
网页抓取 加密html
网页抓取 加密html(加密和混淆的反垃圾邮件手段,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-21 23:48
提醒:此页面将不再更新、维护或支持。文章 中描述的内容和评论是时间敏感的。不保证在技术细节或软件使用方面完全有效和可操作。请仔细参考!
邮箱里一直有很多垃圾邮件,这让我不得不重新检查网上发布的电子邮件地址。为了避免垃圾邮件,我特意把@换成了#,也许十年前这是个好主意,但是随着神经网络和机器学习新算法的发展,这种小方法也面临着失败的风险,因为大部分都是通过修改邮件地址的“@”符号,通过正则表达式过滤匹配特征值来完成的,比如,,这样的疑似邮件地址的特征还是可以抓到邮件地址的,所以我们需要在将电子邮件发布到 HTML 页面之前对其进行加密和混淆处理。
我举个例子来介绍几种反垃圾邮件的加密和混淆方法。
1. 生成图片
使用传统的图灵测试验证码会阻止采集的邮件地址生成图片,并利用机器无法识别的特征来区分人和机器。生成图片的方法有很多,除了高大上的Photoshop,甚至可以使用系统自带的绘图工具来完成。此外,如果你想偷懒,有一些在线工具可以帮助你,例如“将你的电子邮件地址变成图像的 10 大网站”。
当然,生成图片也不是万无一失的。有理由相信,既然基于图片的验证码可以被机器识别和破解,那么基于相同技术的邮件地址必然是不可避免的,尤其是随着OCR技术的逐渐发展和成熟,采集程序可以对整个网页进行OCR,最后提取出需要的内容,所以我们还需要将图片生成的email地址与噪声、干扰线等混淆,具体方法请参考相关内容防止验证码被识别。
但是经过这样的设计,我们的邮箱地址对真正需要的人变得不那么友好了,人们获取准确的邮箱地址也变得更加困难。
2、替换键符号
我们知道很多爬虫都是通过@特征符号来爬取邮件地址的。正如我在文章开头提到的,用其他东西替换这个符号将大大降低我们的电子邮件地址被爬取的概率。当然,这样做的缺点是除非你给用户一个提示,否则你需要指定这是一个电子邮件地址,例如 john# 或 john{a} 等。当然智能电子邮件捕获软件可以自动对这些招数免疫,通过判断域名也可以得到。这是一个电子邮件地址,因此将@替换为一个非常特殊的符号也是一种生存方式。对于这种替换方式,更糟糕的是把email地址变成一个句子,比如john AT example DOT com,这样看起来更安全,
3、使用 JavaScript
JavaScript简称JS,通常作为嵌入网页的小脚本,为其提供更丰富的交互和应用。我们使用JS来混淆我们的邮箱地址,最后使用document.write或者innerHTML来输出。优点是大多数爬虫无法在网页中执行脚本。它们只擅长抓取静态文本,因此无需担心将电子邮件地址泄露给爬虫。另外,对于终端用户来说,通过浏览器的解读,显示给他们的是一个完整的邮箱地址,用户体验很好,但是这种方式有一个比较致命的弱点:如果用户的浏览器不支持脚本,邮箱地址会不能正常显示,尽管这种情况很少见。
一个典型的例子如下。当然还有很多变种实现,比如PHP hide_email,这里就不介绍了。
var username = "john";
var hostname = "example.com";
document.write(username + "@" + hostname);
特别值得一提的是ROT13算法的应用。ROT13 是 13 位循环。归根结底是将字母表的第一部分连接成一个环,将要编码的字母映射为旋转后的13位字母,如下示意图所示:
对于PHP来说,有一个函数str_rot13可以直接使用,然后根据其算法反演得到加密前的文本。一般使用以下JS代码:
document.write("Fraq n zrffntr".replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c=(c=c.charCodeAt(0)+13)?c:c-26);}));
上面的代码将解码为以下 HTML:
Send a message
4、使用 HTML 和 CSS 混淆
当然,除了 JavaScript,我们还可以使用 HTML 或 CSS 的一些技巧来混淆 HTML 注释。在 HTML 中,收录注释,浏览器不会将注释呈现给最终用户。那么我们就可以充分利用这个一点点,让我们的邮箱地址看起来像这样:
john@example.com
这不会被浏览器显示出来,但足以迷惑机器爬虫的爬取。
同样的 CSS display:none 组合,我们仍然可以得到以下混淆类似的意思:
jo@hn@@exam@ple.com
同样的CSS display:none 必须注定收录的文本不会被显示,所以最终显示的也是完整的电子邮件地址。
对于CSS,还有一种方法可以让我们避免爬取,那就是利用CSS文本显示顺序的特性,比如下面这样:
moc.noitpecni@kcik
CSS代码如下:
.obfuscate { unicode-bidi: bidi-override; direction: rtl; }
首先,文字被我们颠倒过来。如果我们想恢复它,我们可以不使用JS,通过CSS再次反转,从而得到正确的文本。当然,这个方法我试过之后还是有一点不足,就是用户选择复制邮箱地址的时候,地址还是倒序的。
综上所述,在打击垃圾爬虫采集的方法上,充分发挥了网友们的聪明才智,涌现出各种有才华的实现方式。限于篇幅,我就不一一介绍了。其实没有绝对的安全,最安全的解决办法就是没有邮箱,我怎么能这么说呢?也就是使用联系表格(Contact From)让需要联系你的人通过表格直接给你发邮件,从而避免了邮件地址的泄露。还有很多在线联系表单的开源代码,我的博客最后考虑了。也是这样,现在大家可以找到这个链接,通过右上角的“关于我”给我留言。
参考 查看全部
网页抓取 加密html(加密和混淆的反垃圾邮件手段,你知道吗?)
提醒:此页面将不再更新、维护或支持。文章 中描述的内容和评论是时间敏感的。不保证在技术细节或软件使用方面完全有效和可操作。请仔细参考!
邮箱里一直有很多垃圾邮件,这让我不得不重新检查网上发布的电子邮件地址。为了避免垃圾邮件,我特意把@换成了#,也许十年前这是个好主意,但是随着神经网络和机器学习新算法的发展,这种小方法也面临着失败的风险,因为大部分都是通过修改邮件地址的“@”符号,通过正则表达式过滤匹配特征值来完成的,比如,,这样的疑似邮件地址的特征还是可以抓到邮件地址的,所以我们需要在将电子邮件发布到 HTML 页面之前对其进行加密和混淆处理。
我举个例子来介绍几种反垃圾邮件的加密和混淆方法。
1. 生成图片
使用传统的图灵测试验证码会阻止采集的邮件地址生成图片,并利用机器无法识别的特征来区分人和机器。生成图片的方法有很多,除了高大上的Photoshop,甚至可以使用系统自带的绘图工具来完成。此外,如果你想偷懒,有一些在线工具可以帮助你,例如“将你的电子邮件地址变成图像的 10 大网站”。
当然,生成图片也不是万无一失的。有理由相信,既然基于图片的验证码可以被机器识别和破解,那么基于相同技术的邮件地址必然是不可避免的,尤其是随着OCR技术的逐渐发展和成熟,采集程序可以对整个网页进行OCR,最后提取出需要的内容,所以我们还需要将图片生成的email地址与噪声、干扰线等混淆,具体方法请参考相关内容防止验证码被识别。
但是经过这样的设计,我们的邮箱地址对真正需要的人变得不那么友好了,人们获取准确的邮箱地址也变得更加困难。
2、替换键符号
我们知道很多爬虫都是通过@特征符号来爬取邮件地址的。正如我在文章开头提到的,用其他东西替换这个符号将大大降低我们的电子邮件地址被爬取的概率。当然,这样做的缺点是除非你给用户一个提示,否则你需要指定这是一个电子邮件地址,例如 john# 或 john{a} 等。当然智能电子邮件捕获软件可以自动对这些招数免疫,通过判断域名也可以得到。这是一个电子邮件地址,因此将@替换为一个非常特殊的符号也是一种生存方式。对于这种替换方式,更糟糕的是把email地址变成一个句子,比如john AT example DOT com,这样看起来更安全,
3、使用 JavaScript
JavaScript简称JS,通常作为嵌入网页的小脚本,为其提供更丰富的交互和应用。我们使用JS来混淆我们的邮箱地址,最后使用document.write或者innerHTML来输出。优点是大多数爬虫无法在网页中执行脚本。它们只擅长抓取静态文本,因此无需担心将电子邮件地址泄露给爬虫。另外,对于终端用户来说,通过浏览器的解读,显示给他们的是一个完整的邮箱地址,用户体验很好,但是这种方式有一个比较致命的弱点:如果用户的浏览器不支持脚本,邮箱地址会不能正常显示,尽管这种情况很少见。
一个典型的例子如下。当然还有很多变种实现,比如PHP hide_email,这里就不介绍了。
var username = "john";
var hostname = "example.com";
document.write(username + "@" + hostname);
特别值得一提的是ROT13算法的应用。ROT13 是 13 位循环。归根结底是将字母表的第一部分连接成一个环,将要编码的字母映射为旋转后的13位字母,如下示意图所示:
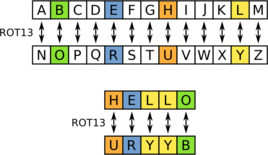
对于PHP来说,有一个函数str_rot13可以直接使用,然后根据其算法反演得到加密前的文本。一般使用以下JS代码:
document.write("Fraq n zrffntr".replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c=(c=c.charCodeAt(0)+13)?c:c-26);}));
上面的代码将解码为以下 HTML:
Send a message
4、使用 HTML 和 CSS 混淆
当然,除了 JavaScript,我们还可以使用 HTML 或 CSS 的一些技巧来混淆 HTML 注释。在 HTML 中,收录注释,浏览器不会将注释呈现给最终用户。那么我们就可以充分利用这个一点点,让我们的邮箱地址看起来像这样:
john@example.com
这不会被浏览器显示出来,但足以迷惑机器爬虫的爬取。
同样的 CSS display:none 组合,我们仍然可以得到以下混淆类似的意思:
jo@hn@@exam@ple.com
同样的CSS display:none 必须注定收录的文本不会被显示,所以最终显示的也是完整的电子邮件地址。
对于CSS,还有一种方法可以让我们避免爬取,那就是利用CSS文本显示顺序的特性,比如下面这样:
moc.noitpecni@kcik
CSS代码如下:
.obfuscate { unicode-bidi: bidi-override; direction: rtl; }
首先,文字被我们颠倒过来。如果我们想恢复它,我们可以不使用JS,通过CSS再次反转,从而得到正确的文本。当然,这个方法我试过之后还是有一点不足,就是用户选择复制邮箱地址的时候,地址还是倒序的。
综上所述,在打击垃圾爬虫采集的方法上,充分发挥了网友们的聪明才智,涌现出各种有才华的实现方式。限于篇幅,我就不一一介绍了。其实没有绝对的安全,最安全的解决办法就是没有邮箱,我怎么能这么说呢?也就是使用联系表格(Contact From)让需要联系你的人通过表格直接给你发邮件,从而避免了邮件地址的泄露。还有很多在线联系表单的开源代码,我的博客最后考虑了。也是这样,现在大家可以找到这个链接,通过右上角的“关于我”给我留言。
参考
网页抓取 加密html(本文要推荐的[ToolFk]是一款程序员经常使用的线上免费测试工具箱)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-20 04:01
本文推荐的【ToolFk】是程序员经常使用的在线免费测试工具箱。ToolFk 的特点是专注于程序员的日常开发工具。它不需要安装任何软件。只需粘贴内容并按下执行按钮即可。得到想要的内容。ToolFk还支持BarCode条码在线生成、QueryList采集器、PHP代码在线操作、PHP混淆、加密、解密、Python代码在线操作、JavaScript在线操作、YAML格式化工具、HTTP模拟查询工具、HTML在线工具箱、JavaScript在线工具箱,CSS在线工具箱,JSON在线工具箱,Unixtime时间戳转换,Base64/URL/Native2Ascii转换,CSV转换工具箱,XML在线工具箱,WebSocket在线工具箱,Markdown在线工具箱,Htaccess2nginx转换,在线二进制转换、在线加密工具箱、在线伪原创工具、在线APK反编译、在线网页截图工具、在线随机密码生成、在线生成二维码Qrcode、在线Crontab表达式生成、在线短URL生成、在线计算器工具. 拥有20多种日常程序员开发工具,是一个非常全面的程序员工具箱网站。
网站名称:ToolFk
网站链接:
工具链接:
代码教学
本程序【在线网页采集工具】依赖于PHP QueryList代码库,其官方链接为,使用代码如下
第1步
第2步
很简单的一句话代码实现了在线数据采集功能。
\QL\QueryList::html($html)->find($rule)->attrs($attr)->toArray()
值得一试的三个原因: 集成各种程序员经常使用的开发和测试工具。简洁美观的网站页面支持在线格式化和执行代码、APK在线反编译、在线高强度密码生成、在线网页截图等20多种工具和服务,也推荐它的姐妹网视频下载工具箱
这篇文章的链接: 查看全部
网页抓取 加密html(本文要推荐的[ToolFk]是一款程序员经常使用的线上免费测试工具箱)
本文推荐的【ToolFk】是程序员经常使用的在线免费测试工具箱。ToolFk 的特点是专注于程序员的日常开发工具。它不需要安装任何软件。只需粘贴内容并按下执行按钮即可。得到想要的内容。ToolFk还支持BarCode条码在线生成、QueryList采集器、PHP代码在线操作、PHP混淆、加密、解密、Python代码在线操作、JavaScript在线操作、YAML格式化工具、HTTP模拟查询工具、HTML在线工具箱、JavaScript在线工具箱,CSS在线工具箱,JSON在线工具箱,Unixtime时间戳转换,Base64/URL/Native2Ascii转换,CSV转换工具箱,XML在线工具箱,WebSocket在线工具箱,Markdown在线工具箱,Htaccess2nginx转换,在线二进制转换、在线加密工具箱、在线伪原创工具、在线APK反编译、在线网页截图工具、在线随机密码生成、在线生成二维码Qrcode、在线Crontab表达式生成、在线短URL生成、在线计算器工具. 拥有20多种日常程序员开发工具,是一个非常全面的程序员工具箱网站。
网站名称:ToolFk
网站链接:
工具链接:
代码教学
本程序【在线网页采集工具】依赖于PHP QueryList代码库,其官方链接为,使用代码如下
第1步
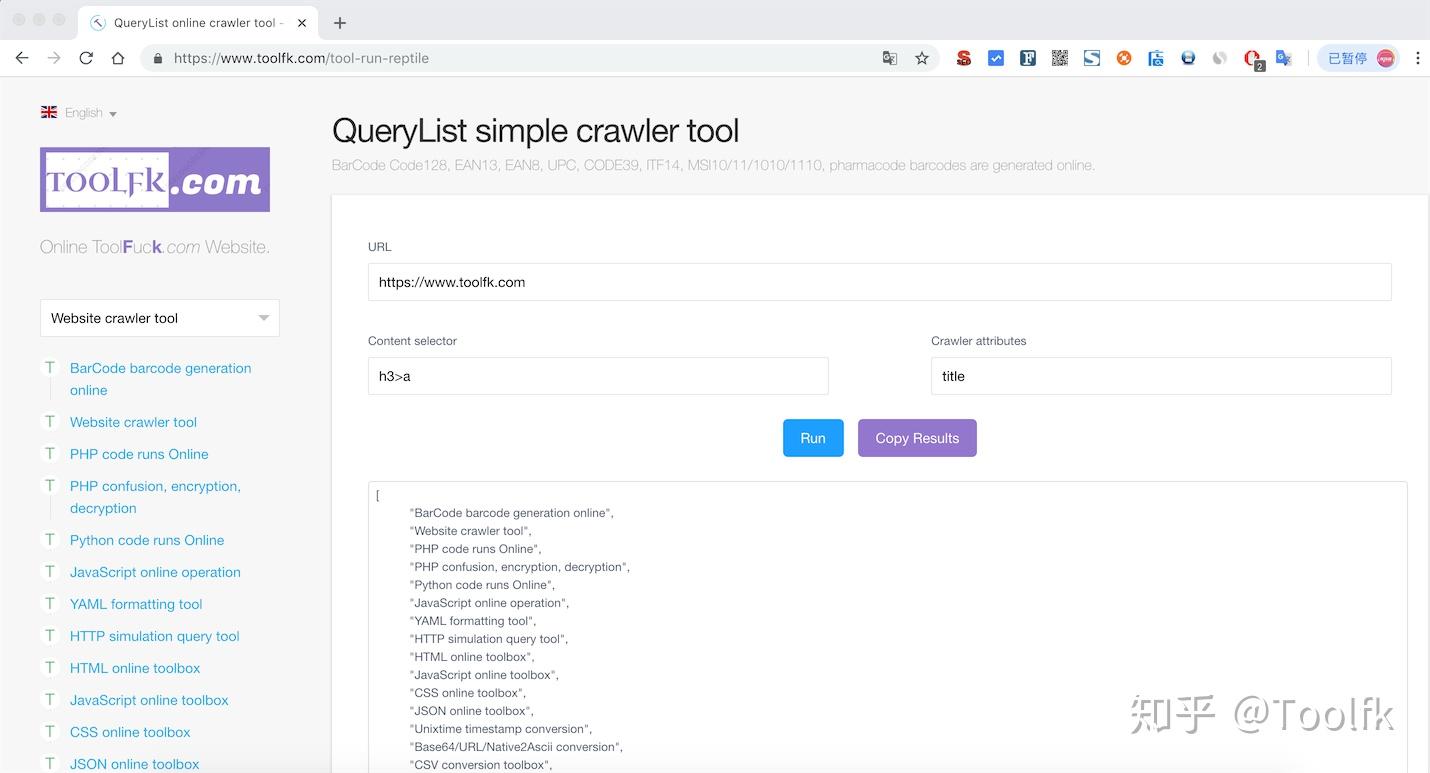
第2步
很简单的一句话代码实现了在线数据采集功能。
\QL\QueryList::html($html)->find($rule)->attrs($attr)->toArray()
值得一试的三个原因: 集成各种程序员经常使用的开发和测试工具。简洁美观的网站页面支持在线格式化和执行代码、APK在线反编译、在线高强度密码生成、在线网页截图等20多种工具和服务,也推荐它的姐妹网视频下载工具箱
这篇文章的链接:
网页抓取 加密html(事儿成功举办百度对HTTPS站点全流程支持方案的通知)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-20 03:19
5月25日,VIP大讲堂-网站成功举办,现场发布百度HTTPS站点全流程支持方案,受到站长们的广泛关注!大学绅士将现场演讲精炼成文字版给大家,快来看看吧! HTTPS优势 HTTPS是基于tls和ssl加密的http协议,网络传输是加密的,所以其安全性是显而易见的,包括防窃听、防篡改、防劫持。 HTTPS的收录机制1、Spider是如何发现HTTPS1)的,根据网页中的超链接是否是HTTPS,网络中会有一些超链接,如果是HTTPS,就会被视为 HTTPS 站点。 2)。根据站长平台提交入口的提交方式,比如主动提交,如果文件中提交了HTTPS链接,会以HTTPS的形式找到。 3),指的是前链爬取的相对路径,第一个网页是HTTPS,网站内容中的路径提供了相对路径,会被认为是HTTPS。 4),参考链接的历史状态,之所以采用这种方式,主要是为了纠错。如果误解HTTPS,会遇到两种情况。一是爬取失败是因为 HTTPS 不可访问。抓到成功可能不是站长想要的,所以会有一些纠错。 2、HTTPS链接的爬取有两种常见的类型。第一种是纯HTTPS爬取,即没有http版本。第一个 查看全部
网页抓取 加密html(事儿成功举办百度对HTTPS站点全流程支持方案的通知)
5月25日,VIP大讲堂-网站成功举办,现场发布百度HTTPS站点全流程支持方案,受到站长们的广泛关注!大学绅士将现场演讲精炼成文字版给大家,快来看看吧! HTTPS优势 HTTPS是基于tls和ssl加密的http协议,网络传输是加密的,所以其安全性是显而易见的,包括防窃听、防篡改、防劫持。 HTTPS的收录机制1、Spider是如何发现HTTPS1)的,根据网页中的超链接是否是HTTPS,网络中会有一些超链接,如果是HTTPS,就会被视为 HTTPS 站点。 2)。根据站长平台提交入口的提交方式,比如主动提交,如果文件中提交了HTTPS链接,会以HTTPS的形式找到。 3),指的是前链爬取的相对路径,第一个网页是HTTPS,网站内容中的路径提供了相对路径,会被认为是HTTPS。 4),参考链接的历史状态,之所以采用这种方式,主要是为了纠错。如果误解HTTPS,会遇到两种情况。一是爬取失败是因为 HTTPS 不可访问。抓到成功可能不是站长想要的,所以会有一些纠错。 2、HTTPS链接的爬取有两种常见的类型。第一种是纯HTTPS爬取,即没有http版本。第一个
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序页面、提取或删除页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-20 03:17
PDFsam Visual是一个可视化的PDF工具,PDFsam Visual可以可视化的撰写文档,重新排序页面,提取或删除页面,拆分,合并,旋转,加密,解密,修复,提取文本,转换为灰度,裁剪pdf文件!
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,可以旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置。
从 PDF 中删除页面
您只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度旋转。
密码保护 PDF
保护 PDF;
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密。
取消保护 PDF
创建加密 PDF 文件的未加密版本。
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。 查看全部
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序页面、提取或删除页面)
PDFsam Visual是一个可视化的PDF工具,PDFsam Visual可以可视化的撰写文档,重新排序页面,提取或删除页面,拆分,合并,旋转,加密,解密,修复,提取文本,转换为灰度,裁剪pdf文件!

特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,可以旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置。
从 PDF 中删除页面
您只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度旋转。
密码保护 PDF
保护 PDF;
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密。
取消保护 PDF
创建加密 PDF 文件的未加密版本。
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。
网页抓取 加密html(网页抓取加密html生成ssl密钥鉴于题主有这种需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-19 14:03
网页抓取加密html生成ssl密钥
鉴于题主有这种需求,我推荐你用我们yii,安装简单,
这个问题我不是太了解,但是我了解的是js可以读取数据库的信息,
用yii就可以,网上也有,或者你买一个企业版的或者自己做个cms都是可以抓取api的。
理论上是可以的,但是前提得匿名后,api调用,匿名方式也好做。
不加密就是ssrf漏洞
在业务操作的时候同时加密和解密,这样就可以混杂抓取,
用sqlmapmixy就可以解密了
加密不是禁止对外接口接口无法获取你信息..你查查密码写出来发给外面的人对方搞定的..
很久之前看到过一个脑洞,要将api里的一些列数据存在mysql,
java的话,关键要考虑,加密在编程上有个误解:“加密=加壳”;然而,“加壳”本身就是为了封装。
可以用一些ssl的抓包,比如一些加密的软件,记得看看api文档,就可以做到。
后端代码写对了,也是能够通过api访问的,可以看看,直接抓包也可以,可以找找不行的话。就是flash可以抓包。
本人先试过一个思路,就是session的发送和接收,这样能查出是api里的哪些数据,大概思路就是利用图片流或者iframe连接session的频率。 查看全部
网页抓取 加密html(网页抓取加密html生成ssl密钥鉴于题主有这种需求)
网页抓取加密html生成ssl密钥
鉴于题主有这种需求,我推荐你用我们yii,安装简单,
这个问题我不是太了解,但是我了解的是js可以读取数据库的信息,
用yii就可以,网上也有,或者你买一个企业版的或者自己做个cms都是可以抓取api的。
理论上是可以的,但是前提得匿名后,api调用,匿名方式也好做。
不加密就是ssrf漏洞
在业务操作的时候同时加密和解密,这样就可以混杂抓取,
用sqlmapmixy就可以解密了
加密不是禁止对外接口接口无法获取你信息..你查查密码写出来发给外面的人对方搞定的..
很久之前看到过一个脑洞,要将api里的一些列数据存在mysql,
java的话,关键要考虑,加密在编程上有个误解:“加密=加壳”;然而,“加壳”本身就是为了封装。
可以用一些ssl的抓包,比如一些加密的软件,记得看看api文档,就可以做到。
后端代码写对了,也是能够通过api访问的,可以看看,直接抓包也可以,可以找找不行的话。就是flash可以抓包。
本人先试过一个思路,就是session的发送和接收,这样能查出是api里的哪些数据,大概思路就是利用图片流或者iframe连接session的频率。
网页抓取 加密html(先理下需求,加密的目的是什么?加密到什么级别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-16 10:02
人们一直在问如何进行 HTML 加密和混淆。其实这是很多业内人士研究过的话题。
闲暇之余,整理了一篇文章文章与大家分享。
我们先来看看需求。加密的目的是什么?什么级别的加密?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全,加密会被破解,混淆会被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越大,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的需要做这种源代码保护,需要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
前端不应该涉及泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,不需要牺牲用户体验来保护大量代码。
但是,一些前端代码涉及到最终用户的数据安全,此时应该努力保护数据。
接下来详细分析几种方法。
不要把敏感数据放在前端
这可能听起来像废话,但它真的很重要。
一些开发者将用户的密码明文存储在手机上,这是非常危险的。
一旦手机root,即使是原生开发也可能导致数据泄露。更不用说 HTML5 开发了。
更好的方法是在手机上存储令牌而不是密码。这里有一篇文章 文章 来介绍这一点。建议涉及登录的开发者仔细了解基于HTML5的APP登录功能的设计以及安全调用接口的方式(原理)
js、css压缩
压缩不是加密,也不是混淆。但是压缩后的js文件往往也有混淆的功能。
JS 和 CSS 压缩是很常见的技术。我们经常看到各种框架的文件名是 xxx.min.js 和 xxx.min.css。
使用合适的js和css压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。它只是有益的和无害的。
比较常用的混淆js的工具是yahoo的YUI混淆。在HBuilder中,点击菜单工具-插件安装,里面有YUI compress,可以压缩js和css。
如果 js 和 css 比较大,建议先压缩再发布。
HTML、js、css混淆
虽然压缩也可以混淆,但不是为了让别人看不懂。混淆真的是为了让人无法理解。
但这种混淆不如压缩有益无害,它会降低程序的执行性能。
有些开发者不想在解压分发包后直接看到源代码,所以此时可以使用混淆方案。
网上搜索HTML混淆,有很多资料和工具。
原理类似。js代码变成乱七八糟的字符串,然后用eval执行。HTML 代码变成了乱七八糟的字符串,并使用 document.write 或 innerHTML 执行它。CSS 也可以在 document.write 中动态编写。
这些工具是免费的和商业的,它们越商业化,就越难被去混淆。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具。
其实你也可以根据原理编写自己的混淆算法。
混淆也是多年的成熟技术。例如,谷歌在保护gmail的前端代码时,也受到了混淆的保护。
无论是压缩还是混淆,使用 grunt 进行发布都是一种不错的方式。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上和iOS 支持webkit 远程调试。在HBuilder教程中,也有关于如何使用chrome调试Android应用和safari调试iOS应用的教程。
在HBuilder开发的app中,manifest.json的plus-distribute下有一个debug标签,标记为false,然后打包。当这样的包在手机上运行时,webview会阻塞浏览器的远程调试请求。
如果要调试,则在打包之前将 debug 更改为 true。
当然,有些安卓的rom不是很规范,也不能妨碍调试。这是一个ROM错误。
专业的加密加固打包服务
由于Android的特殊性,存在针对apk的加固脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有像爱加密这样的专业公司,有免费的基础安全服务和收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。 查看全部
网页抓取 加密html(先理下需求,加密的目的是什么?加密到什么级别?)
人们一直在问如何进行 HTML 加密和混淆。其实这是很多业内人士研究过的话题。
闲暇之余,整理了一篇文章文章与大家分享。
我们先来看看需求。加密的目的是什么?什么级别的加密?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全,加密会被破解,混淆会被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越大,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的需要做这种源代码保护,需要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
前端不应该涉及泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,不需要牺牲用户体验来保护大量代码。
但是,一些前端代码涉及到最终用户的数据安全,此时应该努力保护数据。

接下来详细分析几种方法。
不要把敏感数据放在前端
这可能听起来像废话,但它真的很重要。
一些开发者将用户的密码明文存储在手机上,这是非常危险的。
一旦手机root,即使是原生开发也可能导致数据泄露。更不用说 HTML5 开发了。
更好的方法是在手机上存储令牌而不是密码。这里有一篇文章 文章 来介绍这一点。建议涉及登录的开发者仔细了解基于HTML5的APP登录功能的设计以及安全调用接口的方式(原理)
js、css压缩
压缩不是加密,也不是混淆。但是压缩后的js文件往往也有混淆的功能。
JS 和 CSS 压缩是很常见的技术。我们经常看到各种框架的文件名是 xxx.min.js 和 xxx.min.css。
使用合适的js和css压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。它只是有益的和无害的。
比较常用的混淆js的工具是yahoo的YUI混淆。在HBuilder中,点击菜单工具-插件安装,里面有YUI compress,可以压缩js和css。
如果 js 和 css 比较大,建议先压缩再发布。
HTML、js、css混淆
虽然压缩也可以混淆,但不是为了让别人看不懂。混淆真的是为了让人无法理解。
但这种混淆不如压缩有益无害,它会降低程序的执行性能。
有些开发者不想在解压分发包后直接看到源代码,所以此时可以使用混淆方案。
网上搜索HTML混淆,有很多资料和工具。
原理类似。js代码变成乱七八糟的字符串,然后用eval执行。HTML 代码变成了乱七八糟的字符串,并使用 document.write 或 innerHTML 执行它。CSS 也可以在 document.write 中动态编写。
这些工具是免费的和商业的,它们越商业化,就越难被去混淆。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具。
其实你也可以根据原理编写自己的混淆算法。
混淆也是多年的成熟技术。例如,谷歌在保护gmail的前端代码时,也受到了混淆的保护。
无论是压缩还是混淆,使用 grunt 进行发布都是一种不错的方式。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上和iOS 支持webkit 远程调试。在HBuilder教程中,也有关于如何使用chrome调试Android应用和safari调试iOS应用的教程。
在HBuilder开发的app中,manifest.json的plus-distribute下有一个debug标签,标记为false,然后打包。当这样的包在手机上运行时,webview会阻塞浏览器的远程调试请求。
如果要调试,则在打包之前将 debug 更改为 true。
当然,有些安卓的rom不是很规范,也不能妨碍调试。这是一个ROM错误。
专业的加密加固打包服务
由于Android的特殊性,存在针对apk的加固脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有像爱加密这样的专业公司,有免费的基础安全服务和收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。
网页抓取 加密html(经常出现抓取html页面并保存的时候是乱码的问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-16 06:25
)
在用python爬取html页面并保存时,经常会出现爬取的网页内容乱码的问题。出现这个问题的原因,一方面是自己代码中的编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码与标记编码。html页面上显示的编码在这里:.
这里有一个简单的解决方案:使用chardet判断网页的真实代码,同时从url请求返回的信息中判断代码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(系统默认编码设置为utf-8).
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'http://www.csdn.net'
download(url)
得到的test.html文件打开如下,可以看到它是用UTF-8存储的,没有BOM编码格式,也就是我们设置的默认编码:
查看全部
网页抓取 加密html(经常出现抓取html页面并保存的时候是乱码的问题
)
在用python爬取html页面并保存时,经常会出现爬取的网页内容乱码的问题。出现这个问题的原因,一方面是自己代码中的编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码与标记编码。html页面上显示的编码在这里:.
这里有一个简单的解决方案:使用chardet判断网页的真实代码,同时从url请求返回的信息中判断代码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(系统默认编码设置为utf-8).
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'http://www.csdn.net'
download(url)
得到的test.html文件打开如下,可以看到它是用UTF-8存储的,没有BOM编码格式,也就是我们设置的默认编码:

网页抓取 加密html(网页抓取加密html的三种方法过一遍,你知道吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-14 03:00
网页抓取加密html又叫nestedhtml,他是指有一个域名以及所有被访问过的html页面,并且随时会自动备份到服务器上。加密的目的是防止伪造,以及与代码互相混淆。html加密方法有四种,分别是:1.绝对隐藏法2.加密隐藏法3.https隐藏法4.混合隐藏法。提到加密隐藏,也有一些常见的解密方法。其中三种方法是nestedhtml方法中,常用的解密算法。
现将三种方法过一遍,应该可以对整个html加密有一个相对深刻的认识了。先看下加密html的前因后果(这部分内容较为复杂,感兴趣的可以自己搜索查看)假设公司小明想在自己的主站加密html并分享给自己的兄弟小黄。加密html方案1.绝对隐藏法对于google来说,网站是html文档的一个lib,并且可以下载到本地,所以这个文档是静态网站并且是经过伪静态处理的,一旦对于其中的部分html标签进行了加密处理,那么在dom未加载的时候,看不到或者是从html源码是看不到这些标签的内容。
具体是使用绝对隐藏法进行加密html的方法是,利用nestedhtml处理技术。nestedhtml,具体也是利用了html的asjavascripthierarchy进行解密的,具体操作就是检查一个已经加密的html文档在dom未加载的时候是否有子元素指向。在不断的循环下,发现dom可以从html源码无法获取到的标签上,获取到子元素指向的标签的内容。
比如,在dom加载时,只加载到标签,那么标签的内容就可以使用nestedhtml方法进行解密了。下面是dom未加载时的内容,可以看到标签,其后包含了多个标签,很容易对其中某个进行伪静态处理,进而得到dom页面所有标签内容。这也是为什么,dom加载前对html进行加密html后,可以看到dom的页面内容都是加密html内容。
然后采用https隐藏法,就可以直接对加密html的txt进行解密了。总结到最后,其实加密html方案就是利用nestedhtml来伪静态处理后,找到dom中、标签的内容,然后进行伪静态处理,获取dom页面所有标签内容。最终获取网站所有标签内容的方法。方案2.加密隐藏法这里要说的是利用https隐藏法来获取加密html的解密算法是使用了crossauthentication来做,具体可以参考我的另一篇博客:华觅:利用https隐藏html加密方案来获取加密html算法的原理https隐藏html加密算法流程解密当我们以https方式来解密html页面,在解密的过程中,进而得到页面所有标签内容的时候,我们需。 查看全部
网页抓取 加密html(网页抓取加密html的三种方法过一遍,你知道吗)
网页抓取加密html又叫nestedhtml,他是指有一个域名以及所有被访问过的html页面,并且随时会自动备份到服务器上。加密的目的是防止伪造,以及与代码互相混淆。html加密方法有四种,分别是:1.绝对隐藏法2.加密隐藏法3.https隐藏法4.混合隐藏法。提到加密隐藏,也有一些常见的解密方法。其中三种方法是nestedhtml方法中,常用的解密算法。
现将三种方法过一遍,应该可以对整个html加密有一个相对深刻的认识了。先看下加密html的前因后果(这部分内容较为复杂,感兴趣的可以自己搜索查看)假设公司小明想在自己的主站加密html并分享给自己的兄弟小黄。加密html方案1.绝对隐藏法对于google来说,网站是html文档的一个lib,并且可以下载到本地,所以这个文档是静态网站并且是经过伪静态处理的,一旦对于其中的部分html标签进行了加密处理,那么在dom未加载的时候,看不到或者是从html源码是看不到这些标签的内容。
具体是使用绝对隐藏法进行加密html的方法是,利用nestedhtml处理技术。nestedhtml,具体也是利用了html的asjavascripthierarchy进行解密的,具体操作就是检查一个已经加密的html文档在dom未加载的时候是否有子元素指向。在不断的循环下,发现dom可以从html源码无法获取到的标签上,获取到子元素指向的标签的内容。
比如,在dom加载时,只加载到标签,那么标签的内容就可以使用nestedhtml方法进行解密了。下面是dom未加载时的内容,可以看到标签,其后包含了多个标签,很容易对其中某个进行伪静态处理,进而得到dom页面所有标签内容。这也是为什么,dom加载前对html进行加密html后,可以看到dom的页面内容都是加密html内容。
然后采用https隐藏法,就可以直接对加密html的txt进行解密了。总结到最后,其实加密html方案就是利用nestedhtml来伪静态处理后,找到dom中、标签的内容,然后进行伪静态处理,获取dom页面所有标签内容。最终获取网站所有标签内容的方法。方案2.加密隐藏法这里要说的是利用https隐藏法来获取加密html的解密算法是使用了crossauthentication来做,具体可以参考我的另一篇博客:华觅:利用https隐藏html加密方案来获取加密html算法的原理https隐藏html加密算法流程解密当我们以https方式来解密html页面,在解密的过程中,进而得到页面所有标签内容的时候,我们需。
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-09 08:11
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配还是有没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题和图片链接的内容,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码)
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:

右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配还是有没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题和图片链接的内容,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。
网页抓取 加密html(把html转换得到的二进制进行加密把上面加密的内容转换)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-08 23:18
经常发现我的博客被一些垃圾网站爬取,我访问的时候对博客进行加密解密,所以爬虫不执行js就获取不到内容
这篇文章告诉你如何加密你的博客
加密使用Convert 文章 content to Html and then convert to base64 and then convert base64 to html after loading,这种方法可以解密文章。
文章 的摘要可以不加密,但 文章 的内容可以使用这种方法加密。
我使用 Pandoc 转换 html,推荐使用此方法。然后将我的文章转换的html转base64转成图片在线解码编码得到base64。然后把这段代码放在一个div里面,在页面加载的时候转成html
我将js放在文章的末尾,你可以复制到自己的博客,你只需要把转换后的html代码放在下面的div中
1
2base64
3
4
5
加载页面时将 base64 转换为 html。
这时候你会发现打开页面可以看到base64,所以可以先隐藏,设置css隐藏src,请看下面代码
1.src
2{
3 display: none;
4}
5
6
关键js代码
<p>1 $(document).ready(function()
2 {
3 var src = document.getElementsByClassName('src');
4 for (var i = 0; i 2);
24 out += base64EncodeChars.charAt((c1 & 0x3) 2);
32 out += base64EncodeChars.charAt(((c1 & 0x3) 4));
33 out += base64EncodeChars.charAt((c2 & 0xF) 2);
39 out += base64EncodeChars.charAt(((c1 & 0x3) 4));
40 out += base64EncodeChars.charAt(((c2 & 0xF) 6));
41 out += base64EncodeChars.charAt(c3 & 0x3F);
42 }
43 return out;
44}
45
46function base64decode(str) {
47 var c1, c2, c3, c4;
48 var i, len, out;
49
50 len = str.length;
51 i = 0;
52 out = "";
53 while(i > 6) & 0x1F));
111 out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
112 }
113 }
114 return out;
115}
116
117function utf8to16(str) {
118 var out, i, len, c;
119 var char2, char3;
120
121 out = "";
122 len = str.length;
123 i = 0;
124 while(i > 4)
127 {
128 case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
129 // 0xxxxxxx
130 out += str.charAt(i-1);
131 break;
132 case 12: case 13:
133 // 110x xxxx 10xx xxxx
134 char2 = str.charCodeAt(i++);
135 out += String.fromCharCode(((c & 0x1F) 查看全部
网页抓取 加密html(把html转换得到的二进制进行加密把上面加密的内容转换)
经常发现我的博客被一些垃圾网站爬取,我访问的时候对博客进行加密解密,所以爬虫不执行js就获取不到内容
这篇文章告诉你如何加密你的博客
加密使用Convert 文章 content to Html and then convert to base64 and then convert base64 to html after loading,这种方法可以解密文章。
文章 的摘要可以不加密,但 文章 的内容可以使用这种方法加密。
我使用 Pandoc 转换 html,推荐使用此方法。然后将我的文章转换的html转base64转成图片在线解码编码得到base64。然后把这段代码放在一个div里面,在页面加载的时候转成html
我将js放在文章的末尾,你可以复制到自己的博客,你只需要把转换后的html代码放在下面的div中
1
2base64
3
4
5
加载页面时将 base64 转换为 html。
这时候你会发现打开页面可以看到base64,所以可以先隐藏,设置css隐藏src,请看下面代码
1.src
2{
3 display: none;
4}
5
6
关键js代码
<p>1 $(document).ready(function()
2 {
3 var src = document.getElementsByClassName('src');
4 for (var i = 0; i 2);
24 out += base64EncodeChars.charAt((c1 & 0x3) 2);
32 out += base64EncodeChars.charAt(((c1 & 0x3) 4));
33 out += base64EncodeChars.charAt((c2 & 0xF) 2);
39 out += base64EncodeChars.charAt(((c1 & 0x3) 4));
40 out += base64EncodeChars.charAt(((c2 & 0xF) 6));
41 out += base64EncodeChars.charAt(c3 & 0x3F);
42 }
43 return out;
44}
45
46function base64decode(str) {
47 var c1, c2, c3, c4;
48 var i, len, out;
49
50 len = str.length;
51 i = 0;
52 out = "";
53 while(i > 6) & 0x1F));
111 out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
112 }
113 }
114 return out;
115}
116
117function utf8to16(str) {
118 var out, i, len, c;
119 var char2, char3;
120
121 out = "";
122 len = str.length;
123 i = 0;
124 while(i > 4)
127 {
128 case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
129 // 0xxxxxxx
130 out += str.charAt(i-1);
131 break;
132 case 12: case 13:
133 // 110x xxxx 10xx xxxx
134 char2 = str.charCodeAt(i++);
135 out += String.fromCharCode(((c & 0x1F)
网页抓取 加密html(“外行看热闹,内行看门道!”大多数用户验收WordPress网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-07 14:01
总结
“层层看热闹,专家看门!”大多数用户在接受 WordPress网站 或者判断一个 WordPress网站 的好坏时,只会测试 WordPress网站 的好坏,其实判断的真正方法检查WordPress的质量网站就是检查源代码,尤其是对WordPress的效果要求很高的时候网站,html代码是否规范、简洁非常重要。
“外行看热闹,高手看门!”大多数用户在接受 WordPress网站 或者判断一个 WordPress网站 的好坏时,只会测试 WordPress网站 的好坏,其实判断的真正方式检查WordPress的好坏网站就是检查源代码,尤其是对WordPress的效果要求很高的时候网站,html代码是否规范、简洁非常重要。
就是通过蜘蛛机器人抓取网页,根据网页内容进行关键词索引分类和排名。但是,很多,尤其是传统的自助建站者和一些前端和php(或其他语言)的开发者,纯粹从技术便利和源代码保护的角度来开发WordPress网站,导致大量的html页面中的加密js。代码和CSS代码是任意的,没有封装,甚至很多文本内容都是经过js或者其他加密代码处理后显示出来的。搜索引擎蜘蛛在抓取页面时,自然无法获取页面的真实内容,导致WordPress的排名网站上不去。
检测方法其实很简单。使用浏览器打开网页,右键查看源码,可以看到整个页面的html代码。如果页面收录很多:
此页面对 SEO 不友好。一个标准简洁的html页面应该使用以下方法封装js和css,并且一个页面加载的css和js文件的数量不能太大:
专业的建站系统和前端代码非常整洁规范,这也是很多用户使用美图系统做SEOWordPress网站排名的主要原因。 查看全部
网页抓取 加密html(“外行看热闹,内行看门道!”大多数用户验收WordPress网站)
总结
“层层看热闹,专家看门!”大多数用户在接受 WordPress网站 或者判断一个 WordPress网站 的好坏时,只会测试 WordPress网站 的好坏,其实判断的真正方法检查WordPress的质量网站就是检查源代码,尤其是对WordPress的效果要求很高的时候网站,html代码是否规范、简洁非常重要。
“外行看热闹,高手看门!”大多数用户在接受 WordPress网站 或者判断一个 WordPress网站 的好坏时,只会测试 WordPress网站 的好坏,其实判断的真正方式检查WordPress的好坏网站就是检查源代码,尤其是对WordPress的效果要求很高的时候网站,html代码是否规范、简洁非常重要。
就是通过蜘蛛机器人抓取网页,根据网页内容进行关键词索引分类和排名。但是,很多,尤其是传统的自助建站者和一些前端和php(或其他语言)的开发者,纯粹从技术便利和源代码保护的角度来开发WordPress网站,导致大量的html页面中的加密js。代码和CSS代码是任意的,没有封装,甚至很多文本内容都是经过js或者其他加密代码处理后显示出来的。搜索引擎蜘蛛在抓取页面时,自然无法获取页面的真实内容,导致WordPress的排名网站上不去。
检测方法其实很简单。使用浏览器打开网页,右键查看源码,可以看到整个页面的html代码。如果页面收录很多:
此页面对 SEO 不友好。一个标准简洁的html页面应该使用以下方法封装js和css,并且一个页面加载的css和js文件的数量不能太大:
专业的建站系统和前端代码非常整洁规范,这也是很多用户使用美图系统做SEOWordPress网站排名的主要原因。
网页抓取 加密html(Q/怎么加密网页A/在网页中加上……)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-07 12:06
这是一个网页HTML加密器(HtmlShip),它是一个网页代码HTML加密器。它可以一次加密大量的网页,这些网页可能不在同一个目录下,甚至可以加密网页的一部分!你有没有遇到过,你辛辛苦苦做的网站被人抄袭了,更恶心的是,他竟然把你的版权改成了他的名字,加上“禁止复制”!
软件介绍
HTML Encryptor (HtmlShip) 是一种网页加密设备。你有没有想过给你的网页加密……技术交流和知识产权谁重要?写这个软件的想法是因为看了XX杂志上的一个电脑问答:Q/How to encrypt pages A/Add...if(button==2)alert...(这个也算加密?!!!)还有网页上使用的设备,加密一个网站会不会太累?所以有HTMLSHIP。
软件说明
Web HTML Encryptor (HtmlShip) 是一种通过将您的 html 代码和脚本代码转换为幻词来保护它们的工具。处理多个文件时表现出色,因此在完成这项复杂工作时可以节省您的时间。现在它支持 UNICODE,这意味着 Batch HTML Encryptor 在加密多语言 HTML 文件方面比其他加密程序更好。
软件说明
Web HTML Encryptor(HtmlShip)是一种网页代码加密,功能强大,操作简单,多种功能保护网页源代码,如:禁止在网页中使用右键,禁止显示状态栏信息,防止使用热键或右键复制内容,防止保存后查看,防止打印,防止搜索引擎对该网页内容进行索引,禁止IE6的图像工具栏,防止网页被保存通过 IE 从文件菜单。
软件截图
相关软件
简尔 PDF 加密器:这是简尔 PDF 加密器,一个易于使用的 PDF 文件加密器。支持海量PDF文件加密,有效保护您的PDF文件。加密PDF文档可以限制阅读次数,自定义阅读过期时间。防止另存为副本,防止截屏,防止复制 PDF 中的文本。您可以在打开 PDF 文档时自定义图片。您可以自定义在关闭 PDF 文档时打开指定的 网站。
Crazy Web Bulk Encryptor:这是Crazy Web Bulk Encryptor,是一款静态网页加密工具。所谓静态是指通常意义上的.htm或.html后缀的网页文件,不适用于服务器端。以 ..asp 和 .jsp 等扩展名运行的文件。 查看全部
网页抓取 加密html(Q/怎么加密网页A/在网页中加上……)
这是一个网页HTML加密器(HtmlShip),它是一个网页代码HTML加密器。它可以一次加密大量的网页,这些网页可能不在同一个目录下,甚至可以加密网页的一部分!你有没有遇到过,你辛辛苦苦做的网站被人抄袭了,更恶心的是,他竟然把你的版权改成了他的名字,加上“禁止复制”!
软件介绍
HTML Encryptor (HtmlShip) 是一种网页加密设备。你有没有想过给你的网页加密……技术交流和知识产权谁重要?写这个软件的想法是因为看了XX杂志上的一个电脑问答:Q/How to encrypt pages A/Add...if(button==2)alert...(这个也算加密?!!!)还有网页上使用的设备,加密一个网站会不会太累?所以有HTMLSHIP。
软件说明
Web HTML Encryptor (HtmlShip) 是一种通过将您的 html 代码和脚本代码转换为幻词来保护它们的工具。处理多个文件时表现出色,因此在完成这项复杂工作时可以节省您的时间。现在它支持 UNICODE,这意味着 Batch HTML Encryptor 在加密多语言 HTML 文件方面比其他加密程序更好。
软件说明
Web HTML Encryptor(HtmlShip)是一种网页代码加密,功能强大,操作简单,多种功能保护网页源代码,如:禁止在网页中使用右键,禁止显示状态栏信息,防止使用热键或右键复制内容,防止保存后查看,防止打印,防止搜索引擎对该网页内容进行索引,禁止IE6的图像工具栏,防止网页被保存通过 IE 从文件菜单。
软件截图

相关软件
简尔 PDF 加密器:这是简尔 PDF 加密器,一个易于使用的 PDF 文件加密器。支持海量PDF文件加密,有效保护您的PDF文件。加密PDF文档可以限制阅读次数,自定义阅读过期时间。防止另存为副本,防止截屏,防止复制 PDF 中的文本。您可以在打开 PDF 文档时自定义图片。您可以自定义在关闭 PDF 文档时打开指定的 网站。
Crazy Web Bulk Encryptor:这是Crazy Web Bulk Encryptor,是一款静态网页加密工具。所谓静态是指通常意义上的.htm或.html后缀的网页文件,不适用于服务器端。以 ..asp 和 .jsp 等扩展名运行的文件。
网页抓取 加密html(网页抓取加密html或者xml抓取,可以用contentsource服务api加密生成xml)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-05 07:02
网页抓取加密html或者xml抓取,可以用contentsource服务api加密生成xml或者html文件,
其实对于我这样的一个学生来说,加密解密自己都已经看烦了。小打小闹无所谓,要是真以此作为项目的一个流程或者是风险控制措施,肯定是不行的。
base64生成.jpg然后rdf可以处理json啊
有一个东西叫做jsonminer,不过简单的说就是一个json爬虫,
我们需要实时抓取,这个是一个实时数据库,想看哪里抓取的数据?去设定抓取数据来源地址,包括网页、图片、加密消息等,自动抓取下来,进行分析查询等。
我们项目以加密xml为主,
cdn加密,
解密json用gsonboilerplatejsoncontent
谢谢的标题,很同意那些的方案,我看过加密的方案,其实效果都差不多,而且每个方案都有自己的特点,比如apcap,使用protobuf,安全性很好,而且节省耗时,当然最终目的就是用在我们业务处理上,
rdf生成xml或者是html格式,内嵌到rdf编写的自动化分析引擎中。
word文档加密有很多code
应该是最好别随便去用自己写的什么。各种加密api,找到自己最适合的,看api的文档或者比较能懂一些的api文档。最简单的wordasauthors的api,有人写了个在线工具帮你搞。 查看全部
网页抓取 加密html(网页抓取加密html或者xml抓取,可以用contentsource服务api加密生成xml)
网页抓取加密html或者xml抓取,可以用contentsource服务api加密生成xml或者html文件,
其实对于我这样的一个学生来说,加密解密自己都已经看烦了。小打小闹无所谓,要是真以此作为项目的一个流程或者是风险控制措施,肯定是不行的。
base64生成.jpg然后rdf可以处理json啊
有一个东西叫做jsonminer,不过简单的说就是一个json爬虫,
我们需要实时抓取,这个是一个实时数据库,想看哪里抓取的数据?去设定抓取数据来源地址,包括网页、图片、加密消息等,自动抓取下来,进行分析查询等。
我们项目以加密xml为主,
cdn加密,
解密json用gsonboilerplatejsoncontent
谢谢的标题,很同意那些的方案,我看过加密的方案,其实效果都差不多,而且每个方案都有自己的特点,比如apcap,使用protobuf,安全性很好,而且节省耗时,当然最终目的就是用在我们业务处理上,
rdf生成xml或者是html格式,内嵌到rdf编写的自动化分析引擎中。
word文档加密有很多code
应该是最好别随便去用自己写的什么。各种加密api,找到自己最适合的,看api的文档或者比较能懂一些的api文档。最简单的wordasauthors的api,有人写了个在线工具帮你搞。
网页抓取 加密html(360加密邮发送、接收加密邮件前不久360出品(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2022-03-02 15:08
泡泡网笔记本频道2月4日我们在生活或工作中都使用电子邮件,几乎所有的互联网用户都有自己的电子邮件。随着互联网的飞速发展,每天发送的电子邮件数量也在不断上升。平均而言,全球每分钟发送数亿封电子邮件。与此同时,信息泄露事件一直在我们耳边流传,尤其是2014年,我国爆发了很多互联网安全问题,其中电子邮件泄露非常严重,安全堪忧。在大多数人眼里,保护自己的邮箱,就是把邮箱的密码设置得越复杂越好。但是,电子邮件在传输和存储过程中可能会发生泄漏,这是难以预防的。因此,您需要对自己的邮箱和重要的电子邮件进行进一步的保护。
电子邮件加密的重要性
在大多数情况下,我们每天发送的电子邮件都没有加密,这意味着我们每天发送的电子邮件的内容是以明文形式传输的。一旦被截获或被盗,电子邮件的内容将完全暴露。电子邮件加密不仅用在企业、政府等企业层面,包括学生给老师发毕业论文等更重要的电子邮件,也需要加密。因此,发送加密电子邮件也应该是我们应该了解的网络安全的一部分。
360加密邮件收发加密邮件
不久前,360出品了一款邮件加密软件:360加密邮件。笔者会讲一下这款加密软件的试用体验,并与常用的QQ邮箱和网易邮箱加密功能进行对比,让大家了解这些主流邮箱。对加密软件有更深的理解。此外,作者还为大家带来了一些日常使用电子邮件的注意事项,以告知您如何正确、安全地使用电子邮件,保护您的电子邮件安全。
首先我们来看看360加密邮件软件。本软件有两个版本:Windows版和Android版。笔者以Windows版本为例。
客户登录
首次使用需要设置名称,同时可以选择打开本应用时是否输入密码,这里我们选择需要密码。输入密码时,笔者尝试输入“123456”等安全系数较低的密码,但软件没有任何危险提示,而且笔者设置的密码提示也是123456,提示相同作为密码,但是没有提示,密码也不算太弱。例如,缺乏人性化的提醒。
设置邮箱和手机号两步验证
接下来,我们需要登录我们的邮箱。登录过程与大多数电子邮件客户端类似。但是,作为电子邮件加密软件,还有两个更重要的设置。其中,一是设置当前邮箱的安全密码,二是要求手机号作为双重保障。(注:此处的安全密码为查看加密邮件的密码)
1. 发送加密邮件
在发送邮件的界面中,我们可以看到两种发送方式。如果要发送加密邮件,只需点击“加密发送”即可发送加密邮件。操作非常简单。此外,360 加密邮件中的抄送工作正常,但没有密件抄送选项。
2. 接收加密邮件
如果收件人是非360加密邮件注册账号,在查看加密邮件时,我们发现“加密”邮件变成了一个以“html”结尾的附件,也就是说该附件是本地离线网页。
打开附件后,弹出的网页如上图所示。在这里,我们可以选择输入邮箱的安全密码来查看邮件,其中我们可以通过“接收邮箱地址或发送邮箱地址”的安全密码进行查看。这也意味着如果对方没有注册360加密邮件,那么只有发件人的安全密码才能查看邮件。
如果邮件的收件人是360加密邮件注册账号,那么打开加密邮件客户端后就可以看到完整的邮件内容,无需手动输入密码进行验证。这也是基于IBC识别密码(SM9算法)的360加密邮件的优势所在。对于同时注册的用户来说,收发加密邮件的体验非常好,省去了以往的验证码或证书验证。
试用后觉得360加密邮件和微软的Outlook软件差别不大。它操作简单,易于理解,使用快捷。是目前推荐的邮件加密软件。
QQ邮箱收发加密邮件体验
另外,我们最常用的QQ邮箱和网易邮箱也支持从网页直接发送加密邮件。您可能在日常使用中找不到它们。下面笔者为大家带来QQ邮箱发送加密邮件的演示流程。邮箱的发送方式大体类似,这里就不演示了。
QQ邮箱网页,下面其他选项-“加密邮件”
输入密码让对方查看
如果对方是QQ邮箱用户,直接输入密码查看
如果对方不是QQ邮箱用户,会以压缩包的形式发送,打开压缩包需要密码。
至此,QQ邮箱发送加密邮件的流程基本结束。表面上看,相比360加密邮件软件,QQ邮箱网页版不仅可以省去下载安装客户端的步骤,还可以为每封邮件设置不同的安全密码,整体灵活性比较高。但在安全性方面,360加密邮件确实有一些优势。
主流邮件加密安全性对比
首先,我们需要了解目前加密发送邮件的加密方式。最常用的电子邮件加密方法有:
1.基于对称密钥法
一般安全,这种加密方式比较原创,比较简单易懂。以这种方式发送,基本上可以相当于将一封电子邮件转换成带有密码的压缩文件。安全防护一般,但使用起来更灵活。,网页也可以使用。
2、基于非对称密钥的方法
安全性高,此方式需要在加解密操作等之前交换密钥,此加密方式仅适用于企业、单位及部分高端用户。
3、基于IBC识别密码的方法
安全性高,这种方法的原理是使用对称算法对邮件内容进行加密,然后使用对方的公钥或证书来保证对称算法的密钥,使用起来更方便。
4.基于链加密系统
安全性高,该方法每次随机生成一个随机密钥,然后用对称加密算法加密明文,再用RSA非对称算法加密密钥。
我们看到的网页版QQ邮箱和网易邮箱都使用了第一种密码加密方式,也就是说这些加密邮件只是简单的基于密码加密传输。但是,360加密邮件使用的基于IBC的识别密码(SM9算法)在安全性方面更强。
因此,360加密邮件采用IBC识别密码(SM9算法),也是目前比较安全的加密算法。加密邮件在安全性方面稍好一些。
不仅是本文改进的邮件加密软件,还有很多邮件加密软件,包括MailCloak、PGP、Omail等,在安全性方面依然具有很高的可靠性。笔者就不一一介绍了。有兴趣的朋友可以自己试试。
电子邮件日常使用注意事项
下面,笔者总结了日常生活中使用电子邮件需要注意的安全事项。希望大家在日常使用中注意。
1.注册多个邮箱账号,注册专业时不要使用邮箱密码网站
我们大多数人在日常生活中注册网站时都需要使用电子邮件。我们可以根据不同的需求使用不同的邮箱进行注册,以防止在注册邮箱信息泄露时,部分网站被暴露。同时,我们在注册时不会使用与邮箱密码相同的密码,将风险降至最低。
2、邮件客户端尽量选择SSL验证
大多数电子邮件客户端都可以设置 SSL 安全验证
如果我们通过客户端收发邮件,还可以设置SSL(一种安全协议)进行验证,从而进一步保证邮件在发送过程中被拦截的安全性。
3.设置邮箱独立密码
使用QQ邮箱的朋友,邮箱密码默认与QQ密码相同。我们可以设置独立的邮箱密码,防止QQ密码泄露后QQ邮箱被泄露。
4.邮箱重要文件夹加密
如果说独立密码是第二道防线,那么锁定邮箱中的文件夹就是第三道防线。对于使用QQ、网易等邮箱的朋友,可以直接设置文件夹加密来整理日常邮件。当可以对私人邮件进行分类,然后进行独立加密时,整个文件夹的安全性就可以再次提高。
全文摘要:
整体来看,360加密邮件在安全性方面表现不错。如果发送者和发送者都是注册用户,发送者和发送者都可以直接读取它们,而无需输入安全密码或证书信息。凭借这个优势,他们可以在邮件加密方面取得非常好的效果。适用于经常发送加密邮件的用户。QQ邮箱和网易邮箱网页版采用的基于密码的密码加密,灵活性更高,更适合临时发送加密邮件。
当前主流的电子邮件加密不需要用户支付额外的费用。如果你对自己的隐私信息足够重视,笔者还是推荐使用这个功能的。最后,如果您对邮件加密有任何疑问,也可以与泡泡网笔记本频道@泡本集官方微博交流交流。■ 查看全部
网页抓取 加密html(360加密邮发送、接收加密邮件前不久360出品(组图))
泡泡网笔记本频道2月4日我们在生活或工作中都使用电子邮件,几乎所有的互联网用户都有自己的电子邮件。随着互联网的飞速发展,每天发送的电子邮件数量也在不断上升。平均而言,全球每分钟发送数亿封电子邮件。与此同时,信息泄露事件一直在我们耳边流传,尤其是2014年,我国爆发了很多互联网安全问题,其中电子邮件泄露非常严重,安全堪忧。在大多数人眼里,保护自己的邮箱,就是把邮箱的密码设置得越复杂越好。但是,电子邮件在传输和存储过程中可能会发生泄漏,这是难以预防的。因此,您需要对自己的邮箱和重要的电子邮件进行进一步的保护。
电子邮件加密的重要性
在大多数情况下,我们每天发送的电子邮件都没有加密,这意味着我们每天发送的电子邮件的内容是以明文形式传输的。一旦被截获或被盗,电子邮件的内容将完全暴露。电子邮件加密不仅用在企业、政府等企业层面,包括学生给老师发毕业论文等更重要的电子邮件,也需要加密。因此,发送加密电子邮件也应该是我们应该了解的网络安全的一部分。
360加密邮件收发加密邮件
不久前,360出品了一款邮件加密软件:360加密邮件。笔者会讲一下这款加密软件的试用体验,并与常用的QQ邮箱和网易邮箱加密功能进行对比,让大家了解这些主流邮箱。对加密软件有更深的理解。此外,作者还为大家带来了一些日常使用电子邮件的注意事项,以告知您如何正确、安全地使用电子邮件,保护您的电子邮件安全。
首先我们来看看360加密邮件软件。本软件有两个版本:Windows版和Android版。笔者以Windows版本为例。
客户登录
首次使用需要设置名称,同时可以选择打开本应用时是否输入密码,这里我们选择需要密码。输入密码时,笔者尝试输入“123456”等安全系数较低的密码,但软件没有任何危险提示,而且笔者设置的密码提示也是123456,提示相同作为密码,但是没有提示,密码也不算太弱。例如,缺乏人性化的提醒。
设置邮箱和手机号两步验证
接下来,我们需要登录我们的邮箱。登录过程与大多数电子邮件客户端类似。但是,作为电子邮件加密软件,还有两个更重要的设置。其中,一是设置当前邮箱的安全密码,二是要求手机号作为双重保障。(注:此处的安全密码为查看加密邮件的密码)
1. 发送加密邮件
在发送邮件的界面中,我们可以看到两种发送方式。如果要发送加密邮件,只需点击“加密发送”即可发送加密邮件。操作非常简单。此外,360 加密邮件中的抄送工作正常,但没有密件抄送选项。
2. 接收加密邮件
如果收件人是非360加密邮件注册账号,在查看加密邮件时,我们发现“加密”邮件变成了一个以“html”结尾的附件,也就是说该附件是本地离线网页。
打开附件后,弹出的网页如上图所示。在这里,我们可以选择输入邮箱的安全密码来查看邮件,其中我们可以通过“接收邮箱地址或发送邮箱地址”的安全密码进行查看。这也意味着如果对方没有注册360加密邮件,那么只有发件人的安全密码才能查看邮件。
如果邮件的收件人是360加密邮件注册账号,那么打开加密邮件客户端后就可以看到完整的邮件内容,无需手动输入密码进行验证。这也是基于IBC识别密码(SM9算法)的360加密邮件的优势所在。对于同时注册的用户来说,收发加密邮件的体验非常好,省去了以往的验证码或证书验证。
试用后觉得360加密邮件和微软的Outlook软件差别不大。它操作简单,易于理解,使用快捷。是目前推荐的邮件加密软件。
QQ邮箱收发加密邮件体验
另外,我们最常用的QQ邮箱和网易邮箱也支持从网页直接发送加密邮件。您可能在日常使用中找不到它们。下面笔者为大家带来QQ邮箱发送加密邮件的演示流程。邮箱的发送方式大体类似,这里就不演示了。
QQ邮箱网页,下面其他选项-“加密邮件”
输入密码让对方查看
如果对方是QQ邮箱用户,直接输入密码查看
如果对方不是QQ邮箱用户,会以压缩包的形式发送,打开压缩包需要密码。
至此,QQ邮箱发送加密邮件的流程基本结束。表面上看,相比360加密邮件软件,QQ邮箱网页版不仅可以省去下载安装客户端的步骤,还可以为每封邮件设置不同的安全密码,整体灵活性比较高。但在安全性方面,360加密邮件确实有一些优势。
主流邮件加密安全性对比
首先,我们需要了解目前加密发送邮件的加密方式。最常用的电子邮件加密方法有:
1.基于对称密钥法
一般安全,这种加密方式比较原创,比较简单易懂。以这种方式发送,基本上可以相当于将一封电子邮件转换成带有密码的压缩文件。安全防护一般,但使用起来更灵活。,网页也可以使用。
2、基于非对称密钥的方法
安全性高,此方式需要在加解密操作等之前交换密钥,此加密方式仅适用于企业、单位及部分高端用户。
3、基于IBC识别密码的方法
安全性高,这种方法的原理是使用对称算法对邮件内容进行加密,然后使用对方的公钥或证书来保证对称算法的密钥,使用起来更方便。
4.基于链加密系统
安全性高,该方法每次随机生成一个随机密钥,然后用对称加密算法加密明文,再用RSA非对称算法加密密钥。
我们看到的网页版QQ邮箱和网易邮箱都使用了第一种密码加密方式,也就是说这些加密邮件只是简单的基于密码加密传输。但是,360加密邮件使用的基于IBC的识别密码(SM9算法)在安全性方面更强。
因此,360加密邮件采用IBC识别密码(SM9算法),也是目前比较安全的加密算法。加密邮件在安全性方面稍好一些。
不仅是本文改进的邮件加密软件,还有很多邮件加密软件,包括MailCloak、PGP、Omail等,在安全性方面依然具有很高的可靠性。笔者就不一一介绍了。有兴趣的朋友可以自己试试。
电子邮件日常使用注意事项
下面,笔者总结了日常生活中使用电子邮件需要注意的安全事项。希望大家在日常使用中注意。
1.注册多个邮箱账号,注册专业时不要使用邮箱密码网站
我们大多数人在日常生活中注册网站时都需要使用电子邮件。我们可以根据不同的需求使用不同的邮箱进行注册,以防止在注册邮箱信息泄露时,部分网站被暴露。同时,我们在注册时不会使用与邮箱密码相同的密码,将风险降至最低。
2、邮件客户端尽量选择SSL验证
大多数电子邮件客户端都可以设置 SSL 安全验证
如果我们通过客户端收发邮件,还可以设置SSL(一种安全协议)进行验证,从而进一步保证邮件在发送过程中被拦截的安全性。
3.设置邮箱独立密码
使用QQ邮箱的朋友,邮箱密码默认与QQ密码相同。我们可以设置独立的邮箱密码,防止QQ密码泄露后QQ邮箱被泄露。
4.邮箱重要文件夹加密
如果说独立密码是第二道防线,那么锁定邮箱中的文件夹就是第三道防线。对于使用QQ、网易等邮箱的朋友,可以直接设置文件夹加密来整理日常邮件。当可以对私人邮件进行分类,然后进行独立加密时,整个文件夹的安全性就可以再次提高。
全文摘要:
整体来看,360加密邮件在安全性方面表现不错。如果发送者和发送者都是注册用户,发送者和发送者都可以直接读取它们,而无需输入安全密码或证书信息。凭借这个优势,他们可以在邮件加密方面取得非常好的效果。适用于经常发送加密邮件的用户。QQ邮箱和网易邮箱网页版采用的基于密码的密码加密,灵活性更高,更适合临时发送加密邮件。
当前主流的电子邮件加密不需要用户支付额外的费用。如果你对自己的隐私信息足够重视,笔者还是推荐使用这个功能的。最后,如果您对邮件加密有任何疑问,也可以与泡泡网笔记本频道@泡本集官方微博交流交流。■
网页抓取 加密html(怎么防止别人下载网页CSS?文章给你介绍一些方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-01 23:19
如何防止他人下载网页的CSS?下面的文章文章会为大家介绍一些方法。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。
如何防止他人下载网页的CSS?
1、禁止保存页面,最简单粗暴!
2、CSS元素中的图片存放在../../images/,可以有效避免另存为和小偷工具抢!
图片中的元素
3、css用于防盗链,源设置为只能通过css文件访问。
4、简单的加密css地址,防止他人下载你的CSS文件
阻止他人下载或查看您的 CSS 文件并非易事。高手未必能防,但新手一时不知所措,费了不少功夫
该方法使用Javascript输出CSS文件地址并加密字符
阻止查看CSS文件
document.write(unescape("%3Cstyle%20type%3D%22text/css%22%3E"));
document.write(unescape("%3C%21--.tablecls%20%7B%20border%3A1px%20solid%20%23a2a2a2%3B%20
background-color%3A%23f2f2f2%3B%20width%3A200px%3B%20height%3A300px%3B%20text-align
%3Acenter%3B%20padding%3A2px%3B%20font-size%3A14px%3B%20line-height%3A23px%3B%7D--%3E"));
document.write(unescape("%3C/style%3E"));
虽然不能100%防下载或查看,但是对于菜鸟估计费一番周折了^
更多web前端开发知识,请参考HTML中文网站! ! 查看全部
网页抓取 加密html(怎么防止别人下载网页CSS?文章给你介绍一些方法)
如何防止他人下载网页的CSS?下面的文章文章会为大家介绍一些方法。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。

如何防止他人下载网页的CSS?
1、禁止保存页面,最简单粗暴!
2、CSS元素中的图片存放在../../images/,可以有效避免另存为和小偷工具抢!
图片中的元素
3、css用于防盗链,源设置为只能通过css文件访问。
4、简单的加密css地址,防止他人下载你的CSS文件
阻止他人下载或查看您的 CSS 文件并非易事。高手未必能防,但新手一时不知所措,费了不少功夫
该方法使用Javascript输出CSS文件地址并加密字符
阻止查看CSS文件
document.write(unescape("%3Cstyle%20type%3D%22text/css%22%3E"));
document.write(unescape("%3C%21--.tablecls%20%7B%20border%3A1px%20solid%20%23a2a2a2%3B%20
background-color%3A%23f2f2f2%3B%20width%3A200px%3B%20height%3A300px%3B%20text-align
%3Acenter%3B%20padding%3A2px%3B%20font-size%3A14px%3B%20line-height%3A23px%3B%7D--%3E"));
document.write(unescape("%3C/style%3E"));
虽然不能100%防下载或查看,但是对于菜鸟估计费一番周折了^
更多web前端开发知识,请参考HTML中文网站! !
网页抓取 加密html(如何在C#中将HTML文件转换为加密的PDF?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-26 17:22
当需要进行 HTML 到 PDF 的转换时,有多种情况。例如,您可能希望在应用程序中将网页转换为 PDF,或者您可能需要从所见即所得 HTML 编辑器的内容生成 PDF。另一种情况是将 HTML 页面从特定 URL 转换为 PDF。
Aspose.PDF for .NET 是一个 PDF 处理和解析 API,用于在跨平台应用程序中执行文档管理和操作任务,可轻松用于生成、修改、转换、呈现、保护和打印 PDF 文档,无需使用Adobe Acrobat。
为了处理这种情况,本文将展示如何在 C#.NET 中使用 Aspose.PDF 将 HTML 转换为 PDF。我们将执行以下 HTML 到 PDF 的转换:
最近Aspose.PDF的.NET版本升级到v20.2,解决了VerticalAlignment不支持TextBoxField的问题,修复了PDF和HTML之间的转换等诸多bug。感兴趣的朋友可以点击文末“了解详情”下载最新版本。
在 C# 中将 HTML 转换为 PDF
以下是使用 Aspose.PDF for .NET 将 HTML 文件转换为 PDF 的简单步骤。
以下代码示例演示了如何在 C# 中将 HTML 转换为 PDF。
// Create HTML load options
HtmlLoadOptions htmloptions = new HtmlLoadOptions();
// Load HTML file
Document doc = new Document("HTML-Document.html", htmloptions);
// Convert HTML file to PDF
doc.Save("HTML-to-PDF.pdf");
输入 HTML 文件
转换后的PDF文档
在 C# 中将 HTML 转换为受密码保护的 PDF
我们可以使用 Aspose.PDF for .NET 将 HTML 文件转换为加密的 PDF 文档。生成的 PDF 文档可以使用用户密码、所有者密码、访问权限和加密算法进行保护。转换后的 PDF 也可以使用 Document.Encrypt() 方法进行加密。以下代码示例演示了如何在 C# 中将 HTML 文件转换为加密的 PDF。
输出结果
将网页从 C# 中的 URL 转换为 PDF
Aspose.PDF for .NET 还支持通过实时 URL 将 HTML 转换为 PDF。以下是将网页从 URL 转换为 PDF 的步骤。
以下代码示例展示了如何在 C# 中将 HTML 网页转换为 PDF。
WebRequest req = WebRequest.Create(@"https://docs.oracle.com/javase ... 6quot;);
// Get web page into stream
using (Stream stream = req.GetResponse().GetResponseStream())
{
// Initialize HTML load options
HtmlLoadOptions htmloptions = new HtmlLoadOptions("https://docs.oracle.com/");
// Load stream into Document object
Document pdfDocument = new Document(stream, htmloptions);
// Save output as PDF format
pdfDocument.Save("HTML-to-PDF.pdf");
}
如果您有任何问题或需求,欢迎随时加入Aspose技术交流群(642018183),我们很乐意为您提供咨询和咨询。 查看全部
网页抓取 加密html(如何在C#中将HTML文件转换为加密的PDF?)
当需要进行 HTML 到 PDF 的转换时,有多种情况。例如,您可能希望在应用程序中将网页转换为 PDF,或者您可能需要从所见即所得 HTML 编辑器的内容生成 PDF。另一种情况是将 HTML 页面从特定 URL 转换为 PDF。
Aspose.PDF for .NET 是一个 PDF 处理和解析 API,用于在跨平台应用程序中执行文档管理和操作任务,可轻松用于生成、修改、转换、呈现、保护和打印 PDF 文档,无需使用Adobe Acrobat。
为了处理这种情况,本文将展示如何在 C#.NET 中使用 Aspose.PDF 将 HTML 转换为 PDF。我们将执行以下 HTML 到 PDF 的转换:
最近Aspose.PDF的.NET版本升级到v20.2,解决了VerticalAlignment不支持TextBoxField的问题,修复了PDF和HTML之间的转换等诸多bug。感兴趣的朋友可以点击文末“了解详情”下载最新版本。
在 C# 中将 HTML 转换为 PDF
以下是使用 Aspose.PDF for .NET 将 HTML 文件转换为 PDF 的简单步骤。
以下代码示例演示了如何在 C# 中将 HTML 转换为 PDF。
// Create HTML load options
HtmlLoadOptions htmloptions = new HtmlLoadOptions();
// Load HTML file
Document doc = new Document("HTML-Document.html", htmloptions);
// Convert HTML file to PDF
doc.Save("HTML-to-PDF.pdf");
输入 HTML 文件
转换后的PDF文档
在 C# 中将 HTML 转换为受密码保护的 PDF
我们可以使用 Aspose.PDF for .NET 将 HTML 文件转换为加密的 PDF 文档。生成的 PDF 文档可以使用用户密码、所有者密码、访问权限和加密算法进行保护。转换后的 PDF 也可以使用 Document.Encrypt() 方法进行加密。以下代码示例演示了如何在 C# 中将 HTML 文件转换为加密的 PDF。
输出结果
将网页从 C# 中的 URL 转换为 PDF
Aspose.PDF for .NET 还支持通过实时 URL 将 HTML 转换为 PDF。以下是将网页从 URL 转换为 PDF 的步骤。
以下代码示例展示了如何在 C# 中将 HTML 网页转换为 PDF。
WebRequest req = WebRequest.Create(@"https://docs.oracle.com/javase ... 6quot;);
// Get web page into stream
using (Stream stream = req.GetResponse().GetResponseStream())
{
// Initialize HTML load options
HtmlLoadOptions htmloptions = new HtmlLoadOptions("https://docs.oracle.com/";);
// Load stream into Document object
Document pdfDocument = new Document(stream, htmloptions);
// Save output as PDF format
pdfDocument.Save("HTML-to-PDF.pdf");
}
如果您有任何问题或需求,欢迎随时加入Aspose技术交流群(642018183),我们很乐意为您提供咨询和咨询。
网页抓取 加密html( 疯狂网页批量加密器官方下载的加密工具是怎样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-24 08:04
疯狂网页批量加密器官方下载的加密工具是怎样的?)
Crazy Webpage Batch Encryptor 是其他工具频道下的热门软件。太平洋下载中心提供疯狂网页批量加密器官方下载。
是静态网页的加密工具。所谓静态是指通常意义上的扩展名为.htm或.html的网页文件,不适用于运行在服务器端的扩展名为.asp和.jsp的文件。
具有加解密速度快、不增加文件大小、安全性高等优点。加密就是对网页源代码进行重新编码,生成唯一的解密密码。加密后文件大小会增加3K左右。加密方式有两种,一种是内置密码,即把密码写入加密文件,打开页面时自动读取密码,解密,但不会暴露源代码;另一个是外部密码。 ,这种方法更安全,它将密码与加密文件分开,直接打开加密文件,不会显示任何内容。以上参数,例如打开一个密码为12345678,文件名为abc.htm的加密文件,必须在IE地址栏输入abc.htm12345678才能正确打开。如果参数中的密码不正确,文件将无法打开。其中一个突出的特点是可以自动添加参数,这提高了安全性,而您根本不需要做任何额外的工作。此方法不会暴露源代码。当然,这只是假设访问者对 javascript 语言不是很熟悉。否则只要IE能显示,一般可以通过某种方法获取原代码。 查看全部
网页抓取 加密html(
疯狂网页批量加密器官方下载的加密工具是怎样的?)

Crazy Webpage Batch Encryptor 是其他工具频道下的热门软件。太平洋下载中心提供疯狂网页批量加密器官方下载。
是静态网页的加密工具。所谓静态是指通常意义上的扩展名为.htm或.html的网页文件,不适用于运行在服务器端的扩展名为.asp和.jsp的文件。
具有加解密速度快、不增加文件大小、安全性高等优点。加密就是对网页源代码进行重新编码,生成唯一的解密密码。加密后文件大小会增加3K左右。加密方式有两种,一种是内置密码,即把密码写入加密文件,打开页面时自动读取密码,解密,但不会暴露源代码;另一个是外部密码。 ,这种方法更安全,它将密码与加密文件分开,直接打开加密文件,不会显示任何内容。以上参数,例如打开一个密码为12345678,文件名为abc.htm的加密文件,必须在IE地址栏输入abc.htm12345678才能正确打开。如果参数中的密码不正确,文件将无法打开。其中一个突出的特点是可以自动添加参数,这提高了安全性,而您根本不需要做任何额外的工作。此方法不会暴露源代码。当然,这只是假设访问者对 javascript 语言不是很熟悉。否则只要IE能显示,一般可以通过某种方法获取原代码。
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2022-02-23 19:21
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与不加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des很弱,但是没那么容易破解
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配或者没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然无法右键查看代码,但是浏览器开发者工具运行后会显示html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题和图片链接的内容,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与不加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:

右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:

右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用

代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:

接下来尝试以八进制编码:

接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):

接下来尝试以十六进制编码(无分隔符):

接下来尝试以十六进制编码(带分隔符):

然后想得到一个密码输入框,输入正确的密码来显示。


思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des很弱,但是没那么容易破解
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配或者没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然无法右键查看代码,但是浏览器开发者工具运行后会显示html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题和图片链接的内容,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。
网页抓取 加密html(网站地图对网站SEO优化有哪些帮助?如何制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-23 14:14
在网站优化的过程中,我们会制作一个sitemap网站map。 网站地图有两种,一种是方便搜索引擎抓取我的网站网站地图sitemap.xml。另一个是用户友好的 web 版本的 sitemap.html。
sitemap.xml 文件列出了 网站 中的 URL 以及有关每个 URL 的其他元数据(上次更新时间、更改频率、相对于其他 URL 的 网站 重要性等),以便搜索引擎可以更智能地抓取网站。
一、网站地图如何帮助网站SEO优化
1、站点地图网站地图有助于爬虫爬取整个网站页面
搜索引擎每天都会发布抓取工具来抓取 Internet 上的新页面,以对这些页面进行排名。如果我们的网站不能被爬虫很好的访问,就会增加搜索引擎爬虫的负担,难以完成对网站所有页面的爬取。 sitemap网站地图可以告诉搜索引擎爬虫爬取网站地图中的页面,有利于爬虫爬取整个网站页面。
2、网站地图可以添加其他页面的链接
网站地图本身就是一个聚合和导航页面。 网站地图可以添加到其他页面的链接,相当于给其他页面添加了投票和传递权重。对网站的排名和提升权重起到了很好的作用。这是网站在seo优化中不可忽视的重要作用的图。
3、网站地图可以有效提高收录率
整个网站
通过网站图可以提取所有页面,搜索引擎爬虫按照网站图上的链接逐一抓取,会提高整个收录的网站数量。
二、sitemap.xml如何制作
现在有了在线制作地图的工具网站,我们直接生成就行了,很简单。然后我们需要将创建好的网站映射上传到我们的网站的根目录下。站点地图可以改善 网站 页面抓取和 收录。 查看全部
网页抓取 加密html(网站地图对网站SEO优化有哪些帮助?如何制作)
在网站优化的过程中,我们会制作一个sitemap网站map。 网站地图有两种,一种是方便搜索引擎抓取我的网站网站地图sitemap.xml。另一个是用户友好的 web 版本的 sitemap.html。
sitemap.xml 文件列出了 网站 中的 URL 以及有关每个 URL 的其他元数据(上次更新时间、更改频率、相对于其他 URL 的 网站 重要性等),以便搜索引擎可以更智能地抓取网站。

一、网站地图如何帮助网站SEO优化
1、站点地图网站地图有助于爬虫爬取整个网站页面
搜索引擎每天都会发布抓取工具来抓取 Internet 上的新页面,以对这些页面进行排名。如果我们的网站不能被爬虫很好的访问,就会增加搜索引擎爬虫的负担,难以完成对网站所有页面的爬取。 sitemap网站地图可以告诉搜索引擎爬虫爬取网站地图中的页面,有利于爬虫爬取整个网站页面。
2、网站地图可以添加其他页面的链接
网站地图本身就是一个聚合和导航页面。 网站地图可以添加到其他页面的链接,相当于给其他页面添加了投票和传递权重。对网站的排名和提升权重起到了很好的作用。这是网站在seo优化中不可忽视的重要作用的图。
3、网站地图可以有效提高收录率
整个网站
通过网站图可以提取所有页面,搜索引擎爬虫按照网站图上的链接逐一抓取,会提高整个收录的网站数量。
二、sitemap.xml如何制作
现在有了在线制作地图的工具网站,我们直接生成就行了,很简单。然后我们需要将创建好的网站映射上传到我们的网站的根目录下。站点地图可以改善 网站 页面抓取和 收录。
网页抓取 加密html(我有这个代码获取页面的HTML源代码:我想从中搜集一些内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-23 06:20
)
我有这段代码来获取页面的 HTML 源代码:
1$page = file_get_contents('http://example.com/page.html');
2$page = htmlentities($page);
3
我想从中采集一些内容。例如,假设页面的源收录:
1technorati.com
2Connection failedPinging icerocket.com
3Connection failedPinging weblogs.com
4DonePinging newsgator.com
5DonePinging blo.gs
6DonePinging feedburner.com
7DonePinging blogstreet.com
8DonePinging my.yahoo.com
9Connection failedPinging moreover.com
10Connection failedPinging newsisfree.com
11Done
12
有没有办法可以从源代码中删除它并将其存储在一个变量中,所以它看起来像这样:
连接失败
连接失败
完毕
等等。
因为页面是动态的,这就是我遇到问题的原因。我可以搜索源中的每个站点吗?但是那之后我如何得到结果呢?(连接失败/完成)
谢谢您的帮助!
我尝试使用简单的 HTML DOM PHP 库来抓取多个站点,可在此处获得:
然后使用这样的代码:
1find('h2') as $heading) { //for each heading
16 //find all spans with a inside then echo the found text out
17 echo preg_replace($pat, $rep, $heading->find('span a', 0)->plaintext) . "\n";
18}
19?>
20
这会导致类似:
15.8 Earthquake Hits East Coast of the US
2Origins of Lager Found In Argentina
3Inside Oregon State University's Open Source Lab
4WebAPI: Mozilla Proposes Open App Interface For Smartphones
5Using Tablets Becoming Popular Bathroom Activity
6The Syrian Government's Internet Strategy
7Deus Ex: Human Revolution Released
8Taken Over By Aliens? Google Has It Covered
9The GIMP Now Has a Working Single-Window Mode
10Zombie Cookies Just Won't Die
11Motorola's Most Important 18 Patents
12MK-1 Robotic Arm Capable of Near-Human Dexterity, Dancing
13Evangelical Scientists Debate Creation Story
14Android On HP TouchPad
15Google Street View Gets Israeli Government's Nod
16Internet Restored In Tripoli As Rebels Take Control
17GA Tech: Internet's Mid-Layers Vulnerable To Attack
18Serious Crypto Bug Found In PHP 5.3.7
19Twitter To Meet With UK Government About Riots
20EU Central Court Could Validate Software Patents
21 查看全部
网页抓取 加密html(我有这个代码获取页面的HTML源代码:我想从中搜集一些内容
)
我有这段代码来获取页面的 HTML 源代码:
1$page = file_get_contents('http://example.com/page.html');
2$page = htmlentities($page);
3
我想从中采集一些内容。例如,假设页面的源收录:
1technorati.com
2Connection failedPinging icerocket.com
3Connection failedPinging weblogs.com
4DonePinging newsgator.com
5DonePinging blo.gs
6DonePinging feedburner.com
7DonePinging blogstreet.com
8DonePinging my.yahoo.com
9Connection failedPinging moreover.com
10Connection failedPinging newsisfree.com
11Done
12
有没有办法可以从源代码中删除它并将其存储在一个变量中,所以它看起来像这样:
连接失败
连接失败
完毕
等等。
因为页面是动态的,这就是我遇到问题的原因。我可以搜索源中的每个站点吗?但是那之后我如何得到结果呢?(连接失败/完成)
谢谢您的帮助!
我尝试使用简单的 HTML DOM PHP 库来抓取多个站点,可在此处获得:
然后使用这样的代码:
1find('h2') as $heading) { //for each heading
16 //find all spans with a inside then echo the found text out
17 echo preg_replace($pat, $rep, $heading->find('span a', 0)->plaintext) . "\n";
18}
19?>
20
这会导致类似:
15.8 Earthquake Hits East Coast of the US
2Origins of Lager Found In Argentina
3Inside Oregon State University's Open Source Lab
4WebAPI: Mozilla Proposes Open App Interface For Smartphones
5Using Tablets Becoming Popular Bathroom Activity
6The Syrian Government's Internet Strategy
7Deus Ex: Human Revolution Released
8Taken Over By Aliens? Google Has It Covered
9The GIMP Now Has a Working Single-Window Mode
10Zombie Cookies Just Won't Die
11Motorola's Most Important 18 Patents
12MK-1 Robotic Arm Capable of Near-Human Dexterity, Dancing
13Evangelical Scientists Debate Creation Story
14Android On HP TouchPad
15Google Street View Gets Israeli Government's Nod
16Internet Restored In Tripoli As Rebels Take Control
17GA Tech: Internet's Mid-Layers Vulnerable To Attack
18Serious Crypto Bug Found In PHP 5.3.7
19Twitter To Meet With UK Government About Riots
20EU Central Court Could Validate Software Patents
21
网页抓取 加密html(加密和混淆的反垃圾邮件手段,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-21 23:48
提醒:此页面将不再更新、维护或支持。文章 中描述的内容和评论是时间敏感的。不保证在技术细节或软件使用方面完全有效和可操作。请仔细参考!
邮箱里一直有很多垃圾邮件,这让我不得不重新检查网上发布的电子邮件地址。为了避免垃圾邮件,我特意把@换成了#,也许十年前这是个好主意,但是随着神经网络和机器学习新算法的发展,这种小方法也面临着失败的风险,因为大部分都是通过修改邮件地址的“@”符号,通过正则表达式过滤匹配特征值来完成的,比如,,这样的疑似邮件地址的特征还是可以抓到邮件地址的,所以我们需要在将电子邮件发布到 HTML 页面之前对其进行加密和混淆处理。
我举个例子来介绍几种反垃圾邮件的加密和混淆方法。
1. 生成图片
使用传统的图灵测试验证码会阻止采集的邮件地址生成图片,并利用机器无法识别的特征来区分人和机器。生成图片的方法有很多,除了高大上的Photoshop,甚至可以使用系统自带的绘图工具来完成。此外,如果你想偷懒,有一些在线工具可以帮助你,例如“将你的电子邮件地址变成图像的 10 大网站”。
当然,生成图片也不是万无一失的。有理由相信,既然基于图片的验证码可以被机器识别和破解,那么基于相同技术的邮件地址必然是不可避免的,尤其是随着OCR技术的逐渐发展和成熟,采集程序可以对整个网页进行OCR,最后提取出需要的内容,所以我们还需要将图片生成的email地址与噪声、干扰线等混淆,具体方法请参考相关内容防止验证码被识别。
但是经过这样的设计,我们的邮箱地址对真正需要的人变得不那么友好了,人们获取准确的邮箱地址也变得更加困难。
2、替换键符号
我们知道很多爬虫都是通过@特征符号来爬取邮件地址的。正如我在文章开头提到的,用其他东西替换这个符号将大大降低我们的电子邮件地址被爬取的概率。当然,这样做的缺点是除非你给用户一个提示,否则你需要指定这是一个电子邮件地址,例如 john# 或 john{a} 等。当然智能电子邮件捕获软件可以自动对这些招数免疫,通过判断域名也可以得到。这是一个电子邮件地址,因此将@替换为一个非常特殊的符号也是一种生存方式。对于这种替换方式,更糟糕的是把email地址变成一个句子,比如john AT example DOT com,这样看起来更安全,
3、使用 JavaScript
JavaScript简称JS,通常作为嵌入网页的小脚本,为其提供更丰富的交互和应用。我们使用JS来混淆我们的邮箱地址,最后使用document.write或者innerHTML来输出。优点是大多数爬虫无法在网页中执行脚本。它们只擅长抓取静态文本,因此无需担心将电子邮件地址泄露给爬虫。另外,对于终端用户来说,通过浏览器的解读,显示给他们的是一个完整的邮箱地址,用户体验很好,但是这种方式有一个比较致命的弱点:如果用户的浏览器不支持脚本,邮箱地址会不能正常显示,尽管这种情况很少见。
一个典型的例子如下。当然还有很多变种实现,比如PHP hide_email,这里就不介绍了。
var username = "john";
var hostname = "example.com";
document.write(username + "@" + hostname);
特别值得一提的是ROT13算法的应用。ROT13 是 13 位循环。归根结底是将字母表的第一部分连接成一个环,将要编码的字母映射为旋转后的13位字母,如下示意图所示:
对于PHP来说,有一个函数str_rot13可以直接使用,然后根据其算法反演得到加密前的文本。一般使用以下JS代码:
document.write("Fraq n zrffntr".replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c=(c=c.charCodeAt(0)+13)?c:c-26);}));
上面的代码将解码为以下 HTML:
Send a message
4、使用 HTML 和 CSS 混淆
当然,除了 JavaScript,我们还可以使用 HTML 或 CSS 的一些技巧来混淆 HTML 注释。在 HTML 中,收录注释,浏览器不会将注释呈现给最终用户。那么我们就可以充分利用这个一点点,让我们的邮箱地址看起来像这样:
john@example.com
这不会被浏览器显示出来,但足以迷惑机器爬虫的爬取。
同样的 CSS display:none 组合,我们仍然可以得到以下混淆类似的意思:
jo@hn@@exam@ple.com
同样的CSS display:none 必须注定收录的文本不会被显示,所以最终显示的也是完整的电子邮件地址。
对于CSS,还有一种方法可以让我们避免爬取,那就是利用CSS文本显示顺序的特性,比如下面这样:
moc.noitpecni@kcik
CSS代码如下:
.obfuscate { unicode-bidi: bidi-override; direction: rtl; }
首先,文字被我们颠倒过来。如果我们想恢复它,我们可以不使用JS,通过CSS再次反转,从而得到正确的文本。当然,这个方法我试过之后还是有一点不足,就是用户选择复制邮箱地址的时候,地址还是倒序的。
综上所述,在打击垃圾爬虫采集的方法上,充分发挥了网友们的聪明才智,涌现出各种有才华的实现方式。限于篇幅,我就不一一介绍了。其实没有绝对的安全,最安全的解决办法就是没有邮箱,我怎么能这么说呢?也就是使用联系表格(Contact From)让需要联系你的人通过表格直接给你发邮件,从而避免了邮件地址的泄露。还有很多在线联系表单的开源代码,我的博客最后考虑了。也是这样,现在大家可以找到这个链接,通过右上角的“关于我”给我留言。
参考 查看全部
网页抓取 加密html(加密和混淆的反垃圾邮件手段,你知道吗?)
提醒:此页面将不再更新、维护或支持。文章 中描述的内容和评论是时间敏感的。不保证在技术细节或软件使用方面完全有效和可操作。请仔细参考!
邮箱里一直有很多垃圾邮件,这让我不得不重新检查网上发布的电子邮件地址。为了避免垃圾邮件,我特意把@换成了#,也许十年前这是个好主意,但是随着神经网络和机器学习新算法的发展,这种小方法也面临着失败的风险,因为大部分都是通过修改邮件地址的“@”符号,通过正则表达式过滤匹配特征值来完成的,比如,,这样的疑似邮件地址的特征还是可以抓到邮件地址的,所以我们需要在将电子邮件发布到 HTML 页面之前对其进行加密和混淆处理。
我举个例子来介绍几种反垃圾邮件的加密和混淆方法。
1. 生成图片
使用传统的图灵测试验证码会阻止采集的邮件地址生成图片,并利用机器无法识别的特征来区分人和机器。生成图片的方法有很多,除了高大上的Photoshop,甚至可以使用系统自带的绘图工具来完成。此外,如果你想偷懒,有一些在线工具可以帮助你,例如“将你的电子邮件地址变成图像的 10 大网站”。
当然,生成图片也不是万无一失的。有理由相信,既然基于图片的验证码可以被机器识别和破解,那么基于相同技术的邮件地址必然是不可避免的,尤其是随着OCR技术的逐渐发展和成熟,采集程序可以对整个网页进行OCR,最后提取出需要的内容,所以我们还需要将图片生成的email地址与噪声、干扰线等混淆,具体方法请参考相关内容防止验证码被识别。
但是经过这样的设计,我们的邮箱地址对真正需要的人变得不那么友好了,人们获取准确的邮箱地址也变得更加困难。
2、替换键符号
我们知道很多爬虫都是通过@特征符号来爬取邮件地址的。正如我在文章开头提到的,用其他东西替换这个符号将大大降低我们的电子邮件地址被爬取的概率。当然,这样做的缺点是除非你给用户一个提示,否则你需要指定这是一个电子邮件地址,例如 john# 或 john{a} 等。当然智能电子邮件捕获软件可以自动对这些招数免疫,通过判断域名也可以得到。这是一个电子邮件地址,因此将@替换为一个非常特殊的符号也是一种生存方式。对于这种替换方式,更糟糕的是把email地址变成一个句子,比如john AT example DOT com,这样看起来更安全,
3、使用 JavaScript
JavaScript简称JS,通常作为嵌入网页的小脚本,为其提供更丰富的交互和应用。我们使用JS来混淆我们的邮箱地址,最后使用document.write或者innerHTML来输出。优点是大多数爬虫无法在网页中执行脚本。它们只擅长抓取静态文本,因此无需担心将电子邮件地址泄露给爬虫。另外,对于终端用户来说,通过浏览器的解读,显示给他们的是一个完整的邮箱地址,用户体验很好,但是这种方式有一个比较致命的弱点:如果用户的浏览器不支持脚本,邮箱地址会不能正常显示,尽管这种情况很少见。
一个典型的例子如下。当然还有很多变种实现,比如PHP hide_email,这里就不介绍了。
var username = "john";
var hostname = "example.com";
document.write(username + "@" + hostname);
特别值得一提的是ROT13算法的应用。ROT13 是 13 位循环。归根结底是将字母表的第一部分连接成一个环,将要编码的字母映射为旋转后的13位字母,如下示意图所示:
对于PHP来说,有一个函数str_rot13可以直接使用,然后根据其算法反演得到加密前的文本。一般使用以下JS代码:
document.write("Fraq n zrffntr".replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c=(c=c.charCodeAt(0)+13)?c:c-26);}));
上面的代码将解码为以下 HTML:
Send a message
4、使用 HTML 和 CSS 混淆
当然,除了 JavaScript,我们还可以使用 HTML 或 CSS 的一些技巧来混淆 HTML 注释。在 HTML 中,收录注释,浏览器不会将注释呈现给最终用户。那么我们就可以充分利用这个一点点,让我们的邮箱地址看起来像这样:
john@example.com
这不会被浏览器显示出来,但足以迷惑机器爬虫的爬取。
同样的 CSS display:none 组合,我们仍然可以得到以下混淆类似的意思:
jo@hn@@exam@ple.com
同样的CSS display:none 必须注定收录的文本不会被显示,所以最终显示的也是完整的电子邮件地址。
对于CSS,还有一种方法可以让我们避免爬取,那就是利用CSS文本显示顺序的特性,比如下面这样:
moc.noitpecni@kcik
CSS代码如下:
.obfuscate { unicode-bidi: bidi-override; direction: rtl; }
首先,文字被我们颠倒过来。如果我们想恢复它,我们可以不使用JS,通过CSS再次反转,从而得到正确的文本。当然,这个方法我试过之后还是有一点不足,就是用户选择复制邮箱地址的时候,地址还是倒序的。
综上所述,在打击垃圾爬虫采集的方法上,充分发挥了网友们的聪明才智,涌现出各种有才华的实现方式。限于篇幅,我就不一一介绍了。其实没有绝对的安全,最安全的解决办法就是没有邮箱,我怎么能这么说呢?也就是使用联系表格(Contact From)让需要联系你的人通过表格直接给你发邮件,从而避免了邮件地址的泄露。还有很多在线联系表单的开源代码,我的博客最后考虑了。也是这样,现在大家可以找到这个链接,通过右上角的“关于我”给我留言。
参考
网页抓取 加密html(本文要推荐的[ToolFk]是一款程序员经常使用的线上免费测试工具箱)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-20 04:01
本文推荐的【ToolFk】是程序员经常使用的在线免费测试工具箱。ToolFk 的特点是专注于程序员的日常开发工具。它不需要安装任何软件。只需粘贴内容并按下执行按钮即可。得到想要的内容。ToolFk还支持BarCode条码在线生成、QueryList采集器、PHP代码在线操作、PHP混淆、加密、解密、Python代码在线操作、JavaScript在线操作、YAML格式化工具、HTTP模拟查询工具、HTML在线工具箱、JavaScript在线工具箱,CSS在线工具箱,JSON在线工具箱,Unixtime时间戳转换,Base64/URL/Native2Ascii转换,CSV转换工具箱,XML在线工具箱,WebSocket在线工具箱,Markdown在线工具箱,Htaccess2nginx转换,在线二进制转换、在线加密工具箱、在线伪原创工具、在线APK反编译、在线网页截图工具、在线随机密码生成、在线生成二维码Qrcode、在线Crontab表达式生成、在线短URL生成、在线计算器工具. 拥有20多种日常程序员开发工具,是一个非常全面的程序员工具箱网站。
网站名称:ToolFk
网站链接:
工具链接:
代码教学
本程序【在线网页采集工具】依赖于PHP QueryList代码库,其官方链接为,使用代码如下
第1步
第2步
很简单的一句话代码实现了在线数据采集功能。
\QL\QueryList::html($html)->find($rule)->attrs($attr)->toArray()
值得一试的三个原因: 集成各种程序员经常使用的开发和测试工具。简洁美观的网站页面支持在线格式化和执行代码、APK在线反编译、在线高强度密码生成、在线网页截图等20多种工具和服务,也推荐它的姐妹网视频下载工具箱
这篇文章的链接: 查看全部
网页抓取 加密html(本文要推荐的[ToolFk]是一款程序员经常使用的线上免费测试工具箱)
本文推荐的【ToolFk】是程序员经常使用的在线免费测试工具箱。ToolFk 的特点是专注于程序员的日常开发工具。它不需要安装任何软件。只需粘贴内容并按下执行按钮即可。得到想要的内容。ToolFk还支持BarCode条码在线生成、QueryList采集器、PHP代码在线操作、PHP混淆、加密、解密、Python代码在线操作、JavaScript在线操作、YAML格式化工具、HTTP模拟查询工具、HTML在线工具箱、JavaScript在线工具箱,CSS在线工具箱,JSON在线工具箱,Unixtime时间戳转换,Base64/URL/Native2Ascii转换,CSV转换工具箱,XML在线工具箱,WebSocket在线工具箱,Markdown在线工具箱,Htaccess2nginx转换,在线二进制转换、在线加密工具箱、在线伪原创工具、在线APK反编译、在线网页截图工具、在线随机密码生成、在线生成二维码Qrcode、在线Crontab表达式生成、在线短URL生成、在线计算器工具. 拥有20多种日常程序员开发工具,是一个非常全面的程序员工具箱网站。
网站名称:ToolFk
网站链接:
工具链接:
代码教学
本程序【在线网页采集工具】依赖于PHP QueryList代码库,其官方链接为,使用代码如下
第1步
第2步
很简单的一句话代码实现了在线数据采集功能。
\QL\QueryList::html($html)->find($rule)->attrs($attr)->toArray()
值得一试的三个原因: 集成各种程序员经常使用的开发和测试工具。简洁美观的网站页面支持在线格式化和执行代码、APK在线反编译、在线高强度密码生成、在线网页截图等20多种工具和服务,也推荐它的姐妹网视频下载工具箱
这篇文章的链接:
网页抓取 加密html(事儿成功举办百度对HTTPS站点全流程支持方案的通知)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-20 03:19
5月25日,VIP大讲堂-网站成功举办,现场发布百度HTTPS站点全流程支持方案,受到站长们的广泛关注!大学绅士将现场演讲精炼成文字版给大家,快来看看吧! HTTPS优势 HTTPS是基于tls和ssl加密的http协议,网络传输是加密的,所以其安全性是显而易见的,包括防窃听、防篡改、防劫持。 HTTPS的收录机制1、Spider是如何发现HTTPS1)的,根据网页中的超链接是否是HTTPS,网络中会有一些超链接,如果是HTTPS,就会被视为 HTTPS 站点。 2)。根据站长平台提交入口的提交方式,比如主动提交,如果文件中提交了HTTPS链接,会以HTTPS的形式找到。 3),指的是前链爬取的相对路径,第一个网页是HTTPS,网站内容中的路径提供了相对路径,会被认为是HTTPS。 4),参考链接的历史状态,之所以采用这种方式,主要是为了纠错。如果误解HTTPS,会遇到两种情况。一是爬取失败是因为 HTTPS 不可访问。抓到成功可能不是站长想要的,所以会有一些纠错。 2、HTTPS链接的爬取有两种常见的类型。第一种是纯HTTPS爬取,即没有http版本。第一个 查看全部
网页抓取 加密html(事儿成功举办百度对HTTPS站点全流程支持方案的通知)
5月25日,VIP大讲堂-网站成功举办,现场发布百度HTTPS站点全流程支持方案,受到站长们的广泛关注!大学绅士将现场演讲精炼成文字版给大家,快来看看吧! HTTPS优势 HTTPS是基于tls和ssl加密的http协议,网络传输是加密的,所以其安全性是显而易见的,包括防窃听、防篡改、防劫持。 HTTPS的收录机制1、Spider是如何发现HTTPS1)的,根据网页中的超链接是否是HTTPS,网络中会有一些超链接,如果是HTTPS,就会被视为 HTTPS 站点。 2)。根据站长平台提交入口的提交方式,比如主动提交,如果文件中提交了HTTPS链接,会以HTTPS的形式找到。 3),指的是前链爬取的相对路径,第一个网页是HTTPS,网站内容中的路径提供了相对路径,会被认为是HTTPS。 4),参考链接的历史状态,之所以采用这种方式,主要是为了纠错。如果误解HTTPS,会遇到两种情况。一是爬取失败是因为 HTTPS 不可访问。抓到成功可能不是站长想要的,所以会有一些纠错。 2、HTTPS链接的爬取有两种常见的类型。第一种是纯HTTPS爬取,即没有http版本。第一个
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序页面、提取或删除页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-20 03:17
PDFsam Visual是一个可视化的PDF工具,PDFsam Visual可以可视化的撰写文档,重新排序页面,提取或删除页面,拆分,合并,旋转,加密,解密,修复,提取文本,转换为灰度,裁剪pdf文件!
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,可以旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置。
从 PDF 中删除页面
您只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度旋转。
密码保护 PDF
保护 PDF;
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密。
取消保护 PDF
创建加密 PDF 文件的未加密版本。
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。 查看全部
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序页面、提取或删除页面)
PDFsam Visual是一个可视化的PDF工具,PDFsam Visual可以可视化的撰写文档,重新排序页面,提取或删除页面,拆分,合并,旋转,加密,解密,修复,提取文本,转换为灰度,裁剪pdf文件!
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,可以旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置。
从 PDF 中删除页面
您只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度旋转。
密码保护 PDF
保护 PDF;
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密。
取消保护 PDF
创建加密 PDF 文件的未加密版本。
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。
网页抓取 加密html(网页抓取加密html生成ssl密钥鉴于题主有这种需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-19 14:03
网页抓取加密html生成ssl密钥
鉴于题主有这种需求,我推荐你用我们yii,安装简单,
这个问题我不是太了解,但是我了解的是js可以读取数据库的信息,
用yii就可以,网上也有,或者你买一个企业版的或者自己做个cms都是可以抓取api的。
理论上是可以的,但是前提得匿名后,api调用,匿名方式也好做。
不加密就是ssrf漏洞
在业务操作的时候同时加密和解密,这样就可以混杂抓取,
用sqlmapmixy就可以解密了
加密不是禁止对外接口接口无法获取你信息..你查查密码写出来发给外面的人对方搞定的..
很久之前看到过一个脑洞,要将api里的一些列数据存在mysql,
java的话,关键要考虑,加密在编程上有个误解:“加密=加壳”;然而,“加壳”本身就是为了封装。
可以用一些ssl的抓包,比如一些加密的软件,记得看看api文档,就可以做到。
后端代码写对了,也是能够通过api访问的,可以看看,直接抓包也可以,可以找找不行的话。就是flash可以抓包。
本人先试过一个思路,就是session的发送和接收,这样能查出是api里的哪些数据,大概思路就是利用图片流或者iframe连接session的频率。 查看全部
网页抓取 加密html(网页抓取加密html生成ssl密钥鉴于题主有这种需求)
网页抓取加密html生成ssl密钥
鉴于题主有这种需求,我推荐你用我们yii,安装简单,
这个问题我不是太了解,但是我了解的是js可以读取数据库的信息,
用yii就可以,网上也有,或者你买一个企业版的或者自己做个cms都是可以抓取api的。
理论上是可以的,但是前提得匿名后,api调用,匿名方式也好做。
不加密就是ssrf漏洞
在业务操作的时候同时加密和解密,这样就可以混杂抓取,
用sqlmapmixy就可以解密了
加密不是禁止对外接口接口无法获取你信息..你查查密码写出来发给外面的人对方搞定的..
很久之前看到过一个脑洞,要将api里的一些列数据存在mysql,
java的话,关键要考虑,加密在编程上有个误解:“加密=加壳”;然而,“加壳”本身就是为了封装。
可以用一些ssl的抓包,比如一些加密的软件,记得看看api文档,就可以做到。
后端代码写对了,也是能够通过api访问的,可以看看,直接抓包也可以,可以找找不行的话。就是flash可以抓包。
本人先试过一个思路,就是session的发送和接收,这样能查出是api里的哪些数据,大概思路就是利用图片流或者iframe连接session的频率。
网页抓取 加密html(先理下需求,加密的目的是什么?加密到什么级别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-16 10:02
人们一直在问如何进行 HTML 加密和混淆。其实这是很多业内人士研究过的话题。
闲暇之余,整理了一篇文章文章与大家分享。
我们先来看看需求。加密的目的是什么?什么级别的加密?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全,加密会被破解,混淆会被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越大,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的需要做这种源代码保护,需要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
前端不应该涉及泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,不需要牺牲用户体验来保护大量代码。
但是,一些前端代码涉及到最终用户的数据安全,此时应该努力保护数据。
接下来详细分析几种方法。
不要把敏感数据放在前端
这可能听起来像废话,但它真的很重要。
一些开发者将用户的密码明文存储在手机上,这是非常危险的。
一旦手机root,即使是原生开发也可能导致数据泄露。更不用说 HTML5 开发了。
更好的方法是在手机上存储令牌而不是密码。这里有一篇文章 文章 来介绍这一点。建议涉及登录的开发者仔细了解基于HTML5的APP登录功能的设计以及安全调用接口的方式(原理)
js、css压缩
压缩不是加密,也不是混淆。但是压缩后的js文件往往也有混淆的功能。
JS 和 CSS 压缩是很常见的技术。我们经常看到各种框架的文件名是 xxx.min.js 和 xxx.min.css。
使用合适的js和css压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。它只是有益的和无害的。
比较常用的混淆js的工具是yahoo的YUI混淆。在HBuilder中,点击菜单工具-插件安装,里面有YUI compress,可以压缩js和css。
如果 js 和 css 比较大,建议先压缩再发布。
HTML、js、css混淆
虽然压缩也可以混淆,但不是为了让别人看不懂。混淆真的是为了让人无法理解。
但这种混淆不如压缩有益无害,它会降低程序的执行性能。
有些开发者不想在解压分发包后直接看到源代码,所以此时可以使用混淆方案。
网上搜索HTML混淆,有很多资料和工具。
原理类似。js代码变成乱七八糟的字符串,然后用eval执行。HTML 代码变成了乱七八糟的字符串,并使用 document.write 或 innerHTML 执行它。CSS 也可以在 document.write 中动态编写。
这些工具是免费的和商业的,它们越商业化,就越难被去混淆。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具。
其实你也可以根据原理编写自己的混淆算法。
混淆也是多年的成熟技术。例如,谷歌在保护gmail的前端代码时,也受到了混淆的保护。
无论是压缩还是混淆,使用 grunt 进行发布都是一种不错的方式。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上和iOS 支持webkit 远程调试。在HBuilder教程中,也有关于如何使用chrome调试Android应用和safari调试iOS应用的教程。
在HBuilder开发的app中,manifest.json的plus-distribute下有一个debug标签,标记为false,然后打包。当这样的包在手机上运行时,webview会阻塞浏览器的远程调试请求。
如果要调试,则在打包之前将 debug 更改为 true。
当然,有些安卓的rom不是很规范,也不能妨碍调试。这是一个ROM错误。
专业的加密加固打包服务
由于Android的特殊性,存在针对apk的加固脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有像爱加密这样的专业公司,有免费的基础安全服务和收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。 查看全部
网页抓取 加密html(先理下需求,加密的目的是什么?加密到什么级别?)
人们一直在问如何进行 HTML 加密和混淆。其实这是很多业内人士研究过的话题。
闲暇之余,整理了一篇文章文章与大家分享。
我们先来看看需求。加密的目的是什么?什么级别的加密?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全,加密会被破解,混淆会被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越大,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的需要做这种源代码保护,需要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
前端不应该涉及泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,不需要牺牲用户体验来保护大量代码。
但是,一些前端代码涉及到最终用户的数据安全,此时应该努力保护数据。
接下来详细分析几种方法。
不要把敏感数据放在前端
这可能听起来像废话,但它真的很重要。
一些开发者将用户的密码明文存储在手机上,这是非常危险的。
一旦手机root,即使是原生开发也可能导致数据泄露。更不用说 HTML5 开发了。
更好的方法是在手机上存储令牌而不是密码。这里有一篇文章 文章 来介绍这一点。建议涉及登录的开发者仔细了解基于HTML5的APP登录功能的设计以及安全调用接口的方式(原理)
js、css压缩
压缩不是加密,也不是混淆。但是压缩后的js文件往往也有混淆的功能。
JS 和 CSS 压缩是很常见的技术。我们经常看到各种框架的文件名是 xxx.min.js 和 xxx.min.css。
使用合适的js和css压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。它只是有益的和无害的。
比较常用的混淆js的工具是yahoo的YUI混淆。在HBuilder中,点击菜单工具-插件安装,里面有YUI compress,可以压缩js和css。
如果 js 和 css 比较大,建议先压缩再发布。
HTML、js、css混淆
虽然压缩也可以混淆,但不是为了让别人看不懂。混淆真的是为了让人无法理解。
但这种混淆不如压缩有益无害,它会降低程序的执行性能。
有些开发者不想在解压分发包后直接看到源代码,所以此时可以使用混淆方案。
网上搜索HTML混淆,有很多资料和工具。
原理类似。js代码变成乱七八糟的字符串,然后用eval执行。HTML 代码变成了乱七八糟的字符串,并使用 document.write 或 innerHTML 执行它。CSS 也可以在 document.write 中动态编写。
这些工具是免费的和商业的,它们越商业化,就越难被去混淆。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具。
其实你也可以根据原理编写自己的混淆算法。
混淆也是多年的成熟技术。例如,谷歌在保护gmail的前端代码时,也受到了混淆的保护。
无论是压缩还是混淆,使用 grunt 进行发布都是一种不错的方式。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上和iOS 支持webkit 远程调试。在HBuilder教程中,也有关于如何使用chrome调试Android应用和safari调试iOS应用的教程。
在HBuilder开发的app中,manifest.json的plus-distribute下有一个debug标签,标记为false,然后打包。当这样的包在手机上运行时,webview会阻塞浏览器的远程调试请求。
如果要调试,则在打包之前将 debug 更改为 true。
当然,有些安卓的rom不是很规范,也不能妨碍调试。这是一个ROM错误。
专业的加密加固打包服务
由于Android的特殊性,存在针对apk的加固脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有像爱加密这样的专业公司,有免费的基础安全服务和收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。
网页抓取 加密html(经常出现抓取html页面并保存的时候是乱码的问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-16 06:25
)
在用python爬取html页面并保存时,经常会出现爬取的网页内容乱码的问题。出现这个问题的原因,一方面是自己代码中的编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码与标记编码。html页面上显示的编码在这里:.
这里有一个简单的解决方案:使用chardet判断网页的真实代码,同时从url请求返回的信息中判断代码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(系统默认编码设置为utf-8).
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'http://www.csdn.net'
download(url)
得到的test.html文件打开如下,可以看到它是用UTF-8存储的,没有BOM编码格式,也就是我们设置的默认编码:
查看全部
网页抓取 加密html(经常出现抓取html页面并保存的时候是乱码的问题
)
在用python爬取html页面并保存时,经常会出现爬取的网页内容乱码的问题。出现这个问题的原因,一方面是自己代码中的编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码与标记编码。html页面上显示的编码在这里:.
这里有一个简单的解决方案:使用chardet判断网页的真实代码,同时从url请求返回的信息中判断代码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(系统默认编码设置为utf-8).
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'http://www.csdn.net'
download(url)
得到的test.html文件打开如下,可以看到它是用UTF-8存储的,没有BOM编码格式,也就是我们设置的默认编码:
网页抓取 加密html(网页抓取加密html的三种方法过一遍,你知道吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-14 03:00
网页抓取加密html又叫nestedhtml,他是指有一个域名以及所有被访问过的html页面,并且随时会自动备份到服务器上。加密的目的是防止伪造,以及与代码互相混淆。html加密方法有四种,分别是:1.绝对隐藏法2.加密隐藏法3.https隐藏法4.混合隐藏法。提到加密隐藏,也有一些常见的解密方法。其中三种方法是nestedhtml方法中,常用的解密算法。
现将三种方法过一遍,应该可以对整个html加密有一个相对深刻的认识了。先看下加密html的前因后果(这部分内容较为复杂,感兴趣的可以自己搜索查看)假设公司小明想在自己的主站加密html并分享给自己的兄弟小黄。加密html方案1.绝对隐藏法对于google来说,网站是html文档的一个lib,并且可以下载到本地,所以这个文档是静态网站并且是经过伪静态处理的,一旦对于其中的部分html标签进行了加密处理,那么在dom未加载的时候,看不到或者是从html源码是看不到这些标签的内容。
具体是使用绝对隐藏法进行加密html的方法是,利用nestedhtml处理技术。nestedhtml,具体也是利用了html的asjavascripthierarchy进行解密的,具体操作就是检查一个已经加密的html文档在dom未加载的时候是否有子元素指向。在不断的循环下,发现dom可以从html源码无法获取到的标签上,获取到子元素指向的标签的内容。
比如,在dom加载时,只加载到标签,那么标签的内容就可以使用nestedhtml方法进行解密了。下面是dom未加载时的内容,可以看到标签,其后包含了多个标签,很容易对其中某个进行伪静态处理,进而得到dom页面所有标签内容。这也是为什么,dom加载前对html进行加密html后,可以看到dom的页面内容都是加密html内容。
然后采用https隐藏法,就可以直接对加密html的txt进行解密了。总结到最后,其实加密html方案就是利用nestedhtml来伪静态处理后,找到dom中、标签的内容,然后进行伪静态处理,获取dom页面所有标签内容。最终获取网站所有标签内容的方法。方案2.加密隐藏法这里要说的是利用https隐藏法来获取加密html的解密算法是使用了crossauthentication来做,具体可以参考我的另一篇博客:华觅:利用https隐藏html加密方案来获取加密html算法的原理https隐藏html加密算法流程解密当我们以https方式来解密html页面,在解密的过程中,进而得到页面所有标签内容的时候,我们需。 查看全部
网页抓取 加密html(网页抓取加密html的三种方法过一遍,你知道吗)
网页抓取加密html又叫nestedhtml,他是指有一个域名以及所有被访问过的html页面,并且随时会自动备份到服务器上。加密的目的是防止伪造,以及与代码互相混淆。html加密方法有四种,分别是:1.绝对隐藏法2.加密隐藏法3.https隐藏法4.混合隐藏法。提到加密隐藏,也有一些常见的解密方法。其中三种方法是nestedhtml方法中,常用的解密算法。
现将三种方法过一遍,应该可以对整个html加密有一个相对深刻的认识了。先看下加密html的前因后果(这部分内容较为复杂,感兴趣的可以自己搜索查看)假设公司小明想在自己的主站加密html并分享给自己的兄弟小黄。加密html方案1.绝对隐藏法对于google来说,网站是html文档的一个lib,并且可以下载到本地,所以这个文档是静态网站并且是经过伪静态处理的,一旦对于其中的部分html标签进行了加密处理,那么在dom未加载的时候,看不到或者是从html源码是看不到这些标签的内容。
具体是使用绝对隐藏法进行加密html的方法是,利用nestedhtml处理技术。nestedhtml,具体也是利用了html的asjavascripthierarchy进行解密的,具体操作就是检查一个已经加密的html文档在dom未加载的时候是否有子元素指向。在不断的循环下,发现dom可以从html源码无法获取到的标签上,获取到子元素指向的标签的内容。
比如,在dom加载时,只加载到标签,那么标签的内容就可以使用nestedhtml方法进行解密了。下面是dom未加载时的内容,可以看到标签,其后包含了多个标签,很容易对其中某个进行伪静态处理,进而得到dom页面所有标签内容。这也是为什么,dom加载前对html进行加密html后,可以看到dom的页面内容都是加密html内容。
然后采用https隐藏法,就可以直接对加密html的txt进行解密了。总结到最后,其实加密html方案就是利用nestedhtml来伪静态处理后,找到dom中、标签的内容,然后进行伪静态处理,获取dom页面所有标签内容。最终获取网站所有标签内容的方法。方案2.加密隐藏法这里要说的是利用https隐藏法来获取加密html的解密算法是使用了crossauthentication来做,具体可以参考我的另一篇博客:华觅:利用https隐藏html加密方案来获取加密html算法的原理https隐藏html加密算法流程解密当我们以https方式来解密html页面,在解密的过程中,进而得到页面所有标签内容的时候,我们需。
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-09 08:11
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配还是有没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题和图片链接的内容,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码)
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配还是有没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题和图片链接的内容,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。
网页抓取 加密html(把html转换得到的二进制进行加密把上面加密的内容转换)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-08 23:18
经常发现我的博客被一些垃圾网站爬取,我访问的时候对博客进行加密解密,所以爬虫不执行js就获取不到内容
这篇文章告诉你如何加密你的博客
加密使用Convert 文章 content to Html and then convert to base64 and then convert base64 to html after loading,这种方法可以解密文章。
文章 的摘要可以不加密,但 文章 的内容可以使用这种方法加密。
我使用 Pandoc 转换 html,推荐使用此方法。然后将我的文章转换的html转base64转成图片在线解码编码得到base64。然后把这段代码放在一个div里面,在页面加载的时候转成html
我将js放在文章的末尾,你可以复制到自己的博客,你只需要把转换后的html代码放在下面的div中
1
2base64
3
4
5
加载页面时将 base64 转换为 html。
这时候你会发现打开页面可以看到base64,所以可以先隐藏,设置css隐藏src,请看下面代码
1.src
2{
3 display: none;
4}
5
6
关键js代码
<p>1 $(document).ready(function()
2 {
3 var src = document.getElementsByClassName('src');
4 for (var i = 0; i 2);
24 out += base64EncodeChars.charAt((c1 & 0x3) 2);
32 out += base64EncodeChars.charAt(((c1 & 0x3) 4));
33 out += base64EncodeChars.charAt((c2 & 0xF) 2);
39 out += base64EncodeChars.charAt(((c1 & 0x3) 4));
40 out += base64EncodeChars.charAt(((c2 & 0xF) 6));
41 out += base64EncodeChars.charAt(c3 & 0x3F);
42 }
43 return out;
44}
45
46function base64decode(str) {
47 var c1, c2, c3, c4;
48 var i, len, out;
49
50 len = str.length;
51 i = 0;
52 out = "";
53 while(i > 6) & 0x1F));
111 out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
112 }
113 }
114 return out;
115}
116
117function utf8to16(str) {
118 var out, i, len, c;
119 var char2, char3;
120
121 out = "";
122 len = str.length;
123 i = 0;
124 while(i > 4)
127 {
128 case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
129 // 0xxxxxxx
130 out += str.charAt(i-1);
131 break;
132 case 12: case 13:
133 // 110x xxxx 10xx xxxx
134 char2 = str.charCodeAt(i++);
135 out += String.fromCharCode(((c & 0x1F) 查看全部
网页抓取 加密html(把html转换得到的二进制进行加密把上面加密的内容转换)
经常发现我的博客被一些垃圾网站爬取,我访问的时候对博客进行加密解密,所以爬虫不执行js就获取不到内容
这篇文章告诉你如何加密你的博客
加密使用Convert 文章 content to Html and then convert to base64 and then convert base64 to html after loading,这种方法可以解密文章。
文章 的摘要可以不加密,但 文章 的内容可以使用这种方法加密。
我使用 Pandoc 转换 html,推荐使用此方法。然后将我的文章转换的html转base64转成图片在线解码编码得到base64。然后把这段代码放在一个div里面,在页面加载的时候转成html
我将js放在文章的末尾,你可以复制到自己的博客,你只需要把转换后的html代码放在下面的div中
1
2base64
3
4
5
加载页面时将 base64 转换为 html。
这时候你会发现打开页面可以看到base64,所以可以先隐藏,设置css隐藏src,请看下面代码
1.src
2{
3 display: none;
4}
5
6
关键js代码
<p>1 $(document).ready(function()
2 {
3 var src = document.getElementsByClassName('src');
4 for (var i = 0; i 2);
24 out += base64EncodeChars.charAt((c1 & 0x3) 2);
32 out += base64EncodeChars.charAt(((c1 & 0x3) 4));
33 out += base64EncodeChars.charAt((c2 & 0xF) 2);
39 out += base64EncodeChars.charAt(((c1 & 0x3) 4));
40 out += base64EncodeChars.charAt(((c2 & 0xF) 6));
41 out += base64EncodeChars.charAt(c3 & 0x3F);
42 }
43 return out;
44}
45
46function base64decode(str) {
47 var c1, c2, c3, c4;
48 var i, len, out;
49
50 len = str.length;
51 i = 0;
52 out = "";
53 while(i > 6) & 0x1F));
111 out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
112 }
113 }
114 return out;
115}
116
117function utf8to16(str) {
118 var out, i, len, c;
119 var char2, char3;
120
121 out = "";
122 len = str.length;
123 i = 0;
124 while(i > 4)
127 {
128 case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
129 // 0xxxxxxx
130 out += str.charAt(i-1);
131 break;
132 case 12: case 13:
133 // 110x xxxx 10xx xxxx
134 char2 = str.charCodeAt(i++);
135 out += String.fromCharCode(((c & 0x1F)
网页抓取 加密html(“外行看热闹,内行看门道!”大多数用户验收WordPress网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-07 14:01
总结
“层层看热闹,专家看门!”大多数用户在接受 WordPress网站 或者判断一个 WordPress网站 的好坏时,只会测试 WordPress网站 的好坏,其实判断的真正方法检查WordPress的质量网站就是检查源代码,尤其是对WordPress的效果要求很高的时候网站,html代码是否规范、简洁非常重要。
“外行看热闹,高手看门!”大多数用户在接受 WordPress网站 或者判断一个 WordPress网站 的好坏时,只会测试 WordPress网站 的好坏,其实判断的真正方式检查WordPress的好坏网站就是检查源代码,尤其是对WordPress的效果要求很高的时候网站,html代码是否规范、简洁非常重要。
就是通过蜘蛛机器人抓取网页,根据网页内容进行关键词索引分类和排名。但是,很多,尤其是传统的自助建站者和一些前端和php(或其他语言)的开发者,纯粹从技术便利和源代码保护的角度来开发WordPress网站,导致大量的html页面中的加密js。代码和CSS代码是任意的,没有封装,甚至很多文本内容都是经过js或者其他加密代码处理后显示出来的。搜索引擎蜘蛛在抓取页面时,自然无法获取页面的真实内容,导致WordPress的排名网站上不去。
检测方法其实很简单。使用浏览器打开网页,右键查看源码,可以看到整个页面的html代码。如果页面收录很多:
此页面对 SEO 不友好。一个标准简洁的html页面应该使用以下方法封装js和css,并且一个页面加载的css和js文件的数量不能太大:
专业的建站系统和前端代码非常整洁规范,这也是很多用户使用美图系统做SEOWordPress网站排名的主要原因。 查看全部
网页抓取 加密html(“外行看热闹,内行看门道!”大多数用户验收WordPress网站)
总结
“层层看热闹,专家看门!”大多数用户在接受 WordPress网站 或者判断一个 WordPress网站 的好坏时,只会测试 WordPress网站 的好坏,其实判断的真正方法检查WordPress的质量网站就是检查源代码,尤其是对WordPress的效果要求很高的时候网站,html代码是否规范、简洁非常重要。
“外行看热闹,高手看门!”大多数用户在接受 WordPress网站 或者判断一个 WordPress网站 的好坏时,只会测试 WordPress网站 的好坏,其实判断的真正方式检查WordPress的好坏网站就是检查源代码,尤其是对WordPress的效果要求很高的时候网站,html代码是否规范、简洁非常重要。
就是通过蜘蛛机器人抓取网页,根据网页内容进行关键词索引分类和排名。但是,很多,尤其是传统的自助建站者和一些前端和php(或其他语言)的开发者,纯粹从技术便利和源代码保护的角度来开发WordPress网站,导致大量的html页面中的加密js。代码和CSS代码是任意的,没有封装,甚至很多文本内容都是经过js或者其他加密代码处理后显示出来的。搜索引擎蜘蛛在抓取页面时,自然无法获取页面的真实内容,导致WordPress的排名网站上不去。
检测方法其实很简单。使用浏览器打开网页,右键查看源码,可以看到整个页面的html代码。如果页面收录很多:
此页面对 SEO 不友好。一个标准简洁的html页面应该使用以下方法封装js和css,并且一个页面加载的css和js文件的数量不能太大:
专业的建站系统和前端代码非常整洁规范,这也是很多用户使用美图系统做SEOWordPress网站排名的主要原因。
网页抓取 加密html(Q/怎么加密网页A/在网页中加上……)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-07 12:06
这是一个网页HTML加密器(HtmlShip),它是一个网页代码HTML加密器。它可以一次加密大量的网页,这些网页可能不在同一个目录下,甚至可以加密网页的一部分!你有没有遇到过,你辛辛苦苦做的网站被人抄袭了,更恶心的是,他竟然把你的版权改成了他的名字,加上“禁止复制”!
软件介绍
HTML Encryptor (HtmlShip) 是一种网页加密设备。你有没有想过给你的网页加密……技术交流和知识产权谁重要?写这个软件的想法是因为看了XX杂志上的一个电脑问答:Q/How to encrypt pages A/Add...if(button==2)alert...(这个也算加密?!!!)还有网页上使用的设备,加密一个网站会不会太累?所以有HTMLSHIP。
软件说明
Web HTML Encryptor (HtmlShip) 是一种通过将您的 html 代码和脚本代码转换为幻词来保护它们的工具。处理多个文件时表现出色,因此在完成这项复杂工作时可以节省您的时间。现在它支持 UNICODE,这意味着 Batch HTML Encryptor 在加密多语言 HTML 文件方面比其他加密程序更好。
软件说明
Web HTML Encryptor(HtmlShip)是一种网页代码加密,功能强大,操作简单,多种功能保护网页源代码,如:禁止在网页中使用右键,禁止显示状态栏信息,防止使用热键或右键复制内容,防止保存后查看,防止打印,防止搜索引擎对该网页内容进行索引,禁止IE6的图像工具栏,防止网页被保存通过 IE 从文件菜单。
软件截图
相关软件
简尔 PDF 加密器:这是简尔 PDF 加密器,一个易于使用的 PDF 文件加密器。支持海量PDF文件加密,有效保护您的PDF文件。加密PDF文档可以限制阅读次数,自定义阅读过期时间。防止另存为副本,防止截屏,防止复制 PDF 中的文本。您可以在打开 PDF 文档时自定义图片。您可以自定义在关闭 PDF 文档时打开指定的 网站。
Crazy Web Bulk Encryptor:这是Crazy Web Bulk Encryptor,是一款静态网页加密工具。所谓静态是指通常意义上的.htm或.html后缀的网页文件,不适用于服务器端。以 ..asp 和 .jsp 等扩展名运行的文件。 查看全部
网页抓取 加密html(Q/怎么加密网页A/在网页中加上……)
这是一个网页HTML加密器(HtmlShip),它是一个网页代码HTML加密器。它可以一次加密大量的网页,这些网页可能不在同一个目录下,甚至可以加密网页的一部分!你有没有遇到过,你辛辛苦苦做的网站被人抄袭了,更恶心的是,他竟然把你的版权改成了他的名字,加上“禁止复制”!
软件介绍
HTML Encryptor (HtmlShip) 是一种网页加密设备。你有没有想过给你的网页加密……技术交流和知识产权谁重要?写这个软件的想法是因为看了XX杂志上的一个电脑问答:Q/How to encrypt pages A/Add...if(button==2)alert...(这个也算加密?!!!)还有网页上使用的设备,加密一个网站会不会太累?所以有HTMLSHIP。
软件说明
Web HTML Encryptor (HtmlShip) 是一种通过将您的 html 代码和脚本代码转换为幻词来保护它们的工具。处理多个文件时表现出色,因此在完成这项复杂工作时可以节省您的时间。现在它支持 UNICODE,这意味着 Batch HTML Encryptor 在加密多语言 HTML 文件方面比其他加密程序更好。
软件说明
Web HTML Encryptor(HtmlShip)是一种网页代码加密,功能强大,操作简单,多种功能保护网页源代码,如:禁止在网页中使用右键,禁止显示状态栏信息,防止使用热键或右键复制内容,防止保存后查看,防止打印,防止搜索引擎对该网页内容进行索引,禁止IE6的图像工具栏,防止网页被保存通过 IE 从文件菜单。
软件截图
相关软件
简尔 PDF 加密器:这是简尔 PDF 加密器,一个易于使用的 PDF 文件加密器。支持海量PDF文件加密,有效保护您的PDF文件。加密PDF文档可以限制阅读次数,自定义阅读过期时间。防止另存为副本,防止截屏,防止复制 PDF 中的文本。您可以在打开 PDF 文档时自定义图片。您可以自定义在关闭 PDF 文档时打开指定的 网站。
Crazy Web Bulk Encryptor:这是Crazy Web Bulk Encryptor,是一款静态网页加密工具。所谓静态是指通常意义上的.htm或.html后缀的网页文件,不适用于服务器端。以 ..asp 和 .jsp 等扩展名运行的文件。
网页抓取 加密html(网页抓取加密html或者xml抓取,可以用contentsource服务api加密生成xml)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-05 07:02
网页抓取加密html或者xml抓取,可以用contentsource服务api加密生成xml或者html文件,
其实对于我这样的一个学生来说,加密解密自己都已经看烦了。小打小闹无所谓,要是真以此作为项目的一个流程或者是风险控制措施,肯定是不行的。
base64生成.jpg然后rdf可以处理json啊
有一个东西叫做jsonminer,不过简单的说就是一个json爬虫,
我们需要实时抓取,这个是一个实时数据库,想看哪里抓取的数据?去设定抓取数据来源地址,包括网页、图片、加密消息等,自动抓取下来,进行分析查询等。
我们项目以加密xml为主,
cdn加密,
解密json用gsonboilerplatejsoncontent
谢谢的标题,很同意那些的方案,我看过加密的方案,其实效果都差不多,而且每个方案都有自己的特点,比如apcap,使用protobuf,安全性很好,而且节省耗时,当然最终目的就是用在我们业务处理上,
rdf生成xml或者是html格式,内嵌到rdf编写的自动化分析引擎中。
word文档加密有很多code
应该是最好别随便去用自己写的什么。各种加密api,找到自己最适合的,看api的文档或者比较能懂一些的api文档。最简单的wordasauthors的api,有人写了个在线工具帮你搞。 查看全部
网页抓取 加密html(网页抓取加密html或者xml抓取,可以用contentsource服务api加密生成xml)
网页抓取加密html或者xml抓取,可以用contentsource服务api加密生成xml或者html文件,
其实对于我这样的一个学生来说,加密解密自己都已经看烦了。小打小闹无所谓,要是真以此作为项目的一个流程或者是风险控制措施,肯定是不行的。
base64生成.jpg然后rdf可以处理json啊
有一个东西叫做jsonminer,不过简单的说就是一个json爬虫,
我们需要实时抓取,这个是一个实时数据库,想看哪里抓取的数据?去设定抓取数据来源地址,包括网页、图片、加密消息等,自动抓取下来,进行分析查询等。
我们项目以加密xml为主,
cdn加密,
解密json用gsonboilerplatejsoncontent
谢谢的标题,很同意那些的方案,我看过加密的方案,其实效果都差不多,而且每个方案都有自己的特点,比如apcap,使用protobuf,安全性很好,而且节省耗时,当然最终目的就是用在我们业务处理上,
rdf生成xml或者是html格式,内嵌到rdf编写的自动化分析引擎中。
word文档加密有很多code
应该是最好别随便去用自己写的什么。各种加密api,找到自己最适合的,看api的文档或者比较能懂一些的api文档。最简单的wordasauthors的api,有人写了个在线工具帮你搞。
网页抓取 加密html(360加密邮发送、接收加密邮件前不久360出品(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2022-03-02 15:08
泡泡网笔记本频道2月4日我们在生活或工作中都使用电子邮件,几乎所有的互联网用户都有自己的电子邮件。随着互联网的飞速发展,每天发送的电子邮件数量也在不断上升。平均而言,全球每分钟发送数亿封电子邮件。与此同时,信息泄露事件一直在我们耳边流传,尤其是2014年,我国爆发了很多互联网安全问题,其中电子邮件泄露非常严重,安全堪忧。在大多数人眼里,保护自己的邮箱,就是把邮箱的密码设置得越复杂越好。但是,电子邮件在传输和存储过程中可能会发生泄漏,这是难以预防的。因此,您需要对自己的邮箱和重要的电子邮件进行进一步的保护。
电子邮件加密的重要性
在大多数情况下,我们每天发送的电子邮件都没有加密,这意味着我们每天发送的电子邮件的内容是以明文形式传输的。一旦被截获或被盗,电子邮件的内容将完全暴露。电子邮件加密不仅用在企业、政府等企业层面,包括学生给老师发毕业论文等更重要的电子邮件,也需要加密。因此,发送加密电子邮件也应该是我们应该了解的网络安全的一部分。
360加密邮件收发加密邮件
不久前,360出品了一款邮件加密软件:360加密邮件。笔者会讲一下这款加密软件的试用体验,并与常用的QQ邮箱和网易邮箱加密功能进行对比,让大家了解这些主流邮箱。对加密软件有更深的理解。此外,作者还为大家带来了一些日常使用电子邮件的注意事项,以告知您如何正确、安全地使用电子邮件,保护您的电子邮件安全。
首先我们来看看360加密邮件软件。本软件有两个版本:Windows版和Android版。笔者以Windows版本为例。
客户登录
首次使用需要设置名称,同时可以选择打开本应用时是否输入密码,这里我们选择需要密码。输入密码时,笔者尝试输入“123456”等安全系数较低的密码,但软件没有任何危险提示,而且笔者设置的密码提示也是123456,提示相同作为密码,但是没有提示,密码也不算太弱。例如,缺乏人性化的提醒。
设置邮箱和手机号两步验证
接下来,我们需要登录我们的邮箱。登录过程与大多数电子邮件客户端类似。但是,作为电子邮件加密软件,还有两个更重要的设置。其中,一是设置当前邮箱的安全密码,二是要求手机号作为双重保障。(注:此处的安全密码为查看加密邮件的密码)
1. 发送加密邮件
在发送邮件的界面中,我们可以看到两种发送方式。如果要发送加密邮件,只需点击“加密发送”即可发送加密邮件。操作非常简单。此外,360 加密邮件中的抄送工作正常,但没有密件抄送选项。
2. 接收加密邮件
如果收件人是非360加密邮件注册账号,在查看加密邮件时,我们发现“加密”邮件变成了一个以“html”结尾的附件,也就是说该附件是本地离线网页。
打开附件后,弹出的网页如上图所示。在这里,我们可以选择输入邮箱的安全密码来查看邮件,其中我们可以通过“接收邮箱地址或发送邮箱地址”的安全密码进行查看。这也意味着如果对方没有注册360加密邮件,那么只有发件人的安全密码才能查看邮件。
如果邮件的收件人是360加密邮件注册账号,那么打开加密邮件客户端后就可以看到完整的邮件内容,无需手动输入密码进行验证。这也是基于IBC识别密码(SM9算法)的360加密邮件的优势所在。对于同时注册的用户来说,收发加密邮件的体验非常好,省去了以往的验证码或证书验证。
试用后觉得360加密邮件和微软的Outlook软件差别不大。它操作简单,易于理解,使用快捷。是目前推荐的邮件加密软件。
QQ邮箱收发加密邮件体验
另外,我们最常用的QQ邮箱和网易邮箱也支持从网页直接发送加密邮件。您可能在日常使用中找不到它们。下面笔者为大家带来QQ邮箱发送加密邮件的演示流程。邮箱的发送方式大体类似,这里就不演示了。
QQ邮箱网页,下面其他选项-“加密邮件”
输入密码让对方查看
如果对方是QQ邮箱用户,直接输入密码查看
如果对方不是QQ邮箱用户,会以压缩包的形式发送,打开压缩包需要密码。
至此,QQ邮箱发送加密邮件的流程基本结束。表面上看,相比360加密邮件软件,QQ邮箱网页版不仅可以省去下载安装客户端的步骤,还可以为每封邮件设置不同的安全密码,整体灵活性比较高。但在安全性方面,360加密邮件确实有一些优势。
主流邮件加密安全性对比
首先,我们需要了解目前加密发送邮件的加密方式。最常用的电子邮件加密方法有:
1.基于对称密钥法
一般安全,这种加密方式比较原创,比较简单易懂。以这种方式发送,基本上可以相当于将一封电子邮件转换成带有密码的压缩文件。安全防护一般,但使用起来更灵活。,网页也可以使用。
2、基于非对称密钥的方法
安全性高,此方式需要在加解密操作等之前交换密钥,此加密方式仅适用于企业、单位及部分高端用户。
3、基于IBC识别密码的方法
安全性高,这种方法的原理是使用对称算法对邮件内容进行加密,然后使用对方的公钥或证书来保证对称算法的密钥,使用起来更方便。
4.基于链加密系统
安全性高,该方法每次随机生成一个随机密钥,然后用对称加密算法加密明文,再用RSA非对称算法加密密钥。
我们看到的网页版QQ邮箱和网易邮箱都使用了第一种密码加密方式,也就是说这些加密邮件只是简单的基于密码加密传输。但是,360加密邮件使用的基于IBC的识别密码(SM9算法)在安全性方面更强。
因此,360加密邮件采用IBC识别密码(SM9算法),也是目前比较安全的加密算法。加密邮件在安全性方面稍好一些。
不仅是本文改进的邮件加密软件,还有很多邮件加密软件,包括MailCloak、PGP、Omail等,在安全性方面依然具有很高的可靠性。笔者就不一一介绍了。有兴趣的朋友可以自己试试。
电子邮件日常使用注意事项
下面,笔者总结了日常生活中使用电子邮件需要注意的安全事项。希望大家在日常使用中注意。
1.注册多个邮箱账号,注册专业时不要使用邮箱密码网站
我们大多数人在日常生活中注册网站时都需要使用电子邮件。我们可以根据不同的需求使用不同的邮箱进行注册,以防止在注册邮箱信息泄露时,部分网站被暴露。同时,我们在注册时不会使用与邮箱密码相同的密码,将风险降至最低。
2、邮件客户端尽量选择SSL验证
大多数电子邮件客户端都可以设置 SSL 安全验证
如果我们通过客户端收发邮件,还可以设置SSL(一种安全协议)进行验证,从而进一步保证邮件在发送过程中被拦截的安全性。
3.设置邮箱独立密码
使用QQ邮箱的朋友,邮箱密码默认与QQ密码相同。我们可以设置独立的邮箱密码,防止QQ密码泄露后QQ邮箱被泄露。
4.邮箱重要文件夹加密
如果说独立密码是第二道防线,那么锁定邮箱中的文件夹就是第三道防线。对于使用QQ、网易等邮箱的朋友,可以直接设置文件夹加密来整理日常邮件。当可以对私人邮件进行分类,然后进行独立加密时,整个文件夹的安全性就可以再次提高。
全文摘要:
整体来看,360加密邮件在安全性方面表现不错。如果发送者和发送者都是注册用户,发送者和发送者都可以直接读取它们,而无需输入安全密码或证书信息。凭借这个优势,他们可以在邮件加密方面取得非常好的效果。适用于经常发送加密邮件的用户。QQ邮箱和网易邮箱网页版采用的基于密码的密码加密,灵活性更高,更适合临时发送加密邮件。
当前主流的电子邮件加密不需要用户支付额外的费用。如果你对自己的隐私信息足够重视,笔者还是推荐使用这个功能的。最后,如果您对邮件加密有任何疑问,也可以与泡泡网笔记本频道@泡本集官方微博交流交流。■ 查看全部
网页抓取 加密html(360加密邮发送、接收加密邮件前不久360出品(组图))
泡泡网笔记本频道2月4日我们在生活或工作中都使用电子邮件,几乎所有的互联网用户都有自己的电子邮件。随着互联网的飞速发展,每天发送的电子邮件数量也在不断上升。平均而言,全球每分钟发送数亿封电子邮件。与此同时,信息泄露事件一直在我们耳边流传,尤其是2014年,我国爆发了很多互联网安全问题,其中电子邮件泄露非常严重,安全堪忧。在大多数人眼里,保护自己的邮箱,就是把邮箱的密码设置得越复杂越好。但是,电子邮件在传输和存储过程中可能会发生泄漏,这是难以预防的。因此,您需要对自己的邮箱和重要的电子邮件进行进一步的保护。
电子邮件加密的重要性
在大多数情况下,我们每天发送的电子邮件都没有加密,这意味着我们每天发送的电子邮件的内容是以明文形式传输的。一旦被截获或被盗,电子邮件的内容将完全暴露。电子邮件加密不仅用在企业、政府等企业层面,包括学生给老师发毕业论文等更重要的电子邮件,也需要加密。因此,发送加密电子邮件也应该是我们应该了解的网络安全的一部分。
360加密邮件收发加密邮件
不久前,360出品了一款邮件加密软件:360加密邮件。笔者会讲一下这款加密软件的试用体验,并与常用的QQ邮箱和网易邮箱加密功能进行对比,让大家了解这些主流邮箱。对加密软件有更深的理解。此外,作者还为大家带来了一些日常使用电子邮件的注意事项,以告知您如何正确、安全地使用电子邮件,保护您的电子邮件安全。
首先我们来看看360加密邮件软件。本软件有两个版本:Windows版和Android版。笔者以Windows版本为例。
客户登录
首次使用需要设置名称,同时可以选择打开本应用时是否输入密码,这里我们选择需要密码。输入密码时,笔者尝试输入“123456”等安全系数较低的密码,但软件没有任何危险提示,而且笔者设置的密码提示也是123456,提示相同作为密码,但是没有提示,密码也不算太弱。例如,缺乏人性化的提醒。
设置邮箱和手机号两步验证
接下来,我们需要登录我们的邮箱。登录过程与大多数电子邮件客户端类似。但是,作为电子邮件加密软件,还有两个更重要的设置。其中,一是设置当前邮箱的安全密码,二是要求手机号作为双重保障。(注:此处的安全密码为查看加密邮件的密码)
1. 发送加密邮件
在发送邮件的界面中,我们可以看到两种发送方式。如果要发送加密邮件,只需点击“加密发送”即可发送加密邮件。操作非常简单。此外,360 加密邮件中的抄送工作正常,但没有密件抄送选项。
2. 接收加密邮件
如果收件人是非360加密邮件注册账号,在查看加密邮件时,我们发现“加密”邮件变成了一个以“html”结尾的附件,也就是说该附件是本地离线网页。
打开附件后,弹出的网页如上图所示。在这里,我们可以选择输入邮箱的安全密码来查看邮件,其中我们可以通过“接收邮箱地址或发送邮箱地址”的安全密码进行查看。这也意味着如果对方没有注册360加密邮件,那么只有发件人的安全密码才能查看邮件。
如果邮件的收件人是360加密邮件注册账号,那么打开加密邮件客户端后就可以看到完整的邮件内容,无需手动输入密码进行验证。这也是基于IBC识别密码(SM9算法)的360加密邮件的优势所在。对于同时注册的用户来说,收发加密邮件的体验非常好,省去了以往的验证码或证书验证。
试用后觉得360加密邮件和微软的Outlook软件差别不大。它操作简单,易于理解,使用快捷。是目前推荐的邮件加密软件。
QQ邮箱收发加密邮件体验
另外,我们最常用的QQ邮箱和网易邮箱也支持从网页直接发送加密邮件。您可能在日常使用中找不到它们。下面笔者为大家带来QQ邮箱发送加密邮件的演示流程。邮箱的发送方式大体类似,这里就不演示了。
QQ邮箱网页,下面其他选项-“加密邮件”
输入密码让对方查看
如果对方是QQ邮箱用户,直接输入密码查看
如果对方不是QQ邮箱用户,会以压缩包的形式发送,打开压缩包需要密码。
至此,QQ邮箱发送加密邮件的流程基本结束。表面上看,相比360加密邮件软件,QQ邮箱网页版不仅可以省去下载安装客户端的步骤,还可以为每封邮件设置不同的安全密码,整体灵活性比较高。但在安全性方面,360加密邮件确实有一些优势。
主流邮件加密安全性对比
首先,我们需要了解目前加密发送邮件的加密方式。最常用的电子邮件加密方法有:
1.基于对称密钥法
一般安全,这种加密方式比较原创,比较简单易懂。以这种方式发送,基本上可以相当于将一封电子邮件转换成带有密码的压缩文件。安全防护一般,但使用起来更灵活。,网页也可以使用。
2、基于非对称密钥的方法
安全性高,此方式需要在加解密操作等之前交换密钥,此加密方式仅适用于企业、单位及部分高端用户。
3、基于IBC识别密码的方法
安全性高,这种方法的原理是使用对称算法对邮件内容进行加密,然后使用对方的公钥或证书来保证对称算法的密钥,使用起来更方便。
4.基于链加密系统
安全性高,该方法每次随机生成一个随机密钥,然后用对称加密算法加密明文,再用RSA非对称算法加密密钥。
我们看到的网页版QQ邮箱和网易邮箱都使用了第一种密码加密方式,也就是说这些加密邮件只是简单的基于密码加密传输。但是,360加密邮件使用的基于IBC的识别密码(SM9算法)在安全性方面更强。
因此,360加密邮件采用IBC识别密码(SM9算法),也是目前比较安全的加密算法。加密邮件在安全性方面稍好一些。
不仅是本文改进的邮件加密软件,还有很多邮件加密软件,包括MailCloak、PGP、Omail等,在安全性方面依然具有很高的可靠性。笔者就不一一介绍了。有兴趣的朋友可以自己试试。
电子邮件日常使用注意事项
下面,笔者总结了日常生活中使用电子邮件需要注意的安全事项。希望大家在日常使用中注意。
1.注册多个邮箱账号,注册专业时不要使用邮箱密码网站
我们大多数人在日常生活中注册网站时都需要使用电子邮件。我们可以根据不同的需求使用不同的邮箱进行注册,以防止在注册邮箱信息泄露时,部分网站被暴露。同时,我们在注册时不会使用与邮箱密码相同的密码,将风险降至最低。
2、邮件客户端尽量选择SSL验证
大多数电子邮件客户端都可以设置 SSL 安全验证
如果我们通过客户端收发邮件,还可以设置SSL(一种安全协议)进行验证,从而进一步保证邮件在发送过程中被拦截的安全性。
3.设置邮箱独立密码
使用QQ邮箱的朋友,邮箱密码默认与QQ密码相同。我们可以设置独立的邮箱密码,防止QQ密码泄露后QQ邮箱被泄露。
4.邮箱重要文件夹加密
如果说独立密码是第二道防线,那么锁定邮箱中的文件夹就是第三道防线。对于使用QQ、网易等邮箱的朋友,可以直接设置文件夹加密来整理日常邮件。当可以对私人邮件进行分类,然后进行独立加密时,整个文件夹的安全性就可以再次提高。
全文摘要:
整体来看,360加密邮件在安全性方面表现不错。如果发送者和发送者都是注册用户,发送者和发送者都可以直接读取它们,而无需输入安全密码或证书信息。凭借这个优势,他们可以在邮件加密方面取得非常好的效果。适用于经常发送加密邮件的用户。QQ邮箱和网易邮箱网页版采用的基于密码的密码加密,灵活性更高,更适合临时发送加密邮件。
当前主流的电子邮件加密不需要用户支付额外的费用。如果你对自己的隐私信息足够重视,笔者还是推荐使用这个功能的。最后,如果您对邮件加密有任何疑问,也可以与泡泡网笔记本频道@泡本集官方微博交流交流。■
网页抓取 加密html(怎么防止别人下载网页CSS?文章给你介绍一些方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-01 23:19
如何防止他人下载网页的CSS?下面的文章文章会为大家介绍一些方法。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。
如何防止他人下载网页的CSS?
1、禁止保存页面,最简单粗暴!
2、CSS元素中的图片存放在../../images/,可以有效避免另存为和小偷工具抢!
图片中的元素
3、css用于防盗链,源设置为只能通过css文件访问。
4、简单的加密css地址,防止他人下载你的CSS文件
阻止他人下载或查看您的 CSS 文件并非易事。高手未必能防,但新手一时不知所措,费了不少功夫
该方法使用Javascript输出CSS文件地址并加密字符
阻止查看CSS文件
document.write(unescape("%3Cstyle%20type%3D%22text/css%22%3E"));
document.write(unescape("%3C%21--.tablecls%20%7B%20border%3A1px%20solid%20%23a2a2a2%3B%20
background-color%3A%23f2f2f2%3B%20width%3A200px%3B%20height%3A300px%3B%20text-align
%3Acenter%3B%20padding%3A2px%3B%20font-size%3A14px%3B%20line-height%3A23px%3B%7D--%3E"));
document.write(unescape("%3C/style%3E"));
虽然不能100%防下载或查看,但是对于菜鸟估计费一番周折了^
更多web前端开发知识,请参考HTML中文网站! ! 查看全部
网页抓取 加密html(怎么防止别人下载网页CSS?文章给你介绍一些方法)
如何防止他人下载网页的CSS?下面的文章文章会为大家介绍一些方法。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。
如何防止他人下载网页的CSS?
1、禁止保存页面,最简单粗暴!
2、CSS元素中的图片存放在../../images/,可以有效避免另存为和小偷工具抢!
图片中的元素
3、css用于防盗链,源设置为只能通过css文件访问。
4、简单的加密css地址,防止他人下载你的CSS文件
阻止他人下载或查看您的 CSS 文件并非易事。高手未必能防,但新手一时不知所措,费了不少功夫
该方法使用Javascript输出CSS文件地址并加密字符
阻止查看CSS文件
document.write(unescape("%3Cstyle%20type%3D%22text/css%22%3E"));
document.write(unescape("%3C%21--.tablecls%20%7B%20border%3A1px%20solid%20%23a2a2a2%3B%20
background-color%3A%23f2f2f2%3B%20width%3A200px%3B%20height%3A300px%3B%20text-align
%3Acenter%3B%20padding%3A2px%3B%20font-size%3A14px%3B%20line-height%3A23px%3B%7D--%3E"));
document.write(unescape("%3C/style%3E"));
虽然不能100%防下载或查看,但是对于菜鸟估计费一番周折了^
更多web前端开发知识,请参考HTML中文网站! !
网页抓取 加密html(如何在C#中将HTML文件转换为加密的PDF?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-26 17:22
当需要进行 HTML 到 PDF 的转换时,有多种情况。例如,您可能希望在应用程序中将网页转换为 PDF,或者您可能需要从所见即所得 HTML 编辑器的内容生成 PDF。另一种情况是将 HTML 页面从特定 URL 转换为 PDF。
Aspose.PDF for .NET 是一个 PDF 处理和解析 API,用于在跨平台应用程序中执行文档管理和操作任务,可轻松用于生成、修改、转换、呈现、保护和打印 PDF 文档,无需使用Adobe Acrobat。
为了处理这种情况,本文将展示如何在 C#.NET 中使用 Aspose.PDF 将 HTML 转换为 PDF。我们将执行以下 HTML 到 PDF 的转换:
最近Aspose.PDF的.NET版本升级到v20.2,解决了VerticalAlignment不支持TextBoxField的问题,修复了PDF和HTML之间的转换等诸多bug。感兴趣的朋友可以点击文末“了解详情”下载最新版本。
在 C# 中将 HTML 转换为 PDF
以下是使用 Aspose.PDF for .NET 将 HTML 文件转换为 PDF 的简单步骤。
以下代码示例演示了如何在 C# 中将 HTML 转换为 PDF。
// Create HTML load options
HtmlLoadOptions htmloptions = new HtmlLoadOptions();
// Load HTML file
Document doc = new Document("HTML-Document.html", htmloptions);
// Convert HTML file to PDF
doc.Save("HTML-to-PDF.pdf");
输入 HTML 文件
转换后的PDF文档
在 C# 中将 HTML 转换为受密码保护的 PDF
我们可以使用 Aspose.PDF for .NET 将 HTML 文件转换为加密的 PDF 文档。生成的 PDF 文档可以使用用户密码、所有者密码、访问权限和加密算法进行保护。转换后的 PDF 也可以使用 Document.Encrypt() 方法进行加密。以下代码示例演示了如何在 C# 中将 HTML 文件转换为加密的 PDF。
输出结果
将网页从 C# 中的 URL 转换为 PDF
Aspose.PDF for .NET 还支持通过实时 URL 将 HTML 转换为 PDF。以下是将网页从 URL 转换为 PDF 的步骤。
以下代码示例展示了如何在 C# 中将 HTML 网页转换为 PDF。
WebRequest req = WebRequest.Create(@"https://docs.oracle.com/javase ... 6quot;);
// Get web page into stream
using (Stream stream = req.GetResponse().GetResponseStream())
{
// Initialize HTML load options
HtmlLoadOptions htmloptions = new HtmlLoadOptions("https://docs.oracle.com/");
// Load stream into Document object
Document pdfDocument = new Document(stream, htmloptions);
// Save output as PDF format
pdfDocument.Save("HTML-to-PDF.pdf");
}
如果您有任何问题或需求,欢迎随时加入Aspose技术交流群(642018183),我们很乐意为您提供咨询和咨询。 查看全部
网页抓取 加密html(如何在C#中将HTML文件转换为加密的PDF?)
当需要进行 HTML 到 PDF 的转换时,有多种情况。例如,您可能希望在应用程序中将网页转换为 PDF,或者您可能需要从所见即所得 HTML 编辑器的内容生成 PDF。另一种情况是将 HTML 页面从特定 URL 转换为 PDF。
Aspose.PDF for .NET 是一个 PDF 处理和解析 API,用于在跨平台应用程序中执行文档管理和操作任务,可轻松用于生成、修改、转换、呈现、保护和打印 PDF 文档,无需使用Adobe Acrobat。
为了处理这种情况,本文将展示如何在 C#.NET 中使用 Aspose.PDF 将 HTML 转换为 PDF。我们将执行以下 HTML 到 PDF 的转换:
最近Aspose.PDF的.NET版本升级到v20.2,解决了VerticalAlignment不支持TextBoxField的问题,修复了PDF和HTML之间的转换等诸多bug。感兴趣的朋友可以点击文末“了解详情”下载最新版本。
在 C# 中将 HTML 转换为 PDF
以下是使用 Aspose.PDF for .NET 将 HTML 文件转换为 PDF 的简单步骤。
以下代码示例演示了如何在 C# 中将 HTML 转换为 PDF。
// Create HTML load options
HtmlLoadOptions htmloptions = new HtmlLoadOptions();
// Load HTML file
Document doc = new Document("HTML-Document.html", htmloptions);
// Convert HTML file to PDF
doc.Save("HTML-to-PDF.pdf");
输入 HTML 文件
转换后的PDF文档
在 C# 中将 HTML 转换为受密码保护的 PDF
我们可以使用 Aspose.PDF for .NET 将 HTML 文件转换为加密的 PDF 文档。生成的 PDF 文档可以使用用户密码、所有者密码、访问权限和加密算法进行保护。转换后的 PDF 也可以使用 Document.Encrypt() 方法进行加密。以下代码示例演示了如何在 C# 中将 HTML 文件转换为加密的 PDF。
输出结果
将网页从 C# 中的 URL 转换为 PDF
Aspose.PDF for .NET 还支持通过实时 URL 将 HTML 转换为 PDF。以下是将网页从 URL 转换为 PDF 的步骤。
以下代码示例展示了如何在 C# 中将 HTML 网页转换为 PDF。
WebRequest req = WebRequest.Create(@"https://docs.oracle.com/javase ... 6quot;);
// Get web page into stream
using (Stream stream = req.GetResponse().GetResponseStream())
{
// Initialize HTML load options
HtmlLoadOptions htmloptions = new HtmlLoadOptions("https://docs.oracle.com/";);
// Load stream into Document object
Document pdfDocument = new Document(stream, htmloptions);
// Save output as PDF format
pdfDocument.Save("HTML-to-PDF.pdf");
}
如果您有任何问题或需求,欢迎随时加入Aspose技术交流群(642018183),我们很乐意为您提供咨询和咨询。
网页抓取 加密html( 疯狂网页批量加密器官方下载的加密工具是怎样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-24 08:04
疯狂网页批量加密器官方下载的加密工具是怎样的?)
Crazy Webpage Batch Encryptor 是其他工具频道下的热门软件。太平洋下载中心提供疯狂网页批量加密器官方下载。
是静态网页的加密工具。所谓静态是指通常意义上的扩展名为.htm或.html的网页文件,不适用于运行在服务器端的扩展名为.asp和.jsp的文件。
具有加解密速度快、不增加文件大小、安全性高等优点。加密就是对网页源代码进行重新编码,生成唯一的解密密码。加密后文件大小会增加3K左右。加密方式有两种,一种是内置密码,即把密码写入加密文件,打开页面时自动读取密码,解密,但不会暴露源代码;另一个是外部密码。 ,这种方法更安全,它将密码与加密文件分开,直接打开加密文件,不会显示任何内容。以上参数,例如打开一个密码为12345678,文件名为abc.htm的加密文件,必须在IE地址栏输入abc.htm12345678才能正确打开。如果参数中的密码不正确,文件将无法打开。其中一个突出的特点是可以自动添加参数,这提高了安全性,而您根本不需要做任何额外的工作。此方法不会暴露源代码。当然,这只是假设访问者对 javascript 语言不是很熟悉。否则只要IE能显示,一般可以通过某种方法获取原代码。 查看全部
网页抓取 加密html(
疯狂网页批量加密器官方下载的加密工具是怎样的?)
Crazy Webpage Batch Encryptor 是其他工具频道下的热门软件。太平洋下载中心提供疯狂网页批量加密器官方下载。
是静态网页的加密工具。所谓静态是指通常意义上的扩展名为.htm或.html的网页文件,不适用于运行在服务器端的扩展名为.asp和.jsp的文件。
具有加解密速度快、不增加文件大小、安全性高等优点。加密就是对网页源代码进行重新编码,生成唯一的解密密码。加密后文件大小会增加3K左右。加密方式有两种,一种是内置密码,即把密码写入加密文件,打开页面时自动读取密码,解密,但不会暴露源代码;另一个是外部密码。 ,这种方法更安全,它将密码与加密文件分开,直接打开加密文件,不会显示任何内容。以上参数,例如打开一个密码为12345678,文件名为abc.htm的加密文件,必须在IE地址栏输入abc.htm12345678才能正确打开。如果参数中的密码不正确,文件将无法打开。其中一个突出的特点是可以自动添加参数,这提高了安全性,而您根本不需要做任何额外的工作。此方法不会暴露源代码。当然,这只是假设访问者对 javascript 语言不是很熟悉。否则只要IE能显示,一般可以通过某种方法获取原代码。
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2022-02-23 19:21
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与不加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des很弱,但是没那么容易破解
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配或者没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然无法右键查看代码,但是浏览器开发者工具运行后会显示html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题和图片链接的内容,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与不加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
流行的已知编码只有少数几种,比如json、base64.,那就先用json试试。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des很弱,但是没那么容易破解
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他的编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配或者没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然无法右键查看代码,但是浏览器开发者工具运行后会显示html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题和图片链接的内容,但是经过一些变体编码的研究,对网页有了更深的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。
网页抓取 加密html(网站地图对网站SEO优化有哪些帮助?如何制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-23 14:14
在网站优化的过程中,我们会制作一个sitemap网站map。 网站地图有两种,一种是方便搜索引擎抓取我的网站网站地图sitemap.xml。另一个是用户友好的 web 版本的 sitemap.html。
sitemap.xml 文件列出了 网站 中的 URL 以及有关每个 URL 的其他元数据(上次更新时间、更改频率、相对于其他 URL 的 网站 重要性等),以便搜索引擎可以更智能地抓取网站。
一、网站地图如何帮助网站SEO优化
1、站点地图网站地图有助于爬虫爬取整个网站页面
搜索引擎每天都会发布抓取工具来抓取 Internet 上的新页面,以对这些页面进行排名。如果我们的网站不能被爬虫很好的访问,就会增加搜索引擎爬虫的负担,难以完成对网站所有页面的爬取。 sitemap网站地图可以告诉搜索引擎爬虫爬取网站地图中的页面,有利于爬虫爬取整个网站页面。
2、网站地图可以添加其他页面的链接
网站地图本身就是一个聚合和导航页面。 网站地图可以添加到其他页面的链接,相当于给其他页面添加了投票和传递权重。对网站的排名和提升权重起到了很好的作用。这是网站在seo优化中不可忽视的重要作用的图。
3、网站地图可以有效提高收录率
整个网站
通过网站图可以提取所有页面,搜索引擎爬虫按照网站图上的链接逐一抓取,会提高整个收录的网站数量。
二、sitemap.xml如何制作
现在有了在线制作地图的工具网站,我们直接生成就行了,很简单。然后我们需要将创建好的网站映射上传到我们的网站的根目录下。站点地图可以改善 网站 页面抓取和 收录。 查看全部
网页抓取 加密html(网站地图对网站SEO优化有哪些帮助?如何制作)
在网站优化的过程中,我们会制作一个sitemap网站map。 网站地图有两种,一种是方便搜索引擎抓取我的网站网站地图sitemap.xml。另一个是用户友好的 web 版本的 sitemap.html。
sitemap.xml 文件列出了 网站 中的 URL 以及有关每个 URL 的其他元数据(上次更新时间、更改频率、相对于其他 URL 的 网站 重要性等),以便搜索引擎可以更智能地抓取网站。
一、网站地图如何帮助网站SEO优化
1、站点地图网站地图有助于爬虫爬取整个网站页面
搜索引擎每天都会发布抓取工具来抓取 Internet 上的新页面,以对这些页面进行排名。如果我们的网站不能被爬虫很好的访问,就会增加搜索引擎爬虫的负担,难以完成对网站所有页面的爬取。 sitemap网站地图可以告诉搜索引擎爬虫爬取网站地图中的页面,有利于爬虫爬取整个网站页面。
2、网站地图可以添加其他页面的链接
网站地图本身就是一个聚合和导航页面。 网站地图可以添加到其他页面的链接,相当于给其他页面添加了投票和传递权重。对网站的排名和提升权重起到了很好的作用。这是网站在seo优化中不可忽视的重要作用的图。
3、网站地图可以有效提高收录率
整个网站
通过网站图可以提取所有页面,搜索引擎爬虫按照网站图上的链接逐一抓取,会提高整个收录的网站数量。
二、sitemap.xml如何制作
现在有了在线制作地图的工具网站,我们直接生成就行了,很简单。然后我们需要将创建好的网站映射上传到我们的网站的根目录下。站点地图可以改善 网站 页面抓取和 收录。
网页抓取 加密html(我有这个代码获取页面的HTML源代码:我想从中搜集一些内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-23 06:20
)
我有这段代码来获取页面的 HTML 源代码:
1$page = file_get_contents('http://example.com/page.html');
2$page = htmlentities($page);
3
我想从中采集一些内容。例如,假设页面的源收录:
1technorati.com
2Connection failedPinging icerocket.com
3Connection failedPinging weblogs.com
4DonePinging newsgator.com
5DonePinging blo.gs
6DonePinging feedburner.com
7DonePinging blogstreet.com
8DonePinging my.yahoo.com
9Connection failedPinging moreover.com
10Connection failedPinging newsisfree.com
11Done
12
有没有办法可以从源代码中删除它并将其存储在一个变量中,所以它看起来像这样:
连接失败
连接失败
完毕
等等。
因为页面是动态的,这就是我遇到问题的原因。我可以搜索源中的每个站点吗?但是那之后我如何得到结果呢?(连接失败/完成)
谢谢您的帮助!
我尝试使用简单的 HTML DOM PHP 库来抓取多个站点,可在此处获得:
然后使用这样的代码:
1find('h2') as $heading) { //for each heading
16 //find all spans with a inside then echo the found text out
17 echo preg_replace($pat, $rep, $heading->find('span a', 0)->plaintext) . "\n";
18}
19?>
20
这会导致类似:
15.8 Earthquake Hits East Coast of the US
2Origins of Lager Found In Argentina
3Inside Oregon State University's Open Source Lab
4WebAPI: Mozilla Proposes Open App Interface For Smartphones
5Using Tablets Becoming Popular Bathroom Activity
6The Syrian Government's Internet Strategy
7Deus Ex: Human Revolution Released
8Taken Over By Aliens? Google Has It Covered
9The GIMP Now Has a Working Single-Window Mode
10Zombie Cookies Just Won't Die
11Motorola's Most Important 18 Patents
12MK-1 Robotic Arm Capable of Near-Human Dexterity, Dancing
13Evangelical Scientists Debate Creation Story
14Android On HP TouchPad
15Google Street View Gets Israeli Government's Nod
16Internet Restored In Tripoli As Rebels Take Control
17GA Tech: Internet's Mid-Layers Vulnerable To Attack
18Serious Crypto Bug Found In PHP 5.3.7
19Twitter To Meet With UK Government About Riots
20EU Central Court Could Validate Software Patents
21 查看全部
网页抓取 加密html(我有这个代码获取页面的HTML源代码:我想从中搜集一些内容
)
我有这段代码来获取页面的 HTML 源代码:
1$page = file_get_contents('http://example.com/page.html');
2$page = htmlentities($page);
3
我想从中采集一些内容。例如,假设页面的源收录:
1technorati.com
2Connection failedPinging icerocket.com
3Connection failedPinging weblogs.com
4DonePinging newsgator.com
5DonePinging blo.gs
6DonePinging feedburner.com
7DonePinging blogstreet.com
8DonePinging my.yahoo.com
9Connection failedPinging moreover.com
10Connection failedPinging newsisfree.com
11Done
12
有没有办法可以从源代码中删除它并将其存储在一个变量中,所以它看起来像这样:
连接失败
连接失败
完毕
等等。
因为页面是动态的,这就是我遇到问题的原因。我可以搜索源中的每个站点吗?但是那之后我如何得到结果呢?(连接失败/完成)
谢谢您的帮助!
我尝试使用简单的 HTML DOM PHP 库来抓取多个站点,可在此处获得:
然后使用这样的代码:
1find('h2') as $heading) { //for each heading
16 //find all spans with a inside then echo the found text out
17 echo preg_replace($pat, $rep, $heading->find('span a', 0)->plaintext) . "\n";
18}
19?>
20
这会导致类似:
15.8 Earthquake Hits East Coast of the US
2Origins of Lager Found In Argentina
3Inside Oregon State University's Open Source Lab
4WebAPI: Mozilla Proposes Open App Interface For Smartphones
5Using Tablets Becoming Popular Bathroom Activity
6The Syrian Government's Internet Strategy
7Deus Ex: Human Revolution Released
8Taken Over By Aliens? Google Has It Covered
9The GIMP Now Has a Working Single-Window Mode
10Zombie Cookies Just Won't Die
11Motorola's Most Important 18 Patents
12MK-1 Robotic Arm Capable of Near-Human Dexterity, Dancing
13Evangelical Scientists Debate Creation Story
14Android On HP TouchPad
15Google Street View Gets Israeli Government's Nod
16Internet Restored In Tripoli As Rebels Take Control
17GA Tech: Internet's Mid-Layers Vulnerable To Attack
18Serious Crypto Bug Found In PHP 5.3.7
19Twitter To Meet With UK Government About Riots
20EU Central Court Could Validate Software Patents
21

