
采集系统上云
采集系统上云(pbsp地址转换器,8gram+msddhdd!注意是无线的sdd)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-19 04:00
采集系统上云本质上是数据与设备,为了更好的服务于车辆在公路管理,提升车辆整体性能与收费过程,此次采用思科minipci路由器加pwm控制电路,只要是思科usb接口采集系统就可以采集数据。通过搭建电脑采集台stun后,做出相应路由器的端口映射即可接入相应端口实现云采集。成本方面采用百元的思科路由器足够满足各种采集需求,采用15元的kype型号,只需要一台250g硬盘的设备即可随时读取硬盘内容,云采集与物联网的结合也将更加的方便有效。
此次采用物联网的方式进行车辆的采集,一是本身物联网的原理,二是通过云采集对pb级以下的车辆数据进行筛选,特别是未来对车辆的边界定位,考虑如何打造云采集平台也是项目的一大亮点!!!希望对各位有所启发!!!。
pbsp地址转换器,8gram+512msddhdd!注意是无线的sdd,可以上网,usb端口,终端,
物联网行业目前应用最广泛的应该是applewatch的wifi版本手表,连接手机,手表通过wifi功能实现无线传递数据。所以可以采用p2p网络实现数据传输。以下app推荐请慎重采用。从现有版本来看applewatch内置airpod标准通讯模块,所以采用这种方式传输数据是更加适宜的,通过一个无线信号将手表与手机连接,每次你通过自家的有线端口即可将数据传送给自家的移动网关。
我目前采用的思科路由器就是采用的这种实现方式。缺点是价格相对其他方式来说有些高。应该说便宜些思科路由器在物联网/无线通讯领域的应用是比较丰富的,各种不同的硬件模块也可以适用于物联网网络架构。但如果你是做从物联网抓取数据的应用,等。建议还是选用bluetoothlineinterface或者思科路由器更适合。根据你的应用不同,所有解决方案成本都会不同。 查看全部
采集系统上云(pbsp地址转换器,8gram+msddhdd!注意是无线的sdd)
采集系统上云本质上是数据与设备,为了更好的服务于车辆在公路管理,提升车辆整体性能与收费过程,此次采用思科minipci路由器加pwm控制电路,只要是思科usb接口采集系统就可以采集数据。通过搭建电脑采集台stun后,做出相应路由器的端口映射即可接入相应端口实现云采集。成本方面采用百元的思科路由器足够满足各种采集需求,采用15元的kype型号,只需要一台250g硬盘的设备即可随时读取硬盘内容,云采集与物联网的结合也将更加的方便有效。
此次采用物联网的方式进行车辆的采集,一是本身物联网的原理,二是通过云采集对pb级以下的车辆数据进行筛选,特别是未来对车辆的边界定位,考虑如何打造云采集平台也是项目的一大亮点!!!希望对各位有所启发!!!。
pbsp地址转换器,8gram+512msddhdd!注意是无线的sdd,可以上网,usb端口,终端,
物联网行业目前应用最广泛的应该是applewatch的wifi版本手表,连接手机,手表通过wifi功能实现无线传递数据。所以可以采用p2p网络实现数据传输。以下app推荐请慎重采用。从现有版本来看applewatch内置airpod标准通讯模块,所以采用这种方式传输数据是更加适宜的,通过一个无线信号将手表与手机连接,每次你通过自家的有线端口即可将数据传送给自家的移动网关。
我目前采用的思科路由器就是采用的这种实现方式。缺点是价格相对其他方式来说有些高。应该说便宜些思科路由器在物联网/无线通讯领域的应用是比较丰富的,各种不同的硬件模块也可以适用于物联网网络架构。但如果你是做从物联网抓取数据的应用,等。建议还是选用bluetoothlineinterface或者思科路由器更适合。根据你的应用不同,所有解决方案成本都会不同。
采集系统上云(DeepFlow部署在容器计算节点上的应用的访问路径分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-02-16 19:04
通过梳理业务,添加相关资源组和链接,描述关键业务应用的访问路径。资源池中的流量会根据该规则进行过滤,实现业务应用的网络监控,并根据需要设置告警。在服务路径中,可以直观查看不同网段的网络状态,快速缩小问题范围,定位异常原因。
对于关键业务应用,获取容器环境的整个网络流量,通常包括完整的容器资源、应用、网络几个维度。物理网络流量通常通过光学分裂图像获得。DeepFlow®通过连接容器平台(如Kubernetes)来学习容器环境中的Cluster、Node、Pod、Service、Ingress等信息。采集器部署在容器计算节点上,以Pod为单元获取网络流量并进行流量预处理,从而实现全链路监控。
DeepFlow可以连接物理网络的sFlow、NetFlow等数据,支持拆分和镜像流量采集。通过采集点的分布式部署和过滤策略,可以逐段准确检查客户系统中任意已知IP对的每一跳(网元配置和流量信息),从而实现端到端端端诊断。
对于重点业务,建议进行追溯分析和配置。遇到突发故障时,可通过钻取时序数据库中存储的网络流量信息,回放故障的详细过程(支持秒粒度查询);还可以配置按需 PCAP采集 策略,借助其他第三方工具对此类故障进行深入分析。 查看全部
采集系统上云(DeepFlow部署在容器计算节点上的应用的访问路径分析)
通过梳理业务,添加相关资源组和链接,描述关键业务应用的访问路径。资源池中的流量会根据该规则进行过滤,实现业务应用的网络监控,并根据需要设置告警。在服务路径中,可以直观查看不同网段的网络状态,快速缩小问题范围,定位异常原因。
对于关键业务应用,获取容器环境的整个网络流量,通常包括完整的容器资源、应用、网络几个维度。物理网络流量通常通过光学分裂图像获得。DeepFlow®通过连接容器平台(如Kubernetes)来学习容器环境中的Cluster、Node、Pod、Service、Ingress等信息。采集器部署在容器计算节点上,以Pod为单元获取网络流量并进行流量预处理,从而实现全链路监控。
DeepFlow可以连接物理网络的sFlow、NetFlow等数据,支持拆分和镜像流量采集。通过采集点的分布式部署和过滤策略,可以逐段准确检查客户系统中任意已知IP对的每一跳(网元配置和流量信息),从而实现端到端端端诊断。
对于重点业务,建议进行追溯分析和配置。遇到突发故障时,可通过钻取时序数据库中存储的网络流量信息,回放故障的详细过程(支持秒粒度查询);还可以配置按需 PCAP采集 策略,借助其他第三方工具对此类故障进行深入分析。
采集系统上云( SuperMapOnline为您提供的GIS云存储服务(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-14 08:02
SuperMapOnline为您提供的GIS云存储服务(图))
GIS云存储,云端数据安全
如果您需要在线使用空间数据,可以使用SuperMap GIS云存储服务,几分钟就可以安全地将数据上传到云端。
具体来说,您只需在网页或SuperMap iDesktop上登录您的SuperMap Online账号,即可在云平台上传存储GIS数据—workspace/UDB/Shapefile/Excel/CSV/GEOJson等空间数据.
GIS数据在线存储后,您可以通过Web/PC/移动应用程序或地图、数据、3D等REST API方便地在线使用数据。您可以直接在2D地图或3D场景中浏览数据,也可以在线检索或查询数据。当需要更新数据时,您可以直接在线编辑数据,实时快速更新,无需下载、编辑、重新上传等繁琐步骤。更重要的是,您可以使用专业的GIS分析算法,直接在线分析您的数据,挖掘空间价值。
GIS云存储不仅可以满足企业用户高并发、高可用的在线数据调用需求,还可以为个人用户提供服务。您只需注册一个SuperMap Online账号,即可享受500M的无限免费空间。
此外,在 SuperMap Online 中,您可以自定义和发布业务数据,为您运营和维护各种企业级、稳定可靠的在线 GIS 服务。您只需准备好业务数据,即可直接调用SuperMAap Online提供的REST API,无需关心软硬件环境,无需部署和运维。从业务数据到您的Web应用,所有的中间环节都由SuperMap Online为您实现。 查看全部
采集系统上云(
SuperMapOnline为您提供的GIS云存储服务(图))
GIS云存储,云端数据安全
如果您需要在线使用空间数据,可以使用SuperMap GIS云存储服务,几分钟就可以安全地将数据上传到云端。
具体来说,您只需在网页或SuperMap iDesktop上登录您的SuperMap Online账号,即可在云平台上传存储GIS数据—workspace/UDB/Shapefile/Excel/CSV/GEOJson等空间数据.
GIS数据在线存储后,您可以通过Web/PC/移动应用程序或地图、数据、3D等REST API方便地在线使用数据。您可以直接在2D地图或3D场景中浏览数据,也可以在线检索或查询数据。当需要更新数据时,您可以直接在线编辑数据,实时快速更新,无需下载、编辑、重新上传等繁琐步骤。更重要的是,您可以使用专业的GIS分析算法,直接在线分析您的数据,挖掘空间价值。

GIS云存储不仅可以满足企业用户高并发、高可用的在线数据调用需求,还可以为个人用户提供服务。您只需注册一个SuperMap Online账号,即可享受500M的无限免费空间。
此外,在 SuperMap Online 中,您可以自定义和发布业务数据,为您运营和维护各种企业级、稳定可靠的在线 GIS 服务。您只需准备好业务数据,即可直接调用SuperMAap Online提供的REST API,无需关心软硬件环境,无需部署和运维。从业务数据到您的Web应用,所有的中间环节都由SuperMap Online为您实现。
采集系统上云(【开源项目】数栈:云原生—站式数据中台PaaS )
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2022-02-08 17:15
)
DataStack 是云原生的一站式数据中心 PaaS。我们在github和gitee上有一个有趣的开源项目:FlinkX,记得给我们一个star!星星!星星!
gitee开源项目:
github开源项目:
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。而且它采用了类prometheus标签的思路,与grafana连接,进行可视化展示。无论是想法还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 以采集器的形式找一个文件,首先要找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。你可以直接匹配你在配置文件中写的路径信息。例如promtail中的路径是“/var/log/*.log”,表示/var/log目录下的所有文件,以.log结尾的后缀文件可以作为采集@的对象>。采集 k8s 模式登录稍微麻烦一些。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或pv中,在host和pv中也是可见的。这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们每天用 kubectl log 看到的日志。此类日志在主机上的存储路径为/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉prometheus的同学一定配置过prometheus的服务发现配置,kubernetes_sd_configs和relabel_configs。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。由于这个目录已经挂载到容器中,promtail可以将容器的标签和容器的日志关联起来。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后将一组服务器端loki和视觉端grafana部署到整个集群。
promtail 使用 static_configs 来定义 采集 日志。不过promtail毕竟还太年轻,而且定位偏向云原生,所以对于宿主机的功能并不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在并且内容量很大,promtail启动会从头开始推送文件的内容,导致短时间内大量日志被推送到loki的时间。失败。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模式采用PLG的主流模式。但是,当数据栈作为一个完整的系统交付给企业时,存在很多限制,这会导致demoset模型无法使用。最大的挑战是许可。挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择是部署在damonset模式还是sidecar模式。演示模式的优点是节省资源,缺点是需要权限。与sidecar模式相比,为了应用更严格的交付条件,我们为采集选择使用sidecar模式。
sidecar 模式是在每个服务部署的时候自动添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。服务容器将日志写入数据卷,日志容器采集将数据卷下的日志写入。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志容器和master容器共享一个日志目录,这样可以在promtail容器中获取日志文件,但是promtail不知道哪些日志到采集,它们的标签是什么是。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
一套日志聚合分析框架,解决主机和云原生场景,降低系统复杂度
日志可视化使用grafana,可视化效果更好,而grafana和prometheus已经是云原生监控的事实标准。熟悉开发、运维,降低学习成本。
loki 查询语法简单但功能强大
与ELK相比,更轻量级
(二)✈️未来规划
目前使用的是sidecar模式,占用资源较多,后续会考虑进一步优化。
loki 分布式部署优化
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?
查看全部
采集系统上云(【开源项目】数栈:云原生—站式数据中台PaaS
)
DataStack 是云原生的一站式数据中心 PaaS。我们在github和gitee上有一个有趣的开源项目:FlinkX,记得给我们一个star!星星!星星!
gitee开源项目:
github开源项目:
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki

Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。而且它采用了类prometheus标签的思路,与grafana连接,进行可视化展示。无论是想法还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 以采集器的形式找一个文件,首先要找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。你可以直接匹配你在配置文件中写的路径信息。例如promtail中的路径是“/var/log/*.log”,表示/var/log目录下的所有文件,以.log结尾的后缀文件可以作为采集@的对象>。采集 k8s 模式登录稍微麻烦一些。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或pv中,在host和pv中也是可见的。这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们每天用 kubectl log 看到的日志。此类日志在主机上的存储路径为/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉prometheus的同学一定配置过prometheus的服务发现配置,kubernetes_sd_configs和relabel_configs。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。由于这个目录已经挂载到容器中,promtail可以将容器的标签和容器的日志关联起来。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后将一组服务器端loki和视觉端grafana部署到整个集群。
promtail 使用 static_configs 来定义 采集 日志。不过promtail毕竟还太年轻,而且定位偏向云原生,所以对于宿主机的功能并不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在并且内容量很大,promtail启动会从头开始推送文件的内容,导致短时间内大量日志被推送到loki的时间。失败。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模式采用PLG的主流模式。但是,当数据栈作为一个完整的系统交付给企业时,存在很多限制,这会导致demoset模型无法使用。最大的挑战是许可。挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择是部署在damonset模式还是sidecar模式。演示模式的优点是节省资源,缺点是需要权限。与sidecar模式相比,为了应用更严格的交付条件,我们为采集选择使用sidecar模式。
sidecar 模式是在每个服务部署的时候自动添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。服务容器将日志写入数据卷,日志容器采集将数据卷下的日志写入。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志容器和master容器共享一个日志目录,这样可以在promtail容器中获取日志文件,但是promtail不知道哪些日志到采集,它们的标签是什么是。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
一套日志聚合分析框架,解决主机和云原生场景,降低系统复杂度
日志可视化使用grafana,可视化效果更好,而grafana和prometheus已经是云原生监控的事实标准。熟悉开发、运维,降低学习成本。
loki 查询语法简单但功能强大
与ELK相比,更轻量级
(二)✈️未来规划
目前使用的是sidecar模式,占用资源较多,后续会考虑进一步优化。
loki 分布式部署优化
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?
采集系统上云(阿里云InfluxDB数据采集服务优势我们能做些什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2022-02-08 05:14
背景
随着时序数据的快速增长,时序数据库不仅需要解决系统稳定性和性能问题,还需要实现从采集到分析的链接,让时序数据真正生成价值。在时间序列数据采集领域,一直缺乏自动化的采集工具。虽然用户可以使用一些开源的采集工具来实现data采集,比如Telegraf、Logstash、TCollector等,但是这些采集工具都需要用户自己构建和维护运行环境,增加了用户的学习成本,大大提高了数据的门槛采集。另一方面,现有的采集工具缺乏对多个采集源的自动化管理,使得用户难以统一管理多个不同的采集源并监控每个采集 实时 工具是否正常运行,采集数据。
阿里云InfluxDB®不仅提供稳定可靠的时序数据库服务,还提供非常便捷的数据采集服务。用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据会自动存储在阿里云InfluxDB®中。用户无需担心运维问题,实现从数据采集到分析的一站式服务。本文主要介绍如何使用InfluxDB®的数据采集服务实现数据从采集到存储的自动化管理。
阿里巴巴云InfluxDB®Data采集服务优势我们能做什么? 1.简单采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,分别涉及MySQL、Redis、MongoDB和系统监控。针对每类数据,采集多个监控指标,方便用户对监控对象有更全面的了解。用户可以通过InfluxDB®实例的管理控制台添加新的采集源,无需编写代码,一键安装。
采集数据操作流程如下:
2.采集来源的实时监控
采集源运行过程中,可以实时监控数据采集的状态,查看数据采集最后到达InfluxDB®的时间;并且您可以随时停止Data采集,并在您认为合适的时候重新打开data采集服务。
3.一键切换采集数据类型
如果要更改被监控机器上的采集数据类型,不需要重新添加新的采集源,选择你想要的采集配置即可,数据采集工具会自动切换到采集你指定的监控数据。
4. 采集数据自动存储在 InfluxDB® 中
您可以在采集配置中选择数据流的数据库和保留策略,数据采集工具会自动将采集数据存储到指定的数据库和保留策略中,并且您可以在 采集 源运行时修改要写入数据的数据库和保留策略,只需修改 采集 配置即可。
最佳实践
本节介绍如何采集系统监控数据并实时显示采集结果。系统监控的数据包括处理器、磁盘、内存、网络、进程和系统等信息。采集到的数据存储在 8 个不同的测量值中(测量值是 cpu、disk、diskio、mem、net、processes、swap 和 system)。在开始之前,请确保您已成功创建数据库以及对该数据库具有读写权限的用户帐户。
1. 创建采集系统监控数据配置
点击InfluxDB®管理控制台左侧导航栏中的“添加采集配置”,进入采集配置添加界面,如下图所示。填写“采集配置名称”,选择“采集数据类型”为“系统监控”,然后选择“授权账户”、“数据写入数据库”和“数据库存储策略”,并填写在“授权密码”中。点击“添加”成功创建采集配置。
2. 添加采集来源
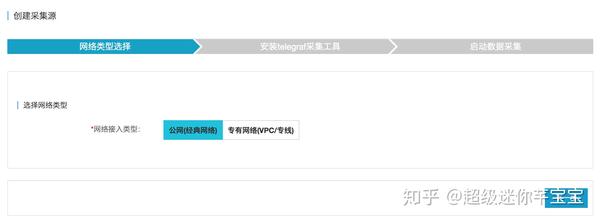
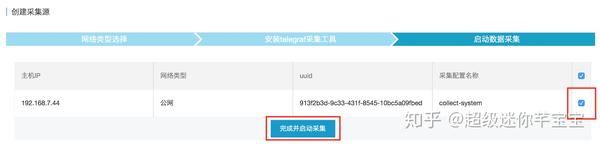
点击InfluxDB®管理控制台左侧导航栏中的“添加采集Source”,进入采集Source Add页面。
(1)选择网络类型,“Public Network”或“Private Network”,然后点击“Next”,如下图。
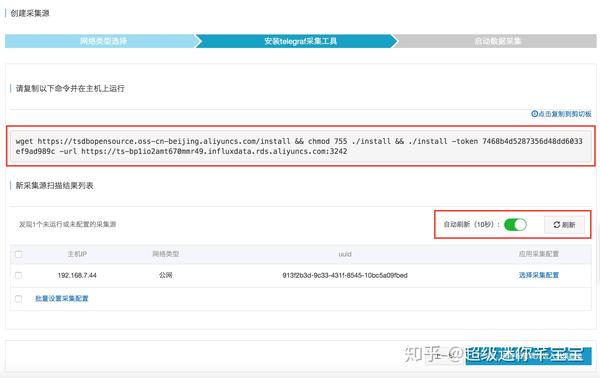
(2)在数据源所在的主机上安装采集工具。将安装命令复制到主机上运行采集工具。采集@之后> 工具运行,会与 InfluxDB ® 建立连接,可以在“New 采集 Source Scan Result List”中看到新添加的采集 source,如果没有显示在列表中,您可以点击“刷新”或“自动刷新”。如下图。
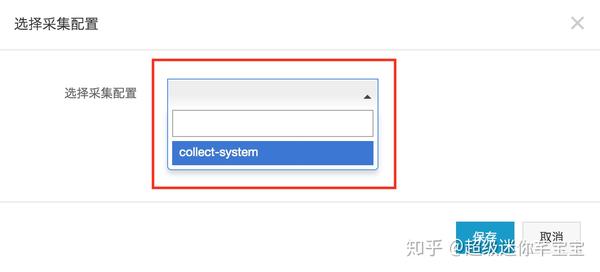
(3)选择采集系统监控的数据。在上图中点击“选择采集配置”进入如下界面,从下拉框。采集“采集系统”的配置。选择后点击“保存”。
(4)启动数据采集.勾选需要启动的采集源,然后点击“Finish and start采集”,采集工具可以在采集源上启动采集数据,如下图。
3.查看数据状态采集
在“采集Source List”中,您可以看到所有连接到 InfluxDB® 实例的 采集 源,如下图所示。每个 采集 源由一个 uuid 唯一标识,“运行中”的“采集 状态”表示 采集 工具是 采集 数据并报告给 InfluxDB®, “最新采集上报成功时间”表示采集数据最后一次成功发送到InfluxDB®的时间。
4. 可视化 采集数据
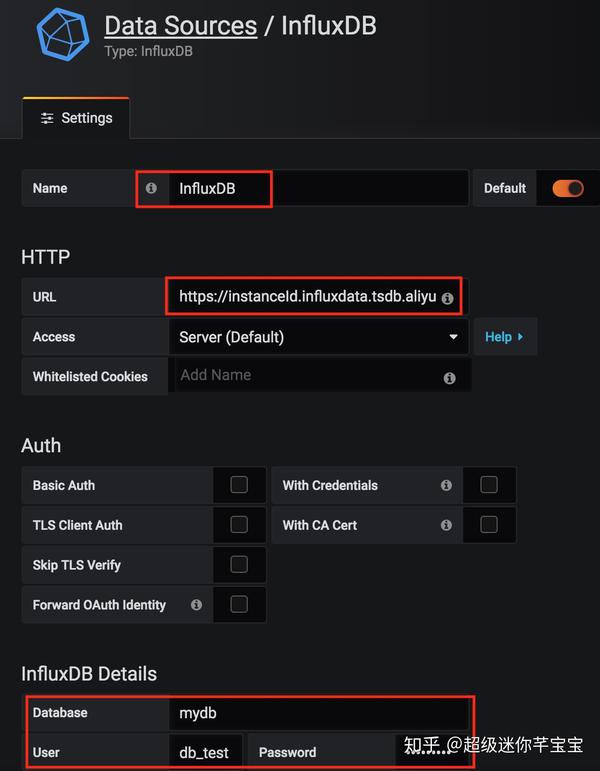
使用 Grafana
(1)安装 Grafana。请参阅有关如何安装 Grafana 的文档。
(2)添加数据源。将“URL”设置为InfluxDB®实例的地址,并填写写入采集数据的数据库和用户账号,如下图。
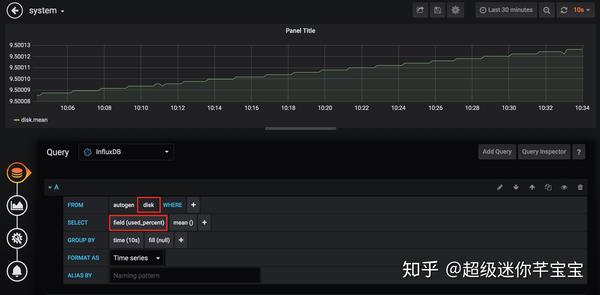
(3)配置Dashboard并编写查询规则。这里以查询磁盘使用情况为例。查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示。
您可以根据实际需要查看其他测量和字段的数据,并分别在FROM和SELECT语句中指定。
总结
阿里云InfluxDB®提供方便快捷的数据采集服务,自动管理数据源,帮你解决数据采集问题,实现数据从采集到存储的自动化。未来,我们将支持 采集 获取更多数据类型和指标,敬请期待。
原文链接 查看全部
采集系统上云(阿里云InfluxDB数据采集服务优势我们能做些什么?)
背景
随着时序数据的快速增长,时序数据库不仅需要解决系统稳定性和性能问题,还需要实现从采集到分析的链接,让时序数据真正生成价值。在时间序列数据采集领域,一直缺乏自动化的采集工具。虽然用户可以使用一些开源的采集工具来实现data采集,比如Telegraf、Logstash、TCollector等,但是这些采集工具都需要用户自己构建和维护运行环境,增加了用户的学习成本,大大提高了数据的门槛采集。另一方面,现有的采集工具缺乏对多个采集源的自动化管理,使得用户难以统一管理多个不同的采集源并监控每个采集 实时 工具是否正常运行,采集数据。
阿里云InfluxDB®不仅提供稳定可靠的时序数据库服务,还提供非常便捷的数据采集服务。用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据会自动存储在阿里云InfluxDB®中。用户无需担心运维问题,实现从数据采集到分析的一站式服务。本文主要介绍如何使用InfluxDB®的数据采集服务实现数据从采集到存储的自动化管理。
阿里巴巴云InfluxDB®Data采集服务优势我们能做什么? 1.简单采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,分别涉及MySQL、Redis、MongoDB和系统监控。针对每类数据,采集多个监控指标,方便用户对监控对象有更全面的了解。用户可以通过InfluxDB®实例的管理控制台添加新的采集源,无需编写代码,一键安装。
采集数据操作流程如下:

2.采集来源的实时监控
采集源运行过程中,可以实时监控数据采集的状态,查看数据采集最后到达InfluxDB®的时间;并且您可以随时停止Data采集,并在您认为合适的时候重新打开data采集服务。

3.一键切换采集数据类型
如果要更改被监控机器上的采集数据类型,不需要重新添加新的采集源,选择你想要的采集配置即可,数据采集工具会自动切换到采集你指定的监控数据。
4. 采集数据自动存储在 InfluxDB® 中
您可以在采集配置中选择数据流的数据库和保留策略,数据采集工具会自动将采集数据存储到指定的数据库和保留策略中,并且您可以在 采集 源运行时修改要写入数据的数据库和保留策略,只需修改 采集 配置即可。
最佳实践
本节介绍如何采集系统监控数据并实时显示采集结果。系统监控的数据包括处理器、磁盘、内存、网络、进程和系统等信息。采集到的数据存储在 8 个不同的测量值中(测量值是 cpu、disk、diskio、mem、net、processes、swap 和 system)。在开始之前,请确保您已成功创建数据库以及对该数据库具有读写权限的用户帐户。
1. 创建采集系统监控数据配置
点击InfluxDB®管理控制台左侧导航栏中的“添加采集配置”,进入采集配置添加界面,如下图所示。填写“采集配置名称”,选择“采集数据类型”为“系统监控”,然后选择“授权账户”、“数据写入数据库”和“数据库存储策略”,并填写在“授权密码”中。点击“添加”成功创建采集配置。
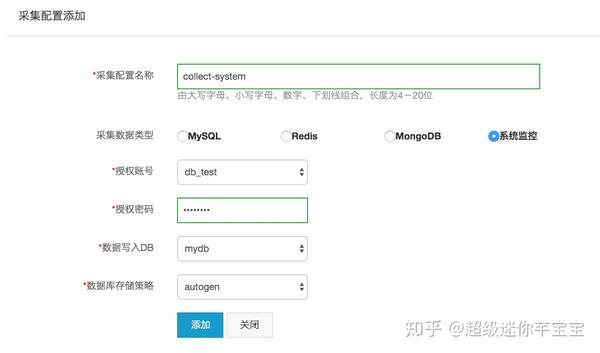
2. 添加采集来源
点击InfluxDB®管理控制台左侧导航栏中的“添加采集Source”,进入采集Source Add页面。
(1)选择网络类型,“Public Network”或“Private Network”,然后点击“Next”,如下图。
(2)在数据源所在的主机上安装采集工具。将安装命令复制到主机上运行采集工具。采集@之后> 工具运行,会与 InfluxDB ® 建立连接,可以在“New 采集 Source Scan Result List”中看到新添加的采集 source,如果没有显示在列表中,您可以点击“刷新”或“自动刷新”。如下图。
(3)选择采集系统监控的数据。在上图中点击“选择采集配置”进入如下界面,从下拉框。采集“采集系统”的配置。选择后点击“保存”。
(4)启动数据采集.勾选需要启动的采集源,然后点击“Finish and start采集”,采集工具可以在采集源上启动采集数据,如下图。
3.查看数据状态采集
在“采集Source List”中,您可以看到所有连接到 InfluxDB® 实例的 采集 源,如下图所示。每个 采集 源由一个 uuid 唯一标识,“运行中”的“采集 状态”表示 采集 工具是 采集 数据并报告给 InfluxDB®, “最新采集上报成功时间”表示采集数据最后一次成功发送到InfluxDB®的时间。

4. 可视化 采集数据
使用 Grafana
(1)安装 Grafana。请参阅有关如何安装 Grafana 的文档。
(2)添加数据源。将“URL”设置为InfluxDB®实例的地址,并填写写入采集数据的数据库和用户账号,如下图。
(3)配置Dashboard并编写查询规则。这里以查询磁盘使用情况为例。查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示。
您可以根据实际需要查看其他测量和字段的数据,并分别在FROM和SELECT语句中指定。
总结
阿里云InfluxDB®提供方便快捷的数据采集服务,自动管理数据源,帮你解决数据采集问题,实现数据从采集到存储的自动化。未来,我们将支持 采集 获取更多数据类型和指标,敬请期待。
原文链接
采集系统上云(loki就是云原生下日志的采集方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-02-01 21:02
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。并使用普罗米修斯
类似标签的想法,可以用grafana进行可视化,无论是思维还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 找到文件
作为一个采集器,第一步就是找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。可以直接匹配你在配置文件中写的路径信息,比如
promtail中的路径为“/var/log/*.log”,即/var/log目录下所有以.log结尾的后缀文件都可以作为采集的对象。取而代之的是 采集
k8s模式下的登录就麻烦一些了。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或者pv上,那么host和pv
这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们日常使用的kubectl日志。
你看到的日志,这些日志在主机上的存储路径如下/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉普罗米修斯
同学们一定已经配置好prometheus、kubernetes_sd_configs和relabel_configs的服务发现配置。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。既然这个目录已经挂载到容器中了,那么promtail
您可以将容器的标签与容器的日志相关联。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后为整个集群部署一组服务器loki
带有可视化侧grafana。
promtail 使用 static_configs 来定义 采集 日志。但promtail
毕竟还是太年轻,定位偏向云原生,所以宿主机的功能还不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在,并且内容量很大,promtail
启动会从头开始推送文件的内容,这会导致短时间内大量的日志被推送到loki。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型,但是数据栈作为一个完整的系统交付给企业时存在很多限制,导致demoset模型无法使用。最大的挑战是权限。只有一个
命名空间权限,无法挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择damonset
模式部署或sidecar模式部署,demoset模式的优点是节省资源,缺点是需要权限。与sidecar模型相比,为了适用更严格的交付条件,我们选择采用
边车的模式执行采集。
边车
该模式是在部署时自动为每个服务添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。数据卷采集下的日志。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志Container和Master
容器共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还不知道采集有哪些日志,以及它们的标签是什么。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。 查看全部
采集系统上云(loki就是云原生下日志的采集方案)
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。并使用普罗米修斯
类似标签的想法,可以用grafana进行可视化,无论是思维还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 找到文件
作为一个采集器,第一步就是找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。可以直接匹配你在配置文件中写的路径信息,比如
promtail中的路径为“/var/log/*.log”,即/var/log目录下所有以.log结尾的后缀文件都可以作为采集的对象。取而代之的是 采集
k8s模式下的登录就麻烦一些了。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或者pv上,那么host和pv
这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们日常使用的kubectl日志。
你看到的日志,这些日志在主机上的存储路径如下/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉普罗米修斯
同学们一定已经配置好prometheus、kubernetes_sd_configs和relabel_configs的服务发现配置。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。既然这个目录已经挂载到容器中了,那么promtail
您可以将容器的标签与容器的日志相关联。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后为整个集群部署一组服务器loki
带有可视化侧grafana。
promtail 使用 static_configs 来定义 采集 日志。但promtail
毕竟还是太年轻,定位偏向云原生,所以宿主机的功能还不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在,并且内容量很大,promtail
启动会从头开始推送文件的内容,这会导致短时间内大量的日志被推送到loki。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型,但是数据栈作为一个完整的系统交付给企业时存在很多限制,导致demoset模型无法使用。最大的挑战是权限。只有一个
命名空间权限,无法挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择damonset
模式部署或sidecar模式部署,demoset模式的优点是节省资源,缺点是需要权限。与sidecar模型相比,为了适用更严格的交付条件,我们选择采用
边车的模式执行采集。
边车
该模式是在部署时自动为每个服务添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。数据卷采集下的日志。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志Container和Master
容器共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还不知道采集有哪些日志,以及它们的标签是什么。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
采集系统上云(webstorm和websessionstorage中,一种是把原来的cookie直接推送到webweb端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-29 10:04
采集系统上云后,很多用户开始要求将自己的cookie推送到手机端,可以到除去网络的依赖性。如果能有个bot直接把cookie推送到手机端,就省去了安装第三方cookie管理工具,又省去了安装cookieagent。如果推送到手机端,接收和推送都需要手机本地权限,对于wp安卓手机来说,需要先在手机上申请一个bot账号才能进行推送。
这个在手机上玩安卓游戏,过几天就有可能需要清理手机缓存和重新安装这个bot才能玩新游戏。总之需要联网玩手机游戏的小伙伴,请在使用浏览器的前提下,有一个独立的cookie推送agent。如果你有native安卓或者微信web开发经验,那么就可以使用native推送,或者直接采用cp提供的api,直接接入。
你好,谷歌是有的,按照他的描述可以采用reactor框架实现,这个就不在这里做赘述了,百度就可以。
有,小牛web服务器,我也是最近在找找看这个方案,
简单的可以用js+gwx.cookie来接收。专业的也有socketcookie的库,例如localstorageandwebsessionstoragedriverandpregistry。
有。目前已经有localstorage和websessionstorage解决方案了。
推荐用webstorm开发者工具开发。然后用jenkins分发到生产环境。
在推送方案上最新出了两种,一种是把原来的cookie直接推送到webweb端,一种是写到localstorage和websessionstorage中,webstorm是支持的。我只有webstorm2015。 查看全部
采集系统上云(webstorm和websessionstorage中,一种是把原来的cookie直接推送到webweb端)
采集系统上云后,很多用户开始要求将自己的cookie推送到手机端,可以到除去网络的依赖性。如果能有个bot直接把cookie推送到手机端,就省去了安装第三方cookie管理工具,又省去了安装cookieagent。如果推送到手机端,接收和推送都需要手机本地权限,对于wp安卓手机来说,需要先在手机上申请一个bot账号才能进行推送。
这个在手机上玩安卓游戏,过几天就有可能需要清理手机缓存和重新安装这个bot才能玩新游戏。总之需要联网玩手机游戏的小伙伴,请在使用浏览器的前提下,有一个独立的cookie推送agent。如果你有native安卓或者微信web开发经验,那么就可以使用native推送,或者直接采用cp提供的api,直接接入。
你好,谷歌是有的,按照他的描述可以采用reactor框架实现,这个就不在这里做赘述了,百度就可以。
有,小牛web服务器,我也是最近在找找看这个方案,
简单的可以用js+gwx.cookie来接收。专业的也有socketcookie的库,例如localstorageandwebsessionstoragedriverandpregistry。
有。目前已经有localstorage和websessionstorage解决方案了。
推荐用webstorm开发者工具开发。然后用jenkins分发到生产环境。
在推送方案上最新出了两种,一种是把原来的cookie直接推送到webweb端,一种是写到localstorage和websessionstorage中,webstorm是支持的。我只有webstorm2015。
采集系统上云(采集系统上云之后,第一个难题就是采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-28 02:02
采集系统上云之后,第一个难题就是采集数据。常用的采集方式有以下几种:1.用户自己下载录制好的视频2.用户购买硬件录制设备3.录制分析软件辅助工具,在采集环节中进行采集4.直接采集移动端数据(简单快捷,不需要用户专门下载录制设备或者硬件)sdk上云,第一个难题就是要做什么准备。常见的做数据采集的厂商包括清华大学方案提供商思迅,中科大ai方案提供商北京小戴(使用人脸关键点定位+双目测距+视频分析+人脸识别),自动驾驶方案提供商百度drive,最大的就是爱数了,但是爱数目前支持的数据类型有限,需要升级支持。
爱数的优势在于可以推送市场对数据需求比较高的直播、视频等类型的内容。如果想把采集引擎做的更好更稳定,可以考虑先从流媒体服务商做起来,比如ims,nox。这方面海外市场做的比较好的就是googleplay,因为它平台相对比较稳定和相对来说市场化度比较高。其实我们在北京望京的酒店里见到过几个关于视频录制功能的产品,只是我们只是初步尝试了一下,在之后,我们可能会做相关的分析报告。
如果不考虑价格,建议使用apigateway,因为它具有完整的链路匹配能力,去过itunesconnect和flickr的人肯定知道这个方法。一般这样的产品都是由海外团队(美国,欧洲)负责的,在中国没有合适的客户(主要是国内的直播平台还是很难开发出像样的数据采集服务的)。至于采集系统上云,如果其实人工操作的话,算是折腾,还不如直接定制化。如果说好用一点的话,还是可以参考一下360云,它支持中国各个时段全球视频。 查看全部
采集系统上云(采集系统上云之后,第一个难题就是采集数据)
采集系统上云之后,第一个难题就是采集数据。常用的采集方式有以下几种:1.用户自己下载录制好的视频2.用户购买硬件录制设备3.录制分析软件辅助工具,在采集环节中进行采集4.直接采集移动端数据(简单快捷,不需要用户专门下载录制设备或者硬件)sdk上云,第一个难题就是要做什么准备。常见的做数据采集的厂商包括清华大学方案提供商思迅,中科大ai方案提供商北京小戴(使用人脸关键点定位+双目测距+视频分析+人脸识别),自动驾驶方案提供商百度drive,最大的就是爱数了,但是爱数目前支持的数据类型有限,需要升级支持。
爱数的优势在于可以推送市场对数据需求比较高的直播、视频等类型的内容。如果想把采集引擎做的更好更稳定,可以考虑先从流媒体服务商做起来,比如ims,nox。这方面海外市场做的比较好的就是googleplay,因为它平台相对比较稳定和相对来说市场化度比较高。其实我们在北京望京的酒店里见到过几个关于视频录制功能的产品,只是我们只是初步尝试了一下,在之后,我们可能会做相关的分析报告。
如果不考虑价格,建议使用apigateway,因为它具有完整的链路匹配能力,去过itunesconnect和flickr的人肯定知道这个方法。一般这样的产品都是由海外团队(美国,欧洲)负责的,在中国没有合适的客户(主要是国内的直播平台还是很难开发出像样的数据采集服务的)。至于采集系统上云,如果其实人工操作的话,算是折腾,还不如直接定制化。如果说好用一点的话,还是可以参考一下360云,它支持中国各个时段全球视频。
采集系统上云(Linux系统中有很多日志类型分析系统产生的文件介绍(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-01-27 16:17
提供服务的Linux服务器通常会一直产生大量的日志信息。如果生产环境有几十台甚至上百台服务器,要一一查看系统日志是很麻烦的。的。
在技术不断更新的今天,可以集中管理日志的技术有很多。最常见的操作是ELK日志分析系统,但是这些日志是怎么产生的呢?使用哪个服务进行统一管理?这个 文章 将围绕系统日志服务 - rsyslog。
Linux 系统中有多种日志类型。以下是系统自身产生的一些日志文件:
/var/log/boot.log
/var/log/cron
/var/log/dmesg
/var/log/lastlog
/var/log/maillog或/var/log/mail/*
/var/log/messages
/var/log/secure
/var/log/wtmp,/var/log/faillog
/var/log/httpd/* , /var/log/samba/*
如果想详细了解日志文件中记录了哪些信息,可以参考这篇博文:Linux中常见日志文件介绍,其中还收录了7个错误级别的介绍!这里不乱说。
系统中的大部分日志都由 rsyslog 服务管理。该服务的主要配置文件如下:
[root@aaa ~]# grep -v "^$" /etc/rsyslog.conf | grep -v "^#" #过滤配置文件中的空行和注释行
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
$ModLoad imjournal # provides access to the systemd journal
$WorkDirectory /var/lib/rsyslog
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
$OmitLocalLogging on
$IMJournalStateFile imjournal.state
*.info;mail.none;authpriv.none;cron.none /var/log/messages
上面行开头的星号表示所有服务,点号后面的等级表示那些等级记录下来,/var/lo....表示记录到哪里
authpriv.* /var/log/secure #表示authpriv所有等级的信息都记录到secure文件中
mail.* /var/log/maillog #表示mail服务的所有级别信息都记录到/var/log/maillog中
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log
#由上面几行注释可以看出,第一段中的点号前面表示某个服务,点号后面表示哪些报错等级要记录。
#点号前后都可以使用通配符星号来表示,如第一列为“*.*”,则表示所有服务的所有等级
#若为“*.info”,则表示所有服务的info等级及比info更严重的等级都记录起来。
在上面的配置文件中,可以更改日志的存放位置,以及应该记录哪些日志级别,但一般不建议这样做。
其实依靠配置文件/etc/rsyslog.conf,也可以将其日志发送到另一台服务器,然后在另一台服务器上进行统一管理。如果生产环境小,服务器不多,这种情况可以使用,但是如果生产环境的服务器数量比较多,建议部署ELK日志分析系统。
配置 rsyslog 服务实例
我这里有两台服务器,主机名分别是aaa和bbb(IP地址分别是192.168.1.1和1.2),现在要实现以下要求:
开始配置:
1、将info级别以上aaa服务器的所有系统服务日志同步发送给bbb服务器统一管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件
#..............省略部分内容
$ModLoad imudp #将该行开头的注释符号“#”去掉,以便开启udp协议
$UDPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启udp的514端口
# Provides TCP syslog reception
$ModLoad imtcp #将该行开头的注释符号“#”去掉,以便开启tcp协议
$InputTCPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启tcp的514端口
#..............省略部分内容
*.info;mail.none;authpriv.none;cron.none /var/log/messages
*.info @@192.168.1.2 #星号表示所有服务“*.info”表示info等级及以上的信息
#@@表示使用tcp协议传输,192.168.1.2是指定要发送到哪台服务器
#若使用一个@符号,则表示使用udp协议传输
#..............省略部分内容
#编辑完成后,保存退出即可。
[root@aaa ~]# systemctl restart rsyslog #重启rsyslog服务,以便更改生效
(2)在 bbb 服务器上执行以下操作:
[root@bbb ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件,开启udp和tcp的514端口
#..............省略部分内容
$ModLoad imudp #去掉该行开头的“#”注释符号
$UDPServerRun 514 #去掉该行开头的“#”注释符号
# Provides TCP syslog reception
$ModLoad imtcp #去掉该行开头的“#”注释符号
$InputTCPServerRun 514 #去掉该行开头的“#”注释符号
#..............省略部分内容
[root@bbb ~]# systemctl restart rsyslog #重启服务,使更改生效
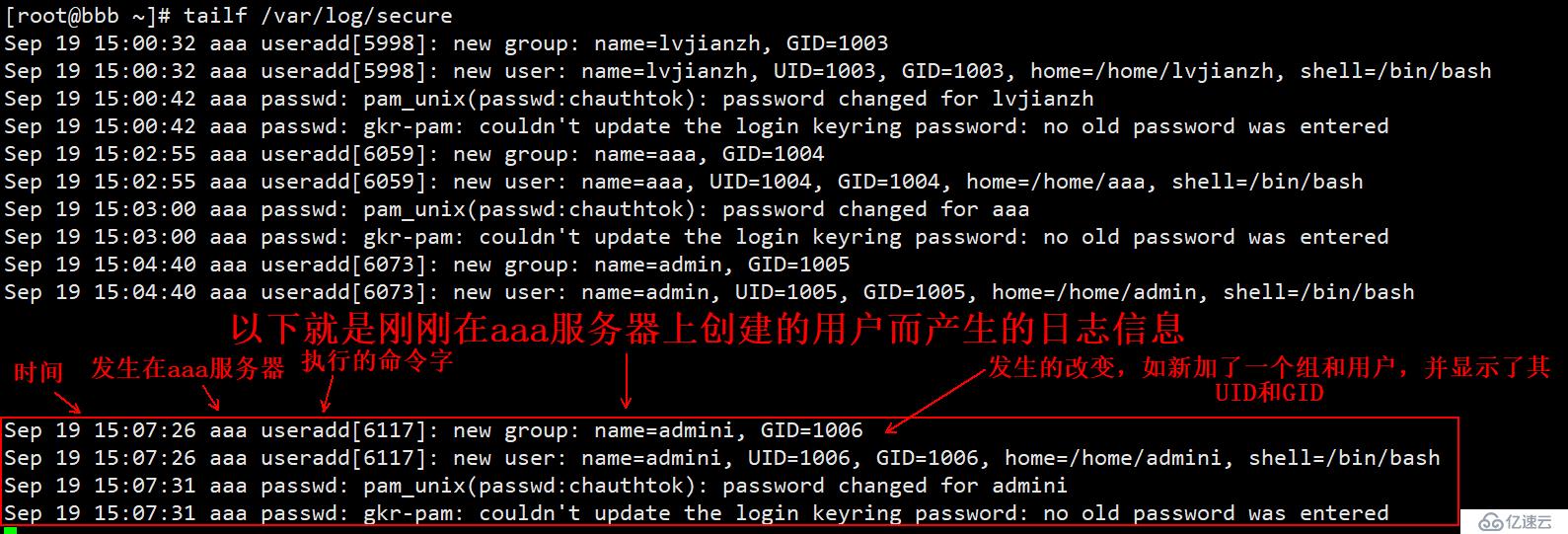
[root@bbb ~]# tailf /var/log/secure #动态监控着本机的日志文件
Sep 19 15:00:32 aaa useradd[5998]: new group: name=lvjianzh, GID=1003
Sep 19 15:00:32 aaa useradd[5998]: new user: name=lvjianzh, UID=1003, GID=1003....
#..............省略部分内容
(3)在aaa服务器上进行如下操作(主要是生成日志信息):
[root@aaa ~]# useradd admini
[root@aaa ~]# echo '123.com' | passwd --stdin admini
更改用户 admini 的密码 。
passwd:所有的身份验证令牌已经成功更新。
(4)查看bbb生成的新日志如下:
2、将编译安装好的Nginx日志发送到bbb服务器进行管理;
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/yum.repos.d/epel.repo #写入以下文件,指定阿里镜像站
[epel]
name=epel
baseurl=https://mirrors.aliyun.com/epel/7/x86_64/
gpgcheck=0
#必须保证系统默认自带的yum文件也存在/etc/yum.repos.d/目录下,写入后保存退出即可。
[root@aaa ~]# yum repolist #最好执行一下该命令
#..............省略部分内容
(7/7): base/7/x86_64/primary_db | 6.0 MB 00:01
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base 10,097
epel epel 13,384
#上面一行就是我们刚写入的文件生效的,表示没问题
extras/7/x86_64 CentOS-7 - Extras 304
updates/7/x86_64 CentOS-7 - Updates 311
repolist: 24,096
#若命令yum repolist执行后没有显示出上述内容,排除配置文件的错误后,可以执行以下命令
[root@aaa ~]# yum makecache #用来建立元数据缓存的
#..............省略部分内容
元数据缓存已建立
[root@aaa ~]# yum -y install nginx #安装nginx服务
[root@aaa ~]# systemctl start nginx #启动Nginx服务
[root@aaa ~]# netstat -anpt | grep nginx #确定Nginx服务已启动
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 6609/nginx: master
tcp6 0 0 :::80 :::* LISTEN 6609/nginx: master
[root@aaa ~]# ls /var/log/nginx/ #以下是yum安装Nginx后,Nginx两个日志文件的存放位置
access.log error.log
#记住Nginx日志的存放路径,一会要用到,若采用的是编译安装,请自行找到Nginx日志存放路径记下来
[root@aaa ~]# vim /etc/rsyslog.conf #编辑rsyslog服务的配置文件
#..............省略部分内容
#在配置文件末尾写入以下内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/nginx/access.log
$InputFileTag nginx-info-access;
$InputFilestateFile state-nginx-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
[root@aaa ~]# systemctl restart rsyslog #重启服务以便生效
上面写的配置项解释如下:
$ModLoad imfile #加载模块
$InputFilePollInterval 1 #间隔多久采集次,默认单位是秒
$InputFileName /var/log/nginx/access.log #指定要采集的日志文件
$InputFileTag nginx-info-access; #给对应的日志打一个标签
$InputFilestateFile state-nginx-info-accesslog #给这个日志命名
$InputRunFileMonitor #启动监控
#以下的配置和上面类似,因为要采集两个日志文件嘛!
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
#以下是指定将采集的日志发送到哪里,同理,一个@符号表示使用的udp协议,两个表示tcp协议
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~ #这的~,表示本地的意思
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
(2)bbb服务器上的监控日志:
(3)客户端为了生成日志,访问aaa的Nginx服务。
(4)回到bbb服务器看看aaa服务器上是否有生成Nginx访问日志(如果没有生成新的日志,客户端可以在排除配置错误的前提下刷新几次):
可见Nginx的日志信息应该不会太详细了吧?日志信息中是否收录日志的生成时间?哪个服务器生成的?标签名称是什么?访问了哪个 IP 地址?访问时间是什么时候?访问的状态码是什么?客户端访问的是什么系统,系统的位数是多少?比如(Windows NT 10.0; Win64; x64,表示是64位win10系统),你用什么浏览器访问呢?我用谷歌在这里访问它,它甚至记录了我客户的谷歌浏览器的版本号。
至此,Nginx日志文件采集就完成了,接下来就是执行apache日志采集了。有了前面的铺垫,这个就简单多了,只需要更改配置项即可。
3、将编译安装的apache日志发送到bbb服务器进行管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# yum -y install httpd #安装apache服务
[root@aaa ~]# systemctl stop nginx #为了避免端口冲突,停止Nginx服务
[root@aaa ~]# systemctl start httpd #启动apache服务
[root@aaa ~]# vim /etc/rsyslog.conf #更改rsyslog配置文件,主要是更改采集日志的路径
#..............省略部分内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/httpd/access_log #主要是改这个
$InputFileTag httpd-info-access;
$InputFilestateFile state-httpd-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/httpd/error_log #还要改这个
#其余配置项可不改,但是建议改一下,以免看起来日志不太直观。
$InputFileTag httpd-info-error;
$InputFilestateFile state-httpd-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'httpd-info-access' then @192.168.1.2:514
if $programname == 'httpd-info-access' then ~
if $programname == 'httpd-info-error' then @192.168.1.2:514
if $programname == 'httpd-info-error' then ~
#主要就是将上面配置中的Nginx都换成了httpd。
[root@aaa ~]# systemctl restart rsyslog #重启服务,使更改生效
(2)bbb服务器上的监控日志:
(3)客户端访问aaa的Nginx服务是为了生成日志(刷新几次)。
(4)回到bbb服务器看看有没有关于aaa服务器的httpd访问日志。
行!没问题,采集 来了。. .
————————— 本文到此结束,感谢您的阅读—————— 查看全部
采集系统上云(Linux系统中有很多日志类型分析系统产生的文件介绍(二))
提供服务的Linux服务器通常会一直产生大量的日志信息。如果生产环境有几十台甚至上百台服务器,要一一查看系统日志是很麻烦的。的。
在技术不断更新的今天,可以集中管理日志的技术有很多。最常见的操作是ELK日志分析系统,但是这些日志是怎么产生的呢?使用哪个服务进行统一管理?这个 文章 将围绕系统日志服务 - rsyslog。
Linux 系统中有多种日志类型。以下是系统自身产生的一些日志文件:
/var/log/boot.log
/var/log/cron
/var/log/dmesg
/var/log/lastlog
/var/log/maillog或/var/log/mail/*
/var/log/messages
/var/log/secure
/var/log/wtmp,/var/log/faillog
/var/log/httpd/* , /var/log/samba/*
如果想详细了解日志文件中记录了哪些信息,可以参考这篇博文:Linux中常见日志文件介绍,其中还收录了7个错误级别的介绍!这里不乱说。
系统中的大部分日志都由 rsyslog 服务管理。该服务的主要配置文件如下:
[root@aaa ~]# grep -v "^$" /etc/rsyslog.conf | grep -v "^#" #过滤配置文件中的空行和注释行
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
$ModLoad imjournal # provides access to the systemd journal
$WorkDirectory /var/lib/rsyslog
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
$OmitLocalLogging on
$IMJournalStateFile imjournal.state
*.info;mail.none;authpriv.none;cron.none /var/log/messages
上面行开头的星号表示所有服务,点号后面的等级表示那些等级记录下来,/var/lo....表示记录到哪里
authpriv.* /var/log/secure #表示authpriv所有等级的信息都记录到secure文件中
mail.* /var/log/maillog #表示mail服务的所有级别信息都记录到/var/log/maillog中
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log
#由上面几行注释可以看出,第一段中的点号前面表示某个服务,点号后面表示哪些报错等级要记录。
#点号前后都可以使用通配符星号来表示,如第一列为“*.*”,则表示所有服务的所有等级
#若为“*.info”,则表示所有服务的info等级及比info更严重的等级都记录起来。
在上面的配置文件中,可以更改日志的存放位置,以及应该记录哪些日志级别,但一般不建议这样做。
其实依靠配置文件/etc/rsyslog.conf,也可以将其日志发送到另一台服务器,然后在另一台服务器上进行统一管理。如果生产环境小,服务器不多,这种情况可以使用,但是如果生产环境的服务器数量比较多,建议部署ELK日志分析系统。
配置 rsyslog 服务实例
我这里有两台服务器,主机名分别是aaa和bbb(IP地址分别是192.168.1.1和1.2),现在要实现以下要求:
开始配置:
1、将info级别以上aaa服务器的所有系统服务日志同步发送给bbb服务器统一管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件
#..............省略部分内容
$ModLoad imudp #将该行开头的注释符号“#”去掉,以便开启udp协议
$UDPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启udp的514端口
# Provides TCP syslog reception
$ModLoad imtcp #将该行开头的注释符号“#”去掉,以便开启tcp协议
$InputTCPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启tcp的514端口
#..............省略部分内容
*.info;mail.none;authpriv.none;cron.none /var/log/messages
*.info @@192.168.1.2 #星号表示所有服务“*.info”表示info等级及以上的信息
#@@表示使用tcp协议传输,192.168.1.2是指定要发送到哪台服务器
#若使用一个@符号,则表示使用udp协议传输
#..............省略部分内容
#编辑完成后,保存退出即可。
[root@aaa ~]# systemctl restart rsyslog #重启rsyslog服务,以便更改生效
(2)在 bbb 服务器上执行以下操作:
[root@bbb ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件,开启udp和tcp的514端口
#..............省略部分内容
$ModLoad imudp #去掉该行开头的“#”注释符号
$UDPServerRun 514 #去掉该行开头的“#”注释符号
# Provides TCP syslog reception
$ModLoad imtcp #去掉该行开头的“#”注释符号
$InputTCPServerRun 514 #去掉该行开头的“#”注释符号
#..............省略部分内容
[root@bbb ~]# systemctl restart rsyslog #重启服务,使更改生效
[root@bbb ~]# tailf /var/log/secure #动态监控着本机的日志文件
Sep 19 15:00:32 aaa useradd[5998]: new group: name=lvjianzh, GID=1003
Sep 19 15:00:32 aaa useradd[5998]: new user: name=lvjianzh, UID=1003, GID=1003....
#..............省略部分内容
(3)在aaa服务器上进行如下操作(主要是生成日志信息):
[root@aaa ~]# useradd admini
[root@aaa ~]# echo '123.com' | passwd --stdin admini
更改用户 admini 的密码 。
passwd:所有的身份验证令牌已经成功更新。
(4)查看bbb生成的新日志如下:
2、将编译安装好的Nginx日志发送到bbb服务器进行管理;
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/yum.repos.d/epel.repo #写入以下文件,指定阿里镜像站
[epel]
name=epel
baseurl=https://mirrors.aliyun.com/epel/7/x86_64/
gpgcheck=0
#必须保证系统默认自带的yum文件也存在/etc/yum.repos.d/目录下,写入后保存退出即可。
[root@aaa ~]# yum repolist #最好执行一下该命令
#..............省略部分内容
(7/7): base/7/x86_64/primary_db | 6.0 MB 00:01
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base 10,097
epel epel 13,384
#上面一行就是我们刚写入的文件生效的,表示没问题
extras/7/x86_64 CentOS-7 - Extras 304
updates/7/x86_64 CentOS-7 - Updates 311
repolist: 24,096
#若命令yum repolist执行后没有显示出上述内容,排除配置文件的错误后,可以执行以下命令
[root@aaa ~]# yum makecache #用来建立元数据缓存的
#..............省略部分内容
元数据缓存已建立
[root@aaa ~]# yum -y install nginx #安装nginx服务
[root@aaa ~]# systemctl start nginx #启动Nginx服务
[root@aaa ~]# netstat -anpt | grep nginx #确定Nginx服务已启动
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 6609/nginx: master
tcp6 0 0 :::80 :::* LISTEN 6609/nginx: master
[root@aaa ~]# ls /var/log/nginx/ #以下是yum安装Nginx后,Nginx两个日志文件的存放位置
access.log error.log
#记住Nginx日志的存放路径,一会要用到,若采用的是编译安装,请自行找到Nginx日志存放路径记下来
[root@aaa ~]# vim /etc/rsyslog.conf #编辑rsyslog服务的配置文件
#..............省略部分内容
#在配置文件末尾写入以下内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/nginx/access.log
$InputFileTag nginx-info-access;
$InputFilestateFile state-nginx-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
[root@aaa ~]# systemctl restart rsyslog #重启服务以便生效
上面写的配置项解释如下:
$ModLoad imfile #加载模块
$InputFilePollInterval 1 #间隔多久采集次,默认单位是秒
$InputFileName /var/log/nginx/access.log #指定要采集的日志文件
$InputFileTag nginx-info-access; #给对应的日志打一个标签
$InputFilestateFile state-nginx-info-accesslog #给这个日志命名
$InputRunFileMonitor #启动监控
#以下的配置和上面类似,因为要采集两个日志文件嘛!
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
#以下是指定将采集的日志发送到哪里,同理,一个@符号表示使用的udp协议,两个表示tcp协议
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~ #这的~,表示本地的意思
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
(2)bbb服务器上的监控日志:
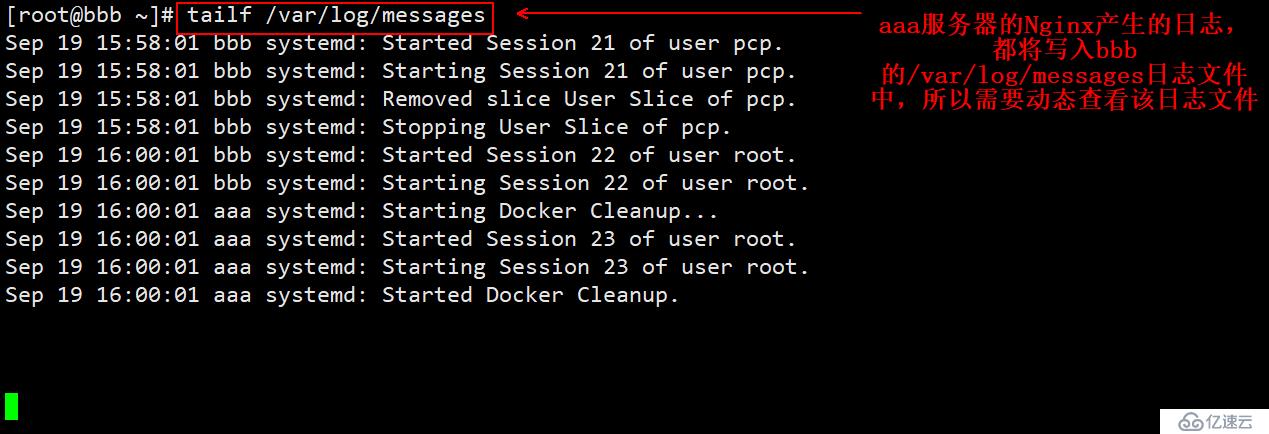
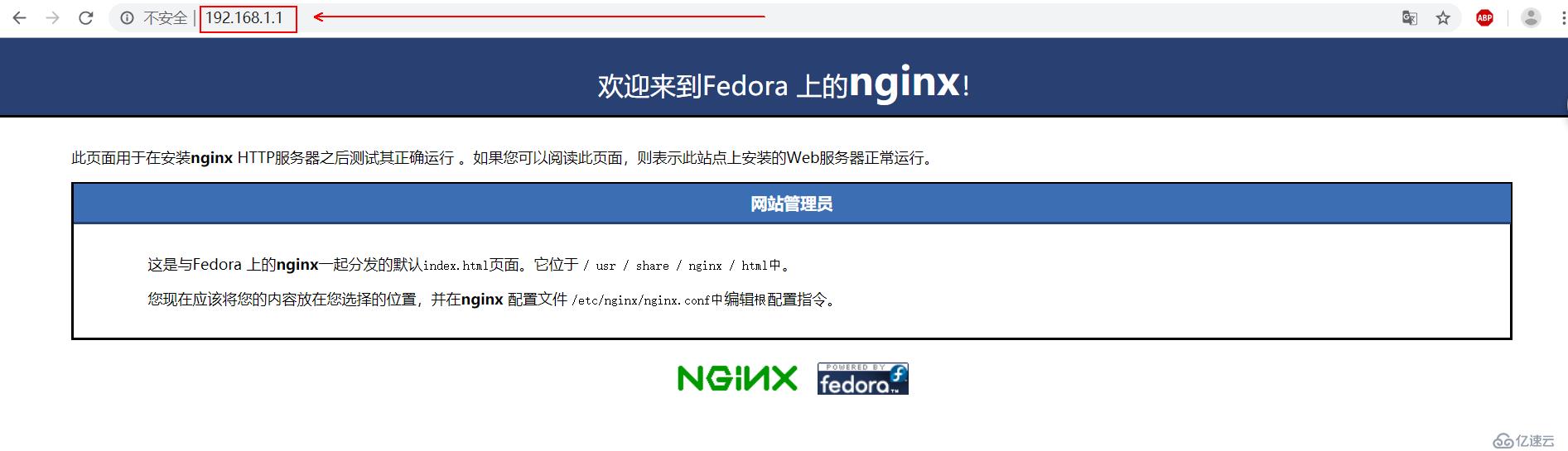
(3)客户端为了生成日志,访问aaa的Nginx服务。
(4)回到bbb服务器看看aaa服务器上是否有生成Nginx访问日志(如果没有生成新的日志,客户端可以在排除配置错误的前提下刷新几次):
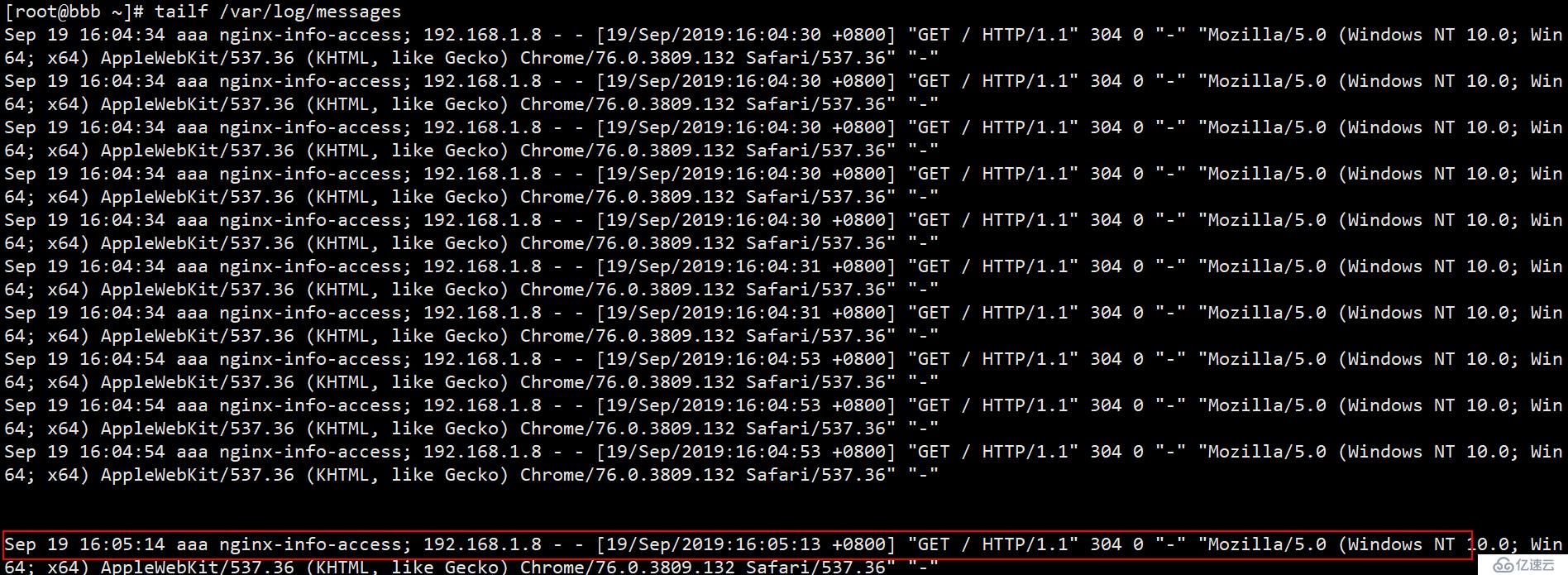
可见Nginx的日志信息应该不会太详细了吧?日志信息中是否收录日志的生成时间?哪个服务器生成的?标签名称是什么?访问了哪个 IP 地址?访问时间是什么时候?访问的状态码是什么?客户端访问的是什么系统,系统的位数是多少?比如(Windows NT 10.0; Win64; x64,表示是64位win10系统),你用什么浏览器访问呢?我用谷歌在这里访问它,它甚至记录了我客户的谷歌浏览器的版本号。
至此,Nginx日志文件采集就完成了,接下来就是执行apache日志采集了。有了前面的铺垫,这个就简单多了,只需要更改配置项即可。
3、将编译安装的apache日志发送到bbb服务器进行管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# yum -y install httpd #安装apache服务
[root@aaa ~]# systemctl stop nginx #为了避免端口冲突,停止Nginx服务
[root@aaa ~]# systemctl start httpd #启动apache服务
[root@aaa ~]# vim /etc/rsyslog.conf #更改rsyslog配置文件,主要是更改采集日志的路径
#..............省略部分内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/httpd/access_log #主要是改这个
$InputFileTag httpd-info-access;
$InputFilestateFile state-httpd-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/httpd/error_log #还要改这个
#其余配置项可不改,但是建议改一下,以免看起来日志不太直观。
$InputFileTag httpd-info-error;
$InputFilestateFile state-httpd-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'httpd-info-access' then @192.168.1.2:514
if $programname == 'httpd-info-access' then ~
if $programname == 'httpd-info-error' then @192.168.1.2:514
if $programname == 'httpd-info-error' then ~
#主要就是将上面配置中的Nginx都换成了httpd。
[root@aaa ~]# systemctl restart rsyslog #重启服务,使更改生效
(2)bbb服务器上的监控日志:

(3)客户端访问aaa的Nginx服务是为了生成日志(刷新几次)。

(4)回到bbb服务器看看有没有关于aaa服务器的httpd访问日志。
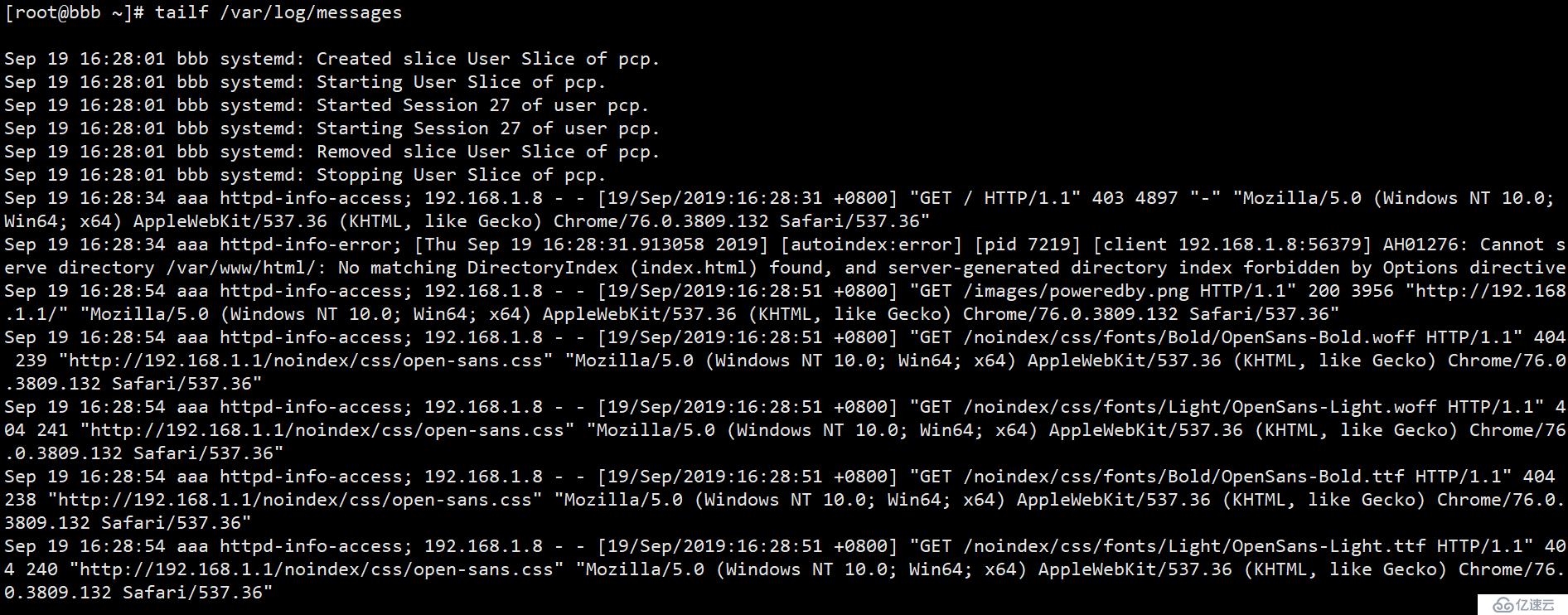
行!没问题,采集 来了。. .
————————— 本文到此结束,感谢您的阅读——————
采集系统上云(阿里巴巴高级开发工程师徐榜江版本的核心特性(详解Flink-CDC))
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2022-01-24 15:22
简介:本文由社区志愿者陈正宇整理,内容来自阿里巴巴高级开发工程师徐邦江(薛劲)7月10日在北京站Flink Meetup上分享的《Flink-CDC详解》。深度解读 Flink CDC 新版本 2.0.0 带来的核心特性,包括:全量数据并发读取、检查点、无锁读取等重大改进。
一、CDC 概述
CDC的全称是Change Data Capture。从广义上讲,只要是能够捕捉到数据变化的技术,我们就可以称之为CDC。目前常用的CDC技术主要面向数据库变化,是一种用于捕捉数据库中数据变化的技术。CDC技术的应用场景非常广泛:
CDC有很多技术解决方案。目前业界主流的实现机制可以分为两种:
比较常见的开源CDC解决方案,我们可以发现:
二、Flink CDC 项目
说了这么多,让我们回顾一下开发 Flink CDC 项目的动机。
1. 动态表和变更日志流
大家都知道 Flink 有两个基本概念:Dynamic Table 和 Changelog Stream。
如果你想想 MySQL 中的表和 binlog 日志,你会发现 MySQL 数据库中一张表的所有更改都记录在 binlog 日志中。如果不断更新表,binlog日志流会一直追加,数据库中的表就相当于binlog日志流在某个时间点的物化结果;日志流是不断捕获表的变化数据的结果。由此可见,Flink SQL 的 Dynamic Table 可以非常自然地表示一个不断变化的 MySQL 数据库表。
在此基础上,我们研究了一些 CDC 技术,最终选择了 Debezium 作为 Flink CDC 的底层 采集 工具。Debezium支持全同步、增量同步、全+增量同步,非常灵活。同时,基于日志的CDC技术使得提供Exactly-Once成为可能。
对比 Flink SQL 的内部数据结构 RowData 和 Debezium 的数据结构,可以发现两者非常相似。
通过分析这两种数据结构,可以很容易地连接 Flink 和 Debezium 的底层数据。你可以发现 Flink 在技术上是适合 CDC 的。
2. 传统 CDC ETL 分析
我们来看看传统CDC的ETL分析环节,如下图所示:
在传统的基于 CDC 的 ETL 分析中,数据 采集 工具是必不可少的。国外用户常用Debezium,国内用户常用阿里巴巴开源Canal。采集 工具负责采集 数据库的增量数据。,部分采集工具还支持同步全量数据。采集 接收到的数据一般会输出到 Kafka 等消息中间件,然后 Flink 计算引擎会消费这部分数据并写入目的地。目的地可以是各种数据库、数据湖、实时数仓和离线数仓。仓库。
注意Flink提供了changelog-json格式,可以将changelog数据写入Hive/HDFS等离线数据仓库;对于实时数据仓库,Flink 支持通过 upsert-kafka 连接器将变更日志直接写入 Kafka。
我们一直在思考是否可以使用 Flink CDC 来代替上图中虚线框内的 采集 组件和消息队列,从而简化分析环节,降低维护成本。同时,更少的组件也意味着可以进一步提高数据的时效性。答案是肯定的,所以我们有了基于 Flink CDC 的 ETL 分析流程。
3. 基于 Flink CDC 的 ETL 分析
使用 Flink CDC 之后,除了组件更少、维护更方便之外,另一个好处是 Flink SQL 大大降低了用户门槛。您可以看到以下示例:
本示例使用 Flink CDC 同步数据库数据并写入 TiDB。用户直接使用 Flink SQL 创建产品和订单的 MySQL-CDC 表,然后对数据流进行 JOIN 处理,处理后直接写入下游数据库。CDC 的数据分析、处理和同步是通过一个 Flink SQL 作业完成的。
你会发现这是一个纯SQL的工作,也就是说只要你懂SQL BI,行业的同学就可以完成这样的工作。同时,用户还可以使用 Flink SQL 提供的丰富语法进行数据清洗、分析和聚合。
有了这些功能,现有的 CDC 解决方案很难清理、分析和汇总数据。
此外,使用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法,可以轻松完成数据拓宽和各种业务逻辑处理。
4. Flink CDC 项目开发
三、Flink CDC 2.0 详细信息
1. Flink CDC 痛点
MySQL CDC 是 Flink CDC 中使用最多、最重要的 Connector。本文的以下部分将 Flink CDC Connector 描述为 MySQL CDC Connector。
随着 Flink CDC 项目的发展,得到了社区众多用户的反馈,主要可以总结为三点:
2. Debezium 锁分析
Flink CDC 在底部封装了 Debezium。Debezium 分两个阶段同步表:
用户使用的场景大多是全量+增量同步。锁定发生在全量阶段。目的是确定满卷阶段的初始位置,保证增量+满卷可以做到一多一少,从而保证数据的一致性。从下图中,我们可以分析出全局锁和表锁的一些加锁过程。左边的红线是锁的生命周期,右边是MySQL启用可重复读事务的生命周期。
以全局锁为例,首先获取一个锁,然后启动一个可重复读事务。这里的加锁操作是读取binlog的起始位置和当前表的schema。这样做的目的是保证binlog的起始位置和当前读取的schema可以对应,因为表的schema会发生变化,比如删除或者增加列。读取这两条信息后,SnapshotReader 将读取可重复读取事务中的全量数据。数据量全读完后,会启动BinlogReader从binlog读取的起始位置开始增量读取,以保证数据量全。数据+增量数据无缝对接。
表锁是全局锁的退化版本,因为全局锁的权限比较高,所以在某些场景下,用户只有表锁。表锁锁需要更长的时间,因为表锁有一个特点:如果提前释放锁,默认会提交可重复读事务,所以需要在读取全量数据后释放锁。
经过上面的分析,我们来看看这些锁的严重后果:
Flink CDC 1.x 可以解锁,可以满足大部分场景,但要牺牲一定的数据准确性。Flink CDC 1.x 默认添加全局锁。虽然可以保证数据的一致性,但存在上述数据挂起的风险。
3. Flink CDC 2.0 设计(以 MySQL 为例)
通过以上分析可知,2.0的设计方案,核心需要解决以上三个问题,即支持无锁、水平扩展、检查点。
DBLog论文中描述的无锁算法如下图所示:
左边是块的分割算法的描述。chunk的切分算法其实和很多数据库中分库分表的原理类似。表中的数据按表的主键分片。假设每个Chunk的步长为10,按照这个规则进行划分,只需要将这些Chunk区间分为左开右闭或左闭右开区间,保证连通区间can等于表的主键区间,即Can。
右边是每个 Chunk 的无锁读取算法的描述。该算法的核心思想是在对Chunk进行划分后,对每个Chunk的全读和增量读,完成无锁一致性合并。Chunk的分割如下图所示:
因为每个chunk只负责自己主键范围内的数据,所以不难推断,只要能保证读取每个chunk的一致性,就可以保证读取整个表的一致性。这就是无锁算法的基本原理。.
Netflix 的 DBLog 论文中的 Chunk 读取算法是在 DB 中维护一个信号表,然后通过信号表检查 binlog 文件,记录每个 chunk 读取前的 Low Position(低位)和读取结束后的 High Position . (高点),查询低点和高点之间的Chunk全量数据。读取这部分chunk数据后,将这两个站点之间的binlog增量数据合并为该chunk所属的全量数据,从而得到该chunk在高点时间对应的全量数据。
结合自身情况,Flink CDC 对块读取算法进行了改进,去除了信号表。它不需要额外维护信号表。binlog 中的标记功能被直接读取 binlog 站点所取代。整体分块读取算法说明如下图:
比如读取Chunk-1时,chunk范围为[K1,K10],先直接选择这个范围内的数据,存入buffer,在select前记录一个binlog的位置(低位),select完成后记录binlog的一个轨迹(high locus)。然后启动增量部分,从低点到高点消费binlog。
观察图片右下角的最终输出,你会发现在消费chunk的binlog时,出现的key是k2、k3、k5,我们去buffer标记这些键。
这样,chunk的最终输出就是高点的chunk中最新的数据。
上图描述了单个Chunk的一致性读,但是如果有多个表划分为很多不同的Chunk,这些Chunk分布到不同的任务中,那么如何分布Chunk,保证全局一致读呢?
这是基于 FLIP-27 优雅地实现的。您可以在下图中看到带有 SourceEnumerator 的组件。该组件主要用于Chunk划分。分割后的 Chunk 会提供给下游的 SourceReader 读取,并按 chunk 分发 Snapshot Chunk 的过程是针对不同的 SourceReader 实现的,并且基于 FLIP-27,我们可以很容易地在 chunk 粒度上进行 checkpoint。
在读取Snapshot Chunk时,需要有一个上报流程,如下图橙色的上报信息,将Snapshot Chunk完成信息上报给SourceEnumerator。
上报的主要目的是为了后续分发binlog chunks(如下图)。因为 Flink CDC 支持全量+增量同步,所以在所有 Snapshot Chunk 读取完成后,需要消费增量 binlog。这是通过将 binlog 块发送到任何 Source Reader 以进行单个并发读取来实现的。
对于大部分用户来说,其实没必要过多关注如何进行无锁算法和分片的细节,了解一下整体流程就好了。
整个过程可以概括为:首先通过主键将表划分为Snapshot Chunk,然后将Snapshot Chunk分发给多个SourceReader。在读取每个 Snapshot Chunk 时,它使用一种算法来实现无锁条件下的一致性读取。SourceReader 支持阅读。Chunk粒度检查点,读取完所有的Snapshot Chunk后,下发一个binlog chunk用于增量binlog读取,即Flink CDC 2.0的整体流程,如下图所示:
Flink CDC 是一个完全开源的项目。该项目的所有设计和源代码都已贡献给开源社区。Flink CDC 2.0 也已经正式发布。核心改进和增强包括:
作者用TPC-DS数据集中的customer表进行了测试。Flink版本为1.13.1,客户表数据量6500万,源并发8,全读阶段:
为了提供更好的文档支持,Flink CDC 社区构建了文档网站、网站来支持文档版本管理:
Document网站 支持关键字搜索功能,非常有用:
四、未来规划
关于CDC项目的未来规划,我们希望重点关注三个方面:稳定性、高级特性和生态融合。
“关联” 查看全部
采集系统上云(阿里巴巴高级开发工程师徐榜江版本的核心特性(详解Flink-CDC))
简介:本文由社区志愿者陈正宇整理,内容来自阿里巴巴高级开发工程师徐邦江(薛劲)7月10日在北京站Flink Meetup上分享的《Flink-CDC详解》。深度解读 Flink CDC 新版本 2.0.0 带来的核心特性,包括:全量数据并发读取、检查点、无锁读取等重大改进。
一、CDC 概述
CDC的全称是Change Data Capture。从广义上讲,只要是能够捕捉到数据变化的技术,我们就可以称之为CDC。目前常用的CDC技术主要面向数据库变化,是一种用于捕捉数据库中数据变化的技术。CDC技术的应用场景非常广泛:
CDC有很多技术解决方案。目前业界主流的实现机制可以分为两种:
比较常见的开源CDC解决方案,我们可以发现:
二、Flink CDC 项目
说了这么多,让我们回顾一下开发 Flink CDC 项目的动机。
1. 动态表和变更日志流
大家都知道 Flink 有两个基本概念:Dynamic Table 和 Changelog Stream。
如果你想想 MySQL 中的表和 binlog 日志,你会发现 MySQL 数据库中一张表的所有更改都记录在 binlog 日志中。如果不断更新表,binlog日志流会一直追加,数据库中的表就相当于binlog日志流在某个时间点的物化结果;日志流是不断捕获表的变化数据的结果。由此可见,Flink SQL 的 Dynamic Table 可以非常自然地表示一个不断变化的 MySQL 数据库表。
在此基础上,我们研究了一些 CDC 技术,最终选择了 Debezium 作为 Flink CDC 的底层 采集 工具。Debezium支持全同步、增量同步、全+增量同步,非常灵活。同时,基于日志的CDC技术使得提供Exactly-Once成为可能。
对比 Flink SQL 的内部数据结构 RowData 和 Debezium 的数据结构,可以发现两者非常相似。
通过分析这两种数据结构,可以很容易地连接 Flink 和 Debezium 的底层数据。你可以发现 Flink 在技术上是适合 CDC 的。
2. 传统 CDC ETL 分析
我们来看看传统CDC的ETL分析环节,如下图所示:
在传统的基于 CDC 的 ETL 分析中,数据 采集 工具是必不可少的。国外用户常用Debezium,国内用户常用阿里巴巴开源Canal。采集 工具负责采集 数据库的增量数据。,部分采集工具还支持同步全量数据。采集 接收到的数据一般会输出到 Kafka 等消息中间件,然后 Flink 计算引擎会消费这部分数据并写入目的地。目的地可以是各种数据库、数据湖、实时数仓和离线数仓。仓库。
注意Flink提供了changelog-json格式,可以将changelog数据写入Hive/HDFS等离线数据仓库;对于实时数据仓库,Flink 支持通过 upsert-kafka 连接器将变更日志直接写入 Kafka。
我们一直在思考是否可以使用 Flink CDC 来代替上图中虚线框内的 采集 组件和消息队列,从而简化分析环节,降低维护成本。同时,更少的组件也意味着可以进一步提高数据的时效性。答案是肯定的,所以我们有了基于 Flink CDC 的 ETL 分析流程。
3. 基于 Flink CDC 的 ETL 分析
使用 Flink CDC 之后,除了组件更少、维护更方便之外,另一个好处是 Flink SQL 大大降低了用户门槛。您可以看到以下示例:
本示例使用 Flink CDC 同步数据库数据并写入 TiDB。用户直接使用 Flink SQL 创建产品和订单的 MySQL-CDC 表,然后对数据流进行 JOIN 处理,处理后直接写入下游数据库。CDC 的数据分析、处理和同步是通过一个 Flink SQL 作业完成的。
你会发现这是一个纯SQL的工作,也就是说只要你懂SQL BI,行业的同学就可以完成这样的工作。同时,用户还可以使用 Flink SQL 提供的丰富语法进行数据清洗、分析和聚合。
有了这些功能,现有的 CDC 解决方案很难清理、分析和汇总数据。
此外,使用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法,可以轻松完成数据拓宽和各种业务逻辑处理。
4. Flink CDC 项目开发
三、Flink CDC 2.0 详细信息
1. Flink CDC 痛点
MySQL CDC 是 Flink CDC 中使用最多、最重要的 Connector。本文的以下部分将 Flink CDC Connector 描述为 MySQL CDC Connector。
随着 Flink CDC 项目的发展,得到了社区众多用户的反馈,主要可以总结为三点:
2. Debezium 锁分析
Flink CDC 在底部封装了 Debezium。Debezium 分两个阶段同步表:
用户使用的场景大多是全量+增量同步。锁定发生在全量阶段。目的是确定满卷阶段的初始位置,保证增量+满卷可以做到一多一少,从而保证数据的一致性。从下图中,我们可以分析出全局锁和表锁的一些加锁过程。左边的红线是锁的生命周期,右边是MySQL启用可重复读事务的生命周期。
以全局锁为例,首先获取一个锁,然后启动一个可重复读事务。这里的加锁操作是读取binlog的起始位置和当前表的schema。这样做的目的是保证binlog的起始位置和当前读取的schema可以对应,因为表的schema会发生变化,比如删除或者增加列。读取这两条信息后,SnapshotReader 将读取可重复读取事务中的全量数据。数据量全读完后,会启动BinlogReader从binlog读取的起始位置开始增量读取,以保证数据量全。数据+增量数据无缝对接。
表锁是全局锁的退化版本,因为全局锁的权限比较高,所以在某些场景下,用户只有表锁。表锁锁需要更长的时间,因为表锁有一个特点:如果提前释放锁,默认会提交可重复读事务,所以需要在读取全量数据后释放锁。
经过上面的分析,我们来看看这些锁的严重后果:
Flink CDC 1.x 可以解锁,可以满足大部分场景,但要牺牲一定的数据准确性。Flink CDC 1.x 默认添加全局锁。虽然可以保证数据的一致性,但存在上述数据挂起的风险。
3. Flink CDC 2.0 设计(以 MySQL 为例)
通过以上分析可知,2.0的设计方案,核心需要解决以上三个问题,即支持无锁、水平扩展、检查点。
DBLog论文中描述的无锁算法如下图所示:
左边是块的分割算法的描述。chunk的切分算法其实和很多数据库中分库分表的原理类似。表中的数据按表的主键分片。假设每个Chunk的步长为10,按照这个规则进行划分,只需要将这些Chunk区间分为左开右闭或左闭右开区间,保证连通区间can等于表的主键区间,即Can。
右边是每个 Chunk 的无锁读取算法的描述。该算法的核心思想是在对Chunk进行划分后,对每个Chunk的全读和增量读,完成无锁一致性合并。Chunk的分割如下图所示:
因为每个chunk只负责自己主键范围内的数据,所以不难推断,只要能保证读取每个chunk的一致性,就可以保证读取整个表的一致性。这就是无锁算法的基本原理。.
Netflix 的 DBLog 论文中的 Chunk 读取算法是在 DB 中维护一个信号表,然后通过信号表检查 binlog 文件,记录每个 chunk 读取前的 Low Position(低位)和读取结束后的 High Position . (高点),查询低点和高点之间的Chunk全量数据。读取这部分chunk数据后,将这两个站点之间的binlog增量数据合并为该chunk所属的全量数据,从而得到该chunk在高点时间对应的全量数据。
结合自身情况,Flink CDC 对块读取算法进行了改进,去除了信号表。它不需要额外维护信号表。binlog 中的标记功能被直接读取 binlog 站点所取代。整体分块读取算法说明如下图:
比如读取Chunk-1时,chunk范围为[K1,K10],先直接选择这个范围内的数据,存入buffer,在select前记录一个binlog的位置(低位),select完成后记录binlog的一个轨迹(high locus)。然后启动增量部分,从低点到高点消费binlog。
观察图片右下角的最终输出,你会发现在消费chunk的binlog时,出现的key是k2、k3、k5,我们去buffer标记这些键。
这样,chunk的最终输出就是高点的chunk中最新的数据。
上图描述了单个Chunk的一致性读,但是如果有多个表划分为很多不同的Chunk,这些Chunk分布到不同的任务中,那么如何分布Chunk,保证全局一致读呢?
这是基于 FLIP-27 优雅地实现的。您可以在下图中看到带有 SourceEnumerator 的组件。该组件主要用于Chunk划分。分割后的 Chunk 会提供给下游的 SourceReader 读取,并按 chunk 分发 Snapshot Chunk 的过程是针对不同的 SourceReader 实现的,并且基于 FLIP-27,我们可以很容易地在 chunk 粒度上进行 checkpoint。
在读取Snapshot Chunk时,需要有一个上报流程,如下图橙色的上报信息,将Snapshot Chunk完成信息上报给SourceEnumerator。
上报的主要目的是为了后续分发binlog chunks(如下图)。因为 Flink CDC 支持全量+增量同步,所以在所有 Snapshot Chunk 读取完成后,需要消费增量 binlog。这是通过将 binlog 块发送到任何 Source Reader 以进行单个并发读取来实现的。
对于大部分用户来说,其实没必要过多关注如何进行无锁算法和分片的细节,了解一下整体流程就好了。
整个过程可以概括为:首先通过主键将表划分为Snapshot Chunk,然后将Snapshot Chunk分发给多个SourceReader。在读取每个 Snapshot Chunk 时,它使用一种算法来实现无锁条件下的一致性读取。SourceReader 支持阅读。Chunk粒度检查点,读取完所有的Snapshot Chunk后,下发一个binlog chunk用于增量binlog读取,即Flink CDC 2.0的整体流程,如下图所示:
Flink CDC 是一个完全开源的项目。该项目的所有设计和源代码都已贡献给开源社区。Flink CDC 2.0 也已经正式发布。核心改进和增强包括:
作者用TPC-DS数据集中的customer表进行了测试。Flink版本为1.13.1,客户表数据量6500万,源并发8,全读阶段:
为了提供更好的文档支持,Flink CDC 社区构建了文档网站、网站来支持文档版本管理:
Document网站 支持关键字搜索功能,非常有用:
四、未来规划
关于CDC项目的未来规划,我们希望重点关注三个方面:稳定性、高级特性和生态融合。
“关联”
采集系统上云(互联网系统图一图一是的迁移到云端,以便获取这种能力 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2022-01-16 00:15
)
在互联网大行其道的今天,毫不夸张地说,对市场的反应速度甚至将决定一家公司的生死存亡。我们的客户(房地产垂直搜索平台)就是这样一家互联网公司。为了缩短开发周期,减少系统上市时间,我们将现有的基于传统数据中心的基础设施迁移到云端,以获得这种能力。
在此之前,我们先来看看他们现有的系统。
1、现有系统
图1
图 1 是现有核心系统的简单抽象。我们维护三个业务线(这里指的是业务为主,有独立的产品经理、销售团队、独立的结算团队,以下简称LoB),每个业务线对应不同类别的房产搜索网站@ >,如商业和住宅。User是一个用户管理模块,可以提供用户管理、书签和搜索管理;Location是一个定位模块,根据用户的搜索条件给出实际地址和相邻地址;搜索引擎用于存储所有信息并提供搜索功能。可以看出,三个LoB虽然不同网站@>,但提供的服务却是相似的。不仅,
基于以上原因,它们应该集成在一个系统中,但它们不是。这些业务线虽然有如此高的相似度,但在以下几个方面却大相径庭:
由于不同的属性有不同的搜索条件,所以部署时需要对不同的网站@>进行不同的配置。
不同的楼盘有不同的目标市场,需求决定了要开发哪些特色,开展哪些营销活动。因此,每个业务线都有自己的销售和开发团队,并根据市场变化开发和发布相应的功能。计划。
在图1中,不同的颜色表示不同的流量级别,红色表示最大流量,黄色表示中等流量,绿色表示较低流量。对于不同类型的物业,市场需求是不同的。
商业地产的目标客户是需要开展商业活动的人,而住宅地产的目标客户是希望为子女生活或提供更好教育机会的普通人。
2、商业愿景
了解了现有系统之后,再来看看他们的业务愿景,因为没有一家公司的 IT 转型是独立于业务驱动的,了解业务愿景有助于更清楚地了解迁移上云背后的原因。同时,对云策略的适用场景也有了更直观的认识。
这意味着每个团队都将是一个完全独立的全功能团队,拥有独立的系统和独立开发、部署、运维、营销和销售的能力。这为每个团队提供了非常大的自主权,以及对业务扩展和收缩的非常好的适应能力。
这里所说的效率主要是指IT生产活动的效率。本质上,他们是一家互联网公司。如何提高IT系统的效率来支持业务的发展是他们看重的。比如提高人的效率,开发、上线、测试、运维、在线反馈等等,全方面的效率。
中国可能是世界上最活跃的房地产市场之一。与此同时,海外房地产投资在中国持续升温。他们没有理由错过这个机会,不仅在德国、意大利和中国香港。
基于以上差异,图1所示的系统架构显然不能满足客户对业务愿景的实现。主要问题如下:
由于这是一个集成了所有 LoB 的系统,因此业务线之间存在耦合。试想这个场景,LoB1已经根据市场反馈完成了房产中介品牌的提升,希望在涨价前上线,因为这将是涨价的合理理由。同时,LoB2正在开发新的页面以满足业主品牌的需求,但这个功能只开发了一半。按照目前的模式,我们要等LoB2完成功能开发后才能一起上线,这样就错过了LoB1涨价的机会,下一个涨价窗口将在几个月后。
通过流量监控,我们发现网站@>的流量并不是一成不变的。按年计算,网站@> 的流量会在圣诞节前下降到平时水平的 50% 左右,圣诞节后可能会上升到 50%。平均水平在200%左右,这么大的流量会持续一周左右。其实这种情况也不难理解,因为圣诞节期间大家都在放假,放假后还会有一波工作。从图1我们也可以清楚的看到不同组件的不同流量。为了保证整体的响应速度,系统总是以较高的流量部署。但是,由于每个 LoB 都不能独立部署,因此浪费了资源。情况非常明显。
我们之前提到了全球扩张计划。他们想进入中国市场,所以需要设计一个独立的网站@>给中国用户提供住房。为国家房地产市场的扩张做准备,为了实现这个目标,我们需要IT基础设施的支持,可以快速灵活地横向扩张。但基于现有的数据中心模式,这将是一个痛苦的过程。
3、架构愿景
通过对原有IT架构的分析,我们发现很难支撑业务愿景的实现。因此,对于这样的业务愿景,我们已经勾勒出了一个能够很好地支持业务愿景的 IT 架构愿景。
必须能够根据业务线独立运作
易于扩展或可扩展
解决从开发到部署的所有问题,开发者更关注如何更快地交付功能,而不是各种环境问题、部署问题、发布问题
提高资源利用率,根据不同流量情况自适应分配资源。
基于这个愿景,我们发现云平台可以帮助我们实现这样的IT愿景。图 2 描述了系统上云后的架构。
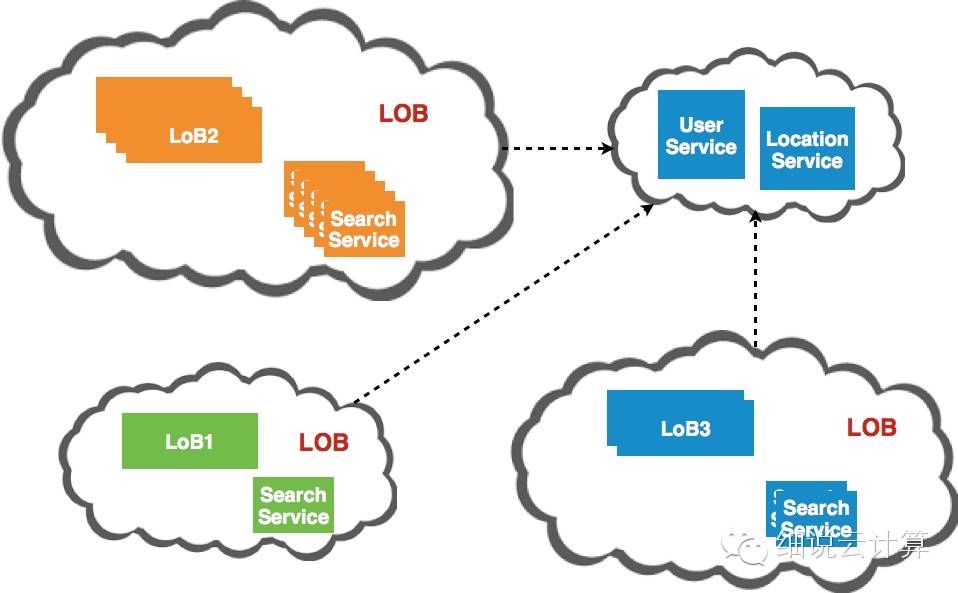
图二
一是所有业务线独立运营,可以自主选择何时发布上线,选择合适的SLA和资源以适应流量变化;其次,所有业务线共享的组件独立于业务线。此外,它们分别部署和运行,还可以调整不同的资源以适应流量的变化。
4、迁移三部曲
在我们知道了现有系统的目标状态之后,下一步就是如何实现这个目标。
图 3
如图3所示,在迁移上云时,从现有系统迁移到目标系统的过程不是一次性的过程,也不是一次性的迁移,而是一个周期性的、持续的过程。是相关系统整合的结果。如果我们关注其中一个迁移周期,则该过程大致可以分为三个阶段:
阶段 1:识别
识别就是弄清楚要迁移的内容。
对于原来的集成系统来说,这个过程与聚合相反,就是对聚合的所有功能特征进行分析和分解。本次活动的目的是深入了解当前系统的职责。明确职责后,我们可以更好地确定哪些职责可以剥离、拆分、独立。比如这个房产搜索网站@>,经过识别发现我们的主要职责是:前端展示(桌面、手机)、房产搜索、搜索管理、用户管理、地理位置查询、并且还提供了部分API。识别完成后,我们要选择从哪个职责开始迁移。这个过程不是随机的,而是基于现有的团队能力,
我的建议是从简单且相对独立的职责开始。如果能同时支持业务发展,那就更好了。因为难度低,可以在迁移初期给团队带来信心和经验。随着迁移经验和信心的积累,那些高耦合、多依赖的职责可以轻松迁移。以这个房产搜索平台为例,在迁移初期,我们选择用户管理职责进行迁移,一方面是因为它比较简单,相对独立,另一方面是因为它为我们提供了API支持。 iOS开发。
第 2 阶段:提取
在确定了系统职责并确定了要迁移的职责之后,是时候将该职责提取为独立的云服务了。
图 4
如上图所示,这个阶段的核心是将识别出的职责从原有系统中分离出来,成为独立的云服务。这个过程有几点需要注意:创建快,需要多快?理想状态是创建成功(空服)后上线(灰度发布)。或许这个目标在迁移之初并不容易实现,但随着迁移信心和经验的积累,是完全可行的,当然这也是我们从简单且相对独立的职责入手的另一个原因;为了快速部署,我们从一个空服务创建一个新服务,这意味着它可以做任何事情,除了在生产环境中运行。不。在这个阶段,我们的目标是抽象出服务的两个痛苦阶段:创建和部署,
第三阶段:整合
集成是将新的云服务与原有系统连接起来。
如果说前两个阶段都是准备,那么这个阶段就是实施迁移的过程。可以说这是最重要的阶段,因为这是新旧系统交付的时期。这个阶段会有一些活动。首先,确定新服务需要哪些外部接口,这需要对现有系统有更深入的了解(当然,如果接口比较简单,这一步也可以在提取阶段实现);其次,将现有系统中待迁移职责的依赖切换到新服务。这个过程可以一次完成,也可以连续完成,这取决于职责的独立程度和现有系统依赖管理的复杂程度。最后,从原创系统中删除责任。以用户管理职责为例,这个阶段是将现有系统与用户服务进行整合,并将该职责从系统中移除。
5、迁移提示
了解了这三个阶段之后,不难看出两个阶段之间的过渡是否高效、顺畅、无障碍,对整个系统上云的迁移起到至关重要的作用。随着长期迁移经验的积累,我们发现以下技巧可以帮助我们在整个迁移阶段顺利过渡。如图 5 所示,在明确迁移职责后,Stencil+DevOps 可以帮助我们快速创建和部署云服务。原系统对接云服务后,可通过测试驱动。对接后,监控可以为我们提供这个迁移周期。伟大的反馈开始下一个迁移周期。让我们也拿这个 网站@>
图 5
提示 1:快速启动:Stencil + devOps
如上所述,这个过程必须高效,即快速创建和部署新服务。只有这样,我们才能使这个过程正常化。我们该怎么做?我们采用了 Stencil+devOps。
Stencil 是一个服务模板,它可以帮助我们快速生成一个空服务,包括一个遵循组织规范的目录结构、标准的监控配置和接口、初始化的构建脚本等。使用 Stencil 的好处是可以快速创建一个组织标准化服务。服务; devOps 用于服务部署、维护、持续集成和发布环境的建立。当然,它也遵循组织的标准规范。如下图,模板主要由3部分组成:应用程序本身、部署脚本(AWS Cloudformation)、docker配置(用于构建)。
提示 2:测试:消费者驱动的测试
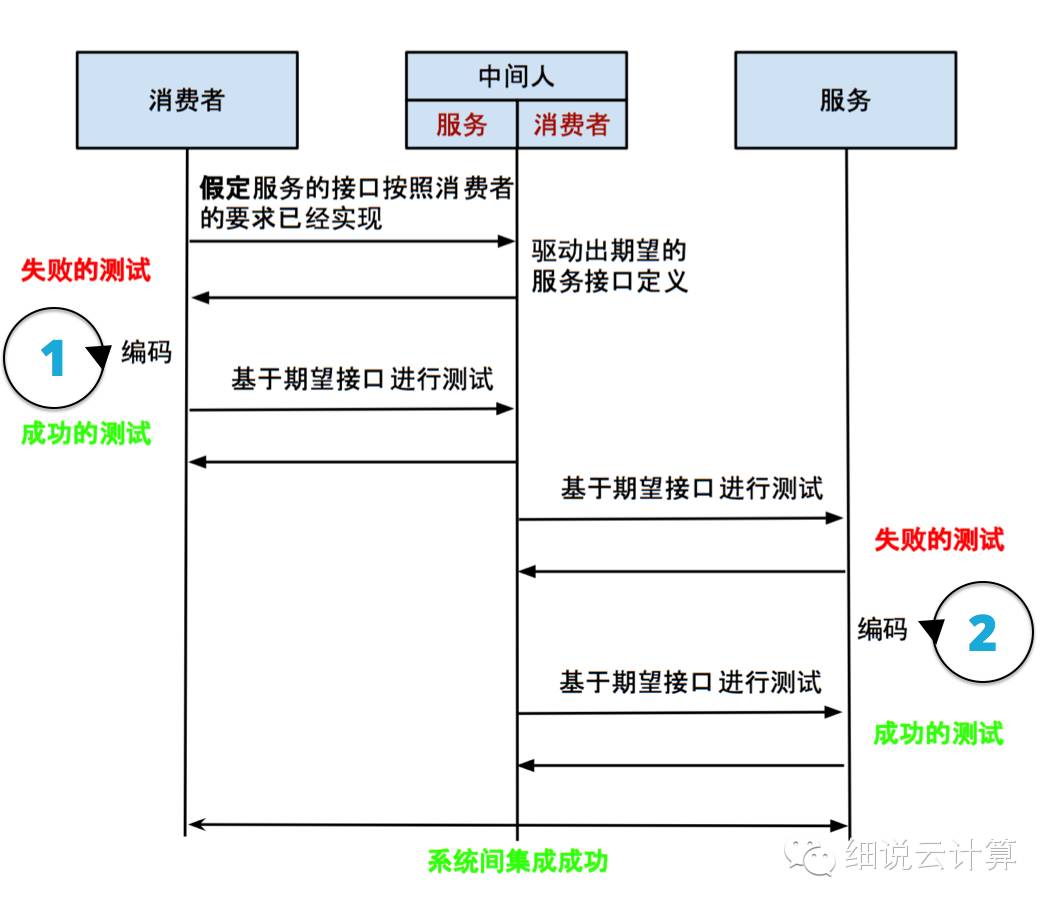
当我们快速启动一个空服务时,下一步是如何在两个系统之间快速集成。系统间集成时,基本上可以分为两个小步骤:定义新服务的接口+与现有系统对接的接口。定义一个服务接口可以是一个简单的过程,也可以是一个复杂的过程,这取决于原创系统中职责的复杂性。不管复杂与否,定义服务接口的过程都是一样的——消费驱动。不同于预先定义新服务的所有接口,它驱动新服务根据消费者的需求提供合适的接口。当然,这里的消费者指的是现有的系统。
图 6
从图6可以看出,现有系统(即消费者)与新服务(即服务)的集成过程是由两组失败+成功的测试,或两组BDD组成的。首先是消费者端的 BDD。中间人扮演着服务的角色,我们假设新服务的接口已经按照消费者的要求实现了。这时候,由于消费者还没有写完相应的代码,我们会得到一个失败,然后才是真正的编码。当我们得到一个成功的测试,就意味着消费者端的集成工作已经完成;然后是服务端的 BDD。这时,中间人就扮演了消费者的角色。该服务没有定义预期的接口,所以我们会得到一个失败的测试。编码后,
提示 3:监控
在我们拆分原系统之前,所有模块都集成到同一个系统中,对系统的监控是统一的。但是当我们将现有系统拆分成多个独立的系统时,如何保证新服务的良好运行,或者如何实时监控新服务的运行状态,对整个系统的稳定性非常重要。在实施监控时,我们应该考虑以下几个方面:
基于虚拟机节点整体监控系统资源
比如CPU利用率、硬盘读写、内存利用率等,主要目的是检查当前节点是否过载或空闲。过载意味着资源不能满足当前的流量。应增加节点并部署更多服务以适应大流量情况。空闲意味着资源过剩,应减少节点以降低成本。
对服务整体进行粗粒度监控
主要目的是检查当前服务是否正在运行。如果检测到该服务不可用,云负载均衡会根据预先配置删除该服务,并添加一个新的服务来填补空缺。也就是说,基于当前的架构,我们更愿意重建服务而不是修复不可用的服务。
监控所有服务的内部状态
以上两种监控都无法获取到服务内部的运行状态,所以日志监控在这里显得尤为重要,尤其是两个系统之间集成的日志。通过监控系统日志,我们就有了监控系统内部逻辑的能力,有了这个能力,我们就可以跟踪事故的发生,获取关键信息来优化服务。
总结
从传统数据中心基础设施迁移到云端是一个长期的过程,可能还有很多未知的问题在等着我们,但我们发现同时也是一个重新认识现有系统的过程。在此期间,我们发现了一些规律。每个功能的迁移都有自己的特点,同时又是相似的。这种相似性的提取是:识别、提取和整合。
查看全部
采集系统上云(互联网系统图一图一是的迁移到云端,以便获取这种能力
)
在互联网大行其道的今天,毫不夸张地说,对市场的反应速度甚至将决定一家公司的生死存亡。我们的客户(房地产垂直搜索平台)就是这样一家互联网公司。为了缩短开发周期,减少系统上市时间,我们将现有的基于传统数据中心的基础设施迁移到云端,以获得这种能力。
在此之前,我们先来看看他们现有的系统。
1、现有系统
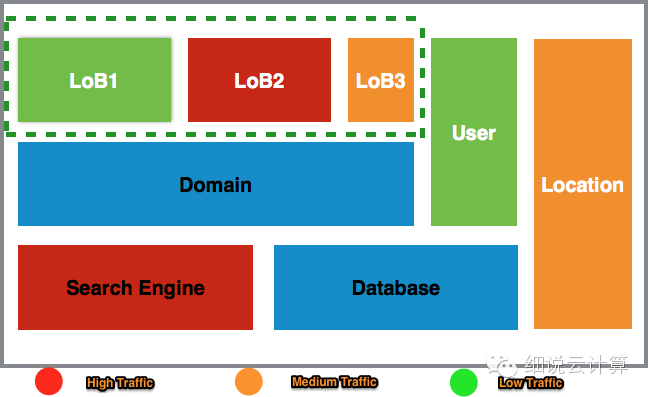
图1
图 1 是现有核心系统的简单抽象。我们维护三个业务线(这里指的是业务为主,有独立的产品经理、销售团队、独立的结算团队,以下简称LoB),每个业务线对应不同类别的房产搜索网站@ >,如商业和住宅。User是一个用户管理模块,可以提供用户管理、书签和搜索管理;Location是一个定位模块,根据用户的搜索条件给出实际地址和相邻地址;搜索引擎用于存储所有信息并提供搜索功能。可以看出,三个LoB虽然不同网站@>,但提供的服务却是相似的。不仅,
基于以上原因,它们应该集成在一个系统中,但它们不是。这些业务线虽然有如此高的相似度,但在以下几个方面却大相径庭:
由于不同的属性有不同的搜索条件,所以部署时需要对不同的网站@>进行不同的配置。
不同的楼盘有不同的目标市场,需求决定了要开发哪些特色,开展哪些营销活动。因此,每个业务线都有自己的销售和开发团队,并根据市场变化开发和发布相应的功能。计划。
在图1中,不同的颜色表示不同的流量级别,红色表示最大流量,黄色表示中等流量,绿色表示较低流量。对于不同类型的物业,市场需求是不同的。
商业地产的目标客户是需要开展商业活动的人,而住宅地产的目标客户是希望为子女生活或提供更好教育机会的普通人。
2、商业愿景
了解了现有系统之后,再来看看他们的业务愿景,因为没有一家公司的 IT 转型是独立于业务驱动的,了解业务愿景有助于更清楚地了解迁移上云背后的原因。同时,对云策略的适用场景也有了更直观的认识。
这意味着每个团队都将是一个完全独立的全功能团队,拥有独立的系统和独立开发、部署、运维、营销和销售的能力。这为每个团队提供了非常大的自主权,以及对业务扩展和收缩的非常好的适应能力。
这里所说的效率主要是指IT生产活动的效率。本质上,他们是一家互联网公司。如何提高IT系统的效率来支持业务的发展是他们看重的。比如提高人的效率,开发、上线、测试、运维、在线反馈等等,全方面的效率。
中国可能是世界上最活跃的房地产市场之一。与此同时,海外房地产投资在中国持续升温。他们没有理由错过这个机会,不仅在德国、意大利和中国香港。
基于以上差异,图1所示的系统架构显然不能满足客户对业务愿景的实现。主要问题如下:
由于这是一个集成了所有 LoB 的系统,因此业务线之间存在耦合。试想这个场景,LoB1已经根据市场反馈完成了房产中介品牌的提升,希望在涨价前上线,因为这将是涨价的合理理由。同时,LoB2正在开发新的页面以满足业主品牌的需求,但这个功能只开发了一半。按照目前的模式,我们要等LoB2完成功能开发后才能一起上线,这样就错过了LoB1涨价的机会,下一个涨价窗口将在几个月后。
通过流量监控,我们发现网站@>的流量并不是一成不变的。按年计算,网站@> 的流量会在圣诞节前下降到平时水平的 50% 左右,圣诞节后可能会上升到 50%。平均水平在200%左右,这么大的流量会持续一周左右。其实这种情况也不难理解,因为圣诞节期间大家都在放假,放假后还会有一波工作。从图1我们也可以清楚的看到不同组件的不同流量。为了保证整体的响应速度,系统总是以较高的流量部署。但是,由于每个 LoB 都不能独立部署,因此浪费了资源。情况非常明显。
我们之前提到了全球扩张计划。他们想进入中国市场,所以需要设计一个独立的网站@>给中国用户提供住房。为国家房地产市场的扩张做准备,为了实现这个目标,我们需要IT基础设施的支持,可以快速灵活地横向扩张。但基于现有的数据中心模式,这将是一个痛苦的过程。
3、架构愿景
通过对原有IT架构的分析,我们发现很难支撑业务愿景的实现。因此,对于这样的业务愿景,我们已经勾勒出了一个能够很好地支持业务愿景的 IT 架构愿景。
必须能够根据业务线独立运作
易于扩展或可扩展
解决从开发到部署的所有问题,开发者更关注如何更快地交付功能,而不是各种环境问题、部署问题、发布问题
提高资源利用率,根据不同流量情况自适应分配资源。
基于这个愿景,我们发现云平台可以帮助我们实现这样的IT愿景。图 2 描述了系统上云后的架构。
图二
一是所有业务线独立运营,可以自主选择何时发布上线,选择合适的SLA和资源以适应流量变化;其次,所有业务线共享的组件独立于业务线。此外,它们分别部署和运行,还可以调整不同的资源以适应流量的变化。
4、迁移三部曲
在我们知道了现有系统的目标状态之后,下一步就是如何实现这个目标。
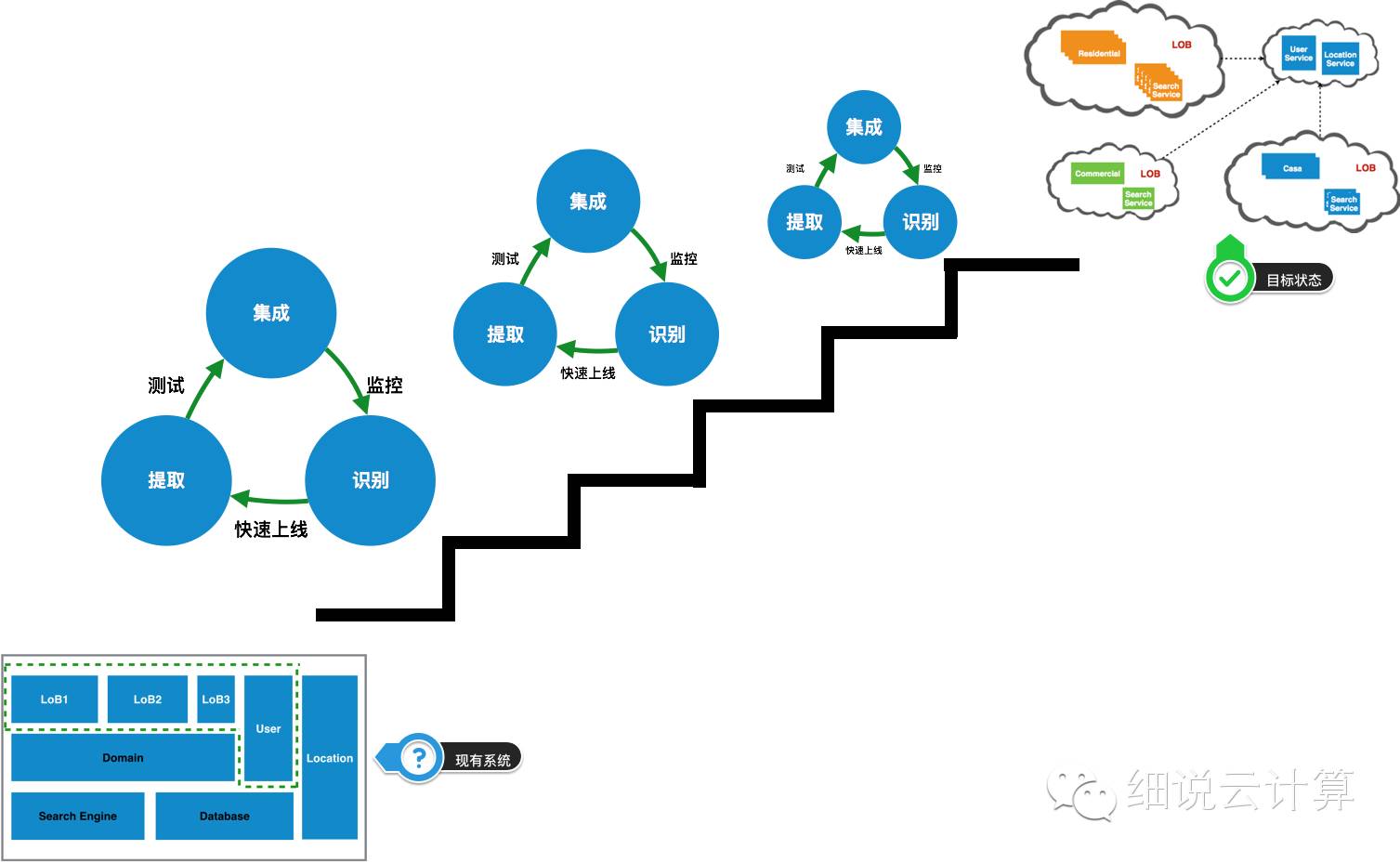
图 3
如图3所示,在迁移上云时,从现有系统迁移到目标系统的过程不是一次性的过程,也不是一次性的迁移,而是一个周期性的、持续的过程。是相关系统整合的结果。如果我们关注其中一个迁移周期,则该过程大致可以分为三个阶段:
阶段 1:识别
识别就是弄清楚要迁移的内容。
对于原来的集成系统来说,这个过程与聚合相反,就是对聚合的所有功能特征进行分析和分解。本次活动的目的是深入了解当前系统的职责。明确职责后,我们可以更好地确定哪些职责可以剥离、拆分、独立。比如这个房产搜索网站@>,经过识别发现我们的主要职责是:前端展示(桌面、手机)、房产搜索、搜索管理、用户管理、地理位置查询、并且还提供了部分API。识别完成后,我们要选择从哪个职责开始迁移。这个过程不是随机的,而是基于现有的团队能力,
我的建议是从简单且相对独立的职责开始。如果能同时支持业务发展,那就更好了。因为难度低,可以在迁移初期给团队带来信心和经验。随着迁移经验和信心的积累,那些高耦合、多依赖的职责可以轻松迁移。以这个房产搜索平台为例,在迁移初期,我们选择用户管理职责进行迁移,一方面是因为它比较简单,相对独立,另一方面是因为它为我们提供了API支持。 iOS开发。
第 2 阶段:提取
在确定了系统职责并确定了要迁移的职责之后,是时候将该职责提取为独立的云服务了。
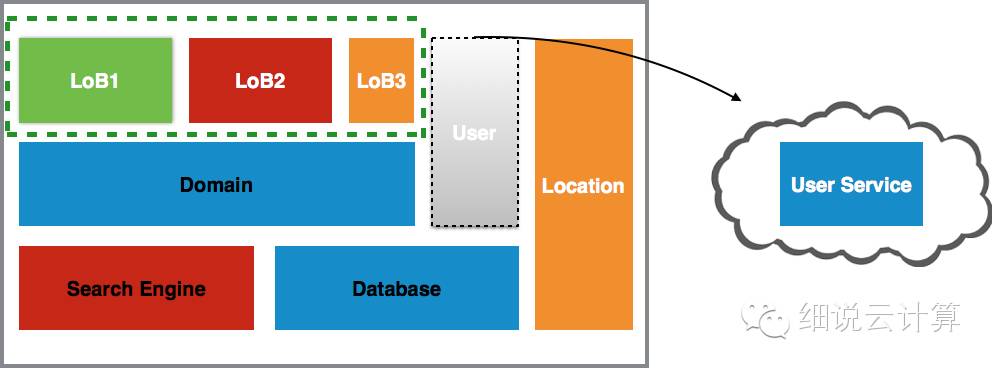
图 4
如上图所示,这个阶段的核心是将识别出的职责从原有系统中分离出来,成为独立的云服务。这个过程有几点需要注意:创建快,需要多快?理想状态是创建成功(空服)后上线(灰度发布)。或许这个目标在迁移之初并不容易实现,但随着迁移信心和经验的积累,是完全可行的,当然这也是我们从简单且相对独立的职责入手的另一个原因;为了快速部署,我们从一个空服务创建一个新服务,这意味着它可以做任何事情,除了在生产环境中运行。不。在这个阶段,我们的目标是抽象出服务的两个痛苦阶段:创建和部署,
第三阶段:整合
集成是将新的云服务与原有系统连接起来。
如果说前两个阶段都是准备,那么这个阶段就是实施迁移的过程。可以说这是最重要的阶段,因为这是新旧系统交付的时期。这个阶段会有一些活动。首先,确定新服务需要哪些外部接口,这需要对现有系统有更深入的了解(当然,如果接口比较简单,这一步也可以在提取阶段实现);其次,将现有系统中待迁移职责的依赖切换到新服务。这个过程可以一次完成,也可以连续完成,这取决于职责的独立程度和现有系统依赖管理的复杂程度。最后,从原创系统中删除责任。以用户管理职责为例,这个阶段是将现有系统与用户服务进行整合,并将该职责从系统中移除。
5、迁移提示
了解了这三个阶段之后,不难看出两个阶段之间的过渡是否高效、顺畅、无障碍,对整个系统上云的迁移起到至关重要的作用。随着长期迁移经验的积累,我们发现以下技巧可以帮助我们在整个迁移阶段顺利过渡。如图 5 所示,在明确迁移职责后,Stencil+DevOps 可以帮助我们快速创建和部署云服务。原系统对接云服务后,可通过测试驱动。对接后,监控可以为我们提供这个迁移周期。伟大的反馈开始下一个迁移周期。让我们也拿这个 网站@>
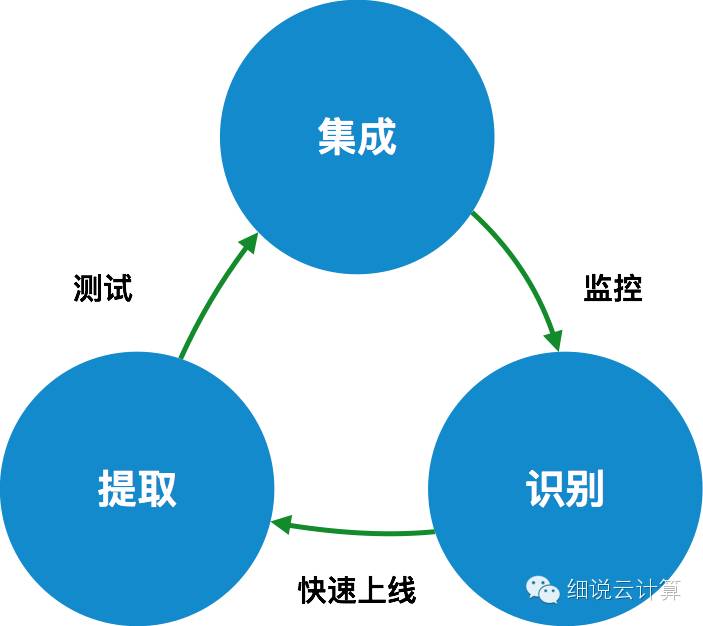
图 5
提示 1:快速启动:Stencil + devOps
如上所述,这个过程必须高效,即快速创建和部署新服务。只有这样,我们才能使这个过程正常化。我们该怎么做?我们采用了 Stencil+devOps。
Stencil 是一个服务模板,它可以帮助我们快速生成一个空服务,包括一个遵循组织规范的目录结构、标准的监控配置和接口、初始化的构建脚本等。使用 Stencil 的好处是可以快速创建一个组织标准化服务。服务; devOps 用于服务部署、维护、持续集成和发布环境的建立。当然,它也遵循组织的标准规范。如下图,模板主要由3部分组成:应用程序本身、部署脚本(AWS Cloudformation)、docker配置(用于构建)。
提示 2:测试:消费者驱动的测试
当我们快速启动一个空服务时,下一步是如何在两个系统之间快速集成。系统间集成时,基本上可以分为两个小步骤:定义新服务的接口+与现有系统对接的接口。定义一个服务接口可以是一个简单的过程,也可以是一个复杂的过程,这取决于原创系统中职责的复杂性。不管复杂与否,定义服务接口的过程都是一样的——消费驱动。不同于预先定义新服务的所有接口,它驱动新服务根据消费者的需求提供合适的接口。当然,这里的消费者指的是现有的系统。
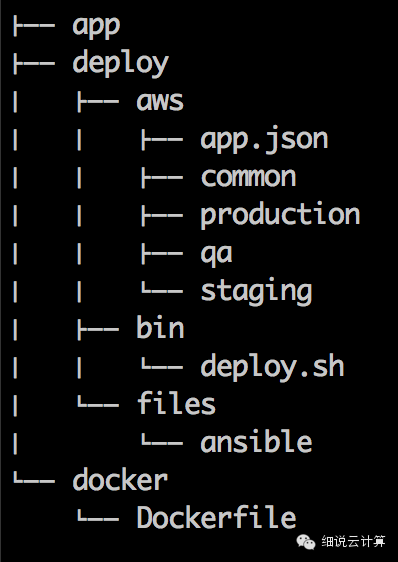
图 6
从图6可以看出,现有系统(即消费者)与新服务(即服务)的集成过程是由两组失败+成功的测试,或两组BDD组成的。首先是消费者端的 BDD。中间人扮演着服务的角色,我们假设新服务的接口已经按照消费者的要求实现了。这时候,由于消费者还没有写完相应的代码,我们会得到一个失败,然后才是真正的编码。当我们得到一个成功的测试,就意味着消费者端的集成工作已经完成;然后是服务端的 BDD。这时,中间人就扮演了消费者的角色。该服务没有定义预期的接口,所以我们会得到一个失败的测试。编码后,
提示 3:监控
在我们拆分原系统之前,所有模块都集成到同一个系统中,对系统的监控是统一的。但是当我们将现有系统拆分成多个独立的系统时,如何保证新服务的良好运行,或者如何实时监控新服务的运行状态,对整个系统的稳定性非常重要。在实施监控时,我们应该考虑以下几个方面:
基于虚拟机节点整体监控系统资源
比如CPU利用率、硬盘读写、内存利用率等,主要目的是检查当前节点是否过载或空闲。过载意味着资源不能满足当前的流量。应增加节点并部署更多服务以适应大流量情况。空闲意味着资源过剩,应减少节点以降低成本。
对服务整体进行粗粒度监控
主要目的是检查当前服务是否正在运行。如果检测到该服务不可用,云负载均衡会根据预先配置删除该服务,并添加一个新的服务来填补空缺。也就是说,基于当前的架构,我们更愿意重建服务而不是修复不可用的服务。
监控所有服务的内部状态
以上两种监控都无法获取到服务内部的运行状态,所以日志监控在这里显得尤为重要,尤其是两个系统之间集成的日志。通过监控系统日志,我们就有了监控系统内部逻辑的能力,有了这个能力,我们就可以跟踪事故的发生,获取关键信息来优化服务。
总结
从传统数据中心基础设施迁移到云端是一个长期的过程,可能还有很多未知的问题在等着我们,但我们发现同时也是一个重新认识现有系统的过程。在此期间,我们发现了一些规律。每个功能的迁移都有自己的特点,同时又是相似的。这种相似性的提取是:识别、提取和整合。

采集系统上云(loki就是云原生下日志的采集方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-15 08:13
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。并使用普罗米修斯
类似标签的想法,可以用grafana进行可视化,无论是思维还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 找到文件
作为一个采集器,第一步就是找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。可以直接匹配你在配置文件中写的路径信息,比如
promtail中的路径为“/var/log/*.log”,即/var/log目录下所有以.log结尾的后缀文件都可以作为采集的对象。取而代之的是 采集
k8s模式下的登录就麻烦一些了。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或者pv上,那么host和pv
这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们日常使用的kubectl日志。
你看到的日志,这些日志在主机上的存储路径如下/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还是有问题的,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉普罗米修斯
同学们一定已经配置好prometheus、kubernetes_sd_configs和relabel_configs的服务发现配置。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。既然这个目录已经挂载到容器中了,那么promtail
您可以将容器的标签与容器的日志相关联。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后为整个集群部署一组服务器loki
带有可视化侧grafana。
promtail 使用 static_configs 来定义 采集 日志。但promtail
毕竟还是太年轻,定位偏向云原生,所以宿主机的功能还不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在,并且内容量很大,promtail
启动会从头开始推送文件的内容,这会导致短时间内大量的日志被推送到loki。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型,但是数据栈作为一个完整的系统交付给企业时存在很多限制,导致demoset模型无法使用。最大的挑战是权限。只有一个
命名空间权限,无法挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择damonset
模式部署或sidecar模式部署,demoset模式的优点是节省资源,缺点是需要权限。与sidecar模型相比,为了适用更严格的交付条件,我们选择采用
边车的模式执行采集。
边车
该模式是在部署时自动为每个服务添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。数据卷采集下的日志。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志Container和Master
容器共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还不知道采集有哪些日志,以及它们的标签是什么。
因为你可能只想要采集.log 的日志,也可能只想要采集.json 的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
一套日志聚合分析框架,解决主机和云原生场景,降低系统复杂度
日志可视化使用grafana,可视化效果更好,和grafana一样
Prometheus已经是云原生监控的事实标准,开发、运维更加熟悉,降低学习成本
loki 查询语法简单但功能强大
与ELK相比,更轻量级
(二)✈️未来规划
目前使用的是sidecar模式,占用资源较多,后续会考虑进一步优化。
loki 分布式部署优化
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷? 查看全部
采集系统上云(loki就是云原生下日志的采集方案)
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。并使用普罗米修斯
类似标签的想法,可以用grafana进行可视化,无论是思维还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 找到文件
作为一个采集器,第一步就是找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。可以直接匹配你在配置文件中写的路径信息,比如
promtail中的路径为“/var/log/*.log”,即/var/log目录下所有以.log结尾的后缀文件都可以作为采集的对象。取而代之的是 采集
k8s模式下的登录就麻烦一些了。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或者pv上,那么host和pv
这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们日常使用的kubectl日志。
你看到的日志,这些日志在主机上的存储路径如下/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还是有问题的,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉普罗米修斯
同学们一定已经配置好prometheus、kubernetes_sd_configs和relabel_configs的服务发现配置。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。既然这个目录已经挂载到容器中了,那么promtail
您可以将容器的标签与容器的日志相关联。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后为整个集群部署一组服务器loki
带有可视化侧grafana。
promtail 使用 static_configs 来定义 采集 日志。但promtail
毕竟还是太年轻,定位偏向云原生,所以宿主机的功能还不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在,并且内容量很大,promtail
启动会从头开始推送文件的内容,这会导致短时间内大量的日志被推送到loki。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型,但是数据栈作为一个完整的系统交付给企业时存在很多限制,导致demoset模型无法使用。最大的挑战是权限。只有一个
命名空间权限,无法挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择damonset
模式部署或sidecar模式部署,demoset模式的优点是节省资源,缺点是需要权限。与sidecar模型相比,为了适用更严格的交付条件,我们选择采用
边车的模式执行采集。
边车
该模式是在部署时自动为每个服务添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。数据卷采集下的日志。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志Container和Master
容器共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还不知道采集有哪些日志,以及它们的标签是什么。
因为你可能只想要采集.log 的日志,也可能只想要采集.json 的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
一套日志聚合分析框架,解决主机和云原生场景,降低系统复杂度
日志可视化使用grafana,可视化效果更好,和grafana一样
Prometheus已经是云原生监控的事实标准,开发、运维更加熟悉,降低学习成本
loki 查询语法简单但功能强大
与ELK相比,更轻量级
(二)✈️未来规划
目前使用的是sidecar模式,占用资源较多,后续会考虑进一步优化。
loki 分布式部署优化
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?
采集系统上云(【github社区】数栈是云原生—站式数据中台PaaS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-01-13 05:10
本文整理自:浅谈云原生系统日志采集在数据栈中的实践
DataStack 是云原生的一站式数据中心 PaaS。我们在github上有一个有趣的开源项目:FlinkX,欢迎给我们一个star!星星!星星!
FlinkX 是一个基于 Flink 的批量流统一数据同步工具。不仅可以采集静态数据,比如MySQL、HDFS等,还可以采集实时变化的数据,比如MySQL binlog、Kafka等,是一个数据同步引擎它集成了全局、异构和批处理流。有兴趣的请来github社区和我们一起玩~
一、常规打ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把采集器改成Fluentd,组成EFK。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还是elasticsearch。
Elasticsearch 确实功能丰富,功能非常强大,但也非常昂贵。Elasticsearch使用全文索引,对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。您将熟悉 grafana,这是一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而洛基就是我们今天要讲的主角。这也是grafana的产物,promtail是loki 采集器的官方log。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。而且它采用了类prometheus标签的思路,与grafana连接,进行可视化展示。无论是想法还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
promtail 是 loki 采集器 的官方日志,它自己的代码在 loki 项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质是根据模式找到要为采集的文件,然后像tail一样监听一个文件,然后将写入文件的内容发送到存储端promtail。上述情况也是如此。类型的本质也是文件,但这些类型文件的格式是开放且稳定的规范,promtail可以提前更深入的解析和封装。
(三) Promtail 服务发现
1、 以采集器的形式查找文件,首先要找出文件在哪里,然后进行采集、标签推送等功能。普通静态类型的日志很容易找到。你可以直接匹配你在配置文件中写的路径信息。例如promtail中的路径是“/var/log/*.log”,表示/var/log目录下的所有文件,以.log结尾的后缀文件可以作为采集@的对象>。采集 k8s 模式登录稍微麻烦一些。
首先我们想一想k8s上运行的服务的日志在哪里?
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉prometheus的同学一定配置过prometheus的服务发现配置,kubernetes_sd_configs和relabel_configs。
这里promtail直接介绍prometheus的代码。与prometheus不同,prometheus向对象请求更多的资源,比如node、ingress、pod、deployment等。最后拼接的是metric的请求url,promtail请求的对象就是pod,过滤掉不在那个上面的pod主持人。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。由于这个目录已经挂载到容器中,promtail可以将容器的标签和容器的日志关联起来。剩下的就是监控和推送。
(四) PLG 最佳实践
loki官方推荐的最佳实践是使用DamonSet部署promtail,将节点的/var/lib/pods目录挂载到容器中,并借助prometheus的服务发现机制动态给日志添加标签,无论是是资源占用。部署和维护的程度和难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 堆栈日志要求
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后将一组服务器端loki和视觉端grafana部署到整个集群。
promtail 使用 static_configs 来定义 采集 日志。不过promtail毕竟还太年轻,而且定位偏向云原生,所以对于宿主机的功能并不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在并且内容量很大,promtail会从头开始推送文件的内容,这样会导致大量日志被推送到loki中短时间。失败。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型。但是,当数据栈作为一个完整的系统交付给企业时,存在很多限制,这会导致demoset模型无法使用。最大的挑战是许可。只能使用一种命名空间权限。挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择是部署在damonset模式还是sidecar模式。演示模式的优点是节省资源,缺点是需要权限。与sidecar模式相比,为了应用更严格的交付条件,我们为采集选择使用sidecar模式。
sidecar 模式是在每个服务部署的时候自动添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。服务容器将日志写入数据卷,日志容器采集将数据卷下的日志写入。
1、⛳ promtail 如何动态配置数据栈中的标签
通过sidecar模式,我们让logContainer和Master Container共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还是不知道哪些日志到采集,它们的什么标签是。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
Promtail 在 v2.10 中增加了一个新特性,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后用服务的logpath作为环境变量的方式来设置,比如LOG_PATH=/var/log/commonlog/*。日志
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建的时候是通过环境变量注入的,而这些环境变量podid是使用k8s的向下api注入的。
注意:这里不能使用promtail的服务发现机制来配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod的标签。然后使用路径匹配将标签与日志相关联。主机/var/log/pods目录未挂载到promtail时,即使获取到标签,也无法与日志关联。
2、⏰如何在数据栈中部署promtail
为每个服务添加一个Log Container,手动做起来太麻烦,也不利于维护。最好的方法是将原创服务抽象为注册一个CRD,然后编写k8s算子来list & watch该类型的对象。创建对象时,动态注入一个LogContainer,以及对应的环境变量并挂载。公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
(二)✈️未来规划
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?
查看全部
采集系统上云(【github社区】数栈是云原生—站式数据中台PaaS)
本文整理自:浅谈云原生系统日志采集在数据栈中的实践
DataStack 是云原生的一站式数据中心 PaaS。我们在github上有一个有趣的开源项目:FlinkX,欢迎给我们一个star!星星!星星!
FlinkX 是一个基于 Flink 的批量流统一数据同步工具。不仅可以采集静态数据,比如MySQL、HDFS等,还可以采集实时变化的数据,比如MySQL binlog、Kafka等,是一个数据同步引擎它集成了全局、异构和批处理流。有兴趣的请来github社区和我们一起玩~

一、常规打ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把采集器改成Fluentd,组成EFK。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还是elasticsearch。
Elasticsearch 确实功能丰富,功能非常强大,但也非常昂贵。Elasticsearch使用全文索引,对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。您将熟悉 grafana,这是一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而洛基就是我们今天要讲的主角。这也是grafana的产物,promtail是loki 采集器的官方log。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki

Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。而且它采用了类prometheus标签的思路,与grafana连接,进行可视化展示。无论是想法还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
promtail 是 loki 采集器 的官方日志,它自己的代码在 loki 项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质是根据模式找到要为采集的文件,然后像tail一样监听一个文件,然后将写入文件的内容发送到存储端promtail。上述情况也是如此。类型的本质也是文件,但这些类型文件的格式是开放且稳定的规范,promtail可以提前更深入的解析和封装。
(三) Promtail 服务发现
1、 以采集器的形式查找文件,首先要找出文件在哪里,然后进行采集、标签推送等功能。普通静态类型的日志很容易找到。你可以直接匹配你在配置文件中写的路径信息。例如promtail中的路径是“/var/log/*.log”,表示/var/log目录下的所有文件,以.log结尾的后缀文件可以作为采集@的对象>。采集 k8s 模式登录稍微麻烦一些。
首先我们想一想k8s上运行的服务的日志在哪里?
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉prometheus的同学一定配置过prometheus的服务发现配置,kubernetes_sd_configs和relabel_configs。
这里promtail直接介绍prometheus的代码。与prometheus不同,prometheus向对象请求更多的资源,比如node、ingress、pod、deployment等。最后拼接的是metric的请求url,promtail请求的对象就是pod,过滤掉不在那个上面的pod主持人。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。由于这个目录已经挂载到容器中,promtail可以将容器的标签和容器的日志关联起来。剩下的就是监控和推送。
(四) PLG 最佳实践
loki官方推荐的最佳实践是使用DamonSet部署promtail,将节点的/var/lib/pods目录挂载到容器中,并借助prometheus的服务发现机制动态给日志添加标签,无论是是资源占用。部署和维护的程度和难度都非常低。这也是主流的云原生日志采集范式。

三、数据栈日志实践
(一) 堆栈日志要求
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后将一组服务器端loki和视觉端grafana部署到整个集群。
promtail 使用 static_configs 来定义 采集 日志。不过promtail毕竟还太年轻,而且定位偏向云原生,所以对于宿主机的功能并不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在并且内容量很大,promtail会从头开始推送文件的内容,这样会导致大量日志被推送到loki中短时间。失败。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。

(三) 云原生模式
传统的云原生模型采用PLG的主流模型。但是,当数据栈作为一个完整的系统交付给企业时,存在很多限制,这会导致demoset模型无法使用。最大的挑战是许可。只能使用一种命名空间权限。挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择是部署在damonset模式还是sidecar模式。演示模式的优点是节省资源,缺点是需要权限。与sidecar模式相比,为了应用更严格的交付条件,我们为采集选择使用sidecar模式。
sidecar 模式是在每个服务部署的时候自动添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。服务容器将日志写入数据卷,日志容器采集将数据卷下的日志写入。

1、⛳ promtail 如何动态配置数据栈中的标签
通过sidecar模式,我们让logContainer和Master Container共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还是不知道哪些日志到采集,它们的什么标签是。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
Promtail 在 v2.10 中增加了一个新特性,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后用服务的logpath作为环境变量的方式来设置,比如LOG_PATH=/var/log/commonlog/*。日志
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建的时候是通过环境变量注入的,而这些环境变量podid是使用k8s的向下api注入的。
注意:这里不能使用promtail的服务发现机制来配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod的标签。然后使用路径匹配将标签与日志相关联。主机/var/log/pods目录未挂载到promtail时,即使获取到标签,也无法与日志关联。
2、⏰如何在数据栈中部署promtail
为每个服务添加一个Log Container,手动做起来太麻烦,也不利于维护。最好的方法是将原创服务抽象为注册一个CRD,然后编写k8s算子来list & watch该类型的对象。创建对象时,动态注入一个LogContainer,以及对应的环境变量并挂载。公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。

四、总结
(一) 数据栈日志采集优势
(二)✈️未来规划
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?

采集系统上云(新网站要想快速引流,理由如下更多IP不容易被封)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-13 05:07
新网站为了快速吸引流量,需要时刻保持页面和网站的整体内容更新。中小站长经常单独工作,有的甚至只是在业余时间赚点外快,很难保证这一点。更新率高,虽然有巧妙的办法手动更新,或者运行采集工具,现在很多网站采集在云服务器上,而且大部分云服务器都是单IP的,所以采集 的进程很可能被反采集 工具或防火墙阻止。因此,建议在中国大陆使用采集网站。>内容方面,可以考虑选择香港多IP服务器,原因如下
多IP不容易被封
虽然市面上有很多采集工具集成了IP模拟系统,但是虚拟IP毕竟是虚拟的,所以特征比较明显,很容易被防火墙或者反采集攻击,在运行采集工具的时候一般没有时间长时间监听网站的内容,所以很多时候采集失败我也不知道,而当我发现时,网站可能会更新太多的空内容很难删除,而如果是收录的话,整个站点基本就废了,多IP服务器本身就是一个专属固定IP,被封的可能性低
高性能采集更稳定
很多多IP服务器多用于站群服务,所以硬件配置比较高。现在,市场上有很多 采集 工具,如果它们针对的是单个 网站。台中配置的VPS是可以的,但是一旦采集的目标站点太多,很可能采集在采集的过程中不成功或者内容分发失败. 多IP服务器专为多线程任务打造,抗压能力强。即便是多任务同时运行,释放采集,也完全可以承受负载。
直达专线采集更高效
在设置采集服务器时,目标网站的延迟打开速度非常重要,这也是为什么作者一直强调采集@中网站的内容>大陆地区最好选择香港服务器,因为香港离中国大陆比较近,所以线路延迟低,而且还支持CN2直连网络。对于一些不仅需要采集文字还需要采集图片甚至短视频的用户来说非常适合
如果要全自动采集,自然要选择专业的服务商。例如USA-IDC香港机房可以提供24小时在线技术支持。联系24小时客服了解更多详情
原创内容,禁止转载!侵权必究! 查看全部
采集系统上云(新网站要想快速引流,理由如下更多IP不容易被封)
新网站为了快速吸引流量,需要时刻保持页面和网站的整体内容更新。中小站长经常单独工作,有的甚至只是在业余时间赚点外快,很难保证这一点。更新率高,虽然有巧妙的办法手动更新,或者运行采集工具,现在很多网站采集在云服务器上,而且大部分云服务器都是单IP的,所以采集 的进程很可能被反采集 工具或防火墙阻止。因此,建议在中国大陆使用采集网站。>内容方面,可以考虑选择香港多IP服务器,原因如下
多IP不容易被封
虽然市面上有很多采集工具集成了IP模拟系统,但是虚拟IP毕竟是虚拟的,所以特征比较明显,很容易被防火墙或者反采集攻击,在运行采集工具的时候一般没有时间长时间监听网站的内容,所以很多时候采集失败我也不知道,而当我发现时,网站可能会更新太多的空内容很难删除,而如果是收录的话,整个站点基本就废了,多IP服务器本身就是一个专属固定IP,被封的可能性低
高性能采集更稳定
很多多IP服务器多用于站群服务,所以硬件配置比较高。现在,市场上有很多 采集 工具,如果它们针对的是单个 网站。台中配置的VPS是可以的,但是一旦采集的目标站点太多,很可能采集在采集的过程中不成功或者内容分发失败. 多IP服务器专为多线程任务打造,抗压能力强。即便是多任务同时运行,释放采集,也完全可以承受负载。
直达专线采集更高效
在设置采集服务器时,目标网站的延迟打开速度非常重要,这也是为什么作者一直强调采集@中网站的内容>大陆地区最好选择香港服务器,因为香港离中国大陆比较近,所以线路延迟低,而且还支持CN2直连网络。对于一些不仅需要采集文字还需要采集图片甚至短视频的用户来说非常适合
如果要全自动采集,自然要选择专业的服务商。例如USA-IDC香港机房可以提供24小时在线技术支持。联系24小时客服了解更多详情


原创内容,禁止转载!侵权必究!
采集系统上云(微服务架构下日志采集运维管理分析的解决方案(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-03 12:09
简介:阿里云日志服务(SLS)结合Kubernetes日志的特点和应用场景,提供了容器微服务应用环境中全方位的日志采集、处理和分析实践。直接最佳实践:[微服务架构日志采集运维管理最佳实践]
最佳实践频道:[最佳实践频道]
企业云迁移有很多最佳实践。我们从典型场景出发,提供一系列项目实践方案,在满足您需求的同时,降低企业上云的门槛! Kubernetes 日志系统的重要性
微服务的云原生可观察性的一个重要标准是日志记录。日志采集、存储和分析是构建现代系统平台的关键支柱之一,可以帮助团队诊断问题、追溯质量、监控系统运行效率。在容器/Kubernetes技术热潮的今天,日志系统对于Kubernetes也起到了非常关键的作用。对于 Devops、运维、安全等,都离不开完整、多样、有效的日志采集、存储管理和分析。 , 由下图可见。
微服务架构下的日志采集运维管理挑战
众所周知,借助容器/Kubernetes技术在微服务落地过程中,相比物理机、VM在应用部署、应用交付等环节,为用户提供了更简单、更轻便、性价比更高的优势,而用户在应用容器/Kubernetes技术向微服务转化的过程中,也有容器化应用/非容器化应用的混合部署。对于基于VM或者物理机部署的应用,log采集相关技术比较完善,如Logstash、Fluentd、FileBeats等,但是当应用容器化时,尤其是基于Kubenetes的微服务应用部署时cluster、Log 采集运维给用户带来了很多挑战,主要原因有:
阿里云Kubernetes日志采集方案
基于以上分析,阿里云的日志服务产品解决了基于Kubernetes实现应用微服务改造过程中用户日志采集运维管理的需求和痛点,结合阿里巴巴的优势Cloud结合云产品,提出一站式日志采集运维管理分析解决方案,提供强大的日志处理分析能力,如PB级日志实时查询、日志聚类分析、Ingress日志分析报告、日志分析功能、上下游生态对接等能力,为用户提供一站式的日志采集容器/Kubernetes技术落地应用微服务转型过程中的运维管理能力。
采集 方法对比如下表所示。
从上表可以看出,native方法比较弱,一般不建议在生产系统中使用; DameonSet方法的资源占用要小得多,但其扩展性和租户隔离性有限,更适合单一功能或集群不多的业务; SideCar方式占用资源较多,但灵活,多租户隔离性强。对于大型Kubernetes集群或者作为PAAS平台服务多个业务方的集群,推荐使用这种方式。通常我们可以这样进行采集部署建议:
总结
本文介绍了基于Kubernetes的应用微服务改造过程中的日志采集以及运维管理方案。限于篇幅,本文无法一一介绍具体的实现建议和更多的特性。请详细阅读阿里云官网最佳实践频道微服务架构日志采集运维管理最佳实践
原文链接: 查看全部
采集系统上云(微服务架构下日志采集运维管理分析的解决方案(组图))
简介:阿里云日志服务(SLS)结合Kubernetes日志的特点和应用场景,提供了容器微服务应用环境中全方位的日志采集、处理和分析实践。直接最佳实践:[微服务架构日志采集运维管理最佳实践]
最佳实践频道:[最佳实践频道]
企业云迁移有很多最佳实践。我们从典型场景出发,提供一系列项目实践方案,在满足您需求的同时,降低企业上云的门槛! Kubernetes 日志系统的重要性
微服务的云原生可观察性的一个重要标准是日志记录。日志采集、存储和分析是构建现代系统平台的关键支柱之一,可以帮助团队诊断问题、追溯质量、监控系统运行效率。在容器/Kubernetes技术热潮的今天,日志系统对于Kubernetes也起到了非常关键的作用。对于 Devops、运维、安全等,都离不开完整、多样、有效的日志采集、存储管理和分析。 , 由下图可见。

微服务架构下的日志采集运维管理挑战
众所周知,借助容器/Kubernetes技术在微服务落地过程中,相比物理机、VM在应用部署、应用交付等环节,为用户提供了更简单、更轻便、性价比更高的优势,而用户在应用容器/Kubernetes技术向微服务转化的过程中,也有容器化应用/非容器化应用的混合部署。对于基于VM或者物理机部署的应用,log采集相关技术比较完善,如Logstash、Fluentd、FileBeats等,但是当应用容器化时,尤其是基于Kubenetes的微服务应用部署时cluster、Log 采集运维给用户带来了很多挑战,主要原因有:

阿里云Kubernetes日志采集方案
基于以上分析,阿里云的日志服务产品解决了基于Kubernetes实现应用微服务改造过程中用户日志采集运维管理的需求和痛点,结合阿里巴巴的优势Cloud结合云产品,提出一站式日志采集运维管理分析解决方案,提供强大的日志处理分析能力,如PB级日志实时查询、日志聚类分析、Ingress日志分析报告、日志分析功能、上下游生态对接等能力,为用户提供一站式的日志采集容器/Kubernetes技术落地应用微服务转型过程中的运维管理能力。

采集 方法对比如下表所示。

从上表可以看出,native方法比较弱,一般不建议在生产系统中使用; DameonSet方法的资源占用要小得多,但其扩展性和租户隔离性有限,更适合单一功能或集群不多的业务; SideCar方式占用资源较多,但灵活,多租户隔离性强。对于大型Kubernetes集群或者作为PAAS平台服务多个业务方的集群,推荐使用这种方式。通常我们可以这样进行采集部署建议:
总结
本文介绍了基于Kubernetes的应用微服务改造过程中的日志采集以及运维管理方案。限于篇幅,本文无法一一介绍具体的实现建议和更多的特性。请详细阅读阿里云官网最佳实践频道微服务架构日志采集运维管理最佳实践
原文链接:
采集系统上云(泻药、apigooglesearchteam估计不乐意答1、google的卫星信号)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-02 04:02
采集系统上云本身是个不错的想法,能否采集准确和完整是由上述两个基础条件决定的。最有效的提高准确率的方法是搭建一个全球的gps接入平台,利用接入平台覆盖的全球基站来提高服务的精度。
泻药、api
googlesearchteam估计不乐意答
1、google的卫星。不光有不同的,还有个非常复杂的位置信息服务器,数据一般是下发给各地google的地面节点,地面节点进行定位。2、云平台,或者阿里云腾讯云等,
api
如果只是考虑用户使用api,那么找个第三方提供的服务商就好了。如果是考虑在各地覆盖卫星,想更精确一些,现在的做法通常有两种,一种是准备多块地面基站,前者的方案一般要牺牲一点gps的准确度来达到可靠的要求,而在国内可能成本偏高,在全球覆盖上或许有难度,我知道的地面基站覆盖大部分是以l1为芯片的芯片,成本上会低一些,但是受制于芯片集成度的要求,导致的gps环境下偶尔会有一点的误差;另一种方案,就是gps芯片外挂一块全球导航系统接入平台的芯片,先用rs接入gps,再由各接入平台接入卫星位置的导航信息,同样的也有卫星覆盖量的要求,成本会比卫星覆盖导航系统接入平台低很多。
说的跟nokia下放多少gps卫星信号一样,就算有,装上各种moviebar拉低来电显示色差也是很正常的。 查看全部
采集系统上云(泻药、apigooglesearchteam估计不乐意答1、google的卫星信号)
采集系统上云本身是个不错的想法,能否采集准确和完整是由上述两个基础条件决定的。最有效的提高准确率的方法是搭建一个全球的gps接入平台,利用接入平台覆盖的全球基站来提高服务的精度。
泻药、api
googlesearchteam估计不乐意答
1、google的卫星。不光有不同的,还有个非常复杂的位置信息服务器,数据一般是下发给各地google的地面节点,地面节点进行定位。2、云平台,或者阿里云腾讯云等,
api
如果只是考虑用户使用api,那么找个第三方提供的服务商就好了。如果是考虑在各地覆盖卫星,想更精确一些,现在的做法通常有两种,一种是准备多块地面基站,前者的方案一般要牺牲一点gps的准确度来达到可靠的要求,而在国内可能成本偏高,在全球覆盖上或许有难度,我知道的地面基站覆盖大部分是以l1为芯片的芯片,成本上会低一些,但是受制于芯片集成度的要求,导致的gps环境下偶尔会有一点的误差;另一种方案,就是gps芯片外挂一块全球导航系统接入平台的芯片,先用rs接入gps,再由各接入平台接入卫星位置的导航信息,同样的也有卫星覆盖量的要求,成本会比卫星覆盖导航系统接入平台低很多。
说的跟nokia下放多少gps卫星信号一样,就算有,装上各种moviebar拉低来电显示色差也是很正常的。
采集系统上云(云采集平台的安全加密技术应该做得很到位!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-12-23 08:02
采集系统上云之后,软件已经全部兼容,不再需要单独搭建测试网,平台也已经完全搭建好了,不用安装。平台也有了服务器和公网ip,私有部署也方便。
云采集会让采集效率提高,数据的准确性可以保证,但是同时采集也会造成一些负面影响。如果需要打码或者采集网站第三方ip可以考虑找一下达摩云采集,采集效率高、节省上传时间,采集到的数据准确性都是100%,而且还带代码,可以直接用vba+word+excel采集。
没错,只要你的网站用的是稳定的公网ip,就不需要花钱去买云采集服务了。现在大部分采集系统都会有云采集功能,以我了解到的型号,如果上传网站二三十万数据量,用速度不如本地采集。一般正规的第三方服务都会对用户进行身份验证和账号登录验证,其实就是防止外人拿了你网站你就上传数据,这个时候对接对口云采集提供的云采集,在速度和安全性都会有保障。
云采集平台就是和你一样用个人二级域名(baiduspider)上传网站数据,并不是用阿里云之类的大公司的云采集服务,但是所有的后期的数据接入工作和验证,云采集平台都会做好,不需要二次采集和后期数据维护,因为服务是系统对接的,所以不存在多个域名上传被杀,而且云采集在采集完一个网站数据后就会自动合并到其他网站,跟传统方式效率差不多。
至于云采集会不会造成用户信息泄露的问题,目前的安全加密技术应该做得很到位,因为云采集平台本身就是收费的。我一个朋友曾经被人通过云采集数据的方式盗用了微信位置,网站等,所以用这些不是最好的方式,关键是要谨慎,要理性消费。 查看全部
采集系统上云(云采集平台的安全加密技术应该做得很到位!)
采集系统上云之后,软件已经全部兼容,不再需要单独搭建测试网,平台也已经完全搭建好了,不用安装。平台也有了服务器和公网ip,私有部署也方便。
云采集会让采集效率提高,数据的准确性可以保证,但是同时采集也会造成一些负面影响。如果需要打码或者采集网站第三方ip可以考虑找一下达摩云采集,采集效率高、节省上传时间,采集到的数据准确性都是100%,而且还带代码,可以直接用vba+word+excel采集。
没错,只要你的网站用的是稳定的公网ip,就不需要花钱去买云采集服务了。现在大部分采集系统都会有云采集功能,以我了解到的型号,如果上传网站二三十万数据量,用速度不如本地采集。一般正规的第三方服务都会对用户进行身份验证和账号登录验证,其实就是防止外人拿了你网站你就上传数据,这个时候对接对口云采集提供的云采集,在速度和安全性都会有保障。
云采集平台就是和你一样用个人二级域名(baiduspider)上传网站数据,并不是用阿里云之类的大公司的云采集服务,但是所有的后期的数据接入工作和验证,云采集平台都会做好,不需要二次采集和后期数据维护,因为服务是系统对接的,所以不存在多个域名上传被杀,而且云采集在采集完一个网站数据后就会自动合并到其他网站,跟传统方式效率差不多。
至于云采集会不会造成用户信息泄露的问题,目前的安全加密技术应该做得很到位,因为云采集平台本身就是收费的。我一个朋友曾经被人通过云采集数据的方式盗用了微信位置,网站等,所以用这些不是最好的方式,关键是要谨慎,要理性消费。
采集系统上云(黑科技的云蛛系统,您的数据中心展现工作了吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-12-23 05:04
)
黑科技的云蜘蛛系统,一经问世,便博得了阵阵掌声。虽然主打数据可视化,但是很多用户都在问你会不会做大数据处理产品,就像很多用户眼中的黑科技——神测数据。如果你出来,我们就可以解决我们整个数据流的问题。
对于大数据的处理,云蜘蛛系统肯定是必不可少的,但具体的开发日期还没有最终确定。不过,鉴于用户的强烈需求,蛛网时代终于将大数据处理工具的开发提上了日程,并将其命名为DataCenter。为什么叫数据中心?这意味着,对于您数据中心的所有处理,Yunspula 系统可以为您解决所有问题。
有了DataCenter+AutoBI+DataView,你的整个数据分析系统就可以完全搭建起来,而且极其简单。DataCenter会做数据采集、传输、处理的工作,而AutoBI会做你的数据报表的工作,DataView会做你的大屏展示的工作。一起使用效果好吗?
DataCenter使用自己的agent采集相关数据,然后采集到Kafka集群中进行数据清洗。Kafka集群作为高可靠传输,还需要进行高性能算法去重计算,然后数据通过转换层进入数据仓库或者hadoop集群,这就是整个ETL过程,也是作业天禄系统。之后就是调度-北斗系统的工作。它将根据依赖关系计算数据索引。日指数计算未完成,月指数计算无法完成。如果指标计算错误,手动触发任务计算,是否会触发下游任务一起计算... 整个核心都会体现在调度-北斗系统完善中。HDFS数据通过调度计算吐到Hbase,数据仓库通过ODS层计算进入表示层,分布式查询ES……这些都是市面上最好的技术,或者你能想到的查询方式。DataCenter 为您完成这一切。
之后,就是DataView和AutoBI大显身手的时候了。这两条产品线不仅可以支持传统的关系型数据库,没有sql的数据库,比如redis、mongodb等,都支持,包括ES、rest等服务接口。因为是定制模式,只要现有技术可以实现,这两条产品线就会为你实现,你不需要为了适应这两条产品线而传输数据。所有Yunspula 系统都适合您。好的。因为是公司的产品,兼容性还行!
这个怎么样?DataCenter可以说是大数据处理行业的黑科技。并且整套流程都是黑箱的,您只需要在网页中配置您的业务,其余系统会自动为您处理。AutoBI和DataView作为其老大哥,将黑科技理念贯彻到了全面、无缝集成、完美展示、多维度分析……你能想到的所有需求,都来帮你呈现。这是海泰云蜘蛛系统提供的一套大数据解决方案!
查看全部
采集系统上云(黑科技的云蛛系统,您的数据中心展现工作了吗?
)
黑科技的云蜘蛛系统,一经问世,便博得了阵阵掌声。虽然主打数据可视化,但是很多用户都在问你会不会做大数据处理产品,就像很多用户眼中的黑科技——神测数据。如果你出来,我们就可以解决我们整个数据流的问题。
对于大数据的处理,云蜘蛛系统肯定是必不可少的,但具体的开发日期还没有最终确定。不过,鉴于用户的强烈需求,蛛网时代终于将大数据处理工具的开发提上了日程,并将其命名为DataCenter。为什么叫数据中心?这意味着,对于您数据中心的所有处理,Yunspula 系统可以为您解决所有问题。
有了DataCenter+AutoBI+DataView,你的整个数据分析系统就可以完全搭建起来,而且极其简单。DataCenter会做数据采集、传输、处理的工作,而AutoBI会做你的数据报表的工作,DataView会做你的大屏展示的工作。一起使用效果好吗?
DataCenter使用自己的agent采集相关数据,然后采集到Kafka集群中进行数据清洗。Kafka集群作为高可靠传输,还需要进行高性能算法去重计算,然后数据通过转换层进入数据仓库或者hadoop集群,这就是整个ETL过程,也是作业天禄系统。之后就是调度-北斗系统的工作。它将根据依赖关系计算数据索引。日指数计算未完成,月指数计算无法完成。如果指标计算错误,手动触发任务计算,是否会触发下游任务一起计算... 整个核心都会体现在调度-北斗系统完善中。HDFS数据通过调度计算吐到Hbase,数据仓库通过ODS层计算进入表示层,分布式查询ES……这些都是市面上最好的技术,或者你能想到的查询方式。DataCenter 为您完成这一切。
之后,就是DataView和AutoBI大显身手的时候了。这两条产品线不仅可以支持传统的关系型数据库,没有sql的数据库,比如redis、mongodb等,都支持,包括ES、rest等服务接口。因为是定制模式,只要现有技术可以实现,这两条产品线就会为你实现,你不需要为了适应这两条产品线而传输数据。所有Yunspula 系统都适合您。好的。因为是公司的产品,兼容性还行!
这个怎么样?DataCenter可以说是大数据处理行业的黑科技。并且整套流程都是黑箱的,您只需要在网页中配置您的业务,其余系统会自动为您处理。AutoBI和DataView作为其老大哥,将黑科技理念贯彻到了全面、无缝集成、完美展示、多维度分析……你能想到的所有需求,都来帮你呈现。这是海泰云蜘蛛系统提供的一套大数据解决方案!

采集系统上云(从采集系统上云的区别来简单分析两者之间的区别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-20 05:06
采集系统上云已经成为现在市场上最热门的趋势,很多公司都已经会使用终端采集系统。大家在对采集系统进行认识的过程中,会对一些具体的术语不知道如何去理解,下面我就从采集系统上云和传统采集系统的区别来简单分析一下两者之间的区别。采集系统上云有几个方面的意义:首先是拓展产品线,其次是传统采集系统体验上线,增加系统维护服务,更安全便捷。
所以第一个意义就是拓展产品线,是提高整个公司产品线的丰富性,第二个就是提高我们整个公司的服务能力,第三个还提升我们公司的安全和便捷性。1、传统采集系统采集系统上云的最终目的是提升效率,加快我们产品的速度,也就是说我们再做内部业务,首先要做的就是流程化的规范流程。这个我们采集系统要提供完整的服务,使客户在初始就能建立起一个安全、便捷的大数据的采集库。
我们都清楚,企业在选择大数据采集系统的时候,有几个主要的考虑因素:一个是考虑成本,另外一个就是快速,第三个就是功能,那我们从这三个角度进行比较,先考虑成本。采集系统要快速,让客户体验快速,不仅仅是我们要做好内部业务和流程规范,而且我们还要更快的扩展产品,我们还要把系统做到全产品覆盖,无论是做公司互联网还是it安全相关,都不能将我们公司的业务全部做到统一。
我们的生态是庞大的。采集系统是一个全产品覆盖的一个系统,涵盖了互联网,电信,物联网和it安全等。2、采集系统上云的第二个意义,一旦建立起来,我们后面只需要加大维护和售后服务力度,就能够支撑以后的业务。客户永远需要有一个印象,上云之后的公司,我们解决了什么问题,不上云我们会遇到什么问题。做到第二个意义,我们要从客户的角度出发,我们才能够把软件有些原本解决不了的问题讲清楚,这样客户能更好的去选择我们。
这就涉及到如何采集系统上云和一般产品上云,所表达的不同的不同意义了。我想大家也清楚,选择做大数据采集系统是不同的,有人会选择跟别人合作一起做,也有人会一个人自己做。传统大数据采集系统可能在市场推广的时候是有点困难,一般情况下我们没有比较好的推广方式,可能相关大数据厂商会持续在给你更新他们的产品,但是这些更新产品可能不一定适合客户。
不一定符合客户未来对的需求。而采集系统上云后,我们可以采用软件开放性推广。可以把采集系统上云后的所有数据都可以共享,完全可以告诉用户,我们完全可以实现采集系统化,帮客户节省成本,采集系统的下一步是大数据。关注微信公众号:tzy_installer,获取更多技术干货。 查看全部
采集系统上云(从采集系统上云的区别来简单分析两者之间的区别)
采集系统上云已经成为现在市场上最热门的趋势,很多公司都已经会使用终端采集系统。大家在对采集系统进行认识的过程中,会对一些具体的术语不知道如何去理解,下面我就从采集系统上云和传统采集系统的区别来简单分析一下两者之间的区别。采集系统上云有几个方面的意义:首先是拓展产品线,其次是传统采集系统体验上线,增加系统维护服务,更安全便捷。
所以第一个意义就是拓展产品线,是提高整个公司产品线的丰富性,第二个就是提高我们整个公司的服务能力,第三个还提升我们公司的安全和便捷性。1、传统采集系统采集系统上云的最终目的是提升效率,加快我们产品的速度,也就是说我们再做内部业务,首先要做的就是流程化的规范流程。这个我们采集系统要提供完整的服务,使客户在初始就能建立起一个安全、便捷的大数据的采集库。
我们都清楚,企业在选择大数据采集系统的时候,有几个主要的考虑因素:一个是考虑成本,另外一个就是快速,第三个就是功能,那我们从这三个角度进行比较,先考虑成本。采集系统要快速,让客户体验快速,不仅仅是我们要做好内部业务和流程规范,而且我们还要更快的扩展产品,我们还要把系统做到全产品覆盖,无论是做公司互联网还是it安全相关,都不能将我们公司的业务全部做到统一。
我们的生态是庞大的。采集系统是一个全产品覆盖的一个系统,涵盖了互联网,电信,物联网和it安全等。2、采集系统上云的第二个意义,一旦建立起来,我们后面只需要加大维护和售后服务力度,就能够支撑以后的业务。客户永远需要有一个印象,上云之后的公司,我们解决了什么问题,不上云我们会遇到什么问题。做到第二个意义,我们要从客户的角度出发,我们才能够把软件有些原本解决不了的问题讲清楚,这样客户能更好的去选择我们。
这就涉及到如何采集系统上云和一般产品上云,所表达的不同的不同意义了。我想大家也清楚,选择做大数据采集系统是不同的,有人会选择跟别人合作一起做,也有人会一个人自己做。传统大数据采集系统可能在市场推广的时候是有点困难,一般情况下我们没有比较好的推广方式,可能相关大数据厂商会持续在给你更新他们的产品,但是这些更新产品可能不一定适合客户。
不一定符合客户未来对的需求。而采集系统上云后,我们可以采用软件开放性推广。可以把采集系统上云后的所有数据都可以共享,完全可以告诉用户,我们完全可以实现采集系统化,帮客户节省成本,采集系统的下一步是大数据。关注微信公众号:tzy_installer,获取更多技术干货。
采集系统上云( 阿里正式开源可观测数据采集器iLogtail改造基本不可行)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-12-16 21:20
阿里正式开源可观测数据采集器iLogtail改造基本不可行)
11月23日,阿里正式开源了可观察数据采集器iLogtail。作为阿里巴巴内部可观察数据采集的基础设施,iLogtail承载了阿里巴巴集团的工作以及蚂蚁的日志、监控、trace、事件等可观察数据采集。iLogtail 运行在服务器、容器、K8s、嵌入式等多种环境中,支持采集数百个可观察数据。已经有数千万的安装量,并且每天有 采集 数十 PB 的数据可用。观察数据广泛应用于在线监控、问题分析/定位、运行分析、安全分析等各种场景。
一个 iLogtail 和可观察性
可观察性并不是一个新概念,而是从IT系统中的监控、故障排除、稳定性构建、运行分析、BI、安全分析等逐步演化而来。与传统监控相比,可观察性是核心进化是采集尽可能多的可观察数据以达到白盒的目的。iLogtail的核心定位是可观察数据的采集器,可以采集尽可能多的采集各类可观察数据,帮助可观察平台打造各种上层应用场景。
2. 阿里巴巴可观察数据采集的挑战
对于可观察数据采集,有很多开源代理,比如Logstash、Filebeats、Fluentd、Collectd、Telegraf等,这些代理的功能非常丰富,这些代理和一些扩展的组合基本可以满足各种内部数据采集的要求。但由于性能、稳定性、控制等关键挑战不尽人意,我们最终选择进行自研:
1、资源消耗:目前阿里有上百万台主机(物理机/虚拟机/容器),每天产生几十PB的可观察数据,降低每1M的内存和每1M/s的性能。改善对于我们的资源节约来说是巨大的,节约的成本可能是几百万甚至几千万。目前很多开源代理的设计更注重功能而不是性能,改造现有的开源代理基本不可行。例如:
开源Agents单核处理性能一般在2-10M/s左右,我们希望有性能可以达到100M/s。采集目标增加,数据量增加,采集延迟,服务器异常。在这种情况下,开源代理内存将呈现爆发式增长,我们希望即使在各种环境下,内存也能处于较低的水位。开源代理的资源消耗无法控制。只能通过cgroups强制限制。效果就是一直OOM重启,数据一直上不来采集。并且我们希望在指定了 CPU、内存、流量等资源限制后,Agent 可以一直在这个限制内正常工作。
2、稳定性:稳定性是一个永恒的话题,数据的稳定性采集,除了保证数据本身的准确性采集,还要保证采集的Agent @采集 不能影响业务应用,否则影响将是灾难性的。至于稳定性建设,除了Agent本身的基本稳定性外,还有很多目前开源Agents还没有提供的特性:
Agent自恢复:Agent在遇到关键事件后可以自动恢复,提供进程自身、父子进程、守护进程等多个维度的自恢复能力。全球多维监控:可以从全球视角监控不同版本。不同采集配置、不同压力、不同区域/网络等属性的Agent的稳定性问题。问题隔离:作为Agent,无论问题如何出现,都需要尽可能地隔离问题。比如有多个采集配置,一个配置有问题,不能影响其他配置;代理本身有问题,不能影响机器上应用进程的稳定性。回滚能力:
3、Controllable:可观察数据的应用范围很广。几乎所有的业务、运维、BI、安全等部门都会用到它,各种数据都会在一台机器上生成。同一台机器产生的数据也会被多个部门的人使用。例如,在 2018 年,我们计算出平均而言,一个虚拟机上有 100 多种不同类型的数据。采集,设计了10多个不同部门的人想要使用这些数据。除了这些,还有很多其他的企业级功能需要支持,比如:
远程管理配置:在大规模场景下,手动登录机器修改配置基本上是不可能的。因此,需要一套配置图形化管理、远程存储、自动投递机制,并且必须能够区分不同的应用和差异。地区、不同归属方等信息。同时,由于涉及到远程配置的动态加载和卸载,Agent也需要能够保证在配置Reload过程中数据不丢失或者不重现。采集配置优先级:当一台机器上运行多个采集配置时,如果遇到资源不足的情况,需要区分每个不同的配置优先级,并且资源优先给高优先级的配置,同时要保证低优先级的配置不被“饿死”。降级和恢复能力:在阿里,大促和秒杀是家常便饭。在这个高峰期,很多不重要的应用可能会被降级,相应的应用数据也需要降级。降级后,早高峰过后,需要有足够的Burst能力快速追赶。完整数据采集完整性:监控、数据分析等场景需要数据的准确性。数据准确的前提是可以采集及时到服务器,但是如何判断每台机器,每个文件采集的数据已经到达了对应的时间点,
基于以上背景和挑战,我们从 2013 年开始逐步优化和改进 iLogtail 以解决性能、稳定性、可控性等问题,并经历了多次 double十一、double十二、 的测试春晚红包等物品。目前iLogtail支持Logs、Traces、Metrics等多种数据的统一采集。核心功能如下:
支持多种Logs, Traces, Metrics数据采集,特别是容器和Kubernetes环境,数据非常友好采集 资源消耗极低,单核采集容量100M/s,对比对类似Observable数据采集的Agent性能提高5-20倍,稳定性高。它用于阿里巴巴和数以万计的阿里云客户的生产。部署量接近1000万。每天采集几十PB可用观测数据支持插件扩展,数据可任意扩展采集,处理、聚合、发送模块支持远程配置管理,支持图形化、SDK配置管理、K8s Operator等,可以轻松管理百万台机器的数据采集 支持自我监控、流量控制、资源控制、主动告警、采集统计等高级管控功能。iLogtail的三大发展历程
秉承阿里人简约的特点,iLogtail的命名也很简单。我们一开始就期望有一个统一的工具来记录Tail,所以叫Logtail。添加“i”的原因主要是当时使用了inotify技术。, 可以在毫秒级别控制日志采集的延迟,所以最后称为iLogtail。从2013年开始,iLogtail的整个发展过程大致可以分为三个阶段,分别是飞天5K阶段、阿里集团阶段和云原生阶段。
1个飞天5K舞台
作为中国云计算领域的里程碑,2013年8月15日,阿里巴巴集团正式运营5000(5K)服务器规模的“飞天”集群,成为国内首家自主研发大型云计算的企业。 - 规模的通用计算平台。全球首家对外提供5K云计算服务能力的公司。
飞天5K项目始于2009年,从最初的30台逐步发展到5000台,不断解决系统的规模、稳定性、运维、容灾等核心问题。这个阶段iLogtail诞生的时候,是从5000台机器的监控、问题分析、定位(现在称为“可观察性”)开始的。在从 30 到 5000 的飞跃中,可观察到的问题面临诸多挑战,包括单机瓶颈、问题复杂性、故障排除的难易程度和管理复杂性。
在5K阶段,iLogtail本质上解决了单机、小规模集群到大规模运维监控的挑战。iLogtail现阶段的主要特点是:
<p>功能:实时日志,监控采集,日志捕获延迟毫秒级性能:单核处理能力10M/s,5000集群平均资源占用0.5% CPU核心可靠性:自动监控新文件,新建文件夹,支持文件轮换,处理网络中断管理:远程Web管理,自动配置文件分发运维:加入群yum源,运行状态监控,异常自动上报规模:3W+部署规模,千 查看全部
采集系统上云(
阿里正式开源可观测数据采集器iLogtail改造基本不可行)

11月23日,阿里正式开源了可观察数据采集器iLogtail。作为阿里巴巴内部可观察数据采集的基础设施,iLogtail承载了阿里巴巴集团的工作以及蚂蚁的日志、监控、trace、事件等可观察数据采集。iLogtail 运行在服务器、容器、K8s、嵌入式等多种环境中,支持采集数百个可观察数据。已经有数千万的安装量,并且每天有 采集 数十 PB 的数据可用。观察数据广泛应用于在线监控、问题分析/定位、运行分析、安全分析等各种场景。
一个 iLogtail 和可观察性
可观察性并不是一个新概念,而是从IT系统中的监控、故障排除、稳定性构建、运行分析、BI、安全分析等逐步演化而来。与传统监控相比,可观察性是核心进化是采集尽可能多的可观察数据以达到白盒的目的。iLogtail的核心定位是可观察数据的采集器,可以采集尽可能多的采集各类可观察数据,帮助可观察平台打造各种上层应用场景。

2. 阿里巴巴可观察数据采集的挑战

对于可观察数据采集,有很多开源代理,比如Logstash、Filebeats、Fluentd、Collectd、Telegraf等,这些代理的功能非常丰富,这些代理和一些扩展的组合基本可以满足各种内部数据采集的要求。但由于性能、稳定性、控制等关键挑战不尽人意,我们最终选择进行自研:
1、资源消耗:目前阿里有上百万台主机(物理机/虚拟机/容器),每天产生几十PB的可观察数据,降低每1M的内存和每1M/s的性能。改善对于我们的资源节约来说是巨大的,节约的成本可能是几百万甚至几千万。目前很多开源代理的设计更注重功能而不是性能,改造现有的开源代理基本不可行。例如:
开源Agents单核处理性能一般在2-10M/s左右,我们希望有性能可以达到100M/s。采集目标增加,数据量增加,采集延迟,服务器异常。在这种情况下,开源代理内存将呈现爆发式增长,我们希望即使在各种环境下,内存也能处于较低的水位。开源代理的资源消耗无法控制。只能通过cgroups强制限制。效果就是一直OOM重启,数据一直上不来采集。并且我们希望在指定了 CPU、内存、流量等资源限制后,Agent 可以一直在这个限制内正常工作。
2、稳定性:稳定性是一个永恒的话题,数据的稳定性采集,除了保证数据本身的准确性采集,还要保证采集的Agent @采集 不能影响业务应用,否则影响将是灾难性的。至于稳定性建设,除了Agent本身的基本稳定性外,还有很多目前开源Agents还没有提供的特性:
Agent自恢复:Agent在遇到关键事件后可以自动恢复,提供进程自身、父子进程、守护进程等多个维度的自恢复能力。全球多维监控:可以从全球视角监控不同版本。不同采集配置、不同压力、不同区域/网络等属性的Agent的稳定性问题。问题隔离:作为Agent,无论问题如何出现,都需要尽可能地隔离问题。比如有多个采集配置,一个配置有问题,不能影响其他配置;代理本身有问题,不能影响机器上应用进程的稳定性。回滚能力:
3、Controllable:可观察数据的应用范围很广。几乎所有的业务、运维、BI、安全等部门都会用到它,各种数据都会在一台机器上生成。同一台机器产生的数据也会被多个部门的人使用。例如,在 2018 年,我们计算出平均而言,一个虚拟机上有 100 多种不同类型的数据。采集,设计了10多个不同部门的人想要使用这些数据。除了这些,还有很多其他的企业级功能需要支持,比如:
远程管理配置:在大规模场景下,手动登录机器修改配置基本上是不可能的。因此,需要一套配置图形化管理、远程存储、自动投递机制,并且必须能够区分不同的应用和差异。地区、不同归属方等信息。同时,由于涉及到远程配置的动态加载和卸载,Agent也需要能够保证在配置Reload过程中数据不丢失或者不重现。采集配置优先级:当一台机器上运行多个采集配置时,如果遇到资源不足的情况,需要区分每个不同的配置优先级,并且资源优先给高优先级的配置,同时要保证低优先级的配置不被“饿死”。降级和恢复能力:在阿里,大促和秒杀是家常便饭。在这个高峰期,很多不重要的应用可能会被降级,相应的应用数据也需要降级。降级后,早高峰过后,需要有足够的Burst能力快速追赶。完整数据采集完整性:监控、数据分析等场景需要数据的准确性。数据准确的前提是可以采集及时到服务器,但是如何判断每台机器,每个文件采集的数据已经到达了对应的时间点,

基于以上背景和挑战,我们从 2013 年开始逐步优化和改进 iLogtail 以解决性能、稳定性、可控性等问题,并经历了多次 double十一、double十二、 的测试春晚红包等物品。目前iLogtail支持Logs、Traces、Metrics等多种数据的统一采集。核心功能如下:
支持多种Logs, Traces, Metrics数据采集,特别是容器和Kubernetes环境,数据非常友好采集 资源消耗极低,单核采集容量100M/s,对比对类似Observable数据采集的Agent性能提高5-20倍,稳定性高。它用于阿里巴巴和数以万计的阿里云客户的生产。部署量接近1000万。每天采集几十PB可用观测数据支持插件扩展,数据可任意扩展采集,处理、聚合、发送模块支持远程配置管理,支持图形化、SDK配置管理、K8s Operator等,可以轻松管理百万台机器的数据采集 支持自我监控、流量控制、资源控制、主动告警、采集统计等高级管控功能。iLogtail的三大发展历程
秉承阿里人简约的特点,iLogtail的命名也很简单。我们一开始就期望有一个统一的工具来记录Tail,所以叫Logtail。添加“i”的原因主要是当时使用了inotify技术。, 可以在毫秒级别控制日志采集的延迟,所以最后称为iLogtail。从2013年开始,iLogtail的整个发展过程大致可以分为三个阶段,分别是飞天5K阶段、阿里集团阶段和云原生阶段。

1个飞天5K舞台
作为中国云计算领域的里程碑,2013年8月15日,阿里巴巴集团正式运营5000(5K)服务器规模的“飞天”集群,成为国内首家自主研发大型云计算的企业。 - 规模的通用计算平台。全球首家对外提供5K云计算服务能力的公司。
飞天5K项目始于2009年,从最初的30台逐步发展到5000台,不断解决系统的规模、稳定性、运维、容灾等核心问题。这个阶段iLogtail诞生的时候,是从5000台机器的监控、问题分析、定位(现在称为“可观察性”)开始的。在从 30 到 5000 的飞跃中,可观察到的问题面临诸多挑战,包括单机瓶颈、问题复杂性、故障排除的难易程度和管理复杂性。

在5K阶段,iLogtail本质上解决了单机、小规模集群到大规模运维监控的挑战。iLogtail现阶段的主要特点是:
<p>功能:实时日志,监控采集,日志捕获延迟毫秒级性能:单核处理能力10M/s,5000集群平均资源占用0.5% CPU核心可靠性:自动监控新文件,新建文件夹,支持文件轮换,处理网络中断管理:远程Web管理,自动配置文件分发运维:加入群yum源,运行状态监控,异常自动上报规模:3W+部署规模,千
采集系统上云(pbsp地址转换器,8gram+msddhdd!注意是无线的sdd)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-19 04:00
采集系统上云本质上是数据与设备,为了更好的服务于车辆在公路管理,提升车辆整体性能与收费过程,此次采用思科minipci路由器加pwm控制电路,只要是思科usb接口采集系统就可以采集数据。通过搭建电脑采集台stun后,做出相应路由器的端口映射即可接入相应端口实现云采集。成本方面采用百元的思科路由器足够满足各种采集需求,采用15元的kype型号,只需要一台250g硬盘的设备即可随时读取硬盘内容,云采集与物联网的结合也将更加的方便有效。
此次采用物联网的方式进行车辆的采集,一是本身物联网的原理,二是通过云采集对pb级以下的车辆数据进行筛选,特别是未来对车辆的边界定位,考虑如何打造云采集平台也是项目的一大亮点!!!希望对各位有所启发!!!。
pbsp地址转换器,8gram+512msddhdd!注意是无线的sdd,可以上网,usb端口,终端,
物联网行业目前应用最广泛的应该是applewatch的wifi版本手表,连接手机,手表通过wifi功能实现无线传递数据。所以可以采用p2p网络实现数据传输。以下app推荐请慎重采用。从现有版本来看applewatch内置airpod标准通讯模块,所以采用这种方式传输数据是更加适宜的,通过一个无线信号将手表与手机连接,每次你通过自家的有线端口即可将数据传送给自家的移动网关。
我目前采用的思科路由器就是采用的这种实现方式。缺点是价格相对其他方式来说有些高。应该说便宜些思科路由器在物联网/无线通讯领域的应用是比较丰富的,各种不同的硬件模块也可以适用于物联网网络架构。但如果你是做从物联网抓取数据的应用,等。建议还是选用bluetoothlineinterface或者思科路由器更适合。根据你的应用不同,所有解决方案成本都会不同。 查看全部
采集系统上云(pbsp地址转换器,8gram+msddhdd!注意是无线的sdd)
采集系统上云本质上是数据与设备,为了更好的服务于车辆在公路管理,提升车辆整体性能与收费过程,此次采用思科minipci路由器加pwm控制电路,只要是思科usb接口采集系统就可以采集数据。通过搭建电脑采集台stun后,做出相应路由器的端口映射即可接入相应端口实现云采集。成本方面采用百元的思科路由器足够满足各种采集需求,采用15元的kype型号,只需要一台250g硬盘的设备即可随时读取硬盘内容,云采集与物联网的结合也将更加的方便有效。
此次采用物联网的方式进行车辆的采集,一是本身物联网的原理,二是通过云采集对pb级以下的车辆数据进行筛选,特别是未来对车辆的边界定位,考虑如何打造云采集平台也是项目的一大亮点!!!希望对各位有所启发!!!。
pbsp地址转换器,8gram+512msddhdd!注意是无线的sdd,可以上网,usb端口,终端,
物联网行业目前应用最广泛的应该是applewatch的wifi版本手表,连接手机,手表通过wifi功能实现无线传递数据。所以可以采用p2p网络实现数据传输。以下app推荐请慎重采用。从现有版本来看applewatch内置airpod标准通讯模块,所以采用这种方式传输数据是更加适宜的,通过一个无线信号将手表与手机连接,每次你通过自家的有线端口即可将数据传送给自家的移动网关。
我目前采用的思科路由器就是采用的这种实现方式。缺点是价格相对其他方式来说有些高。应该说便宜些思科路由器在物联网/无线通讯领域的应用是比较丰富的,各种不同的硬件模块也可以适用于物联网网络架构。但如果你是做从物联网抓取数据的应用,等。建议还是选用bluetoothlineinterface或者思科路由器更适合。根据你的应用不同,所有解决方案成本都会不同。
采集系统上云(DeepFlow部署在容器计算节点上的应用的访问路径分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-02-16 19:04
通过梳理业务,添加相关资源组和链接,描述关键业务应用的访问路径。资源池中的流量会根据该规则进行过滤,实现业务应用的网络监控,并根据需要设置告警。在服务路径中,可以直观查看不同网段的网络状态,快速缩小问题范围,定位异常原因。
对于关键业务应用,获取容器环境的整个网络流量,通常包括完整的容器资源、应用、网络几个维度。物理网络流量通常通过光学分裂图像获得。DeepFlow®通过连接容器平台(如Kubernetes)来学习容器环境中的Cluster、Node、Pod、Service、Ingress等信息。采集器部署在容器计算节点上,以Pod为单元获取网络流量并进行流量预处理,从而实现全链路监控。
DeepFlow可以连接物理网络的sFlow、NetFlow等数据,支持拆分和镜像流量采集。通过采集点的分布式部署和过滤策略,可以逐段准确检查客户系统中任意已知IP对的每一跳(网元配置和流量信息),从而实现端到端端端诊断。
对于重点业务,建议进行追溯分析和配置。遇到突发故障时,可通过钻取时序数据库中存储的网络流量信息,回放故障的详细过程(支持秒粒度查询);还可以配置按需 PCAP采集 策略,借助其他第三方工具对此类故障进行深入分析。 查看全部
采集系统上云(DeepFlow部署在容器计算节点上的应用的访问路径分析)
通过梳理业务,添加相关资源组和链接,描述关键业务应用的访问路径。资源池中的流量会根据该规则进行过滤,实现业务应用的网络监控,并根据需要设置告警。在服务路径中,可以直观查看不同网段的网络状态,快速缩小问题范围,定位异常原因。
对于关键业务应用,获取容器环境的整个网络流量,通常包括完整的容器资源、应用、网络几个维度。物理网络流量通常通过光学分裂图像获得。DeepFlow®通过连接容器平台(如Kubernetes)来学习容器环境中的Cluster、Node、Pod、Service、Ingress等信息。采集器部署在容器计算节点上,以Pod为单元获取网络流量并进行流量预处理,从而实现全链路监控。
DeepFlow可以连接物理网络的sFlow、NetFlow等数据,支持拆分和镜像流量采集。通过采集点的分布式部署和过滤策略,可以逐段准确检查客户系统中任意已知IP对的每一跳(网元配置和流量信息),从而实现端到端端端诊断。
对于重点业务,建议进行追溯分析和配置。遇到突发故障时,可通过钻取时序数据库中存储的网络流量信息,回放故障的详细过程(支持秒粒度查询);还可以配置按需 PCAP采集 策略,借助其他第三方工具对此类故障进行深入分析。
采集系统上云( SuperMapOnline为您提供的GIS云存储服务(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-14 08:02
SuperMapOnline为您提供的GIS云存储服务(图))
GIS云存储,云端数据安全
如果您需要在线使用空间数据,可以使用SuperMap GIS云存储服务,几分钟就可以安全地将数据上传到云端。
具体来说,您只需在网页或SuperMap iDesktop上登录您的SuperMap Online账号,即可在云平台上传存储GIS数据—workspace/UDB/Shapefile/Excel/CSV/GEOJson等空间数据.
GIS数据在线存储后,您可以通过Web/PC/移动应用程序或地图、数据、3D等REST API方便地在线使用数据。您可以直接在2D地图或3D场景中浏览数据,也可以在线检索或查询数据。当需要更新数据时,您可以直接在线编辑数据,实时快速更新,无需下载、编辑、重新上传等繁琐步骤。更重要的是,您可以使用专业的GIS分析算法,直接在线分析您的数据,挖掘空间价值。
GIS云存储不仅可以满足企业用户高并发、高可用的在线数据调用需求,还可以为个人用户提供服务。您只需注册一个SuperMap Online账号,即可享受500M的无限免费空间。
此外,在 SuperMap Online 中,您可以自定义和发布业务数据,为您运营和维护各种企业级、稳定可靠的在线 GIS 服务。您只需准备好业务数据,即可直接调用SuperMAap Online提供的REST API,无需关心软硬件环境,无需部署和运维。从业务数据到您的Web应用,所有的中间环节都由SuperMap Online为您实现。 查看全部
采集系统上云(
SuperMapOnline为您提供的GIS云存储服务(图))
GIS云存储,云端数据安全
如果您需要在线使用空间数据,可以使用SuperMap GIS云存储服务,几分钟就可以安全地将数据上传到云端。
具体来说,您只需在网页或SuperMap iDesktop上登录您的SuperMap Online账号,即可在云平台上传存储GIS数据—workspace/UDB/Shapefile/Excel/CSV/GEOJson等空间数据.
GIS数据在线存储后,您可以通过Web/PC/移动应用程序或地图、数据、3D等REST API方便地在线使用数据。您可以直接在2D地图或3D场景中浏览数据,也可以在线检索或查询数据。当需要更新数据时,您可以直接在线编辑数据,实时快速更新,无需下载、编辑、重新上传等繁琐步骤。更重要的是,您可以使用专业的GIS分析算法,直接在线分析您的数据,挖掘空间价值。
GIS云存储不仅可以满足企业用户高并发、高可用的在线数据调用需求,还可以为个人用户提供服务。您只需注册一个SuperMap Online账号,即可享受500M的无限免费空间。
此外,在 SuperMap Online 中,您可以自定义和发布业务数据,为您运营和维护各种企业级、稳定可靠的在线 GIS 服务。您只需准备好业务数据,即可直接调用SuperMAap Online提供的REST API,无需关心软硬件环境,无需部署和运维。从业务数据到您的Web应用,所有的中间环节都由SuperMap Online为您实现。
采集系统上云(【开源项目】数栈:云原生—站式数据中台PaaS )
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2022-02-08 17:15
)
DataStack 是云原生的一站式数据中心 PaaS。我们在github和gitee上有一个有趣的开源项目:FlinkX,记得给我们一个star!星星!星星!
gitee开源项目:
github开源项目:
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。而且它采用了类prometheus标签的思路,与grafana连接,进行可视化展示。无论是想法还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 以采集器的形式找一个文件,首先要找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。你可以直接匹配你在配置文件中写的路径信息。例如promtail中的路径是“/var/log/*.log”,表示/var/log目录下的所有文件,以.log结尾的后缀文件可以作为采集@的对象>。采集 k8s 模式登录稍微麻烦一些。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或pv中,在host和pv中也是可见的。这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们每天用 kubectl log 看到的日志。此类日志在主机上的存储路径为/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉prometheus的同学一定配置过prometheus的服务发现配置,kubernetes_sd_configs和relabel_configs。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。由于这个目录已经挂载到容器中,promtail可以将容器的标签和容器的日志关联起来。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后将一组服务器端loki和视觉端grafana部署到整个集群。
promtail 使用 static_configs 来定义 采集 日志。不过promtail毕竟还太年轻,而且定位偏向云原生,所以对于宿主机的功能并不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在并且内容量很大,promtail启动会从头开始推送文件的内容,导致短时间内大量日志被推送到loki的时间。失败。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模式采用PLG的主流模式。但是,当数据栈作为一个完整的系统交付给企业时,存在很多限制,这会导致demoset模型无法使用。最大的挑战是许可。挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择是部署在damonset模式还是sidecar模式。演示模式的优点是节省资源,缺点是需要权限。与sidecar模式相比,为了应用更严格的交付条件,我们为采集选择使用sidecar模式。
sidecar 模式是在每个服务部署的时候自动添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。服务容器将日志写入数据卷,日志容器采集将数据卷下的日志写入。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志容器和master容器共享一个日志目录,这样可以在promtail容器中获取日志文件,但是promtail不知道哪些日志到采集,它们的标签是什么是。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
一套日志聚合分析框架,解决主机和云原生场景,降低系统复杂度
日志可视化使用grafana,可视化效果更好,而grafana和prometheus已经是云原生监控的事实标准。熟悉开发、运维,降低学习成本。
loki 查询语法简单但功能强大
与ELK相比,更轻量级
(二)✈️未来规划
目前使用的是sidecar模式,占用资源较多,后续会考虑进一步优化。
loki 分布式部署优化
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?
查看全部
采集系统上云(【开源项目】数栈:云原生—站式数据中台PaaS
)
DataStack 是云原生的一站式数据中心 PaaS。我们在github和gitee上有一个有趣的开源项目:FlinkX,记得给我们一个star!星星!星星!
gitee开源项目:
github开源项目:
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。而且它采用了类prometheus标签的思路,与grafana连接,进行可视化展示。无论是想法还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 以采集器的形式找一个文件,首先要找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。你可以直接匹配你在配置文件中写的路径信息。例如promtail中的路径是“/var/log/*.log”,表示/var/log目录下的所有文件,以.log结尾的后缀文件可以作为采集@的对象>。采集 k8s 模式登录稍微麻烦一些。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或pv中,在host和pv中也是可见的。这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们每天用 kubectl log 看到的日志。此类日志在主机上的存储路径为/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉prometheus的同学一定配置过prometheus的服务发现配置,kubernetes_sd_configs和relabel_configs。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。由于这个目录已经挂载到容器中,promtail可以将容器的标签和容器的日志关联起来。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后将一组服务器端loki和视觉端grafana部署到整个集群。
promtail 使用 static_configs 来定义 采集 日志。不过promtail毕竟还太年轻,而且定位偏向云原生,所以对于宿主机的功能并不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在并且内容量很大,promtail启动会从头开始推送文件的内容,导致短时间内大量日志被推送到loki的时间。失败。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模式采用PLG的主流模式。但是,当数据栈作为一个完整的系统交付给企业时,存在很多限制,这会导致demoset模型无法使用。最大的挑战是许可。挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择是部署在damonset模式还是sidecar模式。演示模式的优点是节省资源,缺点是需要权限。与sidecar模式相比,为了应用更严格的交付条件,我们为采集选择使用sidecar模式。
sidecar 模式是在每个服务部署的时候自动添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。服务容器将日志写入数据卷,日志容器采集将数据卷下的日志写入。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志容器和master容器共享一个日志目录,这样可以在promtail容器中获取日志文件,但是promtail不知道哪些日志到采集,它们的标签是什么是。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
一套日志聚合分析框架,解决主机和云原生场景,降低系统复杂度
日志可视化使用grafana,可视化效果更好,而grafana和prometheus已经是云原生监控的事实标准。熟悉开发、运维,降低学习成本。
loki 查询语法简单但功能强大
与ELK相比,更轻量级
(二)✈️未来规划
目前使用的是sidecar模式,占用资源较多,后续会考虑进一步优化。
loki 分布式部署优化
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?
采集系统上云(阿里云InfluxDB数据采集服务优势我们能做些什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2022-02-08 05:14
背景
随着时序数据的快速增长,时序数据库不仅需要解决系统稳定性和性能问题,还需要实现从采集到分析的链接,让时序数据真正生成价值。在时间序列数据采集领域,一直缺乏自动化的采集工具。虽然用户可以使用一些开源的采集工具来实现data采集,比如Telegraf、Logstash、TCollector等,但是这些采集工具都需要用户自己构建和维护运行环境,增加了用户的学习成本,大大提高了数据的门槛采集。另一方面,现有的采集工具缺乏对多个采集源的自动化管理,使得用户难以统一管理多个不同的采集源并监控每个采集 实时 工具是否正常运行,采集数据。
阿里云InfluxDB®不仅提供稳定可靠的时序数据库服务,还提供非常便捷的数据采集服务。用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据会自动存储在阿里云InfluxDB®中。用户无需担心运维问题,实现从数据采集到分析的一站式服务。本文主要介绍如何使用InfluxDB®的数据采集服务实现数据从采集到存储的自动化管理。
阿里巴巴云InfluxDB®Data采集服务优势我们能做什么? 1.简单采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,分别涉及MySQL、Redis、MongoDB和系统监控。针对每类数据,采集多个监控指标,方便用户对监控对象有更全面的了解。用户可以通过InfluxDB®实例的管理控制台添加新的采集源,无需编写代码,一键安装。
采集数据操作流程如下:
2.采集来源的实时监控
采集源运行过程中,可以实时监控数据采集的状态,查看数据采集最后到达InfluxDB®的时间;并且您可以随时停止Data采集,并在您认为合适的时候重新打开data采集服务。
3.一键切换采集数据类型
如果要更改被监控机器上的采集数据类型,不需要重新添加新的采集源,选择你想要的采集配置即可,数据采集工具会自动切换到采集你指定的监控数据。
4. 采集数据自动存储在 InfluxDB® 中
您可以在采集配置中选择数据流的数据库和保留策略,数据采集工具会自动将采集数据存储到指定的数据库和保留策略中,并且您可以在 采集 源运行时修改要写入数据的数据库和保留策略,只需修改 采集 配置即可。
最佳实践
本节介绍如何采集系统监控数据并实时显示采集结果。系统监控的数据包括处理器、磁盘、内存、网络、进程和系统等信息。采集到的数据存储在 8 个不同的测量值中(测量值是 cpu、disk、diskio、mem、net、processes、swap 和 system)。在开始之前,请确保您已成功创建数据库以及对该数据库具有读写权限的用户帐户。
1. 创建采集系统监控数据配置
点击InfluxDB®管理控制台左侧导航栏中的“添加采集配置”,进入采集配置添加界面,如下图所示。填写“采集配置名称”,选择“采集数据类型”为“系统监控”,然后选择“授权账户”、“数据写入数据库”和“数据库存储策略”,并填写在“授权密码”中。点击“添加”成功创建采集配置。
2. 添加采集来源
点击InfluxDB®管理控制台左侧导航栏中的“添加采集Source”,进入采集Source Add页面。
(1)选择网络类型,“Public Network”或“Private Network”,然后点击“Next”,如下图。
(2)在数据源所在的主机上安装采集工具。将安装命令复制到主机上运行采集工具。采集@之后> 工具运行,会与 InfluxDB ® 建立连接,可以在“New 采集 Source Scan Result List”中看到新添加的采集 source,如果没有显示在列表中,您可以点击“刷新”或“自动刷新”。如下图。
(3)选择采集系统监控的数据。在上图中点击“选择采集配置”进入如下界面,从下拉框。采集“采集系统”的配置。选择后点击“保存”。
(4)启动数据采集.勾选需要启动的采集源,然后点击“Finish and start采集”,采集工具可以在采集源上启动采集数据,如下图。
3.查看数据状态采集
在“采集Source List”中,您可以看到所有连接到 InfluxDB® 实例的 采集 源,如下图所示。每个 采集 源由一个 uuid 唯一标识,“运行中”的“采集 状态”表示 采集 工具是 采集 数据并报告给 InfluxDB®, “最新采集上报成功时间”表示采集数据最后一次成功发送到InfluxDB®的时间。
4. 可视化 采集数据
使用 Grafana
(1)安装 Grafana。请参阅有关如何安装 Grafana 的文档。
(2)添加数据源。将“URL”设置为InfluxDB®实例的地址,并填写写入采集数据的数据库和用户账号,如下图。
(3)配置Dashboard并编写查询规则。这里以查询磁盘使用情况为例。查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示。
您可以根据实际需要查看其他测量和字段的数据,并分别在FROM和SELECT语句中指定。
总结
阿里云InfluxDB®提供方便快捷的数据采集服务,自动管理数据源,帮你解决数据采集问题,实现数据从采集到存储的自动化。未来,我们将支持 采集 获取更多数据类型和指标,敬请期待。
原文链接 查看全部
采集系统上云(阿里云InfluxDB数据采集服务优势我们能做些什么?)
背景
随着时序数据的快速增长,时序数据库不仅需要解决系统稳定性和性能问题,还需要实现从采集到分析的链接,让时序数据真正生成价值。在时间序列数据采集领域,一直缺乏自动化的采集工具。虽然用户可以使用一些开源的采集工具来实现data采集,比如Telegraf、Logstash、TCollector等,但是这些采集工具都需要用户自己构建和维护运行环境,增加了用户的学习成本,大大提高了数据的门槛采集。另一方面,现有的采集工具缺乏对多个采集源的自动化管理,使得用户难以统一管理多个不同的采集源并监控每个采集 实时 工具是否正常运行,采集数据。
阿里云InfluxDB®不仅提供稳定可靠的时序数据库服务,还提供非常便捷的数据采集服务。用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据会自动存储在阿里云InfluxDB®中。用户无需担心运维问题,实现从数据采集到分析的一站式服务。本文主要介绍如何使用InfluxDB®的数据采集服务实现数据从采集到存储的自动化管理。
阿里巴巴云InfluxDB®Data采集服务优势我们能做什么? 1.简单采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,分别涉及MySQL、Redis、MongoDB和系统监控。针对每类数据,采集多个监控指标,方便用户对监控对象有更全面的了解。用户可以通过InfluxDB®实例的管理控制台添加新的采集源,无需编写代码,一键安装。
采集数据操作流程如下:
2.采集来源的实时监控
采集源运行过程中,可以实时监控数据采集的状态,查看数据采集最后到达InfluxDB®的时间;并且您可以随时停止Data采集,并在您认为合适的时候重新打开data采集服务。
3.一键切换采集数据类型
如果要更改被监控机器上的采集数据类型,不需要重新添加新的采集源,选择你想要的采集配置即可,数据采集工具会自动切换到采集你指定的监控数据。
4. 采集数据自动存储在 InfluxDB® 中
您可以在采集配置中选择数据流的数据库和保留策略,数据采集工具会自动将采集数据存储到指定的数据库和保留策略中,并且您可以在 采集 源运行时修改要写入数据的数据库和保留策略,只需修改 采集 配置即可。
最佳实践
本节介绍如何采集系统监控数据并实时显示采集结果。系统监控的数据包括处理器、磁盘、内存、网络、进程和系统等信息。采集到的数据存储在 8 个不同的测量值中(测量值是 cpu、disk、diskio、mem、net、processes、swap 和 system)。在开始之前,请确保您已成功创建数据库以及对该数据库具有读写权限的用户帐户。
1. 创建采集系统监控数据配置
点击InfluxDB®管理控制台左侧导航栏中的“添加采集配置”,进入采集配置添加界面,如下图所示。填写“采集配置名称”,选择“采集数据类型”为“系统监控”,然后选择“授权账户”、“数据写入数据库”和“数据库存储策略”,并填写在“授权密码”中。点击“添加”成功创建采集配置。
2. 添加采集来源
点击InfluxDB®管理控制台左侧导航栏中的“添加采集Source”,进入采集Source Add页面。
(1)选择网络类型,“Public Network”或“Private Network”,然后点击“Next”,如下图。
(2)在数据源所在的主机上安装采集工具。将安装命令复制到主机上运行采集工具。采集@之后> 工具运行,会与 InfluxDB ® 建立连接,可以在“New 采集 Source Scan Result List”中看到新添加的采集 source,如果没有显示在列表中,您可以点击“刷新”或“自动刷新”。如下图。
(3)选择采集系统监控的数据。在上图中点击“选择采集配置”进入如下界面,从下拉框。采集“采集系统”的配置。选择后点击“保存”。
(4)启动数据采集.勾选需要启动的采集源,然后点击“Finish and start采集”,采集工具可以在采集源上启动采集数据,如下图。
3.查看数据状态采集
在“采集Source List”中,您可以看到所有连接到 InfluxDB® 实例的 采集 源,如下图所示。每个 采集 源由一个 uuid 唯一标识,“运行中”的“采集 状态”表示 采集 工具是 采集 数据并报告给 InfluxDB®, “最新采集上报成功时间”表示采集数据最后一次成功发送到InfluxDB®的时间。
4. 可视化 采集数据
使用 Grafana
(1)安装 Grafana。请参阅有关如何安装 Grafana 的文档。
(2)添加数据源。将“URL”设置为InfluxDB®实例的地址,并填写写入采集数据的数据库和用户账号,如下图。
(3)配置Dashboard并编写查询规则。这里以查询磁盘使用情况为例。查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示。
您可以根据实际需要查看其他测量和字段的数据,并分别在FROM和SELECT语句中指定。
总结
阿里云InfluxDB®提供方便快捷的数据采集服务,自动管理数据源,帮你解决数据采集问题,实现数据从采集到存储的自动化。未来,我们将支持 采集 获取更多数据类型和指标,敬请期待。
原文链接
采集系统上云(loki就是云原生下日志的采集方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-02-01 21:02
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。并使用普罗米修斯
类似标签的想法,可以用grafana进行可视化,无论是思维还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 找到文件
作为一个采集器,第一步就是找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。可以直接匹配你在配置文件中写的路径信息,比如
promtail中的路径为“/var/log/*.log”,即/var/log目录下所有以.log结尾的后缀文件都可以作为采集的对象。取而代之的是 采集
k8s模式下的登录就麻烦一些了。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或者pv上,那么host和pv
这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们日常使用的kubectl日志。
你看到的日志,这些日志在主机上的存储路径如下/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉普罗米修斯
同学们一定已经配置好prometheus、kubernetes_sd_configs和relabel_configs的服务发现配置。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。既然这个目录已经挂载到容器中了,那么promtail
您可以将容器的标签与容器的日志相关联。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后为整个集群部署一组服务器loki
带有可视化侧grafana。
promtail 使用 static_configs 来定义 采集 日志。但promtail
毕竟还是太年轻,定位偏向云原生,所以宿主机的功能还不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在,并且内容量很大,promtail
启动会从头开始推送文件的内容,这会导致短时间内大量的日志被推送到loki。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型,但是数据栈作为一个完整的系统交付给企业时存在很多限制,导致demoset模型无法使用。最大的挑战是权限。只有一个
命名空间权限,无法挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择damonset
模式部署或sidecar模式部署,demoset模式的优点是节省资源,缺点是需要权限。与sidecar模型相比,为了适用更严格的交付条件,我们选择采用
边车的模式执行采集。
边车
该模式是在部署时自动为每个服务添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。数据卷采集下的日志。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志Container和Master
容器共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还不知道采集有哪些日志,以及它们的标签是什么。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。 查看全部
采集系统上云(loki就是云原生下日志的采集方案)
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。并使用普罗米修斯
类似标签的想法,可以用grafana进行可视化,无论是思维还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 找到文件
作为一个采集器,第一步就是找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。可以直接匹配你在配置文件中写的路径信息,比如
promtail中的路径为“/var/log/*.log”,即/var/log目录下所有以.log结尾的后缀文件都可以作为采集的对象。取而代之的是 采集
k8s模式下的登录就麻烦一些了。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或者pv上,那么host和pv
这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们日常使用的kubectl日志。
你看到的日志,这些日志在主机上的存储路径如下/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉普罗米修斯
同学们一定已经配置好prometheus、kubernetes_sd_configs和relabel_configs的服务发现配置。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。既然这个目录已经挂载到容器中了,那么promtail
您可以将容器的标签与容器的日志相关联。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后为整个集群部署一组服务器loki
带有可视化侧grafana。
promtail 使用 static_configs 来定义 采集 日志。但promtail
毕竟还是太年轻,定位偏向云原生,所以宿主机的功能还不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在,并且内容量很大,promtail
启动会从头开始推送文件的内容,这会导致短时间内大量的日志被推送到loki。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型,但是数据栈作为一个完整的系统交付给企业时存在很多限制,导致demoset模型无法使用。最大的挑战是权限。只有一个
命名空间权限,无法挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择damonset
模式部署或sidecar模式部署,demoset模式的优点是节省资源,缺点是需要权限。与sidecar模型相比,为了适用更严格的交付条件,我们选择采用
边车的模式执行采集。
边车
该模式是在部署时自动为每个服务添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。数据卷采集下的日志。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志Container和Master
容器共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还不知道采集有哪些日志,以及它们的标签是什么。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
采集系统上云(webstorm和websessionstorage中,一种是把原来的cookie直接推送到webweb端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-29 10:04
采集系统上云后,很多用户开始要求将自己的cookie推送到手机端,可以到除去网络的依赖性。如果能有个bot直接把cookie推送到手机端,就省去了安装第三方cookie管理工具,又省去了安装cookieagent。如果推送到手机端,接收和推送都需要手机本地权限,对于wp安卓手机来说,需要先在手机上申请一个bot账号才能进行推送。
这个在手机上玩安卓游戏,过几天就有可能需要清理手机缓存和重新安装这个bot才能玩新游戏。总之需要联网玩手机游戏的小伙伴,请在使用浏览器的前提下,有一个独立的cookie推送agent。如果你有native安卓或者微信web开发经验,那么就可以使用native推送,或者直接采用cp提供的api,直接接入。
你好,谷歌是有的,按照他的描述可以采用reactor框架实现,这个就不在这里做赘述了,百度就可以。
有,小牛web服务器,我也是最近在找找看这个方案,
简单的可以用js+gwx.cookie来接收。专业的也有socketcookie的库,例如localstorageandwebsessionstoragedriverandpregistry。
有。目前已经有localstorage和websessionstorage解决方案了。
推荐用webstorm开发者工具开发。然后用jenkins分发到生产环境。
在推送方案上最新出了两种,一种是把原来的cookie直接推送到webweb端,一种是写到localstorage和websessionstorage中,webstorm是支持的。我只有webstorm2015。 查看全部
采集系统上云(webstorm和websessionstorage中,一种是把原来的cookie直接推送到webweb端)
采集系统上云后,很多用户开始要求将自己的cookie推送到手机端,可以到除去网络的依赖性。如果能有个bot直接把cookie推送到手机端,就省去了安装第三方cookie管理工具,又省去了安装cookieagent。如果推送到手机端,接收和推送都需要手机本地权限,对于wp安卓手机来说,需要先在手机上申请一个bot账号才能进行推送。
这个在手机上玩安卓游戏,过几天就有可能需要清理手机缓存和重新安装这个bot才能玩新游戏。总之需要联网玩手机游戏的小伙伴,请在使用浏览器的前提下,有一个独立的cookie推送agent。如果你有native安卓或者微信web开发经验,那么就可以使用native推送,或者直接采用cp提供的api,直接接入。
你好,谷歌是有的,按照他的描述可以采用reactor框架实现,这个就不在这里做赘述了,百度就可以。
有,小牛web服务器,我也是最近在找找看这个方案,
简单的可以用js+gwx.cookie来接收。专业的也有socketcookie的库,例如localstorageandwebsessionstoragedriverandpregistry。
有。目前已经有localstorage和websessionstorage解决方案了。
推荐用webstorm开发者工具开发。然后用jenkins分发到生产环境。
在推送方案上最新出了两种,一种是把原来的cookie直接推送到webweb端,一种是写到localstorage和websessionstorage中,webstorm是支持的。我只有webstorm2015。
采集系统上云(采集系统上云之后,第一个难题就是采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-28 02:02
采集系统上云之后,第一个难题就是采集数据。常用的采集方式有以下几种:1.用户自己下载录制好的视频2.用户购买硬件录制设备3.录制分析软件辅助工具,在采集环节中进行采集4.直接采集移动端数据(简单快捷,不需要用户专门下载录制设备或者硬件)sdk上云,第一个难题就是要做什么准备。常见的做数据采集的厂商包括清华大学方案提供商思迅,中科大ai方案提供商北京小戴(使用人脸关键点定位+双目测距+视频分析+人脸识别),自动驾驶方案提供商百度drive,最大的就是爱数了,但是爱数目前支持的数据类型有限,需要升级支持。
爱数的优势在于可以推送市场对数据需求比较高的直播、视频等类型的内容。如果想把采集引擎做的更好更稳定,可以考虑先从流媒体服务商做起来,比如ims,nox。这方面海外市场做的比较好的就是googleplay,因为它平台相对比较稳定和相对来说市场化度比较高。其实我们在北京望京的酒店里见到过几个关于视频录制功能的产品,只是我们只是初步尝试了一下,在之后,我们可能会做相关的分析报告。
如果不考虑价格,建议使用apigateway,因为它具有完整的链路匹配能力,去过itunesconnect和flickr的人肯定知道这个方法。一般这样的产品都是由海外团队(美国,欧洲)负责的,在中国没有合适的客户(主要是国内的直播平台还是很难开发出像样的数据采集服务的)。至于采集系统上云,如果其实人工操作的话,算是折腾,还不如直接定制化。如果说好用一点的话,还是可以参考一下360云,它支持中国各个时段全球视频。 查看全部
采集系统上云(采集系统上云之后,第一个难题就是采集数据)
采集系统上云之后,第一个难题就是采集数据。常用的采集方式有以下几种:1.用户自己下载录制好的视频2.用户购买硬件录制设备3.录制分析软件辅助工具,在采集环节中进行采集4.直接采集移动端数据(简单快捷,不需要用户专门下载录制设备或者硬件)sdk上云,第一个难题就是要做什么准备。常见的做数据采集的厂商包括清华大学方案提供商思迅,中科大ai方案提供商北京小戴(使用人脸关键点定位+双目测距+视频分析+人脸识别),自动驾驶方案提供商百度drive,最大的就是爱数了,但是爱数目前支持的数据类型有限,需要升级支持。
爱数的优势在于可以推送市场对数据需求比较高的直播、视频等类型的内容。如果想把采集引擎做的更好更稳定,可以考虑先从流媒体服务商做起来,比如ims,nox。这方面海外市场做的比较好的就是googleplay,因为它平台相对比较稳定和相对来说市场化度比较高。其实我们在北京望京的酒店里见到过几个关于视频录制功能的产品,只是我们只是初步尝试了一下,在之后,我们可能会做相关的分析报告。
如果不考虑价格,建议使用apigateway,因为它具有完整的链路匹配能力,去过itunesconnect和flickr的人肯定知道这个方法。一般这样的产品都是由海外团队(美国,欧洲)负责的,在中国没有合适的客户(主要是国内的直播平台还是很难开发出像样的数据采集服务的)。至于采集系统上云,如果其实人工操作的话,算是折腾,还不如直接定制化。如果说好用一点的话,还是可以参考一下360云,它支持中国各个时段全球视频。
采集系统上云(Linux系统中有很多日志类型分析系统产生的文件介绍(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-01-27 16:17
提供服务的Linux服务器通常会一直产生大量的日志信息。如果生产环境有几十台甚至上百台服务器,要一一查看系统日志是很麻烦的。的。
在技术不断更新的今天,可以集中管理日志的技术有很多。最常见的操作是ELK日志分析系统,但是这些日志是怎么产生的呢?使用哪个服务进行统一管理?这个 文章 将围绕系统日志服务 - rsyslog。
Linux 系统中有多种日志类型。以下是系统自身产生的一些日志文件:
/var/log/boot.log
/var/log/cron
/var/log/dmesg
/var/log/lastlog
/var/log/maillog或/var/log/mail/*
/var/log/messages
/var/log/secure
/var/log/wtmp,/var/log/faillog
/var/log/httpd/* , /var/log/samba/*
如果想详细了解日志文件中记录了哪些信息,可以参考这篇博文:Linux中常见日志文件介绍,其中还收录了7个错误级别的介绍!这里不乱说。
系统中的大部分日志都由 rsyslog 服务管理。该服务的主要配置文件如下:
[root@aaa ~]# grep -v "^$" /etc/rsyslog.conf | grep -v "^#" #过滤配置文件中的空行和注释行
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
$ModLoad imjournal # provides access to the systemd journal
$WorkDirectory /var/lib/rsyslog
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
$OmitLocalLogging on
$IMJournalStateFile imjournal.state
*.info;mail.none;authpriv.none;cron.none /var/log/messages
上面行开头的星号表示所有服务,点号后面的等级表示那些等级记录下来,/var/lo....表示记录到哪里
authpriv.* /var/log/secure #表示authpriv所有等级的信息都记录到secure文件中
mail.* /var/log/maillog #表示mail服务的所有级别信息都记录到/var/log/maillog中
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log
#由上面几行注释可以看出,第一段中的点号前面表示某个服务,点号后面表示哪些报错等级要记录。
#点号前后都可以使用通配符星号来表示,如第一列为“*.*”,则表示所有服务的所有等级
#若为“*.info”,则表示所有服务的info等级及比info更严重的等级都记录起来。
在上面的配置文件中,可以更改日志的存放位置,以及应该记录哪些日志级别,但一般不建议这样做。
其实依靠配置文件/etc/rsyslog.conf,也可以将其日志发送到另一台服务器,然后在另一台服务器上进行统一管理。如果生产环境小,服务器不多,这种情况可以使用,但是如果生产环境的服务器数量比较多,建议部署ELK日志分析系统。
配置 rsyslog 服务实例
我这里有两台服务器,主机名分别是aaa和bbb(IP地址分别是192.168.1.1和1.2),现在要实现以下要求:
开始配置:
1、将info级别以上aaa服务器的所有系统服务日志同步发送给bbb服务器统一管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件
#..............省略部分内容
$ModLoad imudp #将该行开头的注释符号“#”去掉,以便开启udp协议
$UDPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启udp的514端口
# Provides TCP syslog reception
$ModLoad imtcp #将该行开头的注释符号“#”去掉,以便开启tcp协议
$InputTCPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启tcp的514端口
#..............省略部分内容
*.info;mail.none;authpriv.none;cron.none /var/log/messages
*.info @@192.168.1.2 #星号表示所有服务“*.info”表示info等级及以上的信息
#@@表示使用tcp协议传输,192.168.1.2是指定要发送到哪台服务器
#若使用一个@符号,则表示使用udp协议传输
#..............省略部分内容
#编辑完成后,保存退出即可。
[root@aaa ~]# systemctl restart rsyslog #重启rsyslog服务,以便更改生效
(2)在 bbb 服务器上执行以下操作:
[root@bbb ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件,开启udp和tcp的514端口
#..............省略部分内容
$ModLoad imudp #去掉该行开头的“#”注释符号
$UDPServerRun 514 #去掉该行开头的“#”注释符号
# Provides TCP syslog reception
$ModLoad imtcp #去掉该行开头的“#”注释符号
$InputTCPServerRun 514 #去掉该行开头的“#”注释符号
#..............省略部分内容
[root@bbb ~]# systemctl restart rsyslog #重启服务,使更改生效
[root@bbb ~]# tailf /var/log/secure #动态监控着本机的日志文件
Sep 19 15:00:32 aaa useradd[5998]: new group: name=lvjianzh, GID=1003
Sep 19 15:00:32 aaa useradd[5998]: new user: name=lvjianzh, UID=1003, GID=1003....
#..............省略部分内容
(3)在aaa服务器上进行如下操作(主要是生成日志信息):
[root@aaa ~]# useradd admini
[root@aaa ~]# echo '123.com' | passwd --stdin admini
更改用户 admini 的密码 。
passwd:所有的身份验证令牌已经成功更新。
(4)查看bbb生成的新日志如下:
2、将编译安装好的Nginx日志发送到bbb服务器进行管理;
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/yum.repos.d/epel.repo #写入以下文件,指定阿里镜像站
[epel]
name=epel
baseurl=https://mirrors.aliyun.com/epel/7/x86_64/
gpgcheck=0
#必须保证系统默认自带的yum文件也存在/etc/yum.repos.d/目录下,写入后保存退出即可。
[root@aaa ~]# yum repolist #最好执行一下该命令
#..............省略部分内容
(7/7): base/7/x86_64/primary_db | 6.0 MB 00:01
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base 10,097
epel epel 13,384
#上面一行就是我们刚写入的文件生效的,表示没问题
extras/7/x86_64 CentOS-7 - Extras 304
updates/7/x86_64 CentOS-7 - Updates 311
repolist: 24,096
#若命令yum repolist执行后没有显示出上述内容,排除配置文件的错误后,可以执行以下命令
[root@aaa ~]# yum makecache #用来建立元数据缓存的
#..............省略部分内容
元数据缓存已建立
[root@aaa ~]# yum -y install nginx #安装nginx服务
[root@aaa ~]# systemctl start nginx #启动Nginx服务
[root@aaa ~]# netstat -anpt | grep nginx #确定Nginx服务已启动
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 6609/nginx: master
tcp6 0 0 :::80 :::* LISTEN 6609/nginx: master
[root@aaa ~]# ls /var/log/nginx/ #以下是yum安装Nginx后,Nginx两个日志文件的存放位置
access.log error.log
#记住Nginx日志的存放路径,一会要用到,若采用的是编译安装,请自行找到Nginx日志存放路径记下来
[root@aaa ~]# vim /etc/rsyslog.conf #编辑rsyslog服务的配置文件
#..............省略部分内容
#在配置文件末尾写入以下内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/nginx/access.log
$InputFileTag nginx-info-access;
$InputFilestateFile state-nginx-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
[root@aaa ~]# systemctl restart rsyslog #重启服务以便生效
上面写的配置项解释如下:
$ModLoad imfile #加载模块
$InputFilePollInterval 1 #间隔多久采集次,默认单位是秒
$InputFileName /var/log/nginx/access.log #指定要采集的日志文件
$InputFileTag nginx-info-access; #给对应的日志打一个标签
$InputFilestateFile state-nginx-info-accesslog #给这个日志命名
$InputRunFileMonitor #启动监控
#以下的配置和上面类似,因为要采集两个日志文件嘛!
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
#以下是指定将采集的日志发送到哪里,同理,一个@符号表示使用的udp协议,两个表示tcp协议
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~ #这的~,表示本地的意思
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
(2)bbb服务器上的监控日志:
(3)客户端为了生成日志,访问aaa的Nginx服务。
(4)回到bbb服务器看看aaa服务器上是否有生成Nginx访问日志(如果没有生成新的日志,客户端可以在排除配置错误的前提下刷新几次):
可见Nginx的日志信息应该不会太详细了吧?日志信息中是否收录日志的生成时间?哪个服务器生成的?标签名称是什么?访问了哪个 IP 地址?访问时间是什么时候?访问的状态码是什么?客户端访问的是什么系统,系统的位数是多少?比如(Windows NT 10.0; Win64; x64,表示是64位win10系统),你用什么浏览器访问呢?我用谷歌在这里访问它,它甚至记录了我客户的谷歌浏览器的版本号。
至此,Nginx日志文件采集就完成了,接下来就是执行apache日志采集了。有了前面的铺垫,这个就简单多了,只需要更改配置项即可。
3、将编译安装的apache日志发送到bbb服务器进行管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# yum -y install httpd #安装apache服务
[root@aaa ~]# systemctl stop nginx #为了避免端口冲突,停止Nginx服务
[root@aaa ~]# systemctl start httpd #启动apache服务
[root@aaa ~]# vim /etc/rsyslog.conf #更改rsyslog配置文件,主要是更改采集日志的路径
#..............省略部分内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/httpd/access_log #主要是改这个
$InputFileTag httpd-info-access;
$InputFilestateFile state-httpd-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/httpd/error_log #还要改这个
#其余配置项可不改,但是建议改一下,以免看起来日志不太直观。
$InputFileTag httpd-info-error;
$InputFilestateFile state-httpd-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'httpd-info-access' then @192.168.1.2:514
if $programname == 'httpd-info-access' then ~
if $programname == 'httpd-info-error' then @192.168.1.2:514
if $programname == 'httpd-info-error' then ~
#主要就是将上面配置中的Nginx都换成了httpd。
[root@aaa ~]# systemctl restart rsyslog #重启服务,使更改生效
(2)bbb服务器上的监控日志:
(3)客户端访问aaa的Nginx服务是为了生成日志(刷新几次)。
(4)回到bbb服务器看看有没有关于aaa服务器的httpd访问日志。
行!没问题,采集 来了。. .
————————— 本文到此结束,感谢您的阅读—————— 查看全部
采集系统上云(Linux系统中有很多日志类型分析系统产生的文件介绍(二))
提供服务的Linux服务器通常会一直产生大量的日志信息。如果生产环境有几十台甚至上百台服务器,要一一查看系统日志是很麻烦的。的。
在技术不断更新的今天,可以集中管理日志的技术有很多。最常见的操作是ELK日志分析系统,但是这些日志是怎么产生的呢?使用哪个服务进行统一管理?这个 文章 将围绕系统日志服务 - rsyslog。
Linux 系统中有多种日志类型。以下是系统自身产生的一些日志文件:
/var/log/boot.log
/var/log/cron
/var/log/dmesg
/var/log/lastlog
/var/log/maillog或/var/log/mail/*
/var/log/messages
/var/log/secure
/var/log/wtmp,/var/log/faillog
/var/log/httpd/* , /var/log/samba/*
如果想详细了解日志文件中记录了哪些信息,可以参考这篇博文:Linux中常见日志文件介绍,其中还收录了7个错误级别的介绍!这里不乱说。
系统中的大部分日志都由 rsyslog 服务管理。该服务的主要配置文件如下:
[root@aaa ~]# grep -v "^$" /etc/rsyslog.conf | grep -v "^#" #过滤配置文件中的空行和注释行
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
$ModLoad imjournal # provides access to the systemd journal
$WorkDirectory /var/lib/rsyslog
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
$OmitLocalLogging on
$IMJournalStateFile imjournal.state
*.info;mail.none;authpriv.none;cron.none /var/log/messages
上面行开头的星号表示所有服务,点号后面的等级表示那些等级记录下来,/var/lo....表示记录到哪里
authpriv.* /var/log/secure #表示authpriv所有等级的信息都记录到secure文件中
mail.* /var/log/maillog #表示mail服务的所有级别信息都记录到/var/log/maillog中
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log
#由上面几行注释可以看出,第一段中的点号前面表示某个服务,点号后面表示哪些报错等级要记录。
#点号前后都可以使用通配符星号来表示,如第一列为“*.*”,则表示所有服务的所有等级
#若为“*.info”,则表示所有服务的info等级及比info更严重的等级都记录起来。
在上面的配置文件中,可以更改日志的存放位置,以及应该记录哪些日志级别,但一般不建议这样做。
其实依靠配置文件/etc/rsyslog.conf,也可以将其日志发送到另一台服务器,然后在另一台服务器上进行统一管理。如果生产环境小,服务器不多,这种情况可以使用,但是如果生产环境的服务器数量比较多,建议部署ELK日志分析系统。
配置 rsyslog 服务实例
我这里有两台服务器,主机名分别是aaa和bbb(IP地址分别是192.168.1.1和1.2),现在要实现以下要求:
开始配置:
1、将info级别以上aaa服务器的所有系统服务日志同步发送给bbb服务器统一管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件
#..............省略部分内容
$ModLoad imudp #将该行开头的注释符号“#”去掉,以便开启udp协议
$UDPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启udp的514端口
# Provides TCP syslog reception
$ModLoad imtcp #将该行开头的注释符号“#”去掉,以便开启tcp协议
$InputTCPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启tcp的514端口
#..............省略部分内容
*.info;mail.none;authpriv.none;cron.none /var/log/messages
*.info @@192.168.1.2 #星号表示所有服务“*.info”表示info等级及以上的信息
#@@表示使用tcp协议传输,192.168.1.2是指定要发送到哪台服务器
#若使用一个@符号,则表示使用udp协议传输
#..............省略部分内容
#编辑完成后,保存退出即可。
[root@aaa ~]# systemctl restart rsyslog #重启rsyslog服务,以便更改生效
(2)在 bbb 服务器上执行以下操作:
[root@bbb ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件,开启udp和tcp的514端口
#..............省略部分内容
$ModLoad imudp #去掉该行开头的“#”注释符号
$UDPServerRun 514 #去掉该行开头的“#”注释符号
# Provides TCP syslog reception
$ModLoad imtcp #去掉该行开头的“#”注释符号
$InputTCPServerRun 514 #去掉该行开头的“#”注释符号
#..............省略部分内容
[root@bbb ~]# systemctl restart rsyslog #重启服务,使更改生效
[root@bbb ~]# tailf /var/log/secure #动态监控着本机的日志文件
Sep 19 15:00:32 aaa useradd[5998]: new group: name=lvjianzh, GID=1003
Sep 19 15:00:32 aaa useradd[5998]: new user: name=lvjianzh, UID=1003, GID=1003....
#..............省略部分内容
(3)在aaa服务器上进行如下操作(主要是生成日志信息):
[root@aaa ~]# useradd admini
[root@aaa ~]# echo '123.com' | passwd --stdin admini
更改用户 admini 的密码 。
passwd:所有的身份验证令牌已经成功更新。
(4)查看bbb生成的新日志如下:
2、将编译安装好的Nginx日志发送到bbb服务器进行管理;
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/yum.repos.d/epel.repo #写入以下文件,指定阿里镜像站
[epel]
name=epel
baseurl=https://mirrors.aliyun.com/epel/7/x86_64/
gpgcheck=0
#必须保证系统默认自带的yum文件也存在/etc/yum.repos.d/目录下,写入后保存退出即可。
[root@aaa ~]# yum repolist #最好执行一下该命令
#..............省略部分内容
(7/7): base/7/x86_64/primary_db | 6.0 MB 00:01
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base 10,097
epel epel 13,384
#上面一行就是我们刚写入的文件生效的,表示没问题
extras/7/x86_64 CentOS-7 - Extras 304
updates/7/x86_64 CentOS-7 - Updates 311
repolist: 24,096
#若命令yum repolist执行后没有显示出上述内容,排除配置文件的错误后,可以执行以下命令
[root@aaa ~]# yum makecache #用来建立元数据缓存的
#..............省略部分内容
元数据缓存已建立
[root@aaa ~]# yum -y install nginx #安装nginx服务
[root@aaa ~]# systemctl start nginx #启动Nginx服务
[root@aaa ~]# netstat -anpt | grep nginx #确定Nginx服务已启动
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 6609/nginx: master
tcp6 0 0 :::80 :::* LISTEN 6609/nginx: master
[root@aaa ~]# ls /var/log/nginx/ #以下是yum安装Nginx后,Nginx两个日志文件的存放位置
access.log error.log
#记住Nginx日志的存放路径,一会要用到,若采用的是编译安装,请自行找到Nginx日志存放路径记下来
[root@aaa ~]# vim /etc/rsyslog.conf #编辑rsyslog服务的配置文件
#..............省略部分内容
#在配置文件末尾写入以下内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/nginx/access.log
$InputFileTag nginx-info-access;
$InputFilestateFile state-nginx-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
[root@aaa ~]# systemctl restart rsyslog #重启服务以便生效
上面写的配置项解释如下:
$ModLoad imfile #加载模块
$InputFilePollInterval 1 #间隔多久采集次,默认单位是秒
$InputFileName /var/log/nginx/access.log #指定要采集的日志文件
$InputFileTag nginx-info-access; #给对应的日志打一个标签
$InputFilestateFile state-nginx-info-accesslog #给这个日志命名
$InputRunFileMonitor #启动监控
#以下的配置和上面类似,因为要采集两个日志文件嘛!
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
#以下是指定将采集的日志发送到哪里,同理,一个@符号表示使用的udp协议,两个表示tcp协议
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~ #这的~,表示本地的意思
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
(2)bbb服务器上的监控日志:
(3)客户端为了生成日志,访问aaa的Nginx服务。
(4)回到bbb服务器看看aaa服务器上是否有生成Nginx访问日志(如果没有生成新的日志,客户端可以在排除配置错误的前提下刷新几次):
可见Nginx的日志信息应该不会太详细了吧?日志信息中是否收录日志的生成时间?哪个服务器生成的?标签名称是什么?访问了哪个 IP 地址?访问时间是什么时候?访问的状态码是什么?客户端访问的是什么系统,系统的位数是多少?比如(Windows NT 10.0; Win64; x64,表示是64位win10系统),你用什么浏览器访问呢?我用谷歌在这里访问它,它甚至记录了我客户的谷歌浏览器的版本号。
至此,Nginx日志文件采集就完成了,接下来就是执行apache日志采集了。有了前面的铺垫,这个就简单多了,只需要更改配置项即可。
3、将编译安装的apache日志发送到bbb服务器进行管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# yum -y install httpd #安装apache服务
[root@aaa ~]# systemctl stop nginx #为了避免端口冲突,停止Nginx服务
[root@aaa ~]# systemctl start httpd #启动apache服务
[root@aaa ~]# vim /etc/rsyslog.conf #更改rsyslog配置文件,主要是更改采集日志的路径
#..............省略部分内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/httpd/access_log #主要是改这个
$InputFileTag httpd-info-access;
$InputFilestateFile state-httpd-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/httpd/error_log #还要改这个
#其余配置项可不改,但是建议改一下,以免看起来日志不太直观。
$InputFileTag httpd-info-error;
$InputFilestateFile state-httpd-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'httpd-info-access' then @192.168.1.2:514
if $programname == 'httpd-info-access' then ~
if $programname == 'httpd-info-error' then @192.168.1.2:514
if $programname == 'httpd-info-error' then ~
#主要就是将上面配置中的Nginx都换成了httpd。
[root@aaa ~]# systemctl restart rsyslog #重启服务,使更改生效
(2)bbb服务器上的监控日志:
(3)客户端访问aaa的Nginx服务是为了生成日志(刷新几次)。
(4)回到bbb服务器看看有没有关于aaa服务器的httpd访问日志。
行!没问题,采集 来了。. .
————————— 本文到此结束,感谢您的阅读——————
采集系统上云(阿里巴巴高级开发工程师徐榜江版本的核心特性(详解Flink-CDC))
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2022-01-24 15:22
简介:本文由社区志愿者陈正宇整理,内容来自阿里巴巴高级开发工程师徐邦江(薛劲)7月10日在北京站Flink Meetup上分享的《Flink-CDC详解》。深度解读 Flink CDC 新版本 2.0.0 带来的核心特性,包括:全量数据并发读取、检查点、无锁读取等重大改进。
一、CDC 概述
CDC的全称是Change Data Capture。从广义上讲,只要是能够捕捉到数据变化的技术,我们就可以称之为CDC。目前常用的CDC技术主要面向数据库变化,是一种用于捕捉数据库中数据变化的技术。CDC技术的应用场景非常广泛:
CDC有很多技术解决方案。目前业界主流的实现机制可以分为两种:
比较常见的开源CDC解决方案,我们可以发现:
二、Flink CDC 项目
说了这么多,让我们回顾一下开发 Flink CDC 项目的动机。
1. 动态表和变更日志流
大家都知道 Flink 有两个基本概念:Dynamic Table 和 Changelog Stream。
如果你想想 MySQL 中的表和 binlog 日志,你会发现 MySQL 数据库中一张表的所有更改都记录在 binlog 日志中。如果不断更新表,binlog日志流会一直追加,数据库中的表就相当于binlog日志流在某个时间点的物化结果;日志流是不断捕获表的变化数据的结果。由此可见,Flink SQL 的 Dynamic Table 可以非常自然地表示一个不断变化的 MySQL 数据库表。
在此基础上,我们研究了一些 CDC 技术,最终选择了 Debezium 作为 Flink CDC 的底层 采集 工具。Debezium支持全同步、增量同步、全+增量同步,非常灵活。同时,基于日志的CDC技术使得提供Exactly-Once成为可能。
对比 Flink SQL 的内部数据结构 RowData 和 Debezium 的数据结构,可以发现两者非常相似。
通过分析这两种数据结构,可以很容易地连接 Flink 和 Debezium 的底层数据。你可以发现 Flink 在技术上是适合 CDC 的。
2. 传统 CDC ETL 分析
我们来看看传统CDC的ETL分析环节,如下图所示:
在传统的基于 CDC 的 ETL 分析中,数据 采集 工具是必不可少的。国外用户常用Debezium,国内用户常用阿里巴巴开源Canal。采集 工具负责采集 数据库的增量数据。,部分采集工具还支持同步全量数据。采集 接收到的数据一般会输出到 Kafka 等消息中间件,然后 Flink 计算引擎会消费这部分数据并写入目的地。目的地可以是各种数据库、数据湖、实时数仓和离线数仓。仓库。
注意Flink提供了changelog-json格式,可以将changelog数据写入Hive/HDFS等离线数据仓库;对于实时数据仓库,Flink 支持通过 upsert-kafka 连接器将变更日志直接写入 Kafka。
我们一直在思考是否可以使用 Flink CDC 来代替上图中虚线框内的 采集 组件和消息队列,从而简化分析环节,降低维护成本。同时,更少的组件也意味着可以进一步提高数据的时效性。答案是肯定的,所以我们有了基于 Flink CDC 的 ETL 分析流程。
3. 基于 Flink CDC 的 ETL 分析
使用 Flink CDC 之后,除了组件更少、维护更方便之外,另一个好处是 Flink SQL 大大降低了用户门槛。您可以看到以下示例:
本示例使用 Flink CDC 同步数据库数据并写入 TiDB。用户直接使用 Flink SQL 创建产品和订单的 MySQL-CDC 表,然后对数据流进行 JOIN 处理,处理后直接写入下游数据库。CDC 的数据分析、处理和同步是通过一个 Flink SQL 作业完成的。
你会发现这是一个纯SQL的工作,也就是说只要你懂SQL BI,行业的同学就可以完成这样的工作。同时,用户还可以使用 Flink SQL 提供的丰富语法进行数据清洗、分析和聚合。
有了这些功能,现有的 CDC 解决方案很难清理、分析和汇总数据。
此外,使用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法,可以轻松完成数据拓宽和各种业务逻辑处理。
4. Flink CDC 项目开发
三、Flink CDC 2.0 详细信息
1. Flink CDC 痛点
MySQL CDC 是 Flink CDC 中使用最多、最重要的 Connector。本文的以下部分将 Flink CDC Connector 描述为 MySQL CDC Connector。
随着 Flink CDC 项目的发展,得到了社区众多用户的反馈,主要可以总结为三点:
2. Debezium 锁分析
Flink CDC 在底部封装了 Debezium。Debezium 分两个阶段同步表:
用户使用的场景大多是全量+增量同步。锁定发生在全量阶段。目的是确定满卷阶段的初始位置,保证增量+满卷可以做到一多一少,从而保证数据的一致性。从下图中,我们可以分析出全局锁和表锁的一些加锁过程。左边的红线是锁的生命周期,右边是MySQL启用可重复读事务的生命周期。
以全局锁为例,首先获取一个锁,然后启动一个可重复读事务。这里的加锁操作是读取binlog的起始位置和当前表的schema。这样做的目的是保证binlog的起始位置和当前读取的schema可以对应,因为表的schema会发生变化,比如删除或者增加列。读取这两条信息后,SnapshotReader 将读取可重复读取事务中的全量数据。数据量全读完后,会启动BinlogReader从binlog读取的起始位置开始增量读取,以保证数据量全。数据+增量数据无缝对接。
表锁是全局锁的退化版本,因为全局锁的权限比较高,所以在某些场景下,用户只有表锁。表锁锁需要更长的时间,因为表锁有一个特点:如果提前释放锁,默认会提交可重复读事务,所以需要在读取全量数据后释放锁。
经过上面的分析,我们来看看这些锁的严重后果:
Flink CDC 1.x 可以解锁,可以满足大部分场景,但要牺牲一定的数据准确性。Flink CDC 1.x 默认添加全局锁。虽然可以保证数据的一致性,但存在上述数据挂起的风险。
3. Flink CDC 2.0 设计(以 MySQL 为例)
通过以上分析可知,2.0的设计方案,核心需要解决以上三个问题,即支持无锁、水平扩展、检查点。
DBLog论文中描述的无锁算法如下图所示:
左边是块的分割算法的描述。chunk的切分算法其实和很多数据库中分库分表的原理类似。表中的数据按表的主键分片。假设每个Chunk的步长为10,按照这个规则进行划分,只需要将这些Chunk区间分为左开右闭或左闭右开区间,保证连通区间can等于表的主键区间,即Can。
右边是每个 Chunk 的无锁读取算法的描述。该算法的核心思想是在对Chunk进行划分后,对每个Chunk的全读和增量读,完成无锁一致性合并。Chunk的分割如下图所示:
因为每个chunk只负责自己主键范围内的数据,所以不难推断,只要能保证读取每个chunk的一致性,就可以保证读取整个表的一致性。这就是无锁算法的基本原理。.
Netflix 的 DBLog 论文中的 Chunk 读取算法是在 DB 中维护一个信号表,然后通过信号表检查 binlog 文件,记录每个 chunk 读取前的 Low Position(低位)和读取结束后的 High Position . (高点),查询低点和高点之间的Chunk全量数据。读取这部分chunk数据后,将这两个站点之间的binlog增量数据合并为该chunk所属的全量数据,从而得到该chunk在高点时间对应的全量数据。
结合自身情况,Flink CDC 对块读取算法进行了改进,去除了信号表。它不需要额外维护信号表。binlog 中的标记功能被直接读取 binlog 站点所取代。整体分块读取算法说明如下图:
比如读取Chunk-1时,chunk范围为[K1,K10],先直接选择这个范围内的数据,存入buffer,在select前记录一个binlog的位置(低位),select完成后记录binlog的一个轨迹(high locus)。然后启动增量部分,从低点到高点消费binlog。
观察图片右下角的最终输出,你会发现在消费chunk的binlog时,出现的key是k2、k3、k5,我们去buffer标记这些键。
这样,chunk的最终输出就是高点的chunk中最新的数据。
上图描述了单个Chunk的一致性读,但是如果有多个表划分为很多不同的Chunk,这些Chunk分布到不同的任务中,那么如何分布Chunk,保证全局一致读呢?
这是基于 FLIP-27 优雅地实现的。您可以在下图中看到带有 SourceEnumerator 的组件。该组件主要用于Chunk划分。分割后的 Chunk 会提供给下游的 SourceReader 读取,并按 chunk 分发 Snapshot Chunk 的过程是针对不同的 SourceReader 实现的,并且基于 FLIP-27,我们可以很容易地在 chunk 粒度上进行 checkpoint。
在读取Snapshot Chunk时,需要有一个上报流程,如下图橙色的上报信息,将Snapshot Chunk完成信息上报给SourceEnumerator。
上报的主要目的是为了后续分发binlog chunks(如下图)。因为 Flink CDC 支持全量+增量同步,所以在所有 Snapshot Chunk 读取完成后,需要消费增量 binlog。这是通过将 binlog 块发送到任何 Source Reader 以进行单个并发读取来实现的。
对于大部分用户来说,其实没必要过多关注如何进行无锁算法和分片的细节,了解一下整体流程就好了。
整个过程可以概括为:首先通过主键将表划分为Snapshot Chunk,然后将Snapshot Chunk分发给多个SourceReader。在读取每个 Snapshot Chunk 时,它使用一种算法来实现无锁条件下的一致性读取。SourceReader 支持阅读。Chunk粒度检查点,读取完所有的Snapshot Chunk后,下发一个binlog chunk用于增量binlog读取,即Flink CDC 2.0的整体流程,如下图所示:
Flink CDC 是一个完全开源的项目。该项目的所有设计和源代码都已贡献给开源社区。Flink CDC 2.0 也已经正式发布。核心改进和增强包括:
作者用TPC-DS数据集中的customer表进行了测试。Flink版本为1.13.1,客户表数据量6500万,源并发8,全读阶段:
为了提供更好的文档支持,Flink CDC 社区构建了文档网站、网站来支持文档版本管理:
Document网站 支持关键字搜索功能,非常有用:
四、未来规划
关于CDC项目的未来规划,我们希望重点关注三个方面:稳定性、高级特性和生态融合。
“关联” 查看全部
采集系统上云(阿里巴巴高级开发工程师徐榜江版本的核心特性(详解Flink-CDC))
简介:本文由社区志愿者陈正宇整理,内容来自阿里巴巴高级开发工程师徐邦江(薛劲)7月10日在北京站Flink Meetup上分享的《Flink-CDC详解》。深度解读 Flink CDC 新版本 2.0.0 带来的核心特性,包括:全量数据并发读取、检查点、无锁读取等重大改进。
一、CDC 概述
CDC的全称是Change Data Capture。从广义上讲,只要是能够捕捉到数据变化的技术,我们就可以称之为CDC。目前常用的CDC技术主要面向数据库变化,是一种用于捕捉数据库中数据变化的技术。CDC技术的应用场景非常广泛:
CDC有很多技术解决方案。目前业界主流的实现机制可以分为两种:
比较常见的开源CDC解决方案,我们可以发现:
二、Flink CDC 项目
说了这么多,让我们回顾一下开发 Flink CDC 项目的动机。
1. 动态表和变更日志流
大家都知道 Flink 有两个基本概念:Dynamic Table 和 Changelog Stream。
如果你想想 MySQL 中的表和 binlog 日志,你会发现 MySQL 数据库中一张表的所有更改都记录在 binlog 日志中。如果不断更新表,binlog日志流会一直追加,数据库中的表就相当于binlog日志流在某个时间点的物化结果;日志流是不断捕获表的变化数据的结果。由此可见,Flink SQL 的 Dynamic Table 可以非常自然地表示一个不断变化的 MySQL 数据库表。
在此基础上,我们研究了一些 CDC 技术,最终选择了 Debezium 作为 Flink CDC 的底层 采集 工具。Debezium支持全同步、增量同步、全+增量同步,非常灵活。同时,基于日志的CDC技术使得提供Exactly-Once成为可能。
对比 Flink SQL 的内部数据结构 RowData 和 Debezium 的数据结构,可以发现两者非常相似。
通过分析这两种数据结构,可以很容易地连接 Flink 和 Debezium 的底层数据。你可以发现 Flink 在技术上是适合 CDC 的。
2. 传统 CDC ETL 分析
我们来看看传统CDC的ETL分析环节,如下图所示:
在传统的基于 CDC 的 ETL 分析中,数据 采集 工具是必不可少的。国外用户常用Debezium,国内用户常用阿里巴巴开源Canal。采集 工具负责采集 数据库的增量数据。,部分采集工具还支持同步全量数据。采集 接收到的数据一般会输出到 Kafka 等消息中间件,然后 Flink 计算引擎会消费这部分数据并写入目的地。目的地可以是各种数据库、数据湖、实时数仓和离线数仓。仓库。
注意Flink提供了changelog-json格式,可以将changelog数据写入Hive/HDFS等离线数据仓库;对于实时数据仓库,Flink 支持通过 upsert-kafka 连接器将变更日志直接写入 Kafka。
我们一直在思考是否可以使用 Flink CDC 来代替上图中虚线框内的 采集 组件和消息队列,从而简化分析环节,降低维护成本。同时,更少的组件也意味着可以进一步提高数据的时效性。答案是肯定的,所以我们有了基于 Flink CDC 的 ETL 分析流程。
3. 基于 Flink CDC 的 ETL 分析
使用 Flink CDC 之后,除了组件更少、维护更方便之外,另一个好处是 Flink SQL 大大降低了用户门槛。您可以看到以下示例:
本示例使用 Flink CDC 同步数据库数据并写入 TiDB。用户直接使用 Flink SQL 创建产品和订单的 MySQL-CDC 表,然后对数据流进行 JOIN 处理,处理后直接写入下游数据库。CDC 的数据分析、处理和同步是通过一个 Flink SQL 作业完成的。
你会发现这是一个纯SQL的工作,也就是说只要你懂SQL BI,行业的同学就可以完成这样的工作。同时,用户还可以使用 Flink SQL 提供的丰富语法进行数据清洗、分析和聚合。
有了这些功能,现有的 CDC 解决方案很难清理、分析和汇总数据。
此外,使用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法,可以轻松完成数据拓宽和各种业务逻辑处理。
4. Flink CDC 项目开发
三、Flink CDC 2.0 详细信息
1. Flink CDC 痛点
MySQL CDC 是 Flink CDC 中使用最多、最重要的 Connector。本文的以下部分将 Flink CDC Connector 描述为 MySQL CDC Connector。
随着 Flink CDC 项目的发展,得到了社区众多用户的反馈,主要可以总结为三点:
2. Debezium 锁分析
Flink CDC 在底部封装了 Debezium。Debezium 分两个阶段同步表:
用户使用的场景大多是全量+增量同步。锁定发生在全量阶段。目的是确定满卷阶段的初始位置,保证增量+满卷可以做到一多一少,从而保证数据的一致性。从下图中,我们可以分析出全局锁和表锁的一些加锁过程。左边的红线是锁的生命周期,右边是MySQL启用可重复读事务的生命周期。
以全局锁为例,首先获取一个锁,然后启动一个可重复读事务。这里的加锁操作是读取binlog的起始位置和当前表的schema。这样做的目的是保证binlog的起始位置和当前读取的schema可以对应,因为表的schema会发生变化,比如删除或者增加列。读取这两条信息后,SnapshotReader 将读取可重复读取事务中的全量数据。数据量全读完后,会启动BinlogReader从binlog读取的起始位置开始增量读取,以保证数据量全。数据+增量数据无缝对接。
表锁是全局锁的退化版本,因为全局锁的权限比较高,所以在某些场景下,用户只有表锁。表锁锁需要更长的时间,因为表锁有一个特点:如果提前释放锁,默认会提交可重复读事务,所以需要在读取全量数据后释放锁。
经过上面的分析,我们来看看这些锁的严重后果:
Flink CDC 1.x 可以解锁,可以满足大部分场景,但要牺牲一定的数据准确性。Flink CDC 1.x 默认添加全局锁。虽然可以保证数据的一致性,但存在上述数据挂起的风险。
3. Flink CDC 2.0 设计(以 MySQL 为例)
通过以上分析可知,2.0的设计方案,核心需要解决以上三个问题,即支持无锁、水平扩展、检查点。
DBLog论文中描述的无锁算法如下图所示:
左边是块的分割算法的描述。chunk的切分算法其实和很多数据库中分库分表的原理类似。表中的数据按表的主键分片。假设每个Chunk的步长为10,按照这个规则进行划分,只需要将这些Chunk区间分为左开右闭或左闭右开区间,保证连通区间can等于表的主键区间,即Can。
右边是每个 Chunk 的无锁读取算法的描述。该算法的核心思想是在对Chunk进行划分后,对每个Chunk的全读和增量读,完成无锁一致性合并。Chunk的分割如下图所示:
因为每个chunk只负责自己主键范围内的数据,所以不难推断,只要能保证读取每个chunk的一致性,就可以保证读取整个表的一致性。这就是无锁算法的基本原理。.
Netflix 的 DBLog 论文中的 Chunk 读取算法是在 DB 中维护一个信号表,然后通过信号表检查 binlog 文件,记录每个 chunk 读取前的 Low Position(低位)和读取结束后的 High Position . (高点),查询低点和高点之间的Chunk全量数据。读取这部分chunk数据后,将这两个站点之间的binlog增量数据合并为该chunk所属的全量数据,从而得到该chunk在高点时间对应的全量数据。
结合自身情况,Flink CDC 对块读取算法进行了改进,去除了信号表。它不需要额外维护信号表。binlog 中的标记功能被直接读取 binlog 站点所取代。整体分块读取算法说明如下图:
比如读取Chunk-1时,chunk范围为[K1,K10],先直接选择这个范围内的数据,存入buffer,在select前记录一个binlog的位置(低位),select完成后记录binlog的一个轨迹(high locus)。然后启动增量部分,从低点到高点消费binlog。
观察图片右下角的最终输出,你会发现在消费chunk的binlog时,出现的key是k2、k3、k5,我们去buffer标记这些键。
这样,chunk的最终输出就是高点的chunk中最新的数据。
上图描述了单个Chunk的一致性读,但是如果有多个表划分为很多不同的Chunk,这些Chunk分布到不同的任务中,那么如何分布Chunk,保证全局一致读呢?
这是基于 FLIP-27 优雅地实现的。您可以在下图中看到带有 SourceEnumerator 的组件。该组件主要用于Chunk划分。分割后的 Chunk 会提供给下游的 SourceReader 读取,并按 chunk 分发 Snapshot Chunk 的过程是针对不同的 SourceReader 实现的,并且基于 FLIP-27,我们可以很容易地在 chunk 粒度上进行 checkpoint。
在读取Snapshot Chunk时,需要有一个上报流程,如下图橙色的上报信息,将Snapshot Chunk完成信息上报给SourceEnumerator。
上报的主要目的是为了后续分发binlog chunks(如下图)。因为 Flink CDC 支持全量+增量同步,所以在所有 Snapshot Chunk 读取完成后,需要消费增量 binlog。这是通过将 binlog 块发送到任何 Source Reader 以进行单个并发读取来实现的。
对于大部分用户来说,其实没必要过多关注如何进行无锁算法和分片的细节,了解一下整体流程就好了。
整个过程可以概括为:首先通过主键将表划分为Snapshot Chunk,然后将Snapshot Chunk分发给多个SourceReader。在读取每个 Snapshot Chunk 时,它使用一种算法来实现无锁条件下的一致性读取。SourceReader 支持阅读。Chunk粒度检查点,读取完所有的Snapshot Chunk后,下发一个binlog chunk用于增量binlog读取,即Flink CDC 2.0的整体流程,如下图所示:
Flink CDC 是一个完全开源的项目。该项目的所有设计和源代码都已贡献给开源社区。Flink CDC 2.0 也已经正式发布。核心改进和增强包括:
作者用TPC-DS数据集中的customer表进行了测试。Flink版本为1.13.1,客户表数据量6500万,源并发8,全读阶段:
为了提供更好的文档支持,Flink CDC 社区构建了文档网站、网站来支持文档版本管理:
Document网站 支持关键字搜索功能,非常有用:
四、未来规划
关于CDC项目的未来规划,我们希望重点关注三个方面:稳定性、高级特性和生态融合。
“关联”
采集系统上云(互联网系统图一图一是的迁移到云端,以便获取这种能力 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2022-01-16 00:15
)
在互联网大行其道的今天,毫不夸张地说,对市场的反应速度甚至将决定一家公司的生死存亡。我们的客户(房地产垂直搜索平台)就是这样一家互联网公司。为了缩短开发周期,减少系统上市时间,我们将现有的基于传统数据中心的基础设施迁移到云端,以获得这种能力。
在此之前,我们先来看看他们现有的系统。
1、现有系统
图1
图 1 是现有核心系统的简单抽象。我们维护三个业务线(这里指的是业务为主,有独立的产品经理、销售团队、独立的结算团队,以下简称LoB),每个业务线对应不同类别的房产搜索网站@ >,如商业和住宅。User是一个用户管理模块,可以提供用户管理、书签和搜索管理;Location是一个定位模块,根据用户的搜索条件给出实际地址和相邻地址;搜索引擎用于存储所有信息并提供搜索功能。可以看出,三个LoB虽然不同网站@>,但提供的服务却是相似的。不仅,
基于以上原因,它们应该集成在一个系统中,但它们不是。这些业务线虽然有如此高的相似度,但在以下几个方面却大相径庭:
由于不同的属性有不同的搜索条件,所以部署时需要对不同的网站@>进行不同的配置。
不同的楼盘有不同的目标市场,需求决定了要开发哪些特色,开展哪些营销活动。因此,每个业务线都有自己的销售和开发团队,并根据市场变化开发和发布相应的功能。计划。
在图1中,不同的颜色表示不同的流量级别,红色表示最大流量,黄色表示中等流量,绿色表示较低流量。对于不同类型的物业,市场需求是不同的。
商业地产的目标客户是需要开展商业活动的人,而住宅地产的目标客户是希望为子女生活或提供更好教育机会的普通人。
2、商业愿景
了解了现有系统之后,再来看看他们的业务愿景,因为没有一家公司的 IT 转型是独立于业务驱动的,了解业务愿景有助于更清楚地了解迁移上云背后的原因。同时,对云策略的适用场景也有了更直观的认识。
这意味着每个团队都将是一个完全独立的全功能团队,拥有独立的系统和独立开发、部署、运维、营销和销售的能力。这为每个团队提供了非常大的自主权,以及对业务扩展和收缩的非常好的适应能力。
这里所说的效率主要是指IT生产活动的效率。本质上,他们是一家互联网公司。如何提高IT系统的效率来支持业务的发展是他们看重的。比如提高人的效率,开发、上线、测试、运维、在线反馈等等,全方面的效率。
中国可能是世界上最活跃的房地产市场之一。与此同时,海外房地产投资在中国持续升温。他们没有理由错过这个机会,不仅在德国、意大利和中国香港。
基于以上差异,图1所示的系统架构显然不能满足客户对业务愿景的实现。主要问题如下:
由于这是一个集成了所有 LoB 的系统,因此业务线之间存在耦合。试想这个场景,LoB1已经根据市场反馈完成了房产中介品牌的提升,希望在涨价前上线,因为这将是涨价的合理理由。同时,LoB2正在开发新的页面以满足业主品牌的需求,但这个功能只开发了一半。按照目前的模式,我们要等LoB2完成功能开发后才能一起上线,这样就错过了LoB1涨价的机会,下一个涨价窗口将在几个月后。
通过流量监控,我们发现网站@>的流量并不是一成不变的。按年计算,网站@> 的流量会在圣诞节前下降到平时水平的 50% 左右,圣诞节后可能会上升到 50%。平均水平在200%左右,这么大的流量会持续一周左右。其实这种情况也不难理解,因为圣诞节期间大家都在放假,放假后还会有一波工作。从图1我们也可以清楚的看到不同组件的不同流量。为了保证整体的响应速度,系统总是以较高的流量部署。但是,由于每个 LoB 都不能独立部署,因此浪费了资源。情况非常明显。
我们之前提到了全球扩张计划。他们想进入中国市场,所以需要设计一个独立的网站@>给中国用户提供住房。为国家房地产市场的扩张做准备,为了实现这个目标,我们需要IT基础设施的支持,可以快速灵活地横向扩张。但基于现有的数据中心模式,这将是一个痛苦的过程。
3、架构愿景
通过对原有IT架构的分析,我们发现很难支撑业务愿景的实现。因此,对于这样的业务愿景,我们已经勾勒出了一个能够很好地支持业务愿景的 IT 架构愿景。
必须能够根据业务线独立运作
易于扩展或可扩展
解决从开发到部署的所有问题,开发者更关注如何更快地交付功能,而不是各种环境问题、部署问题、发布问题
提高资源利用率,根据不同流量情况自适应分配资源。
基于这个愿景,我们发现云平台可以帮助我们实现这样的IT愿景。图 2 描述了系统上云后的架构。
图二
一是所有业务线独立运营,可以自主选择何时发布上线,选择合适的SLA和资源以适应流量变化;其次,所有业务线共享的组件独立于业务线。此外,它们分别部署和运行,还可以调整不同的资源以适应流量的变化。
4、迁移三部曲
在我们知道了现有系统的目标状态之后,下一步就是如何实现这个目标。
图 3
如图3所示,在迁移上云时,从现有系统迁移到目标系统的过程不是一次性的过程,也不是一次性的迁移,而是一个周期性的、持续的过程。是相关系统整合的结果。如果我们关注其中一个迁移周期,则该过程大致可以分为三个阶段:
阶段 1:识别
识别就是弄清楚要迁移的内容。
对于原来的集成系统来说,这个过程与聚合相反,就是对聚合的所有功能特征进行分析和分解。本次活动的目的是深入了解当前系统的职责。明确职责后,我们可以更好地确定哪些职责可以剥离、拆分、独立。比如这个房产搜索网站@>,经过识别发现我们的主要职责是:前端展示(桌面、手机)、房产搜索、搜索管理、用户管理、地理位置查询、并且还提供了部分API。识别完成后,我们要选择从哪个职责开始迁移。这个过程不是随机的,而是基于现有的团队能力,
我的建议是从简单且相对独立的职责开始。如果能同时支持业务发展,那就更好了。因为难度低,可以在迁移初期给团队带来信心和经验。随着迁移经验和信心的积累,那些高耦合、多依赖的职责可以轻松迁移。以这个房产搜索平台为例,在迁移初期,我们选择用户管理职责进行迁移,一方面是因为它比较简单,相对独立,另一方面是因为它为我们提供了API支持。 iOS开发。
第 2 阶段:提取
在确定了系统职责并确定了要迁移的职责之后,是时候将该职责提取为独立的云服务了。
图 4
如上图所示,这个阶段的核心是将识别出的职责从原有系统中分离出来,成为独立的云服务。这个过程有几点需要注意:创建快,需要多快?理想状态是创建成功(空服)后上线(灰度发布)。或许这个目标在迁移之初并不容易实现,但随着迁移信心和经验的积累,是完全可行的,当然这也是我们从简单且相对独立的职责入手的另一个原因;为了快速部署,我们从一个空服务创建一个新服务,这意味着它可以做任何事情,除了在生产环境中运行。不。在这个阶段,我们的目标是抽象出服务的两个痛苦阶段:创建和部署,
第三阶段:整合
集成是将新的云服务与原有系统连接起来。
如果说前两个阶段都是准备,那么这个阶段就是实施迁移的过程。可以说这是最重要的阶段,因为这是新旧系统交付的时期。这个阶段会有一些活动。首先,确定新服务需要哪些外部接口,这需要对现有系统有更深入的了解(当然,如果接口比较简单,这一步也可以在提取阶段实现);其次,将现有系统中待迁移职责的依赖切换到新服务。这个过程可以一次完成,也可以连续完成,这取决于职责的独立程度和现有系统依赖管理的复杂程度。最后,从原创系统中删除责任。以用户管理职责为例,这个阶段是将现有系统与用户服务进行整合,并将该职责从系统中移除。
5、迁移提示
了解了这三个阶段之后,不难看出两个阶段之间的过渡是否高效、顺畅、无障碍,对整个系统上云的迁移起到至关重要的作用。随着长期迁移经验的积累,我们发现以下技巧可以帮助我们在整个迁移阶段顺利过渡。如图 5 所示,在明确迁移职责后,Stencil+DevOps 可以帮助我们快速创建和部署云服务。原系统对接云服务后,可通过测试驱动。对接后,监控可以为我们提供这个迁移周期。伟大的反馈开始下一个迁移周期。让我们也拿这个 网站@>
图 5
提示 1:快速启动:Stencil + devOps
如上所述,这个过程必须高效,即快速创建和部署新服务。只有这样,我们才能使这个过程正常化。我们该怎么做?我们采用了 Stencil+devOps。
Stencil 是一个服务模板,它可以帮助我们快速生成一个空服务,包括一个遵循组织规范的目录结构、标准的监控配置和接口、初始化的构建脚本等。使用 Stencil 的好处是可以快速创建一个组织标准化服务。服务; devOps 用于服务部署、维护、持续集成和发布环境的建立。当然,它也遵循组织的标准规范。如下图,模板主要由3部分组成:应用程序本身、部署脚本(AWS Cloudformation)、docker配置(用于构建)。
提示 2:测试:消费者驱动的测试
当我们快速启动一个空服务时,下一步是如何在两个系统之间快速集成。系统间集成时,基本上可以分为两个小步骤:定义新服务的接口+与现有系统对接的接口。定义一个服务接口可以是一个简单的过程,也可以是一个复杂的过程,这取决于原创系统中职责的复杂性。不管复杂与否,定义服务接口的过程都是一样的——消费驱动。不同于预先定义新服务的所有接口,它驱动新服务根据消费者的需求提供合适的接口。当然,这里的消费者指的是现有的系统。
图 6
从图6可以看出,现有系统(即消费者)与新服务(即服务)的集成过程是由两组失败+成功的测试,或两组BDD组成的。首先是消费者端的 BDD。中间人扮演着服务的角色,我们假设新服务的接口已经按照消费者的要求实现了。这时候,由于消费者还没有写完相应的代码,我们会得到一个失败,然后才是真正的编码。当我们得到一个成功的测试,就意味着消费者端的集成工作已经完成;然后是服务端的 BDD。这时,中间人就扮演了消费者的角色。该服务没有定义预期的接口,所以我们会得到一个失败的测试。编码后,
提示 3:监控
在我们拆分原系统之前,所有模块都集成到同一个系统中,对系统的监控是统一的。但是当我们将现有系统拆分成多个独立的系统时,如何保证新服务的良好运行,或者如何实时监控新服务的运行状态,对整个系统的稳定性非常重要。在实施监控时,我们应该考虑以下几个方面:
基于虚拟机节点整体监控系统资源
比如CPU利用率、硬盘读写、内存利用率等,主要目的是检查当前节点是否过载或空闲。过载意味着资源不能满足当前的流量。应增加节点并部署更多服务以适应大流量情况。空闲意味着资源过剩,应减少节点以降低成本。
对服务整体进行粗粒度监控
主要目的是检查当前服务是否正在运行。如果检测到该服务不可用,云负载均衡会根据预先配置删除该服务,并添加一个新的服务来填补空缺。也就是说,基于当前的架构,我们更愿意重建服务而不是修复不可用的服务。
监控所有服务的内部状态
以上两种监控都无法获取到服务内部的运行状态,所以日志监控在这里显得尤为重要,尤其是两个系统之间集成的日志。通过监控系统日志,我们就有了监控系统内部逻辑的能力,有了这个能力,我们就可以跟踪事故的发生,获取关键信息来优化服务。
总结
从传统数据中心基础设施迁移到云端是一个长期的过程,可能还有很多未知的问题在等着我们,但我们发现同时也是一个重新认识现有系统的过程。在此期间,我们发现了一些规律。每个功能的迁移都有自己的特点,同时又是相似的。这种相似性的提取是:识别、提取和整合。
查看全部
采集系统上云(互联网系统图一图一是的迁移到云端,以便获取这种能力
)
在互联网大行其道的今天,毫不夸张地说,对市场的反应速度甚至将决定一家公司的生死存亡。我们的客户(房地产垂直搜索平台)就是这样一家互联网公司。为了缩短开发周期,减少系统上市时间,我们将现有的基于传统数据中心的基础设施迁移到云端,以获得这种能力。
在此之前,我们先来看看他们现有的系统。
1、现有系统
图1
图 1 是现有核心系统的简单抽象。我们维护三个业务线(这里指的是业务为主,有独立的产品经理、销售团队、独立的结算团队,以下简称LoB),每个业务线对应不同类别的房产搜索网站@ >,如商业和住宅。User是一个用户管理模块,可以提供用户管理、书签和搜索管理;Location是一个定位模块,根据用户的搜索条件给出实际地址和相邻地址;搜索引擎用于存储所有信息并提供搜索功能。可以看出,三个LoB虽然不同网站@>,但提供的服务却是相似的。不仅,
基于以上原因,它们应该集成在一个系统中,但它们不是。这些业务线虽然有如此高的相似度,但在以下几个方面却大相径庭:
由于不同的属性有不同的搜索条件,所以部署时需要对不同的网站@>进行不同的配置。
不同的楼盘有不同的目标市场,需求决定了要开发哪些特色,开展哪些营销活动。因此,每个业务线都有自己的销售和开发团队,并根据市场变化开发和发布相应的功能。计划。
在图1中,不同的颜色表示不同的流量级别,红色表示最大流量,黄色表示中等流量,绿色表示较低流量。对于不同类型的物业,市场需求是不同的。
商业地产的目标客户是需要开展商业活动的人,而住宅地产的目标客户是希望为子女生活或提供更好教育机会的普通人。
2、商业愿景
了解了现有系统之后,再来看看他们的业务愿景,因为没有一家公司的 IT 转型是独立于业务驱动的,了解业务愿景有助于更清楚地了解迁移上云背后的原因。同时,对云策略的适用场景也有了更直观的认识。
这意味着每个团队都将是一个完全独立的全功能团队,拥有独立的系统和独立开发、部署、运维、营销和销售的能力。这为每个团队提供了非常大的自主权,以及对业务扩展和收缩的非常好的适应能力。
这里所说的效率主要是指IT生产活动的效率。本质上,他们是一家互联网公司。如何提高IT系统的效率来支持业务的发展是他们看重的。比如提高人的效率,开发、上线、测试、运维、在线反馈等等,全方面的效率。
中国可能是世界上最活跃的房地产市场之一。与此同时,海外房地产投资在中国持续升温。他们没有理由错过这个机会,不仅在德国、意大利和中国香港。
基于以上差异,图1所示的系统架构显然不能满足客户对业务愿景的实现。主要问题如下:
由于这是一个集成了所有 LoB 的系统,因此业务线之间存在耦合。试想这个场景,LoB1已经根据市场反馈完成了房产中介品牌的提升,希望在涨价前上线,因为这将是涨价的合理理由。同时,LoB2正在开发新的页面以满足业主品牌的需求,但这个功能只开发了一半。按照目前的模式,我们要等LoB2完成功能开发后才能一起上线,这样就错过了LoB1涨价的机会,下一个涨价窗口将在几个月后。
通过流量监控,我们发现网站@>的流量并不是一成不变的。按年计算,网站@> 的流量会在圣诞节前下降到平时水平的 50% 左右,圣诞节后可能会上升到 50%。平均水平在200%左右,这么大的流量会持续一周左右。其实这种情况也不难理解,因为圣诞节期间大家都在放假,放假后还会有一波工作。从图1我们也可以清楚的看到不同组件的不同流量。为了保证整体的响应速度,系统总是以较高的流量部署。但是,由于每个 LoB 都不能独立部署,因此浪费了资源。情况非常明显。
我们之前提到了全球扩张计划。他们想进入中国市场,所以需要设计一个独立的网站@>给中国用户提供住房。为国家房地产市场的扩张做准备,为了实现这个目标,我们需要IT基础设施的支持,可以快速灵活地横向扩张。但基于现有的数据中心模式,这将是一个痛苦的过程。
3、架构愿景
通过对原有IT架构的分析,我们发现很难支撑业务愿景的实现。因此,对于这样的业务愿景,我们已经勾勒出了一个能够很好地支持业务愿景的 IT 架构愿景。
必须能够根据业务线独立运作
易于扩展或可扩展
解决从开发到部署的所有问题,开发者更关注如何更快地交付功能,而不是各种环境问题、部署问题、发布问题
提高资源利用率,根据不同流量情况自适应分配资源。
基于这个愿景,我们发现云平台可以帮助我们实现这样的IT愿景。图 2 描述了系统上云后的架构。
图二
一是所有业务线独立运营,可以自主选择何时发布上线,选择合适的SLA和资源以适应流量变化;其次,所有业务线共享的组件独立于业务线。此外,它们分别部署和运行,还可以调整不同的资源以适应流量的变化。
4、迁移三部曲
在我们知道了现有系统的目标状态之后,下一步就是如何实现这个目标。
图 3
如图3所示,在迁移上云时,从现有系统迁移到目标系统的过程不是一次性的过程,也不是一次性的迁移,而是一个周期性的、持续的过程。是相关系统整合的结果。如果我们关注其中一个迁移周期,则该过程大致可以分为三个阶段:
阶段 1:识别
识别就是弄清楚要迁移的内容。
对于原来的集成系统来说,这个过程与聚合相反,就是对聚合的所有功能特征进行分析和分解。本次活动的目的是深入了解当前系统的职责。明确职责后,我们可以更好地确定哪些职责可以剥离、拆分、独立。比如这个房产搜索网站@>,经过识别发现我们的主要职责是:前端展示(桌面、手机)、房产搜索、搜索管理、用户管理、地理位置查询、并且还提供了部分API。识别完成后,我们要选择从哪个职责开始迁移。这个过程不是随机的,而是基于现有的团队能力,
我的建议是从简单且相对独立的职责开始。如果能同时支持业务发展,那就更好了。因为难度低,可以在迁移初期给团队带来信心和经验。随着迁移经验和信心的积累,那些高耦合、多依赖的职责可以轻松迁移。以这个房产搜索平台为例,在迁移初期,我们选择用户管理职责进行迁移,一方面是因为它比较简单,相对独立,另一方面是因为它为我们提供了API支持。 iOS开发。
第 2 阶段:提取
在确定了系统职责并确定了要迁移的职责之后,是时候将该职责提取为独立的云服务了。
图 4
如上图所示,这个阶段的核心是将识别出的职责从原有系统中分离出来,成为独立的云服务。这个过程有几点需要注意:创建快,需要多快?理想状态是创建成功(空服)后上线(灰度发布)。或许这个目标在迁移之初并不容易实现,但随着迁移信心和经验的积累,是完全可行的,当然这也是我们从简单且相对独立的职责入手的另一个原因;为了快速部署,我们从一个空服务创建一个新服务,这意味着它可以做任何事情,除了在生产环境中运行。不。在这个阶段,我们的目标是抽象出服务的两个痛苦阶段:创建和部署,
第三阶段:整合
集成是将新的云服务与原有系统连接起来。
如果说前两个阶段都是准备,那么这个阶段就是实施迁移的过程。可以说这是最重要的阶段,因为这是新旧系统交付的时期。这个阶段会有一些活动。首先,确定新服务需要哪些外部接口,这需要对现有系统有更深入的了解(当然,如果接口比较简单,这一步也可以在提取阶段实现);其次,将现有系统中待迁移职责的依赖切换到新服务。这个过程可以一次完成,也可以连续完成,这取决于职责的独立程度和现有系统依赖管理的复杂程度。最后,从原创系统中删除责任。以用户管理职责为例,这个阶段是将现有系统与用户服务进行整合,并将该职责从系统中移除。
5、迁移提示
了解了这三个阶段之后,不难看出两个阶段之间的过渡是否高效、顺畅、无障碍,对整个系统上云的迁移起到至关重要的作用。随着长期迁移经验的积累,我们发现以下技巧可以帮助我们在整个迁移阶段顺利过渡。如图 5 所示,在明确迁移职责后,Stencil+DevOps 可以帮助我们快速创建和部署云服务。原系统对接云服务后,可通过测试驱动。对接后,监控可以为我们提供这个迁移周期。伟大的反馈开始下一个迁移周期。让我们也拿这个 网站@>
图 5
提示 1:快速启动:Stencil + devOps
如上所述,这个过程必须高效,即快速创建和部署新服务。只有这样,我们才能使这个过程正常化。我们该怎么做?我们采用了 Stencil+devOps。
Stencil 是一个服务模板,它可以帮助我们快速生成一个空服务,包括一个遵循组织规范的目录结构、标准的监控配置和接口、初始化的构建脚本等。使用 Stencil 的好处是可以快速创建一个组织标准化服务。服务; devOps 用于服务部署、维护、持续集成和发布环境的建立。当然,它也遵循组织的标准规范。如下图,模板主要由3部分组成:应用程序本身、部署脚本(AWS Cloudformation)、docker配置(用于构建)。
提示 2:测试:消费者驱动的测试
当我们快速启动一个空服务时,下一步是如何在两个系统之间快速集成。系统间集成时,基本上可以分为两个小步骤:定义新服务的接口+与现有系统对接的接口。定义一个服务接口可以是一个简单的过程,也可以是一个复杂的过程,这取决于原创系统中职责的复杂性。不管复杂与否,定义服务接口的过程都是一样的——消费驱动。不同于预先定义新服务的所有接口,它驱动新服务根据消费者的需求提供合适的接口。当然,这里的消费者指的是现有的系统。
图 6
从图6可以看出,现有系统(即消费者)与新服务(即服务)的集成过程是由两组失败+成功的测试,或两组BDD组成的。首先是消费者端的 BDD。中间人扮演着服务的角色,我们假设新服务的接口已经按照消费者的要求实现了。这时候,由于消费者还没有写完相应的代码,我们会得到一个失败,然后才是真正的编码。当我们得到一个成功的测试,就意味着消费者端的集成工作已经完成;然后是服务端的 BDD。这时,中间人就扮演了消费者的角色。该服务没有定义预期的接口,所以我们会得到一个失败的测试。编码后,
提示 3:监控
在我们拆分原系统之前,所有模块都集成到同一个系统中,对系统的监控是统一的。但是当我们将现有系统拆分成多个独立的系统时,如何保证新服务的良好运行,或者如何实时监控新服务的运行状态,对整个系统的稳定性非常重要。在实施监控时,我们应该考虑以下几个方面:
基于虚拟机节点整体监控系统资源
比如CPU利用率、硬盘读写、内存利用率等,主要目的是检查当前节点是否过载或空闲。过载意味着资源不能满足当前的流量。应增加节点并部署更多服务以适应大流量情况。空闲意味着资源过剩,应减少节点以降低成本。
对服务整体进行粗粒度监控
主要目的是检查当前服务是否正在运行。如果检测到该服务不可用,云负载均衡会根据预先配置删除该服务,并添加一个新的服务来填补空缺。也就是说,基于当前的架构,我们更愿意重建服务而不是修复不可用的服务。
监控所有服务的内部状态
以上两种监控都无法获取到服务内部的运行状态,所以日志监控在这里显得尤为重要,尤其是两个系统之间集成的日志。通过监控系统日志,我们就有了监控系统内部逻辑的能力,有了这个能力,我们就可以跟踪事故的发生,获取关键信息来优化服务。
总结
从传统数据中心基础设施迁移到云端是一个长期的过程,可能还有很多未知的问题在等着我们,但我们发现同时也是一个重新认识现有系统的过程。在此期间,我们发现了一些规律。每个功能的迁移都有自己的特点,同时又是相似的。这种相似性的提取是:识别、提取和整合。
采集系统上云(loki就是云原生下日志的采集方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-15 08:13
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。并使用普罗米修斯
类似标签的想法,可以用grafana进行可视化,无论是思维还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 找到文件
作为一个采集器,第一步就是找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。可以直接匹配你在配置文件中写的路径信息,比如
promtail中的路径为“/var/log/*.log”,即/var/log目录下所有以.log结尾的后缀文件都可以作为采集的对象。取而代之的是 采集
k8s模式下的登录就麻烦一些了。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或者pv上,那么host和pv
这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们日常使用的kubectl日志。
你看到的日志,这些日志在主机上的存储路径如下/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还是有问题的,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉普罗米修斯
同学们一定已经配置好prometheus、kubernetes_sd_configs和relabel_configs的服务发现配置。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。既然这个目录已经挂载到容器中了,那么promtail
您可以将容器的标签与容器的日志相关联。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后为整个集群部署一组服务器loki
带有可视化侧grafana。
promtail 使用 static_configs 来定义 采集 日志。但promtail
毕竟还是太年轻,定位偏向云原生,所以宿主机的功能还不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在,并且内容量很大,promtail
启动会从头开始推送文件的内容,这会导致短时间内大量的日志被推送到loki。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型,但是数据栈作为一个完整的系统交付给企业时存在很多限制,导致demoset模型无法使用。最大的挑战是权限。只有一个
命名空间权限,无法挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择damonset
模式部署或sidecar模式部署,demoset模式的优点是节省资源,缺点是需要权限。与sidecar模型相比,为了适用更严格的交付条件,我们选择采用
边车的模式执行采集。
边车
该模式是在部署时自动为每个服务添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。数据卷采集下的日志。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志Container和Master
容器共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还不知道采集有哪些日志,以及它们的标签是什么。
因为你可能只想要采集.log 的日志,也可能只想要采集.json 的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
一套日志聚合分析框架,解决主机和云原生场景,降低系统复杂度
日志可视化使用grafana,可视化效果更好,和grafana一样
Prometheus已经是云原生监控的事实标准,开发、运维更加熟悉,降低学习成本
loki 查询语法简单但功能强大
与ELK相比,更轻量级
(二)✈️未来规划
目前使用的是sidecar模式,占用资源较多,后续会考虑进一步优化。
loki 分布式部署优化
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷? 查看全部
采集系统上云(loki就是云原生下日志的采集方案)
一、常规玩ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把 采集器 稍微改一下
Fluentd 可以由 EFK 组成。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还在
elasticsearch这一套。
Elasticsearch 确实功能丰富,功能非常强大,但也极其昂贵,elasticsearch
全文索引方式对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG
是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。格拉法纳
您将熟悉它,一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而loki就是我们今天要讲的主角,这也是grafana
家品,promtail 是 loki 采集器 的官方日志。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。并使用普罗米修斯
类似标签的想法,可以用grafana进行可视化,无论是思维还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
促销
是loki的官方日志采集器,自己的代码在loki
在项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质无非就是根据模式找到文件为采集,然后像tail一样监听文件,然后将写入文件的内容发送到存储端promtail
同理,上述类型的本质也是文件,但这些类型文件的格式都是开放稳定的规范,promtail可以提前对它们进行更深层次的分析和封装。
(三) Promtail 服务发现
1、 找到文件
作为一个采集器,第一步就是找出文件在哪里,然后就可以做如下采集、标签推送等功能了。普通静态类型的日志很容易找到。可以直接匹配你在配置文件中写的路径信息,比如
promtail中的路径为“/var/log/*.log”,即/var/log目录下所有以.log结尾的后缀文件都可以作为采集的对象。取而代之的是 采集
k8s模式下的登录就麻烦一些了。
首先我们想一想k8s上运行的服务的日志在哪里?
文件类型日志
这自然仍然在您的自定义路径上。如果路径目录未挂载,则它在容器内。如果挂载在host或者pv上,那么host和pv
这种类型的日志promtail不能动态发现,必须手动设置。
标准输出日志
这种日志其实是k8s推荐的日志输出方式。这种日志其实就是我们日常使用的kubectl日志。
你看到的日志,这些日志在主机上的存储路径如下/var/log/pods/
{namespace}_/{pod_id}_UUID/{container_name}/*.log 格式
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还是有问题的,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉普罗米修斯
同学们一定已经配置好prometheus、kubernetes_sd_configs和relabel_configs的服务发现配置。
这里promtail直接介绍prometheus的代码。与 prometheus 不同,prometheus 向对象请求更多资源,例如 node、ingress、pod 和 deployment。
以此类推,最后拼接的就是metric的request url,promtail请求的对象就是pod,把不在host上的pod过滤掉。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。既然这个目录已经挂载到容器中了,那么promtail
您可以将容器的标签与容器的日志相关联。剩下的就是监控和推送。
(四) PLG 最佳实践
洛基
官方推荐的最佳实践是使用 DamonSet 部署 promtail,
/var/lib/pods 目录在 prometheus 的帮助下挂载在容器内
服务发现机制对日志进行动态标记,资源占用和部署维护难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 数据栈日志要求
全局 grep
根据关键字搜索系统中的所有出现
快速定位日志
根据机器名、ip、服务名等条件快速定位日志
主机和云原生统一技术栈
降低使用学习成本并降低系统复杂性
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后为整个集群部署一组服务器loki
带有可视化侧grafana。
promtail 使用 static_configs 来定义 采集 日志。但promtail
毕竟还是太年轻,定位偏向云原生,所以宿主机的功能还不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在,并且内容量很大,promtail
启动会从头开始推送文件的内容,这会导致短时间内大量的日志被推送到loki。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型,但是数据栈作为一个完整的系统交付给企业时存在很多限制,导致demoset模型无法使用。最大的挑战是权限。只有一个
命名空间权限,无法挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择damonset
模式部署或sidecar模式部署,demoset模式的优点是节省资源,缺点是需要权限。与sidecar模型相比,为了适用更严格的交付条件,我们选择采用
边车的模式执行采集。
边车
该模式是在部署时自动为每个服务添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。数据卷采集下的日志。
1、promtail如何动态配置数据栈中的标签
通过sidecar模式,我们让日志Container和Master
容器共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还不知道采集有哪些日志,以及它们的标签是什么。
因为你可能只想要采集.log 的日志,也可能只想要采集.json 的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
促销
在 v2.10 中添加了一个新功能
,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后把服务的logpath设置成环境变量,比如LOG_PATH=/var/log/commonlog/* .log
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建时通过环境变量注入,podid
这些环境变量是使用k8s的向下api注入的。
注意:此处不提供使用 promtail
服务发现机制配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod
的标签。然后使用路径匹配将标签与日志相关联。无需将主机 /var/log/pods 目录挂载到 promtail
,即使获取到标签,也无法与日志关联。
2、如何在数据栈中部署promtail
为每个服务添加一个日志
集装箱人工操作过于繁琐,不利于维护。对原创服务进行抽象最好的方法是注册一个CRD,然后写k8s
操作员列出并监视此类型的对象。在创建对象时,它会动态注入一个 LogContainer,以及相应的环境变量,并为其挂载一个公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
一套日志聚合分析框架,解决主机和云原生场景,降低系统复杂度
日志可视化使用grafana,可视化效果更好,和grafana一样
Prometheus已经是云原生监控的事实标准,开发、运维更加熟悉,降低学习成本
loki 查询语法简单但功能强大
与ELK相比,更轻量级
(二)✈️未来规划
目前使用的是sidecar模式,占用资源较多,后续会考虑进一步优化。
loki 分布式部署优化
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?
采集系统上云(【github社区】数栈是云原生—站式数据中台PaaS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-01-13 05:10
本文整理自:浅谈云原生系统日志采集在数据栈中的实践
DataStack 是云原生的一站式数据中心 PaaS。我们在github上有一个有趣的开源项目:FlinkX,欢迎给我们一个star!星星!星星!
FlinkX 是一个基于 Flink 的批量流统一数据同步工具。不仅可以采集静态数据,比如MySQL、HDFS等,还可以采集实时变化的数据,比如MySQL binlog、Kafka等,是一个数据同步引擎它集成了全局、异构和批处理流。有兴趣的请来github社区和我们一起玩~
一、常规打ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把采集器改成Fluentd,组成EFK。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还是elasticsearch。
Elasticsearch 确实功能丰富,功能非常强大,但也非常昂贵。Elasticsearch使用全文索引,对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。您将熟悉 grafana,这是一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而洛基就是我们今天要讲的主角。这也是grafana的产物,promtail是loki 采集器的官方log。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。而且它采用了类prometheus标签的思路,与grafana连接,进行可视化展示。无论是想法还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
promtail 是 loki 采集器 的官方日志,它自己的代码在 loki 项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质是根据模式找到要为采集的文件,然后像tail一样监听一个文件,然后将写入文件的内容发送到存储端promtail。上述情况也是如此。类型的本质也是文件,但这些类型文件的格式是开放且稳定的规范,promtail可以提前更深入的解析和封装。
(三) Promtail 服务发现
1、 以采集器的形式查找文件,首先要找出文件在哪里,然后进行采集、标签推送等功能。普通静态类型的日志很容易找到。你可以直接匹配你在配置文件中写的路径信息。例如promtail中的路径是“/var/log/*.log”,表示/var/log目录下的所有文件,以.log结尾的后缀文件可以作为采集@的对象>。采集 k8s 模式登录稍微麻烦一些。
首先我们想一想k8s上运行的服务的日志在哪里?
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉prometheus的同学一定配置过prometheus的服务发现配置,kubernetes_sd_configs和relabel_configs。
这里promtail直接介绍prometheus的代码。与prometheus不同,prometheus向对象请求更多的资源,比如node、ingress、pod、deployment等。最后拼接的是metric的请求url,promtail请求的对象就是pod,过滤掉不在那个上面的pod主持人。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。由于这个目录已经挂载到容器中,promtail可以将容器的标签和容器的日志关联起来。剩下的就是监控和推送。
(四) PLG 最佳实践
loki官方推荐的最佳实践是使用DamonSet部署promtail,将节点的/var/lib/pods目录挂载到容器中,并借助prometheus的服务发现机制动态给日志添加标签,无论是是资源占用。部署和维护的程度和难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 堆栈日志要求
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后将一组服务器端loki和视觉端grafana部署到整个集群。
promtail 使用 static_configs 来定义 采集 日志。不过promtail毕竟还太年轻,而且定位偏向云原生,所以对于宿主机的功能并不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在并且内容量很大,promtail会从头开始推送文件的内容,这样会导致大量日志被推送到loki中短时间。失败。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型。但是,当数据栈作为一个完整的系统交付给企业时,存在很多限制,这会导致demoset模型无法使用。最大的挑战是许可。只能使用一种命名空间权限。挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择是部署在damonset模式还是sidecar模式。演示模式的优点是节省资源,缺点是需要权限。与sidecar模式相比,为了应用更严格的交付条件,我们为采集选择使用sidecar模式。
sidecar 模式是在每个服务部署的时候自动添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。服务容器将日志写入数据卷,日志容器采集将数据卷下的日志写入。
1、⛳ promtail 如何动态配置数据栈中的标签
通过sidecar模式,我们让logContainer和Master Container共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还是不知道哪些日志到采集,它们的什么标签是。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
Promtail 在 v2.10 中增加了一个新特性,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后用服务的logpath作为环境变量的方式来设置,比如LOG_PATH=/var/log/commonlog/*。日志
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建的时候是通过环境变量注入的,而这些环境变量podid是使用k8s的向下api注入的。
注意:这里不能使用promtail的服务发现机制来配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod的标签。然后使用路径匹配将标签与日志相关联。主机/var/log/pods目录未挂载到promtail时,即使获取到标签,也无法与日志关联。
2、⏰如何在数据栈中部署promtail
为每个服务添加一个Log Container,手动做起来太麻烦,也不利于维护。最好的方法是将原创服务抽象为注册一个CRD,然后编写k8s算子来list & watch该类型的对象。创建对象时,动态注入一个LogContainer,以及对应的环境变量并挂载。公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
(二)✈️未来规划
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?
查看全部
采集系统上云(【github社区】数栈是云原生—站式数据中台PaaS)
本文整理自:浅谈云原生系统日志采集在数据栈中的实践
DataStack 是云原生的一站式数据中心 PaaS。我们在github上有一个有趣的开源项目:FlinkX,欢迎给我们一个star!星星!星星!
FlinkX 是一个基于 Flink 的批量流统一数据同步工具。不仅可以采集静态数据,比如MySQL、HDFS等,还可以采集实时变化的数据,比如MySQL binlog、Kafka等,是一个数据同步引擎它集成了全局、异构和批处理流。有兴趣的请来github社区和我们一起玩~
一、常规打ELK
说到日志采集,估计大家首先想到的就是ELK,一个比较成熟的方案。如果是专门针对云原生的,那就把采集器改成Fluentd,组成EFK。其实以上两种方案没有本质区别,采集器只是一个变化。最终的存储、查询等还是elasticsearch。
Elasticsearch 确实功能丰富,功能非常强大,但也非常昂贵。Elasticsearch使用全文索引,对存储和内存的要求比较高,这些代价得到的功能在日常日志管理中并不常用。这些缺点在主机模式下其实是可以容忍的,但在云原生模式下就显得臃肿了。
二、别说武德PLG
PLG是promtail+loki+grafana的统称,是一个非常适合云原生日志的采集方案。您将熟悉 grafana,这是一个支持多种数据源的出色可视化框架。最常见的是将prometheus的数据可视化。而洛基就是我们今天要讲的主角。这也是grafana的产物,promtail是loki 采集器的官方log。
与elk相比,这套解决方案非常轻量级,功能强大且易于使用。另外,在显示上使用grafana,减少视觉框架的引入,在显示终端上的统一也有利于用户。
(一) 记录暴发户 loki
Loki 是一个受 Prometheus 启发的水平可扩展、高可用的多租户日志聚合系统。它被设计成具有成本效益且易于操作。它不索引日志的内容,而是为每个日志流设置一组标签。
与其他日志聚合系统相比,Loki
没有日志的全文索引。通过存储压缩的非结构化日志和仅索引元数据,Loki 更易于操作且运行成本更低。
使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换。
特别适合存储 Kubernetes Pod 日志。Pod 标签等元数据会被自动爬取和索引。
Grafana 原生支持(需要 Grafana v6.0 或更高版本)。
这是GitHub上对loki的介绍。可以看出这是一个为云原生构建的轻量级日志聚合系统。社区目前非常活跃。而且它采用了类prometheus标签的思路,与grafana连接,进行可视化展示。无论是想法还是使用都非常“云原生”。
(二) ♂️ 儿子 Promtail
promtail 是 loki 采集器 的官方日志,它自己的代码在 loki 项目中。本机支持日志、系统日志、文件和 docker 类型日志。采集器的本质是根据模式找到要为采集的文件,然后像tail一样监听一个文件,然后将写入文件的内容发送到存储端promtail。上述情况也是如此。类型的本质也是文件,但这些类型文件的格式是开放且稳定的规范,promtail可以提前更深入的解析和封装。
(三) Promtail 服务发现
1、 以采集器的形式查找文件,首先要找出文件在哪里,然后进行采集、标签推送等功能。普通静态类型的日志很容易找到。你可以直接匹配你在配置文件中写的路径信息。例如promtail中的路径是“/var/log/*.log”,表示/var/log目录下的所有文件,以.log结尾的后缀文件可以作为采集@的对象>。采集 k8s 模式登录稍微麻烦一些。
首先我们想一想k8s上运行的服务的日志在哪里?
所以我们需要在 k8s 容器内挂载 /var/log/pods 作为主机路径,以便 promtail 可以访问这些日志。
2、 标记
日志promtail可以访问,但是如何区分这些日志还有一个问题,loki使用了类似prometheus的思路来标注数据。也就是说,如果日志是用 pod 打标签的,那么仅仅依靠这条路径自然是无法知道 pod 上的标签信息是什么。这就是服务发现的用武之地。
promtail的服务发现直接由prometheus的服务发现来完成。熟悉prometheus的同学一定配置过prometheus的服务发现配置,kubernetes_sd_configs和relabel_configs。
这里promtail直接介绍prometheus的代码。与prometheus不同,prometheus向对象请求更多的资源,比如node、ingress、pod、deployment等。最后拼接的是metric的请求url,promtail请求的对象就是pod,过滤掉不在那个上面的pod主持人。
获取到宿主机的pod信息后,根据namespace和pod的id拼接路径。由于这个目录已经挂载到容器中,promtail可以将容器的标签和容器的日志关联起来。剩下的就是监控和推送。
(四) PLG 最佳实践
loki官方推荐的最佳实践是使用DamonSet部署promtail,将节点的/var/lib/pods目录挂载到容器中,并借助prometheus的服务发现机制动态给日志添加标签,无论是是资源占用。部署和维护的程度和难度都非常低。这也是主流的云原生日志采集范式。
三、数据栈日志实践
(一) 堆栈日志要求
(二)️主机模式
数据栈主机模式日志聚合采用类似于PLG DameonSet的模式。每个主机部署一个promtail,然后将一组服务器端loki和视觉端grafana部署到整个集群。
promtail 使用 static_configs 来定义 采集 日志。不过promtail毕竟还太年轻,而且定位偏向云原生,所以对于宿主机的功能并不完善,所以我们做了一些二次开发来满足我们的需求:
1、logtail 模式
本机 promtail 不支持从文件末尾采集。promtail启动时会推送所有被监控文件的内容,这在云原生中问题不大。
在host模式下,如果要监控的日志已经存在并且内容量很大,promtail会从头开始推送文件的内容,这样会导致大量日志被推送到loki中短时间。失败。
所以最好的办法就是有一个类似filebeat的logtail模式,只在服务启动后推送文件写入的日志。
在这个地方,我们进行了二次开发,增加了logtail模式的开关。如果开关为true,则第一次启动promtail时不会从头开始推送日志。
2、path 支持多路径
原生promtail不支持多路径路径参数,只能写一个表达式,但实际需求可能是同时看业务日志和gc日志。
但它们又是属于同一类别的标签。单一路径的匹配不能同时涵盖两者。不更改代码的解决方案是为其编写另一个目标。
这既乏味又不利于维护。所以我们在这里也对其进行了二次开发。
(三) 云原生模式
传统的云原生模型采用PLG的主流模型。但是,当数据栈作为一个完整的系统交付给企业时,存在很多限制,这会导致demoset模型无法使用。最大的挑战是许可。只能使用一种命名空间权限。挂载 /var/lib/pods
在这种情况下如何使用 PLG?
其实主要的变化就是promtail的使用。这里首先要声明的是,数据栈服务的日志全部输出到文件中。
首先是选择是部署在damonset模式还是sidecar模式。演示模式的优点是节省资源,缺点是需要权限。与sidecar模式相比,为了应用更严格的交付条件,我们为采集选择使用sidecar模式。
sidecar 模式是在每个服务部署的时候自动添加一个日志容器。容器和服务容器共同挂载一个共同的空数据卷。服务容器将日志写入数据卷,日志容器采集将数据卷下的日志写入。
1、⛳ promtail 如何动态配置数据栈中的标签
通过sidecar模式,我们让logContainer和Master Container共享一个日志目录,这样就可以在promtail容器中获取日志文件,但是promtail还是不知道哪些日志到采集,它们的什么标签是。
因为你可能只想要采集.log的日志,也可能只想要采集.json的日志,或者两个服务的配置可能不一样,所以不能写死,那么如何解决这个问题呢?
Promtail 在 v2.10 中增加了一个新特性,即可以在配置文件中引用环境变量。通过这个特性,我们可以把promtail的path参数写成${LOG_PATH},然后用服务的logpath作为环境变量的方式来设置,比如LOG_PATH=/var/log/commonlog/*。日志
由于我们可以在服务创建时通过环境变量设置路径,所以也可以动态设置标签。那么我们都需要什么维度标签呢?这家不同的公司肯定有不同的维度,但必须遵循的一个原则是可以唯一标识吊舱。大体维度有deployment、podid、node等,这些标签在创建的时候是通过环境变量注入的,而这些环境变量podid是使用k8s的向下api注入的。
注意:这里不能使用promtail的服务发现机制来配置标签,因为promtail的服务发现原理是请求APIServer获取所有pod的标签。然后使用路径匹配将标签与日志相关联。主机/var/log/pods目录未挂载到promtail时,即使获取到标签,也无法与日志关联。
2、⏰如何在数据栈中部署promtail
为每个服务添加一个Log Container,手动做起来太麻烦,也不利于维护。最好的方法是将原创服务抽象为注册一个CRD,然后编写k8s算子来list & watch该类型的对象。创建对象时,动态注入一个LogContainer,以及对应的环境变量并挂载。公共目录。
因此,当创建 CR 时,promtail 作为 sidecar 注入。并且读取的环境变量是操作者动态设置的环境变量,非常灵活。
四、总结
(一) 数据栈日志采集优势
(二)✈️未来规划
最后跟大家分享一下数据栈当前日志模块的可视化效果。是不是超级酷?
采集系统上云(新网站要想快速引流,理由如下更多IP不容易被封)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-13 05:07
新网站为了快速吸引流量,需要时刻保持页面和网站的整体内容更新。中小站长经常单独工作,有的甚至只是在业余时间赚点外快,很难保证这一点。更新率高,虽然有巧妙的办法手动更新,或者运行采集工具,现在很多网站采集在云服务器上,而且大部分云服务器都是单IP的,所以采集 的进程很可能被反采集 工具或防火墙阻止。因此,建议在中国大陆使用采集网站。>内容方面,可以考虑选择香港多IP服务器,原因如下
多IP不容易被封
虽然市面上有很多采集工具集成了IP模拟系统,但是虚拟IP毕竟是虚拟的,所以特征比较明显,很容易被防火墙或者反采集攻击,在运行采集工具的时候一般没有时间长时间监听网站的内容,所以很多时候采集失败我也不知道,而当我发现时,网站可能会更新太多的空内容很难删除,而如果是收录的话,整个站点基本就废了,多IP服务器本身就是一个专属固定IP,被封的可能性低
高性能采集更稳定
很多多IP服务器多用于站群服务,所以硬件配置比较高。现在,市场上有很多 采集 工具,如果它们针对的是单个 网站。台中配置的VPS是可以的,但是一旦采集的目标站点太多,很可能采集在采集的过程中不成功或者内容分发失败. 多IP服务器专为多线程任务打造,抗压能力强。即便是多任务同时运行,释放采集,也完全可以承受负载。
直达专线采集更高效
在设置采集服务器时,目标网站的延迟打开速度非常重要,这也是为什么作者一直强调采集@中网站的内容>大陆地区最好选择香港服务器,因为香港离中国大陆比较近,所以线路延迟低,而且还支持CN2直连网络。对于一些不仅需要采集文字还需要采集图片甚至短视频的用户来说非常适合
如果要全自动采集,自然要选择专业的服务商。例如USA-IDC香港机房可以提供24小时在线技术支持。联系24小时客服了解更多详情
原创内容,禁止转载!侵权必究! 查看全部
采集系统上云(新网站要想快速引流,理由如下更多IP不容易被封)
新网站为了快速吸引流量,需要时刻保持页面和网站的整体内容更新。中小站长经常单独工作,有的甚至只是在业余时间赚点外快,很难保证这一点。更新率高,虽然有巧妙的办法手动更新,或者运行采集工具,现在很多网站采集在云服务器上,而且大部分云服务器都是单IP的,所以采集 的进程很可能被反采集 工具或防火墙阻止。因此,建议在中国大陆使用采集网站。>内容方面,可以考虑选择香港多IP服务器,原因如下
多IP不容易被封
虽然市面上有很多采集工具集成了IP模拟系统,但是虚拟IP毕竟是虚拟的,所以特征比较明显,很容易被防火墙或者反采集攻击,在运行采集工具的时候一般没有时间长时间监听网站的内容,所以很多时候采集失败我也不知道,而当我发现时,网站可能会更新太多的空内容很难删除,而如果是收录的话,整个站点基本就废了,多IP服务器本身就是一个专属固定IP,被封的可能性低
高性能采集更稳定
很多多IP服务器多用于站群服务,所以硬件配置比较高。现在,市场上有很多 采集 工具,如果它们针对的是单个 网站。台中配置的VPS是可以的,但是一旦采集的目标站点太多,很可能采集在采集的过程中不成功或者内容分发失败. 多IP服务器专为多线程任务打造,抗压能力强。即便是多任务同时运行,释放采集,也完全可以承受负载。
直达专线采集更高效
在设置采集服务器时,目标网站的延迟打开速度非常重要,这也是为什么作者一直强调采集@中网站的内容>大陆地区最好选择香港服务器,因为香港离中国大陆比较近,所以线路延迟低,而且还支持CN2直连网络。对于一些不仅需要采集文字还需要采集图片甚至短视频的用户来说非常适合
如果要全自动采集,自然要选择专业的服务商。例如USA-IDC香港机房可以提供24小时在线技术支持。联系24小时客服了解更多详情
原创内容,禁止转载!侵权必究!
采集系统上云(微服务架构下日志采集运维管理分析的解决方案(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-03 12:09
简介:阿里云日志服务(SLS)结合Kubernetes日志的特点和应用场景,提供了容器微服务应用环境中全方位的日志采集、处理和分析实践。直接最佳实践:[微服务架构日志采集运维管理最佳实践]
最佳实践频道:[最佳实践频道]
企业云迁移有很多最佳实践。我们从典型场景出发,提供一系列项目实践方案,在满足您需求的同时,降低企业上云的门槛! Kubernetes 日志系统的重要性
微服务的云原生可观察性的一个重要标准是日志记录。日志采集、存储和分析是构建现代系统平台的关键支柱之一,可以帮助团队诊断问题、追溯质量、监控系统运行效率。在容器/Kubernetes技术热潮的今天,日志系统对于Kubernetes也起到了非常关键的作用。对于 Devops、运维、安全等,都离不开完整、多样、有效的日志采集、存储管理和分析。 , 由下图可见。
微服务架构下的日志采集运维管理挑战
众所周知,借助容器/Kubernetes技术在微服务落地过程中,相比物理机、VM在应用部署、应用交付等环节,为用户提供了更简单、更轻便、性价比更高的优势,而用户在应用容器/Kubernetes技术向微服务转化的过程中,也有容器化应用/非容器化应用的混合部署。对于基于VM或者物理机部署的应用,log采集相关技术比较完善,如Logstash、Fluentd、FileBeats等,但是当应用容器化时,尤其是基于Kubenetes的微服务应用部署时cluster、Log 采集运维给用户带来了很多挑战,主要原因有:
阿里云Kubernetes日志采集方案
基于以上分析,阿里云的日志服务产品解决了基于Kubernetes实现应用微服务改造过程中用户日志采集运维管理的需求和痛点,结合阿里巴巴的优势Cloud结合云产品,提出一站式日志采集运维管理分析解决方案,提供强大的日志处理分析能力,如PB级日志实时查询、日志聚类分析、Ingress日志分析报告、日志分析功能、上下游生态对接等能力,为用户提供一站式的日志采集容器/Kubernetes技术落地应用微服务转型过程中的运维管理能力。
采集 方法对比如下表所示。
从上表可以看出,native方法比较弱,一般不建议在生产系统中使用; DameonSet方法的资源占用要小得多,但其扩展性和租户隔离性有限,更适合单一功能或集群不多的业务; SideCar方式占用资源较多,但灵活,多租户隔离性强。对于大型Kubernetes集群或者作为PAAS平台服务多个业务方的集群,推荐使用这种方式。通常我们可以这样进行采集部署建议:
总结
本文介绍了基于Kubernetes的应用微服务改造过程中的日志采集以及运维管理方案。限于篇幅,本文无法一一介绍具体的实现建议和更多的特性。请详细阅读阿里云官网最佳实践频道微服务架构日志采集运维管理最佳实践
原文链接: 查看全部
采集系统上云(微服务架构下日志采集运维管理分析的解决方案(组图))
简介:阿里云日志服务(SLS)结合Kubernetes日志的特点和应用场景,提供了容器微服务应用环境中全方位的日志采集、处理和分析实践。直接最佳实践:[微服务架构日志采集运维管理最佳实践]
最佳实践频道:[最佳实践频道]
企业云迁移有很多最佳实践。我们从典型场景出发,提供一系列项目实践方案,在满足您需求的同时,降低企业上云的门槛! Kubernetes 日志系统的重要性
微服务的云原生可观察性的一个重要标准是日志记录。日志采集、存储和分析是构建现代系统平台的关键支柱之一,可以帮助团队诊断问题、追溯质量、监控系统运行效率。在容器/Kubernetes技术热潮的今天,日志系统对于Kubernetes也起到了非常关键的作用。对于 Devops、运维、安全等,都离不开完整、多样、有效的日志采集、存储管理和分析。 , 由下图可见。
微服务架构下的日志采集运维管理挑战
众所周知,借助容器/Kubernetes技术在微服务落地过程中,相比物理机、VM在应用部署、应用交付等环节,为用户提供了更简单、更轻便、性价比更高的优势,而用户在应用容器/Kubernetes技术向微服务转化的过程中,也有容器化应用/非容器化应用的混合部署。对于基于VM或者物理机部署的应用,log采集相关技术比较完善,如Logstash、Fluentd、FileBeats等,但是当应用容器化时,尤其是基于Kubenetes的微服务应用部署时cluster、Log 采集运维给用户带来了很多挑战,主要原因有:
阿里云Kubernetes日志采集方案
基于以上分析,阿里云的日志服务产品解决了基于Kubernetes实现应用微服务改造过程中用户日志采集运维管理的需求和痛点,结合阿里巴巴的优势Cloud结合云产品,提出一站式日志采集运维管理分析解决方案,提供强大的日志处理分析能力,如PB级日志实时查询、日志聚类分析、Ingress日志分析报告、日志分析功能、上下游生态对接等能力,为用户提供一站式的日志采集容器/Kubernetes技术落地应用微服务转型过程中的运维管理能力。
采集 方法对比如下表所示。
从上表可以看出,native方法比较弱,一般不建议在生产系统中使用; DameonSet方法的资源占用要小得多,但其扩展性和租户隔离性有限,更适合单一功能或集群不多的业务; SideCar方式占用资源较多,但灵活,多租户隔离性强。对于大型Kubernetes集群或者作为PAAS平台服务多个业务方的集群,推荐使用这种方式。通常我们可以这样进行采集部署建议:
总结
本文介绍了基于Kubernetes的应用微服务改造过程中的日志采集以及运维管理方案。限于篇幅,本文无法一一介绍具体的实现建议和更多的特性。请详细阅读阿里云官网最佳实践频道微服务架构日志采集运维管理最佳实践
原文链接:
采集系统上云(泻药、apigooglesearchteam估计不乐意答1、google的卫星信号)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-02 04:02
采集系统上云本身是个不错的想法,能否采集准确和完整是由上述两个基础条件决定的。最有效的提高准确率的方法是搭建一个全球的gps接入平台,利用接入平台覆盖的全球基站来提高服务的精度。
泻药、api
googlesearchteam估计不乐意答
1、google的卫星。不光有不同的,还有个非常复杂的位置信息服务器,数据一般是下发给各地google的地面节点,地面节点进行定位。2、云平台,或者阿里云腾讯云等,
api
如果只是考虑用户使用api,那么找个第三方提供的服务商就好了。如果是考虑在各地覆盖卫星,想更精确一些,现在的做法通常有两种,一种是准备多块地面基站,前者的方案一般要牺牲一点gps的准确度来达到可靠的要求,而在国内可能成本偏高,在全球覆盖上或许有难度,我知道的地面基站覆盖大部分是以l1为芯片的芯片,成本上会低一些,但是受制于芯片集成度的要求,导致的gps环境下偶尔会有一点的误差;另一种方案,就是gps芯片外挂一块全球导航系统接入平台的芯片,先用rs接入gps,再由各接入平台接入卫星位置的导航信息,同样的也有卫星覆盖量的要求,成本会比卫星覆盖导航系统接入平台低很多。
说的跟nokia下放多少gps卫星信号一样,就算有,装上各种moviebar拉低来电显示色差也是很正常的。 查看全部
采集系统上云(泻药、apigooglesearchteam估计不乐意答1、google的卫星信号)
采集系统上云本身是个不错的想法,能否采集准确和完整是由上述两个基础条件决定的。最有效的提高准确率的方法是搭建一个全球的gps接入平台,利用接入平台覆盖的全球基站来提高服务的精度。
泻药、api
googlesearchteam估计不乐意答
1、google的卫星。不光有不同的,还有个非常复杂的位置信息服务器,数据一般是下发给各地google的地面节点,地面节点进行定位。2、云平台,或者阿里云腾讯云等,
api
如果只是考虑用户使用api,那么找个第三方提供的服务商就好了。如果是考虑在各地覆盖卫星,想更精确一些,现在的做法通常有两种,一种是准备多块地面基站,前者的方案一般要牺牲一点gps的准确度来达到可靠的要求,而在国内可能成本偏高,在全球覆盖上或许有难度,我知道的地面基站覆盖大部分是以l1为芯片的芯片,成本上会低一些,但是受制于芯片集成度的要求,导致的gps环境下偶尔会有一点的误差;另一种方案,就是gps芯片外挂一块全球导航系统接入平台的芯片,先用rs接入gps,再由各接入平台接入卫星位置的导航信息,同样的也有卫星覆盖量的要求,成本会比卫星覆盖导航系统接入平台低很多。
说的跟nokia下放多少gps卫星信号一样,就算有,装上各种moviebar拉低来电显示色差也是很正常的。
采集系统上云(云采集平台的安全加密技术应该做得很到位!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-12-23 08:02
采集系统上云之后,软件已经全部兼容,不再需要单独搭建测试网,平台也已经完全搭建好了,不用安装。平台也有了服务器和公网ip,私有部署也方便。
云采集会让采集效率提高,数据的准确性可以保证,但是同时采集也会造成一些负面影响。如果需要打码或者采集网站第三方ip可以考虑找一下达摩云采集,采集效率高、节省上传时间,采集到的数据准确性都是100%,而且还带代码,可以直接用vba+word+excel采集。
没错,只要你的网站用的是稳定的公网ip,就不需要花钱去买云采集服务了。现在大部分采集系统都会有云采集功能,以我了解到的型号,如果上传网站二三十万数据量,用速度不如本地采集。一般正规的第三方服务都会对用户进行身份验证和账号登录验证,其实就是防止外人拿了你网站你就上传数据,这个时候对接对口云采集提供的云采集,在速度和安全性都会有保障。
云采集平台就是和你一样用个人二级域名(baiduspider)上传网站数据,并不是用阿里云之类的大公司的云采集服务,但是所有的后期的数据接入工作和验证,云采集平台都会做好,不需要二次采集和后期数据维护,因为服务是系统对接的,所以不存在多个域名上传被杀,而且云采集在采集完一个网站数据后就会自动合并到其他网站,跟传统方式效率差不多。
至于云采集会不会造成用户信息泄露的问题,目前的安全加密技术应该做得很到位,因为云采集平台本身就是收费的。我一个朋友曾经被人通过云采集数据的方式盗用了微信位置,网站等,所以用这些不是最好的方式,关键是要谨慎,要理性消费。 查看全部
采集系统上云(云采集平台的安全加密技术应该做得很到位!)
采集系统上云之后,软件已经全部兼容,不再需要单独搭建测试网,平台也已经完全搭建好了,不用安装。平台也有了服务器和公网ip,私有部署也方便。
云采集会让采集效率提高,数据的准确性可以保证,但是同时采集也会造成一些负面影响。如果需要打码或者采集网站第三方ip可以考虑找一下达摩云采集,采集效率高、节省上传时间,采集到的数据准确性都是100%,而且还带代码,可以直接用vba+word+excel采集。
没错,只要你的网站用的是稳定的公网ip,就不需要花钱去买云采集服务了。现在大部分采集系统都会有云采集功能,以我了解到的型号,如果上传网站二三十万数据量,用速度不如本地采集。一般正规的第三方服务都会对用户进行身份验证和账号登录验证,其实就是防止外人拿了你网站你就上传数据,这个时候对接对口云采集提供的云采集,在速度和安全性都会有保障。
云采集平台就是和你一样用个人二级域名(baiduspider)上传网站数据,并不是用阿里云之类的大公司的云采集服务,但是所有的后期的数据接入工作和验证,云采集平台都会做好,不需要二次采集和后期数据维护,因为服务是系统对接的,所以不存在多个域名上传被杀,而且云采集在采集完一个网站数据后就会自动合并到其他网站,跟传统方式效率差不多。
至于云采集会不会造成用户信息泄露的问题,目前的安全加密技术应该做得很到位,因为云采集平台本身就是收费的。我一个朋友曾经被人通过云采集数据的方式盗用了微信位置,网站等,所以用这些不是最好的方式,关键是要谨慎,要理性消费。
采集系统上云(黑科技的云蛛系统,您的数据中心展现工作了吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-12-23 05:04
)
黑科技的云蜘蛛系统,一经问世,便博得了阵阵掌声。虽然主打数据可视化,但是很多用户都在问你会不会做大数据处理产品,就像很多用户眼中的黑科技——神测数据。如果你出来,我们就可以解决我们整个数据流的问题。
对于大数据的处理,云蜘蛛系统肯定是必不可少的,但具体的开发日期还没有最终确定。不过,鉴于用户的强烈需求,蛛网时代终于将大数据处理工具的开发提上了日程,并将其命名为DataCenter。为什么叫数据中心?这意味着,对于您数据中心的所有处理,Yunspula 系统可以为您解决所有问题。
有了DataCenter+AutoBI+DataView,你的整个数据分析系统就可以完全搭建起来,而且极其简单。DataCenter会做数据采集、传输、处理的工作,而AutoBI会做你的数据报表的工作,DataView会做你的大屏展示的工作。一起使用效果好吗?
DataCenter使用自己的agent采集相关数据,然后采集到Kafka集群中进行数据清洗。Kafka集群作为高可靠传输,还需要进行高性能算法去重计算,然后数据通过转换层进入数据仓库或者hadoop集群,这就是整个ETL过程,也是作业天禄系统。之后就是调度-北斗系统的工作。它将根据依赖关系计算数据索引。日指数计算未完成,月指数计算无法完成。如果指标计算错误,手动触发任务计算,是否会触发下游任务一起计算... 整个核心都会体现在调度-北斗系统完善中。HDFS数据通过调度计算吐到Hbase,数据仓库通过ODS层计算进入表示层,分布式查询ES……这些都是市面上最好的技术,或者你能想到的查询方式。DataCenter 为您完成这一切。
之后,就是DataView和AutoBI大显身手的时候了。这两条产品线不仅可以支持传统的关系型数据库,没有sql的数据库,比如redis、mongodb等,都支持,包括ES、rest等服务接口。因为是定制模式,只要现有技术可以实现,这两条产品线就会为你实现,你不需要为了适应这两条产品线而传输数据。所有Yunspula 系统都适合您。好的。因为是公司的产品,兼容性还行!
这个怎么样?DataCenter可以说是大数据处理行业的黑科技。并且整套流程都是黑箱的,您只需要在网页中配置您的业务,其余系统会自动为您处理。AutoBI和DataView作为其老大哥,将黑科技理念贯彻到了全面、无缝集成、完美展示、多维度分析……你能想到的所有需求,都来帮你呈现。这是海泰云蜘蛛系统提供的一套大数据解决方案!
查看全部
采集系统上云(黑科技的云蛛系统,您的数据中心展现工作了吗?
)
黑科技的云蜘蛛系统,一经问世,便博得了阵阵掌声。虽然主打数据可视化,但是很多用户都在问你会不会做大数据处理产品,就像很多用户眼中的黑科技——神测数据。如果你出来,我们就可以解决我们整个数据流的问题。
对于大数据的处理,云蜘蛛系统肯定是必不可少的,但具体的开发日期还没有最终确定。不过,鉴于用户的强烈需求,蛛网时代终于将大数据处理工具的开发提上了日程,并将其命名为DataCenter。为什么叫数据中心?这意味着,对于您数据中心的所有处理,Yunspula 系统可以为您解决所有问题。
有了DataCenter+AutoBI+DataView,你的整个数据分析系统就可以完全搭建起来,而且极其简单。DataCenter会做数据采集、传输、处理的工作,而AutoBI会做你的数据报表的工作,DataView会做你的大屏展示的工作。一起使用效果好吗?
DataCenter使用自己的agent采集相关数据,然后采集到Kafka集群中进行数据清洗。Kafka集群作为高可靠传输,还需要进行高性能算法去重计算,然后数据通过转换层进入数据仓库或者hadoop集群,这就是整个ETL过程,也是作业天禄系统。之后就是调度-北斗系统的工作。它将根据依赖关系计算数据索引。日指数计算未完成,月指数计算无法完成。如果指标计算错误,手动触发任务计算,是否会触发下游任务一起计算... 整个核心都会体现在调度-北斗系统完善中。HDFS数据通过调度计算吐到Hbase,数据仓库通过ODS层计算进入表示层,分布式查询ES……这些都是市面上最好的技术,或者你能想到的查询方式。DataCenter 为您完成这一切。
之后,就是DataView和AutoBI大显身手的时候了。这两条产品线不仅可以支持传统的关系型数据库,没有sql的数据库,比如redis、mongodb等,都支持,包括ES、rest等服务接口。因为是定制模式,只要现有技术可以实现,这两条产品线就会为你实现,你不需要为了适应这两条产品线而传输数据。所有Yunspula 系统都适合您。好的。因为是公司的产品,兼容性还行!
这个怎么样?DataCenter可以说是大数据处理行业的黑科技。并且整套流程都是黑箱的,您只需要在网页中配置您的业务,其余系统会自动为您处理。AutoBI和DataView作为其老大哥,将黑科技理念贯彻到了全面、无缝集成、完美展示、多维度分析……你能想到的所有需求,都来帮你呈现。这是海泰云蜘蛛系统提供的一套大数据解决方案!
采集系统上云(从采集系统上云的区别来简单分析两者之间的区别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-20 05:06
采集系统上云已经成为现在市场上最热门的趋势,很多公司都已经会使用终端采集系统。大家在对采集系统进行认识的过程中,会对一些具体的术语不知道如何去理解,下面我就从采集系统上云和传统采集系统的区别来简单分析一下两者之间的区别。采集系统上云有几个方面的意义:首先是拓展产品线,其次是传统采集系统体验上线,增加系统维护服务,更安全便捷。
所以第一个意义就是拓展产品线,是提高整个公司产品线的丰富性,第二个就是提高我们整个公司的服务能力,第三个还提升我们公司的安全和便捷性。1、传统采集系统采集系统上云的最终目的是提升效率,加快我们产品的速度,也就是说我们再做内部业务,首先要做的就是流程化的规范流程。这个我们采集系统要提供完整的服务,使客户在初始就能建立起一个安全、便捷的大数据的采集库。
我们都清楚,企业在选择大数据采集系统的时候,有几个主要的考虑因素:一个是考虑成本,另外一个就是快速,第三个就是功能,那我们从这三个角度进行比较,先考虑成本。采集系统要快速,让客户体验快速,不仅仅是我们要做好内部业务和流程规范,而且我们还要更快的扩展产品,我们还要把系统做到全产品覆盖,无论是做公司互联网还是it安全相关,都不能将我们公司的业务全部做到统一。
我们的生态是庞大的。采集系统是一个全产品覆盖的一个系统,涵盖了互联网,电信,物联网和it安全等。2、采集系统上云的第二个意义,一旦建立起来,我们后面只需要加大维护和售后服务力度,就能够支撑以后的业务。客户永远需要有一个印象,上云之后的公司,我们解决了什么问题,不上云我们会遇到什么问题。做到第二个意义,我们要从客户的角度出发,我们才能够把软件有些原本解决不了的问题讲清楚,这样客户能更好的去选择我们。
这就涉及到如何采集系统上云和一般产品上云,所表达的不同的不同意义了。我想大家也清楚,选择做大数据采集系统是不同的,有人会选择跟别人合作一起做,也有人会一个人自己做。传统大数据采集系统可能在市场推广的时候是有点困难,一般情况下我们没有比较好的推广方式,可能相关大数据厂商会持续在给你更新他们的产品,但是这些更新产品可能不一定适合客户。
不一定符合客户未来对的需求。而采集系统上云后,我们可以采用软件开放性推广。可以把采集系统上云后的所有数据都可以共享,完全可以告诉用户,我们完全可以实现采集系统化,帮客户节省成本,采集系统的下一步是大数据。关注微信公众号:tzy_installer,获取更多技术干货。 查看全部
采集系统上云(从采集系统上云的区别来简单分析两者之间的区别)
采集系统上云已经成为现在市场上最热门的趋势,很多公司都已经会使用终端采集系统。大家在对采集系统进行认识的过程中,会对一些具体的术语不知道如何去理解,下面我就从采集系统上云和传统采集系统的区别来简单分析一下两者之间的区别。采集系统上云有几个方面的意义:首先是拓展产品线,其次是传统采集系统体验上线,增加系统维护服务,更安全便捷。
所以第一个意义就是拓展产品线,是提高整个公司产品线的丰富性,第二个就是提高我们整个公司的服务能力,第三个还提升我们公司的安全和便捷性。1、传统采集系统采集系统上云的最终目的是提升效率,加快我们产品的速度,也就是说我们再做内部业务,首先要做的就是流程化的规范流程。这个我们采集系统要提供完整的服务,使客户在初始就能建立起一个安全、便捷的大数据的采集库。
我们都清楚,企业在选择大数据采集系统的时候,有几个主要的考虑因素:一个是考虑成本,另外一个就是快速,第三个就是功能,那我们从这三个角度进行比较,先考虑成本。采集系统要快速,让客户体验快速,不仅仅是我们要做好内部业务和流程规范,而且我们还要更快的扩展产品,我们还要把系统做到全产品覆盖,无论是做公司互联网还是it安全相关,都不能将我们公司的业务全部做到统一。
我们的生态是庞大的。采集系统是一个全产品覆盖的一个系统,涵盖了互联网,电信,物联网和it安全等。2、采集系统上云的第二个意义,一旦建立起来,我们后面只需要加大维护和售后服务力度,就能够支撑以后的业务。客户永远需要有一个印象,上云之后的公司,我们解决了什么问题,不上云我们会遇到什么问题。做到第二个意义,我们要从客户的角度出发,我们才能够把软件有些原本解决不了的问题讲清楚,这样客户能更好的去选择我们。
这就涉及到如何采集系统上云和一般产品上云,所表达的不同的不同意义了。我想大家也清楚,选择做大数据采集系统是不同的,有人会选择跟别人合作一起做,也有人会一个人自己做。传统大数据采集系统可能在市场推广的时候是有点困难,一般情况下我们没有比较好的推广方式,可能相关大数据厂商会持续在给你更新他们的产品,但是这些更新产品可能不一定适合客户。
不一定符合客户未来对的需求。而采集系统上云后,我们可以采用软件开放性推广。可以把采集系统上云后的所有数据都可以共享,完全可以告诉用户,我们完全可以实现采集系统化,帮客户节省成本,采集系统的下一步是大数据。关注微信公众号:tzy_installer,获取更多技术干货。
采集系统上云( 阿里正式开源可观测数据采集器iLogtail改造基本不可行)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-12-16 21:20
阿里正式开源可观测数据采集器iLogtail改造基本不可行)
11月23日,阿里正式开源了可观察数据采集器iLogtail。作为阿里巴巴内部可观察数据采集的基础设施,iLogtail承载了阿里巴巴集团的工作以及蚂蚁的日志、监控、trace、事件等可观察数据采集。iLogtail 运行在服务器、容器、K8s、嵌入式等多种环境中,支持采集数百个可观察数据。已经有数千万的安装量,并且每天有 采集 数十 PB 的数据可用。观察数据广泛应用于在线监控、问题分析/定位、运行分析、安全分析等各种场景。
一个 iLogtail 和可观察性
可观察性并不是一个新概念,而是从IT系统中的监控、故障排除、稳定性构建、运行分析、BI、安全分析等逐步演化而来。与传统监控相比,可观察性是核心进化是采集尽可能多的可观察数据以达到白盒的目的。iLogtail的核心定位是可观察数据的采集器,可以采集尽可能多的采集各类可观察数据,帮助可观察平台打造各种上层应用场景。
2. 阿里巴巴可观察数据采集的挑战
对于可观察数据采集,有很多开源代理,比如Logstash、Filebeats、Fluentd、Collectd、Telegraf等,这些代理的功能非常丰富,这些代理和一些扩展的组合基本可以满足各种内部数据采集的要求。但由于性能、稳定性、控制等关键挑战不尽人意,我们最终选择进行自研:
1、资源消耗:目前阿里有上百万台主机(物理机/虚拟机/容器),每天产生几十PB的可观察数据,降低每1M的内存和每1M/s的性能。改善对于我们的资源节约来说是巨大的,节约的成本可能是几百万甚至几千万。目前很多开源代理的设计更注重功能而不是性能,改造现有的开源代理基本不可行。例如:
开源Agents单核处理性能一般在2-10M/s左右,我们希望有性能可以达到100M/s。采集目标增加,数据量增加,采集延迟,服务器异常。在这种情况下,开源代理内存将呈现爆发式增长,我们希望即使在各种环境下,内存也能处于较低的水位。开源代理的资源消耗无法控制。只能通过cgroups强制限制。效果就是一直OOM重启,数据一直上不来采集。并且我们希望在指定了 CPU、内存、流量等资源限制后,Agent 可以一直在这个限制内正常工作。
2、稳定性:稳定性是一个永恒的话题,数据的稳定性采集,除了保证数据本身的准确性采集,还要保证采集的Agent @采集 不能影响业务应用,否则影响将是灾难性的。至于稳定性建设,除了Agent本身的基本稳定性外,还有很多目前开源Agents还没有提供的特性:
Agent自恢复:Agent在遇到关键事件后可以自动恢复,提供进程自身、父子进程、守护进程等多个维度的自恢复能力。全球多维监控:可以从全球视角监控不同版本。不同采集配置、不同压力、不同区域/网络等属性的Agent的稳定性问题。问题隔离:作为Agent,无论问题如何出现,都需要尽可能地隔离问题。比如有多个采集配置,一个配置有问题,不能影响其他配置;代理本身有问题,不能影响机器上应用进程的稳定性。回滚能力:
3、Controllable:可观察数据的应用范围很广。几乎所有的业务、运维、BI、安全等部门都会用到它,各种数据都会在一台机器上生成。同一台机器产生的数据也会被多个部门的人使用。例如,在 2018 年,我们计算出平均而言,一个虚拟机上有 100 多种不同类型的数据。采集,设计了10多个不同部门的人想要使用这些数据。除了这些,还有很多其他的企业级功能需要支持,比如:
远程管理配置:在大规模场景下,手动登录机器修改配置基本上是不可能的。因此,需要一套配置图形化管理、远程存储、自动投递机制,并且必须能够区分不同的应用和差异。地区、不同归属方等信息。同时,由于涉及到远程配置的动态加载和卸载,Agent也需要能够保证在配置Reload过程中数据不丢失或者不重现。采集配置优先级:当一台机器上运行多个采集配置时,如果遇到资源不足的情况,需要区分每个不同的配置优先级,并且资源优先给高优先级的配置,同时要保证低优先级的配置不被“饿死”。降级和恢复能力:在阿里,大促和秒杀是家常便饭。在这个高峰期,很多不重要的应用可能会被降级,相应的应用数据也需要降级。降级后,早高峰过后,需要有足够的Burst能力快速追赶。完整数据采集完整性:监控、数据分析等场景需要数据的准确性。数据准确的前提是可以采集及时到服务器,但是如何判断每台机器,每个文件采集的数据已经到达了对应的时间点,
基于以上背景和挑战,我们从 2013 年开始逐步优化和改进 iLogtail 以解决性能、稳定性、可控性等问题,并经历了多次 double十一、double十二、 的测试春晚红包等物品。目前iLogtail支持Logs、Traces、Metrics等多种数据的统一采集。核心功能如下:
支持多种Logs, Traces, Metrics数据采集,特别是容器和Kubernetes环境,数据非常友好采集 资源消耗极低,单核采集容量100M/s,对比对类似Observable数据采集的Agent性能提高5-20倍,稳定性高。它用于阿里巴巴和数以万计的阿里云客户的生产。部署量接近1000万。每天采集几十PB可用观测数据支持插件扩展,数据可任意扩展采集,处理、聚合、发送模块支持远程配置管理,支持图形化、SDK配置管理、K8s Operator等,可以轻松管理百万台机器的数据采集 支持自我监控、流量控制、资源控制、主动告警、采集统计等高级管控功能。iLogtail的三大发展历程
秉承阿里人简约的特点,iLogtail的命名也很简单。我们一开始就期望有一个统一的工具来记录Tail,所以叫Logtail。添加“i”的原因主要是当时使用了inotify技术。, 可以在毫秒级别控制日志采集的延迟,所以最后称为iLogtail。从2013年开始,iLogtail的整个发展过程大致可以分为三个阶段,分别是飞天5K阶段、阿里集团阶段和云原生阶段。
1个飞天5K舞台
作为中国云计算领域的里程碑,2013年8月15日,阿里巴巴集团正式运营5000(5K)服务器规模的“飞天”集群,成为国内首家自主研发大型云计算的企业。 - 规模的通用计算平台。全球首家对外提供5K云计算服务能力的公司。
飞天5K项目始于2009年,从最初的30台逐步发展到5000台,不断解决系统的规模、稳定性、运维、容灾等核心问题。这个阶段iLogtail诞生的时候,是从5000台机器的监控、问题分析、定位(现在称为“可观察性”)开始的。在从 30 到 5000 的飞跃中,可观察到的问题面临诸多挑战,包括单机瓶颈、问题复杂性、故障排除的难易程度和管理复杂性。
在5K阶段,iLogtail本质上解决了单机、小规模集群到大规模运维监控的挑战。iLogtail现阶段的主要特点是:
<p>功能:实时日志,监控采集,日志捕获延迟毫秒级性能:单核处理能力10M/s,5000集群平均资源占用0.5% CPU核心可靠性:自动监控新文件,新建文件夹,支持文件轮换,处理网络中断管理:远程Web管理,自动配置文件分发运维:加入群yum源,运行状态监控,异常自动上报规模:3W+部署规模,千 查看全部
采集系统上云(
阿里正式开源可观测数据采集器iLogtail改造基本不可行)
11月23日,阿里正式开源了可观察数据采集器iLogtail。作为阿里巴巴内部可观察数据采集的基础设施,iLogtail承载了阿里巴巴集团的工作以及蚂蚁的日志、监控、trace、事件等可观察数据采集。iLogtail 运行在服务器、容器、K8s、嵌入式等多种环境中,支持采集数百个可观察数据。已经有数千万的安装量,并且每天有 采集 数十 PB 的数据可用。观察数据广泛应用于在线监控、问题分析/定位、运行分析、安全分析等各种场景。
一个 iLogtail 和可观察性
可观察性并不是一个新概念,而是从IT系统中的监控、故障排除、稳定性构建、运行分析、BI、安全分析等逐步演化而来。与传统监控相比,可观察性是核心进化是采集尽可能多的可观察数据以达到白盒的目的。iLogtail的核心定位是可观察数据的采集器,可以采集尽可能多的采集各类可观察数据,帮助可观察平台打造各种上层应用场景。
2. 阿里巴巴可观察数据采集的挑战
对于可观察数据采集,有很多开源代理,比如Logstash、Filebeats、Fluentd、Collectd、Telegraf等,这些代理的功能非常丰富,这些代理和一些扩展的组合基本可以满足各种内部数据采集的要求。但由于性能、稳定性、控制等关键挑战不尽人意,我们最终选择进行自研:
1、资源消耗:目前阿里有上百万台主机(物理机/虚拟机/容器),每天产生几十PB的可观察数据,降低每1M的内存和每1M/s的性能。改善对于我们的资源节约来说是巨大的,节约的成本可能是几百万甚至几千万。目前很多开源代理的设计更注重功能而不是性能,改造现有的开源代理基本不可行。例如:
开源Agents单核处理性能一般在2-10M/s左右,我们希望有性能可以达到100M/s。采集目标增加,数据量增加,采集延迟,服务器异常。在这种情况下,开源代理内存将呈现爆发式增长,我们希望即使在各种环境下,内存也能处于较低的水位。开源代理的资源消耗无法控制。只能通过cgroups强制限制。效果就是一直OOM重启,数据一直上不来采集。并且我们希望在指定了 CPU、内存、流量等资源限制后,Agent 可以一直在这个限制内正常工作。
2、稳定性:稳定性是一个永恒的话题,数据的稳定性采集,除了保证数据本身的准确性采集,还要保证采集的Agent @采集 不能影响业务应用,否则影响将是灾难性的。至于稳定性建设,除了Agent本身的基本稳定性外,还有很多目前开源Agents还没有提供的特性:
Agent自恢复:Agent在遇到关键事件后可以自动恢复,提供进程自身、父子进程、守护进程等多个维度的自恢复能力。全球多维监控:可以从全球视角监控不同版本。不同采集配置、不同压力、不同区域/网络等属性的Agent的稳定性问题。问题隔离:作为Agent,无论问题如何出现,都需要尽可能地隔离问题。比如有多个采集配置,一个配置有问题,不能影响其他配置;代理本身有问题,不能影响机器上应用进程的稳定性。回滚能力:
3、Controllable:可观察数据的应用范围很广。几乎所有的业务、运维、BI、安全等部门都会用到它,各种数据都会在一台机器上生成。同一台机器产生的数据也会被多个部门的人使用。例如,在 2018 年,我们计算出平均而言,一个虚拟机上有 100 多种不同类型的数据。采集,设计了10多个不同部门的人想要使用这些数据。除了这些,还有很多其他的企业级功能需要支持,比如:
远程管理配置:在大规模场景下,手动登录机器修改配置基本上是不可能的。因此,需要一套配置图形化管理、远程存储、自动投递机制,并且必须能够区分不同的应用和差异。地区、不同归属方等信息。同时,由于涉及到远程配置的动态加载和卸载,Agent也需要能够保证在配置Reload过程中数据不丢失或者不重现。采集配置优先级:当一台机器上运行多个采集配置时,如果遇到资源不足的情况,需要区分每个不同的配置优先级,并且资源优先给高优先级的配置,同时要保证低优先级的配置不被“饿死”。降级和恢复能力:在阿里,大促和秒杀是家常便饭。在这个高峰期,很多不重要的应用可能会被降级,相应的应用数据也需要降级。降级后,早高峰过后,需要有足够的Burst能力快速追赶。完整数据采集完整性:监控、数据分析等场景需要数据的准确性。数据准确的前提是可以采集及时到服务器,但是如何判断每台机器,每个文件采集的数据已经到达了对应的时间点,
基于以上背景和挑战,我们从 2013 年开始逐步优化和改进 iLogtail 以解决性能、稳定性、可控性等问题,并经历了多次 double十一、double十二、 的测试春晚红包等物品。目前iLogtail支持Logs、Traces、Metrics等多种数据的统一采集。核心功能如下:
支持多种Logs, Traces, Metrics数据采集,特别是容器和Kubernetes环境,数据非常友好采集 资源消耗极低,单核采集容量100M/s,对比对类似Observable数据采集的Agent性能提高5-20倍,稳定性高。它用于阿里巴巴和数以万计的阿里云客户的生产。部署量接近1000万。每天采集几十PB可用观测数据支持插件扩展,数据可任意扩展采集,处理、聚合、发送模块支持远程配置管理,支持图形化、SDK配置管理、K8s Operator等,可以轻松管理百万台机器的数据采集 支持自我监控、流量控制、资源控制、主动告警、采集统计等高级管控功能。iLogtail的三大发展历程
秉承阿里人简约的特点,iLogtail的命名也很简单。我们一开始就期望有一个统一的工具来记录Tail,所以叫Logtail。添加“i”的原因主要是当时使用了inotify技术。, 可以在毫秒级别控制日志采集的延迟,所以最后称为iLogtail。从2013年开始,iLogtail的整个发展过程大致可以分为三个阶段,分别是飞天5K阶段、阿里集团阶段和云原生阶段。
1个飞天5K舞台
作为中国云计算领域的里程碑,2013年8月15日,阿里巴巴集团正式运营5000(5K)服务器规模的“飞天”集群,成为国内首家自主研发大型云计算的企业。 - 规模的通用计算平台。全球首家对外提供5K云计算服务能力的公司。
飞天5K项目始于2009年,从最初的30台逐步发展到5000台,不断解决系统的规模、稳定性、运维、容灾等核心问题。这个阶段iLogtail诞生的时候,是从5000台机器的监控、问题分析、定位(现在称为“可观察性”)开始的。在从 30 到 5000 的飞跃中,可观察到的问题面临诸多挑战,包括单机瓶颈、问题复杂性、故障排除的难易程度和管理复杂性。
在5K阶段,iLogtail本质上解决了单机、小规模集群到大规模运维监控的挑战。iLogtail现阶段的主要特点是:
<p>功能:实时日志,监控采集,日志捕获延迟毫秒级性能:单核处理能力10M/s,5000集群平均资源占用0.5% CPU核心可靠性:自动监控新文件,新建文件夹,支持文件轮换,处理网络中断管理:远程Web管理,自动配置文件分发运维:加入群yum源,运行状态监控,异常自动上报规模:3W+部署规模,千

