
采集系统上云
顶尖云采集平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2020-08-25 10:51
顶尖云采集
针对互联网进行网页信息采集、处理、加工、分类。云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取主从形式的体系结构。采集速度快、采集类型全、采集数量多、防止屏蔽、分析加工灵活。
详细信息
顶尖时代推出的互联网大数据“一键采集”云服务是定向针对互联网进行网页信息采集、处理、加工、分类的云服务。
云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取主从形式的体系结构。即有一个主节点控制所有从节点执行抓取任务,这个主节点负责分配URL,保证集群中所有节点的负载均衡。网页采集爬虫系统将网页的非结构化信息采集后,自动提取网页属性信息进行结构化的处理,字段提取(包括站点、来源、日期、标题、内容、收录图片等)。
系统构架
顶尖云采集总体上可以分为四个层次(见上图):互联网(数据源层)、采集层、信息加工、分析层和服务插口。
数据源
由互联网的各种数据和政府/企业内部各种数据组成,互联网数据为互联网上各大新闻网站、门户网站、各类峰会、各类博客、各类微博、微信上的所有信息组成,信息的表现形式为新闻、新闻评论、论坛贴子、博客和播客等。
数据采集加工
采用“顶尖云采集”系统,全面及时采集互联网的各种信息,全文搜索引擎实现对信息的智能剖析处理,包括内容抽取(标题、正文、来源、日期、URL)信息分类、实体提取(人名、地名、机构)、支持文本语义剖析、语义搜索、关键词分析、词频剖析、摘要剖析、相关文章分析、热点剖析等。
服务插口
云采集平台支持基于http请求RESTFul风格的API接口,可以通过JSON格式提供插口数据给各个应用系统。可以通过插口定义须要数据的周期、类型、数量等。通过插口数据可以提供给信息资源库、CMS素材库、情报系统、舆情系统等多种应用。
采集范围
服务特征 查看全部
顶尖云采集平台
顶尖云采集
针对互联网进行网页信息采集、处理、加工、分类。云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取主从形式的体系结构。采集速度快、采集类型全、采集数量多、防止屏蔽、分析加工灵活。
详细信息
顶尖时代推出的互联网大数据“一键采集”云服务是定向针对互联网进行网页信息采集、处理、加工、分类的云服务。
云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取主从形式的体系结构。即有一个主节点控制所有从节点执行抓取任务,这个主节点负责分配URL,保证集群中所有节点的负载均衡。网页采集爬虫系统将网页的非结构化信息采集后,自动提取网页属性信息进行结构化的处理,字段提取(包括站点、来源、日期、标题、内容、收录图片等)。
系统构架

顶尖云采集总体上可以分为四个层次(见上图):互联网(数据源层)、采集层、信息加工、分析层和服务插口。
数据源
由互联网的各种数据和政府/企业内部各种数据组成,互联网数据为互联网上各大新闻网站、门户网站、各类峰会、各类博客、各类微博、微信上的所有信息组成,信息的表现形式为新闻、新闻评论、论坛贴子、博客和播客等。
数据采集加工
采用“顶尖云采集”系统,全面及时采集互联网的各种信息,全文搜索引擎实现对信息的智能剖析处理,包括内容抽取(标题、正文、来源、日期、URL)信息分类、实体提取(人名、地名、机构)、支持文本语义剖析、语义搜索、关键词分析、词频剖析、摘要剖析、相关文章分析、热点剖析等。
服务插口
云采集平台支持基于http请求RESTFul风格的API接口,可以通过JSON格式提供插口数据给各个应用系统。可以通过插口定义须要数据的周期、类型、数量等。通过插口数据可以提供给信息资源库、CMS素材库、情报系统、舆情系统等多种应用。
采集范围

服务特征
上传附件到七牛云正式版 2.0.1
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-08-23 12:43
温馨提示:如果你的网站想用阿里云OSS云存储,请点击这里安装阿里云OSS云存储插件。
【插件介绍】
安装这款插件以后,可以把你峰会、群组、门户上的所有附件,快速迁移到七牛云存储那儿,从而实现网站的程序和附件分离,减轻服务器的负担,提高网站的运行速率,提升图片的打开速率。
应用中心早已有七牛云存储插件,我为何要选择这款??原因如下:
1.基于七牛云存储新版sdk开发,各方面的性能和优势更胜一筹。
2.不用更改Discuz的任何系统文件,安装马上可以使用,某某家的七牛云存储插件要更改Discuz系统底层文件,把FTP类文件完全改掉。
3.自带智能无感知迁移附件到七牛云存储,强大的杀手锏功能,安装以后,你打开所有内容,看到的附件地址秒弄成七牛云存储地址。
4.不用更改【全局 - 上传设置 - 远程附件】,也不用更改和接管Discuz本身的上传图片功能,对你的系统无损安装,安全红色。
5.内置批量手工迁移附件的功能,让你原先旧的附件都联通到七牛云存储,释放你服务器的宝贵空间。
6.本地文件和远程七牛云存储文件可以混和存在,如果来不及把所有的文件都迁移到七牛云存储,本地那些未迁移完成的文件,也能正常显示,就算同一个页面,有一些图片迁移到七牛云存储,有一些没有,图片还是能正常显示。
7.可以用七牛云存储这边的强悍水印功能,水印是直接加到图片上,不是后缀加水印式样名,别人难以盗版你的原创未加水印的图片。
8.峰会的其它附件,比如:zip,rar等类型的附件,也可以迁移到七牛云存储。
9.和早已在应用中心上架的采集插件,无缝手动智能对接,采集出来本地储存的文件,会手动上传到七牛云。
【售后服务和用户保障】
1.严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2.购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员(QQ:2891276344),如果在48小时之内无法解决问题,全额退票给购买者!!大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3.在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员(mail:),在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
4.插件提供免费试用版,请订购前安装试用版真实体验一下插件的各个功能,试用满意再订购。
5.如果首次接触七牛云存储,看了后台教程以后,还是不会配置,售后客服免费帮你,直到调试成功,完全可以用!
6.服务器的PHP运行环境须要curl扩充的支持,如果你的PHP运行环境不支持curl扩充,请联系在线客服帮你解决。
查看全部
上传附件到七牛云正式版 2.0.1
温馨提示:如果你的网站想用阿里云OSS云存储,请点击这里安装阿里云OSS云存储插件。
【插件介绍】
安装这款插件以后,可以把你峰会、群组、门户上的所有附件,快速迁移到七牛云存储那儿,从而实现网站的程序和附件分离,减轻服务器的负担,提高网站的运行速率,提升图片的打开速率。
应用中心早已有七牛云存储插件,我为何要选择这款??原因如下:
1.基于七牛云存储新版sdk开发,各方面的性能和优势更胜一筹。
2.不用更改Discuz的任何系统文件,安装马上可以使用,某某家的七牛云存储插件要更改Discuz系统底层文件,把FTP类文件完全改掉。
3.自带智能无感知迁移附件到七牛云存储,强大的杀手锏功能,安装以后,你打开所有内容,看到的附件地址秒弄成七牛云存储地址。
4.不用更改【全局 - 上传设置 - 远程附件】,也不用更改和接管Discuz本身的上传图片功能,对你的系统无损安装,安全红色。
5.内置批量手工迁移附件的功能,让你原先旧的附件都联通到七牛云存储,释放你服务器的宝贵空间。
6.本地文件和远程七牛云存储文件可以混和存在,如果来不及把所有的文件都迁移到七牛云存储,本地那些未迁移完成的文件,也能正常显示,就算同一个页面,有一些图片迁移到七牛云存储,有一些没有,图片还是能正常显示。
7.可以用七牛云存储这边的强悍水印功能,水印是直接加到图片上,不是后缀加水印式样名,别人难以盗版你的原创未加水印的图片。
8.峰会的其它附件,比如:zip,rar等类型的附件,也可以迁移到七牛云存储。
9.和早已在应用中心上架的采集插件,无缝手动智能对接,采集出来本地储存的文件,会手动上传到七牛云。
【售后服务和用户保障】
1.严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2.购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员(QQ:2891276344),如果在48小时之内无法解决问题,全额退票给购买者!!大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3.在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员(mail:),在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
4.插件提供免费试用版,请订购前安装试用版真实体验一下插件的各个功能,试用满意再订购。
5.如果首次接触七牛云存储,看了后台教程以后,还是不会配置,售后客服免费帮你,直到调试成功,完全可以用!
6.服务器的PHP运行环境须要curl扩充的支持,如果你的PHP运行环境不支持curl扩充,请联系在线客服帮你解决。
众大云采集织梦dedecms版
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2020-08-22 16:46
安装此织梦dedecms模块以后,在发布文章的底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,具有易学,易懂,易用,成熟稳定等特点,是一款织梦dedecms新手站长和网站编辑必备的模块。
温馨提示:
01、安装本模块以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的织梦dedecms网站上。
02、模块可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
03、模块从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,模块功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个织梦站长必备的模块!
本模块功能特性:
01、可以一键获取当前的实时热点内容,然后一键发布。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的织梦dedecms网站上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持单篇采集,跟织梦dedecms的文章发布一模一样的操作界面,易上手。
06、采集过来的内容图片可以正常显示而且保存为织梦dedecms网站文章的附件,图片永远不会遗失。
07、模块外置正文提取算法,支持采集任何网站任何栏目的内容。
08、图片会手动加上您织梦dedecms网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的织梦dedecms网站文章跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的织梦dedecms网站文章的查看数跟真实的一样。
12、可以自定义文章发布者,让您的文章看上去更真实。
13、采集的内容可以发布到织梦dedecms网站的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
此模块给您带来的价值:
1、让您的织梦dedecms网站给人觉得人气太旺,流量很高,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
用户保障:
1、严格遵循织梦dedecms官方的模块开发规范,除此之外,我们的团队也会对模块进行大量的测试,确保模块的安全、稳定、成熟。
2、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心模块升级更新。
2018年3月3日更新升级如下:
1、兼容V5.6版的织梦系统
2、进一步优化实时采集
3、添加可以自己编撰采集规则
4、进一步优化定时采集自动发布 查看全部
众大云采集织梦dedecms版
安装此织梦dedecms模块以后,在发布文章的底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,具有易学,易懂,易用,成熟稳定等特点,是一款织梦dedecms新手站长和网站编辑必备的模块。
温馨提示:
01、安装本模块以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的织梦dedecms网站上。
02、模块可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
03、模块从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,模块功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个织梦站长必备的模块!
本模块功能特性:
01、可以一键获取当前的实时热点内容,然后一键发布。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的织梦dedecms网站上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持单篇采集,跟织梦dedecms的文章发布一模一样的操作界面,易上手。
06、采集过来的内容图片可以正常显示而且保存为织梦dedecms网站文章的附件,图片永远不会遗失。
07、模块外置正文提取算法,支持采集任何网站任何栏目的内容。
08、图片会手动加上您织梦dedecms网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的织梦dedecms网站文章跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的织梦dedecms网站文章的查看数跟真实的一样。
12、可以自定义文章发布者,让您的文章看上去更真实。
13、采集的内容可以发布到织梦dedecms网站的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
此模块给您带来的价值:
1、让您的织梦dedecms网站给人觉得人气太旺,流量很高,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
用户保障:
1、严格遵循织梦dedecms官方的模块开发规范,除此之外,我们的团队也会对模块进行大量的测试,确保模块的安全、稳定、成熟。
2、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心模块升级更新。
2018年3月3日更新升级如下:
1、兼容V5.6版的织梦系统
2、进一步优化实时采集
3、添加可以自己编撰采集规则
4、进一步优化定时采集自动发布
秒杀Redis的KVS上云了!伯克利重磅开源Anna 1.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2020-08-18 04:06
策划编辑 | Natalie
作者 | Anna 研究团队
译者 | 无明
编辑 | Natalie
今年 3 月份,伯克利 RISE 实验室推出了最新的通配符储存数据库 Anna,提供了惊人的存取速率、超强的伸缩性和史无前例的一致性保证。Anna 一经推出即在业界引起热烈讨论,不少读者关心它何时开源、后续有哪些新的进展。过去这半年里,伯克利 RISE 实验室对 Anna 的设计进行了重大变更,新版本的 Anna 能够更好地在云端扩充。实验表明,无论是在性能还是成本效益方面,Anna 都表现突出,明显优于 AWS ElastiCache 的 memcached 以及较早之前的 Masstree,也比 AWS DynamoDB 更具成本优势。与此同时,Anna 所有源码也即将登录 Github,开放给所有开发者。
背 景
在之前的一篇博文中,我们介绍了 Anna 系统,它使用了一个核心对应一个线程的无共享线程构架,通过防止线程间的协调来实现闪电般的速率。Anna 还使用晶格组合来实现多样的无协调一致性级别。第一个版本的 Anna 吊打现有的显存 KV 存储系统:它的性能优于 Masstree 700 倍,优于 TBB 800 倍。你可以重温之前的博文 ,或者阅读完整的论文。我们将第一个 Anna 版本称为“Anna v0”。在这篇文章中,我们介绍怎样将这个最快的 KV 存储系统显得极具成本效益和适应性。
( )
( )
现如今,公共基础设施云用户可选择的储存系统真是太多了。AWS 提供两种对象存储服务(S3 和 Glacier)和两种文件系统服务( EBS 和 EFS),另外还有七种不同的数据库服务,从关系数据库到 NoSQL 键值储存。真是花样繁杂,令人眼花缭乱,用户自然会问,哪个服务才适宜她们。最直接(然而并不豁达)的答案是,把它们全都用上去就对了。
这些储存服务都提供了极其有限的成本与性能之间的权衡。例如,AWS ElastiCache 速度很快,但太贵,而 AWS Glacier 虽然实惠,但速率较慢。因此,用户门面对一个困境:他们必须要么舍弃节省成本的目标,大规模布署高性能储存集群,要么舍弃性能,利用低成本的系统比如 DynamoDB 或者 S3。
更糟糕的是,大多数实际应用凸显出偏移的数据访问模式。频繁被访问的数据是“热”数据,其他则为“冷”数据,而这种服务要么是专门为“热数据”而设计,要么专门为“冷数据”而设计。因此,不想在性能或成本上妥协的用户必须自动将这种解决方案堆砌在一起,跟踪服务间的数据和恳求,以及管理不同的 API,并作出一致性保证。
更糟糕的是,高性能的云存储产品不具备弹性:向集群添加资源或从集群中移除资源都须要人工干预。这意味着云开发者们设计并实现自定义解决方案来监控工作负载变化、修改资源分配以及在储存引擎之间联通数据。
这是十分糟糕的。应用程序开发人员不断被迫重新发明轮子,而不是把精力放到她们最关心的指标上:性能和成本。我们想要改变这些现况。
Anna v1
我们利用 Anna v0 这个显存储存引擎来解决上述的云存储问题。我们的目标是将最快的 Anna 同时发展成为最具适应性和成本效益的 KV 存储系统。我们向 Anna 中添加了 3 个关键的机制:垂直分层、水平弹性和选择性复制。
Anna v1 的核心组件是监控系统和策略引擎,可实现工作负载的响应性和适应性。为了满足用户定义的性能目标( 请求延后)和成本,监控服务对工作负载变化进行监控和调整。存储服务器会搜集恳求和数据的统计信息。监视系统定期搜索和处理那些数据,策略引擎基于这种统计信息执行上述的三个操作。操作的触发规则很简单:
为了实现这种机制,我们不得不对 Anna 的设计作出两个重大变更。
首先,我们使储存引擎支持多种储存介质——目前是显存和闪存。与传统的储存层次结构类似,这些储存层的成本与性能权衡是不一样的。我们还实现了一个路由服务,它将用户恳求发送到目标层的服务器上。无论数据储存在哪些地方,都可以为用户提供统一的 API。这些层都从第一版 Anna 继承了同等丰富的一致性模型,因此开发者可以灵活选购并自定义合适的一致性模型。
我们的实验表明,无论是在性能还是成本效益方面,Anna 都达到了令人印象深刻的水平。在同一成本下,Anna 提供优于 AWS ElastiCache 8 倍的吞吐量和优于 DynamoDB 355 倍的吞吐量。Anna 还能够通过添加节点和恰到好处的数据复制来应对工作负载的变化:
这篇文章只提供了 Anna 的设计概述,如果你有兴趣了解更多,可以在下边的链接中找到完整的论文和代码和这儿找到完整的论文和代码。这个项目的进展使我们很满意,我们也太愿意收到你们的反馈。后续,我们会有更多的计划,将 Anna 的高性能和灵活性拓展到其他的系统中,敬请关注!
完整论文:
开源代码:
关于伯克利 RISELab
RISE 实验室的前身是赫赫有名的伯克利 AMP 实验室,该实验室曾开发出了一大批大获成功的分布式技术,这些技术对高性能估算形成了深远的影响,包括 Spark、Mesos、Tachyon 等。RISE 实验室目前主要关注提供实时智能且安全可解释的决策的系统。实验室核心教员包括 Ion Stoica、Joe Hellerstein、Michael I. Jordan、Dave Patterson 等多位大牛。
过去几年,RISE 实验室把研究重点放到怎样设计一个无需协调的分布式系统上。他们提出了 CALM 基础理论,设计出了新编程语言 Bloom,开发出了跨平台程序剖析框架 Blazes,发布了事务合同 HATs,并推出了志在代替 Spark 的新型分布式执行框架 Ray。
原文链接: 查看全部
秒杀Redis的KVS上云了!伯克利重磅开源Anna 1.0

策划编辑 | Natalie
作者 | Anna 研究团队
译者 | 无明
编辑 | Natalie
今年 3 月份,伯克利 RISE 实验室推出了最新的通配符储存数据库 Anna,提供了惊人的存取速率、超强的伸缩性和史无前例的一致性保证。Anna 一经推出即在业界引起热烈讨论,不少读者关心它何时开源、后续有哪些新的进展。过去这半年里,伯克利 RISE 实验室对 Anna 的设计进行了重大变更,新版本的 Anna 能够更好地在云端扩充。实验表明,无论是在性能还是成本效益方面,Anna 都表现突出,明显优于 AWS ElastiCache 的 memcached 以及较早之前的 Masstree,也比 AWS DynamoDB 更具成本优势。与此同时,Anna 所有源码也即将登录 Github,开放给所有开发者。
背 景
在之前的一篇博文中,我们介绍了 Anna 系统,它使用了一个核心对应一个线程的无共享线程构架,通过防止线程间的协调来实现闪电般的速率。Anna 还使用晶格组合来实现多样的无协调一致性级别。第一个版本的 Anna 吊打现有的显存 KV 存储系统:它的性能优于 Masstree 700 倍,优于 TBB 800 倍。你可以重温之前的博文 ,或者阅读完整的论文。我们将第一个 Anna 版本称为“Anna v0”。在这篇文章中,我们介绍怎样将这个最快的 KV 存储系统显得极具成本效益和适应性。
( )
( )
现如今,公共基础设施云用户可选择的储存系统真是太多了。AWS 提供两种对象存储服务(S3 和 Glacier)和两种文件系统服务( EBS 和 EFS),另外还有七种不同的数据库服务,从关系数据库到 NoSQL 键值储存。真是花样繁杂,令人眼花缭乱,用户自然会问,哪个服务才适宜她们。最直接(然而并不豁达)的答案是,把它们全都用上去就对了。
这些储存服务都提供了极其有限的成本与性能之间的权衡。例如,AWS ElastiCache 速度很快,但太贵,而 AWS Glacier 虽然实惠,但速率较慢。因此,用户门面对一个困境:他们必须要么舍弃节省成本的目标,大规模布署高性能储存集群,要么舍弃性能,利用低成本的系统比如 DynamoDB 或者 S3。
更糟糕的是,大多数实际应用凸显出偏移的数据访问模式。频繁被访问的数据是“热”数据,其他则为“冷”数据,而这种服务要么是专门为“热数据”而设计,要么专门为“冷数据”而设计。因此,不想在性能或成本上妥协的用户必须自动将这种解决方案堆砌在一起,跟踪服务间的数据和恳求,以及管理不同的 API,并作出一致性保证。
更糟糕的是,高性能的云存储产品不具备弹性:向集群添加资源或从集群中移除资源都须要人工干预。这意味着云开发者们设计并实现自定义解决方案来监控工作负载变化、修改资源分配以及在储存引擎之间联通数据。
这是十分糟糕的。应用程序开发人员不断被迫重新发明轮子,而不是把精力放到她们最关心的指标上:性能和成本。我们想要改变这些现况。
Anna v1
我们利用 Anna v0 这个显存储存引擎来解决上述的云存储问题。我们的目标是将最快的 Anna 同时发展成为最具适应性和成本效益的 KV 存储系统。我们向 Anna 中添加了 3 个关键的机制:垂直分层、水平弹性和选择性复制。
Anna v1 的核心组件是监控系统和策略引擎,可实现工作负载的响应性和适应性。为了满足用户定义的性能目标( 请求延后)和成本,监控服务对工作负载变化进行监控和调整。存储服务器会搜集恳求和数据的统计信息。监视系统定期搜索和处理那些数据,策略引擎基于这种统计信息执行上述的三个操作。操作的触发规则很简单:
为了实现这种机制,我们不得不对 Anna 的设计作出两个重大变更。
首先,我们使储存引擎支持多种储存介质——目前是显存和闪存。与传统的储存层次结构类似,这些储存层的成本与性能权衡是不一样的。我们还实现了一个路由服务,它将用户恳求发送到目标层的服务器上。无论数据储存在哪些地方,都可以为用户提供统一的 API。这些层都从第一版 Anna 继承了同等丰富的一致性模型,因此开发者可以灵活选购并自定义合适的一致性模型。
我们的实验表明,无论是在性能还是成本效益方面,Anna 都达到了令人印象深刻的水平。在同一成本下,Anna 提供优于 AWS ElastiCache 8 倍的吞吐量和优于 DynamoDB 355 倍的吞吐量。Anna 还能够通过添加节点和恰到好处的数据复制来应对工作负载的变化:
这篇文章只提供了 Anna 的设计概述,如果你有兴趣了解更多,可以在下边的链接中找到完整的论文和代码和这儿找到完整的论文和代码。这个项目的进展使我们很满意,我们也太愿意收到你们的反馈。后续,我们会有更多的计划,将 Anna 的高性能和灵活性拓展到其他的系统中,敬请关注!
完整论文:
开源代码:
关于伯克利 RISELab
RISE 实验室的前身是赫赫有名的伯克利 AMP 实验室,该实验室曾开发出了一大批大获成功的分布式技术,这些技术对高性能估算形成了深远的影响,包括 Spark、Mesos、Tachyon 等。RISE 实验室目前主要关注提供实时智能且安全可解释的决策的系统。实验室核心教员包括 Ion Stoica、Joe Hellerstein、Michael I. Jordan、Dave Patterson 等多位大牛。
过去几年,RISE 实验室把研究重点放到怎样设计一个无需协调的分布式系统上。他们提出了 CALM 基础理论,设计出了新编程语言 Bloom,开发出了跨平台程序剖析框架 Blazes,发布了事务合同 HATs,并推出了志在代替 Spark 的新型分布式执行框架 Ray。
原文链接:
云原生HSAP系统Hologres产品价值剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2020-08-17 15:00
一、主流实时数仓构架:Lambda
二、阿里Lambda实践
三、云原生HSAP系统Hologres产品
一、主流实时数仓构架:Lambda1.时效性是数据价值的倍增器
企业拥抱数字化变革已成为行业共识。众所周知,数据价值会随着时间的推移而快速增加,因此,时效性是数据价值的倍增器。
此处所言的时效性是广泛概念,首先收录端到端的数据,实时数据的采集、加工以及剖析。其次时效性收录怎么样让实时剖析的疗效快速转化为实时服务,为线上生产系统提供数据服务。同时还收录让现有数据构架的数据能为业务方进行快速自助式的剖析,快速响应业务变化。只有将以上三方面都做好,才能充分彰显数据价值,使数据中台、数据构架可以更好地为业务服务。
1.png
2.主流实时数仓构架——Lambda构架
在企业数字化变革的过程中,许多企业都是摸着石头过河,为了解决业务的问题,不断升级数据构架。目前主流的实时数仓构架是Lambda构架。
美团、知乎、菜鸟等企业都成功进行了Lambda构架的实践。如下图所示,Lambda实时数仓在数据采集之后依照业务需求分为实时层与离线层,分别进行实时处理和离线处理。处理结果在数据服务层对接数据应用之前会进行数据的合并,从而实现实时数据与离线数据同时服务于在线数据应用和数据产品。
离线层处理:采集数据归并到离线数仓以后,首先会统一到ODS层。对ODS层的数据进行简单数据清洗,构建DWD层(明细层)。在企业数据建模的过程中,为了增强数据剖析效率以及进行业务分层,会对DWD层的数据进行进一步的加工和处理,相当于预计算。预估算结果在对接数据服务之前都会轮询到一些离线储存系统中。
实时层处理:逻辑与离线层类似,但是愈发讲求时效性。实时层同样是对上游数据库或则系统的数据进行实时数据的订阅和消费。消费数据然后会将其讲到实时的DWD层或DWS层。实时估算引擎提供的是估算能力,最终处理结果须要讲到一些实时储存中,例如KV Store等。
基于成本和开发效率的考虑,实时层和离线层通常并不完全同步。实时层通常保留两到三天的数据,或者出于极至的要求通常会储存三天的数据。而月、年的数据等更长的数据储存在离线数仓中。
以上是数仓的分层,而实际在业务的剖析应用时,业务方可能并不关心数据处理形式,而须要数据剖析的疗效,因此须要处理实时和离线的全量数据。实时层和离线层处理的数据分别写在两个不同的储存中,在对接数据服务之前须要进行数据合并操作,合并流处理与批处理的结果以后再提供在线服务。
2.png
这个构架看似挺好地解决了离线数仓、数据剖析、数据大屏等众多业务问题。但是这个Lambda构架并不完美,仍存在一些难点。
3. Lambda构架疼点
1)一致性困局:主要彰显在2套语义、2套逻辑、2份数据。
Lambda构架一份数据分为离线层和实时层两条链路分别进行处理,而离线层和实时层引入的估算引擎、存储引擎都不同,也就是说流和批的语义不同,并且须要两套代码,也就是两套逻辑,那么势必数据处理的逻辑不同,导致同一份源数据处理结果不一致。
离线层和实时层的处理结果分别写在两个不同的储存中,一份数据经过批处理和流处理后形成起码两份数据,因此对接数据服务之前须要对多份数据进行合并。在此过程中须要不断地进行数据结构的重新定义,数据的轮询、变化、合并,都会带来数据一致性的问题。
数据一致性问题是构架设计的复杂性造成的,基本无解。目前业界都是从业务层面着手解决,即从业务上进行协商。例如当业务方可接受实时和离线数据的一致性差别率高于3%,就可以运行该构架。
3.png
2)多套系统组合搭建、环环相扣、架构复杂、运维成本高:批处理一般会引入MaxCompute或自建的Hadoop引擎等离线估算引擎。流处理部份可能会引入Flink、Spark等多个新产品。数据处理后会写入到储存,数据服务层引入的产品可能会愈加复杂。例如为了提供高效的点查询引入HBase;为了对离线数仓中的数据进行交互式剖析,会引入Presto,Impala等;也有可能会将数据导出到Mysql中;为了在实时数仓中实现端到端的实时,多会采用Druid、ClickHouse等开源产品。以上系统首先引起系统构架复杂、运维成本高。数据开发朋友须要把握多套系统,系统引入的学习成本很高。同时,一份数据经过层层处理、层层清洗以后,整个链路的数据将发生特别多冗余。实时层、离线层各有一套数据,数据合并之前还有一套数据。数据不断膨胀导致储存资源的巨大消耗。
4.png
3)开发周期长、业务不敏捷:任何一套数据或业务方案上线之前都须要进行数据校对、数据验证。数据校对过程中一旦出现问题,其定位和确诊将非常复杂。因为数据问题可能发生在任何环节,也可能在数据应用层才发觉问题。发现问题后须要排查数据合并、实时估算、离线层、甚至数据采集等环节是否出现问题,过程复杂,导致数据修订和补数周期长。同时,一份数据须要在离线层和实时层分别进行处理,并且处理链路较长。如果须要在链路尤其是偏上游环节新增数组,整条链路都须要一起订正,过程漫长,并且对历史数据进行补数,消耗巨大资源与时间。
4)数据开发完成、业务得到认可,上线驱动业务得到非常好的疗效以后,更多业务方会认识到数据构架的价值,并提出需求。产品营运或则决策层可能觉得该数据非常有价值,会要求开放新的数据剖析报表以进行剖析,或者能够自助式进行实时剖析。而在Lambda构架中,所有估算、分析都是在估算层完成的。例如在离线层加一层业务数据,需要重新开发一个DWS层的作业,将数据讲到DWS层数据储存中,再将其同步到数据服务系统,然后再提供线上报表服务。该过程须要数据开发朋友介入,需要进行数据需求评审与评估,并且开发周期起码将离线处理时间T+1。很多场景时间较紧急时,无法等待T+1的时间,也许就错过了商业机会。另外,新的业务需求要做实时链路的开发也是同样,需要进行实时作业的开发、校对、上线,开发周期长。因此Lambda构架灵活性未能满足线上业务诉求。
5.png
二、阿里Lambda实践1.搜索推荐精细化营运老构架
实际构架比上述Lambda理想构架愈加复杂。阿里巴巴最大的数据场景是搜索推荐场景。下图所示为搜索推荐精细化营运的旧构架在Lambda构架上的实践,与上述Lambda构架非常相像。
下图最右侧为阿里的数据,包括交易数据、用户行为数据、商品属性数据、搜索推荐数据等。将数据统一通过数据集成批量导出到MaxCompute,或者通过实时消息队列DataHub采集数据后通过Flink清洗。
线上构架演变:Fink发展迅猛,阿里的典型业务——双11大屏,是中单上数据通过Flink清洗后写入HBase系统。HBase对接实时大屏提供高效的点查询。
MaxCompute是阿里巴巴发展十年以上的离线数仓产品,承载了阿里特别大的离线数据剖析的场景。实时数据处理完成后就会产生一套离线数据,绝大部分离线数据都储存在MaxCompute。线上营销、对抗竞争等数据都来自MaxCompute。
随着Flink实时估算能力的提高,以及Flink实时数仓、实时报表上的应用的发展,所有的产品营运以及决策层都听到了实时对于业务的价值。因此在MaxCompute提供了多年离线剖析能力、发现Flink强悍估算的实时能力的基础之上,业务方提出同样一份数据能够通过实时形式提供实时的在线剖析服务能力。因此引入了Druid等开源产品,通过Flink将线上日志实时讲到Druid,提供Druid提供实时剖析能力。例如对接实时报表、实时决策、实时库存系统。
综上所示产生了两条链路,实时数据在Druid中做剖析,离线数据在MaxCompute做剖析。但因为Druid的存储容量等各方面性能的要求,在Druid中仅储存两天或两三天内的数据。进行大促等营销活动常常须要对比历史环比或同比数据。比如须要和今年或则是前年的双十一做对比剖析,在营销策略的剖析上须要对上周或则上上周的数据进行剖析,双11正式期须要与预热期数据进行同比剖析等。此时运用的是离线数据和实时数据的结合场景。方式是引入了更多产品。将MaxCompute离线数仓的数据与Druid中的实时数据在Mysql中进行合并,合并完成后再提供线上服务。
6.png
2.多套系统、多种场景、分析服务一体化能力
可见业务上游的数据、数据清洗的链路均未发生变化,而是业务应用层、业务剖析层场景发生了更多变化,出现了更多诉求,因此引入了更多产品进行业务支撑。但是该旧构架依然属于典型Lambda构架,因此在阿里巴巴高速的业务下降和膨胀之下,其一致性、运维复杂、成本高、业务敏捷性等问题逐步显现。
简单剖析在业务场景日渐复杂的情况下为什么引入多种系统,各系统分别提供如何的能力。
KV Store:Redis/Mysql/HBase/Cassandra,应对数据产品高QPS查询场景,提供高效点查询能力。
交互式估算能力:Presto/Drill。
实时数仓:ClickHouse/Druid,实时储存+在线估算能力。
7.png
3..搜索推荐精细化营运新构架
引入多种产品是为了支撑以上三种能力,那么能够在多种业务场景下同时解决相同业务问题并且将多种大数据产品的能力有机统一于一个引擎。使数据才能进行统一储存,然后对下层提供统一服务。因此产生右图所示构架。
上游数据处理和清洗不发生变化,而在对接下层业务应用时提供愈发丰富的能力。例如系统才能同时提供点查询、结果缓存、离线加速、联邦剖析、交互式剖析等能力。将该系统定义为HSAP(Hybrid Serving Analytical Processing)系统,分析服务一体化,能够实现一份数据同时用于实时剖析与在线服务。
Hologres产品是在该背景下推出的云原生HSAP数据库系统。Hologres产品实现实时离线数据统一储存,支持Flink数据或实时估算的实时数据实时写入,支持离线数据批量导出。第二,对接数据服务层面以实时剖析为中心而设计,可同时满足业务实时剖析与在线服务需求。第三,不改变原有实时数仓构架,通过MaxCompute直接加速,利用Hologres估算能力直接对接线上服务。
8.png
三、云原生HSAP系统Hologres产品1. Hologres产品核心优势
云原生HSAP数据库,一份数据同时用于实时剖析与在线服务。
极速响应:实现毫秒级响应,从而轻松满足顾客海量数据复杂多维剖析需求。千万QPS点查询,实时剖析上千QPS简单查询。
实时储存:支持亿级写入TPS,时效性强,写入即可查询。
MaxCompute加速:MaxCompute直接剖析,无数据搬迁,无冗余储存。
PG生态:PG开发者生态,开发人员友好,PG工具(pslq、Navicat、DataGrip)兼容。BI工具无缝对接。
9.png
2019年双十一 Hologres线上服务数据:在双十二当日超大数据量场景下,Hologres支持了高峰1.3亿实时写入TPS,并且数据写入即可查,提供了1.45亿高并发在线查询QPS。
10.png
2.Hologres交互式剖析产品-典型应用场景
离线数据加速查询:目前支持MaxCompute离线数据秒级交互式查询。无需额外ETL工作,便捷地把冷数据转换为便于理解的剖析结果,提升企业决策效率,降低时间成本。
实时数仓:Flink+Hologres,旨在通过搭建用户洞察体系,实时检测平台用户情况,并从不同视角对用户进行实时确诊,进而采取针对性的用户营运策略,从而达到精细化用户营运目的。助力实时精细化营运。
实时离线联合估算:基于离线数仓MaxCompute和实时数仓交互式剖析的联合估算,从商业逻辑出发,实现离线数据剖析实时化,实时离线联邦查询,构筑实时全链路精细化营运。
接下来具体介绍以上三种场景的具体构架以及应用。
11.png
3.MaxCompute加速剖析
传统方案——数据冗余、成本高、开发周期长:如下图所示,左侧数据通过数据集成同步到离线数仓后进行DWD层、DWS层等的加工,加工过后的数据对接线上服务。
一种方案是直接使用MaxCompute的MapReduce估算能力提供线上营销策略、线上实时报表。该方案似乎可以挺好地完成业务需求,但是在MapReduce任务递交后须要一定的等待排队、等待资源分配的时间。很多时侯等待时间小于数据剖析时间,并且剖析时效性所为几十分钟甚至小时级别。效率较低。
因此将数据从MaxCompute离线数仓中转移到线上Redis、Mysql等产品中,利用其交互式剖析或点查询能力提供服务。但是从MaxCompute离线数仓中集成数据到线上Redis、Mysql等产品中存在困难。首先是数据容量方面,例如当离线数仓ADS层数据量十分大,Mysql难以承载时,需要在离线数仓中添加一层ADS作业,再次进行数据加工和预估算,缩小数据量后将数据集成到Mysql中。也就是为了进行数据剖析,需要进行进一步的数据预处理,维护一个数据同步的作业,数据同步后还须要储存到Mysql中。以上流程将会造成数据冗余、并且成本高,开发周期长。
12.png
Hologres——无数据搬迁、数据剖析效率高:Hologres是储存估算分离的构架,与MaxCompute进行了无缝打通。Hologres在该场景下提供估算能力,而MaxCompute相当于Hologres的储存集群。可以直接对MaxCompute储存的数据进行读取与加速。只要数据在MaxCompute中加工完、可查询,通过Hologres可以直接进行数据剖析。在MaxCompute加速剖析场景下,Hologres是围绕交互式剖析场景设计的,发下作业后可立即得到结果,从而满足高效、自助式剖析,并且成本较低。
13.png
Demo演示:可参考文档》实时剖析海量MaxCompute数据进行demo演示,多种功能均可实现微秒级查询,实时返回。
14.png
DataWorks深度集成:Hologres与DataWorks进行了深度集成。MaxCompute数据直接进行加速剖析时须要构建一个Web表,在此支持了一键MaxCompute表结构同步、一键MaxCompute数据同步,以及一键本地上传文件,详情可以参考文档》》HoloStudio。
15.png
4.实时数仓——实时成本高、开发周期长、业务支持不灵活
实时数仓构架是数据采集之后,在ODS层Kafka中通过Flink进行清洗,产生DWD层数据。如果有更进一步的加工需求,再次对DWD层数据进行订阅,写入DWS层。根据不同业务场景引入HBase、MySQL、OLAP等不同产品。
该构架早已挺好地解决了现有问题。但是该构架中所有估算逻辑是在Flink中处理完成后写入DWS层。一旦须要加入新的业务场景或则对现有业务场景进行调整,需要新增数组或估算逻辑时,就须要重新评估链路、重新进行Flink作业的开发,修改或降低一个Flink作业后再讲到DWS层。
因此在该场景中,大部分估算都在Flink层,其业务灵活性不够高。也就是说该构架估算都是预先做好的,无法满足自助式剖析或则剖析之前DWD层数据。
16.png
5.实时、离线、分析、服务一体化方案
为解决上述问题,Hologres与飞天大数据平台(如Flink、MaxCompute)联合推出了新一代实时、离线、分析、服务一体化方案。数据依然在MaxCompute中进行离线数仓清洗,在Flink中进行实时清洗。但是Flink层数据清洗完成后可以将明细层数据直接写入Hologres,由Hologres对接线上大屏。Hologres提供了强悍的实时储存和实时估算能力,意味着明细层数据也可以直接对接线上报表。
实时数据和离线数据的联合剖析,从前存在MaxCompute中的数据可以直接与Hologres进行关联分析,实现联邦查询。
实际Flink估算的业务场景中,如果希望将数据沉淀出来提供线上服务,可以再度订阅Hologres,将Hologres DWD层数据加工为DWS层数据,写回Hologres。同时,Hologres在Flink作业中支持超大维表能力,其他Flink作业可以对Hologres中的数据进行关联剖析。
17.png
上述为实时、离线、分析、服务一体化方案的阐述,实际业务场景中的方案远比以上陈述复杂。
实际业务场景:下图所示为飞天大数据平台产品家族推出的方案构架。数据链愈加复杂,但是本质与上述构架相同,上游数据源通过数据采集到实时数仓,进行关联剖析后最终对下层数据应用提供实时离线联邦查询能力或剖析能力。
18.png
6.互联网-内容资讯顾客案例
Hologres不仅在阿里巴巴集团内部广泛应用外,在云上,互联网行业、传统企业等也早已得到了大量应用。
下图所示为典型的互联网顾客案例。小影是一款在泰国受欢迎的短视频APP。互联网行业不仅实时大屏、实时报表之外都会进行用户剖析、用户画像、用户标签、实时视频推荐等。该场景与阿里巴巴搜索推荐精细化场景相像,因此其构架引用是基于阿里云飞天大数据产品家族的离线数据MaxCompute、实时估算Flink、交互式剖析Hologres搭建上去的。
19.png
7.围绕数据建设、打通全链路
Hologres围绕着大数据生态、PG生态、阿里云生态,围绕着数据建设的全链路建立了数据生态。从数据源对接,导数据同步,到数据加工,到数据运维,到数据剖析和应用都进行了全链路打通。
20.png
Hologres在云上早已即将商业化,提供了包月包年、按量付费等不同计费尺寸,支持估算、存储资源不同配比订购,用户可以按照自身业务需求进行商品采购。同时数据产品、数据加工、数据同步、数据开发工具等支持引用自建、开源等产品。
指定尺寸首月3折,新一代HSAP系统Hologres重磅发布!点击》》立即订购
如果你们对Hologres产品有兴趣,关心产品动态,欢迎访问下方链接进行学习与交流。
21.png 查看全部
云原生HSAP系统Hologres产品价值剖析
一、主流实时数仓构架:Lambda
二、阿里Lambda实践
三、云原生HSAP系统Hologres产品
一、主流实时数仓构架:Lambda1.时效性是数据价值的倍增器
企业拥抱数字化变革已成为行业共识。众所周知,数据价值会随着时间的推移而快速增加,因此,时效性是数据价值的倍增器。
此处所言的时效性是广泛概念,首先收录端到端的数据,实时数据的采集、加工以及剖析。其次时效性收录怎么样让实时剖析的疗效快速转化为实时服务,为线上生产系统提供数据服务。同时还收录让现有数据构架的数据能为业务方进行快速自助式的剖析,快速响应业务变化。只有将以上三方面都做好,才能充分彰显数据价值,使数据中台、数据构架可以更好地为业务服务。

1.png
2.主流实时数仓构架——Lambda构架
在企业数字化变革的过程中,许多企业都是摸着石头过河,为了解决业务的问题,不断升级数据构架。目前主流的实时数仓构架是Lambda构架。
美团、知乎、菜鸟等企业都成功进行了Lambda构架的实践。如下图所示,Lambda实时数仓在数据采集之后依照业务需求分为实时层与离线层,分别进行实时处理和离线处理。处理结果在数据服务层对接数据应用之前会进行数据的合并,从而实现实时数据与离线数据同时服务于在线数据应用和数据产品。
离线层处理:采集数据归并到离线数仓以后,首先会统一到ODS层。对ODS层的数据进行简单数据清洗,构建DWD层(明细层)。在企业数据建模的过程中,为了增强数据剖析效率以及进行业务分层,会对DWD层的数据进行进一步的加工和处理,相当于预计算。预估算结果在对接数据服务之前都会轮询到一些离线储存系统中。
实时层处理:逻辑与离线层类似,但是愈发讲求时效性。实时层同样是对上游数据库或则系统的数据进行实时数据的订阅和消费。消费数据然后会将其讲到实时的DWD层或DWS层。实时估算引擎提供的是估算能力,最终处理结果须要讲到一些实时储存中,例如KV Store等。
基于成本和开发效率的考虑,实时层和离线层通常并不完全同步。实时层通常保留两到三天的数据,或者出于极至的要求通常会储存三天的数据。而月、年的数据等更长的数据储存在离线数仓中。
以上是数仓的分层,而实际在业务的剖析应用时,业务方可能并不关心数据处理形式,而须要数据剖析的疗效,因此须要处理实时和离线的全量数据。实时层和离线层处理的数据分别写在两个不同的储存中,在对接数据服务之前须要进行数据合并操作,合并流处理与批处理的结果以后再提供在线服务。

2.png
这个构架看似挺好地解决了离线数仓、数据剖析、数据大屏等众多业务问题。但是这个Lambda构架并不完美,仍存在一些难点。
3. Lambda构架疼点
1)一致性困局:主要彰显在2套语义、2套逻辑、2份数据。
Lambda构架一份数据分为离线层和实时层两条链路分别进行处理,而离线层和实时层引入的估算引擎、存储引擎都不同,也就是说流和批的语义不同,并且须要两套代码,也就是两套逻辑,那么势必数据处理的逻辑不同,导致同一份源数据处理结果不一致。
离线层和实时层的处理结果分别写在两个不同的储存中,一份数据经过批处理和流处理后形成起码两份数据,因此对接数据服务之前须要对多份数据进行合并。在此过程中须要不断地进行数据结构的重新定义,数据的轮询、变化、合并,都会带来数据一致性的问题。
数据一致性问题是构架设计的复杂性造成的,基本无解。目前业界都是从业务层面着手解决,即从业务上进行协商。例如当业务方可接受实时和离线数据的一致性差别率高于3%,就可以运行该构架。

3.png
2)多套系统组合搭建、环环相扣、架构复杂、运维成本高:批处理一般会引入MaxCompute或自建的Hadoop引擎等离线估算引擎。流处理部份可能会引入Flink、Spark等多个新产品。数据处理后会写入到储存,数据服务层引入的产品可能会愈加复杂。例如为了提供高效的点查询引入HBase;为了对离线数仓中的数据进行交互式剖析,会引入Presto,Impala等;也有可能会将数据导出到Mysql中;为了在实时数仓中实现端到端的实时,多会采用Druid、ClickHouse等开源产品。以上系统首先引起系统构架复杂、运维成本高。数据开发朋友须要把握多套系统,系统引入的学习成本很高。同时,一份数据经过层层处理、层层清洗以后,整个链路的数据将发生特别多冗余。实时层、离线层各有一套数据,数据合并之前还有一套数据。数据不断膨胀导致储存资源的巨大消耗。

4.png
3)开发周期长、业务不敏捷:任何一套数据或业务方案上线之前都须要进行数据校对、数据验证。数据校对过程中一旦出现问题,其定位和确诊将非常复杂。因为数据问题可能发生在任何环节,也可能在数据应用层才发觉问题。发现问题后须要排查数据合并、实时估算、离线层、甚至数据采集等环节是否出现问题,过程复杂,导致数据修订和补数周期长。同时,一份数据须要在离线层和实时层分别进行处理,并且处理链路较长。如果须要在链路尤其是偏上游环节新增数组,整条链路都须要一起订正,过程漫长,并且对历史数据进行补数,消耗巨大资源与时间。
4)数据开发完成、业务得到认可,上线驱动业务得到非常好的疗效以后,更多业务方会认识到数据构架的价值,并提出需求。产品营运或则决策层可能觉得该数据非常有价值,会要求开放新的数据剖析报表以进行剖析,或者能够自助式进行实时剖析。而在Lambda构架中,所有估算、分析都是在估算层完成的。例如在离线层加一层业务数据,需要重新开发一个DWS层的作业,将数据讲到DWS层数据储存中,再将其同步到数据服务系统,然后再提供线上报表服务。该过程须要数据开发朋友介入,需要进行数据需求评审与评估,并且开发周期起码将离线处理时间T+1。很多场景时间较紧急时,无法等待T+1的时间,也许就错过了商业机会。另外,新的业务需求要做实时链路的开发也是同样,需要进行实时作业的开发、校对、上线,开发周期长。因此Lambda构架灵活性未能满足线上业务诉求。

5.png
二、阿里Lambda实践1.搜索推荐精细化营运老构架
实际构架比上述Lambda理想构架愈加复杂。阿里巴巴最大的数据场景是搜索推荐场景。下图所示为搜索推荐精细化营运的旧构架在Lambda构架上的实践,与上述Lambda构架非常相像。
下图最右侧为阿里的数据,包括交易数据、用户行为数据、商品属性数据、搜索推荐数据等。将数据统一通过数据集成批量导出到MaxCompute,或者通过实时消息队列DataHub采集数据后通过Flink清洗。
线上构架演变:Fink发展迅猛,阿里的典型业务——双11大屏,是中单上数据通过Flink清洗后写入HBase系统。HBase对接实时大屏提供高效的点查询。
MaxCompute是阿里巴巴发展十年以上的离线数仓产品,承载了阿里特别大的离线数据剖析的场景。实时数据处理完成后就会产生一套离线数据,绝大部分离线数据都储存在MaxCompute。线上营销、对抗竞争等数据都来自MaxCompute。
随着Flink实时估算能力的提高,以及Flink实时数仓、实时报表上的应用的发展,所有的产品营运以及决策层都听到了实时对于业务的价值。因此在MaxCompute提供了多年离线剖析能力、发现Flink强悍估算的实时能力的基础之上,业务方提出同样一份数据能够通过实时形式提供实时的在线剖析服务能力。因此引入了Druid等开源产品,通过Flink将线上日志实时讲到Druid,提供Druid提供实时剖析能力。例如对接实时报表、实时决策、实时库存系统。
综上所示产生了两条链路,实时数据在Druid中做剖析,离线数据在MaxCompute做剖析。但因为Druid的存储容量等各方面性能的要求,在Druid中仅储存两天或两三天内的数据。进行大促等营销活动常常须要对比历史环比或同比数据。比如须要和今年或则是前年的双十一做对比剖析,在营销策略的剖析上须要对上周或则上上周的数据进行剖析,双11正式期须要与预热期数据进行同比剖析等。此时运用的是离线数据和实时数据的结合场景。方式是引入了更多产品。将MaxCompute离线数仓的数据与Druid中的实时数据在Mysql中进行合并,合并完成后再提供线上服务。

6.png
2.多套系统、多种场景、分析服务一体化能力
可见业务上游的数据、数据清洗的链路均未发生变化,而是业务应用层、业务剖析层场景发生了更多变化,出现了更多诉求,因此引入了更多产品进行业务支撑。但是该旧构架依然属于典型Lambda构架,因此在阿里巴巴高速的业务下降和膨胀之下,其一致性、运维复杂、成本高、业务敏捷性等问题逐步显现。
简单剖析在业务场景日渐复杂的情况下为什么引入多种系统,各系统分别提供如何的能力。
KV Store:Redis/Mysql/HBase/Cassandra,应对数据产品高QPS查询场景,提供高效点查询能力。
交互式估算能力:Presto/Drill。
实时数仓:ClickHouse/Druid,实时储存+在线估算能力。

7.png
3..搜索推荐精细化营运新构架
引入多种产品是为了支撑以上三种能力,那么能够在多种业务场景下同时解决相同业务问题并且将多种大数据产品的能力有机统一于一个引擎。使数据才能进行统一储存,然后对下层提供统一服务。因此产生右图所示构架。
上游数据处理和清洗不发生变化,而在对接下层业务应用时提供愈发丰富的能力。例如系统才能同时提供点查询、结果缓存、离线加速、联邦剖析、交互式剖析等能力。将该系统定义为HSAP(Hybrid Serving Analytical Processing)系统,分析服务一体化,能够实现一份数据同时用于实时剖析与在线服务。
Hologres产品是在该背景下推出的云原生HSAP数据库系统。Hologres产品实现实时离线数据统一储存,支持Flink数据或实时估算的实时数据实时写入,支持离线数据批量导出。第二,对接数据服务层面以实时剖析为中心而设计,可同时满足业务实时剖析与在线服务需求。第三,不改变原有实时数仓构架,通过MaxCompute直接加速,利用Hologres估算能力直接对接线上服务。

8.png
三、云原生HSAP系统Hologres产品1. Hologres产品核心优势
云原生HSAP数据库,一份数据同时用于实时剖析与在线服务。
极速响应:实现毫秒级响应,从而轻松满足顾客海量数据复杂多维剖析需求。千万QPS点查询,实时剖析上千QPS简单查询。
实时储存:支持亿级写入TPS,时效性强,写入即可查询。
MaxCompute加速:MaxCompute直接剖析,无数据搬迁,无冗余储存。
PG生态:PG开发者生态,开发人员友好,PG工具(pslq、Navicat、DataGrip)兼容。BI工具无缝对接。

9.png
2019年双十一 Hologres线上服务数据:在双十二当日超大数据量场景下,Hologres支持了高峰1.3亿实时写入TPS,并且数据写入即可查,提供了1.45亿高并发在线查询QPS。

10.png
2.Hologres交互式剖析产品-典型应用场景
离线数据加速查询:目前支持MaxCompute离线数据秒级交互式查询。无需额外ETL工作,便捷地把冷数据转换为便于理解的剖析结果,提升企业决策效率,降低时间成本。
实时数仓:Flink+Hologres,旨在通过搭建用户洞察体系,实时检测平台用户情况,并从不同视角对用户进行实时确诊,进而采取针对性的用户营运策略,从而达到精细化用户营运目的。助力实时精细化营运。
实时离线联合估算:基于离线数仓MaxCompute和实时数仓交互式剖析的联合估算,从商业逻辑出发,实现离线数据剖析实时化,实时离线联邦查询,构筑实时全链路精细化营运。
接下来具体介绍以上三种场景的具体构架以及应用。

11.png
3.MaxCompute加速剖析
传统方案——数据冗余、成本高、开发周期长:如下图所示,左侧数据通过数据集成同步到离线数仓后进行DWD层、DWS层等的加工,加工过后的数据对接线上服务。
一种方案是直接使用MaxCompute的MapReduce估算能力提供线上营销策略、线上实时报表。该方案似乎可以挺好地完成业务需求,但是在MapReduce任务递交后须要一定的等待排队、等待资源分配的时间。很多时侯等待时间小于数据剖析时间,并且剖析时效性所为几十分钟甚至小时级别。效率较低。
因此将数据从MaxCompute离线数仓中转移到线上Redis、Mysql等产品中,利用其交互式剖析或点查询能力提供服务。但是从MaxCompute离线数仓中集成数据到线上Redis、Mysql等产品中存在困难。首先是数据容量方面,例如当离线数仓ADS层数据量十分大,Mysql难以承载时,需要在离线数仓中添加一层ADS作业,再次进行数据加工和预估算,缩小数据量后将数据集成到Mysql中。也就是为了进行数据剖析,需要进行进一步的数据预处理,维护一个数据同步的作业,数据同步后还须要储存到Mysql中。以上流程将会造成数据冗余、并且成本高,开发周期长。

12.png
Hologres——无数据搬迁、数据剖析效率高:Hologres是储存估算分离的构架,与MaxCompute进行了无缝打通。Hologres在该场景下提供估算能力,而MaxCompute相当于Hologres的储存集群。可以直接对MaxCompute储存的数据进行读取与加速。只要数据在MaxCompute中加工完、可查询,通过Hologres可以直接进行数据剖析。在MaxCompute加速剖析场景下,Hologres是围绕交互式剖析场景设计的,发下作业后可立即得到结果,从而满足高效、自助式剖析,并且成本较低。

13.png
Demo演示:可参考文档》实时剖析海量MaxCompute数据进行demo演示,多种功能均可实现微秒级查询,实时返回。

14.png
DataWorks深度集成:Hologres与DataWorks进行了深度集成。MaxCompute数据直接进行加速剖析时须要构建一个Web表,在此支持了一键MaxCompute表结构同步、一键MaxCompute数据同步,以及一键本地上传文件,详情可以参考文档》》HoloStudio。

15.png
4.实时数仓——实时成本高、开发周期长、业务支持不灵活
实时数仓构架是数据采集之后,在ODS层Kafka中通过Flink进行清洗,产生DWD层数据。如果有更进一步的加工需求,再次对DWD层数据进行订阅,写入DWS层。根据不同业务场景引入HBase、MySQL、OLAP等不同产品。
该构架早已挺好地解决了现有问题。但是该构架中所有估算逻辑是在Flink中处理完成后写入DWS层。一旦须要加入新的业务场景或则对现有业务场景进行调整,需要新增数组或估算逻辑时,就须要重新评估链路、重新进行Flink作业的开发,修改或降低一个Flink作业后再讲到DWS层。
因此在该场景中,大部分估算都在Flink层,其业务灵活性不够高。也就是说该构架估算都是预先做好的,无法满足自助式剖析或则剖析之前DWD层数据。

16.png
5.实时、离线、分析、服务一体化方案
为解决上述问题,Hologres与飞天大数据平台(如Flink、MaxCompute)联合推出了新一代实时、离线、分析、服务一体化方案。数据依然在MaxCompute中进行离线数仓清洗,在Flink中进行实时清洗。但是Flink层数据清洗完成后可以将明细层数据直接写入Hologres,由Hologres对接线上大屏。Hologres提供了强悍的实时储存和实时估算能力,意味着明细层数据也可以直接对接线上报表。
实时数据和离线数据的联合剖析,从前存在MaxCompute中的数据可以直接与Hologres进行关联分析,实现联邦查询。
实际Flink估算的业务场景中,如果希望将数据沉淀出来提供线上服务,可以再度订阅Hologres,将Hologres DWD层数据加工为DWS层数据,写回Hologres。同时,Hologres在Flink作业中支持超大维表能力,其他Flink作业可以对Hologres中的数据进行关联剖析。

17.png
上述为实时、离线、分析、服务一体化方案的阐述,实际业务场景中的方案远比以上陈述复杂。
实际业务场景:下图所示为飞天大数据平台产品家族推出的方案构架。数据链愈加复杂,但是本质与上述构架相同,上游数据源通过数据采集到实时数仓,进行关联剖析后最终对下层数据应用提供实时离线联邦查询能力或剖析能力。

18.png
6.互联网-内容资讯顾客案例
Hologres不仅在阿里巴巴集团内部广泛应用外,在云上,互联网行业、传统企业等也早已得到了大量应用。
下图所示为典型的互联网顾客案例。小影是一款在泰国受欢迎的短视频APP。互联网行业不仅实时大屏、实时报表之外都会进行用户剖析、用户画像、用户标签、实时视频推荐等。该场景与阿里巴巴搜索推荐精细化场景相像,因此其构架引用是基于阿里云飞天大数据产品家族的离线数据MaxCompute、实时估算Flink、交互式剖析Hologres搭建上去的。

19.png
7.围绕数据建设、打通全链路
Hologres围绕着大数据生态、PG生态、阿里云生态,围绕着数据建设的全链路建立了数据生态。从数据源对接,导数据同步,到数据加工,到数据运维,到数据剖析和应用都进行了全链路打通。

20.png
Hologres在云上早已即将商业化,提供了包月包年、按量付费等不同计费尺寸,支持估算、存储资源不同配比订购,用户可以按照自身业务需求进行商品采购。同时数据产品、数据加工、数据同步、数据开发工具等支持引用自建、开源等产品。
指定尺寸首月3折,新一代HSAP系统Hologres重磅发布!点击》》立即订购
如果你们对Hologres产品有兴趣,关心产品动态,欢迎访问下方链接进行学习与交流。

21.png
搭建ELFK日志采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-15 06:29
环境打算操作系统信息
系统系统:centos7.2
三台服务器:10.211.55.11/12/13
安装包:
服务器规划
服务器host11
服务器host12
服务器host13
elasticsearch(master,data,client)
elasticsearch(master,data,client)
elasticsearch(master,data,client)
kibana
logstash
logstash
logstash
filebeat
filebeat
filebeat
整个ELFK的布署构架图大致如下图:
日志采集系统搭建安装elasticsearch集群
照手把手教你搭建一个 Elasticsearch 集群文章所述,elasticsearch集群中节点有多种类型:
以上就是节点几种类型,一个节点虽然可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,但若果一个节点既不是主节点也不是数据节点,那么它就是负载均衡节点。具体的类型可以通过具体的配置文件来设置。
我布署的环境服务器较少,只有三台,因此布署在每位节点上的elasticsearch实例只得饰演master、data、client三种角色了。
在三台服务器上均执行以下命令关掉selinux:
setenforce 0
sed -i -e 's/^SELINUX=.*$/SELINUX=disabled/g' /etc/selinux/config
在三台服务器上均安装java:
yum install -y java
在三台服务器上均安装elasticsearch的rpm包:
yum install -y https://artifacts.elastic.co/d ... 2.rpm
在三台服务器上更改elasticsearch的配置文件:
cat /etc/elasticsearch/elasticsearch.yml
cluster.name: DemoESCluster
# 注意不同节点的node.name要设置得不一样
node.name: demo-es-node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.211.55.11", "10.211.55.12", "10.211.55.13"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
EOF
在三台服务器上启动elasticsearch:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
在任意服务器上检测集群中的节点列表:
yum install -y jq
curl --silent -XGET 'http://localhost:9200/_cluster ... 27%3B|jq '.nodes'
在上述命令的输出里可以看见集群的相关信息,同时 nodes 字段上面收录了每位节点的详尽信息,这样一个基本的elasticsearch集群就布署好了。
安装 Kibana
接下来我们须要安装一个 Kibana 来帮助可视化管理 Elasticsearch,在host12上安装kibana:
yum install -y https://artifacts.elastic.co/d ... 4.rpm
修改kibana的配置文件:
cat /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://localhost:9200"
EOF
注意这儿配置的elasticsearch.url为本机的es实例,这样虽然还是存在单点故障的,在本机布署一个Elasticsearch 协调(Coordinating only node) 的节点,这里配置成协调节点的地址。
启动kibana:
systemctl daemon-reload
systemctl enable kibana
systemctl start kibana
配置认证须要升级License,我这儿是在外网使用,就不进行这个配置了。如果需要配置访问认证可参考这儿。
另外还可以启用SSL,可参考进行配置。
为了防止单点故障,kibana可布署多个,然后由nginx作反向代理,实现对kibana服务的负载均衡访问。
安装logstash
在每台服务器上安装logstash:
yum install -y https://artifacts.elastic.co/d ... 2.rpm
修改logstash的配置文件:
cat /etc/logstash/logstash.yml
path.data: /var/lib/logstash
path.logs: /var/log/logstash
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.url: ["http://10.211.55.11:9200", "http://10.211.55.12:9200", "http://10.211.55.13:9200"]
EOF
cat /etc/logstash/conf.d/beat-elasticsearch.conf
input {
beats {
port => 5044
ssl => false
}
}
filter {
}
output {
elasticsearch {
hosts => ["10.211.55.11:9200","10.211.55.12:9200","10.211.55.13:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
EOF
为了从原创日志中解析出一些有意义的field数组,可以启用一些filter,可用的filter列表在这里。
启动logstash:
systemctl daemon-reload
systemctl enable logstash
systemctl start logstash
安装filebeat
在每台服务器上安装filebeat:
yum install -y https://artifacts.elastic.co/d ... 4.rpm
修改每台服务器上的filebeat配置文件:
# 这里根据在采集的日志路径,编写合适的inputs规则
cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.logstash:
hosts: ["10.211.55.11:5044", "10.211.55.12:5044", "10.211.55.13:5044"]
ssl.enabled: false
index: 'var_log'
EOF
filebeat配置文件选项比较多,完整的参考可查看这儿。
在每台服务器上启动filebeat:
systemctl daemon-reload
systemctl enable filebeat
systemctl start filebeat
其它安全设置
为保证数据安全,filebeat与logstash、filebeat与elasticsearch、logstash与elasticsearch、kibana与elasticsearch之间的通信及kibana自身均能启用SSL加密,具体启用办法就是在配置文件中配一配SSL证书就可以了,这个比较简单,不再赘言。
kibana登陆认证须要升级License,这一点比较不爽,如果考虑成本,还是在前置机nginx上配个HTTP Basic认证处理好了。
部署测试
至此一个较完整的ELFK日志采集系统就搭建好了,用浏览器访问:5601/,在kibana的界面上简单设置下就可以查看到抓取的日志了:
总结
分布式日志采集,ELFK这一套比较成熟了,部署也很方便,不过布署上去还是稍显麻烦。好在还有自动化布署的ansible脚本:ansible-beats、ansible-elasticsearch、ansible-role-logstash、ansible-role-kibana,所以假如有时常布署这一套,还是拿那些ansible脚本成立自动化布署工具集吧。
参考 查看全部
最近的工作涉及搭建一套日志采集系统,采用了业界成熟的ELFK方案,这里将搭建过程记录一下。
环境打算操作系统信息
系统系统:centos7.2
三台服务器:10.211.55.11/12/13
安装包:
服务器规划
服务器host11
服务器host12
服务器host13
elasticsearch(master,data,client)
elasticsearch(master,data,client)
elasticsearch(master,data,client)
kibana
logstash
logstash
logstash
filebeat
filebeat
filebeat
整个ELFK的布署构架图大致如下图:
日志采集系统搭建安装elasticsearch集群
照手把手教你搭建一个 Elasticsearch 集群文章所述,elasticsearch集群中节点有多种类型:
以上就是节点几种类型,一个节点虽然可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,但若果一个节点既不是主节点也不是数据节点,那么它就是负载均衡节点。具体的类型可以通过具体的配置文件来设置。
我布署的环境服务器较少,只有三台,因此布署在每位节点上的elasticsearch实例只得饰演master、data、client三种角色了。
在三台服务器上均执行以下命令关掉selinux:
setenforce 0
sed -i -e 's/^SELINUX=.*$/SELINUX=disabled/g' /etc/selinux/config
在三台服务器上均安装java:
yum install -y java
在三台服务器上均安装elasticsearch的rpm包:
yum install -y https://artifacts.elastic.co/d ... 2.rpm
在三台服务器上更改elasticsearch的配置文件:
cat /etc/elasticsearch/elasticsearch.yml
cluster.name: DemoESCluster
# 注意不同节点的node.name要设置得不一样
node.name: demo-es-node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.211.55.11", "10.211.55.12", "10.211.55.13"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
EOF
在三台服务器上启动elasticsearch:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
在任意服务器上检测集群中的节点列表:
yum install -y jq
curl --silent -XGET 'http://localhost:9200/_cluster ... 27%3B|jq '.nodes'
在上述命令的输出里可以看见集群的相关信息,同时 nodes 字段上面收录了每位节点的详尽信息,这样一个基本的elasticsearch集群就布署好了。
安装 Kibana
接下来我们须要安装一个 Kibana 来帮助可视化管理 Elasticsearch,在host12上安装kibana:
yum install -y https://artifacts.elastic.co/d ... 4.rpm
修改kibana的配置文件:
cat /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://localhost:9200"
EOF
注意这儿配置的elasticsearch.url为本机的es实例,这样虽然还是存在单点故障的,在本机布署一个Elasticsearch 协调(Coordinating only node) 的节点,这里配置成协调节点的地址。
启动kibana:
systemctl daemon-reload
systemctl enable kibana
systemctl start kibana
配置认证须要升级License,我这儿是在外网使用,就不进行这个配置了。如果需要配置访问认证可参考这儿。
另外还可以启用SSL,可参考进行配置。
为了防止单点故障,kibana可布署多个,然后由nginx作反向代理,实现对kibana服务的负载均衡访问。
安装logstash
在每台服务器上安装logstash:
yum install -y https://artifacts.elastic.co/d ... 2.rpm
修改logstash的配置文件:
cat /etc/logstash/logstash.yml
path.data: /var/lib/logstash
path.logs: /var/log/logstash
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.url: ["http://10.211.55.11:9200", "http://10.211.55.12:9200", "http://10.211.55.13:9200"]
EOF
cat /etc/logstash/conf.d/beat-elasticsearch.conf
input {
beats {
port => 5044
ssl => false
}
}
filter {
}
output {
elasticsearch {
hosts => ["10.211.55.11:9200","10.211.55.12:9200","10.211.55.13:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
EOF
为了从原创日志中解析出一些有意义的field数组,可以启用一些filter,可用的filter列表在这里。
启动logstash:
systemctl daemon-reload
systemctl enable logstash
systemctl start logstash
安装filebeat
在每台服务器上安装filebeat:
yum install -y https://artifacts.elastic.co/d ... 4.rpm
修改每台服务器上的filebeat配置文件:
# 这里根据在采集的日志路径,编写合适的inputs规则
cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.logstash:
hosts: ["10.211.55.11:5044", "10.211.55.12:5044", "10.211.55.13:5044"]
ssl.enabled: false
index: 'var_log'
EOF
filebeat配置文件选项比较多,完整的参考可查看这儿。
在每台服务器上启动filebeat:
systemctl daemon-reload
systemctl enable filebeat
systemctl start filebeat
其它安全设置
为保证数据安全,filebeat与logstash、filebeat与elasticsearch、logstash与elasticsearch、kibana与elasticsearch之间的通信及kibana自身均能启用SSL加密,具体启用办法就是在配置文件中配一配SSL证书就可以了,这个比较简单,不再赘言。
kibana登陆认证须要升级License,这一点比较不爽,如果考虑成本,还是在前置机nginx上配个HTTP Basic认证处理好了。
部署测试
至此一个较完整的ELFK日志采集系统就搭建好了,用浏览器访问:5601/,在kibana的界面上简单设置下就可以查看到抓取的日志了:
总结
分布式日志采集,ELFK这一套比较成熟了,部署也很方便,不过布署上去还是稍显麻烦。好在还有自动化布署的ansible脚本:ansible-beats、ansible-elasticsearch、ansible-role-logstash、ansible-role-kibana,所以假如有时常布署这一套,还是拿那些ansible脚本成立自动化布署工具集吧。
参考
紧急扩散:联鹏推出校园疫情上报系统免费布署
采集交流 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2020-08-15 02:57
联鹏对有需求的中高职高校将提供免费布署服务,并提出:
1、联鹏全程技术支持,系统使用全程免费;
2、支持校园私有化布署和公有云布署并承诺竭力保障数据安全;
部署要求(公有云、私有云):
服务器:centos7.0或windows2012R2服务器一台,配置要求:CPU:8核心或以上;内存:8G或以上;硬盘:150G或以上;
网络要求:提供互联网可访问端口一个;
*为保障系统快速上线以及系统的轻量化,系统不提供校园统一身分认证登陆接入。支持接入校园APP\微信小程序等。
部署与使用建议:采用开放式WEB访问,可快速上线。
快速布署咨询请联系如下联系人:
联系人1:方乐/
联系人2:韩东/
联系人3:刘铮/
疫情上报平台-个人信息上报
操作说明
疫情上报平台个人信息上报兼容多端操作,用户可以通过手机、PC浏览器或则陌陌等扫码接入使用。个人信息采集按照“一日一报”要求举办,要求用户每日对个人情况进行上报。
上报内容包括基础信息采集(仅登录系统采集一次)和每日信息上报(每日上报时间节点参照相关规定要求)。
用户登录:
打开手机浏览器或PC浏览器(不支持IE10以下或国产浏览器的兼容模式,请使用Chrome、Firefox、IE10以上或国产浏览器(如360浏览器)极速模式,输入个人信息上报地址即可或使用陌陌等扫描二维码登录;
使用联通校园APP【疫情上报】子应用,进入子应用即可;
用户登陆:
浏览器登陆:输入工号/学号,学校统一身分认证密码点击下一步即可进行登陆;
移动校园APP:无需单独登陆,点击步入早已是登陆状态;
用户信息采集:
同一浏览器或联通应用首次登陆或登入后退出的情况下须要进行个人信息采集。
采集信息为身份证、手机号码、家庭住址与祖籍。填写好点击完成即可完成个人信息采集工作。
每日信息上报:
用户登入后,点击右下角【今日上报】按钮即可进行当天的信息上报。用户也可以及时在该界面浏览最新的疫情防疫工作通知或新闻。
用户根据实际情况,对上报表单进行如实填写。
填写内容包括:
返乡、旅游、接触情况的上报;
用户目前状况的上报,以及用户当前所在位置的上报(用户位置系统早已手动获取,如果系统获取地理位置和实际不符合,用户可点击【设置位置】按钮进行填写;
用户假如有其它与防疫相关的情况须要汇报,请在备注栏目中录入一并上报。
每日上报历史查看:
用户当天上报后,【今日上报】按钮会变为【上报查看】按钮,用户可点击该按键查看个人历史上报情况。
疫情上报平台-后台管理
操作说明
疫情上报平台后台管理致力为疫情联络管理人提供数据剖析,上报报表导入(导出Excel报表)的能力。用户可PC登陆网址,输入身份证号\工号进行登陆。
注意:仅仅疫情联络管理人能够完整使用系统功能、没有权限的用户难以进行相关操作。 查看全部
2020年的这个春节,新型冠状病毒感染麻疹疫情挑动着每个人的心,全国人民上下一心,在这场抵御疫情的战斗中英雄事迹使我们受到鼓舞。为贯彻落实重大突发公共卫生事件响应有关要求,有效防治和控制新型冠状病毒感染的麻疹疫情,进一步增强信息报送的效率,减轻各单位报送信息的负担,联鹏“不忘初心,牢记使命”,快速响应呼吁,立足“专业服务”理念,参考各地方政府对疫情信息采集的明晰要求,尤其是“日报”等具体要求,紧急开发校园疫情上报系统,为打赢教育系统疫情防治阻击战贡献一份绵薄之力。
联鹏对有需求的中高职高校将提供免费布署服务,并提出:
1、联鹏全程技术支持,系统使用全程免费;
2、支持校园私有化布署和公有云布署并承诺竭力保障数据安全;
部署要求(公有云、私有云):
服务器:centos7.0或windows2012R2服务器一台,配置要求:CPU:8核心或以上;内存:8G或以上;硬盘:150G或以上;
网络要求:提供互联网可访问端口一个;
*为保障系统快速上线以及系统的轻量化,系统不提供校园统一身分认证登陆接入。支持接入校园APP\微信小程序等。
部署与使用建议:采用开放式WEB访问,可快速上线。
快速布署咨询请联系如下联系人:
联系人1:方乐/
联系人2:韩东/
联系人3:刘铮/
疫情上报平台-个人信息上报
操作说明
疫情上报平台个人信息上报兼容多端操作,用户可以通过手机、PC浏览器或则陌陌等扫码接入使用。个人信息采集按照“一日一报”要求举办,要求用户每日对个人情况进行上报。
上报内容包括基础信息采集(仅登录系统采集一次)和每日信息上报(每日上报时间节点参照相关规定要求)。
用户登录:
打开手机浏览器或PC浏览器(不支持IE10以下或国产浏览器的兼容模式,请使用Chrome、Firefox、IE10以上或国产浏览器(如360浏览器)极速模式,输入个人信息上报地址即可或使用陌陌等扫描二维码登录;
使用联通校园APP【疫情上报】子应用,进入子应用即可;
用户登陆:
浏览器登陆:输入工号/学号,学校统一身分认证密码点击下一步即可进行登陆;
移动校园APP:无需单独登陆,点击步入早已是登陆状态;

用户信息采集:
同一浏览器或联通应用首次登陆或登入后退出的情况下须要进行个人信息采集。
采集信息为身份证、手机号码、家庭住址与祖籍。填写好点击完成即可完成个人信息采集工作。

每日信息上报:
用户登入后,点击右下角【今日上报】按钮即可进行当天的信息上报。用户也可以及时在该界面浏览最新的疫情防疫工作通知或新闻。

用户根据实际情况,对上报表单进行如实填写。
填写内容包括:
返乡、旅游、接触情况的上报;
用户目前状况的上报,以及用户当前所在位置的上报(用户位置系统早已手动获取,如果系统获取地理位置和实际不符合,用户可点击【设置位置】按钮进行填写;
用户假如有其它与防疫相关的情况须要汇报,请在备注栏目中录入一并上报。
每日上报历史查看:
用户当天上报后,【今日上报】按钮会变为【上报查看】按钮,用户可点击该按键查看个人历史上报情况。
疫情上报平台-后台管理
操作说明
疫情上报平台后台管理致力为疫情联络管理人提供数据剖析,上报报表导入(导出Excel报表)的能力。用户可PC登陆网址,输入身份证号\工号进行登陆。
注意:仅仅疫情联络管理人能够完整使用系统功能、没有权限的用户难以进行相关操作。
系统上云迁移步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-14 10:51
数据库迁移典型的应用场景
1、本地资源受限,从本地自建或传统IDC上迁移到云上。
2、云计算服务厂商变更,需要数据库迁移。
3、业务的地理位置发生变化,需要跨数据中心迁移。
4、云端作为数据灾备,将数据迁移到云上。
MySQL数据库迁移步骤
1、在源机房为MySQL数据库实例创建一个迁移帐号。
2、在源机房配置足够的内网带宽,并能联接到源机房的MySQL实例。
3、通过网段VPN或专线将目标云数据库和源数据库联接,开启目标云数据库的GTID模式,将源MySQL实例数据复制到目标MySQL云数据库。
4、测试数据一致性后,切换应用数据库为华云云数据库,完成数据库迁移工作。
对象储存数据迁移
华云对象存储服务COS是针对非结构化数据的储存,如图片、音视频、文档以及短信数据等。利用COS的迁移工具支持将本地和友商云存储上的数据迁移到华云COS。
网站存储的迁移步骤
1、在华云的目标机房的对象存储服务创建Bucket。
2、设置Bucket的镜像回源地址。
3、设置Bucket的域名绑定。
4、在域名管理服务中心添加信息的CNAME记录。
5、域名全网生效,对源站数据做一次主动的完整迁移到华云COS后,即可下线源站储存。
系统应用和数据迁移
以传统行业为代表,现有的应用系统种类繁杂:办公系统、财务系统、客户管理系统、研发管理系统、生产管理系统等,系统之间业务流比较复杂和冗长,上云迁移过程中须要保证应用迁移的连续性、云上和线下系统的联动性、数据的高可用性等等。由于每位顾客的业务系统都不完全一样,需要按照各自的特征,量身订制上云迁移方案和施行。
系统上云迁移步骤
1、系统评估:包括系统基础环境、业务流程和相关性、系统布署结构、 系统构架等。
2、上云规划:根据系统评估的结果,梳理上云方案和规划,制定割接方案和回滚方案。
3、迁移测试:验证割接方案和回滚方案的可行性。
4、迁移施行:根据验证后的割接方案迁移系统上所有的应用和数据。
5、业务验证:验证云上系统功能,排除故障,完成上云迁移。 查看全部
数据库上云迁移对象储存云迁移应用和数据迁移
数据库迁移典型的应用场景
1、本地资源受限,从本地自建或传统IDC上迁移到云上。
2、云计算服务厂商变更,需要数据库迁移。
3、业务的地理位置发生变化,需要跨数据中心迁移。
4、云端作为数据灾备,将数据迁移到云上。
MySQL数据库迁移步骤
1、在源机房为MySQL数据库实例创建一个迁移帐号。
2、在源机房配置足够的内网带宽,并能联接到源机房的MySQL实例。
3、通过网段VPN或专线将目标云数据库和源数据库联接,开启目标云数据库的GTID模式,将源MySQL实例数据复制到目标MySQL云数据库。
4、测试数据一致性后,切换应用数据库为华云云数据库,完成数据库迁移工作。
对象储存数据迁移
华云对象存储服务COS是针对非结构化数据的储存,如图片、音视频、文档以及短信数据等。利用COS的迁移工具支持将本地和友商云存储上的数据迁移到华云COS。
网站存储的迁移步骤
1、在华云的目标机房的对象存储服务创建Bucket。
2、设置Bucket的镜像回源地址。
3、设置Bucket的域名绑定。
4、在域名管理服务中心添加信息的CNAME记录。
5、域名全网生效,对源站数据做一次主动的完整迁移到华云COS后,即可下线源站储存。
系统应用和数据迁移
以传统行业为代表,现有的应用系统种类繁杂:办公系统、财务系统、客户管理系统、研发管理系统、生产管理系统等,系统之间业务流比较复杂和冗长,上云迁移过程中须要保证应用迁移的连续性、云上和线下系统的联动性、数据的高可用性等等。由于每位顾客的业务系统都不完全一样,需要按照各自的特征,量身订制上云迁移方案和施行。
系统上云迁移步骤
1、系统评估:包括系统基础环境、业务流程和相关性、系统布署结构、 系统构架等。
2、上云规划:根据系统评估的结果,梳理上云方案和规划,制定割接方案和回滚方案。
3、迁移测试:验证割接方案和回滚方案的可行性。
4、迁移施行:根据验证后的割接方案迁移系统上所有的应用和数据。
5、业务验证:验证云上系统功能,排除故障,完成上云迁移。
基于TableStore/MaxCompute的数据采集分析系统介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2020-08-12 19:10
TableStore(表格储存)是阿里云自主研制的专业级分布式NoSQL数据库,是基于共享储存的高性能、低成本、易扩充、全托管的半结构化数据储存平台,支撑互联网和物联网数据的高效估算与剖析。
目前不管是阿里巴巴集团内部,还是外部公有云用户,都有成千上万的系统在使用。覆盖了重吞吐的离线应用,以及重稳定性,性能敏感的在线应用。表格储存的具体的特点可以看下边这张图片。
基于TableStore的数据采集分析系统
一个典型的数据采集分析统计平台,对数据的处理,主要由如下五个步骤组成:
对于上图流程的具体实现,网上有许多可以参考的案例,数据在客户端采集完之后,如果量比较小,我们可能直接在前端的API上做一次透传,然后持久化到RDBMS类型的数据库中就好了,通过Sql可以进行数据剖析。如果数据量很大,就须要一些中间件来辅助搜集和上传,然后分别将数据写入到在线和离线的系统中,比如先上传到Flume,Flume可以做数据的采集与聚合,再将Flume作为消息的生产者,将生产的消息数据通过Kafka Sink发布到Kafka中,Kafka作为消息队列的角色,可以对接前端的在线和离线估算平台。如下图所示:
引入Flume和Kafka的诱因有很多,比如她们可以处理大流量的数据、做数据聚合、保证数据不遗失等,但最关键的缘由是她们拥有高吞吐的能力。引入的组件多,系统的复杂性和成本也会相应的降低,上图中,Spark Streaming/Storm剖析完成之后,结果数据还须要引入另外的储存组件进行储存,比如HBase/MySQL,如果引入MySQL可能还须要再引入Redis做热点数据缓存,这样一来就愈加复杂了。
我们尝试一种基于TableStore和阿里云其他大数据产品的新方案,我们先看构架图:
图中关键路径剖析:
1、Web页、APP等客户端先通过埋点系统搜集数据,然后通过表格储存的SDK将数据写入TableStore的原创数据表。
2、MaxCompute直读TableStore原创数据表的数据进行剖析,然后QuickBI读取MaxCompute的数据进行展示,具体操作可参考:MaxCompute直读直写表格储存、QuickBI新建云数据源。
3、TableStore原创数据表中的数据可增量同步到ElasticSearch或则openSearch中,同步方式参考:TableStore数据同步到ElasticSearch,TableStore数据同步到OpenSearch。
4、TableStore中的数据可增量同步到Blink/Flink进行剖析,分析完之后的数据再写回TableStore的结果数据表中,DavaV读取结果数据表的数据进行展示。
新构架优势剖析:
1、客户端数据直读直写TableStore,不需要再引入API层进行数据透传,降低了复杂度,对于小型应用来说也降低了不少的服务器成本。
2、TableStore早已对接了丰富了大数据组件,包括阿里云的大数据产品和开源大数据产品,数据的同步与读写十分容易。
3、实时剖析与离线剖析后的结果数据再写回TableStore,DataV直接读取结果数据进行展示,因为TableStore具备高性能与高吞吐特性,不需要再引入Redis等缓存组件,可以简化整个系统。
直读直写安全问题:
关于数据直读直写TableStore,大家可能就会想到一个安全的问题,客户端直连TableStore不是要把AccessKey和AccessId曝露在客户端吗?答案是不用,我们使用STSToken授权访问TableStore,过程如下图所示:
TableStore提供的SDK都支持使用STS授权的形式进行访问,示例可参考TableStore NodeJs SDK使用STSToken,使用STS形式访问TableStore须要控制好授权策略,客户端不需要的插口请不要授权。
浏览器跨域访问TableStore:
如果在浏览器端直接访问TableStore,由于浏览器有同源策略的限制,会形成跨域问题。因为TableStore的EndPoint域名与用户Web站点的域名不同。解决这个问题的思路有两个:一是Web端不直接访问TableStore,改为先恳求自己的Web Server端,Web Server端再使用TableStore SDK来发起恳求,这样虽然就是前端访问了,问题解决了但也没了我们直读直写的优势;二是TableStore服务端通过某种形式直接支持js跨域恳求,这条路我们正在支持当中,当前处于开发阶段,支持的方法是cors合同支持跨域。但目前也有快捷的支持方法,如果您有浏览器直接访问TableStore的需求,可以直接联系我们,支持上去也很快。
总结
表格储存因其高性能、高吞吐、高可靠的特点,使得它在数据采集这种对前端吞吐要求很高的场景下特别适用,客户端数据直读直写表格储存,也为前端节约了中间层数据流转这一层服务,减少了复杂性也节约了成本。另外,表格储存对接了丰富的估算、分析、展示工具可以覆盖数据采集与剖析的几乎所有场景,本文所介绍的周边组件也只囊括了一部分,更多的示例与说明请参考表格储存用户手册。 查看全部
TableStore
TableStore(表格储存)是阿里云自主研制的专业级分布式NoSQL数据库,是基于共享储存的高性能、低成本、易扩充、全托管的半结构化数据储存平台,支撑互联网和物联网数据的高效估算与剖析。
目前不管是阿里巴巴集团内部,还是外部公有云用户,都有成千上万的系统在使用。覆盖了重吞吐的离线应用,以及重稳定性,性能敏感的在线应用。表格储存的具体的特点可以看下边这张图片。

基于TableStore的数据采集分析系统
一个典型的数据采集分析统计平台,对数据的处理,主要由如下五个步骤组成:

对于上图流程的具体实现,网上有许多可以参考的案例,数据在客户端采集完之后,如果量比较小,我们可能直接在前端的API上做一次透传,然后持久化到RDBMS类型的数据库中就好了,通过Sql可以进行数据剖析。如果数据量很大,就须要一些中间件来辅助搜集和上传,然后分别将数据写入到在线和离线的系统中,比如先上传到Flume,Flume可以做数据的采集与聚合,再将Flume作为消息的生产者,将生产的消息数据通过Kafka Sink发布到Kafka中,Kafka作为消息队列的角色,可以对接前端的在线和离线估算平台。如下图所示:

引入Flume和Kafka的诱因有很多,比如她们可以处理大流量的数据、做数据聚合、保证数据不遗失等,但最关键的缘由是她们拥有高吞吐的能力。引入的组件多,系统的复杂性和成本也会相应的降低,上图中,Spark Streaming/Storm剖析完成之后,结果数据还须要引入另外的储存组件进行储存,比如HBase/MySQL,如果引入MySQL可能还须要再引入Redis做热点数据缓存,这样一来就愈加复杂了。
我们尝试一种基于TableStore和阿里云其他大数据产品的新方案,我们先看构架图:

图中关键路径剖析:
1、Web页、APP等客户端先通过埋点系统搜集数据,然后通过表格储存的SDK将数据写入TableStore的原创数据表。
2、MaxCompute直读TableStore原创数据表的数据进行剖析,然后QuickBI读取MaxCompute的数据进行展示,具体操作可参考:MaxCompute直读直写表格储存、QuickBI新建云数据源。
3、TableStore原创数据表中的数据可增量同步到ElasticSearch或则openSearch中,同步方式参考:TableStore数据同步到ElasticSearch,TableStore数据同步到OpenSearch。
4、TableStore中的数据可增量同步到Blink/Flink进行剖析,分析完之后的数据再写回TableStore的结果数据表中,DavaV读取结果数据表的数据进行展示。
新构架优势剖析:
1、客户端数据直读直写TableStore,不需要再引入API层进行数据透传,降低了复杂度,对于小型应用来说也降低了不少的服务器成本。
2、TableStore早已对接了丰富了大数据组件,包括阿里云的大数据产品和开源大数据产品,数据的同步与读写十分容易。
3、实时剖析与离线剖析后的结果数据再写回TableStore,DataV直接读取结果数据进行展示,因为TableStore具备高性能与高吞吐特性,不需要再引入Redis等缓存组件,可以简化整个系统。
直读直写安全问题:
关于数据直读直写TableStore,大家可能就会想到一个安全的问题,客户端直连TableStore不是要把AccessKey和AccessId曝露在客户端吗?答案是不用,我们使用STSToken授权访问TableStore,过程如下图所示:

TableStore提供的SDK都支持使用STS授权的形式进行访问,示例可参考TableStore NodeJs SDK使用STSToken,使用STS形式访问TableStore须要控制好授权策略,客户端不需要的插口请不要授权。
浏览器跨域访问TableStore:
如果在浏览器端直接访问TableStore,由于浏览器有同源策略的限制,会形成跨域问题。因为TableStore的EndPoint域名与用户Web站点的域名不同。解决这个问题的思路有两个:一是Web端不直接访问TableStore,改为先恳求自己的Web Server端,Web Server端再使用TableStore SDK来发起恳求,这样虽然就是前端访问了,问题解决了但也没了我们直读直写的优势;二是TableStore服务端通过某种形式直接支持js跨域恳求,这条路我们正在支持当中,当前处于开发阶段,支持的方法是cors合同支持跨域。但目前也有快捷的支持方法,如果您有浏览器直接访问TableStore的需求,可以直接联系我们,支持上去也很快。
总结
表格储存因其高性能、高吞吐、高可靠的特点,使得它在数据采集这种对前端吞吐要求很高的场景下特别适用,客户端数据直读直写表格储存,也为前端节约了中间层数据流转这一层服务,减少了复杂性也节约了成本。另外,表格储存对接了丰富的估算、分析、展示工具可以覆盖数据采集与剖析的几乎所有场景,本文所介绍的周边组件也只囊括了一部分,更多的示例与说明请参考表格储存用户手册。
使用SpreadJS 开发在线问卷系统,构筑CCP(云数据采集)平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-08-12 15:58
图片来自于网路
CCP(云数据采集)平台诞生于大数据时代的背景下,通过实时数据挖掘,在海量的云端数据中发觉隐藏其中的价值。
在线问卷系统,作为CCP(云数据采集)平台的信息采集接口,通过网路信息搜集,帮助问卷设计者和数据分析师剖析消费者在线上的行为特点和心态,批量而精确地抽取目标网页中的任何数据及任何信息,快速实现实时的信息获取。
CCP(云数据采集)平台的数据采集工作能够更简练、更方便、更精准的执行,取决于在线问卷系统的基本功能和构架。
因此,在线问卷系统通常需收录以下四个功能模块:在线设计问卷、数据搜集、数据剖析和导入。
在线问卷系统的基本功能模块
在线设计问卷需具备:
问卷设计方法简单、易操作
可自由地更改问卷外形、可制做带有公司Logo的问卷模板
项目类型丰富, 内置选择题、填空题、打分、排序、个人信息搜集等
应用场景广泛,可设计问卷调查、投票、满意度、表单、测评等模板
数据搜集需具备:
独有的自定义数据搜集渠道
支持手机端填写
支持无缝嵌入网站、APP和小程序
可通过第三方社交平台完成填写
数据剖析需具备:
调查数据可实时查看
支持表格、图表等多元化的数据展示
提供数据筛选、交叉剖析和原创数据下载
提高数据来源溯源,趋势一目了然
导出需具备:
支持导入为xlsx、CSV等格式
提供更安全的数据储存
不限发布数目,支持多并发
在线问卷系统的实现思路
因为须要对搜集到的问卷数据进行数据剖析,并导入剖析结果,所以系统须要支持图表、计算公式和在线导出导入功能。
在充分评估后,发现使用 SpreadJS控件,可以满足上述需求,原因如下:
可生成交叉图表:SpreadJS 提供了单向数据绑定的功能,可以将搜集的数据绑定至表格中,可以便捷的实现数据剖析及展示。
图1 生成交叉图表剖析页面
在线导出导入 Excel 文件:SpreadJS无需利用任何后台代码和第三方组件,可直接在浏览器中完成 Excel文件的导出导入、PDF 导出、打印及预览操作,解决了后端导入Excel、CSV文件的需求,方便用户将问卷统计剖析结果导入至本地,导出的文件对比疗效如下图所示:
图2 导出Excel文件对比
数据可视化:SpreadJS 支持 Excel 的 450 种公式和 32 种图表,可以帮助用户更全面的剖析采集到的数据。
图3 SpreadJS外置多种图表
数据筛选:从后台返回的数据,通过SpreadJS 在后端进行展示,并提供数据筛选、排序、分组、批注、切片器等操作,方便用户对统计结果进一步剖析。
图4 数据筛选
将 SpreadJS 的组件功能嵌入在线问卷系统,我们可以专注于业务逻辑,而不用分散关注点于基本的功能模块怎样实现。借助 SpreadJS 将问卷系统以组件化的形式构建,既增加了后期测试成本,明显减短了项目交付周期,也为项目二期奠定了良好的基础。
如果您也有这种系统开发的需求,请访问SpreadJS产品官网,查看应用场景和各种技术资源,可以为您的系统搭建提供帮助。 查看全部
什么是CCP(云数据采集)平台?

图片来自于网路
CCP(云数据采集)平台诞生于大数据时代的背景下,通过实时数据挖掘,在海量的云端数据中发觉隐藏其中的价值。
在线问卷系统,作为CCP(云数据采集)平台的信息采集接口,通过网路信息搜集,帮助问卷设计者和数据分析师剖析消费者在线上的行为特点和心态,批量而精确地抽取目标网页中的任何数据及任何信息,快速实现实时的信息获取。
CCP(云数据采集)平台的数据采集工作能够更简练、更方便、更精准的执行,取决于在线问卷系统的基本功能和构架。
因此,在线问卷系统通常需收录以下四个功能模块:在线设计问卷、数据搜集、数据剖析和导入。
在线问卷系统的基本功能模块
在线设计问卷需具备:
问卷设计方法简单、易操作
可自由地更改问卷外形、可制做带有公司Logo的问卷模板
项目类型丰富, 内置选择题、填空题、打分、排序、个人信息搜集等
应用场景广泛,可设计问卷调查、投票、满意度、表单、测评等模板
数据搜集需具备:
独有的自定义数据搜集渠道
支持手机端填写
支持无缝嵌入网站、APP和小程序
可通过第三方社交平台完成填写
数据剖析需具备:
调查数据可实时查看
支持表格、图表等多元化的数据展示
提供数据筛选、交叉剖析和原创数据下载
提高数据来源溯源,趋势一目了然
导出需具备:
支持导入为xlsx、CSV等格式
提供更安全的数据储存
不限发布数目,支持多并发
在线问卷系统的实现思路
因为须要对搜集到的问卷数据进行数据剖析,并导入剖析结果,所以系统须要支持图表、计算公式和在线导出导入功能。
在充分评估后,发现使用 SpreadJS控件,可以满足上述需求,原因如下:
可生成交叉图表:SpreadJS 提供了单向数据绑定的功能,可以将搜集的数据绑定至表格中,可以便捷的实现数据剖析及展示。

图1 生成交叉图表剖析页面
在线导出导入 Excel 文件:SpreadJS无需利用任何后台代码和第三方组件,可直接在浏览器中完成 Excel文件的导出导入、PDF 导出、打印及预览操作,解决了后端导入Excel、CSV文件的需求,方便用户将问卷统计剖析结果导入至本地,导出的文件对比疗效如下图所示:

图2 导出Excel文件对比
数据可视化:SpreadJS 支持 Excel 的 450 种公式和 32 种图表,可以帮助用户更全面的剖析采集到的数据。

图3 SpreadJS外置多种图表
数据筛选:从后台返回的数据,通过SpreadJS 在后端进行展示,并提供数据筛选、排序、分组、批注、切片器等操作,方便用户对统计结果进一步剖析。

图4 数据筛选
将 SpreadJS 的组件功能嵌入在线问卷系统,我们可以专注于业务逻辑,而不用分散关注点于基本的功能模块怎样实现。借助 SpreadJS 将问卷系统以组件化的形式构建,既增加了后期测试成本,明显减短了项目交付周期,也为项目二期奠定了良好的基础。
如果您也有这种系统开发的需求,请访问SpreadJS产品官网,查看应用场景和各种技术资源,可以为您的系统搭建提供帮助。
阿里云怎样打破Oracle迁移上云的壁垒
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-10 15:15
2018第九届中国数据库技术会议,阿里云数据库产品专家萧少聪带来以阿里云怎样打破Oracle迁移上云的壁垒为题的讲演。Oracle是指“数据库管理系统”,面对Oracle迁移上云的壁垒,阿里云怎样才能打破它呢?本文提出了Oracle 到云数据库PPAS迁移的方案,这种迁移方案为何比Oracle到 MySQL系列的迁移容易促使呢?答案正式出炉。
直播视频回顾
PPT下载请点击
以下是精彩视频内容整理:
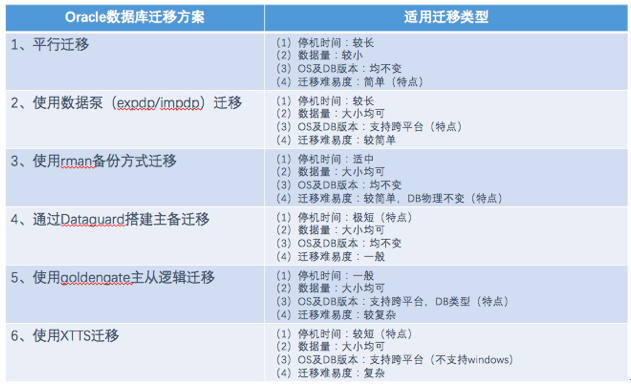
Oracle数据库迁移方案
数据业务构架中就会有服务器、应用及数据库系统和储存系统三大块,服务器与储存系统上云是相对容易解决的,但在解决应用及数据库系统方面是有些难度的。于是,阿里云给出了里面的解决方案。在这个解决方案中,用户可以通过不同的方法,将数据库迁移到云上,我们可以继续在ECS中运行Oracle,也可以迁移到MySQL。当然也可以将应用及数据库系统迁移到云数据库PPAS版,借助其高度兼容Oracle的能力,降低用户迁移上云的难度,并减少系统常年运维的复杂性。
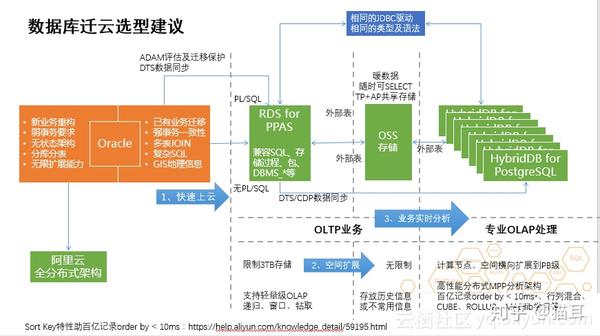
阿里云除了有同城容灾、自动备份、时间点恢复等这种部份会为云的用户去提供。阿里云数据库都会加入高可用的HA,它通常须要两个或两个以上的节点,进行复杂配置。而在阿里云,用户仅需点一下按键就可以有高可用的HA,而且这样的HA集群不单可以在同一数据中心上建立,同时也支持同城双中心异地容灾,同样一键布署完成。同时,阿里云还为用户提供ADAM(Advanced Database & Application Migration “亚当”)工具,以协助用户利用PPAS的Oracle兼容性进行快速迁移。那么接下来如何去迁移的各步骤应当怎样进行呢?
将ADAM采集 器安装在Oracle里面,ADMA将起到三个方面的作用:
Oracle迁移到PPAS相对迁移到其他数据库更为平滑,因为有许多兼容的地方。Oracle数据库到PPAS快速上云的过程中应做到兼容SQL、存储过程、包、DBMS等,因此适宜复杂事务事业务的迁移。云数据库PPAS版,提供最高 3TB的本地高性能储存(据悉这一空间有机会在年内突破到10TB以上)。如果业务数据超过本地储存容量大小,则可以通过OSS储存做外部表处理,如历史数据就可以储存到OSS外部表中,这些信息并不常使用,但对于数据剖析很重要。因此我们可以通过阿里云HybridDB for PostgreSQL,从OSS中直接获取数据进行业务剖析。HybridDB for PostgreSQL是基于开源Greenplum Database分布式MPP数据库的阿里云自有发布版,可实现业务实时剖析,计算节点、空间纵向扩充到PB级、特定场景下百亿记录order by
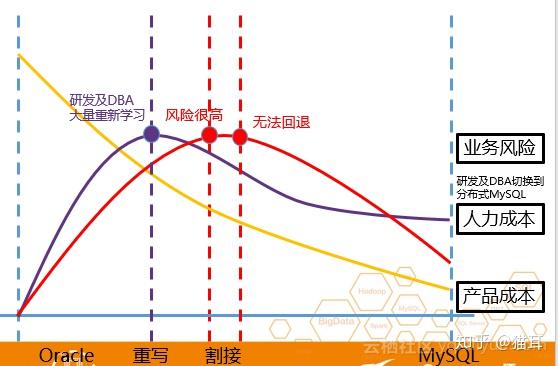
Oracle 数据库到 MySQL、PPAS的比较
为什么Oracle 数据库到 MySQL系列的迁移无法推进呢?原因是Oracle 数据库到 MySQL系列的迁移会导致ISV及企业迁移风险减小,在整个迁移过程中代码、存储过程以及架构需作出大的改动,这会导致研制重新学习、DBA重新学习、代码的句型重画甚至业务架构重画,最终导致业务风险减小、人力成本变高以及产品成本变高。
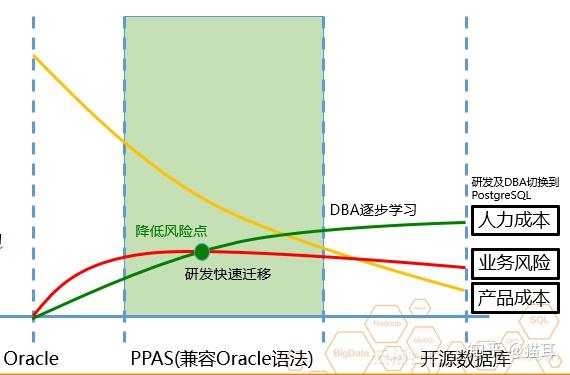
而Oracle 数据库到云数据库PPAS版是相对容易推进的,在推进过程中提升了Oracle迁移上云的成功率。研发可继续写Oracle句型因而减少迁移难度及工作量,阿里云可手动运维提升DBA SQL优化能力,代码的句型几乎不需改动,ADAM协助得以精准剖析。
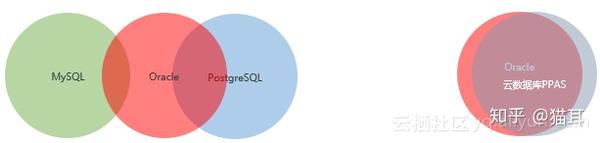
为什么说PPAS兼容Oralce会更好呢?由上图可以看见MySOL与Oracle的交集面积比PostgreSQL与Oracle的交集面积都太小,这并不能达到预期的疗效。期望中云数据库PASS版疗效应该是Oracle的面积与PostgreSQL的面积几乎达到重合。
为什么会须要这么多的兼容部份呢?因为这样才会使企业的开发团队、原有的开发成果以及已有的应用快速的放在云里面去。例如,如果开发商开发的软件都是线下的,但顾客要求上云,到云里面又须要用到互联网思维,那么原有的储存模式都须要改动,为了维护云的构架线上、线下的结构都须要改动,这样会须要大量的人力成本。如果有一个功能直接兼容Oracle 的句型,这个时侯放在云里面去会降低整体的负担。
云数据库PPAS 到Oracle兼容的数据类型有许多种,例如,BLOB、CLOB、DATE等等。它们各自又有各自的别称与类型,例如 BLOB 的别称是LONG RAW,其类型是二进制数据。
ADAM可以协助用户Oracle数据库通过全量以及增量进行上云迁移,如果Oracle数据量很大,这里可能须要一个星期甚至一个月能够传输完。这时就可以通过高速联接以及高速通道降低带宽,不需要通过Internet,防止传输错的数据,同时也不会影响生产库。 通过ADAM平台Oracle数据到云数据库都会提供30天的回流机制,为用户提供迁移割接过程的最大保障。
云数据库PPAS除了是高可用,还支持同城容灾,在不降低任何费用成本的情况下,用户可以选择使用单可用县集群,或是使用多可用县(同城容灾)集群,以提供更有保障的企业级容灾需求保护。
云数据库PPAS 不只是手动备份,还送50%免费备份空间。例如用户订购实例储存空间为1TB,将直接附送500GB免费备份空间。
云数据库PPAS云化管理是按时间点进行实例克隆的,实例克隆功能将于2018年7月提供,并支持历时730天数据备份,当前只提供临时实例。
阿里云PostgreSQL生态系统
Oracle的应用可以迁移到云数据库PPAS版,PPAS通过高性能本地储存空间,以储存热点OLTP业务数据。历史信息储存到外部的OSS里面,OSS里面的数据可以直接被HybridDB for PostgreSQL读取使用,也就是说OLTP可以进行业务处理,OLAP可以直接通过基于开源Greenplum Database分布式MPP构架的阿里云数据库房服务HybridDB for PostgreSQL进行。
同时用户也可以保留原有Oracle系统,只将剖析业务转为使用HybridDB for PostgreSQL,其 OLAP性能优势如下如下:
HybridDB for PostgreSQL混合分区
储存可分为三种存储,分别为行式储存、列式储存以及OSS暖储存,这三种储存的介绍如下:
原文链接 查看全部
摘要: 2018第九届中国数据库技术会议,阿里云数据库产品专家萧少聪带来以阿里云怎样打破Oracle迁移上云的壁垒为题的讲演。Oracle是指“数据库管理系统”,面对Oracle迁移上云的壁垒,阿里云怎样才能打破它呢?本文提出了Oracle 到云数据库PPAS迁移的方案,这种迁移方案为何比Oracle到 MySQL系列的迁移容易促使呢?答案正式出炉。
2018第九届中国数据库技术会议,阿里云数据库产品专家萧少聪带来以阿里云怎样打破Oracle迁移上云的壁垒为题的讲演。Oracle是指“数据库管理系统”,面对Oracle迁移上云的壁垒,阿里云怎样才能打破它呢?本文提出了Oracle 到云数据库PPAS迁移的方案,这种迁移方案为何比Oracle到 MySQL系列的迁移容易促使呢?答案正式出炉。
直播视频回顾
PPT下载请点击
以下是精彩视频内容整理:
Oracle数据库迁移方案
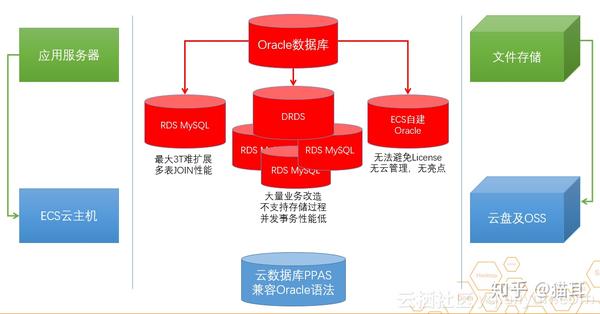
数据业务构架中就会有服务器、应用及数据库系统和储存系统三大块,服务器与储存系统上云是相对容易解决的,但在解决应用及数据库系统方面是有些难度的。于是,阿里云给出了里面的解决方案。在这个解决方案中,用户可以通过不同的方法,将数据库迁移到云上,我们可以继续在ECS中运行Oracle,也可以迁移到MySQL。当然也可以将应用及数据库系统迁移到云数据库PPAS版,借助其高度兼容Oracle的能力,降低用户迁移上云的难度,并减少系统常年运维的复杂性。
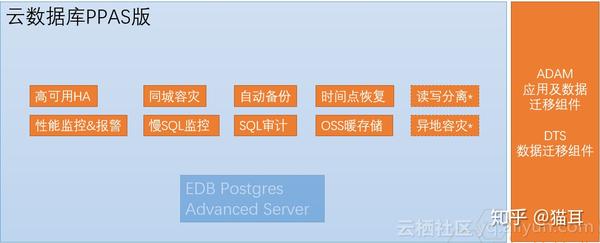
阿里云除了有同城容灾、自动备份、时间点恢复等这种部份会为云的用户去提供。阿里云数据库都会加入高可用的HA,它通常须要两个或两个以上的节点,进行复杂配置。而在阿里云,用户仅需点一下按键就可以有高可用的HA,而且这样的HA集群不单可以在同一数据中心上建立,同时也支持同城双中心异地容灾,同样一键布署完成。同时,阿里云还为用户提供ADAM(Advanced Database & Application Migration “亚当”)工具,以协助用户利用PPAS的Oracle兼容性进行快速迁移。那么接下来如何去迁移的各步骤应当怎样进行呢?
将ADAM采集 器安装在Oracle里面,ADMA将起到三个方面的作用:
Oracle迁移到PPAS相对迁移到其他数据库更为平滑,因为有许多兼容的地方。Oracle数据库到PPAS快速上云的过程中应做到兼容SQL、存储过程、包、DBMS等,因此适宜复杂事务事业务的迁移。云数据库PPAS版,提供最高 3TB的本地高性能储存(据悉这一空间有机会在年内突破到10TB以上)。如果业务数据超过本地储存容量大小,则可以通过OSS储存做外部表处理,如历史数据就可以储存到OSS外部表中,这些信息并不常使用,但对于数据剖析很重要。因此我们可以通过阿里云HybridDB for PostgreSQL,从OSS中直接获取数据进行业务剖析。HybridDB for PostgreSQL是基于开源Greenplum Database分布式MPP数据库的阿里云自有发布版,可实现业务实时剖析,计算节点、空间纵向扩充到PB级、特定场景下百亿记录order by
Oracle 数据库到 MySQL、PPAS的比较
为什么Oracle 数据库到 MySQL系列的迁移无法推进呢?原因是Oracle 数据库到 MySQL系列的迁移会导致ISV及企业迁移风险减小,在整个迁移过程中代码、存储过程以及架构需作出大的改动,这会导致研制重新学习、DBA重新学习、代码的句型重画甚至业务架构重画,最终导致业务风险减小、人力成本变高以及产品成本变高。
而Oracle 数据库到云数据库PPAS版是相对容易推进的,在推进过程中提升了Oracle迁移上云的成功率。研发可继续写Oracle句型因而减少迁移难度及工作量,阿里云可手动运维提升DBA SQL优化能力,代码的句型几乎不需改动,ADAM协助得以精准剖析。
为什么说PPAS兼容Oralce会更好呢?由上图可以看见MySOL与Oracle的交集面积比PostgreSQL与Oracle的交集面积都太小,这并不能达到预期的疗效。期望中云数据库PASS版疗效应该是Oracle的面积与PostgreSQL的面积几乎达到重合。
为什么会须要这么多的兼容部份呢?因为这样才会使企业的开发团队、原有的开发成果以及已有的应用快速的放在云里面去。例如,如果开发商开发的软件都是线下的,但顾客要求上云,到云里面又须要用到互联网思维,那么原有的储存模式都须要改动,为了维护云的构架线上、线下的结构都须要改动,这样会须要大量的人力成本。如果有一个功能直接兼容Oracle 的句型,这个时侯放在云里面去会降低整体的负担。
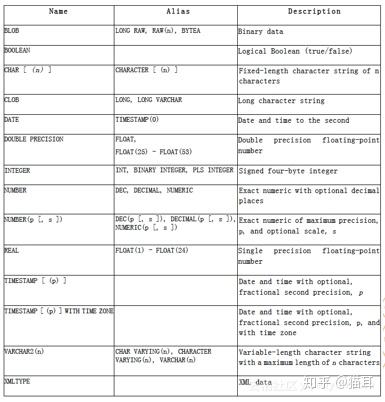
云数据库PPAS 到Oracle兼容的数据类型有许多种,例如,BLOB、CLOB、DATE等等。它们各自又有各自的别称与类型,例如 BLOB 的别称是LONG RAW,其类型是二进制数据。
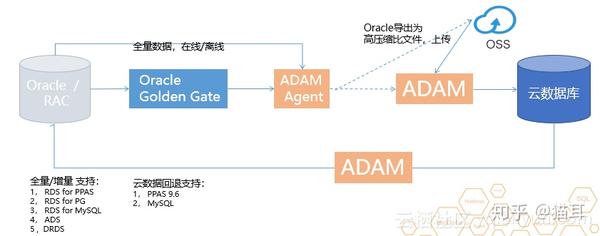
ADAM可以协助用户Oracle数据库通过全量以及增量进行上云迁移,如果Oracle数据量很大,这里可能须要一个星期甚至一个月能够传输完。这时就可以通过高速联接以及高速通道降低带宽,不需要通过Internet,防止传输错的数据,同时也不会影响生产库。 通过ADAM平台Oracle数据到云数据库都会提供30天的回流机制,为用户提供迁移割接过程的最大保障。
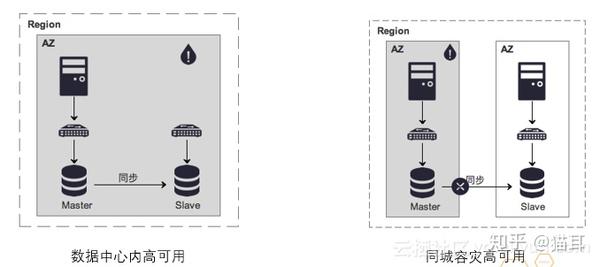
云数据库PPAS除了是高可用,还支持同城容灾,在不降低任何费用成本的情况下,用户可以选择使用单可用县集群,或是使用多可用县(同城容灾)集群,以提供更有保障的企业级容灾需求保护。
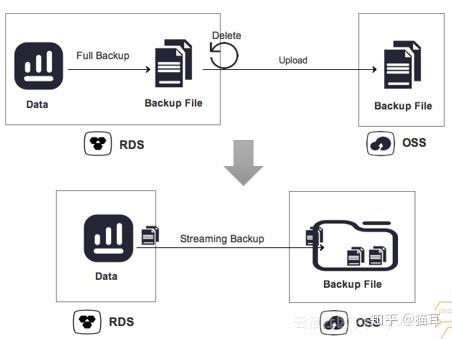
云数据库PPAS 不只是手动备份,还送50%免费备份空间。例如用户订购实例储存空间为1TB,将直接附送500GB免费备份空间。
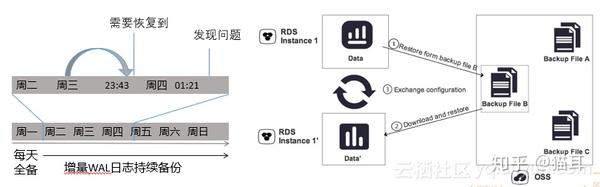
云数据库PPAS云化管理是按时间点进行实例克隆的,实例克隆功能将于2018年7月提供,并支持历时730天数据备份,当前只提供临时实例。
阿里云PostgreSQL生态系统
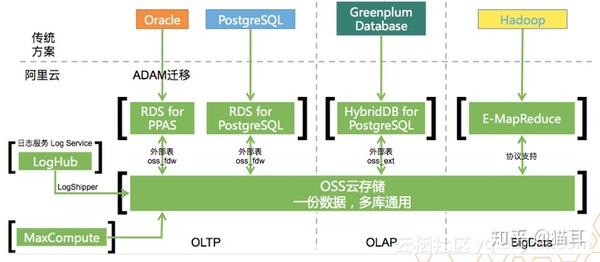
Oracle的应用可以迁移到云数据库PPAS版,PPAS通过高性能本地储存空间,以储存热点OLTP业务数据。历史信息储存到外部的OSS里面,OSS里面的数据可以直接被HybridDB for PostgreSQL读取使用,也就是说OLTP可以进行业务处理,OLAP可以直接通过基于开源Greenplum Database分布式MPP构架的阿里云数据库房服务HybridDB for PostgreSQL进行。
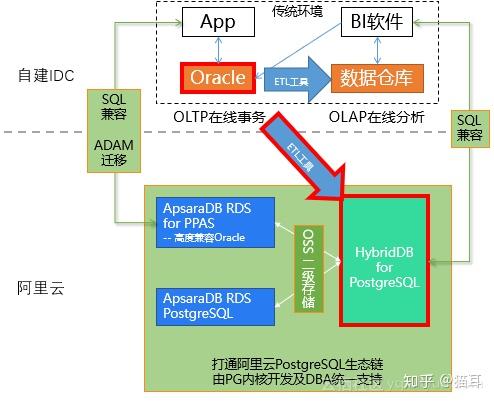
同时用户也可以保留原有Oracle系统,只将剖析业务转为使用HybridDB for PostgreSQL,其 OLAP性能优势如下如下:
HybridDB for PostgreSQL混合分区

储存可分为三种存储,分别为行式储存、列式储存以及OSS暖储存,这三种储存的介绍如下:
原文链接
教程:黑科技之云蛛系统大数据解决方案-数据采集/传输/处理/展现全套流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2020-08-09 16:54
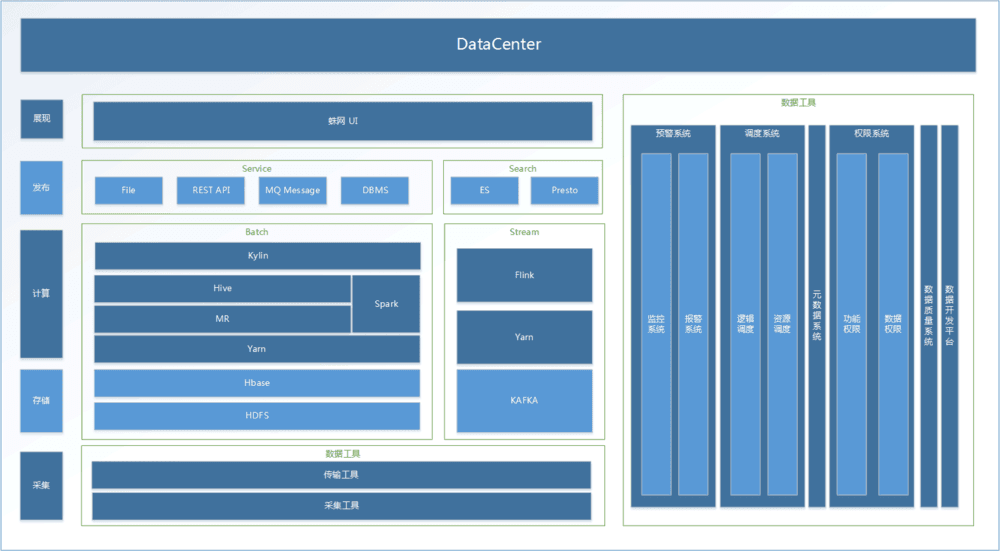
大数据处理,云蛛系统肯定是要有的,但是具体开发的日期,并没有最终确定。但是鉴于用户的强烈需求,蛛网时代总算将大数据处理工具的开发提上日程,并为之命名为DataCenter。为何命名为DataCenter呢,言外之意就是,您的数据中心所有处理,云蛛系统可以为您全部解决。
DataCenter+AutoBI+DataView,您的整套数据剖析系统就可以完整地搭建上去了,而且异常的简单。DataCenter给您做数据采集、传输、处理的工作,而AutoBI会做您的数据报表的工作,DataView做您的大屏诠释工作,是不是配合的太nice?
DataCenter 用自己agent采集相关数据,然后收归至Kafka集群中进行数据清洗处理,作为高可靠性传输,Kafka集群中还须要进行高性能算法的去重估算,之后数据经由转换层步入到数仓或则hadoop集群中,这就是整个ETL过程,也是天路系统的工作。之后就是调度-北斗系统的工作了。其会根据依赖关系,进行数据指标的估算。即日指标估算不完成,无法完成月指标的估算,如果指标估算有误,手工触发任务估算,是否会触发下游任务一并估算......整个核心就会在调度-北斗系统中彰显得淋淋尽致。经由调度估算HDFS数据吐入Hbase,数仓经由ODS层估算步入到诠释层,还有分布式查询ES......这些,凡是市面上最优的技术,或者您能想到的查询模式,DataCenter全部为您做好了。
之后就是DataView和AutoBI大显身手的时侯了,这两个产品线,不仅可以支持传统的关系型数据库,no sql数据库,诸如redis、mongodb等等全部支持,包括ES、rest这样的服务插口等等。因为走多样化的模式,只要现有技术能实现的,这两条产品线就会为您实现,而不需要您为了适应这两个产品线而去中转数据,一切云蛛系统全部为您适配好。因为是一家的产品,兼容性,么么哒!
怎么样?DataCenter算得上大数据处理界的黑科技了吧。而且全套流程,全部黑盒化,您只须要在web页面中配置好您的业务就好,剩下的系统全手动帮您处理。而作为其叔父,AutoBI和DataView更是将黑科技理念贯彻的淋淋尽致,无缝结合,完美展示,多维剖析......所有您能想到的要求,此两者就会帮您呈现。这就是黑科技-云蛛系统,为您提供的一整套大数据解决方案! 查看全部
黑科技的云蛛系统,一经问世,就赢得了满堂喝采。虽然主打的是数据可视化,但是好多用户用上以后都在问,你们是否会出大数据处理的产品,就像在好多用户眼中满满的黑科技-神策数据一样。如果大家出了,就可以解决我们整套数据流程的问题了。

大数据处理,云蛛系统肯定是要有的,但是具体开发的日期,并没有最终确定。但是鉴于用户的强烈需求,蛛网时代总算将大数据处理工具的开发提上日程,并为之命名为DataCenter。为何命名为DataCenter呢,言外之意就是,您的数据中心所有处理,云蛛系统可以为您全部解决。

DataCenter+AutoBI+DataView,您的整套数据剖析系统就可以完整地搭建上去了,而且异常的简单。DataCenter给您做数据采集、传输、处理的工作,而AutoBI会做您的数据报表的工作,DataView做您的大屏诠释工作,是不是配合的太nice?
DataCenter 用自己agent采集相关数据,然后收归至Kafka集群中进行数据清洗处理,作为高可靠性传输,Kafka集群中还须要进行高性能算法的去重估算,之后数据经由转换层步入到数仓或则hadoop集群中,这就是整个ETL过程,也是天路系统的工作。之后就是调度-北斗系统的工作了。其会根据依赖关系,进行数据指标的估算。即日指标估算不完成,无法完成月指标的估算,如果指标估算有误,手工触发任务估算,是否会触发下游任务一并估算......整个核心就会在调度-北斗系统中彰显得淋淋尽致。经由调度估算HDFS数据吐入Hbase,数仓经由ODS层估算步入到诠释层,还有分布式查询ES......这些,凡是市面上最优的技术,或者您能想到的查询模式,DataCenter全部为您做好了。
之后就是DataView和AutoBI大显身手的时侯了,这两个产品线,不仅可以支持传统的关系型数据库,no sql数据库,诸如redis、mongodb等等全部支持,包括ES、rest这样的服务插口等等。因为走多样化的模式,只要现有技术能实现的,这两条产品线就会为您实现,而不需要您为了适应这两个产品线而去中转数据,一切云蛛系统全部为您适配好。因为是一家的产品,兼容性,么么哒!

怎么样?DataCenter算得上大数据处理界的黑科技了吧。而且全套流程,全部黑盒化,您只须要在web页面中配置好您的业务就好,剩下的系统全手动帮您处理。而作为其叔父,AutoBI和DataView更是将黑科技理念贯彻的淋淋尽致,无缝结合,完美展示,多维剖析......所有您能想到的要求,此两者就会帮您呈现。这就是黑科技-云蛛系统,为您提供的一整套大数据解决方案!
云数据采集系统中云爬虫子系统的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-09 00:55
[摘要]: 随着Internet的迅猛发展和数据挖掘技术的发展,Internet上网页数据的价值日益突出. 现有的网络爬虫技术的缺点是不易于使用并且不容易为网络数据采集定制. 本文将云计算技术和Web爬虫技术相结合,基于软件即服务(SaaS)服务模型,设计并实现了云数据采集系统中的云爬虫子系统. 不同的用户可以根据自己的需求,方便地在云采集器子系统提供的独立采集器集群服务上执行数据采集任务. 为了实现分布式爬虫和SaaS模型的有机结合,本文主要研究云爬虫子系统中的两个关键问题: 爬虫节点管理和链接抓取任务调度. 在爬虫节点管理方面,提出了一种在etcd的辅助下的爬虫节点管理方案,该方案规定了子系统中所有爬虫节点的一系列共同行为,以便每个集群的爬虫节点可以混合部署. 互相替换. 该解决方案支持在运行时更新采集器节点配置,支持在运行时为每个采集器集群动态增加或减少节点,以及及时检测集群故障节点,以确保采集器集群服务的可靠性. 在链路爬取任务调度方面,提出了一种基于跳跃一致性哈希算法的改进的调度方案OJCH. OJCH使用跳转一致性哈希算法来计算节点,并获得与跳转一致性算法相似的性能,并使用重新哈希故障节点的方法来克服跳转一致性哈希无法处理任何节点故障的缺点. 已通过实验验证. 此外,本文还提出了一种支持定期链接提取任务的重复数据删除方案. 之后,本文给出了云爬虫子系统的总体设计方案以及每个功能模块的详细设计和实现,包括集群控制模块,网站服务模块,任务队列模块,任务调度模块,任务处理模块和节点管理模块. . 然后根据相关的测试案例对已实现的云爬虫子系统进行测试,并对云爬虫子系统的功能进行验证. 最后,总结全文.
如何开始迁移到云
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2020-08-07 03:06
要将应用程序和数据迁移到云,有必要制定详细的计划和时间表. 迁移是一个非常复杂的过程. 您可以从最简单的应用程序开始,然后考虑复杂和相关的相对较高的业务程度,一些个性化的企业应用程序等.
如上图(来自Internet的图片)所示,它描述了公司稳定进行云迁移的一般步骤. 迁移是一个系统的项目. 迁移速度过快通常会导致成本急剧上升,施工周期延迟甚至失败.
迁移到云的过程可以分为五个步骤. 请注意,这里的主要方案是企业私有云,并且所概括的步骤也适用于私有云,并且不太适合迁移到公共云. 让我们专注于迁移到云的五个阶段.
1. 标准化统一
企业的传统IT业务应用程序通常建立在物理服务器和存储设备上. 当开始进行云迁移时,通常会使用标准化技术来集成以前的服务器和存储资源. 评估需要迁移到云的现有和旧业务的迁移,并根据数据中心的资源状况制定详细的解决方案非常重要;如果是新的应用程序系统,则分配相应的资源,然后直接在计算环境中的云中进行部署. 对于任何想上云的企业来说,评估其实现的难度是评估云化或应用系统转换的风险和收益的重要手段. 整个业务系统的云化分析过程需要包括硬件支持环境转换,操作系统平台变更,平台软件绑定分析,IP地址依赖性消除,API重构,模块化转换,标准化转换,外部依赖性条件等,其中包括多个层次和维度,准确评估业务信息系统云转换的难点和相关困难,只有充分理解痛点,才能为信息系统的云转换做好准备.
当然,虚拟化和体系结构设计也是云业务系统现代化的一部分. 走向云与架构设计密不可分,因为业务最终将被云化. 无论迁移过程有多长,企业通常都使用虚拟服务器而不是物理服务器,并使用存储资源池来统一后端存储. 为了实现异构存储设备的管理,经常进行存储虚拟化和分布式转换. 当然,在此步骤中,它可能还涉及业务转换咨询和程序演示优化,并且您必须开始使用脚本或自动安装工具来适当减少工作量.
2. 购买或自行构建和部署云服务
虚拟化是迁移到云的第一步,迁移的第二步是部署私有云管理平台. 那么是购买还是构建和部署云服务呢?
来自云平台的成本和价值. VMWARE是商业软件. 它的成熟度和稳定性在实际环境中经受了很多考验,但是其高昂的使用成本反映在其许可费和服务费中. 与VMware昂贵的价格相比,OpenStack的免费和开放优势显而易见. VMware的高额投资带来的大多数功能OpenStack可以免费提供给客户. 因此,无论OpenStack还是VMware更有价值,这个问题都没有明确的答案,答案取决于企业实际部署的规模. 尽管OpenStack是免费使用的,但它需要该领域的专业开发人员和专家,并且在体系结构和构造上需要进行大量工作,因为它支持许多部署方案并且安装过程不同. VMware需要花费一些钱来购买许可证和服务,并且安装和运行相对容易. 另外,VMware的学习成本较低,并且操作和维护也很容易学习.
通常,基于上述分析,大型企业购买VMWARE平台更为稳定和可靠. 但是,OpenStack的入门门槛很高. 如果企业没有足够的技术能力储备,就无法解决OPENSTACK大规模部署中遇到的问题和陷阱.
构建私有云需要详细的计划,设计和实施. 在许多情况下,资源集成还包括管理概念的集成和集成. 在此步骤中,您还可以购买或使用一些公共云服务,例如一个或多个SAAS应用程序,开发和测试服务,云存储等. 混合云将公共云和私有云集成在一起,是主要模型和发展方向近年来的云计算. 我们知道私有云主要用于企业用户. 出于安全原因,企业更愿意将数据存储在私有云中,但同时,他们希望获得公共云计算资源以按需扩展. 在这种情况下,混合云随着越来越多的采用,它混合并匹配了公共云和私有云以获得最佳结果. 这种个性化的解决方案实现了节省资金和安全性的目的.
3. 应用程序迁移和数据迁移
部署云基础结构和服务后,有必要统一或升级现有的业务应用程序服务. 如前所述,此步骤可以首先将一些较简单的应用程序迁移到云中,然后逐步解决其余的复杂应用程序.
应用程序迁移的过程不仅仅是单击几个按钮的问题. 我们需要从云平台的环境特征入手,并对我们的产品进行某些调整. 例如,是否支持静默安装,磁盘空间的使用,参数设置应通过API或CLI进行,通过脚本命令或统一平台采集来跟踪和记录信息,等等.
数据迁移对于业务应用程序来说是最重要的事情,它与云上业务的成功或失败直接相关. 数据迁移将业务系统中很少使用或未使用的文件移动到辅助存储系统(例如磁带或光盘),同时将频繁使用的数据从热点迁移到高质量的存储设备(例如SSD或闪存阵列),有点像分层存储管理它. 通常,为了确保数据的安全性和完整性,我们的业务迁移工作通常与备份策略结合在一起,并备份重要数据. 还有一些业务系统会在迁移到云后转为O并用Mysql代替Oracle,这将涉及SQL语法调整,数据转换,新旧系统之间的交互,应用程序转换甚至重构等. 挑战相对较大. . 在迁移阶段需要充分考虑这些问题.
数据迁移的实现可以分为三个阶段: 数据迁移前的准备,数据迁移的实施以及数据迁移后的测试验证. 由于数据迁移的特性,准备阶段需要完成大量工作,充分而周到的准备工作是完成数据迁移的主要基础. 具体来说,对要迁移的数据源的详细描述(包括数据的存储方法,数据量和数据时间跨度);为新旧系统的数据库建立数据字典;对旧系统的历史数据进行质量分析,并对新旧系统的数据进行结构差异分析;分析新旧系统的代码数据之间的差异;建立新旧系统的数据库表之间的映射关系,处理无法映射的字段的方法; ETL工具的开发和部署,数据转换测试计划和验证程序的准备;数据开发紧急转换措施. 其中,数据迁移的实施是数据迁移三个阶段中最重要的环节. 它需要制定详细的实施步骤和数据转换流程;准备数据迁移环境;业务准备,结束未处理的业务事项或结束它们;测试数据迁移所涉及的技术;最后实现数据迁移.
数据迁移后的测试验证是为了检查迁移工作. 数据测试验证的结果是判断业务系统是否可以正式启动的重要基础. 可以通过质量检查工具或书面检查程序来执行数据验证,并且可以通过试用新系统的功能模块(尤其是查询和报告功能)来检查数据的准确性.
当然,为了确保数据迁移的质量和效率,一个好的迁移工具也是分不开的. 商业和开源产品各自具有不同的特性,必须根据特定条件对选择进行分析. 从目前的一些国内大型项目来看,相对成熟的ETL产品主要用于数据迁移. 实际上,我们还可以看到这些项目的一些共同点,主要包括: 迁移期间的大量历史数据,并且允许的停机时间非常长. 它很短,面对大量客户或用户,具有访问第三方系统的权限,一旦失败,影响将是广泛的.
目前,许多数据库供应商还提供相应的数据提取工具,例如Informix的InfoMover,Microsoft SQLServer的DTS和Oracle的Oracle Warehouse Builder. 这些工具解决了一定范围内的数据提取和转换问题,但是这些工具基本上不能自动完成数据提取. 用户还需要使用这些工具来编写适当的转换程序,以提高效率.
由于高度的业务耦合和对传统体系结构的高度依赖,企业中的应用也很复杂,并且通常需要大量的转换和发展. 例如,如果要替换特定的中间件,数据库和商业软件包,则可能需要几年才能完成此步骤. 由于时间相对较长且存在无法控制的风险,因此有必要从投资回报率和可行性方面仔细评估现有系统的迁移.
4. 全自动
在企业中,当将大量业务应用程序迁移到云时,使用云管理平台来自动化业务系统的配置,批准,服务交付,升级和监视变得更加重要. 不断自动化现有IT流程的转换至关重要. 从虚拟机和应用程序的在线资源预订到交付,我们希望将每个业务流程尽可能地自动化到云中,这可以大大缩短部署时间,减少人工成本并提高系统配置的准确性和一致性. 尽管基本自动化已经在标准化和统一阶段开始,但是在完全自动化阶段,需要将大量脚本,应用程序安装程序和自动化工具引入流程编排系统,在该系统中,云管理平台可以使用. 服务和工作流程设计.
5. 操作维护的安全性,冗余性和可持续性
传统的云服务通常需要经过多个环节的批准,例如资源供应,服务交付,运营和维护以及安全流程,因为其中许多流程都需要在云服务完成并在线自动之前进行修改. 交付需要IT安全人员必须预先授权或批准虚拟机模板,基于软件的网络,存储资源,操作系统,应用程序平台等. 在此阶段,还应考虑冗余和可扩展性,包括服务器,虚拟机的连续运行机器,应用程序和云管理平台,以防数据中心部分或完全故障. 在此阶段,还必须完全建立安全运营和IT治理. 最后,五步云迁移计划将使公司进入全面的云运维和维护状态.
业务云迁移是一个复杂的系统项目. 无论是旧应用程序还是构建新应用程序,云迁移团队都需要仔细考虑成本和操作是否与平台模型相匹配. 从当前阶段开始,应用程序分阶段迁移可能是唯一的选择. 目前,一些公司已成功使用此分阶段方法来更改其传统应用程序,并在从云计算中受益的同时最大程度地降低了风险. 将来这可能是云化的主题. 查看全部
在企业中,许多成功的迁移到云的案例都是从更简单的应用程序开始,然后逐步将更多的应用程序和数据迁移到云. 不可能同时传输所有应用程序. 过去迁移.
要将应用程序和数据迁移到云,有必要制定详细的计划和时间表. 迁移是一个非常复杂的过程. 您可以从最简单的应用程序开始,然后考虑复杂和相关的相对较高的业务程度,一些个性化的企业应用程序等.
如上图(来自Internet的图片)所示,它描述了公司稳定进行云迁移的一般步骤. 迁移是一个系统的项目. 迁移速度过快通常会导致成本急剧上升,施工周期延迟甚至失败.
迁移到云的过程可以分为五个步骤. 请注意,这里的主要方案是企业私有云,并且所概括的步骤也适用于私有云,并且不太适合迁移到公共云. 让我们专注于迁移到云的五个阶段.
1. 标准化统一
企业的传统IT业务应用程序通常建立在物理服务器和存储设备上. 当开始进行云迁移时,通常会使用标准化技术来集成以前的服务器和存储资源. 评估需要迁移到云的现有和旧业务的迁移,并根据数据中心的资源状况制定详细的解决方案非常重要;如果是新的应用程序系统,则分配相应的资源,然后直接在计算环境中的云中进行部署. 对于任何想上云的企业来说,评估其实现的难度是评估云化或应用系统转换的风险和收益的重要手段. 整个业务系统的云化分析过程需要包括硬件支持环境转换,操作系统平台变更,平台软件绑定分析,IP地址依赖性消除,API重构,模块化转换,标准化转换,外部依赖性条件等,其中包括多个层次和维度,准确评估业务信息系统云转换的难点和相关困难,只有充分理解痛点,才能为信息系统的云转换做好准备.
当然,虚拟化和体系结构设计也是云业务系统现代化的一部分. 走向云与架构设计密不可分,因为业务最终将被云化. 无论迁移过程有多长,企业通常都使用虚拟服务器而不是物理服务器,并使用存储资源池来统一后端存储. 为了实现异构存储设备的管理,经常进行存储虚拟化和分布式转换. 当然,在此步骤中,它可能还涉及业务转换咨询和程序演示优化,并且您必须开始使用脚本或自动安装工具来适当减少工作量.
2. 购买或自行构建和部署云服务
虚拟化是迁移到云的第一步,迁移的第二步是部署私有云管理平台. 那么是购买还是构建和部署云服务呢?
来自云平台的成本和价值. VMWARE是商业软件. 它的成熟度和稳定性在实际环境中经受了很多考验,但是其高昂的使用成本反映在其许可费和服务费中. 与VMware昂贵的价格相比,OpenStack的免费和开放优势显而易见. VMware的高额投资带来的大多数功能OpenStack可以免费提供给客户. 因此,无论OpenStack还是VMware更有价值,这个问题都没有明确的答案,答案取决于企业实际部署的规模. 尽管OpenStack是免费使用的,但它需要该领域的专业开发人员和专家,并且在体系结构和构造上需要进行大量工作,因为它支持许多部署方案并且安装过程不同. VMware需要花费一些钱来购买许可证和服务,并且安装和运行相对容易. 另外,VMware的学习成本较低,并且操作和维护也很容易学习.
通常,基于上述分析,大型企业购买VMWARE平台更为稳定和可靠. 但是,OpenStack的入门门槛很高. 如果企业没有足够的技术能力储备,就无法解决OPENSTACK大规模部署中遇到的问题和陷阱.
构建私有云需要详细的计划,设计和实施. 在许多情况下,资源集成还包括管理概念的集成和集成. 在此步骤中,您还可以购买或使用一些公共云服务,例如一个或多个SAAS应用程序,开发和测试服务,云存储等. 混合云将公共云和私有云集成在一起,是主要模型和发展方向近年来的云计算. 我们知道私有云主要用于企业用户. 出于安全原因,企业更愿意将数据存储在私有云中,但同时,他们希望获得公共云计算资源以按需扩展. 在这种情况下,混合云随着越来越多的采用,它混合并匹配了公共云和私有云以获得最佳结果. 这种个性化的解决方案实现了节省资金和安全性的目的.
3. 应用程序迁移和数据迁移
部署云基础结构和服务后,有必要统一或升级现有的业务应用程序服务. 如前所述,此步骤可以首先将一些较简单的应用程序迁移到云中,然后逐步解决其余的复杂应用程序.
应用程序迁移的过程不仅仅是单击几个按钮的问题. 我们需要从云平台的环境特征入手,并对我们的产品进行某些调整. 例如,是否支持静默安装,磁盘空间的使用,参数设置应通过API或CLI进行,通过脚本命令或统一平台采集来跟踪和记录信息,等等.
数据迁移对于业务应用程序来说是最重要的事情,它与云上业务的成功或失败直接相关. 数据迁移将业务系统中很少使用或未使用的文件移动到辅助存储系统(例如磁带或光盘),同时将频繁使用的数据从热点迁移到高质量的存储设备(例如SSD或闪存阵列),有点像分层存储管理它. 通常,为了确保数据的安全性和完整性,我们的业务迁移工作通常与备份策略结合在一起,并备份重要数据. 还有一些业务系统会在迁移到云后转为O并用Mysql代替Oracle,这将涉及SQL语法调整,数据转换,新旧系统之间的交互,应用程序转换甚至重构等. 挑战相对较大. . 在迁移阶段需要充分考虑这些问题.
数据迁移的实现可以分为三个阶段: 数据迁移前的准备,数据迁移的实施以及数据迁移后的测试验证. 由于数据迁移的特性,准备阶段需要完成大量工作,充分而周到的准备工作是完成数据迁移的主要基础. 具体来说,对要迁移的数据源的详细描述(包括数据的存储方法,数据量和数据时间跨度);为新旧系统的数据库建立数据字典;对旧系统的历史数据进行质量分析,并对新旧系统的数据进行结构差异分析;分析新旧系统的代码数据之间的差异;建立新旧系统的数据库表之间的映射关系,处理无法映射的字段的方法; ETL工具的开发和部署,数据转换测试计划和验证程序的准备;数据开发紧急转换措施. 其中,数据迁移的实施是数据迁移三个阶段中最重要的环节. 它需要制定详细的实施步骤和数据转换流程;准备数据迁移环境;业务准备,结束未处理的业务事项或结束它们;测试数据迁移所涉及的技术;最后实现数据迁移.
数据迁移后的测试验证是为了检查迁移工作. 数据测试验证的结果是判断业务系统是否可以正式启动的重要基础. 可以通过质量检查工具或书面检查程序来执行数据验证,并且可以通过试用新系统的功能模块(尤其是查询和报告功能)来检查数据的准确性.
当然,为了确保数据迁移的质量和效率,一个好的迁移工具也是分不开的. 商业和开源产品各自具有不同的特性,必须根据特定条件对选择进行分析. 从目前的一些国内大型项目来看,相对成熟的ETL产品主要用于数据迁移. 实际上,我们还可以看到这些项目的一些共同点,主要包括: 迁移期间的大量历史数据,并且允许的停机时间非常长. 它很短,面对大量客户或用户,具有访问第三方系统的权限,一旦失败,影响将是广泛的.
目前,许多数据库供应商还提供相应的数据提取工具,例如Informix的InfoMover,Microsoft SQLServer的DTS和Oracle的Oracle Warehouse Builder. 这些工具解决了一定范围内的数据提取和转换问题,但是这些工具基本上不能自动完成数据提取. 用户还需要使用这些工具来编写适当的转换程序,以提高效率.
由于高度的业务耦合和对传统体系结构的高度依赖,企业中的应用也很复杂,并且通常需要大量的转换和发展. 例如,如果要替换特定的中间件,数据库和商业软件包,则可能需要几年才能完成此步骤. 由于时间相对较长且存在无法控制的风险,因此有必要从投资回报率和可行性方面仔细评估现有系统的迁移.
4. 全自动
在企业中,当将大量业务应用程序迁移到云时,使用云管理平台来自动化业务系统的配置,批准,服务交付,升级和监视变得更加重要. 不断自动化现有IT流程的转换至关重要. 从虚拟机和应用程序的在线资源预订到交付,我们希望将每个业务流程尽可能地自动化到云中,这可以大大缩短部署时间,减少人工成本并提高系统配置的准确性和一致性. 尽管基本自动化已经在标准化和统一阶段开始,但是在完全自动化阶段,需要将大量脚本,应用程序安装程序和自动化工具引入流程编排系统,在该系统中,云管理平台可以使用. 服务和工作流程设计.
5. 操作维护的安全性,冗余性和可持续性
传统的云服务通常需要经过多个环节的批准,例如资源供应,服务交付,运营和维护以及安全流程,因为其中许多流程都需要在云服务完成并在线自动之前进行修改. 交付需要IT安全人员必须预先授权或批准虚拟机模板,基于软件的网络,存储资源,操作系统,应用程序平台等. 在此阶段,还应考虑冗余和可扩展性,包括服务器,虚拟机的连续运行机器,应用程序和云管理平台,以防数据中心部分或完全故障. 在此阶段,还必须完全建立安全运营和IT治理. 最后,五步云迁移计划将使公司进入全面的云运维和维护状态.
业务云迁移是一个复杂的系统项目. 无论是旧应用程序还是构建新应用程序,云迁移团队都需要仔细考虑成本和操作是否与平台模型相匹配. 从当前阶段开始,应用程序分阶段迁移可能是唯一的选择. 目前,一些公司已成功使用此分阶段方法来更改其传统应用程序,并在从云计算中受益的同时最大程度地降低了风险. 将来这可能是云化的主题.
阿里云InfluxDB®数据采集服务的优势
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-08-07 00:24
背景
随着时间序列数据的快速增长,时间序列数据库不仅需要解决系统的稳定性和性能问题,还需要实现数据采集与分析之间的联系,使时间序列数据能够真正生成. 值. 在时间序列数据采集领域,一直缺乏自动采集工具. 尽管用户可以使用某些开源采集工具来实现数据采集,例如Telegraf,Logstash和TCollector等,但是这些采集工具需要用户构建和维护其操作环境,这增加了用户的学习成本并大大增加了数据收款门槛. 另一方面,现有的采集工具缺乏对多个采集源的自动管理,用户难以统一管理多个不同的采集源,难以监控每个采集工具是否正常运行并实时采集数据.
阿里云InfluxDB®不仅提供稳定可靠的时间序列数据库服务,而且还提供非常方便的数据采集服务. 用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据将自动存储在阿里云InfluxDB®中. 用户无需担心操作维护,实现从数据采集到分析的一站式服务. 本文主要介绍如何使用InfluxDB®的数据采集服务来实现从采集到存储的数据自动管理.
阿里云InfluxDB®数据采集服务的优势我们该怎么办? 1.轻松采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,包括MySQL,Redis,MongoDB和系统监视. 对于每种类型的数据,将采集多个监视指标,以帮助用户更全面地了解受监视对象. 通过InfluxDB®实例的管理控制台,用户可以添加新的集合源,一键安装,而无需编写代码.
采集数据的操作过程如下:
2. 实时监控采集源
在采集源运行期间,您可以实时监视数据采集的状态,并检查采集的数据最后到达InfluxDB®的时间;另外,您可以随时停止数据采集,并在认为适当时重新启动它.
3. 一键切换采集数据的类型
如果要更改受监视机器上的采集数据的类型,则无需添加新的采集源,只需选择所需的采集配置,数据采集工具将自动切换以采集监视数据您指定.
4. 采集的数据自动存储在InfluxDB®中.
您可以在采集配置中选择用于数据流入的数据库和保留策略,数据采集工具将自动将采集的数据存储到指定的数据库和保留策略中,并且可以在采集源为正在运行只需要修改采集配置.
最佳做法
本节将介绍如何采集系统监视数据并实时显示采集的结果. 系统监视的数据包括处理器,磁盘,内存,网络,进程和系统信息. 采集的数据存储在8种不同的度量中(度量包括cpu,磁盘,diskio,mem,net,进程,交换和系统). 在开始之前,请确保已成功创建数据库,并且已经成功创建了具有数据库读写权限的用户帐户.
1. 创建用于采集系统监视数据的配置
在InfluxDB®管理控制台的左侧导航栏中单击“添加采集配置”,以进入采集配置添加界面,如下图所示. 填写“采集配置名称”,选择“采集的数据类型”作为“系统监视”,然后选择“授权帐户”,“数据写入数据库”和“数据库存储策略”,并填写“授权密码” . 单击“添加”以成功创建集合配置.
2. 添加采集源
在InfluxDB®管理控制台的左侧导航栏中单击“添加集合源”,以进入用于添加集合源的页面.
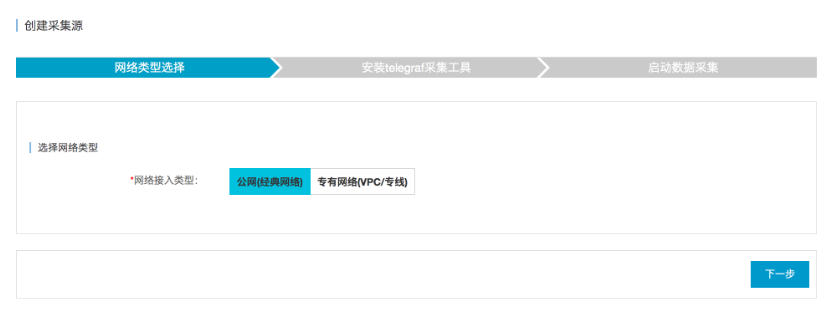
(1)选择网络类型“公共网络”或“专用网络”,然后单击“下一步”,如下图所示.
(2)在数据源所在的主机上安装采集工具. 将安装命令复制到主机以运行采集工具. 采集工具运行后,它将与InfluxDB®建立连接. 您可以在“新采集源扫描结果列表”上看到新添加的采集源. 如果未显示在列表中,则可以单击“刷新”或“自动刷新”. 如下所示.
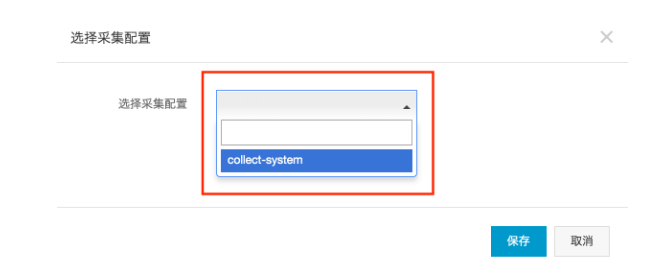
(3)选择采集系统监视的数据. 在上图中,单击“选择采集配置”以进入以下界面,然后从下拉框中选择刚刚创建的名为“ collect-system”的采集配置. 选择后,单击“保存”.
(4)开始数据采集. 选中需要启动的采集源,然后单击“完成并开始采集”,采集工具可以开始在采集源上采集数据,如下图所示.
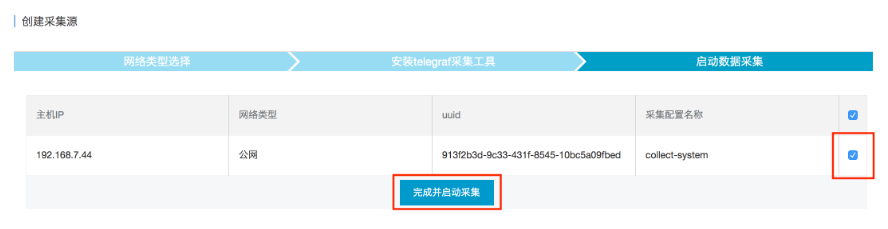
3. 查看数据采集状态
在“集合源列表”中,您可以看到连接到InfluxDB®实例的所有集合源,如下图所示. 每个集合源均由uuid唯一标识. “采集状态”为“正在运行”,这意味着采集工具正在采集数据并将其报告给InfluxDB®. “最新的采集和报告成功时间”是指最后一次将采集的数据成功发送到InfluxDB®的时间.
4. 使用Grafana可视化数据采集
(1)安装Grafana. 请参阅有关如何安装Grafana的文档.
(2)添加数据源. 设置“ URL”作为InfluxDB®实例的地址,并填写写入采集的数据的数据库和用户帐户,如下图所示.
(3)配置仪表板并编写查询规则. 这里的演示是查询磁盘使用率,查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示.
您可以根据实际需要查看其他度量和字段的数据,并分别在FROM和SELECT语句中指定它们.
摘要
阿里云InfluxDB®提供方便,快捷的数据采集服务,自动化数据源管理,帮助您解决数据采集问题,并实现数据采集到存储的自动化. 将来,我们将支持采集更多数据类型和指标,敬请期待.
原创链接 查看全部
行业解决方案和产品招募!如果您想赚钱就通过它! >>>

背景
随着时间序列数据的快速增长,时间序列数据库不仅需要解决系统的稳定性和性能问题,还需要实现数据采集与分析之间的联系,使时间序列数据能够真正生成. 值. 在时间序列数据采集领域,一直缺乏自动采集工具. 尽管用户可以使用某些开源采集工具来实现数据采集,例如Telegraf,Logstash和TCollector等,但是这些采集工具需要用户构建和维护其操作环境,这增加了用户的学习成本并大大增加了数据收款门槛. 另一方面,现有的采集工具缺乏对多个采集源的自动管理,用户难以统一管理多个不同的采集源,难以监控每个采集工具是否正常运行并实时采集数据.
阿里云InfluxDB®不仅提供稳定可靠的时间序列数据库服务,而且还提供非常方便的数据采集服务. 用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据将自动存储在阿里云InfluxDB®中. 用户无需担心操作维护,实现从数据采集到分析的一站式服务. 本文主要介绍如何使用InfluxDB®的数据采集服务来实现从采集到存储的数据自动管理.
阿里云InfluxDB®数据采集服务的优势我们该怎么办? 1.轻松采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,包括MySQL,Redis,MongoDB和系统监视. 对于每种类型的数据,将采集多个监视指标,以帮助用户更全面地了解受监视对象. 通过InfluxDB®实例的管理控制台,用户可以添加新的集合源,一键安装,而无需编写代码.
采集数据的操作过程如下:

2. 实时监控采集源
在采集源运行期间,您可以实时监视数据采集的状态,并检查采集的数据最后到达InfluxDB®的时间;另外,您可以随时停止数据采集,并在认为适当时重新启动它.

3. 一键切换采集数据的类型
如果要更改受监视机器上的采集数据的类型,则无需添加新的采集源,只需选择所需的采集配置,数据采集工具将自动切换以采集监视数据您指定.
4. 采集的数据自动存储在InfluxDB®中.
您可以在采集配置中选择用于数据流入的数据库和保留策略,数据采集工具将自动将采集的数据存储到指定的数据库和保留策略中,并且可以在采集源为正在运行只需要修改采集配置.
最佳做法
本节将介绍如何采集系统监视数据并实时显示采集的结果. 系统监视的数据包括处理器,磁盘,内存,网络,进程和系统信息. 采集的数据存储在8种不同的度量中(度量包括cpu,磁盘,diskio,mem,net,进程,交换和系统). 在开始之前,请确保已成功创建数据库,并且已经成功创建了具有数据库读写权限的用户帐户.
1. 创建用于采集系统监视数据的配置
在InfluxDB®管理控制台的左侧导航栏中单击“添加采集配置”,以进入采集配置添加界面,如下图所示. 填写“采集配置名称”,选择“采集的数据类型”作为“系统监视”,然后选择“授权帐户”,“数据写入数据库”和“数据库存储策略”,并填写“授权密码” . 单击“添加”以成功创建集合配置.

2. 添加采集源
在InfluxDB®管理控制台的左侧导航栏中单击“添加集合源”,以进入用于添加集合源的页面.
(1)选择网络类型“公共网络”或“专用网络”,然后单击“下一步”,如下图所示.
(2)在数据源所在的主机上安装采集工具. 将安装命令复制到主机以运行采集工具. 采集工具运行后,它将与InfluxDB®建立连接. 您可以在“新采集源扫描结果列表”上看到新添加的采集源. 如果未显示在列表中,则可以单击“刷新”或“自动刷新”. 如下所示.

(3)选择采集系统监视的数据. 在上图中,单击“选择采集配置”以进入以下界面,然后从下拉框中选择刚刚创建的名为“ collect-system”的采集配置. 选择后,单击“保存”.
(4)开始数据采集. 选中需要启动的采集源,然后单击“完成并开始采集”,采集工具可以开始在采集源上采集数据,如下图所示.
3. 查看数据采集状态
在“集合源列表”中,您可以看到连接到InfluxDB®实例的所有集合源,如下图所示. 每个集合源均由uuid唯一标识. “采集状态”为“正在运行”,这意味着采集工具正在采集数据并将其报告给InfluxDB®. “最新的采集和报告成功时间”是指最后一次将采集的数据成功发送到InfluxDB®的时间.

4. 使用Grafana可视化数据采集
(1)安装Grafana. 请参阅有关如何安装Grafana的文档.
(2)添加数据源. 设置“ URL”作为InfluxDB®实例的地址,并填写写入采集的数据的数据库和用户帐户,如下图所示.
(3)配置仪表板并编写查询规则. 这里的演示是查询磁盘使用率,查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示.

您可以根据实际需要查看其他度量和字段的数据,并分别在FROM和SELECT语句中指定它们.
摘要
阿里云InfluxDB®提供方便,快捷的数据采集服务,自动化数据源管理,帮助您解决数据采集问题,并实现数据采集到存储的自动化. 将来,我们将支持采集更多数据类型和指标,敬请期待.
原创链接
历史上最全面的企业云流程的详细信息
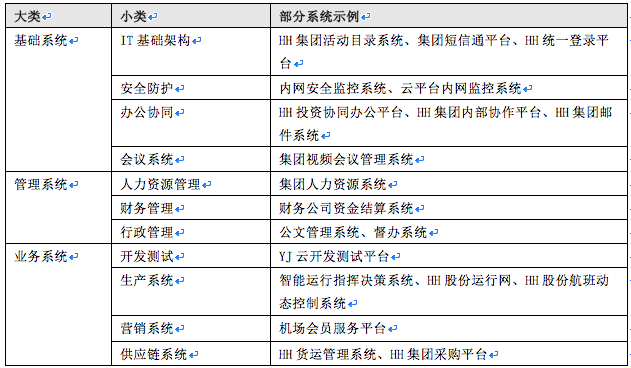
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-06 14:18
“企业上云”的步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
1. 转到云计划
1. 信息采集
“企业云”需要严格而细致的研究工作. 它需要采集硬件和网络环境信息,当前和将来的业务需求,系统配置信息,应用程序系统信息,数据风险等.
2,需求评估
从业务需求的角度,分析每个业务的当前状态,存在的问题,是否可以被云计算以及业务的未来发展需求,并为每个业务系统的迁移目标定制.
从系统的角度分析每个系统的当前状态,包括主机,存储,网络和安全性,分析系统中的问题,并根据评估结果进行计划.
从企业自身的信息化水平的角度进行分析. 对于具有信息化基础,信息系统硬件环境以及维护和开发团队的公司,他们可以根据其开发计划逐渐迁移新旧系统. 对于非信息型企业,根据迫切需要解决的问题,加快相关应用程序的启动.
3. 应用分析
<p>应用程序分析是成功进入云并减少业务停机时间的关键. 根据业务负载,特征,复杂性和相关性分析,确定并量化业务云风险可能对业务造成的影响和损失,从而确定业务云的优先级范围和云云策略. 查看全部
“企业云”是指企业通过智能高速互联网将其基本系统,服务和平台部署到云中,并使用网络轻松获得诸如计算,存储,数据和应用程序之类的服务. 有利于减少企业的信息化建设成本,建设工业互联网创新发展生态,促进实现整个制造过程,整个产业链和整个产品生命周期的优化,提高企业的发展水平. 制造业和互联网的整合.
“企业上云”的步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
1. 转到云计划
1. 信息采集
“企业云”需要严格而细致的研究工作. 它需要采集硬件和网络环境信息,当前和将来的业务需求,系统配置信息,应用程序系统信息,数据风险等.
2,需求评估
从业务需求的角度,分析每个业务的当前状态,存在的问题,是否可以被云计算以及业务的未来发展需求,并为每个业务系统的迁移目标定制.
从系统的角度分析每个系统的当前状态,包括主机,存储,网络和安全性,分析系统中的问题,并根据评估结果进行计划.
从企业自身的信息化水平的角度进行分析. 对于具有信息化基础,信息系统硬件环境以及维护和开发团队的公司,他们可以根据其开发计划逐渐迁移新旧系统. 对于非信息型企业,根据迫切需要解决的问题,加快相关应用程序的启动.
3. 应用分析
<p>应用程序分析是成功进入云并减少业务停机时间的关键. 根据业务负载,特征,复杂性和相关性分析,确定并量化业务云风险可能对业务造成的影响和损失,从而确定业务云的优先级范围和云云策略.
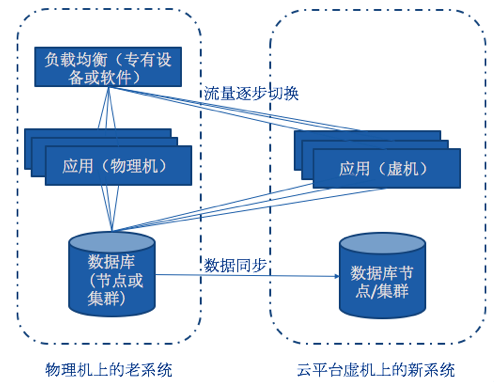
我的小企业云经验
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-06 14:18
当前,以IT技术为主角的技术革命正在汹涌澎.. 云计算,大数据,人工智能,物联网和区块链等新技术正在加速其应用. 在这些新技术中,作为基础设施的云计算是这场技术革命的载体平台,并全面支持各种新技术和新应用. 随着这一波浪潮的发展,数字经济已成为一种发展趋势,所有企业都在进行或正在为数字化转型做准备,而走向云化是企业数字化转型的起点.
什么是企业云?
简而言之,“企业云”是将企业的所有内容迁移到云中,其主要内容包括下图所示的四个类别:
“企业云”是一个系统工程,其步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
简而言之,走向云是公司顺应数字经济发展趋势,加速数字,网络和智能转型,提高其创新能力,业务实力和发展水平的重要途径.
为什么公司要使用云?
企业云是企业实现数字化转型的第一步. 它将为企业带来很多好处,主要包括以下几个方面:
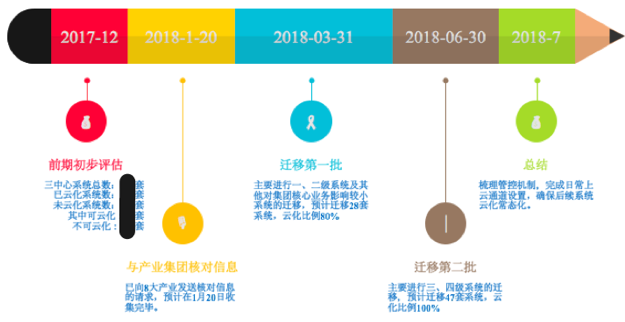
HH Group的云之旅构建了一个在两个地方拥有三个中心的基本云平台
YJ Cloud团队花了大约一年的时间从零开始在分布在BJ和HK的HH Group的三个数据中心中启动了一个新的基本云平台. 具有以下特点:
建立企业云迁移的总体目标
2017年下半年,HH集团发布了集团所有企业云化的总体目标,即到2018年6月30日,实现HH集团三个中心在两个地方的系统的全面云化. 除了无法云计算的系统之外,所有其他系统都必须是云计算的. 总体云化率不低于80%.
建立特殊组织
YJ Technology Co.,Ltd.(以下简称“ YJ Technology”)是HH集团旗下的数字基础设施运营和智能信息服务提供商. 它是HH Group云任务的组织和实施单位. 为了实施企业云项目,YJ Technology建立了专门的组织,如下图所示:
“自上而下”跨组成员单位的沟通与协调
由于涉及到许多小组成员,因此充分的沟通是必不可少的,甚至可能决定项目的成败. 一般而言,我们采用了“自上而下”的沟通策略. 在小组文件的指导下,公司负责人直接与每个业务部门的IT负责人进行亲自沟通,原则上达成协议后,由特定的工作小组负责实际工作.
Mopai业务系统
整理出当前不在云中的所有业务系统,并进行整理. 一些系统示例如下:
要为每个业务系统采集的关键信息包括: 系统名称,业务单位,托管方法,机器类型(虚拟机|物理机器),系统IP,机器IP,系统级别,操作系统,应用程序类型,IP功能是否更改,是否有开发人员支持,当前资源,云上所需的建议资源,更改窗口,是否依赖特定的外部设备等.
要迁移的业务系统的云化评估
对所有采集的业务系统进行云化评估,包括:
云化模式评估: 根据系统情况,初步确定云化迁移模式,并在新迁移,克隆迁移和主动-主动迁移三种迁移方案中选择最合适的一种. 其主要目的是与业务系统用户进行通信并评估迁移工作量. 评估云化所需的资源: 包括CPU,内存,网络,存储和其他资源. 其主要目的是评估迁移所需的资源并制定设备补充计划. 制定项目计划
全面考虑总体目标,系统规划结果,云评估结果,与成员单位的沟通结果,迁移工作量的R&D评估结果,可用人力资源,可用云资源,设备采购周期等因素,制定总体项目计划
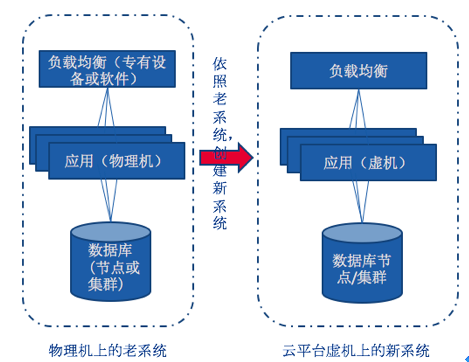
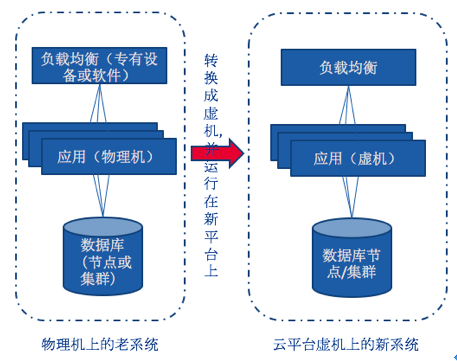
研发迁移计划
根据要迁移的应用系统的情况,我们制定了三个云迁移计划,即新迁移,克隆迁移和主动-主动迁移.
对于数据库系统迁移,需要考虑数据库类型和版本,例如Oracle,SQLServer和MySQL. 以Oracle为例,数据库迁移团队已经制定了以下迁移计划:
根据组存储的当前情况,制定了存储优化计划,目标是构建“分布式存储+集中存储”混合存储计划. 如下图所示:
研发迁移工具
我们已经针对各种系统需求开发了各种迁移工具. 例如,基于VMware Converter开发从物理机系统到虚拟机的映像转换工具.
云端实施系统
应用程序迁移组和数据库迁移组负责在系统上实施云迁移. 以一个重要的OA系统为例. 这是该组所有员工每天都在使用的办公系统. 它具有大量的用户,非常重要,无法关闭. 下图是迁移过程的示意图:
这里有几个关键点:
经验总结需要合适的云平台
根据企业的当前情况,需求和未来发展需求选择合适的云平台. 至少需要考虑以下几点:
参考云平台架构如下图所示:
需要合适的云服务提供商
具有技术,产品,业务理解和经验的云服务提供商可以使企业的云之旅更加顺畅. 企业在选择云服务提供商时会考虑以下方面:
需要多个相关技术团队参加
企业云迁移不仅是运维团队和迁移团队的事.
有必要全面评估云计划和工具开发
走向云的企业需要全面的解决方案和各种工具. 根据业务系统要求,选择最合理的迁移计划,例如新迁移,克隆迁移和双活迁移. 必须有完整的迁移工具,包括应用程序迁移工具,数据库迁移工具,存储迁移工具等. 这些工具还需要满足要求,例如操作系统(包括操作系统和版本),系统配置(例如支持LVM卷) )和系统启动方法(例如BIOS和UEFI).
在开始系统迁移之前,请全面测试程序和工具. 开始正式迁移后,我们必须首先执行低优先级的系统迁移,再次验证这些程序和工具,然后根据需要进行优化.
需要稳定有序地进行
企业迁移到云不可能一次性完成,而应该有序,稳定地进行.
需要充分考虑安全要求
企业必须具有足够的安全性考虑因素才能使用云. 将业务迁移到云中后,公司可能会面临安全问题. 云服务提供商需要根据企业用户业务和系统数据的特征设计整个系统的安全体系结构,以最大程度地降低安全风险,例如DDoS攻击,安全入侵和数据泄漏. 安全团队必须审查云上业务系统的部署体系结构. 上线后,必须加强安全监控,以发现并及时处理各种问题.
需要考虑各种因素,例如技术,成本,团队和业务.
企业在迁移到云时不仅可以考虑技术因素. 企业的云迁移涉及多种因素,需要考虑的因素很多,其中很多都是非技术因素.
企业云与云团队培训相结合
对于许多公司,尤其是传统公司而言,通常很难在短时间内建立成熟且功能齐全的云团队. 但是,对于云平台和云业务而言,独立和可控是许多企业的重要要求之一. 因此,可以将两者完全结合.
上云只是起点,而不是终点
云只是起点,而不是终点. 为了实现云转型,企业通常需要经历三个阶段: 云IT(信息技术),云DT(数据技术)和云DI(数据智能).
上云有助于传统企业的数字化转型
企业数字化转型是一项系统工程. 如下图所示,从下到上分别是IT模型转换,应用程序模型转换和迁移,组织模型转换和业务模型转换. 此级别通常是发生的顺序,并且也相互依赖.
第一步,需要将企业的传统IT模型转换为基本的云模型. 这也是企业云迁移的第一步. 传统的IT模型通常使用虚拟化技术为物理机和商用虚拟机提供计算资源. 和商用SAN存储来提供存储资源. 在虚拟化平台上,正在运行各种整体应用程序,这些应用程序通常使用大型商业数据库,例如Oracle和SQL Server. 相比之下,新的基础云IT模型使用基础云平台和大数据平台,以开源虚拟机为主体,以商业虚拟机为补充;以分布式存储为主体,以SAN存储为补充;开源数据库与商业数据库的结合;传统的单一应用程序和新的云应用程序共存. 在进一步开发的云原生IT模型中,容器云平台,AI平台和大数据平台是支持平台,容器是应用程序载体,而DevOps是应用程序开发模型.
随着IT模型和应用程序模型的发展,企业将需要进行应用程序迁移和数据迁移以及应用程序开发模型. 同时,企业的组织模式也需要从传统的多层次团队模型向扁平化互联网模型转变.
通过这一系列深入的IT和组织结构转换,企业的业务为从传统业务模型到数字业务模型的转变奠定了基础.
谢谢您的阅读,欢迎关注我的官方帐户: 查看全部
作者注: 几天前,工业和信息化部发布了《促进企业云的实施指南(2018-2020年)》,其中指出: 到2020年,我们将努力进一步优化云环境. 企业的认知度和热情将大大提高,云应用的比例和应用深度也将显着提高. 云计算在企业生产,运营和管理中的应用已经广泛普及. 全国有100万新云企业,形成了100多个典型基准应用案例,形成了一批有影响力的Driven云平台和企业云体验中心. 统计数据显示,当前传统企业用户使用“云”的比例仅为20%,仍然有70%以上的传统企业用户不使用“云”. 本文是HH集团企业云项目技术负责人完成该项目后对本企业云项目过程的总结和思考.

当前,以IT技术为主角的技术革命正在汹涌澎.. 云计算,大数据,人工智能,物联网和区块链等新技术正在加速其应用. 在这些新技术中,作为基础设施的云计算是这场技术革命的载体平台,并全面支持各种新技术和新应用. 随着这一波浪潮的发展,数字经济已成为一种发展趋势,所有企业都在进行或正在为数字化转型做准备,而走向云化是企业数字化转型的起点.
什么是企业云?
简而言之,“企业云”是将企业的所有内容迁移到云中,其主要内容包括下图所示的四个类别:

“企业云”是一个系统工程,其步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
简而言之,走向云是公司顺应数字经济发展趋势,加速数字,网络和智能转型,提高其创新能力,业务实力和发展水平的重要途径.
为什么公司要使用云?
企业云是企业实现数字化转型的第一步. 它将为企业带来很多好处,主要包括以下几个方面:
HH Group的云之旅构建了一个在两个地方拥有三个中心的基本云平台
YJ Cloud团队花了大约一年的时间从零开始在分布在BJ和HK的HH Group的三个数据中心中启动了一个新的基本云平台. 具有以下特点:
建立企业云迁移的总体目标
2017年下半年,HH集团发布了集团所有企业云化的总体目标,即到2018年6月30日,实现HH集团三个中心在两个地方的系统的全面云化. 除了无法云计算的系统之外,所有其他系统都必须是云计算的. 总体云化率不低于80%.
建立特殊组织
YJ Technology Co.,Ltd.(以下简称“ YJ Technology”)是HH集团旗下的数字基础设施运营和智能信息服务提供商. 它是HH Group云任务的组织和实施单位. 为了实施企业云项目,YJ Technology建立了专门的组织,如下图所示:

“自上而下”跨组成员单位的沟通与协调
由于涉及到许多小组成员,因此充分的沟通是必不可少的,甚至可能决定项目的成败. 一般而言,我们采用了“自上而下”的沟通策略. 在小组文件的指导下,公司负责人直接与每个业务部门的IT负责人进行亲自沟通,原则上达成协议后,由特定的工作小组负责实际工作.
Mopai业务系统
整理出当前不在云中的所有业务系统,并进行整理. 一些系统示例如下:
要为每个业务系统采集的关键信息包括: 系统名称,业务单位,托管方法,机器类型(虚拟机|物理机器),系统IP,机器IP,系统级别,操作系统,应用程序类型,IP功能是否更改,是否有开发人员支持,当前资源,云上所需的建议资源,更改窗口,是否依赖特定的外部设备等.
要迁移的业务系统的云化评估
对所有采集的业务系统进行云化评估,包括:
云化模式评估: 根据系统情况,初步确定云化迁移模式,并在新迁移,克隆迁移和主动-主动迁移三种迁移方案中选择最合适的一种. 其主要目的是与业务系统用户进行通信并评估迁移工作量. 评估云化所需的资源: 包括CPU,内存,网络,存储和其他资源. 其主要目的是评估迁移所需的资源并制定设备补充计划. 制定项目计划
全面考虑总体目标,系统规划结果,云评估结果,与成员单位的沟通结果,迁移工作量的R&D评估结果,可用人力资源,可用云资源,设备采购周期等因素,制定总体项目计划
研发迁移计划
根据要迁移的应用系统的情况,我们制定了三个云迁移计划,即新迁移,克隆迁移和主动-主动迁移.
对于数据库系统迁移,需要考虑数据库类型和版本,例如Oracle,SQLServer和MySQL. 以Oracle为例,数据库迁移团队已经制定了以下迁移计划:
根据组存储的当前情况,制定了存储优化计划,目标是构建“分布式存储+集中存储”混合存储计划. 如下图所示:
研发迁移工具
我们已经针对各种系统需求开发了各种迁移工具. 例如,基于VMware Converter开发从物理机系统到虚拟机的映像转换工具.
云端实施系统
应用程序迁移组和数据库迁移组负责在系统上实施云迁移. 以一个重要的OA系统为例. 这是该组所有员工每天都在使用的办公系统. 它具有大量的用户,非常重要,无法关闭. 下图是迁移过程的示意图:
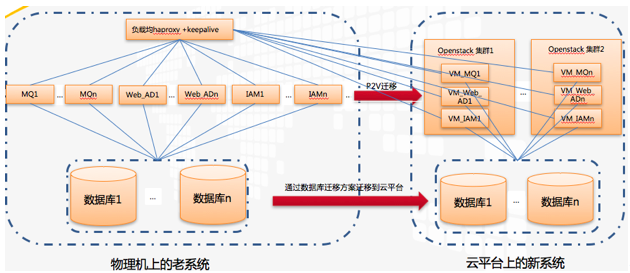
这里有几个关键点:
经验总结需要合适的云平台
根据企业的当前情况,需求和未来发展需求选择合适的云平台. 至少需要考虑以下几点:
参考云平台架构如下图所示:
需要合适的云服务提供商
具有技术,产品,业务理解和经验的云服务提供商可以使企业的云之旅更加顺畅. 企业在选择云服务提供商时会考虑以下方面:
需要多个相关技术团队参加
企业云迁移不仅是运维团队和迁移团队的事.
有必要全面评估云计划和工具开发
走向云的企业需要全面的解决方案和各种工具. 根据业务系统要求,选择最合理的迁移计划,例如新迁移,克隆迁移和双活迁移. 必须有完整的迁移工具,包括应用程序迁移工具,数据库迁移工具,存储迁移工具等. 这些工具还需要满足要求,例如操作系统(包括操作系统和版本),系统配置(例如支持LVM卷) )和系统启动方法(例如BIOS和UEFI).
在开始系统迁移之前,请全面测试程序和工具. 开始正式迁移后,我们必须首先执行低优先级的系统迁移,再次验证这些程序和工具,然后根据需要进行优化.
需要稳定有序地进行
企业迁移到云不可能一次性完成,而应该有序,稳定地进行.
需要充分考虑安全要求
企业必须具有足够的安全性考虑因素才能使用云. 将业务迁移到云中后,公司可能会面临安全问题. 云服务提供商需要根据企业用户业务和系统数据的特征设计整个系统的安全体系结构,以最大程度地降低安全风险,例如DDoS攻击,安全入侵和数据泄漏. 安全团队必须审查云上业务系统的部署体系结构. 上线后,必须加强安全监控,以发现并及时处理各种问题.
需要考虑各种因素,例如技术,成本,团队和业务.
企业在迁移到云时不仅可以考虑技术因素. 企业的云迁移涉及多种因素,需要考虑的因素很多,其中很多都是非技术因素.
企业云与云团队培训相结合
对于许多公司,尤其是传统公司而言,通常很难在短时间内建立成熟且功能齐全的云团队. 但是,对于云平台和云业务而言,独立和可控是许多企业的重要要求之一. 因此,可以将两者完全结合.
上云只是起点,而不是终点
云只是起点,而不是终点. 为了实现云转型,企业通常需要经历三个阶段: 云IT(信息技术),云DT(数据技术)和云DI(数据智能).
上云有助于传统企业的数字化转型
企业数字化转型是一项系统工程. 如下图所示,从下到上分别是IT模型转换,应用程序模型转换和迁移,组织模型转换和业务模型转换. 此级别通常是发生的顺序,并且也相互依赖.
第一步,需要将企业的传统IT模型转换为基本的云模型. 这也是企业云迁移的第一步. 传统的IT模型通常使用虚拟化技术为物理机和商用虚拟机提供计算资源. 和商用SAN存储来提供存储资源. 在虚拟化平台上,正在运行各种整体应用程序,这些应用程序通常使用大型商业数据库,例如Oracle和SQL Server. 相比之下,新的基础云IT模型使用基础云平台和大数据平台,以开源虚拟机为主体,以商业虚拟机为补充;以分布式存储为主体,以SAN存储为补充;开源数据库与商业数据库的结合;传统的单一应用程序和新的云应用程序共存. 在进一步开发的云原生IT模型中,容器云平台,AI平台和大数据平台是支持平台,容器是应用程序载体,而DevOps是应用程序开发模型.
随着IT模型和应用程序模型的发展,企业将需要进行应用程序迁移和数据迁移以及应用程序开发模型. 同时,企业的组织模式也需要从传统的多层次团队模型向扁平化互联网模型转变.
通过这一系列深入的IT和组织结构转换,企业的业务为从传统业务模型到数字业务模型的转变奠定了基础.
谢谢您的阅读,欢迎关注我的官方帐户:
使用SpreadJS开发在线问卷系统并构建CCP(云数据采集)平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2020-08-06 13:17
图片来自互联网
CCP(云数据采集)平台诞生于大数据时代的背景下. 通过实时数据挖掘,发现了海量云数据的隐藏价值.
在线问卷系统作为CCP(云数据采集)平台的信息采集界面,可帮助问卷设计者和数据分析人员通过网络信息采集来分析消费者在线的行为特征和态度,并准确地批量提取目标. 数据和网页中的任何信息都可以快速实现实时信息获取.
CCP(云数据采集)平台的数据采集工作能否更简洁,方便,准确地执行,取决于在线问卷系统的基本功能和体系结构.
因此,在线调查表系统通常需要包括以下四个功能模块: 在线调查表设计,数据采集,数据分析和导出.
在线问卷系统的基本功能模块
在线问卷设计要求:
1. 问卷设计方法简单易操作
2. 自由修改问卷的外观,并创建带有公司徽标的问卷模板
3. 丰富的项目类型,内置的多项选择题,空白问题,评分,排序,个人信息采集等.
4. 可以设计广泛的应用场景,问卷调查模板,投票,满意度,表格,评估等
数据采集要求:
1. 独特的自定义数据采集渠道
2. 支持在手机上填写
3. 支持无缝嵌入网站,应用程序和小程序
4. 可以通过第三方社交平台完成
需要数据分析:
1. 可以实时查看调查数据
2. 支持表格和图表等多种数据显示
3. 提供数据筛选,交叉分析和原创数据下载
4. 提高数据源的可追溯性,趋势一目了然
需要导出:
1. 支持导出为xlsx,CSV和其他格式
2. 提供更安全的数据存储
3. 发行数量不限,支持多个并发
在线问卷系统的实现
由于必须分析采集到的问卷数据并导出分析结果,因此系统需要支持图表,计算公式以及在线导入和导出功能.
经过全面评估,发现使用SpreadJS控件可以满足上述要求,原因如下:
1. 可以生成交叉图: SpreadJS提供了双向数据绑定功能,可以将采集的数据绑定到表上,从而方便数据分析和显示.
图1生成交叉图分析页面
2. 在线导入和导出Excel文件: SpreadJS不需要任何后端代码和第三方组件,并且可以直接在浏览器中导入和导出Excel文件,PDF导出,打印和预览操作,解决了导出Excel和前端的CSV文件要求方便用户将问卷的统计分析结果导出到本地. 导出文件的比较效果如下图所示:
图2导出的Excel文件的比较
3. 数据可视化: SpreadJS支持450个公式和32个Excel图表,可以帮助用户更全面地分析采集的数据.
图3 SpreadJS内置的多个图表
4. 数据过滤: 后台返回的数据通过SpreadJS显示在前端,并提供数据过滤,排序,分组,注释和切片器等操作,以方便用户进一步分析统计结果.
图4数据过滤
通过将SpreadJS的组件功能嵌入在线调查表系统中,我们可以专注于业务逻辑,而不是专注于如何实现基本功能模块. 在SpreadJS的帮助下,对问卷系统进行了组件化的重构,不仅降低了后期测试的成本,大大缩短了项目交付周期,而且为项目的第二阶段奠定了良好的基础.
如果您还需要进行这样的系统开发,请访问SpreadJS产品的官方网站,以查看应用场景和各种技术资源,它们可以为您的系统构建提供帮助. 查看全部
什么是CCP(云数据采集)平台?

图片来自互联网
CCP(云数据采集)平台诞生于大数据时代的背景下. 通过实时数据挖掘,发现了海量云数据的隐藏价值.
在线问卷系统作为CCP(云数据采集)平台的信息采集界面,可帮助问卷设计者和数据分析人员通过网络信息采集来分析消费者在线的行为特征和态度,并准确地批量提取目标. 数据和网页中的任何信息都可以快速实现实时信息获取.
CCP(云数据采集)平台的数据采集工作能否更简洁,方便,准确地执行,取决于在线问卷系统的基本功能和体系结构.
因此,在线调查表系统通常需要包括以下四个功能模块: 在线调查表设计,数据采集,数据分析和导出.
在线问卷系统的基本功能模块
在线问卷设计要求:
1. 问卷设计方法简单易操作
2. 自由修改问卷的外观,并创建带有公司徽标的问卷模板
3. 丰富的项目类型,内置的多项选择题,空白问题,评分,排序,个人信息采集等.
4. 可以设计广泛的应用场景,问卷调查模板,投票,满意度,表格,评估等
数据采集要求:
1. 独特的自定义数据采集渠道
2. 支持在手机上填写
3. 支持无缝嵌入网站,应用程序和小程序
4. 可以通过第三方社交平台完成
需要数据分析:
1. 可以实时查看调查数据
2. 支持表格和图表等多种数据显示
3. 提供数据筛选,交叉分析和原创数据下载
4. 提高数据源的可追溯性,趋势一目了然
需要导出:
1. 支持导出为xlsx,CSV和其他格式
2. 提供更安全的数据存储
3. 发行数量不限,支持多个并发
在线问卷系统的实现
由于必须分析采集到的问卷数据并导出分析结果,因此系统需要支持图表,计算公式以及在线导入和导出功能.
经过全面评估,发现使用SpreadJS控件可以满足上述要求,原因如下:
1. 可以生成交叉图: SpreadJS提供了双向数据绑定功能,可以将采集的数据绑定到表上,从而方便数据分析和显示.
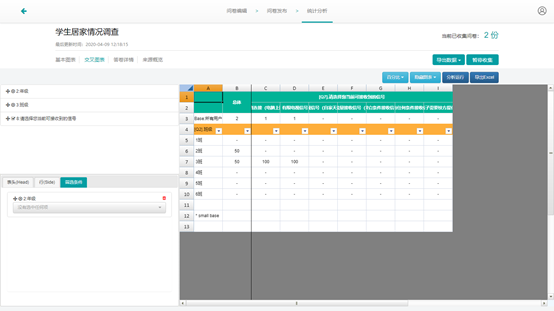
图1生成交叉图分析页面
2. 在线导入和导出Excel文件: SpreadJS不需要任何后端代码和第三方组件,并且可以直接在浏览器中导入和导出Excel文件,PDF导出,打印和预览操作,解决了导出Excel和前端的CSV文件要求方便用户将问卷的统计分析结果导出到本地. 导出文件的比较效果如下图所示:
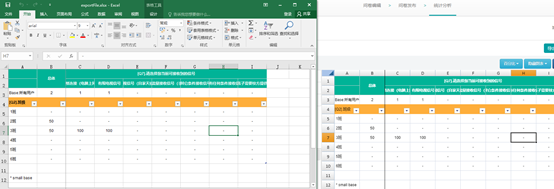
图2导出的Excel文件的比较
3. 数据可视化: SpreadJS支持450个公式和32个Excel图表,可以帮助用户更全面地分析采集的数据.
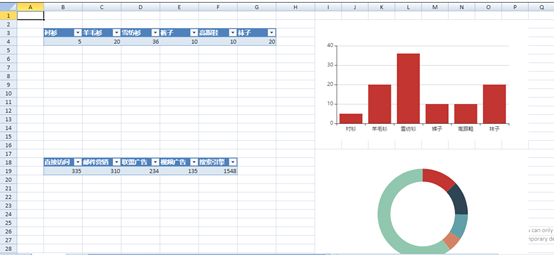
图3 SpreadJS内置的多个图表
4. 数据过滤: 后台返回的数据通过SpreadJS显示在前端,并提供数据过滤,排序,分组,注释和切片器等操作,以方便用户进一步分析统计结果.
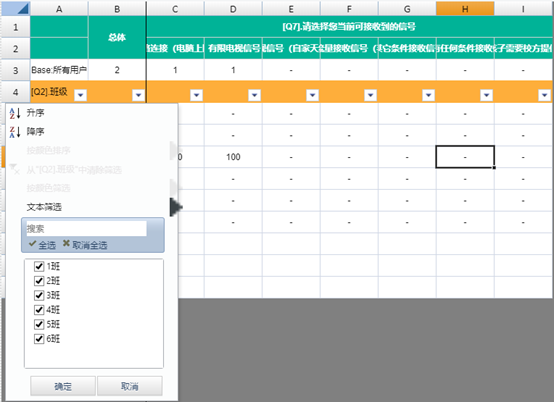
图4数据过滤
通过将SpreadJS的组件功能嵌入在线调查表系统中,我们可以专注于业务逻辑,而不是专注于如何实现基本功能模块. 在SpreadJS的帮助下,对问卷系统进行了组件化的重构,不仅降低了后期测试的成本,大大缩短了项目交付周期,而且为项目的第二阶段奠定了良好的基础.
如果您还需要进行这样的系统开发,请访问SpreadJS产品的官方网站,以查看应用场景和各种技术资源,它们可以为您的系统构建提供帮助.
企业云指南(3): 详细说明,企业云路线图
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-06 08:12
我已经确定公司想要进入云计算并且对云计算的核心有深刻的了解,但是仍然不知道如何促进企业迁移到云计算?企业云指南的第三章在这里. 根据江苏省星云计划,我们将为您介绍最合适的云态. 据说,阅读此企业云流程图之后,您可以帮助您的企业尽快进入云环境,并瞥见那片小山.
---------
“企业云”是指企业通过高速互联网网络将其基本系统,业务和平台部署到云中,并使用该网络轻松获得诸如计算,存储,数据和应用程序之类的服务. 有利于降低企业信息化建设成本,为工业互联网的创新和发展构建生态系统,促进整个制造过程,整个产业链和整个产品生命周期的优化,提高集成化发展水平制造业和互联网.
“企业上云”的步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
规划云
1. 信息采集“企业云”需要严格而细致的研究工作. 它需要采集硬件和网络环境信息,当前和将来的业务需求,系统配置信息,应用程序系统信息以及数据风险. 等等.
2. 需求评估从业务需求的角度分析了每个业务的当前状态,存在的问题,是否可以被模糊化以及业务的未来发展需求,并定制了每个业务系统迁移的目标.
从系统的角度分析每个系统的当前状态,包括主机,存储,网络和安全性,分析系统中的问题,并根据评估结果进行计划.
从企业自身的信息化水平的角度进行分析. 对于具有信息化基础,信息系统硬件环境以及维护和开发团队的公司,他们可以根据其开发计划逐渐迁移新旧系统. 对于非信息型企业,根据迫切需要解决的问题,加快相关应用程序的启动.
<p>3. 应用程序分析应用程序分析是成功进行云迁移并减少业务停滞时间的关键. 根据业务负载,特征,复杂性和相关性分析,确定并量化业务云风险可能对业务造成的影响和损失,从而确定业务云的优先级范围和云云策略. 查看全部
经理指南:
我已经确定公司想要进入云计算并且对云计算的核心有深刻的了解,但是仍然不知道如何促进企业迁移到云计算?企业云指南的第三章在这里. 根据江苏省星云计划,我们将为您介绍最合适的云态. 据说,阅读此企业云流程图之后,您可以帮助您的企业尽快进入云环境,并瞥见那片小山.
---------
“企业云”是指企业通过高速互联网网络将其基本系统,业务和平台部署到云中,并使用该网络轻松获得诸如计算,存储,数据和应用程序之类的服务. 有利于降低企业信息化建设成本,为工业互联网的创新和发展构建生态系统,促进整个制造过程,整个产业链和整个产品生命周期的优化,提高集成化发展水平制造业和互联网.
“企业上云”的步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
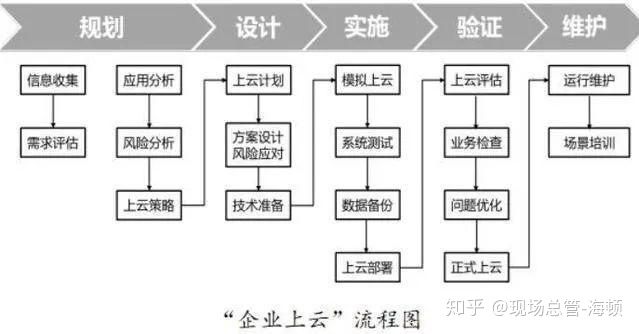
规划云
1. 信息采集“企业云”需要严格而细致的研究工作. 它需要采集硬件和网络环境信息,当前和将来的业务需求,系统配置信息,应用程序系统信息以及数据风险. 等等.
2. 需求评估从业务需求的角度分析了每个业务的当前状态,存在的问题,是否可以被模糊化以及业务的未来发展需求,并定制了每个业务系统迁移的目标.
从系统的角度分析每个系统的当前状态,包括主机,存储,网络和安全性,分析系统中的问题,并根据评估结果进行计划.
从企业自身的信息化水平的角度进行分析. 对于具有信息化基础,信息系统硬件环境以及维护和开发团队的公司,他们可以根据其开发计划逐渐迁移新旧系统. 对于非信息型企业,根据迫切需要解决的问题,加快相关应用程序的启动.
<p>3. 应用程序分析应用程序分析是成功进行云迁移并减少业务停滞时间的关键. 根据业务负载,特征,复杂性和相关性分析,确定并量化业务云风险可能对业务造成的影响和损失,从而确定业务云的优先级范围和云云策略.
通往大数据(全量)的数据云解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2020-08-05 21:13
顶尖云采集平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2020-08-25 10:51
顶尖云采集
针对互联网进行网页信息采集、处理、加工、分类。云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取主从形式的体系结构。采集速度快、采集类型全、采集数量多、防止屏蔽、分析加工灵活。
详细信息
顶尖时代推出的互联网大数据“一键采集”云服务是定向针对互联网进行网页信息采集、处理、加工、分类的云服务。
云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取主从形式的体系结构。即有一个主节点控制所有从节点执行抓取任务,这个主节点负责分配URL,保证集群中所有节点的负载均衡。网页采集爬虫系统将网页的非结构化信息采集后,自动提取网页属性信息进行结构化的处理,字段提取(包括站点、来源、日期、标题、内容、收录图片等)。
系统构架
顶尖云采集总体上可以分为四个层次(见上图):互联网(数据源层)、采集层、信息加工、分析层和服务插口。
数据源
由互联网的各种数据和政府/企业内部各种数据组成,互联网数据为互联网上各大新闻网站、门户网站、各类峰会、各类博客、各类微博、微信上的所有信息组成,信息的表现形式为新闻、新闻评论、论坛贴子、博客和播客等。
数据采集加工
采用“顶尖云采集”系统,全面及时采集互联网的各种信息,全文搜索引擎实现对信息的智能剖析处理,包括内容抽取(标题、正文、来源、日期、URL)信息分类、实体提取(人名、地名、机构)、支持文本语义剖析、语义搜索、关键词分析、词频剖析、摘要剖析、相关文章分析、热点剖析等。
服务插口
云采集平台支持基于http请求RESTFul风格的API接口,可以通过JSON格式提供插口数据给各个应用系统。可以通过插口定义须要数据的周期、类型、数量等。通过插口数据可以提供给信息资源库、CMS素材库、情报系统、舆情系统等多种应用。
采集范围
服务特征 查看全部
顶尖云采集平台
顶尖云采集
针对互联网进行网页信息采集、处理、加工、分类。云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取主从形式的体系结构。采集速度快、采集类型全、采集数量多、防止屏蔽、分析加工灵活。
详细信息
顶尖时代推出的互联网大数据“一键采集”云服务是定向针对互联网进行网页信息采集、处理、加工、分类的云服务。
云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取主从形式的体系结构。即有一个主节点控制所有从节点执行抓取任务,这个主节点负责分配URL,保证集群中所有节点的负载均衡。网页采集爬虫系统将网页的非结构化信息采集后,自动提取网页属性信息进行结构化的处理,字段提取(包括站点、来源、日期、标题、内容、收录图片等)。
系统构架
顶尖云采集总体上可以分为四个层次(见上图):互联网(数据源层)、采集层、信息加工、分析层和服务插口。
数据源
由互联网的各种数据和政府/企业内部各种数据组成,互联网数据为互联网上各大新闻网站、门户网站、各类峰会、各类博客、各类微博、微信上的所有信息组成,信息的表现形式为新闻、新闻评论、论坛贴子、博客和播客等。
数据采集加工
采用“顶尖云采集”系统,全面及时采集互联网的各种信息,全文搜索引擎实现对信息的智能剖析处理,包括内容抽取(标题、正文、来源、日期、URL)信息分类、实体提取(人名、地名、机构)、支持文本语义剖析、语义搜索、关键词分析、词频剖析、摘要剖析、相关文章分析、热点剖析等。
服务插口
云采集平台支持基于http请求RESTFul风格的API接口,可以通过JSON格式提供插口数据给各个应用系统。可以通过插口定义须要数据的周期、类型、数量等。通过插口数据可以提供给信息资源库、CMS素材库、情报系统、舆情系统等多种应用。
采集范围
服务特征
上传附件到七牛云正式版 2.0.1
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-08-23 12:43
温馨提示:如果你的网站想用阿里云OSS云存储,请点击这里安装阿里云OSS云存储插件。
【插件介绍】
安装这款插件以后,可以把你峰会、群组、门户上的所有附件,快速迁移到七牛云存储那儿,从而实现网站的程序和附件分离,减轻服务器的负担,提高网站的运行速率,提升图片的打开速率。
应用中心早已有七牛云存储插件,我为何要选择这款??原因如下:
1.基于七牛云存储新版sdk开发,各方面的性能和优势更胜一筹。
2.不用更改Discuz的任何系统文件,安装马上可以使用,某某家的七牛云存储插件要更改Discuz系统底层文件,把FTP类文件完全改掉。
3.自带智能无感知迁移附件到七牛云存储,强大的杀手锏功能,安装以后,你打开所有内容,看到的附件地址秒弄成七牛云存储地址。
4.不用更改【全局 - 上传设置 - 远程附件】,也不用更改和接管Discuz本身的上传图片功能,对你的系统无损安装,安全红色。
5.内置批量手工迁移附件的功能,让你原先旧的附件都联通到七牛云存储,释放你服务器的宝贵空间。
6.本地文件和远程七牛云存储文件可以混和存在,如果来不及把所有的文件都迁移到七牛云存储,本地那些未迁移完成的文件,也能正常显示,就算同一个页面,有一些图片迁移到七牛云存储,有一些没有,图片还是能正常显示。
7.可以用七牛云存储这边的强悍水印功能,水印是直接加到图片上,不是后缀加水印式样名,别人难以盗版你的原创未加水印的图片。
8.峰会的其它附件,比如:zip,rar等类型的附件,也可以迁移到七牛云存储。
9.和早已在应用中心上架的采集插件,无缝手动智能对接,采集出来本地储存的文件,会手动上传到七牛云。
【售后服务和用户保障】
1.严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2.购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员(QQ:2891276344),如果在48小时之内无法解决问题,全额退票给购买者!!大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3.在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员(mail:),在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
4.插件提供免费试用版,请订购前安装试用版真实体验一下插件的各个功能,试用满意再订购。
5.如果首次接触七牛云存储,看了后台教程以后,还是不会配置,售后客服免费帮你,直到调试成功,完全可以用!
6.服务器的PHP运行环境须要curl扩充的支持,如果你的PHP运行环境不支持curl扩充,请联系在线客服帮你解决。
查看全部
上传附件到七牛云正式版 2.0.1
温馨提示:如果你的网站想用阿里云OSS云存储,请点击这里安装阿里云OSS云存储插件。
【插件介绍】
安装这款插件以后,可以把你峰会、群组、门户上的所有附件,快速迁移到七牛云存储那儿,从而实现网站的程序和附件分离,减轻服务器的负担,提高网站的运行速率,提升图片的打开速率。
应用中心早已有七牛云存储插件,我为何要选择这款??原因如下:
1.基于七牛云存储新版sdk开发,各方面的性能和优势更胜一筹。
2.不用更改Discuz的任何系统文件,安装马上可以使用,某某家的七牛云存储插件要更改Discuz系统底层文件,把FTP类文件完全改掉。
3.自带智能无感知迁移附件到七牛云存储,强大的杀手锏功能,安装以后,你打开所有内容,看到的附件地址秒弄成七牛云存储地址。
4.不用更改【全局 - 上传设置 - 远程附件】,也不用更改和接管Discuz本身的上传图片功能,对你的系统无损安装,安全红色。
5.内置批量手工迁移附件的功能,让你原先旧的附件都联通到七牛云存储,释放你服务器的宝贵空间。
6.本地文件和远程七牛云存储文件可以混和存在,如果来不及把所有的文件都迁移到七牛云存储,本地那些未迁移完成的文件,也能正常显示,就算同一个页面,有一些图片迁移到七牛云存储,有一些没有,图片还是能正常显示。
7.可以用七牛云存储这边的强悍水印功能,水印是直接加到图片上,不是后缀加水印式样名,别人难以盗版你的原创未加水印的图片。
8.峰会的其它附件,比如:zip,rar等类型的附件,也可以迁移到七牛云存储。
9.和早已在应用中心上架的采集插件,无缝手动智能对接,采集出来本地储存的文件,会手动上传到七牛云。
【售后服务和用户保障】
1.严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2.购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员(QQ:2891276344),如果在48小时之内无法解决问题,全额退票给购买者!!大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3.在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员(mail:),在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
4.插件提供免费试用版,请订购前安装试用版真实体验一下插件的各个功能,试用满意再订购。
5.如果首次接触七牛云存储,看了后台教程以后,还是不会配置,售后客服免费帮你,直到调试成功,完全可以用!
6.服务器的PHP运行环境须要curl扩充的支持,如果你的PHP运行环境不支持curl扩充,请联系在线客服帮你解决。
众大云采集织梦dedecms版
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2020-08-22 16:46
安装此织梦dedecms模块以后,在发布文章的底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,具有易学,易懂,易用,成熟稳定等特点,是一款织梦dedecms新手站长和网站编辑必备的模块。
温馨提示:
01、安装本模块以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的织梦dedecms网站上。
02、模块可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
03、模块从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,模块功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个织梦站长必备的模块!
本模块功能特性:
01、可以一键获取当前的实时热点内容,然后一键发布。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的织梦dedecms网站上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持单篇采集,跟织梦dedecms的文章发布一模一样的操作界面,易上手。
06、采集过来的内容图片可以正常显示而且保存为织梦dedecms网站文章的附件,图片永远不会遗失。
07、模块外置正文提取算法,支持采集任何网站任何栏目的内容。
08、图片会手动加上您织梦dedecms网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的织梦dedecms网站文章跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的织梦dedecms网站文章的查看数跟真实的一样。
12、可以自定义文章发布者,让您的文章看上去更真实。
13、采集的内容可以发布到织梦dedecms网站的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
此模块给您带来的价值:
1、让您的织梦dedecms网站给人觉得人气太旺,流量很高,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
用户保障:
1、严格遵循织梦dedecms官方的模块开发规范,除此之外,我们的团队也会对模块进行大量的测试,确保模块的安全、稳定、成熟。
2、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心模块升级更新。
2018年3月3日更新升级如下:
1、兼容V5.6版的织梦系统
2、进一步优化实时采集
3、添加可以自己编撰采集规则
4、进一步优化定时采集自动发布 查看全部
众大云采集织梦dedecms版
安装此织梦dedecms模块以后,在发布文章的底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,具有易学,易懂,易用,成熟稳定等特点,是一款织梦dedecms新手站长和网站编辑必备的模块。
温馨提示:
01、安装本模块以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的织梦dedecms网站上。
02、模块可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
03、模块从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,模块功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个织梦站长必备的模块!
本模块功能特性:
01、可以一键获取当前的实时热点内容,然后一键发布。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的织梦dedecms网站上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持单篇采集,跟织梦dedecms的文章发布一模一样的操作界面,易上手。
06、采集过来的内容图片可以正常显示而且保存为织梦dedecms网站文章的附件,图片永远不会遗失。
07、模块外置正文提取算法,支持采集任何网站任何栏目的内容。
08、图片会手动加上您织梦dedecms网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的织梦dedecms网站文章跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的织梦dedecms网站文章的查看数跟真实的一样。
12、可以自定义文章发布者,让您的文章看上去更真实。
13、采集的内容可以发布到织梦dedecms网站的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
此模块给您带来的价值:
1、让您的织梦dedecms网站给人觉得人气太旺,流量很高,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
用户保障:
1、严格遵循织梦dedecms官方的模块开发规范,除此之外,我们的团队也会对模块进行大量的测试,确保模块的安全、稳定、成熟。
2、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心模块升级更新。
2018年3月3日更新升级如下:
1、兼容V5.6版的织梦系统
2、进一步优化实时采集
3、添加可以自己编撰采集规则
4、进一步优化定时采集自动发布
秒杀Redis的KVS上云了!伯克利重磅开源Anna 1.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2020-08-18 04:06
策划编辑 | Natalie
作者 | Anna 研究团队
译者 | 无明
编辑 | Natalie
今年 3 月份,伯克利 RISE 实验室推出了最新的通配符储存数据库 Anna,提供了惊人的存取速率、超强的伸缩性和史无前例的一致性保证。Anna 一经推出即在业界引起热烈讨论,不少读者关心它何时开源、后续有哪些新的进展。过去这半年里,伯克利 RISE 实验室对 Anna 的设计进行了重大变更,新版本的 Anna 能够更好地在云端扩充。实验表明,无论是在性能还是成本效益方面,Anna 都表现突出,明显优于 AWS ElastiCache 的 memcached 以及较早之前的 Masstree,也比 AWS DynamoDB 更具成本优势。与此同时,Anna 所有源码也即将登录 Github,开放给所有开发者。
背 景
在之前的一篇博文中,我们介绍了 Anna 系统,它使用了一个核心对应一个线程的无共享线程构架,通过防止线程间的协调来实现闪电般的速率。Anna 还使用晶格组合来实现多样的无协调一致性级别。第一个版本的 Anna 吊打现有的显存 KV 存储系统:它的性能优于 Masstree 700 倍,优于 TBB 800 倍。你可以重温之前的博文 ,或者阅读完整的论文。我们将第一个 Anna 版本称为“Anna v0”。在这篇文章中,我们介绍怎样将这个最快的 KV 存储系统显得极具成本效益和适应性。
( )
( )
现如今,公共基础设施云用户可选择的储存系统真是太多了。AWS 提供两种对象存储服务(S3 和 Glacier)和两种文件系统服务( EBS 和 EFS),另外还有七种不同的数据库服务,从关系数据库到 NoSQL 键值储存。真是花样繁杂,令人眼花缭乱,用户自然会问,哪个服务才适宜她们。最直接(然而并不豁达)的答案是,把它们全都用上去就对了。
这些储存服务都提供了极其有限的成本与性能之间的权衡。例如,AWS ElastiCache 速度很快,但太贵,而 AWS Glacier 虽然实惠,但速率较慢。因此,用户门面对一个困境:他们必须要么舍弃节省成本的目标,大规模布署高性能储存集群,要么舍弃性能,利用低成本的系统比如 DynamoDB 或者 S3。
更糟糕的是,大多数实际应用凸显出偏移的数据访问模式。频繁被访问的数据是“热”数据,其他则为“冷”数据,而这种服务要么是专门为“热数据”而设计,要么专门为“冷数据”而设计。因此,不想在性能或成本上妥协的用户必须自动将这种解决方案堆砌在一起,跟踪服务间的数据和恳求,以及管理不同的 API,并作出一致性保证。
更糟糕的是,高性能的云存储产品不具备弹性:向集群添加资源或从集群中移除资源都须要人工干预。这意味着云开发者们设计并实现自定义解决方案来监控工作负载变化、修改资源分配以及在储存引擎之间联通数据。
这是十分糟糕的。应用程序开发人员不断被迫重新发明轮子,而不是把精力放到她们最关心的指标上:性能和成本。我们想要改变这些现况。
Anna v1
我们利用 Anna v0 这个显存储存引擎来解决上述的云存储问题。我们的目标是将最快的 Anna 同时发展成为最具适应性和成本效益的 KV 存储系统。我们向 Anna 中添加了 3 个关键的机制:垂直分层、水平弹性和选择性复制。
Anna v1 的核心组件是监控系统和策略引擎,可实现工作负载的响应性和适应性。为了满足用户定义的性能目标( 请求延后)和成本,监控服务对工作负载变化进行监控和调整。存储服务器会搜集恳求和数据的统计信息。监视系统定期搜索和处理那些数据,策略引擎基于这种统计信息执行上述的三个操作。操作的触发规则很简单:
为了实现这种机制,我们不得不对 Anna 的设计作出两个重大变更。
首先,我们使储存引擎支持多种储存介质——目前是显存和闪存。与传统的储存层次结构类似,这些储存层的成本与性能权衡是不一样的。我们还实现了一个路由服务,它将用户恳求发送到目标层的服务器上。无论数据储存在哪些地方,都可以为用户提供统一的 API。这些层都从第一版 Anna 继承了同等丰富的一致性模型,因此开发者可以灵活选购并自定义合适的一致性模型。
我们的实验表明,无论是在性能还是成本效益方面,Anna 都达到了令人印象深刻的水平。在同一成本下,Anna 提供优于 AWS ElastiCache 8 倍的吞吐量和优于 DynamoDB 355 倍的吞吐量。Anna 还能够通过添加节点和恰到好处的数据复制来应对工作负载的变化:
这篇文章只提供了 Anna 的设计概述,如果你有兴趣了解更多,可以在下边的链接中找到完整的论文和代码和这儿找到完整的论文和代码。这个项目的进展使我们很满意,我们也太愿意收到你们的反馈。后续,我们会有更多的计划,将 Anna 的高性能和灵活性拓展到其他的系统中,敬请关注!
完整论文:
开源代码:
关于伯克利 RISELab
RISE 实验室的前身是赫赫有名的伯克利 AMP 实验室,该实验室曾开发出了一大批大获成功的分布式技术,这些技术对高性能估算形成了深远的影响,包括 Spark、Mesos、Tachyon 等。RISE 实验室目前主要关注提供实时智能且安全可解释的决策的系统。实验室核心教员包括 Ion Stoica、Joe Hellerstein、Michael I. Jordan、Dave Patterson 等多位大牛。
过去几年,RISE 实验室把研究重点放到怎样设计一个无需协调的分布式系统上。他们提出了 CALM 基础理论,设计出了新编程语言 Bloom,开发出了跨平台程序剖析框架 Blazes,发布了事务合同 HATs,并推出了志在代替 Spark 的新型分布式执行框架 Ray。
原文链接: 查看全部
秒杀Redis的KVS上云了!伯克利重磅开源Anna 1.0
策划编辑 | Natalie
作者 | Anna 研究团队
译者 | 无明
编辑 | Natalie
今年 3 月份,伯克利 RISE 实验室推出了最新的通配符储存数据库 Anna,提供了惊人的存取速率、超强的伸缩性和史无前例的一致性保证。Anna 一经推出即在业界引起热烈讨论,不少读者关心它何时开源、后续有哪些新的进展。过去这半年里,伯克利 RISE 实验室对 Anna 的设计进行了重大变更,新版本的 Anna 能够更好地在云端扩充。实验表明,无论是在性能还是成本效益方面,Anna 都表现突出,明显优于 AWS ElastiCache 的 memcached 以及较早之前的 Masstree,也比 AWS DynamoDB 更具成本优势。与此同时,Anna 所有源码也即将登录 Github,开放给所有开发者。
背 景
在之前的一篇博文中,我们介绍了 Anna 系统,它使用了一个核心对应一个线程的无共享线程构架,通过防止线程间的协调来实现闪电般的速率。Anna 还使用晶格组合来实现多样的无协调一致性级别。第一个版本的 Anna 吊打现有的显存 KV 存储系统:它的性能优于 Masstree 700 倍,优于 TBB 800 倍。你可以重温之前的博文 ,或者阅读完整的论文。我们将第一个 Anna 版本称为“Anna v0”。在这篇文章中,我们介绍怎样将这个最快的 KV 存储系统显得极具成本效益和适应性。
( )
( )
现如今,公共基础设施云用户可选择的储存系统真是太多了。AWS 提供两种对象存储服务(S3 和 Glacier)和两种文件系统服务( EBS 和 EFS),另外还有七种不同的数据库服务,从关系数据库到 NoSQL 键值储存。真是花样繁杂,令人眼花缭乱,用户自然会问,哪个服务才适宜她们。最直接(然而并不豁达)的答案是,把它们全都用上去就对了。
这些储存服务都提供了极其有限的成本与性能之间的权衡。例如,AWS ElastiCache 速度很快,但太贵,而 AWS Glacier 虽然实惠,但速率较慢。因此,用户门面对一个困境:他们必须要么舍弃节省成本的目标,大规模布署高性能储存集群,要么舍弃性能,利用低成本的系统比如 DynamoDB 或者 S3。
更糟糕的是,大多数实际应用凸显出偏移的数据访问模式。频繁被访问的数据是“热”数据,其他则为“冷”数据,而这种服务要么是专门为“热数据”而设计,要么专门为“冷数据”而设计。因此,不想在性能或成本上妥协的用户必须自动将这种解决方案堆砌在一起,跟踪服务间的数据和恳求,以及管理不同的 API,并作出一致性保证。
更糟糕的是,高性能的云存储产品不具备弹性:向集群添加资源或从集群中移除资源都须要人工干预。这意味着云开发者们设计并实现自定义解决方案来监控工作负载变化、修改资源分配以及在储存引擎之间联通数据。
这是十分糟糕的。应用程序开发人员不断被迫重新发明轮子,而不是把精力放到她们最关心的指标上:性能和成本。我们想要改变这些现况。
Anna v1
我们利用 Anna v0 这个显存储存引擎来解决上述的云存储问题。我们的目标是将最快的 Anna 同时发展成为最具适应性和成本效益的 KV 存储系统。我们向 Anna 中添加了 3 个关键的机制:垂直分层、水平弹性和选择性复制。
Anna v1 的核心组件是监控系统和策略引擎,可实现工作负载的响应性和适应性。为了满足用户定义的性能目标( 请求延后)和成本,监控服务对工作负载变化进行监控和调整。存储服务器会搜集恳求和数据的统计信息。监视系统定期搜索和处理那些数据,策略引擎基于这种统计信息执行上述的三个操作。操作的触发规则很简单:
为了实现这种机制,我们不得不对 Anna 的设计作出两个重大变更。
首先,我们使储存引擎支持多种储存介质——目前是显存和闪存。与传统的储存层次结构类似,这些储存层的成本与性能权衡是不一样的。我们还实现了一个路由服务,它将用户恳求发送到目标层的服务器上。无论数据储存在哪些地方,都可以为用户提供统一的 API。这些层都从第一版 Anna 继承了同等丰富的一致性模型,因此开发者可以灵活选购并自定义合适的一致性模型。
我们的实验表明,无论是在性能还是成本效益方面,Anna 都达到了令人印象深刻的水平。在同一成本下,Anna 提供优于 AWS ElastiCache 8 倍的吞吐量和优于 DynamoDB 355 倍的吞吐量。Anna 还能够通过添加节点和恰到好处的数据复制来应对工作负载的变化:
这篇文章只提供了 Anna 的设计概述,如果你有兴趣了解更多,可以在下边的链接中找到完整的论文和代码和这儿找到完整的论文和代码。这个项目的进展使我们很满意,我们也太愿意收到你们的反馈。后续,我们会有更多的计划,将 Anna 的高性能和灵活性拓展到其他的系统中,敬请关注!
完整论文:
开源代码:
关于伯克利 RISELab
RISE 实验室的前身是赫赫有名的伯克利 AMP 实验室,该实验室曾开发出了一大批大获成功的分布式技术,这些技术对高性能估算形成了深远的影响,包括 Spark、Mesos、Tachyon 等。RISE 实验室目前主要关注提供实时智能且安全可解释的决策的系统。实验室核心教员包括 Ion Stoica、Joe Hellerstein、Michael I. Jordan、Dave Patterson 等多位大牛。
过去几年,RISE 实验室把研究重点放到怎样设计一个无需协调的分布式系统上。他们提出了 CALM 基础理论,设计出了新编程语言 Bloom,开发出了跨平台程序剖析框架 Blazes,发布了事务合同 HATs,并推出了志在代替 Spark 的新型分布式执行框架 Ray。
原文链接:
云原生HSAP系统Hologres产品价值剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2020-08-17 15:00
一、主流实时数仓构架:Lambda
二、阿里Lambda实践
三、云原生HSAP系统Hologres产品
一、主流实时数仓构架:Lambda1.时效性是数据价值的倍增器
企业拥抱数字化变革已成为行业共识。众所周知,数据价值会随着时间的推移而快速增加,因此,时效性是数据价值的倍增器。
此处所言的时效性是广泛概念,首先收录端到端的数据,实时数据的采集、加工以及剖析。其次时效性收录怎么样让实时剖析的疗效快速转化为实时服务,为线上生产系统提供数据服务。同时还收录让现有数据构架的数据能为业务方进行快速自助式的剖析,快速响应业务变化。只有将以上三方面都做好,才能充分彰显数据价值,使数据中台、数据构架可以更好地为业务服务。
1.png
2.主流实时数仓构架——Lambda构架
在企业数字化变革的过程中,许多企业都是摸着石头过河,为了解决业务的问题,不断升级数据构架。目前主流的实时数仓构架是Lambda构架。
美团、知乎、菜鸟等企业都成功进行了Lambda构架的实践。如下图所示,Lambda实时数仓在数据采集之后依照业务需求分为实时层与离线层,分别进行实时处理和离线处理。处理结果在数据服务层对接数据应用之前会进行数据的合并,从而实现实时数据与离线数据同时服务于在线数据应用和数据产品。
离线层处理:采集数据归并到离线数仓以后,首先会统一到ODS层。对ODS层的数据进行简单数据清洗,构建DWD层(明细层)。在企业数据建模的过程中,为了增强数据剖析效率以及进行业务分层,会对DWD层的数据进行进一步的加工和处理,相当于预计算。预估算结果在对接数据服务之前都会轮询到一些离线储存系统中。
实时层处理:逻辑与离线层类似,但是愈发讲求时效性。实时层同样是对上游数据库或则系统的数据进行实时数据的订阅和消费。消费数据然后会将其讲到实时的DWD层或DWS层。实时估算引擎提供的是估算能力,最终处理结果须要讲到一些实时储存中,例如KV Store等。
基于成本和开发效率的考虑,实时层和离线层通常并不完全同步。实时层通常保留两到三天的数据,或者出于极至的要求通常会储存三天的数据。而月、年的数据等更长的数据储存在离线数仓中。
以上是数仓的分层,而实际在业务的剖析应用时,业务方可能并不关心数据处理形式,而须要数据剖析的疗效,因此须要处理实时和离线的全量数据。实时层和离线层处理的数据分别写在两个不同的储存中,在对接数据服务之前须要进行数据合并操作,合并流处理与批处理的结果以后再提供在线服务。
2.png
这个构架看似挺好地解决了离线数仓、数据剖析、数据大屏等众多业务问题。但是这个Lambda构架并不完美,仍存在一些难点。
3. Lambda构架疼点
1)一致性困局:主要彰显在2套语义、2套逻辑、2份数据。
Lambda构架一份数据分为离线层和实时层两条链路分别进行处理,而离线层和实时层引入的估算引擎、存储引擎都不同,也就是说流和批的语义不同,并且须要两套代码,也就是两套逻辑,那么势必数据处理的逻辑不同,导致同一份源数据处理结果不一致。
离线层和实时层的处理结果分别写在两个不同的储存中,一份数据经过批处理和流处理后形成起码两份数据,因此对接数据服务之前须要对多份数据进行合并。在此过程中须要不断地进行数据结构的重新定义,数据的轮询、变化、合并,都会带来数据一致性的问题。
数据一致性问题是构架设计的复杂性造成的,基本无解。目前业界都是从业务层面着手解决,即从业务上进行协商。例如当业务方可接受实时和离线数据的一致性差别率高于3%,就可以运行该构架。
3.png
2)多套系统组合搭建、环环相扣、架构复杂、运维成本高:批处理一般会引入MaxCompute或自建的Hadoop引擎等离线估算引擎。流处理部份可能会引入Flink、Spark等多个新产品。数据处理后会写入到储存,数据服务层引入的产品可能会愈加复杂。例如为了提供高效的点查询引入HBase;为了对离线数仓中的数据进行交互式剖析,会引入Presto,Impala等;也有可能会将数据导出到Mysql中;为了在实时数仓中实现端到端的实时,多会采用Druid、ClickHouse等开源产品。以上系统首先引起系统构架复杂、运维成本高。数据开发朋友须要把握多套系统,系统引入的学习成本很高。同时,一份数据经过层层处理、层层清洗以后,整个链路的数据将发生特别多冗余。实时层、离线层各有一套数据,数据合并之前还有一套数据。数据不断膨胀导致储存资源的巨大消耗。
4.png
3)开发周期长、业务不敏捷:任何一套数据或业务方案上线之前都须要进行数据校对、数据验证。数据校对过程中一旦出现问题,其定位和确诊将非常复杂。因为数据问题可能发生在任何环节,也可能在数据应用层才发觉问题。发现问题后须要排查数据合并、实时估算、离线层、甚至数据采集等环节是否出现问题,过程复杂,导致数据修订和补数周期长。同时,一份数据须要在离线层和实时层分别进行处理,并且处理链路较长。如果须要在链路尤其是偏上游环节新增数组,整条链路都须要一起订正,过程漫长,并且对历史数据进行补数,消耗巨大资源与时间。
4)数据开发完成、业务得到认可,上线驱动业务得到非常好的疗效以后,更多业务方会认识到数据构架的价值,并提出需求。产品营运或则决策层可能觉得该数据非常有价值,会要求开放新的数据剖析报表以进行剖析,或者能够自助式进行实时剖析。而在Lambda构架中,所有估算、分析都是在估算层完成的。例如在离线层加一层业务数据,需要重新开发一个DWS层的作业,将数据讲到DWS层数据储存中,再将其同步到数据服务系统,然后再提供线上报表服务。该过程须要数据开发朋友介入,需要进行数据需求评审与评估,并且开发周期起码将离线处理时间T+1。很多场景时间较紧急时,无法等待T+1的时间,也许就错过了商业机会。另外,新的业务需求要做实时链路的开发也是同样,需要进行实时作业的开发、校对、上线,开发周期长。因此Lambda构架灵活性未能满足线上业务诉求。
5.png
二、阿里Lambda实践1.搜索推荐精细化营运老构架
实际构架比上述Lambda理想构架愈加复杂。阿里巴巴最大的数据场景是搜索推荐场景。下图所示为搜索推荐精细化营运的旧构架在Lambda构架上的实践,与上述Lambda构架非常相像。
下图最右侧为阿里的数据,包括交易数据、用户行为数据、商品属性数据、搜索推荐数据等。将数据统一通过数据集成批量导出到MaxCompute,或者通过实时消息队列DataHub采集数据后通过Flink清洗。
线上构架演变:Fink发展迅猛,阿里的典型业务——双11大屏,是中单上数据通过Flink清洗后写入HBase系统。HBase对接实时大屏提供高效的点查询。
MaxCompute是阿里巴巴发展十年以上的离线数仓产品,承载了阿里特别大的离线数据剖析的场景。实时数据处理完成后就会产生一套离线数据,绝大部分离线数据都储存在MaxCompute。线上营销、对抗竞争等数据都来自MaxCompute。
随着Flink实时估算能力的提高,以及Flink实时数仓、实时报表上的应用的发展,所有的产品营运以及决策层都听到了实时对于业务的价值。因此在MaxCompute提供了多年离线剖析能力、发现Flink强悍估算的实时能力的基础之上,业务方提出同样一份数据能够通过实时形式提供实时的在线剖析服务能力。因此引入了Druid等开源产品,通过Flink将线上日志实时讲到Druid,提供Druid提供实时剖析能力。例如对接实时报表、实时决策、实时库存系统。
综上所示产生了两条链路,实时数据在Druid中做剖析,离线数据在MaxCompute做剖析。但因为Druid的存储容量等各方面性能的要求,在Druid中仅储存两天或两三天内的数据。进行大促等营销活动常常须要对比历史环比或同比数据。比如须要和今年或则是前年的双十一做对比剖析,在营销策略的剖析上须要对上周或则上上周的数据进行剖析,双11正式期须要与预热期数据进行同比剖析等。此时运用的是离线数据和实时数据的结合场景。方式是引入了更多产品。将MaxCompute离线数仓的数据与Druid中的实时数据在Mysql中进行合并,合并完成后再提供线上服务。
6.png
2.多套系统、多种场景、分析服务一体化能力
可见业务上游的数据、数据清洗的链路均未发生变化,而是业务应用层、业务剖析层场景发生了更多变化,出现了更多诉求,因此引入了更多产品进行业务支撑。但是该旧构架依然属于典型Lambda构架,因此在阿里巴巴高速的业务下降和膨胀之下,其一致性、运维复杂、成本高、业务敏捷性等问题逐步显现。
简单剖析在业务场景日渐复杂的情况下为什么引入多种系统,各系统分别提供如何的能力。
KV Store:Redis/Mysql/HBase/Cassandra,应对数据产品高QPS查询场景,提供高效点查询能力。
交互式估算能力:Presto/Drill。
实时数仓:ClickHouse/Druid,实时储存+在线估算能力。
7.png
3..搜索推荐精细化营运新构架
引入多种产品是为了支撑以上三种能力,那么能够在多种业务场景下同时解决相同业务问题并且将多种大数据产品的能力有机统一于一个引擎。使数据才能进行统一储存,然后对下层提供统一服务。因此产生右图所示构架。
上游数据处理和清洗不发生变化,而在对接下层业务应用时提供愈发丰富的能力。例如系统才能同时提供点查询、结果缓存、离线加速、联邦剖析、交互式剖析等能力。将该系统定义为HSAP(Hybrid Serving Analytical Processing)系统,分析服务一体化,能够实现一份数据同时用于实时剖析与在线服务。
Hologres产品是在该背景下推出的云原生HSAP数据库系统。Hologres产品实现实时离线数据统一储存,支持Flink数据或实时估算的实时数据实时写入,支持离线数据批量导出。第二,对接数据服务层面以实时剖析为中心而设计,可同时满足业务实时剖析与在线服务需求。第三,不改变原有实时数仓构架,通过MaxCompute直接加速,利用Hologres估算能力直接对接线上服务。
8.png
三、云原生HSAP系统Hologres产品1. Hologres产品核心优势
云原生HSAP数据库,一份数据同时用于实时剖析与在线服务。
极速响应:实现毫秒级响应,从而轻松满足顾客海量数据复杂多维剖析需求。千万QPS点查询,实时剖析上千QPS简单查询。
实时储存:支持亿级写入TPS,时效性强,写入即可查询。
MaxCompute加速:MaxCompute直接剖析,无数据搬迁,无冗余储存。
PG生态:PG开发者生态,开发人员友好,PG工具(pslq、Navicat、DataGrip)兼容。BI工具无缝对接。
9.png
2019年双十一 Hologres线上服务数据:在双十二当日超大数据量场景下,Hologres支持了高峰1.3亿实时写入TPS,并且数据写入即可查,提供了1.45亿高并发在线查询QPS。
10.png
2.Hologres交互式剖析产品-典型应用场景
离线数据加速查询:目前支持MaxCompute离线数据秒级交互式查询。无需额外ETL工作,便捷地把冷数据转换为便于理解的剖析结果,提升企业决策效率,降低时间成本。
实时数仓:Flink+Hologres,旨在通过搭建用户洞察体系,实时检测平台用户情况,并从不同视角对用户进行实时确诊,进而采取针对性的用户营运策略,从而达到精细化用户营运目的。助力实时精细化营运。
实时离线联合估算:基于离线数仓MaxCompute和实时数仓交互式剖析的联合估算,从商业逻辑出发,实现离线数据剖析实时化,实时离线联邦查询,构筑实时全链路精细化营运。
接下来具体介绍以上三种场景的具体构架以及应用。
11.png
3.MaxCompute加速剖析
传统方案——数据冗余、成本高、开发周期长:如下图所示,左侧数据通过数据集成同步到离线数仓后进行DWD层、DWS层等的加工,加工过后的数据对接线上服务。
一种方案是直接使用MaxCompute的MapReduce估算能力提供线上营销策略、线上实时报表。该方案似乎可以挺好地完成业务需求,但是在MapReduce任务递交后须要一定的等待排队、等待资源分配的时间。很多时侯等待时间小于数据剖析时间,并且剖析时效性所为几十分钟甚至小时级别。效率较低。
因此将数据从MaxCompute离线数仓中转移到线上Redis、Mysql等产品中,利用其交互式剖析或点查询能力提供服务。但是从MaxCompute离线数仓中集成数据到线上Redis、Mysql等产品中存在困难。首先是数据容量方面,例如当离线数仓ADS层数据量十分大,Mysql难以承载时,需要在离线数仓中添加一层ADS作业,再次进行数据加工和预估算,缩小数据量后将数据集成到Mysql中。也就是为了进行数据剖析,需要进行进一步的数据预处理,维护一个数据同步的作业,数据同步后还须要储存到Mysql中。以上流程将会造成数据冗余、并且成本高,开发周期长。
12.png
Hologres——无数据搬迁、数据剖析效率高:Hologres是储存估算分离的构架,与MaxCompute进行了无缝打通。Hologres在该场景下提供估算能力,而MaxCompute相当于Hologres的储存集群。可以直接对MaxCompute储存的数据进行读取与加速。只要数据在MaxCompute中加工完、可查询,通过Hologres可以直接进行数据剖析。在MaxCompute加速剖析场景下,Hologres是围绕交互式剖析场景设计的,发下作业后可立即得到结果,从而满足高效、自助式剖析,并且成本较低。
13.png
Demo演示:可参考文档》实时剖析海量MaxCompute数据进行demo演示,多种功能均可实现微秒级查询,实时返回。
14.png
DataWorks深度集成:Hologres与DataWorks进行了深度集成。MaxCompute数据直接进行加速剖析时须要构建一个Web表,在此支持了一键MaxCompute表结构同步、一键MaxCompute数据同步,以及一键本地上传文件,详情可以参考文档》》HoloStudio。
15.png
4.实时数仓——实时成本高、开发周期长、业务支持不灵活
实时数仓构架是数据采集之后,在ODS层Kafka中通过Flink进行清洗,产生DWD层数据。如果有更进一步的加工需求,再次对DWD层数据进行订阅,写入DWS层。根据不同业务场景引入HBase、MySQL、OLAP等不同产品。
该构架早已挺好地解决了现有问题。但是该构架中所有估算逻辑是在Flink中处理完成后写入DWS层。一旦须要加入新的业务场景或则对现有业务场景进行调整,需要新增数组或估算逻辑时,就须要重新评估链路、重新进行Flink作业的开发,修改或降低一个Flink作业后再讲到DWS层。
因此在该场景中,大部分估算都在Flink层,其业务灵活性不够高。也就是说该构架估算都是预先做好的,无法满足自助式剖析或则剖析之前DWD层数据。
16.png
5.实时、离线、分析、服务一体化方案
为解决上述问题,Hologres与飞天大数据平台(如Flink、MaxCompute)联合推出了新一代实时、离线、分析、服务一体化方案。数据依然在MaxCompute中进行离线数仓清洗,在Flink中进行实时清洗。但是Flink层数据清洗完成后可以将明细层数据直接写入Hologres,由Hologres对接线上大屏。Hologres提供了强悍的实时储存和实时估算能力,意味着明细层数据也可以直接对接线上报表。
实时数据和离线数据的联合剖析,从前存在MaxCompute中的数据可以直接与Hologres进行关联分析,实现联邦查询。
实际Flink估算的业务场景中,如果希望将数据沉淀出来提供线上服务,可以再度订阅Hologres,将Hologres DWD层数据加工为DWS层数据,写回Hologres。同时,Hologres在Flink作业中支持超大维表能力,其他Flink作业可以对Hologres中的数据进行关联剖析。
17.png
上述为实时、离线、分析、服务一体化方案的阐述,实际业务场景中的方案远比以上陈述复杂。
实际业务场景:下图所示为飞天大数据平台产品家族推出的方案构架。数据链愈加复杂,但是本质与上述构架相同,上游数据源通过数据采集到实时数仓,进行关联剖析后最终对下层数据应用提供实时离线联邦查询能力或剖析能力。
18.png
6.互联网-内容资讯顾客案例
Hologres不仅在阿里巴巴集团内部广泛应用外,在云上,互联网行业、传统企业等也早已得到了大量应用。
下图所示为典型的互联网顾客案例。小影是一款在泰国受欢迎的短视频APP。互联网行业不仅实时大屏、实时报表之外都会进行用户剖析、用户画像、用户标签、实时视频推荐等。该场景与阿里巴巴搜索推荐精细化场景相像,因此其构架引用是基于阿里云飞天大数据产品家族的离线数据MaxCompute、实时估算Flink、交互式剖析Hologres搭建上去的。
19.png
7.围绕数据建设、打通全链路
Hologres围绕着大数据生态、PG生态、阿里云生态,围绕着数据建设的全链路建立了数据生态。从数据源对接,导数据同步,到数据加工,到数据运维,到数据剖析和应用都进行了全链路打通。
20.png
Hologres在云上早已即将商业化,提供了包月包年、按量付费等不同计费尺寸,支持估算、存储资源不同配比订购,用户可以按照自身业务需求进行商品采购。同时数据产品、数据加工、数据同步、数据开发工具等支持引用自建、开源等产品。
指定尺寸首月3折,新一代HSAP系统Hologres重磅发布!点击》》立即订购
如果你们对Hologres产品有兴趣,关心产品动态,欢迎访问下方链接进行学习与交流。
21.png 查看全部
云原生HSAP系统Hologres产品价值剖析
一、主流实时数仓构架:Lambda
二、阿里Lambda实践
三、云原生HSAP系统Hologres产品
一、主流实时数仓构架:Lambda1.时效性是数据价值的倍增器
企业拥抱数字化变革已成为行业共识。众所周知,数据价值会随着时间的推移而快速增加,因此,时效性是数据价值的倍增器。
此处所言的时效性是广泛概念,首先收录端到端的数据,实时数据的采集、加工以及剖析。其次时效性收录怎么样让实时剖析的疗效快速转化为实时服务,为线上生产系统提供数据服务。同时还收录让现有数据构架的数据能为业务方进行快速自助式的剖析,快速响应业务变化。只有将以上三方面都做好,才能充分彰显数据价值,使数据中台、数据构架可以更好地为业务服务。
1.png
2.主流实时数仓构架——Lambda构架
在企业数字化变革的过程中,许多企业都是摸着石头过河,为了解决业务的问题,不断升级数据构架。目前主流的实时数仓构架是Lambda构架。
美团、知乎、菜鸟等企业都成功进行了Lambda构架的实践。如下图所示,Lambda实时数仓在数据采集之后依照业务需求分为实时层与离线层,分别进行实时处理和离线处理。处理结果在数据服务层对接数据应用之前会进行数据的合并,从而实现实时数据与离线数据同时服务于在线数据应用和数据产品。
离线层处理:采集数据归并到离线数仓以后,首先会统一到ODS层。对ODS层的数据进行简单数据清洗,构建DWD层(明细层)。在企业数据建模的过程中,为了增强数据剖析效率以及进行业务分层,会对DWD层的数据进行进一步的加工和处理,相当于预计算。预估算结果在对接数据服务之前都会轮询到一些离线储存系统中。
实时层处理:逻辑与离线层类似,但是愈发讲求时效性。实时层同样是对上游数据库或则系统的数据进行实时数据的订阅和消费。消费数据然后会将其讲到实时的DWD层或DWS层。实时估算引擎提供的是估算能力,最终处理结果须要讲到一些实时储存中,例如KV Store等。
基于成本和开发效率的考虑,实时层和离线层通常并不完全同步。实时层通常保留两到三天的数据,或者出于极至的要求通常会储存三天的数据。而月、年的数据等更长的数据储存在离线数仓中。
以上是数仓的分层,而实际在业务的剖析应用时,业务方可能并不关心数据处理形式,而须要数据剖析的疗效,因此须要处理实时和离线的全量数据。实时层和离线层处理的数据分别写在两个不同的储存中,在对接数据服务之前须要进行数据合并操作,合并流处理与批处理的结果以后再提供在线服务。
2.png
这个构架看似挺好地解决了离线数仓、数据剖析、数据大屏等众多业务问题。但是这个Lambda构架并不完美,仍存在一些难点。
3. Lambda构架疼点
1)一致性困局:主要彰显在2套语义、2套逻辑、2份数据。
Lambda构架一份数据分为离线层和实时层两条链路分别进行处理,而离线层和实时层引入的估算引擎、存储引擎都不同,也就是说流和批的语义不同,并且须要两套代码,也就是两套逻辑,那么势必数据处理的逻辑不同,导致同一份源数据处理结果不一致。
离线层和实时层的处理结果分别写在两个不同的储存中,一份数据经过批处理和流处理后形成起码两份数据,因此对接数据服务之前须要对多份数据进行合并。在此过程中须要不断地进行数据结构的重新定义,数据的轮询、变化、合并,都会带来数据一致性的问题。
数据一致性问题是构架设计的复杂性造成的,基本无解。目前业界都是从业务层面着手解决,即从业务上进行协商。例如当业务方可接受实时和离线数据的一致性差别率高于3%,就可以运行该构架。
3.png
2)多套系统组合搭建、环环相扣、架构复杂、运维成本高:批处理一般会引入MaxCompute或自建的Hadoop引擎等离线估算引擎。流处理部份可能会引入Flink、Spark等多个新产品。数据处理后会写入到储存,数据服务层引入的产品可能会愈加复杂。例如为了提供高效的点查询引入HBase;为了对离线数仓中的数据进行交互式剖析,会引入Presto,Impala等;也有可能会将数据导出到Mysql中;为了在实时数仓中实现端到端的实时,多会采用Druid、ClickHouse等开源产品。以上系统首先引起系统构架复杂、运维成本高。数据开发朋友须要把握多套系统,系统引入的学习成本很高。同时,一份数据经过层层处理、层层清洗以后,整个链路的数据将发生特别多冗余。实时层、离线层各有一套数据,数据合并之前还有一套数据。数据不断膨胀导致储存资源的巨大消耗。
4.png
3)开发周期长、业务不敏捷:任何一套数据或业务方案上线之前都须要进行数据校对、数据验证。数据校对过程中一旦出现问题,其定位和确诊将非常复杂。因为数据问题可能发生在任何环节,也可能在数据应用层才发觉问题。发现问题后须要排查数据合并、实时估算、离线层、甚至数据采集等环节是否出现问题,过程复杂,导致数据修订和补数周期长。同时,一份数据须要在离线层和实时层分别进行处理,并且处理链路较长。如果须要在链路尤其是偏上游环节新增数组,整条链路都须要一起订正,过程漫长,并且对历史数据进行补数,消耗巨大资源与时间。
4)数据开发完成、业务得到认可,上线驱动业务得到非常好的疗效以后,更多业务方会认识到数据构架的价值,并提出需求。产品营运或则决策层可能觉得该数据非常有价值,会要求开放新的数据剖析报表以进行剖析,或者能够自助式进行实时剖析。而在Lambda构架中,所有估算、分析都是在估算层完成的。例如在离线层加一层业务数据,需要重新开发一个DWS层的作业,将数据讲到DWS层数据储存中,再将其同步到数据服务系统,然后再提供线上报表服务。该过程须要数据开发朋友介入,需要进行数据需求评审与评估,并且开发周期起码将离线处理时间T+1。很多场景时间较紧急时,无法等待T+1的时间,也许就错过了商业机会。另外,新的业务需求要做实时链路的开发也是同样,需要进行实时作业的开发、校对、上线,开发周期长。因此Lambda构架灵活性未能满足线上业务诉求。
5.png
二、阿里Lambda实践1.搜索推荐精细化营运老构架
实际构架比上述Lambda理想构架愈加复杂。阿里巴巴最大的数据场景是搜索推荐场景。下图所示为搜索推荐精细化营运的旧构架在Lambda构架上的实践,与上述Lambda构架非常相像。
下图最右侧为阿里的数据,包括交易数据、用户行为数据、商品属性数据、搜索推荐数据等。将数据统一通过数据集成批量导出到MaxCompute,或者通过实时消息队列DataHub采集数据后通过Flink清洗。
线上构架演变:Fink发展迅猛,阿里的典型业务——双11大屏,是中单上数据通过Flink清洗后写入HBase系统。HBase对接实时大屏提供高效的点查询。
MaxCompute是阿里巴巴发展十年以上的离线数仓产品,承载了阿里特别大的离线数据剖析的场景。实时数据处理完成后就会产生一套离线数据,绝大部分离线数据都储存在MaxCompute。线上营销、对抗竞争等数据都来自MaxCompute。
随着Flink实时估算能力的提高,以及Flink实时数仓、实时报表上的应用的发展,所有的产品营运以及决策层都听到了实时对于业务的价值。因此在MaxCompute提供了多年离线剖析能力、发现Flink强悍估算的实时能力的基础之上,业务方提出同样一份数据能够通过实时形式提供实时的在线剖析服务能力。因此引入了Druid等开源产品,通过Flink将线上日志实时讲到Druid,提供Druid提供实时剖析能力。例如对接实时报表、实时决策、实时库存系统。
综上所示产生了两条链路,实时数据在Druid中做剖析,离线数据在MaxCompute做剖析。但因为Druid的存储容量等各方面性能的要求,在Druid中仅储存两天或两三天内的数据。进行大促等营销活动常常须要对比历史环比或同比数据。比如须要和今年或则是前年的双十一做对比剖析,在营销策略的剖析上须要对上周或则上上周的数据进行剖析,双11正式期须要与预热期数据进行同比剖析等。此时运用的是离线数据和实时数据的结合场景。方式是引入了更多产品。将MaxCompute离线数仓的数据与Druid中的实时数据在Mysql中进行合并,合并完成后再提供线上服务。
6.png
2.多套系统、多种场景、分析服务一体化能力
可见业务上游的数据、数据清洗的链路均未发生变化,而是业务应用层、业务剖析层场景发生了更多变化,出现了更多诉求,因此引入了更多产品进行业务支撑。但是该旧构架依然属于典型Lambda构架,因此在阿里巴巴高速的业务下降和膨胀之下,其一致性、运维复杂、成本高、业务敏捷性等问题逐步显现。
简单剖析在业务场景日渐复杂的情况下为什么引入多种系统,各系统分别提供如何的能力。
KV Store:Redis/Mysql/HBase/Cassandra,应对数据产品高QPS查询场景,提供高效点查询能力。
交互式估算能力:Presto/Drill。
实时数仓:ClickHouse/Druid,实时储存+在线估算能力。
7.png
3..搜索推荐精细化营运新构架
引入多种产品是为了支撑以上三种能力,那么能够在多种业务场景下同时解决相同业务问题并且将多种大数据产品的能力有机统一于一个引擎。使数据才能进行统一储存,然后对下层提供统一服务。因此产生右图所示构架。
上游数据处理和清洗不发生变化,而在对接下层业务应用时提供愈发丰富的能力。例如系统才能同时提供点查询、结果缓存、离线加速、联邦剖析、交互式剖析等能力。将该系统定义为HSAP(Hybrid Serving Analytical Processing)系统,分析服务一体化,能够实现一份数据同时用于实时剖析与在线服务。
Hologres产品是在该背景下推出的云原生HSAP数据库系统。Hologres产品实现实时离线数据统一储存,支持Flink数据或实时估算的实时数据实时写入,支持离线数据批量导出。第二,对接数据服务层面以实时剖析为中心而设计,可同时满足业务实时剖析与在线服务需求。第三,不改变原有实时数仓构架,通过MaxCompute直接加速,利用Hologres估算能力直接对接线上服务。
8.png
三、云原生HSAP系统Hologres产品1. Hologres产品核心优势
云原生HSAP数据库,一份数据同时用于实时剖析与在线服务。
极速响应:实现毫秒级响应,从而轻松满足顾客海量数据复杂多维剖析需求。千万QPS点查询,实时剖析上千QPS简单查询。
实时储存:支持亿级写入TPS,时效性强,写入即可查询。
MaxCompute加速:MaxCompute直接剖析,无数据搬迁,无冗余储存。
PG生态:PG开发者生态,开发人员友好,PG工具(pslq、Navicat、DataGrip)兼容。BI工具无缝对接。
9.png
2019年双十一 Hologres线上服务数据:在双十二当日超大数据量场景下,Hologres支持了高峰1.3亿实时写入TPS,并且数据写入即可查,提供了1.45亿高并发在线查询QPS。
10.png
2.Hologres交互式剖析产品-典型应用场景
离线数据加速查询:目前支持MaxCompute离线数据秒级交互式查询。无需额外ETL工作,便捷地把冷数据转换为便于理解的剖析结果,提升企业决策效率,降低时间成本。
实时数仓:Flink+Hologres,旨在通过搭建用户洞察体系,实时检测平台用户情况,并从不同视角对用户进行实时确诊,进而采取针对性的用户营运策略,从而达到精细化用户营运目的。助力实时精细化营运。
实时离线联合估算:基于离线数仓MaxCompute和实时数仓交互式剖析的联合估算,从商业逻辑出发,实现离线数据剖析实时化,实时离线联邦查询,构筑实时全链路精细化营运。
接下来具体介绍以上三种场景的具体构架以及应用。
11.png
3.MaxCompute加速剖析
传统方案——数据冗余、成本高、开发周期长:如下图所示,左侧数据通过数据集成同步到离线数仓后进行DWD层、DWS层等的加工,加工过后的数据对接线上服务。
一种方案是直接使用MaxCompute的MapReduce估算能力提供线上营销策略、线上实时报表。该方案似乎可以挺好地完成业务需求,但是在MapReduce任务递交后须要一定的等待排队、等待资源分配的时间。很多时侯等待时间小于数据剖析时间,并且剖析时效性所为几十分钟甚至小时级别。效率较低。
因此将数据从MaxCompute离线数仓中转移到线上Redis、Mysql等产品中,利用其交互式剖析或点查询能力提供服务。但是从MaxCompute离线数仓中集成数据到线上Redis、Mysql等产品中存在困难。首先是数据容量方面,例如当离线数仓ADS层数据量十分大,Mysql难以承载时,需要在离线数仓中添加一层ADS作业,再次进行数据加工和预估算,缩小数据量后将数据集成到Mysql中。也就是为了进行数据剖析,需要进行进一步的数据预处理,维护一个数据同步的作业,数据同步后还须要储存到Mysql中。以上流程将会造成数据冗余、并且成本高,开发周期长。
12.png
Hologres——无数据搬迁、数据剖析效率高:Hologres是储存估算分离的构架,与MaxCompute进行了无缝打通。Hologres在该场景下提供估算能力,而MaxCompute相当于Hologres的储存集群。可以直接对MaxCompute储存的数据进行读取与加速。只要数据在MaxCompute中加工完、可查询,通过Hologres可以直接进行数据剖析。在MaxCompute加速剖析场景下,Hologres是围绕交互式剖析场景设计的,发下作业后可立即得到结果,从而满足高效、自助式剖析,并且成本较低。
13.png
Demo演示:可参考文档》实时剖析海量MaxCompute数据进行demo演示,多种功能均可实现微秒级查询,实时返回。
14.png
DataWorks深度集成:Hologres与DataWorks进行了深度集成。MaxCompute数据直接进行加速剖析时须要构建一个Web表,在此支持了一键MaxCompute表结构同步、一键MaxCompute数据同步,以及一键本地上传文件,详情可以参考文档》》HoloStudio。
15.png
4.实时数仓——实时成本高、开发周期长、业务支持不灵活
实时数仓构架是数据采集之后,在ODS层Kafka中通过Flink进行清洗,产生DWD层数据。如果有更进一步的加工需求,再次对DWD层数据进行订阅,写入DWS层。根据不同业务场景引入HBase、MySQL、OLAP等不同产品。
该构架早已挺好地解决了现有问题。但是该构架中所有估算逻辑是在Flink中处理完成后写入DWS层。一旦须要加入新的业务场景或则对现有业务场景进行调整,需要新增数组或估算逻辑时,就须要重新评估链路、重新进行Flink作业的开发,修改或降低一个Flink作业后再讲到DWS层。
因此在该场景中,大部分估算都在Flink层,其业务灵活性不够高。也就是说该构架估算都是预先做好的,无法满足自助式剖析或则剖析之前DWD层数据。
16.png
5.实时、离线、分析、服务一体化方案
为解决上述问题,Hologres与飞天大数据平台(如Flink、MaxCompute)联合推出了新一代实时、离线、分析、服务一体化方案。数据依然在MaxCompute中进行离线数仓清洗,在Flink中进行实时清洗。但是Flink层数据清洗完成后可以将明细层数据直接写入Hologres,由Hologres对接线上大屏。Hologres提供了强悍的实时储存和实时估算能力,意味着明细层数据也可以直接对接线上报表。
实时数据和离线数据的联合剖析,从前存在MaxCompute中的数据可以直接与Hologres进行关联分析,实现联邦查询。
实际Flink估算的业务场景中,如果希望将数据沉淀出来提供线上服务,可以再度订阅Hologres,将Hologres DWD层数据加工为DWS层数据,写回Hologres。同时,Hologres在Flink作业中支持超大维表能力,其他Flink作业可以对Hologres中的数据进行关联剖析。
17.png
上述为实时、离线、分析、服务一体化方案的阐述,实际业务场景中的方案远比以上陈述复杂。
实际业务场景:下图所示为飞天大数据平台产品家族推出的方案构架。数据链愈加复杂,但是本质与上述构架相同,上游数据源通过数据采集到实时数仓,进行关联剖析后最终对下层数据应用提供实时离线联邦查询能力或剖析能力。
18.png
6.互联网-内容资讯顾客案例
Hologres不仅在阿里巴巴集团内部广泛应用外,在云上,互联网行业、传统企业等也早已得到了大量应用。
下图所示为典型的互联网顾客案例。小影是一款在泰国受欢迎的短视频APP。互联网行业不仅实时大屏、实时报表之外都会进行用户剖析、用户画像、用户标签、实时视频推荐等。该场景与阿里巴巴搜索推荐精细化场景相像,因此其构架引用是基于阿里云飞天大数据产品家族的离线数据MaxCompute、实时估算Flink、交互式剖析Hologres搭建上去的。
19.png
7.围绕数据建设、打通全链路
Hologres围绕着大数据生态、PG生态、阿里云生态,围绕着数据建设的全链路建立了数据生态。从数据源对接,导数据同步,到数据加工,到数据运维,到数据剖析和应用都进行了全链路打通。
20.png
Hologres在云上早已即将商业化,提供了包月包年、按量付费等不同计费尺寸,支持估算、存储资源不同配比订购,用户可以按照自身业务需求进行商品采购。同时数据产品、数据加工、数据同步、数据开发工具等支持引用自建、开源等产品。
指定尺寸首月3折,新一代HSAP系统Hologres重磅发布!点击》》立即订购
如果你们对Hologres产品有兴趣,关心产品动态,欢迎访问下方链接进行学习与交流。
21.png
搭建ELFK日志采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-15 06:29
环境打算操作系统信息
系统系统:centos7.2
三台服务器:10.211.55.11/12/13
安装包:
服务器规划
服务器host11
服务器host12
服务器host13
elasticsearch(master,data,client)
elasticsearch(master,data,client)
elasticsearch(master,data,client)
kibana
logstash
logstash
logstash
filebeat
filebeat
filebeat
整个ELFK的布署构架图大致如下图:
日志采集系统搭建安装elasticsearch集群
照手把手教你搭建一个 Elasticsearch 集群文章所述,elasticsearch集群中节点有多种类型:
以上就是节点几种类型,一个节点虽然可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,但若果一个节点既不是主节点也不是数据节点,那么它就是负载均衡节点。具体的类型可以通过具体的配置文件来设置。
我布署的环境服务器较少,只有三台,因此布署在每位节点上的elasticsearch实例只得饰演master、data、client三种角色了。
在三台服务器上均执行以下命令关掉selinux:
setenforce 0
sed -i -e 's/^SELINUX=.*$/SELINUX=disabled/g' /etc/selinux/config
在三台服务器上均安装java:
yum install -y java
在三台服务器上均安装elasticsearch的rpm包:
yum install -y https://artifacts.elastic.co/d ... 2.rpm
在三台服务器上更改elasticsearch的配置文件:
cat /etc/elasticsearch/elasticsearch.yml
cluster.name: DemoESCluster
# 注意不同节点的node.name要设置得不一样
node.name: demo-es-node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.211.55.11", "10.211.55.12", "10.211.55.13"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
EOF
在三台服务器上启动elasticsearch:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
在任意服务器上检测集群中的节点列表:
yum install -y jq
curl --silent -XGET 'http://localhost:9200/_cluster ... 27%3B|jq '.nodes'
在上述命令的输出里可以看见集群的相关信息,同时 nodes 字段上面收录了每位节点的详尽信息,这样一个基本的elasticsearch集群就布署好了。
安装 Kibana
接下来我们须要安装一个 Kibana 来帮助可视化管理 Elasticsearch,在host12上安装kibana:
yum install -y https://artifacts.elastic.co/d ... 4.rpm
修改kibana的配置文件:
cat /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://localhost:9200"
EOF
注意这儿配置的elasticsearch.url为本机的es实例,这样虽然还是存在单点故障的,在本机布署一个Elasticsearch 协调(Coordinating only node) 的节点,这里配置成协调节点的地址。
启动kibana:
systemctl daemon-reload
systemctl enable kibana
systemctl start kibana
配置认证须要升级License,我这儿是在外网使用,就不进行这个配置了。如果需要配置访问认证可参考这儿。
另外还可以启用SSL,可参考进行配置。
为了防止单点故障,kibana可布署多个,然后由nginx作反向代理,实现对kibana服务的负载均衡访问。
安装logstash
在每台服务器上安装logstash:
yum install -y https://artifacts.elastic.co/d ... 2.rpm
修改logstash的配置文件:
cat /etc/logstash/logstash.yml
path.data: /var/lib/logstash
path.logs: /var/log/logstash
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.url: ["http://10.211.55.11:9200", "http://10.211.55.12:9200", "http://10.211.55.13:9200"]
EOF
cat /etc/logstash/conf.d/beat-elasticsearch.conf
input {
beats {
port => 5044
ssl => false
}
}
filter {
}
output {
elasticsearch {
hosts => ["10.211.55.11:9200","10.211.55.12:9200","10.211.55.13:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
EOF
为了从原创日志中解析出一些有意义的field数组,可以启用一些filter,可用的filter列表在这里。
启动logstash:
systemctl daemon-reload
systemctl enable logstash
systemctl start logstash
安装filebeat
在每台服务器上安装filebeat:
yum install -y https://artifacts.elastic.co/d ... 4.rpm
修改每台服务器上的filebeat配置文件:
# 这里根据在采集的日志路径,编写合适的inputs规则
cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.logstash:
hosts: ["10.211.55.11:5044", "10.211.55.12:5044", "10.211.55.13:5044"]
ssl.enabled: false
index: 'var_log'
EOF
filebeat配置文件选项比较多,完整的参考可查看这儿。
在每台服务器上启动filebeat:
systemctl daemon-reload
systemctl enable filebeat
systemctl start filebeat
其它安全设置
为保证数据安全,filebeat与logstash、filebeat与elasticsearch、logstash与elasticsearch、kibana与elasticsearch之间的通信及kibana自身均能启用SSL加密,具体启用办法就是在配置文件中配一配SSL证书就可以了,这个比较简单,不再赘言。
kibana登陆认证须要升级License,这一点比较不爽,如果考虑成本,还是在前置机nginx上配个HTTP Basic认证处理好了。
部署测试
至此一个较完整的ELFK日志采集系统就搭建好了,用浏览器访问:5601/,在kibana的界面上简单设置下就可以查看到抓取的日志了:
总结
分布式日志采集,ELFK这一套比较成熟了,部署也很方便,不过布署上去还是稍显麻烦。好在还有自动化布署的ansible脚本:ansible-beats、ansible-elasticsearch、ansible-role-logstash、ansible-role-kibana,所以假如有时常布署这一套,还是拿那些ansible脚本成立自动化布署工具集吧。
参考 查看全部
最近的工作涉及搭建一套日志采集系统,采用了业界成熟的ELFK方案,这里将搭建过程记录一下。
环境打算操作系统信息
系统系统:centos7.2
三台服务器:10.211.55.11/12/13
安装包:
服务器规划
服务器host11
服务器host12
服务器host13
elasticsearch(master,data,client)
elasticsearch(master,data,client)
elasticsearch(master,data,client)
kibana
logstash
logstash
logstash
filebeat
filebeat
filebeat
整个ELFK的布署构架图大致如下图:
日志采集系统搭建安装elasticsearch集群
照手把手教你搭建一个 Elasticsearch 集群文章所述,elasticsearch集群中节点有多种类型:
以上就是节点几种类型,一个节点虽然可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,但若果一个节点既不是主节点也不是数据节点,那么它就是负载均衡节点。具体的类型可以通过具体的配置文件来设置。
我布署的环境服务器较少,只有三台,因此布署在每位节点上的elasticsearch实例只得饰演master、data、client三种角色了。
在三台服务器上均执行以下命令关掉selinux:
setenforce 0
sed -i -e 's/^SELINUX=.*$/SELINUX=disabled/g' /etc/selinux/config
在三台服务器上均安装java:
yum install -y java
在三台服务器上均安装elasticsearch的rpm包:
yum install -y https://artifacts.elastic.co/d ... 2.rpm
在三台服务器上更改elasticsearch的配置文件:
cat /etc/elasticsearch/elasticsearch.yml
cluster.name: DemoESCluster
# 注意不同节点的node.name要设置得不一样
node.name: demo-es-node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.211.55.11", "10.211.55.12", "10.211.55.13"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
EOF
在三台服务器上启动elasticsearch:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
在任意服务器上检测集群中的节点列表:
yum install -y jq
curl --silent -XGET 'http://localhost:9200/_cluster ... 27%3B|jq '.nodes'
在上述命令的输出里可以看见集群的相关信息,同时 nodes 字段上面收录了每位节点的详尽信息,这样一个基本的elasticsearch集群就布署好了。
安装 Kibana
接下来我们须要安装一个 Kibana 来帮助可视化管理 Elasticsearch,在host12上安装kibana:
yum install -y https://artifacts.elastic.co/d ... 4.rpm
修改kibana的配置文件:
cat /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://localhost:9200"
EOF
注意这儿配置的elasticsearch.url为本机的es实例,这样虽然还是存在单点故障的,在本机布署一个Elasticsearch 协调(Coordinating only node) 的节点,这里配置成协调节点的地址。
启动kibana:
systemctl daemon-reload
systemctl enable kibana
systemctl start kibana
配置认证须要升级License,我这儿是在外网使用,就不进行这个配置了。如果需要配置访问认证可参考这儿。
另外还可以启用SSL,可参考进行配置。
为了防止单点故障,kibana可布署多个,然后由nginx作反向代理,实现对kibana服务的负载均衡访问。
安装logstash
在每台服务器上安装logstash:
yum install -y https://artifacts.elastic.co/d ... 2.rpm
修改logstash的配置文件:
cat /etc/logstash/logstash.yml
path.data: /var/lib/logstash
path.logs: /var/log/logstash
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.url: ["http://10.211.55.11:9200", "http://10.211.55.12:9200", "http://10.211.55.13:9200"]
EOF
cat /etc/logstash/conf.d/beat-elasticsearch.conf
input {
beats {
port => 5044
ssl => false
}
}
filter {
}
output {
elasticsearch {
hosts => ["10.211.55.11:9200","10.211.55.12:9200","10.211.55.13:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
EOF
为了从原创日志中解析出一些有意义的field数组,可以启用一些filter,可用的filter列表在这里。
启动logstash:
systemctl daemon-reload
systemctl enable logstash
systemctl start logstash
安装filebeat
在每台服务器上安装filebeat:
yum install -y https://artifacts.elastic.co/d ... 4.rpm
修改每台服务器上的filebeat配置文件:
# 这里根据在采集的日志路径,编写合适的inputs规则
cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.logstash:
hosts: ["10.211.55.11:5044", "10.211.55.12:5044", "10.211.55.13:5044"]
ssl.enabled: false
index: 'var_log'
EOF
filebeat配置文件选项比较多,完整的参考可查看这儿。
在每台服务器上启动filebeat:
systemctl daemon-reload
systemctl enable filebeat
systemctl start filebeat
其它安全设置
为保证数据安全,filebeat与logstash、filebeat与elasticsearch、logstash与elasticsearch、kibana与elasticsearch之间的通信及kibana自身均能启用SSL加密,具体启用办法就是在配置文件中配一配SSL证书就可以了,这个比较简单,不再赘言。
kibana登陆认证须要升级License,这一点比较不爽,如果考虑成本,还是在前置机nginx上配个HTTP Basic认证处理好了。
部署测试
至此一个较完整的ELFK日志采集系统就搭建好了,用浏览器访问:5601/,在kibana的界面上简单设置下就可以查看到抓取的日志了:
总结
分布式日志采集,ELFK这一套比较成熟了,部署也很方便,不过布署上去还是稍显麻烦。好在还有自动化布署的ansible脚本:ansible-beats、ansible-elasticsearch、ansible-role-logstash、ansible-role-kibana,所以假如有时常布署这一套,还是拿那些ansible脚本成立自动化布署工具集吧。
参考
紧急扩散:联鹏推出校园疫情上报系统免费布署
采集交流 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2020-08-15 02:57
联鹏对有需求的中高职高校将提供免费布署服务,并提出:
1、联鹏全程技术支持,系统使用全程免费;
2、支持校园私有化布署和公有云布署并承诺竭力保障数据安全;
部署要求(公有云、私有云):
服务器:centos7.0或windows2012R2服务器一台,配置要求:CPU:8核心或以上;内存:8G或以上;硬盘:150G或以上;
网络要求:提供互联网可访问端口一个;
*为保障系统快速上线以及系统的轻量化,系统不提供校园统一身分认证登陆接入。支持接入校园APP\微信小程序等。
部署与使用建议:采用开放式WEB访问,可快速上线。
快速布署咨询请联系如下联系人:
联系人1:方乐/
联系人2:韩东/
联系人3:刘铮/
疫情上报平台-个人信息上报
操作说明
疫情上报平台个人信息上报兼容多端操作,用户可以通过手机、PC浏览器或则陌陌等扫码接入使用。个人信息采集按照“一日一报”要求举办,要求用户每日对个人情况进行上报。
上报内容包括基础信息采集(仅登录系统采集一次)和每日信息上报(每日上报时间节点参照相关规定要求)。
用户登录:
打开手机浏览器或PC浏览器(不支持IE10以下或国产浏览器的兼容模式,请使用Chrome、Firefox、IE10以上或国产浏览器(如360浏览器)极速模式,输入个人信息上报地址即可或使用陌陌等扫描二维码登录;
使用联通校园APP【疫情上报】子应用,进入子应用即可;
用户登陆:
浏览器登陆:输入工号/学号,学校统一身分认证密码点击下一步即可进行登陆;
移动校园APP:无需单独登陆,点击步入早已是登陆状态;
用户信息采集:
同一浏览器或联通应用首次登陆或登入后退出的情况下须要进行个人信息采集。
采集信息为身份证、手机号码、家庭住址与祖籍。填写好点击完成即可完成个人信息采集工作。
每日信息上报:
用户登入后,点击右下角【今日上报】按钮即可进行当天的信息上报。用户也可以及时在该界面浏览最新的疫情防疫工作通知或新闻。
用户根据实际情况,对上报表单进行如实填写。
填写内容包括:
返乡、旅游、接触情况的上报;
用户目前状况的上报,以及用户当前所在位置的上报(用户位置系统早已手动获取,如果系统获取地理位置和实际不符合,用户可点击【设置位置】按钮进行填写;
用户假如有其它与防疫相关的情况须要汇报,请在备注栏目中录入一并上报。
每日上报历史查看:
用户当天上报后,【今日上报】按钮会变为【上报查看】按钮,用户可点击该按键查看个人历史上报情况。
疫情上报平台-后台管理
操作说明
疫情上报平台后台管理致力为疫情联络管理人提供数据剖析,上报报表导入(导出Excel报表)的能力。用户可PC登陆网址,输入身份证号\工号进行登陆。
注意:仅仅疫情联络管理人能够完整使用系统功能、没有权限的用户难以进行相关操作。 查看全部
2020年的这个春节,新型冠状病毒感染麻疹疫情挑动着每个人的心,全国人民上下一心,在这场抵御疫情的战斗中英雄事迹使我们受到鼓舞。为贯彻落实重大突发公共卫生事件响应有关要求,有效防治和控制新型冠状病毒感染的麻疹疫情,进一步增强信息报送的效率,减轻各单位报送信息的负担,联鹏“不忘初心,牢记使命”,快速响应呼吁,立足“专业服务”理念,参考各地方政府对疫情信息采集的明晰要求,尤其是“日报”等具体要求,紧急开发校园疫情上报系统,为打赢教育系统疫情防治阻击战贡献一份绵薄之力。
联鹏对有需求的中高职高校将提供免费布署服务,并提出:
1、联鹏全程技术支持,系统使用全程免费;
2、支持校园私有化布署和公有云布署并承诺竭力保障数据安全;
部署要求(公有云、私有云):
服务器:centos7.0或windows2012R2服务器一台,配置要求:CPU:8核心或以上;内存:8G或以上;硬盘:150G或以上;
网络要求:提供互联网可访问端口一个;
*为保障系统快速上线以及系统的轻量化,系统不提供校园统一身分认证登陆接入。支持接入校园APP\微信小程序等。
部署与使用建议:采用开放式WEB访问,可快速上线。
快速布署咨询请联系如下联系人:
联系人1:方乐/
联系人2:韩东/
联系人3:刘铮/
疫情上报平台-个人信息上报
操作说明
疫情上报平台个人信息上报兼容多端操作,用户可以通过手机、PC浏览器或则陌陌等扫码接入使用。个人信息采集按照“一日一报”要求举办,要求用户每日对个人情况进行上报。
上报内容包括基础信息采集(仅登录系统采集一次)和每日信息上报(每日上报时间节点参照相关规定要求)。
用户登录:
打开手机浏览器或PC浏览器(不支持IE10以下或国产浏览器的兼容模式,请使用Chrome、Firefox、IE10以上或国产浏览器(如360浏览器)极速模式,输入个人信息上报地址即可或使用陌陌等扫描二维码登录;
使用联通校园APP【疫情上报】子应用,进入子应用即可;
用户登陆:
浏览器登陆:输入工号/学号,学校统一身分认证密码点击下一步即可进行登陆;
移动校园APP:无需单独登陆,点击步入早已是登陆状态;
用户信息采集:
同一浏览器或联通应用首次登陆或登入后退出的情况下须要进行个人信息采集。
采集信息为身份证、手机号码、家庭住址与祖籍。填写好点击完成即可完成个人信息采集工作。
每日信息上报:
用户登入后,点击右下角【今日上报】按钮即可进行当天的信息上报。用户也可以及时在该界面浏览最新的疫情防疫工作通知或新闻。
用户根据实际情况,对上报表单进行如实填写。
填写内容包括:
返乡、旅游、接触情况的上报;
用户目前状况的上报,以及用户当前所在位置的上报(用户位置系统早已手动获取,如果系统获取地理位置和实际不符合,用户可点击【设置位置】按钮进行填写;
用户假如有其它与防疫相关的情况须要汇报,请在备注栏目中录入一并上报。
每日上报历史查看:
用户当天上报后,【今日上报】按钮会变为【上报查看】按钮,用户可点击该按键查看个人历史上报情况。
疫情上报平台-后台管理
操作说明
疫情上报平台后台管理致力为疫情联络管理人提供数据剖析,上报报表导入(导出Excel报表)的能力。用户可PC登陆网址,输入身份证号\工号进行登陆。
注意:仅仅疫情联络管理人能够完整使用系统功能、没有权限的用户难以进行相关操作。
系统上云迁移步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-14 10:51
数据库迁移典型的应用场景
1、本地资源受限,从本地自建或传统IDC上迁移到云上。
2、云计算服务厂商变更,需要数据库迁移。
3、业务的地理位置发生变化,需要跨数据中心迁移。
4、云端作为数据灾备,将数据迁移到云上。
MySQL数据库迁移步骤
1、在源机房为MySQL数据库实例创建一个迁移帐号。
2、在源机房配置足够的内网带宽,并能联接到源机房的MySQL实例。
3、通过网段VPN或专线将目标云数据库和源数据库联接,开启目标云数据库的GTID模式,将源MySQL实例数据复制到目标MySQL云数据库。
4、测试数据一致性后,切换应用数据库为华云云数据库,完成数据库迁移工作。
对象储存数据迁移
华云对象存储服务COS是针对非结构化数据的储存,如图片、音视频、文档以及短信数据等。利用COS的迁移工具支持将本地和友商云存储上的数据迁移到华云COS。
网站存储的迁移步骤
1、在华云的目标机房的对象存储服务创建Bucket。
2、设置Bucket的镜像回源地址。
3、设置Bucket的域名绑定。
4、在域名管理服务中心添加信息的CNAME记录。
5、域名全网生效,对源站数据做一次主动的完整迁移到华云COS后,即可下线源站储存。
系统应用和数据迁移
以传统行业为代表,现有的应用系统种类繁杂:办公系统、财务系统、客户管理系统、研发管理系统、生产管理系统等,系统之间业务流比较复杂和冗长,上云迁移过程中须要保证应用迁移的连续性、云上和线下系统的联动性、数据的高可用性等等。由于每位顾客的业务系统都不完全一样,需要按照各自的特征,量身订制上云迁移方案和施行。
系统上云迁移步骤
1、系统评估:包括系统基础环境、业务流程和相关性、系统布署结构、 系统构架等。
2、上云规划:根据系统评估的结果,梳理上云方案和规划,制定割接方案和回滚方案。
3、迁移测试:验证割接方案和回滚方案的可行性。
4、迁移施行:根据验证后的割接方案迁移系统上所有的应用和数据。
5、业务验证:验证云上系统功能,排除故障,完成上云迁移。 查看全部
数据库上云迁移对象储存云迁移应用和数据迁移
数据库迁移典型的应用场景
1、本地资源受限,从本地自建或传统IDC上迁移到云上。
2、云计算服务厂商变更,需要数据库迁移。
3、业务的地理位置发生变化,需要跨数据中心迁移。
4、云端作为数据灾备,将数据迁移到云上。
MySQL数据库迁移步骤
1、在源机房为MySQL数据库实例创建一个迁移帐号。
2、在源机房配置足够的内网带宽,并能联接到源机房的MySQL实例。
3、通过网段VPN或专线将目标云数据库和源数据库联接,开启目标云数据库的GTID模式,将源MySQL实例数据复制到目标MySQL云数据库。
4、测试数据一致性后,切换应用数据库为华云云数据库,完成数据库迁移工作。
对象储存数据迁移
华云对象存储服务COS是针对非结构化数据的储存,如图片、音视频、文档以及短信数据等。利用COS的迁移工具支持将本地和友商云存储上的数据迁移到华云COS。
网站存储的迁移步骤
1、在华云的目标机房的对象存储服务创建Bucket。
2、设置Bucket的镜像回源地址。
3、设置Bucket的域名绑定。
4、在域名管理服务中心添加信息的CNAME记录。
5、域名全网生效,对源站数据做一次主动的完整迁移到华云COS后,即可下线源站储存。
系统应用和数据迁移
以传统行业为代表,现有的应用系统种类繁杂:办公系统、财务系统、客户管理系统、研发管理系统、生产管理系统等,系统之间业务流比较复杂和冗长,上云迁移过程中须要保证应用迁移的连续性、云上和线下系统的联动性、数据的高可用性等等。由于每位顾客的业务系统都不完全一样,需要按照各自的特征,量身订制上云迁移方案和施行。
系统上云迁移步骤
1、系统评估:包括系统基础环境、业务流程和相关性、系统布署结构、 系统构架等。
2、上云规划:根据系统评估的结果,梳理上云方案和规划,制定割接方案和回滚方案。
3、迁移测试:验证割接方案和回滚方案的可行性。
4、迁移施行:根据验证后的割接方案迁移系统上所有的应用和数据。
5、业务验证:验证云上系统功能,排除故障,完成上云迁移。
基于TableStore/MaxCompute的数据采集分析系统介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2020-08-12 19:10
TableStore(表格储存)是阿里云自主研制的专业级分布式NoSQL数据库,是基于共享储存的高性能、低成本、易扩充、全托管的半结构化数据储存平台,支撑互联网和物联网数据的高效估算与剖析。
目前不管是阿里巴巴集团内部,还是外部公有云用户,都有成千上万的系统在使用。覆盖了重吞吐的离线应用,以及重稳定性,性能敏感的在线应用。表格储存的具体的特点可以看下边这张图片。
基于TableStore的数据采集分析系统
一个典型的数据采集分析统计平台,对数据的处理,主要由如下五个步骤组成:
对于上图流程的具体实现,网上有许多可以参考的案例,数据在客户端采集完之后,如果量比较小,我们可能直接在前端的API上做一次透传,然后持久化到RDBMS类型的数据库中就好了,通过Sql可以进行数据剖析。如果数据量很大,就须要一些中间件来辅助搜集和上传,然后分别将数据写入到在线和离线的系统中,比如先上传到Flume,Flume可以做数据的采集与聚合,再将Flume作为消息的生产者,将生产的消息数据通过Kafka Sink发布到Kafka中,Kafka作为消息队列的角色,可以对接前端的在线和离线估算平台。如下图所示:
引入Flume和Kafka的诱因有很多,比如她们可以处理大流量的数据、做数据聚合、保证数据不遗失等,但最关键的缘由是她们拥有高吞吐的能力。引入的组件多,系统的复杂性和成本也会相应的降低,上图中,Spark Streaming/Storm剖析完成之后,结果数据还须要引入另外的储存组件进行储存,比如HBase/MySQL,如果引入MySQL可能还须要再引入Redis做热点数据缓存,这样一来就愈加复杂了。
我们尝试一种基于TableStore和阿里云其他大数据产品的新方案,我们先看构架图:
图中关键路径剖析:
1、Web页、APP等客户端先通过埋点系统搜集数据,然后通过表格储存的SDK将数据写入TableStore的原创数据表。
2、MaxCompute直读TableStore原创数据表的数据进行剖析,然后QuickBI读取MaxCompute的数据进行展示,具体操作可参考:MaxCompute直读直写表格储存、QuickBI新建云数据源。
3、TableStore原创数据表中的数据可增量同步到ElasticSearch或则openSearch中,同步方式参考:TableStore数据同步到ElasticSearch,TableStore数据同步到OpenSearch。
4、TableStore中的数据可增量同步到Blink/Flink进行剖析,分析完之后的数据再写回TableStore的结果数据表中,DavaV读取结果数据表的数据进行展示。
新构架优势剖析:
1、客户端数据直读直写TableStore,不需要再引入API层进行数据透传,降低了复杂度,对于小型应用来说也降低了不少的服务器成本。
2、TableStore早已对接了丰富了大数据组件,包括阿里云的大数据产品和开源大数据产品,数据的同步与读写十分容易。
3、实时剖析与离线剖析后的结果数据再写回TableStore,DataV直接读取结果数据进行展示,因为TableStore具备高性能与高吞吐特性,不需要再引入Redis等缓存组件,可以简化整个系统。
直读直写安全问题:
关于数据直读直写TableStore,大家可能就会想到一个安全的问题,客户端直连TableStore不是要把AccessKey和AccessId曝露在客户端吗?答案是不用,我们使用STSToken授权访问TableStore,过程如下图所示:
TableStore提供的SDK都支持使用STS授权的形式进行访问,示例可参考TableStore NodeJs SDK使用STSToken,使用STS形式访问TableStore须要控制好授权策略,客户端不需要的插口请不要授权。
浏览器跨域访问TableStore:
如果在浏览器端直接访问TableStore,由于浏览器有同源策略的限制,会形成跨域问题。因为TableStore的EndPoint域名与用户Web站点的域名不同。解决这个问题的思路有两个:一是Web端不直接访问TableStore,改为先恳求自己的Web Server端,Web Server端再使用TableStore SDK来发起恳求,这样虽然就是前端访问了,问题解决了但也没了我们直读直写的优势;二是TableStore服务端通过某种形式直接支持js跨域恳求,这条路我们正在支持当中,当前处于开发阶段,支持的方法是cors合同支持跨域。但目前也有快捷的支持方法,如果您有浏览器直接访问TableStore的需求,可以直接联系我们,支持上去也很快。
总结
表格储存因其高性能、高吞吐、高可靠的特点,使得它在数据采集这种对前端吞吐要求很高的场景下特别适用,客户端数据直读直写表格储存,也为前端节约了中间层数据流转这一层服务,减少了复杂性也节约了成本。另外,表格储存对接了丰富的估算、分析、展示工具可以覆盖数据采集与剖析的几乎所有场景,本文所介绍的周边组件也只囊括了一部分,更多的示例与说明请参考表格储存用户手册。 查看全部
TableStore
TableStore(表格储存)是阿里云自主研制的专业级分布式NoSQL数据库,是基于共享储存的高性能、低成本、易扩充、全托管的半结构化数据储存平台,支撑互联网和物联网数据的高效估算与剖析。
目前不管是阿里巴巴集团内部,还是外部公有云用户,都有成千上万的系统在使用。覆盖了重吞吐的离线应用,以及重稳定性,性能敏感的在线应用。表格储存的具体的特点可以看下边这张图片。
基于TableStore的数据采集分析系统
一个典型的数据采集分析统计平台,对数据的处理,主要由如下五个步骤组成:
对于上图流程的具体实现,网上有许多可以参考的案例,数据在客户端采集完之后,如果量比较小,我们可能直接在前端的API上做一次透传,然后持久化到RDBMS类型的数据库中就好了,通过Sql可以进行数据剖析。如果数据量很大,就须要一些中间件来辅助搜集和上传,然后分别将数据写入到在线和离线的系统中,比如先上传到Flume,Flume可以做数据的采集与聚合,再将Flume作为消息的生产者,将生产的消息数据通过Kafka Sink发布到Kafka中,Kafka作为消息队列的角色,可以对接前端的在线和离线估算平台。如下图所示:
引入Flume和Kafka的诱因有很多,比如她们可以处理大流量的数据、做数据聚合、保证数据不遗失等,但最关键的缘由是她们拥有高吞吐的能力。引入的组件多,系统的复杂性和成本也会相应的降低,上图中,Spark Streaming/Storm剖析完成之后,结果数据还须要引入另外的储存组件进行储存,比如HBase/MySQL,如果引入MySQL可能还须要再引入Redis做热点数据缓存,这样一来就愈加复杂了。
我们尝试一种基于TableStore和阿里云其他大数据产品的新方案,我们先看构架图:
图中关键路径剖析:
1、Web页、APP等客户端先通过埋点系统搜集数据,然后通过表格储存的SDK将数据写入TableStore的原创数据表。
2、MaxCompute直读TableStore原创数据表的数据进行剖析,然后QuickBI读取MaxCompute的数据进行展示,具体操作可参考:MaxCompute直读直写表格储存、QuickBI新建云数据源。
3、TableStore原创数据表中的数据可增量同步到ElasticSearch或则openSearch中,同步方式参考:TableStore数据同步到ElasticSearch,TableStore数据同步到OpenSearch。
4、TableStore中的数据可增量同步到Blink/Flink进行剖析,分析完之后的数据再写回TableStore的结果数据表中,DavaV读取结果数据表的数据进行展示。
新构架优势剖析:
1、客户端数据直读直写TableStore,不需要再引入API层进行数据透传,降低了复杂度,对于小型应用来说也降低了不少的服务器成本。
2、TableStore早已对接了丰富了大数据组件,包括阿里云的大数据产品和开源大数据产品,数据的同步与读写十分容易。
3、实时剖析与离线剖析后的结果数据再写回TableStore,DataV直接读取结果数据进行展示,因为TableStore具备高性能与高吞吐特性,不需要再引入Redis等缓存组件,可以简化整个系统。
直读直写安全问题:
关于数据直读直写TableStore,大家可能就会想到一个安全的问题,客户端直连TableStore不是要把AccessKey和AccessId曝露在客户端吗?答案是不用,我们使用STSToken授权访问TableStore,过程如下图所示:
TableStore提供的SDK都支持使用STS授权的形式进行访问,示例可参考TableStore NodeJs SDK使用STSToken,使用STS形式访问TableStore须要控制好授权策略,客户端不需要的插口请不要授权。
浏览器跨域访问TableStore:
如果在浏览器端直接访问TableStore,由于浏览器有同源策略的限制,会形成跨域问题。因为TableStore的EndPoint域名与用户Web站点的域名不同。解决这个问题的思路有两个:一是Web端不直接访问TableStore,改为先恳求自己的Web Server端,Web Server端再使用TableStore SDK来发起恳求,这样虽然就是前端访问了,问题解决了但也没了我们直读直写的优势;二是TableStore服务端通过某种形式直接支持js跨域恳求,这条路我们正在支持当中,当前处于开发阶段,支持的方法是cors合同支持跨域。但目前也有快捷的支持方法,如果您有浏览器直接访问TableStore的需求,可以直接联系我们,支持上去也很快。
总结
表格储存因其高性能、高吞吐、高可靠的特点,使得它在数据采集这种对前端吞吐要求很高的场景下特别适用,客户端数据直读直写表格储存,也为前端节约了中间层数据流转这一层服务,减少了复杂性也节约了成本。另外,表格储存对接了丰富的估算、分析、展示工具可以覆盖数据采集与剖析的几乎所有场景,本文所介绍的周边组件也只囊括了一部分,更多的示例与说明请参考表格储存用户手册。
使用SpreadJS 开发在线问卷系统,构筑CCP(云数据采集)平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-08-12 15:58
图片来自于网路
CCP(云数据采集)平台诞生于大数据时代的背景下,通过实时数据挖掘,在海量的云端数据中发觉隐藏其中的价值。
在线问卷系统,作为CCP(云数据采集)平台的信息采集接口,通过网路信息搜集,帮助问卷设计者和数据分析师剖析消费者在线上的行为特点和心态,批量而精确地抽取目标网页中的任何数据及任何信息,快速实现实时的信息获取。
CCP(云数据采集)平台的数据采集工作能够更简练、更方便、更精准的执行,取决于在线问卷系统的基本功能和构架。
因此,在线问卷系统通常需收录以下四个功能模块:在线设计问卷、数据搜集、数据剖析和导入。
在线问卷系统的基本功能模块
在线设计问卷需具备:
问卷设计方法简单、易操作
可自由地更改问卷外形、可制做带有公司Logo的问卷模板
项目类型丰富, 内置选择题、填空题、打分、排序、个人信息搜集等
应用场景广泛,可设计问卷调查、投票、满意度、表单、测评等模板
数据搜集需具备:
独有的自定义数据搜集渠道
支持手机端填写
支持无缝嵌入网站、APP和小程序
可通过第三方社交平台完成填写
数据剖析需具备:
调查数据可实时查看
支持表格、图表等多元化的数据展示
提供数据筛选、交叉剖析和原创数据下载
提高数据来源溯源,趋势一目了然
导出需具备:
支持导入为xlsx、CSV等格式
提供更安全的数据储存
不限发布数目,支持多并发
在线问卷系统的实现思路
因为须要对搜集到的问卷数据进行数据剖析,并导入剖析结果,所以系统须要支持图表、计算公式和在线导出导入功能。
在充分评估后,发现使用 SpreadJS控件,可以满足上述需求,原因如下:
可生成交叉图表:SpreadJS 提供了单向数据绑定的功能,可以将搜集的数据绑定至表格中,可以便捷的实现数据剖析及展示。
图1 生成交叉图表剖析页面
在线导出导入 Excel 文件:SpreadJS无需利用任何后台代码和第三方组件,可直接在浏览器中完成 Excel文件的导出导入、PDF 导出、打印及预览操作,解决了后端导入Excel、CSV文件的需求,方便用户将问卷统计剖析结果导入至本地,导出的文件对比疗效如下图所示:
图2 导出Excel文件对比
数据可视化:SpreadJS 支持 Excel 的 450 种公式和 32 种图表,可以帮助用户更全面的剖析采集到的数据。
图3 SpreadJS外置多种图表
数据筛选:从后台返回的数据,通过SpreadJS 在后端进行展示,并提供数据筛选、排序、分组、批注、切片器等操作,方便用户对统计结果进一步剖析。
图4 数据筛选
将 SpreadJS 的组件功能嵌入在线问卷系统,我们可以专注于业务逻辑,而不用分散关注点于基本的功能模块怎样实现。借助 SpreadJS 将问卷系统以组件化的形式构建,既增加了后期测试成本,明显减短了项目交付周期,也为项目二期奠定了良好的基础。
如果您也有这种系统开发的需求,请访问SpreadJS产品官网,查看应用场景和各种技术资源,可以为您的系统搭建提供帮助。 查看全部
什么是CCP(云数据采集)平台?
图片来自于网路
CCP(云数据采集)平台诞生于大数据时代的背景下,通过实时数据挖掘,在海量的云端数据中发觉隐藏其中的价值。
在线问卷系统,作为CCP(云数据采集)平台的信息采集接口,通过网路信息搜集,帮助问卷设计者和数据分析师剖析消费者在线上的行为特点和心态,批量而精确地抽取目标网页中的任何数据及任何信息,快速实现实时的信息获取。
CCP(云数据采集)平台的数据采集工作能够更简练、更方便、更精准的执行,取决于在线问卷系统的基本功能和构架。
因此,在线问卷系统通常需收录以下四个功能模块:在线设计问卷、数据搜集、数据剖析和导入。
在线问卷系统的基本功能模块
在线设计问卷需具备:
问卷设计方法简单、易操作
可自由地更改问卷外形、可制做带有公司Logo的问卷模板
项目类型丰富, 内置选择题、填空题、打分、排序、个人信息搜集等
应用场景广泛,可设计问卷调查、投票、满意度、表单、测评等模板
数据搜集需具备:
独有的自定义数据搜集渠道
支持手机端填写
支持无缝嵌入网站、APP和小程序
可通过第三方社交平台完成填写
数据剖析需具备:
调查数据可实时查看
支持表格、图表等多元化的数据展示
提供数据筛选、交叉剖析和原创数据下载
提高数据来源溯源,趋势一目了然
导出需具备:
支持导入为xlsx、CSV等格式
提供更安全的数据储存
不限发布数目,支持多并发
在线问卷系统的实现思路
因为须要对搜集到的问卷数据进行数据剖析,并导入剖析结果,所以系统须要支持图表、计算公式和在线导出导入功能。
在充分评估后,发现使用 SpreadJS控件,可以满足上述需求,原因如下:
可生成交叉图表:SpreadJS 提供了单向数据绑定的功能,可以将搜集的数据绑定至表格中,可以便捷的实现数据剖析及展示。
图1 生成交叉图表剖析页面
在线导出导入 Excel 文件:SpreadJS无需利用任何后台代码和第三方组件,可直接在浏览器中完成 Excel文件的导出导入、PDF 导出、打印及预览操作,解决了后端导入Excel、CSV文件的需求,方便用户将问卷统计剖析结果导入至本地,导出的文件对比疗效如下图所示:
图2 导出Excel文件对比
数据可视化:SpreadJS 支持 Excel 的 450 种公式和 32 种图表,可以帮助用户更全面的剖析采集到的数据。
图3 SpreadJS外置多种图表
数据筛选:从后台返回的数据,通过SpreadJS 在后端进行展示,并提供数据筛选、排序、分组、批注、切片器等操作,方便用户对统计结果进一步剖析。
图4 数据筛选
将 SpreadJS 的组件功能嵌入在线问卷系统,我们可以专注于业务逻辑,而不用分散关注点于基本的功能模块怎样实现。借助 SpreadJS 将问卷系统以组件化的形式构建,既增加了后期测试成本,明显减短了项目交付周期,也为项目二期奠定了良好的基础。
如果您也有这种系统开发的需求,请访问SpreadJS产品官网,查看应用场景和各种技术资源,可以为您的系统搭建提供帮助。
阿里云怎样打破Oracle迁移上云的壁垒
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-10 15:15
2018第九届中国数据库技术会议,阿里云数据库产品专家萧少聪带来以阿里云怎样打破Oracle迁移上云的壁垒为题的讲演。Oracle是指“数据库管理系统”,面对Oracle迁移上云的壁垒,阿里云怎样才能打破它呢?本文提出了Oracle 到云数据库PPAS迁移的方案,这种迁移方案为何比Oracle到 MySQL系列的迁移容易促使呢?答案正式出炉。
直播视频回顾
PPT下载请点击
以下是精彩视频内容整理:
Oracle数据库迁移方案
数据业务构架中就会有服务器、应用及数据库系统和储存系统三大块,服务器与储存系统上云是相对容易解决的,但在解决应用及数据库系统方面是有些难度的。于是,阿里云给出了里面的解决方案。在这个解决方案中,用户可以通过不同的方法,将数据库迁移到云上,我们可以继续在ECS中运行Oracle,也可以迁移到MySQL。当然也可以将应用及数据库系统迁移到云数据库PPAS版,借助其高度兼容Oracle的能力,降低用户迁移上云的难度,并减少系统常年运维的复杂性。
阿里云除了有同城容灾、自动备份、时间点恢复等这种部份会为云的用户去提供。阿里云数据库都会加入高可用的HA,它通常须要两个或两个以上的节点,进行复杂配置。而在阿里云,用户仅需点一下按键就可以有高可用的HA,而且这样的HA集群不单可以在同一数据中心上建立,同时也支持同城双中心异地容灾,同样一键布署完成。同时,阿里云还为用户提供ADAM(Advanced Database & Application Migration “亚当”)工具,以协助用户利用PPAS的Oracle兼容性进行快速迁移。那么接下来如何去迁移的各步骤应当怎样进行呢?
将ADAM采集 器安装在Oracle里面,ADMA将起到三个方面的作用:
Oracle迁移到PPAS相对迁移到其他数据库更为平滑,因为有许多兼容的地方。Oracle数据库到PPAS快速上云的过程中应做到兼容SQL、存储过程、包、DBMS等,因此适宜复杂事务事业务的迁移。云数据库PPAS版,提供最高 3TB的本地高性能储存(据悉这一空间有机会在年内突破到10TB以上)。如果业务数据超过本地储存容量大小,则可以通过OSS储存做外部表处理,如历史数据就可以储存到OSS外部表中,这些信息并不常使用,但对于数据剖析很重要。因此我们可以通过阿里云HybridDB for PostgreSQL,从OSS中直接获取数据进行业务剖析。HybridDB for PostgreSQL是基于开源Greenplum Database分布式MPP数据库的阿里云自有发布版,可实现业务实时剖析,计算节点、空间纵向扩充到PB级、特定场景下百亿记录order by
Oracle 数据库到 MySQL、PPAS的比较
为什么Oracle 数据库到 MySQL系列的迁移无法推进呢?原因是Oracle 数据库到 MySQL系列的迁移会导致ISV及企业迁移风险减小,在整个迁移过程中代码、存储过程以及架构需作出大的改动,这会导致研制重新学习、DBA重新学习、代码的句型重画甚至业务架构重画,最终导致业务风险减小、人力成本变高以及产品成本变高。
而Oracle 数据库到云数据库PPAS版是相对容易推进的,在推进过程中提升了Oracle迁移上云的成功率。研发可继续写Oracle句型因而减少迁移难度及工作量,阿里云可手动运维提升DBA SQL优化能力,代码的句型几乎不需改动,ADAM协助得以精准剖析。
为什么说PPAS兼容Oralce会更好呢?由上图可以看见MySOL与Oracle的交集面积比PostgreSQL与Oracle的交集面积都太小,这并不能达到预期的疗效。期望中云数据库PASS版疗效应该是Oracle的面积与PostgreSQL的面积几乎达到重合。
为什么会须要这么多的兼容部份呢?因为这样才会使企业的开发团队、原有的开发成果以及已有的应用快速的放在云里面去。例如,如果开发商开发的软件都是线下的,但顾客要求上云,到云里面又须要用到互联网思维,那么原有的储存模式都须要改动,为了维护云的构架线上、线下的结构都须要改动,这样会须要大量的人力成本。如果有一个功能直接兼容Oracle 的句型,这个时侯放在云里面去会降低整体的负担。
云数据库PPAS 到Oracle兼容的数据类型有许多种,例如,BLOB、CLOB、DATE等等。它们各自又有各自的别称与类型,例如 BLOB 的别称是LONG RAW,其类型是二进制数据。
ADAM可以协助用户Oracle数据库通过全量以及增量进行上云迁移,如果Oracle数据量很大,这里可能须要一个星期甚至一个月能够传输完。这时就可以通过高速联接以及高速通道降低带宽,不需要通过Internet,防止传输错的数据,同时也不会影响生产库。 通过ADAM平台Oracle数据到云数据库都会提供30天的回流机制,为用户提供迁移割接过程的最大保障。
云数据库PPAS除了是高可用,还支持同城容灾,在不降低任何费用成本的情况下,用户可以选择使用单可用县集群,或是使用多可用县(同城容灾)集群,以提供更有保障的企业级容灾需求保护。
云数据库PPAS 不只是手动备份,还送50%免费备份空间。例如用户订购实例储存空间为1TB,将直接附送500GB免费备份空间。
云数据库PPAS云化管理是按时间点进行实例克隆的,实例克隆功能将于2018年7月提供,并支持历时730天数据备份,当前只提供临时实例。
阿里云PostgreSQL生态系统
Oracle的应用可以迁移到云数据库PPAS版,PPAS通过高性能本地储存空间,以储存热点OLTP业务数据。历史信息储存到外部的OSS里面,OSS里面的数据可以直接被HybridDB for PostgreSQL读取使用,也就是说OLTP可以进行业务处理,OLAP可以直接通过基于开源Greenplum Database分布式MPP构架的阿里云数据库房服务HybridDB for PostgreSQL进行。
同时用户也可以保留原有Oracle系统,只将剖析业务转为使用HybridDB for PostgreSQL,其 OLAP性能优势如下如下:
HybridDB for PostgreSQL混合分区
储存可分为三种存储,分别为行式储存、列式储存以及OSS暖储存,这三种储存的介绍如下:
原文链接 查看全部
摘要: 2018第九届中国数据库技术会议,阿里云数据库产品专家萧少聪带来以阿里云怎样打破Oracle迁移上云的壁垒为题的讲演。Oracle是指“数据库管理系统”,面对Oracle迁移上云的壁垒,阿里云怎样才能打破它呢?本文提出了Oracle 到云数据库PPAS迁移的方案,这种迁移方案为何比Oracle到 MySQL系列的迁移容易促使呢?答案正式出炉。
2018第九届中国数据库技术会议,阿里云数据库产品专家萧少聪带来以阿里云怎样打破Oracle迁移上云的壁垒为题的讲演。Oracle是指“数据库管理系统”,面对Oracle迁移上云的壁垒,阿里云怎样才能打破它呢?本文提出了Oracle 到云数据库PPAS迁移的方案,这种迁移方案为何比Oracle到 MySQL系列的迁移容易促使呢?答案正式出炉。
直播视频回顾
PPT下载请点击
以下是精彩视频内容整理:
Oracle数据库迁移方案
数据业务构架中就会有服务器、应用及数据库系统和储存系统三大块,服务器与储存系统上云是相对容易解决的,但在解决应用及数据库系统方面是有些难度的。于是,阿里云给出了里面的解决方案。在这个解决方案中,用户可以通过不同的方法,将数据库迁移到云上,我们可以继续在ECS中运行Oracle,也可以迁移到MySQL。当然也可以将应用及数据库系统迁移到云数据库PPAS版,借助其高度兼容Oracle的能力,降低用户迁移上云的难度,并减少系统常年运维的复杂性。
阿里云除了有同城容灾、自动备份、时间点恢复等这种部份会为云的用户去提供。阿里云数据库都会加入高可用的HA,它通常须要两个或两个以上的节点,进行复杂配置。而在阿里云,用户仅需点一下按键就可以有高可用的HA,而且这样的HA集群不单可以在同一数据中心上建立,同时也支持同城双中心异地容灾,同样一键布署完成。同时,阿里云还为用户提供ADAM(Advanced Database & Application Migration “亚当”)工具,以协助用户利用PPAS的Oracle兼容性进行快速迁移。那么接下来如何去迁移的各步骤应当怎样进行呢?
将ADAM采集 器安装在Oracle里面,ADMA将起到三个方面的作用:
Oracle迁移到PPAS相对迁移到其他数据库更为平滑,因为有许多兼容的地方。Oracle数据库到PPAS快速上云的过程中应做到兼容SQL、存储过程、包、DBMS等,因此适宜复杂事务事业务的迁移。云数据库PPAS版,提供最高 3TB的本地高性能储存(据悉这一空间有机会在年内突破到10TB以上)。如果业务数据超过本地储存容量大小,则可以通过OSS储存做外部表处理,如历史数据就可以储存到OSS外部表中,这些信息并不常使用,但对于数据剖析很重要。因此我们可以通过阿里云HybridDB for PostgreSQL,从OSS中直接获取数据进行业务剖析。HybridDB for PostgreSQL是基于开源Greenplum Database分布式MPP数据库的阿里云自有发布版,可实现业务实时剖析,计算节点、空间纵向扩充到PB级、特定场景下百亿记录order by
Oracle 数据库到 MySQL、PPAS的比较
为什么Oracle 数据库到 MySQL系列的迁移无法推进呢?原因是Oracle 数据库到 MySQL系列的迁移会导致ISV及企业迁移风险减小,在整个迁移过程中代码、存储过程以及架构需作出大的改动,这会导致研制重新学习、DBA重新学习、代码的句型重画甚至业务架构重画,最终导致业务风险减小、人力成本变高以及产品成本变高。
而Oracle 数据库到云数据库PPAS版是相对容易推进的,在推进过程中提升了Oracle迁移上云的成功率。研发可继续写Oracle句型因而减少迁移难度及工作量,阿里云可手动运维提升DBA SQL优化能力,代码的句型几乎不需改动,ADAM协助得以精准剖析。
为什么说PPAS兼容Oralce会更好呢?由上图可以看见MySOL与Oracle的交集面积比PostgreSQL与Oracle的交集面积都太小,这并不能达到预期的疗效。期望中云数据库PASS版疗效应该是Oracle的面积与PostgreSQL的面积几乎达到重合。
为什么会须要这么多的兼容部份呢?因为这样才会使企业的开发团队、原有的开发成果以及已有的应用快速的放在云里面去。例如,如果开发商开发的软件都是线下的,但顾客要求上云,到云里面又须要用到互联网思维,那么原有的储存模式都须要改动,为了维护云的构架线上、线下的结构都须要改动,这样会须要大量的人力成本。如果有一个功能直接兼容Oracle 的句型,这个时侯放在云里面去会降低整体的负担。
云数据库PPAS 到Oracle兼容的数据类型有许多种,例如,BLOB、CLOB、DATE等等。它们各自又有各自的别称与类型,例如 BLOB 的别称是LONG RAW,其类型是二进制数据。
ADAM可以协助用户Oracle数据库通过全量以及增量进行上云迁移,如果Oracle数据量很大,这里可能须要一个星期甚至一个月能够传输完。这时就可以通过高速联接以及高速通道降低带宽,不需要通过Internet,防止传输错的数据,同时也不会影响生产库。 通过ADAM平台Oracle数据到云数据库都会提供30天的回流机制,为用户提供迁移割接过程的最大保障。
云数据库PPAS除了是高可用,还支持同城容灾,在不降低任何费用成本的情况下,用户可以选择使用单可用县集群,或是使用多可用县(同城容灾)集群,以提供更有保障的企业级容灾需求保护。
云数据库PPAS 不只是手动备份,还送50%免费备份空间。例如用户订购实例储存空间为1TB,将直接附送500GB免费备份空间。
云数据库PPAS云化管理是按时间点进行实例克隆的,实例克隆功能将于2018年7月提供,并支持历时730天数据备份,当前只提供临时实例。
阿里云PostgreSQL生态系统
Oracle的应用可以迁移到云数据库PPAS版,PPAS通过高性能本地储存空间,以储存热点OLTP业务数据。历史信息储存到外部的OSS里面,OSS里面的数据可以直接被HybridDB for PostgreSQL读取使用,也就是说OLTP可以进行业务处理,OLAP可以直接通过基于开源Greenplum Database分布式MPP构架的阿里云数据库房服务HybridDB for PostgreSQL进行。
同时用户也可以保留原有Oracle系统,只将剖析业务转为使用HybridDB for PostgreSQL,其 OLAP性能优势如下如下:
HybridDB for PostgreSQL混合分区
储存可分为三种存储,分别为行式储存、列式储存以及OSS暖储存,这三种储存的介绍如下:
原文链接
教程:黑科技之云蛛系统大数据解决方案-数据采集/传输/处理/展现全套流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2020-08-09 16:54
大数据处理,云蛛系统肯定是要有的,但是具体开发的日期,并没有最终确定。但是鉴于用户的强烈需求,蛛网时代总算将大数据处理工具的开发提上日程,并为之命名为DataCenter。为何命名为DataCenter呢,言外之意就是,您的数据中心所有处理,云蛛系统可以为您全部解决。
DataCenter+AutoBI+DataView,您的整套数据剖析系统就可以完整地搭建上去了,而且异常的简单。DataCenter给您做数据采集、传输、处理的工作,而AutoBI会做您的数据报表的工作,DataView做您的大屏诠释工作,是不是配合的太nice?
DataCenter 用自己agent采集相关数据,然后收归至Kafka集群中进行数据清洗处理,作为高可靠性传输,Kafka集群中还须要进行高性能算法的去重估算,之后数据经由转换层步入到数仓或则hadoop集群中,这就是整个ETL过程,也是天路系统的工作。之后就是调度-北斗系统的工作了。其会根据依赖关系,进行数据指标的估算。即日指标估算不完成,无法完成月指标的估算,如果指标估算有误,手工触发任务估算,是否会触发下游任务一并估算......整个核心就会在调度-北斗系统中彰显得淋淋尽致。经由调度估算HDFS数据吐入Hbase,数仓经由ODS层估算步入到诠释层,还有分布式查询ES......这些,凡是市面上最优的技术,或者您能想到的查询模式,DataCenter全部为您做好了。
之后就是DataView和AutoBI大显身手的时侯了,这两个产品线,不仅可以支持传统的关系型数据库,no sql数据库,诸如redis、mongodb等等全部支持,包括ES、rest这样的服务插口等等。因为走多样化的模式,只要现有技术能实现的,这两条产品线就会为您实现,而不需要您为了适应这两个产品线而去中转数据,一切云蛛系统全部为您适配好。因为是一家的产品,兼容性,么么哒!
怎么样?DataCenter算得上大数据处理界的黑科技了吧。而且全套流程,全部黑盒化,您只须要在web页面中配置好您的业务就好,剩下的系统全手动帮您处理。而作为其叔父,AutoBI和DataView更是将黑科技理念贯彻的淋淋尽致,无缝结合,完美展示,多维剖析......所有您能想到的要求,此两者就会帮您呈现。这就是黑科技-云蛛系统,为您提供的一整套大数据解决方案! 查看全部
黑科技的云蛛系统,一经问世,就赢得了满堂喝采。虽然主打的是数据可视化,但是好多用户用上以后都在问,你们是否会出大数据处理的产品,就像在好多用户眼中满满的黑科技-神策数据一样。如果大家出了,就可以解决我们整套数据流程的问题了。
大数据处理,云蛛系统肯定是要有的,但是具体开发的日期,并没有最终确定。但是鉴于用户的强烈需求,蛛网时代总算将大数据处理工具的开发提上日程,并为之命名为DataCenter。为何命名为DataCenter呢,言外之意就是,您的数据中心所有处理,云蛛系统可以为您全部解决。
DataCenter+AutoBI+DataView,您的整套数据剖析系统就可以完整地搭建上去了,而且异常的简单。DataCenter给您做数据采集、传输、处理的工作,而AutoBI会做您的数据报表的工作,DataView做您的大屏诠释工作,是不是配合的太nice?
DataCenter 用自己agent采集相关数据,然后收归至Kafka集群中进行数据清洗处理,作为高可靠性传输,Kafka集群中还须要进行高性能算法的去重估算,之后数据经由转换层步入到数仓或则hadoop集群中,这就是整个ETL过程,也是天路系统的工作。之后就是调度-北斗系统的工作了。其会根据依赖关系,进行数据指标的估算。即日指标估算不完成,无法完成月指标的估算,如果指标估算有误,手工触发任务估算,是否会触发下游任务一并估算......整个核心就会在调度-北斗系统中彰显得淋淋尽致。经由调度估算HDFS数据吐入Hbase,数仓经由ODS层估算步入到诠释层,还有分布式查询ES......这些,凡是市面上最优的技术,或者您能想到的查询模式,DataCenter全部为您做好了。
之后就是DataView和AutoBI大显身手的时侯了,这两个产品线,不仅可以支持传统的关系型数据库,no sql数据库,诸如redis、mongodb等等全部支持,包括ES、rest这样的服务插口等等。因为走多样化的模式,只要现有技术能实现的,这两条产品线就会为您实现,而不需要您为了适应这两个产品线而去中转数据,一切云蛛系统全部为您适配好。因为是一家的产品,兼容性,么么哒!
怎么样?DataCenter算得上大数据处理界的黑科技了吧。而且全套流程,全部黑盒化,您只须要在web页面中配置好您的业务就好,剩下的系统全手动帮您处理。而作为其叔父,AutoBI和DataView更是将黑科技理念贯彻的淋淋尽致,无缝结合,完美展示,多维剖析......所有您能想到的要求,此两者就会帮您呈现。这就是黑科技-云蛛系统,为您提供的一整套大数据解决方案!
云数据采集系统中云爬虫子系统的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-09 00:55
[摘要]: 随着Internet的迅猛发展和数据挖掘技术的发展,Internet上网页数据的价值日益突出. 现有的网络爬虫技术的缺点是不易于使用并且不容易为网络数据采集定制. 本文将云计算技术和Web爬虫技术相结合,基于软件即服务(SaaS)服务模型,设计并实现了云数据采集系统中的云爬虫子系统. 不同的用户可以根据自己的需求,方便地在云采集器子系统提供的独立采集器集群服务上执行数据采集任务. 为了实现分布式爬虫和SaaS模型的有机结合,本文主要研究云爬虫子系统中的两个关键问题: 爬虫节点管理和链接抓取任务调度. 在爬虫节点管理方面,提出了一种在etcd的辅助下的爬虫节点管理方案,该方案规定了子系统中所有爬虫节点的一系列共同行为,以便每个集群的爬虫节点可以混合部署. 互相替换. 该解决方案支持在运行时更新采集器节点配置,支持在运行时为每个采集器集群动态增加或减少节点,以及及时检测集群故障节点,以确保采集器集群服务的可靠性. 在链路爬取任务调度方面,提出了一种基于跳跃一致性哈希算法的改进的调度方案OJCH. OJCH使用跳转一致性哈希算法来计算节点,并获得与跳转一致性算法相似的性能,并使用重新哈希故障节点的方法来克服跳转一致性哈希无法处理任何节点故障的缺点. 已通过实验验证. 此外,本文还提出了一种支持定期链接提取任务的重复数据删除方案. 之后,本文给出了云爬虫子系统的总体设计方案以及每个功能模块的详细设计和实现,包括集群控制模块,网站服务模块,任务队列模块,任务调度模块,任务处理模块和节点管理模块. . 然后根据相关的测试案例对已实现的云爬虫子系统进行测试,并对云爬虫子系统的功能进行验证. 最后,总结全文.
如何开始迁移到云
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2020-08-07 03:06
要将应用程序和数据迁移到云,有必要制定详细的计划和时间表. 迁移是一个非常复杂的过程. 您可以从最简单的应用程序开始,然后考虑复杂和相关的相对较高的业务程度,一些个性化的企业应用程序等.
如上图(来自Internet的图片)所示,它描述了公司稳定进行云迁移的一般步骤. 迁移是一个系统的项目. 迁移速度过快通常会导致成本急剧上升,施工周期延迟甚至失败.
迁移到云的过程可以分为五个步骤. 请注意,这里的主要方案是企业私有云,并且所概括的步骤也适用于私有云,并且不太适合迁移到公共云. 让我们专注于迁移到云的五个阶段.
1. 标准化统一
企业的传统IT业务应用程序通常建立在物理服务器和存储设备上. 当开始进行云迁移时,通常会使用标准化技术来集成以前的服务器和存储资源. 评估需要迁移到云的现有和旧业务的迁移,并根据数据中心的资源状况制定详细的解决方案非常重要;如果是新的应用程序系统,则分配相应的资源,然后直接在计算环境中的云中进行部署. 对于任何想上云的企业来说,评估其实现的难度是评估云化或应用系统转换的风险和收益的重要手段. 整个业务系统的云化分析过程需要包括硬件支持环境转换,操作系统平台变更,平台软件绑定分析,IP地址依赖性消除,API重构,模块化转换,标准化转换,外部依赖性条件等,其中包括多个层次和维度,准确评估业务信息系统云转换的难点和相关困难,只有充分理解痛点,才能为信息系统的云转换做好准备.
当然,虚拟化和体系结构设计也是云业务系统现代化的一部分. 走向云与架构设计密不可分,因为业务最终将被云化. 无论迁移过程有多长,企业通常都使用虚拟服务器而不是物理服务器,并使用存储资源池来统一后端存储. 为了实现异构存储设备的管理,经常进行存储虚拟化和分布式转换. 当然,在此步骤中,它可能还涉及业务转换咨询和程序演示优化,并且您必须开始使用脚本或自动安装工具来适当减少工作量.
2. 购买或自行构建和部署云服务
虚拟化是迁移到云的第一步,迁移的第二步是部署私有云管理平台. 那么是购买还是构建和部署云服务呢?
来自云平台的成本和价值. VMWARE是商业软件. 它的成熟度和稳定性在实际环境中经受了很多考验,但是其高昂的使用成本反映在其许可费和服务费中. 与VMware昂贵的价格相比,OpenStack的免费和开放优势显而易见. VMware的高额投资带来的大多数功能OpenStack可以免费提供给客户. 因此,无论OpenStack还是VMware更有价值,这个问题都没有明确的答案,答案取决于企业实际部署的规模. 尽管OpenStack是免费使用的,但它需要该领域的专业开发人员和专家,并且在体系结构和构造上需要进行大量工作,因为它支持许多部署方案并且安装过程不同. VMware需要花费一些钱来购买许可证和服务,并且安装和运行相对容易. 另外,VMware的学习成本较低,并且操作和维护也很容易学习.
通常,基于上述分析,大型企业购买VMWARE平台更为稳定和可靠. 但是,OpenStack的入门门槛很高. 如果企业没有足够的技术能力储备,就无法解决OPENSTACK大规模部署中遇到的问题和陷阱.
构建私有云需要详细的计划,设计和实施. 在许多情况下,资源集成还包括管理概念的集成和集成. 在此步骤中,您还可以购买或使用一些公共云服务,例如一个或多个SAAS应用程序,开发和测试服务,云存储等. 混合云将公共云和私有云集成在一起,是主要模型和发展方向近年来的云计算. 我们知道私有云主要用于企业用户. 出于安全原因,企业更愿意将数据存储在私有云中,但同时,他们希望获得公共云计算资源以按需扩展. 在这种情况下,混合云随着越来越多的采用,它混合并匹配了公共云和私有云以获得最佳结果. 这种个性化的解决方案实现了节省资金和安全性的目的.
3. 应用程序迁移和数据迁移
部署云基础结构和服务后,有必要统一或升级现有的业务应用程序服务. 如前所述,此步骤可以首先将一些较简单的应用程序迁移到云中,然后逐步解决其余的复杂应用程序.
应用程序迁移的过程不仅仅是单击几个按钮的问题. 我们需要从云平台的环境特征入手,并对我们的产品进行某些调整. 例如,是否支持静默安装,磁盘空间的使用,参数设置应通过API或CLI进行,通过脚本命令或统一平台采集来跟踪和记录信息,等等.
数据迁移对于业务应用程序来说是最重要的事情,它与云上业务的成功或失败直接相关. 数据迁移将业务系统中很少使用或未使用的文件移动到辅助存储系统(例如磁带或光盘),同时将频繁使用的数据从热点迁移到高质量的存储设备(例如SSD或闪存阵列),有点像分层存储管理它. 通常,为了确保数据的安全性和完整性,我们的业务迁移工作通常与备份策略结合在一起,并备份重要数据. 还有一些业务系统会在迁移到云后转为O并用Mysql代替Oracle,这将涉及SQL语法调整,数据转换,新旧系统之间的交互,应用程序转换甚至重构等. 挑战相对较大. . 在迁移阶段需要充分考虑这些问题.
数据迁移的实现可以分为三个阶段: 数据迁移前的准备,数据迁移的实施以及数据迁移后的测试验证. 由于数据迁移的特性,准备阶段需要完成大量工作,充分而周到的准备工作是完成数据迁移的主要基础. 具体来说,对要迁移的数据源的详细描述(包括数据的存储方法,数据量和数据时间跨度);为新旧系统的数据库建立数据字典;对旧系统的历史数据进行质量分析,并对新旧系统的数据进行结构差异分析;分析新旧系统的代码数据之间的差异;建立新旧系统的数据库表之间的映射关系,处理无法映射的字段的方法; ETL工具的开发和部署,数据转换测试计划和验证程序的准备;数据开发紧急转换措施. 其中,数据迁移的实施是数据迁移三个阶段中最重要的环节. 它需要制定详细的实施步骤和数据转换流程;准备数据迁移环境;业务准备,结束未处理的业务事项或结束它们;测试数据迁移所涉及的技术;最后实现数据迁移.
数据迁移后的测试验证是为了检查迁移工作. 数据测试验证的结果是判断业务系统是否可以正式启动的重要基础. 可以通过质量检查工具或书面检查程序来执行数据验证,并且可以通过试用新系统的功能模块(尤其是查询和报告功能)来检查数据的准确性.
当然,为了确保数据迁移的质量和效率,一个好的迁移工具也是分不开的. 商业和开源产品各自具有不同的特性,必须根据特定条件对选择进行分析. 从目前的一些国内大型项目来看,相对成熟的ETL产品主要用于数据迁移. 实际上,我们还可以看到这些项目的一些共同点,主要包括: 迁移期间的大量历史数据,并且允许的停机时间非常长. 它很短,面对大量客户或用户,具有访问第三方系统的权限,一旦失败,影响将是广泛的.
目前,许多数据库供应商还提供相应的数据提取工具,例如Informix的InfoMover,Microsoft SQLServer的DTS和Oracle的Oracle Warehouse Builder. 这些工具解决了一定范围内的数据提取和转换问题,但是这些工具基本上不能自动完成数据提取. 用户还需要使用这些工具来编写适当的转换程序,以提高效率.
由于高度的业务耦合和对传统体系结构的高度依赖,企业中的应用也很复杂,并且通常需要大量的转换和发展. 例如,如果要替换特定的中间件,数据库和商业软件包,则可能需要几年才能完成此步骤. 由于时间相对较长且存在无法控制的风险,因此有必要从投资回报率和可行性方面仔细评估现有系统的迁移.
4. 全自动
在企业中,当将大量业务应用程序迁移到云时,使用云管理平台来自动化业务系统的配置,批准,服务交付,升级和监视变得更加重要. 不断自动化现有IT流程的转换至关重要. 从虚拟机和应用程序的在线资源预订到交付,我们希望将每个业务流程尽可能地自动化到云中,这可以大大缩短部署时间,减少人工成本并提高系统配置的准确性和一致性. 尽管基本自动化已经在标准化和统一阶段开始,但是在完全自动化阶段,需要将大量脚本,应用程序安装程序和自动化工具引入流程编排系统,在该系统中,云管理平台可以使用. 服务和工作流程设计.
5. 操作维护的安全性,冗余性和可持续性
传统的云服务通常需要经过多个环节的批准,例如资源供应,服务交付,运营和维护以及安全流程,因为其中许多流程都需要在云服务完成并在线自动之前进行修改. 交付需要IT安全人员必须预先授权或批准虚拟机模板,基于软件的网络,存储资源,操作系统,应用程序平台等. 在此阶段,还应考虑冗余和可扩展性,包括服务器,虚拟机的连续运行机器,应用程序和云管理平台,以防数据中心部分或完全故障. 在此阶段,还必须完全建立安全运营和IT治理. 最后,五步云迁移计划将使公司进入全面的云运维和维护状态.
业务云迁移是一个复杂的系统项目. 无论是旧应用程序还是构建新应用程序,云迁移团队都需要仔细考虑成本和操作是否与平台模型相匹配. 从当前阶段开始,应用程序分阶段迁移可能是唯一的选择. 目前,一些公司已成功使用此分阶段方法来更改其传统应用程序,并在从云计算中受益的同时最大程度地降低了风险. 将来这可能是云化的主题. 查看全部
在企业中,许多成功的迁移到云的案例都是从更简单的应用程序开始,然后逐步将更多的应用程序和数据迁移到云. 不可能同时传输所有应用程序. 过去迁移.
要将应用程序和数据迁移到云,有必要制定详细的计划和时间表. 迁移是一个非常复杂的过程. 您可以从最简单的应用程序开始,然后考虑复杂和相关的相对较高的业务程度,一些个性化的企业应用程序等.
如上图(来自Internet的图片)所示,它描述了公司稳定进行云迁移的一般步骤. 迁移是一个系统的项目. 迁移速度过快通常会导致成本急剧上升,施工周期延迟甚至失败.
迁移到云的过程可以分为五个步骤. 请注意,这里的主要方案是企业私有云,并且所概括的步骤也适用于私有云,并且不太适合迁移到公共云. 让我们专注于迁移到云的五个阶段.
1. 标准化统一
企业的传统IT业务应用程序通常建立在物理服务器和存储设备上. 当开始进行云迁移时,通常会使用标准化技术来集成以前的服务器和存储资源. 评估需要迁移到云的现有和旧业务的迁移,并根据数据中心的资源状况制定详细的解决方案非常重要;如果是新的应用程序系统,则分配相应的资源,然后直接在计算环境中的云中进行部署. 对于任何想上云的企业来说,评估其实现的难度是评估云化或应用系统转换的风险和收益的重要手段. 整个业务系统的云化分析过程需要包括硬件支持环境转换,操作系统平台变更,平台软件绑定分析,IP地址依赖性消除,API重构,模块化转换,标准化转换,外部依赖性条件等,其中包括多个层次和维度,准确评估业务信息系统云转换的难点和相关困难,只有充分理解痛点,才能为信息系统的云转换做好准备.
当然,虚拟化和体系结构设计也是云业务系统现代化的一部分. 走向云与架构设计密不可分,因为业务最终将被云化. 无论迁移过程有多长,企业通常都使用虚拟服务器而不是物理服务器,并使用存储资源池来统一后端存储. 为了实现异构存储设备的管理,经常进行存储虚拟化和分布式转换. 当然,在此步骤中,它可能还涉及业务转换咨询和程序演示优化,并且您必须开始使用脚本或自动安装工具来适当减少工作量.
2. 购买或自行构建和部署云服务
虚拟化是迁移到云的第一步,迁移的第二步是部署私有云管理平台. 那么是购买还是构建和部署云服务呢?
来自云平台的成本和价值. VMWARE是商业软件. 它的成熟度和稳定性在实际环境中经受了很多考验,但是其高昂的使用成本反映在其许可费和服务费中. 与VMware昂贵的价格相比,OpenStack的免费和开放优势显而易见. VMware的高额投资带来的大多数功能OpenStack可以免费提供给客户. 因此,无论OpenStack还是VMware更有价值,这个问题都没有明确的答案,答案取决于企业实际部署的规模. 尽管OpenStack是免费使用的,但它需要该领域的专业开发人员和专家,并且在体系结构和构造上需要进行大量工作,因为它支持许多部署方案并且安装过程不同. VMware需要花费一些钱来购买许可证和服务,并且安装和运行相对容易. 另外,VMware的学习成本较低,并且操作和维护也很容易学习.
通常,基于上述分析,大型企业购买VMWARE平台更为稳定和可靠. 但是,OpenStack的入门门槛很高. 如果企业没有足够的技术能力储备,就无法解决OPENSTACK大规模部署中遇到的问题和陷阱.
构建私有云需要详细的计划,设计和实施. 在许多情况下,资源集成还包括管理概念的集成和集成. 在此步骤中,您还可以购买或使用一些公共云服务,例如一个或多个SAAS应用程序,开发和测试服务,云存储等. 混合云将公共云和私有云集成在一起,是主要模型和发展方向近年来的云计算. 我们知道私有云主要用于企业用户. 出于安全原因,企业更愿意将数据存储在私有云中,但同时,他们希望获得公共云计算资源以按需扩展. 在这种情况下,混合云随着越来越多的采用,它混合并匹配了公共云和私有云以获得最佳结果. 这种个性化的解决方案实现了节省资金和安全性的目的.
3. 应用程序迁移和数据迁移
部署云基础结构和服务后,有必要统一或升级现有的业务应用程序服务. 如前所述,此步骤可以首先将一些较简单的应用程序迁移到云中,然后逐步解决其余的复杂应用程序.
应用程序迁移的过程不仅仅是单击几个按钮的问题. 我们需要从云平台的环境特征入手,并对我们的产品进行某些调整. 例如,是否支持静默安装,磁盘空间的使用,参数设置应通过API或CLI进行,通过脚本命令或统一平台采集来跟踪和记录信息,等等.
数据迁移对于业务应用程序来说是最重要的事情,它与云上业务的成功或失败直接相关. 数据迁移将业务系统中很少使用或未使用的文件移动到辅助存储系统(例如磁带或光盘),同时将频繁使用的数据从热点迁移到高质量的存储设备(例如SSD或闪存阵列),有点像分层存储管理它. 通常,为了确保数据的安全性和完整性,我们的业务迁移工作通常与备份策略结合在一起,并备份重要数据. 还有一些业务系统会在迁移到云后转为O并用Mysql代替Oracle,这将涉及SQL语法调整,数据转换,新旧系统之间的交互,应用程序转换甚至重构等. 挑战相对较大. . 在迁移阶段需要充分考虑这些问题.
数据迁移的实现可以分为三个阶段: 数据迁移前的准备,数据迁移的实施以及数据迁移后的测试验证. 由于数据迁移的特性,准备阶段需要完成大量工作,充分而周到的准备工作是完成数据迁移的主要基础. 具体来说,对要迁移的数据源的详细描述(包括数据的存储方法,数据量和数据时间跨度);为新旧系统的数据库建立数据字典;对旧系统的历史数据进行质量分析,并对新旧系统的数据进行结构差异分析;分析新旧系统的代码数据之间的差异;建立新旧系统的数据库表之间的映射关系,处理无法映射的字段的方法; ETL工具的开发和部署,数据转换测试计划和验证程序的准备;数据开发紧急转换措施. 其中,数据迁移的实施是数据迁移三个阶段中最重要的环节. 它需要制定详细的实施步骤和数据转换流程;准备数据迁移环境;业务准备,结束未处理的业务事项或结束它们;测试数据迁移所涉及的技术;最后实现数据迁移.
数据迁移后的测试验证是为了检查迁移工作. 数据测试验证的结果是判断业务系统是否可以正式启动的重要基础. 可以通过质量检查工具或书面检查程序来执行数据验证,并且可以通过试用新系统的功能模块(尤其是查询和报告功能)来检查数据的准确性.
当然,为了确保数据迁移的质量和效率,一个好的迁移工具也是分不开的. 商业和开源产品各自具有不同的特性,必须根据特定条件对选择进行分析. 从目前的一些国内大型项目来看,相对成熟的ETL产品主要用于数据迁移. 实际上,我们还可以看到这些项目的一些共同点,主要包括: 迁移期间的大量历史数据,并且允许的停机时间非常长. 它很短,面对大量客户或用户,具有访问第三方系统的权限,一旦失败,影响将是广泛的.
目前,许多数据库供应商还提供相应的数据提取工具,例如Informix的InfoMover,Microsoft SQLServer的DTS和Oracle的Oracle Warehouse Builder. 这些工具解决了一定范围内的数据提取和转换问题,但是这些工具基本上不能自动完成数据提取. 用户还需要使用这些工具来编写适当的转换程序,以提高效率.
由于高度的业务耦合和对传统体系结构的高度依赖,企业中的应用也很复杂,并且通常需要大量的转换和发展. 例如,如果要替换特定的中间件,数据库和商业软件包,则可能需要几年才能完成此步骤. 由于时间相对较长且存在无法控制的风险,因此有必要从投资回报率和可行性方面仔细评估现有系统的迁移.
4. 全自动
在企业中,当将大量业务应用程序迁移到云时,使用云管理平台来自动化业务系统的配置,批准,服务交付,升级和监视变得更加重要. 不断自动化现有IT流程的转换至关重要. 从虚拟机和应用程序的在线资源预订到交付,我们希望将每个业务流程尽可能地自动化到云中,这可以大大缩短部署时间,减少人工成本并提高系统配置的准确性和一致性. 尽管基本自动化已经在标准化和统一阶段开始,但是在完全自动化阶段,需要将大量脚本,应用程序安装程序和自动化工具引入流程编排系统,在该系统中,云管理平台可以使用. 服务和工作流程设计.
5. 操作维护的安全性,冗余性和可持续性
传统的云服务通常需要经过多个环节的批准,例如资源供应,服务交付,运营和维护以及安全流程,因为其中许多流程都需要在云服务完成并在线自动之前进行修改. 交付需要IT安全人员必须预先授权或批准虚拟机模板,基于软件的网络,存储资源,操作系统,应用程序平台等. 在此阶段,还应考虑冗余和可扩展性,包括服务器,虚拟机的连续运行机器,应用程序和云管理平台,以防数据中心部分或完全故障. 在此阶段,还必须完全建立安全运营和IT治理. 最后,五步云迁移计划将使公司进入全面的云运维和维护状态.
业务云迁移是一个复杂的系统项目. 无论是旧应用程序还是构建新应用程序,云迁移团队都需要仔细考虑成本和操作是否与平台模型相匹配. 从当前阶段开始,应用程序分阶段迁移可能是唯一的选择. 目前,一些公司已成功使用此分阶段方法来更改其传统应用程序,并在从云计算中受益的同时最大程度地降低了风险. 将来这可能是云化的主题.
阿里云InfluxDB®数据采集服务的优势
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-08-07 00:24
背景
随着时间序列数据的快速增长,时间序列数据库不仅需要解决系统的稳定性和性能问题,还需要实现数据采集与分析之间的联系,使时间序列数据能够真正生成. 值. 在时间序列数据采集领域,一直缺乏自动采集工具. 尽管用户可以使用某些开源采集工具来实现数据采集,例如Telegraf,Logstash和TCollector等,但是这些采集工具需要用户构建和维护其操作环境,这增加了用户的学习成本并大大增加了数据收款门槛. 另一方面,现有的采集工具缺乏对多个采集源的自动管理,用户难以统一管理多个不同的采集源,难以监控每个采集工具是否正常运行并实时采集数据.
阿里云InfluxDB®不仅提供稳定可靠的时间序列数据库服务,而且还提供非常方便的数据采集服务. 用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据将自动存储在阿里云InfluxDB®中. 用户无需担心操作维护,实现从数据采集到分析的一站式服务. 本文主要介绍如何使用InfluxDB®的数据采集服务来实现从采集到存储的数据自动管理.
阿里云InfluxDB®数据采集服务的优势我们该怎么办? 1.轻松采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,包括MySQL,Redis,MongoDB和系统监视. 对于每种类型的数据,将采集多个监视指标,以帮助用户更全面地了解受监视对象. 通过InfluxDB®实例的管理控制台,用户可以添加新的集合源,一键安装,而无需编写代码.
采集数据的操作过程如下:
2. 实时监控采集源
在采集源运行期间,您可以实时监视数据采集的状态,并检查采集的数据最后到达InfluxDB®的时间;另外,您可以随时停止数据采集,并在认为适当时重新启动它.
3. 一键切换采集数据的类型
如果要更改受监视机器上的采集数据的类型,则无需添加新的采集源,只需选择所需的采集配置,数据采集工具将自动切换以采集监视数据您指定.
4. 采集的数据自动存储在InfluxDB®中.
您可以在采集配置中选择用于数据流入的数据库和保留策略,数据采集工具将自动将采集的数据存储到指定的数据库和保留策略中,并且可以在采集源为正在运行只需要修改采集配置.
最佳做法
本节将介绍如何采集系统监视数据并实时显示采集的结果. 系统监视的数据包括处理器,磁盘,内存,网络,进程和系统信息. 采集的数据存储在8种不同的度量中(度量包括cpu,磁盘,diskio,mem,net,进程,交换和系统). 在开始之前,请确保已成功创建数据库,并且已经成功创建了具有数据库读写权限的用户帐户.
1. 创建用于采集系统监视数据的配置
在InfluxDB®管理控制台的左侧导航栏中单击“添加采集配置”,以进入采集配置添加界面,如下图所示. 填写“采集配置名称”,选择“采集的数据类型”作为“系统监视”,然后选择“授权帐户”,“数据写入数据库”和“数据库存储策略”,并填写“授权密码” . 单击“添加”以成功创建集合配置.
2. 添加采集源
在InfluxDB®管理控制台的左侧导航栏中单击“添加集合源”,以进入用于添加集合源的页面.
(1)选择网络类型“公共网络”或“专用网络”,然后单击“下一步”,如下图所示.
(2)在数据源所在的主机上安装采集工具. 将安装命令复制到主机以运行采集工具. 采集工具运行后,它将与InfluxDB®建立连接. 您可以在“新采集源扫描结果列表”上看到新添加的采集源. 如果未显示在列表中,则可以单击“刷新”或“自动刷新”. 如下所示.
(3)选择采集系统监视的数据. 在上图中,单击“选择采集配置”以进入以下界面,然后从下拉框中选择刚刚创建的名为“ collect-system”的采集配置. 选择后,单击“保存”.
(4)开始数据采集. 选中需要启动的采集源,然后单击“完成并开始采集”,采集工具可以开始在采集源上采集数据,如下图所示.
3. 查看数据采集状态
在“集合源列表”中,您可以看到连接到InfluxDB®实例的所有集合源,如下图所示. 每个集合源均由uuid唯一标识. “采集状态”为“正在运行”,这意味着采集工具正在采集数据并将其报告给InfluxDB®. “最新的采集和报告成功时间”是指最后一次将采集的数据成功发送到InfluxDB®的时间.
4. 使用Grafana可视化数据采集
(1)安装Grafana. 请参阅有关如何安装Grafana的文档.
(2)添加数据源. 设置“ URL”作为InfluxDB®实例的地址,并填写写入采集的数据的数据库和用户帐户,如下图所示.
(3)配置仪表板并编写查询规则. 这里的演示是查询磁盘使用率,查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示.
您可以根据实际需要查看其他度量和字段的数据,并分别在FROM和SELECT语句中指定它们.
摘要
阿里云InfluxDB®提供方便,快捷的数据采集服务,自动化数据源管理,帮助您解决数据采集问题,并实现数据采集到存储的自动化. 将来,我们将支持采集更多数据类型和指标,敬请期待.
原创链接 查看全部
行业解决方案和产品招募!如果您想赚钱就通过它! >>>
背景
随着时间序列数据的快速增长,时间序列数据库不仅需要解决系统的稳定性和性能问题,还需要实现数据采集与分析之间的联系,使时间序列数据能够真正生成. 值. 在时间序列数据采集领域,一直缺乏自动采集工具. 尽管用户可以使用某些开源采集工具来实现数据采集,例如Telegraf,Logstash和TCollector等,但是这些采集工具需要用户构建和维护其操作环境,这增加了用户的学习成本并大大增加了数据收款门槛. 另一方面,现有的采集工具缺乏对多个采集源的自动管理,用户难以统一管理多个不同的采集源,难以监控每个采集工具是否正常运行并实时采集数据.
阿里云InfluxDB®不仅提供稳定可靠的时间序列数据库服务,而且还提供非常方便的数据采集服务. 用户可以轻松查看每个采集源的运行状态并进行管理,采集的数据将自动存储在阿里云InfluxDB®中. 用户无需担心操作维护,实现从数据采集到分析的一站式服务. 本文主要介绍如何使用InfluxDB®的数据采集服务来实现从采集到存储的数据自动管理.
阿里云InfluxDB®数据采集服务的优势我们该怎么办? 1.轻松采集数据
目前,阿里云InfluxDB®支持采集四种不同类型的数据,包括MySQL,Redis,MongoDB和系统监视. 对于每种类型的数据,将采集多个监视指标,以帮助用户更全面地了解受监视对象. 通过InfluxDB®实例的管理控制台,用户可以添加新的集合源,一键安装,而无需编写代码.
采集数据的操作过程如下:
2. 实时监控采集源
在采集源运行期间,您可以实时监视数据采集的状态,并检查采集的数据最后到达InfluxDB®的时间;另外,您可以随时停止数据采集,并在认为适当时重新启动它.
3. 一键切换采集数据的类型
如果要更改受监视机器上的采集数据的类型,则无需添加新的采集源,只需选择所需的采集配置,数据采集工具将自动切换以采集监视数据您指定.
4. 采集的数据自动存储在InfluxDB®中.
您可以在采集配置中选择用于数据流入的数据库和保留策略,数据采集工具将自动将采集的数据存储到指定的数据库和保留策略中,并且可以在采集源为正在运行只需要修改采集配置.
最佳做法
本节将介绍如何采集系统监视数据并实时显示采集的结果. 系统监视的数据包括处理器,磁盘,内存,网络,进程和系统信息. 采集的数据存储在8种不同的度量中(度量包括cpu,磁盘,diskio,mem,net,进程,交换和系统). 在开始之前,请确保已成功创建数据库,并且已经成功创建了具有数据库读写权限的用户帐户.
1. 创建用于采集系统监视数据的配置
在InfluxDB®管理控制台的左侧导航栏中单击“添加采集配置”,以进入采集配置添加界面,如下图所示. 填写“采集配置名称”,选择“采集的数据类型”作为“系统监视”,然后选择“授权帐户”,“数据写入数据库”和“数据库存储策略”,并填写“授权密码” . 单击“添加”以成功创建集合配置.
2. 添加采集源
在InfluxDB®管理控制台的左侧导航栏中单击“添加集合源”,以进入用于添加集合源的页面.
(1)选择网络类型“公共网络”或“专用网络”,然后单击“下一步”,如下图所示.
(2)在数据源所在的主机上安装采集工具. 将安装命令复制到主机以运行采集工具. 采集工具运行后,它将与InfluxDB®建立连接. 您可以在“新采集源扫描结果列表”上看到新添加的采集源. 如果未显示在列表中,则可以单击“刷新”或“自动刷新”. 如下所示.
(3)选择采集系统监视的数据. 在上图中,单击“选择采集配置”以进入以下界面,然后从下拉框中选择刚刚创建的名为“ collect-system”的采集配置. 选择后,单击“保存”.
(4)开始数据采集. 选中需要启动的采集源,然后单击“完成并开始采集”,采集工具可以开始在采集源上采集数据,如下图所示.
3. 查看数据采集状态
在“集合源列表”中,您可以看到连接到InfluxDB®实例的所有集合源,如下图所示. 每个集合源均由uuid唯一标识. “采集状态”为“正在运行”,这意味着采集工具正在采集数据并将其报告给InfluxDB®. “最新的采集和报告成功时间”是指最后一次将采集的数据成功发送到InfluxDB®的时间.
4. 使用Grafana可视化数据采集
(1)安装Grafana. 请参阅有关如何安装Grafana的文档.
(2)添加数据源. 设置“ URL”作为InfluxDB®实例的地址,并填写写入采集的数据的数据库和用户帐户,如下图所示.
(3)配置仪表板并编写查询规则. 这里的演示是查询磁盘使用率,查询语句为:
SELECT MEAN("used_percent") FROM "disk" GROUP BY time(10s)
实时查询结果如下图所示.
您可以根据实际需要查看其他度量和字段的数据,并分别在FROM和SELECT语句中指定它们.
摘要
阿里云InfluxDB®提供方便,快捷的数据采集服务,自动化数据源管理,帮助您解决数据采集问题,并实现数据采集到存储的自动化. 将来,我们将支持采集更多数据类型和指标,敬请期待.
原创链接
历史上最全面的企业云流程的详细信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-06 14:18
“企业上云”的步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
1. 转到云计划
1. 信息采集
“企业云”需要严格而细致的研究工作. 它需要采集硬件和网络环境信息,当前和将来的业务需求,系统配置信息,应用程序系统信息,数据风险等.
2,需求评估
从业务需求的角度,分析每个业务的当前状态,存在的问题,是否可以被云计算以及业务的未来发展需求,并为每个业务系统的迁移目标定制.
从系统的角度分析每个系统的当前状态,包括主机,存储,网络和安全性,分析系统中的问题,并根据评估结果进行计划.
从企业自身的信息化水平的角度进行分析. 对于具有信息化基础,信息系统硬件环境以及维护和开发团队的公司,他们可以根据其开发计划逐渐迁移新旧系统. 对于非信息型企业,根据迫切需要解决的问题,加快相关应用程序的启动.
3. 应用分析
<p>应用程序分析是成功进入云并减少业务停机时间的关键. 根据业务负载,特征,复杂性和相关性分析,确定并量化业务云风险可能对业务造成的影响和损失,从而确定业务云的优先级范围和云云策略. 查看全部
“企业云”是指企业通过智能高速互联网将其基本系统,服务和平台部署到云中,并使用网络轻松获得诸如计算,存储,数据和应用程序之类的服务. 有利于减少企业的信息化建设成本,建设工业互联网创新发展生态,促进实现整个制造过程,整个产业链和整个产品生命周期的优化,提高企业的发展水平. 制造业和互联网的整合.
“企业上云”的步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
1. 转到云计划
1. 信息采集
“企业云”需要严格而细致的研究工作. 它需要采集硬件和网络环境信息,当前和将来的业务需求,系统配置信息,应用程序系统信息,数据风险等.
2,需求评估
从业务需求的角度,分析每个业务的当前状态,存在的问题,是否可以被云计算以及业务的未来发展需求,并为每个业务系统的迁移目标定制.
从系统的角度分析每个系统的当前状态,包括主机,存储,网络和安全性,分析系统中的问题,并根据评估结果进行计划.
从企业自身的信息化水平的角度进行分析. 对于具有信息化基础,信息系统硬件环境以及维护和开发团队的公司,他们可以根据其开发计划逐渐迁移新旧系统. 对于非信息型企业,根据迫切需要解决的问题,加快相关应用程序的启动.
3. 应用分析
<p>应用程序分析是成功进入云并减少业务停机时间的关键. 根据业务负载,特征,复杂性和相关性分析,确定并量化业务云风险可能对业务造成的影响和损失,从而确定业务云的优先级范围和云云策略.
我的小企业云经验
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-06 14:18
当前,以IT技术为主角的技术革命正在汹涌澎.. 云计算,大数据,人工智能,物联网和区块链等新技术正在加速其应用. 在这些新技术中,作为基础设施的云计算是这场技术革命的载体平台,并全面支持各种新技术和新应用. 随着这一波浪潮的发展,数字经济已成为一种发展趋势,所有企业都在进行或正在为数字化转型做准备,而走向云化是企业数字化转型的起点.
什么是企业云?
简而言之,“企业云”是将企业的所有内容迁移到云中,其主要内容包括下图所示的四个类别:
“企业云”是一个系统工程,其步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
简而言之,走向云是公司顺应数字经济发展趋势,加速数字,网络和智能转型,提高其创新能力,业务实力和发展水平的重要途径.
为什么公司要使用云?
企业云是企业实现数字化转型的第一步. 它将为企业带来很多好处,主要包括以下几个方面:
HH Group的云之旅构建了一个在两个地方拥有三个中心的基本云平台
YJ Cloud团队花了大约一年的时间从零开始在分布在BJ和HK的HH Group的三个数据中心中启动了一个新的基本云平台. 具有以下特点:
建立企业云迁移的总体目标
2017年下半年,HH集团发布了集团所有企业云化的总体目标,即到2018年6月30日,实现HH集团三个中心在两个地方的系统的全面云化. 除了无法云计算的系统之外,所有其他系统都必须是云计算的. 总体云化率不低于80%.
建立特殊组织
YJ Technology Co.,Ltd.(以下简称“ YJ Technology”)是HH集团旗下的数字基础设施运营和智能信息服务提供商. 它是HH Group云任务的组织和实施单位. 为了实施企业云项目,YJ Technology建立了专门的组织,如下图所示:
“自上而下”跨组成员单位的沟通与协调
由于涉及到许多小组成员,因此充分的沟通是必不可少的,甚至可能决定项目的成败. 一般而言,我们采用了“自上而下”的沟通策略. 在小组文件的指导下,公司负责人直接与每个业务部门的IT负责人进行亲自沟通,原则上达成协议后,由特定的工作小组负责实际工作.
Mopai业务系统
整理出当前不在云中的所有业务系统,并进行整理. 一些系统示例如下:
要为每个业务系统采集的关键信息包括: 系统名称,业务单位,托管方法,机器类型(虚拟机|物理机器),系统IP,机器IP,系统级别,操作系统,应用程序类型,IP功能是否更改,是否有开发人员支持,当前资源,云上所需的建议资源,更改窗口,是否依赖特定的外部设备等.
要迁移的业务系统的云化评估
对所有采集的业务系统进行云化评估,包括:
云化模式评估: 根据系统情况,初步确定云化迁移模式,并在新迁移,克隆迁移和主动-主动迁移三种迁移方案中选择最合适的一种. 其主要目的是与业务系统用户进行通信并评估迁移工作量. 评估云化所需的资源: 包括CPU,内存,网络,存储和其他资源. 其主要目的是评估迁移所需的资源并制定设备补充计划. 制定项目计划
全面考虑总体目标,系统规划结果,云评估结果,与成员单位的沟通结果,迁移工作量的R&D评估结果,可用人力资源,可用云资源,设备采购周期等因素,制定总体项目计划
研发迁移计划
根据要迁移的应用系统的情况,我们制定了三个云迁移计划,即新迁移,克隆迁移和主动-主动迁移.
对于数据库系统迁移,需要考虑数据库类型和版本,例如Oracle,SQLServer和MySQL. 以Oracle为例,数据库迁移团队已经制定了以下迁移计划:
根据组存储的当前情况,制定了存储优化计划,目标是构建“分布式存储+集中存储”混合存储计划. 如下图所示:
研发迁移工具
我们已经针对各种系统需求开发了各种迁移工具. 例如,基于VMware Converter开发从物理机系统到虚拟机的映像转换工具.
云端实施系统
应用程序迁移组和数据库迁移组负责在系统上实施云迁移. 以一个重要的OA系统为例. 这是该组所有员工每天都在使用的办公系统. 它具有大量的用户,非常重要,无法关闭. 下图是迁移过程的示意图:
这里有几个关键点:
经验总结需要合适的云平台
根据企业的当前情况,需求和未来发展需求选择合适的云平台. 至少需要考虑以下几点:
参考云平台架构如下图所示:
需要合适的云服务提供商
具有技术,产品,业务理解和经验的云服务提供商可以使企业的云之旅更加顺畅. 企业在选择云服务提供商时会考虑以下方面:
需要多个相关技术团队参加
企业云迁移不仅是运维团队和迁移团队的事.
有必要全面评估云计划和工具开发
走向云的企业需要全面的解决方案和各种工具. 根据业务系统要求,选择最合理的迁移计划,例如新迁移,克隆迁移和双活迁移. 必须有完整的迁移工具,包括应用程序迁移工具,数据库迁移工具,存储迁移工具等. 这些工具还需要满足要求,例如操作系统(包括操作系统和版本),系统配置(例如支持LVM卷) )和系统启动方法(例如BIOS和UEFI).
在开始系统迁移之前,请全面测试程序和工具. 开始正式迁移后,我们必须首先执行低优先级的系统迁移,再次验证这些程序和工具,然后根据需要进行优化.
需要稳定有序地进行
企业迁移到云不可能一次性完成,而应该有序,稳定地进行.
需要充分考虑安全要求
企业必须具有足够的安全性考虑因素才能使用云. 将业务迁移到云中后,公司可能会面临安全问题. 云服务提供商需要根据企业用户业务和系统数据的特征设计整个系统的安全体系结构,以最大程度地降低安全风险,例如DDoS攻击,安全入侵和数据泄漏. 安全团队必须审查云上业务系统的部署体系结构. 上线后,必须加强安全监控,以发现并及时处理各种问题.
需要考虑各种因素,例如技术,成本,团队和业务.
企业在迁移到云时不仅可以考虑技术因素. 企业的云迁移涉及多种因素,需要考虑的因素很多,其中很多都是非技术因素.
企业云与云团队培训相结合
对于许多公司,尤其是传统公司而言,通常很难在短时间内建立成熟且功能齐全的云团队. 但是,对于云平台和云业务而言,独立和可控是许多企业的重要要求之一. 因此,可以将两者完全结合.
上云只是起点,而不是终点
云只是起点,而不是终点. 为了实现云转型,企业通常需要经历三个阶段: 云IT(信息技术),云DT(数据技术)和云DI(数据智能).
上云有助于传统企业的数字化转型
企业数字化转型是一项系统工程. 如下图所示,从下到上分别是IT模型转换,应用程序模型转换和迁移,组织模型转换和业务模型转换. 此级别通常是发生的顺序,并且也相互依赖.
第一步,需要将企业的传统IT模型转换为基本的云模型. 这也是企业云迁移的第一步. 传统的IT模型通常使用虚拟化技术为物理机和商用虚拟机提供计算资源. 和商用SAN存储来提供存储资源. 在虚拟化平台上,正在运行各种整体应用程序,这些应用程序通常使用大型商业数据库,例如Oracle和SQL Server. 相比之下,新的基础云IT模型使用基础云平台和大数据平台,以开源虚拟机为主体,以商业虚拟机为补充;以分布式存储为主体,以SAN存储为补充;开源数据库与商业数据库的结合;传统的单一应用程序和新的云应用程序共存. 在进一步开发的云原生IT模型中,容器云平台,AI平台和大数据平台是支持平台,容器是应用程序载体,而DevOps是应用程序开发模型.
随着IT模型和应用程序模型的发展,企业将需要进行应用程序迁移和数据迁移以及应用程序开发模型. 同时,企业的组织模式也需要从传统的多层次团队模型向扁平化互联网模型转变.
通过这一系列深入的IT和组织结构转换,企业的业务为从传统业务模型到数字业务模型的转变奠定了基础.
谢谢您的阅读,欢迎关注我的官方帐户: 查看全部
作者注: 几天前,工业和信息化部发布了《促进企业云的实施指南(2018-2020年)》,其中指出: 到2020年,我们将努力进一步优化云环境. 企业的认知度和热情将大大提高,云应用的比例和应用深度也将显着提高. 云计算在企业生产,运营和管理中的应用已经广泛普及. 全国有100万新云企业,形成了100多个典型基准应用案例,形成了一批有影响力的Driven云平台和企业云体验中心. 统计数据显示,当前传统企业用户使用“云”的比例仅为20%,仍然有70%以上的传统企业用户不使用“云”. 本文是HH集团企业云项目技术负责人完成该项目后对本企业云项目过程的总结和思考.
当前,以IT技术为主角的技术革命正在汹涌澎.. 云计算,大数据,人工智能,物联网和区块链等新技术正在加速其应用. 在这些新技术中,作为基础设施的云计算是这场技术革命的载体平台,并全面支持各种新技术和新应用. 随着这一波浪潮的发展,数字经济已成为一种发展趋势,所有企业都在进行或正在为数字化转型做准备,而走向云化是企业数字化转型的起点.
什么是企业云?
简而言之,“企业云”是将企业的所有内容迁移到云中,其主要内容包括下图所示的四个类别:
“企业云”是一个系统工程,其步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
简而言之,走向云是公司顺应数字经济发展趋势,加速数字,网络和智能转型,提高其创新能力,业务实力和发展水平的重要途径.
为什么公司要使用云?
企业云是企业实现数字化转型的第一步. 它将为企业带来很多好处,主要包括以下几个方面:
HH Group的云之旅构建了一个在两个地方拥有三个中心的基本云平台
YJ Cloud团队花了大约一年的时间从零开始在分布在BJ和HK的HH Group的三个数据中心中启动了一个新的基本云平台. 具有以下特点:
建立企业云迁移的总体目标
2017年下半年,HH集团发布了集团所有企业云化的总体目标,即到2018年6月30日,实现HH集团三个中心在两个地方的系统的全面云化. 除了无法云计算的系统之外,所有其他系统都必须是云计算的. 总体云化率不低于80%.
建立特殊组织
YJ Technology Co.,Ltd.(以下简称“ YJ Technology”)是HH集团旗下的数字基础设施运营和智能信息服务提供商. 它是HH Group云任务的组织和实施单位. 为了实施企业云项目,YJ Technology建立了专门的组织,如下图所示:
“自上而下”跨组成员单位的沟通与协调
由于涉及到许多小组成员,因此充分的沟通是必不可少的,甚至可能决定项目的成败. 一般而言,我们采用了“自上而下”的沟通策略. 在小组文件的指导下,公司负责人直接与每个业务部门的IT负责人进行亲自沟通,原则上达成协议后,由特定的工作小组负责实际工作.
Mopai业务系统
整理出当前不在云中的所有业务系统,并进行整理. 一些系统示例如下:
要为每个业务系统采集的关键信息包括: 系统名称,业务单位,托管方法,机器类型(虚拟机|物理机器),系统IP,机器IP,系统级别,操作系统,应用程序类型,IP功能是否更改,是否有开发人员支持,当前资源,云上所需的建议资源,更改窗口,是否依赖特定的外部设备等.
要迁移的业务系统的云化评估
对所有采集的业务系统进行云化评估,包括:
云化模式评估: 根据系统情况,初步确定云化迁移模式,并在新迁移,克隆迁移和主动-主动迁移三种迁移方案中选择最合适的一种. 其主要目的是与业务系统用户进行通信并评估迁移工作量. 评估云化所需的资源: 包括CPU,内存,网络,存储和其他资源. 其主要目的是评估迁移所需的资源并制定设备补充计划. 制定项目计划
全面考虑总体目标,系统规划结果,云评估结果,与成员单位的沟通结果,迁移工作量的R&D评估结果,可用人力资源,可用云资源,设备采购周期等因素,制定总体项目计划
研发迁移计划
根据要迁移的应用系统的情况,我们制定了三个云迁移计划,即新迁移,克隆迁移和主动-主动迁移.
对于数据库系统迁移,需要考虑数据库类型和版本,例如Oracle,SQLServer和MySQL. 以Oracle为例,数据库迁移团队已经制定了以下迁移计划:
根据组存储的当前情况,制定了存储优化计划,目标是构建“分布式存储+集中存储”混合存储计划. 如下图所示:
研发迁移工具
我们已经针对各种系统需求开发了各种迁移工具. 例如,基于VMware Converter开发从物理机系统到虚拟机的映像转换工具.
云端实施系统
应用程序迁移组和数据库迁移组负责在系统上实施云迁移. 以一个重要的OA系统为例. 这是该组所有员工每天都在使用的办公系统. 它具有大量的用户,非常重要,无法关闭. 下图是迁移过程的示意图:
这里有几个关键点:
经验总结需要合适的云平台
根据企业的当前情况,需求和未来发展需求选择合适的云平台. 至少需要考虑以下几点:
参考云平台架构如下图所示:
需要合适的云服务提供商
具有技术,产品,业务理解和经验的云服务提供商可以使企业的云之旅更加顺畅. 企业在选择云服务提供商时会考虑以下方面:
需要多个相关技术团队参加
企业云迁移不仅是运维团队和迁移团队的事.
有必要全面评估云计划和工具开发
走向云的企业需要全面的解决方案和各种工具. 根据业务系统要求,选择最合理的迁移计划,例如新迁移,克隆迁移和双活迁移. 必须有完整的迁移工具,包括应用程序迁移工具,数据库迁移工具,存储迁移工具等. 这些工具还需要满足要求,例如操作系统(包括操作系统和版本),系统配置(例如支持LVM卷) )和系统启动方法(例如BIOS和UEFI).
在开始系统迁移之前,请全面测试程序和工具. 开始正式迁移后,我们必须首先执行低优先级的系统迁移,再次验证这些程序和工具,然后根据需要进行优化.
需要稳定有序地进行
企业迁移到云不可能一次性完成,而应该有序,稳定地进行.
需要充分考虑安全要求
企业必须具有足够的安全性考虑因素才能使用云. 将业务迁移到云中后,公司可能会面临安全问题. 云服务提供商需要根据企业用户业务和系统数据的特征设计整个系统的安全体系结构,以最大程度地降低安全风险,例如DDoS攻击,安全入侵和数据泄漏. 安全团队必须审查云上业务系统的部署体系结构. 上线后,必须加强安全监控,以发现并及时处理各种问题.
需要考虑各种因素,例如技术,成本,团队和业务.
企业在迁移到云时不仅可以考虑技术因素. 企业的云迁移涉及多种因素,需要考虑的因素很多,其中很多都是非技术因素.
企业云与云团队培训相结合
对于许多公司,尤其是传统公司而言,通常很难在短时间内建立成熟且功能齐全的云团队. 但是,对于云平台和云业务而言,独立和可控是许多企业的重要要求之一. 因此,可以将两者完全结合.
上云只是起点,而不是终点
云只是起点,而不是终点. 为了实现云转型,企业通常需要经历三个阶段: 云IT(信息技术),云DT(数据技术)和云DI(数据智能).
上云有助于传统企业的数字化转型
企业数字化转型是一项系统工程. 如下图所示,从下到上分别是IT模型转换,应用程序模型转换和迁移,组织模型转换和业务模型转换. 此级别通常是发生的顺序,并且也相互依赖.
第一步,需要将企业的传统IT模型转换为基本的云模型. 这也是企业云迁移的第一步. 传统的IT模型通常使用虚拟化技术为物理机和商用虚拟机提供计算资源. 和商用SAN存储来提供存储资源. 在虚拟化平台上,正在运行各种整体应用程序,这些应用程序通常使用大型商业数据库,例如Oracle和SQL Server. 相比之下,新的基础云IT模型使用基础云平台和大数据平台,以开源虚拟机为主体,以商业虚拟机为补充;以分布式存储为主体,以SAN存储为补充;开源数据库与商业数据库的结合;传统的单一应用程序和新的云应用程序共存. 在进一步开发的云原生IT模型中,容器云平台,AI平台和大数据平台是支持平台,容器是应用程序载体,而DevOps是应用程序开发模型.
随着IT模型和应用程序模型的发展,企业将需要进行应用程序迁移和数据迁移以及应用程序开发模型. 同时,企业的组织模式也需要从传统的多层次团队模型向扁平化互联网模型转变.
通过这一系列深入的IT和组织结构转换,企业的业务为从传统业务模型到数字业务模型的转变奠定了基础.
谢谢您的阅读,欢迎关注我的官方帐户:
使用SpreadJS开发在线问卷系统并构建CCP(云数据采集)平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2020-08-06 13:17
图片来自互联网
CCP(云数据采集)平台诞生于大数据时代的背景下. 通过实时数据挖掘,发现了海量云数据的隐藏价值.
在线问卷系统作为CCP(云数据采集)平台的信息采集界面,可帮助问卷设计者和数据分析人员通过网络信息采集来分析消费者在线的行为特征和态度,并准确地批量提取目标. 数据和网页中的任何信息都可以快速实现实时信息获取.
CCP(云数据采集)平台的数据采集工作能否更简洁,方便,准确地执行,取决于在线问卷系统的基本功能和体系结构.
因此,在线调查表系统通常需要包括以下四个功能模块: 在线调查表设计,数据采集,数据分析和导出.
在线问卷系统的基本功能模块
在线问卷设计要求:
1. 问卷设计方法简单易操作
2. 自由修改问卷的外观,并创建带有公司徽标的问卷模板
3. 丰富的项目类型,内置的多项选择题,空白问题,评分,排序,个人信息采集等.
4. 可以设计广泛的应用场景,问卷调查模板,投票,满意度,表格,评估等
数据采集要求:
1. 独特的自定义数据采集渠道
2. 支持在手机上填写
3. 支持无缝嵌入网站,应用程序和小程序
4. 可以通过第三方社交平台完成
需要数据分析:
1. 可以实时查看调查数据
2. 支持表格和图表等多种数据显示
3. 提供数据筛选,交叉分析和原创数据下载
4. 提高数据源的可追溯性,趋势一目了然
需要导出:
1. 支持导出为xlsx,CSV和其他格式
2. 提供更安全的数据存储
3. 发行数量不限,支持多个并发
在线问卷系统的实现
由于必须分析采集到的问卷数据并导出分析结果,因此系统需要支持图表,计算公式以及在线导入和导出功能.
经过全面评估,发现使用SpreadJS控件可以满足上述要求,原因如下:
1. 可以生成交叉图: SpreadJS提供了双向数据绑定功能,可以将采集的数据绑定到表上,从而方便数据分析和显示.
图1生成交叉图分析页面
2. 在线导入和导出Excel文件: SpreadJS不需要任何后端代码和第三方组件,并且可以直接在浏览器中导入和导出Excel文件,PDF导出,打印和预览操作,解决了导出Excel和前端的CSV文件要求方便用户将问卷的统计分析结果导出到本地. 导出文件的比较效果如下图所示:
图2导出的Excel文件的比较
3. 数据可视化: SpreadJS支持450个公式和32个Excel图表,可以帮助用户更全面地分析采集的数据.
图3 SpreadJS内置的多个图表
4. 数据过滤: 后台返回的数据通过SpreadJS显示在前端,并提供数据过滤,排序,分组,注释和切片器等操作,以方便用户进一步分析统计结果.
图4数据过滤
通过将SpreadJS的组件功能嵌入在线调查表系统中,我们可以专注于业务逻辑,而不是专注于如何实现基本功能模块. 在SpreadJS的帮助下,对问卷系统进行了组件化的重构,不仅降低了后期测试的成本,大大缩短了项目交付周期,而且为项目的第二阶段奠定了良好的基础.
如果您还需要进行这样的系统开发,请访问SpreadJS产品的官方网站,以查看应用场景和各种技术资源,它们可以为您的系统构建提供帮助. 查看全部
什么是CCP(云数据采集)平台?
图片来自互联网
CCP(云数据采集)平台诞生于大数据时代的背景下. 通过实时数据挖掘,发现了海量云数据的隐藏价值.
在线问卷系统作为CCP(云数据采集)平台的信息采集界面,可帮助问卷设计者和数据分析人员通过网络信息采集来分析消费者在线的行为特征和态度,并准确地批量提取目标. 数据和网页中的任何信息都可以快速实现实时信息获取.
CCP(云数据采集)平台的数据采集工作能否更简洁,方便,准确地执行,取决于在线问卷系统的基本功能和体系结构.
因此,在线调查表系统通常需要包括以下四个功能模块: 在线调查表设计,数据采集,数据分析和导出.
在线问卷系统的基本功能模块
在线问卷设计要求:
1. 问卷设计方法简单易操作
2. 自由修改问卷的外观,并创建带有公司徽标的问卷模板
3. 丰富的项目类型,内置的多项选择题,空白问题,评分,排序,个人信息采集等.
4. 可以设计广泛的应用场景,问卷调查模板,投票,满意度,表格,评估等
数据采集要求:
1. 独特的自定义数据采集渠道
2. 支持在手机上填写
3. 支持无缝嵌入网站,应用程序和小程序
4. 可以通过第三方社交平台完成
需要数据分析:
1. 可以实时查看调查数据
2. 支持表格和图表等多种数据显示
3. 提供数据筛选,交叉分析和原创数据下载
4. 提高数据源的可追溯性,趋势一目了然
需要导出:
1. 支持导出为xlsx,CSV和其他格式
2. 提供更安全的数据存储
3. 发行数量不限,支持多个并发
在线问卷系统的实现
由于必须分析采集到的问卷数据并导出分析结果,因此系统需要支持图表,计算公式以及在线导入和导出功能.
经过全面评估,发现使用SpreadJS控件可以满足上述要求,原因如下:
1. 可以生成交叉图: SpreadJS提供了双向数据绑定功能,可以将采集的数据绑定到表上,从而方便数据分析和显示.
图1生成交叉图分析页面
2. 在线导入和导出Excel文件: SpreadJS不需要任何后端代码和第三方组件,并且可以直接在浏览器中导入和导出Excel文件,PDF导出,打印和预览操作,解决了导出Excel和前端的CSV文件要求方便用户将问卷的统计分析结果导出到本地. 导出文件的比较效果如下图所示:
图2导出的Excel文件的比较
3. 数据可视化: SpreadJS支持450个公式和32个Excel图表,可以帮助用户更全面地分析采集的数据.
图3 SpreadJS内置的多个图表
4. 数据过滤: 后台返回的数据通过SpreadJS显示在前端,并提供数据过滤,排序,分组,注释和切片器等操作,以方便用户进一步分析统计结果.
图4数据过滤
通过将SpreadJS的组件功能嵌入在线调查表系统中,我们可以专注于业务逻辑,而不是专注于如何实现基本功能模块. 在SpreadJS的帮助下,对问卷系统进行了组件化的重构,不仅降低了后期测试的成本,大大缩短了项目交付周期,而且为项目的第二阶段奠定了良好的基础.
如果您还需要进行这样的系统开发,请访问SpreadJS产品的官方网站,以查看应用场景和各种技术资源,它们可以为您的系统构建提供帮助.
企业云指南(3): 详细说明,企业云路线图
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-06 08:12
我已经确定公司想要进入云计算并且对云计算的核心有深刻的了解,但是仍然不知道如何促进企业迁移到云计算?企业云指南的第三章在这里. 根据江苏省星云计划,我们将为您介绍最合适的云态. 据说,阅读此企业云流程图之后,您可以帮助您的企业尽快进入云环境,并瞥见那片小山.
---------
“企业云”是指企业通过高速互联网网络将其基本系统,业务和平台部署到云中,并使用该网络轻松获得诸如计算,存储,数据和应用程序之类的服务. 有利于降低企业信息化建设成本,为工业互联网的创新和发展构建生态系统,促进整个制造过程,整个产业链和整个产品生命周期的优化,提高集成化发展水平制造业和互联网.
“企业上云”的步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
规划云
1. 信息采集“企业云”需要严格而细致的研究工作. 它需要采集硬件和网络环境信息,当前和将来的业务需求,系统配置信息,应用程序系统信息以及数据风险. 等等.
2. 需求评估从业务需求的角度分析了每个业务的当前状态,存在的问题,是否可以被模糊化以及业务的未来发展需求,并定制了每个业务系统迁移的目标.
从系统的角度分析每个系统的当前状态,包括主机,存储,网络和安全性,分析系统中的问题,并根据评估结果进行计划.
从企业自身的信息化水平的角度进行分析. 对于具有信息化基础,信息系统硬件环境以及维护和开发团队的公司,他们可以根据其开发计划逐渐迁移新旧系统. 对于非信息型企业,根据迫切需要解决的问题,加快相关应用程序的启动.
<p>3. 应用程序分析应用程序分析是成功进行云迁移并减少业务停滞时间的关键. 根据业务负载,特征,复杂性和相关性分析,确定并量化业务云风险可能对业务造成的影响和损失,从而确定业务云的优先级范围和云云策略. 查看全部
经理指南:
我已经确定公司想要进入云计算并且对云计算的核心有深刻的了解,但是仍然不知道如何促进企业迁移到云计算?企业云指南的第三章在这里. 根据江苏省星云计划,我们将为您介绍最合适的云态. 据说,阅读此企业云流程图之后,您可以帮助您的企业尽快进入云环境,并瞥见那片小山.
---------
“企业云”是指企业通过高速互联网网络将其基本系统,业务和平台部署到云中,并使用该网络轻松获得诸如计算,存储,数据和应用程序之类的服务. 有利于降低企业信息化建设成本,为工业互联网的创新和发展构建生态系统,促进整个制造过程,整个产业链和整个产品生命周期的优化,提高集成化发展水平制造业和互联网.
“企业上云”的步骤主要分为上云前的规划和设计,上云的实施以及上云后的验证和维护. 具体的“企业云”过程如下:
规划云
1. 信息采集“企业云”需要严格而细致的研究工作. 它需要采集硬件和网络环境信息,当前和将来的业务需求,系统配置信息,应用程序系统信息以及数据风险. 等等.
2. 需求评估从业务需求的角度分析了每个业务的当前状态,存在的问题,是否可以被模糊化以及业务的未来发展需求,并定制了每个业务系统迁移的目标.
从系统的角度分析每个系统的当前状态,包括主机,存储,网络和安全性,分析系统中的问题,并根据评估结果进行计划.
从企业自身的信息化水平的角度进行分析. 对于具有信息化基础,信息系统硬件环境以及维护和开发团队的公司,他们可以根据其开发计划逐渐迁移新旧系统. 对于非信息型企业,根据迫切需要解决的问题,加快相关应用程序的启动.
<p>3. 应用程序分析应用程序分析是成功进行云迁移并减少业务停滞时间的关键. 根据业务负载,特征,复杂性和相关性分析,确定并量化业务云风险可能对业务造成的影响和损失,从而确定业务云的优先级范围和云云策略.
通往大数据(全量)的数据云解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2020-08-05 21:13

