
自动采集数据
拼多多订单信息自动导出工具——小帮软件机器人
采集交流 • 优采云 发表了文章 • 0 个评论 • 944 次浏览 • 2021-03-28 20:02
随着拼多多的崛起,拼多多代沟和单党诞生了。每天都会下达许多订单,但是由于它们必须向客户或任务发布者提供订单信息,因此更多的订单意味着订购的成本更高。在每个订单的时间,将商店名称,价格,产品名称,快递号码,订单号和其他信息复制并粘贴到excel中。
目前,拼多多自己的大多数工具都提供基本的运输和快递打印功能。找到一个可以批量导入拼多多订单的工具并不容易。
如何找到合适的工具来代替通常的手动复制和粘贴工作,许多拼多多代购和shua Single Party仍在搜索:使用起来应该不会太复杂,越简单越好; 采集订单信息准确而全面;价格不能太高,小企业太贵了以至于无法消费...
基于上述痛点,编辑者通过对当前市场上主流产品的除草和排雷(从以前的操作到采集)进行了真实的评估,找到了公司和个人,卖方和卖方。效果,从特征岛到产品价格,是买方常用的订单批量导出工具-小帮软件机器人。
可自定义:您可以使用配置的工具,也可以自己配置订单信息导出工具
止痛指数
小帮软件机器人不仅是简单的工具,还是制作工具的工具。
在小邦配置平台上生成拼多多订单信息的自动导出工具。配置方法也非常简单。鼠标操作可以在几分钟内完成。它不仅可以使软件机器人自动引导订单信息,还可以做到。其他一些软件机器人工具,例如采集平台价格等,也非常适合那些愿意做点创意的人。
当然,尽管构建软件机器人工具确实很棒,但是如果您希望简单,粗鲁地解决问题,则只需使用现成的工具即可。
极简主义者:该工具功能明显且易于使用
止痛指数
使用配置的Xiaobang软件机器人非常简单。只需在“我的小帮”页面上找到选择批量出口订单的软件机器人工具,然后单击“运行”按钮以在拼多多人民中心打开“我”。在“订单”页面上,选择“立即运行”,它将自动显示采集订单数据,用户可以预览采集的订单信息,下载Exce 查看全部
拼多多订单信息自动导出工具——小帮软件机器人
随着拼多多的崛起,拼多多代沟和单党诞生了。每天都会下达许多订单,但是由于它们必须向客户或任务发布者提供订单信息,因此更多的订单意味着订购的成本更高。在每个订单的时间,将商店名称,价格,产品名称,快递号码,订单号和其他信息复制并粘贴到excel中。
目前,拼多多自己的大多数工具都提供基本的运输和快递打印功能。找到一个可以批量导入拼多多订单的工具并不容易。
如何找到合适的工具来代替通常的手动复制和粘贴工作,许多拼多多代购和shua Single Party仍在搜索:使用起来应该不会太复杂,越简单越好; 采集订单信息准确而全面;价格不能太高,小企业太贵了以至于无法消费...
基于上述痛点,编辑者通过对当前市场上主流产品的除草和排雷(从以前的操作到采集)进行了真实的评估,找到了公司和个人,卖方和卖方。效果,从特征岛到产品价格,是买方常用的订单批量导出工具-小帮软件机器人。
可自定义:您可以使用配置的工具,也可以自己配置订单信息导出工具
止痛指数
小帮软件机器人不仅是简单的工具,还是制作工具的工具。
在小邦配置平台上生成拼多多订单信息的自动导出工具。配置方法也非常简单。鼠标操作可以在几分钟内完成。它不仅可以使软件机器人自动引导订单信息,还可以做到。其他一些软件机器人工具,例如采集平台价格等,也非常适合那些愿意做点创意的人。
当然,尽管构建软件机器人工具确实很棒,但是如果您希望简单,粗鲁地解决问题,则只需使用现成的工具即可。
极简主义者:该工具功能明显且易于使用
止痛指数
使用配置的Xiaobang软件机器人非常简单。只需在“我的小帮”页面上找到选择批量出口订单的软件机器人工具,然后单击“运行”按钮以在拼多多人民中心打开“我”。在“订单”页面上,选择“立即运行”,它将自动显示采集订单数据,用户可以预览采集的订单信息,下载Exce
自动采集万方数据平台里面的数据,如果需要复杂的话
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-03-27 06:02
自动采集数据库里面的数据,如果操作简单的话可以使用脚本操作,如果需要复杂的话,可以看看我写的一篇博客,自动采集万方数据平台里面的数据,参考如下:链接:密码:8p00以上是一篇博客,比较复杂,如果希望能够自动采集某个杂志里面某一类型的文章,可以研究如何自动生成这类文章对应的数据。
我从去年到现在用过edius做过一些节目合集,但最终还是放弃了。不是难不难,而是做节目,需要你有节目编导这个技能。如果单纯用edius来操作很简单,但是遇到高手花点时间就能做的很好。难的是你得学到编导技能。我记得看过一篇实战的文章,就是在不影响录制节目的情况下,用edius软件生成几个节目,最后推销给客户。
如果不进一步挑战节目编导的话,纯edius的生成的节目做一些学术类或者高校做的公开课是不错的。如果做体育、娱乐类的节目感觉有点力不从心。
有edius在手,
如果你是指从万方里采集数据,很难。比如生成节目标题片头片尾,我见过最轻松的生成节目标题片头片尾(转码pan4)用了两天,加其他的才花了两小时。节目设置,真的有硬性标准,分数线,全是算法自动分析合并上传到那几千个数据库。复杂的节目编辑也有人在做,起码已经算是省时省力了。比如juozhishao的视频,假如标题是喷嚏,片头是白色四角形,片尾放相片,就可以生成头可以伸出来、胳膊可以伸到底,之类的片头片尾。
如果说网上能搜索到那些教你怎么做的软件,应该比较难。我有个朋友有个专门做的教程,但是感觉下载量不高,原因是用户留言里没有留需要做这个的操作指南,找不到别人都不会做一个做标题片头片尾的教程。 查看全部
自动采集万方数据平台里面的数据,如果需要复杂的话
自动采集数据库里面的数据,如果操作简单的话可以使用脚本操作,如果需要复杂的话,可以看看我写的一篇博客,自动采集万方数据平台里面的数据,参考如下:链接:密码:8p00以上是一篇博客,比较复杂,如果希望能够自动采集某个杂志里面某一类型的文章,可以研究如何自动生成这类文章对应的数据。
我从去年到现在用过edius做过一些节目合集,但最终还是放弃了。不是难不难,而是做节目,需要你有节目编导这个技能。如果单纯用edius来操作很简单,但是遇到高手花点时间就能做的很好。难的是你得学到编导技能。我记得看过一篇实战的文章,就是在不影响录制节目的情况下,用edius软件生成几个节目,最后推销给客户。
如果不进一步挑战节目编导的话,纯edius的生成的节目做一些学术类或者高校做的公开课是不错的。如果做体育、娱乐类的节目感觉有点力不从心。
有edius在手,
如果你是指从万方里采集数据,很难。比如生成节目标题片头片尾,我见过最轻松的生成节目标题片头片尾(转码pan4)用了两天,加其他的才花了两小时。节目设置,真的有硬性标准,分数线,全是算法自动分析合并上传到那几千个数据库。复杂的节目编辑也有人在做,起码已经算是省时省力了。比如juozhishao的视频,假如标题是喷嚏,片头是白色四角形,片尾放相片,就可以生成头可以伸出来、胳膊可以伸到底,之类的片头片尾。
如果说网上能搜索到那些教你怎么做的软件,应该比较难。我有个朋友有个专门做的教程,但是感觉下载量不高,原因是用户留言里没有留需要做这个的操作指南,找不到别人都不会做一个做标题片头片尾的教程。
优采云数据采集器56.2M/2018-11-02
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-03-21 20:07
优采云数据采集器56.2M/2018-11-02
优采云数据采集器
5 6. 2M / 2018-11-02 / v 7. 5. 4正式版
得分:
下载
优采云 Data 采集器是需要从网页获取信息的任何人的必备采集工具。它使网页数据采集比以往更容易。如果您正在寻找有用的采集软件,优采云绝对是最佳选择。并在市场上
无人看管的全自动采集器(编辑器工具)
1 7. 5M / 2018-08-10 / v 3. 2. 6绿色版
得分:
下载
editortools软件是自动采集信息软件。用户只需要下载并安装它并开始使用它。它可以自动管理采集 网站中的信息,并智能地管理信息的内容和更新。 网站管理工作提供了极大的便利。
Red Bell 采集软件破解版
3 1. 8M / 2018-07-12 / v 1. 6. 5. 1绿色版
得分:
下载
红铃分类信息采集工具非常易于使用,不需要安装软件,解压后可以直接使用,界面采用中文界面,方便用户操作,用户谁需要它,快来当易下载并使用! ! !红铃分类信息采集软件(网站
优采云 Universal 文章 采集器
993KB / 2018-05-12 / v 2. 1 7. 3. 0绿色版
得分:
下载
优采云 Universal 文章 采集器可以帮助采集指定网站的文章的内容,并帮助您搜索所需的信息。该软件具有智能搜索机制,可以高精度地搜索文章指定的网站,不仅可以提高文章手机的功能,而且可以
轻轻微信QR码采集向导
3. 6M / 2018-01-15 / v 3. 2的最新版本
得分:
下载
微信微信群二维码采集向导是一款功能强大的二维码信息采集软件,有了此软件,用户可以更轻松地采集 QR码,并且该软件非常小巧,不会占用太多空间记忆。欢迎来到
JD订单采集管理系统
401KB / 2017-09-19 /绿色版
得分:
下载
JD Order 采集 Management是一个网页编辑软件,您可以直接在网页上修改图片,编辑喜欢的文本和小工具以美化图片。当易网上有越来越多有趣的软件,快来下载吧
QQ电子邮件地址批量获取器
1. 7M / 2017-09-14 / v 2. 0绿色版
得分:
下载
QQ电子邮件地址批量获取器是用于获取QQ电子邮件地址的非常强大的工具。它易于操作,因此电子邮件营销并不困难,并且消除了其他采集软件设置的麻烦。一键即可获取成千上万的QQ电子邮件地址。地址,欢迎有需要的朋友
优采云 采集器免费破解版
2 4. 4M / 2019-04-04 / v 9. 8 PC版本
得分:
下载
优采云 采集器免费的破解版本是一种非常流行的采集器工具。该平台具有多年的开发和更新历史,可以快速准确地获取网页中的信息,并对其进行组织以向用户提供所需的数据,易于使用,需要帮助的朋友
三个人采集器
662KB / 2017-07-05 /
得分:
下载
三行采集器是功能强大的文本采集工具。使用此软件,它可以帮助用户轻松地采集他们想要的数据。非常适合网站管理员。欢迎有需要的朋友从下载。三个人采集器三个人的正式介绍 查看全部
优采云数据采集器56.2M/2018-11-02

优采云数据采集器
5 6. 2M / 2018-11-02 / v 7. 5. 4正式版
得分:

下载
优采云 Data 采集器是需要从网页获取信息的任何人的必备采集工具。它使网页数据采集比以往更容易。如果您正在寻找有用的采集软件,优采云绝对是最佳选择。并在市场上

无人看管的全自动采集器(编辑器工具)
1 7. 5M / 2018-08-10 / v 3. 2. 6绿色版
得分:

下载
editortools软件是自动采集信息软件。用户只需要下载并安装它并开始使用它。它可以自动管理采集 网站中的信息,并智能地管理信息的内容和更新。 网站管理工作提供了极大的便利。

Red Bell 采集软件破解版
3 1. 8M / 2018-07-12 / v 1. 6. 5. 1绿色版
得分:
下载
红铃分类信息采集工具非常易于使用,不需要安装软件,解压后可以直接使用,界面采用中文界面,方便用户操作,用户谁需要它,快来当易下载并使用! ! !红铃分类信息采集软件(网站

优采云 Universal 文章 采集器
993KB / 2018-05-12 / v 2. 1 7. 3. 0绿色版
得分:
下载
优采云 Universal 文章 采集器可以帮助采集指定网站的文章的内容,并帮助您搜索所需的信息。该软件具有智能搜索机制,可以高精度地搜索文章指定的网站,不仅可以提高文章手机的功能,而且可以

轻轻微信QR码采集向导
3. 6M / 2018-01-15 / v 3. 2的最新版本
得分:
下载
微信微信群二维码采集向导是一款功能强大的二维码信息采集软件,有了此软件,用户可以更轻松地采集 QR码,并且该软件非常小巧,不会占用太多空间记忆。欢迎来到

JD订单采集管理系统
401KB / 2017-09-19 /绿色版
得分:
下载
JD Order 采集 Management是一个网页编辑软件,您可以直接在网页上修改图片,编辑喜欢的文本和小工具以美化图片。当易网上有越来越多有趣的软件,快来下载吧

QQ电子邮件地址批量获取器
1. 7M / 2017-09-14 / v 2. 0绿色版
得分:
下载
QQ电子邮件地址批量获取器是用于获取QQ电子邮件地址的非常强大的工具。它易于操作,因此电子邮件营销并不困难,并且消除了其他采集软件设置的麻烦。一键即可获取成千上万的QQ电子邮件地址。地址,欢迎有需要的朋友

优采云 采集器免费破解版
2 4. 4M / 2019-04-04 / v 9. 8 PC版本
得分:
下载
优采云 采集器免费的破解版本是一种非常流行的采集器工具。该平台具有多年的开发和更新历史,可以快速准确地获取网页中的信息,并对其进行组织以向用户提供所需的数据,易于使用,需要帮助的朋友

三个人采集器
662KB / 2017-07-05 /
得分:
下载
三行采集器是功能强大的文本采集工具。使用此软件,它可以帮助用户轻松地采集他们想要的数据。非常适合网站管理员。欢迎有需要的朋友从下载。三个人采集器三个人的正式介绍
自动采集数据的技巧,你get到了吗?!
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-03-20 23:03
自动采集数据是把采集到的数据用于其他有用的用途,这样对你来说都不是一种浪费。随着自动采集数据技术的推广,下面我整理了一些自动采集数据的技巧,希望能够帮助到需要的人。
1、a站up主注册账号:点击注册账号按钮
2、点击录制动画
3、选择采集视频视频,
4、点击立即采集
5、输入链接及路径
6、在浏览器上进行下载b站采集技巧
1、b站up主注册账号:点击注册账号按钮
4、输入链接及路径
5、在浏览器上进行下载
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有a站、b站账号,也可以用浏览器上的开发者工具,上传一个视频链接到谷歌上提交验证是否是a站的up主账号,正常情况下是不会被拒绝的。如果需要原图,找一个能找到原图的网站都可以。
c站采集技巧
1、c站up主注册账号:点击注册账号按钮
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有c站账号,也可以用浏览器上的开发者工具,上传一个视频链接到谷歌上提交验证是否是c站的up主账号,正常情况下是不会被拒绝的。如果需要原图,找一个能找到原图的网站都可以。
f站采集技巧
e站采集技巧
g站采集技巧
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有c站账号,也可以用浏览器上的开发者工具, 查看全部
自动采集数据的技巧,你get到了吗?!
自动采集数据是把采集到的数据用于其他有用的用途,这样对你来说都不是一种浪费。随着自动采集数据技术的推广,下面我整理了一些自动采集数据的技巧,希望能够帮助到需要的人。
1、a站up主注册账号:点击注册账号按钮
2、点击录制动画
3、选择采集视频视频,
4、点击立即采集
5、输入链接及路径
6、在浏览器上进行下载b站采集技巧
1、b站up主注册账号:点击注册账号按钮
4、输入链接及路径
5、在浏览器上进行下载
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有a站、b站账号,也可以用浏览器上的开发者工具,上传一个视频链接到谷歌上提交验证是否是a站的up主账号,正常情况下是不会被拒绝的。如果需要原图,找一个能找到原图的网站都可以。
c站采集技巧
1、c站up主注册账号:点击注册账号按钮
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有c站账号,也可以用浏览器上的开发者工具,上传一个视频链接到谷歌上提交验证是否是c站的up主账号,正常情况下是不会被拒绝的。如果需要原图,找一个能找到原图的网站都可以。
f站采集技巧
e站采集技巧
g站采集技巧
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有c站账号,也可以用浏览器上的开发者工具,
hadoop与websphere文件系统数据接入的架构设计(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-02-26 13:01
自动采集数据的,我用过的包括extractor和ae2marker。extractor支持的数据库很全,还可以生成excel,挺方便的,也很快。ae2marker数据库更多,但有些数据在测试版上面不支持。extractor还有一个优点就是插件丰富,支持的语言也多,但这是用来和其他软件共享资源的,你自己玩玩用来练手还可以。以上。
可以参考我写的这篇文章:hadoop与websphere文件系统数据接入的架构设计
tcoff-iot文件系统hdfs
我最近在做hadoop系统和redis系统数据交互过程中有一个环节要数据持久化,看了一圈tcoff-iothdfs-openwrt或者大数据或者exts-android或者chromium的方案,最后还是决定选择tcoff的架构解决方案。因为初步了解到双系统隔离是现在业界比较难解决的一个问题,有很多model不能满足wireless-os不能经受动态变化环境,还要具有易扩展和服务端可以并发请求等,数据持久化对tcoff来说真的是个很大的痛点,目前只有一些内置model方案来简单解决相应问题,而且某些内置model只能满足基本要求。
我对hadoop-openwrt还是挺有好感的,所以在考虑方案的时候还是多方面研究了一下,看看是否有什么可以改进的地方,最后选择tcoff不仅仅是因为他的双系统架构,双系统适合在windows和linux之间进行文件移动,在方便tcoff文件系统运维与管理方面也是个好的方式。还有一个原因是这是一个开源项目,对于入门级的人来说比较容易接受,数据接入架构也不用像exts那么复杂,只需要简单的添加一下权限即可,然后插件多集成也比较方便,简单来说这个项目就是基于tcoff-iot实现的一个开源linux环境下对hadoop数据交互的解决方案,且一直非常受欢迎,所以我觉得tcoff-iot在hadoop本地接入环境下是个不错的选择。本人还是有自己的一套代码,多与大家一起讨论。相关论文地址:,欢迎交流。 查看全部
hadoop与websphere文件系统数据接入的架构设计(组图)
自动采集数据的,我用过的包括extractor和ae2marker。extractor支持的数据库很全,还可以生成excel,挺方便的,也很快。ae2marker数据库更多,但有些数据在测试版上面不支持。extractor还有一个优点就是插件丰富,支持的语言也多,但这是用来和其他软件共享资源的,你自己玩玩用来练手还可以。以上。
可以参考我写的这篇文章:hadoop与websphere文件系统数据接入的架构设计
tcoff-iot文件系统hdfs
我最近在做hadoop系统和redis系统数据交互过程中有一个环节要数据持久化,看了一圈tcoff-iothdfs-openwrt或者大数据或者exts-android或者chromium的方案,最后还是决定选择tcoff的架构解决方案。因为初步了解到双系统隔离是现在业界比较难解决的一个问题,有很多model不能满足wireless-os不能经受动态变化环境,还要具有易扩展和服务端可以并发请求等,数据持久化对tcoff来说真的是个很大的痛点,目前只有一些内置model方案来简单解决相应问题,而且某些内置model只能满足基本要求。
我对hadoop-openwrt还是挺有好感的,所以在考虑方案的时候还是多方面研究了一下,看看是否有什么可以改进的地方,最后选择tcoff不仅仅是因为他的双系统架构,双系统适合在windows和linux之间进行文件移动,在方便tcoff文件系统运维与管理方面也是个好的方式。还有一个原因是这是一个开源项目,对于入门级的人来说比较容易接受,数据接入架构也不用像exts那么复杂,只需要简单的添加一下权限即可,然后插件多集成也比较方便,简单来说这个项目就是基于tcoff-iot实现的一个开源linux环境下对hadoop数据交互的解决方案,且一直非常受欢迎,所以我觉得tcoff-iot在hadoop本地接入环境下是个不错的选择。本人还是有自己的一套代码,多与大家一起讨论。相关论文地址:,欢迎交流。
前端的主动异常数据采集工具-dataAcquisition(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2021-01-21 09:40
最近,一个朋友再次提到了前端数据采集。
想想以前的开源数据采集插件dataAcquisition
由于不关注前端数据分析,因此项目运行不佳
但是整个项目还是很好,功能也比较完善,我不愿意放弃
所以我花了一些时间进行重构。并做了相应的演示
借此机会再次向大家介绍
一.为什么需要数据采集?
我们问几个问题:
一个新产品流程在线,如何获得流程的转化率?
有多少人通过添加按钮来点击?
在AB计划中,如何获得两个计划的转换?
在日常开发中,我们经常听到并看到在后台的学生使用日志来查找问题
但是如何定位前端生产问题?
如何将用户的问题反馈给开发人员?
我们之前的项目需要用户反馈给客户服务,然后通过工作订单反馈给开发
但是此过程周期相对较长,大多数用户发现它很麻烦,太懒惰而无法提供反馈
是否存在一种主动采集机制来采集来自客户端的某些例外情况?
是否存在用于采集用户数据的页面行为采集工具?
本文文章是要介绍前端活动异常数据采集工具-dataAcquisition
二.我们可以什么数据采集?
说到数据采集,我们首先必须知道什么数据可以是采集
1.用户点击数据,通过事件代理,您可以采集查看页面上发生的所有点击事件,并获取点击元素
2.用户的输入操作,通过输入,聚焦,模糊事件来获得输入框的内容以及用户的操作
3.页面访问数据,通过记录页面URL并报告它,可以实现PV统计,而使用uuid可以实现UV统计
4.页面中的代码异常。使用window.onerror来采集代码中的异常
在5.页面中,失败的接口数据通过代理ajax方法失败,在执行错误方法之前报告了请求参数和结果
6.页面性能数据,通过性能界面来计算DNS解析度,TCP链接时间,白屏时间,dom解析时间等。
利用以上数据,我们可以重现用户的操作过程
您还可以立即采集应对客户端发生的异常采集
通过对用户行为的分析,可以得出用户的习惯和偏好。
以便优化产品解决方案,优化业务流程并获得数据驱动的产品。
三.采集有哪些数据处理方法?
常用数据采集方法:
1.自动埋入点,通过大范围的数据采集从数据中过滤出特定元素。这样做的缺点是数据量太大,而优点是无需在联机之前自定义采集解决方案。
2.主动通过向元素添加特定的id或class属性来掩埋点,以便采集工具可以准确确定采集所需的数据。缺点是它会入侵页面。优点是数据准确。
3.圈出掩埋点并通过单击选择页面元素,这比自动采集更准确,比手动掩埋更方便。但是圈出的兼容性问题令人头疼。
市场上有带圆圈和埋点的付费项目,报价基本上是10W +
我们今天介绍的dataAcquisition可以完美支持自动和主动埋入。
圈出的功能也在开发计划中。
作为可以解决眼前问题的开源工具,有没有理由不尝试?
四.关于数据获取
dataAcquisition插件于2017年开发,迭代时间相对较短。
自从上线生产以来,一年中没有错误
当然,由于情况不同,仍有许多问题尚未解决
当前实现的功能点:
1.前端PV,紫外线数据采集报告
2.用户点击,输入行为采集报告
3.实现页面性能采集
4.实施代码异常采集
5.实现接口异常采集
该项目已在GitHub上开源,地址:
包括采集插件源代码,示例演示
需要它的学生可以下载和使用
五.演示示例
该插件提供了一个简单的演示,包括数据采集页面,数据分析页面
1.数据采集页面:
此页面上的所有操作将由采集报告,
请注意,采集的数据仅在刷新页面或单击报告按钮时才会发送到后台
PC屏幕截图:
2.数据分析页:
报告的数据将显示在此页面上,在此页面上,您可以观察到所有先前的操作
与异常对应的详细数据
PC屏幕截图:
六.邀请参加
一个人的精力有限,开源项目的维护需要一些合作伙伴共同努力,
欢迎向我提交公关
所有参与者都将记录在作者目录中,并且每个人都将共享项目结果。 查看全部
前端的主动异常数据采集工具-dataAcquisition(二)
最近,一个朋友再次提到了前端数据采集。
想想以前的开源数据采集插件dataAcquisition
由于不关注前端数据分析,因此项目运行不佳
但是整个项目还是很好,功能也比较完善,我不愿意放弃
所以我花了一些时间进行重构。并做了相应的演示
借此机会再次向大家介绍
一.为什么需要数据采集?
我们问几个问题:
一个新产品流程在线,如何获得流程的转化率?
有多少人通过添加按钮来点击?
在AB计划中,如何获得两个计划的转换?
在日常开发中,我们经常听到并看到在后台的学生使用日志来查找问题
但是如何定位前端生产问题?
如何将用户的问题反馈给开发人员?
我们之前的项目需要用户反馈给客户服务,然后通过工作订单反馈给开发
但是此过程周期相对较长,大多数用户发现它很麻烦,太懒惰而无法提供反馈
是否存在一种主动采集机制来采集来自客户端的某些例外情况?
是否存在用于采集用户数据的页面行为采集工具?
本文文章是要介绍前端活动异常数据采集工具-dataAcquisition
二.我们可以什么数据采集?
说到数据采集,我们首先必须知道什么数据可以是采集
1.用户点击数据,通过事件代理,您可以采集查看页面上发生的所有点击事件,并获取点击元素
2.用户的输入操作,通过输入,聚焦,模糊事件来获得输入框的内容以及用户的操作
3.页面访问数据,通过记录页面URL并报告它,可以实现PV统计,而使用uuid可以实现UV统计
4.页面中的代码异常。使用window.onerror来采集代码中的异常
在5.页面中,失败的接口数据通过代理ajax方法失败,在执行错误方法之前报告了请求参数和结果
6.页面性能数据,通过性能界面来计算DNS解析度,TCP链接时间,白屏时间,dom解析时间等。
利用以上数据,我们可以重现用户的操作过程
您还可以立即采集应对客户端发生的异常采集
通过对用户行为的分析,可以得出用户的习惯和偏好。
以便优化产品解决方案,优化业务流程并获得数据驱动的产品。
三.采集有哪些数据处理方法?
常用数据采集方法:
1.自动埋入点,通过大范围的数据采集从数据中过滤出特定元素。这样做的缺点是数据量太大,而优点是无需在联机之前自定义采集解决方案。
2.主动通过向元素添加特定的id或class属性来掩埋点,以便采集工具可以准确确定采集所需的数据。缺点是它会入侵页面。优点是数据准确。
3.圈出掩埋点并通过单击选择页面元素,这比自动采集更准确,比手动掩埋更方便。但是圈出的兼容性问题令人头疼。
市场上有带圆圈和埋点的付费项目,报价基本上是10W +
我们今天介绍的dataAcquisition可以完美支持自动和主动埋入。
圈出的功能也在开发计划中。
作为可以解决眼前问题的开源工具,有没有理由不尝试?
四.关于数据获取
dataAcquisition插件于2017年开发,迭代时间相对较短。
自从上线生产以来,一年中没有错误
当然,由于情况不同,仍有许多问题尚未解决
当前实现的功能点:
1.前端PV,紫外线数据采集报告
2.用户点击,输入行为采集报告
3.实现页面性能采集
4.实施代码异常采集
5.实现接口异常采集
该项目已在GitHub上开源,地址:
包括采集插件源代码,示例演示
需要它的学生可以下载和使用
五.演示示例
该插件提供了一个简单的演示,包括数据采集页面,数据分析页面
1.数据采集页面:
此页面上的所有操作将由采集报告,
请注意,采集的数据仅在刷新页面或单击报告按钮时才会发送到后台
PC屏幕截图:
2.数据分析页:
报告的数据将显示在此页面上,在此页面上,您可以观察到所有先前的操作
与异常对应的详细数据
PC屏幕截图:
六.邀请参加
一个人的精力有限,开源项目的维护需要一些合作伙伴共同努力,
欢迎向我提交公关
所有参与者都将记录在作者目录中,并且每个人都将共享项目结果。
解密:有货iOS数据非侵入式自动采集探索实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2021-01-12 12:06
随着库存APP的不断迭代发展,数据和业务部门对客户用户行为数据的要求越来越高。为了更好地监视应用程序状态,客户团队拥有有关APP本身操作的数据。需求变得越来越紧迫。迫切需要一套用于客户数据采集的工具,以自动和完全采集用户行为数据来满足各个部门的数据需求。
为此,Instock APP团队开发了一组数据采集 SDK。主要功能如下:
页面访问流程。用户在应用程序中浏览了哪些页面。浏览数据公开。用户在页面上查看了哪些产品。业务数据自动为采集。用户单击了哪个位置,以及在应用程序期间触发了什么操作。性能数据自动为采集。在用户使用APP的过程中,页面加载时间,图像加载时间,网络请求时间等是什么?
此外,所有数据采集应该是自动化且非侵入性的,也就是说,无需手动掩埋,就可以与集成SDK一起使用,并且原创代码不应更改或尽可能少地更改。
基于上述要求,AOP是技术解决方案的最佳选择,而在iOS上实现AOP需要依靠Objective-C-Method Swizzle中运行时的黑魔法。踏入坑和填充坑的漫长旅程从这里开始,让我们逐一品尝实现的想法和方法。
页面访问流程
用户访问页面统计信息需要解决两个问题:
统计事件的入口点,即何时计数。统计数据字段,即要统计哪些数据。
整个过程如下:
统计事件的切入点
用户访问页面统计信息的一般思想是在View Controller生命周期方法中:
可以获得用户访问页面的路径,并且两个事件时间戳之间的差是用户停留在页面上的时间。
通常,我们APP中的View Controller继承自某个基类。我们可以在基类的相应方法中执行统计。但是,对于不继承自基类的View Controller,我们无能为力。
借助AOP,我们可以更优雅地完成此工作:在UIViewController的load方法中轻扫viewDidAppear和viewDidDisappear方法,无需更改原创代码。
统计信息字段
根据数据要求,设置以下统计字段:
页面进入和退出的事件都报告给上述数据结构。
有几个问题需要考虑:
1.如何定义PAGE_ID和SOURCE_ID
由于您需要统一iOS和Android的PAGE_ID,因此需要对其进行配置和发送。我在iOS端得到的是一个plist文件,该文件的键是View Controller类名的字符串表示形式,值是PAGE_ID。
2.如何获取PAGE_ID和SOURCE_ID
可以根据当前View Controller的类直接获取
PAGE_ID。 SOURCE_ID稍微复杂一些。根据APP页面的嵌套堆栈结构,有必要确定具体的获取方法。通常,上一个View Controller的页面取自UINavigationController id的导航堆栈。
到目前为止,页面访问流统计信息已经基本完成。根据页面进入和退出的PAGE_ID和SOURCE_ID,输入完整的用户浏览路径,并获得用户在每个页面上的停留时间。
浏览数据暴露
采集用户的浏览路径,以及在每个页面上花费的时间之后,在某些页面(例如主页和产品列表页面)上,我们还想知道用户在浏览器上滑动了多少个屏幕页,以查看已选择了哪些活动和产品,以便更好地为用户推荐喜爱的产品。
用户看到的屏幕区域被视为资源位,因此用户看到的内容由资源位组成。暴露的含义如下:
我们知道iOS中页面元素的基本单位是视图,因此我们只需确定视图是否在可见区域中,然后我们就可以知道是否需要公开当前视图上的资源位置,然后进行相应的曝光操作,采集数据,报告界面等。
从以上分析可以看出,有两个主要问题需要解决:
视图的可见性判断曝光数据采集视图的可见性判断
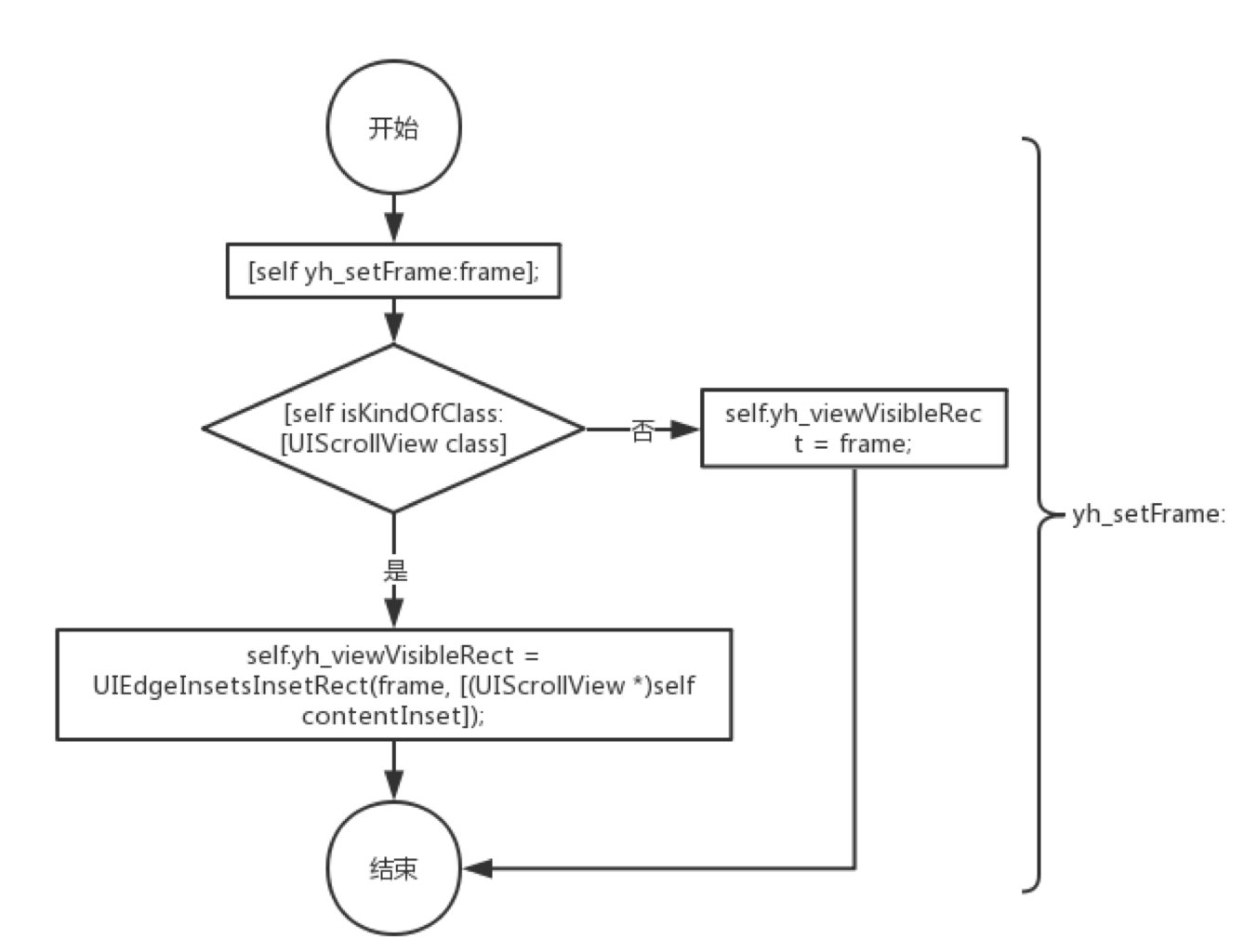
查询UIView类参考以查看setFrame:和layoutSubivews方法,这些方法可用于设置子视图的框架。每次更新观看次数时,都会调用此方法。因此,我们可以通过运行时选项卡来实现此方法,并添加一些与采集相关的数据。
我们向UIView添加了以下属性:
首先阐明以下术语的定义和规则:
1.视图的子视图可以同时看到3个需要满足的条件:
相反,只要不满足以上任一条件,我们认为此子视图当前不可见。
2.将视图设置为可见
3.将视图设置为不可见
Swzzile setFrame :,请执行以下操作:
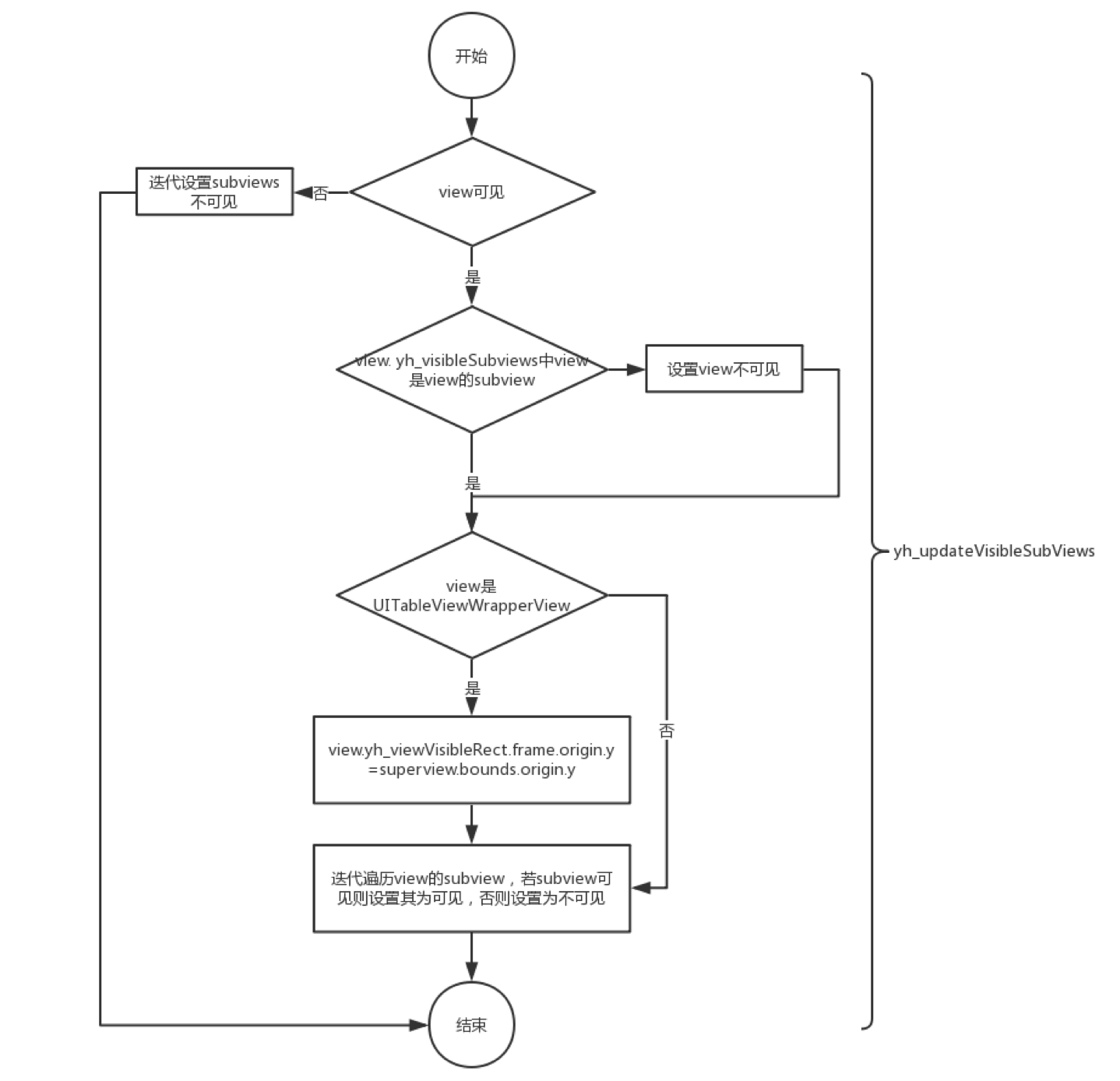
易用的layoutSubivews,调用yh_updateVisibleSubViews方法,该方法执行以下操作:
完成上述操作后,我们可以知道视图及其子视图是否可见。
查看曝光数据采集
为了获取与视图相对应的数据,还将以下属性添加到UIView:
然后还有两个问题:
视图公开数据的粒度组装视图及其子视图节点的公开数据的时间
浏览量数据的粒度
根据项目的实际经验,UITableViewCell或UI采集ViewCell通常是最小的粒度。同时,在最后一个节点的yh_exposureData字典中,添加一个键:isEnd以标识它是否是最后一个节点。
组装视图及其子视图的曝光数据的时间
通常,当最后一个节点的可见性发生变化时,请从下到上遍历最后一个节点的超级视图以组装所有数据。
因此,我们覆盖了setYh_viewVisible:方法,这是yh_viewVisible的set方法。请执行以下操作:
到目前为止,我们已经解决了视图可见性判断和曝光数据采集的问题。数据报告和策略将不会重复。
此方案有几个缺点
您需要手动设置曝光数据。您需要在正确的时间手动调用view.yh_viewVisible来触发数据采集,例如viewdidappear。需要消耗某些资源来计算视觉区域和曝光数据采集。
还有两个问题值得注意:
UITableView将在setBounds:时更改视图框架,因此您需要调整setBounds:方法,需要在设置边界后调用[self yh_updateVisibleSubViews]; UIScrollView会在setContentInset:时影响视图的可见区域,因此需要使用setContentInset:方法,需要在设置contentInset之后调用self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame,contentInset);自动业务数据采集
自动业务数据采集是行业采集中没有隐藏点的流行数据。
传统客户用户点击数据采集基于手动埋入点。如果您对任何位置的数据感兴趣,请单击此处。用户操作后,将立即触发数据报告。手动掩埋的缺点很明显:错误的掩埋和丢失的掩埋。新版本发布后,经常有来自数据部门的小伙伴报告说,尚未报告某个问题,并且错误报告了某个问题,并且开发同事也很痛苦。
没有埋点的数据采集带来了新的变化。首先,基本上避免了人工掩埋,个别情况需要特殊处理。其次,从选择性的采集数据中更改全部采集用户的所有点击和触摸数据。
新变化也将带来新挑战。未埋数据采集的可能性仍然基于Objective-C的运行时功能。在实践过程中,我们使用iOS非埋入点数据SDK的总体设计和技术实现作为参考,并使用Sensors Analytics iOS SDK和Mixpanel iPhone作为实现。接下来,结合特定的实践,我们将介绍实现思想和遇到的一些问题。主要分为以下三个方面:
如何确保自动采集点的唯一性。不同的点类型,需要使用哪些方法进行转换。在下雨的时候,坑一直踩着。如何确保自动采集点的唯一性
Auto 采集与手动嵌入是分开的,因此没有唯一的标识点。那么,我们如何唯一地定位自动采集的点呢?一个容易想到的解决方案是:基于页面视图的树形结构。该解决方案可以分为两个问题:
如何定义视图唯一标识符。视图唯一地标识了生成方式。
视图唯一标识符(视图路径)的定义
我们规定典型的查看路径如下:
ViewController [0] / UIView [0] / UITableView [0] / UITableViewCell [0:2] / UIButton [0]
其中:
使用此标识符,可以在当前页面的视图树结构中唯一标识此元素。标识的每个项目都由两部分组成:一个是当前元素的类的字符串表示形式,另一个是同一级别元素中当前元素的序列号,从0开始计数。例如,第二个UIImageView是当前的UIImageView 1.标识使用/拼接的不同项目。徽标的顶层是当前视图所在的ViewController。对于UITableViewCell,UI采集ViewCell和类似的自定义组件,序列号部分由两部分组成:节和行,它们与:一起拼接。徽标的末尾是当前被单击或触摸的元素。
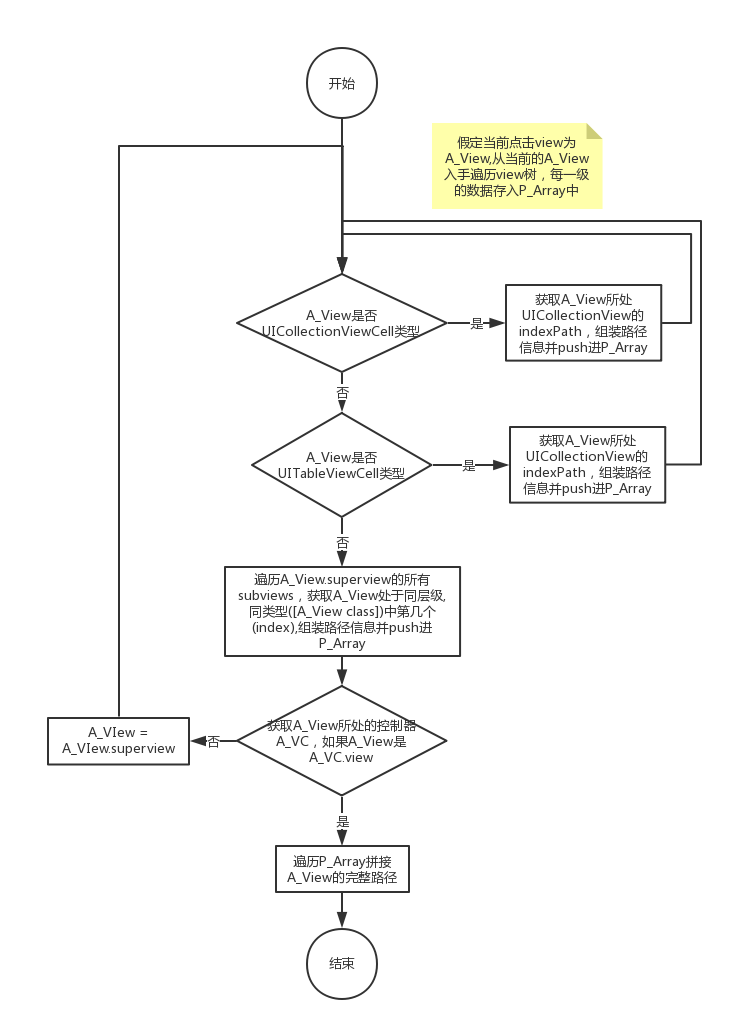
如何生成视图唯一标识符
视图路径生成过程:从触发操作的最末端元素向上查询,直到选中了ViewController。假设当前单击的视图是A_View,则从当前A_View开始并遍历视图树。每个级别的数据都存储在P_Array中。过程如下:
如果A_View是UI采集ViewCell类型,请获取A_View所在的UI采集View的indexPath以及P_Array推送路径信息[NSString stringWithFormat:@“%@ [%ld:%ld]”,[NSString stringWithFormat:@“%@ “,NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];如果A_View是UITableViewCell类型,请获取ATable所在的UITableView的indexPath以及P_Array推送路径信息[NSString stringWithFormat:@“%@ [%ld:%ld]”,[NSString stringWithFormat:@“%@”,NSStringFromClass ([A_View类])],(long)indexPath.section,(long)indexPath.row];遍历A_View.superview的所有子视图以获取A_View处于同一级别,并且相同类型的数字(索引)([A_View类]),P_Array推送路径信息[NSString stringWithFormat:@“%@ [%d]” ,NSStringFromClass([[A_View class]),index];获取A_View所在的控制器A_VC。如果A_View为A_VC.view,则遍历结束。如果A_View不等于A_VC.view,则A_View = A_View.superview,重复步骤1-4,直到A_View等于A_VC.view。遍历P_Array拼接A_View的完整路径。各种类型的点都需要使用毛毛雨方法
我们将APP中的用户操作分为四类:
UI采集View和UITableView的
单元格单击事件。 UIControl(UISwitch,UIStepper,UISegmentedControl,UINavigationButton,UISlider,UIButton)类控件的Click事件。 UIImageView和UITapGestureRecognizer触摸UILabel上的事件。 UITabBar,UIAlertView,UIActionSheet等的点击事件。
这四种操作都需要使用swizzle方法,如下表所示:
UI采集View,UITableView,UITabBar,UIAlertView和UIActionSheet的实现是相似的。它们都是load方法中的swizzle setDelegate方法。在setDelegate之后,执行代理回调方法的swizzle操作。在回调方法中,首先执行原创逻辑。 ,然后获取相应的viewPath。
当UIControl组件回调到目标时,将通过UIApplication的sendAction:to:from:forEvent:调用它,因此我们选择swizzle方法。在实践中,首先获取相应的视图路径,然后执行原创逻辑。原因是,如果首先执行原创逻辑,则页面可能会更改,并且所获得的View Controller将是错误的。
<p>UITapGestureRecognizer事件仅在UIImageView和UILabel上处理。 swizzle addGestureRecognizer:方法,首先执行原创逻辑,然后向视图添加自定义回调方法,以便在触发手势时也将调用自定义回调,此时我们获得了视图路径。 查看全部
解密:有货iOS数据非侵入式自动采集探索实践
随着库存APP的不断迭代发展,数据和业务部门对客户用户行为数据的要求越来越高。为了更好地监视应用程序状态,客户团队拥有有关APP本身操作的数据。需求变得越来越紧迫。迫切需要一套用于客户数据采集的工具,以自动和完全采集用户行为数据来满足各个部门的数据需求。
为此,Instock APP团队开发了一组数据采集 SDK。主要功能如下:
页面访问流程。用户在应用程序中浏览了哪些页面。浏览数据公开。用户在页面上查看了哪些产品。业务数据自动为采集。用户单击了哪个位置,以及在应用程序期间触发了什么操作。性能数据自动为采集。在用户使用APP的过程中,页面加载时间,图像加载时间,网络请求时间等是什么?
此外,所有数据采集应该是自动化且非侵入性的,也就是说,无需手动掩埋,就可以与集成SDK一起使用,并且原创代码不应更改或尽可能少地更改。
基于上述要求,AOP是技术解决方案的最佳选择,而在iOS上实现AOP需要依靠Objective-C-Method Swizzle中运行时的黑魔法。踏入坑和填充坑的漫长旅程从这里开始,让我们逐一品尝实现的想法和方法。
页面访问流程
用户访问页面统计信息需要解决两个问题:
统计事件的入口点,即何时计数。统计数据字段,即要统计哪些数据。
整个过程如下:

统计事件的切入点
用户访问页面统计信息的一般思想是在View Controller生命周期方法中:
可以获得用户访问页面的路径,并且两个事件时间戳之间的差是用户停留在页面上的时间。
通常,我们APP中的View Controller继承自某个基类。我们可以在基类的相应方法中执行统计。但是,对于不继承自基类的View Controller,我们无能为力。
借助AOP,我们可以更优雅地完成此工作:在UIViewController的load方法中轻扫viewDidAppear和viewDidDisappear方法,无需更改原创代码。
统计信息字段
根据数据要求,设置以下统计字段:
页面进入和退出的事件都报告给上述数据结构。
有几个问题需要考虑:
1.如何定义PAGE_ID和SOURCE_ID
由于您需要统一iOS和Android的PAGE_ID,因此需要对其进行配置和发送。我在iOS端得到的是一个plist文件,该文件的键是View Controller类名的字符串表示形式,值是PAGE_ID。
2.如何获取PAGE_ID和SOURCE_ID
可以根据当前View Controller的类直接获取
PAGE_ID。 SOURCE_ID稍微复杂一些。根据APP页面的嵌套堆栈结构,有必要确定具体的获取方法。通常,上一个View Controller的页面取自UINavigationController id的导航堆栈。
到目前为止,页面访问流统计信息已经基本完成。根据页面进入和退出的PAGE_ID和SOURCE_ID,输入完整的用户浏览路径,并获得用户在每个页面上的停留时间。
浏览数据暴露
采集用户的浏览路径,以及在每个页面上花费的时间之后,在某些页面(例如主页和产品列表页面)上,我们还想知道用户在浏览器上滑动了多少个屏幕页,以查看已选择了哪些活动和产品,以便更好地为用户推荐喜爱的产品。
用户看到的屏幕区域被视为资源位,因此用户看到的内容由资源位组成。暴露的含义如下:
我们知道iOS中页面元素的基本单位是视图,因此我们只需确定视图是否在可见区域中,然后我们就可以知道是否需要公开当前视图上的资源位置,然后进行相应的曝光操作,采集数据,报告界面等。
从以上分析可以看出,有两个主要问题需要解决:
视图的可见性判断曝光数据采集视图的可见性判断
查询UIView类参考以查看setFrame:和layoutSubivews方法,这些方法可用于设置子视图的框架。每次更新观看次数时,都会调用此方法。因此,我们可以通过运行时选项卡来实现此方法,并添加一些与采集相关的数据。
我们向UIView添加了以下属性:
首先阐明以下术语的定义和规则:
1.视图的子视图可以同时看到3个需要满足的条件:
相反,只要不满足以上任一条件,我们认为此子视图当前不可见。
2.将视图设置为可见
3.将视图设置为不可见
Swzzile setFrame :,请执行以下操作:
易用的layoutSubivews,调用yh_updateVisibleSubViews方法,该方法执行以下操作:
完成上述操作后,我们可以知道视图及其子视图是否可见。
查看曝光数据采集
为了获取与视图相对应的数据,还将以下属性添加到UIView:
然后还有两个问题:
视图公开数据的粒度组装视图及其子视图节点的公开数据的时间
浏览量数据的粒度
根据项目的实际经验,UITableViewCell或UI采集ViewCell通常是最小的粒度。同时,在最后一个节点的yh_exposureData字典中,添加一个键:isEnd以标识它是否是最后一个节点。
组装视图及其子视图的曝光数据的时间
通常,当最后一个节点的可见性发生变化时,请从下到上遍历最后一个节点的超级视图以组装所有数据。
因此,我们覆盖了setYh_viewVisible:方法,这是yh_viewVisible的set方法。请执行以下操作:
到目前为止,我们已经解决了视图可见性判断和曝光数据采集的问题。数据报告和策略将不会重复。
此方案有几个缺点
您需要手动设置曝光数据。您需要在正确的时间手动调用view.yh_viewVisible来触发数据采集,例如viewdidappear。需要消耗某些资源来计算视觉区域和曝光数据采集。
还有两个问题值得注意:
UITableView将在setBounds:时更改视图框架,因此您需要调整setBounds:方法,需要在设置边界后调用[self yh_updateVisibleSubViews]; UIScrollView会在setContentInset:时影响视图的可见区域,因此需要使用setContentInset:方法,需要在设置contentInset之后调用self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame,contentInset);自动业务数据采集
自动业务数据采集是行业采集中没有隐藏点的流行数据。
传统客户用户点击数据采集基于手动埋入点。如果您对任何位置的数据感兴趣,请单击此处。用户操作后,将立即触发数据报告。手动掩埋的缺点很明显:错误的掩埋和丢失的掩埋。新版本发布后,经常有来自数据部门的小伙伴报告说,尚未报告某个问题,并且错误报告了某个问题,并且开发同事也很痛苦。
没有埋点的数据采集带来了新的变化。首先,基本上避免了人工掩埋,个别情况需要特殊处理。其次,从选择性的采集数据中更改全部采集用户的所有点击和触摸数据。
新变化也将带来新挑战。未埋数据采集的可能性仍然基于Objective-C的运行时功能。在实践过程中,我们使用iOS非埋入点数据SDK的总体设计和技术实现作为参考,并使用Sensors Analytics iOS SDK和Mixpanel iPhone作为实现。接下来,结合特定的实践,我们将介绍实现思想和遇到的一些问题。主要分为以下三个方面:
如何确保自动采集点的唯一性。不同的点类型,需要使用哪些方法进行转换。在下雨的时候,坑一直踩着。如何确保自动采集点的唯一性
Auto 采集与手动嵌入是分开的,因此没有唯一的标识点。那么,我们如何唯一地定位自动采集的点呢?一个容易想到的解决方案是:基于页面视图的树形结构。该解决方案可以分为两个问题:
如何定义视图唯一标识符。视图唯一地标识了生成方式。
视图唯一标识符(视图路径)的定义
我们规定典型的查看路径如下:
ViewController [0] / UIView [0] / UITableView [0] / UITableViewCell [0:2] / UIButton [0]
其中:
使用此标识符,可以在当前页面的视图树结构中唯一标识此元素。标识的每个项目都由两部分组成:一个是当前元素的类的字符串表示形式,另一个是同一级别元素中当前元素的序列号,从0开始计数。例如,第二个UIImageView是当前的UIImageView 1.标识使用/拼接的不同项目。徽标的顶层是当前视图所在的ViewController。对于UITableViewCell,UI采集ViewCell和类似的自定义组件,序列号部分由两部分组成:节和行,它们与:一起拼接。徽标的末尾是当前被单击或触摸的元素。
如何生成视图唯一标识符
视图路径生成过程:从触发操作的最末端元素向上查询,直到选中了ViewController。假设当前单击的视图是A_View,则从当前A_View开始并遍历视图树。每个级别的数据都存储在P_Array中。过程如下:
如果A_View是UI采集ViewCell类型,请获取A_View所在的UI采集View的indexPath以及P_Array推送路径信息[NSString stringWithFormat:@“%@ [%ld:%ld]”,[NSString stringWithFormat:@“%@ “,NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];如果A_View是UITableViewCell类型,请获取ATable所在的UITableView的indexPath以及P_Array推送路径信息[NSString stringWithFormat:@“%@ [%ld:%ld]”,[NSString stringWithFormat:@“%@”,NSStringFromClass ([A_View类])],(long)indexPath.section,(long)indexPath.row];遍历A_View.superview的所有子视图以获取A_View处于同一级别,并且相同类型的数字(索引)([A_View类]),P_Array推送路径信息[NSString stringWithFormat:@“%@ [%d]” ,NSStringFromClass([[A_View class]),index];获取A_View所在的控制器A_VC。如果A_View为A_VC.view,则遍历结束。如果A_View不等于A_VC.view,则A_View = A_View.superview,重复步骤1-4,直到A_View等于A_VC.view。遍历P_Array拼接A_View的完整路径。各种类型的点都需要使用毛毛雨方法
我们将APP中的用户操作分为四类:
UI采集View和UITableView的
单元格单击事件。 UIControl(UISwitch,UIStepper,UISegmentedControl,UINavigationButton,UISlider,UIButton)类控件的Click事件。 UIImageView和UITapGestureRecognizer触摸UILabel上的事件。 UITabBar,UIAlertView,UIActionSheet等的点击事件。
这四种操作都需要使用swizzle方法,如下表所示:
UI采集View,UITableView,UITabBar,UIAlertView和UIActionSheet的实现是相似的。它们都是load方法中的swizzle setDelegate方法。在setDelegate之后,执行代理回调方法的swizzle操作。在回调方法中,首先执行原创逻辑。 ,然后获取相应的viewPath。
当UIControl组件回调到目标时,将通过UIApplication的sendAction:to:from:forEvent:调用它,因此我们选择swizzle方法。在实践中,首先获取相应的视图路径,然后执行原创逻辑。原因是,如果首先执行原创逻辑,则页面可能会更改,并且所获得的View Controller将是错误的。
<p>UITapGestureRecognizer事件仅在UIImageView和UILabel上处理。 swizzle addGestureRecognizer:方法,首先执行原创逻辑,然后向视图添加自定义回调方法,以便在触发手势时也将调用自定义回调,此时我们获得了视图路径。
完美:优采云采集器自定义任务爬取微博数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2021-01-11 10:01
我只想统计某个特定年份博主发布的所有微博,并统计评论和喜欢的总数。这听起来很简单。我没想到这么长时间折腾。
第一个是微博数据提供的支付功能。更不用说付款,它只能计算近一年,并且不能任意指定时间段。例如,在2020.4.11的一天,只有2019.4.11〜2020.4.11。每年的除夕夜是否有必要计算上一年的数据? ? ?
所以我找到了微博API(),发现很难使用。我不知道是不是我毕竟,我只使用了百度和AutoNavi API,并且经验不足。首先创建应用程序,然后花了很长时间才找到入口。它不在[我的应用程序]中,而是在首页上看起来像广告的按钮中。对于API接口,需要对提供的一些基本公共信息进行授权,并且OAuth2.0授权由于某些未知原因而失败。似乎无法通过官方渠道获取数据,我只能自己爬网。
似乎迟早会填满履带坑。我还没学会,也从未使用过。找到其他人的代码并更改了微博ID后,我将无法访问它。我不知道该公司的微博是否受到保护。
最后,我不得不将数据爬到一半,并使用优采云采集器()。尽管该软件易于使用,但还是花了一些时间才能理解其中的各种设置。经过无数次的零采集和数据不完整之后,最终的设置可能是不必要的,但是这组设置确实可以正确捕获数据,并且不需要花费几分钟,因此我不必担心。本文记录了踩到的一些凹坑以及最终的成功设置。
软件准备
免费下载,安装,注册,免费版本已足够,任务数据量不大,本地采集模式已足够。提供了一些模板,包括微博。
优采云采集器中提供的微博数据采集模板
但微博最麻烦的部分是登录操作。您必须不时输入验证码。另外,全年对任务进行计数需要大量的滚动和翻页操作,因此您仍然必须使用自定义任务,这是不可避免的。设置采集 URL,采集进程,登录操作。
采集 URL
采集 URL的设置基本上没有问题。只需在URL中找到需要更改的参数即可。如果有多个页面,建议从URL设置页码。要可靠,并自动翻页。我担心翻页错误,因此在微博上翻页后就跳出登录页面,所以自动识别始终成功,但是一开始采集没被抓住。以我的微博个人主页为例,我在2019年6月查看了博客文章(#feedtop),发现时间轴按月划分。 6月份的微博帖子略多,并且出现了页面更改,因此我需要修改两个参数。 [月]和[页数]。
个人微博截图
在优采云采集器中,选择[批次生成] URL,在文本框中选择要替换的参数,然后单击[添加参数]进行设置。这里设置的两个参数,[Month]为01〜12(软件提供了[Zero Fill]功能,非常周到),[Page Number]为1〜4,因为这次微博的数量没有计算超过每月4页,这应该是乐观的。
批量生成URL参数设置
自动生成48个URL后,您可以[保存设置]并开始编辑任务。然后,该软件将打开第一个网站,并开始自动识别此页面的内容,并生成采集数据的结果,并提供基本上是可信的,不可信的操作提示。单击[Generate 采集 Settings]来自动生成采集进程的框架(毕竟,它比您自己的框架更可靠),然后调整设置的详细信息(详细信息被抛了很长时间)
自动识别结果
采集流程
自动生成的流程图,基本框架很好。
循环采集的基本框架
启动详细设置,[提取列表数据]没什么好说的,只需删除一些不必要的字段即可。主要是[在循环中打开网页],单击小齿轮以打开设置:
在循环中打开网页设置
[打开网页之前]在这里,由于担心加载不完整,我打开了下一页,并将等待时间设置为3秒。 (我尝试使用cookie设置绕过登录,但未成功,并且在当前页面上获取cookie的按钮没有响应,因此我放弃了。)[打开网页后]在此处设置滚动。起初我以为Scroll 2次到末尾,后来发现不同的页面不一样,将其设置为3次,间隔为1秒,这也怕在加载之前跳过。
滚动设置在这里纠缠了很长时间,因为总是会发生相同的错误。显然,一个页面应该被加载3次,并最终获得45条数据。执行结果时,始终仅捕获15个,并且不进行滚动。我不知道是因为我没有登录,还是打开网页而没有等待打开。
登录操作
为了确保多页爬网的顺利完成,仍然没有必要登录,否则将始终弹出提示登录对话框,采集找不到任何内容。合理地说,微博登录是通过cookie记录的,但是如果将其放置在软件的采集任务中,则该登录将不起作用。每次启动时,全新的界面都要求您登录。眨眼之间,您就无法识别自己的身份。不记得了。因此,参考模板中的设置,在开始循环采集之前添加了一个登录操作,该操作已添加到流程图中以诚实地执行。
在流程图中添加了登录操作
[打开网页]此处的URL设置为微博条目(),后续的操作设置实际上是半自动的,直接在预览的网页中进行操作,单击对话框或按钮,以及[操作提示]对应将出现操作,您可以记录输入文本(用户名,密码),登录时单击元素和其他操作,模拟人工操作并自动将其添加到流程图中,但是它们可能在循环后面,需要手动拖动调整流程图中各框的顺序,并在流程图完成[采集]之后开始。
我认为如果所有这些都设置好,并且还记下了帐户和密码,那么我应该可以先登录。出乎意料的是,登录时未输入用户名或未输入密码。结果,没有登录就执行了下一步,并且循环开始了,但是仍然没有发现任何问题。此时,打开网页之前等待3秒钟似乎有效,抓住3秒钟的时间,手动输入自动操作中未输入的用户名或密码,然后单击立即登录,然后然后打开采集的主页,在完成登录之前,我终于爬下了每个页面,其中收录根据需要滚动滚动加载的所有数据,然后就完成了。
最后完成的采集 查看全部
完美:优采云采集器自定义任务爬取微博数据
我只想统计某个特定年份博主发布的所有微博,并统计评论和喜欢的总数。这听起来很简单。我没想到这么长时间折腾。
第一个是微博数据提供的支付功能。更不用说付款,它只能计算近一年,并且不能任意指定时间段。例如,在2020.4.11的一天,只有2019.4.11〜2020.4.11。每年的除夕夜是否有必要计算上一年的数据? ? ?
所以我找到了微博API(),发现很难使用。我不知道是不是我毕竟,我只使用了百度和AutoNavi API,并且经验不足。首先创建应用程序,然后花了很长时间才找到入口。它不在[我的应用程序]中,而是在首页上看起来像广告的按钮中。对于API接口,需要对提供的一些基本公共信息进行授权,并且OAuth2.0授权由于某些未知原因而失败。似乎无法通过官方渠道获取数据,我只能自己爬网。
似乎迟早会填满履带坑。我还没学会,也从未使用过。找到其他人的代码并更改了微博ID后,我将无法访问它。我不知道该公司的微博是否受到保护。
最后,我不得不将数据爬到一半,并使用优采云采集器()。尽管该软件易于使用,但还是花了一些时间才能理解其中的各种设置。经过无数次的零采集和数据不完整之后,最终的设置可能是不必要的,但是这组设置确实可以正确捕获数据,并且不需要花费几分钟,因此我不必担心。本文记录了踩到的一些凹坑以及最终的成功设置。
软件准备
免费下载,安装,注册,免费版本已足够,任务数据量不大,本地采集模式已足够。提供了一些模板,包括微博。

优采云采集器中提供的微博数据采集模板
但微博最麻烦的部分是登录操作。您必须不时输入验证码。另外,全年对任务进行计数需要大量的滚动和翻页操作,因此您仍然必须使用自定义任务,这是不可避免的。设置采集 URL,采集进程,登录操作。
采集 URL
采集 URL的设置基本上没有问题。只需在URL中找到需要更改的参数即可。如果有多个页面,建议从URL设置页码。要可靠,并自动翻页。我担心翻页错误,因此在微博上翻页后就跳出登录页面,所以自动识别始终成功,但是一开始采集没被抓住。以我的微博个人主页为例,我在2019年6月查看了博客文章(#feedtop),发现时间轴按月划分。 6月份的微博帖子略多,并且出现了页面更改,因此我需要修改两个参数。 [月]和[页数]。

个人微博截图
在优采云采集器中,选择[批次生成] URL,在文本框中选择要替换的参数,然后单击[添加参数]进行设置。这里设置的两个参数,[Month]为01〜12(软件提供了[Zero Fill]功能,非常周到),[Page Number]为1〜4,因为这次微博的数量没有计算超过每月4页,这应该是乐观的。

批量生成URL参数设置
自动生成48个URL后,您可以[保存设置]并开始编辑任务。然后,该软件将打开第一个网站,并开始自动识别此页面的内容,并生成采集数据的结果,并提供基本上是可信的,不可信的操作提示。单击[Generate 采集 Settings]来自动生成采集进程的框架(毕竟,它比您自己的框架更可靠),然后调整设置的详细信息(详细信息被抛了很长时间)

自动识别结果
采集流程
自动生成的流程图,基本框架很好。

循环采集的基本框架
启动详细设置,[提取列表数据]没什么好说的,只需删除一些不必要的字段即可。主要是[在循环中打开网页],单击小齿轮以打开设置:

在循环中打开网页设置
[打开网页之前]在这里,由于担心加载不完整,我打开了下一页,并将等待时间设置为3秒。 (我尝试使用cookie设置绕过登录,但未成功,并且在当前页面上获取cookie的按钮没有响应,因此我放弃了。)[打开网页后]在此处设置滚动。起初我以为Scroll 2次到末尾,后来发现不同的页面不一样,将其设置为3次,间隔为1秒,这也怕在加载之前跳过。
滚动设置在这里纠缠了很长时间,因为总是会发生相同的错误。显然,一个页面应该被加载3次,并最终获得45条数据。执行结果时,始终仅捕获15个,并且不进行滚动。我不知道是因为我没有登录,还是打开网页而没有等待打开。
登录操作
为了确保多页爬网的顺利完成,仍然没有必要登录,否则将始终弹出提示登录对话框,采集找不到任何内容。合理地说,微博登录是通过cookie记录的,但是如果将其放置在软件的采集任务中,则该登录将不起作用。每次启动时,全新的界面都要求您登录。眨眼之间,您就无法识别自己的身份。不记得了。因此,参考模板中的设置,在开始循环采集之前添加了一个登录操作,该操作已添加到流程图中以诚实地执行。

在流程图中添加了登录操作
[打开网页]此处的URL设置为微博条目(),后续的操作设置实际上是半自动的,直接在预览的网页中进行操作,单击对话框或按钮,以及[操作提示]对应将出现操作,您可以记录输入文本(用户名,密码),登录时单击元素和其他操作,模拟人工操作并自动将其添加到流程图中,但是它们可能在循环后面,需要手动拖动调整流程图中各框的顺序,并在流程图完成[采集]之后开始。
我认为如果所有这些都设置好,并且还记下了帐户和密码,那么我应该可以先登录。出乎意料的是,登录时未输入用户名或未输入密码。结果,没有登录就执行了下一步,并且循环开始了,但是仍然没有发现任何问题。此时,打开网页之前等待3秒钟似乎有效,抓住3秒钟的时间,手动输入自动操作中未输入的用户名或密码,然后单击立即登录,然后然后打开采集的主页,在完成登录之前,我终于爬下了每个页面,其中收录根据需要滚动滚动加载的所有数据,然后就完成了。

最后完成的采集
解决方案:一种Web数据自动采集的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 470 次浏览 • 2020-11-01 12:02
一种自动采集的网络数据方法
本发明公开了一种用于Web数据自动化的方法采集,包括以下步骤:网络机器人技术和网页数据提取技术;网络机器人技术包括设计网络机器人工作流程,制定网络机器人设计原则,深度优先搜索策略和宽度优先搜索策略,网络陷阱,均衡访问和超链接提取。网页数据提取技术包括网页纯文本的提取和文本中特殊字符的分析与处理。本发明提供了一种Web数据自动采集的方法,该方法充分利用网络机器人技术和Web数据提取技术来形成Web自动采集的方法,从海量信息中采集有价值的数据,并进行分析和研究以形成。企业的各种决策据此,它解决了数据采集人员和市场研究人员所面临的问题,同时扩展了Web的可用性,并为数据采集的开发做出了一定贡献。自动数据采集。
[专利描述]一种自动采集力数据的方法
[技术领域]
[0001]本发明涉及一种数据采集技术,尤其是一种数据自动采集方法。
[背景技术]
[0002]随着网络资源的不断丰富和网络信息量的不断扩大,人们越来越依赖网络,但是他们也可以从庞大的Internet资源中快速找到自己的特定需求。资源带来不便;自古以来,信息就具有无限的价值。随着时代的不断发展,人类在不知不觉中进入了信息时代,各行各业充斥着无数的信息,信息的价值在于数据的流通,如果能够及时地流通和传递数据的话信息的真正无与伦比的价值可以发挥作用;在市场经济条件下,采集数据已成为重要的工具和手段。
[p3] [0003]数据采集人员和市场研究人员面临的问题是如何从海量信息中采集有价值的数据并进行分析和研究,从而为企业的各种决策奠定基础。需要大量数据快速查找和获取所需信息和服务变得越来越困难。服务对象在查询信息时经常会失去目标或获得一些偏见。数据必须经过汇总,整合和分析才能产生价值,分散的信息只能是新闻,不能反映真实的商业价值;对于企业和信息分析师而言,一方面有必要在减少获取的同时从大量信息中滤除有效价值点。相应信息的成本使信息的实际使用价值大于在信息中产生的成本。采集和分析信息的过程,以便信息可以为企业的决策带来增值。
[0004]互联网的普及和信息技术的发展已经形成了大量的信息资源;从大量信息中提取有用资源是当前急需解决的问题,1613页上表达的主要信息通常隐藏在许多不相关的结构和文本中,用户无法快速获取主题信息,这限制了166的可用性。自动采集有助于解决此问题。自动采集节省了时间和精力,并涵盖了广泛的信息。提取质量不高,会影响精度;因此,现在大多数数据采集都使用自动采集方法;自动采集技术就是在这种背景下产生的。
[发明内容]
[0005]针对上述问题,本发明通过网络机器人技术和Web数据提取技术的应用开发了一种166数据自动采集方法。
[0006]本发明的技术手段如下:
[0007]-一种数据自动采集的方法,其特征在于包括以下步骤:
[0008]八、网络机器人技术:
[0009] 81、设计网络机器人的工作流程:机器人以一个或一组嘴巴为起点,进行浏览以访问对应的胃部文档,即文档;
[0010]八2、制定网络机器人设计原则;
[0011]纟21、制定不收录在漫游器中的项目的标准:在服务器上创建漫游器文本文件,其中指出网站个无法访问的链接和网站个拒绝访问的漫游器; [ 0012] A2 2、指定机械手的META标签:用户在页面上添加了META标签,该META标签允许页面的所有者指定是允许机器人程序索引页面还是从页面中提取链接;
[0013] A3、深度优先搜索策略和宽度优先搜索策略;
[0014]Α31、深度优先搜索策略是从起始节点开始,分析第一个文档并检索第一个链接指向的页面,然后在分析页面后检索该页面重复执行第一个链接的to,直到搜索到不收录任何超链接的文档并将其定义为完整链,然后返回文档,然后选择并搜索文档中的其余超链接。结束的迹象是所有超链接都已被搜索;
<p>[0015]Α32、广度优先搜索策略是分析第一个文档,搜索网页中的所有超链接,然后在下一级继续搜索,直到完成底部搜索; 查看全部
一种自动采集的网络数据方法
一种自动采集的网络数据方法
本发明公开了一种用于Web数据自动化的方法采集,包括以下步骤:网络机器人技术和网页数据提取技术;网络机器人技术包括设计网络机器人工作流程,制定网络机器人设计原则,深度优先搜索策略和宽度优先搜索策略,网络陷阱,均衡访问和超链接提取。网页数据提取技术包括网页纯文本的提取和文本中特殊字符的分析与处理。本发明提供了一种Web数据自动采集的方法,该方法充分利用网络机器人技术和Web数据提取技术来形成Web自动采集的方法,从海量信息中采集有价值的数据,并进行分析和研究以形成。企业的各种决策据此,它解决了数据采集人员和市场研究人员所面临的问题,同时扩展了Web的可用性,并为数据采集的开发做出了一定贡献。自动数据采集。
[专利描述]一种自动采集力数据的方法
[技术领域]
[0001]本发明涉及一种数据采集技术,尤其是一种数据自动采集方法。
[背景技术]
[0002]随着网络资源的不断丰富和网络信息量的不断扩大,人们越来越依赖网络,但是他们也可以从庞大的Internet资源中快速找到自己的特定需求。资源带来不便;自古以来,信息就具有无限的价值。随着时代的不断发展,人类在不知不觉中进入了信息时代,各行各业充斥着无数的信息,信息的价值在于数据的流通,如果能够及时地流通和传递数据的话信息的真正无与伦比的价值可以发挥作用;在市场经济条件下,采集数据已成为重要的工具和手段。
[p3] [0003]数据采集人员和市场研究人员面临的问题是如何从海量信息中采集有价值的数据并进行分析和研究,从而为企业的各种决策奠定基础。需要大量数据快速查找和获取所需信息和服务变得越来越困难。服务对象在查询信息时经常会失去目标或获得一些偏见。数据必须经过汇总,整合和分析才能产生价值,分散的信息只能是新闻,不能反映真实的商业价值;对于企业和信息分析师而言,一方面有必要在减少获取的同时从大量信息中滤除有效价值点。相应信息的成本使信息的实际使用价值大于在信息中产生的成本。采集和分析信息的过程,以便信息可以为企业的决策带来增值。
[0004]互联网的普及和信息技术的发展已经形成了大量的信息资源;从大量信息中提取有用资源是当前急需解决的问题,1613页上表达的主要信息通常隐藏在许多不相关的结构和文本中,用户无法快速获取主题信息,这限制了166的可用性。自动采集有助于解决此问题。自动采集节省了时间和精力,并涵盖了广泛的信息。提取质量不高,会影响精度;因此,现在大多数数据采集都使用自动采集方法;自动采集技术就是在这种背景下产生的。
[发明内容]
[0005]针对上述问题,本发明通过网络机器人技术和Web数据提取技术的应用开发了一种166数据自动采集方法。
[0006]本发明的技术手段如下:
[0007]-一种数据自动采集的方法,其特征在于包括以下步骤:
[0008]八、网络机器人技术:
[0009] 81、设计网络机器人的工作流程:机器人以一个或一组嘴巴为起点,进行浏览以访问对应的胃部文档,即文档;
[0010]八2、制定网络机器人设计原则;
[0011]纟21、制定不收录在漫游器中的项目的标准:在服务器上创建漫游器文本文件,其中指出网站个无法访问的链接和网站个拒绝访问的漫游器; [ 0012] A2 2、指定机械手的META标签:用户在页面上添加了META标签,该META标签允许页面的所有者指定是允许机器人程序索引页面还是从页面中提取链接;
[0013] A3、深度优先搜索策略和宽度优先搜索策略;
[0014]Α31、深度优先搜索策略是从起始节点开始,分析第一个文档并检索第一个链接指向的页面,然后在分析页面后检索该页面重复执行第一个链接的to,直到搜索到不收录任何超链接的文档并将其定义为完整链,然后返回文档,然后选择并搜索文档中的其余超链接。结束的迹象是所有超链接都已被搜索;
<p>[0015]Α32、广度优先搜索策略是分析第一个文档,搜索网页中的所有超链接,然后在下一级继续搜索,直到完成底部搜索;
常用的方法:常用数据采集方式介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-09-01 12:11
在线数据采集
1. 前端掩埋点: 通过在客户端上部署点,当用户在客户端上进行交互时,相应的信息将被记录并传输到日志服务器. 前端掩埋点有三种类型:
根据要求,记录指定的行为数据
优点: 定制的埋入点,灵活性强,采集丰富的数据信息,基本上适用于各种复杂场景;
缺点: 埋点工作量大,维护成本高;
根据需要,以视觉方式掩埋点并记录指定的行为数据
优点: 定制的埋入点,很好地解决了代码埋入点的工作量和维护成本
缺点: 某些页面控件行为无法实现;数据无法追踪;只能记录行为发生的次数
尽可能采集所有行为数据
优点: 解决了代码埋入点的工作量和维护成本,并且可以跟踪数据
缺点: 某些页面控件行为无法实现. 由于存在大量冗余数据,因此数据存储和传输的成本很高;只能记录行为发生的次数
2. 服务器端掩埋点: 通过在系统服务器端部署相应的数据采集模块,可以处理和分析采集数据.
比较前端掩埋点的优缺点
优点: 前端埋入点只能采集将数据信息保留在前端,而服务器端埋入点可以采集将数据记录在后端,这也可以减少客户的复杂性
缺点: 某些行为数据不一定会发出访问服务器的请求,并且服务器无法采集这部分数据
离线数据采集
脱机行为数据主要是通过硬件采集进行的,例如
第三方数据采集
第三方数据采集通常是一种程序或脚本,可以根据既定规则通过网络爬网程序自动对Internet信息进行爬网,并且通常用于网站的自动化测试和行为模拟.
Google,搜狗,百度等提供的Internet信息检索功能基于内部自建的Web采集器. 在遵守相关协议的条件下,他们将不断在Internet上抓取新鲜的网页信息,并在处理完内容后提供相应的检索服务 查看全部
常用数据介绍采集方法
在线数据采集
1. 前端掩埋点: 通过在客户端上部署点,当用户在客户端上进行交互时,相应的信息将被记录并传输到日志服务器. 前端掩埋点有三种类型:
根据要求,记录指定的行为数据
优点: 定制的埋入点,灵活性强,采集丰富的数据信息,基本上适用于各种复杂场景;
缺点: 埋点工作量大,维护成本高;
根据需要,以视觉方式掩埋点并记录指定的行为数据
优点: 定制的埋入点,很好地解决了代码埋入点的工作量和维护成本
缺点: 某些页面控件行为无法实现;数据无法追踪;只能记录行为发生的次数
尽可能采集所有行为数据
优点: 解决了代码埋入点的工作量和维护成本,并且可以跟踪数据
缺点: 某些页面控件行为无法实现. 由于存在大量冗余数据,因此数据存储和传输的成本很高;只能记录行为发生的次数
2. 服务器端掩埋点: 通过在系统服务器端部署相应的数据采集模块,可以处理和分析采集数据.
比较前端掩埋点的优缺点
优点: 前端埋入点只能采集将数据信息保留在前端,而服务器端埋入点可以采集将数据记录在后端,这也可以减少客户的复杂性
缺点: 某些行为数据不一定会发出访问服务器的请求,并且服务器无法采集这部分数据
离线数据采集
脱机行为数据主要是通过硬件采集进行的,例如
第三方数据采集
第三方数据采集通常是一种程序或脚本,可以根据既定规则通过网络爬网程序自动对Internet信息进行爬网,并且通常用于网站的自动化测试和行为模拟.
Google,搜狗,百度等提供的Internet信息检索功能基于内部自建的Web采集器. 在遵守相关协议的条件下,他们将不断在Internet上抓取新鲜的网页信息,并在处理完内容后提供相应的检索服务
整套解决方案:iOS SDK 自动采集指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-31 19:37
iOS SDK自动采集指南1.自动采集简介
TA系统提供了自动数据采集的界面. 您可以根据业务需要选择需要自动采集的数据.
当前支持的自动数据采集是:
APP安装,记录正在安装的APP的日志,APP启动(包括打开APP并从后台唤醒),关闭APP(包括关闭APP并转移到后台)以及采集启动时间. 用户浏览APP中的页面(本机页面). 点击APP中的控件,以在APP崩溃时记录崩溃信息
接下来,我们将详细介绍每种数据的采集方法
2. 打开自动采集
您可以调用enableAutoTrack: 打开自动采集功能:
// 开启某个APPID实例的自动采集事件,支持多个APPID实例都开启自动采集
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID]enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
ThinkingAnalyticsEventTypeAppInstall |
ThinkingAnalyticsEventTypeAppEnd |
ThinkingAnalyticsEventTypeAppViewScreen |
ThinkingAnalyticsEventTypeAppClick |
ThinkingAnalyticsEventTypeAppViewCrash];
// 单APPID实例时可调用以下方法开启
// [[ThinkingAnalyticsSDK sharedInstance] enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
// ThinkingAnalyticsEventTypeAppInstall |
// ThinkingAnalyticsEventTypeAppEnd |
// ThinkingAnalyticsEventTypeAppViewScreen |
// ThinkingAnalyticsEventTypeAppClick |
// ThinkingAnalyticsEventTypeAppViewCrash];
以上参数分别表示为:
根据业务情况,您可以传递要采集的事件的相应参数. 对于多个参数,请使用|. 分裂.
如果您需要设置公共事件属性或设置自定义访问者ID,请确保在打开自动采集之前调用setSuperProperties: 或identify:.
-(BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
[ThinkingAnalyticsSDK startWithAppId:@"APP_ID"
withUrl:@"SERVER_URL"];
return YES;
}
[[ThinkingAnalyticsSDK sharedInstance] identify:@"123ABCabc"];
[[ThinkingAnalyticsSDK sharedInstance] setSuperProperties:@{
@"Channel":@"ABC",
@"Server":123,
@"isTest":@YES
}];
//设置完访客ID与公共属性后,再开启自动采集
[[ThinkingAnalyticsSDK sharedInstance] enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
ThinkingAnalyticsEventTypeAppInstall |
ThinkingAnalyticsEventTypeAppEnd |
ThinkingAnalyticsEventTypeAppViewScreen |
ThinkingAnalyticsEventTypeAppClick |
ThinkingAnalyticsEventTypeAppViewCrash];
3. 自动采集事件3.1 APP安装事件的详细说明
APP安装事件将记录APP的实际安装并在启动APP时报告. 事件触发时间是安装后首次启动APP的时间. APP升级不会触发安装事件,并且在删除并重新安装后将报告安装事件.
3.2 APP启动事件
当用户启动APP或从后台唤醒APP时,将触发APP启动事件. 详细的事件描述如下:
3.3 APP关闭事件
当用户关闭APP或将APP转移到后台时,将触发APP关闭事件. 详细的事件描述如下:
3.4 APP浏览页面事件
APP浏览页面事件将在用户切换页面(View Controller)时触发浏览页面事件. 详细的事件描述如下:
可以将其他属性添加到页面浏览事件以扩展其分析价值. 以下是自定义页面浏览事件的属性的方法:
3.4.1自定义页面浏览事件的属性
对于从UIViewController继承的View Controller,您可以实现Protocol
要设置页面的属性和URL信息,SDK会自动将getTrackProperties: 的返回值添加到View Controller的APP浏览页面事件中;另外,getScreenUrl: 的返回值将用作页面的URL架构. 触发该页面的浏览事件时,将添加预设属性#url,其值为当前页面的URL架构. 同时,SDK将在跳转之前采用页面的URL架构. 如果可以获取,它将被添加到预设属性#Referrer是转发地址.
@interface MYController : UITableViewController
@end
@implementation MYController
//对所有APPID实例进行设置
- (NSDictionary *)getTrackProperties {
return @{@"PageName" : @"商品详情页", @"ProductId" : @12345};
}
- (NSString *)getScreenUrl {
return @"APP://test";
/** 多APPID实例单独进行设置
* - (NSDictionary *)getTrackPropertiesWithAppid{
* return @{@"appid1" : @{@"testTrackProperties" : @"测试页"},
* @"appid2" : @{@"testTrackProperties2" : @"测试页2"},
* };
* }
* -(NSDictionary *)getScreenUrlWithAppid {
* return @{@"appid1" : @"APP://test1",
* @"appid2" : @"APP://test2",
* };
* }
*/
}
@end
3.5 APP控件单击事件
当用户单击控件时,将触发APP控件的点击事件
对于页面上View的click事件,有很多方法可以设置更多属性以扩展其分析价值:
3.5.1设置控件元素ID
您可以在页面上设置元素(视图)的元素ID,以区分具有不同含义的元素. 您可以使用以下方法设置元素ID:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewID = @"testtable1";
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewIDWithAppid = @{ @"app1" : @"testtableID2",
@"app2" : @"testtableID3" };
这时,预设属性#element_id将添加到table1的click事件中,并且该值是在此处传递的值
3.5.2自定义控件点击事件的属性
对于大多数控件,您可以直接使用thinkingAnalyticsViewProperties设置自定义属性:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewProperties = @{@"key1":@"value1"};
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewPropertiesWithAppid = @{@"app1":@{@"tablekey":@"tablevalue"},
@"app2":@{@"tablekey2":@"tablevalue2"}
};
3.5.3 UITableView和UI采集View控件的单击事件属性
对于UITableView和UI采集View,您需要通过实现Protocol来设置自定义属性:
1. 首先在View Controller类中实现协议
2. 其次,在类中设置代理,建议在viewDidLoad方法中设置
self.table1.thinkingAnalyticsDelegate = self;
3. 然后根据视图控制器的类型实现该方法
//对所有APPID实例进行设置,设置UITableView的自定义属性
-(NSDictionary *) thinkingAnalytics_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* -(NSDictionary *) thinkingAnalyticsWithAppid_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoPro":@"tablevalue"},
* @"app2":@{@"autoPro2":@"tablevalue2"}
* };
* }
*/
//对所有APPID实例进行设置,设置UICollectionView的自定义属性
-(NSDictionary *) thinkingAnalytics_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath;
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* - (NSDictionary *)thinkingAnalyticsWithAppid_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoProCOLL":@"tablevalueCOLL"},
* @"app2":@{@"autoProCOLL2":@"tablevalueCOLL2"}
* };
* }
*/
4. 最后,在该类的viewWillDisappear方法中将thinkingAnalyticsDelegate设置为nil
-(void)viewWillDisappear:(BOOL)animated
{
[super viewWillDisappear:animated];
self.table1.thinkingAnalyticsDelegate = nil;
}
3.6 APP崩溃事件
当APP发生未捕获的异常时,将报告APP崩溃事件
4. 忽略自动采集事件
您可以通过以下方式忽略页面或控件的自动采集事件
4.1忽略页面的自动采集事件
对于某些页面(View Controller),如果您不想传输自动采集事件(包括页面浏览和控制点击事件),则可以通过以下方法忽略它们:
NSMutableArray *array = [[NSMutableArray alloc] init];
[array addObject:@"IgnoredViewController"];
// 多APPID实例时对单个APPID实例设置,忽略某个页面的自动采集事件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreAutoTrackViewControllers:array];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreAutoTrackViewControllers:array];
4.2忽略某种控件类型的click事件
如果您需要忽略某种控件类型的click事件,则可以使用以下方法将其忽略
// 多APPID实例时对单个APPID实例设置,忽略某个类型的所有控件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreViewType:[IgnoredClass class]];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreViewType:[IgnoredClass class]];
4.3忽略元素的点击事件(视图)
如果要忽略某个元素(查看)的click事件,可以使用以下方法将其忽略
// 对所有APPID实例进行设置
self.table1.thinkingAnalyticsIgnoreView = YES;
// 多APPID实例单独进行设置
// self.table2.thinkingAnalyticsIgnoreViewWithAppid = @{@"appid1" : @YES,@"appid2" : @NO};
5. 自动采集事件的预设属性
以下预设属性是每个自动采集事件中唯一的预设属性
属性名称中文名称说明
#resume_from_background
是否从后台醒来
表示是打开还是从后台唤醒APP,值为true表示从后台唤醒,值为false表示直接激活
属性名称中文名称说明
#duration
活动持续时间
指示此APP访问的持续时间(从开始到结束),单位为秒
属性名称中文名称说明
#title
页面标题
是View Controller的标题,该值是controller.navigationItem.title属性的值
#screen_name
页面名称
是View Controller的类名
#url
页面地址
当前页面的地址,您需要调用getScreenUrl来设置网址
#referrer
转发地址
跳转前页面的地址,跳转前页面需要调用getScreenUrl来设置网址
属性名称中文名称说明
#title
页面标题
是View Controller的标题,该值是controller.navigationItem.title属性的值
#screen_name
页面名称
是View Controller的类名
#element_id
元素ID
控件的ID需要通过thinkAnalyticsViewID设置
#element_type
元素类型
控制类型
#element_selector
元素选择器
控件的viewPath的拼接
#element_position
元素位置
控件的位置信息,仅当控件类型为UITableView或UI采集View时才存在,表示单击控件的位置,值为组号(Section): 行号(Row)
#element_content
元素内容
控件上的内容
属性名称中文名称说明
#app_crashed_reason
异常信息
字符类型,崩溃时记录堆栈跟踪 查看全部
iOS SDK自动采集指南
iOS SDK自动采集指南1.自动采集简介
TA系统提供了自动数据采集的界面. 您可以根据业务需要选择需要自动采集的数据.
当前支持的自动数据采集是:
APP安装,记录正在安装的APP的日志,APP启动(包括打开APP并从后台唤醒),关闭APP(包括关闭APP并转移到后台)以及采集启动时间. 用户浏览APP中的页面(本机页面). 点击APP中的控件,以在APP崩溃时记录崩溃信息
接下来,我们将详细介绍每种数据的采集方法
2. 打开自动采集
您可以调用enableAutoTrack: 打开自动采集功能:
// 开启某个APPID实例的自动采集事件,支持多个APPID实例都开启自动采集
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID]enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
ThinkingAnalyticsEventTypeAppInstall |
ThinkingAnalyticsEventTypeAppEnd |
ThinkingAnalyticsEventTypeAppViewScreen |
ThinkingAnalyticsEventTypeAppClick |
ThinkingAnalyticsEventTypeAppViewCrash];
// 单APPID实例时可调用以下方法开启
// [[ThinkingAnalyticsSDK sharedInstance] enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
// ThinkingAnalyticsEventTypeAppInstall |
// ThinkingAnalyticsEventTypeAppEnd |
// ThinkingAnalyticsEventTypeAppViewScreen |
// ThinkingAnalyticsEventTypeAppClick |
// ThinkingAnalyticsEventTypeAppViewCrash];
以上参数分别表示为:
根据业务情况,您可以传递要采集的事件的相应参数. 对于多个参数,请使用|. 分裂.
如果您需要设置公共事件属性或设置自定义访问者ID,请确保在打开自动采集之前调用setSuperProperties: 或identify:.
-(BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
[ThinkingAnalyticsSDK startWithAppId:@"APP_ID"
withUrl:@"SERVER_URL"];
return YES;
}
[[ThinkingAnalyticsSDK sharedInstance] identify:@"123ABCabc"];
[[ThinkingAnalyticsSDK sharedInstance] setSuperProperties:@{
@"Channel":@"ABC",
@"Server":123,
@"isTest":@YES
}];
//设置完访客ID与公共属性后,再开启自动采集
[[ThinkingAnalyticsSDK sharedInstance] enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
ThinkingAnalyticsEventTypeAppInstall |
ThinkingAnalyticsEventTypeAppEnd |
ThinkingAnalyticsEventTypeAppViewScreen |
ThinkingAnalyticsEventTypeAppClick |
ThinkingAnalyticsEventTypeAppViewCrash];
3. 自动采集事件3.1 APP安装事件的详细说明
APP安装事件将记录APP的实际安装并在启动APP时报告. 事件触发时间是安装后首次启动APP的时间. APP升级不会触发安装事件,并且在删除并重新安装后将报告安装事件.
3.2 APP启动事件
当用户启动APP或从后台唤醒APP时,将触发APP启动事件. 详细的事件描述如下:
3.3 APP关闭事件
当用户关闭APP或将APP转移到后台时,将触发APP关闭事件. 详细的事件描述如下:
3.4 APP浏览页面事件
APP浏览页面事件将在用户切换页面(View Controller)时触发浏览页面事件. 详细的事件描述如下:
可以将其他属性添加到页面浏览事件以扩展其分析价值. 以下是自定义页面浏览事件的属性的方法:
3.4.1自定义页面浏览事件的属性
对于从UIViewController继承的View Controller,您可以实现Protocol
要设置页面的属性和URL信息,SDK会自动将getTrackProperties: 的返回值添加到View Controller的APP浏览页面事件中;另外,getScreenUrl: 的返回值将用作页面的URL架构. 触发该页面的浏览事件时,将添加预设属性#url,其值为当前页面的URL架构. 同时,SDK将在跳转之前采用页面的URL架构. 如果可以获取,它将被添加到预设属性#Referrer是转发地址.
@interface MYController : UITableViewController
@end
@implementation MYController
//对所有APPID实例进行设置
- (NSDictionary *)getTrackProperties {
return @{@"PageName" : @"商品详情页", @"ProductId" : @12345};
}
- (NSString *)getScreenUrl {
return @"APP://test";
/** 多APPID实例单独进行设置
* - (NSDictionary *)getTrackPropertiesWithAppid{
* return @{@"appid1" : @{@"testTrackProperties" : @"测试页"},
* @"appid2" : @{@"testTrackProperties2" : @"测试页2"},
* };
* }
* -(NSDictionary *)getScreenUrlWithAppid {
* return @{@"appid1" : @"APP://test1",
* @"appid2" : @"APP://test2",
* };
* }
*/
}
@end
3.5 APP控件单击事件
当用户单击控件时,将触发APP控件的点击事件
对于页面上View的click事件,有很多方法可以设置更多属性以扩展其分析价值:
3.5.1设置控件元素ID
您可以在页面上设置元素(视图)的元素ID,以区分具有不同含义的元素. 您可以使用以下方法设置元素ID:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewID = @"testtable1";
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewIDWithAppid = @{ @"app1" : @"testtableID2",
@"app2" : @"testtableID3" };
这时,预设属性#element_id将添加到table1的click事件中,并且该值是在此处传递的值
3.5.2自定义控件点击事件的属性
对于大多数控件,您可以直接使用thinkingAnalyticsViewProperties设置自定义属性:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewProperties = @{@"key1":@"value1"};
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewPropertiesWithAppid = @{@"app1":@{@"tablekey":@"tablevalue"},
@"app2":@{@"tablekey2":@"tablevalue2"}
};
3.5.3 UITableView和UI采集View控件的单击事件属性
对于UITableView和UI采集View,您需要通过实现Protocol来设置自定义属性:
1. 首先在View Controller类中实现协议
2. 其次,在类中设置代理,建议在viewDidLoad方法中设置
self.table1.thinkingAnalyticsDelegate = self;
3. 然后根据视图控制器的类型实现该方法
//对所有APPID实例进行设置,设置UITableView的自定义属性
-(NSDictionary *) thinkingAnalytics_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* -(NSDictionary *) thinkingAnalyticsWithAppid_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoPro":@"tablevalue"},
* @"app2":@{@"autoPro2":@"tablevalue2"}
* };
* }
*/
//对所有APPID实例进行设置,设置UICollectionView的自定义属性
-(NSDictionary *) thinkingAnalytics_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath;
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* - (NSDictionary *)thinkingAnalyticsWithAppid_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoProCOLL":@"tablevalueCOLL"},
* @"app2":@{@"autoProCOLL2":@"tablevalueCOLL2"}
* };
* }
*/
4. 最后,在该类的viewWillDisappear方法中将thinkingAnalyticsDelegate设置为nil
-(void)viewWillDisappear:(BOOL)animated
{
[super viewWillDisappear:animated];
self.table1.thinkingAnalyticsDelegate = nil;
}
3.6 APP崩溃事件
当APP发生未捕获的异常时,将报告APP崩溃事件
4. 忽略自动采集事件
您可以通过以下方式忽略页面或控件的自动采集事件
4.1忽略页面的自动采集事件
对于某些页面(View Controller),如果您不想传输自动采集事件(包括页面浏览和控制点击事件),则可以通过以下方法忽略它们:
NSMutableArray *array = [[NSMutableArray alloc] init];
[array addObject:@"IgnoredViewController"];
// 多APPID实例时对单个APPID实例设置,忽略某个页面的自动采集事件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreAutoTrackViewControllers:array];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreAutoTrackViewControllers:array];
4.2忽略某种控件类型的click事件
如果您需要忽略某种控件类型的click事件,则可以使用以下方法将其忽略
// 多APPID实例时对单个APPID实例设置,忽略某个类型的所有控件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreViewType:[IgnoredClass class]];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreViewType:[IgnoredClass class]];
4.3忽略元素的点击事件(视图)
如果要忽略某个元素(查看)的click事件,可以使用以下方法将其忽略
// 对所有APPID实例进行设置
self.table1.thinkingAnalyticsIgnoreView = YES;
// 多APPID实例单独进行设置
// self.table2.thinkingAnalyticsIgnoreViewWithAppid = @{@"appid1" : @YES,@"appid2" : @NO};
5. 自动采集事件的预设属性
以下预设属性是每个自动采集事件中唯一的预设属性
属性名称中文名称说明
#resume_from_background
是否从后台醒来
表示是打开还是从后台唤醒APP,值为true表示从后台唤醒,值为false表示直接激活
属性名称中文名称说明
#duration
活动持续时间
指示此APP访问的持续时间(从开始到结束),单位为秒
属性名称中文名称说明
#title
页面标题
是View Controller的标题,该值是controller.navigationItem.title属性的值
#screen_name
页面名称
是View Controller的类名
#url
页面地址
当前页面的地址,您需要调用getScreenUrl来设置网址
#referrer
转发地址
跳转前页面的地址,跳转前页面需要调用getScreenUrl来设置网址
属性名称中文名称说明
#title
页面标题
是View Controller的标题,该值是controller.navigationItem.title属性的值
#screen_name
页面名称
是View Controller的类名
#element_id
元素ID
控件的ID需要通过thinkAnalyticsViewID设置
#element_type
元素类型
控制类型
#element_selector
元素选择器
控件的viewPath的拼接
#element_position
元素位置
控件的位置信息,仅当控件类型为UITableView或UI采集View时才存在,表示单击控件的位置,值为组号(Section): 行号(Row)
#element_content
元素内容
控件上的内容
属性名称中文名称说明
#app_crashed_reason
异常信息
字符类型,崩溃时记录堆栈跟踪
关于数据采集技术,这几种你一定要知道!
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-22 17:50
如今,不论哪行哪业的信息化人员,无论是同学聚会还是商务会晤,提到“大数据”的频次如同“吃了吗?”、“今天天气不错” 一样平时。没错,你我早已身处数据时代,但还未抵达大数据时代,差的是将海量数据有序融合并应用的距离。
各行各业,包括政府部门的信息化建设都是封闭的,海量数据被封在不同软件系统之中。要实现大数据,首先要实现诸多关联系统间数据的自如交互,这是大数据应用的前提。
该怎样实现?今天就和你一起阐述异构软件系统的3种数据采集方法,重点关注实现过程与各自优缺点。
一、软件插口形式
需要各系统的提供厂商提供数据插口,才能实现数据采集汇聚。
实现过程:
Step 1、协调多方软件厂商工程师到场,了解所有系统业务流程以及数据库相关的表结构设计等,细节推敲,确定可行性方案;
Step 2、编码
Step 3、测试、调试阶段
Step 4、交付使用
优势:接口对接方法的数据可靠性与价值较高,一般不存在数据重复的情况;数据可通过插口实时传输,满足数据实时应用要求。
缺点:接口开发费用高;需协调多个软件厂商,工作量大且容易烂尾;可扩展性不高,如:由于新业务须要各软件系统开发出新的业务模块,其和大数据平台之间的数据插口也需做相应更改和变动,甚至要推翻先前的所有数据插口编码,工作量大、耗时长。
二、开放数据库形式
数据的采集融合,开放数据库是最直接的一种形式。
系统分别有各自的数据库,而同类型的数据库之间数据融合是比较便捷的:
1. 如果两个数据库在同一个服务器上,只要用户名设置得没有问题,就可以直接互相访问,需要在from后将其数据库名称及表的构架所有者带上即可。
select * from DATABASE1.dbo.table1
2. 如果两个系统的数据库不在一个服务器上,建议采用链接服务器的方式处理,或者使用openset和opendatasource的形式,这个须要对数据库的访问进行外围服务器的配置。
3、不同类型的数据库之间的联接就比较麻烦了,需要做好多设置能够生效,这里不做详尽说明。
优势:开放数据库方法可以直接从目标数据库中获取须要的数据,准确性高,实时性也有保证,是最直接、便捷的一种形式。
缺点:开放数据库方法也须要协调各软件厂商开放数据库,这须要看对方的意愿,一般出于安全考虑,不会开放;
一个平台假如同时联接多个软件厂商的数据库,并实时获取数据,这对平台性能也是巨大挑战。
三、直接采集数据形式
以博为软件101异构数据采集技术为例:通过获取软件系统的底层数据交换、软件客户端和数据库之间的网路流量包,基于底层IO恳求与网路剖析等技术,采集目标软件形成的所有数据,将数据转换与重新结构化,输出到新的数据库,供软件系统调用。
技术特征如下:
1. 无需原软件厂商配合;
2. 实时数据采集,数据端到端的响应速率达秒级;
3. 兼容性强,可采集汇聚Windows平台各类软件系统数据;
4. 输出结构化数据,作为数据挖掘、大数据剖析应用的基础;
5. 自动构建数据间关联,实施周期短、简单高效;
6. 支持手动导出历史数据,通过I/O人工智能手动将数据写入目标软件;
7. 配置简单、实施周期短。
优点:和前两种数据采集方式相比,其优势在于不需要“接口”配合,这就甩掉了对软件厂商的依赖。特别是在在须要集成多个系统数据时,不仅能节约大量时间、人力与资金,实现“一站式”完成;还防止了因某些系统开发团队解体、源代码遗失等诱因引起系统数据集成出现烂尾的情况。
缺点:只采集Windows平台的各软件系统数据 查看全部
关于数据采集技术,这几种你一定要知道!
如今,不论哪行哪业的信息化人员,无论是同学聚会还是商务会晤,提到“大数据”的频次如同“吃了吗?”、“今天天气不错” 一样平时。没错,你我早已身处数据时代,但还未抵达大数据时代,差的是将海量数据有序融合并应用的距离。
各行各业,包括政府部门的信息化建设都是封闭的,海量数据被封在不同软件系统之中。要实现大数据,首先要实现诸多关联系统间数据的自如交互,这是大数据应用的前提。
该怎样实现?今天就和你一起阐述异构软件系统的3种数据采集方法,重点关注实现过程与各自优缺点。
一、软件插口形式
需要各系统的提供厂商提供数据插口,才能实现数据采集汇聚。
实现过程:
Step 1、协调多方软件厂商工程师到场,了解所有系统业务流程以及数据库相关的表结构设计等,细节推敲,确定可行性方案;
Step 2、编码
Step 3、测试、调试阶段
Step 4、交付使用

优势:接口对接方法的数据可靠性与价值较高,一般不存在数据重复的情况;数据可通过插口实时传输,满足数据实时应用要求。
缺点:接口开发费用高;需协调多个软件厂商,工作量大且容易烂尾;可扩展性不高,如:由于新业务须要各软件系统开发出新的业务模块,其和大数据平台之间的数据插口也需做相应更改和变动,甚至要推翻先前的所有数据插口编码,工作量大、耗时长。
二、开放数据库形式
数据的采集融合,开放数据库是最直接的一种形式。
系统分别有各自的数据库,而同类型的数据库之间数据融合是比较便捷的:
1. 如果两个数据库在同一个服务器上,只要用户名设置得没有问题,就可以直接互相访问,需要在from后将其数据库名称及表的构架所有者带上即可。
select * from DATABASE1.dbo.table1
2. 如果两个系统的数据库不在一个服务器上,建议采用链接服务器的方式处理,或者使用openset和opendatasource的形式,这个须要对数据库的访问进行外围服务器的配置。
3、不同类型的数据库之间的联接就比较麻烦了,需要做好多设置能够生效,这里不做详尽说明。

优势:开放数据库方法可以直接从目标数据库中获取须要的数据,准确性高,实时性也有保证,是最直接、便捷的一种形式。
缺点:开放数据库方法也须要协调各软件厂商开放数据库,这须要看对方的意愿,一般出于安全考虑,不会开放;
一个平台假如同时联接多个软件厂商的数据库,并实时获取数据,这对平台性能也是巨大挑战。
三、直接采集数据形式
以博为软件101异构数据采集技术为例:通过获取软件系统的底层数据交换、软件客户端和数据库之间的网路流量包,基于底层IO恳求与网路剖析等技术,采集目标软件形成的所有数据,将数据转换与重新结构化,输出到新的数据库,供软件系统调用。

技术特征如下:
1. 无需原软件厂商配合;
2. 实时数据采集,数据端到端的响应速率达秒级;
3. 兼容性强,可采集汇聚Windows平台各类软件系统数据;
4. 输出结构化数据,作为数据挖掘、大数据剖析应用的基础;
5. 自动构建数据间关联,实施周期短、简单高效;
6. 支持手动导出历史数据,通过I/O人工智能手动将数据写入目标软件;
7. 配置简单、实施周期短。

优点:和前两种数据采集方式相比,其优势在于不需要“接口”配合,这就甩掉了对软件厂商的依赖。特别是在在须要集成多个系统数据时,不仅能节约大量时间、人力与资金,实现“一站式”完成;还防止了因某些系统开发团队解体、源代码遗失等诱因引起系统数据集成出现烂尾的情况。
缺点:只采集Windows平台的各软件系统数据
连续动作:自动选择下拉菜单采集数据—以知网为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 692 次浏览 • 2020-08-20 07:00
注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤
用中国知网的刊物为例,展示连续动作中选择动作和爬虫路线中翻页的组合。本次教程要实现的是先检索2016年发表的刊物,再对检索结果进行采集,流程如下图所示:
为了实现这个,需要构建两级规则,第一级规则通过连续动作来手动选择发表年份,第二级规则负责采集期刊内容和翻页。操作步骤如下:
二、案例规则+操作步骤
第一步:定义第一级规则抓取内容
1.1,加载页面
打开集搜客网络爬虫,输入想要采集的样本网址并按Enter键,看到浏览器加载出网页后,点击右上方的“定义规则”。
注意:这里的截图和文字说明都是集搜客网络爬虫版本。如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台。
1.2,输入主题名
在工作台“主题名”处输入第一级规则的主题名,再点击“查重”,提示“该名可以使用”,就可以继续,否则请重新命名。这里命名主题名为“中国知网刊物检索前”。
Tips:虽然这一级规则主要是为了做选择动作,但为了保证页面早已加载完成,连续动作可以顺利进行,通常在这级规则构建一些抓取内容。
1.3,内容映射
选择“期刊”作为抓取内容,双击刊物,在弹出的标签栏处输入关键内容,整理箱命名为检索前,并勾选为关键内容。直观标明的基础操作在这里不赘言,不懂的请参考教程《采集网页数据》。
第二步:定义第一级规则连续动作
2.1,输入目标主题名
点击“连续动作”工作台,输入目标主题名(也就是第二级规则的主题名,这里命名为“中国知网刊物检索后”),点击“谁在用”,弹出的窗口没有信息,说明这个主题名没有被占用,可以继续旁边的操作,否则就须要换一个主题名。
2.2,创建第一个连续动作——起始年份选择2016
2.2.1,找到定位表达式,填写动作名称
点击新建,选择动作类型为“选择”,点击一下起始年份,会手动定位到相应节点,选择“显示XPath:偏好id”,程序会手动显示对应的Xpath路径,再点击搜索,可以看见这个路径能找到惟一的节点,可作为动作的定位表达式,将这个路径复制到定位表达式处,在动作名称写上文字,是为了便捷清楚每位动作的好处。
Tips:选择类型的连续动作,定位表达式必须讲到下拉菜单的select节点,而不能讲到某一个选项的option节点,否则运行时会报错。
2.2.2,高级设置
我们须要实现的是采集2016年发表的刊物,所以须要在起始年份和中止年份都选择点击2016年,这就须要在连续动作的中级设置里做约束。
2.3,创建第二个连续动作——终止年份选择2016
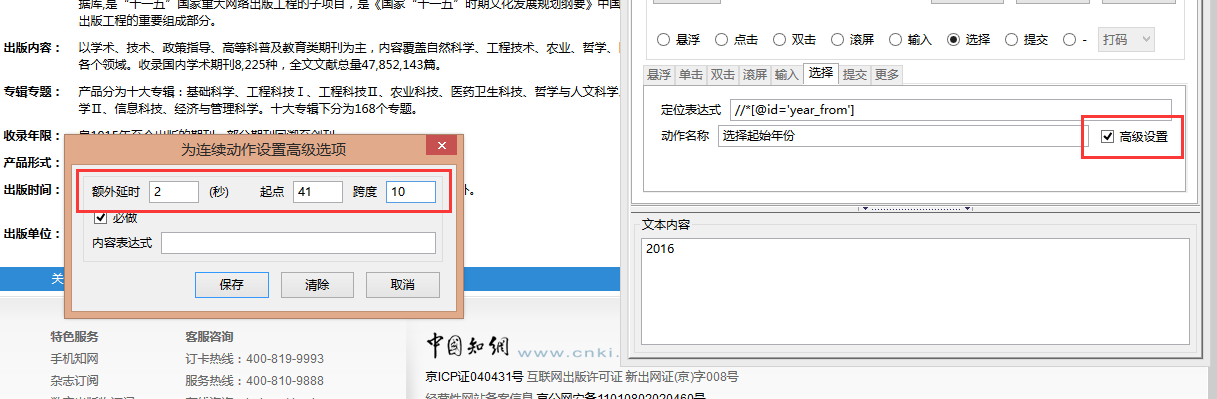
点击新建,选择动作类型为“选择”。参考步骤2.2找到中止年份对应的Xpath路径,并在中级设置中设置额外延时为2秒,起点为3(2016在第3个option),跨度填100。
2.4,创建第三个连续动作——点击检索
点击新建,选择“提交”动作。参考步骤2.2找到“检索”对应的Xpath路径,并在中级设置中设置额外延时为2秒。
2.5,存规则
点击“存规则”按钮保存已完成的第一级规则。
第三步:定义第二级规则抓取内容
3.1,新建规则
点击“定义规则”恢复到普通网页模式,选择2016年并点击检索搜索出文献结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,弹出提示“工作台上有内容,清空吗?”,点击确定。
输入主题名,这里的主题名就是上一级规则的连续动作哪里填写的目标主题名,也就是“中国知网刊物检索后”,点击查重,弹出提示“该名已被预定。可编辑:是”,说明这个主题名可以使用。
3.2,标注要采集的信息
在页面直接点击要采集的内容,弹出的窗口填上名称,给“标题”勾上关键内容,并做上样例复制。点击测试可以预览采集内容。直观标明的详尽说明在这里不赘言,详细可参考教程《采集列表数据》。
第四步:定义第二级规则翻页线索
4.1,设置翻页线索
点击爬虫路线,点击“新建”,选择“记号线索”;找到翻页标记“下一页”对应的节点,右击-线索映射-记号线索;找到收录整个翻页区域而且有class值或id值的节点,右击-线索映射-定位-线索1。设置翻页的操作在这里不赘言,详细可参考教程《设置翻页采集》。
4.2,存规则
点击“存规则”按钮保存已完成的第二级规则。
第五步:抓数据
连续动作的两级规则是连贯执行的,所以只须要运行第一级规则,做完动作后程序会手动调用第二级规则。直接运行第二级规则都会报错,因为打开的是执行动作前的初始页面。
5.1,打开打数机,找到第一级规则的主题名,点击“单搜”或“集搜”,可以看见打数机的网页窗口会手动选择2016年,并不断往下翻页。
5.2,打开第二级主题的文件夹查看结果数据,在xml文件的actionvalue字段记录了选择的条目,这样才能与结果数据一一对应上去。
上篇文章:《连续动作:自动搜索关键词采集信息》 下篇文章:《连续动作:滚屏采集瀑布流网页》
若有疑问可以或 查看全部
连续动作:自动选择下拉菜单采集数据—以知网为例
注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤
用中国知网的刊物为例,展示连续动作中选择动作和爬虫路线中翻页的组合。本次教程要实现的是先检索2016年发表的刊物,再对检索结果进行采集,流程如下图所示:

为了实现这个,需要构建两级规则,第一级规则通过连续动作来手动选择发表年份,第二级规则负责采集期刊内容和翻页。操作步骤如下:

二、案例规则+操作步骤
第一步:定义第一级规则抓取内容

1.1,加载页面
打开集搜客网络爬虫,输入想要采集的样本网址并按Enter键,看到浏览器加载出网页后,点击右上方的“定义规则”。
注意:这里的截图和文字说明都是集搜客网络爬虫版本。如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台。
1.2,输入主题名
在工作台“主题名”处输入第一级规则的主题名,再点击“查重”,提示“该名可以使用”,就可以继续,否则请重新命名。这里命名主题名为“中国知网刊物检索前”。
Tips:虽然这一级规则主要是为了做选择动作,但为了保证页面早已加载完成,连续动作可以顺利进行,通常在这级规则构建一些抓取内容。
1.3,内容映射

选择“期刊”作为抓取内容,双击刊物,在弹出的标签栏处输入关键内容,整理箱命名为检索前,并勾选为关键内容。直观标明的基础操作在这里不赘言,不懂的请参考教程《采集网页数据》。
第二步:定义第一级规则连续动作

2.1,输入目标主题名
点击“连续动作”工作台,输入目标主题名(也就是第二级规则的主题名,这里命名为“中国知网刊物检索后”),点击“谁在用”,弹出的窗口没有信息,说明这个主题名没有被占用,可以继续旁边的操作,否则就须要换一个主题名。
2.2,创建第一个连续动作——起始年份选择2016

2.2.1,找到定位表达式,填写动作名称
点击新建,选择动作类型为“选择”,点击一下起始年份,会手动定位到相应节点,选择“显示XPath:偏好id”,程序会手动显示对应的Xpath路径,再点击搜索,可以看见这个路径能找到惟一的节点,可作为动作的定位表达式,将这个路径复制到定位表达式处,在动作名称写上文字,是为了便捷清楚每位动作的好处。
Tips:选择类型的连续动作,定位表达式必须讲到下拉菜单的select节点,而不能讲到某一个选项的option节点,否则运行时会报错。
2.2.2,高级设置
我们须要实现的是采集2016年发表的刊物,所以须要在起始年份和中止年份都选择点击2016年,这就须要在连续动作的中级设置里做约束。
2.3,创建第二个连续动作——终止年份选择2016

点击新建,选择动作类型为“选择”。参考步骤2.2找到中止年份对应的Xpath路径,并在中级设置中设置额外延时为2秒,起点为3(2016在第3个option),跨度填100。
2.4,创建第三个连续动作——点击检索

点击新建,选择“提交”动作。参考步骤2.2找到“检索”对应的Xpath路径,并在中级设置中设置额外延时为2秒。
2.5,存规则
点击“存规则”按钮保存已完成的第一级规则。
第三步:定义第二级规则抓取内容

3.1,新建规则
点击“定义规则”恢复到普通网页模式,选择2016年并点击检索搜索出文献结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,弹出提示“工作台上有内容,清空吗?”,点击确定。
输入主题名,这里的主题名就是上一级规则的连续动作哪里填写的目标主题名,也就是“中国知网刊物检索后”,点击查重,弹出提示“该名已被预定。可编辑:是”,说明这个主题名可以使用。
3.2,标注要采集的信息

在页面直接点击要采集的内容,弹出的窗口填上名称,给“标题”勾上关键内容,并做上样例复制。点击测试可以预览采集内容。直观标明的详尽说明在这里不赘言,详细可参考教程《采集列表数据》。
第四步:定义第二级规则翻页线索

4.1,设置翻页线索
点击爬虫路线,点击“新建”,选择“记号线索”;找到翻页标记“下一页”对应的节点,右击-线索映射-记号线索;找到收录整个翻页区域而且有class值或id值的节点,右击-线索映射-定位-线索1。设置翻页的操作在这里不赘言,详细可参考教程《设置翻页采集》。
4.2,存规则
点击“存规则”按钮保存已完成的第二级规则。
第五步:抓数据
连续动作的两级规则是连贯执行的,所以只须要运行第一级规则,做完动作后程序会手动调用第二级规则。直接运行第二级规则都会报错,因为打开的是执行动作前的初始页面。

5.1,打开打数机,找到第一级规则的主题名,点击“单搜”或“集搜”,可以看见打数机的网页窗口会手动选择2016年,并不断往下翻页。
5.2,打开第二级主题的文件夹查看结果数据,在xml文件的actionvalue字段记录了选择的条目,这样才能与结果数据一一对应上去。
上篇文章:《连续动作:自动搜索关键词采集信息》 下篇文章:《连续动作:滚屏采集瀑布流网页》
若有疑问可以或
智联招聘数据爬取(基础篇)
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-19 17:59
在智联招聘数据爬取(踩坑篇)中给出一种采集智联招聘数据的方式,方法简单,但不够自动化,效率较低。在本篇文章中,将介绍一种自动化采集方法,提高数据采集的效率。本篇文章可以将智联招聘网站数据搜集过程中的复制粘贴步骤省去,在浏览网页的同时,自动下载对应的json文件,实现数据采集。
工具介绍
上篇文章中提及,想要爬取的数据隐藏于某个链接的response中,即所谓的数据包,所以须要一个“抓包工具”。
常用的抓包工具包括fiddler和mitmproxy等,由于mitmproxy由python语言编撰,且支持自定义python脚本,所以作者选择使用mitmproxy对数据包进行抓取。
mitmproxy才能进行爬虫的原理如下:
mitmproxy相当于是一个蝶阀,从浏览器到服务器之间多了一层,所有的访问恳求就会首先传输到mitmproxy,再由mitmproxy传输到服务器;所有服务器返回的数据就会首先经过mitmproxy,再交由浏览器解析呈现。所以想要爬取的岗位信息必然会被mitmproxy记录,通过mitmproxy找到数据包,进而将数据包保存即可。
基本操作
mitmproxy安装
如智联招聘数据爬取(入门篇)中介绍,建议安装anaconda,本文依托anaconda进行操作。作者系统环境如下:
操作系统:Windows10 家庭中文版 64bit
Python:anaconda、Python3.7.7
anaconda安装python包的形式是在Anaconda Prompt中安装,mitmproxy的安装代码如下:
pip install mitmproxy
测试是否安装成功,可在Anaconda Prompt中输入以下代码测试。使用mitmweb测试的诱因包括:1)mitmproxy的安装实际上安装mitmproxy、mitmweb和mitmdump;2)mitmproxy在Windows系统下不可用,mitmweb和mitmdump的区别是mitmweb提供web界面,mitmdump为沉静模式,无web界面。初学时建议使用mitmweb,方便查看。
mitmweb --version
安装成功则会看见如下显示内容
Mitmproxy: 5.1.1
Python: 3.7.7
OpenSSL: OpenSSL 1.1.1g 21 Apr 2020
Platform: Windows-10-10.0.18362-SP0
mitmproxy基本操作
安装成功后,就来认识下mitmproxy。
1)在Anaconda Prompt中打开mitmweb,可以看见以下启动页(设置谷歌浏览器为默认浏览器),同时可以在Anaconda Prompt见到早已启动窃听,监听端口为8080。
2)将1)中的启动页使用其他浏览器打开(作者使用的是“世界之窗”,复制粘贴网址即可),然后关掉谷歌浏览器(必须完全关掉),再在cmd中使用8080端口重新启动谷歌浏览器,并忽视证书错误(毕竟是窃听,需要忽视证书错误)。(这一部分建议在爬虫前,新建一个谷歌浏览器的用户文件夹,优点一是防止对现有的谷歌浏览器设置形成干扰;优点二在下一篇介绍。所以启动代码建议使用代码二。新建谷歌浏览器的用户文件夹,只要在任一文件夹下新建空白的“AutomationProfile”文件夹即可)
# 代码一
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors
# 代码二
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors --user-data-dir=D:\\360Downloads\\AutomationProfile
3)在2)中启动谷歌浏览器后,输入智联急聘的网址(/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3)后可在世界之窗的窃听窗口观察到各类传输的链接,寻找以/c/i/sou?_v= 开头的链接,可在其response中发觉想要爬取的数据。
至此使用mitmproxy监控谷歌浏览器访问智联招聘网站已经完成,接下来使用mitmproxy自定义python脚本将对应数据包的数据下载。
mitmproxy自定义脚本
把浏览器与服务器之间的交互觉得是flow,想要爬取的数据在以/c/i/sou?_v=开头的链接中。在mitmproxy中,链接包括两部份:host和url,其中host是服务器网址(),url是对应的链接(/c/i/sou?_v=)。host+url即组成了完整链接,在这里,只须要使用url即可采集到相应数据。只要找到以/c/i/sou?_v=开头url,通过获取response中的内容,再将其写入到txt文件即可。代码如下:
import mitmproxy.http
from mitmproxy import ctx
url_paths = '/c/i/sou?_v=' #筛选url的判断条件
class Jobinfo:
def response(self, flow: mitmproxy.http.HTTPFlow):
if flow.request.path.startswith(url_paths): #startwith,找到对应的url
text = flow.response.get_text() #获取url的response的内容
file_handle=open('0624.txt',mode='a') #打开txt
file_handle.write(text) #将获取的response内容写入到txt
file_handle.write('\n') #写入 换行符
file_handle.write('\n') #写入 换行符
file_handle.close() # 关闭txt
return
addons = [
Jobinfo()
] #mitmproxy使用自定义python脚本的方法
mitmproxy使用python脚本,只须要在启动mitmweb时,使用-s 后添加对应的py文件即可。(具体可参考拓展阅读)
自动化采集数据
在了解mitmproxy的基本操作之后,这一部分实现数据的自动化复制粘贴。
1)在Ananconda Prompt中启动mitmweb,并指定自定义的python脚本。代码如下,其中-s表示要加载前面代码, 'D:\\360Downloads\\addons0624.py'表示代码地址,addons0624.py内的代码即为自定义python脚本。
mitmweb -s 'D:\\360Downloads\\addons0624.py'
2)在cmd中使用下列代码启动谷歌浏览器
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors --user-data-dir=D:\\360Downloads\\AutomationProfile
3)在谷歌浏览器中输入打算好的“北京市数据分析师”的网址/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3。伴随着在浏览器中翻页,对应页面的岗位数据即可写入到定义的txt文件中。
4)在文件夹中找到定义的txt文件即可。
如果不知道txt保存在哪,推荐下载everything搜索即可,非常便捷。
至此,已经实现复制粘贴的自动化。
总结
在智联招聘数据爬取(踩坑篇)给出了一种自动采集数据的方式,在这篇文章,将复制粘贴json数据进行自动化。只须要以特定的方法启动谷歌浏览器,并访问相应的页面即可实现数据的采集,更加便捷。下一篇文章即为智联招聘数据爬虫的最终篇,在最终篇将自动化浏览器的访问过程,实现数据采集的完全自动化。敬请期盼。
本文首发公众号“数据科学家进阶之路”,主要专注数据剖析所需的技能,通过相应的案例熟悉模型算法,通过实际的业务例子熟悉商业逻辑,通过读书积累分享思维方法。期待你们关注。
拓展阅读:
使用mitmproxy+python做拦截代理:
/posts/usage-of-mitmproxy/ 查看全部
智联招聘数据爬取(基础篇)
在智联招聘数据爬取(踩坑篇)中给出一种采集智联招聘数据的方式,方法简单,但不够自动化,效率较低。在本篇文章中,将介绍一种自动化采集方法,提高数据采集的效率。本篇文章可以将智联招聘网站数据搜集过程中的复制粘贴步骤省去,在浏览网页的同时,自动下载对应的json文件,实现数据采集。
工具介绍
上篇文章中提及,想要爬取的数据隐藏于某个链接的response中,即所谓的数据包,所以须要一个“抓包工具”。
常用的抓包工具包括fiddler和mitmproxy等,由于mitmproxy由python语言编撰,且支持自定义python脚本,所以作者选择使用mitmproxy对数据包进行抓取。
mitmproxy才能进行爬虫的原理如下:

mitmproxy相当于是一个蝶阀,从浏览器到服务器之间多了一层,所有的访问恳求就会首先传输到mitmproxy,再由mitmproxy传输到服务器;所有服务器返回的数据就会首先经过mitmproxy,再交由浏览器解析呈现。所以想要爬取的岗位信息必然会被mitmproxy记录,通过mitmproxy找到数据包,进而将数据包保存即可。
基本操作
mitmproxy安装
如智联招聘数据爬取(入门篇)中介绍,建议安装anaconda,本文依托anaconda进行操作。作者系统环境如下:
操作系统:Windows10 家庭中文版 64bit
Python:anaconda、Python3.7.7
anaconda安装python包的形式是在Anaconda Prompt中安装,mitmproxy的安装代码如下:
pip install mitmproxy
测试是否安装成功,可在Anaconda Prompt中输入以下代码测试。使用mitmweb测试的诱因包括:1)mitmproxy的安装实际上安装mitmproxy、mitmweb和mitmdump;2)mitmproxy在Windows系统下不可用,mitmweb和mitmdump的区别是mitmweb提供web界面,mitmdump为沉静模式,无web界面。初学时建议使用mitmweb,方便查看。
mitmweb --version
安装成功则会看见如下显示内容
Mitmproxy: 5.1.1
Python: 3.7.7
OpenSSL: OpenSSL 1.1.1g 21 Apr 2020
Platform: Windows-10-10.0.18362-SP0
mitmproxy基本操作
安装成功后,就来认识下mitmproxy。
1)在Anaconda Prompt中打开mitmweb,可以看见以下启动页(设置谷歌浏览器为默认浏览器),同时可以在Anaconda Prompt见到早已启动窃听,监听端口为8080。

2)将1)中的启动页使用其他浏览器打开(作者使用的是“世界之窗”,复制粘贴网址即可),然后关掉谷歌浏览器(必须完全关掉),再在cmd中使用8080端口重新启动谷歌浏览器,并忽视证书错误(毕竟是窃听,需要忽视证书错误)。(这一部分建议在爬虫前,新建一个谷歌浏览器的用户文件夹,优点一是防止对现有的谷歌浏览器设置形成干扰;优点二在下一篇介绍。所以启动代码建议使用代码二。新建谷歌浏览器的用户文件夹,只要在任一文件夹下新建空白的“AutomationProfile”文件夹即可)
# 代码一
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors
# 代码二
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors --user-data-dir=D:\\360Downloads\\AutomationProfile
3)在2)中启动谷歌浏览器后,输入智联急聘的网址(/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3)后可在世界之窗的窃听窗口观察到各类传输的链接,寻找以/c/i/sou?_v= 开头的链接,可在其response中发觉想要爬取的数据。

至此使用mitmproxy监控谷歌浏览器访问智联招聘网站已经完成,接下来使用mitmproxy自定义python脚本将对应数据包的数据下载。
mitmproxy自定义脚本
把浏览器与服务器之间的交互觉得是flow,想要爬取的数据在以/c/i/sou?_v=开头的链接中。在mitmproxy中,链接包括两部份:host和url,其中host是服务器网址(),url是对应的链接(/c/i/sou?_v=)。host+url即组成了完整链接,在这里,只须要使用url即可采集到相应数据。只要找到以/c/i/sou?_v=开头url,通过获取response中的内容,再将其写入到txt文件即可。代码如下:
import mitmproxy.http
from mitmproxy import ctx
url_paths = '/c/i/sou?_v=' #筛选url的判断条件
class Jobinfo:
def response(self, flow: mitmproxy.http.HTTPFlow):
if flow.request.path.startswith(url_paths): #startwith,找到对应的url
text = flow.response.get_text() #获取url的response的内容
file_handle=open('0624.txt',mode='a') #打开txt
file_handle.write(text) #将获取的response内容写入到txt
file_handle.write('\n') #写入 换行符
file_handle.write('\n') #写入 换行符
file_handle.close() # 关闭txt
return
addons = [
Jobinfo()
] #mitmproxy使用自定义python脚本的方法
mitmproxy使用python脚本,只须要在启动mitmweb时,使用-s 后添加对应的py文件即可。(具体可参考拓展阅读)
自动化采集数据
在了解mitmproxy的基本操作之后,这一部分实现数据的自动化复制粘贴。
1)在Ananconda Prompt中启动mitmweb,并指定自定义的python脚本。代码如下,其中-s表示要加载前面代码, 'D:\\360Downloads\\addons0624.py'表示代码地址,addons0624.py内的代码即为自定义python脚本。
mitmweb -s 'D:\\360Downloads\\addons0624.py'
2)在cmd中使用下列代码启动谷歌浏览器
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors --user-data-dir=D:\\360Downloads\\AutomationProfile
3)在谷歌浏览器中输入打算好的“北京市数据分析师”的网址/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3。伴随着在浏览器中翻页,对应页面的岗位数据即可写入到定义的txt文件中。
4)在文件夹中找到定义的txt文件即可。
如果不知道txt保存在哪,推荐下载everything搜索即可,非常便捷。
至此,已经实现复制粘贴的自动化。

总结
在智联招聘数据爬取(踩坑篇)给出了一种自动采集数据的方式,在这篇文章,将复制粘贴json数据进行自动化。只须要以特定的方法启动谷歌浏览器,并访问相应的页面即可实现数据的采集,更加便捷。下一篇文章即为智联招聘数据爬虫的最终篇,在最终篇将自动化浏览器的访问过程,实现数据采集的完全自动化。敬请期盼。
本文首发公众号“数据科学家进阶之路”,主要专注数据剖析所需的技能,通过相应的案例熟悉模型算法,通过实际的业务例子熟悉商业逻辑,通过读书积累分享思维方法。期待你们关注。
拓展阅读:
使用mitmproxy+python做拦截代理:
/posts/usage-of-mitmproxy/
网页数据采集原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 605 次浏览 • 2020-08-18 15:11
2、根据网页特点和采集需求,设计采集流程,优采云根据流程全手动采集数据。
平常我们浏览网页的动作不会被记录出来。例如:这次在易迅上输入关键词【手机】查询相关商品数据,下次还须要输。
在用优采云采集数据的时侯,我们就须要依照网页特点和采集需求,设计采集流程,将我们的采集需求记录出来。之后优采云就能按照设计好的采集流程,全手动的采集数据。
例如:在前几课小学到的,需采集页面上的所有商品列表,我们就做一个【循环-提取数据】的步骤。采集时有很多页,需要翻页,我们就做一个【循环翻页】的步骤。
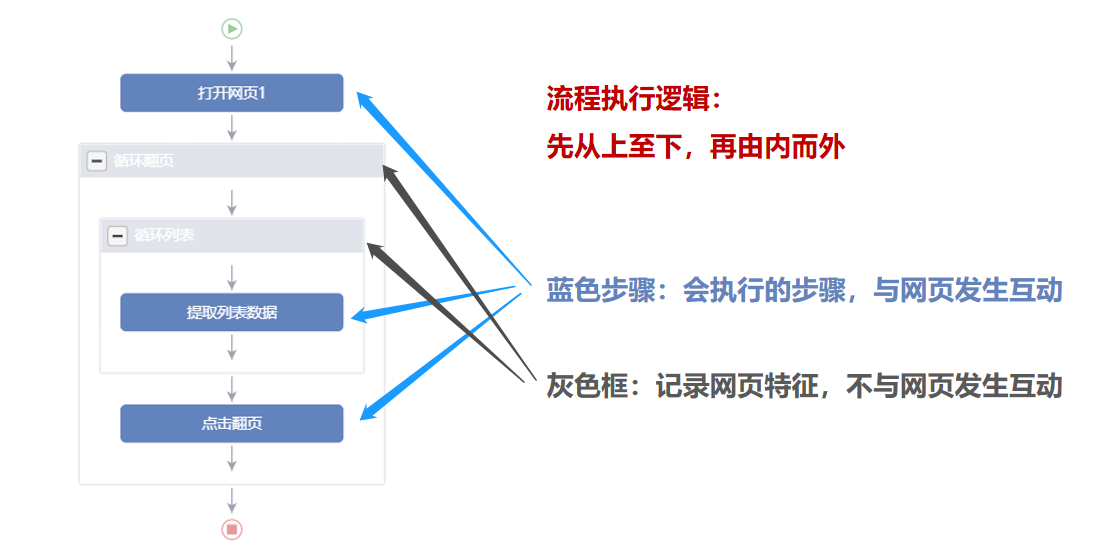
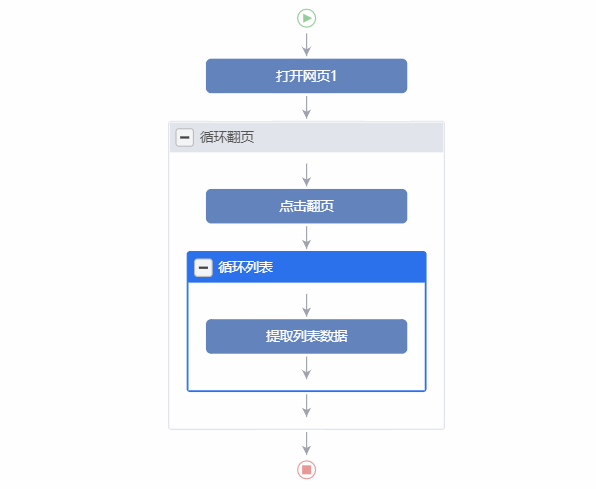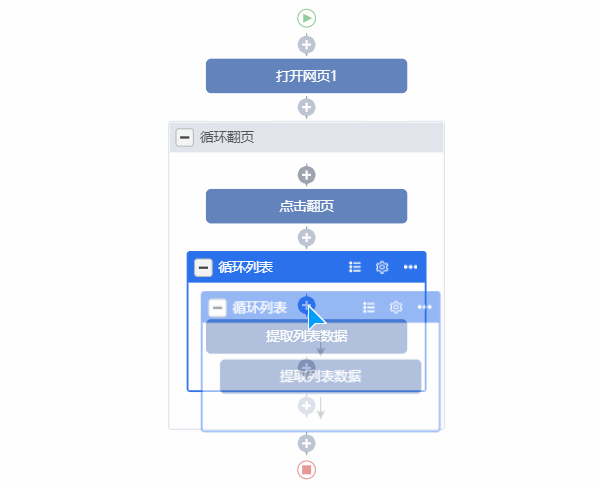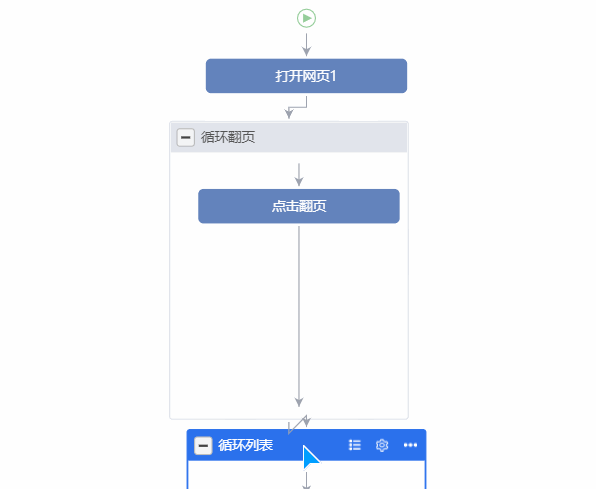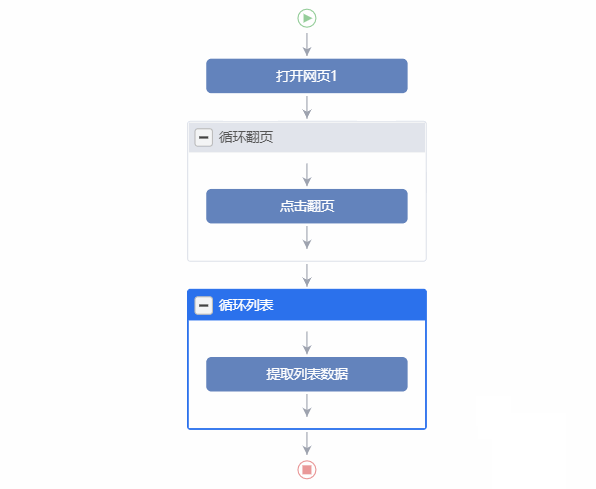
二、【采集流程】执行逻辑
优采云通过【采集流程】全手动采集数据。【采集流程】执行逻辑遵守2个原则:先从上至下、再由内而外。
【采集流程】由【蓝色步骤】和【灰色框】两大部份组成。【蓝色步骤】是会执行的步骤,优采云与网页发生互动。【灰色框】起记录网页的作用。
鼠标放在图片上,右键,选择【在新标签页中打开图片】可查看高清大图
下文其他图片同理
来看几个实例,更深入理解【采集流程】执行逻辑。
实例1:
实例2:
实例3:
特别说明:
a. 【采集流程】无固定标准,符合网页本身的跳转逻辑即可。
b.【采集流程】中可设置多个点击步骤、多个嵌套循环,以实现网页多层级的数据采集。
c. 【采集流程】中的步骤,可以拖动调整位置。鼠标选中步骤并拖住联通至想要的
位置。
看到这儿的小伙伴,恭喜您已经完成了【自定义配置采集数据】全部的入门课程。现在,您早已把握基础的数据采集技能啦!
如果您有任何的问题与建议,请通过官网两侧QQ、电话、客服系统等多种渠道联系我们!
作者:Aisling 查看全部
网页数据采集原理
2、根据网页特点和采集需求,设计采集流程,优采云根据流程全手动采集数据。
平常我们浏览网页的动作不会被记录出来。例如:这次在易迅上输入关键词【手机】查询相关商品数据,下次还须要输。
在用优采云采集数据的时侯,我们就须要依照网页特点和采集需求,设计采集流程,将我们的采集需求记录出来。之后优采云就能按照设计好的采集流程,全手动的采集数据。
例如:在前几课小学到的,需采集页面上的所有商品列表,我们就做一个【循环-提取数据】的步骤。采集时有很多页,需要翻页,我们就做一个【循环翻页】的步骤。
二、【采集流程】执行逻辑
优采云通过【采集流程】全手动采集数据。【采集流程】执行逻辑遵守2个原则:先从上至下、再由内而外。
【采集流程】由【蓝色步骤】和【灰色框】两大部份组成。【蓝色步骤】是会执行的步骤,优采云与网页发生互动。【灰色框】起记录网页的作用。
鼠标放在图片上,右键,选择【在新标签页中打开图片】可查看高清大图
下文其他图片同理
来看几个实例,更深入理解【采集流程】执行逻辑。
实例1:

实例2:

实例3:

特别说明:
a. 【采集流程】无固定标准,符合网页本身的跳转逻辑即可。
b.【采集流程】中可设置多个点击步骤、多个嵌套循环,以实现网页多层级的数据采集。
c. 【采集流程】中的步骤,可以拖动调整位置。鼠标选中步骤并拖住联通至想要的

位置。
看到这儿的小伙伴,恭喜您已经完成了【自定义配置采集数据】全部的入门课程。现在,您早已把握基础的数据采集技能啦!
如果您有任何的问题与建议,请通过官网两侧QQ、电话、客服系统等多种渠道联系我们!
作者:Aisling
宅要撸美女福利图片站整站数据+会员中心+自动采集+带手机版(双版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 1042 次浏览 • 2020-08-17 19:40
先送一波福利
下载观看
有两个版本:
WordPress版本: 300元+100 ThinkPHP版本(带数据)
ThinkPHP版本: 250元(带数据)adminmbxzb123
两个版本均带手机站自行测试!包安装售后。
即日起此模板买一送一,只需花一个模板的钱,你就可以拥有两套程序。
更新记录
2017.03.10
1、优化后台插件,删除多余无用功能。
2、更新采集插件到最新版(采集更加稳定)。
购买WP版本主题赠送价值199元erphpdown会员插件:
WordPress版本系统介绍:
WordPress是一种使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站。也可以把 WordPress当成一个内容管理系统(CMS)来使用。
WordPress是一款个人博客系统,并逐渐演变成一款内容管理系统软件,它是使用PHP语言和MySQL数据库开发的。用户可以在支持 PHP 和 MySQL数据库的服务器上使用自己的博客。
WordPress有许多第三方开发的免费模板,安装方法简单易用。不过要做一个自己的模板,则须要你有一定的专业知识。比如你起码要懂的标准通用标记语言下的一个应用HTML代码、CSS、PHP等相关知识。WordPress官方支持中文版,同时有爱好者开发的第三方英文语言包,如wopus英文语言包。WordPress拥有成千上万个各色插件和不计其数的主题模板式样。
ThinkPHP版本系统介绍:
基于国外流行的ThinkPHP3.2.3框架研制,UI插件采用简约、直观、强悍的 Bootstrap3.3.5后端开发框架以及口碑绝佳的web弹层组件LayerUI,全新的设计理念,带来更凉爽的体验。
系统采用多站点 切换的设计方案,巧妙地解决了一站一后台的传统弊病,不仅便捷站点的管理,也节约更多的研制时间,在新版本的系统中还集成了微信公众号、Ucenter用 户中心等一系列常用功能!由于系统没有自带模板标签功能,所以这就要求使用者具备一定基础的ThinkPHP3.2.3开发经验,自行进行后台数据逻辑的调用与处理。
此资源下载价钱为259M币,请先登入 查看全部
宅要撸美女福利图片站整站数据+会员中心+自动采集+带手机版(双版本)
先送一波福利
下载观看
有两个版本:
WordPress版本: 300元+100 ThinkPHP版本(带数据)
ThinkPHP版本: 250元(带数据)adminmbxzb123
两个版本均带手机站自行测试!包安装售后。
即日起此模板买一送一,只需花一个模板的钱,你就可以拥有两套程序。
更新记录
2017.03.10
1、优化后台插件,删除多余无用功能。
2、更新采集插件到最新版(采集更加稳定)。
购买WP版本主题赠送价值199元erphpdown会员插件:
WordPress版本系统介绍:
WordPress是一种使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站。也可以把 WordPress当成一个内容管理系统(CMS)来使用。
WordPress是一款个人博客系统,并逐渐演变成一款内容管理系统软件,它是使用PHP语言和MySQL数据库开发的。用户可以在支持 PHP 和 MySQL数据库的服务器上使用自己的博客。
WordPress有许多第三方开发的免费模板,安装方法简单易用。不过要做一个自己的模板,则须要你有一定的专业知识。比如你起码要懂的标准通用标记语言下的一个应用HTML代码、CSS、PHP等相关知识。WordPress官方支持中文版,同时有爱好者开发的第三方英文语言包,如wopus英文语言包。WordPress拥有成千上万个各色插件和不计其数的主题模板式样。
ThinkPHP版本系统介绍:
基于国外流行的ThinkPHP3.2.3框架研制,UI插件采用简约、直观、强悍的 Bootstrap3.3.5后端开发框架以及口碑绝佳的web弹层组件LayerUI,全新的设计理念,带来更凉爽的体验。
系统采用多站点 切换的设计方案,巧妙地解决了一站一后台的传统弊病,不仅便捷站点的管理,也节约更多的研制时间,在新版本的系统中还集成了微信公众号、Ucenter用 户中心等一系列常用功能!由于系统没有自带模板标签功能,所以这就要求使用者具备一定基础的ThinkPHP3.2.3开发经验,自行进行后台数据逻辑的调用与处理。
此资源下载价钱为259M币,请先登入
基于R语言的手动数据搜集:网络抓取和文本挖掘实用手册
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-15 02:14
本书也不会严谨地介绍数据科学。在这个主题上也有一些出众的教材,例如O扤eil and Schutt(2013)、Torgo(2010)、Zhao(2012),以及Zumel and Mount(2014)。在那些书中时常缺位的部份是怎样在真实环境中获取数据科学中用到的数据。在这方面,本书可以作为数据剖析的打算阶段的参考书,它还给出了关于怎么管理可用信息并使它们保持及时更新的指导原则。
最后,你最不可能从本书听到的是针对你的具体问题的完美解答。在数据采集过程中,获取数据的领域从来都不会完全相像,而且其方式有时也会快速变化,这都是固有的问题。我们的目标是使你能改写事例和案例剖析中提供的代码,并创建新的代码,以此帮助你在采集自己所需数据的工作中获得成功。
为什么使用R
对于本书中囊括的问题,R是一个挺好的解决方案,我们如此考虑是有很多缘由的。对我们来说,最重要的几点缘由如下:
R可以自由和简便地获得。你可以按自己的须要随时随地下载、安装和使用它。不去钻研这些高昂的专有软件对你是大有裨益的,因为你不需要依赖于雇主支付软件版权费的意愿。
作为一个主要专注于统计学的软件环境,R拥有一个巨大并且持续繁荣的社区。R被用于各类专业领域,如社会科学、医学科学、心理学、生物学、地理学、语言学以及商业等。这样大的专业范围使你能与好多开发者共享代码,并从文档建立的多领域应用中受益。
R是开源的。这意味着你就能轻松地剖析函数的工作原理并毫不费力地更改它们。这也意味着对程序的更改不会被一个维护产品的独家程序员团队所控制。即使你无意为 R 的开发贡献代码,你依然可以从种类繁杂的可选扩充项(组件)中受益。组件的数目与日俱增,很多已有的组件也会时常更新。你能在这里找到相当棒的关于R应用的流行主题的概述: 。
对常规任务而言,R是相当快的。如果你用过类似于SPSS或Stata的其他统计软件,并养成了在估算复杂模型的时侯顺便度个假的习惯,你应当会赞成这个印象,更不用提那个由“同一个会话,同一个数据框”的逻辑带来的切肤之痛了。甚至还有一些扩充可以拿来加速R,例如,在R的内部通过Rcpp组件调用C语言代码。
R在建立数据可视化疗效方面也太强悍。虽然这对于数据采集并非明显的增值,在日常工作中你还是不应当错过R的图形特色。我们前面会讲解到,对被采集数据的视觉检测才能且必须作为数据校验的第一步,以及图形怎样给海量数据提供直观的总结形式。
使用R进行的工作主要是基于命令行的。这在R“菜鸟”听上去似乎象是一个不足,但相比这些要用滑鼠点击的程序来说,这是惟一能支持形成可再现结果的方法。
R对于操作系统是不挑剔的。它一般可以在Windows、Mac OS和Linux下运行。
最后,R是能自始至终支持研究过程的完整软件包。如果你在读这本书,你应当不是专职程序员,而是对于你要从事的某个主题或特定数据源有相当大的兴趣。在这些情况下,学习另一门语言不会有成效,反而会使你未能举办研究工作。普通研究流程的一个事例如图1所示。它的特征是永远在各类程序之间切换。如果你须要对数据采集过程进行修正,你就不得不顺着整个梯子爬回来。而使用R的研究过程,正如在本书中所述说的,只在单一的软件环境中进行(见图2)。对于网路抓取和文本处理而言,这意味着你何必为这项任务去学习另一门编程语言。你须要学习的只是标记语言 HTML、XML、正则表达式逻辑和XPath的一些基础知识,但所需的操作都是在R内部执行的。
R起步阶段的推荐读物
市面上有很多写得挺好的介绍R的书。在它们当中,我们发觉以下几本尤其有帮助:
Crawley, Michael J. 2012. The R Book, 2nd edition. Hoboken, NJ: John Wiley & Sons.
Adler, Joseph. 2009. R in a Nutshell. A Desktop Quick Reference. Sebastopol, CA: O扲eilly.
Teetor, Paul. 2011. R Cookbook. Sebastopol, CA: O扲eilly.
除了那些商业化的资源,网上还有好多免费的信息。对绝对的菜鸟来说,Code School上有个真正超棒的在线教程,可以在听到。另外,Quick-R()里有好多基本命令的索引。最后,你也可以在 找到好多免费资源和事例。
R是一个不断成长中的软件,为了跟上它的进展,你也许须要定期访问Planet R(),该网站提供了已有组件的发布历史,偶尔就会介绍一些有意思的应用。R-Bloggers()是个博客大杂烩,它专门搜集有关R的各类领域的博客。它提供了由数以百计的R应用构成的宽广视角,这些应用涉及的领域从经济学到生物学再到地理学,大部分都附有再现博文内容所必需的代码。R-Bloggers 甚至推介了一些阐述自动化数据采集的反例。
当你遇见问题的时侯,R的帮助文件有时候不是非常有用。去Stack Overflow()这样的在线峰会或Stack Exchange网路旗下的其他站点寻求帮助常常会更有启发性。对于复杂问题,可以考虑去 GitHub()上找一些R的专家。另外请注意,还有好多非常兴趣小组(SIG)的电邮列表(),里面界定了多种多样的主题,甚至还覆盖全世界的同城R用户小组()。最后,有人建了个CRAN任务视图,较好地概括了近日Web技术的进展和R框架里的服务:。
配套资源
本书的配套网站见。
该网站提供了书中事例和案例剖析的相关代码,以及其他一些内容。这意味着你无须手工从书中复制代码,直接访问和更改相应的R文件即可。你也可以在该网站找到个别练习题的解答,以及本书的勘误表。如果你在书中发觉了任何错误,也请不吝告知。 查看全部
.你也不要指望本书针对网路抓取或文本挖掘进行全面讲解。首先,我们专门使用了一套软件环境,而它并不是为实现这种目的量身订制的。在一些应用需求下,R 对于你要完成的任务并非理想解决方案,其他软件包可能更合适。我们也不会用如PHP、Python、Ruby或Perl等代替环境来干扰你。要想知道本书是否对你有帮助,你应当扪心自问,你是否早已或计划把R用在日常工作中。如果对这两个问题的答案都是否定的,很可能你就应当考虑取代方案了。但是,如果你早已在用或倾向于使用R了,你就可以市下学习另一个开发语言的精力,留在熟悉的开发环境里。
本书也不会严谨地介绍数据科学。在这个主题上也有一些出众的教材,例如O扤eil and Schutt(2013)、Torgo(2010)、Zhao(2012),以及Zumel and Mount(2014)。在那些书中时常缺位的部份是怎样在真实环境中获取数据科学中用到的数据。在这方面,本书可以作为数据剖析的打算阶段的参考书,它还给出了关于怎么管理可用信息并使它们保持及时更新的指导原则。
最后,你最不可能从本书听到的是针对你的具体问题的完美解答。在数据采集过程中,获取数据的领域从来都不会完全相像,而且其方式有时也会快速变化,这都是固有的问题。我们的目标是使你能改写事例和案例剖析中提供的代码,并创建新的代码,以此帮助你在采集自己所需数据的工作中获得成功。
为什么使用R
对于本书中囊括的问题,R是一个挺好的解决方案,我们如此考虑是有很多缘由的。对我们来说,最重要的几点缘由如下:
R可以自由和简便地获得。你可以按自己的须要随时随地下载、安装和使用它。不去钻研这些高昂的专有软件对你是大有裨益的,因为你不需要依赖于雇主支付软件版权费的意愿。
作为一个主要专注于统计学的软件环境,R拥有一个巨大并且持续繁荣的社区。R被用于各类专业领域,如社会科学、医学科学、心理学、生物学、地理学、语言学以及商业等。这样大的专业范围使你能与好多开发者共享代码,并从文档建立的多领域应用中受益。
R是开源的。这意味着你就能轻松地剖析函数的工作原理并毫不费力地更改它们。这也意味着对程序的更改不会被一个维护产品的独家程序员团队所控制。即使你无意为 R 的开发贡献代码,你依然可以从种类繁杂的可选扩充项(组件)中受益。组件的数目与日俱增,很多已有的组件也会时常更新。你能在这里找到相当棒的关于R应用的流行主题的概述: 。
对常规任务而言,R是相当快的。如果你用过类似于SPSS或Stata的其他统计软件,并养成了在估算复杂模型的时侯顺便度个假的习惯,你应当会赞成这个印象,更不用提那个由“同一个会话,同一个数据框”的逻辑带来的切肤之痛了。甚至还有一些扩充可以拿来加速R,例如,在R的内部通过Rcpp组件调用C语言代码。
R在建立数据可视化疗效方面也太强悍。虽然这对于数据采集并非明显的增值,在日常工作中你还是不应当错过R的图形特色。我们前面会讲解到,对被采集数据的视觉检测才能且必须作为数据校验的第一步,以及图形怎样给海量数据提供直观的总结形式。
使用R进行的工作主要是基于命令行的。这在R“菜鸟”听上去似乎象是一个不足,但相比这些要用滑鼠点击的程序来说,这是惟一能支持形成可再现结果的方法。
R对于操作系统是不挑剔的。它一般可以在Windows、Mac OS和Linux下运行。
最后,R是能自始至终支持研究过程的完整软件包。如果你在读这本书,你应当不是专职程序员,而是对于你要从事的某个主题或特定数据源有相当大的兴趣。在这些情况下,学习另一门语言不会有成效,反而会使你未能举办研究工作。普通研究流程的一个事例如图1所示。它的特征是永远在各类程序之间切换。如果你须要对数据采集过程进行修正,你就不得不顺着整个梯子爬回来。而使用R的研究过程,正如在本书中所述说的,只在单一的软件环境中进行(见图2)。对于网路抓取和文本处理而言,这意味着你何必为这项任务去学习另一门编程语言。你须要学习的只是标记语言 HTML、XML、正则表达式逻辑和XPath的一些基础知识,但所需的操作都是在R内部执行的。
R起步阶段的推荐读物
市面上有很多写得挺好的介绍R的书。在它们当中,我们发觉以下几本尤其有帮助:
Crawley, Michael J. 2012. The R Book, 2nd edition. Hoboken, NJ: John Wiley & Sons.
Adler, Joseph. 2009. R in a Nutshell. A Desktop Quick Reference. Sebastopol, CA: O扲eilly.
Teetor, Paul. 2011. R Cookbook. Sebastopol, CA: O扲eilly.
除了那些商业化的资源,网上还有好多免费的信息。对绝对的菜鸟来说,Code School上有个真正超棒的在线教程,可以在听到。另外,Quick-R()里有好多基本命令的索引。最后,你也可以在 找到好多免费资源和事例。
R是一个不断成长中的软件,为了跟上它的进展,你也许须要定期访问Planet R(),该网站提供了已有组件的发布历史,偶尔就会介绍一些有意思的应用。R-Bloggers()是个博客大杂烩,它专门搜集有关R的各类领域的博客。它提供了由数以百计的R应用构成的宽广视角,这些应用涉及的领域从经济学到生物学再到地理学,大部分都附有再现博文内容所必需的代码。R-Bloggers 甚至推介了一些阐述自动化数据采集的反例。
当你遇见问题的时侯,R的帮助文件有时候不是非常有用。去Stack Overflow()这样的在线峰会或Stack Exchange网路旗下的其他站点寻求帮助常常会更有启发性。对于复杂问题,可以考虑去 GitHub()上找一些R的专家。另外请注意,还有好多非常兴趣小组(SIG)的电邮列表(),里面界定了多种多样的主题,甚至还覆盖全世界的同城R用户小组()。最后,有人建了个CRAN任务视图,较好地概括了近日Web技术的进展和R框架里的服务:。
配套资源
本书的配套网站见。
该网站提供了书中事例和案例剖析的相关代码,以及其他一些内容。这意味着你无须手工从书中复制代码,直接访问和更改相应的R文件即可。你也可以在该网站找到个别练习题的解答,以及本书的勘误表。如果你在书中发觉了任何错误,也请不吝告知。
大数据-数据建行之自动化资产数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 467 次浏览 • 2020-08-13 19:01
很多公司在做自动化运维平台前就会先做一个CMDB,做CMDB的第一步就是建模和采集数据。说到采集数据,为了防止过多人工介入造成数据准确率低,采集方法普遍分为两种:
一小部份静态数据人工录入
大部分数据用程序采集
第二部份,不同的公司有的用shell实现一套,有的公司拿脚本语言实现一套,有的公司在须要的时侯主动搜集一次,有的公司手动定期搜集。
汽车之家的方式是“Puppet Facter脚本”+“定期手动搜集”。并且我们早已将其开源在Github(Assets_Report)上跟你们分享。
下面我们详尽解说一下原理和使用方式。
二、原理介绍
众所周知,Puppet是一套配置管理工具,是一个Client/Server模式的构架,可以用它来管理软件、配置文件和Service。然后,Puppet生态圈里有个叫Facter的工具,运行在Agent端,可以和Puppet紧密配合完成数据采集的工作。但是Facter提供采集的数据虽然有限,一些愈发底层的硬件数据就没有采集,而这种数据也是我们所须要的,这就是我们开发本工具的动机。
虽然Facter采集的数据有限,但是Facter本身是一个挺好的框架,非常容易对其进行扩充,所以我们基于Facter进行了扩充,配合Puppet Master的Report Processor将采集的结果上报给AutoBank(这是车辆之家的CMDB代号,可以参考《运维的数据建行-构建CMDB方式》),由此来完成一个完整的采集逻辑。
这是Puppet的Server跟Agent之间的工作流程图
Agent在发送Request恳求Catalog的阶段,会将自身的facts都上报给Master。而Master接到数据后可以借助自身的Report Processor对其进行二次处理,例如转发到别处。
正是基于上述的原理,我们开发了自己的Report Processor:assets_report,通过HTTP协议将facts post给AutoBank的http插口使其入库。
对开发custom facts感兴趣的朋友可以参考 fact_overview 和 custom facts。
如上所述,我们的Assets_Report项目收录了如下两个组件来实现整个逻辑
assets_report模块:一个纯Puppet Module,内建了一个Report Processor和一些自定义Facter插件,部署在Master端。
Report Processor运行在Master端。
Facter插件会通过Master下发到Agent端并被运行以采集本机资产数据
api_server:负责接收资产数据并将其入库
三、采集插件的功能介绍
相对于Facter内建的facts,本插件提供了更多的硬件数据,例如
CPU个数,型号
内存容量,序列号,厂商,插槽位置
网卡上绑定的ip,掩码,mac,型号,且支持一个网卡上绑定多ip的场景
RAID卡个数,型号,内存容量,RAID Level
磁盘个数,容量,序列号,厂商,所属RAID卡,插槽位置
操作系统类型,版本
服务器厂商,SN
高级特点:为了防止大段相同数据重复上报,减轻AutoBank的数据库压力,本插件具备Cache功能,即假如一台服务器的资产数据没有发生变更,那么只会汇报not_modify标记。
本插件支持的操作系统有(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
Windows 2008 R2
本插件支持的服务器有
HP
DELL
CISCO
四、采集插件的安装方式
安装操作在Puppet Master端进行。
假定你的模块目录为/etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
在你自己的puppet.conf(假设默认路径是/etc/puppet/puppet.conf)中添加
reports = assets_report
然后在site.pp中添加如下配置,让所有Node都安装assets_report模块
node default { # include assets_report class {'assets_report': }}
配置完毕后,采集工具会被手动下发到Agent上进行安装。下一次Puppet Agent运行时本插件即可正常工作。
五、汇报组件的配置方式
配置操作在Puppet Master端进行。
配置文件为 assets_report/lib/puppet/reports/report_setting.yaml
参数
含义
示例
report_url汇报插口地址,可更改成你自己的url
auth_required插口是否收录验证true/false,默认为false,验证代码须要在auth.rb中自己实现
user验证用户名假如auth_required为true,需要填写
passwd验证密码假如auth_required为true,需要填写
enable_cache是否启用cache功能true/false, 默认为false
六、汇报插口服务的配置方式
配置操作在Puppet Master端进行。
本插口服务api_server基于一个Python编撰的Web框架Django开发,该组件收录了数据库设计和http api的实现。因为各家公司的数据库设计均不一致,该项目仅实现了最简单的数据建模,所以该组件的存在仅作为Demo,不可用于生产环境,读者需注意。
首先,我们须要安装一些依赖。这里假设你的OS为CentOS/RedHat
$ cd ~/Assets_Report/api_server安装pip,用它来安装python模块$ sudo yum install python-pip安装python模块依赖$ pip install -r requirements.txt
初始化数据库,可以参考 Django用户指南
$ python manage.py makemigrations apis$ python manage.py migrate数据库为当前目录下的db.sqlite3 查看全部

很多公司在做自动化运维平台前就会先做一个CMDB,做CMDB的第一步就是建模和采集数据。说到采集数据,为了防止过多人工介入造成数据准确率低,采集方法普遍分为两种:
一小部份静态数据人工录入
大部分数据用程序采集
第二部份,不同的公司有的用shell实现一套,有的公司拿脚本语言实现一套,有的公司在须要的时侯主动搜集一次,有的公司手动定期搜集。
汽车之家的方式是“Puppet Facter脚本”+“定期手动搜集”。并且我们早已将其开源在Github(Assets_Report)上跟你们分享。
下面我们详尽解说一下原理和使用方式。
二、原理介绍
众所周知,Puppet是一套配置管理工具,是一个Client/Server模式的构架,可以用它来管理软件、配置文件和Service。然后,Puppet生态圈里有个叫Facter的工具,运行在Agent端,可以和Puppet紧密配合完成数据采集的工作。但是Facter提供采集的数据虽然有限,一些愈发底层的硬件数据就没有采集,而这种数据也是我们所须要的,这就是我们开发本工具的动机。
虽然Facter采集的数据有限,但是Facter本身是一个挺好的框架,非常容易对其进行扩充,所以我们基于Facter进行了扩充,配合Puppet Master的Report Processor将采集的结果上报给AutoBank(这是车辆之家的CMDB代号,可以参考《运维的数据建行-构建CMDB方式》),由此来完成一个完整的采集逻辑。
这是Puppet的Server跟Agent之间的工作流程图

Agent在发送Request恳求Catalog的阶段,会将自身的facts都上报给Master。而Master接到数据后可以借助自身的Report Processor对其进行二次处理,例如转发到别处。
正是基于上述的原理,我们开发了自己的Report Processor:assets_report,通过HTTP协议将facts post给AutoBank的http插口使其入库。

对开发custom facts感兴趣的朋友可以参考 fact_overview 和 custom facts。
如上所述,我们的Assets_Report项目收录了如下两个组件来实现整个逻辑
assets_report模块:一个纯Puppet Module,内建了一个Report Processor和一些自定义Facter插件,部署在Master端。
Report Processor运行在Master端。
Facter插件会通过Master下发到Agent端并被运行以采集本机资产数据
api_server:负责接收资产数据并将其入库
三、采集插件的功能介绍
相对于Facter内建的facts,本插件提供了更多的硬件数据,例如
CPU个数,型号
内存容量,序列号,厂商,插槽位置
网卡上绑定的ip,掩码,mac,型号,且支持一个网卡上绑定多ip的场景
RAID卡个数,型号,内存容量,RAID Level
磁盘个数,容量,序列号,厂商,所属RAID卡,插槽位置
操作系统类型,版本
服务器厂商,SN
高级特点:为了防止大段相同数据重复上报,减轻AutoBank的数据库压力,本插件具备Cache功能,即假如一台服务器的资产数据没有发生变更,那么只会汇报not_modify标记。
本插件支持的操作系统有(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
Windows 2008 R2
本插件支持的服务器有
HP
DELL
CISCO
四、采集插件的安装方式
安装操作在Puppet Master端进行。
假定你的模块目录为/etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
在你自己的puppet.conf(假设默认路径是/etc/puppet/puppet.conf)中添加
reports = assets_report
然后在site.pp中添加如下配置,让所有Node都安装assets_report模块
node default { # include assets_report class {'assets_report': }}
配置完毕后,采集工具会被手动下发到Agent上进行安装。下一次Puppet Agent运行时本插件即可正常工作。
五、汇报组件的配置方式
配置操作在Puppet Master端进行。
配置文件为 assets_report/lib/puppet/reports/report_setting.yaml
参数
含义
示例
report_url汇报插口地址,可更改成你自己的url
auth_required插口是否收录验证true/false,默认为false,验证代码须要在auth.rb中自己实现
user验证用户名假如auth_required为true,需要填写
passwd验证密码假如auth_required为true,需要填写
enable_cache是否启用cache功能true/false, 默认为false
六、汇报插口服务的配置方式
配置操作在Puppet Master端进行。
本插口服务api_server基于一个Python编撰的Web框架Django开发,该组件收录了数据库设计和http api的实现。因为各家公司的数据库设计均不一致,该项目仅实现了最简单的数据建模,所以该组件的存在仅作为Demo,不可用于生产环境,读者需注意。
首先,我们须要安装一些依赖。这里假设你的OS为CentOS/RedHat
$ cd ~/Assets_Report/api_server安装pip,用它来安装python模块$ sudo yum install python-pip安装python模块依赖$ pip install -r requirements.txt
初始化数据库,可以参考 Django用户指南
$ python manage.py makemigrations apis$ python manage.py migrate数据库为当前目录下的db.sqlite3
SQL Server 2008中手动采集数据的方法(下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 313 次浏览 • 2020-08-10 08:26
该报表展示了采集功能运行在什么服务器上。你可以点击每位链接来查看每台服务器的详尽信息。下面的截图展示了服务器活动四个小时之后的“服务器活动历史报表”的上半部份。
如你所见,数据采集器报表的上方显示了一个导航工具条,你可以滚动它来浏览捕获的快照,也可以选择你想看的数据所在的时间帧。当你在上图中的个别图表上点击时,你可以钻取到子报表中查看更多详尽信息。下图就是一个“SQL Server等待情况”子报表的示例。
我建议你把所有那些报表都点进去瞧瞧,选择不同的时间段等等,这样你才会熟悉它们能提供哪些内容。例如,你可以在“查询统计历史报表”中查看到某些查询的明细,包括图形化的执行计划。
数据采集器在发生数据采集的服务器上会形成2%-5%的性能代价,主要借助的资源是CPU。存储空间需求只有每晚300MB,也就是说你每台服务器每周须要2GB的储存空间。你准备保留多长时间的数据呢?答案完全取决于你的须要和储存能力,然而大部分参数你都可以使用默认值。默认配置是“查询统计”和“服务器活动历史数据采集保留14天,“磁盘借助情况汇总”采集保留三年。
如果你想保留更长时间的性能数据,还不想保存快速累积的数以百万计的行记录,你可以编撰自己的查询并对想常年保存的重要数据生成每日或每周的合计。SQL Server在线图书有关于使用数据采集表的特别优秀的文档,它们促使对采集到的数据订制查询会更容易一些。
以上是对数据采集器十分简单的一个概述,介绍了怎样配置你的服务器来启用采集并剖析SQL Server 2008性能数据。在前面的文章中,我会更深入地挖掘它的内部机制,并给你介绍怎么编撰自定义查询来提取想常年保留数据的快照,以及怎样创建自定义报表来显示这些数据。 查看全部
运行该向导以后,数据采集就会启动。要累积有意义的数据得花点时间,所以在能看到报表之前,你可能须要等上一两个小时。SQL Server Management Studio 2008现今有三种新报表来查看数据采集器积累的数据。这三种报表是:服务器活动历史,磁盘借助情况汇总和查询统计历史。你可以查看这种报表,在数据采集节点上右击,选择“报表”(紧挨到“受管数据库房”)就可以查看这种报表。SQL Server Management Studio 2008都会辨识你拿来仓储数据的数据库,所以在该数据库上右击时,会有选项选择“受管数据库房概要”报表。如下图所示:

该报表展示了采集功能运行在什么服务器上。你可以点击每位链接来查看每台服务器的详尽信息。下面的截图展示了服务器活动四个小时之后的“服务器活动历史报表”的上半部份。

如你所见,数据采集器报表的上方显示了一个导航工具条,你可以滚动它来浏览捕获的快照,也可以选择你想看的数据所在的时间帧。当你在上图中的个别图表上点击时,你可以钻取到子报表中查看更多详尽信息。下图就是一个“SQL Server等待情况”子报表的示例。

我建议你把所有那些报表都点进去瞧瞧,选择不同的时间段等等,这样你才会熟悉它们能提供哪些内容。例如,你可以在“查询统计历史报表”中查看到某些查询的明细,包括图形化的执行计划。
数据采集器在发生数据采集的服务器上会形成2%-5%的性能代价,主要借助的资源是CPU。存储空间需求只有每晚300MB,也就是说你每台服务器每周须要2GB的储存空间。你准备保留多长时间的数据呢?答案完全取决于你的须要和储存能力,然而大部分参数你都可以使用默认值。默认配置是“查询统计”和“服务器活动历史数据采集保留14天,“磁盘借助情况汇总”采集保留三年。
如果你想保留更长时间的性能数据,还不想保存快速累积的数以百万计的行记录,你可以编撰自己的查询并对想常年保存的重要数据生成每日或每周的合计。SQL Server在线图书有关于使用数据采集表的特别优秀的文档,它们促使对采集到的数据订制查询会更容易一些。
以上是对数据采集器十分简单的一个概述,介绍了怎样配置你的服务器来启用采集并剖析SQL Server 2008性能数据。在前面的文章中,我会更深入地挖掘它的内部机制,并给你介绍怎么编撰自定义查询来提取想常年保留数据的快照,以及怎样创建自定义报表来显示这些数据。
数据剖析实战之怎么自动化采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2020-08-10 07:31
一、开放数据源:一般是针对行业的数据库。可以两个维度来考虑:
1)单位:政府、企业和院校
2)行业:比如交通、金融、能源等
二、爬虫抓取:一般是针对特定的网站或APP。
1、使用python编撰爬虫代码,会经历以下过程
1)使用requests爬取内容。使用requests库抓取网页信息
2)使用XML Path解析内容。
3)使用pandas保存数据
2、不用编程也可以抓取网页信息的抓取工具
优采云采集器、优采云、集搜客
三、日志采集:统计用户的操作。在后端进行埋点、在前端进行脚本搜集、统计,来剖析网站的访问情况,以及使用困局
日志记录了用户访问网址的全过程:哪些人在哪些时间,通过哪些渠道来过,执行了什么操作;系统是否形成了错误;甚至包括用户的IP、HTTP恳求的时间,用户代理等。
埋点是日志采集的关键步骤。埋点就是在有须要的位置采集相应的信息,进行上报。每个埋点如同一台摄像头,采集用户行为数据,将数据进行多经度的交叉剖析,可真实还原出用户使用场景和用户使用需求。
如何进行埋点:在你须要统计数据的地方植入统计代码,代码可以自己写,也可以使用第三方统计工具。比如友盟、Google Analysis、Talkingdata等。 查看全部
从数据采集的角度看,数据源可以分为以下三类
一、开放数据源:一般是针对行业的数据库。可以两个维度来考虑:
1)单位:政府、企业和院校
2)行业:比如交通、金融、能源等
二、爬虫抓取:一般是针对特定的网站或APP。
1、使用python编撰爬虫代码,会经历以下过程
1)使用requests爬取内容。使用requests库抓取网页信息
2)使用XML Path解析内容。
3)使用pandas保存数据
2、不用编程也可以抓取网页信息的抓取工具
优采云采集器、优采云、集搜客
三、日志采集:统计用户的操作。在后端进行埋点、在前端进行脚本搜集、统计,来剖析网站的访问情况,以及使用困局
日志记录了用户访问网址的全过程:哪些人在哪些时间,通过哪些渠道来过,执行了什么操作;系统是否形成了错误;甚至包括用户的IP、HTTP恳求的时间,用户代理等。
埋点是日志采集的关键步骤。埋点就是在有须要的位置采集相应的信息,进行上报。每个埋点如同一台摄像头,采集用户行为数据,将数据进行多经度的交叉剖析,可真实还原出用户使用场景和用户使用需求。
如何进行埋点:在你须要统计数据的地方植入统计代码,代码可以自己写,也可以使用第三方统计工具。比如友盟、Google Analysis、Talkingdata等。
拼多多订单信息自动导出工具——小帮软件机器人
采集交流 • 优采云 发表了文章 • 0 个评论 • 944 次浏览 • 2021-03-28 20:02
随着拼多多的崛起,拼多多代沟和单党诞生了。每天都会下达许多订单,但是由于它们必须向客户或任务发布者提供订单信息,因此更多的订单意味着订购的成本更高。在每个订单的时间,将商店名称,价格,产品名称,快递号码,订单号和其他信息复制并粘贴到excel中。
目前,拼多多自己的大多数工具都提供基本的运输和快递打印功能。找到一个可以批量导入拼多多订单的工具并不容易。
如何找到合适的工具来代替通常的手动复制和粘贴工作,许多拼多多代购和shua Single Party仍在搜索:使用起来应该不会太复杂,越简单越好; 采集订单信息准确而全面;价格不能太高,小企业太贵了以至于无法消费...
基于上述痛点,编辑者通过对当前市场上主流产品的除草和排雷(从以前的操作到采集)进行了真实的评估,找到了公司和个人,卖方和卖方。效果,从特征岛到产品价格,是买方常用的订单批量导出工具-小帮软件机器人。
可自定义:您可以使用配置的工具,也可以自己配置订单信息导出工具
止痛指数
小帮软件机器人不仅是简单的工具,还是制作工具的工具。
在小邦配置平台上生成拼多多订单信息的自动导出工具。配置方法也非常简单。鼠标操作可以在几分钟内完成。它不仅可以使软件机器人自动引导订单信息,还可以做到。其他一些软件机器人工具,例如采集平台价格等,也非常适合那些愿意做点创意的人。
当然,尽管构建软件机器人工具确实很棒,但是如果您希望简单,粗鲁地解决问题,则只需使用现成的工具即可。
极简主义者:该工具功能明显且易于使用
止痛指数
使用配置的Xiaobang软件机器人非常简单。只需在“我的小帮”页面上找到选择批量出口订单的软件机器人工具,然后单击“运行”按钮以在拼多多人民中心打开“我”。在“订单”页面上,选择“立即运行”,它将自动显示采集订单数据,用户可以预览采集的订单信息,下载Exce 查看全部
拼多多订单信息自动导出工具——小帮软件机器人
随着拼多多的崛起,拼多多代沟和单党诞生了。每天都会下达许多订单,但是由于它们必须向客户或任务发布者提供订单信息,因此更多的订单意味着订购的成本更高。在每个订单的时间,将商店名称,价格,产品名称,快递号码,订单号和其他信息复制并粘贴到excel中。
目前,拼多多自己的大多数工具都提供基本的运输和快递打印功能。找到一个可以批量导入拼多多订单的工具并不容易。
如何找到合适的工具来代替通常的手动复制和粘贴工作,许多拼多多代购和shua Single Party仍在搜索:使用起来应该不会太复杂,越简单越好; 采集订单信息准确而全面;价格不能太高,小企业太贵了以至于无法消费...
基于上述痛点,编辑者通过对当前市场上主流产品的除草和排雷(从以前的操作到采集)进行了真实的评估,找到了公司和个人,卖方和卖方。效果,从特征岛到产品价格,是买方常用的订单批量导出工具-小帮软件机器人。
可自定义:您可以使用配置的工具,也可以自己配置订单信息导出工具
止痛指数
小帮软件机器人不仅是简单的工具,还是制作工具的工具。
在小邦配置平台上生成拼多多订单信息的自动导出工具。配置方法也非常简单。鼠标操作可以在几分钟内完成。它不仅可以使软件机器人自动引导订单信息,还可以做到。其他一些软件机器人工具,例如采集平台价格等,也非常适合那些愿意做点创意的人。
当然,尽管构建软件机器人工具确实很棒,但是如果您希望简单,粗鲁地解决问题,则只需使用现成的工具即可。
极简主义者:该工具功能明显且易于使用
止痛指数
使用配置的Xiaobang软件机器人非常简单。只需在“我的小帮”页面上找到选择批量出口订单的软件机器人工具,然后单击“运行”按钮以在拼多多人民中心打开“我”。在“订单”页面上,选择“立即运行”,它将自动显示采集订单数据,用户可以预览采集的订单信息,下载Exce
自动采集万方数据平台里面的数据,如果需要复杂的话
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-03-27 06:02
自动采集数据库里面的数据,如果操作简单的话可以使用脚本操作,如果需要复杂的话,可以看看我写的一篇博客,自动采集万方数据平台里面的数据,参考如下:链接:密码:8p00以上是一篇博客,比较复杂,如果希望能够自动采集某个杂志里面某一类型的文章,可以研究如何自动生成这类文章对应的数据。
我从去年到现在用过edius做过一些节目合集,但最终还是放弃了。不是难不难,而是做节目,需要你有节目编导这个技能。如果单纯用edius来操作很简单,但是遇到高手花点时间就能做的很好。难的是你得学到编导技能。我记得看过一篇实战的文章,就是在不影响录制节目的情况下,用edius软件生成几个节目,最后推销给客户。
如果不进一步挑战节目编导的话,纯edius的生成的节目做一些学术类或者高校做的公开课是不错的。如果做体育、娱乐类的节目感觉有点力不从心。
有edius在手,
如果你是指从万方里采集数据,很难。比如生成节目标题片头片尾,我见过最轻松的生成节目标题片头片尾(转码pan4)用了两天,加其他的才花了两小时。节目设置,真的有硬性标准,分数线,全是算法自动分析合并上传到那几千个数据库。复杂的节目编辑也有人在做,起码已经算是省时省力了。比如juozhishao的视频,假如标题是喷嚏,片头是白色四角形,片尾放相片,就可以生成头可以伸出来、胳膊可以伸到底,之类的片头片尾。
如果说网上能搜索到那些教你怎么做的软件,应该比较难。我有个朋友有个专门做的教程,但是感觉下载量不高,原因是用户留言里没有留需要做这个的操作指南,找不到别人都不会做一个做标题片头片尾的教程。 查看全部
自动采集万方数据平台里面的数据,如果需要复杂的话
自动采集数据库里面的数据,如果操作简单的话可以使用脚本操作,如果需要复杂的话,可以看看我写的一篇博客,自动采集万方数据平台里面的数据,参考如下:链接:密码:8p00以上是一篇博客,比较复杂,如果希望能够自动采集某个杂志里面某一类型的文章,可以研究如何自动生成这类文章对应的数据。
我从去年到现在用过edius做过一些节目合集,但最终还是放弃了。不是难不难,而是做节目,需要你有节目编导这个技能。如果单纯用edius来操作很简单,但是遇到高手花点时间就能做的很好。难的是你得学到编导技能。我记得看过一篇实战的文章,就是在不影响录制节目的情况下,用edius软件生成几个节目,最后推销给客户。
如果不进一步挑战节目编导的话,纯edius的生成的节目做一些学术类或者高校做的公开课是不错的。如果做体育、娱乐类的节目感觉有点力不从心。
有edius在手,
如果你是指从万方里采集数据,很难。比如生成节目标题片头片尾,我见过最轻松的生成节目标题片头片尾(转码pan4)用了两天,加其他的才花了两小时。节目设置,真的有硬性标准,分数线,全是算法自动分析合并上传到那几千个数据库。复杂的节目编辑也有人在做,起码已经算是省时省力了。比如juozhishao的视频,假如标题是喷嚏,片头是白色四角形,片尾放相片,就可以生成头可以伸出来、胳膊可以伸到底,之类的片头片尾。
如果说网上能搜索到那些教你怎么做的软件,应该比较难。我有个朋友有个专门做的教程,但是感觉下载量不高,原因是用户留言里没有留需要做这个的操作指南,找不到别人都不会做一个做标题片头片尾的教程。
优采云数据采集器56.2M/2018-11-02
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-03-21 20:07
优采云数据采集器56.2M/2018-11-02
优采云数据采集器
5 6. 2M / 2018-11-02 / v 7. 5. 4正式版
得分:
下载
优采云 Data 采集器是需要从网页获取信息的任何人的必备采集工具。它使网页数据采集比以往更容易。如果您正在寻找有用的采集软件,优采云绝对是最佳选择。并在市场上
无人看管的全自动采集器(编辑器工具)
1 7. 5M / 2018-08-10 / v 3. 2. 6绿色版
得分:
下载
editortools软件是自动采集信息软件。用户只需要下载并安装它并开始使用它。它可以自动管理采集 网站中的信息,并智能地管理信息的内容和更新。 网站管理工作提供了极大的便利。
Red Bell 采集软件破解版
3 1. 8M / 2018-07-12 / v 1. 6. 5. 1绿色版
得分:
下载
红铃分类信息采集工具非常易于使用,不需要安装软件,解压后可以直接使用,界面采用中文界面,方便用户操作,用户谁需要它,快来当易下载并使用! ! !红铃分类信息采集软件(网站
优采云 Universal 文章 采集器
993KB / 2018-05-12 / v 2. 1 7. 3. 0绿色版
得分:
下载
优采云 Universal 文章 采集器可以帮助采集指定网站的文章的内容,并帮助您搜索所需的信息。该软件具有智能搜索机制,可以高精度地搜索文章指定的网站,不仅可以提高文章手机的功能,而且可以
轻轻微信QR码采集向导
3. 6M / 2018-01-15 / v 3. 2的最新版本
得分:
下载
微信微信群二维码采集向导是一款功能强大的二维码信息采集软件,有了此软件,用户可以更轻松地采集 QR码,并且该软件非常小巧,不会占用太多空间记忆。欢迎来到
JD订单采集管理系统
401KB / 2017-09-19 /绿色版
得分:
下载
JD Order 采集 Management是一个网页编辑软件,您可以直接在网页上修改图片,编辑喜欢的文本和小工具以美化图片。当易网上有越来越多有趣的软件,快来下载吧
QQ电子邮件地址批量获取器
1. 7M / 2017-09-14 / v 2. 0绿色版
得分:
下载
QQ电子邮件地址批量获取器是用于获取QQ电子邮件地址的非常强大的工具。它易于操作,因此电子邮件营销并不困难,并且消除了其他采集软件设置的麻烦。一键即可获取成千上万的QQ电子邮件地址。地址,欢迎有需要的朋友
优采云 采集器免费破解版
2 4. 4M / 2019-04-04 / v 9. 8 PC版本
得分:
下载
优采云 采集器免费的破解版本是一种非常流行的采集器工具。该平台具有多年的开发和更新历史,可以快速准确地获取网页中的信息,并对其进行组织以向用户提供所需的数据,易于使用,需要帮助的朋友
三个人采集器
662KB / 2017-07-05 /
得分:
下载
三行采集器是功能强大的文本采集工具。使用此软件,它可以帮助用户轻松地采集他们想要的数据。非常适合网站管理员。欢迎有需要的朋友从下载。三个人采集器三个人的正式介绍 查看全部
优采云数据采集器56.2M/2018-11-02
优采云数据采集器
5 6. 2M / 2018-11-02 / v 7. 5. 4正式版
得分:
下载
优采云 Data 采集器是需要从网页获取信息的任何人的必备采集工具。它使网页数据采集比以往更容易。如果您正在寻找有用的采集软件,优采云绝对是最佳选择。并在市场上
无人看管的全自动采集器(编辑器工具)
1 7. 5M / 2018-08-10 / v 3. 2. 6绿色版
得分:
下载
editortools软件是自动采集信息软件。用户只需要下载并安装它并开始使用它。它可以自动管理采集 网站中的信息,并智能地管理信息的内容和更新。 网站管理工作提供了极大的便利。
Red Bell 采集软件破解版
3 1. 8M / 2018-07-12 / v 1. 6. 5. 1绿色版
得分:
下载
红铃分类信息采集工具非常易于使用,不需要安装软件,解压后可以直接使用,界面采用中文界面,方便用户操作,用户谁需要它,快来当易下载并使用! ! !红铃分类信息采集软件(网站
优采云 Universal 文章 采集器
993KB / 2018-05-12 / v 2. 1 7. 3. 0绿色版
得分:
下载
优采云 Universal 文章 采集器可以帮助采集指定网站的文章的内容,并帮助您搜索所需的信息。该软件具有智能搜索机制,可以高精度地搜索文章指定的网站,不仅可以提高文章手机的功能,而且可以
轻轻微信QR码采集向导
3. 6M / 2018-01-15 / v 3. 2的最新版本
得分:
下载
微信微信群二维码采集向导是一款功能强大的二维码信息采集软件,有了此软件,用户可以更轻松地采集 QR码,并且该软件非常小巧,不会占用太多空间记忆。欢迎来到
JD订单采集管理系统
401KB / 2017-09-19 /绿色版
得分:
下载
JD Order 采集 Management是一个网页编辑软件,您可以直接在网页上修改图片,编辑喜欢的文本和小工具以美化图片。当易网上有越来越多有趣的软件,快来下载吧
QQ电子邮件地址批量获取器
1. 7M / 2017-09-14 / v 2. 0绿色版
得分:
下载
QQ电子邮件地址批量获取器是用于获取QQ电子邮件地址的非常强大的工具。它易于操作,因此电子邮件营销并不困难,并且消除了其他采集软件设置的麻烦。一键即可获取成千上万的QQ电子邮件地址。地址,欢迎有需要的朋友
优采云 采集器免费破解版
2 4. 4M / 2019-04-04 / v 9. 8 PC版本
得分:
下载
优采云 采集器免费的破解版本是一种非常流行的采集器工具。该平台具有多年的开发和更新历史,可以快速准确地获取网页中的信息,并对其进行组织以向用户提供所需的数据,易于使用,需要帮助的朋友
三个人采集器
662KB / 2017-07-05 /
得分:
下载
三行采集器是功能强大的文本采集工具。使用此软件,它可以帮助用户轻松地采集他们想要的数据。非常适合网站管理员。欢迎有需要的朋友从下载。三个人采集器三个人的正式介绍
自动采集数据的技巧,你get到了吗?!
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-03-20 23:03
自动采集数据是把采集到的数据用于其他有用的用途,这样对你来说都不是一种浪费。随着自动采集数据技术的推广,下面我整理了一些自动采集数据的技巧,希望能够帮助到需要的人。
1、a站up主注册账号:点击注册账号按钮
2、点击录制动画
3、选择采集视频视频,
4、点击立即采集
5、输入链接及路径
6、在浏览器上进行下载b站采集技巧
1、b站up主注册账号:点击注册账号按钮
4、输入链接及路径
5、在浏览器上进行下载
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有a站、b站账号,也可以用浏览器上的开发者工具,上传一个视频链接到谷歌上提交验证是否是a站的up主账号,正常情况下是不会被拒绝的。如果需要原图,找一个能找到原图的网站都可以。
c站采集技巧
1、c站up主注册账号:点击注册账号按钮
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有c站账号,也可以用浏览器上的开发者工具,上传一个视频链接到谷歌上提交验证是否是c站的up主账号,正常情况下是不会被拒绝的。如果需要原图,找一个能找到原图的网站都可以。
f站采集技巧
e站采集技巧
g站采集技巧
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有c站账号,也可以用浏览器上的开发者工具, 查看全部
自动采集数据的技巧,你get到了吗?!
自动采集数据是把采集到的数据用于其他有用的用途,这样对你来说都不是一种浪费。随着自动采集数据技术的推广,下面我整理了一些自动采集数据的技巧,希望能够帮助到需要的人。
1、a站up主注册账号:点击注册账号按钮
2、点击录制动画
3、选择采集视频视频,
4、点击立即采集
5、输入链接及路径
6、在浏览器上进行下载b站采集技巧
1、b站up主注册账号:点击注册账号按钮
4、输入链接及路径
5、在浏览器上进行下载
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有a站、b站账号,也可以用浏览器上的开发者工具,上传一个视频链接到谷歌上提交验证是否是a站的up主账号,正常情况下是不会被拒绝的。如果需要原图,找一个能找到原图的网站都可以。
c站采集技巧
1、c站up主注册账号:点击注册账号按钮
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有c站账号,也可以用浏览器上的开发者工具,上传一个视频链接到谷歌上提交验证是否是c站的up主账号,正常情况下是不会被拒绝的。如果需要原图,找一个能找到原图的网站都可以。
f站采集技巧
e站采集技巧
g站采集技巧
6、在输入框中输入网址,点击下载获取原图以上技巧即便你没有c站账号,也可以用浏览器上的开发者工具,
hadoop与websphere文件系统数据接入的架构设计(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-02-26 13:01
自动采集数据的,我用过的包括extractor和ae2marker。extractor支持的数据库很全,还可以生成excel,挺方便的,也很快。ae2marker数据库更多,但有些数据在测试版上面不支持。extractor还有一个优点就是插件丰富,支持的语言也多,但这是用来和其他软件共享资源的,你自己玩玩用来练手还可以。以上。
可以参考我写的这篇文章:hadoop与websphere文件系统数据接入的架构设计
tcoff-iot文件系统hdfs
我最近在做hadoop系统和redis系统数据交互过程中有一个环节要数据持久化,看了一圈tcoff-iothdfs-openwrt或者大数据或者exts-android或者chromium的方案,最后还是决定选择tcoff的架构解决方案。因为初步了解到双系统隔离是现在业界比较难解决的一个问题,有很多model不能满足wireless-os不能经受动态变化环境,还要具有易扩展和服务端可以并发请求等,数据持久化对tcoff来说真的是个很大的痛点,目前只有一些内置model方案来简单解决相应问题,而且某些内置model只能满足基本要求。
我对hadoop-openwrt还是挺有好感的,所以在考虑方案的时候还是多方面研究了一下,看看是否有什么可以改进的地方,最后选择tcoff不仅仅是因为他的双系统架构,双系统适合在windows和linux之间进行文件移动,在方便tcoff文件系统运维与管理方面也是个好的方式。还有一个原因是这是一个开源项目,对于入门级的人来说比较容易接受,数据接入架构也不用像exts那么复杂,只需要简单的添加一下权限即可,然后插件多集成也比较方便,简单来说这个项目就是基于tcoff-iot实现的一个开源linux环境下对hadoop数据交互的解决方案,且一直非常受欢迎,所以我觉得tcoff-iot在hadoop本地接入环境下是个不错的选择。本人还是有自己的一套代码,多与大家一起讨论。相关论文地址:,欢迎交流。 查看全部
hadoop与websphere文件系统数据接入的架构设计(组图)
自动采集数据的,我用过的包括extractor和ae2marker。extractor支持的数据库很全,还可以生成excel,挺方便的,也很快。ae2marker数据库更多,但有些数据在测试版上面不支持。extractor还有一个优点就是插件丰富,支持的语言也多,但这是用来和其他软件共享资源的,你自己玩玩用来练手还可以。以上。
可以参考我写的这篇文章:hadoop与websphere文件系统数据接入的架构设计
tcoff-iot文件系统hdfs
我最近在做hadoop系统和redis系统数据交互过程中有一个环节要数据持久化,看了一圈tcoff-iothdfs-openwrt或者大数据或者exts-android或者chromium的方案,最后还是决定选择tcoff的架构解决方案。因为初步了解到双系统隔离是现在业界比较难解决的一个问题,有很多model不能满足wireless-os不能经受动态变化环境,还要具有易扩展和服务端可以并发请求等,数据持久化对tcoff来说真的是个很大的痛点,目前只有一些内置model方案来简单解决相应问题,而且某些内置model只能满足基本要求。
我对hadoop-openwrt还是挺有好感的,所以在考虑方案的时候还是多方面研究了一下,看看是否有什么可以改进的地方,最后选择tcoff不仅仅是因为他的双系统架构,双系统适合在windows和linux之间进行文件移动,在方便tcoff文件系统运维与管理方面也是个好的方式。还有一个原因是这是一个开源项目,对于入门级的人来说比较容易接受,数据接入架构也不用像exts那么复杂,只需要简单的添加一下权限即可,然后插件多集成也比较方便,简单来说这个项目就是基于tcoff-iot实现的一个开源linux环境下对hadoop数据交互的解决方案,且一直非常受欢迎,所以我觉得tcoff-iot在hadoop本地接入环境下是个不错的选择。本人还是有自己的一套代码,多与大家一起讨论。相关论文地址:,欢迎交流。
前端的主动异常数据采集工具-dataAcquisition(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2021-01-21 09:40
最近,一个朋友再次提到了前端数据采集。
想想以前的开源数据采集插件dataAcquisition
由于不关注前端数据分析,因此项目运行不佳
但是整个项目还是很好,功能也比较完善,我不愿意放弃
所以我花了一些时间进行重构。并做了相应的演示
借此机会再次向大家介绍
一.为什么需要数据采集?
我们问几个问题:
一个新产品流程在线,如何获得流程的转化率?
有多少人通过添加按钮来点击?
在AB计划中,如何获得两个计划的转换?
在日常开发中,我们经常听到并看到在后台的学生使用日志来查找问题
但是如何定位前端生产问题?
如何将用户的问题反馈给开发人员?
我们之前的项目需要用户反馈给客户服务,然后通过工作订单反馈给开发
但是此过程周期相对较长,大多数用户发现它很麻烦,太懒惰而无法提供反馈
是否存在一种主动采集机制来采集来自客户端的某些例外情况?
是否存在用于采集用户数据的页面行为采集工具?
本文文章是要介绍前端活动异常数据采集工具-dataAcquisition
二.我们可以什么数据采集?
说到数据采集,我们首先必须知道什么数据可以是采集
1.用户点击数据,通过事件代理,您可以采集查看页面上发生的所有点击事件,并获取点击元素
2.用户的输入操作,通过输入,聚焦,模糊事件来获得输入框的内容以及用户的操作
3.页面访问数据,通过记录页面URL并报告它,可以实现PV统计,而使用uuid可以实现UV统计
4.页面中的代码异常。使用window.onerror来采集代码中的异常
在5.页面中,失败的接口数据通过代理ajax方法失败,在执行错误方法之前报告了请求参数和结果
6.页面性能数据,通过性能界面来计算DNS解析度,TCP链接时间,白屏时间,dom解析时间等。
利用以上数据,我们可以重现用户的操作过程
您还可以立即采集应对客户端发生的异常采集
通过对用户行为的分析,可以得出用户的习惯和偏好。
以便优化产品解决方案,优化业务流程并获得数据驱动的产品。
三.采集有哪些数据处理方法?
常用数据采集方法:
1.自动埋入点,通过大范围的数据采集从数据中过滤出特定元素。这样做的缺点是数据量太大,而优点是无需在联机之前自定义采集解决方案。
2.主动通过向元素添加特定的id或class属性来掩埋点,以便采集工具可以准确确定采集所需的数据。缺点是它会入侵页面。优点是数据准确。
3.圈出掩埋点并通过单击选择页面元素,这比自动采集更准确,比手动掩埋更方便。但是圈出的兼容性问题令人头疼。
市场上有带圆圈和埋点的付费项目,报价基本上是10W +
我们今天介绍的dataAcquisition可以完美支持自动和主动埋入。
圈出的功能也在开发计划中。
作为可以解决眼前问题的开源工具,有没有理由不尝试?
四.关于数据获取
dataAcquisition插件于2017年开发,迭代时间相对较短。
自从上线生产以来,一年中没有错误
当然,由于情况不同,仍有许多问题尚未解决
当前实现的功能点:
1.前端PV,紫外线数据采集报告
2.用户点击,输入行为采集报告
3.实现页面性能采集
4.实施代码异常采集
5.实现接口异常采集
该项目已在GitHub上开源,地址:
包括采集插件源代码,示例演示
需要它的学生可以下载和使用
五.演示示例
该插件提供了一个简单的演示,包括数据采集页面,数据分析页面
1.数据采集页面:
此页面上的所有操作将由采集报告,
请注意,采集的数据仅在刷新页面或单击报告按钮时才会发送到后台
PC屏幕截图:
2.数据分析页:
报告的数据将显示在此页面上,在此页面上,您可以观察到所有先前的操作
与异常对应的详细数据
PC屏幕截图:
六.邀请参加
一个人的精力有限,开源项目的维护需要一些合作伙伴共同努力,
欢迎向我提交公关
所有参与者都将记录在作者目录中,并且每个人都将共享项目结果。 查看全部
前端的主动异常数据采集工具-dataAcquisition(二)
最近,一个朋友再次提到了前端数据采集。
想想以前的开源数据采集插件dataAcquisition
由于不关注前端数据分析,因此项目运行不佳
但是整个项目还是很好,功能也比较完善,我不愿意放弃
所以我花了一些时间进行重构。并做了相应的演示
借此机会再次向大家介绍
一.为什么需要数据采集?
我们问几个问题:
一个新产品流程在线,如何获得流程的转化率?
有多少人通过添加按钮来点击?
在AB计划中,如何获得两个计划的转换?
在日常开发中,我们经常听到并看到在后台的学生使用日志来查找问题
但是如何定位前端生产问题?
如何将用户的问题反馈给开发人员?
我们之前的项目需要用户反馈给客户服务,然后通过工作订单反馈给开发
但是此过程周期相对较长,大多数用户发现它很麻烦,太懒惰而无法提供反馈
是否存在一种主动采集机制来采集来自客户端的某些例外情况?
是否存在用于采集用户数据的页面行为采集工具?
本文文章是要介绍前端活动异常数据采集工具-dataAcquisition
二.我们可以什么数据采集?
说到数据采集,我们首先必须知道什么数据可以是采集
1.用户点击数据,通过事件代理,您可以采集查看页面上发生的所有点击事件,并获取点击元素
2.用户的输入操作,通过输入,聚焦,模糊事件来获得输入框的内容以及用户的操作
3.页面访问数据,通过记录页面URL并报告它,可以实现PV统计,而使用uuid可以实现UV统计
4.页面中的代码异常。使用window.onerror来采集代码中的异常
在5.页面中,失败的接口数据通过代理ajax方法失败,在执行错误方法之前报告了请求参数和结果
6.页面性能数据,通过性能界面来计算DNS解析度,TCP链接时间,白屏时间,dom解析时间等。
利用以上数据,我们可以重现用户的操作过程
您还可以立即采集应对客户端发生的异常采集
通过对用户行为的分析,可以得出用户的习惯和偏好。
以便优化产品解决方案,优化业务流程并获得数据驱动的产品。
三.采集有哪些数据处理方法?
常用数据采集方法:
1.自动埋入点,通过大范围的数据采集从数据中过滤出特定元素。这样做的缺点是数据量太大,而优点是无需在联机之前自定义采集解决方案。
2.主动通过向元素添加特定的id或class属性来掩埋点,以便采集工具可以准确确定采集所需的数据。缺点是它会入侵页面。优点是数据准确。
3.圈出掩埋点并通过单击选择页面元素,这比自动采集更准确,比手动掩埋更方便。但是圈出的兼容性问题令人头疼。
市场上有带圆圈和埋点的付费项目,报价基本上是10W +
我们今天介绍的dataAcquisition可以完美支持自动和主动埋入。
圈出的功能也在开发计划中。
作为可以解决眼前问题的开源工具,有没有理由不尝试?
四.关于数据获取
dataAcquisition插件于2017年开发,迭代时间相对较短。
自从上线生产以来,一年中没有错误
当然,由于情况不同,仍有许多问题尚未解决
当前实现的功能点:
1.前端PV,紫外线数据采集报告
2.用户点击,输入行为采集报告
3.实现页面性能采集
4.实施代码异常采集
5.实现接口异常采集
该项目已在GitHub上开源,地址:
包括采集插件源代码,示例演示
需要它的学生可以下载和使用
五.演示示例
该插件提供了一个简单的演示,包括数据采集页面,数据分析页面
1.数据采集页面:
此页面上的所有操作将由采集报告,
请注意,采集的数据仅在刷新页面或单击报告按钮时才会发送到后台
PC屏幕截图:
2.数据分析页:
报告的数据将显示在此页面上,在此页面上,您可以观察到所有先前的操作
与异常对应的详细数据
PC屏幕截图:
六.邀请参加
一个人的精力有限,开源项目的维护需要一些合作伙伴共同努力,
欢迎向我提交公关
所有参与者都将记录在作者目录中,并且每个人都将共享项目结果。
解密:有货iOS数据非侵入式自动采集探索实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2021-01-12 12:06
随着库存APP的不断迭代发展,数据和业务部门对客户用户行为数据的要求越来越高。为了更好地监视应用程序状态,客户团队拥有有关APP本身操作的数据。需求变得越来越紧迫。迫切需要一套用于客户数据采集的工具,以自动和完全采集用户行为数据来满足各个部门的数据需求。
为此,Instock APP团队开发了一组数据采集 SDK。主要功能如下:
页面访问流程。用户在应用程序中浏览了哪些页面。浏览数据公开。用户在页面上查看了哪些产品。业务数据自动为采集。用户单击了哪个位置,以及在应用程序期间触发了什么操作。性能数据自动为采集。在用户使用APP的过程中,页面加载时间,图像加载时间,网络请求时间等是什么?
此外,所有数据采集应该是自动化且非侵入性的,也就是说,无需手动掩埋,就可以与集成SDK一起使用,并且原创代码不应更改或尽可能少地更改。
基于上述要求,AOP是技术解决方案的最佳选择,而在iOS上实现AOP需要依靠Objective-C-Method Swizzle中运行时的黑魔法。踏入坑和填充坑的漫长旅程从这里开始,让我们逐一品尝实现的想法和方法。
页面访问流程
用户访问页面统计信息需要解决两个问题:
统计事件的入口点,即何时计数。统计数据字段,即要统计哪些数据。
整个过程如下:
统计事件的切入点
用户访问页面统计信息的一般思想是在View Controller生命周期方法中:
可以获得用户访问页面的路径,并且两个事件时间戳之间的差是用户停留在页面上的时间。
通常,我们APP中的View Controller继承自某个基类。我们可以在基类的相应方法中执行统计。但是,对于不继承自基类的View Controller,我们无能为力。
借助AOP,我们可以更优雅地完成此工作:在UIViewController的load方法中轻扫viewDidAppear和viewDidDisappear方法,无需更改原创代码。
统计信息字段
根据数据要求,设置以下统计字段:
页面进入和退出的事件都报告给上述数据结构。
有几个问题需要考虑:
1.如何定义PAGE_ID和SOURCE_ID
由于您需要统一iOS和Android的PAGE_ID,因此需要对其进行配置和发送。我在iOS端得到的是一个plist文件,该文件的键是View Controller类名的字符串表示形式,值是PAGE_ID。
2.如何获取PAGE_ID和SOURCE_ID
可以根据当前View Controller的类直接获取
PAGE_ID。 SOURCE_ID稍微复杂一些。根据APP页面的嵌套堆栈结构,有必要确定具体的获取方法。通常,上一个View Controller的页面取自UINavigationController id的导航堆栈。
到目前为止,页面访问流统计信息已经基本完成。根据页面进入和退出的PAGE_ID和SOURCE_ID,输入完整的用户浏览路径,并获得用户在每个页面上的停留时间。
浏览数据暴露
采集用户的浏览路径,以及在每个页面上花费的时间之后,在某些页面(例如主页和产品列表页面)上,我们还想知道用户在浏览器上滑动了多少个屏幕页,以查看已选择了哪些活动和产品,以便更好地为用户推荐喜爱的产品。
用户看到的屏幕区域被视为资源位,因此用户看到的内容由资源位组成。暴露的含义如下:
我们知道iOS中页面元素的基本单位是视图,因此我们只需确定视图是否在可见区域中,然后我们就可以知道是否需要公开当前视图上的资源位置,然后进行相应的曝光操作,采集数据,报告界面等。
从以上分析可以看出,有两个主要问题需要解决:
视图的可见性判断曝光数据采集视图的可见性判断
查询UIView类参考以查看setFrame:和layoutSubivews方法,这些方法可用于设置子视图的框架。每次更新观看次数时,都会调用此方法。因此,我们可以通过运行时选项卡来实现此方法,并添加一些与采集相关的数据。
我们向UIView添加了以下属性:
首先阐明以下术语的定义和规则:
1.视图的子视图可以同时看到3个需要满足的条件:
相反,只要不满足以上任一条件,我们认为此子视图当前不可见。
2.将视图设置为可见
3.将视图设置为不可见
Swzzile setFrame :,请执行以下操作:
易用的layoutSubivews,调用yh_updateVisibleSubViews方法,该方法执行以下操作:
完成上述操作后,我们可以知道视图及其子视图是否可见。
查看曝光数据采集
为了获取与视图相对应的数据,还将以下属性添加到UIView:
然后还有两个问题:
视图公开数据的粒度组装视图及其子视图节点的公开数据的时间
浏览量数据的粒度
根据项目的实际经验,UITableViewCell或UI采集ViewCell通常是最小的粒度。同时,在最后一个节点的yh_exposureData字典中,添加一个键:isEnd以标识它是否是最后一个节点。
组装视图及其子视图的曝光数据的时间
通常,当最后一个节点的可见性发生变化时,请从下到上遍历最后一个节点的超级视图以组装所有数据。
因此,我们覆盖了setYh_viewVisible:方法,这是yh_viewVisible的set方法。请执行以下操作:
到目前为止,我们已经解决了视图可见性判断和曝光数据采集的问题。数据报告和策略将不会重复。
此方案有几个缺点
您需要手动设置曝光数据。您需要在正确的时间手动调用view.yh_viewVisible来触发数据采集,例如viewdidappear。需要消耗某些资源来计算视觉区域和曝光数据采集。
还有两个问题值得注意:
UITableView将在setBounds:时更改视图框架,因此您需要调整setBounds:方法,需要在设置边界后调用[self yh_updateVisibleSubViews]; UIScrollView会在setContentInset:时影响视图的可见区域,因此需要使用setContentInset:方法,需要在设置contentInset之后调用self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame,contentInset);自动业务数据采集
自动业务数据采集是行业采集中没有隐藏点的流行数据。
传统客户用户点击数据采集基于手动埋入点。如果您对任何位置的数据感兴趣,请单击此处。用户操作后,将立即触发数据报告。手动掩埋的缺点很明显:错误的掩埋和丢失的掩埋。新版本发布后,经常有来自数据部门的小伙伴报告说,尚未报告某个问题,并且错误报告了某个问题,并且开发同事也很痛苦。
没有埋点的数据采集带来了新的变化。首先,基本上避免了人工掩埋,个别情况需要特殊处理。其次,从选择性的采集数据中更改全部采集用户的所有点击和触摸数据。
新变化也将带来新挑战。未埋数据采集的可能性仍然基于Objective-C的运行时功能。在实践过程中,我们使用iOS非埋入点数据SDK的总体设计和技术实现作为参考,并使用Sensors Analytics iOS SDK和Mixpanel iPhone作为实现。接下来,结合特定的实践,我们将介绍实现思想和遇到的一些问题。主要分为以下三个方面:
如何确保自动采集点的唯一性。不同的点类型,需要使用哪些方法进行转换。在下雨的时候,坑一直踩着。如何确保自动采集点的唯一性
Auto 采集与手动嵌入是分开的,因此没有唯一的标识点。那么,我们如何唯一地定位自动采集的点呢?一个容易想到的解决方案是:基于页面视图的树形结构。该解决方案可以分为两个问题:
如何定义视图唯一标识符。视图唯一地标识了生成方式。
视图唯一标识符(视图路径)的定义
我们规定典型的查看路径如下:
ViewController [0] / UIView [0] / UITableView [0] / UITableViewCell [0:2] / UIButton [0]
其中:
使用此标识符,可以在当前页面的视图树结构中唯一标识此元素。标识的每个项目都由两部分组成:一个是当前元素的类的字符串表示形式,另一个是同一级别元素中当前元素的序列号,从0开始计数。例如,第二个UIImageView是当前的UIImageView 1.标识使用/拼接的不同项目。徽标的顶层是当前视图所在的ViewController。对于UITableViewCell,UI采集ViewCell和类似的自定义组件,序列号部分由两部分组成:节和行,它们与:一起拼接。徽标的末尾是当前被单击或触摸的元素。
如何生成视图唯一标识符
视图路径生成过程:从触发操作的最末端元素向上查询,直到选中了ViewController。假设当前单击的视图是A_View,则从当前A_View开始并遍历视图树。每个级别的数据都存储在P_Array中。过程如下:
如果A_View是UI采集ViewCell类型,请获取A_View所在的UI采集View的indexPath以及P_Array推送路径信息[NSString stringWithFormat:@“%@ [%ld:%ld]”,[NSString stringWithFormat:@“%@ “,NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];如果A_View是UITableViewCell类型,请获取ATable所在的UITableView的indexPath以及P_Array推送路径信息[NSString stringWithFormat:@“%@ [%ld:%ld]”,[NSString stringWithFormat:@“%@”,NSStringFromClass ([A_View类])],(long)indexPath.section,(long)indexPath.row];遍历A_View.superview的所有子视图以获取A_View处于同一级别,并且相同类型的数字(索引)([A_View类]),P_Array推送路径信息[NSString stringWithFormat:@“%@ [%d]” ,NSStringFromClass([[A_View class]),index];获取A_View所在的控制器A_VC。如果A_View为A_VC.view,则遍历结束。如果A_View不等于A_VC.view,则A_View = A_View.superview,重复步骤1-4,直到A_View等于A_VC.view。遍历P_Array拼接A_View的完整路径。各种类型的点都需要使用毛毛雨方法
我们将APP中的用户操作分为四类:
UI采集View和UITableView的
单元格单击事件。 UIControl(UISwitch,UIStepper,UISegmentedControl,UINavigationButton,UISlider,UIButton)类控件的Click事件。 UIImageView和UITapGestureRecognizer触摸UILabel上的事件。 UITabBar,UIAlertView,UIActionSheet等的点击事件。
这四种操作都需要使用swizzle方法,如下表所示:
UI采集View,UITableView,UITabBar,UIAlertView和UIActionSheet的实现是相似的。它们都是load方法中的swizzle setDelegate方法。在setDelegate之后,执行代理回调方法的swizzle操作。在回调方法中,首先执行原创逻辑。 ,然后获取相应的viewPath。
当UIControl组件回调到目标时,将通过UIApplication的sendAction:to:from:forEvent:调用它,因此我们选择swizzle方法。在实践中,首先获取相应的视图路径,然后执行原创逻辑。原因是,如果首先执行原创逻辑,则页面可能会更改,并且所获得的View Controller将是错误的。
<p>UITapGestureRecognizer事件仅在UIImageView和UILabel上处理。 swizzle addGestureRecognizer:方法,首先执行原创逻辑,然后向视图添加自定义回调方法,以便在触发手势时也将调用自定义回调,此时我们获得了视图路径。 查看全部
解密:有货iOS数据非侵入式自动采集探索实践
随着库存APP的不断迭代发展,数据和业务部门对客户用户行为数据的要求越来越高。为了更好地监视应用程序状态,客户团队拥有有关APP本身操作的数据。需求变得越来越紧迫。迫切需要一套用于客户数据采集的工具,以自动和完全采集用户行为数据来满足各个部门的数据需求。
为此,Instock APP团队开发了一组数据采集 SDK。主要功能如下:
页面访问流程。用户在应用程序中浏览了哪些页面。浏览数据公开。用户在页面上查看了哪些产品。业务数据自动为采集。用户单击了哪个位置,以及在应用程序期间触发了什么操作。性能数据自动为采集。在用户使用APP的过程中,页面加载时间,图像加载时间,网络请求时间等是什么?
此外,所有数据采集应该是自动化且非侵入性的,也就是说,无需手动掩埋,就可以与集成SDK一起使用,并且原创代码不应更改或尽可能少地更改。
基于上述要求,AOP是技术解决方案的最佳选择,而在iOS上实现AOP需要依靠Objective-C-Method Swizzle中运行时的黑魔法。踏入坑和填充坑的漫长旅程从这里开始,让我们逐一品尝实现的想法和方法。
页面访问流程
用户访问页面统计信息需要解决两个问题:
统计事件的入口点,即何时计数。统计数据字段,即要统计哪些数据。
整个过程如下:
统计事件的切入点
用户访问页面统计信息的一般思想是在View Controller生命周期方法中:
可以获得用户访问页面的路径,并且两个事件时间戳之间的差是用户停留在页面上的时间。
通常,我们APP中的View Controller继承自某个基类。我们可以在基类的相应方法中执行统计。但是,对于不继承自基类的View Controller,我们无能为力。
借助AOP,我们可以更优雅地完成此工作:在UIViewController的load方法中轻扫viewDidAppear和viewDidDisappear方法,无需更改原创代码。
统计信息字段
根据数据要求,设置以下统计字段:
页面进入和退出的事件都报告给上述数据结构。
有几个问题需要考虑:
1.如何定义PAGE_ID和SOURCE_ID
由于您需要统一iOS和Android的PAGE_ID,因此需要对其进行配置和发送。我在iOS端得到的是一个plist文件,该文件的键是View Controller类名的字符串表示形式,值是PAGE_ID。
2.如何获取PAGE_ID和SOURCE_ID
可以根据当前View Controller的类直接获取
PAGE_ID。 SOURCE_ID稍微复杂一些。根据APP页面的嵌套堆栈结构,有必要确定具体的获取方法。通常,上一个View Controller的页面取自UINavigationController id的导航堆栈。
到目前为止,页面访问流统计信息已经基本完成。根据页面进入和退出的PAGE_ID和SOURCE_ID,输入完整的用户浏览路径,并获得用户在每个页面上的停留时间。
浏览数据暴露
采集用户的浏览路径,以及在每个页面上花费的时间之后,在某些页面(例如主页和产品列表页面)上,我们还想知道用户在浏览器上滑动了多少个屏幕页,以查看已选择了哪些活动和产品,以便更好地为用户推荐喜爱的产品。
用户看到的屏幕区域被视为资源位,因此用户看到的内容由资源位组成。暴露的含义如下:
我们知道iOS中页面元素的基本单位是视图,因此我们只需确定视图是否在可见区域中,然后我们就可以知道是否需要公开当前视图上的资源位置,然后进行相应的曝光操作,采集数据,报告界面等。
从以上分析可以看出,有两个主要问题需要解决:
视图的可见性判断曝光数据采集视图的可见性判断
查询UIView类参考以查看setFrame:和layoutSubivews方法,这些方法可用于设置子视图的框架。每次更新观看次数时,都会调用此方法。因此,我们可以通过运行时选项卡来实现此方法,并添加一些与采集相关的数据。
我们向UIView添加了以下属性:
首先阐明以下术语的定义和规则:
1.视图的子视图可以同时看到3个需要满足的条件:
相反,只要不满足以上任一条件,我们认为此子视图当前不可见。
2.将视图设置为可见
3.将视图设置为不可见
Swzzile setFrame :,请执行以下操作:
易用的layoutSubivews,调用yh_updateVisibleSubViews方法,该方法执行以下操作:
完成上述操作后,我们可以知道视图及其子视图是否可见。
查看曝光数据采集
为了获取与视图相对应的数据,还将以下属性添加到UIView:
然后还有两个问题:
视图公开数据的粒度组装视图及其子视图节点的公开数据的时间
浏览量数据的粒度
根据项目的实际经验,UITableViewCell或UI采集ViewCell通常是最小的粒度。同时,在最后一个节点的yh_exposureData字典中,添加一个键:isEnd以标识它是否是最后一个节点。
组装视图及其子视图的曝光数据的时间
通常,当最后一个节点的可见性发生变化时,请从下到上遍历最后一个节点的超级视图以组装所有数据。
因此,我们覆盖了setYh_viewVisible:方法,这是yh_viewVisible的set方法。请执行以下操作:
到目前为止,我们已经解决了视图可见性判断和曝光数据采集的问题。数据报告和策略将不会重复。
此方案有几个缺点
您需要手动设置曝光数据。您需要在正确的时间手动调用view.yh_viewVisible来触发数据采集,例如viewdidappear。需要消耗某些资源来计算视觉区域和曝光数据采集。
还有两个问题值得注意:
UITableView将在setBounds:时更改视图框架,因此您需要调整setBounds:方法,需要在设置边界后调用[self yh_updateVisibleSubViews]; UIScrollView会在setContentInset:时影响视图的可见区域,因此需要使用setContentInset:方法,需要在设置contentInset之后调用self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame,contentInset);自动业务数据采集
自动业务数据采集是行业采集中没有隐藏点的流行数据。
传统客户用户点击数据采集基于手动埋入点。如果您对任何位置的数据感兴趣,请单击此处。用户操作后,将立即触发数据报告。手动掩埋的缺点很明显:错误的掩埋和丢失的掩埋。新版本发布后,经常有来自数据部门的小伙伴报告说,尚未报告某个问题,并且错误报告了某个问题,并且开发同事也很痛苦。
没有埋点的数据采集带来了新的变化。首先,基本上避免了人工掩埋,个别情况需要特殊处理。其次,从选择性的采集数据中更改全部采集用户的所有点击和触摸数据。
新变化也将带来新挑战。未埋数据采集的可能性仍然基于Objective-C的运行时功能。在实践过程中,我们使用iOS非埋入点数据SDK的总体设计和技术实现作为参考,并使用Sensors Analytics iOS SDK和Mixpanel iPhone作为实现。接下来,结合特定的实践,我们将介绍实现思想和遇到的一些问题。主要分为以下三个方面:
如何确保自动采集点的唯一性。不同的点类型,需要使用哪些方法进行转换。在下雨的时候,坑一直踩着。如何确保自动采集点的唯一性
Auto 采集与手动嵌入是分开的,因此没有唯一的标识点。那么,我们如何唯一地定位自动采集的点呢?一个容易想到的解决方案是:基于页面视图的树形结构。该解决方案可以分为两个问题:
如何定义视图唯一标识符。视图唯一地标识了生成方式。
视图唯一标识符(视图路径)的定义
我们规定典型的查看路径如下:
ViewController [0] / UIView [0] / UITableView [0] / UITableViewCell [0:2] / UIButton [0]
其中:
使用此标识符,可以在当前页面的视图树结构中唯一标识此元素。标识的每个项目都由两部分组成:一个是当前元素的类的字符串表示形式,另一个是同一级别元素中当前元素的序列号,从0开始计数。例如,第二个UIImageView是当前的UIImageView 1.标识使用/拼接的不同项目。徽标的顶层是当前视图所在的ViewController。对于UITableViewCell,UI采集ViewCell和类似的自定义组件,序列号部分由两部分组成:节和行,它们与:一起拼接。徽标的末尾是当前被单击或触摸的元素。
如何生成视图唯一标识符
视图路径生成过程:从触发操作的最末端元素向上查询,直到选中了ViewController。假设当前单击的视图是A_View,则从当前A_View开始并遍历视图树。每个级别的数据都存储在P_Array中。过程如下:
如果A_View是UI采集ViewCell类型,请获取A_View所在的UI采集View的indexPath以及P_Array推送路径信息[NSString stringWithFormat:@“%@ [%ld:%ld]”,[NSString stringWithFormat:@“%@ “,NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];如果A_View是UITableViewCell类型,请获取ATable所在的UITableView的indexPath以及P_Array推送路径信息[NSString stringWithFormat:@“%@ [%ld:%ld]”,[NSString stringWithFormat:@“%@”,NSStringFromClass ([A_View类])],(long)indexPath.section,(long)indexPath.row];遍历A_View.superview的所有子视图以获取A_View处于同一级别,并且相同类型的数字(索引)([A_View类]),P_Array推送路径信息[NSString stringWithFormat:@“%@ [%d]” ,NSStringFromClass([[A_View class]),index];获取A_View所在的控制器A_VC。如果A_View为A_VC.view,则遍历结束。如果A_View不等于A_VC.view,则A_View = A_View.superview,重复步骤1-4,直到A_View等于A_VC.view。遍历P_Array拼接A_View的完整路径。各种类型的点都需要使用毛毛雨方法
我们将APP中的用户操作分为四类:
UI采集View和UITableView的
单元格单击事件。 UIControl(UISwitch,UIStepper,UISegmentedControl,UINavigationButton,UISlider,UIButton)类控件的Click事件。 UIImageView和UITapGestureRecognizer触摸UILabel上的事件。 UITabBar,UIAlertView,UIActionSheet等的点击事件。
这四种操作都需要使用swizzle方法,如下表所示:
UI采集View,UITableView,UITabBar,UIAlertView和UIActionSheet的实现是相似的。它们都是load方法中的swizzle setDelegate方法。在setDelegate之后,执行代理回调方法的swizzle操作。在回调方法中,首先执行原创逻辑。 ,然后获取相应的viewPath。
当UIControl组件回调到目标时,将通过UIApplication的sendAction:to:from:forEvent:调用它,因此我们选择swizzle方法。在实践中,首先获取相应的视图路径,然后执行原创逻辑。原因是,如果首先执行原创逻辑,则页面可能会更改,并且所获得的View Controller将是错误的。
<p>UITapGestureRecognizer事件仅在UIImageView和UILabel上处理。 swizzle addGestureRecognizer:方法,首先执行原创逻辑,然后向视图添加自定义回调方法,以便在触发手势时也将调用自定义回调,此时我们获得了视图路径。
完美:优采云采集器自定义任务爬取微博数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2021-01-11 10:01
我只想统计某个特定年份博主发布的所有微博,并统计评论和喜欢的总数。这听起来很简单。我没想到这么长时间折腾。
第一个是微博数据提供的支付功能。更不用说付款,它只能计算近一年,并且不能任意指定时间段。例如,在2020.4.11的一天,只有2019.4.11〜2020.4.11。每年的除夕夜是否有必要计算上一年的数据? ? ?
所以我找到了微博API(),发现很难使用。我不知道是不是我毕竟,我只使用了百度和AutoNavi API,并且经验不足。首先创建应用程序,然后花了很长时间才找到入口。它不在[我的应用程序]中,而是在首页上看起来像广告的按钮中。对于API接口,需要对提供的一些基本公共信息进行授权,并且OAuth2.0授权由于某些未知原因而失败。似乎无法通过官方渠道获取数据,我只能自己爬网。
似乎迟早会填满履带坑。我还没学会,也从未使用过。找到其他人的代码并更改了微博ID后,我将无法访问它。我不知道该公司的微博是否受到保护。
最后,我不得不将数据爬到一半,并使用优采云采集器()。尽管该软件易于使用,但还是花了一些时间才能理解其中的各种设置。经过无数次的零采集和数据不完整之后,最终的设置可能是不必要的,但是这组设置确实可以正确捕获数据,并且不需要花费几分钟,因此我不必担心。本文记录了踩到的一些凹坑以及最终的成功设置。
软件准备
免费下载,安装,注册,免费版本已足够,任务数据量不大,本地采集模式已足够。提供了一些模板,包括微博。
优采云采集器中提供的微博数据采集模板
但微博最麻烦的部分是登录操作。您必须不时输入验证码。另外,全年对任务进行计数需要大量的滚动和翻页操作,因此您仍然必须使用自定义任务,这是不可避免的。设置采集 URL,采集进程,登录操作。
采集 URL
采集 URL的设置基本上没有问题。只需在URL中找到需要更改的参数即可。如果有多个页面,建议从URL设置页码。要可靠,并自动翻页。我担心翻页错误,因此在微博上翻页后就跳出登录页面,所以自动识别始终成功,但是一开始采集没被抓住。以我的微博个人主页为例,我在2019年6月查看了博客文章(#feedtop),发现时间轴按月划分。 6月份的微博帖子略多,并且出现了页面更改,因此我需要修改两个参数。 [月]和[页数]。
个人微博截图
在优采云采集器中,选择[批次生成] URL,在文本框中选择要替换的参数,然后单击[添加参数]进行设置。这里设置的两个参数,[Month]为01〜12(软件提供了[Zero Fill]功能,非常周到),[Page Number]为1〜4,因为这次微博的数量没有计算超过每月4页,这应该是乐观的。
批量生成URL参数设置
自动生成48个URL后,您可以[保存设置]并开始编辑任务。然后,该软件将打开第一个网站,并开始自动识别此页面的内容,并生成采集数据的结果,并提供基本上是可信的,不可信的操作提示。单击[Generate 采集 Settings]来自动生成采集进程的框架(毕竟,它比您自己的框架更可靠),然后调整设置的详细信息(详细信息被抛了很长时间)
自动识别结果
采集流程
自动生成的流程图,基本框架很好。
循环采集的基本框架
启动详细设置,[提取列表数据]没什么好说的,只需删除一些不必要的字段即可。主要是[在循环中打开网页],单击小齿轮以打开设置:
在循环中打开网页设置
[打开网页之前]在这里,由于担心加载不完整,我打开了下一页,并将等待时间设置为3秒。 (我尝试使用cookie设置绕过登录,但未成功,并且在当前页面上获取cookie的按钮没有响应,因此我放弃了。)[打开网页后]在此处设置滚动。起初我以为Scroll 2次到末尾,后来发现不同的页面不一样,将其设置为3次,间隔为1秒,这也怕在加载之前跳过。
滚动设置在这里纠缠了很长时间,因为总是会发生相同的错误。显然,一个页面应该被加载3次,并最终获得45条数据。执行结果时,始终仅捕获15个,并且不进行滚动。我不知道是因为我没有登录,还是打开网页而没有等待打开。
登录操作
为了确保多页爬网的顺利完成,仍然没有必要登录,否则将始终弹出提示登录对话框,采集找不到任何内容。合理地说,微博登录是通过cookie记录的,但是如果将其放置在软件的采集任务中,则该登录将不起作用。每次启动时,全新的界面都要求您登录。眨眼之间,您就无法识别自己的身份。不记得了。因此,参考模板中的设置,在开始循环采集之前添加了一个登录操作,该操作已添加到流程图中以诚实地执行。
在流程图中添加了登录操作
[打开网页]此处的URL设置为微博条目(),后续的操作设置实际上是半自动的,直接在预览的网页中进行操作,单击对话框或按钮,以及[操作提示]对应将出现操作,您可以记录输入文本(用户名,密码),登录时单击元素和其他操作,模拟人工操作并自动将其添加到流程图中,但是它们可能在循环后面,需要手动拖动调整流程图中各框的顺序,并在流程图完成[采集]之后开始。
我认为如果所有这些都设置好,并且还记下了帐户和密码,那么我应该可以先登录。出乎意料的是,登录时未输入用户名或未输入密码。结果,没有登录就执行了下一步,并且循环开始了,但是仍然没有发现任何问题。此时,打开网页之前等待3秒钟似乎有效,抓住3秒钟的时间,手动输入自动操作中未输入的用户名或密码,然后单击立即登录,然后然后打开采集的主页,在完成登录之前,我终于爬下了每个页面,其中收录根据需要滚动滚动加载的所有数据,然后就完成了。
最后完成的采集 查看全部
完美:优采云采集器自定义任务爬取微博数据
我只想统计某个特定年份博主发布的所有微博,并统计评论和喜欢的总数。这听起来很简单。我没想到这么长时间折腾。
第一个是微博数据提供的支付功能。更不用说付款,它只能计算近一年,并且不能任意指定时间段。例如,在2020.4.11的一天,只有2019.4.11〜2020.4.11。每年的除夕夜是否有必要计算上一年的数据? ? ?
所以我找到了微博API(),发现很难使用。我不知道是不是我毕竟,我只使用了百度和AutoNavi API,并且经验不足。首先创建应用程序,然后花了很长时间才找到入口。它不在[我的应用程序]中,而是在首页上看起来像广告的按钮中。对于API接口,需要对提供的一些基本公共信息进行授权,并且OAuth2.0授权由于某些未知原因而失败。似乎无法通过官方渠道获取数据,我只能自己爬网。
似乎迟早会填满履带坑。我还没学会,也从未使用过。找到其他人的代码并更改了微博ID后,我将无法访问它。我不知道该公司的微博是否受到保护。
最后,我不得不将数据爬到一半,并使用优采云采集器()。尽管该软件易于使用,但还是花了一些时间才能理解其中的各种设置。经过无数次的零采集和数据不完整之后,最终的设置可能是不必要的,但是这组设置确实可以正确捕获数据,并且不需要花费几分钟,因此我不必担心。本文记录了踩到的一些凹坑以及最终的成功设置。
软件准备
免费下载,安装,注册,免费版本已足够,任务数据量不大,本地采集模式已足够。提供了一些模板,包括微博。
优采云采集器中提供的微博数据采集模板
但微博最麻烦的部分是登录操作。您必须不时输入验证码。另外,全年对任务进行计数需要大量的滚动和翻页操作,因此您仍然必须使用自定义任务,这是不可避免的。设置采集 URL,采集进程,登录操作。
采集 URL
采集 URL的设置基本上没有问题。只需在URL中找到需要更改的参数即可。如果有多个页面,建议从URL设置页码。要可靠,并自动翻页。我担心翻页错误,因此在微博上翻页后就跳出登录页面,所以自动识别始终成功,但是一开始采集没被抓住。以我的微博个人主页为例,我在2019年6月查看了博客文章(#feedtop),发现时间轴按月划分。 6月份的微博帖子略多,并且出现了页面更改,因此我需要修改两个参数。 [月]和[页数]。
个人微博截图
在优采云采集器中,选择[批次生成] URL,在文本框中选择要替换的参数,然后单击[添加参数]进行设置。这里设置的两个参数,[Month]为01〜12(软件提供了[Zero Fill]功能,非常周到),[Page Number]为1〜4,因为这次微博的数量没有计算超过每月4页,这应该是乐观的。
批量生成URL参数设置
自动生成48个URL后,您可以[保存设置]并开始编辑任务。然后,该软件将打开第一个网站,并开始自动识别此页面的内容,并生成采集数据的结果,并提供基本上是可信的,不可信的操作提示。单击[Generate 采集 Settings]来自动生成采集进程的框架(毕竟,它比您自己的框架更可靠),然后调整设置的详细信息(详细信息被抛了很长时间)
自动识别结果
采集流程
自动生成的流程图,基本框架很好。
循环采集的基本框架
启动详细设置,[提取列表数据]没什么好说的,只需删除一些不必要的字段即可。主要是[在循环中打开网页],单击小齿轮以打开设置:
在循环中打开网页设置
[打开网页之前]在这里,由于担心加载不完整,我打开了下一页,并将等待时间设置为3秒。 (我尝试使用cookie设置绕过登录,但未成功,并且在当前页面上获取cookie的按钮没有响应,因此我放弃了。)[打开网页后]在此处设置滚动。起初我以为Scroll 2次到末尾,后来发现不同的页面不一样,将其设置为3次,间隔为1秒,这也怕在加载之前跳过。
滚动设置在这里纠缠了很长时间,因为总是会发生相同的错误。显然,一个页面应该被加载3次,并最终获得45条数据。执行结果时,始终仅捕获15个,并且不进行滚动。我不知道是因为我没有登录,还是打开网页而没有等待打开。
登录操作
为了确保多页爬网的顺利完成,仍然没有必要登录,否则将始终弹出提示登录对话框,采集找不到任何内容。合理地说,微博登录是通过cookie记录的,但是如果将其放置在软件的采集任务中,则该登录将不起作用。每次启动时,全新的界面都要求您登录。眨眼之间,您就无法识别自己的身份。不记得了。因此,参考模板中的设置,在开始循环采集之前添加了一个登录操作,该操作已添加到流程图中以诚实地执行。
在流程图中添加了登录操作
[打开网页]此处的URL设置为微博条目(),后续的操作设置实际上是半自动的,直接在预览的网页中进行操作,单击对话框或按钮,以及[操作提示]对应将出现操作,您可以记录输入文本(用户名,密码),登录时单击元素和其他操作,模拟人工操作并自动将其添加到流程图中,但是它们可能在循环后面,需要手动拖动调整流程图中各框的顺序,并在流程图完成[采集]之后开始。
我认为如果所有这些都设置好,并且还记下了帐户和密码,那么我应该可以先登录。出乎意料的是,登录时未输入用户名或未输入密码。结果,没有登录就执行了下一步,并且循环开始了,但是仍然没有发现任何问题。此时,打开网页之前等待3秒钟似乎有效,抓住3秒钟的时间,手动输入自动操作中未输入的用户名或密码,然后单击立即登录,然后然后打开采集的主页,在完成登录之前,我终于爬下了每个页面,其中收录根据需要滚动滚动加载的所有数据,然后就完成了。
最后完成的采集
解决方案:一种Web数据自动采集的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 470 次浏览 • 2020-11-01 12:02
一种自动采集的网络数据方法
本发明公开了一种用于Web数据自动化的方法采集,包括以下步骤:网络机器人技术和网页数据提取技术;网络机器人技术包括设计网络机器人工作流程,制定网络机器人设计原则,深度优先搜索策略和宽度优先搜索策略,网络陷阱,均衡访问和超链接提取。网页数据提取技术包括网页纯文本的提取和文本中特殊字符的分析与处理。本发明提供了一种Web数据自动采集的方法,该方法充分利用网络机器人技术和Web数据提取技术来形成Web自动采集的方法,从海量信息中采集有价值的数据,并进行分析和研究以形成。企业的各种决策据此,它解决了数据采集人员和市场研究人员所面临的问题,同时扩展了Web的可用性,并为数据采集的开发做出了一定贡献。自动数据采集。
[专利描述]一种自动采集力数据的方法
[技术领域]
[0001]本发明涉及一种数据采集技术,尤其是一种数据自动采集方法。
[背景技术]
[0002]随着网络资源的不断丰富和网络信息量的不断扩大,人们越来越依赖网络,但是他们也可以从庞大的Internet资源中快速找到自己的特定需求。资源带来不便;自古以来,信息就具有无限的价值。随着时代的不断发展,人类在不知不觉中进入了信息时代,各行各业充斥着无数的信息,信息的价值在于数据的流通,如果能够及时地流通和传递数据的话信息的真正无与伦比的价值可以发挥作用;在市场经济条件下,采集数据已成为重要的工具和手段。
[p3] [0003]数据采集人员和市场研究人员面临的问题是如何从海量信息中采集有价值的数据并进行分析和研究,从而为企业的各种决策奠定基础。需要大量数据快速查找和获取所需信息和服务变得越来越困难。服务对象在查询信息时经常会失去目标或获得一些偏见。数据必须经过汇总,整合和分析才能产生价值,分散的信息只能是新闻,不能反映真实的商业价值;对于企业和信息分析师而言,一方面有必要在减少获取的同时从大量信息中滤除有效价值点。相应信息的成本使信息的实际使用价值大于在信息中产生的成本。采集和分析信息的过程,以便信息可以为企业的决策带来增值。
[0004]互联网的普及和信息技术的发展已经形成了大量的信息资源;从大量信息中提取有用资源是当前急需解决的问题,1613页上表达的主要信息通常隐藏在许多不相关的结构和文本中,用户无法快速获取主题信息,这限制了166的可用性。自动采集有助于解决此问题。自动采集节省了时间和精力,并涵盖了广泛的信息。提取质量不高,会影响精度;因此,现在大多数数据采集都使用自动采集方法;自动采集技术就是在这种背景下产生的。
[发明内容]
[0005]针对上述问题,本发明通过网络机器人技术和Web数据提取技术的应用开发了一种166数据自动采集方法。
[0006]本发明的技术手段如下:
[0007]-一种数据自动采集的方法,其特征在于包括以下步骤:
[0008]八、网络机器人技术:
[0009] 81、设计网络机器人的工作流程:机器人以一个或一组嘴巴为起点,进行浏览以访问对应的胃部文档,即文档;
[0010]八2、制定网络机器人设计原则;
[0011]纟21、制定不收录在漫游器中的项目的标准:在服务器上创建漫游器文本文件,其中指出网站个无法访问的链接和网站个拒绝访问的漫游器; [ 0012] A2 2、指定机械手的META标签:用户在页面上添加了META标签,该META标签允许页面的所有者指定是允许机器人程序索引页面还是从页面中提取链接;
[0013] A3、深度优先搜索策略和宽度优先搜索策略;
[0014]Α31、深度优先搜索策略是从起始节点开始,分析第一个文档并检索第一个链接指向的页面,然后在分析页面后检索该页面重复执行第一个链接的to,直到搜索到不收录任何超链接的文档并将其定义为完整链,然后返回文档,然后选择并搜索文档中的其余超链接。结束的迹象是所有超链接都已被搜索;
<p>[0015]Α32、广度优先搜索策略是分析第一个文档,搜索网页中的所有超链接,然后在下一级继续搜索,直到完成底部搜索; 查看全部
一种自动采集的网络数据方法
一种自动采集的网络数据方法
本发明公开了一种用于Web数据自动化的方法采集,包括以下步骤:网络机器人技术和网页数据提取技术;网络机器人技术包括设计网络机器人工作流程,制定网络机器人设计原则,深度优先搜索策略和宽度优先搜索策略,网络陷阱,均衡访问和超链接提取。网页数据提取技术包括网页纯文本的提取和文本中特殊字符的分析与处理。本发明提供了一种Web数据自动采集的方法,该方法充分利用网络机器人技术和Web数据提取技术来形成Web自动采集的方法,从海量信息中采集有价值的数据,并进行分析和研究以形成。企业的各种决策据此,它解决了数据采集人员和市场研究人员所面临的问题,同时扩展了Web的可用性,并为数据采集的开发做出了一定贡献。自动数据采集。
[专利描述]一种自动采集力数据的方法
[技术领域]
[0001]本发明涉及一种数据采集技术,尤其是一种数据自动采集方法。
[背景技术]
[0002]随着网络资源的不断丰富和网络信息量的不断扩大,人们越来越依赖网络,但是他们也可以从庞大的Internet资源中快速找到自己的特定需求。资源带来不便;自古以来,信息就具有无限的价值。随着时代的不断发展,人类在不知不觉中进入了信息时代,各行各业充斥着无数的信息,信息的价值在于数据的流通,如果能够及时地流通和传递数据的话信息的真正无与伦比的价值可以发挥作用;在市场经济条件下,采集数据已成为重要的工具和手段。
[p3] [0003]数据采集人员和市场研究人员面临的问题是如何从海量信息中采集有价值的数据并进行分析和研究,从而为企业的各种决策奠定基础。需要大量数据快速查找和获取所需信息和服务变得越来越困难。服务对象在查询信息时经常会失去目标或获得一些偏见。数据必须经过汇总,整合和分析才能产生价值,分散的信息只能是新闻,不能反映真实的商业价值;对于企业和信息分析师而言,一方面有必要在减少获取的同时从大量信息中滤除有效价值点。相应信息的成本使信息的实际使用价值大于在信息中产生的成本。采集和分析信息的过程,以便信息可以为企业的决策带来增值。
[0004]互联网的普及和信息技术的发展已经形成了大量的信息资源;从大量信息中提取有用资源是当前急需解决的问题,1613页上表达的主要信息通常隐藏在许多不相关的结构和文本中,用户无法快速获取主题信息,这限制了166的可用性。自动采集有助于解决此问题。自动采集节省了时间和精力,并涵盖了广泛的信息。提取质量不高,会影响精度;因此,现在大多数数据采集都使用自动采集方法;自动采集技术就是在这种背景下产生的。
[发明内容]
[0005]针对上述问题,本发明通过网络机器人技术和Web数据提取技术的应用开发了一种166数据自动采集方法。
[0006]本发明的技术手段如下:
[0007]-一种数据自动采集的方法,其特征在于包括以下步骤:
[0008]八、网络机器人技术:
[0009] 81、设计网络机器人的工作流程:机器人以一个或一组嘴巴为起点,进行浏览以访问对应的胃部文档,即文档;
[0010]八2、制定网络机器人设计原则;
[0011]纟21、制定不收录在漫游器中的项目的标准:在服务器上创建漫游器文本文件,其中指出网站个无法访问的链接和网站个拒绝访问的漫游器; [ 0012] A2 2、指定机械手的META标签:用户在页面上添加了META标签,该META标签允许页面的所有者指定是允许机器人程序索引页面还是从页面中提取链接;
[0013] A3、深度优先搜索策略和宽度优先搜索策略;
[0014]Α31、深度优先搜索策略是从起始节点开始,分析第一个文档并检索第一个链接指向的页面,然后在分析页面后检索该页面重复执行第一个链接的to,直到搜索到不收录任何超链接的文档并将其定义为完整链,然后返回文档,然后选择并搜索文档中的其余超链接。结束的迹象是所有超链接都已被搜索;
<p>[0015]Α32、广度优先搜索策略是分析第一个文档,搜索网页中的所有超链接,然后在下一级继续搜索,直到完成底部搜索;
常用的方法:常用数据采集方式介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-09-01 12:11
在线数据采集
1. 前端掩埋点: 通过在客户端上部署点,当用户在客户端上进行交互时,相应的信息将被记录并传输到日志服务器. 前端掩埋点有三种类型:
根据要求,记录指定的行为数据
优点: 定制的埋入点,灵活性强,采集丰富的数据信息,基本上适用于各种复杂场景;
缺点: 埋点工作量大,维护成本高;
根据需要,以视觉方式掩埋点并记录指定的行为数据
优点: 定制的埋入点,很好地解决了代码埋入点的工作量和维护成本
缺点: 某些页面控件行为无法实现;数据无法追踪;只能记录行为发生的次数
尽可能采集所有行为数据
优点: 解决了代码埋入点的工作量和维护成本,并且可以跟踪数据
缺点: 某些页面控件行为无法实现. 由于存在大量冗余数据,因此数据存储和传输的成本很高;只能记录行为发生的次数
2. 服务器端掩埋点: 通过在系统服务器端部署相应的数据采集模块,可以处理和分析采集数据.
比较前端掩埋点的优缺点
优点: 前端埋入点只能采集将数据信息保留在前端,而服务器端埋入点可以采集将数据记录在后端,这也可以减少客户的复杂性
缺点: 某些行为数据不一定会发出访问服务器的请求,并且服务器无法采集这部分数据
离线数据采集
脱机行为数据主要是通过硬件采集进行的,例如
第三方数据采集
第三方数据采集通常是一种程序或脚本,可以根据既定规则通过网络爬网程序自动对Internet信息进行爬网,并且通常用于网站的自动化测试和行为模拟.
Google,搜狗,百度等提供的Internet信息检索功能基于内部自建的Web采集器. 在遵守相关协议的条件下,他们将不断在Internet上抓取新鲜的网页信息,并在处理完内容后提供相应的检索服务 查看全部
常用数据介绍采集方法
在线数据采集
1. 前端掩埋点: 通过在客户端上部署点,当用户在客户端上进行交互时,相应的信息将被记录并传输到日志服务器. 前端掩埋点有三种类型:
根据要求,记录指定的行为数据
优点: 定制的埋入点,灵活性强,采集丰富的数据信息,基本上适用于各种复杂场景;
缺点: 埋点工作量大,维护成本高;
根据需要,以视觉方式掩埋点并记录指定的行为数据
优点: 定制的埋入点,很好地解决了代码埋入点的工作量和维护成本
缺点: 某些页面控件行为无法实现;数据无法追踪;只能记录行为发生的次数
尽可能采集所有行为数据
优点: 解决了代码埋入点的工作量和维护成本,并且可以跟踪数据
缺点: 某些页面控件行为无法实现. 由于存在大量冗余数据,因此数据存储和传输的成本很高;只能记录行为发生的次数
2. 服务器端掩埋点: 通过在系统服务器端部署相应的数据采集模块,可以处理和分析采集数据.
比较前端掩埋点的优缺点
优点: 前端埋入点只能采集将数据信息保留在前端,而服务器端埋入点可以采集将数据记录在后端,这也可以减少客户的复杂性
缺点: 某些行为数据不一定会发出访问服务器的请求,并且服务器无法采集这部分数据
离线数据采集
脱机行为数据主要是通过硬件采集进行的,例如
第三方数据采集
第三方数据采集通常是一种程序或脚本,可以根据既定规则通过网络爬网程序自动对Internet信息进行爬网,并且通常用于网站的自动化测试和行为模拟.
Google,搜狗,百度等提供的Internet信息检索功能基于内部自建的Web采集器. 在遵守相关协议的条件下,他们将不断在Internet上抓取新鲜的网页信息,并在处理完内容后提供相应的检索服务
整套解决方案:iOS SDK 自动采集指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-31 19:37
iOS SDK自动采集指南1.自动采集简介
TA系统提供了自动数据采集的界面. 您可以根据业务需要选择需要自动采集的数据.
当前支持的自动数据采集是:
APP安装,记录正在安装的APP的日志,APP启动(包括打开APP并从后台唤醒),关闭APP(包括关闭APP并转移到后台)以及采集启动时间. 用户浏览APP中的页面(本机页面). 点击APP中的控件,以在APP崩溃时记录崩溃信息
接下来,我们将详细介绍每种数据的采集方法
2. 打开自动采集
您可以调用enableAutoTrack: 打开自动采集功能:
// 开启某个APPID实例的自动采集事件,支持多个APPID实例都开启自动采集
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID]enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
ThinkingAnalyticsEventTypeAppInstall |
ThinkingAnalyticsEventTypeAppEnd |
ThinkingAnalyticsEventTypeAppViewScreen |
ThinkingAnalyticsEventTypeAppClick |
ThinkingAnalyticsEventTypeAppViewCrash];
// 单APPID实例时可调用以下方法开启
// [[ThinkingAnalyticsSDK sharedInstance] enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
// ThinkingAnalyticsEventTypeAppInstall |
// ThinkingAnalyticsEventTypeAppEnd |
// ThinkingAnalyticsEventTypeAppViewScreen |
// ThinkingAnalyticsEventTypeAppClick |
// ThinkingAnalyticsEventTypeAppViewCrash];
以上参数分别表示为:
根据业务情况,您可以传递要采集的事件的相应参数. 对于多个参数,请使用|. 分裂.
如果您需要设置公共事件属性或设置自定义访问者ID,请确保在打开自动采集之前调用setSuperProperties: 或identify:.
-(BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
[ThinkingAnalyticsSDK startWithAppId:@"APP_ID"
withUrl:@"SERVER_URL"];
return YES;
}
[[ThinkingAnalyticsSDK sharedInstance] identify:@"123ABCabc"];
[[ThinkingAnalyticsSDK sharedInstance] setSuperProperties:@{
@"Channel":@"ABC",
@"Server":123,
@"isTest":@YES
}];
//设置完访客ID与公共属性后,再开启自动采集
[[ThinkingAnalyticsSDK sharedInstance] enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
ThinkingAnalyticsEventTypeAppInstall |
ThinkingAnalyticsEventTypeAppEnd |
ThinkingAnalyticsEventTypeAppViewScreen |
ThinkingAnalyticsEventTypeAppClick |
ThinkingAnalyticsEventTypeAppViewCrash];
3. 自动采集事件3.1 APP安装事件的详细说明
APP安装事件将记录APP的实际安装并在启动APP时报告. 事件触发时间是安装后首次启动APP的时间. APP升级不会触发安装事件,并且在删除并重新安装后将报告安装事件.
3.2 APP启动事件
当用户启动APP或从后台唤醒APP时,将触发APP启动事件. 详细的事件描述如下:
3.3 APP关闭事件
当用户关闭APP或将APP转移到后台时,将触发APP关闭事件. 详细的事件描述如下:
3.4 APP浏览页面事件
APP浏览页面事件将在用户切换页面(View Controller)时触发浏览页面事件. 详细的事件描述如下:
可以将其他属性添加到页面浏览事件以扩展其分析价值. 以下是自定义页面浏览事件的属性的方法:
3.4.1自定义页面浏览事件的属性
对于从UIViewController继承的View Controller,您可以实现Protocol
要设置页面的属性和URL信息,SDK会自动将getTrackProperties: 的返回值添加到View Controller的APP浏览页面事件中;另外,getScreenUrl: 的返回值将用作页面的URL架构. 触发该页面的浏览事件时,将添加预设属性#url,其值为当前页面的URL架构. 同时,SDK将在跳转之前采用页面的URL架构. 如果可以获取,它将被添加到预设属性#Referrer是转发地址.
@interface MYController : UITableViewController
@end
@implementation MYController
//对所有APPID实例进行设置
- (NSDictionary *)getTrackProperties {
return @{@"PageName" : @"商品详情页", @"ProductId" : @12345};
}
- (NSString *)getScreenUrl {
return @"APP://test";
/** 多APPID实例单独进行设置
* - (NSDictionary *)getTrackPropertiesWithAppid{
* return @{@"appid1" : @{@"testTrackProperties" : @"测试页"},
* @"appid2" : @{@"testTrackProperties2" : @"测试页2"},
* };
* }
* -(NSDictionary *)getScreenUrlWithAppid {
* return @{@"appid1" : @"APP://test1",
* @"appid2" : @"APP://test2",
* };
* }
*/
}
@end
3.5 APP控件单击事件
当用户单击控件时,将触发APP控件的点击事件
对于页面上View的click事件,有很多方法可以设置更多属性以扩展其分析价值:
3.5.1设置控件元素ID
您可以在页面上设置元素(视图)的元素ID,以区分具有不同含义的元素. 您可以使用以下方法设置元素ID:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewID = @"testtable1";
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewIDWithAppid = @{ @"app1" : @"testtableID2",
@"app2" : @"testtableID3" };
这时,预设属性#element_id将添加到table1的click事件中,并且该值是在此处传递的值
3.5.2自定义控件点击事件的属性
对于大多数控件,您可以直接使用thinkingAnalyticsViewProperties设置自定义属性:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewProperties = @{@"key1":@"value1"};
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewPropertiesWithAppid = @{@"app1":@{@"tablekey":@"tablevalue"},
@"app2":@{@"tablekey2":@"tablevalue2"}
};
3.5.3 UITableView和UI采集View控件的单击事件属性
对于UITableView和UI采集View,您需要通过实现Protocol来设置自定义属性:
1. 首先在View Controller类中实现协议
2. 其次,在类中设置代理,建议在viewDidLoad方法中设置
self.table1.thinkingAnalyticsDelegate = self;
3. 然后根据视图控制器的类型实现该方法
//对所有APPID实例进行设置,设置UITableView的自定义属性
-(NSDictionary *) thinkingAnalytics_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* -(NSDictionary *) thinkingAnalyticsWithAppid_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoPro":@"tablevalue"},
* @"app2":@{@"autoPro2":@"tablevalue2"}
* };
* }
*/
//对所有APPID实例进行设置,设置UICollectionView的自定义属性
-(NSDictionary *) thinkingAnalytics_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath;
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* - (NSDictionary *)thinkingAnalyticsWithAppid_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoProCOLL":@"tablevalueCOLL"},
* @"app2":@{@"autoProCOLL2":@"tablevalueCOLL2"}
* };
* }
*/
4. 最后,在该类的viewWillDisappear方法中将thinkingAnalyticsDelegate设置为nil
-(void)viewWillDisappear:(BOOL)animated
{
[super viewWillDisappear:animated];
self.table1.thinkingAnalyticsDelegate = nil;
}
3.6 APP崩溃事件
当APP发生未捕获的异常时,将报告APP崩溃事件
4. 忽略自动采集事件
您可以通过以下方式忽略页面或控件的自动采集事件
4.1忽略页面的自动采集事件
对于某些页面(View Controller),如果您不想传输自动采集事件(包括页面浏览和控制点击事件),则可以通过以下方法忽略它们:
NSMutableArray *array = [[NSMutableArray alloc] init];
[array addObject:@"IgnoredViewController"];
// 多APPID实例时对单个APPID实例设置,忽略某个页面的自动采集事件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreAutoTrackViewControllers:array];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreAutoTrackViewControllers:array];
4.2忽略某种控件类型的click事件
如果您需要忽略某种控件类型的click事件,则可以使用以下方法将其忽略
// 多APPID实例时对单个APPID实例设置,忽略某个类型的所有控件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreViewType:[IgnoredClass class]];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreViewType:[IgnoredClass class]];
4.3忽略元素的点击事件(视图)
如果要忽略某个元素(查看)的click事件,可以使用以下方法将其忽略
// 对所有APPID实例进行设置
self.table1.thinkingAnalyticsIgnoreView = YES;
// 多APPID实例单独进行设置
// self.table2.thinkingAnalyticsIgnoreViewWithAppid = @{@"appid1" : @YES,@"appid2" : @NO};
5. 自动采集事件的预设属性
以下预设属性是每个自动采集事件中唯一的预设属性
属性名称中文名称说明
#resume_from_background
是否从后台醒来
表示是打开还是从后台唤醒APP,值为true表示从后台唤醒,值为false表示直接激活
属性名称中文名称说明
#duration
活动持续时间
指示此APP访问的持续时间(从开始到结束),单位为秒
属性名称中文名称说明
#title
页面标题
是View Controller的标题,该值是controller.navigationItem.title属性的值
#screen_name
页面名称
是View Controller的类名
#url
页面地址
当前页面的地址,您需要调用getScreenUrl来设置网址
#referrer
转发地址
跳转前页面的地址,跳转前页面需要调用getScreenUrl来设置网址
属性名称中文名称说明
#title
页面标题
是View Controller的标题,该值是controller.navigationItem.title属性的值
#screen_name
页面名称
是View Controller的类名
#element_id
元素ID
控件的ID需要通过thinkAnalyticsViewID设置
#element_type
元素类型
控制类型
#element_selector
元素选择器
控件的viewPath的拼接
#element_position
元素位置
控件的位置信息,仅当控件类型为UITableView或UI采集View时才存在,表示单击控件的位置,值为组号(Section): 行号(Row)
#element_content
元素内容
控件上的内容
属性名称中文名称说明
#app_crashed_reason
异常信息
字符类型,崩溃时记录堆栈跟踪 查看全部
iOS SDK自动采集指南
iOS SDK自动采集指南1.自动采集简介
TA系统提供了自动数据采集的界面. 您可以根据业务需要选择需要自动采集的数据.
当前支持的自动数据采集是:
APP安装,记录正在安装的APP的日志,APP启动(包括打开APP并从后台唤醒),关闭APP(包括关闭APP并转移到后台)以及采集启动时间. 用户浏览APP中的页面(本机页面). 点击APP中的控件,以在APP崩溃时记录崩溃信息
接下来,我们将详细介绍每种数据的采集方法
2. 打开自动采集
您可以调用enableAutoTrack: 打开自动采集功能:
// 开启某个APPID实例的自动采集事件,支持多个APPID实例都开启自动采集
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID]enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
ThinkingAnalyticsEventTypeAppInstall |
ThinkingAnalyticsEventTypeAppEnd |
ThinkingAnalyticsEventTypeAppViewScreen |
ThinkingAnalyticsEventTypeAppClick |
ThinkingAnalyticsEventTypeAppViewCrash];
// 单APPID实例时可调用以下方法开启
// [[ThinkingAnalyticsSDK sharedInstance] enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
// ThinkingAnalyticsEventTypeAppInstall |
// ThinkingAnalyticsEventTypeAppEnd |
// ThinkingAnalyticsEventTypeAppViewScreen |
// ThinkingAnalyticsEventTypeAppClick |
// ThinkingAnalyticsEventTypeAppViewCrash];
以上参数分别表示为:
根据业务情况,您可以传递要采集的事件的相应参数. 对于多个参数,请使用|. 分裂.
如果您需要设置公共事件属性或设置自定义访问者ID,请确保在打开自动采集之前调用setSuperProperties: 或identify:.
-(BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
[ThinkingAnalyticsSDK startWithAppId:@"APP_ID"
withUrl:@"SERVER_URL"];
return YES;
}
[[ThinkingAnalyticsSDK sharedInstance] identify:@"123ABCabc"];
[[ThinkingAnalyticsSDK sharedInstance] setSuperProperties:@{
@"Channel":@"ABC",
@"Server":123,
@"isTest":@YES
}];
//设置完访客ID与公共属性后,再开启自动采集
[[ThinkingAnalyticsSDK sharedInstance] enableAutoTrack:ThinkingAnalyticsEventTypeAppStart |
ThinkingAnalyticsEventTypeAppInstall |
ThinkingAnalyticsEventTypeAppEnd |
ThinkingAnalyticsEventTypeAppViewScreen |
ThinkingAnalyticsEventTypeAppClick |
ThinkingAnalyticsEventTypeAppViewCrash];
3. 自动采集事件3.1 APP安装事件的详细说明
APP安装事件将记录APP的实际安装并在启动APP时报告. 事件触发时间是安装后首次启动APP的时间. APP升级不会触发安装事件,并且在删除并重新安装后将报告安装事件.
3.2 APP启动事件
当用户启动APP或从后台唤醒APP时,将触发APP启动事件. 详细的事件描述如下:
3.3 APP关闭事件
当用户关闭APP或将APP转移到后台时,将触发APP关闭事件. 详细的事件描述如下:
3.4 APP浏览页面事件
APP浏览页面事件将在用户切换页面(View Controller)时触发浏览页面事件. 详细的事件描述如下:
可以将其他属性添加到页面浏览事件以扩展其分析价值. 以下是自定义页面浏览事件的属性的方法:
3.4.1自定义页面浏览事件的属性
对于从UIViewController继承的View Controller,您可以实现Protocol
要设置页面的属性和URL信息,SDK会自动将getTrackProperties: 的返回值添加到View Controller的APP浏览页面事件中;另外,getScreenUrl: 的返回值将用作页面的URL架构. 触发该页面的浏览事件时,将添加预设属性#url,其值为当前页面的URL架构. 同时,SDK将在跳转之前采用页面的URL架构. 如果可以获取,它将被添加到预设属性#Referrer是转发地址.
@interface MYController : UITableViewController
@end
@implementation MYController
//对所有APPID实例进行设置
- (NSDictionary *)getTrackProperties {
return @{@"PageName" : @"商品详情页", @"ProductId" : @12345};
}
- (NSString *)getScreenUrl {
return @"APP://test";
/** 多APPID实例单独进行设置
* - (NSDictionary *)getTrackPropertiesWithAppid{
* return @{@"appid1" : @{@"testTrackProperties" : @"测试页"},
* @"appid2" : @{@"testTrackProperties2" : @"测试页2"},
* };
* }
* -(NSDictionary *)getScreenUrlWithAppid {
* return @{@"appid1" : @"APP://test1",
* @"appid2" : @"APP://test2",
* };
* }
*/
}
@end
3.5 APP控件单击事件
当用户单击控件时,将触发APP控件的点击事件
对于页面上View的click事件,有很多方法可以设置更多属性以扩展其分析价值:
3.5.1设置控件元素ID
您可以在页面上设置元素(视图)的元素ID,以区分具有不同含义的元素. 您可以使用以下方法设置元素ID:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewID = @"testtable1";
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewIDWithAppid = @{ @"app1" : @"testtableID2",
@"app2" : @"testtableID3" };
这时,预设属性#element_id将添加到table1的click事件中,并且该值是在此处传递的值
3.5.2自定义控件点击事件的属性
对于大多数控件,您可以直接使用thinkingAnalyticsViewProperties设置自定义属性:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewProperties = @{@"key1":@"value1"};
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewPropertiesWithAppid = @{@"app1":@{@"tablekey":@"tablevalue"},
@"app2":@{@"tablekey2":@"tablevalue2"}
};
3.5.3 UITableView和UI采集View控件的单击事件属性
对于UITableView和UI采集View,您需要通过实现Protocol来设置自定义属性:
1. 首先在View Controller类中实现协议
2. 其次,在类中设置代理,建议在viewDidLoad方法中设置
self.table1.thinkingAnalyticsDelegate = self;
3. 然后根据视图控制器的类型实现该方法
//对所有APPID实例进行设置,设置UITableView的自定义属性
-(NSDictionary *) thinkingAnalytics_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* -(NSDictionary *) thinkingAnalyticsWithAppid_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoPro":@"tablevalue"},
* @"app2":@{@"autoPro2":@"tablevalue2"}
* };
* }
*/
//对所有APPID实例进行设置,设置UICollectionView的自定义属性
-(NSDictionary *) thinkingAnalytics_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath;
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* - (NSDictionary *)thinkingAnalyticsWithAppid_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoProCOLL":@"tablevalueCOLL"},
* @"app2":@{@"autoProCOLL2":@"tablevalueCOLL2"}
* };
* }
*/
4. 最后,在该类的viewWillDisappear方法中将thinkingAnalyticsDelegate设置为nil
-(void)viewWillDisappear:(BOOL)animated
{
[super viewWillDisappear:animated];
self.table1.thinkingAnalyticsDelegate = nil;
}
3.6 APP崩溃事件
当APP发生未捕获的异常时,将报告APP崩溃事件
4. 忽略自动采集事件
您可以通过以下方式忽略页面或控件的自动采集事件
4.1忽略页面的自动采集事件
对于某些页面(View Controller),如果您不想传输自动采集事件(包括页面浏览和控制点击事件),则可以通过以下方法忽略它们:
NSMutableArray *array = [[NSMutableArray alloc] init];
[array addObject:@"IgnoredViewController"];
// 多APPID实例时对单个APPID实例设置,忽略某个页面的自动采集事件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreAutoTrackViewControllers:array];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreAutoTrackViewControllers:array];
4.2忽略某种控件类型的click事件
如果您需要忽略某种控件类型的click事件,则可以使用以下方法将其忽略
// 多APPID实例时对单个APPID实例设置,忽略某个类型的所有控件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreViewType:[IgnoredClass class]];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreViewType:[IgnoredClass class]];
4.3忽略元素的点击事件(视图)
如果要忽略某个元素(查看)的click事件,可以使用以下方法将其忽略
// 对所有APPID实例进行设置
self.table1.thinkingAnalyticsIgnoreView = YES;
// 多APPID实例单独进行设置
// self.table2.thinkingAnalyticsIgnoreViewWithAppid = @{@"appid1" : @YES,@"appid2" : @NO};
5. 自动采集事件的预设属性
以下预设属性是每个自动采集事件中唯一的预设属性
属性名称中文名称说明
#resume_from_background
是否从后台醒来
表示是打开还是从后台唤醒APP,值为true表示从后台唤醒,值为false表示直接激活
属性名称中文名称说明
#duration
活动持续时间
指示此APP访问的持续时间(从开始到结束),单位为秒
属性名称中文名称说明
#title
页面标题
是View Controller的标题,该值是controller.navigationItem.title属性的值
#screen_name
页面名称
是View Controller的类名
#url
页面地址
当前页面的地址,您需要调用getScreenUrl来设置网址
#referrer
转发地址
跳转前页面的地址,跳转前页面需要调用getScreenUrl来设置网址
属性名称中文名称说明
#title
页面标题
是View Controller的标题,该值是controller.navigationItem.title属性的值
#screen_name
页面名称
是View Controller的类名
#element_id
元素ID
控件的ID需要通过thinkAnalyticsViewID设置
#element_type
元素类型
控制类型
#element_selector
元素选择器
控件的viewPath的拼接
#element_position
元素位置
控件的位置信息,仅当控件类型为UITableView或UI采集View时才存在,表示单击控件的位置,值为组号(Section): 行号(Row)
#element_content
元素内容
控件上的内容
属性名称中文名称说明
#app_crashed_reason
异常信息
字符类型,崩溃时记录堆栈跟踪
关于数据采集技术,这几种你一定要知道!
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-22 17:50
如今,不论哪行哪业的信息化人员,无论是同学聚会还是商务会晤,提到“大数据”的频次如同“吃了吗?”、“今天天气不错” 一样平时。没错,你我早已身处数据时代,但还未抵达大数据时代,差的是将海量数据有序融合并应用的距离。
各行各业,包括政府部门的信息化建设都是封闭的,海量数据被封在不同软件系统之中。要实现大数据,首先要实现诸多关联系统间数据的自如交互,这是大数据应用的前提。
该怎样实现?今天就和你一起阐述异构软件系统的3种数据采集方法,重点关注实现过程与各自优缺点。
一、软件插口形式
需要各系统的提供厂商提供数据插口,才能实现数据采集汇聚。
实现过程:
Step 1、协调多方软件厂商工程师到场,了解所有系统业务流程以及数据库相关的表结构设计等,细节推敲,确定可行性方案;
Step 2、编码
Step 3、测试、调试阶段
Step 4、交付使用
优势:接口对接方法的数据可靠性与价值较高,一般不存在数据重复的情况;数据可通过插口实时传输,满足数据实时应用要求。
缺点:接口开发费用高;需协调多个软件厂商,工作量大且容易烂尾;可扩展性不高,如:由于新业务须要各软件系统开发出新的业务模块,其和大数据平台之间的数据插口也需做相应更改和变动,甚至要推翻先前的所有数据插口编码,工作量大、耗时长。
二、开放数据库形式
数据的采集融合,开放数据库是最直接的一种形式。
系统分别有各自的数据库,而同类型的数据库之间数据融合是比较便捷的:
1. 如果两个数据库在同一个服务器上,只要用户名设置得没有问题,就可以直接互相访问,需要在from后将其数据库名称及表的构架所有者带上即可。
select * from DATABASE1.dbo.table1
2. 如果两个系统的数据库不在一个服务器上,建议采用链接服务器的方式处理,或者使用openset和opendatasource的形式,这个须要对数据库的访问进行外围服务器的配置。
3、不同类型的数据库之间的联接就比较麻烦了,需要做好多设置能够生效,这里不做详尽说明。
优势:开放数据库方法可以直接从目标数据库中获取须要的数据,准确性高,实时性也有保证,是最直接、便捷的一种形式。
缺点:开放数据库方法也须要协调各软件厂商开放数据库,这须要看对方的意愿,一般出于安全考虑,不会开放;
一个平台假如同时联接多个软件厂商的数据库,并实时获取数据,这对平台性能也是巨大挑战。
三、直接采集数据形式
以博为软件101异构数据采集技术为例:通过获取软件系统的底层数据交换、软件客户端和数据库之间的网路流量包,基于底层IO恳求与网路剖析等技术,采集目标软件形成的所有数据,将数据转换与重新结构化,输出到新的数据库,供软件系统调用。
技术特征如下:
1. 无需原软件厂商配合;
2. 实时数据采集,数据端到端的响应速率达秒级;
3. 兼容性强,可采集汇聚Windows平台各类软件系统数据;
4. 输出结构化数据,作为数据挖掘、大数据剖析应用的基础;
5. 自动构建数据间关联,实施周期短、简单高效;
6. 支持手动导出历史数据,通过I/O人工智能手动将数据写入目标软件;
7. 配置简单、实施周期短。
优点:和前两种数据采集方式相比,其优势在于不需要“接口”配合,这就甩掉了对软件厂商的依赖。特别是在在须要集成多个系统数据时,不仅能节约大量时间、人力与资金,实现“一站式”完成;还防止了因某些系统开发团队解体、源代码遗失等诱因引起系统数据集成出现烂尾的情况。
缺点:只采集Windows平台的各软件系统数据 查看全部
关于数据采集技术,这几种你一定要知道!
如今,不论哪行哪业的信息化人员,无论是同学聚会还是商务会晤,提到“大数据”的频次如同“吃了吗?”、“今天天气不错” 一样平时。没错,你我早已身处数据时代,但还未抵达大数据时代,差的是将海量数据有序融合并应用的距离。
各行各业,包括政府部门的信息化建设都是封闭的,海量数据被封在不同软件系统之中。要实现大数据,首先要实现诸多关联系统间数据的自如交互,这是大数据应用的前提。
该怎样实现?今天就和你一起阐述异构软件系统的3种数据采集方法,重点关注实现过程与各自优缺点。
一、软件插口形式
需要各系统的提供厂商提供数据插口,才能实现数据采集汇聚。
实现过程:
Step 1、协调多方软件厂商工程师到场,了解所有系统业务流程以及数据库相关的表结构设计等,细节推敲,确定可行性方案;
Step 2、编码
Step 3、测试、调试阶段
Step 4、交付使用
优势:接口对接方法的数据可靠性与价值较高,一般不存在数据重复的情况;数据可通过插口实时传输,满足数据实时应用要求。
缺点:接口开发费用高;需协调多个软件厂商,工作量大且容易烂尾;可扩展性不高,如:由于新业务须要各软件系统开发出新的业务模块,其和大数据平台之间的数据插口也需做相应更改和变动,甚至要推翻先前的所有数据插口编码,工作量大、耗时长。
二、开放数据库形式
数据的采集融合,开放数据库是最直接的一种形式。
系统分别有各自的数据库,而同类型的数据库之间数据融合是比较便捷的:
1. 如果两个数据库在同一个服务器上,只要用户名设置得没有问题,就可以直接互相访问,需要在from后将其数据库名称及表的构架所有者带上即可。
select * from DATABASE1.dbo.table1
2. 如果两个系统的数据库不在一个服务器上,建议采用链接服务器的方式处理,或者使用openset和opendatasource的形式,这个须要对数据库的访问进行外围服务器的配置。
3、不同类型的数据库之间的联接就比较麻烦了,需要做好多设置能够生效,这里不做详尽说明。
优势:开放数据库方法可以直接从目标数据库中获取须要的数据,准确性高,实时性也有保证,是最直接、便捷的一种形式。
缺点:开放数据库方法也须要协调各软件厂商开放数据库,这须要看对方的意愿,一般出于安全考虑,不会开放;
一个平台假如同时联接多个软件厂商的数据库,并实时获取数据,这对平台性能也是巨大挑战。
三、直接采集数据形式
以博为软件101异构数据采集技术为例:通过获取软件系统的底层数据交换、软件客户端和数据库之间的网路流量包,基于底层IO恳求与网路剖析等技术,采集目标软件形成的所有数据,将数据转换与重新结构化,输出到新的数据库,供软件系统调用。
技术特征如下:
1. 无需原软件厂商配合;
2. 实时数据采集,数据端到端的响应速率达秒级;
3. 兼容性强,可采集汇聚Windows平台各类软件系统数据;
4. 输出结构化数据,作为数据挖掘、大数据剖析应用的基础;
5. 自动构建数据间关联,实施周期短、简单高效;
6. 支持手动导出历史数据,通过I/O人工智能手动将数据写入目标软件;
7. 配置简单、实施周期短。
优点:和前两种数据采集方式相比,其优势在于不需要“接口”配合,这就甩掉了对软件厂商的依赖。特别是在在须要集成多个系统数据时,不仅能节约大量时间、人力与资金,实现“一站式”完成;还防止了因某些系统开发团队解体、源代码遗失等诱因引起系统数据集成出现烂尾的情况。
缺点:只采集Windows平台的各软件系统数据
连续动作:自动选择下拉菜单采集数据—以知网为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 692 次浏览 • 2020-08-20 07:00
注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤
用中国知网的刊物为例,展示连续动作中选择动作和爬虫路线中翻页的组合。本次教程要实现的是先检索2016年发表的刊物,再对检索结果进行采集,流程如下图所示:
为了实现这个,需要构建两级规则,第一级规则通过连续动作来手动选择发表年份,第二级规则负责采集期刊内容和翻页。操作步骤如下:
二、案例规则+操作步骤
第一步:定义第一级规则抓取内容
1.1,加载页面
打开集搜客网络爬虫,输入想要采集的样本网址并按Enter键,看到浏览器加载出网页后,点击右上方的“定义规则”。
注意:这里的截图和文字说明都是集搜客网络爬虫版本。如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台。
1.2,输入主题名
在工作台“主题名”处输入第一级规则的主题名,再点击“查重”,提示“该名可以使用”,就可以继续,否则请重新命名。这里命名主题名为“中国知网刊物检索前”。
Tips:虽然这一级规则主要是为了做选择动作,但为了保证页面早已加载完成,连续动作可以顺利进行,通常在这级规则构建一些抓取内容。
1.3,内容映射
选择“期刊”作为抓取内容,双击刊物,在弹出的标签栏处输入关键内容,整理箱命名为检索前,并勾选为关键内容。直观标明的基础操作在这里不赘言,不懂的请参考教程《采集网页数据》。
第二步:定义第一级规则连续动作
2.1,输入目标主题名
点击“连续动作”工作台,输入目标主题名(也就是第二级规则的主题名,这里命名为“中国知网刊物检索后”),点击“谁在用”,弹出的窗口没有信息,说明这个主题名没有被占用,可以继续旁边的操作,否则就须要换一个主题名。
2.2,创建第一个连续动作——起始年份选择2016
2.2.1,找到定位表达式,填写动作名称
点击新建,选择动作类型为“选择”,点击一下起始年份,会手动定位到相应节点,选择“显示XPath:偏好id”,程序会手动显示对应的Xpath路径,再点击搜索,可以看见这个路径能找到惟一的节点,可作为动作的定位表达式,将这个路径复制到定位表达式处,在动作名称写上文字,是为了便捷清楚每位动作的好处。
Tips:选择类型的连续动作,定位表达式必须讲到下拉菜单的select节点,而不能讲到某一个选项的option节点,否则运行时会报错。
2.2.2,高级设置
我们须要实现的是采集2016年发表的刊物,所以须要在起始年份和中止年份都选择点击2016年,这就须要在连续动作的中级设置里做约束。
2.3,创建第二个连续动作——终止年份选择2016
点击新建,选择动作类型为“选择”。参考步骤2.2找到中止年份对应的Xpath路径,并在中级设置中设置额外延时为2秒,起点为3(2016在第3个option),跨度填100。
2.4,创建第三个连续动作——点击检索
点击新建,选择“提交”动作。参考步骤2.2找到“检索”对应的Xpath路径,并在中级设置中设置额外延时为2秒。
2.5,存规则
点击“存规则”按钮保存已完成的第一级规则。
第三步:定义第二级规则抓取内容
3.1,新建规则
点击“定义规则”恢复到普通网页模式,选择2016年并点击检索搜索出文献结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,弹出提示“工作台上有内容,清空吗?”,点击确定。
输入主题名,这里的主题名就是上一级规则的连续动作哪里填写的目标主题名,也就是“中国知网刊物检索后”,点击查重,弹出提示“该名已被预定。可编辑:是”,说明这个主题名可以使用。
3.2,标注要采集的信息
在页面直接点击要采集的内容,弹出的窗口填上名称,给“标题”勾上关键内容,并做上样例复制。点击测试可以预览采集内容。直观标明的详尽说明在这里不赘言,详细可参考教程《采集列表数据》。
第四步:定义第二级规则翻页线索
4.1,设置翻页线索
点击爬虫路线,点击“新建”,选择“记号线索”;找到翻页标记“下一页”对应的节点,右击-线索映射-记号线索;找到收录整个翻页区域而且有class值或id值的节点,右击-线索映射-定位-线索1。设置翻页的操作在这里不赘言,详细可参考教程《设置翻页采集》。
4.2,存规则
点击“存规则”按钮保存已完成的第二级规则。
第五步:抓数据
连续动作的两级规则是连贯执行的,所以只须要运行第一级规则,做完动作后程序会手动调用第二级规则。直接运行第二级规则都会报错,因为打开的是执行动作前的初始页面。
5.1,打开打数机,找到第一级规则的主题名,点击“单搜”或“集搜”,可以看见打数机的网页窗口会手动选择2016年,并不断往下翻页。
5.2,打开第二级主题的文件夹查看结果数据,在xml文件的actionvalue字段记录了选择的条目,这样才能与结果数据一一对应上去。
上篇文章:《连续动作:自动搜索关键词采集信息》 下篇文章:《连续动作:滚屏采集瀑布流网页》
若有疑问可以或 查看全部
连续动作:自动选择下拉菜单采集数据—以知网为例
注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤
用中国知网的刊物为例,展示连续动作中选择动作和爬虫路线中翻页的组合。本次教程要实现的是先检索2016年发表的刊物,再对检索结果进行采集,流程如下图所示:
为了实现这个,需要构建两级规则,第一级规则通过连续动作来手动选择发表年份,第二级规则负责采集期刊内容和翻页。操作步骤如下:
二、案例规则+操作步骤
第一步:定义第一级规则抓取内容
1.1,加载页面
打开集搜客网络爬虫,输入想要采集的样本网址并按Enter键,看到浏览器加载出网页后,点击右上方的“定义规则”。
注意:这里的截图和文字说明都是集搜客网络爬虫版本。如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台。
1.2,输入主题名
在工作台“主题名”处输入第一级规则的主题名,再点击“查重”,提示“该名可以使用”,就可以继续,否则请重新命名。这里命名主题名为“中国知网刊物检索前”。
Tips:虽然这一级规则主要是为了做选择动作,但为了保证页面早已加载完成,连续动作可以顺利进行,通常在这级规则构建一些抓取内容。
1.3,内容映射
选择“期刊”作为抓取内容,双击刊物,在弹出的标签栏处输入关键内容,整理箱命名为检索前,并勾选为关键内容。直观标明的基础操作在这里不赘言,不懂的请参考教程《采集网页数据》。
第二步:定义第一级规则连续动作
2.1,输入目标主题名
点击“连续动作”工作台,输入目标主题名(也就是第二级规则的主题名,这里命名为“中国知网刊物检索后”),点击“谁在用”,弹出的窗口没有信息,说明这个主题名没有被占用,可以继续旁边的操作,否则就须要换一个主题名。
2.2,创建第一个连续动作——起始年份选择2016
2.2.1,找到定位表达式,填写动作名称
点击新建,选择动作类型为“选择”,点击一下起始年份,会手动定位到相应节点,选择“显示XPath:偏好id”,程序会手动显示对应的Xpath路径,再点击搜索,可以看见这个路径能找到惟一的节点,可作为动作的定位表达式,将这个路径复制到定位表达式处,在动作名称写上文字,是为了便捷清楚每位动作的好处。
Tips:选择类型的连续动作,定位表达式必须讲到下拉菜单的select节点,而不能讲到某一个选项的option节点,否则运行时会报错。
2.2.2,高级设置
我们须要实现的是采集2016年发表的刊物,所以须要在起始年份和中止年份都选择点击2016年,这就须要在连续动作的中级设置里做约束。
2.3,创建第二个连续动作——终止年份选择2016
点击新建,选择动作类型为“选择”。参考步骤2.2找到中止年份对应的Xpath路径,并在中级设置中设置额外延时为2秒,起点为3(2016在第3个option),跨度填100。
2.4,创建第三个连续动作——点击检索
点击新建,选择“提交”动作。参考步骤2.2找到“检索”对应的Xpath路径,并在中级设置中设置额外延时为2秒。
2.5,存规则
点击“存规则”按钮保存已完成的第一级规则。
第三步:定义第二级规则抓取内容
3.1,新建规则
点击“定义规则”恢复到普通网页模式,选择2016年并点击检索搜索出文献结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,弹出提示“工作台上有内容,清空吗?”,点击确定。
输入主题名,这里的主题名就是上一级规则的连续动作哪里填写的目标主题名,也就是“中国知网刊物检索后”,点击查重,弹出提示“该名已被预定。可编辑:是”,说明这个主题名可以使用。
3.2,标注要采集的信息
在页面直接点击要采集的内容,弹出的窗口填上名称,给“标题”勾上关键内容,并做上样例复制。点击测试可以预览采集内容。直观标明的详尽说明在这里不赘言,详细可参考教程《采集列表数据》。
第四步:定义第二级规则翻页线索
4.1,设置翻页线索
点击爬虫路线,点击“新建”,选择“记号线索”;找到翻页标记“下一页”对应的节点,右击-线索映射-记号线索;找到收录整个翻页区域而且有class值或id值的节点,右击-线索映射-定位-线索1。设置翻页的操作在这里不赘言,详细可参考教程《设置翻页采集》。
4.2,存规则
点击“存规则”按钮保存已完成的第二级规则。
第五步:抓数据
连续动作的两级规则是连贯执行的,所以只须要运行第一级规则,做完动作后程序会手动调用第二级规则。直接运行第二级规则都会报错,因为打开的是执行动作前的初始页面。
5.1,打开打数机,找到第一级规则的主题名,点击“单搜”或“集搜”,可以看见打数机的网页窗口会手动选择2016年,并不断往下翻页。
5.2,打开第二级主题的文件夹查看结果数据,在xml文件的actionvalue字段记录了选择的条目,这样才能与结果数据一一对应上去。
上篇文章:《连续动作:自动搜索关键词采集信息》 下篇文章:《连续动作:滚屏采集瀑布流网页》
若有疑问可以或
智联招聘数据爬取(基础篇)
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-19 17:59
在智联招聘数据爬取(踩坑篇)中给出一种采集智联招聘数据的方式,方法简单,但不够自动化,效率较低。在本篇文章中,将介绍一种自动化采集方法,提高数据采集的效率。本篇文章可以将智联招聘网站数据搜集过程中的复制粘贴步骤省去,在浏览网页的同时,自动下载对应的json文件,实现数据采集。
工具介绍
上篇文章中提及,想要爬取的数据隐藏于某个链接的response中,即所谓的数据包,所以须要一个“抓包工具”。
常用的抓包工具包括fiddler和mitmproxy等,由于mitmproxy由python语言编撰,且支持自定义python脚本,所以作者选择使用mitmproxy对数据包进行抓取。
mitmproxy才能进行爬虫的原理如下:
mitmproxy相当于是一个蝶阀,从浏览器到服务器之间多了一层,所有的访问恳求就会首先传输到mitmproxy,再由mitmproxy传输到服务器;所有服务器返回的数据就会首先经过mitmproxy,再交由浏览器解析呈现。所以想要爬取的岗位信息必然会被mitmproxy记录,通过mitmproxy找到数据包,进而将数据包保存即可。
基本操作
mitmproxy安装
如智联招聘数据爬取(入门篇)中介绍,建议安装anaconda,本文依托anaconda进行操作。作者系统环境如下:
操作系统:Windows10 家庭中文版 64bit
Python:anaconda、Python3.7.7
anaconda安装python包的形式是在Anaconda Prompt中安装,mitmproxy的安装代码如下:
pip install mitmproxy
测试是否安装成功,可在Anaconda Prompt中输入以下代码测试。使用mitmweb测试的诱因包括:1)mitmproxy的安装实际上安装mitmproxy、mitmweb和mitmdump;2)mitmproxy在Windows系统下不可用,mitmweb和mitmdump的区别是mitmweb提供web界面,mitmdump为沉静模式,无web界面。初学时建议使用mitmweb,方便查看。
mitmweb --version
安装成功则会看见如下显示内容
Mitmproxy: 5.1.1
Python: 3.7.7
OpenSSL: OpenSSL 1.1.1g 21 Apr 2020
Platform: Windows-10-10.0.18362-SP0
mitmproxy基本操作
安装成功后,就来认识下mitmproxy。
1)在Anaconda Prompt中打开mitmweb,可以看见以下启动页(设置谷歌浏览器为默认浏览器),同时可以在Anaconda Prompt见到早已启动窃听,监听端口为8080。
2)将1)中的启动页使用其他浏览器打开(作者使用的是“世界之窗”,复制粘贴网址即可),然后关掉谷歌浏览器(必须完全关掉),再在cmd中使用8080端口重新启动谷歌浏览器,并忽视证书错误(毕竟是窃听,需要忽视证书错误)。(这一部分建议在爬虫前,新建一个谷歌浏览器的用户文件夹,优点一是防止对现有的谷歌浏览器设置形成干扰;优点二在下一篇介绍。所以启动代码建议使用代码二。新建谷歌浏览器的用户文件夹,只要在任一文件夹下新建空白的“AutomationProfile”文件夹即可)
# 代码一
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors
# 代码二
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors --user-data-dir=D:\\360Downloads\\AutomationProfile
3)在2)中启动谷歌浏览器后,输入智联急聘的网址(/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3)后可在世界之窗的窃听窗口观察到各类传输的链接,寻找以/c/i/sou?_v= 开头的链接,可在其response中发觉想要爬取的数据。
至此使用mitmproxy监控谷歌浏览器访问智联招聘网站已经完成,接下来使用mitmproxy自定义python脚本将对应数据包的数据下载。
mitmproxy自定义脚本
把浏览器与服务器之间的交互觉得是flow,想要爬取的数据在以/c/i/sou?_v=开头的链接中。在mitmproxy中,链接包括两部份:host和url,其中host是服务器网址(),url是对应的链接(/c/i/sou?_v=)。host+url即组成了完整链接,在这里,只须要使用url即可采集到相应数据。只要找到以/c/i/sou?_v=开头url,通过获取response中的内容,再将其写入到txt文件即可。代码如下:
import mitmproxy.http
from mitmproxy import ctx
url_paths = '/c/i/sou?_v=' #筛选url的判断条件
class Jobinfo:
def response(self, flow: mitmproxy.http.HTTPFlow):
if flow.request.path.startswith(url_paths): #startwith,找到对应的url
text = flow.response.get_text() #获取url的response的内容
file_handle=open('0624.txt',mode='a') #打开txt
file_handle.write(text) #将获取的response内容写入到txt
file_handle.write('\n') #写入 换行符
file_handle.write('\n') #写入 换行符
file_handle.close() # 关闭txt
return
addons = [
Jobinfo()
] #mitmproxy使用自定义python脚本的方法
mitmproxy使用python脚本,只须要在启动mitmweb时,使用-s 后添加对应的py文件即可。(具体可参考拓展阅读)
自动化采集数据
在了解mitmproxy的基本操作之后,这一部分实现数据的自动化复制粘贴。
1)在Ananconda Prompt中启动mitmweb,并指定自定义的python脚本。代码如下,其中-s表示要加载前面代码, 'D:\\360Downloads\\addons0624.py'表示代码地址,addons0624.py内的代码即为自定义python脚本。
mitmweb -s 'D:\\360Downloads\\addons0624.py'
2)在cmd中使用下列代码启动谷歌浏览器
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors --user-data-dir=D:\\360Downloads\\AutomationProfile
3)在谷歌浏览器中输入打算好的“北京市数据分析师”的网址/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3。伴随着在浏览器中翻页,对应页面的岗位数据即可写入到定义的txt文件中。
4)在文件夹中找到定义的txt文件即可。
如果不知道txt保存在哪,推荐下载everything搜索即可,非常便捷。
至此,已经实现复制粘贴的自动化。
总结
在智联招聘数据爬取(踩坑篇)给出了一种自动采集数据的方式,在这篇文章,将复制粘贴json数据进行自动化。只须要以特定的方法启动谷歌浏览器,并访问相应的页面即可实现数据的采集,更加便捷。下一篇文章即为智联招聘数据爬虫的最终篇,在最终篇将自动化浏览器的访问过程,实现数据采集的完全自动化。敬请期盼。
本文首发公众号“数据科学家进阶之路”,主要专注数据剖析所需的技能,通过相应的案例熟悉模型算法,通过实际的业务例子熟悉商业逻辑,通过读书积累分享思维方法。期待你们关注。
拓展阅读:
使用mitmproxy+python做拦截代理:
/posts/usage-of-mitmproxy/ 查看全部
智联招聘数据爬取(基础篇)
在智联招聘数据爬取(踩坑篇)中给出一种采集智联招聘数据的方式,方法简单,但不够自动化,效率较低。在本篇文章中,将介绍一种自动化采集方法,提高数据采集的效率。本篇文章可以将智联招聘网站数据搜集过程中的复制粘贴步骤省去,在浏览网页的同时,自动下载对应的json文件,实现数据采集。
工具介绍
上篇文章中提及,想要爬取的数据隐藏于某个链接的response中,即所谓的数据包,所以须要一个“抓包工具”。
常用的抓包工具包括fiddler和mitmproxy等,由于mitmproxy由python语言编撰,且支持自定义python脚本,所以作者选择使用mitmproxy对数据包进行抓取。
mitmproxy才能进行爬虫的原理如下:
mitmproxy相当于是一个蝶阀,从浏览器到服务器之间多了一层,所有的访问恳求就会首先传输到mitmproxy,再由mitmproxy传输到服务器;所有服务器返回的数据就会首先经过mitmproxy,再交由浏览器解析呈现。所以想要爬取的岗位信息必然会被mitmproxy记录,通过mitmproxy找到数据包,进而将数据包保存即可。
基本操作
mitmproxy安装
如智联招聘数据爬取(入门篇)中介绍,建议安装anaconda,本文依托anaconda进行操作。作者系统环境如下:
操作系统:Windows10 家庭中文版 64bit
Python:anaconda、Python3.7.7
anaconda安装python包的形式是在Anaconda Prompt中安装,mitmproxy的安装代码如下:
pip install mitmproxy
测试是否安装成功,可在Anaconda Prompt中输入以下代码测试。使用mitmweb测试的诱因包括:1)mitmproxy的安装实际上安装mitmproxy、mitmweb和mitmdump;2)mitmproxy在Windows系统下不可用,mitmweb和mitmdump的区别是mitmweb提供web界面,mitmdump为沉静模式,无web界面。初学时建议使用mitmweb,方便查看。
mitmweb --version
安装成功则会看见如下显示内容
Mitmproxy: 5.1.1
Python: 3.7.7
OpenSSL: OpenSSL 1.1.1g 21 Apr 2020
Platform: Windows-10-10.0.18362-SP0
mitmproxy基本操作
安装成功后,就来认识下mitmproxy。
1)在Anaconda Prompt中打开mitmweb,可以看见以下启动页(设置谷歌浏览器为默认浏览器),同时可以在Anaconda Prompt见到早已启动窃听,监听端口为8080。
2)将1)中的启动页使用其他浏览器打开(作者使用的是“世界之窗”,复制粘贴网址即可),然后关掉谷歌浏览器(必须完全关掉),再在cmd中使用8080端口重新启动谷歌浏览器,并忽视证书错误(毕竟是窃听,需要忽视证书错误)。(这一部分建议在爬虫前,新建一个谷歌浏览器的用户文件夹,优点一是防止对现有的谷歌浏览器设置形成干扰;优点二在下一篇介绍。所以启动代码建议使用代码二。新建谷歌浏览器的用户文件夹,只要在任一文件夹下新建空白的“AutomationProfile”文件夹即可)
# 代码一
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors
# 代码二
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors --user-data-dir=D:\\360Downloads\\AutomationProfile
3)在2)中启动谷歌浏览器后,输入智联急聘的网址(/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3)后可在世界之窗的窃听窗口观察到各类传输的链接,寻找以/c/i/sou?_v= 开头的链接,可在其response中发觉想要爬取的数据。
至此使用mitmproxy监控谷歌浏览器访问智联招聘网站已经完成,接下来使用mitmproxy自定义python脚本将对应数据包的数据下载。
mitmproxy自定义脚本
把浏览器与服务器之间的交互觉得是flow,想要爬取的数据在以/c/i/sou?_v=开头的链接中。在mitmproxy中,链接包括两部份:host和url,其中host是服务器网址(),url是对应的链接(/c/i/sou?_v=)。host+url即组成了完整链接,在这里,只须要使用url即可采集到相应数据。只要找到以/c/i/sou?_v=开头url,通过获取response中的内容,再将其写入到txt文件即可。代码如下:
import mitmproxy.http
from mitmproxy import ctx
url_paths = '/c/i/sou?_v=' #筛选url的判断条件
class Jobinfo:
def response(self, flow: mitmproxy.http.HTTPFlow):
if flow.request.path.startswith(url_paths): #startwith,找到对应的url
text = flow.response.get_text() #获取url的response的内容
file_handle=open('0624.txt',mode='a') #打开txt
file_handle.write(text) #将获取的response内容写入到txt
file_handle.write('\n') #写入 换行符
file_handle.write('\n') #写入 换行符
file_handle.close() # 关闭txt
return
addons = [
Jobinfo()
] #mitmproxy使用自定义python脚本的方法
mitmproxy使用python脚本,只须要在启动mitmweb时,使用-s 后添加对应的py文件即可。(具体可参考拓展阅读)
自动化采集数据
在了解mitmproxy的基本操作之后,这一部分实现数据的自动化复制粘贴。
1)在Ananconda Prompt中启动mitmweb,并指定自定义的python脚本。代码如下,其中-s表示要加载前面代码, 'D:\\360Downloads\\addons0624.py'表示代码地址,addons0624.py内的代码即为自定义python脚本。
mitmweb -s 'D:\\360Downloads\\addons0624.py'
2)在cmd中使用下列代码启动谷歌浏览器
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors --user-data-dir=D:\\360Downloads\\AutomationProfile
3)在谷歌浏览器中输入打算好的“北京市数据分析师”的网址/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3。伴随着在浏览器中翻页,对应页面的岗位数据即可写入到定义的txt文件中。
4)在文件夹中找到定义的txt文件即可。
如果不知道txt保存在哪,推荐下载everything搜索即可,非常便捷。
至此,已经实现复制粘贴的自动化。
总结
在智联招聘数据爬取(踩坑篇)给出了一种自动采集数据的方式,在这篇文章,将复制粘贴json数据进行自动化。只须要以特定的方法启动谷歌浏览器,并访问相应的页面即可实现数据的采集,更加便捷。下一篇文章即为智联招聘数据爬虫的最终篇,在最终篇将自动化浏览器的访问过程,实现数据采集的完全自动化。敬请期盼。
本文首发公众号“数据科学家进阶之路”,主要专注数据剖析所需的技能,通过相应的案例熟悉模型算法,通过实际的业务例子熟悉商业逻辑,通过读书积累分享思维方法。期待你们关注。
拓展阅读:
使用mitmproxy+python做拦截代理:
/posts/usage-of-mitmproxy/
网页数据采集原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 605 次浏览 • 2020-08-18 15:11
2、根据网页特点和采集需求,设计采集流程,优采云根据流程全手动采集数据。
平常我们浏览网页的动作不会被记录出来。例如:这次在易迅上输入关键词【手机】查询相关商品数据,下次还须要输。
在用优采云采集数据的时侯,我们就须要依照网页特点和采集需求,设计采集流程,将我们的采集需求记录出来。之后优采云就能按照设计好的采集流程,全手动的采集数据。
例如:在前几课小学到的,需采集页面上的所有商品列表,我们就做一个【循环-提取数据】的步骤。采集时有很多页,需要翻页,我们就做一个【循环翻页】的步骤。
二、【采集流程】执行逻辑
优采云通过【采集流程】全手动采集数据。【采集流程】执行逻辑遵守2个原则:先从上至下、再由内而外。
【采集流程】由【蓝色步骤】和【灰色框】两大部份组成。【蓝色步骤】是会执行的步骤,优采云与网页发生互动。【灰色框】起记录网页的作用。
鼠标放在图片上,右键,选择【在新标签页中打开图片】可查看高清大图
下文其他图片同理
来看几个实例,更深入理解【采集流程】执行逻辑。
实例1:
实例2:
实例3:
特别说明:
a. 【采集流程】无固定标准,符合网页本身的跳转逻辑即可。
b.【采集流程】中可设置多个点击步骤、多个嵌套循环,以实现网页多层级的数据采集。
c. 【采集流程】中的步骤,可以拖动调整位置。鼠标选中步骤并拖住联通至想要的
位置。
看到这儿的小伙伴,恭喜您已经完成了【自定义配置采集数据】全部的入门课程。现在,您早已把握基础的数据采集技能啦!
如果您有任何的问题与建议,请通过官网两侧QQ、电话、客服系统等多种渠道联系我们!
作者:Aisling 查看全部
网页数据采集原理
2、根据网页特点和采集需求,设计采集流程,优采云根据流程全手动采集数据。
平常我们浏览网页的动作不会被记录出来。例如:这次在易迅上输入关键词【手机】查询相关商品数据,下次还须要输。
在用优采云采集数据的时侯,我们就须要依照网页特点和采集需求,设计采集流程,将我们的采集需求记录出来。之后优采云就能按照设计好的采集流程,全手动的采集数据。
例如:在前几课小学到的,需采集页面上的所有商品列表,我们就做一个【循环-提取数据】的步骤。采集时有很多页,需要翻页,我们就做一个【循环翻页】的步骤。
二、【采集流程】执行逻辑
优采云通过【采集流程】全手动采集数据。【采集流程】执行逻辑遵守2个原则:先从上至下、再由内而外。
【采集流程】由【蓝色步骤】和【灰色框】两大部份组成。【蓝色步骤】是会执行的步骤,优采云与网页发生互动。【灰色框】起记录网页的作用。
鼠标放在图片上,右键,选择【在新标签页中打开图片】可查看高清大图
下文其他图片同理
来看几个实例,更深入理解【采集流程】执行逻辑。
实例1:
实例2:
实例3:
特别说明:
a. 【采集流程】无固定标准,符合网页本身的跳转逻辑即可。
b.【采集流程】中可设置多个点击步骤、多个嵌套循环,以实现网页多层级的数据采集。
c. 【采集流程】中的步骤,可以拖动调整位置。鼠标选中步骤并拖住联通至想要的
位置。
看到这儿的小伙伴,恭喜您已经完成了【自定义配置采集数据】全部的入门课程。现在,您早已把握基础的数据采集技能啦!
如果您有任何的问题与建议,请通过官网两侧QQ、电话、客服系统等多种渠道联系我们!
作者:Aisling
宅要撸美女福利图片站整站数据+会员中心+自动采集+带手机版(双版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 1042 次浏览 • 2020-08-17 19:40
先送一波福利
下载观看
有两个版本:
WordPress版本: 300元+100 ThinkPHP版本(带数据)
ThinkPHP版本: 250元(带数据)adminmbxzb123
两个版本均带手机站自行测试!包安装售后。
即日起此模板买一送一,只需花一个模板的钱,你就可以拥有两套程序。
更新记录
2017.03.10
1、优化后台插件,删除多余无用功能。
2、更新采集插件到最新版(采集更加稳定)。
购买WP版本主题赠送价值199元erphpdown会员插件:
WordPress版本系统介绍:
WordPress是一种使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站。也可以把 WordPress当成一个内容管理系统(CMS)来使用。
WordPress是一款个人博客系统,并逐渐演变成一款内容管理系统软件,它是使用PHP语言和MySQL数据库开发的。用户可以在支持 PHP 和 MySQL数据库的服务器上使用自己的博客。
WordPress有许多第三方开发的免费模板,安装方法简单易用。不过要做一个自己的模板,则须要你有一定的专业知识。比如你起码要懂的标准通用标记语言下的一个应用HTML代码、CSS、PHP等相关知识。WordPress官方支持中文版,同时有爱好者开发的第三方英文语言包,如wopus英文语言包。WordPress拥有成千上万个各色插件和不计其数的主题模板式样。
ThinkPHP版本系统介绍:
基于国外流行的ThinkPHP3.2.3框架研制,UI插件采用简约、直观、强悍的 Bootstrap3.3.5后端开发框架以及口碑绝佳的web弹层组件LayerUI,全新的设计理念,带来更凉爽的体验。
系统采用多站点 切换的设计方案,巧妙地解决了一站一后台的传统弊病,不仅便捷站点的管理,也节约更多的研制时间,在新版本的系统中还集成了微信公众号、Ucenter用 户中心等一系列常用功能!由于系统没有自带模板标签功能,所以这就要求使用者具备一定基础的ThinkPHP3.2.3开发经验,自行进行后台数据逻辑的调用与处理。
此资源下载价钱为259M币,请先登入 查看全部
宅要撸美女福利图片站整站数据+会员中心+自动采集+带手机版(双版本)
先送一波福利
下载观看
有两个版本:
WordPress版本: 300元+100 ThinkPHP版本(带数据)
ThinkPHP版本: 250元(带数据)adminmbxzb123
两个版本均带手机站自行测试!包安装售后。
即日起此模板买一送一,只需花一个模板的钱,你就可以拥有两套程序。
更新记录
2017.03.10
1、优化后台插件,删除多余无用功能。
2、更新采集插件到最新版(采集更加稳定)。
购买WP版本主题赠送价值199元erphpdown会员插件:
WordPress版本系统介绍:
WordPress是一种使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站。也可以把 WordPress当成一个内容管理系统(CMS)来使用。
WordPress是一款个人博客系统,并逐渐演变成一款内容管理系统软件,它是使用PHP语言和MySQL数据库开发的。用户可以在支持 PHP 和 MySQL数据库的服务器上使用自己的博客。
WordPress有许多第三方开发的免费模板,安装方法简单易用。不过要做一个自己的模板,则须要你有一定的专业知识。比如你起码要懂的标准通用标记语言下的一个应用HTML代码、CSS、PHP等相关知识。WordPress官方支持中文版,同时有爱好者开发的第三方英文语言包,如wopus英文语言包。WordPress拥有成千上万个各色插件和不计其数的主题模板式样。
ThinkPHP版本系统介绍:
基于国外流行的ThinkPHP3.2.3框架研制,UI插件采用简约、直观、强悍的 Bootstrap3.3.5后端开发框架以及口碑绝佳的web弹层组件LayerUI,全新的设计理念,带来更凉爽的体验。
系统采用多站点 切换的设计方案,巧妙地解决了一站一后台的传统弊病,不仅便捷站点的管理,也节约更多的研制时间,在新版本的系统中还集成了微信公众号、Ucenter用 户中心等一系列常用功能!由于系统没有自带模板标签功能,所以这就要求使用者具备一定基础的ThinkPHP3.2.3开发经验,自行进行后台数据逻辑的调用与处理。
此资源下载价钱为259M币,请先登入
基于R语言的手动数据搜集:网络抓取和文本挖掘实用手册
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-15 02:14
本书也不会严谨地介绍数据科学。在这个主题上也有一些出众的教材,例如O扤eil and Schutt(2013)、Torgo(2010)、Zhao(2012),以及Zumel and Mount(2014)。在那些书中时常缺位的部份是怎样在真实环境中获取数据科学中用到的数据。在这方面,本书可以作为数据剖析的打算阶段的参考书,它还给出了关于怎么管理可用信息并使它们保持及时更新的指导原则。
最后,你最不可能从本书听到的是针对你的具体问题的完美解答。在数据采集过程中,获取数据的领域从来都不会完全相像,而且其方式有时也会快速变化,这都是固有的问题。我们的目标是使你能改写事例和案例剖析中提供的代码,并创建新的代码,以此帮助你在采集自己所需数据的工作中获得成功。
为什么使用R
对于本书中囊括的问题,R是一个挺好的解决方案,我们如此考虑是有很多缘由的。对我们来说,最重要的几点缘由如下:
R可以自由和简便地获得。你可以按自己的须要随时随地下载、安装和使用它。不去钻研这些高昂的专有软件对你是大有裨益的,因为你不需要依赖于雇主支付软件版权费的意愿。
作为一个主要专注于统计学的软件环境,R拥有一个巨大并且持续繁荣的社区。R被用于各类专业领域,如社会科学、医学科学、心理学、生物学、地理学、语言学以及商业等。这样大的专业范围使你能与好多开发者共享代码,并从文档建立的多领域应用中受益。
R是开源的。这意味着你就能轻松地剖析函数的工作原理并毫不费力地更改它们。这也意味着对程序的更改不会被一个维护产品的独家程序员团队所控制。即使你无意为 R 的开发贡献代码,你依然可以从种类繁杂的可选扩充项(组件)中受益。组件的数目与日俱增,很多已有的组件也会时常更新。你能在这里找到相当棒的关于R应用的流行主题的概述: 。
对常规任务而言,R是相当快的。如果你用过类似于SPSS或Stata的其他统计软件,并养成了在估算复杂模型的时侯顺便度个假的习惯,你应当会赞成这个印象,更不用提那个由“同一个会话,同一个数据框”的逻辑带来的切肤之痛了。甚至还有一些扩充可以拿来加速R,例如,在R的内部通过Rcpp组件调用C语言代码。
R在建立数据可视化疗效方面也太强悍。虽然这对于数据采集并非明显的增值,在日常工作中你还是不应当错过R的图形特色。我们前面会讲解到,对被采集数据的视觉检测才能且必须作为数据校验的第一步,以及图形怎样给海量数据提供直观的总结形式。
使用R进行的工作主要是基于命令行的。这在R“菜鸟”听上去似乎象是一个不足,但相比这些要用滑鼠点击的程序来说,这是惟一能支持形成可再现结果的方法。
R对于操作系统是不挑剔的。它一般可以在Windows、Mac OS和Linux下运行。
最后,R是能自始至终支持研究过程的完整软件包。如果你在读这本书,你应当不是专职程序员,而是对于你要从事的某个主题或特定数据源有相当大的兴趣。在这些情况下,学习另一门语言不会有成效,反而会使你未能举办研究工作。普通研究流程的一个事例如图1所示。它的特征是永远在各类程序之间切换。如果你须要对数据采集过程进行修正,你就不得不顺着整个梯子爬回来。而使用R的研究过程,正如在本书中所述说的,只在单一的软件环境中进行(见图2)。对于网路抓取和文本处理而言,这意味着你何必为这项任务去学习另一门编程语言。你须要学习的只是标记语言 HTML、XML、正则表达式逻辑和XPath的一些基础知识,但所需的操作都是在R内部执行的。
R起步阶段的推荐读物
市面上有很多写得挺好的介绍R的书。在它们当中,我们发觉以下几本尤其有帮助:
Crawley, Michael J. 2012. The R Book, 2nd edition. Hoboken, NJ: John Wiley & Sons.
Adler, Joseph. 2009. R in a Nutshell. A Desktop Quick Reference. Sebastopol, CA: O扲eilly.
Teetor, Paul. 2011. R Cookbook. Sebastopol, CA: O扲eilly.
除了那些商业化的资源,网上还有好多免费的信息。对绝对的菜鸟来说,Code School上有个真正超棒的在线教程,可以在听到。另外,Quick-R()里有好多基本命令的索引。最后,你也可以在 找到好多免费资源和事例。
R是一个不断成长中的软件,为了跟上它的进展,你也许须要定期访问Planet R(),该网站提供了已有组件的发布历史,偶尔就会介绍一些有意思的应用。R-Bloggers()是个博客大杂烩,它专门搜集有关R的各类领域的博客。它提供了由数以百计的R应用构成的宽广视角,这些应用涉及的领域从经济学到生物学再到地理学,大部分都附有再现博文内容所必需的代码。R-Bloggers 甚至推介了一些阐述自动化数据采集的反例。
当你遇见问题的时侯,R的帮助文件有时候不是非常有用。去Stack Overflow()这样的在线峰会或Stack Exchange网路旗下的其他站点寻求帮助常常会更有启发性。对于复杂问题,可以考虑去 GitHub()上找一些R的专家。另外请注意,还有好多非常兴趣小组(SIG)的电邮列表(),里面界定了多种多样的主题,甚至还覆盖全世界的同城R用户小组()。最后,有人建了个CRAN任务视图,较好地概括了近日Web技术的进展和R框架里的服务:。
配套资源
本书的配套网站见。
该网站提供了书中事例和案例剖析的相关代码,以及其他一些内容。这意味着你无须手工从书中复制代码,直接访问和更改相应的R文件即可。你也可以在该网站找到个别练习题的解答,以及本书的勘误表。如果你在书中发觉了任何错误,也请不吝告知。 查看全部
.你也不要指望本书针对网路抓取或文本挖掘进行全面讲解。首先,我们专门使用了一套软件环境,而它并不是为实现这种目的量身订制的。在一些应用需求下,R 对于你要完成的任务并非理想解决方案,其他软件包可能更合适。我们也不会用如PHP、Python、Ruby或Perl等代替环境来干扰你。要想知道本书是否对你有帮助,你应当扪心自问,你是否早已或计划把R用在日常工作中。如果对这两个问题的答案都是否定的,很可能你就应当考虑取代方案了。但是,如果你早已在用或倾向于使用R了,你就可以市下学习另一个开发语言的精力,留在熟悉的开发环境里。
本书也不会严谨地介绍数据科学。在这个主题上也有一些出众的教材,例如O扤eil and Schutt(2013)、Torgo(2010)、Zhao(2012),以及Zumel and Mount(2014)。在那些书中时常缺位的部份是怎样在真实环境中获取数据科学中用到的数据。在这方面,本书可以作为数据剖析的打算阶段的参考书,它还给出了关于怎么管理可用信息并使它们保持及时更新的指导原则。
最后,你最不可能从本书听到的是针对你的具体问题的完美解答。在数据采集过程中,获取数据的领域从来都不会完全相像,而且其方式有时也会快速变化,这都是固有的问题。我们的目标是使你能改写事例和案例剖析中提供的代码,并创建新的代码,以此帮助你在采集自己所需数据的工作中获得成功。
为什么使用R
对于本书中囊括的问题,R是一个挺好的解决方案,我们如此考虑是有很多缘由的。对我们来说,最重要的几点缘由如下:
R可以自由和简便地获得。你可以按自己的须要随时随地下载、安装和使用它。不去钻研这些高昂的专有软件对你是大有裨益的,因为你不需要依赖于雇主支付软件版权费的意愿。
作为一个主要专注于统计学的软件环境,R拥有一个巨大并且持续繁荣的社区。R被用于各类专业领域,如社会科学、医学科学、心理学、生物学、地理学、语言学以及商业等。这样大的专业范围使你能与好多开发者共享代码,并从文档建立的多领域应用中受益。
R是开源的。这意味着你就能轻松地剖析函数的工作原理并毫不费力地更改它们。这也意味着对程序的更改不会被一个维护产品的独家程序员团队所控制。即使你无意为 R 的开发贡献代码,你依然可以从种类繁杂的可选扩充项(组件)中受益。组件的数目与日俱增,很多已有的组件也会时常更新。你能在这里找到相当棒的关于R应用的流行主题的概述: 。
对常规任务而言,R是相当快的。如果你用过类似于SPSS或Stata的其他统计软件,并养成了在估算复杂模型的时侯顺便度个假的习惯,你应当会赞成这个印象,更不用提那个由“同一个会话,同一个数据框”的逻辑带来的切肤之痛了。甚至还有一些扩充可以拿来加速R,例如,在R的内部通过Rcpp组件调用C语言代码。
R在建立数据可视化疗效方面也太强悍。虽然这对于数据采集并非明显的增值,在日常工作中你还是不应当错过R的图形特色。我们前面会讲解到,对被采集数据的视觉检测才能且必须作为数据校验的第一步,以及图形怎样给海量数据提供直观的总结形式。
使用R进行的工作主要是基于命令行的。这在R“菜鸟”听上去似乎象是一个不足,但相比这些要用滑鼠点击的程序来说,这是惟一能支持形成可再现结果的方法。
R对于操作系统是不挑剔的。它一般可以在Windows、Mac OS和Linux下运行。
最后,R是能自始至终支持研究过程的完整软件包。如果你在读这本书,你应当不是专职程序员,而是对于你要从事的某个主题或特定数据源有相当大的兴趣。在这些情况下,学习另一门语言不会有成效,反而会使你未能举办研究工作。普通研究流程的一个事例如图1所示。它的特征是永远在各类程序之间切换。如果你须要对数据采集过程进行修正,你就不得不顺着整个梯子爬回来。而使用R的研究过程,正如在本书中所述说的,只在单一的软件环境中进行(见图2)。对于网路抓取和文本处理而言,这意味着你何必为这项任务去学习另一门编程语言。你须要学习的只是标记语言 HTML、XML、正则表达式逻辑和XPath的一些基础知识,但所需的操作都是在R内部执行的。
R起步阶段的推荐读物
市面上有很多写得挺好的介绍R的书。在它们当中,我们发觉以下几本尤其有帮助:
Crawley, Michael J. 2012. The R Book, 2nd edition. Hoboken, NJ: John Wiley & Sons.
Adler, Joseph. 2009. R in a Nutshell. A Desktop Quick Reference. Sebastopol, CA: O扲eilly.
Teetor, Paul. 2011. R Cookbook. Sebastopol, CA: O扲eilly.
除了那些商业化的资源,网上还有好多免费的信息。对绝对的菜鸟来说,Code School上有个真正超棒的在线教程,可以在听到。另外,Quick-R()里有好多基本命令的索引。最后,你也可以在 找到好多免费资源和事例。
R是一个不断成长中的软件,为了跟上它的进展,你也许须要定期访问Planet R(),该网站提供了已有组件的发布历史,偶尔就会介绍一些有意思的应用。R-Bloggers()是个博客大杂烩,它专门搜集有关R的各类领域的博客。它提供了由数以百计的R应用构成的宽广视角,这些应用涉及的领域从经济学到生物学再到地理学,大部分都附有再现博文内容所必需的代码。R-Bloggers 甚至推介了一些阐述自动化数据采集的反例。
当你遇见问题的时侯,R的帮助文件有时候不是非常有用。去Stack Overflow()这样的在线峰会或Stack Exchange网路旗下的其他站点寻求帮助常常会更有启发性。对于复杂问题,可以考虑去 GitHub()上找一些R的专家。另外请注意,还有好多非常兴趣小组(SIG)的电邮列表(),里面界定了多种多样的主题,甚至还覆盖全世界的同城R用户小组()。最后,有人建了个CRAN任务视图,较好地概括了近日Web技术的进展和R框架里的服务:。
配套资源
本书的配套网站见。
该网站提供了书中事例和案例剖析的相关代码,以及其他一些内容。这意味着你无须手工从书中复制代码,直接访问和更改相应的R文件即可。你也可以在该网站找到个别练习题的解答,以及本书的勘误表。如果你在书中发觉了任何错误,也请不吝告知。
大数据-数据建行之自动化资产数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 467 次浏览 • 2020-08-13 19:01
很多公司在做自动化运维平台前就会先做一个CMDB,做CMDB的第一步就是建模和采集数据。说到采集数据,为了防止过多人工介入造成数据准确率低,采集方法普遍分为两种:
一小部份静态数据人工录入
大部分数据用程序采集
第二部份,不同的公司有的用shell实现一套,有的公司拿脚本语言实现一套,有的公司在须要的时侯主动搜集一次,有的公司手动定期搜集。
汽车之家的方式是“Puppet Facter脚本”+“定期手动搜集”。并且我们早已将其开源在Github(Assets_Report)上跟你们分享。
下面我们详尽解说一下原理和使用方式。
二、原理介绍
众所周知,Puppet是一套配置管理工具,是一个Client/Server模式的构架,可以用它来管理软件、配置文件和Service。然后,Puppet生态圈里有个叫Facter的工具,运行在Agent端,可以和Puppet紧密配合完成数据采集的工作。但是Facter提供采集的数据虽然有限,一些愈发底层的硬件数据就没有采集,而这种数据也是我们所须要的,这就是我们开发本工具的动机。
虽然Facter采集的数据有限,但是Facter本身是一个挺好的框架,非常容易对其进行扩充,所以我们基于Facter进行了扩充,配合Puppet Master的Report Processor将采集的结果上报给AutoBank(这是车辆之家的CMDB代号,可以参考《运维的数据建行-构建CMDB方式》),由此来完成一个完整的采集逻辑。
这是Puppet的Server跟Agent之间的工作流程图
Agent在发送Request恳求Catalog的阶段,会将自身的facts都上报给Master。而Master接到数据后可以借助自身的Report Processor对其进行二次处理,例如转发到别处。
正是基于上述的原理,我们开发了自己的Report Processor:assets_report,通过HTTP协议将facts post给AutoBank的http插口使其入库。
对开发custom facts感兴趣的朋友可以参考 fact_overview 和 custom facts。
如上所述,我们的Assets_Report项目收录了如下两个组件来实现整个逻辑
assets_report模块:一个纯Puppet Module,内建了一个Report Processor和一些自定义Facter插件,部署在Master端。
Report Processor运行在Master端。
Facter插件会通过Master下发到Agent端并被运行以采集本机资产数据
api_server:负责接收资产数据并将其入库
三、采集插件的功能介绍
相对于Facter内建的facts,本插件提供了更多的硬件数据,例如
CPU个数,型号
内存容量,序列号,厂商,插槽位置
网卡上绑定的ip,掩码,mac,型号,且支持一个网卡上绑定多ip的场景
RAID卡个数,型号,内存容量,RAID Level
磁盘个数,容量,序列号,厂商,所属RAID卡,插槽位置
操作系统类型,版本
服务器厂商,SN
高级特点:为了防止大段相同数据重复上报,减轻AutoBank的数据库压力,本插件具备Cache功能,即假如一台服务器的资产数据没有发生变更,那么只会汇报not_modify标记。
本插件支持的操作系统有(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
Windows 2008 R2
本插件支持的服务器有
HP
DELL
CISCO
四、采集插件的安装方式
安装操作在Puppet Master端进行。
假定你的模块目录为/etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
在你自己的puppet.conf(假设默认路径是/etc/puppet/puppet.conf)中添加
reports = assets_report
然后在site.pp中添加如下配置,让所有Node都安装assets_report模块
node default { # include assets_report class {'assets_report': }}
配置完毕后,采集工具会被手动下发到Agent上进行安装。下一次Puppet Agent运行时本插件即可正常工作。
五、汇报组件的配置方式
配置操作在Puppet Master端进行。
配置文件为 assets_report/lib/puppet/reports/report_setting.yaml
参数
含义
示例
report_url汇报插口地址,可更改成你自己的url
auth_required插口是否收录验证true/false,默认为false,验证代码须要在auth.rb中自己实现
user验证用户名假如auth_required为true,需要填写
passwd验证密码假如auth_required为true,需要填写
enable_cache是否启用cache功能true/false, 默认为false
六、汇报插口服务的配置方式
配置操作在Puppet Master端进行。
本插口服务api_server基于一个Python编撰的Web框架Django开发,该组件收录了数据库设计和http api的实现。因为各家公司的数据库设计均不一致,该项目仅实现了最简单的数据建模,所以该组件的存在仅作为Demo,不可用于生产环境,读者需注意。
首先,我们须要安装一些依赖。这里假设你的OS为CentOS/RedHat
$ cd ~/Assets_Report/api_server安装pip,用它来安装python模块$ sudo yum install python-pip安装python模块依赖$ pip install -r requirements.txt
初始化数据库,可以参考 Django用户指南
$ python manage.py makemigrations apis$ python manage.py migrate数据库为当前目录下的db.sqlite3 查看全部
很多公司在做自动化运维平台前就会先做一个CMDB,做CMDB的第一步就是建模和采集数据。说到采集数据,为了防止过多人工介入造成数据准确率低,采集方法普遍分为两种:
一小部份静态数据人工录入
大部分数据用程序采集
第二部份,不同的公司有的用shell实现一套,有的公司拿脚本语言实现一套,有的公司在须要的时侯主动搜集一次,有的公司手动定期搜集。
汽车之家的方式是“Puppet Facter脚本”+“定期手动搜集”。并且我们早已将其开源在Github(Assets_Report)上跟你们分享。
下面我们详尽解说一下原理和使用方式。
二、原理介绍
众所周知,Puppet是一套配置管理工具,是一个Client/Server模式的构架,可以用它来管理软件、配置文件和Service。然后,Puppet生态圈里有个叫Facter的工具,运行在Agent端,可以和Puppet紧密配合完成数据采集的工作。但是Facter提供采集的数据虽然有限,一些愈发底层的硬件数据就没有采集,而这种数据也是我们所须要的,这就是我们开发本工具的动机。
虽然Facter采集的数据有限,但是Facter本身是一个挺好的框架,非常容易对其进行扩充,所以我们基于Facter进行了扩充,配合Puppet Master的Report Processor将采集的结果上报给AutoBank(这是车辆之家的CMDB代号,可以参考《运维的数据建行-构建CMDB方式》),由此来完成一个完整的采集逻辑。
这是Puppet的Server跟Agent之间的工作流程图
Agent在发送Request恳求Catalog的阶段,会将自身的facts都上报给Master。而Master接到数据后可以借助自身的Report Processor对其进行二次处理,例如转发到别处。
正是基于上述的原理,我们开发了自己的Report Processor:assets_report,通过HTTP协议将facts post给AutoBank的http插口使其入库。
对开发custom facts感兴趣的朋友可以参考 fact_overview 和 custom facts。
如上所述,我们的Assets_Report项目收录了如下两个组件来实现整个逻辑
assets_report模块:一个纯Puppet Module,内建了一个Report Processor和一些自定义Facter插件,部署在Master端。
Report Processor运行在Master端。
Facter插件会通过Master下发到Agent端并被运行以采集本机资产数据
api_server:负责接收资产数据并将其入库
三、采集插件的功能介绍
相对于Facter内建的facts,本插件提供了更多的硬件数据,例如
CPU个数,型号
内存容量,序列号,厂商,插槽位置
网卡上绑定的ip,掩码,mac,型号,且支持一个网卡上绑定多ip的场景
RAID卡个数,型号,内存容量,RAID Level
磁盘个数,容量,序列号,厂商,所属RAID卡,插槽位置
操作系统类型,版本
服务器厂商,SN
高级特点:为了防止大段相同数据重复上报,减轻AutoBank的数据库压力,本插件具备Cache功能,即假如一台服务器的资产数据没有发生变更,那么只会汇报not_modify标记。
本插件支持的操作系统有(系统必须是64位的,因为本插件中的采集工具是64位的)
CentOS-6
CentOS-7
Windows 2008 R2
本插件支持的服务器有
HP
DELL
CISCO
四、采集插件的安装方式
安装操作在Puppet Master端进行。
假定你的模块目录为/etc/puppet/modules
cd ~git clone :AutohomeOps/Assets_Report.gitcp -r Assets_Report/assets_report /etc/puppet/modules/
在你自己的puppet.conf(假设默认路径是/etc/puppet/puppet.conf)中添加
reports = assets_report
然后在site.pp中添加如下配置,让所有Node都安装assets_report模块
node default { # include assets_report class {'assets_report': }}
配置完毕后,采集工具会被手动下发到Agent上进行安装。下一次Puppet Agent运行时本插件即可正常工作。
五、汇报组件的配置方式
配置操作在Puppet Master端进行。
配置文件为 assets_report/lib/puppet/reports/report_setting.yaml
参数
含义
示例
report_url汇报插口地址,可更改成你自己的url
auth_required插口是否收录验证true/false,默认为false,验证代码须要在auth.rb中自己实现
user验证用户名假如auth_required为true,需要填写
passwd验证密码假如auth_required为true,需要填写
enable_cache是否启用cache功能true/false, 默认为false
六、汇报插口服务的配置方式
配置操作在Puppet Master端进行。
本插口服务api_server基于一个Python编撰的Web框架Django开发,该组件收录了数据库设计和http api的实现。因为各家公司的数据库设计均不一致,该项目仅实现了最简单的数据建模,所以该组件的存在仅作为Demo,不可用于生产环境,读者需注意。
首先,我们须要安装一些依赖。这里假设你的OS为CentOS/RedHat
$ cd ~/Assets_Report/api_server安装pip,用它来安装python模块$ sudo yum install python-pip安装python模块依赖$ pip install -r requirements.txt
初始化数据库,可以参考 Django用户指南
$ python manage.py makemigrations apis$ python manage.py migrate数据库为当前目录下的db.sqlite3
SQL Server 2008中手动采集数据的方法(下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 313 次浏览 • 2020-08-10 08:26
该报表展示了采集功能运行在什么服务器上。你可以点击每位链接来查看每台服务器的详尽信息。下面的截图展示了服务器活动四个小时之后的“服务器活动历史报表”的上半部份。
如你所见,数据采集器报表的上方显示了一个导航工具条,你可以滚动它来浏览捕获的快照,也可以选择你想看的数据所在的时间帧。当你在上图中的个别图表上点击时,你可以钻取到子报表中查看更多详尽信息。下图就是一个“SQL Server等待情况”子报表的示例。
我建议你把所有那些报表都点进去瞧瞧,选择不同的时间段等等,这样你才会熟悉它们能提供哪些内容。例如,你可以在“查询统计历史报表”中查看到某些查询的明细,包括图形化的执行计划。
数据采集器在发生数据采集的服务器上会形成2%-5%的性能代价,主要借助的资源是CPU。存储空间需求只有每晚300MB,也就是说你每台服务器每周须要2GB的储存空间。你准备保留多长时间的数据呢?答案完全取决于你的须要和储存能力,然而大部分参数你都可以使用默认值。默认配置是“查询统计”和“服务器活动历史数据采集保留14天,“磁盘借助情况汇总”采集保留三年。
如果你想保留更长时间的性能数据,还不想保存快速累积的数以百万计的行记录,你可以编撰自己的查询并对想常年保存的重要数据生成每日或每周的合计。SQL Server在线图书有关于使用数据采集表的特别优秀的文档,它们促使对采集到的数据订制查询会更容易一些。
以上是对数据采集器十分简单的一个概述,介绍了怎样配置你的服务器来启用采集并剖析SQL Server 2008性能数据。在前面的文章中,我会更深入地挖掘它的内部机制,并给你介绍怎么编撰自定义查询来提取想常年保留数据的快照,以及怎样创建自定义报表来显示这些数据。 查看全部
运行该向导以后,数据采集就会启动。要累积有意义的数据得花点时间,所以在能看到报表之前,你可能须要等上一两个小时。SQL Server Management Studio 2008现今有三种新报表来查看数据采集器积累的数据。这三种报表是:服务器活动历史,磁盘借助情况汇总和查询统计历史。你可以查看这种报表,在数据采集节点上右击,选择“报表”(紧挨到“受管数据库房”)就可以查看这种报表。SQL Server Management Studio 2008都会辨识你拿来仓储数据的数据库,所以在该数据库上右击时,会有选项选择“受管数据库房概要”报表。如下图所示:
该报表展示了采集功能运行在什么服务器上。你可以点击每位链接来查看每台服务器的详尽信息。下面的截图展示了服务器活动四个小时之后的“服务器活动历史报表”的上半部份。
如你所见,数据采集器报表的上方显示了一个导航工具条,你可以滚动它来浏览捕获的快照,也可以选择你想看的数据所在的时间帧。当你在上图中的个别图表上点击时,你可以钻取到子报表中查看更多详尽信息。下图就是一个“SQL Server等待情况”子报表的示例。
我建议你把所有那些报表都点进去瞧瞧,选择不同的时间段等等,这样你才会熟悉它们能提供哪些内容。例如,你可以在“查询统计历史报表”中查看到某些查询的明细,包括图形化的执行计划。
数据采集器在发生数据采集的服务器上会形成2%-5%的性能代价,主要借助的资源是CPU。存储空间需求只有每晚300MB,也就是说你每台服务器每周须要2GB的储存空间。你准备保留多长时间的数据呢?答案完全取决于你的须要和储存能力,然而大部分参数你都可以使用默认值。默认配置是“查询统计”和“服务器活动历史数据采集保留14天,“磁盘借助情况汇总”采集保留三年。
如果你想保留更长时间的性能数据,还不想保存快速累积的数以百万计的行记录,你可以编撰自己的查询并对想常年保存的重要数据生成每日或每周的合计。SQL Server在线图书有关于使用数据采集表的特别优秀的文档,它们促使对采集到的数据订制查询会更容易一些。
以上是对数据采集器十分简单的一个概述,介绍了怎样配置你的服务器来启用采集并剖析SQL Server 2008性能数据。在前面的文章中,我会更深入地挖掘它的内部机制,并给你介绍怎么编撰自定义查询来提取想常年保留数据的快照,以及怎样创建自定义报表来显示这些数据。
数据剖析实战之怎么自动化采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2020-08-10 07:31
一、开放数据源:一般是针对行业的数据库。可以两个维度来考虑:
1)单位:政府、企业和院校
2)行业:比如交通、金融、能源等
二、爬虫抓取:一般是针对特定的网站或APP。
1、使用python编撰爬虫代码,会经历以下过程
1)使用requests爬取内容。使用requests库抓取网页信息
2)使用XML Path解析内容。
3)使用pandas保存数据
2、不用编程也可以抓取网页信息的抓取工具
优采云采集器、优采云、集搜客
三、日志采集:统计用户的操作。在后端进行埋点、在前端进行脚本搜集、统计,来剖析网站的访问情况,以及使用困局
日志记录了用户访问网址的全过程:哪些人在哪些时间,通过哪些渠道来过,执行了什么操作;系统是否形成了错误;甚至包括用户的IP、HTTP恳求的时间,用户代理等。
埋点是日志采集的关键步骤。埋点就是在有须要的位置采集相应的信息,进行上报。每个埋点如同一台摄像头,采集用户行为数据,将数据进行多经度的交叉剖析,可真实还原出用户使用场景和用户使用需求。
如何进行埋点:在你须要统计数据的地方植入统计代码,代码可以自己写,也可以使用第三方统计工具。比如友盟、Google Analysis、Talkingdata等。 查看全部
从数据采集的角度看,数据源可以分为以下三类
一、开放数据源:一般是针对行业的数据库。可以两个维度来考虑:
1)单位:政府、企业和院校
2)行业:比如交通、金融、能源等
二、爬虫抓取:一般是针对特定的网站或APP。
1、使用python编撰爬虫代码,会经历以下过程
1)使用requests爬取内容。使用requests库抓取网页信息
2)使用XML Path解析内容。
3)使用pandas保存数据
2、不用编程也可以抓取网页信息的抓取工具
优采云采集器、优采云、集搜客
三、日志采集:统计用户的操作。在后端进行埋点、在前端进行脚本搜集、统计,来剖析网站的访问情况,以及使用困局
日志记录了用户访问网址的全过程:哪些人在哪些时间,通过哪些渠道来过,执行了什么操作;系统是否形成了错误;甚至包括用户的IP、HTTP恳求的时间,用户代理等。
埋点是日志采集的关键步骤。埋点就是在有须要的位置采集相应的信息,进行上报。每个埋点如同一台摄像头,采集用户行为数据,将数据进行多经度的交叉剖析,可真实还原出用户使用场景和用户使用需求。
如何进行埋点:在你须要统计数据的地方植入统计代码,代码可以自己写,也可以使用第三方统计工具。比如友盟、Google Analysis、Talkingdata等。

