
采集自动组合
ET手动采集器 V3.2.2 安全版
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-08-25 12:36
ET手动采集器(ET网站自动采集器)是一款网站内容手动更新神器独立的红色软件。想知道这样能够使网站自动采集呢? 那就快试试红色先锋小编推荐的ET手动采集器吧! 稳定易用,信息采集必备之选。有须要的用户快来绿色先锋下载吧。
【全手动无人值守】
无需人工值守,24小时手动实时监控目标,实时高效采集,昼夜不停为您提供内容更新。满足常年运行需求,将您从繁杂工作中解脱
【适用广泛】
最全能的采集软件,支持任意类型网站采集,适用率高达99.9%,支持发布到所有类型网站程序,更可以采集本地文件,免插口发布。
【信息随心所欲】
支持信息自由组合,通过强悍的数据整理功能对信息深度加工,创造全新内容
【任意格式文件下载】
不论静态或动态,不论是图片、音乐、电影、软件,又或则是PDF文档、WORD文档,甚至种子文件,只要你想
【伪原创】
高速同反义词替换、多词随机替换、段落随机排序,助力内容SEO
【无限多级页面采集】
无论垂直方向多层页面,还是平行方向复数分页,抑或AJAX调用页面,为你轻松采集
【自由扩充】
开放的插口模式,可以自由二次开发,自定义任何功能,实现所有需求
软件外置了包括discuzX,phpwind,dedecms,wordpress,phpcms,帝国cms,动易,joomla,pbdigg,php168,bbsxp,phpbb,dvbbs,typecho,emblog等大量常用系统的范例。
更新日志
1、新增:自动动词模块,可用于手动提取关键词/TAG。
2、新增;数据项可以选择指定内容模式,支持引用其他数据项、随机字符串等预设内容。
3、优化:采集配置根据列表页、采集页、数据项的从属关系优化了界面。
4、优化:数据项如今可以选择是否使用翻译了,以便捷对翻译内容进行整理。
5、优化:数据项如今可以独立选择是否修正网址了。
6、新增:采集页和数据分页的网址合成如今可以引用数据项,适应更复杂的网址合成。
7、优化:方案间隔时间从系统设置窗口移到制定方案窗口,可以为每位方案单独设置间隔时间了。 查看全部
ET手动采集器 V3.2.2 安全版
ET手动采集器(ET网站自动采集器)是一款网站内容手动更新神器独立的红色软件。想知道这样能够使网站自动采集呢? 那就快试试红色先锋小编推荐的ET手动采集器吧! 稳定易用,信息采集必备之选。有须要的用户快来绿色先锋下载吧。
【全手动无人值守】
无需人工值守,24小时手动实时监控目标,实时高效采集,昼夜不停为您提供内容更新。满足常年运行需求,将您从繁杂工作中解脱
【适用广泛】
最全能的采集软件,支持任意类型网站采集,适用率高达99.9%,支持发布到所有类型网站程序,更可以采集本地文件,免插口发布。
【信息随心所欲】
支持信息自由组合,通过强悍的数据整理功能对信息深度加工,创造全新内容
【任意格式文件下载】
不论静态或动态,不论是图片、音乐、电影、软件,又或则是PDF文档、WORD文档,甚至种子文件,只要你想
【伪原创】
高速同反义词替换、多词随机替换、段落随机排序,助力内容SEO
【无限多级页面采集】
无论垂直方向多层页面,还是平行方向复数分页,抑或AJAX调用页面,为你轻松采集
【自由扩充】
开放的插口模式,可以自由二次开发,自定义任何功能,实现所有需求
软件外置了包括discuzX,phpwind,dedecms,wordpress,phpcms,帝国cms,动易,joomla,pbdigg,php168,bbsxp,phpbb,dvbbs,typecho,emblog等大量常用系统的范例。

更新日志
1、新增:自动动词模块,可用于手动提取关键词/TAG。
2、新增;数据项可以选择指定内容模式,支持引用其他数据项、随机字符串等预设内容。
3、优化:采集配置根据列表页、采集页、数据项的从属关系优化了界面。
4、优化:数据项如今可以选择是否使用翻译了,以便捷对翻译内容进行整理。
5、优化:数据项如今可以独立选择是否修正网址了。
6、新增:采集页和数据分页的网址合成如今可以引用数据项,适应更复杂的网址合成。
7、优化:方案间隔时间从系统设置窗口移到制定方案窗口,可以为每位方案单独设置间隔时间了。
优采云采集器官方版 v6.0.1
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-08-22 00:47
优采云采集器官方版是一款强悍的网站采集器,优采云采集器软件才能24小时不间断的运行,一直采集,不死机,不停顿,也不需要人员看守,提高采集的效率,该软件适用于各类平台,无论是网页还是淘宝等,都能采集,而且采集的资源齐全,能够详尽的进行分类,用户也可以自己设置自己要采集的类型早已采集的时间。
优采云采集器官方版简介
优采云采集器是一款采集网页数据的智能软件,优采云数据采集系统以完全自主研制的分布式云计算平台为核心,可以在太短的时间内,轻松从各类不同的网站或者网页获取大量的规范化数据,帮助任何须要从网页获取信息的顾客实现数据自动化采集,编辑,规范化,摆脱对人工搜索及搜集数据的依赖,降低获取信息的成本,提高效率。
优采云采集器官方版特色
简易采集
简易采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的冗长,支持更多网站的采集。
优采云采集器官方版功能
1. 金融数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3. 监控竞争对手最新信息,包括商品价钱及库存; 查看全部
优采云采集器官方版 v6.0.1
优采云采集器官方版是一款强悍的网站采集器,优采云采集器软件才能24小时不间断的运行,一直采集,不死机,不停顿,也不需要人员看守,提高采集的效率,该软件适用于各类平台,无论是网页还是淘宝等,都能采集,而且采集的资源齐全,能够详尽的进行分类,用户也可以自己设置自己要采集的类型早已采集的时间。
优采云采集器官方版简介
优采云采集器是一款采集网页数据的智能软件,优采云数据采集系统以完全自主研制的分布式云计算平台为核心,可以在太短的时间内,轻松从各类不同的网站或者网页获取大量的规范化数据,帮助任何须要从网页获取信息的顾客实现数据自动化采集,编辑,规范化,摆脱对人工搜索及搜集数据的依赖,降低获取信息的成本,提高效率。
优采云采集器官方版特色
简易采集
简易采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的冗长,支持更多网站的采集。
优采云采集器官方版功能
1. 金融数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3. 监控竞争对手最新信息,包括商品价钱及库存;
优采云浏览器(数据库采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-21 14:27
优采云浏览器(数据库采集器)是一款可视化的自动化脚本工具,我们可以通过设置脚本,达到手动登入,识别验证码,自动抓取数据,自动递交数据,点击网页,下载文件,操作数据库,收发短信等操作。
编程语言
优采云浏览器的编程语言是 C#,C#综合了 VB 简单的可视化操作和 C++的高运行效率,增强开发效率的同时也致力于清除编程中可能造成严重结果的错误,以其强悍的操作能力、优雅的句型风格、创新的语言特点和方便的面向组件编程的支持成为软件开发的首选语言。
需要安装.net 4.5:
软件特色
优采云浏览器是一款可视化的自动化脚本工具,我们可以通过设置脚本,达到手动登入,识别验证码,自动抓取数据,自动递交数据,点击网页,下载文件,操作数据库,收发短信等操作。还可以使用逻辑操作,完成判别,循环,跳转等操作。所有的功能完全是自由组合,可以写出功能强悍又独一无二的腿原本辅助我们的工作,还可以生成单独的EXE程序进行销售
浏览器可以读取写入mysql,sqlserver,sqlite,access四种数据库。你可以在将任务数据放到数据库,通过浏览器读取并运行,运行完成后,再使用浏览器标记为已使用过。你可以在浏览器的使用过程中随时使用数据库,十分便捷。
优采云浏览器是可以帮助你们实现自动化的网页操作。也能使你们做的脚本生成程序去销售,生成的程序可以自定义软件名子
产品特性
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理过的内容,jax,瀑布流之类的采集非常简单,一些js加密的数据也能轻易得到,不需要抓取数据包剖析。
自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页上的元素,操作数据库,验证码识别,抓取循环记录,处理列表,条件判定,完全自定义流程,采集就像是搭积木,功能自由组合。
自动打码
采集速度快,程序重视采集效率,页面解析速率飞快,不需要访问的页面或广告之类可以直接屏蔽,加快访问速率。
生成EXE
不只是个采集器,更是营销神器。不光能采集数据保存到数据库或其它地方,还可以群发现有的数据到各个网站。可以做到手动登入,自动辨识验证码,是万能的浏览器。
项目管理
利用解决方案可以直接生成单个应用程序。单个程序可以脱离优采云浏览器并运行,官方提供了一个软件管理平台,用户可以进行授权等管理。每个用户都是开发者,每个人都能从平台中获利。 查看全部
优采云浏览器(数据库采集器)
优采云浏览器(数据库采集器)是一款可视化的自动化脚本工具,我们可以通过设置脚本,达到手动登入,识别验证码,自动抓取数据,自动递交数据,点击网页,下载文件,操作数据库,收发短信等操作。
编程语言
优采云浏览器的编程语言是 C#,C#综合了 VB 简单的可视化操作和 C++的高运行效率,增强开发效率的同时也致力于清除编程中可能造成严重结果的错误,以其强悍的操作能力、优雅的句型风格、创新的语言特点和方便的面向组件编程的支持成为软件开发的首选语言。
需要安装.net 4.5:
软件特色
优采云浏览器是一款可视化的自动化脚本工具,我们可以通过设置脚本,达到手动登入,识别验证码,自动抓取数据,自动递交数据,点击网页,下载文件,操作数据库,收发短信等操作。还可以使用逻辑操作,完成判别,循环,跳转等操作。所有的功能完全是自由组合,可以写出功能强悍又独一无二的腿原本辅助我们的工作,还可以生成单独的EXE程序进行销售
浏览器可以读取写入mysql,sqlserver,sqlite,access四种数据库。你可以在将任务数据放到数据库,通过浏览器读取并运行,运行完成后,再使用浏览器标记为已使用过。你可以在浏览器的使用过程中随时使用数据库,十分便捷。
优采云浏览器是可以帮助你们实现自动化的网页操作。也能使你们做的脚本生成程序去销售,生成的程序可以自定义软件名子

产品特性
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理过的内容,jax,瀑布流之类的采集非常简单,一些js加密的数据也能轻易得到,不需要抓取数据包剖析。
自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页上的元素,操作数据库,验证码识别,抓取循环记录,处理列表,条件判定,完全自定义流程,采集就像是搭积木,功能自由组合。
自动打码
采集速度快,程序重视采集效率,页面解析速率飞快,不需要访问的页面或广告之类可以直接屏蔽,加快访问速率。
生成EXE
不只是个采集器,更是营销神器。不光能采集数据保存到数据库或其它地方,还可以群发现有的数据到各个网站。可以做到手动登入,自动辨识验证码,是万能的浏览器。
项目管理
利用解决方案可以直接生成单个应用程序。单个程序可以脱离优采云浏览器并运行,官方提供了一个软件管理平台,用户可以进行授权等管理。每个用户都是开发者,每个人都能从平台中获利。
数据规整化:清理、转换、合并、重塑
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2020-08-21 05:09
数据剖析和建模方面的大量编程工作都是用在数据打算上的:加载、清理、转换以及塑造。有时候,存放在文件或数据库中的数据并不能满足你的数据处理应用的要求。许多人都选择使用通用编程语言(如python、perl、R或java)或UNIX文本处理工具(sed或awk)对数据格式进行专门处理。幸运的是,pandas和python标准库提供了一组中级的、灵活的、高效的核心函数和算法,它们让你就能轻松地将数据规整化为正确的方式。
1. 合并数据集
pandas对象中的数据可以通过一些外置的方法进行合并:pandas.merge、pandas.concat、combine_first。我们分别对它们进行讲解,并给出一些事例。
1.1 数据库风格的DataFrame合并
数据集的合并(merge)或联接(join)运算是通过一个或多个键将行链接上去的。要注意区别的是:多对一的合并和多对多的合并(多对多联接形成的是行的笛卡尔积。由于左侧的DataFrame有3个”b”行,右边的有2个,所以最终结果中就有6个”b”行)
你须要注意的是,默认情况下,merge做的是”inner”连接;结果中的键是交集。其他方法还有”left”、”right”、以及”outer”。外联接求取的是键的并集,组合了左联接和右联接的疗效:
要依据多个键进行合并,传入一个由列名组成的列表即可:
1.2 轴向联接
1.另一种数据合并运算也被叫做联接、绑定或堆叠。Numpy有一个用于合并原创Numpy链表的concatenation函数。调用concat可以将值和索引黏合在一起,默认情况下,concat是在axis=0(对应的是行)上工作的,最终形成一个新的series。如果传入axis=1,则结果都会弄成一个DataFrame(axis=1是对应列)。
2.传入join=’inner’即可得到它们的交集;你也可以通过join_axes指定要在其他轴上使用的索引
2. 重塑和轴向旋转
2.1 重塑层次化索引
层次化索引为DataFrame数据的重排任务提供了一种具有良好一致性的形式。主要功能有二:
1. stack:将数据的列”旋转”为行。
2. unstack:将数据的行”旋转”为列。
(未完待续……..) 查看全部
数据规整化:清理、转换、合并、重塑
数据剖析和建模方面的大量编程工作都是用在数据打算上的:加载、清理、转换以及塑造。有时候,存放在文件或数据库中的数据并不能满足你的数据处理应用的要求。许多人都选择使用通用编程语言(如python、perl、R或java)或UNIX文本处理工具(sed或awk)对数据格式进行专门处理。幸运的是,pandas和python标准库提供了一组中级的、灵活的、高效的核心函数和算法,它们让你就能轻松地将数据规整化为正确的方式。
1. 合并数据集
pandas对象中的数据可以通过一些外置的方法进行合并:pandas.merge、pandas.concat、combine_first。我们分别对它们进行讲解,并给出一些事例。
1.1 数据库风格的DataFrame合并
数据集的合并(merge)或联接(join)运算是通过一个或多个键将行链接上去的。要注意区别的是:多对一的合并和多对多的合并(多对多联接形成的是行的笛卡尔积。由于左侧的DataFrame有3个”b”行,右边的有2个,所以最终结果中就有6个”b”行)
你须要注意的是,默认情况下,merge做的是”inner”连接;结果中的键是交集。其他方法还有”left”、”right”、以及”outer”。外联接求取的是键的并集,组合了左联接和右联接的疗效:
要依据多个键进行合并,传入一个由列名组成的列表即可:
1.2 轴向联接
1.另一种数据合并运算也被叫做联接、绑定或堆叠。Numpy有一个用于合并原创Numpy链表的concatenation函数。调用concat可以将值和索引黏合在一起,默认情况下,concat是在axis=0(对应的是行)上工作的,最终形成一个新的series。如果传入axis=1,则结果都会弄成一个DataFrame(axis=1是对应列)。
2.传入join=’inner’即可得到它们的交集;你也可以通过join_axes指定要在其他轴上使用的索引
2. 重塑和轴向旋转
2.1 重塑层次化索引
层次化索引为DataFrame数据的重排任务提供了一种具有良好一致性的形式。主要功能有二:
1. stack:将数据的列”旋转”为行。
2. unstack:将数据的行”旋转”为列。
(未完待续……..)
SKYCC组合营销软件新蓝图:多样化采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-08-18 15:31
SKYCC组合营销软件新蓝图:多样化采集自从2012年2月SKYCC组合营销软件的推出,SKYCC组合营销软件的相关报导也是紧跟不断,SKYCC各大特点一一被披露下来。随着组合营销软件的诞生,大家肯定是想在了解它各大特点之余,更想关注它细小的亮点。下面解析SKYCC组合营销软件上面的多元化采集。我们你们都晓得,无论是企业推广人员还是做SEO优化的人员,一篇好的文章对于网站关键词的优化有着重要的作用。但当我们没有时间去写文章,会是因为所需的文章太多的时侯我们怎样办呢?SKYCC多元化的采集就可以解决那些问题。SKYCC组合营销软件的文章添加
分为3种模式(全手动采集,半自动采集,手动添加)。下面介绍一下全手动采集和半自动采集。SKYCC组合营销软件采集功能上面分为两种:第一种采集功能(全手动采集)采集文章功能很简单,只需输入自定义关键词。点击“开始搜索”,就可以全手动快速的采集到收录您关键词的大量文章,让您不用再为写文章发愁。第二种采集功能(半自动采集),需要一点的程序基础,软件会根据您填写的采集规则在特定页面批量采集文章,采集成功的文章会手动添加到“文章管理”列表。采集或者添加完文章后,还可以使用SKYCC组合营销软件外置的伪原创功能,来降低文章的原创性。收录疗效大大提高。直线提高营销疗效。 查看全部
SKYCC组合营销软件新蓝图:多样化采集

SKYCC组合营销软件新蓝图:多样化采集自从2012年2月SKYCC组合营销软件的推出,SKYCC组合营销软件的相关报导也是紧跟不断,SKYCC各大特点一一被披露下来。随着组合营销软件的诞生,大家肯定是想在了解它各大特点之余,更想关注它细小的亮点。下面解析SKYCC组合营销软件上面的多元化采集。我们你们都晓得,无论是企业推广人员还是做SEO优化的人员,一篇好的文章对于网站关键词的优化有着重要的作用。但当我们没有时间去写文章,会是因为所需的文章太多的时侯我们怎样办呢?SKYCC多元化的采集就可以解决那些问题。SKYCC组合营销软件的文章添加

分为3种模式(全手动采集,半自动采集,手动添加)。下面介绍一下全手动采集和半自动采集。SKYCC组合营销软件采集功能上面分为两种:第一种采集功能(全手动采集)采集文章功能很简单,只需输入自定义关键词。点击“开始搜索”,就可以全手动快速的采集到收录您关键词的大量文章,让您不用再为写文章发愁。第二种采集功能(半自动采集),需要一点的程序基础,软件会根据您填写的采集规则在特定页面批量采集文章,采集成功的文章会手动添加到“文章管理”列表。采集或者添加完文章后,还可以使用SKYCC组合营销软件外置的伪原创功能,来降低文章的原创性。收录疗效大大提高。直线提高营销疗效。
KDD 2019 | 自动探求特点组合,第四范式提出新方式AutoCross
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-08-18 05:03
机器之心专栏
作者:罗远飞、王梦硕、周浩、姚权铭
涂威威、陈雨强、杨强、戴文渊
特征组合是提升模型疗效的重要手段,但借助专家自动探求和试错成本过低且过分冗长。于是,第四范式提出了一种新型特点组合方式 AutoCross,该方式可在实际应用中手动实现表数据的特点组合,提高机器学习算法的预测能力,并提高效率和有效性。目前,该论文已被数据挖掘领域顶会 KDD 2019 接收。
论文简介
论文:AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications
论文链接:
本文提出了一种在实际应用中手动实现表数据特点组合的方式 AutoCross。该方式可以获得特点之间有用的相互作用,并提升机器学习算法的预测能力。该方式借助集束搜索策略(beam search strategy)构建有效的组合特点,其中收录仍未被现有工作覆盖的高阶(两个以上)特征组合,弥补了此前工作的不足。
此外,该研究提出了连续小批量梯度增长和多细度离散化,以进一步提升效率和有效性,同时确保简单,无需机器学习专业知识或繁琐的超参数调整。这些算法致力增加分布式估算中涉及的估算、传输和储存成本。在基准数据集和真实业务数据集上的实验结果表明,AutoCross 可以明显提升线性模型和深度模型对表数据的学习能力和性能,优于其他基于搜索和深度学习的特点生成方式,进一步证明了其有效性和效率。
背景介绍
近年来,机器学习似乎已在推荐系统、在线广告、金融市场剖析等众多领域取得了好多成功,但在这种成功的应用中,人类专家参与了机器学习的所有阶段,包括:定义问题、采集数据、特征工程、调整模型超参数,模型评估等。
而这种任务的复杂性常常超出了非机器学习专家的能力范围。机器学习技术使用门槛高、专家成本昂贵等问题成为了阻碍 AI 普及的关键诱因。因此,AutoML 的出现被视为提升机器学习易用性的一种最有效方式,通过技术手段减低对人类专家的依赖,让更多的人应用 AI,获得更大的社会和商业效益。
众所周知,机器学习的性能很大程度上取决于特点的质量。由于原创特点极少形成令人满意的结果,因此一般要对特点进行组合,以更好地表示数据并提升学习性能。例如在新闻推荐中,若只有新闻类型、用户 ID 两类特点,模型只能分别预测不同新闻类型或不同用户 ID 对点击率的影响。通过加入新闻类型 x 用户 ID 组合特点,模型就可学习到一个用户对不同新闻的偏好。再加入时间等特点进行高阶组合,模型就可对一个用户在不同时间对不同新闻的偏好进行预测,提升模型的个性化预测能力。
特征组合作为提升模型疗效的重要手段,以往大多须要建立庞大的数据科学家团队,依靠她们的经验进行探求和试错,但冗长、低效的过程令科学家非常苦闷,且并非所有企业都能承受昂贵的成本。
第四范式从很早便开始关注并精耕 AutoML 领域,从解决顾客业务核心下降的角度出发,构建了反欺诈、个性化推荐等业务场景下的 AutoML,并将其赋能给企业的普通开发人员,取得了接近甚至超过数据科学家的业务疗效。其中,AutoCross 发挥了重要的作用。
痛点
特征组合是对从数据中提取的海量原创特点进行组合的过程,采用稀疏特点叉乘得出组合特点。在线性模型如 LR 只能描画特点间的线性关系、表达能力受限,而非线性模型如 GBDT 不能应用于大规模离散特点场景的情况下,特征组合就能降低数据的非线性,从而提升性能。
但枚举所有组合特点,理论上很难做到,因为可能的组合特点数是指数级的,同时暴力添加特点可能会造成学习性能增长,因为它们可能是无关的或冗余的特点,从而降低学习难度。
虽然深度神经网络可手动建立高阶特点 (generate high-order features),但面对大多数以表方式呈现的业务数据,最先进的基于深度学习的方式难以有效囊括所有高阶组合特点,且存在可解释性差、计算成本高等恶果。该论文投稿时,最先进的深度学习方法是 xDeepFM [1]。这篇论文证明了 xDeepFM 可生成的特点是 AutoCross 可生成特点嵌入(embedding)的子集。
AutoCross 的优势
实现过程
给定训练数据 ,并将其界定为训练集 和验证集 。我们可以用一个特点集合 S 来表示 ,并用学习算法 L 训练一个模型 。之后,用验证集和同一个特点集合 S 计算一个须要被最大化的指标 。特征组合搜索问题可以定义为搜索一个最优子特点集的问题:
其中 F 是 的原创特点集合,收录 F 所有原创特点以及基于 F 可生成的所有组合特点。
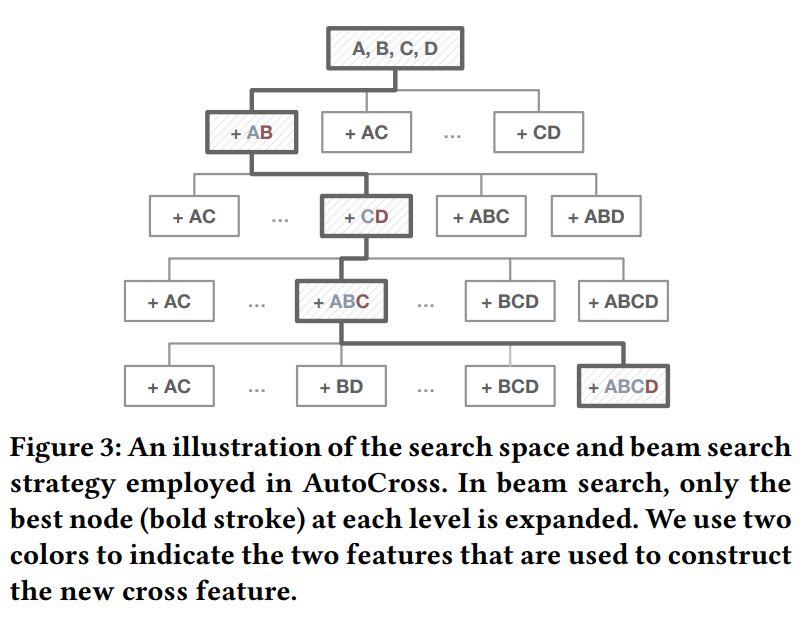
但是,假设原创特点数为 d,则上述问题中所有可能解的数目是 ,搜索空间巨大。为了提升搜索效率,AutoCross 将搜索最优子特点集的问题转换为用贪婪策略逐渐建立较优解的问题。首先,AutoCross 考虑一个树结构的搜索空间 (图 3),其中每一个节点表示一个子特点集。之后,用集束搜索策略在 上搜索较优解。通过这些方式,AutoCross 只须要访问 个候选解,极大地提升了搜索效率。AutoCross 的整体算法如算法 1 所示。
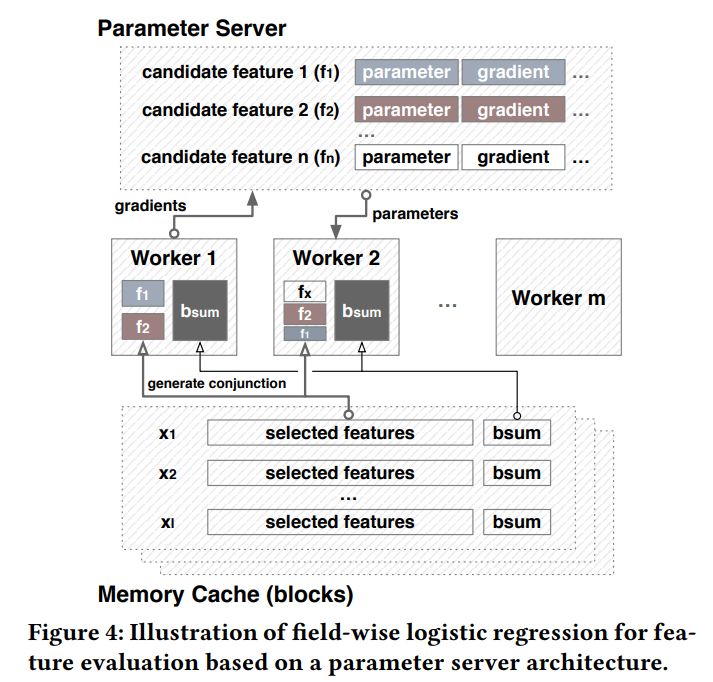
算法 1 中的一个关键步骤是评估候选特征集。最直接的方式是用每位候选特征集训练模型并评估其性能,但是这些方式估算代价巨大,难以在搜索过程中反复执行。为了提升特征集评估的效率,AutoCross 提出了逐域对数概率回归(field-wise logistic regression)和连续批训练梯度增长(successive mini-batch gradient descent)方法。
为了提升特征集评估效率,逐域对数概率回归做出两种近似。首先,用特点集在对数概率回归模型上的表现近似最终将使用这个特点集的模型上的表现;其次,在考虑 中一个节点的子节点时,不改变该节点收录特点对应的权重(weight),仅训练子节点新增特点的权重。
图 4 说明了怎样将逐域对数概率回归布署在参数服务器构架上。逐域对数概率回归与参数服务器的结合可以提升特征集评估的储存效率、传输效率和估算效率。在逐域对数概率回归训练结束后,AutoCross 计算训练得模型的指标,并借此方式来评估每一个候选特征集。
AutoCross 采用连续批训练梯度增长方式进一步提升特征集评估的效率。该方式借鉴 successive halving 算法 [2],认为每一个候选特征集是 multi-arm bandit 问题中的一个 arm,对一个特点集用一个数据块进行权重更新相当于拉了一次对应的 arm,其回报为该次训练后的验证集 AUC。
具体算法见算法 2,算法 2 中惟一的参数是数据块的数目 N。N 可以按照数据的大小和估算环境自适应地确定。在使用连续批训练梯度增长时,用户不需要象使用传统的 subsampling 方法一样调整 mini-batch 的规格和采样率。
为了支持数值特点与离散特点的组合,AutoCross 在预处理时将数值特点离散化为离散特点。AutoCross 提出了多细度离散化(multi-granularity discretization)方法,使得用户不需要反复调整离散化的细度。多细度离散化思想简单:将每一个数值特点,根据不同细度界定为多个离散特点。然后采用逐域对数概率回归选购出最优的离散特点。多个界定细度既可以由用户指定,也可以由 AutoCross 根据数据大小和估算环境来自适应地选择,从而增加了用户的使用难度。
实验结果
该论文在十个数据集(五个公开、五个实际业务)上进行了实验。比较的方式包括:
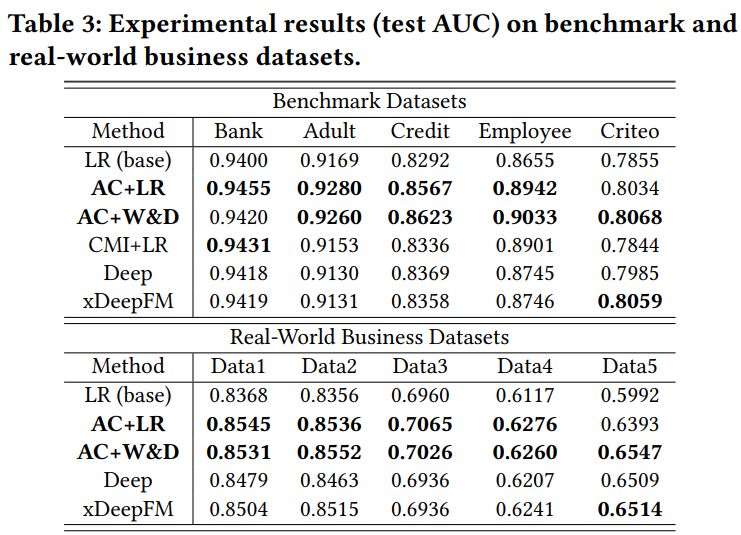
效果比较:如下表 3 所示,AC+LR 和 AC+W&D 在大部分数据集上的排行都在前两位。这彰显了 AutoCross 产生的特点除了可以提高 LR 模型,也可以用于增强深度学习模型的性能,并且 AC+LR 和 AC+W&D 的疗效都优于 xDeepFM。如之前所说,xDeepFM 所生成的特点不能完全收录 AutoCross 生成的特点。这些结果彰显出显式生成高阶组合特点的疗效优势。
高阶特点的作用:见表 5 和图 6。从中可以得出,高阶组合特点可以有效提升模型性能。
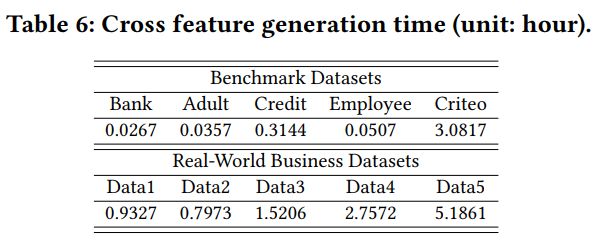
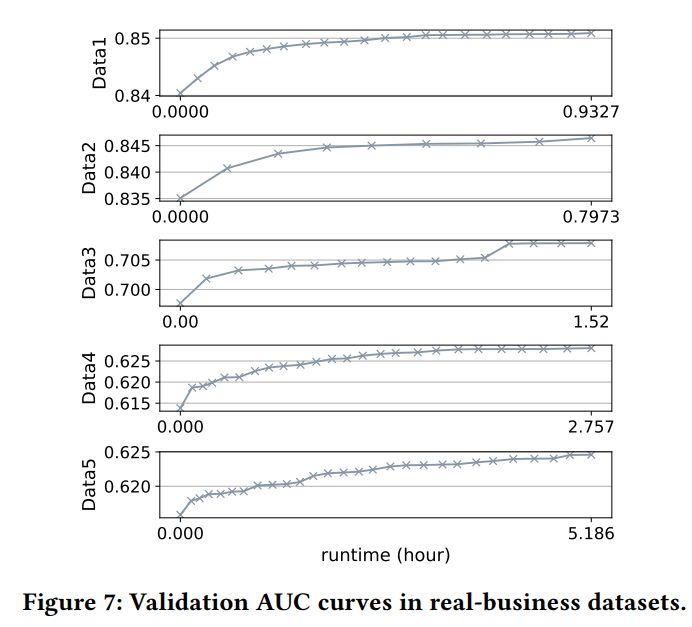
时间消耗:见表 6、图 7(主要做展示用)。
推断延后:见表 7。从中可以得出:AC+LR 的推测速率比 AC+W&D、Deep、xDeepFM 快几个数量级。这说明 AutoCross 不仅可以提升模型表现,同时保证了太低的推论延后。
参考文献
[1] J. Lian, X. Zhou, F. Zhang, Z. Chen, X. Xie, and G. Sun. 2018. xDeepFM: Com- bining Explicit and Implicit Feature Interactions for Recommender Systems. In International Conference on Knowledge Discovery & Data Mining.
[2] K. Jamieson and A. Talwalkar. 2016. Non-stochastic best arm identification and hyperparameter optimization. In Artificial Intelligence and Statistics. 240–248.
[3] O. Chapelle, E. Manavoglu, and R. Rosales. 2015. Simple and scalable response prediction for display advertising. ACM Transactions on Intelligent Systems and Technology (TIST) 5, 4 (2015), 61.
------------------------------------------------
加入机器之心(全职记者 / 实习生):
投稿或寻求报导: 查看全部
KDD 2019 | 自动探求特点组合,第四范式提出新方式AutoCross
机器之心专栏
作者:罗远飞、王梦硕、周浩、姚权铭
涂威威、陈雨强、杨强、戴文渊
特征组合是提升模型疗效的重要手段,但借助专家自动探求和试错成本过低且过分冗长。于是,第四范式提出了一种新型特点组合方式 AutoCross,该方式可在实际应用中手动实现表数据的特点组合,提高机器学习算法的预测能力,并提高效率和有效性。目前,该论文已被数据挖掘领域顶会 KDD 2019 接收。
论文简介
论文:AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications

论文链接:
本文提出了一种在实际应用中手动实现表数据特点组合的方式 AutoCross。该方式可以获得特点之间有用的相互作用,并提升机器学习算法的预测能力。该方式借助集束搜索策略(beam search strategy)构建有效的组合特点,其中收录仍未被现有工作覆盖的高阶(两个以上)特征组合,弥补了此前工作的不足。
此外,该研究提出了连续小批量梯度增长和多细度离散化,以进一步提升效率和有效性,同时确保简单,无需机器学习专业知识或繁琐的超参数调整。这些算法致力增加分布式估算中涉及的估算、传输和储存成本。在基准数据集和真实业务数据集上的实验结果表明,AutoCross 可以明显提升线性模型和深度模型对表数据的学习能力和性能,优于其他基于搜索和深度学习的特点生成方式,进一步证明了其有效性和效率。
背景介绍
近年来,机器学习似乎已在推荐系统、在线广告、金融市场剖析等众多领域取得了好多成功,但在这种成功的应用中,人类专家参与了机器学习的所有阶段,包括:定义问题、采集数据、特征工程、调整模型超参数,模型评估等。
而这种任务的复杂性常常超出了非机器学习专家的能力范围。机器学习技术使用门槛高、专家成本昂贵等问题成为了阻碍 AI 普及的关键诱因。因此,AutoML 的出现被视为提升机器学习易用性的一种最有效方式,通过技术手段减低对人类专家的依赖,让更多的人应用 AI,获得更大的社会和商业效益。
众所周知,机器学习的性能很大程度上取决于特点的质量。由于原创特点极少形成令人满意的结果,因此一般要对特点进行组合,以更好地表示数据并提升学习性能。例如在新闻推荐中,若只有新闻类型、用户 ID 两类特点,模型只能分别预测不同新闻类型或不同用户 ID 对点击率的影响。通过加入新闻类型 x 用户 ID 组合特点,模型就可学习到一个用户对不同新闻的偏好。再加入时间等特点进行高阶组合,模型就可对一个用户在不同时间对不同新闻的偏好进行预测,提升模型的个性化预测能力。
特征组合作为提升模型疗效的重要手段,以往大多须要建立庞大的数据科学家团队,依靠她们的经验进行探求和试错,但冗长、低效的过程令科学家非常苦闷,且并非所有企业都能承受昂贵的成本。
第四范式从很早便开始关注并精耕 AutoML 领域,从解决顾客业务核心下降的角度出发,构建了反欺诈、个性化推荐等业务场景下的 AutoML,并将其赋能给企业的普通开发人员,取得了接近甚至超过数据科学家的业务疗效。其中,AutoCross 发挥了重要的作用。
痛点
特征组合是对从数据中提取的海量原创特点进行组合的过程,采用稀疏特点叉乘得出组合特点。在线性模型如 LR 只能描画特点间的线性关系、表达能力受限,而非线性模型如 GBDT 不能应用于大规模离散特点场景的情况下,特征组合就能降低数据的非线性,从而提升性能。
但枚举所有组合特点,理论上很难做到,因为可能的组合特点数是指数级的,同时暴力添加特点可能会造成学习性能增长,因为它们可能是无关的或冗余的特点,从而降低学习难度。
虽然深度神经网络可手动建立高阶特点 (generate high-order features),但面对大多数以表方式呈现的业务数据,最先进的基于深度学习的方式难以有效囊括所有高阶组合特点,且存在可解释性差、计算成本高等恶果。该论文投稿时,最先进的深度学习方法是 xDeepFM [1]。这篇论文证明了 xDeepFM 可生成的特点是 AutoCross 可生成特点嵌入(embedding)的子集。
AutoCross 的优势
实现过程
给定训练数据 ,并将其界定为训练集 和验证集 。我们可以用一个特点集合 S 来表示 ,并用学习算法 L 训练一个模型 。之后,用验证集和同一个特点集合 S 计算一个须要被最大化的指标 。特征组合搜索问题可以定义为搜索一个最优子特点集的问题:
其中 F 是 的原创特点集合,收录 F 所有原创特点以及基于 F 可生成的所有组合特点。
但是,假设原创特点数为 d,则上述问题中所有可能解的数目是 ,搜索空间巨大。为了提升搜索效率,AutoCross 将搜索最优子特点集的问题转换为用贪婪策略逐渐建立较优解的问题。首先,AutoCross 考虑一个树结构的搜索空间 (图 3),其中每一个节点表示一个子特点集。之后,用集束搜索策略在 上搜索较优解。通过这些方式,AutoCross 只须要访问 个候选解,极大地提升了搜索效率。AutoCross 的整体算法如算法 1 所示。

算法 1 中的一个关键步骤是评估候选特征集。最直接的方式是用每位候选特征集训练模型并评估其性能,但是这些方式估算代价巨大,难以在搜索过程中反复执行。为了提升特征集评估的效率,AutoCross 提出了逐域对数概率回归(field-wise logistic regression)和连续批训练梯度增长(successive mini-batch gradient descent)方法。
为了提升特征集评估效率,逐域对数概率回归做出两种近似。首先,用特点集在对数概率回归模型上的表现近似最终将使用这个特点集的模型上的表现;其次,在考虑 中一个节点的子节点时,不改变该节点收录特点对应的权重(weight),仅训练子节点新增特点的权重。
图 4 说明了怎样将逐域对数概率回归布署在参数服务器构架上。逐域对数概率回归与参数服务器的结合可以提升特征集评估的储存效率、传输效率和估算效率。在逐域对数概率回归训练结束后,AutoCross 计算训练得模型的指标,并借此方式来评估每一个候选特征集。
AutoCross 采用连续批训练梯度增长方式进一步提升特征集评估的效率。该方式借鉴 successive halving 算法 [2],认为每一个候选特征集是 multi-arm bandit 问题中的一个 arm,对一个特点集用一个数据块进行权重更新相当于拉了一次对应的 arm,其回报为该次训练后的验证集 AUC。
具体算法见算法 2,算法 2 中惟一的参数是数据块的数目 N。N 可以按照数据的大小和估算环境自适应地确定。在使用连续批训练梯度增长时,用户不需要象使用传统的 subsampling 方法一样调整 mini-batch 的规格和采样率。

为了支持数值特点与离散特点的组合,AutoCross 在预处理时将数值特点离散化为离散特点。AutoCross 提出了多细度离散化(multi-granularity discretization)方法,使得用户不需要反复调整离散化的细度。多细度离散化思想简单:将每一个数值特点,根据不同细度界定为多个离散特点。然后采用逐域对数概率回归选购出最优的离散特点。多个界定细度既可以由用户指定,也可以由 AutoCross 根据数据大小和估算环境来自适应地选择,从而增加了用户的使用难度。
实验结果
该论文在十个数据集(五个公开、五个实际业务)上进行了实验。比较的方式包括:
效果比较:如下表 3 所示,AC+LR 和 AC+W&D 在大部分数据集上的排行都在前两位。这彰显了 AutoCross 产生的特点除了可以提高 LR 模型,也可以用于增强深度学习模型的性能,并且 AC+LR 和 AC+W&D 的疗效都优于 xDeepFM。如之前所说,xDeepFM 所生成的特点不能完全收录 AutoCross 生成的特点。这些结果彰显出显式生成高阶组合特点的疗效优势。
高阶特点的作用:见表 5 和图 6。从中可以得出,高阶组合特点可以有效提升模型性能。
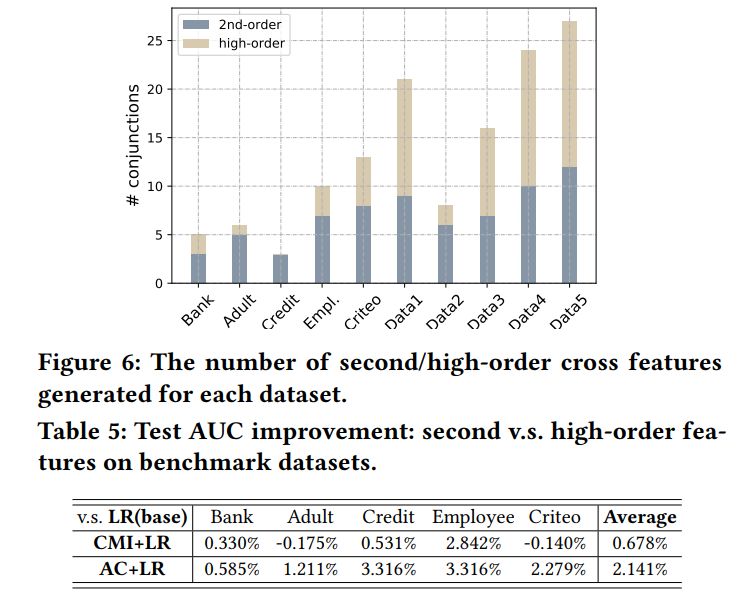
时间消耗:见表 6、图 7(主要做展示用)。
推断延后:见表 7。从中可以得出:AC+LR 的推测速率比 AC+W&D、Deep、xDeepFM 快几个数量级。这说明 AutoCross 不仅可以提升模型表现,同时保证了太低的推论延后。
参考文献
[1] J. Lian, X. Zhou, F. Zhang, Z. Chen, X. Xie, and G. Sun. 2018. xDeepFM: Com- bining Explicit and Implicit Feature Interactions for Recommender Systems. In International Conference on Knowledge Discovery & Data Mining.
[2] K. Jamieson and A. Talwalkar. 2016. Non-stochastic best arm identification and hyperparameter optimization. In Artificial Intelligence and Statistics. 240–248.
[3] O. Chapelle, E. Manavoglu, and R. Rosales. 2015. Simple and scalable response prediction for display advertising. ACM Transactions on Intelligent Systems and Technology (TIST) 5, 4 (2015), 61.
------------------------------------------------
加入机器之心(全职记者 / 实习生):
投稿或寻求报导:
chukwa采集框架中负责将大量小文件进行合并的组件是
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-08-13 07:22
概述
chukwa 的官方网站是这样描述自己的: chukwa 是一个开源的用于监控小型分布式系统的数据搜集系统。这是建立在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 hadoop 的可伸缩性和鲁棒性。Chukwa 还收录了一个强悍和灵活的工具集,可用于展示、监控和剖析已搜集的数据。
在一些网站上,甚至扬言 chukwa 是一个“日志处理/分析的full stack solution”。
说了这么多,你心动了吗?
Chukwa 是哪些?
在泰国神话中Chukwa是一只最古老的龟。它支撑着世界。在它的背上还支撑着一种称作Maha-Pudma的小象,在小象的背上顶着这个月球。呵呵,大象?Hadoop?不难理解为何在Hadoop中的这个子项目称作Chukwa了,或许Chukwa的其中一位开发者是美国人?呵呵,我胡扯的,神话中的Chukwa的,貌似是这样的,如图所示:
Chukwa是由Yahoo贡献,基于Hadoop的大集群监控系统,可以用他来剖析和搜集系统中的数据(日志)。Chukwa运行HDFS中储存数据的采集器和MapReduce框架之上,并承继了Hadoop的可扩展性和鲁棒性, Chukwa使用MapReduce来生成报告,他还包括一个用于检测和剖析结果显示的web-portal工具,通过web-portal工具让这个搜集数据的更佳具有灵活性,这点有点像是类似 linux工具,例如:awk 。这几乎是一个日志处理/分析的full stack solution,国内用hadoop做日志剖析的,或者即将做日志剖析的可以关注下。
Chukwa 由哪几个组件组成的?
Chukwa是Yahoo开发的Hadoop之上的数据采集/分析框架,主要用于日志采集/分析。该框架提供了采集数据的Agent,由Agent采集数据通过HTTP发送数据给Cluster的Collector,collector把数据sink进Hadoop,然后通过定期运行Map reducer来剖析数据,将结果呈现给用户。
Chukwa 有以下4个主要的组成部分:
Agent搜集各服务器的数据
Collectors接收agent的数据;并写进储存
MapReduce jobs归档数据
HICC就是 Hadoop Infrastructure Care Center的四个英语词组的简写,简单来说是个Web工程用于ChukWa的内容展示。
几个部件大致的处理流程如下:
在这个Blog中后续会对ChukWa有进一步的描述,再次感谢你的阅读。
–end–
转自:
chukwa 不能做哪些
1.chukwa 不是一个单机系统. 在单个节点布署一个 chukwa 系统,基本没有哪些好处. chukwa 是一个建立在 hadoop 基础上的分布式日志处理系统.换言之,在搭建 chukwa 环境之前,你须要先建立一个 hadoop 环境,然后在 hadoop 的基础上建立 chukwa 环境,这个关系也可以从稍后的 chukwa 架构图上看下来.这也是由于 chukwa 的假定是要处理的数据量是在 T 级别的.
2.chukwa 不是一个实时错误监控系统.在解决这个问题方面, ganglia,nagios 等等系统早已做得挺好了,这些系统对数据的敏感性都可以达到秒级. chukwa 分析的是数据是分钟级别的,它觉得象集群的整体 cpu 使用率这样的数据,延迟几分钟领到,不是哪些问题.
3.chukwa 不是一个封闭的系统.虽然 chukwa 自带了许多针对 hadoop 集群的剖析项,但是这并不是说它只能监控和剖析 hadoop.chukwa 提供了一个对大数据量日志类数据采集、存储、分析和展示的全套解决方案和框架,在这类数据生命周期的各个阶段, chukwa 都提供了近乎完美的解决方案,这一点也可以从它的构架中看下来.
chukwa 能做哪些
上一节说了好多 chukwa 不是哪些,下面来看下 chukwa 具体是干哪些的一个系统呢?
具体而言, chukwa 致力于以下几个方面的工作:
1.总体而言, chukwa 可以用于监控大规模(2000+ 以上的节点, 每天形成数据量在T级别) hadoop 集群的整体运行情况并对它们的日志进行剖析
2.对于集群的用户而言: chukwa 展示她们的作业早已运行了多久,占用了多少资源,还有多少资源可用,一个作业是为何失败了,一个读写操作在那个节点出了问题.
3.对于集群的运维工程师而言: chukwa 展示了集群中的硬件错误,集群的性能变化,集群的资源困局在那里.
4.对于集群的管理者而言: chukwa 展示了集群的资源消耗情况,集群的整体作业执行情况,可以用以辅助预算和集群资源协调.
5.对于集群的开发者而言: chukwa 展示了集群中主要的性能困局,经常出现的错误,从而可以着重重点解决重要问题.
Chukwa的系统构架
搭建、运行Chukwa要在Linux环境下,要安装MySQL数据库,在Chukwa/conf目录 中有2个SQL脚本 aggregator.sql、database_create_tables.sq l 导入MySQL数据库,此外还要有Hadoo的HDSF运行环境,Chukwa的整个系统构架如图所示:
其中主要的部件为:
1.agents : 负责采集最原创的数据,并发送给 collectors
2.adaptor : 直接采集数据的插口和工具,一个 agent 可以管理多个 adaptor 的数据采集
3.collectors 负责搜集 agents 收送来的数据,并定时写入集群中
4.map/reduce jobs 定时启动,负责把集群中的数据分类、排序、去重和合并
5.HICC 负责数据的展示
相关设计
adaptors 和 agents
在 每个数据的产生端(基本上是集群中每一个节点上), chukwa 使用一个 agent 来采集它感兴趣的数据,每一类数据通过一个 adaptor 来实现, 数据的类型(DataType?)在相应的配置中指定. 默认地, chukwa 对以下常见的数据来源早已提供了相应的 adaptor : 命令行输出、log 文件和 httpSender等等. 这些 adaptor 会定期运行(比如每分钟读一次 df 的结果)或风波驱动地执行(比如 kernel 打了一条错误日志). 如果这种 adaptor 还不够用,用户也可以便捷地自己实现一个 adaptor 来满足需求。
为避免数据采集端的 agent 出现故障,chukwa 的 agent 采用了所谓的 ‘watchdog’ 机制,会手动重启中止的数据采集进程,防止原创数据的遗失。
另一方面, 对于重复采集的数据, 在 chukwa 的数据处理过程中,会手动对它们进行去重. 这样,就可以对于关键的数据在多台机器上布署相同的 agent,从而实现容错的功能.
collectors
agents 采集到的数据,是储存到 hadoop 集群上的. hadoop 集群擅长于处理少量大文件,而对于大量小文件的处理则不是它的强项,针对这一点,chukwa 设计了 collector 这个角色,用于把数据先进行部份合并,再写入集群,防止大量小文件的写入。
另 一方面,为避免 collector 成为性能困局或成为单点,产生故障, chukwa 允许和鼓励设置多个 collector, agents 随机地从 collectors 列表中选择一个 collector 传输数据,如果一个 collector 失败或忙碌,就换下一个 collector. 从而可以实现负载的均衡,实践证明,多个 collector 的负载几乎是平均的.
demux 和 archive
放在集群上的数据,是通过 map/reduce 作业来实现数据剖析的. 在 map/reduce 阶段, chukwa 提供了 demux 和 archive 任务两种外置的作业类型.
demux 作业负责对数据的分类、排序和去重. 在 agent 一节中,我们谈到了数据类型(DataType?)的概念.由 collector 写入集群中的数据,都有自己的类型. demux 作业在执行过程中,通过数据类型和配置文件中指定的数据处理类,执行相应的数据剖析工作,一般是把非结构化的数据结构化,抽取中其中的数据属性.由于 demux 的本质是一个 map/reduce 作业,所以我们可以按照自己的需求制订自己的 demux 作业,进行各类复杂的逻辑剖析. chukwa 提供的 demux interface 可以用 java 语言来便捷地扩充.
而 archive 作业则负责把同类型的数据文件合并,一方面保证了同一类的数据都在一起,便于进一步剖析, 另一方面减轻文件数目, 减轻 hadoop 集群的储存压力。
dbadmin
放在集群上的数据,虽然可以满足数据的常年储存和大数据量估算需求,但是不易于展示.为此, chukwa 做了两方面的努力:
1.使用 mdl 语言,把集群上的数据抽取到 mysql 数据库中,对近一周的数据,完整保存,超过一周的数据,按数据距现今的时间长短作稀释,离如今越久的数据,所保存的数据时间间隔越长.通过 mysql 来作数据源,展示数据.
2.使用 hbase 或类似的技术,直接把索引化的数据在储存在集群上
到 chukwa 0.4.0 版本为止, chukwa 都是用的第一种方式,但是第二种方式更高贵也更方便一些.
hicc
hicc 是 chukwa 的数据展示端的名子.在展示端, chukwa 提供了一些默认的数据展示 widget,可以使用“列表”、“曲线图”、“多曲线图”、“柱状图”、“面积隐喻展示一类或多类数据,给用户直观的数据趋势展示。而且,在 hicc 展示端,对不断生成的新数据和历史数据,采用 robin 策略,防止数据的不断下降减小服务器压力,并对数据在时间轴上“稀释”,可以提供长时间段的数据展示
从 本质上, hicc 是用 jetty 来实现的一个 web 服务端,内部用的是 jsp 技术和 javascript 技术.各种须要展示的数据类型和页面的局都可以通过简直地拖放方法来实现,更复杂的数据展示方法,可以使用 sql 语言组合出各类须要的数据.如果这样还不能满足需求,不用怕,动手更改它的 jsp 代码就可以了.
其它数据插口
如果对原创数据还有新的须要,用户还可以通过 map/reduce 作业或 pig 语言直接访问集群上的原创数据,以生成所须要的结果。chukwa 还提供了命令行的插口,可以直接访问到集群上数据。
默认数据支持
对 于集群各节点的cpu使用率、内存使用率、硬盘使用率、集群整体的 cpu 平均使用率、集群整体的显存使用率、集群整体的储存使用率、集群文件数变化、作业数变化等等 hadoop 相关数据,从采集到展示的一整套流程, chukwa 都提供了内建的支持,只须要配置一下就可以使用.可以说是相当便捷的.
可以看出,chukwa 从数据的形成、采集、存储、分析到展示的整个生命周期都提供了全面的支持。 查看全部
Apache 的开源项目 hadoop, 作为一个分布式存储和估算系统,已经被业界广泛应用。很多小型企业都有了各自基于 hadoop 的应用和相关扩充。当 1000+ 以上个节点的 hadoop 集群显得常见时,集群自身的相关信息怎样搜集和剖析呢?针对这个问题, Apache 同样提出了相应的解决方案,那就是 chukwa。
概述
chukwa 的官方网站是这样描述自己的: chukwa 是一个开源的用于监控小型分布式系统的数据搜集系统。这是建立在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 hadoop 的可伸缩性和鲁棒性。Chukwa 还收录了一个强悍和灵活的工具集,可用于展示、监控和剖析已搜集的数据。
在一些网站上,甚至扬言 chukwa 是一个“日志处理/分析的full stack solution”。
说了这么多,你心动了吗?
Chukwa 是哪些?
在泰国神话中Chukwa是一只最古老的龟。它支撑着世界。在它的背上还支撑着一种称作Maha-Pudma的小象,在小象的背上顶着这个月球。呵呵,大象?Hadoop?不难理解为何在Hadoop中的这个子项目称作Chukwa了,或许Chukwa的其中一位开发者是美国人?呵呵,我胡扯的,神话中的Chukwa的,貌似是这样的,如图所示:

Chukwa是由Yahoo贡献,基于Hadoop的大集群监控系统,可以用他来剖析和搜集系统中的数据(日志)。Chukwa运行HDFS中储存数据的采集器和MapReduce框架之上,并承继了Hadoop的可扩展性和鲁棒性, Chukwa使用MapReduce来生成报告,他还包括一个用于检测和剖析结果显示的web-portal工具,通过web-portal工具让这个搜集数据的更佳具有灵活性,这点有点像是类似 linux工具,例如:awk 。这几乎是一个日志处理/分析的full stack solution,国内用hadoop做日志剖析的,或者即将做日志剖析的可以关注下。
Chukwa 由哪几个组件组成的?
Chukwa是Yahoo开发的Hadoop之上的数据采集/分析框架,主要用于日志采集/分析。该框架提供了采集数据的Agent,由Agent采集数据通过HTTP发送数据给Cluster的Collector,collector把数据sink进Hadoop,然后通过定期运行Map reducer来剖析数据,将结果呈现给用户。
Chukwa 有以下4个主要的组成部分:
Agent搜集各服务器的数据
Collectors接收agent的数据;并写进储存
MapReduce jobs归档数据
HICC就是 Hadoop Infrastructure Care Center的四个英语词组的简写,简单来说是个Web工程用于ChukWa的内容展示。
几个部件大致的处理流程如下:

在这个Blog中后续会对ChukWa有进一步的描述,再次感谢你的阅读。
–end–
转自:
chukwa 不能做哪些
1.chukwa 不是一个单机系统. 在单个节点布署一个 chukwa 系统,基本没有哪些好处. chukwa 是一个建立在 hadoop 基础上的分布式日志处理系统.换言之,在搭建 chukwa 环境之前,你须要先建立一个 hadoop 环境,然后在 hadoop 的基础上建立 chukwa 环境,这个关系也可以从稍后的 chukwa 架构图上看下来.这也是由于 chukwa 的假定是要处理的数据量是在 T 级别的.
2.chukwa 不是一个实时错误监控系统.在解决这个问题方面, ganglia,nagios 等等系统早已做得挺好了,这些系统对数据的敏感性都可以达到秒级. chukwa 分析的是数据是分钟级别的,它觉得象集群的整体 cpu 使用率这样的数据,延迟几分钟领到,不是哪些问题.
3.chukwa 不是一个封闭的系统.虽然 chukwa 自带了许多针对 hadoop 集群的剖析项,但是这并不是说它只能监控和剖析 hadoop.chukwa 提供了一个对大数据量日志类数据采集、存储、分析和展示的全套解决方案和框架,在这类数据生命周期的各个阶段, chukwa 都提供了近乎完美的解决方案,这一点也可以从它的构架中看下来.
chukwa 能做哪些
上一节说了好多 chukwa 不是哪些,下面来看下 chukwa 具体是干哪些的一个系统呢?
具体而言, chukwa 致力于以下几个方面的工作:
1.总体而言, chukwa 可以用于监控大规模(2000+ 以上的节点, 每天形成数据量在T级别) hadoop 集群的整体运行情况并对它们的日志进行剖析
2.对于集群的用户而言: chukwa 展示她们的作业早已运行了多久,占用了多少资源,还有多少资源可用,一个作业是为何失败了,一个读写操作在那个节点出了问题.
3.对于集群的运维工程师而言: chukwa 展示了集群中的硬件错误,集群的性能变化,集群的资源困局在那里.
4.对于集群的管理者而言: chukwa 展示了集群的资源消耗情况,集群的整体作业执行情况,可以用以辅助预算和集群资源协调.
5.对于集群的开发者而言: chukwa 展示了集群中主要的性能困局,经常出现的错误,从而可以着重重点解决重要问题.
Chukwa的系统构架
搭建、运行Chukwa要在Linux环境下,要安装MySQL数据库,在Chukwa/conf目录 中有2个SQL脚本 aggregator.sql、database_create_tables.sq l 导入MySQL数据库,此外还要有Hadoo的HDSF运行环境,Chukwa的整个系统构架如图所示:

其中主要的部件为:
1.agents : 负责采集最原创的数据,并发送给 collectors
2.adaptor : 直接采集数据的插口和工具,一个 agent 可以管理多个 adaptor 的数据采集
3.collectors 负责搜集 agents 收送来的数据,并定时写入集群中
4.map/reduce jobs 定时启动,负责把集群中的数据分类、排序、去重和合并
5.HICC 负责数据的展示
相关设计
adaptors 和 agents
在 每个数据的产生端(基本上是集群中每一个节点上), chukwa 使用一个 agent 来采集它感兴趣的数据,每一类数据通过一个 adaptor 来实现, 数据的类型(DataType?)在相应的配置中指定. 默认地, chukwa 对以下常见的数据来源早已提供了相应的 adaptor : 命令行输出、log 文件和 httpSender等等. 这些 adaptor 会定期运行(比如每分钟读一次 df 的结果)或风波驱动地执行(比如 kernel 打了一条错误日志). 如果这种 adaptor 还不够用,用户也可以便捷地自己实现一个 adaptor 来满足需求。
为避免数据采集端的 agent 出现故障,chukwa 的 agent 采用了所谓的 ‘watchdog’ 机制,会手动重启中止的数据采集进程,防止原创数据的遗失。
另一方面, 对于重复采集的数据, 在 chukwa 的数据处理过程中,会手动对它们进行去重. 这样,就可以对于关键的数据在多台机器上布署相同的 agent,从而实现容错的功能.
collectors
agents 采集到的数据,是储存到 hadoop 集群上的. hadoop 集群擅长于处理少量大文件,而对于大量小文件的处理则不是它的强项,针对这一点,chukwa 设计了 collector 这个角色,用于把数据先进行部份合并,再写入集群,防止大量小文件的写入。
另 一方面,为避免 collector 成为性能困局或成为单点,产生故障, chukwa 允许和鼓励设置多个 collector, agents 随机地从 collectors 列表中选择一个 collector 传输数据,如果一个 collector 失败或忙碌,就换下一个 collector. 从而可以实现负载的均衡,实践证明,多个 collector 的负载几乎是平均的.
demux 和 archive
放在集群上的数据,是通过 map/reduce 作业来实现数据剖析的. 在 map/reduce 阶段, chukwa 提供了 demux 和 archive 任务两种外置的作业类型.
demux 作业负责对数据的分类、排序和去重. 在 agent 一节中,我们谈到了数据类型(DataType?)的概念.由 collector 写入集群中的数据,都有自己的类型. demux 作业在执行过程中,通过数据类型和配置文件中指定的数据处理类,执行相应的数据剖析工作,一般是把非结构化的数据结构化,抽取中其中的数据属性.由于 demux 的本质是一个 map/reduce 作业,所以我们可以按照自己的需求制订自己的 demux 作业,进行各类复杂的逻辑剖析. chukwa 提供的 demux interface 可以用 java 语言来便捷地扩充.
而 archive 作业则负责把同类型的数据文件合并,一方面保证了同一类的数据都在一起,便于进一步剖析, 另一方面减轻文件数目, 减轻 hadoop 集群的储存压力。
dbadmin
放在集群上的数据,虽然可以满足数据的常年储存和大数据量估算需求,但是不易于展示.为此, chukwa 做了两方面的努力:
1.使用 mdl 语言,把集群上的数据抽取到 mysql 数据库中,对近一周的数据,完整保存,超过一周的数据,按数据距现今的时间长短作稀释,离如今越久的数据,所保存的数据时间间隔越长.通过 mysql 来作数据源,展示数据.
2.使用 hbase 或类似的技术,直接把索引化的数据在储存在集群上
到 chukwa 0.4.0 版本为止, chukwa 都是用的第一种方式,但是第二种方式更高贵也更方便一些.
hicc
hicc 是 chukwa 的数据展示端的名子.在展示端, chukwa 提供了一些默认的数据展示 widget,可以使用“列表”、“曲线图”、“多曲线图”、“柱状图”、“面积隐喻展示一类或多类数据,给用户直观的数据趋势展示。而且,在 hicc 展示端,对不断生成的新数据和历史数据,采用 robin 策略,防止数据的不断下降减小服务器压力,并对数据在时间轴上“稀释”,可以提供长时间段的数据展示
从 本质上, hicc 是用 jetty 来实现的一个 web 服务端,内部用的是 jsp 技术和 javascript 技术.各种须要展示的数据类型和页面的局都可以通过简直地拖放方法来实现,更复杂的数据展示方法,可以使用 sql 语言组合出各类须要的数据.如果这样还不能满足需求,不用怕,动手更改它的 jsp 代码就可以了.
其它数据插口
如果对原创数据还有新的须要,用户还可以通过 map/reduce 作业或 pig 语言直接访问集群上的原创数据,以生成所须要的结果。chukwa 还提供了命令行的插口,可以直接访问到集群上数据。
默认数据支持
对 于集群各节点的cpu使用率、内存使用率、硬盘使用率、集群整体的 cpu 平均使用率、集群整体的显存使用率、集群整体的储存使用率、集群文件数变化、作业数变化等等 hadoop 相关数据,从采集到展示的一整套流程, chukwa 都提供了内建的支持,只须要配置一下就可以使用.可以说是相当便捷的.
可以看出,chukwa 从数据的形成、采集、存储、分析到展示的整个生命周期都提供了全面的支持。
Python手动点击易迅商品价钱条件,智能采集价格数据!
采集交流 • 优采云 发表了文章 • 0 个评论 • 313 次浏览 • 2020-08-10 08:17
一、建立第一级主题抓取目标信息
建立第一级主题的规则,把想要的信息映射到整理箱中,建议做完内容映射后,也做上定位标志映射,可以提升定位准确性和规则适应性。
注意:设置了连续动作的规则可以不建整理箱,例如方案2的第一级主题可以不建整理箱,但是用整理箱抓一点数据(选择网页上一定会显示下来的信息),是为了给爬虫判定是否执行采集,否则可能漏采网页。
二、设置连续动作点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 输入目标主题名
连续动作指向的是同一个目标主题。如果有多个动作,并且要指向不同的主题,请拆成多个规则分别设置连续动作。
2.2 选择动作类型
本案例是点击动作,不同动作的适用范围是不同的,请按照实际的操作情况来选择动作类型。
2.3 把定位到动作对象的xpath填入到定位表达式中
2.4 输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.5 高级设置
最初可以不设置,后面调试连续动作时会用到,可以扩大动作的适用范围。如需把动作对象的信息也抓出来,就在中级设置的内容表达式中用xpath定位到动作对象的信息来实现,请依照须要再来设置。
注意:动作类型是否选对以及xpath是否定位确切,决定了连续动作能够执行成功。Xpath是标准的用于定位html节点的语言,请自行把握xpath后再来使用连续动作的功能。
按照人的操作步骤,还要选择版本、购买方法1、购买方法2,所以,我们还要继续新建3个动作,重复以上步骤。
三、调试规则
完成以上步骤后,点击保存规则,再点击爬数据按键进行试抓。发现采集时报错:无法定位到节点***,观察浏览器窗口,看到执行完第一步点击时,其他信息都没加载上来,等到信息都加载上来,又发觉点击了订购方法2后,就难以回挪到执行4步点击的页面,这就造成连续动作没法连贯执行。
针对里面的情况,我们的解决方式是删除第4步动作。因为无论是否点击订购方法2,都不影响商品价钱。所以,可以删除没必要且引起干扰的动作步骤。
修改后再度试抓,把提取到的xml转为excel后,看到价钱和累计评价的数据抓漏或抓错了。这是因为网页很大,加载比较慢,点击后的数据要等待一定时间才会加载完成。
为了抓全数据,需要延长等待时间,给每位动作单独设置延时,点击动作步骤->高级设置->额外延时,输入正整数,单位是秒。输入的时间请按照实际调试。
另外,如果不是置顶窗口,采集时会循环点击。这是因为易迅网页上有反爬举措,必须为当前窗口的操作才能生效。所以,要在中级设置上勾上窗口可见,采集时窗口会置顶。请按照实际情况进行设置。
四、如何把抓到的信息与动作步骤一一对应?
如果希望把抓到的信息与动作步骤一一对应上去,这样就得把动作对象的信息也提取出来,有以下两种方式:
4.1 在连续动作的中级设置的内容表达式中用xpath定位到动作对象的信息节点。
在定位表达式早已定位到动作对象的整个操作范围,也包括其本身的信息,所以,内容表达式只需从定位到的动作对象为起点,继续定位到其信息就行。采集时都会把该步动作的信息记录在actionvalue中,与之对应的是actionno,记录的是该步动作执行的次数。
4.2 在整理箱中抓取动作对象的信息,这里同样要用xpath来定位。
动作对象被执行时,其dom结构是有变化的,找到网页变化的结构特点,用xpath确切定位到节点,通过校准后,就可以设置自定义xpath。 查看全部
注意:如果动作执行前后的网页结构没有变化,可以用一个规则来完成;网页结构前后变化的话,必须用两个或以上的规则来完成;另外涉及翻页的话,也要拆成两个或以上的规则。关于连续动作要做多少个规则请查阅文章《规划采集流程》。
一、建立第一级主题抓取目标信息
建立第一级主题的规则,把想要的信息映射到整理箱中,建议做完内容映射后,也做上定位标志映射,可以提升定位准确性和规则适应性。
注意:设置了连续动作的规则可以不建整理箱,例如方案2的第一级主题可以不建整理箱,但是用整理箱抓一点数据(选择网页上一定会显示下来的信息),是为了给爬虫判定是否执行采集,否则可能漏采网页。
二、设置连续动作点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 输入目标主题名
连续动作指向的是同一个目标主题。如果有多个动作,并且要指向不同的主题,请拆成多个规则分别设置连续动作。
2.2 选择动作类型
本案例是点击动作,不同动作的适用范围是不同的,请按照实际的操作情况来选择动作类型。
2.3 把定位到动作对象的xpath填入到定位表达式中
2.4 输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.5 高级设置
最初可以不设置,后面调试连续动作时会用到,可以扩大动作的适用范围。如需把动作对象的信息也抓出来,就在中级设置的内容表达式中用xpath定位到动作对象的信息来实现,请依照须要再来设置。
注意:动作类型是否选对以及xpath是否定位确切,决定了连续动作能够执行成功。Xpath是标准的用于定位html节点的语言,请自行把握xpath后再来使用连续动作的功能。
按照人的操作步骤,还要选择版本、购买方法1、购买方法2,所以,我们还要继续新建3个动作,重复以上步骤。
三、调试规则
完成以上步骤后,点击保存规则,再点击爬数据按键进行试抓。发现采集时报错:无法定位到节点***,观察浏览器窗口,看到执行完第一步点击时,其他信息都没加载上来,等到信息都加载上来,又发觉点击了订购方法2后,就难以回挪到执行4步点击的页面,这就造成连续动作没法连贯执行。
针对里面的情况,我们的解决方式是删除第4步动作。因为无论是否点击订购方法2,都不影响商品价钱。所以,可以删除没必要且引起干扰的动作步骤。
修改后再度试抓,把提取到的xml转为excel后,看到价钱和累计评价的数据抓漏或抓错了。这是因为网页很大,加载比较慢,点击后的数据要等待一定时间才会加载完成。
为了抓全数据,需要延长等待时间,给每位动作单独设置延时,点击动作步骤->高级设置->额外延时,输入正整数,单位是秒。输入的时间请按照实际调试。
另外,如果不是置顶窗口,采集时会循环点击。这是因为易迅网页上有反爬举措,必须为当前窗口的操作才能生效。所以,要在中级设置上勾上窗口可见,采集时窗口会置顶。请按照实际情况进行设置。
四、如何把抓到的信息与动作步骤一一对应?
如果希望把抓到的信息与动作步骤一一对应上去,这样就得把动作对象的信息也提取出来,有以下两种方式:
4.1 在连续动作的中级设置的内容表达式中用xpath定位到动作对象的信息节点。
在定位表达式早已定位到动作对象的整个操作范围,也包括其本身的信息,所以,内容表达式只需从定位到的动作对象为起点,继续定位到其信息就行。采集时都会把该步动作的信息记录在actionvalue中,与之对应的是actionno,记录的是该步动作执行的次数。
4.2 在整理箱中抓取动作对象的信息,这里同样要用xpath来定位。
动作对象被执行时,其dom结构是有变化的,找到网页变化的结构特点,用xpath确切定位到节点,通过校准后,就可以设置自定义xpath。
关于优采云采集器标签组合功能的使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-10 06:10
优采云的使用似乎还是比较复杂的,甚至对于菜鸟来说学习还是有些费力的,本文上海网站建设编辑就V7版本的便条组合聊聊自己的想法,希望能对需求的同学提供些许帮助。
v7版本降低了一个标签组合的功能,许多同学在使用中发觉组合的结果和自己想要的结果不一致,下面我来说明一下该功能的使用。
1.标签组合组合的是文件下载前的内容
有的同学发觉,a标签中下载了某个文件,原创地址是aaa,下载后或是侦测的地址为bbb,那么,如果您在b标签中组合使用a标签,a标签的值是aaa.为何使用这些处理方式,是因为文件下载是在标签组合以后进行的。如何达到标签内容是文件下载完后的结果呢?可以新建一个标签,选“自定义固定格式数据”,将您标签组合的内容放进去。这里的替换会在文件下载后执行。
2.内容页标签循环采集并添加为新记录
如果组合的两个标签都是内容页标签,这两个标签在组合时,会按循环数最大的记录形成新的同样数量的循环记录。如果某个标签的循环数较少,则新形成的标签中该标签的值为空。例如标签a,b组合生成标签c。a的循环数是5,b的循环数是3,则会生成5个c,其中,前3个标签的值分别是a,b一一对应的。最后两个值中,b的值为空。假设a的值是11,22,33,44,55,b的值为aa,bb,cc.c是由组合, 则形成的c的值为11aa,22bb,33cc,44,55.
3.列表页标签和内容页标签组合
如果两个标签中一个是内容页,一个是列表页,则内容页是会出席第2条中的循环处理,在这个过程中列表页当成一个字符串处理。合并完成后,程序会再进行数据处理操作。最后,组合标签中的列表页标签内容将被替换成实际的值。组合后的结果中,可以再提取下载。比如内容页a和列表页b组合生成c,其中a的值为11,22,22,b的值为bb,那么,c第一次组合结果是 11,22,33,然后进行数据处理。如果b的值是bb,那么最后的结果就可能是11bb,22bb,33bb.
有的上海网页制做的同学可能会说,干嘛将这个功能搞那么复杂的。其实,这个功能主要是为第一条的功能使用的,其它的组合形式可能会形成和原看法不一样的结果。建议你们不要滥用这个功能,不要将它想象成万能的。 查看全部
优采云采集工具想必苏州网络公司的同学都晓得,而且优采云采集器如今也衍生出企业版的优采云浏览器,功能强悍无比,但是其价位也使无锡网站优化站长无法接受。
优采云的使用似乎还是比较复杂的,甚至对于菜鸟来说学习还是有些费力的,本文上海网站建设编辑就V7版本的便条组合聊聊自己的想法,希望能对需求的同学提供些许帮助。
v7版本降低了一个标签组合的功能,许多同学在使用中发觉组合的结果和自己想要的结果不一致,下面我来说明一下该功能的使用。
1.标签组合组合的是文件下载前的内容
有的同学发觉,a标签中下载了某个文件,原创地址是aaa,下载后或是侦测的地址为bbb,那么,如果您在b标签中组合使用a标签,a标签的值是aaa.为何使用这些处理方式,是因为文件下载是在标签组合以后进行的。如何达到标签内容是文件下载完后的结果呢?可以新建一个标签,选“自定义固定格式数据”,将您标签组合的内容放进去。这里的替换会在文件下载后执行。
2.内容页标签循环采集并添加为新记录
如果组合的两个标签都是内容页标签,这两个标签在组合时,会按循环数最大的记录形成新的同样数量的循环记录。如果某个标签的循环数较少,则新形成的标签中该标签的值为空。例如标签a,b组合生成标签c。a的循环数是5,b的循环数是3,则会生成5个c,其中,前3个标签的值分别是a,b一一对应的。最后两个值中,b的值为空。假设a的值是11,22,33,44,55,b的值为aa,bb,cc.c是由组合, 则形成的c的值为11aa,22bb,33cc,44,55.
3.列表页标签和内容页标签组合
如果两个标签中一个是内容页,一个是列表页,则内容页是会出席第2条中的循环处理,在这个过程中列表页当成一个字符串处理。合并完成后,程序会再进行数据处理操作。最后,组合标签中的列表页标签内容将被替换成实际的值。组合后的结果中,可以再提取下载。比如内容页a和列表页b组合生成c,其中a的值为11,22,22,b的值为bb,那么,c第一次组合结果是 11,22,33,然后进行数据处理。如果b的值是bb,那么最后的结果就可能是11bb,22bb,33bb.
有的上海网页制做的同学可能会说,干嘛将这个功能搞那么复杂的。其实,这个功能主要是为第一条的功能使用的,其它的组合形式可能会形成和原看法不一样的结果。建议你们不要滥用这个功能,不要将它想象成万能的。
Shell 命令 curl 和 wget 使用代理采集网页的总结大全
采集交流 • 优采云 发表了文章 • 0 个评论 • 864 次浏览 • 2020-08-09 16:34
米扑代理,作为大数据剖析研究的基础服务,对其做了深入的研究和总结。
curl 和 wget 使用代理
curl 支持 http、https、socks4、socks5
wget 支持 http、https
Shell curl wget 示例
#!/bin/bash
#
# curl 支持 http、https、socks4、socks5
# wget 支持 http、https
#
# 米扑代理示例:
# https://proxy.mimvp.com/demo2.php
#
# 米扑代理购买:
# https://proxy.mimvp.com
#
# mimvp.com
# 2015-11-09
#【米扑代理】:本示例,在CentOS、Ubuntu、MacOS等服务器上,均测试通过
#
# http代理格式 http_proxy=http://IP:Port
# https代理格式 https_proxy=http://IP:Port
## proxy no auth
# curl和wget,爬取http网页
{'http': 'http://120.77.176.179:8888'}
curl -m 30 --retry 3 -x http://120.77.176.179:8888 http://proxy.mimvp.com/test_proxy2.php # http_proxy
wget -T 30 --tries 3 -e "http_proxy=http://120.77.176.179:8888" http://proxy.mimvp.com/test_proxy2.php # http_proxy
# curl和wget,爬取https网页(注意:添加参数,不经过SSL安全验证)
{'https': 'http://46.105.214.133:3128'}
curl -m 30 --retry 3 -x http://46.105.214.133:3128 -k https://proxy.mimvp.com/test_proxy2.php # https_proxy
wget -T 30 --tries 3 -e "https_proxy=http://46.105.214.133:3128" --no-check-certificate https://proxy.mimvp.com/test_proxy2.php # https_proxy
# curl 支持socks
# 其中,socks4和socks5两种协议的代理,都可以同时爬取http和https网页
{'socks4': '101.255.17.145:1080'}
curl -m 30 --retry 3 --socks4 101.255.17.145:1080 http://proxy.mimvp.com/test_proxy2.php
curl -m 30 --retry 3 --socks4 101.255.17.145:1080 https://proxy.mimvp.com/test_proxy2.php
{'socks5': '82.164.233.227:45454'}
curl -m 30 --retry 3 --socks5 82.164.233.227:45454 http://proxy.mimvp.com/test_proxy2.php
curl -m 30 --retry 3 --socks5 82.164.233.227:45454 https://proxy.mimvp.com/test_proxy2.php
# wget 不支持socks
## proxy auth(代理需要用户名和密码验证)
# curl和wget,爬取http网页
curl -m 30 --retry 3 -x http://username:password@210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -x http://username:password@210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 -U username:password -x http://210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -U username:password -x http://210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 --proxy-user username:password -x http://210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 --proxy-user username:password -x http://210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
wget -T 30 --tries 3 -e "http_proxy=http://username:password@2.19.16.5:5718" http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 -e "https_proxy=http://username:password@2.19.16.5:5718" https://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 --proxy-user=username --proxy-password=password -e "http_proxy=http://2.19.16.5:5718" http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 --proxy-user=username --proxy-password=password -e "https_proxy=http://2.19.16.5:5718" https://proxy.mimvp.com/test_proxy2.php
# curl 支持socks
curl -m 30 --retry 3 -U username:password --socks5 21.59.126.22:57216 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -U username:password --socks5 21.59.126.22:57216 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 --proxy-user username:password --socks5 21.59.126.22:57216 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 --proxy-user username:password --socks5 21.59.126.22:57216 https://proxy.mimvp.com/test_proxy2.php # https
# wget 不支持socks
wget 配置文件设置代理
vim ~/.wgetrc
http_proxy=http://120.77.176.179:8888:8080
https_proxy=http://12.7.17.17:8888:8080
use_proxy = on
wait = 30
# 配置文件设置后,立即生效,直接执行wget爬取命令即可
wget -T 30 --tries 3 http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 https://proxy.mimvp.com/test_proxy2.php
Shell设置临时局部代理
# proxy no auth
export http_proxy=http://120.77.176.179:8888:8080
export https_proxy=http://12.7.17.17:8888:8080
# proxy auth(代理需要用户名和密码验证)
export http_proxy=http://username:password@120.77.176.179:8888:8080
export https_proxy=http://username:password@12.7.17.17:8888:8080
# 直接爬取网页
curl -m 30 --retry 3 http://proxy.mimvp.com/test_proxy2.php # http_proxy
curl -m 30 --retry 3 https://proxy.mimvp.com/test_proxy2.php # https_proxy
wget -T 30 --tries 3 http://proxy.mimvp.com/test_proxy2.php # http_proxy
wget -T 30 --tries 3 https://proxy.mimvp.com/test_proxy2.php # https_proxy
# 取消设置
unset http_proxy
unset https_proxy
Shell设置系统全局代理
# 修改 /etc/profile,保存并重启服务器
sudo vim /etc/profile # 所有人有效
或
sudo vim ~/.bashrc # 所有人有效
或
vim ~/.bash_profile # 个人有效
## 在文件末尾,添加如下内容
# proxy no auth
export http_proxy=http://120.77.176.179:8888:8080
export https_proxy=http://12.7.17.17:8888:8080
# proxy auth(代理需要用户名和密码验证)
export http_proxy=http://username:password@120.77.176.179:8888:8080
export https_proxy=http://username:password@12.7.17.17:8888:8080
## 执行source命令,使配置文件生效(临时生效)
source /etc/profile
或
source ~/.bashrc
或
source ~/.bash_profile
## 若需要机器永久生效,则需要重启服务器
sudo reboot
米扑代理示例
米扑代理,专注为企业提供国外大数据研究服务,技术团队来自百度、小米、阿里、创新工场等,为国外企业提供大数据采集、数据建模剖析、结果导入展示等服务。
米扑代理示例,收录Python、Java、PHP、C#、Go、Perl、Ruby、Shell、NodeJS、PhantomJS、Groovy、Delphi、易语言等十多种编程语言或脚本,通过大量的可运行实例,详细讲解了使用代理IP的正确方式,方便网页爬取、数据采集、自动化测试等领域。
米扑代理示例官网: 查看全部
Linux Shell 提供两个十分实用的命令来爬取网页,它们分别是 curl 和 wget
米扑代理,作为大数据剖析研究的基础服务,对其做了深入的研究和总结。
curl 和 wget 使用代理
curl 支持 http、https、socks4、socks5
wget 支持 http、https
Shell curl wget 示例
#!/bin/bash
#
# curl 支持 http、https、socks4、socks5
# wget 支持 http、https
#
# 米扑代理示例:
# https://proxy.mimvp.com/demo2.php
#
# 米扑代理购买:
# https://proxy.mimvp.com
#
# mimvp.com
# 2015-11-09
#【米扑代理】:本示例,在CentOS、Ubuntu、MacOS等服务器上,均测试通过
#
# http代理格式 http_proxy=http://IP:Port
# https代理格式 https_proxy=http://IP:Port
## proxy no auth
# curl和wget,爬取http网页
{'http': 'http://120.77.176.179:8888'}
curl -m 30 --retry 3 -x http://120.77.176.179:8888 http://proxy.mimvp.com/test_proxy2.php # http_proxy
wget -T 30 --tries 3 -e "http_proxy=http://120.77.176.179:8888" http://proxy.mimvp.com/test_proxy2.php # http_proxy
# curl和wget,爬取https网页(注意:添加参数,不经过SSL安全验证)
{'https': 'http://46.105.214.133:3128'}
curl -m 30 --retry 3 -x http://46.105.214.133:3128 -k https://proxy.mimvp.com/test_proxy2.php # https_proxy
wget -T 30 --tries 3 -e "https_proxy=http://46.105.214.133:3128" --no-check-certificate https://proxy.mimvp.com/test_proxy2.php # https_proxy
# curl 支持socks
# 其中,socks4和socks5两种协议的代理,都可以同时爬取http和https网页
{'socks4': '101.255.17.145:1080'}
curl -m 30 --retry 3 --socks4 101.255.17.145:1080 http://proxy.mimvp.com/test_proxy2.php
curl -m 30 --retry 3 --socks4 101.255.17.145:1080 https://proxy.mimvp.com/test_proxy2.php
{'socks5': '82.164.233.227:45454'}
curl -m 30 --retry 3 --socks5 82.164.233.227:45454 http://proxy.mimvp.com/test_proxy2.php
curl -m 30 --retry 3 --socks5 82.164.233.227:45454 https://proxy.mimvp.com/test_proxy2.php
# wget 不支持socks
## proxy auth(代理需要用户名和密码验证)
# curl和wget,爬取http网页
curl -m 30 --retry 3 -x http://username:password@210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -x http://username:password@210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 -U username:password -x http://210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -U username:password -x http://210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 --proxy-user username:password -x http://210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 --proxy-user username:password -x http://210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
wget -T 30 --tries 3 -e "http_proxy=http://username:password@2.19.16.5:5718" http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 -e "https_proxy=http://username:password@2.19.16.5:5718" https://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 --proxy-user=username --proxy-password=password -e "http_proxy=http://2.19.16.5:5718" http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 --proxy-user=username --proxy-password=password -e "https_proxy=http://2.19.16.5:5718" https://proxy.mimvp.com/test_proxy2.php
# curl 支持socks
curl -m 30 --retry 3 -U username:password --socks5 21.59.126.22:57216 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -U username:password --socks5 21.59.126.22:57216 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 --proxy-user username:password --socks5 21.59.126.22:57216 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 --proxy-user username:password --socks5 21.59.126.22:57216 https://proxy.mimvp.com/test_proxy2.php # https
# wget 不支持socks
wget 配置文件设置代理
vim ~/.wgetrc
http_proxy=http://120.77.176.179:8888:8080
https_proxy=http://12.7.17.17:8888:8080
use_proxy = on
wait = 30
# 配置文件设置后,立即生效,直接执行wget爬取命令即可
wget -T 30 --tries 3 http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 https://proxy.mimvp.com/test_proxy2.php
Shell设置临时局部代理
# proxy no auth
export http_proxy=http://120.77.176.179:8888:8080
export https_proxy=http://12.7.17.17:8888:8080
# proxy auth(代理需要用户名和密码验证)
export http_proxy=http://username:password@120.77.176.179:8888:8080
export https_proxy=http://username:password@12.7.17.17:8888:8080
# 直接爬取网页
curl -m 30 --retry 3 http://proxy.mimvp.com/test_proxy2.php # http_proxy
curl -m 30 --retry 3 https://proxy.mimvp.com/test_proxy2.php # https_proxy
wget -T 30 --tries 3 http://proxy.mimvp.com/test_proxy2.php # http_proxy
wget -T 30 --tries 3 https://proxy.mimvp.com/test_proxy2.php # https_proxy
# 取消设置
unset http_proxy
unset https_proxy
Shell设置系统全局代理
# 修改 /etc/profile,保存并重启服务器
sudo vim /etc/profile # 所有人有效
或
sudo vim ~/.bashrc # 所有人有效
或
vim ~/.bash_profile # 个人有效
## 在文件末尾,添加如下内容
# proxy no auth
export http_proxy=http://120.77.176.179:8888:8080
export https_proxy=http://12.7.17.17:8888:8080
# proxy auth(代理需要用户名和密码验证)
export http_proxy=http://username:password@120.77.176.179:8888:8080
export https_proxy=http://username:password@12.7.17.17:8888:8080
## 执行source命令,使配置文件生效(临时生效)
source /etc/profile
或
source ~/.bashrc
或
source ~/.bash_profile
## 若需要机器永久生效,则需要重启服务器
sudo reboot
米扑代理示例
米扑代理,专注为企业提供国外大数据研究服务,技术团队来自百度、小米、阿里、创新工场等,为国外企业提供大数据采集、数据建模剖析、结果导入展示等服务。
米扑代理示例,收录Python、Java、PHP、C#、Go、Perl、Ruby、Shell、NodeJS、PhantomJS、Groovy、Delphi、易语言等十多种编程语言或脚本,通过大量的可运行实例,详细讲解了使用代理IP的正确方式,方便网页爬取、数据采集、自动化测试等领域。

米扑代理示例官网:
如何写出1688黄金标题?一键手动生成标题轻松搞定!
采集交流 • 优采云 发表了文章 • 0 个评论 • 448 次浏览 • 2020-08-09 08:47
然而许多店家上新30分钟,想标题2小时,利用层层工具选词、优化,不仅花费精力,也消耗时间,小编明天告诉你一键手动生成标题的秘密!
在此之前先来瞧瞧往年写标题主要从何入手:
1、用足标题给的30个字的空间。
尽量控制在26个字以上,30个字以内,把产品名,产品特点,促销方法等都写进来,吸引卖家点击,一个好的标题可以把曝光量转化为点击量,促使订单成交的可能性。
2、选词。
选词的方式有很多,常见的选词方式有阿里指数选词、1688搜索下拉框选词、生意参谋等等,通过比对选择与自己的产品关联性强,且竞争力较小的关键词进行组合,放到自己的产品标题里,可以使产品被搜索的概率大大降低。
(1)阿里指数:
相信诸位店家对阿里指数都比较熟悉,登录1688买家工作台,点击服务再搜索阿里指数,就可以直接步入应用。在阿里指数最上方的查找类目栏里找到与自己产品相关的类目,左侧的属性细分会给我们推荐一些与产品相关的热门属性,也可以按照搜索排行榜里上升榜和热搜榜里的词,进行组合标题。
(2)1688搜索下拉框选词:
在1688首页搜索框输入您要找的产品关键词,下拉框会给我们推荐一个相关的关键词,这些词都可以作为我们布关键词的一个参考,这些词都是一定时间内卖家常常搜索的词,参考的比重也是比较大的。
(3)生意参谋:
1688买家中心查找服务[生意参谋],选择打开商品列,左侧点击“搜索排名”通过查找关键词获得相关搜索词、搜索次数等信息,只是生意参谋搜索关键词的功能须要购买豪华版的生意参谋能够使用。
3、增加产品特点描述词。
在标题中,加入产品特点描述的词句。比如:规格、材质、功能、认证等等,这类词的出现会吸引有类似相关须要的顾客去点击我们的产品,把曝光量转化为点击。
4、常用的标题组合。
营销词+核心关键词(产品主名称)+修饰词+属性+近义/二级词
营销词+核心关键词+属性尺寸+服务卖点或产品卖点+品牌产地+经营模式
制作标题时注意:主关键词越靠前排行权重越高以及关键词的连贯性。
5、黄金标题的“2-4-2法则”
2个核心:
尽量只写核心词(马铃薯/土豆、番茄/西红柿)主关键词其实多了但搜索也概率大了,实际上排行增加了,内容过多会分散产品的权重,造成的后果是上架一周后基本无突显。
4个标准:
不能产生拼凑、不能使用符号、字数满足30个、修饰词4-5个为宜。
2个关键:
类目匹配度、类目的相关性、检查标题是否符合要求、生意参谋检测、橱窗有无推荐、类目是否正确、属性是否填写完整、有无低质量交易。
以上介绍了五个标题选词、优化的方式,不知诸位店家有没有又温故而新知了一遍呢,不过在这过程中会消耗我们的好多时间和精力,一个10年营运前辈说他写一个好的标题要花一个小时的时间,然而对于大部分店家来说,一整个过程出来起码也须要2个小时左右,这时候难免感触——
有没有一键手动优化标题生成这些好事情呢?
有!
免费开通慧眼识货你能够做到一键手动生成标题!!
【点击即可免费发放大泽慧眼识货】
免费发放慧眼识货,并授权登陆后,进入【大泽慧眼识货】界面。
选择基础信息:
选择版本,选择您的所属类目,选择模板,上传识货图片,即开始识货。
一键手动生成标题:
已通过上传的图片手动生成标题,点击按键可以一键更换更多标题。
大泽慧眼识货——自动生成标题并经过搜索优化、标题相关性贴切、标题核心关键词确切、标题字数符合26个字以上,满足30字完整丰富,排列组合次序会推动系统收录关键词。
1、自动生成标题并经过搜索优化:
慧眼识货通过AI智能文案生成技术,通过识货的图片结果手动生成标题,且标题经过搜索优化,利于凸显。
2、标题相关性贴切:
通过慧眼识货生成的标题,关键词来源与产品属性,与产品贴切吻合。满足搜索排名第一要素——相关性。
3、标题核心关键词确切:
核心词就是跟产品相关度最高同时搜索量又较大的词。慧眼识货一键生成的标题能同时兼具相关性和搜索量两个指标,核心关键词确切。
4、标题符合字数要求、完整丰富:
标题宽度为30个字(60个字符,一个汉字相当于2个字符),慧眼识货一键生成的标题都符合26个字到30个字的字数要求,标题完整丰富,符合商品质量信息要求。
5、紧密排列组合推动系统收录:
慧眼识货一键生成的标题,利用紧密排列的原理进行了排列组合,权重同等情况下,紧密排列的关键词会优先展示,自动匹配产品标题,把作用发挥到最大,助力系统收录关键词。
慧眼识货核心功能一键手动生成标题,方便广大店家的标题优化需求,让你们在选词、组合、优化等方面才能获得方便的流程,提升效率,简化过程,直接获得黄金标题。
大泽慧眼识货目前支持六大类目,女装、男装、童装、箱包、内衣、鞋鞋行业的店家可以行动上去了,用慧眼识货手动生成标题,快速上新,节省冗长重复的时间。各位商家们赶快开通/使用慧眼识货体验一下吧!
更多信息:
1、大泽慧眼识货免费发放地址: 查看全部
如何编撰标题,如何写出黄金标题,是好多商家们关注的问题。要知道电商界的标题党能收获的不只是点击率这么简单,它而且直接关系到使顾客精准的找到你,突出您产品的特性,促使交易的形成。一个好的标题越发的重要,同时也影响着我们的权重。
然而许多店家上新30分钟,想标题2小时,利用层层工具选词、优化,不仅花费精力,也消耗时间,小编明天告诉你一键手动生成标题的秘密!

在此之前先来瞧瞧往年写标题主要从何入手:
1、用足标题给的30个字的空间。
尽量控制在26个字以上,30个字以内,把产品名,产品特点,促销方法等都写进来,吸引卖家点击,一个好的标题可以把曝光量转化为点击量,促使订单成交的可能性。
2、选词。
选词的方式有很多,常见的选词方式有阿里指数选词、1688搜索下拉框选词、生意参谋等等,通过比对选择与自己的产品关联性强,且竞争力较小的关键词进行组合,放到自己的产品标题里,可以使产品被搜索的概率大大降低。
(1)阿里指数:
相信诸位店家对阿里指数都比较熟悉,登录1688买家工作台,点击服务再搜索阿里指数,就可以直接步入应用。在阿里指数最上方的查找类目栏里找到与自己产品相关的类目,左侧的属性细分会给我们推荐一些与产品相关的热门属性,也可以按照搜索排行榜里上升榜和热搜榜里的词,进行组合标题。

(2)1688搜索下拉框选词:
在1688首页搜索框输入您要找的产品关键词,下拉框会给我们推荐一个相关的关键词,这些词都可以作为我们布关键词的一个参考,这些词都是一定时间内卖家常常搜索的词,参考的比重也是比较大的。

(3)生意参谋:
1688买家中心查找服务[生意参谋],选择打开商品列,左侧点击“搜索排名”通过查找关键词获得相关搜索词、搜索次数等信息,只是生意参谋搜索关键词的功能须要购买豪华版的生意参谋能够使用。
3、增加产品特点描述词。
在标题中,加入产品特点描述的词句。比如:规格、材质、功能、认证等等,这类词的出现会吸引有类似相关须要的顾客去点击我们的产品,把曝光量转化为点击。
4、常用的标题组合。
营销词+核心关键词(产品主名称)+修饰词+属性+近义/二级词
营销词+核心关键词+属性尺寸+服务卖点或产品卖点+品牌产地+经营模式
制作标题时注意:主关键词越靠前排行权重越高以及关键词的连贯性。
5、黄金标题的“2-4-2法则”
2个核心:
尽量只写核心词(马铃薯/土豆、番茄/西红柿)主关键词其实多了但搜索也概率大了,实际上排行增加了,内容过多会分散产品的权重,造成的后果是上架一周后基本无突显。
4个标准:
不能产生拼凑、不能使用符号、字数满足30个、修饰词4-5个为宜。
2个关键:
类目匹配度、类目的相关性、检查标题是否符合要求、生意参谋检测、橱窗有无推荐、类目是否正确、属性是否填写完整、有无低质量交易。
以上介绍了五个标题选词、优化的方式,不知诸位店家有没有又温故而新知了一遍呢,不过在这过程中会消耗我们的好多时间和精力,一个10年营运前辈说他写一个好的标题要花一个小时的时间,然而对于大部分店家来说,一整个过程出来起码也须要2个小时左右,这时候难免感触——
有没有一键手动优化标题生成这些好事情呢?
有!

免费开通慧眼识货你能够做到一键手动生成标题!!
【点击即可免费发放大泽慧眼识货】
免费发放慧眼识货,并授权登陆后,进入【大泽慧眼识货】界面。
选择基础信息:
选择版本,选择您的所属类目,选择模板,上传识货图片,即开始识货。

一键手动生成标题:
已通过上传的图片手动生成标题,点击按键可以一键更换更多标题。

大泽慧眼识货——自动生成标题并经过搜索优化、标题相关性贴切、标题核心关键词确切、标题字数符合26个字以上,满足30字完整丰富,排列组合次序会推动系统收录关键词。
1、自动生成标题并经过搜索优化:
慧眼识货通过AI智能文案生成技术,通过识货的图片结果手动生成标题,且标题经过搜索优化,利于凸显。
2、标题相关性贴切:
通过慧眼识货生成的标题,关键词来源与产品属性,与产品贴切吻合。满足搜索排名第一要素——相关性。
3、标题核心关键词确切:
核心词就是跟产品相关度最高同时搜索量又较大的词。慧眼识货一键生成的标题能同时兼具相关性和搜索量两个指标,核心关键词确切。
4、标题符合字数要求、完整丰富:
标题宽度为30个字(60个字符,一个汉字相当于2个字符),慧眼识货一键生成的标题都符合26个字到30个字的字数要求,标题完整丰富,符合商品质量信息要求。
5、紧密排列组合推动系统收录:
慧眼识货一键生成的标题,利用紧密排列的原理进行了排列组合,权重同等情况下,紧密排列的关键词会优先展示,自动匹配产品标题,把作用发挥到最大,助力系统收录关键词。
慧眼识货核心功能一键手动生成标题,方便广大店家的标题优化需求,让你们在选词、组合、优化等方面才能获得方便的流程,提升效率,简化过程,直接获得黄金标题。
大泽慧眼识货目前支持六大类目,女装、男装、童装、箱包、内衣、鞋鞋行业的店家可以行动上去了,用慧眼识货手动生成标题,快速上新,节省冗长重复的时间。各位商家们赶快开通/使用慧眼识货体验一下吧!
更多信息:
1、大泽慧眼识货免费发放地址:
手动添加多级URL填写链接地址规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-08-08 20:01
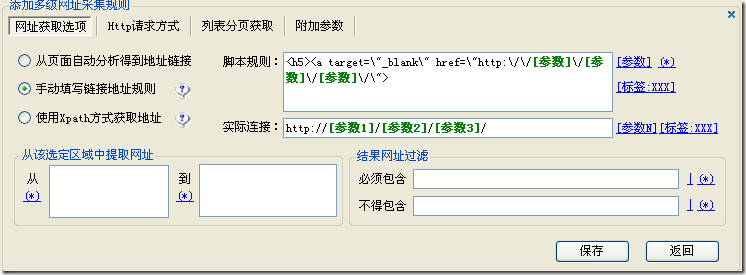
手动填写链接地址规则的原理是编写一个脚本规则以匹配源代码中的内容并获取您自己设置的参数.
使用常规解释
[参数]
用于匹配准备提取信息的标签. 例如,您想在以下代码中提取并合并某种格式. 采取代码“ mClk(this,'108484','134217','168475','1');”以提取并合并新的地址格式为例.
“ mClk(this,'[parameter]','[parameter]','[parameter]','1');”,按顺序,108484参数是参数1,依此类推. 所需的实际地址是以下地址格式: bbs / read.php?id = [parameter 1]&sort = [parameter 3]&action = [parameter 2],上面代码中的3个参数和下面地址中的id, soft和action参数应对应于相应的值,并且顺序不应颠倒. 这会合并为新的地址格式.
(*)
(*)是通配符,可以表示优采云采集器中起始地址的页数,并且可以匹配标签规则,模块或其他设置中的任何字符串,例如(*)可以匹配xxx字符字符串也可以与yy字符串匹配.
二,使用场合和使用方法
1. 通常,可以手动获取可以自动获取URL链接的网页. 手动填写链接地址的灵活性较高!
2. 如果网页源代码中的内容页面链接未标准化,或者URL中没有链接,则可以使用手动填写链接地址规则.
插图:
示例1,例如ajax链接
通过查看源代码,我们可以看到URL链接不是标准化的,因此链接地址不能直接用于获取URL.
解决方案:
脚本规则:
实际链接: [参数1] / [参数2] / [参数3] /
示例2: 例如,列表页面中内容页面只有一个ID,而没有其他URL信息,因此也可以通过手动填写链接地址规则来获取.
列表页面网址:
内容页面网址:
检查源代码表明URL链接也不规则.
解决方案:
脚本规则: |(*),[参数],
实际链接: [参数1] 查看全部
一个. 原理
手动填写链接地址规则的原理是编写一个脚本规则以匹配源代码中的内容并获取您自己设置的参数.
使用常规解释
[参数]
用于匹配准备提取信息的标签. 例如,您想在以下代码中提取并合并某种格式. 采取代码“ mClk(this,'108484','134217','168475','1');”以提取并合并新的地址格式为例.
“ mClk(this,'[parameter]','[parameter]','[parameter]','1');”,按顺序,108484参数是参数1,依此类推. 所需的实际地址是以下地址格式: bbs / read.php?id = [parameter 1]&sort = [parameter 3]&action = [parameter 2],上面代码中的3个参数和下面地址中的id, soft和action参数应对应于相应的值,并且顺序不应颠倒. 这会合并为新的地址格式.
(*)
(*)是通配符,可以表示优采云采集器中起始地址的页数,并且可以匹配标签规则,模块或其他设置中的任何字符串,例如(*)可以匹配xxx字符字符串也可以与yy字符串匹配.
二,使用场合和使用方法
1. 通常,可以手动获取可以自动获取URL链接的网页. 手动填写链接地址的灵活性较高!
2. 如果网页源代码中的内容页面链接未标准化,或者URL中没有链接,则可以使用手动填写链接地址规则.
插图:
示例1,例如ajax链接
通过查看源代码,我们可以看到URL链接不是标准化的,因此链接地址不能直接用于获取URL.

解决方案:
脚本规则:
实际链接: [参数1] / [参数2] / [参数3] /
示例2: 例如,列表页面中内容页面只有一个ID,而没有其他URL信息,因此也可以通过手动填写链接地址规则来获取.
列表页面网址:
内容页面网址:
检查源代码表明URL链接也不规则.

解决方案:
脚本规则: |(*),[参数],
实际链接: [参数1]
[教程步骤13] 优采云采集器版本选择指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2020-08-08 03:20
小蔡为您准备了以下指南,相信它将帮助您选择版本.
首先,让我们看一下免费版本. 优采云采集器的免费版本也可以终身使用,并且不限制使用时间. 它与付费版本仅在功能上有所不同. 伟大的神灵可能暂时没有考虑免费版本的所有功能是否满足您的需求,那么我们将看看免费版本暂时不支持哪些功能,如果您需要使用它,只需选择对应的商业版本〜</p
p1. 无标签组合功能/p
p当需要从两个标签采集的内容中合成一个内容时,需要使用此功能./p
p例如: [标签C] = [标签A] + [标签B],请参见下图:/p
pimg src='https://pic2.zhimg.com/v2-dc6bed9a281e0c62faac43fca663724f_b.jpg' alt=''//p
p2. 无限列表网址集合(支持两个以上级别)/p
p我们在采集网页时经常遇到多级列表. 例如,对于Dianping.com的分类(单击此处以查看共享的相关规则),您需要使用优采云采集器的多级列表功能. 有关功能用法,请参见下图:/p
pimg src='https://pic3.zhimg.com/v2-4ab849de9251f95154f8cccd98856740_b.jpg' alt=''//p
p3. 以任何格式下载文件/p
p在采集过程中,我们会遇到一些要下载的附件文件,例如word文档,压缩文件,PDF和其他格式文件,而免费版本不支持下载图片以外的其他格式文件./p
p4. 使用FTP自动将文件上传到网站/p
p如上所述,提到了任何格式的文件下载. 由于存在下载,因此当我们需要在网站上发布功能时,我们需要上载该功能. 优采云采集器提供了使用FTP自动上传文件的功能,包括图片的自动上传. 您无法在免费版本中使用此功能,只能手动上传文件,也无法同步和自动上传文件. 有关FTP功能,请参见下图:/p
pimg src='https://picb.zhimg.com/v2-e111c284d6cbdbbce4be81dac8be81ab_b.jpg' alt=''//p
p5. 将数据导出为Word,Excel,CSV格式/p
p将采集的数据发布到本地计算机,并将其另存为文件格式. 免费版本不支持Word,Excel,CSV格式,而仅支持TXT和html格式./p
p6,MySql和SqlServer数据库保存数据/p
p免费版本的默认版本是Sqlite数据库. 当数据量很大时,默认数据库将导致软件运行缓慢. 此时,您需要使用MySql或SqlServer数据库./p
p7. 多页采集功能/p
p当我们采集内容时,有时会遇到内容不在同一页面上的情况. 进入内容页面后,我们需要进入另一个页面,称为多页面集合. 点击此处以查看携程的多页采集案例/p
p8. 列表页面标签采集功能/p
p经常遇到要采集的内容在列表页面上,内容页面不可用或内容页面采集不便的情况,因此需要列表页面采集功能./p
p采集内容URL时,将采集列表页面上所需的内容./p
p点击此处查看昭联招募案/p
p9. 计划任务功能/p
p当我们采集一些新闻网站时,我们需要在固定的时间采集它们并自动发布它们,以便计划的任务可以在24小时内自动更新和发布. 单击此处以参考教程/p
p10. 其他一些功能/p
p自动提取第一张图片,自动摘要,将数据发布到MySql \ SqlServer和其他功能始终可以在需要时为您提供帮助. 我不会在这里详细介绍. 以上9个是更常用的功能./p
p如果上述功能已经可以满足大神的需求,那么您可以选择基本版本(商业授权也可以终身使用,没有过期版本可以免费使用)/p
p但是对于一个更专业的上帝来说,上述功能远远不够,所以接下来我将向您介绍更高版本./p
p旗舰版及更高版本的功能/p
p与基本版本相比,旗舰版本及更高版本还具有一些高级功能,可以满足诸神的操作. 让我列出一些更常用的功能./p
p1,二级代理商/p
p采集IP时,您需要使用辅助代理功能. 当然,您需要拥有IP代理资源. 目前,官方机构不提供代理资源/p
p2. 图片会自动加水印/p
p自动为采集的图片添加水印/p
p3. 支持标签处理C#和C#外部插件功能/p
p4. 挖掘时发布功能/p
p例如,需要采集100,000条信息. 基本版本只能在完成所有采集后才能发布,而旗舰版及更高版本则支持同时采集和分发./p
p5,Json提取功能/p
p支持Json格式的数据采集和提取/p
p6. 支持python插件,采集和警告配置,支持SSH(SFTP文件)上传/p
p旗舰版及更高版本需要支持以上功能. 如果您需要使用上述功能的基本版本,那还不够./p
p旗舰版和更高版本之间的区别/p
p那么旗舰版和更高版本之间有什么区别?除了企业版(该企业版还支持向Oracle和Http接口管理采集器发布数据)之外,主要区别在于计算机授权./p
p基本版本和旗舰机器代码版本: 绑定1台授权计算机,您可以免费更改一次授权./p
p旗舰自动许可版本: 绑定一台授权计算机,您可以无限次更改计算机./p
p企业专用版: 绑定了5台授权计算机(2个加密狗版本+ 3个机器代码版本),并且3个授权可以免费更换. 加密狗版本可以在任何计算机上使用./p
p企业豪华版: 绑定10台授权计算机(4台加密狗版本+ 6台自动授权版本),您可以无限次随意更改计算机./p
p注意: 捆绑的授权计算机表示该软件只能在绑定到授权计算机的计算机上运行商业版本. 自授权版本和加密狗版本可以在不同的计算机上使用,即可以在不同的计算机上使用,但同时只能在计算机上使用./p
p现在让我们看看哪个版本最适合您〜/p
p(1)如果您的软件长时间固定在计算机上,则无需经常更换,基本版本的功能已经可以满足您的需求»»»»»选择基本版本/p
p(2)如果您的软件长时间安装在计算机上,则不需要经常更换,但是您需要旗舰版»»»»»的高级功能选择旗舰机器代码版本/p
p(3)如果您的软件未固定在计算机上,则通常需要更改计算机以运行»»»»»选择旗舰自动许可版本/p
p(4)如果需要大规模采集数据,请使用多台计算机同时运行该软件,或者需要多人同时在不同的计算机上进行操作(5套)»»»»»选择企业版高级版/p
p(5)如果需要大规模采集数据,请使用多台计算机同时运行该软件,或者需要多人同时在不同的计算机上进行操作(10套)»»»»»选择企业版豪华版/p
p当然,如果您仍然有无法满足的需求,请联系我们的客户服务经理MM(企业QQ: 800019423),优采云采集器视客户为上帝,并将为您量身定制./p
p回顾以前的教程/p
p☞【教程步骤1】,开始使用优采云采集器/p
p☞[教程步骤2]优采云采集器的URL采集/p
p☞[教程步骤3] 优采云采集器的内容采集/p
p☞[教程步骤4]优采云采集器在线发布/p
p☞[教程步骤5]理解POST以获得URL和捕获数据包的时间/p
p☞[Tutorial step.6]阅读本文后,[Parameter N]不会让您晕眩/p
p☞[教程步骤7]如何按页面采集内容?/p
p☞[教程步骤8],如果您遇到这样的反爬网网站怎么办?/p
p☞[教程步骤9]. 如果您不懂常规,只需写下这些表达式/p
p☞[教程步骤10]优采云采集器数据处理的神奇效果/p
p☞[教程步骤11],看不到吗?尝试多页〜☞[教程步骤12]优采云采集器V9计划任务设置/p
p>>必要提示
优采云采集器用户手册| 优采云 Browser用户手册
>>>>软件咨询
官方网站|价格特色|常见问题 查看全部
最近,许多首次联系优采云采集器的用户都反馈说,优采云采集器 V9具有免费版本,基本版本,最终机器代码版本,最终版本的自动授权版本,独占版本. 企业版,以及企业版如何在豪华版等多个版本之间进行选择?
小蔡为您准备了以下指南,相信它将帮助您选择版本.
首先,让我们看一下免费版本. 优采云采集器的免费版本也可以终身使用,并且不限制使用时间. 它与付费版本仅在功能上有所不同. 伟大的神灵可能暂时没有考虑免费版本的所有功能是否满足您的需求,那么我们将看看免费版本暂时不支持哪些功能,如果您需要使用它,只需选择对应的商业版本〜</p
p1. 无标签组合功能/p
p当需要从两个标签采集的内容中合成一个内容时,需要使用此功能./p
p例如: [标签C] = [标签A] + [标签B],请参见下图:/p
pimg src='https://pic2.zhimg.com/v2-dc6bed9a281e0c62faac43fca663724f_b.jpg' alt=''//p
p2. 无限列表网址集合(支持两个以上级别)/p
p我们在采集网页时经常遇到多级列表. 例如,对于Dianping.com的分类(单击此处以查看共享的相关规则),您需要使用优采云采集器的多级列表功能. 有关功能用法,请参见下图:/p
pimg src='https://pic3.zhimg.com/v2-4ab849de9251f95154f8cccd98856740_b.jpg' alt=''//p
p3. 以任何格式下载文件/p
p在采集过程中,我们会遇到一些要下载的附件文件,例如word文档,压缩文件,PDF和其他格式文件,而免费版本不支持下载图片以外的其他格式文件./p
p4. 使用FTP自动将文件上传到网站/p
p如上所述,提到了任何格式的文件下载. 由于存在下载,因此当我们需要在网站上发布功能时,我们需要上载该功能. 优采云采集器提供了使用FTP自动上传文件的功能,包括图片的自动上传. 您无法在免费版本中使用此功能,只能手动上传文件,也无法同步和自动上传文件. 有关FTP功能,请参见下图:/p
pimg src='https://picb.zhimg.com/v2-e111c284d6cbdbbce4be81dac8be81ab_b.jpg' alt=''//p
p5. 将数据导出为Word,Excel,CSV格式/p
p将采集的数据发布到本地计算机,并将其另存为文件格式. 免费版本不支持Word,Excel,CSV格式,而仅支持TXT和html格式./p
p6,MySql和SqlServer数据库保存数据/p
p免费版本的默认版本是Sqlite数据库. 当数据量很大时,默认数据库将导致软件运行缓慢. 此时,您需要使用MySql或SqlServer数据库./p
p7. 多页采集功能/p
p当我们采集内容时,有时会遇到内容不在同一页面上的情况. 进入内容页面后,我们需要进入另一个页面,称为多页面集合. 点击此处以查看携程的多页采集案例/p
p8. 列表页面标签采集功能/p
p经常遇到要采集的内容在列表页面上,内容页面不可用或内容页面采集不便的情况,因此需要列表页面采集功能./p
p采集内容URL时,将采集列表页面上所需的内容./p
p点击此处查看昭联招募案/p
p9. 计划任务功能/p
p当我们采集一些新闻网站时,我们需要在固定的时间采集它们并自动发布它们,以便计划的任务可以在24小时内自动更新和发布. 单击此处以参考教程/p
p10. 其他一些功能/p
p自动提取第一张图片,自动摘要,将数据发布到MySql \ SqlServer和其他功能始终可以在需要时为您提供帮助. 我不会在这里详细介绍. 以上9个是更常用的功能./p
p如果上述功能已经可以满足大神的需求,那么您可以选择基本版本(商业授权也可以终身使用,没有过期版本可以免费使用)/p
p但是对于一个更专业的上帝来说,上述功能远远不够,所以接下来我将向您介绍更高版本./p
p旗舰版及更高版本的功能/p
p与基本版本相比,旗舰版本及更高版本还具有一些高级功能,可以满足诸神的操作. 让我列出一些更常用的功能./p
p1,二级代理商/p
p采集IP时,您需要使用辅助代理功能. 当然,您需要拥有IP代理资源. 目前,官方机构不提供代理资源/p
p2. 图片会自动加水印/p
p自动为采集的图片添加水印/p
p3. 支持标签处理C#和C#外部插件功能/p
p4. 挖掘时发布功能/p
p例如,需要采集100,000条信息. 基本版本只能在完成所有采集后才能发布,而旗舰版及更高版本则支持同时采集和分发./p
p5,Json提取功能/p
p支持Json格式的数据采集和提取/p
p6. 支持python插件,采集和警告配置,支持SSH(SFTP文件)上传/p
p旗舰版及更高版本需要支持以上功能. 如果您需要使用上述功能的基本版本,那还不够./p
p旗舰版和更高版本之间的区别/p
p那么旗舰版和更高版本之间有什么区别?除了企业版(该企业版还支持向Oracle和Http接口管理采集器发布数据)之外,主要区别在于计算机授权./p
p基本版本和旗舰机器代码版本: 绑定1台授权计算机,您可以免费更改一次授权./p
p旗舰自动许可版本: 绑定一台授权计算机,您可以无限次更改计算机./p
p企业专用版: 绑定了5台授权计算机(2个加密狗版本+ 3个机器代码版本),并且3个授权可以免费更换. 加密狗版本可以在任何计算机上使用./p
p企业豪华版: 绑定10台授权计算机(4台加密狗版本+ 6台自动授权版本),您可以无限次随意更改计算机./p
p注意: 捆绑的授权计算机表示该软件只能在绑定到授权计算机的计算机上运行商业版本. 自授权版本和加密狗版本可以在不同的计算机上使用,即可以在不同的计算机上使用,但同时只能在计算机上使用./p
p现在让我们看看哪个版本最适合您〜/p
p(1)如果您的软件长时间固定在计算机上,则无需经常更换,基本版本的功能已经可以满足您的需求»»»»»选择基本版本/p
p(2)如果您的软件长时间安装在计算机上,则不需要经常更换,但是您需要旗舰版»»»»»的高级功能选择旗舰机器代码版本/p
p(3)如果您的软件未固定在计算机上,则通常需要更改计算机以运行»»»»»选择旗舰自动许可版本/p
p(4)如果需要大规模采集数据,请使用多台计算机同时运行该软件,或者需要多人同时在不同的计算机上进行操作(5套)»»»»»选择企业版高级版/p
p(5)如果需要大规模采集数据,请使用多台计算机同时运行该软件,或者需要多人同时在不同的计算机上进行操作(10套)»»»»»选择企业版豪华版/p
p当然,如果您仍然有无法满足的需求,请联系我们的客户服务经理MM(企业QQ: 800019423),优采云采集器视客户为上帝,并将为您量身定制./p
p回顾以前的教程/p
p☞【教程步骤1】,开始使用优采云采集器/p
p☞[教程步骤2]优采云采集器的URL采集/p
p☞[教程步骤3] 优采云采集器的内容采集/p
p☞[教程步骤4]优采云采集器在线发布/p
p☞[教程步骤5]理解POST以获得URL和捕获数据包的时间/p
p☞[Tutorial step.6]阅读本文后,[Parameter N]不会让您晕眩/p
p☞[教程步骤7]如何按页面采集内容?/p
p☞[教程步骤8],如果您遇到这样的反爬网网站怎么办?/p
p☞[教程步骤9]. 如果您不懂常规,只需写下这些表达式/p
p☞[教程步骤10]优采云采集器数据处理的神奇效果/p
p☞[教程步骤11],看不到吗?尝试多页〜☞[教程步骤12]优采云采集器V9计划任务设置/p
p>>必要提示
优采云采集器用户手册| 优采云 Browser用户手册
>>>>软件咨询
官方网站|价格特色|常见问题
VG捕获浏览器v7.7.6
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2020-08-07 21:19
基本介绍
VG浏览器是由可视脚本驱动的网页自动操作工具. 只需设置一个脚本即可创建自动登录,识别验证码,自动捕获数据,自动提交数据,单击网页并下载文件. 个性化和实用的脚本项目,例如操作数据库,发送和接收电子邮件. 您还可以使用逻辑运算来完成判断,循环,跳转和其他功能. 脚本灵活且易于自由组合. 没有任何编程基础,您可以轻松,快速地编写功能强大且独特的脚本来协助我们的工作. 生成待售的独立EXE程序.
软件功能
视觉操作
操作简单,图形化操作完全可视化,不需要专业的IT人员.
自定义流程
采集就像构建块一样,功能可以自由组合.
自动编码
程序注重采集效率,页面分析速度非常快.
生成EXE
自动登录,自动识别验证码是一种通用浏览器.
使用方法
通过CSS路径定位网页元素的路径是VG浏览器的一项非常有用的功能. 选择需要填写CSS Path规则的任何步骤,然后单击内置浏览器的按钮
单击网页元素以自动生成该元素的CSS路径. 很少有复杂框架的网页可能无法通过内置浏览器生成路径. 您也可以在其他浏览器上复制CSS路径. 当前,各种多核浏览器都支持复制CSS Path. 例如,可以通过按F12键或右键单击页面以选择审阅元素来检查所有Chrome内核浏览器,例如Google Chrome,360安全浏览器,360 Speed浏览器,UC浏览器等.
右键单击目标部分,然后选择“复制CSS路径”以将CSS路径复制到剪贴板,
在Firefox中,您也可以按F12键或右键单击以查看元素. 显示开发人员工具后,右键单击底部节点,然后选择“仅复制选择器”以复制CSS路径.
CSS路径规则与JQuery选择器规则完全兼容. 如果您知道如何编写JQuery选择器,也可以自己编写CSS路径 查看全部
VG浏览器中收录三合一的集合浏览器,营销工件和可视脚本驱动的Web工具. 使用此软件,就等于同时拥有三个软件. 用户可以设置脚本来实现自动登录,识别验证码,自动抓取数据,单击网页,下载文件,操纵数据库,发送和接收电子邮件以及其他操作. 软件中的所有功能均可自由组合. 您还可以使用该软件编写独特的脚本来协助您的工作,也可以生成单独的EXE程序进行出售.

基本介绍
VG浏览器是由可视脚本驱动的网页自动操作工具. 只需设置一个脚本即可创建自动登录,识别验证码,自动捕获数据,自动提交数据,单击网页并下载文件. 个性化和实用的脚本项目,例如操作数据库,发送和接收电子邮件. 您还可以使用逻辑运算来完成判断,循环,跳转和其他功能. 脚本灵活且易于自由组合. 没有任何编程基础,您可以轻松,快速地编写功能强大且独特的脚本来协助我们的工作. 生成待售的独立EXE程序.

软件功能
视觉操作
操作简单,图形化操作完全可视化,不需要专业的IT人员.
自定义流程
采集就像构建块一样,功能可以自由组合.
自动编码
程序注重采集效率,页面分析速度非常快.
生成EXE
自动登录,自动识别验证码是一种通用浏览器.
使用方法
通过CSS路径定位网页元素的路径是VG浏览器的一项非常有用的功能. 选择需要填写CSS Path规则的任何步骤,然后单击内置浏览器的按钮

单击网页元素以自动生成该元素的CSS路径. 很少有复杂框架的网页可能无法通过内置浏览器生成路径. 您也可以在其他浏览器上复制CSS路径. 当前,各种多核浏览器都支持复制CSS Path. 例如,可以通过按F12键或右键单击页面以选择审阅元素来检查所有Chrome内核浏览器,例如Google Chrome,360安全浏览器,360 Speed浏览器,UC浏览器等.

右键单击目标部分,然后选择“复制CSS路径”以将CSS路径复制到剪贴板,

在Firefox中,您也可以按F12键或右键单击以查看元素. 显示开发人员工具后,右键单击底部节点,然后选择“仅复制选择器”以复制CSS路径.


CSS路径规则与JQuery选择器规则完全兼容. 如果您知道如何编写JQuery选择器,也可以自己编写CSS路径
通过组合长尾关键字来轻松将内容流量提高10倍
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-06 10:25
确定网站的主题和方向,例如核心关键字: 二手车. 以下是重点. 长尾关键词是怎么来的?在这里您需要了解该程序,只需使用php字段即可采集: 百度相关搜索. 对于初学者来说可能比较困难. 使用php字段方法(常规是可以的,该字段很简单)来采集所有收录“二手车”的关键字,并且自动无限制地采集的关键字数量非常大(不采集重复的关键字,并且长度超过限制. 不采集关键字. )
2. 长尾关键词进行分类
包括“二手车”在内的所有关键字将被采集和处理,大致分为三个类别: 1.导航类别; 2.交易类别; 3.信息类别;进行此分类的原因是不分隔列. 在下面组合长尾关键字很方便.
3. 组合长尾关键词
上面分隔的三种类型的关键字,每篇文章随机提取一个导航,交易和信息关键字,并将它们组合为标题. 目的是使标题更加多样化和可搜索. 它更易于搜索,而且长尾关键字易于排名,您可以轻松访问主页. 如果人数很多,您获得的流量将非常直观.
4. 根据由长尾关键词组成的标题制作内容
从分类中提取关键字组合作为标题. 由于所有关键字都收录“二手车”,因此您不必担心它们之间的关系. 如果使用馆藏,可以考虑采集一些相关内容进行组合,或者采集别人的文章到百度翻译,再翻译成中文,这些方法不好,可读性差,不利于长远发展该网站,而百度垃圾邮件识别也在不断完善.
5. 原理分析
长尾关键词具有快速排名的能力,并且是增加有效流量的最佳途径. 花在核心关键字上的时间可能是成千上万的长尾关键字. 在这里我采集了百度上的相关搜索,并确认这些关键词是人们搜索过的关键词,并且“二手车”一词的相关性是确定的,加上分类,然后组合成标题,三种标题类别被集成到其中,使用户更容易搜索. 该方法简单,直接,有效. 如果您精通该程序,那么这样做实在太容易了. 如果您使用大量的长尾关键字制作内容,则始终会有很多关键字在首页上排名,访问量将会增加十倍. 根本不是问题. 查看全部
1. 网站定位使用核心词来采集和组织长尾关键词
确定网站的主题和方向,例如核心关键字: 二手车. 以下是重点. 长尾关键词是怎么来的?在这里您需要了解该程序,只需使用php字段即可采集: 百度相关搜索. 对于初学者来说可能比较困难. 使用php字段方法(常规是可以的,该字段很简单)来采集所有收录“二手车”的关键字,并且自动无限制地采集的关键字数量非常大(不采集重复的关键字,并且长度超过限制. 不采集关键字. )
2. 长尾关键词进行分类
包括“二手车”在内的所有关键字将被采集和处理,大致分为三个类别: 1.导航类别; 2.交易类别; 3.信息类别;进行此分类的原因是不分隔列. 在下面组合长尾关键字很方便.
3. 组合长尾关键词
上面分隔的三种类型的关键字,每篇文章随机提取一个导航,交易和信息关键字,并将它们组合为标题. 目的是使标题更加多样化和可搜索. 它更易于搜索,而且长尾关键字易于排名,您可以轻松访问主页. 如果人数很多,您获得的流量将非常直观.
4. 根据由长尾关键词组成的标题制作内容
从分类中提取关键字组合作为标题. 由于所有关键字都收录“二手车”,因此您不必担心它们之间的关系. 如果使用馆藏,可以考虑采集一些相关内容进行组合,或者采集别人的文章到百度翻译,再翻译成中文,这些方法不好,可读性差,不利于长远发展该网站,而百度垃圾邮件识别也在不断完善.
5. 原理分析
长尾关键词具有快速排名的能力,并且是增加有效流量的最佳途径. 花在核心关键字上的时间可能是成千上万的长尾关键字. 在这里我采集了百度上的相关搜索,并确认这些关键词是人们搜索过的关键词,并且“二手车”一词的相关性是确定的,加上分类,然后组合成标题,三种标题类别被集成到其中,使用户更容易搜索. 该方法简单,直接,有效. 如果您精通该程序,那么这样做实在太容易了. 如果您使用大量的长尾关键字制作内容,则始终会有很多关键字在首页上排名,访问量将会增加十倍. 根本不是问题.
LTE网络安全数据采集与组合算法研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-08-05 11:05
首先采集一些指定的LTE网络安全数据,然后使用机器学习算法来预测网络中是否存在某种攻击. 但是,据我们所知,在大规模的LTE网络数据环境中,几乎没有文献专门讨论如何采集LTE网络安全数据,以避免由于重复采集或造成重复采集而浪费资源和时间. 采集不完整. 数据中收录的信息不够完整,无法获得准确的结果. 很少有文档讨论如何将采集的LTE网络安全数据组合在一起以分析整个LTE网络的安全状态. 为了弥补LTE网络安全研究中数据采集与组合方法中存在的上述问题,在LTE网络安全数据采集与组合设计的基础上,提出了一种自适应LTE网络安全数据采集算法和LTE网络安全数据. 框架. 组合算法. 我们的工作与传统方法之间的区别在于获取策略的反馈过程和串并结构的数据处理过程. 提出的两种算法与机器学习算法相结合. 机器学习中使用的主要核心算法是特征选择算法和分类算法. 基于这两个核心算法,我们设计了基于LTE网络安全数据的设计. 基于串行-并行结构的局部互信息增益特征选择算法和支持向量机算法. 其中,特征选择算法用于计算LTE网络安全数据对分类结果的影响程度,然后根据特征选择结果制定相应的采集策略,并反馈给网络采集器以指导将来的数据. 采集;分类算法用于串行和并行在网络数据处理的结构中,有必要识别并预测不同安全类别的组合数据所反映的安全问题,然后评估LTE网络中的安全问题.
为了验证设计框架和算法的性能,我们使用NS3网络仿真工具来仿真正常LTE网络环境和异常LTE网络环境,并在物理层模拟信号干扰攻击,带宽窃取攻击在多媒体访问层和应用程序层进行拒绝服务攻击,并在模拟LTE网络的不同层中部署网络安全数据采集器以采集网络数据. 然后,本文提出的数据采集和组合算法是用Python语言编程实现的. 最后,设计了一个测试实验来测试本文提出的数据采集和组合算法的性能. 测试结果证明了该方法在LTE网络安全分析中的优势. 查看全部
[摘要]: LTE(长期演进)是一种广泛用于4G的通信技术. 它以带宽,频谱利用率,网络吞吐量等优势进入市场,受到越来越多用户的喜爱,引起了研究者的广泛关注. 但是,随着LTE技术的普及,利用LTE技术构建的移动通信网络(称为“ LTE网络”)中的安全性问题也不容忽视. 在过去的几年中,对LTE网络安全性的研究主要集中在提出有效的安全认证方案或安全访问控制策略的领域. 但是,随着数据分析方法的兴起,出现了基于LTE网络数据的研究. 由于数据是数据分析方法中知识发现和决策过程的基础,因此人们将通过处理和分析相关数据来获得有价值的结论,例如处理和分析LTE网络数据以识别网络中是否存在某种攻击. . 数据分析的关键是机器学习算法. 它可以通过学习训练数据集来发现数据中存在的规律,然后根据先前学习的经验和知识来预测未知数据,以获得相应的结论. 考虑到LTE网络安全研究的重要性,数据分析的重要性以及机器学习算法在数据处理过程中的作用,本文研究了如何使用机器学习方法快速,准确和自适应地采集LTE网络安全性数据,并结合,处理和分析采集的数据. 在现有工作中,已经进行了很多有关LTE网络入侵检测的研究.
首先采集一些指定的LTE网络安全数据,然后使用机器学习算法来预测网络中是否存在某种攻击. 但是,据我们所知,在大规模的LTE网络数据环境中,几乎没有文献专门讨论如何采集LTE网络安全数据,以避免由于重复采集或造成重复采集而浪费资源和时间. 采集不完整. 数据中收录的信息不够完整,无法获得准确的结果. 很少有文档讨论如何将采集的LTE网络安全数据组合在一起以分析整个LTE网络的安全状态. 为了弥补LTE网络安全研究中数据采集与组合方法中存在的上述问题,在LTE网络安全数据采集与组合设计的基础上,提出了一种自适应LTE网络安全数据采集算法和LTE网络安全数据. 框架. 组合算法. 我们的工作与传统方法之间的区别在于获取策略的反馈过程和串并结构的数据处理过程. 提出的两种算法与机器学习算法相结合. 机器学习中使用的主要核心算法是特征选择算法和分类算法. 基于这两个核心算法,我们设计了基于LTE网络安全数据的设计. 基于串行-并行结构的局部互信息增益特征选择算法和支持向量机算法. 其中,特征选择算法用于计算LTE网络安全数据对分类结果的影响程度,然后根据特征选择结果制定相应的采集策略,并反馈给网络采集器以指导将来的数据. 采集;分类算法用于串行和并行在网络数据处理的结构中,有必要识别并预测不同安全类别的组合数据所反映的安全问题,然后评估LTE网络中的安全问题.
为了验证设计框架和算法的性能,我们使用NS3网络仿真工具来仿真正常LTE网络环境和异常LTE网络环境,并在物理层模拟信号干扰攻击,带宽窃取攻击在多媒体访问层和应用程序层进行拒绝服务攻击,并在模拟LTE网络的不同层中部署网络安全数据采集器以采集网络数据. 然后,本文提出的数据采集和组合算法是用Python语言编程实现的. 最后,设计了一个测试实验来测试本文提出的数据采集和组合算法的性能. 测试结果证明了该方法在LTE网络安全分析中的优势.
ET手动采集器 V3.2.2 安全版
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-08-25 12:36
ET手动采集器(ET网站自动采集器)是一款网站内容手动更新神器独立的红色软件。想知道这样能够使网站自动采集呢? 那就快试试红色先锋小编推荐的ET手动采集器吧! 稳定易用,信息采集必备之选。有须要的用户快来绿色先锋下载吧。
【全手动无人值守】
无需人工值守,24小时手动实时监控目标,实时高效采集,昼夜不停为您提供内容更新。满足常年运行需求,将您从繁杂工作中解脱
【适用广泛】
最全能的采集软件,支持任意类型网站采集,适用率高达99.9%,支持发布到所有类型网站程序,更可以采集本地文件,免插口发布。
【信息随心所欲】
支持信息自由组合,通过强悍的数据整理功能对信息深度加工,创造全新内容
【任意格式文件下载】
不论静态或动态,不论是图片、音乐、电影、软件,又或则是PDF文档、WORD文档,甚至种子文件,只要你想
【伪原创】
高速同反义词替换、多词随机替换、段落随机排序,助力内容SEO
【无限多级页面采集】
无论垂直方向多层页面,还是平行方向复数分页,抑或AJAX调用页面,为你轻松采集
【自由扩充】
开放的插口模式,可以自由二次开发,自定义任何功能,实现所有需求
软件外置了包括discuzX,phpwind,dedecms,wordpress,phpcms,帝国cms,动易,joomla,pbdigg,php168,bbsxp,phpbb,dvbbs,typecho,emblog等大量常用系统的范例。
更新日志
1、新增:自动动词模块,可用于手动提取关键词/TAG。
2、新增;数据项可以选择指定内容模式,支持引用其他数据项、随机字符串等预设内容。
3、优化:采集配置根据列表页、采集页、数据项的从属关系优化了界面。
4、优化:数据项如今可以选择是否使用翻译了,以便捷对翻译内容进行整理。
5、优化:数据项如今可以独立选择是否修正网址了。
6、新增:采集页和数据分页的网址合成如今可以引用数据项,适应更复杂的网址合成。
7、优化:方案间隔时间从系统设置窗口移到制定方案窗口,可以为每位方案单独设置间隔时间了。 查看全部
ET手动采集器 V3.2.2 安全版
ET手动采集器(ET网站自动采集器)是一款网站内容手动更新神器独立的红色软件。想知道这样能够使网站自动采集呢? 那就快试试红色先锋小编推荐的ET手动采集器吧! 稳定易用,信息采集必备之选。有须要的用户快来绿色先锋下载吧。
【全手动无人值守】
无需人工值守,24小时手动实时监控目标,实时高效采集,昼夜不停为您提供内容更新。满足常年运行需求,将您从繁杂工作中解脱
【适用广泛】
最全能的采集软件,支持任意类型网站采集,适用率高达99.9%,支持发布到所有类型网站程序,更可以采集本地文件,免插口发布。
【信息随心所欲】
支持信息自由组合,通过强悍的数据整理功能对信息深度加工,创造全新内容
【任意格式文件下载】
不论静态或动态,不论是图片、音乐、电影、软件,又或则是PDF文档、WORD文档,甚至种子文件,只要你想
【伪原创】
高速同反义词替换、多词随机替换、段落随机排序,助力内容SEO
【无限多级页面采集】
无论垂直方向多层页面,还是平行方向复数分页,抑或AJAX调用页面,为你轻松采集
【自由扩充】
开放的插口模式,可以自由二次开发,自定义任何功能,实现所有需求
软件外置了包括discuzX,phpwind,dedecms,wordpress,phpcms,帝国cms,动易,joomla,pbdigg,php168,bbsxp,phpbb,dvbbs,typecho,emblog等大量常用系统的范例。
更新日志
1、新增:自动动词模块,可用于手动提取关键词/TAG。
2、新增;数据项可以选择指定内容模式,支持引用其他数据项、随机字符串等预设内容。
3、优化:采集配置根据列表页、采集页、数据项的从属关系优化了界面。
4、优化:数据项如今可以选择是否使用翻译了,以便捷对翻译内容进行整理。
5、优化:数据项如今可以独立选择是否修正网址了。
6、新增:采集页和数据分页的网址合成如今可以引用数据项,适应更复杂的网址合成。
7、优化:方案间隔时间从系统设置窗口移到制定方案窗口,可以为每位方案单独设置间隔时间了。
优采云采集器官方版 v6.0.1
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-08-22 00:47
优采云采集器官方版是一款强悍的网站采集器,优采云采集器软件才能24小时不间断的运行,一直采集,不死机,不停顿,也不需要人员看守,提高采集的效率,该软件适用于各类平台,无论是网页还是淘宝等,都能采集,而且采集的资源齐全,能够详尽的进行分类,用户也可以自己设置自己要采集的类型早已采集的时间。
优采云采集器官方版简介
优采云采集器是一款采集网页数据的智能软件,优采云数据采集系统以完全自主研制的分布式云计算平台为核心,可以在太短的时间内,轻松从各类不同的网站或者网页获取大量的规范化数据,帮助任何须要从网页获取信息的顾客实现数据自动化采集,编辑,规范化,摆脱对人工搜索及搜集数据的依赖,降低获取信息的成本,提高效率。
优采云采集器官方版特色
简易采集
简易采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的冗长,支持更多网站的采集。
优采云采集器官方版功能
1. 金融数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3. 监控竞争对手最新信息,包括商品价钱及库存; 查看全部
优采云采集器官方版 v6.0.1
优采云采集器官方版是一款强悍的网站采集器,优采云采集器软件才能24小时不间断的运行,一直采集,不死机,不停顿,也不需要人员看守,提高采集的效率,该软件适用于各类平台,无论是网页还是淘宝等,都能采集,而且采集的资源齐全,能够详尽的进行分类,用户也可以自己设置自己要采集的类型早已采集的时间。
优采云采集器官方版简介
优采云采集器是一款采集网页数据的智能软件,优采云数据采集系统以完全自主研制的分布式云计算平台为核心,可以在太短的时间内,轻松从各类不同的网站或者网页获取大量的规范化数据,帮助任何须要从网页获取信息的顾客实现数据自动化采集,编辑,规范化,摆脱对人工搜索及搜集数据的依赖,降低获取信息的成本,提高效率。
优采云采集器官方版特色
简易采集
简易采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的冗长,支持更多网站的采集。
优采云采集器官方版功能
1. 金融数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3. 监控竞争对手最新信息,包括商品价钱及库存;
优采云浏览器(数据库采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-21 14:27
优采云浏览器(数据库采集器)是一款可视化的自动化脚本工具,我们可以通过设置脚本,达到手动登入,识别验证码,自动抓取数据,自动递交数据,点击网页,下载文件,操作数据库,收发短信等操作。
编程语言
优采云浏览器的编程语言是 C#,C#综合了 VB 简单的可视化操作和 C++的高运行效率,增强开发效率的同时也致力于清除编程中可能造成严重结果的错误,以其强悍的操作能力、优雅的句型风格、创新的语言特点和方便的面向组件编程的支持成为软件开发的首选语言。
需要安装.net 4.5:
软件特色
优采云浏览器是一款可视化的自动化脚本工具,我们可以通过设置脚本,达到手动登入,识别验证码,自动抓取数据,自动递交数据,点击网页,下载文件,操作数据库,收发短信等操作。还可以使用逻辑操作,完成判别,循环,跳转等操作。所有的功能完全是自由组合,可以写出功能强悍又独一无二的腿原本辅助我们的工作,还可以生成单独的EXE程序进行销售
浏览器可以读取写入mysql,sqlserver,sqlite,access四种数据库。你可以在将任务数据放到数据库,通过浏览器读取并运行,运行完成后,再使用浏览器标记为已使用过。你可以在浏览器的使用过程中随时使用数据库,十分便捷。
优采云浏览器是可以帮助你们实现自动化的网页操作。也能使你们做的脚本生成程序去销售,生成的程序可以自定义软件名子
产品特性
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理过的内容,jax,瀑布流之类的采集非常简单,一些js加密的数据也能轻易得到,不需要抓取数据包剖析。
自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页上的元素,操作数据库,验证码识别,抓取循环记录,处理列表,条件判定,完全自定义流程,采集就像是搭积木,功能自由组合。
自动打码
采集速度快,程序重视采集效率,页面解析速率飞快,不需要访问的页面或广告之类可以直接屏蔽,加快访问速率。
生成EXE
不只是个采集器,更是营销神器。不光能采集数据保存到数据库或其它地方,还可以群发现有的数据到各个网站。可以做到手动登入,自动辨识验证码,是万能的浏览器。
项目管理
利用解决方案可以直接生成单个应用程序。单个程序可以脱离优采云浏览器并运行,官方提供了一个软件管理平台,用户可以进行授权等管理。每个用户都是开发者,每个人都能从平台中获利。 查看全部
优采云浏览器(数据库采集器)
优采云浏览器(数据库采集器)是一款可视化的自动化脚本工具,我们可以通过设置脚本,达到手动登入,识别验证码,自动抓取数据,自动递交数据,点击网页,下载文件,操作数据库,收发短信等操作。
编程语言
优采云浏览器的编程语言是 C#,C#综合了 VB 简单的可视化操作和 C++的高运行效率,增强开发效率的同时也致力于清除编程中可能造成严重结果的错误,以其强悍的操作能力、优雅的句型风格、创新的语言特点和方便的面向组件编程的支持成为软件开发的首选语言。
需要安装.net 4.5:
软件特色
优采云浏览器是一款可视化的自动化脚本工具,我们可以通过设置脚本,达到手动登入,识别验证码,自动抓取数据,自动递交数据,点击网页,下载文件,操作数据库,收发短信等操作。还可以使用逻辑操作,完成判别,循环,跳转等操作。所有的功能完全是自由组合,可以写出功能强悍又独一无二的腿原本辅助我们的工作,还可以生成单独的EXE程序进行销售
浏览器可以读取写入mysql,sqlserver,sqlite,access四种数据库。你可以在将任务数据放到数据库,通过浏览器读取并运行,运行完成后,再使用浏览器标记为已使用过。你可以在浏览器的使用过程中随时使用数据库,十分便捷。
优采云浏览器是可以帮助你们实现自动化的网页操作。也能使你们做的脚本生成程序去销售,生成的程序可以自定义软件名子
产品特性
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。操作的内容是浏览器处理过的内容,jax,瀑布流之类的采集非常简单,一些js加密的数据也能轻易得到,不需要抓取数据包剖析。
自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页上的元素,操作数据库,验证码识别,抓取循环记录,处理列表,条件判定,完全自定义流程,采集就像是搭积木,功能自由组合。
自动打码
采集速度快,程序重视采集效率,页面解析速率飞快,不需要访问的页面或广告之类可以直接屏蔽,加快访问速率。
生成EXE
不只是个采集器,更是营销神器。不光能采集数据保存到数据库或其它地方,还可以群发现有的数据到各个网站。可以做到手动登入,自动辨识验证码,是万能的浏览器。
项目管理
利用解决方案可以直接生成单个应用程序。单个程序可以脱离优采云浏览器并运行,官方提供了一个软件管理平台,用户可以进行授权等管理。每个用户都是开发者,每个人都能从平台中获利。
数据规整化:清理、转换、合并、重塑
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2020-08-21 05:09
数据剖析和建模方面的大量编程工作都是用在数据打算上的:加载、清理、转换以及塑造。有时候,存放在文件或数据库中的数据并不能满足你的数据处理应用的要求。许多人都选择使用通用编程语言(如python、perl、R或java)或UNIX文本处理工具(sed或awk)对数据格式进行专门处理。幸运的是,pandas和python标准库提供了一组中级的、灵活的、高效的核心函数和算法,它们让你就能轻松地将数据规整化为正确的方式。
1. 合并数据集
pandas对象中的数据可以通过一些外置的方法进行合并:pandas.merge、pandas.concat、combine_first。我们分别对它们进行讲解,并给出一些事例。
1.1 数据库风格的DataFrame合并
数据集的合并(merge)或联接(join)运算是通过一个或多个键将行链接上去的。要注意区别的是:多对一的合并和多对多的合并(多对多联接形成的是行的笛卡尔积。由于左侧的DataFrame有3个”b”行,右边的有2个,所以最终结果中就有6个”b”行)
你须要注意的是,默认情况下,merge做的是”inner”连接;结果中的键是交集。其他方法还有”left”、”right”、以及”outer”。外联接求取的是键的并集,组合了左联接和右联接的疗效:
要依据多个键进行合并,传入一个由列名组成的列表即可:
1.2 轴向联接
1.另一种数据合并运算也被叫做联接、绑定或堆叠。Numpy有一个用于合并原创Numpy链表的concatenation函数。调用concat可以将值和索引黏合在一起,默认情况下,concat是在axis=0(对应的是行)上工作的,最终形成一个新的series。如果传入axis=1,则结果都会弄成一个DataFrame(axis=1是对应列)。
2.传入join=’inner’即可得到它们的交集;你也可以通过join_axes指定要在其他轴上使用的索引
2. 重塑和轴向旋转
2.1 重塑层次化索引
层次化索引为DataFrame数据的重排任务提供了一种具有良好一致性的形式。主要功能有二:
1. stack:将数据的列”旋转”为行。
2. unstack:将数据的行”旋转”为列。
(未完待续……..) 查看全部
数据规整化:清理、转换、合并、重塑
数据剖析和建模方面的大量编程工作都是用在数据打算上的:加载、清理、转换以及塑造。有时候,存放在文件或数据库中的数据并不能满足你的数据处理应用的要求。许多人都选择使用通用编程语言(如python、perl、R或java)或UNIX文本处理工具(sed或awk)对数据格式进行专门处理。幸运的是,pandas和python标准库提供了一组中级的、灵活的、高效的核心函数和算法,它们让你就能轻松地将数据规整化为正确的方式。
1. 合并数据集
pandas对象中的数据可以通过一些外置的方法进行合并:pandas.merge、pandas.concat、combine_first。我们分别对它们进行讲解,并给出一些事例。
1.1 数据库风格的DataFrame合并
数据集的合并(merge)或联接(join)运算是通过一个或多个键将行链接上去的。要注意区别的是:多对一的合并和多对多的合并(多对多联接形成的是行的笛卡尔积。由于左侧的DataFrame有3个”b”行,右边的有2个,所以最终结果中就有6个”b”行)
你须要注意的是,默认情况下,merge做的是”inner”连接;结果中的键是交集。其他方法还有”left”、”right”、以及”outer”。外联接求取的是键的并集,组合了左联接和右联接的疗效:
要依据多个键进行合并,传入一个由列名组成的列表即可:
1.2 轴向联接
1.另一种数据合并运算也被叫做联接、绑定或堆叠。Numpy有一个用于合并原创Numpy链表的concatenation函数。调用concat可以将值和索引黏合在一起,默认情况下,concat是在axis=0(对应的是行)上工作的,最终形成一个新的series。如果传入axis=1,则结果都会弄成一个DataFrame(axis=1是对应列)。
2.传入join=’inner’即可得到它们的交集;你也可以通过join_axes指定要在其他轴上使用的索引
2. 重塑和轴向旋转
2.1 重塑层次化索引
层次化索引为DataFrame数据的重排任务提供了一种具有良好一致性的形式。主要功能有二:
1. stack:将数据的列”旋转”为行。
2. unstack:将数据的行”旋转”为列。
(未完待续……..)
SKYCC组合营销软件新蓝图:多样化采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-08-18 15:31
SKYCC组合营销软件新蓝图:多样化采集自从2012年2月SKYCC组合营销软件的推出,SKYCC组合营销软件的相关报导也是紧跟不断,SKYCC各大特点一一被披露下来。随着组合营销软件的诞生,大家肯定是想在了解它各大特点之余,更想关注它细小的亮点。下面解析SKYCC组合营销软件上面的多元化采集。我们你们都晓得,无论是企业推广人员还是做SEO优化的人员,一篇好的文章对于网站关键词的优化有着重要的作用。但当我们没有时间去写文章,会是因为所需的文章太多的时侯我们怎样办呢?SKYCC多元化的采集就可以解决那些问题。SKYCC组合营销软件的文章添加
分为3种模式(全手动采集,半自动采集,手动添加)。下面介绍一下全手动采集和半自动采集。SKYCC组合营销软件采集功能上面分为两种:第一种采集功能(全手动采集)采集文章功能很简单,只需输入自定义关键词。点击“开始搜索”,就可以全手动快速的采集到收录您关键词的大量文章,让您不用再为写文章发愁。第二种采集功能(半自动采集),需要一点的程序基础,软件会根据您填写的采集规则在特定页面批量采集文章,采集成功的文章会手动添加到“文章管理”列表。采集或者添加完文章后,还可以使用SKYCC组合营销软件外置的伪原创功能,来降低文章的原创性。收录疗效大大提高。直线提高营销疗效。 查看全部
SKYCC组合营销软件新蓝图:多样化采集
SKYCC组合营销软件新蓝图:多样化采集自从2012年2月SKYCC组合营销软件的推出,SKYCC组合营销软件的相关报导也是紧跟不断,SKYCC各大特点一一被披露下来。随着组合营销软件的诞生,大家肯定是想在了解它各大特点之余,更想关注它细小的亮点。下面解析SKYCC组合营销软件上面的多元化采集。我们你们都晓得,无论是企业推广人员还是做SEO优化的人员,一篇好的文章对于网站关键词的优化有着重要的作用。但当我们没有时间去写文章,会是因为所需的文章太多的时侯我们怎样办呢?SKYCC多元化的采集就可以解决那些问题。SKYCC组合营销软件的文章添加
分为3种模式(全手动采集,半自动采集,手动添加)。下面介绍一下全手动采集和半自动采集。SKYCC组合营销软件采集功能上面分为两种:第一种采集功能(全手动采集)采集文章功能很简单,只需输入自定义关键词。点击“开始搜索”,就可以全手动快速的采集到收录您关键词的大量文章,让您不用再为写文章发愁。第二种采集功能(半自动采集),需要一点的程序基础,软件会根据您填写的采集规则在特定页面批量采集文章,采集成功的文章会手动添加到“文章管理”列表。采集或者添加完文章后,还可以使用SKYCC组合营销软件外置的伪原创功能,来降低文章的原创性。收录疗效大大提高。直线提高营销疗效。
KDD 2019 | 自动探求特点组合,第四范式提出新方式AutoCross
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-08-18 05:03
机器之心专栏
作者:罗远飞、王梦硕、周浩、姚权铭
涂威威、陈雨强、杨强、戴文渊
特征组合是提升模型疗效的重要手段,但借助专家自动探求和试错成本过低且过分冗长。于是,第四范式提出了一种新型特点组合方式 AutoCross,该方式可在实际应用中手动实现表数据的特点组合,提高机器学习算法的预测能力,并提高效率和有效性。目前,该论文已被数据挖掘领域顶会 KDD 2019 接收。
论文简介
论文:AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications
论文链接:
本文提出了一种在实际应用中手动实现表数据特点组合的方式 AutoCross。该方式可以获得特点之间有用的相互作用,并提升机器学习算法的预测能力。该方式借助集束搜索策略(beam search strategy)构建有效的组合特点,其中收录仍未被现有工作覆盖的高阶(两个以上)特征组合,弥补了此前工作的不足。
此外,该研究提出了连续小批量梯度增长和多细度离散化,以进一步提升效率和有效性,同时确保简单,无需机器学习专业知识或繁琐的超参数调整。这些算法致力增加分布式估算中涉及的估算、传输和储存成本。在基准数据集和真实业务数据集上的实验结果表明,AutoCross 可以明显提升线性模型和深度模型对表数据的学习能力和性能,优于其他基于搜索和深度学习的特点生成方式,进一步证明了其有效性和效率。
背景介绍
近年来,机器学习似乎已在推荐系统、在线广告、金融市场剖析等众多领域取得了好多成功,但在这种成功的应用中,人类专家参与了机器学习的所有阶段,包括:定义问题、采集数据、特征工程、调整模型超参数,模型评估等。
而这种任务的复杂性常常超出了非机器学习专家的能力范围。机器学习技术使用门槛高、专家成本昂贵等问题成为了阻碍 AI 普及的关键诱因。因此,AutoML 的出现被视为提升机器学习易用性的一种最有效方式,通过技术手段减低对人类专家的依赖,让更多的人应用 AI,获得更大的社会和商业效益。
众所周知,机器学习的性能很大程度上取决于特点的质量。由于原创特点极少形成令人满意的结果,因此一般要对特点进行组合,以更好地表示数据并提升学习性能。例如在新闻推荐中,若只有新闻类型、用户 ID 两类特点,模型只能分别预测不同新闻类型或不同用户 ID 对点击率的影响。通过加入新闻类型 x 用户 ID 组合特点,模型就可学习到一个用户对不同新闻的偏好。再加入时间等特点进行高阶组合,模型就可对一个用户在不同时间对不同新闻的偏好进行预测,提升模型的个性化预测能力。
特征组合作为提升模型疗效的重要手段,以往大多须要建立庞大的数据科学家团队,依靠她们的经验进行探求和试错,但冗长、低效的过程令科学家非常苦闷,且并非所有企业都能承受昂贵的成本。
第四范式从很早便开始关注并精耕 AutoML 领域,从解决顾客业务核心下降的角度出发,构建了反欺诈、个性化推荐等业务场景下的 AutoML,并将其赋能给企业的普通开发人员,取得了接近甚至超过数据科学家的业务疗效。其中,AutoCross 发挥了重要的作用。
痛点
特征组合是对从数据中提取的海量原创特点进行组合的过程,采用稀疏特点叉乘得出组合特点。在线性模型如 LR 只能描画特点间的线性关系、表达能力受限,而非线性模型如 GBDT 不能应用于大规模离散特点场景的情况下,特征组合就能降低数据的非线性,从而提升性能。
但枚举所有组合特点,理论上很难做到,因为可能的组合特点数是指数级的,同时暴力添加特点可能会造成学习性能增长,因为它们可能是无关的或冗余的特点,从而降低学习难度。
虽然深度神经网络可手动建立高阶特点 (generate high-order features),但面对大多数以表方式呈现的业务数据,最先进的基于深度学习的方式难以有效囊括所有高阶组合特点,且存在可解释性差、计算成本高等恶果。该论文投稿时,最先进的深度学习方法是 xDeepFM [1]。这篇论文证明了 xDeepFM 可生成的特点是 AutoCross 可生成特点嵌入(embedding)的子集。
AutoCross 的优势
实现过程
给定训练数据 ,并将其界定为训练集 和验证集 。我们可以用一个特点集合 S 来表示 ,并用学习算法 L 训练一个模型 。之后,用验证集和同一个特点集合 S 计算一个须要被最大化的指标 。特征组合搜索问题可以定义为搜索一个最优子特点集的问题:
其中 F 是 的原创特点集合,收录 F 所有原创特点以及基于 F 可生成的所有组合特点。
但是,假设原创特点数为 d,则上述问题中所有可能解的数目是 ,搜索空间巨大。为了提升搜索效率,AutoCross 将搜索最优子特点集的问题转换为用贪婪策略逐渐建立较优解的问题。首先,AutoCross 考虑一个树结构的搜索空间 (图 3),其中每一个节点表示一个子特点集。之后,用集束搜索策略在 上搜索较优解。通过这些方式,AutoCross 只须要访问 个候选解,极大地提升了搜索效率。AutoCross 的整体算法如算法 1 所示。
算法 1 中的一个关键步骤是评估候选特征集。最直接的方式是用每位候选特征集训练模型并评估其性能,但是这些方式估算代价巨大,难以在搜索过程中反复执行。为了提升特征集评估的效率,AutoCross 提出了逐域对数概率回归(field-wise logistic regression)和连续批训练梯度增长(successive mini-batch gradient descent)方法。
为了提升特征集评估效率,逐域对数概率回归做出两种近似。首先,用特点集在对数概率回归模型上的表现近似最终将使用这个特点集的模型上的表现;其次,在考虑 中一个节点的子节点时,不改变该节点收录特点对应的权重(weight),仅训练子节点新增特点的权重。
图 4 说明了怎样将逐域对数概率回归布署在参数服务器构架上。逐域对数概率回归与参数服务器的结合可以提升特征集评估的储存效率、传输效率和估算效率。在逐域对数概率回归训练结束后,AutoCross 计算训练得模型的指标,并借此方式来评估每一个候选特征集。
AutoCross 采用连续批训练梯度增长方式进一步提升特征集评估的效率。该方式借鉴 successive halving 算法 [2],认为每一个候选特征集是 multi-arm bandit 问题中的一个 arm,对一个特点集用一个数据块进行权重更新相当于拉了一次对应的 arm,其回报为该次训练后的验证集 AUC。
具体算法见算法 2,算法 2 中惟一的参数是数据块的数目 N。N 可以按照数据的大小和估算环境自适应地确定。在使用连续批训练梯度增长时,用户不需要象使用传统的 subsampling 方法一样调整 mini-batch 的规格和采样率。
为了支持数值特点与离散特点的组合,AutoCross 在预处理时将数值特点离散化为离散特点。AutoCross 提出了多细度离散化(multi-granularity discretization)方法,使得用户不需要反复调整离散化的细度。多细度离散化思想简单:将每一个数值特点,根据不同细度界定为多个离散特点。然后采用逐域对数概率回归选购出最优的离散特点。多个界定细度既可以由用户指定,也可以由 AutoCross 根据数据大小和估算环境来自适应地选择,从而增加了用户的使用难度。
实验结果
该论文在十个数据集(五个公开、五个实际业务)上进行了实验。比较的方式包括:
效果比较:如下表 3 所示,AC+LR 和 AC+W&D 在大部分数据集上的排行都在前两位。这彰显了 AutoCross 产生的特点除了可以提高 LR 模型,也可以用于增强深度学习模型的性能,并且 AC+LR 和 AC+W&D 的疗效都优于 xDeepFM。如之前所说,xDeepFM 所生成的特点不能完全收录 AutoCross 生成的特点。这些结果彰显出显式生成高阶组合特点的疗效优势。
高阶特点的作用:见表 5 和图 6。从中可以得出,高阶组合特点可以有效提升模型性能。
时间消耗:见表 6、图 7(主要做展示用)。
推断延后:见表 7。从中可以得出:AC+LR 的推测速率比 AC+W&D、Deep、xDeepFM 快几个数量级。这说明 AutoCross 不仅可以提升模型表现,同时保证了太低的推论延后。
参考文献
[1] J. Lian, X. Zhou, F. Zhang, Z. Chen, X. Xie, and G. Sun. 2018. xDeepFM: Com- bining Explicit and Implicit Feature Interactions for Recommender Systems. In International Conference on Knowledge Discovery & Data Mining.
[2] K. Jamieson and A. Talwalkar. 2016. Non-stochastic best arm identification and hyperparameter optimization. In Artificial Intelligence and Statistics. 240–248.
[3] O. Chapelle, E. Manavoglu, and R. Rosales. 2015. Simple and scalable response prediction for display advertising. ACM Transactions on Intelligent Systems and Technology (TIST) 5, 4 (2015), 61.
------------------------------------------------
加入机器之心(全职记者 / 实习生):
投稿或寻求报导: 查看全部
KDD 2019 | 自动探求特点组合,第四范式提出新方式AutoCross
机器之心专栏
作者:罗远飞、王梦硕、周浩、姚权铭
涂威威、陈雨强、杨强、戴文渊
特征组合是提升模型疗效的重要手段,但借助专家自动探求和试错成本过低且过分冗长。于是,第四范式提出了一种新型特点组合方式 AutoCross,该方式可在实际应用中手动实现表数据的特点组合,提高机器学习算法的预测能力,并提高效率和有效性。目前,该论文已被数据挖掘领域顶会 KDD 2019 接收。
论文简介
论文:AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications
论文链接:
本文提出了一种在实际应用中手动实现表数据特点组合的方式 AutoCross。该方式可以获得特点之间有用的相互作用,并提升机器学习算法的预测能力。该方式借助集束搜索策略(beam search strategy)构建有效的组合特点,其中收录仍未被现有工作覆盖的高阶(两个以上)特征组合,弥补了此前工作的不足。
此外,该研究提出了连续小批量梯度增长和多细度离散化,以进一步提升效率和有效性,同时确保简单,无需机器学习专业知识或繁琐的超参数调整。这些算法致力增加分布式估算中涉及的估算、传输和储存成本。在基准数据集和真实业务数据集上的实验结果表明,AutoCross 可以明显提升线性模型和深度模型对表数据的学习能力和性能,优于其他基于搜索和深度学习的特点生成方式,进一步证明了其有效性和效率。
背景介绍
近年来,机器学习似乎已在推荐系统、在线广告、金融市场剖析等众多领域取得了好多成功,但在这种成功的应用中,人类专家参与了机器学习的所有阶段,包括:定义问题、采集数据、特征工程、调整模型超参数,模型评估等。
而这种任务的复杂性常常超出了非机器学习专家的能力范围。机器学习技术使用门槛高、专家成本昂贵等问题成为了阻碍 AI 普及的关键诱因。因此,AutoML 的出现被视为提升机器学习易用性的一种最有效方式,通过技术手段减低对人类专家的依赖,让更多的人应用 AI,获得更大的社会和商业效益。
众所周知,机器学习的性能很大程度上取决于特点的质量。由于原创特点极少形成令人满意的结果,因此一般要对特点进行组合,以更好地表示数据并提升学习性能。例如在新闻推荐中,若只有新闻类型、用户 ID 两类特点,模型只能分别预测不同新闻类型或不同用户 ID 对点击率的影响。通过加入新闻类型 x 用户 ID 组合特点,模型就可学习到一个用户对不同新闻的偏好。再加入时间等特点进行高阶组合,模型就可对一个用户在不同时间对不同新闻的偏好进行预测,提升模型的个性化预测能力。
特征组合作为提升模型疗效的重要手段,以往大多须要建立庞大的数据科学家团队,依靠她们的经验进行探求和试错,但冗长、低效的过程令科学家非常苦闷,且并非所有企业都能承受昂贵的成本。
第四范式从很早便开始关注并精耕 AutoML 领域,从解决顾客业务核心下降的角度出发,构建了反欺诈、个性化推荐等业务场景下的 AutoML,并将其赋能给企业的普通开发人员,取得了接近甚至超过数据科学家的业务疗效。其中,AutoCross 发挥了重要的作用。
痛点
特征组合是对从数据中提取的海量原创特点进行组合的过程,采用稀疏特点叉乘得出组合特点。在线性模型如 LR 只能描画特点间的线性关系、表达能力受限,而非线性模型如 GBDT 不能应用于大规模离散特点场景的情况下,特征组合就能降低数据的非线性,从而提升性能。
但枚举所有组合特点,理论上很难做到,因为可能的组合特点数是指数级的,同时暴力添加特点可能会造成学习性能增长,因为它们可能是无关的或冗余的特点,从而降低学习难度。
虽然深度神经网络可手动建立高阶特点 (generate high-order features),但面对大多数以表方式呈现的业务数据,最先进的基于深度学习的方式难以有效囊括所有高阶组合特点,且存在可解释性差、计算成本高等恶果。该论文投稿时,最先进的深度学习方法是 xDeepFM [1]。这篇论文证明了 xDeepFM 可生成的特点是 AutoCross 可生成特点嵌入(embedding)的子集。
AutoCross 的优势
实现过程
给定训练数据 ,并将其界定为训练集 和验证集 。我们可以用一个特点集合 S 来表示 ,并用学习算法 L 训练一个模型 。之后,用验证集和同一个特点集合 S 计算一个须要被最大化的指标 。特征组合搜索问题可以定义为搜索一个最优子特点集的问题:
其中 F 是 的原创特点集合,收录 F 所有原创特点以及基于 F 可生成的所有组合特点。
但是,假设原创特点数为 d,则上述问题中所有可能解的数目是 ,搜索空间巨大。为了提升搜索效率,AutoCross 将搜索最优子特点集的问题转换为用贪婪策略逐渐建立较优解的问题。首先,AutoCross 考虑一个树结构的搜索空间 (图 3),其中每一个节点表示一个子特点集。之后,用集束搜索策略在 上搜索较优解。通过这些方式,AutoCross 只须要访问 个候选解,极大地提升了搜索效率。AutoCross 的整体算法如算法 1 所示。
算法 1 中的一个关键步骤是评估候选特征集。最直接的方式是用每位候选特征集训练模型并评估其性能,但是这些方式估算代价巨大,难以在搜索过程中反复执行。为了提升特征集评估的效率,AutoCross 提出了逐域对数概率回归(field-wise logistic regression)和连续批训练梯度增长(successive mini-batch gradient descent)方法。
为了提升特征集评估效率,逐域对数概率回归做出两种近似。首先,用特点集在对数概率回归模型上的表现近似最终将使用这个特点集的模型上的表现;其次,在考虑 中一个节点的子节点时,不改变该节点收录特点对应的权重(weight),仅训练子节点新增特点的权重。
图 4 说明了怎样将逐域对数概率回归布署在参数服务器构架上。逐域对数概率回归与参数服务器的结合可以提升特征集评估的储存效率、传输效率和估算效率。在逐域对数概率回归训练结束后,AutoCross 计算训练得模型的指标,并借此方式来评估每一个候选特征集。
AutoCross 采用连续批训练梯度增长方式进一步提升特征集评估的效率。该方式借鉴 successive halving 算法 [2],认为每一个候选特征集是 multi-arm bandit 问题中的一个 arm,对一个特点集用一个数据块进行权重更新相当于拉了一次对应的 arm,其回报为该次训练后的验证集 AUC。
具体算法见算法 2,算法 2 中惟一的参数是数据块的数目 N。N 可以按照数据的大小和估算环境自适应地确定。在使用连续批训练梯度增长时,用户不需要象使用传统的 subsampling 方法一样调整 mini-batch 的规格和采样率。
为了支持数值特点与离散特点的组合,AutoCross 在预处理时将数值特点离散化为离散特点。AutoCross 提出了多细度离散化(multi-granularity discretization)方法,使得用户不需要反复调整离散化的细度。多细度离散化思想简单:将每一个数值特点,根据不同细度界定为多个离散特点。然后采用逐域对数概率回归选购出最优的离散特点。多个界定细度既可以由用户指定,也可以由 AutoCross 根据数据大小和估算环境来自适应地选择,从而增加了用户的使用难度。
实验结果
该论文在十个数据集(五个公开、五个实际业务)上进行了实验。比较的方式包括:
效果比较:如下表 3 所示,AC+LR 和 AC+W&D 在大部分数据集上的排行都在前两位。这彰显了 AutoCross 产生的特点除了可以提高 LR 模型,也可以用于增强深度学习模型的性能,并且 AC+LR 和 AC+W&D 的疗效都优于 xDeepFM。如之前所说,xDeepFM 所生成的特点不能完全收录 AutoCross 生成的特点。这些结果彰显出显式生成高阶组合特点的疗效优势。
高阶特点的作用:见表 5 和图 6。从中可以得出,高阶组合特点可以有效提升模型性能。
时间消耗:见表 6、图 7(主要做展示用)。
推断延后:见表 7。从中可以得出:AC+LR 的推测速率比 AC+W&D、Deep、xDeepFM 快几个数量级。这说明 AutoCross 不仅可以提升模型表现,同时保证了太低的推论延后。
参考文献
[1] J. Lian, X. Zhou, F. Zhang, Z. Chen, X. Xie, and G. Sun. 2018. xDeepFM: Com- bining Explicit and Implicit Feature Interactions for Recommender Systems. In International Conference on Knowledge Discovery & Data Mining.
[2] K. Jamieson and A. Talwalkar. 2016. Non-stochastic best arm identification and hyperparameter optimization. In Artificial Intelligence and Statistics. 240–248.
[3] O. Chapelle, E. Manavoglu, and R. Rosales. 2015. Simple and scalable response prediction for display advertising. ACM Transactions on Intelligent Systems and Technology (TIST) 5, 4 (2015), 61.
------------------------------------------------
加入机器之心(全职记者 / 实习生):
投稿或寻求报导:
chukwa采集框架中负责将大量小文件进行合并的组件是
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-08-13 07:22
概述
chukwa 的官方网站是这样描述自己的: chukwa 是一个开源的用于监控小型分布式系统的数据搜集系统。这是建立在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 hadoop 的可伸缩性和鲁棒性。Chukwa 还收录了一个强悍和灵活的工具集,可用于展示、监控和剖析已搜集的数据。
在一些网站上,甚至扬言 chukwa 是一个“日志处理/分析的full stack solution”。
说了这么多,你心动了吗?
Chukwa 是哪些?
在泰国神话中Chukwa是一只最古老的龟。它支撑着世界。在它的背上还支撑着一种称作Maha-Pudma的小象,在小象的背上顶着这个月球。呵呵,大象?Hadoop?不难理解为何在Hadoop中的这个子项目称作Chukwa了,或许Chukwa的其中一位开发者是美国人?呵呵,我胡扯的,神话中的Chukwa的,貌似是这样的,如图所示:
Chukwa是由Yahoo贡献,基于Hadoop的大集群监控系统,可以用他来剖析和搜集系统中的数据(日志)。Chukwa运行HDFS中储存数据的采集器和MapReduce框架之上,并承继了Hadoop的可扩展性和鲁棒性, Chukwa使用MapReduce来生成报告,他还包括一个用于检测和剖析结果显示的web-portal工具,通过web-portal工具让这个搜集数据的更佳具有灵活性,这点有点像是类似 linux工具,例如:awk 。这几乎是一个日志处理/分析的full stack solution,国内用hadoop做日志剖析的,或者即将做日志剖析的可以关注下。
Chukwa 由哪几个组件组成的?
Chukwa是Yahoo开发的Hadoop之上的数据采集/分析框架,主要用于日志采集/分析。该框架提供了采集数据的Agent,由Agent采集数据通过HTTP发送数据给Cluster的Collector,collector把数据sink进Hadoop,然后通过定期运行Map reducer来剖析数据,将结果呈现给用户。
Chukwa 有以下4个主要的组成部分:
Agent搜集各服务器的数据
Collectors接收agent的数据;并写进储存
MapReduce jobs归档数据
HICC就是 Hadoop Infrastructure Care Center的四个英语词组的简写,简单来说是个Web工程用于ChukWa的内容展示。
几个部件大致的处理流程如下:
在这个Blog中后续会对ChukWa有进一步的描述,再次感谢你的阅读。
–end–
转自:
chukwa 不能做哪些
1.chukwa 不是一个单机系统. 在单个节点布署一个 chukwa 系统,基本没有哪些好处. chukwa 是一个建立在 hadoop 基础上的分布式日志处理系统.换言之,在搭建 chukwa 环境之前,你须要先建立一个 hadoop 环境,然后在 hadoop 的基础上建立 chukwa 环境,这个关系也可以从稍后的 chukwa 架构图上看下来.这也是由于 chukwa 的假定是要处理的数据量是在 T 级别的.
2.chukwa 不是一个实时错误监控系统.在解决这个问题方面, ganglia,nagios 等等系统早已做得挺好了,这些系统对数据的敏感性都可以达到秒级. chukwa 分析的是数据是分钟级别的,它觉得象集群的整体 cpu 使用率这样的数据,延迟几分钟领到,不是哪些问题.
3.chukwa 不是一个封闭的系统.虽然 chukwa 自带了许多针对 hadoop 集群的剖析项,但是这并不是说它只能监控和剖析 hadoop.chukwa 提供了一个对大数据量日志类数据采集、存储、分析和展示的全套解决方案和框架,在这类数据生命周期的各个阶段, chukwa 都提供了近乎完美的解决方案,这一点也可以从它的构架中看下来.
chukwa 能做哪些
上一节说了好多 chukwa 不是哪些,下面来看下 chukwa 具体是干哪些的一个系统呢?
具体而言, chukwa 致力于以下几个方面的工作:
1.总体而言, chukwa 可以用于监控大规模(2000+ 以上的节点, 每天形成数据量在T级别) hadoop 集群的整体运行情况并对它们的日志进行剖析
2.对于集群的用户而言: chukwa 展示她们的作业早已运行了多久,占用了多少资源,还有多少资源可用,一个作业是为何失败了,一个读写操作在那个节点出了问题.
3.对于集群的运维工程师而言: chukwa 展示了集群中的硬件错误,集群的性能变化,集群的资源困局在那里.
4.对于集群的管理者而言: chukwa 展示了集群的资源消耗情况,集群的整体作业执行情况,可以用以辅助预算和集群资源协调.
5.对于集群的开发者而言: chukwa 展示了集群中主要的性能困局,经常出现的错误,从而可以着重重点解决重要问题.
Chukwa的系统构架
搭建、运行Chukwa要在Linux环境下,要安装MySQL数据库,在Chukwa/conf目录 中有2个SQL脚本 aggregator.sql、database_create_tables.sq l 导入MySQL数据库,此外还要有Hadoo的HDSF运行环境,Chukwa的整个系统构架如图所示:
其中主要的部件为:
1.agents : 负责采集最原创的数据,并发送给 collectors
2.adaptor : 直接采集数据的插口和工具,一个 agent 可以管理多个 adaptor 的数据采集
3.collectors 负责搜集 agents 收送来的数据,并定时写入集群中
4.map/reduce jobs 定时启动,负责把集群中的数据分类、排序、去重和合并
5.HICC 负责数据的展示
相关设计
adaptors 和 agents
在 每个数据的产生端(基本上是集群中每一个节点上), chukwa 使用一个 agent 来采集它感兴趣的数据,每一类数据通过一个 adaptor 来实现, 数据的类型(DataType?)在相应的配置中指定. 默认地, chukwa 对以下常见的数据来源早已提供了相应的 adaptor : 命令行输出、log 文件和 httpSender等等. 这些 adaptor 会定期运行(比如每分钟读一次 df 的结果)或风波驱动地执行(比如 kernel 打了一条错误日志). 如果这种 adaptor 还不够用,用户也可以便捷地自己实现一个 adaptor 来满足需求。
为避免数据采集端的 agent 出现故障,chukwa 的 agent 采用了所谓的 ‘watchdog’ 机制,会手动重启中止的数据采集进程,防止原创数据的遗失。
另一方面, 对于重复采集的数据, 在 chukwa 的数据处理过程中,会手动对它们进行去重. 这样,就可以对于关键的数据在多台机器上布署相同的 agent,从而实现容错的功能.
collectors
agents 采集到的数据,是储存到 hadoop 集群上的. hadoop 集群擅长于处理少量大文件,而对于大量小文件的处理则不是它的强项,针对这一点,chukwa 设计了 collector 这个角色,用于把数据先进行部份合并,再写入集群,防止大量小文件的写入。
另 一方面,为避免 collector 成为性能困局或成为单点,产生故障, chukwa 允许和鼓励设置多个 collector, agents 随机地从 collectors 列表中选择一个 collector 传输数据,如果一个 collector 失败或忙碌,就换下一个 collector. 从而可以实现负载的均衡,实践证明,多个 collector 的负载几乎是平均的.
demux 和 archive
放在集群上的数据,是通过 map/reduce 作业来实现数据剖析的. 在 map/reduce 阶段, chukwa 提供了 demux 和 archive 任务两种外置的作业类型.
demux 作业负责对数据的分类、排序和去重. 在 agent 一节中,我们谈到了数据类型(DataType?)的概念.由 collector 写入集群中的数据,都有自己的类型. demux 作业在执行过程中,通过数据类型和配置文件中指定的数据处理类,执行相应的数据剖析工作,一般是把非结构化的数据结构化,抽取中其中的数据属性.由于 demux 的本质是一个 map/reduce 作业,所以我们可以按照自己的需求制订自己的 demux 作业,进行各类复杂的逻辑剖析. chukwa 提供的 demux interface 可以用 java 语言来便捷地扩充.
而 archive 作业则负责把同类型的数据文件合并,一方面保证了同一类的数据都在一起,便于进一步剖析, 另一方面减轻文件数目, 减轻 hadoop 集群的储存压力。
dbadmin
放在集群上的数据,虽然可以满足数据的常年储存和大数据量估算需求,但是不易于展示.为此, chukwa 做了两方面的努力:
1.使用 mdl 语言,把集群上的数据抽取到 mysql 数据库中,对近一周的数据,完整保存,超过一周的数据,按数据距现今的时间长短作稀释,离如今越久的数据,所保存的数据时间间隔越长.通过 mysql 来作数据源,展示数据.
2.使用 hbase 或类似的技术,直接把索引化的数据在储存在集群上
到 chukwa 0.4.0 版本为止, chukwa 都是用的第一种方式,但是第二种方式更高贵也更方便一些.
hicc
hicc 是 chukwa 的数据展示端的名子.在展示端, chukwa 提供了一些默认的数据展示 widget,可以使用“列表”、“曲线图”、“多曲线图”、“柱状图”、“面积隐喻展示一类或多类数据,给用户直观的数据趋势展示。而且,在 hicc 展示端,对不断生成的新数据和历史数据,采用 robin 策略,防止数据的不断下降减小服务器压力,并对数据在时间轴上“稀释”,可以提供长时间段的数据展示
从 本质上, hicc 是用 jetty 来实现的一个 web 服务端,内部用的是 jsp 技术和 javascript 技术.各种须要展示的数据类型和页面的局都可以通过简直地拖放方法来实现,更复杂的数据展示方法,可以使用 sql 语言组合出各类须要的数据.如果这样还不能满足需求,不用怕,动手更改它的 jsp 代码就可以了.
其它数据插口
如果对原创数据还有新的须要,用户还可以通过 map/reduce 作业或 pig 语言直接访问集群上的原创数据,以生成所须要的结果。chukwa 还提供了命令行的插口,可以直接访问到集群上数据。
默认数据支持
对 于集群各节点的cpu使用率、内存使用率、硬盘使用率、集群整体的 cpu 平均使用率、集群整体的显存使用率、集群整体的储存使用率、集群文件数变化、作业数变化等等 hadoop 相关数据,从采集到展示的一整套流程, chukwa 都提供了内建的支持,只须要配置一下就可以使用.可以说是相当便捷的.
可以看出,chukwa 从数据的形成、采集、存储、分析到展示的整个生命周期都提供了全面的支持。 查看全部
Apache 的开源项目 hadoop, 作为一个分布式存储和估算系统,已经被业界广泛应用。很多小型企业都有了各自基于 hadoop 的应用和相关扩充。当 1000+ 以上个节点的 hadoop 集群显得常见时,集群自身的相关信息怎样搜集和剖析呢?针对这个问题, Apache 同样提出了相应的解决方案,那就是 chukwa。
概述
chukwa 的官方网站是这样描述自己的: chukwa 是一个开源的用于监控小型分布式系统的数据搜集系统。这是建立在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 hadoop 的可伸缩性和鲁棒性。Chukwa 还收录了一个强悍和灵活的工具集,可用于展示、监控和剖析已搜集的数据。
在一些网站上,甚至扬言 chukwa 是一个“日志处理/分析的full stack solution”。
说了这么多,你心动了吗?
Chukwa 是哪些?
在泰国神话中Chukwa是一只最古老的龟。它支撑着世界。在它的背上还支撑着一种称作Maha-Pudma的小象,在小象的背上顶着这个月球。呵呵,大象?Hadoop?不难理解为何在Hadoop中的这个子项目称作Chukwa了,或许Chukwa的其中一位开发者是美国人?呵呵,我胡扯的,神话中的Chukwa的,貌似是这样的,如图所示:
Chukwa是由Yahoo贡献,基于Hadoop的大集群监控系统,可以用他来剖析和搜集系统中的数据(日志)。Chukwa运行HDFS中储存数据的采集器和MapReduce框架之上,并承继了Hadoop的可扩展性和鲁棒性, Chukwa使用MapReduce来生成报告,他还包括一个用于检测和剖析结果显示的web-portal工具,通过web-portal工具让这个搜集数据的更佳具有灵活性,这点有点像是类似 linux工具,例如:awk 。这几乎是一个日志处理/分析的full stack solution,国内用hadoop做日志剖析的,或者即将做日志剖析的可以关注下。
Chukwa 由哪几个组件组成的?
Chukwa是Yahoo开发的Hadoop之上的数据采集/分析框架,主要用于日志采集/分析。该框架提供了采集数据的Agent,由Agent采集数据通过HTTP发送数据给Cluster的Collector,collector把数据sink进Hadoop,然后通过定期运行Map reducer来剖析数据,将结果呈现给用户。
Chukwa 有以下4个主要的组成部分:
Agent搜集各服务器的数据
Collectors接收agent的数据;并写进储存
MapReduce jobs归档数据
HICC就是 Hadoop Infrastructure Care Center的四个英语词组的简写,简单来说是个Web工程用于ChukWa的内容展示。
几个部件大致的处理流程如下:
在这个Blog中后续会对ChukWa有进一步的描述,再次感谢你的阅读。
–end–
转自:
chukwa 不能做哪些
1.chukwa 不是一个单机系统. 在单个节点布署一个 chukwa 系统,基本没有哪些好处. chukwa 是一个建立在 hadoop 基础上的分布式日志处理系统.换言之,在搭建 chukwa 环境之前,你须要先建立一个 hadoop 环境,然后在 hadoop 的基础上建立 chukwa 环境,这个关系也可以从稍后的 chukwa 架构图上看下来.这也是由于 chukwa 的假定是要处理的数据量是在 T 级别的.
2.chukwa 不是一个实时错误监控系统.在解决这个问题方面, ganglia,nagios 等等系统早已做得挺好了,这些系统对数据的敏感性都可以达到秒级. chukwa 分析的是数据是分钟级别的,它觉得象集群的整体 cpu 使用率这样的数据,延迟几分钟领到,不是哪些问题.
3.chukwa 不是一个封闭的系统.虽然 chukwa 自带了许多针对 hadoop 集群的剖析项,但是这并不是说它只能监控和剖析 hadoop.chukwa 提供了一个对大数据量日志类数据采集、存储、分析和展示的全套解决方案和框架,在这类数据生命周期的各个阶段, chukwa 都提供了近乎完美的解决方案,这一点也可以从它的构架中看下来.
chukwa 能做哪些
上一节说了好多 chukwa 不是哪些,下面来看下 chukwa 具体是干哪些的一个系统呢?
具体而言, chukwa 致力于以下几个方面的工作:
1.总体而言, chukwa 可以用于监控大规模(2000+ 以上的节点, 每天形成数据量在T级别) hadoop 集群的整体运行情况并对它们的日志进行剖析
2.对于集群的用户而言: chukwa 展示她们的作业早已运行了多久,占用了多少资源,还有多少资源可用,一个作业是为何失败了,一个读写操作在那个节点出了问题.
3.对于集群的运维工程师而言: chukwa 展示了集群中的硬件错误,集群的性能变化,集群的资源困局在那里.
4.对于集群的管理者而言: chukwa 展示了集群的资源消耗情况,集群的整体作业执行情况,可以用以辅助预算和集群资源协调.
5.对于集群的开发者而言: chukwa 展示了集群中主要的性能困局,经常出现的错误,从而可以着重重点解决重要问题.
Chukwa的系统构架
搭建、运行Chukwa要在Linux环境下,要安装MySQL数据库,在Chukwa/conf目录 中有2个SQL脚本 aggregator.sql、database_create_tables.sq l 导入MySQL数据库,此外还要有Hadoo的HDSF运行环境,Chukwa的整个系统构架如图所示:
其中主要的部件为:
1.agents : 负责采集最原创的数据,并发送给 collectors
2.adaptor : 直接采集数据的插口和工具,一个 agent 可以管理多个 adaptor 的数据采集
3.collectors 负责搜集 agents 收送来的数据,并定时写入集群中
4.map/reduce jobs 定时启动,负责把集群中的数据分类、排序、去重和合并
5.HICC 负责数据的展示
相关设计
adaptors 和 agents
在 每个数据的产生端(基本上是集群中每一个节点上), chukwa 使用一个 agent 来采集它感兴趣的数据,每一类数据通过一个 adaptor 来实现, 数据的类型(DataType?)在相应的配置中指定. 默认地, chukwa 对以下常见的数据来源早已提供了相应的 adaptor : 命令行输出、log 文件和 httpSender等等. 这些 adaptor 会定期运行(比如每分钟读一次 df 的结果)或风波驱动地执行(比如 kernel 打了一条错误日志). 如果这种 adaptor 还不够用,用户也可以便捷地自己实现一个 adaptor 来满足需求。
为避免数据采集端的 agent 出现故障,chukwa 的 agent 采用了所谓的 ‘watchdog’ 机制,会手动重启中止的数据采集进程,防止原创数据的遗失。
另一方面, 对于重复采集的数据, 在 chukwa 的数据处理过程中,会手动对它们进行去重. 这样,就可以对于关键的数据在多台机器上布署相同的 agent,从而实现容错的功能.
collectors
agents 采集到的数据,是储存到 hadoop 集群上的. hadoop 集群擅长于处理少量大文件,而对于大量小文件的处理则不是它的强项,针对这一点,chukwa 设计了 collector 这个角色,用于把数据先进行部份合并,再写入集群,防止大量小文件的写入。
另 一方面,为避免 collector 成为性能困局或成为单点,产生故障, chukwa 允许和鼓励设置多个 collector, agents 随机地从 collectors 列表中选择一个 collector 传输数据,如果一个 collector 失败或忙碌,就换下一个 collector. 从而可以实现负载的均衡,实践证明,多个 collector 的负载几乎是平均的.
demux 和 archive
放在集群上的数据,是通过 map/reduce 作业来实现数据剖析的. 在 map/reduce 阶段, chukwa 提供了 demux 和 archive 任务两种外置的作业类型.
demux 作业负责对数据的分类、排序和去重. 在 agent 一节中,我们谈到了数据类型(DataType?)的概念.由 collector 写入集群中的数据,都有自己的类型. demux 作业在执行过程中,通过数据类型和配置文件中指定的数据处理类,执行相应的数据剖析工作,一般是把非结构化的数据结构化,抽取中其中的数据属性.由于 demux 的本质是一个 map/reduce 作业,所以我们可以按照自己的需求制订自己的 demux 作业,进行各类复杂的逻辑剖析. chukwa 提供的 demux interface 可以用 java 语言来便捷地扩充.
而 archive 作业则负责把同类型的数据文件合并,一方面保证了同一类的数据都在一起,便于进一步剖析, 另一方面减轻文件数目, 减轻 hadoop 集群的储存压力。
dbadmin
放在集群上的数据,虽然可以满足数据的常年储存和大数据量估算需求,但是不易于展示.为此, chukwa 做了两方面的努力:
1.使用 mdl 语言,把集群上的数据抽取到 mysql 数据库中,对近一周的数据,完整保存,超过一周的数据,按数据距现今的时间长短作稀释,离如今越久的数据,所保存的数据时间间隔越长.通过 mysql 来作数据源,展示数据.
2.使用 hbase 或类似的技术,直接把索引化的数据在储存在集群上
到 chukwa 0.4.0 版本为止, chukwa 都是用的第一种方式,但是第二种方式更高贵也更方便一些.
hicc
hicc 是 chukwa 的数据展示端的名子.在展示端, chukwa 提供了一些默认的数据展示 widget,可以使用“列表”、“曲线图”、“多曲线图”、“柱状图”、“面积隐喻展示一类或多类数据,给用户直观的数据趋势展示。而且,在 hicc 展示端,对不断生成的新数据和历史数据,采用 robin 策略,防止数据的不断下降减小服务器压力,并对数据在时间轴上“稀释”,可以提供长时间段的数据展示
从 本质上, hicc 是用 jetty 来实现的一个 web 服务端,内部用的是 jsp 技术和 javascript 技术.各种须要展示的数据类型和页面的局都可以通过简直地拖放方法来实现,更复杂的数据展示方法,可以使用 sql 语言组合出各类须要的数据.如果这样还不能满足需求,不用怕,动手更改它的 jsp 代码就可以了.
其它数据插口
如果对原创数据还有新的须要,用户还可以通过 map/reduce 作业或 pig 语言直接访问集群上的原创数据,以生成所须要的结果。chukwa 还提供了命令行的插口,可以直接访问到集群上数据。
默认数据支持
对 于集群各节点的cpu使用率、内存使用率、硬盘使用率、集群整体的 cpu 平均使用率、集群整体的显存使用率、集群整体的储存使用率、集群文件数变化、作业数变化等等 hadoop 相关数据,从采集到展示的一整套流程, chukwa 都提供了内建的支持,只须要配置一下就可以使用.可以说是相当便捷的.
可以看出,chukwa 从数据的形成、采集、存储、分析到展示的整个生命周期都提供了全面的支持。
Python手动点击易迅商品价钱条件,智能采集价格数据!
采集交流 • 优采云 发表了文章 • 0 个评论 • 313 次浏览 • 2020-08-10 08:17
一、建立第一级主题抓取目标信息
建立第一级主题的规则,把想要的信息映射到整理箱中,建议做完内容映射后,也做上定位标志映射,可以提升定位准确性和规则适应性。
注意:设置了连续动作的规则可以不建整理箱,例如方案2的第一级主题可以不建整理箱,但是用整理箱抓一点数据(选择网页上一定会显示下来的信息),是为了给爬虫判定是否执行采集,否则可能漏采网页。
二、设置连续动作点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 输入目标主题名
连续动作指向的是同一个目标主题。如果有多个动作,并且要指向不同的主题,请拆成多个规则分别设置连续动作。
2.2 选择动作类型
本案例是点击动作,不同动作的适用范围是不同的,请按照实际的操作情况来选择动作类型。
2.3 把定位到动作对象的xpath填入到定位表达式中
2.4 输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.5 高级设置
最初可以不设置,后面调试连续动作时会用到,可以扩大动作的适用范围。如需把动作对象的信息也抓出来,就在中级设置的内容表达式中用xpath定位到动作对象的信息来实现,请依照须要再来设置。
注意:动作类型是否选对以及xpath是否定位确切,决定了连续动作能够执行成功。Xpath是标准的用于定位html节点的语言,请自行把握xpath后再来使用连续动作的功能。
按照人的操作步骤,还要选择版本、购买方法1、购买方法2,所以,我们还要继续新建3个动作,重复以上步骤。
三、调试规则
完成以上步骤后,点击保存规则,再点击爬数据按键进行试抓。发现采集时报错:无法定位到节点***,观察浏览器窗口,看到执行完第一步点击时,其他信息都没加载上来,等到信息都加载上来,又发觉点击了订购方法2后,就难以回挪到执行4步点击的页面,这就造成连续动作没法连贯执行。
针对里面的情况,我们的解决方式是删除第4步动作。因为无论是否点击订购方法2,都不影响商品价钱。所以,可以删除没必要且引起干扰的动作步骤。
修改后再度试抓,把提取到的xml转为excel后,看到价钱和累计评价的数据抓漏或抓错了。这是因为网页很大,加载比较慢,点击后的数据要等待一定时间才会加载完成。
为了抓全数据,需要延长等待时间,给每位动作单独设置延时,点击动作步骤->高级设置->额外延时,输入正整数,单位是秒。输入的时间请按照实际调试。
另外,如果不是置顶窗口,采集时会循环点击。这是因为易迅网页上有反爬举措,必须为当前窗口的操作才能生效。所以,要在中级设置上勾上窗口可见,采集时窗口会置顶。请按照实际情况进行设置。
四、如何把抓到的信息与动作步骤一一对应?
如果希望把抓到的信息与动作步骤一一对应上去,这样就得把动作对象的信息也提取出来,有以下两种方式:
4.1 在连续动作的中级设置的内容表达式中用xpath定位到动作对象的信息节点。
在定位表达式早已定位到动作对象的整个操作范围,也包括其本身的信息,所以,内容表达式只需从定位到的动作对象为起点,继续定位到其信息就行。采集时都会把该步动作的信息记录在actionvalue中,与之对应的是actionno,记录的是该步动作执行的次数。
4.2 在整理箱中抓取动作对象的信息,这里同样要用xpath来定位。
动作对象被执行时,其dom结构是有变化的,找到网页变化的结构特点,用xpath确切定位到节点,通过校准后,就可以设置自定义xpath。 查看全部
注意:如果动作执行前后的网页结构没有变化,可以用一个规则来完成;网页结构前后变化的话,必须用两个或以上的规则来完成;另外涉及翻页的话,也要拆成两个或以上的规则。关于连续动作要做多少个规则请查阅文章《规划采集流程》。
一、建立第一级主题抓取目标信息
建立第一级主题的规则,把想要的信息映射到整理箱中,建议做完内容映射后,也做上定位标志映射,可以提升定位准确性和规则适应性。
注意:设置了连续动作的规则可以不建整理箱,例如方案2的第一级主题可以不建整理箱,但是用整理箱抓一点数据(选择网页上一定会显示下来的信息),是为了给爬虫判定是否执行采集,否则可能漏采网页。
二、设置连续动作点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 输入目标主题名
连续动作指向的是同一个目标主题。如果有多个动作,并且要指向不同的主题,请拆成多个规则分别设置连续动作。
2.2 选择动作类型
本案例是点击动作,不同动作的适用范围是不同的,请按照实际的操作情况来选择动作类型。
2.3 把定位到动作对象的xpath填入到定位表达式中
2.4 输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.5 高级设置
最初可以不设置,后面调试连续动作时会用到,可以扩大动作的适用范围。如需把动作对象的信息也抓出来,就在中级设置的内容表达式中用xpath定位到动作对象的信息来实现,请依照须要再来设置。
注意:动作类型是否选对以及xpath是否定位确切,决定了连续动作能够执行成功。Xpath是标准的用于定位html节点的语言,请自行把握xpath后再来使用连续动作的功能。
按照人的操作步骤,还要选择版本、购买方法1、购买方法2,所以,我们还要继续新建3个动作,重复以上步骤。
三、调试规则
完成以上步骤后,点击保存规则,再点击爬数据按键进行试抓。发现采集时报错:无法定位到节点***,观察浏览器窗口,看到执行完第一步点击时,其他信息都没加载上来,等到信息都加载上来,又发觉点击了订购方法2后,就难以回挪到执行4步点击的页面,这就造成连续动作没法连贯执行。
针对里面的情况,我们的解决方式是删除第4步动作。因为无论是否点击订购方法2,都不影响商品价钱。所以,可以删除没必要且引起干扰的动作步骤。
修改后再度试抓,把提取到的xml转为excel后,看到价钱和累计评价的数据抓漏或抓错了。这是因为网页很大,加载比较慢,点击后的数据要等待一定时间才会加载完成。
为了抓全数据,需要延长等待时间,给每位动作单独设置延时,点击动作步骤->高级设置->额外延时,输入正整数,单位是秒。输入的时间请按照实际调试。
另外,如果不是置顶窗口,采集时会循环点击。这是因为易迅网页上有反爬举措,必须为当前窗口的操作才能生效。所以,要在中级设置上勾上窗口可见,采集时窗口会置顶。请按照实际情况进行设置。
四、如何把抓到的信息与动作步骤一一对应?
如果希望把抓到的信息与动作步骤一一对应上去,这样就得把动作对象的信息也提取出来,有以下两种方式:
4.1 在连续动作的中级设置的内容表达式中用xpath定位到动作对象的信息节点。
在定位表达式早已定位到动作对象的整个操作范围,也包括其本身的信息,所以,内容表达式只需从定位到的动作对象为起点,继续定位到其信息就行。采集时都会把该步动作的信息记录在actionvalue中,与之对应的是actionno,记录的是该步动作执行的次数。
4.2 在整理箱中抓取动作对象的信息,这里同样要用xpath来定位。
动作对象被执行时,其dom结构是有变化的,找到网页变化的结构特点,用xpath确切定位到节点,通过校准后,就可以设置自定义xpath。
关于优采云采集器标签组合功能的使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-10 06:10
优采云的使用似乎还是比较复杂的,甚至对于菜鸟来说学习还是有些费力的,本文上海网站建设编辑就V7版本的便条组合聊聊自己的想法,希望能对需求的同学提供些许帮助。
v7版本降低了一个标签组合的功能,许多同学在使用中发觉组合的结果和自己想要的结果不一致,下面我来说明一下该功能的使用。
1.标签组合组合的是文件下载前的内容
有的同学发觉,a标签中下载了某个文件,原创地址是aaa,下载后或是侦测的地址为bbb,那么,如果您在b标签中组合使用a标签,a标签的值是aaa.为何使用这些处理方式,是因为文件下载是在标签组合以后进行的。如何达到标签内容是文件下载完后的结果呢?可以新建一个标签,选“自定义固定格式数据”,将您标签组合的内容放进去。这里的替换会在文件下载后执行。
2.内容页标签循环采集并添加为新记录
如果组合的两个标签都是内容页标签,这两个标签在组合时,会按循环数最大的记录形成新的同样数量的循环记录。如果某个标签的循环数较少,则新形成的标签中该标签的值为空。例如标签a,b组合生成标签c。a的循环数是5,b的循环数是3,则会生成5个c,其中,前3个标签的值分别是a,b一一对应的。最后两个值中,b的值为空。假设a的值是11,22,33,44,55,b的值为aa,bb,cc.c是由组合, 则形成的c的值为11aa,22bb,33cc,44,55.
3.列表页标签和内容页标签组合
如果两个标签中一个是内容页,一个是列表页,则内容页是会出席第2条中的循环处理,在这个过程中列表页当成一个字符串处理。合并完成后,程序会再进行数据处理操作。最后,组合标签中的列表页标签内容将被替换成实际的值。组合后的结果中,可以再提取下载。比如内容页a和列表页b组合生成c,其中a的值为11,22,22,b的值为bb,那么,c第一次组合结果是 11,22,33,然后进行数据处理。如果b的值是bb,那么最后的结果就可能是11bb,22bb,33bb.
有的上海网页制做的同学可能会说,干嘛将这个功能搞那么复杂的。其实,这个功能主要是为第一条的功能使用的,其它的组合形式可能会形成和原看法不一样的结果。建议你们不要滥用这个功能,不要将它想象成万能的。 查看全部
优采云采集工具想必苏州网络公司的同学都晓得,而且优采云采集器如今也衍生出企业版的优采云浏览器,功能强悍无比,但是其价位也使无锡网站优化站长无法接受。
优采云的使用似乎还是比较复杂的,甚至对于菜鸟来说学习还是有些费力的,本文上海网站建设编辑就V7版本的便条组合聊聊自己的想法,希望能对需求的同学提供些许帮助。
v7版本降低了一个标签组合的功能,许多同学在使用中发觉组合的结果和自己想要的结果不一致,下面我来说明一下该功能的使用。
1.标签组合组合的是文件下载前的内容
有的同学发觉,a标签中下载了某个文件,原创地址是aaa,下载后或是侦测的地址为bbb,那么,如果您在b标签中组合使用a标签,a标签的值是aaa.为何使用这些处理方式,是因为文件下载是在标签组合以后进行的。如何达到标签内容是文件下载完后的结果呢?可以新建一个标签,选“自定义固定格式数据”,将您标签组合的内容放进去。这里的替换会在文件下载后执行。
2.内容页标签循环采集并添加为新记录
如果组合的两个标签都是内容页标签,这两个标签在组合时,会按循环数最大的记录形成新的同样数量的循环记录。如果某个标签的循环数较少,则新形成的标签中该标签的值为空。例如标签a,b组合生成标签c。a的循环数是5,b的循环数是3,则会生成5个c,其中,前3个标签的值分别是a,b一一对应的。最后两个值中,b的值为空。假设a的值是11,22,33,44,55,b的值为aa,bb,cc.c是由组合, 则形成的c的值为11aa,22bb,33cc,44,55.
3.列表页标签和内容页标签组合
如果两个标签中一个是内容页,一个是列表页,则内容页是会出席第2条中的循环处理,在这个过程中列表页当成一个字符串处理。合并完成后,程序会再进行数据处理操作。最后,组合标签中的列表页标签内容将被替换成实际的值。组合后的结果中,可以再提取下载。比如内容页a和列表页b组合生成c,其中a的值为11,22,22,b的值为bb,那么,c第一次组合结果是 11,22,33,然后进行数据处理。如果b的值是bb,那么最后的结果就可能是11bb,22bb,33bb.
有的上海网页制做的同学可能会说,干嘛将这个功能搞那么复杂的。其实,这个功能主要是为第一条的功能使用的,其它的组合形式可能会形成和原看法不一样的结果。建议你们不要滥用这个功能,不要将它想象成万能的。
Shell 命令 curl 和 wget 使用代理采集网页的总结大全
采集交流 • 优采云 发表了文章 • 0 个评论 • 864 次浏览 • 2020-08-09 16:34
米扑代理,作为大数据剖析研究的基础服务,对其做了深入的研究和总结。
curl 和 wget 使用代理
curl 支持 http、https、socks4、socks5
wget 支持 http、https
Shell curl wget 示例
#!/bin/bash
#
# curl 支持 http、https、socks4、socks5
# wget 支持 http、https
#
# 米扑代理示例:
# https://proxy.mimvp.com/demo2.php
#
# 米扑代理购买:
# https://proxy.mimvp.com
#
# mimvp.com
# 2015-11-09
#【米扑代理】:本示例,在CentOS、Ubuntu、MacOS等服务器上,均测试通过
#
# http代理格式 http_proxy=http://IP:Port
# https代理格式 https_proxy=http://IP:Port
## proxy no auth
# curl和wget,爬取http网页
{'http': 'http://120.77.176.179:8888'}
curl -m 30 --retry 3 -x http://120.77.176.179:8888 http://proxy.mimvp.com/test_proxy2.php # http_proxy
wget -T 30 --tries 3 -e "http_proxy=http://120.77.176.179:8888" http://proxy.mimvp.com/test_proxy2.php # http_proxy
# curl和wget,爬取https网页(注意:添加参数,不经过SSL安全验证)
{'https': 'http://46.105.214.133:3128'}
curl -m 30 --retry 3 -x http://46.105.214.133:3128 -k https://proxy.mimvp.com/test_proxy2.php # https_proxy
wget -T 30 --tries 3 -e "https_proxy=http://46.105.214.133:3128" --no-check-certificate https://proxy.mimvp.com/test_proxy2.php # https_proxy
# curl 支持socks
# 其中,socks4和socks5两种协议的代理,都可以同时爬取http和https网页
{'socks4': '101.255.17.145:1080'}
curl -m 30 --retry 3 --socks4 101.255.17.145:1080 http://proxy.mimvp.com/test_proxy2.php
curl -m 30 --retry 3 --socks4 101.255.17.145:1080 https://proxy.mimvp.com/test_proxy2.php
{'socks5': '82.164.233.227:45454'}
curl -m 30 --retry 3 --socks5 82.164.233.227:45454 http://proxy.mimvp.com/test_proxy2.php
curl -m 30 --retry 3 --socks5 82.164.233.227:45454 https://proxy.mimvp.com/test_proxy2.php
# wget 不支持socks
## proxy auth(代理需要用户名和密码验证)
# curl和wget,爬取http网页
curl -m 30 --retry 3 -x http://username:password@210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -x http://username:password@210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 -U username:password -x http://210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -U username:password -x http://210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 --proxy-user username:password -x http://210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 --proxy-user username:password -x http://210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
wget -T 30 --tries 3 -e "http_proxy=http://username:password@2.19.16.5:5718" http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 -e "https_proxy=http://username:password@2.19.16.5:5718" https://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 --proxy-user=username --proxy-password=password -e "http_proxy=http://2.19.16.5:5718" http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 --proxy-user=username --proxy-password=password -e "https_proxy=http://2.19.16.5:5718" https://proxy.mimvp.com/test_proxy2.php
# curl 支持socks
curl -m 30 --retry 3 -U username:password --socks5 21.59.126.22:57216 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -U username:password --socks5 21.59.126.22:57216 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 --proxy-user username:password --socks5 21.59.126.22:57216 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 --proxy-user username:password --socks5 21.59.126.22:57216 https://proxy.mimvp.com/test_proxy2.php # https
# wget 不支持socks
wget 配置文件设置代理
vim ~/.wgetrc
http_proxy=http://120.77.176.179:8888:8080
https_proxy=http://12.7.17.17:8888:8080
use_proxy = on
wait = 30
# 配置文件设置后,立即生效,直接执行wget爬取命令即可
wget -T 30 --tries 3 http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 https://proxy.mimvp.com/test_proxy2.php
Shell设置临时局部代理
# proxy no auth
export http_proxy=http://120.77.176.179:8888:8080
export https_proxy=http://12.7.17.17:8888:8080
# proxy auth(代理需要用户名和密码验证)
export http_proxy=http://username:password@120.77.176.179:8888:8080
export https_proxy=http://username:password@12.7.17.17:8888:8080
# 直接爬取网页
curl -m 30 --retry 3 http://proxy.mimvp.com/test_proxy2.php # http_proxy
curl -m 30 --retry 3 https://proxy.mimvp.com/test_proxy2.php # https_proxy
wget -T 30 --tries 3 http://proxy.mimvp.com/test_proxy2.php # http_proxy
wget -T 30 --tries 3 https://proxy.mimvp.com/test_proxy2.php # https_proxy
# 取消设置
unset http_proxy
unset https_proxy
Shell设置系统全局代理
# 修改 /etc/profile,保存并重启服务器
sudo vim /etc/profile # 所有人有效
或
sudo vim ~/.bashrc # 所有人有效
或
vim ~/.bash_profile # 个人有效
## 在文件末尾,添加如下内容
# proxy no auth
export http_proxy=http://120.77.176.179:8888:8080
export https_proxy=http://12.7.17.17:8888:8080
# proxy auth(代理需要用户名和密码验证)
export http_proxy=http://username:password@120.77.176.179:8888:8080
export https_proxy=http://username:password@12.7.17.17:8888:8080
## 执行source命令,使配置文件生效(临时生效)
source /etc/profile
或
source ~/.bashrc
或
source ~/.bash_profile
## 若需要机器永久生效,则需要重启服务器
sudo reboot
米扑代理示例
米扑代理,专注为企业提供国外大数据研究服务,技术团队来自百度、小米、阿里、创新工场等,为国外企业提供大数据采集、数据建模剖析、结果导入展示等服务。
米扑代理示例,收录Python、Java、PHP、C#、Go、Perl、Ruby、Shell、NodeJS、PhantomJS、Groovy、Delphi、易语言等十多种编程语言或脚本,通过大量的可运行实例,详细讲解了使用代理IP的正确方式,方便网页爬取、数据采集、自动化测试等领域。
米扑代理示例官网: 查看全部
Linux Shell 提供两个十分实用的命令来爬取网页,它们分别是 curl 和 wget
米扑代理,作为大数据剖析研究的基础服务,对其做了深入的研究和总结。
curl 和 wget 使用代理
curl 支持 http、https、socks4、socks5
wget 支持 http、https
Shell curl wget 示例
#!/bin/bash
#
# curl 支持 http、https、socks4、socks5
# wget 支持 http、https
#
# 米扑代理示例:
# https://proxy.mimvp.com/demo2.php
#
# 米扑代理购买:
# https://proxy.mimvp.com
#
# mimvp.com
# 2015-11-09
#【米扑代理】:本示例,在CentOS、Ubuntu、MacOS等服务器上,均测试通过
#
# http代理格式 http_proxy=http://IP:Port
# https代理格式 https_proxy=http://IP:Port
## proxy no auth
# curl和wget,爬取http网页
{'http': 'http://120.77.176.179:8888'}
curl -m 30 --retry 3 -x http://120.77.176.179:8888 http://proxy.mimvp.com/test_proxy2.php # http_proxy
wget -T 30 --tries 3 -e "http_proxy=http://120.77.176.179:8888" http://proxy.mimvp.com/test_proxy2.php # http_proxy
# curl和wget,爬取https网页(注意:添加参数,不经过SSL安全验证)
{'https': 'http://46.105.214.133:3128'}
curl -m 30 --retry 3 -x http://46.105.214.133:3128 -k https://proxy.mimvp.com/test_proxy2.php # https_proxy
wget -T 30 --tries 3 -e "https_proxy=http://46.105.214.133:3128" --no-check-certificate https://proxy.mimvp.com/test_proxy2.php # https_proxy
# curl 支持socks
# 其中,socks4和socks5两种协议的代理,都可以同时爬取http和https网页
{'socks4': '101.255.17.145:1080'}
curl -m 30 --retry 3 --socks4 101.255.17.145:1080 http://proxy.mimvp.com/test_proxy2.php
curl -m 30 --retry 3 --socks4 101.255.17.145:1080 https://proxy.mimvp.com/test_proxy2.php
{'socks5': '82.164.233.227:45454'}
curl -m 30 --retry 3 --socks5 82.164.233.227:45454 http://proxy.mimvp.com/test_proxy2.php
curl -m 30 --retry 3 --socks5 82.164.233.227:45454 https://proxy.mimvp.com/test_proxy2.php
# wget 不支持socks
## proxy auth(代理需要用户名和密码验证)
# curl和wget,爬取http网页
curl -m 30 --retry 3 -x http://username:password@210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -x http://username:password@210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 -U username:password -x http://210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -U username:password -x http://210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 --proxy-user username:password -x http://210.159.166.225:5718 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 --proxy-user username:password -x http://210.159.166.225:5718 https://proxy.mimvp.com/test_proxy2.php # https
wget -T 30 --tries 3 -e "http_proxy=http://username:password@2.19.16.5:5718" http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 -e "https_proxy=http://username:password@2.19.16.5:5718" https://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 --proxy-user=username --proxy-password=password -e "http_proxy=http://2.19.16.5:5718" http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 --proxy-user=username --proxy-password=password -e "https_proxy=http://2.19.16.5:5718" https://proxy.mimvp.com/test_proxy2.php
# curl 支持socks
curl -m 30 --retry 3 -U username:password --socks5 21.59.126.22:57216 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 -U username:password --socks5 21.59.126.22:57216 https://proxy.mimvp.com/test_proxy2.php # https
curl -m 30 --retry 3 --proxy-user username:password --socks5 21.59.126.22:57216 http://proxy.mimvp.com/test_proxy2.php # http
curl -m 30 --retry 3 --proxy-user username:password --socks5 21.59.126.22:57216 https://proxy.mimvp.com/test_proxy2.php # https
# wget 不支持socks
wget 配置文件设置代理
vim ~/.wgetrc
http_proxy=http://120.77.176.179:8888:8080
https_proxy=http://12.7.17.17:8888:8080
use_proxy = on
wait = 30
# 配置文件设置后,立即生效,直接执行wget爬取命令即可
wget -T 30 --tries 3 http://proxy.mimvp.com/test_proxy2.php
wget -T 30 --tries 3 https://proxy.mimvp.com/test_proxy2.php
Shell设置临时局部代理
# proxy no auth
export http_proxy=http://120.77.176.179:8888:8080
export https_proxy=http://12.7.17.17:8888:8080
# proxy auth(代理需要用户名和密码验证)
export http_proxy=http://username:password@120.77.176.179:8888:8080
export https_proxy=http://username:password@12.7.17.17:8888:8080
# 直接爬取网页
curl -m 30 --retry 3 http://proxy.mimvp.com/test_proxy2.php # http_proxy
curl -m 30 --retry 3 https://proxy.mimvp.com/test_proxy2.php # https_proxy
wget -T 30 --tries 3 http://proxy.mimvp.com/test_proxy2.php # http_proxy
wget -T 30 --tries 3 https://proxy.mimvp.com/test_proxy2.php # https_proxy
# 取消设置
unset http_proxy
unset https_proxy
Shell设置系统全局代理
# 修改 /etc/profile,保存并重启服务器
sudo vim /etc/profile # 所有人有效
或
sudo vim ~/.bashrc # 所有人有效
或
vim ~/.bash_profile # 个人有效
## 在文件末尾,添加如下内容
# proxy no auth
export http_proxy=http://120.77.176.179:8888:8080
export https_proxy=http://12.7.17.17:8888:8080
# proxy auth(代理需要用户名和密码验证)
export http_proxy=http://username:password@120.77.176.179:8888:8080
export https_proxy=http://username:password@12.7.17.17:8888:8080
## 执行source命令,使配置文件生效(临时生效)
source /etc/profile
或
source ~/.bashrc
或
source ~/.bash_profile
## 若需要机器永久生效,则需要重启服务器
sudo reboot
米扑代理示例
米扑代理,专注为企业提供国外大数据研究服务,技术团队来自百度、小米、阿里、创新工场等,为国外企业提供大数据采集、数据建模剖析、结果导入展示等服务。
米扑代理示例,收录Python、Java、PHP、C#、Go、Perl、Ruby、Shell、NodeJS、PhantomJS、Groovy、Delphi、易语言等十多种编程语言或脚本,通过大量的可运行实例,详细讲解了使用代理IP的正确方式,方便网页爬取、数据采集、自动化测试等领域。
米扑代理示例官网:
如何写出1688黄金标题?一键手动生成标题轻松搞定!
采集交流 • 优采云 发表了文章 • 0 个评论 • 448 次浏览 • 2020-08-09 08:47
然而许多店家上新30分钟,想标题2小时,利用层层工具选词、优化,不仅花费精力,也消耗时间,小编明天告诉你一键手动生成标题的秘密!
在此之前先来瞧瞧往年写标题主要从何入手:
1、用足标题给的30个字的空间。
尽量控制在26个字以上,30个字以内,把产品名,产品特点,促销方法等都写进来,吸引卖家点击,一个好的标题可以把曝光量转化为点击量,促使订单成交的可能性。
2、选词。
选词的方式有很多,常见的选词方式有阿里指数选词、1688搜索下拉框选词、生意参谋等等,通过比对选择与自己的产品关联性强,且竞争力较小的关键词进行组合,放到自己的产品标题里,可以使产品被搜索的概率大大降低。
(1)阿里指数:
相信诸位店家对阿里指数都比较熟悉,登录1688买家工作台,点击服务再搜索阿里指数,就可以直接步入应用。在阿里指数最上方的查找类目栏里找到与自己产品相关的类目,左侧的属性细分会给我们推荐一些与产品相关的热门属性,也可以按照搜索排行榜里上升榜和热搜榜里的词,进行组合标题。
(2)1688搜索下拉框选词:
在1688首页搜索框输入您要找的产品关键词,下拉框会给我们推荐一个相关的关键词,这些词都可以作为我们布关键词的一个参考,这些词都是一定时间内卖家常常搜索的词,参考的比重也是比较大的。
(3)生意参谋:
1688买家中心查找服务[生意参谋],选择打开商品列,左侧点击“搜索排名”通过查找关键词获得相关搜索词、搜索次数等信息,只是生意参谋搜索关键词的功能须要购买豪华版的生意参谋能够使用。
3、增加产品特点描述词。
在标题中,加入产品特点描述的词句。比如:规格、材质、功能、认证等等,这类词的出现会吸引有类似相关须要的顾客去点击我们的产品,把曝光量转化为点击。
4、常用的标题组合。
营销词+核心关键词(产品主名称)+修饰词+属性+近义/二级词
营销词+核心关键词+属性尺寸+服务卖点或产品卖点+品牌产地+经营模式
制作标题时注意:主关键词越靠前排行权重越高以及关键词的连贯性。
5、黄金标题的“2-4-2法则”
2个核心:
尽量只写核心词(马铃薯/土豆、番茄/西红柿)主关键词其实多了但搜索也概率大了,实际上排行增加了,内容过多会分散产品的权重,造成的后果是上架一周后基本无突显。
4个标准:
不能产生拼凑、不能使用符号、字数满足30个、修饰词4-5个为宜。
2个关键:
类目匹配度、类目的相关性、检查标题是否符合要求、生意参谋检测、橱窗有无推荐、类目是否正确、属性是否填写完整、有无低质量交易。
以上介绍了五个标题选词、优化的方式,不知诸位店家有没有又温故而新知了一遍呢,不过在这过程中会消耗我们的好多时间和精力,一个10年营运前辈说他写一个好的标题要花一个小时的时间,然而对于大部分店家来说,一整个过程出来起码也须要2个小时左右,这时候难免感触——
有没有一键手动优化标题生成这些好事情呢?
有!
免费开通慧眼识货你能够做到一键手动生成标题!!
【点击即可免费发放大泽慧眼识货】
免费发放慧眼识货,并授权登陆后,进入【大泽慧眼识货】界面。
选择基础信息:
选择版本,选择您的所属类目,选择模板,上传识货图片,即开始识货。
一键手动生成标题:
已通过上传的图片手动生成标题,点击按键可以一键更换更多标题。
大泽慧眼识货——自动生成标题并经过搜索优化、标题相关性贴切、标题核心关键词确切、标题字数符合26个字以上,满足30字完整丰富,排列组合次序会推动系统收录关键词。
1、自动生成标题并经过搜索优化:
慧眼识货通过AI智能文案生成技术,通过识货的图片结果手动生成标题,且标题经过搜索优化,利于凸显。
2、标题相关性贴切:
通过慧眼识货生成的标题,关键词来源与产品属性,与产品贴切吻合。满足搜索排名第一要素——相关性。
3、标题核心关键词确切:
核心词就是跟产品相关度最高同时搜索量又较大的词。慧眼识货一键生成的标题能同时兼具相关性和搜索量两个指标,核心关键词确切。
4、标题符合字数要求、完整丰富:
标题宽度为30个字(60个字符,一个汉字相当于2个字符),慧眼识货一键生成的标题都符合26个字到30个字的字数要求,标题完整丰富,符合商品质量信息要求。
5、紧密排列组合推动系统收录:
慧眼识货一键生成的标题,利用紧密排列的原理进行了排列组合,权重同等情况下,紧密排列的关键词会优先展示,自动匹配产品标题,把作用发挥到最大,助力系统收录关键词。
慧眼识货核心功能一键手动生成标题,方便广大店家的标题优化需求,让你们在选词、组合、优化等方面才能获得方便的流程,提升效率,简化过程,直接获得黄金标题。
大泽慧眼识货目前支持六大类目,女装、男装、童装、箱包、内衣、鞋鞋行业的店家可以行动上去了,用慧眼识货手动生成标题,快速上新,节省冗长重复的时间。各位商家们赶快开通/使用慧眼识货体验一下吧!
更多信息:
1、大泽慧眼识货免费发放地址: 查看全部
如何编撰标题,如何写出黄金标题,是好多商家们关注的问题。要知道电商界的标题党能收获的不只是点击率这么简单,它而且直接关系到使顾客精准的找到你,突出您产品的特性,促使交易的形成。一个好的标题越发的重要,同时也影响着我们的权重。
然而许多店家上新30分钟,想标题2小时,利用层层工具选词、优化,不仅花费精力,也消耗时间,小编明天告诉你一键手动生成标题的秘密!
在此之前先来瞧瞧往年写标题主要从何入手:
1、用足标题给的30个字的空间。
尽量控制在26个字以上,30个字以内,把产品名,产品特点,促销方法等都写进来,吸引卖家点击,一个好的标题可以把曝光量转化为点击量,促使订单成交的可能性。
2、选词。
选词的方式有很多,常见的选词方式有阿里指数选词、1688搜索下拉框选词、生意参谋等等,通过比对选择与自己的产品关联性强,且竞争力较小的关键词进行组合,放到自己的产品标题里,可以使产品被搜索的概率大大降低。
(1)阿里指数:
相信诸位店家对阿里指数都比较熟悉,登录1688买家工作台,点击服务再搜索阿里指数,就可以直接步入应用。在阿里指数最上方的查找类目栏里找到与自己产品相关的类目,左侧的属性细分会给我们推荐一些与产品相关的热门属性,也可以按照搜索排行榜里上升榜和热搜榜里的词,进行组合标题。
(2)1688搜索下拉框选词:
在1688首页搜索框输入您要找的产品关键词,下拉框会给我们推荐一个相关的关键词,这些词都可以作为我们布关键词的一个参考,这些词都是一定时间内卖家常常搜索的词,参考的比重也是比较大的。
(3)生意参谋:
1688买家中心查找服务[生意参谋],选择打开商品列,左侧点击“搜索排名”通过查找关键词获得相关搜索词、搜索次数等信息,只是生意参谋搜索关键词的功能须要购买豪华版的生意参谋能够使用。
3、增加产品特点描述词。
在标题中,加入产品特点描述的词句。比如:规格、材质、功能、认证等等,这类词的出现会吸引有类似相关须要的顾客去点击我们的产品,把曝光量转化为点击。
4、常用的标题组合。
营销词+核心关键词(产品主名称)+修饰词+属性+近义/二级词
营销词+核心关键词+属性尺寸+服务卖点或产品卖点+品牌产地+经营模式
制作标题时注意:主关键词越靠前排行权重越高以及关键词的连贯性。
5、黄金标题的“2-4-2法则”
2个核心:
尽量只写核心词(马铃薯/土豆、番茄/西红柿)主关键词其实多了但搜索也概率大了,实际上排行增加了,内容过多会分散产品的权重,造成的后果是上架一周后基本无突显。
4个标准:
不能产生拼凑、不能使用符号、字数满足30个、修饰词4-5个为宜。
2个关键:
类目匹配度、类目的相关性、检查标题是否符合要求、生意参谋检测、橱窗有无推荐、类目是否正确、属性是否填写完整、有无低质量交易。
以上介绍了五个标题选词、优化的方式,不知诸位店家有没有又温故而新知了一遍呢,不过在这过程中会消耗我们的好多时间和精力,一个10年营运前辈说他写一个好的标题要花一个小时的时间,然而对于大部分店家来说,一整个过程出来起码也须要2个小时左右,这时候难免感触——
有没有一键手动优化标题生成这些好事情呢?
有!
免费开通慧眼识货你能够做到一键手动生成标题!!
【点击即可免费发放大泽慧眼识货】
免费发放慧眼识货,并授权登陆后,进入【大泽慧眼识货】界面。
选择基础信息:
选择版本,选择您的所属类目,选择模板,上传识货图片,即开始识货。
一键手动生成标题:
已通过上传的图片手动生成标题,点击按键可以一键更换更多标题。
大泽慧眼识货——自动生成标题并经过搜索优化、标题相关性贴切、标题核心关键词确切、标题字数符合26个字以上,满足30字完整丰富,排列组合次序会推动系统收录关键词。
1、自动生成标题并经过搜索优化:
慧眼识货通过AI智能文案生成技术,通过识货的图片结果手动生成标题,且标题经过搜索优化,利于凸显。
2、标题相关性贴切:
通过慧眼识货生成的标题,关键词来源与产品属性,与产品贴切吻合。满足搜索排名第一要素——相关性。
3、标题核心关键词确切:
核心词就是跟产品相关度最高同时搜索量又较大的词。慧眼识货一键生成的标题能同时兼具相关性和搜索量两个指标,核心关键词确切。
4、标题符合字数要求、完整丰富:
标题宽度为30个字(60个字符,一个汉字相当于2个字符),慧眼识货一键生成的标题都符合26个字到30个字的字数要求,标题完整丰富,符合商品质量信息要求。
5、紧密排列组合推动系统收录:
慧眼识货一键生成的标题,利用紧密排列的原理进行了排列组合,权重同等情况下,紧密排列的关键词会优先展示,自动匹配产品标题,把作用发挥到最大,助力系统收录关键词。
慧眼识货核心功能一键手动生成标题,方便广大店家的标题优化需求,让你们在选词、组合、优化等方面才能获得方便的流程,提升效率,简化过程,直接获得黄金标题。
大泽慧眼识货目前支持六大类目,女装、男装、童装、箱包、内衣、鞋鞋行业的店家可以行动上去了,用慧眼识货手动生成标题,快速上新,节省冗长重复的时间。各位商家们赶快开通/使用慧眼识货体验一下吧!
更多信息:
1、大泽慧眼识货免费发放地址:
手动添加多级URL填写链接地址规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-08-08 20:01
手动填写链接地址规则的原理是编写一个脚本规则以匹配源代码中的内容并获取您自己设置的参数.
使用常规解释
[参数]
用于匹配准备提取信息的标签. 例如,您想在以下代码中提取并合并某种格式. 采取代码“ mClk(this,'108484','134217','168475','1');”以提取并合并新的地址格式为例.
“ mClk(this,'[parameter]','[parameter]','[parameter]','1');”,按顺序,108484参数是参数1,依此类推. 所需的实际地址是以下地址格式: bbs / read.php?id = [parameter 1]&sort = [parameter 3]&action = [parameter 2],上面代码中的3个参数和下面地址中的id, soft和action参数应对应于相应的值,并且顺序不应颠倒. 这会合并为新的地址格式.
(*)
(*)是通配符,可以表示优采云采集器中起始地址的页数,并且可以匹配标签规则,模块或其他设置中的任何字符串,例如(*)可以匹配xxx字符字符串也可以与yy字符串匹配.
二,使用场合和使用方法
1. 通常,可以手动获取可以自动获取URL链接的网页. 手动填写链接地址的灵活性较高!
2. 如果网页源代码中的内容页面链接未标准化,或者URL中没有链接,则可以使用手动填写链接地址规则.
插图:
示例1,例如ajax链接
通过查看源代码,我们可以看到URL链接不是标准化的,因此链接地址不能直接用于获取URL.
解决方案:
脚本规则:
实际链接: [参数1] / [参数2] / [参数3] /
示例2: 例如,列表页面中内容页面只有一个ID,而没有其他URL信息,因此也可以通过手动填写链接地址规则来获取.
列表页面网址:
内容页面网址:
检查源代码表明URL链接也不规则.
解决方案:
脚本规则: |(*),[参数],
实际链接: [参数1] 查看全部
一个. 原理
手动填写链接地址规则的原理是编写一个脚本规则以匹配源代码中的内容并获取您自己设置的参数.
使用常规解释
[参数]
用于匹配准备提取信息的标签. 例如,您想在以下代码中提取并合并某种格式. 采取代码“ mClk(this,'108484','134217','168475','1');”以提取并合并新的地址格式为例.
“ mClk(this,'[parameter]','[parameter]','[parameter]','1');”,按顺序,108484参数是参数1,依此类推. 所需的实际地址是以下地址格式: bbs / read.php?id = [parameter 1]&sort = [parameter 3]&action = [parameter 2],上面代码中的3个参数和下面地址中的id, soft和action参数应对应于相应的值,并且顺序不应颠倒. 这会合并为新的地址格式.
(*)
(*)是通配符,可以表示优采云采集器中起始地址的页数,并且可以匹配标签规则,模块或其他设置中的任何字符串,例如(*)可以匹配xxx字符字符串也可以与yy字符串匹配.
二,使用场合和使用方法
1. 通常,可以手动获取可以自动获取URL链接的网页. 手动填写链接地址的灵活性较高!
2. 如果网页源代码中的内容页面链接未标准化,或者URL中没有链接,则可以使用手动填写链接地址规则.
插图:
示例1,例如ajax链接
通过查看源代码,我们可以看到URL链接不是标准化的,因此链接地址不能直接用于获取URL.
解决方案:
脚本规则:
实际链接: [参数1] / [参数2] / [参数3] /
示例2: 例如,列表页面中内容页面只有一个ID,而没有其他URL信息,因此也可以通过手动填写链接地址规则来获取.
列表页面网址:
内容页面网址:
检查源代码表明URL链接也不规则.
解决方案:
脚本规则: |(*),[参数],
实际链接: [参数1]
[教程步骤13] 优采云采集器版本选择指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2020-08-08 03:20
小蔡为您准备了以下指南,相信它将帮助您选择版本.
首先,让我们看一下免费版本. 优采云采集器的免费版本也可以终身使用,并且不限制使用时间. 它与付费版本仅在功能上有所不同. 伟大的神灵可能暂时没有考虑免费版本的所有功能是否满足您的需求,那么我们将看看免费版本暂时不支持哪些功能,如果您需要使用它,只需选择对应的商业版本〜</p
p1. 无标签组合功能/p
p当需要从两个标签采集的内容中合成一个内容时,需要使用此功能./p
p例如: [标签C] = [标签A] + [标签B],请参见下图:/p
pimg src='https://pic2.zhimg.com/v2-dc6bed9a281e0c62faac43fca663724f_b.jpg' alt=''//p
p2. 无限列表网址集合(支持两个以上级别)/p
p我们在采集网页时经常遇到多级列表. 例如,对于Dianping.com的分类(单击此处以查看共享的相关规则),您需要使用优采云采集器的多级列表功能. 有关功能用法,请参见下图:/p
pimg src='https://pic3.zhimg.com/v2-4ab849de9251f95154f8cccd98856740_b.jpg' alt=''//p
p3. 以任何格式下载文件/p
p在采集过程中,我们会遇到一些要下载的附件文件,例如word文档,压缩文件,PDF和其他格式文件,而免费版本不支持下载图片以外的其他格式文件./p
p4. 使用FTP自动将文件上传到网站/p
p如上所述,提到了任何格式的文件下载. 由于存在下载,因此当我们需要在网站上发布功能时,我们需要上载该功能. 优采云采集器提供了使用FTP自动上传文件的功能,包括图片的自动上传. 您无法在免费版本中使用此功能,只能手动上传文件,也无法同步和自动上传文件. 有关FTP功能,请参见下图:/p
pimg src='https://picb.zhimg.com/v2-e111c284d6cbdbbce4be81dac8be81ab_b.jpg' alt=''//p
p5. 将数据导出为Word,Excel,CSV格式/p
p将采集的数据发布到本地计算机,并将其另存为文件格式. 免费版本不支持Word,Excel,CSV格式,而仅支持TXT和html格式./p
p6,MySql和SqlServer数据库保存数据/p
p免费版本的默认版本是Sqlite数据库. 当数据量很大时,默认数据库将导致软件运行缓慢. 此时,您需要使用MySql或SqlServer数据库./p
p7. 多页采集功能/p
p当我们采集内容时,有时会遇到内容不在同一页面上的情况. 进入内容页面后,我们需要进入另一个页面,称为多页面集合. 点击此处以查看携程的多页采集案例/p
p8. 列表页面标签采集功能/p
p经常遇到要采集的内容在列表页面上,内容页面不可用或内容页面采集不便的情况,因此需要列表页面采集功能./p
p采集内容URL时,将采集列表页面上所需的内容./p
p点击此处查看昭联招募案/p
p9. 计划任务功能/p
p当我们采集一些新闻网站时,我们需要在固定的时间采集它们并自动发布它们,以便计划的任务可以在24小时内自动更新和发布. 单击此处以参考教程/p
p10. 其他一些功能/p
p自动提取第一张图片,自动摘要,将数据发布到MySql \ SqlServer和其他功能始终可以在需要时为您提供帮助. 我不会在这里详细介绍. 以上9个是更常用的功能./p
p如果上述功能已经可以满足大神的需求,那么您可以选择基本版本(商业授权也可以终身使用,没有过期版本可以免费使用)/p
p但是对于一个更专业的上帝来说,上述功能远远不够,所以接下来我将向您介绍更高版本./p
p旗舰版及更高版本的功能/p
p与基本版本相比,旗舰版本及更高版本还具有一些高级功能,可以满足诸神的操作. 让我列出一些更常用的功能./p
p1,二级代理商/p
p采集IP时,您需要使用辅助代理功能. 当然,您需要拥有IP代理资源. 目前,官方机构不提供代理资源/p
p2. 图片会自动加水印/p
p自动为采集的图片添加水印/p
p3. 支持标签处理C#和C#外部插件功能/p
p4. 挖掘时发布功能/p
p例如,需要采集100,000条信息. 基本版本只能在完成所有采集后才能发布,而旗舰版及更高版本则支持同时采集和分发./p
p5,Json提取功能/p
p支持Json格式的数据采集和提取/p
p6. 支持python插件,采集和警告配置,支持SSH(SFTP文件)上传/p
p旗舰版及更高版本需要支持以上功能. 如果您需要使用上述功能的基本版本,那还不够./p
p旗舰版和更高版本之间的区别/p
p那么旗舰版和更高版本之间有什么区别?除了企业版(该企业版还支持向Oracle和Http接口管理采集器发布数据)之外,主要区别在于计算机授权./p
p基本版本和旗舰机器代码版本: 绑定1台授权计算机,您可以免费更改一次授权./p
p旗舰自动许可版本: 绑定一台授权计算机,您可以无限次更改计算机./p
p企业专用版: 绑定了5台授权计算机(2个加密狗版本+ 3个机器代码版本),并且3个授权可以免费更换. 加密狗版本可以在任何计算机上使用./p
p企业豪华版: 绑定10台授权计算机(4台加密狗版本+ 6台自动授权版本),您可以无限次随意更改计算机./p
p注意: 捆绑的授权计算机表示该软件只能在绑定到授权计算机的计算机上运行商业版本. 自授权版本和加密狗版本可以在不同的计算机上使用,即可以在不同的计算机上使用,但同时只能在计算机上使用./p
p现在让我们看看哪个版本最适合您〜/p
p(1)如果您的软件长时间固定在计算机上,则无需经常更换,基本版本的功能已经可以满足您的需求»»»»»选择基本版本/p
p(2)如果您的软件长时间安装在计算机上,则不需要经常更换,但是您需要旗舰版»»»»»的高级功能选择旗舰机器代码版本/p
p(3)如果您的软件未固定在计算机上,则通常需要更改计算机以运行»»»»»选择旗舰自动许可版本/p
p(4)如果需要大规模采集数据,请使用多台计算机同时运行该软件,或者需要多人同时在不同的计算机上进行操作(5套)»»»»»选择企业版高级版/p
p(5)如果需要大规模采集数据,请使用多台计算机同时运行该软件,或者需要多人同时在不同的计算机上进行操作(10套)»»»»»选择企业版豪华版/p
p当然,如果您仍然有无法满足的需求,请联系我们的客户服务经理MM(企业QQ: 800019423),优采云采集器视客户为上帝,并将为您量身定制./p
p回顾以前的教程/p
p☞【教程步骤1】,开始使用优采云采集器/p
p☞[教程步骤2]优采云采集器的URL采集/p
p☞[教程步骤3] 优采云采集器的内容采集/p
p☞[教程步骤4]优采云采集器在线发布/p
p☞[教程步骤5]理解POST以获得URL和捕获数据包的时间/p
p☞[Tutorial step.6]阅读本文后,[Parameter N]不会让您晕眩/p
p☞[教程步骤7]如何按页面采集内容?/p
p☞[教程步骤8],如果您遇到这样的反爬网网站怎么办?/p
p☞[教程步骤9]. 如果您不懂常规,只需写下这些表达式/p
p☞[教程步骤10]优采云采集器数据处理的神奇效果/p
p☞[教程步骤11],看不到吗?尝试多页〜☞[教程步骤12]优采云采集器V9计划任务设置/p
p>>必要提示
优采云采集器用户手册| 优采云 Browser用户手册
>>>>软件咨询
官方网站|价格特色|常见问题 查看全部
最近,许多首次联系优采云采集器的用户都反馈说,优采云采集器 V9具有免费版本,基本版本,最终机器代码版本,最终版本的自动授权版本,独占版本. 企业版,以及企业版如何在豪华版等多个版本之间进行选择?
小蔡为您准备了以下指南,相信它将帮助您选择版本.
首先,让我们看一下免费版本. 优采云采集器的免费版本也可以终身使用,并且不限制使用时间. 它与付费版本仅在功能上有所不同. 伟大的神灵可能暂时没有考虑免费版本的所有功能是否满足您的需求,那么我们将看看免费版本暂时不支持哪些功能,如果您需要使用它,只需选择对应的商业版本〜</p
p1. 无标签组合功能/p
p当需要从两个标签采集的内容中合成一个内容时,需要使用此功能./p
p例如: [标签C] = [标签A] + [标签B],请参见下图:/p
pimg src='https://pic2.zhimg.com/v2-dc6bed9a281e0c62faac43fca663724f_b.jpg' alt=''//p
p2. 无限列表网址集合(支持两个以上级别)/p
p我们在采集网页时经常遇到多级列表. 例如,对于Dianping.com的分类(单击此处以查看共享的相关规则),您需要使用优采云采集器的多级列表功能. 有关功能用法,请参见下图:/p
pimg src='https://pic3.zhimg.com/v2-4ab849de9251f95154f8cccd98856740_b.jpg' alt=''//p
p3. 以任何格式下载文件/p
p在采集过程中,我们会遇到一些要下载的附件文件,例如word文档,压缩文件,PDF和其他格式文件,而免费版本不支持下载图片以外的其他格式文件./p
p4. 使用FTP自动将文件上传到网站/p
p如上所述,提到了任何格式的文件下载. 由于存在下载,因此当我们需要在网站上发布功能时,我们需要上载该功能. 优采云采集器提供了使用FTP自动上传文件的功能,包括图片的自动上传. 您无法在免费版本中使用此功能,只能手动上传文件,也无法同步和自动上传文件. 有关FTP功能,请参见下图:/p
pimg src='https://picb.zhimg.com/v2-e111c284d6cbdbbce4be81dac8be81ab_b.jpg' alt=''//p
p5. 将数据导出为Word,Excel,CSV格式/p
p将采集的数据发布到本地计算机,并将其另存为文件格式. 免费版本不支持Word,Excel,CSV格式,而仅支持TXT和html格式./p
p6,MySql和SqlServer数据库保存数据/p
p免费版本的默认版本是Sqlite数据库. 当数据量很大时,默认数据库将导致软件运行缓慢. 此时,您需要使用MySql或SqlServer数据库./p
p7. 多页采集功能/p
p当我们采集内容时,有时会遇到内容不在同一页面上的情况. 进入内容页面后,我们需要进入另一个页面,称为多页面集合. 点击此处以查看携程的多页采集案例/p
p8. 列表页面标签采集功能/p
p经常遇到要采集的内容在列表页面上,内容页面不可用或内容页面采集不便的情况,因此需要列表页面采集功能./p
p采集内容URL时,将采集列表页面上所需的内容./p
p点击此处查看昭联招募案/p
p9. 计划任务功能/p
p当我们采集一些新闻网站时,我们需要在固定的时间采集它们并自动发布它们,以便计划的任务可以在24小时内自动更新和发布. 单击此处以参考教程/p
p10. 其他一些功能/p
p自动提取第一张图片,自动摘要,将数据发布到MySql \ SqlServer和其他功能始终可以在需要时为您提供帮助. 我不会在这里详细介绍. 以上9个是更常用的功能./p
p如果上述功能已经可以满足大神的需求,那么您可以选择基本版本(商业授权也可以终身使用,没有过期版本可以免费使用)/p
p但是对于一个更专业的上帝来说,上述功能远远不够,所以接下来我将向您介绍更高版本./p
p旗舰版及更高版本的功能/p
p与基本版本相比,旗舰版本及更高版本还具有一些高级功能,可以满足诸神的操作. 让我列出一些更常用的功能./p
p1,二级代理商/p
p采集IP时,您需要使用辅助代理功能. 当然,您需要拥有IP代理资源. 目前,官方机构不提供代理资源/p
p2. 图片会自动加水印/p
p自动为采集的图片添加水印/p
p3. 支持标签处理C#和C#外部插件功能/p
p4. 挖掘时发布功能/p
p例如,需要采集100,000条信息. 基本版本只能在完成所有采集后才能发布,而旗舰版及更高版本则支持同时采集和分发./p
p5,Json提取功能/p
p支持Json格式的数据采集和提取/p
p6. 支持python插件,采集和警告配置,支持SSH(SFTP文件)上传/p
p旗舰版及更高版本需要支持以上功能. 如果您需要使用上述功能的基本版本,那还不够./p
p旗舰版和更高版本之间的区别/p
p那么旗舰版和更高版本之间有什么区别?除了企业版(该企业版还支持向Oracle和Http接口管理采集器发布数据)之外,主要区别在于计算机授权./p
p基本版本和旗舰机器代码版本: 绑定1台授权计算机,您可以免费更改一次授权./p
p旗舰自动许可版本: 绑定一台授权计算机,您可以无限次更改计算机./p
p企业专用版: 绑定了5台授权计算机(2个加密狗版本+ 3个机器代码版本),并且3个授权可以免费更换. 加密狗版本可以在任何计算机上使用./p
p企业豪华版: 绑定10台授权计算机(4台加密狗版本+ 6台自动授权版本),您可以无限次随意更改计算机./p
p注意: 捆绑的授权计算机表示该软件只能在绑定到授权计算机的计算机上运行商业版本. 自授权版本和加密狗版本可以在不同的计算机上使用,即可以在不同的计算机上使用,但同时只能在计算机上使用./p
p现在让我们看看哪个版本最适合您〜/p
p(1)如果您的软件长时间固定在计算机上,则无需经常更换,基本版本的功能已经可以满足您的需求»»»»»选择基本版本/p
p(2)如果您的软件长时间安装在计算机上,则不需要经常更换,但是您需要旗舰版»»»»»的高级功能选择旗舰机器代码版本/p
p(3)如果您的软件未固定在计算机上,则通常需要更改计算机以运行»»»»»选择旗舰自动许可版本/p
p(4)如果需要大规模采集数据,请使用多台计算机同时运行该软件,或者需要多人同时在不同的计算机上进行操作(5套)»»»»»选择企业版高级版/p
p(5)如果需要大规模采集数据,请使用多台计算机同时运行该软件,或者需要多人同时在不同的计算机上进行操作(10套)»»»»»选择企业版豪华版/p
p当然,如果您仍然有无法满足的需求,请联系我们的客户服务经理MM(企业QQ: 800019423),优采云采集器视客户为上帝,并将为您量身定制./p
p回顾以前的教程/p
p☞【教程步骤1】,开始使用优采云采集器/p
p☞[教程步骤2]优采云采集器的URL采集/p
p☞[教程步骤3] 优采云采集器的内容采集/p
p☞[教程步骤4]优采云采集器在线发布/p
p☞[教程步骤5]理解POST以获得URL和捕获数据包的时间/p
p☞[Tutorial step.6]阅读本文后,[Parameter N]不会让您晕眩/p
p☞[教程步骤7]如何按页面采集内容?/p
p☞[教程步骤8],如果您遇到这样的反爬网网站怎么办?/p
p☞[教程步骤9]. 如果您不懂常规,只需写下这些表达式/p
p☞[教程步骤10]优采云采集器数据处理的神奇效果/p
p☞[教程步骤11],看不到吗?尝试多页〜☞[教程步骤12]优采云采集器V9计划任务设置/p
p>>必要提示
优采云采集器用户手册| 优采云 Browser用户手册
>>>>软件咨询
官方网站|价格特色|常见问题
VG捕获浏览器v7.7.6
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2020-08-07 21:19
基本介绍
VG浏览器是由可视脚本驱动的网页自动操作工具. 只需设置一个脚本即可创建自动登录,识别验证码,自动捕获数据,自动提交数据,单击网页并下载文件. 个性化和实用的脚本项目,例如操作数据库,发送和接收电子邮件. 您还可以使用逻辑运算来完成判断,循环,跳转和其他功能. 脚本灵活且易于自由组合. 没有任何编程基础,您可以轻松,快速地编写功能强大且独特的脚本来协助我们的工作. 生成待售的独立EXE程序.
软件功能
视觉操作
操作简单,图形化操作完全可视化,不需要专业的IT人员.
自定义流程
采集就像构建块一样,功能可以自由组合.
自动编码
程序注重采集效率,页面分析速度非常快.
生成EXE
自动登录,自动识别验证码是一种通用浏览器.
使用方法
通过CSS路径定位网页元素的路径是VG浏览器的一项非常有用的功能. 选择需要填写CSS Path规则的任何步骤,然后单击内置浏览器的按钮
单击网页元素以自动生成该元素的CSS路径. 很少有复杂框架的网页可能无法通过内置浏览器生成路径. 您也可以在其他浏览器上复制CSS路径. 当前,各种多核浏览器都支持复制CSS Path. 例如,可以通过按F12键或右键单击页面以选择审阅元素来检查所有Chrome内核浏览器,例如Google Chrome,360安全浏览器,360 Speed浏览器,UC浏览器等.
右键单击目标部分,然后选择“复制CSS路径”以将CSS路径复制到剪贴板,
在Firefox中,您也可以按F12键或右键单击以查看元素. 显示开发人员工具后,右键单击底部节点,然后选择“仅复制选择器”以复制CSS路径.
CSS路径规则与JQuery选择器规则完全兼容. 如果您知道如何编写JQuery选择器,也可以自己编写CSS路径 查看全部
VG浏览器中收录三合一的集合浏览器,营销工件和可视脚本驱动的Web工具. 使用此软件,就等于同时拥有三个软件. 用户可以设置脚本来实现自动登录,识别验证码,自动抓取数据,单击网页,下载文件,操纵数据库,发送和接收电子邮件以及其他操作. 软件中的所有功能均可自由组合. 您还可以使用该软件编写独特的脚本来协助您的工作,也可以生成单独的EXE程序进行出售.
基本介绍
VG浏览器是由可视脚本驱动的网页自动操作工具. 只需设置一个脚本即可创建自动登录,识别验证码,自动捕获数据,自动提交数据,单击网页并下载文件. 个性化和实用的脚本项目,例如操作数据库,发送和接收电子邮件. 您还可以使用逻辑运算来完成判断,循环,跳转和其他功能. 脚本灵活且易于自由组合. 没有任何编程基础,您可以轻松,快速地编写功能强大且独特的脚本来协助我们的工作. 生成待售的独立EXE程序.
软件功能
视觉操作
操作简单,图形化操作完全可视化,不需要专业的IT人员.
自定义流程
采集就像构建块一样,功能可以自由组合.
自动编码
程序注重采集效率,页面分析速度非常快.
生成EXE
自动登录,自动识别验证码是一种通用浏览器.
使用方法
通过CSS路径定位网页元素的路径是VG浏览器的一项非常有用的功能. 选择需要填写CSS Path规则的任何步骤,然后单击内置浏览器的按钮
单击网页元素以自动生成该元素的CSS路径. 很少有复杂框架的网页可能无法通过内置浏览器生成路径. 您也可以在其他浏览器上复制CSS路径. 当前,各种多核浏览器都支持复制CSS Path. 例如,可以通过按F12键或右键单击页面以选择审阅元素来检查所有Chrome内核浏览器,例如Google Chrome,360安全浏览器,360 Speed浏览器,UC浏览器等.
右键单击目标部分,然后选择“复制CSS路径”以将CSS路径复制到剪贴板,
在Firefox中,您也可以按F12键或右键单击以查看元素. 显示开发人员工具后,右键单击底部节点,然后选择“仅复制选择器”以复制CSS路径.
CSS路径规则与JQuery选择器规则完全兼容. 如果您知道如何编写JQuery选择器,也可以自己编写CSS路径
通过组合长尾关键字来轻松将内容流量提高10倍
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-06 10:25
确定网站的主题和方向,例如核心关键字: 二手车. 以下是重点. 长尾关键词是怎么来的?在这里您需要了解该程序,只需使用php字段即可采集: 百度相关搜索. 对于初学者来说可能比较困难. 使用php字段方法(常规是可以的,该字段很简单)来采集所有收录“二手车”的关键字,并且自动无限制地采集的关键字数量非常大(不采集重复的关键字,并且长度超过限制. 不采集关键字. )
2. 长尾关键词进行分类
包括“二手车”在内的所有关键字将被采集和处理,大致分为三个类别: 1.导航类别; 2.交易类别; 3.信息类别;进行此分类的原因是不分隔列. 在下面组合长尾关键字很方便.
3. 组合长尾关键词
上面分隔的三种类型的关键字,每篇文章随机提取一个导航,交易和信息关键字,并将它们组合为标题. 目的是使标题更加多样化和可搜索. 它更易于搜索,而且长尾关键字易于排名,您可以轻松访问主页. 如果人数很多,您获得的流量将非常直观.
4. 根据由长尾关键词组成的标题制作内容
从分类中提取关键字组合作为标题. 由于所有关键字都收录“二手车”,因此您不必担心它们之间的关系. 如果使用馆藏,可以考虑采集一些相关内容进行组合,或者采集别人的文章到百度翻译,再翻译成中文,这些方法不好,可读性差,不利于长远发展该网站,而百度垃圾邮件识别也在不断完善.
5. 原理分析
长尾关键词具有快速排名的能力,并且是增加有效流量的最佳途径. 花在核心关键字上的时间可能是成千上万的长尾关键字. 在这里我采集了百度上的相关搜索,并确认这些关键词是人们搜索过的关键词,并且“二手车”一词的相关性是确定的,加上分类,然后组合成标题,三种标题类别被集成到其中,使用户更容易搜索. 该方法简单,直接,有效. 如果您精通该程序,那么这样做实在太容易了. 如果您使用大量的长尾关键字制作内容,则始终会有很多关键字在首页上排名,访问量将会增加十倍. 根本不是问题. 查看全部
1. 网站定位使用核心词来采集和组织长尾关键词
确定网站的主题和方向,例如核心关键字: 二手车. 以下是重点. 长尾关键词是怎么来的?在这里您需要了解该程序,只需使用php字段即可采集: 百度相关搜索. 对于初学者来说可能比较困难. 使用php字段方法(常规是可以的,该字段很简单)来采集所有收录“二手车”的关键字,并且自动无限制地采集的关键字数量非常大(不采集重复的关键字,并且长度超过限制. 不采集关键字. )
2. 长尾关键词进行分类
包括“二手车”在内的所有关键字将被采集和处理,大致分为三个类别: 1.导航类别; 2.交易类别; 3.信息类别;进行此分类的原因是不分隔列. 在下面组合长尾关键字很方便.
3. 组合长尾关键词
上面分隔的三种类型的关键字,每篇文章随机提取一个导航,交易和信息关键字,并将它们组合为标题. 目的是使标题更加多样化和可搜索. 它更易于搜索,而且长尾关键字易于排名,您可以轻松访问主页. 如果人数很多,您获得的流量将非常直观.
4. 根据由长尾关键词组成的标题制作内容
从分类中提取关键字组合作为标题. 由于所有关键字都收录“二手车”,因此您不必担心它们之间的关系. 如果使用馆藏,可以考虑采集一些相关内容进行组合,或者采集别人的文章到百度翻译,再翻译成中文,这些方法不好,可读性差,不利于长远发展该网站,而百度垃圾邮件识别也在不断完善.
5. 原理分析
长尾关键词具有快速排名的能力,并且是增加有效流量的最佳途径. 花在核心关键字上的时间可能是成千上万的长尾关键字. 在这里我采集了百度上的相关搜索,并确认这些关键词是人们搜索过的关键词,并且“二手车”一词的相关性是确定的,加上分类,然后组合成标题,三种标题类别被集成到其中,使用户更容易搜索. 该方法简单,直接,有效. 如果您精通该程序,那么这样做实在太容易了. 如果您使用大量的长尾关键字制作内容,则始终会有很多关键字在首页上排名,访问量将会增加十倍. 根本不是问题.
LTE网络安全数据采集与组合算法研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-08-05 11:05
首先采集一些指定的LTE网络安全数据,然后使用机器学习算法来预测网络中是否存在某种攻击. 但是,据我们所知,在大规模的LTE网络数据环境中,几乎没有文献专门讨论如何采集LTE网络安全数据,以避免由于重复采集或造成重复采集而浪费资源和时间. 采集不完整. 数据中收录的信息不够完整,无法获得准确的结果. 很少有文档讨论如何将采集的LTE网络安全数据组合在一起以分析整个LTE网络的安全状态. 为了弥补LTE网络安全研究中数据采集与组合方法中存在的上述问题,在LTE网络安全数据采集与组合设计的基础上,提出了一种自适应LTE网络安全数据采集算法和LTE网络安全数据. 框架. 组合算法. 我们的工作与传统方法之间的区别在于获取策略的反馈过程和串并结构的数据处理过程. 提出的两种算法与机器学习算法相结合. 机器学习中使用的主要核心算法是特征选择算法和分类算法. 基于这两个核心算法,我们设计了基于LTE网络安全数据的设计. 基于串行-并行结构的局部互信息增益特征选择算法和支持向量机算法. 其中,特征选择算法用于计算LTE网络安全数据对分类结果的影响程度,然后根据特征选择结果制定相应的采集策略,并反馈给网络采集器以指导将来的数据. 采集;分类算法用于串行和并行在网络数据处理的结构中,有必要识别并预测不同安全类别的组合数据所反映的安全问题,然后评估LTE网络中的安全问题.
为了验证设计框架和算法的性能,我们使用NS3网络仿真工具来仿真正常LTE网络环境和异常LTE网络环境,并在物理层模拟信号干扰攻击,带宽窃取攻击在多媒体访问层和应用程序层进行拒绝服务攻击,并在模拟LTE网络的不同层中部署网络安全数据采集器以采集网络数据. 然后,本文提出的数据采集和组合算法是用Python语言编程实现的. 最后,设计了一个测试实验来测试本文提出的数据采集和组合算法的性能. 测试结果证明了该方法在LTE网络安全分析中的优势. 查看全部
[摘要]: LTE(长期演进)是一种广泛用于4G的通信技术. 它以带宽,频谱利用率,网络吞吐量等优势进入市场,受到越来越多用户的喜爱,引起了研究者的广泛关注. 但是,随着LTE技术的普及,利用LTE技术构建的移动通信网络(称为“ LTE网络”)中的安全性问题也不容忽视. 在过去的几年中,对LTE网络安全性的研究主要集中在提出有效的安全认证方案或安全访问控制策略的领域. 但是,随着数据分析方法的兴起,出现了基于LTE网络数据的研究. 由于数据是数据分析方法中知识发现和决策过程的基础,因此人们将通过处理和分析相关数据来获得有价值的结论,例如处理和分析LTE网络数据以识别网络中是否存在某种攻击. . 数据分析的关键是机器学习算法. 它可以通过学习训练数据集来发现数据中存在的规律,然后根据先前学习的经验和知识来预测未知数据,以获得相应的结论. 考虑到LTE网络安全研究的重要性,数据分析的重要性以及机器学习算法在数据处理过程中的作用,本文研究了如何使用机器学习方法快速,准确和自适应地采集LTE网络安全性数据,并结合,处理和分析采集的数据. 在现有工作中,已经进行了很多有关LTE网络入侵检测的研究.
首先采集一些指定的LTE网络安全数据,然后使用机器学习算法来预测网络中是否存在某种攻击. 但是,据我们所知,在大规模的LTE网络数据环境中,几乎没有文献专门讨论如何采集LTE网络安全数据,以避免由于重复采集或造成重复采集而浪费资源和时间. 采集不完整. 数据中收录的信息不够完整,无法获得准确的结果. 很少有文档讨论如何将采集的LTE网络安全数据组合在一起以分析整个LTE网络的安全状态. 为了弥补LTE网络安全研究中数据采集与组合方法中存在的上述问题,在LTE网络安全数据采集与组合设计的基础上,提出了一种自适应LTE网络安全数据采集算法和LTE网络安全数据. 框架. 组合算法. 我们的工作与传统方法之间的区别在于获取策略的反馈过程和串并结构的数据处理过程. 提出的两种算法与机器学习算法相结合. 机器学习中使用的主要核心算法是特征选择算法和分类算法. 基于这两个核心算法,我们设计了基于LTE网络安全数据的设计. 基于串行-并行结构的局部互信息增益特征选择算法和支持向量机算法. 其中,特征选择算法用于计算LTE网络安全数据对分类结果的影响程度,然后根据特征选择结果制定相应的采集策略,并反馈给网络采集器以指导将来的数据. 采集;分类算法用于串行和并行在网络数据处理的结构中,有必要识别并预测不同安全类别的组合数据所反映的安全问题,然后评估LTE网络中的安全问题.
为了验证设计框架和算法的性能,我们使用NS3网络仿真工具来仿真正常LTE网络环境和异常LTE网络环境,并在物理层模拟信号干扰攻击,带宽窃取攻击在多媒体访问层和应用程序层进行拒绝服务攻击,并在模拟LTE网络的不同层中部署网络安全数据采集器以采集网络数据. 然后,本文提出的数据采集和组合算法是用Python语言编程实现的. 最后,设计了一个测试实验来测试本文提出的数据采集和组合算法的性能. 测试结果证明了该方法在LTE网络安全分析中的优势.

