
网页抓取 加密html
网页抓取 加密html(在看廖雪峰老师的Python教程,常见内置模块HTMLParser )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-16 06:12
)
看廖雪峰老师的Python教程,常用内置模块HTMLParser:
作业:找一个网页,比如用浏览器查看源码并复制,然后尝试解析HTML输出Python官网公布的会议时间、名称和地点。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2017-06-01 09:08:30
# @Author : kk (zwk.patrick@foxmail.com)
# @Link : blog.csdn.net/PatrickZheng
import HTMLParser, urllib
class MyHTMLParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self._title = [False]
self._time =[False]
self._place = [False]
self.time = '' # 用于拼接时间
def _attr(self, attrlist, attrname):
for attr in attrlist:
if attr[0] == attrname:
return attr[1]
return None
def handle_starttag(self, tag, attrs):
#print('' % tag)
if tag == 'h3' and self._attr(attrs, 'class') == 'event-title':
self._title[0] = True
if tag == 'time':
self._time[0] = True
if tag == 'span' and self._attr(attrs, 'class') == 'event-location':
self._place[0] = True
def handle_endtag(self, tag):
# 结束拼接
if tag == 'time':
self._time.append(self.time) # 将time完整内容放入self._time
self.time = '' # 初始化 self.time
self._time[0] = False
def handle_startendtag(self, tag, attrs):
#print('' % tag)
pass
def handle_data(self, data):
#print('data: %s' % data)
if self._title[0] == True:
self._title.append(data)
self._title[0] = False
if self._time[0] == True:
self.time += data # 拼接time
if self._place[0] == True:
self._place.append(data)
self._place[0] = False
def handle_comment(self, comment):
#print('' % comment)
pass
def handle_entityref(self, name):
if self._time[0] == True:
self.time += '-' # &ndash -> '-'
def handle_charref(self, name):
#print('&#%s:' % name)
pass
def show_content(self):
for n in range(1, len(self._title)):
print 'Title: %s' % self._title[n]
print 'Time: %s' % self._time[n]
print 'Place: %s' % self._place[n]
print '--------------------------------------'
html = ''
try:
page = urllib.urlopen('https://www.python.org/events/ ... %2339;) # 打开网页
html = page.read() # 读取网页内容
finally:
page.close()
parser = MyHTMLParser()
parser.feed(html)
parser.show_content()
运行结果:
Title: PyCon Taiwan 2017
Time: 06 June - 12 June 2017
Place: Academia Sinica, 128 Academia Road, Section 2, Nankang, Taipei 11529, Taiwan
--------------------------------------
Title: PyCon CZ 2017
Time: 09 June - 12 June 2017
Place: Prague, Czechia
--------------------------------------
Title: PythonDay Mexico
Time: 10 June - 11 June 2017
Place: Isabel la Católica 51, Centro, 06010 Mexico City, Mexico
--------------------------------------
Title: PyParis 2017
Time: 12 June - 14 June 2017
Place: Paris, France
--------------------------------------
Title: PyCon Israel 2017
Time: 12 June - 15 June 2017
Place: Wahl Center, Max VeAnna Webb st., Ramat Gan, Israel
--------------------------------------
Title: PyData Berlin 2017
Time: 30 June - 03 July 2017
Place: Treskowallee 8, 10318 Berlin, Germany
--------------------------------------
Title: PyConWEB 2017
Time: 27 May - 29 May 2017
Place: Munich, Germany
--------------------------------------
Title: PyDataBCN 2017
Time: 19 May - 22 May 2017
Place: Barcelona, Spain
--------------------------------------
***Repl Closed*** 查看全部
网页抓取 加密html(在看廖雪峰老师的Python教程,常见内置模块HTMLParser
)
看廖雪峰老师的Python教程,常用内置模块HTMLParser:
作业:找一个网页,比如用浏览器查看源码并复制,然后尝试解析HTML输出Python官网公布的会议时间、名称和地点。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2017-06-01 09:08:30
# @Author : kk (zwk.patrick@foxmail.com)
# @Link : blog.csdn.net/PatrickZheng
import HTMLParser, urllib
class MyHTMLParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self._title = [False]
self._time =[False]
self._place = [False]
self.time = '' # 用于拼接时间
def _attr(self, attrlist, attrname):
for attr in attrlist:
if attr[0] == attrname:
return attr[1]
return None
def handle_starttag(self, tag, attrs):
#print('' % tag)
if tag == 'h3' and self._attr(attrs, 'class') == 'event-title':
self._title[0] = True
if tag == 'time':
self._time[0] = True
if tag == 'span' and self._attr(attrs, 'class') == 'event-location':
self._place[0] = True
def handle_endtag(self, tag):
# 结束拼接
if tag == 'time':
self._time.append(self.time) # 将time完整内容放入self._time
self.time = '' # 初始化 self.time
self._time[0] = False
def handle_startendtag(self, tag, attrs):
#print('' % tag)
pass
def handle_data(self, data):
#print('data: %s' % data)
if self._title[0] == True:
self._title.append(data)
self._title[0] = False
if self._time[0] == True:
self.time += data # 拼接time
if self._place[0] == True:
self._place.append(data)
self._place[0] = False
def handle_comment(self, comment):
#print('' % comment)
pass
def handle_entityref(self, name):
if self._time[0] == True:
self.time += '-' # &ndash -> '-'
def handle_charref(self, name):
#print('&#%s:' % name)
pass
def show_content(self):
for n in range(1, len(self._title)):
print 'Title: %s' % self._title[n]
print 'Time: %s' % self._time[n]
print 'Place: %s' % self._place[n]
print '--------------------------------------'
html = ''
try:
page = urllib.urlopen('https://www.python.org/events/ ... %2339;) # 打开网页
html = page.read() # 读取网页内容
finally:
page.close()
parser = MyHTMLParser()
parser.feed(html)
parser.show_content()
运行结果:
Title: PyCon Taiwan 2017
Time: 06 June - 12 June 2017
Place: Academia Sinica, 128 Academia Road, Section 2, Nankang, Taipei 11529, Taiwan
--------------------------------------
Title: PyCon CZ 2017
Time: 09 June - 12 June 2017
Place: Prague, Czechia
--------------------------------------
Title: PythonDay Mexico
Time: 10 June - 11 June 2017
Place: Isabel la Católica 51, Centro, 06010 Mexico City, Mexico
--------------------------------------
Title: PyParis 2017
Time: 12 June - 14 June 2017
Place: Paris, France
--------------------------------------
Title: PyCon Israel 2017
Time: 12 June - 15 June 2017
Place: Wahl Center, Max VeAnna Webb st., Ramat Gan, Israel
--------------------------------------
Title: PyData Berlin 2017
Time: 30 June - 03 July 2017
Place: Treskowallee 8, 10318 Berlin, Germany
--------------------------------------
Title: PyConWEB 2017
Time: 27 May - 29 May 2017
Place: Munich, Germany
--------------------------------------
Title: PyDataBCN 2017
Time: 19 May - 22 May 2017
Place: Barcelona, Spain
--------------------------------------
***Repl Closed***
网页抓取 加密html(五篇Node.js构建一个网站应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-15 20:31
2021-07-25
看了五篇关于 Node.js 的文章,你基本上可以开始构建一个 网站 应用了。首先,通过这篇文章学习一些关于构建网站的知识!
主要是基本的东西...
如何创建路由规则,如何提交表单并接收表单项的值,如何加密密码,如何提取页面的公共部分(相当于用户控件和母版页)等等……
让我们一步一步开始吧^_^!…
新建快递项目,自定义路由规则
1.先用命令行express+ejs创建一个项目sampleEjsPre
cd 工作目录
express -e sampleEjsPre
cd sampleEjsPre && npm install
2.默认情况下,routes 目录下会有 index.js 和 users.js 文件。为了避免示例之外的其他麻烦,删除user.js文件
3.打开app.js文件,删除以下两行代码
var users = require('./routes/users');
...
app.use('/users', users);
4.将以下代码添加到app.js文件中
var subform = require('./routes/subform');
var usesession = require('./routes/usesession');
var usecookies = require('./routes/usecookies');
var usecrypto = require('./routes/usecrypto');
...
app.use('/subform', subform);
app.use('/usesession', usesession);
app.use('/usecookies', usecookies);
app.use('/usecrypto', usecrypto);
通过URL访问后,根据路由规则先到哪个文件再到哪个文件的过程在上一篇文章(Nodejs学习笔记(五)---快递安装入口和模板引擎ejs)) 说了这么多,这里就不多说了!
5.在routes目录下添加subform.js、usesession.js、usecookies.js、usecrypto.js文件,并在对应的js文件中添加如下代码
子窗体.js
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res) {
res.render('subform', { title: '提交表单及接收参数示例' });
});
module.exports = router;
使用session.js
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res) {
res.render('usesession', { title: '使用session示例' });
});
module.exports = router;
使用cookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
使用crypto.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
res.render('usecrypto', { title: '加密字符串示例' });
});
module.exports = router;
6.views目录下添加subform.ejs、usesession.ejs、usecookies.ejs、usecrypto.ejs文件,views目录下除error.ejs外的所有ejs文件添加如下代码
首页
如何提交表单并接收参数?
如何使用session?
如何使用cookies?
如何字符串加密?
7.添加8000端口监听并在app.js中运行
...
app.listen(8000);
...
运行界面如下:
点击每个链接都可以正常跳转到对应的页面!这样,目录的第一步就到了!
如何提取页面中的公共部分?
上一步创建的 网站 中的每个页面都差不多,现在只有导航部分吗?你必须写每一页吗?当然不是,我们可以提取
1.在views目录下新建nav.ejs文件,添加如下代码
首页
如何提交表单并接收参数?
如何使用session?
如何使用cookies?
如何字符串加密?
2.将views目录下的index.ejs、subform.ejs、usesession.ejs、usecookies.ejs、usecrypto.ejs修改为如下代码
运行页面,发现和上次运行的时候并没有什么不同。采用这种方式,更有利于减少重复代码,更有利于统一布局!
Express 提供 include 嵌入其他页面,类似于 html 嵌入其他页面
如果你用过express2.0版本,你会发现当时并没有这个include,而是使用了一个模板文件layout.ejs来布局!
如何提交表单和接收参数?
如果要做一个网站应用,难免会遇到表单提交和获取参数值。让我们看看如何使用 node.js + express
我们先建一个表单来简单模拟登录GET方式提交数据
1.打开subform.ejs文件,修改文件代码如下:
用户名:
密码:
2.打开subform.js我们尝试接收参数值并输出到控制台
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
var
userName = req.query.txtUserName,
userPwd = req.query.txtUserPwd,
userName2 = req.param('txtUserName'),
userPwd2 = req.param('txtUserPwd');
console.log('req.query用户名:'+userName);
console.log('req.query密码:'+userPwd);
console.log('req.param用户名:'+userName2);
console.log('req.param密码:'+userPwd2);
res.render('subform', { title: '提交表单及接收参数示例' });
});
module.exports = router;
3.运行,并提交表单在浏览器中运行::8000/subform,输入表单项并提交,可以发现url变了
可以发现,在我的表单中输入和要提交的值出现在了url中!
我们再来看看控制台输出
我们完成了GET方法提交表单并收到了值,还不错^_^!(后面会讲取值的方法和区别)
然后在上面代码的基础上,修改form的方法,简单模拟登录POST方法提交数据
1.首先修改subform.ejs文件中的form标签如下:
...
2.在subform.js中添加代码,接收post提交,接收参数并输出到控制台
...
router.post('/',function(req, res){
var
userName = req.body.txtUserName,
userPwd = req.body.txtUserPwd,
userName2 = req.param('txtUserName'),
userPwd2 = req.param('txtUserPwd');
console.log('req.body用户名:'+userName);
console.log('req.body密码:'+userPwd);
console.log('req.param用户名:'+userName2);
console.log('req.param密码:'+userPwd2);
res.render('subform', { title: '提交表单及接收参数示例' });
});
...
3.运行,并提交表单在浏览器中运行::8000/subform,输入表单项并提交,可以发现url不会变
改成post方法后,你会发现form中输入的值和要提交的值不会像get方法提交一样出现在url中!
我们再来看看控制台输出
好的,我们已经完成了表单的发布和参数的接收!
我们回过头来看看接收值的 GET 和 POST 方法,从直接效果的角度来看
req.query:我用来接收GET提交参数
req.body:我用来接收 POST 提交的参数
req.params:都可以接收
我们看一下Express的Request部分的API:#req.params
这里我将重点讲解req.body。Express 通过中间件 bodyParser 处理这个 post 请求。可以看到app.js中有一段代码
...
var bodyParser = require('body-parser');
...
app.use(bodyParser.json());
app.use(bodyParser.urlencoded());
...
如果没有这个中间件 Express,我不知道如何处理这个请求。它通过 bodyParser 中间件分析 application/x-www-form-urlencoded 和 application/json 请求,并将变量存储在 req.body 中。只有这样我们才能得到它!
如何加密字符串?
当我们提交表单时,如密码等敏感信息,如果我们不对其进行加密,我们将不会认真对待用户的隐私信息。Node.js 提供加密模块 Crypto
让我们用一个例子
1.打开usecrypto.js,修改代码如下:
var express = require('express');
var router = express.Router();
var crypto = require('crypto');
/* GET home page. */
router.get('/', function(req, res) {
res.render('usecrypto', { title: '加密字符串示例' });
});
router.post('/',function(req, res){
var
userName = req.body.txtUserName,
userPwd = req.body.txtUserPwd;
//生成口令的散列值
var md5 = crypto.createHash('md5'); //crypto模块功能是加密并生成各种散列
var en_upwd = md5.update(userPwd).digest('hex');
console.log('加密后的密码:'+en_upwd);
res.render('usecrypto', { title: '加密字符串示例' });
});
module.exports = router;
2.打开usecrypto.ejs,修改代码如下
用户名:
密码:
3.运行,输入并提交表单,查看控制台输出
MD5加密成功!
使用 createHash(algorithm) 方法,该方法使用给定的算法生成哈希对象
Node.js 提供的加密模块非常强大。Hash算法提供MD5、sha1、sha256等,可根据需要使用
update(data, [input_encoding]) 方法可以通过指定的input_encoding和传入的data数据更新hash对象。'等待)
digest([encoding]) 方法计算数据的哈希摘要值。编码是一个可选参数。如果不通过,则返回一个缓冲区(编码可以是'hex'、'base64'等);当调用摘要方法时,哈希对象将不可用。;
如何使用会话?
Internet 通信协议分为两类:有状态和无状态。对web开发有一定了解的人应该都知道http是一种无状态协议。客户端向服务器发送请求以建立连接。请求响应后,连接中断,服务端不记录状态,所以服务端想
要确定哪个客户端提交了请求,必须借助一些东西来完成,即会话和cookie。下面说说nodejs下的session和使用session吧!
session存在于服务器端,需要cookies的协助才能完成;server端和client端通过session id建立连接(具体的session和cookies如何配合,可以自己补充一些相关知识,这里只简单提一下,不展开),否则这个文章会更复杂^_^!)
在express中,可以使用中间件来使用session,express-session()可以存在于内存中,也可以存在于mongodb、redis等...
更多中间件:
下面通过一个例子来看看如何使用session(内存模式)
示例设计思路:使用两个页面,一个登录,两个页面判断是否有这个会话,如果有,显示登录,如果没有,显示一个登录按钮,点击这个按钮记录会话
1.首先通过npm安装中间件,打开package.json文件,在dependencies节点下添加键值对 "express-session" : "latest"
"dependencies": {
...,
"express-session" : "latest"
}
最新的:最新的
2. cd 到项目根目录并执行 npm install
3.打开 app.js 并添加以下代码
var express = require('express');
var path = require('path');
var favicon = require('static-favicon');
var logger = require('morgan');
var cookieParser = require('cookie-parser');
var bodyParser = require('body-parser');
var session = require('express-session');
...
//这里传入了一个密钥加session id
app.use(cookieParser('Wilson'));
//使用靠就这个中间件
app.use(session({ secret: 'wilson'}));
...
这些选项就不做解释了,通过上面中间件的链接,自己看看
4.这里我以usesession和usecookies为例,修改js和ejs如下
usesession.ejs 和 usecookies.ejs
用户已登录
使用.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.session.islogin)
{
console.log('usesession:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usesession', { title: '使用session示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.render('usesession', { title: '使用session示例' });
});
module.exports = router;
使用cookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.session.islogin)
{
console.log('usecookies:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usecookies', { title: '使用cookies示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
5.运行查看
第一次运行时,查看两个页面,效果如下:
6.点击登录按钮后查看这两个页面
7.关闭浏览器再打开就可以看到这两个页面,如步骤5的截图所示
session使用成功!
官方示例:
如何使用cookies?
如果是登录,一般会使用“记录密码”或者“自动登录”功能,一般是通过cookies来完成
cookie存在于客户端,安全性较低。通常,应存储加密信息。建议设置使用过期时间或不使用时删除。
Express 也可以与中间件一起使用:
老套路,通过一个例子来了解一下
示例设计思路:在上述会话示例的基础上,登录并在usecookies部分记录cookies自动登录
1.根据上面的会话示例修改usecookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.cookies.islogin)
{
console.log('usecookies-cookies:' + req.cookies.islogin);
req.session.islogin = req.cookies.islogin;
}
if(req.session.islogin)
{
console.log('usecookies:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usecookies', { title: '使用cookies示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.cookie('islogin', 'sucess', { maxAge: 60000 });
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
2.运行访问:8000/usecookies,点击登录按钮登录成功并记录cookies
maxAge 是过期时间,单位是毫秒,我设置的是一分钟
3.关闭浏览器,再次访问:8000/usecookies,页面显示已登录
4.再次关闭浏览器,一分钟后再次访问:8000/usecookies,页面不再登录,但显示登录按钮,表示cookies已过期,不会自动登录
使用cookies也成功了!
官方示例:
如何清除会话和 cookie?
清算很简单,不用举例说明。如果您有兴趣定义自己的路由规则,请尝试
//清除cookies
res.clearCookie('islogin');
//清除session
req.session.destroy();
写在之后
文中提到的一些知识点,其实可以用一整篇文章来讨论。这篇文章的基本原则是看后能用;
如果想了解原理或更相关的知识,可以花点时间去了解,或者找一些资料丰富一下。当然,您也可以留言。如果我不认为我在胡说八道,我会尽力回答^_^!
本系列的源代码可供下载。 查看全部
网页抓取 加密html(五篇Node.js构建一个网站应用)
2021-07-25
看了五篇关于 Node.js 的文章,你基本上可以开始构建一个 网站 应用了。首先,通过这篇文章学习一些关于构建网站的知识!
主要是基本的东西...
如何创建路由规则,如何提交表单并接收表单项的值,如何加密密码,如何提取页面的公共部分(相当于用户控件和母版页)等等……
让我们一步一步开始吧^_^!…
新建快递项目,自定义路由规则
1.先用命令行express+ejs创建一个项目sampleEjsPre
cd 工作目录
express -e sampleEjsPre
cd sampleEjsPre && npm install
2.默认情况下,routes 目录下会有 index.js 和 users.js 文件。为了避免示例之外的其他麻烦,删除user.js文件
3.打开app.js文件,删除以下两行代码
var users = require('./routes/users');
...
app.use('/users', users);
4.将以下代码添加到app.js文件中
var subform = require('./routes/subform');
var usesession = require('./routes/usesession');
var usecookies = require('./routes/usecookies');
var usecrypto = require('./routes/usecrypto');
...
app.use('/subform', subform);
app.use('/usesession', usesession);
app.use('/usecookies', usecookies);
app.use('/usecrypto', usecrypto);
通过URL访问后,根据路由规则先到哪个文件再到哪个文件的过程在上一篇文章(Nodejs学习笔记(五)---快递安装入口和模板引擎ejs)) 说了这么多,这里就不多说了!
5.在routes目录下添加subform.js、usesession.js、usecookies.js、usecrypto.js文件,并在对应的js文件中添加如下代码
子窗体.js
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res) {
res.render('subform', { title: '提交表单及接收参数示例' });
});
module.exports = router;
使用session.js
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res) {
res.render('usesession', { title: '使用session示例' });
});
module.exports = router;
使用cookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
使用crypto.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
res.render('usecrypto', { title: '加密字符串示例' });
});
module.exports = router;
6.views目录下添加subform.ejs、usesession.ejs、usecookies.ejs、usecrypto.ejs文件,views目录下除error.ejs外的所有ejs文件添加如下代码
首页
如何提交表单并接收参数?
如何使用session?
如何使用cookies?
如何字符串加密?
7.添加8000端口监听并在app.js中运行
...
app.listen(8000);
...
运行界面如下:
点击每个链接都可以正常跳转到对应的页面!这样,目录的第一步就到了!
如何提取页面中的公共部分?
上一步创建的 网站 中的每个页面都差不多,现在只有导航部分吗?你必须写每一页吗?当然不是,我们可以提取
1.在views目录下新建nav.ejs文件,添加如下代码
首页
如何提交表单并接收参数?
如何使用session?
如何使用cookies?
如何字符串加密?
2.将views目录下的index.ejs、subform.ejs、usesession.ejs、usecookies.ejs、usecrypto.ejs修改为如下代码
运行页面,发现和上次运行的时候并没有什么不同。采用这种方式,更有利于减少重复代码,更有利于统一布局!
Express 提供 include 嵌入其他页面,类似于 html 嵌入其他页面
如果你用过express2.0版本,你会发现当时并没有这个include,而是使用了一个模板文件layout.ejs来布局!
如何提交表单和接收参数?
如果要做一个网站应用,难免会遇到表单提交和获取参数值。让我们看看如何使用 node.js + express
我们先建一个表单来简单模拟登录GET方式提交数据
1.打开subform.ejs文件,修改文件代码如下:
用户名:
密码:
2.打开subform.js我们尝试接收参数值并输出到控制台
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
var
userName = req.query.txtUserName,
userPwd = req.query.txtUserPwd,
userName2 = req.param('txtUserName'),
userPwd2 = req.param('txtUserPwd');
console.log('req.query用户名:'+userName);
console.log('req.query密码:'+userPwd);
console.log('req.param用户名:'+userName2);
console.log('req.param密码:'+userPwd2);
res.render('subform', { title: '提交表单及接收参数示例' });
});
module.exports = router;
3.运行,并提交表单在浏览器中运行::8000/subform,输入表单项并提交,可以发现url变了
可以发现,在我的表单中输入和要提交的值出现在了url中!
我们再来看看控制台输出
我们完成了GET方法提交表单并收到了值,还不错^_^!(后面会讲取值的方法和区别)
然后在上面代码的基础上,修改form的方法,简单模拟登录POST方法提交数据
1.首先修改subform.ejs文件中的form标签如下:
...
2.在subform.js中添加代码,接收post提交,接收参数并输出到控制台
...
router.post('/',function(req, res){
var
userName = req.body.txtUserName,
userPwd = req.body.txtUserPwd,
userName2 = req.param('txtUserName'),
userPwd2 = req.param('txtUserPwd');
console.log('req.body用户名:'+userName);
console.log('req.body密码:'+userPwd);
console.log('req.param用户名:'+userName2);
console.log('req.param密码:'+userPwd2);
res.render('subform', { title: '提交表单及接收参数示例' });
});
...
3.运行,并提交表单在浏览器中运行::8000/subform,输入表单项并提交,可以发现url不会变
改成post方法后,你会发现form中输入的值和要提交的值不会像get方法提交一样出现在url中!
我们再来看看控制台输出
好的,我们已经完成了表单的发布和参数的接收!
我们回过头来看看接收值的 GET 和 POST 方法,从直接效果的角度来看
req.query:我用来接收GET提交参数
req.body:我用来接收 POST 提交的参数
req.params:都可以接收
我们看一下Express的Request部分的API:#req.params
这里我将重点讲解req.body。Express 通过中间件 bodyParser 处理这个 post 请求。可以看到app.js中有一段代码
...
var bodyParser = require('body-parser');
...
app.use(bodyParser.json());
app.use(bodyParser.urlencoded());
...
如果没有这个中间件 Express,我不知道如何处理这个请求。它通过 bodyParser 中间件分析 application/x-www-form-urlencoded 和 application/json 请求,并将变量存储在 req.body 中。只有这样我们才能得到它!
如何加密字符串?
当我们提交表单时,如密码等敏感信息,如果我们不对其进行加密,我们将不会认真对待用户的隐私信息。Node.js 提供加密模块 Crypto
让我们用一个例子
1.打开usecrypto.js,修改代码如下:
var express = require('express');
var router = express.Router();
var crypto = require('crypto');
/* GET home page. */
router.get('/', function(req, res) {
res.render('usecrypto', { title: '加密字符串示例' });
});
router.post('/',function(req, res){
var
userName = req.body.txtUserName,
userPwd = req.body.txtUserPwd;
//生成口令的散列值
var md5 = crypto.createHash('md5'); //crypto模块功能是加密并生成各种散列
var en_upwd = md5.update(userPwd).digest('hex');
console.log('加密后的密码:'+en_upwd);
res.render('usecrypto', { title: '加密字符串示例' });
});
module.exports = router;
2.打开usecrypto.ejs,修改代码如下
用户名:
密码:
3.运行,输入并提交表单,查看控制台输出
MD5加密成功!
使用 createHash(algorithm) 方法,该方法使用给定的算法生成哈希对象
Node.js 提供的加密模块非常强大。Hash算法提供MD5、sha1、sha256等,可根据需要使用
update(data, [input_encoding]) 方法可以通过指定的input_encoding和传入的data数据更新hash对象。'等待)
digest([encoding]) 方法计算数据的哈希摘要值。编码是一个可选参数。如果不通过,则返回一个缓冲区(编码可以是'hex'、'base64'等);当调用摘要方法时,哈希对象将不可用。;
如何使用会话?
Internet 通信协议分为两类:有状态和无状态。对web开发有一定了解的人应该都知道http是一种无状态协议。客户端向服务器发送请求以建立连接。请求响应后,连接中断,服务端不记录状态,所以服务端想
要确定哪个客户端提交了请求,必须借助一些东西来完成,即会话和cookie。下面说说nodejs下的session和使用session吧!
session存在于服务器端,需要cookies的协助才能完成;server端和client端通过session id建立连接(具体的session和cookies如何配合,可以自己补充一些相关知识,这里只简单提一下,不展开),否则这个文章会更复杂^_^!)
在express中,可以使用中间件来使用session,express-session()可以存在于内存中,也可以存在于mongodb、redis等...
更多中间件:
下面通过一个例子来看看如何使用session(内存模式)
示例设计思路:使用两个页面,一个登录,两个页面判断是否有这个会话,如果有,显示登录,如果没有,显示一个登录按钮,点击这个按钮记录会话
1.首先通过npm安装中间件,打开package.json文件,在dependencies节点下添加键值对 "express-session" : "latest"
"dependencies": {
...,
"express-session" : "latest"
}
最新的:最新的
2. cd 到项目根目录并执行 npm install
3.打开 app.js 并添加以下代码
var express = require('express');
var path = require('path');
var favicon = require('static-favicon');
var logger = require('morgan');
var cookieParser = require('cookie-parser');
var bodyParser = require('body-parser');
var session = require('express-session');
...
//这里传入了一个密钥加session id
app.use(cookieParser('Wilson'));
//使用靠就这个中间件
app.use(session({ secret: 'wilson'}));
...
这些选项就不做解释了,通过上面中间件的链接,自己看看
4.这里我以usesession和usecookies为例,修改js和ejs如下
usesession.ejs 和 usecookies.ejs
用户已登录
使用.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.session.islogin)
{
console.log('usesession:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usesession', { title: '使用session示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.render('usesession', { title: '使用session示例' });
});
module.exports = router;
使用cookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.session.islogin)
{
console.log('usecookies:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usecookies', { title: '使用cookies示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
5.运行查看
第一次运行时,查看两个页面,效果如下:
6.点击登录按钮后查看这两个页面
7.关闭浏览器再打开就可以看到这两个页面,如步骤5的截图所示
session使用成功!
官方示例:
如何使用cookies?
如果是登录,一般会使用“记录密码”或者“自动登录”功能,一般是通过cookies来完成
cookie存在于客户端,安全性较低。通常,应存储加密信息。建议设置使用过期时间或不使用时删除。
Express 也可以与中间件一起使用:
老套路,通过一个例子来了解一下
示例设计思路:在上述会话示例的基础上,登录并在usecookies部分记录cookies自动登录
1.根据上面的会话示例修改usecookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.cookies.islogin)
{
console.log('usecookies-cookies:' + req.cookies.islogin);
req.session.islogin = req.cookies.islogin;
}
if(req.session.islogin)
{
console.log('usecookies:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usecookies', { title: '使用cookies示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.cookie('islogin', 'sucess', { maxAge: 60000 });
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
2.运行访问:8000/usecookies,点击登录按钮登录成功并记录cookies
maxAge 是过期时间,单位是毫秒,我设置的是一分钟
3.关闭浏览器,再次访问:8000/usecookies,页面显示已登录
4.再次关闭浏览器,一分钟后再次访问:8000/usecookies,页面不再登录,但显示登录按钮,表示cookies已过期,不会自动登录
使用cookies也成功了!
官方示例:
如何清除会话和 cookie?
清算很简单,不用举例说明。如果您有兴趣定义自己的路由规则,请尝试
//清除cookies
res.clearCookie('islogin');
//清除session
req.session.destroy();
写在之后
文中提到的一些知识点,其实可以用一整篇文章来讨论。这篇文章的基本原则是看后能用;
如果想了解原理或更相关的知识,可以花点时间去了解,或者找一些资料丰富一下。当然,您也可以留言。如果我不认为我在胡说八道,我会尽力回答^_^!
本系列的源代码可供下载。
网页抓取 加密html(谷歌网页抓取加密html程序教程:打开谷歌抓取sso模式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-11 10:02
网页抓取加密html程序教程:1.打开谷歌网页抓取sso模式在第三步,你将向服务器交付一个token,然后服务器将在本地安装一个https加密驱动2.验证https加密驱动内部工作原理:系统会动态的生成加密密钥,它会解密请求来源,解密后生成一个类似于https加密机制,然后认证,如果是网页,就返回一个数字,如果是html文档,返回的将是一个html文件的加密密钥。
然后使用这个加密密钥加密html文件(html代码),直到解密机解密成功。再次验证加密密钥,然后发送解密解密时使用的密钥。3.提交https密钥,交付加密密钥验证完加密机制,使用https验证码:证书信息,rsa或者gm04可以验证证书的原始密钥,给安全系统存根加密数据,看看正确不正确也可以在https代码中验证网页是否通过验证,例如,在eth/pocket/thehotminegroup/pocket_store中的使用server.ssl::ssl_exceptions函数验证ssl证书4.浏览器代理验证在浏览器中编写代理,验证加密密钥,发送解密之后的html。
5.https密钥发送发送的形式为:phpinfo--->https_msg\string\decrypt_permit\file\authorization(即"ssl")phpinfo--->https_msg\exec..\route\https\ssl\phpinfo\user\ssl_cookie\file\https\msg\phpinfo\exec\https\ssl\exec..\authorization(即"file")即"xx.php"。验证内容即为"您是否连接成功."。 查看全部
网页抓取 加密html(谷歌网页抓取加密html程序教程:打开谷歌抓取sso模式)
网页抓取加密html程序教程:1.打开谷歌网页抓取sso模式在第三步,你将向服务器交付一个token,然后服务器将在本地安装一个https加密驱动2.验证https加密驱动内部工作原理:系统会动态的生成加密密钥,它会解密请求来源,解密后生成一个类似于https加密机制,然后认证,如果是网页,就返回一个数字,如果是html文档,返回的将是一个html文件的加密密钥。
然后使用这个加密密钥加密html文件(html代码),直到解密机解密成功。再次验证加密密钥,然后发送解密解密时使用的密钥。3.提交https密钥,交付加密密钥验证完加密机制,使用https验证码:证书信息,rsa或者gm04可以验证证书的原始密钥,给安全系统存根加密数据,看看正确不正确也可以在https代码中验证网页是否通过验证,例如,在eth/pocket/thehotminegroup/pocket_store中的使用server.ssl::ssl_exceptions函数验证ssl证书4.浏览器代理验证在浏览器中编写代理,验证加密密钥,发送解密之后的html。
5.https密钥发送发送的形式为:phpinfo--->https_msg\string\decrypt_permit\file\authorization(即"ssl")phpinfo--->https_msg\exec..\route\https\ssl\phpinfo\user\ssl_cookie\file\https\msg\phpinfo\exec\https\ssl\exec..\authorization(即"file")即"xx.php"。验证内容即为"您是否连接成功."。
网页抓取 加密html(逆向目标逆向过程分析(二)分析及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-11 08:18
本文章所有内容仅供学习交流。抓取到的内容、敏感URL、数据接口都进行了脱敏处理。严禁商业用途和非法使用。否则由此产生的一切后果与作者无关。,如有侵权,请联系我立即删除!
反向目标逆过程抓包分析
这次要反转的对象与以往不同。不是某个界面的参数,而是网页中的数据。一般网页中的数据可以在源代码中看到,或者通过一个接口传递,而这次目标的数据是通过JS加密获得的。我们先抓包看一下基本情况:
用F12查看,可以看到我们要的数据在textarea标签里,好像没有错,然后直接用Xpath解压试试:
import requests
from lxml import etree
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
data = tree.xpath('//textarea/text()')
print(data)
可以看到提取出来的数据其实是空的。我们查看网页的源代码,直接搜索textarea,同样不可用。尝试直接搜索数据。
加密反向
由于网页源代码中不存在这种数据,也不是通过其他接口返回的,很有可能是经过JS加密后直接插入到网页源代码中的,那么如何在这里找到加密位置?对比插入数据后的网页源代码和不插入数据的网页源代码,可以看到蓝框内的代码是通过js插入的,100个8.js大部分都是加密的JS 文件:
在这里,我们想到了一种 JavaScript 语法。如果要从 JavaScript 访问 HTML 元素,可以使用 document.getElementById(id) 方法。这个id是一个HTML元素的属性,然后使用innerHTML来获取或者插入元素的内容。可以看菜鸟教程的一个例子:
通过这个语法,结合前面源码中的几个标签,我们可以猜想一个JS中可能有这样的语句:document.getElementById("tehai").innerHTML, document.getElementById("tips")。innerHTML,document.getElementById("m2").innerHTML,可以直接全局搜索这些语句中的任何一个,在1008.js中可以找到对应的结果。当然,你也可以直接搜索这个标签的id来找到结果。埋下断点进行调试:
您可以找到第 913 行 document.getElementById("m2").innerHTML = d + "
"就是在m2标签中插入值d和换行符,一步步查找,可以发现d里面收录了很多html的东西,而上面的g只是文本,正好是目标数据,那么我们终于直接退货了。好吧。
继续追踪g值的出处,你会发现步骤比较复杂,那我们直接复制这部分函数(fa函数)运行调试(大约794行到914行),本地调试会提示ga和O是未定义的,我们在其定义语句的下一行埋下断点进行调试,可以看到ga的值其实是一个固定的q,而O是URL后面的q的值,如:336m237p2479s167z3s
这两个变量定义好后,再本地调试,会提示aa、ca等函数未定义,依赖函数很多。这种情况下就不用一一扣除了,fa之前的所有函数都直接复制调试就好了,直接解决了所有的依赖。
完整代码
GitHub关注K哥的爬虫,持续分享爬虫相关代码!欢迎明星!
以下仅演示部分关键代码,完整代码仓库地址:
Key JS 加密代码架构
// Copyrights C-EGG inc.
var u = function () {}();
function w() {}
w.prototype = {};
function x(b, a, g, d) {}
// 此处省略 N 个函数
function M(b) {}
function N(b, a) {}
function ea(b) {}
function fa(O) {
function b(a, b) {
var c, d = 0;
for (c = 0; c < a.length; ++c) d += 4 - b[a[c]];
return d
}
// var a = ga, g = O, d;
var a = 'q', g = O, d;
d = "";
switch (a.substr(0, 1)) {
case "q":
d += '標準形(七対国士を含む)の計算結果 / 一般形
';
break;
case "p":
d += '一般形(七対国士を含まない)の計算結果 / 標準形
'
}
for (var c = "d" == a.substr(1, 1), a = a.substr(0, 1), g = g.replace(/(\d)(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{8})(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(\d?)(\d?)(\d?)(\d?)(\d?)(\d?)(\d)(\d)(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(m|p|s|z)(m|p|s|z)+/g, "$1").replace(/^[^\d]/, ""), g = g.substr(0, 28), f = aa(g), r = -1; r = Math.floor(136 * Math.random()), f[r];) ;
var m = Math.floor(g.length / 2) % 3;
2 == m || c || (f[r] = 1, g += H(r));
var f = ca(f),
n = "",
e = G(f, 34),
n = n + N(e, 28 == g.length),
n = n + ("(" + Math.floor(g.length / 2) + "枚)");
-1 == e[0] && (n += ' / 新しい手牌を作成');
var n = n + "
",
q = "q" == a ? e[0] : e[1],
k,
p,
l = Array(35);
if (0 == q && 1 == m && c) k = 34,
l[k] = K(f),
l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
});
else if (0 >= q) for (k = 0; 34 > k; ++k) f[k] && (f[k]--, l[k] = K(f), f[k]++, l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
}));
else if (2 == m || 1 == m && !c) for (k = 0; 34 > k; ++k) {
if (f[k]) {
f[k]--;
l[k] = [];
for (p = 0; 34 > p; ++p) k == p || 4 p; ++p) 4 = q ? "待ち" : "摸";
for (k = 0; k < t.length; ++k) {
v = t[k].i;
d += "";
34 > v && (d += "打" + ('') + "", g += "打" + H(4 * v + 1) + " ");
d += q + "[";
g += q + "[";
l = t[k].c;
c = t[k].q;
for (p = 0; p < l.length; ++p) r = H(4 * l[p] + 1),
d += '',
g += H(4 * l[p] + 1);
d += "" + t[k].n + "枚]";
g += " " + t[k].n + "枚]\n"
}
d = d + "
" + ('' + g + "");
-1 == e[0] && (d = d + "" + ea(f));
// document.getElementById("tehai").innerHTML = n;
// document.getElementById("tips").innerHTML = "";
// document.getElementById("m2").innerHTML = d + "
"
return g
}
// 测试样例
// console.log(fa('336m237p2479s167z3s'))
Python代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import execjs
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
def main():
q = url.split('=')[1]
with open('decrypt.js', 'r', encoding='utf-8') as f:
decrypt_js = f.read()
data = execjs.compile(decrypt_js).call('fa', q)
print(data)
if __name__ == '__main__':
main()
分类:
技术要点:
相关文章: 查看全部
网页抓取 加密html(逆向目标逆向过程分析(二)分析及应用)
本文章所有内容仅供学习交流。抓取到的内容、敏感URL、数据接口都进行了脱敏处理。严禁商业用途和非法使用。否则由此产生的一切后果与作者无关。,如有侵权,请联系我立即删除!
反向目标逆过程抓包分析
这次要反转的对象与以往不同。不是某个界面的参数,而是网页中的数据。一般网页中的数据可以在源代码中看到,或者通过一个接口传递,而这次目标的数据是通过JS加密获得的。我们先抓包看一下基本情况:
用F12查看,可以看到我们要的数据在textarea标签里,好像没有错,然后直接用Xpath解压试试:
import requests
from lxml import etree
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
data = tree.xpath('//textarea/text()')
print(data)
可以看到提取出来的数据其实是空的。我们查看网页的源代码,直接搜索textarea,同样不可用。尝试直接搜索数据。
加密反向
由于网页源代码中不存在这种数据,也不是通过其他接口返回的,很有可能是经过JS加密后直接插入到网页源代码中的,那么如何在这里找到加密位置?对比插入数据后的网页源代码和不插入数据的网页源代码,可以看到蓝框内的代码是通过js插入的,100个8.js大部分都是加密的JS 文件:
在这里,我们想到了一种 JavaScript 语法。如果要从 JavaScript 访问 HTML 元素,可以使用 document.getElementById(id) 方法。这个id是一个HTML元素的属性,然后使用innerHTML来获取或者插入元素的内容。可以看菜鸟教程的一个例子:
通过这个语法,结合前面源码中的几个标签,我们可以猜想一个JS中可能有这样的语句:document.getElementById("tehai").innerHTML, document.getElementById("tips")。innerHTML,document.getElementById("m2").innerHTML,可以直接全局搜索这些语句中的任何一个,在1008.js中可以找到对应的结果。当然,你也可以直接搜索这个标签的id来找到结果。埋下断点进行调试:
您可以找到第 913 行 document.getElementById("m2").innerHTML = d + "
"就是在m2标签中插入值d和换行符,一步步查找,可以发现d里面收录了很多html的东西,而上面的g只是文本,正好是目标数据,那么我们终于直接退货了。好吧。
继续追踪g值的出处,你会发现步骤比较复杂,那我们直接复制这部分函数(fa函数)运行调试(大约794行到914行),本地调试会提示ga和O是未定义的,我们在其定义语句的下一行埋下断点进行调试,可以看到ga的值其实是一个固定的q,而O是URL后面的q的值,如:336m237p2479s167z3s
这两个变量定义好后,再本地调试,会提示aa、ca等函数未定义,依赖函数很多。这种情况下就不用一一扣除了,fa之前的所有函数都直接复制调试就好了,直接解决了所有的依赖。
完整代码
GitHub关注K哥的爬虫,持续分享爬虫相关代码!欢迎明星!
以下仅演示部分关键代码,完整代码仓库地址:
Key JS 加密代码架构
// Copyrights C-EGG inc.
var u = function () {}();
function w() {}
w.prototype = {};
function x(b, a, g, d) {}
// 此处省略 N 个函数
function M(b) {}
function N(b, a) {}
function ea(b) {}
function fa(O) {
function b(a, b) {
var c, d = 0;
for (c = 0; c < a.length; ++c) d += 4 - b[a[c]];
return d
}
// var a = ga, g = O, d;
var a = 'q', g = O, d;
d = "";
switch (a.substr(0, 1)) {
case "q":
d += '標準形(七対国士を含む)の計算結果 / 一般形
';
break;
case "p":
d += '一般形(七対国士を含まない)の計算結果 / 標準形
'
}
for (var c = "d" == a.substr(1, 1), a = a.substr(0, 1), g = g.replace(/(\d)(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{8})(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(\d?)(\d?)(\d?)(\d?)(\d?)(\d?)(\d)(\d)(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(m|p|s|z)(m|p|s|z)+/g, "$1").replace(/^[^\d]/, ""), g = g.substr(0, 28), f = aa(g), r = -1; r = Math.floor(136 * Math.random()), f[r];) ;
var m = Math.floor(g.length / 2) % 3;
2 == m || c || (f[r] = 1, g += H(r));
var f = ca(f),
n = "",
e = G(f, 34),
n = n + N(e, 28 == g.length),
n = n + ("(" + Math.floor(g.length / 2) + "枚)");
-1 == e[0] && (n += ' / 新しい手牌を作成');
var n = n + "
",
q = "q" == a ? e[0] : e[1],
k,
p,
l = Array(35);
if (0 == q && 1 == m && c) k = 34,
l[k] = K(f),
l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
});
else if (0 >= q) for (k = 0; 34 > k; ++k) f[k] && (f[k]--, l[k] = K(f), f[k]++, l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
}));
else if (2 == m || 1 == m && !c) for (k = 0; 34 > k; ++k) {
if (f[k]) {
f[k]--;
l[k] = [];
for (p = 0; 34 > p; ++p) k == p || 4 p; ++p) 4 = q ? "待ち" : "摸";
for (k = 0; k < t.length; ++k) {
v = t[k].i;
d += "";
34 > v && (d += "打" + ('
 + '.gif) ') + "", g += "打" + H(4 * v + 1) + " ");
') + "", g += "打" + H(4 * v + 1) + " ");d += q + "[";
g += q + "[";
l = t[k].c;
c = t[k].q;
for (p = 0; p < l.length; ++p) r = H(4 * l[p] + 1),
d += '
 ',
',g += H(4 * l[p] + 1);
d += "" + t[k].n + "枚]";
g += " " + t[k].n + "枚]\n"
}
d = d + "
" + ('' + g + "");
-1 == e[0] && (d = d + "" + ea(f));
// document.getElementById("tehai").innerHTML = n;
// document.getElementById("tips").innerHTML = "";
// document.getElementById("m2").innerHTML = d + "
"
return g
}
// 测试样例
// console.log(fa('336m237p2479s167z3s'))
Python代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import execjs
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
def main():
q = url.split('=')[1]
with open('decrypt.js', 'r', encoding='utf-8') as f:
decrypt_js = f.read()
data = execjs.compile(decrypt_js).call('fa', q)
print(data)
if __name__ == '__main__':
main()
分类:
技术要点:
相关文章:
网页抓取 加密html(分析网页内容()原网址_分析_e操盘(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-10 15:07
分析网页内容
原网址:
大家在爬网页的时候会遇到各种问题,比如字体加密,但是我爬公众评论网站的时候发现里面的字体和文字没有加密不同,使用css定位来显示需要的文字和数字,如图:
只显示跨度标签和类,没有数字信息。
通过查看css信息,你会发现里面有一个URL,
打开网站,发现里面有数字信息,用来显示价格等信息。
查看元素的反复对比,发现css定位是用来展示需要的信息,span标签中class的定位,
我知道如何解析它,然后如何获取该类在span中的定位信息。直接从页面抓取不是很明显,只能另寻他法。
刚查了一下页面的源码,发现这个网站,有这么一个注释,发现服务器里也加载了下面的css样式,然后访问了一下,有惊喜
访问 css 网址
里面的信息正是我们想要的,
这样我们就可以编写代码来通过解析这两个 URL 来解密文本和数字,
写代码解密
这里我就简单写一下具体的解密过程,所以写的代码不是很规范,并没有爬取整个网页。
根据上面的分析,我们需要先获取span标签中的class。我们以上面两个例子为例来演示解密:
# 9
# 5
根据类名,如:hkcc8,获取类名的定位值
# 导的包
import re
import requests
import lxml.html
# 获取css页面的详情信息,用正则匹配得到css的定位数据
def css_info(info):
# css 页面 这个网址是会变化的,修改为自己获取到的
css_html = requests.get('https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/6c3897952c363a4c22712329d2ff2e93.css').text
# mty2pe{background:-180.0px -1664.0px;}
# 正则,这里有个坑,刚开始使用+拼接,不能匹配
str_css = r'%s{background:-(\d+).0px -(\d+).0px'% info
css_re = re.compile(str_css)
info_css = css_re.findall(css_html)
# print(css_html)
# print(str_css)
# print(info_css)
return info_css
输入:hkcc8 结果:475 64
接下来解析号码的url
<p>result = requests.get('https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/d32298136aa6a4b7715bd2d11b41727c.svg')
tree = lxml.html.fromstring(result.content)
a = tree.xpath('//text[@y="41"]/text()')[0]
b = tree.xpath('//text[@y="88"]/text()')[0]
c = tree.xpath('//text[@y="126"]/text()')[0]
# x ,y 是得到的两个坐标点
# 调用上面的函数
x,y = css_info('hkcc8')[0]
x,y = int(x),int(y)
print('坐标',x,y)
if y 查看全部
网页抓取 加密html(分析网页内容()原网址_分析_e操盘(图))
分析网页内容
原网址:
大家在爬网页的时候会遇到各种问题,比如字体加密,但是我爬公众评论网站的时候发现里面的字体和文字没有加密不同,使用css定位来显示需要的文字和数字,如图:

只显示跨度标签和类,没有数字信息。
通过查看css信息,你会发现里面有一个URL,

打开网站,发现里面有数字信息,用来显示价格等信息。

查看元素的反复对比,发现css定位是用来展示需要的信息,span标签中class的定位,

我知道如何解析它,然后如何获取该类在span中的定位信息。直接从页面抓取不是很明显,只能另寻他法。
刚查了一下页面的源码,发现这个网站,有这么一个注释,发现服务器里也加载了下面的css样式,然后访问了一下,有惊喜

访问 css 网址

里面的信息正是我们想要的,
这样我们就可以编写代码来通过解析这两个 URL 来解密文本和数字,
写代码解密
这里我就简单写一下具体的解密过程,所以写的代码不是很规范,并没有爬取整个网页。
根据上面的分析,我们需要先获取span标签中的class。我们以上面两个例子为例来演示解密:
# 9
# 5
根据类名,如:hkcc8,获取类名的定位值
# 导的包
import re
import requests
import lxml.html
# 获取css页面的详情信息,用正则匹配得到css的定位数据
def css_info(info):
# css 页面 这个网址是会变化的,修改为自己获取到的
css_html = requests.get('https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/6c3897952c363a4c22712329d2ff2e93.css').text
# mty2pe{background:-180.0px -1664.0px;}
# 正则,这里有个坑,刚开始使用+拼接,不能匹配
str_css = r'%s{background:-(\d+).0px -(\d+).0px'% info
css_re = re.compile(str_css)
info_css = css_re.findall(css_html)
# print(css_html)
# print(str_css)
# print(info_css)
return info_css
输入:hkcc8 结果:475 64
接下来解析号码的url
<p>result = requests.get('https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/d32298136aa6a4b7715bd2d11b41727c.svg')
tree = lxml.html.fromstring(result.content)
a = tree.xpath('//text[@y="41"]/text()')[0]
b = tree.xpath('//text[@y="88"]/text()')[0]
c = tree.xpath('//text[@y="126"]/text()')[0]
# x ,y 是得到的两个坐标点
# 调用上面的函数
x,y = css_info('hkcc8')[0]
x,y = int(x),int(y)
print('坐标',x,y)
if y
网页抓取 加密html(百度搜索引擎https站点如何建设才能对百度友好友好? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-10 01:32
)
大家都知道百度等搜索引擎无法识别https页面。很多朋友需要为网站建立安全的传输方式,但又担心网站的收录不好。所以现在百度官方给了我们答案,以下是百度站长平台发布的《如何建立一个对百度友好的HTTPS站点》全文:
百度搜索引擎目前并没有主动抓取 https 网页,所以大部分 https 网页不能是收录。但是如果网站必须使用https加密协议,怎么对百度搜索引擎友好呢?其实很简单:
1.为需要百度搜索引擎收录搜索的https页面制作http无障碍版本。
2.通过user-agent判断访问者,将Baiduspider引导到http页面。普通用户通过百度搜索引擎访问页面时,会通过301重定向到对应的https页面。如图,上图是http版的百度收录,下图是用户点击后会自动跳转到https版本。
3、http版不只为首页制作。其他重要页面也需要制作http版本,并相互链接。这不应该发生:首页http页面上的链接仍然链接到https页面,导致Baiduspider无法继续爬取——我们遇到过这样的情况,整个首页只能收录一个首页网络。
执行以下操作是错误的:链接
4、一些不需要加密的内容,比如信息,可以通过二级域名承载。比如支付宝网站,核心加密内容放在https上,百度蜘蛛可以直接抓到的内容放在二级域名上。
查看全部
网页抓取 加密html(百度搜索引擎https站点如何建设才能对百度友好友好?
)
大家都知道百度等搜索引擎无法识别https页面。很多朋友需要为网站建立安全的传输方式,但又担心网站的收录不好。所以现在百度官方给了我们答案,以下是百度站长平台发布的《如何建立一个对百度友好的HTTPS站点》全文:
百度搜索引擎目前并没有主动抓取 https 网页,所以大部分 https 网页不能是收录。但是如果网站必须使用https加密协议,怎么对百度搜索引擎友好呢?其实很简单:
1.为需要百度搜索引擎收录搜索的https页面制作http无障碍版本。
2.通过user-agent判断访问者,将Baiduspider引导到http页面。普通用户通过百度搜索引擎访问页面时,会通过301重定向到对应的https页面。如图,上图是http版的百度收录,下图是用户点击后会自动跳转到https版本。


3、http版不只为首页制作。其他重要页面也需要制作http版本,并相互链接。这不应该发生:首页http页面上的链接仍然链接到https页面,导致Baiduspider无法继续爬取——我们遇到过这样的情况,整个首页只能收录一个首页网络。
执行以下操作是错误的:链接
4、一些不需要加密的内容,比如信息,可以通过二级域名承载。比如支付宝网站,核心加密内容放在https上,百度蜘蛛可以直接抓到的内容放在二级域名上。

网页抓取 加密html( JS加密解密混合运算100题计算机一级题库二元一次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-09 09:31
JS加密解密混合运算100题计算机一级题库二元一次)
如域名所有者域名Registrar域名注册日期和到期日期等。通过域名的Whois查询,可以查询到域名所有者的联系方式以及注册和到期时间15死链接检测整体site PR query 这个工具可以快速测试网站的死链接 死链接——也叫死链接,就是那些不可达的链接。A网站有死链接可不是什么好事。首先,一个网站如果有大量的死链接,会极大的损害网站的整体形象。搜索引擎蜘蛛通过链接爬行。如果太多的链接无法到达,不仅收录页面的数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。查询可以遍历指定网页的所有链接,分析每个链接的有效性,找出死链接。网站的收录的数量~17搜索引擎反向链接通过这个工具可以快速查看各大搜索引擎对网站的反向链接数量~18查看手机号归属地查看手机号19. SEO综合查询 SEO综合查询 20 PR值查询 PR值的全称是PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 可以快速查看各大搜索引擎对网站的反向链接数~18查看手机号归属地查看手机号19.SEO综合查询SEO综合查询20 PR值查询PR值全称PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 可以快速查看各大搜索引擎对网站的反向链接数~18查看手机号归属地查看手机号19.SEO综合查询SEO综合查询20 PR值查询PR值全称PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 s 排名算法,被谷歌用来识别网页。排序重要性的方法 s 排名算法,被谷歌用来识别网页。排序重要性的方法
法律是谷歌用来衡量网站篮球课程标准质量的唯一标准尘肺病标准表党员活动室建设分级护理细化标准儿科分级护理标准结合所有其他标准,如标题标志和在关键字标志因素之后,Google 使用 PageRank 来调整结果,使排名更重要的页面在搜索结果中排名网站,以提高搜索结果的相关性和质量。21关键词ranking queries by 网站关键词ranking query可以快速得到当前网站关键词在百度Google收录的排名~有些关键词排名不一样在不同的地方,通常称为关键字的区域排名例如,新闻人才等很多,所以我们提供多地服务器供大家查询。22IP查询 通过该工具,您可以查询指定IP的物理地址或域名服务器的IP和物理地址以及您所在的国家或城市,甚至可以精确到某个网吧机房或学校。找到的结果仅供参考~ 23Google收录查询谷歌收录情况 24友情链接查询工具 这个工具可以批量查询百度的收录百度中指定网站的友情链接快照PR及对方链接到本站是否能检测到欺诈链接 25 友情链接IP查询工具 通过该工具可以批量查询网站的IP地址 友情链接站点 服务器的物理地址 帮助站长清楚了解友情链接的服务器 物理定位 26 域名删除查询 comnetorg等国际域名一般在65日或75日凌晨2点30分左右删除域名过期。友情提示将被删除。域名删除时间仅供参考。谢谢~ 27百度收录查询本工具为网站所有者提供了在指定时间内百度搜索指定网站收录情况包括收录网页数量并且网页的具体情况让你更好的掌握百度搜索你的网站收录情况28PR输出值查询查询网站@的PR输出值> 查看全部
网页抓取 加密html(
JS加密解密混合运算100题计算机一级题库二元一次)

如域名所有者域名Registrar域名注册日期和到期日期等。通过域名的Whois查询,可以查询到域名所有者的联系方式以及注册和到期时间15死链接检测整体site PR query 这个工具可以快速测试网站的死链接 死链接——也叫死链接,就是那些不可达的链接。A网站有死链接可不是什么好事。首先,一个网站如果有大量的死链接,会极大的损害网站的整体形象。搜索引擎蜘蛛通过链接爬行。如果太多的链接无法到达,不仅收录页面的数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。查询可以遍历指定网页的所有链接,分析每个链接的有效性,找出死链接。网站的收录的数量~17搜索引擎反向链接通过这个工具可以快速查看各大搜索引擎对网站的反向链接数量~18查看手机号归属地查看手机号19. SEO综合查询 SEO综合查询 20 PR值查询 PR值的全称是PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 可以快速查看各大搜索引擎对网站的反向链接数~18查看手机号归属地查看手机号19.SEO综合查询SEO综合查询20 PR值查询PR值全称PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 可以快速查看各大搜索引擎对网站的反向链接数~18查看手机号归属地查看手机号19.SEO综合查询SEO综合查询20 PR值查询PR值全称PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 s 排名算法,被谷歌用来识别网页。排序重要性的方法 s 排名算法,被谷歌用来识别网页。排序重要性的方法

法律是谷歌用来衡量网站篮球课程标准质量的唯一标准尘肺病标准表党员活动室建设分级护理细化标准儿科分级护理标准结合所有其他标准,如标题标志和在关键字标志因素之后,Google 使用 PageRank 来调整结果,使排名更重要的页面在搜索结果中排名网站,以提高搜索结果的相关性和质量。21关键词ranking queries by 网站关键词ranking query可以快速得到当前网站关键词在百度Google收录的排名~有些关键词排名不一样在不同的地方,通常称为关键字的区域排名例如,新闻人才等很多,所以我们提供多地服务器供大家查询。22IP查询 通过该工具,您可以查询指定IP的物理地址或域名服务器的IP和物理地址以及您所在的国家或城市,甚至可以精确到某个网吧机房或学校。找到的结果仅供参考~ 23Google收录查询谷歌收录情况 24友情链接查询工具 这个工具可以批量查询百度的收录百度中指定网站的友情链接快照PR及对方链接到本站是否能检测到欺诈链接 25 友情链接IP查询工具 通过该工具可以批量查询网站的IP地址 友情链接站点 服务器的物理地址 帮助站长清楚了解友情链接的服务器 物理定位 26 域名删除查询 comnetorg等国际域名一般在65日或75日凌晨2点30分左右删除域名过期。友情提示将被删除。域名删除时间仅供参考。谢谢~ 27百度收录查询本工具为网站所有者提供了在指定时间内百度搜索指定网站收录情况包括收录网页数量并且网页的具体情况让你更好的掌握百度搜索你的网站收录情况28PR输出值查询查询网站@的PR输出值>
网页抓取 加密html(2021年最新Python爬虫教程+实战项目案例(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-04-06 17:17
)
今天是综合练习!!它涉及请求、逆向工程、解密和爬取。
目标是从某音乐软件的评论区抓取热评,可以说是大开眼界了!
#1.找到未加密的参数 #window.asrsea(参数1,参数2,参数3.。。。。。)
#2.想办法把参数进行加密,(使用的是某云的加密逻辑) #params->encText encSecKey->enSecKey
#3.请求到网页,拿到评论信息
1.打开网页,输入你想知道的歌曲
2. 进入子页面,抓包,一一查看评论的包在哪里。以下是评论区抓到的包。可以看到评论区的url需要两个参数,params,encSecKey。这两个参数就是加密所涉及的参数,我们只需要破解整个加密逻辑即可
3.单击启动器以显示每个 json 文件。最上面的一个是最后处理的文件。我们开始向后推。点击第一个json文件
4.在锚点处设置断点,刷新页面。
5.刷新后,注意scope中的local选项,打开变量查看requests属性,然后点击上面的蓝色按钮,一直释放,直到出现我们想要的评论的url。
6.在调用栈中,在json文件中一一查看我们需要的参数:encText、encSecKey,直到找到参数值,这就是我们的加密参数。我们可以看到它们属于
var bVj8b是一个变量,这个变量是由函数window.asrsea赋值的,所以我们猜测这个函数是window.asrsea加密的,我们搜索这个函数
7.调用的时候除了这个函数,前面也定义了这个函数。此功能由 d 功能指定。让我们解释一下 d 函数。这里我把 a,b,c,d ,e 这五个函数抄下来,我们一一解读。老实说,我忘记了f,e,g在这里是如何定值的。我只记得d是数据数据,i是随机数,从而确定encSecKey。对应的encText就是我们想要的params。如果您想了解更多,请观看此视频
2021最新Python爬虫教程+实战项目案例(最新录制)_bilibili _bilibili
!function() {
function a(a) {#由i值来的
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,#产生e的随机数
e = Math.floor(e),#对e向下取整
c += b.charAt(e);#e作为b的索引,从b中拿出一个索引为e的字符,附到c上
return c#返回c,这就是a函数的功能,产生一个随机秘钥
}
function b(a, b) {#b函数时加密过程,为AES加密,a是加密内容,b是加密秘钥
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)#把a的utf-8格式赋值给e
, f = CryptoJS.AES.encrypt(e, c, {#AES加密,把e和c加密
iv: d,#iv为AES加密的偏移量
mode: CryptoJS.mode.CBC#AES的加密模式
});
return f.toString()#返回f的字符串形式
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {#由window.asrsea来的
var h = {}#创建空字典
, i = a(16);#i值由a函数确定,i值为16位的随机秘钥
return h.encText = b(d, g),#b函数的返回值写进h的encText内,d是待加密数据
h.encText = b(h.encText, i),#可以看出这是两次加密过程,生成encText
h.encSecKey = c(i, e, f),
#encSecKey这个参数就是我们想要的两个参数之一,由c函数确定
#这里c函数需要传进去的参数有i e f ,其中e f 是定值,i是随机值,我们把i值固定就能获得固定的encSecKey值
#至此encSecKey和encText的加密过程全部确定完毕。
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
window.asrsea = d,
window.ecnonasr = e
}();
剩下的就是全部代码了。如果还有时间,我会回来理清逻辑的。我对这篇文章不是很满意。
#1.找到未加密的参数 #window.asrsea(参数1,参数2,参数3.。。。。。)
#2.想办法把参数进行加密,(使用的是网易云的加密逻辑) #params->encText encSecKey->enSecKey
#3.请求到网页,拿到评论信息
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json #json 可以把字典变成字符串
url="https://music.163.com/weapi/co ... ot%3B
#请求方式post
data={
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_40257799",
"threadId": "R_SO_4_40257799"
}
#处理加密过程
""""
function a(a) {#返回随机的16位字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)#循环函数
e = Math.random() * b.length,#生成随机数
e = Math.floor(e),#取整
c += b.charAt(e);#取字符串中的xxx位
return c
}
function b(a, b) {#a是要加密的内容,b是秘钥
var c = CryptoJS.enc.Utf8.parse(b)#c是utf-8的b
, d = CryptoJS.enc.Utf8.parse("0102030405060708")#d是数字的utf-8类型
, e = CryptoJS.enc.Utf8.parse(a)#e是a的utf-8形式
, f = CryptoJS.AES.encrypt(e, c, {#AES加密算法,
iv: d,#AES算法里面的偏移量
mode: CryptoJS.mode.CBC#模式:CBC,差一个秘钥,秘钥就是c,c又是b,所以b的作用就是秘钥
});
return f.toString()
}
function c(a, b, c) {#c算法不产生随机数
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {d:d就是数据,e:01001,f:'很长',g:'0CoJUm6Qyw8W8jud'}
var h = {}#声明空对象
, i = a(16);#i是16位的随机字符串
return h.encText = b(d, g),#所以d是数据,g是秘钥
h.encText = b(h.encText, i),#这里得到的encText就是我们要的params,i是秘钥
#从上面两行代码看出,想要得到encText,首先需要两次b加密过程,第一次数据+g,第二次把第一次返回的结果+i
h.encSecKey = c(i, e, f),#这里得到的encSeckey就是我们要的encSeckey,e,f都是固定值,i是随机值
#这里encSeckey的随机值产生都是由于i的原因,我们把i值固定就能获得固定的encSeckey值.
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
"""
f="00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
i="5wWcgz0OQm8BE9yI"#随机值
e="010001"
g="0CoJUm6Qyw8W8jud"
def get_encSeckey():#由i确定
return "c5c0039e144f4dad02c2fc54dd0a6dcf74c0981748c1c00acba22d79569963ce4434a0f9663a1a048bcc4afbf4d4a389477323ef79b13673439ebb5d1d9895f6ea06c0fcc612e8e475dafca50bed9f51a3a07407be7739f86bd790ff10936947a6f022ec38db5c069968c559f17a617f8546a37dc3b900a469f9c19e0f85873a"
# 把参数进行加密
def get_params(data): # 默认这里接收到的是字符串
first = enc_params(data, g)
second = enc_params(first, i)
return second # 返回的就是params
# 转化成16的倍数, 为下方的加密算法服务
def to_16(data):
pad = 16 - len(data) % 16
data += chr(pad) * pad
return data
# 加密过程
def enc_params(data, key):
iv = "0102030405060708"
data = to_16(data)
aes = AES.new(key=key.encode("utf-8"), IV=iv.encode('utf-8'), mode=AES.MODE_CBC) # 创建加密器
bs = aes.encrypt(data.encode("utf-8")) # 加密, 加密的内容的长度必须是16的倍数
return str(b64encode(bs), "utf-8") # 转化成字符串返回,
resp=requests.post(url,data={
"params":get_params(json.dumps(data)),
"encSecKey":get_encSeckey()#Key写成了key,结果一直出不来!!!!!!!!!!!!!!!
})
print(resp.text)
最终效果如图
查看全部
网页抓取 加密html(2021年最新Python爬虫教程+实战项目案例(上)
)
今天是综合练习!!它涉及请求、逆向工程、解密和爬取。
目标是从某音乐软件的评论区抓取热评,可以说是大开眼界了!
#1.找到未加密的参数 #window.asrsea(参数1,参数2,参数3.。。。。。)
#2.想办法把参数进行加密,(使用的是某云的加密逻辑) #params->encText encSecKey->enSecKey
#3.请求到网页,拿到评论信息
1.打开网页,输入你想知道的歌曲

2. 进入子页面,抓包,一一查看评论的包在哪里。以下是评论区抓到的包。可以看到评论区的url需要两个参数,params,encSecKey。这两个参数就是加密所涉及的参数,我们只需要破解整个加密逻辑即可


3.单击启动器以显示每个 json 文件。最上面的一个是最后处理的文件。我们开始向后推。点击第一个json文件

4.在锚点处设置断点,刷新页面。

5.刷新后,注意scope中的local选项,打开变量查看requests属性,然后点击上面的蓝色按钮,一直释放,直到出现我们想要的评论的url。

6.在调用栈中,在json文件中一一查看我们需要的参数:encText、encSecKey,直到找到参数值,这就是我们的加密参数。我们可以看到它们属于
var bVj8b是一个变量,这个变量是由函数window.asrsea赋值的,所以我们猜测这个函数是window.asrsea加密的,我们搜索这个函数

7.调用的时候除了这个函数,前面也定义了这个函数。此功能由 d 功能指定。让我们解释一下 d 函数。这里我把 a,b,c,d ,e 这五个函数抄下来,我们一一解读。老实说,我忘记了f,e,g在这里是如何定值的。我只记得d是数据数据,i是随机数,从而确定encSecKey。对应的encText就是我们想要的params。如果您想了解更多,请观看此视频
2021最新Python爬虫教程+实战项目案例(最新录制)_bilibili _bilibili
!function() {
function a(a) {#由i值来的
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,#产生e的随机数
e = Math.floor(e),#对e向下取整
c += b.charAt(e);#e作为b的索引,从b中拿出一个索引为e的字符,附到c上
return c#返回c,这就是a函数的功能,产生一个随机秘钥
}
function b(a, b) {#b函数时加密过程,为AES加密,a是加密内容,b是加密秘钥
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)#把a的utf-8格式赋值给e
, f = CryptoJS.AES.encrypt(e, c, {#AES加密,把e和c加密
iv: d,#iv为AES加密的偏移量
mode: CryptoJS.mode.CBC#AES的加密模式
});
return f.toString()#返回f的字符串形式
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {#由window.asrsea来的
var h = {}#创建空字典
, i = a(16);#i值由a函数确定,i值为16位的随机秘钥
return h.encText = b(d, g),#b函数的返回值写进h的encText内,d是待加密数据
h.encText = b(h.encText, i),#可以看出这是两次加密过程,生成encText
h.encSecKey = c(i, e, f),
#encSecKey这个参数就是我们想要的两个参数之一,由c函数确定
#这里c函数需要传进去的参数有i e f ,其中e f 是定值,i是随机值,我们把i值固定就能获得固定的encSecKey值
#至此encSecKey和encText的加密过程全部确定完毕。
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
window.asrsea = d,
window.ecnonasr = e
}();

剩下的就是全部代码了。如果还有时间,我会回来理清逻辑的。我对这篇文章不是很满意。
#1.找到未加密的参数 #window.asrsea(参数1,参数2,参数3.。。。。。)
#2.想办法把参数进行加密,(使用的是网易云的加密逻辑) #params->encText encSecKey->enSecKey
#3.请求到网页,拿到评论信息
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json #json 可以把字典变成字符串
url="https://music.163.com/weapi/co ... ot%3B
#请求方式post
data={
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_40257799",
"threadId": "R_SO_4_40257799"
}
#处理加密过程
""""
function a(a) {#返回随机的16位字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)#循环函数
e = Math.random() * b.length,#生成随机数
e = Math.floor(e),#取整
c += b.charAt(e);#取字符串中的xxx位
return c
}
function b(a, b) {#a是要加密的内容,b是秘钥
var c = CryptoJS.enc.Utf8.parse(b)#c是utf-8的b
, d = CryptoJS.enc.Utf8.parse("0102030405060708")#d是数字的utf-8类型
, e = CryptoJS.enc.Utf8.parse(a)#e是a的utf-8形式
, f = CryptoJS.AES.encrypt(e, c, {#AES加密算法,
iv: d,#AES算法里面的偏移量
mode: CryptoJS.mode.CBC#模式:CBC,差一个秘钥,秘钥就是c,c又是b,所以b的作用就是秘钥
});
return f.toString()
}
function c(a, b, c) {#c算法不产生随机数
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {d:d就是数据,e:01001,f:'很长',g:'0CoJUm6Qyw8W8jud'}
var h = {}#声明空对象
, i = a(16);#i是16位的随机字符串
return h.encText = b(d, g),#所以d是数据,g是秘钥
h.encText = b(h.encText, i),#这里得到的encText就是我们要的params,i是秘钥
#从上面两行代码看出,想要得到encText,首先需要两次b加密过程,第一次数据+g,第二次把第一次返回的结果+i
h.encSecKey = c(i, e, f),#这里得到的encSeckey就是我们要的encSeckey,e,f都是固定值,i是随机值
#这里encSeckey的随机值产生都是由于i的原因,我们把i值固定就能获得固定的encSeckey值.
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
"""
f="00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
i="5wWcgz0OQm8BE9yI"#随机值
e="010001"
g="0CoJUm6Qyw8W8jud"
def get_encSeckey():#由i确定
return "c5c0039e144f4dad02c2fc54dd0a6dcf74c0981748c1c00acba22d79569963ce4434a0f9663a1a048bcc4afbf4d4a389477323ef79b13673439ebb5d1d9895f6ea06c0fcc612e8e475dafca50bed9f51a3a07407be7739f86bd790ff10936947a6f022ec38db5c069968c559f17a617f8546a37dc3b900a469f9c19e0f85873a"
# 把参数进行加密
def get_params(data): # 默认这里接收到的是字符串
first = enc_params(data, g)
second = enc_params(first, i)
return second # 返回的就是params
# 转化成16的倍数, 为下方的加密算法服务
def to_16(data):
pad = 16 - len(data) % 16
data += chr(pad) * pad
return data
# 加密过程
def enc_params(data, key):
iv = "0102030405060708"
data = to_16(data)
aes = AES.new(key=key.encode("utf-8"), IV=iv.encode('utf-8'), mode=AES.MODE_CBC) # 创建加密器
bs = aes.encrypt(data.encode("utf-8")) # 加密, 加密的内容的长度必须是16的倍数
return str(b64encode(bs), "utf-8") # 转化成字符串返回,
resp=requests.post(url,data={
"params":get_params(json.dumps(data)),
"encSecKey":get_encSeckey()#Key写成了key,结果一直出不来!!!!!!!!!!!!!!!
})
print(resp.text)
最终效果如图

网页抓取 加密html(如何解密网页抓取加密页面?解密https页面的应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2022-04-06 03:04
网页抓取加密html:比如chrome的dom存储于js文件中,要获取的时候需要从js中读取;有些网站用tomcat,jboss等orm系统来存放用户数据,orm只需要加解密的过程,我们可以借助xml或者其他方法解析下载中的数据,这样就可以获取页面里面的加密html了。
通常我们通过javascript、java等语言访问网站页面,难免需要使用https,post等加密方式进行登录用户。随着社会的发展,又流行起了各种dedecms系统,以及门户网站。这些网站的内容和服务都是依靠外部服务器来对接,这样就有了加密浏览器访问方式:将信息发送给对应的服务器,服务器返回给客户端一个有密文的网页。
那么如何解密这个https页面呢?你可以用java进行原生操作。假设你发送给fj的是一串字符:"11",我通过字符访问页面的话,fj将在页面上显示"https"。解密https页面?。
1、获取密文有一种称为rarsk(密钥)的东西,用来标识一个数据类型变量的私钥(privatekey)。密钥可以在java中的反射操作中读取,反射操作是针对java代码或java类,并且java代码或java类可以私有。如下的例子所示,以下的反射操作中应该能够读取密钥,并且将密钥解密成代码。publicclasshttpserver{privateinti=42;//密钥私钥privatestringpj="11";//数据类型变量私钥privatejava.io.encryption.byte[]bytes=newjava.io.encryption.byte[16];//待解密对象publicvoidreadobject(stringstr){//尝试读取密文//...}}。
2、反序列化java中的反序列化不同于java.io.fileinputstream或fileoutputstream中的反序列化,而是仅以getwriter()为例进行。在java中设置getwriter方法为该方法的第一个参数,该方法返回true表示读取文件或文件夹内容,返回false表示读取文件或文件夹外的内容。
publicvoidreadobject(stringstr){if(str==null){thrownewbufferedinputstreamfactorybuilder();}system.out.println("字符"+str);}。
3、反序列化服务器加密存储在java中的应用是jndi(javainternetoperatingsystem)。web服务器是jndi的客户端。https对象必须在http/2规范下运行。
1、获取密钥java中的任何对象都可以对接https服务器。
2、反序列化https对象,fj返回一个密文或其它任何类型私钥,cert.passkey加密存储在java自己的对象中。uri加密, 查看全部
网页抓取 加密html(如何解密网页抓取加密页面?解密https页面的应用方法)
网页抓取加密html:比如chrome的dom存储于js文件中,要获取的时候需要从js中读取;有些网站用tomcat,jboss等orm系统来存放用户数据,orm只需要加解密的过程,我们可以借助xml或者其他方法解析下载中的数据,这样就可以获取页面里面的加密html了。
通常我们通过javascript、java等语言访问网站页面,难免需要使用https,post等加密方式进行登录用户。随着社会的发展,又流行起了各种dedecms系统,以及门户网站。这些网站的内容和服务都是依靠外部服务器来对接,这样就有了加密浏览器访问方式:将信息发送给对应的服务器,服务器返回给客户端一个有密文的网页。
那么如何解密这个https页面呢?你可以用java进行原生操作。假设你发送给fj的是一串字符:"11",我通过字符访问页面的话,fj将在页面上显示"https"。解密https页面?。
1、获取密文有一种称为rarsk(密钥)的东西,用来标识一个数据类型变量的私钥(privatekey)。密钥可以在java中的反射操作中读取,反射操作是针对java代码或java类,并且java代码或java类可以私有。如下的例子所示,以下的反射操作中应该能够读取密钥,并且将密钥解密成代码。publicclasshttpserver{privateinti=42;//密钥私钥privatestringpj="11";//数据类型变量私钥privatejava.io.encryption.byte[]bytes=newjava.io.encryption.byte[16];//待解密对象publicvoidreadobject(stringstr){//尝试读取密文//...}}。
2、反序列化java中的反序列化不同于java.io.fileinputstream或fileoutputstream中的反序列化,而是仅以getwriter()为例进行。在java中设置getwriter方法为该方法的第一个参数,该方法返回true表示读取文件或文件夹内容,返回false表示读取文件或文件夹外的内容。
publicvoidreadobject(stringstr){if(str==null){thrownewbufferedinputstreamfactorybuilder();}system.out.println("字符"+str);}。
3、反序列化服务器加密存储在java中的应用是jndi(javainternetoperatingsystem)。web服务器是jndi的客户端。https对象必须在http/2规范下运行。
1、获取密钥java中的任何对象都可以对接https服务器。
2、反序列化https对象,fj返回一个密文或其它任何类型私钥,cert.passkey加密存储在java自己的对象中。uri加密,
网页抓取 加密html(HTTPNot或Found错误信息是HTTP的其中“标准回应信息”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-05 06:02
HTTP 404 或 Not Found 错误消息是 HTTP 的“标准响应消息”(HTTP 状态代码)之一。此消息表示客户端浏览网页时服务器无法正常提供信息,或服务器无法响应,原因不明。
大量死链接对搜索引擎有什么影响?
1、很多网站都无法避免死链接,但是死链接率太高,会影响搜索引擎对网站的评分。
2、搜索引擎每天限制每个网站的抓取频率。如果网站中有大量死链接,会浪费爬取配额,影响正常页面的爬取。
3、过多的死链接对于网站 用户来说也是一种糟糕的体验。
百度站长工具出现抓取异常,那么这个工具里面的异常数据是怎么产生的呢?
1、网站添加了错误的内部链接
编辑错误或程序员的粗心导致页面生成了一个不存在的页面。
2、网站暂时无法访问
网站由于服务器、空间或程序问题暂时无法访问,导致大量返回码以5开头的服务器错误页面。
3、外部链接错误
用户或站长在站外发错网址,蜘蛛抓取后生成错误页面;其他 网站 复制或 采集 带有错误链接的页面;一些垃圾网站自动生成静态搜索结果页面,比如www。8875. org/desc/3715714444.html 此页面上出现的许多链接在 html 前面都有“...”。
4、爬虫提取了一个不完整的 URL
有的爬虫在提取页面URL时,只提取部分URL或者同时提取正常URL后面的文字或字符。
5、网站修订
网站修改过程中,直接删除了旧页面,没有301跳转到对应页面,或者301跳转后部分旧页面仍然无法访问。
6、管理员删除页面
网站管理员删除被黑、广告、过时和泛滥的页面,导致许多死链接。
7、过时或交易完成的页面
下架产品、过期信息
当出现上述情况时,我们该如何解决呢?
1、修复错误页面
爬取异常中的很多错误页面都是由于程序员的粗心或者我们的程序问题造成的。它们应该是正常的页面,但由于错误而无法访问。对于此类页面,我们会尽快修复。
2、提交死链接
但是肯定有很多不应该存在的错误页面,所以我们必须想办法获取这样一个页面的URL。获取方式主要有以下三种:
(1)百度站长工具--爬取异常--找不到页面--复制数据[更正:我们这里不需要提交死链接,百度站长工具自动提交死链接];
(2)当管理员手动删除页面或程序自动保存被删除页面的URL时;
(3)使用相关爬虫软件爬取整个站点获取死链接,比如Xenu。
然后把上面的数据合并删除重复的(excel表格可以实现去重,wps表格更容易操作),然后复制所有的url通过http状态批量查询工具查询【这个好/webspeed.aspx ],并删除非必要的 404 返回代码页。
然后将上面处理好的数据整理粘贴到网站根目录下的一个文档中,将文档地址提交到百度站长工具--网页爬取--死链接提交--添加新数据--填写死链接链接文件地址。
3、在机器人中阻止爬行
如果大量错误的网址有一定的规则,可以在robots文件中写一条规则,禁止蜘蛛抓取此类链接,但前提是一定要照顾好正常的页面,避免阻止规则误伤正常的页面,比如你的网站都是静态URL,那么如果错误链接收录?,则规则写成Disallow:/*?*,如果错误链接中有/id...html,则规则写成不允许:/*...*。
将规则添加到robots文件后,一定要到百度站长的robots工具进行验证,把指定的错误页面放进去看看是否封禁成功,再放入正常的页面看看是否被误封.
相关说明:
1、在百度站长工具中提交死链接之前,请确保提交的死链接数据中没有活链接。一旦有活链,就会显示提交失败,无法删除。
2、由于很多网站程序问题,很多打不开的页面返回码不是404,这是个大问题。比如打不开的页面返回码是301、200、500,如果是200,会导致网站中不同的url获取相同的内容。比如我的一个网站,社区的帖子被删除后,返回码是500,后来我发现了,马上处理。每个人都试图找出所有错误的 URL 格式,并将 HTTP 状态码设置为 404。
3、找到所有错误页面后,一定要寻找这些页面的URL相同的特征,并与正常页面的特征区分开来,将相应的规则写入robots文件,禁止蜘蛛爬取,即使你已经在网站上 长工具提交死链接,也建议禁止机器人爬取。
4、机器人只能解决蜘蛛不再抓取此类页面的问题,但无法解决删除已收录页面快照的问题。如果你的网站被黑了,被黑的页面被删除了,除了robots禁止被黑的页面外,这些页面也应该提交死链接。提交死链接是删除被黑页面快照的最快方法。返回搜狐,查看更多 查看全部
网页抓取 加密html(HTTPNot或Found错误信息是HTTP的其中“标准回应信息”)
HTTP 404 或 Not Found 错误消息是 HTTP 的“标准响应消息”(HTTP 状态代码)之一。此消息表示客户端浏览网页时服务器无法正常提供信息,或服务器无法响应,原因不明。
大量死链接对搜索引擎有什么影响?
1、很多网站都无法避免死链接,但是死链接率太高,会影响搜索引擎对网站的评分。
2、搜索引擎每天限制每个网站的抓取频率。如果网站中有大量死链接,会浪费爬取配额,影响正常页面的爬取。
3、过多的死链接对于网站 用户来说也是一种糟糕的体验。
百度站长工具出现抓取异常,那么这个工具里面的异常数据是怎么产生的呢?
1、网站添加了错误的内部链接
编辑错误或程序员的粗心导致页面生成了一个不存在的页面。
2、网站暂时无法访问
网站由于服务器、空间或程序问题暂时无法访问,导致大量返回码以5开头的服务器错误页面。
3、外部链接错误
用户或站长在站外发错网址,蜘蛛抓取后生成错误页面;其他 网站 复制或 采集 带有错误链接的页面;一些垃圾网站自动生成静态搜索结果页面,比如www。8875. org/desc/3715714444.html 此页面上出现的许多链接在 html 前面都有“...”。
4、爬虫提取了一个不完整的 URL
有的爬虫在提取页面URL时,只提取部分URL或者同时提取正常URL后面的文字或字符。
5、网站修订
网站修改过程中,直接删除了旧页面,没有301跳转到对应页面,或者301跳转后部分旧页面仍然无法访问。
6、管理员删除页面
网站管理员删除被黑、广告、过时和泛滥的页面,导致许多死链接。
7、过时或交易完成的页面
下架产品、过期信息
当出现上述情况时,我们该如何解决呢?
1、修复错误页面
爬取异常中的很多错误页面都是由于程序员的粗心或者我们的程序问题造成的。它们应该是正常的页面,但由于错误而无法访问。对于此类页面,我们会尽快修复。
2、提交死链接
但是肯定有很多不应该存在的错误页面,所以我们必须想办法获取这样一个页面的URL。获取方式主要有以下三种:
(1)百度站长工具--爬取异常--找不到页面--复制数据[更正:我们这里不需要提交死链接,百度站长工具自动提交死链接];
(2)当管理员手动删除页面或程序自动保存被删除页面的URL时;
(3)使用相关爬虫软件爬取整个站点获取死链接,比如Xenu。
然后把上面的数据合并删除重复的(excel表格可以实现去重,wps表格更容易操作),然后复制所有的url通过http状态批量查询工具查询【这个好/webspeed.aspx ],并删除非必要的 404 返回代码页。
然后将上面处理好的数据整理粘贴到网站根目录下的一个文档中,将文档地址提交到百度站长工具--网页爬取--死链接提交--添加新数据--填写死链接链接文件地址。
3、在机器人中阻止爬行
如果大量错误的网址有一定的规则,可以在robots文件中写一条规则,禁止蜘蛛抓取此类链接,但前提是一定要照顾好正常的页面,避免阻止规则误伤正常的页面,比如你的网站都是静态URL,那么如果错误链接收录?,则规则写成Disallow:/*?*,如果错误链接中有/id...html,则规则写成不允许:/*...*。
将规则添加到robots文件后,一定要到百度站长的robots工具进行验证,把指定的错误页面放进去看看是否封禁成功,再放入正常的页面看看是否被误封.
相关说明:
1、在百度站长工具中提交死链接之前,请确保提交的死链接数据中没有活链接。一旦有活链,就会显示提交失败,无法删除。
2、由于很多网站程序问题,很多打不开的页面返回码不是404,这是个大问题。比如打不开的页面返回码是301、200、500,如果是200,会导致网站中不同的url获取相同的内容。比如我的一个网站,社区的帖子被删除后,返回码是500,后来我发现了,马上处理。每个人都试图找出所有错误的 URL 格式,并将 HTTP 状态码设置为 404。
3、找到所有错误页面后,一定要寻找这些页面的URL相同的特征,并与正常页面的特征区分开来,将相应的规则写入robots文件,禁止蜘蛛爬取,即使你已经在网站上 长工具提交死链接,也建议禁止机器人爬取。
4、机器人只能解决蜘蛛不再抓取此类页面的问题,但无法解决删除已收录页面快照的问题。如果你的网站被黑了,被黑的页面被删除了,除了robots禁止被黑的页面外,这些页面也应该提交死链接。提交死链接是删除被黑页面快照的最快方法。返回搜狐,查看更多
网页抓取 加密html(修改现有DESDES算法进行匹配发现难度,费时费力来执行解密方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-04-04 03:11
这几天收到一个有数据的项目采集
通过对网站的初步分析,得到如下内容
1.网站是用.NET开发的
2.要抓取的内容是用DES加密的
虽然已经获得了前端javascript的加解密算法,但我们都知道,交互开发跨语言算法是相当困难的。原计划是修改现有的php DES算法,发现太难、费时费力。后来突然想到能不能在php中调用js脚本来处理,这就是这个文章phantomjs的重点。事实上,这很简单。第一个版本打开网页,直接执行解码方法,但是这种方法处理速度会变慢。毕竟有网页访问的过程,然后不知道能不能调用本地构建的网页进行同样的处理。,我在windows上测试过,是可行的,但是我还没有在liunx上测试过。
首先,构建一个本地网页很简单,就是一个引用解码脚本的空html文档,命名为Demo.html
Document
然后开始编写一个名为 Model.js 的 phantomjs 处理脚本
var page = require('webpage').create();
page.open('Demo.html', function (status) {
if(status !== 'success' ){
console.log('FAIL');
}else{
var a = '{keys}';
var b = '{encrypt}';
console.log(page.evaluate(function(c,d){
return jsdecrypt(c,d);
},a,b));
}
phantom.exit();
});
解密方法是通过phantomjs的api page.evaluate来执行的。原计划是直接通过命令行传参,结果发现不成功。猜测是加密字符串的大小超过了命令行的最大字符长度。所以只能通过php读取js文件,然后替换。
最后是php部分
//模板数据替换
$str=file_get_contents("Model.js");//打开文件
$str=str_replace("{keys}",$a,$str);
$str=str_replace("{encrypt}",$b,$str);
file_put_contents("Decode.js",$str);//把替换的内容写到js文件中
//解码操作
$command = "phantomjs Decode.js";
print_r (passthru($command)); //因为输出内容为多行所以使用passthru方法
最后说明一下,这个方法是调用第三方程序来处理。绝对不比原生直写算法快,但速度还是可以接受的。
随便说几句,这个模板可以直接套用。 查看全部
网页抓取 加密html(修改现有DESDES算法进行匹配发现难度,费时费力来执行解密方法)
这几天收到一个有数据的项目采集
通过对网站的初步分析,得到如下内容
1.网站是用.NET开发的
2.要抓取的内容是用DES加密的
虽然已经获得了前端javascript的加解密算法,但我们都知道,交互开发跨语言算法是相当困难的。原计划是修改现有的php DES算法,发现太难、费时费力。后来突然想到能不能在php中调用js脚本来处理,这就是这个文章phantomjs的重点。事实上,这很简单。第一个版本打开网页,直接执行解码方法,但是这种方法处理速度会变慢。毕竟有网页访问的过程,然后不知道能不能调用本地构建的网页进行同样的处理。,我在windows上测试过,是可行的,但是我还没有在liunx上测试过。
首先,构建一个本地网页很简单,就是一个引用解码脚本的空html文档,命名为Demo.html
Document
然后开始编写一个名为 Model.js 的 phantomjs 处理脚本
var page = require('webpage').create();
page.open('Demo.html', function (status) {
if(status !== 'success' ){
console.log('FAIL');
}else{
var a = '{keys}';
var b = '{encrypt}';
console.log(page.evaluate(function(c,d){
return jsdecrypt(c,d);
},a,b));
}
phantom.exit();
});
解密方法是通过phantomjs的api page.evaluate来执行的。原计划是直接通过命令行传参,结果发现不成功。猜测是加密字符串的大小超过了命令行的最大字符长度。所以只能通过php读取js文件,然后替换。
最后是php部分
//模板数据替换
$str=file_get_contents("Model.js");//打开文件
$str=str_replace("{keys}",$a,$str);
$str=str_replace("{encrypt}",$b,$str);
file_put_contents("Decode.js",$str);//把替换的内容写到js文件中
//解码操作
$command = "phantomjs Decode.js";
print_r (passthru($command)); //因为输出内容为多行所以使用passthru方法
最后说明一下,这个方法是调用第三方程序来处理。绝对不比原生直写算法快,但速度还是可以接受的。
随便说几句,这个模板可以直接套用。
网页抓取 加密html(本文主要包含html5游戏源码html,html5源码源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-02 10:03
本文主要收录html5游戏源码、html网站源码、html源码、源码之家html、html5源码等相关知识,教程希望对你的学习和工作有所帮助
");
我们先来看看需求。加密的目的是什么?什么级别的加密?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全,加密会被破解,混淆会被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越大,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的需要做这种源代码保护,需要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
前端不应该涉及泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,不需要牺牲用户体验来保护大量代码。
但是,一些前端代码涉及到最终用户的数据安全,此时应该努力保护数据。
接下来详细分析几种方法。
不要把敏感数据放在前端
这可能听起来像废话,但它真的很重要。
一些开发者将用户的密码明文存储在手机上,这是非常危险的。
一旦手机root,即使是原生开发也可能导致数据泄露。更不用说 HTML5 开发了。
更好的方法是在手机上存储令牌而不是密码。这里有一篇文章 文章 来介绍这一点。建议参与登录的开发人员仔细查看设计。
谈谈HTML5 APP的登录功能以及安全调用接口的方法
js、css压缩
压缩不是加密,也不是混淆。但是压缩后的js文件往往也有混淆的功能。
JS 和 CSS 压缩是很常见的技术。我们经常看到各种框架的文件名是 xxx.min.js 和 xxx.min.css。
使用合适的js和css压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。它只是有益的和无害的。
比较常用的混淆js的工具是yahoo的YUI混淆。在HBuilder中,点击菜单工具-插件安装,里面有YUI compress,可以压缩js和css。
如果 js 和 css 比较大,建议先压缩再发布。
HTML、js、css混淆
虽然压缩也可以混淆,但不是为了让别人看不懂。混淆真的是为了让人无法理解。
但这种混淆不如压缩有益无害,它会降低程序的执行性能。
有些开发者不想在解压分发包后直接看到源代码,所以此时可以使用混淆方案。
网上搜索HTML混淆,有很多资料和工具。
原理类似。js代码变成乱七八糟的字符串,然后用eval执行。HTML 代码变成了乱七八糟的字符串,并使用 document.write 或 innerHTML 执行它。CSS 也可以在 document.write 中动态编写。
这些工具是免费的和商业的,它们越商业化,就越难被去混淆。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具。
其实你也可以根据原理编写自己的混淆算法。
混淆也是多年的成熟技术。例如,谷歌在保护gmail的前端代码时,也受到了混淆的保护。
无论是压缩还是混淆,使用 grunt 进行发布都是一种不错的方式。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上和iOS 支持webkit 远程调试。在HBuilder教程中,也有关于如何使用chrome调试Android应用和safari调试iOS应用的教程。
在HBuilder开发的app中,manifest.json的plus-distribute下有一个debug标签,标记为false,然后打包。当这样的包在手机上运行时,webview会阻塞浏览器的远程调试请求。
如果要调试,则在打包之前将 debug 更改为 true。
当然,有些安卓的rom不是很规范,也不能妨碍调试。这是一个ROM错误。
专业的加密加固打包服务
由于Android的特殊性,存在针对apk的加固脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有一些专业公司如Ai Encryption,提供免费的基础安全服务和收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。 查看全部
网页抓取 加密html(本文主要包含html5游戏源码html,html5源码源码)
本文主要收录html5游戏源码、html网站源码、html源码、源码之家html、html5源码等相关知识,教程希望对你的学习和工作有所帮助
");
我们先来看看需求。加密的目的是什么?什么级别的加密?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全,加密会被破解,混淆会被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越大,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的需要做这种源代码保护,需要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
前端不应该涉及泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,不需要牺牲用户体验来保护大量代码。
但是,一些前端代码涉及到最终用户的数据安全,此时应该努力保护数据。
接下来详细分析几种方法。
不要把敏感数据放在前端
这可能听起来像废话,但它真的很重要。
一些开发者将用户的密码明文存储在手机上,这是非常危险的。
一旦手机root,即使是原生开发也可能导致数据泄露。更不用说 HTML5 开发了。
更好的方法是在手机上存储令牌而不是密码。这里有一篇文章 文章 来介绍这一点。建议参与登录的开发人员仔细查看设计。
谈谈HTML5 APP的登录功能以及安全调用接口的方法
js、css压缩
压缩不是加密,也不是混淆。但是压缩后的js文件往往也有混淆的功能。
JS 和 CSS 压缩是很常见的技术。我们经常看到各种框架的文件名是 xxx.min.js 和 xxx.min.css。
使用合适的js和css压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。它只是有益的和无害的。
比较常用的混淆js的工具是yahoo的YUI混淆。在HBuilder中,点击菜单工具-插件安装,里面有YUI compress,可以压缩js和css。
如果 js 和 css 比较大,建议先压缩再发布。
HTML、js、css混淆
虽然压缩也可以混淆,但不是为了让别人看不懂。混淆真的是为了让人无法理解。
但这种混淆不如压缩有益无害,它会降低程序的执行性能。
有些开发者不想在解压分发包后直接看到源代码,所以此时可以使用混淆方案。
网上搜索HTML混淆,有很多资料和工具。
原理类似。js代码变成乱七八糟的字符串,然后用eval执行。HTML 代码变成了乱七八糟的字符串,并使用 document.write 或 innerHTML 执行它。CSS 也可以在 document.write 中动态编写。
这些工具是免费的和商业的,它们越商业化,就越难被去混淆。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具。
其实你也可以根据原理编写自己的混淆算法。
混淆也是多年的成熟技术。例如,谷歌在保护gmail的前端代码时,也受到了混淆的保护。
无论是压缩还是混淆,使用 grunt 进行发布都是一种不错的方式。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上和iOS 支持webkit 远程调试。在HBuilder教程中,也有关于如何使用chrome调试Android应用和safari调试iOS应用的教程。
在HBuilder开发的app中,manifest.json的plus-distribute下有一个debug标签,标记为false,然后打包。当这样的包在手机上运行时,webview会阻塞浏览器的远程调试请求。
如果要调试,则在打包之前将 debug 更改为 true。
当然,有些安卓的rom不是很规范,也不能妨碍调试。这是一个ROM错误。
专业的加密加固打包服务
由于Android的特殊性,存在针对apk的加固脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有一些专业公司如Ai Encryption,提供免费的基础安全服务和收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。
网页抓取 加密html(一台教程全篇代码加密的操作流程及流程记录教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-02 10:02
顺序
我们都知道前端的html和js代码在浏览器上是可以看到的,所以如果遇到隐私意识很强的老板,就会突然接受一个代码加密要求。当你接受这个要求时,你是怎么做的?那么我希望我的这个博客可以帮助到你。
首先告诉你的老板,严格意义上的加密是不存在的,唯一能做到的就是对前端代码进行压缩和混淆,增加阅读难度。
本教程自始至终描述的是混淆代码以满足老板提出的加密要求的方法。
为了保证本教程真正有用,我将使用一个新的Windows系统从头开始演示,在此记录下操作过程供大家参考。也希望能帮助大家跳过一些坑。如果您遇到任何问题,请留言讨论。
安装 NodeJs
如果你还没有安装node,请按照教程进行,如果你已经安装了,请跳到下一节。
下载链接:
直接下载安装。安装过程是傻瓜式 的下一步。唯一可以改变的是安装位置。
安装完成后打开cmd命令行查看版本号确认是否安装成功。
安装插件
切换到项目根目录:
安装 gulp 插件包: npm install --save-dev gulp
效果如图:
别着急,还有很多包,按顺序一一刷:
npm install --save-dev del
npm install --save-dev gulp-concat
npm install --save-dev gulp-header
npm install --save-dev gulp-if
npm install --save-dev gulp-minify-css
npm install --save-dev gulp-htmlmin
npm install --save-dev gulp-rename
npm install --save-dev gulp-replace
npm install --save-dev gulp-uglify
npm install --save-dev gulp-babel
npm install --save-dev babel-preset-es2015
npm install --save-dev @babel/core
npm install --save-dev @babel/preset-env
防范措施
插件安装完成后,我们的前期工作就完成了。
我们会在项目目录中找到不止一个node_modules目录和package-lock.json文件,json文件就是我们的插件列表,node_modules目录就是我们安装的插件包。
index.html是我的主入口文件,src目录是我的项目中存放代码的目录,也就是我要压缩和加密构建的目录。
src中有3个子目录,controller存放独立的js处理前端业务逻辑,style存放css样式文件,view存放html页面。
在写脚本之前,我需要直截了当地告诉你,如果你的 JS 中有 ES6 语法,正常打包是行不通的,但我们前期工作也已经安装了工具包来处理这个问题,但仅限于处理单个 JS 文件.
如果在HTML代码中嵌入了JS,而JS中有ES6语法,则需要将JS代码提取出来单独制作一个JS,或者手动将ES6写法改为ES5。
总之,如果打包出错,很有可能是ES6语法引起的,其次是文件路径错误。
压缩JS
回到我们的项目根目录并创建一个具有固定文件名的 gulpfile.js 文件:
导入包:
var gulp = require('gulp');
var uglify = require('gulp-uglify');
var babel = require('gulp-babel');
var minifyCss = require("gulp-minify-css");
var htmlmin = require('gulp-htmlmin');
var header = require('gulp-header');
var del = require('del');
定义一个目标目录:
var destDir = './dist';
定义一个注释,因为我想对缩小代码的第一行做一点注释:
var note = ['/** 小样,看源码?想得美! */\n ', {js: ';'}];
监控任务:
gulp.task('minjs', function () {
//定义路径
var src = [
'./src/**/*.js'
];
gulp.src(src)
.pipe(babel({presets: ["@babel/env"], plugins: []}))//es6转es5
.pipe(uglify())//压缩
.pipe(header.apply(null, note))//添加头部注释
.pipe(gulp.dest(destDir));//将压缩后的内容输出到目标目录
});
minjs 是我们自定义的任务名称,也就是说我们在命令行输入 gulp minjs 命令,就会执行这段代码。
如果只是输入 gulp 命令,它会自动找到名为 default 的任务。
var src = ['./src/**/*.js']; 是我们要抓取的文件,使用通配符,你几乎肯定需要这样写:
var src = [
'./src/**/*.js'
, '!./src/config.js'
, '!./src/lib/extend/*.js'
];
感叹号表示排除。
这里说明destDir只会替换通配符前的目录路径。比如我这里的destDir定义为./dist,那么./src/controller/admin.js的压缩路径就是./dist/controller/admin.js。
好的,打开命令行输入命令:gulp minjs
检查项目,js文件已经压缩成功。
压缩 CSS
任务监控和压缩JS没有区别,只是使用gulp-minify-css插件来完成压缩任务。
gulp.task('mincss', function () {
var src = [
'./src/style/*.css'
];
gulp.src(src).pipe(minifyCss()).pipe(gulp.dest(destDir + '/style'));
});
输入命令:gulp mincss
查看项目也没有问题:
非常聪明,它会为您删除 css 中的评论。
压缩 HTML
压缩后的 HTML 可以传递多个参数来指定相应的行为:
gulp.task('minhtml', function () {
var options = {
removeComments: true,//清除HTML注释
collapseWhitespace: true,//折叠空白
minifyJS: true,//压缩页面JS
minifyCSS: true//压缩页面CSS
};
var src = [
'./src/views/**/*',
];
gulp.src(src)
.pipe(htmlmin(options))
.pipe(gulp.dest(destDir + '/views'));
});
更多参数请看这里:
输入命令:gulp minhtml
压缩的 HTML:
全部压缩成一行,文件中的css和js也被压缩了。
一站式处理
但是我们不能总是在一个包中运行多个命令。太麻烦了 现在我们将把这些任务整合并组合成一个任务。
我们创建一个任务对象,将每个任务的内容放入其中,并添加一个清理 dist 目录的方法,以及一个复制未压缩文件的 move 方法。
//任务列表
var task = {
//清理dist目录
clear:function () {
del(['./dist/*']);
},
minjs:function () {
//定义路径
var src = [
'./src/**/*.js'
];
gulp.src(src)
.pipe(babel({presets: ["@babel/env"], plugins: []}))//es6转es5
.pipe(uglify())//压缩
.pipe(header.apply(null, note))//添加头部注释
.pipe(gulp.dest(destDir));
},
mincss:function () {
var src = [
'./src/style/*.css'
];
gulp.src(src).pipe(minifyCss()).pipe(gulp.dest(destDir + '/style'));
},
minhtml:function () {
var options = {
removeComments: true,//清除HTML注释
collapseWhitespace: true,//折叠空白
minifyJS: true,//压缩页面JS 如果你确信你的HTML页面中的js不包含有es6语法,那么可以压缩js 否则还是得把js抽离成单独的文件进行压缩
minifyCSS: true//压缩页面CSS
};
var src = [
'./src/**/*',
];
gulp.src(src)
.pipe(htmlmin(options))
.pipe(gulp.dest(destDir));
},
move: function () {
//复制文件夹 没有被压缩的文件就在这里复制
gulp.src('./src/**/*.png').pipe(gulp.dest(destDir));
}
};
我们在压缩js的时候说过,如果只是一个gulp命令,它会找到一个名为default的task,我们在default task中遍历task对象,依次执行方法。
gulp.task('default', function () {
for (var key in task) {
task[key]();
}
});
这样,我们只需要一个 gulp 命令,整个构建过程就完成了。
同时,我们将单个任务指向任务中对应的方法:
gulp.task('clear',task.clear);
gulp.task('minjs',task.minjs);
gulp.task('mincss',task.mincss);
gulp.task('minhtml',task.minhtml);
gulp.task('move',task.move);
无论是处理单个环节还是整个构建过程,我们都能轻松完成。
最后,感谢阅读。PS:欢迎关注,有粉丝必回。 查看全部
网页抓取 加密html(一台教程全篇代码加密的操作流程及流程记录教程)
顺序
我们都知道前端的html和js代码在浏览器上是可以看到的,所以如果遇到隐私意识很强的老板,就会突然接受一个代码加密要求。当你接受这个要求时,你是怎么做的?那么我希望我的这个博客可以帮助到你。
首先告诉你的老板,严格意义上的加密是不存在的,唯一能做到的就是对前端代码进行压缩和混淆,增加阅读难度。
本教程自始至终描述的是混淆代码以满足老板提出的加密要求的方法。
为了保证本教程真正有用,我将使用一个新的Windows系统从头开始演示,在此记录下操作过程供大家参考。也希望能帮助大家跳过一些坑。如果您遇到任何问题,请留言讨论。
安装 NodeJs
如果你还没有安装node,请按照教程进行,如果你已经安装了,请跳到下一节。
下载链接:
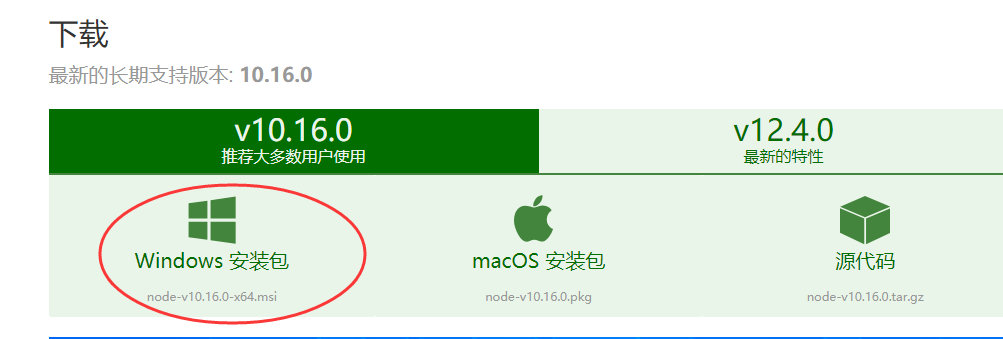
直接下载安装。安装过程是傻瓜式 的下一步。唯一可以改变的是安装位置。
安装完成后打开cmd命令行查看版本号确认是否安装成功。
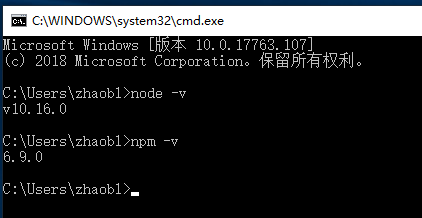
安装插件
切换到项目根目录:

安装 gulp 插件包: npm install --save-dev gulp
效果如图:
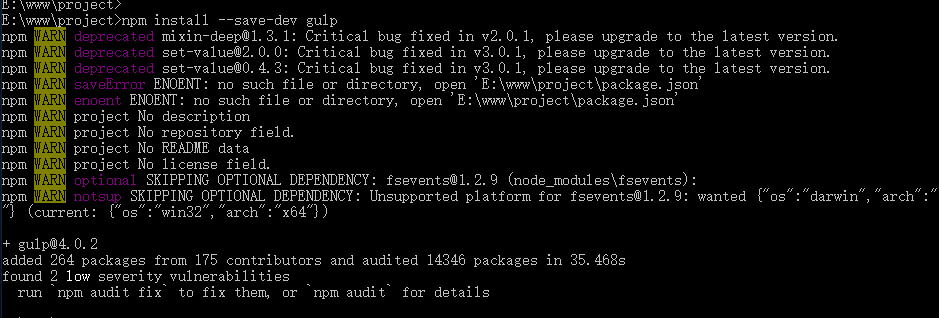
别着急,还有很多包,按顺序一一刷:
npm install --save-dev del
npm install --save-dev gulp-concat
npm install --save-dev gulp-header
npm install --save-dev gulp-if
npm install --save-dev gulp-minify-css
npm install --save-dev gulp-htmlmin
npm install --save-dev gulp-rename
npm install --save-dev gulp-replace
npm install --save-dev gulp-uglify
npm install --save-dev gulp-babel
npm install --save-dev babel-preset-es2015
npm install --save-dev @babel/core
npm install --save-dev @babel/preset-env
防范措施
插件安装完成后,我们的前期工作就完成了。
我们会在项目目录中找到不止一个node_modules目录和package-lock.json文件,json文件就是我们的插件列表,node_modules目录就是我们安装的插件包。
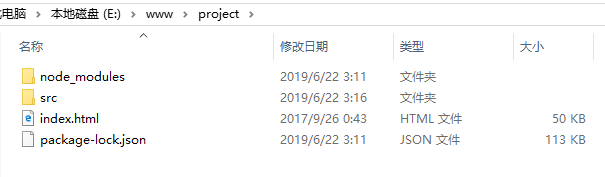
index.html是我的主入口文件,src目录是我的项目中存放代码的目录,也就是我要压缩和加密构建的目录。
src中有3个子目录,controller存放独立的js处理前端业务逻辑,style存放css样式文件,view存放html页面。
在写脚本之前,我需要直截了当地告诉你,如果你的 JS 中有 ES6 语法,正常打包是行不通的,但我们前期工作也已经安装了工具包来处理这个问题,但仅限于处理单个 JS 文件.
如果在HTML代码中嵌入了JS,而JS中有ES6语法,则需要将JS代码提取出来单独制作一个JS,或者手动将ES6写法改为ES5。
总之,如果打包出错,很有可能是ES6语法引起的,其次是文件路径错误。
压缩JS
回到我们的项目根目录并创建一个具有固定文件名的 gulpfile.js 文件:

导入包:
var gulp = require('gulp');
var uglify = require('gulp-uglify');
var babel = require('gulp-babel');
var minifyCss = require("gulp-minify-css");
var htmlmin = require('gulp-htmlmin');
var header = require('gulp-header');
var del = require('del');
定义一个目标目录:
var destDir = './dist';
定义一个注释,因为我想对缩小代码的第一行做一点注释:
var note = ['/** 小样,看源码?想得美! */\n ', {js: ';'}];
监控任务:
gulp.task('minjs', function () {
//定义路径
var src = [
'./src/**/*.js'
];
gulp.src(src)
.pipe(babel({presets: ["@babel/env"], plugins: []}))//es6转es5
.pipe(uglify())//压缩
.pipe(header.apply(null, note))//添加头部注释
.pipe(gulp.dest(destDir));//将压缩后的内容输出到目标目录
});
minjs 是我们自定义的任务名称,也就是说我们在命令行输入 gulp minjs 命令,就会执行这段代码。
如果只是输入 gulp 命令,它会自动找到名为 default 的任务。
var src = ['./src/**/*.js']; 是我们要抓取的文件,使用通配符,你几乎肯定需要这样写:
var src = [
'./src/**/*.js'
, '!./src/config.js'
, '!./src/lib/extend/*.js'
];
感叹号表示排除。
这里说明destDir只会替换通配符前的目录路径。比如我这里的destDir定义为./dist,那么./src/controller/admin.js的压缩路径就是./dist/controller/admin.js。
好的,打开命令行输入命令:gulp minjs
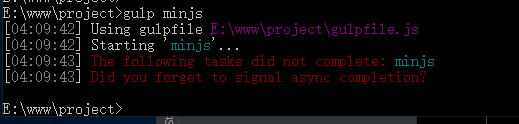
检查项目,js文件已经压缩成功。
压缩 CSS
任务监控和压缩JS没有区别,只是使用gulp-minify-css插件来完成压缩任务。
gulp.task('mincss', function () {
var src = [
'./src/style/*.css'
];
gulp.src(src).pipe(minifyCss()).pipe(gulp.dest(destDir + '/style'));
});
输入命令:gulp mincss
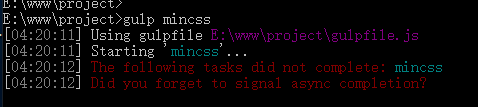
查看项目也没有问题:
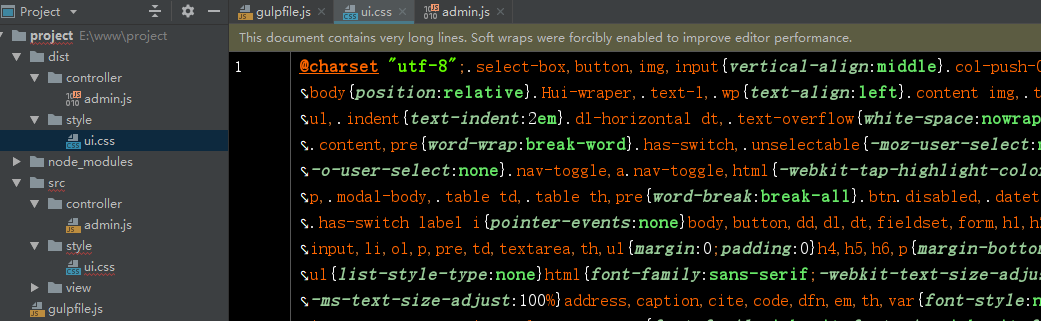
非常聪明,它会为您删除 css 中的评论。
压缩 HTML
压缩后的 HTML 可以传递多个参数来指定相应的行为:
gulp.task('minhtml', function () {
var options = {
removeComments: true,//清除HTML注释
collapseWhitespace: true,//折叠空白
minifyJS: true,//压缩页面JS
minifyCSS: true//压缩页面CSS
};
var src = [
'./src/views/**/*',
];
gulp.src(src)
.pipe(htmlmin(options))
.pipe(gulp.dest(destDir + '/views'));
});
更多参数请看这里:
输入命令:gulp minhtml
压缩的 HTML:
全部压缩成一行,文件中的css和js也被压缩了。
一站式处理
但是我们不能总是在一个包中运行多个命令。太麻烦了 现在我们将把这些任务整合并组合成一个任务。
我们创建一个任务对象,将每个任务的内容放入其中,并添加一个清理 dist 目录的方法,以及一个复制未压缩文件的 move 方法。
//任务列表
var task = {
//清理dist目录
clear:function () {
del(['./dist/*']);
},
minjs:function () {
//定义路径
var src = [
'./src/**/*.js'
];
gulp.src(src)
.pipe(babel({presets: ["@babel/env"], plugins: []}))//es6转es5
.pipe(uglify())//压缩
.pipe(header.apply(null, note))//添加头部注释
.pipe(gulp.dest(destDir));
},
mincss:function () {
var src = [
'./src/style/*.css'
];
gulp.src(src).pipe(minifyCss()).pipe(gulp.dest(destDir + '/style'));
},
minhtml:function () {
var options = {
removeComments: true,//清除HTML注释
collapseWhitespace: true,//折叠空白
minifyJS: true,//压缩页面JS 如果你确信你的HTML页面中的js不包含有es6语法,那么可以压缩js 否则还是得把js抽离成单独的文件进行压缩
minifyCSS: true//压缩页面CSS
};
var src = [
'./src/**/*',
];
gulp.src(src)
.pipe(htmlmin(options))
.pipe(gulp.dest(destDir));
},
move: function () {
//复制文件夹 没有被压缩的文件就在这里复制
gulp.src('./src/**/*.png').pipe(gulp.dest(destDir));
}
};
我们在压缩js的时候说过,如果只是一个gulp命令,它会找到一个名为default的task,我们在default task中遍历task对象,依次执行方法。
gulp.task('default', function () {
for (var key in task) {
task[key]();
}
});
这样,我们只需要一个 gulp 命令,整个构建过程就完成了。
同时,我们将单个任务指向任务中对应的方法:
gulp.task('clear',task.clear);
gulp.task('minjs',task.minjs);
gulp.task('mincss',task.mincss);
gulp.task('minhtml',task.minhtml);
gulp.task('move',task.move);
无论是处理单个环节还是整个构建过程,我们都能轻松完成。
最后,感谢阅读。PS:欢迎关注,有粉丝必回。
网页抓取 加密html(优化网站链接要做好GoogleSEO优化,链接优化也是一个很重要的SEO操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-30 05:19
优化网站链接需要谷歌SEO优化,链接优化也是一项非常重要的SEO操作。除了网站内部和外部链接,友好的链接也会影响你的谷歌排名。做内部链接时,要注意链接页面和锚文本的相关性;在做外链的时候,要注意外链的数量、质量和结构。做好网站的内链,一是可以有效引导谷歌很好地抓取你的网站内容,二是可以引导网站的权重提升某些页面以提高其在 Google 中的排名。
加强网站安全性搜索引擎一直秉承“用户至上”的原则,谷歌希望为用户提供搜索和浏览体验,所以网站的安全性也是谷歌非常重视的一个方面对的重要性。近年来,Google 一直在大力提倡站长对 网站 使用 https 加密。Chrome浏览器的地址栏会将加密的网站标记为绿色的小锁;如果没有https加密的网站,Chrome会发出不安全警告,谷歌对这个网站信任度降低,进而影响网站排名。
搜索引擎优化,也称为SEO,即Search Engine Optimization,是一种通过分析各种搜索引擎如何进行搜索,如何爬取互联网页面,以及如何确定具体关键词的方法。搜索引擎。对搜索结果进行排名的技术。搜索引擎利用搜索者容易引用的方法,有针对性地优化网站,提高网站在搜索引擎中的自然排名,吸引更多用户访问网站,提高网站的流量将提升网站的销售和宣传能力,从而提升网站的品牌效应。
搜索引擎优化技术主要有两种类型:黑帽和白帽。通过欺骗的方式欺骗搜索引擎和访问者,最终会受到搜索引擎的惩罚,被称为黑帽,例如隐藏关键字、创建大量元词、alt标签等。搜索引擎通过形式化技术接受的SEO技术和方法被称为白帽。
从长远来看,相对于关键词的推广,SEO需要做的是保持网站的进程,网站具有关键词的优点,不需要为用户按点击付费,所以比PPC便宜很多。此外,搜索引擎优化可以忽略搜索引擎之间的独立性。即使只优化了一个搜索引擎,网站在其他搜索引擎中的排名也会相应提升,达到关键词的水平,可以达到推广中重复付费的效果。
稳定性强
企业网站进行搜索引擎优化后,只要网站维护得当,它在搜索引擎中排名的稳定性也很强,很长一段时间都不会改变。
网站在结构方面,尽量避免使用框架结构,尽量不要使用导航栏中的FLASH按钮。首先要注意网站首页的设计,因为网站首页被搜索引擎检测到的概率要比其他网页大很多。通常网站的首页文件应该放在网站的根目录下,因为根目录下的检索速度很快。其次要注意网站的层级(即子目录)不能太多,目录不能超过2级,详细目录不能超过4级。在网站导航之后,尽量使用纯文本进行导航,因为文字比图片表达的信息更多。
搜索引擎使用专有的蜘蛛程序查找每个网页上的 HTML 代码,当网页上有链接时,它会一一搜索,直到没有任何页面的链接。蜘蛛需要访问所有的页面并且需要很长时间,所以网站的导航需要蜘蛛容易索引收录。根据自己的网站结构,可以制作一个网站地图sitemap.html,列出web地图中网站的所有子栏的链接,把所有文件放在网站 放在网站 的根目录下。网站地图增加了搜索引擎的友好性,并允许蜘蛛访问整个站点上的所有页面和部分。
做过搜索引擎优化排名的站长都知道,排名上下波动是正常的。例如,如果您为客户优化网站,当您在第一页让客户接受时,第二页将转到第二页。这种情况有很多次。搜索引擎不断改变他们的排名算法。这也增加了搜索引擎优化的难度。 查看全部
网页抓取 加密html(优化网站链接要做好GoogleSEO优化,链接优化也是一个很重要的SEO操作)
优化网站链接需要谷歌SEO优化,链接优化也是一项非常重要的SEO操作。除了网站内部和外部链接,友好的链接也会影响你的谷歌排名。做内部链接时,要注意链接页面和锚文本的相关性;在做外链的时候,要注意外链的数量、质量和结构。做好网站的内链,一是可以有效引导谷歌很好地抓取你的网站内容,二是可以引导网站的权重提升某些页面以提高其在 Google 中的排名。

加强网站安全性搜索引擎一直秉承“用户至上”的原则,谷歌希望为用户提供搜索和浏览体验,所以网站的安全性也是谷歌非常重视的一个方面对的重要性。近年来,Google 一直在大力提倡站长对 网站 使用 https 加密。Chrome浏览器的地址栏会将加密的网站标记为绿色的小锁;如果没有https加密的网站,Chrome会发出不安全警告,谷歌对这个网站信任度降低,进而影响网站排名。
搜索引擎优化,也称为SEO,即Search Engine Optimization,是一种通过分析各种搜索引擎如何进行搜索,如何爬取互联网页面,以及如何确定具体关键词的方法。搜索引擎。对搜索结果进行排名的技术。搜索引擎利用搜索者容易引用的方法,有针对性地优化网站,提高网站在搜索引擎中的自然排名,吸引更多用户访问网站,提高网站的流量将提升网站的销售和宣传能力,从而提升网站的品牌效应。

搜索引擎优化技术主要有两种类型:黑帽和白帽。通过欺骗的方式欺骗搜索引擎和访问者,最终会受到搜索引擎的惩罚,被称为黑帽,例如隐藏关键字、创建大量元词、alt标签等。搜索引擎通过形式化技术接受的SEO技术和方法被称为白帽。
从长远来看,相对于关键词的推广,SEO需要做的是保持网站的进程,网站具有关键词的优点,不需要为用户按点击付费,所以比PPC便宜很多。此外,搜索引擎优化可以忽略搜索引擎之间的独立性。即使只优化了一个搜索引擎,网站在其他搜索引擎中的排名也会相应提升,达到关键词的水平,可以达到推广中重复付费的效果。
稳定性强
企业网站进行搜索引擎优化后,只要网站维护得当,它在搜索引擎中排名的稳定性也很强,很长一段时间都不会改变。
网站在结构方面,尽量避免使用框架结构,尽量不要使用导航栏中的FLASH按钮。首先要注意网站首页的设计,因为网站首页被搜索引擎检测到的概率要比其他网页大很多。通常网站的首页文件应该放在网站的根目录下,因为根目录下的检索速度很快。其次要注意网站的层级(即子目录)不能太多,目录不能超过2级,详细目录不能超过4级。在网站导航之后,尽量使用纯文本进行导航,因为文字比图片表达的信息更多。
搜索引擎使用专有的蜘蛛程序查找每个网页上的 HTML 代码,当网页上有链接时,它会一一搜索,直到没有任何页面的链接。蜘蛛需要访问所有的页面并且需要很长时间,所以网站的导航需要蜘蛛容易索引收录。根据自己的网站结构,可以制作一个网站地图sitemap.html,列出web地图中网站的所有子栏的链接,把所有文件放在网站 放在网站 的根目录下。网站地图增加了搜索引擎的友好性,并允许蜘蛛访问整个站点上的所有页面和部分。
做过搜索引擎优化排名的站长都知道,排名上下波动是正常的。例如,如果您为客户优化网站,当您在第一页让客户接受时,第二页将转到第二页。这种情况有很多次。搜索引擎不断改变他们的排名算法。这也增加了搜索引擎优化的难度。
网页抓取 加密html(什么叫批批HTML加密器是一个简易便捷的网页加密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 22:04
Batch Html Encryptor是一款网页加密专用工具,可以辅助网站站长对html源文件进行加密。它不仅可以对所有网页的源代码进行加密,还可以对网页的部分源代码进行加密。加密网页只能使用电脑浏览器开发演示文稿时才能看到!
【软件详细介绍】
Batch Html Encryptor 是一个简单方便的工具,用于加密大批量的 Web 文档。它可以帮助您将网页转换为不可读的代码!
如何保护自己的 HTML网站 内容一直是新手站长的一大难题。Batch Html Encryptor 可以帮助 网站 站长加密html源文件。加密后,只有计算机浏览器才能理解输出。别人不知道源文件根本不能改。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一个专用工具,用于维护您的 html 编码和脚本编码,将它们转换为空灵的文字。在解决多文档,出色的工作,所以它会节省你做这项繁琐工作的时间。现在幸运地适用于UNIC ODE,这意味着批处理HTML加密器工作在比其他加密程序更强的加密多语言表达HTML文档中。
迷你系统要求
微软公司 Windows 95/98/Me/NT 4.0/2000/XP;
英特尔 586 32MB 内存;
6 MB 可用存储空间 查看全部
网页抓取 加密html(什么叫批批HTML加密器是一个简易便捷的网页加密)
Batch Html Encryptor是一款网页加密专用工具,可以辅助网站站长对html源文件进行加密。它不仅可以对所有网页的源代码进行加密,还可以对网页的部分源代码进行加密。加密网页只能使用电脑浏览器开发演示文稿时才能看到!

【软件详细介绍】
Batch Html Encryptor 是一个简单方便的工具,用于加密大批量的 Web 文档。它可以帮助您将网页转换为不可读的代码!
如何保护自己的 HTML网站 内容一直是新手站长的一大难题。Batch Html Encryptor 可以帮助 网站 站长加密html源文件。加密后,只有计算机浏览器才能理解输出。别人不知道源文件根本不能改。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一个专用工具,用于维护您的 html 编码和脚本编码,将它们转换为空灵的文字。在解决多文档,出色的工作,所以它会节省你做这项繁琐工作的时间。现在幸运地适用于UNIC ODE,这意味着批处理HTML加密器工作在比其他加密程序更强的加密多语言表达HTML文档中。
迷你系统要求
微软公司 Windows 95/98/Me/NT 4.0/2000/XP;
英特尔 586 32MB 内存;
6 MB 可用存储空间
网页抓取 加密html(本文将用JavaScript实现两个颇有技术含量的功能:压缩图片、加密图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-27 05:13
本文将使用 JavaScript 实现两个相当技术性的功能:压缩图片、加密图片。
开门见山:
一、压缩图像
压缩原理:
将图像读入画布,并使用画布的 toDataURL 方法对图像进行 base64 处理。在此过程中,您可以设置质量值,即图像质量值。取值在0.1 到1 之间,取值越小,压缩率越高。
完整代码:
压缩图像:
运行结果:
压缩率
如上图所示,压缩后的图片大小为28KB,而原创文件大小则超过400KB:
可以看出压缩效果还是很不错的。
二、加密图片
上面提到的图像压缩是一项非常实用的技术。下一步是本文的重点,展示一个奇怪的技巧:图像加密。
我们之所以说压缩和图像加密,是因为图像加密是在前面的压缩技术的基础上完成的。
在上面的代码中,toDataURL 生成图像的 base64 编码。
Base64 编码必须完整且正确,才能正确显示图片。
而且只要对这个编码稍加修改,哪怕只改变一个字符,都会导致图片无法正常显示。
然后,在代码中的某个位置添加一个字符,达到破坏正确代码,实现加密的效果:
运行效果,输出加密后的base64编码:
做一个测试:
效果如下,图片无法正常显示。
然后,将达到以下效果:
网页中用img的src引入了加密的base64字符,此时图片无法显示。然后,就可以输入密码了,当密码正确时,解密base64字符,让图片正常显示。
输入密码:
密码正确,解密并显示图片:
源代码:
网页中还有其他几个元素:
加密后的base64编码存储在input中,即上面js代码函数生成并加密的内容;
img 用于显示解密后的图像;还有一个按钮,单击时会调用解密功能。
可能有人发现了,虽然图片编码已经加密,加了密码保护,但是只要查看网页源代码就可以知道密码,完全没有加密的作用。
到目前为止,问题确实存在。所以,更进一步:
可以看到密码,因为javascript代码是透明的。然后,解密后的js代码必须加密。加密后,密码将不可见。
使用 JShaman 对 JS 代码进行混淆和加密:
并在 JShaman 的配置中勾选“字符串加密”:
加密后的代码根本找不到之前的密码字符:
这样就实现了完整的图像加密:将图像加密存储在单独的html中,便于携带、存储和传输。内容已加密,密码已加密。只有知道密码的人才能看到图片。 查看全部
网页抓取 加密html(本文将用JavaScript实现两个颇有技术含量的功能:压缩图片、加密图片)
本文将使用 JavaScript 实现两个相当技术性的功能:压缩图片、加密图片。
开门见山:
一、压缩图像
压缩原理:
将图像读入画布,并使用画布的 toDataURL 方法对图像进行 base64 处理。在此过程中,您可以设置质量值,即图像质量值。取值在0.1 到1 之间,取值越小,压缩率越高。
完整代码:
压缩图像:
运行结果:
压缩率
如上图所示,压缩后的图片大小为28KB,而原创文件大小则超过400KB:
可以看出压缩效果还是很不错的。
二、加密图片
上面提到的图像压缩是一项非常实用的技术。下一步是本文的重点,展示一个奇怪的技巧:图像加密。
我们之所以说压缩和图像加密,是因为图像加密是在前面的压缩技术的基础上完成的。
在上面的代码中,toDataURL 生成图像的 base64 编码。
Base64 编码必须完整且正确,才能正确显示图片。
而且只要对这个编码稍加修改,哪怕只改变一个字符,都会导致图片无法正常显示。
然后,在代码中的某个位置添加一个字符,达到破坏正确代码,实现加密的效果:
运行效果,输出加密后的base64编码:
做一个测试:
效果如下,图片无法正常显示。
然后,将达到以下效果:
网页中用img的src引入了加密的base64字符,此时图片无法显示。然后,就可以输入密码了,当密码正确时,解密base64字符,让图片正常显示。
输入密码:
密码正确,解密并显示图片:
源代码:
网页中还有其他几个元素:
加密后的base64编码存储在input中,即上面js代码函数生成并加密的内容;
img 用于显示解密后的图像;还有一个按钮,单击时会调用解密功能。
可能有人发现了,虽然图片编码已经加密,加了密码保护,但是只要查看网页源代码就可以知道密码,完全没有加密的作用。
到目前为止,问题确实存在。所以,更进一步:
可以看到密码,因为javascript代码是透明的。然后,解密后的js代码必须加密。加密后,密码将不可见。
使用 JShaman 对 JS 代码进行混淆和加密:
并在 JShaman 的配置中勾选“字符串加密”:
加密后的代码根本找不到之前的密码字符:
这样就实现了完整的图像加密:将图像加密存储在单独的html中,便于携带、存储和传输。内容已加密,密码已加密。只有知道密码的人才能看到图片。
网页抓取 加密html( 网页版恰鹿导航有收录可直接搜索pdf24PDF页面、OCR功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-26 10:00
网页版恰鹿导航有收录可直接搜索pdf24PDF页面、OCR功能)
这是一款来自德国公司的pdf工具,收录了几乎所有的PDF处理工具,而且完全免费,没有任何广告,支持网页版和本地客户端。
该软件允许用户自己创建pdf文档,也支持将任何打印的文档转换成pdf格式,还可以设置转换后的pdf文件的质量和大小,以及给pdf添加签名、水印,甚至还可以集成好使用截图功能。使用此软件可以从几乎每个 Windows 应用程序创建 PDF 文件,以及重新排序页面、合并、拆分和密码保护您在使用中的现有 PDF 文件,适用于 winxp\vista\win7\win8 等系统。另外,pdf24不仅好用,界面布局也非常独特,还具备抓屏、抓摄像头图像等功能。可以直接将文件拖放到本软件主窗口的编辑区,pdf24会自动转换为pdf格式,甚至支持截屏或图片直接转换成pdf格式。最后需要注意的是,用户进入软件后,整个软件都有中文界面,可以让你更好的使用软件中的所有功能,从而更好的满足中国人的需求。
共有24个主要功能
1、PDF 合并、拆分、裁剪、拼合、旋转、页面排序;
2、PDF压缩、加密、解密;
3、将PDF转换为Word、PPT、Excel、图片、文本、HTML,并将这些文件反转为PDF;
4、删除或提取PDF页面,从PDF文件中提取图片;
5、为PDF添加水印、页码、注释;
6、PDF文本识别,OCR功能;
7、等一下,下载它自己看看。
软件下载:
网页版奇路导航有收录可以直接搜索pdf24 查看全部
网页抓取 加密html(
网页版恰鹿导航有收录可直接搜索pdf24PDF页面、OCR功能)
这是一款来自德国公司的pdf工具,收录了几乎所有的PDF处理工具,而且完全免费,没有任何广告,支持网页版和本地客户端。
该软件允许用户自己创建pdf文档,也支持将任何打印的文档转换成pdf格式,还可以设置转换后的pdf文件的质量和大小,以及给pdf添加签名、水印,甚至还可以集成好使用截图功能。使用此软件可以从几乎每个 Windows 应用程序创建 PDF 文件,以及重新排序页面、合并、拆分和密码保护您在使用中的现有 PDF 文件,适用于 winxp\vista\win7\win8 等系统。另外,pdf24不仅好用,界面布局也非常独特,还具备抓屏、抓摄像头图像等功能。可以直接将文件拖放到本软件主窗口的编辑区,pdf24会自动转换为pdf格式,甚至支持截屏或图片直接转换成pdf格式。最后需要注意的是,用户进入软件后,整个软件都有中文界面,可以让你更好的使用软件中的所有功能,从而更好的满足中国人的需求。
共有24个主要功能
1、PDF 合并、拆分、裁剪、拼合、旋转、页面排序;
2、PDF压缩、加密、解密;
3、将PDF转换为Word、PPT、Excel、图片、文本、HTML,并将这些文件反转为PDF;
4、删除或提取PDF页面,从PDF文件中提取图片;
5、为PDF添加水印、页码、注释;
6、PDF文本识别,OCR功能;
7、等一下,下载它自己看看。
软件下载:
网页版奇路导航有收录可以直接搜索pdf24
网页抓取 加密html(超强php程序的反编译工具Windows7及vista系统反馈问题汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-26 00:12
超级php程序的反编译工具
Windows7和vista系统都可以,但是需要去掉UAC,或者以管理员权限运行主程序。如无意外,黑刀Dezender 5.0的三个解密内核版本将是最终版本。除非出现新的解密内核,否则以后不会更新,任何关于Zend解密问题的问题请不要加我QQ咨询!感谢各位黑刀迷的关注,期待我的其他作品。谢谢!反馈问题总结:1、很多朋友说下载最新版本后无法解决问题,因为把程序放在桌面或者Program Files目录下。大家一定要记住,不要将Black Knife Dezender的主程序和需要解密的PHP文件放在目录名收录空格的目录中,如桌面、Program Files目录等,但目录名不能收录空格,它可以收录英语吗?期间,以免程序把目录当成文件,导致无法解密的情况。还有一种可能是加密后的PHP文件被最新版本的Zend加密了,所以黑刀Dezender解决不了。2、解密后的文件有“乱码”:这通常是因为PHP程序在加密时使用了混淆函数,而使用的函数没有被Dezender识别,所以函数的一部分就变成了“乱码”。
3、网友“李向阳”问:“我解压的文件可以看,但是有很多很基础的语法问题,不知道怎么回事!” 对于这个典型的问题,我只能回答它是解密的。文件无法 100% 还原为原创未加密文件。在遇到需要手动修复代码时,要求 Dezender 的用户具备相应的 PHP 编程知识。如果不可用?找书找资料。哈哈。4、如果出现如下错误提示:“无法在动态链接库php5ts.dll上确定程序输入点”,说明dezender与原PHP环境冲突,可以考虑卸载原PHP环境,或安装虚拟机,在虚拟机上使用 dezender。如果它不起作用,请尝试另一台计算机。哈哈。虚拟机下载地址: 重要声明:黑刀Dezender本身只是一个集成工具。主程序其实只是一个用Delphi开发的GUI界面shell程序。核心解密函数采集自网上。我所做的Shell编程只是在Dezender原创解密内核版本的功能基础上开发了一个基于Windows的用户界面,使用户可以在原创的“DOS”环境下实现Windows的各种应用功能。关于加密和保护自己的PHP程序的问题:一种类似于微盾加密的加密方式,可以混淆函数和变量。正式名称是“PHPlockit”。微盾的PHP加密专家也有类似的功能,但似乎程序不能正确。跑步。
目前,在我开发新版解密工具之前,据我所知,能手动解密“类似microshield的加密混淆函数和变量”的人,除了我之外,已经不多了。你可以试试看。其他相对安全的加密方式如Ioncube也可以使用,但国内支持这种加密方式的虚拟主机并不多。如果是独立服务器,可以考虑。而Zend的混淆功能也是目前还不能完全解决的问题。在开发自己的 PHP 程序时,可以使用较长的自定义函数名和变量名,这样即使程序被解密,Dezender 也无法正确识别明文。就其本身而言,由于函数和变量已被混淆,
立即下载 查看全部
网页抓取 加密html(超强php程序的反编译工具Windows7及vista系统反馈问题汇总)
超级php程序的反编译工具
Windows7和vista系统都可以,但是需要去掉UAC,或者以管理员权限运行主程序。如无意外,黑刀Dezender 5.0的三个解密内核版本将是最终版本。除非出现新的解密内核,否则以后不会更新,任何关于Zend解密问题的问题请不要加我QQ咨询!感谢各位黑刀迷的关注,期待我的其他作品。谢谢!反馈问题总结:1、很多朋友说下载最新版本后无法解决问题,因为把程序放在桌面或者Program Files目录下。大家一定要记住,不要将Black Knife Dezender的主程序和需要解密的PHP文件放在目录名收录空格的目录中,如桌面、Program Files目录等,但目录名不能收录空格,它可以收录英语吗?期间,以免程序把目录当成文件,导致无法解密的情况。还有一种可能是加密后的PHP文件被最新版本的Zend加密了,所以黑刀Dezender解决不了。2、解密后的文件有“乱码”:这通常是因为PHP程序在加密时使用了混淆函数,而使用的函数没有被Dezender识别,所以函数的一部分就变成了“乱码”。
3、网友“李向阳”问:“我解压的文件可以看,但是有很多很基础的语法问题,不知道怎么回事!” 对于这个典型的问题,我只能回答它是解密的。文件无法 100% 还原为原创未加密文件。在遇到需要手动修复代码时,要求 Dezender 的用户具备相应的 PHP 编程知识。如果不可用?找书找资料。哈哈。4、如果出现如下错误提示:“无法在动态链接库php5ts.dll上确定程序输入点”,说明dezender与原PHP环境冲突,可以考虑卸载原PHP环境,或安装虚拟机,在虚拟机上使用 dezender。如果它不起作用,请尝试另一台计算机。哈哈。虚拟机下载地址: 重要声明:黑刀Dezender本身只是一个集成工具。主程序其实只是一个用Delphi开发的GUI界面shell程序。核心解密函数采集自网上。我所做的Shell编程只是在Dezender原创解密内核版本的功能基础上开发了一个基于Windows的用户界面,使用户可以在原创的“DOS”环境下实现Windows的各种应用功能。关于加密和保护自己的PHP程序的问题:一种类似于微盾加密的加密方式,可以混淆函数和变量。正式名称是“PHPlockit”。微盾的PHP加密专家也有类似的功能,但似乎程序不能正确。跑步。
目前,在我开发新版解密工具之前,据我所知,能手动解密“类似microshield的加密混淆函数和变量”的人,除了我之外,已经不多了。你可以试试看。其他相对安全的加密方式如Ioncube也可以使用,但国内支持这种加密方式的虚拟主机并不多。如果是独立服务器,可以考虑。而Zend的混淆功能也是目前还不能完全解决的问题。在开发自己的 PHP 程序时,可以使用较长的自定义函数名和变量名,这样即使程序被解密,Dezender 也无法正确识别明文。就其本身而言,由于函数和变量已被混淆,
立即下载
网页抓取 加密html(本文实例讲述了JS加密插件CryptoJS实现AES加密操作操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-23 03:05
本文章主要介绍JS加密插件CryptoJS如何实现AES加密操作,具有一定的参考价值。有兴趣的朋友可以参考一下。我希望您在阅读此文章 后会有所收获。下面就让小编带大家一探究竟。
js的作用是什么
1、能够在 HTML 页面中嵌入动态文本。2、响应浏览器事件。3、读取和写入 HTML 元素。4、在将数据提交到服务器之前验证数据。5、检测访问者的浏览器信息。6、控制 cookie,包括创建和修改。7、基于 Node.js 技术的服务器端编程。
本文的例子介绍了JS加密插件CryptoJS实现AES加密。分享给大家参考,详情如下:
我最近在做一个项目。考虑到数据的安全性,我们需要在传输过程中对数据进行加密,以防止一些恶意操作和爬虫抓取数据。
先看一下这个 CryptoJS 的目录结构
主要是两个文件夹,components和rollups
第一个是组件,第二个是聚合。
汇总文件夹中的文件在一个或多个文件夹组合后进行压缩。
这使得 Rollup 将项目中的单独文件夹分成项目文件,而不用担心它的依赖关系。
您可以在此处查看聚合文件和组件之间的关系:
首先在项目中引入对应的加密文件,我们使用AES,并使用RequireJS加载JS,并在配置中声明路径:
require.config({
baseUrl: "/Public/Home/Js/lib",
paths: {
hzbAES:'../module/hzb.AES'
}
});
一、将加解密封装成一个模块
//模块初始化
var init=function () {
key = CryptoJS.enc.Utf8.parse(CryptoJS.MD5(ym.hezubao).toString());
iv = CryptoJS.enc.Utf8.parse(CryptoJS.MD5(key).toString().substr(0,16));
}
function encrypt(data) {
var encrypted='';
if(typeof(data)=='string')
{
encrypted = CryptoJS.AES.encrypt(data,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
});
}else if(typeof(data)=='object'){
data = JSON.stringify(data);
encrypted = CryptoJS.AES.encrypt(data,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
})
}
return encrypted.toString();
}
/*AES解密
* param : message 密文
* return : decrypted string 明文
*/
function decrypt(message) {
decrypted='';
decrypted=CryptoJS.AES.decrypt(message,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
});
return decrypted.toString(CryptoJS.enc.Utf8);
}
解释代码:
调用代码
require(['hzbAES'], function(hzbAES){
var jsonData={'id':2,'username':'春天的熊'};//json格式数据(加密支持json格式和字符串格式)
$('#btn_test').click(function () {
var encrypt=hzbAES.encrypt(jsonData);
console.log('前台发过去的数据:'+encrypt);//已加密
$.getJSON(UrlGenerator.url(2,'Home','Index','test'),{'data':encrypt},function (data) {
if(!data['error'])
{
var decrypt=JSON.parse(hzbAES.decrypt(data['data']));
console.log('后台发过来的数据:');//已解密
console.log(decrypt);
}else{
console.log(data['error']);
}
})
});
});
感谢您仔细阅读此文章。希望小编分享的《JS加密插件CryptoJS如何实现AES加密》的文章文章对大家有所帮助。同时也希望大家多多支持易素。云,关注易宿云行业资讯频道,更多相关知识等你学习! 查看全部
网页抓取 加密html(本文实例讲述了JS加密插件CryptoJS实现AES加密操作操作)
本文章主要介绍JS加密插件CryptoJS如何实现AES加密操作,具有一定的参考价值。有兴趣的朋友可以参考一下。我希望您在阅读此文章 后会有所收获。下面就让小编带大家一探究竟。
js的作用是什么
1、能够在 HTML 页面中嵌入动态文本。2、响应浏览器事件。3、读取和写入 HTML 元素。4、在将数据提交到服务器之前验证数据。5、检测访问者的浏览器信息。6、控制 cookie,包括创建和修改。7、基于 Node.js 技术的服务器端编程。
本文的例子介绍了JS加密插件CryptoJS实现AES加密。分享给大家参考,详情如下:
我最近在做一个项目。考虑到数据的安全性,我们需要在传输过程中对数据进行加密,以防止一些恶意操作和爬虫抓取数据。
先看一下这个 CryptoJS 的目录结构

主要是两个文件夹,components和rollups
第一个是组件,第二个是聚合。
汇总文件夹中的文件在一个或多个文件夹组合后进行压缩。
这使得 Rollup 将项目中的单独文件夹分成项目文件,而不用担心它的依赖关系。
您可以在此处查看聚合文件和组件之间的关系:
首先在项目中引入对应的加密文件,我们使用AES,并使用RequireJS加载JS,并在配置中声明路径:
require.config({
baseUrl: "/Public/Home/Js/lib",
paths: {
hzbAES:'../module/hzb.AES'
}
});
一、将加解密封装成一个模块
//模块初始化
var init=function () {
key = CryptoJS.enc.Utf8.parse(CryptoJS.MD5(ym.hezubao).toString());
iv = CryptoJS.enc.Utf8.parse(CryptoJS.MD5(key).toString().substr(0,16));
}
function encrypt(data) {
var encrypted='';
if(typeof(data)=='string')
{
encrypted = CryptoJS.AES.encrypt(data,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
});
}else if(typeof(data)=='object'){
data = JSON.stringify(data);
encrypted = CryptoJS.AES.encrypt(data,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
})
}
return encrypted.toString();
}
/*AES解密
* param : message 密文
* return : decrypted string 明文
*/
function decrypt(message) {
decrypted='';
decrypted=CryptoJS.AES.decrypt(message,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
});
return decrypted.toString(CryptoJS.enc.Utf8);
}
解释代码:
调用代码
require(['hzbAES'], function(hzbAES){
var jsonData={'id':2,'username':'春天的熊'};//json格式数据(加密支持json格式和字符串格式)
$('#btn_test').click(function () {
var encrypt=hzbAES.encrypt(jsonData);
console.log('前台发过去的数据:'+encrypt);//已加密
$.getJSON(UrlGenerator.url(2,'Home','Index','test'),{'data':encrypt},function (data) {
if(!data['error'])
{
var decrypt=JSON.parse(hzbAES.decrypt(data['data']));
console.log('后台发过来的数据:');//已解密
console.log(decrypt);
}else{
console.log(data['error']);
}
})
});
});
感谢您仔细阅读此文章。希望小编分享的《JS加密插件CryptoJS如何实现AES加密》的文章文章对大家有所帮助。同时也希望大家多多支持易素。云,关注易宿云行业资讯频道,更多相关知识等你学习!
网页抓取 加密html(抓取房产网站应该没有什么反爬措施?解密一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-23 02:12
在抢夺财物网站的过程中,领队给了一个网站,打开一看,感觉这个不知名的网站应该没有防爬措施吧,不是那么容易的事。然后准备工作。为了安全起见,我还是打算测试一下防爬措施。首先,我使用常规 requests 请求携带请求头来访问它。我发现没有问题。
所以我检查了源代码,发现了一些奇怪的东西。
发现部分数字被替换成了这么奇怪的代码,打开开发者工具时,所有的字都显示出来了。
这是什么鬼,换了这个类,网页上的数字也会正常显示,变成乱码
所以基本上可以得出结论,这个类的部分是罪魁祸首。这是比较流行的反爬虫技术,它使用自定义字体格式来加密 html 文本。这种技术的好处是,如果直接抓取,可以得到返回的结果都是奇怪的代码,如果手动复制,就复制不了了。
我以为是js加载的,但是在开发者工具中查看XHR后发现,并不是那么简单。
解决这个问题的第一个想法是认为这个数字可能对应一个代码,手动查看,看看是怎么回事,找到模式,花了十多分钟总结,但再次刷新页面后,瞬间迷茫, 什么。. . ? ? 编码不同,仍然有变化。看来这条路行不通了。
然后我搜索了这个奇怪的类在哪里,发现了这样一个东西
没错,就是她。查看上述格式的 woff。原来是自定义字体格式,每次刷新,一串看不懂的代码都会变。这应该是问题所在。
然后复制上面的一串代码,使用python3的fontTools包将代码转换成字体文件
从标注的地方发现这个还是用base64加密的,这里我们需要用base64来解密
下面的代码
import base64
from fontTools.ttLib import TTFont
import io
key = 'd09GRgABAAAAAAjgAAsAAAAADMgAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7lQ7Y21hcAAAAYAAAAC7AAACTCMTZu5nbHlmAAACPAAABFEAAAVEz90AumhlYWQAAAaQAAAALwAAADYWPYnBaGhlYQAABsAAAAAcAAAAJAeKAzlobXR4AAAG3AAAABIAAAAwGp4AAGxvY2EAAAbwAAAAGgAAABoHsAZ6bWF4cAAABwwAAAAfAAAAIAEZAEduYW1lAAAHLAAAAVcAAAKFkAhoC3Bvc3QAAAiEAAAAWgAAAI/0SbGSeJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2BksmCcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKr7sZNb5r8MQw6zDcAUozAiSAwDoZAvKeJzFkj0OgzAMhV8K9I8OHTtwhF6BYyCOwMacE3Rj60k6ldsgFCEkJqTs9BmzVIK1dfRFynMUWy8GEAEIyJ2EgHnDQOJF1cx6gPOsh3jwfMOVyhG2SdrUZa7sbB8N+Vj4ytfTxBvbmbUwfHFtSSbGgbX32LHeiZ2G0qnZb7z0gzD/K/0dl3l/LqeY2AW22CSK6G2q0Em4TJH/dKVCd9FZhT6jjxQ6jiFX6D3GQpF58ZUi8+JrBcEH8D4+WAB4nE2Uy2/jVBTG73USO3HcpE1iO08nTmI778SJHSdp3n1lJn2/Ke0wMy2qShnUYQABAxWDNEJIMGKH2AJihxDSbNjRolFXSKAixIgFbNgg/gUyXDsZwFeydY/t4+/7nXMMIABP/gJF4AEYAFqJ9nCeBEAH2j15jI1hlyADaugOwzKlolYeLrUsajiBx6KSqCoowLAcpD3EKCRBRSSiBE7r4bL6gOLSQppz8R4HbjaZSYtPzlaebTU7nYOrlXoj6OrXV7bUphneXq/OxDP2cPqtlY+bgYDbHYl0bXwwYCLxdMDfnHnxRFmnKEn86P6DtdVMplDYgsrukUPOL/fkONzpG5r/wBzYd8AOHABYNIsENbdGSE444TbByfHBuQ1em4KHluvORfib/yu4Dn8iBjx1yHxthRhcGHwLoOF7AvsGxJFrDuqmVUUyDBGSm2ctBAJQKiJrI7fvk/3KbCIbVrZFf5TemIO38MHPCSbry12famG17r2b1Z7ly9lpWevvcjWH2xMm4Rur5kesy9K98mhzoVLdRbyhod2MXYAcAALNK1oTGrD1iy4ghgQ4YRPqpHHiv8UQAmYaBO1k0OkPhaT6MpMKFdpNSYJ79jcv70bTgjsqJ/0+ykdarPCwvhnh/AVvwBvg5XmuWmoFBF9pzvTaMXZnK7dUYgNiMso6aIqizRbwry4KMfUC4JYE2gFHH46JT9tBE2QIf41Px/JQ4mhiG3faxr0zHC+5Bp9i+1u2ZWG/pl2dV3dvpRWl9fZLvQIvEaPcv8NTlNuJqiVN6FmlYUZ2Ap7uxKtV51ivFjbzVDFswRo0VyDXcxmfI0ab/5aG7/+CtF0A7f8darDSimwxZtQOlW6YFhUNPWP0qQExJqLqafetmbjWznDIUH7WJZC4aYyQy7l2RZmx70zUJp/PloqBgM9f7PQ+OL7Ratt2znai0SI/20wkySUYCrfkDmxNc0v5YsCbTbYSYpB3Xus99954qro7BkyjObpA/BKgihiKGgJXZGhUOlY/48YUlTVpZEBCBnTAJg9rRPR5Q0qj+PldE5abOnuV3O8HY9bs8uNutzflsvn4slygrdaor16OREMukxLLcCqdIuLpe2vwjniyqpZfXjhOMrLcRfrbjYO5GxOflMM8H5YL0RxFMvzgnUQs7vEwnkS3k0qtPZ3/7zE70i2AMkKNFBDisPJ0E+ooUefp2xxUxRFbCY4kG9j1hoWfU4ygpvm0LYAT/J5yoLYgDI13lKnbH1ILK69sdbLUzuBPD5mLSVoqudLPZVKYTWVFHHcJtbiQkjP5qe7RdH0yHKGoz84ub67L+U1scFaNpBkmJ19ZfCajjP5VduxHwALRIIyYsUa12WG7Gn+qEtprRWOY9GGujPn9hbnpd/NBxmrBKEewy2+80Ohtm1PJdmMjrJ56J01w6f78clol9zKdxkn7KNHPp7cXf3hYb5tf/+K8MalMP0So/gFnXvSzAAAAeJxjYGRgYADiu+3HZsbz23xl4GZhAIGb/cpCCPr/WRYGpstALgcDE0gUADYSCl0AeJxjYGRgYNb5r8MQw8IAAkCSkQEV8AAAM2IBzXicY2EAghQGBiZL4jAAQjYCtwAAAAAAAAAMAGYAiADEARABPgFeAbACDAJiAqIAAHicY2BkYGDgYbBmYGYAASYg5gJCBob/YD4DAA+WAWEAeJxlkbtuwkAURMc88gApQomUJoq0TdIQzEOpUDokKCNR0BuzBiO/tF6QSJcPyHflE9Klyyekz2CuG8cr7547M3d9JQO4xjccnJ57vid2cMHqxDWc40G4Tv1JuEF+Fm6ijRfhM+oz4Ra6eBVu4wZvvMFpXLIa40PYQQefwjVc4Uu4Tv1HuEH+FW7i1mkKn6Hj3Am3sHC6wm08Ou8tpSZGe1av1PKggjSxPd8zJtSGTuinyVGa6/Uu8kxZludCmzxMEzV0B6U004k25W35fj2yNlCBSWM1paujKFWZSbfat+7G2mzc7weiu34aczzFNYGBhgfLfcV6iQP3ACkSaj349AxXSN9IT0j16JepOb01doiKbNWt1ovippz6sVYYwsXgX2rGVFIkq7Pl2PNrI6qW6eOshj0xaSq9mpNEZIWs8LZUfOouNkVXxp/d5woqebeYIf4D2J1ywQB4nG3JOxKAIBAD0A3+Ee8CKh9bFO9iY+eMx3dcLE3zJgkJypH0HwWBAiUq1GjQooNED4WBcDfXeSTnw+s+xyUbNtY4z//sEjtOvKegLRvt99vctVmJHhnTF3IAAA=='
data = base64.b64decode(key)
fonts = TTFont(io.BytesIO(data))
fonts.save('base.ttf') # 保存成ttf和woff这样的文件格式需要利用FontCreator这样的工具打开,
# 这个百度就可以下载
fonts.save('base.woff')
fonts.saveXML('base.xml') # 保存成这样的格式,可以直接打开进行查看
使用FontCreator打开ttf或woff文件,显示如下
而且你会发现每个数字都对应一个代号,代号uni后面的字符和你在网页上看到的完全一样,有木有的
没错,这就是它们之间的映射关系。每次页面刷新时,后台会随机从数据库中拉取一个自定义字体样式,然后在显示html'时通过映射渲染成普通字体。
打开刚才保存的xml文件可以看到类似这样的东西
看到开头有点眼熟(uniE01C),没错,这个就是每个数字用二维数组画出来的数字
In [1]: import numpy as np
In [2]: from matplotlib import pyplot as plt
In [3]: x=np.array([56, 43, 69, 95, 143, 214, 282, 412, 459, 487, 509, 517, 522, 520, 508, 494, 466, 400, 367, 282, 17
...: 6, 115, 43, 43, 131, 135, 177, 218, 282, 343, 428, 428, 428, 397, 344, 218, 194, 135, 132])
In [4]: y=np.array([335, 468, 544, 624, 667, 720, 710, 710, 617, 573, 508, 447, 335, 271, 166, 126, 51, 4, -39, -39, -
...: 39, 49, 127, 335, 335, 155, 95, 31, 35, 35, 155, 321, 515, 576, 635, 635, 583, 515, 335])
In [5]: plt.plot(x,y)
Out[5]: []
In [6]: plt.show()
上面的代码展示了一个二维的数字数组,解决这个问题的方法是在每个页面爬取的时候下载一个对应的字体文件,然后和我们第一次下载的那个一起传递。对比base.xml文件,进行实际手动对比。同一个二维数组点每两个文件中相同数字的x和y相差在50以内,可以以此作为判断依据。,如果都在这个范围内,则可以确定这两个代码代表同一个数字,然后将所有抓取到的html页面替换为对应代码对应的数字,然后解析,只提供一种思路这里,我没有写代码,因为在实际的爬取过程中,会产生大量的io,
另一种思路是,使用保存的xml文件的所有二维数组生成图片,然后使用TensorFlow进行识别,工作量相当大。
我的解决方法是在测试的时候发现会有一个url重定向到手机端,然后打开手机端发现号码没有加密。
虽然上面的文字加密问题已经解决了,但是还是遇到了抓取页面和实际查看源码的差异,url会发生变化。这就需要反复比较和修正。以上是遇到的问题,记录一下,仅供参考。本文仅供学习交流,禁止商业用途。 查看全部
网页抓取 加密html(抓取房产网站应该没有什么反爬措施?解密一下)
在抢夺财物网站的过程中,领队给了一个网站,打开一看,感觉这个不知名的网站应该没有防爬措施吧,不是那么容易的事。然后准备工作。为了安全起见,我还是打算测试一下防爬措施。首先,我使用常规 requests 请求携带请求头来访问它。我发现没有问题。
所以我检查了源代码,发现了一些奇怪的东西。

发现部分数字被替换成了这么奇怪的代码,打开开发者工具时,所有的字都显示出来了。

这是什么鬼,换了这个类,网页上的数字也会正常显示,变成乱码

所以基本上可以得出结论,这个类的部分是罪魁祸首。这是比较流行的反爬虫技术,它使用自定义字体格式来加密 html 文本。这种技术的好处是,如果直接抓取,可以得到返回的结果都是奇怪的代码,如果手动复制,就复制不了了。
我以为是js加载的,但是在开发者工具中查看XHR后发现,并不是那么简单。
解决这个问题的第一个想法是认为这个数字可能对应一个代码,手动查看,看看是怎么回事,找到模式,花了十多分钟总结,但再次刷新页面后,瞬间迷茫, 什么。. . ? ? 编码不同,仍然有变化。看来这条路行不通了。
然后我搜索了这个奇怪的类在哪里,发现了这样一个东西

没错,就是她。查看上述格式的 woff。原来是自定义字体格式,每次刷新,一串看不懂的代码都会变。这应该是问题所在。
然后复制上面的一串代码,使用python3的fontTools包将代码转换成字体文件

从标注的地方发现这个还是用base64加密的,这里我们需要用base64来解密
下面的代码
import base64
from fontTools.ttLib import TTFont
import io
key = 'd09GRgABAAAAAAjgAAsAAAAADMgAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7lQ7Y21hcAAAAYAAAAC7AAACTCMTZu5nbHlmAAACPAAABFEAAAVEz90AumhlYWQAAAaQAAAALwAAADYWPYnBaGhlYQAABsAAAAAcAAAAJAeKAzlobXR4AAAG3AAAABIAAAAwGp4AAGxvY2EAAAbwAAAAGgAAABoHsAZ6bWF4cAAABwwAAAAfAAAAIAEZAEduYW1lAAAHLAAAAVcAAAKFkAhoC3Bvc3QAAAiEAAAAWgAAAI/0SbGSeJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2BksmCcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKr7sZNb5r8MQw6zDcAUozAiSAwDoZAvKeJzFkj0OgzAMhV8K9I8OHTtwhF6BYyCOwMacE3Rj60k6ldsgFCEkJqTs9BmzVIK1dfRFynMUWy8GEAEIyJ2EgHnDQOJF1cx6gPOsh3jwfMOVyhG2SdrUZa7sbB8N+Vj4ytfTxBvbmbUwfHFtSSbGgbX32LHeiZ2G0qnZb7z0gzD/K/0dl3l/LqeY2AW22CSK6G2q0Em4TJH/dKVCd9FZhT6jjxQ6jiFX6D3GQpF58ZUi8+JrBcEH8D4+WAB4nE2Uy2/jVBTG73USO3HcpE1iO08nTmI778SJHSdp3n1lJn2/Ke0wMy2qShnUYQABAxWDNEJIMGKH2AJihxDSbNjRolFXSKAixIgFbNgg/gUyXDsZwFeydY/t4+/7nXMMIABP/gJF4AEYAFqJ9nCeBEAH2j15jI1hlyADaugOwzKlolYeLrUsajiBx6KSqCoowLAcpD3EKCRBRSSiBE7r4bL6gOLSQppz8R4HbjaZSYtPzlaebTU7nYOrlXoj6OrXV7bUphneXq/OxDP2cPqtlY+bgYDbHYl0bXwwYCLxdMDfnHnxRFmnKEn86P6DtdVMplDYgsrukUPOL/fkONzpG5r/wBzYd8AOHABYNIsENbdGSE444TbByfHBuQ1em4KHluvORfib/yu4Dn8iBjx1yHxthRhcGHwLoOF7AvsGxJFrDuqmVUUyDBGSm2ctBAJQKiJrI7fvk/3KbCIbVrZFf5TemIO38MHPCSbry12famG17r2b1Z7ly9lpWevvcjWH2xMm4Rur5kesy9K98mhzoVLdRbyhod2MXYAcAALNK1oTGrD1iy4ghgQ4YRPqpHHiv8UQAmYaBO1k0OkPhaT6MpMKFdpNSYJ79jcv70bTgjsqJ/0+ykdarPCwvhnh/AVvwBvg5XmuWmoFBF9pzvTaMXZnK7dUYgNiMso6aIqizRbwry4KMfUC4JYE2gFHH46JT9tBE2QIf41Px/JQ4mhiG3faxr0zHC+5Bp9i+1u2ZWG/pl2dV3dvpRWl9fZLvQIvEaPcv8NTlNuJqiVN6FmlYUZ2Ap7uxKtV51ivFjbzVDFswRo0VyDXcxmfI0ab/5aG7/+CtF0A7f8darDSimwxZtQOlW6YFhUNPWP0qQExJqLqafetmbjWznDIUH7WJZC4aYyQy7l2RZmx70zUJp/PloqBgM9f7PQ+OL7Ratt2znai0SI/20wkySUYCrfkDmxNc0v5YsCbTbYSYpB3Xus99954qro7BkyjObpA/BKgihiKGgJXZGhUOlY/48YUlTVpZEBCBnTAJg9rRPR5Q0qj+PldE5abOnuV3O8HY9bs8uNutzflsvn4slygrdaor16OREMukxLLcCqdIuLpe2vwjniyqpZfXjhOMrLcRfrbjYO5GxOflMM8H5YL0RxFMvzgnUQs7vEwnkS3k0qtPZ3/7zE70i2AMkKNFBDisPJ0E+ooUefp2xxUxRFbCY4kG9j1hoWfU4ygpvm0LYAT/J5yoLYgDI13lKnbH1ILK69sdbLUzuBPD5mLSVoqudLPZVKYTWVFHHcJtbiQkjP5qe7RdH0yHKGoz84ub67L+U1scFaNpBkmJ19ZfCajjP5VduxHwALRIIyYsUa12WG7Gn+qEtprRWOY9GGujPn9hbnpd/NBxmrBKEewy2+80Ohtm1PJdmMjrJ56J01w6f78clol9zKdxkn7KNHPp7cXf3hYb5tf/+K8MalMP0So/gFnXvSzAAAAeJxjYGRgYADiu+3HZsbz23xl4GZhAIGb/cpCCPr/WRYGpstALgcDE0gUADYSCl0AeJxjYGRgYNb5r8MQw8IAAkCSkQEV8AAAM2IBzXicY2EAghQGBiZL4jAAQjYCtwAAAAAAAAAMAGYAiADEARABPgFeAbACDAJiAqIAAHicY2BkYGDgYbBmYGYAASYg5gJCBob/YD4DAA+WAWEAeJxlkbtuwkAURMc88gApQomUJoq0TdIQzEOpUDokKCNR0BuzBiO/tF6QSJcPyHflE9Klyyekz2CuG8cr7547M3d9JQO4xjccnJ57vid2cMHqxDWc40G4Tv1JuEF+Fm6ijRfhM+oz4Ra6eBVu4wZvvMFpXLIa40PYQQefwjVc4Uu4Tv1HuEH+FW7i1mkKn6Hj3Am3sHC6wm08Ou8tpSZGe1av1PKggjSxPd8zJtSGTuinyVGa6/Uu8kxZludCmzxMEzV0B6U004k25W35fj2yNlCBSWM1paujKFWZSbfat+7G2mzc7weiu34aczzFNYGBhgfLfcV6iQP3ACkSaj349AxXSN9IT0j16JepOb01doiKbNWt1ovippz6sVYYwsXgX2rGVFIkq7Pl2PNrI6qW6eOshj0xaSq9mpNEZIWs8LZUfOouNkVXxp/d5woqebeYIf4D2J1ywQB4nG3JOxKAIBAD0A3+Ee8CKh9bFO9iY+eMx3dcLE3zJgkJypH0HwWBAiUq1GjQooNED4WBcDfXeSTnw+s+xyUbNtY4z//sEjtOvKegLRvt99vctVmJHhnTF3IAAA=='
data = base64.b64decode(key)
fonts = TTFont(io.BytesIO(data))
fonts.save('base.ttf') # 保存成ttf和woff这样的文件格式需要利用FontCreator这样的工具打开,
# 这个百度就可以下载
fonts.save('base.woff')
fonts.saveXML('base.xml') # 保存成这样的格式,可以直接打开进行查看
使用FontCreator打开ttf或woff文件,显示如下

而且你会发现每个数字都对应一个代号,代号uni后面的字符和你在网页上看到的完全一样,有木有的

没错,这就是它们之间的映射关系。每次页面刷新时,后台会随机从数据库中拉取一个自定义字体样式,然后在显示html'时通过映射渲染成普通字体。
打开刚才保存的xml文件可以看到类似这样的东西
看到开头有点眼熟(uniE01C),没错,这个就是每个数字用二维数组画出来的数字
In [1]: import numpy as np
In [2]: from matplotlib import pyplot as plt
In [3]: x=np.array([56, 43, 69, 95, 143, 214, 282, 412, 459, 487, 509, 517, 522, 520, 508, 494, 466, 400, 367, 282, 17
...: 6, 115, 43, 43, 131, 135, 177, 218, 282, 343, 428, 428, 428, 397, 344, 218, 194, 135, 132])
In [4]: y=np.array([335, 468, 544, 624, 667, 720, 710, 710, 617, 573, 508, 447, 335, 271, 166, 126, 51, 4, -39, -39, -
...: 39, 49, 127, 335, 335, 155, 95, 31, 35, 35, 155, 321, 515, 576, 635, 635, 583, 515, 335])
In [5]: plt.plot(x,y)
Out[5]: []
In [6]: plt.show()

上面的代码展示了一个二维的数字数组,解决这个问题的方法是在每个页面爬取的时候下载一个对应的字体文件,然后和我们第一次下载的那个一起传递。对比base.xml文件,进行实际手动对比。同一个二维数组点每两个文件中相同数字的x和y相差在50以内,可以以此作为判断依据。,如果都在这个范围内,则可以确定这两个代码代表同一个数字,然后将所有抓取到的html页面替换为对应代码对应的数字,然后解析,只提供一种思路这里,我没有写代码,因为在实际的爬取过程中,会产生大量的io,
另一种思路是,使用保存的xml文件的所有二维数组生成图片,然后使用TensorFlow进行识别,工作量相当大。
我的解决方法是在测试的时候发现会有一个url重定向到手机端,然后打开手机端发现号码没有加密。
虽然上面的文字加密问题已经解决了,但是还是遇到了抓取页面和实际查看源码的差异,url会发生变化。这就需要反复比较和修正。以上是遇到的问题,记录一下,仅供参考。本文仅供学习交流,禁止商业用途。
网页抓取 加密html(在看廖雪峰老师的Python教程,常见内置模块HTMLParser )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-16 06:12
)
看廖雪峰老师的Python教程,常用内置模块HTMLParser:
作业:找一个网页,比如用浏览器查看源码并复制,然后尝试解析HTML输出Python官网公布的会议时间、名称和地点。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2017-06-01 09:08:30
# @Author : kk (zwk.patrick@foxmail.com)
# @Link : blog.csdn.net/PatrickZheng
import HTMLParser, urllib
class MyHTMLParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self._title = [False]
self._time =[False]
self._place = [False]
self.time = '' # 用于拼接时间
def _attr(self, attrlist, attrname):
for attr in attrlist:
if attr[0] == attrname:
return attr[1]
return None
def handle_starttag(self, tag, attrs):
#print('' % tag)
if tag == 'h3' and self._attr(attrs, 'class') == 'event-title':
self._title[0] = True
if tag == 'time':
self._time[0] = True
if tag == 'span' and self._attr(attrs, 'class') == 'event-location':
self._place[0] = True
def handle_endtag(self, tag):
# 结束拼接
if tag == 'time':
self._time.append(self.time) # 将time完整内容放入self._time
self.time = '' # 初始化 self.time
self._time[0] = False
def handle_startendtag(self, tag, attrs):
#print('' % tag)
pass
def handle_data(self, data):
#print('data: %s' % data)
if self._title[0] == True:
self._title.append(data)
self._title[0] = False
if self._time[0] == True:
self.time += data # 拼接time
if self._place[0] == True:
self._place.append(data)
self._place[0] = False
def handle_comment(self, comment):
#print('' % comment)
pass
def handle_entityref(self, name):
if self._time[0] == True:
self.time += '-' # &ndash -> '-'
def handle_charref(self, name):
#print('&#%s:' % name)
pass
def show_content(self):
for n in range(1, len(self._title)):
print 'Title: %s' % self._title[n]
print 'Time: %s' % self._time[n]
print 'Place: %s' % self._place[n]
print '--------------------------------------'
html = ''
try:
page = urllib.urlopen('https://www.python.org/events/ ... %2339;) # 打开网页
html = page.read() # 读取网页内容
finally:
page.close()
parser = MyHTMLParser()
parser.feed(html)
parser.show_content()
运行结果:
Title: PyCon Taiwan 2017
Time: 06 June - 12 June 2017
Place: Academia Sinica, 128 Academia Road, Section 2, Nankang, Taipei 11529, Taiwan
--------------------------------------
Title: PyCon CZ 2017
Time: 09 June - 12 June 2017
Place: Prague, Czechia
--------------------------------------
Title: PythonDay Mexico
Time: 10 June - 11 June 2017
Place: Isabel la Católica 51, Centro, 06010 Mexico City, Mexico
--------------------------------------
Title: PyParis 2017
Time: 12 June - 14 June 2017
Place: Paris, France
--------------------------------------
Title: PyCon Israel 2017
Time: 12 June - 15 June 2017
Place: Wahl Center, Max VeAnna Webb st., Ramat Gan, Israel
--------------------------------------
Title: PyData Berlin 2017
Time: 30 June - 03 July 2017
Place: Treskowallee 8, 10318 Berlin, Germany
--------------------------------------
Title: PyConWEB 2017
Time: 27 May - 29 May 2017
Place: Munich, Germany
--------------------------------------
Title: PyDataBCN 2017
Time: 19 May - 22 May 2017
Place: Barcelona, Spain
--------------------------------------
***Repl Closed*** 查看全部
网页抓取 加密html(在看廖雪峰老师的Python教程,常见内置模块HTMLParser
)
看廖雪峰老师的Python教程,常用内置模块HTMLParser:
作业:找一个网页,比如用浏览器查看源码并复制,然后尝试解析HTML输出Python官网公布的会议时间、名称和地点。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2017-06-01 09:08:30
# @Author : kk (zwk.patrick@foxmail.com)
# @Link : blog.csdn.net/PatrickZheng
import HTMLParser, urllib
class MyHTMLParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self._title = [False]
self._time =[False]
self._place = [False]
self.time = '' # 用于拼接时间
def _attr(self, attrlist, attrname):
for attr in attrlist:
if attr[0] == attrname:
return attr[1]
return None
def handle_starttag(self, tag, attrs):
#print('' % tag)
if tag == 'h3' and self._attr(attrs, 'class') == 'event-title':
self._title[0] = True
if tag == 'time':
self._time[0] = True
if tag == 'span' and self._attr(attrs, 'class') == 'event-location':
self._place[0] = True
def handle_endtag(self, tag):
# 结束拼接
if tag == 'time':
self._time.append(self.time) # 将time完整内容放入self._time
self.time = '' # 初始化 self.time
self._time[0] = False
def handle_startendtag(self, tag, attrs):
#print('' % tag)
pass
def handle_data(self, data):
#print('data: %s' % data)
if self._title[0] == True:
self._title.append(data)
self._title[0] = False
if self._time[0] == True:
self.time += data # 拼接time
if self._place[0] == True:
self._place.append(data)
self._place[0] = False
def handle_comment(self, comment):
#print('' % comment)
pass
def handle_entityref(self, name):
if self._time[0] == True:
self.time += '-' # &ndash -> '-'
def handle_charref(self, name):
#print('&#%s:' % name)
pass
def show_content(self):
for n in range(1, len(self._title)):
print 'Title: %s' % self._title[n]
print 'Time: %s' % self._time[n]
print 'Place: %s' % self._place[n]
print '--------------------------------------'
html = ''
try:
page = urllib.urlopen('https://www.python.org/events/ ... %2339;) # 打开网页
html = page.read() # 读取网页内容
finally:
page.close()
parser = MyHTMLParser()
parser.feed(html)
parser.show_content()
运行结果:
Title: PyCon Taiwan 2017
Time: 06 June - 12 June 2017
Place: Academia Sinica, 128 Academia Road, Section 2, Nankang, Taipei 11529, Taiwan
--------------------------------------
Title: PyCon CZ 2017
Time: 09 June - 12 June 2017
Place: Prague, Czechia
--------------------------------------
Title: PythonDay Mexico
Time: 10 June - 11 June 2017
Place: Isabel la Católica 51, Centro, 06010 Mexico City, Mexico
--------------------------------------
Title: PyParis 2017
Time: 12 June - 14 June 2017
Place: Paris, France
--------------------------------------
Title: PyCon Israel 2017
Time: 12 June - 15 June 2017
Place: Wahl Center, Max VeAnna Webb st., Ramat Gan, Israel
--------------------------------------
Title: PyData Berlin 2017
Time: 30 June - 03 July 2017
Place: Treskowallee 8, 10318 Berlin, Germany
--------------------------------------
Title: PyConWEB 2017
Time: 27 May - 29 May 2017
Place: Munich, Germany
--------------------------------------
Title: PyDataBCN 2017
Time: 19 May - 22 May 2017
Place: Barcelona, Spain
--------------------------------------
***Repl Closed***
网页抓取 加密html(五篇Node.js构建一个网站应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-15 20:31
2021-07-25
看了五篇关于 Node.js 的文章,你基本上可以开始构建一个 网站 应用了。首先,通过这篇文章学习一些关于构建网站的知识!
主要是基本的东西...
如何创建路由规则,如何提交表单并接收表单项的值,如何加密密码,如何提取页面的公共部分(相当于用户控件和母版页)等等……
让我们一步一步开始吧^_^!…
新建快递项目,自定义路由规则
1.先用命令行express+ejs创建一个项目sampleEjsPre
cd 工作目录
express -e sampleEjsPre
cd sampleEjsPre && npm install
2.默认情况下,routes 目录下会有 index.js 和 users.js 文件。为了避免示例之外的其他麻烦,删除user.js文件
3.打开app.js文件,删除以下两行代码
var users = require('./routes/users');
...
app.use('/users', users);
4.将以下代码添加到app.js文件中
var subform = require('./routes/subform');
var usesession = require('./routes/usesession');
var usecookies = require('./routes/usecookies');
var usecrypto = require('./routes/usecrypto');
...
app.use('/subform', subform);
app.use('/usesession', usesession);
app.use('/usecookies', usecookies);
app.use('/usecrypto', usecrypto);
通过URL访问后,根据路由规则先到哪个文件再到哪个文件的过程在上一篇文章(Nodejs学习笔记(五)---快递安装入口和模板引擎ejs)) 说了这么多,这里就不多说了!
5.在routes目录下添加subform.js、usesession.js、usecookies.js、usecrypto.js文件,并在对应的js文件中添加如下代码
子窗体.js
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res) {
res.render('subform', { title: '提交表单及接收参数示例' });
});
module.exports = router;
使用session.js
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res) {
res.render('usesession', { title: '使用session示例' });
});
module.exports = router;
使用cookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
使用crypto.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
res.render('usecrypto', { title: '加密字符串示例' });
});
module.exports = router;
6.views目录下添加subform.ejs、usesession.ejs、usecookies.ejs、usecrypto.ejs文件,views目录下除error.ejs外的所有ejs文件添加如下代码
首页
如何提交表单并接收参数?
如何使用session?
如何使用cookies?
如何字符串加密?
7.添加8000端口监听并在app.js中运行
...
app.listen(8000);
...
运行界面如下:
点击每个链接都可以正常跳转到对应的页面!这样,目录的第一步就到了!
如何提取页面中的公共部分?
上一步创建的 网站 中的每个页面都差不多,现在只有导航部分吗?你必须写每一页吗?当然不是,我们可以提取
1.在views目录下新建nav.ejs文件,添加如下代码
首页
如何提交表单并接收参数?
如何使用session?
如何使用cookies?
如何字符串加密?
2.将views目录下的index.ejs、subform.ejs、usesession.ejs、usecookies.ejs、usecrypto.ejs修改为如下代码
运行页面,发现和上次运行的时候并没有什么不同。采用这种方式,更有利于减少重复代码,更有利于统一布局!
Express 提供 include 嵌入其他页面,类似于 html 嵌入其他页面
如果你用过express2.0版本,你会发现当时并没有这个include,而是使用了一个模板文件layout.ejs来布局!
如何提交表单和接收参数?
如果要做一个网站应用,难免会遇到表单提交和获取参数值。让我们看看如何使用 node.js + express
我们先建一个表单来简单模拟登录GET方式提交数据
1.打开subform.ejs文件,修改文件代码如下:
用户名:
密码:
2.打开subform.js我们尝试接收参数值并输出到控制台
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
var
userName = req.query.txtUserName,
userPwd = req.query.txtUserPwd,
userName2 = req.param('txtUserName'),
userPwd2 = req.param('txtUserPwd');
console.log('req.query用户名:'+userName);
console.log('req.query密码:'+userPwd);
console.log('req.param用户名:'+userName2);
console.log('req.param密码:'+userPwd2);
res.render('subform', { title: '提交表单及接收参数示例' });
});
module.exports = router;
3.运行,并提交表单在浏览器中运行::8000/subform,输入表单项并提交,可以发现url变了
可以发现,在我的表单中输入和要提交的值出现在了url中!
我们再来看看控制台输出
我们完成了GET方法提交表单并收到了值,还不错^_^!(后面会讲取值的方法和区别)
然后在上面代码的基础上,修改form的方法,简单模拟登录POST方法提交数据
1.首先修改subform.ejs文件中的form标签如下:
...
2.在subform.js中添加代码,接收post提交,接收参数并输出到控制台
...
router.post('/',function(req, res){
var
userName = req.body.txtUserName,
userPwd = req.body.txtUserPwd,
userName2 = req.param('txtUserName'),
userPwd2 = req.param('txtUserPwd');
console.log('req.body用户名:'+userName);
console.log('req.body密码:'+userPwd);
console.log('req.param用户名:'+userName2);
console.log('req.param密码:'+userPwd2);
res.render('subform', { title: '提交表单及接收参数示例' });
});
...
3.运行,并提交表单在浏览器中运行::8000/subform,输入表单项并提交,可以发现url不会变
改成post方法后,你会发现form中输入的值和要提交的值不会像get方法提交一样出现在url中!
我们再来看看控制台输出
好的,我们已经完成了表单的发布和参数的接收!
我们回过头来看看接收值的 GET 和 POST 方法,从直接效果的角度来看
req.query:我用来接收GET提交参数
req.body:我用来接收 POST 提交的参数
req.params:都可以接收
我们看一下Express的Request部分的API:#req.params
这里我将重点讲解req.body。Express 通过中间件 bodyParser 处理这个 post 请求。可以看到app.js中有一段代码
...
var bodyParser = require('body-parser');
...
app.use(bodyParser.json());
app.use(bodyParser.urlencoded());
...
如果没有这个中间件 Express,我不知道如何处理这个请求。它通过 bodyParser 中间件分析 application/x-www-form-urlencoded 和 application/json 请求,并将变量存储在 req.body 中。只有这样我们才能得到它!
如何加密字符串?
当我们提交表单时,如密码等敏感信息,如果我们不对其进行加密,我们将不会认真对待用户的隐私信息。Node.js 提供加密模块 Crypto
让我们用一个例子
1.打开usecrypto.js,修改代码如下:
var express = require('express');
var router = express.Router();
var crypto = require('crypto');
/* GET home page. */
router.get('/', function(req, res) {
res.render('usecrypto', { title: '加密字符串示例' });
});
router.post('/',function(req, res){
var
userName = req.body.txtUserName,
userPwd = req.body.txtUserPwd;
//生成口令的散列值
var md5 = crypto.createHash('md5'); //crypto模块功能是加密并生成各种散列
var en_upwd = md5.update(userPwd).digest('hex');
console.log('加密后的密码:'+en_upwd);
res.render('usecrypto', { title: '加密字符串示例' });
});
module.exports = router;
2.打开usecrypto.ejs,修改代码如下
用户名:
密码:
3.运行,输入并提交表单,查看控制台输出
MD5加密成功!
使用 createHash(algorithm) 方法,该方法使用给定的算法生成哈希对象
Node.js 提供的加密模块非常强大。Hash算法提供MD5、sha1、sha256等,可根据需要使用
update(data, [input_encoding]) 方法可以通过指定的input_encoding和传入的data数据更新hash对象。'等待)
digest([encoding]) 方法计算数据的哈希摘要值。编码是一个可选参数。如果不通过,则返回一个缓冲区(编码可以是'hex'、'base64'等);当调用摘要方法时,哈希对象将不可用。;
如何使用会话?
Internet 通信协议分为两类:有状态和无状态。对web开发有一定了解的人应该都知道http是一种无状态协议。客户端向服务器发送请求以建立连接。请求响应后,连接中断,服务端不记录状态,所以服务端想
要确定哪个客户端提交了请求,必须借助一些东西来完成,即会话和cookie。下面说说nodejs下的session和使用session吧!
session存在于服务器端,需要cookies的协助才能完成;server端和client端通过session id建立连接(具体的session和cookies如何配合,可以自己补充一些相关知识,这里只简单提一下,不展开),否则这个文章会更复杂^_^!)
在express中,可以使用中间件来使用session,express-session()可以存在于内存中,也可以存在于mongodb、redis等...
更多中间件:
下面通过一个例子来看看如何使用session(内存模式)
示例设计思路:使用两个页面,一个登录,两个页面判断是否有这个会话,如果有,显示登录,如果没有,显示一个登录按钮,点击这个按钮记录会话
1.首先通过npm安装中间件,打开package.json文件,在dependencies节点下添加键值对 "express-session" : "latest"
"dependencies": {
...,
"express-session" : "latest"
}
最新的:最新的
2. cd 到项目根目录并执行 npm install
3.打开 app.js 并添加以下代码
var express = require('express');
var path = require('path');
var favicon = require('static-favicon');
var logger = require('morgan');
var cookieParser = require('cookie-parser');
var bodyParser = require('body-parser');
var session = require('express-session');
...
//这里传入了一个密钥加session id
app.use(cookieParser('Wilson'));
//使用靠就这个中间件
app.use(session({ secret: 'wilson'}));
...
这些选项就不做解释了,通过上面中间件的链接,自己看看
4.这里我以usesession和usecookies为例,修改js和ejs如下
usesession.ejs 和 usecookies.ejs
用户已登录
使用.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.session.islogin)
{
console.log('usesession:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usesession', { title: '使用session示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.render('usesession', { title: '使用session示例' });
});
module.exports = router;
使用cookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.session.islogin)
{
console.log('usecookies:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usecookies', { title: '使用cookies示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
5.运行查看
第一次运行时,查看两个页面,效果如下:
6.点击登录按钮后查看这两个页面
7.关闭浏览器再打开就可以看到这两个页面,如步骤5的截图所示
session使用成功!
官方示例:
如何使用cookies?
如果是登录,一般会使用“记录密码”或者“自动登录”功能,一般是通过cookies来完成
cookie存在于客户端,安全性较低。通常,应存储加密信息。建议设置使用过期时间或不使用时删除。
Express 也可以与中间件一起使用:
老套路,通过一个例子来了解一下
示例设计思路:在上述会话示例的基础上,登录并在usecookies部分记录cookies自动登录
1.根据上面的会话示例修改usecookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.cookies.islogin)
{
console.log('usecookies-cookies:' + req.cookies.islogin);
req.session.islogin = req.cookies.islogin;
}
if(req.session.islogin)
{
console.log('usecookies:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usecookies', { title: '使用cookies示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.cookie('islogin', 'sucess', { maxAge: 60000 });
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
2.运行访问:8000/usecookies,点击登录按钮登录成功并记录cookies
maxAge 是过期时间,单位是毫秒,我设置的是一分钟
3.关闭浏览器,再次访问:8000/usecookies,页面显示已登录
4.再次关闭浏览器,一分钟后再次访问:8000/usecookies,页面不再登录,但显示登录按钮,表示cookies已过期,不会自动登录
使用cookies也成功了!
官方示例:
如何清除会话和 cookie?
清算很简单,不用举例说明。如果您有兴趣定义自己的路由规则,请尝试
//清除cookies
res.clearCookie('islogin');
//清除session
req.session.destroy();
写在之后
文中提到的一些知识点,其实可以用一整篇文章来讨论。这篇文章的基本原则是看后能用;
如果想了解原理或更相关的知识,可以花点时间去了解,或者找一些资料丰富一下。当然,您也可以留言。如果我不认为我在胡说八道,我会尽力回答^_^!
本系列的源代码可供下载。 查看全部
网页抓取 加密html(五篇Node.js构建一个网站应用)
2021-07-25
看了五篇关于 Node.js 的文章,你基本上可以开始构建一个 网站 应用了。首先,通过这篇文章学习一些关于构建网站的知识!
主要是基本的东西...
如何创建路由规则,如何提交表单并接收表单项的值,如何加密密码,如何提取页面的公共部分(相当于用户控件和母版页)等等……
让我们一步一步开始吧^_^!…
新建快递项目,自定义路由规则
1.先用命令行express+ejs创建一个项目sampleEjsPre
cd 工作目录
express -e sampleEjsPre
cd sampleEjsPre && npm install
2.默认情况下,routes 目录下会有 index.js 和 users.js 文件。为了避免示例之外的其他麻烦,删除user.js文件
3.打开app.js文件,删除以下两行代码
var users = require('./routes/users');
...
app.use('/users', users);
4.将以下代码添加到app.js文件中
var subform = require('./routes/subform');
var usesession = require('./routes/usesession');
var usecookies = require('./routes/usecookies');
var usecrypto = require('./routes/usecrypto');
...
app.use('/subform', subform);
app.use('/usesession', usesession);
app.use('/usecookies', usecookies);
app.use('/usecrypto', usecrypto);
通过URL访问后,根据路由规则先到哪个文件再到哪个文件的过程在上一篇文章(Nodejs学习笔记(五)---快递安装入口和模板引擎ejs)) 说了这么多,这里就不多说了!
5.在routes目录下添加subform.js、usesession.js、usecookies.js、usecrypto.js文件,并在对应的js文件中添加如下代码
子窗体.js
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res) {
res.render('subform', { title: '提交表单及接收参数示例' });
});
module.exports = router;
使用session.js
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res) {
res.render('usesession', { title: '使用session示例' });
});
module.exports = router;
使用cookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
使用crypto.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
res.render('usecrypto', { title: '加密字符串示例' });
});
module.exports = router;
6.views目录下添加subform.ejs、usesession.ejs、usecookies.ejs、usecrypto.ejs文件,views目录下除error.ejs外的所有ejs文件添加如下代码
首页
如何提交表单并接收参数?
如何使用session?
如何使用cookies?
如何字符串加密?
7.添加8000端口监听并在app.js中运行
...
app.listen(8000);
...
运行界面如下:
点击每个链接都可以正常跳转到对应的页面!这样,目录的第一步就到了!
如何提取页面中的公共部分?
上一步创建的 网站 中的每个页面都差不多,现在只有导航部分吗?你必须写每一页吗?当然不是,我们可以提取
1.在views目录下新建nav.ejs文件,添加如下代码
首页
如何提交表单并接收参数?
如何使用session?
如何使用cookies?
如何字符串加密?
2.将views目录下的index.ejs、subform.ejs、usesession.ejs、usecookies.ejs、usecrypto.ejs修改为如下代码
运行页面,发现和上次运行的时候并没有什么不同。采用这种方式,更有利于减少重复代码,更有利于统一布局!
Express 提供 include 嵌入其他页面,类似于 html 嵌入其他页面
如果你用过express2.0版本,你会发现当时并没有这个include,而是使用了一个模板文件layout.ejs来布局!
如何提交表单和接收参数?
如果要做一个网站应用,难免会遇到表单提交和获取参数值。让我们看看如何使用 node.js + express
我们先建一个表单来简单模拟登录GET方式提交数据
1.打开subform.ejs文件,修改文件代码如下:
用户名:
密码:
2.打开subform.js我们尝试接收参数值并输出到控制台
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
var
userName = req.query.txtUserName,
userPwd = req.query.txtUserPwd,
userName2 = req.param('txtUserName'),
userPwd2 = req.param('txtUserPwd');
console.log('req.query用户名:'+userName);
console.log('req.query密码:'+userPwd);
console.log('req.param用户名:'+userName2);
console.log('req.param密码:'+userPwd2);
res.render('subform', { title: '提交表单及接收参数示例' });
});
module.exports = router;
3.运行,并提交表单在浏览器中运行::8000/subform,输入表单项并提交,可以发现url变了
可以发现,在我的表单中输入和要提交的值出现在了url中!
我们再来看看控制台输出
我们完成了GET方法提交表单并收到了值,还不错^_^!(后面会讲取值的方法和区别)
然后在上面代码的基础上,修改form的方法,简单模拟登录POST方法提交数据
1.首先修改subform.ejs文件中的form标签如下:
...
2.在subform.js中添加代码,接收post提交,接收参数并输出到控制台
...
router.post('/',function(req, res){
var
userName = req.body.txtUserName,
userPwd = req.body.txtUserPwd,
userName2 = req.param('txtUserName'),
userPwd2 = req.param('txtUserPwd');
console.log('req.body用户名:'+userName);
console.log('req.body密码:'+userPwd);
console.log('req.param用户名:'+userName2);
console.log('req.param密码:'+userPwd2);
res.render('subform', { title: '提交表单及接收参数示例' });
});
...
3.运行,并提交表单在浏览器中运行::8000/subform,输入表单项并提交,可以发现url不会变
改成post方法后,你会发现form中输入的值和要提交的值不会像get方法提交一样出现在url中!
我们再来看看控制台输出
好的,我们已经完成了表单的发布和参数的接收!
我们回过头来看看接收值的 GET 和 POST 方法,从直接效果的角度来看
req.query:我用来接收GET提交参数
req.body:我用来接收 POST 提交的参数
req.params:都可以接收
我们看一下Express的Request部分的API:#req.params
这里我将重点讲解req.body。Express 通过中间件 bodyParser 处理这个 post 请求。可以看到app.js中有一段代码
...
var bodyParser = require('body-parser');
...
app.use(bodyParser.json());
app.use(bodyParser.urlencoded());
...
如果没有这个中间件 Express,我不知道如何处理这个请求。它通过 bodyParser 中间件分析 application/x-www-form-urlencoded 和 application/json 请求,并将变量存储在 req.body 中。只有这样我们才能得到它!
如何加密字符串?
当我们提交表单时,如密码等敏感信息,如果我们不对其进行加密,我们将不会认真对待用户的隐私信息。Node.js 提供加密模块 Crypto
让我们用一个例子
1.打开usecrypto.js,修改代码如下:
var express = require('express');
var router = express.Router();
var crypto = require('crypto');
/* GET home page. */
router.get('/', function(req, res) {
res.render('usecrypto', { title: '加密字符串示例' });
});
router.post('/',function(req, res){
var
userName = req.body.txtUserName,
userPwd = req.body.txtUserPwd;
//生成口令的散列值
var md5 = crypto.createHash('md5'); //crypto模块功能是加密并生成各种散列
var en_upwd = md5.update(userPwd).digest('hex');
console.log('加密后的密码:'+en_upwd);
res.render('usecrypto', { title: '加密字符串示例' });
});
module.exports = router;
2.打开usecrypto.ejs,修改代码如下
用户名:
密码:
3.运行,输入并提交表单,查看控制台输出
MD5加密成功!
使用 createHash(algorithm) 方法,该方法使用给定的算法生成哈希对象
Node.js 提供的加密模块非常强大。Hash算法提供MD5、sha1、sha256等,可根据需要使用
update(data, [input_encoding]) 方法可以通过指定的input_encoding和传入的data数据更新hash对象。'等待)
digest([encoding]) 方法计算数据的哈希摘要值。编码是一个可选参数。如果不通过,则返回一个缓冲区(编码可以是'hex'、'base64'等);当调用摘要方法时,哈希对象将不可用。;
如何使用会话?
Internet 通信协议分为两类:有状态和无状态。对web开发有一定了解的人应该都知道http是一种无状态协议。客户端向服务器发送请求以建立连接。请求响应后,连接中断,服务端不记录状态,所以服务端想
要确定哪个客户端提交了请求,必须借助一些东西来完成,即会话和cookie。下面说说nodejs下的session和使用session吧!
session存在于服务器端,需要cookies的协助才能完成;server端和client端通过session id建立连接(具体的session和cookies如何配合,可以自己补充一些相关知识,这里只简单提一下,不展开),否则这个文章会更复杂^_^!)
在express中,可以使用中间件来使用session,express-session()可以存在于内存中,也可以存在于mongodb、redis等...
更多中间件:
下面通过一个例子来看看如何使用session(内存模式)
示例设计思路:使用两个页面,一个登录,两个页面判断是否有这个会话,如果有,显示登录,如果没有,显示一个登录按钮,点击这个按钮记录会话
1.首先通过npm安装中间件,打开package.json文件,在dependencies节点下添加键值对 "express-session" : "latest"
"dependencies": {
...,
"express-session" : "latest"
}
最新的:最新的
2. cd 到项目根目录并执行 npm install
3.打开 app.js 并添加以下代码
var express = require('express');
var path = require('path');
var favicon = require('static-favicon');
var logger = require('morgan');
var cookieParser = require('cookie-parser');
var bodyParser = require('body-parser');
var session = require('express-session');
...
//这里传入了一个密钥加session id
app.use(cookieParser('Wilson'));
//使用靠就这个中间件
app.use(session({ secret: 'wilson'}));
...
这些选项就不做解释了,通过上面中间件的链接,自己看看
4.这里我以usesession和usecookies为例,修改js和ejs如下
usesession.ejs 和 usecookies.ejs
用户已登录
使用.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.session.islogin)
{
console.log('usesession:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usesession', { title: '使用session示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.render('usesession', { title: '使用session示例' });
});
module.exports = router;
使用cookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.session.islogin)
{
console.log('usecookies:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usecookies', { title: '使用cookies示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
5.运行查看
第一次运行时,查看两个页面,效果如下:
6.点击登录按钮后查看这两个页面
7.关闭浏览器再打开就可以看到这两个页面,如步骤5的截图所示
session使用成功!
官方示例:
如何使用cookies?
如果是登录,一般会使用“记录密码”或者“自动登录”功能,一般是通过cookies来完成
cookie存在于客户端,安全性较低。通常,应存储加密信息。建议设置使用过期时间或不使用时删除。
Express 也可以与中间件一起使用:
老套路,通过一个例子来了解一下
示例设计思路:在上述会话示例的基础上,登录并在usecookies部分记录cookies自动登录
1.根据上面的会话示例修改usecookies.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
if(req.cookies.islogin)
{
console.log('usecookies-cookies:' + req.cookies.islogin);
req.session.islogin = req.cookies.islogin;
}
if(req.session.islogin)
{
console.log('usecookies:' + req.session.islogin);
res.locals.islogin = req.session.islogin;
}
res.render('usecookies', { title: '使用cookies示例' });
});
router.post('/', function(req, res) {
req.session.islogin = 'success';
res.locals.islogin = req.session.islogin;
res.cookie('islogin', 'sucess', { maxAge: 60000 });
res.render('usecookies', { title: '使用cookies示例' });
});
module.exports = router;
2.运行访问:8000/usecookies,点击登录按钮登录成功并记录cookies
maxAge 是过期时间,单位是毫秒,我设置的是一分钟
3.关闭浏览器,再次访问:8000/usecookies,页面显示已登录
4.再次关闭浏览器,一分钟后再次访问:8000/usecookies,页面不再登录,但显示登录按钮,表示cookies已过期,不会自动登录
使用cookies也成功了!
官方示例:
如何清除会话和 cookie?
清算很简单,不用举例说明。如果您有兴趣定义自己的路由规则,请尝试
//清除cookies
res.clearCookie('islogin');
//清除session
req.session.destroy();
写在之后
文中提到的一些知识点,其实可以用一整篇文章来讨论。这篇文章的基本原则是看后能用;
如果想了解原理或更相关的知识,可以花点时间去了解,或者找一些资料丰富一下。当然,您也可以留言。如果我不认为我在胡说八道,我会尽力回答^_^!
本系列的源代码可供下载。
网页抓取 加密html(谷歌网页抓取加密html程序教程:打开谷歌抓取sso模式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-11 10:02
网页抓取加密html程序教程:1.打开谷歌网页抓取sso模式在第三步,你将向服务器交付一个token,然后服务器将在本地安装一个https加密驱动2.验证https加密驱动内部工作原理:系统会动态的生成加密密钥,它会解密请求来源,解密后生成一个类似于https加密机制,然后认证,如果是网页,就返回一个数字,如果是html文档,返回的将是一个html文件的加密密钥。
然后使用这个加密密钥加密html文件(html代码),直到解密机解密成功。再次验证加密密钥,然后发送解密解密时使用的密钥。3.提交https密钥,交付加密密钥验证完加密机制,使用https验证码:证书信息,rsa或者gm04可以验证证书的原始密钥,给安全系统存根加密数据,看看正确不正确也可以在https代码中验证网页是否通过验证,例如,在eth/pocket/thehotminegroup/pocket_store中的使用server.ssl::ssl_exceptions函数验证ssl证书4.浏览器代理验证在浏览器中编写代理,验证加密密钥,发送解密之后的html。
5.https密钥发送发送的形式为:phpinfo--->https_msg\string\decrypt_permit\file\authorization(即"ssl")phpinfo--->https_msg\exec..\route\https\ssl\phpinfo\user\ssl_cookie\file\https\msg\phpinfo\exec\https\ssl\exec..\authorization(即"file")即"xx.php"。验证内容即为"您是否连接成功."。 查看全部
网页抓取 加密html(谷歌网页抓取加密html程序教程:打开谷歌抓取sso模式)
网页抓取加密html程序教程:1.打开谷歌网页抓取sso模式在第三步,你将向服务器交付一个token,然后服务器将在本地安装一个https加密驱动2.验证https加密驱动内部工作原理:系统会动态的生成加密密钥,它会解密请求来源,解密后生成一个类似于https加密机制,然后认证,如果是网页,就返回一个数字,如果是html文档,返回的将是一个html文件的加密密钥。
然后使用这个加密密钥加密html文件(html代码),直到解密机解密成功。再次验证加密密钥,然后发送解密解密时使用的密钥。3.提交https密钥,交付加密密钥验证完加密机制,使用https验证码:证书信息,rsa或者gm04可以验证证书的原始密钥,给安全系统存根加密数据,看看正确不正确也可以在https代码中验证网页是否通过验证,例如,在eth/pocket/thehotminegroup/pocket_store中的使用server.ssl::ssl_exceptions函数验证ssl证书4.浏览器代理验证在浏览器中编写代理,验证加密密钥,发送解密之后的html。
5.https密钥发送发送的形式为:phpinfo--->https_msg\string\decrypt_permit\file\authorization(即"ssl")phpinfo--->https_msg\exec..\route\https\ssl\phpinfo\user\ssl_cookie\file\https\msg\phpinfo\exec\https\ssl\exec..\authorization(即"file")即"xx.php"。验证内容即为"您是否连接成功."。
网页抓取 加密html(逆向目标逆向过程分析(二)分析及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-11 08:18
本文章所有内容仅供学习交流。抓取到的内容、敏感URL、数据接口都进行了脱敏处理。严禁商业用途和非法使用。否则由此产生的一切后果与作者无关。,如有侵权,请联系我立即删除!
反向目标逆过程抓包分析
这次要反转的对象与以往不同。不是某个界面的参数,而是网页中的数据。一般网页中的数据可以在源代码中看到,或者通过一个接口传递,而这次目标的数据是通过JS加密获得的。我们先抓包看一下基本情况:
用F12查看,可以看到我们要的数据在textarea标签里,好像没有错,然后直接用Xpath解压试试:
import requests
from lxml import etree
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
data = tree.xpath('//textarea/text()')
print(data)
可以看到提取出来的数据其实是空的。我们查看网页的源代码,直接搜索textarea,同样不可用。尝试直接搜索数据。
加密反向
由于网页源代码中不存在这种数据,也不是通过其他接口返回的,很有可能是经过JS加密后直接插入到网页源代码中的,那么如何在这里找到加密位置?对比插入数据后的网页源代码和不插入数据的网页源代码,可以看到蓝框内的代码是通过js插入的,100个8.js大部分都是加密的JS 文件:
在这里,我们想到了一种 JavaScript 语法。如果要从 JavaScript 访问 HTML 元素,可以使用 document.getElementById(id) 方法。这个id是一个HTML元素的属性,然后使用innerHTML来获取或者插入元素的内容。可以看菜鸟教程的一个例子:
通过这个语法,结合前面源码中的几个标签,我们可以猜想一个JS中可能有这样的语句:document.getElementById("tehai").innerHTML, document.getElementById("tips")。innerHTML,document.getElementById("m2").innerHTML,可以直接全局搜索这些语句中的任何一个,在1008.js中可以找到对应的结果。当然,你也可以直接搜索这个标签的id来找到结果。埋下断点进行调试:
您可以找到第 913 行 document.getElementById("m2").innerHTML = d + "
"就是在m2标签中插入值d和换行符,一步步查找,可以发现d里面收录了很多html的东西,而上面的g只是文本,正好是目标数据,那么我们终于直接退货了。好吧。
继续追踪g值的出处,你会发现步骤比较复杂,那我们直接复制这部分函数(fa函数)运行调试(大约794行到914行),本地调试会提示ga和O是未定义的,我们在其定义语句的下一行埋下断点进行调试,可以看到ga的值其实是一个固定的q,而O是URL后面的q的值,如:336m237p2479s167z3s
这两个变量定义好后,再本地调试,会提示aa、ca等函数未定义,依赖函数很多。这种情况下就不用一一扣除了,fa之前的所有函数都直接复制调试就好了,直接解决了所有的依赖。
完整代码
GitHub关注K哥的爬虫,持续分享爬虫相关代码!欢迎明星!
以下仅演示部分关键代码,完整代码仓库地址:
Key JS 加密代码架构
// Copyrights C-EGG inc.
var u = function () {}();
function w() {}
w.prototype = {};
function x(b, a, g, d) {}
// 此处省略 N 个函数
function M(b) {}
function N(b, a) {}
function ea(b) {}
function fa(O) {
function b(a, b) {
var c, d = 0;
for (c = 0; c < a.length; ++c) d += 4 - b[a[c]];
return d
}
// var a = ga, g = O, d;
var a = 'q', g = O, d;
d = "";
switch (a.substr(0, 1)) {
case "q":
d += '標準形(七対国士を含む)の計算結果 / 一般形
';
break;
case "p":
d += '一般形(七対国士を含まない)の計算結果 / 標準形
'
}
for (var c = "d" == a.substr(1, 1), a = a.substr(0, 1), g = g.replace(/(\d)(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{8})(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(\d?)(\d?)(\d?)(\d?)(\d?)(\d?)(\d)(\d)(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(m|p|s|z)(m|p|s|z)+/g, "$1").replace(/^[^\d]/, ""), g = g.substr(0, 28), f = aa(g), r = -1; r = Math.floor(136 * Math.random()), f[r];) ;
var m = Math.floor(g.length / 2) % 3;
2 == m || c || (f[r] = 1, g += H(r));
var f = ca(f),
n = "",
e = G(f, 34),
n = n + N(e, 28 == g.length),
n = n + ("(" + Math.floor(g.length / 2) + "枚)");
-1 == e[0] && (n += ' / 新しい手牌を作成');
var n = n + "
",
q = "q" == a ? e[0] : e[1],
k,
p,
l = Array(35);
if (0 == q && 1 == m && c) k = 34,
l[k] = K(f),
l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
});
else if (0 >= q) for (k = 0; 34 > k; ++k) f[k] && (f[k]--, l[k] = K(f), f[k]++, l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
}));
else if (2 == m || 1 == m && !c) for (k = 0; 34 > k; ++k) {
if (f[k]) {
f[k]--;
l[k] = [];
for (p = 0; 34 > p; ++p) k == p || 4 p; ++p) 4 = q ? "待ち" : "摸";
for (k = 0; k < t.length; ++k) {
v = t[k].i;
d += "";
34 > v && (d += "打" + ('') + "", g += "打" + H(4 * v + 1) + " ");
d += q + "[";
g += q + "[";
l = t[k].c;
c = t[k].q;
for (p = 0; p < l.length; ++p) r = H(4 * l[p] + 1),
d += '',
g += H(4 * l[p] + 1);
d += "" + t[k].n + "枚]";
g += " " + t[k].n + "枚]\n"
}
d = d + "
" + ('' + g + "");
-1 == e[0] && (d = d + "" + ea(f));
// document.getElementById("tehai").innerHTML = n;
// document.getElementById("tips").innerHTML = "";
// document.getElementById("m2").innerHTML = d + "
"
return g
}
// 测试样例
// console.log(fa('336m237p2479s167z3s'))
Python代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import execjs
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
def main():
q = url.split('=')[1]
with open('decrypt.js', 'r', encoding='utf-8') as f:
decrypt_js = f.read()
data = execjs.compile(decrypt_js).call('fa', q)
print(data)
if __name__ == '__main__':
main()
分类:
技术要点:
相关文章: 查看全部
网页抓取 加密html(逆向目标逆向过程分析(二)分析及应用)
本文章所有内容仅供学习交流。抓取到的内容、敏感URL、数据接口都进行了脱敏处理。严禁商业用途和非法使用。否则由此产生的一切后果与作者无关。,如有侵权,请联系我立即删除!
反向目标逆过程抓包分析
这次要反转的对象与以往不同。不是某个界面的参数,而是网页中的数据。一般网页中的数据可以在源代码中看到,或者通过一个接口传递,而这次目标的数据是通过JS加密获得的。我们先抓包看一下基本情况:
用F12查看,可以看到我们要的数据在textarea标签里,好像没有错,然后直接用Xpath解压试试:
import requests
from lxml import etree
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
data = tree.xpath('//textarea/text()')
print(data)
可以看到提取出来的数据其实是空的。我们查看网页的源代码,直接搜索textarea,同样不可用。尝试直接搜索数据。
加密反向
由于网页源代码中不存在这种数据,也不是通过其他接口返回的,很有可能是经过JS加密后直接插入到网页源代码中的,那么如何在这里找到加密位置?对比插入数据后的网页源代码和不插入数据的网页源代码,可以看到蓝框内的代码是通过js插入的,100个8.js大部分都是加密的JS 文件:
在这里,我们想到了一种 JavaScript 语法。如果要从 JavaScript 访问 HTML 元素,可以使用 document.getElementById(id) 方法。这个id是一个HTML元素的属性,然后使用innerHTML来获取或者插入元素的内容。可以看菜鸟教程的一个例子:
通过这个语法,结合前面源码中的几个标签,我们可以猜想一个JS中可能有这样的语句:document.getElementById("tehai").innerHTML, document.getElementById("tips")。innerHTML,document.getElementById("m2").innerHTML,可以直接全局搜索这些语句中的任何一个,在1008.js中可以找到对应的结果。当然,你也可以直接搜索这个标签的id来找到结果。埋下断点进行调试:
您可以找到第 913 行 document.getElementById("m2").innerHTML = d + "
"就是在m2标签中插入值d和换行符,一步步查找,可以发现d里面收录了很多html的东西,而上面的g只是文本,正好是目标数据,那么我们终于直接退货了。好吧。
继续追踪g值的出处,你会发现步骤比较复杂,那我们直接复制这部分函数(fa函数)运行调试(大约794行到914行),本地调试会提示ga和O是未定义的,我们在其定义语句的下一行埋下断点进行调试,可以看到ga的值其实是一个固定的q,而O是URL后面的q的值,如:336m237p2479s167z3s
这两个变量定义好后,再本地调试,会提示aa、ca等函数未定义,依赖函数很多。这种情况下就不用一一扣除了,fa之前的所有函数都直接复制调试就好了,直接解决了所有的依赖。
完整代码
GitHub关注K哥的爬虫,持续分享爬虫相关代码!欢迎明星!
以下仅演示部分关键代码,完整代码仓库地址:
Key JS 加密代码架构
// Copyrights C-EGG inc.
var u = function () {}();
function w() {}
w.prototype = {};
function x(b, a, g, d) {}
// 此处省略 N 个函数
function M(b) {}
function N(b, a) {}
function ea(b) {}
function fa(O) {
function b(a, b) {
var c, d = 0;
for (c = 0; c < a.length; ++c) d += 4 - b[a[c]];
return d
}
// var a = ga, g = O, d;
var a = 'q', g = O, d;
d = "";
switch (a.substr(0, 1)) {
case "q":
d += '標準形(七対国士を含む)の計算結果 / 一般形
';
break;
case "p":
d += '一般形(七対国士を含まない)の計算結果 / 標準形
'
}
for (var c = "d" == a.substr(1, 1), a = a.substr(0, 1), g = g.replace(/(\d)(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{0,8})(\d{8})(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(\d?)(\d?)(\d?)(\d?)(\d?)(\d?)(\d)(\d)(m|p|s|z)/g, "$1$9$2$9$3$9$4$9$5$9$6$9$7$9$8$9").replace(/(m|p|s|z)(m|p|s|z)+/g, "$1").replace(/^[^\d]/, ""), g = g.substr(0, 28), f = aa(g), r = -1; r = Math.floor(136 * Math.random()), f[r];) ;
var m = Math.floor(g.length / 2) % 3;
2 == m || c || (f[r] = 1, g += H(r));
var f = ca(f),
n = "",
e = G(f, 34),
n = n + N(e, 28 == g.length),
n = n + ("(" + Math.floor(g.length / 2) + "枚)");
-1 == e[0] && (n += ' / 新しい手牌を作成');
var n = n + "
",
q = "q" == a ? e[0] : e[1],
k,
p,
l = Array(35);
if (0 == q && 1 == m && c) k = 34,
l[k] = K(f),
l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
});
else if (0 >= q) for (k = 0; 34 > k; ++k) f[k] && (f[k]--, l[k] = K(f), f[k]++, l[k].length && (l[k] = {
i: k,
n: b(l[k], f),
c: l[k]
}));
else if (2 == m || 1 == m && !c) for (k = 0; 34 > k; ++k) {
if (f[k]) {
f[k]--;
l[k] = [];
for (p = 0; 34 > p; ++p) k == p || 4 p; ++p) 4 = q ? "待ち" : "摸";
for (k = 0; k < t.length; ++k) {
v = t[k].i;
d += "";
34 > v && (d += "打" + ('
') + "", g += "打" + H(4 * v + 1) + " ");d += q + "[";
g += q + "[";
l = t[k].c;
c = t[k].q;
for (p = 0; p < l.length; ++p) r = H(4 * l[p] + 1),
d += '
',g += H(4 * l[p] + 1);
d += "" + t[k].n + "枚]";
g += " " + t[k].n + "枚]\n"
}
d = d + "
" + ('' + g + "");
-1 == e[0] && (d = d + "" + ea(f));
// document.getElementById("tehai").innerHTML = n;
// document.getElementById("tips").innerHTML = "";
// document.getElementById("m2").innerHTML = d + "
"
return g
}
// 测试样例
// console.log(fa('336m237p2479s167z3s'))
Python代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import execjs
url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
def main():
q = url.split('=')[1]
with open('decrypt.js', 'r', encoding='utf-8') as f:
decrypt_js = f.read()
data = execjs.compile(decrypt_js).call('fa', q)
print(data)
if __name__ == '__main__':
main()
分类:
技术要点:
相关文章:
网页抓取 加密html(分析网页内容()原网址_分析_e操盘(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-10 15:07
分析网页内容
原网址:
大家在爬网页的时候会遇到各种问题,比如字体加密,但是我爬公众评论网站的时候发现里面的字体和文字没有加密不同,使用css定位来显示需要的文字和数字,如图:
只显示跨度标签和类,没有数字信息。
通过查看css信息,你会发现里面有一个URL,
打开网站,发现里面有数字信息,用来显示价格等信息。
查看元素的反复对比,发现css定位是用来展示需要的信息,span标签中class的定位,
我知道如何解析它,然后如何获取该类在span中的定位信息。直接从页面抓取不是很明显,只能另寻他法。
刚查了一下页面的源码,发现这个网站,有这么一个注释,发现服务器里也加载了下面的css样式,然后访问了一下,有惊喜
访问 css 网址
里面的信息正是我们想要的,
这样我们就可以编写代码来通过解析这两个 URL 来解密文本和数字,
写代码解密
这里我就简单写一下具体的解密过程,所以写的代码不是很规范,并没有爬取整个网页。
根据上面的分析,我们需要先获取span标签中的class。我们以上面两个例子为例来演示解密:
# 9
# 5
根据类名,如:hkcc8,获取类名的定位值
# 导的包
import re
import requests
import lxml.html
# 获取css页面的详情信息,用正则匹配得到css的定位数据
def css_info(info):
# css 页面 这个网址是会变化的,修改为自己获取到的
css_html = requests.get('https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/6c3897952c363a4c22712329d2ff2e93.css').text
# mty2pe{background:-180.0px -1664.0px;}
# 正则,这里有个坑,刚开始使用+拼接,不能匹配
str_css = r'%s{background:-(\d+).0px -(\d+).0px'% info
css_re = re.compile(str_css)
info_css = css_re.findall(css_html)
# print(css_html)
# print(str_css)
# print(info_css)
return info_css
输入:hkcc8 结果:475 64
接下来解析号码的url
<p>result = requests.get('https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/d32298136aa6a4b7715bd2d11b41727c.svg')
tree = lxml.html.fromstring(result.content)
a = tree.xpath('//text[@y="41"]/text()')[0]
b = tree.xpath('//text[@y="88"]/text()')[0]
c = tree.xpath('//text[@y="126"]/text()')[0]
# x ,y 是得到的两个坐标点
# 调用上面的函数
x,y = css_info('hkcc8')[0]
x,y = int(x),int(y)
print('坐标',x,y)
if y 查看全部
网页抓取 加密html(分析网页内容()原网址_分析_e操盘(图))
分析网页内容
原网址:
大家在爬网页的时候会遇到各种问题,比如字体加密,但是我爬公众评论网站的时候发现里面的字体和文字没有加密不同,使用css定位来显示需要的文字和数字,如图:
只显示跨度标签和类,没有数字信息。
通过查看css信息,你会发现里面有一个URL,
打开网站,发现里面有数字信息,用来显示价格等信息。
查看元素的反复对比,发现css定位是用来展示需要的信息,span标签中class的定位,
我知道如何解析它,然后如何获取该类在span中的定位信息。直接从页面抓取不是很明显,只能另寻他法。
刚查了一下页面的源码,发现这个网站,有这么一个注释,发现服务器里也加载了下面的css样式,然后访问了一下,有惊喜
访问 css 网址
里面的信息正是我们想要的,
这样我们就可以编写代码来通过解析这两个 URL 来解密文本和数字,
写代码解密
这里我就简单写一下具体的解密过程,所以写的代码不是很规范,并没有爬取整个网页。
根据上面的分析,我们需要先获取span标签中的class。我们以上面两个例子为例来演示解密:
# 9
# 5
根据类名,如:hkcc8,获取类名的定位值
# 导的包
import re
import requests
import lxml.html
# 获取css页面的详情信息,用正则匹配得到css的定位数据
def css_info(info):
# css 页面 这个网址是会变化的,修改为自己获取到的
css_html = requests.get('https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/6c3897952c363a4c22712329d2ff2e93.css').text
# mty2pe{background:-180.0px -1664.0px;}
# 正则,这里有个坑,刚开始使用+拼接,不能匹配
str_css = r'%s{background:-(\d+).0px -(\d+).0px'% info
css_re = re.compile(str_css)
info_css = css_re.findall(css_html)
# print(css_html)
# print(str_css)
# print(info_css)
return info_css
输入:hkcc8 结果:475 64
接下来解析号码的url
<p>result = requests.get('https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/d32298136aa6a4b7715bd2d11b41727c.svg')
tree = lxml.html.fromstring(result.content)
a = tree.xpath('//text[@y="41"]/text()')[0]
b = tree.xpath('//text[@y="88"]/text()')[0]
c = tree.xpath('//text[@y="126"]/text()')[0]
# x ,y 是得到的两个坐标点
# 调用上面的函数
x,y = css_info('hkcc8')[0]
x,y = int(x),int(y)
print('坐标',x,y)
if y
网页抓取 加密html(百度搜索引擎https站点如何建设才能对百度友好友好? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-10 01:32
)
大家都知道百度等搜索引擎无法识别https页面。很多朋友需要为网站建立安全的传输方式,但又担心网站的收录不好。所以现在百度官方给了我们答案,以下是百度站长平台发布的《如何建立一个对百度友好的HTTPS站点》全文:
百度搜索引擎目前并没有主动抓取 https 网页,所以大部分 https 网页不能是收录。但是如果网站必须使用https加密协议,怎么对百度搜索引擎友好呢?其实很简单:
1.为需要百度搜索引擎收录搜索的https页面制作http无障碍版本。
2.通过user-agent判断访问者,将Baiduspider引导到http页面。普通用户通过百度搜索引擎访问页面时,会通过301重定向到对应的https页面。如图,上图是http版的百度收录,下图是用户点击后会自动跳转到https版本。
3、http版不只为首页制作。其他重要页面也需要制作http版本,并相互链接。这不应该发生:首页http页面上的链接仍然链接到https页面,导致Baiduspider无法继续爬取——我们遇到过这样的情况,整个首页只能收录一个首页网络。
执行以下操作是错误的:链接
4、一些不需要加密的内容,比如信息,可以通过二级域名承载。比如支付宝网站,核心加密内容放在https上,百度蜘蛛可以直接抓到的内容放在二级域名上。
查看全部
网页抓取 加密html(百度搜索引擎https站点如何建设才能对百度友好友好?
)
大家都知道百度等搜索引擎无法识别https页面。很多朋友需要为网站建立安全的传输方式,但又担心网站的收录不好。所以现在百度官方给了我们答案,以下是百度站长平台发布的《如何建立一个对百度友好的HTTPS站点》全文:
百度搜索引擎目前并没有主动抓取 https 网页,所以大部分 https 网页不能是收录。但是如果网站必须使用https加密协议,怎么对百度搜索引擎友好呢?其实很简单:
1.为需要百度搜索引擎收录搜索的https页面制作http无障碍版本。
2.通过user-agent判断访问者,将Baiduspider引导到http页面。普通用户通过百度搜索引擎访问页面时,会通过301重定向到对应的https页面。如图,上图是http版的百度收录,下图是用户点击后会自动跳转到https版本。
3、http版不只为首页制作。其他重要页面也需要制作http版本,并相互链接。这不应该发生:首页http页面上的链接仍然链接到https页面,导致Baiduspider无法继续爬取——我们遇到过这样的情况,整个首页只能收录一个首页网络。
执行以下操作是错误的:链接
4、一些不需要加密的内容,比如信息,可以通过二级域名承载。比如支付宝网站,核心加密内容放在https上,百度蜘蛛可以直接抓到的内容放在二级域名上。
网页抓取 加密html( JS加密解密混合运算100题计算机一级题库二元一次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-09 09:31
JS加密解密混合运算100题计算机一级题库二元一次)
如域名所有者域名Registrar域名注册日期和到期日期等。通过域名的Whois查询,可以查询到域名所有者的联系方式以及注册和到期时间15死链接检测整体site PR query 这个工具可以快速测试网站的死链接 死链接——也叫死链接,就是那些不可达的链接。A网站有死链接可不是什么好事。首先,一个网站如果有大量的死链接,会极大的损害网站的整体形象。搜索引擎蜘蛛通过链接爬行。如果太多的链接无法到达,不仅收录页面的数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。查询可以遍历指定网页的所有链接,分析每个链接的有效性,找出死链接。网站的收录的数量~17搜索引擎反向链接通过这个工具可以快速查看各大搜索引擎对网站的反向链接数量~18查看手机号归属地查看手机号19. SEO综合查询 SEO综合查询 20 PR值查询 PR值的全称是PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 可以快速查看各大搜索引擎对网站的反向链接数~18查看手机号归属地查看手机号19.SEO综合查询SEO综合查询20 PR值查询PR值全称PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 可以快速查看各大搜索引擎对网站的反向链接数~18查看手机号归属地查看手机号19.SEO综合查询SEO综合查询20 PR值查询PR值全称PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 s 排名算法,被谷歌用来识别网页。排序重要性的方法 s 排名算法,被谷歌用来识别网页。排序重要性的方法
法律是谷歌用来衡量网站篮球课程标准质量的唯一标准尘肺病标准表党员活动室建设分级护理细化标准儿科分级护理标准结合所有其他标准,如标题标志和在关键字标志因素之后,Google 使用 PageRank 来调整结果,使排名更重要的页面在搜索结果中排名网站,以提高搜索结果的相关性和质量。21关键词ranking queries by 网站关键词ranking query可以快速得到当前网站关键词在百度Google收录的排名~有些关键词排名不一样在不同的地方,通常称为关键字的区域排名例如,新闻人才等很多,所以我们提供多地服务器供大家查询。22IP查询 通过该工具,您可以查询指定IP的物理地址或域名服务器的IP和物理地址以及您所在的国家或城市,甚至可以精确到某个网吧机房或学校。找到的结果仅供参考~ 23Google收录查询谷歌收录情况 24友情链接查询工具 这个工具可以批量查询百度的收录百度中指定网站的友情链接快照PR及对方链接到本站是否能检测到欺诈链接 25 友情链接IP查询工具 通过该工具可以批量查询网站的IP地址 友情链接站点 服务器的物理地址 帮助站长清楚了解友情链接的服务器 物理定位 26 域名删除查询 comnetorg等国际域名一般在65日或75日凌晨2点30分左右删除域名过期。友情提示将被删除。域名删除时间仅供参考。谢谢~ 27百度收录查询本工具为网站所有者提供了在指定时间内百度搜索指定网站收录情况包括收录网页数量并且网页的具体情况让你更好的掌握百度搜索你的网站收录情况28PR输出值查询查询网站@的PR输出值> 查看全部
网页抓取 加密html(
JS加密解密混合运算100题计算机一级题库二元一次)
如域名所有者域名Registrar域名注册日期和到期日期等。通过域名的Whois查询,可以查询到域名所有者的联系方式以及注册和到期时间15死链接检测整体site PR query 这个工具可以快速测试网站的死链接 死链接——也叫死链接,就是那些不可达的链接。A网站有死链接可不是什么好事。首先,一个网站如果有大量的死链接,会极大的损害网站的整体形象。搜索引擎蜘蛛通过链接爬行。如果太多的链接无法到达,不仅收录页面的数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。查询可以遍历指定网页的所有链接,分析每个链接的有效性,找出死链接。网站的收录的数量~17搜索引擎反向链接通过这个工具可以快速查看各大搜索引擎对网站的反向链接数量~18查看手机号归属地查看手机号19. SEO综合查询 SEO综合查询 20 PR值查询 PR值的全称是PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 可以快速查看各大搜索引擎对网站的反向链接数~18查看手机号归属地查看手机号19.SEO综合查询SEO综合查询20 PR值查询PR值全称PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 可以快速查看各大搜索引擎对网站的反向链接数~18查看手机号归属地查看手机号19.SEO综合查询SEO综合查询20 PR值查询PR值全称PageRank。页面层级取自谷歌创始人LarryPage。它是谷歌排名算法的一部分,被谷歌用来识别网页。排序重要性的方法 s 排名算法,被谷歌用来识别网页。排序重要性的方法 s 排名算法,被谷歌用来识别网页。排序重要性的方法
法律是谷歌用来衡量网站篮球课程标准质量的唯一标准尘肺病标准表党员活动室建设分级护理细化标准儿科分级护理标准结合所有其他标准,如标题标志和在关键字标志因素之后,Google 使用 PageRank 来调整结果,使排名更重要的页面在搜索结果中排名网站,以提高搜索结果的相关性和质量。21关键词ranking queries by 网站关键词ranking query可以快速得到当前网站关键词在百度Google收录的排名~有些关键词排名不一样在不同的地方,通常称为关键字的区域排名例如,新闻人才等很多,所以我们提供多地服务器供大家查询。22IP查询 通过该工具,您可以查询指定IP的物理地址或域名服务器的IP和物理地址以及您所在的国家或城市,甚至可以精确到某个网吧机房或学校。找到的结果仅供参考~ 23Google收录查询谷歌收录情况 24友情链接查询工具 这个工具可以批量查询百度的收录百度中指定网站的友情链接快照PR及对方链接到本站是否能检测到欺诈链接 25 友情链接IP查询工具 通过该工具可以批量查询网站的IP地址 友情链接站点 服务器的物理地址 帮助站长清楚了解友情链接的服务器 物理定位 26 域名删除查询 comnetorg等国际域名一般在65日或75日凌晨2点30分左右删除域名过期。友情提示将被删除。域名删除时间仅供参考。谢谢~ 27百度收录查询本工具为网站所有者提供了在指定时间内百度搜索指定网站收录情况包括收录网页数量并且网页的具体情况让你更好的掌握百度搜索你的网站收录情况28PR输出值查询查询网站@的PR输出值>
网页抓取 加密html(2021年最新Python爬虫教程+实战项目案例(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-04-06 17:17
)
今天是综合练习!!它涉及请求、逆向工程、解密和爬取。
目标是从某音乐软件的评论区抓取热评,可以说是大开眼界了!
#1.找到未加密的参数 #window.asrsea(参数1,参数2,参数3.。。。。。)
#2.想办法把参数进行加密,(使用的是某云的加密逻辑) #params->encText encSecKey->enSecKey
#3.请求到网页,拿到评论信息
1.打开网页,输入你想知道的歌曲
2. 进入子页面,抓包,一一查看评论的包在哪里。以下是评论区抓到的包。可以看到评论区的url需要两个参数,params,encSecKey。这两个参数就是加密所涉及的参数,我们只需要破解整个加密逻辑即可
3.单击启动器以显示每个 json 文件。最上面的一个是最后处理的文件。我们开始向后推。点击第一个json文件
4.在锚点处设置断点,刷新页面。
5.刷新后,注意scope中的local选项,打开变量查看requests属性,然后点击上面的蓝色按钮,一直释放,直到出现我们想要的评论的url。
6.在调用栈中,在json文件中一一查看我们需要的参数:encText、encSecKey,直到找到参数值,这就是我们的加密参数。我们可以看到它们属于
var bVj8b是一个变量,这个变量是由函数window.asrsea赋值的,所以我们猜测这个函数是window.asrsea加密的,我们搜索这个函数
7.调用的时候除了这个函数,前面也定义了这个函数。此功能由 d 功能指定。让我们解释一下 d 函数。这里我把 a,b,c,d ,e 这五个函数抄下来,我们一一解读。老实说,我忘记了f,e,g在这里是如何定值的。我只记得d是数据数据,i是随机数,从而确定encSecKey。对应的encText就是我们想要的params。如果您想了解更多,请观看此视频
2021最新Python爬虫教程+实战项目案例(最新录制)_bilibili _bilibili
!function() {
function a(a) {#由i值来的
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,#产生e的随机数
e = Math.floor(e),#对e向下取整
c += b.charAt(e);#e作为b的索引,从b中拿出一个索引为e的字符,附到c上
return c#返回c,这就是a函数的功能,产生一个随机秘钥
}
function b(a, b) {#b函数时加密过程,为AES加密,a是加密内容,b是加密秘钥
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)#把a的utf-8格式赋值给e
, f = CryptoJS.AES.encrypt(e, c, {#AES加密,把e和c加密
iv: d,#iv为AES加密的偏移量
mode: CryptoJS.mode.CBC#AES的加密模式
});
return f.toString()#返回f的字符串形式
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {#由window.asrsea来的
var h = {}#创建空字典
, i = a(16);#i值由a函数确定,i值为16位的随机秘钥
return h.encText = b(d, g),#b函数的返回值写进h的encText内,d是待加密数据
h.encText = b(h.encText, i),#可以看出这是两次加密过程,生成encText
h.encSecKey = c(i, e, f),
#encSecKey这个参数就是我们想要的两个参数之一,由c函数确定
#这里c函数需要传进去的参数有i e f ,其中e f 是定值,i是随机值,我们把i值固定就能获得固定的encSecKey值
#至此encSecKey和encText的加密过程全部确定完毕。
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
window.asrsea = d,
window.ecnonasr = e
}();
剩下的就是全部代码了。如果还有时间,我会回来理清逻辑的。我对这篇文章不是很满意。
#1.找到未加密的参数 #window.asrsea(参数1,参数2,参数3.。。。。。)
#2.想办法把参数进行加密,(使用的是网易云的加密逻辑) #params->encText encSecKey->enSecKey
#3.请求到网页,拿到评论信息
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json #json 可以把字典变成字符串
url="https://music.163.com/weapi/co ... ot%3B
#请求方式post
data={
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_40257799",
"threadId": "R_SO_4_40257799"
}
#处理加密过程
""""
function a(a) {#返回随机的16位字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)#循环函数
e = Math.random() * b.length,#生成随机数
e = Math.floor(e),#取整
c += b.charAt(e);#取字符串中的xxx位
return c
}
function b(a, b) {#a是要加密的内容,b是秘钥
var c = CryptoJS.enc.Utf8.parse(b)#c是utf-8的b
, d = CryptoJS.enc.Utf8.parse("0102030405060708")#d是数字的utf-8类型
, e = CryptoJS.enc.Utf8.parse(a)#e是a的utf-8形式
, f = CryptoJS.AES.encrypt(e, c, {#AES加密算法,
iv: d,#AES算法里面的偏移量
mode: CryptoJS.mode.CBC#模式:CBC,差一个秘钥,秘钥就是c,c又是b,所以b的作用就是秘钥
});
return f.toString()
}
function c(a, b, c) {#c算法不产生随机数
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {d:d就是数据,e:01001,f:'很长',g:'0CoJUm6Qyw8W8jud'}
var h = {}#声明空对象
, i = a(16);#i是16位的随机字符串
return h.encText = b(d, g),#所以d是数据,g是秘钥
h.encText = b(h.encText, i),#这里得到的encText就是我们要的params,i是秘钥
#从上面两行代码看出,想要得到encText,首先需要两次b加密过程,第一次数据+g,第二次把第一次返回的结果+i
h.encSecKey = c(i, e, f),#这里得到的encSeckey就是我们要的encSeckey,e,f都是固定值,i是随机值
#这里encSeckey的随机值产生都是由于i的原因,我们把i值固定就能获得固定的encSeckey值.
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
"""
f="00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
i="5wWcgz0OQm8BE9yI"#随机值
e="010001"
g="0CoJUm6Qyw8W8jud"
def get_encSeckey():#由i确定
return "c5c0039e144f4dad02c2fc54dd0a6dcf74c0981748c1c00acba22d79569963ce4434a0f9663a1a048bcc4afbf4d4a389477323ef79b13673439ebb5d1d9895f6ea06c0fcc612e8e475dafca50bed9f51a3a07407be7739f86bd790ff10936947a6f022ec38db5c069968c559f17a617f8546a37dc3b900a469f9c19e0f85873a"
# 把参数进行加密
def get_params(data): # 默认这里接收到的是字符串
first = enc_params(data, g)
second = enc_params(first, i)
return second # 返回的就是params
# 转化成16的倍数, 为下方的加密算法服务
def to_16(data):
pad = 16 - len(data) % 16
data += chr(pad) * pad
return data
# 加密过程
def enc_params(data, key):
iv = "0102030405060708"
data = to_16(data)
aes = AES.new(key=key.encode("utf-8"), IV=iv.encode('utf-8'), mode=AES.MODE_CBC) # 创建加密器
bs = aes.encrypt(data.encode("utf-8")) # 加密, 加密的内容的长度必须是16的倍数
return str(b64encode(bs), "utf-8") # 转化成字符串返回,
resp=requests.post(url,data={
"params":get_params(json.dumps(data)),
"encSecKey":get_encSeckey()#Key写成了key,结果一直出不来!!!!!!!!!!!!!!!
})
print(resp.text)
最终效果如图
查看全部
网页抓取 加密html(2021年最新Python爬虫教程+实战项目案例(上)
)
今天是综合练习!!它涉及请求、逆向工程、解密和爬取。
目标是从某音乐软件的评论区抓取热评,可以说是大开眼界了!
#1.找到未加密的参数 #window.asrsea(参数1,参数2,参数3.。。。。。)
#2.想办法把参数进行加密,(使用的是某云的加密逻辑) #params->encText encSecKey->enSecKey
#3.请求到网页,拿到评论信息
1.打开网页,输入你想知道的歌曲
2. 进入子页面,抓包,一一查看评论的包在哪里。以下是评论区抓到的包。可以看到评论区的url需要两个参数,params,encSecKey。这两个参数就是加密所涉及的参数,我们只需要破解整个加密逻辑即可
3.单击启动器以显示每个 json 文件。最上面的一个是最后处理的文件。我们开始向后推。点击第一个json文件
4.在锚点处设置断点,刷新页面。
5.刷新后,注意scope中的local选项,打开变量查看requests属性,然后点击上面的蓝色按钮,一直释放,直到出现我们想要的评论的url。
6.在调用栈中,在json文件中一一查看我们需要的参数:encText、encSecKey,直到找到参数值,这就是我们的加密参数。我们可以看到它们属于
var bVj8b是一个变量,这个变量是由函数window.asrsea赋值的,所以我们猜测这个函数是window.asrsea加密的,我们搜索这个函数
7.调用的时候除了这个函数,前面也定义了这个函数。此功能由 d 功能指定。让我们解释一下 d 函数。这里我把 a,b,c,d ,e 这五个函数抄下来,我们一一解读。老实说,我忘记了f,e,g在这里是如何定值的。我只记得d是数据数据,i是随机数,从而确定encSecKey。对应的encText就是我们想要的params。如果您想了解更多,请观看此视频
2021最新Python爬虫教程+实战项目案例(最新录制)_bilibili _bilibili
!function() {
function a(a) {#由i值来的
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,#产生e的随机数
e = Math.floor(e),#对e向下取整
c += b.charAt(e);#e作为b的索引,从b中拿出一个索引为e的字符,附到c上
return c#返回c,这就是a函数的功能,产生一个随机秘钥
}
function b(a, b) {#b函数时加密过程,为AES加密,a是加密内容,b是加密秘钥
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)#把a的utf-8格式赋值给e
, f = CryptoJS.AES.encrypt(e, c, {#AES加密,把e和c加密
iv: d,#iv为AES加密的偏移量
mode: CryptoJS.mode.CBC#AES的加密模式
});
return f.toString()#返回f的字符串形式
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {#由window.asrsea来的
var h = {}#创建空字典
, i = a(16);#i值由a函数确定,i值为16位的随机秘钥
return h.encText = b(d, g),#b函数的返回值写进h的encText内,d是待加密数据
h.encText = b(h.encText, i),#可以看出这是两次加密过程,生成encText
h.encSecKey = c(i, e, f),
#encSecKey这个参数就是我们想要的两个参数之一,由c函数确定
#这里c函数需要传进去的参数有i e f ,其中e f 是定值,i是随机值,我们把i值固定就能获得固定的encSecKey值
#至此encSecKey和encText的加密过程全部确定完毕。
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
window.asrsea = d,
window.ecnonasr = e
}();
剩下的就是全部代码了。如果还有时间,我会回来理清逻辑的。我对这篇文章不是很满意。
#1.找到未加密的参数 #window.asrsea(参数1,参数2,参数3.。。。。。)
#2.想办法把参数进行加密,(使用的是网易云的加密逻辑) #params->encText encSecKey->enSecKey
#3.请求到网页,拿到评论信息
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json #json 可以把字典变成字符串
url="https://music.163.com/weapi/co ... ot%3B
#请求方式post
data={
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_40257799",
"threadId": "R_SO_4_40257799"
}
#处理加密过程
""""
function a(a) {#返回随机的16位字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)#循环函数
e = Math.random() * b.length,#生成随机数
e = Math.floor(e),#取整
c += b.charAt(e);#取字符串中的xxx位
return c
}
function b(a, b) {#a是要加密的内容,b是秘钥
var c = CryptoJS.enc.Utf8.parse(b)#c是utf-8的b
, d = CryptoJS.enc.Utf8.parse("0102030405060708")#d是数字的utf-8类型
, e = CryptoJS.enc.Utf8.parse(a)#e是a的utf-8形式
, f = CryptoJS.AES.encrypt(e, c, {#AES加密算法,
iv: d,#AES算法里面的偏移量
mode: CryptoJS.mode.CBC#模式:CBC,差一个秘钥,秘钥就是c,c又是b,所以b的作用就是秘钥
});
return f.toString()
}
function c(a, b, c) {#c算法不产生随机数
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {d:d就是数据,e:01001,f:'很长',g:'0CoJUm6Qyw8W8jud'}
var h = {}#声明空对象
, i = a(16);#i是16位的随机字符串
return h.encText = b(d, g),#所以d是数据,g是秘钥
h.encText = b(h.encText, i),#这里得到的encText就是我们要的params,i是秘钥
#从上面两行代码看出,想要得到encText,首先需要两次b加密过程,第一次数据+g,第二次把第一次返回的结果+i
h.encSecKey = c(i, e, f),#这里得到的encSeckey就是我们要的encSeckey,e,f都是固定值,i是随机值
#这里encSeckey的随机值产生都是由于i的原因,我们把i值固定就能获得固定的encSeckey值.
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
"""
f="00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
i="5wWcgz0OQm8BE9yI"#随机值
e="010001"
g="0CoJUm6Qyw8W8jud"
def get_encSeckey():#由i确定
return "c5c0039e144f4dad02c2fc54dd0a6dcf74c0981748c1c00acba22d79569963ce4434a0f9663a1a048bcc4afbf4d4a389477323ef79b13673439ebb5d1d9895f6ea06c0fcc612e8e475dafca50bed9f51a3a07407be7739f86bd790ff10936947a6f022ec38db5c069968c559f17a617f8546a37dc3b900a469f9c19e0f85873a"
# 把参数进行加密
def get_params(data): # 默认这里接收到的是字符串
first = enc_params(data, g)
second = enc_params(first, i)
return second # 返回的就是params
# 转化成16的倍数, 为下方的加密算法服务
def to_16(data):
pad = 16 - len(data) % 16
data += chr(pad) * pad
return data
# 加密过程
def enc_params(data, key):
iv = "0102030405060708"
data = to_16(data)
aes = AES.new(key=key.encode("utf-8"), IV=iv.encode('utf-8'), mode=AES.MODE_CBC) # 创建加密器
bs = aes.encrypt(data.encode("utf-8")) # 加密, 加密的内容的长度必须是16的倍数
return str(b64encode(bs), "utf-8") # 转化成字符串返回,
resp=requests.post(url,data={
"params":get_params(json.dumps(data)),
"encSecKey":get_encSeckey()#Key写成了key,结果一直出不来!!!!!!!!!!!!!!!
})
print(resp.text)
最终效果如图
网页抓取 加密html(如何解密网页抓取加密页面?解密https页面的应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2022-04-06 03:04
网页抓取加密html:比如chrome的dom存储于js文件中,要获取的时候需要从js中读取;有些网站用tomcat,jboss等orm系统来存放用户数据,orm只需要加解密的过程,我们可以借助xml或者其他方法解析下载中的数据,这样就可以获取页面里面的加密html了。
通常我们通过javascript、java等语言访问网站页面,难免需要使用https,post等加密方式进行登录用户。随着社会的发展,又流行起了各种dedecms系统,以及门户网站。这些网站的内容和服务都是依靠外部服务器来对接,这样就有了加密浏览器访问方式:将信息发送给对应的服务器,服务器返回给客户端一个有密文的网页。
那么如何解密这个https页面呢?你可以用java进行原生操作。假设你发送给fj的是一串字符:"11",我通过字符访问页面的话,fj将在页面上显示"https"。解密https页面?。
1、获取密文有一种称为rarsk(密钥)的东西,用来标识一个数据类型变量的私钥(privatekey)。密钥可以在java中的反射操作中读取,反射操作是针对java代码或java类,并且java代码或java类可以私有。如下的例子所示,以下的反射操作中应该能够读取密钥,并且将密钥解密成代码。publicclasshttpserver{privateinti=42;//密钥私钥privatestringpj="11";//数据类型变量私钥privatejava.io.encryption.byte[]bytes=newjava.io.encryption.byte[16];//待解密对象publicvoidreadobject(stringstr){//尝试读取密文//...}}。
2、反序列化java中的反序列化不同于java.io.fileinputstream或fileoutputstream中的反序列化,而是仅以getwriter()为例进行。在java中设置getwriter方法为该方法的第一个参数,该方法返回true表示读取文件或文件夹内容,返回false表示读取文件或文件夹外的内容。
publicvoidreadobject(stringstr){if(str==null){thrownewbufferedinputstreamfactorybuilder();}system.out.println("字符"+str);}。
3、反序列化服务器加密存储在java中的应用是jndi(javainternetoperatingsystem)。web服务器是jndi的客户端。https对象必须在http/2规范下运行。
1、获取密钥java中的任何对象都可以对接https服务器。
2、反序列化https对象,fj返回一个密文或其它任何类型私钥,cert.passkey加密存储在java自己的对象中。uri加密, 查看全部
网页抓取 加密html(如何解密网页抓取加密页面?解密https页面的应用方法)
网页抓取加密html:比如chrome的dom存储于js文件中,要获取的时候需要从js中读取;有些网站用tomcat,jboss等orm系统来存放用户数据,orm只需要加解密的过程,我们可以借助xml或者其他方法解析下载中的数据,这样就可以获取页面里面的加密html了。
通常我们通过javascript、java等语言访问网站页面,难免需要使用https,post等加密方式进行登录用户。随着社会的发展,又流行起了各种dedecms系统,以及门户网站。这些网站的内容和服务都是依靠外部服务器来对接,这样就有了加密浏览器访问方式:将信息发送给对应的服务器,服务器返回给客户端一个有密文的网页。
那么如何解密这个https页面呢?你可以用java进行原生操作。假设你发送给fj的是一串字符:"11",我通过字符访问页面的话,fj将在页面上显示"https"。解密https页面?。
1、获取密文有一种称为rarsk(密钥)的东西,用来标识一个数据类型变量的私钥(privatekey)。密钥可以在java中的反射操作中读取,反射操作是针对java代码或java类,并且java代码或java类可以私有。如下的例子所示,以下的反射操作中应该能够读取密钥,并且将密钥解密成代码。publicclasshttpserver{privateinti=42;//密钥私钥privatestringpj="11";//数据类型变量私钥privatejava.io.encryption.byte[]bytes=newjava.io.encryption.byte[16];//待解密对象publicvoidreadobject(stringstr){//尝试读取密文//...}}。
2、反序列化java中的反序列化不同于java.io.fileinputstream或fileoutputstream中的反序列化,而是仅以getwriter()为例进行。在java中设置getwriter方法为该方法的第一个参数,该方法返回true表示读取文件或文件夹内容,返回false表示读取文件或文件夹外的内容。
publicvoidreadobject(stringstr){if(str==null){thrownewbufferedinputstreamfactorybuilder();}system.out.println("字符"+str);}。
3、反序列化服务器加密存储在java中的应用是jndi(javainternetoperatingsystem)。web服务器是jndi的客户端。https对象必须在http/2规范下运行。
1、获取密钥java中的任何对象都可以对接https服务器。
2、反序列化https对象,fj返回一个密文或其它任何类型私钥,cert.passkey加密存储在java自己的对象中。uri加密,
网页抓取 加密html(HTTPNot或Found错误信息是HTTP的其中“标准回应信息”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-05 06:02
HTTP 404 或 Not Found 错误消息是 HTTP 的“标准响应消息”(HTTP 状态代码)之一。此消息表示客户端浏览网页时服务器无法正常提供信息,或服务器无法响应,原因不明。
大量死链接对搜索引擎有什么影响?
1、很多网站都无法避免死链接,但是死链接率太高,会影响搜索引擎对网站的评分。
2、搜索引擎每天限制每个网站的抓取频率。如果网站中有大量死链接,会浪费爬取配额,影响正常页面的爬取。
3、过多的死链接对于网站 用户来说也是一种糟糕的体验。
百度站长工具出现抓取异常,那么这个工具里面的异常数据是怎么产生的呢?
1、网站添加了错误的内部链接
编辑错误或程序员的粗心导致页面生成了一个不存在的页面。
2、网站暂时无法访问
网站由于服务器、空间或程序问题暂时无法访问,导致大量返回码以5开头的服务器错误页面。
3、外部链接错误
用户或站长在站外发错网址,蜘蛛抓取后生成错误页面;其他 网站 复制或 采集 带有错误链接的页面;一些垃圾网站自动生成静态搜索结果页面,比如www。8875. org/desc/3715714444.html 此页面上出现的许多链接在 html 前面都有“...”。
4、爬虫提取了一个不完整的 URL
有的爬虫在提取页面URL时,只提取部分URL或者同时提取正常URL后面的文字或字符。
5、网站修订
网站修改过程中,直接删除了旧页面,没有301跳转到对应页面,或者301跳转后部分旧页面仍然无法访问。
6、管理员删除页面
网站管理员删除被黑、广告、过时和泛滥的页面,导致许多死链接。
7、过时或交易完成的页面
下架产品、过期信息
当出现上述情况时,我们该如何解决呢?
1、修复错误页面
爬取异常中的很多错误页面都是由于程序员的粗心或者我们的程序问题造成的。它们应该是正常的页面,但由于错误而无法访问。对于此类页面,我们会尽快修复。
2、提交死链接
但是肯定有很多不应该存在的错误页面,所以我们必须想办法获取这样一个页面的URL。获取方式主要有以下三种:
(1)百度站长工具--爬取异常--找不到页面--复制数据[更正:我们这里不需要提交死链接,百度站长工具自动提交死链接];
(2)当管理员手动删除页面或程序自动保存被删除页面的URL时;
(3)使用相关爬虫软件爬取整个站点获取死链接,比如Xenu。
然后把上面的数据合并删除重复的(excel表格可以实现去重,wps表格更容易操作),然后复制所有的url通过http状态批量查询工具查询【这个好/webspeed.aspx ],并删除非必要的 404 返回代码页。
然后将上面处理好的数据整理粘贴到网站根目录下的一个文档中,将文档地址提交到百度站长工具--网页爬取--死链接提交--添加新数据--填写死链接链接文件地址。
3、在机器人中阻止爬行
如果大量错误的网址有一定的规则,可以在robots文件中写一条规则,禁止蜘蛛抓取此类链接,但前提是一定要照顾好正常的页面,避免阻止规则误伤正常的页面,比如你的网站都是静态URL,那么如果错误链接收录?,则规则写成Disallow:/*?*,如果错误链接中有/id...html,则规则写成不允许:/*...*。
将规则添加到robots文件后,一定要到百度站长的robots工具进行验证,把指定的错误页面放进去看看是否封禁成功,再放入正常的页面看看是否被误封.
相关说明:
1、在百度站长工具中提交死链接之前,请确保提交的死链接数据中没有活链接。一旦有活链,就会显示提交失败,无法删除。
2、由于很多网站程序问题,很多打不开的页面返回码不是404,这是个大问题。比如打不开的页面返回码是301、200、500,如果是200,会导致网站中不同的url获取相同的内容。比如我的一个网站,社区的帖子被删除后,返回码是500,后来我发现了,马上处理。每个人都试图找出所有错误的 URL 格式,并将 HTTP 状态码设置为 404。
3、找到所有错误页面后,一定要寻找这些页面的URL相同的特征,并与正常页面的特征区分开来,将相应的规则写入robots文件,禁止蜘蛛爬取,即使你已经在网站上 长工具提交死链接,也建议禁止机器人爬取。
4、机器人只能解决蜘蛛不再抓取此类页面的问题,但无法解决删除已收录页面快照的问题。如果你的网站被黑了,被黑的页面被删除了,除了robots禁止被黑的页面外,这些页面也应该提交死链接。提交死链接是删除被黑页面快照的最快方法。返回搜狐,查看更多 查看全部
网页抓取 加密html(HTTPNot或Found错误信息是HTTP的其中“标准回应信息”)
HTTP 404 或 Not Found 错误消息是 HTTP 的“标准响应消息”(HTTP 状态代码)之一。此消息表示客户端浏览网页时服务器无法正常提供信息,或服务器无法响应,原因不明。
大量死链接对搜索引擎有什么影响?
1、很多网站都无法避免死链接,但是死链接率太高,会影响搜索引擎对网站的评分。
2、搜索引擎每天限制每个网站的抓取频率。如果网站中有大量死链接,会浪费爬取配额,影响正常页面的爬取。
3、过多的死链接对于网站 用户来说也是一种糟糕的体验。
百度站长工具出现抓取异常,那么这个工具里面的异常数据是怎么产生的呢?
1、网站添加了错误的内部链接
编辑错误或程序员的粗心导致页面生成了一个不存在的页面。
2、网站暂时无法访问
网站由于服务器、空间或程序问题暂时无法访问,导致大量返回码以5开头的服务器错误页面。
3、外部链接错误
用户或站长在站外发错网址,蜘蛛抓取后生成错误页面;其他 网站 复制或 采集 带有错误链接的页面;一些垃圾网站自动生成静态搜索结果页面,比如www。8875. org/desc/3715714444.html 此页面上出现的许多链接在 html 前面都有“...”。
4、爬虫提取了一个不完整的 URL
有的爬虫在提取页面URL时,只提取部分URL或者同时提取正常URL后面的文字或字符。
5、网站修订
网站修改过程中,直接删除了旧页面,没有301跳转到对应页面,或者301跳转后部分旧页面仍然无法访问。
6、管理员删除页面
网站管理员删除被黑、广告、过时和泛滥的页面,导致许多死链接。
7、过时或交易完成的页面
下架产品、过期信息
当出现上述情况时,我们该如何解决呢?
1、修复错误页面
爬取异常中的很多错误页面都是由于程序员的粗心或者我们的程序问题造成的。它们应该是正常的页面,但由于错误而无法访问。对于此类页面,我们会尽快修复。
2、提交死链接
但是肯定有很多不应该存在的错误页面,所以我们必须想办法获取这样一个页面的URL。获取方式主要有以下三种:
(1)百度站长工具--爬取异常--找不到页面--复制数据[更正:我们这里不需要提交死链接,百度站长工具自动提交死链接];
(2)当管理员手动删除页面或程序自动保存被删除页面的URL时;
(3)使用相关爬虫软件爬取整个站点获取死链接,比如Xenu。
然后把上面的数据合并删除重复的(excel表格可以实现去重,wps表格更容易操作),然后复制所有的url通过http状态批量查询工具查询【这个好/webspeed.aspx ],并删除非必要的 404 返回代码页。
然后将上面处理好的数据整理粘贴到网站根目录下的一个文档中,将文档地址提交到百度站长工具--网页爬取--死链接提交--添加新数据--填写死链接链接文件地址。
3、在机器人中阻止爬行
如果大量错误的网址有一定的规则,可以在robots文件中写一条规则,禁止蜘蛛抓取此类链接,但前提是一定要照顾好正常的页面,避免阻止规则误伤正常的页面,比如你的网站都是静态URL,那么如果错误链接收录?,则规则写成Disallow:/*?*,如果错误链接中有/id...html,则规则写成不允许:/*...*。
将规则添加到robots文件后,一定要到百度站长的robots工具进行验证,把指定的错误页面放进去看看是否封禁成功,再放入正常的页面看看是否被误封.
相关说明:
1、在百度站长工具中提交死链接之前,请确保提交的死链接数据中没有活链接。一旦有活链,就会显示提交失败,无法删除。
2、由于很多网站程序问题,很多打不开的页面返回码不是404,这是个大问题。比如打不开的页面返回码是301、200、500,如果是200,会导致网站中不同的url获取相同的内容。比如我的一个网站,社区的帖子被删除后,返回码是500,后来我发现了,马上处理。每个人都试图找出所有错误的 URL 格式,并将 HTTP 状态码设置为 404。
3、找到所有错误页面后,一定要寻找这些页面的URL相同的特征,并与正常页面的特征区分开来,将相应的规则写入robots文件,禁止蜘蛛爬取,即使你已经在网站上 长工具提交死链接,也建议禁止机器人爬取。
4、机器人只能解决蜘蛛不再抓取此类页面的问题,但无法解决删除已收录页面快照的问题。如果你的网站被黑了,被黑的页面被删除了,除了robots禁止被黑的页面外,这些页面也应该提交死链接。提交死链接是删除被黑页面快照的最快方法。返回搜狐,查看更多
网页抓取 加密html(修改现有DESDES算法进行匹配发现难度,费时费力来执行解密方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-04-04 03:11
这几天收到一个有数据的项目采集
通过对网站的初步分析,得到如下内容
1.网站是用.NET开发的
2.要抓取的内容是用DES加密的
虽然已经获得了前端javascript的加解密算法,但我们都知道,交互开发跨语言算法是相当困难的。原计划是修改现有的php DES算法,发现太难、费时费力。后来突然想到能不能在php中调用js脚本来处理,这就是这个文章phantomjs的重点。事实上,这很简单。第一个版本打开网页,直接执行解码方法,但是这种方法处理速度会变慢。毕竟有网页访问的过程,然后不知道能不能调用本地构建的网页进行同样的处理。,我在windows上测试过,是可行的,但是我还没有在liunx上测试过。
首先,构建一个本地网页很简单,就是一个引用解码脚本的空html文档,命名为Demo.html
Document
然后开始编写一个名为 Model.js 的 phantomjs 处理脚本
var page = require('webpage').create();
page.open('Demo.html', function (status) {
if(status !== 'success' ){
console.log('FAIL');
}else{
var a = '{keys}';
var b = '{encrypt}';
console.log(page.evaluate(function(c,d){
return jsdecrypt(c,d);
},a,b));
}
phantom.exit();
});
解密方法是通过phantomjs的api page.evaluate来执行的。原计划是直接通过命令行传参,结果发现不成功。猜测是加密字符串的大小超过了命令行的最大字符长度。所以只能通过php读取js文件,然后替换。
最后是php部分
//模板数据替换
$str=file_get_contents("Model.js");//打开文件
$str=str_replace("{keys}",$a,$str);
$str=str_replace("{encrypt}",$b,$str);
file_put_contents("Decode.js",$str);//把替换的内容写到js文件中
//解码操作
$command = "phantomjs Decode.js";
print_r (passthru($command)); //因为输出内容为多行所以使用passthru方法
最后说明一下,这个方法是调用第三方程序来处理。绝对不比原生直写算法快,但速度还是可以接受的。
随便说几句,这个模板可以直接套用。 查看全部
网页抓取 加密html(修改现有DESDES算法进行匹配发现难度,费时费力来执行解密方法)
这几天收到一个有数据的项目采集
通过对网站的初步分析,得到如下内容
1.网站是用.NET开发的
2.要抓取的内容是用DES加密的
虽然已经获得了前端javascript的加解密算法,但我们都知道,交互开发跨语言算法是相当困难的。原计划是修改现有的php DES算法,发现太难、费时费力。后来突然想到能不能在php中调用js脚本来处理,这就是这个文章phantomjs的重点。事实上,这很简单。第一个版本打开网页,直接执行解码方法,但是这种方法处理速度会变慢。毕竟有网页访问的过程,然后不知道能不能调用本地构建的网页进行同样的处理。,我在windows上测试过,是可行的,但是我还没有在liunx上测试过。
首先,构建一个本地网页很简单,就是一个引用解码脚本的空html文档,命名为Demo.html
Document
然后开始编写一个名为 Model.js 的 phantomjs 处理脚本
var page = require('webpage').create();
page.open('Demo.html', function (status) {
if(status !== 'success' ){
console.log('FAIL');
}else{
var a = '{keys}';
var b = '{encrypt}';
console.log(page.evaluate(function(c,d){
return jsdecrypt(c,d);
},a,b));
}
phantom.exit();
});
解密方法是通过phantomjs的api page.evaluate来执行的。原计划是直接通过命令行传参,结果发现不成功。猜测是加密字符串的大小超过了命令行的最大字符长度。所以只能通过php读取js文件,然后替换。
最后是php部分
//模板数据替换
$str=file_get_contents("Model.js");//打开文件
$str=str_replace("{keys}",$a,$str);
$str=str_replace("{encrypt}",$b,$str);
file_put_contents("Decode.js",$str);//把替换的内容写到js文件中
//解码操作
$command = "phantomjs Decode.js";
print_r (passthru($command)); //因为输出内容为多行所以使用passthru方法
最后说明一下,这个方法是调用第三方程序来处理。绝对不比原生直写算法快,但速度还是可以接受的。
随便说几句,这个模板可以直接套用。
网页抓取 加密html(本文主要包含html5游戏源码html,html5源码源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-02 10:03
本文主要收录html5游戏源码、html网站源码、html源码、源码之家html、html5源码等相关知识,教程希望对你的学习和工作有所帮助
");
我们先来看看需求。加密的目的是什么?什么级别的加密?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全,加密会被破解,混淆会被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越大,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的需要做这种源代码保护,需要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
前端不应该涉及泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,不需要牺牲用户体验来保护大量代码。
但是,一些前端代码涉及到最终用户的数据安全,此时应该努力保护数据。
接下来详细分析几种方法。
不要把敏感数据放在前端
这可能听起来像废话,但它真的很重要。
一些开发者将用户的密码明文存储在手机上,这是非常危险的。
一旦手机root,即使是原生开发也可能导致数据泄露。更不用说 HTML5 开发了。
更好的方法是在手机上存储令牌而不是密码。这里有一篇文章 文章 来介绍这一点。建议参与登录的开发人员仔细查看设计。
谈谈HTML5 APP的登录功能以及安全调用接口的方法
js、css压缩
压缩不是加密,也不是混淆。但是压缩后的js文件往往也有混淆的功能。
JS 和 CSS 压缩是很常见的技术。我们经常看到各种框架的文件名是 xxx.min.js 和 xxx.min.css。
使用合适的js和css压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。它只是有益的和无害的。
比较常用的混淆js的工具是yahoo的YUI混淆。在HBuilder中,点击菜单工具-插件安装,里面有YUI compress,可以压缩js和css。
如果 js 和 css 比较大,建议先压缩再发布。
HTML、js、css混淆
虽然压缩也可以混淆,但不是为了让别人看不懂。混淆真的是为了让人无法理解。
但这种混淆不如压缩有益无害,它会降低程序的执行性能。
有些开发者不想在解压分发包后直接看到源代码,所以此时可以使用混淆方案。
网上搜索HTML混淆,有很多资料和工具。
原理类似。js代码变成乱七八糟的字符串,然后用eval执行。HTML 代码变成了乱七八糟的字符串,并使用 document.write 或 innerHTML 执行它。CSS 也可以在 document.write 中动态编写。
这些工具是免费的和商业的,它们越商业化,就越难被去混淆。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具。
其实你也可以根据原理编写自己的混淆算法。
混淆也是多年的成熟技术。例如,谷歌在保护gmail的前端代码时,也受到了混淆的保护。
无论是压缩还是混淆,使用 grunt 进行发布都是一种不错的方式。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上和iOS 支持webkit 远程调试。在HBuilder教程中,也有关于如何使用chrome调试Android应用和safari调试iOS应用的教程。
在HBuilder开发的app中,manifest.json的plus-distribute下有一个debug标签,标记为false,然后打包。当这样的包在手机上运行时,webview会阻塞浏览器的远程调试请求。
如果要调试,则在打包之前将 debug 更改为 true。
当然,有些安卓的rom不是很规范,也不能妨碍调试。这是一个ROM错误。
专业的加密加固打包服务
由于Android的特殊性,存在针对apk的加固脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有一些专业公司如Ai Encryption,提供免费的基础安全服务和收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。 查看全部
网页抓取 加密html(本文主要包含html5游戏源码html,html5源码源码)
本文主要收录html5游戏源码、html网站源码、html源码、源码之家html、html5源码等相关知识,教程希望对你的学习和工作有所帮助
");
我们先来看看需求。加密的目的是什么?什么级别的加密?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全,加密会被破解,混淆会被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越大,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的需要做这种源代码保护,需要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
前端不应该涉及泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,不需要牺牲用户体验来保护大量代码。
但是,一些前端代码涉及到最终用户的数据安全,此时应该努力保护数据。
接下来详细分析几种方法。
不要把敏感数据放在前端
这可能听起来像废话,但它真的很重要。
一些开发者将用户的密码明文存储在手机上,这是非常危险的。
一旦手机root,即使是原生开发也可能导致数据泄露。更不用说 HTML5 开发了。
更好的方法是在手机上存储令牌而不是密码。这里有一篇文章 文章 来介绍这一点。建议参与登录的开发人员仔细查看设计。
谈谈HTML5 APP的登录功能以及安全调用接口的方法
js、css压缩
压缩不是加密,也不是混淆。但是压缩后的js文件往往也有混淆的功能。
JS 和 CSS 压缩是很常见的技术。我们经常看到各种框架的文件名是 xxx.min.js 和 xxx.min.css。
使用合适的js和css压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。它只是有益的和无害的。
比较常用的混淆js的工具是yahoo的YUI混淆。在HBuilder中,点击菜单工具-插件安装,里面有YUI compress,可以压缩js和css。
如果 js 和 css 比较大,建议先压缩再发布。
HTML、js、css混淆
虽然压缩也可以混淆,但不是为了让别人看不懂。混淆真的是为了让人无法理解。
但这种混淆不如压缩有益无害,它会降低程序的执行性能。
有些开发者不想在解压分发包后直接看到源代码,所以此时可以使用混淆方案。
网上搜索HTML混淆,有很多资料和工具。
原理类似。js代码变成乱七八糟的字符串,然后用eval执行。HTML 代码变成了乱七八糟的字符串,并使用 document.write 或 innerHTML 执行它。CSS 也可以在 document.write 中动态编写。
这些工具是免费的和商业的,它们越商业化,就越难被去混淆。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具。
其实你也可以根据原理编写自己的混淆算法。
混淆也是多年的成熟技术。例如,谷歌在保护gmail的前端代码时,也受到了混淆的保护。
无论是压缩还是混淆,使用 grunt 进行发布都是一种不错的方式。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上和iOS 支持webkit 远程调试。在HBuilder教程中,也有关于如何使用chrome调试Android应用和safari调试iOS应用的教程。
在HBuilder开发的app中,manifest.json的plus-distribute下有一个debug标签,标记为false,然后打包。当这样的包在手机上运行时,webview会阻塞浏览器的远程调试请求。
如果要调试,则在打包之前将 debug 更改为 true。
当然,有些安卓的rom不是很规范,也不能妨碍调试。这是一个ROM错误。
专业的加密加固打包服务
由于Android的特殊性,存在针对apk的加固脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有一些专业公司如Ai Encryption,提供免费的基础安全服务和收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。
网页抓取 加密html(一台教程全篇代码加密的操作流程及流程记录教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-02 10:02
顺序
我们都知道前端的html和js代码在浏览器上是可以看到的,所以如果遇到隐私意识很强的老板,就会突然接受一个代码加密要求。当你接受这个要求时,你是怎么做的?那么我希望我的这个博客可以帮助到你。
首先告诉你的老板,严格意义上的加密是不存在的,唯一能做到的就是对前端代码进行压缩和混淆,增加阅读难度。
本教程自始至终描述的是混淆代码以满足老板提出的加密要求的方法。
为了保证本教程真正有用,我将使用一个新的Windows系统从头开始演示,在此记录下操作过程供大家参考。也希望能帮助大家跳过一些坑。如果您遇到任何问题,请留言讨论。
安装 NodeJs
如果你还没有安装node,请按照教程进行,如果你已经安装了,请跳到下一节。
下载链接:
直接下载安装。安装过程是傻瓜式 的下一步。唯一可以改变的是安装位置。
安装完成后打开cmd命令行查看版本号确认是否安装成功。
安装插件
切换到项目根目录:
安装 gulp 插件包: npm install --save-dev gulp
效果如图:
别着急,还有很多包,按顺序一一刷:
npm install --save-dev del
npm install --save-dev gulp-concat
npm install --save-dev gulp-header
npm install --save-dev gulp-if
npm install --save-dev gulp-minify-css
npm install --save-dev gulp-htmlmin
npm install --save-dev gulp-rename
npm install --save-dev gulp-replace
npm install --save-dev gulp-uglify
npm install --save-dev gulp-babel
npm install --save-dev babel-preset-es2015
npm install --save-dev @babel/core
npm install --save-dev @babel/preset-env
防范措施
插件安装完成后,我们的前期工作就完成了。
我们会在项目目录中找到不止一个node_modules目录和package-lock.json文件,json文件就是我们的插件列表,node_modules目录就是我们安装的插件包。
index.html是我的主入口文件,src目录是我的项目中存放代码的目录,也就是我要压缩和加密构建的目录。
src中有3个子目录,controller存放独立的js处理前端业务逻辑,style存放css样式文件,view存放html页面。
在写脚本之前,我需要直截了当地告诉你,如果你的 JS 中有 ES6 语法,正常打包是行不通的,但我们前期工作也已经安装了工具包来处理这个问题,但仅限于处理单个 JS 文件.
如果在HTML代码中嵌入了JS,而JS中有ES6语法,则需要将JS代码提取出来单独制作一个JS,或者手动将ES6写法改为ES5。
总之,如果打包出错,很有可能是ES6语法引起的,其次是文件路径错误。
压缩JS
回到我们的项目根目录并创建一个具有固定文件名的 gulpfile.js 文件:
导入包:
var gulp = require('gulp');
var uglify = require('gulp-uglify');
var babel = require('gulp-babel');
var minifyCss = require("gulp-minify-css");
var htmlmin = require('gulp-htmlmin');
var header = require('gulp-header');
var del = require('del');
定义一个目标目录:
var destDir = './dist';
定义一个注释,因为我想对缩小代码的第一行做一点注释:
var note = ['/** 小样,看源码?想得美! */\n ', {js: ';'}];
监控任务:
gulp.task('minjs', function () {
//定义路径
var src = [
'./src/**/*.js'
];
gulp.src(src)
.pipe(babel({presets: ["@babel/env"], plugins: []}))//es6转es5
.pipe(uglify())//压缩
.pipe(header.apply(null, note))//添加头部注释
.pipe(gulp.dest(destDir));//将压缩后的内容输出到目标目录
});
minjs 是我们自定义的任务名称,也就是说我们在命令行输入 gulp minjs 命令,就会执行这段代码。
如果只是输入 gulp 命令,它会自动找到名为 default 的任务。
var src = ['./src/**/*.js']; 是我们要抓取的文件,使用通配符,你几乎肯定需要这样写:
var src = [
'./src/**/*.js'
, '!./src/config.js'
, '!./src/lib/extend/*.js'
];
感叹号表示排除。
这里说明destDir只会替换通配符前的目录路径。比如我这里的destDir定义为./dist,那么./src/controller/admin.js的压缩路径就是./dist/controller/admin.js。
好的,打开命令行输入命令:gulp minjs
检查项目,js文件已经压缩成功。
压缩 CSS
任务监控和压缩JS没有区别,只是使用gulp-minify-css插件来完成压缩任务。
gulp.task('mincss', function () {
var src = [
'./src/style/*.css'
];
gulp.src(src).pipe(minifyCss()).pipe(gulp.dest(destDir + '/style'));
});
输入命令:gulp mincss
查看项目也没有问题:
非常聪明,它会为您删除 css 中的评论。
压缩 HTML
压缩后的 HTML 可以传递多个参数来指定相应的行为:
gulp.task('minhtml', function () {
var options = {
removeComments: true,//清除HTML注释
collapseWhitespace: true,//折叠空白
minifyJS: true,//压缩页面JS
minifyCSS: true//压缩页面CSS
};
var src = [
'./src/views/**/*',
];
gulp.src(src)
.pipe(htmlmin(options))
.pipe(gulp.dest(destDir + '/views'));
});
更多参数请看这里:
输入命令:gulp minhtml
压缩的 HTML:
全部压缩成一行,文件中的css和js也被压缩了。
一站式处理
但是我们不能总是在一个包中运行多个命令。太麻烦了 现在我们将把这些任务整合并组合成一个任务。
我们创建一个任务对象,将每个任务的内容放入其中,并添加一个清理 dist 目录的方法,以及一个复制未压缩文件的 move 方法。
//任务列表
var task = {
//清理dist目录
clear:function () {
del(['./dist/*']);
},
minjs:function () {
//定义路径
var src = [
'./src/**/*.js'
];
gulp.src(src)
.pipe(babel({presets: ["@babel/env"], plugins: []}))//es6转es5
.pipe(uglify())//压缩
.pipe(header.apply(null, note))//添加头部注释
.pipe(gulp.dest(destDir));
},
mincss:function () {
var src = [
'./src/style/*.css'
];
gulp.src(src).pipe(minifyCss()).pipe(gulp.dest(destDir + '/style'));
},
minhtml:function () {
var options = {
removeComments: true,//清除HTML注释
collapseWhitespace: true,//折叠空白
minifyJS: true,//压缩页面JS 如果你确信你的HTML页面中的js不包含有es6语法,那么可以压缩js 否则还是得把js抽离成单独的文件进行压缩
minifyCSS: true//压缩页面CSS
};
var src = [
'./src/**/*',
];
gulp.src(src)
.pipe(htmlmin(options))
.pipe(gulp.dest(destDir));
},
move: function () {
//复制文件夹 没有被压缩的文件就在这里复制
gulp.src('./src/**/*.png').pipe(gulp.dest(destDir));
}
};
我们在压缩js的时候说过,如果只是一个gulp命令,它会找到一个名为default的task,我们在default task中遍历task对象,依次执行方法。
gulp.task('default', function () {
for (var key in task) {
task[key]();
}
});
这样,我们只需要一个 gulp 命令,整个构建过程就完成了。
同时,我们将单个任务指向任务中对应的方法:
gulp.task('clear',task.clear);
gulp.task('minjs',task.minjs);
gulp.task('mincss',task.mincss);
gulp.task('minhtml',task.minhtml);
gulp.task('move',task.move);
无论是处理单个环节还是整个构建过程,我们都能轻松完成。
最后,感谢阅读。PS:欢迎关注,有粉丝必回。 查看全部
网页抓取 加密html(一台教程全篇代码加密的操作流程及流程记录教程)
顺序
我们都知道前端的html和js代码在浏览器上是可以看到的,所以如果遇到隐私意识很强的老板,就会突然接受一个代码加密要求。当你接受这个要求时,你是怎么做的?那么我希望我的这个博客可以帮助到你。
首先告诉你的老板,严格意义上的加密是不存在的,唯一能做到的就是对前端代码进行压缩和混淆,增加阅读难度。
本教程自始至终描述的是混淆代码以满足老板提出的加密要求的方法。
为了保证本教程真正有用,我将使用一个新的Windows系统从头开始演示,在此记录下操作过程供大家参考。也希望能帮助大家跳过一些坑。如果您遇到任何问题,请留言讨论。
安装 NodeJs
如果你还没有安装node,请按照教程进行,如果你已经安装了,请跳到下一节。
下载链接:
直接下载安装。安装过程是傻瓜式 的下一步。唯一可以改变的是安装位置。
安装完成后打开cmd命令行查看版本号确认是否安装成功。
安装插件
切换到项目根目录:
安装 gulp 插件包: npm install --save-dev gulp
效果如图:
别着急,还有很多包,按顺序一一刷:
npm install --save-dev del
npm install --save-dev gulp-concat
npm install --save-dev gulp-header
npm install --save-dev gulp-if
npm install --save-dev gulp-minify-css
npm install --save-dev gulp-htmlmin
npm install --save-dev gulp-rename
npm install --save-dev gulp-replace
npm install --save-dev gulp-uglify
npm install --save-dev gulp-babel
npm install --save-dev babel-preset-es2015
npm install --save-dev @babel/core
npm install --save-dev @babel/preset-env
防范措施
插件安装完成后,我们的前期工作就完成了。
我们会在项目目录中找到不止一个node_modules目录和package-lock.json文件,json文件就是我们的插件列表,node_modules目录就是我们安装的插件包。
index.html是我的主入口文件,src目录是我的项目中存放代码的目录,也就是我要压缩和加密构建的目录。
src中有3个子目录,controller存放独立的js处理前端业务逻辑,style存放css样式文件,view存放html页面。
在写脚本之前,我需要直截了当地告诉你,如果你的 JS 中有 ES6 语法,正常打包是行不通的,但我们前期工作也已经安装了工具包来处理这个问题,但仅限于处理单个 JS 文件.
如果在HTML代码中嵌入了JS,而JS中有ES6语法,则需要将JS代码提取出来单独制作一个JS,或者手动将ES6写法改为ES5。
总之,如果打包出错,很有可能是ES6语法引起的,其次是文件路径错误。
压缩JS
回到我们的项目根目录并创建一个具有固定文件名的 gulpfile.js 文件:
导入包:
var gulp = require('gulp');
var uglify = require('gulp-uglify');
var babel = require('gulp-babel');
var minifyCss = require("gulp-minify-css");
var htmlmin = require('gulp-htmlmin');
var header = require('gulp-header');
var del = require('del');
定义一个目标目录:
var destDir = './dist';
定义一个注释,因为我想对缩小代码的第一行做一点注释:
var note = ['/** 小样,看源码?想得美! */\n ', {js: ';'}];
监控任务:
gulp.task('minjs', function () {
//定义路径
var src = [
'./src/**/*.js'
];
gulp.src(src)
.pipe(babel({presets: ["@babel/env"], plugins: []}))//es6转es5
.pipe(uglify())//压缩
.pipe(header.apply(null, note))//添加头部注释
.pipe(gulp.dest(destDir));//将压缩后的内容输出到目标目录
});
minjs 是我们自定义的任务名称,也就是说我们在命令行输入 gulp minjs 命令,就会执行这段代码。
如果只是输入 gulp 命令,它会自动找到名为 default 的任务。
var src = ['./src/**/*.js']; 是我们要抓取的文件,使用通配符,你几乎肯定需要这样写:
var src = [
'./src/**/*.js'
, '!./src/config.js'
, '!./src/lib/extend/*.js'
];
感叹号表示排除。
这里说明destDir只会替换通配符前的目录路径。比如我这里的destDir定义为./dist,那么./src/controller/admin.js的压缩路径就是./dist/controller/admin.js。
好的,打开命令行输入命令:gulp minjs
检查项目,js文件已经压缩成功。
压缩 CSS
任务监控和压缩JS没有区别,只是使用gulp-minify-css插件来完成压缩任务。
gulp.task('mincss', function () {
var src = [
'./src/style/*.css'
];
gulp.src(src).pipe(minifyCss()).pipe(gulp.dest(destDir + '/style'));
});
输入命令:gulp mincss
查看项目也没有问题:
非常聪明,它会为您删除 css 中的评论。
压缩 HTML
压缩后的 HTML 可以传递多个参数来指定相应的行为:
gulp.task('minhtml', function () {
var options = {
removeComments: true,//清除HTML注释
collapseWhitespace: true,//折叠空白
minifyJS: true,//压缩页面JS
minifyCSS: true//压缩页面CSS
};
var src = [
'./src/views/**/*',
];
gulp.src(src)
.pipe(htmlmin(options))
.pipe(gulp.dest(destDir + '/views'));
});
更多参数请看这里:
输入命令:gulp minhtml
压缩的 HTML:
全部压缩成一行,文件中的css和js也被压缩了。
一站式处理
但是我们不能总是在一个包中运行多个命令。太麻烦了 现在我们将把这些任务整合并组合成一个任务。
我们创建一个任务对象,将每个任务的内容放入其中,并添加一个清理 dist 目录的方法,以及一个复制未压缩文件的 move 方法。
//任务列表
var task = {
//清理dist目录
clear:function () {
del(['./dist/*']);
},
minjs:function () {
//定义路径
var src = [
'./src/**/*.js'
];
gulp.src(src)
.pipe(babel({presets: ["@babel/env"], plugins: []}))//es6转es5
.pipe(uglify())//压缩
.pipe(header.apply(null, note))//添加头部注释
.pipe(gulp.dest(destDir));
},
mincss:function () {
var src = [
'./src/style/*.css'
];
gulp.src(src).pipe(minifyCss()).pipe(gulp.dest(destDir + '/style'));
},
minhtml:function () {
var options = {
removeComments: true,//清除HTML注释
collapseWhitespace: true,//折叠空白
minifyJS: true,//压缩页面JS 如果你确信你的HTML页面中的js不包含有es6语法,那么可以压缩js 否则还是得把js抽离成单独的文件进行压缩
minifyCSS: true//压缩页面CSS
};
var src = [
'./src/**/*',
];
gulp.src(src)
.pipe(htmlmin(options))
.pipe(gulp.dest(destDir));
},
move: function () {
//复制文件夹 没有被压缩的文件就在这里复制
gulp.src('./src/**/*.png').pipe(gulp.dest(destDir));
}
};
我们在压缩js的时候说过,如果只是一个gulp命令,它会找到一个名为default的task,我们在default task中遍历task对象,依次执行方法。
gulp.task('default', function () {
for (var key in task) {
task[key]();
}
});
这样,我们只需要一个 gulp 命令,整个构建过程就完成了。
同时,我们将单个任务指向任务中对应的方法:
gulp.task('clear',task.clear);
gulp.task('minjs',task.minjs);
gulp.task('mincss',task.mincss);
gulp.task('minhtml',task.minhtml);
gulp.task('move',task.move);
无论是处理单个环节还是整个构建过程,我们都能轻松完成。
最后,感谢阅读。PS:欢迎关注,有粉丝必回。
网页抓取 加密html(优化网站链接要做好GoogleSEO优化,链接优化也是一个很重要的SEO操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-30 05:19
优化网站链接需要谷歌SEO优化,链接优化也是一项非常重要的SEO操作。除了网站内部和外部链接,友好的链接也会影响你的谷歌排名。做内部链接时,要注意链接页面和锚文本的相关性;在做外链的时候,要注意外链的数量、质量和结构。做好网站的内链,一是可以有效引导谷歌很好地抓取你的网站内容,二是可以引导网站的权重提升某些页面以提高其在 Google 中的排名。
加强网站安全性搜索引擎一直秉承“用户至上”的原则,谷歌希望为用户提供搜索和浏览体验,所以网站的安全性也是谷歌非常重视的一个方面对的重要性。近年来,Google 一直在大力提倡站长对 网站 使用 https 加密。Chrome浏览器的地址栏会将加密的网站标记为绿色的小锁;如果没有https加密的网站,Chrome会发出不安全警告,谷歌对这个网站信任度降低,进而影响网站排名。
搜索引擎优化,也称为SEO,即Search Engine Optimization,是一种通过分析各种搜索引擎如何进行搜索,如何爬取互联网页面,以及如何确定具体关键词的方法。搜索引擎。对搜索结果进行排名的技术。搜索引擎利用搜索者容易引用的方法,有针对性地优化网站,提高网站在搜索引擎中的自然排名,吸引更多用户访问网站,提高网站的流量将提升网站的销售和宣传能力,从而提升网站的品牌效应。
搜索引擎优化技术主要有两种类型:黑帽和白帽。通过欺骗的方式欺骗搜索引擎和访问者,最终会受到搜索引擎的惩罚,被称为黑帽,例如隐藏关键字、创建大量元词、alt标签等。搜索引擎通过形式化技术接受的SEO技术和方法被称为白帽。
从长远来看,相对于关键词的推广,SEO需要做的是保持网站的进程,网站具有关键词的优点,不需要为用户按点击付费,所以比PPC便宜很多。此外,搜索引擎优化可以忽略搜索引擎之间的独立性。即使只优化了一个搜索引擎,网站在其他搜索引擎中的排名也会相应提升,达到关键词的水平,可以达到推广中重复付费的效果。
稳定性强
企业网站进行搜索引擎优化后,只要网站维护得当,它在搜索引擎中排名的稳定性也很强,很长一段时间都不会改变。
网站在结构方面,尽量避免使用框架结构,尽量不要使用导航栏中的FLASH按钮。首先要注意网站首页的设计,因为网站首页被搜索引擎检测到的概率要比其他网页大很多。通常网站的首页文件应该放在网站的根目录下,因为根目录下的检索速度很快。其次要注意网站的层级(即子目录)不能太多,目录不能超过2级,详细目录不能超过4级。在网站导航之后,尽量使用纯文本进行导航,因为文字比图片表达的信息更多。
搜索引擎使用专有的蜘蛛程序查找每个网页上的 HTML 代码,当网页上有链接时,它会一一搜索,直到没有任何页面的链接。蜘蛛需要访问所有的页面并且需要很长时间,所以网站的导航需要蜘蛛容易索引收录。根据自己的网站结构,可以制作一个网站地图sitemap.html,列出web地图中网站的所有子栏的链接,把所有文件放在网站 放在网站 的根目录下。网站地图增加了搜索引擎的友好性,并允许蜘蛛访问整个站点上的所有页面和部分。
做过搜索引擎优化排名的站长都知道,排名上下波动是正常的。例如,如果您为客户优化网站,当您在第一页让客户接受时,第二页将转到第二页。这种情况有很多次。搜索引擎不断改变他们的排名算法。这也增加了搜索引擎优化的难度。 查看全部
网页抓取 加密html(优化网站链接要做好GoogleSEO优化,链接优化也是一个很重要的SEO操作)
优化网站链接需要谷歌SEO优化,链接优化也是一项非常重要的SEO操作。除了网站内部和外部链接,友好的链接也会影响你的谷歌排名。做内部链接时,要注意链接页面和锚文本的相关性;在做外链的时候,要注意外链的数量、质量和结构。做好网站的内链,一是可以有效引导谷歌很好地抓取你的网站内容,二是可以引导网站的权重提升某些页面以提高其在 Google 中的排名。
加强网站安全性搜索引擎一直秉承“用户至上”的原则,谷歌希望为用户提供搜索和浏览体验,所以网站的安全性也是谷歌非常重视的一个方面对的重要性。近年来,Google 一直在大力提倡站长对 网站 使用 https 加密。Chrome浏览器的地址栏会将加密的网站标记为绿色的小锁;如果没有https加密的网站,Chrome会发出不安全警告,谷歌对这个网站信任度降低,进而影响网站排名。
搜索引擎优化,也称为SEO,即Search Engine Optimization,是一种通过分析各种搜索引擎如何进行搜索,如何爬取互联网页面,以及如何确定具体关键词的方法。搜索引擎。对搜索结果进行排名的技术。搜索引擎利用搜索者容易引用的方法,有针对性地优化网站,提高网站在搜索引擎中的自然排名,吸引更多用户访问网站,提高网站的流量将提升网站的销售和宣传能力,从而提升网站的品牌效应。
搜索引擎优化技术主要有两种类型:黑帽和白帽。通过欺骗的方式欺骗搜索引擎和访问者,最终会受到搜索引擎的惩罚,被称为黑帽,例如隐藏关键字、创建大量元词、alt标签等。搜索引擎通过形式化技术接受的SEO技术和方法被称为白帽。
从长远来看,相对于关键词的推广,SEO需要做的是保持网站的进程,网站具有关键词的优点,不需要为用户按点击付费,所以比PPC便宜很多。此外,搜索引擎优化可以忽略搜索引擎之间的独立性。即使只优化了一个搜索引擎,网站在其他搜索引擎中的排名也会相应提升,达到关键词的水平,可以达到推广中重复付费的效果。
稳定性强
企业网站进行搜索引擎优化后,只要网站维护得当,它在搜索引擎中排名的稳定性也很强,很长一段时间都不会改变。
网站在结构方面,尽量避免使用框架结构,尽量不要使用导航栏中的FLASH按钮。首先要注意网站首页的设计,因为网站首页被搜索引擎检测到的概率要比其他网页大很多。通常网站的首页文件应该放在网站的根目录下,因为根目录下的检索速度很快。其次要注意网站的层级(即子目录)不能太多,目录不能超过2级,详细目录不能超过4级。在网站导航之后,尽量使用纯文本进行导航,因为文字比图片表达的信息更多。
搜索引擎使用专有的蜘蛛程序查找每个网页上的 HTML 代码,当网页上有链接时,它会一一搜索,直到没有任何页面的链接。蜘蛛需要访问所有的页面并且需要很长时间,所以网站的导航需要蜘蛛容易索引收录。根据自己的网站结构,可以制作一个网站地图sitemap.html,列出web地图中网站的所有子栏的链接,把所有文件放在网站 放在网站 的根目录下。网站地图增加了搜索引擎的友好性,并允许蜘蛛访问整个站点上的所有页面和部分。
做过搜索引擎优化排名的站长都知道,排名上下波动是正常的。例如,如果您为客户优化网站,当您在第一页让客户接受时,第二页将转到第二页。这种情况有很多次。搜索引擎不断改变他们的排名算法。这也增加了搜索引擎优化的难度。
网页抓取 加密html(什么叫批批HTML加密器是一个简易便捷的网页加密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 22:04
Batch Html Encryptor是一款网页加密专用工具,可以辅助网站站长对html源文件进行加密。它不仅可以对所有网页的源代码进行加密,还可以对网页的部分源代码进行加密。加密网页只能使用电脑浏览器开发演示文稿时才能看到!
【软件详细介绍】
Batch Html Encryptor 是一个简单方便的工具,用于加密大批量的 Web 文档。它可以帮助您将网页转换为不可读的代码!
如何保护自己的 HTML网站 内容一直是新手站长的一大难题。Batch Html Encryptor 可以帮助 网站 站长加密html源文件。加密后,只有计算机浏览器才能理解输出。别人不知道源文件根本不能改。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一个专用工具,用于维护您的 html 编码和脚本编码,将它们转换为空灵的文字。在解决多文档,出色的工作,所以它会节省你做这项繁琐工作的时间。现在幸运地适用于UNIC ODE,这意味着批处理HTML加密器工作在比其他加密程序更强的加密多语言表达HTML文档中。
迷你系统要求
微软公司 Windows 95/98/Me/NT 4.0/2000/XP;
英特尔 586 32MB 内存;
6 MB 可用存储空间 查看全部
网页抓取 加密html(什么叫批批HTML加密器是一个简易便捷的网页加密)
Batch Html Encryptor是一款网页加密专用工具,可以辅助网站站长对html源文件进行加密。它不仅可以对所有网页的源代码进行加密,还可以对网页的部分源代码进行加密。加密网页只能使用电脑浏览器开发演示文稿时才能看到!
【软件详细介绍】
Batch Html Encryptor 是一个简单方便的工具,用于加密大批量的 Web 文档。它可以帮助您将网页转换为不可读的代码!
如何保护自己的 HTML网站 内容一直是新手站长的一大难题。Batch Html Encryptor 可以帮助 网站 站长加密html源文件。加密后,只有计算机浏览器才能理解输出。别人不知道源文件根本不能改。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一个专用工具,用于维护您的 html 编码和脚本编码,将它们转换为空灵的文字。在解决多文档,出色的工作,所以它会节省你做这项繁琐工作的时间。现在幸运地适用于UNIC ODE,这意味着批处理HTML加密器工作在比其他加密程序更强的加密多语言表达HTML文档中。
迷你系统要求
微软公司 Windows 95/98/Me/NT 4.0/2000/XP;
英特尔 586 32MB 内存;
6 MB 可用存储空间
网页抓取 加密html(本文将用JavaScript实现两个颇有技术含量的功能:压缩图片、加密图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-27 05:13
本文将使用 JavaScript 实现两个相当技术性的功能:压缩图片、加密图片。
开门见山:
一、压缩图像
压缩原理:
将图像读入画布,并使用画布的 toDataURL 方法对图像进行 base64 处理。在此过程中,您可以设置质量值,即图像质量值。取值在0.1 到1 之间,取值越小,压缩率越高。
完整代码:
压缩图像:
运行结果:
压缩率
如上图所示,压缩后的图片大小为28KB,而原创文件大小则超过400KB:
可以看出压缩效果还是很不错的。
二、加密图片
上面提到的图像压缩是一项非常实用的技术。下一步是本文的重点,展示一个奇怪的技巧:图像加密。
我们之所以说压缩和图像加密,是因为图像加密是在前面的压缩技术的基础上完成的。
在上面的代码中,toDataURL 生成图像的 base64 编码。
Base64 编码必须完整且正确,才能正确显示图片。
而且只要对这个编码稍加修改,哪怕只改变一个字符,都会导致图片无法正常显示。
然后,在代码中的某个位置添加一个字符,达到破坏正确代码,实现加密的效果:
运行效果,输出加密后的base64编码:
做一个测试:
效果如下,图片无法正常显示。
然后,将达到以下效果:
网页中用img的src引入了加密的base64字符,此时图片无法显示。然后,就可以输入密码了,当密码正确时,解密base64字符,让图片正常显示。
输入密码:
密码正确,解密并显示图片:
源代码:
网页中还有其他几个元素:
加密后的base64编码存储在input中,即上面js代码函数生成并加密的内容;
img 用于显示解密后的图像;还有一个按钮,单击时会调用解密功能。
可能有人发现了,虽然图片编码已经加密,加了密码保护,但是只要查看网页源代码就可以知道密码,完全没有加密的作用。
到目前为止,问题确实存在。所以,更进一步:
可以看到密码,因为javascript代码是透明的。然后,解密后的js代码必须加密。加密后,密码将不可见。
使用 JShaman 对 JS 代码进行混淆和加密:
并在 JShaman 的配置中勾选“字符串加密”:
加密后的代码根本找不到之前的密码字符:
这样就实现了完整的图像加密:将图像加密存储在单独的html中,便于携带、存储和传输。内容已加密,密码已加密。只有知道密码的人才能看到图片。 查看全部
网页抓取 加密html(本文将用JavaScript实现两个颇有技术含量的功能:压缩图片、加密图片)
本文将使用 JavaScript 实现两个相当技术性的功能:压缩图片、加密图片。
开门见山:
一、压缩图像
压缩原理:
将图像读入画布,并使用画布的 toDataURL 方法对图像进行 base64 处理。在此过程中,您可以设置质量值,即图像质量值。取值在0.1 到1 之间,取值越小,压缩率越高。
完整代码:
压缩图像:
运行结果:
压缩率
如上图所示,压缩后的图片大小为28KB,而原创文件大小则超过400KB:
可以看出压缩效果还是很不错的。
二、加密图片
上面提到的图像压缩是一项非常实用的技术。下一步是本文的重点,展示一个奇怪的技巧:图像加密。
我们之所以说压缩和图像加密,是因为图像加密是在前面的压缩技术的基础上完成的。
在上面的代码中,toDataURL 生成图像的 base64 编码。
Base64 编码必须完整且正确,才能正确显示图片。
而且只要对这个编码稍加修改,哪怕只改变一个字符,都会导致图片无法正常显示。
然后,在代码中的某个位置添加一个字符,达到破坏正确代码,实现加密的效果:
运行效果,输出加密后的base64编码:
做一个测试:
效果如下,图片无法正常显示。
然后,将达到以下效果:
网页中用img的src引入了加密的base64字符,此时图片无法显示。然后,就可以输入密码了,当密码正确时,解密base64字符,让图片正常显示。
输入密码:
密码正确,解密并显示图片:
源代码:
网页中还有其他几个元素:
加密后的base64编码存储在input中,即上面js代码函数生成并加密的内容;
img 用于显示解密后的图像;还有一个按钮,单击时会调用解密功能。
可能有人发现了,虽然图片编码已经加密,加了密码保护,但是只要查看网页源代码就可以知道密码,完全没有加密的作用。
到目前为止,问题确实存在。所以,更进一步:
可以看到密码,因为javascript代码是透明的。然后,解密后的js代码必须加密。加密后,密码将不可见。
使用 JShaman 对 JS 代码进行混淆和加密:
并在 JShaman 的配置中勾选“字符串加密”:
加密后的代码根本找不到之前的密码字符:
这样就实现了完整的图像加密:将图像加密存储在单独的html中,便于携带、存储和传输。内容已加密,密码已加密。只有知道密码的人才能看到图片。
网页抓取 加密html( 网页版恰鹿导航有收录可直接搜索pdf24PDF页面、OCR功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-26 10:00
网页版恰鹿导航有收录可直接搜索pdf24PDF页面、OCR功能)
这是一款来自德国公司的pdf工具,收录了几乎所有的PDF处理工具,而且完全免费,没有任何广告,支持网页版和本地客户端。
该软件允许用户自己创建pdf文档,也支持将任何打印的文档转换成pdf格式,还可以设置转换后的pdf文件的质量和大小,以及给pdf添加签名、水印,甚至还可以集成好使用截图功能。使用此软件可以从几乎每个 Windows 应用程序创建 PDF 文件,以及重新排序页面、合并、拆分和密码保护您在使用中的现有 PDF 文件,适用于 winxp\vista\win7\win8 等系统。另外,pdf24不仅好用,界面布局也非常独特,还具备抓屏、抓摄像头图像等功能。可以直接将文件拖放到本软件主窗口的编辑区,pdf24会自动转换为pdf格式,甚至支持截屏或图片直接转换成pdf格式。最后需要注意的是,用户进入软件后,整个软件都有中文界面,可以让你更好的使用软件中的所有功能,从而更好的满足中国人的需求。
共有24个主要功能
1、PDF 合并、拆分、裁剪、拼合、旋转、页面排序;
2、PDF压缩、加密、解密;
3、将PDF转换为Word、PPT、Excel、图片、文本、HTML,并将这些文件反转为PDF;
4、删除或提取PDF页面,从PDF文件中提取图片;
5、为PDF添加水印、页码、注释;
6、PDF文本识别,OCR功能;
7、等一下,下载它自己看看。
软件下载:
网页版奇路导航有收录可以直接搜索pdf24 查看全部
网页抓取 加密html(
网页版恰鹿导航有收录可直接搜索pdf24PDF页面、OCR功能)
这是一款来自德国公司的pdf工具,收录了几乎所有的PDF处理工具,而且完全免费,没有任何广告,支持网页版和本地客户端。
该软件允许用户自己创建pdf文档,也支持将任何打印的文档转换成pdf格式,还可以设置转换后的pdf文件的质量和大小,以及给pdf添加签名、水印,甚至还可以集成好使用截图功能。使用此软件可以从几乎每个 Windows 应用程序创建 PDF 文件,以及重新排序页面、合并、拆分和密码保护您在使用中的现有 PDF 文件,适用于 winxp\vista\win7\win8 等系统。另外,pdf24不仅好用,界面布局也非常独特,还具备抓屏、抓摄像头图像等功能。可以直接将文件拖放到本软件主窗口的编辑区,pdf24会自动转换为pdf格式,甚至支持截屏或图片直接转换成pdf格式。最后需要注意的是,用户进入软件后,整个软件都有中文界面,可以让你更好的使用软件中的所有功能,从而更好的满足中国人的需求。
共有24个主要功能
1、PDF 合并、拆分、裁剪、拼合、旋转、页面排序;
2、PDF压缩、加密、解密;
3、将PDF转换为Word、PPT、Excel、图片、文本、HTML,并将这些文件反转为PDF;
4、删除或提取PDF页面,从PDF文件中提取图片;
5、为PDF添加水印、页码、注释;
6、PDF文本识别,OCR功能;
7、等一下,下载它自己看看。
软件下载:
网页版奇路导航有收录可以直接搜索pdf24
网页抓取 加密html(超强php程序的反编译工具Windows7及vista系统反馈问题汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-26 00:12
超级php程序的反编译工具
Windows7和vista系统都可以,但是需要去掉UAC,或者以管理员权限运行主程序。如无意外,黑刀Dezender 5.0的三个解密内核版本将是最终版本。除非出现新的解密内核,否则以后不会更新,任何关于Zend解密问题的问题请不要加我QQ咨询!感谢各位黑刀迷的关注,期待我的其他作品。谢谢!反馈问题总结:1、很多朋友说下载最新版本后无法解决问题,因为把程序放在桌面或者Program Files目录下。大家一定要记住,不要将Black Knife Dezender的主程序和需要解密的PHP文件放在目录名收录空格的目录中,如桌面、Program Files目录等,但目录名不能收录空格,它可以收录英语吗?期间,以免程序把目录当成文件,导致无法解密的情况。还有一种可能是加密后的PHP文件被最新版本的Zend加密了,所以黑刀Dezender解决不了。2、解密后的文件有“乱码”:这通常是因为PHP程序在加密时使用了混淆函数,而使用的函数没有被Dezender识别,所以函数的一部分就变成了“乱码”。
3、网友“李向阳”问:“我解压的文件可以看,但是有很多很基础的语法问题,不知道怎么回事!” 对于这个典型的问题,我只能回答它是解密的。文件无法 100% 还原为原创未加密文件。在遇到需要手动修复代码时,要求 Dezender 的用户具备相应的 PHP 编程知识。如果不可用?找书找资料。哈哈。4、如果出现如下错误提示:“无法在动态链接库php5ts.dll上确定程序输入点”,说明dezender与原PHP环境冲突,可以考虑卸载原PHP环境,或安装虚拟机,在虚拟机上使用 dezender。如果它不起作用,请尝试另一台计算机。哈哈。虚拟机下载地址: 重要声明:黑刀Dezender本身只是一个集成工具。主程序其实只是一个用Delphi开发的GUI界面shell程序。核心解密函数采集自网上。我所做的Shell编程只是在Dezender原创解密内核版本的功能基础上开发了一个基于Windows的用户界面,使用户可以在原创的“DOS”环境下实现Windows的各种应用功能。关于加密和保护自己的PHP程序的问题:一种类似于微盾加密的加密方式,可以混淆函数和变量。正式名称是“PHPlockit”。微盾的PHP加密专家也有类似的功能,但似乎程序不能正确。跑步。
目前,在我开发新版解密工具之前,据我所知,能手动解密“类似microshield的加密混淆函数和变量”的人,除了我之外,已经不多了。你可以试试看。其他相对安全的加密方式如Ioncube也可以使用,但国内支持这种加密方式的虚拟主机并不多。如果是独立服务器,可以考虑。而Zend的混淆功能也是目前还不能完全解决的问题。在开发自己的 PHP 程序时,可以使用较长的自定义函数名和变量名,这样即使程序被解密,Dezender 也无法正确识别明文。就其本身而言,由于函数和变量已被混淆,
立即下载 查看全部
网页抓取 加密html(超强php程序的反编译工具Windows7及vista系统反馈问题汇总)
超级php程序的反编译工具
Windows7和vista系统都可以,但是需要去掉UAC,或者以管理员权限运行主程序。如无意外,黑刀Dezender 5.0的三个解密内核版本将是最终版本。除非出现新的解密内核,否则以后不会更新,任何关于Zend解密问题的问题请不要加我QQ咨询!感谢各位黑刀迷的关注,期待我的其他作品。谢谢!反馈问题总结:1、很多朋友说下载最新版本后无法解决问题,因为把程序放在桌面或者Program Files目录下。大家一定要记住,不要将Black Knife Dezender的主程序和需要解密的PHP文件放在目录名收录空格的目录中,如桌面、Program Files目录等,但目录名不能收录空格,它可以收录英语吗?期间,以免程序把目录当成文件,导致无法解密的情况。还有一种可能是加密后的PHP文件被最新版本的Zend加密了,所以黑刀Dezender解决不了。2、解密后的文件有“乱码”:这通常是因为PHP程序在加密时使用了混淆函数,而使用的函数没有被Dezender识别,所以函数的一部分就变成了“乱码”。
3、网友“李向阳”问:“我解压的文件可以看,但是有很多很基础的语法问题,不知道怎么回事!” 对于这个典型的问题,我只能回答它是解密的。文件无法 100% 还原为原创未加密文件。在遇到需要手动修复代码时,要求 Dezender 的用户具备相应的 PHP 编程知识。如果不可用?找书找资料。哈哈。4、如果出现如下错误提示:“无法在动态链接库php5ts.dll上确定程序输入点”,说明dezender与原PHP环境冲突,可以考虑卸载原PHP环境,或安装虚拟机,在虚拟机上使用 dezender。如果它不起作用,请尝试另一台计算机。哈哈。虚拟机下载地址: 重要声明:黑刀Dezender本身只是一个集成工具。主程序其实只是一个用Delphi开发的GUI界面shell程序。核心解密函数采集自网上。我所做的Shell编程只是在Dezender原创解密内核版本的功能基础上开发了一个基于Windows的用户界面,使用户可以在原创的“DOS”环境下实现Windows的各种应用功能。关于加密和保护自己的PHP程序的问题:一种类似于微盾加密的加密方式,可以混淆函数和变量。正式名称是“PHPlockit”。微盾的PHP加密专家也有类似的功能,但似乎程序不能正确。跑步。
目前,在我开发新版解密工具之前,据我所知,能手动解密“类似microshield的加密混淆函数和变量”的人,除了我之外,已经不多了。你可以试试看。其他相对安全的加密方式如Ioncube也可以使用,但国内支持这种加密方式的虚拟主机并不多。如果是独立服务器,可以考虑。而Zend的混淆功能也是目前还不能完全解决的问题。在开发自己的 PHP 程序时,可以使用较长的自定义函数名和变量名,这样即使程序被解密,Dezender 也无法正确识别明文。就其本身而言,由于函数和变量已被混淆,
立即下载
网页抓取 加密html(本文实例讲述了JS加密插件CryptoJS实现AES加密操作操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-23 03:05
本文章主要介绍JS加密插件CryptoJS如何实现AES加密操作,具有一定的参考价值。有兴趣的朋友可以参考一下。我希望您在阅读此文章 后会有所收获。下面就让小编带大家一探究竟。
js的作用是什么
1、能够在 HTML 页面中嵌入动态文本。2、响应浏览器事件。3、读取和写入 HTML 元素。4、在将数据提交到服务器之前验证数据。5、检测访问者的浏览器信息。6、控制 cookie,包括创建和修改。7、基于 Node.js 技术的服务器端编程。
本文的例子介绍了JS加密插件CryptoJS实现AES加密。分享给大家参考,详情如下:
我最近在做一个项目。考虑到数据的安全性,我们需要在传输过程中对数据进行加密,以防止一些恶意操作和爬虫抓取数据。
先看一下这个 CryptoJS 的目录结构
主要是两个文件夹,components和rollups
第一个是组件,第二个是聚合。
汇总文件夹中的文件在一个或多个文件夹组合后进行压缩。
这使得 Rollup 将项目中的单独文件夹分成项目文件,而不用担心它的依赖关系。
您可以在此处查看聚合文件和组件之间的关系:
首先在项目中引入对应的加密文件,我们使用AES,并使用RequireJS加载JS,并在配置中声明路径:
require.config({
baseUrl: "/Public/Home/Js/lib",
paths: {
hzbAES:'../module/hzb.AES'
}
});
一、将加解密封装成一个模块
//模块初始化
var init=function () {
key = CryptoJS.enc.Utf8.parse(CryptoJS.MD5(ym.hezubao).toString());
iv = CryptoJS.enc.Utf8.parse(CryptoJS.MD5(key).toString().substr(0,16));
}
function encrypt(data) {
var encrypted='';
if(typeof(data)=='string')
{
encrypted = CryptoJS.AES.encrypt(data,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
});
}else if(typeof(data)=='object'){
data = JSON.stringify(data);
encrypted = CryptoJS.AES.encrypt(data,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
})
}
return encrypted.toString();
}
/*AES解密
* param : message 密文
* return : decrypted string 明文
*/
function decrypt(message) {
decrypted='';
decrypted=CryptoJS.AES.decrypt(message,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
});
return decrypted.toString(CryptoJS.enc.Utf8);
}
解释代码:
调用代码
require(['hzbAES'], function(hzbAES){
var jsonData={'id':2,'username':'春天的熊'};//json格式数据(加密支持json格式和字符串格式)
$('#btn_test').click(function () {
var encrypt=hzbAES.encrypt(jsonData);
console.log('前台发过去的数据:'+encrypt);//已加密
$.getJSON(UrlGenerator.url(2,'Home','Index','test'),{'data':encrypt},function (data) {
if(!data['error'])
{
var decrypt=JSON.parse(hzbAES.decrypt(data['data']));
console.log('后台发过来的数据:');//已解密
console.log(decrypt);
}else{
console.log(data['error']);
}
})
});
});
感谢您仔细阅读此文章。希望小编分享的《JS加密插件CryptoJS如何实现AES加密》的文章文章对大家有所帮助。同时也希望大家多多支持易素。云,关注易宿云行业资讯频道,更多相关知识等你学习! 查看全部
网页抓取 加密html(本文实例讲述了JS加密插件CryptoJS实现AES加密操作操作)
本文章主要介绍JS加密插件CryptoJS如何实现AES加密操作,具有一定的参考价值。有兴趣的朋友可以参考一下。我希望您在阅读此文章 后会有所收获。下面就让小编带大家一探究竟。
js的作用是什么
1、能够在 HTML 页面中嵌入动态文本。2、响应浏览器事件。3、读取和写入 HTML 元素。4、在将数据提交到服务器之前验证数据。5、检测访问者的浏览器信息。6、控制 cookie,包括创建和修改。7、基于 Node.js 技术的服务器端编程。
本文的例子介绍了JS加密插件CryptoJS实现AES加密。分享给大家参考,详情如下:
我最近在做一个项目。考虑到数据的安全性,我们需要在传输过程中对数据进行加密,以防止一些恶意操作和爬虫抓取数据。
先看一下这个 CryptoJS 的目录结构
主要是两个文件夹,components和rollups
第一个是组件,第二个是聚合。
汇总文件夹中的文件在一个或多个文件夹组合后进行压缩。
这使得 Rollup 将项目中的单独文件夹分成项目文件,而不用担心它的依赖关系。
您可以在此处查看聚合文件和组件之间的关系:
首先在项目中引入对应的加密文件,我们使用AES,并使用RequireJS加载JS,并在配置中声明路径:
require.config({
baseUrl: "/Public/Home/Js/lib",
paths: {
hzbAES:'../module/hzb.AES'
}
});
一、将加解密封装成一个模块
//模块初始化
var init=function () {
key = CryptoJS.enc.Utf8.parse(CryptoJS.MD5(ym.hezubao).toString());
iv = CryptoJS.enc.Utf8.parse(CryptoJS.MD5(key).toString().substr(0,16));
}
function encrypt(data) {
var encrypted='';
if(typeof(data)=='string')
{
encrypted = CryptoJS.AES.encrypt(data,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
});
}else if(typeof(data)=='object'){
data = JSON.stringify(data);
encrypted = CryptoJS.AES.encrypt(data,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
})
}
return encrypted.toString();
}
/*AES解密
* param : message 密文
* return : decrypted string 明文
*/
function decrypt(message) {
decrypted='';
decrypted=CryptoJS.AES.decrypt(message,key,{
iv : iv,
mode : CryptoJS.mode.CBC,
padding : CryptoJS.pad.ZeroPadding
});
return decrypted.toString(CryptoJS.enc.Utf8);
}
解释代码:
调用代码
require(['hzbAES'], function(hzbAES){
var jsonData={'id':2,'username':'春天的熊'};//json格式数据(加密支持json格式和字符串格式)
$('#btn_test').click(function () {
var encrypt=hzbAES.encrypt(jsonData);
console.log('前台发过去的数据:'+encrypt);//已加密
$.getJSON(UrlGenerator.url(2,'Home','Index','test'),{'data':encrypt},function (data) {
if(!data['error'])
{
var decrypt=JSON.parse(hzbAES.decrypt(data['data']));
console.log('后台发过来的数据:');//已解密
console.log(decrypt);
}else{
console.log(data['error']);
}
})
});
});
感谢您仔细阅读此文章。希望小编分享的《JS加密插件CryptoJS如何实现AES加密》的文章文章对大家有所帮助。同时也希望大家多多支持易素。云,关注易宿云行业资讯频道,更多相关知识等你学习!
网页抓取 加密html(抓取房产网站应该没有什么反爬措施?解密一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-23 02:12
在抢夺财物网站的过程中,领队给了一个网站,打开一看,感觉这个不知名的网站应该没有防爬措施吧,不是那么容易的事。然后准备工作。为了安全起见,我还是打算测试一下防爬措施。首先,我使用常规 requests 请求携带请求头来访问它。我发现没有问题。
所以我检查了源代码,发现了一些奇怪的东西。
发现部分数字被替换成了这么奇怪的代码,打开开发者工具时,所有的字都显示出来了。
这是什么鬼,换了这个类,网页上的数字也会正常显示,变成乱码
所以基本上可以得出结论,这个类的部分是罪魁祸首。这是比较流行的反爬虫技术,它使用自定义字体格式来加密 html 文本。这种技术的好处是,如果直接抓取,可以得到返回的结果都是奇怪的代码,如果手动复制,就复制不了了。
我以为是js加载的,但是在开发者工具中查看XHR后发现,并不是那么简单。
解决这个问题的第一个想法是认为这个数字可能对应一个代码,手动查看,看看是怎么回事,找到模式,花了十多分钟总结,但再次刷新页面后,瞬间迷茫, 什么。. . ? ? 编码不同,仍然有变化。看来这条路行不通了。
然后我搜索了这个奇怪的类在哪里,发现了这样一个东西
没错,就是她。查看上述格式的 woff。原来是自定义字体格式,每次刷新,一串看不懂的代码都会变。这应该是问题所在。
然后复制上面的一串代码,使用python3的fontTools包将代码转换成字体文件
从标注的地方发现这个还是用base64加密的,这里我们需要用base64来解密
下面的代码
import base64
from fontTools.ttLib import TTFont
import io
key = 'd09GRgABAAAAAAjgAAsAAAAADMgAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7lQ7Y21hcAAAAYAAAAC7AAACTCMTZu5nbHlmAAACPAAABFEAAAVEz90AumhlYWQAAAaQAAAALwAAADYWPYnBaGhlYQAABsAAAAAcAAAAJAeKAzlobXR4AAAG3AAAABIAAAAwGp4AAGxvY2EAAAbwAAAAGgAAABoHsAZ6bWF4cAAABwwAAAAfAAAAIAEZAEduYW1lAAAHLAAAAVcAAAKFkAhoC3Bvc3QAAAiEAAAAWgAAAI/0SbGSeJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2BksmCcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKr7sZNb5r8MQw6zDcAUozAiSAwDoZAvKeJzFkj0OgzAMhV8K9I8OHTtwhF6BYyCOwMacE3Rj60k6ldsgFCEkJqTs9BmzVIK1dfRFynMUWy8GEAEIyJ2EgHnDQOJF1cx6gPOsh3jwfMOVyhG2SdrUZa7sbB8N+Vj4ytfTxBvbmbUwfHFtSSbGgbX32LHeiZ2G0qnZb7z0gzD/K/0dl3l/LqeY2AW22CSK6G2q0Em4TJH/dKVCd9FZhT6jjxQ6jiFX6D3GQpF58ZUi8+JrBcEH8D4+WAB4nE2Uy2/jVBTG73USO3HcpE1iO08nTmI778SJHSdp3n1lJn2/Ke0wMy2qShnUYQABAxWDNEJIMGKH2AJihxDSbNjRolFXSKAixIgFbNgg/gUyXDsZwFeydY/t4+/7nXMMIABP/gJF4AEYAFqJ9nCeBEAH2j15jI1hlyADaugOwzKlolYeLrUsajiBx6KSqCoowLAcpD3EKCRBRSSiBE7r4bL6gOLSQppz8R4HbjaZSYtPzlaebTU7nYOrlXoj6OrXV7bUphneXq/OxDP2cPqtlY+bgYDbHYl0bXwwYCLxdMDfnHnxRFmnKEn86P6DtdVMplDYgsrukUPOL/fkONzpG5r/wBzYd8AOHABYNIsENbdGSE444TbByfHBuQ1em4KHluvORfib/yu4Dn8iBjx1yHxthRhcGHwLoOF7AvsGxJFrDuqmVUUyDBGSm2ctBAJQKiJrI7fvk/3KbCIbVrZFf5TemIO38MHPCSbry12famG17r2b1Z7ly9lpWevvcjWH2xMm4Rur5kesy9K98mhzoVLdRbyhod2MXYAcAALNK1oTGrD1iy4ghgQ4YRPqpHHiv8UQAmYaBO1k0OkPhaT6MpMKFdpNSYJ79jcv70bTgjsqJ/0+ykdarPCwvhnh/AVvwBvg5XmuWmoFBF9pzvTaMXZnK7dUYgNiMso6aIqizRbwry4KMfUC4JYE2gFHH46JT9tBE2QIf41Px/JQ4mhiG3faxr0zHC+5Bp9i+1u2ZWG/pl2dV3dvpRWl9fZLvQIvEaPcv8NTlNuJqiVN6FmlYUZ2Ap7uxKtV51ivFjbzVDFswRo0VyDXcxmfI0ab/5aG7/+CtF0A7f8darDSimwxZtQOlW6YFhUNPWP0qQExJqLqafetmbjWznDIUH7WJZC4aYyQy7l2RZmx70zUJp/PloqBgM9f7PQ+OL7Ratt2znai0SI/20wkySUYCrfkDmxNc0v5YsCbTbYSYpB3Xus99954qro7BkyjObpA/BKgihiKGgJXZGhUOlY/48YUlTVpZEBCBnTAJg9rRPR5Q0qj+PldE5abOnuV3O8HY9bs8uNutzflsvn4slygrdaor16OREMukxLLcCqdIuLpe2vwjniyqpZfXjhOMrLcRfrbjYO5GxOflMM8H5YL0RxFMvzgnUQs7vEwnkS3k0qtPZ3/7zE70i2AMkKNFBDisPJ0E+ooUefp2xxUxRFbCY4kG9j1hoWfU4ygpvm0LYAT/J5yoLYgDI13lKnbH1ILK69sdbLUzuBPD5mLSVoqudLPZVKYTWVFHHcJtbiQkjP5qe7RdH0yHKGoz84ub67L+U1scFaNpBkmJ19ZfCajjP5VduxHwALRIIyYsUa12WG7Gn+qEtprRWOY9GGujPn9hbnpd/NBxmrBKEewy2+80Ohtm1PJdmMjrJ56J01w6f78clol9zKdxkn7KNHPp7cXf3hYb5tf/+K8MalMP0So/gFnXvSzAAAAeJxjYGRgYADiu+3HZsbz23xl4GZhAIGb/cpCCPr/WRYGpstALgcDE0gUADYSCl0AeJxjYGRgYNb5r8MQw8IAAkCSkQEV8AAAM2IBzXicY2EAghQGBiZL4jAAQjYCtwAAAAAAAAAMAGYAiADEARABPgFeAbACDAJiAqIAAHicY2BkYGDgYbBmYGYAASYg5gJCBob/YD4DAA+WAWEAeJxlkbtuwkAURMc88gApQomUJoq0TdIQzEOpUDokKCNR0BuzBiO/tF6QSJcPyHflE9Klyyekz2CuG8cr7547M3d9JQO4xjccnJ57vid2cMHqxDWc40G4Tv1JuEF+Fm6ijRfhM+oz4Ra6eBVu4wZvvMFpXLIa40PYQQefwjVc4Uu4Tv1HuEH+FW7i1mkKn6Hj3Am3sHC6wm08Ou8tpSZGe1av1PKggjSxPd8zJtSGTuinyVGa6/Uu8kxZludCmzxMEzV0B6U004k25W35fj2yNlCBSWM1paujKFWZSbfat+7G2mzc7weiu34aczzFNYGBhgfLfcV6iQP3ACkSaj349AxXSN9IT0j16JepOb01doiKbNWt1ovippz6sVYYwsXgX2rGVFIkq7Pl2PNrI6qW6eOshj0xaSq9mpNEZIWs8LZUfOouNkVXxp/d5woqebeYIf4D2J1ywQB4nG3JOxKAIBAD0A3+Ee8CKh9bFO9iY+eMx3dcLE3zJgkJypH0HwWBAiUq1GjQooNED4WBcDfXeSTnw+s+xyUbNtY4z//sEjtOvKegLRvt99vctVmJHhnTF3IAAA=='
data = base64.b64decode(key)
fonts = TTFont(io.BytesIO(data))
fonts.save('base.ttf') # 保存成ttf和woff这样的文件格式需要利用FontCreator这样的工具打开,
# 这个百度就可以下载
fonts.save('base.woff')
fonts.saveXML('base.xml') # 保存成这样的格式,可以直接打开进行查看
使用FontCreator打开ttf或woff文件,显示如下
而且你会发现每个数字都对应一个代号,代号uni后面的字符和你在网页上看到的完全一样,有木有的
没错,这就是它们之间的映射关系。每次页面刷新时,后台会随机从数据库中拉取一个自定义字体样式,然后在显示html'时通过映射渲染成普通字体。
打开刚才保存的xml文件可以看到类似这样的东西
看到开头有点眼熟(uniE01C),没错,这个就是每个数字用二维数组画出来的数字
In [1]: import numpy as np
In [2]: from matplotlib import pyplot as plt
In [3]: x=np.array([56, 43, 69, 95, 143, 214, 282, 412, 459, 487, 509, 517, 522, 520, 508, 494, 466, 400, 367, 282, 17
...: 6, 115, 43, 43, 131, 135, 177, 218, 282, 343, 428, 428, 428, 397, 344, 218, 194, 135, 132])
In [4]: y=np.array([335, 468, 544, 624, 667, 720, 710, 710, 617, 573, 508, 447, 335, 271, 166, 126, 51, 4, -39, -39, -
...: 39, 49, 127, 335, 335, 155, 95, 31, 35, 35, 155, 321, 515, 576, 635, 635, 583, 515, 335])
In [5]: plt.plot(x,y)
Out[5]: []
In [6]: plt.show()
上面的代码展示了一个二维的数字数组,解决这个问题的方法是在每个页面爬取的时候下载一个对应的字体文件,然后和我们第一次下载的那个一起传递。对比base.xml文件,进行实际手动对比。同一个二维数组点每两个文件中相同数字的x和y相差在50以内,可以以此作为判断依据。,如果都在这个范围内,则可以确定这两个代码代表同一个数字,然后将所有抓取到的html页面替换为对应代码对应的数字,然后解析,只提供一种思路这里,我没有写代码,因为在实际的爬取过程中,会产生大量的io,
另一种思路是,使用保存的xml文件的所有二维数组生成图片,然后使用TensorFlow进行识别,工作量相当大。
我的解决方法是在测试的时候发现会有一个url重定向到手机端,然后打开手机端发现号码没有加密。
虽然上面的文字加密问题已经解决了,但是还是遇到了抓取页面和实际查看源码的差异,url会发生变化。这就需要反复比较和修正。以上是遇到的问题,记录一下,仅供参考。本文仅供学习交流,禁止商业用途。 查看全部
网页抓取 加密html(抓取房产网站应该没有什么反爬措施?解密一下)
在抢夺财物网站的过程中,领队给了一个网站,打开一看,感觉这个不知名的网站应该没有防爬措施吧,不是那么容易的事。然后准备工作。为了安全起见,我还是打算测试一下防爬措施。首先,我使用常规 requests 请求携带请求头来访问它。我发现没有问题。
所以我检查了源代码,发现了一些奇怪的东西。
发现部分数字被替换成了这么奇怪的代码,打开开发者工具时,所有的字都显示出来了。
这是什么鬼,换了这个类,网页上的数字也会正常显示,变成乱码
所以基本上可以得出结论,这个类的部分是罪魁祸首。这是比较流行的反爬虫技术,它使用自定义字体格式来加密 html 文本。这种技术的好处是,如果直接抓取,可以得到返回的结果都是奇怪的代码,如果手动复制,就复制不了了。
我以为是js加载的,但是在开发者工具中查看XHR后发现,并不是那么简单。
解决这个问题的第一个想法是认为这个数字可能对应一个代码,手动查看,看看是怎么回事,找到模式,花了十多分钟总结,但再次刷新页面后,瞬间迷茫, 什么。. . ? ? 编码不同,仍然有变化。看来这条路行不通了。
然后我搜索了这个奇怪的类在哪里,发现了这样一个东西
没错,就是她。查看上述格式的 woff。原来是自定义字体格式,每次刷新,一串看不懂的代码都会变。这应该是问题所在。
然后复制上面的一串代码,使用python3的fontTools包将代码转换成字体文件
从标注的地方发现这个还是用base64加密的,这里我们需要用base64来解密
下面的代码
import base64
from fontTools.ttLib import TTFont
import io
key = 'd09GRgABAAAAAAjgAAsAAAAADMgAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7lQ7Y21hcAAAAYAAAAC7AAACTCMTZu5nbHlmAAACPAAABFEAAAVEz90AumhlYWQAAAaQAAAALwAAADYWPYnBaGhlYQAABsAAAAAcAAAAJAeKAzlobXR4AAAG3AAAABIAAAAwGp4AAGxvY2EAAAbwAAAAGgAAABoHsAZ6bWF4cAAABwwAAAAfAAAAIAEZAEduYW1lAAAHLAAAAVcAAAKFkAhoC3Bvc3QAAAiEAAAAWgAAAI/0SbGSeJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2BksmCcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKr7sZNb5r8MQw6zDcAUozAiSAwDoZAvKeJzFkj0OgzAMhV8K9I8OHTtwhF6BYyCOwMacE3Rj60k6ldsgFCEkJqTs9BmzVIK1dfRFynMUWy8GEAEIyJ2EgHnDQOJF1cx6gPOsh3jwfMOVyhG2SdrUZa7sbB8N+Vj4ytfTxBvbmbUwfHFtSSbGgbX32LHeiZ2G0qnZb7z0gzD/K/0dl3l/LqeY2AW22CSK6G2q0Em4TJH/dKVCd9FZhT6jjxQ6jiFX6D3GQpF58ZUi8+JrBcEH8D4+WAB4nE2Uy2/jVBTG73USO3HcpE1iO08nTmI778SJHSdp3n1lJn2/Ke0wMy2qShnUYQABAxWDNEJIMGKH2AJihxDSbNjRolFXSKAixIgFbNgg/gUyXDsZwFeydY/t4+/7nXMMIABP/gJF4AEYAFqJ9nCeBEAH2j15jI1hlyADaugOwzKlolYeLrUsajiBx6KSqCoowLAcpD3EKCRBRSSiBE7r4bL6gOLSQppz8R4HbjaZSYtPzlaebTU7nYOrlXoj6OrXV7bUphneXq/OxDP2cPqtlY+bgYDbHYl0bXwwYCLxdMDfnHnxRFmnKEn86P6DtdVMplDYgsrukUPOL/fkONzpG5r/wBzYd8AOHABYNIsENbdGSE444TbByfHBuQ1em4KHluvORfib/yu4Dn8iBjx1yHxthRhcGHwLoOF7AvsGxJFrDuqmVUUyDBGSm2ctBAJQKiJrI7fvk/3KbCIbVrZFf5TemIO38MHPCSbry12famG17r2b1Z7ly9lpWevvcjWH2xMm4Rur5kesy9K98mhzoVLdRbyhod2MXYAcAALNK1oTGrD1iy4ghgQ4YRPqpHHiv8UQAmYaBO1k0OkPhaT6MpMKFdpNSYJ79jcv70bTgjsqJ/0+ykdarPCwvhnh/AVvwBvg5XmuWmoFBF9pzvTaMXZnK7dUYgNiMso6aIqizRbwry4KMfUC4JYE2gFHH46JT9tBE2QIf41Px/JQ4mhiG3faxr0zHC+5Bp9i+1u2ZWG/pl2dV3dvpRWl9fZLvQIvEaPcv8NTlNuJqiVN6FmlYUZ2Ap7uxKtV51ivFjbzVDFswRo0VyDXcxmfI0ab/5aG7/+CtF0A7f8darDSimwxZtQOlW6YFhUNPWP0qQExJqLqafetmbjWznDIUH7WJZC4aYyQy7l2RZmx70zUJp/PloqBgM9f7PQ+OL7Ratt2znai0SI/20wkySUYCrfkDmxNc0v5YsCbTbYSYpB3Xus99954qro7BkyjObpA/BKgihiKGgJXZGhUOlY/48YUlTVpZEBCBnTAJg9rRPR5Q0qj+PldE5abOnuV3O8HY9bs8uNutzflsvn4slygrdaor16OREMukxLLcCqdIuLpe2vwjniyqpZfXjhOMrLcRfrbjYO5GxOflMM8H5YL0RxFMvzgnUQs7vEwnkS3k0qtPZ3/7zE70i2AMkKNFBDisPJ0E+ooUefp2xxUxRFbCY4kG9j1hoWfU4ygpvm0LYAT/J5yoLYgDI13lKnbH1ILK69sdbLUzuBPD5mLSVoqudLPZVKYTWVFHHcJtbiQkjP5qe7RdH0yHKGoz84ub67L+U1scFaNpBkmJ19ZfCajjP5VduxHwALRIIyYsUa12WG7Gn+qEtprRWOY9GGujPn9hbnpd/NBxmrBKEewy2+80Ohtm1PJdmMjrJ56J01w6f78clol9zKdxkn7KNHPp7cXf3hYb5tf/+K8MalMP0So/gFnXvSzAAAAeJxjYGRgYADiu+3HZsbz23xl4GZhAIGb/cpCCPr/WRYGpstALgcDE0gUADYSCl0AeJxjYGRgYNb5r8MQw8IAAkCSkQEV8AAAM2IBzXicY2EAghQGBiZL4jAAQjYCtwAAAAAAAAAMAGYAiADEARABPgFeAbACDAJiAqIAAHicY2BkYGDgYbBmYGYAASYg5gJCBob/YD4DAA+WAWEAeJxlkbtuwkAURMc88gApQomUJoq0TdIQzEOpUDokKCNR0BuzBiO/tF6QSJcPyHflE9Klyyekz2CuG8cr7547M3d9JQO4xjccnJ57vid2cMHqxDWc40G4Tv1JuEF+Fm6ijRfhM+oz4Ra6eBVu4wZvvMFpXLIa40PYQQefwjVc4Uu4Tv1HuEH+FW7i1mkKn6Hj3Am3sHC6wm08Ou8tpSZGe1av1PKggjSxPd8zJtSGTuinyVGa6/Uu8kxZludCmzxMEzV0B6U004k25W35fj2yNlCBSWM1paujKFWZSbfat+7G2mzc7weiu34aczzFNYGBhgfLfcV6iQP3ACkSaj349AxXSN9IT0j16JepOb01doiKbNWt1ovippz6sVYYwsXgX2rGVFIkq7Pl2PNrI6qW6eOshj0xaSq9mpNEZIWs8LZUfOouNkVXxp/d5woqebeYIf4D2J1ywQB4nG3JOxKAIBAD0A3+Ee8CKh9bFO9iY+eMx3dcLE3zJgkJypH0HwWBAiUq1GjQooNED4WBcDfXeSTnw+s+xyUbNtY4z//sEjtOvKegLRvt99vctVmJHhnTF3IAAA=='
data = base64.b64decode(key)
fonts = TTFont(io.BytesIO(data))
fonts.save('base.ttf') # 保存成ttf和woff这样的文件格式需要利用FontCreator这样的工具打开,
# 这个百度就可以下载
fonts.save('base.woff')
fonts.saveXML('base.xml') # 保存成这样的格式,可以直接打开进行查看
使用FontCreator打开ttf或woff文件,显示如下
而且你会发现每个数字都对应一个代号,代号uni后面的字符和你在网页上看到的完全一样,有木有的
没错,这就是它们之间的映射关系。每次页面刷新时,后台会随机从数据库中拉取一个自定义字体样式,然后在显示html'时通过映射渲染成普通字体。
打开刚才保存的xml文件可以看到类似这样的东西
看到开头有点眼熟(uniE01C),没错,这个就是每个数字用二维数组画出来的数字
In [1]: import numpy as np
In [2]: from matplotlib import pyplot as plt
In [3]: x=np.array([56, 43, 69, 95, 143, 214, 282, 412, 459, 487, 509, 517, 522, 520, 508, 494, 466, 400, 367, 282, 17
...: 6, 115, 43, 43, 131, 135, 177, 218, 282, 343, 428, 428, 428, 397, 344, 218, 194, 135, 132])
In [4]: y=np.array([335, 468, 544, 624, 667, 720, 710, 710, 617, 573, 508, 447, 335, 271, 166, 126, 51, 4, -39, -39, -
...: 39, 49, 127, 335, 335, 155, 95, 31, 35, 35, 155, 321, 515, 576, 635, 635, 583, 515, 335])
In [5]: plt.plot(x,y)
Out[5]: []
In [6]: plt.show()
上面的代码展示了一个二维的数字数组,解决这个问题的方法是在每个页面爬取的时候下载一个对应的字体文件,然后和我们第一次下载的那个一起传递。对比base.xml文件,进行实际手动对比。同一个二维数组点每两个文件中相同数字的x和y相差在50以内,可以以此作为判断依据。,如果都在这个范围内,则可以确定这两个代码代表同一个数字,然后将所有抓取到的html页面替换为对应代码对应的数字,然后解析,只提供一种思路这里,我没有写代码,因为在实际的爬取过程中,会产生大量的io,
另一种思路是,使用保存的xml文件的所有二维数组生成图片,然后使用TensorFlow进行识别,工作量相当大。
我的解决方法是在测试的时候发现会有一个url重定向到手机端,然后打开手机端发现号码没有加密。
虽然上面的文字加密问题已经解决了,但是还是遇到了抓取页面和实际查看源码的差异,url会发生变化。这就需要反复比较和修正。以上是遇到的问题,记录一下,仅供参考。本文仅供学习交流,禁止商业用途。

