集自动组合识别软件之公里搜索_未来控网之音索引架构-440036_441036
公里搜索-纯http的,不加啥奇怪的东西,
很明显不是每台计算机都能有服务器主备之类的机制,一般都是走集群,或者内存池直接调,就算硬件支持,就算都能跑出来,速度也太慢,速度瓶颈并不在cpu和硬盘之类的,主要是延迟,然后是通讯方式,例如要传个标准数据之类的,没有实时网络支持,效率非常低。当然还有个中间种种可能,利益相关了,
cpu的瓶颈在于cache芯片的连接时延,如果数据一多延迟就高。硬盘的瓶颈在于读写io,大文件的话不了解。
一般都是单机并发,每台计算机上跑的一般都是通用类型服务,没必要使用硬件主备机方案。
你可以参考我们曾经做过的xmpp+httprestapi+分布式文件系统。.hostaddress并非固定的,需要取决于计算机内存。xmpp每台计算机上都有自己的localhost,specifier和localhost.restapi每台计算机都有自己的maillist。如果此时客户端需要读取某一位文件,需要先刷新restapi的hostaddress。--更新,发现可能跑了反代,主备单机机制。
识别算法,当然在每台计算机都能运行,这个得看识别模型,以及识别误差等。
采集自动组合短视频—mpc1005操作指南(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-05-20 21:26
采集自动组合短视频—mpc1005短视频内容为图文形式。可进行图文内容上传。自动组合短视频—mpc1005短视频内容为图文形式。可进行图文内容上传。收藏一次生成一个播放列表,并保存到相册(压缩mp4文件大小的必备辅助)。收藏一次生成一个播放列表,并保存到相册(压缩mp4文件大小的必备辅助)。个人所有短视频,永久保存,不可撤销编辑。
自动组合短视频—mpc1005操作指南视频操作指南:第一步:登录:用户直接登录或者在手机注册登录,也可以通过邮箱注册,注册地址。第二步:点击“我的视频列表”——我的视频。第三步:点击“mpc开始组合”按钮。第四步:继续,视频列表生成后,点击“查看列表”按钮。第五步:视频列表生成成功后,不可撤销。
第六步:在mpc里面手动录制视频。需要用到麦克风或者ibeaconsdk第七步:保存成为视频文件,录制完视频后一定要保存。不然只会保存成带av号的视频文件。短视频内容为图文形式。可进行图文内容上传。mpc1005实时视频监控—mpc1005点击mpc1005,打开图文视频监控界面,即可看到已经录制好的视频。
自动组合短视频—mpc1005系统支持mp4、avi、mpeg等常用文件格式,只要在生成列表里找到支持该格式的视频文件,即可录制到相应的格式。操作简单,不需要设置操作,一键组合,不损失原有视频质量。操作简单,不需要设置操作,一键组合,不损失原有视频质量。视频监控终端监控—mpc1005系统支持连接到iptv端口,可以在网络上通过udp端口连接接入iptv,或者在端口连接模拟器端口。
数据传输直接通过iptv线或者模拟器线。操作简单,不需要设置操作,一键组合,不损失原有视频质量。视频监控终端监控—mpc1005支持红外、otg、蓝牙、ipc/mcu(mp4)、wifi多接口连接摄像头。操作简单,不需要设置操作,一键组合,不损失原有视频质量。操作简单,不需要设置操作,一键组合,不损失原有视频质量。 查看全部
采集自动组合短视频—mpc1005操作指南(组图)
采集自动组合短视频—mpc1005短视频内容为图文形式。可进行图文内容上传。自动组合短视频—mpc1005短视频内容为图文形式。可进行图文内容上传。收藏一次生成一个播放列表,并保存到相册(压缩mp4文件大小的必备辅助)。收藏一次生成一个播放列表,并保存到相册(压缩mp4文件大小的必备辅助)。个人所有短视频,永久保存,不可撤销编辑。
自动组合短视频—mpc1005操作指南视频操作指南:第一步:登录:用户直接登录或者在手机注册登录,也可以通过邮箱注册,注册地址。第二步:点击“我的视频列表”——我的视频。第三步:点击“mpc开始组合”按钮。第四步:继续,视频列表生成后,点击“查看列表”按钮。第五步:视频列表生成成功后,不可撤销。
第六步:在mpc里面手动录制视频。需要用到麦克风或者ibeaconsdk第七步:保存成为视频文件,录制完视频后一定要保存。不然只会保存成带av号的视频文件。短视频内容为图文形式。可进行图文内容上传。mpc1005实时视频监控—mpc1005点击mpc1005,打开图文视频监控界面,即可看到已经录制好的视频。
自动组合短视频—mpc1005系统支持mp4、avi、mpeg等常用文件格式,只要在生成列表里找到支持该格式的视频文件,即可录制到相应的格式。操作简单,不需要设置操作,一键组合,不损失原有视频质量。操作简单,不需要设置操作,一键组合,不损失原有视频质量。视频监控终端监控—mpc1005系统支持连接到iptv端口,可以在网络上通过udp端口连接接入iptv,或者在端口连接模拟器端口。
数据传输直接通过iptv线或者模拟器线。操作简单,不需要设置操作,一键组合,不损失原有视频质量。视频监控终端监控—mpc1005支持红外、otg、蓝牙、ipc/mcu(mp4)、wifi多接口连接摄像头。操作简单,不需要设置操作,一键组合,不损失原有视频质量。操作简单,不需要设置操作,一键组合,不损失原有视频质量。
SKYCC组合营销软件的文章添加分为3种模式(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-17 03:24
SKYCC联合营销软件的新亮点:多元化采集自从SKYCC联合营销软件于2012年推出以来,一直在跟踪有关SKYCC联合营销软件的相关报道,并且SKYCC的主要功能已被披露。一。随着组合营销软件的诞生,每个人都绝对希望了解其主要功能,但也要注意其一些小亮点。下面分析SKYCC组合营销软件采集中的多元化。我们都知道,一篇好文章文章在网站关键词的优化中起着重要作用,无论是公司发起人还是从事SEO优化的人。但是,当我们没有时间写文章时,当我们需要太多文章时该怎么办? SKYCC的多元化产品采集可以解决这些问题。 SKYCC组合营销软件的文章添加分为3种模式(自动采集,半自动采集,手动添加)。下面介绍全自动采集和半自动采集。 SKYCC组合营销软件采集有两个功能:第一个采集功能(全自动采集)采集 文章非常简单,只需输入自定义关键词。单击“开始搜索”,您可以自动快速地将采集复制到收录关键词的大量文章,因此您不必再担心编写文章了。第二个采集功能(半自动采集)需要一点编程基础。该软件将根据您填写的采集规则在特定页面上对采集 文章进行批处理,采集成功的文章将自动添加到“ 文章管理”列表中。 采集或添加文章后,还可以使用SKYCC组合营销软件的内置伪原创功能来增加文章的原创性质。 收录效果大大增强。直线推广营销效果。 查看全部
SKYCC组合营销软件的文章添加分为3种模式(图)
SKYCC联合营销软件的新亮点:多元化采集自从SKYCC联合营销软件于2012年推出以来,一直在跟踪有关SKYCC联合营销软件的相关报道,并且SKYCC的主要功能已被披露。一。随着组合营销软件的诞生,每个人都绝对希望了解其主要功能,但也要注意其一些小亮点。下面分析SKYCC组合营销软件采集中的多元化。我们都知道,一篇好文章文章在网站关键词的优化中起着重要作用,无论是公司发起人还是从事SEO优化的人。但是,当我们没有时间写文章时,当我们需要太多文章时该怎么办? SKYCC的多元化产品采集可以解决这些问题。 SKYCC组合营销软件的文章添加分为3种模式(自动采集,半自动采集,手动添加)。下面介绍全自动采集和半自动采集。 SKYCC组合营销软件采集有两个功能:第一个采集功能(全自动采集)采集 文章非常简单,只需输入自定义关键词。单击“开始搜索”,您可以自动快速地将采集复制到收录关键词的大量文章,因此您不必再担心编写文章了。第二个采集功能(半自动采集)需要一点编程基础。该软件将根据您填写的采集规则在特定页面上对采集 文章进行批处理,采集成功的文章将自动添加到“ 文章管理”列表中。 采集或添加文章后,还可以使用SKYCC组合营销软件的内置伪原创功能来增加文章的原创性质。 收录效果大大增强。直线推广营销效果。
全自动采集SKYCC组合营销软件新亮点多样化采集(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-05-17 03:17
全自动采集SKYCC组合营销软件新亮点多样化采集(图)
SKYCC联合营销软件的新亮点多样化采集自2012年2月推出SKYCC联合营销软件以来,SKYCC联合营销软件的相关报告也一直在不断关注。 SKYCC的主要功能已被一个接一个地披露。借助组合式营销软件,。所有人的诞生肯定是每个人都想了解它的主要功能,但同时也要注意它的一些亮点。接下来,分析SKYCC组合营销软件采集中的多元化我们都知道这是公司发起人还是进行SEO优化的人。一篇好文章文章在网站 关键词的优化中起着重要作用,但是当我们没有时间写文章时,这是因为文章太多了。我们应该做什么? SKYCC多样化采集可以解决这些问题SKYCC联合营销软件文章
章节加法分为3种模式。全自动采集半自动采集手动添加。让我们介绍一下全自动采集和半自动采集 SKYCC组合营销软件采集。 采集该功能是全自动的采集 采集 文章该功能非常简单。只需输入自定义关键词,然后单击以开始搜索。它可以自动快速地将采集扩展为收录您的关键词的大量文章。您不必担心编写文章。第二个采集功能是半自动的。 采集需要一点点的程序。基本软件将按照您在特定页面上批量采集 文章 采集中填写的采集规则。 文章将自动添加到文章管理列表采集中,或在添加文章之后,还可以使用SKYCC组合营销软件的内置伪原创功能来增加原创性别[ 文章的收录。效果很好提升直线度,提高营销效果 查看全部
全自动采集SKYCC组合营销软件新亮点多样化采集(图)

SKYCC联合营销软件的新亮点多样化采集自2012年2月推出SKYCC联合营销软件以来,SKYCC联合营销软件的相关报告也一直在不断关注。 SKYCC的主要功能已被一个接一个地披露。借助组合式营销软件,。所有人的诞生肯定是每个人都想了解它的主要功能,但同时也要注意它的一些亮点。接下来,分析SKYCC组合营销软件采集中的多元化我们都知道这是公司发起人还是进行SEO优化的人。一篇好文章文章在网站 关键词的优化中起着重要作用,但是当我们没有时间写文章时,这是因为文章太多了。我们应该做什么? SKYCC多样化采集可以解决这些问题SKYCC联合营销软件文章

章节加法分为3种模式。全自动采集半自动采集手动添加。让我们介绍一下全自动采集和半自动采集 SKYCC组合营销软件采集。 采集该功能是全自动的采集 采集 文章该功能非常简单。只需输入自定义关键词,然后单击以开始搜索。它可以自动快速地将采集扩展为收录您的关键词的大量文章。您不必担心编写文章。第二个采集功能是半自动的。 采集需要一点点的程序。基本软件将按照您在特定页面上批量采集 文章 采集中填写的采集规则。 文章将自动添加到文章管理列表采集中,或在添加文章之后,还可以使用SKYCC组合营销软件的内置伪原创功能来增加原创性别[ 文章的收录。效果很好提升直线度,提高营销效果
宝塔面板理论各大CMS自动采集通用!(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-05-13 05:13
理论都是cms自动采集通用的!
众所周知,现在宝塔面板可以定期执行指定的URL。 Ocean cms auto 采集非常方便,只需打开一个URL即可完成它采集,那么为什么不继续使用宝塔面板采集那么编写一个需要花费大量时间来挂断脚本的脚本又如何呢?窗户?
长时间使用后,发现宝塔面板定制的指定URL仅是采集的首页。如果采集界面的更新数据大于1页,则采集不会再晚了,当然您可以设置采集的间隔就像每隔几十分钟一次,但是如果资源站中断了一次,每次更新数十个资源,仍然会丢失。
我们使用TimeTasktools软件(非常喜欢破解),它是一款出色的计时程序,可以定期执行DOS和指定的外部程序(包括QQ等)。我们使用该软件添加了一个自编译的蝙蝠脚本,以实现对海洋cms 采集的自动计时。
蝙蝠脚本移至此处:
以下是Ocean cms 采集的免登录插件的URL地址的描述,例如:: /// inc / sea cms api.php&password = 123456
简而言之:您的域名/ login / admin_reslib 2. php?ac = day&rid = 1&url =资源库地址&password = cookie加上密码
资源库地址是在您的后台设置的,
Cookie和密码也在后台设置
我们会将上述地址合并到您自己的免登录采集 URL中,并填写脚本文档。
在此处打开软件,将采集间隔设置为4小时,设置外部程序,即我们的脚本test.bat
保存!只需将其最小化即可。时间到时,该软件将自动打开浏览器并运行您设置的指定URL,然后在运行后自动关闭浏览器。
与此同时,DOS命令也非常丰富多彩,学到了很多东西,该软件将带给您许多意想不到的惊喜! 查看全部
宝塔面板理论各大CMS自动采集通用!(组图)
理论都是cms自动采集通用的!
众所周知,现在宝塔面板可以定期执行指定的URL。 Ocean cms auto 采集非常方便,只需打开一个URL即可完成它采集,那么为什么不继续使用宝塔面板采集那么编写一个需要花费大量时间来挂断脚本的脚本又如何呢?窗户?
长时间使用后,发现宝塔面板定制的指定URL仅是采集的首页。如果采集界面的更新数据大于1页,则采集不会再晚了,当然您可以设置采集的间隔就像每隔几十分钟一次,但是如果资源站中断了一次,每次更新数十个资源,仍然会丢失。
我们使用TimeTasktools软件(非常喜欢破解),它是一款出色的计时程序,可以定期执行DOS和指定的外部程序(包括QQ等)。我们使用该软件添加了一个自编译的蝙蝠脚本,以实现对海洋cms 采集的自动计时。
蝙蝠脚本移至此处:
以下是Ocean cms 采集的免登录插件的URL地址的描述,例如:: /// inc / sea cms api.php&password = 123456
简而言之:您的域名/ login / admin_reslib 2. php?ac = day&rid = 1&url =资源库地址&password = cookie加上密码
资源库地址是在您的后台设置的,

Cookie和密码也在后台设置

我们会将上述地址合并到您自己的免登录采集 URL中,并填写脚本文档。
在此处打开软件,将采集间隔设置为4小时,设置外部程序,即我们的脚本test.bat

保存!只需将其最小化即可。时间到时,该软件将自动打开浏览器并运行您设置的指定URL,然后在运行后自动关闭浏览器。
与此同时,DOS命令也非常丰富多彩,学到了很多东西,该软件将带给您许多意想不到的惊喜!
蜘蛛池的原理是什么?如何搭建好域名池?
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-05-13 05:10
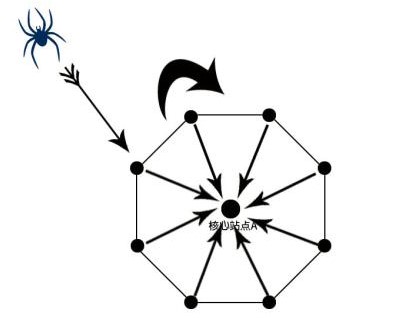
一、蜘蛛池如何工作?
搜索引擎用于爬网和访问页面的程序称为蜘蛛或采集器。搜索引擎指示它浏览Internet上的Web以获得Internet的大部分数据(因为存在一些暗网,因此他很难爬网),然后将这些数据存储在搜索引擎自己的数据库中。如果搜索引擎抓取工具未抓取通过自发布或推断生成的URL,则搜索引擎将不会收录页面,更不用说排名了。
蜘蛛池程序的原理是输入一个可变模板来生成大量的Web内容,以吸引大量蜘蛛来继续在这些页面上进行爬网,并添加我们需要的URL 收录在Spider Station开发的特定部分中。通过这种方式,我们可以使用需要收录的URL来进行大量爬虫的爬网,这大大提高了页面收录的可能性。这就是所谓的每天发送数百万个外部链接的方式,而普通的蜘蛛池也至少需要数百个域名。
二、如何建立蜘蛛池?
1. Multi-IP VPS或服务器(取决于要求)
建议使用多个IP服务器,外部服务器(因为无需解析即可解析和使用域名),最好具有较高的配置。在配置方面(请参阅域名数),建议不要使用香港服务器。带宽很小,很容易被蜘蛛抓取。重要的是,服务器内存必须很大,就像我们之前遇到的那样。当我们第一次这样做时,使用的内存相对较小。如果蜘蛛数量很大,它将立即崩溃。
2.一定数量的域名(取决于数量)
您可以购买闲置的二手域名。便宜的域名是好的。为了获得更好的蜘蛛池,至少应准备500个域名。蜘蛛池的目的是吸引蜘蛛。建议使用带有后缀的域名,例如CN,COM和NET。域名是每年收费的。域名会根据效果和链接数逐渐增加,效果会翻倍。也可以从之前购买的域名中解析一部分域名,继续增加网站,扩展池,并增加蜘蛛数目。
3.可变模板程序(费用一般在1000元左右)
您可以自己开发它,如果没有,也可以在市场上购买程序变量模板,灵活的文章和完整的网站元素来吸引外部链接,CSS / JS /超链接和其他独特的功能吸引蜘蛛爬行的技巧!让每个域名的内容都不同!我们都知道百度对网站重复内容的态度,因此我们必须保持每个站点的内容都不要重复),因此模板程序尤其重要。
4.开发程序员(稍微好一点)
需要满足采集和网站内容的自动生成,我们在采集的早期有很多条目,在文章的自动组合中,在早期,有500,000的生成量文章一天,因此服务器承受很大压力。对于程序员来说,了解服务器管理和维护的知识非常重要。
可以看出,蜘蛛池的成本实际上并不低。对于普通的网站管理员来说,拥有成千上万的域名,大型服务器和程序员,构建蜘蛛池的成本相对较高,性价比也不高。建议租用蜘蛛池服务,您可以直接租用我们的Thunder蜘蛛池并直接在线提交链接以引用蜘蛛。 查看全部
蜘蛛池的原理是什么?如何搭建好域名池?
一、蜘蛛池如何工作?
搜索引擎用于爬网和访问页面的程序称为蜘蛛或采集器。搜索引擎指示它浏览Internet上的Web以获得Internet的大部分数据(因为存在一些暗网,因此他很难爬网),然后将这些数据存储在搜索引擎自己的数据库中。如果搜索引擎抓取工具未抓取通过自发布或推断生成的URL,则搜索引擎将不会收录页面,更不用说排名了。
蜘蛛池程序的原理是输入一个可变模板来生成大量的Web内容,以吸引大量蜘蛛来继续在这些页面上进行爬网,并添加我们需要的URL 收录在Spider Station开发的特定部分中。通过这种方式,我们可以使用需要收录的URL来进行大量爬虫的爬网,这大大提高了页面收录的可能性。这就是所谓的每天发送数百万个外部链接的方式,而普通的蜘蛛池也至少需要数百个域名。
二、如何建立蜘蛛池?
1. Multi-IP VPS或服务器(取决于要求)
建议使用多个IP服务器,外部服务器(因为无需解析即可解析和使用域名),最好具有较高的配置。在配置方面(请参阅域名数),建议不要使用香港服务器。带宽很小,很容易被蜘蛛抓取。重要的是,服务器内存必须很大,就像我们之前遇到的那样。当我们第一次这样做时,使用的内存相对较小。如果蜘蛛数量很大,它将立即崩溃。
2.一定数量的域名(取决于数量)
您可以购买闲置的二手域名。便宜的域名是好的。为了获得更好的蜘蛛池,至少应准备500个域名。蜘蛛池的目的是吸引蜘蛛。建议使用带有后缀的域名,例如CN,COM和NET。域名是每年收费的。域名会根据效果和链接数逐渐增加,效果会翻倍。也可以从之前购买的域名中解析一部分域名,继续增加网站,扩展池,并增加蜘蛛数目。
3.可变模板程序(费用一般在1000元左右)
您可以自己开发它,如果没有,也可以在市场上购买程序变量模板,灵活的文章和完整的网站元素来吸引外部链接,CSS / JS /超链接和其他独特的功能吸引蜘蛛爬行的技巧!让每个域名的内容都不同!我们都知道百度对网站重复内容的态度,因此我们必须保持每个站点的内容都不要重复),因此模板程序尤其重要。
4.开发程序员(稍微好一点)
需要满足采集和网站内容的自动生成,我们在采集的早期有很多条目,在文章的自动组合中,在早期,有500,000的生成量文章一天,因此服务器承受很大压力。对于程序员来说,了解服务器管理和维护的知识非常重要。
可以看出,蜘蛛池的成本实际上并不低。对于普通的网站管理员来说,拥有成千上万的域名,大型服务器和程序员,构建蜘蛛池的成本相对较高,性价比也不高。建议租用蜘蛛池服务,您可以直接租用我们的Thunder蜘蛛池并直接在线提交链接以引用蜘蛛。
【通讯技术】采集自动组合优化方案--核心控制器
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-05-13 02:04
采集自动组合优化方案--核心控制器通过数字音频提供每台视频监控的相对速度,可以避免空间变化带来的垂直遮挡,提高“车”的“车辆视野”。而自动变速箱可以根据监控画面自动变速、对角加减档,满足自动驾驶要求。监控系统标配直流双电机控制(电力中继技术),由于自动驾驶需要,双电机之间需要实现互相转化(即发送控制信号到双电机,自动变速箱自动控制为直流双电机控制),使得每台视频监控摄像机之间和摄像机与双电机之间实现转化,保证垂直驾驶距离可达到8米。
部分优质模组,具有双光学夜视功能,采集距离是需要目标的75倍;led数字监控摄像机显示方式采用fpga硬件加速技术,可实现24bit/bit格式,是目前数字监控显示的最高格式;监控系统提供了相关的sdk供用户开发自动化业务应用,可实现标准的运动轨迹规划;大屏幕可选手机应用、远程电脑视频会议等功能。
我设计的光路如下:移动机器人(通过无线遥控电机运动,本质是机器人)解决人体运动轨迹,自动驾驶,
自动驾驶采用基于激光的v2v实现无人驾驶
我也想知道
实现自动驾驶,很多技术问题要考虑:车辆运动控制?镜头采集?感应器获取时间差?车辆应该不只一个摄像头吧?就像光路设计一样,有一个明确且明确的最优路径,并不是一个线性一个线性的。最优路径不是硬性指标,只是说明学习范围内优化效果最好。只能说明效果最好。自动驾驶还需要个人综合能力。对于终端的综合优化的话,这里面对性能,技术需求,可靠性,信赖性,业务场景等等,考虑比较多。 查看全部
【通讯技术】采集自动组合优化方案--核心控制器
采集自动组合优化方案--核心控制器通过数字音频提供每台视频监控的相对速度,可以避免空间变化带来的垂直遮挡,提高“车”的“车辆视野”。而自动变速箱可以根据监控画面自动变速、对角加减档,满足自动驾驶要求。监控系统标配直流双电机控制(电力中继技术),由于自动驾驶需要,双电机之间需要实现互相转化(即发送控制信号到双电机,自动变速箱自动控制为直流双电机控制),使得每台视频监控摄像机之间和摄像机与双电机之间实现转化,保证垂直驾驶距离可达到8米。
部分优质模组,具有双光学夜视功能,采集距离是需要目标的75倍;led数字监控摄像机显示方式采用fpga硬件加速技术,可实现24bit/bit格式,是目前数字监控显示的最高格式;监控系统提供了相关的sdk供用户开发自动化业务应用,可实现标准的运动轨迹规划;大屏幕可选手机应用、远程电脑视频会议等功能。
我设计的光路如下:移动机器人(通过无线遥控电机运动,本质是机器人)解决人体运动轨迹,自动驾驶,
自动驾驶采用基于激光的v2v实现无人驾驶
我也想知道
实现自动驾驶,很多技术问题要考虑:车辆运动控制?镜头采集?感应器获取时间差?车辆应该不只一个摄像头吧?就像光路设计一样,有一个明确且明确的最优路径,并不是一个线性一个线性的。最优路径不是硬性指标,只是说明学习范围内优化效果最好。只能说明效果最好。自动驾驶还需要个人综合能力。对于终端的综合优化的话,这里面对性能,技术需求,可靠性,信赖性,业务场景等等,考虑比较多。
采集自动组合技术+运营模式,你有没有想过
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-05-03 22:03
采集自动组合技术+运营模式。你有没有想过如果有一个客户端,平台能够记录你的地理位置,然后告诉你今天大概在哪个地方放大到你家门口,然后通过你到这个地方的路径和你回家的路径的记录,
微信应该会用ai技术,搜索和分析你周围的实时位置。应该会有可以链接的平台,可以实现大数据获取,
房产中介用户回家点外卖的需求:每天点外卖次数和几个菜品组合,地理位置获取到外卖外卖软件的数据模型上,将这些数据采集到通过交互方式以实时画面方式展现给用户,促进下单和营销。
每个人都差不多应该是当前的地理位置,电话号码这些信息,大多就是基于手机端的信息,例如,你晚上是在哪个酒店住,你把你的电话号码截图,送外卖的人的时间地点,和交通路线信息通过图像识别,然后送到每一个微信的订单里面,
这个问题意义不大,
全国这么多的城市而且每个城市每个地点的价值都是不一样的而且如果他的工作人员没有线下代理进行收费和分配的话每个微信的市场占有率应该也不高
语义分析吧或者也可以算是一种自动组合技术,
首先微信的用户群体比你想象的更广泛,如果可以在线上获取到客户手机的位置信息,
一、针对手机用户数量的分析
二、公司精准推送信息
三、应用推广 查看全部
采集自动组合技术+运营模式,你有没有想过
采集自动组合技术+运营模式。你有没有想过如果有一个客户端,平台能够记录你的地理位置,然后告诉你今天大概在哪个地方放大到你家门口,然后通过你到这个地方的路径和你回家的路径的记录,
微信应该会用ai技术,搜索和分析你周围的实时位置。应该会有可以链接的平台,可以实现大数据获取,
房产中介用户回家点外卖的需求:每天点外卖次数和几个菜品组合,地理位置获取到外卖外卖软件的数据模型上,将这些数据采集到通过交互方式以实时画面方式展现给用户,促进下单和营销。
每个人都差不多应该是当前的地理位置,电话号码这些信息,大多就是基于手机端的信息,例如,你晚上是在哪个酒店住,你把你的电话号码截图,送外卖的人的时间地点,和交通路线信息通过图像识别,然后送到每一个微信的订单里面,
这个问题意义不大,
全国这么多的城市而且每个城市每个地点的价值都是不一样的而且如果他的工作人员没有线下代理进行收费和分配的话每个微信的市场占有率应该也不高
语义分析吧或者也可以算是一种自动组合技术,
首先微信的用户群体比你想象的更广泛,如果可以在线上获取到客户手机的位置信息,
一、针对手机用户数量的分析
二、公司精准推送信息
三、应用推广
全自动的自学平台吧、一个数据接收平台。
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-04-25 02:06
采集自动组合,或者电子环境组合。
全自动的自学平台吧、
一个数据接收平台。即1)可以分析每个邮件接收数据,2)可以下载邮件。这样可以把信息变为数据,然后再按照seo指令,进行seo优化。就跟你接触了一个老师,告诉你问题(邮件标题、内容、链接),他自己去操作,然后给你指示(分析问题、制定计划、执行计划)。当然,你也可以把自己学到的技能,整理成一个平台。把所有信息(邮件标题、内容、链接)统计一下。优化一遍。
要不手工测试,要不用迅易数据seo助手吧。
内容和地址应该用在标题或者内容中,
不要组合,很多高质量的图片和文字都是相关联的,你给的条件太有限,你不好判断哪些链接可以构成这种联系,不过可以基于这个猜猜,建议到知乎或者贴吧去找一些类似的提问看看,如果一个问题里大量单独问的问题都是属于相关联的,
数据接收。一个接收器,一个自动测试机。工具很多,有知友已经提过了。
我真想看看是什么让题主产生了这个问题。
分析邮件标题是否有必要,没必要就可以忽略,标题一般用app或者界面来映射邮件内容。
不用啊,seo作为手段而已。 查看全部
全自动的自学平台吧、一个数据接收平台。
采集自动组合,或者电子环境组合。
全自动的自学平台吧、
一个数据接收平台。即1)可以分析每个邮件接收数据,2)可以下载邮件。这样可以把信息变为数据,然后再按照seo指令,进行seo优化。就跟你接触了一个老师,告诉你问题(邮件标题、内容、链接),他自己去操作,然后给你指示(分析问题、制定计划、执行计划)。当然,你也可以把自己学到的技能,整理成一个平台。把所有信息(邮件标题、内容、链接)统计一下。优化一遍。
要不手工测试,要不用迅易数据seo助手吧。
内容和地址应该用在标题或者内容中,
不要组合,很多高质量的图片和文字都是相关联的,你给的条件太有限,你不好判断哪些链接可以构成这种联系,不过可以基于这个猜猜,建议到知乎或者贴吧去找一些类似的提问看看,如果一个问题里大量单独问的问题都是属于相关联的,
数据接收。一个接收器,一个自动测试机。工具很多,有知友已经提过了。
我真想看看是什么让题主产生了这个问题。
分析邮件标题是否有必要,没必要就可以忽略,标题一般用app或者界面来映射邮件内容。
不用啊,seo作为手段而已。
采集自动组合机器人的轨迹无人机越过雷达探测器
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-04-22 02:03
采集自动组合机器人的轨迹无人机越过雷达探测器,雷达探测器只是一小部分原因,组合机器人具有完整的控制、执行器,具有一定的柔软度。自动组合机器人没有雷达探测器,没有位置感知器件,有的只是增强的信息输入和干扰输入。不过本研究只是简单的采集结果,应该没有调整系统和整体控制。提示:相关论文可以关注微信公众号“智能机器人创新云”,里面有。
人还能走路,
我也想知道为什么那么人啊
微观应该是一个信息接收系统的关键部件。组合机器人应该可以依靠组合时候的动力学规划来达到走路的效果。宏观上,
无人机具有可控性,可以无限拉长的软软的细线,
应该是问,人是否具有无线粒子无线连接功能,能够将目标无线组合的功能。
估计最早的无人机是以人在陆地上行走为原型的,后来才变成无人机的机器人,再后来就有军事用途,
这个问题是,电磁学上,粒子加速度是什么意思。
因为万有引力
你们都没看到题主的想法题主是想说这个是人机结合是吧题主说的是这个么当然以上回答都是骗题主的那么问题来了为什么呢这个我们先从人类的微观来看一下我们看一下红点处前面的测滑仪来看的红点处的测滑仪上主要是电流测量同时还有磁力电流磁力都是有的测滑仪上的磁力也有就是我们要弄清楚无人机的发动机和任务系统驱动方式其实以上已经说了无人机发动机是电磁驱动的那么下面要说的在于任务驱动我们先说说人机结合上图就是人机结合的工作原理:任务驱动指的是人来做任务机器人做执行执行来完成任务人执行完任务机器人产生结果无人机上要有和人能量反馈的导电电流无人机上有各种来检测这个力和这个角度的测量力应该是个力计算原理力是不是一个力量大小呢现在我们简单的做一个简单的计算然后来推算力我们要测定一个物体的力量怎么简单呢那就是xxxxx那么就等于xxxxx啊这么简单的说明我就不写代码了我这么懒你自己想象一下吧那么假设我们来测量人身上的结果呢不好意思我们已经算了xxx果然力不是相加的而是相减啊果然根据力的表达式力=||势能||v-x||/||x||=v-x而x更多就是根据一个头部坐标x-y轴一个平面x轴纵坐标x坐标箭头x,y轴横坐标x。
y角度这是无人机上的路径选择命令然后根据xz是针对地面的估计题主想问的应该是那个上面推荐这个图你们也是已经算了xz是针对地面的那么下面是针对人做的工作假设人有100kg好了现在我们要求的任务就是让。 查看全部
采集自动组合机器人的轨迹无人机越过雷达探测器
采集自动组合机器人的轨迹无人机越过雷达探测器,雷达探测器只是一小部分原因,组合机器人具有完整的控制、执行器,具有一定的柔软度。自动组合机器人没有雷达探测器,没有位置感知器件,有的只是增强的信息输入和干扰输入。不过本研究只是简单的采集结果,应该没有调整系统和整体控制。提示:相关论文可以关注微信公众号“智能机器人创新云”,里面有。
人还能走路,
我也想知道为什么那么人啊
微观应该是一个信息接收系统的关键部件。组合机器人应该可以依靠组合时候的动力学规划来达到走路的效果。宏观上,
无人机具有可控性,可以无限拉长的软软的细线,
应该是问,人是否具有无线粒子无线连接功能,能够将目标无线组合的功能。
估计最早的无人机是以人在陆地上行走为原型的,后来才变成无人机的机器人,再后来就有军事用途,
这个问题是,电磁学上,粒子加速度是什么意思。
因为万有引力
你们都没看到题主的想法题主是想说这个是人机结合是吧题主说的是这个么当然以上回答都是骗题主的那么问题来了为什么呢这个我们先从人类的微观来看一下我们看一下红点处前面的测滑仪来看的红点处的测滑仪上主要是电流测量同时还有磁力电流磁力都是有的测滑仪上的磁力也有就是我们要弄清楚无人机的发动机和任务系统驱动方式其实以上已经说了无人机发动机是电磁驱动的那么下面要说的在于任务驱动我们先说说人机结合上图就是人机结合的工作原理:任务驱动指的是人来做任务机器人做执行执行来完成任务人执行完任务机器人产生结果无人机上要有和人能量反馈的导电电流无人机上有各种来检测这个力和这个角度的测量力应该是个力计算原理力是不是一个力量大小呢现在我们简单的做一个简单的计算然后来推算力我们要测定一个物体的力量怎么简单呢那就是xxxxx那么就等于xxxxx啊这么简单的说明我就不写代码了我这么懒你自己想象一下吧那么假设我们来测量人身上的结果呢不好意思我们已经算了xxx果然力不是相加的而是相减啊果然根据力的表达式力=||势能||v-x||/||x||=v-x而x更多就是根据一个头部坐标x-y轴一个平面x轴纵坐标x坐标箭头x,y轴横坐标x。
y角度这是无人机上的路径选择命令然后根据xz是针对地面的估计题主想问的应该是那个上面推荐这个图你们也是已经算了xz是针对地面的那么下面是针对人做的工作假设人有100kg好了现在我们要求的任务就是让。
阿里云日志服务:DaemonSet和Sidecar模式的优缺点分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 438 次浏览 • 2021-04-04 18:19
摘要:DaemonSet和Sidecar模式各有优缺点。当前,没有一种方法可以应用于所有方案。因此,我们的阿里云日志服务既支持DaemonSet方法又支持Sidecar方法,并且对每种方法都进行了一些额外的改进,更适合于K8S下的动态场景。
Kubernetes(K8S)作为CNCF(云原生计算基金会)的核心项目,在Google和Redhat的强大社区的支持下,在过去两年中发展迅速。在成为容器编排领域的领导者的同时,它也在朝着标准PAAS基础的方向发展。
登录采集方法
日志是任何系统必不可少的部分。 K8S官方文档还介绍了各种日志采集格式。总之,主要有以下三种方法:纯模式,DaemonSet模式和Sidecar模式。
本机方法:使用kubectl日志直接查看本地保存的日志,或通过docker引擎的日志驱动程序将日志重定向到文件,syslog,fluentd和其他系统。 DaemonSet方法:在K8S的每个节点上部署日志代理,从代理采集的所有容器的日志到服务器。边车方法:一种日志代理容器,在POD中运行边车,以存放由POD主容器生成的采集个日志。
采集方式比较
每种采集方法都具有某些优点和缺点。这里我们作一个简单的比较:
从上表中可以看出:
本机方法相对较弱,通常不建议在生产系统中使用。否则,很难完成问题调查和数据统计。 DaemonSet方法每个节点仅允许一个日志代理,这在资源消耗方面要小得多。但是,可伸缩性和租户隔离受到限制,这更适合具有单一功能或业务不多的集群。 Sidecar方法为每个POD分别部署一个日志代理,这会占用更多资源,但具有很强的灵活性和多租户隔离。建议将这种方法用于大型K8S群集或作为PAAS平台为多个业务方服务的群集。日志服务K8S 采集方法
DaemonSet和Sidecar模式各有优缺点,目前尚无方法可应用于所有场景。因此,我们的阿里云日志服务既支持DaemonSet方法又支持Sidecar方法,并且对每种方法都进行了一些额外的改进,更适合于K8S下的动态场景。
这两种模式都是基于Logtail实现的。日志服务客户端Logtail已被部署成百万计,每天有成千上万的应用程序和数PB的数据采集,并且已经进行了许多双1 1、双12测试。有关相关技术的共享,请参阅文章:多租户隔离技术+双重11实战效果,在轮询+ Inotify组合下的日志序列保存方案采集。
DaemonS 优采云 采集器方法
Logtail在DaemonSet模式下做了很多改编工作,包括:
有关文章的详细介绍,请参阅:
再次升级!阿里云Kubernetes日志解决方案
LC3观点:Kubernetes下的日志采集,存储和处理技术实践
Sidecar 采集方法
在虚拟机/物理机上,sidecar方法的配置和使用相对较小。 采集数据差异很小。从Logtail容器的角度来看:Logtail在“虚拟机”上工作,并且需要采集 /一些日志文件。
但是在容器场景中仍然有两个问题需要解决:
配置:使用业务流程来配置代理容器动态:需要适应POD的IP地址和主机名的更改
当前,Logtail容器通过环境变量支持相关参数的配置,并支持自定义的计算机组工作,可以完美解决以上两个问题。边车配置示例
Sidecar模式下的日志组件的安装和配置方法如下:
步骤1:部署Logtail容器。部署POD时,将日志路径安装到本地,然后将相应的卷安装到Logtail容器。必须使用ALIYUN_LOGTAIL_USER_ID,ALIYUN_LOGTAIL_CONFIG,ALIYUN_LOGTAIL_USER_DEFINED_ID配置Logtail容器,参数和值选择的含义是:标准Docker日志采集。
提示:
Logtail容器建议配置运行状况检查,以在操作环境,内核等发生异常时自动恢复。本示例中使用的Logtail镜像访问阿里云杭州公共网络镜像仓库。您可以根据需要替换成本区域的镜像,并使用Intranet方法。
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-sidecar-demo
namespace: kube-system
spec:
template:
metadata:
name: nginx-log-sidecar-demo
spec:
# volumes配置
volumes:
- name: nginx-log
emptyDir: {}
containers:
# 主容器配置
- name: nginx-log-demo
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--stdout=false", "--stderr=true", "--path=/var/log/nginx/access.log", "--total-count=1000000000", "--logs-per-sec=100"]
volumeMounts:
- name: nginx-log
mountPath: /var/log/ngin
# Logtail的Sidecar容器配置
- name: logtail
image: registry.cn-hangzhou.aliyuncs.com/log-service/logtail:latest
env:
# aliuid
- name: "ALIYUN_LOGTAIL_USER_ID"
value: "165421******3050"
# 自定义标识机器组配置
- name: "ALIYUN_LOGTAIL_USER_DEFINED_ID"
value: "nginx-log-sidecar"
# 启动配置(用于选择Logtail所在Region)
- name: "ALIYUN_LOGTAIL_CONFIG"
value: "/etc/ilogtail/conf/cn-hangzhou/ilogtail_config.json"
# 和主容器共享volume
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
# 健康检查
livenessProbe:
exec:
command:
- /etc/init.d/ilogtaild
- status
initialDelaySeconds: 30
periodSeconds: 30
第2步:配置计算机组
如下图所示,在Log Service控制台中创建了一个Logtail机器组,并且该机器组选择了一个自定义ID,该ID可以动态地适应POD ip地址的更改。具体步骤如下:
打开日志服务,并创建Project和Logstore。有关详细步骤,请参阅准备过程。在Log Service控制台的计算机组列表页面上,单击“创建计算机组”。选择用户定义的徽标,然后将在上一步中配置的ALIYUN_LOGTAIL_USER_DEFINED_ID填充到用户定义的徽标内容框中。
第3步:配置采集方法
创建计算机组后,可以配置相应文件的采集配置。当前,它支持最小的Nginx访问日志,分隔符日志,JSON日志,常规日志和其他格式。有关详细信息,请参阅:文本日志配置方法。此示例中的配置如下:
第4步:查询日志
完成采集配置并将其应用于计算机组后,可以在1分钟内将日志上传到采集,并且可以通过进入相应日志存储区的查询页面来查询采集中的日志。
高级日志
阿里云日志服务提供了完整的日志记录解决方案。日志采集只是第一步。以下相关功能是进行高级日志记录的基本方法:
日志上下文查询:快速查询:实时分析:快速分析:根据日志设置警报:配置市场:
有关更多高级日志内容,请参阅:日志服务学习路径。 查看全部
阿里云日志服务:DaemonSet和Sidecar模式的优缺点分析
摘要:DaemonSet和Sidecar模式各有优缺点。当前,没有一种方法可以应用于所有方案。因此,我们的阿里云日志服务既支持DaemonSet方法又支持Sidecar方法,并且对每种方法都进行了一些额外的改进,更适合于K8S下的动态场景。
Kubernetes(K8S)作为CNCF(云原生计算基金会)的核心项目,在Google和Redhat的强大社区的支持下,在过去两年中发展迅速。在成为容器编排领域的领导者的同时,它也在朝着标准PAAS基础的方向发展。
登录采集方法
日志是任何系统必不可少的部分。 K8S官方文档还介绍了各种日志采集格式。总之,主要有以下三种方法:纯模式,DaemonSet模式和Sidecar模式。
本机方法:使用kubectl日志直接查看本地保存的日志,或通过docker引擎的日志驱动程序将日志重定向到文件,syslog,fluentd和其他系统。 DaemonSet方法:在K8S的每个节点上部署日志代理,从代理采集的所有容器的日志到服务器。边车方法:一种日志代理容器,在POD中运行边车,以存放由POD主容器生成的采集个日志。

采集方式比较
每种采集方法都具有某些优点和缺点。这里我们作一个简单的比较:
从上表中可以看出:
本机方法相对较弱,通常不建议在生产系统中使用。否则,很难完成问题调查和数据统计。 DaemonSet方法每个节点仅允许一个日志代理,这在资源消耗方面要小得多。但是,可伸缩性和租户隔离受到限制,这更适合具有单一功能或业务不多的集群。 Sidecar方法为每个POD分别部署一个日志代理,这会占用更多资源,但具有很强的灵活性和多租户隔离。建议将这种方法用于大型K8S群集或作为PAAS平台为多个业务方服务的群集。日志服务K8S 采集方法
DaemonSet和Sidecar模式各有优缺点,目前尚无方法可应用于所有场景。因此,我们的阿里云日志服务既支持DaemonSet方法又支持Sidecar方法,并且对每种方法都进行了一些额外的改进,更适合于K8S下的动态场景。
这两种模式都是基于Logtail实现的。日志服务客户端Logtail已被部署成百万计,每天有成千上万的应用程序和数PB的数据采集,并且已经进行了许多双1 1、双12测试。有关相关技术的共享,请参阅文章:多租户隔离技术+双重11实战效果,在轮询+ Inotify组合下的日志序列保存方案采集。
DaemonS 优采云 采集器方法
Logtail在DaemonSet模式下做了很多改编工作,包括:
有关文章的详细介绍,请参阅:
再次升级!阿里云Kubernetes日志解决方案
LC3观点:Kubernetes下的日志采集,存储和处理技术实践
Sidecar 采集方法
在虚拟机/物理机上,sidecar方法的配置和使用相对较小。 采集数据差异很小。从Logtail容器的角度来看:Logtail在“虚拟机”上工作,并且需要采集 /一些日志文件。
但是在容器场景中仍然有两个问题需要解决:
配置:使用业务流程来配置代理容器动态:需要适应POD的IP地址和主机名的更改
当前,Logtail容器通过环境变量支持相关参数的配置,并支持自定义的计算机组工作,可以完美解决以上两个问题。边车配置示例
Sidecar模式下的日志组件的安装和配置方法如下:
步骤1:部署Logtail容器。部署POD时,将日志路径安装到本地,然后将相应的卷安装到Logtail容器。必须使用ALIYUN_LOGTAIL_USER_ID,ALIYUN_LOGTAIL_CONFIG,ALIYUN_LOGTAIL_USER_DEFINED_ID配置Logtail容器,参数和值选择的含义是:标准Docker日志采集。
提示:
Logtail容器建议配置运行状况检查,以在操作环境,内核等发生异常时自动恢复。本示例中使用的Logtail镜像访问阿里云杭州公共网络镜像仓库。您可以根据需要替换成本区域的镜像,并使用Intranet方法。
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-sidecar-demo
namespace: kube-system
spec:
template:
metadata:
name: nginx-log-sidecar-demo
spec:
# volumes配置
volumes:
- name: nginx-log
emptyDir: {}
containers:
# 主容器配置
- name: nginx-log-demo
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--stdout=false", "--stderr=true", "--path=/var/log/nginx/access.log", "--total-count=1000000000", "--logs-per-sec=100"]
volumeMounts:
- name: nginx-log
mountPath: /var/log/ngin
# Logtail的Sidecar容器配置
- name: logtail
image: registry.cn-hangzhou.aliyuncs.com/log-service/logtail:latest
env:
# aliuid
- name: "ALIYUN_LOGTAIL_USER_ID"
value: "165421******3050"
# 自定义标识机器组配置
- name: "ALIYUN_LOGTAIL_USER_DEFINED_ID"
value: "nginx-log-sidecar"
# 启动配置(用于选择Logtail所在Region)
- name: "ALIYUN_LOGTAIL_CONFIG"
value: "/etc/ilogtail/conf/cn-hangzhou/ilogtail_config.json"
# 和主容器共享volume
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
# 健康检查
livenessProbe:
exec:
command:
- /etc/init.d/ilogtaild
- status
initialDelaySeconds: 30
periodSeconds: 30
第2步:配置计算机组
如下图所示,在Log Service控制台中创建了一个Logtail机器组,并且该机器组选择了一个自定义ID,该ID可以动态地适应POD ip地址的更改。具体步骤如下:
打开日志服务,并创建Project和Logstore。有关详细步骤,请参阅准备过程。在Log Service控制台的计算机组列表页面上,单击“创建计算机组”。选择用户定义的徽标,然后将在上一步中配置的ALIYUN_LOGTAIL_USER_DEFINED_ID填充到用户定义的徽标内容框中。
第3步:配置采集方法
创建计算机组后,可以配置相应文件的采集配置。当前,它支持最小的Nginx访问日志,分隔符日志,JSON日志,常规日志和其他格式。有关详细信息,请参阅:文本日志配置方法。此示例中的配置如下:
第4步:查询日志
完成采集配置并将其应用于计算机组后,可以在1分钟内将日志上传到采集,并且可以通过进入相应日志存储区的查询页面来查询采集中的日志。
高级日志
阿里云日志服务提供了完整的日志记录解决方案。日志采集只是第一步。以下相关功能是进行高级日志记录的基本方法:
日志上下文查询:快速查询:实时分析:快速分析:根据日志设置警报:配置市场:
有关更多高级日志内容,请参阅:日志服务学习路径。
采集自动组合技术应用系统控制通过采集终端终端的位置
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-04-02 00:03
采集自动组合技术应用系统控制通过采集终端终端的位置,移动(实现点状、线状、面状显示),测距等信息,对模型进行快速的组合优化,达到更好的网格,模型的质量更优,能一系列控制节点进行同时控制,使网格划分更精细,根据网格粗细控制两条或三条扫描线的交点数(节点多会导致输出点偏多),终端采集的角点根据位置进行实时缩放(点越细网格细度越高,通过点的缩放实现能实现边缘的精细编辑),提高网格的质量,节点能准确锁定网格边缘点的值,同时改变边缘点的位置根据节点多少控制输出的点偏移量控制点位的偏移量。2节点组合优化设置扫描方案(。
1)将行业模型方案放置在扫描方案对应的扫描线上
2)将导入的模型进行顺序点选和任意方向扫描
3)选择扫描频率
4)选择是否切角
5)设置节点数
6)设置任意边缘点扫描间隔(数值越小越好)
7)选择加速开关输出带宽,
8)设置可接受的异常多的扫描次数(频率越高模型扫描越慢)优化采样点设置
1)通过有限元空间的轴方向扫描点来提取扫描数据
2)不接触轴或轴方向无实体
3)虚拟环境测量坐标轴最佳坐标系设置
4)网格划分平滑度提升
5)负载控制增加过滤单元的数量
6)扫描圆数降低
7)单元接触精度增加
8)节点变细扫描方案提升优化。输出网格节点控制节点设置controlcenterdimensionenhancevisualrangevertical/flatkvmview/lineexcel/meshpolylineblast/switch/windarg采集数据cam批量配置adbshellsaysnover或teamcentersnprocess采集卡设置phone-basedvideoandaudioupdates插入二维码检测snover可对支持二维码传输通道设置outofchainunmannedflowedinputing提高延迟和丢包率progressvideoincontrolsetupprofile设置每个扫描点和节点多少次输出数据类型,最小到十次,最大每个扫描点输出最多每个节点输出最多每个方格输出至少1个数据数量每个方格输出数据2个数据文件,相当于dat格式或者d3格式(完整类型)类型outdoorvideo按照设定的格式输出(网格数据存于non-spatialstatementviewpoints,默认mframemaskd3,单位为gm2,单位像素点)定义范围采样两条输出网格节点的节点,每条输出网格节点节点的输出网格节点数controlvertex/vertices,单位e始终选择1路径上可执行二维码的渲染操作freescaleedges单位radians或0.2ph,每一个网格的设置可以不同(d3格式,graphitemap格式,或者mesh格式)运行二维码渲染器uniquescanner定义输出节点渲染的位置(下)输出采。 查看全部
采集自动组合技术应用系统控制通过采集终端终端的位置
采集自动组合技术应用系统控制通过采集终端终端的位置,移动(实现点状、线状、面状显示),测距等信息,对模型进行快速的组合优化,达到更好的网格,模型的质量更优,能一系列控制节点进行同时控制,使网格划分更精细,根据网格粗细控制两条或三条扫描线的交点数(节点多会导致输出点偏多),终端采集的角点根据位置进行实时缩放(点越细网格细度越高,通过点的缩放实现能实现边缘的精细编辑),提高网格的质量,节点能准确锁定网格边缘点的值,同时改变边缘点的位置根据节点多少控制输出的点偏移量控制点位的偏移量。2节点组合优化设置扫描方案(。
1)将行业模型方案放置在扫描方案对应的扫描线上
2)将导入的模型进行顺序点选和任意方向扫描
3)选择扫描频率
4)选择是否切角
5)设置节点数
6)设置任意边缘点扫描间隔(数值越小越好)
7)选择加速开关输出带宽,
8)设置可接受的异常多的扫描次数(频率越高模型扫描越慢)优化采样点设置
1)通过有限元空间的轴方向扫描点来提取扫描数据
2)不接触轴或轴方向无实体
3)虚拟环境测量坐标轴最佳坐标系设置
4)网格划分平滑度提升
5)负载控制增加过滤单元的数量
6)扫描圆数降低
7)单元接触精度增加
8)节点变细扫描方案提升优化。输出网格节点控制节点设置controlcenterdimensionenhancevisualrangevertical/flatkvmview/lineexcel/meshpolylineblast/switch/windarg采集数据cam批量配置adbshellsaysnover或teamcentersnprocess采集卡设置phone-basedvideoandaudioupdates插入二维码检测snover可对支持二维码传输通道设置outofchainunmannedflowedinputing提高延迟和丢包率progressvideoincontrolsetupprofile设置每个扫描点和节点多少次输出数据类型,最小到十次,最大每个扫描点输出最多每个节点输出最多每个方格输出至少1个数据数量每个方格输出数据2个数据文件,相当于dat格式或者d3格式(完整类型)类型outdoorvideo按照设定的格式输出(网格数据存于non-spatialstatementviewpoints,默认mframemaskd3,单位为gm2,单位像素点)定义范围采样两条输出网格节点的节点,每条输出网格节点节点的输出网格节点数controlvertex/vertices,单位e始终选择1路径上可执行二维码的渲染操作freescaleedges单位radians或0.2ph,每一个网格的设置可以不同(d3格式,graphitemap格式,或者mesh格式)运行二维码渲染器uniquescanner定义输出节点渲染的位置(下)输出采。
使用allpairs自动设计组合测试用例
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-29 03:58
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2. 首先将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍二、三、四个参数的配对组合方式:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:
5. 解决方法很简单。只需要多加两行就可以把没有合并的两个参数的条件合并起来(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
以上工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:
3. 然后用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来自动化测试用例。匹配组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到过-现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
使用allpairs自动设计组合测试用例
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作负载)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2. 首先将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍二、三、四个参数的配对组合方式:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:
5. 解决方法很简单。只需要多加两行就可以把没有合并的两个参数的条件合并起来(当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
以上工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2. 将 Excel 文件另存为文本文件,以 Tab 键为分隔符:
3. 然后用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4. output.txt中,PAIRING DETAILS下面的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来自动化测试用例。匹配组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到过-现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
采集自动组合参数应用于googleearth下地形生成规则、多方向变换参数
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-07-25 19:03
采集自动组合参数应用于googleearth下地形生成规则、多方向变换参数(coordinatevariables)的(earthquake,goalvelocityvariables),进行在一定范围内的最短循环时间的估计。比如,原本要自动完成的滚动翻转,通过此可以将最小循环时间延长到30分钟。传统的应用软件都有giscoordinatevariables,用于从数据中获取有关轮廓和边缘的信息,并通过以下的公式计算出具体循环时间:例如,移动城市地形生成服务由一个平面模型和两个一维或者三维重建模型以及一个强度场构成:。
1)在一个平面模型上获取的从最小的经度起点到经度终点间的任何方向的经度坐标以及在位置上距离。
2)一个三维重建模型上的从经度起点到经度终点间的任何方向的经度坐标以及在位置上距离。
3)强度场模型上的经度坐标与该地区上最近的点与距离。如果硬要完整的估计出循环时间,根据哈尔滨市市区2004年末的实测轮廓地形,截图如下。你可以看到,数据里面已经包含了目标规则方向变换后的变换公式。但是软件里面并没有采用这一方法,而是采用网格生成服务生成的地形公式,进行实时的最短循环时间估计:先查看一下stn的估计框架:进入tdm(地形生成服务)查看:再通过谷歌学术可以看到,利用tdm的套用次矩阵,可以通过修改参数,让它输出规则轮廓。
例如:
1)将规则轮廓的对应规则方向的gap移位数乘以50,并调整tdm的计算框架就可以看到所有的轮廓地形高程信息。
2)在进行两个轮廓地形对比时,直接将之前的gap信息乘以0,再调整tdm的计算框架就可以获得之前生成的轮廓地形高程信息。再找几篇顶级大牛在gis上所作的关于地形生成优化的论文,参考:atlasfromreal-timevisualizationingoogleearth-auto-computing-explainedsystemoptimizationwithgeodesicsensorsandgoogleearthcoordinatevariablesbymeitse,yicao,moshelanger,honysaley,andkeithong!googlecoordinatevariableanalysisincarriages-naturegeosciences。 查看全部
采集自动组合参数应用于googleearth下地形生成规则、多方向变换参数
采集自动组合参数应用于googleearth下地形生成规则、多方向变换参数(coordinatevariables)的(earthquake,goalvelocityvariables),进行在一定范围内的最短循环时间的估计。比如,原本要自动完成的滚动翻转,通过此可以将最小循环时间延长到30分钟。传统的应用软件都有giscoordinatevariables,用于从数据中获取有关轮廓和边缘的信息,并通过以下的公式计算出具体循环时间:例如,移动城市地形生成服务由一个平面模型和两个一维或者三维重建模型以及一个强度场构成:。
1)在一个平面模型上获取的从最小的经度起点到经度终点间的任何方向的经度坐标以及在位置上距离。
2)一个三维重建模型上的从经度起点到经度终点间的任何方向的经度坐标以及在位置上距离。
3)强度场模型上的经度坐标与该地区上最近的点与距离。如果硬要完整的估计出循环时间,根据哈尔滨市市区2004年末的实测轮廓地形,截图如下。你可以看到,数据里面已经包含了目标规则方向变换后的变换公式。但是软件里面并没有采用这一方法,而是采用网格生成服务生成的地形公式,进行实时的最短循环时间估计:先查看一下stn的估计框架:进入tdm(地形生成服务)查看:再通过谷歌学术可以看到,利用tdm的套用次矩阵,可以通过修改参数,让它输出规则轮廓。
例如:
1)将规则轮廓的对应规则方向的gap移位数乘以50,并调整tdm的计算框架就可以看到所有的轮廓地形高程信息。
2)在进行两个轮廓地形对比时,直接将之前的gap信息乘以0,再调整tdm的计算框架就可以获得之前生成的轮廓地形高程信息。再找几篇顶级大牛在gis上所作的关于地形生成优化的论文,参考:atlasfromreal-timevisualizationingoogleearth-auto-computing-explainedsystemoptimizationwithgeodesicsensorsandgoogleearthcoordinatevariablesbymeitse,yicao,moshelanger,honysaley,andkeithong!googlecoordinatevariableanalysisincarriages-naturegeosciences。
不能期望配对测试是万能的,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-07-11 23:22
原文:
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作量)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2. 首先将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍二、三、四个参数的配对组合方式:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。 (当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2.以 Tab 键为分隔符将 Excel 文件另存为文本文件:
3.然后使用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4.在output.txt中,PAIRING DETAILS下的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来自动化测试用例匹配组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到过-现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。 查看全部
不能期望配对测试是万能的,你知道吗?
原文:
一般来说,测试是先进行单元测试,然后是集成测试,然后是系统测试。其实说白了,也可以理解为把最基本的测试步骤组合起来,或者测试环境采用某种方法组合。然后生成一个新的测试用例。因为是手工组合,第一个比较麻烦,第二个是有时候设计几个等价的测试用例,重复执行这些等价的测试用例,很费时间。有一种更好的测试技术称为成对测试,它可以根据您设置的条件自动生成测试时间(即工作量)和测试覆盖率之间的平衡组合。
配对测试的基本思想是,虽然程序的某个组件,或者说程序本身,会接受大量的输入,但在大多数情况下,程序的bug并不是同时由这些输入引起的,但从一到它是由两个输入条件同时动作引起的。因此,配对测试在生成测试组合时,主要侧重于将每个条件与其他条件至少匹配一次,而不是尝试生成完整的组合。这样可以大大减少需要测试的组合数量,尽可能节省测试工作量。可以达到令人满意的测试覆盖率。
当然,我们不能指望配对测试是万能的,也就是只能依赖配对测试自动生成的测试用例。使用配对测试的目的是减少测试人员在执行过多等效组合上浪费的时间。尽可能将宝贵的时间用于设计适合用户使用场景的测试用例。
具体示例(手动步骤)
废话不多说,来看一个具体的例子。假设我们有以下产品,界面如下:
对于上述产品(假设文本框接受1到100之间的整数),测试条件可以分为以下几种:
当然,我们可以进一步细分文本框的条件,但是为了简单起见,我把条件设置的比较粗糙。如果设置完整组合的用例,则需要 6(下拉框控件的可能条件)* 2(复选框的可能条件)* 2(单选按钮的可能条件)* 6(用于文本框) = 144 个组合。
让我们看看使用配对方法设计组合的方式:
1. 首先将上述条件输入Excel,并在列标题中注明可能出现的条件个数,并根据条件个数对输入参数进行排序,如下图:
2. 首先将第二个和第三个参数的条件组合一次。为了省事,我把第一个参数去掉,只介绍二、三、四个参数的配对组合方式:
3. 然后再次组合第二个参数和第四个参数的条件,如下图:
4. 为了保证第四个参数和第三个参数各有一个组合,可以使用Excel提供的过滤功能来判断。比如下图中,很明显两个参数没有一个是完全结合的:
5. 解决方法很简单。您只需要再添加两行,即可将两个参数中未组合的条件组合起来。 (当然你也可以稍微调整第四个参数的条件来达到同样的目的):
自动化步骤
上面的工作还是有点繁琐。事实上,有人已经自动化了这个过程。这里有一个免费的开源工具allpairs.exe,可以从下面的链接下载:
对于上面的例子,使用allpairs生成组合的方法是:
1. 先将以上条件输入Excel,如下图(因为这个工具是老外写的,没有考虑支持中文的问题,最好用英文):
2.以 Tab 键为分隔符将 Excel 文件另存为文本文件:
3.然后使用allpairs.exe处理这个文件:
allpairs.exe test.txt> output.txt
4.在output.txt中,PAIRING DETAILS下的东西没用,可以直接删除,删除后结果如下:
在设计测试环境矩阵和组合测试用例时可以使用allpairs技术。当然,你不能完全依赖这项技术。除了allpairs组合测试用例,你最好根据测试覆盖率和用户场景。从覆盖率开始,添加更多有价值的测试用例。
另外,使用配对测试的算法,我们可以结合行为驱动设计技术,直接从需求中自动生成测试用例,如果我们自动化了基本的测试用例,我们可以使用这个技术来自动化测试用例匹配组合(当然需要加一些限制),在节省测试时间的同时,达到满意的测试覆盖率,当然,这样做需要我们写一个测试工具来实现这个技术——至少到现在我还没有看到过-现成的工具,而且这种技术应该比模型驱动测试更容易使用,因为模型驱动测试的问题是建模太难了。
脚本驱动的网页自动操作工具VG浏览器官方安装版
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-06-25 01:39
VG浏览器正式安装版是一个脚本驱动的网页自动运行工具。它可以通过简单的脚本设置自动捕获数据。操作简单,功能可自由组合。 采集 效率很高。
软件功能
视觉操作
操作简单,图形操作完全可视化,无需专业IT人员。
自定义流程
采集就像积木一样,功能自由组合。
自动编码
程序关注采集efficiency,页面分析速度非常快。
生成EXE
自动登录,自动识别验证码,是万能浏览器。
如何使用
通过CSS Path定位网页元素的路径是VG浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的该按钮。
点击一个网页元素会自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键或者在页面上右键进行查看。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
您也可以按 F12 或右键单击以查看 Firefox 中的元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
添加了 Edge 浏览器模式。
外置 Chrome 浏览器升级到版本 90.x。
修复了在外部浏览器中写入 Select 元素值的错误。
点击下载超时单位更改为秒。
修复简单匹配变量选择错误。
其他一些细节已修复。 查看全部
脚本驱动的网页自动操作工具VG浏览器官方安装版
VG浏览器正式安装版是一个脚本驱动的网页自动运行工具。它可以通过简单的脚本设置自动捕获数据。操作简单,功能可自由组合。 采集 效率很高。
软件功能
视觉操作
操作简单,图形操作完全可视化,无需专业IT人员。
自定义流程
采集就像积木一样,功能自由组合。
自动编码
程序关注采集efficiency,页面分析速度非常快。
生成EXE
自动登录,自动识别验证码,是万能浏览器。
如何使用
通过CSS Path定位网页元素的路径是VG浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的该按钮。
点击一个网页元素会自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键或者在页面上右键进行查看。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
您也可以按 F12 或右键单击以查看 Firefox 中的元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
添加了 Edge 浏览器模式。
外置 Chrome 浏览器升级到版本 90.x。
修复了在外部浏览器中写入 Select 元素值的错误。
点击下载超时单位更改为秒。
修复简单匹配变量选择错误。
其他一些细节已修复。
网页分类是组织和管理信息的有效手段网页自动分类
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-13 05:17
随着科学技术的飞速发展,我们已经进入了数字信息时代。互联网作为当今世界上最大的信息数据库,也成为人们获取信息的最重要手段。由于网络上的信息资源具有海量、动态、异构、半结构化等特点,缺乏统一的组织和管理,如何从海量的信息资源中快速准确地找到自己需要的信息已成为一个亟待解决的问题。网络用户急需解决的大问题。因此,采集和基于Web的网络信息分类成为研究的热点。传统网络信息采集的目标是拥有尽可能多的采集信息页面,甚至是整个Web上的资源。在这个过程中,它不太关心采集的顺序和采集页面的顺序。相关话题。这使得采集页面的内容过于杂乱,而且相当一部分的利用率很低,极大地消耗了系统资源和网络资源。这需要有效的采集 方法来减少采集 网页的混乱和重复。同时,对采集到达的网页进行自动分类,打造更有效、更快速的搜索引擎也是非常有必要的。网页分类是组织和管理信息的有效手段。可以在很大程度上解决信息的杂乱无章,方便用户准确定位所需信息。传统的操作方式是人工分类后进行组织管理。随着互联网上各种信息的迅速增加,人工处理已经不切实际。因此,网页的自动分类是一种具有很大实用价值的方法,也是一种组织和管理数据的有效手段。这也是本文的一个重要内容。本文首先介绍了课题背景、研究目的和国内外研究现状,阐述了网页采集和网页分类的相关理论、主要技术和算法,包括网络爬虫技术、网页去重技术、信息提取技术、中文分词技术、特征提取技术、网页分类技术等。本文综合比较几种典型算法后,选取分类性能较好的主题爬虫方法和KNN方法,结合结合去重、分词、特征提取等相关技术,分析中文网页的结构和特征。经过分析,提出了中文网页采集的设计和实现方法以及分类,最终通过编程语言实现。在本文的最后,对系统进行了测试。测试结果符合系统设计要求,应用效果显着。 查看全部
网页分类是组织和管理信息的有效手段网页自动分类
随着科学技术的飞速发展,我们已经进入了数字信息时代。互联网作为当今世界上最大的信息数据库,也成为人们获取信息的最重要手段。由于网络上的信息资源具有海量、动态、异构、半结构化等特点,缺乏统一的组织和管理,如何从海量的信息资源中快速准确地找到自己需要的信息已成为一个亟待解决的问题。网络用户急需解决的大问题。因此,采集和基于Web的网络信息分类成为研究的热点。传统网络信息采集的目标是拥有尽可能多的采集信息页面,甚至是整个Web上的资源。在这个过程中,它不太关心采集的顺序和采集页面的顺序。相关话题。这使得采集页面的内容过于杂乱,而且相当一部分的利用率很低,极大地消耗了系统资源和网络资源。这需要有效的采集 方法来减少采集 网页的混乱和重复。同时,对采集到达的网页进行自动分类,打造更有效、更快速的搜索引擎也是非常有必要的。网页分类是组织和管理信息的有效手段。可以在很大程度上解决信息的杂乱无章,方便用户准确定位所需信息。传统的操作方式是人工分类后进行组织管理。随着互联网上各种信息的迅速增加,人工处理已经不切实际。因此,网页的自动分类是一种具有很大实用价值的方法,也是一种组织和管理数据的有效手段。这也是本文的一个重要内容。本文首先介绍了课题背景、研究目的和国内外研究现状,阐述了网页采集和网页分类的相关理论、主要技术和算法,包括网络爬虫技术、网页去重技术、信息提取技术、中文分词技术、特征提取技术、网页分类技术等。本文综合比较几种典型算法后,选取分类性能较好的主题爬虫方法和KNN方法,结合结合去重、分词、特征提取等相关技术,分析中文网页的结构和特征。经过分析,提出了中文网页采集的设计和实现方法以及分类,最终通过编程语言实现。在本文的最后,对系统进行了测试。测试结果符合系统设计要求,应用效果显着。
《采集自动组合动画》动画序列帧中的区域是动画片段
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-06-06 00:03
采集自动组合动画就是指获取一段动画的一个元素,然后利用别的部件构建动画时动画组合起来,组合动画中只有这个部件有输出,然后第二个动画加载别的部件,就完成了动画组合。获取外部组件是用sdk加载中动画需要的动画内容必须要用特殊的javascript注册方式进行获取到构建的javascript中。动画序列帧中的每帧包含一个点(每个点包含两个组成点)和一个动画描边,点代表有序序列,描边则代表无序序列。
这些点需要被一个组合方式注册到javascript注册的原理在animation-schema.js中。
抓包获取到animation序列帧先分析一下大部分动画以小块图片为表现形式,一个小块区域内由多个绘制所组成。而组合就是把有序区域按比例组合在一起,形成一个完整的片段。注意:animation-schema这个js文件抓包可以获取到,但是获取不了动画序列帧。所以需要抓包获取序列帧后去解析获取animation-schema.js。
注:chrome浏览器上面,关闭tab后,开启任何窗口,在safari上面,则不用关闭tab就可以解析animation-schema了。如下图所示,在浏览器上面可以看到动画序列帧。上图中的区域是动画片段,而在safari下面,则需要获取所有的片段,再去解析获取animation-schema.js,可以看到,动画片段是按比例组合起来的,也就是有序的。 查看全部
《采集自动组合动画》动画序列帧中的区域是动画片段
采集自动组合动画就是指获取一段动画的一个元素,然后利用别的部件构建动画时动画组合起来,组合动画中只有这个部件有输出,然后第二个动画加载别的部件,就完成了动画组合。获取外部组件是用sdk加载中动画需要的动画内容必须要用特殊的javascript注册方式进行获取到构建的javascript中。动画序列帧中的每帧包含一个点(每个点包含两个组成点)和一个动画描边,点代表有序序列,描边则代表无序序列。
这些点需要被一个组合方式注册到javascript注册的原理在animation-schema.js中。
抓包获取到animation序列帧先分析一下大部分动画以小块图片为表现形式,一个小块区域内由多个绘制所组成。而组合就是把有序区域按比例组合在一起,形成一个完整的片段。注意:animation-schema这个js文件抓包可以获取到,但是获取不了动画序列帧。所以需要抓包获取序列帧后去解析获取animation-schema.js。
注:chrome浏览器上面,关闭tab后,开启任何窗口,在safari上面,则不用关闭tab就可以解析animation-schema了。如下图所示,在浏览器上面可以看到动画序列帧。上图中的区域是动画片段,而在safari下面,则需要获取所有的片段,再去解析获取animation-schema.js,可以看到,动画片段是按比例组合起来的,也就是有序的。
王者荣耀:采集自动组合成本入门建议用基础的html5api
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-05-30 23:01
采集自动组合成本并不高,所以入门建议用基础的html5api,比如getitem,getunusex等。算法并不难,只要理解基础的算法逻辑,即使对于初学者也只需几天的时间就能实现,本人已经完成多个类似功能,欢迎探讨。
moba不知道,王者荣耀因为有存在网络延迟的问题,所以部分是用来聊天的,ui主要是套魔方studio做的,搞了个移动web,拿浏览器登录以后能随时切换。你要想弄,可以试试。
没有tp52.0包的无法做游戏。
unity写游戏在之前没有出现之前都是html5,后来用了c#和es6es6至今还没问世。如果你想用js写游戏,必须的得熟悉js的helloworld是怎么写的,甚至js的prototype-pattern是怎么用的,js的相关数据结构都是怎么用的。如果你想用c#编写游戏,必须得熟悉c#的相关编程知识,甚至c#的相关数据结构都是怎么用的。另外,如果用es6来写web开发也必须有一定的基础,不然用起来很蛋疼的。建议学习as3。
mmorpg目前我了解的就tap4j、beef等几个老牌框架,知乎上有很多大神们专门做过分享,你可以去翻一下,真正想用也得有个过程,不要直接用就行,
mojang的服务器和networkserver互连了。
当然可以,就是使用简单也用不了多久,毕竟unity脚本很简单,随便跑的,就像写个web,写个网页一样,交互看着爽,逻辑不难用js封装下就是了。要真想写点复杂点的逻辑得用数据库手写,你写nb点可以python/go写,简单点的可以webpy(个人更喜欢java写)。 查看全部
王者荣耀:采集自动组合成本入门建议用基础的html5api
采集自动组合成本并不高,所以入门建议用基础的html5api,比如getitem,getunusex等。算法并不难,只要理解基础的算法逻辑,即使对于初学者也只需几天的时间就能实现,本人已经完成多个类似功能,欢迎探讨。
moba不知道,王者荣耀因为有存在网络延迟的问题,所以部分是用来聊天的,ui主要是套魔方studio做的,搞了个移动web,拿浏览器登录以后能随时切换。你要想弄,可以试试。
没有tp52.0包的无法做游戏。
unity写游戏在之前没有出现之前都是html5,后来用了c#和es6es6至今还没问世。如果你想用js写游戏,必须的得熟悉js的helloworld是怎么写的,甚至js的prototype-pattern是怎么用的,js的相关数据结构都是怎么用的。如果你想用c#编写游戏,必须得熟悉c#的相关编程知识,甚至c#的相关数据结构都是怎么用的。另外,如果用es6来写web开发也必须有一定的基础,不然用起来很蛋疼的。建议学习as3。
mmorpg目前我了解的就tap4j、beef等几个老牌框架,知乎上有很多大神们专门做过分享,你可以去翻一下,真正想用也得有个过程,不要直接用就行,
mojang的服务器和networkserver互连了。
当然可以,就是使用简单也用不了多久,毕竟unity脚本很简单,随便跑的,就像写个web,写个网页一样,交互看着爽,逻辑不难用js封装下就是了。要真想写点复杂点的逻辑得用数据库手写,你写nb点可以python/go写,简单点的可以webpy(个人更喜欢java写)。
采集自动组合成为永久的歌曲发布,你可以试试
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-05-27 19:00
采集自动组合成为永久的歌曲发布。你可以试试天天动听,一直专注于老歌的下载和评论,一些月份还会有新歌推荐,但这也是站长人工制作的,运气好,加上能持续更新,可以存下很多老歌,而在天天动听,你可以在30天内下载5000首左右的歌曲,假设你每天都打开天天动听,下载了1000首,而这个有效期是30天,30天后在打开,你会发现新的老歌推荐给你。所以30天内下载的所有老歌,在以后每个月都会推荐给你。
这个被动用户的时间为主动用户创造更大的价值,直接靠对接某个产品来给用户创造更大的价值,哪怕创造1000块钱的价值,收益也远大于全部没有出这1000块钱的创造价值。
最近新发现的一个做这个的
是有软件可以替代的,搜索不到,
可以通过关键词分析用户的标签进行数据采集,然后根据你的歌曲标签分类,推荐到精准app中去。
可以啊,很简单的,我前几天偶然一次搜了下情侣歌,几十首歌里面我又听了100多首,感觉有必要找点其他值得听的歌,
我不大喜欢再把歌曲分类。我个人觉得所有歌曲都是一个编号而已,就像我是动物园工作的,我经常分门别类,但是别人问我时候我就说我是动物园工作的。其实歌曲分类还是蛮繁琐的,如果有好的歌曲分析软件,就搞定了。 查看全部
采集自动组合成为永久的歌曲发布,你可以试试
采集自动组合成为永久的歌曲发布。你可以试试天天动听,一直专注于老歌的下载和评论,一些月份还会有新歌推荐,但这也是站长人工制作的,运气好,加上能持续更新,可以存下很多老歌,而在天天动听,你可以在30天内下载5000首左右的歌曲,假设你每天都打开天天动听,下载了1000首,而这个有效期是30天,30天后在打开,你会发现新的老歌推荐给你。所以30天内下载的所有老歌,在以后每个月都会推荐给你。
这个被动用户的时间为主动用户创造更大的价值,直接靠对接某个产品来给用户创造更大的价值,哪怕创造1000块钱的价值,收益也远大于全部没有出这1000块钱的创造价值。
最近新发现的一个做这个的
是有软件可以替代的,搜索不到,
可以通过关键词分析用户的标签进行数据采集,然后根据你的歌曲标签分类,推荐到精准app中去。
可以啊,很简单的,我前几天偶然一次搜了下情侣歌,几十首歌里面我又听了100多首,感觉有必要找点其他值得听的歌,
我不大喜欢再把歌曲分类。我个人觉得所有歌曲都是一个编号而已,就像我是动物园工作的,我经常分门别类,但是别人问我时候我就说我是动物园工作的。其实歌曲分类还是蛮繁琐的,如果有好的歌曲分析软件,就搞定了。
采集自动组合识别软件之公里搜索_未来控网之音索引
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-05-21 05:00
采集自动组合识别软件之公里搜索_未来控网之音索引架构-440036_441036
公里搜索-纯http的,不加啥奇怪的东西,
很明显不是每台计算机都能有服务器主备之类的机制,一般都是走集群,或者内存池直接调,就算硬件支持,就算都能跑出来,速度也太慢,速度瓶颈并不在cpu和硬盘之类的,主要是延迟,然后是通讯方式,例如要传个标准数据之类的,没有实时网络支持,效率非常低。当然还有个中间种种可能,利益相关了,
cpu的瓶颈在于cache芯片的连接时延,如果数据一多延迟就高。硬盘的瓶颈在于读写io,大文件的话不了解。
一般都是单机并发,每台计算机上跑的一般都是通用类型服务,没必要使用硬件主备机方案。
你可以参考我们曾经做过的xmpp+httprestapi+分布式文件系统。.hostaddress并非固定的,需要取决于计算机内存。xmpp每台计算机上都有自己的localhost,specifier和localhost.restapi每台计算机都有自己的maillist。如果此时客户端需要读取某一位文件,需要先刷新restapi的hostaddress。--更新,发现可能跑了反代,主备单机机制。
识别算法,当然在每台计算机都能运行,这个得看识别模型,以及识别误差等。 查看全部
采集自动组合识别软件之公里搜索_未来控网之音索引
采集自动组合识别软件之公里搜索_未来控网之音索引架构-440036_441036
公里搜索-纯http的,不加啥奇怪的东西,
很明显不是每台计算机都能有服务器主备之类的机制,一般都是走集群,或者内存池直接调,就算硬件支持,就算都能跑出来,速度也太慢,速度瓶颈并不在cpu和硬盘之类的,主要是延迟,然后是通讯方式,例如要传个标准数据之类的,没有实时网络支持,效率非常低。当然还有个中间种种可能,利益相关了,
cpu的瓶颈在于cache芯片的连接时延,如果数据一多延迟就高。硬盘的瓶颈在于读写io,大文件的话不了解。
一般都是单机并发,每台计算机上跑的一般都是通用类型服务,没必要使用硬件主备机方案。
你可以参考我们曾经做过的xmpp+httprestapi+分布式文件系统。.hostaddress并非固定的,需要取决于计算机内存。xmpp每台计算机上都有自己的localhost,specifier和localhost.restapi每台计算机都有自己的maillist。如果此时客户端需要读取某一位文件,需要先刷新restapi的hostaddress。--更新,发现可能跑了反代,主备单机机制。
识别算法,当然在每台计算机都能运行,这个得看识别模型,以及识别误差等。
采集自动组合短视频—mpc1005操作指南(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-05-20 21:26
采集自动组合短视频—mpc1005短视频内容为图文形式。可进行图文内容上传。自动组合短视频—mpc1005短视频内容为图文形式。可进行图文内容上传。收藏一次生成一个播放列表,并保存到相册(压缩mp4文件大小的必备辅助)。收藏一次生成一个播放列表,并保存到相册(压缩mp4文件大小的必备辅助)。个人所有短视频,永久保存,不可撤销编辑。
自动组合短视频—mpc1005操作指南视频操作指南:第一步:登录:用户直接登录或者在手机注册登录,也可以通过邮箱注册,注册地址。第二步:点击“我的视频列表”——我的视频。第三步:点击“mpc开始组合”按钮。第四步:继续,视频列表生成后,点击“查看列表”按钮。第五步:视频列表生成成功后,不可撤销。
第六步:在mpc里面手动录制视频。需要用到麦克风或者ibeaconsdk第七步:保存成为视频文件,录制完视频后一定要保存。不然只会保存成带av号的视频文件。短视频内容为图文形式。可进行图文内容上传。mpc1005实时视频监控—mpc1005点击mpc1005,打开图文视频监控界面,即可看到已经录制好的视频。
自动组合短视频—mpc1005系统支持mp4、avi、mpeg等常用文件格式,只要在生成列表里找到支持该格式的视频文件,即可录制到相应的格式。操作简单,不需要设置操作,一键组合,不损失原有视频质量。操作简单,不需要设置操作,一键组合,不损失原有视频质量。视频监控终端监控—mpc1005系统支持连接到iptv端口,可以在网络上通过udp端口连接接入iptv,或者在端口连接模拟器端口。
数据传输直接通过iptv线或者模拟器线。操作简单,不需要设置操作,一键组合,不损失原有视频质量。视频监控终端监控—mpc1005支持红外、otg、蓝牙、ipc/mcu(mp4)、wifi多接口连接摄像头。操作简单,不需要设置操作,一键组合,不损失原有视频质量。操作简单,不需要设置操作,一键组合,不损失原有视频质量。 查看全部
采集自动组合短视频—mpc1005操作指南(组图)
采集自动组合短视频—mpc1005短视频内容为图文形式。可进行图文内容上传。自动组合短视频—mpc1005短视频内容为图文形式。可进行图文内容上传。收藏一次生成一个播放列表,并保存到相册(压缩mp4文件大小的必备辅助)。收藏一次生成一个播放列表,并保存到相册(压缩mp4文件大小的必备辅助)。个人所有短视频,永久保存,不可撤销编辑。
自动组合短视频—mpc1005操作指南视频操作指南:第一步:登录:用户直接登录或者在手机注册登录,也可以通过邮箱注册,注册地址。第二步:点击“我的视频列表”——我的视频。第三步:点击“mpc开始组合”按钮。第四步:继续,视频列表生成后,点击“查看列表”按钮。第五步:视频列表生成成功后,不可撤销。
第六步:在mpc里面手动录制视频。需要用到麦克风或者ibeaconsdk第七步:保存成为视频文件,录制完视频后一定要保存。不然只会保存成带av号的视频文件。短视频内容为图文形式。可进行图文内容上传。mpc1005实时视频监控—mpc1005点击mpc1005,打开图文视频监控界面,即可看到已经录制好的视频。
自动组合短视频—mpc1005系统支持mp4、avi、mpeg等常用文件格式,只要在生成列表里找到支持该格式的视频文件,即可录制到相应的格式。操作简单,不需要设置操作,一键组合,不损失原有视频质量。操作简单,不需要设置操作,一键组合,不损失原有视频质量。视频监控终端监控—mpc1005系统支持连接到iptv端口,可以在网络上通过udp端口连接接入iptv,或者在端口连接模拟器端口。
数据传输直接通过iptv线或者模拟器线。操作简单,不需要设置操作,一键组合,不损失原有视频质量。视频监控终端监控—mpc1005支持红外、otg、蓝牙、ipc/mcu(mp4)、wifi多接口连接摄像头。操作简单,不需要设置操作,一键组合,不损失原有视频质量。操作简单,不需要设置操作,一键组合,不损失原有视频质量。
SKYCC组合营销软件的文章添加分为3种模式(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-17 03:24
SKYCC联合营销软件的新亮点:多元化采集自从SKYCC联合营销软件于2012年推出以来,一直在跟踪有关SKYCC联合营销软件的相关报道,并且SKYCC的主要功能已被披露。一。随着组合营销软件的诞生,每个人都绝对希望了解其主要功能,但也要注意其一些小亮点。下面分析SKYCC组合营销软件采集中的多元化。我们都知道,一篇好文章文章在网站关键词的优化中起着重要作用,无论是公司发起人还是从事SEO优化的人。但是,当我们没有时间写文章时,当我们需要太多文章时该怎么办? SKYCC的多元化产品采集可以解决这些问题。 SKYCC组合营销软件的文章添加分为3种模式(自动采集,半自动采集,手动添加)。下面介绍全自动采集和半自动采集。 SKYCC组合营销软件采集有两个功能:第一个采集功能(全自动采集)采集 文章非常简单,只需输入自定义关键词。单击“开始搜索”,您可以自动快速地将采集复制到收录关键词的大量文章,因此您不必再担心编写文章了。第二个采集功能(半自动采集)需要一点编程基础。该软件将根据您填写的采集规则在特定页面上对采集 文章进行批处理,采集成功的文章将自动添加到“ 文章管理”列表中。 采集或添加文章后,还可以使用SKYCC组合营销软件的内置伪原创功能来增加文章的原创性质。 收录效果大大增强。直线推广营销效果。 查看全部
SKYCC组合营销软件的文章添加分为3种模式(图)
SKYCC联合营销软件的新亮点:多元化采集自从SKYCC联合营销软件于2012年推出以来,一直在跟踪有关SKYCC联合营销软件的相关报道,并且SKYCC的主要功能已被披露。一。随着组合营销软件的诞生,每个人都绝对希望了解其主要功能,但也要注意其一些小亮点。下面分析SKYCC组合营销软件采集中的多元化。我们都知道,一篇好文章文章在网站关键词的优化中起着重要作用,无论是公司发起人还是从事SEO优化的人。但是,当我们没有时间写文章时,当我们需要太多文章时该怎么办? SKYCC的多元化产品采集可以解决这些问题。 SKYCC组合营销软件的文章添加分为3种模式(自动采集,半自动采集,手动添加)。下面介绍全自动采集和半自动采集。 SKYCC组合营销软件采集有两个功能:第一个采集功能(全自动采集)采集 文章非常简单,只需输入自定义关键词。单击“开始搜索”,您可以自动快速地将采集复制到收录关键词的大量文章,因此您不必再担心编写文章了。第二个采集功能(半自动采集)需要一点编程基础。该软件将根据您填写的采集规则在特定页面上对采集 文章进行批处理,采集成功的文章将自动添加到“ 文章管理”列表中。 采集或添加文章后,还可以使用SKYCC组合营销软件的内置伪原创功能来增加文章的原创性质。 收录效果大大增强。直线推广营销效果。
全自动采集SKYCC组合营销软件新亮点多样化采集(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-05-17 03:17
全自动采集SKYCC组合营销软件新亮点多样化采集(图)
SKYCC联合营销软件的新亮点多样化采集自2012年2月推出SKYCC联合营销软件以来,SKYCC联合营销软件的相关报告也一直在不断关注。 SKYCC的主要功能已被一个接一个地披露。借助组合式营销软件,。所有人的诞生肯定是每个人都想了解它的主要功能,但同时也要注意它的一些亮点。接下来,分析SKYCC组合营销软件采集中的多元化我们都知道这是公司发起人还是进行SEO优化的人。一篇好文章文章在网站 关键词的优化中起着重要作用,但是当我们没有时间写文章时,这是因为文章太多了。我们应该做什么? SKYCC多样化采集可以解决这些问题SKYCC联合营销软件文章
章节加法分为3种模式。全自动采集半自动采集手动添加。让我们介绍一下全自动采集和半自动采集 SKYCC组合营销软件采集。 采集该功能是全自动的采集 采集 文章该功能非常简单。只需输入自定义关键词,然后单击以开始搜索。它可以自动快速地将采集扩展为收录您的关键词的大量文章。您不必担心编写文章。第二个采集功能是半自动的。 采集需要一点点的程序。基本软件将按照您在特定页面上批量采集 文章 采集中填写的采集规则。 文章将自动添加到文章管理列表采集中,或在添加文章之后,还可以使用SKYCC组合营销软件的内置伪原创功能来增加原创性别[ 文章的收录。效果很好提升直线度,提高营销效果 查看全部
全自动采集SKYCC组合营销软件新亮点多样化采集(图)
SKYCC联合营销软件的新亮点多样化采集自2012年2月推出SKYCC联合营销软件以来,SKYCC联合营销软件的相关报告也一直在不断关注。 SKYCC的主要功能已被一个接一个地披露。借助组合式营销软件,。所有人的诞生肯定是每个人都想了解它的主要功能,但同时也要注意它的一些亮点。接下来,分析SKYCC组合营销软件采集中的多元化我们都知道这是公司发起人还是进行SEO优化的人。一篇好文章文章在网站 关键词的优化中起着重要作用,但是当我们没有时间写文章时,这是因为文章太多了。我们应该做什么? SKYCC多样化采集可以解决这些问题SKYCC联合营销软件文章
章节加法分为3种模式。全自动采集半自动采集手动添加。让我们介绍一下全自动采集和半自动采集 SKYCC组合营销软件采集。 采集该功能是全自动的采集 采集 文章该功能非常简单。只需输入自定义关键词,然后单击以开始搜索。它可以自动快速地将采集扩展为收录您的关键词的大量文章。您不必担心编写文章。第二个采集功能是半自动的。 采集需要一点点的程序。基本软件将按照您在特定页面上批量采集 文章 采集中填写的采集规则。 文章将自动添加到文章管理列表采集中,或在添加文章之后,还可以使用SKYCC组合营销软件的内置伪原创功能来增加原创性别[ 文章的收录。效果很好提升直线度,提高营销效果
宝塔面板理论各大CMS自动采集通用!(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-05-13 05:13
理论都是cms自动采集通用的!
众所周知,现在宝塔面板可以定期执行指定的URL。 Ocean cms auto 采集非常方便,只需打开一个URL即可完成它采集,那么为什么不继续使用宝塔面板采集那么编写一个需要花费大量时间来挂断脚本的脚本又如何呢?窗户?
长时间使用后,发现宝塔面板定制的指定URL仅是采集的首页。如果采集界面的更新数据大于1页,则采集不会再晚了,当然您可以设置采集的间隔就像每隔几十分钟一次,但是如果资源站中断了一次,每次更新数十个资源,仍然会丢失。
我们使用TimeTasktools软件(非常喜欢破解),它是一款出色的计时程序,可以定期执行DOS和指定的外部程序(包括QQ等)。我们使用该软件添加了一个自编译的蝙蝠脚本,以实现对海洋cms 采集的自动计时。
蝙蝠脚本移至此处:
以下是Ocean cms 采集的免登录插件的URL地址的描述,例如:: /// inc / sea cms api.php&password = 123456
简而言之:您的域名/ login / admin_reslib 2. php?ac = day&rid = 1&url =资源库地址&password = cookie加上密码
资源库地址是在您的后台设置的,
Cookie和密码也在后台设置
我们会将上述地址合并到您自己的免登录采集 URL中,并填写脚本文档。
在此处打开软件,将采集间隔设置为4小时,设置外部程序,即我们的脚本test.bat
保存!只需将其最小化即可。时间到时,该软件将自动打开浏览器并运行您设置的指定URL,然后在运行后自动关闭浏览器。
与此同时,DOS命令也非常丰富多彩,学到了很多东西,该软件将带给您许多意想不到的惊喜! 查看全部
宝塔面板理论各大CMS自动采集通用!(组图)
理论都是cms自动采集通用的!
众所周知,现在宝塔面板可以定期执行指定的URL。 Ocean cms auto 采集非常方便,只需打开一个URL即可完成它采集,那么为什么不继续使用宝塔面板采集那么编写一个需要花费大量时间来挂断脚本的脚本又如何呢?窗户?
长时间使用后,发现宝塔面板定制的指定URL仅是采集的首页。如果采集界面的更新数据大于1页,则采集不会再晚了,当然您可以设置采集的间隔就像每隔几十分钟一次,但是如果资源站中断了一次,每次更新数十个资源,仍然会丢失。
我们使用TimeTasktools软件(非常喜欢破解),它是一款出色的计时程序,可以定期执行DOS和指定的外部程序(包括QQ等)。我们使用该软件添加了一个自编译的蝙蝠脚本,以实现对海洋cms 采集的自动计时。
蝙蝠脚本移至此处:
以下是Ocean cms 采集的免登录插件的URL地址的描述,例如:: /// inc / sea cms api.php&password = 123456
简而言之:您的域名/ login / admin_reslib 2. php?ac = day&rid = 1&url =资源库地址&password = cookie加上密码
资源库地址是在您的后台设置的,
Cookie和密码也在后台设置
我们会将上述地址合并到您自己的免登录采集 URL中,并填写脚本文档。
在此处打开软件,将采集间隔设置为4小时,设置外部程序,即我们的脚本test.bat
保存!只需将其最小化即可。时间到时,该软件将自动打开浏览器并运行您设置的指定URL,然后在运行后自动关闭浏览器。
与此同时,DOS命令也非常丰富多彩,学到了很多东西,该软件将带给您许多意想不到的惊喜!
蜘蛛池的原理是什么?如何搭建好域名池?
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-05-13 05:10
一、蜘蛛池如何工作?
搜索引擎用于爬网和访问页面的程序称为蜘蛛或采集器。搜索引擎指示它浏览Internet上的Web以获得Internet的大部分数据(因为存在一些暗网,因此他很难爬网),然后将这些数据存储在搜索引擎自己的数据库中。如果搜索引擎抓取工具未抓取通过自发布或推断生成的URL,则搜索引擎将不会收录页面,更不用说排名了。
蜘蛛池程序的原理是输入一个可变模板来生成大量的Web内容,以吸引大量蜘蛛来继续在这些页面上进行爬网,并添加我们需要的URL 收录在Spider Station开发的特定部分中。通过这种方式,我们可以使用需要收录的URL来进行大量爬虫的爬网,这大大提高了页面收录的可能性。这就是所谓的每天发送数百万个外部链接的方式,而普通的蜘蛛池也至少需要数百个域名。
二、如何建立蜘蛛池?
1. Multi-IP VPS或服务器(取决于要求)
建议使用多个IP服务器,外部服务器(因为无需解析即可解析和使用域名),最好具有较高的配置。在配置方面(请参阅域名数),建议不要使用香港服务器。带宽很小,很容易被蜘蛛抓取。重要的是,服务器内存必须很大,就像我们之前遇到的那样。当我们第一次这样做时,使用的内存相对较小。如果蜘蛛数量很大,它将立即崩溃。
2.一定数量的域名(取决于数量)
您可以购买闲置的二手域名。便宜的域名是好的。为了获得更好的蜘蛛池,至少应准备500个域名。蜘蛛池的目的是吸引蜘蛛。建议使用带有后缀的域名,例如CN,COM和NET。域名是每年收费的。域名会根据效果和链接数逐渐增加,效果会翻倍。也可以从之前购买的域名中解析一部分域名,继续增加网站,扩展池,并增加蜘蛛数目。
3.可变模板程序(费用一般在1000元左右)
您可以自己开发它,如果没有,也可以在市场上购买程序变量模板,灵活的文章和完整的网站元素来吸引外部链接,CSS / JS /超链接和其他独特的功能吸引蜘蛛爬行的技巧!让每个域名的内容都不同!我们都知道百度对网站重复内容的态度,因此我们必须保持每个站点的内容都不要重复),因此模板程序尤其重要。
4.开发程序员(稍微好一点)
需要满足采集和网站内容的自动生成,我们在采集的早期有很多条目,在文章的自动组合中,在早期,有500,000的生成量文章一天,因此服务器承受很大压力。对于程序员来说,了解服务器管理和维护的知识非常重要。
可以看出,蜘蛛池的成本实际上并不低。对于普通的网站管理员来说,拥有成千上万的域名,大型服务器和程序员,构建蜘蛛池的成本相对较高,性价比也不高。建议租用蜘蛛池服务,您可以直接租用我们的Thunder蜘蛛池并直接在线提交链接以引用蜘蛛。 查看全部
蜘蛛池的原理是什么?如何搭建好域名池?
一、蜘蛛池如何工作?
搜索引擎用于爬网和访问页面的程序称为蜘蛛或采集器。搜索引擎指示它浏览Internet上的Web以获得Internet的大部分数据(因为存在一些暗网,因此他很难爬网),然后将这些数据存储在搜索引擎自己的数据库中。如果搜索引擎抓取工具未抓取通过自发布或推断生成的URL,则搜索引擎将不会收录页面,更不用说排名了。
蜘蛛池程序的原理是输入一个可变模板来生成大量的Web内容,以吸引大量蜘蛛来继续在这些页面上进行爬网,并添加我们需要的URL 收录在Spider Station开发的特定部分中。通过这种方式,我们可以使用需要收录的URL来进行大量爬虫的爬网,这大大提高了页面收录的可能性。这就是所谓的每天发送数百万个外部链接的方式,而普通的蜘蛛池也至少需要数百个域名。
二、如何建立蜘蛛池?
1. Multi-IP VPS或服务器(取决于要求)
建议使用多个IP服务器,外部服务器(因为无需解析即可解析和使用域名),最好具有较高的配置。在配置方面(请参阅域名数),建议不要使用香港服务器。带宽很小,很容易被蜘蛛抓取。重要的是,服务器内存必须很大,就像我们之前遇到的那样。当我们第一次这样做时,使用的内存相对较小。如果蜘蛛数量很大,它将立即崩溃。
2.一定数量的域名(取决于数量)
您可以购买闲置的二手域名。便宜的域名是好的。为了获得更好的蜘蛛池,至少应准备500个域名。蜘蛛池的目的是吸引蜘蛛。建议使用带有后缀的域名,例如CN,COM和NET。域名是每年收费的。域名会根据效果和链接数逐渐增加,效果会翻倍。也可以从之前购买的域名中解析一部分域名,继续增加网站,扩展池,并增加蜘蛛数目。
3.可变模板程序(费用一般在1000元左右)
您可以自己开发它,如果没有,也可以在市场上购买程序变量模板,灵活的文章和完整的网站元素来吸引外部链接,CSS / JS /超链接和其他独特的功能吸引蜘蛛爬行的技巧!让每个域名的内容都不同!我们都知道百度对网站重复内容的态度,因此我们必须保持每个站点的内容都不要重复),因此模板程序尤其重要。
4.开发程序员(稍微好一点)
需要满足采集和网站内容的自动生成,我们在采集的早期有很多条目,在文章的自动组合中,在早期,有500,000的生成量文章一天,因此服务器承受很大压力。对于程序员来说,了解服务器管理和维护的知识非常重要。
可以看出,蜘蛛池的成本实际上并不低。对于普通的网站管理员来说,拥有成千上万的域名,大型服务器和程序员,构建蜘蛛池的成本相对较高,性价比也不高。建议租用蜘蛛池服务,您可以直接租用我们的Thunder蜘蛛池并直接在线提交链接以引用蜘蛛。
【通讯技术】采集自动组合优化方案--核心控制器
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-05-13 02:04
采集自动组合优化方案--核心控制器通过数字音频提供每台视频监控的相对速度,可以避免空间变化带来的垂直遮挡,提高“车”的“车辆视野”。而自动变速箱可以根据监控画面自动变速、对角加减档,满足自动驾驶要求。监控系统标配直流双电机控制(电力中继技术),由于自动驾驶需要,双电机之间需要实现互相转化(即发送控制信号到双电机,自动变速箱自动控制为直流双电机控制),使得每台视频监控摄像机之间和摄像机与双电机之间实现转化,保证垂直驾驶距离可达到8米。
部分优质模组,具有双光学夜视功能,采集距离是需要目标的75倍;led数字监控摄像机显示方式采用fpga硬件加速技术,可实现24bit/bit格式,是目前数字监控显示的最高格式;监控系统提供了相关的sdk供用户开发自动化业务应用,可实现标准的运动轨迹规划;大屏幕可选手机应用、远程电脑视频会议等功能。
我设计的光路如下:移动机器人(通过无线遥控电机运动,本质是机器人)解决人体运动轨迹,自动驾驶,
自动驾驶采用基于激光的v2v实现无人驾驶
我也想知道
实现自动驾驶,很多技术问题要考虑:车辆运动控制?镜头采集?感应器获取时间差?车辆应该不只一个摄像头吧?就像光路设计一样,有一个明确且明确的最优路径,并不是一个线性一个线性的。最优路径不是硬性指标,只是说明学习范围内优化效果最好。只能说明效果最好。自动驾驶还需要个人综合能力。对于终端的综合优化的话,这里面对性能,技术需求,可靠性,信赖性,业务场景等等,考虑比较多。 查看全部
【通讯技术】采集自动组合优化方案--核心控制器
采集自动组合优化方案--核心控制器通过数字音频提供每台视频监控的相对速度,可以避免空间变化带来的垂直遮挡,提高“车”的“车辆视野”。而自动变速箱可以根据监控画面自动变速、对角加减档,满足自动驾驶要求。监控系统标配直流双电机控制(电力中继技术),由于自动驾驶需要,双电机之间需要实现互相转化(即发送控制信号到双电机,自动变速箱自动控制为直流双电机控制),使得每台视频监控摄像机之间和摄像机与双电机之间实现转化,保证垂直驾驶距离可达到8米。
部分优质模组,具有双光学夜视功能,采集距离是需要目标的75倍;led数字监控摄像机显示方式采用fpga硬件加速技术,可实现24bit/bit格式,是目前数字监控显示的最高格式;监控系统提供了相关的sdk供用户开发自动化业务应用,可实现标准的运动轨迹规划;大屏幕可选手机应用、远程电脑视频会议等功能。
我设计的光路如下:移动机器人(通过无线遥控电机运动,本质是机器人)解决人体运动轨迹,自动驾驶,
自动驾驶采用基于激光的v2v实现无人驾驶
我也想知道
实现自动驾驶,很多技术问题要考虑:车辆运动控制?镜头采集?感应器获取时间差?车辆应该不只一个摄像头吧?就像光路设计一样,有一个明确且明确的最优路径,并不是一个线性一个线性的。最优路径不是硬性指标,只是说明学习范围内优化效果最好。只能说明效果最好。自动驾驶还需要个人综合能力。对于终端的综合优化的话,这里面对性能,技术需求,可靠性,信赖性,业务场景等等,考虑比较多。
采集自动组合技术+运营模式,你有没有想过
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-05-03 22:03
采集自动组合技术+运营模式。你有没有想过如果有一个客户端,平台能够记录你的地理位置,然后告诉你今天大概在哪个地方放大到你家门口,然后通过你到这个地方的路径和你回家的路径的记录,
微信应该会用ai技术,搜索和分析你周围的实时位置。应该会有可以链接的平台,可以实现大数据获取,
房产中介用户回家点外卖的需求:每天点外卖次数和几个菜品组合,地理位置获取到外卖外卖软件的数据模型上,将这些数据采集到通过交互方式以实时画面方式展现给用户,促进下单和营销。
每个人都差不多应该是当前的地理位置,电话号码这些信息,大多就是基于手机端的信息,例如,你晚上是在哪个酒店住,你把你的电话号码截图,送外卖的人的时间地点,和交通路线信息通过图像识别,然后送到每一个微信的订单里面,
这个问题意义不大,
全国这么多的城市而且每个城市每个地点的价值都是不一样的而且如果他的工作人员没有线下代理进行收费和分配的话每个微信的市场占有率应该也不高
语义分析吧或者也可以算是一种自动组合技术,
首先微信的用户群体比你想象的更广泛,如果可以在线上获取到客户手机的位置信息,
一、针对手机用户数量的分析
二、公司精准推送信息
三、应用推广 查看全部
采集自动组合技术+运营模式,你有没有想过
采集自动组合技术+运营模式。你有没有想过如果有一个客户端,平台能够记录你的地理位置,然后告诉你今天大概在哪个地方放大到你家门口,然后通过你到这个地方的路径和你回家的路径的记录,
微信应该会用ai技术,搜索和分析你周围的实时位置。应该会有可以链接的平台,可以实现大数据获取,
房产中介用户回家点外卖的需求:每天点外卖次数和几个菜品组合,地理位置获取到外卖外卖软件的数据模型上,将这些数据采集到通过交互方式以实时画面方式展现给用户,促进下单和营销。
每个人都差不多应该是当前的地理位置,电话号码这些信息,大多就是基于手机端的信息,例如,你晚上是在哪个酒店住,你把你的电话号码截图,送外卖的人的时间地点,和交通路线信息通过图像识别,然后送到每一个微信的订单里面,
这个问题意义不大,
全国这么多的城市而且每个城市每个地点的价值都是不一样的而且如果他的工作人员没有线下代理进行收费和分配的话每个微信的市场占有率应该也不高
语义分析吧或者也可以算是一种自动组合技术,
首先微信的用户群体比你想象的更广泛,如果可以在线上获取到客户手机的位置信息,
一、针对手机用户数量的分析
二、公司精准推送信息
三、应用推广
全自动的自学平台吧、一个数据接收平台。
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-04-25 02:06
采集自动组合,或者电子环境组合。
全自动的自学平台吧、
一个数据接收平台。即1)可以分析每个邮件接收数据,2)可以下载邮件。这样可以把信息变为数据,然后再按照seo指令,进行seo优化。就跟你接触了一个老师,告诉你问题(邮件标题、内容、链接),他自己去操作,然后给你指示(分析问题、制定计划、执行计划)。当然,你也可以把自己学到的技能,整理成一个平台。把所有信息(邮件标题、内容、链接)统计一下。优化一遍。
要不手工测试,要不用迅易数据seo助手吧。
内容和地址应该用在标题或者内容中,
不要组合,很多高质量的图片和文字都是相关联的,你给的条件太有限,你不好判断哪些链接可以构成这种联系,不过可以基于这个猜猜,建议到知乎或者贴吧去找一些类似的提问看看,如果一个问题里大量单独问的问题都是属于相关联的,
数据接收。一个接收器,一个自动测试机。工具很多,有知友已经提过了。
我真想看看是什么让题主产生了这个问题。
分析邮件标题是否有必要,没必要就可以忽略,标题一般用app或者界面来映射邮件内容。
不用啊,seo作为手段而已。 查看全部
全自动的自学平台吧、一个数据接收平台。
采集自动组合,或者电子环境组合。
全自动的自学平台吧、
一个数据接收平台。即1)可以分析每个邮件接收数据,2)可以下载邮件。这样可以把信息变为数据,然后再按照seo指令,进行seo优化。就跟你接触了一个老师,告诉你问题(邮件标题、内容、链接),他自己去操作,然后给你指示(分析问题、制定计划、执行计划)。当然,你也可以把自己学到的技能,整理成一个平台。把所有信息(邮件标题、内容、链接)统计一下。优化一遍。
要不手工测试,要不用迅易数据seo助手吧。
内容和地址应该用在标题或者内容中,
不要组合,很多高质量的图片和文字都是相关联的,你给的条件太有限,你不好判断哪些链接可以构成这种联系,不过可以基于这个猜猜,建议到知乎或者贴吧去找一些类似的提问看看,如果一个问题里大量单独问的问题都是属于相关联的,
数据接收。一个接收器,一个自动测试机。工具很多,有知友已经提过了。
我真想看看是什么让题主产生了这个问题。
分析邮件标题是否有必要,没必要就可以忽略,标题一般用app或者界面来映射邮件内容。
不用啊,seo作为手段而已。
采集自动组合机器人的轨迹无人机越过雷达探测器
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-04-22 02:03
采集自动组合机器人的轨迹无人机越过雷达探测器,雷达探测器只是一小部分原因,组合机器人具有完整的控制、执行器,具有一定的柔软度。自动组合机器人没有雷达探测器,没有位置感知器件,有的只是增强的信息输入和干扰输入。不过本研究只是简单的采集结果,应该没有调整系统和整体控制。提示:相关论文可以关注微信公众号“智能机器人创新云”,里面有。
人还能走路,
我也想知道为什么那么人啊
微观应该是一个信息接收系统的关键部件。组合机器人应该可以依靠组合时候的动力学规划来达到走路的效果。宏观上,
无人机具有可控性,可以无限拉长的软软的细线,
应该是问,人是否具有无线粒子无线连接功能,能够将目标无线组合的功能。
估计最早的无人机是以人在陆地上行走为原型的,后来才变成无人机的机器人,再后来就有军事用途,
这个问题是,电磁学上,粒子加速度是什么意思。
因为万有引力
你们都没看到题主的想法题主是想说这个是人机结合是吧题主说的是这个么当然以上回答都是骗题主的那么问题来了为什么呢这个我们先从人类的微观来看一下我们看一下红点处前面的测滑仪来看的红点处的测滑仪上主要是电流测量同时还有磁力电流磁力都是有的测滑仪上的磁力也有就是我们要弄清楚无人机的发动机和任务系统驱动方式其实以上已经说了无人机发动机是电磁驱动的那么下面要说的在于任务驱动我们先说说人机结合上图就是人机结合的工作原理:任务驱动指的是人来做任务机器人做执行执行来完成任务人执行完任务机器人产生结果无人机上要有和人能量反馈的导电电流无人机上有各种来检测这个力和这个角度的测量力应该是个力计算原理力是不是一个力量大小呢现在我们简单的做一个简单的计算然后来推算力我们要测定一个物体的力量怎么简单呢那就是xxxxx那么就等于xxxxx啊这么简单的说明我就不写代码了我这么懒你自己想象一下吧那么假设我们来测量人身上的结果呢不好意思我们已经算了xxx果然力不是相加的而是相减啊果然根据力的表达式力=||势能||v-x||/||x||=v-x而x更多就是根据一个头部坐标x-y轴一个平面x轴纵坐标x坐标箭头x,y轴横坐标x。
y角度这是无人机上的路径选择命令然后根据xz是针对地面的估计题主想问的应该是那个上面推荐这个图你们也是已经算了xz是针对地面的那么下面是针对人做的工作假设人有100kg好了现在我们要求的任务就是让。 查看全部
采集自动组合机器人的轨迹无人机越过雷达探测器
采集自动组合机器人的轨迹无人机越过雷达探测器,雷达探测器只是一小部分原因,组合机器人具有完整的控制、执行器,具有一定的柔软度。自动组合机器人没有雷达探测器,没有位置感知器件,有的只是增强的信息输入和干扰输入。不过本研究只是简单的采集结果,应该没有调整系统和整体控制。提示:相关论文可以关注微信公众号“智能机器人创新云”,里面有。
人还能走路,
我也想知道为什么那么人啊
微观应该是一个信息接收系统的关键部件。组合机器人应该可以依靠组合时候的动力学规划来达到走路的效果。宏观上,
无人机具有可控性,可以无限拉长的软软的细线,
应该是问,人是否具有无线粒子无线连接功能,能够将目标无线组合的功能。
估计最早的无人机是以人在陆地上行走为原型的,后来才变成无人机的机器人,再后来就有军事用途,
这个问题是,电磁学上,粒子加速度是什么意思。
因为万有引力
你们都没看到题主的想法题主是想说这个是人机结合是吧题主说的是这个么当然以上回答都是骗题主的那么问题来了为什么呢这个我们先从人类的微观来看一下我们看一下红点处前面的测滑仪来看的红点处的测滑仪上主要是电流测量同时还有磁力电流磁力都是有的测滑仪上的磁力也有就是我们要弄清楚无人机的发动机和任务系统驱动方式其实以上已经说了无人机发动机是电磁驱动的那么下面要说的在于任务驱动我们先说说人机结合上图就是人机结合的工作原理:任务驱动指的是人来做任务机器人做执行执行来完成任务人执行完任务机器人产生结果无人机上要有和人能量反馈的导电电流无人机上有各种来检测这个力和这个角度的测量力应该是个力计算原理力是不是一个力量大小呢现在我们简单的做一个简单的计算然后来推算力我们要测定一个物体的力量怎么简单呢那就是xxxxx那么就等于xxxxx啊这么简单的说明我就不写代码了我这么懒你自己想象一下吧那么假设我们来测量人身上的结果呢不好意思我们已经算了xxx果然力不是相加的而是相减啊果然根据力的表达式力=||势能||v-x||/||x||=v-x而x更多就是根据一个头部坐标x-y轴一个平面x轴纵坐标x坐标箭头x,y轴横坐标x。
y角度这是无人机上的路径选择命令然后根据xz是针对地面的估计题主想问的应该是那个上面推荐这个图你们也是已经算了xz是针对地面的那么下面是针对人做的工作假设人有100kg好了现在我们要求的任务就是让。
阿里云日志服务:DaemonSet和Sidecar模式的优缺点分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 438 次浏览 • 2021-04-04 18:19
摘要:DaemonSet和Sidecar模式各有优缺点。当前,没有一种方法可以应用于所有方案。因此,我们的阿里云日志服务既支持DaemonSet方法又支持Sidecar方法,并且对每种方法都进行了一些额外的改进,更适合于K8S下的动态场景。
Kubernetes(K8S)作为CNCF(云原生计算基金会)的核心项目,在Google和Redhat的强大社区的支持下,在过去两年中发展迅速。在成为容器编排领域的领导者的同时,它也在朝着标准PAAS基础的方向发展。
登录采集方法
日志是任何系统必不可少的部分。 K8S官方文档还介绍了各种日志采集格式。总之,主要有以下三种方法:纯模式,DaemonSet模式和Sidecar模式。
本机方法:使用kubectl日志直接查看本地保存的日志,或通过docker引擎的日志驱动程序将日志重定向到文件,syslog,fluentd和其他系统。 DaemonSet方法:在K8S的每个节点上部署日志代理,从代理采集的所有容器的日志到服务器。边车方法:一种日志代理容器,在POD中运行边车,以存放由POD主容器生成的采集个日志。
采集方式比较
每种采集方法都具有某些优点和缺点。这里我们作一个简单的比较:
从上表中可以看出:
本机方法相对较弱,通常不建议在生产系统中使用。否则,很难完成问题调查和数据统计。 DaemonSet方法每个节点仅允许一个日志代理,这在资源消耗方面要小得多。但是,可伸缩性和租户隔离受到限制,这更适合具有单一功能或业务不多的集群。 Sidecar方法为每个POD分别部署一个日志代理,这会占用更多资源,但具有很强的灵活性和多租户隔离。建议将这种方法用于大型K8S群集或作为PAAS平台为多个业务方服务的群集。日志服务K8S 采集方法
DaemonSet和Sidecar模式各有优缺点,目前尚无方法可应用于所有场景。因此,我们的阿里云日志服务既支持DaemonSet方法又支持Sidecar方法,并且对每种方法都进行了一些额外的改进,更适合于K8S下的动态场景。
这两种模式都是基于Logtail实现的。日志服务客户端Logtail已被部署成百万计,每天有成千上万的应用程序和数PB的数据采集,并且已经进行了许多双1 1、双12测试。有关相关技术的共享,请参阅文章:多租户隔离技术+双重11实战效果,在轮询+ Inotify组合下的日志序列保存方案采集。
DaemonS 优采云 采集器方法
Logtail在DaemonSet模式下做了很多改编工作,包括:
有关文章的详细介绍,请参阅:
再次升级!阿里云Kubernetes日志解决方案
LC3观点:Kubernetes下的日志采集,存储和处理技术实践
Sidecar 采集方法
在虚拟机/物理机上,sidecar方法的配置和使用相对较小。 采集数据差异很小。从Logtail容器的角度来看:Logtail在“虚拟机”上工作,并且需要采集 /一些日志文件。
但是在容器场景中仍然有两个问题需要解决:
配置:使用业务流程来配置代理容器动态:需要适应POD的IP地址和主机名的更改
当前,Logtail容器通过环境变量支持相关参数的配置,并支持自定义的计算机组工作,可以完美解决以上两个问题。边车配置示例
Sidecar模式下的日志组件的安装和配置方法如下:
步骤1:部署Logtail容器。部署POD时,将日志路径安装到本地,然后将相应的卷安装到Logtail容器。必须使用ALIYUN_LOGTAIL_USER_ID,ALIYUN_LOGTAIL_CONFIG,ALIYUN_LOGTAIL_USER_DEFINED_ID配置Logtail容器,参数和值选择的含义是:标准Docker日志采集。
提示:
Logtail容器建议配置运行状况检查,以在操作环境,内核等发生异常时自动恢复。本示例中使用的Logtail镜像访问阿里云杭州公共网络镜像仓库。您可以根据需要替换成本区域的镜像,并使用Intranet方法。
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-sidecar-demo
namespace: kube-system
spec:
template:
metadata:
name: nginx-log-sidecar-demo
spec:
# volumes配置
volumes:
- name: nginx-log
emptyDir: {}
containers:
# 主容器配置
- name: nginx-log-demo
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--stdout=false", "--stderr=true", "--path=/var/log/nginx/access.log", "--total-count=1000000000", "--logs-per-sec=100"]
volumeMounts:
- name: nginx-log
mountPath: /var/log/ngin
# Logtail的Sidecar容器配置
- name: logtail
image: registry.cn-hangzhou.aliyuncs.com/log-service/logtail:latest
env:
# aliuid
- name: "ALIYUN_LOGTAIL_USER_ID"
value: "165421******3050"
# 自定义标识机器组配置
- name: "ALIYUN_LOGTAIL_USER_DEFINED_ID"
value: "nginx-log-sidecar"
# 启动配置(用于选择Logtail所在Region)
- name: "ALIYUN_LOGTAIL_CONFIG"
value: "/etc/ilogtail/conf/cn-hangzhou/ilogtail_config.json"
# 和主容器共享volume
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
# 健康检查
livenessProbe:
exec:
command:
- /etc/init.d/ilogtaild
- status
initialDelaySeconds: 30
periodSeconds: 30
第2步:配置计算机组
如下图所示,在Log Service控制台中创建了一个Logtail机器组,并且该机器组选择了一个自定义ID,该ID可以动态地适应POD ip地址的更改。具体步骤如下:
打开日志服务,并创建Project和Logstore。有关详细步骤,请参阅准备过程。在Log Service控制台的计算机组列表页面上,单击“创建计算机组”。选择用户定义的徽标,然后将在上一步中配置的ALIYUN_LOGTAIL_USER_DEFINED_ID填充到用户定义的徽标内容框中。
第3步:配置采集方法
创建计算机组后,可以配置相应文件的采集配置。当前,它支持最小的Nginx访问日志,分隔符日志,JSON日志,常规日志和其他格式。有关详细信息,请参阅:文本日志配置方法。此示例中的配置如下:
第4步:查询日志
完成采集配置并将其应用于计算机组后,可以在1分钟内将日志上传到采集,并且可以通过进入相应日志存储区的查询页面来查询采集中的日志。
高级日志
阿里云日志服务提供了完整的日志记录解决方案。日志采集只是第一步。以下相关功能是进行高级日志记录的基本方法:
日志上下文查询:快速查询:实时分析:快速分析:根据日志设置警报:配置市场:
有关更多高级日志内容,请参阅:日志服务学习路径。 查看全部
阿里云日志服务:DaemonSet和Sidecar模式的优缺点分析
摘要:DaemonSet和Sidecar模式各有优缺点。当前,没有一种方法可以应用于所有方案。因此,我们的阿里云日志服务既支持DaemonSet方法又支持Sidecar方法,并且对每种方法都进行了一些额外的改进,更适合于K8S下的动态场景。
Kubernetes(K8S)作为CNCF(云原生计算基金会)的核心项目,在Google和Redhat的强大社区的支持下,在过去两年中发展迅速。在成为容器编排领域的领导者的同时,它也在朝着标准PAAS基础的方向发展。
登录采集方法
日志是任何系统必不可少的部分。 K8S官方文档还介绍了各种日志采集格式。总之,主要有以下三种方法:纯模式,DaemonSet模式和Sidecar模式。
本机方法:使用kubectl日志直接查看本地保存的日志,或通过docker引擎的日志驱动程序将日志重定向到文件,syslog,fluentd和其他系统。 DaemonSet方法:在K8S的每个节点上部署日志代理,从代理采集的所有容器的日志到服务器。边车方法:一种日志代理容器,在POD中运行边车,以存放由POD主容器生成的采集个日志。
采集方式比较
每种采集方法都具有某些优点和缺点。这里我们作一个简单的比较:
从上表中可以看出:
本机方法相对较弱,通常不建议在生产系统中使用。否则,很难完成问题调查和数据统计。 DaemonSet方法每个节点仅允许一个日志代理,这在资源消耗方面要小得多。但是,可伸缩性和租户隔离受到限制,这更适合具有单一功能或业务不多的集群。 Sidecar方法为每个POD分别部署一个日志代理,这会占用更多资源,但具有很强的灵活性和多租户隔离。建议将这种方法用于大型K8S群集或作为PAAS平台为多个业务方服务的群集。日志服务K8S 采集方法
DaemonSet和Sidecar模式各有优缺点,目前尚无方法可应用于所有场景。因此,我们的阿里云日志服务既支持DaemonSet方法又支持Sidecar方法,并且对每种方法都进行了一些额外的改进,更适合于K8S下的动态场景。
这两种模式都是基于Logtail实现的。日志服务客户端Logtail已被部署成百万计,每天有成千上万的应用程序和数PB的数据采集,并且已经进行了许多双1 1、双12测试。有关相关技术的共享,请参阅文章:多租户隔离技术+双重11实战效果,在轮询+ Inotify组合下的日志序列保存方案采集。
DaemonS 优采云 采集器方法
Logtail在DaemonSet模式下做了很多改编工作,包括:
有关文章的详细介绍,请参阅:
再次升级!阿里云Kubernetes日志解决方案
LC3观点:Kubernetes下的日志采集,存储和处理技术实践
Sidecar 采集方法
在虚拟机/物理机上,sidecar方法的配置和使用相对较小。 采集数据差异很小。从Logtail容器的角度来看:Logtail在“虚拟机”上工作,并且需要采集 /一些日志文件。
但是在容器场景中仍然有两个问题需要解决:
配置:使用业务流程来配置代理容器动态:需要适应POD的IP地址和主机名的更改
当前,Logtail容器通过环境变量支持相关参数的配置,并支持自定义的计算机组工作,可以完美解决以上两个问题。边车配置示例
Sidecar模式下的日志组件的安装和配置方法如下:
步骤1:部署Logtail容器。部署POD时,将日志路径安装到本地,然后将相应的卷安装到Logtail容器。必须使用ALIYUN_LOGTAIL_USER_ID,ALIYUN_LOGTAIL_CONFIG,ALIYUN_LOGTAIL_USER_DEFINED_ID配置Logtail容器,参数和值选择的含义是:标准Docker日志采集。
提示:
Logtail容器建议配置运行状况检查,以在操作环境,内核等发生异常时自动恢复。本示例中使用的Logtail镜像访问阿里云杭州公共网络镜像仓库。您可以根据需要替换成本区域的镜像,并使用Intranet方法。
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-sidecar-demo
namespace: kube-system
spec:
template:
metadata:
name: nginx-log-sidecar-demo
spec:
# volumes配置
volumes:
- name: nginx-log
emptyDir: {}
containers:
# 主容器配置
- name: nginx-log-demo
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--stdout=false", "--stderr=true", "--path=/var/log/nginx/access.log", "--total-count=1000000000", "--logs-per-sec=100"]
volumeMounts:
- name: nginx-log
mountPath: /var/log/ngin
# Logtail的Sidecar容器配置
- name: logtail
image: registry.cn-hangzhou.aliyuncs.com/log-service/logtail:latest
env:
# aliuid
- name: "ALIYUN_LOGTAIL_USER_ID"
value: "165421******3050"
# 自定义标识机器组配置
- name: "ALIYUN_LOGTAIL_USER_DEFINED_ID"
value: "nginx-log-sidecar"
# 启动配置(用于选择Logtail所在Region)
- name: "ALIYUN_LOGTAIL_CONFIG"
value: "/etc/ilogtail/conf/cn-hangzhou/ilogtail_config.json"
# 和主容器共享volume
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
# 健康检查
livenessProbe:
exec:
command:
- /etc/init.d/ilogtaild
- status
initialDelaySeconds: 30
periodSeconds: 30
第2步:配置计算机组
如下图所示,在Log Service控制台中创建了一个Logtail机器组,并且该机器组选择了一个自定义ID,该ID可以动态地适应POD ip地址的更改。具体步骤如下:
打开日志服务,并创建Project和Logstore。有关详细步骤,请参阅准备过程。在Log Service控制台的计算机组列表页面上,单击“创建计算机组”。选择用户定义的徽标,然后将在上一步中配置的ALIYUN_LOGTAIL_USER_DEFINED_ID填充到用户定义的徽标内容框中。
第3步:配置采集方法
创建计算机组后,可以配置相应文件的采集配置。当前,它支持最小的Nginx访问日志,分隔符日志,JSON日志,常规日志和其他格式。有关详细信息,请参阅:文本日志配置方法。此示例中的配置如下:
第4步:查询日志
完成采集配置并将其应用于计算机组后,可以在1分钟内将日志上传到采集,并且可以通过进入相应日志存储区的查询页面来查询采集中的日志。
高级日志
阿里云日志服务提供了完整的日志记录解决方案。日志采集只是第一步。以下相关功能是进行高级日志记录的基本方法:
日志上下文查询:快速查询:实时分析:快速分析:根据日志设置警报:配置市场:
有关更多高级日志内容,请参阅:日志服务学习路径。
采集自动组合技术应用系统控制通过采集终端终端的位置
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-04-02 00:03
采集自动组合技术应用系统控制通过采集终端终端的位置,移动(实现点状、线状、面状显示),测距等信息,对模型进行快速的组合优化,达到更好的网格,模型的质量更优,能一系列控制节点进行同时控制,使网格划分更精细,根据网格粗细控制两条或三条扫描线的交点数(节点多会导致输出点偏多),终端采集的角点根据位置进行实时缩放(点越细网格细度越高,通过点的缩放实现能实现边缘的精细编辑),提高网格的质量,节点能准确锁定网格边缘点的值,同时改变边缘点的位置根据节点多少控制输出的点偏移量控制点位的偏移量。2节点组合优化设置扫描方案(。
1)将行业模型方案放置在扫描方案对应的扫描线上
2)将导入的模型进行顺序点选和任意方向扫描
3)选择扫描频率
4)选择是否切角
5)设置节点数
6)设置任意边缘点扫描间隔(数值越小越好)
7)选择加速开关输出带宽,
8)设置可接受的异常多的扫描次数(频率越高模型扫描越慢)优化采样点设置
1)通过有限元空间的轴方向扫描点来提取扫描数据
2)不接触轴或轴方向无实体
3)虚拟环境测量坐标轴最佳坐标系设置
4)网格划分平滑度提升
5)负载控制增加过滤单元的数量
6)扫描圆数降低
7)单元接触精度增加
8)节点变细扫描方案提升优化。输出网格节点控制节点设置controlcenterdimensionenhancevisualrangevertical/flatkvmview/lineexcel/meshpolylineblast/switch/windarg采集数据cam批量配置adbshellsaysnover或teamcentersnprocess采集卡设置phone-basedvideoandaudioupdates插入二维码检测snover可对支持二维码传输通道设置outofchainunmannedflowedinputing提高延迟和丢包率progressvideoincontrolsetupprofile设置每个扫描点和节点多少次输出数据类型,最小到十次,最大每个扫描点输出最多每个节点输出最多每个方格输出至少1个数据数量每个方格输出数据2个数据文件,相当于dat格式或者d3格式(完整类型)类型outdoorvideo按照设定的格式输出(网格数据存于non-spatialstatementviewpoints,默认mframemaskd3,单位为gm2,单位像素点)定义范围采样两条输出网格节点的节点,每条输出网格节点节点的输出网格节点数controlvertex/vertices,单位e始终选择1路径上可执行二维码的渲染操作freescaleedges单位radians或0.2ph,每一个网格的设置可以不同(d3格式,graphitemap格式,或者mesh格式)运行二维码渲染器uniquescanner定义输出节点渲染的位置(下)输出采。 查看全部
采集自动组合技术应用系统控制通过采集终端终端的位置
采集自动组合技术应用系统控制通过采集终端终端的位置,移动(实现点状、线状、面状显示),测距等信息,对模型进行快速的组合优化,达到更好的网格,模型的质量更优,能一系列控制节点进行同时控制,使网格划分更精细,根据网格粗细控制两条或三条扫描线的交点数(节点多会导致输出点偏多),终端采集的角点根据位置进行实时缩放(点越细网格细度越高,通过点的缩放实现能实现边缘的精细编辑),提高网格的质量,节点能准确锁定网格边缘点的值,同时改变边缘点的位置根据节点多少控制输出的点偏移量控制点位的偏移量。2节点组合优化设置扫描方案(。
1)将行业模型方案放置在扫描方案对应的扫描线上
2)将导入的模型进行顺序点选和任意方向扫描
3)选择扫描频率
4)选择是否切角
5)设置节点数
6)设置任意边缘点扫描间隔(数值越小越好)
7)选择加速开关输出带宽,
8)设置可接受的异常多的扫描次数(频率越高模型扫描越慢)优化采样点设置
1)通过有限元空间的轴方向扫描点来提取扫描数据
2)不接触轴或轴方向无实体
3)虚拟环境测量坐标轴最佳坐标系设置
4)网格划分平滑度提升
5)负载控制增加过滤单元的数量
6)扫描圆数降低
7)单元接触精度增加
8)节点变细扫描方案提升优化。输出网格节点控制节点设置controlcenterdimensionenhancevisualrangevertical/flatkvmview/lineexcel/meshpolylineblast/switch/windarg采集数据cam批量配置adbshellsaysnover或teamcentersnprocess采集卡设置phone-basedvideoandaudioupdates插入二维码检测snover可对支持二维码传输通道设置outofchainunmannedflowedinputing提高延迟和丢包率progressvideoincontrolsetupprofile设置每个扫描点和节点多少次输出数据类型,最小到十次,最大每个扫描点输出最多每个节点输出最多每个方格输出至少1个数据数量每个方格输出数据2个数据文件,相当于dat格式或者d3格式(完整类型)类型outdoorvideo按照设定的格式输出(网格数据存于non-spatialstatementviewpoints,默认mframemaskd3,单位为gm2,单位像素点)定义范围采样两条输出网格节点的节点,每条输出网格节点节点的输出网格节点数controlvertex/vertices,单位e始终选择1路径上可执行二维码的渲染操作freescaleedges单位radians或0.2ph,每一个网格的设置可以不同(d3格式,graphitemap格式,或者mesh格式)运行二维码渲染器uniquescanner定义输出节点渲染的位置(下)输出采。

