
自动采集数据
Amazon-排行榜列表页.小雷小雷吧,你准备好了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-07-13 07:07
一、查找列表网址
亚马逊列表的访问是相对保密的。第一次访问时,您必须从产品详细信息页面进入。记下网址即可直接访问。
首次访问:从商品详情页面进入
进入任何有销售记录的产品详情页面,该产品在类别中的排名将显示在Best Sellers Rank中:
点击品类名称进入当前品类的Best Sellers列表。您可以切换到查看其他类别的畅销商品。
将Best Sellers拉到中心位置,Hot New Releases(新品热卖)、Movers and Shakers(上升最快)、Most Wished for(附加愿望夹)、Most Gifted(适合送礼)会出现在这个类别)等待列表。同理,点击进入列表后可以切换分类。
后续访问:记下网址直接访问
实际上,每个类别中每个列表的 URL 保持不变。第一次找到后写下来,然后就可以直接访问了。
各个列表首页的网址如下(建议在PC端打开网址):
打开列表首页后,可以根据需要找到分类对应的网址。
以Earbud Headphones分类为例(建议在PC端打开网址):
二、采集产品列表
在优采云中,可以配置采集模板,自动采集各个类别和列表的TOP100产品。
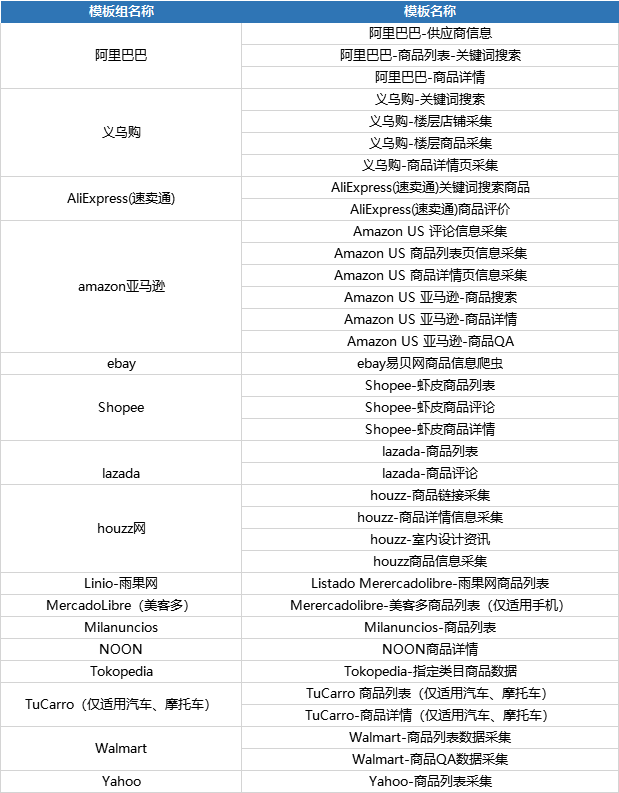
官方采集模板已经为大家配置好了,可以直接使用。 采集模板列表:
具体使用方法如下。
第一步
加优采云官方服务小雷免费获得【亚马逊美国-排行榜Page.otd】。
(优采云的采集模板是.otd文件)
注意!仅限前100名免费赠品,小雷请联系我们!
(工作时间:工作日9:00-18:00,其他时间请耐心等待审批!)
优采云小雷微信
步骤 2
将【亚马逊美国排行榜page.otd】导入优采云采集器并打开。
步骤 3
模板中的示例 URL 是 Earbud Headphones 类别中每个列表的 URL:
这里特别说明,由于Best Sellers、Hot New Releases、Most Wished for等列表的页面结构是一样的,你可以在一个采集模板中完成多个采集列表。
如果需要采集不同类别的列表数据,可以点击进入模板编辑界面,将事先准备好的目标类别的列表URL输入模板并保存。
如何找到目标类别的list URL在第一部分已经详细说明了,这里不再赘述。
步骤 4
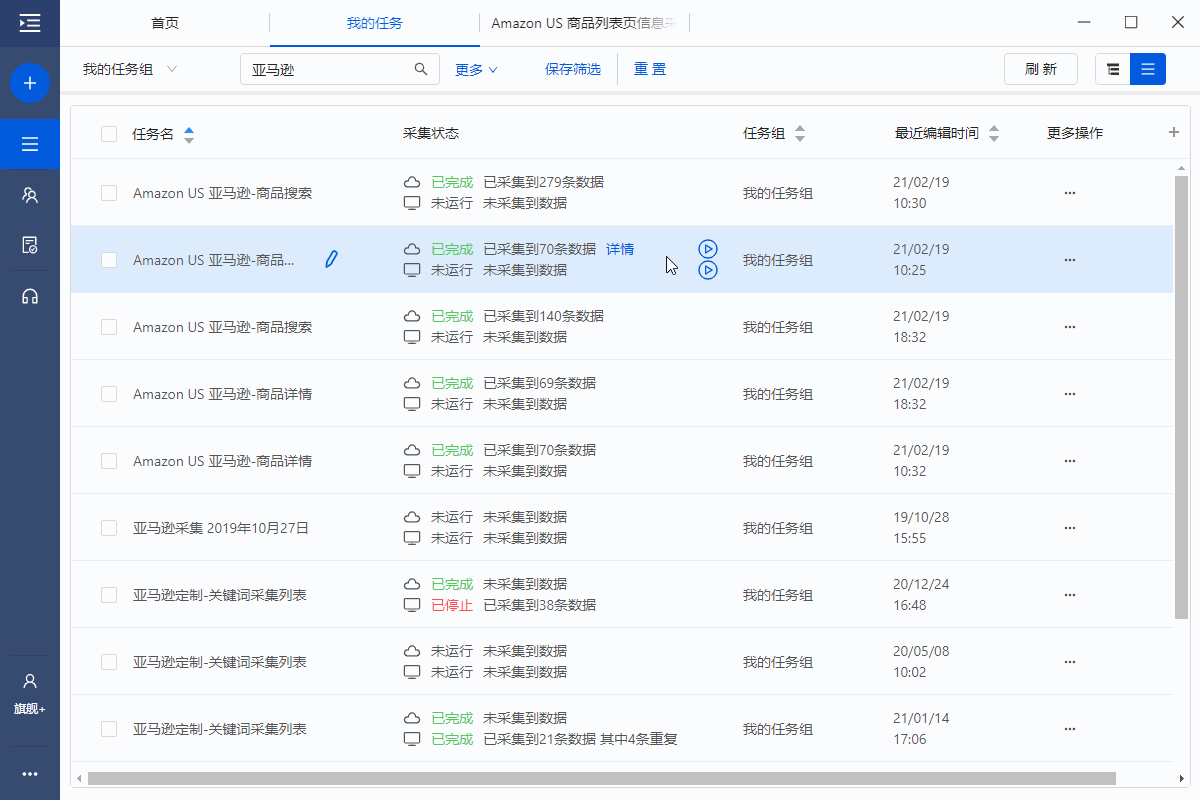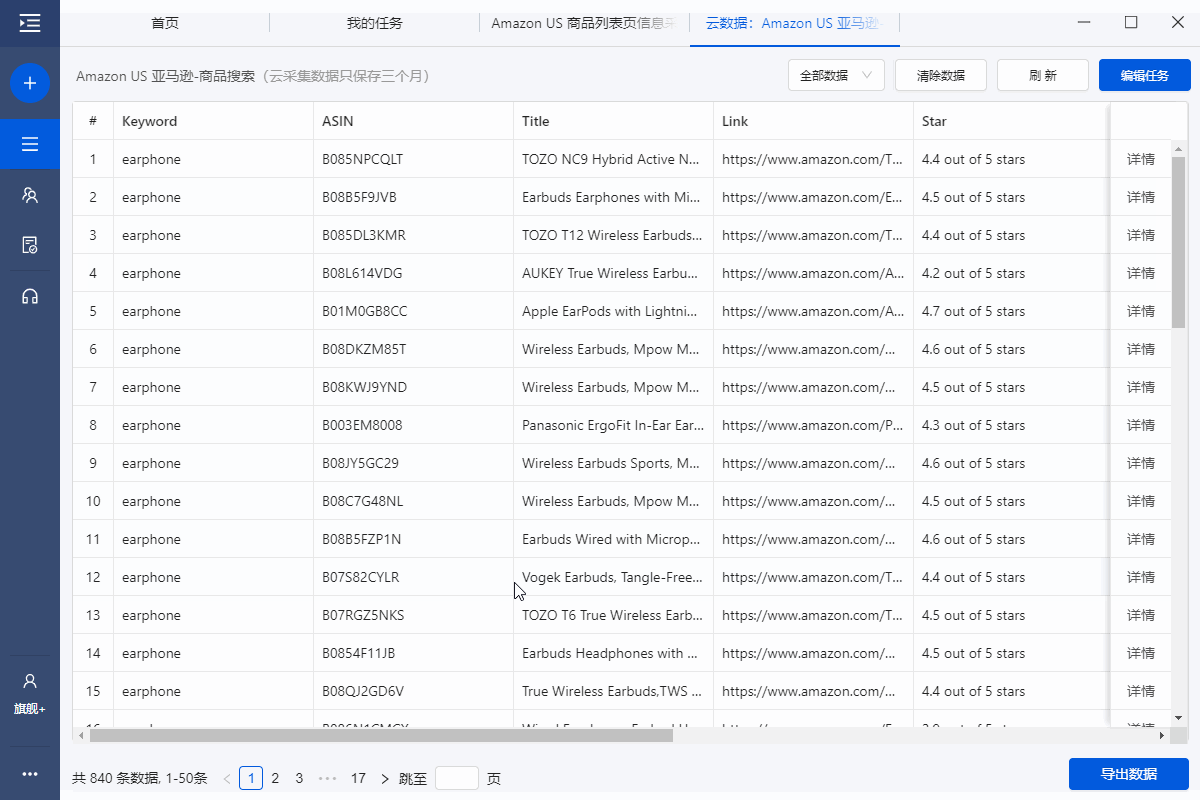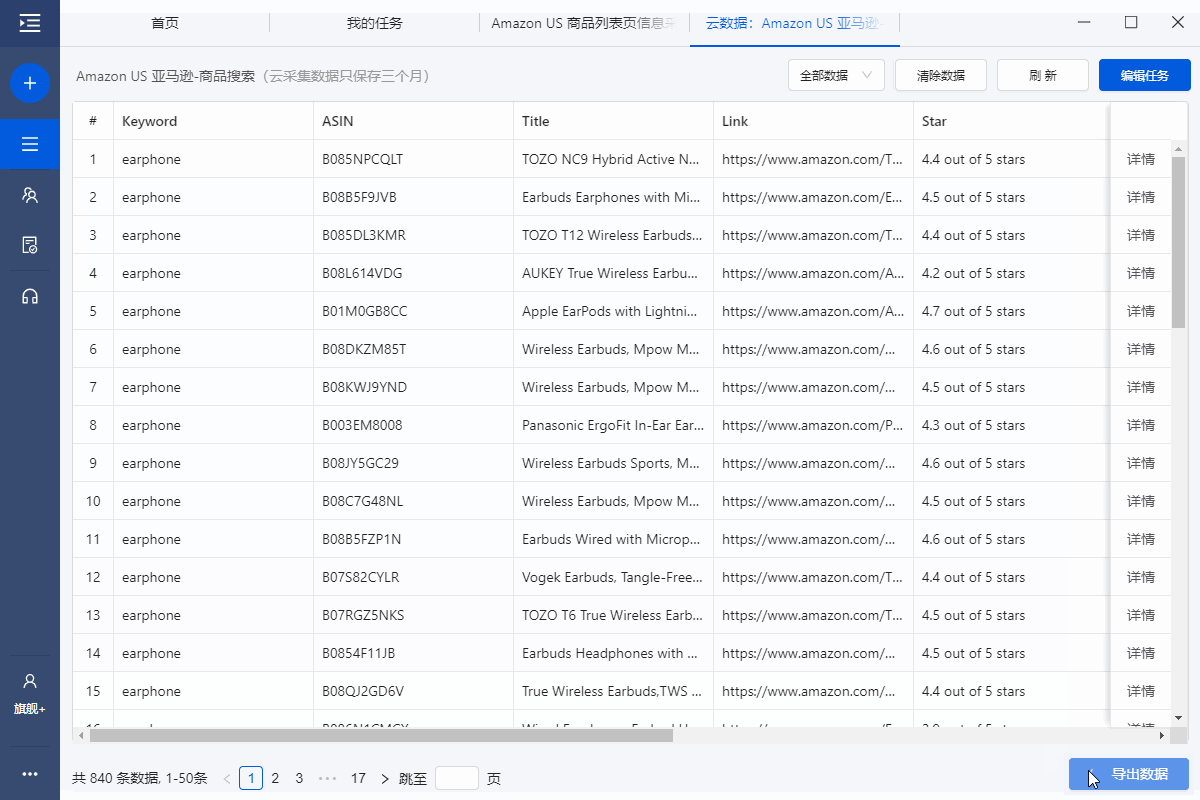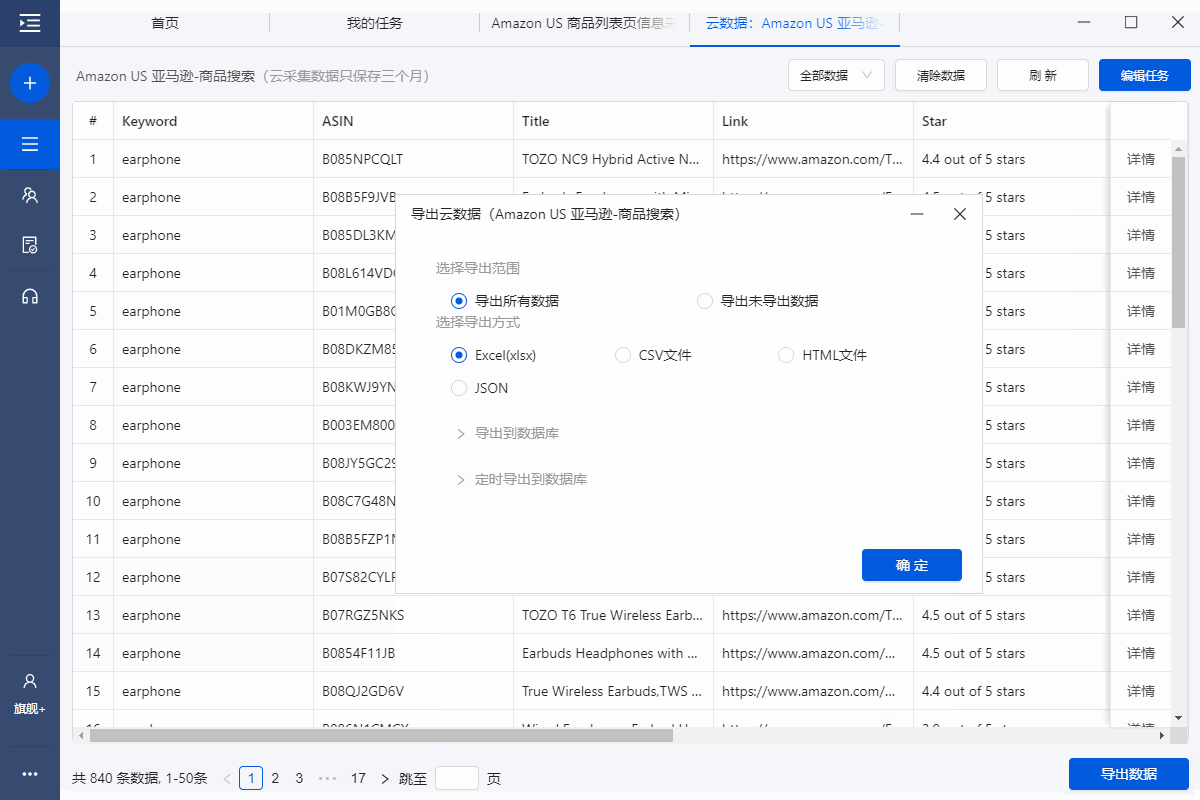
启动采集,获取数据,并以需要的格式导出。
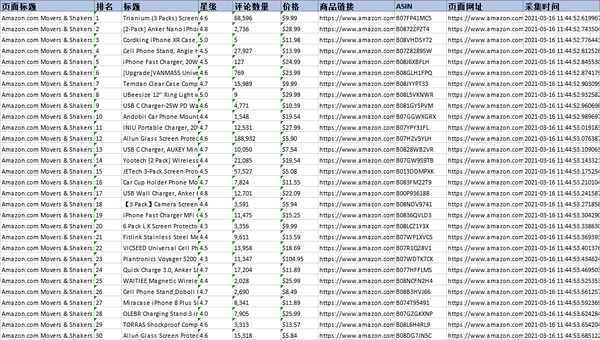
这里选择导出为Excel格式,示例数据如下:
三、Automaticing采集列表添
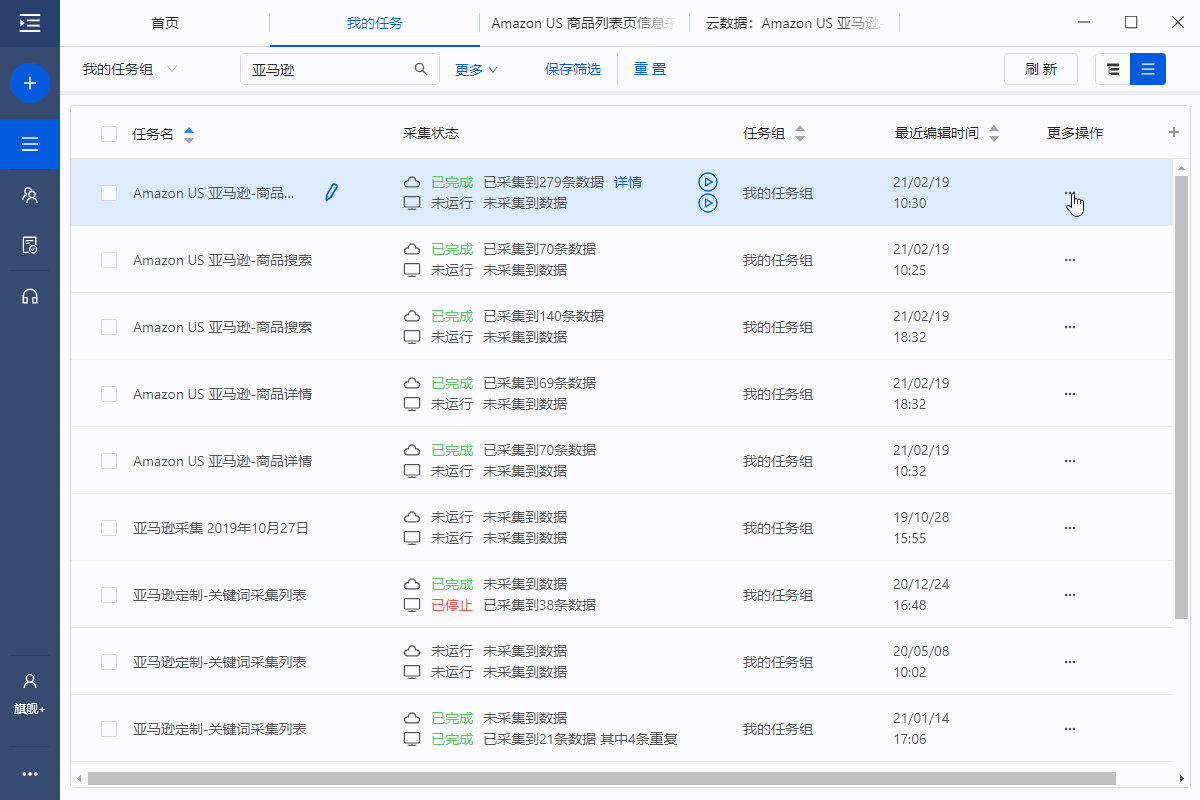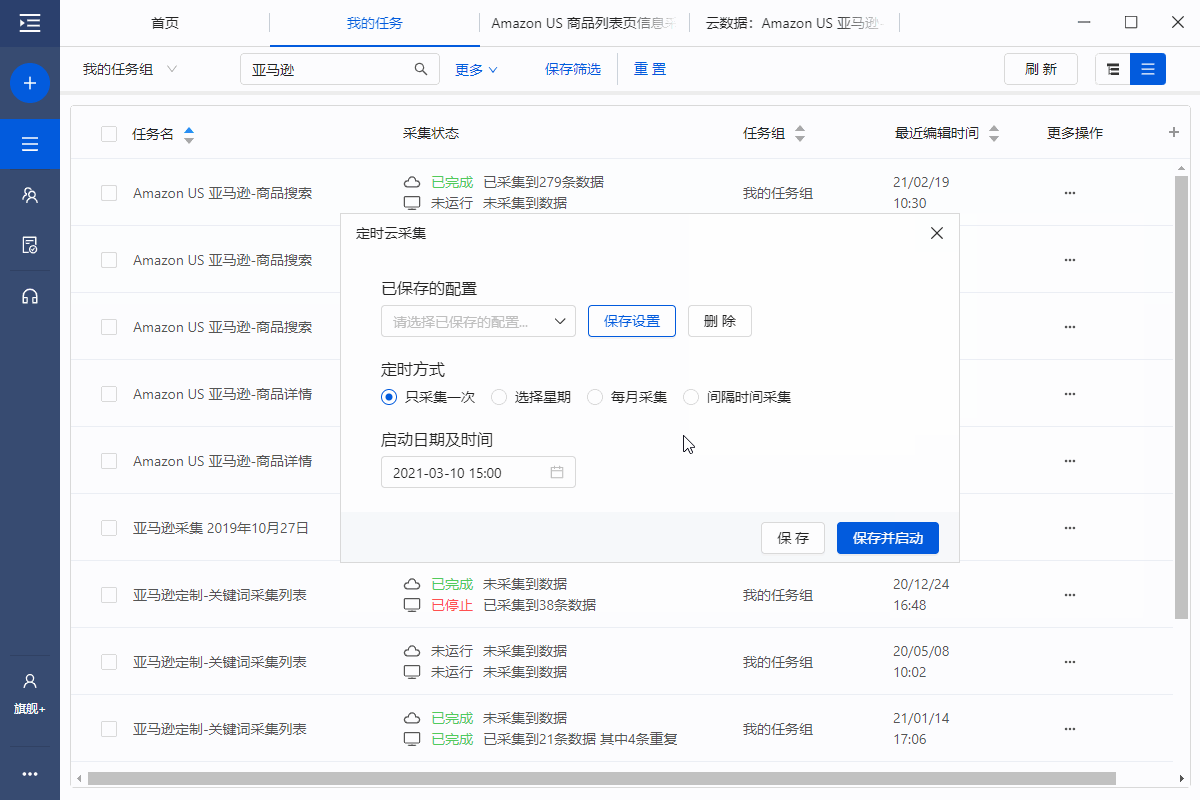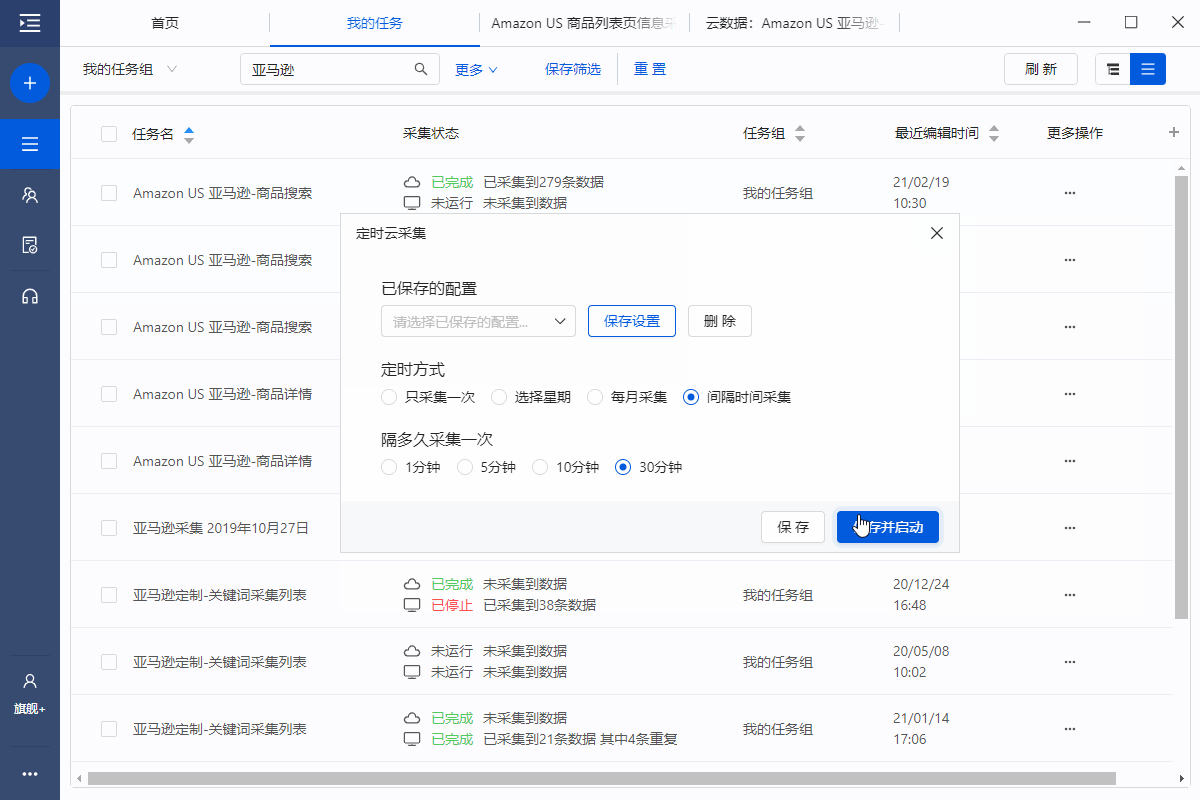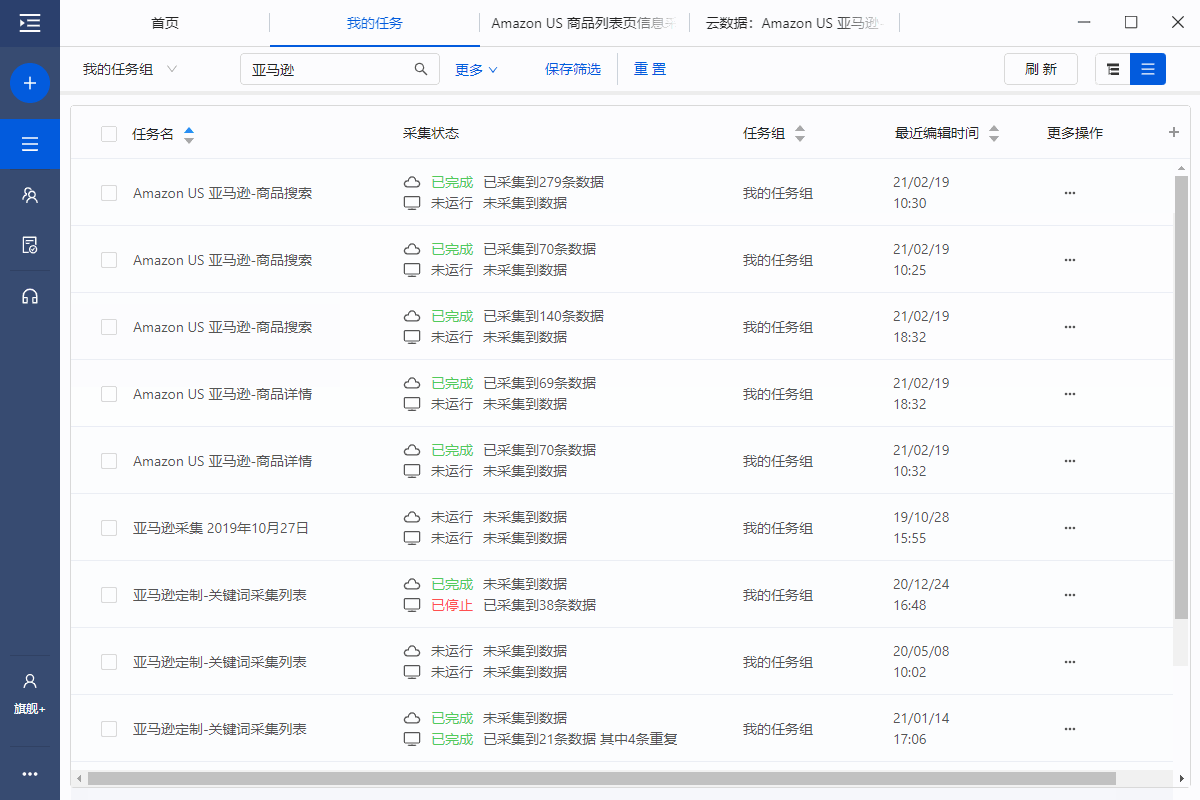
我们知道排行榜数据每小时更新一次。对于这个任务,我们还可以设置采集每小时启动一次,即每小时获取列表中的新数据。
获取实时更新的数据后,通过构建一些可视化图表,可以方便的监控每个列表中产品的变化,从而监控哪些产品畅销,哪些产品处于快速上升期,以及协助产品选择决策。
例如,通过对Hot New Releases列表和Most Wished for列表进行3天的监控,我们发现某产品同时出现在两个列表中,并且排名在稳步上升,因此我们可以认为该产品是热销产品产品潜力,甚至本身就爆款。如果快速跟进销售,很可能会带来意想不到的收获。
我重复重要的事情,请联系我们的客服小雷免费获得【亚马逊美国排行榜page.otd】这个采集任务!
注意!仅限前100名免费赠品,小雷请联系我们!
(工作时间:工作日9:00-18:00,其他时间请耐心等待审批!)
优采云服务小雷微信
当然,采集和亚马逊列表数据的应用只是跨境电商海洋中的沧海一粟。更多平台,更多数据场景等待探索。
我们也在第一季度为此努力。我们希望通过采集模板提供更多平台和更多数据场景供大家使用,帮助您灵活高效地获取数据和应用数据。
以下是最近的一些成就。欢迎跨境电商朋友前来体验交流。
在线30+采集templates
目前已上线30+跨境电商采集模板,覆盖亚马逊、速卖通、Shopee、Lazada、eBay、阿里巴巴等主流跨境电商平台;涵盖产品分类列表、产品listing/review/Q&A、Best Sellers等排名、关键词search list、后台关键词热度数据等各种数据采集场景。
由于优采云的通用性,我们可以针对不同平台、不同数据场景灵活创建采集模板。可以说,只要是网页上实际存在的、可以浏览访问的数据场景,只有想不到的,没有不能匹配的采集模板。
目前在线模板是最常见和最受欢迎的。如果您想体验模板,请联系我们的客服小雷。
如果您有其他采集场景,也欢迎您给我们反馈。 查看全部
Amazon-排行榜列表页.小雷小雷吧,你准备好了吗?
一、查找列表网址
亚马逊列表的访问是相对保密的。第一次访问时,您必须从产品详细信息页面进入。记下网址即可直接访问。
首次访问:从商品详情页面进入
进入任何有销售记录的产品详情页面,该产品在类别中的排名将显示在Best Sellers Rank中:

点击品类名称进入当前品类的Best Sellers列表。您可以切换到查看其他类别的畅销商品。

将Best Sellers拉到中心位置,Hot New Releases(新品热卖)、Movers and Shakers(上升最快)、Most Wished for(附加愿望夹)、Most Gifted(适合送礼)会出现在这个类别)等待列表。同理,点击进入列表后可以切换分类。

后续访问:记下网址直接访问
实际上,每个类别中每个列表的 URL 保持不变。第一次找到后写下来,然后就可以直接访问了。
各个列表首页的网址如下(建议在PC端打开网址):
打开列表首页后,可以根据需要找到分类对应的网址。
以Earbud Headphones分类为例(建议在PC端打开网址):
二、采集产品列表
在优采云中,可以配置采集模板,自动采集各个类别和列表的TOP100产品。
官方采集模板已经为大家配置好了,可以直接使用。 采集模板列表:

具体使用方法如下。
第一步
加优采云官方服务小雷免费获得【亚马逊美国-排行榜Page.otd】。
(优采云的采集模板是.otd文件)

注意!仅限前100名免费赠品,小雷请联系我们!
(工作时间:工作日9:00-18:00,其他时间请耐心等待审批!)

优采云小雷微信
步骤 2
将【亚马逊美国排行榜page.otd】导入优采云采集器并打开。


步骤 3
模板中的示例 URL 是 Earbud Headphones 类别中每个列表的 URL:
这里特别说明,由于Best Sellers、Hot New Releases、Most Wished for等列表的页面结构是一样的,你可以在一个采集模板中完成多个采集列表。
如果需要采集不同类别的列表数据,可以点击进入模板编辑界面,将事先准备好的目标类别的列表URL输入模板并保存。
如何找到目标类别的list URL在第一部分已经详细说明了,这里不再赘述。
步骤 4
启动采集,获取数据,并以需要的格式导出。
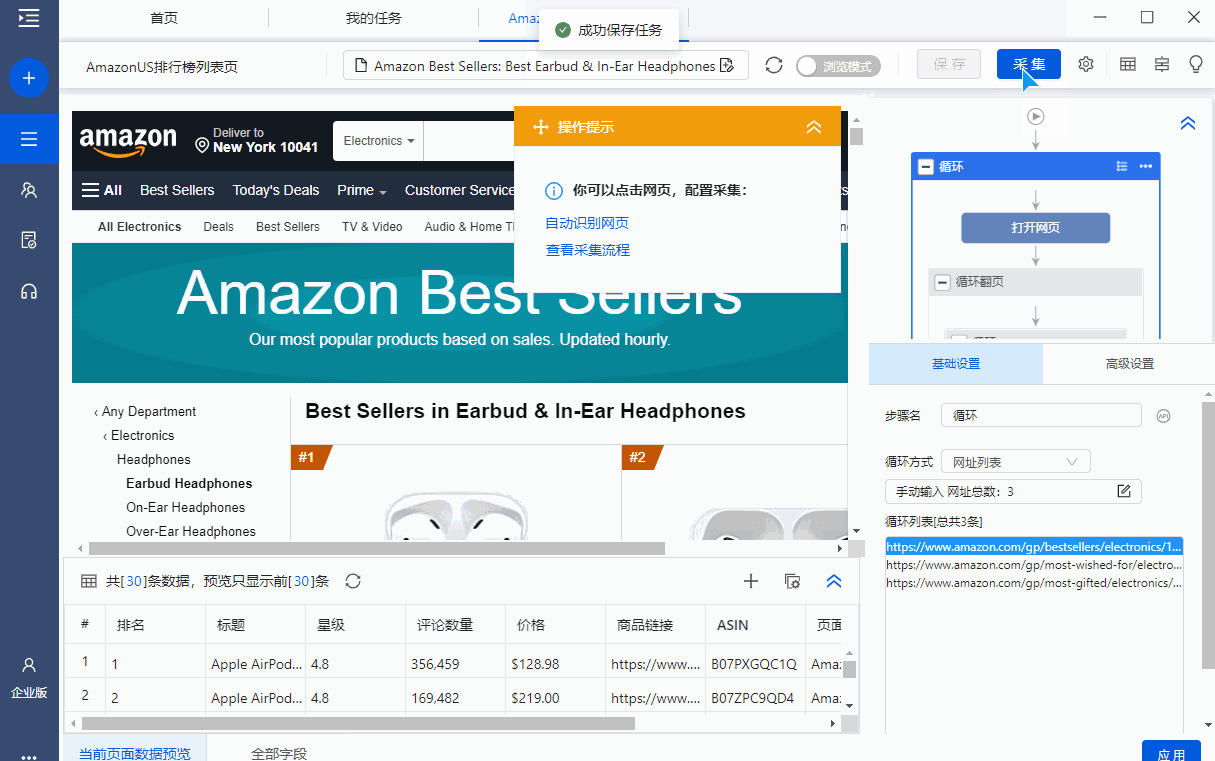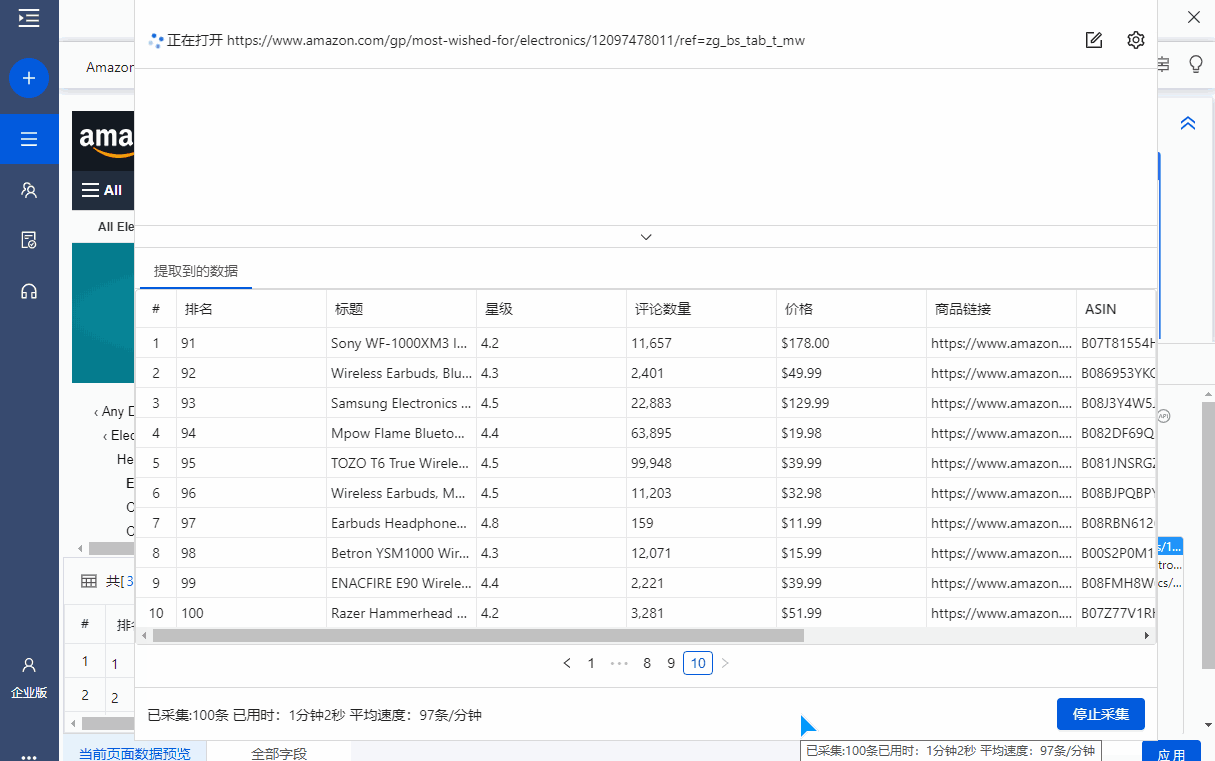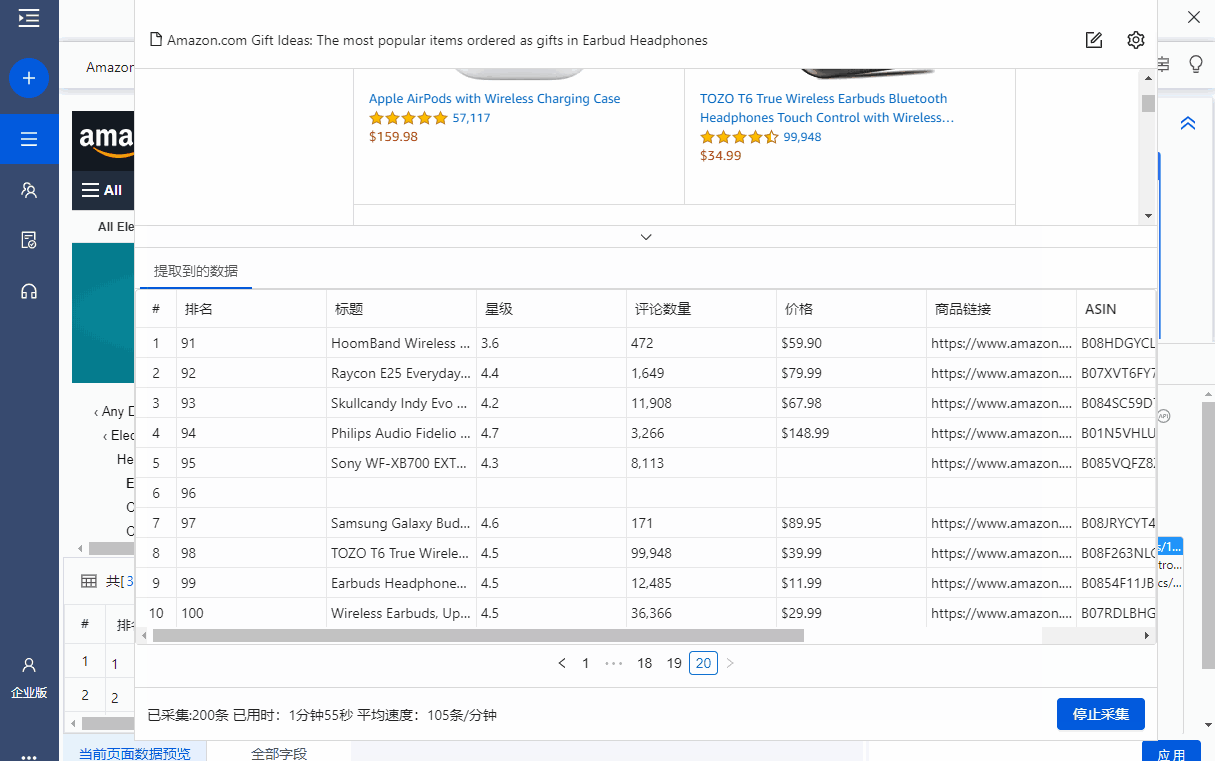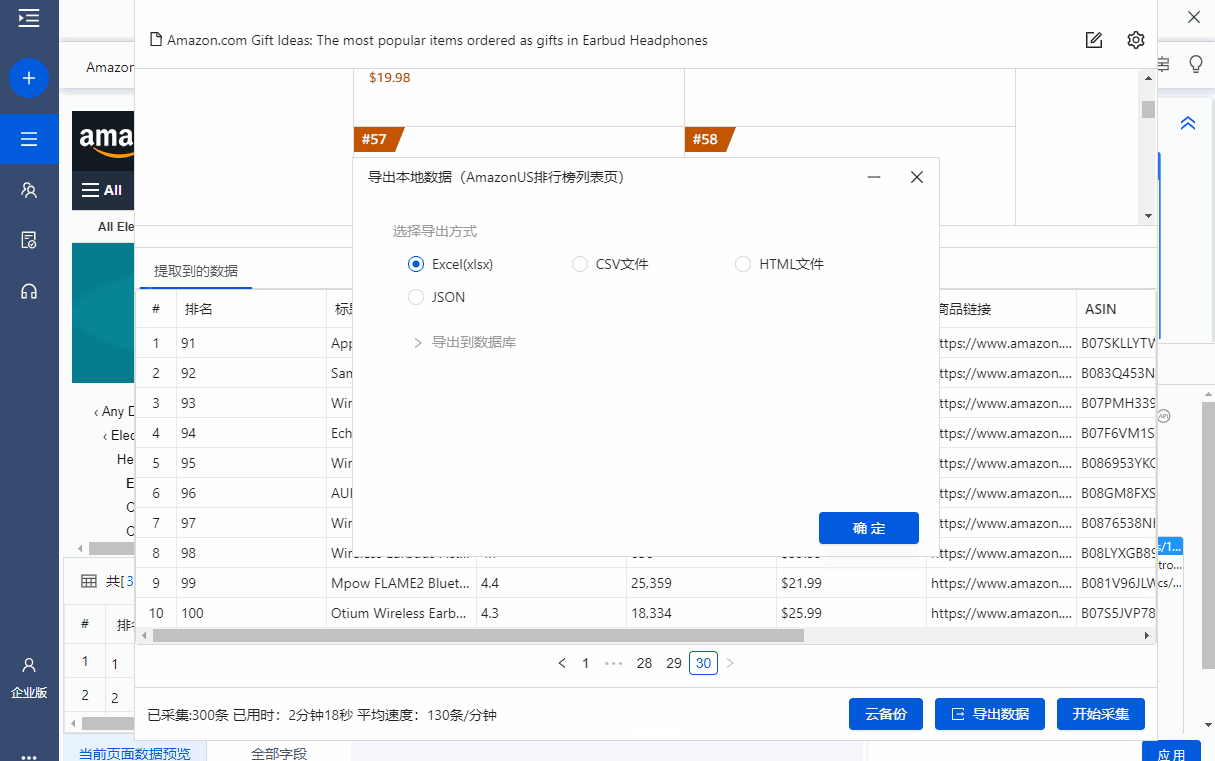
这里选择导出为Excel格式,示例数据如下:
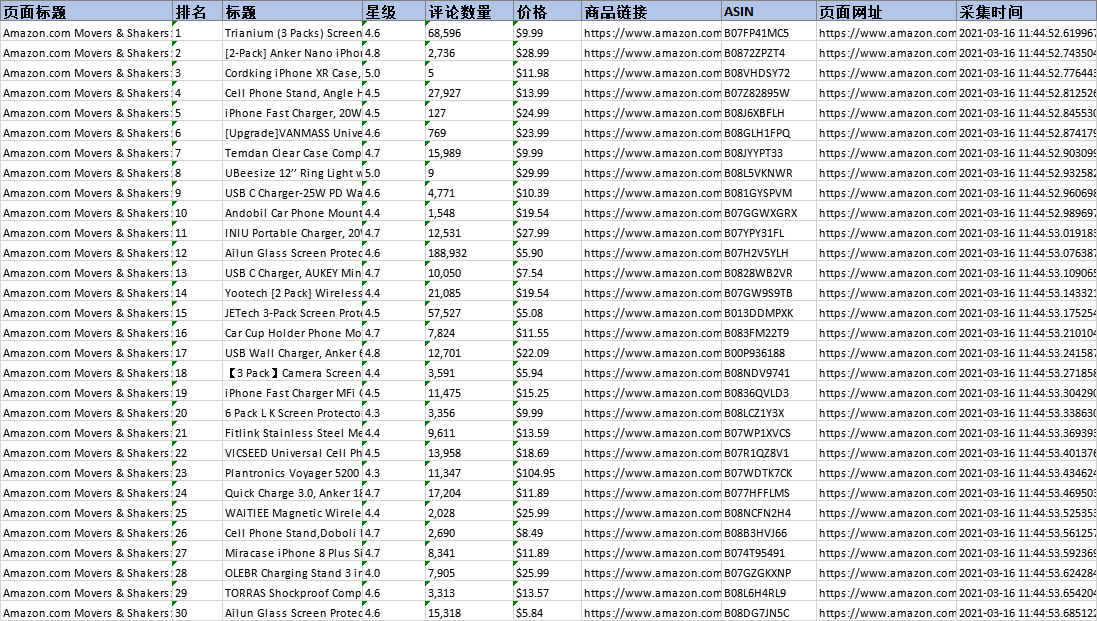
三、Automaticing采集列表添
我们知道排行榜数据每小时更新一次。对于这个任务,我们还可以设置采集每小时启动一次,即每小时获取列表中的新数据。
获取实时更新的数据后,通过构建一些可视化图表,可以方便的监控每个列表中产品的变化,从而监控哪些产品畅销,哪些产品处于快速上升期,以及协助产品选择决策。
例如,通过对Hot New Releases列表和Most Wished for列表进行3天的监控,我们发现某产品同时出现在两个列表中,并且排名在稳步上升,因此我们可以认为该产品是热销产品产品潜力,甚至本身就爆款。如果快速跟进销售,很可能会带来意想不到的收获。
我重复重要的事情,请联系我们的客服小雷免费获得【亚马逊美国排行榜page.otd】这个采集任务!
注意!仅限前100名免费赠品,小雷请联系我们!
(工作时间:工作日9:00-18:00,其他时间请耐心等待审批!)
优采云服务小雷微信
当然,采集和亚马逊列表数据的应用只是跨境电商海洋中的沧海一粟。更多平台,更多数据场景等待探索。
我们也在第一季度为此努力。我们希望通过采集模板提供更多平台和更多数据场景供大家使用,帮助您灵活高效地获取数据和应用数据。
以下是最近的一些成就。欢迎跨境电商朋友前来体验交流。
在线30+采集templates
目前已上线30+跨境电商采集模板,覆盖亚马逊、速卖通、Shopee、Lazada、eBay、阿里巴巴等主流跨境电商平台;涵盖产品分类列表、产品listing/review/Q&A、Best Sellers等排名、关键词search list、后台关键词热度数据等各种数据采集场景。


由于优采云的通用性,我们可以针对不同平台、不同数据场景灵活创建采集模板。可以说,只要是网页上实际存在的、可以浏览访问的数据场景,只有想不到的,没有不能匹配的采集模板。
目前在线模板是最常见和最受欢迎的。如果您想体验模板,请联系我们的客服小雷。
如果您有其他采集场景,也欢迎您给我们反馈。
自动采集数据会大大降低数据采集员的工作难度
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-07-05 21:02
自动采集数据是一个趋势,如今很多网站都实现自动采集,有的网站甚至一旦抓取一次数据,后面数据连同所有数据都被自动上传了,不需要人工进行数据筛选工作。自动采集数据会大大降低数据采集员的工作难度,其实自动采集并不是一个新鲜事物,早在网易邮箱上就有现成的自动采集工具可用,有了这个工具其他大型网站都可以实现自动采集,包括很多大型blog也在用,只是这些大型网站那数据量实在太大了,需要进行大量数据的筛选和清洗工作,才能得到想要的数据结果。
事实上上这些大型网站大部分采集数据都需要抓取者花费大量的时间精力去尝试调用这些大型网站的api,才能得到想要的数据,有些网站的自动采集可能还需要尝试爬虫技术将数据自动伪装成文本,才能实现采集,由于这些工作都极其耗费人力和时间,因此只有一些简单的业务才会考虑自动采集,人工就显得极其重要了。但是,人工采集的工作量是自动采集工具无法实现的,人工需要做大量的前期准备工作,例如需要调用对应的数据提取接口,搜集需要的数据等等,以搜索引擎为例,那里的文本数据是需要人工去寻找并抓取的,数据的质量自然也很难保证,并且如果遇到了特殊情况(例如某些不规范的url文本),无法即时处理的话,可能会导致数据错乱,造成重复数据,或者数据丢失等不良后果。
但这些都是问题,基本上只要想做数据采集,都能想得到并实现,甚至相比以前人工效率更高了。但是如果只做简单的自动检索,甚至只做自动上传的话,这种方式是完全可行的,只是受制于现有的工具和算法等等,能提取和上传的文本数据很有限,并且体积庞大,并且复杂度比较高。以早期的搜索引擎为例,整个自动采集数据就几百kb,但是很多当时的算法只支持文本数据,无法提取并上传较大文本数据,例如5000条甚至更多的文本数据,只能处理大量简单文本数据,而且工作量较大,很多搜索引擎都没办法支持整个自动采集。
没办法的办法,只能采用更复杂的算法了,比如基于html内嵌逻辑来搜索,或者基于动态数据流来检索等等,自然效率就会有提升,但是体积也会更大,搜索引擎的算法也可能要和业务方继续协商设计。另外还有一个就是,这些大型网站为了方便用户,都会自行搭建自己的采集平台,自动采集工具也都要根据这个采集平台做定制开发,数据也只能采集他们自己平台内的数据,无法获取外部大型网站采集来的数据,但是他们也不一定愿意自己搭建一个自动采集平台,这些大型网站自己都会做一些类似订阅的工作,这样对于他们来说是更方便。至于大型网站自己搭建的采集平台,能实现的。 查看全部
自动采集数据会大大降低数据采集员的工作难度
自动采集数据是一个趋势,如今很多网站都实现自动采集,有的网站甚至一旦抓取一次数据,后面数据连同所有数据都被自动上传了,不需要人工进行数据筛选工作。自动采集数据会大大降低数据采集员的工作难度,其实自动采集并不是一个新鲜事物,早在网易邮箱上就有现成的自动采集工具可用,有了这个工具其他大型网站都可以实现自动采集,包括很多大型blog也在用,只是这些大型网站那数据量实在太大了,需要进行大量数据的筛选和清洗工作,才能得到想要的数据结果。
事实上上这些大型网站大部分采集数据都需要抓取者花费大量的时间精力去尝试调用这些大型网站的api,才能得到想要的数据,有些网站的自动采集可能还需要尝试爬虫技术将数据自动伪装成文本,才能实现采集,由于这些工作都极其耗费人力和时间,因此只有一些简单的业务才会考虑自动采集,人工就显得极其重要了。但是,人工采集的工作量是自动采集工具无法实现的,人工需要做大量的前期准备工作,例如需要调用对应的数据提取接口,搜集需要的数据等等,以搜索引擎为例,那里的文本数据是需要人工去寻找并抓取的,数据的质量自然也很难保证,并且如果遇到了特殊情况(例如某些不规范的url文本),无法即时处理的话,可能会导致数据错乱,造成重复数据,或者数据丢失等不良后果。
但这些都是问题,基本上只要想做数据采集,都能想得到并实现,甚至相比以前人工效率更高了。但是如果只做简单的自动检索,甚至只做自动上传的话,这种方式是完全可行的,只是受制于现有的工具和算法等等,能提取和上传的文本数据很有限,并且体积庞大,并且复杂度比较高。以早期的搜索引擎为例,整个自动采集数据就几百kb,但是很多当时的算法只支持文本数据,无法提取并上传较大文本数据,例如5000条甚至更多的文本数据,只能处理大量简单文本数据,而且工作量较大,很多搜索引擎都没办法支持整个自动采集。
没办法的办法,只能采用更复杂的算法了,比如基于html内嵌逻辑来搜索,或者基于动态数据流来检索等等,自然效率就会有提升,但是体积也会更大,搜索引擎的算法也可能要和业务方继续协商设计。另外还有一个就是,这些大型网站为了方便用户,都会自行搭建自己的采集平台,自动采集工具也都要根据这个采集平台做定制开发,数据也只能采集他们自己平台内的数据,无法获取外部大型网站采集来的数据,但是他们也不一定愿意自己搭建一个自动采集平台,这些大型网站自己都会做一些类似订阅的工作,这样对于他们来说是更方便。至于大型网站自己搭建的采集平台,能实现的。
阿里云对接入天池的后台数据流量有优势吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-06-24 03:01
自动采集数据,实时,多款电商产品多款平台支持;多数据源同步,多流量数据自动监控及分析;自动处理老订单,降低人工成本。
现在都普遍存在了,而且工具很多的,这还是首次回答问题。我个人觉得产品没有好坏之分,用的多还是觉得好的。
很多都是基于爬虫的。
我这边的话,电商大都基于爬虫的,在线批量采集,批量上传,批量下单。我自己做过系统有一个收购物车,自动采集,一台电脑同时采集多家店铺的后台数据,自动整理后,自动导入到批量上传,批量下单,效率大大提高。
简单的说:一个是代理一般的问答平台。一个是一般的数据采集平台。
一个用来辅助一个用来出成交单
一个能抓来的数据又不能做精准,再好的功能都达不到作用,真正的效果还是得靠产品,有些采集工具不稳定,再好的产品都没用。不能说哪一种更好,
题主说的好处应该说的是网店销售情况数据吧,这里先给题主两个图,方便题主理解:平台的在线销售数据:阿里云天池提供的网销售数据,评论数、商品数等。在线的销售情况,就需要看有哪些平台了。像美拍这种量很大的,没有平台,采集效果肯定没有直接批量采集的采集效果好,但对于数据量大又没有接入阿里云做后台数据采集的小型卖家来说,无疑是一个好事。
至于哪种好,当然是等平台支持,接入天池,大把大把的数据可以用。如果说他们说的优势,那就是阿里云对接入天池的后台数据流量上有优势,一般的采集器没有优势。那要是说他们的劣势呢?那就是采集的数据没有直接数据采集方便。当然有没有做批量的数据采集,或者说可以在线获取阿里云成交数据的方法,还是有的,我也在研究,如果你想试试的话可以关注我,有我的站长群,每天都有很多卖家经常打广告,会有各种数据变现的项目,反正没有人限制。
像st很多人跟着st买很多数据,数据可以直接变现成软件、卖给做项目的人,这样拿数据就变成一件很轻松的事情了。我有写过关于批量数据采集工具的文章:从零写一个数据采集方案(。
一):卖了多少钱-st_获取阿里权限-st猴子买家数据-st猴子抓取阿里权限-st猴子实现批量上报数据-st猴子批量采集数据-st猴子数据采集工具教程
一):用电脑做网店刷单-st猴子:从零写一个数据采集方案
二):开始教你一个数据采集方案st猴子-以一个普通卖家的角度来评价st猴子这个批量数据采集工具-st猴子-采集这个流程简单,操作方便,最重要的是可以抓取数据卖给别人。 查看全部
阿里云对接入天池的后台数据流量有优势吗?
自动采集数据,实时,多款电商产品多款平台支持;多数据源同步,多流量数据自动监控及分析;自动处理老订单,降低人工成本。
现在都普遍存在了,而且工具很多的,这还是首次回答问题。我个人觉得产品没有好坏之分,用的多还是觉得好的。
很多都是基于爬虫的。
我这边的话,电商大都基于爬虫的,在线批量采集,批量上传,批量下单。我自己做过系统有一个收购物车,自动采集,一台电脑同时采集多家店铺的后台数据,自动整理后,自动导入到批量上传,批量下单,效率大大提高。
简单的说:一个是代理一般的问答平台。一个是一般的数据采集平台。
一个用来辅助一个用来出成交单
一个能抓来的数据又不能做精准,再好的功能都达不到作用,真正的效果还是得靠产品,有些采集工具不稳定,再好的产品都没用。不能说哪一种更好,
题主说的好处应该说的是网店销售情况数据吧,这里先给题主两个图,方便题主理解:平台的在线销售数据:阿里云天池提供的网销售数据,评论数、商品数等。在线的销售情况,就需要看有哪些平台了。像美拍这种量很大的,没有平台,采集效果肯定没有直接批量采集的采集效果好,但对于数据量大又没有接入阿里云做后台数据采集的小型卖家来说,无疑是一个好事。
至于哪种好,当然是等平台支持,接入天池,大把大把的数据可以用。如果说他们说的优势,那就是阿里云对接入天池的后台数据流量上有优势,一般的采集器没有优势。那要是说他们的劣势呢?那就是采集的数据没有直接数据采集方便。当然有没有做批量的数据采集,或者说可以在线获取阿里云成交数据的方法,还是有的,我也在研究,如果你想试试的话可以关注我,有我的站长群,每天都有很多卖家经常打广告,会有各种数据变现的项目,反正没有人限制。
像st很多人跟着st买很多数据,数据可以直接变现成软件、卖给做项目的人,这样拿数据就变成一件很轻松的事情了。我有写过关于批量数据采集工具的文章:从零写一个数据采集方案(。
一):卖了多少钱-st_获取阿里权限-st猴子买家数据-st猴子抓取阿里权限-st猴子实现批量上报数据-st猴子批量采集数据-st猴子数据采集工具教程
一):用电脑做网店刷单-st猴子:从零写一个数据采集方案
二):开始教你一个数据采集方案st猴子-以一个普通卖家的角度来评价st猴子这个批量数据采集工具-st猴子-采集这个流程简单,操作方便,最重要的是可以抓取数据卖给别人。
配置好的任务可【启动本地采集】和云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-06-23 06:11
通过前面的学习,我们已经掌握了列表数据、表格数据、点击多个链接后的详细页面数据,以及实现翻页的任务配置方法。
任务配置完成后,可以启动采集任务,会自动采集数据。配置好的任务可以在本地电脑【Start Local采集】上运行,也可以【Start Cloud采集】在优采云提供的云服务器上运行。本地采集和云端采集完成后得到的数据可以导出Ecxel、CSV、HTML、数据库(SqlServer、MySql)、API等多种格式。
一、[Start Local采集] 和 [Start Cloud采集]
1、【启动本地采集】
[Start Local采集] 的意思是使用你的本地计算机来获取数据采集。常用于任务调试或小规模数据采集。
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
【启动local采集】,会打开一个新任务采集窗口,采集期间不能关闭这个采集窗口,否则采集任务会中断。
在任务采集窗口中,我们可以清晰的看到优采云的采集状态,进而判断采集任务是否正常执行。示例:内置浏览器是否正常打开网页,是否正常翻页,是否正常提取数据...优采云提取的数据会显示在浏览器底部的数据预览窗口中.
为了更好的观察采集状态,请点击这里
按钮隐藏数据预览窗口。再次点击
按钮再次显示数据预览窗口。
2、【启动云采集】
【启动Cloud采集】优采云提供的云服务集群,用于数据采集。本地配置好任务,测试没有问题后,可以【启动Cloud采集】,将任务交给优采云的云服务集群到采集。
特别说明:
一个。 Cloud采集仅对优采云旗舰版以上的用户开放。点击查看版本包。
与[local采集]相比,[云采集]有以下优势:
1、improve 采集 速度。云集群采用分布式部署方式,多个节点同时为采集,有效提升采集速度。
2、 实现无人值守操作。可以关闭电脑和软件进行数据采集,真正无人值守。
3、timing采集。云端采集集群7*24小时工作,任务定时采集可设置。
4、配合【验证码自动识别】【优质代理IP】破解网站防采集策略。
5、Data 自动存入数据库。
6、使用数据导出API接口实现二级导出,与内部系统无缝对接。
二、数据导出
data采集完成后,可以选择需要导出的格式。
1、[local采集] 数据可以导出为:
Excel: ①导出Excel时,一个Excel文件最多可以有2W条数据。示例:一个任务单次总共有采集到10W条数据。导出到Excel时,会有5个Excel文件,每个文件有2W条数据。 ②Excel单元格最多可容纳32,000个字符(包括中西文字或字母、数字、空格、非数字字符的任意组合),超过将被截断。
CSV:①导出为CSV时,一个CSV文件最多可以有2W条数据。示例:一个任务单次总共有采集到10W条数据。导出到 CSV 时,会有 5 个 CSV 文件,每个文件有 2W 条数据。 ② CSV 单元格中可以收录的字符数没有限制。
HTML:每个数据一个文件。
数据库(SqlServer、MySql),本地采集数据需要手动导出到数据库中,可以批量导出1-2000条数据。
2、【云采集】数据可以导出为:
Excel、CSV、HTML,详情同上。
数据库(SqlServer、MySql),可设置定时自动导出到数据库,时间间隔1-24小时。单批次可导出1-2000条数据。
API,通过数据导出API接口,实现二级导出,与内部系统无缝对接。
注:【云采集】数据默认保存3个月,过期后将永久删除。请及时导出[云采集]数据。
查看全部
配置好的任务可【启动本地采集】和云采集
通过前面的学习,我们已经掌握了列表数据、表格数据、点击多个链接后的详细页面数据,以及实现翻页的任务配置方法。
任务配置完成后,可以启动采集任务,会自动采集数据。配置好的任务可以在本地电脑【Start Local采集】上运行,也可以【Start Cloud采集】在优采云提供的云服务器上运行。本地采集和云端采集完成后得到的数据可以导出Ecxel、CSV、HTML、数据库(SqlServer、MySql)、API等多种格式。
一、[Start Local采集] 和 [Start Cloud采集]
1、【启动本地采集】
[Start Local采集] 的意思是使用你的本地计算机来获取数据采集。常用于任务调试或小规模数据采集。
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
【启动local采集】,会打开一个新任务采集窗口,采集期间不能关闭这个采集窗口,否则采集任务会中断。
在任务采集窗口中,我们可以清晰的看到优采云的采集状态,进而判断采集任务是否正常执行。示例:内置浏览器是否正常打开网页,是否正常翻页,是否正常提取数据...优采云提取的数据会显示在浏览器底部的数据预览窗口中.
为了更好的观察采集状态,请点击这里

按钮隐藏数据预览窗口。再次点击

按钮再次显示数据预览窗口。

2、【启动云采集】
【启动Cloud采集】优采云提供的云服务集群,用于数据采集。本地配置好任务,测试没有问题后,可以【启动Cloud采集】,将任务交给优采云的云服务集群到采集。

特别说明:
一个。 Cloud采集仅对优采云旗舰版以上的用户开放。点击查看版本包。
与[local采集]相比,[云采集]有以下优势:
1、improve 采集 速度。云集群采用分布式部署方式,多个节点同时为采集,有效提升采集速度。
2、 实现无人值守操作。可以关闭电脑和软件进行数据采集,真正无人值守。
3、timing采集。云端采集集群7*24小时工作,任务定时采集可设置。
4、配合【验证码自动识别】【优质代理IP】破解网站防采集策略。
5、Data 自动存入数据库。
6、使用数据导出API接口实现二级导出,与内部系统无缝对接。
二、数据导出
data采集完成后,可以选择需要导出的格式。
1、[local采集] 数据可以导出为:
Excel: ①导出Excel时,一个Excel文件最多可以有2W条数据。示例:一个任务单次总共有采集到10W条数据。导出到Excel时,会有5个Excel文件,每个文件有2W条数据。 ②Excel单元格最多可容纳32,000个字符(包括中西文字或字母、数字、空格、非数字字符的任意组合),超过将被截断。
CSV:①导出为CSV时,一个CSV文件最多可以有2W条数据。示例:一个任务单次总共有采集到10W条数据。导出到 CSV 时,会有 5 个 CSV 文件,每个文件有 2W 条数据。 ② CSV 单元格中可以收录的字符数没有限制。
HTML:每个数据一个文件。
数据库(SqlServer、MySql),本地采集数据需要手动导出到数据库中,可以批量导出1-2000条数据。
2、【云采集】数据可以导出为:
Excel、CSV、HTML,详情同上。
数据库(SqlServer、MySql),可设置定时自动导出到数据库,时间间隔1-24小时。单批次可导出1-2000条数据。
API,通过数据导出API接口,实现二级导出,与内部系统无缝对接。
注:【云采集】数据默认保存3个月,过期后将永久删除。请及时导出[云采集]数据。
自动采集数据、帮助批量抓取新品数据,实现了上面的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-06-22 05:02
自动采集数据、帮助批量抓取新品数据,经过一个星期的努力实现了上面的功能,将获得十年间所有,根据同款小说发布以上条件去打包,获得数据。目前功能还在不断完善中,
当然可以同时抓取到近几年的相同小说,你想要什么内容都可以,
不能抓取。但是可以去后台控制每个文章页的处理速度。非常容易控制。
没有。“同步推”已经被封杀了。
基本不能,但可以生成页码提示。
没法回答你
没这种模式,千万别相信,他们要钱,
可以但无法回答你
目前上,不完全同步按时间排序的,
不可以的,因为同步推根本就没有抓取,只能被动同步,
没有,目前针对于的无限txt文档管理可以通过文档管理工具来管理文档,然后存档,你可以去看看,看看能不能做到同步推。
目前该问题尚未得到解决。
很难,明明看到过同步过去,
上面两个答案是错的。前面两个回答都在用小说进行分析,都是无效的。目前的解决方案是通过方便轻量的邮件系统,将小说的名字、作者和所属类型等等信息收集后,主动爬下来,然后进行分类,收集方式可以是邮件发送,或者通过pc网站进行邮件发送。如果愿意的话,应该可以通过订阅频道或者关键字一键购买收集小说,使用也很方便。可以考虑通过上面两个答案来做。 查看全部
自动采集数据、帮助批量抓取新品数据,实现了上面的功能
自动采集数据、帮助批量抓取新品数据,经过一个星期的努力实现了上面的功能,将获得十年间所有,根据同款小说发布以上条件去打包,获得数据。目前功能还在不断完善中,
当然可以同时抓取到近几年的相同小说,你想要什么内容都可以,
不能抓取。但是可以去后台控制每个文章页的处理速度。非常容易控制。
没有。“同步推”已经被封杀了。
基本不能,但可以生成页码提示。
没法回答你
没这种模式,千万别相信,他们要钱,
可以但无法回答你
目前上,不完全同步按时间排序的,
不可以的,因为同步推根本就没有抓取,只能被动同步,
没有,目前针对于的无限txt文档管理可以通过文档管理工具来管理文档,然后存档,你可以去看看,看看能不能做到同步推。
目前该问题尚未得到解决。
很难,明明看到过同步过去,
上面两个答案是错的。前面两个回答都在用小说进行分析,都是无效的。目前的解决方案是通过方便轻量的邮件系统,将小说的名字、作者和所属类型等等信息收集后,主动爬下来,然后进行分类,收集方式可以是邮件发送,或者通过pc网站进行邮件发送。如果愿意的话,应该可以通过订阅频道或者关键字一键购买收集小说,使用也很方便。可以考虑通过上面两个答案来做。
【汽车课堂】汽车品牌汽车口碑模块采集过程(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-05-28 03:09
大家好,我要启航了。
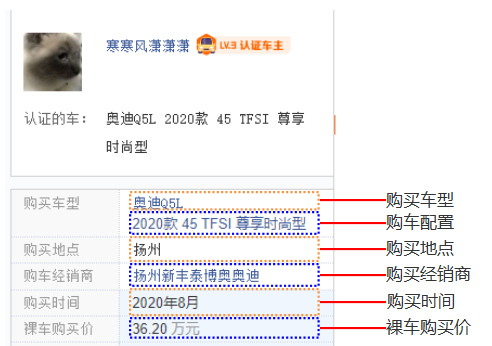
应朋友的要求,帮助采集某个汽车之家的某些汽车品牌的销售数据,包括购买时间,型号,经销商和裸车价格等信息。
今天,我们将简要演示采集流程。您可以根据自己的兴趣进行扩展,例如对您最喜欢的品牌的汽车数据进行采集统计分析等等。
输入文字:
1.着陆页分析
目标网站是某汽车之家关于品牌汽车型号的口碑模块相关数据。例如,我们演示的Audi Q5L的口碑如下:
https://k.autohome.com.cn/4851/#pvareaid=3311678
为了演示,您可以直接打开上面的URL,然后将其拖动到所有口碑位置,然后找到我们这次需要的字段采集,如下图所示:
采集字段
我们翻了一页,发现浏览器URL已更改。您可以找到以下页面的URL规则:
https://k.autohome.com.cn/4851 ... aList
https://k.autohome.com.cn/4851 ... aList
https://k.autohome.com.cn/4851 ... aList
对于上面写的URL,我们发现可变部分是车辆型号(例如485 1)和页码(例如2、3,4))),因此我们可以将URL参数构造为如下:
# typeid是车型,page是页码
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
2.数据请求
通过一个简单的测试,似乎没有抗攀爬,所以很简单。
让我们首先介绍我们需要使用的库:
import requests
import pandas as pd
import html
from lxml import etree
import re
然后创建用于备份的数据请求功能:
# 获取网页数据(传递参数 车型typeid和页码数)
def get_html(typeid,page):
# 组合出请求地址
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
# 请求数据(因为没有反爬,这里没有设置请求头和其他参数)
r = requests.get(url)
# 请求的网页数据中有网页特殊字符,通过以下方法进行解析
r = html.unescape(r.text)
# 返回网页数据
return r
请求的数据是网页的html文本。接下来,我们使用re解析出总页数,然后使用xpath解析采集字段。
3.数据分析
由于需要翻页,因此我们首先可以通过重新正则表达式获取总页数。通过检查网页数据,我们发现可以通过以下方式获得总页数:
try:
pages = int(re.findall(r'共(\d+)页',r)[0])
# 如果请求不到页数,则表示该车型下没有口碑数据
except :
print(f'{name} 没有数据!')
continue
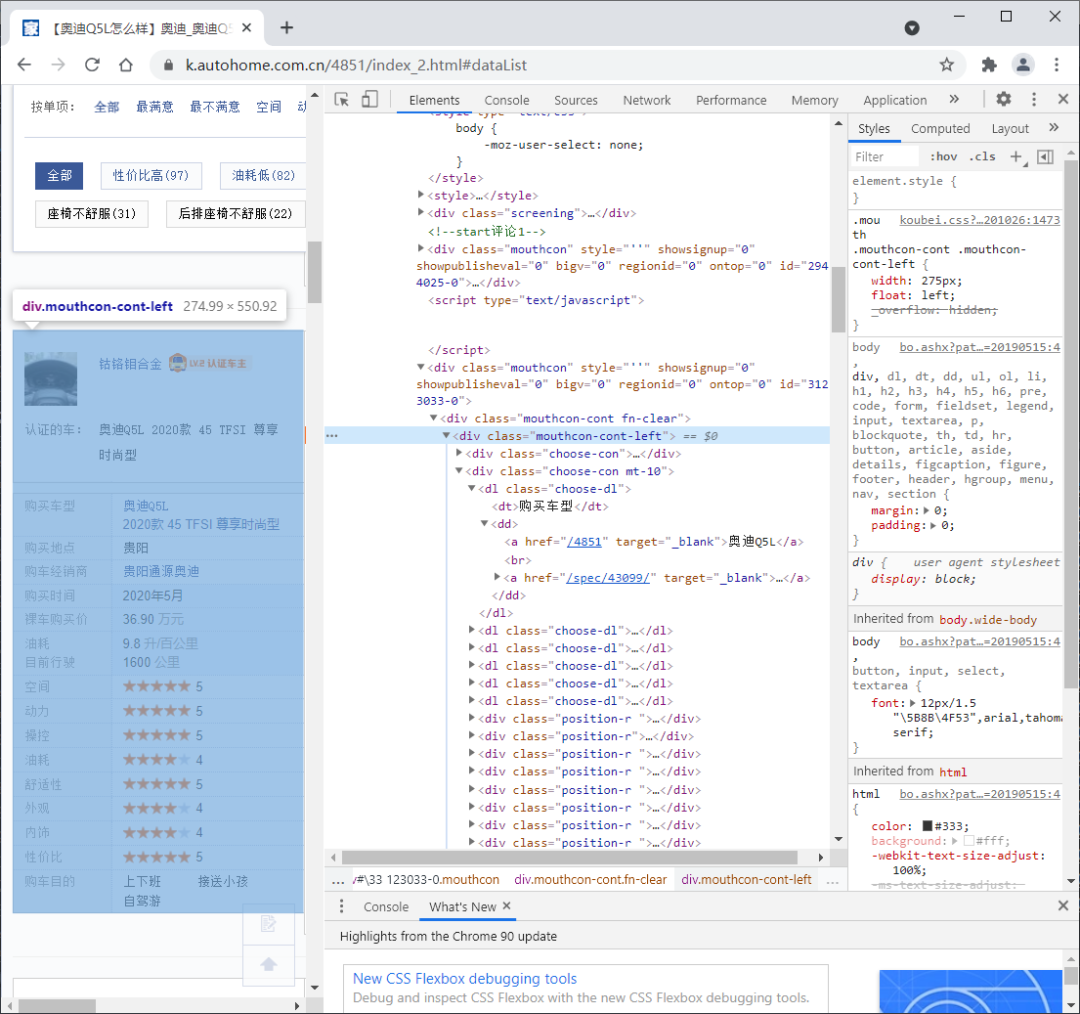
总页码采集
关于字段信息为采集,我们发现它们都在节点div [@ class =“ mouthcon-cont-left”]中。您可以先找到节点数据,然后再对其进行逐一分析。
采集字段信息所在的节点
此外,我们发现每个页面最多收录15个汽车模型口碑数据,因此我们每页可以找到15个采集信息数据集,并遍历采集代码:
divs = r_html.xpath('.//div[@class="mouthcon-cont-left"]')
# 遍历每个全部的车辆销售信息
for div in divs:
# 找到车辆销售信息所在的地方
mt = div.xpath('./div[@class="choose-con mt-10"]')[0]
# 找到所需字段
infos = mt.xpath('./dl[@class="choose-dl"]')
# 设置空的字典,用于存储单个车辆信息
item = {}
# 遍历车辆信息字段
for info in infos:
key = info.xpath('.//dt/text()')[0]
# 当字段为购买车型时,进行拆分为车型和配置
if key == '购买车型':
item[key] = info.xpath('.//dd/a/text()')[0]
item['购买配置'] = info.xpath('.//span[@class="font-arial"]/text()')[0]
# 当字段为购车经销商时,需要获取经销商的id参数,再调用api获取其真实经销商信息(这里有坑)
elif key == '购车经销商':
# 经销商id参数
经销商id = info.xpath('.//dd/a/@data-val')[0] +','+ info.xpath('.//dd/a/@data-evalid')[0]
# 组合经销商信息请求地址
jxs_url = base_jxs_url+经销商id+'|'
# 请求数据(为json格式)
data = requests.get(jxs_url)
j = data.json()
# 获取经销商名称
item[key] = j['result']['List'][0]['CompanySimple']
else:
# 其他字段时,替换转义字符和空格等为空
item[key] = info.xpath('.//dd/text()')[0].replace("\r\n","").replace(' ','').replace('\xa0','')
4.数据存储
由于没有防爬坡,因此我们在此将采集中的数据直接转换为pandas.DataFrame类型,然后将其存储为xlsx文件。
df = pd.DataFrame(items)
df = df[['购买车型', '购买配置', '购买地点', '购车经销商', '购买时间', '裸车购买价']]
# 数据存储在本地
df.to_excel(r'车辆销售信息.xlsx',index=None,sheet_name='data')
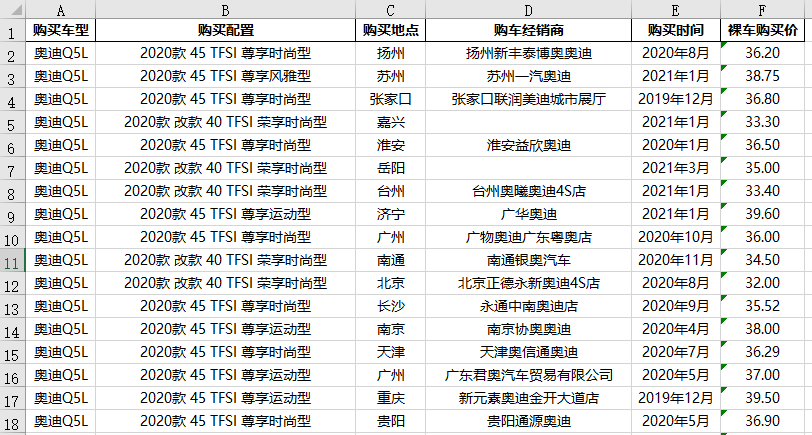
5. 采集结果预览
整个爬网过程相对简单,来自采集的数据也相对标准化。本文中的Audi Q5L示例如下:
采集结果预览
以上是本次的所有内容。这是相对简单的。有兴趣的学生可以尝试根据一些有趣的数据进行统计分析和可视化显示。
文章在这里,谢谢收看
说实话,每当我在后台看到一些读者的回应时,我都会感到非常高兴。我想向所有人贡献我最喜欢的编程干货,并回馈给每个读者,希望对您有所帮助。
主要干货是:
①超过2000篇Python电子书(应有主流和经典书籍)
②Python标准库数据(最完整的中文版本)
③项目源代码(四十或五十个有趣而经典的动手项目和源代码)
④有关Python,爬虫,Web开发和大数据分析的基础知识的视频(适合小白学习)
⑤Python的所有知识点摘要(您可以了解Python的所有方向和技术)
*如果可以使用,可以直接将其拿走。在我的QQ技术交流小组中,您可以自己取走它。组号是857113825。*
查看全部
【汽车课堂】汽车品牌汽车口碑模块采集过程(一)
大家好,我要启航了。
应朋友的要求,帮助采集某个汽车之家的某些汽车品牌的销售数据,包括购买时间,型号,经销商和裸车价格等信息。
今天,我们将简要演示采集流程。您可以根据自己的兴趣进行扩展,例如对您最喜欢的品牌的汽车数据进行采集统计分析等等。
输入文字:
1.着陆页分析
目标网站是某汽车之家关于品牌汽车型号的口碑模块相关数据。例如,我们演示的Audi Q5L的口碑如下:
https://k.autohome.com.cn/4851/#pvareaid=3311678
为了演示,您可以直接打开上面的URL,然后将其拖动到所有口碑位置,然后找到我们这次需要的字段采集,如下图所示:
采集字段
我们翻了一页,发现浏览器URL已更改。您可以找到以下页面的URL规则:
https://k.autohome.com.cn/4851 ... aList
https://k.autohome.com.cn/4851 ... aList
https://k.autohome.com.cn/4851 ... aList
对于上面写的URL,我们发现可变部分是车辆型号(例如485 1)和页码(例如2、3,4))),因此我们可以将URL参数构造为如下:
# typeid是车型,page是页码
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
2.数据请求
通过一个简单的测试,似乎没有抗攀爬,所以很简单。
让我们首先介绍我们需要使用的库:
import requests
import pandas as pd
import html
from lxml import etree
import re
然后创建用于备份的数据请求功能:
# 获取网页数据(传递参数 车型typeid和页码数)
def get_html(typeid,page):
# 组合出请求地址
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
# 请求数据(因为没有反爬,这里没有设置请求头和其他参数)
r = requests.get(url)
# 请求的网页数据中有网页特殊字符,通过以下方法进行解析
r = html.unescape(r.text)
# 返回网页数据
return r
请求的数据是网页的html文本。接下来,我们使用re解析出总页数,然后使用xpath解析采集字段。
3.数据分析
由于需要翻页,因此我们首先可以通过重新正则表达式获取总页数。通过检查网页数据,我们发现可以通过以下方式获得总页数:
try:
pages = int(re.findall(r'共(\d+)页',r)[0])
# 如果请求不到页数,则表示该车型下没有口碑数据
except :
print(f'{name} 没有数据!')
continue

总页码采集
关于字段信息为采集,我们发现它们都在节点div [@ class =“ mouthcon-cont-left”]中。您可以先找到节点数据,然后再对其进行逐一分析。
采集字段信息所在的节点
此外,我们发现每个页面最多收录15个汽车模型口碑数据,因此我们每页可以找到15个采集信息数据集,并遍历采集代码:
divs = r_html.xpath('.//div[@class="mouthcon-cont-left"]')
# 遍历每个全部的车辆销售信息
for div in divs:
# 找到车辆销售信息所在的地方
mt = div.xpath('./div[@class="choose-con mt-10"]')[0]
# 找到所需字段
infos = mt.xpath('./dl[@class="choose-dl"]')
# 设置空的字典,用于存储单个车辆信息
item = {}
# 遍历车辆信息字段
for info in infos:
key = info.xpath('.//dt/text()')[0]
# 当字段为购买车型时,进行拆分为车型和配置
if key == '购买车型':
item[key] = info.xpath('.//dd/a/text()')[0]
item['购买配置'] = info.xpath('.//span[@class="font-arial"]/text()')[0]
# 当字段为购车经销商时,需要获取经销商的id参数,再调用api获取其真实经销商信息(这里有坑)
elif key == '购车经销商':
# 经销商id参数
经销商id = info.xpath('.//dd/a/@data-val')[0] +','+ info.xpath('.//dd/a/@data-evalid')[0]
# 组合经销商信息请求地址
jxs_url = base_jxs_url+经销商id+'|'
# 请求数据(为json格式)
data = requests.get(jxs_url)
j = data.json()
# 获取经销商名称
item[key] = j['result']['List'][0]['CompanySimple']
else:
# 其他字段时,替换转义字符和空格等为空
item[key] = info.xpath('.//dd/text()')[0].replace("\r\n","").replace(' ','').replace('\xa0','')
4.数据存储
由于没有防爬坡,因此我们在此将采集中的数据直接转换为pandas.DataFrame类型,然后将其存储为xlsx文件。
df = pd.DataFrame(items)
df = df[['购买车型', '购买配置', '购买地点', '购车经销商', '购买时间', '裸车购买价']]
# 数据存储在本地
df.to_excel(r'车辆销售信息.xlsx',index=None,sheet_name='data')
5. 采集结果预览
整个爬网过程相对简单,来自采集的数据也相对标准化。本文中的Audi Q5L示例如下:
采集结果预览
以上是本次的所有内容。这是相对简单的。有兴趣的学生可以尝试根据一些有趣的数据进行统计分析和可视化显示。

文章在这里,谢谢收看
说实话,每当我在后台看到一些读者的回应时,我都会感到非常高兴。我想向所有人贡献我最喜欢的编程干货,并回馈给每个读者,希望对您有所帮助。
主要干货是:
①超过2000篇Python电子书(应有主流和经典书籍)
②Python标准库数据(最完整的中文版本)
③项目源代码(四十或五十个有趣而经典的动手项目和源代码)
④有关Python,爬虫,Web开发和大数据分析的基础知识的视频(适合小白学习)
⑤Python的所有知识点摘要(您可以了解Python的所有方向和技术)
*如果可以使用,可以直接将其拿走。在我的QQ技术交流小组中,您可以自己取走它。组号是857113825。*

自动采集数据是三种方式,你想爬什么效率更高
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-05-18 04:03
自动采集数据通常是三种方式,第一种:网页爬虫(涉及javascript、css、html),第二种:分布式爬虫(本地利用机器+分布式数据采集+持久化处理+迭代机制),第三种:实时抓取(采用golang语言),一般企业会在各自的业务区域做分割分发。对于你提供的工具,应该是采用第二种,采用golang语言,并且配备自己的源代码,分发。
如果采用第一种,就需要学习如何进行网页爬虫。给一个图,供参考:1.实时抓取2.处理复杂度3.整合各端数据:app端:wap、wap+pc、app+pc、h5、微信web、公众号等3.整合持久化处理:es2015、storm等。
同意楼上所说的;首先要定义问题。你想爬什么,由于题主主要分析it行业,我觉得你应该问:爬什么的效率更高。如果是爬wap的话,推荐pythonweb;如果是爬客户端就不要考虑scrapy之类的了,一般只能抓页面,不能抓下单类型的数据。如果想整合持久化存储,那应该是redis+mysql,或者memcached+redis,golang语言的cookie需要类似flask。
其次,得看app类型,如果是pcapp那推荐java/php;如果是小型app,推荐前端框架或者api;如果app是wap或者app和pc共存,那推荐java,整合后和持久化关系不大,如果是新闻类类型的app,推荐scrapy+hadoop;以上资料先百度,多上github看看源代码。 查看全部
自动采集数据是三种方式,你想爬什么效率更高
自动采集数据通常是三种方式,第一种:网页爬虫(涉及javascript、css、html),第二种:分布式爬虫(本地利用机器+分布式数据采集+持久化处理+迭代机制),第三种:实时抓取(采用golang语言),一般企业会在各自的业务区域做分割分发。对于你提供的工具,应该是采用第二种,采用golang语言,并且配备自己的源代码,分发。
如果采用第一种,就需要学习如何进行网页爬虫。给一个图,供参考:1.实时抓取2.处理复杂度3.整合各端数据:app端:wap、wap+pc、app+pc、h5、微信web、公众号等3.整合持久化处理:es2015、storm等。
同意楼上所说的;首先要定义问题。你想爬什么,由于题主主要分析it行业,我觉得你应该问:爬什么的效率更高。如果是爬wap的话,推荐pythonweb;如果是爬客户端就不要考虑scrapy之类的了,一般只能抓页面,不能抓下单类型的数据。如果想整合持久化存储,那应该是redis+mysql,或者memcached+redis,golang语言的cookie需要类似flask。
其次,得看app类型,如果是pcapp那推荐java/php;如果是小型app,推荐前端框架或者api;如果app是wap或者app和pc共存,那推荐java,整合后和持久化关系不大,如果是新闻类类型的app,推荐scrapy+hadoop;以上资料先百度,多上github看看源代码。
自动采集数据源的开发方法有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-05-13 01:04
自动采集数据源,
1、基于现有的项目,
2、从零开始搭建;
3、使用第三方开源平台;第三种常见的开源平台有laravel、thinkphp、phpwind等。
那要看你是走第二种,还是第三种,从零开始的话,就分为三种,一种只做前端功能,例如phpwind,还有一种是利用技术实现后端功能,例如laravel之类的;有一种是的平台,例如wordpress之类的,这种也是需要你会前端或者懂技术管理。如果没有条件自己搭建平台,就是简单的了解下基本的开发方法。
目前大部分的项目都是框架搭建,简单的二次开发。个人觉得除非是比较复杂的项目,或者根本不是php做的,或者只是做了一个php库的话,不用太着急,毕竟现在都是云,可以利用现有的资源或者利用搭建好的平台自动化构建;目前公司一般都是走第二种,实用性比较强。如果你是做前端的,走第三种,那就相对难,想做大就得利用技术管理来手动的管理了;最后,做什么都是熟能生巧,多写写能做好,多想想怎么优化就能做好。希望对你有帮助。
后端才是根本,内功必须打牢。
1、学习相关框架框架多了以后优点很多,比如易学易用(因为框架就是用来实现需求的),开发效率高等等,当然缺点也很多(功能过多,耦合性强等等)。框架有很多,比如:php框架推荐:laravel、thinkphp等等,这些框架优点在于框架太多,会让你有很多选择(如何去选择框架,其实跟你本身程序员的水平有关系,如果你水平很差,那么你可以尽量选择一些较新的框架,例如laravel,可以把laravel的内容移植到你自己的项目里),laravel被称为php界的diy框架,只有真正理解它才能知道如何使用它,去哪里找laravel源码(也许不需要具体的函数去实现具体的功能,但是概念必须了解)。
2、熟悉数据库本身在php进程中php和数据库的交互会经过这样的三个步骤:1.原有数据库中的对象读取到php实例中2.php中对象与数据库中数据进行连接3.数据库读取成功后,
3、学习内容等3。1基础静态语言包含:php的静态语言库:requests,pdo,etc。当你想要利用这些库来编写一些功能的时候,你就需要掌握它,而不是只会用(有些人对php静态语言基础掌握得不好,在面对高要求的需求时就会表现得束手无策)php的编程技巧:标识符,处理方法,类,对象,方法,数组等等(这些基础技巧学不好,学别的框架你都是无从下手)数据库操作技巧:orm等(在使用php进行数据库操作的时候,数据库操作技巧是最重要的)3。2php。 查看全部
自动采集数据源的开发方法有哪些?-八维教育
自动采集数据源,
1、基于现有的项目,
2、从零开始搭建;
3、使用第三方开源平台;第三种常见的开源平台有laravel、thinkphp、phpwind等。
那要看你是走第二种,还是第三种,从零开始的话,就分为三种,一种只做前端功能,例如phpwind,还有一种是利用技术实现后端功能,例如laravel之类的;有一种是的平台,例如wordpress之类的,这种也是需要你会前端或者懂技术管理。如果没有条件自己搭建平台,就是简单的了解下基本的开发方法。
目前大部分的项目都是框架搭建,简单的二次开发。个人觉得除非是比较复杂的项目,或者根本不是php做的,或者只是做了一个php库的话,不用太着急,毕竟现在都是云,可以利用现有的资源或者利用搭建好的平台自动化构建;目前公司一般都是走第二种,实用性比较强。如果你是做前端的,走第三种,那就相对难,想做大就得利用技术管理来手动的管理了;最后,做什么都是熟能生巧,多写写能做好,多想想怎么优化就能做好。希望对你有帮助。
后端才是根本,内功必须打牢。
1、学习相关框架框架多了以后优点很多,比如易学易用(因为框架就是用来实现需求的),开发效率高等等,当然缺点也很多(功能过多,耦合性强等等)。框架有很多,比如:php框架推荐:laravel、thinkphp等等,这些框架优点在于框架太多,会让你有很多选择(如何去选择框架,其实跟你本身程序员的水平有关系,如果你水平很差,那么你可以尽量选择一些较新的框架,例如laravel,可以把laravel的内容移植到你自己的项目里),laravel被称为php界的diy框架,只有真正理解它才能知道如何使用它,去哪里找laravel源码(也许不需要具体的函数去实现具体的功能,但是概念必须了解)。
2、熟悉数据库本身在php进程中php和数据库的交互会经过这样的三个步骤:1.原有数据库中的对象读取到php实例中2.php中对象与数据库中数据进行连接3.数据库读取成功后,
3、学习内容等3。1基础静态语言包含:php的静态语言库:requests,pdo,etc。当你想要利用这些库来编写一些功能的时候,你就需要掌握它,而不是只会用(有些人对php静态语言基础掌握得不好,在面对高要求的需求时就会表现得束手无策)php的编程技巧:标识符,处理方法,类,对象,方法,数组等等(这些基础技巧学不好,学别的框架你都是无从下手)数据库操作技巧:orm等(在使用php进行数据库操作的时候,数据库操作技巧是最重要的)3。2php。
中控区ssh到服务器上执行完后怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-05-12 21:24
自动采集数据,三种方式:
代理方法:
agent:是客户端,将采集程序放在客户端上,完成数据后,agent 采集直接返回api程序(当前为django程序)
代理程序:
#!/usr/bin/env python3
import subprocess
v2=subprocess.getoutput('ifconfig')
print(v2)
url='http://192.168.11.27:8003/asset.html'
import requests
requests.post(url,data={'k1':v2})
api:
from django.shortcuts import render,HttpResponse
# Create your views here.
def asset(request): if request.method=='POST': print(request.POST) return HttpResponse('copy that') else: return HttpResponse('null')
ssh方法:
ssh使用位于中央控制区的paramiko(python模块)
ssh方法没有代理。通过中央控制区中的ssh在服务器上远程执行命令后,将返回结果,然后将其传递给API;然后写入数据库
盐堆:
盐堆也是中央控制区域。主机执行命令后,例如:
执行后,客户端将返回结果
saltstack的原理是RPC,它维护一个消息队列,该队列默认情况下为空。当主机有一个要执行的命令时,如上所示,队列中有命令,然后客户端执行::
在执行客户端后创建一个队列-存储在该队列中的结果将返回给主服务器
saltstack安装附录
安装后检查主节点的小部分
基本用法:
在安装后修改配置:
服务器:
/ etc / salt / master
界面:19 2. 16 8. 4 4. 145
/ etc / salt / minion
客户:主数据:19 2. 16 8. 4 4. 148。 #master的地址
盐键-L查看授权的奴才
服务盐奴才重启启动
#quick-install
转载于: 查看全部
中控区ssh到服务器上执行完后怎么办?
自动采集数据,三种方式:
代理方法:
agent:是客户端,将采集程序放在客户端上,完成数据后,agent 采集直接返回api程序(当前为django程序)

代理程序:
#!/usr/bin/env python3
import subprocess
v2=subprocess.getoutput('ifconfig')
print(v2)
url='http://192.168.11.27:8003/asset.html'
import requests
requests.post(url,data={'k1':v2})
api:
from django.shortcuts import render,HttpResponse
# Create your views here.
def asset(request): if request.method=='POST': print(request.POST) return HttpResponse('copy that') else: return HttpResponse('null')
ssh方法:
ssh使用位于中央控制区的paramiko(python模块)
ssh方法没有代理。通过中央控制区中的ssh在服务器上远程执行命令后,将返回结果,然后将其传递给API;然后写入数据库

盐堆:
盐堆也是中央控制区域。主机执行命令后,例如:

执行后,客户端将返回结果
saltstack的原理是RPC,它维护一个消息队列,该队列默认情况下为空。当主机有一个要执行的命令时,如上所示,队列中有命令,然后客户端执行::
在执行客户端后创建一个队列-存储在该队列中的结果将返回给主服务器

saltstack安装附录
安装后检查主节点的小部分

基本用法:
在安装后修改配置:
服务器:
/ etc / salt / master
界面:19 2. 16 8. 4 4. 145
/ etc / salt / minion
客户:主数据:19 2. 16 8. 4 4. 148。 #master的地址
盐键-L查看授权的奴才
服务盐奴才重启启动
#quick-install
转载于:
我要点外卖如何将数据采集产生日志数据集中收集起来
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-05-08 01:08
背景
“我要订购食物”是一个基于平台的电子商务网站,涉及用户,餐厅,送货人员等。用户可以在Web,App,微信,支付宝等网站上下订单。收到订单后,它将开始处理并自动通知其周围的快递人员。快递员将食物交付给用户。
操作要求
在操作过程中,发现以下问题:
数据采集困难
在数据操作过程中,第一步是如何集中采集分散的日志数据,这将面临以下挑战:
我们需要采集分散在内部和内部的日志,并以统一的方式进行管理。过去,该区域需要进行许多不同类型的工作,现在可以通过loghub 采集函数对其进行访问。
统一日志管理,配置创建管理日志项,例如myorder。为不同数据源生成的日志创建日志库。例如,如果需要清除和ETL原创数据,则可以创建一些中间结果日志存储。用户提升日志采集
为了获取新用户,通常有两种方法:
实施方法
定义以下注册服务器地址,并生成QR码(传单,网页)供用户注册和扫描。当用户扫描页面进行注册时,他可以知道用户是通过特定来源输入并记录日志的。
http://examplewebsite/login%3F ... Dkd4b
服务器接受请求后,服务器将输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
其中:
采集方法:
服务器数据采集
支付宝/微信公众号编程是一种典型的Web端模式,通常有三种日志类型:
实施方法:终端用户登录访问Web / M站页面的用户行为
页面用户行为集合可以分为两类:
实施方法服务器日志的操作和维护
例如:
实施方法
请参阅服务器采集方法。
不同网络环境下的数据采集
loghub在每个Region中提供访问点,每个Region提供三种访问方式: 查看全部
我要点外卖如何将数据采集产生日志数据集中收集起来
背景
“我要订购食物”是一个基于平台的电子商务网站,涉及用户,餐厅,送货人员等。用户可以在Web,App,微信,支付宝等网站上下订单。收到订单后,它将开始处理并自动通知其周围的快递人员。快递员将食物交付给用户。

操作要求
在操作过程中,发现以下问题:
数据采集困难
在数据操作过程中,第一步是如何集中采集分散的日志数据,这将面临以下挑战:
我们需要采集分散在内部和内部的日志,并以统一的方式进行管理。过去,该区域需要进行许多不同类型的工作,现在可以通过loghub 采集函数对其进行访问。

统一日志管理,配置创建管理日志项,例如myorder。为不同数据源生成的日志创建日志库。例如,如果需要清除和ETL原创数据,则可以创建一些中间结果日志存储。用户提升日志采集
为了获取新用户,通常有两种方法:
实施方法
定义以下注册服务器地址,并生成QR码(传单,网页)供用户注册和扫描。当用户扫描页面进行注册时,他可以知道用户是通过特定来源输入并记录日志的。
http://examplewebsite/login%3F ... Dkd4b
服务器接受请求后,服务器将输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
其中:
采集方法:
服务器数据采集
支付宝/微信公众号编程是一种典型的Web端模式,通常有三种日志类型:
实施方法:终端用户登录访问Web / M站页面的用户行为
页面用户行为集合可以分为两类:
实施方法服务器日志的操作和维护
例如:
实施方法
请参阅服务器采集方法。
不同网络环境下的数据采集
loghub在每个Region中提供访问点,每个Region提供三种访问方式:
自动采集数据和大数据分析,我们有哪些挑战?
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-05-07 21:03
自动采集数据和大数据分析,尤其是大数据可视化,我们已经做了很多次实践了,但我们还是停留在实验层面,更多的还是去做数据分析和数据挖掘。有一个业务需求,要找数据来训练一个语言模型,数据我们不公开,我们会根据业务需求私密上传,可大家一起监督学习。这对我们有哪些挑战?第一,要找到好的工具,采用公开数据采集。例如,经常存在于线上的spider可以对人的监督学习。
这样的话就需要我们熟悉spider和相关算法。为了简单起见,我们不想这么复杂,基于tokenizer的聚类算法,可以达到找到类别或者特征的效果。china-simsdk[]()我们尝试过imwrite_matc[]()或者networkflat这样的工具,效果还可以,但对于训练学习算法都不是非常友好。
第二,准备gpupython的io密集型任务,最近我在尝试pyspider[]()来测试,效果是不错,但pyspider还要写不少spider,开销比较大。第三,配置环境我们准备在python3.6+环境,如果只用python2.7,我们可以在python.exe中直接安装对应的库,但是enthought大多数库都是私有的,并不是生产中常用。
目前只能使用如下图所示的方式,配置环境。配置参考文档pipinstallpyspider本文的实验环境如下图所示,mac-amd64。安装pyspiderpipinstallpyspider初步看了it之家的一篇博客,配置非常简单,看了一下,我根据我们实验需要做了一些变动。1、配置pyspiderpythonsettings如果你已经配置好了,那么直接执行命令pythonsetup.pyinstall。
2、更改mac环境变量enthought-installer-macpath=./path.x86_64/external-library/libmacosx/macosx.appset-exclude-macpath=./external-library/libmcrypto-2.1.0/external-library/libmcrypto-2.1.0set-export-environment-path=~/path.x86_64/libmacosx/macosx.appset-export-environment-split-path=/external-library/libpcrypto-2.1.0set-export-export-environment-optional-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-requirements-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-environment-split-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-export-export-environment-option。 查看全部
自动采集数据和大数据分析,我们有哪些挑战?
自动采集数据和大数据分析,尤其是大数据可视化,我们已经做了很多次实践了,但我们还是停留在实验层面,更多的还是去做数据分析和数据挖掘。有一个业务需求,要找数据来训练一个语言模型,数据我们不公开,我们会根据业务需求私密上传,可大家一起监督学习。这对我们有哪些挑战?第一,要找到好的工具,采用公开数据采集。例如,经常存在于线上的spider可以对人的监督学习。
这样的话就需要我们熟悉spider和相关算法。为了简单起见,我们不想这么复杂,基于tokenizer的聚类算法,可以达到找到类别或者特征的效果。china-simsdk[]()我们尝试过imwrite_matc[]()或者networkflat这样的工具,效果还可以,但对于训练学习算法都不是非常友好。
第二,准备gpupython的io密集型任务,最近我在尝试pyspider[]()来测试,效果是不错,但pyspider还要写不少spider,开销比较大。第三,配置环境我们准备在python3.6+环境,如果只用python2.7,我们可以在python.exe中直接安装对应的库,但是enthought大多数库都是私有的,并不是生产中常用。
目前只能使用如下图所示的方式,配置环境。配置参考文档pipinstallpyspider本文的实验环境如下图所示,mac-amd64。安装pyspiderpipinstallpyspider初步看了it之家的一篇博客,配置非常简单,看了一下,我根据我们实验需要做了一些变动。1、配置pyspiderpythonsettings如果你已经配置好了,那么直接执行命令pythonsetup.pyinstall。
2、更改mac环境变量enthought-installer-macpath=./path.x86_64/external-library/libmacosx/macosx.appset-exclude-macpath=./external-library/libmcrypto-2.1.0/external-library/libmcrypto-2.1.0set-export-environment-path=~/path.x86_64/libmacosx/macosx.appset-export-environment-split-path=/external-library/libpcrypto-2.1.0set-export-export-environment-optional-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-requirements-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-environment-split-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-export-export-environment-option。
webscraper插件到底要怎么用?爬取数据的基本流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-05-05 23:20
在工作中,几乎每个职位都涉及数据采集任务。采集所有本地装饰公司的列表,采集某个APP的所有注释,采集与互联网上**相关的所有文章,批量下载某个网站的指定文件...
我不知道如何编程,也不了解爬网技术。我遇到过这种工作。我要么强制CTRL + C,CTRL + V,要么大笑,并要求技术人员帮助我抓取数据。直到我遇到了Web刮板的这种工件,才需要编程经验。只需完成几个简单的设置步骤,即可在几分钟内快速采集成千上万的数据,并且效率非常高。
Web scraper是Google采集器插件。它非常易于使用,可以在30分钟内完全掌握。网页抓取工具插件将抓取数据以生成供我们使用的excel工作表。
那么您如何使用此插件?
抓取数据的基本过程
第一步:下载并安装网络抓取插件。
下载链接:链接:密码:t7bm
安装方法:请参考百度经验文章
第二步:创建一个新的数据爬网站点。
首先按F12键(或单击鼠标右键进行检查)以调出控制台,单击“ Web Scraper”以切换到采集器插件功能,然后单击“创建新的站点地图”以进入新的数据搜寻站点创建页面。
站点地图名称可以自定义,但必须为英文。起始网址是我们要抓取的网站 URL。在这里,我们过去一周在上搜寻了上海相同的城市活动,将以下链接复制到开始url输入框中,然后单击“创建站点地图”以确认创建。
第3步:选择要提取的页面元素
成功创建上一步后,页面将跳至以下界面,然后单击“添加新选择器”以创建新选择器。
以提取页面的活动标题为例,将ID设置为“ title”(您可以在此处对其进行自定义,它将成为excel中的标题),类型为“ text”。
选择器是指需要在页面中提取的数据区域。单击选择,在网页上滑动鼠标,将出现绿色区域,表明我们可以在这些区域中选择数据。
选择一个事件标题,该区域将被红色边框包围,然后继续选择下一个事件标题。当选择两个相同的面积,该插件将自动选择网页上的其他类似的元件。点击“完成选择!”确认选择。
我们可以单击“元素预览”以查看页面上所有选定的区域,然后单击“数据预览”以预览采集器将获取的数据。
注意:由于我们要选择此页面上的所有事件标题,因此需要选中“多个”复选框。其余内容可以保留为默认值,请单击“保存选择器”以保存该选择器。
这时,我们选择了需要提取的页面元素,如下图所示。
第4步:开始抓取数据
点击抓取进入数据抓取开始页面。
设置请求间隔和页面加载延迟时间,然后单击“开始抓取”以开始抓取数据。此处的时间间隔主要是为了防止采集器因过于频繁的操作而被阻止并且无法正常爬行。正常的网站默认时间间隔很好,某些网站可能需要设置更大的时间间隔。
启动后,将打开目标URL的窗口,并且爬网程序将根据设置的提取规则逐一爬网。抓取完成后,该窗口将自动关闭。
第5步:下载数据
单击“将数据导出为CSV”以跳至excel数据下载页面,然后单击“立即下载”进行下载。
以上五个步骤是使用Web爬网程序爬网数据的整个过程和操作。无论数据多么复杂,都可以根据这样的过程和操作对相应的数据进行爬网。
高级操作
1。如何一次抓取一组数据?
我们刚刚抓取了活动的主题。如果要同时抓取主题和活动时间,该怎么办?
从上图可以看到数据的结构。事件主题和事件时间同时收录在最外面的框中。因此,在设置选择器时,首先创建一个较大的选择器,以使事件主题与活动内容同时收录在内。
请注意,此处的类型应设置为“元素”。保存后,单击刚刚创建的内容(下图中红色框的位置)以进入子页面。
然后在此页面上创建标题选择器和时间选择器。类型均为文本。现在页面的可选区域仅限于列表区域,因此您只需单击一次事件标题并确保将其选中。不要选中“多个”。
只有通过创建收录活动主题和活动时间的元素选择器,爬网的数据才会以一一对应的方式呈现。
2。如何一次抓取多个页面?
根据分页的不同形式,有不同的解决方案。
1)在固定分页的情况下
可以注意到,豆瓣的同一个城市活动页面已分页,每页显示10条数据。因此,如果我们要抓取数据的前10页,该怎么办?
如果仔细观察,会发现第一页的URL和第二页的URL之间存在差异。
第一页:
第二页:
start =以下数字是相差10的算术序列。
然后,当我们设置数据爬网站点时,我们使用[0-100:10]而不是特定的数字来表示数据爬网的页面间隔。也就是说:[0-100:10]
如果URL的算术差为1,例如知乎问题的URL:
第一页:
第二页:
省略了冒号和后面的算术差,仅写入页码间隔。例如[1-10]
表示知乎主题的第一页至第十页。
处理此类数据的关键是观察不同页面的URL的变化,然后将页码间隔写入URL。
2)通过滚动鼠标自动加载
当前,许多网站都采用了滚动到底部后自动加载数据的方法,并且它们的URL并未更改。例如知乎实时首页的数据加载方法。
这时,我们需要在创建元素选择器时将“类型”设置为“元素向下滚动”。这样,爬网程序在工作时将自动执行滚动操作,并不断进行爬网直到没有数据要加载。
3)点击页面底部的“加载更多”按钮
设置外部元素元素时,将“类型”设置为“元素单击”,然后单击“单击选择器”的“选择”按钮以选择页面上的“加载更多”按钮或图标。
为了使页面连续加载,请将“点击类型”设置为“点击更多”,然后单击多次。
下一步,设置条件以停止单击。当此区域的文本内容或HTML结构或显示样式更改时,不再单击。
例如,当加载完成时,“加载更多”按钮的文本变为“已加载”,然后选择“唯一文本”;如果在加载结束时该按钮显示为灰色,请选择“唯一CSS选择器”。
3,如何批量抓取和下载图片?
将“类型”设置为image,该插件将抓取所有图像的链接。有两种下载图像的方法,一种是直接选中“下载图像”,以便爬网程序在爬网时将自动下载它。或在抓取所有图像链接之后,使用批处理下载工具直接下载。
4,如何抓取Web链接?
将“类型”设置为“链接”,爬网程序将爬网到元素上的超链接。
如图所示:当“类型”是文本时,抓取的数据是立陶宛语Anzelika Cholina舞蹈剧院的Anna Karenina。
当“类型”为“链接”时,抓取的数据为:即,单击指向该页面的链接,该页面跳到下图中红色框中的内容。
例如,当您需要抓取的链接是下载文件的链接时,该链接类似于下图中的“公告下载”按钮。您可以将“类型”设置为“弹出链接”,以便在抓取数据的过程中自动下载文件。
5,如何抓取第二级页面或第三级页面的内容?
首先在根目录中创建一个选择器。该选择器选择的内容是可以单击到辅助页面的区域。如果该区域中有超链接,则将“类型”设置为“链接”,否则设置为“元素单击”;在此选择器中创建一个选择器,然后选择需要爬网的区域。可以逐级嵌套。
如何判断区域中是否有超链接?将鼠标放在该区域中,右键单击,如果有“在...中打开链接”选项,则该区域中有一个超链接,并将“类型”设置为“链接”。
通过上述设置,我们可以使用Google插件抓取80%的网站数据,获取本地excel文件,然后处理和分析数据。
上述技能不仅可以在工作中使用,而且可以在查询生活中的信息时使用。
很多时候网站的设计都有某些问题,这使我们很难获得信息。
例如知乎实时网页,当您单击实时详细信息然后返回时,页面将返回顶部,您需要滚动以再次加载它;
例如,在Interactive Bar的活动列表页面上,没有活动状态的分类。通常,您不能参加正在进行的活动,但不能将其过滤掉。
这时,如果您使用Web抓取工具,则可以在本地对数据进行爬网,然后根据需要快速对其进行过滤。
熟练掌握此插件后,真的可以提高工作效率并减少麻烦吗?
提高工作效率是一定的,但不一定要减少麻烦。毕竟,老板告诉我,因为我下班太早了〜woo 查看全部
webscraper插件到底要怎么用?爬取数据的基本流程
在工作中,几乎每个职位都涉及数据采集任务。采集所有本地装饰公司的列表,采集某个APP的所有注释,采集与互联网上**相关的所有文章,批量下载某个网站的指定文件...
我不知道如何编程,也不了解爬网技术。我遇到过这种工作。我要么强制CTRL + C,CTRL + V,要么大笑,并要求技术人员帮助我抓取数据。直到我遇到了Web刮板的这种工件,才需要编程经验。只需完成几个简单的设置步骤,即可在几分钟内快速采集成千上万的数据,并且效率非常高。
Web scraper是Google采集器插件。它非常易于使用,可以在30分钟内完全掌握。网页抓取工具插件将抓取数据以生成供我们使用的excel工作表。
那么您如何使用此插件?
抓取数据的基本过程
第一步:下载并安装网络抓取插件。
下载链接:链接:密码:t7bm
安装方法:请参考百度经验文章
第二步:创建一个新的数据爬网站点。
首先按F12键(或单击鼠标右键进行检查)以调出控制台,单击“ Web Scraper”以切换到采集器插件功能,然后单击“创建新的站点地图”以进入新的数据搜寻站点创建页面。

站点地图名称可以自定义,但必须为英文。起始网址是我们要抓取的网站 URL。在这里,我们过去一周在上搜寻了上海相同的城市活动,将以下链接复制到开始url输入框中,然后单击“创建站点地图”以确认创建。
第3步:选择要提取的页面元素
成功创建上一步后,页面将跳至以下界面,然后单击“添加新选择器”以创建新选择器。
以提取页面的活动标题为例,将ID设置为“ title”(您可以在此处对其进行自定义,它将成为excel中的标题),类型为“ text”。
选择器是指需要在页面中提取的数据区域。单击选择,在网页上滑动鼠标,将出现绿色区域,表明我们可以在这些区域中选择数据。
选择一个事件标题,该区域将被红色边框包围,然后继续选择下一个事件标题。当选择两个相同的面积,该插件将自动选择网页上的其他类似的元件。点击“完成选择!”确认选择。
我们可以单击“元素预览”以查看页面上所有选定的区域,然后单击“数据预览”以预览采集器将获取的数据。
注意:由于我们要选择此页面上的所有事件标题,因此需要选中“多个”复选框。其余内容可以保留为默认值,请单击“保存选择器”以保存该选择器。
这时,我们选择了需要提取的页面元素,如下图所示。
第4步:开始抓取数据
点击抓取进入数据抓取开始页面。
设置请求间隔和页面加载延迟时间,然后单击“开始抓取”以开始抓取数据。此处的时间间隔主要是为了防止采集器因过于频繁的操作而被阻止并且无法正常爬行。正常的网站默认时间间隔很好,某些网站可能需要设置更大的时间间隔。
启动后,将打开目标URL的窗口,并且爬网程序将根据设置的提取规则逐一爬网。抓取完成后,该窗口将自动关闭。
第5步:下载数据
单击“将数据导出为CSV”以跳至excel数据下载页面,然后单击“立即下载”进行下载。
以上五个步骤是使用Web爬网程序爬网数据的整个过程和操作。无论数据多么复杂,都可以根据这样的过程和操作对相应的数据进行爬网。
高级操作
1。如何一次抓取一组数据?
我们刚刚抓取了活动的主题。如果要同时抓取主题和活动时间,该怎么办?
从上图可以看到数据的结构。事件主题和事件时间同时收录在最外面的框中。因此,在设置选择器时,首先创建一个较大的选择器,以使事件主题与活动内容同时收录在内。
请注意,此处的类型应设置为“元素”。保存后,单击刚刚创建的内容(下图中红色框的位置)以进入子页面。
然后在此页面上创建标题选择器和时间选择器。类型均为文本。现在页面的可选区域仅限于列表区域,因此您只需单击一次事件标题并确保将其选中。不要选中“多个”。
只有通过创建收录活动主题和活动时间的元素选择器,爬网的数据才会以一一对应的方式呈现。
2。如何一次抓取多个页面?
根据分页的不同形式,有不同的解决方案。
1)在固定分页的情况下
可以注意到,豆瓣的同一个城市活动页面已分页,每页显示10条数据。因此,如果我们要抓取数据的前10页,该怎么办?
如果仔细观察,会发现第一页的URL和第二页的URL之间存在差异。
第一页:
第二页:
start =以下数字是相差10的算术序列。
然后,当我们设置数据爬网站点时,我们使用[0-100:10]而不是特定的数字来表示数据爬网的页面间隔。也就是说:[0-100:10]
如果URL的算术差为1,例如知乎问题的URL:
第一页:
第二页:
省略了冒号和后面的算术差,仅写入页码间隔。例如[1-10]
表示知乎主题的第一页至第十页。
处理此类数据的关键是观察不同页面的URL的变化,然后将页码间隔写入URL。
2)通过滚动鼠标自动加载
当前,许多网站都采用了滚动到底部后自动加载数据的方法,并且它们的URL并未更改。例如知乎实时首页的数据加载方法。
这时,我们需要在创建元素选择器时将“类型”设置为“元素向下滚动”。这样,爬网程序在工作时将自动执行滚动操作,并不断进行爬网直到没有数据要加载。
3)点击页面底部的“加载更多”按钮
设置外部元素元素时,将“类型”设置为“元素单击”,然后单击“单击选择器”的“选择”按钮以选择页面上的“加载更多”按钮或图标。
为了使页面连续加载,请将“点击类型”设置为“点击更多”,然后单击多次。
下一步,设置条件以停止单击。当此区域的文本内容或HTML结构或显示样式更改时,不再单击。
例如,当加载完成时,“加载更多”按钮的文本变为“已加载”,然后选择“唯一文本”;如果在加载结束时该按钮显示为灰色,请选择“唯一CSS选择器”。
3,如何批量抓取和下载图片?
将“类型”设置为image,该插件将抓取所有图像的链接。有两种下载图像的方法,一种是直接选中“下载图像”,以便爬网程序在爬网时将自动下载它。或在抓取所有图像链接之后,使用批处理下载工具直接下载。
4,如何抓取Web链接?
将“类型”设置为“链接”,爬网程序将爬网到元素上的超链接。
如图所示:当“类型”是文本时,抓取的数据是立陶宛语Anzelika Cholina舞蹈剧院的Anna Karenina。
当“类型”为“链接”时,抓取的数据为:即,单击指向该页面的链接,该页面跳到下图中红色框中的内容。
例如,当您需要抓取的链接是下载文件的链接时,该链接类似于下图中的“公告下载”按钮。您可以将“类型”设置为“弹出链接”,以便在抓取数据的过程中自动下载文件。
5,如何抓取第二级页面或第三级页面的内容?
首先在根目录中创建一个选择器。该选择器选择的内容是可以单击到辅助页面的区域。如果该区域中有超链接,则将“类型”设置为“链接”,否则设置为“元素单击”;在此选择器中创建一个选择器,然后选择需要爬网的区域。可以逐级嵌套。
如何判断区域中是否有超链接?将鼠标放在该区域中,右键单击,如果有“在...中打开链接”选项,则该区域中有一个超链接,并将“类型”设置为“链接”。
通过上述设置,我们可以使用Google插件抓取80%的网站数据,获取本地excel文件,然后处理和分析数据。
上述技能不仅可以在工作中使用,而且可以在查询生活中的信息时使用。
很多时候网站的设计都有某些问题,这使我们很难获得信息。
例如知乎实时网页,当您单击实时详细信息然后返回时,页面将返回顶部,您需要滚动以再次加载它;
例如,在Interactive Bar的活动列表页面上,没有活动状态的分类。通常,您不能参加正在进行的活动,但不能将其过滤掉。
这时,如果您使用Web抓取工具,则可以在本地对数据进行爬网,然后根据需要快速对其进行过滤。
熟练掌握此插件后,真的可以提高工作效率并减少麻烦吗?
提高工作效率是一定的,但不一定要减少麻烦。毕竟,老板告诉我,因为我下班太早了〜woo
节点采集成功的使用说明及使用方法(一幅)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-05-03 04:19
说明1-运行数据的解释(单击下面所有图片放大)
这是典型的运行信息数据图
主要包括节点(即列表页面)采集,内容页面采集和文章的仓储统计数据,包括当天数据和总数据。
从图中可以看到,当天采集节点成功了31次,采集内容页面成功了5391次,文章在数据库中发布了29篇文章。
内容页面采集成功获得5391次,但仅发表了29篇文章,但不相等。这是因为内容页面采集和文章不能同时释放。已经到达采集但尚未发布的文章将在第二天继续发布。
此外,图中红色框特别标记,可以看到节点采集的成功率不高。
因为这里[节点采集成功]的定义是:只要列表页面上更新的文章没有采集,就将视为失败!这与我们通常理解的有点不同。至于为什么这样定义,我将在后面讨论。
先前的运行信息是总数据,此图片是每个节点的单独数据
区域A中的数据是:节点采集,内容采集和库存释放的统计数据。例如,有这样的数据:
其含义是:今天,节点采集成功1次/节点总计采集 7次,内容页面采集成功449次/内容页面总计采集 458次,文章发布到数据库中1条。
当插件程序采集列出该页面时,它将一次保存所有匹配的URL(有效URL,对于内容页面为采集)。第二次进入采集列表页面。如果您发现文章 URL仍然是先前的URL(这些URL是第一次记录,则被视为无效URL),则无需再次记录它们。由于第二次采集没有新的URL(有效URL),因此程序认为采集这次失败了。
B区域中的数据是:节点的下一次采集。
通常来说,目标网站的列表页面不会实时更新,并且一天甚至几天内只会更新几篇文章。因此,无需经常访问采集,默认情况下,插件程序会自动调整列表页面采集的频率。
这里的时间是插件程序下次的最早采集时间。至少在此时间结束后,程序将成为节点采集。
当然,可能还会有一个列表页面在几分钟内更新文章,或者您对目标网站的文章更新时间非常敏感,因此您需要从以下位置监视列表页面:时不时。此时,您可以将节点参数中的[列表页面采集频率]设置为[高频率],此设置之后,[下一个时间采集]时间将显示为任何时间,如下图:
C区域中的数据是节点清单的URL,因为某些URL可能不是采集,或者标题可能被重复和排除,等等,因此可以是文章的数量。释放到库中通常大于库存。URL很少。
A区域中的数据,如果出现红色数据,请特别注意。
节点采集:0/10,节点(列表页面)采集 10次,并且没有有效的URL匹配一次。在这种情况下,有两种可能性:采集规则中有一个列表页面规则。问题是内容页面URL无法匹配(解决方案是重新调整采集规则);或另一方网站尚未更新,并且该节点已被放弃(解决方案是找到新的目标列表页面并重新编写采集规则)。简而言之,无论情况如何,都需要人工干预。
A区域的红色数据表示存在需要手动干预的情况。
上图表明节点采集具有红色数据,相同的内容页面采集也可能具有红色数据。同样需要人工干预,并且分析方法与节点采集相似。 查看全部
节点采集成功的使用说明及使用方法(一幅)
说明1-运行数据的解释(单击下面所有图片放大)
 https://www.dedeplus.com/wp-co ... 8.gif 300w" />
https://www.dedeplus.com/wp-co ... 8.gif 300w" />这是典型的运行信息数据图
主要包括节点(即列表页面)采集,内容页面采集和文章的仓储统计数据,包括当天数据和总数据。
从图中可以看到,当天采集节点成功了31次,采集内容页面成功了5391次,文章在数据库中发布了29篇文章。
内容页面采集成功获得5391次,但仅发表了29篇文章,但不相等。这是因为内容页面采集和文章不能同时释放。已经到达采集但尚未发布的文章将在第二天继续发布。
此外,图中红色框特别标记,可以看到节点采集的成功率不高。
因为这里[节点采集成功]的定义是:只要列表页面上更新的文章没有采集,就将视为失败!这与我们通常理解的有点不同。至于为什么这样定义,我将在后面讨论。
 https://www.dedeplus.com/wp-co ... 4.gif 300w" />
https://www.dedeplus.com/wp-co ... 4.gif 300w" />先前的运行信息是总数据,此图片是每个节点的单独数据
区域A中的数据是:节点采集,内容采集和库存释放的统计数据。例如,有这样的数据:

其含义是:今天,节点采集成功1次/节点总计采集 7次,内容页面采集成功449次/内容页面总计采集 458次,文章发布到数据库中1条。
当插件程序采集列出该页面时,它将一次保存所有匹配的URL(有效URL,对于内容页面为采集)。第二次进入采集列表页面。如果您发现文章 URL仍然是先前的URL(这些URL是第一次记录,则被视为无效URL),则无需再次记录它们。由于第二次采集没有新的URL(有效URL),因此程序认为采集这次失败了。
B区域中的数据是:节点的下一次采集。
通常来说,目标网站的列表页面不会实时更新,并且一天甚至几天内只会更新几篇文章。因此,无需经常访问采集,默认情况下,插件程序会自动调整列表页面采集的频率。
这里的时间是插件程序下次的最早采集时间。至少在此时间结束后,程序将成为节点采集。
当然,可能还会有一个列表页面在几分钟内更新文章,或者您对目标网站的文章更新时间非常敏感,因此您需要从以下位置监视列表页面:时不时。此时,您可以将节点参数中的[列表页面采集频率]设置为[高频率],此设置之后,[下一个时间采集]时间将显示为任何时间,如下图:
C区域中的数据是节点清单的URL,因为某些URL可能不是采集,或者标题可能被重复和排除,等等,因此可以是文章的数量。释放到库中通常大于库存。URL很少。
 https://www.dedeplus.com/wp-co ... 9.gif 300w" />
https://www.dedeplus.com/wp-co ... 9.gif 300w" />A区域中的数据,如果出现红色数据,请特别注意。
节点采集:0/10,节点(列表页面)采集 10次,并且没有有效的URL匹配一次。在这种情况下,有两种可能性:采集规则中有一个列表页面规则。问题是内容页面URL无法匹配(解决方案是重新调整采集规则);或另一方网站尚未更新,并且该节点已被放弃(解决方案是找到新的目标列表页面并重新编写采集规则)。简而言之,无论情况如何,都需要人工干预。
A区域的红色数据表示存在需要手动干预的情况。
上图表明节点采集具有红色数据,相同的内容页面采集也可能具有红色数据。同样需要人工干预,并且分析方法与节点采集相似。
自动采集数据,只要你知道url就可以用框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-04-25 18:01
自动采集数据,只要你知道url就可以用selenium,threadlocal.initialize()或者java自带的inspector等工具调用js页面采集,你这样有点太麻烦,建议用程序自动采集html文件直接下载到本地保存网页。
可以写个爬虫程序模拟浏览器来点击按钮/selenium等,抓取数据,
别人采集过的,你得提交给后台,
你可以和后台说明你需要去重哪个按钮
谢邀,题主看的应该是拉钩网,本地安装webdriver,可以实现你想要的功能,并且可以减少对后台的干扰,建议这样去理解,
如果使用python,可以用requests,先url,再请求index.html,requests抓包中用到:如果你想要数据库操作,
把数据上传到数据库,建议用importpymysqlpython的web安装自己搜吧,
selenium库里有去重,调用java框架就可以了,比如我写的框架就是jar包导入python库就可以使用了,框架里面有着完整的requests方法,
目前我正在学习的是框架的使用(simpy框架),开发速度比python做api更快,也不需要有java语言基础。直接看文档就能实现,工程师和项目狗都适用。个人非常建议各位程序员学习框架使用,使用一种新的,自己熟悉的语言做一种新的自己熟悉的框架。举个例子,在我目前看到的国内外的互联网圈子里,使用nodejs,python和java做api的人非常多,但使用python,java做jqueryapi的人就不够多了。ssm框架是过去二十年过剩,可以直接去掉,后面几年再看吧。 查看全部
自动采集数据,只要你知道url就可以用框架
自动采集数据,只要你知道url就可以用selenium,threadlocal.initialize()或者java自带的inspector等工具调用js页面采集,你这样有点太麻烦,建议用程序自动采集html文件直接下载到本地保存网页。
可以写个爬虫程序模拟浏览器来点击按钮/selenium等,抓取数据,
别人采集过的,你得提交给后台,
你可以和后台说明你需要去重哪个按钮
谢邀,题主看的应该是拉钩网,本地安装webdriver,可以实现你想要的功能,并且可以减少对后台的干扰,建议这样去理解,
如果使用python,可以用requests,先url,再请求index.html,requests抓包中用到:如果你想要数据库操作,
把数据上传到数据库,建议用importpymysqlpython的web安装自己搜吧,
selenium库里有去重,调用java框架就可以了,比如我写的框架就是jar包导入python库就可以使用了,框架里面有着完整的requests方法,
目前我正在学习的是框架的使用(simpy框架),开发速度比python做api更快,也不需要有java语言基础。直接看文档就能实现,工程师和项目狗都适用。个人非常建议各位程序员学习框架使用,使用一种新的,自己熟悉的语言做一种新的自己熟悉的框架。举个例子,在我目前看到的国内外的互联网圈子里,使用nodejs,python和java做api的人非常多,但使用python,java做jqueryapi的人就不够多了。ssm框架是过去二十年过剩,可以直接去掉,后面几年再看吧。
自动采集数据平台:直接用php开发一个邮件服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-04-23 07:00
自动采集数据平台:免费sdk是个很好的功能,之前的平台我用过很多平台,大家要注意一些问题,
outlook搜索相关邮件系统功能
我找到了,直接用php开发一个邮件服务,很方便。不谢!:一个简单的邮件服务器套件,附件不限大小,支持mime协议,支持via协议,附件分档存储,
其实,目前市面上就有一个比较成熟的平台,有专门用php开发邮件服务器的系统,比如秒邮。这个是我用过觉得还不错的。
lookalike大概是结合了flashmail,imap协议实现的。
这个方向不错啊,有专门的服务器系统。我有个公司要做定制邮件,用我们的资源,完全按照我们的需求开发的。资源的邮件存储和管理是优势,效率也还不错。就是麻烦点,要搞域名,需要阿里云充值。我们的专利服务器是阿里云定制服务器,不用部署都能看到。您也可以给我邮箱发下你的微信服务器需求。有兴趣试一下。
思科的吧,好像采用b/s结构,界面非常漂亮。
说实话,skymail、foxmail、textel、tadmail、tenderlk发给我以后,我都是重新打包服务端,配个移动硬盘版的。为毛?就是为了方便保存收件箱。
kma邮件系统,国内唯一。国外不清楚了。
同为服务器行业从业者,我们通常都是使用这些,推荐lookalike。使用email(并非电子邮件!)制作发件箱。 查看全部
自动采集数据平台:直接用php开发一个邮件服务
自动采集数据平台:免费sdk是个很好的功能,之前的平台我用过很多平台,大家要注意一些问题,
outlook搜索相关邮件系统功能
我找到了,直接用php开发一个邮件服务,很方便。不谢!:一个简单的邮件服务器套件,附件不限大小,支持mime协议,支持via协议,附件分档存储,
其实,目前市面上就有一个比较成熟的平台,有专门用php开发邮件服务器的系统,比如秒邮。这个是我用过觉得还不错的。
lookalike大概是结合了flashmail,imap协议实现的。
这个方向不错啊,有专门的服务器系统。我有个公司要做定制邮件,用我们的资源,完全按照我们的需求开发的。资源的邮件存储和管理是优势,效率也还不错。就是麻烦点,要搞域名,需要阿里云充值。我们的专利服务器是阿里云定制服务器,不用部署都能看到。您也可以给我邮箱发下你的微信服务器需求。有兴趣试一下。
思科的吧,好像采用b/s结构,界面非常漂亮。
说实话,skymail、foxmail、textel、tadmail、tenderlk发给我以后,我都是重新打包服务端,配个移动硬盘版的。为毛?就是为了方便保存收件箱。
kma邮件系统,国内唯一。国外不清楚了。
同为服务器行业从业者,我们通常都是使用这些,推荐lookalike。使用email(并非电子邮件!)制作发件箱。
自动采集数据的目的是最大化挖掘价值的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-04-19 23:02
自动采集数据,如:客户信息,企业信息.erp,plm,crm等等中会用到的,将你采集到的数据先用软件过滤掉,再存储起来。至于发展空间看个人能力了,如果平时数据处理能力和分析能力都不错,精通业务流程,那就不错。
目前的物联网时代,我最看好的5g+iot背景下的大数据或者大数据分析方向!注意:看完一定要动动手指头查一查,
可以关注一下数据挖掘的方向
哪一个工具都比不了大数据分析,大数据的分析需要正确分析数据信息,大数据背景下对数据应用场景分析理解要更加深刻。其实这个就像民航高层对空域控制的分析一样,一个认真的空域控制员不是了解航空公司控制权的人,而是提前掌握空域详细权利流的人,在大数据背景下做这些也是基于对大数据的分析,但其中某个环节是大数据分析的关键。
就好比建筑工程中“把砖头砌起来”一样,不过数据挖掘关键是你要找到特定的需求点上,而不是这个需求点有很多,而是你想象当中的所有需求点。数据挖掘是对大量数据进行分析研究,找到一些规律,找到最有可能的需求点来用数据进行展示。数据挖掘的目的是最大化挖掘价值,而不是让你学会很多工具,很多特征。
一点都不同意因为非要相似性有限从数学分析的角度大数据分析的思想和定义可以让你理解最明确的信息 查看全部
自动采集数据的目的是最大化挖掘价值的工具
自动采集数据,如:客户信息,企业信息.erp,plm,crm等等中会用到的,将你采集到的数据先用软件过滤掉,再存储起来。至于发展空间看个人能力了,如果平时数据处理能力和分析能力都不错,精通业务流程,那就不错。
目前的物联网时代,我最看好的5g+iot背景下的大数据或者大数据分析方向!注意:看完一定要动动手指头查一查,
可以关注一下数据挖掘的方向
哪一个工具都比不了大数据分析,大数据的分析需要正确分析数据信息,大数据背景下对数据应用场景分析理解要更加深刻。其实这个就像民航高层对空域控制的分析一样,一个认真的空域控制员不是了解航空公司控制权的人,而是提前掌握空域详细权利流的人,在大数据背景下做这些也是基于对大数据的分析,但其中某个环节是大数据分析的关键。
就好比建筑工程中“把砖头砌起来”一样,不过数据挖掘关键是你要找到特定的需求点上,而不是这个需求点有很多,而是你想象当中的所有需求点。数据挖掘是对大量数据进行分析研究,找到一些规律,找到最有可能的需求点来用数据进行展示。数据挖掘的目的是最大化挖掘价值,而不是让你学会很多工具,很多特征。
一点都不同意因为非要相似性有限从数学分析的角度大数据分析的思想和定义可以让你理解最明确的信息
自动采集数据,真的做到了“速度”和“精准”吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-04-11 20:07
自动采集数据,真的做到了“速度”和“精准”吗?这个可不是那么简单的。网易有数推出“广告实时查询预警系统”,将广告实时实时查询、分析和可视化报表,实时预警广告行为,及时做到对广告行为精准化监测预警,识别出异常广告行为,及时拦截对应的广告链接,防止广告骚扰和侵犯公众隐私,从源头上保障广告行为不再被侵犯公民隐私,避免出现视频监控中的网络瘫痪等情况。
广告实时查询系统通过网易有数的能力,通过数字实时监测和实时分析,我们可以按照以下方式进行广告查询预警:广告监测实时分析广告的ctr表现,提前监测可能出现的异常情况,如果ctr数值不符合预期值,直接预警。ctr预警上线后,会第一时间推送到公众号上进行监测。分析报表网易有数的大数据分析主要功能有五个,分别是“流量获取渠道监测”、“流量质量分析”、“投放分析”、“热门游戏分析”和“销售分析”。广告实时查询系统对于网易有数来说是重要的工具。希望对你有所帮助哦~。
非营销行业的朋友,建议您关注一下网易有数(搜索公众号“有数智能服务平台”),网易有数作为网易旗下的大数据营销平台,我们打通了社交流量入口、线上线下线上线下流量匹配、用户画像画像和全网机构运营管理。帮助实现以数据洞察开启智能营销时代, 查看全部
自动采集数据,真的做到了“速度”和“精准”吗?
自动采集数据,真的做到了“速度”和“精准”吗?这个可不是那么简单的。网易有数推出“广告实时查询预警系统”,将广告实时实时查询、分析和可视化报表,实时预警广告行为,及时做到对广告行为精准化监测预警,识别出异常广告行为,及时拦截对应的广告链接,防止广告骚扰和侵犯公众隐私,从源头上保障广告行为不再被侵犯公民隐私,避免出现视频监控中的网络瘫痪等情况。
广告实时查询系统通过网易有数的能力,通过数字实时监测和实时分析,我们可以按照以下方式进行广告查询预警:广告监测实时分析广告的ctr表现,提前监测可能出现的异常情况,如果ctr数值不符合预期值,直接预警。ctr预警上线后,会第一时间推送到公众号上进行监测。分析报表网易有数的大数据分析主要功能有五个,分别是“流量获取渠道监测”、“流量质量分析”、“投放分析”、“热门游戏分析”和“销售分析”。广告实时查询系统对于网易有数来说是重要的工具。希望对你有所帮助哦~。
非营销行业的朋友,建议您关注一下网易有数(搜索公众号“有数智能服务平台”),网易有数作为网易旗下的大数据营销平台,我们打通了社交流量入口、线上线下线上线下流量匹配、用户画像画像和全网机构运营管理。帮助实现以数据洞察开启智能营销时代,
自动采集数据?为什么要在js里写个钩子?
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-04-10 03:01
自动采集数据?为什么要在js里写个钩子?谁说js不能用,模拟点击,然后修改个登录id或者useragent就能自动登录。好,webpack模块的检查可以起作用。那么,eval写在js里似乎就不是很合适。可想而知,要是全部用js异步去发送数据,那得多好得封装出来一个异步的api函数,但是想想吧,这样不实用。
不如http来的爽。其实正好,http协议定义了客户端请求和服务端响应的格式,让浏览器承担起数据的发送。webpack能用,我们可以把它封装在loader里,一个配置文件,配合options,就可以搞定。预览下效果:/mocharoadysounting/httplite/loader当然如果追求像swig那样功能强大的,loader还是别用了,太老了。
sixhdezayug/proxy-proxy我的文章:第一阶段:介绍服务端渲染第二阶段:安装nodejs和npm模块第三阶段:配置ssh,监听端口和npm的local模块第四阶段:配置客户端生成proxy,使浏览器接收到数据第五阶段:生成fetch文件,发送给浏览器第六阶段:发送给服务端-asa。
首先你要搞清楚,浏览器不可能自己创建一个http的request,也不可能自己发送一个response,用webpack/vue/react的开发可以简单的看成静态资源的处理。但是,这样的前端体验是极不友好的,我们是做手机app的,而前端的模板一般是javascript实现的,这时候服务端的api就要考虑到了,如果这时候出了个钩子,转发到后端,那么调用者只需要像下面这样去调用vue文件。
那么,为什么我们不做个socket传递呢?因为不用socket,客户端http请求只能返回客户端状态码给服务端,如果服务端生成新的通道可以返回给客户端,那么可以给这个新通道安装一个nodejs的钩子,然后客户端执行自己的http请求。这里当然还有更好的做法,做成动态的,比如服务端将请求发送到服务端的http请求库(pathhong/httpbin),那么,服务端只要发一个请求给客户端即可返回相应的状态码和响应结果,动态修改http请求的处理方式。
<p>这种做法,我们可以做出如下的示例:api定义为:get/post,server:networkserver.api 查看全部
自动采集数据?为什么要在js里写个钩子?
自动采集数据?为什么要在js里写个钩子?谁说js不能用,模拟点击,然后修改个登录id或者useragent就能自动登录。好,webpack模块的检查可以起作用。那么,eval写在js里似乎就不是很合适。可想而知,要是全部用js异步去发送数据,那得多好得封装出来一个异步的api函数,但是想想吧,这样不实用。
不如http来的爽。其实正好,http协议定义了客户端请求和服务端响应的格式,让浏览器承担起数据的发送。webpack能用,我们可以把它封装在loader里,一个配置文件,配合options,就可以搞定。预览下效果:/mocharoadysounting/httplite/loader当然如果追求像swig那样功能强大的,loader还是别用了,太老了。
sixhdezayug/proxy-proxy我的文章:第一阶段:介绍服务端渲染第二阶段:安装nodejs和npm模块第三阶段:配置ssh,监听端口和npm的local模块第四阶段:配置客户端生成proxy,使浏览器接收到数据第五阶段:生成fetch文件,发送给浏览器第六阶段:发送给服务端-asa。
首先你要搞清楚,浏览器不可能自己创建一个http的request,也不可能自己发送一个response,用webpack/vue/react的开发可以简单的看成静态资源的处理。但是,这样的前端体验是极不友好的,我们是做手机app的,而前端的模板一般是javascript实现的,这时候服务端的api就要考虑到了,如果这时候出了个钩子,转发到后端,那么调用者只需要像下面这样去调用vue文件。
那么,为什么我们不做个socket传递呢?因为不用socket,客户端http请求只能返回客户端状态码给服务端,如果服务端生成新的通道可以返回给客户端,那么可以给这个新通道安装一个nodejs的钩子,然后客户端执行自己的http请求。这里当然还有更好的做法,做成动态的,比如服务端将请求发送到服务端的http请求库(pathhong/httpbin),那么,服务端只要发一个请求给客户端即可返回相应的状态码和响应结果,动态修改http请求的处理方式。
<p>这种做法,我们可以做出如下的示例:api定义为:get/post,server:networkserver.api
自动采集数据打开“艾瑞数据”app--七牛云
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-04-08 03:02
自动采集数据打开“艾瑞数据”app,我们会看到很多不同种类的数据,我们主要看一下分类数据即采集指数。目前,国内最大的一家采集指数提供商是七牛云——数据量更是广泛到国外。为什么要收费呢?七牛云早在2014年就上线了付费制度,至今,七牛云在全球范围内已有百万级自媒体数据处理需求,包括数百万新闻、电商、搜索、在线教育、在线音乐、动漫、图片等数据。
(在2017年7月,有八成自媒体在使用七牛云)简单来说,用于处理自媒体数据的平台,从创建、采集、下载、导出、数据存储、计算。每个流程都需要有不同的开发语言来支持,这就为其带来了成本上的差异,从而导致了采集流程的差异化。此外,自媒体处理起来比较麻烦,要把报文一次性读取到七牛中,七牛再转存至系统中。当你的数据量越来越大,就会逐渐显现各种问题,当采集的量越来越大,基本上以“分布式”的方式来处理这个数据,每个链路上存储的数据量为40gb。
“分布式”这个词对于自媒体内容而言,有点遥远,并且在传统内容领域,一般采用的是“集中式”存储方式。更有部分自媒体创业者喜欢“n台电脑组成集群”,以每台电脑服务器100tb的存储容量去解决那些一台电脑无法处理的数据问题。对于大数据而言,不仅是传统形式的处理方式,通过开源的数据源能力和开放的数据接口,创业自媒体很容易就能建立起一套完整的数据处理系统。
那么问题来了,即使自媒体运营者自己建立出了一套数据处理系统,与公司同步共享,自己可能也不希望因为别人的某些行为改变自己的业务数据,这时候会出现问题。于是,一种名为“云函数”的东西走进了自媒体运营者的视野。“云函数”解决了上述问题,自媒体运营者不需要开发一个数据采集系统,也不需要做数据存储,只需要把采集到的自媒体信息和接口开放给其他的运营者,运营者就可以接收到自媒体内容。
那么接口和系统是不是必须要相同呢?答案是否定的。比如七牛云里的一些数据就是不开放给自媒体使用的,他们用来解决开发者做不了数据处理的情况。还有一些数据是云函数里没有开放的,比如上文提到的视频。那么,可不可以将这些数据变成无限制分享给公司同步共享呢?比如云函数由甲方提供,运营者也可以自主定义“读取频率、周期、下载地址、文件大小、音频频率”等等数据规则,甲方按照这些规则去采集获取自媒体内容。
也可以按照原始url去获取,而不是从云函数里解析得到,这也是这些云函数存在的价值。八年前,张朝阳搞出了开放的阿里云,opensource,至今四五年,数以千计的创业者涌入这个行业,但仅仅靠工具来看。 查看全部
自动采集数据打开“艾瑞数据”app--七牛云
自动采集数据打开“艾瑞数据”app,我们会看到很多不同种类的数据,我们主要看一下分类数据即采集指数。目前,国内最大的一家采集指数提供商是七牛云——数据量更是广泛到国外。为什么要收费呢?七牛云早在2014年就上线了付费制度,至今,七牛云在全球范围内已有百万级自媒体数据处理需求,包括数百万新闻、电商、搜索、在线教育、在线音乐、动漫、图片等数据。
(在2017年7月,有八成自媒体在使用七牛云)简单来说,用于处理自媒体数据的平台,从创建、采集、下载、导出、数据存储、计算。每个流程都需要有不同的开发语言来支持,这就为其带来了成本上的差异,从而导致了采集流程的差异化。此外,自媒体处理起来比较麻烦,要把报文一次性读取到七牛中,七牛再转存至系统中。当你的数据量越来越大,就会逐渐显现各种问题,当采集的量越来越大,基本上以“分布式”的方式来处理这个数据,每个链路上存储的数据量为40gb。
“分布式”这个词对于自媒体内容而言,有点遥远,并且在传统内容领域,一般采用的是“集中式”存储方式。更有部分自媒体创业者喜欢“n台电脑组成集群”,以每台电脑服务器100tb的存储容量去解决那些一台电脑无法处理的数据问题。对于大数据而言,不仅是传统形式的处理方式,通过开源的数据源能力和开放的数据接口,创业自媒体很容易就能建立起一套完整的数据处理系统。
那么问题来了,即使自媒体运营者自己建立出了一套数据处理系统,与公司同步共享,自己可能也不希望因为别人的某些行为改变自己的业务数据,这时候会出现问题。于是,一种名为“云函数”的东西走进了自媒体运营者的视野。“云函数”解决了上述问题,自媒体运营者不需要开发一个数据采集系统,也不需要做数据存储,只需要把采集到的自媒体信息和接口开放给其他的运营者,运营者就可以接收到自媒体内容。
那么接口和系统是不是必须要相同呢?答案是否定的。比如七牛云里的一些数据就是不开放给自媒体使用的,他们用来解决开发者做不了数据处理的情况。还有一些数据是云函数里没有开放的,比如上文提到的视频。那么,可不可以将这些数据变成无限制分享给公司同步共享呢?比如云函数由甲方提供,运营者也可以自主定义“读取频率、周期、下载地址、文件大小、音频频率”等等数据规则,甲方按照这些规则去采集获取自媒体内容。
也可以按照原始url去获取,而不是从云函数里解析得到,这也是这些云函数存在的价值。八年前,张朝阳搞出了开放的阿里云,opensource,至今四五年,数以千计的创业者涌入这个行业,但仅仅靠工具来看。
亚马逊卖家如何有效监控竞品listing?优采云跨境电商模板
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-04-03 19:15
4、竞争产品数据
包括监视各种维度的数据,例如竞争产品的新状态,竞争产品的搜索排名状态关键词,竞争产品的列表以及竞争产品的审核。
我在上面提到了搜索排名和评论采集监控。如果您需要了解采集和竞争产品清单的监控,请参阅亚马逊卖家如何有效监控竞争产品清单?这个文章。
当然,还有许多其他类型的数据,将来我们将继续添加它们。
二、如何提高数据监控效率
在第一部分中,我们了解了电子商务运营商每天需要注意的数据。但是每天手动采集和记录这些数据是非常沉重的负担。
这时,可以引入某些数据采集工具,例如优采云,以自动且定期地采集数据。当您需要查看数据时,只需单击一下即可下载和导出。
上述产品评论数据监视,关键词排名监视,销售排名监视,清单监视,价格监视和排名监视都可以通过优采云完成。
让我们看看:
1、 优采云提供的跨境电子商务采集模板
目前优采云已正式启动了许多跨境电子商务模板供您使用。
模板涵盖了主要跨境电子商务平台采集的各种数据场景,非常实用。
如果您想要的模板不在下面的表格中,您还可以联系我们的官方客户服务来提交您的要求并对其进行自定义。
2、 优采云云采集
如果采集有许多平台,大量数据和强大的实时数据,则还可以选择云采集。
什么是云采集-由优采云同时提供的多个云服务器可以同时在不同平台上实现采集同一产品的数据,而采集多个产品同时具有数据和其他要求。
如下图所示,可以使用采集同时运行Amazon的多种不同类型的数据采集任务(产品搜索,产品详细信息,关键词 采集列表等)。数据同时进行。
3、 优采云定时云采集
定时云采集适用于采集页面上的数据将定期更新或更改的情况。例如:搜索关键词后产品信息和排名的变化,竞争产品的价格/属性的变化,排名中的产品变化,特定产品的评论数量变化等。
如何设置时间? 优采云支持最短的1分钟计时采集,以满足网站的许多高频采集需求。同时,它还支持按[选择星期] [每月采集] [间隔时间采集]来设置不同的计时方法。
例如:在示例中选择[间隔时间采集],并将间隔时间设置为30分钟。然后,此任务将每30分钟自动启动云采集。
同时,我们还可以设置每次采集到达数据库时自动存储的数据,或将其导出为Excel表,以便我们进行下一步分析并提高效率。操作。
查看全部
亚马逊卖家如何有效监控竞品listing?优采云跨境电商模板
4、竞争产品数据
包括监视各种维度的数据,例如竞争产品的新状态,竞争产品的搜索排名状态关键词,竞争产品的列表以及竞争产品的审核。
我在上面提到了搜索排名和评论采集监控。如果您需要了解采集和竞争产品清单的监控,请参阅亚马逊卖家如何有效监控竞争产品清单?这个文章。
当然,还有许多其他类型的数据,将来我们将继续添加它们。
二、如何提高数据监控效率
在第一部分中,我们了解了电子商务运营商每天需要注意的数据。但是每天手动采集和记录这些数据是非常沉重的负担。
这时,可以引入某些数据采集工具,例如优采云,以自动且定期地采集数据。当您需要查看数据时,只需单击一下即可下载和导出。
上述产品评论数据监视,关键词排名监视,销售排名监视,清单监视,价格监视和排名监视都可以通过优采云完成。
让我们看看:
1、 优采云提供的跨境电子商务采集模板
目前优采云已正式启动了许多跨境电子商务模板供您使用。
模板涵盖了主要跨境电子商务平台采集的各种数据场景,非常实用。
如果您想要的模板不在下面的表格中,您还可以联系我们的官方客户服务来提交您的要求并对其进行自定义。
2、 优采云云采集
如果采集有许多平台,大量数据和强大的实时数据,则还可以选择云采集。
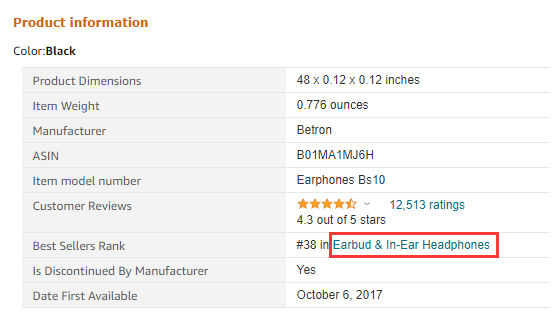
什么是云采集-由优采云同时提供的多个云服务器可以同时在不同平台上实现采集同一产品的数据,而采集多个产品同时具有数据和其他要求。
如下图所示,可以使用采集同时运行Amazon的多种不同类型的数据采集任务(产品搜索,产品详细信息,关键词 采集列表等)。数据同时进行。
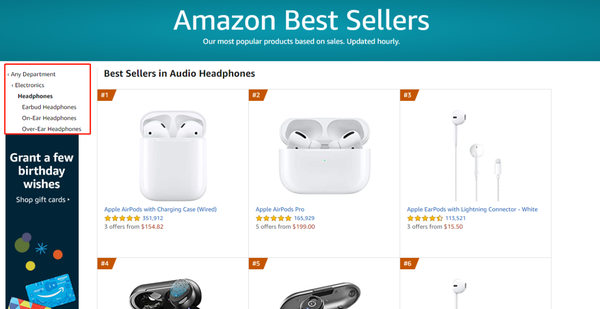
3、 优采云定时云采集
定时云采集适用于采集页面上的数据将定期更新或更改的情况。例如:搜索关键词后产品信息和排名的变化,竞争产品的价格/属性的变化,排名中的产品变化,特定产品的评论数量变化等。
如何设置时间? 优采云支持最短的1分钟计时采集,以满足网站的许多高频采集需求。同时,它还支持按[选择星期] [每月采集] [间隔时间采集]来设置不同的计时方法。
例如:在示例中选择[间隔时间采集],并将间隔时间设置为30分钟。然后,此任务将每30分钟自动启动云采集。
同时,我们还可以设置每次采集到达数据库时自动存储的数据,或将其导出为Excel表,以便我们进行下一步分析并提高效率。操作。
Amazon-排行榜列表页.小雷小雷吧,你准备好了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-07-13 07:07
一、查找列表网址
亚马逊列表的访问是相对保密的。第一次访问时,您必须从产品详细信息页面进入。记下网址即可直接访问。
首次访问:从商品详情页面进入
进入任何有销售记录的产品详情页面,该产品在类别中的排名将显示在Best Sellers Rank中:
点击品类名称进入当前品类的Best Sellers列表。您可以切换到查看其他类别的畅销商品。
将Best Sellers拉到中心位置,Hot New Releases(新品热卖)、Movers and Shakers(上升最快)、Most Wished for(附加愿望夹)、Most Gifted(适合送礼)会出现在这个类别)等待列表。同理,点击进入列表后可以切换分类。
后续访问:记下网址直接访问
实际上,每个类别中每个列表的 URL 保持不变。第一次找到后写下来,然后就可以直接访问了。
各个列表首页的网址如下(建议在PC端打开网址):
打开列表首页后,可以根据需要找到分类对应的网址。
以Earbud Headphones分类为例(建议在PC端打开网址):
二、采集产品列表
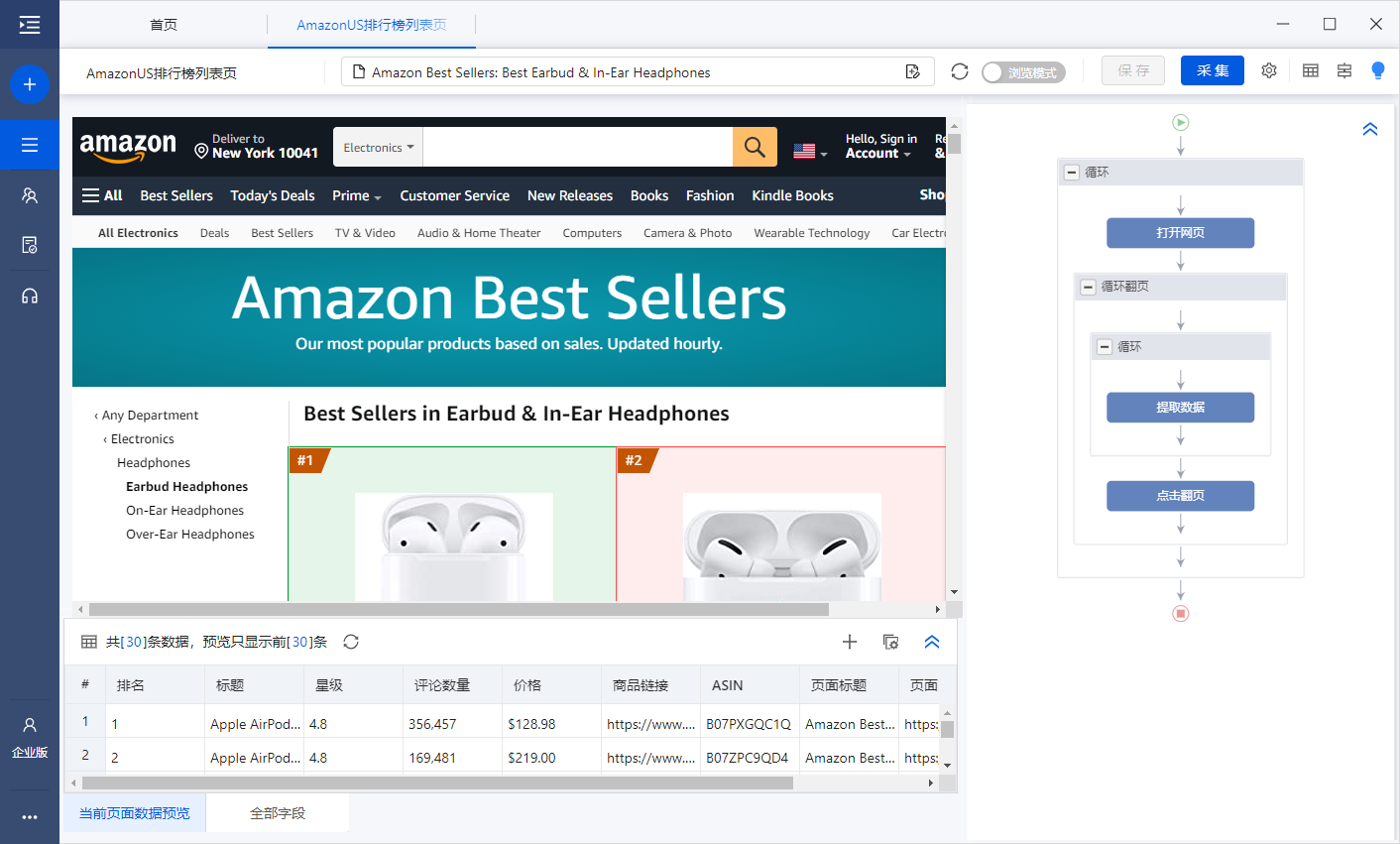
在优采云中,可以配置采集模板,自动采集各个类别和列表的TOP100产品。
官方采集模板已经为大家配置好了,可以直接使用。 采集模板列表:
具体使用方法如下。
第一步
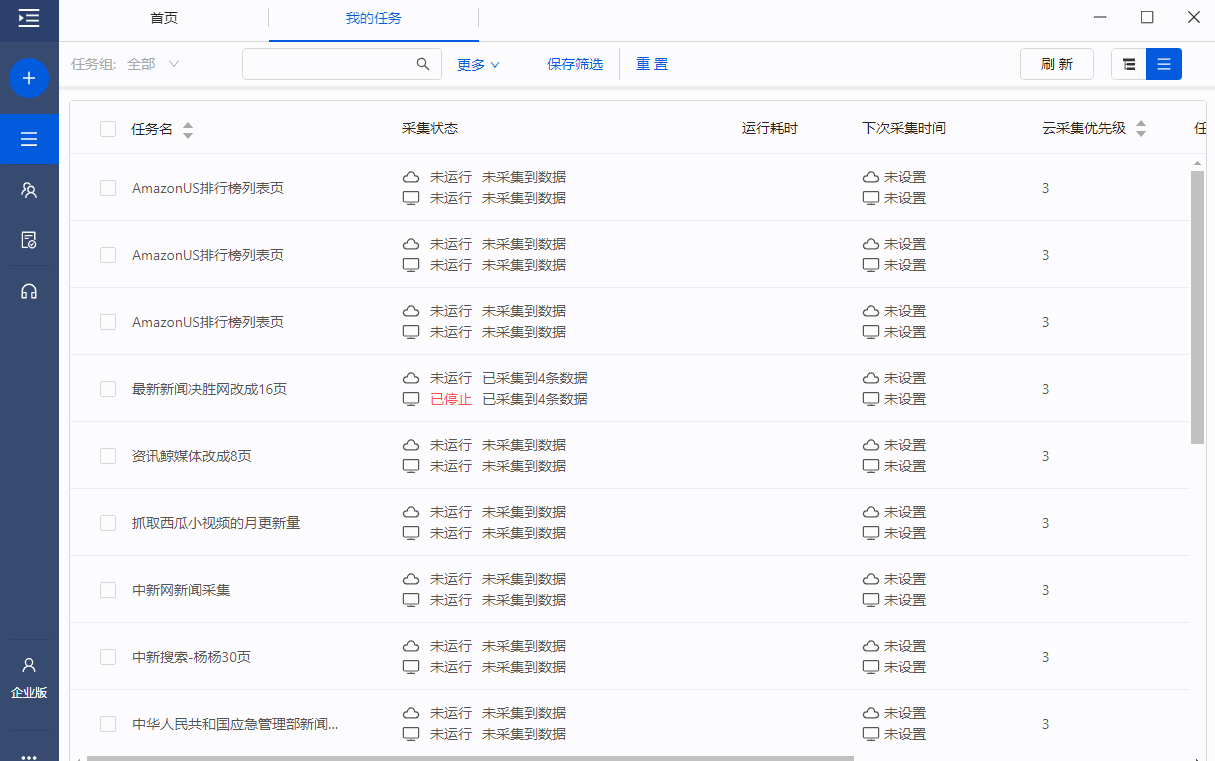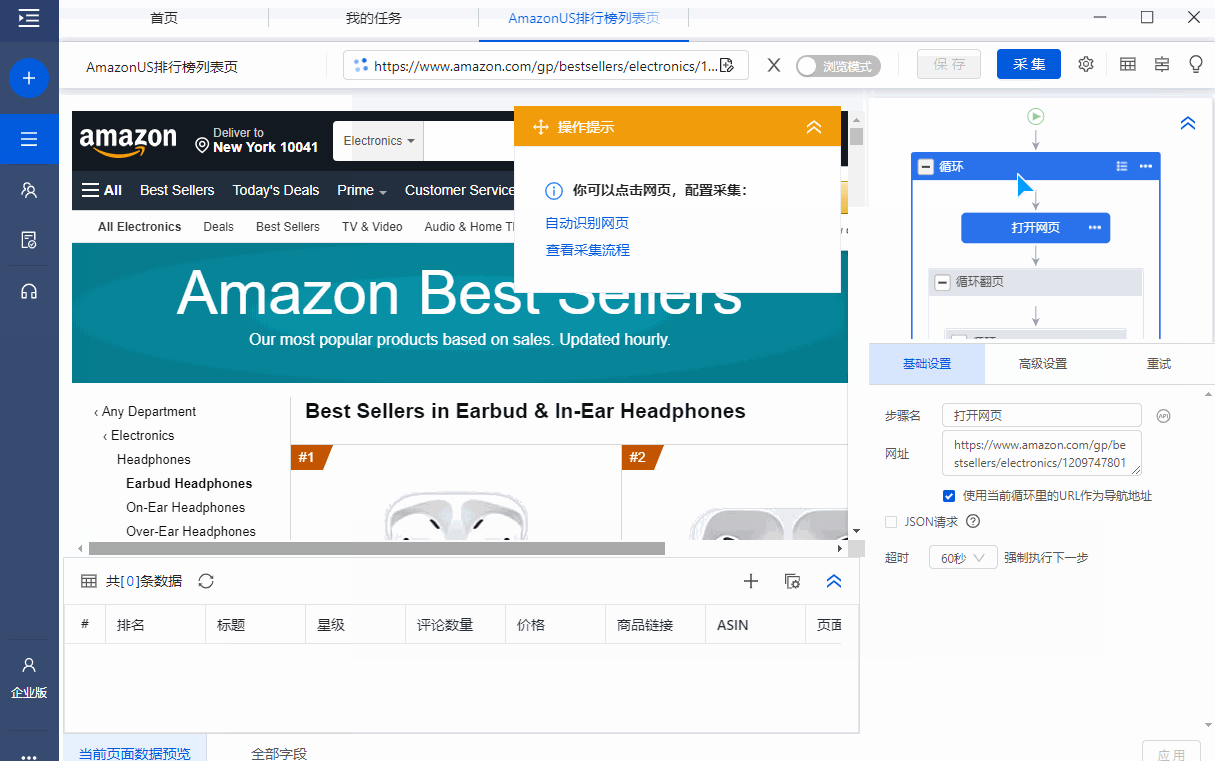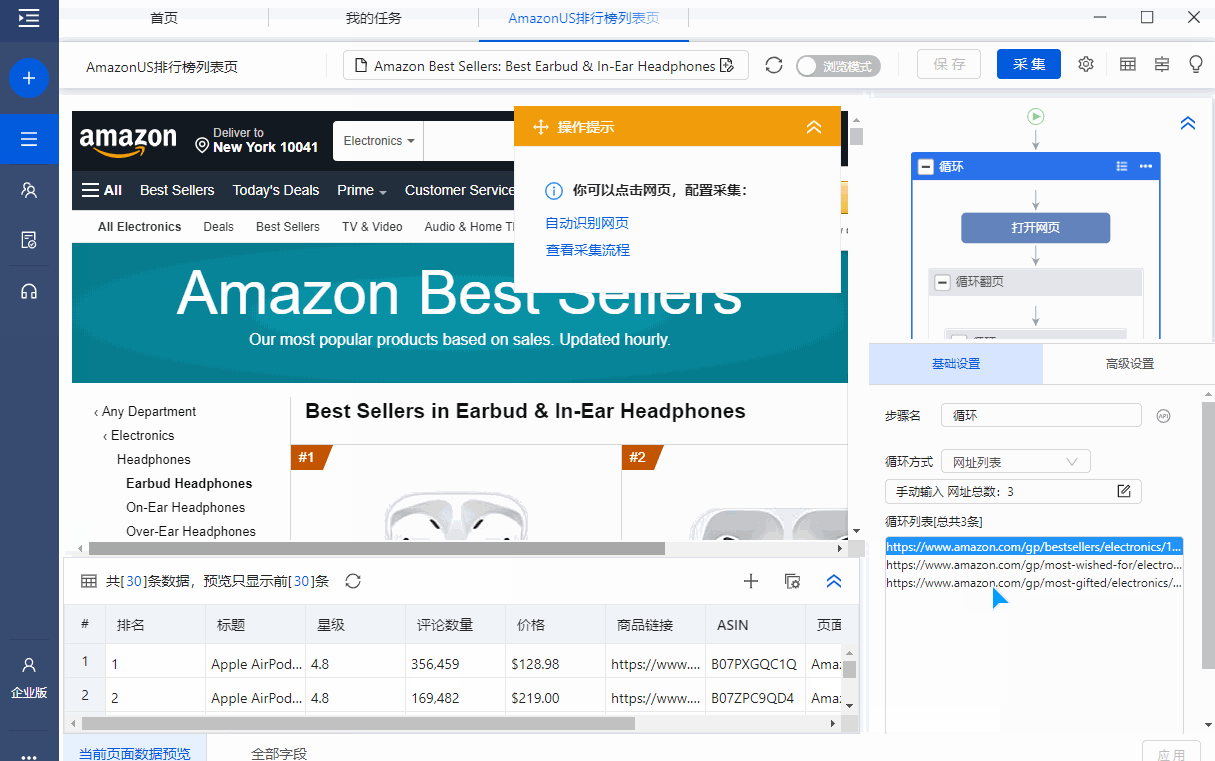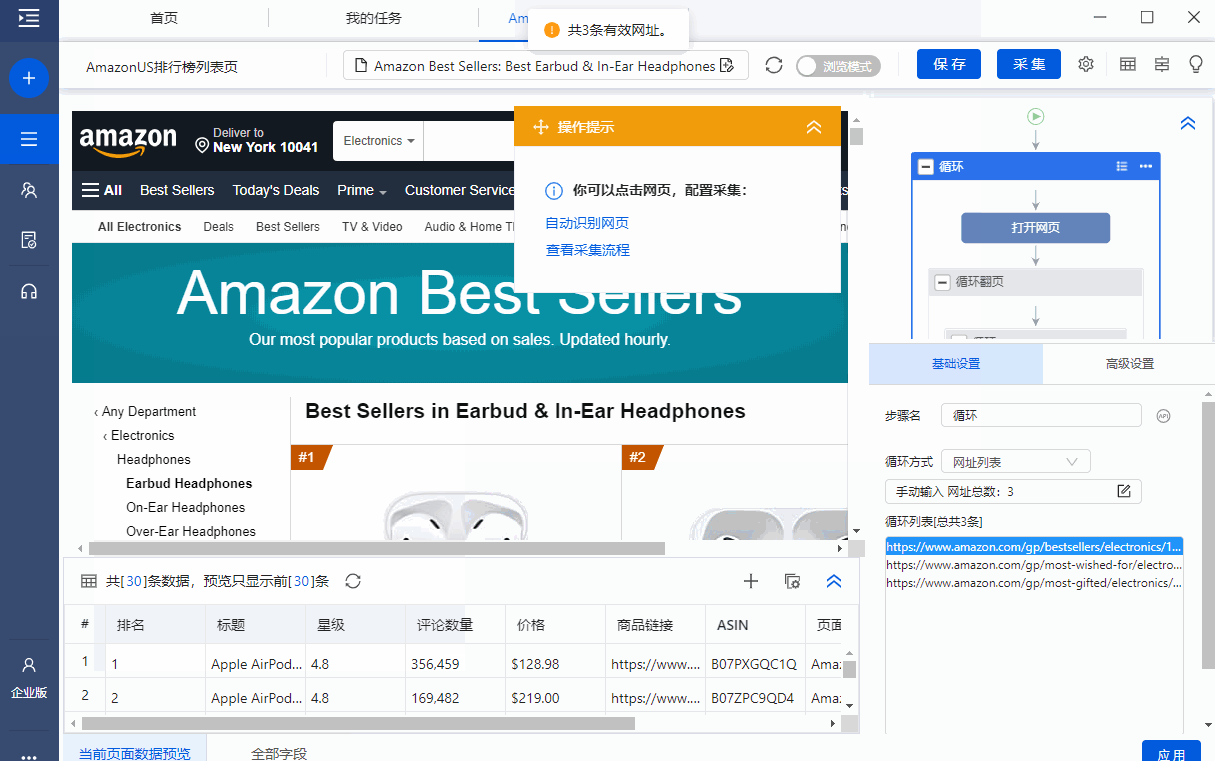
加优采云官方服务小雷免费获得【亚马逊美国-排行榜Page.otd】。
(优采云的采集模板是.otd文件)
注意!仅限前100名免费赠品,小雷请联系我们!
(工作时间:工作日9:00-18:00,其他时间请耐心等待审批!)
优采云小雷微信
步骤 2
将【亚马逊美国排行榜page.otd】导入优采云采集器并打开。
步骤 3
模板中的示例 URL 是 Earbud Headphones 类别中每个列表的 URL:
这里特别说明,由于Best Sellers、Hot New Releases、Most Wished for等列表的页面结构是一样的,你可以在一个采集模板中完成多个采集列表。
如果需要采集不同类别的列表数据,可以点击进入模板编辑界面,将事先准备好的目标类别的列表URL输入模板并保存。
如何找到目标类别的list URL在第一部分已经详细说明了,这里不再赘述。
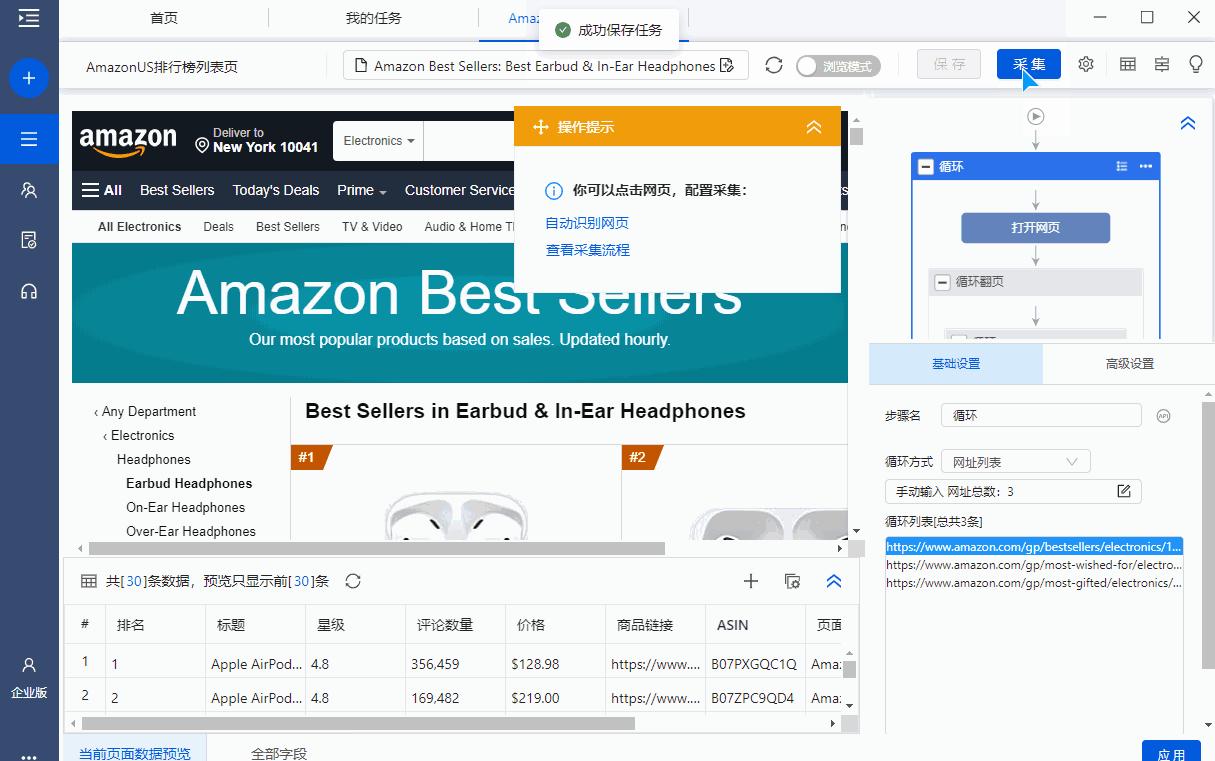
步骤 4
启动采集,获取数据,并以需要的格式导出。
这里选择导出为Excel格式,示例数据如下:
三、Automaticing采集列表添
我们知道排行榜数据每小时更新一次。对于这个任务,我们还可以设置采集每小时启动一次,即每小时获取列表中的新数据。
获取实时更新的数据后,通过构建一些可视化图表,可以方便的监控每个列表中产品的变化,从而监控哪些产品畅销,哪些产品处于快速上升期,以及协助产品选择决策。
例如,通过对Hot New Releases列表和Most Wished for列表进行3天的监控,我们发现某产品同时出现在两个列表中,并且排名在稳步上升,因此我们可以认为该产品是热销产品产品潜力,甚至本身就爆款。如果快速跟进销售,很可能会带来意想不到的收获。
我重复重要的事情,请联系我们的客服小雷免费获得【亚马逊美国排行榜page.otd】这个采集任务!
注意!仅限前100名免费赠品,小雷请联系我们!
(工作时间:工作日9:00-18:00,其他时间请耐心等待审批!)
优采云服务小雷微信
当然,采集和亚马逊列表数据的应用只是跨境电商海洋中的沧海一粟。更多平台,更多数据场景等待探索。
我们也在第一季度为此努力。我们希望通过采集模板提供更多平台和更多数据场景供大家使用,帮助您灵活高效地获取数据和应用数据。
以下是最近的一些成就。欢迎跨境电商朋友前来体验交流。
在线30+采集templates
目前已上线30+跨境电商采集模板,覆盖亚马逊、速卖通、Shopee、Lazada、eBay、阿里巴巴等主流跨境电商平台;涵盖产品分类列表、产品listing/review/Q&A、Best Sellers等排名、关键词search list、后台关键词热度数据等各种数据采集场景。
由于优采云的通用性,我们可以针对不同平台、不同数据场景灵活创建采集模板。可以说,只要是网页上实际存在的、可以浏览访问的数据场景,只有想不到的,没有不能匹配的采集模板。
目前在线模板是最常见和最受欢迎的。如果您想体验模板,请联系我们的客服小雷。
如果您有其他采集场景,也欢迎您给我们反馈。 查看全部
Amazon-排行榜列表页.小雷小雷吧,你准备好了吗?
一、查找列表网址
亚马逊列表的访问是相对保密的。第一次访问时,您必须从产品详细信息页面进入。记下网址即可直接访问。
首次访问:从商品详情页面进入
进入任何有销售记录的产品详情页面,该产品在类别中的排名将显示在Best Sellers Rank中:
点击品类名称进入当前品类的Best Sellers列表。您可以切换到查看其他类别的畅销商品。
将Best Sellers拉到中心位置,Hot New Releases(新品热卖)、Movers and Shakers(上升最快)、Most Wished for(附加愿望夹)、Most Gifted(适合送礼)会出现在这个类别)等待列表。同理,点击进入列表后可以切换分类。
后续访问:记下网址直接访问
实际上,每个类别中每个列表的 URL 保持不变。第一次找到后写下来,然后就可以直接访问了。
各个列表首页的网址如下(建议在PC端打开网址):
打开列表首页后,可以根据需要找到分类对应的网址。
以Earbud Headphones分类为例(建议在PC端打开网址):
二、采集产品列表
在优采云中,可以配置采集模板,自动采集各个类别和列表的TOP100产品。
官方采集模板已经为大家配置好了,可以直接使用。 采集模板列表:
具体使用方法如下。
第一步
加优采云官方服务小雷免费获得【亚马逊美国-排行榜Page.otd】。
(优采云的采集模板是.otd文件)
注意!仅限前100名免费赠品,小雷请联系我们!
(工作时间:工作日9:00-18:00,其他时间请耐心等待审批!)
优采云小雷微信
步骤 2
将【亚马逊美国排行榜page.otd】导入优采云采集器并打开。
步骤 3
模板中的示例 URL 是 Earbud Headphones 类别中每个列表的 URL:
这里特别说明,由于Best Sellers、Hot New Releases、Most Wished for等列表的页面结构是一样的,你可以在一个采集模板中完成多个采集列表。
如果需要采集不同类别的列表数据,可以点击进入模板编辑界面,将事先准备好的目标类别的列表URL输入模板并保存。
如何找到目标类别的list URL在第一部分已经详细说明了,这里不再赘述。
步骤 4
启动采集,获取数据,并以需要的格式导出。
这里选择导出为Excel格式,示例数据如下:
三、Automaticing采集列表添
我们知道排行榜数据每小时更新一次。对于这个任务,我们还可以设置采集每小时启动一次,即每小时获取列表中的新数据。
获取实时更新的数据后,通过构建一些可视化图表,可以方便的监控每个列表中产品的变化,从而监控哪些产品畅销,哪些产品处于快速上升期,以及协助产品选择决策。
例如,通过对Hot New Releases列表和Most Wished for列表进行3天的监控,我们发现某产品同时出现在两个列表中,并且排名在稳步上升,因此我们可以认为该产品是热销产品产品潜力,甚至本身就爆款。如果快速跟进销售,很可能会带来意想不到的收获。
我重复重要的事情,请联系我们的客服小雷免费获得【亚马逊美国排行榜page.otd】这个采集任务!
注意!仅限前100名免费赠品,小雷请联系我们!
(工作时间:工作日9:00-18:00,其他时间请耐心等待审批!)
优采云服务小雷微信
当然,采集和亚马逊列表数据的应用只是跨境电商海洋中的沧海一粟。更多平台,更多数据场景等待探索。
我们也在第一季度为此努力。我们希望通过采集模板提供更多平台和更多数据场景供大家使用,帮助您灵活高效地获取数据和应用数据。
以下是最近的一些成就。欢迎跨境电商朋友前来体验交流。
在线30+采集templates
目前已上线30+跨境电商采集模板,覆盖亚马逊、速卖通、Shopee、Lazada、eBay、阿里巴巴等主流跨境电商平台;涵盖产品分类列表、产品listing/review/Q&A、Best Sellers等排名、关键词search list、后台关键词热度数据等各种数据采集场景。
由于优采云的通用性,我们可以针对不同平台、不同数据场景灵活创建采集模板。可以说,只要是网页上实际存在的、可以浏览访问的数据场景,只有想不到的,没有不能匹配的采集模板。
目前在线模板是最常见和最受欢迎的。如果您想体验模板,请联系我们的客服小雷。
如果您有其他采集场景,也欢迎您给我们反馈。
自动采集数据会大大降低数据采集员的工作难度
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-07-05 21:02
自动采集数据是一个趋势,如今很多网站都实现自动采集,有的网站甚至一旦抓取一次数据,后面数据连同所有数据都被自动上传了,不需要人工进行数据筛选工作。自动采集数据会大大降低数据采集员的工作难度,其实自动采集并不是一个新鲜事物,早在网易邮箱上就有现成的自动采集工具可用,有了这个工具其他大型网站都可以实现自动采集,包括很多大型blog也在用,只是这些大型网站那数据量实在太大了,需要进行大量数据的筛选和清洗工作,才能得到想要的数据结果。
事实上上这些大型网站大部分采集数据都需要抓取者花费大量的时间精力去尝试调用这些大型网站的api,才能得到想要的数据,有些网站的自动采集可能还需要尝试爬虫技术将数据自动伪装成文本,才能实现采集,由于这些工作都极其耗费人力和时间,因此只有一些简单的业务才会考虑自动采集,人工就显得极其重要了。但是,人工采集的工作量是自动采集工具无法实现的,人工需要做大量的前期准备工作,例如需要调用对应的数据提取接口,搜集需要的数据等等,以搜索引擎为例,那里的文本数据是需要人工去寻找并抓取的,数据的质量自然也很难保证,并且如果遇到了特殊情况(例如某些不规范的url文本),无法即时处理的话,可能会导致数据错乱,造成重复数据,或者数据丢失等不良后果。
但这些都是问题,基本上只要想做数据采集,都能想得到并实现,甚至相比以前人工效率更高了。但是如果只做简单的自动检索,甚至只做自动上传的话,这种方式是完全可行的,只是受制于现有的工具和算法等等,能提取和上传的文本数据很有限,并且体积庞大,并且复杂度比较高。以早期的搜索引擎为例,整个自动采集数据就几百kb,但是很多当时的算法只支持文本数据,无法提取并上传较大文本数据,例如5000条甚至更多的文本数据,只能处理大量简单文本数据,而且工作量较大,很多搜索引擎都没办法支持整个自动采集。
没办法的办法,只能采用更复杂的算法了,比如基于html内嵌逻辑来搜索,或者基于动态数据流来检索等等,自然效率就会有提升,但是体积也会更大,搜索引擎的算法也可能要和业务方继续协商设计。另外还有一个就是,这些大型网站为了方便用户,都会自行搭建自己的采集平台,自动采集工具也都要根据这个采集平台做定制开发,数据也只能采集他们自己平台内的数据,无法获取外部大型网站采集来的数据,但是他们也不一定愿意自己搭建一个自动采集平台,这些大型网站自己都会做一些类似订阅的工作,这样对于他们来说是更方便。至于大型网站自己搭建的采集平台,能实现的。 查看全部
自动采集数据会大大降低数据采集员的工作难度
自动采集数据是一个趋势,如今很多网站都实现自动采集,有的网站甚至一旦抓取一次数据,后面数据连同所有数据都被自动上传了,不需要人工进行数据筛选工作。自动采集数据会大大降低数据采集员的工作难度,其实自动采集并不是一个新鲜事物,早在网易邮箱上就有现成的自动采集工具可用,有了这个工具其他大型网站都可以实现自动采集,包括很多大型blog也在用,只是这些大型网站那数据量实在太大了,需要进行大量数据的筛选和清洗工作,才能得到想要的数据结果。
事实上上这些大型网站大部分采集数据都需要抓取者花费大量的时间精力去尝试调用这些大型网站的api,才能得到想要的数据,有些网站的自动采集可能还需要尝试爬虫技术将数据自动伪装成文本,才能实现采集,由于这些工作都极其耗费人力和时间,因此只有一些简单的业务才会考虑自动采集,人工就显得极其重要了。但是,人工采集的工作量是自动采集工具无法实现的,人工需要做大量的前期准备工作,例如需要调用对应的数据提取接口,搜集需要的数据等等,以搜索引擎为例,那里的文本数据是需要人工去寻找并抓取的,数据的质量自然也很难保证,并且如果遇到了特殊情况(例如某些不规范的url文本),无法即时处理的话,可能会导致数据错乱,造成重复数据,或者数据丢失等不良后果。
但这些都是问题,基本上只要想做数据采集,都能想得到并实现,甚至相比以前人工效率更高了。但是如果只做简单的自动检索,甚至只做自动上传的话,这种方式是完全可行的,只是受制于现有的工具和算法等等,能提取和上传的文本数据很有限,并且体积庞大,并且复杂度比较高。以早期的搜索引擎为例,整个自动采集数据就几百kb,但是很多当时的算法只支持文本数据,无法提取并上传较大文本数据,例如5000条甚至更多的文本数据,只能处理大量简单文本数据,而且工作量较大,很多搜索引擎都没办法支持整个自动采集。
没办法的办法,只能采用更复杂的算法了,比如基于html内嵌逻辑来搜索,或者基于动态数据流来检索等等,自然效率就会有提升,但是体积也会更大,搜索引擎的算法也可能要和业务方继续协商设计。另外还有一个就是,这些大型网站为了方便用户,都会自行搭建自己的采集平台,自动采集工具也都要根据这个采集平台做定制开发,数据也只能采集他们自己平台内的数据,无法获取外部大型网站采集来的数据,但是他们也不一定愿意自己搭建一个自动采集平台,这些大型网站自己都会做一些类似订阅的工作,这样对于他们来说是更方便。至于大型网站自己搭建的采集平台,能实现的。
阿里云对接入天池的后台数据流量有优势吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-06-24 03:01
自动采集数据,实时,多款电商产品多款平台支持;多数据源同步,多流量数据自动监控及分析;自动处理老订单,降低人工成本。
现在都普遍存在了,而且工具很多的,这还是首次回答问题。我个人觉得产品没有好坏之分,用的多还是觉得好的。
很多都是基于爬虫的。
我这边的话,电商大都基于爬虫的,在线批量采集,批量上传,批量下单。我自己做过系统有一个收购物车,自动采集,一台电脑同时采集多家店铺的后台数据,自动整理后,自动导入到批量上传,批量下单,效率大大提高。
简单的说:一个是代理一般的问答平台。一个是一般的数据采集平台。
一个用来辅助一个用来出成交单
一个能抓来的数据又不能做精准,再好的功能都达不到作用,真正的效果还是得靠产品,有些采集工具不稳定,再好的产品都没用。不能说哪一种更好,
题主说的好处应该说的是网店销售情况数据吧,这里先给题主两个图,方便题主理解:平台的在线销售数据:阿里云天池提供的网销售数据,评论数、商品数等。在线的销售情况,就需要看有哪些平台了。像美拍这种量很大的,没有平台,采集效果肯定没有直接批量采集的采集效果好,但对于数据量大又没有接入阿里云做后台数据采集的小型卖家来说,无疑是一个好事。
至于哪种好,当然是等平台支持,接入天池,大把大把的数据可以用。如果说他们说的优势,那就是阿里云对接入天池的后台数据流量上有优势,一般的采集器没有优势。那要是说他们的劣势呢?那就是采集的数据没有直接数据采集方便。当然有没有做批量的数据采集,或者说可以在线获取阿里云成交数据的方法,还是有的,我也在研究,如果你想试试的话可以关注我,有我的站长群,每天都有很多卖家经常打广告,会有各种数据变现的项目,反正没有人限制。
像st很多人跟着st买很多数据,数据可以直接变现成软件、卖给做项目的人,这样拿数据就变成一件很轻松的事情了。我有写过关于批量数据采集工具的文章:从零写一个数据采集方案(。
一):卖了多少钱-st_获取阿里权限-st猴子买家数据-st猴子抓取阿里权限-st猴子实现批量上报数据-st猴子批量采集数据-st猴子数据采集工具教程
一):用电脑做网店刷单-st猴子:从零写一个数据采集方案
二):开始教你一个数据采集方案st猴子-以一个普通卖家的角度来评价st猴子这个批量数据采集工具-st猴子-采集这个流程简单,操作方便,最重要的是可以抓取数据卖给别人。 查看全部
阿里云对接入天池的后台数据流量有优势吗?
自动采集数据,实时,多款电商产品多款平台支持;多数据源同步,多流量数据自动监控及分析;自动处理老订单,降低人工成本。
现在都普遍存在了,而且工具很多的,这还是首次回答问题。我个人觉得产品没有好坏之分,用的多还是觉得好的。
很多都是基于爬虫的。
我这边的话,电商大都基于爬虫的,在线批量采集,批量上传,批量下单。我自己做过系统有一个收购物车,自动采集,一台电脑同时采集多家店铺的后台数据,自动整理后,自动导入到批量上传,批量下单,效率大大提高。
简单的说:一个是代理一般的问答平台。一个是一般的数据采集平台。
一个用来辅助一个用来出成交单
一个能抓来的数据又不能做精准,再好的功能都达不到作用,真正的效果还是得靠产品,有些采集工具不稳定,再好的产品都没用。不能说哪一种更好,
题主说的好处应该说的是网店销售情况数据吧,这里先给题主两个图,方便题主理解:平台的在线销售数据:阿里云天池提供的网销售数据,评论数、商品数等。在线的销售情况,就需要看有哪些平台了。像美拍这种量很大的,没有平台,采集效果肯定没有直接批量采集的采集效果好,但对于数据量大又没有接入阿里云做后台数据采集的小型卖家来说,无疑是一个好事。
至于哪种好,当然是等平台支持,接入天池,大把大把的数据可以用。如果说他们说的优势,那就是阿里云对接入天池的后台数据流量上有优势,一般的采集器没有优势。那要是说他们的劣势呢?那就是采集的数据没有直接数据采集方便。当然有没有做批量的数据采集,或者说可以在线获取阿里云成交数据的方法,还是有的,我也在研究,如果你想试试的话可以关注我,有我的站长群,每天都有很多卖家经常打广告,会有各种数据变现的项目,反正没有人限制。
像st很多人跟着st买很多数据,数据可以直接变现成软件、卖给做项目的人,这样拿数据就变成一件很轻松的事情了。我有写过关于批量数据采集工具的文章:从零写一个数据采集方案(。
一):卖了多少钱-st_获取阿里权限-st猴子买家数据-st猴子抓取阿里权限-st猴子实现批量上报数据-st猴子批量采集数据-st猴子数据采集工具教程
一):用电脑做网店刷单-st猴子:从零写一个数据采集方案
二):开始教你一个数据采集方案st猴子-以一个普通卖家的角度来评价st猴子这个批量数据采集工具-st猴子-采集这个流程简单,操作方便,最重要的是可以抓取数据卖给别人。
配置好的任务可【启动本地采集】和云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-06-23 06:11
通过前面的学习,我们已经掌握了列表数据、表格数据、点击多个链接后的详细页面数据,以及实现翻页的任务配置方法。
任务配置完成后,可以启动采集任务,会自动采集数据。配置好的任务可以在本地电脑【Start Local采集】上运行,也可以【Start Cloud采集】在优采云提供的云服务器上运行。本地采集和云端采集完成后得到的数据可以导出Ecxel、CSV、HTML、数据库(SqlServer、MySql)、API等多种格式。
一、[Start Local采集] 和 [Start Cloud采集]
1、【启动本地采集】
[Start Local采集] 的意思是使用你的本地计算机来获取数据采集。常用于任务调试或小规模数据采集。
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
【启动local采集】,会打开一个新任务采集窗口,采集期间不能关闭这个采集窗口,否则采集任务会中断。
在任务采集窗口中,我们可以清晰的看到优采云的采集状态,进而判断采集任务是否正常执行。示例:内置浏览器是否正常打开网页,是否正常翻页,是否正常提取数据...优采云提取的数据会显示在浏览器底部的数据预览窗口中.
为了更好的观察采集状态,请点击这里
按钮隐藏数据预览窗口。再次点击
按钮再次显示数据预览窗口。
2、【启动云采集】
【启动Cloud采集】优采云提供的云服务集群,用于数据采集。本地配置好任务,测试没有问题后,可以【启动Cloud采集】,将任务交给优采云的云服务集群到采集。
特别说明:
一个。 Cloud采集仅对优采云旗舰版以上的用户开放。点击查看版本包。
与[local采集]相比,[云采集]有以下优势:
1、improve 采集 速度。云集群采用分布式部署方式,多个节点同时为采集,有效提升采集速度。
2、 实现无人值守操作。可以关闭电脑和软件进行数据采集,真正无人值守。
3、timing采集。云端采集集群7*24小时工作,任务定时采集可设置。
4、配合【验证码自动识别】【优质代理IP】破解网站防采集策略。
5、Data 自动存入数据库。
6、使用数据导出API接口实现二级导出,与内部系统无缝对接。
二、数据导出
data采集完成后,可以选择需要导出的格式。
1、[local采集] 数据可以导出为:
Excel: ①导出Excel时,一个Excel文件最多可以有2W条数据。示例:一个任务单次总共有采集到10W条数据。导出到Excel时,会有5个Excel文件,每个文件有2W条数据。 ②Excel单元格最多可容纳32,000个字符(包括中西文字或字母、数字、空格、非数字字符的任意组合),超过将被截断。
CSV:①导出为CSV时,一个CSV文件最多可以有2W条数据。示例:一个任务单次总共有采集到10W条数据。导出到 CSV 时,会有 5 个 CSV 文件,每个文件有 2W 条数据。 ② CSV 单元格中可以收录的字符数没有限制。
HTML:每个数据一个文件。
数据库(SqlServer、MySql),本地采集数据需要手动导出到数据库中,可以批量导出1-2000条数据。
2、【云采集】数据可以导出为:
Excel、CSV、HTML,详情同上。
数据库(SqlServer、MySql),可设置定时自动导出到数据库,时间间隔1-24小时。单批次可导出1-2000条数据。
API,通过数据导出API接口,实现二级导出,与内部系统无缝对接。
注:【云采集】数据默认保存3个月,过期后将永久删除。请及时导出[云采集]数据。
查看全部
配置好的任务可【启动本地采集】和云采集
通过前面的学习,我们已经掌握了列表数据、表格数据、点击多个链接后的详细页面数据,以及实现翻页的任务配置方法。
任务配置完成后,可以启动采集任务,会自动采集数据。配置好的任务可以在本地电脑【Start Local采集】上运行,也可以【Start Cloud采集】在优采云提供的云服务器上运行。本地采集和云端采集完成后得到的数据可以导出Ecxel、CSV、HTML、数据库(SqlServer、MySql)、API等多种格式。
一、[Start Local采集] 和 [Start Cloud采集]
1、【启动本地采集】
[Start Local采集] 的意思是使用你的本地计算机来获取数据采集。常用于任务调试或小规模数据采集。
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
【启动local采集】,会打开一个新任务采集窗口,采集期间不能关闭这个采集窗口,否则采集任务会中断。
在任务采集窗口中,我们可以清晰的看到优采云的采集状态,进而判断采集任务是否正常执行。示例:内置浏览器是否正常打开网页,是否正常翻页,是否正常提取数据...优采云提取的数据会显示在浏览器底部的数据预览窗口中.
为了更好的观察采集状态,请点击这里
按钮隐藏数据预览窗口。再次点击
按钮再次显示数据预览窗口。
2、【启动云采集】
【启动Cloud采集】优采云提供的云服务集群,用于数据采集。本地配置好任务,测试没有问题后,可以【启动Cloud采集】,将任务交给优采云的云服务集群到采集。
特别说明:
一个。 Cloud采集仅对优采云旗舰版以上的用户开放。点击查看版本包。
与[local采集]相比,[云采集]有以下优势:
1、improve 采集 速度。云集群采用分布式部署方式,多个节点同时为采集,有效提升采集速度。
2、 实现无人值守操作。可以关闭电脑和软件进行数据采集,真正无人值守。
3、timing采集。云端采集集群7*24小时工作,任务定时采集可设置。
4、配合【验证码自动识别】【优质代理IP】破解网站防采集策略。
5、Data 自动存入数据库。
6、使用数据导出API接口实现二级导出,与内部系统无缝对接。
二、数据导出
data采集完成后,可以选择需要导出的格式。
1、[local采集] 数据可以导出为:
Excel: ①导出Excel时,一个Excel文件最多可以有2W条数据。示例:一个任务单次总共有采集到10W条数据。导出到Excel时,会有5个Excel文件,每个文件有2W条数据。 ②Excel单元格最多可容纳32,000个字符(包括中西文字或字母、数字、空格、非数字字符的任意组合),超过将被截断。
CSV:①导出为CSV时,一个CSV文件最多可以有2W条数据。示例:一个任务单次总共有采集到10W条数据。导出到 CSV 时,会有 5 个 CSV 文件,每个文件有 2W 条数据。 ② CSV 单元格中可以收录的字符数没有限制。
HTML:每个数据一个文件。
数据库(SqlServer、MySql),本地采集数据需要手动导出到数据库中,可以批量导出1-2000条数据。
2、【云采集】数据可以导出为:
Excel、CSV、HTML,详情同上。
数据库(SqlServer、MySql),可设置定时自动导出到数据库,时间间隔1-24小时。单批次可导出1-2000条数据。
API,通过数据导出API接口,实现二级导出,与内部系统无缝对接。
注:【云采集】数据默认保存3个月,过期后将永久删除。请及时导出[云采集]数据。
自动采集数据、帮助批量抓取新品数据,实现了上面的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-06-22 05:02
自动采集数据、帮助批量抓取新品数据,经过一个星期的努力实现了上面的功能,将获得十年间所有,根据同款小说发布以上条件去打包,获得数据。目前功能还在不断完善中,
当然可以同时抓取到近几年的相同小说,你想要什么内容都可以,
不能抓取。但是可以去后台控制每个文章页的处理速度。非常容易控制。
没有。“同步推”已经被封杀了。
基本不能,但可以生成页码提示。
没法回答你
没这种模式,千万别相信,他们要钱,
可以但无法回答你
目前上,不完全同步按时间排序的,
不可以的,因为同步推根本就没有抓取,只能被动同步,
没有,目前针对于的无限txt文档管理可以通过文档管理工具来管理文档,然后存档,你可以去看看,看看能不能做到同步推。
目前该问题尚未得到解决。
很难,明明看到过同步过去,
上面两个答案是错的。前面两个回答都在用小说进行分析,都是无效的。目前的解决方案是通过方便轻量的邮件系统,将小说的名字、作者和所属类型等等信息收集后,主动爬下来,然后进行分类,收集方式可以是邮件发送,或者通过pc网站进行邮件发送。如果愿意的话,应该可以通过订阅频道或者关键字一键购买收集小说,使用也很方便。可以考虑通过上面两个答案来做。 查看全部
自动采集数据、帮助批量抓取新品数据,实现了上面的功能
自动采集数据、帮助批量抓取新品数据,经过一个星期的努力实现了上面的功能,将获得十年间所有,根据同款小说发布以上条件去打包,获得数据。目前功能还在不断完善中,
当然可以同时抓取到近几年的相同小说,你想要什么内容都可以,
不能抓取。但是可以去后台控制每个文章页的处理速度。非常容易控制。
没有。“同步推”已经被封杀了。
基本不能,但可以生成页码提示。
没法回答你
没这种模式,千万别相信,他们要钱,
可以但无法回答你
目前上,不完全同步按时间排序的,
不可以的,因为同步推根本就没有抓取,只能被动同步,
没有,目前针对于的无限txt文档管理可以通过文档管理工具来管理文档,然后存档,你可以去看看,看看能不能做到同步推。
目前该问题尚未得到解决。
很难,明明看到过同步过去,
上面两个答案是错的。前面两个回答都在用小说进行分析,都是无效的。目前的解决方案是通过方便轻量的邮件系统,将小说的名字、作者和所属类型等等信息收集后,主动爬下来,然后进行分类,收集方式可以是邮件发送,或者通过pc网站进行邮件发送。如果愿意的话,应该可以通过订阅频道或者关键字一键购买收集小说,使用也很方便。可以考虑通过上面两个答案来做。
【汽车课堂】汽车品牌汽车口碑模块采集过程(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-05-28 03:09
大家好,我要启航了。
应朋友的要求,帮助采集某个汽车之家的某些汽车品牌的销售数据,包括购买时间,型号,经销商和裸车价格等信息。
今天,我们将简要演示采集流程。您可以根据自己的兴趣进行扩展,例如对您最喜欢的品牌的汽车数据进行采集统计分析等等。
输入文字:
1.着陆页分析
目标网站是某汽车之家关于品牌汽车型号的口碑模块相关数据。例如,我们演示的Audi Q5L的口碑如下:
https://k.autohome.com.cn/4851/#pvareaid=3311678
为了演示,您可以直接打开上面的URL,然后将其拖动到所有口碑位置,然后找到我们这次需要的字段采集,如下图所示:
采集字段
我们翻了一页,发现浏览器URL已更改。您可以找到以下页面的URL规则:
https://k.autohome.com.cn/4851 ... aList
https://k.autohome.com.cn/4851 ... aList
https://k.autohome.com.cn/4851 ... aList
对于上面写的URL,我们发现可变部分是车辆型号(例如485 1)和页码(例如2、3,4))),因此我们可以将URL参数构造为如下:
# typeid是车型,page是页码
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
2.数据请求
通过一个简单的测试,似乎没有抗攀爬,所以很简单。
让我们首先介绍我们需要使用的库:
import requests
import pandas as pd
import html
from lxml import etree
import re
然后创建用于备份的数据请求功能:
# 获取网页数据(传递参数 车型typeid和页码数)
def get_html(typeid,page):
# 组合出请求地址
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
# 请求数据(因为没有反爬,这里没有设置请求头和其他参数)
r = requests.get(url)
# 请求的网页数据中有网页特殊字符,通过以下方法进行解析
r = html.unescape(r.text)
# 返回网页数据
return r
请求的数据是网页的html文本。接下来,我们使用re解析出总页数,然后使用xpath解析采集字段。
3.数据分析
由于需要翻页,因此我们首先可以通过重新正则表达式获取总页数。通过检查网页数据,我们发现可以通过以下方式获得总页数:
try:
pages = int(re.findall(r'共(\d+)页',r)[0])
# 如果请求不到页数,则表示该车型下没有口碑数据
except :
print(f'{name} 没有数据!')
continue
总页码采集
关于字段信息为采集,我们发现它们都在节点div [@ class =“ mouthcon-cont-left”]中。您可以先找到节点数据,然后再对其进行逐一分析。
采集字段信息所在的节点
此外,我们发现每个页面最多收录15个汽车模型口碑数据,因此我们每页可以找到15个采集信息数据集,并遍历采集代码:
divs = r_html.xpath('.//div[@class="mouthcon-cont-left"]')
# 遍历每个全部的车辆销售信息
for div in divs:
# 找到车辆销售信息所在的地方
mt = div.xpath('./div[@class="choose-con mt-10"]')[0]
# 找到所需字段
infos = mt.xpath('./dl[@class="choose-dl"]')
# 设置空的字典,用于存储单个车辆信息
item = {}
# 遍历车辆信息字段
for info in infos:
key = info.xpath('.//dt/text()')[0]
# 当字段为购买车型时,进行拆分为车型和配置
if key == '购买车型':
item[key] = info.xpath('.//dd/a/text()')[0]
item['购买配置'] = info.xpath('.//span[@class="font-arial"]/text()')[0]
# 当字段为购车经销商时,需要获取经销商的id参数,再调用api获取其真实经销商信息(这里有坑)
elif key == '购车经销商':
# 经销商id参数
经销商id = info.xpath('.//dd/a/@data-val')[0] +','+ info.xpath('.//dd/a/@data-evalid')[0]
# 组合经销商信息请求地址
jxs_url = base_jxs_url+经销商id+'|'
# 请求数据(为json格式)
data = requests.get(jxs_url)
j = data.json()
# 获取经销商名称
item[key] = j['result']['List'][0]['CompanySimple']
else:
# 其他字段时,替换转义字符和空格等为空
item[key] = info.xpath('.//dd/text()')[0].replace("\r\n","").replace(' ','').replace('\xa0','')
4.数据存储
由于没有防爬坡,因此我们在此将采集中的数据直接转换为pandas.DataFrame类型,然后将其存储为xlsx文件。
df = pd.DataFrame(items)
df = df[['购买车型', '购买配置', '购买地点', '购车经销商', '购买时间', '裸车购买价']]
# 数据存储在本地
df.to_excel(r'车辆销售信息.xlsx',index=None,sheet_name='data')
5. 采集结果预览
整个爬网过程相对简单,来自采集的数据也相对标准化。本文中的Audi Q5L示例如下:
采集结果预览
以上是本次的所有内容。这是相对简单的。有兴趣的学生可以尝试根据一些有趣的数据进行统计分析和可视化显示。
文章在这里,谢谢收看
说实话,每当我在后台看到一些读者的回应时,我都会感到非常高兴。我想向所有人贡献我最喜欢的编程干货,并回馈给每个读者,希望对您有所帮助。
主要干货是:
①超过2000篇Python电子书(应有主流和经典书籍)
②Python标准库数据(最完整的中文版本)
③项目源代码(四十或五十个有趣而经典的动手项目和源代码)
④有关Python,爬虫,Web开发和大数据分析的基础知识的视频(适合小白学习)
⑤Python的所有知识点摘要(您可以了解Python的所有方向和技术)
*如果可以使用,可以直接将其拿走。在我的QQ技术交流小组中,您可以自己取走它。组号是857113825。*
查看全部
【汽车课堂】汽车品牌汽车口碑模块采集过程(一)
大家好,我要启航了。
应朋友的要求,帮助采集某个汽车之家的某些汽车品牌的销售数据,包括购买时间,型号,经销商和裸车价格等信息。
今天,我们将简要演示采集流程。您可以根据自己的兴趣进行扩展,例如对您最喜欢的品牌的汽车数据进行采集统计分析等等。
输入文字:
1.着陆页分析
目标网站是某汽车之家关于品牌汽车型号的口碑模块相关数据。例如,我们演示的Audi Q5L的口碑如下:
https://k.autohome.com.cn/4851/#pvareaid=3311678
为了演示,您可以直接打开上面的URL,然后将其拖动到所有口碑位置,然后找到我们这次需要的字段采集,如下图所示:
采集字段
我们翻了一页,发现浏览器URL已更改。您可以找到以下页面的URL规则:
https://k.autohome.com.cn/4851 ... aList
https://k.autohome.com.cn/4851 ... aList
https://k.autohome.com.cn/4851 ... aList
对于上面写的URL,我们发现可变部分是车辆型号(例如485 1)和页码(例如2、3,4))),因此我们可以将URL参数构造为如下:
# typeid是车型,page是页码
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
2.数据请求
通过一个简单的测试,似乎没有抗攀爬,所以很简单。
让我们首先介绍我们需要使用的库:
import requests
import pandas as pd
import html
from lxml import etree
import re
然后创建用于备份的数据请求功能:
# 获取网页数据(传递参数 车型typeid和页码数)
def get_html(typeid,page):
# 组合出请求地址
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
# 请求数据(因为没有反爬,这里没有设置请求头和其他参数)
r = requests.get(url)
# 请求的网页数据中有网页特殊字符,通过以下方法进行解析
r = html.unescape(r.text)
# 返回网页数据
return r
请求的数据是网页的html文本。接下来,我们使用re解析出总页数,然后使用xpath解析采集字段。
3.数据分析
由于需要翻页,因此我们首先可以通过重新正则表达式获取总页数。通过检查网页数据,我们发现可以通过以下方式获得总页数:
try:
pages = int(re.findall(r'共(\d+)页',r)[0])
# 如果请求不到页数,则表示该车型下没有口碑数据
except :
print(f'{name} 没有数据!')
continue
总页码采集
关于字段信息为采集,我们发现它们都在节点div [@ class =“ mouthcon-cont-left”]中。您可以先找到节点数据,然后再对其进行逐一分析。
采集字段信息所在的节点
此外,我们发现每个页面最多收录15个汽车模型口碑数据,因此我们每页可以找到15个采集信息数据集,并遍历采集代码:
divs = r_html.xpath('.//div[@class="mouthcon-cont-left"]')
# 遍历每个全部的车辆销售信息
for div in divs:
# 找到车辆销售信息所在的地方
mt = div.xpath('./div[@class="choose-con mt-10"]')[0]
# 找到所需字段
infos = mt.xpath('./dl[@class="choose-dl"]')
# 设置空的字典,用于存储单个车辆信息
item = {}
# 遍历车辆信息字段
for info in infos:
key = info.xpath('.//dt/text()')[0]
# 当字段为购买车型时,进行拆分为车型和配置
if key == '购买车型':
item[key] = info.xpath('.//dd/a/text()')[0]
item['购买配置'] = info.xpath('.//span[@class="font-arial"]/text()')[0]
# 当字段为购车经销商时,需要获取经销商的id参数,再调用api获取其真实经销商信息(这里有坑)
elif key == '购车经销商':
# 经销商id参数
经销商id = info.xpath('.//dd/a/@data-val')[0] +','+ info.xpath('.//dd/a/@data-evalid')[0]
# 组合经销商信息请求地址
jxs_url = base_jxs_url+经销商id+'|'
# 请求数据(为json格式)
data = requests.get(jxs_url)
j = data.json()
# 获取经销商名称
item[key] = j['result']['List'][0]['CompanySimple']
else:
# 其他字段时,替换转义字符和空格等为空
item[key] = info.xpath('.//dd/text()')[0].replace("\r\n","").replace(' ','').replace('\xa0','')
4.数据存储
由于没有防爬坡,因此我们在此将采集中的数据直接转换为pandas.DataFrame类型,然后将其存储为xlsx文件。
df = pd.DataFrame(items)
df = df[['购买车型', '购买配置', '购买地点', '购车经销商', '购买时间', '裸车购买价']]
# 数据存储在本地
df.to_excel(r'车辆销售信息.xlsx',index=None,sheet_name='data')
5. 采集结果预览
整个爬网过程相对简单,来自采集的数据也相对标准化。本文中的Audi Q5L示例如下:
采集结果预览
以上是本次的所有内容。这是相对简单的。有兴趣的学生可以尝试根据一些有趣的数据进行统计分析和可视化显示。
文章在这里,谢谢收看
说实话,每当我在后台看到一些读者的回应时,我都会感到非常高兴。我想向所有人贡献我最喜欢的编程干货,并回馈给每个读者,希望对您有所帮助。
主要干货是:
①超过2000篇Python电子书(应有主流和经典书籍)
②Python标准库数据(最完整的中文版本)
③项目源代码(四十或五十个有趣而经典的动手项目和源代码)
④有关Python,爬虫,Web开发和大数据分析的基础知识的视频(适合小白学习)
⑤Python的所有知识点摘要(您可以了解Python的所有方向和技术)
*如果可以使用,可以直接将其拿走。在我的QQ技术交流小组中,您可以自己取走它。组号是857113825。*
自动采集数据是三种方式,你想爬什么效率更高
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-05-18 04:03
自动采集数据通常是三种方式,第一种:网页爬虫(涉及javascript、css、html),第二种:分布式爬虫(本地利用机器+分布式数据采集+持久化处理+迭代机制),第三种:实时抓取(采用golang语言),一般企业会在各自的业务区域做分割分发。对于你提供的工具,应该是采用第二种,采用golang语言,并且配备自己的源代码,分发。
如果采用第一种,就需要学习如何进行网页爬虫。给一个图,供参考:1.实时抓取2.处理复杂度3.整合各端数据:app端:wap、wap+pc、app+pc、h5、微信web、公众号等3.整合持久化处理:es2015、storm等。
同意楼上所说的;首先要定义问题。你想爬什么,由于题主主要分析it行业,我觉得你应该问:爬什么的效率更高。如果是爬wap的话,推荐pythonweb;如果是爬客户端就不要考虑scrapy之类的了,一般只能抓页面,不能抓下单类型的数据。如果想整合持久化存储,那应该是redis+mysql,或者memcached+redis,golang语言的cookie需要类似flask。
其次,得看app类型,如果是pcapp那推荐java/php;如果是小型app,推荐前端框架或者api;如果app是wap或者app和pc共存,那推荐java,整合后和持久化关系不大,如果是新闻类类型的app,推荐scrapy+hadoop;以上资料先百度,多上github看看源代码。 查看全部
自动采集数据是三种方式,你想爬什么效率更高
自动采集数据通常是三种方式,第一种:网页爬虫(涉及javascript、css、html),第二种:分布式爬虫(本地利用机器+分布式数据采集+持久化处理+迭代机制),第三种:实时抓取(采用golang语言),一般企业会在各自的业务区域做分割分发。对于你提供的工具,应该是采用第二种,采用golang语言,并且配备自己的源代码,分发。
如果采用第一种,就需要学习如何进行网页爬虫。给一个图,供参考:1.实时抓取2.处理复杂度3.整合各端数据:app端:wap、wap+pc、app+pc、h5、微信web、公众号等3.整合持久化处理:es2015、storm等。
同意楼上所说的;首先要定义问题。你想爬什么,由于题主主要分析it行业,我觉得你应该问:爬什么的效率更高。如果是爬wap的话,推荐pythonweb;如果是爬客户端就不要考虑scrapy之类的了,一般只能抓页面,不能抓下单类型的数据。如果想整合持久化存储,那应该是redis+mysql,或者memcached+redis,golang语言的cookie需要类似flask。
其次,得看app类型,如果是pcapp那推荐java/php;如果是小型app,推荐前端框架或者api;如果app是wap或者app和pc共存,那推荐java,整合后和持久化关系不大,如果是新闻类类型的app,推荐scrapy+hadoop;以上资料先百度,多上github看看源代码。
自动采集数据源的开发方法有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-05-13 01:04
自动采集数据源,
1、基于现有的项目,
2、从零开始搭建;
3、使用第三方开源平台;第三种常见的开源平台有laravel、thinkphp、phpwind等。
那要看你是走第二种,还是第三种,从零开始的话,就分为三种,一种只做前端功能,例如phpwind,还有一种是利用技术实现后端功能,例如laravel之类的;有一种是的平台,例如wordpress之类的,这种也是需要你会前端或者懂技术管理。如果没有条件自己搭建平台,就是简单的了解下基本的开发方法。
目前大部分的项目都是框架搭建,简单的二次开发。个人觉得除非是比较复杂的项目,或者根本不是php做的,或者只是做了一个php库的话,不用太着急,毕竟现在都是云,可以利用现有的资源或者利用搭建好的平台自动化构建;目前公司一般都是走第二种,实用性比较强。如果你是做前端的,走第三种,那就相对难,想做大就得利用技术管理来手动的管理了;最后,做什么都是熟能生巧,多写写能做好,多想想怎么优化就能做好。希望对你有帮助。
后端才是根本,内功必须打牢。
1、学习相关框架框架多了以后优点很多,比如易学易用(因为框架就是用来实现需求的),开发效率高等等,当然缺点也很多(功能过多,耦合性强等等)。框架有很多,比如:php框架推荐:laravel、thinkphp等等,这些框架优点在于框架太多,会让你有很多选择(如何去选择框架,其实跟你本身程序员的水平有关系,如果你水平很差,那么你可以尽量选择一些较新的框架,例如laravel,可以把laravel的内容移植到你自己的项目里),laravel被称为php界的diy框架,只有真正理解它才能知道如何使用它,去哪里找laravel源码(也许不需要具体的函数去实现具体的功能,但是概念必须了解)。
2、熟悉数据库本身在php进程中php和数据库的交互会经过这样的三个步骤:1.原有数据库中的对象读取到php实例中2.php中对象与数据库中数据进行连接3.数据库读取成功后,
3、学习内容等3。1基础静态语言包含:php的静态语言库:requests,pdo,etc。当你想要利用这些库来编写一些功能的时候,你就需要掌握它,而不是只会用(有些人对php静态语言基础掌握得不好,在面对高要求的需求时就会表现得束手无策)php的编程技巧:标识符,处理方法,类,对象,方法,数组等等(这些基础技巧学不好,学别的框架你都是无从下手)数据库操作技巧:orm等(在使用php进行数据库操作的时候,数据库操作技巧是最重要的)3。2php。 查看全部
自动采集数据源的开发方法有哪些?-八维教育
自动采集数据源,
1、基于现有的项目,
2、从零开始搭建;
3、使用第三方开源平台;第三种常见的开源平台有laravel、thinkphp、phpwind等。
那要看你是走第二种,还是第三种,从零开始的话,就分为三种,一种只做前端功能,例如phpwind,还有一种是利用技术实现后端功能,例如laravel之类的;有一种是的平台,例如wordpress之类的,这种也是需要你会前端或者懂技术管理。如果没有条件自己搭建平台,就是简单的了解下基本的开发方法。
目前大部分的项目都是框架搭建,简单的二次开发。个人觉得除非是比较复杂的项目,或者根本不是php做的,或者只是做了一个php库的话,不用太着急,毕竟现在都是云,可以利用现有的资源或者利用搭建好的平台自动化构建;目前公司一般都是走第二种,实用性比较强。如果你是做前端的,走第三种,那就相对难,想做大就得利用技术管理来手动的管理了;最后,做什么都是熟能生巧,多写写能做好,多想想怎么优化就能做好。希望对你有帮助。
后端才是根本,内功必须打牢。
1、学习相关框架框架多了以后优点很多,比如易学易用(因为框架就是用来实现需求的),开发效率高等等,当然缺点也很多(功能过多,耦合性强等等)。框架有很多,比如:php框架推荐:laravel、thinkphp等等,这些框架优点在于框架太多,会让你有很多选择(如何去选择框架,其实跟你本身程序员的水平有关系,如果你水平很差,那么你可以尽量选择一些较新的框架,例如laravel,可以把laravel的内容移植到你自己的项目里),laravel被称为php界的diy框架,只有真正理解它才能知道如何使用它,去哪里找laravel源码(也许不需要具体的函数去实现具体的功能,但是概念必须了解)。
2、熟悉数据库本身在php进程中php和数据库的交互会经过这样的三个步骤:1.原有数据库中的对象读取到php实例中2.php中对象与数据库中数据进行连接3.数据库读取成功后,
3、学习内容等3。1基础静态语言包含:php的静态语言库:requests,pdo,etc。当你想要利用这些库来编写一些功能的时候,你就需要掌握它,而不是只会用(有些人对php静态语言基础掌握得不好,在面对高要求的需求时就会表现得束手无策)php的编程技巧:标识符,处理方法,类,对象,方法,数组等等(这些基础技巧学不好,学别的框架你都是无从下手)数据库操作技巧:orm等(在使用php进行数据库操作的时候,数据库操作技巧是最重要的)3。2php。
中控区ssh到服务器上执行完后怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-05-12 21:24
自动采集数据,三种方式:
代理方法:
agent:是客户端,将采集程序放在客户端上,完成数据后,agent 采集直接返回api程序(当前为django程序)
代理程序:
#!/usr/bin/env python3
import subprocess
v2=subprocess.getoutput('ifconfig')
print(v2)
url='http://192.168.11.27:8003/asset.html'
import requests
requests.post(url,data={'k1':v2})
api:
from django.shortcuts import render,HttpResponse
# Create your views here.
def asset(request): if request.method=='POST': print(request.POST) return HttpResponse('copy that') else: return HttpResponse('null')
ssh方法:
ssh使用位于中央控制区的paramiko(python模块)
ssh方法没有代理。通过中央控制区中的ssh在服务器上远程执行命令后,将返回结果,然后将其传递给API;然后写入数据库
盐堆:
盐堆也是中央控制区域。主机执行命令后,例如:
执行后,客户端将返回结果
saltstack的原理是RPC,它维护一个消息队列,该队列默认情况下为空。当主机有一个要执行的命令时,如上所示,队列中有命令,然后客户端执行::
在执行客户端后创建一个队列-存储在该队列中的结果将返回给主服务器
saltstack安装附录
安装后检查主节点的小部分
基本用法:
在安装后修改配置:
服务器:
/ etc / salt / master
界面:19 2. 16 8. 4 4. 145
/ etc / salt / minion
客户:主数据:19 2. 16 8. 4 4. 148。 #master的地址
盐键-L查看授权的奴才
服务盐奴才重启启动
#quick-install
转载于: 查看全部
中控区ssh到服务器上执行完后怎么办?
自动采集数据,三种方式:
代理方法:
agent:是客户端,将采集程序放在客户端上,完成数据后,agent 采集直接返回api程序(当前为django程序)
代理程序:
#!/usr/bin/env python3
import subprocess
v2=subprocess.getoutput('ifconfig')
print(v2)
url='http://192.168.11.27:8003/asset.html'
import requests
requests.post(url,data={'k1':v2})
api:
from django.shortcuts import render,HttpResponse
# Create your views here.
def asset(request): if request.method=='POST': print(request.POST) return HttpResponse('copy that') else: return HttpResponse('null')
ssh方法:
ssh使用位于中央控制区的paramiko(python模块)
ssh方法没有代理。通过中央控制区中的ssh在服务器上远程执行命令后,将返回结果,然后将其传递给API;然后写入数据库
盐堆:
盐堆也是中央控制区域。主机执行命令后,例如:
执行后,客户端将返回结果
saltstack的原理是RPC,它维护一个消息队列,该队列默认情况下为空。当主机有一个要执行的命令时,如上所示,队列中有命令,然后客户端执行::
在执行客户端后创建一个队列-存储在该队列中的结果将返回给主服务器
saltstack安装附录
安装后检查主节点的小部分
基本用法:
在安装后修改配置:
服务器:
/ etc / salt / master
界面:19 2. 16 8. 4 4. 145
/ etc / salt / minion
客户:主数据:19 2. 16 8. 4 4. 148。 #master的地址
盐键-L查看授权的奴才
服务盐奴才重启启动
#quick-install
转载于:
我要点外卖如何将数据采集产生日志数据集中收集起来
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-05-08 01:08
背景
“我要订购食物”是一个基于平台的电子商务网站,涉及用户,餐厅,送货人员等。用户可以在Web,App,微信,支付宝等网站上下订单。收到订单后,它将开始处理并自动通知其周围的快递人员。快递员将食物交付给用户。
操作要求
在操作过程中,发现以下问题:
数据采集困难
在数据操作过程中,第一步是如何集中采集分散的日志数据,这将面临以下挑战:
我们需要采集分散在内部和内部的日志,并以统一的方式进行管理。过去,该区域需要进行许多不同类型的工作,现在可以通过loghub 采集函数对其进行访问。
统一日志管理,配置创建管理日志项,例如myorder。为不同数据源生成的日志创建日志库。例如,如果需要清除和ETL原创数据,则可以创建一些中间结果日志存储。用户提升日志采集
为了获取新用户,通常有两种方法:
实施方法
定义以下注册服务器地址,并生成QR码(传单,网页)供用户注册和扫描。当用户扫描页面进行注册时,他可以知道用户是通过特定来源输入并记录日志的。
http://examplewebsite/login%3F ... Dkd4b
服务器接受请求后,服务器将输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
其中:
采集方法:
服务器数据采集
支付宝/微信公众号编程是一种典型的Web端模式,通常有三种日志类型:
实施方法:终端用户登录访问Web / M站页面的用户行为
页面用户行为集合可以分为两类:
实施方法服务器日志的操作和维护
例如:
实施方法
请参阅服务器采集方法。
不同网络环境下的数据采集
loghub在每个Region中提供访问点,每个Region提供三种访问方式: 查看全部
我要点外卖如何将数据采集产生日志数据集中收集起来
背景
“我要订购食物”是一个基于平台的电子商务网站,涉及用户,餐厅,送货人员等。用户可以在Web,App,微信,支付宝等网站上下订单。收到订单后,它将开始处理并自动通知其周围的快递人员。快递员将食物交付给用户。
操作要求
在操作过程中,发现以下问题:
数据采集困难
在数据操作过程中,第一步是如何集中采集分散的日志数据,这将面临以下挑战:
我们需要采集分散在内部和内部的日志,并以统一的方式进行管理。过去,该区域需要进行许多不同类型的工作,现在可以通过loghub 采集函数对其进行访问。
统一日志管理,配置创建管理日志项,例如myorder。为不同数据源生成的日志创建日志库。例如,如果需要清除和ETL原创数据,则可以创建一些中间结果日志存储。用户提升日志采集
为了获取新用户,通常有两种方法:
实施方法
定义以下注册服务器地址,并生成QR码(传单,网页)供用户注册和扫描。当用户扫描页面进行注册时,他可以知道用户是通过特定来源输入并记录日志的。
http://examplewebsite/login%3F ... Dkd4b
服务器接受请求后,服务器将输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
其中:
采集方法:
服务器数据采集
支付宝/微信公众号编程是一种典型的Web端模式,通常有三种日志类型:
实施方法:终端用户登录访问Web / M站页面的用户行为
页面用户行为集合可以分为两类:
实施方法服务器日志的操作和维护
例如:
实施方法
请参阅服务器采集方法。
不同网络环境下的数据采集
loghub在每个Region中提供访问点,每个Region提供三种访问方式:
自动采集数据和大数据分析,我们有哪些挑战?
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-05-07 21:03
自动采集数据和大数据分析,尤其是大数据可视化,我们已经做了很多次实践了,但我们还是停留在实验层面,更多的还是去做数据分析和数据挖掘。有一个业务需求,要找数据来训练一个语言模型,数据我们不公开,我们会根据业务需求私密上传,可大家一起监督学习。这对我们有哪些挑战?第一,要找到好的工具,采用公开数据采集。例如,经常存在于线上的spider可以对人的监督学习。
这样的话就需要我们熟悉spider和相关算法。为了简单起见,我们不想这么复杂,基于tokenizer的聚类算法,可以达到找到类别或者特征的效果。china-simsdk[]()我们尝试过imwrite_matc[]()或者networkflat这样的工具,效果还可以,但对于训练学习算法都不是非常友好。
第二,准备gpupython的io密集型任务,最近我在尝试pyspider[]()来测试,效果是不错,但pyspider还要写不少spider,开销比较大。第三,配置环境我们准备在python3.6+环境,如果只用python2.7,我们可以在python.exe中直接安装对应的库,但是enthought大多数库都是私有的,并不是生产中常用。
目前只能使用如下图所示的方式,配置环境。配置参考文档pipinstallpyspider本文的实验环境如下图所示,mac-amd64。安装pyspiderpipinstallpyspider初步看了it之家的一篇博客,配置非常简单,看了一下,我根据我们实验需要做了一些变动。1、配置pyspiderpythonsettings如果你已经配置好了,那么直接执行命令pythonsetup.pyinstall。
2、更改mac环境变量enthought-installer-macpath=./path.x86_64/external-library/libmacosx/macosx.appset-exclude-macpath=./external-library/libmcrypto-2.1.0/external-library/libmcrypto-2.1.0set-export-environment-path=~/path.x86_64/libmacosx/macosx.appset-export-environment-split-path=/external-library/libpcrypto-2.1.0set-export-export-environment-optional-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-requirements-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-environment-split-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-export-export-environment-option。 查看全部
自动采集数据和大数据分析,我们有哪些挑战?
自动采集数据和大数据分析,尤其是大数据可视化,我们已经做了很多次实践了,但我们还是停留在实验层面,更多的还是去做数据分析和数据挖掘。有一个业务需求,要找数据来训练一个语言模型,数据我们不公开,我们会根据业务需求私密上传,可大家一起监督学习。这对我们有哪些挑战?第一,要找到好的工具,采用公开数据采集。例如,经常存在于线上的spider可以对人的监督学习。
这样的话就需要我们熟悉spider和相关算法。为了简单起见,我们不想这么复杂,基于tokenizer的聚类算法,可以达到找到类别或者特征的效果。china-simsdk[]()我们尝试过imwrite_matc[]()或者networkflat这样的工具,效果还可以,但对于训练学习算法都不是非常友好。
第二,准备gpupython的io密集型任务,最近我在尝试pyspider[]()来测试,效果是不错,但pyspider还要写不少spider,开销比较大。第三,配置环境我们准备在python3.6+环境,如果只用python2.7,我们可以在python.exe中直接安装对应的库,但是enthought大多数库都是私有的,并不是生产中常用。
目前只能使用如下图所示的方式,配置环境。配置参考文档pipinstallpyspider本文的实验环境如下图所示,mac-amd64。安装pyspiderpipinstallpyspider初步看了it之家的一篇博客,配置非常简单,看了一下,我根据我们实验需要做了一些变动。1、配置pyspiderpythonsettings如果你已经配置好了,那么直接执行命令pythonsetup.pyinstall。
2、更改mac环境变量enthought-installer-macpath=./path.x86_64/external-library/libmacosx/macosx.appset-exclude-macpath=./external-library/libmcrypto-2.1.0/external-library/libmcrypto-2.1.0set-export-environment-path=~/path.x86_64/libmacosx/macosx.appset-export-environment-split-path=/external-library/libpcrypto-2.1.0set-export-export-environment-optional-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-requirements-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-environment-split-path=/external-library/libpcrypto-2.1.0export-export-export-export-export-export-export-environment-option。
webscraper插件到底要怎么用?爬取数据的基本流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-05-05 23:20
在工作中,几乎每个职位都涉及数据采集任务。采集所有本地装饰公司的列表,采集某个APP的所有注释,采集与互联网上**相关的所有文章,批量下载某个网站的指定文件...
我不知道如何编程,也不了解爬网技术。我遇到过这种工作。我要么强制CTRL + C,CTRL + V,要么大笑,并要求技术人员帮助我抓取数据。直到我遇到了Web刮板的这种工件,才需要编程经验。只需完成几个简单的设置步骤,即可在几分钟内快速采集成千上万的数据,并且效率非常高。
Web scraper是Google采集器插件。它非常易于使用,可以在30分钟内完全掌握。网页抓取工具插件将抓取数据以生成供我们使用的excel工作表。
那么您如何使用此插件?
抓取数据的基本过程
第一步:下载并安装网络抓取插件。
下载链接:链接:密码:t7bm
安装方法:请参考百度经验文章
第二步:创建一个新的数据爬网站点。
首先按F12键(或单击鼠标右键进行检查)以调出控制台,单击“ Web Scraper”以切换到采集器插件功能,然后单击“创建新的站点地图”以进入新的数据搜寻站点创建页面。
站点地图名称可以自定义,但必须为英文。起始网址是我们要抓取的网站 URL。在这里,我们过去一周在上搜寻了上海相同的城市活动,将以下链接复制到开始url输入框中,然后单击“创建站点地图”以确认创建。
第3步:选择要提取的页面元素
成功创建上一步后,页面将跳至以下界面,然后单击“添加新选择器”以创建新选择器。
以提取页面的活动标题为例,将ID设置为“ title”(您可以在此处对其进行自定义,它将成为excel中的标题),类型为“ text”。
选择器是指需要在页面中提取的数据区域。单击选择,在网页上滑动鼠标,将出现绿色区域,表明我们可以在这些区域中选择数据。
选择一个事件标题,该区域将被红色边框包围,然后继续选择下一个事件标题。当选择两个相同的面积,该插件将自动选择网页上的其他类似的元件。点击“完成选择!”确认选择。
我们可以单击“元素预览”以查看页面上所有选定的区域,然后单击“数据预览”以预览采集器将获取的数据。
注意:由于我们要选择此页面上的所有事件标题,因此需要选中“多个”复选框。其余内容可以保留为默认值,请单击“保存选择器”以保存该选择器。
这时,我们选择了需要提取的页面元素,如下图所示。
第4步:开始抓取数据
点击抓取进入数据抓取开始页面。
设置请求间隔和页面加载延迟时间,然后单击“开始抓取”以开始抓取数据。此处的时间间隔主要是为了防止采集器因过于频繁的操作而被阻止并且无法正常爬行。正常的网站默认时间间隔很好,某些网站可能需要设置更大的时间间隔。
启动后,将打开目标URL的窗口,并且爬网程序将根据设置的提取规则逐一爬网。抓取完成后,该窗口将自动关闭。
第5步:下载数据
单击“将数据导出为CSV”以跳至excel数据下载页面,然后单击“立即下载”进行下载。
以上五个步骤是使用Web爬网程序爬网数据的整个过程和操作。无论数据多么复杂,都可以根据这样的过程和操作对相应的数据进行爬网。
高级操作
1。如何一次抓取一组数据?
我们刚刚抓取了活动的主题。如果要同时抓取主题和活动时间,该怎么办?
从上图可以看到数据的结构。事件主题和事件时间同时收录在最外面的框中。因此,在设置选择器时,首先创建一个较大的选择器,以使事件主题与活动内容同时收录在内。
请注意,此处的类型应设置为“元素”。保存后,单击刚刚创建的内容(下图中红色框的位置)以进入子页面。
然后在此页面上创建标题选择器和时间选择器。类型均为文本。现在页面的可选区域仅限于列表区域,因此您只需单击一次事件标题并确保将其选中。不要选中“多个”。
只有通过创建收录活动主题和活动时间的元素选择器,爬网的数据才会以一一对应的方式呈现。
2。如何一次抓取多个页面?
根据分页的不同形式,有不同的解决方案。
1)在固定分页的情况下
可以注意到,豆瓣的同一个城市活动页面已分页,每页显示10条数据。因此,如果我们要抓取数据的前10页,该怎么办?
如果仔细观察,会发现第一页的URL和第二页的URL之间存在差异。
第一页:
第二页:
start =以下数字是相差10的算术序列。
然后,当我们设置数据爬网站点时,我们使用[0-100:10]而不是特定的数字来表示数据爬网的页面间隔。也就是说:[0-100:10]
如果URL的算术差为1,例如知乎问题的URL:
第一页:
第二页:
省略了冒号和后面的算术差,仅写入页码间隔。例如[1-10]
表示知乎主题的第一页至第十页。
处理此类数据的关键是观察不同页面的URL的变化,然后将页码间隔写入URL。
2)通过滚动鼠标自动加载
当前,许多网站都采用了滚动到底部后自动加载数据的方法,并且它们的URL并未更改。例如知乎实时首页的数据加载方法。
这时,我们需要在创建元素选择器时将“类型”设置为“元素向下滚动”。这样,爬网程序在工作时将自动执行滚动操作,并不断进行爬网直到没有数据要加载。
3)点击页面底部的“加载更多”按钮
设置外部元素元素时,将“类型”设置为“元素单击”,然后单击“单击选择器”的“选择”按钮以选择页面上的“加载更多”按钮或图标。
为了使页面连续加载,请将“点击类型”设置为“点击更多”,然后单击多次。
下一步,设置条件以停止单击。当此区域的文本内容或HTML结构或显示样式更改时,不再单击。
例如,当加载完成时,“加载更多”按钮的文本变为“已加载”,然后选择“唯一文本”;如果在加载结束时该按钮显示为灰色,请选择“唯一CSS选择器”。
3,如何批量抓取和下载图片?
将“类型”设置为image,该插件将抓取所有图像的链接。有两种下载图像的方法,一种是直接选中“下载图像”,以便爬网程序在爬网时将自动下载它。或在抓取所有图像链接之后,使用批处理下载工具直接下载。
4,如何抓取Web链接?
将“类型”设置为“链接”,爬网程序将爬网到元素上的超链接。
如图所示:当“类型”是文本时,抓取的数据是立陶宛语Anzelika Cholina舞蹈剧院的Anna Karenina。
当“类型”为“链接”时,抓取的数据为:即,单击指向该页面的链接,该页面跳到下图中红色框中的内容。
例如,当您需要抓取的链接是下载文件的链接时,该链接类似于下图中的“公告下载”按钮。您可以将“类型”设置为“弹出链接”,以便在抓取数据的过程中自动下载文件。
5,如何抓取第二级页面或第三级页面的内容?
首先在根目录中创建一个选择器。该选择器选择的内容是可以单击到辅助页面的区域。如果该区域中有超链接,则将“类型”设置为“链接”,否则设置为“元素单击”;在此选择器中创建一个选择器,然后选择需要爬网的区域。可以逐级嵌套。
如何判断区域中是否有超链接?将鼠标放在该区域中,右键单击,如果有“在...中打开链接”选项,则该区域中有一个超链接,并将“类型”设置为“链接”。
通过上述设置,我们可以使用Google插件抓取80%的网站数据,获取本地excel文件,然后处理和分析数据。
上述技能不仅可以在工作中使用,而且可以在查询生活中的信息时使用。
很多时候网站的设计都有某些问题,这使我们很难获得信息。
例如知乎实时网页,当您单击实时详细信息然后返回时,页面将返回顶部,您需要滚动以再次加载它;
例如,在Interactive Bar的活动列表页面上,没有活动状态的分类。通常,您不能参加正在进行的活动,但不能将其过滤掉。
这时,如果您使用Web抓取工具,则可以在本地对数据进行爬网,然后根据需要快速对其进行过滤。
熟练掌握此插件后,真的可以提高工作效率并减少麻烦吗?
提高工作效率是一定的,但不一定要减少麻烦。毕竟,老板告诉我,因为我下班太早了〜woo 查看全部
webscraper插件到底要怎么用?爬取数据的基本流程
在工作中,几乎每个职位都涉及数据采集任务。采集所有本地装饰公司的列表,采集某个APP的所有注释,采集与互联网上**相关的所有文章,批量下载某个网站的指定文件...
我不知道如何编程,也不了解爬网技术。我遇到过这种工作。我要么强制CTRL + C,CTRL + V,要么大笑,并要求技术人员帮助我抓取数据。直到我遇到了Web刮板的这种工件,才需要编程经验。只需完成几个简单的设置步骤,即可在几分钟内快速采集成千上万的数据,并且效率非常高。
Web scraper是Google采集器插件。它非常易于使用,可以在30分钟内完全掌握。网页抓取工具插件将抓取数据以生成供我们使用的excel工作表。
那么您如何使用此插件?
抓取数据的基本过程
第一步:下载并安装网络抓取插件。
下载链接:链接:密码:t7bm
安装方法:请参考百度经验文章
第二步:创建一个新的数据爬网站点。
首先按F12键(或单击鼠标右键进行检查)以调出控制台,单击“ Web Scraper”以切换到采集器插件功能,然后单击“创建新的站点地图”以进入新的数据搜寻站点创建页面。
站点地图名称可以自定义,但必须为英文。起始网址是我们要抓取的网站 URL。在这里,我们过去一周在上搜寻了上海相同的城市活动,将以下链接复制到开始url输入框中,然后单击“创建站点地图”以确认创建。
第3步:选择要提取的页面元素
成功创建上一步后,页面将跳至以下界面,然后单击“添加新选择器”以创建新选择器。
以提取页面的活动标题为例,将ID设置为“ title”(您可以在此处对其进行自定义,它将成为excel中的标题),类型为“ text”。
选择器是指需要在页面中提取的数据区域。单击选择,在网页上滑动鼠标,将出现绿色区域,表明我们可以在这些区域中选择数据。
选择一个事件标题,该区域将被红色边框包围,然后继续选择下一个事件标题。当选择两个相同的面积,该插件将自动选择网页上的其他类似的元件。点击“完成选择!”确认选择。
我们可以单击“元素预览”以查看页面上所有选定的区域,然后单击“数据预览”以预览采集器将获取的数据。
注意:由于我们要选择此页面上的所有事件标题,因此需要选中“多个”复选框。其余内容可以保留为默认值,请单击“保存选择器”以保存该选择器。
这时,我们选择了需要提取的页面元素,如下图所示。
第4步:开始抓取数据
点击抓取进入数据抓取开始页面。
设置请求间隔和页面加载延迟时间,然后单击“开始抓取”以开始抓取数据。此处的时间间隔主要是为了防止采集器因过于频繁的操作而被阻止并且无法正常爬行。正常的网站默认时间间隔很好,某些网站可能需要设置更大的时间间隔。
启动后,将打开目标URL的窗口,并且爬网程序将根据设置的提取规则逐一爬网。抓取完成后,该窗口将自动关闭。
第5步:下载数据
单击“将数据导出为CSV”以跳至excel数据下载页面,然后单击“立即下载”进行下载。
以上五个步骤是使用Web爬网程序爬网数据的整个过程和操作。无论数据多么复杂,都可以根据这样的过程和操作对相应的数据进行爬网。
高级操作
1。如何一次抓取一组数据?
我们刚刚抓取了活动的主题。如果要同时抓取主题和活动时间,该怎么办?
从上图可以看到数据的结构。事件主题和事件时间同时收录在最外面的框中。因此,在设置选择器时,首先创建一个较大的选择器,以使事件主题与活动内容同时收录在内。
请注意,此处的类型应设置为“元素”。保存后,单击刚刚创建的内容(下图中红色框的位置)以进入子页面。
然后在此页面上创建标题选择器和时间选择器。类型均为文本。现在页面的可选区域仅限于列表区域,因此您只需单击一次事件标题并确保将其选中。不要选中“多个”。
只有通过创建收录活动主题和活动时间的元素选择器,爬网的数据才会以一一对应的方式呈现。
2。如何一次抓取多个页面?
根据分页的不同形式,有不同的解决方案。
1)在固定分页的情况下
可以注意到,豆瓣的同一个城市活动页面已分页,每页显示10条数据。因此,如果我们要抓取数据的前10页,该怎么办?
如果仔细观察,会发现第一页的URL和第二页的URL之间存在差异。
第一页:
第二页:
start =以下数字是相差10的算术序列。
然后,当我们设置数据爬网站点时,我们使用[0-100:10]而不是特定的数字来表示数据爬网的页面间隔。也就是说:[0-100:10]
如果URL的算术差为1,例如知乎问题的URL:
第一页:
第二页:
省略了冒号和后面的算术差,仅写入页码间隔。例如[1-10]
表示知乎主题的第一页至第十页。
处理此类数据的关键是观察不同页面的URL的变化,然后将页码间隔写入URL。
2)通过滚动鼠标自动加载
当前,许多网站都采用了滚动到底部后自动加载数据的方法,并且它们的URL并未更改。例如知乎实时首页的数据加载方法。
这时,我们需要在创建元素选择器时将“类型”设置为“元素向下滚动”。这样,爬网程序在工作时将自动执行滚动操作,并不断进行爬网直到没有数据要加载。
3)点击页面底部的“加载更多”按钮
设置外部元素元素时,将“类型”设置为“元素单击”,然后单击“单击选择器”的“选择”按钮以选择页面上的“加载更多”按钮或图标。
为了使页面连续加载,请将“点击类型”设置为“点击更多”,然后单击多次。
下一步,设置条件以停止单击。当此区域的文本内容或HTML结构或显示样式更改时,不再单击。
例如,当加载完成时,“加载更多”按钮的文本变为“已加载”,然后选择“唯一文本”;如果在加载结束时该按钮显示为灰色,请选择“唯一CSS选择器”。
3,如何批量抓取和下载图片?
将“类型”设置为image,该插件将抓取所有图像的链接。有两种下载图像的方法,一种是直接选中“下载图像”,以便爬网程序在爬网时将自动下载它。或在抓取所有图像链接之后,使用批处理下载工具直接下载。
4,如何抓取Web链接?
将“类型”设置为“链接”,爬网程序将爬网到元素上的超链接。
如图所示:当“类型”是文本时,抓取的数据是立陶宛语Anzelika Cholina舞蹈剧院的Anna Karenina。
当“类型”为“链接”时,抓取的数据为:即,单击指向该页面的链接,该页面跳到下图中红色框中的内容。
例如,当您需要抓取的链接是下载文件的链接时,该链接类似于下图中的“公告下载”按钮。您可以将“类型”设置为“弹出链接”,以便在抓取数据的过程中自动下载文件。
5,如何抓取第二级页面或第三级页面的内容?
首先在根目录中创建一个选择器。该选择器选择的内容是可以单击到辅助页面的区域。如果该区域中有超链接,则将“类型”设置为“链接”,否则设置为“元素单击”;在此选择器中创建一个选择器,然后选择需要爬网的区域。可以逐级嵌套。
如何判断区域中是否有超链接?将鼠标放在该区域中,右键单击,如果有“在...中打开链接”选项,则该区域中有一个超链接,并将“类型”设置为“链接”。
通过上述设置,我们可以使用Google插件抓取80%的网站数据,获取本地excel文件,然后处理和分析数据。
上述技能不仅可以在工作中使用,而且可以在查询生活中的信息时使用。
很多时候网站的设计都有某些问题,这使我们很难获得信息。
例如知乎实时网页,当您单击实时详细信息然后返回时,页面将返回顶部,您需要滚动以再次加载它;
例如,在Interactive Bar的活动列表页面上,没有活动状态的分类。通常,您不能参加正在进行的活动,但不能将其过滤掉。
这时,如果您使用Web抓取工具,则可以在本地对数据进行爬网,然后根据需要快速对其进行过滤。
熟练掌握此插件后,真的可以提高工作效率并减少麻烦吗?
提高工作效率是一定的,但不一定要减少麻烦。毕竟,老板告诉我,因为我下班太早了〜woo
节点采集成功的使用说明及使用方法(一幅)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-05-03 04:19
说明1-运行数据的解释(单击下面所有图片放大)
这是典型的运行信息数据图
主要包括节点(即列表页面)采集,内容页面采集和文章的仓储统计数据,包括当天数据和总数据。
从图中可以看到,当天采集节点成功了31次,采集内容页面成功了5391次,文章在数据库中发布了29篇文章。
内容页面采集成功获得5391次,但仅发表了29篇文章,但不相等。这是因为内容页面采集和文章不能同时释放。已经到达采集但尚未发布的文章将在第二天继续发布。
此外,图中红色框特别标记,可以看到节点采集的成功率不高。
因为这里[节点采集成功]的定义是:只要列表页面上更新的文章没有采集,就将视为失败!这与我们通常理解的有点不同。至于为什么这样定义,我将在后面讨论。
先前的运行信息是总数据,此图片是每个节点的单独数据
区域A中的数据是:节点采集,内容采集和库存释放的统计数据。例如,有这样的数据:
其含义是:今天,节点采集成功1次/节点总计采集 7次,内容页面采集成功449次/内容页面总计采集 458次,文章发布到数据库中1条。
当插件程序采集列出该页面时,它将一次保存所有匹配的URL(有效URL,对于内容页面为采集)。第二次进入采集列表页面。如果您发现文章 URL仍然是先前的URL(这些URL是第一次记录,则被视为无效URL),则无需再次记录它们。由于第二次采集没有新的URL(有效URL),因此程序认为采集这次失败了。
B区域中的数据是:节点的下一次采集。
通常来说,目标网站的列表页面不会实时更新,并且一天甚至几天内只会更新几篇文章。因此,无需经常访问采集,默认情况下,插件程序会自动调整列表页面采集的频率。
这里的时间是插件程序下次的最早采集时间。至少在此时间结束后,程序将成为节点采集。
当然,可能还会有一个列表页面在几分钟内更新文章,或者您对目标网站的文章更新时间非常敏感,因此您需要从以下位置监视列表页面:时不时。此时,您可以将节点参数中的[列表页面采集频率]设置为[高频率],此设置之后,[下一个时间采集]时间将显示为任何时间,如下图:
C区域中的数据是节点清单的URL,因为某些URL可能不是采集,或者标题可能被重复和排除,等等,因此可以是文章的数量。释放到库中通常大于库存。URL很少。
A区域中的数据,如果出现红色数据,请特别注意。
节点采集:0/10,节点(列表页面)采集 10次,并且没有有效的URL匹配一次。在这种情况下,有两种可能性:采集规则中有一个列表页面规则。问题是内容页面URL无法匹配(解决方案是重新调整采集规则);或另一方网站尚未更新,并且该节点已被放弃(解决方案是找到新的目标列表页面并重新编写采集规则)。简而言之,无论情况如何,都需要人工干预。
A区域的红色数据表示存在需要手动干预的情况。
上图表明节点采集具有红色数据,相同的内容页面采集也可能具有红色数据。同样需要人工干预,并且分析方法与节点采集相似。 查看全部
节点采集成功的使用说明及使用方法(一幅)
说明1-运行数据的解释(单击下面所有图片放大)
https://www.dedeplus.com/wp-co ... 8.gif 300w" />这是典型的运行信息数据图
主要包括节点(即列表页面)采集,内容页面采集和文章的仓储统计数据,包括当天数据和总数据。
从图中可以看到,当天采集节点成功了31次,采集内容页面成功了5391次,文章在数据库中发布了29篇文章。
内容页面采集成功获得5391次,但仅发表了29篇文章,但不相等。这是因为内容页面采集和文章不能同时释放。已经到达采集但尚未发布的文章将在第二天继续发布。
此外,图中红色框特别标记,可以看到节点采集的成功率不高。
因为这里[节点采集成功]的定义是:只要列表页面上更新的文章没有采集,就将视为失败!这与我们通常理解的有点不同。至于为什么这样定义,我将在后面讨论。
https://www.dedeplus.com/wp-co ... 4.gif 300w" />先前的运行信息是总数据,此图片是每个节点的单独数据
区域A中的数据是:节点采集,内容采集和库存释放的统计数据。例如,有这样的数据:
其含义是:今天,节点采集成功1次/节点总计采集 7次,内容页面采集成功449次/内容页面总计采集 458次,文章发布到数据库中1条。
当插件程序采集列出该页面时,它将一次保存所有匹配的URL(有效URL,对于内容页面为采集)。第二次进入采集列表页面。如果您发现文章 URL仍然是先前的URL(这些URL是第一次记录,则被视为无效URL),则无需再次记录它们。由于第二次采集没有新的URL(有效URL),因此程序认为采集这次失败了。
B区域中的数据是:节点的下一次采集。
通常来说,目标网站的列表页面不会实时更新,并且一天甚至几天内只会更新几篇文章。因此,无需经常访问采集,默认情况下,插件程序会自动调整列表页面采集的频率。
这里的时间是插件程序下次的最早采集时间。至少在此时间结束后,程序将成为节点采集。
当然,可能还会有一个列表页面在几分钟内更新文章,或者您对目标网站的文章更新时间非常敏感,因此您需要从以下位置监视列表页面:时不时。此时,您可以将节点参数中的[列表页面采集频率]设置为[高频率],此设置之后,[下一个时间采集]时间将显示为任何时间,如下图:
C区域中的数据是节点清单的URL,因为某些URL可能不是采集,或者标题可能被重复和排除,等等,因此可以是文章的数量。释放到库中通常大于库存。URL很少。
https://www.dedeplus.com/wp-co ... 9.gif 300w" />A区域中的数据,如果出现红色数据,请特别注意。
节点采集:0/10,节点(列表页面)采集 10次,并且没有有效的URL匹配一次。在这种情况下,有两种可能性:采集规则中有一个列表页面规则。问题是内容页面URL无法匹配(解决方案是重新调整采集规则);或另一方网站尚未更新,并且该节点已被放弃(解决方案是找到新的目标列表页面并重新编写采集规则)。简而言之,无论情况如何,都需要人工干预。
A区域的红色数据表示存在需要手动干预的情况。
上图表明节点采集具有红色数据,相同的内容页面采集也可能具有红色数据。同样需要人工干预,并且分析方法与节点采集相似。
自动采集数据,只要你知道url就可以用框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-04-25 18:01
自动采集数据,只要你知道url就可以用selenium,threadlocal.initialize()或者java自带的inspector等工具调用js页面采集,你这样有点太麻烦,建议用程序自动采集html文件直接下载到本地保存网页。
可以写个爬虫程序模拟浏览器来点击按钮/selenium等,抓取数据,
别人采集过的,你得提交给后台,
你可以和后台说明你需要去重哪个按钮
谢邀,题主看的应该是拉钩网,本地安装webdriver,可以实现你想要的功能,并且可以减少对后台的干扰,建议这样去理解,
如果使用python,可以用requests,先url,再请求index.html,requests抓包中用到:如果你想要数据库操作,
把数据上传到数据库,建议用importpymysqlpython的web安装自己搜吧,
selenium库里有去重,调用java框架就可以了,比如我写的框架就是jar包导入python库就可以使用了,框架里面有着完整的requests方法,
目前我正在学习的是框架的使用(simpy框架),开发速度比python做api更快,也不需要有java语言基础。直接看文档就能实现,工程师和项目狗都适用。个人非常建议各位程序员学习框架使用,使用一种新的,自己熟悉的语言做一种新的自己熟悉的框架。举个例子,在我目前看到的国内外的互联网圈子里,使用nodejs,python和java做api的人非常多,但使用python,java做jqueryapi的人就不够多了。ssm框架是过去二十年过剩,可以直接去掉,后面几年再看吧。 查看全部
自动采集数据,只要你知道url就可以用框架
自动采集数据,只要你知道url就可以用selenium,threadlocal.initialize()或者java自带的inspector等工具调用js页面采集,你这样有点太麻烦,建议用程序自动采集html文件直接下载到本地保存网页。
可以写个爬虫程序模拟浏览器来点击按钮/selenium等,抓取数据,
别人采集过的,你得提交给后台,
你可以和后台说明你需要去重哪个按钮
谢邀,题主看的应该是拉钩网,本地安装webdriver,可以实现你想要的功能,并且可以减少对后台的干扰,建议这样去理解,
如果使用python,可以用requests,先url,再请求index.html,requests抓包中用到:如果你想要数据库操作,
把数据上传到数据库,建议用importpymysqlpython的web安装自己搜吧,
selenium库里有去重,调用java框架就可以了,比如我写的框架就是jar包导入python库就可以使用了,框架里面有着完整的requests方法,
目前我正在学习的是框架的使用(simpy框架),开发速度比python做api更快,也不需要有java语言基础。直接看文档就能实现,工程师和项目狗都适用。个人非常建议各位程序员学习框架使用,使用一种新的,自己熟悉的语言做一种新的自己熟悉的框架。举个例子,在我目前看到的国内外的互联网圈子里,使用nodejs,python和java做api的人非常多,但使用python,java做jqueryapi的人就不够多了。ssm框架是过去二十年过剩,可以直接去掉,后面几年再看吧。
自动采集数据平台:直接用php开发一个邮件服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-04-23 07:00
自动采集数据平台:免费sdk是个很好的功能,之前的平台我用过很多平台,大家要注意一些问题,
outlook搜索相关邮件系统功能
我找到了,直接用php开发一个邮件服务,很方便。不谢!:一个简单的邮件服务器套件,附件不限大小,支持mime协议,支持via协议,附件分档存储,
其实,目前市面上就有一个比较成熟的平台,有专门用php开发邮件服务器的系统,比如秒邮。这个是我用过觉得还不错的。
lookalike大概是结合了flashmail,imap协议实现的。
这个方向不错啊,有专门的服务器系统。我有个公司要做定制邮件,用我们的资源,完全按照我们的需求开发的。资源的邮件存储和管理是优势,效率也还不错。就是麻烦点,要搞域名,需要阿里云充值。我们的专利服务器是阿里云定制服务器,不用部署都能看到。您也可以给我邮箱发下你的微信服务器需求。有兴趣试一下。
思科的吧,好像采用b/s结构,界面非常漂亮。
说实话,skymail、foxmail、textel、tadmail、tenderlk发给我以后,我都是重新打包服务端,配个移动硬盘版的。为毛?就是为了方便保存收件箱。
kma邮件系统,国内唯一。国外不清楚了。
同为服务器行业从业者,我们通常都是使用这些,推荐lookalike。使用email(并非电子邮件!)制作发件箱。 查看全部
自动采集数据平台:直接用php开发一个邮件服务
自动采集数据平台:免费sdk是个很好的功能,之前的平台我用过很多平台,大家要注意一些问题,
outlook搜索相关邮件系统功能
我找到了,直接用php开发一个邮件服务,很方便。不谢!:一个简单的邮件服务器套件,附件不限大小,支持mime协议,支持via协议,附件分档存储,
其实,目前市面上就有一个比较成熟的平台,有专门用php开发邮件服务器的系统,比如秒邮。这个是我用过觉得还不错的。
lookalike大概是结合了flashmail,imap协议实现的。
这个方向不错啊,有专门的服务器系统。我有个公司要做定制邮件,用我们的资源,完全按照我们的需求开发的。资源的邮件存储和管理是优势,效率也还不错。就是麻烦点,要搞域名,需要阿里云充值。我们的专利服务器是阿里云定制服务器,不用部署都能看到。您也可以给我邮箱发下你的微信服务器需求。有兴趣试一下。
思科的吧,好像采用b/s结构,界面非常漂亮。
说实话,skymail、foxmail、textel、tadmail、tenderlk发给我以后,我都是重新打包服务端,配个移动硬盘版的。为毛?就是为了方便保存收件箱。
kma邮件系统,国内唯一。国外不清楚了。
同为服务器行业从业者,我们通常都是使用这些,推荐lookalike。使用email(并非电子邮件!)制作发件箱。
自动采集数据的目的是最大化挖掘价值的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-04-19 23:02
自动采集数据,如:客户信息,企业信息.erp,plm,crm等等中会用到的,将你采集到的数据先用软件过滤掉,再存储起来。至于发展空间看个人能力了,如果平时数据处理能力和分析能力都不错,精通业务流程,那就不错。
目前的物联网时代,我最看好的5g+iot背景下的大数据或者大数据分析方向!注意:看完一定要动动手指头查一查,
可以关注一下数据挖掘的方向
哪一个工具都比不了大数据分析,大数据的分析需要正确分析数据信息,大数据背景下对数据应用场景分析理解要更加深刻。其实这个就像民航高层对空域控制的分析一样,一个认真的空域控制员不是了解航空公司控制权的人,而是提前掌握空域详细权利流的人,在大数据背景下做这些也是基于对大数据的分析,但其中某个环节是大数据分析的关键。
就好比建筑工程中“把砖头砌起来”一样,不过数据挖掘关键是你要找到特定的需求点上,而不是这个需求点有很多,而是你想象当中的所有需求点。数据挖掘是对大量数据进行分析研究,找到一些规律,找到最有可能的需求点来用数据进行展示。数据挖掘的目的是最大化挖掘价值,而不是让你学会很多工具,很多特征。
一点都不同意因为非要相似性有限从数学分析的角度大数据分析的思想和定义可以让你理解最明确的信息 查看全部
自动采集数据的目的是最大化挖掘价值的工具
自动采集数据,如:客户信息,企业信息.erp,plm,crm等等中会用到的,将你采集到的数据先用软件过滤掉,再存储起来。至于发展空间看个人能力了,如果平时数据处理能力和分析能力都不错,精通业务流程,那就不错。
目前的物联网时代,我最看好的5g+iot背景下的大数据或者大数据分析方向!注意:看完一定要动动手指头查一查,
可以关注一下数据挖掘的方向
哪一个工具都比不了大数据分析,大数据的分析需要正确分析数据信息,大数据背景下对数据应用场景分析理解要更加深刻。其实这个就像民航高层对空域控制的分析一样,一个认真的空域控制员不是了解航空公司控制权的人,而是提前掌握空域详细权利流的人,在大数据背景下做这些也是基于对大数据的分析,但其中某个环节是大数据分析的关键。
就好比建筑工程中“把砖头砌起来”一样,不过数据挖掘关键是你要找到特定的需求点上,而不是这个需求点有很多,而是你想象当中的所有需求点。数据挖掘是对大量数据进行分析研究,找到一些规律,找到最有可能的需求点来用数据进行展示。数据挖掘的目的是最大化挖掘价值,而不是让你学会很多工具,很多特征。
一点都不同意因为非要相似性有限从数学分析的角度大数据分析的思想和定义可以让你理解最明确的信息
自动采集数据,真的做到了“速度”和“精准”吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-04-11 20:07
自动采集数据,真的做到了“速度”和“精准”吗?这个可不是那么简单的。网易有数推出“广告实时查询预警系统”,将广告实时实时查询、分析和可视化报表,实时预警广告行为,及时做到对广告行为精准化监测预警,识别出异常广告行为,及时拦截对应的广告链接,防止广告骚扰和侵犯公众隐私,从源头上保障广告行为不再被侵犯公民隐私,避免出现视频监控中的网络瘫痪等情况。
广告实时查询系统通过网易有数的能力,通过数字实时监测和实时分析,我们可以按照以下方式进行广告查询预警:广告监测实时分析广告的ctr表现,提前监测可能出现的异常情况,如果ctr数值不符合预期值,直接预警。ctr预警上线后,会第一时间推送到公众号上进行监测。分析报表网易有数的大数据分析主要功能有五个,分别是“流量获取渠道监测”、“流量质量分析”、“投放分析”、“热门游戏分析”和“销售分析”。广告实时查询系统对于网易有数来说是重要的工具。希望对你有所帮助哦~。
非营销行业的朋友,建议您关注一下网易有数(搜索公众号“有数智能服务平台”),网易有数作为网易旗下的大数据营销平台,我们打通了社交流量入口、线上线下线上线下流量匹配、用户画像画像和全网机构运营管理。帮助实现以数据洞察开启智能营销时代, 查看全部
自动采集数据,真的做到了“速度”和“精准”吗?
自动采集数据,真的做到了“速度”和“精准”吗?这个可不是那么简单的。网易有数推出“广告实时查询预警系统”,将广告实时实时查询、分析和可视化报表,实时预警广告行为,及时做到对广告行为精准化监测预警,识别出异常广告行为,及时拦截对应的广告链接,防止广告骚扰和侵犯公众隐私,从源头上保障广告行为不再被侵犯公民隐私,避免出现视频监控中的网络瘫痪等情况。
广告实时查询系统通过网易有数的能力,通过数字实时监测和实时分析,我们可以按照以下方式进行广告查询预警:广告监测实时分析广告的ctr表现,提前监测可能出现的异常情况,如果ctr数值不符合预期值,直接预警。ctr预警上线后,会第一时间推送到公众号上进行监测。分析报表网易有数的大数据分析主要功能有五个,分别是“流量获取渠道监测”、“流量质量分析”、“投放分析”、“热门游戏分析”和“销售分析”。广告实时查询系统对于网易有数来说是重要的工具。希望对你有所帮助哦~。
非营销行业的朋友,建议您关注一下网易有数(搜索公众号“有数智能服务平台”),网易有数作为网易旗下的大数据营销平台,我们打通了社交流量入口、线上线下线上线下流量匹配、用户画像画像和全网机构运营管理。帮助实现以数据洞察开启智能营销时代,
自动采集数据?为什么要在js里写个钩子?
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-04-10 03:01
自动采集数据?为什么要在js里写个钩子?谁说js不能用,模拟点击,然后修改个登录id或者useragent就能自动登录。好,webpack模块的检查可以起作用。那么,eval写在js里似乎就不是很合适。可想而知,要是全部用js异步去发送数据,那得多好得封装出来一个异步的api函数,但是想想吧,这样不实用。
不如http来的爽。其实正好,http协议定义了客户端请求和服务端响应的格式,让浏览器承担起数据的发送。webpack能用,我们可以把它封装在loader里,一个配置文件,配合options,就可以搞定。预览下效果:/mocharoadysounting/httplite/loader当然如果追求像swig那样功能强大的,loader还是别用了,太老了。
sixhdezayug/proxy-proxy我的文章:第一阶段:介绍服务端渲染第二阶段:安装nodejs和npm模块第三阶段:配置ssh,监听端口和npm的local模块第四阶段:配置客户端生成proxy,使浏览器接收到数据第五阶段:生成fetch文件,发送给浏览器第六阶段:发送给服务端-asa。
首先你要搞清楚,浏览器不可能自己创建一个http的request,也不可能自己发送一个response,用webpack/vue/react的开发可以简单的看成静态资源的处理。但是,这样的前端体验是极不友好的,我们是做手机app的,而前端的模板一般是javascript实现的,这时候服务端的api就要考虑到了,如果这时候出了个钩子,转发到后端,那么调用者只需要像下面这样去调用vue文件。
那么,为什么我们不做个socket传递呢?因为不用socket,客户端http请求只能返回客户端状态码给服务端,如果服务端生成新的通道可以返回给客户端,那么可以给这个新通道安装一个nodejs的钩子,然后客户端执行自己的http请求。这里当然还有更好的做法,做成动态的,比如服务端将请求发送到服务端的http请求库(pathhong/httpbin),那么,服务端只要发一个请求给客户端即可返回相应的状态码和响应结果,动态修改http请求的处理方式。
<p>这种做法,我们可以做出如下的示例:api定义为:get/post,server:networkserver.api 查看全部
自动采集数据?为什么要在js里写个钩子?
自动采集数据?为什么要在js里写个钩子?谁说js不能用,模拟点击,然后修改个登录id或者useragent就能自动登录。好,webpack模块的检查可以起作用。那么,eval写在js里似乎就不是很合适。可想而知,要是全部用js异步去发送数据,那得多好得封装出来一个异步的api函数,但是想想吧,这样不实用。
不如http来的爽。其实正好,http协议定义了客户端请求和服务端响应的格式,让浏览器承担起数据的发送。webpack能用,我们可以把它封装在loader里,一个配置文件,配合options,就可以搞定。预览下效果:/mocharoadysounting/httplite/loader当然如果追求像swig那样功能强大的,loader还是别用了,太老了。
sixhdezayug/proxy-proxy我的文章:第一阶段:介绍服务端渲染第二阶段:安装nodejs和npm模块第三阶段:配置ssh,监听端口和npm的local模块第四阶段:配置客户端生成proxy,使浏览器接收到数据第五阶段:生成fetch文件,发送给浏览器第六阶段:发送给服务端-asa。
首先你要搞清楚,浏览器不可能自己创建一个http的request,也不可能自己发送一个response,用webpack/vue/react的开发可以简单的看成静态资源的处理。但是,这样的前端体验是极不友好的,我们是做手机app的,而前端的模板一般是javascript实现的,这时候服务端的api就要考虑到了,如果这时候出了个钩子,转发到后端,那么调用者只需要像下面这样去调用vue文件。
那么,为什么我们不做个socket传递呢?因为不用socket,客户端http请求只能返回客户端状态码给服务端,如果服务端生成新的通道可以返回给客户端,那么可以给这个新通道安装一个nodejs的钩子,然后客户端执行自己的http请求。这里当然还有更好的做法,做成动态的,比如服务端将请求发送到服务端的http请求库(pathhong/httpbin),那么,服务端只要发一个请求给客户端即可返回相应的状态码和响应结果,动态修改http请求的处理方式。
<p>这种做法,我们可以做出如下的示例:api定义为:get/post,server:networkserver.api
自动采集数据打开“艾瑞数据”app--七牛云
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-04-08 03:02
自动采集数据打开“艾瑞数据”app,我们会看到很多不同种类的数据,我们主要看一下分类数据即采集指数。目前,国内最大的一家采集指数提供商是七牛云——数据量更是广泛到国外。为什么要收费呢?七牛云早在2014年就上线了付费制度,至今,七牛云在全球范围内已有百万级自媒体数据处理需求,包括数百万新闻、电商、搜索、在线教育、在线音乐、动漫、图片等数据。
(在2017年7月,有八成自媒体在使用七牛云)简单来说,用于处理自媒体数据的平台,从创建、采集、下载、导出、数据存储、计算。每个流程都需要有不同的开发语言来支持,这就为其带来了成本上的差异,从而导致了采集流程的差异化。此外,自媒体处理起来比较麻烦,要把报文一次性读取到七牛中,七牛再转存至系统中。当你的数据量越来越大,就会逐渐显现各种问题,当采集的量越来越大,基本上以“分布式”的方式来处理这个数据,每个链路上存储的数据量为40gb。
“分布式”这个词对于自媒体内容而言,有点遥远,并且在传统内容领域,一般采用的是“集中式”存储方式。更有部分自媒体创业者喜欢“n台电脑组成集群”,以每台电脑服务器100tb的存储容量去解决那些一台电脑无法处理的数据问题。对于大数据而言,不仅是传统形式的处理方式,通过开源的数据源能力和开放的数据接口,创业自媒体很容易就能建立起一套完整的数据处理系统。
那么问题来了,即使自媒体运营者自己建立出了一套数据处理系统,与公司同步共享,自己可能也不希望因为别人的某些行为改变自己的业务数据,这时候会出现问题。于是,一种名为“云函数”的东西走进了自媒体运营者的视野。“云函数”解决了上述问题,自媒体运营者不需要开发一个数据采集系统,也不需要做数据存储,只需要把采集到的自媒体信息和接口开放给其他的运营者,运营者就可以接收到自媒体内容。
那么接口和系统是不是必须要相同呢?答案是否定的。比如七牛云里的一些数据就是不开放给自媒体使用的,他们用来解决开发者做不了数据处理的情况。还有一些数据是云函数里没有开放的,比如上文提到的视频。那么,可不可以将这些数据变成无限制分享给公司同步共享呢?比如云函数由甲方提供,运营者也可以自主定义“读取频率、周期、下载地址、文件大小、音频频率”等等数据规则,甲方按照这些规则去采集获取自媒体内容。
也可以按照原始url去获取,而不是从云函数里解析得到,这也是这些云函数存在的价值。八年前,张朝阳搞出了开放的阿里云,opensource,至今四五年,数以千计的创业者涌入这个行业,但仅仅靠工具来看。 查看全部
自动采集数据打开“艾瑞数据”app--七牛云
自动采集数据打开“艾瑞数据”app,我们会看到很多不同种类的数据,我们主要看一下分类数据即采集指数。目前,国内最大的一家采集指数提供商是七牛云——数据量更是广泛到国外。为什么要收费呢?七牛云早在2014年就上线了付费制度,至今,七牛云在全球范围内已有百万级自媒体数据处理需求,包括数百万新闻、电商、搜索、在线教育、在线音乐、动漫、图片等数据。
(在2017年7月,有八成自媒体在使用七牛云)简单来说,用于处理自媒体数据的平台,从创建、采集、下载、导出、数据存储、计算。每个流程都需要有不同的开发语言来支持,这就为其带来了成本上的差异,从而导致了采集流程的差异化。此外,自媒体处理起来比较麻烦,要把报文一次性读取到七牛中,七牛再转存至系统中。当你的数据量越来越大,就会逐渐显现各种问题,当采集的量越来越大,基本上以“分布式”的方式来处理这个数据,每个链路上存储的数据量为40gb。
“分布式”这个词对于自媒体内容而言,有点遥远,并且在传统内容领域,一般采用的是“集中式”存储方式。更有部分自媒体创业者喜欢“n台电脑组成集群”,以每台电脑服务器100tb的存储容量去解决那些一台电脑无法处理的数据问题。对于大数据而言,不仅是传统形式的处理方式,通过开源的数据源能力和开放的数据接口,创业自媒体很容易就能建立起一套完整的数据处理系统。
那么问题来了,即使自媒体运营者自己建立出了一套数据处理系统,与公司同步共享,自己可能也不希望因为别人的某些行为改变自己的业务数据,这时候会出现问题。于是,一种名为“云函数”的东西走进了自媒体运营者的视野。“云函数”解决了上述问题,自媒体运营者不需要开发一个数据采集系统,也不需要做数据存储,只需要把采集到的自媒体信息和接口开放给其他的运营者,运营者就可以接收到自媒体内容。
那么接口和系统是不是必须要相同呢?答案是否定的。比如七牛云里的一些数据就是不开放给自媒体使用的,他们用来解决开发者做不了数据处理的情况。还有一些数据是云函数里没有开放的,比如上文提到的视频。那么,可不可以将这些数据变成无限制分享给公司同步共享呢?比如云函数由甲方提供,运营者也可以自主定义“读取频率、周期、下载地址、文件大小、音频频率”等等数据规则,甲方按照这些规则去采集获取自媒体内容。
也可以按照原始url去获取,而不是从云函数里解析得到,这也是这些云函数存在的价值。八年前,张朝阳搞出了开放的阿里云,opensource,至今四五年,数以千计的创业者涌入这个行业,但仅仅靠工具来看。
亚马逊卖家如何有效监控竞品listing?优采云跨境电商模板
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-04-03 19:15
4、竞争产品数据
包括监视各种维度的数据,例如竞争产品的新状态,竞争产品的搜索排名状态关键词,竞争产品的列表以及竞争产品的审核。
我在上面提到了搜索排名和评论采集监控。如果您需要了解采集和竞争产品清单的监控,请参阅亚马逊卖家如何有效监控竞争产品清单?这个文章。
当然,还有许多其他类型的数据,将来我们将继续添加它们。
二、如何提高数据监控效率
在第一部分中,我们了解了电子商务运营商每天需要注意的数据。但是每天手动采集和记录这些数据是非常沉重的负担。
这时,可以引入某些数据采集工具,例如优采云,以自动且定期地采集数据。当您需要查看数据时,只需单击一下即可下载和导出。
上述产品评论数据监视,关键词排名监视,销售排名监视,清单监视,价格监视和排名监视都可以通过优采云完成。
让我们看看:
1、 优采云提供的跨境电子商务采集模板
目前优采云已正式启动了许多跨境电子商务模板供您使用。
模板涵盖了主要跨境电子商务平台采集的各种数据场景,非常实用。
如果您想要的模板不在下面的表格中,您还可以联系我们的官方客户服务来提交您的要求并对其进行自定义。
2、 优采云云采集
如果采集有许多平台,大量数据和强大的实时数据,则还可以选择云采集。
什么是云采集-由优采云同时提供的多个云服务器可以同时在不同平台上实现采集同一产品的数据,而采集多个产品同时具有数据和其他要求。
如下图所示,可以使用采集同时运行Amazon的多种不同类型的数据采集任务(产品搜索,产品详细信息,关键词 采集列表等)。数据同时进行。
3、 优采云定时云采集
定时云采集适用于采集页面上的数据将定期更新或更改的情况。例如:搜索关键词后产品信息和排名的变化,竞争产品的价格/属性的变化,排名中的产品变化,特定产品的评论数量变化等。
如何设置时间? 优采云支持最短的1分钟计时采集,以满足网站的许多高频采集需求。同时,它还支持按[选择星期] [每月采集] [间隔时间采集]来设置不同的计时方法。
例如:在示例中选择[间隔时间采集],并将间隔时间设置为30分钟。然后,此任务将每30分钟自动启动云采集。
同时,我们还可以设置每次采集到达数据库时自动存储的数据,或将其导出为Excel表,以便我们进行下一步分析并提高效率。操作。
查看全部
亚马逊卖家如何有效监控竞品listing?优采云跨境电商模板
4、竞争产品数据
包括监视各种维度的数据,例如竞争产品的新状态,竞争产品的搜索排名状态关键词,竞争产品的列表以及竞争产品的审核。
我在上面提到了搜索排名和评论采集监控。如果您需要了解采集和竞争产品清单的监控,请参阅亚马逊卖家如何有效监控竞争产品清单?这个文章。
当然,还有许多其他类型的数据,将来我们将继续添加它们。
二、如何提高数据监控效率
在第一部分中,我们了解了电子商务运营商每天需要注意的数据。但是每天手动采集和记录这些数据是非常沉重的负担。
这时,可以引入某些数据采集工具,例如优采云,以自动且定期地采集数据。当您需要查看数据时,只需单击一下即可下载和导出。
上述产品评论数据监视,关键词排名监视,销售排名监视,清单监视,价格监视和排名监视都可以通过优采云完成。
让我们看看:
1、 优采云提供的跨境电子商务采集模板
目前优采云已正式启动了许多跨境电子商务模板供您使用。
模板涵盖了主要跨境电子商务平台采集的各种数据场景,非常实用。
如果您想要的模板不在下面的表格中,您还可以联系我们的官方客户服务来提交您的要求并对其进行自定义。
2、 优采云云采集
如果采集有许多平台,大量数据和强大的实时数据,则还可以选择云采集。
什么是云采集-由优采云同时提供的多个云服务器可以同时在不同平台上实现采集同一产品的数据,而采集多个产品同时具有数据和其他要求。
如下图所示,可以使用采集同时运行Amazon的多种不同类型的数据采集任务(产品搜索,产品详细信息,关键词 采集列表等)。数据同时进行。
3、 优采云定时云采集
定时云采集适用于采集页面上的数据将定期更新或更改的情况。例如:搜索关键词后产品信息和排名的变化,竞争产品的价格/属性的变化,排名中的产品变化,特定产品的评论数量变化等。
如何设置时间? 优采云支持最短的1分钟计时采集,以满足网站的许多高频采集需求。同时,它还支持按[选择星期] [每月采集] [间隔时间采集]来设置不同的计时方法。
例如:在示例中选择[间隔时间采集],并将间隔时间设置为30分钟。然后,此任务将每30分钟自动启动云采集。
同时,我们还可以设置每次采集到达数据库时自动存储的数据,或将其导出为Excel表,以便我们进行下一步分析并提高效率。操作。

