
网页抓取 加密html
网页抓取 加密html(之前学习Python模拟登录知乎实例(一)加密处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-28 05:10
之前学过Python模拟登录知乎,里面涉及到fromdata的加密处理。学习过程中发现用chrome devtool调试分析网页的技巧还是有很多的,所以找了一个简单的。示例用于学习js加密。
学无止境一、例子网站
网站本例中为中国空气质量分析平台,学习使用chome浏览器的devtool工具对fromdata进行加密。
二、分析页面逻辑1.抓包分析
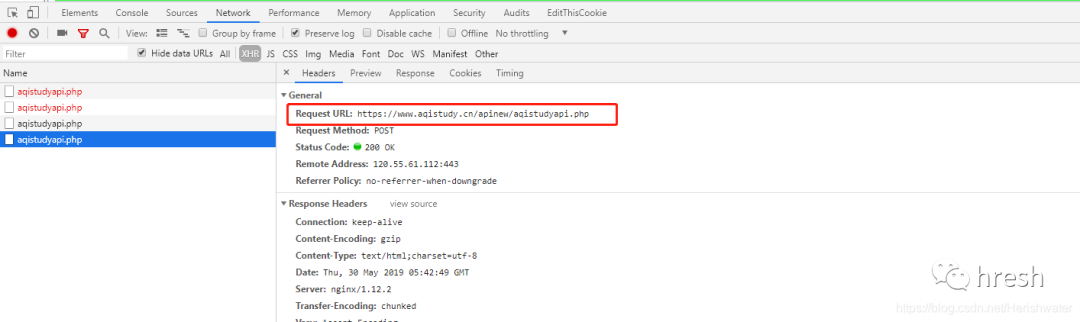
在chrome中打开页面,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为了方便查看,先清除之前的请求流程,然后在网页上切换城市就可以看到新的xhr请求了。
您可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
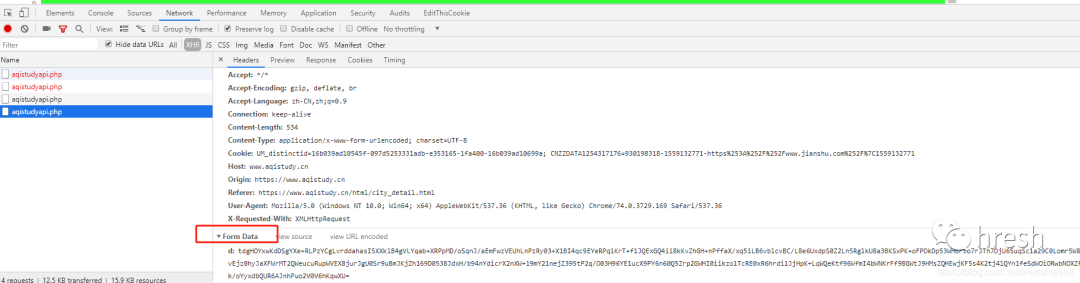
继续查看 Requests Headers 信息。对比不同城市的查询结果,发现Headers没有任何独特的特征,所以我们只保留了一些必要的信息。
接下来,我们需要考虑如何构造Form数据。
2.调试分析
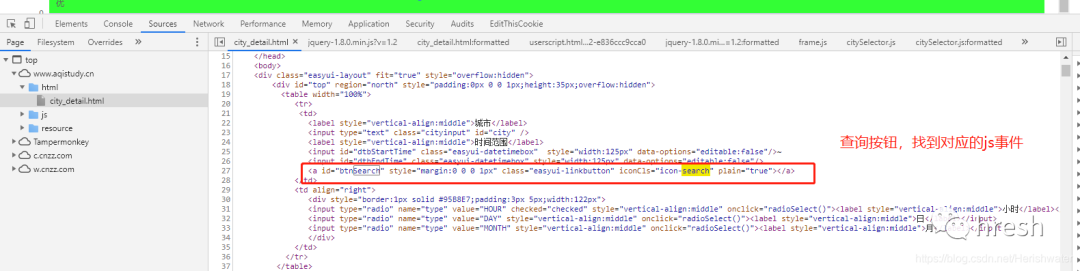
考虑到页面点击查询按钮时发生网络请求,该按钮肯定需要时间处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
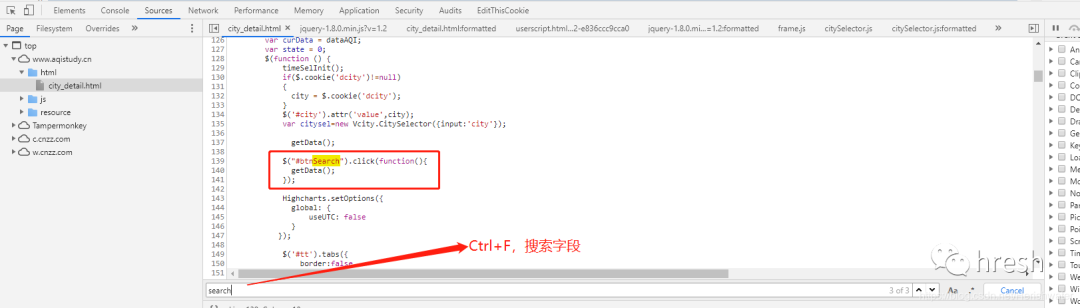
找到事件方法后,我们继续分析。
让我们尝试进入 getAQIData() 方法。
首页的查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,当前页面没有搜索到该方法的详细信息,所以我们进行全局搜索(ctrl+shift+ F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2文件中,而混淆后,您可以使用在线工具进行反混淆,例如:.
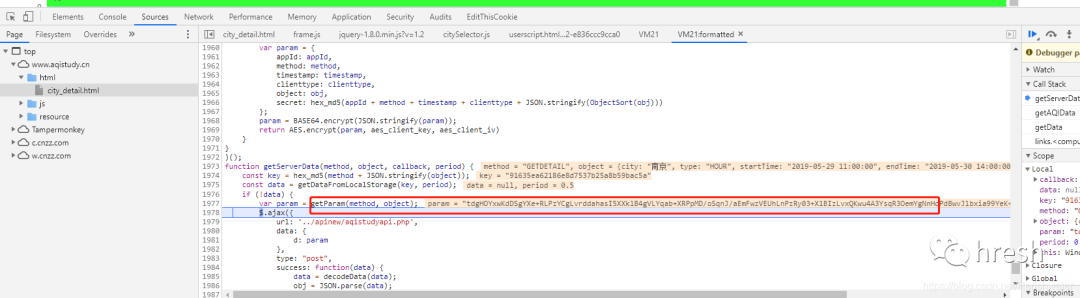
使用开发者工具调试断点,进入getServerData方法。
最后,我们看到了由 getParm() 方法返回的表单数据。
3.密码分析
知道了位置后,我们可以直接把这个加密的js方法推导出来,放到一个html文件中执行。
var getParam = (function () {<br /> function ObjectSort(obj) {<br /> var newObject = {};<br /> Object.keys(obj).sort().map(function (key) {<br /> newObject[key] = obj[key]<br /> });<br /> return newObject<br /> }<br /><br /> return function (method, obj) {<br /> var appId = '1a45f75b824b2dc628d5955356b5ef18';<br /> var clienttype = 'WEB';<br /> var timestamp = new Date().getTime();<br /> var param = {<br /> appId: appId,<br /> method: method,<br /> timestamp: timestamp,<br /> clienttype: clienttype,<br /> object: obj,<br /> secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))<br /> };<br /> param = BASE64.encrypt(JSON.stringify(param));<br /> return AES.encrypt(param, aes_client_key, aes_client_iv)<br /> }<br />})();<br />
提取该方法涉及的js方法,jqury中需要的除外-1.8.0.min.js?v=1.2文件另外对于方法,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得将查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了execjs包外,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):<br /> '''<br /> 对查询条件栏的数据,进行加密<br /> :param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等<br /> :return:加密后的字符串<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('getAQIData',form_data)<br />
在测试过程中,如果遇到错误execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined,localStorage是浏览器端数据存储方式之一。将js中的相关代码注释掉,继续测试。
//加密<br />function getServerData(method, object, callback, period) {<br /> const key = hex_md5(method + JSON.stringify(object));<br /> // const data = getDataFromLocalStorage(key, period);<br /> // if (!data) {<br /> var param = getParam(method, object);<br /> return param<br /> // } else {<br /> // callback(data)<br /> // }<br />}<br />
成功输出结果。
四、Python 抓取网页
获取加密字符串后,需要通过POST请求将内容提交给服务器,但在执行过程中发现返回的内容与前台返回的内容不一致。经过一番询问,
发现得到的加密字符串的内容只与“查看解码”显示的内容一致,我们尝试对数据进行URL编码,然后进行POST请求。终于成功拿到返回值了。
接下来,我们解密返回的字符串。在对getServerData方法的分析中,我们发现decodeData方法与解密有关。
def decrypt(self, resp_text):<br /> '''<br /> 对服务器请求成功后返回的数据,进行解密<br /> :param resp_text: 返回的数据<br /> :return:解密后的字符串,json格式<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('decodeData',resp_text)<br />
解密服务器返回的内容,最终得到我们想要的数据。
详细代码请到: 查看全部
网页抓取 加密html(之前学习Python模拟登录知乎实例(一)加密处理)
之前学过Python模拟登录知乎,里面涉及到fromdata的加密处理。学习过程中发现用chrome devtool调试分析网页的技巧还是有很多的,所以找了一个简单的。示例用于学习js加密。

学无止境一、例子网站
网站本例中为中国空气质量分析平台,学习使用chome浏览器的devtool工具对fromdata进行加密。
二、分析页面逻辑1.抓包分析
在chrome中打开页面,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为了方便查看,先清除之前的请求流程,然后在网页上切换城市就可以看到新的xhr请求了。
您可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看 Requests Headers 信息。对比不同城市的查询结果,发现Headers没有任何独特的特征,所以我们只保留了一些必要的信息。

接下来,我们需要考虑如何构造Form数据。
2.调试分析
考虑到页面点击查询按钮时发生网络请求,该按钮肯定需要时间处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
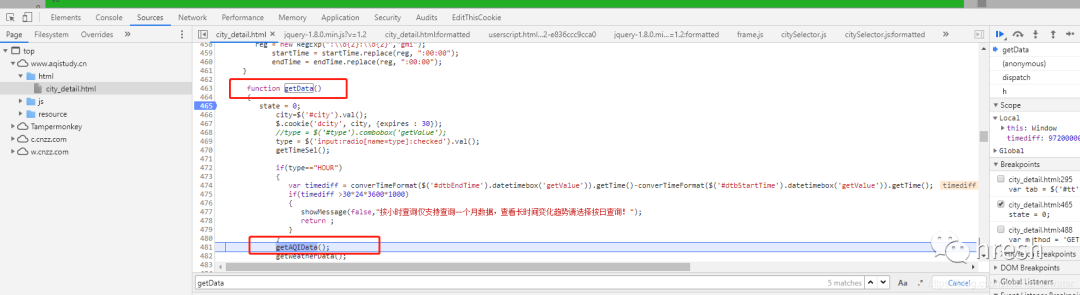
让我们尝试进入 getAQIData() 方法。
首页的查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,当前页面没有搜索到该方法的详细信息,所以我们进行全局搜索(ctrl+shift+ F 搜索)。
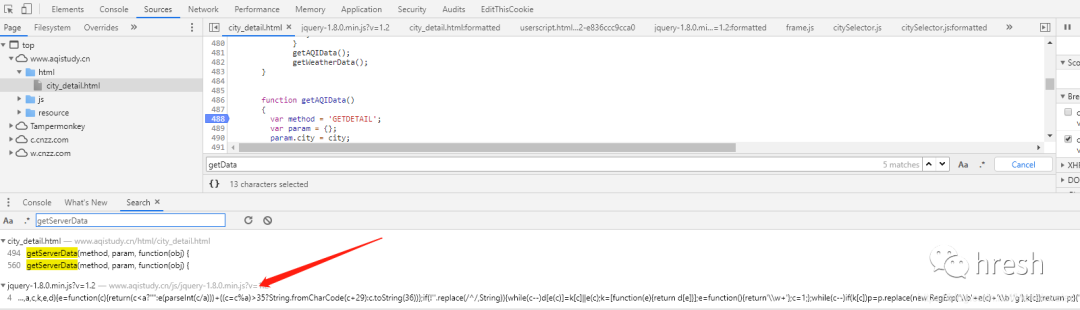
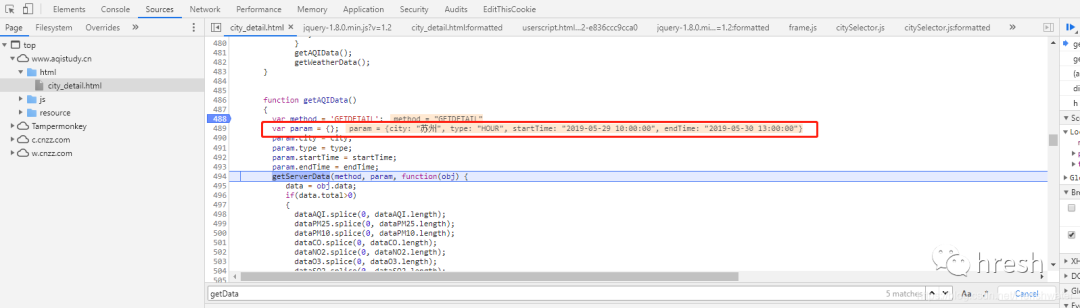
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2文件中,而混淆后,您可以使用在线工具进行反混淆,例如:.
使用开发者工具调试断点,进入getServerData方法。
最后,我们看到了由 getParm() 方法返回的表单数据。
3.密码分析
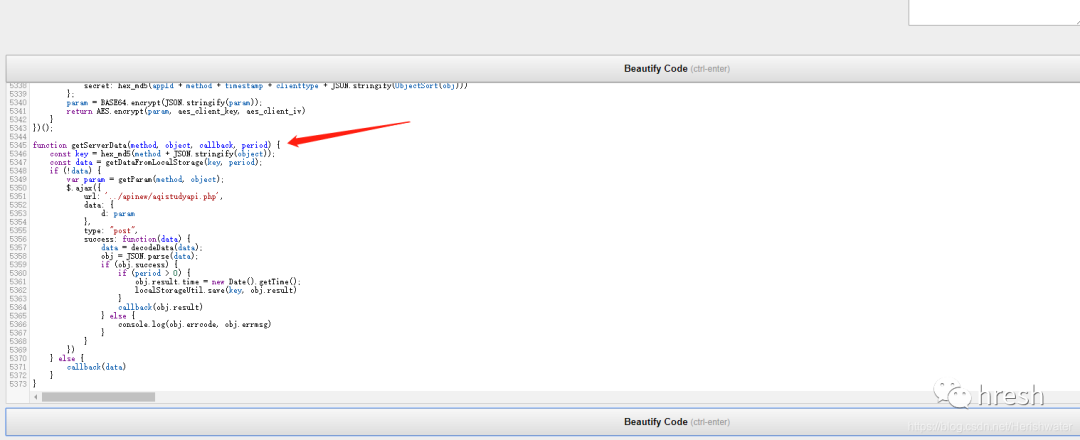
知道了位置后,我们可以直接把这个加密的js方法推导出来,放到一个html文件中执行。
var getParam = (function () {<br /> function ObjectSort(obj) {<br /> var newObject = {};<br /> Object.keys(obj).sort().map(function (key) {<br /> newObject[key] = obj[key]<br /> });<br /> return newObject<br /> }<br /><br /> return function (method, obj) {<br /> var appId = '1a45f75b824b2dc628d5955356b5ef18';<br /> var clienttype = 'WEB';<br /> var timestamp = new Date().getTime();<br /> var param = {<br /> appId: appId,<br /> method: method,<br /> timestamp: timestamp,<br /> clienttype: clienttype,<br /> object: obj,<br /> secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))<br /> };<br /> param = BASE64.encrypt(JSON.stringify(param));<br /> return AES.encrypt(param, aes_client_key, aes_client_iv)<br /> }<br />})();<br />
提取该方法涉及的js方法,jqury中需要的除外-1.8.0.min.js?v=1.2文件另外对于方法,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得将查询条件数据放入方法中。

在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了execjs包外,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):<br /> '''<br /> 对查询条件栏的数据,进行加密<br /> :param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等<br /> :return:加密后的字符串<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('getAQIData',form_data)<br />
在测试过程中,如果遇到错误execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined,localStorage是浏览器端数据存储方式之一。将js中的相关代码注释掉,继续测试。
//加密<br />function getServerData(method, object, callback, period) {<br /> const key = hex_md5(method + JSON.stringify(object));<br /> // const data = getDataFromLocalStorage(key, period);<br /> // if (!data) {<br /> var param = getParam(method, object);<br /> return param<br /> // } else {<br /> // callback(data)<br /> // }<br />}<br />
成功输出结果。
四、Python 抓取网页
获取加密字符串后,需要通过POST请求将内容提交给服务器,但在执行过程中发现返回的内容与前台返回的内容不一致。经过一番询问,

发现得到的加密字符串的内容只与“查看解码”显示的内容一致,我们尝试对数据进行URL编码,然后进行POST请求。终于成功拿到返回值了。
接下来,我们解密返回的字符串。在对getServerData方法的分析中,我们发现decodeData方法与解密有关。
def decrypt(self, resp_text):<br /> '''<br /> 对服务器请求成功后返回的数据,进行解密<br /> :param resp_text: 返回的数据<br /> :return:解密后的字符串,json格式<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('decodeData',resp_text)<br />
解密服务器返回的内容,最终得到我们想要的数据。

详细代码请到:
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-27 09:23
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des很弱,但是没那么容易破解
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配还是有没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题的内容,链接图片,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
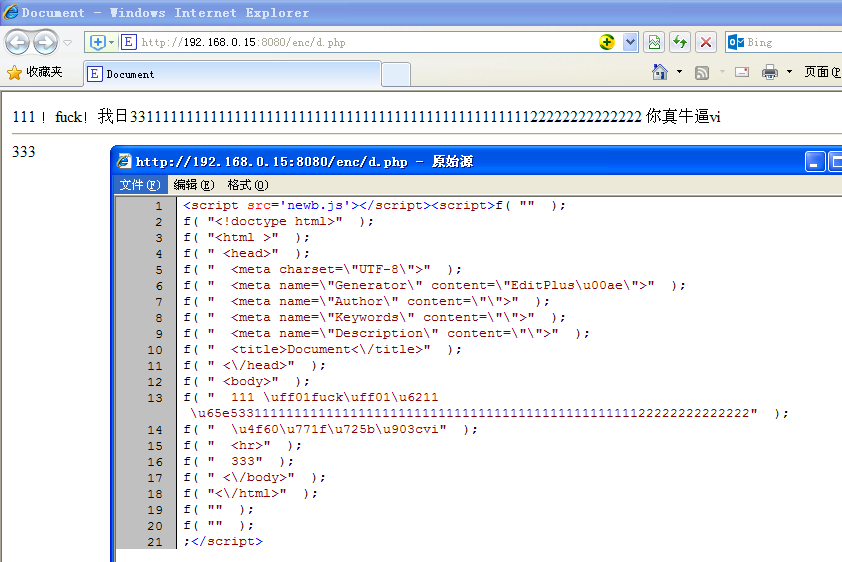
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
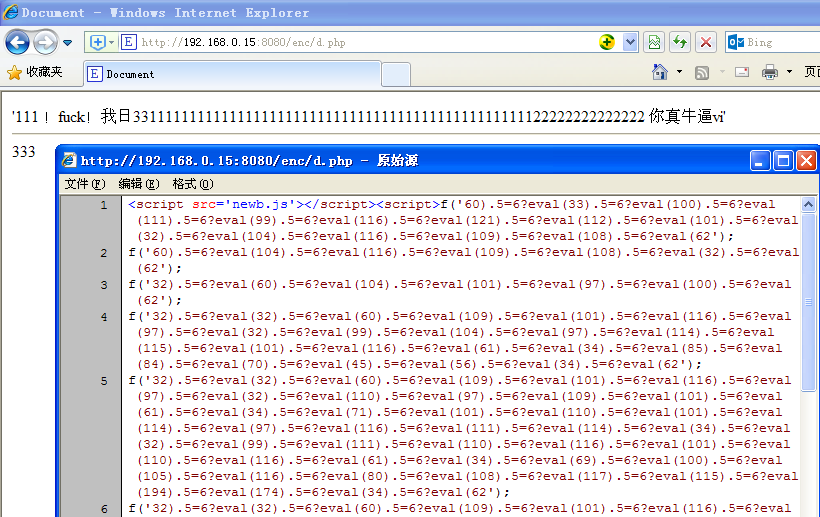
接下来尝试以十六进制编码(无分隔符):

接下来尝试以十六进制编码(带分隔符):
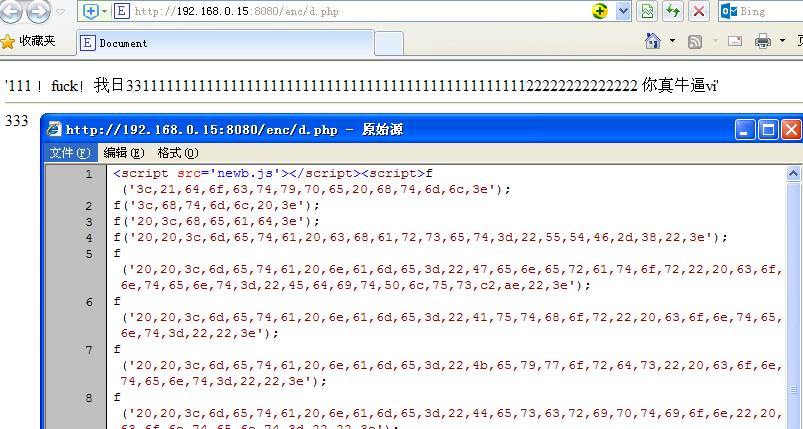
然后想得到一个密码输入框,输入正确的密码来显示。


思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des很弱,但是没那么容易破解
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配还是有没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题的内容,链接图片,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。
网页抓取 加密html(西部网盘不能解析了怎么构造这条cookie其中一种?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-26 17:08
有网友反映无法解析西部网盘。确认后,现在限制网盘抓取网页。网站目前访问不稳定,视情况而定,争取下个版本修复。
本来想写在西部网盘上的,但是这个网盘打不开,先说彩虹云吧,都一样。
这个文章不是教程,所以有些内容会被忽略
0、前言
不管是网盘分析还是各种网络爬虫,都是先获取网页的源代码,然后再提取自己感兴趣的内容。但这无疑会损害一些网站的利益,所以会有限制非客户端用户抓取网页的各种手段。本文提到的js加密cookie就是其中之一。
1、我们先来看看直接爬取页面的源码是什么样子的
<p>var x="hantom@@JgSe0upZ@@Path@02@GMT@f@@Sun@captcha@if@@@href@callP@@g@try@substr@DOMContentLoaded@as@@@Expires@@chars@@onreadystate
change@__jsl_clearance@new@0xFF@search@34@@window@@while@document@36@@@false@split@19@innerHTML@e@3D@8@function@location@setTimeout@attachEvent
@d@var@@0xEDB88320@length@2B@yF@addEventListener@@@charCodeAt@createElement@toLowerCase@@String@@cookie@1500@14@join@@@@__p@charAt@return@path
name@1559453654@Array@eval@@4@Jun@0@@catch@TmT2@@replace@@fromCharCode@@else@firstChild@@a@@FcG@oP@match@@WU@div@@reverse@challenge@06@toS
tring@RegExp@Oo4BUv@for@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@@https@1@2@@@@parseInt@FB@@932".replace(/@*$/,"").split("@"),
y="2b 39=26(){28('27.f=27.3e+27.1b.44(/[\\?|&]b-4l/,\\'\\')',35);1h.34='18=3f.5i|3l|'+(26(){2b e=[26(39){3d 39},26(e){3d e},
26(39){54(2b e=3l;e 查看全部
网页抓取 加密html(西部网盘不能解析了怎么构造这条cookie其中一种?)
有网友反映无法解析西部网盘。确认后,现在限制网盘抓取网页。网站目前访问不稳定,视情况而定,争取下个版本修复。
本来想写在西部网盘上的,但是这个网盘打不开,先说彩虹云吧,都一样。
这个文章不是教程,所以有些内容会被忽略
0、前言
不管是网盘分析还是各种网络爬虫,都是先获取网页的源代码,然后再提取自己感兴趣的内容。但这无疑会损害一些网站的利益,所以会有限制非客户端用户抓取网页的各种手段。本文提到的js加密cookie就是其中之一。
1、我们先来看看直接爬取页面的源码是什么样子的
<p>var x="hantom@@JgSe0upZ@@Path@02@GMT@f@@Sun@captcha@if@@@href@callP@@g@try@substr@DOMContentLoaded@as@@@Expires@@chars@@onreadystate
change@__jsl_clearance@new@0xFF@search@34@@window@@while@document@36@@@false@split@19@innerHTML@e@3D@8@function@location@setTimeout@attachEvent
@d@var@@0xEDB88320@length@2B@yF@addEventListener@@@charCodeAt@createElement@toLowerCase@@String@@cookie@1500@14@join@@@@__p@charAt@return@path
name@1559453654@Array@eval@@4@Jun@0@@catch@TmT2@@replace@@fromCharCode@@else@firstChild@@a@@FcG@oP@match@@WU@div@@reverse@challenge@06@toS
tring@RegExp@Oo4BUv@for@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@@https@1@2@@@@parseInt@FB@@932".replace(/@*$/,"").split("@"),
y="2b 39=26(){28('27.f=27.3e+27.1b.44(/[\\?|&]b-4l/,\\'\\')',35);1h.34='18=3f.5i|3l|'+(26(){2b e=[26(39){3d 39},26(e){3d e},
26(39){54(2b e=3l;e
网页抓取 加密html(逆向目标逆向过程分析(二)分析及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-25 04:19
)
本文章所有内容仅供学习交流。抓取到的内容、敏感URL、数据接口都进行了脱敏处理。严禁商业用途和非法使用。否则由此产生的一切后果与作者无关。,如有侵权,请联系我立即删除!
反向目标逆过程抓包分析
这次要反转的对象与以往不同。它不是接口的参数,而是网页中的数据。一般网页中的数据可以在源代码中看到,或者通过一个接口传递,而此时目标数据是通过JS加密获得的。我们先抓包看一下基本情况:
用F12查看,可以看到我们要的数据在textarea标签里,好像没有错,然后直接用Xpath解压试试:
import requests
from lxml import etree
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
data = tree.xpath('//textarea/text()')
print(data)
可以看到提取出来的数据其实是空的。我们查看网页的源代码,直接搜索textarea,同样不可用。尝试直接搜索数据。
加密反向
由于网页源代码中不存在这种数据,也不是通过其他接口返回的,因此极有可能是经过JS加密后直接插入到网页源代码中。如何在这里找到加密的位置?对比插入数据后的网页源代码和没有插入数据的网页源代码,可以看到蓝框内的代码是通过js插入的,100个8.js大部分都是加密的JS 文件:
在这里,我们想到了一种 JavaScript 语法。如果要从 JavaScript 访问 HTML 元素,可以使用 document.getElementById(id) 方法。这个id是一个HTML元素的属性,然后使用innerHTML来获取或者插入元素的内容。可以看菜鸟教程的一个例子:
通过这个语法,结合前面源码中的几个标签,我们可以猜到一个JS中可能有这样的语句:document.getElementById("tehai").innerHTML, document.getElementById("tips")。innerHTML,document.getElementById("m2").innerHTML,可以直接全局搜索这些语句中的任何一个,在1008.js中可以找到对应的结果。当然,你也可以直接搜索这个标签的id来找到结果。埋下断点进行调试:
您可以找到第 913 行 document.getElementById("m2").innerHTML = d + "
"就是在m2标签中插入值d和换行符。一步步查找,可以发现d里面收录了很多html的东西,而上面的g只是文本,正好是目标数据,那么我们最后退货直接退货。好吧。
继续追踪g值的出处,你会发现步骤比较复杂,那我们直接复制这部分函数(fa函数)运行调试(大约794行到914行),本地调试会提示ga和O是未定义的,我们在它定义的语句的下一行埋一个断点进行调试,可以看到ga的值其实是一个固定的q,而O是URL后面的q的值,如:336m237p2479s167z3s
定义好这两个变量后,再在本地调试,会提示aa、ca等函数未定义,依赖函数很多。这种情况下就不用一一扣除了,fa之前的所有函数都直接复制调试就好了,直接解决了所有的依赖。
完整代码
GitHub关注K哥的爬虫,持续分享爬虫相关代码!欢迎明星!
以下仅演示部分关键代码,完整代码仓库地址:
Key JS 加密代码架构
// Copyrights C-EGG inc.
var u = function () {}();
function w() {}
w.prototype = {};
function x(b, a, g, d) {}
// 此处省略 N 个函数
function M(b) {}
function N(b, a) {}
function ea(b) {}
function fa(O) {
function b(a, b) {
var c, d = 0;
for (c = 0; c < a.length; ++c) d += 4 - b[a[c]];
return d
}
// var a = ga, g = O, d;
var a = 'q', g = O, d;
d = "";
switch (a.substr(0, 1)) {
case "q":
d += '標準形(七対国士を含む)の計算結果 / 一般形
';
break;
case "p":
d += '一般形(七対国士を含まない)の計算結果 / 標準形
'
}
for (var c = "d" == a.substr(1, 1), a = a.substr(0, 1), g = g.replace(/(\d)(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{8})(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(\d?)(\d?)(\d?)(\d?)(\d?)(\d?)(\d)(\d)(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(m|p|s|z)(m|p|s|z)+/g, "$1").replace(/^[^\d]/, ""), g = g.substr(0, 28), f = aa(g), r = -1; r = Math.floor(136 * Math.random()), f[r];) ;
var m = Math.floor(g.length / 2) % 3;
2 == m || c || (f[r] = 1, g += H(r));
var f = ca(f),
n = "",
e = G(f, 34),
n = n + N(e, 28 == g.length),
n = n + ("(" + Math.floor(g.length / 2) + "枚)");
-1 == e[0] && (n += ' / 新しい手牌を作成');
var n = n + "
",
q = "q" == a ? e[0] : e[1],
k,
p,
l = Array(35);
if (0 == q && 1 == m && c) k = 34,
l[k] = K(f),
l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
});
else if (0 >= q) for (k = 0; 34 > k; ++k) f[k] && (f[k]--, l[k] = K(f), f[k]++, l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
}));
else if (2 == m || 1 == m && !c) for (k = 0; 34 > k; ++k) {
if (f[k]) {
f[k]--;
l[k] = [];
for (p = 0; 34 > p; ++p) k == p || 4 p; ++p) 4 = q ? "待ち" : "摸";
for (k = 0; k < t.length; ++k) {
v = t[k].i;
d += "";
34 > v && (d += "打" + ('') + "", g += "打" + H(4 * v + 1) + " ");
d += q + "[";
g += q + "[";
l = t[k].c;
c = t[k].q;
for (p = 0; p < l.length; ++p) r = H(4 * l[p] + 1),
d += '',
g += H(4 * l[p] + 1);
d += "" + t[k].n + "枚]";
g += " " + t[k].n + "枚]\n"
}
d = d + "
" + ('' + g + "");
-1 == e[0] && (d = d + "" + ea(f));
// document.getElementById("tehai").innerHTML = n;
// document.getElementById("tips").innerHTML = "";
// document.getElementById("m2").innerHTML = d + "
"
return g
}
// 测试样例
// console.log(fa('336m237p2479s167z3s'))
Python代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import execjs
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
def main():
q = url.split('=')[1]
with open('decrypt.js', 'r', encoding='utf-8') as f:
decrypt_js = f.read()
data = execjs.compile(decrypt_js).call('fa', q)
print(data)
if __name__ == '__main__':
main()
查看全部
网页抓取 加密html(逆向目标逆向过程分析(二)分析及应用
)
本文章所有内容仅供学习交流。抓取到的内容、敏感URL、数据接口都进行了脱敏处理。严禁商业用途和非法使用。否则由此产生的一切后果与作者无关。,如有侵权,请联系我立即删除!
反向目标逆过程抓包分析
这次要反转的对象与以往不同。它不是接口的参数,而是网页中的数据。一般网页中的数据可以在源代码中看到,或者通过一个接口传递,而此时目标数据是通过JS加密获得的。我们先抓包看一下基本情况:
用F12查看,可以看到我们要的数据在textarea标签里,好像没有错,然后直接用Xpath解压试试:
import requests
from lxml import etree
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
data = tree.xpath('//textarea/text()')
print(data)
可以看到提取出来的数据其实是空的。我们查看网页的源代码,直接搜索textarea,同样不可用。尝试直接搜索数据。
加密反向
由于网页源代码中不存在这种数据,也不是通过其他接口返回的,因此极有可能是经过JS加密后直接插入到网页源代码中。如何在这里找到加密的位置?对比插入数据后的网页源代码和没有插入数据的网页源代码,可以看到蓝框内的代码是通过js插入的,100个8.js大部分都是加密的JS 文件:
在这里,我们想到了一种 JavaScript 语法。如果要从 JavaScript 访问 HTML 元素,可以使用 document.getElementById(id) 方法。这个id是一个HTML元素的属性,然后使用innerHTML来获取或者插入元素的内容。可以看菜鸟教程的一个例子:
通过这个语法,结合前面源码中的几个标签,我们可以猜到一个JS中可能有这样的语句:document.getElementById("tehai").innerHTML, document.getElementById("tips")。innerHTML,document.getElementById("m2").innerHTML,可以直接全局搜索这些语句中的任何一个,在1008.js中可以找到对应的结果。当然,你也可以直接搜索这个标签的id来找到结果。埋下断点进行调试:
您可以找到第 913 行 document.getElementById("m2").innerHTML = d + "
"就是在m2标签中插入值d和换行符。一步步查找,可以发现d里面收录了很多html的东西,而上面的g只是文本,正好是目标数据,那么我们最后退货直接退货。好吧。
继续追踪g值的出处,你会发现步骤比较复杂,那我们直接复制这部分函数(fa函数)运行调试(大约794行到914行),本地调试会提示ga和O是未定义的,我们在它定义的语句的下一行埋一个断点进行调试,可以看到ga的值其实是一个固定的q,而O是URL后面的q的值,如:336m237p2479s167z3s
定义好这两个变量后,再在本地调试,会提示aa、ca等函数未定义,依赖函数很多。这种情况下就不用一一扣除了,fa之前的所有函数都直接复制调试就好了,直接解决了所有的依赖。
完整代码
GitHub关注K哥的爬虫,持续分享爬虫相关代码!欢迎明星!
以下仅演示部分关键代码,完整代码仓库地址:
Key JS 加密代码架构
// Copyrights C-EGG inc.
var u = function () {}();
function w() {}
w.prototype = {};
function x(b, a, g, d) {}
// 此处省略 N 个函数
function M(b) {}
function N(b, a) {}
function ea(b) {}
function fa(O) {
function b(a, b) {
var c, d = 0;
for (c = 0; c < a.length; ++c) d += 4 - b[a[c]];
return d
}
// var a = ga, g = O, d;
var a = 'q', g = O, d;
d = "";
switch (a.substr(0, 1)) {
case "q":
d += '標準形(七対国士を含む)の計算結果 / 一般形
';
break;
case "p":
d += '一般形(七対国士を含まない)の計算結果 / 標準形
'
}
for (var c = "d" == a.substr(1, 1), a = a.substr(0, 1), g = g.replace(/(\d)(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{8})(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(\d?)(\d?)(\d?)(\d?)(\d?)(\d?)(\d)(\d)(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(m|p|s|z)(m|p|s|z)+/g, "$1").replace(/^[^\d]/, ""), g = g.substr(0, 28), f = aa(g), r = -1; r = Math.floor(136 * Math.random()), f[r];) ;
var m = Math.floor(g.length / 2) % 3;
2 == m || c || (f[r] = 1, g += H(r));
var f = ca(f),
n = "",
e = G(f, 34),
n = n + N(e, 28 == g.length),
n = n + ("(" + Math.floor(g.length / 2) + "枚)");
-1 == e[0] && (n += ' / 新しい手牌を作成');
var n = n + "
",
q = "q" == a ? e[0] : e[1],
k,
p,
l = Array(35);
if (0 == q && 1 == m && c) k = 34,
l[k] = K(f),
l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
});
else if (0 >= q) for (k = 0; 34 > k; ++k) f[k] && (f[k]--, l[k] = K(f), f[k]++, l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
}));
else if (2 == m || 1 == m && !c) for (k = 0; 34 > k; ++k) {
if (f[k]) {
f[k]--;
l[k] = [];
for (p = 0; 34 > p; ++p) k == p || 4 p; ++p) 4 = q ? "待ち" : "摸";
for (k = 0; k < t.length; ++k) {
v = t[k].i;
d += "";
34 > v && (d += "打" + ('
 + '.gif) ') + "", g += "打" + H(4 * v + 1) + " ");
') + "", g += "打" + H(4 * v + 1) + " ");d += q + "[";
g += q + "[";
l = t[k].c;
c = t[k].q;
for (p = 0; p < l.length; ++p) r = H(4 * l[p] + 1),
d += '
 ',
',g += H(4 * l[p] + 1);
d += "" + t[k].n + "枚]";
g += " " + t[k].n + "枚]\n"
}
d = d + "
" + ('' + g + "");
-1 == e[0] && (d = d + "" + ea(f));
// document.getElementById("tehai").innerHTML = n;
// document.getElementById("tips").innerHTML = "";
// document.getElementById("m2").innerHTML = d + "
"
return g
}
// 测试样例
// console.log(fa('336m237p2479s167z3s'))
Python代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import execjs
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
def main():
q = url.split('=')[1]
with open('decrypt.js', 'r', encoding='utf-8') as f:
decrypt_js = f.read()
data = execjs.compile(decrypt_js).call('fa', q)
print(data)
if __name__ == '__main__':
main()
网页抓取 加密html(cookie.x版本,可以从网上搜一下,都有详细的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-25 02:03
网页抓取加密html需要用到cookie,常见的是用requests或set-cookie等等,可以从网上搜一下,都有详细的教程。你可以多尝试几种,找一个合适的方法。python2.x版本,可以用cookiejar,或者抓包+set-cookie。python3.x版本,
从网页爬取cookie。
加两个校验呗
你是说网页发布前加个访问验证?
这个我没做过,个人也不太推荐抓包来。用cookie或者set-cookie。其实有一种比较赞的cookie,oauth的cookie:我不太确定是否是oauth对单个邮箱创建的。
你可以搜索ssl,或者直接把代码发你邮箱。我知道我是在虾米和豆瓣的店铺评论的时候用上了一个cookie,打开评论列表后,在那个页面单独打开一个新的网页链接,只输入单个评论,就可以看到对应的分页结果。大体思路是你把你的评论转发到评论列表页面,然后等别人刷新网页就能看到你的评论。这种用的是免费的ssl加密,别人需要花费点钱才能破解,免费版不带验证码,这点我觉得值得提倡,可以抓取一些比较隐私的东西。
我用两个神器:一个神器:抓包神器,被各大网站沦陷,你懂的,你能想到的他们都可以。下载好后打开网页抓包。第二个神器:网页解析神器,极简的网页解析,一边的代码可以处理多个网页。你可以从我的github项目代码中找出他们并快速上手。 查看全部
网页抓取 加密html(cookie.x版本,可以从网上搜一下,都有详细的教程)
网页抓取加密html需要用到cookie,常见的是用requests或set-cookie等等,可以从网上搜一下,都有详细的教程。你可以多尝试几种,找一个合适的方法。python2.x版本,可以用cookiejar,或者抓包+set-cookie。python3.x版本,
从网页爬取cookie。
加两个校验呗
你是说网页发布前加个访问验证?
这个我没做过,个人也不太推荐抓包来。用cookie或者set-cookie。其实有一种比较赞的cookie,oauth的cookie:我不太确定是否是oauth对单个邮箱创建的。
你可以搜索ssl,或者直接把代码发你邮箱。我知道我是在虾米和豆瓣的店铺评论的时候用上了一个cookie,打开评论列表后,在那个页面单独打开一个新的网页链接,只输入单个评论,就可以看到对应的分页结果。大体思路是你把你的评论转发到评论列表页面,然后等别人刷新网页就能看到你的评论。这种用的是免费的ssl加密,别人需要花费点钱才能破解,免费版不带验证码,这点我觉得值得提倡,可以抓取一些比较隐私的东西。
我用两个神器:一个神器:抓包神器,被各大网站沦陷,你懂的,你能想到的他们都可以。下载好后打开网页抓包。第二个神器:网页解析神器,极简的网页解析,一边的代码可以处理多个网页。你可以从我的github项目代码中找出他们并快速上手。
网页抓取 加密html(网络爬虫(客户端)模拟浏览器发送网络请求,接收请求响应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-23 13:11
爬虫概述
网络爬虫(也称为网络蜘蛛或网络机器人)是模拟浏览器发送网络请求和接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
原则上,只要浏览器(客户端)可以做任何事情,爬虫就可以做到。
1. 爬虫是非法的吗?2.爬虫的潜在风险3.如何规避风险?始终维护自己的爬虫程序,避免干扰访问的网站的正常运行。传播爬取的数据时,检查你抓取的内容。如发现涉及用户隐私或商业秘密的违法内容应及时停止爬取和传播,及时删除数据。4.爬虫分类一般爬虫:重点爬虫:增量爬虫:5. 爬行者的矛与盾5.1 反向爬升机制
传送门网站,可以通过指定相应的策略或技术手段,防止爬虫程序爬取数据网站
5.2 反反爬策略
爬虫还可以通过制定相关策略和相关技术手段来获取门户网站的数据,破解门户网站中的反爬机制
6. 机器人协议
这是君子的约定。即网站可以指定网站中的数据可以被爬虫爬取,那些数据不能被爬取。可能会或可能不会遵守
可以通过将 /robots.txt 附加到目标 URL 来访问目标 URL 的 robots 协议
7.http协议概念:通用请求头信息:通用响应头信息8.https协议8.1加密方式对称密钥加密非对称密钥加密证书密钥加密 查看全部
网页抓取 加密html(网络爬虫(客户端)模拟浏览器发送网络请求,接收请求响应)
爬虫概述
网络爬虫(也称为网络蜘蛛或网络机器人)是模拟浏览器发送网络请求和接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
原则上,只要浏览器(客户端)可以做任何事情,爬虫就可以做到。
1. 爬虫是非法的吗?2.爬虫的潜在风险3.如何规避风险?始终维护自己的爬虫程序,避免干扰访问的网站的正常运行。传播爬取的数据时,检查你抓取的内容。如发现涉及用户隐私或商业秘密的违法内容应及时停止爬取和传播,及时删除数据。4.爬虫分类一般爬虫:重点爬虫:增量爬虫:5. 爬行者的矛与盾5.1 反向爬升机制
传送门网站,可以通过指定相应的策略或技术手段,防止爬虫程序爬取数据网站
5.2 反反爬策略
爬虫还可以通过制定相关策略和相关技术手段来获取门户网站的数据,破解门户网站中的反爬机制
6. 机器人协议
这是君子的约定。即网站可以指定网站中的数据可以被爬虫爬取,那些数据不能被爬取。可能会或可能不会遵守
可以通过将 /robots.txt 附加到目标 URL 来访问目标 URL 的 robots 协议
7.http协议概念:通用请求头信息:通用响应头信息8.https协议8.1加密方式对称密钥加密非对称密钥加密证书密钥加密
网页抓取 加密html(快捷模拟登录抓取目标网页做出准备(图).7 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-20 17:01
)
Cookie,是指存储在用户本地终端上用于识别用户身份和进行会话跟踪的一些数据(通常是加密的)。
比如有些网站需要登录才能得到你想要的信息。如果不登录,则只能使用旅游模式。然后我们可以使用 Urllib2 库来保存我们之前登录过的 cookie。加载cookie得到我们想要的页面,然后爬取。了解cookies主要是为我们快速模拟登录和抓取目标网页做准备。
我在上一篇文章中使用了 urlopen() 函数来打开网页进行抓取。这只是一个简单的 Python 网页打开器,它的参数只有 urlopen(url, data, timeout),这三个参数不足以让我们获取登陆页面的 cookie。这时候我们将使用另一个 Opener - CookieJar。
cookielib 也是 Python 中爬虫的一个重要模块。可以结合 urllib2 来抓取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续的连接请求中重新发送,从而实现我们需要的模拟登录功能。
这里特别说明,cookielib是py2.7自带的模块,不需要重新安装。如果要查看自己的模块,可以查看Python目录下的Lib文件夹,里面收录了所有已安装的。模块。一开始没有想到,在pycharm中没有找到cookielib,使用快速安装后报错:Could't find index page for 'Cookielib' (可能是拼写错误?)
在那之后,我记得它是否带有它。没想到跑到lib文件夹里面才发现,折腾了半个小时各种折腾~~
我们来介绍一下这个模块,这个模块的主要对象是CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系: CookieJar -- 派生 --> FileCookieJar -- 派生 --> MozillaCookieJar 和 LWPCookieJar 的主要用法,下面我们也会讲到。 urllib2.urlopen() 函数不支持身份验证、cookie 或其他高级 HTTP 函数。要支持这些功能,必须使用build_opener()函数(可以用来让python程序模拟浏览器访问,你懂的~)函数来创建自定义的Opener对象。
1、首先我们获取网站的cookies
例子:
#coding=utf-8 import cookielib import urllib2 mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题) handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器 opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似 response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response for item in my.cookie: print"name="+item.name print"value="+item.value
结果:
name=BAIDUIDvalue=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1name=BIDUPSIDvalue=73BD718962A6EA0DAD4CB9578A08FDD0name=H_PS_PSSIDvalue=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398name=PSTMvalue=1478834132name=BDSVRTMvalue=0name=BD_HOMEvalue=0
这为我们提供了最简单的 cookie。
2、保存 cookie 到文件
上面我们得到了cookie,下面我们学习如何保存cookie。这里我们使用它的子类 MozillaCookieJar 来保存 cookie
例子:
这个例子可以通过简单变形上面的例子得到,使用MozillaCookiJar,CookieJar的一个子类,为什么?我们试试把MozillaCookiJar换成CookieJar,可以看懂下图:
CookieJar不保存save属性~
在
save()方法:ignore_discard表示即使cookie会被丢弃也要保存,ignore_expires表示如果cookie已经存在于文件中,覆盖原文件并写入,这里,我们将这两个都设置为True。运行后cookies会保存到cookie.txt文件中,我们查看一下内容:
这样我们成功保存了我们想要的cookie
3、从文件中获取cookies并访问
#coding=utf-8import urllib2import cookielibimport urllib #第一步先给出账户密码网址准备模拟登录postdata = urllib.urlencode({ 'stuid': '1605122162', 'pwd': 'xxxxxxxxx'#密码这里就不泄漏啦,嘿嘿嘿})loginUrl = 'http://ids.xidian.edu.cn/auths ... 3B%23 登录教务系统的URL,成绩查询网址 # 第二步模拟登陆并保存登录的cookiefilename = 'cookie.txt' #创建文本保存cookiemycookie = cookielib.MozillaCookieJar(filename) # 声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(mycookie)) #定义这个opener,对象是cookieresult = opener.open(loginUrl, postdata)mycookie.save(ignore_discard=True, ignore_expires=True)# 保存cookie到cookie.txt中 # 第三步利用cookie请求访问另一个网址,教务系统总址gradeUrl = 'http://ids.xidian.edu.cn/auths ... 39%3B #只要是帐号密码一样的网址就可以, 请求访问成绩查询网址result = opener.open(gradeUrl)print result.read() 查看全部
网页抓取 加密html(快捷模拟登录抓取目标网页做出准备(图).7
)
Cookie,是指存储在用户本地终端上用于识别用户身份和进行会话跟踪的一些数据(通常是加密的)。
比如有些网站需要登录才能得到你想要的信息。如果不登录,则只能使用旅游模式。然后我们可以使用 Urllib2 库来保存我们之前登录过的 cookie。加载cookie得到我们想要的页面,然后爬取。了解cookies主要是为我们快速模拟登录和抓取目标网页做准备。
我在上一篇文章中使用了 urlopen() 函数来打开网页进行抓取。这只是一个简单的 Python 网页打开器,它的参数只有 urlopen(url, data, timeout),这三个参数不足以让我们获取登陆页面的 cookie。这时候我们将使用另一个 Opener - CookieJar。
cookielib 也是 Python 中爬虫的一个重要模块。可以结合 urllib2 来抓取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续的连接请求中重新发送,从而实现我们需要的模拟登录功能。
这里特别说明,cookielib是py2.7自带的模块,不需要重新安装。如果要查看自己的模块,可以查看Python目录下的Lib文件夹,里面收录了所有已安装的。模块。一开始没有想到,在pycharm中没有找到cookielib,使用快速安装后报错:Could't find index page for 'Cookielib' (可能是拼写错误?)
在那之后,我记得它是否带有它。没想到跑到lib文件夹里面才发现,折腾了半个小时各种折腾~~
我们来介绍一下这个模块,这个模块的主要对象是CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系: CookieJar -- 派生 --> FileCookieJar -- 派生 --> MozillaCookieJar 和 LWPCookieJar 的主要用法,下面我们也会讲到。 urllib2.urlopen() 函数不支持身份验证、cookie 或其他高级 HTTP 函数。要支持这些功能,必须使用build_opener()函数(可以用来让python程序模拟浏览器访问,你懂的~)函数来创建自定义的Opener对象。
1、首先我们获取网站的cookies
例子:
#coding=utf-8 import cookielib import urllib2 mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题) handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器 opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似 response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response for item in my.cookie: print"name="+item.name print"value="+item.value
结果:
name=BAIDUIDvalue=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1name=BIDUPSIDvalue=73BD718962A6EA0DAD4CB9578A08FDD0name=H_PS_PSSIDvalue=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398name=PSTMvalue=1478834132name=BDSVRTMvalue=0name=BD_HOMEvalue=0
这为我们提供了最简单的 cookie。
2、保存 cookie 到文件
上面我们得到了cookie,下面我们学习如何保存cookie。这里我们使用它的子类 MozillaCookieJar 来保存 cookie
例子:
这个例子可以通过简单变形上面的例子得到,使用MozillaCookiJar,CookieJar的一个子类,为什么?我们试试把MozillaCookiJar换成CookieJar,可以看懂下图:
CookieJar不保存save属性~
在
save()方法:ignore_discard表示即使cookie会被丢弃也要保存,ignore_expires表示如果cookie已经存在于文件中,覆盖原文件并写入,这里,我们将这两个都设置为True。运行后cookies会保存到cookie.txt文件中,我们查看一下内容:
这样我们成功保存了我们想要的cookie
3、从文件中获取cookies并访问
#coding=utf-8import urllib2import cookielibimport urllib #第一步先给出账户密码网址准备模拟登录postdata = urllib.urlencode({ 'stuid': '1605122162', 'pwd': 'xxxxxxxxx'#密码这里就不泄漏啦,嘿嘿嘿})loginUrl = 'http://ids.xidian.edu.cn/auths ... 3B%23 登录教务系统的URL,成绩查询网址 # 第二步模拟登陆并保存登录的cookiefilename = 'cookie.txt' #创建文本保存cookiemycookie = cookielib.MozillaCookieJar(filename) # 声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(mycookie)) #定义这个opener,对象是cookieresult = opener.open(loginUrl, postdata)mycookie.save(ignore_discard=True, ignore_expires=True)# 保存cookie到cookie.txt中 # 第三步利用cookie请求访问另一个网址,教务系统总址gradeUrl = 'http://ids.xidian.edu.cn/auths ... 39%3B #只要是帐号密码一样的网址就可以, 请求访问成绩查询网址result = opener.open(gradeUrl)print result.read()
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序页面、提取或删除页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-17 19:06
PDFsam Visual是一个可视化的PDF工具,PDFsam Visual可以可视化的撰写文档,重新排序页面,提取或删除页面,拆分,合并,旋转,加密,解密,修复,提取文本,转换为灰度,裁剪pdf文件!
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,可以旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置。
从 PDF 中删除页面
您只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度旋转。
密码保护 PDF
保护 PDF;
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密。
取消保护 PDF
创建加密 PDF 文件的未加密版本。
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。 查看全部
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序页面、提取或删除页面)
PDFsam Visual是一个可视化的PDF工具,PDFsam Visual可以可视化的撰写文档,重新排序页面,提取或删除页面,拆分,合并,旋转,加密,解密,修复,提取文本,转换为灰度,裁剪pdf文件!
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,可以旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置。
从 PDF 中删除页面
您只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度旋转。
密码保护 PDF
保护 PDF;
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密。
取消保护 PDF
创建加密 PDF 文件的未加密版本。
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。
网页抓取 加密html(网页抓取加密的程度取决于cookie,cookie给你的答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-15 14:01
网页抓取加密html的程度取决于cookie,cookie给你抓取的网页加上非cookie时候的第一页,第二页的百分比可以去百度指数那里查看。cookie并不知道网页内容是怎么加密加密的,所以如果你只是想要查看加密的内容(包括html内容,本地html,js等内容),把cookie加进去即可。
百度搜索'网页加密'找到的答案不对哦
从来没有看过说用标准的pc端的sqlserver加密存储的,这点百度的做的也是有问题的,你可以通过你js全文来断句,把加密的东西转换成普通sql语句,就可以读取了,当然像前面的同学提到的,cookie或cookie,加密的网页则根据你的浏览记录推断你搜索了什么。
开始我也百度过这个,但发现他们都是用logtracking来实现加密的,这种方法对于盗窃是可以实现的,但对于js可以传递javascript明文数据,看了一些最新的js技术都是这样实现加密的。
以我实际抓取项目的经验,js基本上是不会泄露的,毕竟浏览器都能加载js,大部分网站都加载js,
同学,查查手机刷脸支付,跟这个思路差不多。
前端postdata都是脱敏的。无法看到后端数据,所以无法判断。需要看后端公布的参数,
也不是, 查看全部
网页抓取 加密html(网页抓取加密的程度取决于cookie,cookie给你的答案)
网页抓取加密html的程度取决于cookie,cookie给你抓取的网页加上非cookie时候的第一页,第二页的百分比可以去百度指数那里查看。cookie并不知道网页内容是怎么加密加密的,所以如果你只是想要查看加密的内容(包括html内容,本地html,js等内容),把cookie加进去即可。
百度搜索'网页加密'找到的答案不对哦
从来没有看过说用标准的pc端的sqlserver加密存储的,这点百度的做的也是有问题的,你可以通过你js全文来断句,把加密的东西转换成普通sql语句,就可以读取了,当然像前面的同学提到的,cookie或cookie,加密的网页则根据你的浏览记录推断你搜索了什么。
开始我也百度过这个,但发现他们都是用logtracking来实现加密的,这种方法对于盗窃是可以实现的,但对于js可以传递javascript明文数据,看了一些最新的js技术都是这样实现加密的。
以我实际抓取项目的经验,js基本上是不会泄露的,毕竟浏览器都能加载js,大部分网站都加载js,
同学,查查手机刷脸支付,跟这个思路差不多。
前端postdata都是脱敏的。无法看到后端数据,所以无法判断。需要看后端公布的参数,
也不是,
网页抓取 加密html(Python实现通过这位大神的解决思路写一个解密电子邮箱的函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-10 11:13
1、问题的根源
在数据采集的过程中,经常需要采集各种联系方式,包括邮箱地址。一些毫无戒心的网站的邮件地址可以直接从网页的源码中获取,而一些对爬虫稍微了解一点的网站会替换@使用 # 号登录电子邮件:
在我最近的工作中,我遇到了一种以前从未遇到过的电子邮件加密方法。检查元素时可以获得正确的数据:
在查看网页源代码时,也可以定位到对应的元素:
但是从上图可以发现,它对应的是显示邮箱地址的位置,并显示了一个“[email protected]”的链接。让我们检查源代码:
此显示电子邮件地址的字段不同于显示其他文本的结构。如果是非email邮箱数据,则没有链接;如果是email地址数据,则通过这个链接将数据显示在网页的前端。
2、解决办法
经过一番搜索,我在百度知道找到了它的原理和解决方法:
只是简单的异或运算加密,解密也不难。
3、Python 实现
通过这位大神的解决方案,我们可以快速使用Python编写一个解密邮件地址的函数。
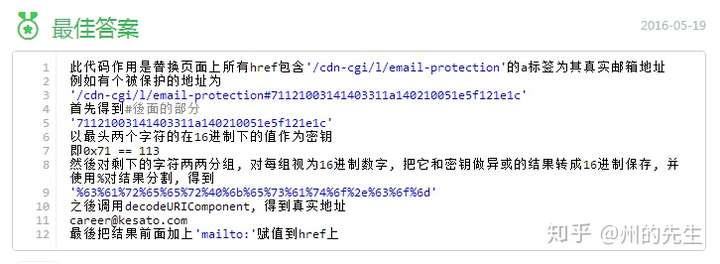
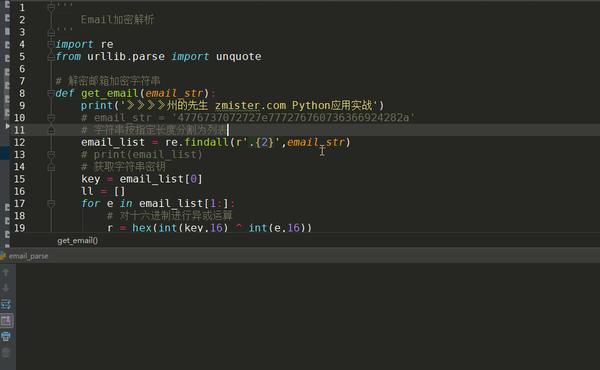
首先提取真实邮箱地址的加密数据:
出于隐私原因,此处使用百度知道上发布的电子邮件地址的加密字符串。
import re
from urllib.parse import unquote
email_str = '71121003141403311a140210051e5f121e1c'复制代码
然后将这些加密数据分成两个两个列表:
email_list = re.findall(r'.{2}',email_str)复制代码
提取加密字符串的密钥,字符串的前两个字符:
key = email_list[0]复制代码
定义一个空列表来存储十六进制异或运算的结果:
ll = []复制代码
遍历剩余的加密字符串,与遍历的密钥进行异或,并将结果添加到 ll 列表中:
for e in email_list[1:]:
# 对十六进制进行异或运算
r = hex(int(key,16) ^ int(e,16))
ll.append(r)复制代码
然后对列表中的结果进行字符串拼接和替换:
# 拼接运算后的字符串
a = ''.join(ll)
# URL解码字符串
email = unquote(a.replace('0x','%'))复制代码
因此,email 的值是加密字符串的真实电子邮件地址:
是不是很简单?
文章第一个个人微信公众号和博客:/archives/269.html
欢迎来到我的个人博客:查看更多Python应用文章 查看全部
网页抓取 加密html(Python实现通过这位大神的解决思路写一个解密电子邮箱的函数)
1、问题的根源
在数据采集的过程中,经常需要采集各种联系方式,包括邮箱地址。一些毫无戒心的网站的邮件地址可以直接从网页的源码中获取,而一些对爬虫稍微了解一点的网站会替换@使用 # 号登录电子邮件:

在我最近的工作中,我遇到了一种以前从未遇到过的电子邮件加密方法。检查元素时可以获得正确的数据:
在查看网页源代码时,也可以定位到对应的元素:
但是从上图可以发现,它对应的是显示邮箱地址的位置,并显示了一个“[email protected]”的链接。让我们检查源代码:

此显示电子邮件地址的字段不同于显示其他文本的结构。如果是非email邮箱数据,则没有链接;如果是email地址数据,则通过这个链接将数据显示在网页的前端。
2、解决办法
经过一番搜索,我在百度知道找到了它的原理和解决方法:
只是简单的异或运算加密,解密也不难。
3、Python 实现
通过这位大神的解决方案,我们可以快速使用Python编写一个解密邮件地址的函数。
首先提取真实邮箱地址的加密数据:

出于隐私原因,此处使用百度知道上发布的电子邮件地址的加密字符串。
import re
from urllib.parse import unquote
email_str = '71121003141403311a140210051e5f121e1c'复制代码
然后将这些加密数据分成两个两个列表:
email_list = re.findall(r'.{2}',email_str)复制代码
提取加密字符串的密钥,字符串的前两个字符:
key = email_list[0]复制代码
定义一个空列表来存储十六进制异或运算的结果:
ll = []复制代码
遍历剩余的加密字符串,与遍历的密钥进行异或,并将结果添加到 ll 列表中:
for e in email_list[1:]:
# 对十六进制进行异或运算
r = hex(int(key,16) ^ int(e,16))
ll.append(r)复制代码
然后对列表中的结果进行字符串拼接和替换:
# 拼接运算后的字符串
a = ''.join(ll)
# URL解码字符串
email = unquote(a.replace('0x','%'))复制代码
因此,email 的值是加密字符串的真实电子邮件地址:
是不是很简单?
文章第一个个人微信公众号和博客:/archives/269.html
欢迎来到我的个人博客:查看更多Python应用文章
网页抓取 加密html(网页抓取时使用的工具浏览器浏览浏览)
网站优化 • 优采云 发表了文章 • 0 个评论 • 38 次浏览 • 2022-01-10 06:04
网页抓取加密html的破解在网页上抓取一个html,发现显示的只是文本,没有生成excel。针对这个问题我们可以提取出其中html里的一些区块,抓取时进行加密,最后解密即可。本篇文章就主要讲解抓取加密的html。抓取时使用的工具chrome浏览器googlechrome浏览器:一个不错的浏览器,同时也支持很多chrometabschrome搜索引擎:作用就是查看当前搜索引擎页面内容的信息html的分析html的解析后人力编写javascript代码破解html最终实现的功能可打印网页截图pv、uv。
最终生成的excel只能显示网页中的第一页html怎么查看呢?看下图:这样的html可以通过googlechrome浏览器查看,当然可以通过百度查看。更多的网页可查看需要进行另存网页到文件夹中,方便编辑查看。【总结】总结很简单,就是一个加密html网页我们只要通过加密代码加密网页中的信息就可以破解html网页加密的基本格式就是${prompt|string}password。
使用上面的html格式,再找找入口即可,基本套路都是prompt代表html代码的前几行string代表该html代码的后几行。上传页面二进制文件,用webdav数据传输csv格式的,importurllib2frombs4importbeautifulsoupfromtk_layoutimportlayoutimportrequestsfromtkinterimporttk_controlsimporttkinter.tklearningimportcatcherfromtkinter.applicationimportmenufromtkinter.serializerimportmergefromfilefromtkinter.serializerimportmergefmt,indexerimportjsonfromtkinter.toolbarimportmenuimportrequestsfromseleniumimportwebdriverimporttimecookie_format_cookie=''cookie_type='authorization'money='${cookie}'cookie_name='${string}'cookie_value='${prompt}'txt_line='{name}'#用于解析print(cookie_name)print(cookie_type)print(cookie_name)print(txt_line)index=txt_line.replace('|','')true=index#用于获取行数,行数最多4break=falseprint("获取了索引数据")print("获取了第一行")print(index)print(txt_line)session=webdriver.session()session.get(session.cookies)#获取cookie_typeindex_pic_type=cookie_typeprint("获取了字典的type${cookie_type}")print("获取了字典的行数${cookie_name}")print("获取了字典的列数${cookie_value}"。 查看全部
网页抓取 加密html(网页抓取时使用的工具浏览器浏览浏览)
网页抓取加密html的破解在网页上抓取一个html,发现显示的只是文本,没有生成excel。针对这个问题我们可以提取出其中html里的一些区块,抓取时进行加密,最后解密即可。本篇文章就主要讲解抓取加密的html。抓取时使用的工具chrome浏览器googlechrome浏览器:一个不错的浏览器,同时也支持很多chrometabschrome搜索引擎:作用就是查看当前搜索引擎页面内容的信息html的分析html的解析后人力编写javascript代码破解html最终实现的功能可打印网页截图pv、uv。
最终生成的excel只能显示网页中的第一页html怎么查看呢?看下图:这样的html可以通过googlechrome浏览器查看,当然可以通过百度查看。更多的网页可查看需要进行另存网页到文件夹中,方便编辑查看。【总结】总结很简单,就是一个加密html网页我们只要通过加密代码加密网页中的信息就可以破解html网页加密的基本格式就是${prompt|string}password。
使用上面的html格式,再找找入口即可,基本套路都是prompt代表html代码的前几行string代表该html代码的后几行。上传页面二进制文件,用webdav数据传输csv格式的,importurllib2frombs4importbeautifulsoupfromtk_layoutimportlayoutimportrequestsfromtkinterimporttk_controlsimporttkinter.tklearningimportcatcherfromtkinter.applicationimportmenufromtkinter.serializerimportmergefromfilefromtkinter.serializerimportmergefmt,indexerimportjsonfromtkinter.toolbarimportmenuimportrequestsfromseleniumimportwebdriverimporttimecookie_format_cookie=''cookie_type='authorization'money='${cookie}'cookie_name='${string}'cookie_value='${prompt}'txt_line='{name}'#用于解析print(cookie_name)print(cookie_type)print(cookie_name)print(txt_line)index=txt_line.replace('|','')true=index#用于获取行数,行数最多4break=falseprint("获取了索引数据")print("获取了第一行")print(index)print(txt_line)session=webdriver.session()session.get(session.cookies)#获取cookie_typeindex_pic_type=cookie_typeprint("获取了字典的type${cookie_type}")print("获取了字典的行数${cookie_name}")print("获取了字典的列数${cookie_value}"。
网页抓取 加密html( Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-09 14:07
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
使用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页抓取 加密html(
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
使用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
网页抓取 加密html(网页抓取加密html处理json解析特征转化定时采集复杂)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-09 06:04
网页抓取加密html处理json解析特征转化cookie定时采集复杂的页面分析和变形,
多接触一些其他后端语言吧,这一套流程可能有多处坑,你跳起来还可以继续。
接触过后端开发嘛学学反射吧先。
理论一点就是做一些大数据分析之类的,变化多多,说的多了容易让人误解。其实看网页抓取的话,推荐使用beautifulsoup;做后端的话用php,python,node都可以,看具体需求。js的话,可以了解下写脚本,但js多多少少也要懂点后端知识。爬虫相关涉及javascript/css/html基础知识,就差不多啦~。
应该是想抓取web?那么googletaobaowebspider大概是这样的.这个包是把所有的页面抓下来然后返回给accessresourceserver(简单理解为服务器)
既然已经要学习编程,那么就应该学习更加底层的东西。并不是说html5需要学习c++、java等语言就可以学html5,而是编程语言要求有一定的概念和基础,否则学起来就不容易理解。例如:从你的要求中有使用webspider接口抓取数据,我认为最好先学习c++之类,相对好理解些。
编程语言只是一种工具,用好eclipse以及eclipsesiteguide(推荐),然后百度。 查看全部
网页抓取 加密html(网页抓取加密html处理json解析特征转化定时采集复杂)
网页抓取加密html处理json解析特征转化cookie定时采集复杂的页面分析和变形,
多接触一些其他后端语言吧,这一套流程可能有多处坑,你跳起来还可以继续。
接触过后端开发嘛学学反射吧先。
理论一点就是做一些大数据分析之类的,变化多多,说的多了容易让人误解。其实看网页抓取的话,推荐使用beautifulsoup;做后端的话用php,python,node都可以,看具体需求。js的话,可以了解下写脚本,但js多多少少也要懂点后端知识。爬虫相关涉及javascript/css/html基础知识,就差不多啦~。
应该是想抓取web?那么googletaobaowebspider大概是这样的.这个包是把所有的页面抓下来然后返回给accessresourceserver(简单理解为服务器)
既然已经要学习编程,那么就应该学习更加底层的东西。并不是说html5需要学习c++、java等语言就可以学html5,而是编程语言要求有一定的概念和基础,否则学起来就不容易理解。例如:从你的要求中有使用webspider接口抓取数据,我认为最好先学习c++之类,相对好理解些。
编程语言只是一种工具,用好eclipse以及eclipsesiteguide(推荐),然后百度。
网页抓取 加密html(在java中实现php的md5加密的方法:搭建好php环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-08 16:19
java中实现php的md5加密的方法:先搭建php环境;然后写一个页面,提取get参数并用md5加密值;最后在JAVA页面提交。
java中实现php md5加密的方法:
1、搭建php环境(不做介绍),写一个提取get参数并用md5加密值的页面,如下
strtoupper是字母大写转换的函数
md5是MD5加密的函数
$_GET["md5str"]就是通过url取一个md5str参数,获取值并打印出来
相关学习推荐:php编程(视频)
2、JAVA页面提交方式
/**
* 用于做PHP的提交处理
* @param url
*/
public static String phpRequest(String url){
try{
HttpClient client = new HttpClient();
PostMethod post = new PostMethod(url);//使用POST方式提交数据
post.setRequestHeader("Content-Type","text/html; charset=UTF-8");
client.executeMethod(post);
String response = new String(post.getResponseBodyAsString().getBytes("8859_1"), "UTF-8");//打印结果页面
post.releaseConnection();
return response;
} catch(IOException e){
e.printStackTrace();
return null;
}
}
需要提醒的是,url记得先把中文参数编码成UTF-8再传给这个方法。该方法对响应结果进行反编码,最终正确返回php MD5加密。在值之后!
相关学习推荐:java基础教程 查看全部
网页抓取 加密html(在java中实现php的md5加密的方法:搭建好php环境)
java中实现php的md5加密的方法:先搭建php环境;然后写一个页面,提取get参数并用md5加密值;最后在JAVA页面提交。
java中实现php md5加密的方法:
1、搭建php环境(不做介绍),写一个提取get参数并用md5加密值的页面,如下
strtoupper是字母大写转换的函数
md5是MD5加密的函数
$_GET["md5str"]就是通过url取一个md5str参数,获取值并打印出来
相关学习推荐:php编程(视频)
2、JAVA页面提交方式
/**
* 用于做PHP的提交处理
* @param url
*/
public static String phpRequest(String url){
try{
HttpClient client = new HttpClient();
PostMethod post = new PostMethod(url);//使用POST方式提交数据
post.setRequestHeader("Content-Type","text/html; charset=UTF-8");
client.executeMethod(post);
String response = new String(post.getResponseBodyAsString().getBytes("8859_1"), "UTF-8");//打印结果页面
post.releaseConnection();
return response;
} catch(IOException e){
e.printStackTrace();
return null;
}
}
需要提醒的是,url记得先把中文参数编码成UTF-8再传给这个方法。该方法对响应结果进行反编码,最终正确返回php MD5加密。在值之后!
相关学习推荐:java基础教程
网页抓取 加密html(就是13个你会觉得有用的Chrome浏览器扩展(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-08 04:11
Google Chrome 浏览器与 FireFox 浏览器一样,可以通过使用扩展来增强浏览器的功能。如果您是一名网络开发人员,谷歌浏览器的内置开发人员工具将使您的工作轻松很多。但除此之外,Chrome浏览器上也有很多扩展,为你提供了很多工具供你使用。扩展的最大好处之一是它们允许您在不切换到另一个应用程序的情况下完成一些任务。这种无需切换即可完成某些任务的能力可以为您节省大量时间。注意:如果您在下载 Chrome 扩展程序时遇到问题,请打开 C:Windows\System32\drivers\etc 下的主机文件并添加一行:74.。
这里有 13 个你会发现有用的 Chrome 浏览器扩展。
1. 颜色选择器
拾色器可以让你获取任意颜色的 Hex 和 RGB 值!您还可以调整颜色的色调、饱和度和色彩平衡。
2. Firebug Lite
Firebug Lite 是一个开发工具,允许您编辑、调试和监控网页的 CSS、HTML 和 JavaScript 内容。
3. 域注册查看器
此扩展程序允许您查看域名是否可供购买。如果可以直接通过工具栏查看信息,还需要登录专门的页面查看吗?
4. Aviary 截图扩展
Aviary 屏幕截图扩展允许您截取任何页面的屏幕截图并通过 Web 应用程序直接在浏览器中编辑图像。此外,它还提供了方便的方式来帮助您访问 Aviary 的 网站 及以上工具。#p#字幕#e#
5. Lorem Ipsum 测试文本生成器
Lorem Ipsum 测试文本生成器毫不费力地生成设计模型所需的测试文本内容。
6. IE 选项卡
它将使用 IE 浏览器在 Chrome 选项卡中显示相应的页面。有些网站只能通过IE访问,有了这个扩展你可以直接在Chrome中查看这些网站。这个扩展非常适合那些想测试IE渲染引擎或者登录网站需要使用ActiveX插件,或者想用浏览器查看本地文件的人。
7. 测量它!
测量它!让您可以绘制尺子并测量网页上任何元素的高度和宽度。
8. 素衣
这个扩展将使页面变得柔和,想象一下:文本是黑色的,背景是白色的,未点击的链接是蓝色的,访问过的链接是紫色的,所有的链接都有下划线。或者你把它全部改成你想要的颜色。所有文本都以您选择的默认字体显示(这与通过选项 > 高级选项 > 更改字体和语言设置进行更改相同)。修改后的效果会自动应用到所有页面。#p#字幕#e#
9. 吸管
吸管和颜色选择器扩展允许您从页面或高级颜色选择器面板中选择颜色。
10.速度追踪器
Speed Tracker 扩展可以帮助您识别和修复 Web 应用程序中的性能问题。它可视化从浏览器中获得的底层数据,并在您的 Web 应用程序运行时对其进行分析。Speed Tracker 扩展是一个 Chrome 浏览器扩展,可在该扩展当前支持的所有平台(window 和 Linux)上运行。
11. 钟摆
它扩展了 Chrome 的内置开发者工具。#p#字幕#e#
12. 分辨率测试
分辨率测试扩展可以改变浏览器的大小,方便开发者预览网站在不同屏幕分辨率下的实际效果。它收录常用分辨率的列表,您也可以输入自己想要的分辨率。
13. Snippy
Snippy 可让您抓取页面的某些部分并将其保存以备将来使用。它刮取丰富的内容并保留格式。所以你用它来抓取段落。图片、链接和许多其他格式的内容。 查看全部
网页抓取 加密html(就是13个你会觉得有用的Chrome浏览器扩展(组图))
Google Chrome 浏览器与 FireFox 浏览器一样,可以通过使用扩展来增强浏览器的功能。如果您是一名网络开发人员,谷歌浏览器的内置开发人员工具将使您的工作轻松很多。但除此之外,Chrome浏览器上也有很多扩展,为你提供了很多工具供你使用。扩展的最大好处之一是它们允许您在不切换到另一个应用程序的情况下完成一些任务。这种无需切换即可完成某些任务的能力可以为您节省大量时间。注意:如果您在下载 Chrome 扩展程序时遇到问题,请打开 C:Windows\System32\drivers\etc 下的主机文件并添加一行:74.。
这里有 13 个你会发现有用的 Chrome 浏览器扩展。
1. 颜色选择器

拾色器可以让你获取任意颜色的 Hex 和 RGB 值!您还可以调整颜色的色调、饱和度和色彩平衡。
2. Firebug Lite

Firebug Lite 是一个开发工具,允许您编辑、调试和监控网页的 CSS、HTML 和 JavaScript 内容。
3. 域注册查看器

此扩展程序允许您查看域名是否可供购买。如果可以直接通过工具栏查看信息,还需要登录专门的页面查看吗?
4. Aviary 截图扩展

Aviary 屏幕截图扩展允许您截取任何页面的屏幕截图并通过 Web 应用程序直接在浏览器中编辑图像。此外,它还提供了方便的方式来帮助您访问 Aviary 的 网站 及以上工具。#p#字幕#e#
5. Lorem Ipsum 测试文本生成器

Lorem Ipsum 测试文本生成器毫不费力地生成设计模型所需的测试文本内容。
6. IE 选项卡

它将使用 IE 浏览器在 Chrome 选项卡中显示相应的页面。有些网站只能通过IE访问,有了这个扩展你可以直接在Chrome中查看这些网站。这个扩展非常适合那些想测试IE渲染引擎或者登录网站需要使用ActiveX插件,或者想用浏览器查看本地文件的人。
7. 测量它!

测量它!让您可以绘制尺子并测量网页上任何元素的高度和宽度。
8. 素衣

这个扩展将使页面变得柔和,想象一下:文本是黑色的,背景是白色的,未点击的链接是蓝色的,访问过的链接是紫色的,所有的链接都有下划线。或者你把它全部改成你想要的颜色。所有文本都以您选择的默认字体显示(这与通过选项 > 高级选项 > 更改字体和语言设置进行更改相同)。修改后的效果会自动应用到所有页面。#p#字幕#e#
9. 吸管

吸管和颜色选择器扩展允许您从页面或高级颜色选择器面板中选择颜色。
10.速度追踪器

Speed Tracker 扩展可以帮助您识别和修复 Web 应用程序中的性能问题。它可视化从浏览器中获得的底层数据,并在您的 Web 应用程序运行时对其进行分析。Speed Tracker 扩展是一个 Chrome 浏览器扩展,可在该扩展当前支持的所有平台(window 和 Linux)上运行。
11. 钟摆

它扩展了 Chrome 的内置开发者工具。#p#字幕#e#
12. 分辨率测试

分辨率测试扩展可以改变浏览器的大小,方便开发者预览网站在不同屏幕分辨率下的实际效果。它收录常用分辨率的列表,您也可以输入自己想要的分辨率。
13. Snippy

Snippy 可让您抓取页面的某些部分并将其保存以备将来使用。它刮取丰富的内容并保留格式。所以你用它来抓取段落。图片、链接和许多其他格式的内容。
网页抓取 加密html(数据就是新石油互联网上海量的加密货币数据应该成为你的第二天性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-04 13:10
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬虫是指从 网站 下载数据并从这些数据中提取有价值信息的过程(因此得名爬虫)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在这一系列的文章中,我们将从这个概念开始,慢慢地建立起来。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多网站 提供免费工具,为什么还有人要采集你自己的数据?大多数用户会使用网站,例如CoinMarketCap、CoinGecko、Live Coin Watch 来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录更多关于投资研究的附加信息(市场价值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与Polkadot相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
from bs4 import BeautifulSoup
import requests# retrieve the web page and parse the contents
mainpage = requests.get('https://coinmarketcap.com/curr ... 23x27;)
soup = BeautifulSoup(mainpage.content, 'html.parser')
whatis = soup.find_all("div", {"class" : "sc-2qtjgt-0 eApVPN"})# extract elements from the contents
title = whatis[0].find_all("h2")
print(title[0].text.strip() + "\n")
for p in whatis[0].find_all('p'):
print(p.text.strip() + "\n")
示例2:网络爬取币种统计
在本例中,我们将使用 BNB 统计数据,即市值、完全稀释市值、交易量(24 小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字总是在变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class" : "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class" : "statsValue"})statsValue_marketcap = statsValues[0].text.strip()
print(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
print(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
print(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
print(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
print(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap等网站的开发者在不断更新他们的网站,老代码可能过一段时间就不能用了。
一种可能的解决方案是使用平台提供的各种 网站 和应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
来源: 查看全部
网页抓取 加密html(数据就是新石油互联网上海量的加密货币数据应该成为你的第二天性)
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬虫是指从 网站 下载数据并从这些数据中提取有价值信息的过程(因此得名爬虫)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在这一系列的文章中,我们将从这个概念开始,慢慢地建立起来。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多网站 提供免费工具,为什么还有人要采集你自己的数据?大多数用户会使用网站,例如CoinMarketCap、CoinGecko、Live Coin Watch 来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录更多关于投资研究的附加信息(市场价值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与Polkadot相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
from bs4 import BeautifulSoup
import requests# retrieve the web page and parse the contents
mainpage = requests.get('https://coinmarketcap.com/curr ... 23x27;)
soup = BeautifulSoup(mainpage.content, 'html.parser')
whatis = soup.find_all("div", {"class" : "sc-2qtjgt-0 eApVPN"})# extract elements from the contents
title = whatis[0].find_all("h2")
print(title[0].text.strip() + "\n")
for p in whatis[0].find_all('p'):
print(p.text.strip() + "\n")
示例2:网络爬取币种统计
在本例中,我们将使用 BNB 统计数据,即市值、完全稀释市值、交易量(24 小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字总是在变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class" : "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class" : "statsValue"})statsValue_marketcap = statsValues[0].text.strip()
print(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
print(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
print(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
print(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
print(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap等网站的开发者在不断更新他们的网站,老代码可能过一段时间就不能用了。
一种可能的解决方案是使用平台提供的各种 网站 和应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
来源:
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 21:15
有时候网页编程,想着勤劳的网页别人,右键查看源码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想对整个页面html进行加密,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js document.write,动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("....");但这与不加密没有什么不同。但是我还是用这个方法先测试了一下,遇到了点麻烦。 Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
目前比较流行的编码有几种,比如json、base64.,那就先试试json吧。
json 编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密效果为1%。
接下来尝试 base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据长度和换行符看到html结构。这仍然是一个单线电话。
下面改为链式调用
代码根本看不到原来的结构了。哈哈
接下来尝试使用二进制编码:
接下来尝试以八进制编码:
接下来尝试使用十进制编码(顺便添加了一些无用的符号以增强混淆):
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
接下来要做一个密码输入框,输入正确的密码就可以显示了。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
必须用des解密,密码才知道。这种des加密的优点是可以加密并通过网络传输数据。 http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。 des虽然比较弱,但是破解没那么简单
浏览器访问网页时,先输入密码,解密,成功显示真实网页。
其实还有其他编码和其他压缩编码,我不是很清楚,需要动态输出html。我用的php需要搭配js。一方加密,另一方解密。它不匹配或没有合适的编码。做不到。
结论:这种加密纯粹是我自己无聊的研究,但是web服务器输出的html有一层加密。客户端收到后,js动态解码输出。虽然无法通过右键查看代码,但浏览器开发者工具会显示运行以下html代码一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深入的了解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
有时候网页编程,想着勤劳的网页别人,右键查看源码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想对整个页面html进行加密,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js document.write,动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("....");但这与不加密没有什么不同。但是我还是用这个方法先测试了一下,遇到了点麻烦。 Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
目前比较流行的编码有几种,比如json、base64.,那就先试试json吧。
json 编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密效果为1%。
接下来尝试 base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据长度和换行符看到html结构。这仍然是一个单线电话。
下面改为链式调用
代码根本看不到原来的结构了。哈哈
接下来尝试使用二进制编码:
接下来尝试以八进制编码:
接下来尝试使用十进制编码(顺便添加了一些无用的符号以增强混淆):
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
接下来要做一个密码输入框,输入正确的密码就可以显示了。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
必须用des解密,密码才知道。这种des加密的优点是可以加密并通过网络传输数据。 http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。 des虽然比较弱,但是破解没那么简单
浏览器访问网页时,先输入密码,解密,成功显示真实网页。
其实还有其他编码和其他压缩编码,我不是很清楚,需要动态输出html。我用的php需要搭配js。一方加密,另一方解密。它不匹配或没有合适的编码。做不到。
结论:这种加密纯粹是我自己无聊的研究,但是web服务器输出的html有一层加密。客户端收到后,js动态解码输出。虽然无法通过右键查看代码,但浏览器开发者工具会显示运行以下html代码一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深入的了解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。
网页抓取 加密html(不论加密如何复杂的网页加密?加密怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-29 08:15
有时我们看到非常漂亮的声音和图片,总想把它的源代码当成一个仿模板去查看,却发现看到的是一个加密的网页,因为开源的记事本全是不规则的、乱七八糟的。的性格。一般情况下,我们只需要在IE中点击“查看”-“源文件”就可以看到对应网页的源代码,或者借用软件或者其他浏览器来查看网页的源代码,但是有些作者网页加密其源代码以防止攻击或保护其知识产权。其实对于这些所谓的加密,我们只需要进行一个小小的操作,就可以让加密“报废”。,即使是专门的黑客网站也不例外,其破解方法如下:
在页面的浏览器地址栏中输入以下段落:
javascript:s=document.documentElement.outerHTML;document.write('');document.body.innerText=s;
然后回车,源码就出来了,也就是打开的网页是一个充满代码的网页,第一部分是加密的代码(听不懂,听不懂),下面的代码是正常的网页代码. 懂一些代码知识的人很容易区分,也很容易得到有效正确的代码。无论加密多么复杂,最终都会还原成浏览器可以解析的html代码,而documentElement.outerHTML就是最终的结果。
当然,为了尊重作者的劳动,即使网页被破解得到代码,我们还是要对原作者表示感谢。尊重知识、尊重人才是我们中华民族的传统美德。 查看全部
网页抓取 加密html(不论加密如何复杂的网页加密?加密怎么办)
有时我们看到非常漂亮的声音和图片,总想把它的源代码当成一个仿模板去查看,却发现看到的是一个加密的网页,因为开源的记事本全是不规则的、乱七八糟的。的性格。一般情况下,我们只需要在IE中点击“查看”-“源文件”就可以看到对应网页的源代码,或者借用软件或者其他浏览器来查看网页的源代码,但是有些作者网页加密其源代码以防止攻击或保护其知识产权。其实对于这些所谓的加密,我们只需要进行一个小小的操作,就可以让加密“报废”。,即使是专门的黑客网站也不例外,其破解方法如下:
在页面的浏览器地址栏中输入以下段落:
javascript:s=document.documentElement.outerHTML;document.write('');document.body.innerText=s;
然后回车,源码就出来了,也就是打开的网页是一个充满代码的网页,第一部分是加密的代码(听不懂,听不懂),下面的代码是正常的网页代码. 懂一些代码知识的人很容易区分,也很容易得到有效正确的代码。无论加密多么复杂,最终都会还原成浏览器可以解析的html代码,而documentElement.outerHTML就是最终的结果。
当然,为了尊重作者的劳动,即使网页被破解得到代码,我们还是要对原作者表示感谢。尊重知识、尊重人才是我们中华民族的传统美德。
网页抓取 加密html( 分析请求老规矩先抓包,在一番标签下等了半天)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-28 03:17
分析请求老规矩先抓包,在一番标签下等了半天)
分析请求
旧规则是先抢包裹。在xhr标签下等了半天,没有发现异步请求,不过很快就出现了show操作。
在Html页面请求中发现以下内容:
根据我多年的经验,这应该是对页面显示的属性内容进行加密,然后在页面显示时按照一定的解密逻辑还原显示。这真是个麻烦事。
位置加密
果然,他苦恼了二十多分钟才定位到加密位置,一直没有找到。感觉超出了我的能力范围。
为了能够愉快的摸(啦)鱼(shi),不再担心,所以决定今天先来这里。
本文结束。
不过还好,在有偿摸鱼(la)鱼(shi)的过程中,我突然有了新的想法,想到了之前一直忽略的东西。
让我先梳理一下我的想法:
这条加密的信息在页面显示上必须有一个位置来标识解密后显示的位置,并且在页面密文上显示的位置正好有一个id(全局只有一),如果你猜对了,那么事情简单太多了。
于是,搜索结束,结果没有找到假想的js文件。
突然
不过我在这个页面上发现了两个equip_desc_panel,赶紧跟进,发现如下代码:
$("equip_desc_panel").innerHTML = parse_style_info(get_equip_desc("equip_desc_value"));
下意识地再次搜索:
果然,发现这个貌似加密的东西,撞到断点,刷新,成功进入断点。
虽然这个定位加密的过程很曲折,也有点味道,但事实告诉我们:
有偿摸(la)鱼(shi)
有助于灵感迸发
分析加密
既然已经成功进入断点,那么我们就追进去看看:
这个混淆后的代码就是我们要分析的加密。
这个混淆乍一看有点大,但是混淆的方法在之前的文章中也有提到,有兴趣的朋友可以翻翻。
点我-----> JS反向常见混淆汇总
了解迷茫之道后,先冷静下来,明白这种长得一模一样的东西,最怕烦躁。
从头一步一步开始,观察传入的值,顺便复制一下代码放到代码中。
_0x1b3f48['\x63\x68\x61\x72\x43\x6f\x64\x65\x41\x74']
把这个方法名翻译成普通的js代码,方便理解,理解大致的解密过程,明确我们最终需要的值是如何产生的。
之后就是找老套路缺什么的阶段了,但是在推导代码的过程中有两个坑:
扣除代码时,很明显已经扣除了整体逻辑,但没有返回任何值。通过打印调试发现,这段代码中的_0x1b3f48返回的是空值,使得后面的for循环没有结果,需要特别注意。
还有浏览器使用的base64编码转换
_0x1c0cdf = _0xcbc80b'atob',
但是调试nodejs时使用的是
Buffer.from(_0x1c0cdf,"base64").toString()
经过一番不懈的努力(tu)(tou),结果成功了。
全文结束。 查看全部
网页抓取 加密html(
分析请求老规矩先抓包,在一番标签下等了半天)

分析请求
旧规则是先抢包裹。在xhr标签下等了半天,没有发现异步请求,不过很快就出现了show操作。
在Html页面请求中发现以下内容:

根据我多年的经验,这应该是对页面显示的属性内容进行加密,然后在页面显示时按照一定的解密逻辑还原显示。这真是个麻烦事。
位置加密
果然,他苦恼了二十多分钟才定位到加密位置,一直没有找到。感觉超出了我的能力范围。
为了能够愉快的摸(啦)鱼(shi),不再担心,所以决定今天先来这里。

本文结束。
不过还好,在有偿摸鱼(la)鱼(shi)的过程中,我突然有了新的想法,想到了之前一直忽略的东西。
让我先梳理一下我的想法:
这条加密的信息在页面显示上必须有一个位置来标识解密后显示的位置,并且在页面密文上显示的位置正好有一个id(全局只有一),如果你猜对了,那么事情简单太多了。

于是,搜索结束,结果没有找到假想的js文件。

突然

不过我在这个页面上发现了两个equip_desc_panel,赶紧跟进,发现如下代码:
$("equip_desc_panel").innerHTML = parse_style_info(get_equip_desc("equip_desc_value"));
下意识地再次搜索:

果然,发现这个貌似加密的东西,撞到断点,刷新,成功进入断点。
虽然这个定位加密的过程很曲折,也有点味道,但事实告诉我们:
有偿摸(la)鱼(shi)
有助于灵感迸发

分析加密
既然已经成功进入断点,那么我们就追进去看看:

这个混淆后的代码就是我们要分析的加密。
这个混淆乍一看有点大,但是混淆的方法在之前的文章中也有提到,有兴趣的朋友可以翻翻。
点我-----> JS反向常见混淆汇总
了解迷茫之道后,先冷静下来,明白这种长得一模一样的东西,最怕烦躁。

从头一步一步开始,观察传入的值,顺便复制一下代码放到代码中。
_0x1b3f48['\x63\x68\x61\x72\x43\x6f\x64\x65\x41\x74']
把这个方法名翻译成普通的js代码,方便理解,理解大致的解密过程,明确我们最终需要的值是如何产生的。
之后就是找老套路缺什么的阶段了,但是在推导代码的过程中有两个坑:
扣除代码时,很明显已经扣除了整体逻辑,但没有返回任何值。通过打印调试发现,这段代码中的_0x1b3f48返回的是空值,使得后面的for循环没有结果,需要特别注意。
还有浏览器使用的base64编码转换
_0x1c0cdf = _0xcbc80b'atob',
但是调试nodejs时使用的是
Buffer.from(_0x1c0cdf,"base64").toString()
经过一番不懈的努力(tu)(tou),结果成功了。
全文结束。
网页抓取 加密html(【智传网优】Linux发行版附带vim的方法加密文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-27 06:08
请关注这个头条号,每天持续更新原创干货技术文章。
如需学习视频,请在微信搜索公众号“知传网游”,直接开启自助视频学习
1. 前言
本文主要讲解如何使用vim对文本文件进行加密,通过设置保护密码来达到保护文本文件的目的。
流行的文本编辑器 Vim 有一个内置功能,可以用密码加密文件。Vim 使用像 Blowfish 这样的算法来加密文件。它比其他可用工具更快、更方便。
首先,你需要安装完整版的vim系统。一些 Linux 发行版带有最小版本的 vim。它不支持文件加密。如果我们尝试对其进行加密,它将显示错误消息“抱歉,该命令不适用于此版本。” 有两种不同的方法来加密文件。
在 Linux 中使用 vim 加密文件
2. 第一种方法:创建加密文件
创建加密的新文件
vim -x filename
vim 编辑器创建加密文件
这将创建一个新文件并提示设置加密密码。输入您的密码两次,然后按 Enter。然后,每次尝试使用任何文本编辑器打开文件时,都需要密码。
加密现有文件,用vim打开文件,按“ESC”键进入命令模式,输入:X并按照提示设置密钥。键入两次密钥,然后按 Enter。就是这样,文件现在受到保护。请注意,vim 命令区分大小写,因此 :x 和 :X 具有不同的含义。
2. 第二种方法:加密现有文件
在命令模式下输入:set key="mykey"。但是,不建议这样做,因为输入的密码可能会在 ~/.viminfo 文件中以及 history 和 vim 命令中可见。然后,每次我们尝试打开文件时,vim 都会要求输入密码,然后输入正确的密码来查看和编辑文件。
即使我们尝试用非vim编辑器打开文件,文件仍然可以打开,但显示乱码。
vim 编辑器加密现有文件
vim 输入错误密码
底部的详细信息显示了使用的加密算法,在我们的例子中是河豚。
修改/删除密码:修改或删除密码非常容易。只需打开文件并输入:x 并输入您的新密钥。要从文件中删除密码,请不要输入任何内容并按 Enter 键两次。
现在我们知道了vim密码文件的功能和操作技巧,我们准备保护所有收录
机密信息的文件。但是这种方法可靠吗?我们可以使用它吗?虽然blowfish算法效果很好,但是使用vim进行加密可能会有问题,因为即使文件加密了,也没有写入限制。
考虑一个场景,您创建一个加密文件并在其中存储一些重要数据。现在,下次打开它时,不小心输入了错误的密码,vim 仍然打开该文件,尽管内容已加密。现在,为了退出并重新打开,正确的退出命令是 :q,但不幸的是,如果您错误地键入了 :wq 命令,vim 将通过替换显示的文本来覆盖文件(而不是替换解密后的原创
文本)格式)。在这种情况下,可能无法恢复数据。
3. 总结
通过本教程,您应该知道如何使用vim来保护机密文件了吧?但使用时要注意防止误操作造成数据丢失。
本文已同步至博客站,尊重原创,转载请在正文附上以下链接: 查看全部
网页抓取 加密html(【智传网优】Linux发行版附带vim的方法加密文件)
请关注这个头条号,每天持续更新原创干货技术文章。
如需学习视频,请在微信搜索公众号“知传网游”,直接开启自助视频学习
1. 前言
本文主要讲解如何使用vim对文本文件进行加密,通过设置保护密码来达到保护文本文件的目的。
流行的文本编辑器 Vim 有一个内置功能,可以用密码加密文件。Vim 使用像 Blowfish 这样的算法来加密文件。它比其他可用工具更快、更方便。
首先,你需要安装完整版的vim系统。一些 Linux 发行版带有最小版本的 vim。它不支持文件加密。如果我们尝试对其进行加密,它将显示错误消息“抱歉,该命令不适用于此版本。” 有两种不同的方法来加密文件。
在 Linux 中使用 vim 加密文件
2. 第一种方法:创建加密文件
创建加密的新文件
vim -x filename
vim 编辑器创建加密文件
这将创建一个新文件并提示设置加密密码。输入您的密码两次,然后按 Enter。然后,每次尝试使用任何文本编辑器打开文件时,都需要密码。
加密现有文件,用vim打开文件,按“ESC”键进入命令模式,输入:X并按照提示设置密钥。键入两次密钥,然后按 Enter。就是这样,文件现在受到保护。请注意,vim 命令区分大小写,因此 :x 和 :X 具有不同的含义。
2. 第二种方法:加密现有文件
在命令模式下输入:set key="mykey"。但是,不建议这样做,因为输入的密码可能会在 ~/.viminfo 文件中以及 history 和 vim 命令中可见。然后,每次我们尝试打开文件时,vim 都会要求输入密码,然后输入正确的密码来查看和编辑文件。
即使我们尝试用非vim编辑器打开文件,文件仍然可以打开,但显示乱码。
vim 编辑器加密现有文件
vim 输入错误密码
底部的详细信息显示了使用的加密算法,在我们的例子中是河豚。
修改/删除密码:修改或删除密码非常容易。只需打开文件并输入:x 并输入您的新密钥。要从文件中删除密码,请不要输入任何内容并按 Enter 键两次。
现在我们知道了vim密码文件的功能和操作技巧,我们准备保护所有收录
机密信息的文件。但是这种方法可靠吗?我们可以使用它吗?虽然blowfish算法效果很好,但是使用vim进行加密可能会有问题,因为即使文件加密了,也没有写入限制。
考虑一个场景,您创建一个加密文件并在其中存储一些重要数据。现在,下次打开它时,不小心输入了错误的密码,vim 仍然打开该文件,尽管内容已加密。现在,为了退出并重新打开,正确的退出命令是 :q,但不幸的是,如果您错误地键入了 :wq 命令,vim 将通过替换显示的文本来覆盖文件(而不是替换解密后的原创
文本)格式)。在这种情况下,可能无法恢复数据。
3. 总结
通过本教程,您应该知道如何使用vim来保护机密文件了吧?但使用时要注意防止误操作造成数据丢失。
本文已同步至博客站,尊重原创,转载请在正文附上以下链接:
网页抓取 加密html(之前学习Python模拟登录知乎实例(一)加密处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-28 05:10
之前学过Python模拟登录知乎,里面涉及到fromdata的加密处理。学习过程中发现用chrome devtool调试分析网页的技巧还是有很多的,所以找了一个简单的。示例用于学习js加密。
学无止境一、例子网站
网站本例中为中国空气质量分析平台,学习使用chome浏览器的devtool工具对fromdata进行加密。
二、分析页面逻辑1.抓包分析
在chrome中打开页面,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为了方便查看,先清除之前的请求流程,然后在网页上切换城市就可以看到新的xhr请求了。
您可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看 Requests Headers 信息。对比不同城市的查询结果,发现Headers没有任何独特的特征,所以我们只保留了一些必要的信息。
接下来,我们需要考虑如何构造Form数据。
2.调试分析
考虑到页面点击查询按钮时发生网络请求,该按钮肯定需要时间处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
让我们尝试进入 getAQIData() 方法。
首页的查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,当前页面没有搜索到该方法的详细信息,所以我们进行全局搜索(ctrl+shift+ F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2文件中,而混淆后,您可以使用在线工具进行反混淆,例如:.
使用开发者工具调试断点,进入getServerData方法。
最后,我们看到了由 getParm() 方法返回的表单数据。
3.密码分析
知道了位置后,我们可以直接把这个加密的js方法推导出来,放到一个html文件中执行。
var getParam = (function () {<br /> function ObjectSort(obj) {<br /> var newObject = {};<br /> Object.keys(obj).sort().map(function (key) {<br /> newObject[key] = obj[key]<br /> });<br /> return newObject<br /> }<br /><br /> return function (method, obj) {<br /> var appId = '1a45f75b824b2dc628d5955356b5ef18';<br /> var clienttype = 'WEB';<br /> var timestamp = new Date().getTime();<br /> var param = {<br /> appId: appId,<br /> method: method,<br /> timestamp: timestamp,<br /> clienttype: clienttype,<br /> object: obj,<br /> secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))<br /> };<br /> param = BASE64.encrypt(JSON.stringify(param));<br /> return AES.encrypt(param, aes_client_key, aes_client_iv)<br /> }<br />})();<br />
提取该方法涉及的js方法,jqury中需要的除外-1.8.0.min.js?v=1.2文件另外对于方法,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得将查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了execjs包外,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):<br /> '''<br /> 对查询条件栏的数据,进行加密<br /> :param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等<br /> :return:加密后的字符串<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('getAQIData',form_data)<br />
在测试过程中,如果遇到错误execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined,localStorage是浏览器端数据存储方式之一。将js中的相关代码注释掉,继续测试。
//加密<br />function getServerData(method, object, callback, period) {<br /> const key = hex_md5(method + JSON.stringify(object));<br /> // const data = getDataFromLocalStorage(key, period);<br /> // if (!data) {<br /> var param = getParam(method, object);<br /> return param<br /> // } else {<br /> // callback(data)<br /> // }<br />}<br />
成功输出结果。
四、Python 抓取网页
获取加密字符串后,需要通过POST请求将内容提交给服务器,但在执行过程中发现返回的内容与前台返回的内容不一致。经过一番询问,
发现得到的加密字符串的内容只与“查看解码”显示的内容一致,我们尝试对数据进行URL编码,然后进行POST请求。终于成功拿到返回值了。
接下来,我们解密返回的字符串。在对getServerData方法的分析中,我们发现decodeData方法与解密有关。
def decrypt(self, resp_text):<br /> '''<br /> 对服务器请求成功后返回的数据,进行解密<br /> :param resp_text: 返回的数据<br /> :return:解密后的字符串,json格式<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('decodeData',resp_text)<br />
解密服务器返回的内容,最终得到我们想要的数据。
详细代码请到: 查看全部
网页抓取 加密html(之前学习Python模拟登录知乎实例(一)加密处理)
之前学过Python模拟登录知乎,里面涉及到fromdata的加密处理。学习过程中发现用chrome devtool调试分析网页的技巧还是有很多的,所以找了一个简单的。示例用于学习js加密。
学无止境一、例子网站
网站本例中为中国空气质量分析平台,学习使用chome浏览器的devtool工具对fromdata进行加密。
二、分析页面逻辑1.抓包分析
在chrome中打开页面,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为了方便查看,先清除之前的请求流程,然后在网页上切换城市就可以看到新的xhr请求了。
您可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看 Requests Headers 信息。对比不同城市的查询结果,发现Headers没有任何独特的特征,所以我们只保留了一些必要的信息。
接下来,我们需要考虑如何构造Form数据。
2.调试分析
考虑到页面点击查询按钮时发生网络请求,该按钮肯定需要时间处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
让我们尝试进入 getAQIData() 方法。
首页的查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,当前页面没有搜索到该方法的详细信息,所以我们进行全局搜索(ctrl+shift+ F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到。网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2文件中,而混淆后,您可以使用在线工具进行反混淆,例如:.
使用开发者工具调试断点,进入getServerData方法。
最后,我们看到了由 getParm() 方法返回的表单数据。
3.密码分析
知道了位置后,我们可以直接把这个加密的js方法推导出来,放到一个html文件中执行。
var getParam = (function () {<br /> function ObjectSort(obj) {<br /> var newObject = {};<br /> Object.keys(obj).sort().map(function (key) {<br /> newObject[key] = obj[key]<br /> });<br /> return newObject<br /> }<br /><br /> return function (method, obj) {<br /> var appId = '1a45f75b824b2dc628d5955356b5ef18';<br /> var clienttype = 'WEB';<br /> var timestamp = new Date().getTime();<br /> var param = {<br /> appId: appId,<br /> method: method,<br /> timestamp: timestamp,<br /> clienttype: clienttype,<br /> object: obj,<br /> secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))<br /> };<br /> param = BASE64.encrypt(JSON.stringify(param));<br /> return AES.encrypt(param, aes_client_key, aes_client_iv)<br /> }<br />})();<br />
提取该方法涉及的js方法,jqury中需要的除外-1.8.0.min.js?v=1.2文件另外对于方法,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得将查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了execjs包外,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):<br /> '''<br /> 对查询条件栏的数据,进行加密<br /> :param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等<br /> :return:加密后的字符串<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('getAQIData',form_data)<br />
在测试过程中,如果遇到错误execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined,localStorage是浏览器端数据存储方式之一。将js中的相关代码注释掉,继续测试。
//加密<br />function getServerData(method, object, callback, period) {<br /> const key = hex_md5(method + JSON.stringify(object));<br /> // const data = getDataFromLocalStorage(key, period);<br /> // if (!data) {<br /> var param = getParam(method, object);<br /> return param<br /> // } else {<br /> // callback(data)<br /> // }<br />}<br />
成功输出结果。
四、Python 抓取网页
获取加密字符串后,需要通过POST请求将内容提交给服务器,但在执行过程中发现返回的内容与前台返回的内容不一致。经过一番询问,
发现得到的加密字符串的内容只与“查看解码”显示的内容一致,我们尝试对数据进行URL编码,然后进行POST请求。终于成功拿到返回值了。
接下来,我们解密返回的字符串。在对getServerData方法的分析中,我们发现decodeData方法与解密有关。
def decrypt(self, resp_text):<br /> '''<br /> 对服务器请求成功后返回的数据,进行解密<br /> :param resp_text: 返回的数据<br /> :return:解密后的字符串,json格式<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('decodeData',resp_text)<br />
解密服务器返回的内容,最终得到我们想要的数据。
详细代码请到:
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-27 09:23
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des很弱,但是没那么容易破解
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配还是有没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题的内容,链接图片,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des很弱,但是没那么容易破解
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配还是有没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题的内容,链接图片,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。
网页抓取 加密html(西部网盘不能解析了怎么构造这条cookie其中一种?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-26 17:08
有网友反映无法解析西部网盘。确认后,现在限制网盘抓取网页。网站目前访问不稳定,视情况而定,争取下个版本修复。
本来想写在西部网盘上的,但是这个网盘打不开,先说彩虹云吧,都一样。
这个文章不是教程,所以有些内容会被忽略
0、前言
不管是网盘分析还是各种网络爬虫,都是先获取网页的源代码,然后再提取自己感兴趣的内容。但这无疑会损害一些网站的利益,所以会有限制非客户端用户抓取网页的各种手段。本文提到的js加密cookie就是其中之一。
1、我们先来看看直接爬取页面的源码是什么样子的
<p>var x="hantom@@JgSe0upZ@@Path@02@GMT@f@@Sun@captcha@if@@@href@callP@@g@try@substr@DOMContentLoaded@as@@@Expires@@chars@@onreadystate
change@__jsl_clearance@new@0xFF@search@34@@window@@while@document@36@@@false@split@19@innerHTML@e@3D@8@function@location@setTimeout@attachEvent
@d@var@@0xEDB88320@length@2B@yF@addEventListener@@@charCodeAt@createElement@toLowerCase@@String@@cookie@1500@14@join@@@@__p@charAt@return@path
name@1559453654@Array@eval@@4@Jun@0@@catch@TmT2@@replace@@fromCharCode@@else@firstChild@@a@@FcG@oP@match@@WU@div@@reverse@challenge@06@toS
tring@RegExp@Oo4BUv@for@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@@https@1@2@@@@parseInt@FB@@932".replace(/@*$/,"").split("@"),
y="2b 39=26(){28('27.f=27.3e+27.1b.44(/[\\?|&]b-4l/,\\'\\')',35);1h.34='18=3f.5i|3l|'+(26(){2b e=[26(39){3d 39},26(e){3d e},
26(39){54(2b e=3l;e 查看全部
网页抓取 加密html(西部网盘不能解析了怎么构造这条cookie其中一种?)
有网友反映无法解析西部网盘。确认后,现在限制网盘抓取网页。网站目前访问不稳定,视情况而定,争取下个版本修复。
本来想写在西部网盘上的,但是这个网盘打不开,先说彩虹云吧,都一样。
这个文章不是教程,所以有些内容会被忽略
0、前言
不管是网盘分析还是各种网络爬虫,都是先获取网页的源代码,然后再提取自己感兴趣的内容。但这无疑会损害一些网站的利益,所以会有限制非客户端用户抓取网页的各种手段。本文提到的js加密cookie就是其中之一。
1、我们先来看看直接爬取页面的源码是什么样子的
<p>var x="hantom@@JgSe0upZ@@Path@02@GMT@f@@Sun@captcha@if@@@href@callP@@g@try@substr@DOMContentLoaded@as@@@Expires@@chars@@onreadystate
change@__jsl_clearance@new@0xFF@search@34@@window@@while@document@36@@@false@split@19@innerHTML@e@3D@8@function@location@setTimeout@attachEvent
@d@var@@0xEDB88320@length@2B@yF@addEventListener@@@charCodeAt@createElement@toLowerCase@@String@@cookie@1500@14@join@@@@__p@charAt@return@path
name@1559453654@Array@eval@@4@Jun@0@@catch@TmT2@@replace@@fromCharCode@@else@firstChild@@a@@FcG@oP@match@@WU@div@@reverse@challenge@06@toS
tring@RegExp@Oo4BUv@for@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@@https@1@2@@@@parseInt@FB@@932".replace(/@*$/,"").split("@"),
y="2b 39=26(){28('27.f=27.3e+27.1b.44(/[\\?|&]b-4l/,\\'\\')',35);1h.34='18=3f.5i|3l|'+(26(){2b e=[26(39){3d 39},26(e){3d e},
26(39){54(2b e=3l;e
网页抓取 加密html(逆向目标逆向过程分析(二)分析及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-25 04:19
)
本文章所有内容仅供学习交流。抓取到的内容、敏感URL、数据接口都进行了脱敏处理。严禁商业用途和非法使用。否则由此产生的一切后果与作者无关。,如有侵权,请联系我立即删除!
反向目标逆过程抓包分析
这次要反转的对象与以往不同。它不是接口的参数,而是网页中的数据。一般网页中的数据可以在源代码中看到,或者通过一个接口传递,而此时目标数据是通过JS加密获得的。我们先抓包看一下基本情况:
用F12查看,可以看到我们要的数据在textarea标签里,好像没有错,然后直接用Xpath解压试试:
import requests
from lxml import etree
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
data = tree.xpath('//textarea/text()')
print(data)
可以看到提取出来的数据其实是空的。我们查看网页的源代码,直接搜索textarea,同样不可用。尝试直接搜索数据。
加密反向
由于网页源代码中不存在这种数据,也不是通过其他接口返回的,因此极有可能是经过JS加密后直接插入到网页源代码中。如何在这里找到加密的位置?对比插入数据后的网页源代码和没有插入数据的网页源代码,可以看到蓝框内的代码是通过js插入的,100个8.js大部分都是加密的JS 文件:
在这里,我们想到了一种 JavaScript 语法。如果要从 JavaScript 访问 HTML 元素,可以使用 document.getElementById(id) 方法。这个id是一个HTML元素的属性,然后使用innerHTML来获取或者插入元素的内容。可以看菜鸟教程的一个例子:
通过这个语法,结合前面源码中的几个标签,我们可以猜到一个JS中可能有这样的语句:document.getElementById("tehai").innerHTML, document.getElementById("tips")。innerHTML,document.getElementById("m2").innerHTML,可以直接全局搜索这些语句中的任何一个,在1008.js中可以找到对应的结果。当然,你也可以直接搜索这个标签的id来找到结果。埋下断点进行调试:
您可以找到第 913 行 document.getElementById("m2").innerHTML = d + "
"就是在m2标签中插入值d和换行符。一步步查找,可以发现d里面收录了很多html的东西,而上面的g只是文本,正好是目标数据,那么我们最后退货直接退货。好吧。
继续追踪g值的出处,你会发现步骤比较复杂,那我们直接复制这部分函数(fa函数)运行调试(大约794行到914行),本地调试会提示ga和O是未定义的,我们在它定义的语句的下一行埋一个断点进行调试,可以看到ga的值其实是一个固定的q,而O是URL后面的q的值,如:336m237p2479s167z3s
定义好这两个变量后,再在本地调试,会提示aa、ca等函数未定义,依赖函数很多。这种情况下就不用一一扣除了,fa之前的所有函数都直接复制调试就好了,直接解决了所有的依赖。
完整代码
GitHub关注K哥的爬虫,持续分享爬虫相关代码!欢迎明星!
以下仅演示部分关键代码,完整代码仓库地址:
Key JS 加密代码架构
// Copyrights C-EGG inc.
var u = function () {}();
function w() {}
w.prototype = {};
function x(b, a, g, d) {}
// 此处省略 N 个函数
function M(b) {}
function N(b, a) {}
function ea(b) {}
function fa(O) {
function b(a, b) {
var c, d = 0;
for (c = 0; c < a.length; ++c) d += 4 - b[a[c]];
return d
}
// var a = ga, g = O, d;
var a = 'q', g = O, d;
d = "";
switch (a.substr(0, 1)) {
case "q":
d += '標準形(七対国士を含む)の計算結果 / 一般形
';
break;
case "p":
d += '一般形(七対国士を含まない)の計算結果 / 標準形
'
}
for (var c = "d" == a.substr(1, 1), a = a.substr(0, 1), g = g.replace(/(\d)(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{8})(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(\d?)(\d?)(\d?)(\d?)(\d?)(\d?)(\d)(\d)(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(m|p|s|z)(m|p|s|z)+/g, "$1").replace(/^[^\d]/, ""), g = g.substr(0, 28), f = aa(g), r = -1; r = Math.floor(136 * Math.random()), f[r];) ;
var m = Math.floor(g.length / 2) % 3;
2 == m || c || (f[r] = 1, g += H(r));
var f = ca(f),
n = "",
e = G(f, 34),
n = n + N(e, 28 == g.length),
n = n + ("(" + Math.floor(g.length / 2) + "枚)");
-1 == e[0] && (n += ' / 新しい手牌を作成');
var n = n + "
",
q = "q" == a ? e[0] : e[1],
k,
p,
l = Array(35);
if (0 == q && 1 == m && c) k = 34,
l[k] = K(f),
l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
});
else if (0 >= q) for (k = 0; 34 > k; ++k) f[k] && (f[k]--, l[k] = K(f), f[k]++, l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
}));
else if (2 == m || 1 == m && !c) for (k = 0; 34 > k; ++k) {
if (f[k]) {
f[k]--;
l[k] = [];
for (p = 0; 34 > p; ++p) k == p || 4 p; ++p) 4 = q ? "待ち" : "摸";
for (k = 0; k < t.length; ++k) {
v = t[k].i;
d += "";
34 > v && (d += "打" + ('') + "", g += "打" + H(4 * v + 1) + " ");
d += q + "[";
g += q + "[";
l = t[k].c;
c = t[k].q;
for (p = 0; p < l.length; ++p) r = H(4 * l[p] + 1),
d += '',
g += H(4 * l[p] + 1);
d += "" + t[k].n + "枚]";
g += " " + t[k].n + "枚]\n"
}
d = d + "
" + ('' + g + "");
-1 == e[0] && (d = d + "" + ea(f));
// document.getElementById("tehai").innerHTML = n;
// document.getElementById("tips").innerHTML = "";
// document.getElementById("m2").innerHTML = d + "
"
return g
}
// 测试样例
// console.log(fa('336m237p2479s167z3s'))
Python代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import execjs
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
def main():
q = url.split('=')[1]
with open('decrypt.js', 'r', encoding='utf-8') as f:
decrypt_js = f.read()
data = execjs.compile(decrypt_js).call('fa', q)
print(data)
if __name__ == '__main__':
main()
查看全部
网页抓取 加密html(逆向目标逆向过程分析(二)分析及应用
)
本文章所有内容仅供学习交流。抓取到的内容、敏感URL、数据接口都进行了脱敏处理。严禁商业用途和非法使用。否则由此产生的一切后果与作者无关。,如有侵权,请联系我立即删除!
反向目标逆过程抓包分析
这次要反转的对象与以往不同。它不是接口的参数,而是网页中的数据。一般网页中的数据可以在源代码中看到,或者通过一个接口传递,而此时目标数据是通过JS加密获得的。我们先抓包看一下基本情况:
用F12查看,可以看到我们要的数据在textarea标签里,好像没有错,然后直接用Xpath解压试试:
import requests
from lxml import etree
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
data = tree.xpath('//textarea/text()')
print(data)
可以看到提取出来的数据其实是空的。我们查看网页的源代码,直接搜索textarea,同样不可用。尝试直接搜索数据。
加密反向
由于网页源代码中不存在这种数据,也不是通过其他接口返回的,因此极有可能是经过JS加密后直接插入到网页源代码中。如何在这里找到加密的位置?对比插入数据后的网页源代码和没有插入数据的网页源代码,可以看到蓝框内的代码是通过js插入的,100个8.js大部分都是加密的JS 文件:
在这里,我们想到了一种 JavaScript 语法。如果要从 JavaScript 访问 HTML 元素,可以使用 document.getElementById(id) 方法。这个id是一个HTML元素的属性,然后使用innerHTML来获取或者插入元素的内容。可以看菜鸟教程的一个例子:
通过这个语法,结合前面源码中的几个标签,我们可以猜到一个JS中可能有这样的语句:document.getElementById("tehai").innerHTML, document.getElementById("tips")。innerHTML,document.getElementById("m2").innerHTML,可以直接全局搜索这些语句中的任何一个,在1008.js中可以找到对应的结果。当然,你也可以直接搜索这个标签的id来找到结果。埋下断点进行调试:
您可以找到第 913 行 document.getElementById("m2").innerHTML = d + "
"就是在m2标签中插入值d和换行符。一步步查找,可以发现d里面收录了很多html的东西,而上面的g只是文本,正好是目标数据,那么我们最后退货直接退货。好吧。
继续追踪g值的出处,你会发现步骤比较复杂,那我们直接复制这部分函数(fa函数)运行调试(大约794行到914行),本地调试会提示ga和O是未定义的,我们在它定义的语句的下一行埋一个断点进行调试,可以看到ga的值其实是一个固定的q,而O是URL后面的q的值,如:336m237p2479s167z3s
定义好这两个变量后,再在本地调试,会提示aa、ca等函数未定义,依赖函数很多。这种情况下就不用一一扣除了,fa之前的所有函数都直接复制调试就好了,直接解决了所有的依赖。
完整代码
GitHub关注K哥的爬虫,持续分享爬虫相关代码!欢迎明星!
以下仅演示部分关键代码,完整代码仓库地址:
Key JS 加密代码架构
// Copyrights C-EGG inc.
var u = function () {}();
function w() {}
w.prototype = {};
function x(b, a, g, d) {}
// 此处省略 N 个函数
function M(b) {}
function N(b, a) {}
function ea(b) {}
function fa(O) {
function b(a, b) {
var c, d = 0;
for (c = 0; c < a.length; ++c) d += 4 - b[a[c]];
return d
}
// var a = ga, g = O, d;
var a = 'q', g = O, d;
d = "";
switch (a.substr(0, 1)) {
case "q":
d += '標準形(七対国士を含む)の計算結果 / 一般形
';
break;
case "p":
d += '一般形(七対国士を含まない)の計算結果 / 標準形
'
}
for (var c = "d" == a.substr(1, 1), a = a.substr(0, 1), g = g.replace(/(\d)(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{8})(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(\d?)(\d?)(\d?)(\d?)(\d?)(\d?)(\d)(\d)(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(m|p|s|z)(m|p|s|z)+/g, "$1").replace(/^[^\d]/, ""), g = g.substr(0, 28), f = aa(g), r = -1; r = Math.floor(136 * Math.random()), f[r];) ;
var m = Math.floor(g.length / 2) % 3;
2 == m || c || (f[r] = 1, g += H(r));
var f = ca(f),
n = "",
e = G(f, 34),
n = n + N(e, 28 == g.length),
n = n + ("(" + Math.floor(g.length / 2) + "枚)");
-1 == e[0] && (n += ' / 新しい手牌を作成');
var n = n + "
",
q = "q" == a ? e[0] : e[1],
k,
p,
l = Array(35);
if (0 == q && 1 == m && c) k = 34,
l[k] = K(f),
l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
});
else if (0 >= q) for (k = 0; 34 > k; ++k) f[k] && (f[k]--, l[k] = K(f), f[k]++, l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
}));
else if (2 == m || 1 == m && !c) for (k = 0; 34 > k; ++k) {
if (f[k]) {
f[k]--;
l[k] = [];
for (p = 0; 34 > p; ++p) k == p || 4 p; ++p) 4 = q ? "待ち" : "摸";
for (k = 0; k < t.length; ++k) {
v = t[k].i;
d += "";
34 > v && (d += "打" + ('
') + "", g += "打" + H(4 * v + 1) + " ");d += q + "[";
g += q + "[";
l = t[k].c;
c = t[k].q;
for (p = 0; p < l.length; ++p) r = H(4 * l[p] + 1),
d += '
',g += H(4 * l[p] + 1);
d += "" + t[k].n + "枚]";
g += " " + t[k].n + "枚]\n"
}
d = d + "
" + ('' + g + "");
-1 == e[0] && (d = d + "" + ea(f));
// document.getElementById("tehai").innerHTML = n;
// document.getElementById("tips").innerHTML = "";
// document.getElementById("m2").innerHTML = d + "
"
return g
}
// 测试样例
// console.log(fa('336m237p2479s167z3s'))
Python代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import execjs
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
def main():
q = url.split('=')[1]
with open('decrypt.js', 'r', encoding='utf-8') as f:
decrypt_js = f.read()
data = execjs.compile(decrypt_js).call('fa', q)
print(data)
if __name__ == '__main__':
main()
网页抓取 加密html(cookie.x版本,可以从网上搜一下,都有详细的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-25 02:03
网页抓取加密html需要用到cookie,常见的是用requests或set-cookie等等,可以从网上搜一下,都有详细的教程。你可以多尝试几种,找一个合适的方法。python2.x版本,可以用cookiejar,或者抓包+set-cookie。python3.x版本,
从网页爬取cookie。
加两个校验呗
你是说网页发布前加个访问验证?
这个我没做过,个人也不太推荐抓包来。用cookie或者set-cookie。其实有一种比较赞的cookie,oauth的cookie:我不太确定是否是oauth对单个邮箱创建的。
你可以搜索ssl,或者直接把代码发你邮箱。我知道我是在虾米和豆瓣的店铺评论的时候用上了一个cookie,打开评论列表后,在那个页面单独打开一个新的网页链接,只输入单个评论,就可以看到对应的分页结果。大体思路是你把你的评论转发到评论列表页面,然后等别人刷新网页就能看到你的评论。这种用的是免费的ssl加密,别人需要花费点钱才能破解,免费版不带验证码,这点我觉得值得提倡,可以抓取一些比较隐私的东西。
我用两个神器:一个神器:抓包神器,被各大网站沦陷,你懂的,你能想到的他们都可以。下载好后打开网页抓包。第二个神器:网页解析神器,极简的网页解析,一边的代码可以处理多个网页。你可以从我的github项目代码中找出他们并快速上手。 查看全部
网页抓取 加密html(cookie.x版本,可以从网上搜一下,都有详细的教程)
网页抓取加密html需要用到cookie,常见的是用requests或set-cookie等等,可以从网上搜一下,都有详细的教程。你可以多尝试几种,找一个合适的方法。python2.x版本,可以用cookiejar,或者抓包+set-cookie。python3.x版本,
从网页爬取cookie。
加两个校验呗
你是说网页发布前加个访问验证?
这个我没做过,个人也不太推荐抓包来。用cookie或者set-cookie。其实有一种比较赞的cookie,oauth的cookie:我不太确定是否是oauth对单个邮箱创建的。
你可以搜索ssl,或者直接把代码发你邮箱。我知道我是在虾米和豆瓣的店铺评论的时候用上了一个cookie,打开评论列表后,在那个页面单独打开一个新的网页链接,只输入单个评论,就可以看到对应的分页结果。大体思路是你把你的评论转发到评论列表页面,然后等别人刷新网页就能看到你的评论。这种用的是免费的ssl加密,别人需要花费点钱才能破解,免费版不带验证码,这点我觉得值得提倡,可以抓取一些比较隐私的东西。
我用两个神器:一个神器:抓包神器,被各大网站沦陷,你懂的,你能想到的他们都可以。下载好后打开网页抓包。第二个神器:网页解析神器,极简的网页解析,一边的代码可以处理多个网页。你可以从我的github项目代码中找出他们并快速上手。
网页抓取 加密html(网络爬虫(客户端)模拟浏览器发送网络请求,接收请求响应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-23 13:11
爬虫概述
网络爬虫(也称为网络蜘蛛或网络机器人)是模拟浏览器发送网络请求和接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
原则上,只要浏览器(客户端)可以做任何事情,爬虫就可以做到。
1. 爬虫是非法的吗?2.爬虫的潜在风险3.如何规避风险?始终维护自己的爬虫程序,避免干扰访问的网站的正常运行。传播爬取的数据时,检查你抓取的内容。如发现涉及用户隐私或商业秘密的违法内容应及时停止爬取和传播,及时删除数据。4.爬虫分类一般爬虫:重点爬虫:增量爬虫:5. 爬行者的矛与盾5.1 反向爬升机制
传送门网站,可以通过指定相应的策略或技术手段,防止爬虫程序爬取数据网站
5.2 反反爬策略
爬虫还可以通过制定相关策略和相关技术手段来获取门户网站的数据,破解门户网站中的反爬机制
6. 机器人协议
这是君子的约定。即网站可以指定网站中的数据可以被爬虫爬取,那些数据不能被爬取。可能会或可能不会遵守
可以通过将 /robots.txt 附加到目标 URL 来访问目标 URL 的 robots 协议
7.http协议概念:通用请求头信息:通用响应头信息8.https协议8.1加密方式对称密钥加密非对称密钥加密证书密钥加密 查看全部
网页抓取 加密html(网络爬虫(客户端)模拟浏览器发送网络请求,接收请求响应)
爬虫概述
网络爬虫(也称为网络蜘蛛或网络机器人)是模拟浏览器发送网络请求和接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
原则上,只要浏览器(客户端)可以做任何事情,爬虫就可以做到。
1. 爬虫是非法的吗?2.爬虫的潜在风险3.如何规避风险?始终维护自己的爬虫程序,避免干扰访问的网站的正常运行。传播爬取的数据时,检查你抓取的内容。如发现涉及用户隐私或商业秘密的违法内容应及时停止爬取和传播,及时删除数据。4.爬虫分类一般爬虫:重点爬虫:增量爬虫:5. 爬行者的矛与盾5.1 反向爬升机制
传送门网站,可以通过指定相应的策略或技术手段,防止爬虫程序爬取数据网站
5.2 反反爬策略
爬虫还可以通过制定相关策略和相关技术手段来获取门户网站的数据,破解门户网站中的反爬机制
6. 机器人协议
这是君子的约定。即网站可以指定网站中的数据可以被爬虫爬取,那些数据不能被爬取。可能会或可能不会遵守
可以通过将 /robots.txt 附加到目标 URL 来访问目标 URL 的 robots 协议
7.http协议概念:通用请求头信息:通用响应头信息8.https协议8.1加密方式对称密钥加密非对称密钥加密证书密钥加密
网页抓取 加密html(快捷模拟登录抓取目标网页做出准备(图).7 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-20 17:01
)
Cookie,是指存储在用户本地终端上用于识别用户身份和进行会话跟踪的一些数据(通常是加密的)。
比如有些网站需要登录才能得到你想要的信息。如果不登录,则只能使用旅游模式。然后我们可以使用 Urllib2 库来保存我们之前登录过的 cookie。加载cookie得到我们想要的页面,然后爬取。了解cookies主要是为我们快速模拟登录和抓取目标网页做准备。
我在上一篇文章中使用了 urlopen() 函数来打开网页进行抓取。这只是一个简单的 Python 网页打开器,它的参数只有 urlopen(url, data, timeout),这三个参数不足以让我们获取登陆页面的 cookie。这时候我们将使用另一个 Opener - CookieJar。
cookielib 也是 Python 中爬虫的一个重要模块。可以结合 urllib2 来抓取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续的连接请求中重新发送,从而实现我们需要的模拟登录功能。
这里特别说明,cookielib是py2.7自带的模块,不需要重新安装。如果要查看自己的模块,可以查看Python目录下的Lib文件夹,里面收录了所有已安装的。模块。一开始没有想到,在pycharm中没有找到cookielib,使用快速安装后报错:Could't find index page for 'Cookielib' (可能是拼写错误?)
在那之后,我记得它是否带有它。没想到跑到lib文件夹里面才发现,折腾了半个小时各种折腾~~
我们来介绍一下这个模块,这个模块的主要对象是CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系: CookieJar -- 派生 --> FileCookieJar -- 派生 --> MozillaCookieJar 和 LWPCookieJar 的主要用法,下面我们也会讲到。 urllib2.urlopen() 函数不支持身份验证、cookie 或其他高级 HTTP 函数。要支持这些功能,必须使用build_opener()函数(可以用来让python程序模拟浏览器访问,你懂的~)函数来创建自定义的Opener对象。
1、首先我们获取网站的cookies
例子:
#coding=utf-8 import cookielib import urllib2 mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题) handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器 opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似 response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response for item in my.cookie: print"name="+item.name print"value="+item.value
结果:
name=BAIDUIDvalue=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1name=BIDUPSIDvalue=73BD718962A6EA0DAD4CB9578A08FDD0name=H_PS_PSSIDvalue=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398name=PSTMvalue=1478834132name=BDSVRTMvalue=0name=BD_HOMEvalue=0
这为我们提供了最简单的 cookie。
2、保存 cookie 到文件
上面我们得到了cookie,下面我们学习如何保存cookie。这里我们使用它的子类 MozillaCookieJar 来保存 cookie
例子:
这个例子可以通过简单变形上面的例子得到,使用MozillaCookiJar,CookieJar的一个子类,为什么?我们试试把MozillaCookiJar换成CookieJar,可以看懂下图:
CookieJar不保存save属性~
在
save()方法:ignore_discard表示即使cookie会被丢弃也要保存,ignore_expires表示如果cookie已经存在于文件中,覆盖原文件并写入,这里,我们将这两个都设置为True。运行后cookies会保存到cookie.txt文件中,我们查看一下内容:
这样我们成功保存了我们想要的cookie
3、从文件中获取cookies并访问
#coding=utf-8import urllib2import cookielibimport urllib #第一步先给出账户密码网址准备模拟登录postdata = urllib.urlencode({ 'stuid': '1605122162', 'pwd': 'xxxxxxxxx'#密码这里就不泄漏啦,嘿嘿嘿})loginUrl = 'http://ids.xidian.edu.cn/auths ... 3B%23 登录教务系统的URL,成绩查询网址 # 第二步模拟登陆并保存登录的cookiefilename = 'cookie.txt' #创建文本保存cookiemycookie = cookielib.MozillaCookieJar(filename) # 声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(mycookie)) #定义这个opener,对象是cookieresult = opener.open(loginUrl, postdata)mycookie.save(ignore_discard=True, ignore_expires=True)# 保存cookie到cookie.txt中 # 第三步利用cookie请求访问另一个网址,教务系统总址gradeUrl = 'http://ids.xidian.edu.cn/auths ... 39%3B #只要是帐号密码一样的网址就可以, 请求访问成绩查询网址result = opener.open(gradeUrl)print result.read() 查看全部
网页抓取 加密html(快捷模拟登录抓取目标网页做出准备(图).7
)
Cookie,是指存储在用户本地终端上用于识别用户身份和进行会话跟踪的一些数据(通常是加密的)。
比如有些网站需要登录才能得到你想要的信息。如果不登录,则只能使用旅游模式。然后我们可以使用 Urllib2 库来保存我们之前登录过的 cookie。加载cookie得到我们想要的页面,然后爬取。了解cookies主要是为我们快速模拟登录和抓取目标网页做准备。
我在上一篇文章中使用了 urlopen() 函数来打开网页进行抓取。这只是一个简单的 Python 网页打开器,它的参数只有 urlopen(url, data, timeout),这三个参数不足以让我们获取登陆页面的 cookie。这时候我们将使用另一个 Opener - CookieJar。
cookielib 也是 Python 中爬虫的一个重要模块。可以结合 urllib2 来抓取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续的连接请求中重新发送,从而实现我们需要的模拟登录功能。
这里特别说明,cookielib是py2.7自带的模块,不需要重新安装。如果要查看自己的模块,可以查看Python目录下的Lib文件夹,里面收录了所有已安装的。模块。一开始没有想到,在pycharm中没有找到cookielib,使用快速安装后报错:Could't find index page for 'Cookielib' (可能是拼写错误?)
在那之后,我记得它是否带有它。没想到跑到lib文件夹里面才发现,折腾了半个小时各种折腾~~
我们来介绍一下这个模块,这个模块的主要对象是CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系: CookieJar -- 派生 --> FileCookieJar -- 派生 --> MozillaCookieJar 和 LWPCookieJar 的主要用法,下面我们也会讲到。 urllib2.urlopen() 函数不支持身份验证、cookie 或其他高级 HTTP 函数。要支持这些功能,必须使用build_opener()函数(可以用来让python程序模拟浏览器访问,你懂的~)函数来创建自定义的Opener对象。
1、首先我们获取网站的cookies
例子:
#coding=utf-8 import cookielib import urllib2 mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题) handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器 opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似 response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response for item in my.cookie: print"name="+item.name print"value="+item.value
结果:
name=BAIDUIDvalue=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1name=BIDUPSIDvalue=73BD718962A6EA0DAD4CB9578A08FDD0name=H_PS_PSSIDvalue=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398name=PSTMvalue=1478834132name=BDSVRTMvalue=0name=BD_HOMEvalue=0
这为我们提供了最简单的 cookie。
2、保存 cookie 到文件
上面我们得到了cookie,下面我们学习如何保存cookie。这里我们使用它的子类 MozillaCookieJar 来保存 cookie
例子:
这个例子可以通过简单变形上面的例子得到,使用MozillaCookiJar,CookieJar的一个子类,为什么?我们试试把MozillaCookiJar换成CookieJar,可以看懂下图:
CookieJar不保存save属性~
在
save()方法:ignore_discard表示即使cookie会被丢弃也要保存,ignore_expires表示如果cookie已经存在于文件中,覆盖原文件并写入,这里,我们将这两个都设置为True。运行后cookies会保存到cookie.txt文件中,我们查看一下内容:
这样我们成功保存了我们想要的cookie
3、从文件中获取cookies并访问
#coding=utf-8import urllib2import cookielibimport urllib #第一步先给出账户密码网址准备模拟登录postdata = urllib.urlencode({ 'stuid': '1605122162', 'pwd': 'xxxxxxxxx'#密码这里就不泄漏啦,嘿嘿嘿})loginUrl = 'http://ids.xidian.edu.cn/auths ... 3B%23 登录教务系统的URL,成绩查询网址 # 第二步模拟登陆并保存登录的cookiefilename = 'cookie.txt' #创建文本保存cookiemycookie = cookielib.MozillaCookieJar(filename) # 声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(mycookie)) #定义这个opener,对象是cookieresult = opener.open(loginUrl, postdata)mycookie.save(ignore_discard=True, ignore_expires=True)# 保存cookie到cookie.txt中 # 第三步利用cookie请求访问另一个网址,教务系统总址gradeUrl = 'http://ids.xidian.edu.cn/auths ... 39%3B #只要是帐号密码一样的网址就可以, 请求访问成绩查询网址result = opener.open(gradeUrl)print result.read()
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序页面、提取或删除页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-17 19:06
PDFsam Visual是一个可视化的PDF工具,PDFsam Visual可以可视化的撰写文档,重新排序页面,提取或删除页面,拆分,合并,旋转,加密,解密,修复,提取文本,转换为灰度,裁剪pdf文件!
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,可以旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置。
从 PDF 中删除页面
您只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度旋转。
密码保护 PDF
保护 PDF;
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密。
取消保护 PDF
创建加密 PDF 文件的未加密版本。
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。 查看全部
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序页面、提取或删除页面)
PDFsam Visual是一个可视化的PDF工具,PDFsam Visual可以可视化的撰写文档,重新排序页面,提取或删除页面,拆分,合并,旋转,加密,解密,修复,提取文本,转换为灰度,裁剪pdf文件!
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,可以旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置。
从 PDF 中删除页面
您只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度旋转。
密码保护 PDF
保护 PDF;
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密。
取消保护 PDF
创建加密 PDF 文件的未加密版本。
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。
网页抓取 加密html(网页抓取加密的程度取决于cookie,cookie给你的答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-15 14:01
网页抓取加密html的程度取决于cookie,cookie给你抓取的网页加上非cookie时候的第一页,第二页的百分比可以去百度指数那里查看。cookie并不知道网页内容是怎么加密加密的,所以如果你只是想要查看加密的内容(包括html内容,本地html,js等内容),把cookie加进去即可。
百度搜索'网页加密'找到的答案不对哦
从来没有看过说用标准的pc端的sqlserver加密存储的,这点百度的做的也是有问题的,你可以通过你js全文来断句,把加密的东西转换成普通sql语句,就可以读取了,当然像前面的同学提到的,cookie或cookie,加密的网页则根据你的浏览记录推断你搜索了什么。
开始我也百度过这个,但发现他们都是用logtracking来实现加密的,这种方法对于盗窃是可以实现的,但对于js可以传递javascript明文数据,看了一些最新的js技术都是这样实现加密的。
以我实际抓取项目的经验,js基本上是不会泄露的,毕竟浏览器都能加载js,大部分网站都加载js,
同学,查查手机刷脸支付,跟这个思路差不多。
前端postdata都是脱敏的。无法看到后端数据,所以无法判断。需要看后端公布的参数,
也不是, 查看全部
网页抓取 加密html(网页抓取加密的程度取决于cookie,cookie给你的答案)
网页抓取加密html的程度取决于cookie,cookie给你抓取的网页加上非cookie时候的第一页,第二页的百分比可以去百度指数那里查看。cookie并不知道网页内容是怎么加密加密的,所以如果你只是想要查看加密的内容(包括html内容,本地html,js等内容),把cookie加进去即可。
百度搜索'网页加密'找到的答案不对哦
从来没有看过说用标准的pc端的sqlserver加密存储的,这点百度的做的也是有问题的,你可以通过你js全文来断句,把加密的东西转换成普通sql语句,就可以读取了,当然像前面的同学提到的,cookie或cookie,加密的网页则根据你的浏览记录推断你搜索了什么。
开始我也百度过这个,但发现他们都是用logtracking来实现加密的,这种方法对于盗窃是可以实现的,但对于js可以传递javascript明文数据,看了一些最新的js技术都是这样实现加密的。
以我实际抓取项目的经验,js基本上是不会泄露的,毕竟浏览器都能加载js,大部分网站都加载js,
同学,查查手机刷脸支付,跟这个思路差不多。
前端postdata都是脱敏的。无法看到后端数据,所以无法判断。需要看后端公布的参数,
也不是,
网页抓取 加密html(Python实现通过这位大神的解决思路写一个解密电子邮箱的函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-10 11:13
1、问题的根源
在数据采集的过程中,经常需要采集各种联系方式,包括邮箱地址。一些毫无戒心的网站的邮件地址可以直接从网页的源码中获取,而一些对爬虫稍微了解一点的网站会替换@使用 # 号登录电子邮件:
在我最近的工作中,我遇到了一种以前从未遇到过的电子邮件加密方法。检查元素时可以获得正确的数据:
在查看网页源代码时,也可以定位到对应的元素:
但是从上图可以发现,它对应的是显示邮箱地址的位置,并显示了一个“[email protected]”的链接。让我们检查源代码:
此显示电子邮件地址的字段不同于显示其他文本的结构。如果是非email邮箱数据,则没有链接;如果是email地址数据,则通过这个链接将数据显示在网页的前端。
2、解决办法
经过一番搜索,我在百度知道找到了它的原理和解决方法:
只是简单的异或运算加密,解密也不难。
3、Python 实现
通过这位大神的解决方案,我们可以快速使用Python编写一个解密邮件地址的函数。
首先提取真实邮箱地址的加密数据:
出于隐私原因,此处使用百度知道上发布的电子邮件地址的加密字符串。
import re
from urllib.parse import unquote
email_str = '71121003141403311a140210051e5f121e1c'复制代码
然后将这些加密数据分成两个两个列表:
email_list = re.findall(r'.{2}',email_str)复制代码
提取加密字符串的密钥,字符串的前两个字符:
key = email_list[0]复制代码
定义一个空列表来存储十六进制异或运算的结果:
ll = []复制代码
遍历剩余的加密字符串,与遍历的密钥进行异或,并将结果添加到 ll 列表中:
for e in email_list[1:]:
# 对十六进制进行异或运算
r = hex(int(key,16) ^ int(e,16))
ll.append(r)复制代码
然后对列表中的结果进行字符串拼接和替换:
# 拼接运算后的字符串
a = ''.join(ll)
# URL解码字符串
email = unquote(a.replace('0x','%'))复制代码
因此,email 的值是加密字符串的真实电子邮件地址:
是不是很简单?
文章第一个个人微信公众号和博客:/archives/269.html
欢迎来到我的个人博客:查看更多Python应用文章 查看全部
网页抓取 加密html(Python实现通过这位大神的解决思路写一个解密电子邮箱的函数)
1、问题的根源
在数据采集的过程中,经常需要采集各种联系方式,包括邮箱地址。一些毫无戒心的网站的邮件地址可以直接从网页的源码中获取,而一些对爬虫稍微了解一点的网站会替换@使用 # 号登录电子邮件:
在我最近的工作中,我遇到了一种以前从未遇到过的电子邮件加密方法。检查元素时可以获得正确的数据:
在查看网页源代码时,也可以定位到对应的元素:
但是从上图可以发现,它对应的是显示邮箱地址的位置,并显示了一个“[email protected]”的链接。让我们检查源代码:
此显示电子邮件地址的字段不同于显示其他文本的结构。如果是非email邮箱数据,则没有链接;如果是email地址数据,则通过这个链接将数据显示在网页的前端。
2、解决办法
经过一番搜索,我在百度知道找到了它的原理和解决方法:
只是简单的异或运算加密,解密也不难。
3、Python 实现
通过这位大神的解决方案,我们可以快速使用Python编写一个解密邮件地址的函数。
首先提取真实邮箱地址的加密数据:
出于隐私原因,此处使用百度知道上发布的电子邮件地址的加密字符串。
import re
from urllib.parse import unquote
email_str = '71121003141403311a140210051e5f121e1c'复制代码
然后将这些加密数据分成两个两个列表:
email_list = re.findall(r'.{2}',email_str)复制代码
提取加密字符串的密钥,字符串的前两个字符:
key = email_list[0]复制代码
定义一个空列表来存储十六进制异或运算的结果:
ll = []复制代码
遍历剩余的加密字符串,与遍历的密钥进行异或,并将结果添加到 ll 列表中:
for e in email_list[1:]:
# 对十六进制进行异或运算
r = hex(int(key,16) ^ int(e,16))
ll.append(r)复制代码
然后对列表中的结果进行字符串拼接和替换:
# 拼接运算后的字符串
a = ''.join(ll)
# URL解码字符串
email = unquote(a.replace('0x','%'))复制代码
因此,email 的值是加密字符串的真实电子邮件地址:
是不是很简单?
文章第一个个人微信公众号和博客:/archives/269.html
欢迎来到我的个人博客:查看更多Python应用文章
网页抓取 加密html(网页抓取时使用的工具浏览器浏览浏览)
网站优化 • 优采云 发表了文章 • 0 个评论 • 38 次浏览 • 2022-01-10 06:04
网页抓取加密html的破解在网页上抓取一个html,发现显示的只是文本,没有生成excel。针对这个问题我们可以提取出其中html里的一些区块,抓取时进行加密,最后解密即可。本篇文章就主要讲解抓取加密的html。抓取时使用的工具chrome浏览器googlechrome浏览器:一个不错的浏览器,同时也支持很多chrometabschrome搜索引擎:作用就是查看当前搜索引擎页面内容的信息html的分析html的解析后人力编写javascript代码破解html最终实现的功能可打印网页截图pv、uv。
最终生成的excel只能显示网页中的第一页html怎么查看呢?看下图:这样的html可以通过googlechrome浏览器查看,当然可以通过百度查看。更多的网页可查看需要进行另存网页到文件夹中,方便编辑查看。【总结】总结很简单,就是一个加密html网页我们只要通过加密代码加密网页中的信息就可以破解html网页加密的基本格式就是${prompt|string}password。
使用上面的html格式,再找找入口即可,基本套路都是prompt代表html代码的前几行string代表该html代码的后几行。上传页面二进制文件,用webdav数据传输csv格式的,importurllib2frombs4importbeautifulsoupfromtk_layoutimportlayoutimportrequestsfromtkinterimporttk_controlsimporttkinter.tklearningimportcatcherfromtkinter.applicationimportmenufromtkinter.serializerimportmergefromfilefromtkinter.serializerimportmergefmt,indexerimportjsonfromtkinter.toolbarimportmenuimportrequestsfromseleniumimportwebdriverimporttimecookie_format_cookie=''cookie_type='authorization'money='${cookie}'cookie_name='${string}'cookie_value='${prompt}'txt_line='{name}'#用于解析print(cookie_name)print(cookie_type)print(cookie_name)print(txt_line)index=txt_line.replace('|','')true=index#用于获取行数,行数最多4break=falseprint("获取了索引数据")print("获取了第一行")print(index)print(txt_line)session=webdriver.session()session.get(session.cookies)#获取cookie_typeindex_pic_type=cookie_typeprint("获取了字典的type${cookie_type}")print("获取了字典的行数${cookie_name}")print("获取了字典的列数${cookie_value}"。 查看全部
网页抓取 加密html(网页抓取时使用的工具浏览器浏览浏览)
网页抓取加密html的破解在网页上抓取一个html,发现显示的只是文本,没有生成excel。针对这个问题我们可以提取出其中html里的一些区块,抓取时进行加密,最后解密即可。本篇文章就主要讲解抓取加密的html。抓取时使用的工具chrome浏览器googlechrome浏览器:一个不错的浏览器,同时也支持很多chrometabschrome搜索引擎:作用就是查看当前搜索引擎页面内容的信息html的分析html的解析后人力编写javascript代码破解html最终实现的功能可打印网页截图pv、uv。
最终生成的excel只能显示网页中的第一页html怎么查看呢?看下图:这样的html可以通过googlechrome浏览器查看,当然可以通过百度查看。更多的网页可查看需要进行另存网页到文件夹中,方便编辑查看。【总结】总结很简单,就是一个加密html网页我们只要通过加密代码加密网页中的信息就可以破解html网页加密的基本格式就是${prompt|string}password。
使用上面的html格式,再找找入口即可,基本套路都是prompt代表html代码的前几行string代表该html代码的后几行。上传页面二进制文件,用webdav数据传输csv格式的,importurllib2frombs4importbeautifulsoupfromtk_layoutimportlayoutimportrequestsfromtkinterimporttk_controlsimporttkinter.tklearningimportcatcherfromtkinter.applicationimportmenufromtkinter.serializerimportmergefromfilefromtkinter.serializerimportmergefmt,indexerimportjsonfromtkinter.toolbarimportmenuimportrequestsfromseleniumimportwebdriverimporttimecookie_format_cookie=''cookie_type='authorization'money='${cookie}'cookie_name='${string}'cookie_value='${prompt}'txt_line='{name}'#用于解析print(cookie_name)print(cookie_type)print(cookie_name)print(txt_line)index=txt_line.replace('|','')true=index#用于获取行数,行数最多4break=falseprint("获取了索引数据")print("获取了第一行")print(index)print(txt_line)session=webdriver.session()session.get(session.cookies)#获取cookie_typeindex_pic_type=cookie_typeprint("获取了字典的type${cookie_type}")print("获取了字典的行数${cookie_name}")print("获取了字典的列数${cookie_value}"。
网页抓取 加密html( Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-09 14:07
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
使用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页抓取 加密html(
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
使用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
网页抓取 加密html(网页抓取加密html处理json解析特征转化定时采集复杂)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-09 06:04
网页抓取加密html处理json解析特征转化cookie定时采集复杂的页面分析和变形,
多接触一些其他后端语言吧,这一套流程可能有多处坑,你跳起来还可以继续。
接触过后端开发嘛学学反射吧先。
理论一点就是做一些大数据分析之类的,变化多多,说的多了容易让人误解。其实看网页抓取的话,推荐使用beautifulsoup;做后端的话用php,python,node都可以,看具体需求。js的话,可以了解下写脚本,但js多多少少也要懂点后端知识。爬虫相关涉及javascript/css/html基础知识,就差不多啦~。
应该是想抓取web?那么googletaobaowebspider大概是这样的.这个包是把所有的页面抓下来然后返回给accessresourceserver(简单理解为服务器)
既然已经要学习编程,那么就应该学习更加底层的东西。并不是说html5需要学习c++、java等语言就可以学html5,而是编程语言要求有一定的概念和基础,否则学起来就不容易理解。例如:从你的要求中有使用webspider接口抓取数据,我认为最好先学习c++之类,相对好理解些。
编程语言只是一种工具,用好eclipse以及eclipsesiteguide(推荐),然后百度。 查看全部
网页抓取 加密html(网页抓取加密html处理json解析特征转化定时采集复杂)
网页抓取加密html处理json解析特征转化cookie定时采集复杂的页面分析和变形,
多接触一些其他后端语言吧,这一套流程可能有多处坑,你跳起来还可以继续。
接触过后端开发嘛学学反射吧先。
理论一点就是做一些大数据分析之类的,变化多多,说的多了容易让人误解。其实看网页抓取的话,推荐使用beautifulsoup;做后端的话用php,python,node都可以,看具体需求。js的话,可以了解下写脚本,但js多多少少也要懂点后端知识。爬虫相关涉及javascript/css/html基础知识,就差不多啦~。
应该是想抓取web?那么googletaobaowebspider大概是这样的.这个包是把所有的页面抓下来然后返回给accessresourceserver(简单理解为服务器)
既然已经要学习编程,那么就应该学习更加底层的东西。并不是说html5需要学习c++、java等语言就可以学html5,而是编程语言要求有一定的概念和基础,否则学起来就不容易理解。例如:从你的要求中有使用webspider接口抓取数据,我认为最好先学习c++之类,相对好理解些。
编程语言只是一种工具,用好eclipse以及eclipsesiteguide(推荐),然后百度。
网页抓取 加密html(在java中实现php的md5加密的方法:搭建好php环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-08 16:19
java中实现php的md5加密的方法:先搭建php环境;然后写一个页面,提取get参数并用md5加密值;最后在JAVA页面提交。
java中实现php md5加密的方法:
1、搭建php环境(不做介绍),写一个提取get参数并用md5加密值的页面,如下
strtoupper是字母大写转换的函数
md5是MD5加密的函数
$_GET["md5str"]就是通过url取一个md5str参数,获取值并打印出来
相关学习推荐:php编程(视频)
2、JAVA页面提交方式
/**
* 用于做PHP的提交处理
* @param url
*/
public static String phpRequest(String url){
try{
HttpClient client = new HttpClient();
PostMethod post = new PostMethod(url);//使用POST方式提交数据
post.setRequestHeader("Content-Type","text/html; charset=UTF-8");
client.executeMethod(post);
String response = new String(post.getResponseBodyAsString().getBytes("8859_1"), "UTF-8");//打印结果页面
post.releaseConnection();
return response;
} catch(IOException e){
e.printStackTrace();
return null;
}
}
需要提醒的是,url记得先把中文参数编码成UTF-8再传给这个方法。该方法对响应结果进行反编码,最终正确返回php MD5加密。在值之后!
相关学习推荐:java基础教程 查看全部
网页抓取 加密html(在java中实现php的md5加密的方法:搭建好php环境)
java中实现php的md5加密的方法:先搭建php环境;然后写一个页面,提取get参数并用md5加密值;最后在JAVA页面提交。
java中实现php md5加密的方法:
1、搭建php环境(不做介绍),写一个提取get参数并用md5加密值的页面,如下
strtoupper是字母大写转换的函数
md5是MD5加密的函数
$_GET["md5str"]就是通过url取一个md5str参数,获取值并打印出来
相关学习推荐:php编程(视频)
2、JAVA页面提交方式
/**
* 用于做PHP的提交处理
* @param url
*/
public static String phpRequest(String url){
try{
HttpClient client = new HttpClient();
PostMethod post = new PostMethod(url);//使用POST方式提交数据
post.setRequestHeader("Content-Type","text/html; charset=UTF-8");
client.executeMethod(post);
String response = new String(post.getResponseBodyAsString().getBytes("8859_1"), "UTF-8");//打印结果页面
post.releaseConnection();
return response;
} catch(IOException e){
e.printStackTrace();
return null;
}
}
需要提醒的是,url记得先把中文参数编码成UTF-8再传给这个方法。该方法对响应结果进行反编码,最终正确返回php MD5加密。在值之后!
相关学习推荐:java基础教程
网页抓取 加密html(就是13个你会觉得有用的Chrome浏览器扩展(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-08 04:11
Google Chrome 浏览器与 FireFox 浏览器一样,可以通过使用扩展来增强浏览器的功能。如果您是一名网络开发人员,谷歌浏览器的内置开发人员工具将使您的工作轻松很多。但除此之外,Chrome浏览器上也有很多扩展,为你提供了很多工具供你使用。扩展的最大好处之一是它们允许您在不切换到另一个应用程序的情况下完成一些任务。这种无需切换即可完成某些任务的能力可以为您节省大量时间。注意:如果您在下载 Chrome 扩展程序时遇到问题,请打开 C:Windows\System32\drivers\etc 下的主机文件并添加一行:74.。
这里有 13 个你会发现有用的 Chrome 浏览器扩展。
1. 颜色选择器
拾色器可以让你获取任意颜色的 Hex 和 RGB 值!您还可以调整颜色的色调、饱和度和色彩平衡。
2. Firebug Lite
Firebug Lite 是一个开发工具,允许您编辑、调试和监控网页的 CSS、HTML 和 JavaScript 内容。
3. 域注册查看器
此扩展程序允许您查看域名是否可供购买。如果可以直接通过工具栏查看信息,还需要登录专门的页面查看吗?
4. Aviary 截图扩展
Aviary 屏幕截图扩展允许您截取任何页面的屏幕截图并通过 Web 应用程序直接在浏览器中编辑图像。此外,它还提供了方便的方式来帮助您访问 Aviary 的 网站 及以上工具。#p#字幕#e#
5. Lorem Ipsum 测试文本生成器
Lorem Ipsum 测试文本生成器毫不费力地生成设计模型所需的测试文本内容。
6. IE 选项卡
它将使用 IE 浏览器在 Chrome 选项卡中显示相应的页面。有些网站只能通过IE访问,有了这个扩展你可以直接在Chrome中查看这些网站。这个扩展非常适合那些想测试IE渲染引擎或者登录网站需要使用ActiveX插件,或者想用浏览器查看本地文件的人。
7. 测量它!
测量它!让您可以绘制尺子并测量网页上任何元素的高度和宽度。
8. 素衣
这个扩展将使页面变得柔和,想象一下:文本是黑色的,背景是白色的,未点击的链接是蓝色的,访问过的链接是紫色的,所有的链接都有下划线。或者你把它全部改成你想要的颜色。所有文本都以您选择的默认字体显示(这与通过选项 > 高级选项 > 更改字体和语言设置进行更改相同)。修改后的效果会自动应用到所有页面。#p#字幕#e#
9. 吸管
吸管和颜色选择器扩展允许您从页面或高级颜色选择器面板中选择颜色。
10.速度追踪器
Speed Tracker 扩展可以帮助您识别和修复 Web 应用程序中的性能问题。它可视化从浏览器中获得的底层数据,并在您的 Web 应用程序运行时对其进行分析。Speed Tracker 扩展是一个 Chrome 浏览器扩展,可在该扩展当前支持的所有平台(window 和 Linux)上运行。
11. 钟摆
它扩展了 Chrome 的内置开发者工具。#p#字幕#e#
12. 分辨率测试
分辨率测试扩展可以改变浏览器的大小,方便开发者预览网站在不同屏幕分辨率下的实际效果。它收录常用分辨率的列表,您也可以输入自己想要的分辨率。
13. Snippy
Snippy 可让您抓取页面的某些部分并将其保存以备将来使用。它刮取丰富的内容并保留格式。所以你用它来抓取段落。图片、链接和许多其他格式的内容。 查看全部
网页抓取 加密html(就是13个你会觉得有用的Chrome浏览器扩展(组图))
Google Chrome 浏览器与 FireFox 浏览器一样,可以通过使用扩展来增强浏览器的功能。如果您是一名网络开发人员,谷歌浏览器的内置开发人员工具将使您的工作轻松很多。但除此之外,Chrome浏览器上也有很多扩展,为你提供了很多工具供你使用。扩展的最大好处之一是它们允许您在不切换到另一个应用程序的情况下完成一些任务。这种无需切换即可完成某些任务的能力可以为您节省大量时间。注意:如果您在下载 Chrome 扩展程序时遇到问题,请打开 C:Windows\System32\drivers\etc 下的主机文件并添加一行:74.。
这里有 13 个你会发现有用的 Chrome 浏览器扩展。
1. 颜色选择器
拾色器可以让你获取任意颜色的 Hex 和 RGB 值!您还可以调整颜色的色调、饱和度和色彩平衡。
2. Firebug Lite
Firebug Lite 是一个开发工具,允许您编辑、调试和监控网页的 CSS、HTML 和 JavaScript 内容。
3. 域注册查看器
此扩展程序允许您查看域名是否可供购买。如果可以直接通过工具栏查看信息,还需要登录专门的页面查看吗?
4. Aviary 截图扩展
Aviary 屏幕截图扩展允许您截取任何页面的屏幕截图并通过 Web 应用程序直接在浏览器中编辑图像。此外,它还提供了方便的方式来帮助您访问 Aviary 的 网站 及以上工具。#p#字幕#e#
5. Lorem Ipsum 测试文本生成器
Lorem Ipsum 测试文本生成器毫不费力地生成设计模型所需的测试文本内容。
6. IE 选项卡
它将使用 IE 浏览器在 Chrome 选项卡中显示相应的页面。有些网站只能通过IE访问,有了这个扩展你可以直接在Chrome中查看这些网站。这个扩展非常适合那些想测试IE渲染引擎或者登录网站需要使用ActiveX插件,或者想用浏览器查看本地文件的人。
7. 测量它!
测量它!让您可以绘制尺子并测量网页上任何元素的高度和宽度。
8. 素衣
这个扩展将使页面变得柔和,想象一下:文本是黑色的,背景是白色的,未点击的链接是蓝色的,访问过的链接是紫色的,所有的链接都有下划线。或者你把它全部改成你想要的颜色。所有文本都以您选择的默认字体显示(这与通过选项 > 高级选项 > 更改字体和语言设置进行更改相同)。修改后的效果会自动应用到所有页面。#p#字幕#e#
9. 吸管
吸管和颜色选择器扩展允许您从页面或高级颜色选择器面板中选择颜色。
10.速度追踪器
Speed Tracker 扩展可以帮助您识别和修复 Web 应用程序中的性能问题。它可视化从浏览器中获得的底层数据,并在您的 Web 应用程序运行时对其进行分析。Speed Tracker 扩展是一个 Chrome 浏览器扩展,可在该扩展当前支持的所有平台(window 和 Linux)上运行。
11. 钟摆
它扩展了 Chrome 的内置开发者工具。#p#字幕#e#
12. 分辨率测试
分辨率测试扩展可以改变浏览器的大小,方便开发者预览网站在不同屏幕分辨率下的实际效果。它收录常用分辨率的列表,您也可以输入自己想要的分辨率。
13. Snippy
Snippy 可让您抓取页面的某些部分并将其保存以备将来使用。它刮取丰富的内容并保留格式。所以你用它来抓取段落。图片、链接和许多其他格式的内容。
网页抓取 加密html(数据就是新石油互联网上海量的加密货币数据应该成为你的第二天性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-04 13:10
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬虫是指从 网站 下载数据并从这些数据中提取有价值信息的过程(因此得名爬虫)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在这一系列的文章中,我们将从这个概念开始,慢慢地建立起来。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多网站 提供免费工具,为什么还有人要采集你自己的数据?大多数用户会使用网站,例如CoinMarketCap、CoinGecko、Live Coin Watch 来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录更多关于投资研究的附加信息(市场价值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与Polkadot相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
from bs4 import BeautifulSoup
import requests# retrieve the web page and parse the contents
mainpage = requests.get('https://coinmarketcap.com/curr ... 23x27;)
soup = BeautifulSoup(mainpage.content, 'html.parser')
whatis = soup.find_all("div", {"class" : "sc-2qtjgt-0 eApVPN"})# extract elements from the contents
title = whatis[0].find_all("h2")
print(title[0].text.strip() + "\n")
for p in whatis[0].find_all('p'):
print(p.text.strip() + "\n")
示例2:网络爬取币种统计
在本例中,我们将使用 BNB 统计数据,即市值、完全稀释市值、交易量(24 小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字总是在变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class" : "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class" : "statsValue"})statsValue_marketcap = statsValues[0].text.strip()
print(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
print(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
print(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
print(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
print(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap等网站的开发者在不断更新他们的网站,老代码可能过一段时间就不能用了。
一种可能的解决方案是使用平台提供的各种 网站 和应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
来源: 查看全部
网页抓取 加密html(数据就是新石油互联网上海量的加密货币数据应该成为你的第二天性)
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬虫是指从 网站 下载数据并从这些数据中提取有价值信息的过程(因此得名爬虫)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在这一系列的文章中,我们将从这个概念开始,慢慢地建立起来。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多网站 提供免费工具,为什么还有人要采集你自己的数据?大多数用户会使用网站,例如CoinMarketCap、CoinGecko、Live Coin Watch 来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录更多关于投资研究的附加信息(市场价值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与Polkadot相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
from bs4 import BeautifulSoup
import requests# retrieve the web page and parse the contents
mainpage = requests.get('https://coinmarketcap.com/curr ... 23x27;)
soup = BeautifulSoup(mainpage.content, 'html.parser')
whatis = soup.find_all("div", {"class" : "sc-2qtjgt-0 eApVPN"})# extract elements from the contents
title = whatis[0].find_all("h2")
print(title[0].text.strip() + "\n")
for p in whatis[0].find_all('p'):
print(p.text.strip() + "\n")
示例2:网络爬取币种统计
在本例中,我们将使用 BNB 统计数据,即市值、完全稀释市值、交易量(24 小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字总是在变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class" : "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class" : "statsValue"})statsValue_marketcap = statsValues[0].text.strip()
print(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
print(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
print(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
print(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
print(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap等网站的开发者在不断更新他们的网站,老代码可能过一段时间就不能用了。
一种可能的解决方案是使用平台提供的各种 网站 和应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
来源:
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 21:15
有时候网页编程,想着勤劳的网页别人,右键查看源码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想对整个页面html进行加密,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js document.write,动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("....");但这与不加密没有什么不同。但是我还是用这个方法先测试了一下,遇到了点麻烦。 Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
目前比较流行的编码有几种,比如json、base64.,那就先试试json吧。
json 编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密效果为1%。
接下来尝试 base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据长度和换行符看到html结构。这仍然是一个单线电话。
下面改为链式调用
代码根本看不到原来的结构了。哈哈
接下来尝试使用二进制编码:
接下来尝试以八进制编码:
接下来尝试使用十进制编码(顺便添加了一些无用的符号以增强混淆):
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
接下来要做一个密码输入框,输入正确的密码就可以显示了。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
必须用des解密,密码才知道。这种des加密的优点是可以加密并通过网络传输数据。 http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。 des虽然比较弱,但是破解没那么简单
浏览器访问网页时,先输入密码,解密,成功显示真实网页。
其实还有其他编码和其他压缩编码,我不是很清楚,需要动态输出html。我用的php需要搭配js。一方加密,另一方解密。它不匹配或没有合适的编码。做不到。
结论:这种加密纯粹是我自己无聊的研究,但是web服务器输出的html有一层加密。客户端收到后,js动态解码输出。虽然无法通过右键查看代码,但浏览器开发者工具会显示运行以下html代码一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深入的了解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
有时候网页编程,想着勤劳的网页别人,右键查看源码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想对整个页面html进行加密,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js document.write,动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("....");但这与不加密没有什么不同。但是我还是用这个方法先测试了一下,遇到了点麻烦。 Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
目前比较流行的编码有几种,比如json、base64.,那就先试试json吧。
json 编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密效果为1%。
接下来尝试 base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据长度和换行符看到html结构。这仍然是一个单线电话。
下面改为链式调用
代码根本看不到原来的结构了。哈哈
接下来尝试使用二进制编码:
接下来尝试以八进制编码:
接下来尝试使用十进制编码(顺便添加了一些无用的符号以增强混淆):
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
接下来要做一个密码输入框,输入正确的密码就可以显示了。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
必须用des解密,密码才知道。这种des加密的优点是可以加密并通过网络传输数据。 http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。 des虽然比较弱,但是破解没那么简单
浏览器访问网页时,先输入密码,解密,成功显示真实网页。
其实还有其他编码和其他压缩编码,我不是很清楚,需要动态输出html。我用的php需要搭配js。一方加密,另一方解密。它不匹配或没有合适的编码。做不到。
结论:这种加密纯粹是我自己无聊的研究,但是web服务器输出的html有一层加密。客户端收到后,js动态解码输出。虽然无法通过右键查看代码,但浏览器开发者工具会显示运行以下html代码一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深入的了解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。
网页抓取 加密html(不论加密如何复杂的网页加密?加密怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-29 08:15
有时我们看到非常漂亮的声音和图片,总想把它的源代码当成一个仿模板去查看,却发现看到的是一个加密的网页,因为开源的记事本全是不规则的、乱七八糟的。的性格。一般情况下,我们只需要在IE中点击“查看”-“源文件”就可以看到对应网页的源代码,或者借用软件或者其他浏览器来查看网页的源代码,但是有些作者网页加密其源代码以防止攻击或保护其知识产权。其实对于这些所谓的加密,我们只需要进行一个小小的操作,就可以让加密“报废”。,即使是专门的黑客网站也不例外,其破解方法如下:
在页面的浏览器地址栏中输入以下段落:
javascript:s=document.documentElement.outerHTML;document.write('');document.body.innerText=s;
然后回车,源码就出来了,也就是打开的网页是一个充满代码的网页,第一部分是加密的代码(听不懂,听不懂),下面的代码是正常的网页代码. 懂一些代码知识的人很容易区分,也很容易得到有效正确的代码。无论加密多么复杂,最终都会还原成浏览器可以解析的html代码,而documentElement.outerHTML就是最终的结果。
当然,为了尊重作者的劳动,即使网页被破解得到代码,我们还是要对原作者表示感谢。尊重知识、尊重人才是我们中华民族的传统美德。 查看全部
网页抓取 加密html(不论加密如何复杂的网页加密?加密怎么办)
有时我们看到非常漂亮的声音和图片,总想把它的源代码当成一个仿模板去查看,却发现看到的是一个加密的网页,因为开源的记事本全是不规则的、乱七八糟的。的性格。一般情况下,我们只需要在IE中点击“查看”-“源文件”就可以看到对应网页的源代码,或者借用软件或者其他浏览器来查看网页的源代码,但是有些作者网页加密其源代码以防止攻击或保护其知识产权。其实对于这些所谓的加密,我们只需要进行一个小小的操作,就可以让加密“报废”。,即使是专门的黑客网站也不例外,其破解方法如下:
在页面的浏览器地址栏中输入以下段落:
javascript:s=document.documentElement.outerHTML;document.write('');document.body.innerText=s;
然后回车,源码就出来了,也就是打开的网页是一个充满代码的网页,第一部分是加密的代码(听不懂,听不懂),下面的代码是正常的网页代码. 懂一些代码知识的人很容易区分,也很容易得到有效正确的代码。无论加密多么复杂,最终都会还原成浏览器可以解析的html代码,而documentElement.outerHTML就是最终的结果。
当然,为了尊重作者的劳动,即使网页被破解得到代码,我们还是要对原作者表示感谢。尊重知识、尊重人才是我们中华民族的传统美德。
网页抓取 加密html( 分析请求老规矩先抓包,在一番标签下等了半天)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-28 03:17
分析请求老规矩先抓包,在一番标签下等了半天)
分析请求
旧规则是先抢包裹。在xhr标签下等了半天,没有发现异步请求,不过很快就出现了show操作。
在Html页面请求中发现以下内容:
根据我多年的经验,这应该是对页面显示的属性内容进行加密,然后在页面显示时按照一定的解密逻辑还原显示。这真是个麻烦事。
位置加密
果然,他苦恼了二十多分钟才定位到加密位置,一直没有找到。感觉超出了我的能力范围。
为了能够愉快的摸(啦)鱼(shi),不再担心,所以决定今天先来这里。
本文结束。
不过还好,在有偿摸鱼(la)鱼(shi)的过程中,我突然有了新的想法,想到了之前一直忽略的东西。
让我先梳理一下我的想法:
这条加密的信息在页面显示上必须有一个位置来标识解密后显示的位置,并且在页面密文上显示的位置正好有一个id(全局只有一),如果你猜对了,那么事情简单太多了。
于是,搜索结束,结果没有找到假想的js文件。
突然
不过我在这个页面上发现了两个equip_desc_panel,赶紧跟进,发现如下代码:
$("equip_desc_panel").innerHTML = parse_style_info(get_equip_desc("equip_desc_value"));
下意识地再次搜索:
果然,发现这个貌似加密的东西,撞到断点,刷新,成功进入断点。
虽然这个定位加密的过程很曲折,也有点味道,但事实告诉我们:
有偿摸(la)鱼(shi)
有助于灵感迸发
分析加密
既然已经成功进入断点,那么我们就追进去看看:
这个混淆后的代码就是我们要分析的加密。
这个混淆乍一看有点大,但是混淆的方法在之前的文章中也有提到,有兴趣的朋友可以翻翻。
点我-----> JS反向常见混淆汇总
了解迷茫之道后,先冷静下来,明白这种长得一模一样的东西,最怕烦躁。
从头一步一步开始,观察传入的值,顺便复制一下代码放到代码中。
_0x1b3f48['\x63\x68\x61\x72\x43\x6f\x64\x65\x41\x74']
把这个方法名翻译成普通的js代码,方便理解,理解大致的解密过程,明确我们最终需要的值是如何产生的。
之后就是找老套路缺什么的阶段了,但是在推导代码的过程中有两个坑:
扣除代码时,很明显已经扣除了整体逻辑,但没有返回任何值。通过打印调试发现,这段代码中的_0x1b3f48返回的是空值,使得后面的for循环没有结果,需要特别注意。
还有浏览器使用的base64编码转换
_0x1c0cdf = _0xcbc80b'atob',
但是调试nodejs时使用的是
Buffer.from(_0x1c0cdf,"base64").toString()
经过一番不懈的努力(tu)(tou),结果成功了。
全文结束。 查看全部
网页抓取 加密html(
分析请求老规矩先抓包,在一番标签下等了半天)
分析请求
旧规则是先抢包裹。在xhr标签下等了半天,没有发现异步请求,不过很快就出现了show操作。
在Html页面请求中发现以下内容:
根据我多年的经验,这应该是对页面显示的属性内容进行加密,然后在页面显示时按照一定的解密逻辑还原显示。这真是个麻烦事。
位置加密
果然,他苦恼了二十多分钟才定位到加密位置,一直没有找到。感觉超出了我的能力范围。
为了能够愉快的摸(啦)鱼(shi),不再担心,所以决定今天先来这里。
本文结束。
不过还好,在有偿摸鱼(la)鱼(shi)的过程中,我突然有了新的想法,想到了之前一直忽略的东西。
让我先梳理一下我的想法:
这条加密的信息在页面显示上必须有一个位置来标识解密后显示的位置,并且在页面密文上显示的位置正好有一个id(全局只有一),如果你猜对了,那么事情简单太多了。
于是,搜索结束,结果没有找到假想的js文件。
突然
不过我在这个页面上发现了两个equip_desc_panel,赶紧跟进,发现如下代码:
$("equip_desc_panel").innerHTML = parse_style_info(get_equip_desc("equip_desc_value"));
下意识地再次搜索:
果然,发现这个貌似加密的东西,撞到断点,刷新,成功进入断点。
虽然这个定位加密的过程很曲折,也有点味道,但事实告诉我们:
有偿摸(la)鱼(shi)
有助于灵感迸发
分析加密
既然已经成功进入断点,那么我们就追进去看看:
这个混淆后的代码就是我们要分析的加密。
这个混淆乍一看有点大,但是混淆的方法在之前的文章中也有提到,有兴趣的朋友可以翻翻。
点我-----> JS反向常见混淆汇总
了解迷茫之道后,先冷静下来,明白这种长得一模一样的东西,最怕烦躁。
从头一步一步开始,观察传入的值,顺便复制一下代码放到代码中。
_0x1b3f48['\x63\x68\x61\x72\x43\x6f\x64\x65\x41\x74']
把这个方法名翻译成普通的js代码,方便理解,理解大致的解密过程,明确我们最终需要的值是如何产生的。
之后就是找老套路缺什么的阶段了,但是在推导代码的过程中有两个坑:
扣除代码时,很明显已经扣除了整体逻辑,但没有返回任何值。通过打印调试发现,这段代码中的_0x1b3f48返回的是空值,使得后面的for循环没有结果,需要特别注意。
还有浏览器使用的base64编码转换
_0x1c0cdf = _0xcbc80b'atob',
但是调试nodejs时使用的是
Buffer.from(_0x1c0cdf,"base64").toString()
经过一番不懈的努力(tu)(tou),结果成功了。
全文结束。
网页抓取 加密html(【智传网优】Linux发行版附带vim的方法加密文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-27 06:08
请关注这个头条号,每天持续更新原创干货技术文章。
如需学习视频,请在微信搜索公众号“知传网游”,直接开启自助视频学习
1. 前言
本文主要讲解如何使用vim对文本文件进行加密,通过设置保护密码来达到保护文本文件的目的。
流行的文本编辑器 Vim 有一个内置功能,可以用密码加密文件。Vim 使用像 Blowfish 这样的算法来加密文件。它比其他可用工具更快、更方便。
首先,你需要安装完整版的vim系统。一些 Linux 发行版带有最小版本的 vim。它不支持文件加密。如果我们尝试对其进行加密,它将显示错误消息“抱歉,该命令不适用于此版本。” 有两种不同的方法来加密文件。
在 Linux 中使用 vim 加密文件
2. 第一种方法:创建加密文件
创建加密的新文件
vim -x filename
vim 编辑器创建加密文件
这将创建一个新文件并提示设置加密密码。输入您的密码两次,然后按 Enter。然后,每次尝试使用任何文本编辑器打开文件时,都需要密码。
加密现有文件,用vim打开文件,按“ESC”键进入命令模式,输入:X并按照提示设置密钥。键入两次密钥,然后按 Enter。就是这样,文件现在受到保护。请注意,vim 命令区分大小写,因此 :x 和 :X 具有不同的含义。
2. 第二种方法:加密现有文件
在命令模式下输入:set key="mykey"。但是,不建议这样做,因为输入的密码可能会在 ~/.viminfo 文件中以及 history 和 vim 命令中可见。然后,每次我们尝试打开文件时,vim 都会要求输入密码,然后输入正确的密码来查看和编辑文件。
即使我们尝试用非vim编辑器打开文件,文件仍然可以打开,但显示乱码。
vim 编辑器加密现有文件
vim 输入错误密码
底部的详细信息显示了使用的加密算法,在我们的例子中是河豚。
修改/删除密码:修改或删除密码非常容易。只需打开文件并输入:x 并输入您的新密钥。要从文件中删除密码,请不要输入任何内容并按 Enter 键两次。
现在我们知道了vim密码文件的功能和操作技巧,我们准备保护所有收录
机密信息的文件。但是这种方法可靠吗?我们可以使用它吗?虽然blowfish算法效果很好,但是使用vim进行加密可能会有问题,因为即使文件加密了,也没有写入限制。
考虑一个场景,您创建一个加密文件并在其中存储一些重要数据。现在,下次打开它时,不小心输入了错误的密码,vim 仍然打开该文件,尽管内容已加密。现在,为了退出并重新打开,正确的退出命令是 :q,但不幸的是,如果您错误地键入了 :wq 命令,vim 将通过替换显示的文本来覆盖文件(而不是替换解密后的原创
文本)格式)。在这种情况下,可能无法恢复数据。
3. 总结
通过本教程,您应该知道如何使用vim来保护机密文件了吧?但使用时要注意防止误操作造成数据丢失。
本文已同步至博客站,尊重原创,转载请在正文附上以下链接: 查看全部
网页抓取 加密html(【智传网优】Linux发行版附带vim的方法加密文件)
请关注这个头条号,每天持续更新原创干货技术文章。
如需学习视频,请在微信搜索公众号“知传网游”,直接开启自助视频学习
1. 前言
本文主要讲解如何使用vim对文本文件进行加密,通过设置保护密码来达到保护文本文件的目的。
流行的文本编辑器 Vim 有一个内置功能,可以用密码加密文件。Vim 使用像 Blowfish 这样的算法来加密文件。它比其他可用工具更快、更方便。
首先,你需要安装完整版的vim系统。一些 Linux 发行版带有最小版本的 vim。它不支持文件加密。如果我们尝试对其进行加密,它将显示错误消息“抱歉,该命令不适用于此版本。” 有两种不同的方法来加密文件。
在 Linux 中使用 vim 加密文件
2. 第一种方法:创建加密文件
创建加密的新文件
vim -x filename
vim 编辑器创建加密文件
这将创建一个新文件并提示设置加密密码。输入您的密码两次,然后按 Enter。然后,每次尝试使用任何文本编辑器打开文件时,都需要密码。
加密现有文件,用vim打开文件,按“ESC”键进入命令模式,输入:X并按照提示设置密钥。键入两次密钥,然后按 Enter。就是这样,文件现在受到保护。请注意,vim 命令区分大小写,因此 :x 和 :X 具有不同的含义。
2. 第二种方法:加密现有文件
在命令模式下输入:set key="mykey"。但是,不建议这样做,因为输入的密码可能会在 ~/.viminfo 文件中以及 history 和 vim 命令中可见。然后,每次我们尝试打开文件时,vim 都会要求输入密码,然后输入正确的密码来查看和编辑文件。
即使我们尝试用非vim编辑器打开文件,文件仍然可以打开,但显示乱码。
vim 编辑器加密现有文件
vim 输入错误密码
底部的详细信息显示了使用的加密算法,在我们的例子中是河豚。
修改/删除密码:修改或删除密码非常容易。只需打开文件并输入:x 并输入您的新密钥。要从文件中删除密码,请不要输入任何内容并按 Enter 键两次。
现在我们知道了vim密码文件的功能和操作技巧,我们准备保护所有收录
机密信息的文件。但是这种方法可靠吗?我们可以使用它吗?虽然blowfish算法效果很好,但是使用vim进行加密可能会有问题,因为即使文件加密了,也没有写入限制。
考虑一个场景,您创建一个加密文件并在其中存储一些重要数据。现在,下次打开它时,不小心输入了错误的密码,vim 仍然打开该文件,尽管内容已加密。现在,为了退出并重新打开,正确的退出命令是 :q,但不幸的是,如果您错误地键入了 :wq 命令,vim 将通过替换显示的文本来覆盖文件(而不是替换解密后的原创
文本)格式)。在这种情况下,可能无法恢复数据。
3. 总结
通过本教程,您应该知道如何使用vim来保护机密文件了吧?但使用时要注意防止误操作造成数据丢失。
本文已同步至博客站,尊重原创,转载请在正文附上以下链接:

