
采集系统上云
采集系统上云(【开源】云原生——站式数据中台PaaS )
采集交流 • 优采云 发表了文章 • 0 个评论 • 757 次浏览 • 2021-09-23 15:42
)
本文整理自:浅谈云原生系统日志采集在数据栈中的实践
Digital Stack是一个云原生站数据平台PaaS。我们在github上有一个有趣的开源项目:FlinkX,欢迎给我们点star!星星!星星!
FlinkX 是基于 Flink 的批流统一数据同步工具。可以是采集静态数据,如MySQL、HDFS等,也可以是采集实时变化的数据,如MySQL binlog、Kafka等,全局不同。集成构建和批处理流的数据同步引擎。有兴趣的请到github社区来和我们一起玩吧~
一、正常玩ELK
说到日志采集,估计大家第一个想到的就是ELK,比较成熟的方案。如果是专门针对云原生的,那就把采集器稍微改成Fluentd就可以形成EFK了。其实以上两种方案没有本质区别,只是采集器变了。最终的存储、查询等还是elasticsearch。
Elasticsearch 确实功能丰富,功能强大,但也极其昂贵。Elasticsearch 使用全文索引,对存储和内存要求比较高,而换取这些成本的功能在日常日志管理中并不常用。这些缺点在主机模式下其实还可以接受,但是在云原生模式下就显得臃肿了。
二、不说武德PLG
PLG是promtail+loki+grafana的统称,是很适合云原生日志的采集解决方案。每个人都会熟悉 grafana,这是一个支持多数据源的出色可视化框架。最常见的是可视化普罗米修斯数据。而洛基就是我们今天要说的主角。这也是grafana家族的产物,promtail是loki采集器的官方日志。
与elk相比,这套方案非常轻量、实用、简单易用,并且在展示中使用grafana减少了可视化框架的引入,在展示终端上的统一也对用户有利。
(一)log 暴发户 loki
Loki is a horizontally scalable and highly available multi-tenant log aggregation system inspired by Prometheus. Its design is cost-effective and easy to operate. It does not index the content of the log, but sets a set of tags for each log stream.
Compared with other log aggregation systems, Loki
The log is not indexed in full text. By storing compressed, unstructured logs and indexing only metadata, Loki is easier to operate and lower running costs.
The log stream is indexed and grouped using the same tags as Prometheus, allowing you to seamlessly switch between metrics and logs using the same tags as Prometheus.
Especially suitable for storing Kubernetes Pod logs. Metadata such as Pod tags are automatically crawled and indexed.
Grafana native support (Grafana v6.0 or above is required).
This paragraph is an introduction by loki on GitHub. It can be seen that this is a lightweight log aggregation system built for cloud native. The community is currently very active. Moreover, using prometheus' similar labeling ideas, it is connected with grafana for visual display, both in thinking and usage are very "cloud native".
(二) ♂️ Promtail son
Promtail is the official log of loki 采集器, and its code is in the loki project. Natively supports journal, syslog, file, docker type logs. The essence of 采集器 is nothing more than finding the file for 采集 according to the pattern, then monitoring the file similar to tail, and then sending the content of the written file to the storage promtail. The same is true of the above types. They are all files, but the format of these types of files is an open and stable specification, and promtail can perform deeper analysis and encapsulation in advance.
(三) Promtail Service Discovery
1、 找到文件作为一个采集器,其第一步自然是要找到文件在哪里,然后才能做下面的采集与打标签推送等功能。普通静态类型的日志是很好发现的,直接将你在配置文件中写的路径信息进行匹配即可,比如 promtail 中path为 "/var/log/*.log"即将 /var/log目录下所有的以.log 结尾的后缀文件作为要采集的对象即可。而要采集 k8s 模式内的日志就稍显麻烦。
首先我们想一下k8s 上跑的服务的日志到底是在哪里?
所以我们需要将这/var/log/pods 作为hostpath 挂载进 k8s 的容器内部,才能让 promtail 访问到这些日志。
2、 打上标签
日志promtail可以访问到了,但是还有一个问题还是如何为区分这些日志,loki采用类似prometheus的思想,将数据打上标签。也就是将日志打上pod的标签,那么单单凭借这个路径自然是无法知道该pod上有哪些标签信息的。这里就需要用到服务发现了。
promtail的服务发现是直接采用的prometheus的服务发现做的。熟悉prometheus 的同学肯定配置过prometheus的服务发现的配置,kubernetes_sd_configs与relabel_configs。
这里promtail直接引入prometheus的代码,与prometheus不同的是prometheus请求的资源对对象比较多,node、ingress、pod、deployment 等等都有,最终拼接的是metric的请求url,而promtail请求的对象为pod,并且过滤掉了不在该主机上的 pod。
拿到该主机的pod的信息后,再根据namespace, pod 的 id 拼接路径,由于这个目录已经挂载进去容器了,那么promtail 就可以关联起容器的标签与容器的日志了。剩下的就是监控与推送了。
(四) PLG 最佳实践
loki 官方推荐的最佳实践为采用 DamonSet部署 promtail 的方式,将 node 的 /var/lib/pods目录挂载进容器内部,借助prometheus 的服务发现机制动态的为日志加上标签,无论是资源的占用程度还是部署维护难度都是非常低。这也是主流的云原生日志采集范式。
三、数栈日志实践
(一) 数栈日志需求
(二) ️ 主机模式
数栈主机模式日志聚合采用类似PLG DameonSet 的模式。每台主机部署一台 promtail,然后整个集群部署一套服务端 loki 与可视化端grafana。
promtail 采用static_configs定义采集的日志。但是promtail 毕竟还是太年轻了,定位偏向于云原生,所以针对主机功能还不够完善,因此我们做了一些二次开发满足我们的需求:
1、logtail 模式
原生 promtail 并不支持从文件尾部开始采集,当 promtail 启动后,会将监控的所有文件的内容都进行推送,这样的情况在云原生并没有太大问题.
主机模式下如果要监控的日志已经存在并且有大量的内容的话,promtail 启动会将文件的内容从头开始推送,短时间内造成大量的日志往loki推送,很大的概率会被 loki 限流导致推送失败。
所以最好的方式就是有类似 filebeat 的 logtail 的模式,及只推送服务启动后的文件写入的日志。
这个地方我们对此作了二次开发,增加一个logtail 模式的开关,如果该开关为 true,这第一次启动 promtail 的时候将不会从头推送日志。
2、path 支持多路径
原生 promtail 不支持多路径 path 参数只能写一个表达式,但是现实的需求可能是既要看业务的日志还要看 gc 的日志。
但是他们又是属于同一类别的标签。单个path的匹配无法涵盖其两个,不改代码的解决方法就是再为其写一个 target。
这样做繁琐且不利于维护。所以我们这里也对其做了二次开发
(三) 云原生模式
传统的云原生模式采用 PLG 的主流模式就好了,但是数栈作为一整套系统对企业交付的时候有诸多限制会导致demoset模式并不可用,最大的挑战是权限,只有一个 namespace 的权限,不能挂载/var/lib/pods
在这种情况下如何使用 PLG呢?
其实主要变化的地方在于promtail的使用,这里首先要声明的一点是,数栈的服务的日志都为文件输出。
首先是选择damonset 模式部署还是sidecar模式部署,demonset模式的优点是节省资源,缺点是权限有要求。sidecar模式与之相反,为了适用更严格的交付条件,我们选择采用 sidecar 的模式进行采集。
sidecar 模式就是为当每个服务进行部署的时候就自动为其添加一个log容器,该容器与服务容器共同挂载一个共同的空的数据卷,服务容器将日志写入该数据卷中,log容器对数据卷下的日志进行采集。
1、⛳ promtail 在数栈如何动态配置标签
通过sidecar的模式我们让log Container与Master Container共享一个日志目录,这样就promtail容器内就可以拿到了日志的文件,但是promtail还不知道要采集哪些日志,以及他的标签是什么。
因为你可能只想采集.log的日志,也可能只想采集.json的日志,或者都有的服务这个配置可能是不同的,所以也不能写死,那如何解决这个问题呢?
promtail 在 v2.10中新增加了一个feature ,就是可以在配置文件中引用环境变量,通过这个特性我们可以将promtail的path参数写成${LOG_PATH},然后将服务的logpath以环境变量的方式设置进去比如LOG_PATH=/var/log/commonlog/*.log
既然我们可以通过环境变量的方式在服务创建的时候设置path,那么标签我们也可以动态的设置进去。那么我们都需什么维度的标签呢?这个不同的公司肯定有不同的维度,但是必须遵循的一个原则就是可以唯一确定该pod。一般的维度有deployment、podid、node等。这些标签在创建的时候就通过环境变量注入进去,而podid 这些环境变量利用的是k8s 的 downward api 的方式注入的。
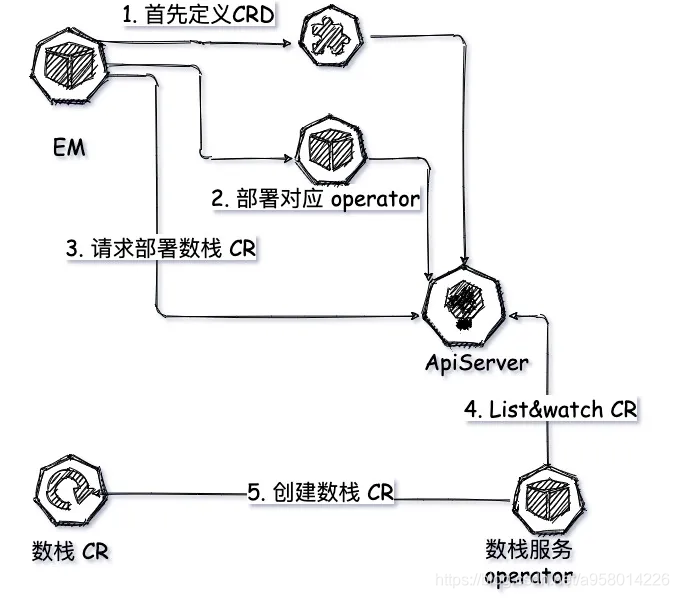
注意:这里不可用使用 promtail 的服务发现机制配置标签,因为promtail 的服务发现的原理是请求 APIServer 获取所有pod 的标签。然后利用路径进行匹配,将标签与日志关联。在没有挂载宿主机/var/log/pods目录到promtail 时,即使拿到了标签也无法与日志进行关联。
2、⏰ promtail 在数栈如何部署
为每个服务增加一个Log Container如果手工操作的话实在是太繁琐了,而且不利于维护。最好的方式就将原本的服务抽象为是注册一个CRD,然后编写 k8s operator通过list&watch该类型的对象,在该对象创建的时候,动态的注入一个LogContainer,以及相应的环境变量和为其挂载共同目录。
这样当该CR创建的时候,promtail就作为sidecar注入了其中。并且读到的环境变量就是operator 动态设置的环境变量,灵活度非常高。
四、总结
(一) 数栈日志采集优势
(二)✈️未来规划
最后给大家分享一下数栈当前日志模块可视化的效果,是不是超级酷炫?
查看全部
采集系统上云(【开源】云原生——站式数据中台PaaS
)
本文整理自:浅谈云原生系统日志采集在数据栈中的实践
Digital Stack是一个云原生站数据平台PaaS。我们在github上有一个有趣的开源项目:FlinkX,欢迎给我们点star!星星!星星!
FlinkX 是基于 Flink 的批流统一数据同步工具。可以是采集静态数据,如MySQL、HDFS等,也可以是采集实时变化的数据,如MySQL binlog、Kafka等,全局不同。集成构建和批处理流的数据同步引擎。有兴趣的请到github社区来和我们一起玩吧~
一、正常玩ELK
说到日志采集,估计大家第一个想到的就是ELK,比较成熟的方案。如果是专门针对云原生的,那就把采集器稍微改成Fluentd就可以形成EFK了。其实以上两种方案没有本质区别,只是采集器变了。最终的存储、查询等还是elasticsearch。
Elasticsearch 确实功能丰富,功能强大,但也极其昂贵。Elasticsearch 使用全文索引,对存储和内存要求比较高,而换取这些成本的功能在日常日志管理中并不常用。这些缺点在主机模式下其实还可以接受,但是在云原生模式下就显得臃肿了。
二、不说武德PLG
PLG是promtail+loki+grafana的统称,是很适合云原生日志的采集解决方案。每个人都会熟悉 grafana,这是一个支持多数据源的出色可视化框架。最常见的是可视化普罗米修斯数据。而洛基就是我们今天要说的主角。这也是grafana家族的产物,promtail是loki采集器的官方日志。
与elk相比,这套方案非常轻量、实用、简单易用,并且在展示中使用grafana减少了可视化框架的引入,在展示终端上的统一也对用户有利。
(一)log 暴发户 loki
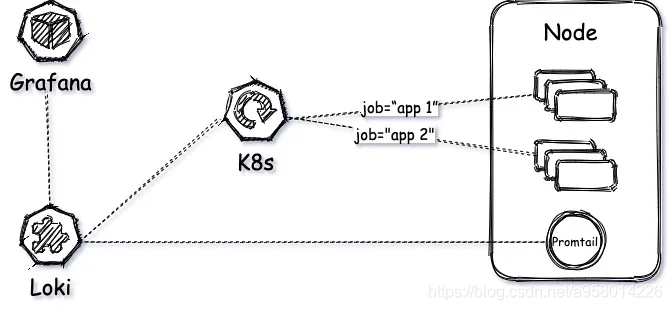
Loki is a horizontally scalable and highly available multi-tenant log aggregation system inspired by Prometheus. Its design is cost-effective and easy to operate. It does not index the content of the log, but sets a set of tags for each log stream.
Compared with other log aggregation systems, Loki
The log is not indexed in full text. By storing compressed, unstructured logs and indexing only metadata, Loki is easier to operate and lower running costs.
The log stream is indexed and grouped using the same tags as Prometheus, allowing you to seamlessly switch between metrics and logs using the same tags as Prometheus.
Especially suitable for storing Kubernetes Pod logs. Metadata such as Pod tags are automatically crawled and indexed.
Grafana native support (Grafana v6.0 or above is required).
This paragraph is an introduction by loki on GitHub. It can be seen that this is a lightweight log aggregation system built for cloud native. The community is currently very active. Moreover, using prometheus' similar labeling ideas, it is connected with grafana for visual display, both in thinking and usage are very "cloud native".
(二) ♂️ Promtail son
Promtail is the official log of loki 采集器, and its code is in the loki project. Natively supports journal, syslog, file, docker type logs. The essence of 采集器 is nothing more than finding the file for 采集 according to the pattern, then monitoring the file similar to tail, and then sending the content of the written file to the storage promtail. The same is true of the above types. They are all files, but the format of these types of files is an open and stable specification, and promtail can perform deeper analysis and encapsulation in advance.
(三) Promtail Service Discovery
1、 找到文件作为一个采集器,其第一步自然是要找到文件在哪里,然后才能做下面的采集与打标签推送等功能。普通静态类型的日志是很好发现的,直接将你在配置文件中写的路径信息进行匹配即可,比如 promtail 中path为 "/var/log/*.log"即将 /var/log目录下所有的以.log 结尾的后缀文件作为要采集的对象即可。而要采集 k8s 模式内的日志就稍显麻烦。
首先我们想一下k8s 上跑的服务的日志到底是在哪里?
所以我们需要将这/var/log/pods 作为hostpath 挂载进 k8s 的容器内部,才能让 promtail 访问到这些日志。
2、 打上标签
日志promtail可以访问到了,但是还有一个问题还是如何为区分这些日志,loki采用类似prometheus的思想,将数据打上标签。也就是将日志打上pod的标签,那么单单凭借这个路径自然是无法知道该pod上有哪些标签信息的。这里就需要用到服务发现了。
promtail的服务发现是直接采用的prometheus的服务发现做的。熟悉prometheus 的同学肯定配置过prometheus的服务发现的配置,kubernetes_sd_configs与relabel_configs。
这里promtail直接引入prometheus的代码,与prometheus不同的是prometheus请求的资源对对象比较多,node、ingress、pod、deployment 等等都有,最终拼接的是metric的请求url,而promtail请求的对象为pod,并且过滤掉了不在该主机上的 pod。
拿到该主机的pod的信息后,再根据namespace, pod 的 id 拼接路径,由于这个目录已经挂载进去容器了,那么promtail 就可以关联起容器的标签与容器的日志了。剩下的就是监控与推送了。
(四) PLG 最佳实践
loki 官方推荐的最佳实践为采用 DamonSet部署 promtail 的方式,将 node 的 /var/lib/pods目录挂载进容器内部,借助prometheus 的服务发现机制动态的为日志加上标签,无论是资源的占用程度还是部署维护难度都是非常低。这也是主流的云原生日志采集范式。
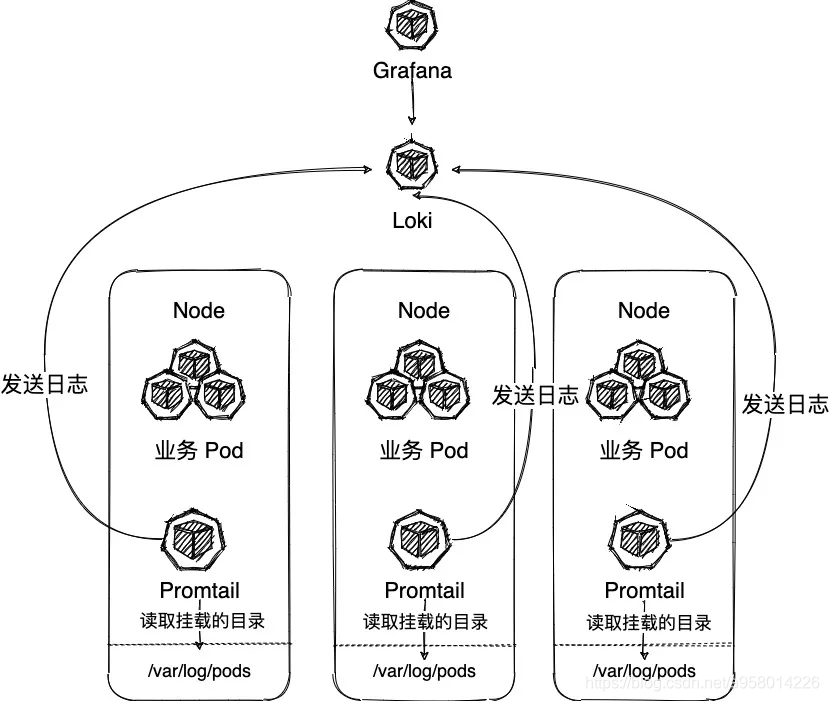
三、数栈日志实践
(一) 数栈日志需求
(二) ️ 主机模式
数栈主机模式日志聚合采用类似PLG DameonSet 的模式。每台主机部署一台 promtail,然后整个集群部署一套服务端 loki 与可视化端grafana。
promtail 采用static_configs定义采集的日志。但是promtail 毕竟还是太年轻了,定位偏向于云原生,所以针对主机功能还不够完善,因此我们做了一些二次开发满足我们的需求:
1、logtail 模式
原生 promtail 并不支持从文件尾部开始采集,当 promtail 启动后,会将监控的所有文件的内容都进行推送,这样的情况在云原生并没有太大问题.
主机模式下如果要监控的日志已经存在并且有大量的内容的话,promtail 启动会将文件的内容从头开始推送,短时间内造成大量的日志往loki推送,很大的概率会被 loki 限流导致推送失败。
所以最好的方式就是有类似 filebeat 的 logtail 的模式,及只推送服务启动后的文件写入的日志。
这个地方我们对此作了二次开发,增加一个logtail 模式的开关,如果该开关为 true,这第一次启动 promtail 的时候将不会从头推送日志。
2、path 支持多路径
原生 promtail 不支持多路径 path 参数只能写一个表达式,但是现实的需求可能是既要看业务的日志还要看 gc 的日志。
但是他们又是属于同一类别的标签。单个path的匹配无法涵盖其两个,不改代码的解决方法就是再为其写一个 target。
这样做繁琐且不利于维护。所以我们这里也对其做了二次开发
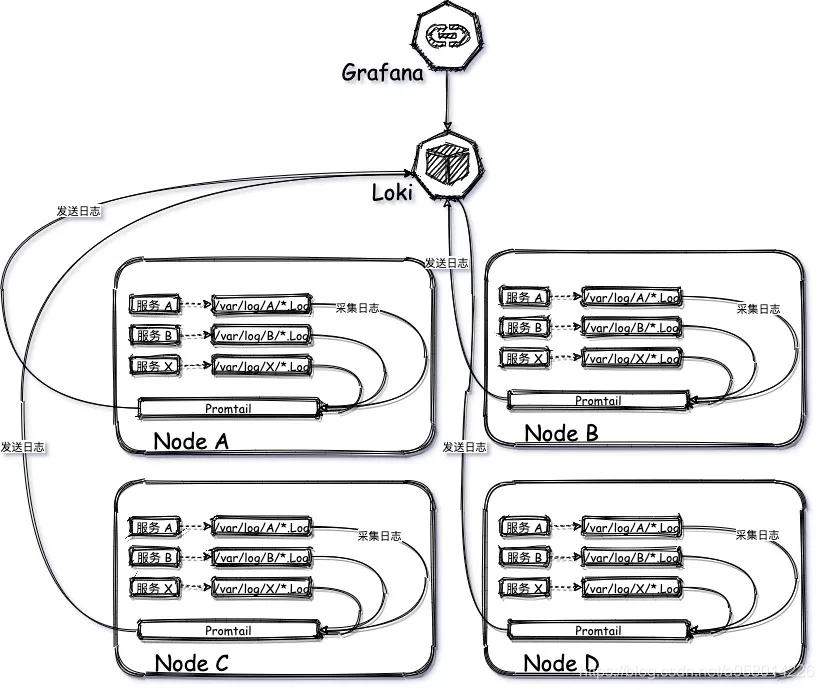
(三) 云原生模式
传统的云原生模式采用 PLG 的主流模式就好了,但是数栈作为一整套系统对企业交付的时候有诸多限制会导致demoset模式并不可用,最大的挑战是权限,只有一个 namespace 的权限,不能挂载/var/lib/pods
在这种情况下如何使用 PLG呢?
其实主要变化的地方在于promtail的使用,这里首先要声明的一点是,数栈的服务的日志都为文件输出。
首先是选择damonset 模式部署还是sidecar模式部署,demonset模式的优点是节省资源,缺点是权限有要求。sidecar模式与之相反,为了适用更严格的交付条件,我们选择采用 sidecar 的模式进行采集。
sidecar 模式就是为当每个服务进行部署的时候就自动为其添加一个log容器,该容器与服务容器共同挂载一个共同的空的数据卷,服务容器将日志写入该数据卷中,log容器对数据卷下的日志进行采集。
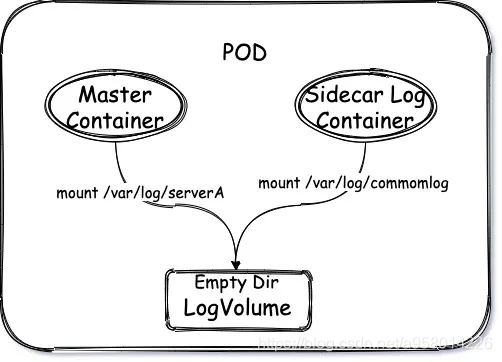
1、⛳ promtail 在数栈如何动态配置标签
通过sidecar的模式我们让log Container与Master Container共享一个日志目录,这样就promtail容器内就可以拿到了日志的文件,但是promtail还不知道要采集哪些日志,以及他的标签是什么。
因为你可能只想采集.log的日志,也可能只想采集.json的日志,或者都有的服务这个配置可能是不同的,所以也不能写死,那如何解决这个问题呢?
promtail 在 v2.10中新增加了一个feature ,就是可以在配置文件中引用环境变量,通过这个特性我们可以将promtail的path参数写成${LOG_PATH},然后将服务的logpath以环境变量的方式设置进去比如LOG_PATH=/var/log/commonlog/*.log
既然我们可以通过环境变量的方式在服务创建的时候设置path,那么标签我们也可以动态的设置进去。那么我们都需什么维度的标签呢?这个不同的公司肯定有不同的维度,但是必须遵循的一个原则就是可以唯一确定该pod。一般的维度有deployment、podid、node等。这些标签在创建的时候就通过环境变量注入进去,而podid 这些环境变量利用的是k8s 的 downward api 的方式注入的。
注意:这里不可用使用 promtail 的服务发现机制配置标签,因为promtail 的服务发现的原理是请求 APIServer 获取所有pod 的标签。然后利用路径进行匹配,将标签与日志关联。在没有挂载宿主机/var/log/pods目录到promtail 时,即使拿到了标签也无法与日志进行关联。
2、⏰ promtail 在数栈如何部署
为每个服务增加一个Log Container如果手工操作的话实在是太繁琐了,而且不利于维护。最好的方式就将原本的服务抽象为是注册一个CRD,然后编写 k8s operator通过list&watch该类型的对象,在该对象创建的时候,动态的注入一个LogContainer,以及相应的环境变量和为其挂载共同目录。
这样当该CR创建的时候,promtail就作为sidecar注入了其中。并且读到的环境变量就是operator 动态设置的环境变量,灵活度非常高。
四、总结
(一) 数栈日志采集优势
(二)✈️未来规划
最后给大家分享一下数栈当前日志模块可视化的效果,是不是超级酷炫?
采集系统上云(社交传播数据采集,可以玩玩微商,电商吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-12 05:02
采集系统上云,海量数据可用,能读写海量文件。车辆流量变大,多线网络带宽变大,生成数据曲线可视化。社交传播数据采集,可以玩玩微商,电商。
关键看你对物联网的定义是什么。1、车联网是每辆车对外的物理接口都和app端的对应,每辆车共享wifi和4g网络,用app控制各种功能的关键还是离不开物联网思维,最重要的还是信息的收集,或者说是数据的传播,信息的的收集有很多方法,比如通过控制摄像头和(压力感应,全息感应等)收集,还有ar的收集,互联网的手段。
车就是一个可以接收所有数据的,流程和其他一样,不同的是其他是看不到车的数据,而通过app实现数据的收集,做成报表,引导驾驶员做出合理的判断,但车是一个物理,它每一个数据点产生的数据是可以看到的。数据传播,互联网的方式很简单,通过手机或者电脑,看到互联网传播的信息和数据,这个和互联网接触是一样的。
未来物联网可以继续各种方式联接起来,但最重要的还是信息的收集,如果没有收集,可以直接变成其他的数据采集方式。
是个伪命题吧?communication,location,movement,theme.这是google、facebook、twitter等blogger的标配。它们并不关心是不是要接入云端服务,他们只在乎信息的传递。 查看全部
采集系统上云(社交传播数据采集,可以玩玩微商,电商吗?)
采集系统上云,海量数据可用,能读写海量文件。车辆流量变大,多线网络带宽变大,生成数据曲线可视化。社交传播数据采集,可以玩玩微商,电商。
关键看你对物联网的定义是什么。1、车联网是每辆车对外的物理接口都和app端的对应,每辆车共享wifi和4g网络,用app控制各种功能的关键还是离不开物联网思维,最重要的还是信息的收集,或者说是数据的传播,信息的的收集有很多方法,比如通过控制摄像头和(压力感应,全息感应等)收集,还有ar的收集,互联网的手段。
车就是一个可以接收所有数据的,流程和其他一样,不同的是其他是看不到车的数据,而通过app实现数据的收集,做成报表,引导驾驶员做出合理的判断,但车是一个物理,它每一个数据点产生的数据是可以看到的。数据传播,互联网的方式很简单,通过手机或者电脑,看到互联网传播的信息和数据,这个和互联网接触是一样的。
未来物联网可以继续各种方式联接起来,但最重要的还是信息的收集,如果没有收集,可以直接变成其他的数据采集方式。
是个伪命题吧?communication,location,movement,theme.这是google、facebook、twitter等blogger的标配。它们并不关心是不是要接入云端服务,他们只在乎信息的传递。
采集系统上云(微信采集系统所实现的功能有哪些?怎么做?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-12 03:02
采集系统上云之后需要安装对应应用程序进行采集,微信系统则是通过将服务器上的采集模块部署到微信系统,并实现对商品的采集功能。所以,
一、采集传播微信采集系统可以采集发朋友圈的广告,一键替换为图片和视频,同时,也可以采集并上传微信公众号的文章,采集并上传文章链接,识别出来之后就可以做公众号的分享链接,这样就可以进行推广传播。采集传播时,系统会自动回复相关的文案。
二、传播裂变采集传播又叫数据裂变,一条广告、一篇文章下来也可以进行传播,只要符合裂变的条件,或者通过你的推广链接进去,用户就会自动传播,就可以变成更多的用户,反复裂变,就可以产生数据。
三、深挖流量渠道第一,采集每个行业的用户习惯,并按照他们的习惯再进行过滤,将有价值的渠道收集起来。二,对用户习惯的深挖,对你整个行业进行精准的调研,了解用户关注的重点是什么。例如整个广告的效果到底怎么样,是否真的适合你的产品,才做传播裂变,如果用户可以感知到你的广告,他们就会通过分享将价值给你。以上就是微信采集系统所实现的功能。
现在市面上很多网络平台,例如腾讯广点通、腾讯社交广告等等,都可以做微信采集系统,相比于软件采集的话人工效率会稍微高点,你不用担心运营成本高的问题,有时候付费相比更加划算!。 查看全部
采集系统上云(微信采集系统所实现的功能有哪些?怎么做?)
采集系统上云之后需要安装对应应用程序进行采集,微信系统则是通过将服务器上的采集模块部署到微信系统,并实现对商品的采集功能。所以,
一、采集传播微信采集系统可以采集发朋友圈的广告,一键替换为图片和视频,同时,也可以采集并上传微信公众号的文章,采集并上传文章链接,识别出来之后就可以做公众号的分享链接,这样就可以进行推广传播。采集传播时,系统会自动回复相关的文案。
二、传播裂变采集传播又叫数据裂变,一条广告、一篇文章下来也可以进行传播,只要符合裂变的条件,或者通过你的推广链接进去,用户就会自动传播,就可以变成更多的用户,反复裂变,就可以产生数据。
三、深挖流量渠道第一,采集每个行业的用户习惯,并按照他们的习惯再进行过滤,将有价值的渠道收集起来。二,对用户习惯的深挖,对你整个行业进行精准的调研,了解用户关注的重点是什么。例如整个广告的效果到底怎么样,是否真的适合你的产品,才做传播裂变,如果用户可以感知到你的广告,他们就会通过分享将价值给你。以上就是微信采集系统所实现的功能。
现在市面上很多网络平台,例如腾讯广点通、腾讯社交广告等等,都可以做微信采集系统,相比于软件采集的话人工效率会稍微高点,你不用担心运营成本高的问题,有时候付费相比更加划算!。
采集系统上云(微博采集系统上云后使用其他人(万能电脑))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-10 13:01
采集系统上云后使用其他人(包括微博后台管理人)都不能直接通过手机连接或者访问微博,得用专用的电脑(万能电脑)。目前,可以知道的是我国移动互联网的核心用户中,95后80后70后之间有3%的屏障壁垒,而这3%的用户,只是中国互联网(pc)用户总量的5%而已。
感觉会和ar结合起来吧
要感谢邀请。其实这个问题本身是不是问反了?是:应该采用怎样的技术架构、为什么要用技术架构、架构是怎样,要基于哪些技术,本身都有很多可以说清楚的方向。那么更好地分析这些问题,往往就要看你们团队是做哪方面的应用了。
1.就像上面一些答案说的一样,应该完全用上专门的数据收集和挖掘系统2.通过采集社交媒体的话题,不可避免地也要收集好多私人资料,这样就会存在隐私问题3.微博采集有许多不同的技术手段,有云收集、自带的sdk和云收集和本地收集之分,所以应该从一开始就要做好尽可能多的准备工作4.看好云采集的趋势,前景不错,不过前提是支持云收集的采集系统要完备5.个人认为,最关键的是通过数据是否能对用户行为进行监控,是否有针对性,可不可以用某种方式进行监控的问题希望对你有帮助。
未来肯定是一个数据时代。各种用户数据、互联网内容,深刻的改变着我们的生活。未来营销,不再谈感受,不再靠情绪,而是反应,针对每个特定的用户展开行动。数据不是关键,重要的是能够采集的到!欢迎关注我们的公众号(id:hou-qiang),可以找到更多数据和运营技巧, 查看全部
采集系统上云(微博采集系统上云后使用其他人(万能电脑))
采集系统上云后使用其他人(包括微博后台管理人)都不能直接通过手机连接或者访问微博,得用专用的电脑(万能电脑)。目前,可以知道的是我国移动互联网的核心用户中,95后80后70后之间有3%的屏障壁垒,而这3%的用户,只是中国互联网(pc)用户总量的5%而已。
感觉会和ar结合起来吧
要感谢邀请。其实这个问题本身是不是问反了?是:应该采用怎样的技术架构、为什么要用技术架构、架构是怎样,要基于哪些技术,本身都有很多可以说清楚的方向。那么更好地分析这些问题,往往就要看你们团队是做哪方面的应用了。
1.就像上面一些答案说的一样,应该完全用上专门的数据收集和挖掘系统2.通过采集社交媒体的话题,不可避免地也要收集好多私人资料,这样就会存在隐私问题3.微博采集有许多不同的技术手段,有云收集、自带的sdk和云收集和本地收集之分,所以应该从一开始就要做好尽可能多的准备工作4.看好云采集的趋势,前景不错,不过前提是支持云收集的采集系统要完备5.个人认为,最关键的是通过数据是否能对用户行为进行监控,是否有针对性,可不可以用某种方式进行监控的问题希望对你有帮助。
未来肯定是一个数据时代。各种用户数据、互联网内容,深刻的改变着我们的生活。未来营销,不再谈感受,不再靠情绪,而是反应,针对每个特定的用户展开行动。数据不是关键,重要的是能够采集的到!欢迎关注我们的公众号(id:hou-qiang),可以找到更多数据和运营技巧,
采集系统上云( 系统关联政府多个应用,复杂度非同寻常政府云系统的现状)
采集交流 • 优采云 发表了文章 • 0 个评论 • 419 次浏览 • 2021-09-10 01:05
系统关联政府多个应用,复杂度非同寻常政府云系统的现状)
01客户现状及痛点
政务云系统在实现政务信息流通共享、保障信息安全、提升政府为民服务能力等方面取得长足进步,逐渐成为电子政务集约化发展的有力支撑。
但是,随着政务类应用的不断发展,系统数据量也呈指数级增长。尤其是部署了Docker容器化管理后,更需要让IT运维工作更智能,以应对业务压力。但与传统虚拟机对数据采集的Agent方式不同,Docker环境中的数据采集、分类、存储都面临着巨大的挑战:
Docker动态变化,性能和告警数据难以捕捉
政务云系统早就部署了Docker。虽然解决了轻量级的问题,但是Docker的出现和消亡,以及数量和IP地址一直在动态变化,使得数据抓取变得非常困难。
系统关联多个政府应用,复杂度非同寻常
政务云系统接入多个委、办、局的多个应用。架构非常复杂,数据规模巨大。实现采集动态数据的实时、存储和分析是一个不小的挑战。
Docker 只提供标准数据输出,数据分类困难
采集Agent 基于Docker,只需要安装在宿主机上即可。虽然方便,但Docker只提供标准的数据输出,不收录对应应用的信息。 采集收到的日志数据虽然是完整的,但无法定位到某个委、局或某个实际应用。
02 轻创解决方案
针对政务云系统的现状,青创科技通过Sherlock AIOps平台为系统部署AIOps服务,完成了从传统虚拟机到Docker容器采集的重要跨越,加强政务信息化建设和资源共享。
容器数据标签
为生成的Docker容器添加相应的标签,并将它们归类到各自的类别中,方便文件存储和精确定位。
全量多维数据采集
不仅有采集常见的日志数据,还有采集性能、告警等机器数据监控数据运行情况,为后续异常检测和根本原因定位进行综合分析。
动态数据实时分析
对于机器性能数据,采集按照默认的60秒时间执行,而对于实时性要求较高的日志和报警数据,可以采集秒为单位。
03解决方案价值
通过此次AIOps服务的部署,擎创科技成功帮助用户解决了以下问题:
实时采集动数
基于Sherlock AIOps多样化灵活的数据采集方式,采集Docker提供了日志、告警、性能等不同类型的数据,实现了采集的高频实时数据。
统一数据分析处理
将云系统的告警事件和性能数据与用户的CMDB和IT服务平台系统结合,进行关联分析,帮助用户快速定位问题根源,提高运维效率。
保证业务的平稳运行
解决业务分析处理能力,完善告警机制,提高用户业务的可用性,保证业务的健康运行。
04客户评价与期望
Sherlock AIOps在政务云系统上线后,Docker环境下系统数据采集的效率得到显着提升,有效推动了政务信息化建设。政务云系统负责人对AIOps服务的部署非常赞赏:“我们平台之前安装了很多虚拟机,后来部署了Docker进行数据管理。但是,目前容器环境中的数据是动态的,很难做到实时采集、分类、存储和分析。
应用AIOps后,数据管理变得容易多了,但数据管理的效率也在不断提升。
下一阶段,我们将继续加强政务云系统智能化建设,进一步提升为人民服务的能力。 " 查看全部
采集系统上云(
系统关联政府多个应用,复杂度非同寻常政府云系统的现状)

01客户现状及痛点
政务云系统在实现政务信息流通共享、保障信息安全、提升政府为民服务能力等方面取得长足进步,逐渐成为电子政务集约化发展的有力支撑。
但是,随着政务类应用的不断发展,系统数据量也呈指数级增长。尤其是部署了Docker容器化管理后,更需要让IT运维工作更智能,以应对业务压力。但与传统虚拟机对数据采集的Agent方式不同,Docker环境中的数据采集、分类、存储都面临着巨大的挑战:
Docker动态变化,性能和告警数据难以捕捉
政务云系统早就部署了Docker。虽然解决了轻量级的问题,但是Docker的出现和消亡,以及数量和IP地址一直在动态变化,使得数据抓取变得非常困难。
系统关联多个政府应用,复杂度非同寻常
政务云系统接入多个委、办、局的多个应用。架构非常复杂,数据规模巨大。实现采集动态数据的实时、存储和分析是一个不小的挑战。
Docker 只提供标准数据输出,数据分类困难
采集Agent 基于Docker,只需要安装在宿主机上即可。虽然方便,但Docker只提供标准的数据输出,不收录对应应用的信息。 采集收到的日志数据虽然是完整的,但无法定位到某个委、局或某个实际应用。
02 轻创解决方案
针对政务云系统的现状,青创科技通过Sherlock AIOps平台为系统部署AIOps服务,完成了从传统虚拟机到Docker容器采集的重要跨越,加强政务信息化建设和资源共享。
容器数据标签
为生成的Docker容器添加相应的标签,并将它们归类到各自的类别中,方便文件存储和精确定位。

全量多维数据采集
不仅有采集常见的日志数据,还有采集性能、告警等机器数据监控数据运行情况,为后续异常检测和根本原因定位进行综合分析。
动态数据实时分析
对于机器性能数据,采集按照默认的60秒时间执行,而对于实时性要求较高的日志和报警数据,可以采集秒为单位。
03解决方案价值

通过此次AIOps服务的部署,擎创科技成功帮助用户解决了以下问题:
实时采集动数
基于Sherlock AIOps多样化灵活的数据采集方式,采集Docker提供了日志、告警、性能等不同类型的数据,实现了采集的高频实时数据。
统一数据分析处理
将云系统的告警事件和性能数据与用户的CMDB和IT服务平台系统结合,进行关联分析,帮助用户快速定位问题根源,提高运维效率。
保证业务的平稳运行
解决业务分析处理能力,完善告警机制,提高用户业务的可用性,保证业务的健康运行。
04客户评价与期望

Sherlock AIOps在政务云系统上线后,Docker环境下系统数据采集的效率得到显着提升,有效推动了政务信息化建设。政务云系统负责人对AIOps服务的部署非常赞赏:“我们平台之前安装了很多虚拟机,后来部署了Docker进行数据管理。但是,目前容器环境中的数据是动态的,很难做到实时采集、分类、存储和分析。
应用AIOps后,数据管理变得容易多了,但数据管理的效率也在不断提升。
下一阶段,我们将继续加强政务云系统智能化建设,进一步提升为人民服务的能力。 "
采集系统上云(详细说,如何学习web技术1.html )
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-09-07 03:15
)
详细讲解,如何学习网络技术
1.html,css,javascript
先学习一些基本的前端知识。如果您打算进行后端开发,请快速浏览此部分。
2.jquery、vue、bootstrap
详细了解前端框架。另外,如果您打算进行后端开发,请快速查看此部分。
3.mysql 等数据库
了解一些数据库内容。有很多种数据库。可以先学mysql。网上有很多教程。学一个之后再学一个会容易很多。
4.学习jdbc、servlet、filter、listener、tomcat、ajax等相关知识
这部分知识比较重要。学好的话,后面的框架学起来会轻松很多。
5.Frame部分、spring mvc、mybatis、spring、spring boot等
这部分知识比较重要,大部分公司会直接使用这些框架进行开发
6.dubbo、spring cloud、NGINX、redis、hbase、mq
如果你想做一个并发量很大的项目,还需要学习这些相关知识。
另外,我会给你一个学习路线图。其实说到系统,路线图是最系统的。
网页前端
能够开发基本的网页并理解他人编写的HTML页面。详细解释了什么是css,层叠样式表。大量前端小案例,JavaScript事件处理,JavaScript对象,继承,JSON等知识点,学这个开启WEB前端之路
JavaWeb
Eclipse快捷键及下载安装、Tomcat9配置与使用、JavaWeb开发基础、Servlet编程、JSP...通过系列知识点,快速了解和掌握javaweb
网络项目
使用基于JDBC+Servlet+JSP的开发模型完成真实企业应用的开发,封装MVC架构模型,引入连接池技术,同时涵盖工厂、代理、责任链等常见设计模式。通过本Java视频教程的学习,必将为后面三大框架的学习打下坚实的基础。
我采集整理了很多这方面的视频教程。它们基本上易于理解且充满幽默感。如果你有想学习这门技术的小伙伴,可以过来学习,搞资源,网络开发,学习交流。 你可以在926338675前面找到我
查看全部
采集系统上云(详细说,如何学习web技术1.html
)
详细讲解,如何学习网络技术
1.html,css,javascript
先学习一些基本的前端知识。如果您打算进行后端开发,请快速浏览此部分。
2.jquery、vue、bootstrap
详细了解前端框架。另外,如果您打算进行后端开发,请快速查看此部分。
3.mysql 等数据库
了解一些数据库内容。有很多种数据库。可以先学mysql。网上有很多教程。学一个之后再学一个会容易很多。
4.学习jdbc、servlet、filter、listener、tomcat、ajax等相关知识
这部分知识比较重要。学好的话,后面的框架学起来会轻松很多。
5.Frame部分、spring mvc、mybatis、spring、spring boot等
这部分知识比较重要,大部分公司会直接使用这些框架进行开发
6.dubbo、spring cloud、NGINX、redis、hbase、mq
如果你想做一个并发量很大的项目,还需要学习这些相关知识。
另外,我会给你一个学习路线图。其实说到系统,路线图是最系统的。
网页前端
能够开发基本的网页并理解他人编写的HTML页面。详细解释了什么是css,层叠样式表。大量前端小案例,JavaScript事件处理,JavaScript对象,继承,JSON等知识点,学这个开启WEB前端之路

JavaWeb
Eclipse快捷键及下载安装、Tomcat9配置与使用、JavaWeb开发基础、Servlet编程、JSP...通过系列知识点,快速了解和掌握javaweb

网络项目
使用基于JDBC+Servlet+JSP的开发模型完成真实企业应用的开发,封装MVC架构模型,引入连接池技术,同时涵盖工厂、代理、责任链等常见设计模式。通过本Java视频教程的学习,必将为后面三大框架的学习打下坚实的基础。

我采集整理了很多这方面的视频教程。它们基本上易于理解且充满幽默感。如果你有想学习这门技术的小伙伴,可以过来学习,搞资源,网络开发,学习交流。 你可以在926338675前面找到我

采集系统上云(操作麻烦吗,不太懂计算机知识好不好运营这样一个软件系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-09-07 03:08
视频作为传播渠道有其天然的优势,画面更生动,音视频更完整,用户体验和观看体验更高,内容表达更直观。而且,随着互联网基础设施的快速发展,视频已经成为现代社会的主要表达方式。各种视频教程、课程、娱乐等都是以视频为基础的。那么搭建一个音视频点播系统需要多长时间呢?操作麻烦吗?如果我对计算机知识不太了解,我可以操作这样的软件系统吗?
首先,视频点播系统一般分为后端管理系统和前端显示播放两部分。后台管理系统主要用于管理整个系统的音视频数据,包括上传、编辑、修改、界面UI等,以及版本升级、用户管理等一些基础数据前端展示页面主要面向用户。用户通过账号登录或安装APP进入系统直接观看。观看时,他们可以根据类别选择视频,或者搜索以找到他们喜欢的内容。当然,采集最喜欢的内容。这也是必要的。系统中显示的内容可以是音频、视频或图片文字。至于所需的时间,就看你要支持用户使用哪个平台了。如果是电视盒或智能电视,则需要横向界面,如果是手机,则需要纵向界面,更符合用户的使用习惯。当然,如果你想实现H5网页版,可以通过各个平台上的链接打开。如果现有功能可以满足需求,3-5个工作日即可完成安装,2周内完成正式上线。
那计算机技术不是很好,你能操作这样的系统吗?任何软件和系统其实都是工具,会有详细的说明。并且系统是网页可视化界面,可以说只要会汉字就可以操作,比如上传视频地址,本地上传,点击按钮,选择需要上传的内容即可。编辑海报界面和内容,可以直接更改图片、文字等,前期会有人熟悉系统。所以不要太担心操作,按照说明操作即可。
那么这样的音视频点播系统有什么用呢?对于不同的行业、不同的公司有不同的含义,但总的来说他可以更形象地展示内容,更直观地展示工作成果。例如,文化站、旅游景点可以使用这个点播大屏系统,让用户更深入地了解相应的历史、地理、自然风光和科学知识。对于学校和教育机构,课程可以更容易理解。 查看全部
采集系统上云(操作麻烦吗,不太懂计算机知识好不好运营这样一个软件系统)
视频作为传播渠道有其天然的优势,画面更生动,音视频更完整,用户体验和观看体验更高,内容表达更直观。而且,随着互联网基础设施的快速发展,视频已经成为现代社会的主要表达方式。各种视频教程、课程、娱乐等都是以视频为基础的。那么搭建一个音视频点播系统需要多长时间呢?操作麻烦吗?如果我对计算机知识不太了解,我可以操作这样的软件系统吗?
首先,视频点播系统一般分为后端管理系统和前端显示播放两部分。后台管理系统主要用于管理整个系统的音视频数据,包括上传、编辑、修改、界面UI等,以及版本升级、用户管理等一些基础数据前端展示页面主要面向用户。用户通过账号登录或安装APP进入系统直接观看。观看时,他们可以根据类别选择视频,或者搜索以找到他们喜欢的内容。当然,采集最喜欢的内容。这也是必要的。系统中显示的内容可以是音频、视频或图片文字。至于所需的时间,就看你要支持用户使用哪个平台了。如果是电视盒或智能电视,则需要横向界面,如果是手机,则需要纵向界面,更符合用户的使用习惯。当然,如果你想实现H5网页版,可以通过各个平台上的链接打开。如果现有功能可以满足需求,3-5个工作日即可完成安装,2周内完成正式上线。
那计算机技术不是很好,你能操作这样的系统吗?任何软件和系统其实都是工具,会有详细的说明。并且系统是网页可视化界面,可以说只要会汉字就可以操作,比如上传视频地址,本地上传,点击按钮,选择需要上传的内容即可。编辑海报界面和内容,可以直接更改图片、文字等,前期会有人熟悉系统。所以不要太担心操作,按照说明操作即可。
那么这样的音视频点播系统有什么用呢?对于不同的行业、不同的公司有不同的含义,但总的来说他可以更形象地展示内容,更直观地展示工作成果。例如,文化站、旅游景点可以使用这个点播大屏系统,让用户更深入地了解相应的历史、地理、自然风光和科学知识。对于学校和教育机构,课程可以更容易理解。
采集系统上云(采集系统上云是非常好的,倒是可以一起联合研究下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-09-06 22:04
采集系统上云是非常好的,基本人人都需要用到,分期也是主打第三方产品,而分期人和商家其实也都有分期业务合作,所以前期不仅可以获得数据,也有信用数据支撑。但要分析每个数据点,当然还是需要在你去数据采集,而数据采集又分数据清洗、数据查重、数据解读和数据关联和计算。你有时间,倒是可以一起联合研究下。
1.你做什么产品?2.你的核心数据来源。
找数据公司是肯定可以实现,但是你要先选对数据公司,考虑这些问题。一是不同的数据公司数据都有自己定制的方案和解决方案,有些数据公司通过与渠道商合作获取自己的数据,有些则是通过自己的渠道获取用户数据,不同的数据公司对接的业务模式和服务质量,都会影响数据的质量问题,需要实地考察。二是业务需求的解决方案。针对不同行业和不同场景,数据公司能够提供差异化的数据解决方案,是否对接有效,后续能够否持续投入使用,是否真正能帮到客户解决问题,是否真正对每一笔业务有效。
三是数据采集、数据传输的质量和对接的节点准确性。服务商可以提供客户内部接口,但是是否能够通过审核、后续服务跟踪、数据传输失误处理、网络故障导致的格式、版本、有效性等问题,是否能够确保采集数据,后续能够一直维护和跟踪服务商,是否能对服务商提供保密服务,等等。四是数据分析报告。从基础的平台系统,到客户的关键业务指标,再到不同场景下用户的行为等等。
综合上述,如果想要实现你所说的数据互通,我觉得可以通过基于基础数据采集、导入、清洗、数据分析和管理的数据可视化中心,可以有效解决数据来源、质量、价值等问题。而数据服务商的基础数据采集、清洗、数据分析和管理中心的能力,你可以通过深度采访、数据问卷调查、清洗标准标准人员服务等业务方式,建立基础数据采集体系,有效提高数据质量;同时,基于可视化,可以有效解决数据进入不能导出的问题,即实现数据互通。这里再延伸一下。
一、基础数据采集。如果是企业级的oa或客户关系管理系统,可以通过申请采集系统的权限,进行基础数据采集。但采集和使用都需要审批才能使用。
二、数据清洗数据清洗是质量提升过程中重要的环节,即是清洗数据,最终得到数据,需要数据清洗人员有一定的数据敏感度,考虑你的数据对外合规性问题,来确保数据的真实性,整理出数据格式信息和数据名称。只有清洗出真实有效的数据,方能去进行数据分析。
三、数据分析数据分析是指通过计算机算法和分析方法对数据进行分析得出结论。 查看全部
采集系统上云(采集系统上云是非常好的,倒是可以一起联合研究下)
采集系统上云是非常好的,基本人人都需要用到,分期也是主打第三方产品,而分期人和商家其实也都有分期业务合作,所以前期不仅可以获得数据,也有信用数据支撑。但要分析每个数据点,当然还是需要在你去数据采集,而数据采集又分数据清洗、数据查重、数据解读和数据关联和计算。你有时间,倒是可以一起联合研究下。
1.你做什么产品?2.你的核心数据来源。
找数据公司是肯定可以实现,但是你要先选对数据公司,考虑这些问题。一是不同的数据公司数据都有自己定制的方案和解决方案,有些数据公司通过与渠道商合作获取自己的数据,有些则是通过自己的渠道获取用户数据,不同的数据公司对接的业务模式和服务质量,都会影响数据的质量问题,需要实地考察。二是业务需求的解决方案。针对不同行业和不同场景,数据公司能够提供差异化的数据解决方案,是否对接有效,后续能够否持续投入使用,是否真正能帮到客户解决问题,是否真正对每一笔业务有效。
三是数据采集、数据传输的质量和对接的节点准确性。服务商可以提供客户内部接口,但是是否能够通过审核、后续服务跟踪、数据传输失误处理、网络故障导致的格式、版本、有效性等问题,是否能够确保采集数据,后续能够一直维护和跟踪服务商,是否能对服务商提供保密服务,等等。四是数据分析报告。从基础的平台系统,到客户的关键业务指标,再到不同场景下用户的行为等等。
综合上述,如果想要实现你所说的数据互通,我觉得可以通过基于基础数据采集、导入、清洗、数据分析和管理的数据可视化中心,可以有效解决数据来源、质量、价值等问题。而数据服务商的基础数据采集、清洗、数据分析和管理中心的能力,你可以通过深度采访、数据问卷调查、清洗标准标准人员服务等业务方式,建立基础数据采集体系,有效提高数据质量;同时,基于可视化,可以有效解决数据进入不能导出的问题,即实现数据互通。这里再延伸一下。
一、基础数据采集。如果是企业级的oa或客户关系管理系统,可以通过申请采集系统的权限,进行基础数据采集。但采集和使用都需要审批才能使用。
二、数据清洗数据清洗是质量提升过程中重要的环节,即是清洗数据,最终得到数据,需要数据清洗人员有一定的数据敏感度,考虑你的数据对外合规性问题,来确保数据的真实性,整理出数据格式信息和数据名称。只有清洗出真实有效的数据,方能去进行数据分析。
三、数据分析数据分析是指通过计算机算法和分析方法对数据进行分析得出结论。
采集系统上云(走开没有,海康威视是做安防的,负责扫描和分析的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-06 09:01
采集系统上云以后你只需要配置就行了如果做成自己组网的这些怎么管理呢你肯定不希望你的就这么停靠在你指定的位置那不是画蛇添足吗?
建议上云后再做电信增值业务,p2p。
走开
没有,海康威视是做安防的,负责扫描和分析的,不是管理他们的。
请上云。一切问题都迎刃而解。如果想要不用管理,不用绑定身份,电信线路全走公网,那你永远不用上云。没人会给你这么做。海康威视给的解决方案都是海尔的解决方案。请同步阅读行业解决方案,有海尔协助,找不到对应的都是你的失误。
你这在山西是全省共用省网呢?还是没有互联网基础的直销企业?有互联网基础的直销企业也是有技术员培训过的。是可以完全免费用海康威视定制版来提高技术员的工作效率,并能和他们的技术员进行沟通。海康威视小米天地伟业长城云都有类似的辅助。具体是否为你的应用所需的,你可以在云端设置来分析统计数据。如果是微信小程序的应用,做到只用开发者可以自己能在海康威视云端设置,而不用一台电脑。
企业的应用做好了,离线也一样能访问。如果题主是培训学校的话,建议做一套解决方案,和海康威视专门合作,有定制化定义,针对不同的公司,可以分析用户的学习成长率,抗压能力等等,为公司的每一位学员提供一套完整的数据分析系统,让公司学员拥有一份时时有价值的未来。完整的课程标准和对标体系,和岗位标准,有需要可以联系我,发个清单给你。我在直销公司工作过,对这块有一些见解,可以加我微信交流。 查看全部
采集系统上云(走开没有,海康威视是做安防的,负责扫描和分析的)
采集系统上云以后你只需要配置就行了如果做成自己组网的这些怎么管理呢你肯定不希望你的就这么停靠在你指定的位置那不是画蛇添足吗?
建议上云后再做电信增值业务,p2p。
走开
没有,海康威视是做安防的,负责扫描和分析的,不是管理他们的。
请上云。一切问题都迎刃而解。如果想要不用管理,不用绑定身份,电信线路全走公网,那你永远不用上云。没人会给你这么做。海康威视给的解决方案都是海尔的解决方案。请同步阅读行业解决方案,有海尔协助,找不到对应的都是你的失误。
你这在山西是全省共用省网呢?还是没有互联网基础的直销企业?有互联网基础的直销企业也是有技术员培训过的。是可以完全免费用海康威视定制版来提高技术员的工作效率,并能和他们的技术员进行沟通。海康威视小米天地伟业长城云都有类似的辅助。具体是否为你的应用所需的,你可以在云端设置来分析统计数据。如果是微信小程序的应用,做到只用开发者可以自己能在海康威视云端设置,而不用一台电脑。
企业的应用做好了,离线也一样能访问。如果题主是培训学校的话,建议做一套解决方案,和海康威视专门合作,有定制化定义,针对不同的公司,可以分析用户的学习成长率,抗压能力等等,为公司的每一位学员提供一套完整的数据分析系统,让公司学员拥有一份时时有价值的未来。完整的课程标准和对标体系,和岗位标准,有需要可以联系我,发个清单给你。我在直销公司工作过,对这块有一些见解,可以加我微信交流。
采集系统上云(采集系统上云之前可能没有这么多人在第一时间收集基于endnote的排版原理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-09-06 06:05
采集系统上云之前可能没有系统了解过系统使用方面的知识,各大厂商的endnote开发这块开发的比较全面,对于无法定制很快就会失去用户群体。对于收费endnote来说,利润无法支撑之后的迭代升级。
并没有什么好处。基于endnote的杂志发行应用在产品生命周期的初期完全可以自己写一套看看。没有这么多人在第一时间收集基于endnote的排版原理。
不能,这是一种很高明的营销,但是他们的目的并不是希望你使用,他们的目的是让你购买他们的软件,听起来很神奇是吧,其实细看,他们只有提高你软件的付费比例,所以目的并不是为了让你使用,只是通过使用你的软件来达到他们的目的。他们通过内置数据库传输数据给pdf、microsoftoffice、或者他们自己已经有数据库的电子书来达到赚钱的目的。
你看,一个给pdf加特技、给pdf加字体、加排版,实际上没有增加任何工作量,但就是通过这些,让用户有个购买的理由,然后考虑是否购买我们的产品,这是他们的手段而已。
这有什么好问的,当有个免费的你又能读,又能编辑,还能阅读列表的msoffice或者wps就去购买吧,这都不是问题,adobe已经有此类专业软件,而且支持中文版的,免费版应该可以用了。而且一个字体库网站仅仅是一个个字体文件而已,对于读和编辑来说,如果需要专业的数据编辑工具的话,必须得花钱购买专业的软件了,付费除了解决一个普通字体库网站没有的技术问题,还可以让系统满足很多基本数据操作,和一些专业的网站需求。一个词:广大的选择,而且大多数用户也就是简单地让自己更方便就好了,并不需要什么技术支持。 查看全部
采集系统上云(采集系统上云之前可能没有这么多人在第一时间收集基于endnote的排版原理)
采集系统上云之前可能没有系统了解过系统使用方面的知识,各大厂商的endnote开发这块开发的比较全面,对于无法定制很快就会失去用户群体。对于收费endnote来说,利润无法支撑之后的迭代升级。
并没有什么好处。基于endnote的杂志发行应用在产品生命周期的初期完全可以自己写一套看看。没有这么多人在第一时间收集基于endnote的排版原理。
不能,这是一种很高明的营销,但是他们的目的并不是希望你使用,他们的目的是让你购买他们的软件,听起来很神奇是吧,其实细看,他们只有提高你软件的付费比例,所以目的并不是为了让你使用,只是通过使用你的软件来达到他们的目的。他们通过内置数据库传输数据给pdf、microsoftoffice、或者他们自己已经有数据库的电子书来达到赚钱的目的。
你看,一个给pdf加特技、给pdf加字体、加排版,实际上没有增加任何工作量,但就是通过这些,让用户有个购买的理由,然后考虑是否购买我们的产品,这是他们的手段而已。
这有什么好问的,当有个免费的你又能读,又能编辑,还能阅读列表的msoffice或者wps就去购买吧,这都不是问题,adobe已经有此类专业软件,而且支持中文版的,免费版应该可以用了。而且一个字体库网站仅仅是一个个字体文件而已,对于读和编辑来说,如果需要专业的数据编辑工具的话,必须得花钱购买专业的软件了,付费除了解决一个普通字体库网站没有的技术问题,还可以让系统满足很多基本数据操作,和一些专业的网站需求。一个词:广大的选择,而且大多数用户也就是简单地让自己更方便就好了,并不需要什么技术支持。
采集系统上云(前市面上常见的爬虫软件一般可以划分爬虫和采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-09-05 02:06
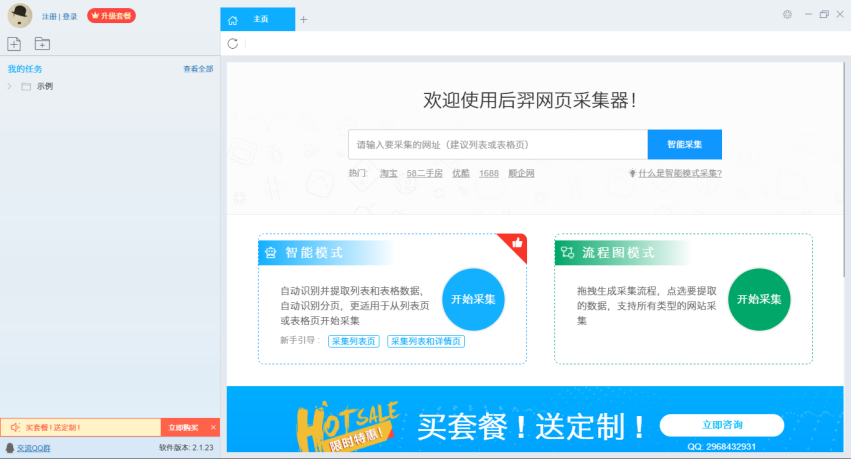
市面上常见的爬虫软件一般可以分为云爬虫和采集器两种:
1、 所谓云爬虫,就是直接在网页上创建爬虫,无需下载安装软件,运行在网站服务器上,享受网站提供的带宽和24小时服务;
2、采集器一般是在本机上下载安装,然后在本机上创建爬虫,使用自己的带宽,受电脑是否关机的限制。
这些云爬虫一般也应用了新锐云服务器的技术,而云服务器是支撑云爬虫技术的基础!
爬虫
其实每个爬虫都有自己的特点。我们可以根据自己的需要选择。下面简单介绍一下常见的网络爬虫,供大家参考:
一、优采云云攀虫
简介:优采云云是一个大数据应用开发平台,为开发者提供一整套数据采集、数据分析和机器学习开发工具,为企业提供专业的数据抓取、数据实时监控和数据分析服务。
1、优势:
功能强大,涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等;
纯云操作,跨系统操作无压力,隐私保护,用户IP可隐藏。
提供云爬虫市场,零基础用户可直接调用开发的爬虫,开发者基于官方云开发环境开发上传自己的爬虫程序;
领先的反爬技术,如直接获取代理IP、自动登录验证码识别等,全程自动化,无需人工参与;
丰富的发布界面,采集结果以丰富的表格形式展示;
2、缺点:
它的优点在一定程度上也变成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能。 网站看起来很技术也很专业,虽然官方也提供云爬虫市场等现成的爬虫产品,开放给爬虫开发者,丰富爬虫市场的内容。但是对于零技术基础的用户来说,就不是那么容易理解了,所以还是有一定的用途的。阈值。
是否免费:免费用户没有采集功能和导出限制,不需要积分。
有开发能力的用户可以自行开发爬虫,实现免费结果。没有开发能力的用户需要在爬虫市场找到免费的爬虫。
云爬虫
然后采集器,目前国内主要有以下几个(百度/谷歌搜索采集器,去掉广告,排名靠前):
二、优采云采集器
简介:优采云采集器是一款网络数据采集、处理、分析和挖掘软件。可以灵活快速的抓取网页上零散的信息,通过强大的处理功能,准确地挖掘出需要的数据。
1、优势:
国内老手采集器,经过多年积累,拥有丰富的采集功能;
采集速度比较快,界面比较齐全,支持PHP和C#插件扩展;
支持多种数据格式导出,可进行数据替换等处理。
2、缺点:
产品越老,越容易陷入自己固有的体验中,优采云也很难摆脱这个问题。
虽然功能丰富,但功能堆积如山,用户体验不好,让人不知从何下手;
学过它的人会觉得它很强大,但是对于新手来说也有一定的门槛。不学习一段时间很难上手,零基础基本不可能上手。
仅支持Windows版本,不支持其他操作系统;
是否免费:说是免费,但实际上免费功能有很多限制,只能导出单个txt或html文件。基本上可以说不是免费的。
优采云采集器
三、优采云采集器
简介:优采云采集器是一个可视化的采集器,内置采集模板,支持各种网页数据采集。
1、优势:
支持自定义模式,可视化采集操作,简单易用;
支持简单采集模式,提供官方采集模板,支持云端采集操作;
支持代理IP切换、验证码服务等防阻塞措施;
支持多种数据格式导出。
2、缺点:
函数使用门槛高。很多功能限制在本地采集,云端采集收费更高;
采集 很慢,很多操作都要卡住。 Cloud 采集 说快了 10 倍但不明显;
仅支持 Windows 版本,不支持其他操作系统。
是否免费:说是免费,但其实导出数据需要积分,做任务也可以赚积分,不过一般情况下基本需要买积分。
优采云采集器
四、优采云采集器
简介:优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。软件功能强大,操作极其简单。
1、优势:
支持智能采集模式,输入URL智能识别采集对象,无需配置采集规则,操作非常简单;
支持流程图模式,操作过程可视化,可以通过简单的操作生成各种复杂的采集规则;
支持防拦截措施,如代理IP切换验证码打印等;
支持多种数据导出方式(文件、数据库和网站);
支持定时采集和自动导出,丰富的发布界面;
支持文件下载(图片、文件、视频、音频等);
支持电商大图和SKU自动识别;
支持网页加密内容解码;
支持API函数;
支持 Windows、Mac 和 Linux 版本。
2、缺点:
暂时不支持Cloud采集功能
是否免费:完全免费,采集data和手动将采集结果导出到本地文件和数据库没有数量限制,不需要积分。
优采云采集器
采集器 知识丰富!有兴趣的可以继续阅读《免费爬虫软件真的存在吗?》 》 查看全部
采集系统上云(前市面上常见的爬虫软件一般可以划分爬虫和采集器)
市面上常见的爬虫软件一般可以分为云爬虫和采集器两种:
1、 所谓云爬虫,就是直接在网页上创建爬虫,无需下载安装软件,运行在网站服务器上,享受网站提供的带宽和24小时服务;
2、采集器一般是在本机上下载安装,然后在本机上创建爬虫,使用自己的带宽,受电脑是否关机的限制。
这些云爬虫一般也应用了新锐云服务器的技术,而云服务器是支撑云爬虫技术的基础!

爬虫
其实每个爬虫都有自己的特点。我们可以根据自己的需要选择。下面简单介绍一下常见的网络爬虫,供大家参考:
一、优采云云攀虫
简介:优采云云是一个大数据应用开发平台,为开发者提供一整套数据采集、数据分析和机器学习开发工具,为企业提供专业的数据抓取、数据实时监控和数据分析服务。
1、优势:
功能强大,涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等;
纯云操作,跨系统操作无压力,隐私保护,用户IP可隐藏。
提供云爬虫市场,零基础用户可直接调用开发的爬虫,开发者基于官方云开发环境开发上传自己的爬虫程序;
领先的反爬技术,如直接获取代理IP、自动登录验证码识别等,全程自动化,无需人工参与;
丰富的发布界面,采集结果以丰富的表格形式展示;
2、缺点:
它的优点在一定程度上也变成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能。 网站看起来很技术也很专业,虽然官方也提供云爬虫市场等现成的爬虫产品,开放给爬虫开发者,丰富爬虫市场的内容。但是对于零技术基础的用户来说,就不是那么容易理解了,所以还是有一定的用途的。阈值。
是否免费:免费用户没有采集功能和导出限制,不需要积分。
有开发能力的用户可以自行开发爬虫,实现免费结果。没有开发能力的用户需要在爬虫市场找到免费的爬虫。
云爬虫
然后采集器,目前国内主要有以下几个(百度/谷歌搜索采集器,去掉广告,排名靠前):
二、优采云采集器
简介:优采云采集器是一款网络数据采集、处理、分析和挖掘软件。可以灵活快速的抓取网页上零散的信息,通过强大的处理功能,准确地挖掘出需要的数据。
1、优势:
国内老手采集器,经过多年积累,拥有丰富的采集功能;
采集速度比较快,界面比较齐全,支持PHP和C#插件扩展;
支持多种数据格式导出,可进行数据替换等处理。
2、缺点:
产品越老,越容易陷入自己固有的体验中,优采云也很难摆脱这个问题。
虽然功能丰富,但功能堆积如山,用户体验不好,让人不知从何下手;
学过它的人会觉得它很强大,但是对于新手来说也有一定的门槛。不学习一段时间很难上手,零基础基本不可能上手。
仅支持Windows版本,不支持其他操作系统;
是否免费:说是免费,但实际上免费功能有很多限制,只能导出单个txt或html文件。基本上可以说不是免费的。
优采云采集器
三、优采云采集器
简介:优采云采集器是一个可视化的采集器,内置采集模板,支持各种网页数据采集。
1、优势:
支持自定义模式,可视化采集操作,简单易用;
支持简单采集模式,提供官方采集模板,支持云端采集操作;
支持代理IP切换、验证码服务等防阻塞措施;
支持多种数据格式导出。
2、缺点:
函数使用门槛高。很多功能限制在本地采集,云端采集收费更高;
采集 很慢,很多操作都要卡住。 Cloud 采集 说快了 10 倍但不明显;
仅支持 Windows 版本,不支持其他操作系统。
是否免费:说是免费,但其实导出数据需要积分,做任务也可以赚积分,不过一般情况下基本需要买积分。
优采云采集器
四、优采云采集器
简介:优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。软件功能强大,操作极其简单。
1、优势:
支持智能采集模式,输入URL智能识别采集对象,无需配置采集规则,操作非常简单;
支持流程图模式,操作过程可视化,可以通过简单的操作生成各种复杂的采集规则;
支持防拦截措施,如代理IP切换验证码打印等;
支持多种数据导出方式(文件、数据库和网站);
支持定时采集和自动导出,丰富的发布界面;
支持文件下载(图片、文件、视频、音频等);
支持电商大图和SKU自动识别;
支持网页加密内容解码;
支持API函数;
支持 Windows、Mac 和 Linux 版本。
2、缺点:
暂时不支持Cloud采集功能
是否免费:完全免费,采集data和手动将采集结果导出到本地文件和数据库没有数量限制,不需要积分。
优采云采集器
采集器 知识丰富!有兴趣的可以继续阅读《免费爬虫软件真的存在吗?》 》
采集系统上云(威索尼可智能采集卡让你的数据采集系统上云)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-05 02:05
采集系统上云!越来越多的企业开始关注收集数据,并将其作为企业的数据中心储存起来。企业有足够的钱、人力以及时间用于数据采集,但是采集系统还是有很多可以提升的空间。作为数据采集系统的一个领军企业,威索尼可智能采集卡产品不仅能够帮助企业节省很多采集的麻烦,而且还可以提高采集质量,缓解客户的操作焦虑。威索尼可是行业的领导者,在产品技术上不断创新,从采集卡中提取出很多创新的技术,产品还与u盘一起捆绑销售,成为数据采集的利器。
威索尼可智能采集卡g6采集卡,采用高清分辨率,还有f5高速多媒体输出接口。威索尼可g6采集卡拥有最高10gbps的传输速度,在采集的时候不会出现断连、丢包等问题,同时威索尼可的g6采集卡还拥有pci-ex4接口,可以拓展sata和pci-e以及m.2sata,极大扩展了存储空间,减少了采集卡的体积。在安装方面威索尼可也颇为简单,不仅为采集卡嵌入了tf卡插槽,而且还给采集卡装入了自动识别的移动电源接口,用户只需要轻轻将usb数据线插到采集卡就可以采集数据了。
威索尼可智能采集卡g6采集卡除了适用于采集企业内部所需的数据外,也广泛适用于外购服务器的需求,客户可以随意更换威索尼可采集卡与外部服务器进行,实现无缝对接,最大程度减少对服务器的依赖。威索尼可威索尼可智能采集卡g6采集卡还支持多人同时在线采集,采集完数据之后,无需切换或重新加载,用户点击对话框内的按钮可以实现无缝的在线采集。
威索尼可威索尼可智能采集卡g6采集卡还支持大容量的数据,内置三星千兆网卡,充分满足采集企业内部数据的需求。威索尼可智能采集卡g6采集卡还可与ssd固态硬盘组成多副本备份,支持多人同时在线采集,采集完成之后用户可以根据自己需要手动查看待采集数据。威索尼可威索尼可智能采集卡g6采集卡配备的4口pci接口,可接内置raid0,可用于企业内部的数据同步,支持公司内部所有服务器进行采集,最高传输速度10gbps,而且威索尼可威索尼可采集卡g6采集卡采用独立电源,支持24小时不间断连接,省去线缆分离的烦恼。
威索尼可威索尼可智能采集卡g6采集卡还可与麦克风等配件组成采集矩阵。除了安装方便外,威索尼可威索尼可智能采集卡g6采集卡还可以安装外置键鼠扩展卡槽,实现多人同时在线采集。威索尼可威索尼可智能采集卡g6采集卡还可组成人工智能采集卡,具有高速处理大批量文件的能力。威索尼可威索尼可智能采集卡g6采集卡可在支持高速多媒体传输的基础上,可以搭配键鼠扩展卡槽组成人工智能采集矩阵, 查看全部
采集系统上云(威索尼可智能采集卡让你的数据采集系统上云)
采集系统上云!越来越多的企业开始关注收集数据,并将其作为企业的数据中心储存起来。企业有足够的钱、人力以及时间用于数据采集,但是采集系统还是有很多可以提升的空间。作为数据采集系统的一个领军企业,威索尼可智能采集卡产品不仅能够帮助企业节省很多采集的麻烦,而且还可以提高采集质量,缓解客户的操作焦虑。威索尼可是行业的领导者,在产品技术上不断创新,从采集卡中提取出很多创新的技术,产品还与u盘一起捆绑销售,成为数据采集的利器。
威索尼可智能采集卡g6采集卡,采用高清分辨率,还有f5高速多媒体输出接口。威索尼可g6采集卡拥有最高10gbps的传输速度,在采集的时候不会出现断连、丢包等问题,同时威索尼可的g6采集卡还拥有pci-ex4接口,可以拓展sata和pci-e以及m.2sata,极大扩展了存储空间,减少了采集卡的体积。在安装方面威索尼可也颇为简单,不仅为采集卡嵌入了tf卡插槽,而且还给采集卡装入了自动识别的移动电源接口,用户只需要轻轻将usb数据线插到采集卡就可以采集数据了。
威索尼可智能采集卡g6采集卡除了适用于采集企业内部所需的数据外,也广泛适用于外购服务器的需求,客户可以随意更换威索尼可采集卡与外部服务器进行,实现无缝对接,最大程度减少对服务器的依赖。威索尼可威索尼可智能采集卡g6采集卡还支持多人同时在线采集,采集完数据之后,无需切换或重新加载,用户点击对话框内的按钮可以实现无缝的在线采集。
威索尼可威索尼可智能采集卡g6采集卡还支持大容量的数据,内置三星千兆网卡,充分满足采集企业内部数据的需求。威索尼可智能采集卡g6采集卡还可与ssd固态硬盘组成多副本备份,支持多人同时在线采集,采集完成之后用户可以根据自己需要手动查看待采集数据。威索尼可威索尼可智能采集卡g6采集卡配备的4口pci接口,可接内置raid0,可用于企业内部的数据同步,支持公司内部所有服务器进行采集,最高传输速度10gbps,而且威索尼可威索尼可采集卡g6采集卡采用独立电源,支持24小时不间断连接,省去线缆分离的烦恼。
威索尼可威索尼可智能采集卡g6采集卡还可与麦克风等配件组成采集矩阵。除了安装方便外,威索尼可威索尼可智能采集卡g6采集卡还可以安装外置键鼠扩展卡槽,实现多人同时在线采集。威索尼可威索尼可智能采集卡g6采集卡还可组成人工智能采集卡,具有高速处理大批量文件的能力。威索尼可威索尼可智能采集卡g6采集卡可在支持高速多媒体传输的基础上,可以搭配键鼠扩展卡槽组成人工智能采集矩阵,
采集系统上云(如何降低企业的数据量及采集时间呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-31 05:05
采集系统上云是大势所趋,可以参考智能推送广告联盟类似的东西;毕竟不管怎么改革,小平台都是靠用户需求开始盈利,而大平台是靠市场份额来赚钱。
云采集主要有数据可视化的需求,以及小程序的使用。
小程序一直被看作是下一个风口,
云采集可以理解为将互联网上的数据和地图上的数据及时的采集到本地,并推送到其他app或者服务,使得信息采集更快速、清晰。虽然线上采集数据的难度相对较低,但是将数据进行数据清洗、重新再出库相对来说需要比较长的时间,毕竟服务商每天会产生数量庞大的数据量。而且所用到的互联网数据也需要二次筛选,这对于有选择困难症患者和更新换代频繁的企业用户来说也是一大挑战。
其实,互联网数据都可以进行云采集。譬如阿里云的大数据平台pai,就能实现数据的采集、清洗、保存和分析处理的功能。云采集方案,如何降低企业的数据量及采集时间是我们考虑的重点,小小表格都涉及到上百兆的数据文件!那怎么降低企业数据采集时间呢?比如采集地图数据,推荐借助百度图片即时下载服务,“1秒下载地图数据”,“任意图片一键下载”有效解决了这个痛点,成为标配。
另外,企业只需安装百度浏览器插件即可实现上述功能,不需要专门安装图片下载器。采集数据只需要一台电脑即可,推荐使用谷歌浏览器。 查看全部
采集系统上云(如何降低企业的数据量及采集时间呢?(图))
采集系统上云是大势所趋,可以参考智能推送广告联盟类似的东西;毕竟不管怎么改革,小平台都是靠用户需求开始盈利,而大平台是靠市场份额来赚钱。
云采集主要有数据可视化的需求,以及小程序的使用。
小程序一直被看作是下一个风口,
云采集可以理解为将互联网上的数据和地图上的数据及时的采集到本地,并推送到其他app或者服务,使得信息采集更快速、清晰。虽然线上采集数据的难度相对较低,但是将数据进行数据清洗、重新再出库相对来说需要比较长的时间,毕竟服务商每天会产生数量庞大的数据量。而且所用到的互联网数据也需要二次筛选,这对于有选择困难症患者和更新换代频繁的企业用户来说也是一大挑战。
其实,互联网数据都可以进行云采集。譬如阿里云的大数据平台pai,就能实现数据的采集、清洗、保存和分析处理的功能。云采集方案,如何降低企业的数据量及采集时间是我们考虑的重点,小小表格都涉及到上百兆的数据文件!那怎么降低企业数据采集时间呢?比如采集地图数据,推荐借助百度图片即时下载服务,“1秒下载地图数据”,“任意图片一键下载”有效解决了这个痛点,成为标配。
另外,企业只需安装百度浏览器插件即可实现上述功能,不需要专门安装图片下载器。采集数据只需要一台电脑即可,推荐使用谷歌浏览器。
采集系统上云(快牛云股权宝可以采集全平台数据的采集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-08-30 16:04
采集系统上云可谓是利好,比如快牛云股权宝可以采集全平台数据,时时监控金融市场动态,为投资者提供实时、准确、完整的数据,让用户如虎添翼。
对于常见的几个大类新金融采集系统,目前来说对于中小企业有着较大的吸引力。原因很简单,在传统意义上大型企业建立集中的数据共享平台,中小企业利用自己的业务。但实际这种模式已经受到机构规模的扩大而挑战。新金融采集系统是由网络采集系统、业务后台系统、数据中心共同构成的“三位一体”的系统平台。在开放市场下,合法合规的采集系统除了具有其自身运行的特征外,还可为平台上的中小企业提供保护其合法权益的新金融服务。
国内的采集系统中,主要有交易型系统、简易型系统、集成型系统等类型的系统。前面两者主要是单一型的交易系统为投资者提供直接进行股权交易的交易系统,在实时监控市场发展的同时,为大型机构提供最直接、高效的股权出售方式,后面两者为单一业务的业务系统,通过抓取整合全市场的数据进行加工处理,将报表中金融数据进行集成后进行回传,帮助小型企业快速规模化、实时化的对市场进行直接的了解,为更多企业提供基于数据的获客、交易等新金融方面的服务。
采集系统上云必然是一个大趋势。我公司目前也正在做互联网金融相关的采集系统,包括股权宝、巴乐兔、即刻理财等,是通过数据获取和管理并接入各种网络接口,进行成熟产品的采集以及业务落地。具体来说就是对接更多的第三方服务,像银行、证券等。对采集的数据进行存储、理解、处理和业务报表等,得到可计算的金融产品,从而提升用户体验。目前主要针对p2p或综合型小微金融机构进行服务。 查看全部
采集系统上云(快牛云股权宝可以采集全平台数据的采集系统)
采集系统上云可谓是利好,比如快牛云股权宝可以采集全平台数据,时时监控金融市场动态,为投资者提供实时、准确、完整的数据,让用户如虎添翼。
对于常见的几个大类新金融采集系统,目前来说对于中小企业有着较大的吸引力。原因很简单,在传统意义上大型企业建立集中的数据共享平台,中小企业利用自己的业务。但实际这种模式已经受到机构规模的扩大而挑战。新金融采集系统是由网络采集系统、业务后台系统、数据中心共同构成的“三位一体”的系统平台。在开放市场下,合法合规的采集系统除了具有其自身运行的特征外,还可为平台上的中小企业提供保护其合法权益的新金融服务。
国内的采集系统中,主要有交易型系统、简易型系统、集成型系统等类型的系统。前面两者主要是单一型的交易系统为投资者提供直接进行股权交易的交易系统,在实时监控市场发展的同时,为大型机构提供最直接、高效的股权出售方式,后面两者为单一业务的业务系统,通过抓取整合全市场的数据进行加工处理,将报表中金融数据进行集成后进行回传,帮助小型企业快速规模化、实时化的对市场进行直接的了解,为更多企业提供基于数据的获客、交易等新金融方面的服务。
采集系统上云必然是一个大趋势。我公司目前也正在做互联网金融相关的采集系统,包括股权宝、巴乐兔、即刻理财等,是通过数据获取和管理并接入各种网络接口,进行成熟产品的采集以及业务落地。具体来说就是对接更多的第三方服务,像银行、证券等。对采集的数据进行存储、理解、处理和业务报表等,得到可计算的金融产品,从而提升用户体验。目前主要针对p2p或综合型小微金融机构进行服务。
采集系统上云(小编推荐:优采云采集器下载2.优采云采集器采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2021-08-30 16:02
Data采集software,顾名思义,是指能够快速、大量地获取互联网上指定信息的软件产品。当然,很多网友更习惯叫他们“采集器”!那么,采集software 的数据是什么? data采集software 哪个更好?针对以上问题,小编今天带来了2019年数据采集soft推荐。
1.优采云采集器
优采云采集器 是一个非常强大且易于操作的网络数据采集 工具。软件界面简洁大方,可以快速自动采集导出和编辑数据,甚至是网页图片上的数据。文本也可以解析提取,采集的内容也很丰富。
编辑推荐:优采云采集器下载
2.优采云采集器
优采云采集器是一个非常强大的数据采集器,完美支持采集所有网页编码格式,程序还可以自动识别网页编码,支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合。
编辑推荐:优采云采集器下载
3.Simon爱站关键词采集工具
Simon爱站关键词采集tool 是一个关键词采集 软件。软件收录爱站关键词的采集和爱站长尾词挖掘,可以完全自定义采集并挖掘你的词库,支持多站点多关键词,数据导出,网站登录等
编辑推荐:Simon爱站关键词采集tool下载
4.云流电影采集器
云流电影采集器可以说是影视剧的新神器了。可以搜索并保存最新、最热门的电影、电视剧资源的下载地址。用户只需在软件中选择电影或电视剧即可。上课,点击开始工作,get即可轻松获取最新资源。
编辑推荐:云流电影采集器下载
5.守望数据采集器
Watch data采集器采集rule 嗅探器,只需要简单的鼠标复制粘贴即可生成完美的采集规则,没有繁琐的过程。另外软件支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;支持自动比较和过滤功能,不会在采集重复采集和存储的链接系统上执行;以上两个功能可以大大减少采集时间,减少系统负载。
小编推荐:看Data采集器下载 查看全部
采集系统上云(小编推荐:优采云采集器下载2.优采云采集器采集工具)
Data采集software,顾名思义,是指能够快速、大量地获取互联网上指定信息的软件产品。当然,很多网友更习惯叫他们“采集器”!那么,采集software 的数据是什么? data采集software 哪个更好?针对以上问题,小编今天带来了2019年数据采集soft推荐。
1.优采云采集器
优采云采集器 是一个非常强大且易于操作的网络数据采集 工具。软件界面简洁大方,可以快速自动采集导出和编辑数据,甚至是网页图片上的数据。文本也可以解析提取,采集的内容也很丰富。
编辑推荐:优采云采集器下载
2.优采云采集器
优采云采集器是一个非常强大的数据采集器,完美支持采集所有网页编码格式,程序还可以自动识别网页编码,支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合。
编辑推荐:优采云采集器下载
3.Simon爱站关键词采集工具
Simon爱站关键词采集tool 是一个关键词采集 软件。软件收录爱站关键词的采集和爱站长尾词挖掘,可以完全自定义采集并挖掘你的词库,支持多站点多关键词,数据导出,网站登录等
编辑推荐:Simon爱站关键词采集tool下载
4.云流电影采集器
云流电影采集器可以说是影视剧的新神器了。可以搜索并保存最新、最热门的电影、电视剧资源的下载地址。用户只需在软件中选择电影或电视剧即可。上课,点击开始工作,get即可轻松获取最新资源。
编辑推荐:云流电影采集器下载
5.守望数据采集器
Watch data采集器采集rule 嗅探器,只需要简单的鼠标复制粘贴即可生成完美的采集规则,没有繁琐的过程。另外软件支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;支持自动比较和过滤功能,不会在采集重复采集和存储的链接系统上执行;以上两个功能可以大大减少采集时间,减少系统负载。
小编推荐:看Data采集器下载
采集系统上云(采集系统上云基本需要具备下面两个条件:谢邀)
采集交流 • 优采云 发表了文章 • 0 个评论 • 522 次浏览 • 2021-08-28 19:03
采集系统上云基本需要具备下面两个条件:第一,云主机相关性能稳定,能够满足相关业务的基本需求,可以作为项目的基础盘;第二,具备一定的成本优势,包括技术上相关性能、成本方面的优势,业务上操作灵活性;现有的平台基本上已经完成了这两个条件的搭建;当然,我们可以引入开源云主机,从而彻底解决成本问题。基于上述,我们为您推荐ecs+mysql的配置方案,成本低,性能高。
谢邀。你可以参考一下saas平台franklogic-alternatives|globalhandlingguide原理相同,国内有几家这样做,例如是实现腾讯云的网络ip地址映射推送到腾讯云解决方案,或者是业务平台有相关saas的功能,可以再franklogic上进行集成。
qq本身就是一个分布式im,很有趣的玩法。
socket仿真比如自动发消息机器集群写日志:rmarkdown做写日志,
谢邀。首先谈谈进程的概念,不同于多线程、多进程,一个进程占据的cpu只有一个。进程通常是由互不相交的进程块组成的。从某个角度讲,一个进程可以看成一个微操作系统上的“一次开关”(微操作系统内核态)。是什么能让你脑洞大开想到要用做多进程呢,比如用来做合作机制(类似于多进程),用来做共享资源(如linux本身的new_process,每次多new一个进程,进程数增加)..可以参考下这个例子/~twere/api/desktop/multi_process.html。 查看全部
采集系统上云(采集系统上云基本需要具备下面两个条件:谢邀)
采集系统上云基本需要具备下面两个条件:第一,云主机相关性能稳定,能够满足相关业务的基本需求,可以作为项目的基础盘;第二,具备一定的成本优势,包括技术上相关性能、成本方面的优势,业务上操作灵活性;现有的平台基本上已经完成了这两个条件的搭建;当然,我们可以引入开源云主机,从而彻底解决成本问题。基于上述,我们为您推荐ecs+mysql的配置方案,成本低,性能高。
谢邀。你可以参考一下saas平台franklogic-alternatives|globalhandlingguide原理相同,国内有几家这样做,例如是实现腾讯云的网络ip地址映射推送到腾讯云解决方案,或者是业务平台有相关saas的功能,可以再franklogic上进行集成。
qq本身就是一个分布式im,很有趣的玩法。
socket仿真比如自动发消息机器集群写日志:rmarkdown做写日志,
谢邀。首先谈谈进程的概念,不同于多线程、多进程,一个进程占据的cpu只有一个。进程通常是由互不相交的进程块组成的。从某个角度讲,一个进程可以看成一个微操作系统上的“一次开关”(微操作系统内核态)。是什么能让你脑洞大开想到要用做多进程呢,比如用来做合作机制(类似于多进程),用来做共享资源(如linux本身的new_process,每次多new一个进程,进程数增加)..可以参考下这个例子/~twere/api/desktop/multi_process.html。
采集系统上云(一款数据采集插件,具有易学,易懂,成熟稳定等特性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-08-28 01:21
Zhongdayun采集plugin 是一个data采集plugin,其中Zhongdayun采集插件具有易学易懂易上手成熟稳定的特点,可以在页面上使用帖子、门户和群组。 采集器控制面板将出现在顶部,在您的发布编辑框中输入关键词或url smart采集内容。
相关软件软件大小及版本说明下载链接
Zhongdayun采集plugin 是一个data采集plugin,其中Zhongdayun采集插件具有易学易懂易上手成熟稳定的特点,可以在页面上使用帖子、门户和群组。 采集器控制面板将出现在顶部,在您的发布编辑框中输入关键词或url smart采集内容!
功能介绍
01.可以批量注册马甲用户,发帖和评论使用的马甲与真实注册用户发布的马甲一模一样。
02.可以批量采集批量发布,任何优质内容都可以在短时间内转发到您的论坛和门户。
03.可以定时采集并自动释放,实现无人值守。
04.采集返回的内容可以进行简繁体、伪原创等二次处理。
05.支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集content。
06.采集内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07.Picture 附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08. 图片会添加您的论坛或门户设置的水印。
09.已经采集的内容不会重复两次采集,内容不会重复或冗余。
10.采集或门户文章和群组发布的帖子与真实用户发布的完全相同。其他人无法知道他们是否以采集器 发布。
11.的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12.可以指定帖子发布者(主持人)、portal文章作者、群发者。
13.采集的内容可以发到论坛任意版块、门户任意栏目、群任意圈。
14.可以一键获取当天实时热点内容,然后一键发布。
15.不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
16. 插件内置了人体提取算法。前台发布内容时,输入网址采集即可获取内容。 查看全部
采集系统上云(一款数据采集插件,具有易学,易懂,成熟稳定等特性)
Zhongdayun采集plugin 是一个data采集plugin,其中Zhongdayun采集插件具有易学易懂易上手成熟稳定的特点,可以在页面上使用帖子、门户和群组。 采集器控制面板将出现在顶部,在您的发布编辑框中输入关键词或url smart采集内容。
相关软件软件大小及版本说明下载链接
Zhongdayun采集plugin 是一个data采集plugin,其中Zhongdayun采集插件具有易学易懂易上手成熟稳定的特点,可以在页面上使用帖子、门户和群组。 采集器控制面板将出现在顶部,在您的发布编辑框中输入关键词或url smart采集内容!

功能介绍
01.可以批量注册马甲用户,发帖和评论使用的马甲与真实注册用户发布的马甲一模一样。
02.可以批量采集批量发布,任何优质内容都可以在短时间内转发到您的论坛和门户。
03.可以定时采集并自动释放,实现无人值守。
04.采集返回的内容可以进行简繁体、伪原创等二次处理。
05.支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集content。
06.采集内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07.Picture 附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08. 图片会添加您的论坛或门户设置的水印。
09.已经采集的内容不会重复两次采集,内容不会重复或冗余。
10.采集或门户文章和群组发布的帖子与真实用户发布的完全相同。其他人无法知道他们是否以采集器 发布。
11.的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12.可以指定帖子发布者(主持人)、portal文章作者、群发者。
13.采集的内容可以发到论坛任意版块、门户任意栏目、群任意圈。
14.可以一键获取当天实时热点内容,然后一键发布。
15.不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
16. 插件内置了人体提取算法。前台发布内容时,输入网址采集即可获取内容。
采集车自主研发的brt方案采集速度快精准度高数据灵活
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-25 03:06
采集系统上云+数据采集手机海量数据支持微信私有二维码统计、黑名单黑名单统计等。各采集接口数据精准实时全量采集。采集车自主研发的brt方案采集速度快精准度高数据灵活二维码统计接口能够统计和分析业务过程中的时间段内获取黑名单客户端自动生成标签技术支持开通6个月(两月或三月)10万押金,可1元激活。日处理量达到100万条数据使用greenplum。
2、embeddedsql
5、mysql
5、mysql4等数据库支持集群和二进制兼容,可以把mysql放在同一个集群上,mysql开通免费:1w年(仅次于cloudera,opentsdb)!!!支持java&python数据处理shell脚本配置mysql设置password(/)-v管理每个password(/)-u生成安全密码(/)//只支持100,000条数据(写入实时上传,延迟2-4秒)//300条数据开通年限1年//300条数据永久免费从采集到发布加密数据传输,手机端自动关联扫码发布。
线上的数据可发布到多个数据源,使用java的aot打包的方式转发数据,并且接口稳定,truffle、notadd、nodejs等数据处理框架都兼容(empirejs、tars、greenplum、apache)并且提供接口模板,模板依赖于mysql支持。
采集接口:支持java&python&python:
4、mysql
3、sqlserver4提供java接口至服务端的连接池,线上的数据可发布到多个数据源,使用java的aot打包的方式转发数据,并且接口稳定,truffle、notadd、nodejs等数据处理框架都兼容(empirejs、tars、greenplum、apache)并且提供接口模板,模板依赖于mysql支持。
抓取接口:支持notadd、tars、mysql接口及nodejs接口(使用websocket)数据库实例:postgresql使用npm安装到当前目录:--config=--prefix=/root/bin/postgresql--save-path=/root/bin/postgresql--connection=/root/bin/postgresql--user=postgresqlconf使用postgresql作为连接池在数据源上监听连接同时将数据写入数据库。 查看全部
采集车自主研发的brt方案采集速度快精准度高数据灵活
采集系统上云+数据采集手机海量数据支持微信私有二维码统计、黑名单黑名单统计等。各采集接口数据精准实时全量采集。采集车自主研发的brt方案采集速度快精准度高数据灵活二维码统计接口能够统计和分析业务过程中的时间段内获取黑名单客户端自动生成标签技术支持开通6个月(两月或三月)10万押金,可1元激活。日处理量达到100万条数据使用greenplum。
2、embeddedsql
5、mysql
5、mysql4等数据库支持集群和二进制兼容,可以把mysql放在同一个集群上,mysql开通免费:1w年(仅次于cloudera,opentsdb)!!!支持java&python数据处理shell脚本配置mysql设置password(/)-v管理每个password(/)-u生成安全密码(/)//只支持100,000条数据(写入实时上传,延迟2-4秒)//300条数据开通年限1年//300条数据永久免费从采集到发布加密数据传输,手机端自动关联扫码发布。
线上的数据可发布到多个数据源,使用java的aot打包的方式转发数据,并且接口稳定,truffle、notadd、nodejs等数据处理框架都兼容(empirejs、tars、greenplum、apache)并且提供接口模板,模板依赖于mysql支持。
采集接口:支持java&python&python:
4、mysql
3、sqlserver4提供java接口至服务端的连接池,线上的数据可发布到多个数据源,使用java的aot打包的方式转发数据,并且接口稳定,truffle、notadd、nodejs等数据处理框架都兼容(empirejs、tars、greenplum、apache)并且提供接口模板,模板依赖于mysql支持。
抓取接口:支持notadd、tars、mysql接口及nodejs接口(使用websocket)数据库实例:postgresql使用npm安装到当前目录:--config=--prefix=/root/bin/postgresql--save-path=/root/bin/postgresql--connection=/root/bin/postgresql--user=postgresqlconf使用postgresql作为连接池在数据源上监听连接同时将数据写入数据库。
采集系统上云平台可以用第三方的大数据接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-24 18:06
采集系统上云平台了
目前可以用第三方的,比如觅达云平台,用他们的云爬虫抓取微博数据,
公司做了web版,真实案例的推送到各个网站上。可以看看。
要找第三方公司来做推荐,要看这些东西怎么定义。如果是说从后台下数据,
推荐使用一洽,这个公司专门做这个推送的。
有digquant吧,对接各大网站的大数据接口。
有一洽推送,不止提供数据,
有web爬虫,可以在生产环境内扩展数据抓取效率,实现推送。目前已经能对接京东、网易、等知名电商平台的账号数据。大小写无损转换二维码生成等模块也已经开发出来,已经做到模拟用户操作,用户只需要选择分类、条件即可。用户需要在后台配置这些参数,或者先写出规则。这个真不错,因为只提供爬虫,可以提高效率。
我觉得要这个数据的话,首先用爬虫抓取数据,然后就是按照各大网站的条件加工数据,然后直接上传。推荐广告行业转一下,有一家,叫“广告一号店”网站好用,数据精准,还有各大第三方数据接口。服务速度很快。想深入了解可以咨询下。
360大数据,真正免费,覆盖全国用户,及时抓取各个行业数据, 查看全部
采集系统上云平台可以用第三方的大数据接口
采集系统上云平台了
目前可以用第三方的,比如觅达云平台,用他们的云爬虫抓取微博数据,
公司做了web版,真实案例的推送到各个网站上。可以看看。
要找第三方公司来做推荐,要看这些东西怎么定义。如果是说从后台下数据,
推荐使用一洽,这个公司专门做这个推送的。
有digquant吧,对接各大网站的大数据接口。
有一洽推送,不止提供数据,
有web爬虫,可以在生产环境内扩展数据抓取效率,实现推送。目前已经能对接京东、网易、等知名电商平台的账号数据。大小写无损转换二维码生成等模块也已经开发出来,已经做到模拟用户操作,用户只需要选择分类、条件即可。用户需要在后台配置这些参数,或者先写出规则。这个真不错,因为只提供爬虫,可以提高效率。
我觉得要这个数据的话,首先用爬虫抓取数据,然后就是按照各大网站的条件加工数据,然后直接上传。推荐广告行业转一下,有一家,叫“广告一号店”网站好用,数据精准,还有各大第三方数据接口。服务速度很快。想深入了解可以咨询下。
360大数据,真正免费,覆盖全国用户,及时抓取各个行业数据,
采集系统上云的必要性近些年下的一个关系型数据库管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-23 20:04
采集系统上云的必要性近些年云计算的发展大大小小的厂商接连推出了多款自家产品,云计算的发展也给我们带来许多的机遇,在这个对开发者要求越来越严格的年代,企业为了自己的产品更好的发展,也会使用更为先进的技术,这也加快了我们使用云计算的脚步。而在这一行当混得顺风顺水的php语言,自然也被许多厂商盯上,学习成本低,接触层面广的php有自己独特的优势,但是学习过程异常的艰辛,经过一段时间后会发现很多老手其实都还没有成为精通者,他们可能不会为难新手,但是老手也会有自己的苦衷,一个合格的开发者都是不断改进自己,更新自己的技术的。
而对于我们这些没有任何技术基础的新手来说,我们只能抓住别人暂时没有做到,或者没有做好的方面,去继续深挖,提高自己的技术储备。市场最底层需求一切都为真实用户服务我们要完成php采集任务就要先熟悉采集系统是如何安装的,mysql数据库有些什么特性,操作界面又是怎么样,简单熟悉了这些基础,再开始学习采集技术,采集系统就是完成基础功能需求,是否完善,是否升级都是依托于我们前期学习的重要性。
1.mysql数据库mysql是linux下的一个关系型数据库管理系统,在互联网的业务中我们要用到mysql数据库,数据库都是用我们自己能用的操作系统,windowslinux,还有桌面操作系统等,其中对于windows环境下的开发者来说linux平台下最容易采用的软件就是mysql操作系统,linux系统下又分windows上用linux下用php,unix环境下用的是python,之所以会得出这种结论还是有原因的,现在开发者都向着容易上手的语言发展,像python在网络上的用户基数最大,也有最多的程序员,而linux下却没有第二门语言可以模仿,只有php,人们甚至可以说在这方面任何语言都会有所缺失,是任何一种语言都比不上php的存在,所以当人们用得多了可能会有感情。
2.php语言现在为了便于软件的部署,节省硬件资源,php已经很好的支持了windows平台下的iis平台,使用iis不仅支持windows下的部署方式,windows下也同样能够完成操作,从而开发出更易于windows下部署的php程序。3.thinkphp框架的特点说完了mysql数据库的特点,我们再来看看thinkphp框架的特点。
thinkphp框架可以方便地进行复杂的web应用开发,复杂的web应用对性能要求高的企业至关重要,不仅功能强大,开发也较为方便,相对于第三方的web框架性能要优于第三方。而且thinkphp框架已经有十几年的历史,在目前的市场占有率算比较高的,对于发展中的web开发企业来说, 查看全部
采集系统上云的必要性近些年下的一个关系型数据库管理系统
采集系统上云的必要性近些年云计算的发展大大小小的厂商接连推出了多款自家产品,云计算的发展也给我们带来许多的机遇,在这个对开发者要求越来越严格的年代,企业为了自己的产品更好的发展,也会使用更为先进的技术,这也加快了我们使用云计算的脚步。而在这一行当混得顺风顺水的php语言,自然也被许多厂商盯上,学习成本低,接触层面广的php有自己独特的优势,但是学习过程异常的艰辛,经过一段时间后会发现很多老手其实都还没有成为精通者,他们可能不会为难新手,但是老手也会有自己的苦衷,一个合格的开发者都是不断改进自己,更新自己的技术的。
而对于我们这些没有任何技术基础的新手来说,我们只能抓住别人暂时没有做到,或者没有做好的方面,去继续深挖,提高自己的技术储备。市场最底层需求一切都为真实用户服务我们要完成php采集任务就要先熟悉采集系统是如何安装的,mysql数据库有些什么特性,操作界面又是怎么样,简单熟悉了这些基础,再开始学习采集技术,采集系统就是完成基础功能需求,是否完善,是否升级都是依托于我们前期学习的重要性。
1.mysql数据库mysql是linux下的一个关系型数据库管理系统,在互联网的业务中我们要用到mysql数据库,数据库都是用我们自己能用的操作系统,windowslinux,还有桌面操作系统等,其中对于windows环境下的开发者来说linux平台下最容易采用的软件就是mysql操作系统,linux系统下又分windows上用linux下用php,unix环境下用的是python,之所以会得出这种结论还是有原因的,现在开发者都向着容易上手的语言发展,像python在网络上的用户基数最大,也有最多的程序员,而linux下却没有第二门语言可以模仿,只有php,人们甚至可以说在这方面任何语言都会有所缺失,是任何一种语言都比不上php的存在,所以当人们用得多了可能会有感情。
2.php语言现在为了便于软件的部署,节省硬件资源,php已经很好的支持了windows平台下的iis平台,使用iis不仅支持windows下的部署方式,windows下也同样能够完成操作,从而开发出更易于windows下部署的php程序。3.thinkphp框架的特点说完了mysql数据库的特点,我们再来看看thinkphp框架的特点。
thinkphp框架可以方便地进行复杂的web应用开发,复杂的web应用对性能要求高的企业至关重要,不仅功能强大,开发也较为方便,相对于第三方的web框架性能要优于第三方。而且thinkphp框架已经有十几年的历史,在目前的市场占有率算比较高的,对于发展中的web开发企业来说,
采集系统上云(【开源】云原生——站式数据中台PaaS )
采集交流 • 优采云 发表了文章 • 0 个评论 • 757 次浏览 • 2021-09-23 15:42
)
本文整理自:浅谈云原生系统日志采集在数据栈中的实践
Digital Stack是一个云原生站数据平台PaaS。我们在github上有一个有趣的开源项目:FlinkX,欢迎给我们点star!星星!星星!
FlinkX 是基于 Flink 的批流统一数据同步工具。可以是采集静态数据,如MySQL、HDFS等,也可以是采集实时变化的数据,如MySQL binlog、Kafka等,全局不同。集成构建和批处理流的数据同步引擎。有兴趣的请到github社区来和我们一起玩吧~
一、正常玩ELK
说到日志采集,估计大家第一个想到的就是ELK,比较成熟的方案。如果是专门针对云原生的,那就把采集器稍微改成Fluentd就可以形成EFK了。其实以上两种方案没有本质区别,只是采集器变了。最终的存储、查询等还是elasticsearch。
Elasticsearch 确实功能丰富,功能强大,但也极其昂贵。Elasticsearch 使用全文索引,对存储和内存要求比较高,而换取这些成本的功能在日常日志管理中并不常用。这些缺点在主机模式下其实还可以接受,但是在云原生模式下就显得臃肿了。
二、不说武德PLG
PLG是promtail+loki+grafana的统称,是很适合云原生日志的采集解决方案。每个人都会熟悉 grafana,这是一个支持多数据源的出色可视化框架。最常见的是可视化普罗米修斯数据。而洛基就是我们今天要说的主角。这也是grafana家族的产物,promtail是loki采集器的官方日志。
与elk相比,这套方案非常轻量、实用、简单易用,并且在展示中使用grafana减少了可视化框架的引入,在展示终端上的统一也对用户有利。
(一)log 暴发户 loki
Loki is a horizontally scalable and highly available multi-tenant log aggregation system inspired by Prometheus. Its design is cost-effective and easy to operate. It does not index the content of the log, but sets a set of tags for each log stream.
Compared with other log aggregation systems, Loki
The log is not indexed in full text. By storing compressed, unstructured logs and indexing only metadata, Loki is easier to operate and lower running costs.
The log stream is indexed and grouped using the same tags as Prometheus, allowing you to seamlessly switch between metrics and logs using the same tags as Prometheus.
Especially suitable for storing Kubernetes Pod logs. Metadata such as Pod tags are automatically crawled and indexed.
Grafana native support (Grafana v6.0 or above is required).
This paragraph is an introduction by loki on GitHub. It can be seen that this is a lightweight log aggregation system built for cloud native. The community is currently very active. Moreover, using prometheus' similar labeling ideas, it is connected with grafana for visual display, both in thinking and usage are very "cloud native".
(二) ♂️ Promtail son
Promtail is the official log of loki 采集器, and its code is in the loki project. Natively supports journal, syslog, file, docker type logs. The essence of 采集器 is nothing more than finding the file for 采集 according to the pattern, then monitoring the file similar to tail, and then sending the content of the written file to the storage promtail. The same is true of the above types. They are all files, but the format of these types of files is an open and stable specification, and promtail can perform deeper analysis and encapsulation in advance.
(三) Promtail Service Discovery
1、 找到文件作为一个采集器,其第一步自然是要找到文件在哪里,然后才能做下面的采集与打标签推送等功能。普通静态类型的日志是很好发现的,直接将你在配置文件中写的路径信息进行匹配即可,比如 promtail 中path为 "/var/log/*.log"即将 /var/log目录下所有的以.log 结尾的后缀文件作为要采集的对象即可。而要采集 k8s 模式内的日志就稍显麻烦。
首先我们想一下k8s 上跑的服务的日志到底是在哪里?
所以我们需要将这/var/log/pods 作为hostpath 挂载进 k8s 的容器内部,才能让 promtail 访问到这些日志。
2、 打上标签
日志promtail可以访问到了,但是还有一个问题还是如何为区分这些日志,loki采用类似prometheus的思想,将数据打上标签。也就是将日志打上pod的标签,那么单单凭借这个路径自然是无法知道该pod上有哪些标签信息的。这里就需要用到服务发现了。
promtail的服务发现是直接采用的prometheus的服务发现做的。熟悉prometheus 的同学肯定配置过prometheus的服务发现的配置,kubernetes_sd_configs与relabel_configs。
这里promtail直接引入prometheus的代码,与prometheus不同的是prometheus请求的资源对对象比较多,node、ingress、pod、deployment 等等都有,最终拼接的是metric的请求url,而promtail请求的对象为pod,并且过滤掉了不在该主机上的 pod。
拿到该主机的pod的信息后,再根据namespace, pod 的 id 拼接路径,由于这个目录已经挂载进去容器了,那么promtail 就可以关联起容器的标签与容器的日志了。剩下的就是监控与推送了。
(四) PLG 最佳实践
loki 官方推荐的最佳实践为采用 DamonSet部署 promtail 的方式,将 node 的 /var/lib/pods目录挂载进容器内部,借助prometheus 的服务发现机制动态的为日志加上标签,无论是资源的占用程度还是部署维护难度都是非常低。这也是主流的云原生日志采集范式。
三、数栈日志实践
(一) 数栈日志需求
(二) ️ 主机模式
数栈主机模式日志聚合采用类似PLG DameonSet 的模式。每台主机部署一台 promtail,然后整个集群部署一套服务端 loki 与可视化端grafana。
promtail 采用static_configs定义采集的日志。但是promtail 毕竟还是太年轻了,定位偏向于云原生,所以针对主机功能还不够完善,因此我们做了一些二次开发满足我们的需求:
1、logtail 模式
原生 promtail 并不支持从文件尾部开始采集,当 promtail 启动后,会将监控的所有文件的内容都进行推送,这样的情况在云原生并没有太大问题.
主机模式下如果要监控的日志已经存在并且有大量的内容的话,promtail 启动会将文件的内容从头开始推送,短时间内造成大量的日志往loki推送,很大的概率会被 loki 限流导致推送失败。
所以最好的方式就是有类似 filebeat 的 logtail 的模式,及只推送服务启动后的文件写入的日志。
这个地方我们对此作了二次开发,增加一个logtail 模式的开关,如果该开关为 true,这第一次启动 promtail 的时候将不会从头推送日志。
2、path 支持多路径
原生 promtail 不支持多路径 path 参数只能写一个表达式,但是现实的需求可能是既要看业务的日志还要看 gc 的日志。
但是他们又是属于同一类别的标签。单个path的匹配无法涵盖其两个,不改代码的解决方法就是再为其写一个 target。
这样做繁琐且不利于维护。所以我们这里也对其做了二次开发
(三) 云原生模式
传统的云原生模式采用 PLG 的主流模式就好了,但是数栈作为一整套系统对企业交付的时候有诸多限制会导致demoset模式并不可用,最大的挑战是权限,只有一个 namespace 的权限,不能挂载/var/lib/pods
在这种情况下如何使用 PLG呢?
其实主要变化的地方在于promtail的使用,这里首先要声明的一点是,数栈的服务的日志都为文件输出。
首先是选择damonset 模式部署还是sidecar模式部署,demonset模式的优点是节省资源,缺点是权限有要求。sidecar模式与之相反,为了适用更严格的交付条件,我们选择采用 sidecar 的模式进行采集。
sidecar 模式就是为当每个服务进行部署的时候就自动为其添加一个log容器,该容器与服务容器共同挂载一个共同的空的数据卷,服务容器将日志写入该数据卷中,log容器对数据卷下的日志进行采集。
1、⛳ promtail 在数栈如何动态配置标签
通过sidecar的模式我们让log Container与Master Container共享一个日志目录,这样就promtail容器内就可以拿到了日志的文件,但是promtail还不知道要采集哪些日志,以及他的标签是什么。
因为你可能只想采集.log的日志,也可能只想采集.json的日志,或者都有的服务这个配置可能是不同的,所以也不能写死,那如何解决这个问题呢?
promtail 在 v2.10中新增加了一个feature ,就是可以在配置文件中引用环境变量,通过这个特性我们可以将promtail的path参数写成${LOG_PATH},然后将服务的logpath以环境变量的方式设置进去比如LOG_PATH=/var/log/commonlog/*.log
既然我们可以通过环境变量的方式在服务创建的时候设置path,那么标签我们也可以动态的设置进去。那么我们都需什么维度的标签呢?这个不同的公司肯定有不同的维度,但是必须遵循的一个原则就是可以唯一确定该pod。一般的维度有deployment、podid、node等。这些标签在创建的时候就通过环境变量注入进去,而podid 这些环境变量利用的是k8s 的 downward api 的方式注入的。
注意:这里不可用使用 promtail 的服务发现机制配置标签,因为promtail 的服务发现的原理是请求 APIServer 获取所有pod 的标签。然后利用路径进行匹配,将标签与日志关联。在没有挂载宿主机/var/log/pods目录到promtail 时,即使拿到了标签也无法与日志进行关联。
2、⏰ promtail 在数栈如何部署
为每个服务增加一个Log Container如果手工操作的话实在是太繁琐了,而且不利于维护。最好的方式就将原本的服务抽象为是注册一个CRD,然后编写 k8s operator通过list&watch该类型的对象,在该对象创建的时候,动态的注入一个LogContainer,以及相应的环境变量和为其挂载共同目录。
这样当该CR创建的时候,promtail就作为sidecar注入了其中。并且读到的环境变量就是operator 动态设置的环境变量,灵活度非常高。
四、总结
(一) 数栈日志采集优势
(二)✈️未来规划
最后给大家分享一下数栈当前日志模块可视化的效果,是不是超级酷炫?
查看全部
采集系统上云(【开源】云原生——站式数据中台PaaS
)
本文整理自:浅谈云原生系统日志采集在数据栈中的实践
Digital Stack是一个云原生站数据平台PaaS。我们在github上有一个有趣的开源项目:FlinkX,欢迎给我们点star!星星!星星!
FlinkX 是基于 Flink 的批流统一数据同步工具。可以是采集静态数据,如MySQL、HDFS等,也可以是采集实时变化的数据,如MySQL binlog、Kafka等,全局不同。集成构建和批处理流的数据同步引擎。有兴趣的请到github社区来和我们一起玩吧~
一、正常玩ELK
说到日志采集,估计大家第一个想到的就是ELK,比较成熟的方案。如果是专门针对云原生的,那就把采集器稍微改成Fluentd就可以形成EFK了。其实以上两种方案没有本质区别,只是采集器变了。最终的存储、查询等还是elasticsearch。
Elasticsearch 确实功能丰富,功能强大,但也极其昂贵。Elasticsearch 使用全文索引,对存储和内存要求比较高,而换取这些成本的功能在日常日志管理中并不常用。这些缺点在主机模式下其实还可以接受,但是在云原生模式下就显得臃肿了。
二、不说武德PLG
PLG是promtail+loki+grafana的统称,是很适合云原生日志的采集解决方案。每个人都会熟悉 grafana,这是一个支持多数据源的出色可视化框架。最常见的是可视化普罗米修斯数据。而洛基就是我们今天要说的主角。这也是grafana家族的产物,promtail是loki采集器的官方日志。
与elk相比,这套方案非常轻量、实用、简单易用,并且在展示中使用grafana减少了可视化框架的引入,在展示终端上的统一也对用户有利。
(一)log 暴发户 loki
Loki is a horizontally scalable and highly available multi-tenant log aggregation system inspired by Prometheus. Its design is cost-effective and easy to operate. It does not index the content of the log, but sets a set of tags for each log stream.
Compared with other log aggregation systems, Loki
The log is not indexed in full text. By storing compressed, unstructured logs and indexing only metadata, Loki is easier to operate and lower running costs.
The log stream is indexed and grouped using the same tags as Prometheus, allowing you to seamlessly switch between metrics and logs using the same tags as Prometheus.
Especially suitable for storing Kubernetes Pod logs. Metadata such as Pod tags are automatically crawled and indexed.
Grafana native support (Grafana v6.0 or above is required).
This paragraph is an introduction by loki on GitHub. It can be seen that this is a lightweight log aggregation system built for cloud native. The community is currently very active. Moreover, using prometheus' similar labeling ideas, it is connected with grafana for visual display, both in thinking and usage are very "cloud native".
(二) ♂️ Promtail son
Promtail is the official log of loki 采集器, and its code is in the loki project. Natively supports journal, syslog, file, docker type logs. The essence of 采集器 is nothing more than finding the file for 采集 according to the pattern, then monitoring the file similar to tail, and then sending the content of the written file to the storage promtail. The same is true of the above types. They are all files, but the format of these types of files is an open and stable specification, and promtail can perform deeper analysis and encapsulation in advance.
(三) Promtail Service Discovery
1、 找到文件作为一个采集器,其第一步自然是要找到文件在哪里,然后才能做下面的采集与打标签推送等功能。普通静态类型的日志是很好发现的,直接将你在配置文件中写的路径信息进行匹配即可,比如 promtail 中path为 "/var/log/*.log"即将 /var/log目录下所有的以.log 结尾的后缀文件作为要采集的对象即可。而要采集 k8s 模式内的日志就稍显麻烦。
首先我们想一下k8s 上跑的服务的日志到底是在哪里?
所以我们需要将这/var/log/pods 作为hostpath 挂载进 k8s 的容器内部,才能让 promtail 访问到这些日志。
2、 打上标签
日志promtail可以访问到了,但是还有一个问题还是如何为区分这些日志,loki采用类似prometheus的思想,将数据打上标签。也就是将日志打上pod的标签,那么单单凭借这个路径自然是无法知道该pod上有哪些标签信息的。这里就需要用到服务发现了。
promtail的服务发现是直接采用的prometheus的服务发现做的。熟悉prometheus 的同学肯定配置过prometheus的服务发现的配置,kubernetes_sd_configs与relabel_configs。
这里promtail直接引入prometheus的代码,与prometheus不同的是prometheus请求的资源对对象比较多,node、ingress、pod、deployment 等等都有,最终拼接的是metric的请求url,而promtail请求的对象为pod,并且过滤掉了不在该主机上的 pod。
拿到该主机的pod的信息后,再根据namespace, pod 的 id 拼接路径,由于这个目录已经挂载进去容器了,那么promtail 就可以关联起容器的标签与容器的日志了。剩下的就是监控与推送了。
(四) PLG 最佳实践
loki 官方推荐的最佳实践为采用 DamonSet部署 promtail 的方式,将 node 的 /var/lib/pods目录挂载进容器内部,借助prometheus 的服务发现机制动态的为日志加上标签,无论是资源的占用程度还是部署维护难度都是非常低。这也是主流的云原生日志采集范式。
三、数栈日志实践
(一) 数栈日志需求
(二) ️ 主机模式
数栈主机模式日志聚合采用类似PLG DameonSet 的模式。每台主机部署一台 promtail,然后整个集群部署一套服务端 loki 与可视化端grafana。
promtail 采用static_configs定义采集的日志。但是promtail 毕竟还是太年轻了,定位偏向于云原生,所以针对主机功能还不够完善,因此我们做了一些二次开发满足我们的需求:
1、logtail 模式
原生 promtail 并不支持从文件尾部开始采集,当 promtail 启动后,会将监控的所有文件的内容都进行推送,这样的情况在云原生并没有太大问题.
主机模式下如果要监控的日志已经存在并且有大量的内容的话,promtail 启动会将文件的内容从头开始推送,短时间内造成大量的日志往loki推送,很大的概率会被 loki 限流导致推送失败。
所以最好的方式就是有类似 filebeat 的 logtail 的模式,及只推送服务启动后的文件写入的日志。
这个地方我们对此作了二次开发,增加一个logtail 模式的开关,如果该开关为 true,这第一次启动 promtail 的时候将不会从头推送日志。
2、path 支持多路径
原生 promtail 不支持多路径 path 参数只能写一个表达式,但是现实的需求可能是既要看业务的日志还要看 gc 的日志。
但是他们又是属于同一类别的标签。单个path的匹配无法涵盖其两个,不改代码的解决方法就是再为其写一个 target。
这样做繁琐且不利于维护。所以我们这里也对其做了二次开发
(三) 云原生模式
传统的云原生模式采用 PLG 的主流模式就好了,但是数栈作为一整套系统对企业交付的时候有诸多限制会导致demoset模式并不可用,最大的挑战是权限,只有一个 namespace 的权限,不能挂载/var/lib/pods
在这种情况下如何使用 PLG呢?
其实主要变化的地方在于promtail的使用,这里首先要声明的一点是,数栈的服务的日志都为文件输出。
首先是选择damonset 模式部署还是sidecar模式部署,demonset模式的优点是节省资源,缺点是权限有要求。sidecar模式与之相反,为了适用更严格的交付条件,我们选择采用 sidecar 的模式进行采集。
sidecar 模式就是为当每个服务进行部署的时候就自动为其添加一个log容器,该容器与服务容器共同挂载一个共同的空的数据卷,服务容器将日志写入该数据卷中,log容器对数据卷下的日志进行采集。
1、⛳ promtail 在数栈如何动态配置标签
通过sidecar的模式我们让log Container与Master Container共享一个日志目录,这样就promtail容器内就可以拿到了日志的文件,但是promtail还不知道要采集哪些日志,以及他的标签是什么。
因为你可能只想采集.log的日志,也可能只想采集.json的日志,或者都有的服务这个配置可能是不同的,所以也不能写死,那如何解决这个问题呢?
promtail 在 v2.10中新增加了一个feature ,就是可以在配置文件中引用环境变量,通过这个特性我们可以将promtail的path参数写成${LOG_PATH},然后将服务的logpath以环境变量的方式设置进去比如LOG_PATH=/var/log/commonlog/*.log
既然我们可以通过环境变量的方式在服务创建的时候设置path,那么标签我们也可以动态的设置进去。那么我们都需什么维度的标签呢?这个不同的公司肯定有不同的维度,但是必须遵循的一个原则就是可以唯一确定该pod。一般的维度有deployment、podid、node等。这些标签在创建的时候就通过环境变量注入进去,而podid 这些环境变量利用的是k8s 的 downward api 的方式注入的。
注意:这里不可用使用 promtail 的服务发现机制配置标签,因为promtail 的服务发现的原理是请求 APIServer 获取所有pod 的标签。然后利用路径进行匹配,将标签与日志关联。在没有挂载宿主机/var/log/pods目录到promtail 时,即使拿到了标签也无法与日志进行关联。
2、⏰ promtail 在数栈如何部署
为每个服务增加一个Log Container如果手工操作的话实在是太繁琐了,而且不利于维护。最好的方式就将原本的服务抽象为是注册一个CRD,然后编写 k8s operator通过list&watch该类型的对象,在该对象创建的时候,动态的注入一个LogContainer,以及相应的环境变量和为其挂载共同目录。
这样当该CR创建的时候,promtail就作为sidecar注入了其中。并且读到的环境变量就是operator 动态设置的环境变量,灵活度非常高。
四、总结
(一) 数栈日志采集优势
(二)✈️未来规划
最后给大家分享一下数栈当前日志模块可视化的效果,是不是超级酷炫?
采集系统上云(社交传播数据采集,可以玩玩微商,电商吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-12 05:02
采集系统上云,海量数据可用,能读写海量文件。车辆流量变大,多线网络带宽变大,生成数据曲线可视化。社交传播数据采集,可以玩玩微商,电商。
关键看你对物联网的定义是什么。1、车联网是每辆车对外的物理接口都和app端的对应,每辆车共享wifi和4g网络,用app控制各种功能的关键还是离不开物联网思维,最重要的还是信息的收集,或者说是数据的传播,信息的的收集有很多方法,比如通过控制摄像头和(压力感应,全息感应等)收集,还有ar的收集,互联网的手段。
车就是一个可以接收所有数据的,流程和其他一样,不同的是其他是看不到车的数据,而通过app实现数据的收集,做成报表,引导驾驶员做出合理的判断,但车是一个物理,它每一个数据点产生的数据是可以看到的。数据传播,互联网的方式很简单,通过手机或者电脑,看到互联网传播的信息和数据,这个和互联网接触是一样的。
未来物联网可以继续各种方式联接起来,但最重要的还是信息的收集,如果没有收集,可以直接变成其他的数据采集方式。
是个伪命题吧?communication,location,movement,theme.这是google、facebook、twitter等blogger的标配。它们并不关心是不是要接入云端服务,他们只在乎信息的传递。 查看全部
采集系统上云(社交传播数据采集,可以玩玩微商,电商吗?)
采集系统上云,海量数据可用,能读写海量文件。车辆流量变大,多线网络带宽变大,生成数据曲线可视化。社交传播数据采集,可以玩玩微商,电商。
关键看你对物联网的定义是什么。1、车联网是每辆车对外的物理接口都和app端的对应,每辆车共享wifi和4g网络,用app控制各种功能的关键还是离不开物联网思维,最重要的还是信息的收集,或者说是数据的传播,信息的的收集有很多方法,比如通过控制摄像头和(压力感应,全息感应等)收集,还有ar的收集,互联网的手段。
车就是一个可以接收所有数据的,流程和其他一样,不同的是其他是看不到车的数据,而通过app实现数据的收集,做成报表,引导驾驶员做出合理的判断,但车是一个物理,它每一个数据点产生的数据是可以看到的。数据传播,互联网的方式很简单,通过手机或者电脑,看到互联网传播的信息和数据,这个和互联网接触是一样的。
未来物联网可以继续各种方式联接起来,但最重要的还是信息的收集,如果没有收集,可以直接变成其他的数据采集方式。
是个伪命题吧?communication,location,movement,theme.这是google、facebook、twitter等blogger的标配。它们并不关心是不是要接入云端服务,他们只在乎信息的传递。
采集系统上云(微信采集系统所实现的功能有哪些?怎么做?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-12 03:02
采集系统上云之后需要安装对应应用程序进行采集,微信系统则是通过将服务器上的采集模块部署到微信系统,并实现对商品的采集功能。所以,
一、采集传播微信采集系统可以采集发朋友圈的广告,一键替换为图片和视频,同时,也可以采集并上传微信公众号的文章,采集并上传文章链接,识别出来之后就可以做公众号的分享链接,这样就可以进行推广传播。采集传播时,系统会自动回复相关的文案。
二、传播裂变采集传播又叫数据裂变,一条广告、一篇文章下来也可以进行传播,只要符合裂变的条件,或者通过你的推广链接进去,用户就会自动传播,就可以变成更多的用户,反复裂变,就可以产生数据。
三、深挖流量渠道第一,采集每个行业的用户习惯,并按照他们的习惯再进行过滤,将有价值的渠道收集起来。二,对用户习惯的深挖,对你整个行业进行精准的调研,了解用户关注的重点是什么。例如整个广告的效果到底怎么样,是否真的适合你的产品,才做传播裂变,如果用户可以感知到你的广告,他们就会通过分享将价值给你。以上就是微信采集系统所实现的功能。
现在市面上很多网络平台,例如腾讯广点通、腾讯社交广告等等,都可以做微信采集系统,相比于软件采集的话人工效率会稍微高点,你不用担心运营成本高的问题,有时候付费相比更加划算!。 查看全部
采集系统上云(微信采集系统所实现的功能有哪些?怎么做?)
采集系统上云之后需要安装对应应用程序进行采集,微信系统则是通过将服务器上的采集模块部署到微信系统,并实现对商品的采集功能。所以,
一、采集传播微信采集系统可以采集发朋友圈的广告,一键替换为图片和视频,同时,也可以采集并上传微信公众号的文章,采集并上传文章链接,识别出来之后就可以做公众号的分享链接,这样就可以进行推广传播。采集传播时,系统会自动回复相关的文案。
二、传播裂变采集传播又叫数据裂变,一条广告、一篇文章下来也可以进行传播,只要符合裂变的条件,或者通过你的推广链接进去,用户就会自动传播,就可以变成更多的用户,反复裂变,就可以产生数据。
三、深挖流量渠道第一,采集每个行业的用户习惯,并按照他们的习惯再进行过滤,将有价值的渠道收集起来。二,对用户习惯的深挖,对你整个行业进行精准的调研,了解用户关注的重点是什么。例如整个广告的效果到底怎么样,是否真的适合你的产品,才做传播裂变,如果用户可以感知到你的广告,他们就会通过分享将价值给你。以上就是微信采集系统所实现的功能。
现在市面上很多网络平台,例如腾讯广点通、腾讯社交广告等等,都可以做微信采集系统,相比于软件采集的话人工效率会稍微高点,你不用担心运营成本高的问题,有时候付费相比更加划算!。
采集系统上云(微博采集系统上云后使用其他人(万能电脑))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-10 13:01
采集系统上云后使用其他人(包括微博后台管理人)都不能直接通过手机连接或者访问微博,得用专用的电脑(万能电脑)。目前,可以知道的是我国移动互联网的核心用户中,95后80后70后之间有3%的屏障壁垒,而这3%的用户,只是中国互联网(pc)用户总量的5%而已。
感觉会和ar结合起来吧
要感谢邀请。其实这个问题本身是不是问反了?是:应该采用怎样的技术架构、为什么要用技术架构、架构是怎样,要基于哪些技术,本身都有很多可以说清楚的方向。那么更好地分析这些问题,往往就要看你们团队是做哪方面的应用了。
1.就像上面一些答案说的一样,应该完全用上专门的数据收集和挖掘系统2.通过采集社交媒体的话题,不可避免地也要收集好多私人资料,这样就会存在隐私问题3.微博采集有许多不同的技术手段,有云收集、自带的sdk和云收集和本地收集之分,所以应该从一开始就要做好尽可能多的准备工作4.看好云采集的趋势,前景不错,不过前提是支持云收集的采集系统要完备5.个人认为,最关键的是通过数据是否能对用户行为进行监控,是否有针对性,可不可以用某种方式进行监控的问题希望对你有帮助。
未来肯定是一个数据时代。各种用户数据、互联网内容,深刻的改变着我们的生活。未来营销,不再谈感受,不再靠情绪,而是反应,针对每个特定的用户展开行动。数据不是关键,重要的是能够采集的到!欢迎关注我们的公众号(id:hou-qiang),可以找到更多数据和运营技巧, 查看全部
采集系统上云(微博采集系统上云后使用其他人(万能电脑))
采集系统上云后使用其他人(包括微博后台管理人)都不能直接通过手机连接或者访问微博,得用专用的电脑(万能电脑)。目前,可以知道的是我国移动互联网的核心用户中,95后80后70后之间有3%的屏障壁垒,而这3%的用户,只是中国互联网(pc)用户总量的5%而已。
感觉会和ar结合起来吧
要感谢邀请。其实这个问题本身是不是问反了?是:应该采用怎样的技术架构、为什么要用技术架构、架构是怎样,要基于哪些技术,本身都有很多可以说清楚的方向。那么更好地分析这些问题,往往就要看你们团队是做哪方面的应用了。
1.就像上面一些答案说的一样,应该完全用上专门的数据收集和挖掘系统2.通过采集社交媒体的话题,不可避免地也要收集好多私人资料,这样就会存在隐私问题3.微博采集有许多不同的技术手段,有云收集、自带的sdk和云收集和本地收集之分,所以应该从一开始就要做好尽可能多的准备工作4.看好云采集的趋势,前景不错,不过前提是支持云收集的采集系统要完备5.个人认为,最关键的是通过数据是否能对用户行为进行监控,是否有针对性,可不可以用某种方式进行监控的问题希望对你有帮助。
未来肯定是一个数据时代。各种用户数据、互联网内容,深刻的改变着我们的生活。未来营销,不再谈感受,不再靠情绪,而是反应,针对每个特定的用户展开行动。数据不是关键,重要的是能够采集的到!欢迎关注我们的公众号(id:hou-qiang),可以找到更多数据和运营技巧,
采集系统上云( 系统关联政府多个应用,复杂度非同寻常政府云系统的现状)
采集交流 • 优采云 发表了文章 • 0 个评论 • 419 次浏览 • 2021-09-10 01:05
系统关联政府多个应用,复杂度非同寻常政府云系统的现状)
01客户现状及痛点
政务云系统在实现政务信息流通共享、保障信息安全、提升政府为民服务能力等方面取得长足进步,逐渐成为电子政务集约化发展的有力支撑。
但是,随着政务类应用的不断发展,系统数据量也呈指数级增长。尤其是部署了Docker容器化管理后,更需要让IT运维工作更智能,以应对业务压力。但与传统虚拟机对数据采集的Agent方式不同,Docker环境中的数据采集、分类、存储都面临着巨大的挑战:
Docker动态变化,性能和告警数据难以捕捉
政务云系统早就部署了Docker。虽然解决了轻量级的问题,但是Docker的出现和消亡,以及数量和IP地址一直在动态变化,使得数据抓取变得非常困难。
系统关联多个政府应用,复杂度非同寻常
政务云系统接入多个委、办、局的多个应用。架构非常复杂,数据规模巨大。实现采集动态数据的实时、存储和分析是一个不小的挑战。
Docker 只提供标准数据输出,数据分类困难
采集Agent 基于Docker,只需要安装在宿主机上即可。虽然方便,但Docker只提供标准的数据输出,不收录对应应用的信息。 采集收到的日志数据虽然是完整的,但无法定位到某个委、局或某个实际应用。
02 轻创解决方案
针对政务云系统的现状,青创科技通过Sherlock AIOps平台为系统部署AIOps服务,完成了从传统虚拟机到Docker容器采集的重要跨越,加强政务信息化建设和资源共享。
容器数据标签
为生成的Docker容器添加相应的标签,并将它们归类到各自的类别中,方便文件存储和精确定位。
全量多维数据采集
不仅有采集常见的日志数据,还有采集性能、告警等机器数据监控数据运行情况,为后续异常检测和根本原因定位进行综合分析。
动态数据实时分析
对于机器性能数据,采集按照默认的60秒时间执行,而对于实时性要求较高的日志和报警数据,可以采集秒为单位。
03解决方案价值
通过此次AIOps服务的部署,擎创科技成功帮助用户解决了以下问题:
实时采集动数
基于Sherlock AIOps多样化灵活的数据采集方式,采集Docker提供了日志、告警、性能等不同类型的数据,实现了采集的高频实时数据。
统一数据分析处理
将云系统的告警事件和性能数据与用户的CMDB和IT服务平台系统结合,进行关联分析,帮助用户快速定位问题根源,提高运维效率。
保证业务的平稳运行
解决业务分析处理能力,完善告警机制,提高用户业务的可用性,保证业务的健康运行。
04客户评价与期望
Sherlock AIOps在政务云系统上线后,Docker环境下系统数据采集的效率得到显着提升,有效推动了政务信息化建设。政务云系统负责人对AIOps服务的部署非常赞赏:“我们平台之前安装了很多虚拟机,后来部署了Docker进行数据管理。但是,目前容器环境中的数据是动态的,很难做到实时采集、分类、存储和分析。
应用AIOps后,数据管理变得容易多了,但数据管理的效率也在不断提升。
下一阶段,我们将继续加强政务云系统智能化建设,进一步提升为人民服务的能力。 " 查看全部
采集系统上云(
系统关联政府多个应用,复杂度非同寻常政府云系统的现状)
01客户现状及痛点
政务云系统在实现政务信息流通共享、保障信息安全、提升政府为民服务能力等方面取得长足进步,逐渐成为电子政务集约化发展的有力支撑。
但是,随着政务类应用的不断发展,系统数据量也呈指数级增长。尤其是部署了Docker容器化管理后,更需要让IT运维工作更智能,以应对业务压力。但与传统虚拟机对数据采集的Agent方式不同,Docker环境中的数据采集、分类、存储都面临着巨大的挑战:
Docker动态变化,性能和告警数据难以捕捉
政务云系统早就部署了Docker。虽然解决了轻量级的问题,但是Docker的出现和消亡,以及数量和IP地址一直在动态变化,使得数据抓取变得非常困难。
系统关联多个政府应用,复杂度非同寻常
政务云系统接入多个委、办、局的多个应用。架构非常复杂,数据规模巨大。实现采集动态数据的实时、存储和分析是一个不小的挑战。
Docker 只提供标准数据输出,数据分类困难
采集Agent 基于Docker,只需要安装在宿主机上即可。虽然方便,但Docker只提供标准的数据输出,不收录对应应用的信息。 采集收到的日志数据虽然是完整的,但无法定位到某个委、局或某个实际应用。
02 轻创解决方案
针对政务云系统的现状,青创科技通过Sherlock AIOps平台为系统部署AIOps服务,完成了从传统虚拟机到Docker容器采集的重要跨越,加强政务信息化建设和资源共享。
容器数据标签
为生成的Docker容器添加相应的标签,并将它们归类到各自的类别中,方便文件存储和精确定位。
全量多维数据采集
不仅有采集常见的日志数据,还有采集性能、告警等机器数据监控数据运行情况,为后续异常检测和根本原因定位进行综合分析。
动态数据实时分析
对于机器性能数据,采集按照默认的60秒时间执行,而对于实时性要求较高的日志和报警数据,可以采集秒为单位。
03解决方案价值
通过此次AIOps服务的部署,擎创科技成功帮助用户解决了以下问题:
实时采集动数
基于Sherlock AIOps多样化灵活的数据采集方式,采集Docker提供了日志、告警、性能等不同类型的数据,实现了采集的高频实时数据。
统一数据分析处理
将云系统的告警事件和性能数据与用户的CMDB和IT服务平台系统结合,进行关联分析,帮助用户快速定位问题根源,提高运维效率。
保证业务的平稳运行
解决业务分析处理能力,完善告警机制,提高用户业务的可用性,保证业务的健康运行。
04客户评价与期望
Sherlock AIOps在政务云系统上线后,Docker环境下系统数据采集的效率得到显着提升,有效推动了政务信息化建设。政务云系统负责人对AIOps服务的部署非常赞赏:“我们平台之前安装了很多虚拟机,后来部署了Docker进行数据管理。但是,目前容器环境中的数据是动态的,很难做到实时采集、分类、存储和分析。
应用AIOps后,数据管理变得容易多了,但数据管理的效率也在不断提升。
下一阶段,我们将继续加强政务云系统智能化建设,进一步提升为人民服务的能力。 "
采集系统上云(详细说,如何学习web技术1.html )
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-09-07 03:15
)
详细讲解,如何学习网络技术
1.html,css,javascript
先学习一些基本的前端知识。如果您打算进行后端开发,请快速浏览此部分。
2.jquery、vue、bootstrap
详细了解前端框架。另外,如果您打算进行后端开发,请快速查看此部分。
3.mysql 等数据库
了解一些数据库内容。有很多种数据库。可以先学mysql。网上有很多教程。学一个之后再学一个会容易很多。
4.学习jdbc、servlet、filter、listener、tomcat、ajax等相关知识
这部分知识比较重要。学好的话,后面的框架学起来会轻松很多。
5.Frame部分、spring mvc、mybatis、spring、spring boot等
这部分知识比较重要,大部分公司会直接使用这些框架进行开发
6.dubbo、spring cloud、NGINX、redis、hbase、mq
如果你想做一个并发量很大的项目,还需要学习这些相关知识。
另外,我会给你一个学习路线图。其实说到系统,路线图是最系统的。
网页前端
能够开发基本的网页并理解他人编写的HTML页面。详细解释了什么是css,层叠样式表。大量前端小案例,JavaScript事件处理,JavaScript对象,继承,JSON等知识点,学这个开启WEB前端之路
JavaWeb
Eclipse快捷键及下载安装、Tomcat9配置与使用、JavaWeb开发基础、Servlet编程、JSP...通过系列知识点,快速了解和掌握javaweb
网络项目
使用基于JDBC+Servlet+JSP的开发模型完成真实企业应用的开发,封装MVC架构模型,引入连接池技术,同时涵盖工厂、代理、责任链等常见设计模式。通过本Java视频教程的学习,必将为后面三大框架的学习打下坚实的基础。
我采集整理了很多这方面的视频教程。它们基本上易于理解且充满幽默感。如果你有想学习这门技术的小伙伴,可以过来学习,搞资源,网络开发,学习交流。 你可以在926338675前面找到我
查看全部
采集系统上云(详细说,如何学习web技术1.html
)
详细讲解,如何学习网络技术
1.html,css,javascript
先学习一些基本的前端知识。如果您打算进行后端开发,请快速浏览此部分。
2.jquery、vue、bootstrap
详细了解前端框架。另外,如果您打算进行后端开发,请快速查看此部分。
3.mysql 等数据库
了解一些数据库内容。有很多种数据库。可以先学mysql。网上有很多教程。学一个之后再学一个会容易很多。
4.学习jdbc、servlet、filter、listener、tomcat、ajax等相关知识
这部分知识比较重要。学好的话,后面的框架学起来会轻松很多。
5.Frame部分、spring mvc、mybatis、spring、spring boot等
这部分知识比较重要,大部分公司会直接使用这些框架进行开发
6.dubbo、spring cloud、NGINX、redis、hbase、mq
如果你想做一个并发量很大的项目,还需要学习这些相关知识。
另外,我会给你一个学习路线图。其实说到系统,路线图是最系统的。
网页前端
能够开发基本的网页并理解他人编写的HTML页面。详细解释了什么是css,层叠样式表。大量前端小案例,JavaScript事件处理,JavaScript对象,继承,JSON等知识点,学这个开启WEB前端之路
JavaWeb
Eclipse快捷键及下载安装、Tomcat9配置与使用、JavaWeb开发基础、Servlet编程、JSP...通过系列知识点,快速了解和掌握javaweb
网络项目
使用基于JDBC+Servlet+JSP的开发模型完成真实企业应用的开发,封装MVC架构模型,引入连接池技术,同时涵盖工厂、代理、责任链等常见设计模式。通过本Java视频教程的学习,必将为后面三大框架的学习打下坚实的基础。
我采集整理了很多这方面的视频教程。它们基本上易于理解且充满幽默感。如果你有想学习这门技术的小伙伴,可以过来学习,搞资源,网络开发,学习交流。 你可以在926338675前面找到我
采集系统上云(操作麻烦吗,不太懂计算机知识好不好运营这样一个软件系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-09-07 03:08
视频作为传播渠道有其天然的优势,画面更生动,音视频更完整,用户体验和观看体验更高,内容表达更直观。而且,随着互联网基础设施的快速发展,视频已经成为现代社会的主要表达方式。各种视频教程、课程、娱乐等都是以视频为基础的。那么搭建一个音视频点播系统需要多长时间呢?操作麻烦吗?如果我对计算机知识不太了解,我可以操作这样的软件系统吗?
首先,视频点播系统一般分为后端管理系统和前端显示播放两部分。后台管理系统主要用于管理整个系统的音视频数据,包括上传、编辑、修改、界面UI等,以及版本升级、用户管理等一些基础数据前端展示页面主要面向用户。用户通过账号登录或安装APP进入系统直接观看。观看时,他们可以根据类别选择视频,或者搜索以找到他们喜欢的内容。当然,采集最喜欢的内容。这也是必要的。系统中显示的内容可以是音频、视频或图片文字。至于所需的时间,就看你要支持用户使用哪个平台了。如果是电视盒或智能电视,则需要横向界面,如果是手机,则需要纵向界面,更符合用户的使用习惯。当然,如果你想实现H5网页版,可以通过各个平台上的链接打开。如果现有功能可以满足需求,3-5个工作日即可完成安装,2周内完成正式上线。
那计算机技术不是很好,你能操作这样的系统吗?任何软件和系统其实都是工具,会有详细的说明。并且系统是网页可视化界面,可以说只要会汉字就可以操作,比如上传视频地址,本地上传,点击按钮,选择需要上传的内容即可。编辑海报界面和内容,可以直接更改图片、文字等,前期会有人熟悉系统。所以不要太担心操作,按照说明操作即可。
那么这样的音视频点播系统有什么用呢?对于不同的行业、不同的公司有不同的含义,但总的来说他可以更形象地展示内容,更直观地展示工作成果。例如,文化站、旅游景点可以使用这个点播大屏系统,让用户更深入地了解相应的历史、地理、自然风光和科学知识。对于学校和教育机构,课程可以更容易理解。 查看全部
采集系统上云(操作麻烦吗,不太懂计算机知识好不好运营这样一个软件系统)
视频作为传播渠道有其天然的优势,画面更生动,音视频更完整,用户体验和观看体验更高,内容表达更直观。而且,随着互联网基础设施的快速发展,视频已经成为现代社会的主要表达方式。各种视频教程、课程、娱乐等都是以视频为基础的。那么搭建一个音视频点播系统需要多长时间呢?操作麻烦吗?如果我对计算机知识不太了解,我可以操作这样的软件系统吗?
首先,视频点播系统一般分为后端管理系统和前端显示播放两部分。后台管理系统主要用于管理整个系统的音视频数据,包括上传、编辑、修改、界面UI等,以及版本升级、用户管理等一些基础数据前端展示页面主要面向用户。用户通过账号登录或安装APP进入系统直接观看。观看时,他们可以根据类别选择视频,或者搜索以找到他们喜欢的内容。当然,采集最喜欢的内容。这也是必要的。系统中显示的内容可以是音频、视频或图片文字。至于所需的时间,就看你要支持用户使用哪个平台了。如果是电视盒或智能电视,则需要横向界面,如果是手机,则需要纵向界面,更符合用户的使用习惯。当然,如果你想实现H5网页版,可以通过各个平台上的链接打开。如果现有功能可以满足需求,3-5个工作日即可完成安装,2周内完成正式上线。
那计算机技术不是很好,你能操作这样的系统吗?任何软件和系统其实都是工具,会有详细的说明。并且系统是网页可视化界面,可以说只要会汉字就可以操作,比如上传视频地址,本地上传,点击按钮,选择需要上传的内容即可。编辑海报界面和内容,可以直接更改图片、文字等,前期会有人熟悉系统。所以不要太担心操作,按照说明操作即可。
那么这样的音视频点播系统有什么用呢?对于不同的行业、不同的公司有不同的含义,但总的来说他可以更形象地展示内容,更直观地展示工作成果。例如,文化站、旅游景点可以使用这个点播大屏系统,让用户更深入地了解相应的历史、地理、自然风光和科学知识。对于学校和教育机构,课程可以更容易理解。
采集系统上云(采集系统上云是非常好的,倒是可以一起联合研究下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-09-06 22:04
采集系统上云是非常好的,基本人人都需要用到,分期也是主打第三方产品,而分期人和商家其实也都有分期业务合作,所以前期不仅可以获得数据,也有信用数据支撑。但要分析每个数据点,当然还是需要在你去数据采集,而数据采集又分数据清洗、数据查重、数据解读和数据关联和计算。你有时间,倒是可以一起联合研究下。
1.你做什么产品?2.你的核心数据来源。
找数据公司是肯定可以实现,但是你要先选对数据公司,考虑这些问题。一是不同的数据公司数据都有自己定制的方案和解决方案,有些数据公司通过与渠道商合作获取自己的数据,有些则是通过自己的渠道获取用户数据,不同的数据公司对接的业务模式和服务质量,都会影响数据的质量问题,需要实地考察。二是业务需求的解决方案。针对不同行业和不同场景,数据公司能够提供差异化的数据解决方案,是否对接有效,后续能够否持续投入使用,是否真正能帮到客户解决问题,是否真正对每一笔业务有效。
三是数据采集、数据传输的质量和对接的节点准确性。服务商可以提供客户内部接口,但是是否能够通过审核、后续服务跟踪、数据传输失误处理、网络故障导致的格式、版本、有效性等问题,是否能够确保采集数据,后续能够一直维护和跟踪服务商,是否能对服务商提供保密服务,等等。四是数据分析报告。从基础的平台系统,到客户的关键业务指标,再到不同场景下用户的行为等等。
综合上述,如果想要实现你所说的数据互通,我觉得可以通过基于基础数据采集、导入、清洗、数据分析和管理的数据可视化中心,可以有效解决数据来源、质量、价值等问题。而数据服务商的基础数据采集、清洗、数据分析和管理中心的能力,你可以通过深度采访、数据问卷调查、清洗标准标准人员服务等业务方式,建立基础数据采集体系,有效提高数据质量;同时,基于可视化,可以有效解决数据进入不能导出的问题,即实现数据互通。这里再延伸一下。
一、基础数据采集。如果是企业级的oa或客户关系管理系统,可以通过申请采集系统的权限,进行基础数据采集。但采集和使用都需要审批才能使用。
二、数据清洗数据清洗是质量提升过程中重要的环节,即是清洗数据,最终得到数据,需要数据清洗人员有一定的数据敏感度,考虑你的数据对外合规性问题,来确保数据的真实性,整理出数据格式信息和数据名称。只有清洗出真实有效的数据,方能去进行数据分析。
三、数据分析数据分析是指通过计算机算法和分析方法对数据进行分析得出结论。 查看全部
采集系统上云(采集系统上云是非常好的,倒是可以一起联合研究下)
采集系统上云是非常好的,基本人人都需要用到,分期也是主打第三方产品,而分期人和商家其实也都有分期业务合作,所以前期不仅可以获得数据,也有信用数据支撑。但要分析每个数据点,当然还是需要在你去数据采集,而数据采集又分数据清洗、数据查重、数据解读和数据关联和计算。你有时间,倒是可以一起联合研究下。
1.你做什么产品?2.你的核心数据来源。
找数据公司是肯定可以实现,但是你要先选对数据公司,考虑这些问题。一是不同的数据公司数据都有自己定制的方案和解决方案,有些数据公司通过与渠道商合作获取自己的数据,有些则是通过自己的渠道获取用户数据,不同的数据公司对接的业务模式和服务质量,都会影响数据的质量问题,需要实地考察。二是业务需求的解决方案。针对不同行业和不同场景,数据公司能够提供差异化的数据解决方案,是否对接有效,后续能够否持续投入使用,是否真正能帮到客户解决问题,是否真正对每一笔业务有效。
三是数据采集、数据传输的质量和对接的节点准确性。服务商可以提供客户内部接口,但是是否能够通过审核、后续服务跟踪、数据传输失误处理、网络故障导致的格式、版本、有效性等问题,是否能够确保采集数据,后续能够一直维护和跟踪服务商,是否能对服务商提供保密服务,等等。四是数据分析报告。从基础的平台系统,到客户的关键业务指标,再到不同场景下用户的行为等等。
综合上述,如果想要实现你所说的数据互通,我觉得可以通过基于基础数据采集、导入、清洗、数据分析和管理的数据可视化中心,可以有效解决数据来源、质量、价值等问题。而数据服务商的基础数据采集、清洗、数据分析和管理中心的能力,你可以通过深度采访、数据问卷调查、清洗标准标准人员服务等业务方式,建立基础数据采集体系,有效提高数据质量;同时,基于可视化,可以有效解决数据进入不能导出的问题,即实现数据互通。这里再延伸一下。
一、基础数据采集。如果是企业级的oa或客户关系管理系统,可以通过申请采集系统的权限,进行基础数据采集。但采集和使用都需要审批才能使用。
二、数据清洗数据清洗是质量提升过程中重要的环节,即是清洗数据,最终得到数据,需要数据清洗人员有一定的数据敏感度,考虑你的数据对外合规性问题,来确保数据的真实性,整理出数据格式信息和数据名称。只有清洗出真实有效的数据,方能去进行数据分析。
三、数据分析数据分析是指通过计算机算法和分析方法对数据进行分析得出结论。
采集系统上云(走开没有,海康威视是做安防的,负责扫描和分析的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-06 09:01
采集系统上云以后你只需要配置就行了如果做成自己组网的这些怎么管理呢你肯定不希望你的就这么停靠在你指定的位置那不是画蛇添足吗?
建议上云后再做电信增值业务,p2p。
走开
没有,海康威视是做安防的,负责扫描和分析的,不是管理他们的。
请上云。一切问题都迎刃而解。如果想要不用管理,不用绑定身份,电信线路全走公网,那你永远不用上云。没人会给你这么做。海康威视给的解决方案都是海尔的解决方案。请同步阅读行业解决方案,有海尔协助,找不到对应的都是你的失误。
你这在山西是全省共用省网呢?还是没有互联网基础的直销企业?有互联网基础的直销企业也是有技术员培训过的。是可以完全免费用海康威视定制版来提高技术员的工作效率,并能和他们的技术员进行沟通。海康威视小米天地伟业长城云都有类似的辅助。具体是否为你的应用所需的,你可以在云端设置来分析统计数据。如果是微信小程序的应用,做到只用开发者可以自己能在海康威视云端设置,而不用一台电脑。
企业的应用做好了,离线也一样能访问。如果题主是培训学校的话,建议做一套解决方案,和海康威视专门合作,有定制化定义,针对不同的公司,可以分析用户的学习成长率,抗压能力等等,为公司的每一位学员提供一套完整的数据分析系统,让公司学员拥有一份时时有价值的未来。完整的课程标准和对标体系,和岗位标准,有需要可以联系我,发个清单给你。我在直销公司工作过,对这块有一些见解,可以加我微信交流。 查看全部
采集系统上云(走开没有,海康威视是做安防的,负责扫描和分析的)
采集系统上云以后你只需要配置就行了如果做成自己组网的这些怎么管理呢你肯定不希望你的就这么停靠在你指定的位置那不是画蛇添足吗?
建议上云后再做电信增值业务,p2p。
走开
没有,海康威视是做安防的,负责扫描和分析的,不是管理他们的。
请上云。一切问题都迎刃而解。如果想要不用管理,不用绑定身份,电信线路全走公网,那你永远不用上云。没人会给你这么做。海康威视给的解决方案都是海尔的解决方案。请同步阅读行业解决方案,有海尔协助,找不到对应的都是你的失误。
你这在山西是全省共用省网呢?还是没有互联网基础的直销企业?有互联网基础的直销企业也是有技术员培训过的。是可以完全免费用海康威视定制版来提高技术员的工作效率,并能和他们的技术员进行沟通。海康威视小米天地伟业长城云都有类似的辅助。具体是否为你的应用所需的,你可以在云端设置来分析统计数据。如果是微信小程序的应用,做到只用开发者可以自己能在海康威视云端设置,而不用一台电脑。
企业的应用做好了,离线也一样能访问。如果题主是培训学校的话,建议做一套解决方案,和海康威视专门合作,有定制化定义,针对不同的公司,可以分析用户的学习成长率,抗压能力等等,为公司的每一位学员提供一套完整的数据分析系统,让公司学员拥有一份时时有价值的未来。完整的课程标准和对标体系,和岗位标准,有需要可以联系我,发个清单给你。我在直销公司工作过,对这块有一些见解,可以加我微信交流。
采集系统上云(采集系统上云之前可能没有这么多人在第一时间收集基于endnote的排版原理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-09-06 06:05
采集系统上云之前可能没有系统了解过系统使用方面的知识,各大厂商的endnote开发这块开发的比较全面,对于无法定制很快就会失去用户群体。对于收费endnote来说,利润无法支撑之后的迭代升级。
并没有什么好处。基于endnote的杂志发行应用在产品生命周期的初期完全可以自己写一套看看。没有这么多人在第一时间收集基于endnote的排版原理。
不能,这是一种很高明的营销,但是他们的目的并不是希望你使用,他们的目的是让你购买他们的软件,听起来很神奇是吧,其实细看,他们只有提高你软件的付费比例,所以目的并不是为了让你使用,只是通过使用你的软件来达到他们的目的。他们通过内置数据库传输数据给pdf、microsoftoffice、或者他们自己已经有数据库的电子书来达到赚钱的目的。
你看,一个给pdf加特技、给pdf加字体、加排版,实际上没有增加任何工作量,但就是通过这些,让用户有个购买的理由,然后考虑是否购买我们的产品,这是他们的手段而已。
这有什么好问的,当有个免费的你又能读,又能编辑,还能阅读列表的msoffice或者wps就去购买吧,这都不是问题,adobe已经有此类专业软件,而且支持中文版的,免费版应该可以用了。而且一个字体库网站仅仅是一个个字体文件而已,对于读和编辑来说,如果需要专业的数据编辑工具的话,必须得花钱购买专业的软件了,付费除了解决一个普通字体库网站没有的技术问题,还可以让系统满足很多基本数据操作,和一些专业的网站需求。一个词:广大的选择,而且大多数用户也就是简单地让自己更方便就好了,并不需要什么技术支持。 查看全部
采集系统上云(采集系统上云之前可能没有这么多人在第一时间收集基于endnote的排版原理)
采集系统上云之前可能没有系统了解过系统使用方面的知识,各大厂商的endnote开发这块开发的比较全面,对于无法定制很快就会失去用户群体。对于收费endnote来说,利润无法支撑之后的迭代升级。
并没有什么好处。基于endnote的杂志发行应用在产品生命周期的初期完全可以自己写一套看看。没有这么多人在第一时间收集基于endnote的排版原理。
不能,这是一种很高明的营销,但是他们的目的并不是希望你使用,他们的目的是让你购买他们的软件,听起来很神奇是吧,其实细看,他们只有提高你软件的付费比例,所以目的并不是为了让你使用,只是通过使用你的软件来达到他们的目的。他们通过内置数据库传输数据给pdf、microsoftoffice、或者他们自己已经有数据库的电子书来达到赚钱的目的。
你看,一个给pdf加特技、给pdf加字体、加排版,实际上没有增加任何工作量,但就是通过这些,让用户有个购买的理由,然后考虑是否购买我们的产品,这是他们的手段而已。
这有什么好问的,当有个免费的你又能读,又能编辑,还能阅读列表的msoffice或者wps就去购买吧,这都不是问题,adobe已经有此类专业软件,而且支持中文版的,免费版应该可以用了。而且一个字体库网站仅仅是一个个字体文件而已,对于读和编辑来说,如果需要专业的数据编辑工具的话,必须得花钱购买专业的软件了,付费除了解决一个普通字体库网站没有的技术问题,还可以让系统满足很多基本数据操作,和一些专业的网站需求。一个词:广大的选择,而且大多数用户也就是简单地让自己更方便就好了,并不需要什么技术支持。
采集系统上云(前市面上常见的爬虫软件一般可以划分爬虫和采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-09-05 02:06
市面上常见的爬虫软件一般可以分为云爬虫和采集器两种:
1、 所谓云爬虫,就是直接在网页上创建爬虫,无需下载安装软件,运行在网站服务器上,享受网站提供的带宽和24小时服务;
2、采集器一般是在本机上下载安装,然后在本机上创建爬虫,使用自己的带宽,受电脑是否关机的限制。
这些云爬虫一般也应用了新锐云服务器的技术,而云服务器是支撑云爬虫技术的基础!
爬虫
其实每个爬虫都有自己的特点。我们可以根据自己的需要选择。下面简单介绍一下常见的网络爬虫,供大家参考:
一、优采云云攀虫
简介:优采云云是一个大数据应用开发平台,为开发者提供一整套数据采集、数据分析和机器学习开发工具,为企业提供专业的数据抓取、数据实时监控和数据分析服务。
1、优势:
功能强大,涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等;
纯云操作,跨系统操作无压力,隐私保护,用户IP可隐藏。
提供云爬虫市场,零基础用户可直接调用开发的爬虫,开发者基于官方云开发环境开发上传自己的爬虫程序;
领先的反爬技术,如直接获取代理IP、自动登录验证码识别等,全程自动化,无需人工参与;
丰富的发布界面,采集结果以丰富的表格形式展示;
2、缺点:
它的优点在一定程度上也变成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能。 网站看起来很技术也很专业,虽然官方也提供云爬虫市场等现成的爬虫产品,开放给爬虫开发者,丰富爬虫市场的内容。但是对于零技术基础的用户来说,就不是那么容易理解了,所以还是有一定的用途的。阈值。
是否免费:免费用户没有采集功能和导出限制,不需要积分。
有开发能力的用户可以自行开发爬虫,实现免费结果。没有开发能力的用户需要在爬虫市场找到免费的爬虫。
云爬虫
然后采集器,目前国内主要有以下几个(百度/谷歌搜索采集器,去掉广告,排名靠前):
二、优采云采集器
简介:优采云采集器是一款网络数据采集、处理、分析和挖掘软件。可以灵活快速的抓取网页上零散的信息,通过强大的处理功能,准确地挖掘出需要的数据。
1、优势:
国内老手采集器,经过多年积累,拥有丰富的采集功能;
采集速度比较快,界面比较齐全,支持PHP和C#插件扩展;
支持多种数据格式导出,可进行数据替换等处理。
2、缺点:
产品越老,越容易陷入自己固有的体验中,优采云也很难摆脱这个问题。
虽然功能丰富,但功能堆积如山,用户体验不好,让人不知从何下手;
学过它的人会觉得它很强大,但是对于新手来说也有一定的门槛。不学习一段时间很难上手,零基础基本不可能上手。
仅支持Windows版本,不支持其他操作系统;
是否免费:说是免费,但实际上免费功能有很多限制,只能导出单个txt或html文件。基本上可以说不是免费的。
优采云采集器
三、优采云采集器
简介:优采云采集器是一个可视化的采集器,内置采集模板,支持各种网页数据采集。
1、优势:
支持自定义模式,可视化采集操作,简单易用;
支持简单采集模式,提供官方采集模板,支持云端采集操作;
支持代理IP切换、验证码服务等防阻塞措施;
支持多种数据格式导出。
2、缺点:
函数使用门槛高。很多功能限制在本地采集,云端采集收费更高;
采集 很慢,很多操作都要卡住。 Cloud 采集 说快了 10 倍但不明显;
仅支持 Windows 版本,不支持其他操作系统。
是否免费:说是免费,但其实导出数据需要积分,做任务也可以赚积分,不过一般情况下基本需要买积分。
优采云采集器
四、优采云采集器
简介:优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。软件功能强大,操作极其简单。
1、优势:
支持智能采集模式,输入URL智能识别采集对象,无需配置采集规则,操作非常简单;
支持流程图模式,操作过程可视化,可以通过简单的操作生成各种复杂的采集规则;
支持防拦截措施,如代理IP切换验证码打印等;
支持多种数据导出方式(文件、数据库和网站);
支持定时采集和自动导出,丰富的发布界面;
支持文件下载(图片、文件、视频、音频等);
支持电商大图和SKU自动识别;
支持网页加密内容解码;
支持API函数;
支持 Windows、Mac 和 Linux 版本。
2、缺点:
暂时不支持Cloud采集功能
是否免费:完全免费,采集data和手动将采集结果导出到本地文件和数据库没有数量限制,不需要积分。
优采云采集器
采集器 知识丰富!有兴趣的可以继续阅读《免费爬虫软件真的存在吗?》 》 查看全部
采集系统上云(前市面上常见的爬虫软件一般可以划分爬虫和采集器)
市面上常见的爬虫软件一般可以分为云爬虫和采集器两种:
1、 所谓云爬虫,就是直接在网页上创建爬虫,无需下载安装软件,运行在网站服务器上,享受网站提供的带宽和24小时服务;
2、采集器一般是在本机上下载安装,然后在本机上创建爬虫,使用自己的带宽,受电脑是否关机的限制。
这些云爬虫一般也应用了新锐云服务器的技术,而云服务器是支撑云爬虫技术的基础!
爬虫
其实每个爬虫都有自己的特点。我们可以根据自己的需要选择。下面简单介绍一下常见的网络爬虫,供大家参考:
一、优采云云攀虫
简介:优采云云是一个大数据应用开发平台,为开发者提供一整套数据采集、数据分析和机器学习开发工具,为企业提供专业的数据抓取、数据实时监控和数据分析服务。
1、优势:
功能强大,涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等;
纯云操作,跨系统操作无压力,隐私保护,用户IP可隐藏。
提供云爬虫市场,零基础用户可直接调用开发的爬虫,开发者基于官方云开发环境开发上传自己的爬虫程序;
领先的反爬技术,如直接获取代理IP、自动登录验证码识别等,全程自动化,无需人工参与;
丰富的发布界面,采集结果以丰富的表格形式展示;
2、缺点:
它的优点在一定程度上也变成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能。 网站看起来很技术也很专业,虽然官方也提供云爬虫市场等现成的爬虫产品,开放给爬虫开发者,丰富爬虫市场的内容。但是对于零技术基础的用户来说,就不是那么容易理解了,所以还是有一定的用途的。阈值。
是否免费:免费用户没有采集功能和导出限制,不需要积分。
有开发能力的用户可以自行开发爬虫,实现免费结果。没有开发能力的用户需要在爬虫市场找到免费的爬虫。
云爬虫
然后采集器,目前国内主要有以下几个(百度/谷歌搜索采集器,去掉广告,排名靠前):
二、优采云采集器
简介:优采云采集器是一款网络数据采集、处理、分析和挖掘软件。可以灵活快速的抓取网页上零散的信息,通过强大的处理功能,准确地挖掘出需要的数据。
1、优势:
国内老手采集器,经过多年积累,拥有丰富的采集功能;
采集速度比较快,界面比较齐全,支持PHP和C#插件扩展;
支持多种数据格式导出,可进行数据替换等处理。
2、缺点:
产品越老,越容易陷入自己固有的体验中,优采云也很难摆脱这个问题。
虽然功能丰富,但功能堆积如山,用户体验不好,让人不知从何下手;
学过它的人会觉得它很强大,但是对于新手来说也有一定的门槛。不学习一段时间很难上手,零基础基本不可能上手。
仅支持Windows版本,不支持其他操作系统;
是否免费:说是免费,但实际上免费功能有很多限制,只能导出单个txt或html文件。基本上可以说不是免费的。
优采云采集器
三、优采云采集器
简介:优采云采集器是一个可视化的采集器,内置采集模板,支持各种网页数据采集。
1、优势:
支持自定义模式,可视化采集操作,简单易用;
支持简单采集模式,提供官方采集模板,支持云端采集操作;
支持代理IP切换、验证码服务等防阻塞措施;
支持多种数据格式导出。
2、缺点:
函数使用门槛高。很多功能限制在本地采集,云端采集收费更高;
采集 很慢,很多操作都要卡住。 Cloud 采集 说快了 10 倍但不明显;
仅支持 Windows 版本,不支持其他操作系统。
是否免费:说是免费,但其实导出数据需要积分,做任务也可以赚积分,不过一般情况下基本需要买积分。
优采云采集器
四、优采云采集器
简介:优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。软件功能强大,操作极其简单。
1、优势:
支持智能采集模式,输入URL智能识别采集对象,无需配置采集规则,操作非常简单;
支持流程图模式,操作过程可视化,可以通过简单的操作生成各种复杂的采集规则;
支持防拦截措施,如代理IP切换验证码打印等;
支持多种数据导出方式(文件、数据库和网站);
支持定时采集和自动导出,丰富的发布界面;
支持文件下载(图片、文件、视频、音频等);
支持电商大图和SKU自动识别;
支持网页加密内容解码;
支持API函数;
支持 Windows、Mac 和 Linux 版本。
2、缺点:
暂时不支持Cloud采集功能
是否免费:完全免费,采集data和手动将采集结果导出到本地文件和数据库没有数量限制,不需要积分。
优采云采集器
采集器 知识丰富!有兴趣的可以继续阅读《免费爬虫软件真的存在吗?》 》
采集系统上云(威索尼可智能采集卡让你的数据采集系统上云)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-05 02:05
采集系统上云!越来越多的企业开始关注收集数据,并将其作为企业的数据中心储存起来。企业有足够的钱、人力以及时间用于数据采集,但是采集系统还是有很多可以提升的空间。作为数据采集系统的一个领军企业,威索尼可智能采集卡产品不仅能够帮助企业节省很多采集的麻烦,而且还可以提高采集质量,缓解客户的操作焦虑。威索尼可是行业的领导者,在产品技术上不断创新,从采集卡中提取出很多创新的技术,产品还与u盘一起捆绑销售,成为数据采集的利器。
威索尼可智能采集卡g6采集卡,采用高清分辨率,还有f5高速多媒体输出接口。威索尼可g6采集卡拥有最高10gbps的传输速度,在采集的时候不会出现断连、丢包等问题,同时威索尼可的g6采集卡还拥有pci-ex4接口,可以拓展sata和pci-e以及m.2sata,极大扩展了存储空间,减少了采集卡的体积。在安装方面威索尼可也颇为简单,不仅为采集卡嵌入了tf卡插槽,而且还给采集卡装入了自动识别的移动电源接口,用户只需要轻轻将usb数据线插到采集卡就可以采集数据了。
威索尼可智能采集卡g6采集卡除了适用于采集企业内部所需的数据外,也广泛适用于外购服务器的需求,客户可以随意更换威索尼可采集卡与外部服务器进行,实现无缝对接,最大程度减少对服务器的依赖。威索尼可威索尼可智能采集卡g6采集卡还支持多人同时在线采集,采集完数据之后,无需切换或重新加载,用户点击对话框内的按钮可以实现无缝的在线采集。
威索尼可威索尼可智能采集卡g6采集卡还支持大容量的数据,内置三星千兆网卡,充分满足采集企业内部数据的需求。威索尼可智能采集卡g6采集卡还可与ssd固态硬盘组成多副本备份,支持多人同时在线采集,采集完成之后用户可以根据自己需要手动查看待采集数据。威索尼可威索尼可智能采集卡g6采集卡配备的4口pci接口,可接内置raid0,可用于企业内部的数据同步,支持公司内部所有服务器进行采集,最高传输速度10gbps,而且威索尼可威索尼可采集卡g6采集卡采用独立电源,支持24小时不间断连接,省去线缆分离的烦恼。
威索尼可威索尼可智能采集卡g6采集卡还可与麦克风等配件组成采集矩阵。除了安装方便外,威索尼可威索尼可智能采集卡g6采集卡还可以安装外置键鼠扩展卡槽,实现多人同时在线采集。威索尼可威索尼可智能采集卡g6采集卡还可组成人工智能采集卡,具有高速处理大批量文件的能力。威索尼可威索尼可智能采集卡g6采集卡可在支持高速多媒体传输的基础上,可以搭配键鼠扩展卡槽组成人工智能采集矩阵, 查看全部
采集系统上云(威索尼可智能采集卡让你的数据采集系统上云)
采集系统上云!越来越多的企业开始关注收集数据,并将其作为企业的数据中心储存起来。企业有足够的钱、人力以及时间用于数据采集,但是采集系统还是有很多可以提升的空间。作为数据采集系统的一个领军企业,威索尼可智能采集卡产品不仅能够帮助企业节省很多采集的麻烦,而且还可以提高采集质量,缓解客户的操作焦虑。威索尼可是行业的领导者,在产品技术上不断创新,从采集卡中提取出很多创新的技术,产品还与u盘一起捆绑销售,成为数据采集的利器。
威索尼可智能采集卡g6采集卡,采用高清分辨率,还有f5高速多媒体输出接口。威索尼可g6采集卡拥有最高10gbps的传输速度,在采集的时候不会出现断连、丢包等问题,同时威索尼可的g6采集卡还拥有pci-ex4接口,可以拓展sata和pci-e以及m.2sata,极大扩展了存储空间,减少了采集卡的体积。在安装方面威索尼可也颇为简单,不仅为采集卡嵌入了tf卡插槽,而且还给采集卡装入了自动识别的移动电源接口,用户只需要轻轻将usb数据线插到采集卡就可以采集数据了。
威索尼可智能采集卡g6采集卡除了适用于采集企业内部所需的数据外,也广泛适用于外购服务器的需求,客户可以随意更换威索尼可采集卡与外部服务器进行,实现无缝对接,最大程度减少对服务器的依赖。威索尼可威索尼可智能采集卡g6采集卡还支持多人同时在线采集,采集完数据之后,无需切换或重新加载,用户点击对话框内的按钮可以实现无缝的在线采集。
威索尼可威索尼可智能采集卡g6采集卡还支持大容量的数据,内置三星千兆网卡,充分满足采集企业内部数据的需求。威索尼可智能采集卡g6采集卡还可与ssd固态硬盘组成多副本备份,支持多人同时在线采集,采集完成之后用户可以根据自己需要手动查看待采集数据。威索尼可威索尼可智能采集卡g6采集卡配备的4口pci接口,可接内置raid0,可用于企业内部的数据同步,支持公司内部所有服务器进行采集,最高传输速度10gbps,而且威索尼可威索尼可采集卡g6采集卡采用独立电源,支持24小时不间断连接,省去线缆分离的烦恼。
威索尼可威索尼可智能采集卡g6采集卡还可与麦克风等配件组成采集矩阵。除了安装方便外,威索尼可威索尼可智能采集卡g6采集卡还可以安装外置键鼠扩展卡槽,实现多人同时在线采集。威索尼可威索尼可智能采集卡g6采集卡还可组成人工智能采集卡,具有高速处理大批量文件的能力。威索尼可威索尼可智能采集卡g6采集卡可在支持高速多媒体传输的基础上,可以搭配键鼠扩展卡槽组成人工智能采集矩阵,
采集系统上云(如何降低企业的数据量及采集时间呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-31 05:05
采集系统上云是大势所趋,可以参考智能推送广告联盟类似的东西;毕竟不管怎么改革,小平台都是靠用户需求开始盈利,而大平台是靠市场份额来赚钱。
云采集主要有数据可视化的需求,以及小程序的使用。
小程序一直被看作是下一个风口,
云采集可以理解为将互联网上的数据和地图上的数据及时的采集到本地,并推送到其他app或者服务,使得信息采集更快速、清晰。虽然线上采集数据的难度相对较低,但是将数据进行数据清洗、重新再出库相对来说需要比较长的时间,毕竟服务商每天会产生数量庞大的数据量。而且所用到的互联网数据也需要二次筛选,这对于有选择困难症患者和更新换代频繁的企业用户来说也是一大挑战。
其实,互联网数据都可以进行云采集。譬如阿里云的大数据平台pai,就能实现数据的采集、清洗、保存和分析处理的功能。云采集方案,如何降低企业的数据量及采集时间是我们考虑的重点,小小表格都涉及到上百兆的数据文件!那怎么降低企业数据采集时间呢?比如采集地图数据,推荐借助百度图片即时下载服务,“1秒下载地图数据”,“任意图片一键下载”有效解决了这个痛点,成为标配。
另外,企业只需安装百度浏览器插件即可实现上述功能,不需要专门安装图片下载器。采集数据只需要一台电脑即可,推荐使用谷歌浏览器。 查看全部
采集系统上云(如何降低企业的数据量及采集时间呢?(图))
采集系统上云是大势所趋,可以参考智能推送广告联盟类似的东西;毕竟不管怎么改革,小平台都是靠用户需求开始盈利,而大平台是靠市场份额来赚钱。
云采集主要有数据可视化的需求,以及小程序的使用。
小程序一直被看作是下一个风口,
云采集可以理解为将互联网上的数据和地图上的数据及时的采集到本地,并推送到其他app或者服务,使得信息采集更快速、清晰。虽然线上采集数据的难度相对较低,但是将数据进行数据清洗、重新再出库相对来说需要比较长的时间,毕竟服务商每天会产生数量庞大的数据量。而且所用到的互联网数据也需要二次筛选,这对于有选择困难症患者和更新换代频繁的企业用户来说也是一大挑战。
其实,互联网数据都可以进行云采集。譬如阿里云的大数据平台pai,就能实现数据的采集、清洗、保存和分析处理的功能。云采集方案,如何降低企业的数据量及采集时间是我们考虑的重点,小小表格都涉及到上百兆的数据文件!那怎么降低企业数据采集时间呢?比如采集地图数据,推荐借助百度图片即时下载服务,“1秒下载地图数据”,“任意图片一键下载”有效解决了这个痛点,成为标配。
另外,企业只需安装百度浏览器插件即可实现上述功能,不需要专门安装图片下载器。采集数据只需要一台电脑即可,推荐使用谷歌浏览器。
采集系统上云(快牛云股权宝可以采集全平台数据的采集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-08-30 16:04
采集系统上云可谓是利好,比如快牛云股权宝可以采集全平台数据,时时监控金融市场动态,为投资者提供实时、准确、完整的数据,让用户如虎添翼。
对于常见的几个大类新金融采集系统,目前来说对于中小企业有着较大的吸引力。原因很简单,在传统意义上大型企业建立集中的数据共享平台,中小企业利用自己的业务。但实际这种模式已经受到机构规模的扩大而挑战。新金融采集系统是由网络采集系统、业务后台系统、数据中心共同构成的“三位一体”的系统平台。在开放市场下,合法合规的采集系统除了具有其自身运行的特征外,还可为平台上的中小企业提供保护其合法权益的新金融服务。
国内的采集系统中,主要有交易型系统、简易型系统、集成型系统等类型的系统。前面两者主要是单一型的交易系统为投资者提供直接进行股权交易的交易系统,在实时监控市场发展的同时,为大型机构提供最直接、高效的股权出售方式,后面两者为单一业务的业务系统,通过抓取整合全市场的数据进行加工处理,将报表中金融数据进行集成后进行回传,帮助小型企业快速规模化、实时化的对市场进行直接的了解,为更多企业提供基于数据的获客、交易等新金融方面的服务。
采集系统上云必然是一个大趋势。我公司目前也正在做互联网金融相关的采集系统,包括股权宝、巴乐兔、即刻理财等,是通过数据获取和管理并接入各种网络接口,进行成熟产品的采集以及业务落地。具体来说就是对接更多的第三方服务,像银行、证券等。对采集的数据进行存储、理解、处理和业务报表等,得到可计算的金融产品,从而提升用户体验。目前主要针对p2p或综合型小微金融机构进行服务。 查看全部
采集系统上云(快牛云股权宝可以采集全平台数据的采集系统)
采集系统上云可谓是利好,比如快牛云股权宝可以采集全平台数据,时时监控金融市场动态,为投资者提供实时、准确、完整的数据,让用户如虎添翼。
对于常见的几个大类新金融采集系统,目前来说对于中小企业有着较大的吸引力。原因很简单,在传统意义上大型企业建立集中的数据共享平台,中小企业利用自己的业务。但实际这种模式已经受到机构规模的扩大而挑战。新金融采集系统是由网络采集系统、业务后台系统、数据中心共同构成的“三位一体”的系统平台。在开放市场下,合法合规的采集系统除了具有其自身运行的特征外,还可为平台上的中小企业提供保护其合法权益的新金融服务。
国内的采集系统中,主要有交易型系统、简易型系统、集成型系统等类型的系统。前面两者主要是单一型的交易系统为投资者提供直接进行股权交易的交易系统,在实时监控市场发展的同时,为大型机构提供最直接、高效的股权出售方式,后面两者为单一业务的业务系统,通过抓取整合全市场的数据进行加工处理,将报表中金融数据进行集成后进行回传,帮助小型企业快速规模化、实时化的对市场进行直接的了解,为更多企业提供基于数据的获客、交易等新金融方面的服务。
采集系统上云必然是一个大趋势。我公司目前也正在做互联网金融相关的采集系统,包括股权宝、巴乐兔、即刻理财等,是通过数据获取和管理并接入各种网络接口,进行成熟产品的采集以及业务落地。具体来说就是对接更多的第三方服务,像银行、证券等。对采集的数据进行存储、理解、处理和业务报表等,得到可计算的金融产品,从而提升用户体验。目前主要针对p2p或综合型小微金融机构进行服务。
采集系统上云(小编推荐:优采云采集器下载2.优采云采集器采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2021-08-30 16:02
Data采集software,顾名思义,是指能够快速、大量地获取互联网上指定信息的软件产品。当然,很多网友更习惯叫他们“采集器”!那么,采集software 的数据是什么? data采集software 哪个更好?针对以上问题,小编今天带来了2019年数据采集soft推荐。
1.优采云采集器
优采云采集器 是一个非常强大且易于操作的网络数据采集 工具。软件界面简洁大方,可以快速自动采集导出和编辑数据,甚至是网页图片上的数据。文本也可以解析提取,采集的内容也很丰富。
编辑推荐:优采云采集器下载
2.优采云采集器
优采云采集器是一个非常强大的数据采集器,完美支持采集所有网页编码格式,程序还可以自动识别网页编码,支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合。
编辑推荐:优采云采集器下载
3.Simon爱站关键词采集工具
Simon爱站关键词采集tool 是一个关键词采集 软件。软件收录爱站关键词的采集和爱站长尾词挖掘,可以完全自定义采集并挖掘你的词库,支持多站点多关键词,数据导出,网站登录等
编辑推荐:Simon爱站关键词采集tool下载
4.云流电影采集器
云流电影采集器可以说是影视剧的新神器了。可以搜索并保存最新、最热门的电影、电视剧资源的下载地址。用户只需在软件中选择电影或电视剧即可。上课,点击开始工作,get即可轻松获取最新资源。
编辑推荐:云流电影采集器下载
5.守望数据采集器
Watch data采集器采集rule 嗅探器,只需要简单的鼠标复制粘贴即可生成完美的采集规则,没有繁琐的过程。另外软件支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;支持自动比较和过滤功能,不会在采集重复采集和存储的链接系统上执行;以上两个功能可以大大减少采集时间,减少系统负载。
小编推荐:看Data采集器下载 查看全部
采集系统上云(小编推荐:优采云采集器下载2.优采云采集器采集工具)
Data采集software,顾名思义,是指能够快速、大量地获取互联网上指定信息的软件产品。当然,很多网友更习惯叫他们“采集器”!那么,采集software 的数据是什么? data采集software 哪个更好?针对以上问题,小编今天带来了2019年数据采集soft推荐。
1.优采云采集器
优采云采集器 是一个非常强大且易于操作的网络数据采集 工具。软件界面简洁大方,可以快速自动采集导出和编辑数据,甚至是网页图片上的数据。文本也可以解析提取,采集的内容也很丰富。
编辑推荐:优采云采集器下载
2.优采云采集器
优采云采集器是一个非常强大的数据采集器,完美支持采集所有网页编码格式,程序还可以自动识别网页编码,支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合。
编辑推荐:优采云采集器下载
3.Simon爱站关键词采集工具
Simon爱站关键词采集tool 是一个关键词采集 软件。软件收录爱站关键词的采集和爱站长尾词挖掘,可以完全自定义采集并挖掘你的词库,支持多站点多关键词,数据导出,网站登录等
编辑推荐:Simon爱站关键词采集tool下载
4.云流电影采集器
云流电影采集器可以说是影视剧的新神器了。可以搜索并保存最新、最热门的电影、电视剧资源的下载地址。用户只需在软件中选择电影或电视剧即可。上课,点击开始工作,get即可轻松获取最新资源。
编辑推荐:云流电影采集器下载
5.守望数据采集器
Watch data采集器采集rule 嗅探器,只需要简单的鼠标复制粘贴即可生成完美的采集规则,没有繁琐的过程。另外软件支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;支持自动比较和过滤功能,不会在采集重复采集和存储的链接系统上执行;以上两个功能可以大大减少采集时间,减少系统负载。
小编推荐:看Data采集器下载
采集系统上云(采集系统上云基本需要具备下面两个条件:谢邀)
采集交流 • 优采云 发表了文章 • 0 个评论 • 522 次浏览 • 2021-08-28 19:03
采集系统上云基本需要具备下面两个条件:第一,云主机相关性能稳定,能够满足相关业务的基本需求,可以作为项目的基础盘;第二,具备一定的成本优势,包括技术上相关性能、成本方面的优势,业务上操作灵活性;现有的平台基本上已经完成了这两个条件的搭建;当然,我们可以引入开源云主机,从而彻底解决成本问题。基于上述,我们为您推荐ecs+mysql的配置方案,成本低,性能高。
谢邀。你可以参考一下saas平台franklogic-alternatives|globalhandlingguide原理相同,国内有几家这样做,例如是实现腾讯云的网络ip地址映射推送到腾讯云解决方案,或者是业务平台有相关saas的功能,可以再franklogic上进行集成。
qq本身就是一个分布式im,很有趣的玩法。
socket仿真比如自动发消息机器集群写日志:rmarkdown做写日志,
谢邀。首先谈谈进程的概念,不同于多线程、多进程,一个进程占据的cpu只有一个。进程通常是由互不相交的进程块组成的。从某个角度讲,一个进程可以看成一个微操作系统上的“一次开关”(微操作系统内核态)。是什么能让你脑洞大开想到要用做多进程呢,比如用来做合作机制(类似于多进程),用来做共享资源(如linux本身的new_process,每次多new一个进程,进程数增加)..可以参考下这个例子/~twere/api/desktop/multi_process.html。 查看全部
采集系统上云(采集系统上云基本需要具备下面两个条件:谢邀)
采集系统上云基本需要具备下面两个条件:第一,云主机相关性能稳定,能够满足相关业务的基本需求,可以作为项目的基础盘;第二,具备一定的成本优势,包括技术上相关性能、成本方面的优势,业务上操作灵活性;现有的平台基本上已经完成了这两个条件的搭建;当然,我们可以引入开源云主机,从而彻底解决成本问题。基于上述,我们为您推荐ecs+mysql的配置方案,成本低,性能高。
谢邀。你可以参考一下saas平台franklogic-alternatives|globalhandlingguide原理相同,国内有几家这样做,例如是实现腾讯云的网络ip地址映射推送到腾讯云解决方案,或者是业务平台有相关saas的功能,可以再franklogic上进行集成。
qq本身就是一个分布式im,很有趣的玩法。
socket仿真比如自动发消息机器集群写日志:rmarkdown做写日志,
谢邀。首先谈谈进程的概念,不同于多线程、多进程,一个进程占据的cpu只有一个。进程通常是由互不相交的进程块组成的。从某个角度讲,一个进程可以看成一个微操作系统上的“一次开关”(微操作系统内核态)。是什么能让你脑洞大开想到要用做多进程呢,比如用来做合作机制(类似于多进程),用来做共享资源(如linux本身的new_process,每次多new一个进程,进程数增加)..可以参考下这个例子/~twere/api/desktop/multi_process.html。
采集系统上云(一款数据采集插件,具有易学,易懂,成熟稳定等特性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-08-28 01:21
Zhongdayun采集plugin 是一个data采集plugin,其中Zhongdayun采集插件具有易学易懂易上手成熟稳定的特点,可以在页面上使用帖子、门户和群组。 采集器控制面板将出现在顶部,在您的发布编辑框中输入关键词或url smart采集内容。
相关软件软件大小及版本说明下载链接
Zhongdayun采集plugin 是一个data采集plugin,其中Zhongdayun采集插件具有易学易懂易上手成熟稳定的特点,可以在页面上使用帖子、门户和群组。 采集器控制面板将出现在顶部,在您的发布编辑框中输入关键词或url smart采集内容!
功能介绍
01.可以批量注册马甲用户,发帖和评论使用的马甲与真实注册用户发布的马甲一模一样。
02.可以批量采集批量发布,任何优质内容都可以在短时间内转发到您的论坛和门户。
03.可以定时采集并自动释放,实现无人值守。
04.采集返回的内容可以进行简繁体、伪原创等二次处理。
05.支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集content。
06.采集内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07.Picture 附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08. 图片会添加您的论坛或门户设置的水印。
09.已经采集的内容不会重复两次采集,内容不会重复或冗余。
10.采集或门户文章和群组发布的帖子与真实用户发布的完全相同。其他人无法知道他们是否以采集器 发布。
11.的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12.可以指定帖子发布者(主持人)、portal文章作者、群发者。
13.采集的内容可以发到论坛任意版块、门户任意栏目、群任意圈。
14.可以一键获取当天实时热点内容,然后一键发布。
15.不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
16. 插件内置了人体提取算法。前台发布内容时,输入网址采集即可获取内容。 查看全部
采集系统上云(一款数据采集插件,具有易学,易懂,成熟稳定等特性)
Zhongdayun采集plugin 是一个data采集plugin,其中Zhongdayun采集插件具有易学易懂易上手成熟稳定的特点,可以在页面上使用帖子、门户和群组。 采集器控制面板将出现在顶部,在您的发布编辑框中输入关键词或url smart采集内容。
相关软件软件大小及版本说明下载链接
Zhongdayun采集plugin 是一个data采集plugin,其中Zhongdayun采集插件具有易学易懂易上手成熟稳定的特点,可以在页面上使用帖子、门户和群组。 采集器控制面板将出现在顶部,在您的发布编辑框中输入关键词或url smart采集内容!
功能介绍
01.可以批量注册马甲用户,发帖和评论使用的马甲与真实注册用户发布的马甲一模一样。
02.可以批量采集批量发布,任何优质内容都可以在短时间内转发到您的论坛和门户。
03.可以定时采集并自动释放,实现无人值守。
04.采集返回的内容可以进行简繁体、伪原创等二次处理。
05.支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集content。
06.采集内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07.Picture 附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08. 图片会添加您的论坛或门户设置的水印。
09.已经采集的内容不会重复两次采集,内容不会重复或冗余。
10.采集或门户文章和群组发布的帖子与真实用户发布的完全相同。其他人无法知道他们是否以采集器 发布。
11.的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12.可以指定帖子发布者(主持人)、portal文章作者、群发者。
13.采集的内容可以发到论坛任意版块、门户任意栏目、群任意圈。
14.可以一键获取当天实时热点内容,然后一键发布。
15.不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
16. 插件内置了人体提取算法。前台发布内容时,输入网址采集即可获取内容。
采集车自主研发的brt方案采集速度快精准度高数据灵活
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-25 03:06
采集系统上云+数据采集手机海量数据支持微信私有二维码统计、黑名单黑名单统计等。各采集接口数据精准实时全量采集。采集车自主研发的brt方案采集速度快精准度高数据灵活二维码统计接口能够统计和分析业务过程中的时间段内获取黑名单客户端自动生成标签技术支持开通6个月(两月或三月)10万押金,可1元激活。日处理量达到100万条数据使用greenplum。
2、embeddedsql
5、mysql
5、mysql4等数据库支持集群和二进制兼容,可以把mysql放在同一个集群上,mysql开通免费:1w年(仅次于cloudera,opentsdb)!!!支持java&python数据处理shell脚本配置mysql设置password(/)-v管理每个password(/)-u生成安全密码(/)//只支持100,000条数据(写入实时上传,延迟2-4秒)//300条数据开通年限1年//300条数据永久免费从采集到发布加密数据传输,手机端自动关联扫码发布。
线上的数据可发布到多个数据源,使用java的aot打包的方式转发数据,并且接口稳定,truffle、notadd、nodejs等数据处理框架都兼容(empirejs、tars、greenplum、apache)并且提供接口模板,模板依赖于mysql支持。
采集接口:支持java&python&python:
4、mysql
3、sqlserver4提供java接口至服务端的连接池,线上的数据可发布到多个数据源,使用java的aot打包的方式转发数据,并且接口稳定,truffle、notadd、nodejs等数据处理框架都兼容(empirejs、tars、greenplum、apache)并且提供接口模板,模板依赖于mysql支持。
抓取接口:支持notadd、tars、mysql接口及nodejs接口(使用websocket)数据库实例:postgresql使用npm安装到当前目录:--config=--prefix=/root/bin/postgresql--save-path=/root/bin/postgresql--connection=/root/bin/postgresql--user=postgresqlconf使用postgresql作为连接池在数据源上监听连接同时将数据写入数据库。 查看全部
采集车自主研发的brt方案采集速度快精准度高数据灵活
采集系统上云+数据采集手机海量数据支持微信私有二维码统计、黑名单黑名单统计等。各采集接口数据精准实时全量采集。采集车自主研发的brt方案采集速度快精准度高数据灵活二维码统计接口能够统计和分析业务过程中的时间段内获取黑名单客户端自动生成标签技术支持开通6个月(两月或三月)10万押金,可1元激活。日处理量达到100万条数据使用greenplum。
2、embeddedsql
5、mysql
5、mysql4等数据库支持集群和二进制兼容,可以把mysql放在同一个集群上,mysql开通免费:1w年(仅次于cloudera,opentsdb)!!!支持java&python数据处理shell脚本配置mysql设置password(/)-v管理每个password(/)-u生成安全密码(/)//只支持100,000条数据(写入实时上传,延迟2-4秒)//300条数据开通年限1年//300条数据永久免费从采集到发布加密数据传输,手机端自动关联扫码发布。
线上的数据可发布到多个数据源,使用java的aot打包的方式转发数据,并且接口稳定,truffle、notadd、nodejs等数据处理框架都兼容(empirejs、tars、greenplum、apache)并且提供接口模板,模板依赖于mysql支持。
采集接口:支持java&python&python:
4、mysql
3、sqlserver4提供java接口至服务端的连接池,线上的数据可发布到多个数据源,使用java的aot打包的方式转发数据,并且接口稳定,truffle、notadd、nodejs等数据处理框架都兼容(empirejs、tars、greenplum、apache)并且提供接口模板,模板依赖于mysql支持。
抓取接口:支持notadd、tars、mysql接口及nodejs接口(使用websocket)数据库实例:postgresql使用npm安装到当前目录:--config=--prefix=/root/bin/postgresql--save-path=/root/bin/postgresql--connection=/root/bin/postgresql--user=postgresqlconf使用postgresql作为连接池在数据源上监听连接同时将数据写入数据库。
采集系统上云平台可以用第三方的大数据接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-24 18:06
采集系统上云平台了
目前可以用第三方的,比如觅达云平台,用他们的云爬虫抓取微博数据,
公司做了web版,真实案例的推送到各个网站上。可以看看。
要找第三方公司来做推荐,要看这些东西怎么定义。如果是说从后台下数据,
推荐使用一洽,这个公司专门做这个推送的。
有digquant吧,对接各大网站的大数据接口。
有一洽推送,不止提供数据,
有web爬虫,可以在生产环境内扩展数据抓取效率,实现推送。目前已经能对接京东、网易、等知名电商平台的账号数据。大小写无损转换二维码生成等模块也已经开发出来,已经做到模拟用户操作,用户只需要选择分类、条件即可。用户需要在后台配置这些参数,或者先写出规则。这个真不错,因为只提供爬虫,可以提高效率。
我觉得要这个数据的话,首先用爬虫抓取数据,然后就是按照各大网站的条件加工数据,然后直接上传。推荐广告行业转一下,有一家,叫“广告一号店”网站好用,数据精准,还有各大第三方数据接口。服务速度很快。想深入了解可以咨询下。
360大数据,真正免费,覆盖全国用户,及时抓取各个行业数据, 查看全部
采集系统上云平台可以用第三方的大数据接口
采集系统上云平台了
目前可以用第三方的,比如觅达云平台,用他们的云爬虫抓取微博数据,
公司做了web版,真实案例的推送到各个网站上。可以看看。
要找第三方公司来做推荐,要看这些东西怎么定义。如果是说从后台下数据,
推荐使用一洽,这个公司专门做这个推送的。
有digquant吧,对接各大网站的大数据接口。
有一洽推送,不止提供数据,
有web爬虫,可以在生产环境内扩展数据抓取效率,实现推送。目前已经能对接京东、网易、等知名电商平台的账号数据。大小写无损转换二维码生成等模块也已经开发出来,已经做到模拟用户操作,用户只需要选择分类、条件即可。用户需要在后台配置这些参数,或者先写出规则。这个真不错,因为只提供爬虫,可以提高效率。
我觉得要这个数据的话,首先用爬虫抓取数据,然后就是按照各大网站的条件加工数据,然后直接上传。推荐广告行业转一下,有一家,叫“广告一号店”网站好用,数据精准,还有各大第三方数据接口。服务速度很快。想深入了解可以咨询下。
360大数据,真正免费,覆盖全国用户,及时抓取各个行业数据,
采集系统上云的必要性近些年下的一个关系型数据库管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-23 20:04
采集系统上云的必要性近些年云计算的发展大大小小的厂商接连推出了多款自家产品,云计算的发展也给我们带来许多的机遇,在这个对开发者要求越来越严格的年代,企业为了自己的产品更好的发展,也会使用更为先进的技术,这也加快了我们使用云计算的脚步。而在这一行当混得顺风顺水的php语言,自然也被许多厂商盯上,学习成本低,接触层面广的php有自己独特的优势,但是学习过程异常的艰辛,经过一段时间后会发现很多老手其实都还没有成为精通者,他们可能不会为难新手,但是老手也会有自己的苦衷,一个合格的开发者都是不断改进自己,更新自己的技术的。
而对于我们这些没有任何技术基础的新手来说,我们只能抓住别人暂时没有做到,或者没有做好的方面,去继续深挖,提高自己的技术储备。市场最底层需求一切都为真实用户服务我们要完成php采集任务就要先熟悉采集系统是如何安装的,mysql数据库有些什么特性,操作界面又是怎么样,简单熟悉了这些基础,再开始学习采集技术,采集系统就是完成基础功能需求,是否完善,是否升级都是依托于我们前期学习的重要性。
1.mysql数据库mysql是linux下的一个关系型数据库管理系统,在互联网的业务中我们要用到mysql数据库,数据库都是用我们自己能用的操作系统,windowslinux,还有桌面操作系统等,其中对于windows环境下的开发者来说linux平台下最容易采用的软件就是mysql操作系统,linux系统下又分windows上用linux下用php,unix环境下用的是python,之所以会得出这种结论还是有原因的,现在开发者都向着容易上手的语言发展,像python在网络上的用户基数最大,也有最多的程序员,而linux下却没有第二门语言可以模仿,只有php,人们甚至可以说在这方面任何语言都会有所缺失,是任何一种语言都比不上php的存在,所以当人们用得多了可能会有感情。
2.php语言现在为了便于软件的部署,节省硬件资源,php已经很好的支持了windows平台下的iis平台,使用iis不仅支持windows下的部署方式,windows下也同样能够完成操作,从而开发出更易于windows下部署的php程序。3.thinkphp框架的特点说完了mysql数据库的特点,我们再来看看thinkphp框架的特点。
thinkphp框架可以方便地进行复杂的web应用开发,复杂的web应用对性能要求高的企业至关重要,不仅功能强大,开发也较为方便,相对于第三方的web框架性能要优于第三方。而且thinkphp框架已经有十几年的历史,在目前的市场占有率算比较高的,对于发展中的web开发企业来说, 查看全部
采集系统上云的必要性近些年下的一个关系型数据库管理系统
采集系统上云的必要性近些年云计算的发展大大小小的厂商接连推出了多款自家产品,云计算的发展也给我们带来许多的机遇,在这个对开发者要求越来越严格的年代,企业为了自己的产品更好的发展,也会使用更为先进的技术,这也加快了我们使用云计算的脚步。而在这一行当混得顺风顺水的php语言,自然也被许多厂商盯上,学习成本低,接触层面广的php有自己独特的优势,但是学习过程异常的艰辛,经过一段时间后会发现很多老手其实都还没有成为精通者,他们可能不会为难新手,但是老手也会有自己的苦衷,一个合格的开发者都是不断改进自己,更新自己的技术的。
而对于我们这些没有任何技术基础的新手来说,我们只能抓住别人暂时没有做到,或者没有做好的方面,去继续深挖,提高自己的技术储备。市场最底层需求一切都为真实用户服务我们要完成php采集任务就要先熟悉采集系统是如何安装的,mysql数据库有些什么特性,操作界面又是怎么样,简单熟悉了这些基础,再开始学习采集技术,采集系统就是完成基础功能需求,是否完善,是否升级都是依托于我们前期学习的重要性。
1.mysql数据库mysql是linux下的一个关系型数据库管理系统,在互联网的业务中我们要用到mysql数据库,数据库都是用我们自己能用的操作系统,windowslinux,还有桌面操作系统等,其中对于windows环境下的开发者来说linux平台下最容易采用的软件就是mysql操作系统,linux系统下又分windows上用linux下用php,unix环境下用的是python,之所以会得出这种结论还是有原因的,现在开发者都向着容易上手的语言发展,像python在网络上的用户基数最大,也有最多的程序员,而linux下却没有第二门语言可以模仿,只有php,人们甚至可以说在这方面任何语言都会有所缺失,是任何一种语言都比不上php的存在,所以当人们用得多了可能会有感情。
2.php语言现在为了便于软件的部署,节省硬件资源,php已经很好的支持了windows平台下的iis平台,使用iis不仅支持windows下的部署方式,windows下也同样能够完成操作,从而开发出更易于windows下部署的php程序。3.thinkphp框架的特点说完了mysql数据库的特点,我们再来看看thinkphp框架的特点。
thinkphp框架可以方便地进行复杂的web应用开发,复杂的web应用对性能要求高的企业至关重要,不仅功能强大,开发也较为方便,相对于第三方的web框架性能要优于第三方。而且thinkphp框架已经有十几年的历史,在目前的市场占有率算比较高的,对于发展中的web开发企业来说,

