
自动采集数据
采集科研文献和数据,我告诉你一个能手动采集的黑科技
采集交流 • 优采云 发表了文章 • 0 个评论 • 533 次浏览 • 2020-08-10 05:35
一般的,我需要在这种网站去搜集论文文献和实验数据。
论文数据库:Wiley InterScience、EBSCO ASP、Blackwell、Springer等;
科研数据库:NCBI、EMBL、ICPSR等。
为什么搜集论文文献和实验数据会耗费这么长的时间?
因为搜集过程中,进行的是大量的重复机械性的工作。
很长的时间里,我遭受重复机械性采集工作的苦闷。直到有三天,研究室的朋友推荐给我了一个叫“小帮”的软件机器人。它可以手动执行搜索、复制、粘贴、下载等操作,将各数据库中的论文文献和实验数据采集出来。
软件机器人是通过模拟人工操作各类软件,来自动执行这种重复规律的工作。所以为了自动化执行我的工作流程,我需要告诉我工作流程的步骤。整体来说,软件机器人的配置过程很简单,我只花了一小多时,就配置了6个针对不同网站的科研数据搜集工具。配置完之后,重复的采集工作就全部由软件机器人代劳了。
现在,我上班前,会开启小帮,它会手动地遍历我所关注的论文文献和实验数据的数据库,并完成手动采集和下载工作。第二天下班,我能够直接看见小帮手动采集到的数据,节省了大量宝贵时间,不影响当日的科研任务。
不能不说,小帮软件机器人为我们科研人员解决了自动搜集数据的困局。
今天分享下来,是希望帮同行们解决搜集科研数据难且费时的问题,我们宝贵的时间应当置于科研的攻关上。 查看全部
我是某高校信息学院的老师,我的研究方向是生物科技。平时的科研工作须要采集国外论文文献和实验数据。其实,在整个科研过程中,花时间最多的环节就在论文文献和实验数据的采集,几乎占到总时间的1/3。
一般的,我需要在这种网站去搜集论文文献和实验数据。
论文数据库:Wiley InterScience、EBSCO ASP、Blackwell、Springer等;
科研数据库:NCBI、EMBL、ICPSR等。
为什么搜集论文文献和实验数据会耗费这么长的时间?
因为搜集过程中,进行的是大量的重复机械性的工作。
很长的时间里,我遭受重复机械性采集工作的苦闷。直到有三天,研究室的朋友推荐给我了一个叫“小帮”的软件机器人。它可以手动执行搜索、复制、粘贴、下载等操作,将各数据库中的论文文献和实验数据采集出来。

软件机器人是通过模拟人工操作各类软件,来自动执行这种重复规律的工作。所以为了自动化执行我的工作流程,我需要告诉我工作流程的步骤。整体来说,软件机器人的配置过程很简单,我只花了一小多时,就配置了6个针对不同网站的科研数据搜集工具。配置完之后,重复的采集工作就全部由软件机器人代劳了。
现在,我上班前,会开启小帮,它会手动地遍历我所关注的论文文献和实验数据的数据库,并完成手动采集和下载工作。第二天下班,我能够直接看见小帮手动采集到的数据,节省了大量宝贵时间,不影响当日的科研任务。
不能不说,小帮软件机器人为我们科研人员解决了自动搜集数据的困局。

今天分享下来,是希望帮同行们解决搜集科研数据难且费时的问题,我们宝贵的时间应当置于科研的攻关上。
python数据剖析4之手动采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-09 19:17
数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。很多时侯,我们拥有多少数据源,多少数据量,以及数据质量怎样,将决定我们挖掘产出的成果会如何
2 四类采集方式
3 如何使用开放是数据源
4 爬虫形式
(1) 使用request爬取内容。
(2)使用xpath解析内容,可以通过元素属性进行位置索引
(3)使用panda保存数据。最后通过panda写入XLS或则mysql数据中
(3)scapy
5 常用抓取工具
(1)优采云采集器
它除了可以做抓取工具,也可以做数据清洗、数据剖析、数据挖掘和可视化等工作。数据源适用于绝大部分的网页,网页中能看到的内容都可以通过采集规则进行抓取
(2)优采云
免费采集电商类,生活服务类等
云采集配置采集任务,一共有5000台服务器,通过云端节点采集,自动切换多个IP等
(3)集搜客
没有云采集功能,所有爬虫在自己的笔记本进行
6 如何使用日志采集工具
(1) 最大的作用就是通过剖析用户访问情况,提升系统的性能。
(2)记载的内容通常包括通过哪些渠道访问,执行了什么操i做,用户IP等
(3)埋点是哪些
埋点就是在你须要统计数据的那地方统计代码。友盟 google analysis talkingdata 常用的的埋点工具。
7 总结
数据的采集渠道好多,可以自己通过爬虫,也可以使用开源的数据源,线程的工具。
可以直接从Kaggle上下载,不需要自己爬取。
另一方面依照我们的需求,需要采集的数据也不同,比如交通行业,数据采集会和摄像头或则测速仪有关。对于运维人员,日志采集和剖析则是关 查看全部
1 数据采集的重要性
数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。很多时侯,我们拥有多少数据源,多少数据量,以及数据质量怎样,将决定我们挖掘产出的成果会如何
2 四类采集方式

3 如何使用开放是数据源

4 爬虫形式
(1) 使用request爬取内容。
(2)使用xpath解析内容,可以通过元素属性进行位置索引
(3)使用panda保存数据。最后通过panda写入XLS或则mysql数据中
(3)scapy
5 常用抓取工具
(1)优采云采集器
它除了可以做抓取工具,也可以做数据清洗、数据剖析、数据挖掘和可视化等工作。数据源适用于绝大部分的网页,网页中能看到的内容都可以通过采集规则进行抓取
(2)优采云
免费采集电商类,生活服务类等
云采集配置采集任务,一共有5000台服务器,通过云端节点采集,自动切换多个IP等
(3)集搜客
没有云采集功能,所有爬虫在自己的笔记本进行
6 如何使用日志采集工具
(1) 最大的作用就是通过剖析用户访问情况,提升系统的性能。
(2)记载的内容通常包括通过哪些渠道访问,执行了什么操i做,用户IP等

(3)埋点是哪些
埋点就是在你须要统计数据的那地方统计代码。友盟 google analysis talkingdata 常用的的埋点工具。
7 总结
数据的采集渠道好多,可以自己通过爬虫,也可以使用开源的数据源,线程的工具。
可以直接从Kaggle上下载,不需要自己爬取。
另一方面依照我们的需求,需要采集的数据也不同,比如交通行业,数据采集会和摄像头或则测速仪有关。对于运维人员,日志采集和剖析则是关
优采云采集数据并导出mysql数据库(手动和自动两种方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-08-09 07:18
配置以下字段: 服务器: Mysql服务器地址端口: Mysql实例的端口用户名: 登录Mysql的用户名密码: 登录Mysql 优采云采集服务平台数据库密码: 填写以下代码数据库,则无法指定导入后会有乱码. 例如,如果导出为中文,则可以将其设置为utf8. 此外,用户自己的数据库表和字段需要设置为utf8. 数据库名称: 选择一个现有数据库,然后单击“测试连接”以验证配置是否正确. 此处的配置正确,因此下面提供了连接. 如果配置不正确,下面将显示一条错误消息. 数据导出到mysql数据库-图4配置数据库连接后,单击“下一步”进入数据字段映射界面优采云采集服务平台步骤4: 配置数据库连接后,单击“下一步”进入数据字段映射界面选择数据表选择目标数据字段(此处,如果源数据字段和目标数据字段具有相同的名称,它将被自动配置,如果不同,则需要手动选择它)如果这些字段之一不想重复,您可以检查一下并将其设置为唯一标识符. 检查后,在导入时,它将根据此字段确定是将新记录添加到数据库还是覆盖原创记录. 单击Next进入数据导出页面并导出mysql数据库-图5提示: 如果下次需要继续导出,您可以在此处设置和保存配置.
(选中“保存配置”,输入保存的配置名称),下次导出时,可以直接选择此配置. 优采云 采集 Service Platform步骤5: 选择导出提示. 数据已导入到指定的数据库中. 将数据导出到mysql数据库-图6 优采云 Cloud 采集 Service Platform数据导出到MySQL数据库-图7提示: 在导出过程中检查忽略如果遇到错误并尝试不终止导出操作,则意味着您当某些数据导入错误时,将继续导出其他数据. 以下是数据库数据的示例: 优采云采集服务平台数据导出mysql数据库-图8 2.自动导出到数据库请注意,此方法仅支持云采集,可以在采集和导出时实现. 当前已导出尚未导出的数据. 步骤1: 与之前的手动导出到musql的基本步骤相同(单击任务以选择要导出的任务数据,单击更多操作以查看数据云采集数据),进入查看数据界面步骤2: 选择在弹出窗口中导出数据在操作界面上,选择导出所有数据或未导出的数据. 选择自动导出到数据库. 单击“确定”进入数据导出向导. 选择下一步进入数据库配置界面. 优采云采集服务平台云数据导出mysql数据库-图9优采云采集服务平台云数据导出到mysql数据库-图10步骤3和步骤4,与上面相同. 按照前面的步骤3和4进行配置后,选择“下一步”进入设置执行计划页面. 步骤5: 设置执行计划名称,然后设置实时计划.
此处的实时计划是指每小时自动启动执行计划并导出当前未导出的数据. 设置后,单击“下一步”以将数据从优采云采集服务平台导出到mysql数据库-图11步骤6: 选择完成,以便配置自动导出计划. 优采云采集服务平台将数据导出到mysql数据库-图12步骤7: 然后单击工具箱中的定时存储工具以选择激活. (系统将立即执行数据库导出,执行完成后将在指定的时间间隔自动启动)优采云采集服务平台数据导出mysql数据库-图13相关采集教程: 天猫产品信息采集新浪微博数据采集点屏评估集合优采云-70万用户选择的Web数据采集器. 优采云云采集服务平台1.易于操作,任何人都可以使用: 没有技术背景,可以在互联网上采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.它具有强大的功能,可以在任何网站上采集: 单击,登录,翻页,标识验证码,瀑布流和Ajax脚本,以异步方式加载网页并提供可以通过简单设置采集的数据. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此不必担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,已经建立了一些增值服务(例如私有云)来满足高端付费企业用户的需求. 查看全部
优采云云采集服务平台优采云采集数据以导出到mysql数据库(手动和自动方法)本教程将说明如何将采集的数据导出到mysql数据库,这是两种导出方法: 方法1: 手动导出数据库. 此方法只能在采集任务后将采集的数据导出到数据库. 2.自动导出数据库该方法可以同时实现采集和指导,并按照设置的时间间隔启动导出计划. 此方法仅支持云采集. 目前,优采云支持在Mysql,SqlServer和Oracle中导出数据库. 本地数据和云采集的数据都可以导出到数据库. 本教程以云采集的数据为例向您解释. 提示: 导出之前,需要构建数据库和数据表. 手动导出mysql数据库的步骤如下: 步骤1: 单击任务以选择要导出的任务数据,单击更多操作以查看数据云采集数据优采云采集服务平台将数据导出到mysql数据库-图1步骤2: 选择导出数据. 在弹出的操作界面上,选择导出所有数据或未导出的数据. 选择导出到数据库. 单击确定以导入到数据导出向导. 选择下一步以导入到数据库配置界面. 云云采集服务平台数据导出mysql数据库-图2优采云云采集服务平台数据导出mysql数据库-图3步骤3: 进入数据库配置界面后,配置数据库的相关信息.
配置以下字段: 服务器: Mysql服务器地址端口: Mysql实例的端口用户名: 登录Mysql的用户名密码: 登录Mysql 优采云采集服务平台数据库密码: 填写以下代码数据库,则无法指定导入后会有乱码. 例如,如果导出为中文,则可以将其设置为utf8. 此外,用户自己的数据库表和字段需要设置为utf8. 数据库名称: 选择一个现有数据库,然后单击“测试连接”以验证配置是否正确. 此处的配置正确,因此下面提供了连接. 如果配置不正确,下面将显示一条错误消息. 数据导出到mysql数据库-图4配置数据库连接后,单击“下一步”进入数据字段映射界面优采云采集服务平台步骤4: 配置数据库连接后,单击“下一步”进入数据字段映射界面选择数据表选择目标数据字段(此处,如果源数据字段和目标数据字段具有相同的名称,它将被自动配置,如果不同,则需要手动选择它)如果这些字段之一不想重复,您可以检查一下并将其设置为唯一标识符. 检查后,在导入时,它将根据此字段确定是将新记录添加到数据库还是覆盖原创记录. 单击Next进入数据导出页面并导出mysql数据库-图5提示: 如果下次需要继续导出,您可以在此处设置和保存配置.
(选中“保存配置”,输入保存的配置名称),下次导出时,可以直接选择此配置. 优采云 采集 Service Platform步骤5: 选择导出提示. 数据已导入到指定的数据库中. 将数据导出到mysql数据库-图6 优采云 Cloud 采集 Service Platform数据导出到MySQL数据库-图7提示: 在导出过程中检查忽略如果遇到错误并尝试不终止导出操作,则意味着您当某些数据导入错误时,将继续导出其他数据. 以下是数据库数据的示例: 优采云采集服务平台数据导出mysql数据库-图8 2.自动导出到数据库请注意,此方法仅支持云采集,可以在采集和导出时实现. 当前已导出尚未导出的数据. 步骤1: 与之前的手动导出到musql的基本步骤相同(单击任务以选择要导出的任务数据,单击更多操作以查看数据云采集数据),进入查看数据界面步骤2: 选择在弹出窗口中导出数据在操作界面上,选择导出所有数据或未导出的数据. 选择自动导出到数据库. 单击“确定”进入数据导出向导. 选择下一步进入数据库配置界面. 优采云采集服务平台云数据导出mysql数据库-图9优采云采集服务平台云数据导出到mysql数据库-图10步骤3和步骤4,与上面相同. 按照前面的步骤3和4进行配置后,选择“下一步”进入设置执行计划页面. 步骤5: 设置执行计划名称,然后设置实时计划.
此处的实时计划是指每小时自动启动执行计划并导出当前未导出的数据. 设置后,单击“下一步”以将数据从优采云采集服务平台导出到mysql数据库-图11步骤6: 选择完成,以便配置自动导出计划. 优采云采集服务平台将数据导出到mysql数据库-图12步骤7: 然后单击工具箱中的定时存储工具以选择激活. (系统将立即执行数据库导出,执行完成后将在指定的时间间隔自动启动)优采云采集服务平台数据导出mysql数据库-图13相关采集教程: 天猫产品信息采集新浪微博数据采集点屏评估集合优采云-70万用户选择的Web数据采集器. 优采云云采集服务平台1.易于操作,任何人都可以使用: 没有技术背景,可以在互联网上采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.它具有强大的功能,可以在任何网站上采集: 单击,登录,翻页,标识验证码,瀑布流和Ajax脚本,以异步方式加载网页并提供可以通过简单设置采集的数据. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此不必担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,已经建立了一些增值服务(例如私有云)来满足高端付费企业用户的需求.
[智能模式] [流程图模式]如何配置采集任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2020-08-08 02:18
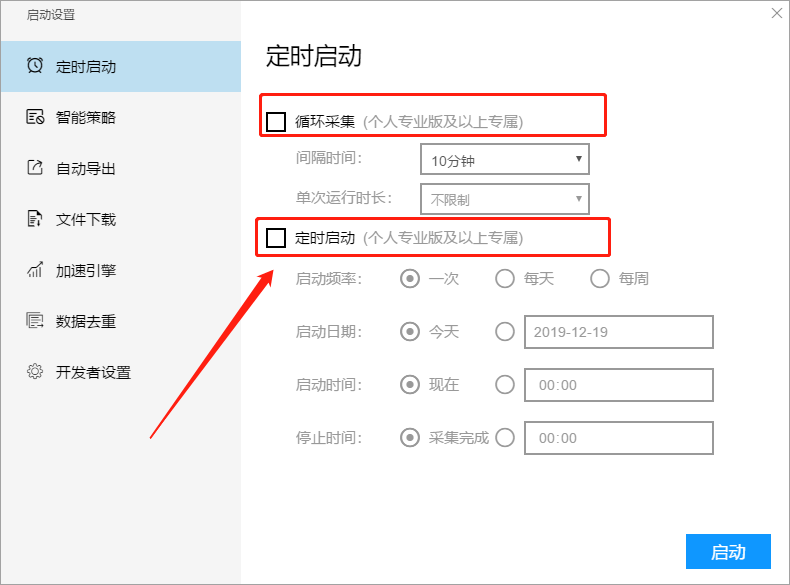
1. 定时开始
定时启动功能包括循环采集和定时采集. 周期性采集是按照固定的时间间隔(从上一个任务的停止到下一个任务的开始)周期性地启动采集任务. 定时获取将按照设置的时间周期循环. 开始采集任务.
有关更多详细信息,请参阅以下教程:
如何设置时间采集
2. 明智的策略
智能策略设置包括代理设置,智能切换设置和手动切换设置. 有关更多详细信息,请参阅以下教程:
如何设置智能策略
3,自动导出
使用此功能,您可以在数据采集过程中将采集到的结果自动导出到本地文件和数据库,而无需等待任务运行并手动导出数据.
有关更多详细信息,请参阅以下教程:
如何设置自动导出
4. 文件下载
该软件支持在采集过程中下载文件. 文件类型包括: 图片,音频,视频,文档和其他文件. 用户可以选择保存路径并创建独立的文件夹,也可以根据规则重命名下载的文件.
有关更多详细信息,请参阅以下教程:
如何设置文件下载
5,加速引擎
加速引擎功能可以加速采集任务. 加速效果与网页加载速度和采集任务的设置有关,通常可以达到3到10倍的加速效果.
有关更多详细信息,请参阅以下教程:
如何使用加速引擎
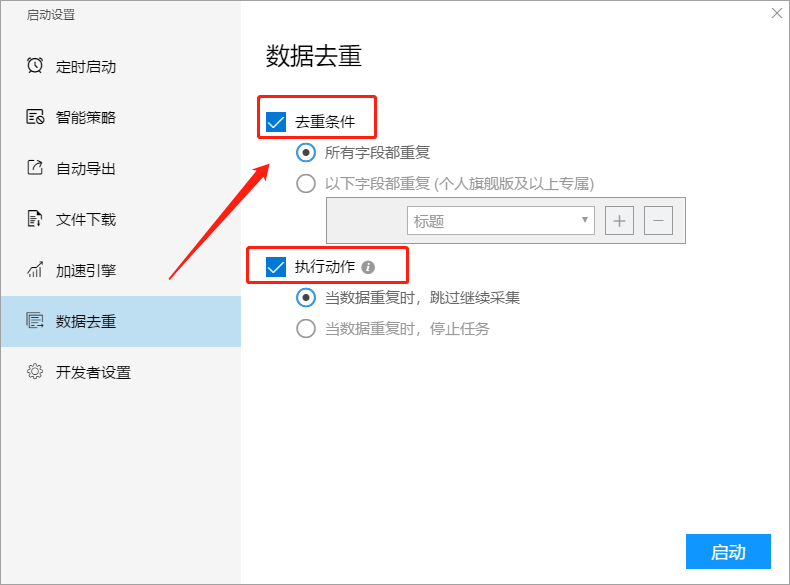
6. 重复数据删除
重复数据删除功能是在任务采集过程中将当前采集的数据与采集的数据进行比较. 如果发现数据重复,则会根据设置的条件进行处理.
当前任务中保存的数据越多,重复数据删除比较过程将越慢. 因此,启用此功能将减慢采集速度. 请谨慎使用.
有关更多详细信息,请参阅以下教程:
如何设置重复数据删除
7. 开发者设置
优采云采集器支持Webhook功能. 通过使用此功能,优采云采集器可以将采集的数据发布到HTTP地址.
有关更多详细信息,请参阅以下教程:
如何设置Webhook功能 查看全部
在编辑任务界面中,单击右下角的“开始采集”按钮,跳至任务开始界面,我们可以在其中配置任务.
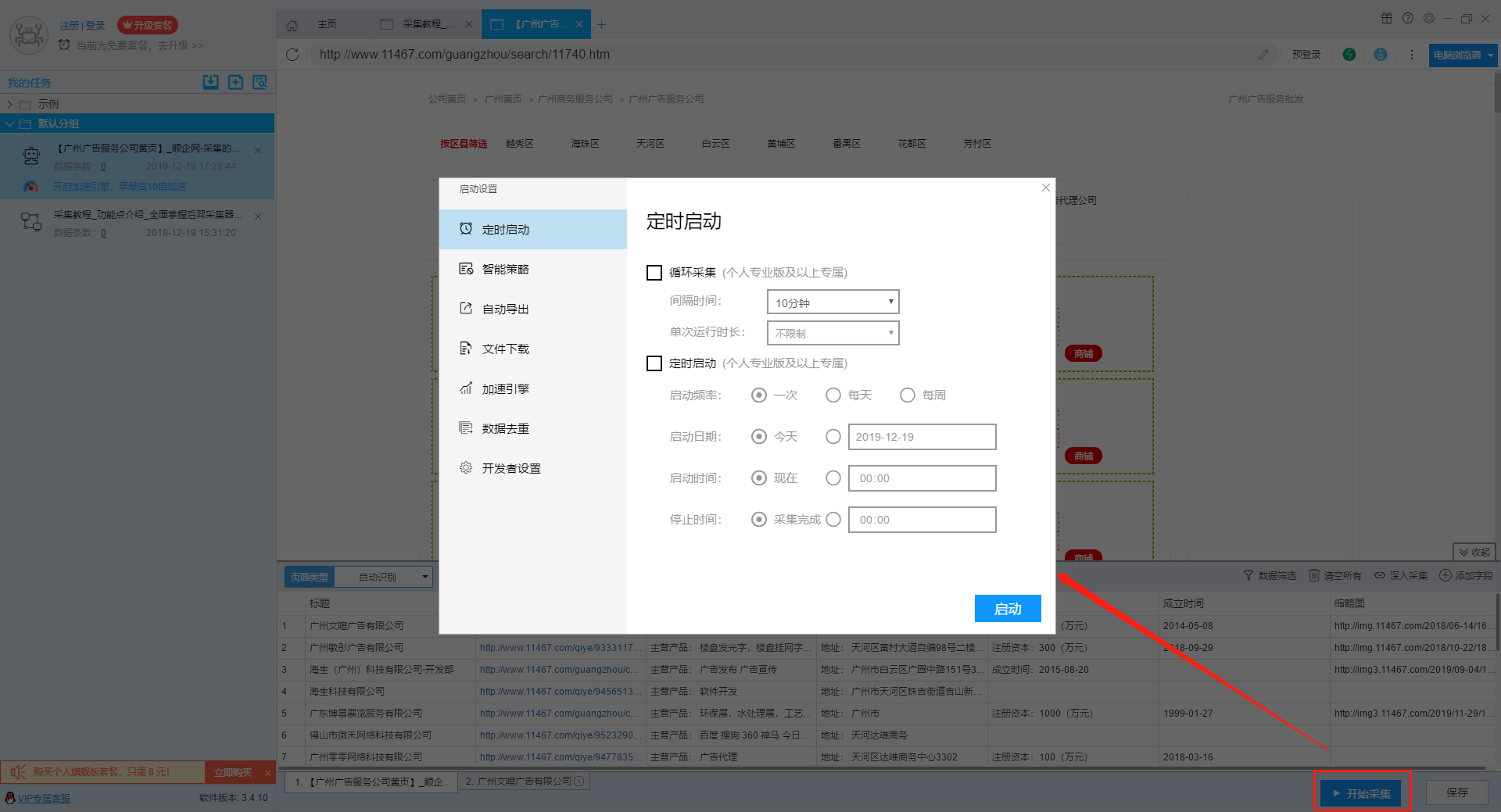
1. 定时开始
定时启动功能包括循环采集和定时采集. 周期性采集是按照固定的时间间隔(从上一个任务的停止到下一个任务的开始)周期性地启动采集任务. 定时获取将按照设置的时间周期循环. 开始采集任务.
有关更多详细信息,请参阅以下教程:
如何设置时间采集
2. 明智的策略
智能策略设置包括代理设置,智能切换设置和手动切换设置. 有关更多详细信息,请参阅以下教程:
如何设置智能策略
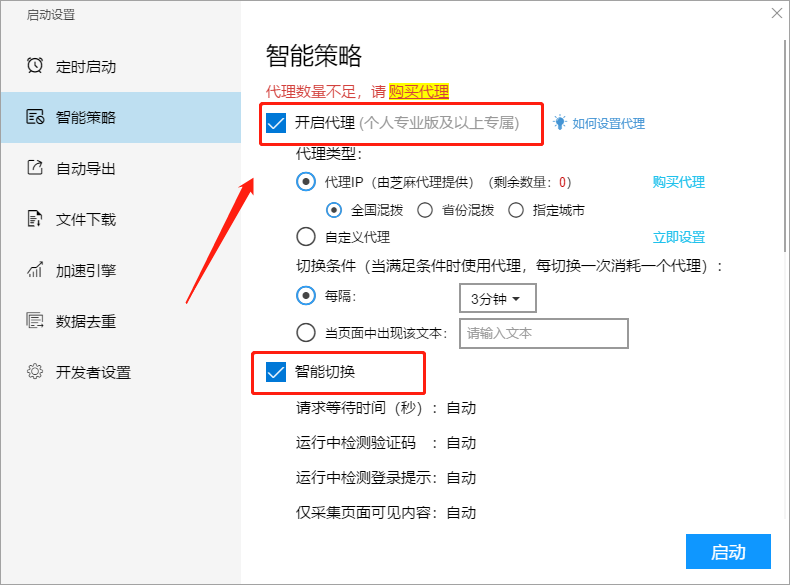
3,自动导出
使用此功能,您可以在数据采集过程中将采集到的结果自动导出到本地文件和数据库,而无需等待任务运行并手动导出数据.
有关更多详细信息,请参阅以下教程:
如何设置自动导出
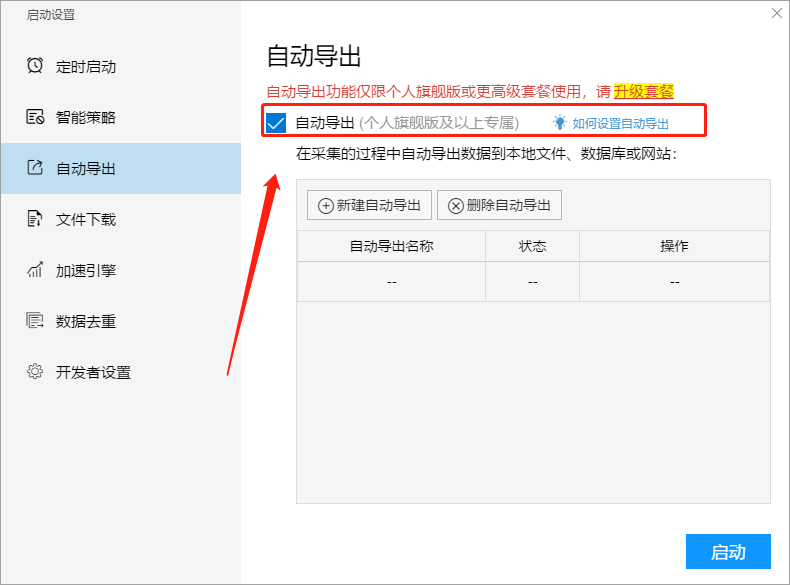
4. 文件下载
该软件支持在采集过程中下载文件. 文件类型包括: 图片,音频,视频,文档和其他文件. 用户可以选择保存路径并创建独立的文件夹,也可以根据规则重命名下载的文件.
有关更多详细信息,请参阅以下教程:
如何设置文件下载

5,加速引擎
加速引擎功能可以加速采集任务. 加速效果与网页加载速度和采集任务的设置有关,通常可以达到3到10倍的加速效果.
有关更多详细信息,请参阅以下教程:
如何使用加速引擎
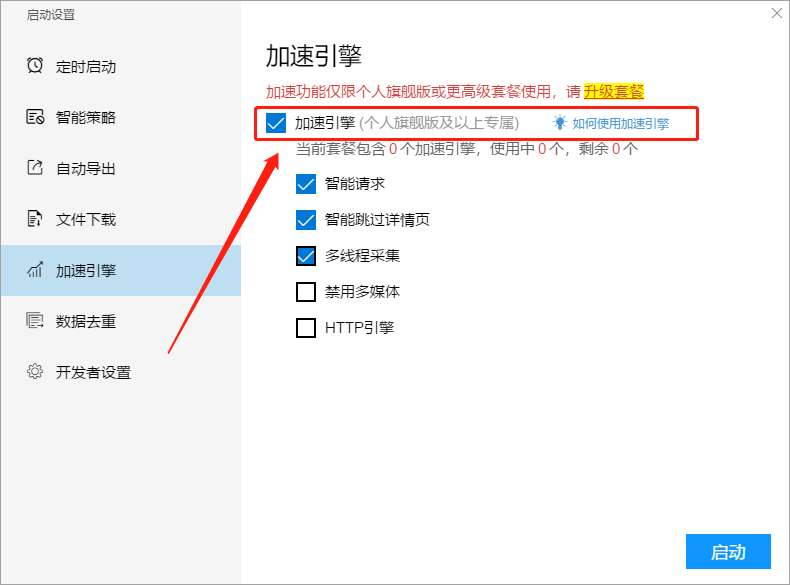
6. 重复数据删除
重复数据删除功能是在任务采集过程中将当前采集的数据与采集的数据进行比较. 如果发现数据重复,则会根据设置的条件进行处理.
当前任务中保存的数据越多,重复数据删除比较过程将越慢. 因此,启用此功能将减慢采集速度. 请谨慎使用.
有关更多详细信息,请参阅以下教程:
如何设置重复数据删除
7. 开发者设置
优采云采集器支持Webhook功能. 通过使用此功能,优采云采集器可以将采集的数据发布到HTTP地址.
有关更多详细信息,请参阅以下教程:
如何设置Webhook功能
连续操作: 自动选择下拉菜单采集数据-以HowNet为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 546 次浏览 • 2020-08-07 16:11
I. 操作步骤
以CNKI期刊为例,显示连续动作中的选择动作和爬虫路径中的翻页的组合. 本教程要实现的是首先搜索2016年出版的期刊,然后采集搜索结果. 该过程如下图所示:
为了实现这一点,需要建立两个级别的规则. 第一层规则通过连续的操作自动选择出版年份,第二层规则负责采集期刊内容和翻页. 步骤如下:
两个,案例规则+操作步骤
第一步: 定义捕获内容的第一级规则
1.1,加载页面
打开Jishouke Web采集器,输入要采集的样本的URL,然后按Enter. 看到浏览器加载网页后,单击右上角的“定义规则”.
注意: 此处的屏幕快照和文字描述均为Jishouke Web采集器的所有版本. 如果要安装Firefox插件版本,则没有“定义规则”按钮,但是您应该运行MS.
1.2,输入主题名称
在工作台的“主题名称”中输入一级规则的主题名称,然后单击“检查重复项”,将提示“可以使用该名称”,您可以继续,否则请重命名它. 此处的命名主题为“检索CNKI期刊之前”.
提示: 尽管此级别的规则主要用于选择操作,但是为了确保页面已加载并且连续的操作可以顺利进行,通常会在此级别的规则中建立一些爬网内容.
1.3,内容映射
选择“日志”作为爬网内容,双击日志,在弹出的标签栏中输入关键内容,在检索前命名排序框,然后检查关键内容. 视觉注释的基本操作在此不再重复. 如果您不了解,请参阅教程“采集网页数据”.
第2步: 定义一级规则的连续动作
2.1,输入目标主题名称
单击“连续操作”工作台,输入目标主题名称(即第二级规则的主题名称,此处名为“检索中国CNKI期刊后”),然后单击“正在使用谁” ,弹出窗口不显示该消息表明主题名称未被占用,您可以继续以下操作,否则需要更改主题名称.
2.2,创建第一个连续动作-选择起始年份2016
2.2.1,找到定位表达式,填写动作名称
单击“新建”,将操作类型选择为“选择”,单击开始年份,它将自动找到相应的节点,选择“显示XPath: 首选项ID”,程序将自动显示相应的Xpath路径,然后单击搜索,您可以看到此路径可以找到唯一的节点,该节点可用作动作的定位表达式. 将此路径复制到定位表达式,并在操作名称中写入文本,以使阐明每个操作的用法更加容易.
提示: 选择类型的连续动作. 定位表达式必须写入下拉菜单的选择节点,而不是某个选项的选项节点,否则将在运行时报告错误.
2.2.2,高级设置
我们需要实现的是采集2016年出版的期刊,因此我们需要在开始年度和结束年度都选择2016年. 这需要对连续操作的高级设置进行限制.
2.3,创建第二个连续的行动结束年度选择2016
单击“新建”,然后将操作类型选择为“选择”. 请参阅步骤2.2,找到与结束年份相对应的Xpath路径,然后在高级设置中将额外延迟设置为2秒,起点为3(2016是第三选项),跨度为100.
2.4,创建第三个连续动作,单击以进行检索
单击“新建”,然后选择“提交”操作. 请参阅步骤2.2,找到与“搜索”相对应的Xpath路径,然后在高级设置中将额外延迟设置为2秒.
2.5,保存规则
点击“保存规则”按钮以保存已完成的一级规则.
第3步: 定义第二级规则以捕获内容
3.1,创建新规则
单击“定义规则”返回到正常的网页模式,选择2016并单击搜索以找到文档结果,再次单击“定义规则”以切换到规则模式,然后单击左上角的“规则”菜单->“新建”,弹出提示“工作台上有内容,清除了吗?”,单击确定.
输入主题名称,其中主题名称是在上级规则的连续操作中填写的目标主题名称,即“在检索CNKI日记帐之后”,单击“检查重复项”,并弹出提示“名称已保留. ”可编辑: 是”,表示可以使用此主题名称.
3.2,标记要采集的信息
在页面上,直接单击要采集的内容,在弹出窗口中填写名称,勾选“标题”的关键内容,然后复制示例. 单击测试预览采集的内容. 在此不再重复视觉标签的详细描述. 有关详细信息,请参阅教程“集合列表数据”.
第4步: 定义二级规则页面的转换线索
4.1,设置翻页线索
单击爬虫路线,单击“新建”,选择“标记提示”;找到与页面翻页标记“ Next Page”相对应的节点,右键单击Cue Mapping-Marker Cue;查找整个翻页区域并具有一个类值或具有id值的节点,右键单击线索mapping-location-clue 1.在此不重复设置翻页的操作. 有关详细信息,请参阅教程“设置翻页集合”.
4.2,保存规则
点击“保存规则”按钮以保存已完成的第二级规则.
第5步: 捕获数据
连续动作的两级规则是连续执行的,因此只需要运行第一级规则,动作完成后程序将自动调用第二级规则. 如果直接运行第二级规则,则会出现错误,因为打开操作之前的初始页面.
5.1,打开计数机,找到一级规则的主题名称,单击“单一搜索”或“采集”,您会看到计数机Web窗口将自动选择2016,并继续向下翻页.
5.2,打开第二级主题的文件夹以查看结果数据,并将所选项目记录在xml文件的actionvalue字段中,以使其可以与结果数据一一对应.
上一篇: “连续操作: 自动搜索关键字以采集信息”下一篇文章: “连续操作: 滚动以采集瀑布流网页”
如果有任何疑问,可以或 查看全部
注意: 从GooSeeker采集器的V9.0.2版本开始,采集器术语“主题”已更改为“任务”. 在采集器浏览器中,首先命名任务,然后创建规则,然后登录到Jisuke官方网站的成员中心. 在“任务管理”中,您可以查看任务采集和执行,管理线程URL以及进行计划设置.
I. 操作步骤
以CNKI期刊为例,显示连续动作中的选择动作和爬虫路径中的翻页的组合. 本教程要实现的是首先搜索2016年出版的期刊,然后采集搜索结果. 该过程如下图所示:

为了实现这一点,需要建立两个级别的规则. 第一层规则通过连续的操作自动选择出版年份,第二层规则负责采集期刊内容和翻页. 步骤如下:

两个,案例规则+操作步骤
第一步: 定义捕获内容的第一级规则

1.1,加载页面
打开Jishouke Web采集器,输入要采集的样本的URL,然后按Enter. 看到浏览器加载网页后,单击右上角的“定义规则”.
注意: 此处的屏幕快照和文字描述均为Jishouke Web采集器的所有版本. 如果要安装Firefox插件版本,则没有“定义规则”按钮,但是您应该运行MS.
1.2,输入主题名称
在工作台的“主题名称”中输入一级规则的主题名称,然后单击“检查重复项”,将提示“可以使用该名称”,您可以继续,否则请重命名它. 此处的命名主题为“检索CNKI期刊之前”.
提示: 尽管此级别的规则主要用于选择操作,但是为了确保页面已加载并且连续的操作可以顺利进行,通常会在此级别的规则中建立一些爬网内容.
1.3,内容映射

选择“日志”作为爬网内容,双击日志,在弹出的标签栏中输入关键内容,在检索前命名排序框,然后检查关键内容. 视觉注释的基本操作在此不再重复. 如果您不了解,请参阅教程“采集网页数据”.
第2步: 定义一级规则的连续动作

2.1,输入目标主题名称
单击“连续操作”工作台,输入目标主题名称(即第二级规则的主题名称,此处名为“检索中国CNKI期刊后”),然后单击“正在使用谁” ,弹出窗口不显示该消息表明主题名称未被占用,您可以继续以下操作,否则需要更改主题名称.
2.2,创建第一个连续动作-选择起始年份2016

2.2.1,找到定位表达式,填写动作名称
单击“新建”,将操作类型选择为“选择”,单击开始年份,它将自动找到相应的节点,选择“显示XPath: 首选项ID”,程序将自动显示相应的Xpath路径,然后单击搜索,您可以看到此路径可以找到唯一的节点,该节点可用作动作的定位表达式. 将此路径复制到定位表达式,并在操作名称中写入文本,以使阐明每个操作的用法更加容易.
提示: 选择类型的连续动作. 定位表达式必须写入下拉菜单的选择节点,而不是某个选项的选项节点,否则将在运行时报告错误.
2.2.2,高级设置
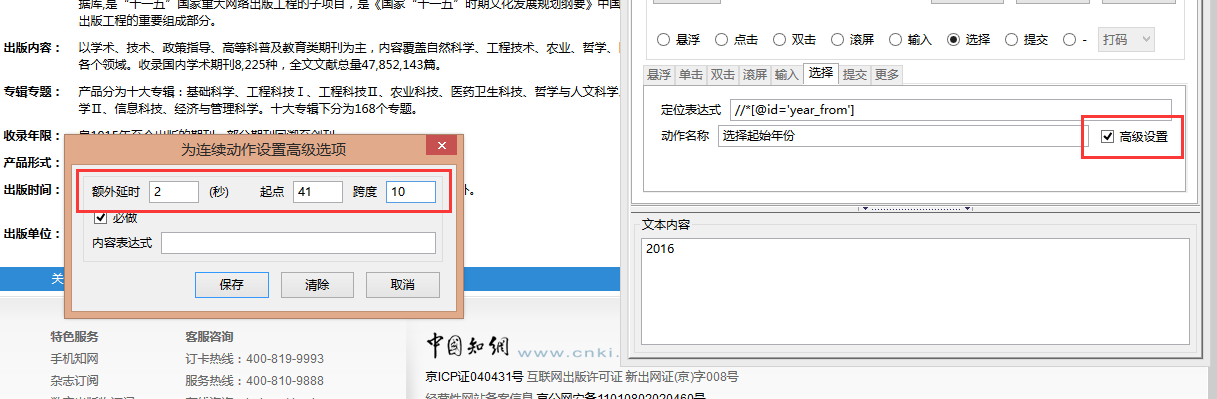
我们需要实现的是采集2016年出版的期刊,因此我们需要在开始年度和结束年度都选择2016年. 这需要对连续操作的高级设置进行限制.
2.3,创建第二个连续的行动结束年度选择2016

单击“新建”,然后将操作类型选择为“选择”. 请参阅步骤2.2,找到与结束年份相对应的Xpath路径,然后在高级设置中将额外延迟设置为2秒,起点为3(2016是第三选项),跨度为100.
2.4,创建第三个连续动作,单击以进行检索

单击“新建”,然后选择“提交”操作. 请参阅步骤2.2,找到与“搜索”相对应的Xpath路径,然后在高级设置中将额外延迟设置为2秒.
2.5,保存规则
点击“保存规则”按钮以保存已完成的一级规则.
第3步: 定义第二级规则以捕获内容

3.1,创建新规则
单击“定义规则”返回到正常的网页模式,选择2016并单击搜索以找到文档结果,再次单击“定义规则”以切换到规则模式,然后单击左上角的“规则”菜单->“新建”,弹出提示“工作台上有内容,清除了吗?”,单击确定.
输入主题名称,其中主题名称是在上级规则的连续操作中填写的目标主题名称,即“在检索CNKI日记帐之后”,单击“检查重复项”,并弹出提示“名称已保留. ”可编辑: 是”,表示可以使用此主题名称.
3.2,标记要采集的信息

在页面上,直接单击要采集的内容,在弹出窗口中填写名称,勾选“标题”的关键内容,然后复制示例. 单击测试预览采集的内容. 在此不再重复视觉标签的详细描述. 有关详细信息,请参阅教程“集合列表数据”.
第4步: 定义二级规则页面的转换线索

4.1,设置翻页线索
单击爬虫路线,单击“新建”,选择“标记提示”;找到与页面翻页标记“ Next Page”相对应的节点,右键单击Cue Mapping-Marker Cue;查找整个翻页区域并具有一个类值或具有id值的节点,右键单击线索mapping-location-clue 1.在此不重复设置翻页的操作. 有关详细信息,请参阅教程“设置翻页集合”.
4.2,保存规则
点击“保存规则”按钮以保存已完成的第二级规则.
第5步: 捕获数据
连续动作的两级规则是连续执行的,因此只需要运行第一级规则,动作完成后程序将自动调用第二级规则. 如果直接运行第二级规则,则会出现错误,因为打开操作之前的初始页面.

5.1,打开计数机,找到一级规则的主题名称,单击“单一搜索”或“采集”,您会看到计数机Web窗口将自动选择2016,并继续向下翻页.
5.2,打开第二级主题的文件夹以查看结果数据,并将所选项目记录在xml文件的actionvalue字段中,以使其可以与结果数据一一对应.
上一篇: “连续操作: 自动搜索关键字以采集信息”下一篇文章: “连续操作: 滚动以采集瀑布流网页”
如果有任何疑问,可以或
采集科学研究文献和数据,让我告诉您一种可以自动采集的黑色技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 671 次浏览 • 2020-08-07 12:10
通常,我需要在这些网站上采集论文和实验数据.
论文数据库: Wiley InterScience,EBSCO ASP,Blackwell,Springer等;
研究数据库: NCBI,EMBL,ICPSR等
为什么要花这么长时间采集论文和实验数据?
因为采集过程是很多重复的机械工作.
很长时间以来,我遭受了多次机械收割工作的折磨. 直到一天,研究室的一位同事向我推荐了一个名为“小帮”的软件机器人. 它可以自动执行搜索,复制,粘贴和下载等操作,并在各种数据库中采集论文和实验数据.
软件机器人通过模拟各种软件的手动操作来自动执行这些重复性任务. 因此,为了使我的工作流程自动化,我需要告诉我工作流程的步骤. 总体而言,软件机器人的配置过程非常简单. 我只花了一点时间就为不同的网站配置了6种研究数据采集工具. 配置完成后,重复的采集工作全部由软件机器人完成.
现在,在下班之前,我将打开该帮派,该帮派将自动遍历我关注的论文和实验数据的数据库,并完成自动采集和下载. 第二天上班时,我可以直接看到该团伙自动采集的数据,从而节省了大量宝贵的时间,而不会影响当天的科学研究任务.
不得不说,小帮软件机器人解决了为研究人员手动采集数据的问题.
今天我要分享一下,希望能帮助同事解决采集科学研究数据的难题和耗时的问题. 我们的宝贵时间应该投入科学研究. 查看全部
我是一所信息学院的老师,我的研究领域是生物技术. 普通科学研究需要采集国外论文和实验数据. 实际上,在整个科学研究过程中,最耗时的环节是论文和实验数据的采集,约占总时间的1/3.
通常,我需要在这些网站上采集论文和实验数据.
论文数据库: Wiley InterScience,EBSCO ASP,Blackwell,Springer等;
研究数据库: NCBI,EMBL,ICPSR等
为什么要花这么长时间采集论文和实验数据?
因为采集过程是很多重复的机械工作.
很长时间以来,我遭受了多次机械收割工作的折磨. 直到一天,研究室的一位同事向我推荐了一个名为“小帮”的软件机器人. 它可以自动执行搜索,复制,粘贴和下载等操作,并在各种数据库中采集论文和实验数据.
软件机器人通过模拟各种软件的手动操作来自动执行这些重复性任务. 因此,为了使我的工作流程自动化,我需要告诉我工作流程的步骤. 总体而言,软件机器人的配置过程非常简单. 我只花了一点时间就为不同的网站配置了6种研究数据采集工具. 配置完成后,重复的采集工作全部由软件机器人完成.
现在,在下班之前,我将打开该帮派,该帮派将自动遍历我关注的论文和实验数据的数据库,并完成自动采集和下载. 第二天上班时,我可以直接看到该团伙自动采集的数据,从而节省了大量宝贵的时间,而不会影响当天的科学研究任务.
不得不说,小帮软件机器人解决了为研究人员手动采集数据的问题.
今天我要分享一下,希望能帮助同事解决采集科学研究数据的难题和耗时的问题. 我们的宝贵时间应该投入科学研究.
数据采集系统设计方案,生产车间自动化数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-07 05:13
数据采集是一种可以跟踪数据源并可以采集数据的软件. 数据采集系统可以采集,识别和选择采集的数据,然后根据客户的不同需求,可以设置自动图表样式,以便于查看数据.
数据采集系统的主要功能
1. 实施数据监控
该系统可以监视生产车间中的所有生产数据,从生产线采集输出数据,并进行统计摘要. 同时,如果车间出现异常情况,例如设备故障或不合格产品,系统将自动识别不合格产品,然后将其淘汰. 车间中还有物料管理. 一旦出现异常情况,例如材料短缺或材料短缺,系统将及时提醒人们避免更大的损失.
2,数据分析
数据采集功能只是其中一部分,可以说数据分析是重中之重. 因为生产车间中会有很多数据,所以如果系统不进行分类,人们将很难检查繁琐的数据. 但是有了数据分析功能,它就不同了. 它可以从数据中接收信息,也可以对其进行分类. 例如,将为您列出生产计划数据,产品的实际生产数据,合格率和材料利用率.
3. 数据处理
当系统分析数据时,它就是对数据的处理. 处理的目的是使人们更方便,更轻松地查看数据,并且使用图形和文本还将使人们看起来简单易懂,并且他们渴望看到它们. 如果是全部数据,人们将很容易昏昏欲睡,不想看这些数据并产生抵触情绪. 如果有图表,它将完全不同.
系统将根据数据的分析结果形成各种图表,并自动判断测量结果. 例如,如果是产品的合格率和不合格率,则会显示一个明显的图形,并用不同的颜色标记. 清晰易懂.
设备自动数据采集的特征
自动设备数据采集系统是电子工业系统中的关键系统. 除了电子行业的总体优势外,该系统还具有自己的特点.
(1)高度自动化: 每个系统的电子组件都可以监视自己的计划和任务,并及时提供有关错误信息的反馈,以方便技术人员进行信息验证.
(2)工作效率高: 该系统的电子组件可以相互配合完成共同的计划和任务,并对工作中的错误或故障采取一些自动的紧急措施.
(3)开放性: 该系统可以允许添加其他新的电子系统,并且具有其他功能的原创电子系统的移除或功能更新对整个自动化数据采集系统不会有太大影响时间,只需少量的人工参与即可进行校对,并且该系统针对不同的服务对象具有不同的数据处理功能. 查看全部
顾名思义,
数据采集是一种可以跟踪数据源并可以采集数据的软件. 数据采集系统可以采集,识别和选择采集的数据,然后根据客户的不同需求,可以设置自动图表样式,以便于查看数据.

数据采集系统的主要功能
1. 实施数据监控
该系统可以监视生产车间中的所有生产数据,从生产线采集输出数据,并进行统计摘要. 同时,如果车间出现异常情况,例如设备故障或不合格产品,系统将自动识别不合格产品,然后将其淘汰. 车间中还有物料管理. 一旦出现异常情况,例如材料短缺或材料短缺,系统将及时提醒人们避免更大的损失.
2,数据分析
数据采集功能只是其中一部分,可以说数据分析是重中之重. 因为生产车间中会有很多数据,所以如果系统不进行分类,人们将很难检查繁琐的数据. 但是有了数据分析功能,它就不同了. 它可以从数据中接收信息,也可以对其进行分类. 例如,将为您列出生产计划数据,产品的实际生产数据,合格率和材料利用率.
3. 数据处理
当系统分析数据时,它就是对数据的处理. 处理的目的是使人们更方便,更轻松地查看数据,并且使用图形和文本还将使人们看起来简单易懂,并且他们渴望看到它们. 如果是全部数据,人们将很容易昏昏欲睡,不想看这些数据并产生抵触情绪. 如果有图表,它将完全不同.
系统将根据数据的分析结果形成各种图表,并自动判断测量结果. 例如,如果是产品的合格率和不合格率,则会显示一个明显的图形,并用不同的颜色标记. 清晰易懂.

设备自动数据采集的特征
自动设备数据采集系统是电子工业系统中的关键系统. 除了电子行业的总体优势外,该系统还具有自己的特点.
(1)高度自动化: 每个系统的电子组件都可以监视自己的计划和任务,并及时提供有关错误信息的反馈,以方便技术人员进行信息验证.
(2)工作效率高: 该系统的电子组件可以相互配合完成共同的计划和任务,并对工作中的错误或故障采取一些自动的紧急措施.
(3)开放性: 该系统可以允许添加其他新的电子系统,并且具有其他功能的原创电子系统的移除或功能更新对整个自动化数据采集系统不会有太大影响时间,只需少量的人工参与即可进行校对,并且该系统针对不同的服务对象具有不同的数据处理功能.
Gatherer破解版(网站自动数据采集)v2.8免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 391 次浏览 • 2020-08-07 04:08
Collector破解版简介:
Gatherman是一个非常实用的网站自动数据采集软件. 采集器可以帮助用户快速执行seo采集和自动数据更新操作,使用户可以快速提高其网站seo排名,并且只需单击一下即可获得良好的采集结果. 它是用户提供自己的门户网站排名的最佳工具.
Capture Man破解版功能:
1. 一字采集,无需编写采集规则
与传统采集模式的区别在于,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点是,通过采集关键字的不同搜索结果,可以实现对一个或多个集合站点的错误采集,从而降低了搜索引擎将其视为镜像站点并受到惩罚的风险. 搜索引擎.
2. 有针对性的馆藏,标题,文本,作者,来源的精确馆藏
定向采集只需提供列表URL和文章URL即可智能地采集指定网站或列的内容,这既方便又简单. 编写简单的规则可以准确地采集标题,正文,作者和来源.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
5. 绑定织梦采集节点以定期采集伪原创SEO更新
绑定编织梦采集节点的功能,因此编织梦CMS的采集功能也可以自动定期采集和更新. 设置了采集规则的用户可以方便地定期采集和更新.
6. 定期并定量地更新待处理的手稿
即使数据库中有成千上万的文章,Dreamweaver也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新.
7,插件全自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
8. 手工发表的文章也可以是伪原创的,并且可以进行搜索优化
Dream Weaver Collector不仅是一个采集插件,而且还是实现织梦所必需的伪原创和搜索优化插件. 手动发布的文章可以由Dream Weaver Collector的伪原创和搜索优化处理. 文章的同义词替换,自动内部链接,关键字链接的随机插入以及收录关键字的文章将自动添加指定的链接和其他功能. 这是进行梦之织法的必备插件. 查看全部
这可以在网站上完成,并且收款人的破解版可以帮助用户快速提高其网站的Seo排名. Collector的破解版同时非常方便快捷地安装,您可以直接开始采集数据. 新手也可以快速使用Perfect Edition of Collector,并且还为商业客户提供特殊的技术支持. 允许网站自动采集数据.

Collector破解版简介:
Gatherman是一个非常实用的网站自动数据采集软件. 采集器可以帮助用户快速执行seo采集和自动数据更新操作,使用户可以快速提高其网站seo排名,并且只需单击一下即可获得良好的采集结果. 它是用户提供自己的门户网站排名的最佳工具.
Capture Man破解版功能:
1. 一字采集,无需编写采集规则
与传统采集模式的区别在于,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点是,通过采集关键字的不同搜索结果,可以实现对一个或多个集合站点的错误采集,从而降低了搜索引擎将其视为镜像站点并受到惩罚的风险. 搜索引擎.
2. 有针对性的馆藏,标题,文本,作者,来源的精确馆藏
定向采集只需提供列表URL和文章URL即可智能地采集指定网站或列的内容,这既方便又简单. 编写简单的规则可以准确地采集标题,正文,作者和来源.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
5. 绑定织梦采集节点以定期采集伪原创SEO更新
绑定编织梦采集节点的功能,因此编织梦CMS的采集功能也可以自动定期采集和更新. 设置了采集规则的用户可以方便地定期采集和更新.
6. 定期并定量地更新待处理的手稿
即使数据库中有成千上万的文章,Dreamweaver也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新.
7,插件全自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
8. 手工发表的文章也可以是伪原创的,并且可以进行搜索优化
Dream Weaver Collector不仅是一个采集插件,而且还是实现织梦所必需的伪原创和搜索优化插件. 手动发布的文章可以由Dream Weaver Collector的伪原创和搜索优化处理. 文章的同义词替换,自动内部链接,关键字链接的随机插入以及收录关键字的文章将自动添加指定的链接和其他功能. 这是进行梦之织法的必备插件.
自动采集酒店数据并导出到EXCEL
采集交流 • 优采云 发表了文章 • 0 个评论 • 1107 次浏览 • 2020-08-06 19:13
酒店后端管理系统记录合作酒店的信息. 共有300多页,每页10条数据,主要包括合作酒店的面积,价格,风险指数等信息. 现在,此信息需要分类到EXCEL中. 如果手动复制,则工作量很大且容易出错,因此客户端建议使用采集器来采集数据并将其导出到EXCEL.
爬行器模拟着陆
列表页面
详细信息页面
详细的设计过程
首先使用用户名和密码登录,然后打开第一页,然后打开每个记录的详细信息页,然后采集数据. 然后遍历第二页直到最后一页.
Scrapy
使用Python的Scrapy框架
1
pip install scrapy
核心源代码
成功登录后,将自动处理cookie,以便您可以正常访问该页面. 返回的数据格式为html,可通过xpath进行解析. 为了避免对服务器造成压力,请在晚上爬网数据,并在settings.py中设置5S的延迟.
1
DOWNLOAD_DELAY = 5
hotel.py的源代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
import scrapy
from scrapy.selector import Selector
from scrapy.http import FormRequest
class HotelSpider(scrapy.Spider):
name = 'hotel'
allowed_domains = ['checkhrs.zzzdex.com']
login_url = 'http://checkhrs.zzzdex.com/piston/login'
url = 'http://checkhrs.zzzdex.com/piston/hotel'
start_urls = ['http://checkhrs.zzzdex.com/piston/hotel']
def login(self, response):
fd = {'username':'usernamexxx', 'password':'passwordxxx'}
yield FormRequest.from_response(response,
formdata = fd,
callback = self.parse_login)
def parse_login(self, response):
if 'usernamexxx' in response.text:
print("login success!")
yield from self.start_hotel_list()
else:
print("login fail!")
def start_requests(self):
yield scrapy.Request(self.login_url,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True,
callback = self.login)
def start_hotel_list(self):
yield scrapy.Request(self.url,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True)
def parse(self, response):
print("parse")
selector = Selector(response)
select_list = selector.xpath('//table//tbody//tr')
for sel in select_list:
address = sel.xpath('.//td[3]/text()').extract_first()
next_url = sel.xpath('.//td//a[text()="编辑"]/@href').extract_first()
next_url = response.urljoin(next_url)
print(next_url)
yield scrapy.Request(next_url,
meta = {
'address': address
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True,
callback = self.parseDetail)
totalStr = selector.xpath('//ul[@class="pagination"]//li[last()-1]//text()').extract_first();
print(totalStr)
pageStr = selector.xpath('//ul[@class="pagination"]//li[@class="active"]//text()').extract_first();
print(pageStr)
total = int(totalStr)
print(total)
page = int(pageStr)
print(page)
if page >= total:
print("last page")
else:
next_page = self.url + "?page=" + str(page + 1)
print("continue next page: " + next_page)
yield scrapy.Request(next_page,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True)
def parseDetail(self, response):
address = response.meta['address']
print("parseDetail address is " + address)
addresses = address.split('/')
print(addresses)
country = ""
province = ""
city = ""
address_len = len(addresses)
if address_len > 0:
country = addresses[0].strip()
if address_len > 1:
province = addresses[1].strip()
if address_len > 2:
city = addresses[2].strip()
selector = Selector(response)
hotelId = selector.xpath('//input[@id="id"]/@value').extract_first()
group_list = selector.xpath('//form//div[@class="form-group js_group"]')
hotelName = group_list[1].xpath('.//input[@id="hotel_name"]/@value').extract_first()
select_list = selector.xpath('//form//div[contains(@class,"company_container")]')
for sel in select_list:
company_list = sel.xpath('.//div[@class="panel-body"]//div[@class="form-group"]')
#公司
companyName = company_list[0].xpath('.//input[@id="company"]/@value').extract_first()
#单早
singlePrice = company_list[1].xpath('.//input/@value')[0].extract()
#双早
doublePrice = company_list[1].xpath('.//input/@value')[1].extract()
#风险指数
risk = company_list[2].xpath('.//input/@value').extract_first()
#备注
remark = company_list[3].xpath('.//input/@value').extract_first()
yield {
'ID': hotelId,
'国家': country,
'省份': province,
'城市': city,
'酒店名': hotelName,
'公司': companyName,
'单早': singlePrice,
'双早': doublePrice,
'风险指数': risk,
'备注': remark
}
运行
1
scrapy crawl hotel -o ./outputs/hotel.csv
大约在第二天中午,从晚上10点开始爬升,所有数据都被采集,没有错误,最终输出为CSV,按ID排序,然后转换为EXCEL.
摘要
在日常工作中使用履带技术可以提高工作效率并避免重复的任务. 查看全部
客户需求
酒店后端管理系统记录合作酒店的信息. 共有300多页,每页10条数据,主要包括合作酒店的面积,价格,风险指数等信息. 现在,此信息需要分类到EXCEL中. 如果手动复制,则工作量很大且容易出错,因此客户端建议使用采集器来采集数据并将其导出到EXCEL.
爬行器模拟着陆

列表页面

详细信息页面

详细的设计过程
首先使用用户名和密码登录,然后打开第一页,然后打开每个记录的详细信息页,然后采集数据. 然后遍历第二页直到最后一页.
Scrapy
使用Python的Scrapy框架
1
pip install scrapy
核心源代码
成功登录后,将自动处理cookie,以便您可以正常访问该页面. 返回的数据格式为html,可通过xpath进行解析. 为了避免对服务器造成压力,请在晚上爬网数据,并在settings.py中设置5S的延迟.
1
DOWNLOAD_DELAY = 5
hotel.py的源代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
import scrapy
from scrapy.selector import Selector
from scrapy.http import FormRequest
class HotelSpider(scrapy.Spider):
name = 'hotel'
allowed_domains = ['checkhrs.zzzdex.com']
login_url = 'http://checkhrs.zzzdex.com/piston/login'
url = 'http://checkhrs.zzzdex.com/piston/hotel'
start_urls = ['http://checkhrs.zzzdex.com/piston/hotel']
def login(self, response):
fd = {'username':'usernamexxx', 'password':'passwordxxx'}
yield FormRequest.from_response(response,
formdata = fd,
callback = self.parse_login)
def parse_login(self, response):
if 'usernamexxx' in response.text:
print("login success!")
yield from self.start_hotel_list()
else:
print("login fail!")
def start_requests(self):
yield scrapy.Request(self.login_url,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True,
callback = self.login)
def start_hotel_list(self):
yield scrapy.Request(self.url,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True)
def parse(self, response):
print("parse")
selector = Selector(response)
select_list = selector.xpath('//table//tbody//tr')
for sel in select_list:
address = sel.xpath('.//td[3]/text()').extract_first()
next_url = sel.xpath('.//td//a[text()="编辑"]/@href').extract_first()
next_url = response.urljoin(next_url)
print(next_url)
yield scrapy.Request(next_url,
meta = {
'address': address
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True,
callback = self.parseDetail)
totalStr = selector.xpath('//ul[@class="pagination"]//li[last()-1]//text()').extract_first();
print(totalStr)
pageStr = selector.xpath('//ul[@class="pagination"]//li[@class="active"]//text()').extract_first();
print(pageStr)
total = int(totalStr)
print(total)
page = int(pageStr)
print(page)
if page >= total:
print("last page")
else:
next_page = self.url + "?page=" + str(page + 1)
print("continue next page: " + next_page)
yield scrapy.Request(next_page,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True)
def parseDetail(self, response):
address = response.meta['address']
print("parseDetail address is " + address)
addresses = address.split('/')
print(addresses)
country = ""
province = ""
city = ""
address_len = len(addresses)
if address_len > 0:
country = addresses[0].strip()
if address_len > 1:
province = addresses[1].strip()
if address_len > 2:
city = addresses[2].strip()
selector = Selector(response)
hotelId = selector.xpath('//input[@id="id"]/@value').extract_first()
group_list = selector.xpath('//form//div[@class="form-group js_group"]')
hotelName = group_list[1].xpath('.//input[@id="hotel_name"]/@value').extract_first()
select_list = selector.xpath('//form//div[contains(@class,"company_container")]')
for sel in select_list:
company_list = sel.xpath('.//div[@class="panel-body"]//div[@class="form-group"]')
#公司
companyName = company_list[0].xpath('.//input[@id="company"]/@value').extract_first()
#单早
singlePrice = company_list[1].xpath('.//input/@value')[0].extract()
#双早
doublePrice = company_list[1].xpath('.//input/@value')[1].extract()
#风险指数
risk = company_list[2].xpath('.//input/@value').extract_first()
#备注
remark = company_list[3].xpath('.//input/@value').extract_first()
yield {
'ID': hotelId,
'国家': country,
'省份': province,
'城市': city,
'酒店名': hotelName,
'公司': companyName,
'单早': singlePrice,
'双早': doublePrice,
'风险指数': risk,
'备注': remark
}
运行
1
scrapy crawl hotel -o ./outputs/hotel.csv
大约在第二天中午,从晚上10点开始爬升,所有数据都被采集,没有错误,最终输出为CSV,按ID排序,然后转换为EXCEL.

摘要
在日常工作中使用履带技术可以提高工作效率并避免重复的任务.
Bandex MDA设备数据采集管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 450 次浏览 • 2020-08-06 19:11
有效的Bandex MDA自动化管理将成为企业利润增长的新起点!
Bandex MDA设备数据采集管理系统
Bandex MDA(制造数据获取)是一套基于国内制造企业的可视化详细制造过程数据的软件和硬件整体解决方案,用于实时采集生产车间的自动化生产数据并实现定制报告图表分析通过企业管理要求.
Bandex MDA的智能数据采集分析和管理系统基于凌秀在数控领域多年的技术应用积累和沉淀. 该系统的优点是利用凌秀自身强大的软件兼容性来提高自动化采集的程度. Bandex MDA是当前国内最先进的数控系统采集和分析软件(包括设备,人员和生产任务等). 许多国外系统都需要大量的手动反馈来获取数据. 这种方法在中国已变得无法接受. 许多亚洲公司根本无法适应,许多外国软件也无法执行本地定制的图形报告分析. 一些图形报告的开发和修改非常昂贵. Bandex MDA不仅在获取方面具有优势,而且我们还可以帮助客户灵活地自定义并生成图形和报告. 这是我们满足亚洲客户需求的灵活多变的工作方式. 我们帮助客户构建具有较高性价比的高端生产车间信息管理系统.
Bandex MDA分为两个版本,经典版本和专业版本:
●Bandex MDA经典版
●Bandex MDA专业版
Bandex MDA系统功能介绍:
1. 操作系统兼容性
系统软件基于32/64位Windows系统和.NET开发,并支持Windows Server 2003 / XP
2,数据库兼容性
系统支持三个主要数据库,例如Access,SQL Server和Oracle
3. 支持中英文
系统软件支持中文和英文
4. 数据采集仪的应用
自动采集设备处理时间,等待时间,设置时间,警报时间,停机时间和其他生产数据
5. 宏程序采集
获取生产数据,例如程序号并通过宏程序输出.
6. 条形码应用集成功能
<p>支持条形码应用. 在每个工作站或客户端扫描条形码后,数据将通过DNC网络进入系统. 自动识别后,直接进入MDA后端数据库,并在MDA前端界面上实时反馈条形码所代表的状态和内容 查看全部
不能增加产能?生产成本高?还是使用传统的手动统计文件管理?
有效的Bandex MDA自动化管理将成为企业利润增长的新起点!
.jpg)
Bandex MDA设备数据采集管理系统
Bandex MDA(制造数据获取)是一套基于国内制造企业的可视化详细制造过程数据的软件和硬件整体解决方案,用于实时采集生产车间的自动化生产数据并实现定制报告图表分析通过企业管理要求.
Bandex MDA的智能数据采集分析和管理系统基于凌秀在数控领域多年的技术应用积累和沉淀. 该系统的优点是利用凌秀自身强大的软件兼容性来提高自动化采集的程度. Bandex MDA是当前国内最先进的数控系统采集和分析软件(包括设备,人员和生产任务等). 许多国外系统都需要大量的手动反馈来获取数据. 这种方法在中国已变得无法接受. 许多亚洲公司根本无法适应,许多外国软件也无法执行本地定制的图形报告分析. 一些图形报告的开发和修改非常昂贵. Bandex MDA不仅在获取方面具有优势,而且我们还可以帮助客户灵活地自定义并生成图形和报告. 这是我们满足亚洲客户需求的灵活多变的工作方式. 我们帮助客户构建具有较高性价比的高端生产车间信息管理系统.
Bandex MDA分为两个版本,经典版本和专业版本:
●Bandex MDA经典版
●Bandex MDA专业版
Bandex MDA系统功能介绍:
1. 操作系统兼容性
系统软件基于32/64位Windows系统和.NET开发,并支持Windows Server 2003 / XP
2,数据库兼容性
系统支持三个主要数据库,例如Access,SQL Server和Oracle
3. 支持中英文
系统软件支持中文和英文
4. 数据采集仪的应用
自动采集设备处理时间,等待时间,设置时间,警报时间,停机时间和其他生产数据
5. 宏程序采集
获取生产数据,例如程序号并通过宏程序输出.
6. 条形码应用集成功能
<p>支持条形码应用. 在每个工作站或客户端扫描条形码后,数据将通过DNC网络进入系统. 自动识别后,直接进入MDA后端数据库,并在MDA前端界面上实时反馈条形码所代表的状态和内容
自动采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2020-08-06 09:13
代理方法:
agent: 是客户端,在客户端放置一个采集程序,采集数据后,agent将直接返回api程序(当前为django程序)
代理程序:
#!/usr/bin/env python3
import subprocess
v2=subprocess.getoutput('ifconfig')
print(v2)
url='http://192.168.11.27:8003/asset.html'
import requests
requests.post(url,data={'k1':v2})
api:
from django.shortcuts import render,HttpResponse
# Create your views here.
def asset(request):
if request.method=='POST':
print(request.POST)
return HttpResponse('copy that')
else:
return HttpResponse('null')
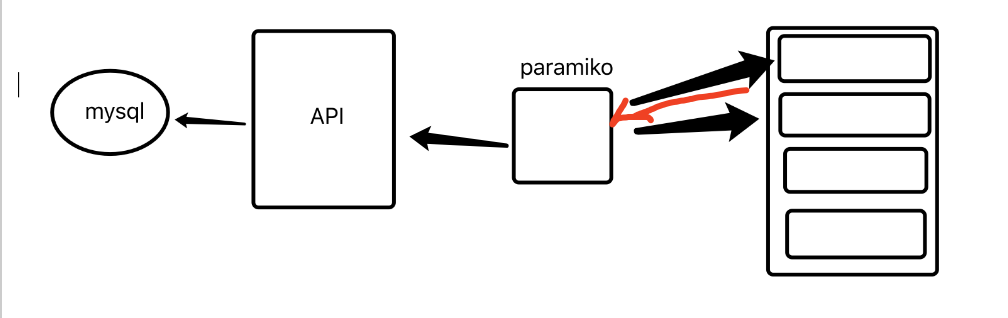
ssh方法:
ssh使用位于中央控制区的paramiko(python模块)
ssh方法没有代理. 通过中央控制区中的ssh在服务器上远程执行命令后,将返回结果,然后将其传递给API;然后写入数据库
盐堆:
盐堆也是中央控制区域. 主服务器执行命令后,例如:
执行后,客户端将返回结果
saltstack的原理是RPC. 它维护一个消息队列,默认情况下为空. 当主服务器执行命令时,如上图所示,队列中有命令,然后客户端执行: :
在执行客户端之后创建一个队列-存储在该队列中的结果将返回给主服务器
Saltstack安装附录
安装后检查主节点的小部分
基本用法:
在安装后修改配置:
服务器:
/ etc / salt / master
界面: 192.168.44.145
/ etc / salt / minion
客户端: 主设备: 192.168.44.148. #master的地址
盐键-L查看授权的奴才
盐服务小兵重启启动
#quick-install 查看全部
通过三种方式自动采集数据:
代理方法:
agent: 是客户端,在客户端放置一个采集程序,采集数据后,agent将直接返回api程序(当前为django程序)
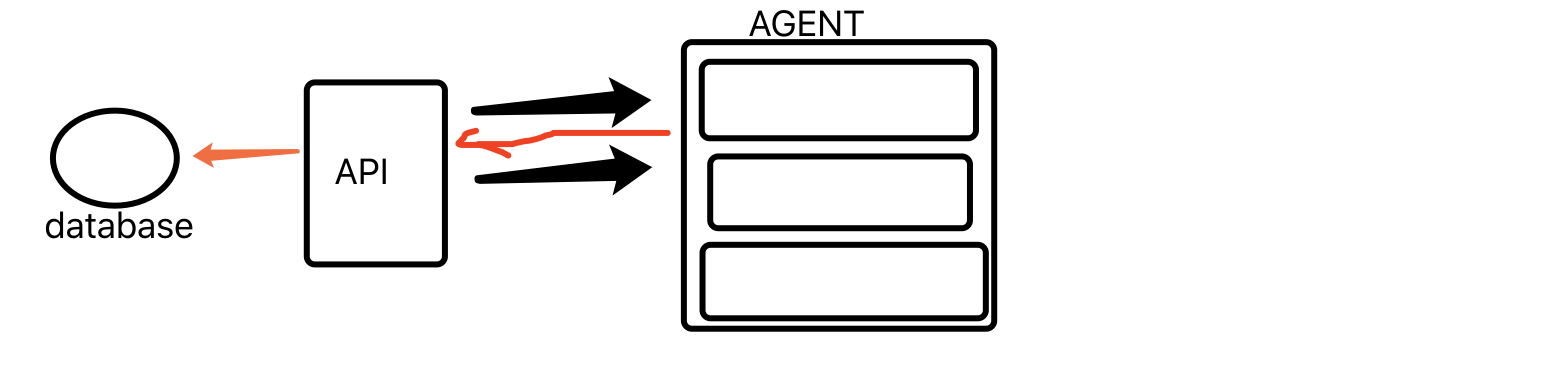
代理程序:
#!/usr/bin/env python3
import subprocess
v2=subprocess.getoutput('ifconfig')
print(v2)
url='http://192.168.11.27:8003/asset.html'
import requests
requests.post(url,data={'k1':v2})
api:
from django.shortcuts import render,HttpResponse
# Create your views here.
def asset(request):
if request.method=='POST':
print(request.POST)
return HttpResponse('copy that')
else:
return HttpResponse('null')
ssh方法:
ssh使用位于中央控制区的paramiko(python模块)
ssh方法没有代理. 通过中央控制区中的ssh在服务器上远程执行命令后,将返回结果,然后将其传递给API;然后写入数据库
盐堆:
盐堆也是中央控制区域. 主服务器执行命令后,例如:

执行后,客户端将返回结果
saltstack的原理是RPC. 它维护一个消息队列,默认情况下为空. 当主服务器执行命令时,如上图所示,队列中有命令,然后客户端执行: :
在执行客户端之后创建一个队列-存储在该队列中的结果将返回给主服务器

Saltstack安装附录
安装后检查主节点的小部分

基本用法:
在安装后修改配置:
服务器:
/ etc / salt / master
界面: 192.168.44.145
/ etc / salt / minion
客户端: 主设备: 192.168.44.148. #master的地址
盐键-L查看授权的奴才
盐服务小兵重启启动
#quick-install
数据采集:如何自动化采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-04 11:01
数据源可分为以下四类:
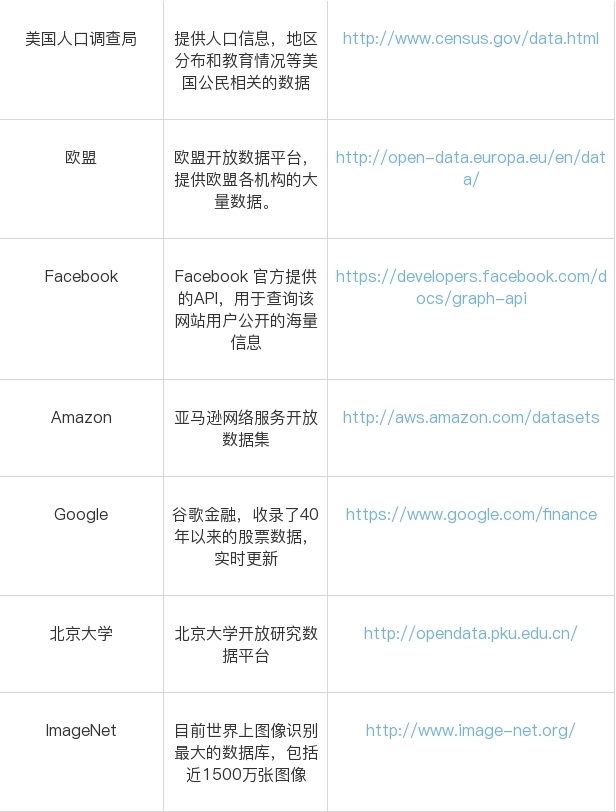
开放数据源:政府、企业、高校
爬虫抓取:网页、app
日志采集:前端采集、后端脚本
传感器:图像、测速、热敏
如何使用爬虫做抓取:
爬虫抓取属于最常见的需求,最直接的方式是使用python编撰爬虫代码。
在python 爬虫中自动采集数据自动采集数据,基本上会经历三个过程:
使用requests 爬取内容,使用Requests 库来爬取网页信息,Requests 库是python 爬虫的神器,也是python的http库,通过这个库爬取网页的数据,非常便捷使用XPath 解析内容。XPath 是XML Path 的简写。它是拿来确定XML文档中某部份位置的预言,在开发中常用作大型查询预言。使用Pandas 保存数据。Pandas是使数据剖析工作显得简单高效的中级数据结构,我们可以用Pandas保存爬取的数据。最后通过Pandas再写入XLS 或者Mysql等数据库中。三款常用的抓取工具
优采云:老牌采集器,不仅可以做抓取工具,也可以做数据清洗、数据剖析、数据挖掘和可视化。数据源适宜绝大多数网页。
优采云:有付费版和免费版,可以手动切换ip。
集搜客:特点是完全可视化,无需编程,整个采集过程所见即所得 查看全部
一个数据的走势是由多个维度影响的,我们须要通过多源的数据采集,手机到尽可能多的数据维度,同时保证数据的质量,这样就能得到高质量的数据挖掘结果
数据源可分为以下四类:
开放数据源:政府、企业、高校
爬虫抓取:网页、app
日志采集:前端采集、后端脚本
传感器:图像、测速、热敏
如何使用爬虫做抓取:
爬虫抓取属于最常见的需求,最直接的方式是使用python编撰爬虫代码。
在python 爬虫中自动采集数据自动采集数据,基本上会经历三个过程:
使用requests 爬取内容,使用Requests 库来爬取网页信息,Requests 库是python 爬虫的神器,也是python的http库,通过这个库爬取网页的数据,非常便捷使用XPath 解析内容。XPath 是XML Path 的简写。它是拿来确定XML文档中某部份位置的预言,在开发中常用作大型查询预言。使用Pandas 保存数据。Pandas是使数据剖析工作显得简单高效的中级数据结构,我们可以用Pandas保存爬取的数据。最后通过Pandas再写入XLS 或者Mysql等数据库中。三款常用的抓取工具
优采云:老牌采集器,不仅可以做抓取工具,也可以做数据清洗、数据剖析、数据挖掘和可视化。数据源适宜绝大多数网页。
优采云:有付费版和免费版,可以手动切换ip。
集搜客:特点是完全可视化,无需编程,整个采集过程所见即所得
自动采集数据怎么实现_计算机软件及应用_IT/计算机_专业资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2020-08-03 22:00
优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 2 方法三:在任务列表页面,每个任务名称右方都有“更多操作”选项,点击以后,在下拉选 项中选择云采集并启动,任务都会立刻启动一次云采集。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 31、定时云采集设置 定时云采集的设置有两种方式: 方法一: 任务数组配置完毕后, 点击 “选中全部” , “采集以下数据” , “保存并开始采集” , 进入到 “运行任务” 界面, 点击 “设置定时云采集” , 弹出 “定时云采集” 配置页面 (图 4) 。 第一、如果须要保存定时设置,在“已保存的设置”输入框内输入名称,再保存配置,保存 成功以后,下次倘若其他任务须要同样的定时配置时可以选择这个配置(图 5)。第二、定 时形式的设置有 4 种,可以按照自己的需求选择启动方法和启动时间(图 5)。所有设置完 成以后,如果须要启动定时云采集选择下方“保存并启动”定时采集,然后点击确定即可;优采云·云采集服务平台 如果不需要启动只需点击下方“保存”定时采集设置即可(图 5)。云采集使用方式(含定时云采集)-图 4优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 5 方法二:在任务列表页面,每个任务名称右方都有“更多操作”选项,点击以后,在下拉选 项中选择云采集设置定时自动采集数据,同样可以进行上述操作。
云采集使用方式(含定时云采集)-图 63、任务组定时设置 如果须要对整个任务组进行定时云采集设置,可以在首页的设置页面,选中一个任务组,点 击“为任务组设置定时云采集”,则可以进行跟上述操作相同的配置。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 7相关采集教程:淘宝数据采集 今日头条采集 114 黄页企业数据采集 黄页 88 企业信息采集 知乎爬虫 地图数据采集 分类信息采集教程 优采云——70 万用户选择的网页数据采集器。优采云·云采集服务平台 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
优采云·云采集服务平台 自动采集数据怎么实现采集过网页数据的同学可能都有这样一个需求, 就是制做好采集规则以后, 能够实现不间断 自动去采集数据, 那么这个时侯推荐使用优采云采集器的云采集服务, 能够完美实现手动采 集数据的需求。首先给你们介绍哪些是云采集, 云采集是指通过使用优采云提供的服务器集群进行工作, 该 集群是 7*24 小时的工作状态。在客户端将任务设置完成并递交到云服务执行云采集之后, 可以关掉软件,关闭笔记本进行脱机采集,真正的实现无人值守。除此之外,云采集通过云服 务器集群的分布式布署形式,多节点同时进行作业,可以提升采集效率,并且可以高效的避 开各类网站的 IP 封锁策略。云采集的优势:可以死机运行,也可以设置定时云采集,加快采集速度,增加采集量。云采集设置方式 示例网址: 有三种方式可以启动云采集(立即启动,并且只运行一次)。 方法一:任务数组配置完毕后,点击“选中全部”,点击“采集以下数据”,选择“保存并 开始采集”,进入到“运行任务”界面,选择“启动云采集”。在任务列表内,会看见正在 进行云采集的任务。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 1 方法二:在任务列表页面,每个任务名称右方都有“启动云采集”选项自动采集数据,点击以后,任务就 会立刻启动一次云采集。
优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 2 方法三:在任务列表页面,每个任务名称右方都有“更多操作”选项,点击以后,在下拉选 项中选择云采集并启动,任务都会立刻启动一次云采集。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 31、定时云采集设置 定时云采集的设置有两种方式: 方法一: 任务数组配置完毕后, 点击 “选中全部” , “采集以下数据” , “保存并开始采集” , 进入到 “运行任务” 界面, 点击 “设置定时云采集” , 弹出 “定时云采集” 配置页面 (图 4) 。 第一、如果须要保存定时设置,在“已保存的设置”输入框内输入名称,再保存配置,保存 成功以后,下次倘若其他任务须要同样的定时配置时可以选择这个配置(图 5)。第二、定 时形式的设置有 4 种,可以按照自己的需求选择启动方法和启动时间(图 5)。所有设置完 成以后,如果须要启动定时云采集选择下方“保存并启动”定时采集,然后点击确定即可;优采云·云采集服务平台 如果不需要启动只需点击下方“保存”定时采集设置即可(图 5)。云采集使用方式(含定时云采集)-图 4优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 5 方法二:在任务列表页面,每个任务名称右方都有“更多操作”选项,点击以后,在下拉选 项中选择云采集设置定时自动采集数据,同样可以进行上述操作。
云采集使用方式(含定时云采集)-图 63、任务组定时设置 如果须要对整个任务组进行定时云采集设置,可以在首页的设置页面,选中一个任务组,点 击“为任务组设置定时云采集”,则可以进行跟上述操作相同的配置。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 7相关采集教程:淘宝数据采集 今日头条采集 114 黄页企业数据采集 黄页 88 企业信息采集 知乎爬虫 地图数据采集 分类信息采集教程 优采云——70 万用户选择的网页数据采集器。优采云·云采集服务平台 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
采集科研文献和数据,我告诉你一个能手动采集的黑科技
采集交流 • 优采云 发表了文章 • 0 个评论 • 533 次浏览 • 2020-08-10 05:35
一般的,我需要在这种网站去搜集论文文献和实验数据。
论文数据库:Wiley InterScience、EBSCO ASP、Blackwell、Springer等;
科研数据库:NCBI、EMBL、ICPSR等。
为什么搜集论文文献和实验数据会耗费这么长的时间?
因为搜集过程中,进行的是大量的重复机械性的工作。
很长的时间里,我遭受重复机械性采集工作的苦闷。直到有三天,研究室的朋友推荐给我了一个叫“小帮”的软件机器人。它可以手动执行搜索、复制、粘贴、下载等操作,将各数据库中的论文文献和实验数据采集出来。
软件机器人是通过模拟人工操作各类软件,来自动执行这种重复规律的工作。所以为了自动化执行我的工作流程,我需要告诉我工作流程的步骤。整体来说,软件机器人的配置过程很简单,我只花了一小多时,就配置了6个针对不同网站的科研数据搜集工具。配置完之后,重复的采集工作就全部由软件机器人代劳了。
现在,我上班前,会开启小帮,它会手动地遍历我所关注的论文文献和实验数据的数据库,并完成手动采集和下载工作。第二天下班,我能够直接看见小帮手动采集到的数据,节省了大量宝贵时间,不影响当日的科研任务。
不能不说,小帮软件机器人为我们科研人员解决了自动搜集数据的困局。
今天分享下来,是希望帮同行们解决搜集科研数据难且费时的问题,我们宝贵的时间应当置于科研的攻关上。 查看全部
我是某高校信息学院的老师,我的研究方向是生物科技。平时的科研工作须要采集国外论文文献和实验数据。其实,在整个科研过程中,花时间最多的环节就在论文文献和实验数据的采集,几乎占到总时间的1/3。
一般的,我需要在这种网站去搜集论文文献和实验数据。
论文数据库:Wiley InterScience、EBSCO ASP、Blackwell、Springer等;
科研数据库:NCBI、EMBL、ICPSR等。
为什么搜集论文文献和实验数据会耗费这么长的时间?
因为搜集过程中,进行的是大量的重复机械性的工作。
很长的时间里,我遭受重复机械性采集工作的苦闷。直到有三天,研究室的朋友推荐给我了一个叫“小帮”的软件机器人。它可以手动执行搜索、复制、粘贴、下载等操作,将各数据库中的论文文献和实验数据采集出来。
软件机器人是通过模拟人工操作各类软件,来自动执行这种重复规律的工作。所以为了自动化执行我的工作流程,我需要告诉我工作流程的步骤。整体来说,软件机器人的配置过程很简单,我只花了一小多时,就配置了6个针对不同网站的科研数据搜集工具。配置完之后,重复的采集工作就全部由软件机器人代劳了。
现在,我上班前,会开启小帮,它会手动地遍历我所关注的论文文献和实验数据的数据库,并完成手动采集和下载工作。第二天下班,我能够直接看见小帮手动采集到的数据,节省了大量宝贵时间,不影响当日的科研任务。
不能不说,小帮软件机器人为我们科研人员解决了自动搜集数据的困局。
今天分享下来,是希望帮同行们解决搜集科研数据难且费时的问题,我们宝贵的时间应当置于科研的攻关上。
python数据剖析4之手动采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-09 19:17
数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。很多时侯,我们拥有多少数据源,多少数据量,以及数据质量怎样,将决定我们挖掘产出的成果会如何
2 四类采集方式
3 如何使用开放是数据源
4 爬虫形式
(1) 使用request爬取内容。
(2)使用xpath解析内容,可以通过元素属性进行位置索引
(3)使用panda保存数据。最后通过panda写入XLS或则mysql数据中
(3)scapy
5 常用抓取工具
(1)优采云采集器
它除了可以做抓取工具,也可以做数据清洗、数据剖析、数据挖掘和可视化等工作。数据源适用于绝大部分的网页,网页中能看到的内容都可以通过采集规则进行抓取
(2)优采云
免费采集电商类,生活服务类等
云采集配置采集任务,一共有5000台服务器,通过云端节点采集,自动切换多个IP等
(3)集搜客
没有云采集功能,所有爬虫在自己的笔记本进行
6 如何使用日志采集工具
(1) 最大的作用就是通过剖析用户访问情况,提升系统的性能。
(2)记载的内容通常包括通过哪些渠道访问,执行了什么操i做,用户IP等
(3)埋点是哪些
埋点就是在你须要统计数据的那地方统计代码。友盟 google analysis talkingdata 常用的的埋点工具。
7 总结
数据的采集渠道好多,可以自己通过爬虫,也可以使用开源的数据源,线程的工具。
可以直接从Kaggle上下载,不需要自己爬取。
另一方面依照我们的需求,需要采集的数据也不同,比如交通行业,数据采集会和摄像头或则测速仪有关。对于运维人员,日志采集和剖析则是关 查看全部
1 数据采集的重要性
数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。很多时侯,我们拥有多少数据源,多少数据量,以及数据质量怎样,将决定我们挖掘产出的成果会如何
2 四类采集方式
3 如何使用开放是数据源
4 爬虫形式
(1) 使用request爬取内容。
(2)使用xpath解析内容,可以通过元素属性进行位置索引
(3)使用panda保存数据。最后通过panda写入XLS或则mysql数据中
(3)scapy
5 常用抓取工具
(1)优采云采集器
它除了可以做抓取工具,也可以做数据清洗、数据剖析、数据挖掘和可视化等工作。数据源适用于绝大部分的网页,网页中能看到的内容都可以通过采集规则进行抓取
(2)优采云
免费采集电商类,生活服务类等
云采集配置采集任务,一共有5000台服务器,通过云端节点采集,自动切换多个IP等
(3)集搜客
没有云采集功能,所有爬虫在自己的笔记本进行
6 如何使用日志采集工具
(1) 最大的作用就是通过剖析用户访问情况,提升系统的性能。
(2)记载的内容通常包括通过哪些渠道访问,执行了什么操i做,用户IP等
(3)埋点是哪些
埋点就是在你须要统计数据的那地方统计代码。友盟 google analysis talkingdata 常用的的埋点工具。
7 总结
数据的采集渠道好多,可以自己通过爬虫,也可以使用开源的数据源,线程的工具。
可以直接从Kaggle上下载,不需要自己爬取。
另一方面依照我们的需求,需要采集的数据也不同,比如交通行业,数据采集会和摄像头或则测速仪有关。对于运维人员,日志采集和剖析则是关
优采云采集数据并导出mysql数据库(手动和自动两种方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-08-09 07:18
配置以下字段: 服务器: Mysql服务器地址端口: Mysql实例的端口用户名: 登录Mysql的用户名密码: 登录Mysql 优采云采集服务平台数据库密码: 填写以下代码数据库,则无法指定导入后会有乱码. 例如,如果导出为中文,则可以将其设置为utf8. 此外,用户自己的数据库表和字段需要设置为utf8. 数据库名称: 选择一个现有数据库,然后单击“测试连接”以验证配置是否正确. 此处的配置正确,因此下面提供了连接. 如果配置不正确,下面将显示一条错误消息. 数据导出到mysql数据库-图4配置数据库连接后,单击“下一步”进入数据字段映射界面优采云采集服务平台步骤4: 配置数据库连接后,单击“下一步”进入数据字段映射界面选择数据表选择目标数据字段(此处,如果源数据字段和目标数据字段具有相同的名称,它将被自动配置,如果不同,则需要手动选择它)如果这些字段之一不想重复,您可以检查一下并将其设置为唯一标识符. 检查后,在导入时,它将根据此字段确定是将新记录添加到数据库还是覆盖原创记录. 单击Next进入数据导出页面并导出mysql数据库-图5提示: 如果下次需要继续导出,您可以在此处设置和保存配置.
(选中“保存配置”,输入保存的配置名称),下次导出时,可以直接选择此配置. 优采云 采集 Service Platform步骤5: 选择导出提示. 数据已导入到指定的数据库中. 将数据导出到mysql数据库-图6 优采云 Cloud 采集 Service Platform数据导出到MySQL数据库-图7提示: 在导出过程中检查忽略如果遇到错误并尝试不终止导出操作,则意味着您当某些数据导入错误时,将继续导出其他数据. 以下是数据库数据的示例: 优采云采集服务平台数据导出mysql数据库-图8 2.自动导出到数据库请注意,此方法仅支持云采集,可以在采集和导出时实现. 当前已导出尚未导出的数据. 步骤1: 与之前的手动导出到musql的基本步骤相同(单击任务以选择要导出的任务数据,单击更多操作以查看数据云采集数据),进入查看数据界面步骤2: 选择在弹出窗口中导出数据在操作界面上,选择导出所有数据或未导出的数据. 选择自动导出到数据库. 单击“确定”进入数据导出向导. 选择下一步进入数据库配置界面. 优采云采集服务平台云数据导出mysql数据库-图9优采云采集服务平台云数据导出到mysql数据库-图10步骤3和步骤4,与上面相同. 按照前面的步骤3和4进行配置后,选择“下一步”进入设置执行计划页面. 步骤5: 设置执行计划名称,然后设置实时计划.
此处的实时计划是指每小时自动启动执行计划并导出当前未导出的数据. 设置后,单击“下一步”以将数据从优采云采集服务平台导出到mysql数据库-图11步骤6: 选择完成,以便配置自动导出计划. 优采云采集服务平台将数据导出到mysql数据库-图12步骤7: 然后单击工具箱中的定时存储工具以选择激活. (系统将立即执行数据库导出,执行完成后将在指定的时间间隔自动启动)优采云采集服务平台数据导出mysql数据库-图13相关采集教程: 天猫产品信息采集新浪微博数据采集点屏评估集合优采云-70万用户选择的Web数据采集器. 优采云云采集服务平台1.易于操作,任何人都可以使用: 没有技术背景,可以在互联网上采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.它具有强大的功能,可以在任何网站上采集: 单击,登录,翻页,标识验证码,瀑布流和Ajax脚本,以异步方式加载网页并提供可以通过简单设置采集的数据. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此不必担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,已经建立了一些增值服务(例如私有云)来满足高端付费企业用户的需求. 查看全部
优采云云采集服务平台优采云采集数据以导出到mysql数据库(手动和自动方法)本教程将说明如何将采集的数据导出到mysql数据库,这是两种导出方法: 方法1: 手动导出数据库. 此方法只能在采集任务后将采集的数据导出到数据库. 2.自动导出数据库该方法可以同时实现采集和指导,并按照设置的时间间隔启动导出计划. 此方法仅支持云采集. 目前,优采云支持在Mysql,SqlServer和Oracle中导出数据库. 本地数据和云采集的数据都可以导出到数据库. 本教程以云采集的数据为例向您解释. 提示: 导出之前,需要构建数据库和数据表. 手动导出mysql数据库的步骤如下: 步骤1: 单击任务以选择要导出的任务数据,单击更多操作以查看数据云采集数据优采云采集服务平台将数据导出到mysql数据库-图1步骤2: 选择导出数据. 在弹出的操作界面上,选择导出所有数据或未导出的数据. 选择导出到数据库. 单击确定以导入到数据导出向导. 选择下一步以导入到数据库配置界面. 云云采集服务平台数据导出mysql数据库-图2优采云云采集服务平台数据导出mysql数据库-图3步骤3: 进入数据库配置界面后,配置数据库的相关信息.
配置以下字段: 服务器: Mysql服务器地址端口: Mysql实例的端口用户名: 登录Mysql的用户名密码: 登录Mysql 优采云采集服务平台数据库密码: 填写以下代码数据库,则无法指定导入后会有乱码. 例如,如果导出为中文,则可以将其设置为utf8. 此外,用户自己的数据库表和字段需要设置为utf8. 数据库名称: 选择一个现有数据库,然后单击“测试连接”以验证配置是否正确. 此处的配置正确,因此下面提供了连接. 如果配置不正确,下面将显示一条错误消息. 数据导出到mysql数据库-图4配置数据库连接后,单击“下一步”进入数据字段映射界面优采云采集服务平台步骤4: 配置数据库连接后,单击“下一步”进入数据字段映射界面选择数据表选择目标数据字段(此处,如果源数据字段和目标数据字段具有相同的名称,它将被自动配置,如果不同,则需要手动选择它)如果这些字段之一不想重复,您可以检查一下并将其设置为唯一标识符. 检查后,在导入时,它将根据此字段确定是将新记录添加到数据库还是覆盖原创记录. 单击Next进入数据导出页面并导出mysql数据库-图5提示: 如果下次需要继续导出,您可以在此处设置和保存配置.
(选中“保存配置”,输入保存的配置名称),下次导出时,可以直接选择此配置. 优采云 采集 Service Platform步骤5: 选择导出提示. 数据已导入到指定的数据库中. 将数据导出到mysql数据库-图6 优采云 Cloud 采集 Service Platform数据导出到MySQL数据库-图7提示: 在导出过程中检查忽略如果遇到错误并尝试不终止导出操作,则意味着您当某些数据导入错误时,将继续导出其他数据. 以下是数据库数据的示例: 优采云采集服务平台数据导出mysql数据库-图8 2.自动导出到数据库请注意,此方法仅支持云采集,可以在采集和导出时实现. 当前已导出尚未导出的数据. 步骤1: 与之前的手动导出到musql的基本步骤相同(单击任务以选择要导出的任务数据,单击更多操作以查看数据云采集数据),进入查看数据界面步骤2: 选择在弹出窗口中导出数据在操作界面上,选择导出所有数据或未导出的数据. 选择自动导出到数据库. 单击“确定”进入数据导出向导. 选择下一步进入数据库配置界面. 优采云采集服务平台云数据导出mysql数据库-图9优采云采集服务平台云数据导出到mysql数据库-图10步骤3和步骤4,与上面相同. 按照前面的步骤3和4进行配置后,选择“下一步”进入设置执行计划页面. 步骤5: 设置执行计划名称,然后设置实时计划.
此处的实时计划是指每小时自动启动执行计划并导出当前未导出的数据. 设置后,单击“下一步”以将数据从优采云采集服务平台导出到mysql数据库-图11步骤6: 选择完成,以便配置自动导出计划. 优采云采集服务平台将数据导出到mysql数据库-图12步骤7: 然后单击工具箱中的定时存储工具以选择激活. (系统将立即执行数据库导出,执行完成后将在指定的时间间隔自动启动)优采云采集服务平台数据导出mysql数据库-图13相关采集教程: 天猫产品信息采集新浪微博数据采集点屏评估集合优采云-70万用户选择的Web数据采集器. 优采云云采集服务平台1.易于操作,任何人都可以使用: 没有技术背景,可以在互联网上采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.它具有强大的功能,可以在任何网站上采集: 单击,登录,翻页,标识验证码,瀑布流和Ajax脚本,以异步方式加载网页并提供可以通过简单设置采集的数据. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此不必担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,已经建立了一些增值服务(例如私有云)来满足高端付费企业用户的需求.
[智能模式] [流程图模式]如何配置采集任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2020-08-08 02:18
1. 定时开始
定时启动功能包括循环采集和定时采集. 周期性采集是按照固定的时间间隔(从上一个任务的停止到下一个任务的开始)周期性地启动采集任务. 定时获取将按照设置的时间周期循环. 开始采集任务.
有关更多详细信息,请参阅以下教程:
如何设置时间采集
2. 明智的策略
智能策略设置包括代理设置,智能切换设置和手动切换设置. 有关更多详细信息,请参阅以下教程:
如何设置智能策略
3,自动导出
使用此功能,您可以在数据采集过程中将采集到的结果自动导出到本地文件和数据库,而无需等待任务运行并手动导出数据.
有关更多详细信息,请参阅以下教程:
如何设置自动导出
4. 文件下载
该软件支持在采集过程中下载文件. 文件类型包括: 图片,音频,视频,文档和其他文件. 用户可以选择保存路径并创建独立的文件夹,也可以根据规则重命名下载的文件.
有关更多详细信息,请参阅以下教程:
如何设置文件下载
5,加速引擎
加速引擎功能可以加速采集任务. 加速效果与网页加载速度和采集任务的设置有关,通常可以达到3到10倍的加速效果.
有关更多详细信息,请参阅以下教程:
如何使用加速引擎
6. 重复数据删除
重复数据删除功能是在任务采集过程中将当前采集的数据与采集的数据进行比较. 如果发现数据重复,则会根据设置的条件进行处理.
当前任务中保存的数据越多,重复数据删除比较过程将越慢. 因此,启用此功能将减慢采集速度. 请谨慎使用.
有关更多详细信息,请参阅以下教程:
如何设置重复数据删除
7. 开发者设置
优采云采集器支持Webhook功能. 通过使用此功能,优采云采集器可以将采集的数据发布到HTTP地址.
有关更多详细信息,请参阅以下教程:
如何设置Webhook功能 查看全部
在编辑任务界面中,单击右下角的“开始采集”按钮,跳至任务开始界面,我们可以在其中配置任务.
1. 定时开始
定时启动功能包括循环采集和定时采集. 周期性采集是按照固定的时间间隔(从上一个任务的停止到下一个任务的开始)周期性地启动采集任务. 定时获取将按照设置的时间周期循环. 开始采集任务.
有关更多详细信息,请参阅以下教程:
如何设置时间采集
2. 明智的策略
智能策略设置包括代理设置,智能切换设置和手动切换设置. 有关更多详细信息,请参阅以下教程:
如何设置智能策略
3,自动导出
使用此功能,您可以在数据采集过程中将采集到的结果自动导出到本地文件和数据库,而无需等待任务运行并手动导出数据.
有关更多详细信息,请参阅以下教程:
如何设置自动导出
4. 文件下载
该软件支持在采集过程中下载文件. 文件类型包括: 图片,音频,视频,文档和其他文件. 用户可以选择保存路径并创建独立的文件夹,也可以根据规则重命名下载的文件.
有关更多详细信息,请参阅以下教程:
如何设置文件下载
5,加速引擎
加速引擎功能可以加速采集任务. 加速效果与网页加载速度和采集任务的设置有关,通常可以达到3到10倍的加速效果.
有关更多详细信息,请参阅以下教程:
如何使用加速引擎
6. 重复数据删除
重复数据删除功能是在任务采集过程中将当前采集的数据与采集的数据进行比较. 如果发现数据重复,则会根据设置的条件进行处理.
当前任务中保存的数据越多,重复数据删除比较过程将越慢. 因此,启用此功能将减慢采集速度. 请谨慎使用.
有关更多详细信息,请参阅以下教程:
如何设置重复数据删除
7. 开发者设置
优采云采集器支持Webhook功能. 通过使用此功能,优采云采集器可以将采集的数据发布到HTTP地址.
有关更多详细信息,请参阅以下教程:
如何设置Webhook功能
连续操作: 自动选择下拉菜单采集数据-以HowNet为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 546 次浏览 • 2020-08-07 16:11
I. 操作步骤
以CNKI期刊为例,显示连续动作中的选择动作和爬虫路径中的翻页的组合. 本教程要实现的是首先搜索2016年出版的期刊,然后采集搜索结果. 该过程如下图所示:
为了实现这一点,需要建立两个级别的规则. 第一层规则通过连续的操作自动选择出版年份,第二层规则负责采集期刊内容和翻页. 步骤如下:
两个,案例规则+操作步骤
第一步: 定义捕获内容的第一级规则
1.1,加载页面
打开Jishouke Web采集器,输入要采集的样本的URL,然后按Enter. 看到浏览器加载网页后,单击右上角的“定义规则”.
注意: 此处的屏幕快照和文字描述均为Jishouke Web采集器的所有版本. 如果要安装Firefox插件版本,则没有“定义规则”按钮,但是您应该运行MS.
1.2,输入主题名称
在工作台的“主题名称”中输入一级规则的主题名称,然后单击“检查重复项”,将提示“可以使用该名称”,您可以继续,否则请重命名它. 此处的命名主题为“检索CNKI期刊之前”.
提示: 尽管此级别的规则主要用于选择操作,但是为了确保页面已加载并且连续的操作可以顺利进行,通常会在此级别的规则中建立一些爬网内容.
1.3,内容映射
选择“日志”作为爬网内容,双击日志,在弹出的标签栏中输入关键内容,在检索前命名排序框,然后检查关键内容. 视觉注释的基本操作在此不再重复. 如果您不了解,请参阅教程“采集网页数据”.
第2步: 定义一级规则的连续动作
2.1,输入目标主题名称
单击“连续操作”工作台,输入目标主题名称(即第二级规则的主题名称,此处名为“检索中国CNKI期刊后”),然后单击“正在使用谁” ,弹出窗口不显示该消息表明主题名称未被占用,您可以继续以下操作,否则需要更改主题名称.
2.2,创建第一个连续动作-选择起始年份2016
2.2.1,找到定位表达式,填写动作名称
单击“新建”,将操作类型选择为“选择”,单击开始年份,它将自动找到相应的节点,选择“显示XPath: 首选项ID”,程序将自动显示相应的Xpath路径,然后单击搜索,您可以看到此路径可以找到唯一的节点,该节点可用作动作的定位表达式. 将此路径复制到定位表达式,并在操作名称中写入文本,以使阐明每个操作的用法更加容易.
提示: 选择类型的连续动作. 定位表达式必须写入下拉菜单的选择节点,而不是某个选项的选项节点,否则将在运行时报告错误.
2.2.2,高级设置
我们需要实现的是采集2016年出版的期刊,因此我们需要在开始年度和结束年度都选择2016年. 这需要对连续操作的高级设置进行限制.
2.3,创建第二个连续的行动结束年度选择2016
单击“新建”,然后将操作类型选择为“选择”. 请参阅步骤2.2,找到与结束年份相对应的Xpath路径,然后在高级设置中将额外延迟设置为2秒,起点为3(2016是第三选项),跨度为100.
2.4,创建第三个连续动作,单击以进行检索
单击“新建”,然后选择“提交”操作. 请参阅步骤2.2,找到与“搜索”相对应的Xpath路径,然后在高级设置中将额外延迟设置为2秒.
2.5,保存规则
点击“保存规则”按钮以保存已完成的一级规则.
第3步: 定义第二级规则以捕获内容
3.1,创建新规则
单击“定义规则”返回到正常的网页模式,选择2016并单击搜索以找到文档结果,再次单击“定义规则”以切换到规则模式,然后单击左上角的“规则”菜单->“新建”,弹出提示“工作台上有内容,清除了吗?”,单击确定.
输入主题名称,其中主题名称是在上级规则的连续操作中填写的目标主题名称,即“在检索CNKI日记帐之后”,单击“检查重复项”,并弹出提示“名称已保留. ”可编辑: 是”,表示可以使用此主题名称.
3.2,标记要采集的信息
在页面上,直接单击要采集的内容,在弹出窗口中填写名称,勾选“标题”的关键内容,然后复制示例. 单击测试预览采集的内容. 在此不再重复视觉标签的详细描述. 有关详细信息,请参阅教程“集合列表数据”.
第4步: 定义二级规则页面的转换线索
4.1,设置翻页线索
单击爬虫路线,单击“新建”,选择“标记提示”;找到与页面翻页标记“ Next Page”相对应的节点,右键单击Cue Mapping-Marker Cue;查找整个翻页区域并具有一个类值或具有id值的节点,右键单击线索mapping-location-clue 1.在此不重复设置翻页的操作. 有关详细信息,请参阅教程“设置翻页集合”.
4.2,保存规则
点击“保存规则”按钮以保存已完成的第二级规则.
第5步: 捕获数据
连续动作的两级规则是连续执行的,因此只需要运行第一级规则,动作完成后程序将自动调用第二级规则. 如果直接运行第二级规则,则会出现错误,因为打开操作之前的初始页面.
5.1,打开计数机,找到一级规则的主题名称,单击“单一搜索”或“采集”,您会看到计数机Web窗口将自动选择2016,并继续向下翻页.
5.2,打开第二级主题的文件夹以查看结果数据,并将所选项目记录在xml文件的actionvalue字段中,以使其可以与结果数据一一对应.
上一篇: “连续操作: 自动搜索关键字以采集信息”下一篇文章: “连续操作: 滚动以采集瀑布流网页”
如果有任何疑问,可以或 查看全部
注意: 从GooSeeker采集器的V9.0.2版本开始,采集器术语“主题”已更改为“任务”. 在采集器浏览器中,首先命名任务,然后创建规则,然后登录到Jisuke官方网站的成员中心. 在“任务管理”中,您可以查看任务采集和执行,管理线程URL以及进行计划设置.
I. 操作步骤
以CNKI期刊为例,显示连续动作中的选择动作和爬虫路径中的翻页的组合. 本教程要实现的是首先搜索2016年出版的期刊,然后采集搜索结果. 该过程如下图所示:
为了实现这一点,需要建立两个级别的规则. 第一层规则通过连续的操作自动选择出版年份,第二层规则负责采集期刊内容和翻页. 步骤如下:
两个,案例规则+操作步骤
第一步: 定义捕获内容的第一级规则
1.1,加载页面
打开Jishouke Web采集器,输入要采集的样本的URL,然后按Enter. 看到浏览器加载网页后,单击右上角的“定义规则”.
注意: 此处的屏幕快照和文字描述均为Jishouke Web采集器的所有版本. 如果要安装Firefox插件版本,则没有“定义规则”按钮,但是您应该运行MS.
1.2,输入主题名称
在工作台的“主题名称”中输入一级规则的主题名称,然后单击“检查重复项”,将提示“可以使用该名称”,您可以继续,否则请重命名它. 此处的命名主题为“检索CNKI期刊之前”.
提示: 尽管此级别的规则主要用于选择操作,但是为了确保页面已加载并且连续的操作可以顺利进行,通常会在此级别的规则中建立一些爬网内容.
1.3,内容映射
选择“日志”作为爬网内容,双击日志,在弹出的标签栏中输入关键内容,在检索前命名排序框,然后检查关键内容. 视觉注释的基本操作在此不再重复. 如果您不了解,请参阅教程“采集网页数据”.
第2步: 定义一级规则的连续动作
2.1,输入目标主题名称
单击“连续操作”工作台,输入目标主题名称(即第二级规则的主题名称,此处名为“检索中国CNKI期刊后”),然后单击“正在使用谁” ,弹出窗口不显示该消息表明主题名称未被占用,您可以继续以下操作,否则需要更改主题名称.
2.2,创建第一个连续动作-选择起始年份2016
2.2.1,找到定位表达式,填写动作名称
单击“新建”,将操作类型选择为“选择”,单击开始年份,它将自动找到相应的节点,选择“显示XPath: 首选项ID”,程序将自动显示相应的Xpath路径,然后单击搜索,您可以看到此路径可以找到唯一的节点,该节点可用作动作的定位表达式. 将此路径复制到定位表达式,并在操作名称中写入文本,以使阐明每个操作的用法更加容易.
提示: 选择类型的连续动作. 定位表达式必须写入下拉菜单的选择节点,而不是某个选项的选项节点,否则将在运行时报告错误.
2.2.2,高级设置
我们需要实现的是采集2016年出版的期刊,因此我们需要在开始年度和结束年度都选择2016年. 这需要对连续操作的高级设置进行限制.
2.3,创建第二个连续的行动结束年度选择2016
单击“新建”,然后将操作类型选择为“选择”. 请参阅步骤2.2,找到与结束年份相对应的Xpath路径,然后在高级设置中将额外延迟设置为2秒,起点为3(2016是第三选项),跨度为100.
2.4,创建第三个连续动作,单击以进行检索
单击“新建”,然后选择“提交”操作. 请参阅步骤2.2,找到与“搜索”相对应的Xpath路径,然后在高级设置中将额外延迟设置为2秒.
2.5,保存规则
点击“保存规则”按钮以保存已完成的一级规则.
第3步: 定义第二级规则以捕获内容
3.1,创建新规则
单击“定义规则”返回到正常的网页模式,选择2016并单击搜索以找到文档结果,再次单击“定义规则”以切换到规则模式,然后单击左上角的“规则”菜单->“新建”,弹出提示“工作台上有内容,清除了吗?”,单击确定.
输入主题名称,其中主题名称是在上级规则的连续操作中填写的目标主题名称,即“在检索CNKI日记帐之后”,单击“检查重复项”,并弹出提示“名称已保留. ”可编辑: 是”,表示可以使用此主题名称.
3.2,标记要采集的信息
在页面上,直接单击要采集的内容,在弹出窗口中填写名称,勾选“标题”的关键内容,然后复制示例. 单击测试预览采集的内容. 在此不再重复视觉标签的详细描述. 有关详细信息,请参阅教程“集合列表数据”.
第4步: 定义二级规则页面的转换线索
4.1,设置翻页线索
单击爬虫路线,单击“新建”,选择“标记提示”;找到与页面翻页标记“ Next Page”相对应的节点,右键单击Cue Mapping-Marker Cue;查找整个翻页区域并具有一个类值或具有id值的节点,右键单击线索mapping-location-clue 1.在此不重复设置翻页的操作. 有关详细信息,请参阅教程“设置翻页集合”.
4.2,保存规则
点击“保存规则”按钮以保存已完成的第二级规则.
第5步: 捕获数据
连续动作的两级规则是连续执行的,因此只需要运行第一级规则,动作完成后程序将自动调用第二级规则. 如果直接运行第二级规则,则会出现错误,因为打开操作之前的初始页面.
5.1,打开计数机,找到一级规则的主题名称,单击“单一搜索”或“采集”,您会看到计数机Web窗口将自动选择2016,并继续向下翻页.
5.2,打开第二级主题的文件夹以查看结果数据,并将所选项目记录在xml文件的actionvalue字段中,以使其可以与结果数据一一对应.
上一篇: “连续操作: 自动搜索关键字以采集信息”下一篇文章: “连续操作: 滚动以采集瀑布流网页”
如果有任何疑问,可以或
采集科学研究文献和数据,让我告诉您一种可以自动采集的黑色技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 671 次浏览 • 2020-08-07 12:10
通常,我需要在这些网站上采集论文和实验数据.
论文数据库: Wiley InterScience,EBSCO ASP,Blackwell,Springer等;
研究数据库: NCBI,EMBL,ICPSR等
为什么要花这么长时间采集论文和实验数据?
因为采集过程是很多重复的机械工作.
很长时间以来,我遭受了多次机械收割工作的折磨. 直到一天,研究室的一位同事向我推荐了一个名为“小帮”的软件机器人. 它可以自动执行搜索,复制,粘贴和下载等操作,并在各种数据库中采集论文和实验数据.
软件机器人通过模拟各种软件的手动操作来自动执行这些重复性任务. 因此,为了使我的工作流程自动化,我需要告诉我工作流程的步骤. 总体而言,软件机器人的配置过程非常简单. 我只花了一点时间就为不同的网站配置了6种研究数据采集工具. 配置完成后,重复的采集工作全部由软件机器人完成.
现在,在下班之前,我将打开该帮派,该帮派将自动遍历我关注的论文和实验数据的数据库,并完成自动采集和下载. 第二天上班时,我可以直接看到该团伙自动采集的数据,从而节省了大量宝贵的时间,而不会影响当天的科学研究任务.
不得不说,小帮软件机器人解决了为研究人员手动采集数据的问题.
今天我要分享一下,希望能帮助同事解决采集科学研究数据的难题和耗时的问题. 我们的宝贵时间应该投入科学研究. 查看全部
我是一所信息学院的老师,我的研究领域是生物技术. 普通科学研究需要采集国外论文和实验数据. 实际上,在整个科学研究过程中,最耗时的环节是论文和实验数据的采集,约占总时间的1/3.
通常,我需要在这些网站上采集论文和实验数据.
论文数据库: Wiley InterScience,EBSCO ASP,Blackwell,Springer等;
研究数据库: NCBI,EMBL,ICPSR等
为什么要花这么长时间采集论文和实验数据?
因为采集过程是很多重复的机械工作.
很长时间以来,我遭受了多次机械收割工作的折磨. 直到一天,研究室的一位同事向我推荐了一个名为“小帮”的软件机器人. 它可以自动执行搜索,复制,粘贴和下载等操作,并在各种数据库中采集论文和实验数据.
软件机器人通过模拟各种软件的手动操作来自动执行这些重复性任务. 因此,为了使我的工作流程自动化,我需要告诉我工作流程的步骤. 总体而言,软件机器人的配置过程非常简单. 我只花了一点时间就为不同的网站配置了6种研究数据采集工具. 配置完成后,重复的采集工作全部由软件机器人完成.
现在,在下班之前,我将打开该帮派,该帮派将自动遍历我关注的论文和实验数据的数据库,并完成自动采集和下载. 第二天上班时,我可以直接看到该团伙自动采集的数据,从而节省了大量宝贵的时间,而不会影响当天的科学研究任务.
不得不说,小帮软件机器人解决了为研究人员手动采集数据的问题.
今天我要分享一下,希望能帮助同事解决采集科学研究数据的难题和耗时的问题. 我们的宝贵时间应该投入科学研究.
数据采集系统设计方案,生产车间自动化数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-07 05:13
数据采集是一种可以跟踪数据源并可以采集数据的软件. 数据采集系统可以采集,识别和选择采集的数据,然后根据客户的不同需求,可以设置自动图表样式,以便于查看数据.
数据采集系统的主要功能
1. 实施数据监控
该系统可以监视生产车间中的所有生产数据,从生产线采集输出数据,并进行统计摘要. 同时,如果车间出现异常情况,例如设备故障或不合格产品,系统将自动识别不合格产品,然后将其淘汰. 车间中还有物料管理. 一旦出现异常情况,例如材料短缺或材料短缺,系统将及时提醒人们避免更大的损失.
2,数据分析
数据采集功能只是其中一部分,可以说数据分析是重中之重. 因为生产车间中会有很多数据,所以如果系统不进行分类,人们将很难检查繁琐的数据. 但是有了数据分析功能,它就不同了. 它可以从数据中接收信息,也可以对其进行分类. 例如,将为您列出生产计划数据,产品的实际生产数据,合格率和材料利用率.
3. 数据处理
当系统分析数据时,它就是对数据的处理. 处理的目的是使人们更方便,更轻松地查看数据,并且使用图形和文本还将使人们看起来简单易懂,并且他们渴望看到它们. 如果是全部数据,人们将很容易昏昏欲睡,不想看这些数据并产生抵触情绪. 如果有图表,它将完全不同.
系统将根据数据的分析结果形成各种图表,并自动判断测量结果. 例如,如果是产品的合格率和不合格率,则会显示一个明显的图形,并用不同的颜色标记. 清晰易懂.
设备自动数据采集的特征
自动设备数据采集系统是电子工业系统中的关键系统. 除了电子行业的总体优势外,该系统还具有自己的特点.
(1)高度自动化: 每个系统的电子组件都可以监视自己的计划和任务,并及时提供有关错误信息的反馈,以方便技术人员进行信息验证.
(2)工作效率高: 该系统的电子组件可以相互配合完成共同的计划和任务,并对工作中的错误或故障采取一些自动的紧急措施.
(3)开放性: 该系统可以允许添加其他新的电子系统,并且具有其他功能的原创电子系统的移除或功能更新对整个自动化数据采集系统不会有太大影响时间,只需少量的人工参与即可进行校对,并且该系统针对不同的服务对象具有不同的数据处理功能. 查看全部
顾名思义,
数据采集是一种可以跟踪数据源并可以采集数据的软件. 数据采集系统可以采集,识别和选择采集的数据,然后根据客户的不同需求,可以设置自动图表样式,以便于查看数据.
数据采集系统的主要功能
1. 实施数据监控
该系统可以监视生产车间中的所有生产数据,从生产线采集输出数据,并进行统计摘要. 同时,如果车间出现异常情况,例如设备故障或不合格产品,系统将自动识别不合格产品,然后将其淘汰. 车间中还有物料管理. 一旦出现异常情况,例如材料短缺或材料短缺,系统将及时提醒人们避免更大的损失.
2,数据分析
数据采集功能只是其中一部分,可以说数据分析是重中之重. 因为生产车间中会有很多数据,所以如果系统不进行分类,人们将很难检查繁琐的数据. 但是有了数据分析功能,它就不同了. 它可以从数据中接收信息,也可以对其进行分类. 例如,将为您列出生产计划数据,产品的实际生产数据,合格率和材料利用率.
3. 数据处理
当系统分析数据时,它就是对数据的处理. 处理的目的是使人们更方便,更轻松地查看数据,并且使用图形和文本还将使人们看起来简单易懂,并且他们渴望看到它们. 如果是全部数据,人们将很容易昏昏欲睡,不想看这些数据并产生抵触情绪. 如果有图表,它将完全不同.
系统将根据数据的分析结果形成各种图表,并自动判断测量结果. 例如,如果是产品的合格率和不合格率,则会显示一个明显的图形,并用不同的颜色标记. 清晰易懂.
设备自动数据采集的特征
自动设备数据采集系统是电子工业系统中的关键系统. 除了电子行业的总体优势外,该系统还具有自己的特点.
(1)高度自动化: 每个系统的电子组件都可以监视自己的计划和任务,并及时提供有关错误信息的反馈,以方便技术人员进行信息验证.
(2)工作效率高: 该系统的电子组件可以相互配合完成共同的计划和任务,并对工作中的错误或故障采取一些自动的紧急措施.
(3)开放性: 该系统可以允许添加其他新的电子系统,并且具有其他功能的原创电子系统的移除或功能更新对整个自动化数据采集系统不会有太大影响时间,只需少量的人工参与即可进行校对,并且该系统针对不同的服务对象具有不同的数据处理功能.
Gatherer破解版(网站自动数据采集)v2.8免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 391 次浏览 • 2020-08-07 04:08
Collector破解版简介:
Gatherman是一个非常实用的网站自动数据采集软件. 采集器可以帮助用户快速执行seo采集和自动数据更新操作,使用户可以快速提高其网站seo排名,并且只需单击一下即可获得良好的采集结果. 它是用户提供自己的门户网站排名的最佳工具.
Capture Man破解版功能:
1. 一字采集,无需编写采集规则
与传统采集模式的区别在于,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点是,通过采集关键字的不同搜索结果,可以实现对一个或多个集合站点的错误采集,从而降低了搜索引擎将其视为镜像站点并受到惩罚的风险. 搜索引擎.
2. 有针对性的馆藏,标题,文本,作者,来源的精确馆藏
定向采集只需提供列表URL和文章URL即可智能地采集指定网站或列的内容,这既方便又简单. 编写简单的规则可以准确地采集标题,正文,作者和来源.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
5. 绑定织梦采集节点以定期采集伪原创SEO更新
绑定编织梦采集节点的功能,因此编织梦CMS的采集功能也可以自动定期采集和更新. 设置了采集规则的用户可以方便地定期采集和更新.
6. 定期并定量地更新待处理的手稿
即使数据库中有成千上万的文章,Dreamweaver也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新.
7,插件全自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
8. 手工发表的文章也可以是伪原创的,并且可以进行搜索优化
Dream Weaver Collector不仅是一个采集插件,而且还是实现织梦所必需的伪原创和搜索优化插件. 手动发布的文章可以由Dream Weaver Collector的伪原创和搜索优化处理. 文章的同义词替换,自动内部链接,关键字链接的随机插入以及收录关键字的文章将自动添加指定的链接和其他功能. 这是进行梦之织法的必备插件. 查看全部
这可以在网站上完成,并且收款人的破解版可以帮助用户快速提高其网站的Seo排名. Collector的破解版同时非常方便快捷地安装,您可以直接开始采集数据. 新手也可以快速使用Perfect Edition of Collector,并且还为商业客户提供特殊的技术支持. 允许网站自动采集数据.
Collector破解版简介:
Gatherman是一个非常实用的网站自动数据采集软件. 采集器可以帮助用户快速执行seo采集和自动数据更新操作,使用户可以快速提高其网站seo排名,并且只需单击一下即可获得良好的采集结果. 它是用户提供自己的门户网站排名的最佳工具.
Capture Man破解版功能:
1. 一字采集,无需编写采集规则
与传统采集模式的区别在于,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点是,通过采集关键字的不同搜索结果,可以实现对一个或多个集合站点的错误采集,从而降低了搜索引擎将其视为镜像站点并受到惩罚的风险. 搜索引擎.
2. 有针对性的馆藏,标题,文本,作者,来源的精确馆藏
定向采集只需提供列表URL和文章URL即可智能地采集指定网站或列的内容,这既方便又简单. 编写简单的规则可以准确地采集标题,正文,作者和来源.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
5. 绑定织梦采集节点以定期采集伪原创SEO更新
绑定编织梦采集节点的功能,因此编织梦CMS的采集功能也可以自动定期采集和更新. 设置了采集规则的用户可以方便地定期采集和更新.
6. 定期并定量地更新待处理的手稿
即使数据库中有成千上万的文章,Dreamweaver也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新.
7,插件全自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
8. 手工发表的文章也可以是伪原创的,并且可以进行搜索优化
Dream Weaver Collector不仅是一个采集插件,而且还是实现织梦所必需的伪原创和搜索优化插件. 手动发布的文章可以由Dream Weaver Collector的伪原创和搜索优化处理. 文章的同义词替换,自动内部链接,关键字链接的随机插入以及收录关键字的文章将自动添加指定的链接和其他功能. 这是进行梦之织法的必备插件.
自动采集酒店数据并导出到EXCEL
采集交流 • 优采云 发表了文章 • 0 个评论 • 1107 次浏览 • 2020-08-06 19:13
酒店后端管理系统记录合作酒店的信息. 共有300多页,每页10条数据,主要包括合作酒店的面积,价格,风险指数等信息. 现在,此信息需要分类到EXCEL中. 如果手动复制,则工作量很大且容易出错,因此客户端建议使用采集器来采集数据并将其导出到EXCEL.
爬行器模拟着陆
列表页面
详细信息页面
详细的设计过程
首先使用用户名和密码登录,然后打开第一页,然后打开每个记录的详细信息页,然后采集数据. 然后遍历第二页直到最后一页.
Scrapy
使用Python的Scrapy框架
1
pip install scrapy
核心源代码
成功登录后,将自动处理cookie,以便您可以正常访问该页面. 返回的数据格式为html,可通过xpath进行解析. 为了避免对服务器造成压力,请在晚上爬网数据,并在settings.py中设置5S的延迟.
1
DOWNLOAD_DELAY = 5
hotel.py的源代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
import scrapy
from scrapy.selector import Selector
from scrapy.http import FormRequest
class HotelSpider(scrapy.Spider):
name = 'hotel'
allowed_domains = ['checkhrs.zzzdex.com']
login_url = 'http://checkhrs.zzzdex.com/piston/login'
url = 'http://checkhrs.zzzdex.com/piston/hotel'
start_urls = ['http://checkhrs.zzzdex.com/piston/hotel']
def login(self, response):
fd = {'username':'usernamexxx', 'password':'passwordxxx'}
yield FormRequest.from_response(response,
formdata = fd,
callback = self.parse_login)
def parse_login(self, response):
if 'usernamexxx' in response.text:
print("login success!")
yield from self.start_hotel_list()
else:
print("login fail!")
def start_requests(self):
yield scrapy.Request(self.login_url,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True,
callback = self.login)
def start_hotel_list(self):
yield scrapy.Request(self.url,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True)
def parse(self, response):
print("parse")
selector = Selector(response)
select_list = selector.xpath('//table//tbody//tr')
for sel in select_list:
address = sel.xpath('.//td[3]/text()').extract_first()
next_url = sel.xpath('.//td//a[text()="编辑"]/@href').extract_first()
next_url = response.urljoin(next_url)
print(next_url)
yield scrapy.Request(next_url,
meta = {
'address': address
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True,
callback = self.parseDetail)
totalStr = selector.xpath('//ul[@class="pagination"]//li[last()-1]//text()').extract_first();
print(totalStr)
pageStr = selector.xpath('//ul[@class="pagination"]//li[@class="active"]//text()').extract_first();
print(pageStr)
total = int(totalStr)
print(total)
page = int(pageStr)
print(page)
if page >= total:
print("last page")
else:
next_page = self.url + "?page=" + str(page + 1)
print("continue next page: " + next_page)
yield scrapy.Request(next_page,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True)
def parseDetail(self, response):
address = response.meta['address']
print("parseDetail address is " + address)
addresses = address.split('/')
print(addresses)
country = ""
province = ""
city = ""
address_len = len(addresses)
if address_len > 0:
country = addresses[0].strip()
if address_len > 1:
province = addresses[1].strip()
if address_len > 2:
city = addresses[2].strip()
selector = Selector(response)
hotelId = selector.xpath('//input[@id="id"]/@value').extract_first()
group_list = selector.xpath('//form//div[@class="form-group js_group"]')
hotelName = group_list[1].xpath('.//input[@id="hotel_name"]/@value').extract_first()
select_list = selector.xpath('//form//div[contains(@class,"company_container")]')
for sel in select_list:
company_list = sel.xpath('.//div[@class="panel-body"]//div[@class="form-group"]')
#公司
companyName = company_list[0].xpath('.//input[@id="company"]/@value').extract_first()
#单早
singlePrice = company_list[1].xpath('.//input/@value')[0].extract()
#双早
doublePrice = company_list[1].xpath('.//input/@value')[1].extract()
#风险指数
risk = company_list[2].xpath('.//input/@value').extract_first()
#备注
remark = company_list[3].xpath('.//input/@value').extract_first()
yield {
'ID': hotelId,
'国家': country,
'省份': province,
'城市': city,
'酒店名': hotelName,
'公司': companyName,
'单早': singlePrice,
'双早': doublePrice,
'风险指数': risk,
'备注': remark
}
运行
1
scrapy crawl hotel -o ./outputs/hotel.csv
大约在第二天中午,从晚上10点开始爬升,所有数据都被采集,没有错误,最终输出为CSV,按ID排序,然后转换为EXCEL.
摘要
在日常工作中使用履带技术可以提高工作效率并避免重复的任务. 查看全部
客户需求
酒店后端管理系统记录合作酒店的信息. 共有300多页,每页10条数据,主要包括合作酒店的面积,价格,风险指数等信息. 现在,此信息需要分类到EXCEL中. 如果手动复制,则工作量很大且容易出错,因此客户端建议使用采集器来采集数据并将其导出到EXCEL.
爬行器模拟着陆
列表页面
详细信息页面
详细的设计过程
首先使用用户名和密码登录,然后打开第一页,然后打开每个记录的详细信息页,然后采集数据. 然后遍历第二页直到最后一页.
Scrapy
使用Python的Scrapy框架
1
pip install scrapy
核心源代码
成功登录后,将自动处理cookie,以便您可以正常访问该页面. 返回的数据格式为html,可通过xpath进行解析. 为了避免对服务器造成压力,请在晚上爬网数据,并在settings.py中设置5S的延迟.
1
DOWNLOAD_DELAY = 5
hotel.py的源代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
import scrapy
from scrapy.selector import Selector
from scrapy.http import FormRequest
class HotelSpider(scrapy.Spider):
name = 'hotel'
allowed_domains = ['checkhrs.zzzdex.com']
login_url = 'http://checkhrs.zzzdex.com/piston/login'
url = 'http://checkhrs.zzzdex.com/piston/hotel'
start_urls = ['http://checkhrs.zzzdex.com/piston/hotel']
def login(self, response):
fd = {'username':'usernamexxx', 'password':'passwordxxx'}
yield FormRequest.from_response(response,
formdata = fd,
callback = self.parse_login)
def parse_login(self, response):
if 'usernamexxx' in response.text:
print("login success!")
yield from self.start_hotel_list()
else:
print("login fail!")
def start_requests(self):
yield scrapy.Request(self.login_url,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True,
callback = self.login)
def start_hotel_list(self):
yield scrapy.Request(self.url,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True)
def parse(self, response):
print("parse")
selector = Selector(response)
select_list = selector.xpath('//table//tbody//tr')
for sel in select_list:
address = sel.xpath('.//td[3]/text()').extract_first()
next_url = sel.xpath('.//td//a[text()="编辑"]/@href').extract_first()
next_url = response.urljoin(next_url)
print(next_url)
yield scrapy.Request(next_url,
meta = {
'address': address
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True,
callback = self.parseDetail)
totalStr = selector.xpath('//ul[@class="pagination"]//li[last()-1]//text()').extract_first();
print(totalStr)
pageStr = selector.xpath('//ul[@class="pagination"]//li[@class="active"]//text()').extract_first();
print(pageStr)
total = int(totalStr)
print(total)
page = int(pageStr)
print(page)
if page >= total:
print("last page")
else:
next_page = self.url + "?page=" + str(page + 1)
print("continue next page: " + next_page)
yield scrapy.Request(next_page,
meta = {
},
encoding = 'utf8',
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
},
dont_filter = True)
def parseDetail(self, response):
address = response.meta['address']
print("parseDetail address is " + address)
addresses = address.split('/')
print(addresses)
country = ""
province = ""
city = ""
address_len = len(addresses)
if address_len > 0:
country = addresses[0].strip()
if address_len > 1:
province = addresses[1].strip()
if address_len > 2:
city = addresses[2].strip()
selector = Selector(response)
hotelId = selector.xpath('//input[@id="id"]/@value').extract_first()
group_list = selector.xpath('//form//div[@class="form-group js_group"]')
hotelName = group_list[1].xpath('.//input[@id="hotel_name"]/@value').extract_first()
select_list = selector.xpath('//form//div[contains(@class,"company_container")]')
for sel in select_list:
company_list = sel.xpath('.//div[@class="panel-body"]//div[@class="form-group"]')
#公司
companyName = company_list[0].xpath('.//input[@id="company"]/@value').extract_first()
#单早
singlePrice = company_list[1].xpath('.//input/@value')[0].extract()
#双早
doublePrice = company_list[1].xpath('.//input/@value')[1].extract()
#风险指数
risk = company_list[2].xpath('.//input/@value').extract_first()
#备注
remark = company_list[3].xpath('.//input/@value').extract_first()
yield {
'ID': hotelId,
'国家': country,
'省份': province,
'城市': city,
'酒店名': hotelName,
'公司': companyName,
'单早': singlePrice,
'双早': doublePrice,
'风险指数': risk,
'备注': remark
}
运行
1
scrapy crawl hotel -o ./outputs/hotel.csv
大约在第二天中午,从晚上10点开始爬升,所有数据都被采集,没有错误,最终输出为CSV,按ID排序,然后转换为EXCEL.
摘要
在日常工作中使用履带技术可以提高工作效率并避免重复的任务.
Bandex MDA设备数据采集管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 450 次浏览 • 2020-08-06 19:11
有效的Bandex MDA自动化管理将成为企业利润增长的新起点!
Bandex MDA设备数据采集管理系统
Bandex MDA(制造数据获取)是一套基于国内制造企业的可视化详细制造过程数据的软件和硬件整体解决方案,用于实时采集生产车间的自动化生产数据并实现定制报告图表分析通过企业管理要求.
Bandex MDA的智能数据采集分析和管理系统基于凌秀在数控领域多年的技术应用积累和沉淀. 该系统的优点是利用凌秀自身强大的软件兼容性来提高自动化采集的程度. Bandex MDA是当前国内最先进的数控系统采集和分析软件(包括设备,人员和生产任务等). 许多国外系统都需要大量的手动反馈来获取数据. 这种方法在中国已变得无法接受. 许多亚洲公司根本无法适应,许多外国软件也无法执行本地定制的图形报告分析. 一些图形报告的开发和修改非常昂贵. Bandex MDA不仅在获取方面具有优势,而且我们还可以帮助客户灵活地自定义并生成图形和报告. 这是我们满足亚洲客户需求的灵活多变的工作方式. 我们帮助客户构建具有较高性价比的高端生产车间信息管理系统.
Bandex MDA分为两个版本,经典版本和专业版本:
●Bandex MDA经典版
●Bandex MDA专业版
Bandex MDA系统功能介绍:
1. 操作系统兼容性
系统软件基于32/64位Windows系统和.NET开发,并支持Windows Server 2003 / XP
2,数据库兼容性
系统支持三个主要数据库,例如Access,SQL Server和Oracle
3. 支持中英文
系统软件支持中文和英文
4. 数据采集仪的应用
自动采集设备处理时间,等待时间,设置时间,警报时间,停机时间和其他生产数据
5. 宏程序采集
获取生产数据,例如程序号并通过宏程序输出.
6. 条形码应用集成功能
<p>支持条形码应用. 在每个工作站或客户端扫描条形码后,数据将通过DNC网络进入系统. 自动识别后,直接进入MDA后端数据库,并在MDA前端界面上实时反馈条形码所代表的状态和内容 查看全部
不能增加产能?生产成本高?还是使用传统的手动统计文件管理?
有效的Bandex MDA自动化管理将成为企业利润增长的新起点!
Bandex MDA设备数据采集管理系统
Bandex MDA(制造数据获取)是一套基于国内制造企业的可视化详细制造过程数据的软件和硬件整体解决方案,用于实时采集生产车间的自动化生产数据并实现定制报告图表分析通过企业管理要求.
Bandex MDA的智能数据采集分析和管理系统基于凌秀在数控领域多年的技术应用积累和沉淀. 该系统的优点是利用凌秀自身强大的软件兼容性来提高自动化采集的程度. Bandex MDA是当前国内最先进的数控系统采集和分析软件(包括设备,人员和生产任务等). 许多国外系统都需要大量的手动反馈来获取数据. 这种方法在中国已变得无法接受. 许多亚洲公司根本无法适应,许多外国软件也无法执行本地定制的图形报告分析. 一些图形报告的开发和修改非常昂贵. Bandex MDA不仅在获取方面具有优势,而且我们还可以帮助客户灵活地自定义并生成图形和报告. 这是我们满足亚洲客户需求的灵活多变的工作方式. 我们帮助客户构建具有较高性价比的高端生产车间信息管理系统.
Bandex MDA分为两个版本,经典版本和专业版本:
●Bandex MDA经典版
●Bandex MDA专业版
Bandex MDA系统功能介绍:
1. 操作系统兼容性
系统软件基于32/64位Windows系统和.NET开发,并支持Windows Server 2003 / XP
2,数据库兼容性
系统支持三个主要数据库,例如Access,SQL Server和Oracle
3. 支持中英文
系统软件支持中文和英文
4. 数据采集仪的应用
自动采集设备处理时间,等待时间,设置时间,警报时间,停机时间和其他生产数据
5. 宏程序采集
获取生产数据,例如程序号并通过宏程序输出.
6. 条形码应用集成功能
<p>支持条形码应用. 在每个工作站或客户端扫描条形码后,数据将通过DNC网络进入系统. 自动识别后,直接进入MDA后端数据库,并在MDA前端界面上实时反馈条形码所代表的状态和内容
自动采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2020-08-06 09:13
代理方法:
agent: 是客户端,在客户端放置一个采集程序,采集数据后,agent将直接返回api程序(当前为django程序)
代理程序:
#!/usr/bin/env python3
import subprocess
v2=subprocess.getoutput('ifconfig')
print(v2)
url='http://192.168.11.27:8003/asset.html'
import requests
requests.post(url,data={'k1':v2})
api:
from django.shortcuts import render,HttpResponse
# Create your views here.
def asset(request):
if request.method=='POST':
print(request.POST)
return HttpResponse('copy that')
else:
return HttpResponse('null')
ssh方法:
ssh使用位于中央控制区的paramiko(python模块)
ssh方法没有代理. 通过中央控制区中的ssh在服务器上远程执行命令后,将返回结果,然后将其传递给API;然后写入数据库
盐堆:
盐堆也是中央控制区域. 主服务器执行命令后,例如:
执行后,客户端将返回结果
saltstack的原理是RPC. 它维护一个消息队列,默认情况下为空. 当主服务器执行命令时,如上图所示,队列中有命令,然后客户端执行: :
在执行客户端之后创建一个队列-存储在该队列中的结果将返回给主服务器
Saltstack安装附录
安装后检查主节点的小部分
基本用法:
在安装后修改配置:
服务器:
/ etc / salt / master
界面: 192.168.44.145
/ etc / salt / minion
客户端: 主设备: 192.168.44.148. #master的地址
盐键-L查看授权的奴才
盐服务小兵重启启动
#quick-install 查看全部
通过三种方式自动采集数据:
代理方法:
agent: 是客户端,在客户端放置一个采集程序,采集数据后,agent将直接返回api程序(当前为django程序)
代理程序:
#!/usr/bin/env python3
import subprocess
v2=subprocess.getoutput('ifconfig')
print(v2)
url='http://192.168.11.27:8003/asset.html'
import requests
requests.post(url,data={'k1':v2})
api:
from django.shortcuts import render,HttpResponse
# Create your views here.
def asset(request):
if request.method=='POST':
print(request.POST)
return HttpResponse('copy that')
else:
return HttpResponse('null')
ssh方法:
ssh使用位于中央控制区的paramiko(python模块)
ssh方法没有代理. 通过中央控制区中的ssh在服务器上远程执行命令后,将返回结果,然后将其传递给API;然后写入数据库
盐堆:
盐堆也是中央控制区域. 主服务器执行命令后,例如:
执行后,客户端将返回结果
saltstack的原理是RPC. 它维护一个消息队列,默认情况下为空. 当主服务器执行命令时,如上图所示,队列中有命令,然后客户端执行: :
在执行客户端之后创建一个队列-存储在该队列中的结果将返回给主服务器
Saltstack安装附录
安装后检查主节点的小部分
基本用法:
在安装后修改配置:
服务器:
/ etc / salt / master
界面: 192.168.44.145
/ etc / salt / minion
客户端: 主设备: 192.168.44.148. #master的地址
盐键-L查看授权的奴才
盐服务小兵重启启动
#quick-install
数据采集:如何自动化采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-04 11:01
数据源可分为以下四类:
开放数据源:政府、企业、高校
爬虫抓取:网页、app
日志采集:前端采集、后端脚本
传感器:图像、测速、热敏
如何使用爬虫做抓取:
爬虫抓取属于最常见的需求,最直接的方式是使用python编撰爬虫代码。
在python 爬虫中自动采集数据自动采集数据,基本上会经历三个过程:
使用requests 爬取内容,使用Requests 库来爬取网页信息,Requests 库是python 爬虫的神器,也是python的http库,通过这个库爬取网页的数据,非常便捷使用XPath 解析内容。XPath 是XML Path 的简写。它是拿来确定XML文档中某部份位置的预言,在开发中常用作大型查询预言。使用Pandas 保存数据。Pandas是使数据剖析工作显得简单高效的中级数据结构,我们可以用Pandas保存爬取的数据。最后通过Pandas再写入XLS 或者Mysql等数据库中。三款常用的抓取工具
优采云:老牌采集器,不仅可以做抓取工具,也可以做数据清洗、数据剖析、数据挖掘和可视化。数据源适宜绝大多数网页。
优采云:有付费版和免费版,可以手动切换ip。
集搜客:特点是完全可视化,无需编程,整个采集过程所见即所得 查看全部
一个数据的走势是由多个维度影响的,我们须要通过多源的数据采集,手机到尽可能多的数据维度,同时保证数据的质量,这样就能得到高质量的数据挖掘结果
数据源可分为以下四类:
开放数据源:政府、企业、高校
爬虫抓取:网页、app
日志采集:前端采集、后端脚本
传感器:图像、测速、热敏
如何使用爬虫做抓取:
爬虫抓取属于最常见的需求,最直接的方式是使用python编撰爬虫代码。
在python 爬虫中自动采集数据自动采集数据,基本上会经历三个过程:
使用requests 爬取内容,使用Requests 库来爬取网页信息,Requests 库是python 爬虫的神器,也是python的http库,通过这个库爬取网页的数据,非常便捷使用XPath 解析内容。XPath 是XML Path 的简写。它是拿来确定XML文档中某部份位置的预言,在开发中常用作大型查询预言。使用Pandas 保存数据。Pandas是使数据剖析工作显得简单高效的中级数据结构,我们可以用Pandas保存爬取的数据。最后通过Pandas再写入XLS 或者Mysql等数据库中。三款常用的抓取工具
优采云:老牌采集器,不仅可以做抓取工具,也可以做数据清洗、数据剖析、数据挖掘和可视化。数据源适宜绝大多数网页。
优采云:有付费版和免费版,可以手动切换ip。
集搜客:特点是完全可视化,无需编程,整个采集过程所见即所得
自动采集数据怎么实现_计算机软件及应用_IT/计算机_专业资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2020-08-03 22:00
优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 2 方法三:在任务列表页面,每个任务名称右方都有“更多操作”选项,点击以后,在下拉选 项中选择云采集并启动,任务都会立刻启动一次云采集。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 31、定时云采集设置 定时云采集的设置有两种方式: 方法一: 任务数组配置完毕后, 点击 “选中全部” , “采集以下数据” , “保存并开始采集” , 进入到 “运行任务” 界面, 点击 “设置定时云采集” , 弹出 “定时云采集” 配置页面 (图 4) 。 第一、如果须要保存定时设置,在“已保存的设置”输入框内输入名称,再保存配置,保存 成功以后,下次倘若其他任务须要同样的定时配置时可以选择这个配置(图 5)。第二、定 时形式的设置有 4 种,可以按照自己的需求选择启动方法和启动时间(图 5)。所有设置完 成以后,如果须要启动定时云采集选择下方“保存并启动”定时采集,然后点击确定即可;优采云·云采集服务平台 如果不需要启动只需点击下方“保存”定时采集设置即可(图 5)。云采集使用方式(含定时云采集)-图 4优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 5 方法二:在任务列表页面,每个任务名称右方都有“更多操作”选项,点击以后,在下拉选 项中选择云采集设置定时自动采集数据,同样可以进行上述操作。
云采集使用方式(含定时云采集)-图 63、任务组定时设置 如果须要对整个任务组进行定时云采集设置,可以在首页的设置页面,选中一个任务组,点 击“为任务组设置定时云采集”,则可以进行跟上述操作相同的配置。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 7相关采集教程:淘宝数据采集 今日头条采集 114 黄页企业数据采集 黄页 88 企业信息采集 知乎爬虫 地图数据采集 分类信息采集教程 优采云——70 万用户选择的网页数据采集器。优采云·云采集服务平台 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
优采云·云采集服务平台 自动采集数据怎么实现采集过网页数据的同学可能都有这样一个需求, 就是制做好采集规则以后, 能够实现不间断 自动去采集数据, 那么这个时侯推荐使用优采云采集器的云采集服务, 能够完美实现手动采 集数据的需求。首先给你们介绍哪些是云采集, 云采集是指通过使用优采云提供的服务器集群进行工作, 该 集群是 7*24 小时的工作状态。在客户端将任务设置完成并递交到云服务执行云采集之后, 可以关掉软件,关闭笔记本进行脱机采集,真正的实现无人值守。除此之外,云采集通过云服 务器集群的分布式布署形式,多节点同时进行作业,可以提升采集效率,并且可以高效的避 开各类网站的 IP 封锁策略。云采集的优势:可以死机运行,也可以设置定时云采集,加快采集速度,增加采集量。云采集设置方式 示例网址: 有三种方式可以启动云采集(立即启动,并且只运行一次)。 方法一:任务数组配置完毕后,点击“选中全部”,点击“采集以下数据”,选择“保存并 开始采集”,进入到“运行任务”界面,选择“启动云采集”。在任务列表内,会看见正在 进行云采集的任务。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 1 方法二:在任务列表页面,每个任务名称右方都有“启动云采集”选项自动采集数据,点击以后,任务就 会立刻启动一次云采集。
优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 2 方法三:在任务列表页面,每个任务名称右方都有“更多操作”选项,点击以后,在下拉选 项中选择云采集并启动,任务都会立刻启动一次云采集。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 31、定时云采集设置 定时云采集的设置有两种方式: 方法一: 任务数组配置完毕后, 点击 “选中全部” , “采集以下数据” , “保存并开始采集” , 进入到 “运行任务” 界面, 点击 “设置定时云采集” , 弹出 “定时云采集” 配置页面 (图 4) 。 第一、如果须要保存定时设置,在“已保存的设置”输入框内输入名称,再保存配置,保存 成功以后,下次倘若其他任务须要同样的定时配置时可以选择这个配置(图 5)。第二、定 时形式的设置有 4 种,可以按照自己的需求选择启动方法和启动时间(图 5)。所有设置完 成以后,如果须要启动定时云采集选择下方“保存并启动”定时采集,然后点击确定即可;优采云·云采集服务平台 如果不需要启动只需点击下方“保存”定时采集设置即可(图 5)。云采集使用方式(含定时云采集)-图 4优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 5 方法二:在任务列表页面,每个任务名称右方都有“更多操作”选项,点击以后,在下拉选 项中选择云采集设置定时自动采集数据,同样可以进行上述操作。
云采集使用方式(含定时云采集)-图 63、任务组定时设置 如果须要对整个任务组进行定时云采集设置,可以在首页的设置页面,选中一个任务组,点 击“为任务组设置定时云采集”,则可以进行跟上述操作相同的配置。优采云·云采集服务平台 云采集使用方式(含定时云采集)-图 7相关采集教程:淘宝数据采集 今日头条采集 114 黄页企业数据采集 黄页 88 企业信息采集 知乎爬虫 地图数据采集 分类信息采集教程 优采云——70 万用户选择的网页数据采集器。优采云·云采集服务平台 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。

