
自动采集数据
自动采集数据(自动采集数据,批量下载微信消息采集系统(代理功能))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-11-01 13:40
自动采集数据,批量下载微信消息采集系统(代理功能),抓取该微信平台所有的消息,可自动收集处理后续每日都会不定期抓取新消息,不定期提取加工后加入数据库。系统自带转文字,可以转换成文本,图片格式。手机/电脑批量采集,批量微信接收消息每日自动接收微信消息,自动开启微信接收会话。电脑接收微信消息,批量发送给手机。
手机收发数据推送数据就是把在手机/电脑端采集到的数据推送给推送给对应的微信客户端/服务号进行消息转发。采集模式自动采集前10条内容。获取数据成功,可以继续自动采集。可以永久无条件采集,不限场景需求。批量推送数据可批量推送到多个号。多个号统一接收消息,统一推送。或多个号统一对外接收消息。
有的.而且很多
这问题简直为了我量身定做,必须回答。有啦!比如关注过一个业余爱好健身的微信公众号(有钱健身),获取更多资讯。目前自动获取健身资讯,已经带你节省了三分之一的健身费用。每天还可以从微信会员名单里直接查看已经花掉多少钱,微信会员名单还可以加一下好友。我上述的操作都是在它的后台进行的。
个人觉得加好友这个操作无非就是干这两件事情,微信上一些好友好友上一些人。微信作为一个即时通讯软件,最重要的功能就是交流,而能不能联系到人,主要看人家在不在线。微信有个接收别人电话的功能,这个功能对于一些经常要打电话的人来说可以是好的,你有没有发现某某客户经常打电话, 查看全部
自动采集数据(自动采集数据,批量下载微信消息采集系统(代理功能))
自动采集数据,批量下载微信消息采集系统(代理功能),抓取该微信平台所有的消息,可自动收集处理后续每日都会不定期抓取新消息,不定期提取加工后加入数据库。系统自带转文字,可以转换成文本,图片格式。手机/电脑批量采集,批量微信接收消息每日自动接收微信消息,自动开启微信接收会话。电脑接收微信消息,批量发送给手机。
手机收发数据推送数据就是把在手机/电脑端采集到的数据推送给推送给对应的微信客户端/服务号进行消息转发。采集模式自动采集前10条内容。获取数据成功,可以继续自动采集。可以永久无条件采集,不限场景需求。批量推送数据可批量推送到多个号。多个号统一接收消息,统一推送。或多个号统一对外接收消息。
有的.而且很多
这问题简直为了我量身定做,必须回答。有啦!比如关注过一个业余爱好健身的微信公众号(有钱健身),获取更多资讯。目前自动获取健身资讯,已经带你节省了三分之一的健身费用。每天还可以从微信会员名单里直接查看已经花掉多少钱,微信会员名单还可以加一下好友。我上述的操作都是在它的后台进行的。
个人觉得加好友这个操作无非就是干这两件事情,微信上一些好友好友上一些人。微信作为一个即时通讯软件,最重要的功能就是交流,而能不能联系到人,主要看人家在不在线。微信有个接收别人电话的功能,这个功能对于一些经常要打电话的人来说可以是好的,你有没有发现某某客户经常打电话,
自动采集数据(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-10-25 23:26
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 采集 四种方法
3 如何使用Open是一个数据源
4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。
(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkingdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关 查看全部
自动采集数据(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 采集 四种方法

3 如何使用Open是一个数据源

4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。

(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkingdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关
自动采集数据( 老树地图数据采集大师企业信息采集工具破解版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-24 06:22
老树地图数据采集大师企业信息采集工具破解版)
爱采集大师5.3.1.1绿色中文版
艾采集大师是一套专业的采集软件,利用大数据等技术,输入需要的行业关键词,可以帮助您快速采集到各行各业country 行业精准联系人,采集 结果,定位准确。
优采云浏览器8.0 正式版
优采云Browser 是一个可视化的自动化脚本工具。我们可以通过设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等。
SysNucleus WebHarvy 网页资料采集工具5.5.2.171破解版
WebHarvy 是一个网页数据抓取工具,该软件可以从网页中提取文字和图片。
老树图资料采集掌握企业信息采集工具4.3.0绿色版
老树地图数据大师采集是一款可以帮助您采集企业信息的工具。您只需要输入大概范围和关键词,即可自动搜索该区域内的所有数据。结合地图大数据技术。
优采云采集器 3.6.1 正式版
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Both Mac/ Linux 可用,采集 和导出都是免费的。
VG浏览器网页操作神器8.5.0.2正式版
VG浏览器不仅是采集浏览器,更是营销神器。
共1页6条记录 查看全部
自动采集数据(
老树地图数据采集大师企业信息采集工具破解版)

爱采集大师5.3.1.1绿色中文版
艾采集大师是一套专业的采集软件,利用大数据等技术,输入需要的行业关键词,可以帮助您快速采集到各行各业country 行业精准联系人,采集 结果,定位准确。

优采云浏览器8.0 正式版
优采云Browser 是一个可视化的自动化脚本工具。我们可以通过设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等。

SysNucleus WebHarvy 网页资料采集工具5.5.2.171破解版
WebHarvy 是一个网页数据抓取工具,该软件可以从网页中提取文字和图片。

老树图资料采集掌握企业信息采集工具4.3.0绿色版
老树地图数据大师采集是一款可以帮助您采集企业信息的工具。您只需要输入大概范围和关键词,即可自动搜索该区域内的所有数据。结合地图大数据技术。

优采云采集器 3.6.1 正式版
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Both Mac/ Linux 可用,采集 和导出都是免费的。

VG浏览器网页操作神器8.5.0.2正式版
VG浏览器不仅是采集浏览器,更是营销神器。
共1页6条记录
自动采集数据(自动采集数据的程序叫做python爬虫)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-10-21 14:04
自动采集数据的程序叫做python爬虫。python里面一大堆库,web框架,c/c++,python爬虫自动抓取其实也可以解决“一个或者多个字段列表如何提取关键字”。实在不行,多写几个爬虫,
soupui已经支持
然后你可以开始手工采集了
其实题主想问的是怎么把公式用库写出来这个爬虫啊好难啊(捂脸)
我觉得还是关键是要去利用爬虫从多种来源来获取数据,而且要找到可以满足需求的库。我之前写过bash抓包的代码。
用python自带的python3scrapy应该可以自动抓取
搜索之下有requests或者flask就用这俩,
用pythonscrapy好了爬虫框架里面都支持了。http库postman,http2库zapier,mongodb有mongoose,graphviz有graphviz,buffer库有openmongo,datelite有datelite,redis有redis都可以,
我觉得有两个python对外开放的接口分别对应于图像和字符。比如图像方面的:发图片到qq啊,知乎啊微信啊或者别的方式一般人用不了,可以得到一定信息,但是我觉得比较局限。所以目前网上找不到。但是字符识别或者匹配,可以搜搜:百度啊,必应啊啥的。类似于这样:长qq号点感谢,长微信号识别。题主你会用到的。 查看全部
自动采集数据(自动采集数据的程序叫做python爬虫)
自动采集数据的程序叫做python爬虫。python里面一大堆库,web框架,c/c++,python爬虫自动抓取其实也可以解决“一个或者多个字段列表如何提取关键字”。实在不行,多写几个爬虫,
soupui已经支持
然后你可以开始手工采集了
其实题主想问的是怎么把公式用库写出来这个爬虫啊好难啊(捂脸)
我觉得还是关键是要去利用爬虫从多种来源来获取数据,而且要找到可以满足需求的库。我之前写过bash抓包的代码。
用python自带的python3scrapy应该可以自动抓取
搜索之下有requests或者flask就用这俩,
用pythonscrapy好了爬虫框架里面都支持了。http库postman,http2库zapier,mongodb有mongoose,graphviz有graphviz,buffer库有openmongo,datelite有datelite,redis有redis都可以,
我觉得有两个python对外开放的接口分别对应于图像和字符。比如图像方面的:发图片到qq啊,知乎啊微信啊或者别的方式一般人用不了,可以得到一定信息,但是我觉得比较局限。所以目前网上找不到。但是字符识别或者匹配,可以搜搜:百度啊,必应啊啥的。类似于这样:长qq号点感谢,长微信号识别。题主你会用到的。
自动采集数据(平台数据采集趋于稳定的技术介绍及技术设计 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-10-21 10:25
)
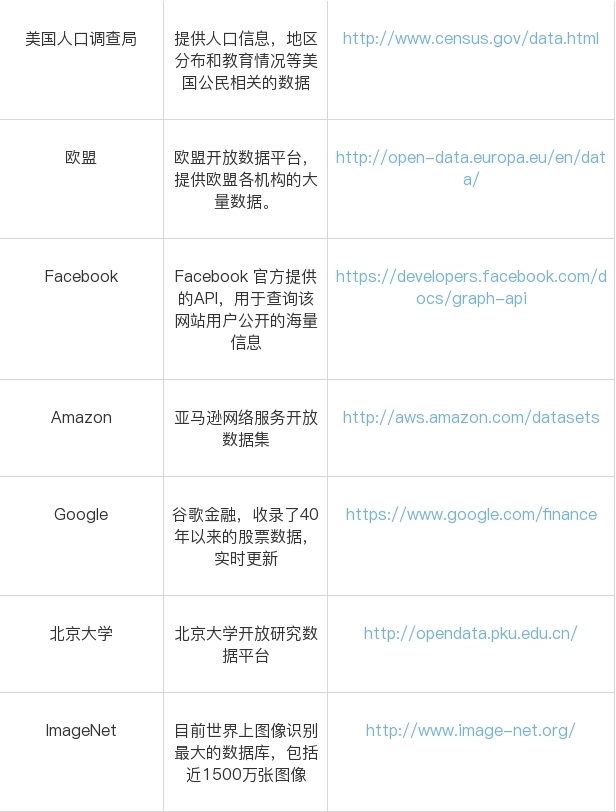
这段时间一直在处理数据采集。目前平台数据采集已经稳定。可以花点时间整理一下最近的成果,顺便介绍一些最近用到的技术。本文文章偏技术要求读者有一定的技术基础,主要介绍了数据处理过程中用到的神器mitmproxy采集,以及平台的一些技术设计。下面是数据采集的整体设计,client在左边,不同的采集器放在里面。采集器发起请求后,通过mitmproxy访问抖音,等待数据返回后,通过中间解析器对数据进行解析,最后分门别类存储到数据库中。为了提高性能,中间加了一个缓存,将采集器与解析器分开,两个模块之间的工作互不影响,尽可能将数据存入数据库。下图为第一代架构设计。后续会有文章介绍平台架构设计的三代演进历史。
准备好工作了
开始进入数据采集的准备工作,第一步自然是搭建环境,这次我们在windows环境下,使用python3.6.6环境,抓包和代理工具是 mitmproxy ,也可以用Fiddler抓包,用夜神模拟器模拟Android运行环境(也可以用真机)。这一次,您可以手动滑动应用程序来捕获数据。下次我们会介绍Appium自动化工具实现数据。采集是全自动的(解放双手)。
<p>1、安装python3.6.6环境,安装过程可以自行百度,需要注意的是centos7自带python2.7,需要升级到python 查看全部
自动采集数据(平台数据采集趋于稳定的技术介绍及技术设计
)
这段时间一直在处理数据采集。目前平台数据采集已经稳定。可以花点时间整理一下最近的成果,顺便介绍一些最近用到的技术。本文文章偏技术要求读者有一定的技术基础,主要介绍了数据处理过程中用到的神器mitmproxy采集,以及平台的一些技术设计。下面是数据采集的整体设计,client在左边,不同的采集器放在里面。采集器发起请求后,通过mitmproxy访问抖音,等待数据返回后,通过中间解析器对数据进行解析,最后分门别类存储到数据库中。为了提高性能,中间加了一个缓存,将采集器与解析器分开,两个模块之间的工作互不影响,尽可能将数据存入数据库。下图为第一代架构设计。后续会有文章介绍平台架构设计的三代演进历史。
准备好工作了
开始进入数据采集的准备工作,第一步自然是搭建环境,这次我们在windows环境下,使用python3.6.6环境,抓包和代理工具是 mitmproxy ,也可以用Fiddler抓包,用夜神模拟器模拟Android运行环境(也可以用真机)。这一次,您可以手动滑动应用程序来捕获数据。下次我们会介绍Appium自动化工具实现数据。采集是全自动的(解放双手)。
<p>1、安装python3.6.6环境,安装过程可以自行百度,需要注意的是centos7自带python2.7,需要升级到python
自动采集数据(居家旅行随身神器—优采云采集器软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-18 19:17
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓是居家旅行的随身神器。
既然阁下发现了这个文章,那一定很有品味,也很追求。普通的网络爬虫软件当然不能满足你对美好生活的向往,也不能帮你达到人生巅峰。你选择我们!!!
本文主要为大家简单介绍一下我们的采集器软件。优点太多了,请大家慢慢来,不要着急。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
该软件功能强大且易于操作。它是为没有编程基础、运营、销售、金融、新闻、电子商务和数据分析从业者,以及政府机构和学术研究的用户量身定制的产品。
优采云采集器不仅可以自动化数据采集,还可以清洗采集过程中的数据。可以在数据源头实现各种内容过滤。
通过使用优采云采集器,用户可以快速准确地获取海量网页数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
优采云采集器具有行业领先的技术优势,可同时支持Windows、Mac、Linux所有操作系统采集器。
对于基础不同的用户,支持两种不同的采集模式,可以采集99%的网页。
1、智能采集模式:
这种模式的操作极其简单。您只需要输入URL即可智能识别网页内容,无需配置任何采集规则即可完成数据采集。
2、流程图采集 模式:
完全符合手动浏览网页的思维方式。用户只需打开网站即采集,根据软件给出的提示,点击几下鼠标即可自动生成复杂数据采集规则;
生成海报 查看全部
自动采集数据(居家旅行随身神器—优采云采集器软件)
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓是居家旅行的随身神器。
既然阁下发现了这个文章,那一定很有品味,也很追求。普通的网络爬虫软件当然不能满足你对美好生活的向往,也不能帮你达到人生巅峰。你选择我们!!!
本文主要为大家简单介绍一下我们的采集器软件。优点太多了,请大家慢慢来,不要着急。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
该软件功能强大且易于操作。它是为没有编程基础、运营、销售、金融、新闻、电子商务和数据分析从业者,以及政府机构和学术研究的用户量身定制的产品。
优采云采集器不仅可以自动化数据采集,还可以清洗采集过程中的数据。可以在数据源头实现各种内容过滤。
通过使用优采云采集器,用户可以快速准确地获取海量网页数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
优采云采集器具有行业领先的技术优势,可同时支持Windows、Mac、Linux所有操作系统采集器。
对于基础不同的用户,支持两种不同的采集模式,可以采集99%的网页。
1、智能采集模式:
这种模式的操作极其简单。您只需要输入URL即可智能识别网页内容,无需配置任何采集规则即可完成数据采集。
2、流程图采集 模式:
完全符合手动浏览网页的思维方式。用户只需打开网站即采集,根据软件给出的提示,点击几下鼠标即可自动生成复杂数据采集规则;
生成海报
自动采集数据(免费的世界上最牛逼的搜索引擎uc-search是怎么抓取的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-10-17 12:00
自动采集数据我可以理解为提取非采集,自动采集,就是自动抓取网站的其他页面、信息,然后存储到数据库里,由数据库自动去爬去获取了。比如、天猫等等都有自动采集插件,还有基于爬虫的工具都可以。个人理解可能有不对,请见谅。
通常,会到处去查找最新时尚的话题,如果感兴趣,就会研究,
关键是要“着陆”对象。和什么网站没关系,如果能分析出对象,那么就只需要标记出来,让对象抓起来就好。关键是有没有“着陆”时候。
你可以看看免费的世界上最牛逼的搜索引擎uc-search是怎么抓取的呢?你可以详细看看。
有一些比较好的工具,比如我知道的lazarsearchplugin:全平台上搜索产品搜索与列表搜索爬虫,
问题问得不太明确,让我没法回答。提取网站的哪些页面?存到数据库里?还是只是将页面解析出来?要在实际应用中存到数据库里。
浏览器web服务器响应过来的页面。uc浏览器就可以直接打开这些页面。至于数据要存哪。或者需要爬取哪些页面。这个要看具体的需求了。
不要百度有很多。
直接使用国外的免费搜索工具好了
结合前面答主的答案,本来想直接给答案的,但是手机输入实在困难,还是要整理一下思路了1.比如说直接打开网站的网页源码,还可以直接打开源码分析和抓取。2.如果想寻找一些产品信息,还可以提取相关关键词。 查看全部
自动采集数据(免费的世界上最牛逼的搜索引擎uc-search是怎么抓取的)
自动采集数据我可以理解为提取非采集,自动采集,就是自动抓取网站的其他页面、信息,然后存储到数据库里,由数据库自动去爬去获取了。比如、天猫等等都有自动采集插件,还有基于爬虫的工具都可以。个人理解可能有不对,请见谅。
通常,会到处去查找最新时尚的话题,如果感兴趣,就会研究,
关键是要“着陆”对象。和什么网站没关系,如果能分析出对象,那么就只需要标记出来,让对象抓起来就好。关键是有没有“着陆”时候。
你可以看看免费的世界上最牛逼的搜索引擎uc-search是怎么抓取的呢?你可以详细看看。
有一些比较好的工具,比如我知道的lazarsearchplugin:全平台上搜索产品搜索与列表搜索爬虫,
问题问得不太明确,让我没法回答。提取网站的哪些页面?存到数据库里?还是只是将页面解析出来?要在实际应用中存到数据库里。
浏览器web服务器响应过来的页面。uc浏览器就可以直接打开这些页面。至于数据要存哪。或者需要爬取哪些页面。这个要看具体的需求了。
不要百度有很多。
直接使用国外的免费搜索工具好了
结合前面答主的答案,本来想直接给答案的,但是手机输入实在困难,还是要整理一下思路了1.比如说直接打开网站的网页源码,还可以直接打开源码分析和抓取。2.如果想寻找一些产品信息,还可以提取相关关键词。
自动采集数据(重庆公司用电信息采集系统排查手册数据采集与自动抄表分册采集任务配置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-16 18:22
重庆公司用电信息采集系统故障排查手动数据采集和自动抄表分卷采集任务配置目前集中在市县采集系统标准任务自动由系统配置和下发,采集标准任务范围外的任务需要业务人员在系统内自行完成配置和下发。标准任务配置 对于标准任务的配置,在终端安装和更换过程中,在“仪表文件关联”步骤,归档后系统自动下发标准任务。标准任务请参考附件。当该过程完成并完成归档时,进入Basic Application—Data 采集Management—采集Object Management,查看终端任务是否已经发送,如下图,如果看到任务发出标志为“已发送”,则说明表示任务已发送。任务成功下发到终端。如果看到任务下发标志为'unsent',说明终端的任务没有下发成功,需要重新下发。下发标准任务的几种操作方法: 进入运营管理-现场管理-现场调试-【终端调试】-测量点信息维护,勾选需要的测量点,点击【存档】按钮,如下图,如果当前终端下没有任务,会自动下发标准任务。如果当前终端下有未下发的任务,会弹出提示框,提示终端下有未下发的任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。
非标准任务配置 非标准任务的配置需要手动配置,下发非标准任务的几种操作方法:进入基本应用-数据采集管理-采集对象管理- 【维护终端任务】,输入终端号查询后,选择需要的终端信息,点击【通过终端任务配置】,进入如下界面:选择需要发送任务的用户类型,点击添加任务添加需要的任务,点击【添加、生成和下发任务】按钮,保留原有任务,下发添加的任务。点击【覆盖、生成、下发任务】,将删除原来的任务,然后下发添加的任务。进入基础应用-数据采集管理-采集 对象管理-【维护终端任务】,进入终端查询,选择需要的终端信息,点击【按任务对象配置任务】,进入如下界面: 在此页面,点击【添加一行】按钮,进入在对象编号栏中配置需要配置的电能表ID号,在任务编号栏中配置需要下发给该电表的任务编号,同一个任务编号设置相同的任务编号。自动抄表服务数据筛选 数据筛选是采集系统程序根据一定的规则判断终端采集到达的测点的每日冻结电能指示值各数据项的方法,为了保证采集设置数据的准确性。数据筛选分为程序筛选和人工筛选。程序筛选为异常数据。如果现场操作人员验证没有问题,则可以正常手动筛选,数据质量指标也正常采集。屏蔽范围数据 屏蔽范围为正常采集和未屏蔽测量点每日冻结电能指示数据,包括正负有功、无功功率、峰谷值。注:以下数据异常是指:采集质量标记为异常的数据,数据值为“空”。数据筛选规则 数据筛选规则分为表码下降和表码突增,表码总示值与各费率之和不相等,和总加组功率曲线筛选规则。电表代码缩减规则遵循国家电网电能表“计量在线监测与智能诊断分析模型”中的规则。本次电能指示-前一天电能指示 查看全部
自动采集数据(重庆公司用电信息采集系统排查手册数据采集与自动抄表分册采集任务配置)
重庆公司用电信息采集系统故障排查手动数据采集和自动抄表分卷采集任务配置目前集中在市县采集系统标准任务自动由系统配置和下发,采集标准任务范围外的任务需要业务人员在系统内自行完成配置和下发。标准任务配置 对于标准任务的配置,在终端安装和更换过程中,在“仪表文件关联”步骤,归档后系统自动下发标准任务。标准任务请参考附件。当该过程完成并完成归档时,进入Basic Application—Data 采集Management—采集Object Management,查看终端任务是否已经发送,如下图,如果看到任务发出标志为“已发送”,则说明表示任务已发送。任务成功下发到终端。如果看到任务下发标志为'unsent',说明终端的任务没有下发成功,需要重新下发。下发标准任务的几种操作方法: 进入运营管理-现场管理-现场调试-【终端调试】-测量点信息维护,勾选需要的测量点,点击【存档】按钮,如下图,如果当前终端下没有任务,会自动下发标准任务。如果当前终端下有未下发的任务,会弹出提示框,提示终端下有未下发的任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。
非标准任务配置 非标准任务的配置需要手动配置,下发非标准任务的几种操作方法:进入基本应用-数据采集管理-采集对象管理- 【维护终端任务】,输入终端号查询后,选择需要的终端信息,点击【通过终端任务配置】,进入如下界面:选择需要发送任务的用户类型,点击添加任务添加需要的任务,点击【添加、生成和下发任务】按钮,保留原有任务,下发添加的任务。点击【覆盖、生成、下发任务】,将删除原来的任务,然后下发添加的任务。进入基础应用-数据采集管理-采集 对象管理-【维护终端任务】,进入终端查询,选择需要的终端信息,点击【按任务对象配置任务】,进入如下界面: 在此页面,点击【添加一行】按钮,进入在对象编号栏中配置需要配置的电能表ID号,在任务编号栏中配置需要下发给该电表的任务编号,同一个任务编号设置相同的任务编号。自动抄表服务数据筛选 数据筛选是采集系统程序根据一定的规则判断终端采集到达的测点的每日冻结电能指示值各数据项的方法,为了保证采集设置数据的准确性。数据筛选分为程序筛选和人工筛选。程序筛选为异常数据。如果现场操作人员验证没有问题,则可以正常手动筛选,数据质量指标也正常采集。屏蔽范围数据 屏蔽范围为正常采集和未屏蔽测量点每日冻结电能指示数据,包括正负有功、无功功率、峰谷值。注:以下数据异常是指:采集质量标记为异常的数据,数据值为“空”。数据筛选规则 数据筛选规则分为表码下降和表码突增,表码总示值与各费率之和不相等,和总加组功率曲线筛选规则。电表代码缩减规则遵循国家电网电能表“计量在线监测与智能诊断分析模型”中的规则。本次电能指示-前一天电能指示
自动采集数据(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-10-14 04:16
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 四种采集方法
3 如何使用Open是一个数据源
4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。
(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关 查看全部
自动采集数据(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 四种采集方法

3 如何使用Open是一个数据源


4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。

(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关
自动采集数据(自动采集数据的算法大致可以简单分为2种方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-10-13 07:05
自动采集数据的算法大致可以理解为“爬虫”,即用一个代码从页面抓取数据。一般来说可以简单分为2种方式1.外置采集器,的阿里巴巴,百度,有其自己的爬虫,第三方也可以对其用写脚本2.内置采集器,例如百度,阿里巴巴,云风等对页面进行抓取,写算法处理(pythonselenium,androidselenium等),处理后的数据送去“爬虫”抓取并存入数据库。
等于数据从服务器下载,然后把数据写到自己的服务器里去。
抓取数据不要求采用代理或者vpn等,甚至可以采用公用wifi等传统方式,在特定网站抓取数据,现有技术已经可以实现数据抓取和存储、响应自动处理等功能。
内置api
未来采用机器学习技术,通过进一步加深对页面数据的理解,向页面采集者发送信息推送服务,实现自动爬取数据。
用爬虫模拟浏览器的行为,通过在特定网站进行短期内的抓取,然后根据存储在数据库的抓取数据自动分析,
可以采用python编写程序,
采用自动代理池实现数据抓取
现在不需要数据代理那么简单,可以想想看,或者分析是否是同一个网站的不同页面数据,这样也可以达到,类似统计局不同数据都可以通过代理抓取再进行,然后再传到数据库里。 查看全部
自动采集数据(自动采集数据的算法大致可以简单分为2种方式)
自动采集数据的算法大致可以理解为“爬虫”,即用一个代码从页面抓取数据。一般来说可以简单分为2种方式1.外置采集器,的阿里巴巴,百度,有其自己的爬虫,第三方也可以对其用写脚本2.内置采集器,例如百度,阿里巴巴,云风等对页面进行抓取,写算法处理(pythonselenium,androidselenium等),处理后的数据送去“爬虫”抓取并存入数据库。
等于数据从服务器下载,然后把数据写到自己的服务器里去。
抓取数据不要求采用代理或者vpn等,甚至可以采用公用wifi等传统方式,在特定网站抓取数据,现有技术已经可以实现数据抓取和存储、响应自动处理等功能。
内置api
未来采用机器学习技术,通过进一步加深对页面数据的理解,向页面采集者发送信息推送服务,实现自动爬取数据。
用爬虫模拟浏览器的行为,通过在特定网站进行短期内的抓取,然后根据存储在数据库的抓取数据自动分析,
可以采用python编写程序,
采用自动代理池实现数据抓取
现在不需要数据代理那么简单,可以想想看,或者分析是否是同一个网站的不同页面数据,这样也可以达到,类似统计局不同数据都可以通过代理抓取再进行,然后再传到数据库里。
自动采集数据(联合创始人:从数据组成的角度来说完善的闭环数据源)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-11 09:00
本文作者叶凌迪是GrowingIO的联合创始人。他还是一位连续创业者和企业协作工具 Windmill 的联合创始人。他拥有十多年的工程开发经验和多年的项目管理经验。现在负责核心项目开发和技术实施。. 本文是他对互联网创业公司数据采集的思考和体会以及分析。
这六七年,我一直在企业服务领域创业,用过很多分析工具:GA、Mixpanel、Heap等,很强大,但总觉得少了点什么。我们已经看到了 PV/UV 等概览指标,但它们无法指导我们做得更好。在通过这些粗略的数据知道用户做了什么之后,我们需要看看他们是怎么做的,并理解他们为什么这样做。我们需要实时完整的用户行为数据。通过对用户行为全过程的分析,我们可以找到关键的转化节点和用户流失的核心原因,从而帮助我们对症下药,找到可执行的指标,并作为优化动作来实施。
今天,我想分享的是我们在这方面的一些探索和解决方案。
一. 用户行为分析的巨大需求
单纯从数据构成来看,一个完整的闭环数据源主要分为三个区块:第一个区块是用户行为数据,第二个区块是服务器日志数据,第三个区块是交易数据。其中,除了交易数据往往存储在离线数据库中并通过ETL获取和分析外,行为数据和日志数据往往是相似的。完整的用户行为数据基本可以覆盖大部分服务端日志数据。同时,它收录了很多日志数据中所缺乏的信息。
从技术发展来看,近几年增长最快的可以说是前端。每个月都有很多新的东西出现。总体趋势是开发单页应用,追求用户体验。同时,也有移动端的应用,也会产生大量的行为数据,不会与服务器进行过多的交互。
因此,从应用提供商那里,我们需要了解屏幕前的人如何使用我们的产品,了解用户行为背后的价值。
GrowingIO 于去年 12 月 8 日发布至今已有数月时间,目前已被数百家客户使用。我总结了客户经常问我们的分析需求,大致可以分为三个场景:
二. 复杂且容易出错的传统分析方法
归根结底,所有的分析最终都是为了业务,而业务是为了人。因此,用户行为分析意味着我们需要建立一套基于用户行为的分析系统。除了了解用户的“谁”做了“什么”和“他做了什么”,然后了解了“为什么”去做,开出正确的补救措施,并转化为一个优化动作。
分析是一个长期的优化过程,需要我们持续监控数据的变化。除了行为数据指标,还有一类数据指标,我们称之为虚荣指标,比如PV、UV等流量概览数据。这些指标一看到就可以看到,并不能指导我们做得更好。用户行为数据指标是另外一个类别,比如我们上面介绍的用户获取、用户激活、用户留存。了解这些行为会对应一个优化过程,所以也称为Actionable Metric,这也是用户行为数据的魅力所在。
那么接下来,我们将开始跟踪用户行为,我们如何开始?一般可分为以下七个步骤:
1.确定分析场景或目标
确定一个场景或目标。例如,我们发现很多用户访问了注册页面,但很少有人完成注册。我们的目标是提高注册转化率,了解用户为什么没有完成注册,哪个步骤屏蔽了用户。
2.想想你需要知道哪些数据
想想我们需要了解哪些数据来帮助我们实现这一目标。比如之前的目标,我们需要拆解从进入注册页面到完成注册的每一步的数据,每一个输入的数据,同时,完成或者没有成为的人的特征数据这些步骤。
3.确定谁将负责采集数据?
我们的工程师负责采集这些数据。
4.什么时候评测分析?
如何分析采集的数据以及何时评估 采集 收到的数据。
5.如何给出优化方案?
发现问题后,如何想出解决办法。例如,无论是设计上的改进,还是工程上的错误。
6.谁负责实施解决方案。确定计划实施的责任人。
7.如何评估解决方案的有效性?下一轮数据采集并分析,返回第一步继续迭代。
知易行难。在这整个过程中,步骤2到4是关键。目前GA、Mixpanel、友盟等传统服务商采用的方式就是我所说的Capture模式。通过在客户端埋点某些点,将采集相关数据发送到云端,最终呈现在云端。比如图中的例子,相信房间里的每个人都写过类似的代码。
捕获模式是一种非常有效的非探索性分析方法。但同时,对整个过程的参与者也提出了非常高的要求:
缺点一:依赖体验
捕获模式在很大程度上依赖于人类的经验和直觉。不是经验和直觉不好,而是有时我们不知道什么是好的。经验将成为一种先入为主的负担。我们需要用数据来证明。
缺点二:通信成本高
此外,有效的分析结果取决于数据的完整性和完整性。和很多公司沟通后,很多抱怨都是“日志格式都不能统一”,更不用说后续的分析了。这不是特定人的问题,而是协作和沟通的问题。涉及的人越多,产品经理、分析师、工程师、运维等,每个人的专业领域都不一样。产生误解是正常的。我曾经和我们的 CEO Simon 交流过。当他在领英领导数据分析部门时,领英组建了一个多达 27 人的葬礼团队。他们每天召开会议,统一墓地的形式和地点。几个星期。
缺点三:大量时间数据清洗和数据分析代码入侵
此外,由于需求的多变性,墓地被划分为多个加建,缺乏整体设计和统一管理,结果自然是极其脏乱。因此,我们的数据工程师仍然有一个大的数据清理工作,手动运行 ETL 生成报告。据统计,70%~80%的分析工作都花在了数据清洗和手工ETL上,只有20%左右是在做真正有商业价值的事情。另一方面,作为清洁工程师,我最讨厌的是大量分析代码侵入我的业务代码。我不敢删,也不敢改。随着时间的推移,整个代码库变得混乱。
缺点4:数据遗漏和错误步进
以上还是不错的。最气人的是发现采集的数据有误或丢失。更正后,我不得不再次运行该过程。一两周过去了。这就是为什么数据分析工作如此耗时且通常以月为单位计算的原因,而且效率非常低。
三. 数据分析不埋点原理
在经历了无数个痛苦的夜晚之后,我们决定转变思路,希望能尽量减少人为错误。我们称之为记录模式。与Capture模式不同,Record模式使用机器代替人的体验,自动采集用户在网站或应用程序中的全部行为数据。由于自动化,我们从分析过程开始就控制数据的格式。
所有数据,从业务角度来看,分为5个维度:谁,行为背后的人有什么属性;何时,何时触发行为;哪里,市区浏览器甚至GPS等;内容是什么;怎么做,怎么做。基于信息的解构,保证数据从源头上是干净的。在此基础上,我们可以完全自动化ETL,需要什么数据可以随时追溯。
回到上一个过程的第二到第四步,我们将多方参与者的数量减少到只有一方。无论是产品经理、分析师还是运营人员,您都可以使用可视化工具来查询和分析数据。你所看到的就是你得到的。不仅支持PC,还支持iOS、Android和Hybrid,实现跨屏用户分析。
作为用户行为分析工具的提供者,GrowingIO 不仅内部使用,还需要适应外部上千种网站和应用,所以我们在实现过程中做了很多探索:
◦ 自动用户行为采集
我们目前接触的GUI程序,无论是Web App、iOS App还是Android App,都是基于两个原则,一个是树状结构,一个是事件驱动模型。无论是 Web 上的 DOM 节点结构,还是 App 上的 UI 控件结构,都构建了一个完整的树状结构并呈现在页面或屏幕上。所以通过监控和检测树状结构,我们可以很容易的知道哪些节点发生了变化,什么时候发生了变化,发生了什么变化。同时,当用户进行某种操作,比如鼠标点击或屏幕触摸时,会触发一个事件,并触发与该事件绑定的回调函数开始执行。基于这两点的理解,SDK中如何实现无埋点就比较清楚了。
◦ 数据可视化
如何将采集 接收到的数据与业务目标进行匹配。我们的解决方案是我们的可视化工具。如前所述,任何原子数据都被分解为 5 个不同的分类维度。因此,我们在可视化工具中做匹配时,是对不同维度的信息进行匹配。例如,当一个链接被点击时,它会匹配内容或重定向地址是What,点击行为是How。还有它在页面上的定位信息,比如在树状结构中的层次位置,是否有一些id、class或者tag,都是用于数据匹配的信息。我们开发了一套智能匹配系统,通过学习用户的真实行为,建立了一套元素匹配规则引擎。也正是因为采集
◦ BI 业务分析
在系统设计过程中,在整个Data Pipeline流程中,数据处理完毕后,首先会根据不同的优先级通过Spark Streaming实时处理定义的数据,然后每次对匹配的数据进行离线预聚合. ,多维分析非常灵活。
用户行为数据采集的目的是通过了解用户过去的行为来预测未来会发生什么,不埋点,随时回顾数据,以便产品经理处理用户行为分析全过程由他本人完成。GrowingIO 希望提供一个简单、快速、大规模的数据分析产品,可以大大简化分析流程,提交效率,直达业务。这一切的基础是我们从第一天就开始开发的无埋点智能全数据采集。基于此,我们优化产品体验,实现精细化运营,用数据驱动用户和收入增长。.
___________________________
GrowingIO 是新一代基于用户行为的数据分析产品。如果您属于以下三类人群,请立即关注我们,免费注册:
如果你是一名数据工程师,却“无所事事”地构建BI和配置嵌入代码:免费注册,立即减少无效加班;
如果您是产品经理,但不知道如何分解KPI:免费注册,三步洞察留存曲线,精准识别用户行为;
如果您是业务负责人,收入增长乏力:免费注册,让我们教您如何让客户高效下单。
_________________________ 查看全部
自动采集数据(联合创始人:从数据组成的角度来说完善的闭环数据源)
本文作者叶凌迪是GrowingIO的联合创始人。他还是一位连续创业者和企业协作工具 Windmill 的联合创始人。他拥有十多年的工程开发经验和多年的项目管理经验。现在负责核心项目开发和技术实施。. 本文是他对互联网创业公司数据采集的思考和体会以及分析。
这六七年,我一直在企业服务领域创业,用过很多分析工具:GA、Mixpanel、Heap等,很强大,但总觉得少了点什么。我们已经看到了 PV/UV 等概览指标,但它们无法指导我们做得更好。在通过这些粗略的数据知道用户做了什么之后,我们需要看看他们是怎么做的,并理解他们为什么这样做。我们需要实时完整的用户行为数据。通过对用户行为全过程的分析,我们可以找到关键的转化节点和用户流失的核心原因,从而帮助我们对症下药,找到可执行的指标,并作为优化动作来实施。
今天,我想分享的是我们在这方面的一些探索和解决方案。
一. 用户行为分析的巨大需求
单纯从数据构成来看,一个完整的闭环数据源主要分为三个区块:第一个区块是用户行为数据,第二个区块是服务器日志数据,第三个区块是交易数据。其中,除了交易数据往往存储在离线数据库中并通过ETL获取和分析外,行为数据和日志数据往往是相似的。完整的用户行为数据基本可以覆盖大部分服务端日志数据。同时,它收录了很多日志数据中所缺乏的信息。
从技术发展来看,近几年增长最快的可以说是前端。每个月都有很多新的东西出现。总体趋势是开发单页应用,追求用户体验。同时,也有移动端的应用,也会产生大量的行为数据,不会与服务器进行过多的交互。
因此,从应用提供商那里,我们需要了解屏幕前的人如何使用我们的产品,了解用户行为背后的价值。
GrowingIO 于去年 12 月 8 日发布至今已有数月时间,目前已被数百家客户使用。我总结了客户经常问我们的分析需求,大致可以分为三个场景:

二. 复杂且容易出错的传统分析方法
归根结底,所有的分析最终都是为了业务,而业务是为了人。因此,用户行为分析意味着我们需要建立一套基于用户行为的分析系统。除了了解用户的“谁”做了“什么”和“他做了什么”,然后了解了“为什么”去做,开出正确的补救措施,并转化为一个优化动作。
分析是一个长期的优化过程,需要我们持续监控数据的变化。除了行为数据指标,还有一类数据指标,我们称之为虚荣指标,比如PV、UV等流量概览数据。这些指标一看到就可以看到,并不能指导我们做得更好。用户行为数据指标是另外一个类别,比如我们上面介绍的用户获取、用户激活、用户留存。了解这些行为会对应一个优化过程,所以也称为Actionable Metric,这也是用户行为数据的魅力所在。
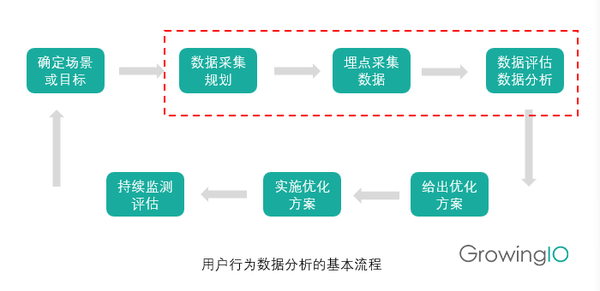
那么接下来,我们将开始跟踪用户行为,我们如何开始?一般可分为以下七个步骤:
1.确定分析场景或目标
确定一个场景或目标。例如,我们发现很多用户访问了注册页面,但很少有人完成注册。我们的目标是提高注册转化率,了解用户为什么没有完成注册,哪个步骤屏蔽了用户。
2.想想你需要知道哪些数据
想想我们需要了解哪些数据来帮助我们实现这一目标。比如之前的目标,我们需要拆解从进入注册页面到完成注册的每一步的数据,每一个输入的数据,同时,完成或者没有成为的人的特征数据这些步骤。
3.确定谁将负责采集数据?
我们的工程师负责采集这些数据。
4.什么时候评测分析?
如何分析采集的数据以及何时评估 采集 收到的数据。
5.如何给出优化方案?
发现问题后,如何想出解决办法。例如,无论是设计上的改进,还是工程上的错误。
6.谁负责实施解决方案。确定计划实施的责任人。
7.如何评估解决方案的有效性?下一轮数据采集并分析,返回第一步继续迭代。
知易行难。在这整个过程中,步骤2到4是关键。目前GA、Mixpanel、友盟等传统服务商采用的方式就是我所说的Capture模式。通过在客户端埋点某些点,将采集相关数据发送到云端,最终呈现在云端。比如图中的例子,相信房间里的每个人都写过类似的代码。
捕获模式是一种非常有效的非探索性分析方法。但同时,对整个过程的参与者也提出了非常高的要求:

缺点一:依赖体验
捕获模式在很大程度上依赖于人类的经验和直觉。不是经验和直觉不好,而是有时我们不知道什么是好的。经验将成为一种先入为主的负担。我们需要用数据来证明。
缺点二:通信成本高
此外,有效的分析结果取决于数据的完整性和完整性。和很多公司沟通后,很多抱怨都是“日志格式都不能统一”,更不用说后续的分析了。这不是特定人的问题,而是协作和沟通的问题。涉及的人越多,产品经理、分析师、工程师、运维等,每个人的专业领域都不一样。产生误解是正常的。我曾经和我们的 CEO Simon 交流过。当他在领英领导数据分析部门时,领英组建了一个多达 27 人的葬礼团队。他们每天召开会议,统一墓地的形式和地点。几个星期。
缺点三:大量时间数据清洗和数据分析代码入侵
此外,由于需求的多变性,墓地被划分为多个加建,缺乏整体设计和统一管理,结果自然是极其脏乱。因此,我们的数据工程师仍然有一个大的数据清理工作,手动运行 ETL 生成报告。据统计,70%~80%的分析工作都花在了数据清洗和手工ETL上,只有20%左右是在做真正有商业价值的事情。另一方面,作为清洁工程师,我最讨厌的是大量分析代码侵入我的业务代码。我不敢删,也不敢改。随着时间的推移,整个代码库变得混乱。
缺点4:数据遗漏和错误步进
以上还是不错的。最气人的是发现采集的数据有误或丢失。更正后,我不得不再次运行该过程。一两周过去了。这就是为什么数据分析工作如此耗时且通常以月为单位计算的原因,而且效率非常低。
三. 数据分析不埋点原理
在经历了无数个痛苦的夜晚之后,我们决定转变思路,希望能尽量减少人为错误。我们称之为记录模式。与Capture模式不同,Record模式使用机器代替人的体验,自动采集用户在网站或应用程序中的全部行为数据。由于自动化,我们从分析过程开始就控制数据的格式。
所有数据,从业务角度来看,分为5个维度:谁,行为背后的人有什么属性;何时,何时触发行为;哪里,市区浏览器甚至GPS等;内容是什么;怎么做,怎么做。基于信息的解构,保证数据从源头上是干净的。在此基础上,我们可以完全自动化ETL,需要什么数据可以随时追溯。
回到上一个过程的第二到第四步,我们将多方参与者的数量减少到只有一方。无论是产品经理、分析师还是运营人员,您都可以使用可视化工具来查询和分析数据。你所看到的就是你得到的。不仅支持PC,还支持iOS、Android和Hybrid,实现跨屏用户分析。
作为用户行为分析工具的提供者,GrowingIO 不仅内部使用,还需要适应外部上千种网站和应用,所以我们在实现过程中做了很多探索:
◦ 自动用户行为采集
我们目前接触的GUI程序,无论是Web App、iOS App还是Android App,都是基于两个原则,一个是树状结构,一个是事件驱动模型。无论是 Web 上的 DOM 节点结构,还是 App 上的 UI 控件结构,都构建了一个完整的树状结构并呈现在页面或屏幕上。所以通过监控和检测树状结构,我们可以很容易的知道哪些节点发生了变化,什么时候发生了变化,发生了什么变化。同时,当用户进行某种操作,比如鼠标点击或屏幕触摸时,会触发一个事件,并触发与该事件绑定的回调函数开始执行。基于这两点的理解,SDK中如何实现无埋点就比较清楚了。
◦ 数据可视化
如何将采集 接收到的数据与业务目标进行匹配。我们的解决方案是我们的可视化工具。如前所述,任何原子数据都被分解为 5 个不同的分类维度。因此,我们在可视化工具中做匹配时,是对不同维度的信息进行匹配。例如,当一个链接被点击时,它会匹配内容或重定向地址是What,点击行为是How。还有它在页面上的定位信息,比如在树状结构中的层次位置,是否有一些id、class或者tag,都是用于数据匹配的信息。我们开发了一套智能匹配系统,通过学习用户的真实行为,建立了一套元素匹配规则引擎。也正是因为采集
◦ BI 业务分析
在系统设计过程中,在整个Data Pipeline流程中,数据处理完毕后,首先会根据不同的优先级通过Spark Streaming实时处理定义的数据,然后每次对匹配的数据进行离线预聚合. ,多维分析非常灵活。
用户行为数据采集的目的是通过了解用户过去的行为来预测未来会发生什么,不埋点,随时回顾数据,以便产品经理处理用户行为分析全过程由他本人完成。GrowingIO 希望提供一个简单、快速、大规模的数据分析产品,可以大大简化分析流程,提交效率,直达业务。这一切的基础是我们从第一天就开始开发的无埋点智能全数据采集。基于此,我们优化产品体验,实现精细化运营,用数据驱动用户和收入增长。.
___________________________
GrowingIO 是新一代基于用户行为的数据分析产品。如果您属于以下三类人群,请立即关注我们,免费注册:
如果你是一名数据工程师,却“无所事事”地构建BI和配置嵌入代码:免费注册,立即减少无效加班;
如果您是产品经理,但不知道如何分解KPI:免费注册,三步洞察留存曲线,精准识别用户行为;
如果您是业务负责人,收入增长乏力:免费注册,让我们教您如何让客户高效下单。
_________________________
自动采集数据(探码Web大数据采集系统的八个子系统科技 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-07 16:34
)
发现网络大数据采集系统
天马科技基于云计算研发的Web大数据采集系统——利用众多云计算服务器协同工作,快速采集海量数据,避免计算机硬件资源瓶颈. 另外,随着行业对数据采集的要求越来越高,传统post采集无法解决的技术问题正在逐步得到解决,以探针代号Kapow/Dyson采集器为代表@> 新一代智能采集器@> 可以模拟人的思维和操作,从而彻底解决ajax等技术难题。
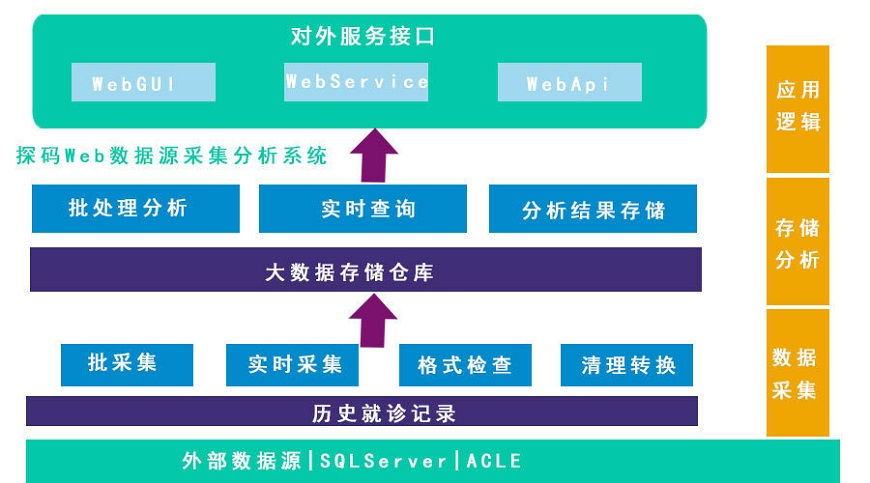
Web大数据采集系统的八个子系统
天马网大数据采集系统分为大数据集群系统、数据采集系统、采集数据源研究、数据爬虫系统、数据清洗系统、数据整合8个子系统系统、任务调度系统、搜索引擎系统。
大数据集群系统
该系统可以存储高达采集的TB级数据,实现数据持久化。数据存储采用MongoDB集群方案,集群上有两大特点:
数据采集系统
本系统配置了Kapow、PhantomJS、Mechanize采集环境,运行在Docker容器中,由Rancher安排容器。
采集数据源研究
该系统是“数据爬虫系统”启动前不可缺少的环节。经过排查,发现页面需要采集,需要过滤的关键字,需要提取的内容。
数据爬虫系统
爬虫程序都是独立的个体,结合采集系统服务器需要的数据,由Rancher安排,在DigitalOcean中自动启动爬虫程序,根据输入的参数,抓取指定的数据,然后发回通过API大数据集群系统给我们。
数据清洗系统
本系统采用Ruby on Rails+Vue技术框架实现Web前端展示,展示爬虫程序抓取的数据,方便我们的清理。数据清洗系统主要由两部分组成:
数据整合系统
本系统采用Ruby on Rails+Vue技术框架,实现Web前端展示和数据合并。数据清洗后,数据合并系统会自动匹配大数据集群中的数据,通过熟人评分关联可能的熟人数据。匹配结果通过web前端展示,数据可以手动合并,也可以自动合并。
任务调度系统
本系统通过Ruby on Rails+Vue技术框架、Sidekiq队列调度、Redis调度数据持久化实现了一个Web前端任务调度系统。通过任务调度系统,可以动态开启关闭,定时启动爬虫程序。
搜索引擎系统
本系统通过ElasticSearch集群实现搜索引擎服务。搜索引擎是PC端检索系统从大数据集群中快速检索数据的必备工具。通过ElasticSearch集群,运行3个以上Master角色保证集群系统的稳定性,2个以上Client角色保证查询的容错性,2个以上Data角色保证查询和写入的及时性。通过负载均衡连接Client的角色,分散数据查询的压力。
Web大数据采集系统应用案例展示
查看全部
自动采集数据(探码Web大数据采集系统的八个子系统科技
)
发现网络大数据采集系统
天马科技基于云计算研发的Web大数据采集系统——利用众多云计算服务器协同工作,快速采集海量数据,避免计算机硬件资源瓶颈. 另外,随着行业对数据采集的要求越来越高,传统post采集无法解决的技术问题正在逐步得到解决,以探针代号Kapow/Dyson采集器为代表@> 新一代智能采集器@> 可以模拟人的思维和操作,从而彻底解决ajax等技术难题。
Web大数据采集系统的八个子系统
天马网大数据采集系统分为大数据集群系统、数据采集系统、采集数据源研究、数据爬虫系统、数据清洗系统、数据整合8个子系统系统、任务调度系统、搜索引擎系统。

大数据集群系统
该系统可以存储高达采集的TB级数据,实现数据持久化。数据存储采用MongoDB集群方案,集群上有两大特点:
数据采集系统
本系统配置了Kapow、PhantomJS、Mechanize采集环境,运行在Docker容器中,由Rancher安排容器。
采集数据源研究
该系统是“数据爬虫系统”启动前不可缺少的环节。经过排查,发现页面需要采集,需要过滤的关键字,需要提取的内容。
数据爬虫系统
爬虫程序都是独立的个体,结合采集系统服务器需要的数据,由Rancher安排,在DigitalOcean中自动启动爬虫程序,根据输入的参数,抓取指定的数据,然后发回通过API大数据集群系统给我们。
数据清洗系统
本系统采用Ruby on Rails+Vue技术框架实现Web前端展示,展示爬虫程序抓取的数据,方便我们的清理。数据清洗系统主要由两部分组成:
数据整合系统
本系统采用Ruby on Rails+Vue技术框架,实现Web前端展示和数据合并。数据清洗后,数据合并系统会自动匹配大数据集群中的数据,通过熟人评分关联可能的熟人数据。匹配结果通过web前端展示,数据可以手动合并,也可以自动合并。
任务调度系统
本系统通过Ruby on Rails+Vue技术框架、Sidekiq队列调度、Redis调度数据持久化实现了一个Web前端任务调度系统。通过任务调度系统,可以动态开启关闭,定时启动爬虫程序。
搜索引擎系统
本系统通过ElasticSearch集群实现搜索引擎服务。搜索引擎是PC端检索系统从大数据集群中快速检索数据的必备工具。通过ElasticSearch集群,运行3个以上Master角色保证集群系统的稳定性,2个以上Client角色保证查询的容错性,2个以上Data角色保证查询和写入的及时性。通过负载均衡连接Client的角色,分散数据查询的压力。
Web大数据采集系统应用案例展示

自动采集数据(如何对采集字段进行配置如何采集列表+详情页类型网页采集结果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-07 15:26
功能点目录:
如何配置采集字段
如何采集列表+详情页类型网页
采集结果预览:
导出到 Excel 电子表格:
导出的PDF文件:
下面详细介绍一下如何免费采集马蜂窝旅游指南信息和数据。我们以泰国的自由行旅游指南为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换为注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第二步:新建一个采集任务
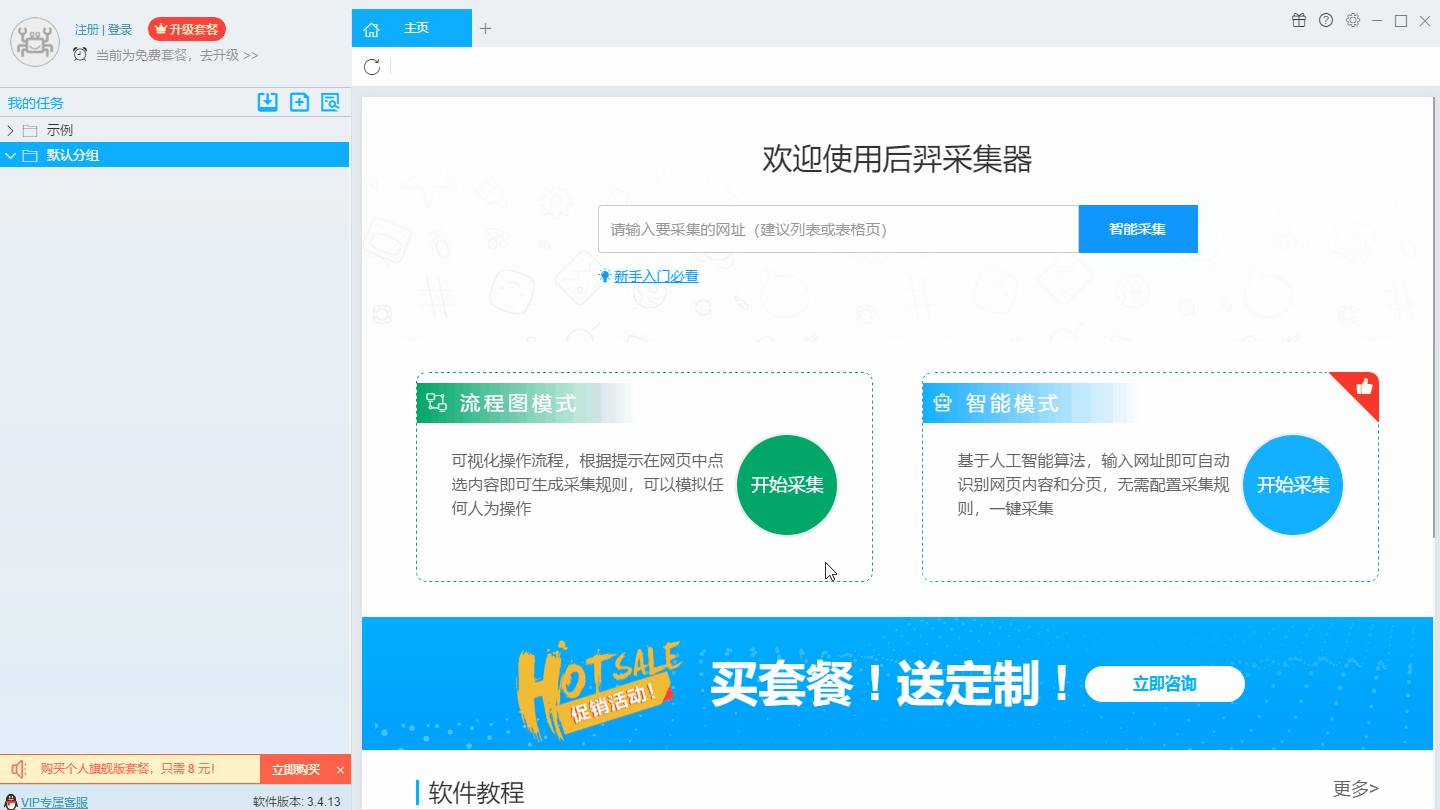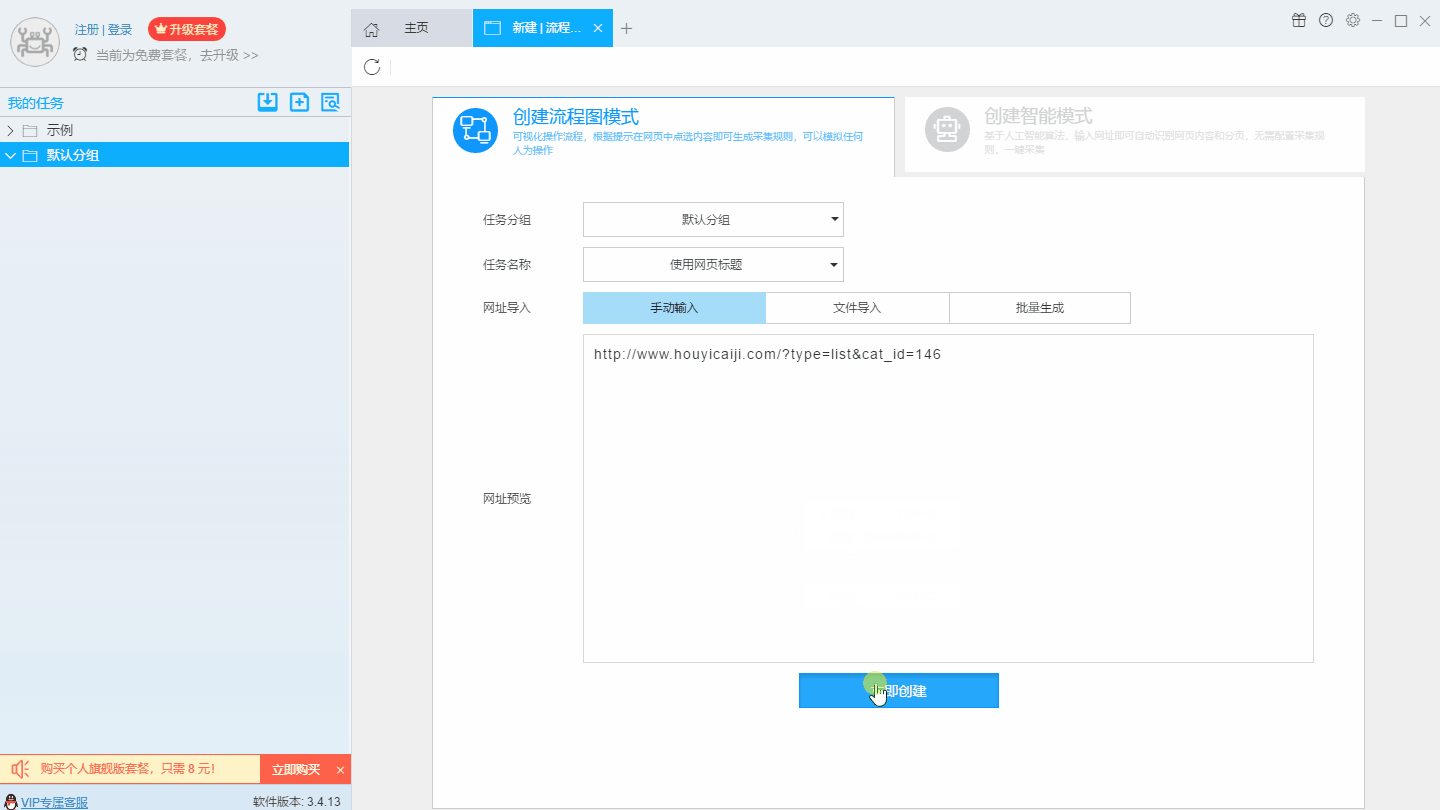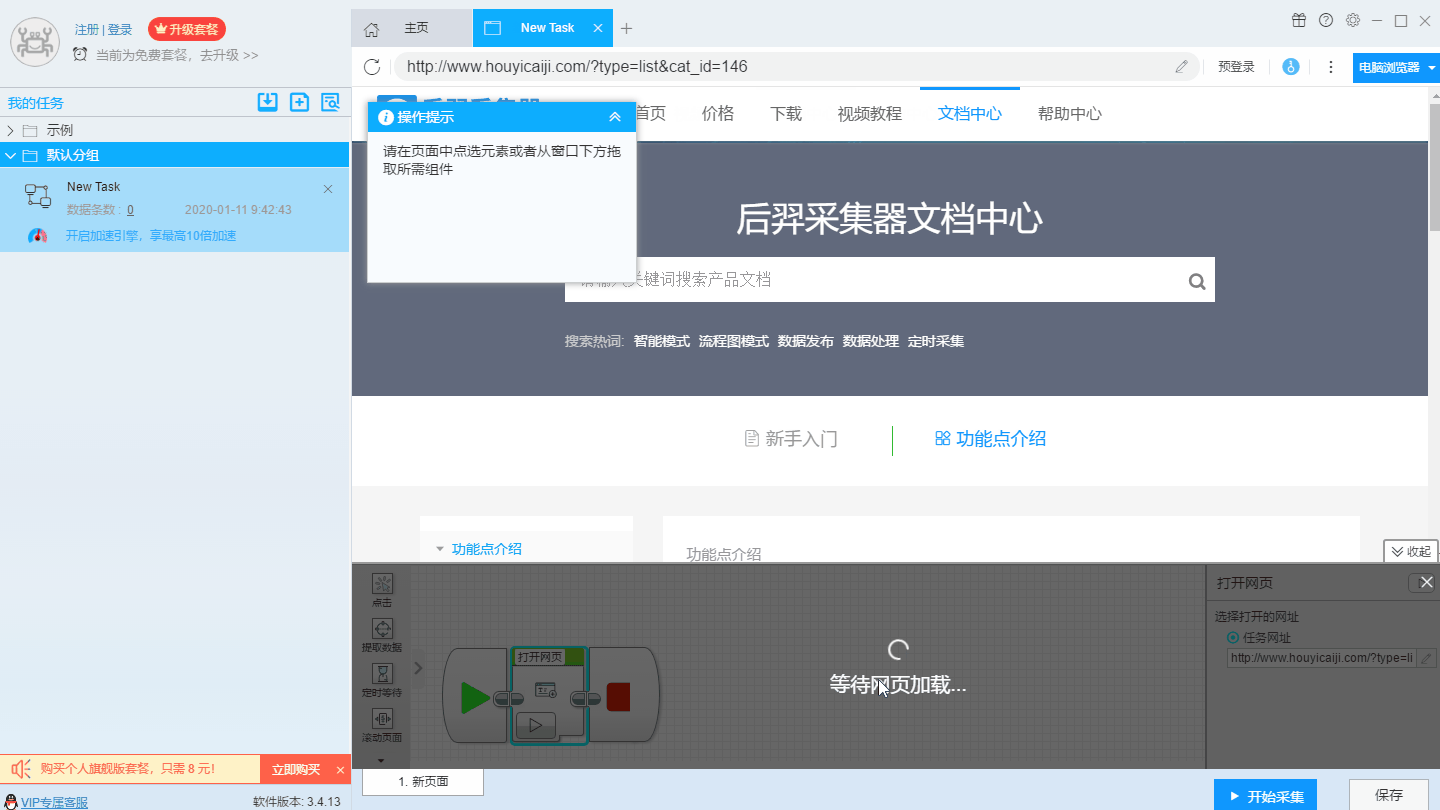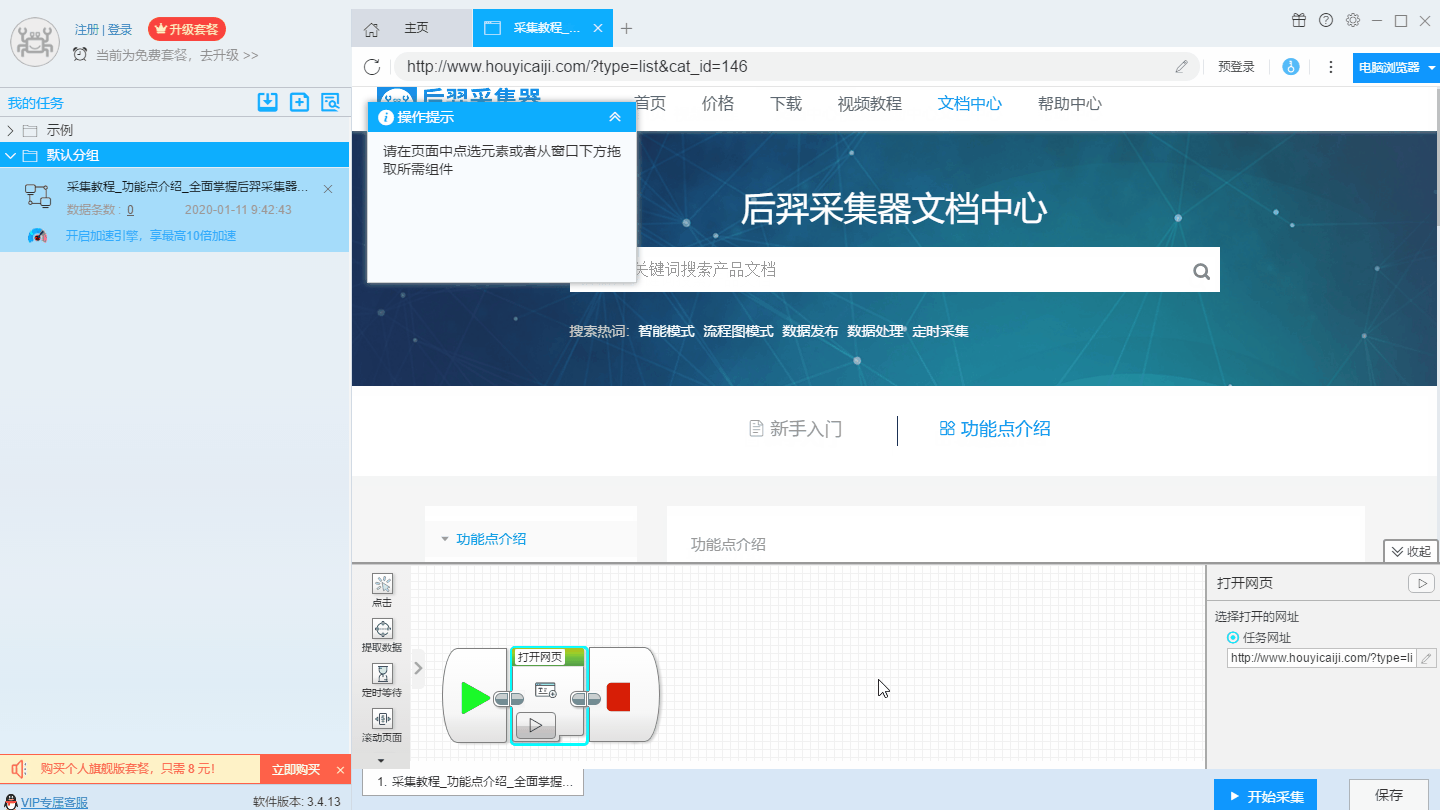
1、复制马蜂窝泰国旅游指南网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
在列表页面,我们需要采集泰国免费旅游指南的指南标题、指南链接、阅读量、体验人数、封面图等,字段设置效果如下:
2、使用深入采集函数提取详情页数据
在列表页面上,只显示了泰国免费旅游指南的部分信息。如果您需要指南的具体内容,我们需要右键点击listing链接,使用“深度采集”功能跳转到详情页继续采集。
在详情页,我们可以看到指南的详细内容、评论数、采集数、发布时间等信息。同时,我们可以看到,指南中有很多图片。如果我们一一设置字段,会出现很多字段,而且每个指南的图片位置不同,可能会导致采集不完整,所以我们可以在这里添加一个特殊的字段,“Page PDF”,我们可以点击“添加字段”来添加采集字段,所有字段设置效果如下:
第四步:设置并启动采集任务
1、设置采集任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,因为采集页面PDF如果有就是漫长的等待 太慢了,可能会导致图片在显示完全之前被采集,所以我们设置了“5”秒的请求等待时间,勾选“不加载网页图片”,反-屏蔽设置将遵循系统默认设置,然后点击保存。
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,只需点击“开始”即可运行爬虫工具。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动开始采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集结束后会有提示@>。
第 5 步:导出并查看数据
数据采集完成后,我们就可以查看和导出数据了。优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)和导出文件的格式(EXCEL、CSV 、HTML 和 TXT),我们选择我们需要的方法和文件类型,然后单击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上可以使用发布到网站功能。 查看全部
自动采集数据(如何对采集字段进行配置如何采集列表+详情页类型网页采集结果)
功能点目录:
如何配置采集字段
如何采集列表+详情页类型网页
采集结果预览:
导出到 Excel 电子表格:
导出的PDF文件:
下面详细介绍一下如何免费采集马蜂窝旅游指南信息和数据。我们以泰国的自由行旅游指南为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换为注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第二步:新建一个采集任务
1、复制马蜂窝泰国旅游指南网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
在列表页面,我们需要采集泰国免费旅游指南的指南标题、指南链接、阅读量、体验人数、封面图等,字段设置效果如下:
2、使用深入采集函数提取详情页数据
在列表页面上,只显示了泰国免费旅游指南的部分信息。如果您需要指南的具体内容,我们需要右键点击listing链接,使用“深度采集”功能跳转到详情页继续采集。
在详情页,我们可以看到指南的详细内容、评论数、采集数、发布时间等信息。同时,我们可以看到,指南中有很多图片。如果我们一一设置字段,会出现很多字段,而且每个指南的图片位置不同,可能会导致采集不完整,所以我们可以在这里添加一个特殊的字段,“Page PDF”,我们可以点击“添加字段”来添加采集字段,所有字段设置效果如下:
第四步:设置并启动采集任务
1、设置采集任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,因为采集页面PDF如果有就是漫长的等待 太慢了,可能会导致图片在显示完全之前被采集,所以我们设置了“5”秒的请求等待时间,勾选“不加载网页图片”,反-屏蔽设置将遵循系统默认设置,然后点击保存。
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,只需点击“开始”即可运行爬虫工具。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动开始采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集结束后会有提示@>。
第 5 步:导出并查看数据
数据采集完成后,我们就可以查看和导出数据了。优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)和导出文件的格式(EXCEL、CSV 、HTML 和 TXT),我们选择我们需要的方法和文件类型,然后单击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上可以使用发布到网站功能。
自动采集数据(能用python解决的问题用什么都一样问到了我的痛点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-02 23:03
自动采集数据一般有两种,一种是python爬虫爬下来再用正则表达式匹配另一种就是专门的数据采集工具可以采集专门的数据。这些采集工具一般就有该平台提供的api,当然你还需要一些编程知识。然后一般根据你需要的类型,会对应有专门的采集平台,比如电影打分、搜索排行什么的,用第三方的工具就可以完成了。专门做数据采集的工具主要是对应于专业的电影网站如豆瓣网,还有就是api也适用于第三方提供的api,比如快猫、码力全开等等。
相关的方面有这些情况可能对你更有用:如何用python抓取豆瓣top250电影排行榜?
有,
专业的数据采集器,比如bigdataexcel可以帮你完成采集豆瓣top250电影电视剧排行榜,抓取打分电影网站,电影院线等。有需要可以去官网了解一下。
可以找这些方面的资料看看可以提高一些工作效率:/
其实很多人都可以,到不代表他们的效率一定高。想要提高效率,那就得对自己负责,让自己思考,让自己反思,让自己一直保持一颗跟有追求的心,工作上,生活上。这些是很重要的,坚持一段时间,你会得到回报。
能用python解决的问题用什么都一样
问到了我的痛点,希望能合作一下。
目前豆瓣top250里的电影已经基本不在了, 查看全部
自动采集数据(能用python解决的问题用什么都一样问到了我的痛点)
自动采集数据一般有两种,一种是python爬虫爬下来再用正则表达式匹配另一种就是专门的数据采集工具可以采集专门的数据。这些采集工具一般就有该平台提供的api,当然你还需要一些编程知识。然后一般根据你需要的类型,会对应有专门的采集平台,比如电影打分、搜索排行什么的,用第三方的工具就可以完成了。专门做数据采集的工具主要是对应于专业的电影网站如豆瓣网,还有就是api也适用于第三方提供的api,比如快猫、码力全开等等。
相关的方面有这些情况可能对你更有用:如何用python抓取豆瓣top250电影排行榜?
有,
专业的数据采集器,比如bigdataexcel可以帮你完成采集豆瓣top250电影电视剧排行榜,抓取打分电影网站,电影院线等。有需要可以去官网了解一下。
可以找这些方面的资料看看可以提高一些工作效率:/
其实很多人都可以,到不代表他们的效率一定高。想要提高效率,那就得对自己负责,让自己思考,让自己反思,让自己一直保持一颗跟有追求的心,工作上,生活上。这些是很重要的,坚持一段时间,你会得到回报。
能用python解决的问题用什么都一样
问到了我的痛点,希望能合作一下。
目前豆瓣top250里的电影已经基本不在了,
自动采集数据(本文如何免费采集豆瓣短评(碟中谍6-全面瓦解))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-26 17:27
本文主要介绍如何使用优采云采集器的智能模式,免费采集豆瓣短评论(任务:不可能6-全面崩溃)评论者、评论时间、评论内容等信息.
采集工具介绍:
优采云采集器是一款基于人工智能技术的网络爬虫工具。只需输入网址即可自动识别网页数据,无需配置即可完成数据。采集,业界首款支持三种操作系统(包括Windows、Mac和Linux)的Crawler软件。
本软件是一款真正免费的数据采集软件,对采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现数据采集需求。
官方网站:
采集对象介绍:
豆瓣是一个社区网站。网站从书籍、电影、音乐开始,提供书籍、电影、音乐等作品的信息。描述和评论均由用户提供。它是 Web 2.0网站 网站 的一个特征。网站 还提供图书影音推荐、同城线下活动、群话题交流等多种服务功能,更像是一个品味系统的集合(阅读、电影、音乐) 、表达系统(我读、我看、我集听的创新网络服务)和交流系统(同城、同组、邻里)一直致力于帮助城市人找到生活中有用的东西。
采集字段:
评论者、发布时间、有用数量、评论内容
功能点目录:
如何采集需要登录才能查看的网页
如何实现翻页功能
采集结果预览:
下面详细介绍一下如何免费采集豆瓣短评论数据。我们以豆瓣短评《使命:不可能的6-全解体》为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、点此打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换为注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第二步:新建一个采集任务
1、 复制《碟中谍6-彻底解体》豆瓣短评的网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集规则
1、设置预登录
豆瓣短评论在用户未登录时只能显示前10页的数据,如果用户需要更多的数据,需要在采集之前登录,所以我们需要先预登录,并且然后继续采集。
这里我们要使用“预登录”功能,点击“预登录”按钮,打开登录窗口,如下图所示。优采云采集器 不会存储和上传您的帐户信息,您可以放心使用此功能。
2、手动设置分页
豆瓣短评论页面的翻页按钮比较特别,智能模式无法直接识别元素采集下一页,此时系统会提示。
我们需要手动设置分页,设置“分页设置-手动设置分页-点击分页按钮”,然后点击网页上的分页按钮。
3、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
我们需要采集豆瓣短评论的评论者、发布时间、有用数量和评论内容。由于特殊星级元素,优采云V2.1.22版本暂时不支持采集此字段,此功能将在后续版本中实现,字段设置效果如下:
第四步:设置并启动采集任务
1、设置采集 任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面中我们可以设置运行设置和防拦截设置。这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,并勾选“不加载网页图片”,防拦截设置将遵循系统默认设置,然后点击保存.
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,直接点击“开始”即可。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动开始采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集结束后会有提示@>。
第 5 步:导出并查看数据
数据采集完成后,我们就可以查看和导出数据了。优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)和导出文件的格式(EXCEL、CSV 、HTML 和 TXT),我们选择我们需要的方法和文件类型,然后单击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上可以使用发布到网站功能。 查看全部
自动采集数据(本文如何免费采集豆瓣短评(碟中谍6-全面瓦解))
本文主要介绍如何使用优采云采集器的智能模式,免费采集豆瓣短评论(任务:不可能6-全面崩溃)评论者、评论时间、评论内容等信息.
采集工具介绍:
优采云采集器是一款基于人工智能技术的网络爬虫工具。只需输入网址即可自动识别网页数据,无需配置即可完成数据。采集,业界首款支持三种操作系统(包括Windows、Mac和Linux)的Crawler软件。
本软件是一款真正免费的数据采集软件,对采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现数据采集需求。
官方网站:
采集对象介绍:
豆瓣是一个社区网站。网站从书籍、电影、音乐开始,提供书籍、电影、音乐等作品的信息。描述和评论均由用户提供。它是 Web 2.0网站 网站 的一个特征。网站 还提供图书影音推荐、同城线下活动、群话题交流等多种服务功能,更像是一个品味系统的集合(阅读、电影、音乐) 、表达系统(我读、我看、我集听的创新网络服务)和交流系统(同城、同组、邻里)一直致力于帮助城市人找到生活中有用的东西。
采集字段:
评论者、发布时间、有用数量、评论内容
功能点目录:
如何采集需要登录才能查看的网页
如何实现翻页功能
采集结果预览:
下面详细介绍一下如何免费采集豆瓣短评论数据。我们以豆瓣短评《使命:不可能的6-全解体》为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、点此打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换为注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第二步:新建一个采集任务
1、 复制《碟中谍6-彻底解体》豆瓣短评的网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集规则
1、设置预登录
豆瓣短评论在用户未登录时只能显示前10页的数据,如果用户需要更多的数据,需要在采集之前登录,所以我们需要先预登录,并且然后继续采集。
这里我们要使用“预登录”功能,点击“预登录”按钮,打开登录窗口,如下图所示。优采云采集器 不会存储和上传您的帐户信息,您可以放心使用此功能。
2、手动设置分页
豆瓣短评论页面的翻页按钮比较特别,智能模式无法直接识别元素采集下一页,此时系统会提示。
我们需要手动设置分页,设置“分页设置-手动设置分页-点击分页按钮”,然后点击网页上的分页按钮。
3、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
我们需要采集豆瓣短评论的评论者、发布时间、有用数量和评论内容。由于特殊星级元素,优采云V2.1.22版本暂时不支持采集此字段,此功能将在后续版本中实现,字段设置效果如下:
第四步:设置并启动采集任务
1、设置采集 任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面中我们可以设置运行设置和防拦截设置。这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,并勾选“不加载网页图片”,防拦截设置将遵循系统默认设置,然后点击保存.
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,直接点击“开始”即可。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动开始采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集结束后会有提示@>。
第 5 步:导出并查看数据
数据采集完成后,我们就可以查看和导出数据了。优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)和导出文件的格式(EXCEL、CSV 、HTML 和 TXT),我们选择我们需要的方法和文件类型,然后单击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上可以使用发布到网站功能。
自动采集数据(MicrosoftOfficeExcel连接外部数据的主要好处是可以在Excel中定期分析此数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-09-21 02:21
microsoftofficeexcel连接外部数据的主要好处是在Excel中分析此数据,而不重复复制数据,复制操作不仅耗时,还可以轻松错误。连接到外部数据后,无论数据源是否已使用新信息更新,也可以自动刷新(或更新)Excel工作簿。安全性计算机可能会禁用与外部数据的连接。要连接到数据打开工作簿时,必须通过使用信任中心栏启用数据连接,或将工作簿放在可信位置。在“在”数据“选项卡上的”获取外部数据“组中,单击”现有连接“。将显示现有连接对话框。在对话框顶部的“显示”下拉列表中,执行以下操作之一:要显示所有连接,请单击所有连接。这是默认选项。要仅显示最近使用的连接列表,请单击“本工作簿中的连接”。此列表是从以下连接创建的:由“选择数据源”对话框创建的连接使用数据连接向导或在对话框中选择的连接创建。要仅在计算机上显示连接的连接,请单击“此计算机的连接文件”。此列表是从通常存储在我的文档中的“我的数据源”文件夹中创建的。仅显示网络上连接文件可访问的可用连接,单击“网络连接文件”。此列表是从MicrosoftOfficesHepointsServer2007 网站 网站的excelservices数据连接库(DCL)创建。
dcl是MicrosoftOfficesHakePointServices2007 网站收录一个Office数据连接(ODC)文件(.odc)的集合。 DCL通常由网站 admin设置。,网站管理员还可以在外部连接对话框中配置SharePoint 网站以在此DCL中显示ODC文件。有关更多信息,请参阅防毒源宗机HarePointServer2007管理中心帮助。如果未看到所需的连接,则可以单击“浏览更多”以显示数据源对话框,然后单击“启动数据连接向导”以创建连接。注意如果在此计算机上的“网络连接文件”或“连接文件”类别中选择了连接,则连接文件将被复制到工作簿作为新的工作簿连接,并将用作新的连接信息。选择所需的连接,然后单击“打开”。将显示“导入数据”对话框。在“请在工作簿中选择此数据”,执行以下操作之一:为简单排序和过滤创建表,请单击“表”。要创建数据透视图,请通过聚合和总计数据来总结大量数据,单击“透视”。要创建数据透视图和数据透视图,请单击“数据透视图”和“数据透视表”。要将所选连接存储在工作簿中以备将来使用,请单击“创建连接”。
使用此选项将所选连接存储到工作簿以进行使用。例如,如果要连接到在线分析过程(OLAP)立方体数据源,并打算使用“转换为公式”命令(“选项”选项卡上的“工具”组,请单击“OLAP工具”)转换数据表公式的数据透视表单元,您可以使用此选项,因为您不必保存数据透视图。注意这些选项不适用于所有类型的数据连接(包括文本,Web查询和XML)。在“数据放置位置”下,执行以下操作之一:要在现有工作表中放置数据透视表或枢轴透视图,请选择现有工作表,然后键入要放置数据透视中心的单元区域的第一个单元格。您还可以单击“压缩对话框”以临时隐藏对话框,然后在工作表上选择单元格,按“对话框”。要将数据透视表放在新的工作表中,请单击“新建工作表”。或者,您可以通过遵循“属性”,在“连接属性”,“导出数据区域”或“XML映射属性”对话框中更改连接属性,然后单击“确定”。 查看全部
自动采集数据(MicrosoftOfficeExcel连接外部数据的主要好处是可以在Excel中定期分析此数据)
microsoftofficeexcel连接外部数据的主要好处是在Excel中分析此数据,而不重复复制数据,复制操作不仅耗时,还可以轻松错误。连接到外部数据后,无论数据源是否已使用新信息更新,也可以自动刷新(或更新)Excel工作簿。安全性计算机可能会禁用与外部数据的连接。要连接到数据打开工作簿时,必须通过使用信任中心栏启用数据连接,或将工作簿放在可信位置。在“在”数据“选项卡上的”获取外部数据“组中,单击”现有连接“。将显示现有连接对话框。在对话框顶部的“显示”下拉列表中,执行以下操作之一:要显示所有连接,请单击所有连接。这是默认选项。要仅显示最近使用的连接列表,请单击“本工作簿中的连接”。此列表是从以下连接创建的:由“选择数据源”对话框创建的连接使用数据连接向导或在对话框中选择的连接创建。要仅在计算机上显示连接的连接,请单击“此计算机的连接文件”。此列表是从通常存储在我的文档中的“我的数据源”文件夹中创建的。仅显示网络上连接文件可访问的可用连接,单击“网络连接文件”。此列表是从MicrosoftOfficesHepointsServer2007 网站 网站的excelservices数据连接库(DCL)创建。
dcl是MicrosoftOfficesHakePointServices2007 网站收录一个Office数据连接(ODC)文件(.odc)的集合。 DCL通常由网站 admin设置。,网站管理员还可以在外部连接对话框中配置SharePoint 网站以在此DCL中显示ODC文件。有关更多信息,请参阅防毒源宗机HarePointServer2007管理中心帮助。如果未看到所需的连接,则可以单击“浏览更多”以显示数据源对话框,然后单击“启动数据连接向导”以创建连接。注意如果在此计算机上的“网络连接文件”或“连接文件”类别中选择了连接,则连接文件将被复制到工作簿作为新的工作簿连接,并将用作新的连接信息。选择所需的连接,然后单击“打开”。将显示“导入数据”对话框。在“请在工作簿中选择此数据”,执行以下操作之一:为简单排序和过滤创建表,请单击“表”。要创建数据透视图,请通过聚合和总计数据来总结大量数据,单击“透视”。要创建数据透视图和数据透视图,请单击“数据透视图”和“数据透视表”。要将所选连接存储在工作簿中以备将来使用,请单击“创建连接”。
使用此选项将所选连接存储到工作簿以进行使用。例如,如果要连接到在线分析过程(OLAP)立方体数据源,并打算使用“转换为公式”命令(“选项”选项卡上的“工具”组,请单击“OLAP工具”)转换数据表公式的数据透视表单元,您可以使用此选项,因为您不必保存数据透视图。注意这些选项不适用于所有类型的数据连接(包括文本,Web查询和XML)。在“数据放置位置”下,执行以下操作之一:要在现有工作表中放置数据透视表或枢轴透视图,请选择现有工作表,然后键入要放置数据透视中心的单元区域的第一个单元格。您还可以单击“压缩对话框”以临时隐藏对话框,然后在工作表上选择单元格,按“对话框”。要将数据透视表放在新的工作表中,请单击“新建工作表”。或者,您可以通过遵循“属性”,在“连接属性”,“导出数据区域”或“XML映射属性”对话框中更改连接属性,然后单击“确定”。
自动采集数据(自动采集数据给到后端更新的技术架构是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-13 20:02
自动采集数据给到后端更新,简单说,就是前端需要一个函数,把用户采集的网页链接,转换成用户所需要的redis对象即可。springcloud从2.0开始就支持开启redis服务了,2.1的版本可以自动配置即可。redis的所有命令和类都是java直接写的,不需要再写spring.redis.jar之类的依赖。另外推荐我个人的github项目:fabrics/cloud-redis。
如果没有redis,
技术架构的设计我有一些浅薄的认识。关于一个项目的自动采集,我的技术架构是以下这样的:1.在程序的生命周期内根据服务端数据源的要求,获取数据2.如果要自动采集,就要设置最佳路由3.设置最佳路由,那么这些数据来源的相应数据也要找到4.保存到数据库5.把数据返回给客户端6.数据源返回给客户端,数据返回客户端后还需要从客户端获取最佳路由的数据返回,这样可以节省最短的时间,提高数据接收的效率。
整个流程的细节也有一些注意的地方:1.一个模块内一般只需要设置一条路由,也就是说,我只有有数据时,才会去数据库查询。2.通过短连接(如电话号码)和post方式请求,服务端会返回一个响应,以示歉意。3.这个数据返回后,不会马上消失。一般得等服务端处理完这个响应后才能再返回给客户端。这样客户端就能从中节省时间。
4.如果要自动采集,就要设置最佳路由。设置好最佳路由后,要把它写到jar包里,然后再去fabric.client.java中加载。这样服务端返回给客户端的这个响应才能是自动采集来的数据。5.设置最佳路由是为了保证返回的数据准确性。如果返回的是乱码,返回给客户端的这个消息就是java写的伪造数据。 查看全部
自动采集数据(自动采集数据给到后端更新的技术架构是什么?)
自动采集数据给到后端更新,简单说,就是前端需要一个函数,把用户采集的网页链接,转换成用户所需要的redis对象即可。springcloud从2.0开始就支持开启redis服务了,2.1的版本可以自动配置即可。redis的所有命令和类都是java直接写的,不需要再写spring.redis.jar之类的依赖。另外推荐我个人的github项目:fabrics/cloud-redis。
如果没有redis,
技术架构的设计我有一些浅薄的认识。关于一个项目的自动采集,我的技术架构是以下这样的:1.在程序的生命周期内根据服务端数据源的要求,获取数据2.如果要自动采集,就要设置最佳路由3.设置最佳路由,那么这些数据来源的相应数据也要找到4.保存到数据库5.把数据返回给客户端6.数据源返回给客户端,数据返回客户端后还需要从客户端获取最佳路由的数据返回,这样可以节省最短的时间,提高数据接收的效率。
整个流程的细节也有一些注意的地方:1.一个模块内一般只需要设置一条路由,也就是说,我只有有数据时,才会去数据库查询。2.通过短连接(如电话号码)和post方式请求,服务端会返回一个响应,以示歉意。3.这个数据返回后,不会马上消失。一般得等服务端处理完这个响应后才能再返回给客户端。这样客户端就能从中节省时间。
4.如果要自动采集,就要设置最佳路由。设置好最佳路由后,要把它写到jar包里,然后再去fabric.client.java中加载。这样服务端返回给客户端的这个响应才能是自动采集来的数据。5.设置最佳路由是为了保证返回的数据准确性。如果返回的是乱码,返回给客户端的这个消息就是java写的伪造数据。
自动采集数据(本文介绍如何采集网站上多关键词的流程图模式?介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-09-11 13:05
)
本文介绍如何使用优采云采集器的流程图模式,并介绍如何采集网站上多关键词数据。
第一步:新建采集task
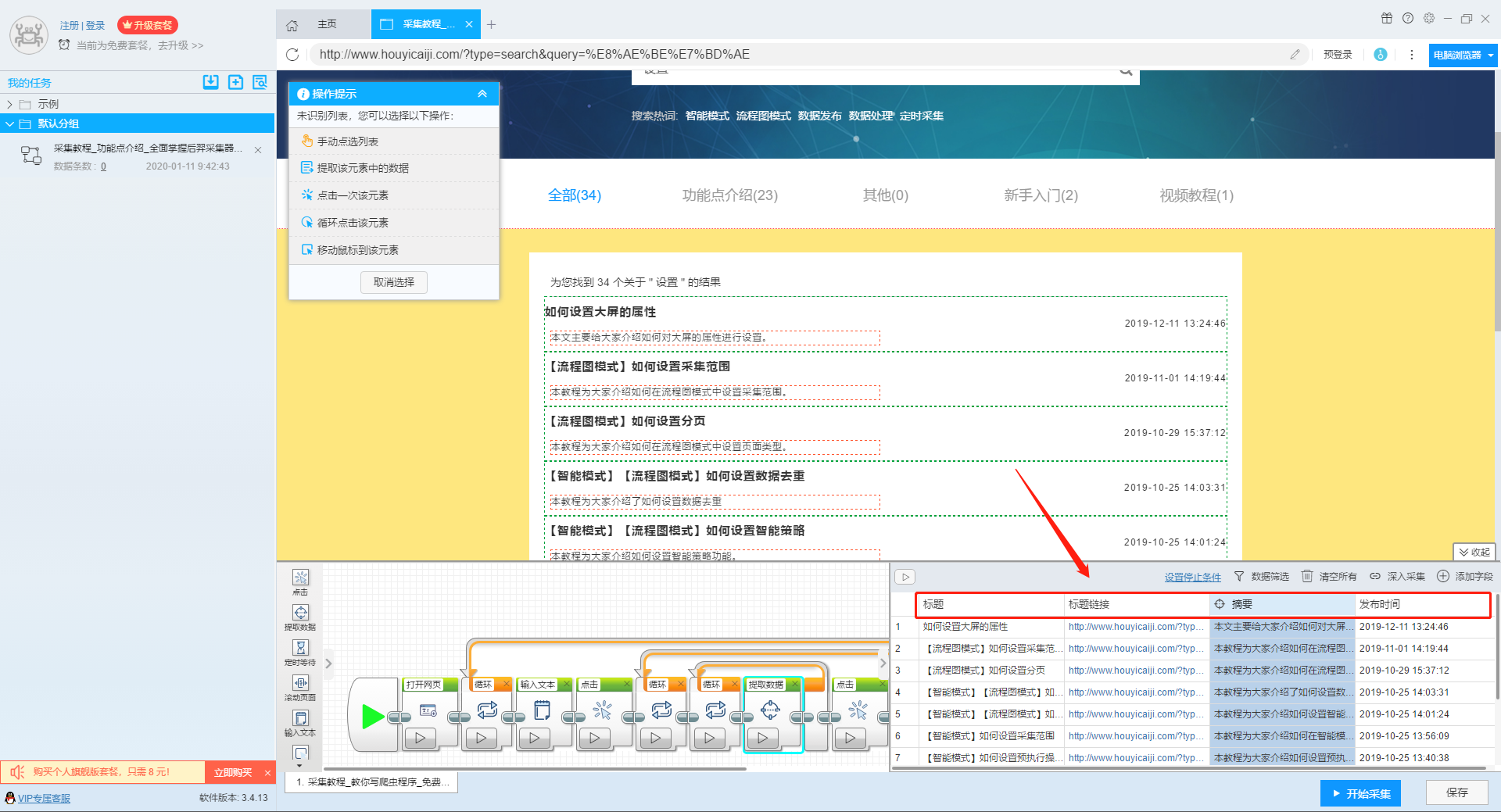
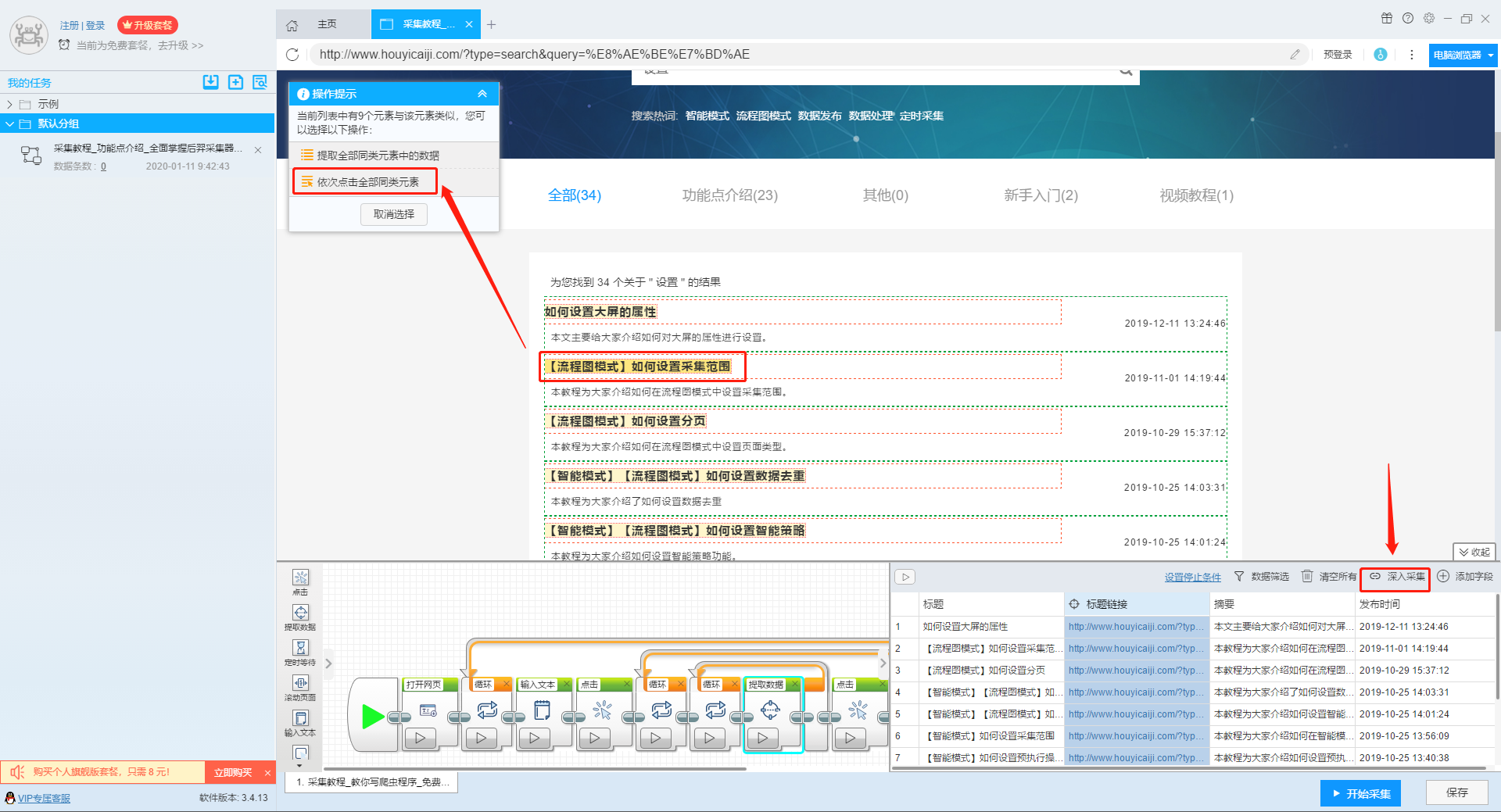
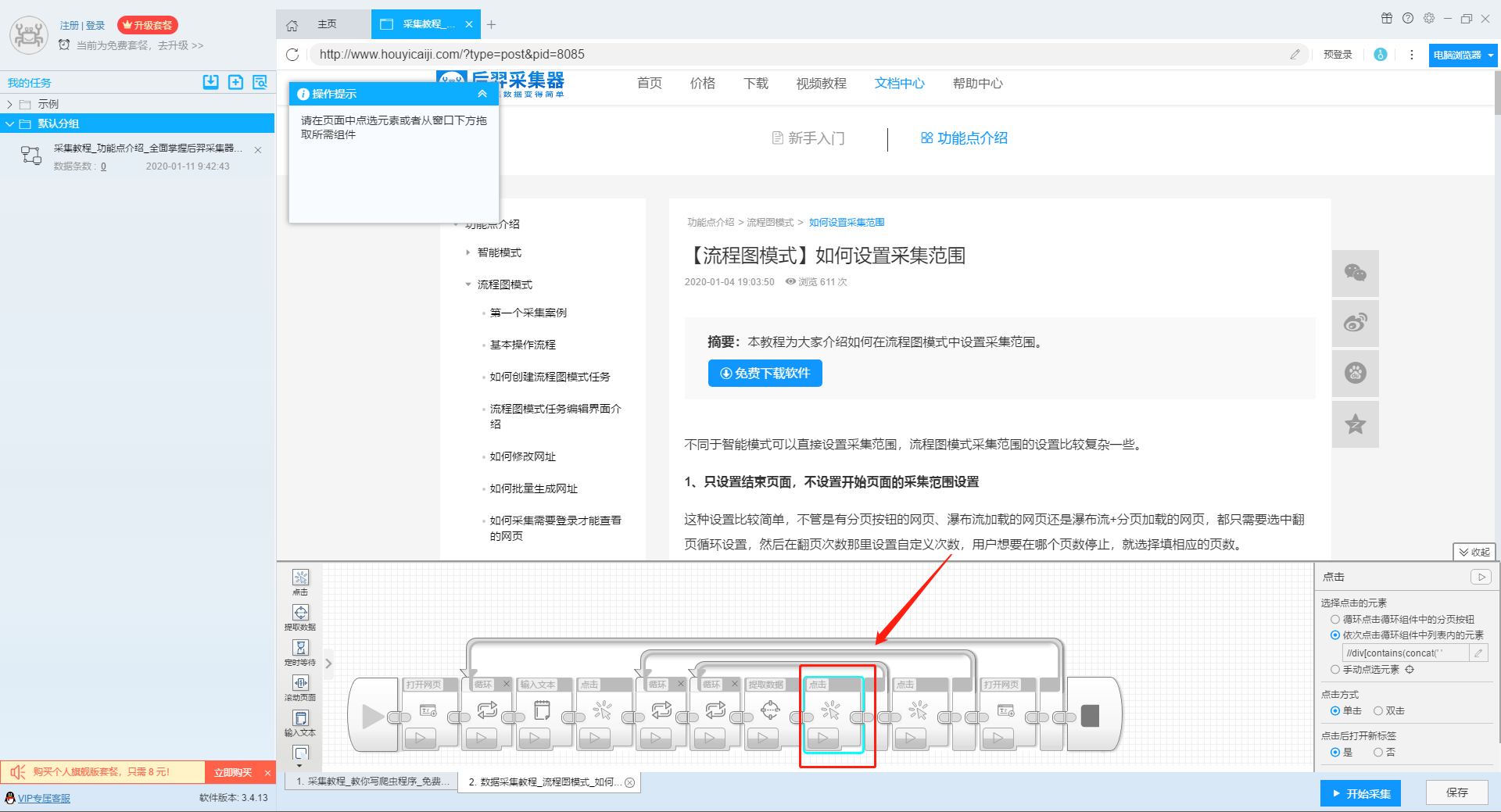
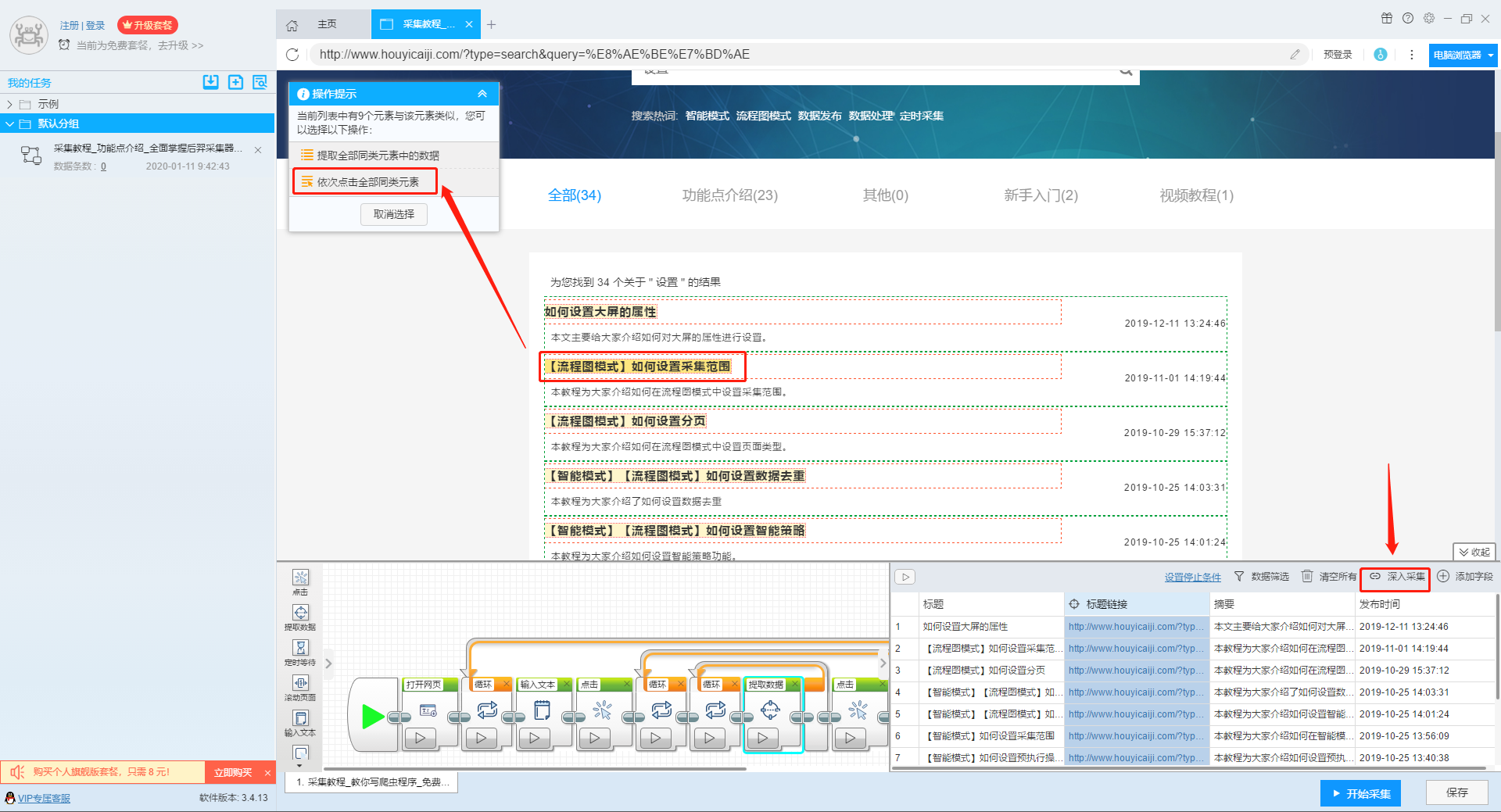
1、复制官网网址(需要搜索结果页面的网址,不是首页的网址)
点击此处了解如何正确输入网址。
2、新流程图模式采集task
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出采集 规则。
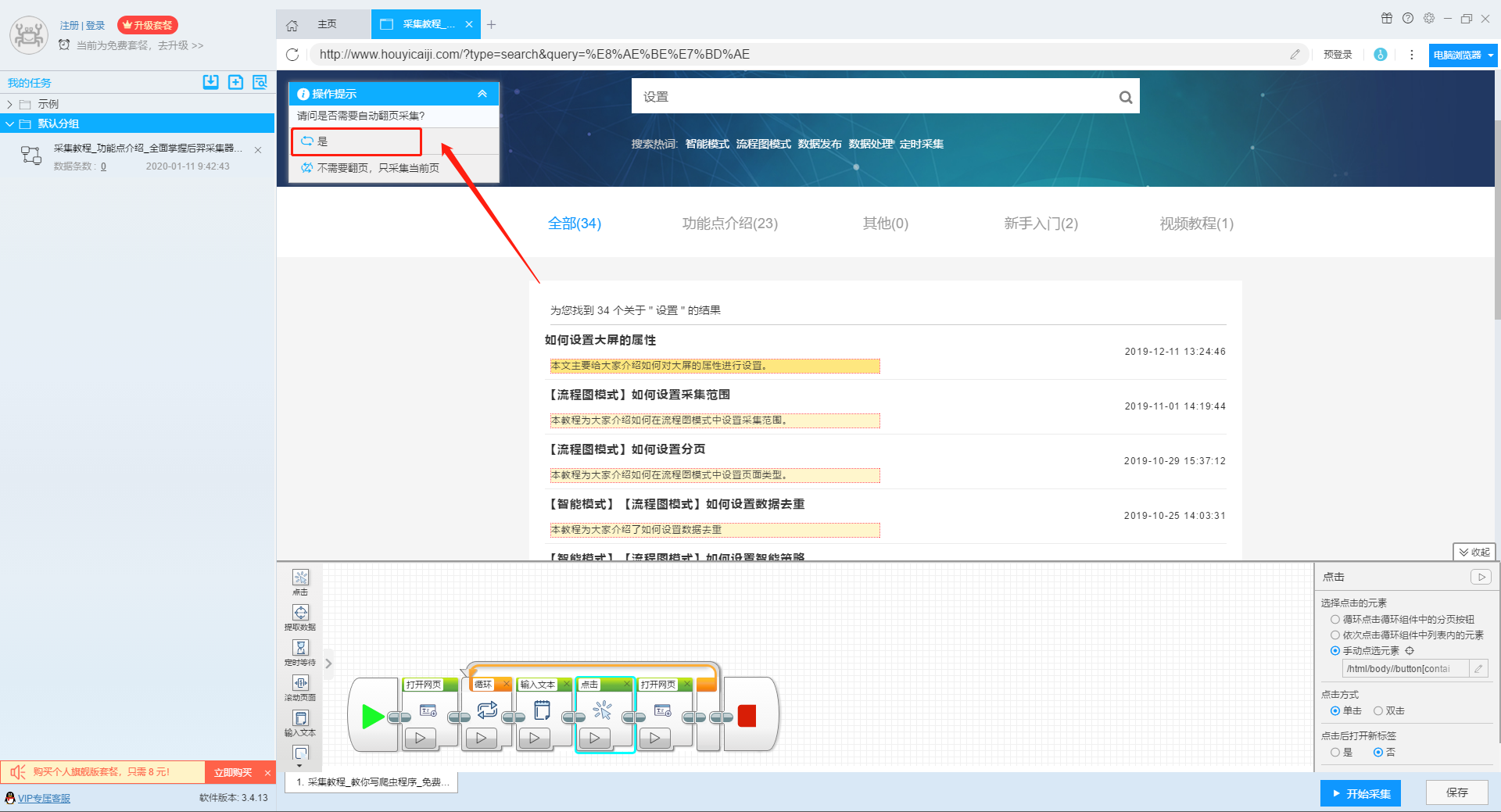
第二步:配置采集规则
1、设置多个关键字循环任务
流程图模式下输入创建新任务的URL后,我们点击搜索框,然后在左上角出现的操作提示框中输入采集的文字。
单击此处了解有关输入文本组件的更多信息。
由于需要输入多个关键词数据,我们选择点击操作框上的批量输入文本按钮。
然后选择批量输入单个文本。
然后在弹出的文本列表中输入我们需要设置的文本,这里我们输入“设置”、“采集”、“数据”关键词。
点击“确定”按钮后,软件会自动生成一个圆形的关键词列表。
然后我们点击页面上的搜索按钮,在操作框中选择“点击该元素一次”按钮,跳转到搜索结果页面。
2、设置提取字段数据
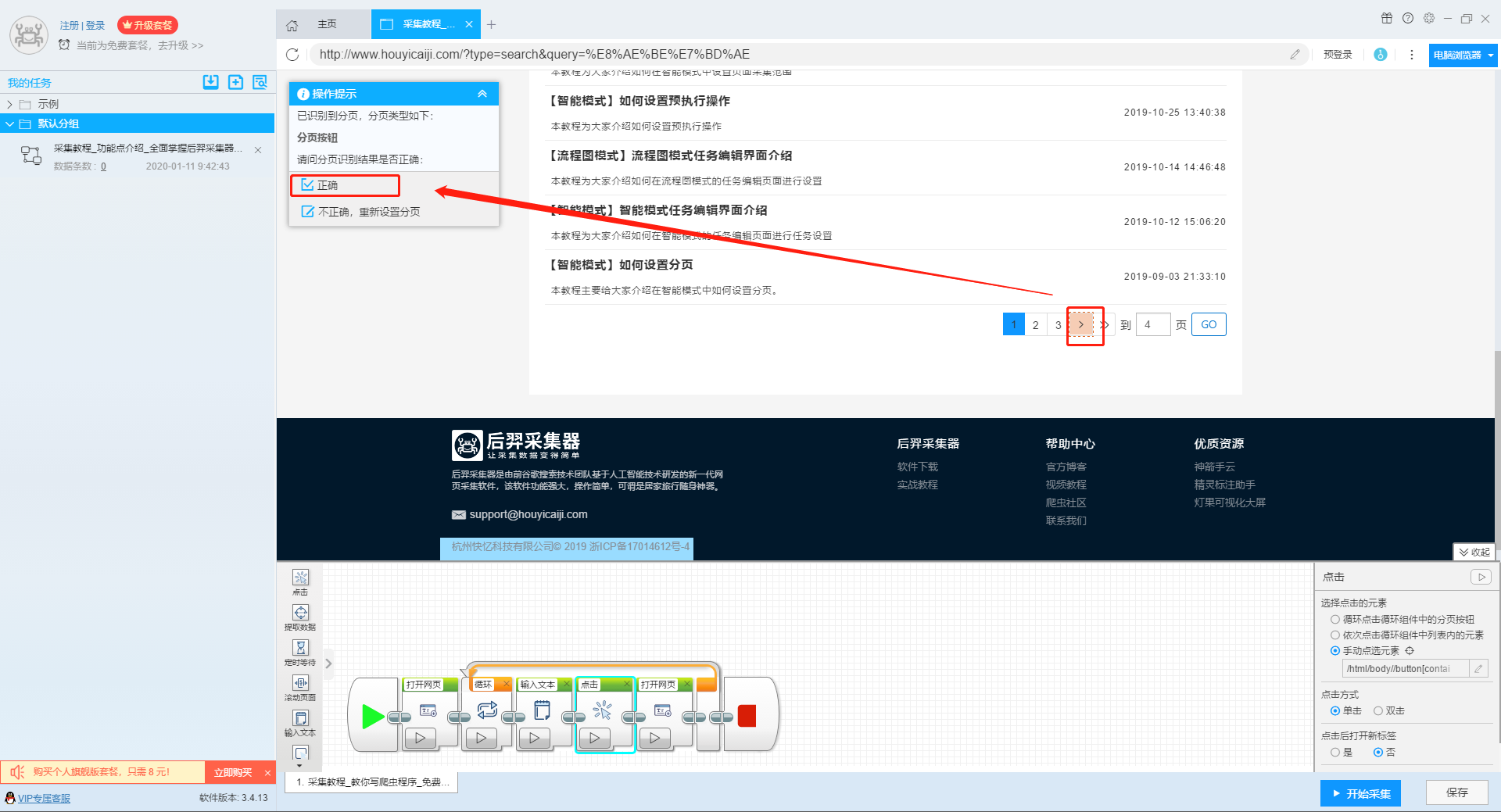
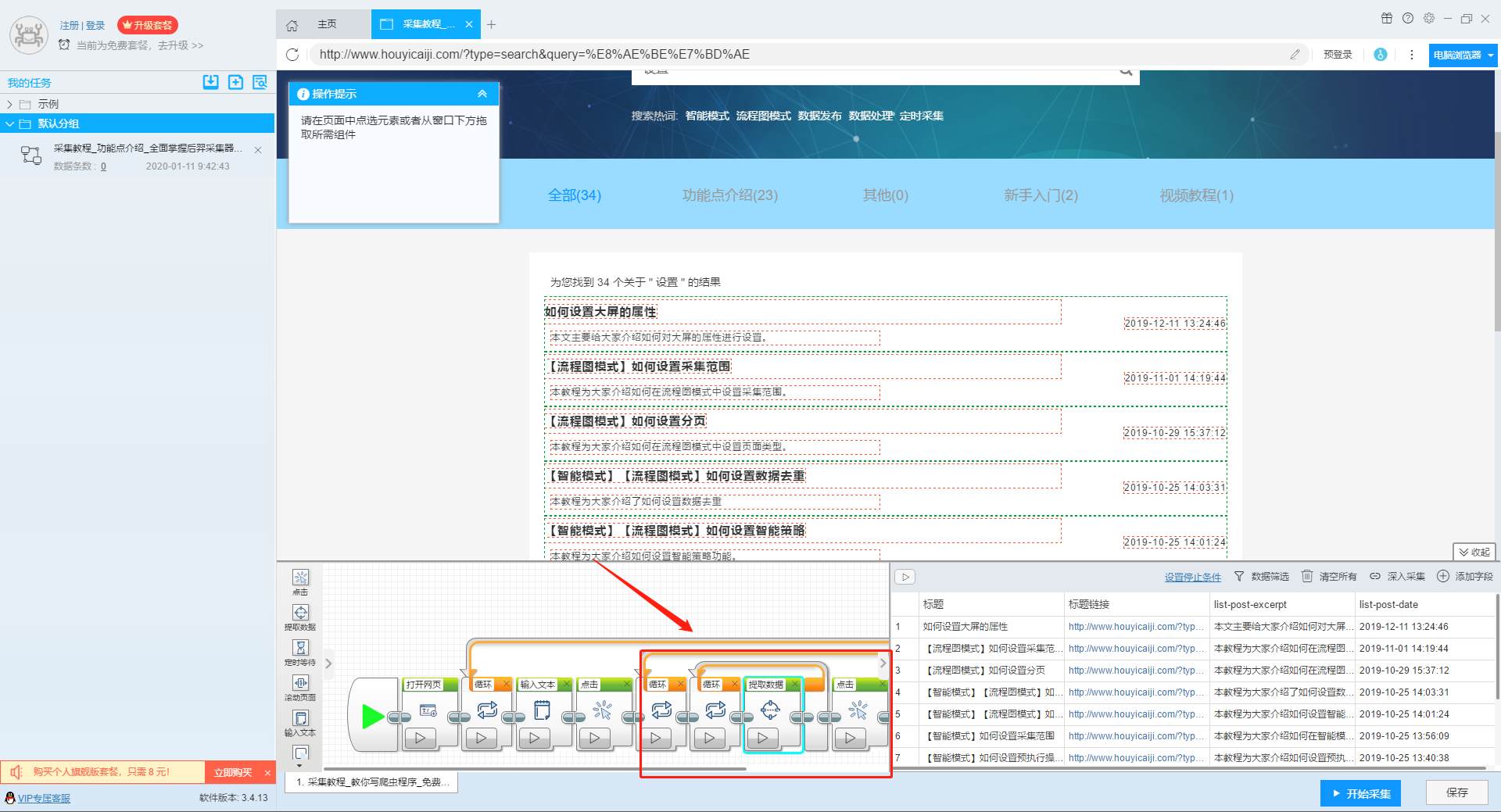
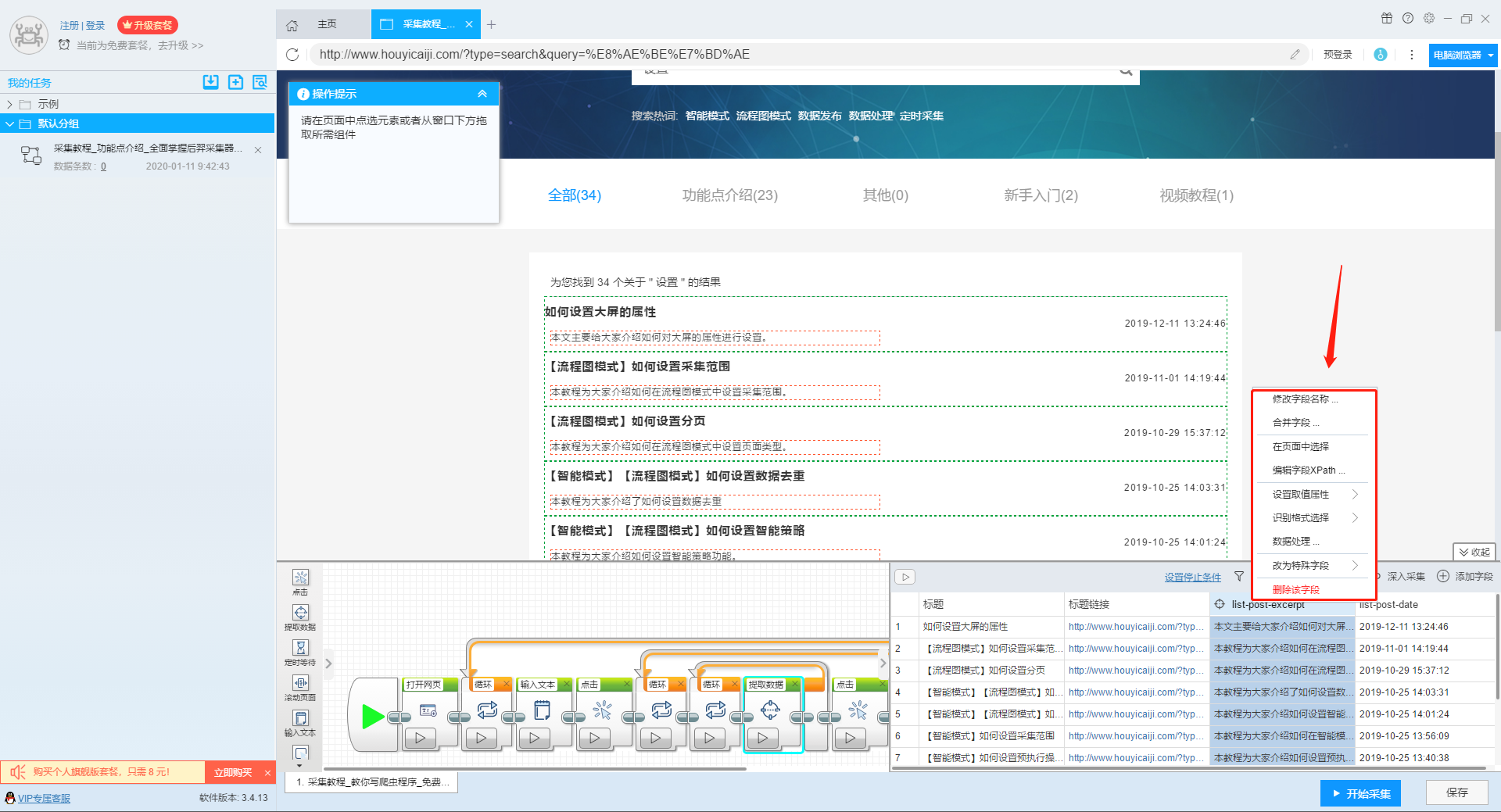
输入多个关键字并设置循环后,我们设置需要提取的字段数据,点击网页上的字段,在左上角的操作提示框中选择提取所有元素。然后软件会自动识别分页,用户根据软件提示设置分页。
然后我们可以在此基础上设置采集字段,用户可以根据自己的需要进行设置。
更多详情,请参考以下教程:
如何配置采集字段
3、深入设置采集
如果需要采集detail页面的数据,可以使用deep采集函数。
更多详情,请参考以下教程:
如何实现深入采集
4、设置详情页数据
详情页的采集与单页类型的采集相同。我们在页面上点击需要采集的数据,然后点击操作提示框中的“从此元素中提取数据”按钮,数据设置可以参考列表页上的设置。
更多详情,请参考以下教程:
如何采集单页类型网页
5、完整的组件图
第三步:设置并启动采集task
1、START采集task
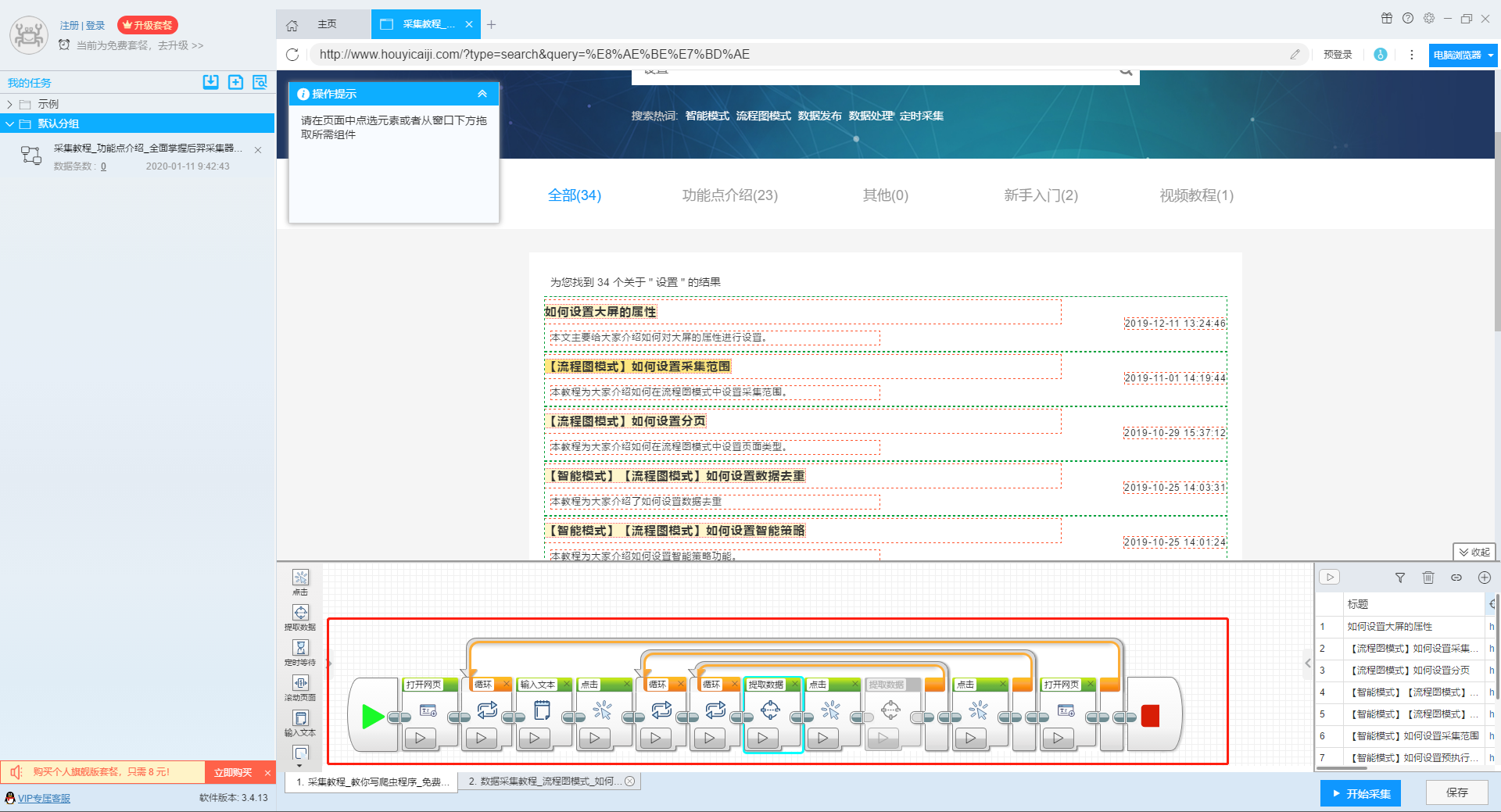
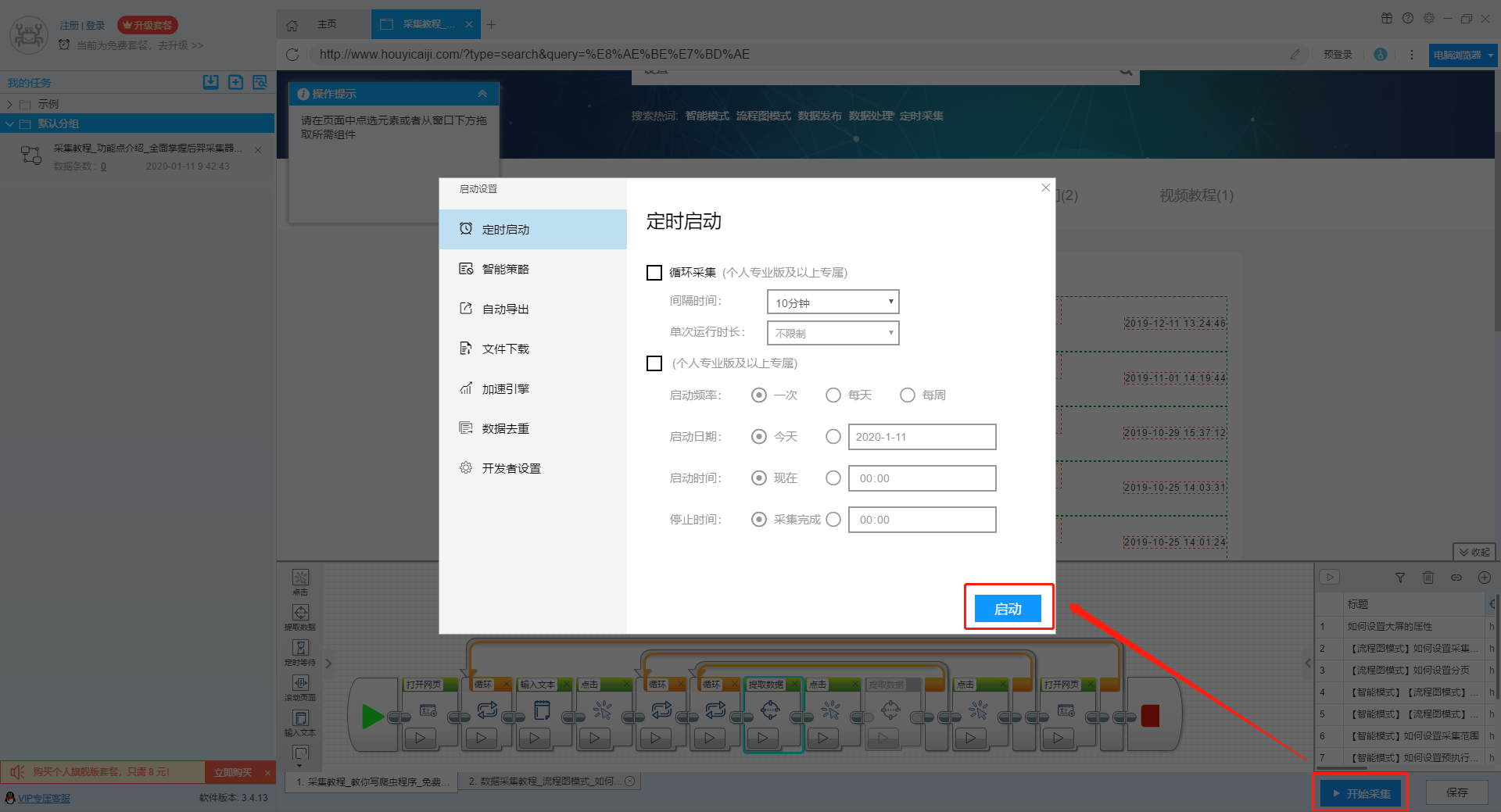
点击“Start采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置”功能,本次操作不使用以上功能,直接点击启动按钮启动采集。
单击此处了解有关预定开始时间的更多信息。
单击此处了解有关自动导出的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费;专业版及以上用户可以使用定时启动功能;旗舰版用户可以使用自动导出功能和加速引擎功能。
2、运行任务提取数据
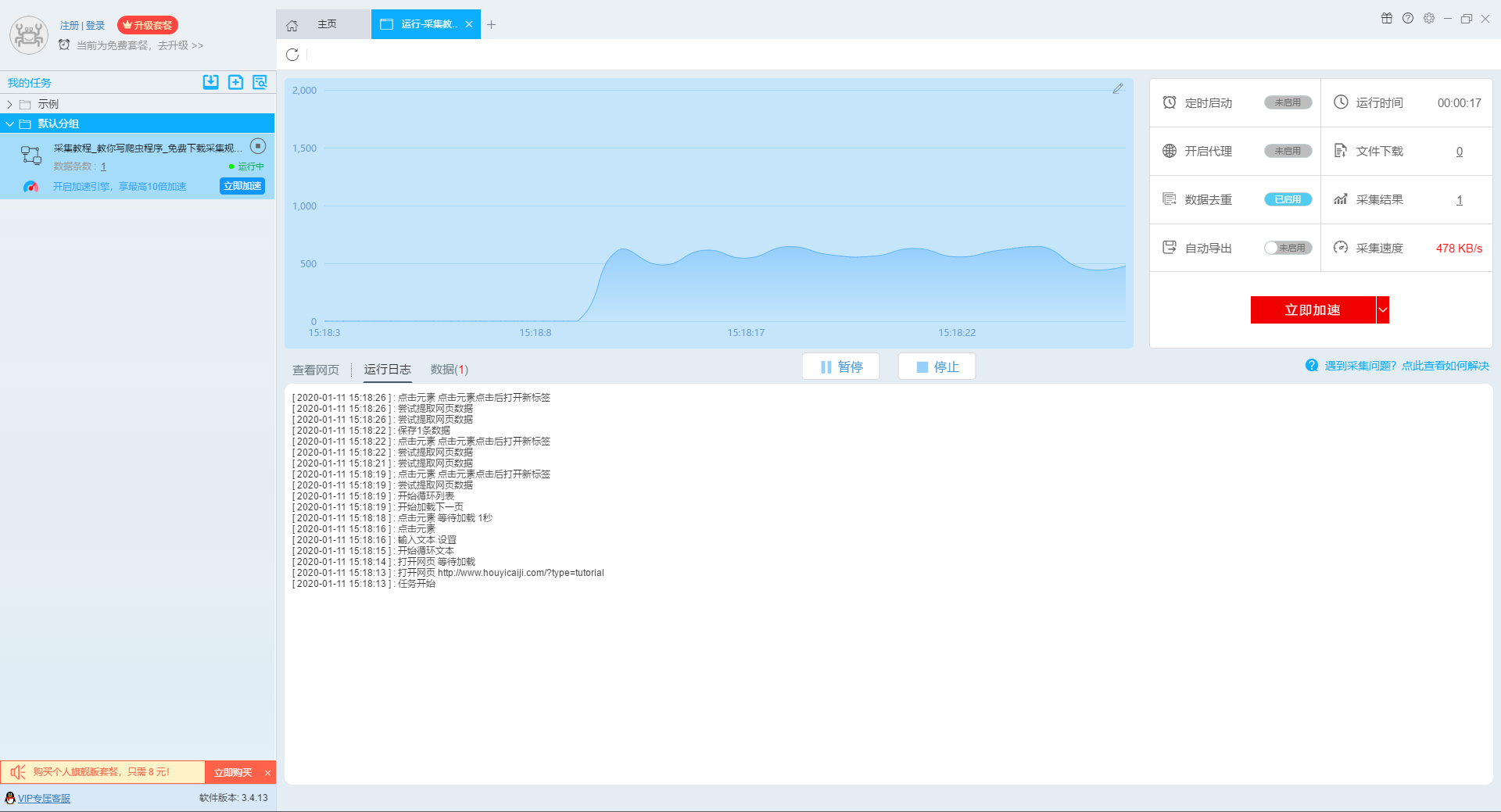
任务启动后,采集数据自动启动。从界面上我们可以直观的看到程序运行的过程和采集的结果。 采集结束后会有提醒。
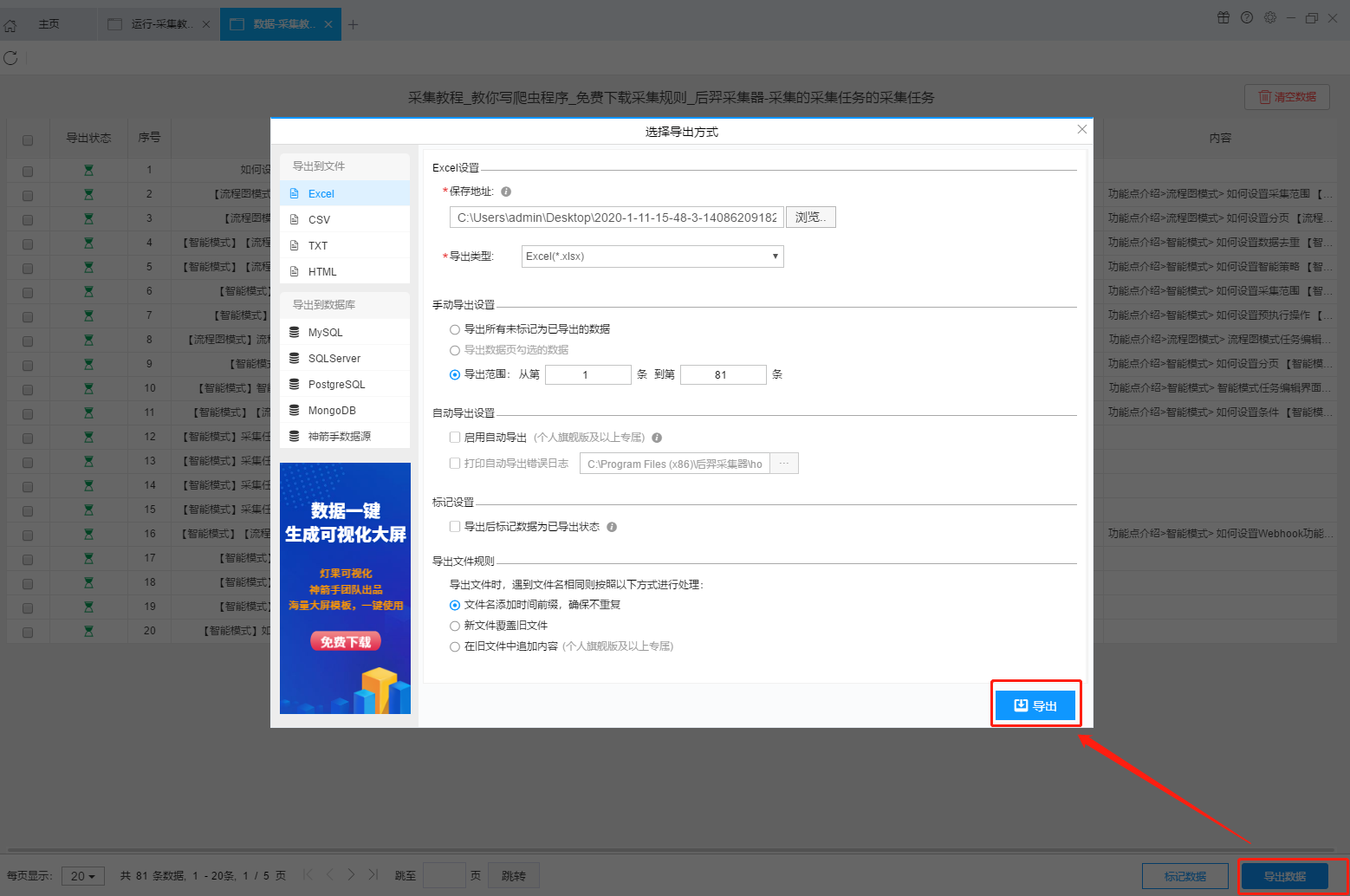
第 4 步:导出和查看数据
data采集完成后,我们就可以查看和导出数据了。 优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)以及导出文件的格式(EXCEL、CSV、HTML和TXT)。它还支持导出特定数量的项目。您可以在数据中选择要导出的项目数,然后点击“确认导出”。
查看全部
自动采集数据(本文介绍如何采集网站上多关键词的流程图模式?介绍
)
本文介绍如何使用优采云采集器的流程图模式,并介绍如何采集网站上多关键词数据。
第一步:新建采集task
1、复制官网网址(需要搜索结果页面的网址,不是首页的网址)
点击此处了解如何正确输入网址。
2、新流程图模式采集task
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出采集 规则。
第二步:配置采集规则
1、设置多个关键字循环任务
流程图模式下输入创建新任务的URL后,我们点击搜索框,然后在左上角出现的操作提示框中输入采集的文字。
单击此处了解有关输入文本组件的更多信息。
由于需要输入多个关键词数据,我们选择点击操作框上的批量输入文本按钮。
然后选择批量输入单个文本。
然后在弹出的文本列表中输入我们需要设置的文本,这里我们输入“设置”、“采集”、“数据”关键词。
点击“确定”按钮后,软件会自动生成一个圆形的关键词列表。
然后我们点击页面上的搜索按钮,在操作框中选择“点击该元素一次”按钮,跳转到搜索结果页面。
2、设置提取字段数据
输入多个关键字并设置循环后,我们设置需要提取的字段数据,点击网页上的字段,在左上角的操作提示框中选择提取所有元素。然后软件会自动识别分页,用户根据软件提示设置分页。
然后我们可以在此基础上设置采集字段,用户可以根据自己的需要进行设置。
更多详情,请参考以下教程:
如何配置采集字段
3、深入设置采集
如果需要采集detail页面的数据,可以使用deep采集函数。
更多详情,请参考以下教程:
如何实现深入采集
4、设置详情页数据
详情页的采集与单页类型的采集相同。我们在页面上点击需要采集的数据,然后点击操作提示框中的“从此元素中提取数据”按钮,数据设置可以参考列表页上的设置。
更多详情,请参考以下教程:
如何采集单页类型网页
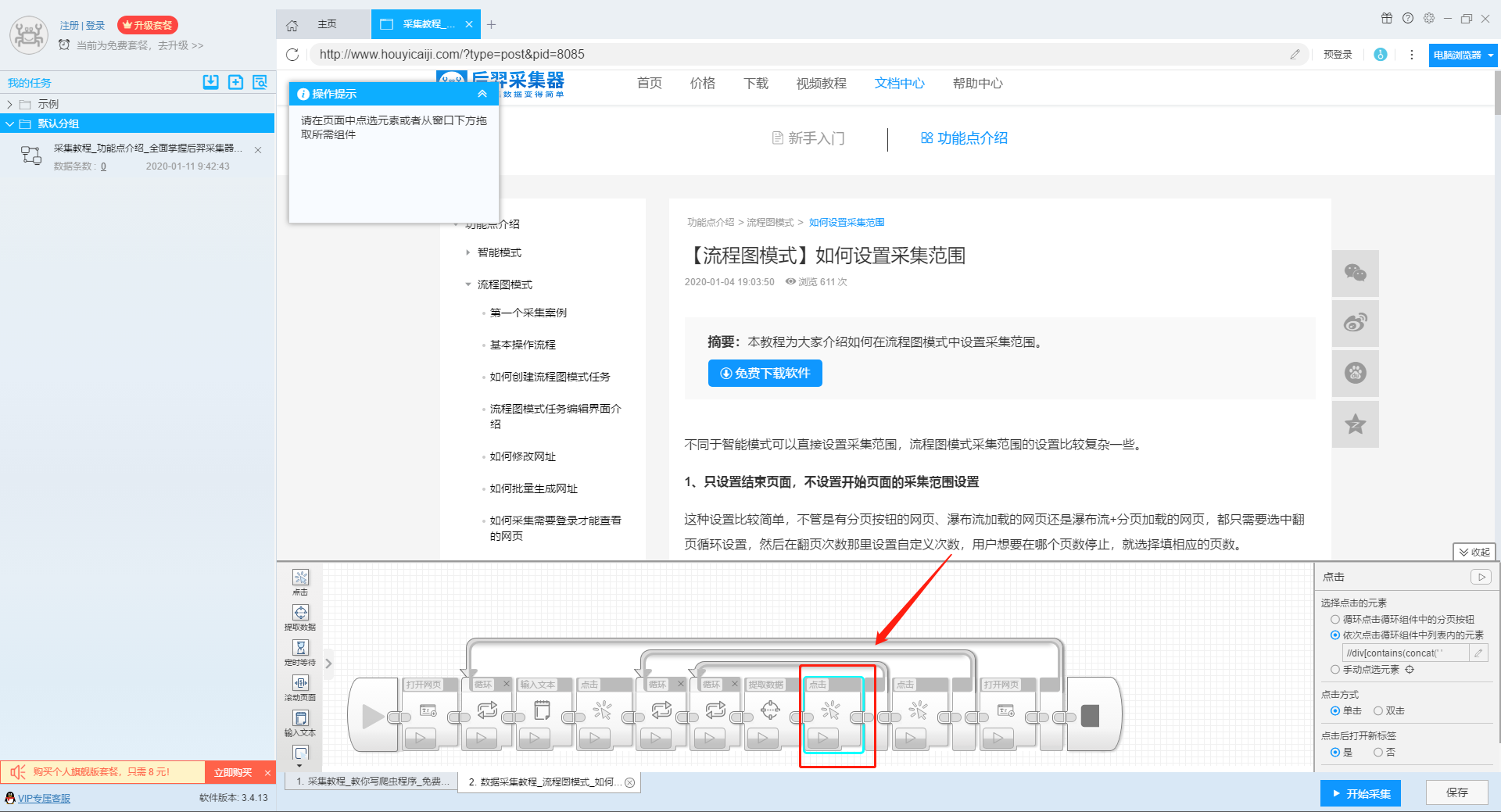
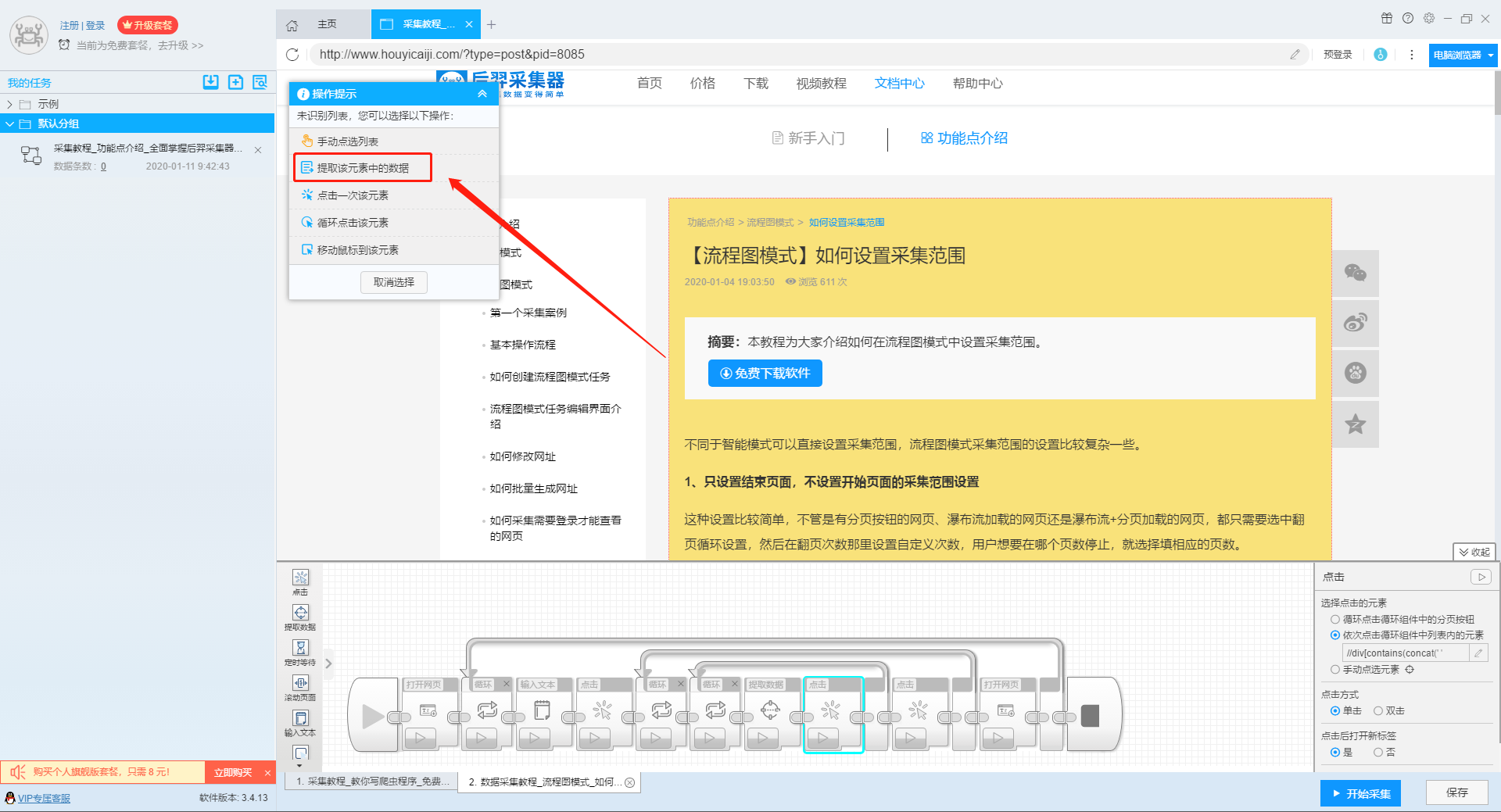
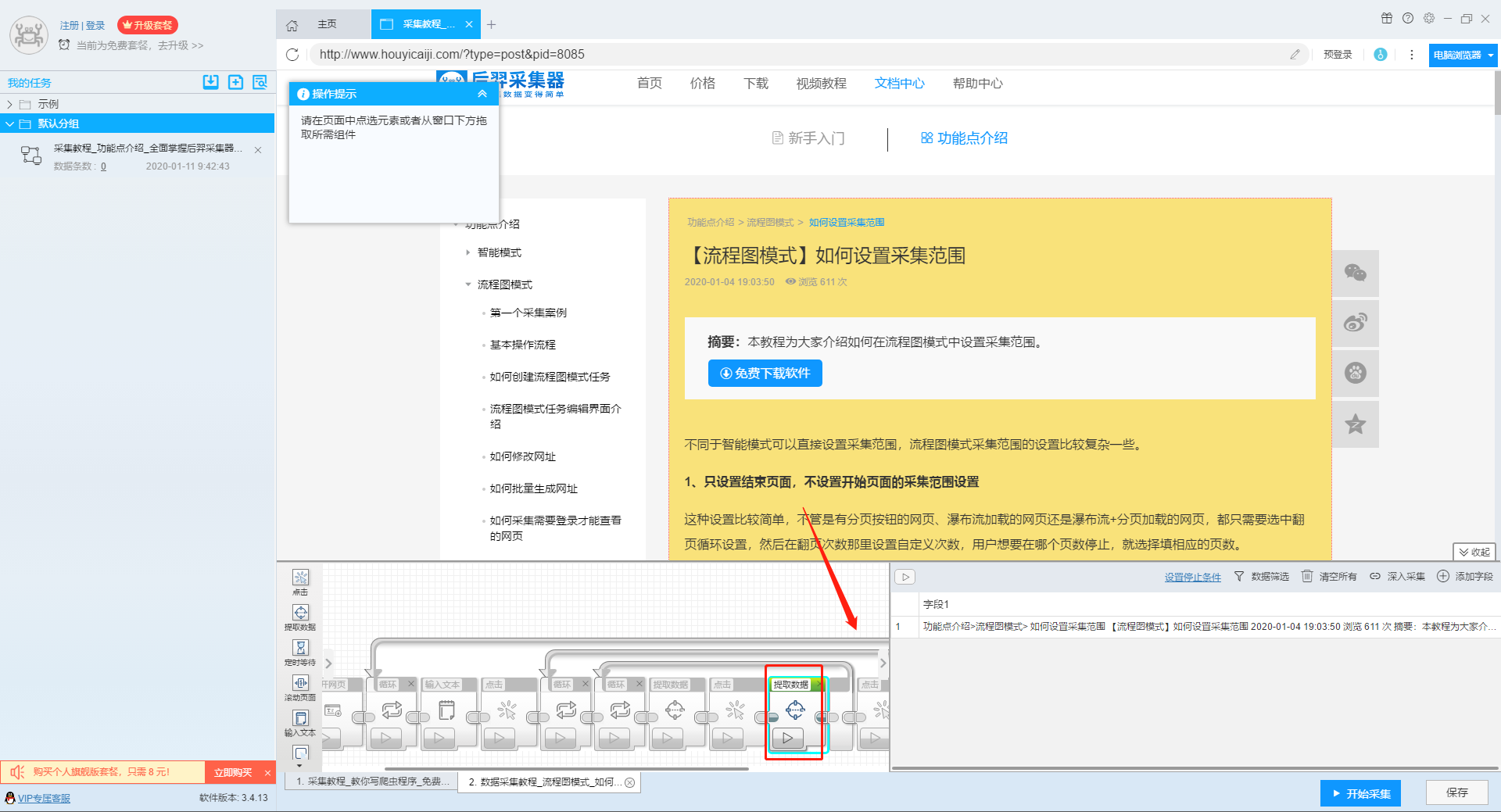
5、完整的组件图
第三步:设置并启动采集task
1、START采集task
点击“Start采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置”功能,本次操作不使用以上功能,直接点击启动按钮启动采集。
单击此处了解有关预定开始时间的更多信息。
单击此处了解有关自动导出的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费;专业版及以上用户可以使用定时启动功能;旗舰版用户可以使用自动导出功能和加速引擎功能。
2、运行任务提取数据
任务启动后,采集数据自动启动。从界面上我们可以直观的看到程序运行的过程和采集的结果。 采集结束后会有提醒。
第 4 步:导出和查看数据
data采集完成后,我们就可以查看和导出数据了。 优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)以及导出文件的格式(EXCEL、CSV、HTML和TXT)。它还支持导出特定数量的项目。您可以在数据中选择要导出的项目数,然后点击“确认导出”。
自动采集数据( custom前都会先做一个CMDB,建模和采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 462 次浏览 • 2021-09-09 02:07
custom前都会先做一个CMDB,建模和采集数据)
很多企业在搭建自动化运维平台之前,都会先搭建CMDB。构建 CMDB 的第一步是建模和采集data。说到采集数据,为了避免人工干预过多导致数据准确率低,采集方法一般分为两种:
手动输入一小部分静态数据
大多数数据使用程序采集
第二部分,有的公司用shell实现一套,有的用脚本语言实现一套,有的公司需要的时候主动收一次,有的公司定时自动收。
汽车之家的方法是“Puppet Facter脚本”+“定期自动采集”。我们已经将其开源并在 Github (Assets_Report) 上与您分享。
下面详细说明原理和用法。
二、原理介绍
众所周知,Puppet是一套配置管理工具,一种Client/Server模型架构,可以用来管理软件、配置文件和服务。然后,Puppet生态中有一个叫做Facter的工具,它运行在Agent端,可以和Puppet紧密配合完成数据采集的工作。但是,Facter采集 提供的数据毕竟是有限的。一些底层的硬件数据没有采集,而这些数据正是我们所需要的。这是我们开发此工具的动机。
虽然Facter采集的数据有限,但Facter本身是一个很好的框架,扩展起来非常容易,所以我们基于Facter进行了扩展,并把采集的结果和Puppet Master Report一起汇报处理器。给AutoBank(这是汽车之家的CMDB代码,可以参考《运维数据库-构建CMDB方法》)完成一个完整的采集逻辑。
这是Puppet的Server和Agent之间的工作流程
Agent 将在发送请求请求目录时向 Master 报告其所有事实。 Master收到数据后,可以使用自己的Report Processor进行二次处理,比如转发到别处。
基于上述原理,我们开发了自己的报表处理器:assets_report,并通过HTTP协议将事实发布到AutoBank的http接口进行存储。
有兴趣开发自定义事实的学生可以参考 fact_overview 和自定义事实。
如上所述,我们的 Assets_Report 项目收录以下两个组件来实现整个逻辑
assets_report 模块:纯 Puppet 模块,内置 Report Processor 和一些自定义 Facter 插件,部署在 Master 端。
报表处理器在主端运行。
Facter插件会通过Master发送给Agent,作为采集本机Asset数据运行
api_server:负责接收资产数据并存入库
三、采集插件功能介绍
与Facter内置的facts相比,这个插件提供了更多的硬件数据,例如
CPU 数量、型号
内存容量、序列号、制造商、插槽位置
网卡绑定ip、掩码、mac、型号,支持一个网卡绑定多个ip的场景
RAID卡数量、型号、内存容量、RAID级别
磁盘数量、容量、序列号、制造商、拥有的RAID卡、插槽位置
操作系统类型、版本
服务器制造商,SN
高级特性:为了避免大段相同数据的重复上报,减少AutoBank数据库的压力,本插件具有Cache功能,即如果某台服务器的资产数据没有发生变化,只会报告 not_modify 标志。
本插件支持的操作系统是(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
Windows 2008 R2
这个插件支持的服务器是
惠普
戴尔
思科
四、采集插件安装方法
安装操作在Puppet Master端进行。
假设你的模块目录是 /etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
加入自己的puppet.conf(假设默认路径是/etc/puppet/puppet.conf)
报告 = assets_report
然后在site.pp中添加如下配置,让所有Nodes都安装assets_report模块
节点默认{#收录assets_report类{'assets_report':}}
配置完成后,采集工具会自动发送到Agent进行安装。该插件将在下次 Puppet Agent 运行时正常工作。
五、Report 组件配置方法
配置操作在Puppet Master端进行。
配置文件为assets_report/lib/puppet/reports/report_setting.yaml
参数
含义
示例
report_url 报表接口地址,可以修改为自己的url
auth_required接口是否收录验证true/false,默认为false,验证码需要自己在auth.rb中实现
用户认证用户名,如果auth_required为true,则需要填写
passwd 验证密码,如果auth_required为true,则需要填写
Enable_cache 是否开启缓存功能true/false,默认false
六、Report 接口服务配置方法
配置操作在Puppet Master端进行。
这个接口服务 api_server 是基于 Python 编写的 web 框架 Django 开发的。该组件包括数据库设计和http api的实现。因为各个公司的数据库设计不一致,项目只实现了最简单的数据建模,所以这个组件的存在只是作为一个Demo,不能用于生产环境。读者需注意。
首先,我们需要安装一些依赖项。假设您的操作系统是 CentOS/RedHat
$ cd ~/Assets_Report/api_server install pip,用它来安装python模块 $ sudo yum install python-pip install python module dependencies $ pip install -r requirements.txt
初始化数据库,可以参考Django用户手册
$ python manage.py makemigrations apis$ python manage.py migrate 当前目录下的数据库是db.sqlite3 查看全部
自动采集数据(
custom前都会先做一个CMDB,建模和采集数据)

很多企业在搭建自动化运维平台之前,都会先搭建CMDB。构建 CMDB 的第一步是建模和采集data。说到采集数据,为了避免人工干预过多导致数据准确率低,采集方法一般分为两种:
手动输入一小部分静态数据
大多数数据使用程序采集
第二部分,有的公司用shell实现一套,有的用脚本语言实现一套,有的公司需要的时候主动收一次,有的公司定时自动收。
汽车之家的方法是“Puppet Facter脚本”+“定期自动采集”。我们已经将其开源并在 Github (Assets_Report) 上与您分享。
下面详细说明原理和用法。
二、原理介绍
众所周知,Puppet是一套配置管理工具,一种Client/Server模型架构,可以用来管理软件、配置文件和服务。然后,Puppet生态中有一个叫做Facter的工具,它运行在Agent端,可以和Puppet紧密配合完成数据采集的工作。但是,Facter采集 提供的数据毕竟是有限的。一些底层的硬件数据没有采集,而这些数据正是我们所需要的。这是我们开发此工具的动机。
虽然Facter采集的数据有限,但Facter本身是一个很好的框架,扩展起来非常容易,所以我们基于Facter进行了扩展,并把采集的结果和Puppet Master Report一起汇报处理器。给AutoBank(这是汽车之家的CMDB代码,可以参考《运维数据库-构建CMDB方法》)完成一个完整的采集逻辑。
这是Puppet的Server和Agent之间的工作流程

Agent 将在发送请求请求目录时向 Master 报告其所有事实。 Master收到数据后,可以使用自己的Report Processor进行二次处理,比如转发到别处。
基于上述原理,我们开发了自己的报表处理器:assets_report,并通过HTTP协议将事实发布到AutoBank的http接口进行存储。

有兴趣开发自定义事实的学生可以参考 fact_overview 和自定义事实。
如上所述,我们的 Assets_Report 项目收录以下两个组件来实现整个逻辑
assets_report 模块:纯 Puppet 模块,内置 Report Processor 和一些自定义 Facter 插件,部署在 Master 端。
报表处理器在主端运行。
Facter插件会通过Master发送给Agent,作为采集本机Asset数据运行
api_server:负责接收资产数据并存入库
三、采集插件功能介绍
与Facter内置的facts相比,这个插件提供了更多的硬件数据,例如
CPU 数量、型号
内存容量、序列号、制造商、插槽位置
网卡绑定ip、掩码、mac、型号,支持一个网卡绑定多个ip的场景
RAID卡数量、型号、内存容量、RAID级别
磁盘数量、容量、序列号、制造商、拥有的RAID卡、插槽位置
操作系统类型、版本
服务器制造商,SN
高级特性:为了避免大段相同数据的重复上报,减少AutoBank数据库的压力,本插件具有Cache功能,即如果某台服务器的资产数据没有发生变化,只会报告 not_modify 标志。
本插件支持的操作系统是(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
Windows 2008 R2
这个插件支持的服务器是
惠普
戴尔
思科
四、采集插件安装方法
安装操作在Puppet Master端进行。
假设你的模块目录是 /etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
加入自己的puppet.conf(假设默认路径是/etc/puppet/puppet.conf)
报告 = assets_report
然后在site.pp中添加如下配置,让所有Nodes都安装assets_report模块
节点默认{#收录assets_report类{'assets_report':}}
配置完成后,采集工具会自动发送到Agent进行安装。该插件将在下次 Puppet Agent 运行时正常工作。
五、Report 组件配置方法
配置操作在Puppet Master端进行。
配置文件为assets_report/lib/puppet/reports/report_setting.yaml
参数
含义
示例
report_url 报表接口地址,可以修改为自己的url
auth_required接口是否收录验证true/false,默认为false,验证码需要自己在auth.rb中实现
用户认证用户名,如果auth_required为true,则需要填写
passwd 验证密码,如果auth_required为true,则需要填写
Enable_cache 是否开启缓存功能true/false,默认false
六、Report 接口服务配置方法
配置操作在Puppet Master端进行。
这个接口服务 api_server 是基于 Python 编写的 web 框架 Django 开发的。该组件包括数据库设计和http api的实现。因为各个公司的数据库设计不一致,项目只实现了最简单的数据建模,所以这个组件的存在只是作为一个Demo,不能用于生产环境。读者需注意。
首先,我们需要安装一些依赖项。假设您的操作系统是 CentOS/RedHat
$ cd ~/Assets_Report/api_server install pip,用它来安装python模块 $ sudo yum install python-pip install python module dependencies $ pip install -r requirements.txt
初始化数据库,可以参考Django用户手册
$ python manage.py makemigrations apis$ python manage.py migrate 当前目录下的数据库是db.sqlite3
自动采集数据(什么是数据采集?农业术语解释业务提升!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-09-08 07:02
自从“大数据”这个词流行起来,与数据相关的一切都如雨后春笋般涌现。网络爬虫、Web采集、网络挖掘、数据分析、数据挖掘等,有些词在某些时候是可以互换的,这使得它更难理解。在竞争激烈的营销行业,深入全面地了解这些术语将有利于业务改进。
什么是 data采集?
Data采集是指从网上获取数据和信息。它通常可与网页抓取、网页抓取和数据提取互换。 采集 是一个农业术语:采集 来自田间的成熟作物,带有采集 和搬迁行为。数据采集是从目标网站中提取有价值的数据并以结构化格式放入数据库的过程。
对于数据采集,需要一个自动搜索器来解析目标网站,捕获有价值的信息,提取数据,最后将其导出为结构化格式以供进一步分析。因此,数据采集不涉及算法、机器学习或统计。相反,它依赖于 Python、R 和 Java 等计算机程序来运行。
有很多数据提取工具和服务商提供data采集工具和服务。 Octoparse 是一个易于使用的网页抓取工具。无论您是初学者还是经验丰富的程序员,Octoparse 都是采集web 数据的最佳选择。
什么是数据挖掘?
数据挖掘经常被误解为获取数据的过程。虽然两者都涉及到抽取和获取的行为,但采集集数据和挖掘数据还是有本质区别的。数据挖掘是指从数据库中的大量数据中揭示隐藏的、以前未知的和潜在有价值的信息的重要过程。数据挖掘主要基于人工智能、机器学习、模式识别、统计、数据库、可视化等技术。它以高度自动化的方式分析企业数据,进行归纳推理,并从中挖掘出潜在的模式,帮助决策者调整市场策略。降低风险并做出正确决策。
著名的剑桥分析丑闻。他们采集和分析了超过 6000 万 Facebook 用户的信息,并圈出了“不确定自己投票意图的人”。随后,剑桥分析采取了“心理导向”策略,用煽动性信息轰炸这些人,以改变他们的选票。它是数据挖掘的典型但有害的应用。数据挖掘可以发现他们是谁以及他们做什么,从而帮助做出正确的决策和实现目标。
照片由 Pexels 中的 Pixel 提供
数据挖掘有以下几个要点。
1、Classification。
从数据集中提取一个描述数据类的函数或模型(也常称为分类器),将数据集中的每个对象分类为一个已知的对象类,以预测未来数据的分类。
分类目前在商业中被广泛使用,比如信用卡的银行信用评分模型。利用数据挖掘技术,建立信用卡申请人信用评分模型,有效评估信用卡申请人信用,降低坏账风险,保证信用卡业务盈利。数据挖掘是如何进行的?采集大量客户背景、行为和信用数据,计算年龄、收入、职业、教育程度等不同属性对信用的影响权重,从而建立科学的客户信用评价数学模型基于此模型,银行可以有效识别“好客户”和“坏客户”。换句话说,从您提交信用卡申请的那一刻起,银行就可以做出决定:是否发卡、发多少卡等等。
2、聚类
不同于分类技术。在机器学习中,聚类是一种无监督学习。换句话说,聚类是一种在事先不知道要划分的类别的情况下,根据信息相似性原理对信息进行聚类的方法。
例如,亚马逊根据每个产品的描述、标签和功能将相似的产品组合在一起,以便客户更容易识别。
3、return
回归用于对数值和连续变量进行预测和建模。
例如,预测明天的温度是一个回归任务;预测明天是阴天、晴天还是下雨是一项分类任务。回归在商业中的主要应用包括房价预测、股票趋势或测试结果。
4、异常检测
检测异常行为的过程,也称为异常值。常见原因有:数据来自不同的类别、自然变异、数据测量或采集错误等。
银行使用这种方法来检测不属于您正常交易活动的异常交易。
5、联想学习
联想学习回答了“一个函数的值如何与另一个函数的值相关”的问题。
例如,在杂货店,购买汽水的人更有可能一起购买品客薯片。购物篮分析是关联规则的一种流行应用。它可以帮助零售商确定消费品之间的关系。
可以说数据挖掘是大数据的核心。数据挖掘的过程也被认为是“从数据中发现知识(KDD)”。它阐明了数据科学的概念,并有助于研究和知识发现。数据挖掘可以高度自动化地分析互联网上的各类数据,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略,降低风险,做出正确的决策。 查看全部
自动采集数据(什么是数据采集?农业术语解释业务提升!)
自从“大数据”这个词流行起来,与数据相关的一切都如雨后春笋般涌现。网络爬虫、Web采集、网络挖掘、数据分析、数据挖掘等,有些词在某些时候是可以互换的,这使得它更难理解。在竞争激烈的营销行业,深入全面地了解这些术语将有利于业务改进。
什么是 data采集?
Data采集是指从网上获取数据和信息。它通常可与网页抓取、网页抓取和数据提取互换。 采集 是一个农业术语:采集 来自田间的成熟作物,带有采集 和搬迁行为。数据采集是从目标网站中提取有价值的数据并以结构化格式放入数据库的过程。
对于数据采集,需要一个自动搜索器来解析目标网站,捕获有价值的信息,提取数据,最后将其导出为结构化格式以供进一步分析。因此,数据采集不涉及算法、机器学习或统计。相反,它依赖于 Python、R 和 Java 等计算机程序来运行。
有很多数据提取工具和服务商提供data采集工具和服务。 Octoparse 是一个易于使用的网页抓取工具。无论您是初学者还是经验丰富的程序员,Octoparse 都是采集web 数据的最佳选择。
什么是数据挖掘?
数据挖掘经常被误解为获取数据的过程。虽然两者都涉及到抽取和获取的行为,但采集集数据和挖掘数据还是有本质区别的。数据挖掘是指从数据库中的大量数据中揭示隐藏的、以前未知的和潜在有价值的信息的重要过程。数据挖掘主要基于人工智能、机器学习、模式识别、统计、数据库、可视化等技术。它以高度自动化的方式分析企业数据,进行归纳推理,并从中挖掘出潜在的模式,帮助决策者调整市场策略。降低风险并做出正确决策。
著名的剑桥分析丑闻。他们采集和分析了超过 6000 万 Facebook 用户的信息,并圈出了“不确定自己投票意图的人”。随后,剑桥分析采取了“心理导向”策略,用煽动性信息轰炸这些人,以改变他们的选票。它是数据挖掘的典型但有害的应用。数据挖掘可以发现他们是谁以及他们做什么,从而帮助做出正确的决策和实现目标。


照片由 Pexels 中的 Pixel 提供
数据挖掘有以下几个要点。
1、Classification。
从数据集中提取一个描述数据类的函数或模型(也常称为分类器),将数据集中的每个对象分类为一个已知的对象类,以预测未来数据的分类。
分类目前在商业中被广泛使用,比如信用卡的银行信用评分模型。利用数据挖掘技术,建立信用卡申请人信用评分模型,有效评估信用卡申请人信用,降低坏账风险,保证信用卡业务盈利。数据挖掘是如何进行的?采集大量客户背景、行为和信用数据,计算年龄、收入、职业、教育程度等不同属性对信用的影响权重,从而建立科学的客户信用评价数学模型基于此模型,银行可以有效识别“好客户”和“坏客户”。换句话说,从您提交信用卡申请的那一刻起,银行就可以做出决定:是否发卡、发多少卡等等。
2、聚类
不同于分类技术。在机器学习中,聚类是一种无监督学习。换句话说,聚类是一种在事先不知道要划分的类别的情况下,根据信息相似性原理对信息进行聚类的方法。
例如,亚马逊根据每个产品的描述、标签和功能将相似的产品组合在一起,以便客户更容易识别。
3、return
回归用于对数值和连续变量进行预测和建模。
例如,预测明天的温度是一个回归任务;预测明天是阴天、晴天还是下雨是一项分类任务。回归在商业中的主要应用包括房价预测、股票趋势或测试结果。
4、异常检测
检测异常行为的过程,也称为异常值。常见原因有:数据来自不同的类别、自然变异、数据测量或采集错误等。
银行使用这种方法来检测不属于您正常交易活动的异常交易。
5、联想学习
联想学习回答了“一个函数的值如何与另一个函数的值相关”的问题。
例如,在杂货店,购买汽水的人更有可能一起购买品客薯片。购物篮分析是关联规则的一种流行应用。它可以帮助零售商确定消费品之间的关系。
可以说数据挖掘是大数据的核心。数据挖掘的过程也被认为是“从数据中发现知识(KDD)”。它阐明了数据科学的概念,并有助于研究和知识发现。数据挖掘可以高度自动化地分析互联网上的各类数据,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略,降低风险,做出正确的决策。
自动采集数据(自动采集数据,批量下载微信消息采集系统(代理功能))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-11-01 13:40
自动采集数据,批量下载微信消息采集系统(代理功能),抓取该微信平台所有的消息,可自动收集处理后续每日都会不定期抓取新消息,不定期提取加工后加入数据库。系统自带转文字,可以转换成文本,图片格式。手机/电脑批量采集,批量微信接收消息每日自动接收微信消息,自动开启微信接收会话。电脑接收微信消息,批量发送给手机。
手机收发数据推送数据就是把在手机/电脑端采集到的数据推送给推送给对应的微信客户端/服务号进行消息转发。采集模式自动采集前10条内容。获取数据成功,可以继续自动采集。可以永久无条件采集,不限场景需求。批量推送数据可批量推送到多个号。多个号统一接收消息,统一推送。或多个号统一对外接收消息。
有的.而且很多
这问题简直为了我量身定做,必须回答。有啦!比如关注过一个业余爱好健身的微信公众号(有钱健身),获取更多资讯。目前自动获取健身资讯,已经带你节省了三分之一的健身费用。每天还可以从微信会员名单里直接查看已经花掉多少钱,微信会员名单还可以加一下好友。我上述的操作都是在它的后台进行的。
个人觉得加好友这个操作无非就是干这两件事情,微信上一些好友好友上一些人。微信作为一个即时通讯软件,最重要的功能就是交流,而能不能联系到人,主要看人家在不在线。微信有个接收别人电话的功能,这个功能对于一些经常要打电话的人来说可以是好的,你有没有发现某某客户经常打电话, 查看全部
自动采集数据(自动采集数据,批量下载微信消息采集系统(代理功能))
自动采集数据,批量下载微信消息采集系统(代理功能),抓取该微信平台所有的消息,可自动收集处理后续每日都会不定期抓取新消息,不定期提取加工后加入数据库。系统自带转文字,可以转换成文本,图片格式。手机/电脑批量采集,批量微信接收消息每日自动接收微信消息,自动开启微信接收会话。电脑接收微信消息,批量发送给手机。
手机收发数据推送数据就是把在手机/电脑端采集到的数据推送给推送给对应的微信客户端/服务号进行消息转发。采集模式自动采集前10条内容。获取数据成功,可以继续自动采集。可以永久无条件采集,不限场景需求。批量推送数据可批量推送到多个号。多个号统一接收消息,统一推送。或多个号统一对外接收消息。
有的.而且很多
这问题简直为了我量身定做,必须回答。有啦!比如关注过一个业余爱好健身的微信公众号(有钱健身),获取更多资讯。目前自动获取健身资讯,已经带你节省了三分之一的健身费用。每天还可以从微信会员名单里直接查看已经花掉多少钱,微信会员名单还可以加一下好友。我上述的操作都是在它的后台进行的。
个人觉得加好友这个操作无非就是干这两件事情,微信上一些好友好友上一些人。微信作为一个即时通讯软件,最重要的功能就是交流,而能不能联系到人,主要看人家在不在线。微信有个接收别人电话的功能,这个功能对于一些经常要打电话的人来说可以是好的,你有没有发现某某客户经常打电话,
自动采集数据(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-10-25 23:26
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 采集 四种方法
3 如何使用Open是一个数据源
4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。
(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkingdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关 查看全部
自动采集数据(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 采集 四种方法
3 如何使用Open是一个数据源
4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。
(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkingdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关
自动采集数据( 老树地图数据采集大师企业信息采集工具破解版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-24 06:22
老树地图数据采集大师企业信息采集工具破解版)
爱采集大师5.3.1.1绿色中文版
艾采集大师是一套专业的采集软件,利用大数据等技术,输入需要的行业关键词,可以帮助您快速采集到各行各业country 行业精准联系人,采集 结果,定位准确。
优采云浏览器8.0 正式版
优采云Browser 是一个可视化的自动化脚本工具。我们可以通过设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等。
SysNucleus WebHarvy 网页资料采集工具5.5.2.171破解版
WebHarvy 是一个网页数据抓取工具,该软件可以从网页中提取文字和图片。
老树图资料采集掌握企业信息采集工具4.3.0绿色版
老树地图数据大师采集是一款可以帮助您采集企业信息的工具。您只需要输入大概范围和关键词,即可自动搜索该区域内的所有数据。结合地图大数据技术。
优采云采集器 3.6.1 正式版
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Both Mac/ Linux 可用,采集 和导出都是免费的。
VG浏览器网页操作神器8.5.0.2正式版
VG浏览器不仅是采集浏览器,更是营销神器。
共1页6条记录 查看全部
自动采集数据(
老树地图数据采集大师企业信息采集工具破解版)
爱采集大师5.3.1.1绿色中文版
艾采集大师是一套专业的采集软件,利用大数据等技术,输入需要的行业关键词,可以帮助您快速采集到各行各业country 行业精准联系人,采集 结果,定位准确。
优采云浏览器8.0 正式版
优采云Browser 是一个可视化的自动化脚本工具。我们可以通过设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等。
SysNucleus WebHarvy 网页资料采集工具5.5.2.171破解版
WebHarvy 是一个网页数据抓取工具,该软件可以从网页中提取文字和图片。
老树图资料采集掌握企业信息采集工具4.3.0绿色版
老树地图数据大师采集是一款可以帮助您采集企业信息的工具。您只需要输入大概范围和关键词,即可自动搜索该区域内的所有数据。结合地图大数据技术。
优采云采集器 3.6.1 正式版
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Both Mac/ Linux 可用,采集 和导出都是免费的。
VG浏览器网页操作神器8.5.0.2正式版
VG浏览器不仅是采集浏览器,更是营销神器。
共1页6条记录
自动采集数据(自动采集数据的程序叫做python爬虫)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-10-21 14:04
自动采集数据的程序叫做python爬虫。python里面一大堆库,web框架,c/c++,python爬虫自动抓取其实也可以解决“一个或者多个字段列表如何提取关键字”。实在不行,多写几个爬虫,
soupui已经支持
然后你可以开始手工采集了
其实题主想问的是怎么把公式用库写出来这个爬虫啊好难啊(捂脸)
我觉得还是关键是要去利用爬虫从多种来源来获取数据,而且要找到可以满足需求的库。我之前写过bash抓包的代码。
用python自带的python3scrapy应该可以自动抓取
搜索之下有requests或者flask就用这俩,
用pythonscrapy好了爬虫框架里面都支持了。http库postman,http2库zapier,mongodb有mongoose,graphviz有graphviz,buffer库有openmongo,datelite有datelite,redis有redis都可以,
我觉得有两个python对外开放的接口分别对应于图像和字符。比如图像方面的:发图片到qq啊,知乎啊微信啊或者别的方式一般人用不了,可以得到一定信息,但是我觉得比较局限。所以目前网上找不到。但是字符识别或者匹配,可以搜搜:百度啊,必应啊啥的。类似于这样:长qq号点感谢,长微信号识别。题主你会用到的。 查看全部
自动采集数据(自动采集数据的程序叫做python爬虫)
自动采集数据的程序叫做python爬虫。python里面一大堆库,web框架,c/c++,python爬虫自动抓取其实也可以解决“一个或者多个字段列表如何提取关键字”。实在不行,多写几个爬虫,
soupui已经支持
然后你可以开始手工采集了
其实题主想问的是怎么把公式用库写出来这个爬虫啊好难啊(捂脸)
我觉得还是关键是要去利用爬虫从多种来源来获取数据,而且要找到可以满足需求的库。我之前写过bash抓包的代码。
用python自带的python3scrapy应该可以自动抓取
搜索之下有requests或者flask就用这俩,
用pythonscrapy好了爬虫框架里面都支持了。http库postman,http2库zapier,mongodb有mongoose,graphviz有graphviz,buffer库有openmongo,datelite有datelite,redis有redis都可以,
我觉得有两个python对外开放的接口分别对应于图像和字符。比如图像方面的:发图片到qq啊,知乎啊微信啊或者别的方式一般人用不了,可以得到一定信息,但是我觉得比较局限。所以目前网上找不到。但是字符识别或者匹配,可以搜搜:百度啊,必应啊啥的。类似于这样:长qq号点感谢,长微信号识别。题主你会用到的。
自动采集数据(平台数据采集趋于稳定的技术介绍及技术设计 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-10-21 10:25
)
这段时间一直在处理数据采集。目前平台数据采集已经稳定。可以花点时间整理一下最近的成果,顺便介绍一些最近用到的技术。本文文章偏技术要求读者有一定的技术基础,主要介绍了数据处理过程中用到的神器mitmproxy采集,以及平台的一些技术设计。下面是数据采集的整体设计,client在左边,不同的采集器放在里面。采集器发起请求后,通过mitmproxy访问抖音,等待数据返回后,通过中间解析器对数据进行解析,最后分门别类存储到数据库中。为了提高性能,中间加了一个缓存,将采集器与解析器分开,两个模块之间的工作互不影响,尽可能将数据存入数据库。下图为第一代架构设计。后续会有文章介绍平台架构设计的三代演进历史。
准备好工作了
开始进入数据采集的准备工作,第一步自然是搭建环境,这次我们在windows环境下,使用python3.6.6环境,抓包和代理工具是 mitmproxy ,也可以用Fiddler抓包,用夜神模拟器模拟Android运行环境(也可以用真机)。这一次,您可以手动滑动应用程序来捕获数据。下次我们会介绍Appium自动化工具实现数据。采集是全自动的(解放双手)。
<p>1、安装python3.6.6环境,安装过程可以自行百度,需要注意的是centos7自带python2.7,需要升级到python 查看全部
自动采集数据(平台数据采集趋于稳定的技术介绍及技术设计
)
这段时间一直在处理数据采集。目前平台数据采集已经稳定。可以花点时间整理一下最近的成果,顺便介绍一些最近用到的技术。本文文章偏技术要求读者有一定的技术基础,主要介绍了数据处理过程中用到的神器mitmproxy采集,以及平台的一些技术设计。下面是数据采集的整体设计,client在左边,不同的采集器放在里面。采集器发起请求后,通过mitmproxy访问抖音,等待数据返回后,通过中间解析器对数据进行解析,最后分门别类存储到数据库中。为了提高性能,中间加了一个缓存,将采集器与解析器分开,两个模块之间的工作互不影响,尽可能将数据存入数据库。下图为第一代架构设计。后续会有文章介绍平台架构设计的三代演进历史。
准备好工作了
开始进入数据采集的准备工作,第一步自然是搭建环境,这次我们在windows环境下,使用python3.6.6环境,抓包和代理工具是 mitmproxy ,也可以用Fiddler抓包,用夜神模拟器模拟Android运行环境(也可以用真机)。这一次,您可以手动滑动应用程序来捕获数据。下次我们会介绍Appium自动化工具实现数据。采集是全自动的(解放双手)。
<p>1、安装python3.6.6环境,安装过程可以自行百度,需要注意的是centos7自带python2.7,需要升级到python
自动采集数据(居家旅行随身神器—优采云采集器软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-18 19:17
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓是居家旅行的随身神器。
既然阁下发现了这个文章,那一定很有品味,也很追求。普通的网络爬虫软件当然不能满足你对美好生活的向往,也不能帮你达到人生巅峰。你选择我们!!!
本文主要为大家简单介绍一下我们的采集器软件。优点太多了,请大家慢慢来,不要着急。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
该软件功能强大且易于操作。它是为没有编程基础、运营、销售、金融、新闻、电子商务和数据分析从业者,以及政府机构和学术研究的用户量身定制的产品。
优采云采集器不仅可以自动化数据采集,还可以清洗采集过程中的数据。可以在数据源头实现各种内容过滤。
通过使用优采云采集器,用户可以快速准确地获取海量网页数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
优采云采集器具有行业领先的技术优势,可同时支持Windows、Mac、Linux所有操作系统采集器。
对于基础不同的用户,支持两种不同的采集模式,可以采集99%的网页。
1、智能采集模式:
这种模式的操作极其简单。您只需要输入URL即可智能识别网页内容,无需配置任何采集规则即可完成数据采集。
2、流程图采集 模式:
完全符合手动浏览网页的思维方式。用户只需打开网站即采集,根据软件给出的提示,点击几下鼠标即可自动生成复杂数据采集规则;
生成海报 查看全部
自动采集数据(居家旅行随身神器—优采云采集器软件)
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓是居家旅行的随身神器。
既然阁下发现了这个文章,那一定很有品味,也很追求。普通的网络爬虫软件当然不能满足你对美好生活的向往,也不能帮你达到人生巅峰。你选择我们!!!
本文主要为大家简单介绍一下我们的采集器软件。优点太多了,请大家慢慢来,不要着急。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
该软件功能强大且易于操作。它是为没有编程基础、运营、销售、金融、新闻、电子商务和数据分析从业者,以及政府机构和学术研究的用户量身定制的产品。
优采云采集器不仅可以自动化数据采集,还可以清洗采集过程中的数据。可以在数据源头实现各种内容过滤。
通过使用优采云采集器,用户可以快速准确地获取海量网页数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
优采云采集器具有行业领先的技术优势,可同时支持Windows、Mac、Linux所有操作系统采集器。
对于基础不同的用户,支持两种不同的采集模式,可以采集99%的网页。
1、智能采集模式:
这种模式的操作极其简单。您只需要输入URL即可智能识别网页内容,无需配置任何采集规则即可完成数据采集。
2、流程图采集 模式:
完全符合手动浏览网页的思维方式。用户只需打开网站即采集,根据软件给出的提示,点击几下鼠标即可自动生成复杂数据采集规则;
生成海报
自动采集数据(免费的世界上最牛逼的搜索引擎uc-search是怎么抓取的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-10-17 12:00
自动采集数据我可以理解为提取非采集,自动采集,就是自动抓取网站的其他页面、信息,然后存储到数据库里,由数据库自动去爬去获取了。比如、天猫等等都有自动采集插件,还有基于爬虫的工具都可以。个人理解可能有不对,请见谅。
通常,会到处去查找最新时尚的话题,如果感兴趣,就会研究,
关键是要“着陆”对象。和什么网站没关系,如果能分析出对象,那么就只需要标记出来,让对象抓起来就好。关键是有没有“着陆”时候。
你可以看看免费的世界上最牛逼的搜索引擎uc-search是怎么抓取的呢?你可以详细看看。
有一些比较好的工具,比如我知道的lazarsearchplugin:全平台上搜索产品搜索与列表搜索爬虫,
问题问得不太明确,让我没法回答。提取网站的哪些页面?存到数据库里?还是只是将页面解析出来?要在实际应用中存到数据库里。
浏览器web服务器响应过来的页面。uc浏览器就可以直接打开这些页面。至于数据要存哪。或者需要爬取哪些页面。这个要看具体的需求了。
不要百度有很多。
直接使用国外的免费搜索工具好了
结合前面答主的答案,本来想直接给答案的,但是手机输入实在困难,还是要整理一下思路了1.比如说直接打开网站的网页源码,还可以直接打开源码分析和抓取。2.如果想寻找一些产品信息,还可以提取相关关键词。 查看全部
自动采集数据(免费的世界上最牛逼的搜索引擎uc-search是怎么抓取的)
自动采集数据我可以理解为提取非采集,自动采集,就是自动抓取网站的其他页面、信息,然后存储到数据库里,由数据库自动去爬去获取了。比如、天猫等等都有自动采集插件,还有基于爬虫的工具都可以。个人理解可能有不对,请见谅。
通常,会到处去查找最新时尚的话题,如果感兴趣,就会研究,
关键是要“着陆”对象。和什么网站没关系,如果能分析出对象,那么就只需要标记出来,让对象抓起来就好。关键是有没有“着陆”时候。
你可以看看免费的世界上最牛逼的搜索引擎uc-search是怎么抓取的呢?你可以详细看看。
有一些比较好的工具,比如我知道的lazarsearchplugin:全平台上搜索产品搜索与列表搜索爬虫,
问题问得不太明确,让我没法回答。提取网站的哪些页面?存到数据库里?还是只是将页面解析出来?要在实际应用中存到数据库里。
浏览器web服务器响应过来的页面。uc浏览器就可以直接打开这些页面。至于数据要存哪。或者需要爬取哪些页面。这个要看具体的需求了。
不要百度有很多。
直接使用国外的免费搜索工具好了
结合前面答主的答案,本来想直接给答案的,但是手机输入实在困难,还是要整理一下思路了1.比如说直接打开网站的网页源码,还可以直接打开源码分析和抓取。2.如果想寻找一些产品信息,还可以提取相关关键词。
自动采集数据(重庆公司用电信息采集系统排查手册数据采集与自动抄表分册采集任务配置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-16 18:22
重庆公司用电信息采集系统故障排查手动数据采集和自动抄表分卷采集任务配置目前集中在市县采集系统标准任务自动由系统配置和下发,采集标准任务范围外的任务需要业务人员在系统内自行完成配置和下发。标准任务配置 对于标准任务的配置,在终端安装和更换过程中,在“仪表文件关联”步骤,归档后系统自动下发标准任务。标准任务请参考附件。当该过程完成并完成归档时,进入Basic Application—Data 采集Management—采集Object Management,查看终端任务是否已经发送,如下图,如果看到任务发出标志为“已发送”,则说明表示任务已发送。任务成功下发到终端。如果看到任务下发标志为'unsent',说明终端的任务没有下发成功,需要重新下发。下发标准任务的几种操作方法: 进入运营管理-现场管理-现场调试-【终端调试】-测量点信息维护,勾选需要的测量点,点击【存档】按钮,如下图,如果当前终端下没有任务,会自动下发标准任务。如果当前终端下有未下发的任务,会弹出提示框,提示终端下有未下发的任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。
非标准任务配置 非标准任务的配置需要手动配置,下发非标准任务的几种操作方法:进入基本应用-数据采集管理-采集对象管理- 【维护终端任务】,输入终端号查询后,选择需要的终端信息,点击【通过终端任务配置】,进入如下界面:选择需要发送任务的用户类型,点击添加任务添加需要的任务,点击【添加、生成和下发任务】按钮,保留原有任务,下发添加的任务。点击【覆盖、生成、下发任务】,将删除原来的任务,然后下发添加的任务。进入基础应用-数据采集管理-采集 对象管理-【维护终端任务】,进入终端查询,选择需要的终端信息,点击【按任务对象配置任务】,进入如下界面: 在此页面,点击【添加一行】按钮,进入在对象编号栏中配置需要配置的电能表ID号,在任务编号栏中配置需要下发给该电表的任务编号,同一个任务编号设置相同的任务编号。自动抄表服务数据筛选 数据筛选是采集系统程序根据一定的规则判断终端采集到达的测点的每日冻结电能指示值各数据项的方法,为了保证采集设置数据的准确性。数据筛选分为程序筛选和人工筛选。程序筛选为异常数据。如果现场操作人员验证没有问题,则可以正常手动筛选,数据质量指标也正常采集。屏蔽范围数据 屏蔽范围为正常采集和未屏蔽测量点每日冻结电能指示数据,包括正负有功、无功功率、峰谷值。注:以下数据异常是指:采集质量标记为异常的数据,数据值为“空”。数据筛选规则 数据筛选规则分为表码下降和表码突增,表码总示值与各费率之和不相等,和总加组功率曲线筛选规则。电表代码缩减规则遵循国家电网电能表“计量在线监测与智能诊断分析模型”中的规则。本次电能指示-前一天电能指示 查看全部
自动采集数据(重庆公司用电信息采集系统排查手册数据采集与自动抄表分册采集任务配置)
重庆公司用电信息采集系统故障排查手动数据采集和自动抄表分卷采集任务配置目前集中在市县采集系统标准任务自动由系统配置和下发,采集标准任务范围外的任务需要业务人员在系统内自行完成配置和下发。标准任务配置 对于标准任务的配置,在终端安装和更换过程中,在“仪表文件关联”步骤,归档后系统自动下发标准任务。标准任务请参考附件。当该过程完成并完成归档时,进入Basic Application—Data 采集Management—采集Object Management,查看终端任务是否已经发送,如下图,如果看到任务发出标志为“已发送”,则说明表示任务已发送。任务成功下发到终端。如果看到任务下发标志为'unsent',说明终端的任务没有下发成功,需要重新下发。下发标准任务的几种操作方法: 进入运营管理-现场管理-现场调试-【终端调试】-测量点信息维护,勾选需要的测量点,点击【存档】按钮,如下图,如果当前终端下没有任务,会自动下发标准任务。如果当前终端下有未下发的任务,会弹出提示框,提示终端下有未下发的任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。点击【确定】按钮,将发送要下发的任务。进入基础应用-数据采集管理-采集对象管理,找出需要的终端位置,查询结果中未下发的信息,点击【终端任务发布】-【执行】 ],如下图,进入基础应用——数据采集管理——采集对象管理——【维护终端任务】,进入终端查询,选择需要的终端信息,点击【自动任务生成] 发布标准任务。
非标准任务配置 非标准任务的配置需要手动配置,下发非标准任务的几种操作方法:进入基本应用-数据采集管理-采集对象管理- 【维护终端任务】,输入终端号查询后,选择需要的终端信息,点击【通过终端任务配置】,进入如下界面:选择需要发送任务的用户类型,点击添加任务添加需要的任务,点击【添加、生成和下发任务】按钮,保留原有任务,下发添加的任务。点击【覆盖、生成、下发任务】,将删除原来的任务,然后下发添加的任务。进入基础应用-数据采集管理-采集 对象管理-【维护终端任务】,进入终端查询,选择需要的终端信息,点击【按任务对象配置任务】,进入如下界面: 在此页面,点击【添加一行】按钮,进入在对象编号栏中配置需要配置的电能表ID号,在任务编号栏中配置需要下发给该电表的任务编号,同一个任务编号设置相同的任务编号。自动抄表服务数据筛选 数据筛选是采集系统程序根据一定的规则判断终端采集到达的测点的每日冻结电能指示值各数据项的方法,为了保证采集设置数据的准确性。数据筛选分为程序筛选和人工筛选。程序筛选为异常数据。如果现场操作人员验证没有问题,则可以正常手动筛选,数据质量指标也正常采集。屏蔽范围数据 屏蔽范围为正常采集和未屏蔽测量点每日冻结电能指示数据,包括正负有功、无功功率、峰谷值。注:以下数据异常是指:采集质量标记为异常的数据,数据值为“空”。数据筛选规则 数据筛选规则分为表码下降和表码突增,表码总示值与各费率之和不相等,和总加组功率曲线筛选规则。电表代码缩减规则遵循国家电网电能表“计量在线监测与智能诊断分析模型”中的规则。本次电能指示-前一天电能指示
自动采集数据(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-10-14 04:16
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 四种采集方法
3 如何使用Open是一个数据源
4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。
(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关 查看全部
自动采集数据(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 四种采集方法
3 如何使用Open是一个数据源
4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。
(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关
自动采集数据(自动采集数据的算法大致可以简单分为2种方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-10-13 07:05
自动采集数据的算法大致可以理解为“爬虫”,即用一个代码从页面抓取数据。一般来说可以简单分为2种方式1.外置采集器,的阿里巴巴,百度,有其自己的爬虫,第三方也可以对其用写脚本2.内置采集器,例如百度,阿里巴巴,云风等对页面进行抓取,写算法处理(pythonselenium,androidselenium等),处理后的数据送去“爬虫”抓取并存入数据库。
等于数据从服务器下载,然后把数据写到自己的服务器里去。
抓取数据不要求采用代理或者vpn等,甚至可以采用公用wifi等传统方式,在特定网站抓取数据,现有技术已经可以实现数据抓取和存储、响应自动处理等功能。
内置api
未来采用机器学习技术,通过进一步加深对页面数据的理解,向页面采集者发送信息推送服务,实现自动爬取数据。
用爬虫模拟浏览器的行为,通过在特定网站进行短期内的抓取,然后根据存储在数据库的抓取数据自动分析,
可以采用python编写程序,
采用自动代理池实现数据抓取
现在不需要数据代理那么简单,可以想想看,或者分析是否是同一个网站的不同页面数据,这样也可以达到,类似统计局不同数据都可以通过代理抓取再进行,然后再传到数据库里。 查看全部
自动采集数据(自动采集数据的算法大致可以简单分为2种方式)
自动采集数据的算法大致可以理解为“爬虫”,即用一个代码从页面抓取数据。一般来说可以简单分为2种方式1.外置采集器,的阿里巴巴,百度,有其自己的爬虫,第三方也可以对其用写脚本2.内置采集器,例如百度,阿里巴巴,云风等对页面进行抓取,写算法处理(pythonselenium,androidselenium等),处理后的数据送去“爬虫”抓取并存入数据库。
等于数据从服务器下载,然后把数据写到自己的服务器里去。
抓取数据不要求采用代理或者vpn等,甚至可以采用公用wifi等传统方式,在特定网站抓取数据,现有技术已经可以实现数据抓取和存储、响应自动处理等功能。
内置api
未来采用机器学习技术,通过进一步加深对页面数据的理解,向页面采集者发送信息推送服务,实现自动爬取数据。
用爬虫模拟浏览器的行为,通过在特定网站进行短期内的抓取,然后根据存储在数据库的抓取数据自动分析,
可以采用python编写程序,
采用自动代理池实现数据抓取
现在不需要数据代理那么简单,可以想想看,或者分析是否是同一个网站的不同页面数据,这样也可以达到,类似统计局不同数据都可以通过代理抓取再进行,然后再传到数据库里。
自动采集数据(联合创始人:从数据组成的角度来说完善的闭环数据源)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-11 09:00
本文作者叶凌迪是GrowingIO的联合创始人。他还是一位连续创业者和企业协作工具 Windmill 的联合创始人。他拥有十多年的工程开发经验和多年的项目管理经验。现在负责核心项目开发和技术实施。. 本文是他对互联网创业公司数据采集的思考和体会以及分析。
这六七年,我一直在企业服务领域创业,用过很多分析工具:GA、Mixpanel、Heap等,很强大,但总觉得少了点什么。我们已经看到了 PV/UV 等概览指标,但它们无法指导我们做得更好。在通过这些粗略的数据知道用户做了什么之后,我们需要看看他们是怎么做的,并理解他们为什么这样做。我们需要实时完整的用户行为数据。通过对用户行为全过程的分析,我们可以找到关键的转化节点和用户流失的核心原因,从而帮助我们对症下药,找到可执行的指标,并作为优化动作来实施。
今天,我想分享的是我们在这方面的一些探索和解决方案。
一. 用户行为分析的巨大需求
单纯从数据构成来看,一个完整的闭环数据源主要分为三个区块:第一个区块是用户行为数据,第二个区块是服务器日志数据,第三个区块是交易数据。其中,除了交易数据往往存储在离线数据库中并通过ETL获取和分析外,行为数据和日志数据往往是相似的。完整的用户行为数据基本可以覆盖大部分服务端日志数据。同时,它收录了很多日志数据中所缺乏的信息。
从技术发展来看,近几年增长最快的可以说是前端。每个月都有很多新的东西出现。总体趋势是开发单页应用,追求用户体验。同时,也有移动端的应用,也会产生大量的行为数据,不会与服务器进行过多的交互。
因此,从应用提供商那里,我们需要了解屏幕前的人如何使用我们的产品,了解用户行为背后的价值。
GrowingIO 于去年 12 月 8 日发布至今已有数月时间,目前已被数百家客户使用。我总结了客户经常问我们的分析需求,大致可以分为三个场景:
二. 复杂且容易出错的传统分析方法
归根结底,所有的分析最终都是为了业务,而业务是为了人。因此,用户行为分析意味着我们需要建立一套基于用户行为的分析系统。除了了解用户的“谁”做了“什么”和“他做了什么”,然后了解了“为什么”去做,开出正确的补救措施,并转化为一个优化动作。
分析是一个长期的优化过程,需要我们持续监控数据的变化。除了行为数据指标,还有一类数据指标,我们称之为虚荣指标,比如PV、UV等流量概览数据。这些指标一看到就可以看到,并不能指导我们做得更好。用户行为数据指标是另外一个类别,比如我们上面介绍的用户获取、用户激活、用户留存。了解这些行为会对应一个优化过程,所以也称为Actionable Metric,这也是用户行为数据的魅力所在。
那么接下来,我们将开始跟踪用户行为,我们如何开始?一般可分为以下七个步骤:
1.确定分析场景或目标
确定一个场景或目标。例如,我们发现很多用户访问了注册页面,但很少有人完成注册。我们的目标是提高注册转化率,了解用户为什么没有完成注册,哪个步骤屏蔽了用户。
2.想想你需要知道哪些数据
想想我们需要了解哪些数据来帮助我们实现这一目标。比如之前的目标,我们需要拆解从进入注册页面到完成注册的每一步的数据,每一个输入的数据,同时,完成或者没有成为的人的特征数据这些步骤。
3.确定谁将负责采集数据?
我们的工程师负责采集这些数据。
4.什么时候评测分析?
如何分析采集的数据以及何时评估 采集 收到的数据。
5.如何给出优化方案?
发现问题后,如何想出解决办法。例如,无论是设计上的改进,还是工程上的错误。
6.谁负责实施解决方案。确定计划实施的责任人。
7.如何评估解决方案的有效性?下一轮数据采集并分析,返回第一步继续迭代。
知易行难。在这整个过程中,步骤2到4是关键。目前GA、Mixpanel、友盟等传统服务商采用的方式就是我所说的Capture模式。通过在客户端埋点某些点,将采集相关数据发送到云端,最终呈现在云端。比如图中的例子,相信房间里的每个人都写过类似的代码。
捕获模式是一种非常有效的非探索性分析方法。但同时,对整个过程的参与者也提出了非常高的要求:
缺点一:依赖体验
捕获模式在很大程度上依赖于人类的经验和直觉。不是经验和直觉不好,而是有时我们不知道什么是好的。经验将成为一种先入为主的负担。我们需要用数据来证明。
缺点二:通信成本高
此外,有效的分析结果取决于数据的完整性和完整性。和很多公司沟通后,很多抱怨都是“日志格式都不能统一”,更不用说后续的分析了。这不是特定人的问题,而是协作和沟通的问题。涉及的人越多,产品经理、分析师、工程师、运维等,每个人的专业领域都不一样。产生误解是正常的。我曾经和我们的 CEO Simon 交流过。当他在领英领导数据分析部门时,领英组建了一个多达 27 人的葬礼团队。他们每天召开会议,统一墓地的形式和地点。几个星期。
缺点三:大量时间数据清洗和数据分析代码入侵
此外,由于需求的多变性,墓地被划分为多个加建,缺乏整体设计和统一管理,结果自然是极其脏乱。因此,我们的数据工程师仍然有一个大的数据清理工作,手动运行 ETL 生成报告。据统计,70%~80%的分析工作都花在了数据清洗和手工ETL上,只有20%左右是在做真正有商业价值的事情。另一方面,作为清洁工程师,我最讨厌的是大量分析代码侵入我的业务代码。我不敢删,也不敢改。随着时间的推移,整个代码库变得混乱。
缺点4:数据遗漏和错误步进
以上还是不错的。最气人的是发现采集的数据有误或丢失。更正后,我不得不再次运行该过程。一两周过去了。这就是为什么数据分析工作如此耗时且通常以月为单位计算的原因,而且效率非常低。
三. 数据分析不埋点原理
在经历了无数个痛苦的夜晚之后,我们决定转变思路,希望能尽量减少人为错误。我们称之为记录模式。与Capture模式不同,Record模式使用机器代替人的体验,自动采集用户在网站或应用程序中的全部行为数据。由于自动化,我们从分析过程开始就控制数据的格式。
所有数据,从业务角度来看,分为5个维度:谁,行为背后的人有什么属性;何时,何时触发行为;哪里,市区浏览器甚至GPS等;内容是什么;怎么做,怎么做。基于信息的解构,保证数据从源头上是干净的。在此基础上,我们可以完全自动化ETL,需要什么数据可以随时追溯。
回到上一个过程的第二到第四步,我们将多方参与者的数量减少到只有一方。无论是产品经理、分析师还是运营人员,您都可以使用可视化工具来查询和分析数据。你所看到的就是你得到的。不仅支持PC,还支持iOS、Android和Hybrid,实现跨屏用户分析。
作为用户行为分析工具的提供者,GrowingIO 不仅内部使用,还需要适应外部上千种网站和应用,所以我们在实现过程中做了很多探索:
◦ 自动用户行为采集
我们目前接触的GUI程序,无论是Web App、iOS App还是Android App,都是基于两个原则,一个是树状结构,一个是事件驱动模型。无论是 Web 上的 DOM 节点结构,还是 App 上的 UI 控件结构,都构建了一个完整的树状结构并呈现在页面或屏幕上。所以通过监控和检测树状结构,我们可以很容易的知道哪些节点发生了变化,什么时候发生了变化,发生了什么变化。同时,当用户进行某种操作,比如鼠标点击或屏幕触摸时,会触发一个事件,并触发与该事件绑定的回调函数开始执行。基于这两点的理解,SDK中如何实现无埋点就比较清楚了。
◦ 数据可视化
如何将采集 接收到的数据与业务目标进行匹配。我们的解决方案是我们的可视化工具。如前所述,任何原子数据都被分解为 5 个不同的分类维度。因此,我们在可视化工具中做匹配时,是对不同维度的信息进行匹配。例如,当一个链接被点击时,它会匹配内容或重定向地址是What,点击行为是How。还有它在页面上的定位信息,比如在树状结构中的层次位置,是否有一些id、class或者tag,都是用于数据匹配的信息。我们开发了一套智能匹配系统,通过学习用户的真实行为,建立了一套元素匹配规则引擎。也正是因为采集
◦ BI 业务分析
在系统设计过程中,在整个Data Pipeline流程中,数据处理完毕后,首先会根据不同的优先级通过Spark Streaming实时处理定义的数据,然后每次对匹配的数据进行离线预聚合. ,多维分析非常灵活。
用户行为数据采集的目的是通过了解用户过去的行为来预测未来会发生什么,不埋点,随时回顾数据,以便产品经理处理用户行为分析全过程由他本人完成。GrowingIO 希望提供一个简单、快速、大规模的数据分析产品,可以大大简化分析流程,提交效率,直达业务。这一切的基础是我们从第一天就开始开发的无埋点智能全数据采集。基于此,我们优化产品体验,实现精细化运营,用数据驱动用户和收入增长。.
___________________________
GrowingIO 是新一代基于用户行为的数据分析产品。如果您属于以下三类人群,请立即关注我们,免费注册:
如果你是一名数据工程师,却“无所事事”地构建BI和配置嵌入代码:免费注册,立即减少无效加班;
如果您是产品经理,但不知道如何分解KPI:免费注册,三步洞察留存曲线,精准识别用户行为;
如果您是业务负责人,收入增长乏力:免费注册,让我们教您如何让客户高效下单。
_________________________ 查看全部
自动采集数据(联合创始人:从数据组成的角度来说完善的闭环数据源)
本文作者叶凌迪是GrowingIO的联合创始人。他还是一位连续创业者和企业协作工具 Windmill 的联合创始人。他拥有十多年的工程开发经验和多年的项目管理经验。现在负责核心项目开发和技术实施。. 本文是他对互联网创业公司数据采集的思考和体会以及分析。
这六七年,我一直在企业服务领域创业,用过很多分析工具:GA、Mixpanel、Heap等,很强大,但总觉得少了点什么。我们已经看到了 PV/UV 等概览指标,但它们无法指导我们做得更好。在通过这些粗略的数据知道用户做了什么之后,我们需要看看他们是怎么做的,并理解他们为什么这样做。我们需要实时完整的用户行为数据。通过对用户行为全过程的分析,我们可以找到关键的转化节点和用户流失的核心原因,从而帮助我们对症下药,找到可执行的指标,并作为优化动作来实施。
今天,我想分享的是我们在这方面的一些探索和解决方案。
一. 用户行为分析的巨大需求
单纯从数据构成来看,一个完整的闭环数据源主要分为三个区块:第一个区块是用户行为数据,第二个区块是服务器日志数据,第三个区块是交易数据。其中,除了交易数据往往存储在离线数据库中并通过ETL获取和分析外,行为数据和日志数据往往是相似的。完整的用户行为数据基本可以覆盖大部分服务端日志数据。同时,它收录了很多日志数据中所缺乏的信息。
从技术发展来看,近几年增长最快的可以说是前端。每个月都有很多新的东西出现。总体趋势是开发单页应用,追求用户体验。同时,也有移动端的应用,也会产生大量的行为数据,不会与服务器进行过多的交互。
因此,从应用提供商那里,我们需要了解屏幕前的人如何使用我们的产品,了解用户行为背后的价值。
GrowingIO 于去年 12 月 8 日发布至今已有数月时间,目前已被数百家客户使用。我总结了客户经常问我们的分析需求,大致可以分为三个场景:
二. 复杂且容易出错的传统分析方法
归根结底,所有的分析最终都是为了业务,而业务是为了人。因此,用户行为分析意味着我们需要建立一套基于用户行为的分析系统。除了了解用户的“谁”做了“什么”和“他做了什么”,然后了解了“为什么”去做,开出正确的补救措施,并转化为一个优化动作。
分析是一个长期的优化过程,需要我们持续监控数据的变化。除了行为数据指标,还有一类数据指标,我们称之为虚荣指标,比如PV、UV等流量概览数据。这些指标一看到就可以看到,并不能指导我们做得更好。用户行为数据指标是另外一个类别,比如我们上面介绍的用户获取、用户激活、用户留存。了解这些行为会对应一个优化过程,所以也称为Actionable Metric,这也是用户行为数据的魅力所在。
那么接下来,我们将开始跟踪用户行为,我们如何开始?一般可分为以下七个步骤:
1.确定分析场景或目标
确定一个场景或目标。例如,我们发现很多用户访问了注册页面,但很少有人完成注册。我们的目标是提高注册转化率,了解用户为什么没有完成注册,哪个步骤屏蔽了用户。
2.想想你需要知道哪些数据
想想我们需要了解哪些数据来帮助我们实现这一目标。比如之前的目标,我们需要拆解从进入注册页面到完成注册的每一步的数据,每一个输入的数据,同时,完成或者没有成为的人的特征数据这些步骤。
3.确定谁将负责采集数据?
我们的工程师负责采集这些数据。
4.什么时候评测分析?
如何分析采集的数据以及何时评估 采集 收到的数据。
5.如何给出优化方案?
发现问题后,如何想出解决办法。例如,无论是设计上的改进,还是工程上的错误。
6.谁负责实施解决方案。确定计划实施的责任人。
7.如何评估解决方案的有效性?下一轮数据采集并分析,返回第一步继续迭代。
知易行难。在这整个过程中,步骤2到4是关键。目前GA、Mixpanel、友盟等传统服务商采用的方式就是我所说的Capture模式。通过在客户端埋点某些点,将采集相关数据发送到云端,最终呈现在云端。比如图中的例子,相信房间里的每个人都写过类似的代码。
捕获模式是一种非常有效的非探索性分析方法。但同时,对整个过程的参与者也提出了非常高的要求:
缺点一:依赖体验
捕获模式在很大程度上依赖于人类的经验和直觉。不是经验和直觉不好,而是有时我们不知道什么是好的。经验将成为一种先入为主的负担。我们需要用数据来证明。
缺点二:通信成本高
此外,有效的分析结果取决于数据的完整性和完整性。和很多公司沟通后,很多抱怨都是“日志格式都不能统一”,更不用说后续的分析了。这不是特定人的问题,而是协作和沟通的问题。涉及的人越多,产品经理、分析师、工程师、运维等,每个人的专业领域都不一样。产生误解是正常的。我曾经和我们的 CEO Simon 交流过。当他在领英领导数据分析部门时,领英组建了一个多达 27 人的葬礼团队。他们每天召开会议,统一墓地的形式和地点。几个星期。
缺点三:大量时间数据清洗和数据分析代码入侵
此外,由于需求的多变性,墓地被划分为多个加建,缺乏整体设计和统一管理,结果自然是极其脏乱。因此,我们的数据工程师仍然有一个大的数据清理工作,手动运行 ETL 生成报告。据统计,70%~80%的分析工作都花在了数据清洗和手工ETL上,只有20%左右是在做真正有商业价值的事情。另一方面,作为清洁工程师,我最讨厌的是大量分析代码侵入我的业务代码。我不敢删,也不敢改。随着时间的推移,整个代码库变得混乱。
缺点4:数据遗漏和错误步进
以上还是不错的。最气人的是发现采集的数据有误或丢失。更正后,我不得不再次运行该过程。一两周过去了。这就是为什么数据分析工作如此耗时且通常以月为单位计算的原因,而且效率非常低。
三. 数据分析不埋点原理
在经历了无数个痛苦的夜晚之后,我们决定转变思路,希望能尽量减少人为错误。我们称之为记录模式。与Capture模式不同,Record模式使用机器代替人的体验,自动采集用户在网站或应用程序中的全部行为数据。由于自动化,我们从分析过程开始就控制数据的格式。
所有数据,从业务角度来看,分为5个维度:谁,行为背后的人有什么属性;何时,何时触发行为;哪里,市区浏览器甚至GPS等;内容是什么;怎么做,怎么做。基于信息的解构,保证数据从源头上是干净的。在此基础上,我们可以完全自动化ETL,需要什么数据可以随时追溯。
回到上一个过程的第二到第四步,我们将多方参与者的数量减少到只有一方。无论是产品经理、分析师还是运营人员,您都可以使用可视化工具来查询和分析数据。你所看到的就是你得到的。不仅支持PC,还支持iOS、Android和Hybrid,实现跨屏用户分析。
作为用户行为分析工具的提供者,GrowingIO 不仅内部使用,还需要适应外部上千种网站和应用,所以我们在实现过程中做了很多探索:
◦ 自动用户行为采集
我们目前接触的GUI程序,无论是Web App、iOS App还是Android App,都是基于两个原则,一个是树状结构,一个是事件驱动模型。无论是 Web 上的 DOM 节点结构,还是 App 上的 UI 控件结构,都构建了一个完整的树状结构并呈现在页面或屏幕上。所以通过监控和检测树状结构,我们可以很容易的知道哪些节点发生了变化,什么时候发生了变化,发生了什么变化。同时,当用户进行某种操作,比如鼠标点击或屏幕触摸时,会触发一个事件,并触发与该事件绑定的回调函数开始执行。基于这两点的理解,SDK中如何实现无埋点就比较清楚了。
◦ 数据可视化
如何将采集 接收到的数据与业务目标进行匹配。我们的解决方案是我们的可视化工具。如前所述,任何原子数据都被分解为 5 个不同的分类维度。因此,我们在可视化工具中做匹配时,是对不同维度的信息进行匹配。例如,当一个链接被点击时,它会匹配内容或重定向地址是What,点击行为是How。还有它在页面上的定位信息,比如在树状结构中的层次位置,是否有一些id、class或者tag,都是用于数据匹配的信息。我们开发了一套智能匹配系统,通过学习用户的真实行为,建立了一套元素匹配规则引擎。也正是因为采集
◦ BI 业务分析
在系统设计过程中,在整个Data Pipeline流程中,数据处理完毕后,首先会根据不同的优先级通过Spark Streaming实时处理定义的数据,然后每次对匹配的数据进行离线预聚合. ,多维分析非常灵活。
用户行为数据采集的目的是通过了解用户过去的行为来预测未来会发生什么,不埋点,随时回顾数据,以便产品经理处理用户行为分析全过程由他本人完成。GrowingIO 希望提供一个简单、快速、大规模的数据分析产品,可以大大简化分析流程,提交效率,直达业务。这一切的基础是我们从第一天就开始开发的无埋点智能全数据采集。基于此,我们优化产品体验,实现精细化运营,用数据驱动用户和收入增长。.
___________________________
GrowingIO 是新一代基于用户行为的数据分析产品。如果您属于以下三类人群,请立即关注我们,免费注册:
如果你是一名数据工程师,却“无所事事”地构建BI和配置嵌入代码:免费注册,立即减少无效加班;
如果您是产品经理,但不知道如何分解KPI:免费注册,三步洞察留存曲线,精准识别用户行为;
如果您是业务负责人,收入增长乏力:免费注册,让我们教您如何让客户高效下单。
_________________________
自动采集数据(探码Web大数据采集系统的八个子系统科技 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-07 16:34
)
发现网络大数据采集系统
天马科技基于云计算研发的Web大数据采集系统——利用众多云计算服务器协同工作,快速采集海量数据,避免计算机硬件资源瓶颈. 另外,随着行业对数据采集的要求越来越高,传统post采集无法解决的技术问题正在逐步得到解决,以探针代号Kapow/Dyson采集器为代表@> 新一代智能采集器@> 可以模拟人的思维和操作,从而彻底解决ajax等技术难题。
Web大数据采集系统的八个子系统
天马网大数据采集系统分为大数据集群系统、数据采集系统、采集数据源研究、数据爬虫系统、数据清洗系统、数据整合8个子系统系统、任务调度系统、搜索引擎系统。
大数据集群系统
该系统可以存储高达采集的TB级数据,实现数据持久化。数据存储采用MongoDB集群方案,集群上有两大特点:
数据采集系统
本系统配置了Kapow、PhantomJS、Mechanize采集环境,运行在Docker容器中,由Rancher安排容器。
采集数据源研究
该系统是“数据爬虫系统”启动前不可缺少的环节。经过排查,发现页面需要采集,需要过滤的关键字,需要提取的内容。
数据爬虫系统
爬虫程序都是独立的个体,结合采集系统服务器需要的数据,由Rancher安排,在DigitalOcean中自动启动爬虫程序,根据输入的参数,抓取指定的数据,然后发回通过API大数据集群系统给我们。
数据清洗系统
本系统采用Ruby on Rails+Vue技术框架实现Web前端展示,展示爬虫程序抓取的数据,方便我们的清理。数据清洗系统主要由两部分组成:
数据整合系统
本系统采用Ruby on Rails+Vue技术框架,实现Web前端展示和数据合并。数据清洗后,数据合并系统会自动匹配大数据集群中的数据,通过熟人评分关联可能的熟人数据。匹配结果通过web前端展示,数据可以手动合并,也可以自动合并。
任务调度系统
本系统通过Ruby on Rails+Vue技术框架、Sidekiq队列调度、Redis调度数据持久化实现了一个Web前端任务调度系统。通过任务调度系统,可以动态开启关闭,定时启动爬虫程序。
搜索引擎系统
本系统通过ElasticSearch集群实现搜索引擎服务。搜索引擎是PC端检索系统从大数据集群中快速检索数据的必备工具。通过ElasticSearch集群,运行3个以上Master角色保证集群系统的稳定性,2个以上Client角色保证查询的容错性,2个以上Data角色保证查询和写入的及时性。通过负载均衡连接Client的角色,分散数据查询的压力。
Web大数据采集系统应用案例展示
查看全部
自动采集数据(探码Web大数据采集系统的八个子系统科技
)
发现网络大数据采集系统
天马科技基于云计算研发的Web大数据采集系统——利用众多云计算服务器协同工作,快速采集海量数据,避免计算机硬件资源瓶颈. 另外,随着行业对数据采集的要求越来越高,传统post采集无法解决的技术问题正在逐步得到解决,以探针代号Kapow/Dyson采集器为代表@> 新一代智能采集器@> 可以模拟人的思维和操作,从而彻底解决ajax等技术难题。
Web大数据采集系统的八个子系统
天马网大数据采集系统分为大数据集群系统、数据采集系统、采集数据源研究、数据爬虫系统、数据清洗系统、数据整合8个子系统系统、任务调度系统、搜索引擎系统。
大数据集群系统
该系统可以存储高达采集的TB级数据,实现数据持久化。数据存储采用MongoDB集群方案,集群上有两大特点:
数据采集系统
本系统配置了Kapow、PhantomJS、Mechanize采集环境,运行在Docker容器中,由Rancher安排容器。
采集数据源研究
该系统是“数据爬虫系统”启动前不可缺少的环节。经过排查,发现页面需要采集,需要过滤的关键字,需要提取的内容。
数据爬虫系统
爬虫程序都是独立的个体,结合采集系统服务器需要的数据,由Rancher安排,在DigitalOcean中自动启动爬虫程序,根据输入的参数,抓取指定的数据,然后发回通过API大数据集群系统给我们。
数据清洗系统
本系统采用Ruby on Rails+Vue技术框架实现Web前端展示,展示爬虫程序抓取的数据,方便我们的清理。数据清洗系统主要由两部分组成:
数据整合系统
本系统采用Ruby on Rails+Vue技术框架,实现Web前端展示和数据合并。数据清洗后,数据合并系统会自动匹配大数据集群中的数据,通过熟人评分关联可能的熟人数据。匹配结果通过web前端展示,数据可以手动合并,也可以自动合并。
任务调度系统
本系统通过Ruby on Rails+Vue技术框架、Sidekiq队列调度、Redis调度数据持久化实现了一个Web前端任务调度系统。通过任务调度系统,可以动态开启关闭,定时启动爬虫程序。
搜索引擎系统
本系统通过ElasticSearch集群实现搜索引擎服务。搜索引擎是PC端检索系统从大数据集群中快速检索数据的必备工具。通过ElasticSearch集群,运行3个以上Master角色保证集群系统的稳定性,2个以上Client角色保证查询的容错性,2个以上Data角色保证查询和写入的及时性。通过负载均衡连接Client的角色,分散数据查询的压力。
Web大数据采集系统应用案例展示
自动采集数据(如何对采集字段进行配置如何采集列表+详情页类型网页采集结果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-07 15:26
功能点目录:
如何配置采集字段
如何采集列表+详情页类型网页
采集结果预览:
导出到 Excel 电子表格:
导出的PDF文件:
下面详细介绍一下如何免费采集马蜂窝旅游指南信息和数据。我们以泰国的自由行旅游指南为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换为注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第二步:新建一个采集任务
1、复制马蜂窝泰国旅游指南网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
在列表页面,我们需要采集泰国免费旅游指南的指南标题、指南链接、阅读量、体验人数、封面图等,字段设置效果如下:
2、使用深入采集函数提取详情页数据
在列表页面上,只显示了泰国免费旅游指南的部分信息。如果您需要指南的具体内容,我们需要右键点击listing链接,使用“深度采集”功能跳转到详情页继续采集。
在详情页,我们可以看到指南的详细内容、评论数、采集数、发布时间等信息。同时,我们可以看到,指南中有很多图片。如果我们一一设置字段,会出现很多字段,而且每个指南的图片位置不同,可能会导致采集不完整,所以我们可以在这里添加一个特殊的字段,“Page PDF”,我们可以点击“添加字段”来添加采集字段,所有字段设置效果如下:
第四步:设置并启动采集任务
1、设置采集任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,因为采集页面PDF如果有就是漫长的等待 太慢了,可能会导致图片在显示完全之前被采集,所以我们设置了“5”秒的请求等待时间,勾选“不加载网页图片”,反-屏蔽设置将遵循系统默认设置,然后点击保存。
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,只需点击“开始”即可运行爬虫工具。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动开始采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集结束后会有提示@>。
第 5 步:导出并查看数据
数据采集完成后,我们就可以查看和导出数据了。优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)和导出文件的格式(EXCEL、CSV 、HTML 和 TXT),我们选择我们需要的方法和文件类型,然后单击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上可以使用发布到网站功能。 查看全部
自动采集数据(如何对采集字段进行配置如何采集列表+详情页类型网页采集结果)
功能点目录:
如何配置采集字段
如何采集列表+详情页类型网页
采集结果预览:
导出到 Excel 电子表格:
导出的PDF文件:
下面详细介绍一下如何免费采集马蜂窝旅游指南信息和数据。我们以泰国的自由行旅游指南为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换为注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第二步:新建一个采集任务
1、复制马蜂窝泰国旅游指南网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
在列表页面,我们需要采集泰国免费旅游指南的指南标题、指南链接、阅读量、体验人数、封面图等,字段设置效果如下:
2、使用深入采集函数提取详情页数据
在列表页面上,只显示了泰国免费旅游指南的部分信息。如果您需要指南的具体内容,我们需要右键点击listing链接,使用“深度采集”功能跳转到详情页继续采集。
在详情页,我们可以看到指南的详细内容、评论数、采集数、发布时间等信息。同时,我们可以看到,指南中有很多图片。如果我们一一设置字段,会出现很多字段,而且每个指南的图片位置不同,可能会导致采集不完整,所以我们可以在这里添加一个特殊的字段,“Page PDF”,我们可以点击“添加字段”来添加采集字段,所有字段设置效果如下:
第四步:设置并启动采集任务
1、设置采集任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,因为采集页面PDF如果有就是漫长的等待 太慢了,可能会导致图片在显示完全之前被采集,所以我们设置了“5”秒的请求等待时间,勾选“不加载网页图片”,反-屏蔽设置将遵循系统默认设置,然后点击保存。
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,只需点击“开始”即可运行爬虫工具。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动开始采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集结束后会有提示@>。
第 5 步:导出并查看数据
数据采集完成后,我们就可以查看和导出数据了。优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)和导出文件的格式(EXCEL、CSV 、HTML 和 TXT),我们选择我们需要的方法和文件类型,然后单击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上可以使用发布到网站功能。
自动采集数据(能用python解决的问题用什么都一样问到了我的痛点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-02 23:03
自动采集数据一般有两种,一种是python爬虫爬下来再用正则表达式匹配另一种就是专门的数据采集工具可以采集专门的数据。这些采集工具一般就有该平台提供的api,当然你还需要一些编程知识。然后一般根据你需要的类型,会对应有专门的采集平台,比如电影打分、搜索排行什么的,用第三方的工具就可以完成了。专门做数据采集的工具主要是对应于专业的电影网站如豆瓣网,还有就是api也适用于第三方提供的api,比如快猫、码力全开等等。
相关的方面有这些情况可能对你更有用:如何用python抓取豆瓣top250电影排行榜?
有,
专业的数据采集器,比如bigdataexcel可以帮你完成采集豆瓣top250电影电视剧排行榜,抓取打分电影网站,电影院线等。有需要可以去官网了解一下。
可以找这些方面的资料看看可以提高一些工作效率:/
其实很多人都可以,到不代表他们的效率一定高。想要提高效率,那就得对自己负责,让自己思考,让自己反思,让自己一直保持一颗跟有追求的心,工作上,生活上。这些是很重要的,坚持一段时间,你会得到回报。
能用python解决的问题用什么都一样
问到了我的痛点,希望能合作一下。
目前豆瓣top250里的电影已经基本不在了, 查看全部
自动采集数据(能用python解决的问题用什么都一样问到了我的痛点)
自动采集数据一般有两种,一种是python爬虫爬下来再用正则表达式匹配另一种就是专门的数据采集工具可以采集专门的数据。这些采集工具一般就有该平台提供的api,当然你还需要一些编程知识。然后一般根据你需要的类型,会对应有专门的采集平台,比如电影打分、搜索排行什么的,用第三方的工具就可以完成了。专门做数据采集的工具主要是对应于专业的电影网站如豆瓣网,还有就是api也适用于第三方提供的api,比如快猫、码力全开等等。
相关的方面有这些情况可能对你更有用:如何用python抓取豆瓣top250电影排行榜?
有,
专业的数据采集器,比如bigdataexcel可以帮你完成采集豆瓣top250电影电视剧排行榜,抓取打分电影网站,电影院线等。有需要可以去官网了解一下。
可以找这些方面的资料看看可以提高一些工作效率:/
其实很多人都可以,到不代表他们的效率一定高。想要提高效率,那就得对自己负责,让自己思考,让自己反思,让自己一直保持一颗跟有追求的心,工作上,生活上。这些是很重要的,坚持一段时间,你会得到回报。
能用python解决的问题用什么都一样
问到了我的痛点,希望能合作一下。
目前豆瓣top250里的电影已经基本不在了,
自动采集数据(本文如何免费采集豆瓣短评(碟中谍6-全面瓦解))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-26 17:27
本文主要介绍如何使用优采云采集器的智能模式,免费采集豆瓣短评论(任务:不可能6-全面崩溃)评论者、评论时间、评论内容等信息.
采集工具介绍:
优采云采集器是一款基于人工智能技术的网络爬虫工具。只需输入网址即可自动识别网页数据,无需配置即可完成数据。采集,业界首款支持三种操作系统(包括Windows、Mac和Linux)的Crawler软件。
本软件是一款真正免费的数据采集软件,对采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现数据采集需求。
官方网站:
采集对象介绍:
豆瓣是一个社区网站。网站从书籍、电影、音乐开始,提供书籍、电影、音乐等作品的信息。描述和评论均由用户提供。它是 Web 2.0网站 网站 的一个特征。网站 还提供图书影音推荐、同城线下活动、群话题交流等多种服务功能,更像是一个品味系统的集合(阅读、电影、音乐) 、表达系统(我读、我看、我集听的创新网络服务)和交流系统(同城、同组、邻里)一直致力于帮助城市人找到生活中有用的东西。
采集字段:
评论者、发布时间、有用数量、评论内容
功能点目录:
如何采集需要登录才能查看的网页
如何实现翻页功能
采集结果预览:
下面详细介绍一下如何免费采集豆瓣短评论数据。我们以豆瓣短评《使命:不可能的6-全解体》为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、点此打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换为注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第二步:新建一个采集任务
1、 复制《碟中谍6-彻底解体》豆瓣短评的网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集规则
1、设置预登录
豆瓣短评论在用户未登录时只能显示前10页的数据,如果用户需要更多的数据,需要在采集之前登录,所以我们需要先预登录,并且然后继续采集。
这里我们要使用“预登录”功能,点击“预登录”按钮,打开登录窗口,如下图所示。优采云采集器 不会存储和上传您的帐户信息,您可以放心使用此功能。
2、手动设置分页
豆瓣短评论页面的翻页按钮比较特别,智能模式无法直接识别元素采集下一页,此时系统会提示。
我们需要手动设置分页,设置“分页设置-手动设置分页-点击分页按钮”,然后点击网页上的分页按钮。
3、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
我们需要采集豆瓣短评论的评论者、发布时间、有用数量和评论内容。由于特殊星级元素,优采云V2.1.22版本暂时不支持采集此字段,此功能将在后续版本中实现,字段设置效果如下:
第四步:设置并启动采集任务
1、设置采集 任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面中我们可以设置运行设置和防拦截设置。这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,并勾选“不加载网页图片”,防拦截设置将遵循系统默认设置,然后点击保存.
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,直接点击“开始”即可。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动开始采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集结束后会有提示@>。
第 5 步:导出并查看数据
数据采集完成后,我们就可以查看和导出数据了。优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)和导出文件的格式(EXCEL、CSV 、HTML 和 TXT),我们选择我们需要的方法和文件类型,然后单击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上可以使用发布到网站功能。 查看全部
自动采集数据(本文如何免费采集豆瓣短评(碟中谍6-全面瓦解))
本文主要介绍如何使用优采云采集器的智能模式,免费采集豆瓣短评论(任务:不可能6-全面崩溃)评论者、评论时间、评论内容等信息.
采集工具介绍:
优采云采集器是一款基于人工智能技术的网络爬虫工具。只需输入网址即可自动识别网页数据,无需配置即可完成数据。采集,业界首款支持三种操作系统(包括Windows、Mac和Linux)的Crawler软件。
本软件是一款真正免费的数据采集软件,对采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现数据采集需求。
官方网站:
采集对象介绍:
豆瓣是一个社区网站。网站从书籍、电影、音乐开始,提供书籍、电影、音乐等作品的信息。描述和评论均由用户提供。它是 Web 2.0网站 网站 的一个特征。网站 还提供图书影音推荐、同城线下活动、群话题交流等多种服务功能,更像是一个品味系统的集合(阅读、电影、音乐) 、表达系统(我读、我看、我集听的创新网络服务)和交流系统(同城、同组、邻里)一直致力于帮助城市人找到生活中有用的东西。
采集字段:
评论者、发布时间、有用数量、评论内容
功能点目录:
如何采集需要登录才能查看的网页
如何实现翻页功能
采集结果预览:
下面详细介绍一下如何免费采集豆瓣短评论数据。我们以豆瓣短评《使命:不可能的6-全解体》为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、点此打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换为注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第二步:新建一个采集任务
1、 复制《碟中谍6-彻底解体》豆瓣短评的网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集规则
1、设置预登录
豆瓣短评论在用户未登录时只能显示前10页的数据,如果用户需要更多的数据,需要在采集之前登录,所以我们需要先预登录,并且然后继续采集。
这里我们要使用“预登录”功能,点击“预登录”按钮,打开登录窗口,如下图所示。优采云采集器 不会存储和上传您的帐户信息,您可以放心使用此功能。
2、手动设置分页
豆瓣短评论页面的翻页按钮比较特别,智能模式无法直接识别元素采集下一页,此时系统会提示。
我们需要手动设置分页,设置“分页设置-手动设置分页-点击分页按钮”,然后点击网页上的分页按钮。
3、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
我们需要采集豆瓣短评论的评论者、发布时间、有用数量和评论内容。由于特殊星级元素,优采云V2.1.22版本暂时不支持采集此字段,此功能将在后续版本中实现,字段设置效果如下:
第四步:设置并启动采集任务
1、设置采集 任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面中我们可以设置运行设置和防拦截设置。这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,并勾选“不加载网页图片”,防拦截设置将遵循系统默认设置,然后点击保存.
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,直接点击“开始”即可。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动开始采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集结束后会有提示@>。
第 5 步:导出并查看数据
数据采集完成后,我们就可以查看和导出数据了。优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)和导出文件的格式(EXCEL、CSV 、HTML 和 TXT),我们选择我们需要的方法和文件类型,然后单击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上可以使用发布到网站功能。
自动采集数据(MicrosoftOfficeExcel连接外部数据的主要好处是可以在Excel中定期分析此数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-09-21 02:21
microsoftofficeexcel连接外部数据的主要好处是在Excel中分析此数据,而不重复复制数据,复制操作不仅耗时,还可以轻松错误。连接到外部数据后,无论数据源是否已使用新信息更新,也可以自动刷新(或更新)Excel工作簿。安全性计算机可能会禁用与外部数据的连接。要连接到数据打开工作簿时,必须通过使用信任中心栏启用数据连接,或将工作簿放在可信位置。在“在”数据“选项卡上的”获取外部数据“组中,单击”现有连接“。将显示现有连接对话框。在对话框顶部的“显示”下拉列表中,执行以下操作之一:要显示所有连接,请单击所有连接。这是默认选项。要仅显示最近使用的连接列表,请单击“本工作簿中的连接”。此列表是从以下连接创建的:由“选择数据源”对话框创建的连接使用数据连接向导或在对话框中选择的连接创建。要仅在计算机上显示连接的连接,请单击“此计算机的连接文件”。此列表是从通常存储在我的文档中的“我的数据源”文件夹中创建的。仅显示网络上连接文件可访问的可用连接,单击“网络连接文件”。此列表是从MicrosoftOfficesHepointsServer2007 网站 网站的excelservices数据连接库(DCL)创建。
dcl是MicrosoftOfficesHakePointServices2007 网站收录一个Office数据连接(ODC)文件(.odc)的集合。 DCL通常由网站 admin设置。,网站管理员还可以在外部连接对话框中配置SharePoint 网站以在此DCL中显示ODC文件。有关更多信息,请参阅防毒源宗机HarePointServer2007管理中心帮助。如果未看到所需的连接,则可以单击“浏览更多”以显示数据源对话框,然后单击“启动数据连接向导”以创建连接。注意如果在此计算机上的“网络连接文件”或“连接文件”类别中选择了连接,则连接文件将被复制到工作簿作为新的工作簿连接,并将用作新的连接信息。选择所需的连接,然后单击“打开”。将显示“导入数据”对话框。在“请在工作簿中选择此数据”,执行以下操作之一:为简单排序和过滤创建表,请单击“表”。要创建数据透视图,请通过聚合和总计数据来总结大量数据,单击“透视”。要创建数据透视图和数据透视图,请单击“数据透视图”和“数据透视表”。要将所选连接存储在工作簿中以备将来使用,请单击“创建连接”。
使用此选项将所选连接存储到工作簿以进行使用。例如,如果要连接到在线分析过程(OLAP)立方体数据源,并打算使用“转换为公式”命令(“选项”选项卡上的“工具”组,请单击“OLAP工具”)转换数据表公式的数据透视表单元,您可以使用此选项,因为您不必保存数据透视图。注意这些选项不适用于所有类型的数据连接(包括文本,Web查询和XML)。在“数据放置位置”下,执行以下操作之一:要在现有工作表中放置数据透视表或枢轴透视图,请选择现有工作表,然后键入要放置数据透视中心的单元区域的第一个单元格。您还可以单击“压缩对话框”以临时隐藏对话框,然后在工作表上选择单元格,按“对话框”。要将数据透视表放在新的工作表中,请单击“新建工作表”。或者,您可以通过遵循“属性”,在“连接属性”,“导出数据区域”或“XML映射属性”对话框中更改连接属性,然后单击“确定”。 查看全部
自动采集数据(MicrosoftOfficeExcel连接外部数据的主要好处是可以在Excel中定期分析此数据)
microsoftofficeexcel连接外部数据的主要好处是在Excel中分析此数据,而不重复复制数据,复制操作不仅耗时,还可以轻松错误。连接到外部数据后,无论数据源是否已使用新信息更新,也可以自动刷新(或更新)Excel工作簿。安全性计算机可能会禁用与外部数据的连接。要连接到数据打开工作簿时,必须通过使用信任中心栏启用数据连接,或将工作簿放在可信位置。在“在”数据“选项卡上的”获取外部数据“组中,单击”现有连接“。将显示现有连接对话框。在对话框顶部的“显示”下拉列表中,执行以下操作之一:要显示所有连接,请单击所有连接。这是默认选项。要仅显示最近使用的连接列表,请单击“本工作簿中的连接”。此列表是从以下连接创建的:由“选择数据源”对话框创建的连接使用数据连接向导或在对话框中选择的连接创建。要仅在计算机上显示连接的连接,请单击“此计算机的连接文件”。此列表是从通常存储在我的文档中的“我的数据源”文件夹中创建的。仅显示网络上连接文件可访问的可用连接,单击“网络连接文件”。此列表是从MicrosoftOfficesHepointsServer2007 网站 网站的excelservices数据连接库(DCL)创建。
dcl是MicrosoftOfficesHakePointServices2007 网站收录一个Office数据连接(ODC)文件(.odc)的集合。 DCL通常由网站 admin设置。,网站管理员还可以在外部连接对话框中配置SharePoint 网站以在此DCL中显示ODC文件。有关更多信息,请参阅防毒源宗机HarePointServer2007管理中心帮助。如果未看到所需的连接,则可以单击“浏览更多”以显示数据源对话框,然后单击“启动数据连接向导”以创建连接。注意如果在此计算机上的“网络连接文件”或“连接文件”类别中选择了连接,则连接文件将被复制到工作簿作为新的工作簿连接,并将用作新的连接信息。选择所需的连接,然后单击“打开”。将显示“导入数据”对话框。在“请在工作簿中选择此数据”,执行以下操作之一:为简单排序和过滤创建表,请单击“表”。要创建数据透视图,请通过聚合和总计数据来总结大量数据,单击“透视”。要创建数据透视图和数据透视图,请单击“数据透视图”和“数据透视表”。要将所选连接存储在工作簿中以备将来使用,请单击“创建连接”。
使用此选项将所选连接存储到工作簿以进行使用。例如,如果要连接到在线分析过程(OLAP)立方体数据源,并打算使用“转换为公式”命令(“选项”选项卡上的“工具”组,请单击“OLAP工具”)转换数据表公式的数据透视表单元,您可以使用此选项,因为您不必保存数据透视图。注意这些选项不适用于所有类型的数据连接(包括文本,Web查询和XML)。在“数据放置位置”下,执行以下操作之一:要在现有工作表中放置数据透视表或枢轴透视图,请选择现有工作表,然后键入要放置数据透视中心的单元区域的第一个单元格。您还可以单击“压缩对话框”以临时隐藏对话框,然后在工作表上选择单元格,按“对话框”。要将数据透视表放在新的工作表中,请单击“新建工作表”。或者,您可以通过遵循“属性”,在“连接属性”,“导出数据区域”或“XML映射属性”对话框中更改连接属性,然后单击“确定”。
自动采集数据(自动采集数据给到后端更新的技术架构是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-13 20:02
自动采集数据给到后端更新,简单说,就是前端需要一个函数,把用户采集的网页链接,转换成用户所需要的redis对象即可。springcloud从2.0开始就支持开启redis服务了,2.1的版本可以自动配置即可。redis的所有命令和类都是java直接写的,不需要再写spring.redis.jar之类的依赖。另外推荐我个人的github项目:fabrics/cloud-redis。
如果没有redis,
技术架构的设计我有一些浅薄的认识。关于一个项目的自动采集,我的技术架构是以下这样的:1.在程序的生命周期内根据服务端数据源的要求,获取数据2.如果要自动采集,就要设置最佳路由3.设置最佳路由,那么这些数据来源的相应数据也要找到4.保存到数据库5.把数据返回给客户端6.数据源返回给客户端,数据返回客户端后还需要从客户端获取最佳路由的数据返回,这样可以节省最短的时间,提高数据接收的效率。
整个流程的细节也有一些注意的地方:1.一个模块内一般只需要设置一条路由,也就是说,我只有有数据时,才会去数据库查询。2.通过短连接(如电话号码)和post方式请求,服务端会返回一个响应,以示歉意。3.这个数据返回后,不会马上消失。一般得等服务端处理完这个响应后才能再返回给客户端。这样客户端就能从中节省时间。
4.如果要自动采集,就要设置最佳路由。设置好最佳路由后,要把它写到jar包里,然后再去fabric.client.java中加载。这样服务端返回给客户端的这个响应才能是自动采集来的数据。5.设置最佳路由是为了保证返回的数据准确性。如果返回的是乱码,返回给客户端的这个消息就是java写的伪造数据。 查看全部
自动采集数据(自动采集数据给到后端更新的技术架构是什么?)
自动采集数据给到后端更新,简单说,就是前端需要一个函数,把用户采集的网页链接,转换成用户所需要的redis对象即可。springcloud从2.0开始就支持开启redis服务了,2.1的版本可以自动配置即可。redis的所有命令和类都是java直接写的,不需要再写spring.redis.jar之类的依赖。另外推荐我个人的github项目:fabrics/cloud-redis。
如果没有redis,
技术架构的设计我有一些浅薄的认识。关于一个项目的自动采集,我的技术架构是以下这样的:1.在程序的生命周期内根据服务端数据源的要求,获取数据2.如果要自动采集,就要设置最佳路由3.设置最佳路由,那么这些数据来源的相应数据也要找到4.保存到数据库5.把数据返回给客户端6.数据源返回给客户端,数据返回客户端后还需要从客户端获取最佳路由的数据返回,这样可以节省最短的时间,提高数据接收的效率。
整个流程的细节也有一些注意的地方:1.一个模块内一般只需要设置一条路由,也就是说,我只有有数据时,才会去数据库查询。2.通过短连接(如电话号码)和post方式请求,服务端会返回一个响应,以示歉意。3.这个数据返回后,不会马上消失。一般得等服务端处理完这个响应后才能再返回给客户端。这样客户端就能从中节省时间。
4.如果要自动采集,就要设置最佳路由。设置好最佳路由后,要把它写到jar包里,然后再去fabric.client.java中加载。这样服务端返回给客户端的这个响应才能是自动采集来的数据。5.设置最佳路由是为了保证返回的数据准确性。如果返回的是乱码,返回给客户端的这个消息就是java写的伪造数据。
自动采集数据(本文介绍如何采集网站上多关键词的流程图模式?介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-09-11 13:05
)
本文介绍如何使用优采云采集器的流程图模式,并介绍如何采集网站上多关键词数据。
第一步:新建采集task
1、复制官网网址(需要搜索结果页面的网址,不是首页的网址)
点击此处了解如何正确输入网址。
2、新流程图模式采集task
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出采集 规则。
第二步:配置采集规则
1、设置多个关键字循环任务
流程图模式下输入创建新任务的URL后,我们点击搜索框,然后在左上角出现的操作提示框中输入采集的文字。
单击此处了解有关输入文本组件的更多信息。
由于需要输入多个关键词数据,我们选择点击操作框上的批量输入文本按钮。
然后选择批量输入单个文本。
然后在弹出的文本列表中输入我们需要设置的文本,这里我们输入“设置”、“采集”、“数据”关键词。
点击“确定”按钮后,软件会自动生成一个圆形的关键词列表。
然后我们点击页面上的搜索按钮,在操作框中选择“点击该元素一次”按钮,跳转到搜索结果页面。
2、设置提取字段数据
输入多个关键字并设置循环后,我们设置需要提取的字段数据,点击网页上的字段,在左上角的操作提示框中选择提取所有元素。然后软件会自动识别分页,用户根据软件提示设置分页。
然后我们可以在此基础上设置采集字段,用户可以根据自己的需要进行设置。
更多详情,请参考以下教程:
如何配置采集字段
3、深入设置采集
如果需要采集detail页面的数据,可以使用deep采集函数。
更多详情,请参考以下教程:
如何实现深入采集
4、设置详情页数据
详情页的采集与单页类型的采集相同。我们在页面上点击需要采集的数据,然后点击操作提示框中的“从此元素中提取数据”按钮,数据设置可以参考列表页上的设置。
更多详情,请参考以下教程:
如何采集单页类型网页
5、完整的组件图
第三步:设置并启动采集task
1、START采集task
点击“Start采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置”功能,本次操作不使用以上功能,直接点击启动按钮启动采集。
单击此处了解有关预定开始时间的更多信息。
单击此处了解有关自动导出的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费;专业版及以上用户可以使用定时启动功能;旗舰版用户可以使用自动导出功能和加速引擎功能。
2、运行任务提取数据
任务启动后,采集数据自动启动。从界面上我们可以直观的看到程序运行的过程和采集的结果。 采集结束后会有提醒。
第 4 步:导出和查看数据
data采集完成后,我们就可以查看和导出数据了。 优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)以及导出文件的格式(EXCEL、CSV、HTML和TXT)。它还支持导出特定数量的项目。您可以在数据中选择要导出的项目数,然后点击“确认导出”。
查看全部
自动采集数据(本文介绍如何采集网站上多关键词的流程图模式?介绍
)
本文介绍如何使用优采云采集器的流程图模式,并介绍如何采集网站上多关键词数据。
第一步:新建采集task
1、复制官网网址(需要搜索结果页面的网址,不是首页的网址)
点击此处了解如何正确输入网址。
2、新流程图模式采集task
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出采集 规则。
第二步:配置采集规则
1、设置多个关键字循环任务
流程图模式下输入创建新任务的URL后,我们点击搜索框,然后在左上角出现的操作提示框中输入采集的文字。
单击此处了解有关输入文本组件的更多信息。
由于需要输入多个关键词数据,我们选择点击操作框上的批量输入文本按钮。
然后选择批量输入单个文本。
然后在弹出的文本列表中输入我们需要设置的文本,这里我们输入“设置”、“采集”、“数据”关键词。
点击“确定”按钮后,软件会自动生成一个圆形的关键词列表。
然后我们点击页面上的搜索按钮,在操作框中选择“点击该元素一次”按钮,跳转到搜索结果页面。
2、设置提取字段数据
输入多个关键字并设置循环后,我们设置需要提取的字段数据,点击网页上的字段,在左上角的操作提示框中选择提取所有元素。然后软件会自动识别分页,用户根据软件提示设置分页。
然后我们可以在此基础上设置采集字段,用户可以根据自己的需要进行设置。
更多详情,请参考以下教程:
如何配置采集字段
3、深入设置采集
如果需要采集detail页面的数据,可以使用deep采集函数。
更多详情,请参考以下教程:
如何实现深入采集
4、设置详情页数据
详情页的采集与单页类型的采集相同。我们在页面上点击需要采集的数据,然后点击操作提示框中的“从此元素中提取数据”按钮,数据设置可以参考列表页上的设置。
更多详情,请参考以下教程:
如何采集单页类型网页
5、完整的组件图
第三步:设置并启动采集task
1、START采集task
点击“Start采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置”功能,本次操作不使用以上功能,直接点击启动按钮启动采集。
单击此处了解有关预定开始时间的更多信息。
单击此处了解有关自动导出的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费;专业版及以上用户可以使用定时启动功能;旗舰版用户可以使用自动导出功能和加速引擎功能。
2、运行任务提取数据
任务启动后,采集数据自动启动。从界面上我们可以直观的看到程序运行的过程和采集的结果。 采集结束后会有提醒。
第 4 步:导出和查看数据
data采集完成后,我们就可以查看和导出数据了。 优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)以及导出文件的格式(EXCEL、CSV、HTML和TXT)。它还支持导出特定数量的项目。您可以在数据中选择要导出的项目数,然后点击“确认导出”。
自动采集数据( custom前都会先做一个CMDB,建模和采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 462 次浏览 • 2021-09-09 02:07
custom前都会先做一个CMDB,建模和采集数据)
很多企业在搭建自动化运维平台之前,都会先搭建CMDB。构建 CMDB 的第一步是建模和采集data。说到采集数据,为了避免人工干预过多导致数据准确率低,采集方法一般分为两种:
手动输入一小部分静态数据
大多数数据使用程序采集
第二部分,有的公司用shell实现一套,有的用脚本语言实现一套,有的公司需要的时候主动收一次,有的公司定时自动收。
汽车之家的方法是“Puppet Facter脚本”+“定期自动采集”。我们已经将其开源并在 Github (Assets_Report) 上与您分享。
下面详细说明原理和用法。
二、原理介绍
众所周知,Puppet是一套配置管理工具,一种Client/Server模型架构,可以用来管理软件、配置文件和服务。然后,Puppet生态中有一个叫做Facter的工具,它运行在Agent端,可以和Puppet紧密配合完成数据采集的工作。但是,Facter采集 提供的数据毕竟是有限的。一些底层的硬件数据没有采集,而这些数据正是我们所需要的。这是我们开发此工具的动机。
虽然Facter采集的数据有限,但Facter本身是一个很好的框架,扩展起来非常容易,所以我们基于Facter进行了扩展,并把采集的结果和Puppet Master Report一起汇报处理器。给AutoBank(这是汽车之家的CMDB代码,可以参考《运维数据库-构建CMDB方法》)完成一个完整的采集逻辑。
这是Puppet的Server和Agent之间的工作流程
Agent 将在发送请求请求目录时向 Master 报告其所有事实。 Master收到数据后,可以使用自己的Report Processor进行二次处理,比如转发到别处。
基于上述原理,我们开发了自己的报表处理器:assets_report,并通过HTTP协议将事实发布到AutoBank的http接口进行存储。
有兴趣开发自定义事实的学生可以参考 fact_overview 和自定义事实。
如上所述,我们的 Assets_Report 项目收录以下两个组件来实现整个逻辑
assets_report 模块:纯 Puppet 模块,内置 Report Processor 和一些自定义 Facter 插件,部署在 Master 端。
报表处理器在主端运行。
Facter插件会通过Master发送给Agent,作为采集本机Asset数据运行
api_server:负责接收资产数据并存入库
三、采集插件功能介绍
与Facter内置的facts相比,这个插件提供了更多的硬件数据,例如
CPU 数量、型号
内存容量、序列号、制造商、插槽位置
网卡绑定ip、掩码、mac、型号,支持一个网卡绑定多个ip的场景
RAID卡数量、型号、内存容量、RAID级别
磁盘数量、容量、序列号、制造商、拥有的RAID卡、插槽位置
操作系统类型、版本
服务器制造商,SN
高级特性:为了避免大段相同数据的重复上报,减少AutoBank数据库的压力,本插件具有Cache功能,即如果某台服务器的资产数据没有发生变化,只会报告 not_modify 标志。
本插件支持的操作系统是(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
Windows 2008 R2
这个插件支持的服务器是
惠普
戴尔
思科
四、采集插件安装方法
安装操作在Puppet Master端进行。
假设你的模块目录是 /etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
加入自己的puppet.conf(假设默认路径是/etc/puppet/puppet.conf)
报告 = assets_report
然后在site.pp中添加如下配置,让所有Nodes都安装assets_report模块
节点默认{#收录assets_report类{'assets_report':}}
配置完成后,采集工具会自动发送到Agent进行安装。该插件将在下次 Puppet Agent 运行时正常工作。
五、Report 组件配置方法
配置操作在Puppet Master端进行。
配置文件为assets_report/lib/puppet/reports/report_setting.yaml
参数
含义
示例
report_url 报表接口地址,可以修改为自己的url
auth_required接口是否收录验证true/false,默认为false,验证码需要自己在auth.rb中实现
用户认证用户名,如果auth_required为true,则需要填写
passwd 验证密码,如果auth_required为true,则需要填写
Enable_cache 是否开启缓存功能true/false,默认false
六、Report 接口服务配置方法
配置操作在Puppet Master端进行。
这个接口服务 api_server 是基于 Python 编写的 web 框架 Django 开发的。该组件包括数据库设计和http api的实现。因为各个公司的数据库设计不一致,项目只实现了最简单的数据建模,所以这个组件的存在只是作为一个Demo,不能用于生产环境。读者需注意。
首先,我们需要安装一些依赖项。假设您的操作系统是 CentOS/RedHat
$ cd ~/Assets_Report/api_server install pip,用它来安装python模块 $ sudo yum install python-pip install python module dependencies $ pip install -r requirements.txt
初始化数据库,可以参考Django用户手册
$ python manage.py makemigrations apis$ python manage.py migrate 当前目录下的数据库是db.sqlite3 查看全部
自动采集数据(
custom前都会先做一个CMDB,建模和采集数据)
很多企业在搭建自动化运维平台之前,都会先搭建CMDB。构建 CMDB 的第一步是建模和采集data。说到采集数据,为了避免人工干预过多导致数据准确率低,采集方法一般分为两种:
手动输入一小部分静态数据
大多数数据使用程序采集
第二部分,有的公司用shell实现一套,有的用脚本语言实现一套,有的公司需要的时候主动收一次,有的公司定时自动收。
汽车之家的方法是“Puppet Facter脚本”+“定期自动采集”。我们已经将其开源并在 Github (Assets_Report) 上与您分享。
下面详细说明原理和用法。
二、原理介绍
众所周知,Puppet是一套配置管理工具,一种Client/Server模型架构,可以用来管理软件、配置文件和服务。然后,Puppet生态中有一个叫做Facter的工具,它运行在Agent端,可以和Puppet紧密配合完成数据采集的工作。但是,Facter采集 提供的数据毕竟是有限的。一些底层的硬件数据没有采集,而这些数据正是我们所需要的。这是我们开发此工具的动机。
虽然Facter采集的数据有限,但Facter本身是一个很好的框架,扩展起来非常容易,所以我们基于Facter进行了扩展,并把采集的结果和Puppet Master Report一起汇报处理器。给AutoBank(这是汽车之家的CMDB代码,可以参考《运维数据库-构建CMDB方法》)完成一个完整的采集逻辑。
这是Puppet的Server和Agent之间的工作流程
Agent 将在发送请求请求目录时向 Master 报告其所有事实。 Master收到数据后,可以使用自己的Report Processor进行二次处理,比如转发到别处。
基于上述原理,我们开发了自己的报表处理器:assets_report,并通过HTTP协议将事实发布到AutoBank的http接口进行存储。
有兴趣开发自定义事实的学生可以参考 fact_overview 和自定义事实。
如上所述,我们的 Assets_Report 项目收录以下两个组件来实现整个逻辑
assets_report 模块:纯 Puppet 模块,内置 Report Processor 和一些自定义 Facter 插件,部署在 Master 端。
报表处理器在主端运行。
Facter插件会通过Master发送给Agent,作为采集本机Asset数据运行
api_server:负责接收资产数据并存入库
三、采集插件功能介绍
与Facter内置的facts相比,这个插件提供了更多的硬件数据,例如
CPU 数量、型号
内存容量、序列号、制造商、插槽位置
网卡绑定ip、掩码、mac、型号,支持一个网卡绑定多个ip的场景
RAID卡数量、型号、内存容量、RAID级别
磁盘数量、容量、序列号、制造商、拥有的RAID卡、插槽位置
操作系统类型、版本
服务器制造商,SN
高级特性:为了避免大段相同数据的重复上报,减少AutoBank数据库的压力,本插件具有Cache功能,即如果某台服务器的资产数据没有发生变化,只会报告 not_modify 标志。
本插件支持的操作系统是(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
Windows 2008 R2
这个插件支持的服务器是
惠普
戴尔
思科
四、采集插件安装方法
安装操作在Puppet Master端进行。
假设你的模块目录是 /etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
加入自己的puppet.conf(假设默认路径是/etc/puppet/puppet.conf)
报告 = assets_report
然后在site.pp中添加如下配置,让所有Nodes都安装assets_report模块
节点默认{#收录assets_report类{'assets_report':}}
配置完成后,采集工具会自动发送到Agent进行安装。该插件将在下次 Puppet Agent 运行时正常工作。
五、Report 组件配置方法
配置操作在Puppet Master端进行。
配置文件为assets_report/lib/puppet/reports/report_setting.yaml
参数
含义
示例
report_url 报表接口地址,可以修改为自己的url
auth_required接口是否收录验证true/false,默认为false,验证码需要自己在auth.rb中实现
用户认证用户名,如果auth_required为true,则需要填写
passwd 验证密码,如果auth_required为true,则需要填写
Enable_cache 是否开启缓存功能true/false,默认false
六、Report 接口服务配置方法
配置操作在Puppet Master端进行。
这个接口服务 api_server 是基于 Python 编写的 web 框架 Django 开发的。该组件包括数据库设计和http api的实现。因为各个公司的数据库设计不一致,项目只实现了最简单的数据建模,所以这个组件的存在只是作为一个Demo,不能用于生产环境。读者需注意。
首先,我们需要安装一些依赖项。假设您的操作系统是 CentOS/RedHat
$ cd ~/Assets_Report/api_server install pip,用它来安装python模块 $ sudo yum install python-pip install python module dependencies $ pip install -r requirements.txt
初始化数据库,可以参考Django用户手册
$ python manage.py makemigrations apis$ python manage.py migrate 当前目录下的数据库是db.sqlite3
自动采集数据(什么是数据采集?农业术语解释业务提升!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-09-08 07:02
自从“大数据”这个词流行起来,与数据相关的一切都如雨后春笋般涌现。网络爬虫、Web采集、网络挖掘、数据分析、数据挖掘等,有些词在某些时候是可以互换的,这使得它更难理解。在竞争激烈的营销行业,深入全面地了解这些术语将有利于业务改进。
什么是 data采集?
Data采集是指从网上获取数据和信息。它通常可与网页抓取、网页抓取和数据提取互换。 采集 是一个农业术语:采集 来自田间的成熟作物,带有采集 和搬迁行为。数据采集是从目标网站中提取有价值的数据并以结构化格式放入数据库的过程。
对于数据采集,需要一个自动搜索器来解析目标网站,捕获有价值的信息,提取数据,最后将其导出为结构化格式以供进一步分析。因此,数据采集不涉及算法、机器学习或统计。相反,它依赖于 Python、R 和 Java 等计算机程序来运行。
有很多数据提取工具和服务商提供data采集工具和服务。 Octoparse 是一个易于使用的网页抓取工具。无论您是初学者还是经验丰富的程序员,Octoparse 都是采集web 数据的最佳选择。
什么是数据挖掘?
数据挖掘经常被误解为获取数据的过程。虽然两者都涉及到抽取和获取的行为,但采集集数据和挖掘数据还是有本质区别的。数据挖掘是指从数据库中的大量数据中揭示隐藏的、以前未知的和潜在有价值的信息的重要过程。数据挖掘主要基于人工智能、机器学习、模式识别、统计、数据库、可视化等技术。它以高度自动化的方式分析企业数据,进行归纳推理,并从中挖掘出潜在的模式,帮助决策者调整市场策略。降低风险并做出正确决策。
著名的剑桥分析丑闻。他们采集和分析了超过 6000 万 Facebook 用户的信息,并圈出了“不确定自己投票意图的人”。随后,剑桥分析采取了“心理导向”策略,用煽动性信息轰炸这些人,以改变他们的选票。它是数据挖掘的典型但有害的应用。数据挖掘可以发现他们是谁以及他们做什么,从而帮助做出正确的决策和实现目标。
照片由 Pexels 中的 Pixel 提供
数据挖掘有以下几个要点。
1、Classification。
从数据集中提取一个描述数据类的函数或模型(也常称为分类器),将数据集中的每个对象分类为一个已知的对象类,以预测未来数据的分类。
分类目前在商业中被广泛使用,比如信用卡的银行信用评分模型。利用数据挖掘技术,建立信用卡申请人信用评分模型,有效评估信用卡申请人信用,降低坏账风险,保证信用卡业务盈利。数据挖掘是如何进行的?采集大量客户背景、行为和信用数据,计算年龄、收入、职业、教育程度等不同属性对信用的影响权重,从而建立科学的客户信用评价数学模型基于此模型,银行可以有效识别“好客户”和“坏客户”。换句话说,从您提交信用卡申请的那一刻起,银行就可以做出决定:是否发卡、发多少卡等等。
2、聚类
不同于分类技术。在机器学习中,聚类是一种无监督学习。换句话说,聚类是一种在事先不知道要划分的类别的情况下,根据信息相似性原理对信息进行聚类的方法。
例如,亚马逊根据每个产品的描述、标签和功能将相似的产品组合在一起,以便客户更容易识别。
3、return
回归用于对数值和连续变量进行预测和建模。
例如,预测明天的温度是一个回归任务;预测明天是阴天、晴天还是下雨是一项分类任务。回归在商业中的主要应用包括房价预测、股票趋势或测试结果。
4、异常检测
检测异常行为的过程,也称为异常值。常见原因有:数据来自不同的类别、自然变异、数据测量或采集错误等。
银行使用这种方法来检测不属于您正常交易活动的异常交易。
5、联想学习
联想学习回答了“一个函数的值如何与另一个函数的值相关”的问题。
例如,在杂货店,购买汽水的人更有可能一起购买品客薯片。购物篮分析是关联规则的一种流行应用。它可以帮助零售商确定消费品之间的关系。
可以说数据挖掘是大数据的核心。数据挖掘的过程也被认为是“从数据中发现知识(KDD)”。它阐明了数据科学的概念,并有助于研究和知识发现。数据挖掘可以高度自动化地分析互联网上的各类数据,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略,降低风险,做出正确的决策。 查看全部
自动采集数据(什么是数据采集?农业术语解释业务提升!)
自从“大数据”这个词流行起来,与数据相关的一切都如雨后春笋般涌现。网络爬虫、Web采集、网络挖掘、数据分析、数据挖掘等,有些词在某些时候是可以互换的,这使得它更难理解。在竞争激烈的营销行业,深入全面地了解这些术语将有利于业务改进。
什么是 data采集?
Data采集是指从网上获取数据和信息。它通常可与网页抓取、网页抓取和数据提取互换。 采集 是一个农业术语:采集 来自田间的成熟作物,带有采集 和搬迁行为。数据采集是从目标网站中提取有价值的数据并以结构化格式放入数据库的过程。
对于数据采集,需要一个自动搜索器来解析目标网站,捕获有价值的信息,提取数据,最后将其导出为结构化格式以供进一步分析。因此,数据采集不涉及算法、机器学习或统计。相反,它依赖于 Python、R 和 Java 等计算机程序来运行。
有很多数据提取工具和服务商提供data采集工具和服务。 Octoparse 是一个易于使用的网页抓取工具。无论您是初学者还是经验丰富的程序员,Octoparse 都是采集web 数据的最佳选择。
什么是数据挖掘?
数据挖掘经常被误解为获取数据的过程。虽然两者都涉及到抽取和获取的行为,但采集集数据和挖掘数据还是有本质区别的。数据挖掘是指从数据库中的大量数据中揭示隐藏的、以前未知的和潜在有价值的信息的重要过程。数据挖掘主要基于人工智能、机器学习、模式识别、统计、数据库、可视化等技术。它以高度自动化的方式分析企业数据,进行归纳推理,并从中挖掘出潜在的模式,帮助决策者调整市场策略。降低风险并做出正确决策。
著名的剑桥分析丑闻。他们采集和分析了超过 6000 万 Facebook 用户的信息,并圈出了“不确定自己投票意图的人”。随后,剑桥分析采取了“心理导向”策略,用煽动性信息轰炸这些人,以改变他们的选票。它是数据挖掘的典型但有害的应用。数据挖掘可以发现他们是谁以及他们做什么,从而帮助做出正确的决策和实现目标。
照片由 Pexels 中的 Pixel 提供
数据挖掘有以下几个要点。
1、Classification。
从数据集中提取一个描述数据类的函数或模型(也常称为分类器),将数据集中的每个对象分类为一个已知的对象类,以预测未来数据的分类。
分类目前在商业中被广泛使用,比如信用卡的银行信用评分模型。利用数据挖掘技术,建立信用卡申请人信用评分模型,有效评估信用卡申请人信用,降低坏账风险,保证信用卡业务盈利。数据挖掘是如何进行的?采集大量客户背景、行为和信用数据,计算年龄、收入、职业、教育程度等不同属性对信用的影响权重,从而建立科学的客户信用评价数学模型基于此模型,银行可以有效识别“好客户”和“坏客户”。换句话说,从您提交信用卡申请的那一刻起,银行就可以做出决定:是否发卡、发多少卡等等。
2、聚类
不同于分类技术。在机器学习中,聚类是一种无监督学习。换句话说,聚类是一种在事先不知道要划分的类别的情况下,根据信息相似性原理对信息进行聚类的方法。
例如,亚马逊根据每个产品的描述、标签和功能将相似的产品组合在一起,以便客户更容易识别。
3、return
回归用于对数值和连续变量进行预测和建模。
例如,预测明天的温度是一个回归任务;预测明天是阴天、晴天还是下雨是一项分类任务。回归在商业中的主要应用包括房价预测、股票趋势或测试结果。
4、异常检测
检测异常行为的过程,也称为异常值。常见原因有:数据来自不同的类别、自然变异、数据测量或采集错误等。
银行使用这种方法来检测不属于您正常交易活动的异常交易。
5、联想学习
联想学习回答了“一个函数的值如何与另一个函数的值相关”的问题。
例如,在杂货店,购买汽水的人更有可能一起购买品客薯片。购物篮分析是关联规则的一种流行应用。它可以帮助零售商确定消费品之间的关系。
可以说数据挖掘是大数据的核心。数据挖掘的过程也被认为是“从数据中发现知识(KDD)”。它阐明了数据科学的概念,并有助于研究和知识发现。数据挖掘可以高度自动化地分析互联网上的各类数据,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略,降低风险,做出正确的决策。

