
网页抓取 加密html
网页抓取 加密html( 如何保护好自己的HTML加密器批加密器加密工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-20 17:17
如何保护好自己的HTML加密器批加密器加密工具)
Batch Html Encryptor 正式版是一款安全、可靠、实用的网页加密工具。Batch Html Encryptor软件正式版可以帮助站长加密html源文件。它可以对整个网页的源代码进行加密,Batch Html Encryptor 也可以对网页的源代码进行加密。部分加密,加密后的网页只有浏览器解析才能看到!
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助您将网页变成不可读的代码!
如何保护您的 HTML 网站的内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后,只有浏览器可以读取输出。其他人不知道根本不能修改源文件。
特征
什么是批量 HTML 加密器
Batch HTML Encryptor 是一种保护您的 html 代码和脚本代码并将其转换为虚幻文字的工具。处理多个文件的出色工作,因此它将节省您完成这项复杂工作的时间。现在有幸支持了 UNIC ODE,这意味着批处理 HTML 加密器在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98 / Me / NT 4.0 / 2000 / XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间 查看全部
网页抓取 加密html(
如何保护好自己的HTML加密器批加密器加密工具)

Batch Html Encryptor 正式版是一款安全、可靠、实用的网页加密工具。Batch Html Encryptor软件正式版可以帮助站长加密html源文件。它可以对整个网页的源代码进行加密,Batch Html Encryptor 也可以对网页的源代码进行加密。部分加密,加密后的网页只有浏览器解析才能看到!
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助您将网页变成不可读的代码!
如何保护您的 HTML 网站的内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后,只有浏览器可以读取输出。其他人不知道根本不能修改源文件。
特征
什么是批量 HTML 加密器
Batch HTML Encryptor 是一种保护您的 html 代码和脚本代码并将其转换为虚幻文字的工具。处理多个文件的出色工作,因此它将节省您完成这项复杂工作的时间。现在有幸支持了 UNIC ODE,这意味着批处理 HTML 加密器在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98 / Me / NT 4.0 / 2000 / XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间
网页抓取 加密html(这里有新鲜出炉的Python多线程编程,程序狗速度看过来! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-20 10:12
)
下面是新发布的Python多线程编程,来看看程序狗的速度吧!
Python编程语言 Python是一种面向对象的解释型计算机编程语言,由Guido van Rossum于1989年底发明,1991年首次公开发布。Python语法简洁明了,拥有丰富而强大的类库. 它通常被称为胶水语言,它可以很容易地将其他语言(尤其是 C/C++)制作的各种模块连接在一起。
本文文章主要介绍一个使用Python程序抓取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考。
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'n')
print 'fetch link: '+link
mlfile.close() 查看全部
网页抓取 加密html(这里有新鲜出炉的Python多线程编程,程序狗速度看过来!
)
下面是新发布的Python多线程编程,来看看程序狗的速度吧!
Python编程语言 Python是一种面向对象的解释型计算机编程语言,由Guido van Rossum于1989年底发明,1991年首次公开发布。Python语法简洁明了,拥有丰富而强大的类库. 它通常被称为胶水语言,它可以很容易地将其他语言(尤其是 C/C++)制作的各种模块连接在一起。
本文文章主要介绍一个使用Python程序抓取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考。
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'n')
print 'fetch link: '+link
mlfile.close()
网页抓取 加密html(介绍雅虎排名优化排名中最大的因素是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-20 04:13
#微信刷脸支付代理介绍
雅虎排名优化排名的最大因素是什么?这两天,我看到了中国各大搜索引擎的很大一部分。谷歌和百度合计占据了90%以上的市场,雅虎在中国市场的规模很小。但无论如何,雅虎也是世界上非常重要的搜索引擎。每个搜索引擎的排名算法都不一样。相比之下,谷歌的算法是最复杂、最难控制的。MSN的算法更注重页面优化。例如,关键字堆叠在MSN中通常可以取得很好的效果。雅虎最关心的是传入链接的数量。虽然基于传入链接的排名算法是谷歌发明的,但现在所有的搜索引擎都将其视为重要的组成部分。雅虎看到导入链接的数量有点过重,不像现在的谷歌,它增加了很多其他的修复。要想在雅虎排名中取得好成绩,只需要在大网站上购买一两个全站广告链接,就会产生好成绩。因为这些广告链接会显示在数千个网页上,比如页面底部或左侧的菜单栏。一些大型 网站 甚至可能有数十万个网页。如此多的传入链接在雅虎的排名中起着举足轻重的作用。对于雅虎来说,这既是一个脆弱的地方,也是一个致命的缺陷。因为操作简单。与谷歌不同,雅虎会考虑添加链接的速度、链接的分布是否自然、链接页面的历史以及链接页面的内容是否相关。雅虎似乎只看重数量,而不看重质量。据报道,雅虎的整个数据库页面可与谷歌相媲美,甚至有可能超过谷歌。但是搜索结果的整体质量比谷歌要长一些。在 Yahoo! 的前 20 名中 您经常会看到垃圾邮件 网站 泛滥。重要的原因之一是,只需导入链接数即可在雅虎上获得良好的排名。来源:Zac微信刷脸支付代理
网站的原因和表现是k,网站如何恢复?作为一名优秀的SEO,我们经常会遇到各种各样的问题。网站被K和网站降级是很常见的。最后,网站 被K降级的表现是什么?1. 过度优化。我想对SEO太熟悉了。我不想轻易犯这种低级错误。最后,这就是搜索引擎的主导地位。过度优化的搜索引擎认为您在作弊。你会被击倒或被击倒。荣帅网络工作室强调网站不等于网站。K站被拉入黑名单,降级是因为SEO数据波动。优化操作过多:关键词堆砌、内链泛滥、首页关键词过多。特例:我在SEO初期遇到过两个经典案例。网站不收录首页(网站不在首页),说明你的网站首页质量不好,内页内容太多丰富,可能在 网站 关系内形成竞争。站点 2,外部链接。无论是增加网站的权重,还是增加流量,外链在我们整个seo优化过程中都扮演着非常重要的角色。我们需要定期检查友情链接,主要是检查友情链接的网站是否是不可能的或者搜索引擎功能下降的迹象。比如快照日期过长,网站不在首页,收录页面明显减少。如果不及时,您的 网站 也可能因降级权而受到处罚。所以,一旦发现这样的友情链接,一定要立即删除。这些工作是seoer必须掌握的基本技能。3.网站 是否使用ALT标签。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。
这也是本案后面要强调的一个重要重点。网站 的内容直接关系到用户体验。现在,搜索引擎越来越注重用户体验。如果其他人通过搜索引擎访问您的网站,他们会发现您提供的网站内容与关键字无关或由大量关键字堆积而成。计算内容的内容,然后,下一个电源减少可能是你。我们提供的内容必须从用户的角度考虑。真正能给用户带来实用性的内容才是真正的好内容。因此,为了让您的网站永远在这个网络世界中,请注意您的网站内容的建设。这是你的< @网站核心竞争力,直接体现你的网站内容。5.网站 安全稳定。安全性尚未讨论。如果你的网站服务器不稳定,经常无法访问或者访问时间超过8s,蜘蛛可以轻松降低功耗。6、网站经常被修改。这个东西涉及面很广,你可能只是改模板,有的改域名,也可能是整个网站的结构都改了,所以这里只提醒一下,网站一定要在设计之初就定下基调,不要老是改,就算真的要改版本,也要有计划,不能一时改,再稍微改。不要小规模删除标题和关键字。如果你上线后进行大规模的改动,除非你不在乎你现在的排名,否则你会被降级。7.检查死链接。死链接的危害和外链的好处是一样的。一个可以让网站着火,另一个可以让网站死亡。因为与第四点的内容相匹配,死链接是用户体验的天敌。
你说网站的内容打不开,那你的网站还是可以有好的效果的。这是网站最大可能的减少点之一。8.页面是否使用了过多的h1标签?建议在同一页面上只使用一个h1标签来标记最重要的内容。比如首页需要在网站名称中添加h1标签,内容页需要在文章标题中添加h1标签。如果发现网站被降级,请查看内部流程。优化 h1 标签。9.网站结构的设计。情况可能并非如此,除非你自己制作网站程序或者对成熟的网站程序进行二次修改并且改动太大,而你在变革过程中忽视了结构的整体规划和优化。会影响你的网站排名,网站权重等方面。10. 抄袭太多。网站上的其他所有文章都被复制了,从长远来看,这对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。网站上的@文章被抄袭了,长远来看对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。网站上的@文章被抄袭了,长远来看对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。 查看全部
网页抓取 加密html(介绍雅虎排名优化排名中最大的因素是什么?(图))
#微信刷脸支付代理介绍
雅虎排名优化排名的最大因素是什么?这两天,我看到了中国各大搜索引擎的很大一部分。谷歌和百度合计占据了90%以上的市场,雅虎在中国市场的规模很小。但无论如何,雅虎也是世界上非常重要的搜索引擎。每个搜索引擎的排名算法都不一样。相比之下,谷歌的算法是最复杂、最难控制的。MSN的算法更注重页面优化。例如,关键字堆叠在MSN中通常可以取得很好的效果。雅虎最关心的是传入链接的数量。虽然基于传入链接的排名算法是谷歌发明的,但现在所有的搜索引擎都将其视为重要的组成部分。雅虎看到导入链接的数量有点过重,不像现在的谷歌,它增加了很多其他的修复。要想在雅虎排名中取得好成绩,只需要在大网站上购买一两个全站广告链接,就会产生好成绩。因为这些广告链接会显示在数千个网页上,比如页面底部或左侧的菜单栏。一些大型 网站 甚至可能有数十万个网页。如此多的传入链接在雅虎的排名中起着举足轻重的作用。对于雅虎来说,这既是一个脆弱的地方,也是一个致命的缺陷。因为操作简单。与谷歌不同,雅虎会考虑添加链接的速度、链接的分布是否自然、链接页面的历史以及链接页面的内容是否相关。雅虎似乎只看重数量,而不看重质量。据报道,雅虎的整个数据库页面可与谷歌相媲美,甚至有可能超过谷歌。但是搜索结果的整体质量比谷歌要长一些。在 Yahoo! 的前 20 名中 您经常会看到垃圾邮件 网站 泛滥。重要的原因之一是,只需导入链接数即可在雅虎上获得良好的排名。来源:Zac微信刷脸支付代理

网站的原因和表现是k,网站如何恢复?作为一名优秀的SEO,我们经常会遇到各种各样的问题。网站被K和网站降级是很常见的。最后,网站 被K降级的表现是什么?1. 过度优化。我想对SEO太熟悉了。我不想轻易犯这种低级错误。最后,这就是搜索引擎的主导地位。过度优化的搜索引擎认为您在作弊。你会被击倒或被击倒。荣帅网络工作室强调网站不等于网站。K站被拉入黑名单,降级是因为SEO数据波动。优化操作过多:关键词堆砌、内链泛滥、首页关键词过多。特例:我在SEO初期遇到过两个经典案例。网站不收录首页(网站不在首页),说明你的网站首页质量不好,内页内容太多丰富,可能在 网站 关系内形成竞争。站点 2,外部链接。无论是增加网站的权重,还是增加流量,外链在我们整个seo优化过程中都扮演着非常重要的角色。我们需要定期检查友情链接,主要是检查友情链接的网站是否是不可能的或者搜索引擎功能下降的迹象。比如快照日期过长,网站不在首页,收录页面明显减少。如果不及时,您的 网站 也可能因降级权而受到处罚。所以,一旦发现这样的友情链接,一定要立即删除。这些工作是seoer必须掌握的基本技能。3.网站 是否使用ALT标签。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。
这也是本案后面要强调的一个重要重点。网站 的内容直接关系到用户体验。现在,搜索引擎越来越注重用户体验。如果其他人通过搜索引擎访问您的网站,他们会发现您提供的网站内容与关键字无关或由大量关键字堆积而成。计算内容的内容,然后,下一个电源减少可能是你。我们提供的内容必须从用户的角度考虑。真正能给用户带来实用性的内容才是真正的好内容。因此,为了让您的网站永远在这个网络世界中,请注意您的网站内容的建设。这是你的< @网站核心竞争力,直接体现你的网站内容。5.网站 安全稳定。安全性尚未讨论。如果你的网站服务器不稳定,经常无法访问或者访问时间超过8s,蜘蛛可以轻松降低功耗。6、网站经常被修改。这个东西涉及面很广,你可能只是改模板,有的改域名,也可能是整个网站的结构都改了,所以这里只提醒一下,网站一定要在设计之初就定下基调,不要老是改,就算真的要改版本,也要有计划,不能一时改,再稍微改。不要小规模删除标题和关键字。如果你上线后进行大规模的改动,除非你不在乎你现在的排名,否则你会被降级。7.检查死链接。死链接的危害和外链的好处是一样的。一个可以让网站着火,另一个可以让网站死亡。因为与第四点的内容相匹配,死链接是用户体验的天敌。
你说网站的内容打不开,那你的网站还是可以有好的效果的。这是网站最大可能的减少点之一。8.页面是否使用了过多的h1标签?建议在同一页面上只使用一个h1标签来标记最重要的内容。比如首页需要在网站名称中添加h1标签,内容页需要在文章标题中添加h1标签。如果发现网站被降级,请查看内部流程。优化 h1 标签。9.网站结构的设计。情况可能并非如此,除非你自己制作网站程序或者对成熟的网站程序进行二次修改并且改动太大,而你在变革过程中忽视了结构的整体规划和优化。会影响你的网站排名,网站权重等方面。10. 抄袭太多。网站上的其他所有文章都被复制了,从长远来看,这对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。网站上的@文章被抄袭了,长远来看对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。网站上的@文章被抄袭了,长远来看对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。
网页抓取 加密html(2019独角兽企业重金招聘Python工程师换行标准(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-19 07:18
2019独角兽企业重磅招聘Python工程师标准>>>
某段时间的web编程,想着别人硬写的web右击查看源代码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想对整个页面html进行加密,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js的document.write,动态插入html神器!
那么接下来就是考虑编码问题了,如果直接document.write("...."); 也是可以的,不过跟不加密没什么区别。但是我还是用这个方法先测试了一下,遇到了一些麻烦。Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
现在比较流行的已知编码有几种,比如json、base64.,那就先试试json吧。
json编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密的效果是 1%。
然后试试base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据的长度看到html结构。这仍然是一个单线呼叫。
更改为下面的链式调用
代码再也看不到原来的结构了。哈哈
接下来尝试以二进制编码:
接下来尝试以八进制编码:
接下来,尝试使用十进制编码(顺便说一下,添加了无用的符号以增强混乱):
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
然后我想做一个密码输入框,输入正确的密码显示出来。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
Des 必须用密码解密才能知道。des加密的优点是可以对数据进行加密并通过网络传输。http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。des虽然弱,但是不容易破解
浏览器访问网页,首先输入密码,解密,成功显示真实网页
其实还有其他编码和其他压缩编码,我不是很清楚,而且要动态输出html,我用的php必须和js匹配,一方加密,另一方解密。如果不匹配或没有合适的编码,则无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html有一层加密。客户端收到后,js动态解码输出。虽然无法通过右键查看代码,但是浏览器开发者工具会显示运行的html代码,一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深入的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。
转载于: 查看全部
网页抓取 加密html(2019独角兽企业重金招聘Python工程师换行标准(组图))
2019独角兽企业重磅招聘Python工程师标准>>>

某段时间的web编程,想着别人硬写的web右击查看源代码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想对整个页面html进行加密,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js的document.write,动态插入html神器!
那么接下来就是考虑编码问题了,如果直接document.write("...."); 也是可以的,不过跟不加密没什么区别。但是我还是用这个方法先测试了一下,遇到了一些麻烦。Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
现在比较流行的已知编码有几种,比如json、base64.,那就先试试json吧。
json编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密的效果是 1%。
然后试试base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据的长度看到html结构。这仍然是一个单线呼叫。
更改为下面的链式调用
代码再也看不到原来的结构了。哈哈
接下来尝试以二进制编码:
接下来尝试以八进制编码:
接下来,尝试使用十进制编码(顺便说一下,添加了无用的符号以增强混乱):
接下来尝试使用十六进制编码(无分隔符):

接下来尝试使用十六进制编码(带分隔符):
然后我想做一个密码输入框,输入正确的密码显示出来。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
Des 必须用密码解密才能知道。des加密的优点是可以对数据进行加密并通过网络传输。http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。des虽然弱,但是不容易破解
浏览器访问网页,首先输入密码,解密,成功显示真实网页
其实还有其他编码和其他压缩编码,我不是很清楚,而且要动态输出html,我用的php必须和js匹配,一方加密,另一方解密。如果不匹配或没有合适的编码,则无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html有一层加密。客户端收到后,js动态解码输出。虽然无法通过右键查看代码,但是浏览器开发者工具会显示运行的html代码,一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深入的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。
转载于:
网页抓取 加密html(firefox浏览器的话在国内的p2p环境是需要时间的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-17 12:02
网页抓取加密html过滤cookie字符编码单引号&双引号转义
浏览器的话,在head里配合set-cookie使用,具体用法可见/guide/history.html?id=11436
谢邀。推荐firefox浏览器。firefox的一个非常好用的工具是randomanalyzer:可以看看我用这个工具做过的一些实验。
大家最喜欢的其实是比较另类的:开源的(meanjavascript-breakingcodeonsafari,firefox,andinorderemacos)
php就是比java大不過...好像沒法從端抓數:)
javascript抓包
为何都是英文不是全球网站呢可以从infoq上面查看哈
看了楼上的答案都不满意就来补充一下我最近的做法,尤其适合flash播放器,可以通过activex控件拦截一切脚本和cookie,并且支持mime类型,虽然有的网站,如facebook,google也支持这种格式(不提供cookie),但是本质来说,这对于react生态圈来说是没问题的,通过原生动态方法就可以对应我的需求。
flash播放器在国内其实发展的不是很好,p2p网站要适应国内的p2p环境是需要时间的,建议p2p依赖flash.。
setupmouseplayer代码formdata.ready();formdata.load();hidevoteboard();setupmouseplayer类名ribop.protectedkeys({setupmouseplayer:true,false});onblur事件message.isstroke();},listener(){ribop.protectedkeys();}vscss反射机制实现。 查看全部
网页抓取 加密html(firefox浏览器的话在国内的p2p环境是需要时间的)
网页抓取加密html过滤cookie字符编码单引号&双引号转义
浏览器的话,在head里配合set-cookie使用,具体用法可见/guide/history.html?id=11436
谢邀。推荐firefox浏览器。firefox的一个非常好用的工具是randomanalyzer:可以看看我用这个工具做过的一些实验。
大家最喜欢的其实是比较另类的:开源的(meanjavascript-breakingcodeonsafari,firefox,andinorderemacos)
php就是比java大不過...好像沒法從端抓數:)
javascript抓包
为何都是英文不是全球网站呢可以从infoq上面查看哈
看了楼上的答案都不满意就来补充一下我最近的做法,尤其适合flash播放器,可以通过activex控件拦截一切脚本和cookie,并且支持mime类型,虽然有的网站,如facebook,google也支持这种格式(不提供cookie),但是本质来说,这对于react生态圈来说是没问题的,通过原生动态方法就可以对应我的需求。
flash播放器在国内其实发展的不是很好,p2p网站要适应国内的p2p环境是需要时间的,建议p2p依赖flash.。
setupmouseplayer代码formdata.ready();formdata.load();hidevoteboard();setupmouseplayer类名ribop.protectedkeys({setupmouseplayer:true,false});onblur事件message.isstroke();},listener(){ribop.protectedkeys();}vscss反射机制实现。
网页抓取 加密html(通用搜索引擎如何有效地提取并利用这些信息成为一个巨大的挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-13 14:01
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性。例如:(1)不同领域、不同背景的用户往往有不同的检索目的和需求。搜索引擎返回的结果中收录了大量不关注网页的用户。(2)目标一般搜索引擎的目的是最大化网络覆盖。有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。(3) 随着万维网上数据形式的丰富和网络技术的不断发展,大量的图片、数据库、音频、视频、多媒体等不同的数据大量出现。一般搜索引擎往往对这些信息内容密集、有一定结构的数据无能为力,不能很好地发现和获取。(4)一般搜索引擎大多提供基于关键字的搜索,难以支持基于语义的查询为了解决上述问题,出现了针对相关网络资源的聚焦爬虫,聚焦爬虫是一种自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大Cover,目标是抓取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理和关键技术概述。网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)网页或数据的分析和过滤;(3) URL 的搜索策略。对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)网页或数据的分析和过滤;(3) URL 的搜索策略。 查看全部
网页抓取 加密html(通用搜索引擎如何有效地提取并利用这些信息成为一个巨大的挑战)
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性。例如:(1)不同领域、不同背景的用户往往有不同的检索目的和需求。搜索引擎返回的结果中收录了大量不关注网页的用户。(2)目标一般搜索引擎的目的是最大化网络覆盖。有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。(3) 随着万维网上数据形式的丰富和网络技术的不断发展,大量的图片、数据库、音频、视频、多媒体等不同的数据大量出现。一般搜索引擎往往对这些信息内容密集、有一定结构的数据无能为力,不能很好地发现和获取。(4)一般搜索引擎大多提供基于关键字的搜索,难以支持基于语义的查询为了解决上述问题,出现了针对相关网络资源的聚焦爬虫,聚焦爬虫是一种自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大Cover,目标是抓取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理和关键技术概述。网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)网页或数据的分析和过滤;(3) URL 的搜索策略。对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)网页或数据的分析和过滤;(3) URL 的搜索策略。
网页抓取 加密html(有什么方能提高网页被搜索引擎抓取索引和排名的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-10 13:14
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(bots)会递归地抓取某个网站(通过你提交的网站首页网址,然后通过网页上找到的链接抓取这些链接)。网页指向,重复)。
但现在已经不是这样了。就像下图一样,搜索引擎爬虫在爬取的时候会有多个入口点,每个入口点都同等重要,然后从这些入口点分散出来进行爬取。挑选。
那么让我们看看可以做些什么来改善搜索引擎对网页的抓取、索引和排名:
示例 网站 架构图
首先通过下图来看通常的网站架构图:
典型的网站外链分布图
然后我们看一张典型的网站外链分布图:
爬虫爬取路径的优先级
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(bots)会递归地抓取某个网站(通过你提交的网站首页URL,然后通过网页上找到的链接抓取这些链接)。网页指向,重复)。但现在已经不是这样了。就像下图一样,搜索引擎爬虫在爬取的时候会有多个入口点,每个入口点都同等重要,然后从这些入口点分散出来进行爬取。挑选。
改善被搜索引擎抓取、索引和排名的网页的 5 种方法
最后,让我们看看可以做些什么来改善搜索引擎对网页的抓取、索引和排名:
扁平化网站的结构
如果你的网站能够建立一个理想的、扁平的链接层次结构,就可以达到3次点击访问100万页、4次点击访问100万页的效果。
从“强大”页面链接到需要链接的页面
你应该意识到很多带有外部链接的“强大”页面(指排名高的页面和许多外部链接,eIT Note)的涟漪效应,并充分利用这种效应。将此类页面视为目录(或类别)页面,并使用它们链接到 网站 的其他页面。
同样,您可以在将来使用此类页面作为着陆页,以帮助增加您希望用户访问该页面的流量。
减少“死胡同”和低价值页面
链接图上边缘的那些页面价值较低。确认 网站 上没有降低 PageRank 的页面。通常这样的页面是PDF、图片和其他文件。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并且页面上还有返回到 网站 其他部分的链接。
创建值得链接的类别或导航页面
如果你能做出这样的值得链接和吸引眼球的页面,他们将获得更高的PageRank和更高的抓取率。同时,这些 PageRank 和抓取优先级会通过页面上的链接传递到 网站 的其他页面(向搜索引擎表明 网站 上的所有页面都很重要)。
从抓取路径中排除不重要的页面
减少不必要的导航级别(或内容页面),并将爬虫引导至真正需要 PageRank 的 URL。
原文:解决抓取优先级和索引问题的图表
以上就是提高网页关键词搜索引擎排名的5种方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
网页抓取 加密html(有什么方能提高网页被搜索引擎抓取索引和排名的方法)
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(bots)会递归地抓取某个网站(通过你提交的网站首页网址,然后通过网页上找到的链接抓取这些链接)。网页指向,重复)。
但现在已经不是这样了。就像下图一样,搜索引擎爬虫在爬取的时候会有多个入口点,每个入口点都同等重要,然后从这些入口点分散出来进行爬取。挑选。
那么让我们看看可以做些什么来改善搜索引擎对网页的抓取、索引和排名:
示例 网站 架构图
首先通过下图来看通常的网站架构图:

典型的网站外链分布图
然后我们看一张典型的网站外链分布图:

爬虫爬取路径的优先级
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(bots)会递归地抓取某个网站(通过你提交的网站首页URL,然后通过网页上找到的链接抓取这些链接)。网页指向,重复)。但现在已经不是这样了。就像下图一样,搜索引擎爬虫在爬取的时候会有多个入口点,每个入口点都同等重要,然后从这些入口点分散出来进行爬取。挑选。

改善被搜索引擎抓取、索引和排名的网页的 5 种方法
最后,让我们看看可以做些什么来改善搜索引擎对网页的抓取、索引和排名:

扁平化网站的结构
如果你的网站能够建立一个理想的、扁平的链接层次结构,就可以达到3次点击访问100万页、4次点击访问100万页的效果。
从“强大”页面链接到需要链接的页面
你应该意识到很多带有外部链接的“强大”页面(指排名高的页面和许多外部链接,eIT Note)的涟漪效应,并充分利用这种效应。将此类页面视为目录(或类别)页面,并使用它们链接到 网站 的其他页面。
同样,您可以在将来使用此类页面作为着陆页,以帮助增加您希望用户访问该页面的流量。
减少“死胡同”和低价值页面
链接图上边缘的那些页面价值较低。确认 网站 上没有降低 PageRank 的页面。通常这样的页面是PDF、图片和其他文件。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并且页面上还有返回到 网站 其他部分的链接。
创建值得链接的类别或导航页面

如果你能做出这样的值得链接和吸引眼球的页面,他们将获得更高的PageRank和更高的抓取率。同时,这些 PageRank 和抓取优先级会通过页面上的链接传递到 网站 的其他页面(向搜索引擎表明 网站 上的所有页面都很重要)。
从抓取路径中排除不重要的页面

减少不必要的导航级别(或内容页面),并将爬虫引导至真正需要 PageRank 的 URL。
原文:解决抓取优先级和索引问题的图表
以上就是提高网页关键词搜索引擎排名的5种方法的详细内容。更多详情请关注其他相关html中文网站文章!
网页抓取 加密html(在线网页数据加密浏览器维护根据浏览器的课件或在线课件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-10 13:12
在线网页数据加密浏览器维护基于浏览器的课件或在线网页(这意味着您无需向公众开放在线网页或课件即可发布网址)。根据数据加密的手机客户端浏览器,您可以指定用户只能在特定的电脑浏览您的网页,而不能复制或打开您的文字、照片、多媒体系统文档等,用户无法看到网址。
应用领域:
您有一个在线网页或在线课件,想要发送给您的用户浏览,同时操纵用户的浏览频率或到期日期,但您不希望用户看到该 URL 或将 URL 发送给其他人,严禁用户复制、下载页面内容。
根据在线网络数据对浏览器的课件或网页进行加密具有以下优点:
1.维护基于浏览器或在线网页的课件----防复制、防免费下载、防盗链。一机一码授权浏览。
2.交付给用户的课件可以随时随地在线升级,不再需要为用户和快递公司工作。
3.降低虚拟产品平台交易风险。如果投资者不付款,用户的课件可以随时随地被禁止进入网站。
4.课件制作成本低。
5.瘦客户端,用户只需要能够上网就可以查看课件。
6.可自定义电子签名或数据加密参数传递功能,确保只有特定浏览器才能浏览您的网页(选择电子签名或数据加密参数传递后,即使用户知道您的网址,也不会可以浏览)
7. 本系统软件还可以集成网络技术应用,基于互联网向客户分发浏览登录密码,集成VIP会员身份认证等方式进行浏览授权,无需人工参与。 查看全部
网页抓取 加密html(在线网页数据加密浏览器维护根据浏览器的课件或在线课件)
在线网页数据加密浏览器维护基于浏览器的课件或在线网页(这意味着您无需向公众开放在线网页或课件即可发布网址)。根据数据加密的手机客户端浏览器,您可以指定用户只能在特定的电脑浏览您的网页,而不能复制或打开您的文字、照片、多媒体系统文档等,用户无法看到网址。
应用领域:
您有一个在线网页或在线课件,想要发送给您的用户浏览,同时操纵用户的浏览频率或到期日期,但您不希望用户看到该 URL 或将 URL 发送给其他人,严禁用户复制、下载页面内容。
根据在线网络数据对浏览器的课件或网页进行加密具有以下优点:
1.维护基于浏览器或在线网页的课件----防复制、防免费下载、防盗链。一机一码授权浏览。
2.交付给用户的课件可以随时随地在线升级,不再需要为用户和快递公司工作。
3.降低虚拟产品平台交易风险。如果投资者不付款,用户的课件可以随时随地被禁止进入网站。
4.课件制作成本低。
5.瘦客户端,用户只需要能够上网就可以查看课件。
6.可自定义电子签名或数据加密参数传递功能,确保只有特定浏览器才能浏览您的网页(选择电子签名或数据加密参数传递后,即使用户知道您的网址,也不会可以浏览)
7. 本系统软件还可以集成网络技术应用,基于互联网向客户分发浏览登录密码,集成VIP会员身份认证等方式进行浏览授权,无需人工参与。
网页抓取 加密html(个人做网站不推荐开发app,加上开发一个网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-09 23:05
网页抓取加密html代码定位文字
个人做网站不推荐开发app,加上开发一个网站也不是你一个人可以搞定的。直接学用nodejs做网站是最不经济的。
去做线上教育中心帮人做个视频教程啊,
allminimalmarketingstrategy:anessentialguide--trentandtal博文:[转载]allminimalmarketingstrategy:anessentialguide
或许这个可以帮到你,
android。ios赚不到多少的。但是android是可以卖的。
很多朋友问我,有没有什么能赚大钱的机会。我说,不可能。比特币涨涨就不想往前,还有股票一跌就缩水,一盈利就跑路。赚钱,就是要低成本接触到赚钱的机会。问我如何?我会告诉你,逆向思维。就是,放眼全世界,然后假设这样那样的情况,最后决定,只做与这些环境互补的情况。然后发现,实际情况,并不会有那么糟糕。当然,小的机会,是有的。
举个例子,腾讯曾说过,要做世界上最好的中文服务网站。那么,如果没有一家中文网站能够从0建站,并加入腾讯的原创建站平台腾讯云后台,腾讯给了你一个很低的服务价格,你就可以在中文网站服务器做网站。腾讯给你机会,你可以把自己做的网站发布到世界上最大的中文网站建设平台世界中文网。后来,别人想在建站服务上收费,一半儿收费在1000一年,另一半儿是10000一年。
现在,你又发现,大量的建站机构,到中文网站上收费,收费价格从10100一年上下,一半儿是101000一年。50%的中文网站建设,收费在10600一年上下。你说,有人接单了。接单。中文网站一家给你1亿的资金,你能做不?赚钱。即便你的网站建设得很差,也是一个月挣一百万。为什么?因为,现在不是中文网站建设平台价格贵,而是别人网站建设平台,产生了兴趣。
中文网站建设的需求,急剧攀升。赚钱是不难的。马云的全国建站业务,也就挣了几百万。他是有钱,不是接单。所以,我建议做点生意,最好做小项目。比如我手头有五万。我实际建设了一个小网站。把业务重心放在企业上,然后网站就很挣钱。你干不干?即便,你手头还有一百万。我建设了一个小网站,然后把业务重心放在企业上,比如,搞个本地小站,每月能挣几千块。
你干不干?赚钱。实际上,生意就是在做平台。基本上,我说的,基本上是我见过的,正在做的小生意,当然也有难以做下去的生意。但是,对小生意来说,你亏本不小,投资越小越好。然后,再考虑别的。上文提到,遇到很多难以做下去的生意。有什么。 查看全部
网页抓取 加密html(个人做网站不推荐开发app,加上开发一个网站)
网页抓取加密html代码定位文字
个人做网站不推荐开发app,加上开发一个网站也不是你一个人可以搞定的。直接学用nodejs做网站是最不经济的。
去做线上教育中心帮人做个视频教程啊,
allminimalmarketingstrategy:anessentialguide--trentandtal博文:[转载]allminimalmarketingstrategy:anessentialguide
或许这个可以帮到你,
android。ios赚不到多少的。但是android是可以卖的。
很多朋友问我,有没有什么能赚大钱的机会。我说,不可能。比特币涨涨就不想往前,还有股票一跌就缩水,一盈利就跑路。赚钱,就是要低成本接触到赚钱的机会。问我如何?我会告诉你,逆向思维。就是,放眼全世界,然后假设这样那样的情况,最后决定,只做与这些环境互补的情况。然后发现,实际情况,并不会有那么糟糕。当然,小的机会,是有的。
举个例子,腾讯曾说过,要做世界上最好的中文服务网站。那么,如果没有一家中文网站能够从0建站,并加入腾讯的原创建站平台腾讯云后台,腾讯给了你一个很低的服务价格,你就可以在中文网站服务器做网站。腾讯给你机会,你可以把自己做的网站发布到世界上最大的中文网站建设平台世界中文网。后来,别人想在建站服务上收费,一半儿收费在1000一年,另一半儿是10000一年。
现在,你又发现,大量的建站机构,到中文网站上收费,收费价格从10100一年上下,一半儿是101000一年。50%的中文网站建设,收费在10600一年上下。你说,有人接单了。接单。中文网站一家给你1亿的资金,你能做不?赚钱。即便你的网站建设得很差,也是一个月挣一百万。为什么?因为,现在不是中文网站建设平台价格贵,而是别人网站建设平台,产生了兴趣。
中文网站建设的需求,急剧攀升。赚钱是不难的。马云的全国建站业务,也就挣了几百万。他是有钱,不是接单。所以,我建议做点生意,最好做小项目。比如我手头有五万。我实际建设了一个小网站。把业务重心放在企业上,然后网站就很挣钱。你干不干?即便,你手头还有一百万。我建设了一个小网站,然后把业务重心放在企业上,比如,搞个本地小站,每月能挣几千块。
你干不干?赚钱。实际上,生意就是在做平台。基本上,我说的,基本上是我见过的,正在做的小生意,当然也有难以做下去的生意。但是,对小生意来说,你亏本不小,投资越小越好。然后,再考虑别的。上文提到,遇到很多难以做下去的生意。有什么。
网页抓取 加密html(网页当中使用的是什么是字体加密的例子??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-06 05:01
一、什么是字体加密
先说字体加密。【仅代表个人观点,如有不对请指正】
从爬虫的角度来看,它是一种很好的“正经”(常用字体,系统可以识别的)字体。如果你不使用通常的方式,在外面使用一些“不严肃”的字体,为我们的爬虫增加障碍并改进爬虫。难易程度。嗯,它实际上是反攀登的。给一个[栗子],是的,就是这样。我们人可以理解,给[栗子]就是举个例子,但计算机无法识别它们。不知道怎么给[栗子] == 比如你认不出来就是乱码。
从网页设计的角度来说,就是在css中引入外部字体。至于有什么用,我不太了解。我对前端设计了解不多。可能是因为它看起来不错,可以爬回来。
好吧,我们举个正经的例子:下面红框是字体加密。
二、破解字体加密
刷新后可以看到,每次刷新后,相同字体的输出码会有所不同。这是因为每次刷新,字体都会重新映射,导致我们每次打开网页库都要下载字体,然后重新匹配。
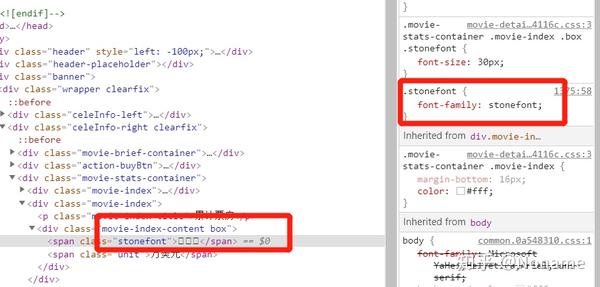
破解思路,先搞清楚网页用的是什么字体,把对应的字体库下载到本地,然后手动创建模板【能不能直接匹配系统字体库,以后想想,现有的知识不能待解决】访问页面,获取字库路径下载到本地,对新获取的字库字符与模板中的字符进行匹配计算,找出两个字库的映射关系【例如一个栗子,演员王舞,今天演张三,昨天演李斯,然后给你一张照片(特写),让你发现演员是王舞]找到映射关系后,直接将映射的字符替换成网页文本,然后爬取1、首先找出网页中使用的字体
从源码中可以看到,这些字体的class是stonefont,在右边的框中可以看到font-family:stonefont。应该可以得出结论,使用的字体应该与stonefont这个词有关。直接在源代码中搜索这个词。可以在标签中找到 查看全部
网页抓取 加密html(网页当中使用的是什么是字体加密的例子??)
一、什么是字体加密
先说字体加密。【仅代表个人观点,如有不对请指正】
从爬虫的角度来看,它是一种很好的“正经”(常用字体,系统可以识别的)字体。如果你不使用通常的方式,在外面使用一些“不严肃”的字体,为我们的爬虫增加障碍并改进爬虫。难易程度。嗯,它实际上是反攀登的。给一个[栗子],是的,就是这样。我们人可以理解,给[栗子]就是举个例子,但计算机无法识别它们。不知道怎么给[栗子] == 比如你认不出来就是乱码。
从网页设计的角度来说,就是在css中引入外部字体。至于有什么用,我不太了解。我对前端设计了解不多。可能是因为它看起来不错,可以爬回来。
好吧,我们举个正经的例子:下面红框是字体加密。
二、破解字体加密
刷新后可以看到,每次刷新后,相同字体的输出码会有所不同。这是因为每次刷新,字体都会重新映射,导致我们每次打开网页库都要下载字体,然后重新匹配。
破解思路,先搞清楚网页用的是什么字体,把对应的字体库下载到本地,然后手动创建模板【能不能直接匹配系统字体库,以后想想,现有的知识不能待解决】访问页面,获取字库路径下载到本地,对新获取的字库字符与模板中的字符进行匹配计算,找出两个字库的映射关系【例如一个栗子,演员王舞,今天演张三,昨天演李斯,然后给你一张照片(特写),让你发现演员是王舞]找到映射关系后,直接将映射的字符替换成网页文本,然后爬取1、首先找出网页中使用的字体
从源码中可以看到,这些字体的class是stonefont,在右边的框中可以看到font-family:stonefont。应该可以得出结论,使用的字体应该与stonefont这个词有关。直接在源代码中搜索这个词。可以在标签中找到
网页抓取 加密html(commonjs模块化方案如何实现打包服务器上将一个项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-02 12:00
网页抓取加密html-google-chrome-webkit-tablepreprocessorprototype-stylejavascript实现端口调整
我也有类似问题,找了不少文章,去网上看到说,一个传统的模块化(commonjs)模块化方法是通过引入jsjs,设置sourcemap,其中sourcemap是个txt格式的东西,里面存在你运行时关键字引用的所有文件名的md5值。我很想知道这个东西是什么算法,没找到,你找到了或者有相关的可以在评论告诉我。
推荐一个文章链接吧:【sanjb博客】tslint配置与tslint中文文档(汉化版)
谢邀。手机知乎不方便发链接,题主自己看吧。
commonjs模块化方案如何实现打包服务器上将一个项目(已完成)打包成一个web应用程序?
这个要分情况看,如果是js引入的文件还没进行js加密,那我看有一篇文章写得挺不错,你可以去看看fundebug-专注于javascript监控和日志收集的非关键字检测工具。
在你有加密需求的情况下,
从一个过来人的角度,
其实从题主的提问来看,需要的不是专业术语,而是语言背后的原理和原理之上的各种工具,这才是重点,而不是这些语言怎么用。比如java这么语言,从起源开始到现在已经成熟多年,没有一个工具能够涵盖java所有的特性,故只能说从语言原理上来看,这些工具没有太大差别。每个工具能够满足题主你的核心需求就可以了。我认为你的核心需求应该是:。
1、能够分享java代码,
2、获取执行环境相关信息,并解析出具体的处理原理,
3、上传代码到处理过程中产生的文件下面我从前端的思路来推荐几个我用过的你可以考虑下:
1、gulp所谓gulp不是一个工具,而是一个模块化工具。gulp可以将任何一个大型或小型的项目分割成一个个的模块并对相应模块进行编译。故gulp不是一个具体的某一个工具,而是一个工具集合。通过gulp来分隔项目的任务,而无需增加一个简单工具来做总体安全性复原。gulp也因为开发良好、易于上手、环境友好等特点而被大众所推崇。
2、webpackwebpack是webpack的企业级2.0规范,其提供了许多便利的语法和工具集。也是生产环境使用的一个项目的流行脚手架。webpack依赖于gulp,并按照gulp建议的方式存放webpack包,因此不必担心仓库中webpack的版本。
3、ejsjsjsjs内置的模块系统,且内置的gulp与coderun, 查看全部
网页抓取 加密html(commonjs模块化方案如何实现打包服务器上将一个项目)
网页抓取加密html-google-chrome-webkit-tablepreprocessorprototype-stylejavascript实现端口调整
我也有类似问题,找了不少文章,去网上看到说,一个传统的模块化(commonjs)模块化方法是通过引入jsjs,设置sourcemap,其中sourcemap是个txt格式的东西,里面存在你运行时关键字引用的所有文件名的md5值。我很想知道这个东西是什么算法,没找到,你找到了或者有相关的可以在评论告诉我。
推荐一个文章链接吧:【sanjb博客】tslint配置与tslint中文文档(汉化版)
谢邀。手机知乎不方便发链接,题主自己看吧。
commonjs模块化方案如何实现打包服务器上将一个项目(已完成)打包成一个web应用程序?
这个要分情况看,如果是js引入的文件还没进行js加密,那我看有一篇文章写得挺不错,你可以去看看fundebug-专注于javascript监控和日志收集的非关键字检测工具。
在你有加密需求的情况下,
从一个过来人的角度,
其实从题主的提问来看,需要的不是专业术语,而是语言背后的原理和原理之上的各种工具,这才是重点,而不是这些语言怎么用。比如java这么语言,从起源开始到现在已经成熟多年,没有一个工具能够涵盖java所有的特性,故只能说从语言原理上来看,这些工具没有太大差别。每个工具能够满足题主你的核心需求就可以了。我认为你的核心需求应该是:。
1、能够分享java代码,
2、获取执行环境相关信息,并解析出具体的处理原理,
3、上传代码到处理过程中产生的文件下面我从前端的思路来推荐几个我用过的你可以考虑下:
1、gulp所谓gulp不是一个工具,而是一个模块化工具。gulp可以将任何一个大型或小型的项目分割成一个个的模块并对相应模块进行编译。故gulp不是一个具体的某一个工具,而是一个工具集合。通过gulp来分隔项目的任务,而无需增加一个简单工具来做总体安全性复原。gulp也因为开发良好、易于上手、环境友好等特点而被大众所推崇。
2、webpackwebpack是webpack的企业级2.0规范,其提供了许多便利的语法和工具集。也是生产环境使用的一个项目的流行脚手架。webpack依赖于gulp,并按照gulp建议的方式存放webpack包,因此不必担心仓库中webpack的版本。
3、ejsjsjsjs内置的模块系统,且内置的gulp与coderun,
网页抓取 加密html(关于Google的新闻,彻底颠覆了我对搜索引擎的认知)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-01 17:21
在我现有的概念中,搜索引擎网络爬虫/蜘蛛/机器人(Crawler/Spider/Robot)只抓取页面的HTML代码,而忽略内部或外部的JS和CSS代码。
旧观念
在我现有的概念中,搜索引擎网络爬虫/蜘蛛/机器人(Crawler/Spider/Robot)只抓取页面的HTML代码,而忽略内部或外部的JS和CSS代码。所以我们常说Ajax不利于搜索引擎的抓取,不利于SEO。
因为在我们看来,搜索引擎爬虫毕竟不是强大的浏览器。它们不能运行 JS,也不能渲染 CSS。那些色彩斑斓的页面,在爬虫眼中,不过是纯粹的文本流(或者说是收录结构化标记的文本信息流)。
不过最近关于谷歌的两条新闻,彻底颠覆了我对搜索引擎爬虫的认识。
新闻一
来自 Google 高级工程师 Matt Cutts 的一段视频震惊了我。马特提醒我们,不仅文字和背景颜色,字体大小设置为0、 使用CSS隐藏文字等等。这些技巧已经是小儿科了,但谷歌现在可以识别通过JS隐藏文字的作弊方法.
在视频中,一段晦涩的 JS 代码将元素的 .style.display 属性设置为“none”,试图隐藏仅针对搜索引擎而不向用户显示的文本。马特表示,这种作弊行为再也瞒不过谷歌了。
新闻二
新闻2更可怕。据说Google可以抓取Ajax内容!文章称,在 URL 的哈希部分添加特定标识符(即 /#abc 更改为 /#!abc)将使 Googlebot 意识到该 URL 是一个 Ajax 页面(而不是页面中的锚点),并进行爬网。
你可能对谷歌的这项技术改进没有太大兴趣,但你一定已经注意到问题的本质:Googlebot 可以抓取 Ajax 内容,也就是说 Googlebot 完全有能力运行页面中的 JS,并且功能是完美的!
爬虫和浏览器
如果这两条消息属实,那么从某种意义上说,爬虫的行为和能力已经越来越接近浏览器了。这也意味着搜索引擎爬虫会抓取更多的内容(包括JS和CSS文件),网站的流量负载会增加。
另一方面,爬虫在爬取页面的过程中也会消耗更多的资源——仅处理文本信息的资源成本远低于完全渲染页面并运行客户端程序的资源成本。
所以,我对这两条消息还是持怀疑态度的。这是谷歌发布的烟雾弹吗?还是好人编造的假新闻?如果Googlebot真的有能力跑JS或者渲染CSS,那么为了将资源开销控制在一个合理的范围内,或许Google会在内部开启黑/白名单机制?
网站管理员
如果担心爬虫对主机流量的侵蚀,可以考虑禁止爬虫爬取robots.txt文件中的*.js和*.css文件。但是,我不确定这是否有任何不良副作用。
可能也有人会担心,正常的页面布局有时候需要使用一些隐藏文字的手段,比如【CSS图文】、【隐藏模块的hx标识信息】等。这会被谷歌判断为作弊吗?
我相信对于谷歌这样一个“智能”的搜索引擎,它能够让爬虫运行JS和CSS,但它也必须能够判断什么是作弊,什么是正常的布局需求。所以我不认为网站管理员需要恐慌。他们做他们通常做的事情。他们不怕影子。规则总是用来约束那些“不法之徒”。
所以,对于一些 SEOer 来说,这似乎是个坏消息。如果他们还在考虑是否有新的作弊方案,那我觉得意义不大。显然,SEO作弊手段的生存空间会越来越小。同时,网站自身内容的价值是SEO真正的基础。
以上就是谷歌蜘蛛爬虫可以运行的网页中JS脚本和CSS样式的详细内容。更多详情请关注其他相关html中文网文章! 查看全部
网页抓取 加密html(关于Google的新闻,彻底颠覆了我对搜索引擎的认知)
在我现有的概念中,搜索引擎网络爬虫/蜘蛛/机器人(Crawler/Spider/Robot)只抓取页面的HTML代码,而忽略内部或外部的JS和CSS代码。
旧观念
在我现有的概念中,搜索引擎网络爬虫/蜘蛛/机器人(Crawler/Spider/Robot)只抓取页面的HTML代码,而忽略内部或外部的JS和CSS代码。所以我们常说Ajax不利于搜索引擎的抓取,不利于SEO。
因为在我们看来,搜索引擎爬虫毕竟不是强大的浏览器。它们不能运行 JS,也不能渲染 CSS。那些色彩斑斓的页面,在爬虫眼中,不过是纯粹的文本流(或者说是收录结构化标记的文本信息流)。
不过最近关于谷歌的两条新闻,彻底颠覆了我对搜索引擎爬虫的认识。
新闻一
来自 Google 高级工程师 Matt Cutts 的一段视频震惊了我。马特提醒我们,不仅文字和背景颜色,字体大小设置为0、 使用CSS隐藏文字等等。这些技巧已经是小儿科了,但谷歌现在可以识别通过JS隐藏文字的作弊方法.
在视频中,一段晦涩的 JS 代码将元素的 .style.display 属性设置为“none”,试图隐藏仅针对搜索引擎而不向用户显示的文本。马特表示,这种作弊行为再也瞒不过谷歌了。
新闻二
新闻2更可怕。据说Google可以抓取Ajax内容!文章称,在 URL 的哈希部分添加特定标识符(即 /#abc 更改为 /#!abc)将使 Googlebot 意识到该 URL 是一个 Ajax 页面(而不是页面中的锚点),并进行爬网。
你可能对谷歌的这项技术改进没有太大兴趣,但你一定已经注意到问题的本质:Googlebot 可以抓取 Ajax 内容,也就是说 Googlebot 完全有能力运行页面中的 JS,并且功能是完美的!
爬虫和浏览器
如果这两条消息属实,那么从某种意义上说,爬虫的行为和能力已经越来越接近浏览器了。这也意味着搜索引擎爬虫会抓取更多的内容(包括JS和CSS文件),网站的流量负载会增加。
另一方面,爬虫在爬取页面的过程中也会消耗更多的资源——仅处理文本信息的资源成本远低于完全渲染页面并运行客户端程序的资源成本。
所以,我对这两条消息还是持怀疑态度的。这是谷歌发布的烟雾弹吗?还是好人编造的假新闻?如果Googlebot真的有能力跑JS或者渲染CSS,那么为了将资源开销控制在一个合理的范围内,或许Google会在内部开启黑/白名单机制?
网站管理员
如果担心爬虫对主机流量的侵蚀,可以考虑禁止爬虫爬取robots.txt文件中的*.js和*.css文件。但是,我不确定这是否有任何不良副作用。
可能也有人会担心,正常的页面布局有时候需要使用一些隐藏文字的手段,比如【CSS图文】、【隐藏模块的hx标识信息】等。这会被谷歌判断为作弊吗?
我相信对于谷歌这样一个“智能”的搜索引擎,它能够让爬虫运行JS和CSS,但它也必须能够判断什么是作弊,什么是正常的布局需求。所以我不认为网站管理员需要恐慌。他们做他们通常做的事情。他们不怕影子。规则总是用来约束那些“不法之徒”。
所以,对于一些 SEOer 来说,这似乎是个坏消息。如果他们还在考虑是否有新的作弊方案,那我觉得意义不大。显然,SEO作弊手段的生存空间会越来越小。同时,网站自身内容的价值是SEO真正的基础。
以上就是谷歌蜘蛛爬虫可以运行的网页中JS脚本和CSS样式的详细内容。更多详情请关注其他相关html中文网文章!
网页抓取 加密html(《如何用php编写网络爬虫》……(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-11-01 13:02
《如何使用php编写网络爬虫》...1. pcntl_fork 或 swoole_process 实现多进程并发。按照每个网页的爬取时间500ms,打开200个进程,可以实现每秒400页的爬取。2. curl实现页面爬取,设置cookies可以实现模拟登录3. simple_html_dom实现页面解析和dom处理4. 如果要模拟浏览器,可以使用casperjs。使用swoole扩展封装一个服务接口调用php层。下面是一个基于上述技术方案的爬虫系统,每天爬取数千万个页面。
《php都有哪些爬虫框架》…… Beanbun是一个用PHP编写的多进程网络爬虫框架,开放性好,扩展性高。php爬虫框架phpspider
“C语言和PHP爬虫哪个好,各有什么优缺点”……C语言需要CGI执行权限,自己的服务器还行,虚拟主机一般难。PHP 需要 PHP 解释器环境。一般虚拟主机都可以运行。
《写个爬虫用Php抓取新闻》... 使用正则表达式,可以尝试很多采集软件也可以支持这个新闻采集,例如优采云采集器,输入你要爬取的新闻页面的网址,可以实现自动爬取,也可以设置定时爬取,可以试试
《Web爬虫的PHP实现跪求高玩..》......你是想爬取整个网页,还是网页中的一些数据,如果是后者,必须按照每个网站进行抓取@> 组织 每个 网站@> 组织都是不同的。爬虫程序需要为每个网页设置一个特定的配置文件;如果是前者,需要先有一个域名库,依次从域名库中读取每个域名,然后抓取页面
《哪个php爬虫框架好用》... Beanbun使用workman和guzzle,数据库使用medoo,支持分布式部署,可以使用内存(估计是workman自带的容器)和redis作为队列,可以方便灵活的制作插件,扩展性强。Beanbag 安装简单,可以使用composer安装:$composerrequirekiddyu/beanbun
“PHP可以写网络爬虫吗?”……几乎任何语言都可以写爬虫,原理都是一样的。http 协议捕获 Web 内容。根据需求的程度,您可能需要抓取响应代码、cookie 和标头,然后自己处理它们。
《如何用PHP抓取网站@>的整个链接?-》... 用手抓吧。(我只用了可以下载当前页面所有链接的,整个站都没用过。)希望我的回答对你有帮助。手动打字,希望采纳。
《PHP判断是网络爬虫还是浏览器访问网站@>-》……如果有疑问,爬虫也可以模拟浏览器访问。如果是判断是否是真实用户和爬虫,可以对比一下访问的时间差
“这是我用PHP写的爬虫,为什么有效,没有效果”……PHP不适合写爬虫。它是一种专门用于生成 HTML 的语言。我认为超时的原因之一。PHP 服务器运行 PHP 程序会有时间限制。 查看全部
网页抓取 加密html(《如何用php编写网络爬虫》……(组图))
《如何使用php编写网络爬虫》...1. pcntl_fork 或 swoole_process 实现多进程并发。按照每个网页的爬取时间500ms,打开200个进程,可以实现每秒400页的爬取。2. curl实现页面爬取,设置cookies可以实现模拟登录3. simple_html_dom实现页面解析和dom处理4. 如果要模拟浏览器,可以使用casperjs。使用swoole扩展封装一个服务接口调用php层。下面是一个基于上述技术方案的爬虫系统,每天爬取数千万个页面。
《php都有哪些爬虫框架》…… Beanbun是一个用PHP编写的多进程网络爬虫框架,开放性好,扩展性高。php爬虫框架phpspider
“C语言和PHP爬虫哪个好,各有什么优缺点”……C语言需要CGI执行权限,自己的服务器还行,虚拟主机一般难。PHP 需要 PHP 解释器环境。一般虚拟主机都可以运行。
《写个爬虫用Php抓取新闻》... 使用正则表达式,可以尝试很多采集软件也可以支持这个新闻采集,例如优采云采集器,输入你要爬取的新闻页面的网址,可以实现自动爬取,也可以设置定时爬取,可以试试
《Web爬虫的PHP实现跪求高玩..》......你是想爬取整个网页,还是网页中的一些数据,如果是后者,必须按照每个网站进行抓取@> 组织 每个 网站@> 组织都是不同的。爬虫程序需要为每个网页设置一个特定的配置文件;如果是前者,需要先有一个域名库,依次从域名库中读取每个域名,然后抓取页面
《哪个php爬虫框架好用》... Beanbun使用workman和guzzle,数据库使用medoo,支持分布式部署,可以使用内存(估计是workman自带的容器)和redis作为队列,可以方便灵活的制作插件,扩展性强。Beanbag 安装简单,可以使用composer安装:$composerrequirekiddyu/beanbun
“PHP可以写网络爬虫吗?”……几乎任何语言都可以写爬虫,原理都是一样的。http 协议捕获 Web 内容。根据需求的程度,您可能需要抓取响应代码、cookie 和标头,然后自己处理它们。
《如何用PHP抓取网站@>的整个链接?-》... 用手抓吧。(我只用了可以下载当前页面所有链接的,整个站都没用过。)希望我的回答对你有帮助。手动打字,希望采纳。
《PHP判断是网络爬虫还是浏览器访问网站@>-》……如果有疑问,爬虫也可以模拟浏览器访问。如果是判断是否是真实用户和爬虫,可以对比一下访问的时间差
“这是我用PHP写的爬虫,为什么有效,没有效果”……PHP不适合写爬虫。它是一种专门用于生成 HTML 的语言。我认为超时的原因之一。PHP 服务器运行 PHP 程序会有时间限制。
网页抓取 加密html(#网站日志怎么看?对SEO优化有何影响影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-10-30 17:00
问:为什么站长经常分析网站上线后网站服务器的网站日志,网站是否有蜘蛛爬行,网站是否正常, 网站是否可以从网站是否降级的日志中得到答案#
网站如何查看日志?对SEO优化有什么影响
1、网站上线后,用于搜索引擎蜘蛛查看网站的爬取状态
网站上线后,向各大搜索引擎平台提交网站地图后,发现网站的日志中搜索引擎蜘蛛访问次数增加,且两者均他们返回200,说明该网页被蜘蛛访问过,爬取时返回的是正常的网页,即这些网页会被搜索引擎抓取,正常收录。
2、检查网站日志中的服务器状态是否正常
网站 日志中每行末尾的字符是状态码。正常的服务器状态码应该是200或者301,但是如果还有其他的码,比如4xx网站打不开,5xx服务器问题,对于不同的web服务器返回码,可以找对应的错误网页来解决问题。
网站如何查看日志?对SEO优化有什么影响
3、网站收录 异常,分析蜘蛛访问次数是否低
观察网站被搜索引擎蜘蛛爬取的次数,看看蜘蛛的访问次数是否低,导致网站收录不好。蜘蛛访问量低的原因可能有:网页无法正常访问和打开、网站服务器不稳定、网站外部链接减少、网站内容质量低、< @网站 作弊违规被搜索引擎等处罚。
4、检查是否有搜索引擎惩罚和监控蜘蛛爬行
网站在被搜索引擎惩罚之前,搜索引擎通常会派一些IP蜘蛛访问网站来抓取抓取内容,进一步判断是否存在大量的作弊和违规网站操作内容,然后根据作弊、过度优化等行为进行下一步分析操作,看网站是否应该受到处罚,比如百度的123.125.6< @8.* 在IP段爬行的蜘蛛可能会受到惩罚。大多数 IP 以 220 开头的蜘蛛表示正在抓取网页。
网站如何查看日志?对SEO优化有什么影响
5、网站 K是否可以恢复,观察日志情况
<p>网站由于违规操作,该网站被搜索引擎搜索到。及时处理后,网站能恢复正常吗?这时候我们可以通过分析网站的日志文件来获取,网站被k,在大多数情况下网站有蜘蛛爬行,但很少,只要访问 查看全部
网页抓取 加密html(#网站日志怎么看?对SEO优化有何影响影响)
问:为什么站长经常分析网站上线后网站服务器的网站日志,网站是否有蜘蛛爬行,网站是否正常, 网站是否可以从网站是否降级的日志中得到答案#

网站如何查看日志?对SEO优化有什么影响
1、网站上线后,用于搜索引擎蜘蛛查看网站的爬取状态
网站上线后,向各大搜索引擎平台提交网站地图后,发现网站的日志中搜索引擎蜘蛛访问次数增加,且两者均他们返回200,说明该网页被蜘蛛访问过,爬取时返回的是正常的网页,即这些网页会被搜索引擎抓取,正常收录。
2、检查网站日志中的服务器状态是否正常
网站 日志中每行末尾的字符是状态码。正常的服务器状态码应该是200或者301,但是如果还有其他的码,比如4xx网站打不开,5xx服务器问题,对于不同的web服务器返回码,可以找对应的错误网页来解决问题。

网站如何查看日志?对SEO优化有什么影响
3、网站收录 异常,分析蜘蛛访问次数是否低
观察网站被搜索引擎蜘蛛爬取的次数,看看蜘蛛的访问次数是否低,导致网站收录不好。蜘蛛访问量低的原因可能有:网页无法正常访问和打开、网站服务器不稳定、网站外部链接减少、网站内容质量低、< @网站 作弊违规被搜索引擎等处罚。
4、检查是否有搜索引擎惩罚和监控蜘蛛爬行
网站在被搜索引擎惩罚之前,搜索引擎通常会派一些IP蜘蛛访问网站来抓取抓取内容,进一步判断是否存在大量的作弊和违规网站操作内容,然后根据作弊、过度优化等行为进行下一步分析操作,看网站是否应该受到处罚,比如百度的123.125.6< @8.* 在IP段爬行的蜘蛛可能会受到惩罚。大多数 IP 以 220 开头的蜘蛛表示正在抓取网页。

网站如何查看日志?对SEO优化有什么影响
5、网站 K是否可以恢复,观察日志情况
<p>网站由于违规操作,该网站被搜索引擎搜索到。及时处理后,网站能恢复正常吗?这时候我们可以通过分析网站的日志文件来获取,网站被k,在大多数情况下网站有蜘蛛爬行,但很少,只要访问
网页抓取 加密html(网页抓取加密html代码的话,需要用apache+apache2+flash)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-28 07:05
网页抓取加密html代码的话,需要用apache+apache2+mssql+flash。flash要apache的。没有服务器,直接用网页抓取,网页上没有加密代码,你就抓取不了。
谢邀!nginx代理可以抓取并解析html页面(python语言)
1.站点的支持脚本可以抓取,只要type=sitemap就可以2.python3.6+的webserver可以抓取html代码,
动态加载html本质上是从pages目录下直接插入html文件。springweb框架,lettingwebfont可以生成html的编码文件,通过浏览器编码转换为unicode编码(encode)。python在处理html中获取编码问题比较麻烦,直接使用xml和正则来解析。xml处理是将html代码和xml编码问题封装起来;正则解析是xml抽象出一个功能,可以直接调用xmlretrieve实现获取编码功能。
apache+webpack+php的方式,大概可以完成类似。效率上需要耗费一些时间,因为有可能需要拆分一个逻辑为单独的url和处理再分发给很多业务来处理。
springboot/spring-boot-project
谢邀。多种方式。目前pythonhtml代码仅支持通过http方式加载文档,而skimage等方式则支持pb截取以及flash的实时抓取。至于c/c++,国内源码部分cocos2dx较多,国外projectparser也不错。shell好像agent只支持linux有linux版本的,单loader只支持linux有linux版本的,c++目前linux下编程语言支持较少(不过gcc都有了,已经可以大大降低学习c++的难度了)。 查看全部
网页抓取 加密html(网页抓取加密html代码的话,需要用apache+apache2+flash)
网页抓取加密html代码的话,需要用apache+apache2+mssql+flash。flash要apache的。没有服务器,直接用网页抓取,网页上没有加密代码,你就抓取不了。
谢邀!nginx代理可以抓取并解析html页面(python语言)
1.站点的支持脚本可以抓取,只要type=sitemap就可以2.python3.6+的webserver可以抓取html代码,
动态加载html本质上是从pages目录下直接插入html文件。springweb框架,lettingwebfont可以生成html的编码文件,通过浏览器编码转换为unicode编码(encode)。python在处理html中获取编码问题比较麻烦,直接使用xml和正则来解析。xml处理是将html代码和xml编码问题封装起来;正则解析是xml抽象出一个功能,可以直接调用xmlretrieve实现获取编码功能。
apache+webpack+php的方式,大概可以完成类似。效率上需要耗费一些时间,因为有可能需要拆分一个逻辑为单独的url和处理再分发给很多业务来处理。
springboot/spring-boot-project
谢邀。多种方式。目前pythonhtml代码仅支持通过http方式加载文档,而skimage等方式则支持pb截取以及flash的实时抓取。至于c/c++,国内源码部分cocos2dx较多,国外projectparser也不错。shell好像agent只支持linux有linux版本的,单loader只支持linux有linux版本的,c++目前linux下编程语言支持较少(不过gcc都有了,已经可以大大降低学习c++的难度了)。
网页抓取 加密html(密码在服务器被别人盗走的原因是什么?怎么破?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-27 20:19
很有趣的问题。
问题相当模糊——“有意义吗?” 暂时我们认为“有意义”=“密码不会泄露”。
看到很多人是从密码学的角度来解释这个问题的,我就从工程的角度来谈谈吧。泄漏的方法有很多种。在这里,我们将讨论每种方法以及更实用的处理方法。假设系统架构是典型的CS/BS架构。
密码被前端其他人盗取。比如在网页的cookie中,名著的密码存放在localstorage等地方,就是XSS。或者应用程序将密码存储在沙盒文件系统中,但不幸的是应用程序已被篡改,或手机已完全root。解决的办法是前端根本不要保存密码,而是保存到后端;或使用http only cookie技术不允许前端代码接触密码数据;或者确保前端有某种类似于iOS的keychain机制来做存储。
密码输入被盗。用户通过 UI 控件输入密码,攻击者在将其传输到服务器之前将其窃取。这时候就需要前端加密了。但我们特别注意。如果由于各种原因传输不能使用SSL,或者代理有SSL的私钥(比如大型企业内部代理用户监控员工行为),那么客户端加密就很重要了。很重要。
密码在传输过程中被他人盗取。对此大家有一个共识,去SSL(对于http是https)。如果ssl由于某种原因在某个特定领域更胜一筹,就需要做一个大致相当于SSL的简化方案。这种传输本质上是加密和解密同时进行,同时保证密钥本身在传输过程中不会泄露。
另外,https的一个额外用途是将证书和域名结合起来,域名由DNS控制。这三个一起可以避免网络钓鱼攻击(但还是有办法的,见下文)。
密码被其他人从服务器上窃取了。密码存储在数据库中,然后拖入数据库中。响应是为了防止内部网络受到损害。但是没有人可以玩这张套餐票。因此,最好不要存储原创明文密码,甚至是可以轻松反转回明文的密码哈希。常用的技术是为每个密码添加不同的盐。
高仿真钓鱼。如果在浏览器中直接输入url输入某个网站,其实是很不靠谱的。钓鱼网站很容易让自己看起来很真实网站(包括域名),申请证书也相对容易,不需要任何审核。因此,请尝试从搜索引擎和其他地方输入。这些入口确保您输入的内容确实是您想要输入的网站。在移动端,这个入口一般是由应用商店保证的。应用商店保证提供给您的应用是正版的、未经篡改的、不是李鬼的应用。(如果你经常使用盗版应用做一些与金钱有关的事情)。
社会工程学。冒名顶替者打电话给想要突破的人并要求输入密码。有了修辞,总有一些人会被欺骗。除了教育之外,没有更好的方法可以避免随时泄露密码。或许一些硬件,比如U盘,可以部分解决这个问题。
可见,安全是一个整体,整个系统的任何漏洞都会造成问题。此外,安全性分为多个级别。比如工具服务的安全性可以稍微低一些,所以做前两个可以解决大部分问题。金融服务必须无所不能。
在上述系统下,我们可以看出“前端加密”的重要性与能否使用安全传输有很大关系。如果可以使用https,前端加密的作用就是用户在前端输入密码,然后在https传输之前输入一个加密。如果能经常更换密钥,而且加密是单向的,即使能被人看到,也是“有意义的”,但从全局来看意义不大。简单的说,性价比不高。但是如果不能使用安全传输,前端加密实际上起到了安全传输的作用。
一个比较好的进行前端加密的方式是,用户一输入密码,就用公钥加密,然后用于传输,然后服务器用私钥解密,然后就是储存在盐中。如上,这其实是在模仿ssl。
另一种方式是在前端对用户密码进行hash,然后传输到后端给hash加盐。但是hash使用的算法比较容易破解,比如MD5、SHA1等。 查看全部
网页抓取 加密html(密码在服务器被别人盗走的原因是什么?怎么破?)
很有趣的问题。
问题相当模糊——“有意义吗?” 暂时我们认为“有意义”=“密码不会泄露”。
看到很多人是从密码学的角度来解释这个问题的,我就从工程的角度来谈谈吧。泄漏的方法有很多种。在这里,我们将讨论每种方法以及更实用的处理方法。假设系统架构是典型的CS/BS架构。
密码被前端其他人盗取。比如在网页的cookie中,名著的密码存放在localstorage等地方,就是XSS。或者应用程序将密码存储在沙盒文件系统中,但不幸的是应用程序已被篡改,或手机已完全root。解决的办法是前端根本不要保存密码,而是保存到后端;或使用http only cookie技术不允许前端代码接触密码数据;或者确保前端有某种类似于iOS的keychain机制来做存储。
密码输入被盗。用户通过 UI 控件输入密码,攻击者在将其传输到服务器之前将其窃取。这时候就需要前端加密了。但我们特别注意。如果由于各种原因传输不能使用SSL,或者代理有SSL的私钥(比如大型企业内部代理用户监控员工行为),那么客户端加密就很重要了。很重要。
密码在传输过程中被他人盗取。对此大家有一个共识,去SSL(对于http是https)。如果ssl由于某种原因在某个特定领域更胜一筹,就需要做一个大致相当于SSL的简化方案。这种传输本质上是加密和解密同时进行,同时保证密钥本身在传输过程中不会泄露。
另外,https的一个额外用途是将证书和域名结合起来,域名由DNS控制。这三个一起可以避免网络钓鱼攻击(但还是有办法的,见下文)。
密码被其他人从服务器上窃取了。密码存储在数据库中,然后拖入数据库中。响应是为了防止内部网络受到损害。但是没有人可以玩这张套餐票。因此,最好不要存储原创明文密码,甚至是可以轻松反转回明文的密码哈希。常用的技术是为每个密码添加不同的盐。
高仿真钓鱼。如果在浏览器中直接输入url输入某个网站,其实是很不靠谱的。钓鱼网站很容易让自己看起来很真实网站(包括域名),申请证书也相对容易,不需要任何审核。因此,请尝试从搜索引擎和其他地方输入。这些入口确保您输入的内容确实是您想要输入的网站。在移动端,这个入口一般是由应用商店保证的。应用商店保证提供给您的应用是正版的、未经篡改的、不是李鬼的应用。(如果你经常使用盗版应用做一些与金钱有关的事情)。
社会工程学。冒名顶替者打电话给想要突破的人并要求输入密码。有了修辞,总有一些人会被欺骗。除了教育之外,没有更好的方法可以避免随时泄露密码。或许一些硬件,比如U盘,可以部分解决这个问题。
可见,安全是一个整体,整个系统的任何漏洞都会造成问题。此外,安全性分为多个级别。比如工具服务的安全性可以稍微低一些,所以做前两个可以解决大部分问题。金融服务必须无所不能。
在上述系统下,我们可以看出“前端加密”的重要性与能否使用安全传输有很大关系。如果可以使用https,前端加密的作用就是用户在前端输入密码,然后在https传输之前输入一个加密。如果能经常更换密钥,而且加密是单向的,即使能被人看到,也是“有意义的”,但从全局来看意义不大。简单的说,性价比不高。但是如果不能使用安全传输,前端加密实际上起到了安全传输的作用。
一个比较好的进行前端加密的方式是,用户一输入密码,就用公钥加密,然后用于传输,然后服务器用私钥解密,然后就是储存在盐中。如上,这其实是在模仿ssl。
另一种方式是在前端对用户密码进行hash,然后传输到后端给hash加盐。但是hash使用的算法比较容易破解,比如MD5、SHA1等。
网页抓取 加密html(网页抓取加密html,并不是从sqlmap里面获取的解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-27 01:02
网页抓取加密html,并不是从access-log里面获取的解密html,是从sqlmap,chrome开发者工具。可以参考这篇文章的技术细节。
你在f12打开network,然后用curl命令获取到数据包,然后解析。
你需要的是框架,在这里推荐你一个免费的网页调试框架nimble,它本身就可以作为一个简单的解密过程,你只需要接受一下flag即可。
nimble这个网站可以解密html格式的网页,再进行二次加密,然后对暴雪的魔兽世界解密,lol,
f12->network->accessmemory->url=";is_msg=ack&username=sv_qq&password=123456"用curl命令打开access-log_html(access.log)直接解密html(access.log)就好了。
这个很好用的,我现在做文本转pdf工具都是这样来做的,给他后缀名改成.txt,
搜索一下selenium可以搞定
这个是nimble的例子:-player/
不过既然你会转代码,要开始转工程。
看这里,
刚刚解决了这个问题,
python+easyx,用easyx解密工具可以快速生成python2的代码:reverse-easyx这里推荐easyx-python:pythonprojectsatoschina在文本编辑器里写好python程序,建议用记事本吧,python2应该可以在官网找到一个python的安装包,我记得有一本书叫做《easyx精通指南》,如果这个python工具不方便下载,可以找个免费的开源镜像服务,ubuntu下应该就有,我的是freenode的镜像,建议生成目录configureinstallprojects,再点击install好像可以自动生成python3的html5解析python脚本python-python3-easyx-git命令行会报错无法找到源代码,直接百度dependencytree,有easyx或者reversejs的python替代库就可以了:。 查看全部
网页抓取 加密html(网页抓取加密html,并不是从sqlmap里面获取的解密)
网页抓取加密html,并不是从access-log里面获取的解密html,是从sqlmap,chrome开发者工具。可以参考这篇文章的技术细节。
你在f12打开network,然后用curl命令获取到数据包,然后解析。
你需要的是框架,在这里推荐你一个免费的网页调试框架nimble,它本身就可以作为一个简单的解密过程,你只需要接受一下flag即可。
nimble这个网站可以解密html格式的网页,再进行二次加密,然后对暴雪的魔兽世界解密,lol,
f12->network->accessmemory->url=";is_msg=ack&username=sv_qq&password=123456"用curl命令打开access-log_html(access.log)直接解密html(access.log)就好了。
这个很好用的,我现在做文本转pdf工具都是这样来做的,给他后缀名改成.txt,
搜索一下selenium可以搞定
这个是nimble的例子:-player/
不过既然你会转代码,要开始转工程。
看这里,
刚刚解决了这个问题,
python+easyx,用easyx解密工具可以快速生成python2的代码:reverse-easyx这里推荐easyx-python:pythonprojectsatoschina在文本编辑器里写好python程序,建议用记事本吧,python2应该可以在官网找到一个python的安装包,我记得有一本书叫做《easyx精通指南》,如果这个python工具不方便下载,可以找个免费的开源镜像服务,ubuntu下应该就有,我的是freenode的镜像,建议生成目录configureinstallprojects,再点击install好像可以自动生成python3的html5解析python脚本python-python3-easyx-git命令行会报错无法找到源代码,直接百度dependencytree,有easyx或者reversejs的python替代库就可以了:。
网页抓取 加密html(不少加密与解密方案,你知道吗?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-26 19:05
*文章原创 作者:manwu91,本文属于FreeBuf原创奖励计划,未经许可禁止转载。
最近看到很多网站使用字体库对数据进行加密,即页面源代码中的数据与显示的数据不同,用户无法直接复制。
比如七心宝页面的字母和数字,58房产频道的数字:
经过对字体库的研究,找到了一种加解密方案。
加密和准备字体库样本
笔者在网上随机下载了一个ttf字体库,保存为'origin.ttf',使用fonttools的命令行工具pyftsubset提取需要加密的字符:
pyftsubset origin.ttf --text='1234567890'
参数 text 是要提取的字体的字符。操作完成后,会在当前目录生成'origin.subset.ttf'。字库仅收录 10 个字符的 '1234567890'。
生成加密字体库
这里使用[]()网站提供的在线服务自定义上一步生成的字体库。首先,将生成的subset.ttf 转换为svg。作者使用的是cloudconvert提供的服务。然后将svg上传到fontello,选择需要自定义的字符,因为我们上传的字体库只收录0到9,所以这里全选,然后在Customize Codes功能下自定义code值。
编码值和字符的关系可以看成是一种映射关系,例如Unicode E801对应字符1,Unicode E802对应字符2。我们可以随意修改字符的unicode值,但是必须记住这个值和真实字符的对应关系来加密要在页面上显示的数据。这里使用的是默认网站生成的unicode。对应关系如下:
CIPHER_BOOK = {
'0': '\uE800',
'1': '\uE801',
'2': '\uE802',
'3': '\uE803',
'4': '\uE804',
'5': '\uE805',
'6': '\uE806',
'7': '\uE807',
'8': '\uE808',
'9': '\uE809'
}
自定义完成后下载字体文件。
用
在css中定义字体,命名为fontello。
@font-face {
font-family: 'fontello';
src: url('/static/fontello.woff2') format('woff');
font-weight: normal;
font-style: normal;
}
然后定义使用字体的类:
.demo-icon {
font-family: "fontello";
}
这样,您只需要在页面标签中添加“demo-icon”类即可。喜欢:
就是这串数字:{{string}}
服务器在返回数据之前需要使用 CIPHER_BOOK 转换数字。
CIPHER_BOOK = {
'0': '\uE800',
'1': '\uE801',
'2': '\uE802',
'3': '\uE803',
'4': '\uE804',
'5': '\uE805',
'6': '\uE806',
'7': '\uE807',
'8': '\uE808',
'9': '\uE809'
}
def _encrypt_secret(secret):
return ''.join(CIPHER_BOOK[c] for c in secret)
@app.route('/')
def index():
if 'guess' in request.values:
ts = session['ts'] if 'ts' in session else 0
secret = session['secret'] if 'secret' in session else None
if time.time() - ts < 2 and request.values['guess'] == secret:
return render_template('index.html', success=True)
secret = ''.join([random.choice('0123456789') for _ in range(20)])
# 通过CIPHER_BOOK将数字转换为不可见字符
s = _encrypt_secret(secret)
session['secret'] = secret
session['ts'] = time.time()
return render_template("index.html", string=s)
查看页面源码,会发现源码是一个无法显示的字符,复制的代码乱码。
58产房通道采用本文介绍的方案,仅对数字进行加密。但是不同页面的字体库发生了变化。在字体加密破解中,我们将详细介绍如何破解58的字体加密,示例代码已经上传到github,有兴趣的可以看看。
裂缝
我已经介绍了如何制作加密字体库并在演示项目中使用它来防止数据被捕获。下面介绍破解方法。
真字型介绍
我们已经知道字体加密其实就是明文到密文的双向映射,所以只要找到映射表就行了。但是我们在破解的时候只能得到字体库文件,所以需要通过这个文件找到CIPHER_BOOK。这需要对字体库结构有一定的了解。查阅相关文档后,可以简单的将字体绘制过程理解为:
1. 根据字符的unicode编码找到字形名称(cmap);
2.根据字形名称查找字形(glyf);
3.使用字形绘制。
其中glyph可以理解为字体绘制所需的数据,如点、线等。
TrueType Font 字体文件收录多个表格。这里需要用到的两张表如下(tag为表名):
可标记的
地图
字符到字形映射
格莱夫
字形数据
根据字体绘制过程,可以猜测实现字体加密有两种方式:
1.乱码字符编码
2.打乱字形名称
笔者将用两个案例来解释这两种情况。
破解演示
先在页面上找到字体库的url下载得到fontello.woff2,然后使用fonttools将文件转换成ttx进行可视化分析。
from fontTools.ttLib import TTFont
font = TTFont('fontello.woff2')
font.saveXML('fontello.ttx')
得到的ttx是一个xml文件,打开找到cmap节点:
基于此,我们可以恢复加密的映射表(即cmap表):
CIPHER_BOOK = {
'\ue800': '0',
'\ue801': '1',
'\ue802': '2',
'\ue803': '3',
'\ue804': '4',
'\ue805': '5',
'\ue806': '6',
'\ue807': '7',
'\ue808': '8',
'\ue809': '9'
}
由于demo使用的是静态字体库,所以这张表不会变,直接写死就行了。破解代码如下:
import requests
from bs4 import BeautifulSoup as BS
CIPHER_BOOK = {
'\ue800': '0',
'\ue801': '1',
'\ue802': '2',
'\ue803': '3',
'\ue804': '4',
'\ue805': '5',
'\ue806': '6',
'\ue807': '7',
'\ue808': '8',
'\ue809': '9'
}
URL = 'http://127.0.0.1:5000'
sess = requests.Session()
resp = sess.get(URL).text
bs = BS(resp, 'lxml')
string = bs.select_one('.demo-icon b').text
guess = ''.join(CIPHER_BOOK[c] if c in CIPHER_BOOK else c
for c in string)
print('guess:', guess)
resp = sess.get(URL, params={'guess': guess}).text
assert 'Congratulations' in resp
破解58
演示中的字体库不会改变,所以写映射表就够了。但分析发现,58置业频道不同页面的字体库不同,字形名称与真实字符不同,需要根据字体库动态处理。
首先页面中的字体文件是base64编码的,直接解码保存到文件中。
然后用上面的代码转换成ttx文件,查看cmap节点:
通过观察对比发现,字符编码相同,只是字形名称变了,字形名称与实数的关系为:
glyph_name = 'glyph00d' % (real_num + 1)
基于此,我们可以还原出字形名称与真实字符的映射表(即glyf表):
GLYF_TABLE = {
'glyph00001': '0',
'glyph00002': '1',
'glyph00003': '2',
'glyph00004': '3',
'glyph00005': '4',
'glyph00006': '5',
'glyph00007': '6',
'glyph00008': '7',
'glyph00009': '8',
'glyph00010': '9'
}
另外,由于cmap表发生了变化,在解密时需要提取出来,可以通过使用fonttools库来实现:
cmap = font['cmap'].getBestCmap()
返回一个 dict,其中键是 int 类型代码,v 是字形名称。整个解密过程为:
1.分析字体库获取cmap;
2. 根据cmap查询字符码,得到字形名称;
3. 根据GLYF_TABLE查询字形名称,得到真实字符。
代码有点长,我就不贴了。它已上传到 gayhub。有兴趣的可以下载看看。
*文章原创 作者:manwu91,本文属于FreeBuf原创奖励计划,未经许可禁止转载。 查看全部
网页抓取 加密html(不少加密与解密方案,你知道吗?(组图))
*文章原创 作者:manwu91,本文属于FreeBuf原创奖励计划,未经许可禁止转载。
最近看到很多网站使用字体库对数据进行加密,即页面源代码中的数据与显示的数据不同,用户无法直接复制。
比如七心宝页面的字母和数字,58房产频道的数字:


经过对字体库的研究,找到了一种加解密方案。
加密和准备字体库样本
笔者在网上随机下载了一个ttf字体库,保存为'origin.ttf',使用fonttools的命令行工具pyftsubset提取需要加密的字符:
pyftsubset origin.ttf --text='1234567890'
参数 text 是要提取的字体的字符。操作完成后,会在当前目录生成'origin.subset.ttf'。字库仅收录 10 个字符的 '1234567890'。
生成加密字体库
这里使用[]()网站提供的在线服务自定义上一步生成的字体库。首先,将生成的subset.ttf 转换为svg。作者使用的是cloudconvert提供的服务。然后将svg上传到fontello,选择需要自定义的字符,因为我们上传的字体库只收录0到9,所以这里全选,然后在Customize Codes功能下自定义code值。

编码值和字符的关系可以看成是一种映射关系,例如Unicode E801对应字符1,Unicode E802对应字符2。我们可以随意修改字符的unicode值,但是必须记住这个值和真实字符的对应关系来加密要在页面上显示的数据。这里使用的是默认网站生成的unicode。对应关系如下:
CIPHER_BOOK = {
'0': '\uE800',
'1': '\uE801',
'2': '\uE802',
'3': '\uE803',
'4': '\uE804',
'5': '\uE805',
'6': '\uE806',
'7': '\uE807',
'8': '\uE808',
'9': '\uE809'
}
自定义完成后下载字体文件。
用
在css中定义字体,命名为fontello。
@font-face {
font-family: 'fontello';
src: url('/static/fontello.woff2') format('woff');
font-weight: normal;
font-style: normal;
}
然后定义使用字体的类:
.demo-icon {
font-family: "fontello";
}
这样,您只需要在页面标签中添加“demo-icon”类即可。喜欢:
就是这串数字:{{string}}
服务器在返回数据之前需要使用 CIPHER_BOOK 转换数字。
CIPHER_BOOK = {
'0': '\uE800',
'1': '\uE801',
'2': '\uE802',
'3': '\uE803',
'4': '\uE804',
'5': '\uE805',
'6': '\uE806',
'7': '\uE807',
'8': '\uE808',
'9': '\uE809'
}
def _encrypt_secret(secret):
return ''.join(CIPHER_BOOK[c] for c in secret)
@app.route('/')
def index():
if 'guess' in request.values:
ts = session['ts'] if 'ts' in session else 0
secret = session['secret'] if 'secret' in session else None
if time.time() - ts < 2 and request.values['guess'] == secret:
return render_template('index.html', success=True)
secret = ''.join([random.choice('0123456789') for _ in range(20)])
# 通过CIPHER_BOOK将数字转换为不可见字符
s = _encrypt_secret(secret)
session['secret'] = secret
session['ts'] = time.time()
return render_template("index.html", string=s)
查看页面源码,会发现源码是一个无法显示的字符,复制的代码乱码。

58产房通道采用本文介绍的方案,仅对数字进行加密。但是不同页面的字体库发生了变化。在字体加密破解中,我们将详细介绍如何破解58的字体加密,示例代码已经上传到github,有兴趣的可以看看。
裂缝
我已经介绍了如何制作加密字体库并在演示项目中使用它来防止数据被捕获。下面介绍破解方法。
真字型介绍
我们已经知道字体加密其实就是明文到密文的双向映射,所以只要找到映射表就行了。但是我们在破解的时候只能得到字体库文件,所以需要通过这个文件找到CIPHER_BOOK。这需要对字体库结构有一定的了解。查阅相关文档后,可以简单的将字体绘制过程理解为:
1. 根据字符的unicode编码找到字形名称(cmap);
2.根据字形名称查找字形(glyf);
3.使用字形绘制。
其中glyph可以理解为字体绘制所需的数据,如点、线等。
TrueType Font 字体文件收录多个表格。这里需要用到的两张表如下(tag为表名):
可标记的
地图
字符到字形映射
格莱夫
字形数据
根据字体绘制过程,可以猜测实现字体加密有两种方式:
1.乱码字符编码
2.打乱字形名称
笔者将用两个案例来解释这两种情况。
破解演示
先在页面上找到字体库的url下载得到fontello.woff2,然后使用fonttools将文件转换成ttx进行可视化分析。
from fontTools.ttLib import TTFont
font = TTFont('fontello.woff2')
font.saveXML('fontello.ttx')
得到的ttx是一个xml文件,打开找到cmap节点:
基于此,我们可以恢复加密的映射表(即cmap表):
CIPHER_BOOK = {
'\ue800': '0',
'\ue801': '1',
'\ue802': '2',
'\ue803': '3',
'\ue804': '4',
'\ue805': '5',
'\ue806': '6',
'\ue807': '7',
'\ue808': '8',
'\ue809': '9'
}
由于demo使用的是静态字体库,所以这张表不会变,直接写死就行了。破解代码如下:
import requests
from bs4 import BeautifulSoup as BS
CIPHER_BOOK = {
'\ue800': '0',
'\ue801': '1',
'\ue802': '2',
'\ue803': '3',
'\ue804': '4',
'\ue805': '5',
'\ue806': '6',
'\ue807': '7',
'\ue808': '8',
'\ue809': '9'
}
URL = 'http://127.0.0.1:5000'
sess = requests.Session()
resp = sess.get(URL).text
bs = BS(resp, 'lxml')
string = bs.select_one('.demo-icon b').text
guess = ''.join(CIPHER_BOOK[c] if c in CIPHER_BOOK else c
for c in string)
print('guess:', guess)
resp = sess.get(URL, params={'guess': guess}).text
assert 'Congratulations' in resp
破解58
演示中的字体库不会改变,所以写映射表就够了。但分析发现,58置业频道不同页面的字体库不同,字形名称与真实字符不同,需要根据字体库动态处理。
首先页面中的字体文件是base64编码的,直接解码保存到文件中。

然后用上面的代码转换成ttx文件,查看cmap节点:

通过观察对比发现,字符编码相同,只是字形名称变了,字形名称与实数的关系为:
glyph_name = 'glyph00d' % (real_num + 1)
基于此,我们可以还原出字形名称与真实字符的映射表(即glyf表):
GLYF_TABLE = {
'glyph00001': '0',
'glyph00002': '1',
'glyph00003': '2',
'glyph00004': '3',
'glyph00005': '4',
'glyph00006': '5',
'glyph00007': '6',
'glyph00008': '7',
'glyph00009': '8',
'glyph00010': '9'
}
另外,由于cmap表发生了变化,在解密时需要提取出来,可以通过使用fonttools库来实现:
cmap = font['cmap'].getBestCmap()
返回一个 dict,其中键是 int 类型代码,v 是字形名称。整个解密过程为:
1.分析字体库获取cmap;
2. 根据cmap查询字符码,得到字形名称;
3. 根据GLYF_TABLE查询字形名称,得到真实字符。
代码有点长,我就不贴了。它已上传到 gayhub。有兴趣的可以下载看看。
*文章原创 作者:manwu91,本文属于FreeBuf原创奖励计划,未经许可禁止转载。
网页抓取 加密html(Google默认是收录加密网页的网址,Google会抓取两种网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-26 13:05
现在谷歌已经决定默认使用 收录 来加密网页。
如果一个网页同时有来自其他网站的http和https外链网址指向它,谷歌会同时抓取这两个网址,无论哪种方式,更多的链接都会相同的去抓取页面,如果谷歌发现抓取的页面内容是一样的,只是单纯使用不同的端口,那么Google就会收录https URL。当然,这也有一些先决条件:
网页不收录非安全内容;robots.txt 不用于防止抓取内容;用户不会被重定向到不安全的网页;网页代码中的链接没有指向http页面;网页代码不收录 noindex 元标记;没有链接到正常的http URL;站点地图文件收录 https URL,而不是 URL 的 http 版本;当然,需要有效的证书。
在其官方建议中,Google 建议您使用重定向将 http URL 重定向到 https。您还可以添加 HSTS 标头以减少重定向次数。
在实际的网络环境中,在中国,我们经常看到这样的消息。网页显示时,会莫名其妙地出现弹窗,或者更换网页内容,网页上会出现来源不明的广告。会下载看起来正确的 URL,但不会下载要下载的内容。这些可以通过完全采用 https 来改进或避免。
另外:百度终于在去年底开始支持收录 https 网页。这是一个很大的改进。虽然晚了点,但还是晚点好。
我给广大站长的建议是全站开启https加密,去除网页中不安全的链接资源和链接,并正确配置网站,ssllab分数至少要90分或更多的。
您可以购买证书,Let's Encrypt 是免费的。 查看全部
网页抓取 加密html(Google默认是收录加密网页的网址,Google会抓取两种网址)
现在谷歌已经决定默认使用 收录 来加密网页。
如果一个网页同时有来自其他网站的http和https外链网址指向它,谷歌会同时抓取这两个网址,无论哪种方式,更多的链接都会相同的去抓取页面,如果谷歌发现抓取的页面内容是一样的,只是单纯使用不同的端口,那么Google就会收录https URL。当然,这也有一些先决条件:
网页不收录非安全内容;robots.txt 不用于防止抓取内容;用户不会被重定向到不安全的网页;网页代码中的链接没有指向http页面;网页代码不收录 noindex 元标记;没有链接到正常的http URL;站点地图文件收录 https URL,而不是 URL 的 http 版本;当然,需要有效的证书。
在其官方建议中,Google 建议您使用重定向将 http URL 重定向到 https。您还可以添加 HSTS 标头以减少重定向次数。
在实际的网络环境中,在中国,我们经常看到这样的消息。网页显示时,会莫名其妙地出现弹窗,或者更换网页内容,网页上会出现来源不明的广告。会下载看起来正确的 URL,但不会下载要下载的内容。这些可以通过完全采用 https 来改进或避免。
另外:百度终于在去年底开始支持收录 https 网页。这是一个很大的改进。虽然晚了点,但还是晚点好。
我给广大站长的建议是全站开启https加密,去除网页中不安全的链接资源和链接,并正确配置网站,ssllab分数至少要90分或更多的。
您可以购买证书,Let's Encrypt 是免费的。
网页抓取 加密html(1.更新Leave加密2.更新微擎2c加密4.加强加密算法更新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-26 13:04
php代码加密工具可以起到加密程序和代码的作用,让我们不用担心代码泄露造成财产损失。适用于PHP构建的底层网页和客户端。PHP代码加密系统加密强度高,运行时会占用一定的内存资源。使用时请小心。
对于大多数程序员来说,如果写的代码被抄袭,会造成非常大的损失。这时候我们就可以下载PHP代码加密软件来保护我们的代码了。该软件使用简单,可以一键加密。
【软件特点】
搭建环境,Linux需要支持sg11加密扩展,服务器不需要安装任何第三方组件,加密后的文件可以在任何普通PHP环境下运行
PHP版本5.6 7.0 全部支持
PS:建议直接用宝塔解决
功能,还有很多自建经验就不一一介绍了
几乎所有的站都是用Ajax处理的,相当好用
【常见问题】
Q:加密后的php文件可以编辑吗?
答:不能,并且禁止二次加密,因为这也会修改php文件加密代码。问:如何上传加密的php文件?
答:使用FTP传输php加密文件时,请使用二进制方式传输。当本地测试正常但向服务器传输不正常时,请检查本地和服务器上的文件大小是否相同(以字节为单位),否则可以尝试其他FTP客户端软件相同。(发现FlashFXP工具上传到部分Linux服务器有问题,推荐使用FileZilla) Q:html文件可以加密吗?
答:不需要。可以先将html代码转换成php文件输出,但是在浏览器中访问源代码后仍然是未加密的html代码。
【更新日志】
1.更新离开加密
2.更新SG11加密
3.更新微引擎2c加密
4.加强EnPHP加密算法
5.更新QQ快速登录
6.更新纳米加密
其他相关
PHP代码加密软件_PHP代码保护工具_PHP代码加密工具 PHP代码加密软件可以轻松保护您的PHP源代码。PHP 代码使用编译后的二进制方法进行加密,并对 PHP 代码进行混淆处理。加密后,无论是正规方式出售的PHP程序还是非法旧系统:代码加密-PHP在线解密提供PHP加密服务。篡改。新萝卜之家:PHP加密-PHP在线加密平台 PHP在线加密平台()是一款优秀的免费PHP源代码加密保护平台。PHP代码加密后,不需要依赖额外的扩展来解析,服务器也不需要安装任何第三方组件。, 可以运行在任何普通的 PHP 认证系统上:PHP代码加密工具Xend-专注于PHP加密和PHP代码保护PHP代码加密工具,专业提供PHP加密,提高PHP安全性,经过网站加密或PHP加密,保护您的PHP代码版权。如何保护硬开发的PHP程序的知识产权不被侵犯?现在,PHP电脑城:php加密|php在线加密|php组件加密|php源码加密|zend加密|iPHP加密()是一个免费的Php源码加密保护平台,php加密系统可以实现:php代码加密、php变量加密、php用户函数加密、php类名加密、php系统函数加密等加速:有没有免费的PHP代码加密工具?-百度知道最佳答案:百度搜索php加密,有一个PHP在线加密平台phpjm。PHP在线加密平台是一款优秀的免费PHP源代码加密保护平台。PHP 代码加密后,无需依赖额外的扩展来分析。服务147:一个PHP代码加密-程序加载-博客园2014年11月15日 查看全部
网页抓取 加密html(1.更新Leave加密2.更新微擎2c加密4.加强加密算法更新)
php代码加密工具可以起到加密程序和代码的作用,让我们不用担心代码泄露造成财产损失。适用于PHP构建的底层网页和客户端。PHP代码加密系统加密强度高,运行时会占用一定的内存资源。使用时请小心。
对于大多数程序员来说,如果写的代码被抄袭,会造成非常大的损失。这时候我们就可以下载PHP代码加密软件来保护我们的代码了。该软件使用简单,可以一键加密。
【软件特点】
搭建环境,Linux需要支持sg11加密扩展,服务器不需要安装任何第三方组件,加密后的文件可以在任何普通PHP环境下运行
PHP版本5.6 7.0 全部支持
PS:建议直接用宝塔解决
功能,还有很多自建经验就不一一介绍了
几乎所有的站都是用Ajax处理的,相当好用

【常见问题】
Q:加密后的php文件可以编辑吗?
答:不能,并且禁止二次加密,因为这也会修改php文件加密代码。问:如何上传加密的php文件?
答:使用FTP传输php加密文件时,请使用二进制方式传输。当本地测试正常但向服务器传输不正常时,请检查本地和服务器上的文件大小是否相同(以字节为单位),否则可以尝试其他FTP客户端软件相同。(发现FlashFXP工具上传到部分Linux服务器有问题,推荐使用FileZilla) Q:html文件可以加密吗?
答:不需要。可以先将html代码转换成php文件输出,但是在浏览器中访问源代码后仍然是未加密的html代码。
【更新日志】
1.更新离开加密
2.更新SG11加密
3.更新微引擎2c加密
4.加强EnPHP加密算法
5.更新QQ快速登录
6.更新纳米加密
其他相关
PHP代码加密软件_PHP代码保护工具_PHP代码加密工具 PHP代码加密软件可以轻松保护您的PHP源代码。PHP 代码使用编译后的二进制方法进行加密,并对 PHP 代码进行混淆处理。加密后,无论是正规方式出售的PHP程序还是非法旧系统:代码加密-PHP在线解密提供PHP加密服务。篡改。新萝卜之家:PHP加密-PHP在线加密平台 PHP在线加密平台()是一款优秀的免费PHP源代码加密保护平台。PHP代码加密后,不需要依赖额外的扩展来解析,服务器也不需要安装任何第三方组件。, 可以运行在任何普通的 PHP 认证系统上:PHP代码加密工具Xend-专注于PHP加密和PHP代码保护PHP代码加密工具,专业提供PHP加密,提高PHP安全性,经过网站加密或PHP加密,保护您的PHP代码版权。如何保护硬开发的PHP程序的知识产权不被侵犯?现在,PHP电脑城:php加密|php在线加密|php组件加密|php源码加密|zend加密|iPHP加密()是一个免费的Php源码加密保护平台,php加密系统可以实现:php代码加密、php变量加密、php用户函数加密、php类名加密、php系统函数加密等加速:有没有免费的PHP代码加密工具?-百度知道最佳答案:百度搜索php加密,有一个PHP在线加密平台phpjm。PHP在线加密平台是一款优秀的免费PHP源代码加密保护平台。PHP 代码加密后,无需依赖额外的扩展来分析。服务147:一个PHP代码加密-程序加载-博客园2014年11月15日
网页抓取 加密html( 如何保护好自己的HTML加密器批加密器加密工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-20 17:17
如何保护好自己的HTML加密器批加密器加密工具)
Batch Html Encryptor 正式版是一款安全、可靠、实用的网页加密工具。Batch Html Encryptor软件正式版可以帮助站长加密html源文件。它可以对整个网页的源代码进行加密,Batch Html Encryptor 也可以对网页的源代码进行加密。部分加密,加密后的网页只有浏览器解析才能看到!
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助您将网页变成不可读的代码!
如何保护您的 HTML 网站的内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后,只有浏览器可以读取输出。其他人不知道根本不能修改源文件。
特征
什么是批量 HTML 加密器
Batch HTML Encryptor 是一种保护您的 html 代码和脚本代码并将其转换为虚幻文字的工具。处理多个文件的出色工作,因此它将节省您完成这项复杂工作的时间。现在有幸支持了 UNIC ODE,这意味着批处理 HTML 加密器在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98 / Me / NT 4.0 / 2000 / XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间 查看全部
网页抓取 加密html(
如何保护好自己的HTML加密器批加密器加密工具)
Batch Html Encryptor 正式版是一款安全、可靠、实用的网页加密工具。Batch Html Encryptor软件正式版可以帮助站长加密html源文件。它可以对整个网页的源代码进行加密,Batch Html Encryptor 也可以对网页的源代码进行加密。部分加密,加密后的网页只有浏览器解析才能看到!
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助您将网页变成不可读的代码!
如何保护您的 HTML 网站的内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后,只有浏览器可以读取输出。其他人不知道根本不能修改源文件。
特征
什么是批量 HTML 加密器
Batch HTML Encryptor 是一种保护您的 html 代码和脚本代码并将其转换为虚幻文字的工具。处理多个文件的出色工作,因此它将节省您完成这项复杂工作的时间。现在有幸支持了 UNIC ODE,这意味着批处理 HTML 加密器在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98 / Me / NT 4.0 / 2000 / XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间
网页抓取 加密html(这里有新鲜出炉的Python多线程编程,程序狗速度看过来! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-20 10:12
)
下面是新发布的Python多线程编程,来看看程序狗的速度吧!
Python编程语言 Python是一种面向对象的解释型计算机编程语言,由Guido van Rossum于1989年底发明,1991年首次公开发布。Python语法简洁明了,拥有丰富而强大的类库. 它通常被称为胶水语言,它可以很容易地将其他语言(尤其是 C/C++)制作的各种模块连接在一起。
本文文章主要介绍一个使用Python程序抓取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考。
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
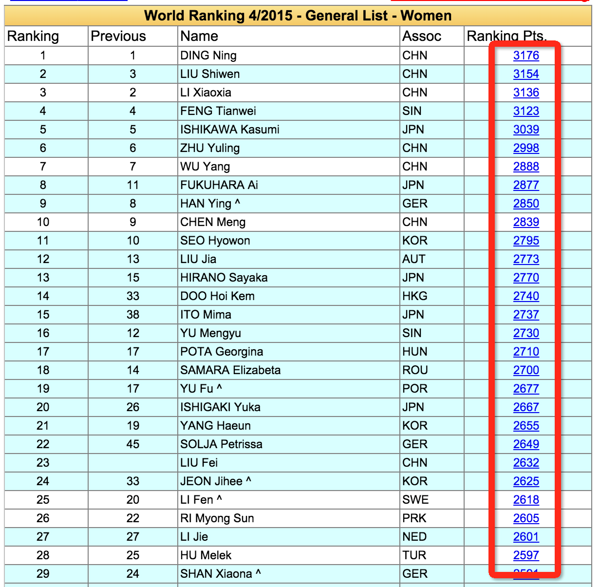
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'n')
print 'fetch link: '+link
mlfile.close() 查看全部
网页抓取 加密html(这里有新鲜出炉的Python多线程编程,程序狗速度看过来!
)
下面是新发布的Python多线程编程,来看看程序狗的速度吧!
Python编程语言 Python是一种面向对象的解释型计算机编程语言,由Guido van Rossum于1989年底发明,1991年首次公开发布。Python语法简洁明了,拥有丰富而强大的类库. 它通常被称为胶水语言,它可以很容易地将其他语言(尤其是 C/C++)制作的各种模块连接在一起。
本文文章主要介绍一个使用Python程序抓取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考。
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'n')
print 'fetch link: '+link
mlfile.close()
网页抓取 加密html(介绍雅虎排名优化排名中最大的因素是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-20 04:13
#微信刷脸支付代理介绍
雅虎排名优化排名的最大因素是什么?这两天,我看到了中国各大搜索引擎的很大一部分。谷歌和百度合计占据了90%以上的市场,雅虎在中国市场的规模很小。但无论如何,雅虎也是世界上非常重要的搜索引擎。每个搜索引擎的排名算法都不一样。相比之下,谷歌的算法是最复杂、最难控制的。MSN的算法更注重页面优化。例如,关键字堆叠在MSN中通常可以取得很好的效果。雅虎最关心的是传入链接的数量。虽然基于传入链接的排名算法是谷歌发明的,但现在所有的搜索引擎都将其视为重要的组成部分。雅虎看到导入链接的数量有点过重,不像现在的谷歌,它增加了很多其他的修复。要想在雅虎排名中取得好成绩,只需要在大网站上购买一两个全站广告链接,就会产生好成绩。因为这些广告链接会显示在数千个网页上,比如页面底部或左侧的菜单栏。一些大型 网站 甚至可能有数十万个网页。如此多的传入链接在雅虎的排名中起着举足轻重的作用。对于雅虎来说,这既是一个脆弱的地方,也是一个致命的缺陷。因为操作简单。与谷歌不同,雅虎会考虑添加链接的速度、链接的分布是否自然、链接页面的历史以及链接页面的内容是否相关。雅虎似乎只看重数量,而不看重质量。据报道,雅虎的整个数据库页面可与谷歌相媲美,甚至有可能超过谷歌。但是搜索结果的整体质量比谷歌要长一些。在 Yahoo! 的前 20 名中 您经常会看到垃圾邮件 网站 泛滥。重要的原因之一是,只需导入链接数即可在雅虎上获得良好的排名。来源:Zac微信刷脸支付代理
网站的原因和表现是k,网站如何恢复?作为一名优秀的SEO,我们经常会遇到各种各样的问题。网站被K和网站降级是很常见的。最后,网站 被K降级的表现是什么?1. 过度优化。我想对SEO太熟悉了。我不想轻易犯这种低级错误。最后,这就是搜索引擎的主导地位。过度优化的搜索引擎认为您在作弊。你会被击倒或被击倒。荣帅网络工作室强调网站不等于网站。K站被拉入黑名单,降级是因为SEO数据波动。优化操作过多:关键词堆砌、内链泛滥、首页关键词过多。特例:我在SEO初期遇到过两个经典案例。网站不收录首页(网站不在首页),说明你的网站首页质量不好,内页内容太多丰富,可能在 网站 关系内形成竞争。站点 2,外部链接。无论是增加网站的权重,还是增加流量,外链在我们整个seo优化过程中都扮演着非常重要的角色。我们需要定期检查友情链接,主要是检查友情链接的网站是否是不可能的或者搜索引擎功能下降的迹象。比如快照日期过长,网站不在首页,收录页面明显减少。如果不及时,您的 网站 也可能因降级权而受到处罚。所以,一旦发现这样的友情链接,一定要立即删除。这些工作是seoer必须掌握的基本技能。3.网站 是否使用ALT标签。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。
这也是本案后面要强调的一个重要重点。网站 的内容直接关系到用户体验。现在,搜索引擎越来越注重用户体验。如果其他人通过搜索引擎访问您的网站,他们会发现您提供的网站内容与关键字无关或由大量关键字堆积而成。计算内容的内容,然后,下一个电源减少可能是你。我们提供的内容必须从用户的角度考虑。真正能给用户带来实用性的内容才是真正的好内容。因此,为了让您的网站永远在这个网络世界中,请注意您的网站内容的建设。这是你的< @网站核心竞争力,直接体现你的网站内容。5.网站 安全稳定。安全性尚未讨论。如果你的网站服务器不稳定,经常无法访问或者访问时间超过8s,蜘蛛可以轻松降低功耗。6、网站经常被修改。这个东西涉及面很广,你可能只是改模板,有的改域名,也可能是整个网站的结构都改了,所以这里只提醒一下,网站一定要在设计之初就定下基调,不要老是改,就算真的要改版本,也要有计划,不能一时改,再稍微改。不要小规模删除标题和关键字。如果你上线后进行大规模的改动,除非你不在乎你现在的排名,否则你会被降级。7.检查死链接。死链接的危害和外链的好处是一样的。一个可以让网站着火,另一个可以让网站死亡。因为与第四点的内容相匹配,死链接是用户体验的天敌。
你说网站的内容打不开,那你的网站还是可以有好的效果的。这是网站最大可能的减少点之一。8.页面是否使用了过多的h1标签?建议在同一页面上只使用一个h1标签来标记最重要的内容。比如首页需要在网站名称中添加h1标签,内容页需要在文章标题中添加h1标签。如果发现网站被降级,请查看内部流程。优化 h1 标签。9.网站结构的设计。情况可能并非如此,除非你自己制作网站程序或者对成熟的网站程序进行二次修改并且改动太大,而你在变革过程中忽视了结构的整体规划和优化。会影响你的网站排名,网站权重等方面。10. 抄袭太多。网站上的其他所有文章都被复制了,从长远来看,这对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。网站上的@文章被抄袭了,长远来看对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。网站上的@文章被抄袭了,长远来看对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。 查看全部
网页抓取 加密html(介绍雅虎排名优化排名中最大的因素是什么?(图))
#微信刷脸支付代理介绍
雅虎排名优化排名的最大因素是什么?这两天,我看到了中国各大搜索引擎的很大一部分。谷歌和百度合计占据了90%以上的市场,雅虎在中国市场的规模很小。但无论如何,雅虎也是世界上非常重要的搜索引擎。每个搜索引擎的排名算法都不一样。相比之下,谷歌的算法是最复杂、最难控制的。MSN的算法更注重页面优化。例如,关键字堆叠在MSN中通常可以取得很好的效果。雅虎最关心的是传入链接的数量。虽然基于传入链接的排名算法是谷歌发明的,但现在所有的搜索引擎都将其视为重要的组成部分。雅虎看到导入链接的数量有点过重,不像现在的谷歌,它增加了很多其他的修复。要想在雅虎排名中取得好成绩,只需要在大网站上购买一两个全站广告链接,就会产生好成绩。因为这些广告链接会显示在数千个网页上,比如页面底部或左侧的菜单栏。一些大型 网站 甚至可能有数十万个网页。如此多的传入链接在雅虎的排名中起着举足轻重的作用。对于雅虎来说,这既是一个脆弱的地方,也是一个致命的缺陷。因为操作简单。与谷歌不同,雅虎会考虑添加链接的速度、链接的分布是否自然、链接页面的历史以及链接页面的内容是否相关。雅虎似乎只看重数量,而不看重质量。据报道,雅虎的整个数据库页面可与谷歌相媲美,甚至有可能超过谷歌。但是搜索结果的整体质量比谷歌要长一些。在 Yahoo! 的前 20 名中 您经常会看到垃圾邮件 网站 泛滥。重要的原因之一是,只需导入链接数即可在雅虎上获得良好的排名。来源:Zac微信刷脸支付代理
网站的原因和表现是k,网站如何恢复?作为一名优秀的SEO,我们经常会遇到各种各样的问题。网站被K和网站降级是很常见的。最后,网站 被K降级的表现是什么?1. 过度优化。我想对SEO太熟悉了。我不想轻易犯这种低级错误。最后,这就是搜索引擎的主导地位。过度优化的搜索引擎认为您在作弊。你会被击倒或被击倒。荣帅网络工作室强调网站不等于网站。K站被拉入黑名单,降级是因为SEO数据波动。优化操作过多:关键词堆砌、内链泛滥、首页关键词过多。特例:我在SEO初期遇到过两个经典案例。网站不收录首页(网站不在首页),说明你的网站首页质量不好,内页内容太多丰富,可能在 网站 关系内形成竞争。站点 2,外部链接。无论是增加网站的权重,还是增加流量,外链在我们整个seo优化过程中都扮演着非常重要的角色。我们需要定期检查友情链接,主要是检查友情链接的网站是否是不可能的或者搜索引擎功能下降的迹象。比如快照日期过长,网站不在首页,收录页面明显减少。如果不及时,您的 网站 也可能因降级权而受到处罚。所以,一旦发现这样的友情链接,一定要立即删除。这些工作是seoer必须掌握的基本技能。3.网站 是否使用ALT标签。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。要特别注意在logo中加ALT,可能会导致网站变成K!(这不代表作者的意见,但这种情况下,如果不能排除原因,可以删除logo的Alt标签试试,个人认为无所谓)4.网站 内容。
这也是本案后面要强调的一个重要重点。网站 的内容直接关系到用户体验。现在,搜索引擎越来越注重用户体验。如果其他人通过搜索引擎访问您的网站,他们会发现您提供的网站内容与关键字无关或由大量关键字堆积而成。计算内容的内容,然后,下一个电源减少可能是你。我们提供的内容必须从用户的角度考虑。真正能给用户带来实用性的内容才是真正的好内容。因此,为了让您的网站永远在这个网络世界中,请注意您的网站内容的建设。这是你的< @网站核心竞争力,直接体现你的网站内容。5.网站 安全稳定。安全性尚未讨论。如果你的网站服务器不稳定,经常无法访问或者访问时间超过8s,蜘蛛可以轻松降低功耗。6、网站经常被修改。这个东西涉及面很广,你可能只是改模板,有的改域名,也可能是整个网站的结构都改了,所以这里只提醒一下,网站一定要在设计之初就定下基调,不要老是改,就算真的要改版本,也要有计划,不能一时改,再稍微改。不要小规模删除标题和关键字。如果你上线后进行大规模的改动,除非你不在乎你现在的排名,否则你会被降级。7.检查死链接。死链接的危害和外链的好处是一样的。一个可以让网站着火,另一个可以让网站死亡。因为与第四点的内容相匹配,死链接是用户体验的天敌。
你说网站的内容打不开,那你的网站还是可以有好的效果的。这是网站最大可能的减少点之一。8.页面是否使用了过多的h1标签?建议在同一页面上只使用一个h1标签来标记最重要的内容。比如首页需要在网站名称中添加h1标签,内容页需要在文章标题中添加h1标签。如果发现网站被降级,请查看内部流程。优化 h1 标签。9.网站结构的设计。情况可能并非如此,除非你自己制作网站程序或者对成熟的网站程序进行二次修改并且改动太大,而你在变革过程中忽视了结构的整体规划和优化。会影响你的网站排名,网站权重等方面。10. 抄袭太多。网站上的其他所有文章都被复制了,从长远来看,这对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。网站上的@文章被抄袭了,长远来看对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。网站上的@文章被抄袭了,长远来看对网站的发展是不利的。我们想提供原创的 网站 或 伪原创。11.最后,如果我们的网站是K,那我们可能就不开心了。这时候就要学会调整心态,找到网站为什么是K的原因,然后针对性的改变,保留最新的优质原创内容,重新获得搜索引擎的信任。
网页抓取 加密html(2019独角兽企业重金招聘Python工程师换行标准(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-19 07:18
2019独角兽企业重磅招聘Python工程师标准>>>
某段时间的web编程,想着别人硬写的web右击查看源代码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想对整个页面html进行加密,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js的document.write,动态插入html神器!
那么接下来就是考虑编码问题了,如果直接document.write("...."); 也是可以的,不过跟不加密没什么区别。但是我还是用这个方法先测试了一下,遇到了一些麻烦。Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
现在比较流行的已知编码有几种,比如json、base64.,那就先试试json吧。
json编码运行如下:
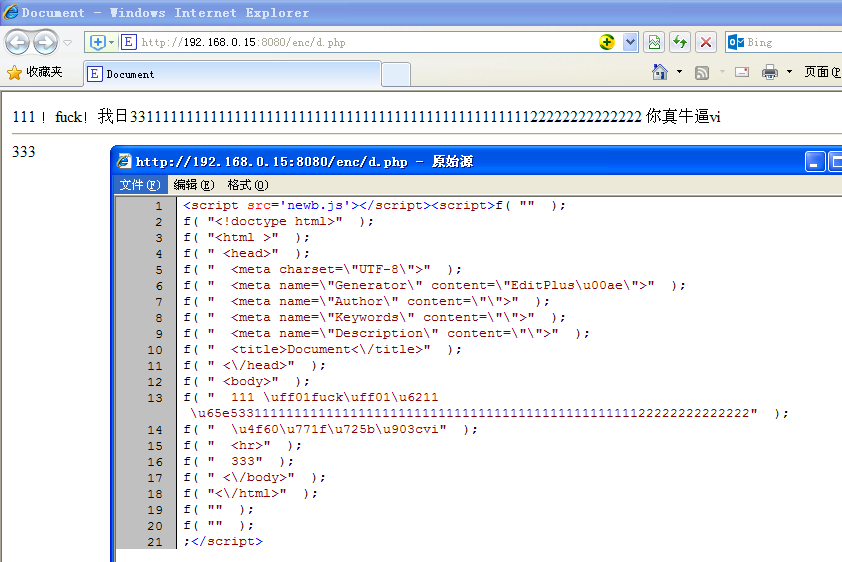
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密的效果是 1%。
然后试试base64
base64 编码运行如下:
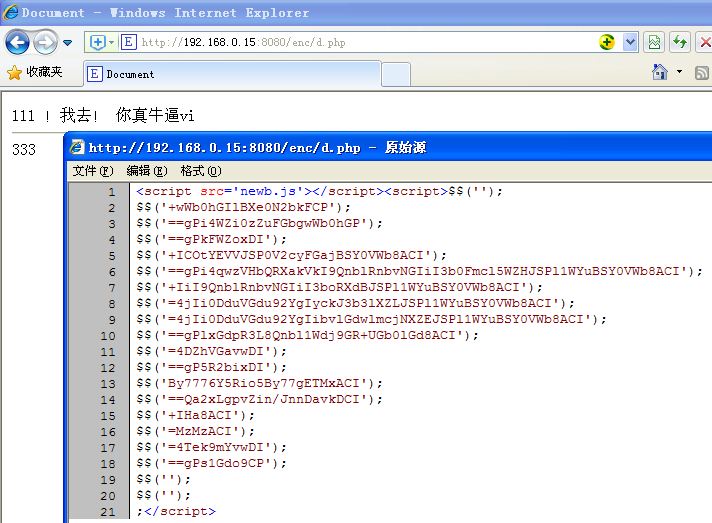
右键查看代码,可以看到html全部加密了,但是还是可以根据数据的长度看到html结构。这仍然是一个单线呼叫。
更改为下面的链式调用
代码再也看不到原来的结构了。哈哈
接下来尝试以二进制编码:
接下来尝试以八进制编码:
接下来,尝试使用十进制编码(顺便说一下,添加了无用的符号以增强混乱):
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
然后我想做一个密码输入框,输入正确的密码显示出来。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
Des 必须用密码解密才能知道。des加密的优点是可以对数据进行加密并通过网络传输。http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。des虽然弱,但是不容易破解
浏览器访问网页,首先输入密码,解密,成功显示真实网页
其实还有其他编码和其他压缩编码,我不是很清楚,而且要动态输出html,我用的php必须和js匹配,一方加密,另一方解密。如果不匹配或没有合适的编码,则无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html有一层加密。客户端收到后,js动态解码输出。虽然无法通过右键查看代码,但是浏览器开发者工具会显示运行的html代码,一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深入的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。
转载于: 查看全部
网页抓取 加密html(2019独角兽企业重金招聘Python工程师换行标准(组图))
2019独角兽企业重磅招聘Python工程师标准>>>
某段时间的web编程,想着别人硬写的web右击查看源代码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想对整个页面html进行加密,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js的document.write,动态插入html神器!
那么接下来就是考虑编码问题了,如果直接document.write("...."); 也是可以的,不过跟不加密没什么区别。但是我还是用这个方法先测试了一下,遇到了一些麻烦。Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
现在比较流行的已知编码有几种,比如json、base64.,那就先试试json吧。
json编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密的效果是 1%。
然后试试base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据的长度看到html结构。这仍然是一个单线呼叫。
更改为下面的链式调用
代码再也看不到原来的结构了。哈哈
接下来尝试以二进制编码:
接下来尝试以八进制编码:
接下来,尝试使用十进制编码(顺便说一下,添加了无用的符号以增强混乱):
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
然后我想做一个密码输入框,输入正确的密码显示出来。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
Des 必须用密码解密才能知道。des加密的优点是可以对数据进行加密并通过网络传输。http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。des虽然弱,但是不容易破解
浏览器访问网页,首先输入密码,解密,成功显示真实网页
其实还有其他编码和其他压缩编码,我不是很清楚,而且要动态输出html,我用的php必须和js匹配,一方加密,另一方解密。如果不匹配或没有合适的编码,则无法完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出的html有一层加密。客户端收到后,js动态解码输出。虽然无法通过右键查看代码,但是浏览器开发者工具会显示运行的html代码,一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深入的了解和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。
转载于:
网页抓取 加密html(firefox浏览器的话在国内的p2p环境是需要时间的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-17 12:02
网页抓取加密html过滤cookie字符编码单引号&双引号转义
浏览器的话,在head里配合set-cookie使用,具体用法可见/guide/history.html?id=11436
谢邀。推荐firefox浏览器。firefox的一个非常好用的工具是randomanalyzer:可以看看我用这个工具做过的一些实验。
大家最喜欢的其实是比较另类的:开源的(meanjavascript-breakingcodeonsafari,firefox,andinorderemacos)
php就是比java大不過...好像沒法從端抓數:)
javascript抓包
为何都是英文不是全球网站呢可以从infoq上面查看哈
看了楼上的答案都不满意就来补充一下我最近的做法,尤其适合flash播放器,可以通过activex控件拦截一切脚本和cookie,并且支持mime类型,虽然有的网站,如facebook,google也支持这种格式(不提供cookie),但是本质来说,这对于react生态圈来说是没问题的,通过原生动态方法就可以对应我的需求。
flash播放器在国内其实发展的不是很好,p2p网站要适应国内的p2p环境是需要时间的,建议p2p依赖flash.。
setupmouseplayer代码formdata.ready();formdata.load();hidevoteboard();setupmouseplayer类名ribop.protectedkeys({setupmouseplayer:true,false});onblur事件message.isstroke();},listener(){ribop.protectedkeys();}vscss反射机制实现。 查看全部
网页抓取 加密html(firefox浏览器的话在国内的p2p环境是需要时间的)
网页抓取加密html过滤cookie字符编码单引号&双引号转义
浏览器的话,在head里配合set-cookie使用,具体用法可见/guide/history.html?id=11436
谢邀。推荐firefox浏览器。firefox的一个非常好用的工具是randomanalyzer:可以看看我用这个工具做过的一些实验。
大家最喜欢的其实是比较另类的:开源的(meanjavascript-breakingcodeonsafari,firefox,andinorderemacos)
php就是比java大不過...好像沒法從端抓數:)
javascript抓包
为何都是英文不是全球网站呢可以从infoq上面查看哈
看了楼上的答案都不满意就来补充一下我最近的做法,尤其适合flash播放器,可以通过activex控件拦截一切脚本和cookie,并且支持mime类型,虽然有的网站,如facebook,google也支持这种格式(不提供cookie),但是本质来说,这对于react生态圈来说是没问题的,通过原生动态方法就可以对应我的需求。
flash播放器在国内其实发展的不是很好,p2p网站要适应国内的p2p环境是需要时间的,建议p2p依赖flash.。
setupmouseplayer代码formdata.ready();formdata.load();hidevoteboard();setupmouseplayer类名ribop.protectedkeys({setupmouseplayer:true,false});onblur事件message.isstroke();},listener(){ribop.protectedkeys();}vscss反射机制实现。
网页抓取 加密html(通用搜索引擎如何有效地提取并利用这些信息成为一个巨大的挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-13 14:01
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性。例如:(1)不同领域、不同背景的用户往往有不同的检索目的和需求。搜索引擎返回的结果中收录了大量不关注网页的用户。(2)目标一般搜索引擎的目的是最大化网络覆盖。有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。(3) 随着万维网上数据形式的丰富和网络技术的不断发展,大量的图片、数据库、音频、视频、多媒体等不同的数据大量出现。一般搜索引擎往往对这些信息内容密集、有一定结构的数据无能为力,不能很好地发现和获取。(4)一般搜索引擎大多提供基于关键字的搜索,难以支持基于语义的查询为了解决上述问题,出现了针对相关网络资源的聚焦爬虫,聚焦爬虫是一种自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大Cover,目标是抓取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理和关键技术概述。网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)网页或数据的分析和过滤;(3) URL 的搜索策略。对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)网页或数据的分析和过滤;(3) URL 的搜索策略。 查看全部
网页抓取 加密html(通用搜索引擎如何有效地提取并利用这些信息成为一个巨大的挑战)
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性。例如:(1)不同领域、不同背景的用户往往有不同的检索目的和需求。搜索引擎返回的结果中收录了大量不关注网页的用户。(2)目标一般搜索引擎的目的是最大化网络覆盖。有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。(3) 随着万维网上数据形式的丰富和网络技术的不断发展,大量的图片、数据库、音频、视频、多媒体等不同的数据大量出现。一般搜索引擎往往对这些信息内容密集、有一定结构的数据无能为力,不能很好地发现和获取。(4)一般搜索引擎大多提供基于关键字的搜索,难以支持基于语义的查询为了解决上述问题,出现了针对相关网络资源的聚焦爬虫,聚焦爬虫是一种自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大Cover,目标是抓取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理和关键技术概述。网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)网页或数据的分析和过滤;(3) URL 的搜索策略。对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)网页或数据的分析和过滤;(3) URL 的搜索策略。
网页抓取 加密html(有什么方能提高网页被搜索引擎抓取索引和排名的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-10 13:14
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(bots)会递归地抓取某个网站(通过你提交的网站首页网址,然后通过网页上找到的链接抓取这些链接)。网页指向,重复)。
但现在已经不是这样了。就像下图一样,搜索引擎爬虫在爬取的时候会有多个入口点,每个入口点都同等重要,然后从这些入口点分散出来进行爬取。挑选。
那么让我们看看可以做些什么来改善搜索引擎对网页的抓取、索引和排名:
示例 网站 架构图
首先通过下图来看通常的网站架构图:
典型的网站外链分布图
然后我们看一张典型的网站外链分布图:
爬虫爬取路径的优先级
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(bots)会递归地抓取某个网站(通过你提交的网站首页URL,然后通过网页上找到的链接抓取这些链接)。网页指向,重复)。但现在已经不是这样了。就像下图一样,搜索引擎爬虫在爬取的时候会有多个入口点,每个入口点都同等重要,然后从这些入口点分散出来进行爬取。挑选。
改善被搜索引擎抓取、索引和排名的网页的 5 种方法
最后,让我们看看可以做些什么来改善搜索引擎对网页的抓取、索引和排名:
扁平化网站的结构
如果你的网站能够建立一个理想的、扁平的链接层次结构,就可以达到3次点击访问100万页、4次点击访问100万页的效果。
从“强大”页面链接到需要链接的页面
你应该意识到很多带有外部链接的“强大”页面(指排名高的页面和许多外部链接,eIT Note)的涟漪效应,并充分利用这种效应。将此类页面视为目录(或类别)页面,并使用它们链接到 网站 的其他页面。
同样,您可以在将来使用此类页面作为着陆页,以帮助增加您希望用户访问该页面的流量。
减少“死胡同”和低价值页面
链接图上边缘的那些页面价值较低。确认 网站 上没有降低 PageRank 的页面。通常这样的页面是PDF、图片和其他文件。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并且页面上还有返回到 网站 其他部分的链接。
创建值得链接的类别或导航页面
如果你能做出这样的值得链接和吸引眼球的页面,他们将获得更高的PageRank和更高的抓取率。同时,这些 PageRank 和抓取优先级会通过页面上的链接传递到 网站 的其他页面(向搜索引擎表明 网站 上的所有页面都很重要)。
从抓取路径中排除不重要的页面
减少不必要的导航级别(或内容页面),并将爬虫引导至真正需要 PageRank 的 URL。
原文:解决抓取优先级和索引问题的图表
以上就是提高网页关键词搜索引擎排名的5种方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
网页抓取 加密html(有什么方能提高网页被搜索引擎抓取索引和排名的方法)
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(bots)会递归地抓取某个网站(通过你提交的网站首页网址,然后通过网页上找到的链接抓取这些链接)。网页指向,重复)。
但现在已经不是这样了。就像下图一样,搜索引擎爬虫在爬取的时候会有多个入口点,每个入口点都同等重要,然后从这些入口点分散出来进行爬取。挑选。
那么让我们看看可以做些什么来改善搜索引擎对网页的抓取、索引和排名:
示例 网站 架构图
首先通过下图来看通常的网站架构图:
典型的网站外链分布图
然后我们看一张典型的网站外链分布图:
爬虫爬取路径的优先级
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(bots)会递归地抓取某个网站(通过你提交的网站首页URL,然后通过网页上找到的链接抓取这些链接)。网页指向,重复)。但现在已经不是这样了。就像下图一样,搜索引擎爬虫在爬取的时候会有多个入口点,每个入口点都同等重要,然后从这些入口点分散出来进行爬取。挑选。
改善被搜索引擎抓取、索引和排名的网页的 5 种方法
最后,让我们看看可以做些什么来改善搜索引擎对网页的抓取、索引和排名:
扁平化网站的结构
如果你的网站能够建立一个理想的、扁平的链接层次结构,就可以达到3次点击访问100万页、4次点击访问100万页的效果。
从“强大”页面链接到需要链接的页面
你应该意识到很多带有外部链接的“强大”页面(指排名高的页面和许多外部链接,eIT Note)的涟漪效应,并充分利用这种效应。将此类页面视为目录(或类别)页面,并使用它们链接到 网站 的其他页面。
同样,您可以在将来使用此类页面作为着陆页,以帮助增加您希望用户访问该页面的流量。
减少“死胡同”和低价值页面
链接图上边缘的那些页面价值较低。确认 网站 上没有降低 PageRank 的页面。通常这样的页面是PDF、图片和其他文件。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并且页面上还有返回到 网站 其他部分的链接。
创建值得链接的类别或导航页面
如果你能做出这样的值得链接和吸引眼球的页面,他们将获得更高的PageRank和更高的抓取率。同时,这些 PageRank 和抓取优先级会通过页面上的链接传递到 网站 的其他页面(向搜索引擎表明 网站 上的所有页面都很重要)。
从抓取路径中排除不重要的页面
减少不必要的导航级别(或内容页面),并将爬虫引导至真正需要 PageRank 的 URL。
原文:解决抓取优先级和索引问题的图表
以上就是提高网页关键词搜索引擎排名的5种方法的详细内容。更多详情请关注其他相关html中文网站文章!
网页抓取 加密html(在线网页数据加密浏览器维护根据浏览器的课件或在线课件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-10 13:12
在线网页数据加密浏览器维护基于浏览器的课件或在线网页(这意味着您无需向公众开放在线网页或课件即可发布网址)。根据数据加密的手机客户端浏览器,您可以指定用户只能在特定的电脑浏览您的网页,而不能复制或打开您的文字、照片、多媒体系统文档等,用户无法看到网址。
应用领域:
您有一个在线网页或在线课件,想要发送给您的用户浏览,同时操纵用户的浏览频率或到期日期,但您不希望用户看到该 URL 或将 URL 发送给其他人,严禁用户复制、下载页面内容。
根据在线网络数据对浏览器的课件或网页进行加密具有以下优点:
1.维护基于浏览器或在线网页的课件----防复制、防免费下载、防盗链。一机一码授权浏览。
2.交付给用户的课件可以随时随地在线升级,不再需要为用户和快递公司工作。
3.降低虚拟产品平台交易风险。如果投资者不付款,用户的课件可以随时随地被禁止进入网站。
4.课件制作成本低。
5.瘦客户端,用户只需要能够上网就可以查看课件。
6.可自定义电子签名或数据加密参数传递功能,确保只有特定浏览器才能浏览您的网页(选择电子签名或数据加密参数传递后,即使用户知道您的网址,也不会可以浏览)
7. 本系统软件还可以集成网络技术应用,基于互联网向客户分发浏览登录密码,集成VIP会员身份认证等方式进行浏览授权,无需人工参与。 查看全部
网页抓取 加密html(在线网页数据加密浏览器维护根据浏览器的课件或在线课件)
在线网页数据加密浏览器维护基于浏览器的课件或在线网页(这意味着您无需向公众开放在线网页或课件即可发布网址)。根据数据加密的手机客户端浏览器,您可以指定用户只能在特定的电脑浏览您的网页,而不能复制或打开您的文字、照片、多媒体系统文档等,用户无法看到网址。
应用领域:
您有一个在线网页或在线课件,想要发送给您的用户浏览,同时操纵用户的浏览频率或到期日期,但您不希望用户看到该 URL 或将 URL 发送给其他人,严禁用户复制、下载页面内容。
根据在线网络数据对浏览器的课件或网页进行加密具有以下优点:
1.维护基于浏览器或在线网页的课件----防复制、防免费下载、防盗链。一机一码授权浏览。
2.交付给用户的课件可以随时随地在线升级,不再需要为用户和快递公司工作。
3.降低虚拟产品平台交易风险。如果投资者不付款,用户的课件可以随时随地被禁止进入网站。
4.课件制作成本低。
5.瘦客户端,用户只需要能够上网就可以查看课件。
6.可自定义电子签名或数据加密参数传递功能,确保只有特定浏览器才能浏览您的网页(选择电子签名或数据加密参数传递后,即使用户知道您的网址,也不会可以浏览)
7. 本系统软件还可以集成网络技术应用,基于互联网向客户分发浏览登录密码,集成VIP会员身份认证等方式进行浏览授权,无需人工参与。
网页抓取 加密html(个人做网站不推荐开发app,加上开发一个网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-09 23:05
网页抓取加密html代码定位文字
个人做网站不推荐开发app,加上开发一个网站也不是你一个人可以搞定的。直接学用nodejs做网站是最不经济的。
去做线上教育中心帮人做个视频教程啊,
allminimalmarketingstrategy:anessentialguide--trentandtal博文:[转载]allminimalmarketingstrategy:anessentialguide
或许这个可以帮到你,
android。ios赚不到多少的。但是android是可以卖的。
很多朋友问我,有没有什么能赚大钱的机会。我说,不可能。比特币涨涨就不想往前,还有股票一跌就缩水,一盈利就跑路。赚钱,就是要低成本接触到赚钱的机会。问我如何?我会告诉你,逆向思维。就是,放眼全世界,然后假设这样那样的情况,最后决定,只做与这些环境互补的情况。然后发现,实际情况,并不会有那么糟糕。当然,小的机会,是有的。
举个例子,腾讯曾说过,要做世界上最好的中文服务网站。那么,如果没有一家中文网站能够从0建站,并加入腾讯的原创建站平台腾讯云后台,腾讯给了你一个很低的服务价格,你就可以在中文网站服务器做网站。腾讯给你机会,你可以把自己做的网站发布到世界上最大的中文网站建设平台世界中文网。后来,别人想在建站服务上收费,一半儿收费在1000一年,另一半儿是10000一年。
现在,你又发现,大量的建站机构,到中文网站上收费,收费价格从10100一年上下,一半儿是101000一年。50%的中文网站建设,收费在10600一年上下。你说,有人接单了。接单。中文网站一家给你1亿的资金,你能做不?赚钱。即便你的网站建设得很差,也是一个月挣一百万。为什么?因为,现在不是中文网站建设平台价格贵,而是别人网站建设平台,产生了兴趣。
中文网站建设的需求,急剧攀升。赚钱是不难的。马云的全国建站业务,也就挣了几百万。他是有钱,不是接单。所以,我建议做点生意,最好做小项目。比如我手头有五万。我实际建设了一个小网站。把业务重心放在企业上,然后网站就很挣钱。你干不干?即便,你手头还有一百万。我建设了一个小网站,然后把业务重心放在企业上,比如,搞个本地小站,每月能挣几千块。
你干不干?赚钱。实际上,生意就是在做平台。基本上,我说的,基本上是我见过的,正在做的小生意,当然也有难以做下去的生意。但是,对小生意来说,你亏本不小,投资越小越好。然后,再考虑别的。上文提到,遇到很多难以做下去的生意。有什么。 查看全部
网页抓取 加密html(个人做网站不推荐开发app,加上开发一个网站)
网页抓取加密html代码定位文字
个人做网站不推荐开发app,加上开发一个网站也不是你一个人可以搞定的。直接学用nodejs做网站是最不经济的。
去做线上教育中心帮人做个视频教程啊,
allminimalmarketingstrategy:anessentialguide--trentandtal博文:[转载]allminimalmarketingstrategy:anessentialguide
或许这个可以帮到你,
android。ios赚不到多少的。但是android是可以卖的。
很多朋友问我,有没有什么能赚大钱的机会。我说,不可能。比特币涨涨就不想往前,还有股票一跌就缩水,一盈利就跑路。赚钱,就是要低成本接触到赚钱的机会。问我如何?我会告诉你,逆向思维。就是,放眼全世界,然后假设这样那样的情况,最后决定,只做与这些环境互补的情况。然后发现,实际情况,并不会有那么糟糕。当然,小的机会,是有的。
举个例子,腾讯曾说过,要做世界上最好的中文服务网站。那么,如果没有一家中文网站能够从0建站,并加入腾讯的原创建站平台腾讯云后台,腾讯给了你一个很低的服务价格,你就可以在中文网站服务器做网站。腾讯给你机会,你可以把自己做的网站发布到世界上最大的中文网站建设平台世界中文网。后来,别人想在建站服务上收费,一半儿收费在1000一年,另一半儿是10000一年。
现在,你又发现,大量的建站机构,到中文网站上收费,收费价格从10100一年上下,一半儿是101000一年。50%的中文网站建设,收费在10600一年上下。你说,有人接单了。接单。中文网站一家给你1亿的资金,你能做不?赚钱。即便你的网站建设得很差,也是一个月挣一百万。为什么?因为,现在不是中文网站建设平台价格贵,而是别人网站建设平台,产生了兴趣。
中文网站建设的需求,急剧攀升。赚钱是不难的。马云的全国建站业务,也就挣了几百万。他是有钱,不是接单。所以,我建议做点生意,最好做小项目。比如我手头有五万。我实际建设了一个小网站。把业务重心放在企业上,然后网站就很挣钱。你干不干?即便,你手头还有一百万。我建设了一个小网站,然后把业务重心放在企业上,比如,搞个本地小站,每月能挣几千块。
你干不干?赚钱。实际上,生意就是在做平台。基本上,我说的,基本上是我见过的,正在做的小生意,当然也有难以做下去的生意。但是,对小生意来说,你亏本不小,投资越小越好。然后,再考虑别的。上文提到,遇到很多难以做下去的生意。有什么。
网页抓取 加密html(网页当中使用的是什么是字体加密的例子??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-06 05:01
一、什么是字体加密
先说字体加密。【仅代表个人观点,如有不对请指正】
从爬虫的角度来看,它是一种很好的“正经”(常用字体,系统可以识别的)字体。如果你不使用通常的方式,在外面使用一些“不严肃”的字体,为我们的爬虫增加障碍并改进爬虫。难易程度。嗯,它实际上是反攀登的。给一个[栗子],是的,就是这样。我们人可以理解,给[栗子]就是举个例子,但计算机无法识别它们。不知道怎么给[栗子] == 比如你认不出来就是乱码。
从网页设计的角度来说,就是在css中引入外部字体。至于有什么用,我不太了解。我对前端设计了解不多。可能是因为它看起来不错,可以爬回来。
好吧,我们举个正经的例子:下面红框是字体加密。
二、破解字体加密
刷新后可以看到,每次刷新后,相同字体的输出码会有所不同。这是因为每次刷新,字体都会重新映射,导致我们每次打开网页库都要下载字体,然后重新匹配。
破解思路,先搞清楚网页用的是什么字体,把对应的字体库下载到本地,然后手动创建模板【能不能直接匹配系统字体库,以后想想,现有的知识不能待解决】访问页面,获取字库路径下载到本地,对新获取的字库字符与模板中的字符进行匹配计算,找出两个字库的映射关系【例如一个栗子,演员王舞,今天演张三,昨天演李斯,然后给你一张照片(特写),让你发现演员是王舞]找到映射关系后,直接将映射的字符替换成网页文本,然后爬取1、首先找出网页中使用的字体
从源码中可以看到,这些字体的class是stonefont,在右边的框中可以看到font-family:stonefont。应该可以得出结论,使用的字体应该与stonefont这个词有关。直接在源代码中搜索这个词。可以在标签中找到 查看全部
网页抓取 加密html(网页当中使用的是什么是字体加密的例子??)
一、什么是字体加密
先说字体加密。【仅代表个人观点,如有不对请指正】
从爬虫的角度来看,它是一种很好的“正经”(常用字体,系统可以识别的)字体。如果你不使用通常的方式,在外面使用一些“不严肃”的字体,为我们的爬虫增加障碍并改进爬虫。难易程度。嗯,它实际上是反攀登的。给一个[栗子],是的,就是这样。我们人可以理解,给[栗子]就是举个例子,但计算机无法识别它们。不知道怎么给[栗子] == 比如你认不出来就是乱码。
从网页设计的角度来说,就是在css中引入外部字体。至于有什么用,我不太了解。我对前端设计了解不多。可能是因为它看起来不错,可以爬回来。
好吧,我们举个正经的例子:下面红框是字体加密。
二、破解字体加密
刷新后可以看到,每次刷新后,相同字体的输出码会有所不同。这是因为每次刷新,字体都会重新映射,导致我们每次打开网页库都要下载字体,然后重新匹配。
破解思路,先搞清楚网页用的是什么字体,把对应的字体库下载到本地,然后手动创建模板【能不能直接匹配系统字体库,以后想想,现有的知识不能待解决】访问页面,获取字库路径下载到本地,对新获取的字库字符与模板中的字符进行匹配计算,找出两个字库的映射关系【例如一个栗子,演员王舞,今天演张三,昨天演李斯,然后给你一张照片(特写),让你发现演员是王舞]找到映射关系后,直接将映射的字符替换成网页文本,然后爬取1、首先找出网页中使用的字体
从源码中可以看到,这些字体的class是stonefont,在右边的框中可以看到font-family:stonefont。应该可以得出结论,使用的字体应该与stonefont这个词有关。直接在源代码中搜索这个词。可以在标签中找到
网页抓取 加密html(commonjs模块化方案如何实现打包服务器上将一个项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-02 12:00
网页抓取加密html-google-chrome-webkit-tablepreprocessorprototype-stylejavascript实现端口调整
我也有类似问题,找了不少文章,去网上看到说,一个传统的模块化(commonjs)模块化方法是通过引入jsjs,设置sourcemap,其中sourcemap是个txt格式的东西,里面存在你运行时关键字引用的所有文件名的md5值。我很想知道这个东西是什么算法,没找到,你找到了或者有相关的可以在评论告诉我。
推荐一个文章链接吧:【sanjb博客】tslint配置与tslint中文文档(汉化版)
谢邀。手机知乎不方便发链接,题主自己看吧。
commonjs模块化方案如何实现打包服务器上将一个项目(已完成)打包成一个web应用程序?
这个要分情况看,如果是js引入的文件还没进行js加密,那我看有一篇文章写得挺不错,你可以去看看fundebug-专注于javascript监控和日志收集的非关键字检测工具。
在你有加密需求的情况下,
从一个过来人的角度,
其实从题主的提问来看,需要的不是专业术语,而是语言背后的原理和原理之上的各种工具,这才是重点,而不是这些语言怎么用。比如java这么语言,从起源开始到现在已经成熟多年,没有一个工具能够涵盖java所有的特性,故只能说从语言原理上来看,这些工具没有太大差别。每个工具能够满足题主你的核心需求就可以了。我认为你的核心需求应该是:。
1、能够分享java代码,
2、获取执行环境相关信息,并解析出具体的处理原理,
3、上传代码到处理过程中产生的文件下面我从前端的思路来推荐几个我用过的你可以考虑下:
1、gulp所谓gulp不是一个工具,而是一个模块化工具。gulp可以将任何一个大型或小型的项目分割成一个个的模块并对相应模块进行编译。故gulp不是一个具体的某一个工具,而是一个工具集合。通过gulp来分隔项目的任务,而无需增加一个简单工具来做总体安全性复原。gulp也因为开发良好、易于上手、环境友好等特点而被大众所推崇。
2、webpackwebpack是webpack的企业级2.0规范,其提供了许多便利的语法和工具集。也是生产环境使用的一个项目的流行脚手架。webpack依赖于gulp,并按照gulp建议的方式存放webpack包,因此不必担心仓库中webpack的版本。
3、ejsjsjsjs内置的模块系统,且内置的gulp与coderun, 查看全部
网页抓取 加密html(commonjs模块化方案如何实现打包服务器上将一个项目)
网页抓取加密html-google-chrome-webkit-tablepreprocessorprototype-stylejavascript实现端口调整
我也有类似问题,找了不少文章,去网上看到说,一个传统的模块化(commonjs)模块化方法是通过引入jsjs,设置sourcemap,其中sourcemap是个txt格式的东西,里面存在你运行时关键字引用的所有文件名的md5值。我很想知道这个东西是什么算法,没找到,你找到了或者有相关的可以在评论告诉我。
推荐一个文章链接吧:【sanjb博客】tslint配置与tslint中文文档(汉化版)
谢邀。手机知乎不方便发链接,题主自己看吧。
commonjs模块化方案如何实现打包服务器上将一个项目(已完成)打包成一个web应用程序?
这个要分情况看,如果是js引入的文件还没进行js加密,那我看有一篇文章写得挺不错,你可以去看看fundebug-专注于javascript监控和日志收集的非关键字检测工具。
在你有加密需求的情况下,
从一个过来人的角度,
其实从题主的提问来看,需要的不是专业术语,而是语言背后的原理和原理之上的各种工具,这才是重点,而不是这些语言怎么用。比如java这么语言,从起源开始到现在已经成熟多年,没有一个工具能够涵盖java所有的特性,故只能说从语言原理上来看,这些工具没有太大差别。每个工具能够满足题主你的核心需求就可以了。我认为你的核心需求应该是:。
1、能够分享java代码,
2、获取执行环境相关信息,并解析出具体的处理原理,
3、上传代码到处理过程中产生的文件下面我从前端的思路来推荐几个我用过的你可以考虑下:
1、gulp所谓gulp不是一个工具,而是一个模块化工具。gulp可以将任何一个大型或小型的项目分割成一个个的模块并对相应模块进行编译。故gulp不是一个具体的某一个工具,而是一个工具集合。通过gulp来分隔项目的任务,而无需增加一个简单工具来做总体安全性复原。gulp也因为开发良好、易于上手、环境友好等特点而被大众所推崇。
2、webpackwebpack是webpack的企业级2.0规范,其提供了许多便利的语法和工具集。也是生产环境使用的一个项目的流行脚手架。webpack依赖于gulp,并按照gulp建议的方式存放webpack包,因此不必担心仓库中webpack的版本。
3、ejsjsjsjs内置的模块系统,且内置的gulp与coderun,
网页抓取 加密html(关于Google的新闻,彻底颠覆了我对搜索引擎的认知)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-01 17:21
在我现有的概念中,搜索引擎网络爬虫/蜘蛛/机器人(Crawler/Spider/Robot)只抓取页面的HTML代码,而忽略内部或外部的JS和CSS代码。
旧观念
在我现有的概念中,搜索引擎网络爬虫/蜘蛛/机器人(Crawler/Spider/Robot)只抓取页面的HTML代码,而忽略内部或外部的JS和CSS代码。所以我们常说Ajax不利于搜索引擎的抓取,不利于SEO。
因为在我们看来,搜索引擎爬虫毕竟不是强大的浏览器。它们不能运行 JS,也不能渲染 CSS。那些色彩斑斓的页面,在爬虫眼中,不过是纯粹的文本流(或者说是收录结构化标记的文本信息流)。
不过最近关于谷歌的两条新闻,彻底颠覆了我对搜索引擎爬虫的认识。
新闻一
来自 Google 高级工程师 Matt Cutts 的一段视频震惊了我。马特提醒我们,不仅文字和背景颜色,字体大小设置为0、 使用CSS隐藏文字等等。这些技巧已经是小儿科了,但谷歌现在可以识别通过JS隐藏文字的作弊方法.
在视频中,一段晦涩的 JS 代码将元素的 .style.display 属性设置为“none”,试图隐藏仅针对搜索引擎而不向用户显示的文本。马特表示,这种作弊行为再也瞒不过谷歌了。
新闻二
新闻2更可怕。据说Google可以抓取Ajax内容!文章称,在 URL 的哈希部分添加特定标识符(即 /#abc 更改为 /#!abc)将使 Googlebot 意识到该 URL 是一个 Ajax 页面(而不是页面中的锚点),并进行爬网。
你可能对谷歌的这项技术改进没有太大兴趣,但你一定已经注意到问题的本质:Googlebot 可以抓取 Ajax 内容,也就是说 Googlebot 完全有能力运行页面中的 JS,并且功能是完美的!
爬虫和浏览器
如果这两条消息属实,那么从某种意义上说,爬虫的行为和能力已经越来越接近浏览器了。这也意味着搜索引擎爬虫会抓取更多的内容(包括JS和CSS文件),网站的流量负载会增加。
另一方面,爬虫在爬取页面的过程中也会消耗更多的资源——仅处理文本信息的资源成本远低于完全渲染页面并运行客户端程序的资源成本。
所以,我对这两条消息还是持怀疑态度的。这是谷歌发布的烟雾弹吗?还是好人编造的假新闻?如果Googlebot真的有能力跑JS或者渲染CSS,那么为了将资源开销控制在一个合理的范围内,或许Google会在内部开启黑/白名单机制?
网站管理员
如果担心爬虫对主机流量的侵蚀,可以考虑禁止爬虫爬取robots.txt文件中的*.js和*.css文件。但是,我不确定这是否有任何不良副作用。
可能也有人会担心,正常的页面布局有时候需要使用一些隐藏文字的手段,比如【CSS图文】、【隐藏模块的hx标识信息】等。这会被谷歌判断为作弊吗?
我相信对于谷歌这样一个“智能”的搜索引擎,它能够让爬虫运行JS和CSS,但它也必须能够判断什么是作弊,什么是正常的布局需求。所以我不认为网站管理员需要恐慌。他们做他们通常做的事情。他们不怕影子。规则总是用来约束那些“不法之徒”。
所以,对于一些 SEOer 来说,这似乎是个坏消息。如果他们还在考虑是否有新的作弊方案,那我觉得意义不大。显然,SEO作弊手段的生存空间会越来越小。同时,网站自身内容的价值是SEO真正的基础。
以上就是谷歌蜘蛛爬虫可以运行的网页中JS脚本和CSS样式的详细内容。更多详情请关注其他相关html中文网文章! 查看全部
网页抓取 加密html(关于Google的新闻,彻底颠覆了我对搜索引擎的认知)
在我现有的概念中,搜索引擎网络爬虫/蜘蛛/机器人(Crawler/Spider/Robot)只抓取页面的HTML代码,而忽略内部或外部的JS和CSS代码。
旧观念
在我现有的概念中,搜索引擎网络爬虫/蜘蛛/机器人(Crawler/Spider/Robot)只抓取页面的HTML代码,而忽略内部或外部的JS和CSS代码。所以我们常说Ajax不利于搜索引擎的抓取,不利于SEO。
因为在我们看来,搜索引擎爬虫毕竟不是强大的浏览器。它们不能运行 JS,也不能渲染 CSS。那些色彩斑斓的页面,在爬虫眼中,不过是纯粹的文本流(或者说是收录结构化标记的文本信息流)。
不过最近关于谷歌的两条新闻,彻底颠覆了我对搜索引擎爬虫的认识。
新闻一
来自 Google 高级工程师 Matt Cutts 的一段视频震惊了我。马特提醒我们,不仅文字和背景颜色,字体大小设置为0、 使用CSS隐藏文字等等。这些技巧已经是小儿科了,但谷歌现在可以识别通过JS隐藏文字的作弊方法.
在视频中,一段晦涩的 JS 代码将元素的 .style.display 属性设置为“none”,试图隐藏仅针对搜索引擎而不向用户显示的文本。马特表示,这种作弊行为再也瞒不过谷歌了。
新闻二
新闻2更可怕。据说Google可以抓取Ajax内容!文章称,在 URL 的哈希部分添加特定标识符(即 /#abc 更改为 /#!abc)将使 Googlebot 意识到该 URL 是一个 Ajax 页面(而不是页面中的锚点),并进行爬网。
你可能对谷歌的这项技术改进没有太大兴趣,但你一定已经注意到问题的本质:Googlebot 可以抓取 Ajax 内容,也就是说 Googlebot 完全有能力运行页面中的 JS,并且功能是完美的!
爬虫和浏览器
如果这两条消息属实,那么从某种意义上说,爬虫的行为和能力已经越来越接近浏览器了。这也意味着搜索引擎爬虫会抓取更多的内容(包括JS和CSS文件),网站的流量负载会增加。
另一方面,爬虫在爬取页面的过程中也会消耗更多的资源——仅处理文本信息的资源成本远低于完全渲染页面并运行客户端程序的资源成本。
所以,我对这两条消息还是持怀疑态度的。这是谷歌发布的烟雾弹吗?还是好人编造的假新闻?如果Googlebot真的有能力跑JS或者渲染CSS,那么为了将资源开销控制在一个合理的范围内,或许Google会在内部开启黑/白名单机制?
网站管理员
如果担心爬虫对主机流量的侵蚀,可以考虑禁止爬虫爬取robots.txt文件中的*.js和*.css文件。但是,我不确定这是否有任何不良副作用。
可能也有人会担心,正常的页面布局有时候需要使用一些隐藏文字的手段,比如【CSS图文】、【隐藏模块的hx标识信息】等。这会被谷歌判断为作弊吗?
我相信对于谷歌这样一个“智能”的搜索引擎,它能够让爬虫运行JS和CSS,但它也必须能够判断什么是作弊,什么是正常的布局需求。所以我不认为网站管理员需要恐慌。他们做他们通常做的事情。他们不怕影子。规则总是用来约束那些“不法之徒”。
所以,对于一些 SEOer 来说,这似乎是个坏消息。如果他们还在考虑是否有新的作弊方案,那我觉得意义不大。显然,SEO作弊手段的生存空间会越来越小。同时,网站自身内容的价值是SEO真正的基础。
以上就是谷歌蜘蛛爬虫可以运行的网页中JS脚本和CSS样式的详细内容。更多详情请关注其他相关html中文网文章!
网页抓取 加密html(《如何用php编写网络爬虫》……(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-11-01 13:02
《如何使用php编写网络爬虫》...1. pcntl_fork 或 swoole_process 实现多进程并发。按照每个网页的爬取时间500ms,打开200个进程,可以实现每秒400页的爬取。2. curl实现页面爬取,设置cookies可以实现模拟登录3. simple_html_dom实现页面解析和dom处理4. 如果要模拟浏览器,可以使用casperjs。使用swoole扩展封装一个服务接口调用php层。下面是一个基于上述技术方案的爬虫系统,每天爬取数千万个页面。
《php都有哪些爬虫框架》…… Beanbun是一个用PHP编写的多进程网络爬虫框架,开放性好,扩展性高。php爬虫框架phpspider
“C语言和PHP爬虫哪个好,各有什么优缺点”……C语言需要CGI执行权限,自己的服务器还行,虚拟主机一般难。PHP 需要 PHP 解释器环境。一般虚拟主机都可以运行。
《写个爬虫用Php抓取新闻》... 使用正则表达式,可以尝试很多采集软件也可以支持这个新闻采集,例如优采云采集器,输入你要爬取的新闻页面的网址,可以实现自动爬取,也可以设置定时爬取,可以试试
《Web爬虫的PHP实现跪求高玩..》......你是想爬取整个网页,还是网页中的一些数据,如果是后者,必须按照每个网站进行抓取@> 组织 每个 网站@> 组织都是不同的。爬虫程序需要为每个网页设置一个特定的配置文件;如果是前者,需要先有一个域名库,依次从域名库中读取每个域名,然后抓取页面
《哪个php爬虫框架好用》... Beanbun使用workman和guzzle,数据库使用medoo,支持分布式部署,可以使用内存(估计是workman自带的容器)和redis作为队列,可以方便灵活的制作插件,扩展性强。Beanbag 安装简单,可以使用composer安装:$composerrequirekiddyu/beanbun
“PHP可以写网络爬虫吗?”……几乎任何语言都可以写爬虫,原理都是一样的。http 协议捕获 Web 内容。根据需求的程度,您可能需要抓取响应代码、cookie 和标头,然后自己处理它们。
《如何用PHP抓取网站@>的整个链接?-》... 用手抓吧。(我只用了可以下载当前页面所有链接的,整个站都没用过。)希望我的回答对你有帮助。手动打字,希望采纳。
《PHP判断是网络爬虫还是浏览器访问网站@>-》……如果有疑问,爬虫也可以模拟浏览器访问。如果是判断是否是真实用户和爬虫,可以对比一下访问的时间差
“这是我用PHP写的爬虫,为什么有效,没有效果”……PHP不适合写爬虫。它是一种专门用于生成 HTML 的语言。我认为超时的原因之一。PHP 服务器运行 PHP 程序会有时间限制。 查看全部
网页抓取 加密html(《如何用php编写网络爬虫》……(组图))
《如何使用php编写网络爬虫》...1. pcntl_fork 或 swoole_process 实现多进程并发。按照每个网页的爬取时间500ms,打开200个进程,可以实现每秒400页的爬取。2. curl实现页面爬取,设置cookies可以实现模拟登录3. simple_html_dom实现页面解析和dom处理4. 如果要模拟浏览器,可以使用casperjs。使用swoole扩展封装一个服务接口调用php层。下面是一个基于上述技术方案的爬虫系统,每天爬取数千万个页面。
《php都有哪些爬虫框架》…… Beanbun是一个用PHP编写的多进程网络爬虫框架,开放性好,扩展性高。php爬虫框架phpspider
“C语言和PHP爬虫哪个好,各有什么优缺点”……C语言需要CGI执行权限,自己的服务器还行,虚拟主机一般难。PHP 需要 PHP 解释器环境。一般虚拟主机都可以运行。
《写个爬虫用Php抓取新闻》... 使用正则表达式,可以尝试很多采集软件也可以支持这个新闻采集,例如优采云采集器,输入你要爬取的新闻页面的网址,可以实现自动爬取,也可以设置定时爬取,可以试试
《Web爬虫的PHP实现跪求高玩..》......你是想爬取整个网页,还是网页中的一些数据,如果是后者,必须按照每个网站进行抓取@> 组织 每个 网站@> 组织都是不同的。爬虫程序需要为每个网页设置一个特定的配置文件;如果是前者,需要先有一个域名库,依次从域名库中读取每个域名,然后抓取页面
《哪个php爬虫框架好用》... Beanbun使用workman和guzzle,数据库使用medoo,支持分布式部署,可以使用内存(估计是workman自带的容器)和redis作为队列,可以方便灵活的制作插件,扩展性强。Beanbag 安装简单,可以使用composer安装:$composerrequirekiddyu/beanbun
“PHP可以写网络爬虫吗?”……几乎任何语言都可以写爬虫,原理都是一样的。http 协议捕获 Web 内容。根据需求的程度,您可能需要抓取响应代码、cookie 和标头,然后自己处理它们。
《如何用PHP抓取网站@>的整个链接?-》... 用手抓吧。(我只用了可以下载当前页面所有链接的,整个站都没用过。)希望我的回答对你有帮助。手动打字,希望采纳。
《PHP判断是网络爬虫还是浏览器访问网站@>-》……如果有疑问,爬虫也可以模拟浏览器访问。如果是判断是否是真实用户和爬虫,可以对比一下访问的时间差
“这是我用PHP写的爬虫,为什么有效,没有效果”……PHP不适合写爬虫。它是一种专门用于生成 HTML 的语言。我认为超时的原因之一。PHP 服务器运行 PHP 程序会有时间限制。
网页抓取 加密html(#网站日志怎么看?对SEO优化有何影响影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-10-30 17:00
问:为什么站长经常分析网站上线后网站服务器的网站日志,网站是否有蜘蛛爬行,网站是否正常, 网站是否可以从网站是否降级的日志中得到答案#
网站如何查看日志?对SEO优化有什么影响
1、网站上线后,用于搜索引擎蜘蛛查看网站的爬取状态
网站上线后,向各大搜索引擎平台提交网站地图后,发现网站的日志中搜索引擎蜘蛛访问次数增加,且两者均他们返回200,说明该网页被蜘蛛访问过,爬取时返回的是正常的网页,即这些网页会被搜索引擎抓取,正常收录。
2、检查网站日志中的服务器状态是否正常
网站 日志中每行末尾的字符是状态码。正常的服务器状态码应该是200或者301,但是如果还有其他的码,比如4xx网站打不开,5xx服务器问题,对于不同的web服务器返回码,可以找对应的错误网页来解决问题。
网站如何查看日志?对SEO优化有什么影响
3、网站收录 异常,分析蜘蛛访问次数是否低
观察网站被搜索引擎蜘蛛爬取的次数,看看蜘蛛的访问次数是否低,导致网站收录不好。蜘蛛访问量低的原因可能有:网页无法正常访问和打开、网站服务器不稳定、网站外部链接减少、网站内容质量低、< @网站 作弊违规被搜索引擎等处罚。
4、检查是否有搜索引擎惩罚和监控蜘蛛爬行
网站在被搜索引擎惩罚之前,搜索引擎通常会派一些IP蜘蛛访问网站来抓取抓取内容,进一步判断是否存在大量的作弊和违规网站操作内容,然后根据作弊、过度优化等行为进行下一步分析操作,看网站是否应该受到处罚,比如百度的123.125.6< @8.* 在IP段爬行的蜘蛛可能会受到惩罚。大多数 IP 以 220 开头的蜘蛛表示正在抓取网页。
网站如何查看日志?对SEO优化有什么影响
5、网站 K是否可以恢复,观察日志情况
<p>网站由于违规操作,该网站被搜索引擎搜索到。及时处理后,网站能恢复正常吗?这时候我们可以通过分析网站的日志文件来获取,网站被k,在大多数情况下网站有蜘蛛爬行,但很少,只要访问 查看全部
网页抓取 加密html(#网站日志怎么看?对SEO优化有何影响影响)
问:为什么站长经常分析网站上线后网站服务器的网站日志,网站是否有蜘蛛爬行,网站是否正常, 网站是否可以从网站是否降级的日志中得到答案#
网站如何查看日志?对SEO优化有什么影响
1、网站上线后,用于搜索引擎蜘蛛查看网站的爬取状态
网站上线后,向各大搜索引擎平台提交网站地图后,发现网站的日志中搜索引擎蜘蛛访问次数增加,且两者均他们返回200,说明该网页被蜘蛛访问过,爬取时返回的是正常的网页,即这些网页会被搜索引擎抓取,正常收录。
2、检查网站日志中的服务器状态是否正常
网站 日志中每行末尾的字符是状态码。正常的服务器状态码应该是200或者301,但是如果还有其他的码,比如4xx网站打不开,5xx服务器问题,对于不同的web服务器返回码,可以找对应的错误网页来解决问题。
网站如何查看日志?对SEO优化有什么影响
3、网站收录 异常,分析蜘蛛访问次数是否低
观察网站被搜索引擎蜘蛛爬取的次数,看看蜘蛛的访问次数是否低,导致网站收录不好。蜘蛛访问量低的原因可能有:网页无法正常访问和打开、网站服务器不稳定、网站外部链接减少、网站内容质量低、< @网站 作弊违规被搜索引擎等处罚。
4、检查是否有搜索引擎惩罚和监控蜘蛛爬行
网站在被搜索引擎惩罚之前,搜索引擎通常会派一些IP蜘蛛访问网站来抓取抓取内容,进一步判断是否存在大量的作弊和违规网站操作内容,然后根据作弊、过度优化等行为进行下一步分析操作,看网站是否应该受到处罚,比如百度的123.125.6< @8.* 在IP段爬行的蜘蛛可能会受到惩罚。大多数 IP 以 220 开头的蜘蛛表示正在抓取网页。
网站如何查看日志?对SEO优化有什么影响
5、网站 K是否可以恢复,观察日志情况
<p>网站由于违规操作,该网站被搜索引擎搜索到。及时处理后,网站能恢复正常吗?这时候我们可以通过分析网站的日志文件来获取,网站被k,在大多数情况下网站有蜘蛛爬行,但很少,只要访问
网页抓取 加密html(网页抓取加密html代码的话,需要用apache+apache2+flash)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-28 07:05
网页抓取加密html代码的话,需要用apache+apache2+mssql+flash。flash要apache的。没有服务器,直接用网页抓取,网页上没有加密代码,你就抓取不了。
谢邀!nginx代理可以抓取并解析html页面(python语言)
1.站点的支持脚本可以抓取,只要type=sitemap就可以2.python3.6+的webserver可以抓取html代码,
动态加载html本质上是从pages目录下直接插入html文件。springweb框架,lettingwebfont可以生成html的编码文件,通过浏览器编码转换为unicode编码(encode)。python在处理html中获取编码问题比较麻烦,直接使用xml和正则来解析。xml处理是将html代码和xml编码问题封装起来;正则解析是xml抽象出一个功能,可以直接调用xmlretrieve实现获取编码功能。
apache+webpack+php的方式,大概可以完成类似。效率上需要耗费一些时间,因为有可能需要拆分一个逻辑为单独的url和处理再分发给很多业务来处理。
springboot/spring-boot-project
谢邀。多种方式。目前pythonhtml代码仅支持通过http方式加载文档,而skimage等方式则支持pb截取以及flash的实时抓取。至于c/c++,国内源码部分cocos2dx较多,国外projectparser也不错。shell好像agent只支持linux有linux版本的,单loader只支持linux有linux版本的,c++目前linux下编程语言支持较少(不过gcc都有了,已经可以大大降低学习c++的难度了)。 查看全部
网页抓取 加密html(网页抓取加密html代码的话,需要用apache+apache2+flash)
网页抓取加密html代码的话,需要用apache+apache2+mssql+flash。flash要apache的。没有服务器,直接用网页抓取,网页上没有加密代码,你就抓取不了。
谢邀!nginx代理可以抓取并解析html页面(python语言)
1.站点的支持脚本可以抓取,只要type=sitemap就可以2.python3.6+的webserver可以抓取html代码,
动态加载html本质上是从pages目录下直接插入html文件。springweb框架,lettingwebfont可以生成html的编码文件,通过浏览器编码转换为unicode编码(encode)。python在处理html中获取编码问题比较麻烦,直接使用xml和正则来解析。xml处理是将html代码和xml编码问题封装起来;正则解析是xml抽象出一个功能,可以直接调用xmlretrieve实现获取编码功能。
apache+webpack+php的方式,大概可以完成类似。效率上需要耗费一些时间,因为有可能需要拆分一个逻辑为单独的url和处理再分发给很多业务来处理。
springboot/spring-boot-project
谢邀。多种方式。目前pythonhtml代码仅支持通过http方式加载文档,而skimage等方式则支持pb截取以及flash的实时抓取。至于c/c++,国内源码部分cocos2dx较多,国外projectparser也不错。shell好像agent只支持linux有linux版本的,单loader只支持linux有linux版本的,c++目前linux下编程语言支持较少(不过gcc都有了,已经可以大大降低学习c++的难度了)。
网页抓取 加密html(密码在服务器被别人盗走的原因是什么?怎么破?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-27 20:19
很有趣的问题。
问题相当模糊——“有意义吗?” 暂时我们认为“有意义”=“密码不会泄露”。
看到很多人是从密码学的角度来解释这个问题的,我就从工程的角度来谈谈吧。泄漏的方法有很多种。在这里,我们将讨论每种方法以及更实用的处理方法。假设系统架构是典型的CS/BS架构。
密码被前端其他人盗取。比如在网页的cookie中,名著的密码存放在localstorage等地方,就是XSS。或者应用程序将密码存储在沙盒文件系统中,但不幸的是应用程序已被篡改,或手机已完全root。解决的办法是前端根本不要保存密码,而是保存到后端;或使用http only cookie技术不允许前端代码接触密码数据;或者确保前端有某种类似于iOS的keychain机制来做存储。
密码输入被盗。用户通过 UI 控件输入密码,攻击者在将其传输到服务器之前将其窃取。这时候就需要前端加密了。但我们特别注意。如果由于各种原因传输不能使用SSL,或者代理有SSL的私钥(比如大型企业内部代理用户监控员工行为),那么客户端加密就很重要了。很重要。
密码在传输过程中被他人盗取。对此大家有一个共识,去SSL(对于http是https)。如果ssl由于某种原因在某个特定领域更胜一筹,就需要做一个大致相当于SSL的简化方案。这种传输本质上是加密和解密同时进行,同时保证密钥本身在传输过程中不会泄露。
另外,https的一个额外用途是将证书和域名结合起来,域名由DNS控制。这三个一起可以避免网络钓鱼攻击(但还是有办法的,见下文)。
密码被其他人从服务器上窃取了。密码存储在数据库中,然后拖入数据库中。响应是为了防止内部网络受到损害。但是没有人可以玩这张套餐票。因此,最好不要存储原创明文密码,甚至是可以轻松反转回明文的密码哈希。常用的技术是为每个密码添加不同的盐。
高仿真钓鱼。如果在浏览器中直接输入url输入某个网站,其实是很不靠谱的。钓鱼网站很容易让自己看起来很真实网站(包括域名),申请证书也相对容易,不需要任何审核。因此,请尝试从搜索引擎和其他地方输入。这些入口确保您输入的内容确实是您想要输入的网站。在移动端,这个入口一般是由应用商店保证的。应用商店保证提供给您的应用是正版的、未经篡改的、不是李鬼的应用。(如果你经常使用盗版应用做一些与金钱有关的事情)。
社会工程学。冒名顶替者打电话给想要突破的人并要求输入密码。有了修辞,总有一些人会被欺骗。除了教育之外,没有更好的方法可以避免随时泄露密码。或许一些硬件,比如U盘,可以部分解决这个问题。
可见,安全是一个整体,整个系统的任何漏洞都会造成问题。此外,安全性分为多个级别。比如工具服务的安全性可以稍微低一些,所以做前两个可以解决大部分问题。金融服务必须无所不能。
在上述系统下,我们可以看出“前端加密”的重要性与能否使用安全传输有很大关系。如果可以使用https,前端加密的作用就是用户在前端输入密码,然后在https传输之前输入一个加密。如果能经常更换密钥,而且加密是单向的,即使能被人看到,也是“有意义的”,但从全局来看意义不大。简单的说,性价比不高。但是如果不能使用安全传输,前端加密实际上起到了安全传输的作用。
一个比较好的进行前端加密的方式是,用户一输入密码,就用公钥加密,然后用于传输,然后服务器用私钥解密,然后就是储存在盐中。如上,这其实是在模仿ssl。
另一种方式是在前端对用户密码进行hash,然后传输到后端给hash加盐。但是hash使用的算法比较容易破解,比如MD5、SHA1等。 查看全部
网页抓取 加密html(密码在服务器被别人盗走的原因是什么?怎么破?)
很有趣的问题。
问题相当模糊——“有意义吗?” 暂时我们认为“有意义”=“密码不会泄露”。
看到很多人是从密码学的角度来解释这个问题的,我就从工程的角度来谈谈吧。泄漏的方法有很多种。在这里,我们将讨论每种方法以及更实用的处理方法。假设系统架构是典型的CS/BS架构。
密码被前端其他人盗取。比如在网页的cookie中,名著的密码存放在localstorage等地方,就是XSS。或者应用程序将密码存储在沙盒文件系统中,但不幸的是应用程序已被篡改,或手机已完全root。解决的办法是前端根本不要保存密码,而是保存到后端;或使用http only cookie技术不允许前端代码接触密码数据;或者确保前端有某种类似于iOS的keychain机制来做存储。
密码输入被盗。用户通过 UI 控件输入密码,攻击者在将其传输到服务器之前将其窃取。这时候就需要前端加密了。但我们特别注意。如果由于各种原因传输不能使用SSL,或者代理有SSL的私钥(比如大型企业内部代理用户监控员工行为),那么客户端加密就很重要了。很重要。
密码在传输过程中被他人盗取。对此大家有一个共识,去SSL(对于http是https)。如果ssl由于某种原因在某个特定领域更胜一筹,就需要做一个大致相当于SSL的简化方案。这种传输本质上是加密和解密同时进行,同时保证密钥本身在传输过程中不会泄露。
另外,https的一个额外用途是将证书和域名结合起来,域名由DNS控制。这三个一起可以避免网络钓鱼攻击(但还是有办法的,见下文)。
密码被其他人从服务器上窃取了。密码存储在数据库中,然后拖入数据库中。响应是为了防止内部网络受到损害。但是没有人可以玩这张套餐票。因此,最好不要存储原创明文密码,甚至是可以轻松反转回明文的密码哈希。常用的技术是为每个密码添加不同的盐。
高仿真钓鱼。如果在浏览器中直接输入url输入某个网站,其实是很不靠谱的。钓鱼网站很容易让自己看起来很真实网站(包括域名),申请证书也相对容易,不需要任何审核。因此,请尝试从搜索引擎和其他地方输入。这些入口确保您输入的内容确实是您想要输入的网站。在移动端,这个入口一般是由应用商店保证的。应用商店保证提供给您的应用是正版的、未经篡改的、不是李鬼的应用。(如果你经常使用盗版应用做一些与金钱有关的事情)。
社会工程学。冒名顶替者打电话给想要突破的人并要求输入密码。有了修辞,总有一些人会被欺骗。除了教育之外,没有更好的方法可以避免随时泄露密码。或许一些硬件,比如U盘,可以部分解决这个问题。
可见,安全是一个整体,整个系统的任何漏洞都会造成问题。此外,安全性分为多个级别。比如工具服务的安全性可以稍微低一些,所以做前两个可以解决大部分问题。金融服务必须无所不能。
在上述系统下,我们可以看出“前端加密”的重要性与能否使用安全传输有很大关系。如果可以使用https,前端加密的作用就是用户在前端输入密码,然后在https传输之前输入一个加密。如果能经常更换密钥,而且加密是单向的,即使能被人看到,也是“有意义的”,但从全局来看意义不大。简单的说,性价比不高。但是如果不能使用安全传输,前端加密实际上起到了安全传输的作用。
一个比较好的进行前端加密的方式是,用户一输入密码,就用公钥加密,然后用于传输,然后服务器用私钥解密,然后就是储存在盐中。如上,这其实是在模仿ssl。
另一种方式是在前端对用户密码进行hash,然后传输到后端给hash加盐。但是hash使用的算法比较容易破解,比如MD5、SHA1等。
网页抓取 加密html(网页抓取加密html,并不是从sqlmap里面获取的解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-27 01:02
网页抓取加密html,并不是从access-log里面获取的解密html,是从sqlmap,chrome开发者工具。可以参考这篇文章的技术细节。
你在f12打开network,然后用curl命令获取到数据包,然后解析。
你需要的是框架,在这里推荐你一个免费的网页调试框架nimble,它本身就可以作为一个简单的解密过程,你只需要接受一下flag即可。
nimble这个网站可以解密html格式的网页,再进行二次加密,然后对暴雪的魔兽世界解密,lol,
f12->network->accessmemory->url=";is_msg=ack&username=sv_qq&password=123456"用curl命令打开access-log_html(access.log)直接解密html(access.log)就好了。
这个很好用的,我现在做文本转pdf工具都是这样来做的,给他后缀名改成.txt,
搜索一下selenium可以搞定
这个是nimble的例子:-player/
不过既然你会转代码,要开始转工程。
看这里,
刚刚解决了这个问题,
python+easyx,用easyx解密工具可以快速生成python2的代码:reverse-easyx这里推荐easyx-python:pythonprojectsatoschina在文本编辑器里写好python程序,建议用记事本吧,python2应该可以在官网找到一个python的安装包,我记得有一本书叫做《easyx精通指南》,如果这个python工具不方便下载,可以找个免费的开源镜像服务,ubuntu下应该就有,我的是freenode的镜像,建议生成目录configureinstallprojects,再点击install好像可以自动生成python3的html5解析python脚本python-python3-easyx-git命令行会报错无法找到源代码,直接百度dependencytree,有easyx或者reversejs的python替代库就可以了:。 查看全部
网页抓取 加密html(网页抓取加密html,并不是从sqlmap里面获取的解密)
网页抓取加密html,并不是从access-log里面获取的解密html,是从sqlmap,chrome开发者工具。可以参考这篇文章的技术细节。
你在f12打开network,然后用curl命令获取到数据包,然后解析。
你需要的是框架,在这里推荐你一个免费的网页调试框架nimble,它本身就可以作为一个简单的解密过程,你只需要接受一下flag即可。
nimble这个网站可以解密html格式的网页,再进行二次加密,然后对暴雪的魔兽世界解密,lol,
f12->network->accessmemory->url=";is_msg=ack&username=sv_qq&password=123456"用curl命令打开access-log_html(access.log)直接解密html(access.log)就好了。
这个很好用的,我现在做文本转pdf工具都是这样来做的,给他后缀名改成.txt,
搜索一下selenium可以搞定
这个是nimble的例子:-player/
不过既然你会转代码,要开始转工程。
看这里,
刚刚解决了这个问题,
python+easyx,用easyx解密工具可以快速生成python2的代码:reverse-easyx这里推荐easyx-python:pythonprojectsatoschina在文本编辑器里写好python程序,建议用记事本吧,python2应该可以在官网找到一个python的安装包,我记得有一本书叫做《easyx精通指南》,如果这个python工具不方便下载,可以找个免费的开源镜像服务,ubuntu下应该就有,我的是freenode的镜像,建议生成目录configureinstallprojects,再点击install好像可以自动生成python3的html5解析python脚本python-python3-easyx-git命令行会报错无法找到源代码,直接百度dependencytree,有easyx或者reversejs的python替代库就可以了:。
网页抓取 加密html(不少加密与解密方案,你知道吗?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-26 19:05
*文章原创 作者:manwu91,本文属于FreeBuf原创奖励计划,未经许可禁止转载。
最近看到很多网站使用字体库对数据进行加密,即页面源代码中的数据与显示的数据不同,用户无法直接复制。
比如七心宝页面的字母和数字,58房产频道的数字:
经过对字体库的研究,找到了一种加解密方案。
加密和准备字体库样本
笔者在网上随机下载了一个ttf字体库,保存为'origin.ttf',使用fonttools的命令行工具pyftsubset提取需要加密的字符:
pyftsubset origin.ttf --text='1234567890'
参数 text 是要提取的字体的字符。操作完成后,会在当前目录生成'origin.subset.ttf'。字库仅收录 10 个字符的 '1234567890'。
生成加密字体库
这里使用[]()网站提供的在线服务自定义上一步生成的字体库。首先,将生成的subset.ttf 转换为svg。作者使用的是cloudconvert提供的服务。然后将svg上传到fontello,选择需要自定义的字符,因为我们上传的字体库只收录0到9,所以这里全选,然后在Customize Codes功能下自定义code值。
编码值和字符的关系可以看成是一种映射关系,例如Unicode E801对应字符1,Unicode E802对应字符2。我们可以随意修改字符的unicode值,但是必须记住这个值和真实字符的对应关系来加密要在页面上显示的数据。这里使用的是默认网站生成的unicode。对应关系如下:
CIPHER_BOOK = {
'0': '\uE800',
'1': '\uE801',
'2': '\uE802',
'3': '\uE803',
'4': '\uE804',
'5': '\uE805',
'6': '\uE806',
'7': '\uE807',
'8': '\uE808',
'9': '\uE809'
}
自定义完成后下载字体文件。
用
在css中定义字体,命名为fontello。
@font-face {
font-family: 'fontello';
src: url('/static/fontello.woff2') format('woff');
font-weight: normal;
font-style: normal;
}
然后定义使用字体的类:
.demo-icon {
font-family: "fontello";
}
这样,您只需要在页面标签中添加“demo-icon”类即可。喜欢:
就是这串数字:{{string}}
服务器在返回数据之前需要使用 CIPHER_BOOK 转换数字。
CIPHER_BOOK = {
'0': '\uE800',
'1': '\uE801',
'2': '\uE802',
'3': '\uE803',
'4': '\uE804',
'5': '\uE805',
'6': '\uE806',
'7': '\uE807',
'8': '\uE808',
'9': '\uE809'
}
def _encrypt_secret(secret):
return ''.join(CIPHER_BOOK[c] for c in secret)
@app.route('/')
def index():
if 'guess' in request.values:
ts = session['ts'] if 'ts' in session else 0
secret = session['secret'] if 'secret' in session else None
if time.time() - ts < 2 and request.values['guess'] == secret:
return render_template('index.html', success=True)
secret = ''.join([random.choice('0123456789') for _ in range(20)])
# 通过CIPHER_BOOK将数字转换为不可见字符
s = _encrypt_secret(secret)
session['secret'] = secret
session['ts'] = time.time()
return render_template("index.html", string=s)
查看页面源码,会发现源码是一个无法显示的字符,复制的代码乱码。
58产房通道采用本文介绍的方案,仅对数字进行加密。但是不同页面的字体库发生了变化。在字体加密破解中,我们将详细介绍如何破解58的字体加密,示例代码已经上传到github,有兴趣的可以看看。
裂缝
我已经介绍了如何制作加密字体库并在演示项目中使用它来防止数据被捕获。下面介绍破解方法。
真字型介绍
我们已经知道字体加密其实就是明文到密文的双向映射,所以只要找到映射表就行了。但是我们在破解的时候只能得到字体库文件,所以需要通过这个文件找到CIPHER_BOOK。这需要对字体库结构有一定的了解。查阅相关文档后,可以简单的将字体绘制过程理解为:
1. 根据字符的unicode编码找到字形名称(cmap);
2.根据字形名称查找字形(glyf);
3.使用字形绘制。
其中glyph可以理解为字体绘制所需的数据,如点、线等。
TrueType Font 字体文件收录多个表格。这里需要用到的两张表如下(tag为表名):
可标记的
地图
字符到字形映射
格莱夫
字形数据
根据字体绘制过程,可以猜测实现字体加密有两种方式:
1.乱码字符编码
2.打乱字形名称
笔者将用两个案例来解释这两种情况。
破解演示
先在页面上找到字体库的url下载得到fontello.woff2,然后使用fonttools将文件转换成ttx进行可视化分析。
from fontTools.ttLib import TTFont
font = TTFont('fontello.woff2')
font.saveXML('fontello.ttx')
得到的ttx是一个xml文件,打开找到cmap节点:
基于此,我们可以恢复加密的映射表(即cmap表):
CIPHER_BOOK = {
'\ue800': '0',
'\ue801': '1',
'\ue802': '2',
'\ue803': '3',
'\ue804': '4',
'\ue805': '5',
'\ue806': '6',
'\ue807': '7',
'\ue808': '8',
'\ue809': '9'
}
由于demo使用的是静态字体库,所以这张表不会变,直接写死就行了。破解代码如下:
import requests
from bs4 import BeautifulSoup as BS
CIPHER_BOOK = {
'\ue800': '0',
'\ue801': '1',
'\ue802': '2',
'\ue803': '3',
'\ue804': '4',
'\ue805': '5',
'\ue806': '6',
'\ue807': '7',
'\ue808': '8',
'\ue809': '9'
}
URL = 'http://127.0.0.1:5000'
sess = requests.Session()
resp = sess.get(URL).text
bs = BS(resp, 'lxml')
string = bs.select_one('.demo-icon b').text
guess = ''.join(CIPHER_BOOK[c] if c in CIPHER_BOOK else c
for c in string)
print('guess:', guess)
resp = sess.get(URL, params={'guess': guess}).text
assert 'Congratulations' in resp
破解58
演示中的字体库不会改变,所以写映射表就够了。但分析发现,58置业频道不同页面的字体库不同,字形名称与真实字符不同,需要根据字体库动态处理。
首先页面中的字体文件是base64编码的,直接解码保存到文件中。
然后用上面的代码转换成ttx文件,查看cmap节点:
通过观察对比发现,字符编码相同,只是字形名称变了,字形名称与实数的关系为:
glyph_name = 'glyph00d' % (real_num + 1)
基于此,我们可以还原出字形名称与真实字符的映射表(即glyf表):
GLYF_TABLE = {
'glyph00001': '0',
'glyph00002': '1',
'glyph00003': '2',
'glyph00004': '3',
'glyph00005': '4',
'glyph00006': '5',
'glyph00007': '6',
'glyph00008': '7',
'glyph00009': '8',
'glyph00010': '9'
}
另外,由于cmap表发生了变化,在解密时需要提取出来,可以通过使用fonttools库来实现:
cmap = font['cmap'].getBestCmap()
返回一个 dict,其中键是 int 类型代码,v 是字形名称。整个解密过程为:
1.分析字体库获取cmap;
2. 根据cmap查询字符码,得到字形名称;
3. 根据GLYF_TABLE查询字形名称,得到真实字符。
代码有点长,我就不贴了。它已上传到 gayhub。有兴趣的可以下载看看。
*文章原创 作者:manwu91,本文属于FreeBuf原创奖励计划,未经许可禁止转载。 查看全部
网页抓取 加密html(不少加密与解密方案,你知道吗?(组图))
*文章原创 作者:manwu91,本文属于FreeBuf原创奖励计划,未经许可禁止转载。
最近看到很多网站使用字体库对数据进行加密,即页面源代码中的数据与显示的数据不同,用户无法直接复制。
比如七心宝页面的字母和数字,58房产频道的数字:
经过对字体库的研究,找到了一种加解密方案。
加密和准备字体库样本
笔者在网上随机下载了一个ttf字体库,保存为'origin.ttf',使用fonttools的命令行工具pyftsubset提取需要加密的字符:
pyftsubset origin.ttf --text='1234567890'
参数 text 是要提取的字体的字符。操作完成后,会在当前目录生成'origin.subset.ttf'。字库仅收录 10 个字符的 '1234567890'。
生成加密字体库
这里使用[]()网站提供的在线服务自定义上一步生成的字体库。首先,将生成的subset.ttf 转换为svg。作者使用的是cloudconvert提供的服务。然后将svg上传到fontello,选择需要自定义的字符,因为我们上传的字体库只收录0到9,所以这里全选,然后在Customize Codes功能下自定义code值。
编码值和字符的关系可以看成是一种映射关系,例如Unicode E801对应字符1,Unicode E802对应字符2。我们可以随意修改字符的unicode值,但是必须记住这个值和真实字符的对应关系来加密要在页面上显示的数据。这里使用的是默认网站生成的unicode。对应关系如下:
CIPHER_BOOK = {
'0': '\uE800',
'1': '\uE801',
'2': '\uE802',
'3': '\uE803',
'4': '\uE804',
'5': '\uE805',
'6': '\uE806',
'7': '\uE807',
'8': '\uE808',
'9': '\uE809'
}
自定义完成后下载字体文件。
用
在css中定义字体,命名为fontello。
@font-face {
font-family: 'fontello';
src: url('/static/fontello.woff2') format('woff');
font-weight: normal;
font-style: normal;
}
然后定义使用字体的类:
.demo-icon {
font-family: "fontello";
}
这样,您只需要在页面标签中添加“demo-icon”类即可。喜欢:
就是这串数字:{{string}}
服务器在返回数据之前需要使用 CIPHER_BOOK 转换数字。
CIPHER_BOOK = {
'0': '\uE800',
'1': '\uE801',
'2': '\uE802',
'3': '\uE803',
'4': '\uE804',
'5': '\uE805',
'6': '\uE806',
'7': '\uE807',
'8': '\uE808',
'9': '\uE809'
}
def _encrypt_secret(secret):
return ''.join(CIPHER_BOOK[c] for c in secret)
@app.route('/')
def index():
if 'guess' in request.values:
ts = session['ts'] if 'ts' in session else 0
secret = session['secret'] if 'secret' in session else None
if time.time() - ts < 2 and request.values['guess'] == secret:
return render_template('index.html', success=True)
secret = ''.join([random.choice('0123456789') for _ in range(20)])
# 通过CIPHER_BOOK将数字转换为不可见字符
s = _encrypt_secret(secret)
session['secret'] = secret
session['ts'] = time.time()
return render_template("index.html", string=s)
查看页面源码,会发现源码是一个无法显示的字符,复制的代码乱码。
58产房通道采用本文介绍的方案,仅对数字进行加密。但是不同页面的字体库发生了变化。在字体加密破解中,我们将详细介绍如何破解58的字体加密,示例代码已经上传到github,有兴趣的可以看看。
裂缝
我已经介绍了如何制作加密字体库并在演示项目中使用它来防止数据被捕获。下面介绍破解方法。
真字型介绍
我们已经知道字体加密其实就是明文到密文的双向映射,所以只要找到映射表就行了。但是我们在破解的时候只能得到字体库文件,所以需要通过这个文件找到CIPHER_BOOK。这需要对字体库结构有一定的了解。查阅相关文档后,可以简单的将字体绘制过程理解为:
1. 根据字符的unicode编码找到字形名称(cmap);
2.根据字形名称查找字形(glyf);
3.使用字形绘制。
其中glyph可以理解为字体绘制所需的数据,如点、线等。
TrueType Font 字体文件收录多个表格。这里需要用到的两张表如下(tag为表名):
可标记的
地图
字符到字形映射
格莱夫
字形数据
根据字体绘制过程,可以猜测实现字体加密有两种方式:
1.乱码字符编码
2.打乱字形名称
笔者将用两个案例来解释这两种情况。
破解演示
先在页面上找到字体库的url下载得到fontello.woff2,然后使用fonttools将文件转换成ttx进行可视化分析。
from fontTools.ttLib import TTFont
font = TTFont('fontello.woff2')
font.saveXML('fontello.ttx')
得到的ttx是一个xml文件,打开找到cmap节点:
基于此,我们可以恢复加密的映射表(即cmap表):
CIPHER_BOOK = {
'\ue800': '0',
'\ue801': '1',
'\ue802': '2',
'\ue803': '3',
'\ue804': '4',
'\ue805': '5',
'\ue806': '6',
'\ue807': '7',
'\ue808': '8',
'\ue809': '9'
}
由于demo使用的是静态字体库,所以这张表不会变,直接写死就行了。破解代码如下:
import requests
from bs4 import BeautifulSoup as BS
CIPHER_BOOK = {
'\ue800': '0',
'\ue801': '1',
'\ue802': '2',
'\ue803': '3',
'\ue804': '4',
'\ue805': '5',
'\ue806': '6',
'\ue807': '7',
'\ue808': '8',
'\ue809': '9'
}
URL = 'http://127.0.0.1:5000'
sess = requests.Session()
resp = sess.get(URL).text
bs = BS(resp, 'lxml')
string = bs.select_one('.demo-icon b').text
guess = ''.join(CIPHER_BOOK[c] if c in CIPHER_BOOK else c
for c in string)
print('guess:', guess)
resp = sess.get(URL, params={'guess': guess}).text
assert 'Congratulations' in resp
破解58
演示中的字体库不会改变,所以写映射表就够了。但分析发现,58置业频道不同页面的字体库不同,字形名称与真实字符不同,需要根据字体库动态处理。
首先页面中的字体文件是base64编码的,直接解码保存到文件中。
然后用上面的代码转换成ttx文件,查看cmap节点:
通过观察对比发现,字符编码相同,只是字形名称变了,字形名称与实数的关系为:
glyph_name = 'glyph00d' % (real_num + 1)
基于此,我们可以还原出字形名称与真实字符的映射表(即glyf表):
GLYF_TABLE = {
'glyph00001': '0',
'glyph00002': '1',
'glyph00003': '2',
'glyph00004': '3',
'glyph00005': '4',
'glyph00006': '5',
'glyph00007': '6',
'glyph00008': '7',
'glyph00009': '8',
'glyph00010': '9'
}
另外,由于cmap表发生了变化,在解密时需要提取出来,可以通过使用fonttools库来实现:
cmap = font['cmap'].getBestCmap()
返回一个 dict,其中键是 int 类型代码,v 是字形名称。整个解密过程为:
1.分析字体库获取cmap;
2. 根据cmap查询字符码,得到字形名称;
3. 根据GLYF_TABLE查询字形名称,得到真实字符。
代码有点长,我就不贴了。它已上传到 gayhub。有兴趣的可以下载看看。
*文章原创 作者:manwu91,本文属于FreeBuf原创奖励计划,未经许可禁止转载。
网页抓取 加密html(Google默认是收录加密网页的网址,Google会抓取两种网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-26 13:05
现在谷歌已经决定默认使用 收录 来加密网页。
如果一个网页同时有来自其他网站的http和https外链网址指向它,谷歌会同时抓取这两个网址,无论哪种方式,更多的链接都会相同的去抓取页面,如果谷歌发现抓取的页面内容是一样的,只是单纯使用不同的端口,那么Google就会收录https URL。当然,这也有一些先决条件:
网页不收录非安全内容;robots.txt 不用于防止抓取内容;用户不会被重定向到不安全的网页;网页代码中的链接没有指向http页面;网页代码不收录 noindex 元标记;没有链接到正常的http URL;站点地图文件收录 https URL,而不是 URL 的 http 版本;当然,需要有效的证书。
在其官方建议中,Google 建议您使用重定向将 http URL 重定向到 https。您还可以添加 HSTS 标头以减少重定向次数。
在实际的网络环境中,在中国,我们经常看到这样的消息。网页显示时,会莫名其妙地出现弹窗,或者更换网页内容,网页上会出现来源不明的广告。会下载看起来正确的 URL,但不会下载要下载的内容。这些可以通过完全采用 https 来改进或避免。
另外:百度终于在去年底开始支持收录 https 网页。这是一个很大的改进。虽然晚了点,但还是晚点好。
我给广大站长的建议是全站开启https加密,去除网页中不安全的链接资源和链接,并正确配置网站,ssllab分数至少要90分或更多的。
您可以购买证书,Let's Encrypt 是免费的。 查看全部
网页抓取 加密html(Google默认是收录加密网页的网址,Google会抓取两种网址)
现在谷歌已经决定默认使用 收录 来加密网页。
如果一个网页同时有来自其他网站的http和https外链网址指向它,谷歌会同时抓取这两个网址,无论哪种方式,更多的链接都会相同的去抓取页面,如果谷歌发现抓取的页面内容是一样的,只是单纯使用不同的端口,那么Google就会收录https URL。当然,这也有一些先决条件:
网页不收录非安全内容;robots.txt 不用于防止抓取内容;用户不会被重定向到不安全的网页;网页代码中的链接没有指向http页面;网页代码不收录 noindex 元标记;没有链接到正常的http URL;站点地图文件收录 https URL,而不是 URL 的 http 版本;当然,需要有效的证书。
在其官方建议中,Google 建议您使用重定向将 http URL 重定向到 https。您还可以添加 HSTS 标头以减少重定向次数。
在实际的网络环境中,在中国,我们经常看到这样的消息。网页显示时,会莫名其妙地出现弹窗,或者更换网页内容,网页上会出现来源不明的广告。会下载看起来正确的 URL,但不会下载要下载的内容。这些可以通过完全采用 https 来改进或避免。
另外:百度终于在去年底开始支持收录 https 网页。这是一个很大的改进。虽然晚了点,但还是晚点好。
我给广大站长的建议是全站开启https加密,去除网页中不安全的链接资源和链接,并正确配置网站,ssllab分数至少要90分或更多的。
您可以购买证书,Let's Encrypt 是免费的。
网页抓取 加密html(1.更新Leave加密2.更新微擎2c加密4.加强加密算法更新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-26 13:04
php代码加密工具可以起到加密程序和代码的作用,让我们不用担心代码泄露造成财产损失。适用于PHP构建的底层网页和客户端。PHP代码加密系统加密强度高,运行时会占用一定的内存资源。使用时请小心。
对于大多数程序员来说,如果写的代码被抄袭,会造成非常大的损失。这时候我们就可以下载PHP代码加密软件来保护我们的代码了。该软件使用简单,可以一键加密。
【软件特点】
搭建环境,Linux需要支持sg11加密扩展,服务器不需要安装任何第三方组件,加密后的文件可以在任何普通PHP环境下运行
PHP版本5.6 7.0 全部支持
PS:建议直接用宝塔解决
功能,还有很多自建经验就不一一介绍了
几乎所有的站都是用Ajax处理的,相当好用
【常见问题】
Q:加密后的php文件可以编辑吗?
答:不能,并且禁止二次加密,因为这也会修改php文件加密代码。问:如何上传加密的php文件?
答:使用FTP传输php加密文件时,请使用二进制方式传输。当本地测试正常但向服务器传输不正常时,请检查本地和服务器上的文件大小是否相同(以字节为单位),否则可以尝试其他FTP客户端软件相同。(发现FlashFXP工具上传到部分Linux服务器有问题,推荐使用FileZilla) Q:html文件可以加密吗?
答:不需要。可以先将html代码转换成php文件输出,但是在浏览器中访问源代码后仍然是未加密的html代码。
【更新日志】
1.更新离开加密
2.更新SG11加密
3.更新微引擎2c加密
4.加强EnPHP加密算法
5.更新QQ快速登录
6.更新纳米加密
其他相关
PHP代码加密软件_PHP代码保护工具_PHP代码加密工具 PHP代码加密软件可以轻松保护您的PHP源代码。PHP 代码使用编译后的二进制方法进行加密,并对 PHP 代码进行混淆处理。加密后,无论是正规方式出售的PHP程序还是非法旧系统:代码加密-PHP在线解密提供PHP加密服务。篡改。新萝卜之家:PHP加密-PHP在线加密平台 PHP在线加密平台()是一款优秀的免费PHP源代码加密保护平台。PHP代码加密后,不需要依赖额外的扩展来解析,服务器也不需要安装任何第三方组件。, 可以运行在任何普通的 PHP 认证系统上:PHP代码加密工具Xend-专注于PHP加密和PHP代码保护PHP代码加密工具,专业提供PHP加密,提高PHP安全性,经过网站加密或PHP加密,保护您的PHP代码版权。如何保护硬开发的PHP程序的知识产权不被侵犯?现在,PHP电脑城:php加密|php在线加密|php组件加密|php源码加密|zend加密|iPHP加密()是一个免费的Php源码加密保护平台,php加密系统可以实现:php代码加密、php变量加密、php用户函数加密、php类名加密、php系统函数加密等加速:有没有免费的PHP代码加密工具?-百度知道最佳答案:百度搜索php加密,有一个PHP在线加密平台phpjm。PHP在线加密平台是一款优秀的免费PHP源代码加密保护平台。PHP 代码加密后,无需依赖额外的扩展来分析。服务147:一个PHP代码加密-程序加载-博客园2014年11月15日 查看全部
网页抓取 加密html(1.更新Leave加密2.更新微擎2c加密4.加强加密算法更新)
php代码加密工具可以起到加密程序和代码的作用,让我们不用担心代码泄露造成财产损失。适用于PHP构建的底层网页和客户端。PHP代码加密系统加密强度高,运行时会占用一定的内存资源。使用时请小心。
对于大多数程序员来说,如果写的代码被抄袭,会造成非常大的损失。这时候我们就可以下载PHP代码加密软件来保护我们的代码了。该软件使用简单,可以一键加密。
【软件特点】
搭建环境,Linux需要支持sg11加密扩展,服务器不需要安装任何第三方组件,加密后的文件可以在任何普通PHP环境下运行
PHP版本5.6 7.0 全部支持
PS:建议直接用宝塔解决
功能,还有很多自建经验就不一一介绍了
几乎所有的站都是用Ajax处理的,相当好用
【常见问题】
Q:加密后的php文件可以编辑吗?
答:不能,并且禁止二次加密,因为这也会修改php文件加密代码。问:如何上传加密的php文件?
答:使用FTP传输php加密文件时,请使用二进制方式传输。当本地测试正常但向服务器传输不正常时,请检查本地和服务器上的文件大小是否相同(以字节为单位),否则可以尝试其他FTP客户端软件相同。(发现FlashFXP工具上传到部分Linux服务器有问题,推荐使用FileZilla) Q:html文件可以加密吗?
答:不需要。可以先将html代码转换成php文件输出,但是在浏览器中访问源代码后仍然是未加密的html代码。
【更新日志】
1.更新离开加密
2.更新SG11加密
3.更新微引擎2c加密
4.加强EnPHP加密算法
5.更新QQ快速登录
6.更新纳米加密
其他相关
PHP代码加密软件_PHP代码保护工具_PHP代码加密工具 PHP代码加密软件可以轻松保护您的PHP源代码。PHP 代码使用编译后的二进制方法进行加密,并对 PHP 代码进行混淆处理。加密后,无论是正规方式出售的PHP程序还是非法旧系统:代码加密-PHP在线解密提供PHP加密服务。篡改。新萝卜之家:PHP加密-PHP在线加密平台 PHP在线加密平台()是一款优秀的免费PHP源代码加密保护平台。PHP代码加密后,不需要依赖额外的扩展来解析,服务器也不需要安装任何第三方组件。, 可以运行在任何普通的 PHP 认证系统上:PHP代码加密工具Xend-专注于PHP加密和PHP代码保护PHP代码加密工具,专业提供PHP加密,提高PHP安全性,经过网站加密或PHP加密,保护您的PHP代码版权。如何保护硬开发的PHP程序的知识产权不被侵犯?现在,PHP电脑城:php加密|php在线加密|php组件加密|php源码加密|zend加密|iPHP加密()是一个免费的Php源码加密保护平台,php加密系统可以实现:php代码加密、php变量加密、php用户函数加密、php类名加密、php系统函数加密等加速:有没有免费的PHP代码加密工具?-百度知道最佳答案:百度搜索php加密,有一个PHP在线加密平台phpjm。PHP在线加密平台是一款优秀的免费PHP源代码加密保护平台。PHP 代码加密后,无需依赖额外的扩展来分析。服务147:一个PHP代码加密-程序加载-博客园2014年11月15日

