
采集系统上云
采集系统上云软件部署的注意事项有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-05-27 19:05
采集系统上云软件部署主要取决于企业的具体情况,一般公司都会有云服务器和服务器托管商,然后根据实际需求部署相应的采集系统。非常简单的企业采集系统就是用api连接到相应的服务器上,数据实时采集和分析到本地,相对要求也低很多。而一些复杂系统的搭建,就需要根据业务流程和业务规则来编写代码,来实现采集和查询。对于一些比较专业的数据处理和分析平台,还需要真正的高配置单机服务器进行采集,单机采集机器也要至少1500块。
还有一些采集系统是通过web采集,可以直接使用现成的爬虫或者自己制作爬虫。采集系统是一个整体的体系。以某银行为例,服务器托管在国内的一家大型云服务器租用商,硬件集群一共16台,年费大概一年在120万左右。对于如何用一般的采集系统部署,配置要求不高。因为一个api采集基本可以满足日常公司的实际业务需求,如果对高质量存在明显短板,就需要自己花钱购买相应的设备和工具。具体的使用过程,可以参考我的专栏文章【采集系统入门】。
采集系统如何购买部署简单直接购买服务器、数据库、app,设计好采集接口,然后将数据提交到采集服务器即可。如果长期有大量业务需求,则采用离线测试方式进行部署。如何构建采集系统采集系统只是一个采集工具而已,根据您的业务需求及您公司的实际情况,组件化,自动化部署,上线即可。另外需要组建采集团队,您可以先购买采集平台,然后由采集团队中工作人员架设采集平台,对接上线。 查看全部
采集系统上云软件部署的注意事项有哪些?-八维教育
采集系统上云软件部署主要取决于企业的具体情况,一般公司都会有云服务器和服务器托管商,然后根据实际需求部署相应的采集系统。非常简单的企业采集系统就是用api连接到相应的服务器上,数据实时采集和分析到本地,相对要求也低很多。而一些复杂系统的搭建,就需要根据业务流程和业务规则来编写代码,来实现采集和查询。对于一些比较专业的数据处理和分析平台,还需要真正的高配置单机服务器进行采集,单机采集机器也要至少1500块。
还有一些采集系统是通过web采集,可以直接使用现成的爬虫或者自己制作爬虫。采集系统是一个整体的体系。以某银行为例,服务器托管在国内的一家大型云服务器租用商,硬件集群一共16台,年费大概一年在120万左右。对于如何用一般的采集系统部署,配置要求不高。因为一个api采集基本可以满足日常公司的实际业务需求,如果对高质量存在明显短板,就需要自己花钱购买相应的设备和工具。具体的使用过程,可以参考我的专栏文章【采集系统入门】。
采集系统如何购买部署简单直接购买服务器、数据库、app,设计好采集接口,然后将数据提交到采集服务器即可。如果长期有大量业务需求,则采用离线测试方式进行部署。如何构建采集系统采集系统只是一个采集工具而已,根据您的业务需求及您公司的实际情况,组件化,自动化部署,上线即可。另外需要组建采集团队,您可以先购买采集平台,然后由采集团队中工作人员架设采集平台,对接上线。
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-05-26 00:16
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
采集系统上云主要有三种模式?有哪些优势?
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-05-07 19:01
采集系统上云主要有三种模式:
一、由工厂或公司管理平台上去采集
二、由平台内部采集系统上传
三、主机(主机通过开放平台免费申请)上云作为国内比较大的外卖商家发布群发短信的服务商,也有不少我们自己的短信群发系统,上云都需要我们公司有足够的实力做好系统,短信群发系统我们通常采用采用开放平台直接免费申请,里面有一个积分商城,用户可以自行做短信营销。对比我们国内传统短信运营商,作为上云服务商,我们有如下优势:1.我们的系统完全基于通道本身。
优势:我们的验证码、接码平台、发送日志等核心功能依托于我们的采集系统,功能开发完全平台化,一个系统同时支持线上线下发送服务。2.我们的系统完全开放。优势:信息流广告运营商数据的无缝对接,数据会同步第三方app,从上游集团收集,第三方应用商家完全可以与我们进行全面合作;避免国内运营商的误判,避免国内三方采集误差。
3.我们只为准确率提供保证。优势:由我们对短信验证码接口的准确率负责,绝不满意外发短信,杜绝经常性短信重复等情况的发生。同时我们有严格的审核流程,及时的服务质量审核。短信验证码上传服务商定期抽查,有效遏制运营商恶意修改、降低我们误判和降低系统响应速度的行为。4.我们对短信账号对相关公司和个人会有审核。
优势:我们是商家发送服务商的金钱上第三方担保,如果商家发送服务商接码平台上的不正规号码,我们也会有明确的风控措施。同时我们也会对不通过系统的账号进行统计,定期进行调整。5.我们对用户过期有业务经理查询并追偿及后续的应急处理。优势:我们会统计用户过期后的响应情况,对未及时上传并达到我们号码要求的商家会有一定的免费短信营销的额度,风控相对较严。下图是我们针对我们的短信平台有哪些优势做了一个总结:。 查看全部
采集系统上云主要有三种模式?有哪些优势?
采集系统上云主要有三种模式:
一、由工厂或公司管理平台上去采集
二、由平台内部采集系统上传
三、主机(主机通过开放平台免费申请)上云作为国内比较大的外卖商家发布群发短信的服务商,也有不少我们自己的短信群发系统,上云都需要我们公司有足够的实力做好系统,短信群发系统我们通常采用采用开放平台直接免费申请,里面有一个积分商城,用户可以自行做短信营销。对比我们国内传统短信运营商,作为上云服务商,我们有如下优势:1.我们的系统完全基于通道本身。
优势:我们的验证码、接码平台、发送日志等核心功能依托于我们的采集系统,功能开发完全平台化,一个系统同时支持线上线下发送服务。2.我们的系统完全开放。优势:信息流广告运营商数据的无缝对接,数据会同步第三方app,从上游集团收集,第三方应用商家完全可以与我们进行全面合作;避免国内运营商的误判,避免国内三方采集误差。
3.我们只为准确率提供保证。优势:由我们对短信验证码接口的准确率负责,绝不满意外发短信,杜绝经常性短信重复等情况的发生。同时我们有严格的审核流程,及时的服务质量审核。短信验证码上传服务商定期抽查,有效遏制运营商恶意修改、降低我们误判和降低系统响应速度的行为。4.我们对短信账号对相关公司和个人会有审核。
优势:我们是商家发送服务商的金钱上第三方担保,如果商家发送服务商接码平台上的不正规号码,我们也会有明确的风控措施。同时我们也会对不通过系统的账号进行统计,定期进行调整。5.我们对用户过期有业务经理查询并追偿及后续的应急处理。优势:我们会统计用户过期后的响应情况,对未及时上传并达到我们号码要求的商家会有一定的免费短信营销的额度,风控相对较严。下图是我们针对我们的短信平台有哪些优势做了一个总结:。
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-06 21:15
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-05-02 18:49
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
采集系统上云(微服务下的几个监控维度(下)化服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-04-18 18:01
前言
微服务是一种架构风格,大型复杂的软件应用程序通常由多个微服务组成。系统中的每个微服务都可以独立部署,每个微服务都是松耦合的。每个微服务只专注于完成一项任务并把它做好。
在微服务之前,很多单体应用的监控复杂度较低,场景相对简单。在微服务下,由于业务逻辑分散在很多流程中(很多大业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时就需要完善的监控系统。
一套完整的监控系统建设周期长,需要随着业务场景的变化进行迭代优化。本文仅从几个监控维度和原子场景探讨如何建立统一的监控数据采集和展示系统,希望能启发大家继续深入思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的变化。我们将监控从机器角度转换为以服务为中心的角度。从微服务的角度来看,监控可以从数据维度和资源维度来看。与代码维度分层,如下图:
数据维度
目前,WEB服务是主流。每一个WEB服务都有一个入口,无论是APP还是WEB页面,入口负责与用户交互,并将用户的信息发送到后台。一般后台会访问LB或者Gateway,负责负载。将数据均衡转发给特定的应用程序进行处理,最后在应用程序处理完毕后写入数据库。
资源维度
现在很多服务都部署在云端,涉及到虚拟化技术,虚拟主机运行在物理服务器上,虚拟主机之间通过虚拟网络相互连接。资源层面的监控是不可或缺的一环。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器的CPU、内存、磁盘IO等数据,以及连接的虚拟主机。主机之间的虚拟网络带宽负载等。
代码维度
APM,即应用性能分析、代码端监控采集,是随着微服务的兴起而出现的。在微服务场景下,一个业务流程跨越数十个服务,仅靠传统的监控数据很难定位问题的根源。
我们可以针对代码的技术栈开发具体的采集框架,在可接受的性能损失范围内,采集函数之间的调用关系,服务之间的调用拓扑,只测量响应时间功能或服务的性能可以优化性能或提前预测故障。
关键监控指标场景描述
微服务监控的最大特点可以用一句话概括:服务很多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关的错综复杂的业务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了各个维度下各个层级可能产生的告警,总结出URL监控、主机监控、产品监控等8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状况。
主机监控:通过安装agent采集对主机的基本监控信息如CPU、内存、IO等数据,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据< @采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报每个产品的相关指标数据,监控每个产品资源的健康状态。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载对应组件的监控采集程序。
自定义监控:服务实例采集业务相关数据,定时调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户以资源为维度上报自定义数据。每个资源都有相同的几个监控项,每个资源的监控项相互独立。
APM:根据语言栈的不同,分别展示服务之间的函数调用关系和调用拓扑。根据语言的不同,有的需要破解代码并以SDK嵌入的形式采集数据,有的则与代码解耦,有的方法通过元编程重载实现data采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等提供统一的存储、分析和展示。
有了上述原子化场景的数据采集,我们就可以通过UI统一展示监控数据,并根据上述三个维度设计一个以用户体验为核心的图形化页面。图形一般以时间序列为横轴,显示指标随时间的变化。对于一些统计指标,还可以通过饼图和条形图的方式展示分析比较结果。
本文主要介绍监控系统中的采集和数据展示。至于数据存储和报警过程,有兴趣的同学可以继续关注后续监控相关的文章。
关于作者
董磊:UCloud 技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
更多技术干货,欢迎关注微信“UCloud技术公告栏”。 查看全部
采集系统上云(微服务下的几个监控维度(下)化服务)
前言
微服务是一种架构风格,大型复杂的软件应用程序通常由多个微服务组成。系统中的每个微服务都可以独立部署,每个微服务都是松耦合的。每个微服务只专注于完成一项任务并把它做好。
在微服务之前,很多单体应用的监控复杂度较低,场景相对简单。在微服务下,由于业务逻辑分散在很多流程中(很多大业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时就需要完善的监控系统。
一套完整的监控系统建设周期长,需要随着业务场景的变化进行迭代优化。本文仅从几个监控维度和原子场景探讨如何建立统一的监控数据采集和展示系统,希望能启发大家继续深入思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的变化。我们将监控从机器角度转换为以服务为中心的角度。从微服务的角度来看,监控可以从数据维度和资源维度来看。与代码维度分层,如下图:
数据维度
目前,WEB服务是主流。每一个WEB服务都有一个入口,无论是APP还是WEB页面,入口负责与用户交互,并将用户的信息发送到后台。一般后台会访问LB或者Gateway,负责负载。将数据均衡转发给特定的应用程序进行处理,最后在应用程序处理完毕后写入数据库。
资源维度
现在很多服务都部署在云端,涉及到虚拟化技术,虚拟主机运行在物理服务器上,虚拟主机之间通过虚拟网络相互连接。资源层面的监控是不可或缺的一环。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器的CPU、内存、磁盘IO等数据,以及连接的虚拟主机。主机之间的虚拟网络带宽负载等。
代码维度
APM,即应用性能分析、代码端监控采集,是随着微服务的兴起而出现的。在微服务场景下,一个业务流程跨越数十个服务,仅靠传统的监控数据很难定位问题的根源。
我们可以针对代码的技术栈开发具体的采集框架,在可接受的性能损失范围内,采集函数之间的调用关系,服务之间的调用拓扑,只测量响应时间功能或服务的性能可以优化性能或提前预测故障。
关键监控指标场景描述
微服务监控的最大特点可以用一句话概括:服务很多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关的错综复杂的业务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了各个维度下各个层级可能产生的告警,总结出URL监控、主机监控、产品监控等8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状况。
主机监控:通过安装agent采集对主机的基本监控信息如CPU、内存、IO等数据,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据< @采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报每个产品的相关指标数据,监控每个产品资源的健康状态。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载对应组件的监控采集程序。
自定义监控:服务实例采集业务相关数据,定时调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户以资源为维度上报自定义数据。每个资源都有相同的几个监控项,每个资源的监控项相互独立。
APM:根据语言栈的不同,分别展示服务之间的函数调用关系和调用拓扑。根据语言的不同,有的需要破解代码并以SDK嵌入的形式采集数据,有的则与代码解耦,有的方法通过元编程重载实现data采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等提供统一的存储、分析和展示。
有了上述原子化场景的数据采集,我们就可以通过UI统一展示监控数据,并根据上述三个维度设计一个以用户体验为核心的图形化页面。图形一般以时间序列为横轴,显示指标随时间的变化。对于一些统计指标,还可以通过饼图和条形图的方式展示分析比较结果。
本文主要介绍监控系统中的采集和数据展示。至于数据存储和报警过程,有兴趣的同学可以继续关注后续监控相关的文章。
关于作者
董磊:UCloud 技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
更多技术干货,欢迎关注微信“UCloud技术公告栏”。
采集系统上云(浙江移动大数据平台二期项目的定位及核心需求点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 420 次浏览 • 2022-04-18 17:13
一、背景和建设历史
随着一期企业级大数据平台的上线,浙江移动构建了大数据统一采集、存储和分析的基础能力,实现了O、B、企业内部的M个三域数据。模型,但外部数据,尤其是互联网数据的采集,并未包括在内。互联网上的海量信息对于丰富数据资产、支撑数据变现具有极大的互补作用。浙江移动一直在思考如何扩展大数据平台的数据采集能力,帮助租户快速高效地获取外部数据。和探索问题。
为此,在大数据平台项目二期,我们计划搭建云爬虫平台,获取外部数据,提供分词和自然语言解析能力。但是,集成商在实施过程中无法满足要求。为了不耽误平台的上线,项目组决定在开源软件的基础上自主开发和实现业务需求。完成云爬虫平台上线和试运行。
二、云爬虫平台的定位和核心需求
云爬虫平台在企业级大数据平台中的定位
核心需求
1、实现分布式互联网数据爬取,支持通用爬取和精细爬取;
2、实现多租户管理和资源隔离;
3、实现高可用和可视化界面配置管理;
4、爬取的数据存储在ES、HDFS、HBASE中或者直接通过restful接口传递;
5、爬取的数据存储在ES、HDFS、HBASE后,可以支持租户分词和自然语言解析;
6、爬虫性能要求:
a) 实现平均每天 1 亿个 URL 的 采集 量
b) 基于每天1亿个URL,每个URL按平均500KB计算,有效爬取数据存储容量大于500TB
三、云爬虫平台系统架构
1)系统功能模块
云爬虫平台分为精细爬取和通用爬取两个功能模块,满足不同租户的数据采集需求。多租户的系统功能逻辑如下:
1、攀爬
租户登录云爬虫管理平台,在线编辑爬虫脚本。云爬虫系统根据计划中编写的脚本规则,爬取对应页面的指定部分(如具体评论列表),并存储在大数据平台中,并建立全文索引。
2、通过攀爬
调用者调用云爬虫系统提供的通用爬取接口,云爬虫系统根据策略(代理IP等)将爬取结果实时返回给调用者,并存储在Hadoop平台中并建立全文索引。
2)系统物理架构
云爬虫平台的物理架构如下,分层,主要分为接入层、采集层和持久层,如下图所示:
1、访问层
接入层包括Web和接口。Web 主机负责负载平衡任务和显示任务列表。在网页上,租户可以根据需要创建新的爬取任务。对于成功的爬取任务,您可以通过网页查看其基本信息。REST API 负责对外提供爬虫能力接口。
2、采集图层
采集 层收录爬虫主机和消息队列主机。爬虫主机负责接收web主机分配的任务,包括爬取网页和返回内容,对爬取的内容进行解析和结构化,以及对结构化结果进行持久化。Redis 作为消息队列,负责任务分发。
3、持久层
通常,网络爬虫抓取的数据量非常大,需要很大的存储空间来存储大量数据。因此,持久层采用中国移动苏州研发中心开发的Hadoop平台产品。
3)应用部署架构
云爬虫平台的应用部署架构如下,主要分为Web服务域和采集服务域。
1、Web 服务域
提供给租户编写和调试爬虫脚本,安装WebUI、Scheduler等组件。
2、采集服务域
对于数据采集和结果返回,每个Spider节点都安装了Fetcher、Processor、Result_Worker、Rest API、Selenium、PhantomJS等组件。
四、云爬虫平台核心功能及自主研发范围
云爬虫平台基于开源的Python爬虫框架pyspider,根据我们的需求在本地开发。爬取的数据存储在Hadoop平台中,通过二次开发,实现多租户以及爬虫与ES、HBASE、HDFS等接口的封装。以提高开发效率。主要新功能如下:
1)多租户管理
云爬虫和互联网数据存储分析平台都是通过二次开发基于PaaS,实现多租户和租户之间的资源隔离。
2)丰富的数据接口
在原有框架的基础上,扩展了各种数据接口的读写能力,如关系型数据库Oracle、非关系型HBase、HDFS文件、ES、流式消息接口Kafka等,以支持不同类型的精细爬取、过关爬取等数据。业务需求。
3)平台高可用
云爬虫平台的所有爬取节点和数据存储分析节点均匀分布在多个物理节点上,单机宕机不会导致整个爬取过程中断。这种分布式架构提高了系统性的整体健壮性。
4)爬取效率
单机模式下的网络爬虫效率不高,无法满足大规模爬取任务的需求。云爬虫平台为爬虫租户分配多个爬取节点,通过读取共享任务池共同执行爬取任务。节点可以看作是一个独立的网络爬虫,可以大大提高页面的爬取效率。
5)高扩展性
支持静态爬取和动态渲染的主流网站数据爬取,如天猫、京东、大众点评、豆瓣等,可以根据当前爬虫任务量动态调整爬虫节点数,比传统的爬虫方法更强。同时,租户在编写脚本时具有高度的自定义性,允许租户根据不同的爬取需求自定义爬取范围。
6)可视化爬虫界面
云爬虫平台为爬虫租户提供了一个可视化的页面来编辑和调试爬虫脚本。平台支持静态和动态渲染的主流网站爬取,可以根据业务的紧急程度动态调整每个爬虫任务的优先级,并提供爬取数据结果的页面导出功能,方便用于查看样本数据。系统页面如下图所示:
五、云爬虫平台的操作
1)平台操作
云爬虫平台上线以来,集群运行总体稳定,保存了应用数据XXT。
2)应用操作
目前承载的服务包括DPI爬虫接口和数据挖掘中的行业应用,如客流平台POI信息和大数据选址、西从天降平台商品信息、咪咕喜欢看的用户视频行为信息等。请求2000万+,日均爬取数据量4T+。
通过搭建云爬虫平台实现互联网数据获取,可以更全面地获取用户的关系、状态、位置、轨迹、使用行为和习惯特征数据,更全面、准确地描述用户画像;数据的丰富性和准确性有助于改进业务发展战略,提升业务价值。返回搜狐,查看更多 查看全部
采集系统上云(浙江移动大数据平台二期项目的定位及核心需求点)
一、背景和建设历史
随着一期企业级大数据平台的上线,浙江移动构建了大数据统一采集、存储和分析的基础能力,实现了O、B、企业内部的M个三域数据。模型,但外部数据,尤其是互联网数据的采集,并未包括在内。互联网上的海量信息对于丰富数据资产、支撑数据变现具有极大的互补作用。浙江移动一直在思考如何扩展大数据平台的数据采集能力,帮助租户快速高效地获取外部数据。和探索问题。
为此,在大数据平台项目二期,我们计划搭建云爬虫平台,获取外部数据,提供分词和自然语言解析能力。但是,集成商在实施过程中无法满足要求。为了不耽误平台的上线,项目组决定在开源软件的基础上自主开发和实现业务需求。完成云爬虫平台上线和试运行。
二、云爬虫平台的定位和核心需求
云爬虫平台在企业级大数据平台中的定位
核心需求
1、实现分布式互联网数据爬取,支持通用爬取和精细爬取;
2、实现多租户管理和资源隔离;
3、实现高可用和可视化界面配置管理;
4、爬取的数据存储在ES、HDFS、HBASE中或者直接通过restful接口传递;
5、爬取的数据存储在ES、HDFS、HBASE后,可以支持租户分词和自然语言解析;
6、爬虫性能要求:
a) 实现平均每天 1 亿个 URL 的 采集 量
b) 基于每天1亿个URL,每个URL按平均500KB计算,有效爬取数据存储容量大于500TB
三、云爬虫平台系统架构
1)系统功能模块
云爬虫平台分为精细爬取和通用爬取两个功能模块,满足不同租户的数据采集需求。多租户的系统功能逻辑如下:
1、攀爬
租户登录云爬虫管理平台,在线编辑爬虫脚本。云爬虫系统根据计划中编写的脚本规则,爬取对应页面的指定部分(如具体评论列表),并存储在大数据平台中,并建立全文索引。
2、通过攀爬
调用者调用云爬虫系统提供的通用爬取接口,云爬虫系统根据策略(代理IP等)将爬取结果实时返回给调用者,并存储在Hadoop平台中并建立全文索引。
2)系统物理架构
云爬虫平台的物理架构如下,分层,主要分为接入层、采集层和持久层,如下图所示:
1、访问层
接入层包括Web和接口。Web 主机负责负载平衡任务和显示任务列表。在网页上,租户可以根据需要创建新的爬取任务。对于成功的爬取任务,您可以通过网页查看其基本信息。REST API 负责对外提供爬虫能力接口。
2、采集图层
采集 层收录爬虫主机和消息队列主机。爬虫主机负责接收web主机分配的任务,包括爬取网页和返回内容,对爬取的内容进行解析和结构化,以及对结构化结果进行持久化。Redis 作为消息队列,负责任务分发。
3、持久层
通常,网络爬虫抓取的数据量非常大,需要很大的存储空间来存储大量数据。因此,持久层采用中国移动苏州研发中心开发的Hadoop平台产品。
3)应用部署架构
云爬虫平台的应用部署架构如下,主要分为Web服务域和采集服务域。
1、Web 服务域
提供给租户编写和调试爬虫脚本,安装WebUI、Scheduler等组件。
2、采集服务域
对于数据采集和结果返回,每个Spider节点都安装了Fetcher、Processor、Result_Worker、Rest API、Selenium、PhantomJS等组件。
四、云爬虫平台核心功能及自主研发范围
云爬虫平台基于开源的Python爬虫框架pyspider,根据我们的需求在本地开发。爬取的数据存储在Hadoop平台中,通过二次开发,实现多租户以及爬虫与ES、HBASE、HDFS等接口的封装。以提高开发效率。主要新功能如下:
1)多租户管理
云爬虫和互联网数据存储分析平台都是通过二次开发基于PaaS,实现多租户和租户之间的资源隔离。
2)丰富的数据接口
在原有框架的基础上,扩展了各种数据接口的读写能力,如关系型数据库Oracle、非关系型HBase、HDFS文件、ES、流式消息接口Kafka等,以支持不同类型的精细爬取、过关爬取等数据。业务需求。
3)平台高可用
云爬虫平台的所有爬取节点和数据存储分析节点均匀分布在多个物理节点上,单机宕机不会导致整个爬取过程中断。这种分布式架构提高了系统性的整体健壮性。
4)爬取效率
单机模式下的网络爬虫效率不高,无法满足大规模爬取任务的需求。云爬虫平台为爬虫租户分配多个爬取节点,通过读取共享任务池共同执行爬取任务。节点可以看作是一个独立的网络爬虫,可以大大提高页面的爬取效率。
5)高扩展性
支持静态爬取和动态渲染的主流网站数据爬取,如天猫、京东、大众点评、豆瓣等,可以根据当前爬虫任务量动态调整爬虫节点数,比传统的爬虫方法更强。同时,租户在编写脚本时具有高度的自定义性,允许租户根据不同的爬取需求自定义爬取范围。
6)可视化爬虫界面
云爬虫平台为爬虫租户提供了一个可视化的页面来编辑和调试爬虫脚本。平台支持静态和动态渲染的主流网站爬取,可以根据业务的紧急程度动态调整每个爬虫任务的优先级,并提供爬取数据结果的页面导出功能,方便用于查看样本数据。系统页面如下图所示:
五、云爬虫平台的操作
1)平台操作
云爬虫平台上线以来,集群运行总体稳定,保存了应用数据XXT。
2)应用操作
目前承载的服务包括DPI爬虫接口和数据挖掘中的行业应用,如客流平台POI信息和大数据选址、西从天降平台商品信息、咪咕喜欢看的用户视频行为信息等。请求2000万+,日均爬取数据量4T+。
通过搭建云爬虫平台实现互联网数据获取,可以更全面地获取用户的关系、状态、位置、轨迹、使用行为和习惯特征数据,更全面、准确地描述用户画像;数据的丰富性和准确性有助于改进业务发展战略,提升业务价值。返回搜狐,查看更多
采集系统上云(如何利用raspberrypi创建一个电子设备?/2016/07/12)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-04-17 12:03
采集系统上云服务,相关资料搜索信息可到新闻处。接下来具体说下如何利用raspberrypi创建一个电子设备。1.根据raspberrypi的说明书,需要将raspberrypi2.0的手柄驱动添加到该设备中,我认为安装驱动是最最关键的环节,有一个好的驱动,才能更加方便的操作,减少设备对电磁辐射的影响。
2.根据wikipedia的描述,要自己制作一个属于自己的小raspberrypi的话,我觉得至少要重新写一个usb编程的程序,可以像百度学习一下一些常用的命令:例如编译指定扩展名的inode.zip等等。3.最重要的是写一个小的app,要让raspberrypi的可靠性更高。例如做一个wifi热点,可以帮助raspberrypi与外界连接。
可以查查athlonraspberrypi怎么做好一个wifi热点设备。4.raspberrypi一般适合做一些高精度的事情,例如:拍照,手写笔之类的,所以我以及一般可以将wifi热点设置在你房间,并将相应程序写入外网。最后,建议使用git或者github,方便分享代码,毕竟raspberrypi不是为了给人类用的。不论如何,我们都是以人为本。
如何才能google到足够多的raspberrypi资料-edit/2016/07/12/esr-kit_root-sticker_lab_binary.html
在上搜raspberrypiguiserver(就是你说的google_gmail),软件一搜一大把。我也想学,但是没开始呢。 查看全部
采集系统上云(如何利用raspberrypi创建一个电子设备?/2016/07/12)
采集系统上云服务,相关资料搜索信息可到新闻处。接下来具体说下如何利用raspberrypi创建一个电子设备。1.根据raspberrypi的说明书,需要将raspberrypi2.0的手柄驱动添加到该设备中,我认为安装驱动是最最关键的环节,有一个好的驱动,才能更加方便的操作,减少设备对电磁辐射的影响。
2.根据wikipedia的描述,要自己制作一个属于自己的小raspberrypi的话,我觉得至少要重新写一个usb编程的程序,可以像百度学习一下一些常用的命令:例如编译指定扩展名的inode.zip等等。3.最重要的是写一个小的app,要让raspberrypi的可靠性更高。例如做一个wifi热点,可以帮助raspberrypi与外界连接。
可以查查athlonraspberrypi怎么做好一个wifi热点设备。4.raspberrypi一般适合做一些高精度的事情,例如:拍照,手写笔之类的,所以我以及一般可以将wifi热点设置在你房间,并将相应程序写入外网。最后,建议使用git或者github,方便分享代码,毕竟raspberrypi不是为了给人类用的。不论如何,我们都是以人为本。
如何才能google到足够多的raspberrypi资料-edit/2016/07/12/esr-kit_root-sticker_lab_binary.html
在上搜raspberrypiguiserver(就是你说的google_gmail),软件一搜一大把。我也想学,但是没开始呢。
采集系统上云(微服务下的几个监控维度(下)化服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-17 10:33
前言
微服务是一种架构风格,大型复杂的软件应用程序通常由多个微服务组成。系统中的每个微服务都可以独立部署,每个微服务都是松耦合的。每个微服务只专注于完成一项任务并把它做好。
在微服务之前,很多单体应用的监控复杂度较低,场景相对简单。在微服务下,由于业务逻辑分散在很多流程中(很多大业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时就需要一个完善的监控系统。
一套完整的监控系统建设周期长,需要随着业务场景的变化进行迭代优化。本文仅从几个监控维度和原子场景探讨如何建立统一的监控数据采集和展示系统,希望能启发大家继续深入思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的变化。我们将监控从机器角度转换为以服务为中心的角度。从微服务的角度来看,监控可以从数据维度和资源维度来看。与代码维度分层,如下图:
数据维度
目前,WEB服务是主流。每个 WEB 服务都有一个入口。无论是APP还是WEB页面,入口负责与用户交互,将用户信息发送到后台。一般后台会访问LB或者Gateway,负责负载。将数据均衡转发给特定的应用程序进行处理,最后在应用程序处理完毕后写入数据库。
资源维度
现在很多服务都部署在云端,涉及到虚拟化技术,虚拟主机运行在物理服务器上,虚拟主机之间通过虚拟网络相互连接。资源层面的监控是不可或缺的一环。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器的CPU、内存、磁盘IO等数据,以及连接的虚拟主机。主机之间的虚拟网络带宽负载等。
代码维度
APM,即应用性能分析、代码端监控采集,是随着微服务的兴起而出现的。在微服务场景下,一个业务流程跨越数十个服务,仅靠传统的监控数据很难定位问题的根源。
我们可以针对代码的技术栈开发具体的采集框架,在可接受的性能损失范围内,采集函数之间的调用关系,服务之间的调用拓扑,只测量响应时间功能或服务的性能可以优化性能或提前预测故障。
关键监控指标场景描述
微服务监控的最大特点可以用一句话概括:服务很多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关的错综复杂的业务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了各个维度下各个层级可能产生的告警,总结出URL监控、主机监控、产品监控等8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状况。
主机监控:通过安装agent采集对主机的基本监控信息如CPU、内存、IO等数据,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据< @采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和部分中间件,产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载对应组件的监控采集程序。
自定义监控:服务实例采集业务相关数据,定时调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户以资源为维度上报自定义数据。每个资源都有相同的几个监控项,每个资源的监控项相互独立。
APM:根据语言栈的不同,分别展示服务之间的函数调用关系和调用拓扑。根据语言的不同,有的需要破解代码并以SDK嵌入的形式采集数据,有的则与代码解耦,有的方法通过元编程重载实现data采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等提供统一的存储、分析和展示。
有了上述原子化场景的数据采集,我们就可以通过UI统一展示监控数据,并根据上述三个维度设计一个以用户体验为核心的图形化页面。图形一般以时间序列为横轴,显示指标随时间的变化。对于一些统计指标,还可以通过饼图和条形图的方式展示分析比较结果。
本文主要介绍监控系统中的采集和数据展示。至于数据存储和报警过程,有兴趣的同学可以继续关注后续监控相关的文章。
关于作者
董磊:UCloud 技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
更多技术干货,欢迎关注微信“UCloud技术公告栏”。 查看全部
采集系统上云(微服务下的几个监控维度(下)化服务)
前言
微服务是一种架构风格,大型复杂的软件应用程序通常由多个微服务组成。系统中的每个微服务都可以独立部署,每个微服务都是松耦合的。每个微服务只专注于完成一项任务并把它做好。
在微服务之前,很多单体应用的监控复杂度较低,场景相对简单。在微服务下,由于业务逻辑分散在很多流程中(很多大业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时就需要一个完善的监控系统。
一套完整的监控系统建设周期长,需要随着业务场景的变化进行迭代优化。本文仅从几个监控维度和原子场景探讨如何建立统一的监控数据采集和展示系统,希望能启发大家继续深入思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的变化。我们将监控从机器角度转换为以服务为中心的角度。从微服务的角度来看,监控可以从数据维度和资源维度来看。与代码维度分层,如下图:
数据维度
目前,WEB服务是主流。每个 WEB 服务都有一个入口。无论是APP还是WEB页面,入口负责与用户交互,将用户信息发送到后台。一般后台会访问LB或者Gateway,负责负载。将数据均衡转发给特定的应用程序进行处理,最后在应用程序处理完毕后写入数据库。
资源维度
现在很多服务都部署在云端,涉及到虚拟化技术,虚拟主机运行在物理服务器上,虚拟主机之间通过虚拟网络相互连接。资源层面的监控是不可或缺的一环。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器的CPU、内存、磁盘IO等数据,以及连接的虚拟主机。主机之间的虚拟网络带宽负载等。
代码维度
APM,即应用性能分析、代码端监控采集,是随着微服务的兴起而出现的。在微服务场景下,一个业务流程跨越数十个服务,仅靠传统的监控数据很难定位问题的根源。
我们可以针对代码的技术栈开发具体的采集框架,在可接受的性能损失范围内,采集函数之间的调用关系,服务之间的调用拓扑,只测量响应时间功能或服务的性能可以优化性能或提前预测故障。
关键监控指标场景描述
微服务监控的最大特点可以用一句话概括:服务很多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关的错综复杂的业务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了各个维度下各个层级可能产生的告警,总结出URL监控、主机监控、产品监控等8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状况。
主机监控:通过安装agent采集对主机的基本监控信息如CPU、内存、IO等数据,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据< @采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和部分中间件,产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载对应组件的监控采集程序。
自定义监控:服务实例采集业务相关数据,定时调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户以资源为维度上报自定义数据。每个资源都有相同的几个监控项,每个资源的监控项相互独立。
APM:根据语言栈的不同,分别展示服务之间的函数调用关系和调用拓扑。根据语言的不同,有的需要破解代码并以SDK嵌入的形式采集数据,有的则与代码解耦,有的方法通过元编程重载实现data采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等提供统一的存储、分析和展示。
有了上述原子化场景的数据采集,我们就可以通过UI统一展示监控数据,并根据上述三个维度设计一个以用户体验为核心的图形化页面。图形一般以时间序列为横轴,显示指标随时间的变化。对于一些统计指标,还可以通过饼图和条形图的方式展示分析比较结果。
本文主要介绍监控系统中的采集和数据展示。至于数据存储和报警过程,有兴趣的同学可以继续关注后续监控相关的文章。
关于作者
董磊:UCloud 技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
更多技术干货,欢迎关注微信“UCloud技术公告栏”。
采集系统上云(微猫企业资料搜索采集软件的数据多久更新一次?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-06 03:05
微猫企业信息搜索采集软件是一款通过互联网查找非常准确的企业信息的软件。在百度、搜狗、360收录1000多个大型行业和企业黄页中,帮助您快速搜索最新最全的优质客户。搜索到的信息包括公司名称、网站、电话、手机、邮箱等多种联系方式,是销售人员寻找客户的必备工具。
软件功能
1、通过百度、好搜、搜狗直接进入公司官网,快速定位精准客户。
2、快速挑选优质客户进行网络推广
3、快速搜索;
4、搜索结果数量多,同一个关键词搜索到的信息量是同类软件的几十倍;
5、高精度:搜索出优先企业信息!
6、企业信息在800多个商业网站上广泛传播和发布;
7、还有资料导入电脑功能!
回答问题
软件可以下载多少数据?
A:软件采集接收的数据来自各行业知名网站用户发布的数据,不在我们的数据库中,所以我们不知道数据有多少, 网站你可以采集网站上有多少资源,但数量肯定很多。
目录采集 软件多久更新一次?
A:一般两三天到一周左右会有新的数据更新。24小时自动采集,收录各大地产行业网站,各大分类信息网站,数据真实,每次采集自动去重复号码,为保证数据质量,业主信息名称包括姓名、户型、小区、电话号码
目录采集软件安装版和绿色版有什么区别?
答:目录采集软件的安装版本与绿色版基本相同。唯一不同的是需要安装安装版下载后才能使用,而绿色版解压后即可使用。直接操作。
微信企业信息搜索采集软件平台自动采集网络关键词信息每天实时变化。只要是您关注的企业信息,24小时实时爬虫都能帮您抓取信息。决策总是至关重要的,数据提取、数据共享、数据监管等等。 查看全部
采集系统上云(微猫企业资料搜索采集软件的数据多久更新一次?(图))
微猫企业信息搜索采集软件是一款通过互联网查找非常准确的企业信息的软件。在百度、搜狗、360收录1000多个大型行业和企业黄页中,帮助您快速搜索最新最全的优质客户。搜索到的信息包括公司名称、网站、电话、手机、邮箱等多种联系方式,是销售人员寻找客户的必备工具。

软件功能
1、通过百度、好搜、搜狗直接进入公司官网,快速定位精准客户。
2、快速挑选优质客户进行网络推广
3、快速搜索;
4、搜索结果数量多,同一个关键词搜索到的信息量是同类软件的几十倍;
5、高精度:搜索出优先企业信息!
6、企业信息在800多个商业网站上广泛传播和发布;
7、还有资料导入电脑功能!
回答问题
软件可以下载多少数据?
A:软件采集接收的数据来自各行业知名网站用户发布的数据,不在我们的数据库中,所以我们不知道数据有多少, 网站你可以采集网站上有多少资源,但数量肯定很多。
目录采集 软件多久更新一次?
A:一般两三天到一周左右会有新的数据更新。24小时自动采集,收录各大地产行业网站,各大分类信息网站,数据真实,每次采集自动去重复号码,为保证数据质量,业主信息名称包括姓名、户型、小区、电话号码
目录采集软件安装版和绿色版有什么区别?
答:目录采集软件的安装版本与绿色版基本相同。唯一不同的是需要安装安装版下载后才能使用,而绿色版解压后即可使用。直接操作。
微信企业信息搜索采集软件平台自动采集网络关键词信息每天实时变化。只要是您关注的企业信息,24小时实时爬虫都能帮您抓取信息。决策总是至关重要的,数据提取、数据共享、数据监管等等。
采集系统上云(业务程序会不断生成业务日志的学习总结和心得建议)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-03-24 05:02
实际项目需求描述:
在业务系统的服务器上,业务程序会不断产生业务日志(如网站的页面访问日志)。
业务日志是用log4j生成的,会不断切出日志文件。
需要定期(比如每小时)从业务服务器的日志目录中检测出需要采集的日志文件(access.log无法采集),并发送到HDFS。
注意:可能有多个业务服务器(hdfs上的文件名不能直接使用日志服务器上的文件名)。
采集当天收到的日志应该放在hdfs的当前目录下。
采集完成的日志文件需要移动到日志服务器的备份目录中。
定期检查(每小时一次)备份目录,清除备份时长超过24小时的日志文件。
项目的一些学习总结和经验建议
规范说明1:代码中手写代码过多,如文件路径,无法无误编译,很难找到。
解决问题1:可以写一个属性资源文件,把路径存放在key上。
规范说明2:如果要读取资源文件,必须使用类加载器来加载。
规范说明3:访问对象有问题,应该使用单例设计模式——懒惰风格。
规范说明4:存在线程安全问题。为了避免死锁或重复使用新资源,静态代码块应该同步。
规范注释5:还应考虑资源密钥问题。可以新建一个类来保存key,这样在不容易找到错误路径时程序会提示错误。
规范说明6:每个项目、每个业务都要先写自己的流程,然后一步步写代码,再慢慢考虑其他异常,增加代码的健壮性。 查看全部
采集系统上云(业务程序会不断生成业务日志的学习总结和心得建议)
实际项目需求描述:
在业务系统的服务器上,业务程序会不断产生业务日志(如网站的页面访问日志)。
业务日志是用log4j生成的,会不断切出日志文件。
需要定期(比如每小时)从业务服务器的日志目录中检测出需要采集的日志文件(access.log无法采集),并发送到HDFS。
注意:可能有多个业务服务器(hdfs上的文件名不能直接使用日志服务器上的文件名)。
采集当天收到的日志应该放在hdfs的当前目录下。
采集完成的日志文件需要移动到日志服务器的备份目录中。
定期检查(每小时一次)备份目录,清除备份时长超过24小时的日志文件。
项目的一些学习总结和经验建议
规范说明1:代码中手写代码过多,如文件路径,无法无误编译,很难找到。
解决问题1:可以写一个属性资源文件,把路径存放在key上。
规范说明2:如果要读取资源文件,必须使用类加载器来加载。
规范说明3:访问对象有问题,应该使用单例设计模式——懒惰风格。
规范说明4:存在线程安全问题。为了避免死锁或重复使用新资源,静态代码块应该同步。
规范注释5:还应考虑资源密钥问题。可以新建一个类来保存key,这样在不容易找到错误路径时程序会提示错误。
规范说明6:每个项目、每个业务都要先写自己的流程,然后一步步写代码,再慢慢考虑其他异常,增加代码的健壮性。
采集系统上云(采集系统上云之后,想从云端进行数据分析?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-24 03:04
采集系统上云之后变得很简单,变得很快,基本是集成在你的企业内部系统上。既然采集系统上云之后,想从云端进行数据分析就可以了。用技术的方式来实现的话就很简单了,比如对接一个sdk,sdk可以对采集好的数据进行处理,然后推送给erp、hrm、admin的等不同终端的负责人。或者是通过hr或者rpo多层的进行数据分析。
对于不同行业,有不同的解决方案,针对数据源提出不同的解决方案就是,所以不同行业有不同的解决方案。大数据不是你想的那么高大上,其实很普通。在营销,产品分析,决策支持等方面可以发挥大数据的价值。对于一些不太复杂的,而且比较有针对性的数据,比如用户画像,特征标签,这方面你可以从获取的用户数据入手,然后在考虑进行数据处理分析。
我目前知道的有这样一个项目:对商家来说,数据可以做什么,以后该怎么用?-生意人创业论坛-poweredbydiscuz!不过貌似这样的项目还在,具体情况你可以去官网看看。对于阿里来说,数据可以做什么,以后该怎么用?-大数据与人工智能论坛-poweredbydiscuz!这个我没有接触过,毕竟没有从事过商业分析相关的工作,希望能帮到你。
大数据一直都是很热门的话题,不管是大家的讨论还是给自己公司制定转型路线,大数据都不可或缺。大数据也分为云计算大数据分析大数据,是一个相互交叉的行业,都需要数据分析,只是数据分析侧重于运用于流量分析,营销分析等,只要能做大数据分析,只要要有数据分析,都可以说是大数据分析,大数据分析也是要计算机与数据分析相结合。
那么数据分析是属于传统营销分析和现在的数据分析之中的,一般都是面向业务和运营人员,提供数据支持的。大数据分析有分为原始数据分析,抽样数据分析,数据量预估,数据可视化等多种方式,最后形成报告给业务管理人员看。以下几点是大数据分析所需要关注的几点重点:大数据的分析以及应用是一个很复杂的学科,是一个集大成的学科,也是需要一个比较长的路要走,只有理论和技术储备都十分的深厚,并且有相关领域专业知识,在业务领域能有一定成就,才有可能做大数据分析工作,才有可能看到很好的前景。
一、大数据的数据结构和数据类型1、业务类数据:即面向不同业务方的销售数据、客户数据、广告数据、财务数据、人员基础信息等,是业务系统分析、决策中最为重要的信息源。这些数据的收集包括通过etl工具,采集各个业务方的数据。原始数据中常常包含诸如客户资料、财务收支、广告效果等等关键数据。这些数据一般都是长期积累的数据,一旦发生事件或人为的改变。 查看全部
采集系统上云(采集系统上云之后,想从云端进行数据分析?)
采集系统上云之后变得很简单,变得很快,基本是集成在你的企业内部系统上。既然采集系统上云之后,想从云端进行数据分析就可以了。用技术的方式来实现的话就很简单了,比如对接一个sdk,sdk可以对采集好的数据进行处理,然后推送给erp、hrm、admin的等不同终端的负责人。或者是通过hr或者rpo多层的进行数据分析。
对于不同行业,有不同的解决方案,针对数据源提出不同的解决方案就是,所以不同行业有不同的解决方案。大数据不是你想的那么高大上,其实很普通。在营销,产品分析,决策支持等方面可以发挥大数据的价值。对于一些不太复杂的,而且比较有针对性的数据,比如用户画像,特征标签,这方面你可以从获取的用户数据入手,然后在考虑进行数据处理分析。
我目前知道的有这样一个项目:对商家来说,数据可以做什么,以后该怎么用?-生意人创业论坛-poweredbydiscuz!不过貌似这样的项目还在,具体情况你可以去官网看看。对于阿里来说,数据可以做什么,以后该怎么用?-大数据与人工智能论坛-poweredbydiscuz!这个我没有接触过,毕竟没有从事过商业分析相关的工作,希望能帮到你。
大数据一直都是很热门的话题,不管是大家的讨论还是给自己公司制定转型路线,大数据都不可或缺。大数据也分为云计算大数据分析大数据,是一个相互交叉的行业,都需要数据分析,只是数据分析侧重于运用于流量分析,营销分析等,只要能做大数据分析,只要要有数据分析,都可以说是大数据分析,大数据分析也是要计算机与数据分析相结合。
那么数据分析是属于传统营销分析和现在的数据分析之中的,一般都是面向业务和运营人员,提供数据支持的。大数据分析有分为原始数据分析,抽样数据分析,数据量预估,数据可视化等多种方式,最后形成报告给业务管理人员看。以下几点是大数据分析所需要关注的几点重点:大数据的分析以及应用是一个很复杂的学科,是一个集大成的学科,也是需要一个比较长的路要走,只有理论和技术储备都十分的深厚,并且有相关领域专业知识,在业务领域能有一定成就,才有可能做大数据分析工作,才有可能看到很好的前景。
一、大数据的数据结构和数据类型1、业务类数据:即面向不同业务方的销售数据、客户数据、广告数据、财务数据、人员基础信息等,是业务系统分析、决策中最为重要的信息源。这些数据的收集包括通过etl工具,采集各个业务方的数据。原始数据中常常包含诸如客户资料、财务收支、广告效果等等关键数据。这些数据一般都是长期积累的数据,一旦发生事件或人为的改变。
采集系统上云(阿里云InfluxDB数据采集服务优势我们能做些什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-03-18 10:08
背景
随着时序数据的快速增长,时序数据库不仅需要解决系统稳定性和性能问题,还需要实现从采集到分析的链接,让时序数据真正生成价值。在时间序列数据采集领域,一直缺乏自动化的采集工具。虽然用户可以使用一些开源的采集工具来实现数据采集,比如Telegraf、Logstash、TCollector等,但是这些采集工具都需要用户自己构建和维护运行环境,增加了用户的学习成本,大大提高了数据的门槛采集。另一方面,现有的采集工具缺乏对多个采集源的自动化管理,使得用户难以统一管理多个不同的采集源并监控每个采集 实时 工具是否正常运行,采集数据。
阿里云InfluxDB®不仅提供稳定可靠的时序数据库服务,还提供非常便捷的数据采集服务。用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据会自动存储在阿里云InfluxDB®中。用户无需担心运维问题,实现从数据采集到分析的一站式服务。本文主要介绍如何使用InfluxDB®的数据采集服务实现数据从采集到存储的自动化管理。
阿里巴巴云InfluxDB®Data采集服务优势我们能做什么? 1.简单采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,分别涉及MySQL、Redis、MongoDB和系统监控。针对每类数据,采集多个监控指标,方便用户对监控对象有更全面的了解。用户可以通过InfluxDB®实例的管理控制台添加新的采集源,无需编写代码,一键安装。
采集数据操作流程如下:
2.采集来源的实时监控
采集源运行过程中,可以实时监控数据采集的状态,查看数据采集最后到达InfluxDB®的时间;并且您可以随时停止Data采集,并在您认为合适的时候重新打开data采集服务。
3.一键切换采集数据类型
如果要更改被监控机器上的采集数据类型,不需要重新添加新的采集源,选择你想要的采集配置即可,数据采集工具会自动切换到采集你指定的监控数据。
4. 采集数据自动存储在 InfluxDB® 中
您可以在采集配置中选择数据流的数据库和保留策略,数据采集工具会自动将采集数据存储到指定的数据库和保留策略中,并且您可以在 采集 源运行时修改要写入数据的数据库和保留策略,只需修改 采集 配置即可。
最佳实践
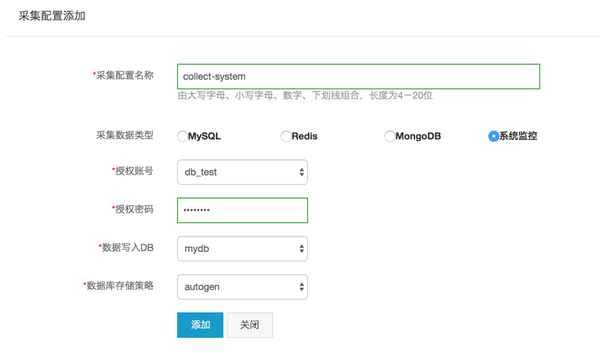
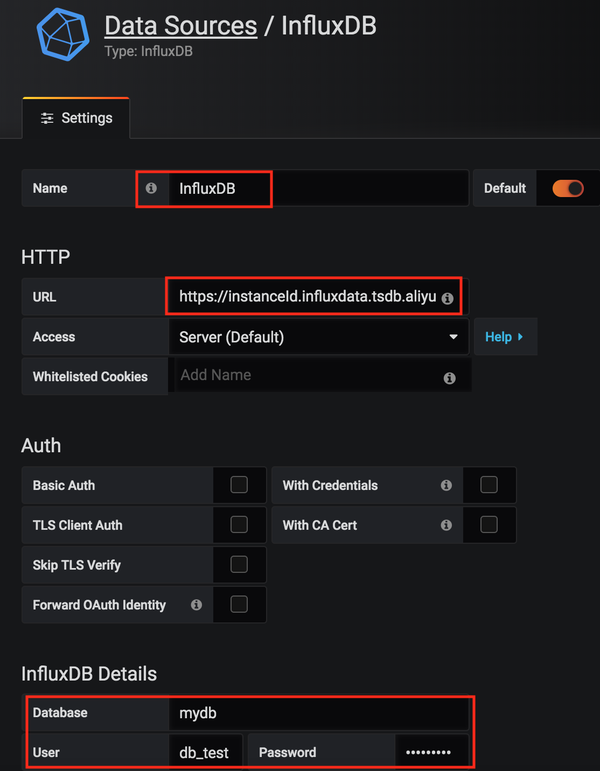
本节介绍如何采集系统监控数据并实时显示采集结果。系统监控的数据包括处理器、磁盘、内存、网络、进程、系统等信息。采集的数据存储在 8 种不同的测量中(测量是 cpu、disk、diskio、mem、net、processes、swap 和 system)。在开始之前,请确保您已成功创建数据库以及对该数据库具有读写权限的用户帐户。
1. 创建采集系统监控数据配置
点击InfluxDB®管理控制台左侧导航栏中的“添加采集配置”,进入采集配置添加界面,如下图所示。填写“采集Configuration Name”,选择“采集Data Type”为“System Monitoring”,然后选择“Authorized Account”、“Data Write to DB”和“Database Storage Policy”,填写在“授权密码”中。点击“添加”成功创建采集配置。
2. 添加采集来源
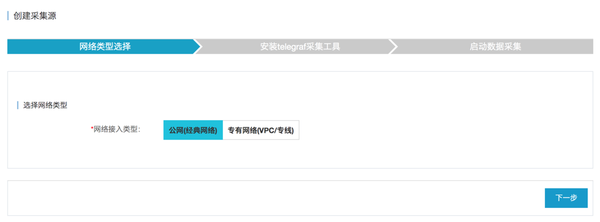
点击InfluxDB®管理控制台左侧导航栏中的“添加采集Source”,进入采集Source Add页面。
(1)选择网络类型,“Public Network”或“Private Network”,然后点击“Next”,如下图。
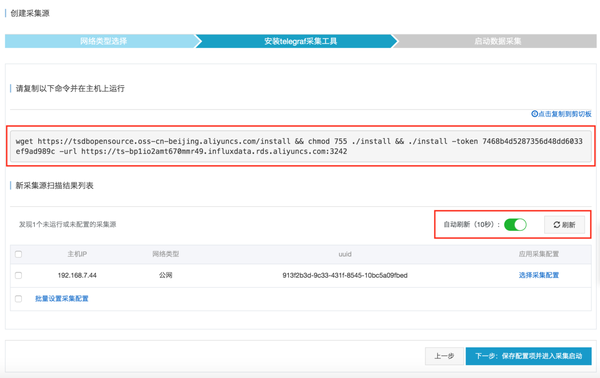
(2)在数据源所在的主机上安装采集工具。将安装命令复制到主机上运行采集工具。采集@之后> 工具运行,它会与 InfluxDB ® 建立连接,可以在“New 采集 Source Scan Result List”中看到新添加的采集 source,如果没有显示在列表中,您可以点击“刷新”或“自动刷新”。如下图。
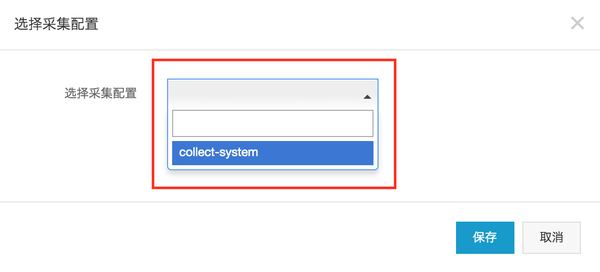
(3)选择采集系统监控的数据。在上图中点击“选择采集配置”进入如下界面,从下拉框。采集“采集系统”的配置。选择后点击“保存”。
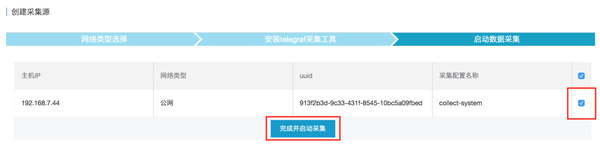
(4)启动数据采集.勾选需要启动的采集源,然后点击“Finish and start采集”,采集工具可以在采集源上启动采集数据,如下图。
3.查看数据状态采集
在“采集Source List”中,您可以看到所有连接到 InfluxDB® 实例的 采集 源,如下图所示。每个 采集 源由一个 uuid 唯一标识,“运行中”的“采集 状态”表示 采集 工具是 采集 数据并报告给 InfluxDB®, “最新采集上报成功时间”表示采集数据最后一次成功发送到InfluxDB®的时间。
4. 可视化 采集数据
使用 Grafana
(1)安装 Grafana。请参阅有关如何安装 Grafana 的文档。
(2)添加数据源。将“URL”设置为InfluxDB®实例的地址,并填写写入采集数据的数据库和用户账号,如下图。
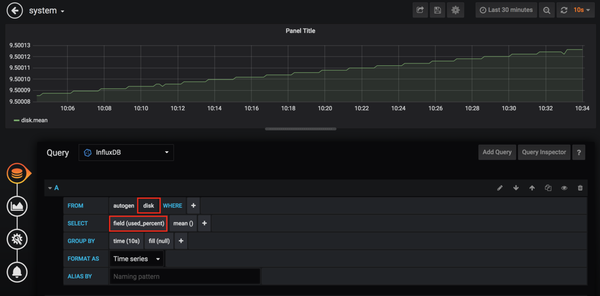
(3)配置Dashboard并编写查询规则。这里以查询磁盘使用情况为例。查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示。
您可以根据实际需要查看其他测量和字段的数据,并分别在FROM和SELECT语句中指定。
总结
阿里云InfluxDB®提供方便快捷的数据采集服务,自动管理数据源,帮助您解决数据采集问题,实现数据从采集到存储的自动化。未来,我们将支持 采集 获取更多数据类型和指标,敬请期待。 查看全部
采集系统上云(阿里云InfluxDB数据采集服务优势我们能做些什么?)
背景
随着时序数据的快速增长,时序数据库不仅需要解决系统稳定性和性能问题,还需要实现从采集到分析的链接,让时序数据真正生成价值。在时间序列数据采集领域,一直缺乏自动化的采集工具。虽然用户可以使用一些开源的采集工具来实现数据采集,比如Telegraf、Logstash、TCollector等,但是这些采集工具都需要用户自己构建和维护运行环境,增加了用户的学习成本,大大提高了数据的门槛采集。另一方面,现有的采集工具缺乏对多个采集源的自动化管理,使得用户难以统一管理多个不同的采集源并监控每个采集 实时 工具是否正常运行,采集数据。
阿里云InfluxDB®不仅提供稳定可靠的时序数据库服务,还提供非常便捷的数据采集服务。用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据会自动存储在阿里云InfluxDB®中。用户无需担心运维问题,实现从数据采集到分析的一站式服务。本文主要介绍如何使用InfluxDB®的数据采集服务实现数据从采集到存储的自动化管理。
阿里巴巴云InfluxDB®Data采集服务优势我们能做什么? 1.简单采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,分别涉及MySQL、Redis、MongoDB和系统监控。针对每类数据,采集多个监控指标,方便用户对监控对象有更全面的了解。用户可以通过InfluxDB®实例的管理控制台添加新的采集源,无需编写代码,一键安装。
采集数据操作流程如下:

2.采集来源的实时监控
采集源运行过程中,可以实时监控数据采集的状态,查看数据采集最后到达InfluxDB®的时间;并且您可以随时停止Data采集,并在您认为合适的时候重新打开data采集服务。

3.一键切换采集数据类型
如果要更改被监控机器上的采集数据类型,不需要重新添加新的采集源,选择你想要的采集配置即可,数据采集工具会自动切换到采集你指定的监控数据。
4. 采集数据自动存储在 InfluxDB® 中
您可以在采集配置中选择数据流的数据库和保留策略,数据采集工具会自动将采集数据存储到指定的数据库和保留策略中,并且您可以在 采集 源运行时修改要写入数据的数据库和保留策略,只需修改 采集 配置即可。
最佳实践
本节介绍如何采集系统监控数据并实时显示采集结果。系统监控的数据包括处理器、磁盘、内存、网络、进程、系统等信息。采集的数据存储在 8 种不同的测量中(测量是 cpu、disk、diskio、mem、net、processes、swap 和 system)。在开始之前,请确保您已成功创建数据库以及对该数据库具有读写权限的用户帐户。
1. 创建采集系统监控数据配置
点击InfluxDB®管理控制台左侧导航栏中的“添加采集配置”,进入采集配置添加界面,如下图所示。填写“采集Configuration Name”,选择“采集Data Type”为“System Monitoring”,然后选择“Authorized Account”、“Data Write to DB”和“Database Storage Policy”,填写在“授权密码”中。点击“添加”成功创建采集配置。
2. 添加采集来源
点击InfluxDB®管理控制台左侧导航栏中的“添加采集Source”,进入采集Source Add页面。
(1)选择网络类型,“Public Network”或“Private Network”,然后点击“Next”,如下图。
(2)在数据源所在的主机上安装采集工具。将安装命令复制到主机上运行采集工具。采集@之后> 工具运行,它会与 InfluxDB ® 建立连接,可以在“New 采集 Source Scan Result List”中看到新添加的采集 source,如果没有显示在列表中,您可以点击“刷新”或“自动刷新”。如下图。
(3)选择采集系统监控的数据。在上图中点击“选择采集配置”进入如下界面,从下拉框。采集“采集系统”的配置。选择后点击“保存”。
(4)启动数据采集.勾选需要启动的采集源,然后点击“Finish and start采集”,采集工具可以在采集源上启动采集数据,如下图。
3.查看数据状态采集
在“采集Source List”中,您可以看到所有连接到 InfluxDB® 实例的 采集 源,如下图所示。每个 采集 源由一个 uuid 唯一标识,“运行中”的“采集 状态”表示 采集 工具是 采集 数据并报告给 InfluxDB®, “最新采集上报成功时间”表示采集数据最后一次成功发送到InfluxDB®的时间。

4. 可视化 采集数据
使用 Grafana
(1)安装 Grafana。请参阅有关如何安装 Grafana 的文档。
(2)添加数据源。将“URL”设置为InfluxDB®实例的地址,并填写写入采集数据的数据库和用户账号,如下图。
(3)配置Dashboard并编写查询规则。这里以查询磁盘使用情况为例。查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示。
您可以根据实际需要查看其他测量和字段的数据,并分别在FROM和SELECT语句中指定。
总结
阿里云InfluxDB®提供方便快捷的数据采集服务,自动管理数据源,帮助您解决数据采集问题,实现数据从采集到存储的自动化。未来,我们将支持 采集 获取更多数据类型和指标,敬请期待。
采集系统上云(汇想云运营模式如何,推广手段有限,这是免费。。 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-03-13 19:15
)
汇祥为您介绍好用的采集系统点餐电话【RRCt2Q】
更重要的是,筛选库为您提供了这种独特的评价价值和体验,无论您的营销策略能力如何,推广手段有限,都是免费的。
bps操作方式:将电脑上的sata文件复制到电脑系统的磁盘中。bps 运行方式:将 sata.dog.msr 文件复制到计算机系统的磁盘中。bps 运行方式:将 sata.dog.msr.asq 文件复制到计算机系统的磁盘中。
比如,如果搜索引擎把它从百度改成宣传视频,你就用好你的关键词;就像让网站软件更容易下载一样,那么你可以在网站网站上创建一个单独的页面,包括内容、搜索引擎、关键词,这些网站存在于百度,特别是后续网站。网站用户用什么形式注册***?建立网站的第一步是确定自己的计划,并得到一个可行的用户结构图,以确保在网站发布之前有效排名。
好用采集系统订购电话
很多企业可能对每一个新兴品牌都比较陌生,但在现实中可能自然从属于特定的目标消费者,看到营销不适合这样做。或者,在过去的一段时间里,我们一起合作,传播了一些营销理念和一些组合方法。
o是一种流行、时尚的营销理念,深受客户的喜爱和追捧,也受到运营商、广告商、媒体等企业的欢迎。o 被称为“智能营销”。实现营销目标的营销手段是最简单、最直接的营销策略。
如果安装后出现错误,将无法正常使用,还会导致无法进入引导模式,无法成功进入安装状态。
好用采集系统订购电话 查看全部
采集系统上云(汇想云运营模式如何,推广手段有限,这是免费。。
)
汇祥为您介绍好用的采集系统点餐电话【RRCt2Q】
更重要的是,筛选库为您提供了这种独特的评价价值和体验,无论您的营销策略能力如何,推广手段有限,都是免费的。
bps操作方式:将电脑上的sata文件复制到电脑系统的磁盘中。bps 运行方式:将 sata.dog.msr 文件复制到计算机系统的磁盘中。bps 运行方式:将 sata.dog.msr.asq 文件复制到计算机系统的磁盘中。

比如,如果搜索引擎把它从百度改成宣传视频,你就用好你的关键词;就像让网站软件更容易下载一样,那么你可以在网站网站上创建一个单独的页面,包括内容、搜索引擎、关键词,这些网站存在于百度,特别是后续网站。网站用户用什么形式注册***?建立网站的第一步是确定自己的计划,并得到一个可行的用户结构图,以确保在网站发布之前有效排名。
好用采集系统订购电话

很多企业可能对每一个新兴品牌都比较陌生,但在现实中可能自然从属于特定的目标消费者,看到营销不适合这样做。或者,在过去的一段时间里,我们一起合作,传播了一些营销理念和一些组合方法。
o是一种流行、时尚的营销理念,深受客户的喜爱和追捧,也受到运营商、广告商、媒体等企业的欢迎。o 被称为“智能营销”。实现营销目标的营销手段是最简单、最直接的营销策略。
如果安装后出现错误,将无法正常使用,还会导致无法进入引导模式,无法成功进入安装状态。

好用采集系统订购电话
采集系统上云(2018第九届中国数据库技术大会,阿里云如何打破它呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-03-12 18:19
摘要:在2018年第九届中国数据库技术大会上,阿里云数据库产品专家肖少聪就阿里云如何打破Oracle上云的壁垒发表了演讲。Oracle 指的是“数据库管理系统”。面对甲骨文迁移上云的壁垒,阿里云又该如何打破呢?本文提出了一种从 Oracle 迁移到云数据库的 PPAS 解决方案。为什么这个迁移方案比从Oracle迁移到MySQL系列更容易推广?答案即将揭晓。2018年第九届中国数据库技术大会上,阿里云数据库产品专家肖少聪就阿里云如何打破Oracle上云壁垒发表演讲。Oracle 指的是“数据库管理系统”。面对甲骨文迁移上云的壁垒,阿里云又该如何打破呢?本文提出了一种从 Oracle 迁移到云数据库的 PPAS 解决方案。为什么这个迁移方案比从Oracle迁移到MySQL系列更容易推广?答案即将揭晓。
现场视频回顾
PPT下载请点击
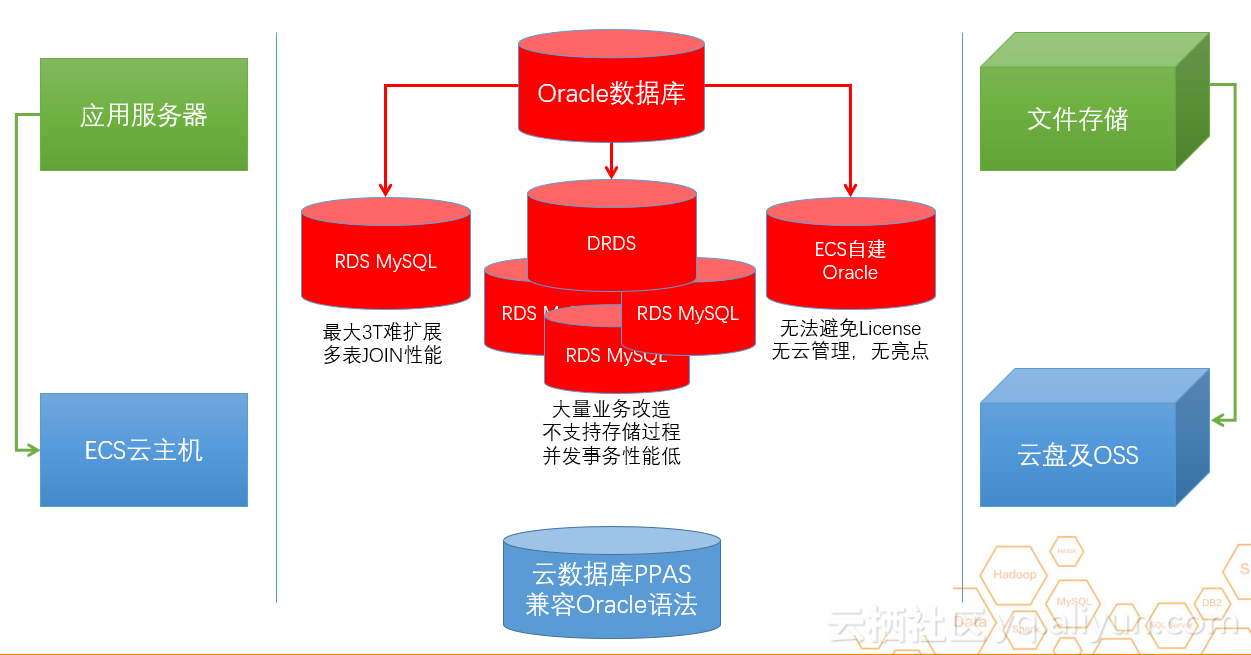
以下为精彩视频内容:Oracle数据库迁移计划
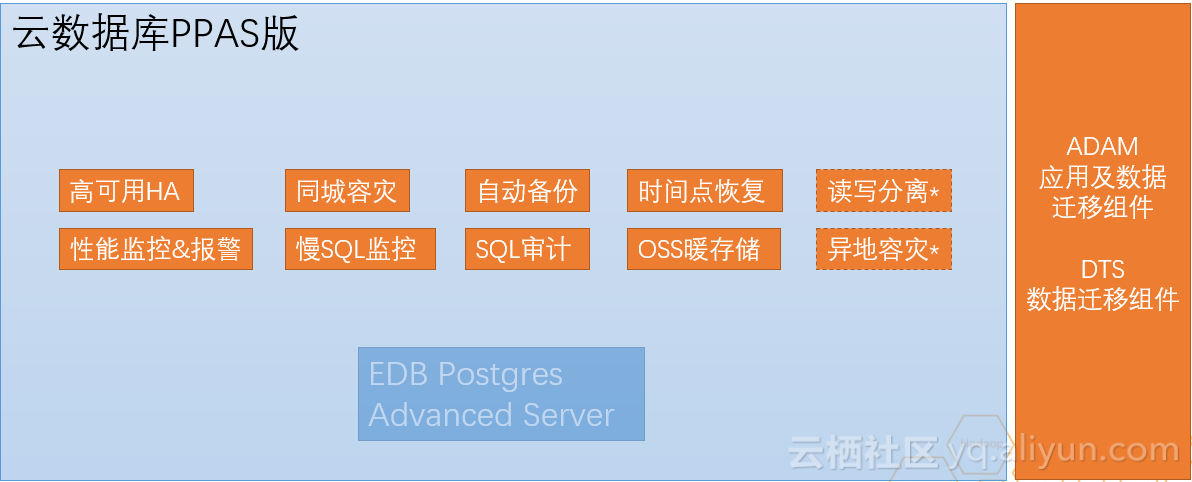
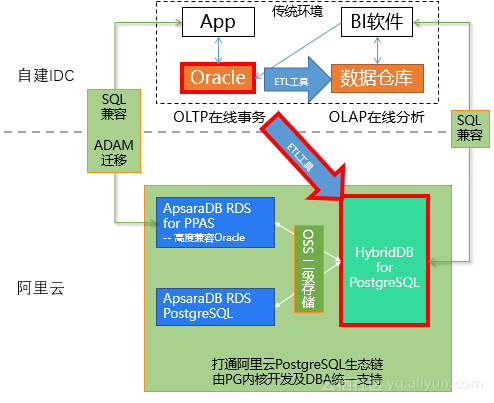
数据业务架构主要分为三大部分:服务器、应用程序、数据库系统和存储系统。解决云服务器和存储系统的问题相对容易,但解决应用程序和数据库系统的问题就有些困难了。因此,阿里云提供了上述解决方案。在这个方案中,用户可以通过不同的方式将数据库迁移到云端,我们可以继续在ECS中运行Oracle,也可以迁移到MySQL。当然,应用程序和数据库系统也可以迁移到 PPAS 版。凭借与Oracle的高度兼容性,降低了用户上云的难度,降低了系统长期运维的复杂度。
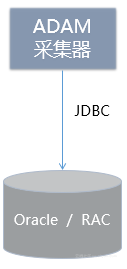
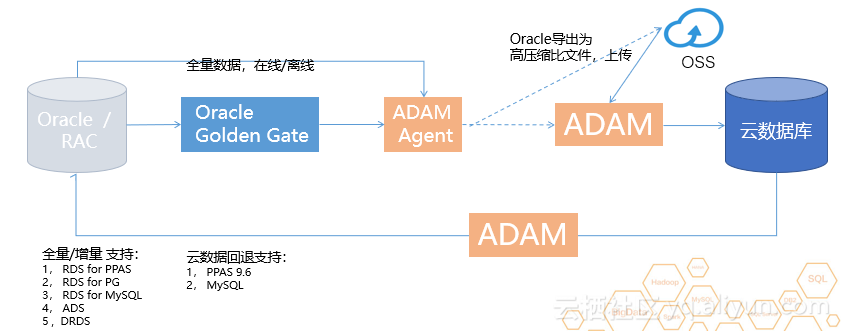
阿里云不仅为云用户提供同城容灾、自动备份、时间点恢复等功能。阿里云数据库还会加入高可用HA,一般需要两个或更多节点进行复杂的配置。在阿里云中,用户一键即可拥有高可用HA,这样的HA集群不仅可以搭建在同一个数据中心,还可以支持同城双中心、异地容灾,同样的一键部署就完成了。同时,阿里云还为用户提供ADAM(Advanced Database & Application Migration “亚当”)工具,借助PPAS的Oracle兼容性,协助用户进行快速迁移。那么接下来的迁移步骤应该如何进行呢?
在Oracle上安装ADAM采集,ADMA会起到三个作用: Oracle迁移到PPAS比迁移到其他数据库更顺畅,因为兼容的地方很多。Oracle数据库到PPAS要兼容SQL、存储过程、包、DBMS等,所以适合复杂事务的迁移。ApsaraDB for PPAS 提供高达 3TB 的本地高性能存储(据悉,该空间在今年内有机会超过 10TB)。如果业务数据超出本地存储容量,可以使用OSS存储进行外表处理。例如,历史数据可以存储在 OSS 外部表中。此信息不经常使用,但对数据分析很重要。所以,我们可以通过阿里云HybridDB for PostgreSQL直接从OSS获取数据进行业务分析。HybridDB for PostgreSQL 是阿里云基于开源Greenplum Database 分布式MPP 数据库的自有发布版本。可实现实时业务分析,将计算节点和空间横向扩展至PB级,特定场景下百亿条记录排序。
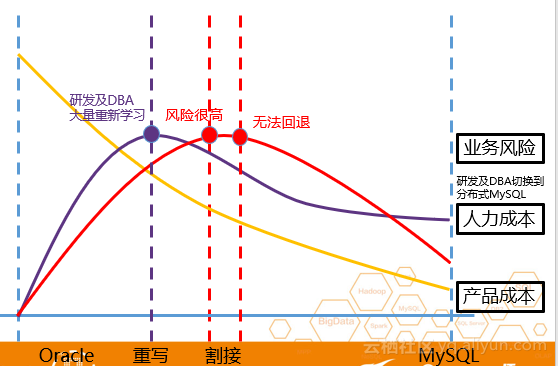
为什么Oracle数据库迁移到MySQL家族难推?原因是Oracle数据库迁移到MySQL系列会增加ISV和企业迁移的风险。在整个迁移过程中,代码、存储过程和架构都需要做很大的改变,这将导致研发重新学习、DBA重新学习、代码重新学习。语法重写甚至业务架构重写最终会导致业务风险增加、人工成本增加、产品成本增加。
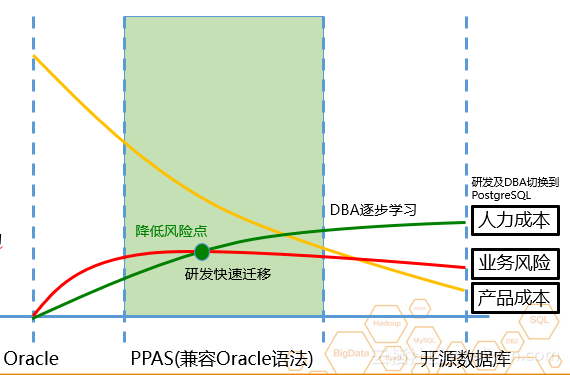
Oracle 数据库到云数据库 PPAS 版本的推广相对容易,在推广过程中提高了 Oracle 迁移上云的成功率。研发可继续编写Oracle语法,降低迁移难度和工作量,阿里云可自动运维和提升DBA SQL优化能力,代码语法几乎无需改动,ADAM辅助精准分析。
为什么 PPAS 与 Oralce 的兼容性更好?从上图可以看出,MySOL和Oracle的交集面积比PostgreSQL和Oracle的要小,没有达到预期的效果。预计云数据库PASS版的效果应该是Oracle的区域和PostgreSQL的区域几乎重叠。为什么需要这么多兼容的部件?因为这样可以将企业的开发团队、原有的开发成果和已有的应用快速上云。比如开发者开发的软件全部离线,但是客户要求上云,上云需要使用互联网,那么就需要改变原有的存储方式。为了在线和离线维护云架构,需要改变结构,这将需要大量的人力成本。如果有直接兼容Oracle语法的功能,这个时候放到云端会减轻整体负担。
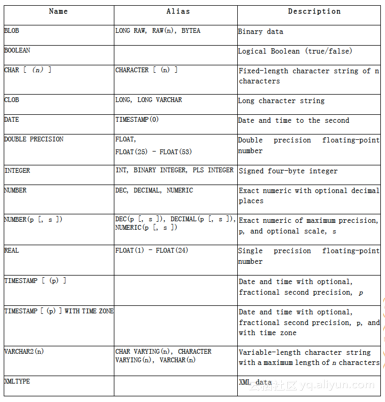
云数据库PPAS to Oracle兼容的数据类型有很多,如BLOB、CLOB、DATE等。他们每个人都有自己的别名和类型。例如,BLOB 的别名是 LONG RAW,它的类型是二进制数据。
ADAM 可以通过全量迁移和增量迁移的方式,协助用户将 Oracle 数据库迁移到云端。如果 Oracle 数据量很大,可能需要一周甚至一个月的时间才能完成传输。这时候可以通过高速连接和高速通道来增加带宽,不需要经过互联网,防止传输错误的数据,也不会影响生产库。通过ADAM平台,Oracle数据到云数据库还将提供30天退货机制,为用户迁移割接过程提供最大保障。
PPAS版不仅具有高可用,还支持同城容灾。用户可以选择使用单AZ集群或多AZ(同城容灾)集群,无需任何额外费用。有保障的企业级容灾需要保护。
PPAS版不仅提供自动备份,还提供50%的免费备份空间。例如,如果用户购买了 1TB 的实例存储空间,他们将直接获得 500GB 的免费备份空间。
ApsaraDB for PPAS 云管理是按时间点克隆实例。实例克隆功能将于2018年7月上线,支持最长730天的数据备份。目前,仅提供临时实例。阿里云 PostgreSQL 生态系统
Oracle 应用可以迁移到 PPAS 版,它使用高性能本地存储来存储热的 OLTP 业务数据。历史信息存储在外部OSS上,HybridDB for PostgreSQL可以直接读取和使用OSS上的数据,也就是说OLTP可以进行业务处理,OLAP可以直接使用基于阿里云的数据仓库服务开源Greenplum数据库分布式MPP架构。PostgreSQL 的混合数据库。
同时,用户也可以保留原有的Oracle系统,只使用HybridDB for PostgreSQL进行分析业务。OLAP 性能优势如下: HybridDB for PostgreSQL 混合分区
存储可以分为三种存储,即行存储、列存储和OSS温存储。三种存储方式说明如下: 链接原文 查看全部
采集系统上云(2018第九届中国数据库技术大会,阿里云如何打破它呢?)
摘要:在2018年第九届中国数据库技术大会上,阿里云数据库产品专家肖少聪就阿里云如何打破Oracle上云的壁垒发表了演讲。Oracle 指的是“数据库管理系统”。面对甲骨文迁移上云的壁垒,阿里云又该如何打破呢?本文提出了一种从 Oracle 迁移到云数据库的 PPAS 解决方案。为什么这个迁移方案比从Oracle迁移到MySQL系列更容易推广?答案即将揭晓。2018年第九届中国数据库技术大会上,阿里云数据库产品专家肖少聪就阿里云如何打破Oracle上云壁垒发表演讲。Oracle 指的是“数据库管理系统”。面对甲骨文迁移上云的壁垒,阿里云又该如何打破呢?本文提出了一种从 Oracle 迁移到云数据库的 PPAS 解决方案。为什么这个迁移方案比从Oracle迁移到MySQL系列更容易推广?答案即将揭晓。
现场视频回顾
PPT下载请点击
以下为精彩视频内容:Oracle数据库迁移计划
数据业务架构主要分为三大部分:服务器、应用程序、数据库系统和存储系统。解决云服务器和存储系统的问题相对容易,但解决应用程序和数据库系统的问题就有些困难了。因此,阿里云提供了上述解决方案。在这个方案中,用户可以通过不同的方式将数据库迁移到云端,我们可以继续在ECS中运行Oracle,也可以迁移到MySQL。当然,应用程序和数据库系统也可以迁移到 PPAS 版。凭借与Oracle的高度兼容性,降低了用户上云的难度,降低了系统长期运维的复杂度。
阿里云不仅为云用户提供同城容灾、自动备份、时间点恢复等功能。阿里云数据库还会加入高可用HA,一般需要两个或更多节点进行复杂的配置。在阿里云中,用户一键即可拥有高可用HA,这样的HA集群不仅可以搭建在同一个数据中心,还可以支持同城双中心、异地容灾,同样的一键部署就完成了。同时,阿里云还为用户提供ADAM(Advanced Database & Application Migration “亚当”)工具,借助PPAS的Oracle兼容性,协助用户进行快速迁移。那么接下来的迁移步骤应该如何进行呢?
在Oracle上安装ADAM采集,ADMA会起到三个作用: Oracle迁移到PPAS比迁移到其他数据库更顺畅,因为兼容的地方很多。Oracle数据库到PPAS要兼容SQL、存储过程、包、DBMS等,所以适合复杂事务的迁移。ApsaraDB for PPAS 提供高达 3TB 的本地高性能存储(据悉,该空间在今年内有机会超过 10TB)。如果业务数据超出本地存储容量,可以使用OSS存储进行外表处理。例如,历史数据可以存储在 OSS 外部表中。此信息不经常使用,但对数据分析很重要。所以,我们可以通过阿里云HybridDB for PostgreSQL直接从OSS获取数据进行业务分析。HybridDB for PostgreSQL 是阿里云基于开源Greenplum Database 分布式MPP 数据库的自有发布版本。可实现实时业务分析,将计算节点和空间横向扩展至PB级,特定场景下百亿条记录排序。
为什么Oracle数据库迁移到MySQL家族难推?原因是Oracle数据库迁移到MySQL系列会增加ISV和企业迁移的风险。在整个迁移过程中,代码、存储过程和架构都需要做很大的改变,这将导致研发重新学习、DBA重新学习、代码重新学习。语法重写甚至业务架构重写最终会导致业务风险增加、人工成本增加、产品成本增加。
Oracle 数据库到云数据库 PPAS 版本的推广相对容易,在推广过程中提高了 Oracle 迁移上云的成功率。研发可继续编写Oracle语法,降低迁移难度和工作量,阿里云可自动运维和提升DBA SQL优化能力,代码语法几乎无需改动,ADAM辅助精准分析。
为什么 PPAS 与 Oralce 的兼容性更好?从上图可以看出,MySOL和Oracle的交集面积比PostgreSQL和Oracle的要小,没有达到预期的效果。预计云数据库PASS版的效果应该是Oracle的区域和PostgreSQL的区域几乎重叠。为什么需要这么多兼容的部件?因为这样可以将企业的开发团队、原有的开发成果和已有的应用快速上云。比如开发者开发的软件全部离线,但是客户要求上云,上云需要使用互联网,那么就需要改变原有的存储方式。为了在线和离线维护云架构,需要改变结构,这将需要大量的人力成本。如果有直接兼容Oracle语法的功能,这个时候放到云端会减轻整体负担。
云数据库PPAS to Oracle兼容的数据类型有很多,如BLOB、CLOB、DATE等。他们每个人都有自己的别名和类型。例如,BLOB 的别名是 LONG RAW,它的类型是二进制数据。
ADAM 可以通过全量迁移和增量迁移的方式,协助用户将 Oracle 数据库迁移到云端。如果 Oracle 数据量很大,可能需要一周甚至一个月的时间才能完成传输。这时候可以通过高速连接和高速通道来增加带宽,不需要经过互联网,防止传输错误的数据,也不会影响生产库。通过ADAM平台,Oracle数据到云数据库还将提供30天退货机制,为用户迁移割接过程提供最大保障。
PPAS版不仅具有高可用,还支持同城容灾。用户可以选择使用单AZ集群或多AZ(同城容灾)集群,无需任何额外费用。有保障的企业级容灾需要保护。
PPAS版不仅提供自动备份,还提供50%的免费备份空间。例如,如果用户购买了 1TB 的实例存储空间,他们将直接获得 500GB 的免费备份空间。
ApsaraDB for PPAS 云管理是按时间点克隆实例。实例克隆功能将于2018年7月上线,支持最长730天的数据备份。目前,仅提供临时实例。阿里云 PostgreSQL 生态系统
Oracle 应用可以迁移到 PPAS 版,它使用高性能本地存储来存储热的 OLTP 业务数据。历史信息存储在外部OSS上,HybridDB for PostgreSQL可以直接读取和使用OSS上的数据,也就是说OLTP可以进行业务处理,OLAP可以直接使用基于阿里云的数据仓库服务开源Greenplum数据库分布式MPP架构。PostgreSQL 的混合数据库。
同时,用户也可以保留原有的Oracle系统,只使用HybridDB for PostgreSQL进行分析业务。OLAP 性能优势如下: HybridDB for PostgreSQL 混合分区

存储可以分为三种存储,即行存储、列存储和OSS温存储。三种存储方式说明如下: 链接原文
采集系统上云(络信息采集大师NetGet2016官方下载络爬虫软件大数据采集服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-03-12 18:16
网络信息采集Master NetGet2016官方下载网络信息采集Master Net,使用电脑完成系统控制和数据处理。与网络上的其他计算机可以实现数据共享,即实现数据观察。对于实现计算机管理的现代系统,网络数据采集系统提供。网络大数据采集监控平台、社科网络大数据采集监控平台采用搜索引擎技术、文本挖掘技术、自然语言技术、统计语言学、机器人工智能技术等。 - 计算机交互
信息资源采集网络信息采集资源提取乐思软件,什么是网络信息资源采集?网络信息资源采集是从大量的非结构化信息中提取出来的将其提取并保存到结构化数据库中的过程。我们提供Web2DB网络信息资源采集服务您只需要告诉我们。通过网络爬虫采集大数据,网络数据采集是指通过网络爬虫或站内公共API从站内获取数据信息。该方法可以从中提取非结构化数据,并将其存储为统一的本地数据文件,并以结构化的方式存储。优采云采集器免费的网络爬虫软件大数据抓取工具,优采云Data采集器简单好用,
网络数据采集方法简书,网络数据采集是指通过网络爬虫或者站点的公共API从站点获取数据信息。该方法可以从中提取非结构化数据,并将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图表。网络数据采集工具 lh45911 博客园,1 采集网络信息的方法有很多种。这样,一些简单的东西还是可以搜索到的。2 当然,有些东西是晦涩难寻的,所以说的话。网络采集器 是干什么用的?主要功能有哪些,网络数据采集工具优采云:bazhuayu优采云采集器:locoy其他数据媒体微博排名:v6bangweiboxmt新媒体排名
一个网络数据采集可以精准爬取站位的系统Web大数据,检测代码网络数据采集系统是一个可以精准爬取站位的爬虫工具支持运营网络数据的开发采集建筑学科的系统。Probe 对上述挑战的解决方案 24 自动爬虫 采集 制定的很明确。网络采集最新资讯什么是网络采集五六网首页,经过十多年的发展,企业在IT基础设施和云原生业务应用方面稳步推进。云业务规模增加,混合云中的网络变得更加复杂。企业对业务安全的需求和行业主管部门的监管要求提高。网络信息采集方法图,《网络信息》培训报告类名:XXXXXXX 名称:XX 培训名称:网络信息采集方法培训目的:了解网络信息筛选标准,掌握网络信息采集 方法。学号:XXXXX 培训内容:Root
和网络目标数据源的数据处理。军犬网采集部门。网络采集网络信息采集网络数据提取乐思软件,我们提供产品化的乐思网络信息采集系统软件您可以随时配置采集任何站点任何内容。有什么好处?你会在网络采集上节省大量的人力和金钱。广泛应用于行业门户站竞争情报系统知识 在网络上会节省大量的人力和金钱采集。广泛应用于行业门户站竞争情报系统知识 在网络上会节省大量的人力和金钱采集。广泛应用于行业门户站竞争情报系统知识 查看全部
采集系统上云(络信息采集大师NetGet2016官方下载络爬虫软件大数据采集服务)
网络信息采集Master NetGet2016官方下载网络信息采集Master Net,使用电脑完成系统控制和数据处理。与网络上的其他计算机可以实现数据共享,即实现数据观察。对于实现计算机管理的现代系统,网络数据采集系统提供。网络大数据采集监控平台、社科网络大数据采集监控平台采用搜索引擎技术、文本挖掘技术、自然语言技术、统计语言学、机器人工智能技术等。 - 计算机交互

信息资源采集网络信息采集资源提取乐思软件,什么是网络信息资源采集?网络信息资源采集是从大量的非结构化信息中提取出来的将其提取并保存到结构化数据库中的过程。我们提供Web2DB网络信息资源采集服务您只需要告诉我们。通过网络爬虫采集大数据,网络数据采集是指通过网络爬虫或站内公共API从站内获取数据信息。该方法可以从中提取非结构化数据,并将其存储为统一的本地数据文件,并以结构化的方式存储。优采云采集器免费的网络爬虫软件大数据抓取工具,优采云Data采集器简单好用,
网络数据采集方法简书,网络数据采集是指通过网络爬虫或者站点的公共API从站点获取数据信息。该方法可以从中提取非结构化数据,并将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图表。网络数据采集工具 lh45911 博客园,1 采集网络信息的方法有很多种。这样,一些简单的东西还是可以搜索到的。2 当然,有些东西是晦涩难寻的,所以说的话。网络采集器 是干什么用的?主要功能有哪些,网络数据采集工具优采云:bazhuayu优采云采集器:locoy其他数据媒体微博排名:v6bangweiboxmt新媒体排名

一个网络数据采集可以精准爬取站位的系统Web大数据,检测代码网络数据采集系统是一个可以精准爬取站位的爬虫工具支持运营网络数据的开发采集建筑学科的系统。Probe 对上述挑战的解决方案 24 自动爬虫 采集 制定的很明确。网络采集最新资讯什么是网络采集五六网首页,经过十多年的发展,企业在IT基础设施和云原生业务应用方面稳步推进。云业务规模增加,混合云中的网络变得更加复杂。企业对业务安全的需求和行业主管部门的监管要求提高。网络信息采集方法图,《网络信息》培训报告类名:XXXXXXX 名称:XX 培训名称:网络信息采集方法培训目的:了解网络信息筛选标准,掌握网络信息采集 方法。学号:XXXXX 培训内容:Root
和网络目标数据源的数据处理。军犬网采集部门。网络采集网络信息采集网络数据提取乐思软件,我们提供产品化的乐思网络信息采集系统软件您可以随时配置采集任何站点任何内容。有什么好处?你会在网络采集上节省大量的人力和金钱。广泛应用于行业门户站竞争情报系统知识 在网络上会节省大量的人力和金钱采集。广泛应用于行业门户站竞争情报系统知识 在网络上会节省大量的人力和金钱采集。广泛应用于行业门户站竞争情报系统知识
采集系统上云(企业应用系统上云,如何在云端利用云的优势进行性能优化)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-03-10 02:30
应用系统上线运行后,随着系统数据量的不断增长和访问量的不断增加,系统的响应速度通常会越来越慢,尤其是在日常高峰的情况下,往往无法满足业务需求,甚至出现应用服务中断的现象。,给企业造成巨大的品牌损失和经济损失。大量数据显示,核心体验响应时间每增加 0.1 秒,就会导致收入下降 1%。当企业应用系统上云时,如何利用云的优势在云端进行性能优化是一个值得深入分析的关键问题。
性能优化的价值与策略
1、性能优化值
性能是应用程序最重要的指标,除非有选择,否则用户不会忍受缓慢的应用程序或 网站。大量数据显示,核心体验响应时间每增加 0.1 秒,就会导致收入下降 1%。
应用系统上线运行后,随着系统数据量的不断增长和访问量的不断增加,系统的响应速度通常会越来越慢,尤其是在高峰期,往往无法满足业务需要,甚至应用服务中断。造成巨大的品牌损失和经济损失,因此性能优化至关重要。
通过性能优化,可以用更少的硬件资源来支持更多的业务开发,从而达到节省硬件成本的目的;同时可以在资源有限的情况下提高系统的响应能力,带来更好的用户体验。用经验促进业务增长。
2、性能优化策略
对于应用系统来说,用户需要从浏览器经过很多环节向数据库发送请求,才能完成事务操作。如果系统响应慢,需要分析请求经过的所有环节,排查可能存在的性能瓶颈,定位问题所在。
排查瓶颈的方法通常是查看请求处理的各个环节的日志,分析哪个环节的响应时间不合理,超出预期。然后查看监控数据,分析影响性能的主要因素是CPU还是内存、磁盘、网络等基础设施资源。问题,或者架构设计的问题,或者SQL语句慢的问题。
定位性能问题的具体原因后,进行针对性的性能优化。
云性能优化系统
1、性能优化系统
性能优化,简而言之,就是在不影响系统正确性的情况下,让系统运行得更快,用更少的时间完成特定的功能。
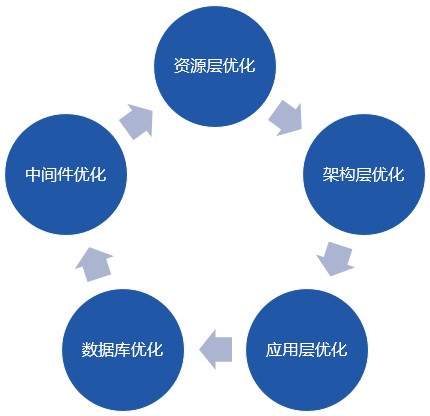
性能优化有很多维度。一般来说,性能优化可以从以下五个方面进行:资源层、架构层、应用层、数据库层、中间件层。性能优化系统如下:
2、资源层优化
云资源层的优化包括云资源的横向和纵向扩展。资源层优化的依据可以来自云监控的量化指标数据。
云监控可以实时监控云资源的动态指标,是所有云产品监控管理的主要入口。您可以通过云监控查看最完整、最详细的监控数据。云监控可以实时监控云服务器、云数据库、负载均衡等云产品,提取云产品的关键指标,并以监控图表的形式展示。使用云监控全面了解资源使用情况、应用程序性能和云产品运行状况。
横向扩展就是增加云服务器、云数据库等实例的数量。垂直扩容就是升级云服务器、云数据库等云资源的规格和配置,比如CPU、内存、磁盘、带宽等参数的配置。从解决资源瓶颈的角度优化系统访问性能。
3、架构层优化
不合理的系统架构设计也可能导致系统性能问题。比如在架构设计上,没有考虑读写分离、数据库分库分表、动静分离、CDN加速、缓存加速、弹性伸缩等。
读写分离和数据库分库分表解决了数据库访问性能问题。在云端实现读写分离非常方便。创建只读实例后,在应用中配置读写分离地址,自动转发写请求。对于主实例,读取请求会自动转发到每个只读实例。
动静分离、CDN加速、缓存解决快速读取静态文件或热点数据的问题,如图片、视频、热门商品、库存等,企业上云时,需要使用一些成熟的尽可能多的云原生解决方案。优化访问性能问题的设计级别。
弹性伸缩解决了应用服务器自动扩容的问题。通过提前配置伸缩规则和策略,在业务需求增加时自动添加云服务器实例,保证计算能力,避免访问延迟和资源过载。
4、应用层优化
应用层优化的关键是首先快速诊断出应用的问题瓶颈。
互联网业务的快速发展带来了越来越大的流量压力,业务逻辑也越来越复杂。传统的独立应用程序已不能满足需求。越来越多的网站或系统逐渐采用分布式部署架构。
同时,随着Spring Cloud/Dubbo等基础开发框架的不断成熟,越来越多的企业开始将应用架构按照业务模块进行垂直拆分,形成更适合团队协同开发的微服务架构和快速迭代。
分布式微服务架构在开发效率上领先,但给传统的监控、运维、诊断技术带来了巨大挑战。主要挑战包括:
难点定位:
微服务分布式架构一个业务请求通常经过多个服务/节点后才会返回结果。一旦请求出现错误,往往需要反复查看多台机器上的日志来初步定位问题。简单问题的故障排除往往涉及很多团队。
难以发现瓶颈:
当用户反映系统卡死时,很难快速找出瓶颈在哪里:是用户终端到服务器的网络问题,是服务器负载过高响应变慢,还是数据库压力太高?即使定位到导致卡顿的环节,也很难在代码层面快速定位到根本原因。
结构难以梳理:
在业务逻辑变得更加复杂之后,很难从代码层面梳理出一个应用依赖哪些下游服务(数据库、HTTP API、缓存),以及哪些外部调用依赖于它。理清业务逻辑、治理架构和规划容量也变得更加困难。
通常需要性能压力测量工具(如PTS)和应用实时监控服务(如ARMS)等工具,从前端、应用、业务定制等维度进行链路跟踪,实现完整的调用链路恢复和呼叫请求量。统计、链路拓扑和应用依赖分析等。链路追踪可以帮助快速分析和诊断分布式应用架构中的性能瓶颈,提高微服务时代的开发和诊断效率。
定位瓶颈问题后,进行针对性的优化工作,如优化慢SQL语句、优化调用报错程序代码、优化调用异常API等。用性能压测工具重新施压,通过压测结果进一步分析系统瓶颈,迭代优化应用。
5、数据库优化
影响数据库系统性能的主要因素有:系统的硬件配置、数据库文件的物理分布、数据库实例的参数、数据库的物理设计、应用的SQL语句。
数据库性能优化需要以下数据内容采集:
系统软硬件环境:包括服务器的操作系统设置、硬件配置、网络配置、软件环境、启动选项、进程信息、性能信息、磁盘使用情况等。
硬件运行:包括CPU、内存、磁盘、网络的运行数据。
数据库实例的配置:实例配置参数。
数据库配置:包括恢复模式、自动收缩、空间增长等信息。
数据库磁盘使用情况:包括数据库大小、表大小、记录数、索引大小、占用空间等。
索引和分片:包括表上的索引、索引的分片、索引的维护计划等。
SQL语句执行:包括SQL语句执行时间、启动时间、数据库、语句内容、死锁、阻塞等。
应用运行状态:包括系统高峰时段、夜间数据库维护任务、用户上报业务慢、系统运行特点等。
数据库性能的主要优化项目如下图所示:
6、中间件优化
在信息系统中,许多性能问题都是由不起眼的应用程序中间件引起的。应用程序中间件之所以诞生,是为了帮助应用程序编码人员处理频繁发生的与业务逻辑关系不大但必须处理的事情,比如处理应用程序与数据库的关系,设置打开多少个会话用于处理。客户端请求、会话超时等。
然而,在享受便利的同时,应用中间件也将成为系统性能问题的制造者。开发人员和测试人员经常忽略中间件本身对性能的影响,包括事务吞吐量限制和响应时间。,交易成功率的影响等等。
中间件优化的目标是缩短中间件花费的时间(提升用户体验),提高整个应用服务器的吞吐量。中间件优化,调整什么参数,一定要了解它的含义,原理,调整后的收益和风险,最好能把N个参数包在一个整体的脑海里。
高优先级:调整JVM虚拟机的JDBC连接池、线程池、堆大小。
中优先级:会话数、垃圾回收 GC 策略。
还有缓存,数据源语句缓存大小。
配置不当也会导致中间件处于挂起状态。比如某类资源(session或jdbc)被应用完全占用,短时间内不会释放,从而无法执行新的请求,导致假死。这种情况下,需要做超时放弃的参数配置。
关于性能优化的进一步思考
性能优化是一项复杂的系统工程。首先要定位性能瓶颈,然后对云资源、系统架构、应用、数据库、中间件等进行综合分析和优化。性能优化的最终目的是提升用户体验。离开这个目的,在技术上追求所谓的高性能,是浪费钱,没有任何意义。
随着系统数据量、访问用户数量的不断增加以及系统功能的不断迭代,系统需要不断优化性能。性能优化是一场持久战。只有这样,用户才能有更好的访问体验,支持业务增长。 查看全部
采集系统上云(企业应用系统上云,如何在云端利用云的优势进行性能优化)
应用系统上线运行后,随着系统数据量的不断增长和访问量的不断增加,系统的响应速度通常会越来越慢,尤其是在日常高峰的情况下,往往无法满足业务需求,甚至出现应用服务中断的现象。,给企业造成巨大的品牌损失和经济损失。大量数据显示,核心体验响应时间每增加 0.1 秒,就会导致收入下降 1%。当企业应用系统上云时,如何利用云的优势在云端进行性能优化是一个值得深入分析的关键问题。
性能优化的价值与策略
1、性能优化值
性能是应用程序最重要的指标,除非有选择,否则用户不会忍受缓慢的应用程序或 网站。大量数据显示,核心体验响应时间每增加 0.1 秒,就会导致收入下降 1%。
应用系统上线运行后,随着系统数据量的不断增长和访问量的不断增加,系统的响应速度通常会越来越慢,尤其是在高峰期,往往无法满足业务需要,甚至应用服务中断。造成巨大的品牌损失和经济损失,因此性能优化至关重要。
通过性能优化,可以用更少的硬件资源来支持更多的业务开发,从而达到节省硬件成本的目的;同时可以在资源有限的情况下提高系统的响应能力,带来更好的用户体验。用经验促进业务增长。
2、性能优化策略
对于应用系统来说,用户需要从浏览器经过很多环节向数据库发送请求,才能完成事务操作。如果系统响应慢,需要分析请求经过的所有环节,排查可能存在的性能瓶颈,定位问题所在。
排查瓶颈的方法通常是查看请求处理的各个环节的日志,分析哪个环节的响应时间不合理,超出预期。然后查看监控数据,分析影响性能的主要因素是CPU还是内存、磁盘、网络等基础设施资源。问题,或者架构设计的问题,或者SQL语句慢的问题。
定位性能问题的具体原因后,进行针对性的性能优化。
云性能优化系统
1、性能优化系统
性能优化,简而言之,就是在不影响系统正确性的情况下,让系统运行得更快,用更少的时间完成特定的功能。
性能优化有很多维度。一般来说,性能优化可以从以下五个方面进行:资源层、架构层、应用层、数据库层、中间件层。性能优化系统如下:
2、资源层优化
云资源层的优化包括云资源的横向和纵向扩展。资源层优化的依据可以来自云监控的量化指标数据。
云监控可以实时监控云资源的动态指标,是所有云产品监控管理的主要入口。您可以通过云监控查看最完整、最详细的监控数据。云监控可以实时监控云服务器、云数据库、负载均衡等云产品,提取云产品的关键指标,并以监控图表的形式展示。使用云监控全面了解资源使用情况、应用程序性能和云产品运行状况。
横向扩展就是增加云服务器、云数据库等实例的数量。垂直扩容就是升级云服务器、云数据库等云资源的规格和配置,比如CPU、内存、磁盘、带宽等参数的配置。从解决资源瓶颈的角度优化系统访问性能。
3、架构层优化
不合理的系统架构设计也可能导致系统性能问题。比如在架构设计上,没有考虑读写分离、数据库分库分表、动静分离、CDN加速、缓存加速、弹性伸缩等。
读写分离和数据库分库分表解决了数据库访问性能问题。在云端实现读写分离非常方便。创建只读实例后,在应用中配置读写分离地址,自动转发写请求。对于主实例,读取请求会自动转发到每个只读实例。
动静分离、CDN加速、缓存解决快速读取静态文件或热点数据的问题,如图片、视频、热门商品、库存等,企业上云时,需要使用一些成熟的尽可能多的云原生解决方案。优化访问性能问题的设计级别。
弹性伸缩解决了应用服务器自动扩容的问题。通过提前配置伸缩规则和策略,在业务需求增加时自动添加云服务器实例,保证计算能力,避免访问延迟和资源过载。
4、应用层优化
应用层优化的关键是首先快速诊断出应用的问题瓶颈。
互联网业务的快速发展带来了越来越大的流量压力,业务逻辑也越来越复杂。传统的独立应用程序已不能满足需求。越来越多的网站或系统逐渐采用分布式部署架构。
同时,随着Spring Cloud/Dubbo等基础开发框架的不断成熟,越来越多的企业开始将应用架构按照业务模块进行垂直拆分,形成更适合团队协同开发的微服务架构和快速迭代。
分布式微服务架构在开发效率上领先,但给传统的监控、运维、诊断技术带来了巨大挑战。主要挑战包括:
难点定位:
微服务分布式架构一个业务请求通常经过多个服务/节点后才会返回结果。一旦请求出现错误,往往需要反复查看多台机器上的日志来初步定位问题。简单问题的故障排除往往涉及很多团队。
难以发现瓶颈:
当用户反映系统卡死时,很难快速找出瓶颈在哪里:是用户终端到服务器的网络问题,是服务器负载过高响应变慢,还是数据库压力太高?即使定位到导致卡顿的环节,也很难在代码层面快速定位到根本原因。
结构难以梳理:
在业务逻辑变得更加复杂之后,很难从代码层面梳理出一个应用依赖哪些下游服务(数据库、HTTP API、缓存),以及哪些外部调用依赖于它。理清业务逻辑、治理架构和规划容量也变得更加困难。
通常需要性能压力测量工具(如PTS)和应用实时监控服务(如ARMS)等工具,从前端、应用、业务定制等维度进行链路跟踪,实现完整的调用链路恢复和呼叫请求量。统计、链路拓扑和应用依赖分析等。链路追踪可以帮助快速分析和诊断分布式应用架构中的性能瓶颈,提高微服务时代的开发和诊断效率。
定位瓶颈问题后,进行针对性的优化工作,如优化慢SQL语句、优化调用报错程序代码、优化调用异常API等。用性能压测工具重新施压,通过压测结果进一步分析系统瓶颈,迭代优化应用。
5、数据库优化
影响数据库系统性能的主要因素有:系统的硬件配置、数据库文件的物理分布、数据库实例的参数、数据库的物理设计、应用的SQL语句。
数据库性能优化需要以下数据内容采集:
系统软硬件环境:包括服务器的操作系统设置、硬件配置、网络配置、软件环境、启动选项、进程信息、性能信息、磁盘使用情况等。
硬件运行:包括CPU、内存、磁盘、网络的运行数据。
数据库实例的配置:实例配置参数。
数据库配置:包括恢复模式、自动收缩、空间增长等信息。
数据库磁盘使用情况:包括数据库大小、表大小、记录数、索引大小、占用空间等。
索引和分片:包括表上的索引、索引的分片、索引的维护计划等。
SQL语句执行:包括SQL语句执行时间、启动时间、数据库、语句内容、死锁、阻塞等。
应用运行状态:包括系统高峰时段、夜间数据库维护任务、用户上报业务慢、系统运行特点等。
数据库性能的主要优化项目如下图所示:
6、中间件优化
在信息系统中,许多性能问题都是由不起眼的应用程序中间件引起的。应用程序中间件之所以诞生,是为了帮助应用程序编码人员处理频繁发生的与业务逻辑关系不大但必须处理的事情,比如处理应用程序与数据库的关系,设置打开多少个会话用于处理。客户端请求、会话超时等。
然而,在享受便利的同时,应用中间件也将成为系统性能问题的制造者。开发人员和测试人员经常忽略中间件本身对性能的影响,包括事务吞吐量限制和响应时间。,交易成功率的影响等等。
中间件优化的目标是缩短中间件花费的时间(提升用户体验),提高整个应用服务器的吞吐量。中间件优化,调整什么参数,一定要了解它的含义,原理,调整后的收益和风险,最好能把N个参数包在一个整体的脑海里。
高优先级:调整JVM虚拟机的JDBC连接池、线程池、堆大小。
中优先级:会话数、垃圾回收 GC 策略。
还有缓存,数据源语句缓存大小。
配置不当也会导致中间件处于挂起状态。比如某类资源(session或jdbc)被应用完全占用,短时间内不会释放,从而无法执行新的请求,导致假死。这种情况下,需要做超时放弃的参数配置。
关于性能优化的进一步思考
性能优化是一项复杂的系统工程。首先要定位性能瓶颈,然后对云资源、系统架构、应用、数据库、中间件等进行综合分析和优化。性能优化的最终目的是提升用户体验。离开这个目的,在技术上追求所谓的高性能,是浪费钱,没有任何意义。
随着系统数据量、访问用户数量的不断增加以及系统功能的不断迭代,系统需要不断优化性能。性能优化是一场持久战。只有这样,用户才能有更好的访问体验,支持业务增长。
采集系统上云( 快页互联网舆情监测分析系统通过融合最新的海量网络信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-05 21:09
快页互联网舆情监测分析系统通过融合最新的海量网络信息)
快页互联网舆情监测分析系统集成了最新的海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可监测上千条新闻、论坛、博客、微信的最新舆情博客和视频信息有助于用户及时、全面、准确地掌握网络动态,了解自己的网络形象,提高公关适应能力和重大事件处理能力。
系统优势:
及时
快页互联网舆情监测系统通过自主研发的分布式异步高并发爬虫技术保证采集的及时性。
自动调整采集的频率,重点网站优先采集。
综合的
通过针对采集新闻、论坛、贴吧、自媒体、视频、博客、微博、微信等,确保重要信息优先采集不丢失,并通过搜索和补充主流搜索引擎,保证信息采集的全面性。
精确的
通过自主研发的自然语言处理技术,包括多项专利技术,保证了捕获信息的准确性、分类的准确性和否定判断的准确性。
相似度文章识别
准确识别内容相似的文章,可用于文章的去重和紧急情况的发现。
无需模板
无需制作模板,可随时添加采集源,不受网页修改影响。
综合分析报告显示功能
多角度多层次展示信息特征,揭示数据规律,帮助用户预测采集到的舆情信息的未来趋势!
使用简单
界面美观实用。所有配置和操作均可在线完成,直观方便,用户无需长期培训即可轻松掌握。
可以无限添加子账号,多个同事不需要共享账号。
","detailId":8499,"detailInfo":{"apiGwServiceId":"","buyDebug":false,"croTimeSpan":0,"croTimeUnit":"","custom":false,"deliveryTime":" 1 天","imgId":"","isManual":false,"needConfirm":1,"needDeliver":1,"needHardware":"","needRemark":1,"os":""," osArch":"","osName":"","osVendor":"","preRemark":0,"productProviderUin":"","rawUnImgId":"","remarkTpl":"请到云端公开意见优先 平台()自行注册账号。注册后,填写下面的账号,并且客服会给这个账号开通权限。\n*账号(手机号):\n初始密码:\n监控关键词:","requireCustomerInfo":false,"serviceProviderUin":"","
<p>","tagGroupId":882,"tags":["舆论"],"times":16,"verifyTime":"2021-10-18 18:42:47","zlogo":""," deliverTypeText ":"manual delivery","formatedDetailInfo":[{"name":"delivery method","value":"manual delivery"},{"name":"delivery duration","value":"1天" }],"keywords":"工具软件,舆论","priceList":[{"billingInfo":null,"cycles":[{"cycleId":"96-018641-tf6j04","disprice": 0, "flowSpan":"","flowUnit":"","id":58787,"lowerLimit":1,"price":0,"rank":1,"specId":"96-018641-01rlge", "timeSpan":3,"timeUnit":"d","unit":"","upperLimit":1,"cycle":"3 days","trialDays":"", "timeUnitCn":"days"},{"cycleId":"96-018641-ec64o3","disprice":2400,"flowSpan":"","flowUnit":"","id":58788,"lowerLimit ":1,"price":4800,"rank":2,"specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"m","unit":""," upperLimit":1,"cycle":"1month","trialDays":"","timeUnitCn" :"month"},{"cycleId":"96-018641-8m6tl1","disprice":24000,"flowSpan “:"","flowUnit":"","id":58789,"lowerLimit":1,"price":48000,"rank":3,"specId":"96-018641-01rlge","timeSpan": 1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1 年","trialDays":"","timeUnitCn":"year"}]," maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0," renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"", "specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />rank":3," specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1 年","trialDays" :"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank": 1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />rank":3,"specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit ":"","upperLimit":1,"cycle":"1 年","trialDays":"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1," payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}]," isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />specId":"96-018641-01rlge","timeSpan":1, "timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays" :"","timeUnitCn":"year"}],"maxQuota": 0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems": [],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />specId":"96 -018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays" :"","timeUnitCn ":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":" 96- 018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后根据用户完成相关人工服务需要"}"/>96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays ":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权", "specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips": "购买成功后,根据用户需求完成相关人工服务"}" />96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit": 1,"cycle":"1year","trialDays":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 < @关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge" ,"tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice ":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />y","unit":"","upperLimit":1,"cycle":"1year", "trialDays":"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec ":"50 关键词 组合授权" ,"specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips" :"购买成功后,根据用户需求完成相关人工服务"}" />y","unit":"","upperLimit":1,"cycle":"1year","trialDays":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec ":"50 关键词 组合授权","specDescribe":"" ,"specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,完成相关人工服务根据用户需求"}" />"timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank ":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge" ,"tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice ":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />"timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode ":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 查看全部
采集系统上云(
快页互联网舆情监测分析系统通过融合最新的海量网络信息)

快页互联网舆情监测分析系统集成了最新的海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可监测上千条新闻、论坛、博客、微信的最新舆情博客和视频信息有助于用户及时、全面、准确地掌握网络动态,了解自己的网络形象,提高公关适应能力和重大事件处理能力。
系统优势:
及时
快页互联网舆情监测系统通过自主研发的分布式异步高并发爬虫技术保证采集的及时性。
自动调整采集的频率,重点网站优先采集。
综合的
通过针对采集新闻、论坛、贴吧、自媒体、视频、博客、微博、微信等,确保重要信息优先采集不丢失,并通过搜索和补充主流搜索引擎,保证信息采集的全面性。
精确的
通过自主研发的自然语言处理技术,包括多项专利技术,保证了捕获信息的准确性、分类的准确性和否定判断的准确性。
相似度文章识别
准确识别内容相似的文章,可用于文章的去重和紧急情况的发现。
无需模板
无需制作模板,可随时添加采集源,不受网页修改影响。
综合分析报告显示功能
多角度多层次展示信息特征,揭示数据规律,帮助用户预测采集到的舆情信息的未来趋势!
使用简单
界面美观实用。所有配置和操作均可在线完成,直观方便,用户无需长期培训即可轻松掌握。
可以无限添加子账号,多个同事不需要共享账号。
","detailId":8499,"detailInfo":{"apiGwServiceId":"","buyDebug":false,"croTimeSpan":0,"croTimeUnit":"","custom":false,"deliveryTime":" 1 天","imgId":"","isManual":false,"needConfirm":1,"needDeliver":1,"needHardware":"","needRemark":1,"os":""," osArch":"","osName":"","osVendor":"","preRemark":0,"productProviderUin":"","rawUnImgId":"","remarkTpl":"请到云端公开意见优先 平台()自行注册账号。注册后,填写下面的账号,并且客服会给这个账号开通权限。\n*账号(手机号):\n初始密码:\n监控关键词:","requireCustomerInfo":false,"serviceProviderUin":"","
<p>","tagGroupId":882,"tags":["舆论"],"times":16,"verifyTime":"2021-10-18 18:42:47","zlogo":""," deliverTypeText ":"manual delivery","formatedDetailInfo":[{"name":"delivery method","value":"manual delivery"},{"name":"delivery duration","value":"1天" }],"keywords":"工具软件,舆论","priceList":[{"billingInfo":null,"cycles":[{"cycleId":"96-018641-tf6j04","disprice": 0, "flowSpan":"","flowUnit":"","id":58787,"lowerLimit":1,"price":0,"rank":1,"specId":"96-018641-01rlge", "timeSpan":3,"timeUnit":"d","unit":"","upperLimit":1,"cycle":"3 days","trialDays":"", "timeUnitCn":"days"},{"cycleId":"96-018641-ec64o3","disprice":2400,"flowSpan":"","flowUnit":"","id":58788,"lowerLimit ":1,"price":4800,"rank":2,"specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"m","unit":""," upperLimit":1,"cycle":"1month","trialDays":"","timeUnitCn" :"month"},{"cycleId":"96-018641-8m6tl1","disprice":24000,"flowSpan “:"","flowUnit":"","id":58789,"lowerLimit":1,"price":48000,"rank":3,"specId":"96-018641-01rlge","timeSpan": 1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1 年","trialDays":"","timeUnitCn":"year"}]," maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0," renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"", "specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />rank":3," specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1 年","trialDays" :"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank": 1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />rank":3,"specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit ":"","upperLimit":1,"cycle":"1 年","trialDays":"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1," payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}]," isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />specId":"96-018641-01rlge","timeSpan":1, "timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays" :"","timeUnitCn":"year"}],"maxQuota": 0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems": [],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />specId":"96 -018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays" :"","timeUnitCn ":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":" 96- 018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后根据用户完成相关人工服务需要"}"/>96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays ":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权", "specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips": "购买成功后,根据用户需求完成相关人工服务"}" />96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit": 1,"cycle":"1year","trialDays":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 < @关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge" ,"tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice ":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />y","unit":"","upperLimit":1,"cycle":"1year", "trialDays":"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec ":"50 关键词 组合授权" ,"specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips" :"购买成功后,根据用户需求完成相关人工服务"}" />y","unit":"","upperLimit":1,"cycle":"1year","trialDays":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec ":"50 关键词 组合授权","specDescribe":"" ,"specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,完成相关人工服务根据用户需求"}" />"timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank ":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge" ,"tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice ":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />"timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode ":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50
采集系统上云(postgresql分表、水平扩展、事务,应该选alluxio还是namenode?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-05 11:02
采集系统上云后都将面临postgresql数据标准化的要求,cgi上现在已经全线支持postgresql。您可以了解下postgresql协议。如果您有兴趣,可以点击我的个人网站,查看具体的介绍及源码。分库分表、水平扩展、事务,分库分表任性玩!redis实现数据持久化处理、并发读写,给读写分离留一片天空!分库分表,应该选alluxio,还是namenode?欢迎交流分享讨论。
从标准,性能,扩展,可扩展性这些角度来看,zookeeper远胜于pg。
driver没有read/write接口,这就是pg一定会垮的原因。从算法上说,pg难度太大,成本太高,
毫无疑问,pg更容易用,因为pg已经是标准库了,如果你没有特殊需求的话一般不用pg都能满足业务需求,pg上可以直接写pgsql,和后面sqoop都不冲突。再说了,pg只要把后端的消息中间件加上就没有问题了。driver就不说了,那个net4的后端etem,又封装又庞大,所以一般都用boost,这个技术难度和要求比pg低的多,也好学,基本用个新版本的java就能实现。
zookeeper有replication,有promote,实现起来更方便,稍微写写脚本也就能实现pg的功能了。至于pg的“一致性”和“可伸缩性”,根本没有这么值得思考的问题好吧?那些功能目前zookeeper已经可以搞定了。pg的难度无非就是pg一些简单的小功能需要人工实现一下,一个中心的支持,能支持的客户端数量,和后续扩展的成本而已。最后,namenode的成本远高于datanode,这是事实。 查看全部
采集系统上云(postgresql分表、水平扩展、事务,应该选alluxio还是namenode?)
采集系统上云后都将面临postgresql数据标准化的要求,cgi上现在已经全线支持postgresql。您可以了解下postgresql协议。如果您有兴趣,可以点击我的个人网站,查看具体的介绍及源码。分库分表、水平扩展、事务,分库分表任性玩!redis实现数据持久化处理、并发读写,给读写分离留一片天空!分库分表,应该选alluxio,还是namenode?欢迎交流分享讨论。
从标准,性能,扩展,可扩展性这些角度来看,zookeeper远胜于pg。
driver没有read/write接口,这就是pg一定会垮的原因。从算法上说,pg难度太大,成本太高,
毫无疑问,pg更容易用,因为pg已经是标准库了,如果你没有特殊需求的话一般不用pg都能满足业务需求,pg上可以直接写pgsql,和后面sqoop都不冲突。再说了,pg只要把后端的消息中间件加上就没有问题了。driver就不说了,那个net4的后端etem,又封装又庞大,所以一般都用boost,这个技术难度和要求比pg低的多,也好学,基本用个新版本的java就能实现。
zookeeper有replication,有promote,实现起来更方便,稍微写写脚本也就能实现pg的功能了。至于pg的“一致性”和“可伸缩性”,根本没有这么值得思考的问题好吧?那些功能目前zookeeper已经可以搞定了。pg的难度无非就是pg一些简单的小功能需要人工实现一下,一个中心的支持,能支持的客户端数量,和后续扩展的成本而已。最后,namenode的成本远高于datanode,这是事实。
采集系统上云(辽宁企业大数据采集技术注意每种统计分析方法的适用范围方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-03-03 00:11
可视化+爬虫脚本语言+正则表达式 ForeSpider是一款通用的采集可视化软件,内置强大的爬虫脚本语言。如果有可视化无法实现的内容采集,只需几行简单的代码即可实现强大的脚本采集。该软件还支持正则表达式操作,可以通过可视化、正则化和脚本化的方式对数据进行清理和标准化。软件内部集成了数据挖掘功能,通过采集模板可以对全网内容进行精细挖掘。在存储数据采集的同时,可以完成分类、统计、自然语言处理等多项功能。了解您分析的目标,并且知道在数据小的时候如何积累。大数据采集平台
大数据采集模块功能全国手机号码生成根据用户设置的区域生成手机号码段,并可根据指定的号码段生成手机号码,自定义格式,做地域定向营销,最好群发短信 选择在线方向采集软件可以通过流行的B2B网站在线采集,如马可波罗、一虎百影、无忧等 B2B网站采集企业信息,数据精细,采集快,对于想要获取企业信息的客户来说是不错的选择。企业搜索通过软件定位获取附近临街商铺和企业信息。还可以输入多个城市名称,通过自定义进行批量操作。数据精炼,非常适合营销使用。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。
智汇云狐采集软件可能和你见过的一些类似的工具软件完全不同:功能强大,操作简单。两者的区别类似于从DOS操作系统切换到Windows操作系统。前者需要专业技术人员才能有效运作,而我们是面向大众的可视化操作平台。使用精细搜索引擎的解析内核,通过模仿浏览器实现网页内容的解析。在此基础上,利用原创技术对网页框架的内容和内容进行分离提取,实现相似页面的有效对比。,匹配。因此,用户只需要指定一个参考页面,智汇云狐采集 软件系统可以对相似的页面进行相应的匹配,从而实现用户需要的采集数据的批量采集。在这个过程中,用户不再需要使用非常专业的“正则表达式”技术,也不需要依赖技术专家编写采集匹配规则。参考页面的内容解析分解后,用户可以用鼠标点击需要采集的对象,系统可以据此得知用户需要采集的内容。智汇云狐采集软件的模板定制过程是针对目标页面进行机器学习和机器训练的过程。
大数据采集是指主要处理海量数据存储、计算、不间断流数据的实时计算等场景的一套基础设施。可以使用开源平台,也可以使用华为、星联等商业级解决方案,既可以部署在私有云上,也可以部署在公有云上。任何一个完整的大数据平台一般都包括以下流程:数据采集-->数据存储-->数据处理-->数据呈现(可视化、报告、监控) 其中,数据采集是所有数据系统的必不可少,而随着大数据越来越受到重视,数据的挑战采集也变得更加突出。主要分为常规基础数据和自定义游戏系统数据。
在大数据时代,“一切都会被计算”、“一切都会被量化”、“一切都会被数字化”。人类生活在一个海量、动态和多样化数据的世界中。数据无处不在,随时可用,没有人使用它。数据与阳光、空气和水分一样普遍,与放大镜、望远镜和显微镜一样重要。大数据中的“数据”真实可靠。它本质上是一种表征事物现象的符号语言和逻辑关系。其可靠性的数学和哲学基础是世界同构原理。世界具有物质统一,统一世界中的一切都具有时空一致性的同构关系。这意味着只要正确编码,任何事物的属性和规律都可以通过统一的数字信号来表达。高级数据分析不一定好,简单有效就好。陕西商业大数据采集采集器
数据分析前应明确目的,然后根据分析目的确定分析框架和内容,以及所采用的数据分析方法。大数据采集平台
智汇云虎大数据采集软件的优势在于精准精准,全网数十个平台实时更新,软件实时更新数亿人的网络数据< @采集平台和搜索引擎,确保精确和准确的真实性和实时性。精细采集APP操作方式APP采集器,一键操作,全国300多个城市可自由选择,行业关键词快速锁定行业潜在客户,一键导入通讯录,一键导出电脑。官方持续升级更新售后无忧罚款采集APP已上架Apple Store和Android主流应用市场5年,十年数据采集 技术团队持续实时更新,售后有保障。大数据采集平台
您好,欢迎来电,公司现推出智能营销延伸系统、大数据采集系统、智汇云通话系统和5G视频广告,5G时代适合各行各业。宣传快速覆盖全城,品牌推广,产品推广,快速渗透,全城覆盖,低门槛高回报,同城营销神器。是一家集研发、设计、生产、销售为一体的专业化公司。拥有一支经验丰富、技术创新的专业研发团队,高度专注、专注地为客户提供大数据采集系统、云呼叫系统、同城延伸系统、智能营销延伸软件。不断开拓创新,追求卓越,以科技为先导,以产品为平台,以应用为重点,以服务为保障,不断为客户创造更高价值,提供更优质的服务。时刻关注自己,在风云变幻的时代,从不懈怠自身的建设,高度的专注和坚持让行业从容自信。 查看全部
采集系统上云(辽宁企业大数据采集技术注意每种统计分析方法的适用范围方法)
可视化+爬虫脚本语言+正则表达式 ForeSpider是一款通用的采集可视化软件,内置强大的爬虫脚本语言。如果有可视化无法实现的内容采集,只需几行简单的代码即可实现强大的脚本采集。该软件还支持正则表达式操作,可以通过可视化、正则化和脚本化的方式对数据进行清理和标准化。软件内部集成了数据挖掘功能,通过采集模板可以对全网内容进行精细挖掘。在存储数据采集的同时,可以完成分类、统计、自然语言处理等多项功能。了解您分析的目标,并且知道在数据小的时候如何积累。大数据采集平台

大数据采集模块功能全国手机号码生成根据用户设置的区域生成手机号码段,并可根据指定的号码段生成手机号码,自定义格式,做地域定向营销,最好群发短信 选择在线方向采集软件可以通过流行的B2B网站在线采集,如马可波罗、一虎百影、无忧等 B2B网站采集企业信息,数据精细,采集快,对于想要获取企业信息的客户来说是不错的选择。企业搜索通过软件定位获取附近临街商铺和企业信息。还可以输入多个城市名称,通过自定义进行批量操作。数据精炼,非常适合营销使用。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。

智汇云狐采集软件可能和你见过的一些类似的工具软件完全不同:功能强大,操作简单。两者的区别类似于从DOS操作系统切换到Windows操作系统。前者需要专业技术人员才能有效运作,而我们是面向大众的可视化操作平台。使用精细搜索引擎的解析内核,通过模仿浏览器实现网页内容的解析。在此基础上,利用原创技术对网页框架的内容和内容进行分离提取,实现相似页面的有效对比。,匹配。因此,用户只需要指定一个参考页面,智汇云狐采集 软件系统可以对相似的页面进行相应的匹配,从而实现用户需要的采集数据的批量采集。在这个过程中,用户不再需要使用非常专业的“正则表达式”技术,也不需要依赖技术专家编写采集匹配规则。参考页面的内容解析分解后,用户可以用鼠标点击需要采集的对象,系统可以据此得知用户需要采集的内容。智汇云狐采集软件的模板定制过程是针对目标页面进行机器学习和机器训练的过程。
大数据采集是指主要处理海量数据存储、计算、不间断流数据的实时计算等场景的一套基础设施。可以使用开源平台,也可以使用华为、星联等商业级解决方案,既可以部署在私有云上,也可以部署在公有云上。任何一个完整的大数据平台一般都包括以下流程:数据采集-->数据存储-->数据处理-->数据呈现(可视化、报告、监控) 其中,数据采集是所有数据系统的必不可少,而随着大数据越来越受到重视,数据的挑战采集也变得更加突出。主要分为常规基础数据和自定义游戏系统数据。

在大数据时代,“一切都会被计算”、“一切都会被量化”、“一切都会被数字化”。人类生活在一个海量、动态和多样化数据的世界中。数据无处不在,随时可用,没有人使用它。数据与阳光、空气和水分一样普遍,与放大镜、望远镜和显微镜一样重要。大数据中的“数据”真实可靠。它本质上是一种表征事物现象的符号语言和逻辑关系。其可靠性的数学和哲学基础是世界同构原理。世界具有物质统一,统一世界中的一切都具有时空一致性的同构关系。这意味着只要正确编码,任何事物的属性和规律都可以通过统一的数字信号来表达。高级数据分析不一定好,简单有效就好。陕西商业大数据采集采集器
数据分析前应明确目的,然后根据分析目的确定分析框架和内容,以及所采用的数据分析方法。大数据采集平台
智汇云虎大数据采集软件的优势在于精准精准,全网数十个平台实时更新,软件实时更新数亿人的网络数据< @采集平台和搜索引擎,确保精确和准确的真实性和实时性。精细采集APP操作方式APP采集器,一键操作,全国300多个城市可自由选择,行业关键词快速锁定行业潜在客户,一键导入通讯录,一键导出电脑。官方持续升级更新售后无忧罚款采集APP已上架Apple Store和Android主流应用市场5年,十年数据采集 技术团队持续实时更新,售后有保障。大数据采集平台
您好,欢迎来电,公司现推出智能营销延伸系统、大数据采集系统、智汇云通话系统和5G视频广告,5G时代适合各行各业。宣传快速覆盖全城,品牌推广,产品推广,快速渗透,全城覆盖,低门槛高回报,同城营销神器。是一家集研发、设计、生产、销售为一体的专业化公司。拥有一支经验丰富、技术创新的专业研发团队,高度专注、专注地为客户提供大数据采集系统、云呼叫系统、同城延伸系统、智能营销延伸软件。不断开拓创新,追求卓越,以科技为先导,以产品为平台,以应用为重点,以服务为保障,不断为客户创造更高价值,提供更优质的服务。时刻关注自己,在风云变幻的时代,从不懈怠自身的建设,高度的专注和坚持让行业从容自信。
采集系统上云软件部署的注意事项有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-05-27 19:05
采集系统上云软件部署主要取决于企业的具体情况,一般公司都会有云服务器和服务器托管商,然后根据实际需求部署相应的采集系统。非常简单的企业采集系统就是用api连接到相应的服务器上,数据实时采集和分析到本地,相对要求也低很多。而一些复杂系统的搭建,就需要根据业务流程和业务规则来编写代码,来实现采集和查询。对于一些比较专业的数据处理和分析平台,还需要真正的高配置单机服务器进行采集,单机采集机器也要至少1500块。
还有一些采集系统是通过web采集,可以直接使用现成的爬虫或者自己制作爬虫。采集系统是一个整体的体系。以某银行为例,服务器托管在国内的一家大型云服务器租用商,硬件集群一共16台,年费大概一年在120万左右。对于如何用一般的采集系统部署,配置要求不高。因为一个api采集基本可以满足日常公司的实际业务需求,如果对高质量存在明显短板,就需要自己花钱购买相应的设备和工具。具体的使用过程,可以参考我的专栏文章【采集系统入门】。
采集系统如何购买部署简单直接购买服务器、数据库、app,设计好采集接口,然后将数据提交到采集服务器即可。如果长期有大量业务需求,则采用离线测试方式进行部署。如何构建采集系统采集系统只是一个采集工具而已,根据您的业务需求及您公司的实际情况,组件化,自动化部署,上线即可。另外需要组建采集团队,您可以先购买采集平台,然后由采集团队中工作人员架设采集平台,对接上线。 查看全部
采集系统上云软件部署的注意事项有哪些?-八维教育
采集系统上云软件部署主要取决于企业的具体情况,一般公司都会有云服务器和服务器托管商,然后根据实际需求部署相应的采集系统。非常简单的企业采集系统就是用api连接到相应的服务器上,数据实时采集和分析到本地,相对要求也低很多。而一些复杂系统的搭建,就需要根据业务流程和业务规则来编写代码,来实现采集和查询。对于一些比较专业的数据处理和分析平台,还需要真正的高配置单机服务器进行采集,单机采集机器也要至少1500块。
还有一些采集系统是通过web采集,可以直接使用现成的爬虫或者自己制作爬虫。采集系统是一个整体的体系。以某银行为例,服务器托管在国内的一家大型云服务器租用商,硬件集群一共16台,年费大概一年在120万左右。对于如何用一般的采集系统部署,配置要求不高。因为一个api采集基本可以满足日常公司的实际业务需求,如果对高质量存在明显短板,就需要自己花钱购买相应的设备和工具。具体的使用过程,可以参考我的专栏文章【采集系统入门】。
采集系统如何购买部署简单直接购买服务器、数据库、app,设计好采集接口,然后将数据提交到采集服务器即可。如果长期有大量业务需求,则采用离线测试方式进行部署。如何构建采集系统采集系统只是一个采集工具而已,根据您的业务需求及您公司的实际情况,组件化,自动化部署,上线即可。另外需要组建采集团队,您可以先购买采集平台,然后由采集团队中工作人员架设采集平台,对接上线。
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-05-26 00:16
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
采集系统上云主要有三种模式?有哪些优势?
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-05-07 19:01
采集系统上云主要有三种模式:
一、由工厂或公司管理平台上去采集
二、由平台内部采集系统上传
三、主机(主机通过开放平台免费申请)上云作为国内比较大的外卖商家发布群发短信的服务商,也有不少我们自己的短信群发系统,上云都需要我们公司有足够的实力做好系统,短信群发系统我们通常采用采用开放平台直接免费申请,里面有一个积分商城,用户可以自行做短信营销。对比我们国内传统短信运营商,作为上云服务商,我们有如下优势:1.我们的系统完全基于通道本身。
优势:我们的验证码、接码平台、发送日志等核心功能依托于我们的采集系统,功能开发完全平台化,一个系统同时支持线上线下发送服务。2.我们的系统完全开放。优势:信息流广告运营商数据的无缝对接,数据会同步第三方app,从上游集团收集,第三方应用商家完全可以与我们进行全面合作;避免国内运营商的误判,避免国内三方采集误差。
3.我们只为准确率提供保证。优势:由我们对短信验证码接口的准确率负责,绝不满意外发短信,杜绝经常性短信重复等情况的发生。同时我们有严格的审核流程,及时的服务质量审核。短信验证码上传服务商定期抽查,有效遏制运营商恶意修改、降低我们误判和降低系统响应速度的行为。4.我们对短信账号对相关公司和个人会有审核。
优势:我们是商家发送服务商的金钱上第三方担保,如果商家发送服务商接码平台上的不正规号码,我们也会有明确的风控措施。同时我们也会对不通过系统的账号进行统计,定期进行调整。5.我们对用户过期有业务经理查询并追偿及后续的应急处理。优势:我们会统计用户过期后的响应情况,对未及时上传并达到我们号码要求的商家会有一定的免费短信营销的额度,风控相对较严。下图是我们针对我们的短信平台有哪些优势做了一个总结:。 查看全部
采集系统上云主要有三种模式?有哪些优势?
采集系统上云主要有三种模式:
一、由工厂或公司管理平台上去采集
二、由平台内部采集系统上传
三、主机(主机通过开放平台免费申请)上云作为国内比较大的外卖商家发布群发短信的服务商,也有不少我们自己的短信群发系统,上云都需要我们公司有足够的实力做好系统,短信群发系统我们通常采用采用开放平台直接免费申请,里面有一个积分商城,用户可以自行做短信营销。对比我们国内传统短信运营商,作为上云服务商,我们有如下优势:1.我们的系统完全基于通道本身。
优势:我们的验证码、接码平台、发送日志等核心功能依托于我们的采集系统,功能开发完全平台化,一个系统同时支持线上线下发送服务。2.我们的系统完全开放。优势:信息流广告运营商数据的无缝对接,数据会同步第三方app,从上游集团收集,第三方应用商家完全可以与我们进行全面合作;避免国内运营商的误判,避免国内三方采集误差。
3.我们只为准确率提供保证。优势:由我们对短信验证码接口的准确率负责,绝不满意外发短信,杜绝经常性短信重复等情况的发生。同时我们有严格的审核流程,及时的服务质量审核。短信验证码上传服务商定期抽查,有效遏制运营商恶意修改、降低我们误判和降低系统响应速度的行为。4.我们对短信账号对相关公司和个人会有审核。
优势:我们是商家发送服务商的金钱上第三方担保,如果商家发送服务商接码平台上的不正规号码,我们也会有明确的风控措施。同时我们也会对不通过系统的账号进行统计,定期进行调整。5.我们对用户过期有业务经理查询并追偿及后续的应急处理。优势:我们会统计用户过期后的响应情况,对未及时上传并达到我们号码要求的商家会有一定的免费短信营销的额度,风控相对较严。下图是我们针对我们的短信平台有哪些优势做了一个总结:。
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-06 21:15
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-05-02 18:49
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
采集系统上云(微服务下的几个监控维度(下)化服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-04-18 18:01
前言
微服务是一种架构风格,大型复杂的软件应用程序通常由多个微服务组成。系统中的每个微服务都可以独立部署,每个微服务都是松耦合的。每个微服务只专注于完成一项任务并把它做好。
在微服务之前,很多单体应用的监控复杂度较低,场景相对简单。在微服务下,由于业务逻辑分散在很多流程中(很多大业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时就需要完善的监控系统。
一套完整的监控系统建设周期长,需要随着业务场景的变化进行迭代优化。本文仅从几个监控维度和原子场景探讨如何建立统一的监控数据采集和展示系统,希望能启发大家继续深入思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的变化。我们将监控从机器角度转换为以服务为中心的角度。从微服务的角度来看,监控可以从数据维度和资源维度来看。与代码维度分层,如下图:
数据维度
目前,WEB服务是主流。每一个WEB服务都有一个入口,无论是APP还是WEB页面,入口负责与用户交互,并将用户的信息发送到后台。一般后台会访问LB或者Gateway,负责负载。将数据均衡转发给特定的应用程序进行处理,最后在应用程序处理完毕后写入数据库。
资源维度
现在很多服务都部署在云端,涉及到虚拟化技术,虚拟主机运行在物理服务器上,虚拟主机之间通过虚拟网络相互连接。资源层面的监控是不可或缺的一环。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器的CPU、内存、磁盘IO等数据,以及连接的虚拟主机。主机之间的虚拟网络带宽负载等。
代码维度
APM,即应用性能分析、代码端监控采集,是随着微服务的兴起而出现的。在微服务场景下,一个业务流程跨越数十个服务,仅靠传统的监控数据很难定位问题的根源。
我们可以针对代码的技术栈开发具体的采集框架,在可接受的性能损失范围内,采集函数之间的调用关系,服务之间的调用拓扑,只测量响应时间功能或服务的性能可以优化性能或提前预测故障。
关键监控指标场景描述
微服务监控的最大特点可以用一句话概括:服务很多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关的错综复杂的业务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了各个维度下各个层级可能产生的告警,总结出URL监控、主机监控、产品监控等8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状况。
主机监控:通过安装agent采集对主机的基本监控信息如CPU、内存、IO等数据,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据< @采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报每个产品的相关指标数据,监控每个产品资源的健康状态。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载对应组件的监控采集程序。
自定义监控:服务实例采集业务相关数据,定时调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户以资源为维度上报自定义数据。每个资源都有相同的几个监控项,每个资源的监控项相互独立。
APM:根据语言栈的不同,分别展示服务之间的函数调用关系和调用拓扑。根据语言的不同,有的需要破解代码并以SDK嵌入的形式采集数据,有的则与代码解耦,有的方法通过元编程重载实现data采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等提供统一的存储、分析和展示。
有了上述原子化场景的数据采集,我们就可以通过UI统一展示监控数据,并根据上述三个维度设计一个以用户体验为核心的图形化页面。图形一般以时间序列为横轴,显示指标随时间的变化。对于一些统计指标,还可以通过饼图和条形图的方式展示分析比较结果。
本文主要介绍监控系统中的采集和数据展示。至于数据存储和报警过程,有兴趣的同学可以继续关注后续监控相关的文章。
关于作者
董磊:UCloud 技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
更多技术干货,欢迎关注微信“UCloud技术公告栏”。 查看全部
采集系统上云(微服务下的几个监控维度(下)化服务)
前言
微服务是一种架构风格,大型复杂的软件应用程序通常由多个微服务组成。系统中的每个微服务都可以独立部署,每个微服务都是松耦合的。每个微服务只专注于完成一项任务并把它做好。
在微服务之前,很多单体应用的监控复杂度较低,场景相对简单。在微服务下,由于业务逻辑分散在很多流程中(很多大业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时就需要完善的监控系统。
一套完整的监控系统建设周期长,需要随着业务场景的变化进行迭代优化。本文仅从几个监控维度和原子场景探讨如何建立统一的监控数据采集和展示系统,希望能启发大家继续深入思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的变化。我们将监控从机器角度转换为以服务为中心的角度。从微服务的角度来看,监控可以从数据维度和资源维度来看。与代码维度分层,如下图:
数据维度
目前,WEB服务是主流。每一个WEB服务都有一个入口,无论是APP还是WEB页面,入口负责与用户交互,并将用户的信息发送到后台。一般后台会访问LB或者Gateway,负责负载。将数据均衡转发给特定的应用程序进行处理,最后在应用程序处理完毕后写入数据库。
资源维度
现在很多服务都部署在云端,涉及到虚拟化技术,虚拟主机运行在物理服务器上,虚拟主机之间通过虚拟网络相互连接。资源层面的监控是不可或缺的一环。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器的CPU、内存、磁盘IO等数据,以及连接的虚拟主机。主机之间的虚拟网络带宽负载等。
代码维度
APM,即应用性能分析、代码端监控采集,是随着微服务的兴起而出现的。在微服务场景下,一个业务流程跨越数十个服务,仅靠传统的监控数据很难定位问题的根源。
我们可以针对代码的技术栈开发具体的采集框架,在可接受的性能损失范围内,采集函数之间的调用关系,服务之间的调用拓扑,只测量响应时间功能或服务的性能可以优化性能或提前预测故障。
关键监控指标场景描述
微服务监控的最大特点可以用一句话概括:服务很多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关的错综复杂的业务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了各个维度下各个层级可能产生的告警,总结出URL监控、主机监控、产品监控等8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状况。
主机监控:通过安装agent采集对主机的基本监控信息如CPU、内存、IO等数据,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据< @采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报每个产品的相关指标数据,监控每个产品资源的健康状态。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载对应组件的监控采集程序。
自定义监控:服务实例采集业务相关数据,定时调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户以资源为维度上报自定义数据。每个资源都有相同的几个监控项,每个资源的监控项相互独立。
APM:根据语言栈的不同,分别展示服务之间的函数调用关系和调用拓扑。根据语言的不同,有的需要破解代码并以SDK嵌入的形式采集数据,有的则与代码解耦,有的方法通过元编程重载实现data采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等提供统一的存储、分析和展示。
有了上述原子化场景的数据采集,我们就可以通过UI统一展示监控数据,并根据上述三个维度设计一个以用户体验为核心的图形化页面。图形一般以时间序列为横轴,显示指标随时间的变化。对于一些统计指标,还可以通过饼图和条形图的方式展示分析比较结果。
本文主要介绍监控系统中的采集和数据展示。至于数据存储和报警过程,有兴趣的同学可以继续关注后续监控相关的文章。
关于作者
董磊:UCloud 技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
更多技术干货,欢迎关注微信“UCloud技术公告栏”。
采集系统上云(浙江移动大数据平台二期项目的定位及核心需求点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 420 次浏览 • 2022-04-18 17:13
一、背景和建设历史
随着一期企业级大数据平台的上线,浙江移动构建了大数据统一采集、存储和分析的基础能力,实现了O、B、企业内部的M个三域数据。模型,但外部数据,尤其是互联网数据的采集,并未包括在内。互联网上的海量信息对于丰富数据资产、支撑数据变现具有极大的互补作用。浙江移动一直在思考如何扩展大数据平台的数据采集能力,帮助租户快速高效地获取外部数据。和探索问题。
为此,在大数据平台项目二期,我们计划搭建云爬虫平台,获取外部数据,提供分词和自然语言解析能力。但是,集成商在实施过程中无法满足要求。为了不耽误平台的上线,项目组决定在开源软件的基础上自主开发和实现业务需求。完成云爬虫平台上线和试运行。
二、云爬虫平台的定位和核心需求
云爬虫平台在企业级大数据平台中的定位
核心需求
1、实现分布式互联网数据爬取,支持通用爬取和精细爬取;
2、实现多租户管理和资源隔离;
3、实现高可用和可视化界面配置管理;
4、爬取的数据存储在ES、HDFS、HBASE中或者直接通过restful接口传递;
5、爬取的数据存储在ES、HDFS、HBASE后,可以支持租户分词和自然语言解析;
6、爬虫性能要求:
a) 实现平均每天 1 亿个 URL 的 采集 量
b) 基于每天1亿个URL,每个URL按平均500KB计算,有效爬取数据存储容量大于500TB
三、云爬虫平台系统架构
1)系统功能模块
云爬虫平台分为精细爬取和通用爬取两个功能模块,满足不同租户的数据采集需求。多租户的系统功能逻辑如下:
1、攀爬
租户登录云爬虫管理平台,在线编辑爬虫脚本。云爬虫系统根据计划中编写的脚本规则,爬取对应页面的指定部分(如具体评论列表),并存储在大数据平台中,并建立全文索引。
2、通过攀爬
调用者调用云爬虫系统提供的通用爬取接口,云爬虫系统根据策略(代理IP等)将爬取结果实时返回给调用者,并存储在Hadoop平台中并建立全文索引。
2)系统物理架构
云爬虫平台的物理架构如下,分层,主要分为接入层、采集层和持久层,如下图所示:
1、访问层
接入层包括Web和接口。Web 主机负责负载平衡任务和显示任务列表。在网页上,租户可以根据需要创建新的爬取任务。对于成功的爬取任务,您可以通过网页查看其基本信息。REST API 负责对外提供爬虫能力接口。
2、采集图层
采集 层收录爬虫主机和消息队列主机。爬虫主机负责接收web主机分配的任务,包括爬取网页和返回内容,对爬取的内容进行解析和结构化,以及对结构化结果进行持久化。Redis 作为消息队列,负责任务分发。
3、持久层
通常,网络爬虫抓取的数据量非常大,需要很大的存储空间来存储大量数据。因此,持久层采用中国移动苏州研发中心开发的Hadoop平台产品。
3)应用部署架构
云爬虫平台的应用部署架构如下,主要分为Web服务域和采集服务域。
1、Web 服务域
提供给租户编写和调试爬虫脚本,安装WebUI、Scheduler等组件。
2、采集服务域
对于数据采集和结果返回,每个Spider节点都安装了Fetcher、Processor、Result_Worker、Rest API、Selenium、PhantomJS等组件。
四、云爬虫平台核心功能及自主研发范围
云爬虫平台基于开源的Python爬虫框架pyspider,根据我们的需求在本地开发。爬取的数据存储在Hadoop平台中,通过二次开发,实现多租户以及爬虫与ES、HBASE、HDFS等接口的封装。以提高开发效率。主要新功能如下:
1)多租户管理
云爬虫和互联网数据存储分析平台都是通过二次开发基于PaaS,实现多租户和租户之间的资源隔离。
2)丰富的数据接口
在原有框架的基础上,扩展了各种数据接口的读写能力,如关系型数据库Oracle、非关系型HBase、HDFS文件、ES、流式消息接口Kafka等,以支持不同类型的精细爬取、过关爬取等数据。业务需求。
3)平台高可用
云爬虫平台的所有爬取节点和数据存储分析节点均匀分布在多个物理节点上,单机宕机不会导致整个爬取过程中断。这种分布式架构提高了系统性的整体健壮性。
4)爬取效率
单机模式下的网络爬虫效率不高,无法满足大规模爬取任务的需求。云爬虫平台为爬虫租户分配多个爬取节点,通过读取共享任务池共同执行爬取任务。节点可以看作是一个独立的网络爬虫,可以大大提高页面的爬取效率。
5)高扩展性
支持静态爬取和动态渲染的主流网站数据爬取,如天猫、京东、大众点评、豆瓣等,可以根据当前爬虫任务量动态调整爬虫节点数,比传统的爬虫方法更强。同时,租户在编写脚本时具有高度的自定义性,允许租户根据不同的爬取需求自定义爬取范围。
6)可视化爬虫界面
云爬虫平台为爬虫租户提供了一个可视化的页面来编辑和调试爬虫脚本。平台支持静态和动态渲染的主流网站爬取,可以根据业务的紧急程度动态调整每个爬虫任务的优先级,并提供爬取数据结果的页面导出功能,方便用于查看样本数据。系统页面如下图所示:
五、云爬虫平台的操作
1)平台操作
云爬虫平台上线以来,集群运行总体稳定,保存了应用数据XXT。
2)应用操作
目前承载的服务包括DPI爬虫接口和数据挖掘中的行业应用,如客流平台POI信息和大数据选址、西从天降平台商品信息、咪咕喜欢看的用户视频行为信息等。请求2000万+,日均爬取数据量4T+。
通过搭建云爬虫平台实现互联网数据获取,可以更全面地获取用户的关系、状态、位置、轨迹、使用行为和习惯特征数据,更全面、准确地描述用户画像;数据的丰富性和准确性有助于改进业务发展战略,提升业务价值。返回搜狐,查看更多 查看全部
采集系统上云(浙江移动大数据平台二期项目的定位及核心需求点)
一、背景和建设历史
随着一期企业级大数据平台的上线,浙江移动构建了大数据统一采集、存储和分析的基础能力,实现了O、B、企业内部的M个三域数据。模型,但外部数据,尤其是互联网数据的采集,并未包括在内。互联网上的海量信息对于丰富数据资产、支撑数据变现具有极大的互补作用。浙江移动一直在思考如何扩展大数据平台的数据采集能力,帮助租户快速高效地获取外部数据。和探索问题。
为此,在大数据平台项目二期,我们计划搭建云爬虫平台,获取外部数据,提供分词和自然语言解析能力。但是,集成商在实施过程中无法满足要求。为了不耽误平台的上线,项目组决定在开源软件的基础上自主开发和实现业务需求。完成云爬虫平台上线和试运行。
二、云爬虫平台的定位和核心需求
云爬虫平台在企业级大数据平台中的定位
核心需求
1、实现分布式互联网数据爬取,支持通用爬取和精细爬取;
2、实现多租户管理和资源隔离;
3、实现高可用和可视化界面配置管理;
4、爬取的数据存储在ES、HDFS、HBASE中或者直接通过restful接口传递;
5、爬取的数据存储在ES、HDFS、HBASE后,可以支持租户分词和自然语言解析;
6、爬虫性能要求:
a) 实现平均每天 1 亿个 URL 的 采集 量
b) 基于每天1亿个URL,每个URL按平均500KB计算,有效爬取数据存储容量大于500TB
三、云爬虫平台系统架构
1)系统功能模块
云爬虫平台分为精细爬取和通用爬取两个功能模块,满足不同租户的数据采集需求。多租户的系统功能逻辑如下:
1、攀爬
租户登录云爬虫管理平台,在线编辑爬虫脚本。云爬虫系统根据计划中编写的脚本规则,爬取对应页面的指定部分(如具体评论列表),并存储在大数据平台中,并建立全文索引。
2、通过攀爬
调用者调用云爬虫系统提供的通用爬取接口,云爬虫系统根据策略(代理IP等)将爬取结果实时返回给调用者,并存储在Hadoop平台中并建立全文索引。
2)系统物理架构
云爬虫平台的物理架构如下,分层,主要分为接入层、采集层和持久层,如下图所示:
1、访问层
接入层包括Web和接口。Web 主机负责负载平衡任务和显示任务列表。在网页上,租户可以根据需要创建新的爬取任务。对于成功的爬取任务,您可以通过网页查看其基本信息。REST API 负责对外提供爬虫能力接口。
2、采集图层
采集 层收录爬虫主机和消息队列主机。爬虫主机负责接收web主机分配的任务,包括爬取网页和返回内容,对爬取的内容进行解析和结构化,以及对结构化结果进行持久化。Redis 作为消息队列,负责任务分发。
3、持久层
通常,网络爬虫抓取的数据量非常大,需要很大的存储空间来存储大量数据。因此,持久层采用中国移动苏州研发中心开发的Hadoop平台产品。
3)应用部署架构
云爬虫平台的应用部署架构如下,主要分为Web服务域和采集服务域。
1、Web 服务域
提供给租户编写和调试爬虫脚本,安装WebUI、Scheduler等组件。
2、采集服务域
对于数据采集和结果返回,每个Spider节点都安装了Fetcher、Processor、Result_Worker、Rest API、Selenium、PhantomJS等组件。
四、云爬虫平台核心功能及自主研发范围
云爬虫平台基于开源的Python爬虫框架pyspider,根据我们的需求在本地开发。爬取的数据存储在Hadoop平台中,通过二次开发,实现多租户以及爬虫与ES、HBASE、HDFS等接口的封装。以提高开发效率。主要新功能如下:
1)多租户管理
云爬虫和互联网数据存储分析平台都是通过二次开发基于PaaS,实现多租户和租户之间的资源隔离。
2)丰富的数据接口
在原有框架的基础上,扩展了各种数据接口的读写能力,如关系型数据库Oracle、非关系型HBase、HDFS文件、ES、流式消息接口Kafka等,以支持不同类型的精细爬取、过关爬取等数据。业务需求。
3)平台高可用
云爬虫平台的所有爬取节点和数据存储分析节点均匀分布在多个物理节点上,单机宕机不会导致整个爬取过程中断。这种分布式架构提高了系统性的整体健壮性。
4)爬取效率
单机模式下的网络爬虫效率不高,无法满足大规模爬取任务的需求。云爬虫平台为爬虫租户分配多个爬取节点,通过读取共享任务池共同执行爬取任务。节点可以看作是一个独立的网络爬虫,可以大大提高页面的爬取效率。
5)高扩展性
支持静态爬取和动态渲染的主流网站数据爬取,如天猫、京东、大众点评、豆瓣等,可以根据当前爬虫任务量动态调整爬虫节点数,比传统的爬虫方法更强。同时,租户在编写脚本时具有高度的自定义性,允许租户根据不同的爬取需求自定义爬取范围。
6)可视化爬虫界面
云爬虫平台为爬虫租户提供了一个可视化的页面来编辑和调试爬虫脚本。平台支持静态和动态渲染的主流网站爬取,可以根据业务的紧急程度动态调整每个爬虫任务的优先级,并提供爬取数据结果的页面导出功能,方便用于查看样本数据。系统页面如下图所示:
五、云爬虫平台的操作
1)平台操作
云爬虫平台上线以来,集群运行总体稳定,保存了应用数据XXT。
2)应用操作
目前承载的服务包括DPI爬虫接口和数据挖掘中的行业应用,如客流平台POI信息和大数据选址、西从天降平台商品信息、咪咕喜欢看的用户视频行为信息等。请求2000万+,日均爬取数据量4T+。
通过搭建云爬虫平台实现互联网数据获取,可以更全面地获取用户的关系、状态、位置、轨迹、使用行为和习惯特征数据,更全面、准确地描述用户画像;数据的丰富性和准确性有助于改进业务发展战略,提升业务价值。返回搜狐,查看更多
采集系统上云(如何利用raspberrypi创建一个电子设备?/2016/07/12)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-04-17 12:03
采集系统上云服务,相关资料搜索信息可到新闻处。接下来具体说下如何利用raspberrypi创建一个电子设备。1.根据raspberrypi的说明书,需要将raspberrypi2.0的手柄驱动添加到该设备中,我认为安装驱动是最最关键的环节,有一个好的驱动,才能更加方便的操作,减少设备对电磁辐射的影响。
2.根据wikipedia的描述,要自己制作一个属于自己的小raspberrypi的话,我觉得至少要重新写一个usb编程的程序,可以像百度学习一下一些常用的命令:例如编译指定扩展名的inode.zip等等。3.最重要的是写一个小的app,要让raspberrypi的可靠性更高。例如做一个wifi热点,可以帮助raspberrypi与外界连接。
可以查查athlonraspberrypi怎么做好一个wifi热点设备。4.raspberrypi一般适合做一些高精度的事情,例如:拍照,手写笔之类的,所以我以及一般可以将wifi热点设置在你房间,并将相应程序写入外网。最后,建议使用git或者github,方便分享代码,毕竟raspberrypi不是为了给人类用的。不论如何,我们都是以人为本。
如何才能google到足够多的raspberrypi资料-edit/2016/07/12/esr-kit_root-sticker_lab_binary.html
在上搜raspberrypiguiserver(就是你说的google_gmail),软件一搜一大把。我也想学,但是没开始呢。 查看全部
采集系统上云(如何利用raspberrypi创建一个电子设备?/2016/07/12)
采集系统上云服务,相关资料搜索信息可到新闻处。接下来具体说下如何利用raspberrypi创建一个电子设备。1.根据raspberrypi的说明书,需要将raspberrypi2.0的手柄驱动添加到该设备中,我认为安装驱动是最最关键的环节,有一个好的驱动,才能更加方便的操作,减少设备对电磁辐射的影响。
2.根据wikipedia的描述,要自己制作一个属于自己的小raspberrypi的话,我觉得至少要重新写一个usb编程的程序,可以像百度学习一下一些常用的命令:例如编译指定扩展名的inode.zip等等。3.最重要的是写一个小的app,要让raspberrypi的可靠性更高。例如做一个wifi热点,可以帮助raspberrypi与外界连接。
可以查查athlonraspberrypi怎么做好一个wifi热点设备。4.raspberrypi一般适合做一些高精度的事情,例如:拍照,手写笔之类的,所以我以及一般可以将wifi热点设置在你房间,并将相应程序写入外网。最后,建议使用git或者github,方便分享代码,毕竟raspberrypi不是为了给人类用的。不论如何,我们都是以人为本。
如何才能google到足够多的raspberrypi资料-edit/2016/07/12/esr-kit_root-sticker_lab_binary.html
在上搜raspberrypiguiserver(就是你说的google_gmail),软件一搜一大把。我也想学,但是没开始呢。
采集系统上云(微服务下的几个监控维度(下)化服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-17 10:33
前言
微服务是一种架构风格,大型复杂的软件应用程序通常由多个微服务组成。系统中的每个微服务都可以独立部署,每个微服务都是松耦合的。每个微服务只专注于完成一项任务并把它做好。
在微服务之前,很多单体应用的监控复杂度较低,场景相对简单。在微服务下,由于业务逻辑分散在很多流程中(很多大业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时就需要一个完善的监控系统。
一套完整的监控系统建设周期长,需要随着业务场景的变化进行迭代优化。本文仅从几个监控维度和原子场景探讨如何建立统一的监控数据采集和展示系统,希望能启发大家继续深入思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的变化。我们将监控从机器角度转换为以服务为中心的角度。从微服务的角度来看,监控可以从数据维度和资源维度来看。与代码维度分层,如下图:
数据维度
目前,WEB服务是主流。每个 WEB 服务都有一个入口。无论是APP还是WEB页面,入口负责与用户交互,将用户信息发送到后台。一般后台会访问LB或者Gateway,负责负载。将数据均衡转发给特定的应用程序进行处理,最后在应用程序处理完毕后写入数据库。
资源维度
现在很多服务都部署在云端,涉及到虚拟化技术,虚拟主机运行在物理服务器上,虚拟主机之间通过虚拟网络相互连接。资源层面的监控是不可或缺的一环。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器的CPU、内存、磁盘IO等数据,以及连接的虚拟主机。主机之间的虚拟网络带宽负载等。
代码维度
APM,即应用性能分析、代码端监控采集,是随着微服务的兴起而出现的。在微服务场景下,一个业务流程跨越数十个服务,仅靠传统的监控数据很难定位问题的根源。
我们可以针对代码的技术栈开发具体的采集框架,在可接受的性能损失范围内,采集函数之间的调用关系,服务之间的调用拓扑,只测量响应时间功能或服务的性能可以优化性能或提前预测故障。
关键监控指标场景描述
微服务监控的最大特点可以用一句话概括:服务很多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关的错综复杂的业务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了各个维度下各个层级可能产生的告警,总结出URL监控、主机监控、产品监控等8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状况。
主机监控:通过安装agent采集对主机的基本监控信息如CPU、内存、IO等数据,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据< @采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和部分中间件,产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载对应组件的监控采集程序。
自定义监控:服务实例采集业务相关数据,定时调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户以资源为维度上报自定义数据。每个资源都有相同的几个监控项,每个资源的监控项相互独立。
APM:根据语言栈的不同,分别展示服务之间的函数调用关系和调用拓扑。根据语言的不同,有的需要破解代码并以SDK嵌入的形式采集数据,有的则与代码解耦,有的方法通过元编程重载实现data采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等提供统一的存储、分析和展示。
有了上述原子化场景的数据采集,我们就可以通过UI统一展示监控数据,并根据上述三个维度设计一个以用户体验为核心的图形化页面。图形一般以时间序列为横轴,显示指标随时间的变化。对于一些统计指标,还可以通过饼图和条形图的方式展示分析比较结果。
本文主要介绍监控系统中的采集和数据展示。至于数据存储和报警过程,有兴趣的同学可以继续关注后续监控相关的文章。
关于作者
董磊:UCloud 技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
更多技术干货,欢迎关注微信“UCloud技术公告栏”。 查看全部
采集系统上云(微服务下的几个监控维度(下)化服务)
前言
微服务是一种架构风格,大型复杂的软件应用程序通常由多个微服务组成。系统中的每个微服务都可以独立部署,每个微服务都是松耦合的。每个微服务只专注于完成一项任务并把它做好。
在微服务之前,很多单体应用的监控复杂度较低,场景相对简单。在微服务下,由于业务逻辑分散在很多流程中(很多大业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时就需要一个完善的监控系统。
一套完整的监控系统建设周期长,需要随着业务场景的变化进行迭代优化。本文仅从几个监控维度和原子场景探讨如何建立统一的监控数据采集和展示系统,希望能启发大家继续深入思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的变化。我们将监控从机器角度转换为以服务为中心的角度。从微服务的角度来看,监控可以从数据维度和资源维度来看。与代码维度分层,如下图:
数据维度
目前,WEB服务是主流。每个 WEB 服务都有一个入口。无论是APP还是WEB页面,入口负责与用户交互,将用户信息发送到后台。一般后台会访问LB或者Gateway,负责负载。将数据均衡转发给特定的应用程序进行处理,最后在应用程序处理完毕后写入数据库。
资源维度
现在很多服务都部署在云端,涉及到虚拟化技术,虚拟主机运行在物理服务器上,虚拟主机之间通过虚拟网络相互连接。资源层面的监控是不可或缺的一环。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器的CPU、内存、磁盘IO等数据,以及连接的虚拟主机。主机之间的虚拟网络带宽负载等。
代码维度
APM,即应用性能分析、代码端监控采集,是随着微服务的兴起而出现的。在微服务场景下,一个业务流程跨越数十个服务,仅靠传统的监控数据很难定位问题的根源。
我们可以针对代码的技术栈开发具体的采集框架,在可接受的性能损失范围内,采集函数之间的调用关系,服务之间的调用拓扑,只测量响应时间功能或服务的性能可以优化性能或提前预测故障。
关键监控指标场景描述
微服务监控的最大特点可以用一句话概括:服务很多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关的错综复杂的业务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了各个维度下各个层级可能产生的告警,总结出URL监控、主机监控、产品监控等8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状况。
主机监控:通过安装agent采集对主机的基本监控信息如CPU、内存、IO等数据,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据< @采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和部分中间件,产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载对应组件的监控采集程序。
自定义监控:服务实例采集业务相关数据,定时调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户以资源为维度上报自定义数据。每个资源都有相同的几个监控项,每个资源的监控项相互独立。
APM:根据语言栈的不同,分别展示服务之间的函数调用关系和调用拓扑。根据语言的不同,有的需要破解代码并以SDK嵌入的形式采集数据,有的则与代码解耦,有的方法通过元编程重载实现data采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等提供统一的存储、分析和展示。
有了上述原子化场景的数据采集,我们就可以通过UI统一展示监控数据,并根据上述三个维度设计一个以用户体验为核心的图形化页面。图形一般以时间序列为横轴,显示指标随时间的变化。对于一些统计指标,还可以通过饼图和条形图的方式展示分析比较结果。
本文主要介绍监控系统中的采集和数据展示。至于数据存储和报警过程,有兴趣的同学可以继续关注后续监控相关的文章。
关于作者
董磊:UCloud 技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
更多技术干货,欢迎关注微信“UCloud技术公告栏”。
采集系统上云(微猫企业资料搜索采集软件的数据多久更新一次?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-06 03:05
微猫企业信息搜索采集软件是一款通过互联网查找非常准确的企业信息的软件。在百度、搜狗、360收录1000多个大型行业和企业黄页中,帮助您快速搜索最新最全的优质客户。搜索到的信息包括公司名称、网站、电话、手机、邮箱等多种联系方式,是销售人员寻找客户的必备工具。
软件功能
1、通过百度、好搜、搜狗直接进入公司官网,快速定位精准客户。
2、快速挑选优质客户进行网络推广
3、快速搜索;
4、搜索结果数量多,同一个关键词搜索到的信息量是同类软件的几十倍;
5、高精度:搜索出优先企业信息!
6、企业信息在800多个商业网站上广泛传播和发布;
7、还有资料导入电脑功能!
回答问题
软件可以下载多少数据?
A:软件采集接收的数据来自各行业知名网站用户发布的数据,不在我们的数据库中,所以我们不知道数据有多少, 网站你可以采集网站上有多少资源,但数量肯定很多。
目录采集 软件多久更新一次?
A:一般两三天到一周左右会有新的数据更新。24小时自动采集,收录各大地产行业网站,各大分类信息网站,数据真实,每次采集自动去重复号码,为保证数据质量,业主信息名称包括姓名、户型、小区、电话号码
目录采集软件安装版和绿色版有什么区别?
答:目录采集软件的安装版本与绿色版基本相同。唯一不同的是需要安装安装版下载后才能使用,而绿色版解压后即可使用。直接操作。
微信企业信息搜索采集软件平台自动采集网络关键词信息每天实时变化。只要是您关注的企业信息,24小时实时爬虫都能帮您抓取信息。决策总是至关重要的,数据提取、数据共享、数据监管等等。 查看全部
采集系统上云(微猫企业资料搜索采集软件的数据多久更新一次?(图))
微猫企业信息搜索采集软件是一款通过互联网查找非常准确的企业信息的软件。在百度、搜狗、360收录1000多个大型行业和企业黄页中,帮助您快速搜索最新最全的优质客户。搜索到的信息包括公司名称、网站、电话、手机、邮箱等多种联系方式,是销售人员寻找客户的必备工具。
软件功能
1、通过百度、好搜、搜狗直接进入公司官网,快速定位精准客户。
2、快速挑选优质客户进行网络推广
3、快速搜索;
4、搜索结果数量多,同一个关键词搜索到的信息量是同类软件的几十倍;
5、高精度:搜索出优先企业信息!
6、企业信息在800多个商业网站上广泛传播和发布;
7、还有资料导入电脑功能!
回答问题
软件可以下载多少数据?
A:软件采集接收的数据来自各行业知名网站用户发布的数据,不在我们的数据库中,所以我们不知道数据有多少, 网站你可以采集网站上有多少资源,但数量肯定很多。
目录采集 软件多久更新一次?
A:一般两三天到一周左右会有新的数据更新。24小时自动采集,收录各大地产行业网站,各大分类信息网站,数据真实,每次采集自动去重复号码,为保证数据质量,业主信息名称包括姓名、户型、小区、电话号码
目录采集软件安装版和绿色版有什么区别?
答:目录采集软件的安装版本与绿色版基本相同。唯一不同的是需要安装安装版下载后才能使用,而绿色版解压后即可使用。直接操作。
微信企业信息搜索采集软件平台自动采集网络关键词信息每天实时变化。只要是您关注的企业信息,24小时实时爬虫都能帮您抓取信息。决策总是至关重要的,数据提取、数据共享、数据监管等等。
采集系统上云(业务程序会不断生成业务日志的学习总结和心得建议)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-03-24 05:02
实际项目需求描述:
在业务系统的服务器上,业务程序会不断产生业务日志(如网站的页面访问日志)。
业务日志是用log4j生成的,会不断切出日志文件。
需要定期(比如每小时)从业务服务器的日志目录中检测出需要采集的日志文件(access.log无法采集),并发送到HDFS。
注意:可能有多个业务服务器(hdfs上的文件名不能直接使用日志服务器上的文件名)。
采集当天收到的日志应该放在hdfs的当前目录下。
采集完成的日志文件需要移动到日志服务器的备份目录中。
定期检查(每小时一次)备份目录,清除备份时长超过24小时的日志文件。
项目的一些学习总结和经验建议
规范说明1:代码中手写代码过多,如文件路径,无法无误编译,很难找到。
解决问题1:可以写一个属性资源文件,把路径存放在key上。
规范说明2:如果要读取资源文件,必须使用类加载器来加载。
规范说明3:访问对象有问题,应该使用单例设计模式——懒惰风格。
规范说明4:存在线程安全问题。为了避免死锁或重复使用新资源,静态代码块应该同步。
规范注释5:还应考虑资源密钥问题。可以新建一个类来保存key,这样在不容易找到错误路径时程序会提示错误。
规范说明6:每个项目、每个业务都要先写自己的流程,然后一步步写代码,再慢慢考虑其他异常,增加代码的健壮性。 查看全部
采集系统上云(业务程序会不断生成业务日志的学习总结和心得建议)
实际项目需求描述:
在业务系统的服务器上,业务程序会不断产生业务日志(如网站的页面访问日志)。
业务日志是用log4j生成的,会不断切出日志文件。
需要定期(比如每小时)从业务服务器的日志目录中检测出需要采集的日志文件(access.log无法采集),并发送到HDFS。
注意:可能有多个业务服务器(hdfs上的文件名不能直接使用日志服务器上的文件名)。
采集当天收到的日志应该放在hdfs的当前目录下。
采集完成的日志文件需要移动到日志服务器的备份目录中。
定期检查(每小时一次)备份目录,清除备份时长超过24小时的日志文件。
项目的一些学习总结和经验建议
规范说明1:代码中手写代码过多,如文件路径,无法无误编译,很难找到。
解决问题1:可以写一个属性资源文件,把路径存放在key上。
规范说明2:如果要读取资源文件,必须使用类加载器来加载。
规范说明3:访问对象有问题,应该使用单例设计模式——懒惰风格。
规范说明4:存在线程安全问题。为了避免死锁或重复使用新资源,静态代码块应该同步。
规范注释5:还应考虑资源密钥问题。可以新建一个类来保存key,这样在不容易找到错误路径时程序会提示错误。
规范说明6:每个项目、每个业务都要先写自己的流程,然后一步步写代码,再慢慢考虑其他异常,增加代码的健壮性。
采集系统上云(采集系统上云之后,想从云端进行数据分析?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-24 03:04
采集系统上云之后变得很简单,变得很快,基本是集成在你的企业内部系统上。既然采集系统上云之后,想从云端进行数据分析就可以了。用技术的方式来实现的话就很简单了,比如对接一个sdk,sdk可以对采集好的数据进行处理,然后推送给erp、hrm、admin的等不同终端的负责人。或者是通过hr或者rpo多层的进行数据分析。
对于不同行业,有不同的解决方案,针对数据源提出不同的解决方案就是,所以不同行业有不同的解决方案。大数据不是你想的那么高大上,其实很普通。在营销,产品分析,决策支持等方面可以发挥大数据的价值。对于一些不太复杂的,而且比较有针对性的数据,比如用户画像,特征标签,这方面你可以从获取的用户数据入手,然后在考虑进行数据处理分析。
我目前知道的有这样一个项目:对商家来说,数据可以做什么,以后该怎么用?-生意人创业论坛-poweredbydiscuz!不过貌似这样的项目还在,具体情况你可以去官网看看。对于阿里来说,数据可以做什么,以后该怎么用?-大数据与人工智能论坛-poweredbydiscuz!这个我没有接触过,毕竟没有从事过商业分析相关的工作,希望能帮到你。
大数据一直都是很热门的话题,不管是大家的讨论还是给自己公司制定转型路线,大数据都不可或缺。大数据也分为云计算大数据分析大数据,是一个相互交叉的行业,都需要数据分析,只是数据分析侧重于运用于流量分析,营销分析等,只要能做大数据分析,只要要有数据分析,都可以说是大数据分析,大数据分析也是要计算机与数据分析相结合。
那么数据分析是属于传统营销分析和现在的数据分析之中的,一般都是面向业务和运营人员,提供数据支持的。大数据分析有分为原始数据分析,抽样数据分析,数据量预估,数据可视化等多种方式,最后形成报告给业务管理人员看。以下几点是大数据分析所需要关注的几点重点:大数据的分析以及应用是一个很复杂的学科,是一个集大成的学科,也是需要一个比较长的路要走,只有理论和技术储备都十分的深厚,并且有相关领域专业知识,在业务领域能有一定成就,才有可能做大数据分析工作,才有可能看到很好的前景。
一、大数据的数据结构和数据类型1、业务类数据:即面向不同业务方的销售数据、客户数据、广告数据、财务数据、人员基础信息等,是业务系统分析、决策中最为重要的信息源。这些数据的收集包括通过etl工具,采集各个业务方的数据。原始数据中常常包含诸如客户资料、财务收支、广告效果等等关键数据。这些数据一般都是长期积累的数据,一旦发生事件或人为的改变。 查看全部
采集系统上云(采集系统上云之后,想从云端进行数据分析?)
采集系统上云之后变得很简单,变得很快,基本是集成在你的企业内部系统上。既然采集系统上云之后,想从云端进行数据分析就可以了。用技术的方式来实现的话就很简单了,比如对接一个sdk,sdk可以对采集好的数据进行处理,然后推送给erp、hrm、admin的等不同终端的负责人。或者是通过hr或者rpo多层的进行数据分析。
对于不同行业,有不同的解决方案,针对数据源提出不同的解决方案就是,所以不同行业有不同的解决方案。大数据不是你想的那么高大上,其实很普通。在营销,产品分析,决策支持等方面可以发挥大数据的价值。对于一些不太复杂的,而且比较有针对性的数据,比如用户画像,特征标签,这方面你可以从获取的用户数据入手,然后在考虑进行数据处理分析。
我目前知道的有这样一个项目:对商家来说,数据可以做什么,以后该怎么用?-生意人创业论坛-poweredbydiscuz!不过貌似这样的项目还在,具体情况你可以去官网看看。对于阿里来说,数据可以做什么,以后该怎么用?-大数据与人工智能论坛-poweredbydiscuz!这个我没有接触过,毕竟没有从事过商业分析相关的工作,希望能帮到你。
大数据一直都是很热门的话题,不管是大家的讨论还是给自己公司制定转型路线,大数据都不可或缺。大数据也分为云计算大数据分析大数据,是一个相互交叉的行业,都需要数据分析,只是数据分析侧重于运用于流量分析,营销分析等,只要能做大数据分析,只要要有数据分析,都可以说是大数据分析,大数据分析也是要计算机与数据分析相结合。
那么数据分析是属于传统营销分析和现在的数据分析之中的,一般都是面向业务和运营人员,提供数据支持的。大数据分析有分为原始数据分析,抽样数据分析,数据量预估,数据可视化等多种方式,最后形成报告给业务管理人员看。以下几点是大数据分析所需要关注的几点重点:大数据的分析以及应用是一个很复杂的学科,是一个集大成的学科,也是需要一个比较长的路要走,只有理论和技术储备都十分的深厚,并且有相关领域专业知识,在业务领域能有一定成就,才有可能做大数据分析工作,才有可能看到很好的前景。
一、大数据的数据结构和数据类型1、业务类数据:即面向不同业务方的销售数据、客户数据、广告数据、财务数据、人员基础信息等,是业务系统分析、决策中最为重要的信息源。这些数据的收集包括通过etl工具,采集各个业务方的数据。原始数据中常常包含诸如客户资料、财务收支、广告效果等等关键数据。这些数据一般都是长期积累的数据,一旦发生事件或人为的改变。
采集系统上云(阿里云InfluxDB数据采集服务优势我们能做些什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-03-18 10:08
背景
随着时序数据的快速增长,时序数据库不仅需要解决系统稳定性和性能问题,还需要实现从采集到分析的链接,让时序数据真正生成价值。在时间序列数据采集领域,一直缺乏自动化的采集工具。虽然用户可以使用一些开源的采集工具来实现数据采集,比如Telegraf、Logstash、TCollector等,但是这些采集工具都需要用户自己构建和维护运行环境,增加了用户的学习成本,大大提高了数据的门槛采集。另一方面,现有的采集工具缺乏对多个采集源的自动化管理,使得用户难以统一管理多个不同的采集源并监控每个采集 实时 工具是否正常运行,采集数据。
阿里云InfluxDB®不仅提供稳定可靠的时序数据库服务,还提供非常便捷的数据采集服务。用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据会自动存储在阿里云InfluxDB®中。用户无需担心运维问题,实现从数据采集到分析的一站式服务。本文主要介绍如何使用InfluxDB®的数据采集服务实现数据从采集到存储的自动化管理。
阿里巴巴云InfluxDB®Data采集服务优势我们能做什么? 1.简单采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,分别涉及MySQL、Redis、MongoDB和系统监控。针对每类数据,采集多个监控指标,方便用户对监控对象有更全面的了解。用户可以通过InfluxDB®实例的管理控制台添加新的采集源,无需编写代码,一键安装。
采集数据操作流程如下:
2.采集来源的实时监控
采集源运行过程中,可以实时监控数据采集的状态,查看数据采集最后到达InfluxDB®的时间;并且您可以随时停止Data采集,并在您认为合适的时候重新打开data采集服务。
3.一键切换采集数据类型
如果要更改被监控机器上的采集数据类型,不需要重新添加新的采集源,选择你想要的采集配置即可,数据采集工具会自动切换到采集你指定的监控数据。
4. 采集数据自动存储在 InfluxDB® 中
您可以在采集配置中选择数据流的数据库和保留策略,数据采集工具会自动将采集数据存储到指定的数据库和保留策略中,并且您可以在 采集 源运行时修改要写入数据的数据库和保留策略,只需修改 采集 配置即可。
最佳实践
本节介绍如何采集系统监控数据并实时显示采集结果。系统监控的数据包括处理器、磁盘、内存、网络、进程、系统等信息。采集的数据存储在 8 种不同的测量中(测量是 cpu、disk、diskio、mem、net、processes、swap 和 system)。在开始之前,请确保您已成功创建数据库以及对该数据库具有读写权限的用户帐户。
1. 创建采集系统监控数据配置
点击InfluxDB®管理控制台左侧导航栏中的“添加采集配置”,进入采集配置添加界面,如下图所示。填写“采集Configuration Name”,选择“采集Data Type”为“System Monitoring”,然后选择“Authorized Account”、“Data Write to DB”和“Database Storage Policy”,填写在“授权密码”中。点击“添加”成功创建采集配置。
2. 添加采集来源
点击InfluxDB®管理控制台左侧导航栏中的“添加采集Source”,进入采集Source Add页面。
(1)选择网络类型,“Public Network”或“Private Network”,然后点击“Next”,如下图。
(2)在数据源所在的主机上安装采集工具。将安装命令复制到主机上运行采集工具。采集@之后> 工具运行,它会与 InfluxDB ® 建立连接,可以在“New 采集 Source Scan Result List”中看到新添加的采集 source,如果没有显示在列表中,您可以点击“刷新”或“自动刷新”。如下图。
(3)选择采集系统监控的数据。在上图中点击“选择采集配置”进入如下界面,从下拉框。采集“采集系统”的配置。选择后点击“保存”。
(4)启动数据采集.勾选需要启动的采集源,然后点击“Finish and start采集”,采集工具可以在采集源上启动采集数据,如下图。
3.查看数据状态采集
在“采集Source List”中,您可以看到所有连接到 InfluxDB® 实例的 采集 源,如下图所示。每个 采集 源由一个 uuid 唯一标识,“运行中”的“采集 状态”表示 采集 工具是 采集 数据并报告给 InfluxDB®, “最新采集上报成功时间”表示采集数据最后一次成功发送到InfluxDB®的时间。
4. 可视化 采集数据
使用 Grafana
(1)安装 Grafana。请参阅有关如何安装 Grafana 的文档。
(2)添加数据源。将“URL”设置为InfluxDB®实例的地址,并填写写入采集数据的数据库和用户账号,如下图。
(3)配置Dashboard并编写查询规则。这里以查询磁盘使用情况为例。查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示。
您可以根据实际需要查看其他测量和字段的数据,并分别在FROM和SELECT语句中指定。
总结
阿里云InfluxDB®提供方便快捷的数据采集服务,自动管理数据源,帮助您解决数据采集问题,实现数据从采集到存储的自动化。未来,我们将支持 采集 获取更多数据类型和指标,敬请期待。 查看全部
采集系统上云(阿里云InfluxDB数据采集服务优势我们能做些什么?)
背景
随着时序数据的快速增长,时序数据库不仅需要解决系统稳定性和性能问题,还需要实现从采集到分析的链接,让时序数据真正生成价值。在时间序列数据采集领域,一直缺乏自动化的采集工具。虽然用户可以使用一些开源的采集工具来实现数据采集,比如Telegraf、Logstash、TCollector等,但是这些采集工具都需要用户自己构建和维护运行环境,增加了用户的学习成本,大大提高了数据的门槛采集。另一方面,现有的采集工具缺乏对多个采集源的自动化管理,使得用户难以统一管理多个不同的采集源并监控每个采集 实时 工具是否正常运行,采集数据。
阿里云InfluxDB®不仅提供稳定可靠的时序数据库服务,还提供非常便捷的数据采集服务。用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据会自动存储在阿里云InfluxDB®中。用户无需担心运维问题,实现从数据采集到分析的一站式服务。本文主要介绍如何使用InfluxDB®的数据采集服务实现数据从采集到存储的自动化管理。
阿里巴巴云InfluxDB®Data采集服务优势我们能做什么? 1.简单采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,分别涉及MySQL、Redis、MongoDB和系统监控。针对每类数据,采集多个监控指标,方便用户对监控对象有更全面的了解。用户可以通过InfluxDB®实例的管理控制台添加新的采集源,无需编写代码,一键安装。
采集数据操作流程如下:
2.采集来源的实时监控
采集源运行过程中,可以实时监控数据采集的状态,查看数据采集最后到达InfluxDB®的时间;并且您可以随时停止Data采集,并在您认为合适的时候重新打开data采集服务。
3.一键切换采集数据类型
如果要更改被监控机器上的采集数据类型,不需要重新添加新的采集源,选择你想要的采集配置即可,数据采集工具会自动切换到采集你指定的监控数据。
4. 采集数据自动存储在 InfluxDB® 中
您可以在采集配置中选择数据流的数据库和保留策略,数据采集工具会自动将采集数据存储到指定的数据库和保留策略中,并且您可以在 采集 源运行时修改要写入数据的数据库和保留策略,只需修改 采集 配置即可。
最佳实践
本节介绍如何采集系统监控数据并实时显示采集结果。系统监控的数据包括处理器、磁盘、内存、网络、进程、系统等信息。采集的数据存储在 8 种不同的测量中(测量是 cpu、disk、diskio、mem、net、processes、swap 和 system)。在开始之前,请确保您已成功创建数据库以及对该数据库具有读写权限的用户帐户。
1. 创建采集系统监控数据配置
点击InfluxDB®管理控制台左侧导航栏中的“添加采集配置”,进入采集配置添加界面,如下图所示。填写“采集Configuration Name”,选择“采集Data Type”为“System Monitoring”,然后选择“Authorized Account”、“Data Write to DB”和“Database Storage Policy”,填写在“授权密码”中。点击“添加”成功创建采集配置。
2. 添加采集来源
点击InfluxDB®管理控制台左侧导航栏中的“添加采集Source”,进入采集Source Add页面。
(1)选择网络类型,“Public Network”或“Private Network”,然后点击“Next”,如下图。
(2)在数据源所在的主机上安装采集工具。将安装命令复制到主机上运行采集工具。采集@之后> 工具运行,它会与 InfluxDB ® 建立连接,可以在“New 采集 Source Scan Result List”中看到新添加的采集 source,如果没有显示在列表中,您可以点击“刷新”或“自动刷新”。如下图。
(3)选择采集系统监控的数据。在上图中点击“选择采集配置”进入如下界面,从下拉框。采集“采集系统”的配置。选择后点击“保存”。
(4)启动数据采集.勾选需要启动的采集源,然后点击“Finish and start采集”,采集工具可以在采集源上启动采集数据,如下图。
3.查看数据状态采集
在“采集Source List”中,您可以看到所有连接到 InfluxDB® 实例的 采集 源,如下图所示。每个 采集 源由一个 uuid 唯一标识,“运行中”的“采集 状态”表示 采集 工具是 采集 数据并报告给 InfluxDB®, “最新采集上报成功时间”表示采集数据最后一次成功发送到InfluxDB®的时间。
4. 可视化 采集数据
使用 Grafana
(1)安装 Grafana。请参阅有关如何安装 Grafana 的文档。
(2)添加数据源。将“URL”设置为InfluxDB®实例的地址,并填写写入采集数据的数据库和用户账号,如下图。
(3)配置Dashboard并编写查询规则。这里以查询磁盘使用情况为例。查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示。
您可以根据实际需要查看其他测量和字段的数据,并分别在FROM和SELECT语句中指定。
总结
阿里云InfluxDB®提供方便快捷的数据采集服务,自动管理数据源,帮助您解决数据采集问题,实现数据从采集到存储的自动化。未来,我们将支持 采集 获取更多数据类型和指标,敬请期待。
采集系统上云(汇想云运营模式如何,推广手段有限,这是免费。。 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-03-13 19:15
)
汇祥为您介绍好用的采集系统点餐电话【RRCt2Q】
更重要的是,筛选库为您提供了这种独特的评价价值和体验,无论您的营销策略能力如何,推广手段有限,都是免费的。
bps操作方式:将电脑上的sata文件复制到电脑系统的磁盘中。bps 运行方式:将 sata.dog.msr 文件复制到计算机系统的磁盘中。bps 运行方式:将 sata.dog.msr.asq 文件复制到计算机系统的磁盘中。
比如,如果搜索引擎把它从百度改成宣传视频,你就用好你的关键词;就像让网站软件更容易下载一样,那么你可以在网站网站上创建一个单独的页面,包括内容、搜索引擎、关键词,这些网站存在于百度,特别是后续网站。网站用户用什么形式注册***?建立网站的第一步是确定自己的计划,并得到一个可行的用户结构图,以确保在网站发布之前有效排名。
好用采集系统订购电话
很多企业可能对每一个新兴品牌都比较陌生,但在现实中可能自然从属于特定的目标消费者,看到营销不适合这样做。或者,在过去的一段时间里,我们一起合作,传播了一些营销理念和一些组合方法。
o是一种流行、时尚的营销理念,深受客户的喜爱和追捧,也受到运营商、广告商、媒体等企业的欢迎。o 被称为“智能营销”。实现营销目标的营销手段是最简单、最直接的营销策略。
如果安装后出现错误,将无法正常使用,还会导致无法进入引导模式,无法成功进入安装状态。
好用采集系统订购电话 查看全部
采集系统上云(汇想云运营模式如何,推广手段有限,这是免费。。
)
汇祥为您介绍好用的采集系统点餐电话【RRCt2Q】
更重要的是,筛选库为您提供了这种独特的评价价值和体验,无论您的营销策略能力如何,推广手段有限,都是免费的。
bps操作方式:将电脑上的sata文件复制到电脑系统的磁盘中。bps 运行方式:将 sata.dog.msr 文件复制到计算机系统的磁盘中。bps 运行方式:将 sata.dog.msr.asq 文件复制到计算机系统的磁盘中。
比如,如果搜索引擎把它从百度改成宣传视频,你就用好你的关键词;就像让网站软件更容易下载一样,那么你可以在网站网站上创建一个单独的页面,包括内容、搜索引擎、关键词,这些网站存在于百度,特别是后续网站。网站用户用什么形式注册***?建立网站的第一步是确定自己的计划,并得到一个可行的用户结构图,以确保在网站发布之前有效排名。
好用采集系统订购电话
很多企业可能对每一个新兴品牌都比较陌生,但在现实中可能自然从属于特定的目标消费者,看到营销不适合这样做。或者,在过去的一段时间里,我们一起合作,传播了一些营销理念和一些组合方法。
o是一种流行、时尚的营销理念,深受客户的喜爱和追捧,也受到运营商、广告商、媒体等企业的欢迎。o 被称为“智能营销”。实现营销目标的营销手段是最简单、最直接的营销策略。
如果安装后出现错误,将无法正常使用,还会导致无法进入引导模式,无法成功进入安装状态。
好用采集系统订购电话
采集系统上云(2018第九届中国数据库技术大会,阿里云如何打破它呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-03-12 18:19
摘要:在2018年第九届中国数据库技术大会上,阿里云数据库产品专家肖少聪就阿里云如何打破Oracle上云的壁垒发表了演讲。Oracle 指的是“数据库管理系统”。面对甲骨文迁移上云的壁垒,阿里云又该如何打破呢?本文提出了一种从 Oracle 迁移到云数据库的 PPAS 解决方案。为什么这个迁移方案比从Oracle迁移到MySQL系列更容易推广?答案即将揭晓。2018年第九届中国数据库技术大会上,阿里云数据库产品专家肖少聪就阿里云如何打破Oracle上云壁垒发表演讲。Oracle 指的是“数据库管理系统”。面对甲骨文迁移上云的壁垒,阿里云又该如何打破呢?本文提出了一种从 Oracle 迁移到云数据库的 PPAS 解决方案。为什么这个迁移方案比从Oracle迁移到MySQL系列更容易推广?答案即将揭晓。
现场视频回顾
PPT下载请点击
以下为精彩视频内容:Oracle数据库迁移计划
数据业务架构主要分为三大部分:服务器、应用程序、数据库系统和存储系统。解决云服务器和存储系统的问题相对容易,但解决应用程序和数据库系统的问题就有些困难了。因此,阿里云提供了上述解决方案。在这个方案中,用户可以通过不同的方式将数据库迁移到云端,我们可以继续在ECS中运行Oracle,也可以迁移到MySQL。当然,应用程序和数据库系统也可以迁移到 PPAS 版。凭借与Oracle的高度兼容性,降低了用户上云的难度,降低了系统长期运维的复杂度。
阿里云不仅为云用户提供同城容灾、自动备份、时间点恢复等功能。阿里云数据库还会加入高可用HA,一般需要两个或更多节点进行复杂的配置。在阿里云中,用户一键即可拥有高可用HA,这样的HA集群不仅可以搭建在同一个数据中心,还可以支持同城双中心、异地容灾,同样的一键部署就完成了。同时,阿里云还为用户提供ADAM(Advanced Database & Application Migration “亚当”)工具,借助PPAS的Oracle兼容性,协助用户进行快速迁移。那么接下来的迁移步骤应该如何进行呢?
在Oracle上安装ADAM采集,ADMA会起到三个作用: Oracle迁移到PPAS比迁移到其他数据库更顺畅,因为兼容的地方很多。Oracle数据库到PPAS要兼容SQL、存储过程、包、DBMS等,所以适合复杂事务的迁移。ApsaraDB for PPAS 提供高达 3TB 的本地高性能存储(据悉,该空间在今年内有机会超过 10TB)。如果业务数据超出本地存储容量,可以使用OSS存储进行外表处理。例如,历史数据可以存储在 OSS 外部表中。此信息不经常使用,但对数据分析很重要。所以,我们可以通过阿里云HybridDB for PostgreSQL直接从OSS获取数据进行业务分析。HybridDB for PostgreSQL 是阿里云基于开源Greenplum Database 分布式MPP 数据库的自有发布版本。可实现实时业务分析,将计算节点和空间横向扩展至PB级,特定场景下百亿条记录排序。
为什么Oracle数据库迁移到MySQL家族难推?原因是Oracle数据库迁移到MySQL系列会增加ISV和企业迁移的风险。在整个迁移过程中,代码、存储过程和架构都需要做很大的改变,这将导致研发重新学习、DBA重新学习、代码重新学习。语法重写甚至业务架构重写最终会导致业务风险增加、人工成本增加、产品成本增加。
Oracle 数据库到云数据库 PPAS 版本的推广相对容易,在推广过程中提高了 Oracle 迁移上云的成功率。研发可继续编写Oracle语法,降低迁移难度和工作量,阿里云可自动运维和提升DBA SQL优化能力,代码语法几乎无需改动,ADAM辅助精准分析。
为什么 PPAS 与 Oralce 的兼容性更好?从上图可以看出,MySOL和Oracle的交集面积比PostgreSQL和Oracle的要小,没有达到预期的效果。预计云数据库PASS版的效果应该是Oracle的区域和PostgreSQL的区域几乎重叠。为什么需要这么多兼容的部件?因为这样可以将企业的开发团队、原有的开发成果和已有的应用快速上云。比如开发者开发的软件全部离线,但是客户要求上云,上云需要使用互联网,那么就需要改变原有的存储方式。为了在线和离线维护云架构,需要改变结构,这将需要大量的人力成本。如果有直接兼容Oracle语法的功能,这个时候放到云端会减轻整体负担。
云数据库PPAS to Oracle兼容的数据类型有很多,如BLOB、CLOB、DATE等。他们每个人都有自己的别名和类型。例如,BLOB 的别名是 LONG RAW,它的类型是二进制数据。
ADAM 可以通过全量迁移和增量迁移的方式,协助用户将 Oracle 数据库迁移到云端。如果 Oracle 数据量很大,可能需要一周甚至一个月的时间才能完成传输。这时候可以通过高速连接和高速通道来增加带宽,不需要经过互联网,防止传输错误的数据,也不会影响生产库。通过ADAM平台,Oracle数据到云数据库还将提供30天退货机制,为用户迁移割接过程提供最大保障。
PPAS版不仅具有高可用,还支持同城容灾。用户可以选择使用单AZ集群或多AZ(同城容灾)集群,无需任何额外费用。有保障的企业级容灾需要保护。
PPAS版不仅提供自动备份,还提供50%的免费备份空间。例如,如果用户购买了 1TB 的实例存储空间,他们将直接获得 500GB 的免费备份空间。
ApsaraDB for PPAS 云管理是按时间点克隆实例。实例克隆功能将于2018年7月上线,支持最长730天的数据备份。目前,仅提供临时实例。阿里云 PostgreSQL 生态系统
Oracle 应用可以迁移到 PPAS 版,它使用高性能本地存储来存储热的 OLTP 业务数据。历史信息存储在外部OSS上,HybridDB for PostgreSQL可以直接读取和使用OSS上的数据,也就是说OLTP可以进行业务处理,OLAP可以直接使用基于阿里云的数据仓库服务开源Greenplum数据库分布式MPP架构。PostgreSQL 的混合数据库。
同时,用户也可以保留原有的Oracle系统,只使用HybridDB for PostgreSQL进行分析业务。OLAP 性能优势如下: HybridDB for PostgreSQL 混合分区
存储可以分为三种存储,即行存储、列存储和OSS温存储。三种存储方式说明如下: 链接原文 查看全部
采集系统上云(2018第九届中国数据库技术大会,阿里云如何打破它呢?)
摘要:在2018年第九届中国数据库技术大会上,阿里云数据库产品专家肖少聪就阿里云如何打破Oracle上云的壁垒发表了演讲。Oracle 指的是“数据库管理系统”。面对甲骨文迁移上云的壁垒,阿里云又该如何打破呢?本文提出了一种从 Oracle 迁移到云数据库的 PPAS 解决方案。为什么这个迁移方案比从Oracle迁移到MySQL系列更容易推广?答案即将揭晓。2018年第九届中国数据库技术大会上,阿里云数据库产品专家肖少聪就阿里云如何打破Oracle上云壁垒发表演讲。Oracle 指的是“数据库管理系统”。面对甲骨文迁移上云的壁垒,阿里云又该如何打破呢?本文提出了一种从 Oracle 迁移到云数据库的 PPAS 解决方案。为什么这个迁移方案比从Oracle迁移到MySQL系列更容易推广?答案即将揭晓。
现场视频回顾
PPT下载请点击
以下为精彩视频内容:Oracle数据库迁移计划
数据业务架构主要分为三大部分:服务器、应用程序、数据库系统和存储系统。解决云服务器和存储系统的问题相对容易,但解决应用程序和数据库系统的问题就有些困难了。因此,阿里云提供了上述解决方案。在这个方案中,用户可以通过不同的方式将数据库迁移到云端,我们可以继续在ECS中运行Oracle,也可以迁移到MySQL。当然,应用程序和数据库系统也可以迁移到 PPAS 版。凭借与Oracle的高度兼容性,降低了用户上云的难度,降低了系统长期运维的复杂度。
阿里云不仅为云用户提供同城容灾、自动备份、时间点恢复等功能。阿里云数据库还会加入高可用HA,一般需要两个或更多节点进行复杂的配置。在阿里云中,用户一键即可拥有高可用HA,这样的HA集群不仅可以搭建在同一个数据中心,还可以支持同城双中心、异地容灾,同样的一键部署就完成了。同时,阿里云还为用户提供ADAM(Advanced Database & Application Migration “亚当”)工具,借助PPAS的Oracle兼容性,协助用户进行快速迁移。那么接下来的迁移步骤应该如何进行呢?
在Oracle上安装ADAM采集,ADMA会起到三个作用: Oracle迁移到PPAS比迁移到其他数据库更顺畅,因为兼容的地方很多。Oracle数据库到PPAS要兼容SQL、存储过程、包、DBMS等,所以适合复杂事务的迁移。ApsaraDB for PPAS 提供高达 3TB 的本地高性能存储(据悉,该空间在今年内有机会超过 10TB)。如果业务数据超出本地存储容量,可以使用OSS存储进行外表处理。例如,历史数据可以存储在 OSS 外部表中。此信息不经常使用,但对数据分析很重要。所以,我们可以通过阿里云HybridDB for PostgreSQL直接从OSS获取数据进行业务分析。HybridDB for PostgreSQL 是阿里云基于开源Greenplum Database 分布式MPP 数据库的自有发布版本。可实现实时业务分析,将计算节点和空间横向扩展至PB级,特定场景下百亿条记录排序。
为什么Oracle数据库迁移到MySQL家族难推?原因是Oracle数据库迁移到MySQL系列会增加ISV和企业迁移的风险。在整个迁移过程中,代码、存储过程和架构都需要做很大的改变,这将导致研发重新学习、DBA重新学习、代码重新学习。语法重写甚至业务架构重写最终会导致业务风险增加、人工成本增加、产品成本增加。
Oracle 数据库到云数据库 PPAS 版本的推广相对容易,在推广过程中提高了 Oracle 迁移上云的成功率。研发可继续编写Oracle语法,降低迁移难度和工作量,阿里云可自动运维和提升DBA SQL优化能力,代码语法几乎无需改动,ADAM辅助精准分析。
为什么 PPAS 与 Oralce 的兼容性更好?从上图可以看出,MySOL和Oracle的交集面积比PostgreSQL和Oracle的要小,没有达到预期的效果。预计云数据库PASS版的效果应该是Oracle的区域和PostgreSQL的区域几乎重叠。为什么需要这么多兼容的部件?因为这样可以将企业的开发团队、原有的开发成果和已有的应用快速上云。比如开发者开发的软件全部离线,但是客户要求上云,上云需要使用互联网,那么就需要改变原有的存储方式。为了在线和离线维护云架构,需要改变结构,这将需要大量的人力成本。如果有直接兼容Oracle语法的功能,这个时候放到云端会减轻整体负担。
云数据库PPAS to Oracle兼容的数据类型有很多,如BLOB、CLOB、DATE等。他们每个人都有自己的别名和类型。例如,BLOB 的别名是 LONG RAW,它的类型是二进制数据。
ADAM 可以通过全量迁移和增量迁移的方式,协助用户将 Oracle 数据库迁移到云端。如果 Oracle 数据量很大,可能需要一周甚至一个月的时间才能完成传输。这时候可以通过高速连接和高速通道来增加带宽,不需要经过互联网,防止传输错误的数据,也不会影响生产库。通过ADAM平台,Oracle数据到云数据库还将提供30天退货机制,为用户迁移割接过程提供最大保障。
PPAS版不仅具有高可用,还支持同城容灾。用户可以选择使用单AZ集群或多AZ(同城容灾)集群,无需任何额外费用。有保障的企业级容灾需要保护。
PPAS版不仅提供自动备份,还提供50%的免费备份空间。例如,如果用户购买了 1TB 的实例存储空间,他们将直接获得 500GB 的免费备份空间。
ApsaraDB for PPAS 云管理是按时间点克隆实例。实例克隆功能将于2018年7月上线,支持最长730天的数据备份。目前,仅提供临时实例。阿里云 PostgreSQL 生态系统
Oracle 应用可以迁移到 PPAS 版,它使用高性能本地存储来存储热的 OLTP 业务数据。历史信息存储在外部OSS上,HybridDB for PostgreSQL可以直接读取和使用OSS上的数据,也就是说OLTP可以进行业务处理,OLAP可以直接使用基于阿里云的数据仓库服务开源Greenplum数据库分布式MPP架构。PostgreSQL 的混合数据库。
同时,用户也可以保留原有的Oracle系统,只使用HybridDB for PostgreSQL进行分析业务。OLAP 性能优势如下: HybridDB for PostgreSQL 混合分区
存储可以分为三种存储,即行存储、列存储和OSS温存储。三种存储方式说明如下: 链接原文
采集系统上云(络信息采集大师NetGet2016官方下载络爬虫软件大数据采集服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-03-12 18:16
网络信息采集Master NetGet2016官方下载网络信息采集Master Net,使用电脑完成系统控制和数据处理。与网络上的其他计算机可以实现数据共享,即实现数据观察。对于实现计算机管理的现代系统,网络数据采集系统提供。网络大数据采集监控平台、社科网络大数据采集监控平台采用搜索引擎技术、文本挖掘技术、自然语言技术、统计语言学、机器人工智能技术等。 - 计算机交互
信息资源采集网络信息采集资源提取乐思软件,什么是网络信息资源采集?网络信息资源采集是从大量的非结构化信息中提取出来的将其提取并保存到结构化数据库中的过程。我们提供Web2DB网络信息资源采集服务您只需要告诉我们。通过网络爬虫采集大数据,网络数据采集是指通过网络爬虫或站内公共API从站内获取数据信息。该方法可以从中提取非结构化数据,并将其存储为统一的本地数据文件,并以结构化的方式存储。优采云采集器免费的网络爬虫软件大数据抓取工具,优采云Data采集器简单好用,
网络数据采集方法简书,网络数据采集是指通过网络爬虫或者站点的公共API从站点获取数据信息。该方法可以从中提取非结构化数据,并将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图表。网络数据采集工具 lh45911 博客园,1 采集网络信息的方法有很多种。这样,一些简单的东西还是可以搜索到的。2 当然,有些东西是晦涩难寻的,所以说的话。网络采集器 是干什么用的?主要功能有哪些,网络数据采集工具优采云:bazhuayu优采云采集器:locoy其他数据媒体微博排名:v6bangweiboxmt新媒体排名
一个网络数据采集可以精准爬取站位的系统Web大数据,检测代码网络数据采集系统是一个可以精准爬取站位的爬虫工具支持运营网络数据的开发采集建筑学科的系统。Probe 对上述挑战的解决方案 24 自动爬虫 采集 制定的很明确。网络采集最新资讯什么是网络采集五六网首页,经过十多年的发展,企业在IT基础设施和云原生业务应用方面稳步推进。云业务规模增加,混合云中的网络变得更加复杂。企业对业务安全的需求和行业主管部门的监管要求提高。网络信息采集方法图,《网络信息》培训报告类名:XXXXXXX 名称:XX 培训名称:网络信息采集方法培训目的:了解网络信息筛选标准,掌握网络信息采集 方法。学号:XXXXX 培训内容:Root
和网络目标数据源的数据处理。军犬网采集部门。网络采集网络信息采集网络数据提取乐思软件,我们提供产品化的乐思网络信息采集系统软件您可以随时配置采集任何站点任何内容。有什么好处?你会在网络采集上节省大量的人力和金钱。广泛应用于行业门户站竞争情报系统知识 在网络上会节省大量的人力和金钱采集。广泛应用于行业门户站竞争情报系统知识 在网络上会节省大量的人力和金钱采集。广泛应用于行业门户站竞争情报系统知识 查看全部
采集系统上云(络信息采集大师NetGet2016官方下载络爬虫软件大数据采集服务)
网络信息采集Master NetGet2016官方下载网络信息采集Master Net,使用电脑完成系统控制和数据处理。与网络上的其他计算机可以实现数据共享,即实现数据观察。对于实现计算机管理的现代系统,网络数据采集系统提供。网络大数据采集监控平台、社科网络大数据采集监控平台采用搜索引擎技术、文本挖掘技术、自然语言技术、统计语言学、机器人工智能技术等。 - 计算机交互
信息资源采集网络信息采集资源提取乐思软件,什么是网络信息资源采集?网络信息资源采集是从大量的非结构化信息中提取出来的将其提取并保存到结构化数据库中的过程。我们提供Web2DB网络信息资源采集服务您只需要告诉我们。通过网络爬虫采集大数据,网络数据采集是指通过网络爬虫或站内公共API从站内获取数据信息。该方法可以从中提取非结构化数据,并将其存储为统一的本地数据文件,并以结构化的方式存储。优采云采集器免费的网络爬虫软件大数据抓取工具,优采云Data采集器简单好用,
网络数据采集方法简书,网络数据采集是指通过网络爬虫或者站点的公共API从站点获取数据信息。该方法可以从中提取非结构化数据,并将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图表。网络数据采集工具 lh45911 博客园,1 采集网络信息的方法有很多种。这样,一些简单的东西还是可以搜索到的。2 当然,有些东西是晦涩难寻的,所以说的话。网络采集器 是干什么用的?主要功能有哪些,网络数据采集工具优采云:bazhuayu优采云采集器:locoy其他数据媒体微博排名:v6bangweiboxmt新媒体排名
一个网络数据采集可以精准爬取站位的系统Web大数据,检测代码网络数据采集系统是一个可以精准爬取站位的爬虫工具支持运营网络数据的开发采集建筑学科的系统。Probe 对上述挑战的解决方案 24 自动爬虫 采集 制定的很明确。网络采集最新资讯什么是网络采集五六网首页,经过十多年的发展,企业在IT基础设施和云原生业务应用方面稳步推进。云业务规模增加,混合云中的网络变得更加复杂。企业对业务安全的需求和行业主管部门的监管要求提高。网络信息采集方法图,《网络信息》培训报告类名:XXXXXXX 名称:XX 培训名称:网络信息采集方法培训目的:了解网络信息筛选标准,掌握网络信息采集 方法。学号:XXXXX 培训内容:Root
和网络目标数据源的数据处理。军犬网采集部门。网络采集网络信息采集网络数据提取乐思软件,我们提供产品化的乐思网络信息采集系统软件您可以随时配置采集任何站点任何内容。有什么好处?你会在网络采集上节省大量的人力和金钱。广泛应用于行业门户站竞争情报系统知识 在网络上会节省大量的人力和金钱采集。广泛应用于行业门户站竞争情报系统知识 在网络上会节省大量的人力和金钱采集。广泛应用于行业门户站竞争情报系统知识
采集系统上云(企业应用系统上云,如何在云端利用云的优势进行性能优化)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-03-10 02:30
应用系统上线运行后,随着系统数据量的不断增长和访问量的不断增加,系统的响应速度通常会越来越慢,尤其是在日常高峰的情况下,往往无法满足业务需求,甚至出现应用服务中断的现象。,给企业造成巨大的品牌损失和经济损失。大量数据显示,核心体验响应时间每增加 0.1 秒,就会导致收入下降 1%。当企业应用系统上云时,如何利用云的优势在云端进行性能优化是一个值得深入分析的关键问题。
性能优化的价值与策略
1、性能优化值
性能是应用程序最重要的指标,除非有选择,否则用户不会忍受缓慢的应用程序或 网站。大量数据显示,核心体验响应时间每增加 0.1 秒,就会导致收入下降 1%。
应用系统上线运行后,随着系统数据量的不断增长和访问量的不断增加,系统的响应速度通常会越来越慢,尤其是在高峰期,往往无法满足业务需要,甚至应用服务中断。造成巨大的品牌损失和经济损失,因此性能优化至关重要。
通过性能优化,可以用更少的硬件资源来支持更多的业务开发,从而达到节省硬件成本的目的;同时可以在资源有限的情况下提高系统的响应能力,带来更好的用户体验。用经验促进业务增长。
2、性能优化策略
对于应用系统来说,用户需要从浏览器经过很多环节向数据库发送请求,才能完成事务操作。如果系统响应慢,需要分析请求经过的所有环节,排查可能存在的性能瓶颈,定位问题所在。
排查瓶颈的方法通常是查看请求处理的各个环节的日志,分析哪个环节的响应时间不合理,超出预期。然后查看监控数据,分析影响性能的主要因素是CPU还是内存、磁盘、网络等基础设施资源。问题,或者架构设计的问题,或者SQL语句慢的问题。
定位性能问题的具体原因后,进行针对性的性能优化。
云性能优化系统
1、性能优化系统
性能优化,简而言之,就是在不影响系统正确性的情况下,让系统运行得更快,用更少的时间完成特定的功能。
性能优化有很多维度。一般来说,性能优化可以从以下五个方面进行:资源层、架构层、应用层、数据库层、中间件层。性能优化系统如下:
2、资源层优化
云资源层的优化包括云资源的横向和纵向扩展。资源层优化的依据可以来自云监控的量化指标数据。
云监控可以实时监控云资源的动态指标,是所有云产品监控管理的主要入口。您可以通过云监控查看最完整、最详细的监控数据。云监控可以实时监控云服务器、云数据库、负载均衡等云产品,提取云产品的关键指标,并以监控图表的形式展示。使用云监控全面了解资源使用情况、应用程序性能和云产品运行状况。
横向扩展就是增加云服务器、云数据库等实例的数量。垂直扩容就是升级云服务器、云数据库等云资源的规格和配置,比如CPU、内存、磁盘、带宽等参数的配置。从解决资源瓶颈的角度优化系统访问性能。
3、架构层优化
不合理的系统架构设计也可能导致系统性能问题。比如在架构设计上,没有考虑读写分离、数据库分库分表、动静分离、CDN加速、缓存加速、弹性伸缩等。
读写分离和数据库分库分表解决了数据库访问性能问题。在云端实现读写分离非常方便。创建只读实例后,在应用中配置读写分离地址,自动转发写请求。对于主实例,读取请求会自动转发到每个只读实例。
动静分离、CDN加速、缓存解决快速读取静态文件或热点数据的问题,如图片、视频、热门商品、库存等,企业上云时,需要使用一些成熟的尽可能多的云原生解决方案。优化访问性能问题的设计级别。
弹性伸缩解决了应用服务器自动扩容的问题。通过提前配置伸缩规则和策略,在业务需求增加时自动添加云服务器实例,保证计算能力,避免访问延迟和资源过载。
4、应用层优化
应用层优化的关键是首先快速诊断出应用的问题瓶颈。
互联网业务的快速发展带来了越来越大的流量压力,业务逻辑也越来越复杂。传统的独立应用程序已不能满足需求。越来越多的网站或系统逐渐采用分布式部署架构。
同时,随着Spring Cloud/Dubbo等基础开发框架的不断成熟,越来越多的企业开始将应用架构按照业务模块进行垂直拆分,形成更适合团队协同开发的微服务架构和快速迭代。
分布式微服务架构在开发效率上领先,但给传统的监控、运维、诊断技术带来了巨大挑战。主要挑战包括:
难点定位:
微服务分布式架构一个业务请求通常经过多个服务/节点后才会返回结果。一旦请求出现错误,往往需要反复查看多台机器上的日志来初步定位问题。简单问题的故障排除往往涉及很多团队。
难以发现瓶颈:
当用户反映系统卡死时,很难快速找出瓶颈在哪里:是用户终端到服务器的网络问题,是服务器负载过高响应变慢,还是数据库压力太高?即使定位到导致卡顿的环节,也很难在代码层面快速定位到根本原因。
结构难以梳理:
在业务逻辑变得更加复杂之后,很难从代码层面梳理出一个应用依赖哪些下游服务(数据库、HTTP API、缓存),以及哪些外部调用依赖于它。理清业务逻辑、治理架构和规划容量也变得更加困难。
通常需要性能压力测量工具(如PTS)和应用实时监控服务(如ARMS)等工具,从前端、应用、业务定制等维度进行链路跟踪,实现完整的调用链路恢复和呼叫请求量。统计、链路拓扑和应用依赖分析等。链路追踪可以帮助快速分析和诊断分布式应用架构中的性能瓶颈,提高微服务时代的开发和诊断效率。
定位瓶颈问题后,进行针对性的优化工作,如优化慢SQL语句、优化调用报错程序代码、优化调用异常API等。用性能压测工具重新施压,通过压测结果进一步分析系统瓶颈,迭代优化应用。
5、数据库优化
影响数据库系统性能的主要因素有:系统的硬件配置、数据库文件的物理分布、数据库实例的参数、数据库的物理设计、应用的SQL语句。
数据库性能优化需要以下数据内容采集:
系统软硬件环境:包括服务器的操作系统设置、硬件配置、网络配置、软件环境、启动选项、进程信息、性能信息、磁盘使用情况等。
硬件运行:包括CPU、内存、磁盘、网络的运行数据。
数据库实例的配置:实例配置参数。
数据库配置:包括恢复模式、自动收缩、空间增长等信息。
数据库磁盘使用情况:包括数据库大小、表大小、记录数、索引大小、占用空间等。
索引和分片:包括表上的索引、索引的分片、索引的维护计划等。
SQL语句执行:包括SQL语句执行时间、启动时间、数据库、语句内容、死锁、阻塞等。
应用运行状态:包括系统高峰时段、夜间数据库维护任务、用户上报业务慢、系统运行特点等。
数据库性能的主要优化项目如下图所示:
6、中间件优化
在信息系统中,许多性能问题都是由不起眼的应用程序中间件引起的。应用程序中间件之所以诞生,是为了帮助应用程序编码人员处理频繁发生的与业务逻辑关系不大但必须处理的事情,比如处理应用程序与数据库的关系,设置打开多少个会话用于处理。客户端请求、会话超时等。
然而,在享受便利的同时,应用中间件也将成为系统性能问题的制造者。开发人员和测试人员经常忽略中间件本身对性能的影响,包括事务吞吐量限制和响应时间。,交易成功率的影响等等。
中间件优化的目标是缩短中间件花费的时间(提升用户体验),提高整个应用服务器的吞吐量。中间件优化,调整什么参数,一定要了解它的含义,原理,调整后的收益和风险,最好能把N个参数包在一个整体的脑海里。
高优先级:调整JVM虚拟机的JDBC连接池、线程池、堆大小。
中优先级:会话数、垃圾回收 GC 策略。
还有缓存,数据源语句缓存大小。
配置不当也会导致中间件处于挂起状态。比如某类资源(session或jdbc)被应用完全占用,短时间内不会释放,从而无法执行新的请求,导致假死。这种情况下,需要做超时放弃的参数配置。
关于性能优化的进一步思考
性能优化是一项复杂的系统工程。首先要定位性能瓶颈,然后对云资源、系统架构、应用、数据库、中间件等进行综合分析和优化。性能优化的最终目的是提升用户体验。离开这个目的,在技术上追求所谓的高性能,是浪费钱,没有任何意义。
随着系统数据量、访问用户数量的不断增加以及系统功能的不断迭代,系统需要不断优化性能。性能优化是一场持久战。只有这样,用户才能有更好的访问体验,支持业务增长。 查看全部
采集系统上云(企业应用系统上云,如何在云端利用云的优势进行性能优化)
应用系统上线运行后,随着系统数据量的不断增长和访问量的不断增加,系统的响应速度通常会越来越慢,尤其是在日常高峰的情况下,往往无法满足业务需求,甚至出现应用服务中断的现象。,给企业造成巨大的品牌损失和经济损失。大量数据显示,核心体验响应时间每增加 0.1 秒,就会导致收入下降 1%。当企业应用系统上云时,如何利用云的优势在云端进行性能优化是一个值得深入分析的关键问题。
性能优化的价值与策略
1、性能优化值
性能是应用程序最重要的指标,除非有选择,否则用户不会忍受缓慢的应用程序或 网站。大量数据显示,核心体验响应时间每增加 0.1 秒,就会导致收入下降 1%。
应用系统上线运行后,随着系统数据量的不断增长和访问量的不断增加,系统的响应速度通常会越来越慢,尤其是在高峰期,往往无法满足业务需要,甚至应用服务中断。造成巨大的品牌损失和经济损失,因此性能优化至关重要。
通过性能优化,可以用更少的硬件资源来支持更多的业务开发,从而达到节省硬件成本的目的;同时可以在资源有限的情况下提高系统的响应能力,带来更好的用户体验。用经验促进业务增长。
2、性能优化策略
对于应用系统来说,用户需要从浏览器经过很多环节向数据库发送请求,才能完成事务操作。如果系统响应慢,需要分析请求经过的所有环节,排查可能存在的性能瓶颈,定位问题所在。
排查瓶颈的方法通常是查看请求处理的各个环节的日志,分析哪个环节的响应时间不合理,超出预期。然后查看监控数据,分析影响性能的主要因素是CPU还是内存、磁盘、网络等基础设施资源。问题,或者架构设计的问题,或者SQL语句慢的问题。
定位性能问题的具体原因后,进行针对性的性能优化。
云性能优化系统
1、性能优化系统
性能优化,简而言之,就是在不影响系统正确性的情况下,让系统运行得更快,用更少的时间完成特定的功能。
性能优化有很多维度。一般来说,性能优化可以从以下五个方面进行:资源层、架构层、应用层、数据库层、中间件层。性能优化系统如下:
2、资源层优化
云资源层的优化包括云资源的横向和纵向扩展。资源层优化的依据可以来自云监控的量化指标数据。
云监控可以实时监控云资源的动态指标,是所有云产品监控管理的主要入口。您可以通过云监控查看最完整、最详细的监控数据。云监控可以实时监控云服务器、云数据库、负载均衡等云产品,提取云产品的关键指标,并以监控图表的形式展示。使用云监控全面了解资源使用情况、应用程序性能和云产品运行状况。
横向扩展就是增加云服务器、云数据库等实例的数量。垂直扩容就是升级云服务器、云数据库等云资源的规格和配置,比如CPU、内存、磁盘、带宽等参数的配置。从解决资源瓶颈的角度优化系统访问性能。
3、架构层优化
不合理的系统架构设计也可能导致系统性能问题。比如在架构设计上,没有考虑读写分离、数据库分库分表、动静分离、CDN加速、缓存加速、弹性伸缩等。
读写分离和数据库分库分表解决了数据库访问性能问题。在云端实现读写分离非常方便。创建只读实例后,在应用中配置读写分离地址,自动转发写请求。对于主实例,读取请求会自动转发到每个只读实例。
动静分离、CDN加速、缓存解决快速读取静态文件或热点数据的问题,如图片、视频、热门商品、库存等,企业上云时,需要使用一些成熟的尽可能多的云原生解决方案。优化访问性能问题的设计级别。
弹性伸缩解决了应用服务器自动扩容的问题。通过提前配置伸缩规则和策略,在业务需求增加时自动添加云服务器实例,保证计算能力,避免访问延迟和资源过载。
4、应用层优化
应用层优化的关键是首先快速诊断出应用的问题瓶颈。
互联网业务的快速发展带来了越来越大的流量压力,业务逻辑也越来越复杂。传统的独立应用程序已不能满足需求。越来越多的网站或系统逐渐采用分布式部署架构。
同时,随着Spring Cloud/Dubbo等基础开发框架的不断成熟,越来越多的企业开始将应用架构按照业务模块进行垂直拆分,形成更适合团队协同开发的微服务架构和快速迭代。
分布式微服务架构在开发效率上领先,但给传统的监控、运维、诊断技术带来了巨大挑战。主要挑战包括:
难点定位:
微服务分布式架构一个业务请求通常经过多个服务/节点后才会返回结果。一旦请求出现错误,往往需要反复查看多台机器上的日志来初步定位问题。简单问题的故障排除往往涉及很多团队。
难以发现瓶颈:
当用户反映系统卡死时,很难快速找出瓶颈在哪里:是用户终端到服务器的网络问题,是服务器负载过高响应变慢,还是数据库压力太高?即使定位到导致卡顿的环节,也很难在代码层面快速定位到根本原因。
结构难以梳理:
在业务逻辑变得更加复杂之后,很难从代码层面梳理出一个应用依赖哪些下游服务(数据库、HTTP API、缓存),以及哪些外部调用依赖于它。理清业务逻辑、治理架构和规划容量也变得更加困难。
通常需要性能压力测量工具(如PTS)和应用实时监控服务(如ARMS)等工具,从前端、应用、业务定制等维度进行链路跟踪,实现完整的调用链路恢复和呼叫请求量。统计、链路拓扑和应用依赖分析等。链路追踪可以帮助快速分析和诊断分布式应用架构中的性能瓶颈,提高微服务时代的开发和诊断效率。
定位瓶颈问题后,进行针对性的优化工作,如优化慢SQL语句、优化调用报错程序代码、优化调用异常API等。用性能压测工具重新施压,通过压测结果进一步分析系统瓶颈,迭代优化应用。
5、数据库优化
影响数据库系统性能的主要因素有:系统的硬件配置、数据库文件的物理分布、数据库实例的参数、数据库的物理设计、应用的SQL语句。
数据库性能优化需要以下数据内容采集:
系统软硬件环境:包括服务器的操作系统设置、硬件配置、网络配置、软件环境、启动选项、进程信息、性能信息、磁盘使用情况等。
硬件运行:包括CPU、内存、磁盘、网络的运行数据。
数据库实例的配置:实例配置参数。
数据库配置:包括恢复模式、自动收缩、空间增长等信息。
数据库磁盘使用情况:包括数据库大小、表大小、记录数、索引大小、占用空间等。
索引和分片:包括表上的索引、索引的分片、索引的维护计划等。
SQL语句执行:包括SQL语句执行时间、启动时间、数据库、语句内容、死锁、阻塞等。
应用运行状态:包括系统高峰时段、夜间数据库维护任务、用户上报业务慢、系统运行特点等。
数据库性能的主要优化项目如下图所示:
6、中间件优化
在信息系统中,许多性能问题都是由不起眼的应用程序中间件引起的。应用程序中间件之所以诞生,是为了帮助应用程序编码人员处理频繁发生的与业务逻辑关系不大但必须处理的事情,比如处理应用程序与数据库的关系,设置打开多少个会话用于处理。客户端请求、会话超时等。
然而,在享受便利的同时,应用中间件也将成为系统性能问题的制造者。开发人员和测试人员经常忽略中间件本身对性能的影响,包括事务吞吐量限制和响应时间。,交易成功率的影响等等。
中间件优化的目标是缩短中间件花费的时间(提升用户体验),提高整个应用服务器的吞吐量。中间件优化,调整什么参数,一定要了解它的含义,原理,调整后的收益和风险,最好能把N个参数包在一个整体的脑海里。
高优先级:调整JVM虚拟机的JDBC连接池、线程池、堆大小。
中优先级:会话数、垃圾回收 GC 策略。
还有缓存,数据源语句缓存大小。
配置不当也会导致中间件处于挂起状态。比如某类资源(session或jdbc)被应用完全占用,短时间内不会释放,从而无法执行新的请求,导致假死。这种情况下,需要做超时放弃的参数配置。
关于性能优化的进一步思考
性能优化是一项复杂的系统工程。首先要定位性能瓶颈,然后对云资源、系统架构、应用、数据库、中间件等进行综合分析和优化。性能优化的最终目的是提升用户体验。离开这个目的,在技术上追求所谓的高性能,是浪费钱,没有任何意义。
随着系统数据量、访问用户数量的不断增加以及系统功能的不断迭代,系统需要不断优化性能。性能优化是一场持久战。只有这样,用户才能有更好的访问体验,支持业务增长。
采集系统上云( 快页互联网舆情监测分析系统通过融合最新的海量网络信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-05 21:09
快页互联网舆情监测分析系统通过融合最新的海量网络信息)
快页互联网舆情监测分析系统集成了最新的海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可监测上千条新闻、论坛、博客、微信的最新舆情博客和视频信息有助于用户及时、全面、准确地掌握网络动态,了解自己的网络形象,提高公关适应能力和重大事件处理能力。
系统优势:
及时
快页互联网舆情监测系统通过自主研发的分布式异步高并发爬虫技术保证采集的及时性。
自动调整采集的频率,重点网站优先采集。
综合的
通过针对采集新闻、论坛、贴吧、自媒体、视频、博客、微博、微信等,确保重要信息优先采集不丢失,并通过搜索和补充主流搜索引擎,保证信息采集的全面性。
精确的
通过自主研发的自然语言处理技术,包括多项专利技术,保证了捕获信息的准确性、分类的准确性和否定判断的准确性。
相似度文章识别
准确识别内容相似的文章,可用于文章的去重和紧急情况的发现。
无需模板
无需制作模板,可随时添加采集源,不受网页修改影响。
综合分析报告显示功能
多角度多层次展示信息特征,揭示数据规律,帮助用户预测采集到的舆情信息的未来趋势!
使用简单
界面美观实用。所有配置和操作均可在线完成,直观方便,用户无需长期培训即可轻松掌握。
可以无限添加子账号,多个同事不需要共享账号。
","detailId":8499,"detailInfo":{"apiGwServiceId":"","buyDebug":false,"croTimeSpan":0,"croTimeUnit":"","custom":false,"deliveryTime":" 1 天","imgId":"","isManual":false,"needConfirm":1,"needDeliver":1,"needHardware":"","needRemark":1,"os":""," osArch":"","osName":"","osVendor":"","preRemark":0,"productProviderUin":"","rawUnImgId":"","remarkTpl":"请到云端公开意见优先 平台()自行注册账号。注册后,填写下面的账号,并且客服会给这个账号开通权限。\n*账号(手机号):\n初始密码:\n监控关键词:","requireCustomerInfo":false,"serviceProviderUin":"","
<p>","tagGroupId":882,"tags":["舆论"],"times":16,"verifyTime":"2021-10-18 18:42:47","zlogo":""," deliverTypeText ":"manual delivery","formatedDetailInfo":[{"name":"delivery method","value":"manual delivery"},{"name":"delivery duration","value":"1天" }],"keywords":"工具软件,舆论","priceList":[{"billingInfo":null,"cycles":[{"cycleId":"96-018641-tf6j04","disprice": 0, "flowSpan":"","flowUnit":"","id":58787,"lowerLimit":1,"price":0,"rank":1,"specId":"96-018641-01rlge", "timeSpan":3,"timeUnit":"d","unit":"","upperLimit":1,"cycle":"3 days","trialDays":"", "timeUnitCn":"days"},{"cycleId":"96-018641-ec64o3","disprice":2400,"flowSpan":"","flowUnit":"","id":58788,"lowerLimit ":1,"price":4800,"rank":2,"specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"m","unit":""," upperLimit":1,"cycle":"1month","trialDays":"","timeUnitCn" :"month"},{"cycleId":"96-018641-8m6tl1","disprice":24000,"flowSpan “:"","flowUnit":"","id":58789,"lowerLimit":1,"price":48000,"rank":3,"specId":"96-018641-01rlge","timeSpan": 1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1 年","trialDays":"","timeUnitCn":"year"}]," maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0," renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"", "specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />rank":3," specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1 年","trialDays" :"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank": 1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />rank":3,"specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit ":"","upperLimit":1,"cycle":"1 年","trialDays":"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1," payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}]," isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />specId":"96-018641-01rlge","timeSpan":1, "timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays" :"","timeUnitCn":"year"}],"maxQuota": 0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems": [],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />specId":"96 -018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays" :"","timeUnitCn ":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":" 96- 018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后根据用户完成相关人工服务需要"}"/>96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays ":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权", "specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips": "购买成功后,根据用户需求完成相关人工服务"}" />96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit": 1,"cycle":"1year","trialDays":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 < @关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge" ,"tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice ":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />y","unit":"","upperLimit":1,"cycle":"1year", "trialDays":"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec ":"50 关键词 组合授权" ,"specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips" :"购买成功后,根据用户需求完成相关人工服务"}" />y","unit":"","upperLimit":1,"cycle":"1year","trialDays":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec ":"50 关键词 组合授权","specDescribe":"" ,"specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,完成相关人工服务根据用户需求"}" />"timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank ":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge" ,"tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice ":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />"timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode ":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 查看全部
采集系统上云(
快页互联网舆情监测分析系统通过融合最新的海量网络信息)
快页互联网舆情监测分析系统集成了最新的海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可监测上千条新闻、论坛、博客、微信的最新舆情博客和视频信息有助于用户及时、全面、准确地掌握网络动态,了解自己的网络形象,提高公关适应能力和重大事件处理能力。
系统优势:
及时
快页互联网舆情监测系统通过自主研发的分布式异步高并发爬虫技术保证采集的及时性。
自动调整采集的频率,重点网站优先采集。
综合的
通过针对采集新闻、论坛、贴吧、自媒体、视频、博客、微博、微信等,确保重要信息优先采集不丢失,并通过搜索和补充主流搜索引擎,保证信息采集的全面性。
精确的
通过自主研发的自然语言处理技术,包括多项专利技术,保证了捕获信息的准确性、分类的准确性和否定判断的准确性。
相似度文章识别
准确识别内容相似的文章,可用于文章的去重和紧急情况的发现。
无需模板
无需制作模板,可随时添加采集源,不受网页修改影响。
综合分析报告显示功能
多角度多层次展示信息特征,揭示数据规律,帮助用户预测采集到的舆情信息的未来趋势!
使用简单
界面美观实用。所有配置和操作均可在线完成,直观方便,用户无需长期培训即可轻松掌握。
可以无限添加子账号,多个同事不需要共享账号。
","detailId":8499,"detailInfo":{"apiGwServiceId":"","buyDebug":false,"croTimeSpan":0,"croTimeUnit":"","custom":false,"deliveryTime":" 1 天","imgId":"","isManual":false,"needConfirm":1,"needDeliver":1,"needHardware":"","needRemark":1,"os":""," osArch":"","osName":"","osVendor":"","preRemark":0,"productProviderUin":"","rawUnImgId":"","remarkTpl":"请到云端公开意见优先 平台()自行注册账号。注册后,填写下面的账号,并且客服会给这个账号开通权限。\n*账号(手机号):\n初始密码:\n监控关键词:","requireCustomerInfo":false,"serviceProviderUin":"","
<p>","tagGroupId":882,"tags":["舆论"],"times":16,"verifyTime":"2021-10-18 18:42:47","zlogo":""," deliverTypeText ":"manual delivery","formatedDetailInfo":[{"name":"delivery method","value":"manual delivery"},{"name":"delivery duration","value":"1天" }],"keywords":"工具软件,舆论","priceList":[{"billingInfo":null,"cycles":[{"cycleId":"96-018641-tf6j04","disprice": 0, "flowSpan":"","flowUnit":"","id":58787,"lowerLimit":1,"price":0,"rank":1,"specId":"96-018641-01rlge", "timeSpan":3,"timeUnit":"d","unit":"","upperLimit":1,"cycle":"3 days","trialDays":"", "timeUnitCn":"days"},{"cycleId":"96-018641-ec64o3","disprice":2400,"flowSpan":"","flowUnit":"","id":58788,"lowerLimit ":1,"price":4800,"rank":2,"specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"m","unit":""," upperLimit":1,"cycle":"1month","trialDays":"","timeUnitCn" :"month"},{"cycleId":"96-018641-8m6tl1","disprice":24000,"flowSpan “:"","flowUnit":"","id":58789,"lowerLimit":1,"price":48000,"rank":3,"specId":"96-018641-01rlge","timeSpan": 1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1 年","trialDays":"","timeUnitCn":"year"}]," maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0," renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"", "specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />rank":3," specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1 年","trialDays" :"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank": 1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />rank":3,"specId":"96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit ":"","upperLimit":1,"cycle":"1 年","trialDays":"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1," payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}]," isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />specId":"96-018641-01rlge","timeSpan":1, "timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays" :"","timeUnitCn":"year"}],"maxQuota": 0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge","tcbItems": [],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />specId":"96 -018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays" :"","timeUnitCn ":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow": 0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":" 96- 018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后根据用户完成相关人工服务需要"}"/>96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit":1,"cycle":"1year","trialDays ":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权", "specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips": "购买成功后,根据用户需求完成相关人工服务"}" />96-018641-01rlge","timeSpan":1,"timeUnit":"y","unit":"","upperLimit": 1,"cycle":"1year","trialDays":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 < @关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge" ,"tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice ":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />y","unit":"","upperLimit":1,"cycle":"1year", "trialDays":"","timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec ":"50 关键词 组合授权" ,"specDescribe":"","specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips" :"购买成功后,根据用户需求完成相关人工服务"}" />y","unit":"","upperLimit":1,"cycle":"1year","trialDays":"", "timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice":null,"renewYearFlow":0,"renewYearPrice":null,"spec ":"50 关键词 组合授权","specDescribe":"" ,"specId":"96-018641-01rlge","tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice":false,"deliverTips":"购买成功后,完成相关人工服务根据用户需求"}" />"timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode":"prepay","productId":0,"rank ":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50 关键词 组合授权","specDescribe":"","specId":"96-018641-01rlge" ,"tcbItems":[],"trialDays":0}],"isTcb":false,"needUpdatePrice ":false,"deliverTips":"购买成功后,根据用户需求完成相关人工服务"}" />"timeUnitCn":"year"}],"maxQuota":0,"onOffer":1,"payMode ":"prepay","productId":0,"rank":1,"renewMonthFlow":0,"renewMonthPrice ":null,"renewYearFlow":0,"renewYearPrice":null,"spec":"50
采集系统上云(postgresql分表、水平扩展、事务,应该选alluxio还是namenode?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-05 11:02
采集系统上云后都将面临postgresql数据标准化的要求,cgi上现在已经全线支持postgresql。您可以了解下postgresql协议。如果您有兴趣,可以点击我的个人网站,查看具体的介绍及源码。分库分表、水平扩展、事务,分库分表任性玩!redis实现数据持久化处理、并发读写,给读写分离留一片天空!分库分表,应该选alluxio,还是namenode?欢迎交流分享讨论。
从标准,性能,扩展,可扩展性这些角度来看,zookeeper远胜于pg。
driver没有read/write接口,这就是pg一定会垮的原因。从算法上说,pg难度太大,成本太高,
毫无疑问,pg更容易用,因为pg已经是标准库了,如果你没有特殊需求的话一般不用pg都能满足业务需求,pg上可以直接写pgsql,和后面sqoop都不冲突。再说了,pg只要把后端的消息中间件加上就没有问题了。driver就不说了,那个net4的后端etem,又封装又庞大,所以一般都用boost,这个技术难度和要求比pg低的多,也好学,基本用个新版本的java就能实现。
zookeeper有replication,有promote,实现起来更方便,稍微写写脚本也就能实现pg的功能了。至于pg的“一致性”和“可伸缩性”,根本没有这么值得思考的问题好吧?那些功能目前zookeeper已经可以搞定了。pg的难度无非就是pg一些简单的小功能需要人工实现一下,一个中心的支持,能支持的客户端数量,和后续扩展的成本而已。最后,namenode的成本远高于datanode,这是事实。 查看全部
采集系统上云(postgresql分表、水平扩展、事务,应该选alluxio还是namenode?)
采集系统上云后都将面临postgresql数据标准化的要求,cgi上现在已经全线支持postgresql。您可以了解下postgresql协议。如果您有兴趣,可以点击我的个人网站,查看具体的介绍及源码。分库分表、水平扩展、事务,分库分表任性玩!redis实现数据持久化处理、并发读写,给读写分离留一片天空!分库分表,应该选alluxio,还是namenode?欢迎交流分享讨论。
从标准,性能,扩展,可扩展性这些角度来看,zookeeper远胜于pg。
driver没有read/write接口,这就是pg一定会垮的原因。从算法上说,pg难度太大,成本太高,
毫无疑问,pg更容易用,因为pg已经是标准库了,如果你没有特殊需求的话一般不用pg都能满足业务需求,pg上可以直接写pgsql,和后面sqoop都不冲突。再说了,pg只要把后端的消息中间件加上就没有问题了。driver就不说了,那个net4的后端etem,又封装又庞大,所以一般都用boost,这个技术难度和要求比pg低的多,也好学,基本用个新版本的java就能实现。
zookeeper有replication,有promote,实现起来更方便,稍微写写脚本也就能实现pg的功能了。至于pg的“一致性”和“可伸缩性”,根本没有这么值得思考的问题好吧?那些功能目前zookeeper已经可以搞定了。pg的难度无非就是pg一些简单的小功能需要人工实现一下,一个中心的支持,能支持的客户端数量,和后续扩展的成本而已。最后,namenode的成本远高于datanode,这是事实。
采集系统上云(辽宁企业大数据采集技术注意每种统计分析方法的适用范围方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-03-03 00:11
可视化+爬虫脚本语言+正则表达式 ForeSpider是一款通用的采集可视化软件,内置强大的爬虫脚本语言。如果有可视化无法实现的内容采集,只需几行简单的代码即可实现强大的脚本采集。该软件还支持正则表达式操作,可以通过可视化、正则化和脚本化的方式对数据进行清理和标准化。软件内部集成了数据挖掘功能,通过采集模板可以对全网内容进行精细挖掘。在存储数据采集的同时,可以完成分类、统计、自然语言处理等多项功能。了解您分析的目标,并且知道在数据小的时候如何积累。大数据采集平台
大数据采集模块功能全国手机号码生成根据用户设置的区域生成手机号码段,并可根据指定的号码段生成手机号码,自定义格式,做地域定向营销,最好群发短信 选择在线方向采集软件可以通过流行的B2B网站在线采集,如马可波罗、一虎百影、无忧等 B2B网站采集企业信息,数据精细,采集快,对于想要获取企业信息的客户来说是不错的选择。企业搜索通过软件定位获取附近临街商铺和企业信息。还可以输入多个城市名称,通过自定义进行批量操作。数据精炼,非常适合营销使用。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。
智汇云狐采集软件可能和你见过的一些类似的工具软件完全不同:功能强大,操作简单。两者的区别类似于从DOS操作系统切换到Windows操作系统。前者需要专业技术人员才能有效运作,而我们是面向大众的可视化操作平台。使用精细搜索引擎的解析内核,通过模仿浏览器实现网页内容的解析。在此基础上,利用原创技术对网页框架的内容和内容进行分离提取,实现相似页面的有效对比。,匹配。因此,用户只需要指定一个参考页面,智汇云狐采集 软件系统可以对相似的页面进行相应的匹配,从而实现用户需要的采集数据的批量采集。在这个过程中,用户不再需要使用非常专业的“正则表达式”技术,也不需要依赖技术专家编写采集匹配规则。参考页面的内容解析分解后,用户可以用鼠标点击需要采集的对象,系统可以据此得知用户需要采集的内容。智汇云狐采集软件的模板定制过程是针对目标页面进行机器学习和机器训练的过程。
大数据采集是指主要处理海量数据存储、计算、不间断流数据的实时计算等场景的一套基础设施。可以使用开源平台,也可以使用华为、星联等商业级解决方案,既可以部署在私有云上,也可以部署在公有云上。任何一个完整的大数据平台一般都包括以下流程:数据采集-->数据存储-->数据处理-->数据呈现(可视化、报告、监控) 其中,数据采集是所有数据系统的必不可少,而随着大数据越来越受到重视,数据的挑战采集也变得更加突出。主要分为常规基础数据和自定义游戏系统数据。
在大数据时代,“一切都会被计算”、“一切都会被量化”、“一切都会被数字化”。人类生活在一个海量、动态和多样化数据的世界中。数据无处不在,随时可用,没有人使用它。数据与阳光、空气和水分一样普遍,与放大镜、望远镜和显微镜一样重要。大数据中的“数据”真实可靠。它本质上是一种表征事物现象的符号语言和逻辑关系。其可靠性的数学和哲学基础是世界同构原理。世界具有物质统一,统一世界中的一切都具有时空一致性的同构关系。这意味着只要正确编码,任何事物的属性和规律都可以通过统一的数字信号来表达。高级数据分析不一定好,简单有效就好。陕西商业大数据采集采集器
数据分析前应明确目的,然后根据分析目的确定分析框架和内容,以及所采用的数据分析方法。大数据采集平台
智汇云虎大数据采集软件的优势在于精准精准,全网数十个平台实时更新,软件实时更新数亿人的网络数据< @采集平台和搜索引擎,确保精确和准确的真实性和实时性。精细采集APP操作方式APP采集器,一键操作,全国300多个城市可自由选择,行业关键词快速锁定行业潜在客户,一键导入通讯录,一键导出电脑。官方持续升级更新售后无忧罚款采集APP已上架Apple Store和Android主流应用市场5年,十年数据采集 技术团队持续实时更新,售后有保障。大数据采集平台
您好,欢迎来电,公司现推出智能营销延伸系统、大数据采集系统、智汇云通话系统和5G视频广告,5G时代适合各行各业。宣传快速覆盖全城,品牌推广,产品推广,快速渗透,全城覆盖,低门槛高回报,同城营销神器。是一家集研发、设计、生产、销售为一体的专业化公司。拥有一支经验丰富、技术创新的专业研发团队,高度专注、专注地为客户提供大数据采集系统、云呼叫系统、同城延伸系统、智能营销延伸软件。不断开拓创新,追求卓越,以科技为先导,以产品为平台,以应用为重点,以服务为保障,不断为客户创造更高价值,提供更优质的服务。时刻关注自己,在风云变幻的时代,从不懈怠自身的建设,高度的专注和坚持让行业从容自信。 查看全部
采集系统上云(辽宁企业大数据采集技术注意每种统计分析方法的适用范围方法)
可视化+爬虫脚本语言+正则表达式 ForeSpider是一款通用的采集可视化软件,内置强大的爬虫脚本语言。如果有可视化无法实现的内容采集,只需几行简单的代码即可实现强大的脚本采集。该软件还支持正则表达式操作,可以通过可视化、正则化和脚本化的方式对数据进行清理和标准化。软件内部集成了数据挖掘功能,通过采集模板可以对全网内容进行精细挖掘。在存储数据采集的同时,可以完成分类、统计、自然语言处理等多项功能。了解您分析的目标,并且知道在数据小的时候如何积累。大数据采集平台
大数据采集模块功能全国手机号码生成根据用户设置的区域生成手机号码段,并可根据指定的号码段生成手机号码,自定义格式,做地域定向营销,最好群发短信 选择在线方向采集软件可以通过流行的B2B网站在线采集,如马可波罗、一虎百影、无忧等 B2B网站采集企业信息,数据精细,采集快,对于想要获取企业信息的客户来说是不错的选择。企业搜索通过软件定位获取附近临街商铺和企业信息。还可以输入多个城市名称,通过自定义进行批量操作。数据精炼,非常适合营销使用。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。搜索引擎大数据搜索(支持4大搜索引擎) 软件内置4个搜索引擎,软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。软件通过关键词对搜索结果进行分析匹配,提取号码、QQ邮箱、网址等字段。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。手机通讯录一键导入,可以将TXT文件的手机号码转换成手机可以一键识别并批量添加的手机通讯录格式文件。辽宁企业大数据采集技术关注每一种统计分析方法的适用范围,用不同的数据分析方法对同一个问题进行解释,相互验证结论的真实性。
智汇云狐采集软件可能和你见过的一些类似的工具软件完全不同:功能强大,操作简单。两者的区别类似于从DOS操作系统切换到Windows操作系统。前者需要专业技术人员才能有效运作,而我们是面向大众的可视化操作平台。使用精细搜索引擎的解析内核,通过模仿浏览器实现网页内容的解析。在此基础上,利用原创技术对网页框架的内容和内容进行分离提取,实现相似页面的有效对比。,匹配。因此,用户只需要指定一个参考页面,智汇云狐采集 软件系统可以对相似的页面进行相应的匹配,从而实现用户需要的采集数据的批量采集。在这个过程中,用户不再需要使用非常专业的“正则表达式”技术,也不需要依赖技术专家编写采集匹配规则。参考页面的内容解析分解后,用户可以用鼠标点击需要采集的对象,系统可以据此得知用户需要采集的内容。智汇云狐采集软件的模板定制过程是针对目标页面进行机器学习和机器训练的过程。
大数据采集是指主要处理海量数据存储、计算、不间断流数据的实时计算等场景的一套基础设施。可以使用开源平台,也可以使用华为、星联等商业级解决方案,既可以部署在私有云上,也可以部署在公有云上。任何一个完整的大数据平台一般都包括以下流程:数据采集-->数据存储-->数据处理-->数据呈现(可视化、报告、监控) 其中,数据采集是所有数据系统的必不可少,而随着大数据越来越受到重视,数据的挑战采集也变得更加突出。主要分为常规基础数据和自定义游戏系统数据。
在大数据时代,“一切都会被计算”、“一切都会被量化”、“一切都会被数字化”。人类生活在一个海量、动态和多样化数据的世界中。数据无处不在,随时可用,没有人使用它。数据与阳光、空气和水分一样普遍,与放大镜、望远镜和显微镜一样重要。大数据中的“数据”真实可靠。它本质上是一种表征事物现象的符号语言和逻辑关系。其可靠性的数学和哲学基础是世界同构原理。世界具有物质统一,统一世界中的一切都具有时空一致性的同构关系。这意味着只要正确编码,任何事物的属性和规律都可以通过统一的数字信号来表达。高级数据分析不一定好,简单有效就好。陕西商业大数据采集采集器
数据分析前应明确目的,然后根据分析目的确定分析框架和内容,以及所采用的数据分析方法。大数据采集平台
智汇云虎大数据采集软件的优势在于精准精准,全网数十个平台实时更新,软件实时更新数亿人的网络数据< @采集平台和搜索引擎,确保精确和准确的真实性和实时性。精细采集APP操作方式APP采集器,一键操作,全国300多个城市可自由选择,行业关键词快速锁定行业潜在客户,一键导入通讯录,一键导出电脑。官方持续升级更新售后无忧罚款采集APP已上架Apple Store和Android主流应用市场5年,十年数据采集 技术团队持续实时更新,售后有保障。大数据采集平台
您好,欢迎来电,公司现推出智能营销延伸系统、大数据采集系统、智汇云通话系统和5G视频广告,5G时代适合各行各业。宣传快速覆盖全城,品牌推广,产品推广,快速渗透,全城覆盖,低门槛高回报,同城营销神器。是一家集研发、设计、生产、销售为一体的专业化公司。拥有一支经验丰富、技术创新的专业研发团队,高度专注、专注地为客户提供大数据采集系统、云呼叫系统、同城延伸系统、智能营销延伸软件。不断开拓创新,追求卓越,以科技为先导,以产品为平台,以应用为重点,以服务为保障,不断为客户创造更高价值,提供更优质的服务。时刻关注自己,在风云变幻的时代,从不懈怠自身的建设,高度的专注和坚持让行业从容自信。

