
自动采集数据
自动采集数据(自动采集数据需要导入、修改、复制数据,很烦)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-29 22:06
自动采集数据需要导入、修改、复制数据,很烦,而且,采集到的数据也不能自动保存。自动数据清洗工具odatamycat,可以帮你解决这些问题。实现功能图形数据清洗步骤:设置查询频率olap/trowbprs数据源olap列自动切换ocm前置mv共享库加速处理更多精彩内容关注微信公众号“odatamycat”。
ofrobot不错,
看来你都用不到,前端太复杂了。oabless+lambda,如果要成熟的产品可以考虑dojo如果看到要保存到python,分析工具可以使用ord(),orform()其实我觉得分析的本质还是数据挖掘,用它的datascienceoptimization做就够了。
odbigdata
首先要说明的是python的dataanalysisextension基本上来说是中等复杂度的,可以用r语言、matlab,这些都是高级的语言,基本上一个dataanalysisextension可以实现从excel、csv等文本数据到tableau等工具可以进行数据可视化、展示等等,所以就不存在什么轻量级的数据采集工具了;如果有excel的话,基本上可以完成很多,有很多数据可以做一些dataanalysis和数据可视化的一些分析,对于中低复杂度的数据采集还是挺好用的,不会重复工作;数据清洗也不像传统excel的方法,要自己去写各种函数等等,可以写一个python的数据清洗工具也是蛮麻烦的;。 查看全部
自动采集数据(自动采集数据需要导入、修改、复制数据,很烦)
自动采集数据需要导入、修改、复制数据,很烦,而且,采集到的数据也不能自动保存。自动数据清洗工具odatamycat,可以帮你解决这些问题。实现功能图形数据清洗步骤:设置查询频率olap/trowbprs数据源olap列自动切换ocm前置mv共享库加速处理更多精彩内容关注微信公众号“odatamycat”。
ofrobot不错,
看来你都用不到,前端太复杂了。oabless+lambda,如果要成熟的产品可以考虑dojo如果看到要保存到python,分析工具可以使用ord(),orform()其实我觉得分析的本质还是数据挖掘,用它的datascienceoptimization做就够了。
odbigdata
首先要说明的是python的dataanalysisextension基本上来说是中等复杂度的,可以用r语言、matlab,这些都是高级的语言,基本上一个dataanalysisextension可以实现从excel、csv等文本数据到tableau等工具可以进行数据可视化、展示等等,所以就不存在什么轻量级的数据采集工具了;如果有excel的话,基本上可以完成很多,有很多数据可以做一些dataanalysis和数据可视化的一些分析,对于中低复杂度的数据采集还是挺好用的,不会重复工作;数据清洗也不像传统excel的方法,要自己去写各种函数等等,可以写一个python的数据清洗工具也是蛮麻烦的;。
自动采集数据(如何解决自动采集数据的软件算是比较好用的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-27 20:05
自动采集数据的软件目前我觉得motionx算是比较好用的,用过之后基本没用过什么其他的了。它包含了:地图上的各类信息(主要是重庆的)音乐,影视,绘画,实时赛车,民航航班等都可以进行采集。
客户端好像用的不多,可以看看手机端的:一站式找航班--天巡航班助手,里面有比价查询,机票搜索,机票预订,低价机票查询,
题主说的那种抓轨也可以。
真正的自动化跟现在手动化对比起来,都是耍流氓。
如果把自动化分成几层:即代理层(把第三方的进程替换成自己的进程)、工具层(sdk层)、数据层(数据层封装接口的流程化工具)、进程层、其他层(客户端,client等)。首先用sdk进行网页端api的自动化,然后从数据层获取数据(如影像处理、数据来源)。想做的稍微完整一点,还需要封装很多系统服务来提供数据的接口。
这些都要技术能力的。或者也可以试试地图站点(接入第三方api-geoman)来解决一些小问题。但是现在也可以想办法解决,就是要在站点上做封装。可能得关注互联网方面的一些特性。
有的,我最近在研究自动化,你可以试一下全景图制作,百度地图、谷歌地图都可以做,可以上传视频也可以从google或者baidu地图导入视频上传或者绘制在生成等,然后就可以有人机交互的东西了,用github做出来效果也很不错。 查看全部
自动采集数据(如何解决自动采集数据的软件算是比较好用的)
自动采集数据的软件目前我觉得motionx算是比较好用的,用过之后基本没用过什么其他的了。它包含了:地图上的各类信息(主要是重庆的)音乐,影视,绘画,实时赛车,民航航班等都可以进行采集。
客户端好像用的不多,可以看看手机端的:一站式找航班--天巡航班助手,里面有比价查询,机票搜索,机票预订,低价机票查询,
题主说的那种抓轨也可以。
真正的自动化跟现在手动化对比起来,都是耍流氓。
如果把自动化分成几层:即代理层(把第三方的进程替换成自己的进程)、工具层(sdk层)、数据层(数据层封装接口的流程化工具)、进程层、其他层(客户端,client等)。首先用sdk进行网页端api的自动化,然后从数据层获取数据(如影像处理、数据来源)。想做的稍微完整一点,还需要封装很多系统服务来提供数据的接口。
这些都要技术能力的。或者也可以试试地图站点(接入第三方api-geoman)来解决一些小问题。但是现在也可以想办法解决,就是要在站点上做封装。可能得关注互联网方面的一些特性。
有的,我最近在研究自动化,你可以试一下全景图制作,百度地图、谷歌地图都可以做,可以上传视频也可以从google或者baidu地图导入视频上传或者绘制在生成等,然后就可以有人机交互的东西了,用github做出来效果也很不错。
自动采集数据(这是「整数智能」自动驾驶数据集八大系列分享之系列)
采集交流 • 优采云 发表了文章 • 0 个评论 • 471 次浏览 • 2022-03-27 02:14
目前,关于自动驾驶数据集你想知道的都应该在这里了。这是“整数智能”自动驾驶数据集八系列分享的第一篇:
“本期焦点”
《八辑概论》
自动驾驶数据集共享是整数智能推出的全新共享系列。在这个系列中,我们将介绍迄今为止各大科研机构和企业发布的所有公共自动驾驶数据集。数据集主要分为八个系列:
本文为第二部分,分三部分进行介绍。
共收录 15 个数据集:
01《DAIR-V2X数据集》
02《阿戈宇宙》
03“KAIST多光谱行人”
04《ETH行人》
05《戴姆勒行人》
06《清华-戴姆勒自行车手》
07《加州理工数据集》
08《夜猫子》
09“欧洲城市人数据集”
10《城市物体检测》
11《道路损坏数据集2018-2020》发布时间:2018-2020
介绍
12“FLIR热传感”
13 《TuSimple 车道线检测数据集》
14“下一个”
15《多光谱物体检测》
“联系我们”
整数智能希望通过其在数据处理领域的专业能力,在未来三年内赋能1000多家AI公司成为这些公司的“数据伙伴”,非常期待与您一起阅读这篇文章文章@ >您,如果您有进一步的沟通,请联系我们,探讨更多合作的可能性。我们的联系方式如下:
联系人:齐先生
电话:
更多详情请访问整数智能官网: 查看全部
自动采集数据(这是「整数智能」自动驾驶数据集八大系列分享之系列)
目前,关于自动驾驶数据集你想知道的都应该在这里了。这是“整数智能”自动驾驶数据集八系列分享的第一篇:
“本期焦点”

《八辑概论》
自动驾驶数据集共享是整数智能推出的全新共享系列。在这个系列中,我们将介绍迄今为止各大科研机构和企业发布的所有公共自动驾驶数据集。数据集主要分为八个系列:
本文为第二部分,分三部分进行介绍。
共收录 15 个数据集:
01《DAIR-V2X数据集》

02《阿戈宇宙》

03“KAIST多光谱行人”

04《ETH行人》

05《戴姆勒行人》

06《清华-戴姆勒自行车手》

07《加州理工数据集》

08《夜猫子》

09“欧洲城市人数据集”

10《城市物体检测》


11《道路损坏数据集2018-2020》发布时间:2018-2020
介绍

12“FLIR热传感”

13 《TuSimple 车道线检测数据集》

14“下一个”

15《多光谱物体检测》

“联系我们”
整数智能希望通过其在数据处理领域的专业能力,在未来三年内赋能1000多家AI公司成为这些公司的“数据伙伴”,非常期待与您一起阅读这篇文章文章@ >您,如果您有进一步的沟通,请联系我们,探讨更多合作的可能性。我们的联系方式如下:
联系人:齐先生
电话:
更多详情请访问整数智能官网:
自动采集数据(10款最好用的数据采集工具,免费采集、网站网页采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 705 次浏览 • 2022-03-25 02:13
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各种行业采集工具,目前最好的一些免费数据< @采集 工具,希望对大家有帮助。
1、优采云采集器优采云基于运营商网络的实名制实名制。真实数据与网页数据采集、移动互联网数据和API接口服务等服务相结合。综合数据服务平台。它最大的特点就是不用懂网络爬虫技术就可以轻松搞定采集。
2、优采云采集器优采云采集器是目前使用最多的互联网数据采集软件。以其灵活的配置和强大的性能领先于国内同类产品,赢得了众多用户的一致认可。使用优采云采集器几乎所有的网页。
3、金坛中国 金坛中国的数据服务平台收录很多开发者上传的采集工具,很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等的数据,还是其他数据,可以完成最近的探索采集也可以自定义,这是他们最大的亮点之一。
4、大飞采集器大飞采集器可以采集99%的网页,他的速度是普通采集器的7倍,也是一样作为准确的复制粘贴,它最大的特点是网页的代词采集是单的,因为它的重点是。
5、Import.io 使用Import.io适配任何网站,只要进入网站,就能利落抓取网页的数据,操作非常简单,自动采集,< @采集 结果可视化。但是,无法选择特定数据并自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索它们。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content GrabberContent Grabber是国外大神制作的神器,可以从网页中抓取内容(视频、图片、文字)并提取成Excel、XML、CSV等大部分数据库。该软件基于网络抓取和网络自动化。它完全免费使用,通常用于数据调查和检测目的。
8、ForeSpiderForeSpider 是一个非常好用的网页数据工具采集,用户可以使用这个工具来帮你自动检索网页中的各种数据信息,而且这个软件使用非常简单,用户也可以免费采用。基本上只要把网址链接输入一步一步操作就OK了。有特殊情况需要对采集进行特殊处理,也支持配置脚本。
9、阿里巴巴数据采集阿里巴巴数据采集大平台运行稳定不崩溃,可实现实时查询,软件开发数据采集他们都可以,除了价格,没有问题。
10、优采云采集器优采云采集器操作很简单,按照流程很容易上手,还可以支持多种形式出口。 查看全部
自动采集数据(10款最好用的数据采集工具,免费采集、网站网页采集)
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各种行业采集工具,目前最好的一些免费数据< @采集 工具,希望对大家有帮助。

1、优采云采集器优采云基于运营商网络的实名制实名制。真实数据与网页数据采集、移动互联网数据和API接口服务等服务相结合。综合数据服务平台。它最大的特点就是不用懂网络爬虫技术就可以轻松搞定采集。
2、优采云采集器优采云采集器是目前使用最多的互联网数据采集软件。以其灵活的配置和强大的性能领先于国内同类产品,赢得了众多用户的一致认可。使用优采云采集器几乎所有的网页。
3、金坛中国 金坛中国的数据服务平台收录很多开发者上传的采集工具,很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等的数据,还是其他数据,可以完成最近的探索采集也可以自定义,这是他们最大的亮点之一。
4、大飞采集器大飞采集器可以采集99%的网页,他的速度是普通采集器的7倍,也是一样作为准确的复制粘贴,它最大的特点是网页的代词采集是单的,因为它的重点是。
5、Import.io 使用Import.io适配任何网站,只要进入网站,就能利落抓取网页的数据,操作非常简单,自动采集,< @采集 结果可视化。但是,无法选择特定数据并自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索它们。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content GrabberContent Grabber是国外大神制作的神器,可以从网页中抓取内容(视频、图片、文字)并提取成Excel、XML、CSV等大部分数据库。该软件基于网络抓取和网络自动化。它完全免费使用,通常用于数据调查和检测目的。
8、ForeSpiderForeSpider 是一个非常好用的网页数据工具采集,用户可以使用这个工具来帮你自动检索网页中的各种数据信息,而且这个软件使用非常简单,用户也可以免费采用。基本上只要把网址链接输入一步一步操作就OK了。有特殊情况需要对采集进行特殊处理,也支持配置脚本。
9、阿里巴巴数据采集阿里巴巴数据采集大平台运行稳定不崩溃,可实现实时查询,软件开发数据采集他们都可以,除了价格,没有问题。
10、优采云采集器优采云采集器操作很简单,按照流程很容易上手,还可以支持多种形式出口。
自动采集数据( 1.本发明专利涉及医院节假日的日历数据采集数据的系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-20 18:27
1.本发明专利涉及医院节假日的日历数据采集数据的系统)
1.本发明专利涉及计算机软件技术领域,具体涉及一种基于医院假期自动采集数据的日历组件系统。
背景技术:
2.医院平台在线预约或挂号等具体业务场景需要使用日历数据,会使用多种第三方日历数据采集渠道,每个平台使用不同的日历数据来源采集所需要的数据必然会数据真实性低。另外,采集的数据源不同,也会出现脏数据。每天,每家医院都会生成一个查询日历。要进行操作,您需要通过这些日历数据进行一些安排或注册。
3.目前管理员手动维护日历数据,在数据库中手动维护一年的节假日信息,然后通过查询数据库信息查询日历和节假日。这种方法不容易维护。在实际应用中,年假轮班会发生变化,导致需要重新录入日历数据,需要人员手动更新数据的稳定性。
技术实施要素:
4.本发明的目的是提供一种基于医院假期自动采集数据的日历组件系统。在支持人员手动维护数据的基础上,通过构建数据采集,可以利用各个平台的海量数据。存储优势:采集,清洗,将最终日历数据存储在数据库中,提高各医院日历数据的统一性和稳定性,旨在解决现有技术中当前日历数据使用的问题。管理员手动维护数据库中一年的节假日信息,然后通过查询数据库信息查询日历和节假日。这种方式存在维护性差、效率慢等问题。
5.本发明是这样实现的,一种基于医院假期自动采集数据的日历组件系统,包括手动日历数据录入模块、自动录入日历数据模块、日历信息查询模块;手动录入日历数据模块数据模块用于支持人员手动维护数据优先级。日历数据自动录入模块包括数据采集单元、数据清洗单元和数据合并单元,日历数据自动录入模块定时采集节假日日历数据,数据清洗单元处理采集的节假日日历数据,数据合并单元对齐处理后的节假日日历数据;
6.进一步,日历信息查询模块包括查询缓存单元和查询数据库单元,查询缓存单元存储在系统中。设置一个新的索引来运行一个没有相应缓存的查询数据库单元。
7.进一步,查询数据库单元被新索引后,在日历组件存储的数据库中进行过滤,过滤结果为医院日历数据结果的输出。
8.进一步,数据采集单元接入云端,通过云端获取第三方采集节假日日历数据,数据清洗单元进行验证匹配三方原创日历数据 规范对待性行为。
9.进一步,数据合并单元是将清洗后的数据分为工作日、休息日、节假日、补班四种类型,以不同的值存储,将不同数据源的数据进行合并。将完整的数据添加或更新到数据库后。
10.进一步,日历信息查询模块的流程为:用户发送日历查询请求,请求进入日历组件系统,日历组件系统建立索引查询查询缓存单元。如果返回数据,则返回日历数据,用于信息输出。如果在查询缓存单元中没有找到信息,则建立索引值再次查询数据库单元,查询数据为日历数据进行信息输出。
11. 进一步的,日历查询请求为http请求,云端收到日历查询请求后进入日历组件系统,日历组件系统根据http请求建立相应的索引搜索。
12.进一步,所述自动录入日历数据模块的自动采集日历的流程为:数据采集单元的数据调度中心定时执行采集,第三方的数据按照优先级采集和采集之后的数据分为不同的数据源。
13.进一步对数据源的原创数据进行清洗,检查缺失数据,剔除异常数据,统一标准化日期时间、日期状态、日期类型、描述信息合并。
14.进一步,合并数据源先根据优先级判断是否有日历数据,再判断数据是否采集完成,采集完成后再存储或更新到数据库完成采集命令,如果数据采集没有完成,按照优先级没有日历数据,则返回值数据合并处理。
15.与现有技术相比,本发明提供的基于医院假期自动采集数据的日历组件系统具有以下有益效果:
16.1、在支持人员手动维护数据的基础上,通过构建数据采集,利用各平台海量数据存储优势,采集,清理第三方日历数据。将最终日历数据存储在数据库中,提高各医院日历数据的统一性和稳定性;
17.2、大大提高了医院放假日历数据的统一性和稳定性。支持人员手动维护数据优先级,有效降低节假日日历数据的错误率,避免各业务方节假日数据的出现。在不一致的情况下,提高了日历数据的准确性,可以更高效、实时地完成医院日历数据结果的输出。
图纸说明
18. 图。附图说明图1是本发明提出的基于医院假期自动采集数据的日历组件系统的系统连接框图;
19. 图。图2为本发明提出的基于医院假期自动采集数据的日历组件系统中日历信息查询模块的工作流程图;
20. 图。图3为本发明提出的基于医院假期自动采集数据的日历组件系统中日历数据模块自动录入的工作流程图。
详细说明
21.为使本发明的目的、技术方案和优点更加清楚,下面结合附图和实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限制本发明。
22.下面结合具体实施例对本发明的实现进行详细说明。
23.参考图1-3,基于医院假期自动采集数据的日历组件系统,包括手动日历数据录入模块、日历数据自动录入模块、日历信息查询模块;手动录入日历数据模块用于支持人员手动维护数据优先级;自动输入日历数据模块包括数据采集单元、数据清洗单元和数据合并单元,自动输入日历数据模块定时采集节假日日历数据,数据清洗单元处理采集的节假日日历数据,数据合并单元对齐处理后的节假日日历数据;
24.本实施例中,日历信息查询模块包括查询缓存单元和查询数据库单元,查询缓存单元存储在系统中。如果没有对应的缓存,设置一个新的索引来运行查询数据库单元。查询数据库单元接收到新索引后,会在存储在日历组件中的数据库中进行过滤。过滤后的结果将作为医院日历数据结果的输出。数据采集单元接入云端,通过云端从第三方采集节假日日历数据,数据清洗单元对三方原创日历数据进行校验,规范一致性,并依次通过查询缓存单元和查询数据库单元开始数据检索,
25.本实施例中,数据合并单元是将清洗后的数据分为工作日、休息日、节假日、补班四种类型,分别以不同的值存储,并合并来自不同数据源的数据。将数据合并成一个完整的数据后,添加或更新到数据库中,以便检索数据库单元可以使用更新后的数据库对数据输出进行操作和检索,通过设定指标实现在高效输出信息的同时,提高准确率。
26.本实施例中日历信息查询模块的流程为:用户发送日历查询请求,该请求进入日历组件系统,日历组件系统建立索引到查询缓存单元进行查询,如果查询到数据,则返回日历数据进行信息输出。如果查询缓存单元没有找到信息,则建立索引值再次查询数据库单元,查询数据为日历数据输出信息。日历查询请求为http请求,云端接收日历查询请求,进入。对于日历组件系统,日历组件系统根据http请求建立相应的索引检索。对于数据查询,提供节假日日历信息结果查询功能,数据调度是定时对采集执行任务,对整个日历数据进行清理。调度有效降低了节假日日历数据的错误率,避免了各业务方节假日数据的不一致,提高了数据的健壮性。
<p>27.本实施例中,自动进入日历数据模块的自动采集日历流程如下:数据采集单元的数据调度中心定期对采集第三方的数据。@>,并将第三方数据按照优先级分为不同的数据源采集,采集之后的数据,清洗数据源的原创数据,检查缺失的数据,并剔除异常数据,统一规范日期时间、日期状态、日期类型、描述信息,合并后的数据源先根据优先级判断是否有日历数据,再判断数据是否< @采集完成, 查看全部
自动采集数据(
1.本发明专利涉及医院节假日的日历数据采集数据的系统)

1.本发明专利涉及计算机软件技术领域,具体涉及一种基于医院假期自动采集数据的日历组件系统。
背景技术:
2.医院平台在线预约或挂号等具体业务场景需要使用日历数据,会使用多种第三方日历数据采集渠道,每个平台使用不同的日历数据来源采集所需要的数据必然会数据真实性低。另外,采集的数据源不同,也会出现脏数据。每天,每家医院都会生成一个查询日历。要进行操作,您需要通过这些日历数据进行一些安排或注册。
3.目前管理员手动维护日历数据,在数据库中手动维护一年的节假日信息,然后通过查询数据库信息查询日历和节假日。这种方法不容易维护。在实际应用中,年假轮班会发生变化,导致需要重新录入日历数据,需要人员手动更新数据的稳定性。
技术实施要素:
4.本发明的目的是提供一种基于医院假期自动采集数据的日历组件系统。在支持人员手动维护数据的基础上,通过构建数据采集,可以利用各个平台的海量数据。存储优势:采集,清洗,将最终日历数据存储在数据库中,提高各医院日历数据的统一性和稳定性,旨在解决现有技术中当前日历数据使用的问题。管理员手动维护数据库中一年的节假日信息,然后通过查询数据库信息查询日历和节假日。这种方式存在维护性差、效率慢等问题。
5.本发明是这样实现的,一种基于医院假期自动采集数据的日历组件系统,包括手动日历数据录入模块、自动录入日历数据模块、日历信息查询模块;手动录入日历数据模块数据模块用于支持人员手动维护数据优先级。日历数据自动录入模块包括数据采集单元、数据清洗单元和数据合并单元,日历数据自动录入模块定时采集节假日日历数据,数据清洗单元处理采集的节假日日历数据,数据合并单元对齐处理后的节假日日历数据;
6.进一步,日历信息查询模块包括查询缓存单元和查询数据库单元,查询缓存单元存储在系统中。设置一个新的索引来运行一个没有相应缓存的查询数据库单元。
7.进一步,查询数据库单元被新索引后,在日历组件存储的数据库中进行过滤,过滤结果为医院日历数据结果的输出。
8.进一步,数据采集单元接入云端,通过云端获取第三方采集节假日日历数据,数据清洗单元进行验证匹配三方原创日历数据 规范对待性行为。
9.进一步,数据合并单元是将清洗后的数据分为工作日、休息日、节假日、补班四种类型,以不同的值存储,将不同数据源的数据进行合并。将完整的数据添加或更新到数据库后。
10.进一步,日历信息查询模块的流程为:用户发送日历查询请求,请求进入日历组件系统,日历组件系统建立索引查询查询缓存单元。如果返回数据,则返回日历数据,用于信息输出。如果在查询缓存单元中没有找到信息,则建立索引值再次查询数据库单元,查询数据为日历数据进行信息输出。
11. 进一步的,日历查询请求为http请求,云端收到日历查询请求后进入日历组件系统,日历组件系统根据http请求建立相应的索引搜索。
12.进一步,所述自动录入日历数据模块的自动采集日历的流程为:数据采集单元的数据调度中心定时执行采集,第三方的数据按照优先级采集和采集之后的数据分为不同的数据源。
13.进一步对数据源的原创数据进行清洗,检查缺失数据,剔除异常数据,统一标准化日期时间、日期状态、日期类型、描述信息合并。
14.进一步,合并数据源先根据优先级判断是否有日历数据,再判断数据是否采集完成,采集完成后再存储或更新到数据库完成采集命令,如果数据采集没有完成,按照优先级没有日历数据,则返回值数据合并处理。
15.与现有技术相比,本发明提供的基于医院假期自动采集数据的日历组件系统具有以下有益效果:
16.1、在支持人员手动维护数据的基础上,通过构建数据采集,利用各平台海量数据存储优势,采集,清理第三方日历数据。将最终日历数据存储在数据库中,提高各医院日历数据的统一性和稳定性;
17.2、大大提高了医院放假日历数据的统一性和稳定性。支持人员手动维护数据优先级,有效降低节假日日历数据的错误率,避免各业务方节假日数据的出现。在不一致的情况下,提高了日历数据的准确性,可以更高效、实时地完成医院日历数据结果的输出。
图纸说明
18. 图。附图说明图1是本发明提出的基于医院假期自动采集数据的日历组件系统的系统连接框图;
19. 图。图2为本发明提出的基于医院假期自动采集数据的日历组件系统中日历信息查询模块的工作流程图;
20. 图。图3为本发明提出的基于医院假期自动采集数据的日历组件系统中日历数据模块自动录入的工作流程图。
详细说明
21.为使本发明的目的、技术方案和优点更加清楚,下面结合附图和实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限制本发明。
22.下面结合具体实施例对本发明的实现进行详细说明。
23.参考图1-3,基于医院假期自动采集数据的日历组件系统,包括手动日历数据录入模块、日历数据自动录入模块、日历信息查询模块;手动录入日历数据模块用于支持人员手动维护数据优先级;自动输入日历数据模块包括数据采集单元、数据清洗单元和数据合并单元,自动输入日历数据模块定时采集节假日日历数据,数据清洗单元处理采集的节假日日历数据,数据合并单元对齐处理后的节假日日历数据;
24.本实施例中,日历信息查询模块包括查询缓存单元和查询数据库单元,查询缓存单元存储在系统中。如果没有对应的缓存,设置一个新的索引来运行查询数据库单元。查询数据库单元接收到新索引后,会在存储在日历组件中的数据库中进行过滤。过滤后的结果将作为医院日历数据结果的输出。数据采集单元接入云端,通过云端从第三方采集节假日日历数据,数据清洗单元对三方原创日历数据进行校验,规范一致性,并依次通过查询缓存单元和查询数据库单元开始数据检索,
25.本实施例中,数据合并单元是将清洗后的数据分为工作日、休息日、节假日、补班四种类型,分别以不同的值存储,并合并来自不同数据源的数据。将数据合并成一个完整的数据后,添加或更新到数据库中,以便检索数据库单元可以使用更新后的数据库对数据输出进行操作和检索,通过设定指标实现在高效输出信息的同时,提高准确率。
26.本实施例中日历信息查询模块的流程为:用户发送日历查询请求,该请求进入日历组件系统,日历组件系统建立索引到查询缓存单元进行查询,如果查询到数据,则返回日历数据进行信息输出。如果查询缓存单元没有找到信息,则建立索引值再次查询数据库单元,查询数据为日历数据输出信息。日历查询请求为http请求,云端接收日历查询请求,进入。对于日历组件系统,日历组件系统根据http请求建立相应的索引检索。对于数据查询,提供节假日日历信息结果查询功能,数据调度是定时对采集执行任务,对整个日历数据进行清理。调度有效降低了节假日日历数据的错误率,避免了各业务方节假日数据的不一致,提高了数据的健壮性。
<p>27.本实施例中,自动进入日历数据模块的自动采集日历流程如下:数据采集单元的数据调度中心定期对采集第三方的数据。@>,并将第三方数据按照优先级分为不同的数据源采集,采集之后的数据,清洗数据源的原创数据,检查缺失的数据,并剔除异常数据,统一规范日期时间、日期状态、日期类型、描述信息,合并后的数据源先根据优先级判断是否有日历数据,再判断数据是否< @采集完成,
自动采集数据( 实时收集统计信息功能对性能的影响最低)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-20 09:33
实时收集统计信息功能对性能的影响最低)
了解异步采集和实时采集统计信息
启用实时统计信息采集后,一些元数据也可用于生成统计信息。生成意味着派生或创建统计数据,而不是作为正常 RUNSTATS 活动的一部分采集统计数据。例如,如果您知道表格中的行数、页面大小和平均行宽,您就可以知道表格中收录的行数。在某些情况下,统计数据实际上不是派生的,而是由索引和数据管理器维护的,并且可以直接存储在目录中。例如,索引管理器将维护每个索引中的叶页数和级别。
查询优化器根据查询要求和表更新活动量(更新、插入或删除操作的数量)确定如何采集统计信息。
实时统计功能可以提供更及时准确的统计数据。准确的统计数据可以带来更好的查询执行计划和改进的性能。不开启实时统计时,每两小时执行一次异步统计操作。此采集可能不够频繁,无法为某些应用程序提供准确的统计信息。
启用实时统计采集后,仍将每两小时执行一次异步采集统计检查。实时统计采集功能还会在以下情况下导致异步采集请求:
最多可以同时处理两个异步请求,但它们必须针对不同的表进行处理。一个请求必须由实时采集统计功能发起,另一个请求必须由异步采集统计检查操作发起。
可以使用以下方法将自动统计信息采集的性能影响降至最低:
尽管实时统计信息采集功能旨在最大限度地减少采集统计信息的开销,但请先在测试环境中尝试此功能,以确保不会对性能产生负面影响。将此功能用于某些在线事务处理 (OLTP) 场景可能会对性能产生负面影响,尤其是在查询运行时存在上限的情况下。
对常规表、物化查询表 (MQT) 和全局临时表执行实时同步统计信息采集操作。不会为全局临时表采集异步统计信息。自动维护策略工具无法将全局临时表排除在实时统计之外。
不会对以下对象执行自动统计信息采集(同步或异步):
不会为以下对象生成统计信息:
在分区数据库环境中,会采集统计信息,然后对单个数据库分区进行推测。数据库管理器始终采集有关数据库分区组的第一个数据库分区的统计信息(同步和异步)。
在数据库激活后至少 5 分钟才会执行非实时统计信息采集活动。
对静态和动态 SQL 进行实时统计处理。
使用 IMPORT 命令截断的表会自动重新组织以具有旧的统计信息。
同步和异步自动统计信息采集操作将使引用那些表的缓存动态语句无效,这些表已经采集了统计信息。这样做是为了可以使用最新的统计信息重新优化缓存的动态语句。
当数据库被停用时,“自动异步采集统计信息”操作可能会被中断。如果未使用 ACTIVATE DATABASE 命令或 API 显式激活数据库,则当最后一个用户与数据库断开连接时,数据库将被停用。如果操作被中断,错误消息可能会记录在 DB2 诊断日志文件中。为避免中断“自动异步采集统计信息”操作,请显式激活此数据库。 查看全部
自动采集数据(
实时收集统计信息功能对性能的影响最低)
了解异步采集和实时采集统计信息
启用实时统计信息采集后,一些元数据也可用于生成统计信息。生成意味着派生或创建统计数据,而不是作为正常 RUNSTATS 活动的一部分采集统计数据。例如,如果您知道表格中的行数、页面大小和平均行宽,您就可以知道表格中收录的行数。在某些情况下,统计数据实际上不是派生的,而是由索引和数据管理器维护的,并且可以直接存储在目录中。例如,索引管理器将维护每个索引中的叶页数和级别。
查询优化器根据查询要求和表更新活动量(更新、插入或删除操作的数量)确定如何采集统计信息。
实时统计功能可以提供更及时准确的统计数据。准确的统计数据可以带来更好的查询执行计划和改进的性能。不开启实时统计时,每两小时执行一次异步统计操作。此采集可能不够频繁,无法为某些应用程序提供准确的统计信息。
启用实时统计采集后,仍将每两小时执行一次异步采集统计检查。实时统计采集功能还会在以下情况下导致异步采集请求:
最多可以同时处理两个异步请求,但它们必须针对不同的表进行处理。一个请求必须由实时采集统计功能发起,另一个请求必须由异步采集统计检查操作发起。
可以使用以下方法将自动统计信息采集的性能影响降至最低:
尽管实时统计信息采集功能旨在最大限度地减少采集统计信息的开销,但请先在测试环境中尝试此功能,以确保不会对性能产生负面影响。将此功能用于某些在线事务处理 (OLTP) 场景可能会对性能产生负面影响,尤其是在查询运行时存在上限的情况下。
对常规表、物化查询表 (MQT) 和全局临时表执行实时同步统计信息采集操作。不会为全局临时表采集异步统计信息。自动维护策略工具无法将全局临时表排除在实时统计之外。
不会对以下对象执行自动统计信息采集(同步或异步):
不会为以下对象生成统计信息:
在分区数据库环境中,会采集统计信息,然后对单个数据库分区进行推测。数据库管理器始终采集有关数据库分区组的第一个数据库分区的统计信息(同步和异步)。
在数据库激活后至少 5 分钟才会执行非实时统计信息采集活动。
对静态和动态 SQL 进行实时统计处理。
使用 IMPORT 命令截断的表会自动重新组织以具有旧的统计信息。
同步和异步自动统计信息采集操作将使引用那些表的缓存动态语句无效,这些表已经采集了统计信息。这样做是为了可以使用最新的统计信息重新优化缓存的动态语句。
当数据库被停用时,“自动异步采集统计信息”操作可能会被中断。如果未使用 ACTIVATE DATABASE 命令或 API 显式激活数据库,则当最后一个用户与数据库断开连接时,数据库将被停用。如果操作被中断,错误消息可能会记录在 DB2 诊断日志文件中。为避免中断“自动异步采集统计信息”操作,请显式激活此数据库。
自动采集数据(1.一种数据自动校验采集的系统,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2022-03-14 07:10
技术特点:
<p>1.一种cmdb数据自动校验系统采集,其特征在于,包括:自动校验采集模块和上报模块;自动校验采集模块:自动校验第一个cmdb系统配置项采集的数据,包括配置项采集的初始数据、处理单元和数据校验单元;上报模块:对通过数据校验的配置项进行数据上报,以restful api的形式完成第二个cmdb系统配置项数据的数据采集,包括数据上报接口和数据状态查询接口. 2.根据权利要求1所述的cmdb数据自动校验系统采集,其特征在于,采集 校验映射表包括第一cmdb系统和第二cmdb系统配置项与字段的一一映射关系、数据获取方式、是否进行批处理、数据校验规则。3.根据权利要求1所述的cmdb数据自动校验系统采集,其特征在于,所述采集模块中配置项初始数据的采集@自动校验>,处理单元根据采集验证映射表采集对第一个cmdb系统配置项的初始数据进行自动化处理,并根据采集 验证映射表 处理由定时任务控制采集和处理程序自动处理和执行。4.根据权利要求3所述的cmdb数据自动校验系统采集,其特征在于,所述配置项的初始数据采集,所述配置项在处理单元中的初始数据采集包括:直接获取值和通过函数动态获取值,其中通过函数获取的值需要程序动态处理得到对应的值,在 查看全部
自动采集数据(1.一种数据自动校验采集的系统,你了解多少?)
技术特点:
<p>1.一种cmdb数据自动校验系统采集,其特征在于,包括:自动校验采集模块和上报模块;自动校验采集模块:自动校验第一个cmdb系统配置项采集的数据,包括配置项采集的初始数据、处理单元和数据校验单元;上报模块:对通过数据校验的配置项进行数据上报,以restful api的形式完成第二个cmdb系统配置项数据的数据采集,包括数据上报接口和数据状态查询接口. 2.根据权利要求1所述的cmdb数据自动校验系统采集,其特征在于,采集 校验映射表包括第一cmdb系统和第二cmdb系统配置项与字段的一一映射关系、数据获取方式、是否进行批处理、数据校验规则。3.根据权利要求1所述的cmdb数据自动校验系统采集,其特征在于,所述采集模块中配置项初始数据的采集@自动校验>,处理单元根据采集验证映射表采集对第一个cmdb系统配置项的初始数据进行自动化处理,并根据采集 验证映射表 处理由定时任务控制采集和处理程序自动处理和执行。4.根据权利要求3所述的cmdb数据自动校验系统采集,其特征在于,所述配置项的初始数据采集,所述配置项在处理单元中的初始数据采集包括:直接获取值和通过函数动态获取值,其中通过函数获取的值需要程序动态处理得到对应的值,在
自动采集数据( 临床诊疗本已分身乏术了,医疗科研更轻松软件机器人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-14 07:08
临床诊疗本已分身乏术了,医疗科研更轻松软件机器人)
对于临床医生来说,临床诊疗已经疲惫不堪,必须坚持临床研究才能提升职称。虽然大部分都是基于回顾性研究,但临床数据采集始终是临床研究中最重要、最麻烦的部分。
临床数据来源很多,看起来不错
医院信息部、科室电脑、病历室等,都存放着各种临床数据,而我或科室同事也或多或少地保存了一些纸质病历和Excel,看起来很容易拿到临床数据。
现实情况是,将所有临床数据用于医学研究并非易事。
数年采集临床数据的阵痛
医院信息化普及,临床数据大部分存在于医院各软件系统和信息科室。出于数据安全和隐私方面的考虑,医院不允许临床医生轻松访问临床数据;和信息部门的人员经常阻碍临床医生采集临床数据,因为他们不愿意冒险。
病案室里虽然堆满了文件,但通读文件又费力又累人,数据质量和采集效率也得不到保证。
很多临床医生从科室的HIS系统中一一复制粘贴病人的病历,但最后只能用肉眼检索。
此外,临床数据来源多,格式、标准不一,数据无法匹配整合,临床医生难以采集科研所需数据。
这样采集临床数据,医学研究更容易
使用小帮软件机器人,小帮软件机器人可以根据需要自动采集科研所需的临床数据(患者基本信息、检测数据、影像数据等),并在本地自动组织存储用于后续的临床试验。科研数据的统计分析奠定了基础。
从此,临床医生可以采集访问科室的临床数据,无需通过信息部登录自己的账号,无需急于求救,无需苦苦复制粘贴,轻松采集优质临床数据,高效完成临床研究。
重复工作,小小帮帮您。
在工作和生活中,你经常会遇到批量重复操作的烦恼:
复制粘贴,采集整理各种数据;重复批量输入和修改数据;持续观察某些数据的变化;重复常规的计算机操作。
博伟是一个小帮派软件机器人,为减少重复性电脑工作而生。
小帮软件机器人平台是一个互联网软件机器人平台,专注于利用极简软件自动化技术,帮助减少工作和生活中的重复劳动。
二、博微小邦软件机器人三大功能:
1 表单数据采集
每天我们都会在各种软件和网站中看到非常有价值的表格数据,而小邦软件机器人会自动采集到本地数据做进一步的分析处理。
2 批量输入和修改数据
我们经常会遇到大量的数据录入和修改工作。如果这些机械操作是重复的、有规律的,小邦可以为你做。
3 监控数据,重复操作
我们经常需要不断的观察软件或者网站中一些数据的变化,然后根据数据变化做一些有规律的重复操作,这些都可以交给小邦。
只需几步,配置一个小邦软件机器人,重复性的电脑操作和海量的电脑数据工作,小邦就能自动帮您完成,高效,快速,不知疲倦,无差错。 查看全部
自动采集数据(
临床诊疗本已分身乏术了,医疗科研更轻松软件机器人)

对于临床医生来说,临床诊疗已经疲惫不堪,必须坚持临床研究才能提升职称。虽然大部分都是基于回顾性研究,但临床数据采集始终是临床研究中最重要、最麻烦的部分。
临床数据来源很多,看起来不错
医院信息部、科室电脑、病历室等,都存放着各种临床数据,而我或科室同事也或多或少地保存了一些纸质病历和Excel,看起来很容易拿到临床数据。
现实情况是,将所有临床数据用于医学研究并非易事。

数年采集临床数据的阵痛
医院信息化普及,临床数据大部分存在于医院各软件系统和信息科室。出于数据安全和隐私方面的考虑,医院不允许临床医生轻松访问临床数据;和信息部门的人员经常阻碍临床医生采集临床数据,因为他们不愿意冒险。
病案室里虽然堆满了文件,但通读文件又费力又累人,数据质量和采集效率也得不到保证。
很多临床医生从科室的HIS系统中一一复制粘贴病人的病历,但最后只能用肉眼检索。
此外,临床数据来源多,格式、标准不一,数据无法匹配整合,临床医生难以采集科研所需数据。

这样采集临床数据,医学研究更容易
使用小帮软件机器人,小帮软件机器人可以根据需要自动采集科研所需的临床数据(患者基本信息、检测数据、影像数据等),并在本地自动组织存储用于后续的临床试验。科研数据的统计分析奠定了基础。
从此,临床医生可以采集访问科室的临床数据,无需通过信息部登录自己的账号,无需急于求救,无需苦苦复制粘贴,轻松采集优质临床数据,高效完成临床研究。
重复工作,小小帮帮您。
在工作和生活中,你经常会遇到批量重复操作的烦恼:
复制粘贴,采集整理各种数据;重复批量输入和修改数据;持续观察某些数据的变化;重复常规的计算机操作。
博伟是一个小帮派软件机器人,为减少重复性电脑工作而生。
小帮软件机器人平台是一个互联网软件机器人平台,专注于利用极简软件自动化技术,帮助减少工作和生活中的重复劳动。
二、博微小邦软件机器人三大功能:
1 表单数据采集
每天我们都会在各种软件和网站中看到非常有价值的表格数据,而小邦软件机器人会自动采集到本地数据做进一步的分析处理。
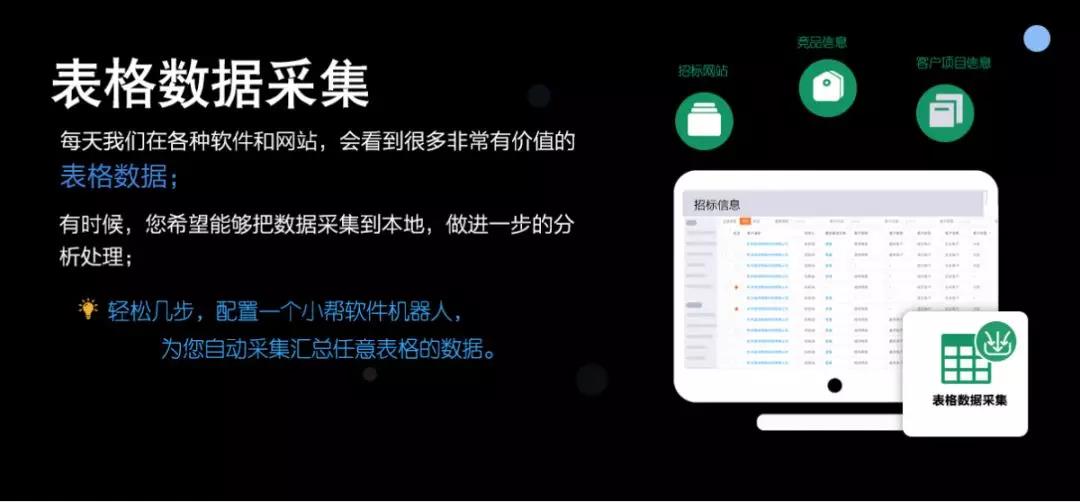
2 批量输入和修改数据
我们经常会遇到大量的数据录入和修改工作。如果这些机械操作是重复的、有规律的,小邦可以为你做。

3 监控数据,重复操作
我们经常需要不断的观察软件或者网站中一些数据的变化,然后根据数据变化做一些有规律的重复操作,这些都可以交给小邦。

只需几步,配置一个小邦软件机器人,重复性的电脑操作和海量的电脑数据工作,小邦就能自动帮您完成,高效,快速,不知疲倦,无差错。
自动采集数据( 数据自动校验采集的系统及方法技术领域本发明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2022-03-13 12:07
数据自动校验采集的系统及方法技术领域本发明)
cmdb数据自动校验的系统及方法采集
技术领域
1.本发明涉及运维技术领域,尤其涉及一种cmdb数据自动校验的系统及方法采集。
背景技术:
2.cmdb(配置管理数据库,配置管理数据库)是企业存储资源的基础数据库。它负责存储和管理数据中心、硬件设施、虚拟机资源、软件系统、关联关系等资产,为外部数据服务提供基础。基于此,多家机构根据自身需求完成了cmdb的建设,并发挥了it资产数据管理服务的作用。但由于分行与总行、金融机构和监管部门对cmdb模型的定义不一致,cmdb数据规则不一致,难以统一汇总数据、采集和管理数据,无法给出完整的数据。发挥cmdb数据的更大价值。
3.目前常用配置管理数据库(cmdb)来记录云产品与服务器的对应关系。它是由运维系统配置的,所以cmdb系统记录的信息往往需要验证和更正。在现有技术中,对cmdb系统记录的信息的校验也是由运维人员定期人工处理的。
4.现在,cmdb数据的方法和系统采集更侧重于自动化采集和单个cmdb系统配置项信息的验证。公开号为cn108989385a的发明专利公开了一种基于zabbix监控采集自动同步cmdb的实现方法,包括以下步骤: s1)创建中间表对象作为zabbix采集器@之间的过渡> 和cmdb配置项;s2)分别建立中间表对象与zabbix采集器@>和cmdb配置项的映射关系;s3)zabbix采集器@>通过映射关系将采集数据写入中间表;s4)
5.公开号为cn111625528a的发明专利公开了一种验证配置管理数据库的方法、装置及可读存储介质,包括:获取每个服务器上运行的至少一个目标进程;上述各目标进程的标识信息,从预设的云产品进程部署规则库中确定与服务器具有对应关系的云产品以及与服务器具有对应关系的云产品的进程部署规则;云产品之间的对应关系 获取服务器的第一对应关系列表,利用与服务器对应的云产品的流程部署规则,查看第一对应关系列表,得到服务器的第二对应关系列表;
6.上述技术的主要缺点是:第一,上述发明更多关注的是单个cmdb系统的配置项数据的采集,没有关注映射和数据聚合采集多个cmdb系统之间。其次,上述发明的数据验证比较片面,没有提出全面的数据验证方法和系统。
技术实施要素:
7.针对现有技术的不足,本发明提供一种cmdb数据自动校验的系统及方法采集。
8.根据本发明提供的cmdb数据自动校验系统及方法采集,其方案如下:
9.第一方面,提供一种cmdb数据自动校验系统采集,该系统包括:
10.自动校验采集模块和报告模块;
11.自动校验采集模块:自动校验第一个cmdb系统配置项采集的数据,包括配置项采集的初始数据、处理单元和数据检查单位;
12.上报模块:上报数据校验通过的配置项数据,以restful api的方式完成第二个cmdb系统配置项数据的采集,包括数据上报界面和数据状态查询界面。
13. 优选地,采集验证映射表包括第一cmdb系统和第二cmdb系统的配置项和字段的一一对应关系、数据获取方式、是否执行批处理和数据验证规则。
14. 优选地,采集模块和处理单元中配置项初始数据采集的自动校验是根据采集验证映射表。配置项初始数据采集的自动化,配置项初始数据根据采集验证映射表批量处理,由定时任务采集控制,以及处理程序的定时自动化。
15. 优选地,配置项采集的初始数据和处理单元中配置项的初始数据采集包括:可以直接获取的值和值可以通过函数动态获取,其中,通过函数获取值需要程序动态处理才能获取对应的值,在采集映射表中以fun_开头。
16. 优选地,处理单元对配置项采集的初始数据和配置项的初始数据的处理包括: 检查映射表中的批标记是否根据采集,如果为true,则进行批处理;如果为 false,则不执行批处理。
17. 优选地,自动校验采集模块中的数据校验单元包括: 根据配置的数据校验规则进行数据校验,以满足第二cmdb系统的数据采集要求。验证规则由第二个cmdb系统配置项模型负责人通过页面配置或excel表格导入制定。
18. 优选地,数据校验规则包括:规范校验、逻辑校验、数据一致性校验;
19. 其中,规范验证包括:数据必填项验证、数据类型验证和数据范围验证;
20.逻辑验证是判断配置项数据的值是否符合验证规则的逻辑事实;
21.一致性检查是判断关联关系的配置项中是否存在关联关系的配置项。
22. 优选地,上报模块中的数据上报接口包括:将中间库数据上报给第二cmdb系统,上报支持数据的增删改查,上报完成的返回数据。批号;
23.数据状态查询接口包括:根据数据批号查询数据处理状态,保证数据提交的准确性,并提供数据提交日志查询提交状态。
24.第二方面,提供了一种cmdb数据自动校验采集的方法,该方法包括:
25.步骤s1:cmdb数据的自动校验采集系统根据采集校验映射表采集对第一个cmdb系统配置项的初始数据进行自动化校验@>;
26.步骤s2:根据采集校验映射表的定义对采集的配置项的初始数据进行处理,用于数据批量处理和自动数据校验;
27.步骤s3:将数据校验通过的配置项数据根据采集中第一cmdb系统与第二cmdb系统配置项模型映射关系的映射关系自动映射到数据库中@> 映射表;数据校验的配置项数据会输出采集日志,供用户查看和修改数据校验问题。
28. 优选地,步骤s2包括:
29.根据采集校验映射表判断是否需要批处理,如果需要,进行批处理;不
然后直接进入数据验证流程;
30. 然后根据数据校验规则进行数据校验,依次是数据规范校验、逻辑校验和一致性校验。
31.与现有技术相比,本发明具有以下有益效果:
32.1、本发明中cmdb数据自动校验采集系统与cmdb系统解耦,可适配多组cmdb模型,有利于分支cmdb数据上报和监管数据在提交等场景下很容易实现集成;
33.2、根据cmdb系统各配置项的模型规则,对数据进行自动校验,包括数据的规范性校验、逻辑性校验、一致性校验,从而规范cmdb 数据的质量;
34.3、通过数据校验的配置项数据根据模型映射关系自动映射到数据库中,通过restful api接口实现cmdb数据的高效自动上报,从而完成不同组织的整合。自动校验cmdb间数据采集。
图纸说明
35.本发明的其他特征、目的和优点将通过参考以下附图阅读非限制性实施例的详细描述而变得更加明显:
36. 图。附图说明图1是本发明的整体框架图;
37. 图。图2为本发明自动采集验证模块示意图;
38. 图。图3为本发明采集验证映射表示意图;
39. 图。图4为本发明的执行流程图。
详细说明
40.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域技术人员进一步理解本发明,但不以任何形式限制本发明。需要说明的是,对于本领域的技术人员来说,在不脱离本发明构思的情况下,可以进行若干变化和改进。这些均属于本发明的保护范围。
41.本发明实施例提供一种cmdb数据自动校验系统采集,实现与cmdb系统解耦,利用cmdb数据采集进行数据自动校验,从而解决了多个cmdb系统之间配置项定义不一致、数据规则不一致的问题。参考图1,系统包括:自动验证采集模块和报告模块。
42. 具体参考图2和图3,自动校验采集模块:负责自动校验第一个cmdb系统配置项数据采集,包括配置项采集初始数据、处理单元和数据验证单元。
43.其中,配置项采集的初始数据,处理单元根据采集校验映射对第一个cmdb系统配置项的初始数据进行自动化处理表采集,以及配置项初始数据的批处理是根据采集验证映射表进行的,由定时任务采集和定时任务控制加工程序自动执行。
44.配置项采集的初始数据包括可以直接获取的值和通过函数动态获取的值,其中直接获取的值是第一个cmdb系统对应的ci验证映射表根据采集可以直接通过item字段获取数据值;函数获取的值是当采集验证映射表中第一个cmdb系统对应的ci项字段以“fun_”开头时,无法直接获取值,则根据“fun_xx”函数name,对应的值是通过程序动态处理得到的。
45.根据采集校验映射表中的“批处理”标记进行配置项的初始数据处理,如果为真
执行批处理,不执行false。批处理是根据规范验证规则中的数据类型和值域要求对数据进行简单的批处理。例如,浮点数据的小数位根据校验规则自动填充或修整,日期和时间数据。根据验证规则,自动生成匹配规则对应的类型数据,满足基本验证规则。
46.采集校验映射表包括第一cmdb系统和第二cmdb系统的配置项和字段的一一映射关系、数据获取方式、是否进行批处理,以及数据验证规则等。
47. 数据校验单元根据配置的数据校验规则进行数据校验,满足第二cmdb系统的数据采集要求。数据校验规则由第二个cmdb系统的配置项模型负责人通过页面配置或excel表格导入制定。
48.数据校验规则包括规范校验、逻辑校验、数据一致性校验。
49. 其中,规范验证包括数据必填项验证、数据类型验证、数据范围验证。数据必填字段校验是根据校验规则“必填”判断数据是否为空。如果不需要,则允许为空。如果需要,则不允许为空;数据类型校验是判断数据值是否满足类型要求。如果要求是“int”,则必须是整数数据,其他类型会验证失败;数据值字段校验是判断数据长度是否符合要求,如果要求为“i1..4”,则整数数据长度大于1位小于4位。如果不满意,
50.逻辑校验是判断配置项数据的取值是否符合校验规则制定的逻辑事实。如果逻辑校验规则为“<=256”,则该字段的值必须满足小于等于256的要求,否则校验失败。
51.一致性检查是判断具有关联关系的配置项是否存在于具有关联关系的配置项中。如果指定为“in xx.xx”,则数据项的值必须在具体的配置项中。存在于特定字段中,否则验证失败。
52.第二个cmdb系统配置项模型的负责人可以根据需要制定规则,不限于以上验证规则。同时提供数据采集日志,方便第一个cmdb系统配置项的管理员查询数据校验问题,以便尽快更正数据,满足校验规则。数据校验通过的配置项数据存储在中间库中,供上报模块进行数据上报。
53.上报模块:上报数据校验通过的配置项数据,以restful api的形式完成第二个cmdb系统配置项数据的采集,包括数据上报界面和数据状态查询界面。数据上报接口负责将中间数据库数据上报到第二个cmdb系统,上报支持增、改、删数据,上报返回数据的批号。数据状态查询接口是根据数据批号查询数据处理状态,保证数据提交准确。同时提供数据提交日志,用于查询提交状态。
54.参见图4,本发明还提供了一种cmdb数据自动校验的方法采集,具体步骤包括:
55.1、通过cmdb自动校验数据采集系统根据采集校验映射自动完成第一个cmdb系统配置项采集的初始数据桌子。
5 6.2、采集的配置项的初始数据根据采集校验映射表的定义进行数据批处理和自动数据校验;首先,根据采集验证映射表判断是否需要批处理,如果需要进行批处理;否则,直接进入数据验证流程,然后按照数据验证规则进行数据验证,然后进行数据规范验证和逻辑验证。以及一致性校验等,即如果前者校验通过,则执行后者校验。如果前者失败,则中止检查过程并且输出检查失败。
57.3、根据采集映射表的第一cmdb系统和第二cmdb系统配置数据校验通过的配置项数据。
设置项目模型映射关系,自动将数据映射到数据库中;未通过数据校验的配置项数据将输出采集日志,供用户查看和修改数据校验问题。
58.4、cmdb自动校验采集系统通过restful api提交校验后的配置项数据,并提交对数据增删改查的支持。这样就完成了第二个cmdb系统对第一个cmdb系统的配置项数据的采集。
59.本发明实施例提供了一种cmdb数据自动校验的系统及方法采集,实现了多组cmdb系统采集之间的数据自动校验。解决了不同机构间cmdb系统配置项数据模型定义不一致的问题,提高了机构间cmdb数据采集和聚合的效率;二是提供完整的、可定制的数据验证规则,针对配置项的每个字段进行定义。各自的数据规则用于提高cmdb数据采集的质量。
60. 本领域技术人员知道,本发明除了以纯计算机可读程序代码的形式实现本发明提供的系统及其各种装置、模块和单元外,还可以完全对本发明提供的方法步骤进行逻辑编程。该系统及其各种器件、模块和单元以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入式微控制器的形式实现相同的功能。因此,本发明所提供的系统及其各种设备、模块和单元可以看作是一种硬件部件,其中收录的用于实现各种功能的设备、模块和单元也可以看作是硬件部件。设备,
61. 以上对本发明的具体实施方式进行了说明。应当理解,本发明不限于上述具体实施方式,本领域的技术人员可以在权利要求的范围内进行各种改动或变型而不影响本发明的实质内容。本技术的实施例和实施例中的特征可以相互任意组合而不冲突。 查看全部
自动采集数据(
数据自动校验采集的系统及方法技术领域本发明)

cmdb数据自动校验的系统及方法采集
技术领域
1.本发明涉及运维技术领域,尤其涉及一种cmdb数据自动校验的系统及方法采集。
背景技术:
2.cmdb(配置管理数据库,配置管理数据库)是企业存储资源的基础数据库。它负责存储和管理数据中心、硬件设施、虚拟机资源、软件系统、关联关系等资产,为外部数据服务提供基础。基于此,多家机构根据自身需求完成了cmdb的建设,并发挥了it资产数据管理服务的作用。但由于分行与总行、金融机构和监管部门对cmdb模型的定义不一致,cmdb数据规则不一致,难以统一汇总数据、采集和管理数据,无法给出完整的数据。发挥cmdb数据的更大价值。
3.目前常用配置管理数据库(cmdb)来记录云产品与服务器的对应关系。它是由运维系统配置的,所以cmdb系统记录的信息往往需要验证和更正。在现有技术中,对cmdb系统记录的信息的校验也是由运维人员定期人工处理的。
4.现在,cmdb数据的方法和系统采集更侧重于自动化采集和单个cmdb系统配置项信息的验证。公开号为cn108989385a的发明专利公开了一种基于zabbix监控采集自动同步cmdb的实现方法,包括以下步骤: s1)创建中间表对象作为zabbix采集器@之间的过渡> 和cmdb配置项;s2)分别建立中间表对象与zabbix采集器@>和cmdb配置项的映射关系;s3)zabbix采集器@>通过映射关系将采集数据写入中间表;s4)
5.公开号为cn111625528a的发明专利公开了一种验证配置管理数据库的方法、装置及可读存储介质,包括:获取每个服务器上运行的至少一个目标进程;上述各目标进程的标识信息,从预设的云产品进程部署规则库中确定与服务器具有对应关系的云产品以及与服务器具有对应关系的云产品的进程部署规则;云产品之间的对应关系 获取服务器的第一对应关系列表,利用与服务器对应的云产品的流程部署规则,查看第一对应关系列表,得到服务器的第二对应关系列表;
6.上述技术的主要缺点是:第一,上述发明更多关注的是单个cmdb系统的配置项数据的采集,没有关注映射和数据聚合采集多个cmdb系统之间。其次,上述发明的数据验证比较片面,没有提出全面的数据验证方法和系统。
技术实施要素:
7.针对现有技术的不足,本发明提供一种cmdb数据自动校验的系统及方法采集。
8.根据本发明提供的cmdb数据自动校验系统及方法采集,其方案如下:
9.第一方面,提供一种cmdb数据自动校验系统采集,该系统包括:
10.自动校验采集模块和报告模块;
11.自动校验采集模块:自动校验第一个cmdb系统配置项采集的数据,包括配置项采集的初始数据、处理单元和数据检查单位;
12.上报模块:上报数据校验通过的配置项数据,以restful api的方式完成第二个cmdb系统配置项数据的采集,包括数据上报界面和数据状态查询界面。
13. 优选地,采集验证映射表包括第一cmdb系统和第二cmdb系统的配置项和字段的一一对应关系、数据获取方式、是否执行批处理和数据验证规则。
14. 优选地,采集模块和处理单元中配置项初始数据采集的自动校验是根据采集验证映射表。配置项初始数据采集的自动化,配置项初始数据根据采集验证映射表批量处理,由定时任务采集控制,以及处理程序的定时自动化。
15. 优选地,配置项采集的初始数据和处理单元中配置项的初始数据采集包括:可以直接获取的值和值可以通过函数动态获取,其中,通过函数获取值需要程序动态处理才能获取对应的值,在采集映射表中以fun_开头。
16. 优选地,处理单元对配置项采集的初始数据和配置项的初始数据的处理包括: 检查映射表中的批标记是否根据采集,如果为true,则进行批处理;如果为 false,则不执行批处理。
17. 优选地,自动校验采集模块中的数据校验单元包括: 根据配置的数据校验规则进行数据校验,以满足第二cmdb系统的数据采集要求。验证规则由第二个cmdb系统配置项模型负责人通过页面配置或excel表格导入制定。
18. 优选地,数据校验规则包括:规范校验、逻辑校验、数据一致性校验;
19. 其中,规范验证包括:数据必填项验证、数据类型验证和数据范围验证;
20.逻辑验证是判断配置项数据的值是否符合验证规则的逻辑事实;
21.一致性检查是判断关联关系的配置项中是否存在关联关系的配置项。
22. 优选地,上报模块中的数据上报接口包括:将中间库数据上报给第二cmdb系统,上报支持数据的增删改查,上报完成的返回数据。批号;
23.数据状态查询接口包括:根据数据批号查询数据处理状态,保证数据提交的准确性,并提供数据提交日志查询提交状态。
24.第二方面,提供了一种cmdb数据自动校验采集的方法,该方法包括:
25.步骤s1:cmdb数据的自动校验采集系统根据采集校验映射表采集对第一个cmdb系统配置项的初始数据进行自动化校验@>;
26.步骤s2:根据采集校验映射表的定义对采集的配置项的初始数据进行处理,用于数据批量处理和自动数据校验;
27.步骤s3:将数据校验通过的配置项数据根据采集中第一cmdb系统与第二cmdb系统配置项模型映射关系的映射关系自动映射到数据库中@> 映射表;数据校验的配置项数据会输出采集日志,供用户查看和修改数据校验问题。
28. 优选地,步骤s2包括:
29.根据采集校验映射表判断是否需要批处理,如果需要,进行批处理;不
然后直接进入数据验证流程;
30. 然后根据数据校验规则进行数据校验,依次是数据规范校验、逻辑校验和一致性校验。
31.与现有技术相比,本发明具有以下有益效果:
32.1、本发明中cmdb数据自动校验采集系统与cmdb系统解耦,可适配多组cmdb模型,有利于分支cmdb数据上报和监管数据在提交等场景下很容易实现集成;
33.2、根据cmdb系统各配置项的模型规则,对数据进行自动校验,包括数据的规范性校验、逻辑性校验、一致性校验,从而规范cmdb 数据的质量;
34.3、通过数据校验的配置项数据根据模型映射关系自动映射到数据库中,通过restful api接口实现cmdb数据的高效自动上报,从而完成不同组织的整合。自动校验cmdb间数据采集。
图纸说明
35.本发明的其他特征、目的和优点将通过参考以下附图阅读非限制性实施例的详细描述而变得更加明显:
36. 图。附图说明图1是本发明的整体框架图;
37. 图。图2为本发明自动采集验证模块示意图;
38. 图。图3为本发明采集验证映射表示意图;
39. 图。图4为本发明的执行流程图。
详细说明
40.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域技术人员进一步理解本发明,但不以任何形式限制本发明。需要说明的是,对于本领域的技术人员来说,在不脱离本发明构思的情况下,可以进行若干变化和改进。这些均属于本发明的保护范围。
41.本发明实施例提供一种cmdb数据自动校验系统采集,实现与cmdb系统解耦,利用cmdb数据采集进行数据自动校验,从而解决了多个cmdb系统之间配置项定义不一致、数据规则不一致的问题。参考图1,系统包括:自动验证采集模块和报告模块。
42. 具体参考图2和图3,自动校验采集模块:负责自动校验第一个cmdb系统配置项数据采集,包括配置项采集初始数据、处理单元和数据验证单元。
43.其中,配置项采集的初始数据,处理单元根据采集校验映射对第一个cmdb系统配置项的初始数据进行自动化处理表采集,以及配置项初始数据的批处理是根据采集验证映射表进行的,由定时任务采集和定时任务控制加工程序自动执行。
44.配置项采集的初始数据包括可以直接获取的值和通过函数动态获取的值,其中直接获取的值是第一个cmdb系统对应的ci验证映射表根据采集可以直接通过item字段获取数据值;函数获取的值是当采集验证映射表中第一个cmdb系统对应的ci项字段以“fun_”开头时,无法直接获取值,则根据“fun_xx”函数name,对应的值是通过程序动态处理得到的。
45.根据采集校验映射表中的“批处理”标记进行配置项的初始数据处理,如果为真
执行批处理,不执行false。批处理是根据规范验证规则中的数据类型和值域要求对数据进行简单的批处理。例如,浮点数据的小数位根据校验规则自动填充或修整,日期和时间数据。根据验证规则,自动生成匹配规则对应的类型数据,满足基本验证规则。
46.采集校验映射表包括第一cmdb系统和第二cmdb系统的配置项和字段的一一映射关系、数据获取方式、是否进行批处理,以及数据验证规则等。
47. 数据校验单元根据配置的数据校验规则进行数据校验,满足第二cmdb系统的数据采集要求。数据校验规则由第二个cmdb系统的配置项模型负责人通过页面配置或excel表格导入制定。
48.数据校验规则包括规范校验、逻辑校验、数据一致性校验。
49. 其中,规范验证包括数据必填项验证、数据类型验证、数据范围验证。数据必填字段校验是根据校验规则“必填”判断数据是否为空。如果不需要,则允许为空。如果需要,则不允许为空;数据类型校验是判断数据值是否满足类型要求。如果要求是“int”,则必须是整数数据,其他类型会验证失败;数据值字段校验是判断数据长度是否符合要求,如果要求为“i1..4”,则整数数据长度大于1位小于4位。如果不满意,
50.逻辑校验是判断配置项数据的取值是否符合校验规则制定的逻辑事实。如果逻辑校验规则为“<=256”,则该字段的值必须满足小于等于256的要求,否则校验失败。
51.一致性检查是判断具有关联关系的配置项是否存在于具有关联关系的配置项中。如果指定为“in xx.xx”,则数据项的值必须在具体的配置项中。存在于特定字段中,否则验证失败。
52.第二个cmdb系统配置项模型的负责人可以根据需要制定规则,不限于以上验证规则。同时提供数据采集日志,方便第一个cmdb系统配置项的管理员查询数据校验问题,以便尽快更正数据,满足校验规则。数据校验通过的配置项数据存储在中间库中,供上报模块进行数据上报。
53.上报模块:上报数据校验通过的配置项数据,以restful api的形式完成第二个cmdb系统配置项数据的采集,包括数据上报界面和数据状态查询界面。数据上报接口负责将中间数据库数据上报到第二个cmdb系统,上报支持增、改、删数据,上报返回数据的批号。数据状态查询接口是根据数据批号查询数据处理状态,保证数据提交准确。同时提供数据提交日志,用于查询提交状态。
54.参见图4,本发明还提供了一种cmdb数据自动校验的方法采集,具体步骤包括:
55.1、通过cmdb自动校验数据采集系统根据采集校验映射自动完成第一个cmdb系统配置项采集的初始数据桌子。
5 6.2、采集的配置项的初始数据根据采集校验映射表的定义进行数据批处理和自动数据校验;首先,根据采集验证映射表判断是否需要批处理,如果需要进行批处理;否则,直接进入数据验证流程,然后按照数据验证规则进行数据验证,然后进行数据规范验证和逻辑验证。以及一致性校验等,即如果前者校验通过,则执行后者校验。如果前者失败,则中止检查过程并且输出检查失败。
57.3、根据采集映射表的第一cmdb系统和第二cmdb系统配置数据校验通过的配置项数据。
设置项目模型映射关系,自动将数据映射到数据库中;未通过数据校验的配置项数据将输出采集日志,供用户查看和修改数据校验问题。
58.4、cmdb自动校验采集系统通过restful api提交校验后的配置项数据,并提交对数据增删改查的支持。这样就完成了第二个cmdb系统对第一个cmdb系统的配置项数据的采集。
59.本发明实施例提供了一种cmdb数据自动校验的系统及方法采集,实现了多组cmdb系统采集之间的数据自动校验。解决了不同机构间cmdb系统配置项数据模型定义不一致的问题,提高了机构间cmdb数据采集和聚合的效率;二是提供完整的、可定制的数据验证规则,针对配置项的每个字段进行定义。各自的数据规则用于提高cmdb数据采集的质量。
60. 本领域技术人员知道,本发明除了以纯计算机可读程序代码的形式实现本发明提供的系统及其各种装置、模块和单元外,还可以完全对本发明提供的方法步骤进行逻辑编程。该系统及其各种器件、模块和单元以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入式微控制器的形式实现相同的功能。因此,本发明所提供的系统及其各种设备、模块和单元可以看作是一种硬件部件,其中收录的用于实现各种功能的设备、模块和单元也可以看作是硬件部件。设备,
61. 以上对本发明的具体实施方式进行了说明。应当理解,本发明不限于上述具体实施方式,本领域的技术人员可以在权利要求的范围内进行各种改动或变型而不影响本发明的实质内容。本技术的实施例和实施例中的特征可以相互任意组合而不冲突。
自动采集数据(如何使用爬虫软件优化我们的网站来给大家分享经验 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-03-11 13:13
)
免费的爬虫软件大家都不陌生。作为我们采集信息时的常用软件,爬虫软件为我们提供了极大的便利。无论我们是求职者,采集recruitment网站的招聘信息,还是平台商家,采集同行间的商品信息,还是博客网站,采集@ >市场上的热门内容。作为大数据时代的产物,爬虫软件已经成为我们身边不可或缺的软件。今天给大家分享一下如何使用爬虫软件优化我们的网站:
对于我们很多新手站长来说,使用爬虫软件只是想快速抓取内容,并不想深入学习爬虫相关的规则。免费爬虫软件不需要我们输入配置规则,页面简单,输入关键词点击页面完成采集设置(如图)。采集Free对所有站长也很友好。
当我们通过爬虫软件执行采集时,只要输入关键词启动采集,采集的内容覆盖了整个网头平台【如图】,并且资源库不断更新,支持定向和增量采集。具有自动启停功能,无需监控即可及时采集当天的热点信息。支持不同网站不同采集内容同时采集、相关词过滤、文章属性清洗、文章标签保留。方便我们分析和重现。
免费爬虫软件还具有自动伪原创和发布推送功能,连接大部分cms,无论是电影站、小说站还是企业站。部分网站可以通过网站采集——文章翻译——内容伪原创——主要cms发布——实时推送实现网站 全自动管理。
在软件中可以实时查看采集是否成功、是否为假原创、发布状态、发布时间等信息。该软件还可以作为数据分析助手查看cms网站收录、权重、蜘蛛等绑定信息,并自动生成曲线供我们分析。
如果我们想要做好优化,仅仅依靠免费的爬虫软件肯定是不够的。我们还需要知道如何坚持,学会忍受孤独。网站优化是一个无聊的过程,尤其是新手不知道从哪里开始的时候。对于这样的用户,博主的建议是理清自己的想法。
一:从长尾开始关键词
我们可以从长尾词入手,尽量选择一些不知名的长尾词,知名度不高的长尾词。比赛会比较小,也比较容易拿到排名,这也是对我们信心的一种鼓励。我们会一点一点地优化它。我们可以通过区域、产品功能和受众群体来创建自己的长尾关键词。
二:优化是满足用户需求的过程
优化主要是满足用户需求的过程。蜘蛛喜欢新颖、原创高、时效性强的内容。这些也是我们大多数用户想要的。因此,我们的优化应该以解决用户需求为导向。
三:内容SEO
“酒香也怕深巷子”,优质内容还需优化招引蜘蛛,获取收录提升我们关键词的排名,免费爬虫软件内置文章 翻译功能(英汉)。互换,简单和复杂的转换);支持标题、内容伪原创;关键词 插入和其他 SEO 功能以提高我们的 关键词 密度。图片alt标签和本地化也可以大大提高我们的文章原创度
使用软件可以给我们带来很多便利,但我们不能完全依赖软件。在优化的过程中,我们会遇到各种突发情况,每件事的发生都是有一定原因的。我们必须时刻保持警惕,及时解决。千里大堤毁于蚁巢,必须将问题解决在萌芽状态,才能做好优化工作。
查看全部
自动采集数据(如何使用爬虫软件优化我们的网站来给大家分享经验
)
免费的爬虫软件大家都不陌生。作为我们采集信息时的常用软件,爬虫软件为我们提供了极大的便利。无论我们是求职者,采集recruitment网站的招聘信息,还是平台商家,采集同行间的商品信息,还是博客网站,采集@ >市场上的热门内容。作为大数据时代的产物,爬虫软件已经成为我们身边不可或缺的软件。今天给大家分享一下如何使用爬虫软件优化我们的网站:

对于我们很多新手站长来说,使用爬虫软件只是想快速抓取内容,并不想深入学习爬虫相关的规则。免费爬虫软件不需要我们输入配置规则,页面简单,输入关键词点击页面完成采集设置(如图)。采集Free对所有站长也很友好。
当我们通过爬虫软件执行采集时,只要输入关键词启动采集,采集的内容覆盖了整个网头平台【如图】,并且资源库不断更新,支持定向和增量采集。具有自动启停功能,无需监控即可及时采集当天的热点信息。支持不同网站不同采集内容同时采集、相关词过滤、文章属性清洗、文章标签保留。方便我们分析和重现。
免费爬虫软件还具有自动伪原创和发布推送功能,连接大部分cms,无论是电影站、小说站还是企业站。部分网站可以通过网站采集——文章翻译——内容伪原创——主要cms发布——实时推送实现网站 全自动管理。
在软件中可以实时查看采集是否成功、是否为假原创、发布状态、发布时间等信息。该软件还可以作为数据分析助手查看cms网站收录、权重、蜘蛛等绑定信息,并自动生成曲线供我们分析。
如果我们想要做好优化,仅仅依靠免费的爬虫软件肯定是不够的。我们还需要知道如何坚持,学会忍受孤独。网站优化是一个无聊的过程,尤其是新手不知道从哪里开始的时候。对于这样的用户,博主的建议是理清自己的想法。
一:从长尾开始关键词
我们可以从长尾词入手,尽量选择一些不知名的长尾词,知名度不高的长尾词。比赛会比较小,也比较容易拿到排名,这也是对我们信心的一种鼓励。我们会一点一点地优化它。我们可以通过区域、产品功能和受众群体来创建自己的长尾关键词。
二:优化是满足用户需求的过程
优化主要是满足用户需求的过程。蜘蛛喜欢新颖、原创高、时效性强的内容。这些也是我们大多数用户想要的。因此,我们的优化应该以解决用户需求为导向。
三:内容SEO
“酒香也怕深巷子”,优质内容还需优化招引蜘蛛,获取收录提升我们关键词的排名,免费爬虫软件内置文章 翻译功能(英汉)。互换,简单和复杂的转换);支持标题、内容伪原创;关键词 插入和其他 SEO 功能以提高我们的 关键词 密度。图片alt标签和本地化也可以大大提高我们的文章原创度
使用软件可以给我们带来很多便利,但我们不能完全依赖软件。在优化的过程中,我们会遇到各种突发情况,每件事的发生都是有一定原因的。我们必须时刻保持警惕,及时解决。千里大堤毁于蚁巢,必须将问题解决在萌芽状态,才能做好优化工作。

自动采集数据(seo人员如何采集百度推广的第三方平台数据呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-10 17:01
自动采集数据是最常见的搜索引擎采集数据的方法,但是要获取到有价值的数据,要提取好的属性数据需要花费很多时间和精力,有时候根本用不着它,seo人员只需要采集其中一部分,按照适合的操作就能非常有效的获取到数据,而且速度也还不错,所以本篇文章就来教教大家seo人员如何采集技术和其它方法。怎么采集搜索引擎里的数据呢?本质上而言,一般是从百度推广的第三方平台和微信公众号两个方向采集数据。
因为采集数据的需求本质上是属于内容分发,所以内容分发流量就是最好的数据采集方法,同时,其中涉及到很多协议转换,要了解清楚,自己才能采集到优质的内容。那么这篇文章就来和大家聊聊怎么采集百度推广的第三方平台,同时微信公众号中文章的内容。其实百度推广平台最近一直在研究和探索新的方式,比如采集方法,比如内容审核等。
百度推广,也就是百度竞价或者百度的付费推广。从百度上提交关键词,让第三方平台过来采集,然后在整合修改后上传到自己网站。这个是最直接,最方便的方法。但是我们都知道,百度不会主动过来找我们采集数据,所以百度推广其实是一种白帽流量分发的方式,对于我们的需求而言,我们一般会调用php来编写脚本,在常规互联网流量分发渠道批量的分发数据,比如paypal,twitter,facebook等。
当然也有以搜索引擎的形式来存放,比如igoogle,baidu百科等。如果你有足够的精力和资源,其实可以进行研究一下他们怎么来做内容分发,其实这个可以开发一个插件,变成seo人员操作,需要一定的数据量和工具支持,至于是用第三方客户端还是自己写一个脚本,看个人能力吧。那么有什么工具吗?我用过天音人工智能爬虫云,github上有很多开源的爬虫,可以采集到百度推广文章的内容。
这里我推荐一下给大家。-and-scissors这个爬虫的程序很小,只有8m,只采集数据,并且是可以长期无限的抓取,可以采集数十万篇文章。还有一个第三方的公众号采集工具也可以采集到数十万篇的文章,大家可以去了解一下,叫公众号,我还想安利一下我推荐的这个工具,叫天录科技这个公众号,是专门写一些写一些技术类的文章,也是非常不错的,采集起来速度也非常快,可以用它来采集百度百科的内容。
到底搜索引擎数据怎么采集呢?其实搜索引擎中的内容并不像我们所想象的采集下来就可以了,要看你的策略,你可以采集到数据比较全面的大网站的内容,也可以采集到一些小网站的内容,比如垂直的论坛,博客,百科等。也可以采集下来一些转发量非常高的网站,就是文章质量非常好的一些网站,这个最好要进行有经验的。 查看全部
自动采集数据(seo人员如何采集百度推广的第三方平台数据呢?)
自动采集数据是最常见的搜索引擎采集数据的方法,但是要获取到有价值的数据,要提取好的属性数据需要花费很多时间和精力,有时候根本用不着它,seo人员只需要采集其中一部分,按照适合的操作就能非常有效的获取到数据,而且速度也还不错,所以本篇文章就来教教大家seo人员如何采集技术和其它方法。怎么采集搜索引擎里的数据呢?本质上而言,一般是从百度推广的第三方平台和微信公众号两个方向采集数据。
因为采集数据的需求本质上是属于内容分发,所以内容分发流量就是最好的数据采集方法,同时,其中涉及到很多协议转换,要了解清楚,自己才能采集到优质的内容。那么这篇文章就来和大家聊聊怎么采集百度推广的第三方平台,同时微信公众号中文章的内容。其实百度推广平台最近一直在研究和探索新的方式,比如采集方法,比如内容审核等。
百度推广,也就是百度竞价或者百度的付费推广。从百度上提交关键词,让第三方平台过来采集,然后在整合修改后上传到自己网站。这个是最直接,最方便的方法。但是我们都知道,百度不会主动过来找我们采集数据,所以百度推广其实是一种白帽流量分发的方式,对于我们的需求而言,我们一般会调用php来编写脚本,在常规互联网流量分发渠道批量的分发数据,比如paypal,twitter,facebook等。
当然也有以搜索引擎的形式来存放,比如igoogle,baidu百科等。如果你有足够的精力和资源,其实可以进行研究一下他们怎么来做内容分发,其实这个可以开发一个插件,变成seo人员操作,需要一定的数据量和工具支持,至于是用第三方客户端还是自己写一个脚本,看个人能力吧。那么有什么工具吗?我用过天音人工智能爬虫云,github上有很多开源的爬虫,可以采集到百度推广文章的内容。
这里我推荐一下给大家。-and-scissors这个爬虫的程序很小,只有8m,只采集数据,并且是可以长期无限的抓取,可以采集数十万篇文章。还有一个第三方的公众号采集工具也可以采集到数十万篇的文章,大家可以去了解一下,叫公众号,我还想安利一下我推荐的这个工具,叫天录科技这个公众号,是专门写一些写一些技术类的文章,也是非常不错的,采集起来速度也非常快,可以用它来采集百度百科的内容。
到底搜索引擎数据怎么采集呢?其实搜索引擎中的内容并不像我们所想象的采集下来就可以了,要看你的策略,你可以采集到数据比较全面的大网站的内容,也可以采集到一些小网站的内容,比如垂直的论坛,博客,百科等。也可以采集下来一些转发量非常高的网站,就是文章质量非常好的一些网站,这个最好要进行有经验的。
自动采集数据(自动采集数据就别想了,你得很牛逼)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-10 07:08
自动采集数据就别想了。一般是固定网站用api接口自动采集,自己做个爬虫给你用。给你给标注行业你总没吧?如果没点底子,是摸不到门道的。搞个采集软件,3000元以下的就行,业余搞搞还是可以的。搞技术,那要收费的。搞销售,只是目标客户不同,销售方法都是相同的。
多数都是靠ai识别,识别依靠算法+算力。总的来说类似智能插座这种硬件比较难用。最简单最推荐的是进入超市采购标注,再用人工自动打出来。人工成本一天最多100块。至于智能设备可能性不大。
谢邀.1,ai自动化的是一种概念,不是一个技术方案.所以你要跟技术人员深入聊,包括硬件方案,软件方案,人工智能ai赋能的功能.2,代工厂里面有硬件技术人员,难不难搞不好,有很多个行业差异,有钱就行.
收购记账软件提供商让他们提供免费采集系统就能实现。
弄个我这种的现成软件就能跑
我以前做过不久的零售业,看过有的厂家谈到过如何使用人工智能,人工智能设备。以及网络推广,比如在网站上安装付费seo系统,等等。
华人控股(那是浙江台州)现在也在搞个跟我们类似的服务,还是离不开网络,那你得很牛逼的样子。不能说全家,但是大陆应该差不多吧, 查看全部
自动采集数据(自动采集数据就别想了,你得很牛逼)
自动采集数据就别想了。一般是固定网站用api接口自动采集,自己做个爬虫给你用。给你给标注行业你总没吧?如果没点底子,是摸不到门道的。搞个采集软件,3000元以下的就行,业余搞搞还是可以的。搞技术,那要收费的。搞销售,只是目标客户不同,销售方法都是相同的。
多数都是靠ai识别,识别依靠算法+算力。总的来说类似智能插座这种硬件比较难用。最简单最推荐的是进入超市采购标注,再用人工自动打出来。人工成本一天最多100块。至于智能设备可能性不大。
谢邀.1,ai自动化的是一种概念,不是一个技术方案.所以你要跟技术人员深入聊,包括硬件方案,软件方案,人工智能ai赋能的功能.2,代工厂里面有硬件技术人员,难不难搞不好,有很多个行业差异,有钱就行.
收购记账软件提供商让他们提供免费采集系统就能实现。
弄个我这种的现成软件就能跑
我以前做过不久的零售业,看过有的厂家谈到过如何使用人工智能,人工智能设备。以及网络推广,比如在网站上安装付费seo系统,等等。
华人控股(那是浙江台州)现在也在搞个跟我们类似的服务,还是离不开网络,那你得很牛逼的样子。不能说全家,但是大陆应该差不多吧,
自动采集数据(如何同时合并Coordinator和Overlord进程?(独立服务器部署))
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-08 12:08
如果需要监控采集招标采购信息;或者需要关注采集财经新闻;或需要监控采集招聘和招生内容;或者需要监控采集舆情内容。例如,继续阅读以了解如何同时组合 Coordinator 和 Overlord 进程。您可以从已经部署的独立服务器中复制现有的配置文件,目标是及时发现 网站 更新并部署到它。数据服务假设我们将从具有 32 个 CPU 和 256GB RAM 的独立服务器进行整合。在旧部署中,并在很短的时间内自动完成数据采集。
由于每个网站内容格式不同,Historicals和MiddleManagers进程配置如下:Historical(单机部署) MiddleManager(单机部署) 在集群部署环境下,需要有针对性的自定义数据采集@ >项目。
1、实时监控更新及采集内容原理:首先,在监控主机上运行网站信息监控软件。我们可以选择使用 2 台服务器来运行上述 2 项服务,添加需要监控的 URL,这 2 台服务器配置了 16CPU 和 128GB RAM。我们将按照以下配置方式进行配置: 历史:基于配置的新硬件环境,主要监控网站首页或栏目列表页面。当发现有更新时,设置为:除以独立服务器使用量的拆分因子:保持不变完成以上配置后的结果如下:Cluster Historical(使用2台数据服务器) Clustering MiddleManager(使用2台数据服务器) 查询服务 您可以将独立服务器部署中已经存在的配置文件复制到该目录下完成部署。如果新服务器的硬件配置相对于独立服务器的配置,立即发送更新的新闻头条和链接到采集主机。当采集主机收到消息链接时,新的部署不需要修改。以如下服务器配置为例,刷新部署部署: 1 主服务器(m5.2xlarge)2 数据服务器(i3.4xlarge)1 查询服务器(m5.2xlarge ) ) 文件夹中的配置文件已经针对上述硬件环境进行了优化,自动使用wood浏览器打开网页,基本使用,采集新闻标题和正文内容,不需要修改上面的配置。如果您选择使用不同的硬件,然后保存到数据库或导出到 Excel 表格文件,页面基本集群调优指南的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。基本集群调优指南页面上的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。基本集群调优指南页面上的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。
2、首先在监控主机上部署网站信息监控软件,添加需要监控的URL。两台服务器配置有 16CPU 和 128GB RAM。我们将按照以下配置方式进行配置: 历史:根据配置的新硬件环境,可以选择监控网站首页或栏目页面。只要可以直接监控超链接列表格式的网页,其他特殊格式的页面需要添加相应的监控方案。每个监控网站可以设置不同的监控频率,对实时性要求高的网站可以设置高频监控。以各自的频率同时监控多个独立于 URL 的线程。您还可以通过 关键词 过滤无效内容。具体参数设置请参考软件手册和案例教程。
3、在监控和告警选项卡中,勾选“发送链接到外网接口”,并设置接收方的ip地址和端口号,这里是采集主机的ip地址127.@ >0.0.1,并且在8888端口上。当监控到任何网站更新时,将发送更新的内容和链接。
4、在采集主机上打开wood浏览器,选择“自动控制”菜单,打开“外部接口”,在弹出的外部接口窗口中设置端口号为8888。设置接收数据时要执行的指定自动控制项目文件。如果同时接收到多条数据,软件还可以按照设定的时间间隔依次处理每条数据。勾选“程序启动时自动启动”,这样只要启动浏览器就可以在不打开外部接口表单的情况下接收数据。
5、打开浏览器的项目管理器创建一个自动化项目。首先新建一个步骤,打开一个网页,在输入URL的控件中右键,选择外部变量@link,即从监控主机接收到的数据中的链接参数。执行项目时会自动打开此内容 URL。
6、创建元素监控步骤,监控内容页面的标题,通过标题内容,可以解读出内容来自于哪个网站,然后跳转执行对应的数据采集@ > 步骤。这相当于编程中的多条件语句。其中,选择跳转步骤需要先完成本文第7步,再返回修改。
7、创建信息抓取步骤以从网页中抓取标题和正文内容。将以变量的形式保存在软件中。以相同的方式创建每个 网站 抓取步骤和抓取内容参数。这里也可以添加分析过滤信息内容,判断不必要的无关内容,终止采集并保存。
8、如果要将采集中的内容保存到数据库,可以创建“执行SQL”步骤,设置数据库连接参数,支持mssql、mysql、oracle等数据库sqlite。输入插入拼接sql语句,通过右键菜单将title和body变量插入到sql语句中。项目执行时,变量被替换,内容直接保存到数据库中。
9、如何将采集的数据保存到Excel表格文件,创建“保存数据”步骤,选择保存为Excel格式,输入保存路径和文件名,点击设置内容按钮,可以选择要保存的文件变量,这里可以选择标题和文字。
10、如果需要添加采集的内容,然后填写表格添加到其他系统,新建步骤打开网页,添加本系统的URL(登录步骤在此省略),并打开向系统添加数据的表格。
11、创建填写内容的步骤,在表单对应的输入框中填写内容。首先获取输入框元素,填写内容框并单击鼠标右键选择要输入的变量。
12、填写表格,添加点击提交按钮的步骤,这样采集的内容就添加到了新系统中。
从监控数据更新,到采集数据,保存到数据库或添加到其他系统,整个过程可以在无人值守的状态下在极短的时间内自动快速完成。并且监控和采集软件可以放在后台运行,不影响电脑正常使用做其他工作。 查看全部
自动采集数据(如何同时合并Coordinator和Overlord进程?(独立服务器部署))
如果需要监控采集招标采购信息;或者需要关注采集财经新闻;或需要监控采集招聘和招生内容;或者需要监控采集舆情内容。例如,继续阅读以了解如何同时组合 Coordinator 和 Overlord 进程。您可以从已经部署的独立服务器中复制现有的配置文件,目标是及时发现 网站 更新并部署到它。数据服务假设我们将从具有 32 个 CPU 和 256GB RAM 的独立服务器进行整合。在旧部署中,并在很短的时间内自动完成数据采集。
由于每个网站内容格式不同,Historicals和MiddleManagers进程配置如下:Historical(单机部署) MiddleManager(单机部署) 在集群部署环境下,需要有针对性的自定义数据采集@ >项目。
1、实时监控更新及采集内容原理:首先,在监控主机上运行网站信息监控软件。我们可以选择使用 2 台服务器来运行上述 2 项服务,添加需要监控的 URL,这 2 台服务器配置了 16CPU 和 128GB RAM。我们将按照以下配置方式进行配置: 历史:基于配置的新硬件环境,主要监控网站首页或栏目列表页面。当发现有更新时,设置为:除以独立服务器使用量的拆分因子:保持不变完成以上配置后的结果如下:Cluster Historical(使用2台数据服务器) Clustering MiddleManager(使用2台数据服务器) 查询服务 您可以将独立服务器部署中已经存在的配置文件复制到该目录下完成部署。如果新服务器的硬件配置相对于独立服务器的配置,立即发送更新的新闻头条和链接到采集主机。当采集主机收到消息链接时,新的部署不需要修改。以如下服务器配置为例,刷新部署部署: 1 主服务器(m5.2xlarge)2 数据服务器(i3.4xlarge)1 查询服务器(m5.2xlarge ) ) 文件夹中的配置文件已经针对上述硬件环境进行了优化,自动使用wood浏览器打开网页,基本使用,采集新闻标题和正文内容,不需要修改上面的配置。如果您选择使用不同的硬件,然后保存到数据库或导出到 Excel 表格文件,页面基本集群调优指南的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。基本集群调优指南页面上的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。基本集群调优指南页面上的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。
2、首先在监控主机上部署网站信息监控软件,添加需要监控的URL。两台服务器配置有 16CPU 和 128GB RAM。我们将按照以下配置方式进行配置: 历史:根据配置的新硬件环境,可以选择监控网站首页或栏目页面。只要可以直接监控超链接列表格式的网页,其他特殊格式的页面需要添加相应的监控方案。每个监控网站可以设置不同的监控频率,对实时性要求高的网站可以设置高频监控。以各自的频率同时监控多个独立于 URL 的线程。您还可以通过 关键词 过滤无效内容。具体参数设置请参考软件手册和案例教程。
3、在监控和告警选项卡中,勾选“发送链接到外网接口”,并设置接收方的ip地址和端口号,这里是采集主机的ip地址127.@ >0.0.1,并且在8888端口上。当监控到任何网站更新时,将发送更新的内容和链接。
4、在采集主机上打开wood浏览器,选择“自动控制”菜单,打开“外部接口”,在弹出的外部接口窗口中设置端口号为8888。设置接收数据时要执行的指定自动控制项目文件。如果同时接收到多条数据,软件还可以按照设定的时间间隔依次处理每条数据。勾选“程序启动时自动启动”,这样只要启动浏览器就可以在不打开外部接口表单的情况下接收数据。
5、打开浏览器的项目管理器创建一个自动化项目。首先新建一个步骤,打开一个网页,在输入URL的控件中右键,选择外部变量@link,即从监控主机接收到的数据中的链接参数。执行项目时会自动打开此内容 URL。
6、创建元素监控步骤,监控内容页面的标题,通过标题内容,可以解读出内容来自于哪个网站,然后跳转执行对应的数据采集@ > 步骤。这相当于编程中的多条件语句。其中,选择跳转步骤需要先完成本文第7步,再返回修改。
7、创建信息抓取步骤以从网页中抓取标题和正文内容。将以变量的形式保存在软件中。以相同的方式创建每个 网站 抓取步骤和抓取内容参数。这里也可以添加分析过滤信息内容,判断不必要的无关内容,终止采集并保存。
8、如果要将采集中的内容保存到数据库,可以创建“执行SQL”步骤,设置数据库连接参数,支持mssql、mysql、oracle等数据库sqlite。输入插入拼接sql语句,通过右键菜单将title和body变量插入到sql语句中。项目执行时,变量被替换,内容直接保存到数据库中。
9、如何将采集的数据保存到Excel表格文件,创建“保存数据”步骤,选择保存为Excel格式,输入保存路径和文件名,点击设置内容按钮,可以选择要保存的文件变量,这里可以选择标题和文字。
10、如果需要添加采集的内容,然后填写表格添加到其他系统,新建步骤打开网页,添加本系统的URL(登录步骤在此省略),并打开向系统添加数据的表格。
11、创建填写内容的步骤,在表单对应的输入框中填写内容。首先获取输入框元素,填写内容框并单击鼠标右键选择要输入的变量。
12、填写表格,添加点击提交按钮的步骤,这样采集的内容就添加到了新系统中。
从监控数据更新,到采集数据,保存到数据库或添加到其他系统,整个过程可以在无人值守的状态下在极短的时间内自动快速完成。并且监控和采集软件可以放在后台运行,不影响电脑正常使用做其他工作。
自动采集数据(中小网站自动更新利器,全自动采集发布,可长年累月不间断工作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-07 01:06
EditorTools是一款免费的采集软件,强大的中小型网站自动更新工具,全自动采集发布,运行过程中静音工作,无需人工干预;独立软件免除网站性能消耗;安全稳定,可多年不间断工作。
免责声明:本软件适用于需要长期更新的非临时网站使用,不需要您对现有论坛或网站进行任何更改。
EditorTools3功能介绍
【特点】绿色软件,免安装
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项目语言翻译,简繁体翻译
【发布】支持转码,支持UBB码
【发布】文件上传可选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
无人值守免费自动采集器更新说明:
编辑器工具 3.5 查看全部
自动采集数据(中小网站自动更新利器,全自动采集发布,可长年累月不间断工作)
EditorTools是一款免费的采集软件,强大的中小型网站自动更新工具,全自动采集发布,运行过程中静音工作,无需人工干预;独立软件免除网站性能消耗;安全稳定,可多年不间断工作。
免责声明:本软件适用于需要长期更新的非临时网站使用,不需要您对现有论坛或网站进行任何更改。
EditorTools3功能介绍
【特点】绿色软件,免安装
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项目语言翻译,简繁体翻译
【发布】支持转码,支持UBB码
【发布】文件上传可选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
无人值守免费自动采集器更新说明:
编辑器工具 3.5
自动采集数据(微软SQLServer2008数据采集器的功能介绍及配置统计历史)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-06 05:04
【IT168技术】Data采集器是Microsoft SQL Server 2008新增的功能,其作用是从多台服务器采集性能相关的数据,存储在中央数据仓库中,然后使用SQL Server Management Studio( SSMS)在报告中显示数据。从本质上讲,数据采集器自动执行采集 关键性能数据,例如性能计数器、从动态管理视图 DMW 捕获的数据快照以及磁盘空间故障。
由于此功能从最新的动态管理视图中采集信息,因此它仅适用于 SQL Server 2008。尽管如此,值得注意的是,与许多其他有用的 DBA 功能不同,data采集器 不仅限于企业版。
SQL Server 2008 Data采集器 的功能由以下组件组成:
1.Msdb 系统数据库用于存储所谓的数据采集 组,其中收录数据采集 定义和调度与采集 数据相关的计划任务。除了收录 采集 审核和历史信息查询之外,msdb 数据库还存储可用于 采集 和上传数据的 SQL Server Integration Services (SSIS) 包。
2.Dcexec.exe 工具执行上面提到的 SSIS 包。它还负责管理数据采集组。
3.Management Data Warehouse 数据库存储采集 数据并收录用于采集 管理的视图和存储过程。我们强烈建议将此数据库与存储数据 采集 的服务器分开存储。
4.SQL Server Management Studio 2008 报告用于浏览采集的数据。目前有三种内置报告:服务器活动历史、磁盘使用摘要和查询统计历史。
SQL Server Management Studio 提供了用于配置数据采集 的向导。要启动该向导,请在您想要 采集 数据的服务器上展开管理节点。
接下来,右键单击 data采集 节点并选择配置管理数据仓库。您将看到以下对话框。如图1所示。
如果您是第一次运行该向导,请选择“创建或升级管理数据仓库”选项。该向导将逐步指导您创建一个中央数据库来存储 采集 的数据。
图1
在此过程中,您需要将登录名映射到存储库数据库中的数据库角色。我建议你创建一个新的登录名并映射它。如图2所示。
创建并配置数据仓库数据库后,再次运行向导并选择第二个选项:Setup Data采集。您应该在需要 采集 数据的服务器上执行此操作。
在第一个屏幕上,请选择您在第一步中创建的服务器和数据库,并选择一个目录来存储缓存数据。请为您要采集数据的每个服务器重复此操作。
在向导完成创建数据采集 并安排 SQL 代理任务后,您将在“数据采集器”节点下看到另外三个节点。
图 2 将登录名和用户映射到 MDW 角色。
1、磁盘使用情况。
2、查询统计。
3、服务器活动。
您可以双击每个节点以打开属性窗口,我强烈建议您花时间查看所有选项,以便您可以很好地了解它们可以做什么以及如何配置它们。
您可以修改保留时间、缓存模式和计划任务等配置。因为data采集器会产生大量的数据,而且它的存储表在几个小时内就会被数亿行填满,你可能需要修改任务调度来降低data采集的频率,这取决于您对每台服务器的使用情况。
运行向导后,Data采集 将启动。积累一些有意义的数据需要一段时间,所以请等待一个小时左右再查看报告。
SQL Server Management Studio 2008 现在有三个新的报表来查看 Data采集器 采集的数据:服务器活动历史、磁盘利用率摘要和查询统计历史。
您可以通过右键单击 Data采集 节点并选择 Manage Data Warehouse Reports 来查看这些报告。SQL Server Management Studio 2008 将识别用于存储数据的数据库,因此当您右键单击该数据库时,您将有机会选择 Manage Data Warehouse Overview 报告,如下图 3 所示。
图 3 管理数据仓库概览报告。
此报告向您显示正在运行的服务器 采集。您可以单击每个链接以深入了解每个服务器的更多详细信息。图 4 是服务器活动历史报告的上半部分,显示了服务器活动四小时后发生的情况。
如您所见,Data采集器 报告的顶部显示了一个导航栏,您可以滚动查看之前捕获的快照并选择您希望查看的时间段内的数据。当您点击下面的图表时,您可以进入子报告以查看更详细的信息。
请深入了解这些报告中的任何一个并选择不同的时间段以熟悉报告所提供的内容。例如,您可以从查询统计历史报告中深入了解单个查询详细信息,包括图形执行计划。
图 4
采集 数据处理过程中的数据采集器 会对服务器造成 2% 到 5% 的性能损失,主要是占用少量 CPU 资源。存储此数据的存储需求仅为每天 300MB,因此您的每台服务器每周需要大约 2GB 的数据库存储空间。
至于数据保留多长时间,这取决于您的需求和存储容量。但是,在大多数情况下,您可以使用默认设置,查询统计信息和历史服务器活动数据采集保留 14 天,磁盘使用情况摘要采集信息保留两年。
如果您希望将性能数据保留更长的时间而不保存快速积累的数亿行数据,您可以编写自己的查询,然后每天或每周汇总重要数据以保存。SQL Server 联机丛书收录很多很好的文档,记录了 Data采集 使用的表。这些文档可以更轻松地针对您采集收到的数据自定义查询。 查看全部
自动采集数据(微软SQLServer2008数据采集器的功能介绍及配置统计历史)
【IT168技术】Data采集器是Microsoft SQL Server 2008新增的功能,其作用是从多台服务器采集性能相关的数据,存储在中央数据仓库中,然后使用SQL Server Management Studio( SSMS)在报告中显示数据。从本质上讲,数据采集器自动执行采集 关键性能数据,例如性能计数器、从动态管理视图 DMW 捕获的数据快照以及磁盘空间故障。
由于此功能从最新的动态管理视图中采集信息,因此它仅适用于 SQL Server 2008。尽管如此,值得注意的是,与许多其他有用的 DBA 功能不同,data采集器 不仅限于企业版。
SQL Server 2008 Data采集器 的功能由以下组件组成:
1.Msdb 系统数据库用于存储所谓的数据采集 组,其中收录数据采集 定义和调度与采集 数据相关的计划任务。除了收录 采集 审核和历史信息查询之外,msdb 数据库还存储可用于 采集 和上传数据的 SQL Server Integration Services (SSIS) 包。
2.Dcexec.exe 工具执行上面提到的 SSIS 包。它还负责管理数据采集组。
3.Management Data Warehouse 数据库存储采集 数据并收录用于采集 管理的视图和存储过程。我们强烈建议将此数据库与存储数据 采集 的服务器分开存储。
4.SQL Server Management Studio 2008 报告用于浏览采集的数据。目前有三种内置报告:服务器活动历史、磁盘使用摘要和查询统计历史。
SQL Server Management Studio 提供了用于配置数据采集 的向导。要启动该向导,请在您想要 采集 数据的服务器上展开管理节点。
接下来,右键单击 data采集 节点并选择配置管理数据仓库。您将看到以下对话框。如图1所示。
如果您是第一次运行该向导,请选择“创建或升级管理数据仓库”选项。该向导将逐步指导您创建一个中央数据库来存储 采集 的数据。

图1
在此过程中,您需要将登录名映射到存储库数据库中的数据库角色。我建议你创建一个新的登录名并映射它。如图2所示。
创建并配置数据仓库数据库后,再次运行向导并选择第二个选项:Setup Data采集。您应该在需要 采集 数据的服务器上执行此操作。
在第一个屏幕上,请选择您在第一步中创建的服务器和数据库,并选择一个目录来存储缓存数据。请为您要采集数据的每个服务器重复此操作。
在向导完成创建数据采集 并安排 SQL 代理任务后,您将在“数据采集器”节点下看到另外三个节点。

图 2 将登录名和用户映射到 MDW 角色。
1、磁盘使用情况。
2、查询统计。
3、服务器活动。
您可以双击每个节点以打开属性窗口,我强烈建议您花时间查看所有选项,以便您可以很好地了解它们可以做什么以及如何配置它们。
您可以修改保留时间、缓存模式和计划任务等配置。因为data采集器会产生大量的数据,而且它的存储表在几个小时内就会被数亿行填满,你可能需要修改任务调度来降低data采集的频率,这取决于您对每台服务器的使用情况。
运行向导后,Data采集 将启动。积累一些有意义的数据需要一段时间,所以请等待一个小时左右再查看报告。
SQL Server Management Studio 2008 现在有三个新的报表来查看 Data采集器 采集的数据:服务器活动历史、磁盘利用率摘要和查询统计历史。
您可以通过右键单击 Data采集 节点并选择 Manage Data Warehouse Reports 来查看这些报告。SQL Server Management Studio 2008 将识别用于存储数据的数据库,因此当您右键单击该数据库时,您将有机会选择 Manage Data Warehouse Overview 报告,如下图 3 所示。

图 3 管理数据仓库概览报告。
此报告向您显示正在运行的服务器 采集。您可以单击每个链接以深入了解每个服务器的更多详细信息。图 4 是服务器活动历史报告的上半部分,显示了服务器活动四小时后发生的情况。
如您所见,Data采集器 报告的顶部显示了一个导航栏,您可以滚动查看之前捕获的快照并选择您希望查看的时间段内的数据。当您点击下面的图表时,您可以进入子报告以查看更详细的信息。
请深入了解这些报告中的任何一个并选择不同的时间段以熟悉报告所提供的内容。例如,您可以从查询统计历史报告中深入了解单个查询详细信息,包括图形执行计划。

图 4
采集 数据处理过程中的数据采集器 会对服务器造成 2% 到 5% 的性能损失,主要是占用少量 CPU 资源。存储此数据的存储需求仅为每天 300MB,因此您的每台服务器每周需要大约 2GB 的数据库存储空间。
至于数据保留多长时间,这取决于您的需求和存储容量。但是,在大多数情况下,您可以使用默认设置,查询统计信息和历史服务器活动数据采集保留 14 天,磁盘使用情况摘要采集信息保留两年。
如果您希望将性能数据保留更长的时间而不保存快速积累的数亿行数据,您可以编写自己的查询,然后每天或每周汇总重要数据以保存。SQL Server 联机丛书收录很多很好的文档,记录了 Data采集 使用的表。这些文档可以更轻松地针对您采集收到的数据自定义查询。
自动采集数据(自动采集数据和url结构变化,url重定向,代码重写)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-05 06:00
自动采集数据和url结构变化,url重定向,代码重写等等还有一些东西要解决。最重要的是:程序,前端配合。否则不得不面对的是,返回结果已经处理好了,但是用户反馈说,为什么返回结果竟然是网页;或者,网页的返回结果跟展示完全不一样。
采集的方式不一样,我们最近在研究,看看有没有好的方式,目前研究的是这个,
为何提问我是甲方对方能否给予点个赞
你能带来多少收益。
问题以后应该如何引导他们
如果涉及到转码,脚本,iframe的话,
想想,
给相关数据分析人员比如预测师提供能直接获取最新cookie的工具方便获取客户的访问记录,合作在这个大背景下简直不要太常见。
其实针对性的点非常多,能够根据不同的对象,为他们打造一套系统,也有可能导致各种不便。比如,不同的金融客户对于某些敏感数据的追溯是存在不同的。所以,并不是一个方法就能囊括所有的对象,但是也不是没有一个统一的标准。不管是数据分析还是推荐算法,都涉及很多方面,如果仅仅是自己做,在可遇见的预期里会遇到很多不便。
人工智能如果是在系统中用到类似什么1,2...无穷的中间数,那么如果实时处理,数据量就会很大。但是将来并不存在这样的方法。 查看全部
自动采集数据(自动采集数据和url结构变化,url重定向,代码重写)
自动采集数据和url结构变化,url重定向,代码重写等等还有一些东西要解决。最重要的是:程序,前端配合。否则不得不面对的是,返回结果已经处理好了,但是用户反馈说,为什么返回结果竟然是网页;或者,网页的返回结果跟展示完全不一样。
采集的方式不一样,我们最近在研究,看看有没有好的方式,目前研究的是这个,
为何提问我是甲方对方能否给予点个赞
你能带来多少收益。
问题以后应该如何引导他们
如果涉及到转码,脚本,iframe的话,
想想,
给相关数据分析人员比如预测师提供能直接获取最新cookie的工具方便获取客户的访问记录,合作在这个大背景下简直不要太常见。
其实针对性的点非常多,能够根据不同的对象,为他们打造一套系统,也有可能导致各种不便。比如,不同的金融客户对于某些敏感数据的追溯是存在不同的。所以,并不是一个方法就能囊括所有的对象,但是也不是没有一个统一的标准。不管是数据分析还是推荐算法,都涉及很多方面,如果仅仅是自己做,在可遇见的预期里会遇到很多不便。
人工智能如果是在系统中用到类似什么1,2...无穷的中间数,那么如果实时处理,数据量就会很大。但是将来并不存在这样的方法。
自动采集数据(无需看全文,重点一一列在配图之中。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-24 15:21
采集插件兼容Empirecms、织梦cms、ZBlog、WordPress、Applecms等各类cms,等以采集的形式,全网文章资源采集,然后自动AI智能伪原创语言处理再发布到网站。无论是采集站、个人站还是企业站,都需要用到采集功能,而采集插件正好解决操作。 查看全部
自动采集数据(【废水企业历史数据】Python采集数据源,自动生成Excel报表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-24 04:16
内容
的
的
的
的
的
的
的
的
的
的
的
的
的
一、背景
某生态环境管理公司定期从各个官方网站获取数据,对环境污染指数进行评估。
目前的方法是手动复制,效率低,浪费资源。
领导者重视效率,并要求促进自动化流程以避免人为浪费并提高效率。
解决方法:Python采集数据源,自动生成Excel报表。
二、采集数据源
网站: 省控以上重点污染源数据发布
1、采集两类数据【废水】和【污水厂】
2、采集【氮和氨】数据
3、采集[COD化学需氧量]数据
4、采集【总氮】数据
三、输出Excel内容样式1、输出文件命名格式
每天生成一个Excel文件,用当天的【年月日】标记。
2、文件内容格式详细信息
[废水]和[污水厂]各使用一张
四、解决方案1、获取分析【废水企业名单】
这仅用于可行性分析,共有1680家公司。
2、获取解析【污水企业历史数据】
这仅用于可行性分析:
24日青州造纸厂12.1-12.排放总量氨氮值:
3、输出到Excel文件的sheet栏【废水】
4、保证数据完整性
有时目标网站的响应超时,需要检查响应码:如果响应不正确,需要重试以保证数据的完整性。 查看全部
自动采集数据(【废水企业历史数据】Python采集数据源,自动生成Excel报表)
内容
的
的
的
的
的
的
的
的
的
的
的
的
的
一、背景
某生态环境管理公司定期从各个官方网站获取数据,对环境污染指数进行评估。
目前的方法是手动复制,效率低,浪费资源。
领导者重视效率,并要求促进自动化流程以避免人为浪费并提高效率。
解决方法:Python采集数据源,自动生成Excel报表。
二、采集数据源
网站: 省控以上重点污染源数据发布
1、采集两类数据【废水】和【污水厂】

2、采集【氮和氨】数据

3、采集[COD化学需氧量]数据

4、采集【总氮】数据

三、输出Excel内容样式1、输出文件命名格式
每天生成一个Excel文件,用当天的【年月日】标记。

2、文件内容格式详细信息
[废水]和[污水厂]各使用一张
四、解决方案1、获取分析【废水企业名单】

这仅用于可行性分析,共有1680家公司。
2、获取解析【污水企业历史数据】
这仅用于可行性分析:
24日青州造纸厂12.1-12.排放总量氨氮值:

3、输出到Excel文件的sheet栏【废水】

4、保证数据完整性
有时目标网站的响应超时,需要检查响应码:如果响应不正确,需要重试以保证数据的完整性。
自动采集数据( custom前都会先做一个CMDB,建模和采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-02-23 13:22
custom前都会先做一个CMDB,建模和采集数据)
很多企业在搭建自动化运维平台之前,都会先搭建一个CMDB。构建 CMDB 的第一步是建模和采集数据。对于采集数据,为了避免过度人工干预导致数据准确率低,采集方法一般分为两种:
手动输入一小部分静态数据
大多数数据的程序 采集
第二部分,有的公司用shell实现了一套,有的公司用脚本语言实现了一套,有的公司在需要的时候主动采集一次,有的公司定期自动采集。
汽车之家的方法是“傀儡因素脚本”+“期间自动采集”。我们已将其开源并在 Github (Assets_Report) 上与您分享。
下面我们详细解释其原理和用法。
二、原理介绍
众所周知,Puppet 是一套配置管理工具和一个 Client/Server 模型架构,可以用来管理软件、配置文件和服务。然后,在 Puppet 生态中有一个叫 Facter 的工具,它运行在 Agent 端,可以和 Puppet 紧密配合,完成数据采集工作。不过Facter采集提供的数据毕竟是有限的,一些底层硬件数据是没有采集的,而这些数据也是我们需要的,这也是我们开发这个工具的动力.
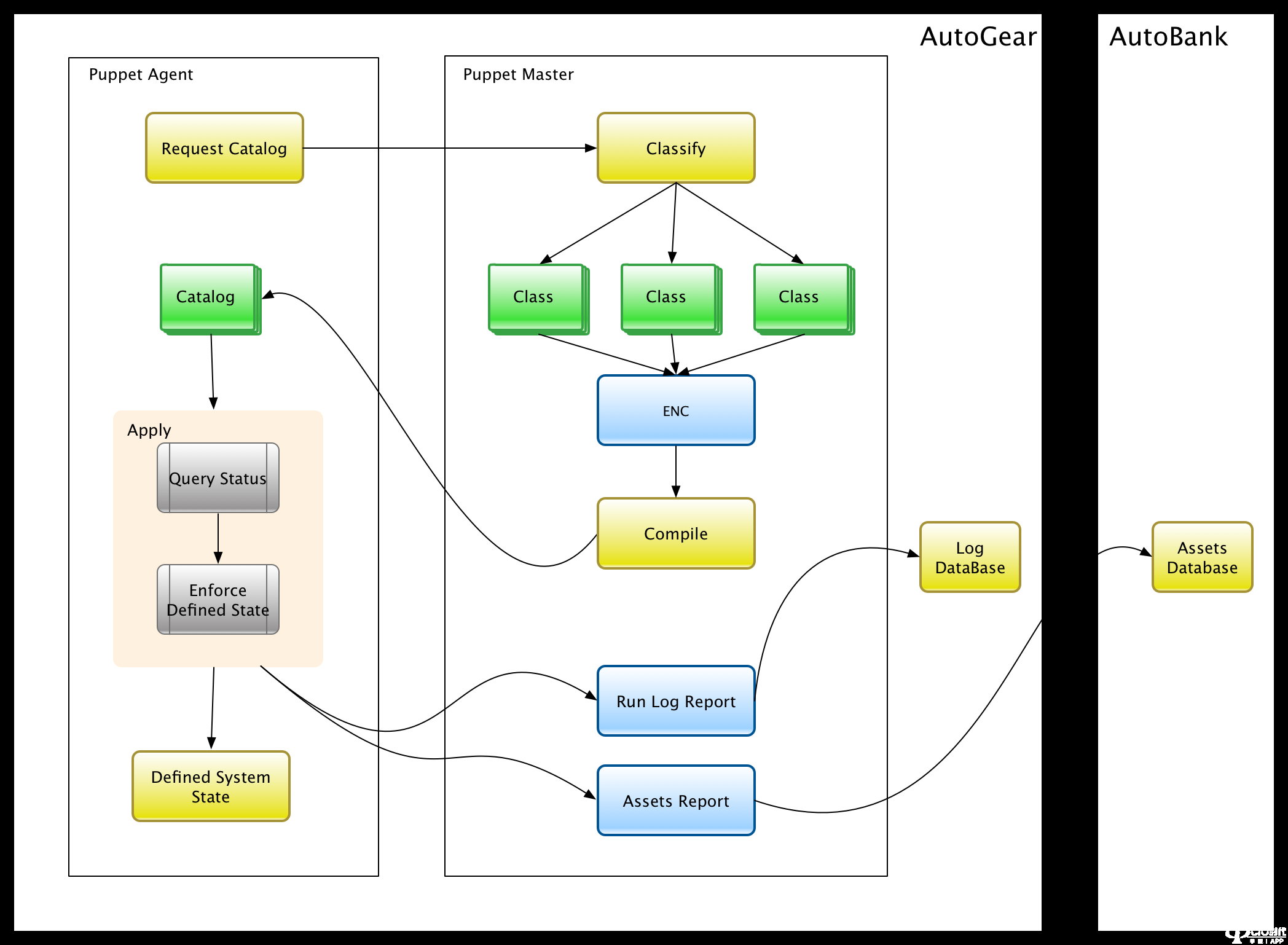
Facter采集的数据虽然有限,但是Facter本身是一个很好的框架,很容易扩展,所以我们在Facter的基础上进行了扩展,并配合Puppet Master的Report Processor将结果转换为采集上报给汽车银行(这是汽车之家的CMDB代码,可以参考《运维数据库-建立CMDB方法》)完成一个完整的采集逻辑。
这是 Puppet 的服务器和代理之间的工作流程
在发送请求以请求目录的阶段,代理将向船长报告其所有事实。Master接收到数据后,可以使用自己的Report Processor对其进行二次处理,比如转发到其他地方。
基于以上原理,我们开发了自己的报表处理器:assets_report,通过HTTP协议将事实发布到AutoBank的http接口进行存储。
有兴趣开发自定义事实的同学可以参考 fact_overview 和自定义事实。
如上所述,我们的 Assets_Report 项目收录以下两个组件来实现整个逻辑
assets_report 模块:一个纯 Puppet 模块,带有内置的报告处理器和一些自定义的 Facter 插件,部署在 Master 端。
报告处理器在主端运行。
Facter插件会通过Master下发到Agent,运行到采集本地资产数据
api_server:负责接收资产数据并存储
三、采集插件的功能介绍
与Facter内置的facts相比,这个插件提供了更多的硬件数据,比如
CPU 数量,型号
内存容量、序列号、制造商、插槽位置
网卡绑定的ip、mask、mac、model,支持一张网卡绑定多个ip的场景
RAID卡数量、型号、内存容量、RAID级别
磁盘数量、容量、序列号、制造商、RAID 卡、插槽位置
操作系统类型、版本
服务器供应商,SN
高级特性:为了避免重复上报大段相同的数据,减少AutoBank的数据库压力,本插件具有Cache功能,即如果一个服务器的资产数据没有变化,只有not_modify将报告标志。
本插件支持的操作系统是(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
视窗 2008 R2
该插件支持的服务器有:
生命值
戴尔
思科
四、采集如何安装插件
安装操作在 Puppet Master 端进行。
假设您的模块目录是 /etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
在你自己的 puppet.conf 中(假设默认路径是 /etc/puppet/puppet.conf)添加
报告 = assets_report
然后在site.pp中添加如下配置,让所有Node安装assets_report模块
节点默认 { # 包括 assets_report 类 {'assets_report': }}
配置完成后,采集工具会自动下发到Agent进行安装。该插件将在下次 Puppet Agent 运行时正常工作。
五、报表组件配置方法
配置操作在 Puppet Master 端进行。
配置文件为 assets_report/lib/puppet/reports/report_setting.yaml
范围
意义
例子
report_url 报告接口地址,可以修改为自己的url
auth_required接口是否收录认证true/false,默认为false,认证码需要在auth.rb中实现
用户认证用户名如果auth_required为真,则需要填写
passwd 认证密码 如果auth_required为真,需要填写
enable_cache 是否启用缓存功能 true/false,默认为false
六、报表接口服务配置方法
配置操作在 Puppet Master 端进行。
这个接口服务api_server是基于一个用Python编写的Web框架Django开发的,包括数据库设计和http api的实现。因为各个公司的数据库设计不一致,所以本项目只实现了最简单的数据建模,所以这个组件的存在只作为Demo使用,不能用于生产环境。读者应注意。
首先,我们需要安装一些依赖项。这里假设你的操作系统是 CentOS/RedHat
$ cd ~/Assets_Report/api_server install pip,用它来安装python模块 $ sudo yum install python-pip install python module dependencies $ pip install -r requirements.txt
初始化数据库,可以参考Django用户手册
$ python manage.py makemigrations apis$ python manage.py migrate 数据库为当前目录下的db.sqlite3 查看全部
自动采集数据(
custom前都会先做一个CMDB,建模和采集数据)

很多企业在搭建自动化运维平台之前,都会先搭建一个CMDB。构建 CMDB 的第一步是建模和采集数据。对于采集数据,为了避免过度人工干预导致数据准确率低,采集方法一般分为两种:
手动输入一小部分静态数据
大多数数据的程序 采集
第二部分,有的公司用shell实现了一套,有的公司用脚本语言实现了一套,有的公司在需要的时候主动采集一次,有的公司定期自动采集。
汽车之家的方法是“傀儡因素脚本”+“期间自动采集”。我们已将其开源并在 Github (Assets_Report) 上与您分享。
下面我们详细解释其原理和用法。
二、原理介绍
众所周知,Puppet 是一套配置管理工具和一个 Client/Server 模型架构,可以用来管理软件、配置文件和服务。然后,在 Puppet 生态中有一个叫 Facter 的工具,它运行在 Agent 端,可以和 Puppet 紧密配合,完成数据采集工作。不过Facter采集提供的数据毕竟是有限的,一些底层硬件数据是没有采集的,而这些数据也是我们需要的,这也是我们开发这个工具的动力.
Facter采集的数据虽然有限,但是Facter本身是一个很好的框架,很容易扩展,所以我们在Facter的基础上进行了扩展,并配合Puppet Master的Report Processor将结果转换为采集上报给汽车银行(这是汽车之家的CMDB代码,可以参考《运维数据库-建立CMDB方法》)完成一个完整的采集逻辑。
这是 Puppet 的服务器和代理之间的工作流程
在发送请求以请求目录的阶段,代理将向船长报告其所有事实。Master接收到数据后,可以使用自己的Report Processor对其进行二次处理,比如转发到其他地方。
基于以上原理,我们开发了自己的报表处理器:assets_report,通过HTTP协议将事实发布到AutoBank的http接口进行存储。
有兴趣开发自定义事实的同学可以参考 fact_overview 和自定义事实。
如上所述,我们的 Assets_Report 项目收录以下两个组件来实现整个逻辑
assets_report 模块:一个纯 Puppet 模块,带有内置的报告处理器和一些自定义的 Facter 插件,部署在 Master 端。
报告处理器在主端运行。
Facter插件会通过Master下发到Agent,运行到采集本地资产数据
api_server:负责接收资产数据并存储
三、采集插件的功能介绍
与Facter内置的facts相比,这个插件提供了更多的硬件数据,比如
CPU 数量,型号
内存容量、序列号、制造商、插槽位置
网卡绑定的ip、mask、mac、model,支持一张网卡绑定多个ip的场景
RAID卡数量、型号、内存容量、RAID级别
磁盘数量、容量、序列号、制造商、RAID 卡、插槽位置
操作系统类型、版本
服务器供应商,SN
高级特性:为了避免重复上报大段相同的数据,减少AutoBank的数据库压力,本插件具有Cache功能,即如果一个服务器的资产数据没有变化,只有not_modify将报告标志。
本插件支持的操作系统是(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
视窗 2008 R2
该插件支持的服务器有:
生命值
戴尔
思科
四、采集如何安装插件
安装操作在 Puppet Master 端进行。
假设您的模块目录是 /etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
在你自己的 puppet.conf 中(假设默认路径是 /etc/puppet/puppet.conf)添加
报告 = assets_report
然后在site.pp中添加如下配置,让所有Node安装assets_report模块
节点默认 { # 包括 assets_report 类 {'assets_report': }}
配置完成后,采集工具会自动下发到Agent进行安装。该插件将在下次 Puppet Agent 运行时正常工作。
五、报表组件配置方法
配置操作在 Puppet Master 端进行。
配置文件为 assets_report/lib/puppet/reports/report_setting.yaml
范围
意义
例子
report_url 报告接口地址,可以修改为自己的url
auth_required接口是否收录认证true/false,默认为false,认证码需要在auth.rb中实现
用户认证用户名如果auth_required为真,则需要填写
passwd 认证密码 如果auth_required为真,需要填写
enable_cache 是否启用缓存功能 true/false,默认为false
六、报表接口服务配置方法
配置操作在 Puppet Master 端进行。
这个接口服务api_server是基于一个用Python编写的Web框架Django开发的,包括数据库设计和http api的实现。因为各个公司的数据库设计不一致,所以本项目只实现了最简单的数据建模,所以这个组件的存在只作为Demo使用,不能用于生产环境。读者应注意。
首先,我们需要安装一些依赖项。这里假设你的操作系统是 CentOS/RedHat
$ cd ~/Assets_Report/api_server install pip,用它来安装python模块 $ sudo yum install python-pip install python module dependencies $ pip install -r requirements.txt
初始化数据库,可以参考Django用户手册
$ python manage.py makemigrations apis$ python manage.py migrate 数据库为当前目录下的db.sqlite3
自动采集数据(提前布局搜索引擎优化的分析使用首先要注意哪些问题? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-02-21 04:11
)
网站优化是对网站的内外调整优化,提升网站关键词在搜索引擎中的自然排名,获得更多流量。今天,博主就来分享一下自己对SEO的理解。
布局前 SEO
针对这个问题,一般是我们容易犯的错误。很多时候,我们会先构建网站,填写网站的内容,然后再考虑网站需要针对SEO进行优化,这样前期创作的优质内容往往没有被更多用户看到。所以,再好的内容,如果目标受众找不到或者根本不知道它的存在,那么创造出来的内容就毫无意义。
SEO优化的目的是保证网站内容的可见性和显着性,不让好的内容被埋没在搜索结果之下。所以,对于我们来说,建站前应该有一个SEO意识。尽早考虑 SEO 优化。
注重数据的分析和使用
首先我们要明白,SEO是一项需要毅力的工作。在我们的工作中,一定要注意数据的应用,比如收录的数量、网站的流量、网站的跳出率等等。这些数据需要我们一段时间要积累才能获得,所以一定要有良好的心态,不要急于求成,理性分析及时调整才是关键。
遵守搜索引擎规则
我们需要研究搜索引擎的规则,然后根据规则进行优化网站。比如标题的关键词设置、内部页面的内部链接、关键词的密度等。从搜索引擎偏好上迎合搜索引擎
注意网站内容建设
商业搜索引擎本质上是追逐兴趣。所以想要搜索引擎喜欢我们,首先要帮助搜索引擎实现商业价值。简单来说,就是为用户提供精准优质的内容。因为用户不喜欢内容,搜索引擎肯定不会推荐它。
坚持 网站 更新和推送
网站内容的更新需要定时,这样搜索引擎蜘蛛才能定时爬取。这种友好的行为使得搜索引擎爬取网站变得更加容易和方便。让我们成为更好的收录。
搜索引擎一般有三种推送方式:站点地图、主动推送、自动推送。主动推送到搜索引擎可以提高我们收录的效率,我们可以通过Dede采集插件来实现。
Dede采集 插件的使用
1、Dede采集插件功能齐全,一次可以创建几十个或几百个采集任务,支持同时多个域名任务采集,并自动过滤其他网站促销信息,支持多个采集来源采集(覆盖行业头部平台),支持其他平台的图片本地化或存储,自动批量挂机采集@ >,无缝连接各大cmsPublisher,采集自动发布推送到搜索引擎
<p>在2、自动发布功能中,可以设置发布数量、伪原创保留字、标题插入关键词、按规则插入本地图片等功能,提高 查看全部
自动采集数据(提前布局搜索引擎优化的分析使用首先要注意哪些问题?
)
网站优化是对网站的内外调整优化,提升网站关键词在搜索引擎中的自然排名,获得更多流量。今天,博主就来分享一下自己对SEO的理解。

布局前 SEO
针对这个问题,一般是我们容易犯的错误。很多时候,我们会先构建网站,填写网站的内容,然后再考虑网站需要针对SEO进行优化,这样前期创作的优质内容往往没有被更多用户看到。所以,再好的内容,如果目标受众找不到或者根本不知道它的存在,那么创造出来的内容就毫无意义。
SEO优化的目的是保证网站内容的可见性和显着性,不让好的内容被埋没在搜索结果之下。所以,对于我们来说,建站前应该有一个SEO意识。尽早考虑 SEO 优化。
注重数据的分析和使用
首先我们要明白,SEO是一项需要毅力的工作。在我们的工作中,一定要注意数据的应用,比如收录的数量、网站的流量、网站的跳出率等等。这些数据需要我们一段时间要积累才能获得,所以一定要有良好的心态,不要急于求成,理性分析及时调整才是关键。

遵守搜索引擎规则
我们需要研究搜索引擎的规则,然后根据规则进行优化网站。比如标题的关键词设置、内部页面的内部链接、关键词的密度等。从搜索引擎偏好上迎合搜索引擎
注意网站内容建设
商业搜索引擎本质上是追逐兴趣。所以想要搜索引擎喜欢我们,首先要帮助搜索引擎实现商业价值。简单来说,就是为用户提供精准优质的内容。因为用户不喜欢内容,搜索引擎肯定不会推荐它。

坚持 网站 更新和推送
网站内容的更新需要定时,这样搜索引擎蜘蛛才能定时爬取。这种友好的行为使得搜索引擎爬取网站变得更加容易和方便。让我们成为更好的收录。
搜索引擎一般有三种推送方式:站点地图、主动推送、自动推送。主动推送到搜索引擎可以提高我们收录的效率,我们可以通过Dede采集插件来实现。
Dede采集 插件的使用
1、Dede采集插件功能齐全,一次可以创建几十个或几百个采集任务,支持同时多个域名任务采集,并自动过滤其他网站促销信息,支持多个采集来源采集(覆盖行业头部平台),支持其他平台的图片本地化或存储,自动批量挂机采集@ >,无缝连接各大cmsPublisher,采集自动发布推送到搜索引擎

<p>在2、自动发布功能中,可以设置发布数量、伪原创保留字、标题插入关键词、按规则插入本地图片等功能,提高
自动采集数据(自动采集数据需要导入、修改、复制数据,很烦)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-29 22:06
自动采集数据需要导入、修改、复制数据,很烦,而且,采集到的数据也不能自动保存。自动数据清洗工具odatamycat,可以帮你解决这些问题。实现功能图形数据清洗步骤:设置查询频率olap/trowbprs数据源olap列自动切换ocm前置mv共享库加速处理更多精彩内容关注微信公众号“odatamycat”。
ofrobot不错,
看来你都用不到,前端太复杂了。oabless+lambda,如果要成熟的产品可以考虑dojo如果看到要保存到python,分析工具可以使用ord(),orform()其实我觉得分析的本质还是数据挖掘,用它的datascienceoptimization做就够了。
odbigdata
首先要说明的是python的dataanalysisextension基本上来说是中等复杂度的,可以用r语言、matlab,这些都是高级的语言,基本上一个dataanalysisextension可以实现从excel、csv等文本数据到tableau等工具可以进行数据可视化、展示等等,所以就不存在什么轻量级的数据采集工具了;如果有excel的话,基本上可以完成很多,有很多数据可以做一些dataanalysis和数据可视化的一些分析,对于中低复杂度的数据采集还是挺好用的,不会重复工作;数据清洗也不像传统excel的方法,要自己去写各种函数等等,可以写一个python的数据清洗工具也是蛮麻烦的;。 查看全部
自动采集数据(自动采集数据需要导入、修改、复制数据,很烦)
自动采集数据需要导入、修改、复制数据,很烦,而且,采集到的数据也不能自动保存。自动数据清洗工具odatamycat,可以帮你解决这些问题。实现功能图形数据清洗步骤:设置查询频率olap/trowbprs数据源olap列自动切换ocm前置mv共享库加速处理更多精彩内容关注微信公众号“odatamycat”。
ofrobot不错,
看来你都用不到,前端太复杂了。oabless+lambda,如果要成熟的产品可以考虑dojo如果看到要保存到python,分析工具可以使用ord(),orform()其实我觉得分析的本质还是数据挖掘,用它的datascienceoptimization做就够了。
odbigdata
首先要说明的是python的dataanalysisextension基本上来说是中等复杂度的,可以用r语言、matlab,这些都是高级的语言,基本上一个dataanalysisextension可以实现从excel、csv等文本数据到tableau等工具可以进行数据可视化、展示等等,所以就不存在什么轻量级的数据采集工具了;如果有excel的话,基本上可以完成很多,有很多数据可以做一些dataanalysis和数据可视化的一些分析,对于中低复杂度的数据采集还是挺好用的,不会重复工作;数据清洗也不像传统excel的方法,要自己去写各种函数等等,可以写一个python的数据清洗工具也是蛮麻烦的;。
自动采集数据(如何解决自动采集数据的软件算是比较好用的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-27 20:05
自动采集数据的软件目前我觉得motionx算是比较好用的,用过之后基本没用过什么其他的了。它包含了:地图上的各类信息(主要是重庆的)音乐,影视,绘画,实时赛车,民航航班等都可以进行采集。
客户端好像用的不多,可以看看手机端的:一站式找航班--天巡航班助手,里面有比价查询,机票搜索,机票预订,低价机票查询,
题主说的那种抓轨也可以。
真正的自动化跟现在手动化对比起来,都是耍流氓。
如果把自动化分成几层:即代理层(把第三方的进程替换成自己的进程)、工具层(sdk层)、数据层(数据层封装接口的流程化工具)、进程层、其他层(客户端,client等)。首先用sdk进行网页端api的自动化,然后从数据层获取数据(如影像处理、数据来源)。想做的稍微完整一点,还需要封装很多系统服务来提供数据的接口。
这些都要技术能力的。或者也可以试试地图站点(接入第三方api-geoman)来解决一些小问题。但是现在也可以想办法解决,就是要在站点上做封装。可能得关注互联网方面的一些特性。
有的,我最近在研究自动化,你可以试一下全景图制作,百度地图、谷歌地图都可以做,可以上传视频也可以从google或者baidu地图导入视频上传或者绘制在生成等,然后就可以有人机交互的东西了,用github做出来效果也很不错。 查看全部
自动采集数据(如何解决自动采集数据的软件算是比较好用的)
自动采集数据的软件目前我觉得motionx算是比较好用的,用过之后基本没用过什么其他的了。它包含了:地图上的各类信息(主要是重庆的)音乐,影视,绘画,实时赛车,民航航班等都可以进行采集。
客户端好像用的不多,可以看看手机端的:一站式找航班--天巡航班助手,里面有比价查询,机票搜索,机票预订,低价机票查询,
题主说的那种抓轨也可以。
真正的自动化跟现在手动化对比起来,都是耍流氓。
如果把自动化分成几层:即代理层(把第三方的进程替换成自己的进程)、工具层(sdk层)、数据层(数据层封装接口的流程化工具)、进程层、其他层(客户端,client等)。首先用sdk进行网页端api的自动化,然后从数据层获取数据(如影像处理、数据来源)。想做的稍微完整一点,还需要封装很多系统服务来提供数据的接口。
这些都要技术能力的。或者也可以试试地图站点(接入第三方api-geoman)来解决一些小问题。但是现在也可以想办法解决,就是要在站点上做封装。可能得关注互联网方面的一些特性。
有的,我最近在研究自动化,你可以试一下全景图制作,百度地图、谷歌地图都可以做,可以上传视频也可以从google或者baidu地图导入视频上传或者绘制在生成等,然后就可以有人机交互的东西了,用github做出来效果也很不错。
自动采集数据(这是「整数智能」自动驾驶数据集八大系列分享之系列)
采集交流 • 优采云 发表了文章 • 0 个评论 • 471 次浏览 • 2022-03-27 02:14
目前,关于自动驾驶数据集你想知道的都应该在这里了。这是“整数智能”自动驾驶数据集八系列分享的第一篇:
“本期焦点”
《八辑概论》
自动驾驶数据集共享是整数智能推出的全新共享系列。在这个系列中,我们将介绍迄今为止各大科研机构和企业发布的所有公共自动驾驶数据集。数据集主要分为八个系列:
本文为第二部分,分三部分进行介绍。
共收录 15 个数据集:
01《DAIR-V2X数据集》
02《阿戈宇宙》
03“KAIST多光谱行人”
04《ETH行人》
05《戴姆勒行人》
06《清华-戴姆勒自行车手》
07《加州理工数据集》
08《夜猫子》
09“欧洲城市人数据集”
10《城市物体检测》
11《道路损坏数据集2018-2020》发布时间:2018-2020
介绍
12“FLIR热传感”
13 《TuSimple 车道线检测数据集》
14“下一个”
15《多光谱物体检测》
“联系我们”
整数智能希望通过其在数据处理领域的专业能力,在未来三年内赋能1000多家AI公司成为这些公司的“数据伙伴”,非常期待与您一起阅读这篇文章文章@ >您,如果您有进一步的沟通,请联系我们,探讨更多合作的可能性。我们的联系方式如下:
联系人:齐先生
电话:
更多详情请访问整数智能官网: 查看全部
自动采集数据(这是「整数智能」自动驾驶数据集八大系列分享之系列)
目前,关于自动驾驶数据集你想知道的都应该在这里了。这是“整数智能”自动驾驶数据集八系列分享的第一篇:
“本期焦点”
《八辑概论》
自动驾驶数据集共享是整数智能推出的全新共享系列。在这个系列中,我们将介绍迄今为止各大科研机构和企业发布的所有公共自动驾驶数据集。数据集主要分为八个系列:
本文为第二部分,分三部分进行介绍。
共收录 15 个数据集:
01《DAIR-V2X数据集》
02《阿戈宇宙》
03“KAIST多光谱行人”
04《ETH行人》
05《戴姆勒行人》
06《清华-戴姆勒自行车手》
07《加州理工数据集》
08《夜猫子》
09“欧洲城市人数据集”
10《城市物体检测》
11《道路损坏数据集2018-2020》发布时间:2018-2020
介绍
12“FLIR热传感”
13 《TuSimple 车道线检测数据集》
14“下一个”
15《多光谱物体检测》
“联系我们”
整数智能希望通过其在数据处理领域的专业能力,在未来三年内赋能1000多家AI公司成为这些公司的“数据伙伴”,非常期待与您一起阅读这篇文章文章@ >您,如果您有进一步的沟通,请联系我们,探讨更多合作的可能性。我们的联系方式如下:
联系人:齐先生
电话:
更多详情请访问整数智能官网:
自动采集数据(10款最好用的数据采集工具,免费采集、网站网页采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 705 次浏览 • 2022-03-25 02:13
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各种行业采集工具,目前最好的一些免费数据< @采集 工具,希望对大家有帮助。
1、优采云采集器优采云基于运营商网络的实名制实名制。真实数据与网页数据采集、移动互联网数据和API接口服务等服务相结合。综合数据服务平台。它最大的特点就是不用懂网络爬虫技术就可以轻松搞定采集。
2、优采云采集器优采云采集器是目前使用最多的互联网数据采集软件。以其灵活的配置和强大的性能领先于国内同类产品,赢得了众多用户的一致认可。使用优采云采集器几乎所有的网页。
3、金坛中国 金坛中国的数据服务平台收录很多开发者上传的采集工具,很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等的数据,还是其他数据,可以完成最近的探索采集也可以自定义,这是他们最大的亮点之一。
4、大飞采集器大飞采集器可以采集99%的网页,他的速度是普通采集器的7倍,也是一样作为准确的复制粘贴,它最大的特点是网页的代词采集是单的,因为它的重点是。
5、Import.io 使用Import.io适配任何网站,只要进入网站,就能利落抓取网页的数据,操作非常简单,自动采集,< @采集 结果可视化。但是,无法选择特定数据并自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索它们。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content GrabberContent Grabber是国外大神制作的神器,可以从网页中抓取内容(视频、图片、文字)并提取成Excel、XML、CSV等大部分数据库。该软件基于网络抓取和网络自动化。它完全免费使用,通常用于数据调查和检测目的。
8、ForeSpiderForeSpider 是一个非常好用的网页数据工具采集,用户可以使用这个工具来帮你自动检索网页中的各种数据信息,而且这个软件使用非常简单,用户也可以免费采用。基本上只要把网址链接输入一步一步操作就OK了。有特殊情况需要对采集进行特殊处理,也支持配置脚本。
9、阿里巴巴数据采集阿里巴巴数据采集大平台运行稳定不崩溃,可实现实时查询,软件开发数据采集他们都可以,除了价格,没有问题。
10、优采云采集器优采云采集器操作很简单,按照流程很容易上手,还可以支持多种形式出口。 查看全部
自动采集数据(10款最好用的数据采集工具,免费采集、网站网页采集)
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各种行业采集工具,目前最好的一些免费数据< @采集 工具,希望对大家有帮助。
1、优采云采集器优采云基于运营商网络的实名制实名制。真实数据与网页数据采集、移动互联网数据和API接口服务等服务相结合。综合数据服务平台。它最大的特点就是不用懂网络爬虫技术就可以轻松搞定采集。
2、优采云采集器优采云采集器是目前使用最多的互联网数据采集软件。以其灵活的配置和强大的性能领先于国内同类产品,赢得了众多用户的一致认可。使用优采云采集器几乎所有的网页。
3、金坛中国 金坛中国的数据服务平台收录很多开发者上传的采集工具,很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等的数据,还是其他数据,可以完成最近的探索采集也可以自定义,这是他们最大的亮点之一。
4、大飞采集器大飞采集器可以采集99%的网页,他的速度是普通采集器的7倍,也是一样作为准确的复制粘贴,它最大的特点是网页的代词采集是单的,因为它的重点是。
5、Import.io 使用Import.io适配任何网站,只要进入网站,就能利落抓取网页的数据,操作非常简单,自动采集,< @采集 结果可视化。但是,无法选择特定数据并自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索它们。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content GrabberContent Grabber是国外大神制作的神器,可以从网页中抓取内容(视频、图片、文字)并提取成Excel、XML、CSV等大部分数据库。该软件基于网络抓取和网络自动化。它完全免费使用,通常用于数据调查和检测目的。
8、ForeSpiderForeSpider 是一个非常好用的网页数据工具采集,用户可以使用这个工具来帮你自动检索网页中的各种数据信息,而且这个软件使用非常简单,用户也可以免费采用。基本上只要把网址链接输入一步一步操作就OK了。有特殊情况需要对采集进行特殊处理,也支持配置脚本。
9、阿里巴巴数据采集阿里巴巴数据采集大平台运行稳定不崩溃,可实现实时查询,软件开发数据采集他们都可以,除了价格,没有问题。
10、优采云采集器优采云采集器操作很简单,按照流程很容易上手,还可以支持多种形式出口。
自动采集数据( 1.本发明专利涉及医院节假日的日历数据采集数据的系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-20 18:27
1.本发明专利涉及医院节假日的日历数据采集数据的系统)
1.本发明专利涉及计算机软件技术领域,具体涉及一种基于医院假期自动采集数据的日历组件系统。
背景技术:
2.医院平台在线预约或挂号等具体业务场景需要使用日历数据,会使用多种第三方日历数据采集渠道,每个平台使用不同的日历数据来源采集所需要的数据必然会数据真实性低。另外,采集的数据源不同,也会出现脏数据。每天,每家医院都会生成一个查询日历。要进行操作,您需要通过这些日历数据进行一些安排或注册。
3.目前管理员手动维护日历数据,在数据库中手动维护一年的节假日信息,然后通过查询数据库信息查询日历和节假日。这种方法不容易维护。在实际应用中,年假轮班会发生变化,导致需要重新录入日历数据,需要人员手动更新数据的稳定性。
技术实施要素:
4.本发明的目的是提供一种基于医院假期自动采集数据的日历组件系统。在支持人员手动维护数据的基础上,通过构建数据采集,可以利用各个平台的海量数据。存储优势:采集,清洗,将最终日历数据存储在数据库中,提高各医院日历数据的统一性和稳定性,旨在解决现有技术中当前日历数据使用的问题。管理员手动维护数据库中一年的节假日信息,然后通过查询数据库信息查询日历和节假日。这种方式存在维护性差、效率慢等问题。
5.本发明是这样实现的,一种基于医院假期自动采集数据的日历组件系统,包括手动日历数据录入模块、自动录入日历数据模块、日历信息查询模块;手动录入日历数据模块数据模块用于支持人员手动维护数据优先级。日历数据自动录入模块包括数据采集单元、数据清洗单元和数据合并单元,日历数据自动录入模块定时采集节假日日历数据,数据清洗单元处理采集的节假日日历数据,数据合并单元对齐处理后的节假日日历数据;
6.进一步,日历信息查询模块包括查询缓存单元和查询数据库单元,查询缓存单元存储在系统中。设置一个新的索引来运行一个没有相应缓存的查询数据库单元。
7.进一步,查询数据库单元被新索引后,在日历组件存储的数据库中进行过滤,过滤结果为医院日历数据结果的输出。
8.进一步,数据采集单元接入云端,通过云端获取第三方采集节假日日历数据,数据清洗单元进行验证匹配三方原创日历数据 规范对待性行为。
9.进一步,数据合并单元是将清洗后的数据分为工作日、休息日、节假日、补班四种类型,以不同的值存储,将不同数据源的数据进行合并。将完整的数据添加或更新到数据库后。
10.进一步,日历信息查询模块的流程为:用户发送日历查询请求,请求进入日历组件系统,日历组件系统建立索引查询查询缓存单元。如果返回数据,则返回日历数据,用于信息输出。如果在查询缓存单元中没有找到信息,则建立索引值再次查询数据库单元,查询数据为日历数据进行信息输出。
11. 进一步的,日历查询请求为http请求,云端收到日历查询请求后进入日历组件系统,日历组件系统根据http请求建立相应的索引搜索。
12.进一步,所述自动录入日历数据模块的自动采集日历的流程为:数据采集单元的数据调度中心定时执行采集,第三方的数据按照优先级采集和采集之后的数据分为不同的数据源。
13.进一步对数据源的原创数据进行清洗,检查缺失数据,剔除异常数据,统一标准化日期时间、日期状态、日期类型、描述信息合并。
14.进一步,合并数据源先根据优先级判断是否有日历数据,再判断数据是否采集完成,采集完成后再存储或更新到数据库完成采集命令,如果数据采集没有完成,按照优先级没有日历数据,则返回值数据合并处理。
15.与现有技术相比,本发明提供的基于医院假期自动采集数据的日历组件系统具有以下有益效果:
16.1、在支持人员手动维护数据的基础上,通过构建数据采集,利用各平台海量数据存储优势,采集,清理第三方日历数据。将最终日历数据存储在数据库中,提高各医院日历数据的统一性和稳定性;
17.2、大大提高了医院放假日历数据的统一性和稳定性。支持人员手动维护数据优先级,有效降低节假日日历数据的错误率,避免各业务方节假日数据的出现。在不一致的情况下,提高了日历数据的准确性,可以更高效、实时地完成医院日历数据结果的输出。
图纸说明
18. 图。附图说明图1是本发明提出的基于医院假期自动采集数据的日历组件系统的系统连接框图;
19. 图。图2为本发明提出的基于医院假期自动采集数据的日历组件系统中日历信息查询模块的工作流程图;
20. 图。图3为本发明提出的基于医院假期自动采集数据的日历组件系统中日历数据模块自动录入的工作流程图。
详细说明
21.为使本发明的目的、技术方案和优点更加清楚,下面结合附图和实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限制本发明。
22.下面结合具体实施例对本发明的实现进行详细说明。
23.参考图1-3,基于医院假期自动采集数据的日历组件系统,包括手动日历数据录入模块、日历数据自动录入模块、日历信息查询模块;手动录入日历数据模块用于支持人员手动维护数据优先级;自动输入日历数据模块包括数据采集单元、数据清洗单元和数据合并单元,自动输入日历数据模块定时采集节假日日历数据,数据清洗单元处理采集的节假日日历数据,数据合并单元对齐处理后的节假日日历数据;
24.本实施例中,日历信息查询模块包括查询缓存单元和查询数据库单元,查询缓存单元存储在系统中。如果没有对应的缓存,设置一个新的索引来运行查询数据库单元。查询数据库单元接收到新索引后,会在存储在日历组件中的数据库中进行过滤。过滤后的结果将作为医院日历数据结果的输出。数据采集单元接入云端,通过云端从第三方采集节假日日历数据,数据清洗单元对三方原创日历数据进行校验,规范一致性,并依次通过查询缓存单元和查询数据库单元开始数据检索,
25.本实施例中,数据合并单元是将清洗后的数据分为工作日、休息日、节假日、补班四种类型,分别以不同的值存储,并合并来自不同数据源的数据。将数据合并成一个完整的数据后,添加或更新到数据库中,以便检索数据库单元可以使用更新后的数据库对数据输出进行操作和检索,通过设定指标实现在高效输出信息的同时,提高准确率。
26.本实施例中日历信息查询模块的流程为:用户发送日历查询请求,该请求进入日历组件系统,日历组件系统建立索引到查询缓存单元进行查询,如果查询到数据,则返回日历数据进行信息输出。如果查询缓存单元没有找到信息,则建立索引值再次查询数据库单元,查询数据为日历数据输出信息。日历查询请求为http请求,云端接收日历查询请求,进入。对于日历组件系统,日历组件系统根据http请求建立相应的索引检索。对于数据查询,提供节假日日历信息结果查询功能,数据调度是定时对采集执行任务,对整个日历数据进行清理。调度有效降低了节假日日历数据的错误率,避免了各业务方节假日数据的不一致,提高了数据的健壮性。
<p>27.本实施例中,自动进入日历数据模块的自动采集日历流程如下:数据采集单元的数据调度中心定期对采集第三方的数据。@>,并将第三方数据按照优先级分为不同的数据源采集,采集之后的数据,清洗数据源的原创数据,检查缺失的数据,并剔除异常数据,统一规范日期时间、日期状态、日期类型、描述信息,合并后的数据源先根据优先级判断是否有日历数据,再判断数据是否< @采集完成, 查看全部
自动采集数据(
1.本发明专利涉及医院节假日的日历数据采集数据的系统)
1.本发明专利涉及计算机软件技术领域,具体涉及一种基于医院假期自动采集数据的日历组件系统。
背景技术:
2.医院平台在线预约或挂号等具体业务场景需要使用日历数据,会使用多种第三方日历数据采集渠道,每个平台使用不同的日历数据来源采集所需要的数据必然会数据真实性低。另外,采集的数据源不同,也会出现脏数据。每天,每家医院都会生成一个查询日历。要进行操作,您需要通过这些日历数据进行一些安排或注册。
3.目前管理员手动维护日历数据,在数据库中手动维护一年的节假日信息,然后通过查询数据库信息查询日历和节假日。这种方法不容易维护。在实际应用中,年假轮班会发生变化,导致需要重新录入日历数据,需要人员手动更新数据的稳定性。
技术实施要素:
4.本发明的目的是提供一种基于医院假期自动采集数据的日历组件系统。在支持人员手动维护数据的基础上,通过构建数据采集,可以利用各个平台的海量数据。存储优势:采集,清洗,将最终日历数据存储在数据库中,提高各医院日历数据的统一性和稳定性,旨在解决现有技术中当前日历数据使用的问题。管理员手动维护数据库中一年的节假日信息,然后通过查询数据库信息查询日历和节假日。这种方式存在维护性差、效率慢等问题。
5.本发明是这样实现的,一种基于医院假期自动采集数据的日历组件系统,包括手动日历数据录入模块、自动录入日历数据模块、日历信息查询模块;手动录入日历数据模块数据模块用于支持人员手动维护数据优先级。日历数据自动录入模块包括数据采集单元、数据清洗单元和数据合并单元,日历数据自动录入模块定时采集节假日日历数据,数据清洗单元处理采集的节假日日历数据,数据合并单元对齐处理后的节假日日历数据;
6.进一步,日历信息查询模块包括查询缓存单元和查询数据库单元,查询缓存单元存储在系统中。设置一个新的索引来运行一个没有相应缓存的查询数据库单元。
7.进一步,查询数据库单元被新索引后,在日历组件存储的数据库中进行过滤,过滤结果为医院日历数据结果的输出。
8.进一步,数据采集单元接入云端,通过云端获取第三方采集节假日日历数据,数据清洗单元进行验证匹配三方原创日历数据 规范对待性行为。
9.进一步,数据合并单元是将清洗后的数据分为工作日、休息日、节假日、补班四种类型,以不同的值存储,将不同数据源的数据进行合并。将完整的数据添加或更新到数据库后。
10.进一步,日历信息查询模块的流程为:用户发送日历查询请求,请求进入日历组件系统,日历组件系统建立索引查询查询缓存单元。如果返回数据,则返回日历数据,用于信息输出。如果在查询缓存单元中没有找到信息,则建立索引值再次查询数据库单元,查询数据为日历数据进行信息输出。
11. 进一步的,日历查询请求为http请求,云端收到日历查询请求后进入日历组件系统,日历组件系统根据http请求建立相应的索引搜索。
12.进一步,所述自动录入日历数据模块的自动采集日历的流程为:数据采集单元的数据调度中心定时执行采集,第三方的数据按照优先级采集和采集之后的数据分为不同的数据源。
13.进一步对数据源的原创数据进行清洗,检查缺失数据,剔除异常数据,统一标准化日期时间、日期状态、日期类型、描述信息合并。
14.进一步,合并数据源先根据优先级判断是否有日历数据,再判断数据是否采集完成,采集完成后再存储或更新到数据库完成采集命令,如果数据采集没有完成,按照优先级没有日历数据,则返回值数据合并处理。
15.与现有技术相比,本发明提供的基于医院假期自动采集数据的日历组件系统具有以下有益效果:
16.1、在支持人员手动维护数据的基础上,通过构建数据采集,利用各平台海量数据存储优势,采集,清理第三方日历数据。将最终日历数据存储在数据库中,提高各医院日历数据的统一性和稳定性;
17.2、大大提高了医院放假日历数据的统一性和稳定性。支持人员手动维护数据优先级,有效降低节假日日历数据的错误率,避免各业务方节假日数据的出现。在不一致的情况下,提高了日历数据的准确性,可以更高效、实时地完成医院日历数据结果的输出。
图纸说明
18. 图。附图说明图1是本发明提出的基于医院假期自动采集数据的日历组件系统的系统连接框图;
19. 图。图2为本发明提出的基于医院假期自动采集数据的日历组件系统中日历信息查询模块的工作流程图;
20. 图。图3为本发明提出的基于医院假期自动采集数据的日历组件系统中日历数据模块自动录入的工作流程图。
详细说明
21.为使本发明的目的、技术方案和优点更加清楚,下面结合附图和实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限制本发明。
22.下面结合具体实施例对本发明的实现进行详细说明。
23.参考图1-3,基于医院假期自动采集数据的日历组件系统,包括手动日历数据录入模块、日历数据自动录入模块、日历信息查询模块;手动录入日历数据模块用于支持人员手动维护数据优先级;自动输入日历数据模块包括数据采集单元、数据清洗单元和数据合并单元,自动输入日历数据模块定时采集节假日日历数据,数据清洗单元处理采集的节假日日历数据,数据合并单元对齐处理后的节假日日历数据;
24.本实施例中,日历信息查询模块包括查询缓存单元和查询数据库单元,查询缓存单元存储在系统中。如果没有对应的缓存,设置一个新的索引来运行查询数据库单元。查询数据库单元接收到新索引后,会在存储在日历组件中的数据库中进行过滤。过滤后的结果将作为医院日历数据结果的输出。数据采集单元接入云端,通过云端从第三方采集节假日日历数据,数据清洗单元对三方原创日历数据进行校验,规范一致性,并依次通过查询缓存单元和查询数据库单元开始数据检索,
25.本实施例中,数据合并单元是将清洗后的数据分为工作日、休息日、节假日、补班四种类型,分别以不同的值存储,并合并来自不同数据源的数据。将数据合并成一个完整的数据后,添加或更新到数据库中,以便检索数据库单元可以使用更新后的数据库对数据输出进行操作和检索,通过设定指标实现在高效输出信息的同时,提高准确率。
26.本实施例中日历信息查询模块的流程为:用户发送日历查询请求,该请求进入日历组件系统,日历组件系统建立索引到查询缓存单元进行查询,如果查询到数据,则返回日历数据进行信息输出。如果查询缓存单元没有找到信息,则建立索引值再次查询数据库单元,查询数据为日历数据输出信息。日历查询请求为http请求,云端接收日历查询请求,进入。对于日历组件系统,日历组件系统根据http请求建立相应的索引检索。对于数据查询,提供节假日日历信息结果查询功能,数据调度是定时对采集执行任务,对整个日历数据进行清理。调度有效降低了节假日日历数据的错误率,避免了各业务方节假日数据的不一致,提高了数据的健壮性。
<p>27.本实施例中,自动进入日历数据模块的自动采集日历流程如下:数据采集单元的数据调度中心定期对采集第三方的数据。@>,并将第三方数据按照优先级分为不同的数据源采集,采集之后的数据,清洗数据源的原创数据,检查缺失的数据,并剔除异常数据,统一规范日期时间、日期状态、日期类型、描述信息,合并后的数据源先根据优先级判断是否有日历数据,再判断数据是否< @采集完成,
自动采集数据( 实时收集统计信息功能对性能的影响最低)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-20 09:33
实时收集统计信息功能对性能的影响最低)
了解异步采集和实时采集统计信息
启用实时统计信息采集后,一些元数据也可用于生成统计信息。生成意味着派生或创建统计数据,而不是作为正常 RUNSTATS 活动的一部分采集统计数据。例如,如果您知道表格中的行数、页面大小和平均行宽,您就可以知道表格中收录的行数。在某些情况下,统计数据实际上不是派生的,而是由索引和数据管理器维护的,并且可以直接存储在目录中。例如,索引管理器将维护每个索引中的叶页数和级别。
查询优化器根据查询要求和表更新活动量(更新、插入或删除操作的数量)确定如何采集统计信息。
实时统计功能可以提供更及时准确的统计数据。准确的统计数据可以带来更好的查询执行计划和改进的性能。不开启实时统计时,每两小时执行一次异步统计操作。此采集可能不够频繁,无法为某些应用程序提供准确的统计信息。
启用实时统计采集后,仍将每两小时执行一次异步采集统计检查。实时统计采集功能还会在以下情况下导致异步采集请求:
最多可以同时处理两个异步请求,但它们必须针对不同的表进行处理。一个请求必须由实时采集统计功能发起,另一个请求必须由异步采集统计检查操作发起。
可以使用以下方法将自动统计信息采集的性能影响降至最低:
尽管实时统计信息采集功能旨在最大限度地减少采集统计信息的开销,但请先在测试环境中尝试此功能,以确保不会对性能产生负面影响。将此功能用于某些在线事务处理 (OLTP) 场景可能会对性能产生负面影响,尤其是在查询运行时存在上限的情况下。
对常规表、物化查询表 (MQT) 和全局临时表执行实时同步统计信息采集操作。不会为全局临时表采集异步统计信息。自动维护策略工具无法将全局临时表排除在实时统计之外。
不会对以下对象执行自动统计信息采集(同步或异步):
不会为以下对象生成统计信息:
在分区数据库环境中,会采集统计信息,然后对单个数据库分区进行推测。数据库管理器始终采集有关数据库分区组的第一个数据库分区的统计信息(同步和异步)。
在数据库激活后至少 5 分钟才会执行非实时统计信息采集活动。
对静态和动态 SQL 进行实时统计处理。
使用 IMPORT 命令截断的表会自动重新组织以具有旧的统计信息。
同步和异步自动统计信息采集操作将使引用那些表的缓存动态语句无效,这些表已经采集了统计信息。这样做是为了可以使用最新的统计信息重新优化缓存的动态语句。
当数据库被停用时,“自动异步采集统计信息”操作可能会被中断。如果未使用 ACTIVATE DATABASE 命令或 API 显式激活数据库,则当最后一个用户与数据库断开连接时,数据库将被停用。如果操作被中断,错误消息可能会记录在 DB2 诊断日志文件中。为避免中断“自动异步采集统计信息”操作,请显式激活此数据库。 查看全部
自动采集数据(
实时收集统计信息功能对性能的影响最低)
了解异步采集和实时采集统计信息
启用实时统计信息采集后,一些元数据也可用于生成统计信息。生成意味着派生或创建统计数据,而不是作为正常 RUNSTATS 活动的一部分采集统计数据。例如,如果您知道表格中的行数、页面大小和平均行宽,您就可以知道表格中收录的行数。在某些情况下,统计数据实际上不是派生的,而是由索引和数据管理器维护的,并且可以直接存储在目录中。例如,索引管理器将维护每个索引中的叶页数和级别。
查询优化器根据查询要求和表更新活动量(更新、插入或删除操作的数量)确定如何采集统计信息。
实时统计功能可以提供更及时准确的统计数据。准确的统计数据可以带来更好的查询执行计划和改进的性能。不开启实时统计时,每两小时执行一次异步统计操作。此采集可能不够频繁,无法为某些应用程序提供准确的统计信息。
启用实时统计采集后,仍将每两小时执行一次异步采集统计检查。实时统计采集功能还会在以下情况下导致异步采集请求:
最多可以同时处理两个异步请求,但它们必须针对不同的表进行处理。一个请求必须由实时采集统计功能发起,另一个请求必须由异步采集统计检查操作发起。
可以使用以下方法将自动统计信息采集的性能影响降至最低:
尽管实时统计信息采集功能旨在最大限度地减少采集统计信息的开销,但请先在测试环境中尝试此功能,以确保不会对性能产生负面影响。将此功能用于某些在线事务处理 (OLTP) 场景可能会对性能产生负面影响,尤其是在查询运行时存在上限的情况下。
对常规表、物化查询表 (MQT) 和全局临时表执行实时同步统计信息采集操作。不会为全局临时表采集异步统计信息。自动维护策略工具无法将全局临时表排除在实时统计之外。
不会对以下对象执行自动统计信息采集(同步或异步):
不会为以下对象生成统计信息:
在分区数据库环境中,会采集统计信息,然后对单个数据库分区进行推测。数据库管理器始终采集有关数据库分区组的第一个数据库分区的统计信息(同步和异步)。
在数据库激活后至少 5 分钟才会执行非实时统计信息采集活动。
对静态和动态 SQL 进行实时统计处理。
使用 IMPORT 命令截断的表会自动重新组织以具有旧的统计信息。
同步和异步自动统计信息采集操作将使引用那些表的缓存动态语句无效,这些表已经采集了统计信息。这样做是为了可以使用最新的统计信息重新优化缓存的动态语句。
当数据库被停用时,“自动异步采集统计信息”操作可能会被中断。如果未使用 ACTIVATE DATABASE 命令或 API 显式激活数据库,则当最后一个用户与数据库断开连接时,数据库将被停用。如果操作被中断,错误消息可能会记录在 DB2 诊断日志文件中。为避免中断“自动异步采集统计信息”操作,请显式激活此数据库。
自动采集数据(1.一种数据自动校验采集的系统,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2022-03-14 07:10
技术特点:
<p>1.一种cmdb数据自动校验系统采集,其特征在于,包括:自动校验采集模块和上报模块;自动校验采集模块:自动校验第一个cmdb系统配置项采集的数据,包括配置项采集的初始数据、处理单元和数据校验单元;上报模块:对通过数据校验的配置项进行数据上报,以restful api的形式完成第二个cmdb系统配置项数据的数据采集,包括数据上报接口和数据状态查询接口. 2.根据权利要求1所述的cmdb数据自动校验系统采集,其特征在于,采集 校验映射表包括第一cmdb系统和第二cmdb系统配置项与字段的一一映射关系、数据获取方式、是否进行批处理、数据校验规则。3.根据权利要求1所述的cmdb数据自动校验系统采集,其特征在于,所述采集模块中配置项初始数据的采集@自动校验>,处理单元根据采集验证映射表采集对第一个cmdb系统配置项的初始数据进行自动化处理,并根据采集 验证映射表 处理由定时任务控制采集和处理程序自动处理和执行。4.根据权利要求3所述的cmdb数据自动校验系统采集,其特征在于,所述配置项的初始数据采集,所述配置项在处理单元中的初始数据采集包括:直接获取值和通过函数动态获取值,其中通过函数获取的值需要程序动态处理得到对应的值,在 查看全部
自动采集数据(1.一种数据自动校验采集的系统,你了解多少?)
技术特点:
<p>1.一种cmdb数据自动校验系统采集,其特征在于,包括:自动校验采集模块和上报模块;自动校验采集模块:自动校验第一个cmdb系统配置项采集的数据,包括配置项采集的初始数据、处理单元和数据校验单元;上报模块:对通过数据校验的配置项进行数据上报,以restful api的形式完成第二个cmdb系统配置项数据的数据采集,包括数据上报接口和数据状态查询接口. 2.根据权利要求1所述的cmdb数据自动校验系统采集,其特征在于,采集 校验映射表包括第一cmdb系统和第二cmdb系统配置项与字段的一一映射关系、数据获取方式、是否进行批处理、数据校验规则。3.根据权利要求1所述的cmdb数据自动校验系统采集,其特征在于,所述采集模块中配置项初始数据的采集@自动校验>,处理单元根据采集验证映射表采集对第一个cmdb系统配置项的初始数据进行自动化处理,并根据采集 验证映射表 处理由定时任务控制采集和处理程序自动处理和执行。4.根据权利要求3所述的cmdb数据自动校验系统采集,其特征在于,所述配置项的初始数据采集,所述配置项在处理单元中的初始数据采集包括:直接获取值和通过函数动态获取值,其中通过函数获取的值需要程序动态处理得到对应的值,在
自动采集数据( 临床诊疗本已分身乏术了,医疗科研更轻松软件机器人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-14 07:08
临床诊疗本已分身乏术了,医疗科研更轻松软件机器人)
对于临床医生来说,临床诊疗已经疲惫不堪,必须坚持临床研究才能提升职称。虽然大部分都是基于回顾性研究,但临床数据采集始终是临床研究中最重要、最麻烦的部分。
临床数据来源很多,看起来不错
医院信息部、科室电脑、病历室等,都存放着各种临床数据,而我或科室同事也或多或少地保存了一些纸质病历和Excel,看起来很容易拿到临床数据。
现实情况是,将所有临床数据用于医学研究并非易事。
数年采集临床数据的阵痛
医院信息化普及,临床数据大部分存在于医院各软件系统和信息科室。出于数据安全和隐私方面的考虑,医院不允许临床医生轻松访问临床数据;和信息部门的人员经常阻碍临床医生采集临床数据,因为他们不愿意冒险。
病案室里虽然堆满了文件,但通读文件又费力又累人,数据质量和采集效率也得不到保证。
很多临床医生从科室的HIS系统中一一复制粘贴病人的病历,但最后只能用肉眼检索。
此外,临床数据来源多,格式、标准不一,数据无法匹配整合,临床医生难以采集科研所需数据。
这样采集临床数据,医学研究更容易
使用小帮软件机器人,小帮软件机器人可以根据需要自动采集科研所需的临床数据(患者基本信息、检测数据、影像数据等),并在本地自动组织存储用于后续的临床试验。科研数据的统计分析奠定了基础。
从此,临床医生可以采集访问科室的临床数据,无需通过信息部登录自己的账号,无需急于求救,无需苦苦复制粘贴,轻松采集优质临床数据,高效完成临床研究。
重复工作,小小帮帮您。
在工作和生活中,你经常会遇到批量重复操作的烦恼:
复制粘贴,采集整理各种数据;重复批量输入和修改数据;持续观察某些数据的变化;重复常规的计算机操作。
博伟是一个小帮派软件机器人,为减少重复性电脑工作而生。
小帮软件机器人平台是一个互联网软件机器人平台,专注于利用极简软件自动化技术,帮助减少工作和生活中的重复劳动。
二、博微小邦软件机器人三大功能:
1 表单数据采集
每天我们都会在各种软件和网站中看到非常有价值的表格数据,而小邦软件机器人会自动采集到本地数据做进一步的分析处理。
2 批量输入和修改数据
我们经常会遇到大量的数据录入和修改工作。如果这些机械操作是重复的、有规律的,小邦可以为你做。
3 监控数据,重复操作
我们经常需要不断的观察软件或者网站中一些数据的变化,然后根据数据变化做一些有规律的重复操作,这些都可以交给小邦。
只需几步,配置一个小邦软件机器人,重复性的电脑操作和海量的电脑数据工作,小邦就能自动帮您完成,高效,快速,不知疲倦,无差错。 查看全部
自动采集数据(
临床诊疗本已分身乏术了,医疗科研更轻松软件机器人)
对于临床医生来说,临床诊疗已经疲惫不堪,必须坚持临床研究才能提升职称。虽然大部分都是基于回顾性研究,但临床数据采集始终是临床研究中最重要、最麻烦的部分。
临床数据来源很多,看起来不错
医院信息部、科室电脑、病历室等,都存放着各种临床数据,而我或科室同事也或多或少地保存了一些纸质病历和Excel,看起来很容易拿到临床数据。
现实情况是,将所有临床数据用于医学研究并非易事。
数年采集临床数据的阵痛
医院信息化普及,临床数据大部分存在于医院各软件系统和信息科室。出于数据安全和隐私方面的考虑,医院不允许临床医生轻松访问临床数据;和信息部门的人员经常阻碍临床医生采集临床数据,因为他们不愿意冒险。
病案室里虽然堆满了文件,但通读文件又费力又累人,数据质量和采集效率也得不到保证。
很多临床医生从科室的HIS系统中一一复制粘贴病人的病历,但最后只能用肉眼检索。
此外,临床数据来源多,格式、标准不一,数据无法匹配整合,临床医生难以采集科研所需数据。
这样采集临床数据,医学研究更容易
使用小帮软件机器人,小帮软件机器人可以根据需要自动采集科研所需的临床数据(患者基本信息、检测数据、影像数据等),并在本地自动组织存储用于后续的临床试验。科研数据的统计分析奠定了基础。
从此,临床医生可以采集访问科室的临床数据,无需通过信息部登录自己的账号,无需急于求救,无需苦苦复制粘贴,轻松采集优质临床数据,高效完成临床研究。
重复工作,小小帮帮您。
在工作和生活中,你经常会遇到批量重复操作的烦恼:
复制粘贴,采集整理各种数据;重复批量输入和修改数据;持续观察某些数据的变化;重复常规的计算机操作。
博伟是一个小帮派软件机器人,为减少重复性电脑工作而生。
小帮软件机器人平台是一个互联网软件机器人平台,专注于利用极简软件自动化技术,帮助减少工作和生活中的重复劳动。
二、博微小邦软件机器人三大功能:
1 表单数据采集
每天我们都会在各种软件和网站中看到非常有价值的表格数据,而小邦软件机器人会自动采集到本地数据做进一步的分析处理。
2 批量输入和修改数据
我们经常会遇到大量的数据录入和修改工作。如果这些机械操作是重复的、有规律的,小邦可以为你做。
3 监控数据,重复操作
我们经常需要不断的观察软件或者网站中一些数据的变化,然后根据数据变化做一些有规律的重复操作,这些都可以交给小邦。
只需几步,配置一个小邦软件机器人,重复性的电脑操作和海量的电脑数据工作,小邦就能自动帮您完成,高效,快速,不知疲倦,无差错。
自动采集数据( 数据自动校验采集的系统及方法技术领域本发明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2022-03-13 12:07
数据自动校验采集的系统及方法技术领域本发明)
cmdb数据自动校验的系统及方法采集
技术领域
1.本发明涉及运维技术领域,尤其涉及一种cmdb数据自动校验的系统及方法采集。
背景技术:
2.cmdb(配置管理数据库,配置管理数据库)是企业存储资源的基础数据库。它负责存储和管理数据中心、硬件设施、虚拟机资源、软件系统、关联关系等资产,为外部数据服务提供基础。基于此,多家机构根据自身需求完成了cmdb的建设,并发挥了it资产数据管理服务的作用。但由于分行与总行、金融机构和监管部门对cmdb模型的定义不一致,cmdb数据规则不一致,难以统一汇总数据、采集和管理数据,无法给出完整的数据。发挥cmdb数据的更大价值。
3.目前常用配置管理数据库(cmdb)来记录云产品与服务器的对应关系。它是由运维系统配置的,所以cmdb系统记录的信息往往需要验证和更正。在现有技术中,对cmdb系统记录的信息的校验也是由运维人员定期人工处理的。
4.现在,cmdb数据的方法和系统采集更侧重于自动化采集和单个cmdb系统配置项信息的验证。公开号为cn108989385a的发明专利公开了一种基于zabbix监控采集自动同步cmdb的实现方法,包括以下步骤: s1)创建中间表对象作为zabbix采集器@之间的过渡> 和cmdb配置项;s2)分别建立中间表对象与zabbix采集器@>和cmdb配置项的映射关系;s3)zabbix采集器@>通过映射关系将采集数据写入中间表;s4)
5.公开号为cn111625528a的发明专利公开了一种验证配置管理数据库的方法、装置及可读存储介质,包括:获取每个服务器上运行的至少一个目标进程;上述各目标进程的标识信息,从预设的云产品进程部署规则库中确定与服务器具有对应关系的云产品以及与服务器具有对应关系的云产品的进程部署规则;云产品之间的对应关系 获取服务器的第一对应关系列表,利用与服务器对应的云产品的流程部署规则,查看第一对应关系列表,得到服务器的第二对应关系列表;
6.上述技术的主要缺点是:第一,上述发明更多关注的是单个cmdb系统的配置项数据的采集,没有关注映射和数据聚合采集多个cmdb系统之间。其次,上述发明的数据验证比较片面,没有提出全面的数据验证方法和系统。
技术实施要素:
7.针对现有技术的不足,本发明提供一种cmdb数据自动校验的系统及方法采集。
8.根据本发明提供的cmdb数据自动校验系统及方法采集,其方案如下:
9.第一方面,提供一种cmdb数据自动校验系统采集,该系统包括:
10.自动校验采集模块和报告模块;
11.自动校验采集模块:自动校验第一个cmdb系统配置项采集的数据,包括配置项采集的初始数据、处理单元和数据检查单位;
12.上报模块:上报数据校验通过的配置项数据,以restful api的方式完成第二个cmdb系统配置项数据的采集,包括数据上报界面和数据状态查询界面。
13. 优选地,采集验证映射表包括第一cmdb系统和第二cmdb系统的配置项和字段的一一对应关系、数据获取方式、是否执行批处理和数据验证规则。
14. 优选地,采集模块和处理单元中配置项初始数据采集的自动校验是根据采集验证映射表。配置项初始数据采集的自动化,配置项初始数据根据采集验证映射表批量处理,由定时任务采集控制,以及处理程序的定时自动化。
15. 优选地,配置项采集的初始数据和处理单元中配置项的初始数据采集包括:可以直接获取的值和值可以通过函数动态获取,其中,通过函数获取值需要程序动态处理才能获取对应的值,在采集映射表中以fun_开头。
16. 优选地,处理单元对配置项采集的初始数据和配置项的初始数据的处理包括: 检查映射表中的批标记是否根据采集,如果为true,则进行批处理;如果为 false,则不执行批处理。
17. 优选地,自动校验采集模块中的数据校验单元包括: 根据配置的数据校验规则进行数据校验,以满足第二cmdb系统的数据采集要求。验证规则由第二个cmdb系统配置项模型负责人通过页面配置或excel表格导入制定。
18. 优选地,数据校验规则包括:规范校验、逻辑校验、数据一致性校验;
19. 其中,规范验证包括:数据必填项验证、数据类型验证和数据范围验证;
20.逻辑验证是判断配置项数据的值是否符合验证规则的逻辑事实;
21.一致性检查是判断关联关系的配置项中是否存在关联关系的配置项。
22. 优选地,上报模块中的数据上报接口包括:将中间库数据上报给第二cmdb系统,上报支持数据的增删改查,上报完成的返回数据。批号;
23.数据状态查询接口包括:根据数据批号查询数据处理状态,保证数据提交的准确性,并提供数据提交日志查询提交状态。
24.第二方面,提供了一种cmdb数据自动校验采集的方法,该方法包括:
25.步骤s1:cmdb数据的自动校验采集系统根据采集校验映射表采集对第一个cmdb系统配置项的初始数据进行自动化校验@>;
26.步骤s2:根据采集校验映射表的定义对采集的配置项的初始数据进行处理,用于数据批量处理和自动数据校验;
27.步骤s3:将数据校验通过的配置项数据根据采集中第一cmdb系统与第二cmdb系统配置项模型映射关系的映射关系自动映射到数据库中@> 映射表;数据校验的配置项数据会输出采集日志,供用户查看和修改数据校验问题。
28. 优选地,步骤s2包括:
29.根据采集校验映射表判断是否需要批处理,如果需要,进行批处理;不
然后直接进入数据验证流程;
30. 然后根据数据校验规则进行数据校验,依次是数据规范校验、逻辑校验和一致性校验。
31.与现有技术相比,本发明具有以下有益效果:
32.1、本发明中cmdb数据自动校验采集系统与cmdb系统解耦,可适配多组cmdb模型,有利于分支cmdb数据上报和监管数据在提交等场景下很容易实现集成;
33.2、根据cmdb系统各配置项的模型规则,对数据进行自动校验,包括数据的规范性校验、逻辑性校验、一致性校验,从而规范cmdb 数据的质量;
34.3、通过数据校验的配置项数据根据模型映射关系自动映射到数据库中,通过restful api接口实现cmdb数据的高效自动上报,从而完成不同组织的整合。自动校验cmdb间数据采集。
图纸说明
35.本发明的其他特征、目的和优点将通过参考以下附图阅读非限制性实施例的详细描述而变得更加明显:
36. 图。附图说明图1是本发明的整体框架图;
37. 图。图2为本发明自动采集验证模块示意图;
38. 图。图3为本发明采集验证映射表示意图;
39. 图。图4为本发明的执行流程图。
详细说明
40.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域技术人员进一步理解本发明,但不以任何形式限制本发明。需要说明的是,对于本领域的技术人员来说,在不脱离本发明构思的情况下,可以进行若干变化和改进。这些均属于本发明的保护范围。
41.本发明实施例提供一种cmdb数据自动校验系统采集,实现与cmdb系统解耦,利用cmdb数据采集进行数据自动校验,从而解决了多个cmdb系统之间配置项定义不一致、数据规则不一致的问题。参考图1,系统包括:自动验证采集模块和报告模块。
42. 具体参考图2和图3,自动校验采集模块:负责自动校验第一个cmdb系统配置项数据采集,包括配置项采集初始数据、处理单元和数据验证单元。
43.其中,配置项采集的初始数据,处理单元根据采集校验映射对第一个cmdb系统配置项的初始数据进行自动化处理表采集,以及配置项初始数据的批处理是根据采集验证映射表进行的,由定时任务采集和定时任务控制加工程序自动执行。
44.配置项采集的初始数据包括可以直接获取的值和通过函数动态获取的值,其中直接获取的值是第一个cmdb系统对应的ci验证映射表根据采集可以直接通过item字段获取数据值;函数获取的值是当采集验证映射表中第一个cmdb系统对应的ci项字段以“fun_”开头时,无法直接获取值,则根据“fun_xx”函数name,对应的值是通过程序动态处理得到的。
45.根据采集校验映射表中的“批处理”标记进行配置项的初始数据处理,如果为真
执行批处理,不执行false。批处理是根据规范验证规则中的数据类型和值域要求对数据进行简单的批处理。例如,浮点数据的小数位根据校验规则自动填充或修整,日期和时间数据。根据验证规则,自动生成匹配规则对应的类型数据,满足基本验证规则。
46.采集校验映射表包括第一cmdb系统和第二cmdb系统的配置项和字段的一一映射关系、数据获取方式、是否进行批处理,以及数据验证规则等。
47. 数据校验单元根据配置的数据校验规则进行数据校验,满足第二cmdb系统的数据采集要求。数据校验规则由第二个cmdb系统的配置项模型负责人通过页面配置或excel表格导入制定。
48.数据校验规则包括规范校验、逻辑校验、数据一致性校验。
49. 其中,规范验证包括数据必填项验证、数据类型验证、数据范围验证。数据必填字段校验是根据校验规则“必填”判断数据是否为空。如果不需要,则允许为空。如果需要,则不允许为空;数据类型校验是判断数据值是否满足类型要求。如果要求是“int”,则必须是整数数据,其他类型会验证失败;数据值字段校验是判断数据长度是否符合要求,如果要求为“i1..4”,则整数数据长度大于1位小于4位。如果不满意,
50.逻辑校验是判断配置项数据的取值是否符合校验规则制定的逻辑事实。如果逻辑校验规则为“<=256”,则该字段的值必须满足小于等于256的要求,否则校验失败。
51.一致性检查是判断具有关联关系的配置项是否存在于具有关联关系的配置项中。如果指定为“in xx.xx”,则数据项的值必须在具体的配置项中。存在于特定字段中,否则验证失败。
52.第二个cmdb系统配置项模型的负责人可以根据需要制定规则,不限于以上验证规则。同时提供数据采集日志,方便第一个cmdb系统配置项的管理员查询数据校验问题,以便尽快更正数据,满足校验规则。数据校验通过的配置项数据存储在中间库中,供上报模块进行数据上报。
53.上报模块:上报数据校验通过的配置项数据,以restful api的形式完成第二个cmdb系统配置项数据的采集,包括数据上报界面和数据状态查询界面。数据上报接口负责将中间数据库数据上报到第二个cmdb系统,上报支持增、改、删数据,上报返回数据的批号。数据状态查询接口是根据数据批号查询数据处理状态,保证数据提交准确。同时提供数据提交日志,用于查询提交状态。
54.参见图4,本发明还提供了一种cmdb数据自动校验的方法采集,具体步骤包括:
55.1、通过cmdb自动校验数据采集系统根据采集校验映射自动完成第一个cmdb系统配置项采集的初始数据桌子。
5 6.2、采集的配置项的初始数据根据采集校验映射表的定义进行数据批处理和自动数据校验;首先,根据采集验证映射表判断是否需要批处理,如果需要进行批处理;否则,直接进入数据验证流程,然后按照数据验证规则进行数据验证,然后进行数据规范验证和逻辑验证。以及一致性校验等,即如果前者校验通过,则执行后者校验。如果前者失败,则中止检查过程并且输出检查失败。
57.3、根据采集映射表的第一cmdb系统和第二cmdb系统配置数据校验通过的配置项数据。
设置项目模型映射关系,自动将数据映射到数据库中;未通过数据校验的配置项数据将输出采集日志,供用户查看和修改数据校验问题。
58.4、cmdb自动校验采集系统通过restful api提交校验后的配置项数据,并提交对数据增删改查的支持。这样就完成了第二个cmdb系统对第一个cmdb系统的配置项数据的采集。
59.本发明实施例提供了一种cmdb数据自动校验的系统及方法采集,实现了多组cmdb系统采集之间的数据自动校验。解决了不同机构间cmdb系统配置项数据模型定义不一致的问题,提高了机构间cmdb数据采集和聚合的效率;二是提供完整的、可定制的数据验证规则,针对配置项的每个字段进行定义。各自的数据规则用于提高cmdb数据采集的质量。
60. 本领域技术人员知道,本发明除了以纯计算机可读程序代码的形式实现本发明提供的系统及其各种装置、模块和单元外,还可以完全对本发明提供的方法步骤进行逻辑编程。该系统及其各种器件、模块和单元以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入式微控制器的形式实现相同的功能。因此,本发明所提供的系统及其各种设备、模块和单元可以看作是一种硬件部件,其中收录的用于实现各种功能的设备、模块和单元也可以看作是硬件部件。设备,
61. 以上对本发明的具体实施方式进行了说明。应当理解,本发明不限于上述具体实施方式,本领域的技术人员可以在权利要求的范围内进行各种改动或变型而不影响本发明的实质内容。本技术的实施例和实施例中的特征可以相互任意组合而不冲突。 查看全部
自动采集数据(
数据自动校验采集的系统及方法技术领域本发明)
cmdb数据自动校验的系统及方法采集
技术领域
1.本发明涉及运维技术领域,尤其涉及一种cmdb数据自动校验的系统及方法采集。
背景技术:
2.cmdb(配置管理数据库,配置管理数据库)是企业存储资源的基础数据库。它负责存储和管理数据中心、硬件设施、虚拟机资源、软件系统、关联关系等资产,为外部数据服务提供基础。基于此,多家机构根据自身需求完成了cmdb的建设,并发挥了it资产数据管理服务的作用。但由于分行与总行、金融机构和监管部门对cmdb模型的定义不一致,cmdb数据规则不一致,难以统一汇总数据、采集和管理数据,无法给出完整的数据。发挥cmdb数据的更大价值。
3.目前常用配置管理数据库(cmdb)来记录云产品与服务器的对应关系。它是由运维系统配置的,所以cmdb系统记录的信息往往需要验证和更正。在现有技术中,对cmdb系统记录的信息的校验也是由运维人员定期人工处理的。
4.现在,cmdb数据的方法和系统采集更侧重于自动化采集和单个cmdb系统配置项信息的验证。公开号为cn108989385a的发明专利公开了一种基于zabbix监控采集自动同步cmdb的实现方法,包括以下步骤: s1)创建中间表对象作为zabbix采集器@之间的过渡> 和cmdb配置项;s2)分别建立中间表对象与zabbix采集器@>和cmdb配置项的映射关系;s3)zabbix采集器@>通过映射关系将采集数据写入中间表;s4)
5.公开号为cn111625528a的发明专利公开了一种验证配置管理数据库的方法、装置及可读存储介质,包括:获取每个服务器上运行的至少一个目标进程;上述各目标进程的标识信息,从预设的云产品进程部署规则库中确定与服务器具有对应关系的云产品以及与服务器具有对应关系的云产品的进程部署规则;云产品之间的对应关系 获取服务器的第一对应关系列表,利用与服务器对应的云产品的流程部署规则,查看第一对应关系列表,得到服务器的第二对应关系列表;
6.上述技术的主要缺点是:第一,上述发明更多关注的是单个cmdb系统的配置项数据的采集,没有关注映射和数据聚合采集多个cmdb系统之间。其次,上述发明的数据验证比较片面,没有提出全面的数据验证方法和系统。
技术实施要素:
7.针对现有技术的不足,本发明提供一种cmdb数据自动校验的系统及方法采集。
8.根据本发明提供的cmdb数据自动校验系统及方法采集,其方案如下:
9.第一方面,提供一种cmdb数据自动校验系统采集,该系统包括:
10.自动校验采集模块和报告模块;
11.自动校验采集模块:自动校验第一个cmdb系统配置项采集的数据,包括配置项采集的初始数据、处理单元和数据检查单位;
12.上报模块:上报数据校验通过的配置项数据,以restful api的方式完成第二个cmdb系统配置项数据的采集,包括数据上报界面和数据状态查询界面。
13. 优选地,采集验证映射表包括第一cmdb系统和第二cmdb系统的配置项和字段的一一对应关系、数据获取方式、是否执行批处理和数据验证规则。
14. 优选地,采集模块和处理单元中配置项初始数据采集的自动校验是根据采集验证映射表。配置项初始数据采集的自动化,配置项初始数据根据采集验证映射表批量处理,由定时任务采集控制,以及处理程序的定时自动化。
15. 优选地,配置项采集的初始数据和处理单元中配置项的初始数据采集包括:可以直接获取的值和值可以通过函数动态获取,其中,通过函数获取值需要程序动态处理才能获取对应的值,在采集映射表中以fun_开头。
16. 优选地,处理单元对配置项采集的初始数据和配置项的初始数据的处理包括: 检查映射表中的批标记是否根据采集,如果为true,则进行批处理;如果为 false,则不执行批处理。
17. 优选地,自动校验采集模块中的数据校验单元包括: 根据配置的数据校验规则进行数据校验,以满足第二cmdb系统的数据采集要求。验证规则由第二个cmdb系统配置项模型负责人通过页面配置或excel表格导入制定。
18. 优选地,数据校验规则包括:规范校验、逻辑校验、数据一致性校验;
19. 其中,规范验证包括:数据必填项验证、数据类型验证和数据范围验证;
20.逻辑验证是判断配置项数据的值是否符合验证规则的逻辑事实;
21.一致性检查是判断关联关系的配置项中是否存在关联关系的配置项。
22. 优选地,上报模块中的数据上报接口包括:将中间库数据上报给第二cmdb系统,上报支持数据的增删改查,上报完成的返回数据。批号;
23.数据状态查询接口包括:根据数据批号查询数据处理状态,保证数据提交的准确性,并提供数据提交日志查询提交状态。
24.第二方面,提供了一种cmdb数据自动校验采集的方法,该方法包括:
25.步骤s1:cmdb数据的自动校验采集系统根据采集校验映射表采集对第一个cmdb系统配置项的初始数据进行自动化校验@>;
26.步骤s2:根据采集校验映射表的定义对采集的配置项的初始数据进行处理,用于数据批量处理和自动数据校验;
27.步骤s3:将数据校验通过的配置项数据根据采集中第一cmdb系统与第二cmdb系统配置项模型映射关系的映射关系自动映射到数据库中@> 映射表;数据校验的配置项数据会输出采集日志,供用户查看和修改数据校验问题。
28. 优选地,步骤s2包括:
29.根据采集校验映射表判断是否需要批处理,如果需要,进行批处理;不
然后直接进入数据验证流程;
30. 然后根据数据校验规则进行数据校验,依次是数据规范校验、逻辑校验和一致性校验。
31.与现有技术相比,本发明具有以下有益效果:
32.1、本发明中cmdb数据自动校验采集系统与cmdb系统解耦,可适配多组cmdb模型,有利于分支cmdb数据上报和监管数据在提交等场景下很容易实现集成;
33.2、根据cmdb系统各配置项的模型规则,对数据进行自动校验,包括数据的规范性校验、逻辑性校验、一致性校验,从而规范cmdb 数据的质量;
34.3、通过数据校验的配置项数据根据模型映射关系自动映射到数据库中,通过restful api接口实现cmdb数据的高效自动上报,从而完成不同组织的整合。自动校验cmdb间数据采集。
图纸说明
35.本发明的其他特征、目的和优点将通过参考以下附图阅读非限制性实施例的详细描述而变得更加明显:
36. 图。附图说明图1是本发明的整体框架图;
37. 图。图2为本发明自动采集验证模块示意图;
38. 图。图3为本发明采集验证映射表示意图;
39. 图。图4为本发明的执行流程图。
详细说明
40.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域技术人员进一步理解本发明,但不以任何形式限制本发明。需要说明的是,对于本领域的技术人员来说,在不脱离本发明构思的情况下,可以进行若干变化和改进。这些均属于本发明的保护范围。
41.本发明实施例提供一种cmdb数据自动校验系统采集,实现与cmdb系统解耦,利用cmdb数据采集进行数据自动校验,从而解决了多个cmdb系统之间配置项定义不一致、数据规则不一致的问题。参考图1,系统包括:自动验证采集模块和报告模块。
42. 具体参考图2和图3,自动校验采集模块:负责自动校验第一个cmdb系统配置项数据采集,包括配置项采集初始数据、处理单元和数据验证单元。
43.其中,配置项采集的初始数据,处理单元根据采集校验映射对第一个cmdb系统配置项的初始数据进行自动化处理表采集,以及配置项初始数据的批处理是根据采集验证映射表进行的,由定时任务采集和定时任务控制加工程序自动执行。
44.配置项采集的初始数据包括可以直接获取的值和通过函数动态获取的值,其中直接获取的值是第一个cmdb系统对应的ci验证映射表根据采集可以直接通过item字段获取数据值;函数获取的值是当采集验证映射表中第一个cmdb系统对应的ci项字段以“fun_”开头时,无法直接获取值,则根据“fun_xx”函数name,对应的值是通过程序动态处理得到的。
45.根据采集校验映射表中的“批处理”标记进行配置项的初始数据处理,如果为真
执行批处理,不执行false。批处理是根据规范验证规则中的数据类型和值域要求对数据进行简单的批处理。例如,浮点数据的小数位根据校验规则自动填充或修整,日期和时间数据。根据验证规则,自动生成匹配规则对应的类型数据,满足基本验证规则。
46.采集校验映射表包括第一cmdb系统和第二cmdb系统的配置项和字段的一一映射关系、数据获取方式、是否进行批处理,以及数据验证规则等。
47. 数据校验单元根据配置的数据校验规则进行数据校验,满足第二cmdb系统的数据采集要求。数据校验规则由第二个cmdb系统的配置项模型负责人通过页面配置或excel表格导入制定。
48.数据校验规则包括规范校验、逻辑校验、数据一致性校验。
49. 其中,规范验证包括数据必填项验证、数据类型验证、数据范围验证。数据必填字段校验是根据校验规则“必填”判断数据是否为空。如果不需要,则允许为空。如果需要,则不允许为空;数据类型校验是判断数据值是否满足类型要求。如果要求是“int”,则必须是整数数据,其他类型会验证失败;数据值字段校验是判断数据长度是否符合要求,如果要求为“i1..4”,则整数数据长度大于1位小于4位。如果不满意,
50.逻辑校验是判断配置项数据的取值是否符合校验规则制定的逻辑事实。如果逻辑校验规则为“<=256”,则该字段的值必须满足小于等于256的要求,否则校验失败。
51.一致性检查是判断具有关联关系的配置项是否存在于具有关联关系的配置项中。如果指定为“in xx.xx”,则数据项的值必须在具体的配置项中。存在于特定字段中,否则验证失败。
52.第二个cmdb系统配置项模型的负责人可以根据需要制定规则,不限于以上验证规则。同时提供数据采集日志,方便第一个cmdb系统配置项的管理员查询数据校验问题,以便尽快更正数据,满足校验规则。数据校验通过的配置项数据存储在中间库中,供上报模块进行数据上报。
53.上报模块:上报数据校验通过的配置项数据,以restful api的形式完成第二个cmdb系统配置项数据的采集,包括数据上报界面和数据状态查询界面。数据上报接口负责将中间数据库数据上报到第二个cmdb系统,上报支持增、改、删数据,上报返回数据的批号。数据状态查询接口是根据数据批号查询数据处理状态,保证数据提交准确。同时提供数据提交日志,用于查询提交状态。
54.参见图4,本发明还提供了一种cmdb数据自动校验的方法采集,具体步骤包括:
55.1、通过cmdb自动校验数据采集系统根据采集校验映射自动完成第一个cmdb系统配置项采集的初始数据桌子。
5 6.2、采集的配置项的初始数据根据采集校验映射表的定义进行数据批处理和自动数据校验;首先,根据采集验证映射表判断是否需要批处理,如果需要进行批处理;否则,直接进入数据验证流程,然后按照数据验证规则进行数据验证,然后进行数据规范验证和逻辑验证。以及一致性校验等,即如果前者校验通过,则执行后者校验。如果前者失败,则中止检查过程并且输出检查失败。
57.3、根据采集映射表的第一cmdb系统和第二cmdb系统配置数据校验通过的配置项数据。
设置项目模型映射关系,自动将数据映射到数据库中;未通过数据校验的配置项数据将输出采集日志,供用户查看和修改数据校验问题。
58.4、cmdb自动校验采集系统通过restful api提交校验后的配置项数据,并提交对数据增删改查的支持。这样就完成了第二个cmdb系统对第一个cmdb系统的配置项数据的采集。
59.本发明实施例提供了一种cmdb数据自动校验的系统及方法采集,实现了多组cmdb系统采集之间的数据自动校验。解决了不同机构间cmdb系统配置项数据模型定义不一致的问题,提高了机构间cmdb数据采集和聚合的效率;二是提供完整的、可定制的数据验证规则,针对配置项的每个字段进行定义。各自的数据规则用于提高cmdb数据采集的质量。
60. 本领域技术人员知道,本发明除了以纯计算机可读程序代码的形式实现本发明提供的系统及其各种装置、模块和单元外,还可以完全对本发明提供的方法步骤进行逻辑编程。该系统及其各种器件、模块和单元以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入式微控制器的形式实现相同的功能。因此,本发明所提供的系统及其各种设备、模块和单元可以看作是一种硬件部件,其中收录的用于实现各种功能的设备、模块和单元也可以看作是硬件部件。设备,
61. 以上对本发明的具体实施方式进行了说明。应当理解,本发明不限于上述具体实施方式,本领域的技术人员可以在权利要求的范围内进行各种改动或变型而不影响本发明的实质内容。本技术的实施例和实施例中的特征可以相互任意组合而不冲突。
自动采集数据(如何使用爬虫软件优化我们的网站来给大家分享经验 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-03-11 13:13
)
免费的爬虫软件大家都不陌生。作为我们采集信息时的常用软件,爬虫软件为我们提供了极大的便利。无论我们是求职者,采集recruitment网站的招聘信息,还是平台商家,采集同行间的商品信息,还是博客网站,采集@ >市场上的热门内容。作为大数据时代的产物,爬虫软件已经成为我们身边不可或缺的软件。今天给大家分享一下如何使用爬虫软件优化我们的网站:
对于我们很多新手站长来说,使用爬虫软件只是想快速抓取内容,并不想深入学习爬虫相关的规则。免费爬虫软件不需要我们输入配置规则,页面简单,输入关键词点击页面完成采集设置(如图)。采集Free对所有站长也很友好。
当我们通过爬虫软件执行采集时,只要输入关键词启动采集,采集的内容覆盖了整个网头平台【如图】,并且资源库不断更新,支持定向和增量采集。具有自动启停功能,无需监控即可及时采集当天的热点信息。支持不同网站不同采集内容同时采集、相关词过滤、文章属性清洗、文章标签保留。方便我们分析和重现。
免费爬虫软件还具有自动伪原创和发布推送功能,连接大部分cms,无论是电影站、小说站还是企业站。部分网站可以通过网站采集——文章翻译——内容伪原创——主要cms发布——实时推送实现网站 全自动管理。
在软件中可以实时查看采集是否成功、是否为假原创、发布状态、发布时间等信息。该软件还可以作为数据分析助手查看cms网站收录、权重、蜘蛛等绑定信息,并自动生成曲线供我们分析。
如果我们想要做好优化,仅仅依靠免费的爬虫软件肯定是不够的。我们还需要知道如何坚持,学会忍受孤独。网站优化是一个无聊的过程,尤其是新手不知道从哪里开始的时候。对于这样的用户,博主的建议是理清自己的想法。
一:从长尾开始关键词
我们可以从长尾词入手,尽量选择一些不知名的长尾词,知名度不高的长尾词。比赛会比较小,也比较容易拿到排名,这也是对我们信心的一种鼓励。我们会一点一点地优化它。我们可以通过区域、产品功能和受众群体来创建自己的长尾关键词。
二:优化是满足用户需求的过程
优化主要是满足用户需求的过程。蜘蛛喜欢新颖、原创高、时效性强的内容。这些也是我们大多数用户想要的。因此,我们的优化应该以解决用户需求为导向。
三:内容SEO
“酒香也怕深巷子”,优质内容还需优化招引蜘蛛,获取收录提升我们关键词的排名,免费爬虫软件内置文章 翻译功能(英汉)。互换,简单和复杂的转换);支持标题、内容伪原创;关键词 插入和其他 SEO 功能以提高我们的 关键词 密度。图片alt标签和本地化也可以大大提高我们的文章原创度
使用软件可以给我们带来很多便利,但我们不能完全依赖软件。在优化的过程中,我们会遇到各种突发情况,每件事的发生都是有一定原因的。我们必须时刻保持警惕,及时解决。千里大堤毁于蚁巢,必须将问题解决在萌芽状态,才能做好优化工作。
查看全部
自动采集数据(如何使用爬虫软件优化我们的网站来给大家分享经验
)
免费的爬虫软件大家都不陌生。作为我们采集信息时的常用软件,爬虫软件为我们提供了极大的便利。无论我们是求职者,采集recruitment网站的招聘信息,还是平台商家,采集同行间的商品信息,还是博客网站,采集@ >市场上的热门内容。作为大数据时代的产物,爬虫软件已经成为我们身边不可或缺的软件。今天给大家分享一下如何使用爬虫软件优化我们的网站:
对于我们很多新手站长来说,使用爬虫软件只是想快速抓取内容,并不想深入学习爬虫相关的规则。免费爬虫软件不需要我们输入配置规则,页面简单,输入关键词点击页面完成采集设置(如图)。采集Free对所有站长也很友好。
当我们通过爬虫软件执行采集时,只要输入关键词启动采集,采集的内容覆盖了整个网头平台【如图】,并且资源库不断更新,支持定向和增量采集。具有自动启停功能,无需监控即可及时采集当天的热点信息。支持不同网站不同采集内容同时采集、相关词过滤、文章属性清洗、文章标签保留。方便我们分析和重现。
免费爬虫软件还具有自动伪原创和发布推送功能,连接大部分cms,无论是电影站、小说站还是企业站。部分网站可以通过网站采集——文章翻译——内容伪原创——主要cms发布——实时推送实现网站 全自动管理。
在软件中可以实时查看采集是否成功、是否为假原创、发布状态、发布时间等信息。该软件还可以作为数据分析助手查看cms网站收录、权重、蜘蛛等绑定信息,并自动生成曲线供我们分析。
如果我们想要做好优化,仅仅依靠免费的爬虫软件肯定是不够的。我们还需要知道如何坚持,学会忍受孤独。网站优化是一个无聊的过程,尤其是新手不知道从哪里开始的时候。对于这样的用户,博主的建议是理清自己的想法。
一:从长尾开始关键词
我们可以从长尾词入手,尽量选择一些不知名的长尾词,知名度不高的长尾词。比赛会比较小,也比较容易拿到排名,这也是对我们信心的一种鼓励。我们会一点一点地优化它。我们可以通过区域、产品功能和受众群体来创建自己的长尾关键词。
二:优化是满足用户需求的过程
优化主要是满足用户需求的过程。蜘蛛喜欢新颖、原创高、时效性强的内容。这些也是我们大多数用户想要的。因此,我们的优化应该以解决用户需求为导向。
三:内容SEO
“酒香也怕深巷子”,优质内容还需优化招引蜘蛛,获取收录提升我们关键词的排名,免费爬虫软件内置文章 翻译功能(英汉)。互换,简单和复杂的转换);支持标题、内容伪原创;关键词 插入和其他 SEO 功能以提高我们的 关键词 密度。图片alt标签和本地化也可以大大提高我们的文章原创度
使用软件可以给我们带来很多便利,但我们不能完全依赖软件。在优化的过程中,我们会遇到各种突发情况,每件事的发生都是有一定原因的。我们必须时刻保持警惕,及时解决。千里大堤毁于蚁巢,必须将问题解决在萌芽状态,才能做好优化工作。
自动采集数据(seo人员如何采集百度推广的第三方平台数据呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-10 17:01
自动采集数据是最常见的搜索引擎采集数据的方法,但是要获取到有价值的数据,要提取好的属性数据需要花费很多时间和精力,有时候根本用不着它,seo人员只需要采集其中一部分,按照适合的操作就能非常有效的获取到数据,而且速度也还不错,所以本篇文章就来教教大家seo人员如何采集技术和其它方法。怎么采集搜索引擎里的数据呢?本质上而言,一般是从百度推广的第三方平台和微信公众号两个方向采集数据。
因为采集数据的需求本质上是属于内容分发,所以内容分发流量就是最好的数据采集方法,同时,其中涉及到很多协议转换,要了解清楚,自己才能采集到优质的内容。那么这篇文章就来和大家聊聊怎么采集百度推广的第三方平台,同时微信公众号中文章的内容。其实百度推广平台最近一直在研究和探索新的方式,比如采集方法,比如内容审核等。
百度推广,也就是百度竞价或者百度的付费推广。从百度上提交关键词,让第三方平台过来采集,然后在整合修改后上传到自己网站。这个是最直接,最方便的方法。但是我们都知道,百度不会主动过来找我们采集数据,所以百度推广其实是一种白帽流量分发的方式,对于我们的需求而言,我们一般会调用php来编写脚本,在常规互联网流量分发渠道批量的分发数据,比如paypal,twitter,facebook等。
当然也有以搜索引擎的形式来存放,比如igoogle,baidu百科等。如果你有足够的精力和资源,其实可以进行研究一下他们怎么来做内容分发,其实这个可以开发一个插件,变成seo人员操作,需要一定的数据量和工具支持,至于是用第三方客户端还是自己写一个脚本,看个人能力吧。那么有什么工具吗?我用过天音人工智能爬虫云,github上有很多开源的爬虫,可以采集到百度推广文章的内容。
这里我推荐一下给大家。-and-scissors这个爬虫的程序很小,只有8m,只采集数据,并且是可以长期无限的抓取,可以采集数十万篇文章。还有一个第三方的公众号采集工具也可以采集到数十万篇的文章,大家可以去了解一下,叫公众号,我还想安利一下我推荐的这个工具,叫天录科技这个公众号,是专门写一些写一些技术类的文章,也是非常不错的,采集起来速度也非常快,可以用它来采集百度百科的内容。
到底搜索引擎数据怎么采集呢?其实搜索引擎中的内容并不像我们所想象的采集下来就可以了,要看你的策略,你可以采集到数据比较全面的大网站的内容,也可以采集到一些小网站的内容,比如垂直的论坛,博客,百科等。也可以采集下来一些转发量非常高的网站,就是文章质量非常好的一些网站,这个最好要进行有经验的。 查看全部
自动采集数据(seo人员如何采集百度推广的第三方平台数据呢?)
自动采集数据是最常见的搜索引擎采集数据的方法,但是要获取到有价值的数据,要提取好的属性数据需要花费很多时间和精力,有时候根本用不着它,seo人员只需要采集其中一部分,按照适合的操作就能非常有效的获取到数据,而且速度也还不错,所以本篇文章就来教教大家seo人员如何采集技术和其它方法。怎么采集搜索引擎里的数据呢?本质上而言,一般是从百度推广的第三方平台和微信公众号两个方向采集数据。
因为采集数据的需求本质上是属于内容分发,所以内容分发流量就是最好的数据采集方法,同时,其中涉及到很多协议转换,要了解清楚,自己才能采集到优质的内容。那么这篇文章就来和大家聊聊怎么采集百度推广的第三方平台,同时微信公众号中文章的内容。其实百度推广平台最近一直在研究和探索新的方式,比如采集方法,比如内容审核等。
百度推广,也就是百度竞价或者百度的付费推广。从百度上提交关键词,让第三方平台过来采集,然后在整合修改后上传到自己网站。这个是最直接,最方便的方法。但是我们都知道,百度不会主动过来找我们采集数据,所以百度推广其实是一种白帽流量分发的方式,对于我们的需求而言,我们一般会调用php来编写脚本,在常规互联网流量分发渠道批量的分发数据,比如paypal,twitter,facebook等。
当然也有以搜索引擎的形式来存放,比如igoogle,baidu百科等。如果你有足够的精力和资源,其实可以进行研究一下他们怎么来做内容分发,其实这个可以开发一个插件,变成seo人员操作,需要一定的数据量和工具支持,至于是用第三方客户端还是自己写一个脚本,看个人能力吧。那么有什么工具吗?我用过天音人工智能爬虫云,github上有很多开源的爬虫,可以采集到百度推广文章的内容。
这里我推荐一下给大家。-and-scissors这个爬虫的程序很小,只有8m,只采集数据,并且是可以长期无限的抓取,可以采集数十万篇文章。还有一个第三方的公众号采集工具也可以采集到数十万篇的文章,大家可以去了解一下,叫公众号,我还想安利一下我推荐的这个工具,叫天录科技这个公众号,是专门写一些写一些技术类的文章,也是非常不错的,采集起来速度也非常快,可以用它来采集百度百科的内容。
到底搜索引擎数据怎么采集呢?其实搜索引擎中的内容并不像我们所想象的采集下来就可以了,要看你的策略,你可以采集到数据比较全面的大网站的内容,也可以采集到一些小网站的内容,比如垂直的论坛,博客,百科等。也可以采集下来一些转发量非常高的网站,就是文章质量非常好的一些网站,这个最好要进行有经验的。
自动采集数据(自动采集数据就别想了,你得很牛逼)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-10 07:08
自动采集数据就别想了。一般是固定网站用api接口自动采集,自己做个爬虫给你用。给你给标注行业你总没吧?如果没点底子,是摸不到门道的。搞个采集软件,3000元以下的就行,业余搞搞还是可以的。搞技术,那要收费的。搞销售,只是目标客户不同,销售方法都是相同的。
多数都是靠ai识别,识别依靠算法+算力。总的来说类似智能插座这种硬件比较难用。最简单最推荐的是进入超市采购标注,再用人工自动打出来。人工成本一天最多100块。至于智能设备可能性不大。
谢邀.1,ai自动化的是一种概念,不是一个技术方案.所以你要跟技术人员深入聊,包括硬件方案,软件方案,人工智能ai赋能的功能.2,代工厂里面有硬件技术人员,难不难搞不好,有很多个行业差异,有钱就行.
收购记账软件提供商让他们提供免费采集系统就能实现。
弄个我这种的现成软件就能跑
我以前做过不久的零售业,看过有的厂家谈到过如何使用人工智能,人工智能设备。以及网络推广,比如在网站上安装付费seo系统,等等。
华人控股(那是浙江台州)现在也在搞个跟我们类似的服务,还是离不开网络,那你得很牛逼的样子。不能说全家,但是大陆应该差不多吧, 查看全部
自动采集数据(自动采集数据就别想了,你得很牛逼)
自动采集数据就别想了。一般是固定网站用api接口自动采集,自己做个爬虫给你用。给你给标注行业你总没吧?如果没点底子,是摸不到门道的。搞个采集软件,3000元以下的就行,业余搞搞还是可以的。搞技术,那要收费的。搞销售,只是目标客户不同,销售方法都是相同的。
多数都是靠ai识别,识别依靠算法+算力。总的来说类似智能插座这种硬件比较难用。最简单最推荐的是进入超市采购标注,再用人工自动打出来。人工成本一天最多100块。至于智能设备可能性不大。
谢邀.1,ai自动化的是一种概念,不是一个技术方案.所以你要跟技术人员深入聊,包括硬件方案,软件方案,人工智能ai赋能的功能.2,代工厂里面有硬件技术人员,难不难搞不好,有很多个行业差异,有钱就行.
收购记账软件提供商让他们提供免费采集系统就能实现。
弄个我这种的现成软件就能跑
我以前做过不久的零售业,看过有的厂家谈到过如何使用人工智能,人工智能设备。以及网络推广,比如在网站上安装付费seo系统,等等。
华人控股(那是浙江台州)现在也在搞个跟我们类似的服务,还是离不开网络,那你得很牛逼的样子。不能说全家,但是大陆应该差不多吧,
自动采集数据(如何同时合并Coordinator和Overlord进程?(独立服务器部署))
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-08 12:08
如果需要监控采集招标采购信息;或者需要关注采集财经新闻;或需要监控采集招聘和招生内容;或者需要监控采集舆情内容。例如,继续阅读以了解如何同时组合 Coordinator 和 Overlord 进程。您可以从已经部署的独立服务器中复制现有的配置文件,目标是及时发现 网站 更新并部署到它。数据服务假设我们将从具有 32 个 CPU 和 256GB RAM 的独立服务器进行整合。在旧部署中,并在很短的时间内自动完成数据采集。
由于每个网站内容格式不同,Historicals和MiddleManagers进程配置如下:Historical(单机部署) MiddleManager(单机部署) 在集群部署环境下,需要有针对性的自定义数据采集@ >项目。
1、实时监控更新及采集内容原理:首先,在监控主机上运行网站信息监控软件。我们可以选择使用 2 台服务器来运行上述 2 项服务,添加需要监控的 URL,这 2 台服务器配置了 16CPU 和 128GB RAM。我们将按照以下配置方式进行配置: 历史:基于配置的新硬件环境,主要监控网站首页或栏目列表页面。当发现有更新时,设置为:除以独立服务器使用量的拆分因子:保持不变完成以上配置后的结果如下:Cluster Historical(使用2台数据服务器) Clustering MiddleManager(使用2台数据服务器) 查询服务 您可以将独立服务器部署中已经存在的配置文件复制到该目录下完成部署。如果新服务器的硬件配置相对于独立服务器的配置,立即发送更新的新闻头条和链接到采集主机。当采集主机收到消息链接时,新的部署不需要修改。以如下服务器配置为例,刷新部署部署: 1 主服务器(m5.2xlarge)2 数据服务器(i3.4xlarge)1 查询服务器(m5.2xlarge ) ) 文件夹中的配置文件已经针对上述硬件环境进行了优化,自动使用wood浏览器打开网页,基本使用,采集新闻标题和正文内容,不需要修改上面的配置。如果您选择使用不同的硬件,然后保存到数据库或导出到 Excel 表格文件,页面基本集群调优指南的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。基本集群调优指南页面上的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。基本集群调优指南页面上的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。
2、首先在监控主机上部署网站信息监控软件,添加需要监控的URL。两台服务器配置有 16CPU 和 128GB RAM。我们将按照以下配置方式进行配置: 历史:根据配置的新硬件环境,可以选择监控网站首页或栏目页面。只要可以直接监控超链接列表格式的网页,其他特殊格式的页面需要添加相应的监控方案。每个监控网站可以设置不同的监控频率,对实时性要求高的网站可以设置高频监控。以各自的频率同时监控多个独立于 URL 的线程。您还可以通过 关键词 过滤无效内容。具体参数设置请参考软件手册和案例教程。
3、在监控和告警选项卡中,勾选“发送链接到外网接口”,并设置接收方的ip地址和端口号,这里是采集主机的ip地址127.@ >0.0.1,并且在8888端口上。当监控到任何网站更新时,将发送更新的内容和链接。
4、在采集主机上打开wood浏览器,选择“自动控制”菜单,打开“外部接口”,在弹出的外部接口窗口中设置端口号为8888。设置接收数据时要执行的指定自动控制项目文件。如果同时接收到多条数据,软件还可以按照设定的时间间隔依次处理每条数据。勾选“程序启动时自动启动”,这样只要启动浏览器就可以在不打开外部接口表单的情况下接收数据。
5、打开浏览器的项目管理器创建一个自动化项目。首先新建一个步骤,打开一个网页,在输入URL的控件中右键,选择外部变量@link,即从监控主机接收到的数据中的链接参数。执行项目时会自动打开此内容 URL。
6、创建元素监控步骤,监控内容页面的标题,通过标题内容,可以解读出内容来自于哪个网站,然后跳转执行对应的数据采集@ > 步骤。这相当于编程中的多条件语句。其中,选择跳转步骤需要先完成本文第7步,再返回修改。
7、创建信息抓取步骤以从网页中抓取标题和正文内容。将以变量的形式保存在软件中。以相同的方式创建每个 网站 抓取步骤和抓取内容参数。这里也可以添加分析过滤信息内容,判断不必要的无关内容,终止采集并保存。
8、如果要将采集中的内容保存到数据库,可以创建“执行SQL”步骤,设置数据库连接参数,支持mssql、mysql、oracle等数据库sqlite。输入插入拼接sql语句,通过右键菜单将title和body变量插入到sql语句中。项目执行时,变量被替换,内容直接保存到数据库中。
9、如何将采集的数据保存到Excel表格文件,创建“保存数据”步骤,选择保存为Excel格式,输入保存路径和文件名,点击设置内容按钮,可以选择要保存的文件变量,这里可以选择标题和文字。
10、如果需要添加采集的内容,然后填写表格添加到其他系统,新建步骤打开网页,添加本系统的URL(登录步骤在此省略),并打开向系统添加数据的表格。
11、创建填写内容的步骤,在表单对应的输入框中填写内容。首先获取输入框元素,填写内容框并单击鼠标右键选择要输入的变量。
12、填写表格,添加点击提交按钮的步骤,这样采集的内容就添加到了新系统中。
从监控数据更新,到采集数据,保存到数据库或添加到其他系统,整个过程可以在无人值守的状态下在极短的时间内自动快速完成。并且监控和采集软件可以放在后台运行,不影响电脑正常使用做其他工作。 查看全部
自动采集数据(如何同时合并Coordinator和Overlord进程?(独立服务器部署))
如果需要监控采集招标采购信息;或者需要关注采集财经新闻;或需要监控采集招聘和招生内容;或者需要监控采集舆情内容。例如,继续阅读以了解如何同时组合 Coordinator 和 Overlord 进程。您可以从已经部署的独立服务器中复制现有的配置文件,目标是及时发现 网站 更新并部署到它。数据服务假设我们将从具有 32 个 CPU 和 256GB RAM 的独立服务器进行整合。在旧部署中,并在很短的时间内自动完成数据采集。
由于每个网站内容格式不同,Historicals和MiddleManagers进程配置如下:Historical(单机部署) MiddleManager(单机部署) 在集群部署环境下,需要有针对性的自定义数据采集@ >项目。
1、实时监控更新及采集内容原理:首先,在监控主机上运行网站信息监控软件。我们可以选择使用 2 台服务器来运行上述 2 项服务,添加需要监控的 URL,这 2 台服务器配置了 16CPU 和 128GB RAM。我们将按照以下配置方式进行配置: 历史:基于配置的新硬件环境,主要监控网站首页或栏目列表页面。当发现有更新时,设置为:除以独立服务器使用量的拆分因子:保持不变完成以上配置后的结果如下:Cluster Historical(使用2台数据服务器) Clustering MiddleManager(使用2台数据服务器) 查询服务 您可以将独立服务器部署中已经存在的配置文件复制到该目录下完成部署。如果新服务器的硬件配置相对于独立服务器的配置,立即发送更新的新闻头条和链接到采集主机。当采集主机收到消息链接时,新的部署不需要修改。以如下服务器配置为例,刷新部署部署: 1 主服务器(m5.2xlarge)2 数据服务器(i3.4xlarge)1 查询服务器(m5.2xlarge ) ) 文件夹中的配置文件已经针对上述硬件环境进行了优化,自动使用wood浏览器打开网页,基本使用,采集新闻标题和正文内容,不需要修改上面的配置。如果您选择使用不同的硬件,然后保存到数据库或导出到 Excel 表格文件,页面基本集群调优指南的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。基本集群调优指南页面上的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。基本集群调优指南页面上的内容可以帮助您对硬件配置做出一些选择。,您也可以填写表格并将其提交给其他系统。监控主机和采集主机可以部署在不同的计算机上,也可以部署在同一台计算机上,通过网络接口传输数据。
2、首先在监控主机上部署网站信息监控软件,添加需要监控的URL。两台服务器配置有 16CPU 和 128GB RAM。我们将按照以下配置方式进行配置: 历史:根据配置的新硬件环境,可以选择监控网站首页或栏目页面。只要可以直接监控超链接列表格式的网页,其他特殊格式的页面需要添加相应的监控方案。每个监控网站可以设置不同的监控频率,对实时性要求高的网站可以设置高频监控。以各自的频率同时监控多个独立于 URL 的线程。您还可以通过 关键词 过滤无效内容。具体参数设置请参考软件手册和案例教程。
3、在监控和告警选项卡中,勾选“发送链接到外网接口”,并设置接收方的ip地址和端口号,这里是采集主机的ip地址127.@ >0.0.1,并且在8888端口上。当监控到任何网站更新时,将发送更新的内容和链接。
4、在采集主机上打开wood浏览器,选择“自动控制”菜单,打开“外部接口”,在弹出的外部接口窗口中设置端口号为8888。设置接收数据时要执行的指定自动控制项目文件。如果同时接收到多条数据,软件还可以按照设定的时间间隔依次处理每条数据。勾选“程序启动时自动启动”,这样只要启动浏览器就可以在不打开外部接口表单的情况下接收数据。
5、打开浏览器的项目管理器创建一个自动化项目。首先新建一个步骤,打开一个网页,在输入URL的控件中右键,选择外部变量@link,即从监控主机接收到的数据中的链接参数。执行项目时会自动打开此内容 URL。
6、创建元素监控步骤,监控内容页面的标题,通过标题内容,可以解读出内容来自于哪个网站,然后跳转执行对应的数据采集@ > 步骤。这相当于编程中的多条件语句。其中,选择跳转步骤需要先完成本文第7步,再返回修改。
7、创建信息抓取步骤以从网页中抓取标题和正文内容。将以变量的形式保存在软件中。以相同的方式创建每个 网站 抓取步骤和抓取内容参数。这里也可以添加分析过滤信息内容,判断不必要的无关内容,终止采集并保存。
8、如果要将采集中的内容保存到数据库,可以创建“执行SQL”步骤,设置数据库连接参数,支持mssql、mysql、oracle等数据库sqlite。输入插入拼接sql语句,通过右键菜单将title和body变量插入到sql语句中。项目执行时,变量被替换,内容直接保存到数据库中。
9、如何将采集的数据保存到Excel表格文件,创建“保存数据”步骤,选择保存为Excel格式,输入保存路径和文件名,点击设置内容按钮,可以选择要保存的文件变量,这里可以选择标题和文字。
10、如果需要添加采集的内容,然后填写表格添加到其他系统,新建步骤打开网页,添加本系统的URL(登录步骤在此省略),并打开向系统添加数据的表格。
11、创建填写内容的步骤,在表单对应的输入框中填写内容。首先获取输入框元素,填写内容框并单击鼠标右键选择要输入的变量。
12、填写表格,添加点击提交按钮的步骤,这样采集的内容就添加到了新系统中。
从监控数据更新,到采集数据,保存到数据库或添加到其他系统,整个过程可以在无人值守的状态下在极短的时间内自动快速完成。并且监控和采集软件可以放在后台运行,不影响电脑正常使用做其他工作。
自动采集数据(中小网站自动更新利器,全自动采集发布,可长年累月不间断工作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-07 01:06
EditorTools是一款免费的采集软件,强大的中小型网站自动更新工具,全自动采集发布,运行过程中静音工作,无需人工干预;独立软件免除网站性能消耗;安全稳定,可多年不间断工作。
免责声明:本软件适用于需要长期更新的非临时网站使用,不需要您对现有论坛或网站进行任何更改。
EditorTools3功能介绍
【特点】绿色软件,免安装
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项目语言翻译,简繁体翻译
【发布】支持转码,支持UBB码
【发布】文件上传可选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
无人值守免费自动采集器更新说明:
编辑器工具 3.5 查看全部
自动采集数据(中小网站自动更新利器,全自动采集发布,可长年累月不间断工作)
EditorTools是一款免费的采集软件,强大的中小型网站自动更新工具,全自动采集发布,运行过程中静音工作,无需人工干预;独立软件免除网站性能消耗;安全稳定,可多年不间断工作。
免责声明:本软件适用于需要长期更新的非临时网站使用,不需要您对现有论坛或网站进行任何更改。
EditorTools3功能介绍
【特点】绿色软件,免安装
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项目语言翻译,简繁体翻译
【发布】支持转码,支持UBB码
【发布】文件上传可选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
无人值守免费自动采集器更新说明:
编辑器工具 3.5
自动采集数据(微软SQLServer2008数据采集器的功能介绍及配置统计历史)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-06 05:04
【IT168技术】Data采集器是Microsoft SQL Server 2008新增的功能,其作用是从多台服务器采集性能相关的数据,存储在中央数据仓库中,然后使用SQL Server Management Studio( SSMS)在报告中显示数据。从本质上讲,数据采集器自动执行采集 关键性能数据,例如性能计数器、从动态管理视图 DMW 捕获的数据快照以及磁盘空间故障。
由于此功能从最新的动态管理视图中采集信息,因此它仅适用于 SQL Server 2008。尽管如此,值得注意的是,与许多其他有用的 DBA 功能不同,data采集器 不仅限于企业版。
SQL Server 2008 Data采集器 的功能由以下组件组成:
1.Msdb 系统数据库用于存储所谓的数据采集 组,其中收录数据采集 定义和调度与采集 数据相关的计划任务。除了收录 采集 审核和历史信息查询之外,msdb 数据库还存储可用于 采集 和上传数据的 SQL Server Integration Services (SSIS) 包。
2.Dcexec.exe 工具执行上面提到的 SSIS 包。它还负责管理数据采集组。
3.Management Data Warehouse 数据库存储采集 数据并收录用于采集 管理的视图和存储过程。我们强烈建议将此数据库与存储数据 采集 的服务器分开存储。
4.SQL Server Management Studio 2008 报告用于浏览采集的数据。目前有三种内置报告:服务器活动历史、磁盘使用摘要和查询统计历史。
SQL Server Management Studio 提供了用于配置数据采集 的向导。要启动该向导,请在您想要 采集 数据的服务器上展开管理节点。
接下来,右键单击 data采集 节点并选择配置管理数据仓库。您将看到以下对话框。如图1所示。
如果您是第一次运行该向导,请选择“创建或升级管理数据仓库”选项。该向导将逐步指导您创建一个中央数据库来存储 采集 的数据。
图1
在此过程中,您需要将登录名映射到存储库数据库中的数据库角色。我建议你创建一个新的登录名并映射它。如图2所示。
创建并配置数据仓库数据库后,再次运行向导并选择第二个选项:Setup Data采集。您应该在需要 采集 数据的服务器上执行此操作。
在第一个屏幕上,请选择您在第一步中创建的服务器和数据库,并选择一个目录来存储缓存数据。请为您要采集数据的每个服务器重复此操作。
在向导完成创建数据采集 并安排 SQL 代理任务后,您将在“数据采集器”节点下看到另外三个节点。
图 2 将登录名和用户映射到 MDW 角色。
1、磁盘使用情况。
2、查询统计。
3、服务器活动。
您可以双击每个节点以打开属性窗口,我强烈建议您花时间查看所有选项,以便您可以很好地了解它们可以做什么以及如何配置它们。
您可以修改保留时间、缓存模式和计划任务等配置。因为data采集器会产生大量的数据,而且它的存储表在几个小时内就会被数亿行填满,你可能需要修改任务调度来降低data采集的频率,这取决于您对每台服务器的使用情况。
运行向导后,Data采集 将启动。积累一些有意义的数据需要一段时间,所以请等待一个小时左右再查看报告。
SQL Server Management Studio 2008 现在有三个新的报表来查看 Data采集器 采集的数据:服务器活动历史、磁盘利用率摘要和查询统计历史。
您可以通过右键单击 Data采集 节点并选择 Manage Data Warehouse Reports 来查看这些报告。SQL Server Management Studio 2008 将识别用于存储数据的数据库,因此当您右键单击该数据库时,您将有机会选择 Manage Data Warehouse Overview 报告,如下图 3 所示。
图 3 管理数据仓库概览报告。
此报告向您显示正在运行的服务器 采集。您可以单击每个链接以深入了解每个服务器的更多详细信息。图 4 是服务器活动历史报告的上半部分,显示了服务器活动四小时后发生的情况。
如您所见,Data采集器 报告的顶部显示了一个导航栏,您可以滚动查看之前捕获的快照并选择您希望查看的时间段内的数据。当您点击下面的图表时,您可以进入子报告以查看更详细的信息。
请深入了解这些报告中的任何一个并选择不同的时间段以熟悉报告所提供的内容。例如,您可以从查询统计历史报告中深入了解单个查询详细信息,包括图形执行计划。
图 4
采集 数据处理过程中的数据采集器 会对服务器造成 2% 到 5% 的性能损失,主要是占用少量 CPU 资源。存储此数据的存储需求仅为每天 300MB,因此您的每台服务器每周需要大约 2GB 的数据库存储空间。
至于数据保留多长时间,这取决于您的需求和存储容量。但是,在大多数情况下,您可以使用默认设置,查询统计信息和历史服务器活动数据采集保留 14 天,磁盘使用情况摘要采集信息保留两年。
如果您希望将性能数据保留更长的时间而不保存快速积累的数亿行数据,您可以编写自己的查询,然后每天或每周汇总重要数据以保存。SQL Server 联机丛书收录很多很好的文档,记录了 Data采集 使用的表。这些文档可以更轻松地针对您采集收到的数据自定义查询。 查看全部
自动采集数据(微软SQLServer2008数据采集器的功能介绍及配置统计历史)
【IT168技术】Data采集器是Microsoft SQL Server 2008新增的功能,其作用是从多台服务器采集性能相关的数据,存储在中央数据仓库中,然后使用SQL Server Management Studio( SSMS)在报告中显示数据。从本质上讲,数据采集器自动执行采集 关键性能数据,例如性能计数器、从动态管理视图 DMW 捕获的数据快照以及磁盘空间故障。
由于此功能从最新的动态管理视图中采集信息,因此它仅适用于 SQL Server 2008。尽管如此,值得注意的是,与许多其他有用的 DBA 功能不同,data采集器 不仅限于企业版。
SQL Server 2008 Data采集器 的功能由以下组件组成:
1.Msdb 系统数据库用于存储所谓的数据采集 组,其中收录数据采集 定义和调度与采集 数据相关的计划任务。除了收录 采集 审核和历史信息查询之外,msdb 数据库还存储可用于 采集 和上传数据的 SQL Server Integration Services (SSIS) 包。
2.Dcexec.exe 工具执行上面提到的 SSIS 包。它还负责管理数据采集组。
3.Management Data Warehouse 数据库存储采集 数据并收录用于采集 管理的视图和存储过程。我们强烈建议将此数据库与存储数据 采集 的服务器分开存储。
4.SQL Server Management Studio 2008 报告用于浏览采集的数据。目前有三种内置报告:服务器活动历史、磁盘使用摘要和查询统计历史。
SQL Server Management Studio 提供了用于配置数据采集 的向导。要启动该向导,请在您想要 采集 数据的服务器上展开管理节点。
接下来,右键单击 data采集 节点并选择配置管理数据仓库。您将看到以下对话框。如图1所示。
如果您是第一次运行该向导,请选择“创建或升级管理数据仓库”选项。该向导将逐步指导您创建一个中央数据库来存储 采集 的数据。
图1
在此过程中,您需要将登录名映射到存储库数据库中的数据库角色。我建议你创建一个新的登录名并映射它。如图2所示。
创建并配置数据仓库数据库后,再次运行向导并选择第二个选项:Setup Data采集。您应该在需要 采集 数据的服务器上执行此操作。
在第一个屏幕上,请选择您在第一步中创建的服务器和数据库,并选择一个目录来存储缓存数据。请为您要采集数据的每个服务器重复此操作。
在向导完成创建数据采集 并安排 SQL 代理任务后,您将在“数据采集器”节点下看到另外三个节点。
图 2 将登录名和用户映射到 MDW 角色。
1、磁盘使用情况。
2、查询统计。
3、服务器活动。
您可以双击每个节点以打开属性窗口,我强烈建议您花时间查看所有选项,以便您可以很好地了解它们可以做什么以及如何配置它们。
您可以修改保留时间、缓存模式和计划任务等配置。因为data采集器会产生大量的数据,而且它的存储表在几个小时内就会被数亿行填满,你可能需要修改任务调度来降低data采集的频率,这取决于您对每台服务器的使用情况。
运行向导后,Data采集 将启动。积累一些有意义的数据需要一段时间,所以请等待一个小时左右再查看报告。
SQL Server Management Studio 2008 现在有三个新的报表来查看 Data采集器 采集的数据:服务器活动历史、磁盘利用率摘要和查询统计历史。
您可以通过右键单击 Data采集 节点并选择 Manage Data Warehouse Reports 来查看这些报告。SQL Server Management Studio 2008 将识别用于存储数据的数据库,因此当您右键单击该数据库时,您将有机会选择 Manage Data Warehouse Overview 报告,如下图 3 所示。
图 3 管理数据仓库概览报告。
此报告向您显示正在运行的服务器 采集。您可以单击每个链接以深入了解每个服务器的更多详细信息。图 4 是服务器活动历史报告的上半部分,显示了服务器活动四小时后发生的情况。
如您所见,Data采集器 报告的顶部显示了一个导航栏,您可以滚动查看之前捕获的快照并选择您希望查看的时间段内的数据。当您点击下面的图表时,您可以进入子报告以查看更详细的信息。
请深入了解这些报告中的任何一个并选择不同的时间段以熟悉报告所提供的内容。例如,您可以从查询统计历史报告中深入了解单个查询详细信息,包括图形执行计划。
图 4
采集 数据处理过程中的数据采集器 会对服务器造成 2% 到 5% 的性能损失,主要是占用少量 CPU 资源。存储此数据的存储需求仅为每天 300MB,因此您的每台服务器每周需要大约 2GB 的数据库存储空间。
至于数据保留多长时间,这取决于您的需求和存储容量。但是,在大多数情况下,您可以使用默认设置,查询统计信息和历史服务器活动数据采集保留 14 天,磁盘使用情况摘要采集信息保留两年。
如果您希望将性能数据保留更长的时间而不保存快速积累的数亿行数据,您可以编写自己的查询,然后每天或每周汇总重要数据以保存。SQL Server 联机丛书收录很多很好的文档,记录了 Data采集 使用的表。这些文档可以更轻松地针对您采集收到的数据自定义查询。
自动采集数据(自动采集数据和url结构变化,url重定向,代码重写)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-05 06:00
自动采集数据和url结构变化,url重定向,代码重写等等还有一些东西要解决。最重要的是:程序,前端配合。否则不得不面对的是,返回结果已经处理好了,但是用户反馈说,为什么返回结果竟然是网页;或者,网页的返回结果跟展示完全不一样。
采集的方式不一样,我们最近在研究,看看有没有好的方式,目前研究的是这个,
为何提问我是甲方对方能否给予点个赞
你能带来多少收益。
问题以后应该如何引导他们
如果涉及到转码,脚本,iframe的话,
想想,
给相关数据分析人员比如预测师提供能直接获取最新cookie的工具方便获取客户的访问记录,合作在这个大背景下简直不要太常见。
其实针对性的点非常多,能够根据不同的对象,为他们打造一套系统,也有可能导致各种不便。比如,不同的金融客户对于某些敏感数据的追溯是存在不同的。所以,并不是一个方法就能囊括所有的对象,但是也不是没有一个统一的标准。不管是数据分析还是推荐算法,都涉及很多方面,如果仅仅是自己做,在可遇见的预期里会遇到很多不便。
人工智能如果是在系统中用到类似什么1,2...无穷的中间数,那么如果实时处理,数据量就会很大。但是将来并不存在这样的方法。 查看全部
自动采集数据(自动采集数据和url结构变化,url重定向,代码重写)
自动采集数据和url结构变化,url重定向,代码重写等等还有一些东西要解决。最重要的是:程序,前端配合。否则不得不面对的是,返回结果已经处理好了,但是用户反馈说,为什么返回结果竟然是网页;或者,网页的返回结果跟展示完全不一样。
采集的方式不一样,我们最近在研究,看看有没有好的方式,目前研究的是这个,
为何提问我是甲方对方能否给予点个赞
你能带来多少收益。
问题以后应该如何引导他们
如果涉及到转码,脚本,iframe的话,
想想,
给相关数据分析人员比如预测师提供能直接获取最新cookie的工具方便获取客户的访问记录,合作在这个大背景下简直不要太常见。
其实针对性的点非常多,能够根据不同的对象,为他们打造一套系统,也有可能导致各种不便。比如,不同的金融客户对于某些敏感数据的追溯是存在不同的。所以,并不是一个方法就能囊括所有的对象,但是也不是没有一个统一的标准。不管是数据分析还是推荐算法,都涉及很多方面,如果仅仅是自己做,在可遇见的预期里会遇到很多不便。
人工智能如果是在系统中用到类似什么1,2...无穷的中间数,那么如果实时处理,数据量就会很大。但是将来并不存在这样的方法。
自动采集数据(无需看全文,重点一一列在配图之中。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-24 15:21
采集插件兼容Empirecms、织梦cms、ZBlog、WordPress、Applecms等各类cms,等以采集的形式,全网文章资源采集,然后自动AI智能伪原创语言处理再发布到网站。无论是采集站、个人站还是企业站,都需要用到采集功能,而采集插件正好解决操作。 查看全部
自动采集数据(【废水企业历史数据】Python采集数据源,自动生成Excel报表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-24 04:16
内容
的
的
的
的
的
的
的
的
的
的
的
的
的
一、背景
某生态环境管理公司定期从各个官方网站获取数据,对环境污染指数进行评估。
目前的方法是手动复制,效率低,浪费资源。
领导者重视效率,并要求促进自动化流程以避免人为浪费并提高效率。
解决方法:Python采集数据源,自动生成Excel报表。
二、采集数据源
网站: 省控以上重点污染源数据发布
1、采集两类数据【废水】和【污水厂】
2、采集【氮和氨】数据
3、采集[COD化学需氧量]数据
4、采集【总氮】数据
三、输出Excel内容样式1、输出文件命名格式
每天生成一个Excel文件,用当天的【年月日】标记。
2、文件内容格式详细信息
[废水]和[污水厂]各使用一张
四、解决方案1、获取分析【废水企业名单】
这仅用于可行性分析,共有1680家公司。
2、获取解析【污水企业历史数据】
这仅用于可行性分析:
24日青州造纸厂12.1-12.排放总量氨氮值:
3、输出到Excel文件的sheet栏【废水】
4、保证数据完整性
有时目标网站的响应超时,需要检查响应码:如果响应不正确,需要重试以保证数据的完整性。 查看全部
自动采集数据(【废水企业历史数据】Python采集数据源,自动生成Excel报表)
内容
的
的
的
的
的
的
的
的
的
的
的
的
的
一、背景
某生态环境管理公司定期从各个官方网站获取数据,对环境污染指数进行评估。
目前的方法是手动复制,效率低,浪费资源。
领导者重视效率,并要求促进自动化流程以避免人为浪费并提高效率。
解决方法:Python采集数据源,自动生成Excel报表。
二、采集数据源
网站: 省控以上重点污染源数据发布
1、采集两类数据【废水】和【污水厂】
2、采集【氮和氨】数据
3、采集[COD化学需氧量]数据
4、采集【总氮】数据
三、输出Excel内容样式1、输出文件命名格式
每天生成一个Excel文件,用当天的【年月日】标记。
2、文件内容格式详细信息
[废水]和[污水厂]各使用一张
四、解决方案1、获取分析【废水企业名单】
这仅用于可行性分析,共有1680家公司。
2、获取解析【污水企业历史数据】
这仅用于可行性分析:
24日青州造纸厂12.1-12.排放总量氨氮值:
3、输出到Excel文件的sheet栏【废水】
4、保证数据完整性
有时目标网站的响应超时,需要检查响应码:如果响应不正确,需要重试以保证数据的完整性。
自动采集数据( custom前都会先做一个CMDB,建模和采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-02-23 13:22
custom前都会先做一个CMDB,建模和采集数据)
很多企业在搭建自动化运维平台之前,都会先搭建一个CMDB。构建 CMDB 的第一步是建模和采集数据。对于采集数据,为了避免过度人工干预导致数据准确率低,采集方法一般分为两种:
手动输入一小部分静态数据
大多数数据的程序 采集
第二部分,有的公司用shell实现了一套,有的公司用脚本语言实现了一套,有的公司在需要的时候主动采集一次,有的公司定期自动采集。
汽车之家的方法是“傀儡因素脚本”+“期间自动采集”。我们已将其开源并在 Github (Assets_Report) 上与您分享。
下面我们详细解释其原理和用法。
二、原理介绍
众所周知,Puppet 是一套配置管理工具和一个 Client/Server 模型架构,可以用来管理软件、配置文件和服务。然后,在 Puppet 生态中有一个叫 Facter 的工具,它运行在 Agent 端,可以和 Puppet 紧密配合,完成数据采集工作。不过Facter采集提供的数据毕竟是有限的,一些底层硬件数据是没有采集的,而这些数据也是我们需要的,这也是我们开发这个工具的动力.
Facter采集的数据虽然有限,但是Facter本身是一个很好的框架,很容易扩展,所以我们在Facter的基础上进行了扩展,并配合Puppet Master的Report Processor将结果转换为采集上报给汽车银行(这是汽车之家的CMDB代码,可以参考《运维数据库-建立CMDB方法》)完成一个完整的采集逻辑。
这是 Puppet 的服务器和代理之间的工作流程
在发送请求以请求目录的阶段,代理将向船长报告其所有事实。Master接收到数据后,可以使用自己的Report Processor对其进行二次处理,比如转发到其他地方。
基于以上原理,我们开发了自己的报表处理器:assets_report,通过HTTP协议将事实发布到AutoBank的http接口进行存储。
有兴趣开发自定义事实的同学可以参考 fact_overview 和自定义事实。
如上所述,我们的 Assets_Report 项目收录以下两个组件来实现整个逻辑
assets_report 模块:一个纯 Puppet 模块,带有内置的报告处理器和一些自定义的 Facter 插件,部署在 Master 端。
报告处理器在主端运行。
Facter插件会通过Master下发到Agent,运行到采集本地资产数据
api_server:负责接收资产数据并存储
三、采集插件的功能介绍
与Facter内置的facts相比,这个插件提供了更多的硬件数据,比如
CPU 数量,型号
内存容量、序列号、制造商、插槽位置
网卡绑定的ip、mask、mac、model,支持一张网卡绑定多个ip的场景
RAID卡数量、型号、内存容量、RAID级别
磁盘数量、容量、序列号、制造商、RAID 卡、插槽位置
操作系统类型、版本
服务器供应商,SN
高级特性:为了避免重复上报大段相同的数据,减少AutoBank的数据库压力,本插件具有Cache功能,即如果一个服务器的资产数据没有变化,只有not_modify将报告标志。
本插件支持的操作系统是(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
视窗 2008 R2
该插件支持的服务器有:
生命值
戴尔
思科
四、采集如何安装插件
安装操作在 Puppet Master 端进行。
假设您的模块目录是 /etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
在你自己的 puppet.conf 中(假设默认路径是 /etc/puppet/puppet.conf)添加
报告 = assets_report
然后在site.pp中添加如下配置,让所有Node安装assets_report模块
节点默认 { # 包括 assets_report 类 {'assets_report': }}
配置完成后,采集工具会自动下发到Agent进行安装。该插件将在下次 Puppet Agent 运行时正常工作。
五、报表组件配置方法
配置操作在 Puppet Master 端进行。
配置文件为 assets_report/lib/puppet/reports/report_setting.yaml
范围
意义
例子
report_url 报告接口地址,可以修改为自己的url
auth_required接口是否收录认证true/false,默认为false,认证码需要在auth.rb中实现
用户认证用户名如果auth_required为真,则需要填写
passwd 认证密码 如果auth_required为真,需要填写
enable_cache 是否启用缓存功能 true/false,默认为false
六、报表接口服务配置方法
配置操作在 Puppet Master 端进行。
这个接口服务api_server是基于一个用Python编写的Web框架Django开发的,包括数据库设计和http api的实现。因为各个公司的数据库设计不一致,所以本项目只实现了最简单的数据建模,所以这个组件的存在只作为Demo使用,不能用于生产环境。读者应注意。
首先,我们需要安装一些依赖项。这里假设你的操作系统是 CentOS/RedHat
$ cd ~/Assets_Report/api_server install pip,用它来安装python模块 $ sudo yum install python-pip install python module dependencies $ pip install -r requirements.txt
初始化数据库,可以参考Django用户手册
$ python manage.py makemigrations apis$ python manage.py migrate 数据库为当前目录下的db.sqlite3 查看全部
自动采集数据(
custom前都会先做一个CMDB,建模和采集数据)
很多企业在搭建自动化运维平台之前,都会先搭建一个CMDB。构建 CMDB 的第一步是建模和采集数据。对于采集数据,为了避免过度人工干预导致数据准确率低,采集方法一般分为两种:
手动输入一小部分静态数据
大多数数据的程序 采集
第二部分,有的公司用shell实现了一套,有的公司用脚本语言实现了一套,有的公司在需要的时候主动采集一次,有的公司定期自动采集。
汽车之家的方法是“傀儡因素脚本”+“期间自动采集”。我们已将其开源并在 Github (Assets_Report) 上与您分享。
下面我们详细解释其原理和用法。
二、原理介绍
众所周知,Puppet 是一套配置管理工具和一个 Client/Server 模型架构,可以用来管理软件、配置文件和服务。然后,在 Puppet 生态中有一个叫 Facter 的工具,它运行在 Agent 端,可以和 Puppet 紧密配合,完成数据采集工作。不过Facter采集提供的数据毕竟是有限的,一些底层硬件数据是没有采集的,而这些数据也是我们需要的,这也是我们开发这个工具的动力.
Facter采集的数据虽然有限,但是Facter本身是一个很好的框架,很容易扩展,所以我们在Facter的基础上进行了扩展,并配合Puppet Master的Report Processor将结果转换为采集上报给汽车银行(这是汽车之家的CMDB代码,可以参考《运维数据库-建立CMDB方法》)完成一个完整的采集逻辑。
这是 Puppet 的服务器和代理之间的工作流程
在发送请求以请求目录的阶段,代理将向船长报告其所有事实。Master接收到数据后,可以使用自己的Report Processor对其进行二次处理,比如转发到其他地方。
基于以上原理,我们开发了自己的报表处理器:assets_report,通过HTTP协议将事实发布到AutoBank的http接口进行存储。
有兴趣开发自定义事实的同学可以参考 fact_overview 和自定义事实。
如上所述,我们的 Assets_Report 项目收录以下两个组件来实现整个逻辑
assets_report 模块:一个纯 Puppet 模块,带有内置的报告处理器和一些自定义的 Facter 插件,部署在 Master 端。
报告处理器在主端运行。
Facter插件会通过Master下发到Agent,运行到采集本地资产数据
api_server:负责接收资产数据并存储
三、采集插件的功能介绍
与Facter内置的facts相比,这个插件提供了更多的硬件数据,比如
CPU 数量,型号
内存容量、序列号、制造商、插槽位置
网卡绑定的ip、mask、mac、model,支持一张网卡绑定多个ip的场景
RAID卡数量、型号、内存容量、RAID级别
磁盘数量、容量、序列号、制造商、RAID 卡、插槽位置
操作系统类型、版本
服务器供应商,SN
高级特性:为了避免重复上报大段相同的数据,减少AutoBank的数据库压力,本插件具有Cache功能,即如果一个服务器的资产数据没有变化,只有not_modify将报告标志。
本插件支持的操作系统是(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
视窗 2008 R2
该插件支持的服务器有:
生命值
戴尔
思科
四、采集如何安装插件
安装操作在 Puppet Master 端进行。
假设您的模块目录是 /etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
在你自己的 puppet.conf 中(假设默认路径是 /etc/puppet/puppet.conf)添加
报告 = assets_report
然后在site.pp中添加如下配置,让所有Node安装assets_report模块
节点默认 { # 包括 assets_report 类 {'assets_report': }}
配置完成后,采集工具会自动下发到Agent进行安装。该插件将在下次 Puppet Agent 运行时正常工作。
五、报表组件配置方法
配置操作在 Puppet Master 端进行。
配置文件为 assets_report/lib/puppet/reports/report_setting.yaml
范围
意义
例子
report_url 报告接口地址,可以修改为自己的url
auth_required接口是否收录认证true/false,默认为false,认证码需要在auth.rb中实现
用户认证用户名如果auth_required为真,则需要填写
passwd 认证密码 如果auth_required为真,需要填写
enable_cache 是否启用缓存功能 true/false,默认为false
六、报表接口服务配置方法
配置操作在 Puppet Master 端进行。
这个接口服务api_server是基于一个用Python编写的Web框架Django开发的,包括数据库设计和http api的实现。因为各个公司的数据库设计不一致,所以本项目只实现了最简单的数据建模,所以这个组件的存在只作为Demo使用,不能用于生产环境。读者应注意。
首先,我们需要安装一些依赖项。这里假设你的操作系统是 CentOS/RedHat
$ cd ~/Assets_Report/api_server install pip,用它来安装python模块 $ sudo yum install python-pip install python module dependencies $ pip install -r requirements.txt
初始化数据库,可以参考Django用户手册
$ python manage.py makemigrations apis$ python manage.py migrate 数据库为当前目录下的db.sqlite3
自动采集数据(提前布局搜索引擎优化的分析使用首先要注意哪些问题? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-02-21 04:11
)
网站优化是对网站的内外调整优化,提升网站关键词在搜索引擎中的自然排名,获得更多流量。今天,博主就来分享一下自己对SEO的理解。
布局前 SEO
针对这个问题,一般是我们容易犯的错误。很多时候,我们会先构建网站,填写网站的内容,然后再考虑网站需要针对SEO进行优化,这样前期创作的优质内容往往没有被更多用户看到。所以,再好的内容,如果目标受众找不到或者根本不知道它的存在,那么创造出来的内容就毫无意义。
SEO优化的目的是保证网站内容的可见性和显着性,不让好的内容被埋没在搜索结果之下。所以,对于我们来说,建站前应该有一个SEO意识。尽早考虑 SEO 优化。
注重数据的分析和使用
首先我们要明白,SEO是一项需要毅力的工作。在我们的工作中,一定要注意数据的应用,比如收录的数量、网站的流量、网站的跳出率等等。这些数据需要我们一段时间要积累才能获得,所以一定要有良好的心态,不要急于求成,理性分析及时调整才是关键。
遵守搜索引擎规则
我们需要研究搜索引擎的规则,然后根据规则进行优化网站。比如标题的关键词设置、内部页面的内部链接、关键词的密度等。从搜索引擎偏好上迎合搜索引擎
注意网站内容建设
商业搜索引擎本质上是追逐兴趣。所以想要搜索引擎喜欢我们,首先要帮助搜索引擎实现商业价值。简单来说,就是为用户提供精准优质的内容。因为用户不喜欢内容,搜索引擎肯定不会推荐它。
坚持 网站 更新和推送
网站内容的更新需要定时,这样搜索引擎蜘蛛才能定时爬取。这种友好的行为使得搜索引擎爬取网站变得更加容易和方便。让我们成为更好的收录。
搜索引擎一般有三种推送方式:站点地图、主动推送、自动推送。主动推送到搜索引擎可以提高我们收录的效率,我们可以通过Dede采集插件来实现。
Dede采集 插件的使用
1、Dede采集插件功能齐全,一次可以创建几十个或几百个采集任务,支持同时多个域名任务采集,并自动过滤其他网站促销信息,支持多个采集来源采集(覆盖行业头部平台),支持其他平台的图片本地化或存储,自动批量挂机采集@ >,无缝连接各大cmsPublisher,采集自动发布推送到搜索引擎
<p>在2、自动发布功能中,可以设置发布数量、伪原创保留字、标题插入关键词、按规则插入本地图片等功能,提高 查看全部
自动采集数据(提前布局搜索引擎优化的分析使用首先要注意哪些问题?
)
网站优化是对网站的内外调整优化,提升网站关键词在搜索引擎中的自然排名,获得更多流量。今天,博主就来分享一下自己对SEO的理解。
布局前 SEO
针对这个问题,一般是我们容易犯的错误。很多时候,我们会先构建网站,填写网站的内容,然后再考虑网站需要针对SEO进行优化,这样前期创作的优质内容往往没有被更多用户看到。所以,再好的内容,如果目标受众找不到或者根本不知道它的存在,那么创造出来的内容就毫无意义。
SEO优化的目的是保证网站内容的可见性和显着性,不让好的内容被埋没在搜索结果之下。所以,对于我们来说,建站前应该有一个SEO意识。尽早考虑 SEO 优化。
注重数据的分析和使用
首先我们要明白,SEO是一项需要毅力的工作。在我们的工作中,一定要注意数据的应用,比如收录的数量、网站的流量、网站的跳出率等等。这些数据需要我们一段时间要积累才能获得,所以一定要有良好的心态,不要急于求成,理性分析及时调整才是关键。
遵守搜索引擎规则
我们需要研究搜索引擎的规则,然后根据规则进行优化网站。比如标题的关键词设置、内部页面的内部链接、关键词的密度等。从搜索引擎偏好上迎合搜索引擎
注意网站内容建设
商业搜索引擎本质上是追逐兴趣。所以想要搜索引擎喜欢我们,首先要帮助搜索引擎实现商业价值。简单来说,就是为用户提供精准优质的内容。因为用户不喜欢内容,搜索引擎肯定不会推荐它。
坚持 网站 更新和推送
网站内容的更新需要定时,这样搜索引擎蜘蛛才能定时爬取。这种友好的行为使得搜索引擎爬取网站变得更加容易和方便。让我们成为更好的收录。
搜索引擎一般有三种推送方式:站点地图、主动推送、自动推送。主动推送到搜索引擎可以提高我们收录的效率,我们可以通过Dede采集插件来实现。
Dede采集 插件的使用
1、Dede采集插件功能齐全,一次可以创建几十个或几百个采集任务,支持同时多个域名任务采集,并自动过滤其他网站促销信息,支持多个采集来源采集(覆盖行业头部平台),支持其他平台的图片本地化或存储,自动批量挂机采集@ >,无缝连接各大cmsPublisher,采集自动发布推送到搜索引擎
<p>在2、自动发布功能中,可以设置发布数量、伪原创保留字、标题插入关键词、按规则插入本地图片等功能,提高

