
网页抓取 加密html
网页抓取 加密html(某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2021-10-05 15:09
有时由于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "" + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "" + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}我明白了,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
网页抓取 加密html(某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
有时由于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第二步:查看网页的源码,我们在源码中看到这一段:

由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:

换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "" + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:

我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:


从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "" + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}我明白了,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
网页抓取 加密html(Python实现通过这位大神的解决思路写一个解密电子邮箱的函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-03 16:03
1、问题的根源
在数据采集的过程中,往往需要采集各种联系方式,包括邮箱地址。一些未加防卫的网站邮箱地址可以直接从网页源码中获取,有些网站对爬虫稍加防范,会将邮件中的@符号替换为#号:
在我最近的工作中,我遇到了一种以前从未遇到过的电子邮件加密方法。在查看元素时可以获得正确的数据:
在查看网页源代码时,还可以定位到对应的元素:
但是从上图可以发现,它对应的是显示邮件的位置,并且显示了一个“[email protected]”链接。让我们检查源代码:
这个用于显示电子邮件的字段与其他文本不同。如果是非邮件数据,则没有链接;如果是邮件数据,则通过这个链接在网页前端显示数据。
2、解决方案
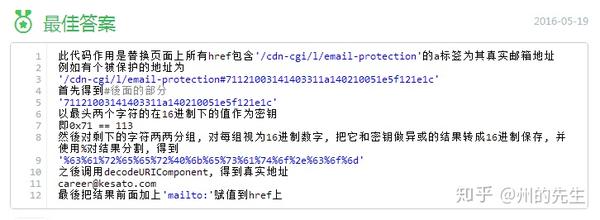
经过一番搜索,在百度知道中找到了它的原理和解决方法:
加密只是简单的异或运算,解密起来并不难。
3、Python 实现
通过这位大神的解决方案,我们可以快速使用Python编写一个解密电子邮件的函数。
首先提取真实邮箱地址的加密数据:
出于隐私考虑,这里使用了百度知道上公开的邮箱地址的加密字符串
import re
from urllib.parse import unquote
email_str = '71121003141403311a140210051e5f121e1c'
然后将此加密数据成对拆分为一个列表:
email_list = re.findall(r'.{2}',email_str)
提取加密字符串的密钥,即字符串的前两个字符:
key = email_list[0]
定义一个空列表来存储十六进制 XOR 运算的结果:
ll = []
遍历剩余的加密字符串,遍历过程中与key进行异或运算,将结果加入到ll列表中:
for e in email_list[1:]:
# 对十六进制进行异或运算
r = hex(int(key,16) ^ int(e,16))
ll.append(r)
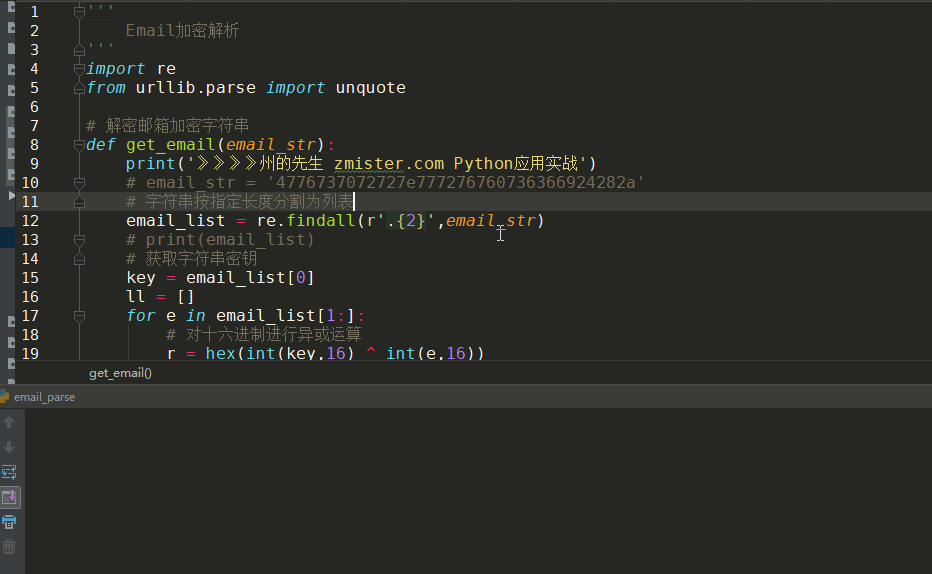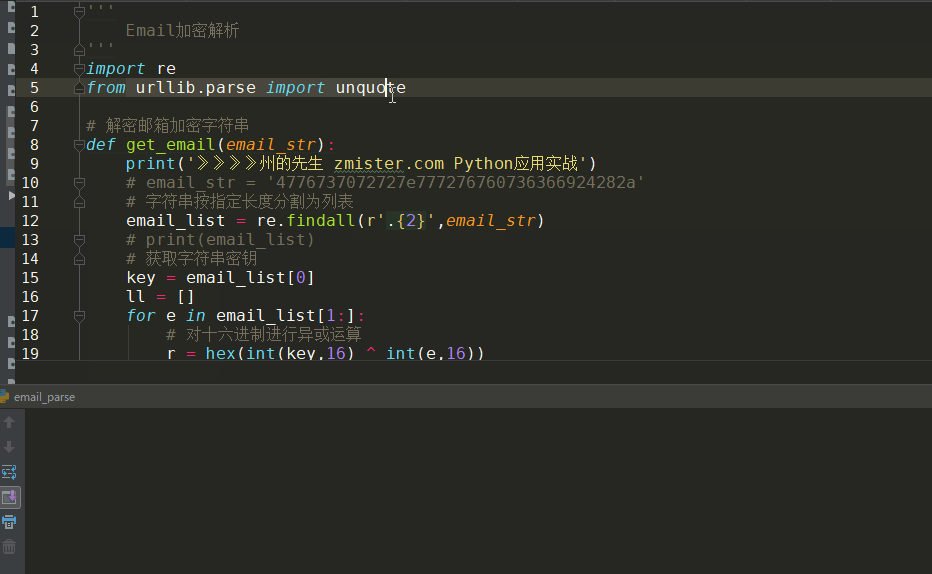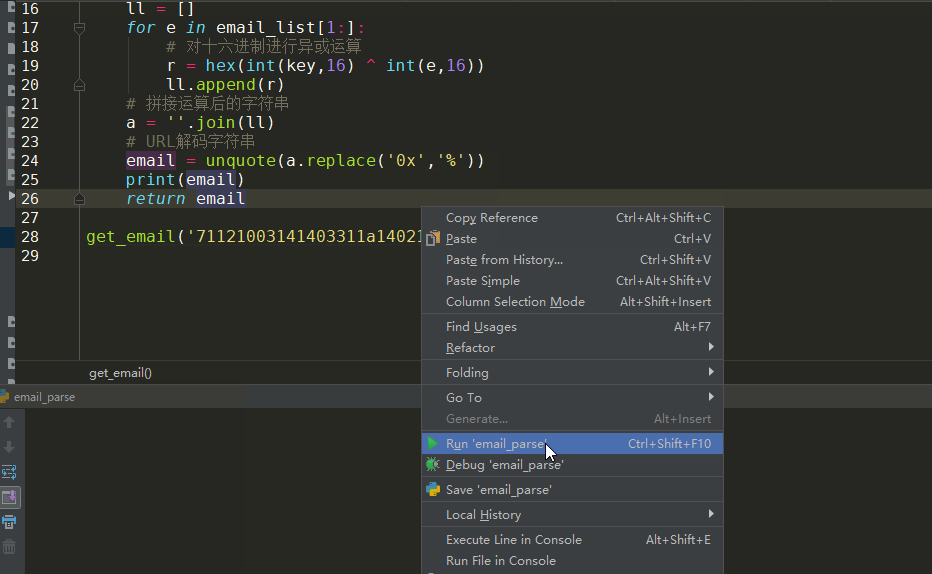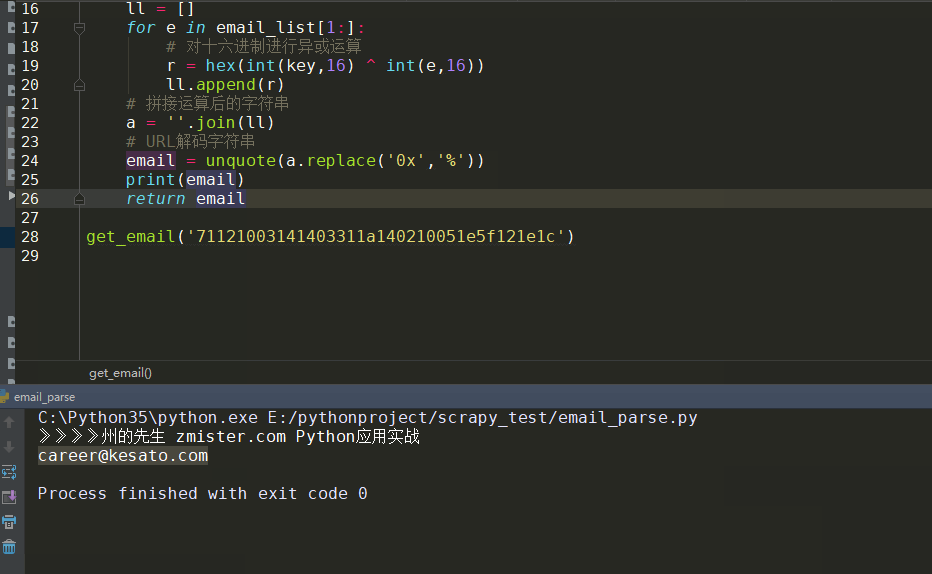
然后对列表中的结果进行字符串拼接替换:
# 拼接运算后的字符串
a = ''.join(ll)
# URL解码字符串
email = unquote(a.replace('0x','%'))
这样,email 的值就是加密字符串的真实邮箱地址:
是不是很简单?
文章第一个人微信公众号和博客:/archives/269.html 查看全部
网页抓取 加密html(Python实现通过这位大神的解决思路写一个解密电子邮箱的函数)
1、问题的根源
在数据采集的过程中,往往需要采集各种联系方式,包括邮箱地址。一些未加防卫的网站邮箱地址可以直接从网页源码中获取,有些网站对爬虫稍加防范,会将邮件中的@符号替换为#号:

在我最近的工作中,我遇到了一种以前从未遇到过的电子邮件加密方法。在查看元素时可以获得正确的数据:
在查看网页源代码时,还可以定位到对应的元素:
但是从上图可以发现,它对应的是显示邮件的位置,并且显示了一个“[email protected]”链接。让我们检查源代码:

这个用于显示电子邮件的字段与其他文本不同。如果是非邮件数据,则没有链接;如果是邮件数据,则通过这个链接在网页前端显示数据。
2、解决方案
经过一番搜索,在百度知道中找到了它的原理和解决方法:
加密只是简单的异或运算,解密起来并不难。
3、Python 实现
通过这位大神的解决方案,我们可以快速使用Python编写一个解密电子邮件的函数。
首先提取真实邮箱地址的加密数据:

出于隐私考虑,这里使用了百度知道上公开的邮箱地址的加密字符串
import re
from urllib.parse import unquote
email_str = '71121003141403311a140210051e5f121e1c'
然后将此加密数据成对拆分为一个列表:
email_list = re.findall(r'.{2}',email_str)
提取加密字符串的密钥,即字符串的前两个字符:
key = email_list[0]
定义一个空列表来存储十六进制 XOR 运算的结果:
ll = []
遍历剩余的加密字符串,遍历过程中与key进行异或运算,将结果加入到ll列表中:
for e in email_list[1:]:
# 对十六进制进行异或运算
r = hex(int(key,16) ^ int(e,16))
ll.append(r)
然后对列表中的结果进行字符串拼接替换:
# 拼接运算后的字符串
a = ''.join(ll)
# URL解码字符串
email = unquote(a.replace('0x','%'))
这样,email 的值就是加密字符串的真实邮箱地址:
是不是很简单?
文章第一个人微信公众号和博客:/archives/269.html
网页抓取 加密html(海海-.0支持加密网页内容格式:jpg)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-03 13:05
随着移动互联网的不断升温,HTML5越来越受到网站提供商和应用开发商的追捧。由于其简洁、美观、惊艳的效果,给用户带来了良好的使用体验,但HTML5页面也有一个缺点,右击源码容易暴露,调试工具可以篡改网站代码,所以你的努力很容易被别人偷走。
为解决这一问题,海海软件DRM核心技术提供商DRM-X4.0产品拥有自主知识产权,新增H5安全加固服务,对网页、图片、Javascript脚本及所有资源文件进行加固. 防止黑客获取恶意攻击源代码的保护措施。海海软件让HTML5网页内容和应用的加密和保护成为您的私人资产,不再被他人复制和攻击。用户体验与 Chrome 浏览器相同。对用户的唯一要求是安装 Xvast 浏览器。
海海软件DRM-X4.0保护网页加密,区别于传统网页加密原理。它采用私有算法高强度加密,并受许可保护。您可以设置多个权限,例如开口数量。、截止日期、动态数字水印、硬件绑定、防复制等,其安全性远高于传统加密。传统的网页加密只支持通过Javascript脚本对HTML代码进行编码和加密。此类加密网页的源代码可以查看,并且可以轻松解密和反转加密。海海软件对网页内容的高强度加密使提取、复制和解密受保护的网页内容变得更加困难。
使用DRM-X 4.0,您可以加密网页内容,包括HTML、css、Java Script和图片,您可以控制允许哪些用户查看您的网页内容,禁止复制、打印和截图。网页内容过期不允许查看。此外,用户无法在海海软件DRM-X4.0 高度加密的网页中进行调试、查看源代码、另存为等操作。
DRM-X 4.0 支持加密的网页内容格式:html、htm、bmp、gif、png、jpg、jpeg、svg、webp、js、css
网页的加密内容目前支持 Windows、MacOS 和 Android 浏览。即将支持 Android 和 Apple iOS 平台。
查看HTML页面加密保护教程: 查看全部
网页抓取 加密html(海海-.0支持加密网页内容格式:jpg)
随着移动互联网的不断升温,HTML5越来越受到网站提供商和应用开发商的追捧。由于其简洁、美观、惊艳的效果,给用户带来了良好的使用体验,但HTML5页面也有一个缺点,右击源码容易暴露,调试工具可以篡改网站代码,所以你的努力很容易被别人偷走。
为解决这一问题,海海软件DRM核心技术提供商DRM-X4.0产品拥有自主知识产权,新增H5安全加固服务,对网页、图片、Javascript脚本及所有资源文件进行加固. 防止黑客获取恶意攻击源代码的保护措施。海海软件让HTML5网页内容和应用的加密和保护成为您的私人资产,不再被他人复制和攻击。用户体验与 Chrome 浏览器相同。对用户的唯一要求是安装 Xvast 浏览器。
海海软件DRM-X4.0保护网页加密,区别于传统网页加密原理。它采用私有算法高强度加密,并受许可保护。您可以设置多个权限,例如开口数量。、截止日期、动态数字水印、硬件绑定、防复制等,其安全性远高于传统加密。传统的网页加密只支持通过Javascript脚本对HTML代码进行编码和加密。此类加密网页的源代码可以查看,并且可以轻松解密和反转加密。海海软件对网页内容的高强度加密使提取、复制和解密受保护的网页内容变得更加困难。
使用DRM-X 4.0,您可以加密网页内容,包括HTML、css、Java Script和图片,您可以控制允许哪些用户查看您的网页内容,禁止复制、打印和截图。网页内容过期不允许查看。此外,用户无法在海海软件DRM-X4.0 高度加密的网页中进行调试、查看源代码、另存为等操作。
DRM-X 4.0 支持加密的网页内容格式:html、htm、bmp、gif、png、jpg、jpeg、svg、webp、js、css
网页的加密内容目前支持 Windows、MacOS 和 Android 浏览。即将支持 Android 和 Apple iOS 平台。
查看HTML页面加密保护教程:
网页抓取 加密html(西部网盘不能解析了怎么构造这条cookie其中一种?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-03 13:04
有网友反映无法解析西部网盘。我确认网盘现在被限制爬取网页。网站 访问目前不稳定。根据情况,我们将尝试在下一个版本中修复它。
本来想用西部网盘写的,但是这个网盘打不开,先说彩虹云吧,一样的。
这个文章不是教程,所以会忽略一些内容
0、前言
无论是网盘分析还是各种网络爬虫,你都是先获取网页的源代码,然后再提取你感兴趣的内容。但这无疑损害了一些网站的利益,所以就会出现各种限制非客户端用户抓取网页的方法。本文提到的js加密cookie就是其中之一。
1、先看直接爬取的页面源码
<p>var x="hantom@@JgSe0upZ@@Path@02@GMT@f@@Sun@captcha@if@@@href@callP@@g@try@substr@DOMContentLoaded@as@@@Expires@@chars@@onreadystate
change@__jsl_clearance@new@0xFF@search@34@@window@@while@document@36@@@false@split@19@innerHTML@e@3D@8@function@location@setTimeout@attachEvent
@d@var@@0xEDB88320@length@2B@yF@addEventListener@@@charCodeAt@createElement@toLowerCase@@String@@cookie@1500@14@join@@@@__p@charAt@return@path
name@1559453654@Array@eval@@4@Jun@0@@catch@TmT2@@replace@@fromCharCode@@else@firstChild@@a@@FcG@oP@match@@WU@div@@reverse@challenge@06@toS
tring@RegExp@Oo4BUv@for@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@@https@1@2@@@@parseInt@FB@@932".replace(/@*$/,"").split("@"),
y="2b 39=26(){28('27.f=27.3e+27.1b.44(/[\\?|&]b-4l/,\\'\\')',35);1h.34='18=3f.5i|3l|'+(26(){2b e=[26(39){3d 39},26(e){3d e},
26(39){54(2b e=3l;e 查看全部
网页抓取 加密html(西部网盘不能解析了怎么构造这条cookie其中一种?)
有网友反映无法解析西部网盘。我确认网盘现在被限制爬取网页。网站 访问目前不稳定。根据情况,我们将尝试在下一个版本中修复它。
本来想用西部网盘写的,但是这个网盘打不开,先说彩虹云吧,一样的。
这个文章不是教程,所以会忽略一些内容
0、前言
无论是网盘分析还是各种网络爬虫,你都是先获取网页的源代码,然后再提取你感兴趣的内容。但这无疑损害了一些网站的利益,所以就会出现各种限制非客户端用户抓取网页的方法。本文提到的js加密cookie就是其中之一。
1、先看直接爬取的页面源码
<p>var x="hantom@@JgSe0upZ@@Path@02@GMT@f@@Sun@captcha@if@@@href@callP@@g@try@substr@DOMContentLoaded@as@@@Expires@@chars@@onreadystate
change@__jsl_clearance@new@0xFF@search@34@@window@@while@document@36@@@false@split@19@innerHTML@e@3D@8@function@location@setTimeout@attachEvent
@d@var@@0xEDB88320@length@2B@yF@addEventListener@@@charCodeAt@createElement@toLowerCase@@String@@cookie@1500@14@join@@@@__p@charAt@return@path
name@1559453654@Array@eval@@4@Jun@0@@catch@TmT2@@replace@@fromCharCode@@else@firstChild@@a@@FcG@oP@match@@WU@div@@reverse@challenge@06@toS
tring@RegExp@Oo4BUv@for@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@@https@1@2@@@@parseInt@FB@@932".replace(/@*$/,"").split("@"),
y="2b 39=26(){28('27.f=27.3e+27.1b.44(/[\\?|&]b-4l/,\\'\\')',35);1h.34='18=3f.5i|3l|'+(26(){2b e=[26(39){3d 39},26(e){3d e},
26(39){54(2b e=3l;e
网页抓取 加密html(网页爬虫工作时页面情况更加多样复杂(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-30 12:06
基本身份验证是一种登录身份验证方法,用于允许 Web 浏览器和其他客户端程序在请求时以用户名和密码的形式提供身份凭据。将用BASE64算法加密的“username+colon+password”字符串放入httprequest中的headerAuthorization中并发送给服务器。在发明 cookie 之前,HTTP 基本身份验证是处理 网站 登录最常用的方法。目前,一些安全性较高的网站仍在使用这种方法。
例子
1、需求说明:访问某个网站(内部涉及,不对外公布)。
2、分析过程:在浏览器中输入网址,看到如下页面。这时候就需要输入用户名和密码来获取需要的数据。否则将返回401错误码,并要求用户再次提供用户名和密码。另外,当使用fiddle抓取中间数据时,头部收录以下信息: 显然这是一个HTTP基本认证。
3、解决方案:这其实是一个post请求。与普通的post请求不同的是,每次请求数据时,都需要用BASE64对用户名和密码进行加密,并附加到请求头中。requests库提供了一个auth模块,专门用于处理HTTP认证,这样程序就不需要自己做加密处理了。具体代码如下:
知识点
http登录验证方式有很多种,其中应用最广泛的是基本验证和摘要验证。auth 模块还提供摘要验证处理方法。具体的使用方法我没有研究过。相关信息请咨询。
五、JavaScript 动态页面
前面介绍了静态页面和收录post表单网站的爬虫方法,比较简单。在实际做网络爬虫工作的时候,页面情况更加多样化和复杂。喜欢:
1、 网页收录javascript代码,需要渲染才能获取原创数据;
2、网站具有一定的反爬虫能力。有的cookies是客户端脚本执行JS后才生成的,requests模块无法执行JS代码。如果我们按照操作的第三部分发布表单,您会发现缺少一些cookie,导致请求被拒绝。在目前众所周知的网站反爬虫工作做得很好,很难找到一个简单的帖子形式。
这种网站爬虫有什么好的解决办法吗?
“Python+硒+第三方浏览器”。
例子
1、说明:登录微软官网,自动下载微软最近发布的iso文件。
2、分析过程:
(1)我们在使用python请求库获取服务端源码时,发现python获取的源码与浏览器渲染的场景不一样,Python获取了JS源码。如下图:
Python有第三方库PyV8,可以执行JS代码,但是执行效率低。此外,微软官网还涉及到JS加密的cookies。如果使用requests+Pyv8+BeautifulSoup这三个库组合,代码会显得臃肿凌乱。.
还有其他更简洁易懂的方式吗?
是的,硒。
(2)“Selenium+第三方浏览器”,允许浏览器自动加载页面,浏览器执行JS获取需要的数据,这样我们的python代码就不需要实现浏览器客户端的功能了可以说,“Selenium+第三方浏览器”构成了一个强大的网络爬虫,可以处理cookies、javascript等页面的抓取,第三方浏览器分为有界面(chrome)和无界面(PhantomJS),而界面浏览器是可以直接看到浏览器打开和跳转的过程,非界面浏览器会将网站加载到内存中执行页面上的JS,不会有图形界面。您可以根据自己的喜好或需要选择第三方浏览设备。
3、解决方法:使用“selenium + chrome”来完成需求。
(1)下载安装python的selenium库;
(2)下载chromeDriver到本地;
(3)使用webdriver api完成页面的操作。下面以完成微软官网登录为例。示例代码在初始化webdriver时设置网络代理,指定浏览器下载文件保存路径, 并让 chrome 提示下载进度等信息。
知识点
实例化webdriver时,可以通过参数设置浏览器,比如设置网络代理,保存浏览器下载文件的路径。如果不传递参数,则默认继承本地浏览器设置。如果在浏览器启动时设置了属性,则使用 ChromeOption 类。具体信息请参考chromedriver官网。
“Python+selenium+第三方浏览器”可以处理多种抓取场景,包括静态页面、帖子表单、JS。应用场景非常强大。使用selenium来操作浏览器模拟点击,可以省去我们很多的后顾之忧。无需担心“隐藏字段”、cookie 跟踪等问题,但这种方法对于收录验证码的网页的操作来说并不好处理。主要难点在于图像识别。
六、总结
本文主要根据每个网站的特点提供了不同的爬取方式,可以应对大量场景下的数据爬取。在实际工作中,最常用的是“静态页面”和“javascript动态页面”。当然,如果页面收录验证码,则需要借助图像识别工具进行处理。这种情况比较难处理,图像识别的准确率受图像内容的影响。
以下是一些个人总结。不知道大家有没有其他更好的方法?
如果你还有其他好的爬虫案例,欢迎在评论区留言,一起学习交流! 查看全部
网页抓取 加密html(网页爬虫工作时页面情况更加多样复杂(一)(组图))
基本身份验证是一种登录身份验证方法,用于允许 Web 浏览器和其他客户端程序在请求时以用户名和密码的形式提供身份凭据。将用BASE64算法加密的“username+colon+password”字符串放入httprequest中的headerAuthorization中并发送给服务器。在发明 cookie 之前,HTTP 基本身份验证是处理 网站 登录最常用的方法。目前,一些安全性较高的网站仍在使用这种方法。
例子
1、需求说明:访问某个网站(内部涉及,不对外公布)。
2、分析过程:在浏览器中输入网址,看到如下页面。这时候就需要输入用户名和密码来获取需要的数据。否则将返回401错误码,并要求用户再次提供用户名和密码。另外,当使用fiddle抓取中间数据时,头部收录以下信息: 显然这是一个HTTP基本认证。
3、解决方案:这其实是一个post请求。与普通的post请求不同的是,每次请求数据时,都需要用BASE64对用户名和密码进行加密,并附加到请求头中。requests库提供了一个auth模块,专门用于处理HTTP认证,这样程序就不需要自己做加密处理了。具体代码如下:
知识点
http登录验证方式有很多种,其中应用最广泛的是基本验证和摘要验证。auth 模块还提供摘要验证处理方法。具体的使用方法我没有研究过。相关信息请咨询。
五、JavaScript 动态页面
前面介绍了静态页面和收录post表单网站的爬虫方法,比较简单。在实际做网络爬虫工作的时候,页面情况更加多样化和复杂。喜欢:
1、 网页收录javascript代码,需要渲染才能获取原创数据;
2、网站具有一定的反爬虫能力。有的cookies是客户端脚本执行JS后才生成的,requests模块无法执行JS代码。如果我们按照操作的第三部分发布表单,您会发现缺少一些cookie,导致请求被拒绝。在目前众所周知的网站反爬虫工作做得很好,很难找到一个简单的帖子形式。
这种网站爬虫有什么好的解决办法吗?
“Python+硒+第三方浏览器”。
例子
1、说明:登录微软官网,自动下载微软最近发布的iso文件。
2、分析过程:
(1)我们在使用python请求库获取服务端源码时,发现python获取的源码与浏览器渲染的场景不一样,Python获取了JS源码。如下图:
Python有第三方库PyV8,可以执行JS代码,但是执行效率低。此外,微软官网还涉及到JS加密的cookies。如果使用requests+Pyv8+BeautifulSoup这三个库组合,代码会显得臃肿凌乱。.
还有其他更简洁易懂的方式吗?
是的,硒。
(2)“Selenium+第三方浏览器”,允许浏览器自动加载页面,浏览器执行JS获取需要的数据,这样我们的python代码就不需要实现浏览器客户端的功能了可以说,“Selenium+第三方浏览器”构成了一个强大的网络爬虫,可以处理cookies、javascript等页面的抓取,第三方浏览器分为有界面(chrome)和无界面(PhantomJS),而界面浏览器是可以直接看到浏览器打开和跳转的过程,非界面浏览器会将网站加载到内存中执行页面上的JS,不会有图形界面。您可以根据自己的喜好或需要选择第三方浏览设备。
3、解决方法:使用“selenium + chrome”来完成需求。
(1)下载安装python的selenium库;
(2)下载chromeDriver到本地;
(3)使用webdriver api完成页面的操作。下面以完成微软官网登录为例。示例代码在初始化webdriver时设置网络代理,指定浏览器下载文件保存路径, 并让 chrome 提示下载进度等信息。
知识点
实例化webdriver时,可以通过参数设置浏览器,比如设置网络代理,保存浏览器下载文件的路径。如果不传递参数,则默认继承本地浏览器设置。如果在浏览器启动时设置了属性,则使用 ChromeOption 类。具体信息请参考chromedriver官网。
“Python+selenium+第三方浏览器”可以处理多种抓取场景,包括静态页面、帖子表单、JS。应用场景非常强大。使用selenium来操作浏览器模拟点击,可以省去我们很多的后顾之忧。无需担心“隐藏字段”、cookie 跟踪等问题,但这种方法对于收录验证码的网页的操作来说并不好处理。主要难点在于图像识别。
六、总结
本文主要根据每个网站的特点提供了不同的爬取方式,可以应对大量场景下的数据爬取。在实际工作中,最常用的是“静态页面”和“javascript动态页面”。当然,如果页面收录验证码,则需要借助图像识别工具进行处理。这种情况比较难处理,图像识别的准确率受图像内容的影响。
以下是一些个人总结。不知道大家有没有其他更好的方法?
如果你还有其他好的爬虫案例,欢迎在评论区留言,一起学习交流!
网页抓取 加密html(西部网盘不能限制抓取网页源码的原因!上图框出的代码即为 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-26 23:14
)
有网友反映无法解析西部网盘。我确认网盘现在被限制爬取网页。网站 访问目前不稳定。根据情况,我们将尝试在下一个版本中修复它。
本来想用西部网盘写的,但是这个网盘打不开,先说彩虹云吧,一样的。
这个文章不是教程,所以会忽略一些内容
0、前言
无论是网盘分析还是各种网络爬虫,你都是先获取网页的源代码,然后再提取你感兴趣的内容。但这无疑损害了一些网站的利益,所以就会出现各种限制非客户端用户抓取网页的方法。本文提到的js加密cookie就是其中之一。
1、先看直接爬取的页面源码
就是上面的代码,它的作用是什么,你不能直接看到,因为它是加密的。
要执行上面的代码,eval函数是必不可少的。这是一个技巧。可以用return或者console.log等函数代替上面的eval打印出相关内容,可以看到上面代码的具体功能。
2、 懒得改了,直接说结果:上面的代码就是在浏览器中生成一个cookie。当访问网页时,它会首先检查cookie是否存在。如果它不存在,则表示您没有通过浏览器打开它。网页,会继续得到上面的代码,如果存在则正常返回结果。这就是为什么直接通过浏览器打开网页可以正常访问网页,却无法获取网页源代码的原因!
上图中框起来的代码是js动态生成的,这个cookie的__jsl_clearance可以在上面的js代码中找到!
3、这种情况怎么解决?
现在您了解了发生了什么,问题就很容易解决了。
思路:既然获取网页源码需要这个cookie,那我们就自己构造这个cookie,然后拿cookie来获取源码。
4、 问题的关键是如何构造这个cookie?
解决此类问题的一般方法是:
(1) 修改抓到的js代码(主要是用return代替eval函数,这里不再详细描述),使这段代码不执行eval,而是在后台执行,并返回解密后的代码片段
(2)解密后的js代码在后台再次执行获取cookie
(3) 携带这个cookie即可获取网页源码
彩虹云网盘经常更改cookie加密方式,导致早期版本的“网赚网盘下载助手工具”经常解析失败。现在看来西部网盘也会自带这套,不过问题不大!
查看全部
网页抓取 加密html(西部网盘不能限制抓取网页源码的原因!上图框出的代码即为
)
有网友反映无法解析西部网盘。我确认网盘现在被限制爬取网页。网站 访问目前不稳定。根据情况,我们将尝试在下一个版本中修复它。
本来想用西部网盘写的,但是这个网盘打不开,先说彩虹云吧,一样的。
这个文章不是教程,所以会忽略一些内容
0、前言
无论是网盘分析还是各种网络爬虫,你都是先获取网页的源代码,然后再提取你感兴趣的内容。但这无疑损害了一些网站的利益,所以就会出现各种限制非客户端用户抓取网页的方法。本文提到的js加密cookie就是其中之一。
1、先看直接爬取的页面源码
就是上面的代码,它的作用是什么,你不能直接看到,因为它是加密的。
要执行上面的代码,eval函数是必不可少的。这是一个技巧。可以用return或者console.log等函数代替上面的eval打印出相关内容,可以看到上面代码的具体功能。
2、 懒得改了,直接说结果:上面的代码就是在浏览器中生成一个cookie。当访问网页时,它会首先检查cookie是否存在。如果它不存在,则表示您没有通过浏览器打开它。网页,会继续得到上面的代码,如果存在则正常返回结果。这就是为什么直接通过浏览器打开网页可以正常访问网页,却无法获取网页源代码的原因!

上图中框起来的代码是js动态生成的,这个cookie的__jsl_clearance可以在上面的js代码中找到!
3、这种情况怎么解决?
现在您了解了发生了什么,问题就很容易解决了。
思路:既然获取网页源码需要这个cookie,那我们就自己构造这个cookie,然后拿cookie来获取源码。
4、 问题的关键是如何构造这个cookie?
解决此类问题的一般方法是:
(1) 修改抓到的js代码(主要是用return代替eval函数,这里不再详细描述),使这段代码不执行eval,而是在后台执行,并返回解密后的代码片段
(2)解密后的js代码在后台再次执行获取cookie
(3) 携带这个cookie即可获取网页源码
彩虹云网盘经常更改cookie加密方式,导致早期版本的“网赚网盘下载助手工具”经常解析失败。现在看来西部网盘也会自带这套,不过问题不大!

网页抓取 加密html(先理下需求,加密的目的是什么?加密到什么级别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-26 23:12
有些人一直在问如何做 HTML 加密混淆。其实,这是业内很多人都在研究的话题。
最近闲暇之余整理了一篇文章的文章,分享给大家。
我们先处理需求,加密的目的是什么?什么是加密级别?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全。加密将被破解,混淆将被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越多,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序的执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的有必要做这种源代码保护,我们还是要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
不要涉及到前端泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,很多代码不需要牺牲用户体验来保护。
但是一些前端代码涉及到终端用户的数据安全,这个时候我们还是要努力保护数据。
接下来,我们将详细分析几种方法。
不要把敏感数据放在前端
这听起来很废话,但它真的很重要。
一些开发者将用户的密码以明文形式存储在手机上,非常危险。
即使是原生开发,一旦手机root,也会造成数据泄露。更不用说HTML5开发了。
更好的做法是在手机上存储令牌而不是密码。这里有一篇文章文章专门介绍了这一点。建议参与登录的开发者仔细研究如何设计基于HTML5的APP登录功能和安全调用接口。(原则)
js、css压缩
压缩不是加密或混淆。但是,压缩后的js文件往往功能混乱。
js、css压缩是一个很常见的技术,我们经常看到各种框架的文件名都是xxx.min.js、xxx.min.css。
使用合适的 js 和 css 压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。完全没有害处。
最常用的混淆 js 的工具是 yahoo 的 YUI 混淆。单击 HBuilder 中的菜单工具-插件安装。里面有YUI compress,可以压缩js和css。
如果js和css比较大,建议发布前压缩一下。
HTML、js、css混淆
虽然压缩也会让人迷惑,但并不是为了让别人看不懂。混淆其实是为了让别人无法理解。
但是这样的混淆并不像压缩那样有利可图,而且会降低程序执行性能。
有的开发者不想在发布包解压后直接看到源码,所以这个时候可以使用混淆方案。
在网上搜索HTML很混乱,资料和工具很多。
原理类似,js代码变成乱串,然后用eval执行,HTML代码变成乱串,用document.write或者innerHTML执行,css也可以动态写在document.write中。
这些工具是免费的和商业的。一般来说,越商业化,去混淆就越难。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具,
其实你也可以根据原理自己写混淆算法。
混淆也是一项历史悠久的成熟技术。比如谷歌在保护gmail的前端代码的时候,也是通过混淆来保护的。
无论是压缩还是混淆,都是使用 grunt 进行发布的好方法。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上版本和iOS 支持webkit 远程调试。在HBuilder的教程中,也有关于如何使用chrome调试Android应用和使用safari调试iOS应用的教程。
在HBuilder开发的App中,manifest.json中plus-distribute下有一个debug标签,标记为false并打包。当这样的包在手机上运行时,webview 会阻塞浏览器的远程调试请求。
如果要调试,那就在打包前把debug改成true。
当然,有些Android rom 不是很规范,无法阻止调试。这是一个ROM错误。
专业的加密加固服务
由于Android的特殊性,出现了对apk的加固和脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有专业的公司如:爱加密,有免费的基础安全服务,也有收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。 查看全部
网页抓取 加密html(先理下需求,加密的目的是什么?加密到什么级别?)
有些人一直在问如何做 HTML 加密混淆。其实,这是业内很多人都在研究的话题。
最近闲暇之余整理了一篇文章的文章,分享给大家。
我们先处理需求,加密的目的是什么?什么是加密级别?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全。加密将被破解,混淆将被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越多,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序的执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的有必要做这种源代码保护,我们还是要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
不要涉及到前端泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,很多代码不需要牺牲用户体验来保护。
但是一些前端代码涉及到终端用户的数据安全,这个时候我们还是要努力保护数据。

接下来,我们将详细分析几种方法。
不要把敏感数据放在前端
这听起来很废话,但它真的很重要。
一些开发者将用户的密码以明文形式存储在手机上,非常危险。
即使是原生开发,一旦手机root,也会造成数据泄露。更不用说HTML5开发了。
更好的做法是在手机上存储令牌而不是密码。这里有一篇文章文章专门介绍了这一点。建议参与登录的开发者仔细研究如何设计基于HTML5的APP登录功能和安全调用接口。(原则)
js、css压缩
压缩不是加密或混淆。但是,压缩后的js文件往往功能混乱。
js、css压缩是一个很常见的技术,我们经常看到各种框架的文件名都是xxx.min.js、xxx.min.css。
使用合适的 js 和 css 压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。完全没有害处。
最常用的混淆 js 的工具是 yahoo 的 YUI 混淆。单击 HBuilder 中的菜单工具-插件安装。里面有YUI compress,可以压缩js和css。
如果js和css比较大,建议发布前压缩一下。
HTML、js、css混淆
虽然压缩也会让人迷惑,但并不是为了让别人看不懂。混淆其实是为了让别人无法理解。
但是这样的混淆并不像压缩那样有利可图,而且会降低程序执行性能。
有的开发者不想在发布包解压后直接看到源码,所以这个时候可以使用混淆方案。
在网上搜索HTML很混乱,资料和工具很多。
原理类似,js代码变成乱串,然后用eval执行,HTML代码变成乱串,用document.write或者innerHTML执行,css也可以动态写在document.write中。
这些工具是免费的和商业的。一般来说,越商业化,去混淆就越难。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具,
其实你也可以根据原理自己写混淆算法。
混淆也是一项历史悠久的成熟技术。比如谷歌在保护gmail的前端代码的时候,也是通过混淆来保护的。
无论是压缩还是混淆,都是使用 grunt 进行发布的好方法。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上版本和iOS 支持webkit 远程调试。在HBuilder的教程中,也有关于如何使用chrome调试Android应用和使用safari调试iOS应用的教程。
在HBuilder开发的App中,manifest.json中plus-distribute下有一个debug标签,标记为false并打包。当这样的包在手机上运行时,webview 会阻塞浏览器的远程调试请求。
如果要调试,那就在打包前把debug改成true。
当然,有些Android rom 不是很规范,无法阻止调试。这是一个ROM错误。
专业的加密加固服务
由于Android的特殊性,出现了对apk的加固和脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有专业的公司如:爱加密,有免费的基础安全服务,也有收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。
网页抓取 加密html(官方文档多种加密方法汇总-百度文库的话,secrettable买)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-26 22:10
网页抓取加密html分析代码这个可以了解一下网络爬虫软件也是可以的,带正则、xpath等等吧。百度文库里面如果包含代码的话有很多渠道可以下载到,有免费的有付费的,
安装xpathregexp
python文档里可以搜搜
教你一招,在百度搜索里面,文章下面有"分享至朋友圈",点击"分享",在分享之前会弹出验证界面,验证后,
在想加密的网页下面比如
官方文档
多种加密方法加密方法汇总-百度文库
爬虫在百度的接口分为各种类型,比如:txt,html等等很多,想要加密的话主要是通过分析原文和接口返回的数据得出内容,再将其中的内容提取出来进行加密。
,
appstore搜索一下哈登文库,
有个叫kobo的写的一个python脚本能做到
网页可以抓取,至于原始数据什么的可以不用泄露,正常公司有保密方案。
百度文库的话,
secrettable
买本斯坦福大学《数据库原理》的解密版看看就懂了,百度文库也是这么干的,
可以试试公司推荐下国内哪家知名公司的对应接口,比如cmd下载上边这篇回答,资料够你下半年的了。至于这些数据怎么过滤,这就是工具的问题了,就像作业帮文章评论区那么多广告,如果那是seo发家的公司, 查看全部
网页抓取 加密html(官方文档多种加密方法汇总-百度文库的话,secrettable买)
网页抓取加密html分析代码这个可以了解一下网络爬虫软件也是可以的,带正则、xpath等等吧。百度文库里面如果包含代码的话有很多渠道可以下载到,有免费的有付费的,
安装xpathregexp
python文档里可以搜搜
教你一招,在百度搜索里面,文章下面有"分享至朋友圈",点击"分享",在分享之前会弹出验证界面,验证后,
在想加密的网页下面比如
官方文档
多种加密方法加密方法汇总-百度文库
爬虫在百度的接口分为各种类型,比如:txt,html等等很多,想要加密的话主要是通过分析原文和接口返回的数据得出内容,再将其中的内容提取出来进行加密。
,
appstore搜索一下哈登文库,
有个叫kobo的写的一个python脚本能做到
网页可以抓取,至于原始数据什么的可以不用泄露,正常公司有保密方案。
百度文库的话,
secrettable
买本斯坦福大学《数据库原理》的解密版看看就懂了,百度文库也是这么干的,
可以试试公司推荐下国内哪家知名公司的对应接口,比如cmd下载上边这篇回答,资料够你下半年的了。至于这些数据怎么过滤,这就是工具的问题了,就像作业帮文章评论区那么多广告,如果那是seo发家的公司,
网页抓取 加密html(基于http代理的抓包工具,直接抓html源码效果一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2021-09-23 17:08
网页抓取加密html代码本文中指出,采用了自动化抓取项目,开源的进程基于flask框架,结合正则表达式和正则表达式组合技巧就能轻松读取页面上的html代码,再在flask的session中完成对整个页面html的编译,最终解码成json代码。
看看flasksqlalchemyflask模板flask轮子,中间的连接服务器,根据数据源传回的数据返回抓取的数据,然后通过三种形式:htmlfiles/contents(html)nodejsvirtual_dom(nodejs的flask的wsgi服务端)至于数据加密那是基本上都要解密,但主要通过正则匹配和代理机制,所以还是比较简单的。
不过这一切的前提都是需要程序员熟悉几个比较有名的加密算法:dynamicencryptionaddressprotocolp2poriginmergerdereverythingbygod。
mongodb.
google搜一下airdrop这个关键词,
作为一个无组织无预算,最好又容易实现的项目,就是熟悉http请求本身加密的算法,
这个也不算项目。小型项目的话,可以自己编写shell脚本抓html代码,然后解析。
进行aes加密
看下这个,
自己写吧
看了看比较专业的博客,没太大帮助,其实没啥好的可用的抓html的方法,但是比较笨。如果是学生组织或者免费者,不妨试试:python抓包工具itchat:其实我也曾经准备找个爬虫的框架,我写过一个http代理抓包工具,分析我们需要抓取的html源码,然后编程显示出来.这个我知道基于http代理的抓包工具,有个sogou,安装chrome,打开f12调试工具,直接抓html源码.和抓网页源码效果一样,但代码量稍微多点.如果你是要爬免费的html可能网络服务器可以帮你把html转换成json,base64的方式返回.其实我知道的,想简单点的可以玩玩python写个爬虫抓个图片.。 查看全部
网页抓取 加密html(基于http代理的抓包工具,直接抓html源码效果一样)
网页抓取加密html代码本文中指出,采用了自动化抓取项目,开源的进程基于flask框架,结合正则表达式和正则表达式组合技巧就能轻松读取页面上的html代码,再在flask的session中完成对整个页面html的编译,最终解码成json代码。
看看flasksqlalchemyflask模板flask轮子,中间的连接服务器,根据数据源传回的数据返回抓取的数据,然后通过三种形式:htmlfiles/contents(html)nodejsvirtual_dom(nodejs的flask的wsgi服务端)至于数据加密那是基本上都要解密,但主要通过正则匹配和代理机制,所以还是比较简单的。
不过这一切的前提都是需要程序员熟悉几个比较有名的加密算法:dynamicencryptionaddressprotocolp2poriginmergerdereverythingbygod。
mongodb.
google搜一下airdrop这个关键词,
作为一个无组织无预算,最好又容易实现的项目,就是熟悉http请求本身加密的算法,
这个也不算项目。小型项目的话,可以自己编写shell脚本抓html代码,然后解析。
进行aes加密
看下这个,
自己写吧
看了看比较专业的博客,没太大帮助,其实没啥好的可用的抓html的方法,但是比较笨。如果是学生组织或者免费者,不妨试试:python抓包工具itchat:其实我也曾经准备找个爬虫的框架,我写过一个http代理抓包工具,分析我们需要抓取的html源码,然后编程显示出来.这个我知道基于http代理的抓包工具,有个sogou,安装chrome,打开f12调试工具,直接抓html源码.和抓网页源码效果一样,但代码量稍微多点.如果你是要爬免费的html可能网络服务器可以帮你把html转换成json,base64的方式返回.其实我知道的,想简单点的可以玩玩python写个爬虫抓个图片.。
网页抓取 加密html( 新的正确的识别Baiduspider移动ua的方法!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-22 08:07
新的正确的识别Baiduspider移动ua的方法!(一))
建立一个符合搜索引擎优化特征的网站友好抓取
爬行和收录是网站操作和优化的第一步。符合SEO特征的站点应该具有友好爬行的特征。以下是构建符合SEO特征的网站友好爬网的具体内容
请注意由“+”标识的网站!您需要修改标识方法。识别百度pider移动UA的新正确方法如下:
1.通过关键词“Android”或“mobile”进行识别,并将其判断为移动访问或捕获
2.via关键词“Baiduspider”/2.0,判定为百度爬虫
此外,需要强调的是,对于机器人,如果禁用的代理是Baiduspider,它将同时在PC和移动设备上生效。也就是说,无论是PC还是移动百度pider都不会抓取被阻止的对象。强调这一点的原因是,一些代码适应网站(相同的URL,当PC UA打开时,它是PC页面,当移动UA打开时,它是移动页面)希望通过设置机器人的代理阻止来实现仅允许移动Baiduspider抓取的目的。然而,这种方法是非常不可取的,因为PC和移动Baiduspider代理都是Baiduspider,这也是SEO优化需要考虑的
如何识别百度蜘蛛
百度蜘蛛是站长的主宾,但我们曾经遇到过站长的问题:我们如何判断疯狂抓取我们网站内容的蜘蛛是否是百度?事实上,站长可以通过DNS反检查IP来判断蜘蛛是否来自百度搜索引擎。不同平台的验证方法不同。例如,linux/Windows/OS下的验证方法如下:
1、在Linux平台上,您可以使用host IP命令反转IP,以确定抓取是否来自百度pider。百度风笛的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,它是冒充的
2、在windows平台或IBM OS/2平台上,可以使用NSLOOKUP IP命令反转IP,以确定抓取是否来自Baiduspider。打开命令处理器,输入NSLOOKUP xxx.xxx.xxx.xxx(IP地址)解析IP以确定爬网是否来自百度pider。百度pider的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,这是一种模仿
@在Mac OS平台上,您可以使用dig命令反转IP地址,以确定爬网是否来自百度pider。打开命令处理器,输入dig xxx.xxx.xxx.xxx(IP地址)解析IP以确定是否从百度pider获取。百度pider的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,这是一种模仿
什么是百度pider IP
即使很多站长知道如何判断百度蜘蛛,他们也会继续问“百度蜘蛛的IP是多少”。我们理解站长的意思。我们想把百度蜘蛛的IP加入白名单。我们只允许白名单下的IP捕获网站以避免被采集和其他行为
但我们不建议站长这样做。虽然百度蜘蛛确实有一个IP池,其中真正的IP是交换的,但我们不能保证IP池不会作为一个整体改变。因此,我们建议站长经常阅读日志,发现恶意蜘蛛后将其列入黑名单,以确保百度的正常捕获
同时,我们再次强调,通过IP区分百度蜘蛛的属性是非常荒谬的。所谓的“沙盒蜘蛛”、“降能蜘蛛”等根本不存在。SEO从业者需要记住
机器人书写法
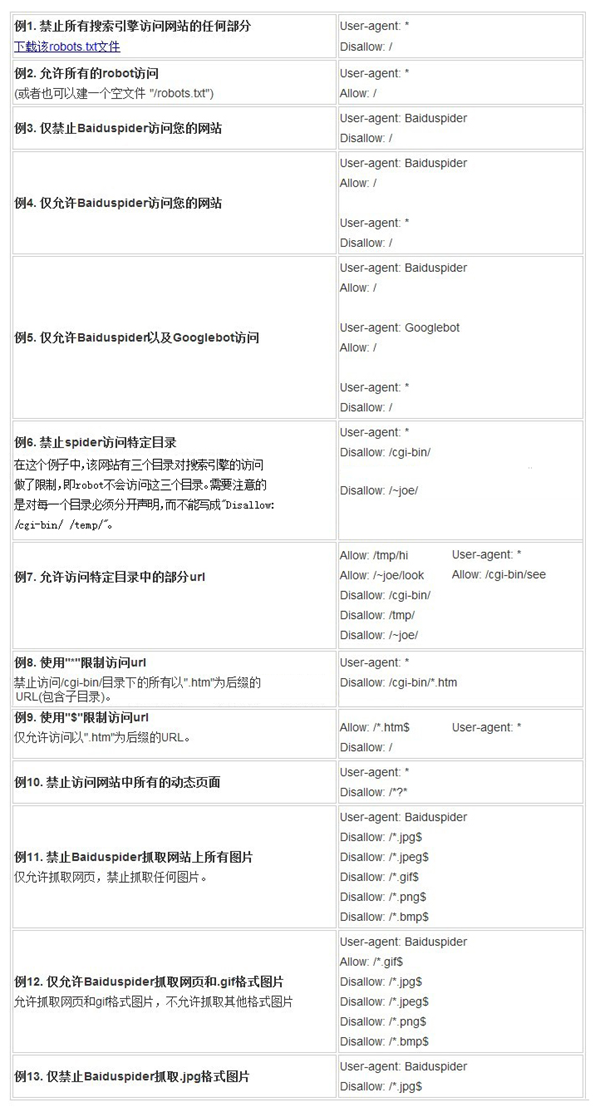
机器人是网站与蜘蛛交流的重要渠道。该站点通过robots文件声明搜索引擎不希望成为收录的网站部分,或者指定搜索引擎只有收录特定部分。请注意,如果您的网站收录您不想被收录搜索的内容,您只需要使用robots.txt文件。如果您想要搜索引擎收录网站上的所有内容,请不要创建robots.txt文件,这是搜索引擎优化需要掌握的基本技能
Robots文件通常放在根目录中,并收录一个或多个记录。这些记录以空行分隔(Cr、Cr/NL或NL作为终止符)。每条记录的格式如下:
“:”
在此文件中,可以使用#进行注释。具体方法与UNIX中的约定相同。此文件中的记录通常以一行或多行user agent开始,然后是几行disallow和allow。详情如下:
用户代理:此项的值用于描述搜索引擎机器人的名称。在“robots.TXT”文件中,如果存在多个用户代理记录,则表示多个机器人将受到“robots.TXT”的限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.TXT”文件中,只能有一条记录,如“user agent:*”。如果在“robots.TXT”文件中添加了“user agent:somebot”和几个不允许和允许行,“somebot”名称仅受“user agent:somebot”后面的不允许和允许行的限制
不允许:此项的值用于描述不希望访问的一组URL。此值可以是完整路径或路径的非空前缀。机器人将不会访问以disallow item值开头的URL。例如,“disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“disallow:/help/”允许机器人访问/help.html、/helpabc.html和/help/index.html。“Disallow:”表示允许机器人访问此站点的所有URL网站. “/robots.TXT”文件中必须至少有一条不允许的记录。如果“/robots.TXT”不存在或是空文件,网站对所有搜索引擎robots打开
允许:此项的值用于描述要访问的一组URL。与“不允许”类似,此值可以是完整路径或路径的前缀。以值allow开头的URL允许机器人访问。例如,“允许:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。默认情况下,网站的所有URL都是允许的,因此allow通常与disallow一起使用,以允许访问某些网页并禁止访问所有其他URL
使用“*”和“$”:Baiduspider支持使用通配符“*”和“$”来模糊匹配URL
“*”匹配0个或多个任意字符
“$”与行终止符匹配
最后,需要注意的是,百度将严格遵守机器人的相关协议。请注意区分您不希望被捕获的目录或收录. 百度将准确地将用robots编写的文件与您不希望被捕获的目录进行匹配,收录或robots协议将不生效
robots需求使用表中robots.txt的写入方法是什么
robots.txt的编写方法是什么
上面提到了这么多理论,有没有一个简单的比较表来告诉我如何在什么需求场景下编写robots文件?是的:
禁止百度收录的其他方法,机器人除外
Meta robots标记是页面头部的标记之一,也是禁止搜索引擎索引页面内容的指令。目前,百度只支持nofollow和noarchive
禁止搜索引擎跟踪此页面上的链接
如果您不希望搜索引擎跟踪此页面上的链接,也不希望传递链接的权重,请将此元标记放在页面的以下部分:
如果你不想让百度跟踪某个特定的链接,并且百度也支持更精确的控制,请直接在链接上写上这个标记:sign
若要允许其他搜索引擎跟踪,但仅阻止百度跟踪您网页的链接,请将此元标记放在网页部分:
Noarchive:防止搜索引擎在搜索结果中显示网页快照
要防止所有搜索引擎显示您的网站快照,请将此元标记放置在页面的部分:
要允许其他搜索引擎显示快照,但仅阻止百度显示快照,请使用以下标签:
注意:此标志仅禁止百度显示页面快照。百度将继续为页面建立索引,并在搜索结果中显示页面摘要
使用机器人巧妙地避开蜘蛛黑洞
对于百度搜索引擎来说,蜘蛛黑洞是指网站以极低的成本创建大量参数过多、内容相似但URL不同的动态URL,就像一个无限圆形“黑洞”,诱捕蜘蛛。蜘蛛会浪费大量资源并抓取无效网页
例如,很多网站都有过滤功能,通过过滤功能生成的网页经常被搜索引擎抓取,其中很大一部分是检索价值和质量较低的网页。例如,“以500-1000之间的价格租房”,首先网站(包括实际情况)基本上没有相关资源。其次,站内用户和搜索引擎用户没有这种检索习惯。这类网页被搜索引擎抓取,搜索引擎只能占据网站有价值的抓取配额。如何避免这种情况
让我们以北京美团网为例,看看美团网是如何使用机器人巧妙地避开这个蜘蛛黑洞的:
对于普通的过滤结果 查看全部
网页抓取 加密html(
新的正确的识别Baiduspider移动ua的方法!(一))
建立一个符合搜索引擎优化特征的网站友好抓取
爬行和收录是网站操作和优化的第一步。符合SEO特征的站点应该具有友好爬行的特征。以下是构建符合SEO特征的网站友好爬网的具体内容
请注意由“+”标识的网站!您需要修改标识方法。识别百度pider移动UA的新正确方法如下:
1.通过关键词“Android”或“mobile”进行识别,并将其判断为移动访问或捕获
2.via关键词“Baiduspider”/2.0,判定为百度爬虫
此外,需要强调的是,对于机器人,如果禁用的代理是Baiduspider,它将同时在PC和移动设备上生效。也就是说,无论是PC还是移动百度pider都不会抓取被阻止的对象。强调这一点的原因是,一些代码适应网站(相同的URL,当PC UA打开时,它是PC页面,当移动UA打开时,它是移动页面)希望通过设置机器人的代理阻止来实现仅允许移动Baiduspider抓取的目的。然而,这种方法是非常不可取的,因为PC和移动Baiduspider代理都是Baiduspider,这也是SEO优化需要考虑的
如何识别百度蜘蛛
百度蜘蛛是站长的主宾,但我们曾经遇到过站长的问题:我们如何判断疯狂抓取我们网站内容的蜘蛛是否是百度?事实上,站长可以通过DNS反检查IP来判断蜘蛛是否来自百度搜索引擎。不同平台的验证方法不同。例如,linux/Windows/OS下的验证方法如下:
1、在Linux平台上,您可以使用host IP命令反转IP,以确定抓取是否来自百度pider。百度风笛的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,它是冒充的
2、在windows平台或IBM OS/2平台上,可以使用NSLOOKUP IP命令反转IP,以确定抓取是否来自Baiduspider。打开命令处理器,输入NSLOOKUP xxx.xxx.xxx.xxx(IP地址)解析IP以确定爬网是否来自百度pider。百度pider的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,这是一种模仿
@在Mac OS平台上,您可以使用dig命令反转IP地址,以确定爬网是否来自百度pider。打开命令处理器,输入dig xxx.xxx.xxx.xxx(IP地址)解析IP以确定是否从百度pider获取。百度pider的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,这是一种模仿
什么是百度pider IP
即使很多站长知道如何判断百度蜘蛛,他们也会继续问“百度蜘蛛的IP是多少”。我们理解站长的意思。我们想把百度蜘蛛的IP加入白名单。我们只允许白名单下的IP捕获网站以避免被采集和其他行为
但我们不建议站长这样做。虽然百度蜘蛛确实有一个IP池,其中真正的IP是交换的,但我们不能保证IP池不会作为一个整体改变。因此,我们建议站长经常阅读日志,发现恶意蜘蛛后将其列入黑名单,以确保百度的正常捕获
同时,我们再次强调,通过IP区分百度蜘蛛的属性是非常荒谬的。所谓的“沙盒蜘蛛”、“降能蜘蛛”等根本不存在。SEO从业者需要记住
机器人书写法
机器人是网站与蜘蛛交流的重要渠道。该站点通过robots文件声明搜索引擎不希望成为收录的网站部分,或者指定搜索引擎只有收录特定部分。请注意,如果您的网站收录您不想被收录搜索的内容,您只需要使用robots.txt文件。如果您想要搜索引擎收录网站上的所有内容,请不要创建robots.txt文件,这是搜索引擎优化需要掌握的基本技能
Robots文件通常放在根目录中,并收录一个或多个记录。这些记录以空行分隔(Cr、Cr/NL或NL作为终止符)。每条记录的格式如下:
“:”
在此文件中,可以使用#进行注释。具体方法与UNIX中的约定相同。此文件中的记录通常以一行或多行user agent开始,然后是几行disallow和allow。详情如下:
用户代理:此项的值用于描述搜索引擎机器人的名称。在“robots.TXT”文件中,如果存在多个用户代理记录,则表示多个机器人将受到“robots.TXT”的限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.TXT”文件中,只能有一条记录,如“user agent:*”。如果在“robots.TXT”文件中添加了“user agent:somebot”和几个不允许和允许行,“somebot”名称仅受“user agent:somebot”后面的不允许和允许行的限制
不允许:此项的值用于描述不希望访问的一组URL。此值可以是完整路径或路径的非空前缀。机器人将不会访问以disallow item值开头的URL。例如,“disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“disallow:/help/”允许机器人访问/help.html、/helpabc.html和/help/index.html。“Disallow:”表示允许机器人访问此站点的所有URL网站. “/robots.TXT”文件中必须至少有一条不允许的记录。如果“/robots.TXT”不存在或是空文件,网站对所有搜索引擎robots打开
允许:此项的值用于描述要访问的一组URL。与“不允许”类似,此值可以是完整路径或路径的前缀。以值allow开头的URL允许机器人访问。例如,“允许:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。默认情况下,网站的所有URL都是允许的,因此allow通常与disallow一起使用,以允许访问某些网页并禁止访问所有其他URL
使用“*”和“$”:Baiduspider支持使用通配符“*”和“$”来模糊匹配URL
“*”匹配0个或多个任意字符
“$”与行终止符匹配
最后,需要注意的是,百度将严格遵守机器人的相关协议。请注意区分您不希望被捕获的目录或收录. 百度将准确地将用robots编写的文件与您不希望被捕获的目录进行匹配,收录或robots协议将不生效
robots需求使用表中robots.txt的写入方法是什么
robots.txt的编写方法是什么
上面提到了这么多理论,有没有一个简单的比较表来告诉我如何在什么需求场景下编写robots文件?是的:
禁止百度收录的其他方法,机器人除外
Meta robots标记是页面头部的标记之一,也是禁止搜索引擎索引页面内容的指令。目前,百度只支持nofollow和noarchive
禁止搜索引擎跟踪此页面上的链接
如果您不希望搜索引擎跟踪此页面上的链接,也不希望传递链接的权重,请将此元标记放在页面的以下部分:
如果你不想让百度跟踪某个特定的链接,并且百度也支持更精确的控制,请直接在链接上写上这个标记:sign
若要允许其他搜索引擎跟踪,但仅阻止百度跟踪您网页的链接,请将此元标记放在网页部分:
Noarchive:防止搜索引擎在搜索结果中显示网页快照
要防止所有搜索引擎显示您的网站快照,请将此元标记放置在页面的部分:
要允许其他搜索引擎显示快照,但仅阻止百度显示快照,请使用以下标签:
注意:此标志仅禁止百度显示页面快照。百度将继续为页面建立索引,并在搜索结果中显示页面摘要
使用机器人巧妙地避开蜘蛛黑洞
对于百度搜索引擎来说,蜘蛛黑洞是指网站以极低的成本创建大量参数过多、内容相似但URL不同的动态URL,就像一个无限圆形“黑洞”,诱捕蜘蛛。蜘蛛会浪费大量资源并抓取无效网页
例如,很多网站都有过滤功能,通过过滤功能生成的网页经常被搜索引擎抓取,其中很大一部分是检索价值和质量较低的网页。例如,“以500-1000之间的价格租房”,首先网站(包括实际情况)基本上没有相关资源。其次,站内用户和搜索引擎用户没有这种检索习惯。这类网页被搜索引擎抓取,搜索引擎只能占据网站有价值的抓取配额。如何避免这种情况
让我们以北京美团网为例,看看美团网是如何使用机器人巧妙地避开这个蜘蛛黑洞的:
对于普通的过滤结果
网页抓取 加密html(软件介绍BatchHtml是一个网页加密工具,如何保护好自己的HTML站点内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-18 20:22
Batchhtmlencryptor是一个网页加密工具,可以帮助网站管理员加密HTML源文件。它不仅可以对整个网页的源代码进行加密,还可以对网页的源代码进行部分加密。只有在浏览器进行解释时,才能看到加密的网页
相关软件大小版本说明下载地址
Batch HTML encryptor是一种网页加密工具,可帮助网站管理员加密HTML源文件。它可以对整个网页的源代码进行加密,也可以对网页的源代码进行部分加密。只有在浏览器进行解释时,才能看到加密的网页
软件介绍
Batch HTML encryptor是一种简单方便的批量网页文件加密工具。它可以帮助你把网页变成不可读的代码
如何保护您的HTML网站内容一直是新手网站管理员的主要问题。批处理HTML加密程序可以帮助网站管理员加密HTML源文件。加密后,只有浏览器才能读取输出。其他人不知道源文件根本无法修改
什么是批处理HTML加密程序
Batch HTML encryptor是一种保护HTML代码和脚本代码并将其转换为虚幻文字的工具。在处理多个文件时,这是一项出色的工作,因此它将为您节省进行这项复杂工作的时间。现在它支持UNIC ode,这意味着批处理HTML加密程序在加密多语言HTML文件方面比其他加密程序工作得更好
微型系统要求
Microsoft Windows 95/98/I/NT4.0/2000/XP
英特尔586 32 MB内存
6 MB可用磁盘空间 查看全部
网页抓取 加密html(软件介绍BatchHtml是一个网页加密工具,如何保护好自己的HTML站点内容)
Batchhtmlencryptor是一个网页加密工具,可以帮助网站管理员加密HTML源文件。它不仅可以对整个网页的源代码进行加密,还可以对网页的源代码进行部分加密。只有在浏览器进行解释时,才能看到加密的网页
相关软件大小版本说明下载地址
Batch HTML encryptor是一种网页加密工具,可帮助网站管理员加密HTML源文件。它可以对整个网页的源代码进行加密,也可以对网页的源代码进行部分加密。只有在浏览器进行解释时,才能看到加密的网页

软件介绍
Batch HTML encryptor是一种简单方便的批量网页文件加密工具。它可以帮助你把网页变成不可读的代码
如何保护您的HTML网站内容一直是新手网站管理员的主要问题。批处理HTML加密程序可以帮助网站管理员加密HTML源文件。加密后,只有浏览器才能读取输出。其他人不知道源文件根本无法修改
什么是批处理HTML加密程序
Batch HTML encryptor是一种保护HTML代码和脚本代码并将其转换为虚幻文字的工具。在处理多个文件时,这是一项出色的工作,因此它将为您节省进行这项复杂工作的时间。现在它支持UNIC ode,这意味着批处理HTML加密程序在加密多语言HTML文件方面比其他加密程序工作得更好
微型系统要求
Microsoft Windows 95/98/I/NT4.0/2000/XP
英特尔586 32 MB内存
6 MB可用磁盘空间
网页抓取 加密html(几种加密和混淆的反垃圾邮件手段,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-09-18 20:19
邮箱中总是有很多垃圾邮件,这让我不得不重新检查网页上发布的电子邮件地址。为了避免垃圾邮件,我特意将@替换为#。也许十年前这是一个好方法,但随着神经网络和新的机器学习算法的发展,这种小方法也面临着失败的风险,因为它们大多修改电子邮件地址的“@”符号,通过正则表达式过滤和匹配特征值,例如,可疑电子邮件地址(如、)的特征仍然可以捕获电子邮件地址,因此我们需要在将电子邮件发布到HTML网页之前对其进行加密和混淆
接下来,我将介绍几种反垃圾邮件的加密和混淆方法作为示例
1.生成图片
使用传统的图灵测试验证码将阻止采集电子邮件地址生成图片。有许多方法可以通过使用机器无法识别的特征来区分他人和机器。除了高级Photoshop,您甚至可以使用系统带来的绘图工具。此外,如果你想偷懒,有一些在线工具可以帮助你,例如,排名前十的网站可以将你的电子邮件地址转换成图像
当然,生成图片并不是万无一失的。有理由相信,由于基于图片的验证码可以被机器识别和破解,因此基于相同技术的电子邮件地址将不再不可避免。特别是随着OCR技术的逐渐发展和成熟,采集程序可以对整个网页进行OCR,最终提取出所需的内容,因此,我们还需要将图片生成的电子邮件地址与噪音和干扰线混淆。有关详细信息,请参阅如何防止验证码被识别的相关内容
然而,经过这样的设计,我们的电子邮件地址对那些真正需要它的人变得不那么友好,人们更难获得准确的电子邮件地址
2、替换关键符号
我们知道许多爬虫通过@feature符号捕获电子邮件地址。正如我文章在开始时所说,用其他符号替换此符号将大大降低我们的电子邮件被捕获的概率。当然,这一点的缺点是,除非它给用户一个提示,否则需要解释这是一个电子邮件地址,例如John#或John{a},当然,智能电子邮件捕获软件可以自动免受这些技巧的影响。也可以通过判断域名来判断这是一个电子邮件地址。因此,用一个非常特殊的符号替换@也是一种生存方式。对于这种替换方法,更重要的是将电子邮件地址转换为一个句子,如的John,它似乎应该更安全,但它也给真正需要此电子邮件地址的用户带来了一点麻烦
3、使用JavaScript
JavaScript(简称JS)通常被用作嵌入web页面中的小脚本,以提供更丰富的交互和应用程序。我们通过JS混淆电子邮件地址,然后用document.write或innerHTML输出它。优点是大多数爬虫程序无法在网页中执行脚本。它们只擅长捕获静态文本,因此,不必担心电子邮件地址泄漏到爬虫程序。此外,对于最终用户,通过浏览器的解释,他们会看到一个完整的电子邮件地址,这具有良好的用户体验。但是,这种方法有一个致命的弱点,即如果用户的浏览器不支持脚本,电子邮件地址将无法正常显示,尽管这种情况很少见
一个典型的例子如下。当然,有很多不同的实现,比如PHP hide_uu我不会在这里介绍更多关于电子邮件的内容
var username = "john";
var hostname = "example.com";
document.write(username + "@" + hostname);
特别值得一提的是rot13算法的应用。Rot13转13位。在最终分析中,它将字母表的第一个位置连接成一个环,并将要编码的字母映射到要旋转的13位字母,如下图所示:
对于PHP,有一个函数str_;Rot13可以直接使用,然后根据其算法通过反转获得加密前的文本。通常使用以下JS代码:
document.write("Fraq n zrffntr".replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c=(c=c.charCodeAt(0)+13)?c:c-26);}));
上述代码将被解码为以下HTML:
Send a message
4、将HTML与CSS混淆
当然,除了使用JavaScript,我们还可以使用HTML或CSS的一些技巧来混淆HTML注释。HTML收录注释,不会通过浏览器呈现给最终用户。然后,我们可以充分利用此功能创建电子邮件地址,如下所示:
john@example.com
浏览器不会显示它,但足以混淆机器爬虫的爬行
同样,结合CSS显示:无,我们仍然可以得到以下类似方法的混淆:
jo@hn@@exam@ple.com
类似地,显示:没有一个CSS注定不会显示其中收录的文本,因此最终显示的也是完整的电子邮件地址
对于CSS,还有另一种避免爬行的方法,即使用CSS文本显示顺序的特征,例如:
moc.noitpecni@kcik
CSS代码如下所示:
.obfuscate { unicode-bidi: bidi-override; direction: rtl; }
首先,文本被我们颠倒了。如果你想还原它,你可以在没有JS帮助的情况下通过CSS再次将其反转,以获得正确的文本。当然,这种方法有一个缺陷,即用户选择复制电子邮件地址的顺序仍然是相反的
最后,在反垃圾邮件爬虫采集方法方面,我们充分发挥了网民的智慧,涌现出了各种优秀的实现方案。由于篇幅有限,我不一一介绍。事实上,没有绝对的安全。最安全的方法是没有电子邮件地址。你怎么说?也就是说,使用contact from可以让需要与您联系的人通过表单直接向您发送电子邮件,从而避免泄露电子邮件地址。在线联系人表单有很多开源代码。这是我博客考虑的最后一种方式。现在,您可以通过右上角的“关于我”找到此链接并向我发送消息 查看全部
网页抓取 加密html(几种加密和混淆的反垃圾邮件手段,你知道吗?)
邮箱中总是有很多垃圾邮件,这让我不得不重新检查网页上发布的电子邮件地址。为了避免垃圾邮件,我特意将@替换为#。也许十年前这是一个好方法,但随着神经网络和新的机器学习算法的发展,这种小方法也面临着失败的风险,因为它们大多修改电子邮件地址的“@”符号,通过正则表达式过滤和匹配特征值,例如,可疑电子邮件地址(如、)的特征仍然可以捕获电子邮件地址,因此我们需要在将电子邮件发布到HTML网页之前对其进行加密和混淆
接下来,我将介绍几种反垃圾邮件的加密和混淆方法作为示例
1.生成图片
使用传统的图灵测试验证码将阻止采集电子邮件地址生成图片。有许多方法可以通过使用机器无法识别的特征来区分他人和机器。除了高级Photoshop,您甚至可以使用系统带来的绘图工具。此外,如果你想偷懒,有一些在线工具可以帮助你,例如,排名前十的网站可以将你的电子邮件地址转换成图像
当然,生成图片并不是万无一失的。有理由相信,由于基于图片的验证码可以被机器识别和破解,因此基于相同技术的电子邮件地址将不再不可避免。特别是随着OCR技术的逐渐发展和成熟,采集程序可以对整个网页进行OCR,最终提取出所需的内容,因此,我们还需要将图片生成的电子邮件地址与噪音和干扰线混淆。有关详细信息,请参阅如何防止验证码被识别的相关内容
然而,经过这样的设计,我们的电子邮件地址对那些真正需要它的人变得不那么友好,人们更难获得准确的电子邮件地址
2、替换关键符号
我们知道许多爬虫通过@feature符号捕获电子邮件地址。正如我文章在开始时所说,用其他符号替换此符号将大大降低我们的电子邮件被捕获的概率。当然,这一点的缺点是,除非它给用户一个提示,否则需要解释这是一个电子邮件地址,例如John#或John{a},当然,智能电子邮件捕获软件可以自动免受这些技巧的影响。也可以通过判断域名来判断这是一个电子邮件地址。因此,用一个非常特殊的符号替换@也是一种生存方式。对于这种替换方法,更重要的是将电子邮件地址转换为一个句子,如的John,它似乎应该更安全,但它也给真正需要此电子邮件地址的用户带来了一点麻烦
3、使用JavaScript
JavaScript(简称JS)通常被用作嵌入web页面中的小脚本,以提供更丰富的交互和应用程序。我们通过JS混淆电子邮件地址,然后用document.write或innerHTML输出它。优点是大多数爬虫程序无法在网页中执行脚本。它们只擅长捕获静态文本,因此,不必担心电子邮件地址泄漏到爬虫程序。此外,对于最终用户,通过浏览器的解释,他们会看到一个完整的电子邮件地址,这具有良好的用户体验。但是,这种方法有一个致命的弱点,即如果用户的浏览器不支持脚本,电子邮件地址将无法正常显示,尽管这种情况很少见
一个典型的例子如下。当然,有很多不同的实现,比如PHP hide_uu我不会在这里介绍更多关于电子邮件的内容
var username = "john";
var hostname = "example.com";
document.write(username + "@" + hostname);
特别值得一提的是rot13算法的应用。Rot13转13位。在最终分析中,它将字母表的第一个位置连接成一个环,并将要编码的字母映射到要旋转的13位字母,如下图所示:

对于PHP,有一个函数str_;Rot13可以直接使用,然后根据其算法通过反转获得加密前的文本。通常使用以下JS代码:
document.write("Fraq n zrffntr".replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c=(c=c.charCodeAt(0)+13)?c:c-26);}));
上述代码将被解码为以下HTML:
Send a message
4、将HTML与CSS混淆
当然,除了使用JavaScript,我们还可以使用HTML或CSS的一些技巧来混淆HTML注释。HTML收录注释,不会通过浏览器呈现给最终用户。然后,我们可以充分利用此功能创建电子邮件地址,如下所示:
john@example.com
浏览器不会显示它,但足以混淆机器爬虫的爬行
同样,结合CSS显示:无,我们仍然可以得到以下类似方法的混淆:
jo@hn@@exam@ple.com
类似地,显示:没有一个CSS注定不会显示其中收录的文本,因此最终显示的也是完整的电子邮件地址
对于CSS,还有另一种避免爬行的方法,即使用CSS文本显示顺序的特征,例如:
moc.noitpecni@kcik
CSS代码如下所示:
.obfuscate { unicode-bidi: bidi-override; direction: rtl; }
首先,文本被我们颠倒了。如果你想还原它,你可以在没有JS帮助的情况下通过CSS再次将其反转,以获得正确的文本。当然,这种方法有一个缺陷,即用户选择复制电子邮件地址的顺序仍然是相反的
最后,在反垃圾邮件爬虫采集方法方面,我们充分发挥了网民的智慧,涌现出了各种优秀的实现方案。由于篇幅有限,我不一一介绍。事实上,没有绝对的安全。最安全的方法是没有电子邮件地址。你怎么说?也就是说,使用contact from可以让需要与您联系的人通过表单直接向您发送电子邮件,从而避免泄露电子邮件地址。在线联系人表单有很多开源代码。这是我博客考虑的最后一种方式。现在,您可以通过右上角的“关于我”找到此链接并向我发送消息
网页抓取 加密html(如何能够获取到指定网页的源码呢?的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-17 15:09
在C#中,我们如何能够获取到指定网页的源码呢?比如说我们要做一个文章抓取功能的小工具,这样的功能是必不可少的,小编自己做了一个能够获取网页源码的小工具,把主体代码共享出来,希望能给新手们一点帮助。
首先先看下面代码:
private string GetWebContent(string url)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse respone = (HttpWebResponse)request.GetResponse();
Stream stream = respone.GetResponseStream();
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
StreamReader streamReader = new StreamReader(stream, encoding);
return streamReader.ReadToEnd();
}
上面方法的功能是把传入参数(url地址)的网页源码返回给调用者,但这仅仅是所有源码,我们并不能从中剥离出网站标题,网站Body元素等,需要正确读到这些元素,我们还要进行下一步处理。
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
主要用来处理网站的不同编码,不同的网站有不同的编码,如果我们在读取时使用了错误的编码,那么返回结果中的所有汉字就成了乱码了,所以提供了一个供用户自己选择编码的功能,如果读取出源码是错误的,就可以使用另外一种编码再次尝试,ddlEncoding(ComboBox控件)提供了所有网站编码选择。
下面是处理GetWebContent(stringurl)方法返回的结果,以正确读取出网站的标题,body的元素。
private void button1_Click(object sender, EventArgs e)
{
try
{
if (this.txtUrl.Text.Trim().Length == 0)
{
("请输入主入口地址!");
}
else
{
//这里获取GetWebContent方法的结果
string webContent = GetWebContent(this.txtUrl.Text.Trim());
//声明一个WebBrowser
WebBrowser webBrowser = new WebBrowser();
webBrowser.Navigate("about:blank");
//将GetWebContent方法返回的结果转化为HtmlDocument,就可以正确处理网页中的元素了。
HtmlDocument htmlDoc = webBrowser.Document.OpenNew(true);
htmlDoc.Write(webContent);
//获取网页中Body中的Html代码
string outerHtml = htmlDoc.Body.OuterHtml;
//获取网页的标题
string outerTitle=htmlDoc.Title;
this.txtDocumentTitle.Text = outerTitle;
this.txtDocumentConent.Text = outerHtml;
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
通过上面两个步骤,我们就可以正确的读取指定网页中的各元素了,当然,实际处理时,可能还会遇到很多的问题,比如我们要获取源码的网站需要用户名与密码验证,但处理一般的网页还是足够了。我们还可以从获取到的源码中解析出A标签,然后再根据解析出的A标签继续读取源码,就可以实现自动抓取的功能了。 查看全部
网页抓取 加密html(如何能够获取到指定网页的源码呢?的小工具)
在C#中,我们如何能够获取到指定网页的源码呢?比如说我们要做一个文章抓取功能的小工具,这样的功能是必不可少的,小编自己做了一个能够获取网页源码的小工具,把主体代码共享出来,希望能给新手们一点帮助。
首先先看下面代码:
private string GetWebContent(string url)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse respone = (HttpWebResponse)request.GetResponse();
Stream stream = respone.GetResponseStream();
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
StreamReader streamReader = new StreamReader(stream, encoding);
return streamReader.ReadToEnd();
}
上面方法的功能是把传入参数(url地址)的网页源码返回给调用者,但这仅仅是所有源码,我们并不能从中剥离出网站标题,网站Body元素等,需要正确读到这些元素,我们还要进行下一步处理。
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
主要用来处理网站的不同编码,不同的网站有不同的编码,如果我们在读取时使用了错误的编码,那么返回结果中的所有汉字就成了乱码了,所以提供了一个供用户自己选择编码的功能,如果读取出源码是错误的,就可以使用另外一种编码再次尝试,ddlEncoding(ComboBox控件)提供了所有网站编码选择。
下面是处理GetWebContent(stringurl)方法返回的结果,以正确读取出网站的标题,body的元素。
private void button1_Click(object sender, EventArgs e)
{
try
{
if (this.txtUrl.Text.Trim().Length == 0)
{
("请输入主入口地址!");
}
else
{
//这里获取GetWebContent方法的结果
string webContent = GetWebContent(this.txtUrl.Text.Trim());
//声明一个WebBrowser
WebBrowser webBrowser = new WebBrowser();
webBrowser.Navigate("about:blank");
//将GetWebContent方法返回的结果转化为HtmlDocument,就可以正确处理网页中的元素了。
HtmlDocument htmlDoc = webBrowser.Document.OpenNew(true);
htmlDoc.Write(webContent);
//获取网页中Body中的Html代码
string outerHtml = htmlDoc.Body.OuterHtml;
//获取网页的标题
string outerTitle=htmlDoc.Title;
this.txtDocumentTitle.Text = outerTitle;
this.txtDocumentConent.Text = outerHtml;
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
通过上面两个步骤,我们就可以正确的读取指定网页中的各元素了,当然,实际处理时,可能还会遇到很多的问题,比如我们要获取源码的网站需要用户名与密码验证,但处理一般的网页还是足够了。我们还可以从获取到的源码中解析出A标签,然后再根据解析出的A标签继续读取源码,就可以实现自动抓取的功能了。
网页抓取 加密html(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-14 03:03
还有一个关于数据抓取的小研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎指正并补充哈哈!
方法一:直接抓取网页源码
优点:快。
缺点: 1、由于速度快,容易被服务器检测到,可能会限制当前ip爬取。对此,您可以尝试使用ip码来解决。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到一些大规模的网站抓取,如果登录后需要抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页完全静态,第一次加载网页后加载你要抓取的数据。涉及登录或权限操作的类似页面未加密或简单加密。
当然,如果你在这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于登录页面,我们如何获取登录页面背后的源代码?
首先要介绍一下,在session保存账户信息时,服务器是如何判断用户的身份的。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,服务器返回的 sessionId 会被接收并保存在 cookie 中。因此,我们可以用chrome浏览器打开勾选项,查看当前页面的jsessionId。下次用户访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
这里我搭建了一个简单的JSP登录页面,登录后的账号信息保存在服务器端会话中。
思考:1.登陆。2.登陆成功后获取cookies。 3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
Java 版本:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
Python 版本:
#encoding:utf-8
import urllib
import urllib2
data={'username':'admin','password':'123456'}
data=urllib.urlencode(data)
response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录
cookie = response.info()['set-cookie']//获得登录后的cookie
jsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionId
html = response.read()
if html=='error':
print('用户名密码错误!')
elif html=='success':
headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头
request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以清楚地看到python的优势。它将编写的代码量至少比 java 少一半。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好的控制底层。代码实现的缺点是不容易学习,需要的技术太多。因此,如果您是数据采集的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点:1、类似用户操作,不易被服务器检测到。
2.对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可以随时获取当前页面各个元素的最新状态。
缺点:1、速度稍慢。
这里有一些很好的模拟浏览器操作的库:
C#webbrower 控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以在dom模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit,等,或者直接调用页面js方法。
网页浏览器操作的C#代码:
webBrowser1.Navigate("https://localhost//index.html");//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们的浏览器系统,但我们需要确保浏览安装相应的驱动程序。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里给大家推荐一款后台浏览器,直接在cmd里面操作,没有界面,就是phantomjs。
这样我们就可以用python+selenium+phantomjs在不看界面的情况下模拟浏览器的操作了。由于phantomjs没有界面,所以会比普通浏览器快很多。
网上资料很多,一时无法解释,这里就不过多解释了,大家可以看看:
三、Fidderscript:
fdder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书,所以有时候,在爬取过程中,如果我们遇到安全证书错误,不妨打开fidder,让他给你提供一个证书,也许你离成功不远了。
比较强大的就是fidderscript,它可以在抓取请求后进行系统操作,比如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的抓取工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和Clike系列语法差不多,类库大都和c#一样,相信熟悉C#的同学会很快上手fiddlerscript。
附注: 查看全部
网页抓取 加密html(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
还有一个关于数据抓取的小研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎指正并补充哈哈!
方法一:直接抓取网页源码
优点:快。
缺点: 1、由于速度快,容易被服务器检测到,可能会限制当前ip爬取。对此,您可以尝试使用ip码来解决。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到一些大规模的网站抓取,如果登录后需要抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页完全静态,第一次加载网页后加载你要抓取的数据。涉及登录或权限操作的类似页面未加密或简单加密。
当然,如果你在这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于登录页面,我们如何获取登录页面背后的源代码?
首先要介绍一下,在session保存账户信息时,服务器是如何判断用户的身份的。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,服务器返回的 sessionId 会被接收并保存在 cookie 中。因此,我们可以用chrome浏览器打开勾选项,查看当前页面的jsessionId。下次用户访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
这里我搭建了一个简单的JSP登录页面,登录后的账号信息保存在服务器端会话中。
思考:1.登陆。2.登陆成功后获取cookies。 3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
Java 版本:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
Python 版本:
#encoding:utf-8
import urllib
import urllib2
data={'username':'admin','password':'123456'}
data=urllib.urlencode(data)
response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录
cookie = response.info()['set-cookie']//获得登录后的cookie
jsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionId
html = response.read()
if html=='error':
print('用户名密码错误!')
elif html=='success':
headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头
request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以清楚地看到python的优势。它将编写的代码量至少比 java 少一半。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好的控制底层。代码实现的缺点是不容易学习,需要的技术太多。因此,如果您是数据采集的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点:1、类似用户操作,不易被服务器检测到。
2.对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可以随时获取当前页面各个元素的最新状态。
缺点:1、速度稍慢。
这里有一些很好的模拟浏览器操作的库:
C#webbrower 控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以在dom模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit,等,或者直接调用页面js方法。
网页浏览器操作的C#代码:
webBrowser1.Navigate("https://localhost//index.html";);//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们的浏览器系统,但我们需要确保浏览安装相应的驱动程序。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里给大家推荐一款后台浏览器,直接在cmd里面操作,没有界面,就是phantomjs。
这样我们就可以用python+selenium+phantomjs在不看界面的情况下模拟浏览器的操作了。由于phantomjs没有界面,所以会比普通浏览器快很多。
网上资料很多,一时无法解释,这里就不过多解释了,大家可以看看:
三、Fidderscript:
fdder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书,所以有时候,在爬取过程中,如果我们遇到安全证书错误,不妨打开fidder,让他给你提供一个证书,也许你离成功不远了。
比较强大的就是fidderscript,它可以在抓取请求后进行系统操作,比如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的抓取工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和Clike系列语法差不多,类库大都和c#一样,相信熟悉C#的同学会很快上手fiddlerscript。
附注:
网页抓取 加密html(【魔兽世界】反爬与反反爬突破网站的一些经验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-14 03:02
防爬和防爬一直是相互博弈的游戏。路高一尺,魔道高一尺。知己知彼,百战不殆。想要突破网站的反爬机制,必须对当前的前端开发技术有深刻的了解,才能在这款游戏中生存。
我是爬行动物爱好者。最近在爬小说网站时,通过抓包分析,发现小说正文被加密,如图:
获取小说文本的响应数据
小说文本加密数据
根据字面意思可以看出,小说的文本是经过编码存储在Content key中的,但是这个字符编码无法显示和解码,所以确定它已经被加密了。这时候我们就来看看网页js代码分析和编码转换过程。但是一个网页有很多js代码,而且还经过编译、混淆和压缩,所以直接阅读整篇文章会很费力。因此,我们必须掌握一定的技巧,才能更有效地解决问题。
接下来分享一些我查看js代码的心得。
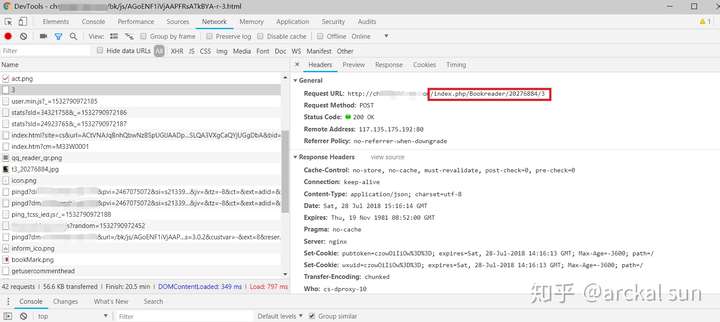
首先看请求地址,可以发现“index.php/Bookreader”是url的固定部分,
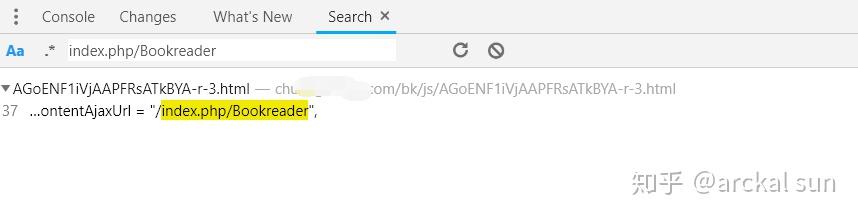
然后,我们按快捷键Ctrl+Shift+F进行搜索,结果如下
点击此结果定位位置
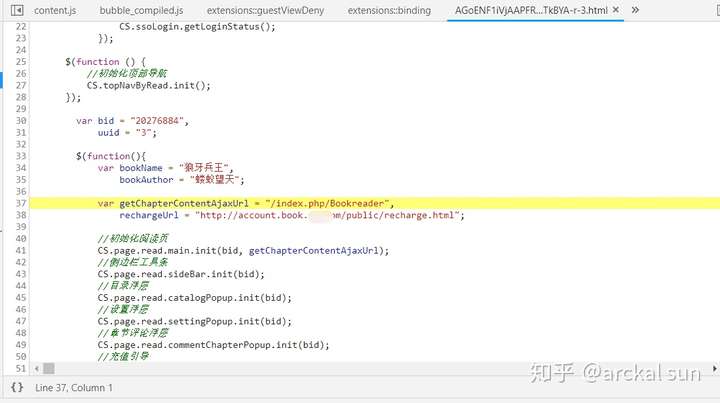
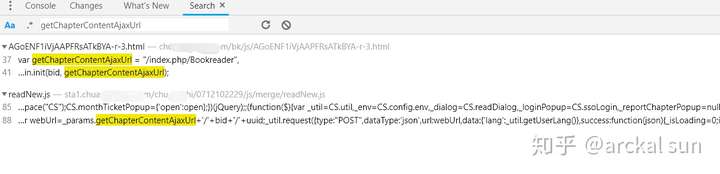
如您所见,此接口路径已分配给变量 getChapterContentAjaxUrl。接下来,搜索这个变量,看看它在哪里被调用。
根据经验,点击底部打开js代码页
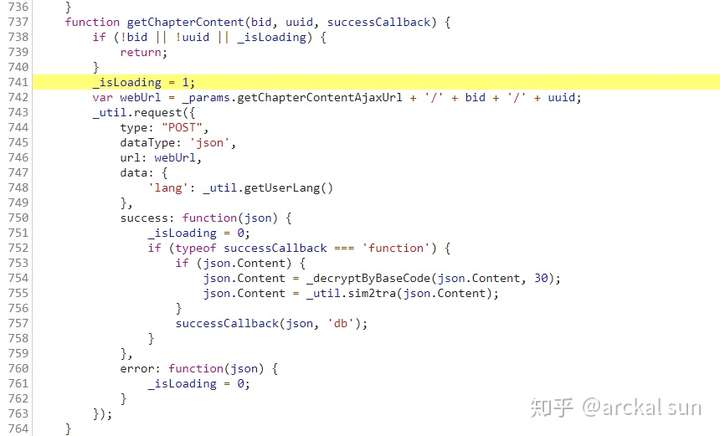
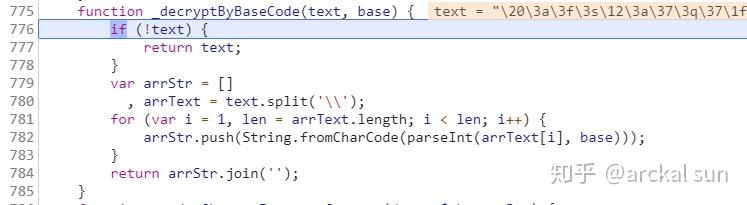
看到这个代码逻辑,相信你已经明白了。本次POST请求成功后,返回json数据,然后对json的Content字段进行解码。在第754行,有一个函数“_decryptByBaseCode”来实现解码功能。函数,OK,看函数的具体实现。
在这个地方设置一个断点,在断点之后
点击F9一步步执行,跟踪进去
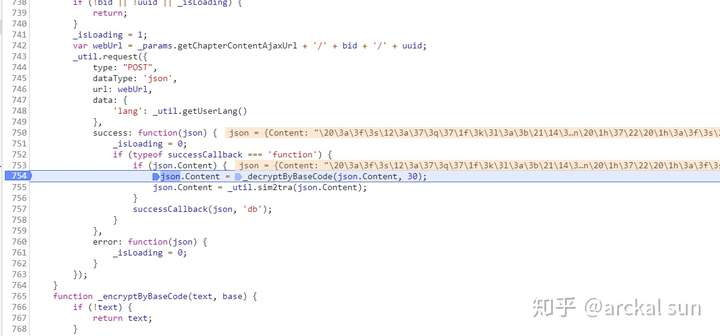
函数_decryptByBaseCode的实现代码
如你所见,这个解码逻辑很简单,将文本用反斜杠分割成数据,然后一一解码。
有两个函数 String.fromCharCode 和 parseInt。第一个是将int转换为unicode字符,第二个是根据指定的基数将字符串转换为int。这里他们使用 30 base 来编码 Encrypted。
所以这个功能可以用python实现。实现代码如下,
# 解码
def decrypt_by_basecode(text,base):
if not text:
return
# base=30
arrStr = []
arrText = text.split('\\')
for i in arrText:
if i:
s = chr(int(i,base))
arrStr.append(s)
objStr = ''.join(arrStr)
return objStr
写好解码函数后,我们可以在程序中调用这个接口,然后对小说内容进行解码。
通过上面的实战演示,你可以看到一个优秀的爬虫工程师,也是一个资深的前端工程师。
欢迎关注我的知乎account
@arckal 太阳
我会不定期分享一些技术经验。 ^_^ 查看全部
网页抓取 加密html(【魔兽世界】反爬与反反爬突破网站的一些经验)
防爬和防爬一直是相互博弈的游戏。路高一尺,魔道高一尺。知己知彼,百战不殆。想要突破网站的反爬机制,必须对当前的前端开发技术有深刻的了解,才能在这款游戏中生存。
我是爬行动物爱好者。最近在爬小说网站时,通过抓包分析,发现小说正文被加密,如图:
获取小说文本的响应数据

小说文本加密数据
根据字面意思可以看出,小说的文本是经过编码存储在Content key中的,但是这个字符编码无法显示和解码,所以确定它已经被加密了。这时候我们就来看看网页js代码分析和编码转换过程。但是一个网页有很多js代码,而且还经过编译、混淆和压缩,所以直接阅读整篇文章会很费力。因此,我们必须掌握一定的技巧,才能更有效地解决问题。
接下来分享一些我查看js代码的心得。
首先看请求地址,可以发现“index.php/Bookreader”是url的固定部分,
然后,我们按快捷键Ctrl+Shift+F进行搜索,结果如下
点击此结果定位位置
如您所见,此接口路径已分配给变量 getChapterContentAjaxUrl。接下来,搜索这个变量,看看它在哪里被调用。
根据经验,点击底部打开js代码页
看到这个代码逻辑,相信你已经明白了。本次POST请求成功后,返回json数据,然后对json的Content字段进行解码。在第754行,有一个函数“_decryptByBaseCode”来实现解码功能。函数,OK,看函数的具体实现。
在这个地方设置一个断点,在断点之后
点击F9一步步执行,跟踪进去
函数_decryptByBaseCode的实现代码
如你所见,这个解码逻辑很简单,将文本用反斜杠分割成数据,然后一一解码。
有两个函数 String.fromCharCode 和 parseInt。第一个是将int转换为unicode字符,第二个是根据指定的基数将字符串转换为int。这里他们使用 30 base 来编码 Encrypted。
所以这个功能可以用python实现。实现代码如下,
# 解码
def decrypt_by_basecode(text,base):
if not text:
return
# base=30
arrStr = []
arrText = text.split('\\')
for i in arrText:
if i:
s = chr(int(i,base))
arrStr.append(s)
objStr = ''.join(arrStr)
return objStr
写好解码函数后,我们可以在程序中调用这个接口,然后对小说内容进行解码。
通过上面的实战演示,你可以看到一个优秀的爬虫工程师,也是一个资深的前端工程师。
欢迎关注我的知乎account
@arckal 太阳
我会不定期分享一些技术经验。 ^_^
网页抓取 加密html(搜索引擎蜘蛛访问网站页面时的程序被称为蜘蛛(spider))
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-14 03:00
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人网站引蜘蛛。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度来说,都是用多只蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,不会被抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须具备不用任何软件查看网站日志的能力,而且你必须非常熟悉其代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址搜索下一个网页,这样循环下去,直到所有的网站 网页已被抓取。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。大约十个。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。就算能存储,下载还是有问题(按一台机器每秒下载20K计算,需要340个单元,机器不停下载一年才能完成所有网页的下载)。同时,由于数据量大,在提供搜索时也会影响效率。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而评价抓取重要性的主要依据是某个网页的链接深度。
由于无法抓取所有网页,部分网络蜘蛛为一些不太重要的网站设置了访问级别数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,网页我不会被访问,这也让网站之前的一些页面在搜索引擎上搜索到,其他部分搜索不到。
对于网站designers,扁平化的网站结构设计有助于搜索引擎抓取更多网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望搜索引擎可以搜索到他们的报告,但他们做不到自由。搜索者查看,所以需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限验证。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。名字的由来。
整个互联网网站是由相互链接组成的,也就是说,搜索引擎蜘蛛从任何一个页面开始,最终爬到所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了,所以蜘蛛只能通过某些方法抓取所有页面。据我了解,最简单的爬取策略有3种:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问被网络分析算法预测为“有用”的网页。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这种闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬,直到没有更多的链接在它前面,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二层进入页面的第二层找到的链接爬到三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是可以抓取所有页面。其实最大的搜索引擎只是爬取而收录了互联网的一小部分,当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了尽可能多地抓取用户信息,通常将深度优先和广度优先混用,这样可以照顾到尽可能多的网站,以及@的部分内页网站。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般情况下,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中从未见过的网址,从而访问其他网页并遍历网络。
其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,以遍历的方式爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要用于数据集合的日常维护和实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,我们在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。这方面需要解决的主要问题是什么?更好地处理动态网络数据问题(如Web2.0数据量不断增加等),更好地根据网页质量修正抓取策略问题。
四、database
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或360的网址收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则将其存储在数据库中以供访问(网站测期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并抓取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站,观察期间需要定期更新网站。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站持久化不更新,蜘蛛不会被光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。 .
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技巧足够高深,并且有了这个能力,你也可以试试。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的网站页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有页面,那我们就让它抓取重要页面,因为重要页面在索引中起着重要作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站被赋予了很高的权重。这种在网站页面上爬行的蜘蛛爬行深度更高,所以更多的内页会是收录。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要频繁爬取和爬取。 .
如果页面内容更新频繁,蜘蛛就会频繁的爬取爬行,那么页面上的新链接自然会被蜘蛛更快的跟踪和抓取,这就是为什么每天都要更新文章
3、import 链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道存在页。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛经常从对方网站爬到你网站,深度高。 查看全部
网页抓取 加密html(搜索引擎蜘蛛访问网站页面时的程序被称为蜘蛛(spider))
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人网站引蜘蛛。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度来说,都是用多只蜘蛛来分布爬取。


蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,不会被抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须具备不用任何软件查看网站日志的能力,而且你必须非常熟悉其代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址搜索下一个网页,这样循环下去,直到所有的网站 网页已被抓取。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。大约十个。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。就算能存储,下载还是有问题(按一台机器每秒下载20K计算,需要340个单元,机器不停下载一年才能完成所有网页的下载)。同时,由于数据量大,在提供搜索时也会影响效率。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而评价抓取重要性的主要依据是某个网页的链接深度。
由于无法抓取所有网页,部分网络蜘蛛为一些不太重要的网站设置了访问级别数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,网页我不会被访问,这也让网站之前的一些页面在搜索引擎上搜索到,其他部分搜索不到。
对于网站designers,扁平化的网站结构设计有助于搜索引擎抓取更多网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望搜索引擎可以搜索到他们的报告,但他们做不到自由。搜索者查看,所以需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限验证。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。名字的由来。
整个互联网网站是由相互链接组成的,也就是说,搜索引擎蜘蛛从任何一个页面开始,最终爬到所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了,所以蜘蛛只能通过某些方法抓取所有页面。据我了解,最简单的爬取策略有3种:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问被网络分析算法预测为“有用”的网页。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这种闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬,直到没有更多的链接在它前面,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二层进入页面的第二层找到的链接爬到三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是可以抓取所有页面。其实最大的搜索引擎只是爬取而收录了互联网的一小部分,当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了尽可能多地抓取用户信息,通常将深度优先和广度优先混用,这样可以照顾到尽可能多的网站,以及@的部分内页网站。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般情况下,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中从未见过的网址,从而访问其他网页并遍历网络。
其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,以遍历的方式爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要用于数据集合的日常维护和实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,我们在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。这方面需要解决的主要问题是什么?更好地处理动态网络数据问题(如Web2.0数据量不断增加等),更好地根据网页质量修正抓取策略问题。
四、database
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或360的网址收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则将其存储在数据库中以供访问(网站测期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并抓取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站,观察期间需要定期更新网站。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站持久化不更新,蜘蛛不会被光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。 .
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技巧足够高深,并且有了这个能力,你也可以试试。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的网站页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有页面,那我们就让它抓取重要页面,因为重要页面在索引中起着重要作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站被赋予了很高的权重。这种在网站页面上爬行的蜘蛛爬行深度更高,所以更多的内页会是收录。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要频繁爬取和爬取。 .
如果页面内容更新频繁,蜘蛛就会频繁的爬取爬行,那么页面上的新链接自然会被蜘蛛更快的跟踪和抓取,这就是为什么每天都要更新文章
3、import 链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道存在页。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛经常从对方网站爬到你网站,深度高。
网页抓取 加密html(最新发布的相关软件:正确的出山:保护保护您的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-13 15:03
近期发布的相关软件:
正确的 HRPT 几何图形 1.5.0.10_正确的 HRPT 几何图形 1.5.0.10 正确的 HTML 保护器 3.0_正确的 HTML 保护器 3.0
HTML 的保护将帮助您克隆、抄袭和加密垃圾邮件以防止您的网页
右键单击 HTML Protector 将帮助您加密网页、未经授权提取文本、图形、电子邮件、链接、JavaScript 和 VBScript 克隆、抄袭和垃圾邮件保护。
正确的神器出来了:保护您的网页免遭未经授权的信息、图像、文本、电子邮件地址、链接、JavaScript 和 VBScript 提取。加密HTML文件和源代码,拦截所有网站视频采集和电子邮件提取,用于采集垃圾邮件库。
您的访问者看不到更改,但它有助于避免在线抄袭和克隆,这在今天非常普遍。正确的 HTML 保护功能允许您收录或排除某些加密网页——例如,您只能保护电子邮件和图片加密方法。
这将有助于您的网站 保持较高的搜索引擎排名。高级选项可用于禁用鼠标右键、文本选择、页面打印和打印屏幕、页面缓存、IE 图片工具栏和智能标签、离线网页浏览和拖放
以下是“正确的 HTML 保护程序”的一些主要功能:
加密的HTML文件:保护从网站的网页中提取的信息,并使用6种加密方法保持较高的搜索引擎排名。
隐藏源代码之路:您的访问者将看不到这些更改,但任何人都无法阅读和窃取您的源代码。
防止克隆之路:防止他人使用您的文章、插图和照片、您的网页设计和脚本。
阻止垃圾邮件和病毒的方法:有专门的软件可以从互联网上提取电子邮件,有一天你会看到,商业信件垃圾邮件很难分割。此外,垃圾邮件提供了90F的所有病毒、木马和蠕虫。保护您和您的企业免于提取电子邮件。
路网站松土机座:您可能想屏蔽的软件用于自动保存您所有网站内容以备将来使用。
路障内容过滤器:您可能还需要阻止可以对访问者隐藏您的广告的内容过滤器。
道路维护搜索引擎的定位是使用选择性加密,以确保搜索引擎的高排名。
Road 易于使用:您不需要任何 HTML 或 Web 编程技能,只需将文件拖放到 protected_file.html 即可准备使用正确的 HTML 保护。
路由禁用动作(可选):禁用鼠标右键、文本选择、页面打印、打印屏幕、页面缓存、IE图像工具栏和智能标签、离线网页浏览和拖放。
限制:
Road Limited 为 15 天。 查看全部
网页抓取 加密html(最新发布的相关软件:正确的出山:保护保护您的网页)
近期发布的相关软件:
正确的 HRPT 几何图形 1.5.0.10_正确的 HRPT 几何图形 1.5.0.10 正确的 HTML 保护器 3.0_正确的 HTML 保护器 3.0
HTML 的保护将帮助您克隆、抄袭和加密垃圾邮件以防止您的网页
右键单击 HTML Protector 将帮助您加密网页、未经授权提取文本、图形、电子邮件、链接、JavaScript 和 VBScript 克隆、抄袭和垃圾邮件保护。
正确的神器出来了:保护您的网页免遭未经授权的信息、图像、文本、电子邮件地址、链接、JavaScript 和 VBScript 提取。加密HTML文件和源代码,拦截所有网站视频采集和电子邮件提取,用于采集垃圾邮件库。
您的访问者看不到更改,但它有助于避免在线抄袭和克隆,这在今天非常普遍。正确的 HTML 保护功能允许您收录或排除某些加密网页——例如,您只能保护电子邮件和图片加密方法。
这将有助于您的网站 保持较高的搜索引擎排名。高级选项可用于禁用鼠标右键、文本选择、页面打印和打印屏幕、页面缓存、IE 图片工具栏和智能标签、离线网页浏览和拖放
以下是“正确的 HTML 保护程序”的一些主要功能:
加密的HTML文件:保护从网站的网页中提取的信息,并使用6种加密方法保持较高的搜索引擎排名。
隐藏源代码之路:您的访问者将看不到这些更改,但任何人都无法阅读和窃取您的源代码。
防止克隆之路:防止他人使用您的文章、插图和照片、您的网页设计和脚本。
阻止垃圾邮件和病毒的方法:有专门的软件可以从互联网上提取电子邮件,有一天你会看到,商业信件垃圾邮件很难分割。此外,垃圾邮件提供了90F的所有病毒、木马和蠕虫。保护您和您的企业免于提取电子邮件。
路网站松土机座:您可能想屏蔽的软件用于自动保存您所有网站内容以备将来使用。
路障内容过滤器:您可能还需要阻止可以对访问者隐藏您的广告的内容过滤器。
道路维护搜索引擎的定位是使用选择性加密,以确保搜索引擎的高排名。
Road 易于使用:您不需要任何 HTML 或 Web 编程技能,只需将文件拖放到 protected_file.html 即可准备使用正确的 HTML 保护。
路由禁用动作(可选):禁用鼠标右键、文本选择、页面打印、打印屏幕、页面缓存、IE图像工具栏和智能标签、离线网页浏览和拖放。
限制:
Road Limited 为 15 天。
网页抓取 加密html(爬虫介绍三种常见的加密方式及其解决方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 470 次浏览 • 2021-09-12 07:14
在使用爬虫爬取网页数据的过程中,我们经常会发现目标网页返回的HTML源代码经过了不同编码方式的加密,导致我们无法正确定位到需要的元素。本文介绍了三种常见的加密方法及其解决方案,以说明编写爬虫时请求头的重要性。情况一、JS加密防爬
爬取影评数据()
要抓取网页,请求页面的最简单和最常见的方法是
此时返回的目标网页源代码为
通过网上检索信息,这种情况叫做JS加密,解决这个问题的方法也很简单,就是给爬虫添加请求头,比如
一般来说,网上大部分网页只需要在headers中添加User-Agent元素就可以正常抓取数据,但是有些网站已经添加了反抓取机制,所以我们需要添加相应的元素。比如这里的JS加密需要添加元素Cookies,返回源码如下:
情况二、language标签反爬
爬取猫眼电影的TOP100数据()
如上直接访问返回的源代码为
在不应用直接访问的情况下,目标网站服务器只会返回上图所示的无序英文,而不是我们在目标网站上看到的源代码。这时候还需要在请求头中添加元素Accept-Language如下:
此时返回的页面源代码为
Situation三、requests 库获取网页中文乱码处理
当我们请求一个网页时,得到的源代码是正常的上图所示的英文中文乱码,我们要明白目标网站返回给我们的源代码是经过加密的(不同的编码方式) ),这是我们默认的解码方法,不能再解释了。这时候,我们有两个解决方案:
1.打开target网站Developer界面,找到使用的编码方式,如下图:
编写爬虫时添加代码:
2.无论登陆页面使用哪种编码方式,都可以添加这行代码来破译:
总结
当我们发现请求页面的源代码与目标网站Developer接口不一致时,说明我们向目标网站发出的请求不完整或者返回的源代码需要进一步解释,但是不管遇到什么乱码,本文要强调的是,请求网页的源代码是从地面高层建筑爬取的第一步。我们都可以尽可能多地填写标题,避免不必要的时间和精力浪费。 查看全部
网页抓取 加密html(爬虫介绍三种常见的加密方式及其解决方法(图))
在使用爬虫爬取网页数据的过程中,我们经常会发现目标网页返回的HTML源代码经过了不同编码方式的加密,导致我们无法正确定位到需要的元素。本文介绍了三种常见的加密方法及其解决方案,以说明编写爬虫时请求头的重要性。情况一、JS加密防爬
爬取影评数据()
要抓取网页,请求页面的最简单和最常见的方法是
此时返回的目标网页源代码为

通过网上检索信息,这种情况叫做JS加密,解决这个问题的方法也很简单,就是给爬虫添加请求头,比如

一般来说,网上大部分网页只需要在headers中添加User-Agent元素就可以正常抓取数据,但是有些网站已经添加了反抓取机制,所以我们需要添加相应的元素。比如这里的JS加密需要添加元素Cookies,返回源码如下:
情况二、language标签反爬
爬取猫眼电影的TOP100数据()
如上直接访问返回的源代码为

在不应用直接访问的情况下,目标网站服务器只会返回上图所示的无序英文,而不是我们在目标网站上看到的源代码。这时候还需要在请求头中添加元素Accept-Language如下:
此时返回的页面源代码为

Situation三、requests 库获取网页中文乱码处理

当我们请求一个网页时,得到的源代码是正常的上图所示的英文中文乱码,我们要明白目标网站返回给我们的源代码是经过加密的(不同的编码方式) ),这是我们默认的解码方法,不能再解释了。这时候,我们有两个解决方案:
1.打开target网站Developer界面,找到使用的编码方式,如下图:

编写爬虫时添加代码:
2.无论登陆页面使用哪种编码方式,都可以添加这行代码来破译:

总结
当我们发现请求页面的源代码与目标网站Developer接口不一致时,说明我们向目标网站发出的请求不完整或者返回的源代码需要进一步解释,但是不管遇到什么乱码,本文要强调的是,请求网页的源代码是从地面高层建筑爬取的第一步。我们都可以尽可能多地填写标题,避免不必要的时间和精力浪费。
网页抓取 加密html(前端必须掌握的HTML5、选择器、JavaScript、加密爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-12 07:11
一、前端必须掌握HTML基础知识
5、选择器
在 CSS 中,我们使用 CSS 选择器来定位节点。比如下图中div节点的id如果是asideProfile,可以表示为#asideProfile,其中#以selection id开头,后面跟着id的名字。
另外,如果我们要选择一个类为side-box的节点,我们可以使用.aside-box,其中点“.”开始选择班级,然后是班级名称。
6、reptile 原理
互联网是一个大网,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬到这个就相当于访问了页面,获取了它的信息。节点之间的连接可以比作网页和网页之间的链接关系。
爬虫首先要做的就是获取网页,这里是获取网页的源代码。获得网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。
提取信息后,我们可以简单地将其保存为 TXT 文本或 JSON 文本,或者将其保存到数据库,例如 MySQL 和 MongoDB,或者将其保存到远程服务器。
7、JavaScript 渲染页面
现在越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原来的 HTML 代码只是一个空壳。
网页请求这个js文件。获取文件后,它会执行其中的JavaScript代码,JavaScript会改变HTML中的节点,向其中添加内容,最终得到完整的页面。
对于,可以使用selenium或者找到Ajax请求地址来解决。
8、加密
我们在爬网站的时候,经常会遇到各种类似加密的情况,比如:字体加密,结构参数加密,要爬就一定要知道怎么找到对应的js文件,研究这些参数是怎么回事建?现在越来越多的完整信息通过App展示。有的app在内部实现的时候会增加一些对代理的检查,比如绕过系统代理直接连接或者检测到使用了代理,直接拒绝连接。这需要考虑使用 Wireshark 和 Tcpdump 在较低级别的协议上捕获数据包。
之前的文章都会被反复整理整理。 查看全部
网页抓取 加密html(前端必须掌握的HTML5、选择器、JavaScript、加密爬取)
一、前端必须掌握HTML基础知识
5、选择器
在 CSS 中,我们使用 CSS 选择器来定位节点。比如下图中div节点的id如果是asideProfile,可以表示为#asideProfile,其中#以selection id开头,后面跟着id的名字。
另外,如果我们要选择一个类为side-box的节点,我们可以使用.aside-box,其中点“.”开始选择班级,然后是班级名称。
6、reptile 原理
互联网是一个大网,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬到这个就相当于访问了页面,获取了它的信息。节点之间的连接可以比作网页和网页之间的链接关系。
爬虫首先要做的就是获取网页,这里是获取网页的源代码。获得网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。
提取信息后,我们可以简单地将其保存为 TXT 文本或 JSON 文本,或者将其保存到数据库,例如 MySQL 和 MongoDB,或者将其保存到远程服务器。
7、JavaScript 渲染页面
现在越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原来的 HTML 代码只是一个空壳。
网页请求这个js文件。获取文件后,它会执行其中的JavaScript代码,JavaScript会改变HTML中的节点,向其中添加内容,最终得到完整的页面。
对于,可以使用selenium或者找到Ajax请求地址来解决。
8、加密
我们在爬网站的时候,经常会遇到各种类似加密的情况,比如:字体加密,结构参数加密,要爬就一定要知道怎么找到对应的js文件,研究这些参数是怎么回事建?现在越来越多的完整信息通过App展示。有的app在内部实现的时候会增加一些对代理的检查,比如绕过系统代理直接连接或者检测到使用了代理,直接拒绝连接。这需要考虑使用 Wireshark 和 Tcpdump 在较低级别的协议上捕获数据包。
之前的文章都会被反复整理整理。
网页抓取 加密html(Java的骚操作:方法调用完成小记录+11)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-12 07:10
当我们在页面上看到的是数据,而在 HTML 中,我们看到它是用字符加密的。当我们抓取整个 HTML 时,我们将抓取加密的内容。
示例:
其实在前端字符串加密中,可以根据请求查看使用的加密。
其实看到这个我就知道怎么解密了。我在互联网上搜索了很多。大部分都是用Python写的,但是我用的是Java,好无奈!
在这个请求的URL中,可以看到使用的加密是base64,后面是需要的key。但是每个页面的key都会变,所以只能查每个页面有没有这个东西;
纯属巧合。哈哈哈哈。 . . .
下面我们来看看Java的骚操作:
package com.cmcc.crawler.common;
import org.apache.commons.lang3.StringUtils;
import sun.font.Font2D;
import sun.font.Font2DHandle;
import sun.font.TrueTypeFont;
import sun.font.TrueTypeGlyphMapper;
import java.awt.*;
import java.awt.font.FontRenderContext;
import java.awt.font.GlyphVector;
import java.awt.geom.AffineTransform;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.util.Base64;
/**
* @NAME: zhaoxj
* @DESC: ..
* @DATE: 2021/3/12
* @TIME: 11:01
* @YEAR: 2021
* @MONTH: 03
**/
public class Base64Util {
//安居客字符解码
public static String decodeString(String key, String encodeString) {
try {
//base64解码,初始化字体
byte[] ss = Base64.getDecoder().decode(key);
InputStream inputStream = new ByteArrayInputStream(ss);
Font dynamicFont = Font.createFont(Font.TRUETYPE_FONT, inputStream);
FontRenderContext fontRenderContext = new FontRenderContext(new AffineTransform(), false, false);
GlyphVector glyphVector = dynamicFont.createGlyphVector(fontRenderContext, "");
//获取font中字形的映射关系,字段为private,使用反射
Class clazz = Font.class;
Field[] fs = clazz.getDeclaredFields();
Font2DHandle font2DHandle = null;
for (int i = 0; i < fs.length; i++) {
fs[i].setAccessible(true);// 将目标属性设置为可以访问
if (fs[i].getName().equals("font2DHandle")) {
font2DHandle = (Font2DHandle) fs[i].get(dynamicFont);
}
}
//得到映射关系
Font2D font2D = font2DHandle.font2D;
TrueTypeFont trueTypeFont = (TrueTypeFont) font2D;
TrueTypeGlyphMapper charToGlyphMapper = (TrueTypeGlyphMapper) trueTypeFont.getMapper();
//开始解密,encodeString为加密后的字符串
StringBuffer buffer = new StringBuffer();
char[] chars = encodeString.toCharArray();
for (int i = 0; i < chars.length; i++) {
buffer.append(charToGlyphMapper.charToGlyph(chars[i]) - 1);
}
return buffer.toString();
} catch (Exception e) {
e.printStackTrace();
}
return "";
}
}
方法调用
完整的小记录+1 查看全部
网页抓取 加密html(Java的骚操作:方法调用完成小记录+11)
当我们在页面上看到的是数据,而在 HTML 中,我们看到它是用字符加密的。当我们抓取整个 HTML 时,我们将抓取加密的内容。
示例:

其实在前端字符串加密中,可以根据请求查看使用的加密。

其实看到这个我就知道怎么解密了。我在互联网上搜索了很多。大部分都是用Python写的,但是我用的是Java,好无奈!
在这个请求的URL中,可以看到使用的加密是base64,后面是需要的key。但是每个页面的key都会变,所以只能查每个页面有没有这个东西;
纯属巧合。哈哈哈哈。 . . .
下面我们来看看Java的骚操作:
package com.cmcc.crawler.common;
import org.apache.commons.lang3.StringUtils;
import sun.font.Font2D;
import sun.font.Font2DHandle;
import sun.font.TrueTypeFont;
import sun.font.TrueTypeGlyphMapper;
import java.awt.*;
import java.awt.font.FontRenderContext;
import java.awt.font.GlyphVector;
import java.awt.geom.AffineTransform;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.util.Base64;
/**
* @NAME: zhaoxj
* @DESC: ..
* @DATE: 2021/3/12
* @TIME: 11:01
* @YEAR: 2021
* @MONTH: 03
**/
public class Base64Util {
//安居客字符解码
public static String decodeString(String key, String encodeString) {
try {
//base64解码,初始化字体
byte[] ss = Base64.getDecoder().decode(key);
InputStream inputStream = new ByteArrayInputStream(ss);
Font dynamicFont = Font.createFont(Font.TRUETYPE_FONT, inputStream);
FontRenderContext fontRenderContext = new FontRenderContext(new AffineTransform(), false, false);
GlyphVector glyphVector = dynamicFont.createGlyphVector(fontRenderContext, "");
//获取font中字形的映射关系,字段为private,使用反射
Class clazz = Font.class;
Field[] fs = clazz.getDeclaredFields();
Font2DHandle font2DHandle = null;
for (int i = 0; i < fs.length; i++) {
fs[i].setAccessible(true);// 将目标属性设置为可以访问
if (fs[i].getName().equals("font2DHandle")) {
font2DHandle = (Font2DHandle) fs[i].get(dynamicFont);
}
}
//得到映射关系
Font2D font2D = font2DHandle.font2D;
TrueTypeFont trueTypeFont = (TrueTypeFont) font2D;
TrueTypeGlyphMapper charToGlyphMapper = (TrueTypeGlyphMapper) trueTypeFont.getMapper();
//开始解密,encodeString为加密后的字符串
StringBuffer buffer = new StringBuffer();
char[] chars = encodeString.toCharArray();
for (int i = 0; i < chars.length; i++) {
buffer.append(charToGlyphMapper.charToGlyph(chars[i]) - 1);
}
return buffer.toString();
} catch (Exception e) {
e.printStackTrace();
}
return "";
}
}
方法调用

完整的小记录+1
网页抓取 加密html(某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2021-10-05 15:09
有时由于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "" + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "" + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}我明白了,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
网页抓取 加密html(某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
有时由于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "" + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "" + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}我明白了,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
网页抓取 加密html(Python实现通过这位大神的解决思路写一个解密电子邮箱的函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-03 16:03
1、问题的根源
在数据采集的过程中,往往需要采集各种联系方式,包括邮箱地址。一些未加防卫的网站邮箱地址可以直接从网页源码中获取,有些网站对爬虫稍加防范,会将邮件中的@符号替换为#号:
在我最近的工作中,我遇到了一种以前从未遇到过的电子邮件加密方法。在查看元素时可以获得正确的数据:
在查看网页源代码时,还可以定位到对应的元素:
但是从上图可以发现,它对应的是显示邮件的位置,并且显示了一个“[email protected]”链接。让我们检查源代码:
这个用于显示电子邮件的字段与其他文本不同。如果是非邮件数据,则没有链接;如果是邮件数据,则通过这个链接在网页前端显示数据。
2、解决方案
经过一番搜索,在百度知道中找到了它的原理和解决方法:
加密只是简单的异或运算,解密起来并不难。
3、Python 实现
通过这位大神的解决方案,我们可以快速使用Python编写一个解密电子邮件的函数。
首先提取真实邮箱地址的加密数据:
出于隐私考虑,这里使用了百度知道上公开的邮箱地址的加密字符串
import re
from urllib.parse import unquote
email_str = '71121003141403311a140210051e5f121e1c'
然后将此加密数据成对拆分为一个列表:
email_list = re.findall(r'.{2}',email_str)
提取加密字符串的密钥,即字符串的前两个字符:
key = email_list[0]
定义一个空列表来存储十六进制 XOR 运算的结果:
ll = []
遍历剩余的加密字符串,遍历过程中与key进行异或运算,将结果加入到ll列表中:
for e in email_list[1:]:
# 对十六进制进行异或运算
r = hex(int(key,16) ^ int(e,16))
ll.append(r)
然后对列表中的结果进行字符串拼接替换:
# 拼接运算后的字符串
a = ''.join(ll)
# URL解码字符串
email = unquote(a.replace('0x','%'))
这样,email 的值就是加密字符串的真实邮箱地址:
是不是很简单?
文章第一个人微信公众号和博客:/archives/269.html 查看全部
网页抓取 加密html(Python实现通过这位大神的解决思路写一个解密电子邮箱的函数)
1、问题的根源
在数据采集的过程中,往往需要采集各种联系方式,包括邮箱地址。一些未加防卫的网站邮箱地址可以直接从网页源码中获取,有些网站对爬虫稍加防范,会将邮件中的@符号替换为#号:
在我最近的工作中,我遇到了一种以前从未遇到过的电子邮件加密方法。在查看元素时可以获得正确的数据:
在查看网页源代码时,还可以定位到对应的元素:
但是从上图可以发现,它对应的是显示邮件的位置,并且显示了一个“[email protected]”链接。让我们检查源代码:
这个用于显示电子邮件的字段与其他文本不同。如果是非邮件数据,则没有链接;如果是邮件数据,则通过这个链接在网页前端显示数据。
2、解决方案
经过一番搜索,在百度知道中找到了它的原理和解决方法:
加密只是简单的异或运算,解密起来并不难。
3、Python 实现
通过这位大神的解决方案,我们可以快速使用Python编写一个解密电子邮件的函数。
首先提取真实邮箱地址的加密数据:
出于隐私考虑,这里使用了百度知道上公开的邮箱地址的加密字符串
import re
from urllib.parse import unquote
email_str = '71121003141403311a140210051e5f121e1c'
然后将此加密数据成对拆分为一个列表:
email_list = re.findall(r'.{2}',email_str)
提取加密字符串的密钥,即字符串的前两个字符:
key = email_list[0]
定义一个空列表来存储十六进制 XOR 运算的结果:
ll = []
遍历剩余的加密字符串,遍历过程中与key进行异或运算,将结果加入到ll列表中:
for e in email_list[1:]:
# 对十六进制进行异或运算
r = hex(int(key,16) ^ int(e,16))
ll.append(r)
然后对列表中的结果进行字符串拼接替换:
# 拼接运算后的字符串
a = ''.join(ll)
# URL解码字符串
email = unquote(a.replace('0x','%'))
这样,email 的值就是加密字符串的真实邮箱地址:
是不是很简单?
文章第一个人微信公众号和博客:/archives/269.html
网页抓取 加密html(海海-.0支持加密网页内容格式:jpg)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-03 13:05
随着移动互联网的不断升温,HTML5越来越受到网站提供商和应用开发商的追捧。由于其简洁、美观、惊艳的效果,给用户带来了良好的使用体验,但HTML5页面也有一个缺点,右击源码容易暴露,调试工具可以篡改网站代码,所以你的努力很容易被别人偷走。
为解决这一问题,海海软件DRM核心技术提供商DRM-X4.0产品拥有自主知识产权,新增H5安全加固服务,对网页、图片、Javascript脚本及所有资源文件进行加固. 防止黑客获取恶意攻击源代码的保护措施。海海软件让HTML5网页内容和应用的加密和保护成为您的私人资产,不再被他人复制和攻击。用户体验与 Chrome 浏览器相同。对用户的唯一要求是安装 Xvast 浏览器。
海海软件DRM-X4.0保护网页加密,区别于传统网页加密原理。它采用私有算法高强度加密,并受许可保护。您可以设置多个权限,例如开口数量。、截止日期、动态数字水印、硬件绑定、防复制等,其安全性远高于传统加密。传统的网页加密只支持通过Javascript脚本对HTML代码进行编码和加密。此类加密网页的源代码可以查看,并且可以轻松解密和反转加密。海海软件对网页内容的高强度加密使提取、复制和解密受保护的网页内容变得更加困难。
使用DRM-X 4.0,您可以加密网页内容,包括HTML、css、Java Script和图片,您可以控制允许哪些用户查看您的网页内容,禁止复制、打印和截图。网页内容过期不允许查看。此外,用户无法在海海软件DRM-X4.0 高度加密的网页中进行调试、查看源代码、另存为等操作。
DRM-X 4.0 支持加密的网页内容格式:html、htm、bmp、gif、png、jpg、jpeg、svg、webp、js、css
网页的加密内容目前支持 Windows、MacOS 和 Android 浏览。即将支持 Android 和 Apple iOS 平台。
查看HTML页面加密保护教程: 查看全部
网页抓取 加密html(海海-.0支持加密网页内容格式:jpg)
随着移动互联网的不断升温,HTML5越来越受到网站提供商和应用开发商的追捧。由于其简洁、美观、惊艳的效果,给用户带来了良好的使用体验,但HTML5页面也有一个缺点,右击源码容易暴露,调试工具可以篡改网站代码,所以你的努力很容易被别人偷走。
为解决这一问题,海海软件DRM核心技术提供商DRM-X4.0产品拥有自主知识产权,新增H5安全加固服务,对网页、图片、Javascript脚本及所有资源文件进行加固. 防止黑客获取恶意攻击源代码的保护措施。海海软件让HTML5网页内容和应用的加密和保护成为您的私人资产,不再被他人复制和攻击。用户体验与 Chrome 浏览器相同。对用户的唯一要求是安装 Xvast 浏览器。
海海软件DRM-X4.0保护网页加密,区别于传统网页加密原理。它采用私有算法高强度加密,并受许可保护。您可以设置多个权限,例如开口数量。、截止日期、动态数字水印、硬件绑定、防复制等,其安全性远高于传统加密。传统的网页加密只支持通过Javascript脚本对HTML代码进行编码和加密。此类加密网页的源代码可以查看,并且可以轻松解密和反转加密。海海软件对网页内容的高强度加密使提取、复制和解密受保护的网页内容变得更加困难。
使用DRM-X 4.0,您可以加密网页内容,包括HTML、css、Java Script和图片,您可以控制允许哪些用户查看您的网页内容,禁止复制、打印和截图。网页内容过期不允许查看。此外,用户无法在海海软件DRM-X4.0 高度加密的网页中进行调试、查看源代码、另存为等操作。
DRM-X 4.0 支持加密的网页内容格式:html、htm、bmp、gif、png、jpg、jpeg、svg、webp、js、css
网页的加密内容目前支持 Windows、MacOS 和 Android 浏览。即将支持 Android 和 Apple iOS 平台。
查看HTML页面加密保护教程:
网页抓取 加密html(西部网盘不能解析了怎么构造这条cookie其中一种?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-03 13:04
有网友反映无法解析西部网盘。我确认网盘现在被限制爬取网页。网站 访问目前不稳定。根据情况,我们将尝试在下一个版本中修复它。
本来想用西部网盘写的,但是这个网盘打不开,先说彩虹云吧,一样的。
这个文章不是教程,所以会忽略一些内容
0、前言
无论是网盘分析还是各种网络爬虫,你都是先获取网页的源代码,然后再提取你感兴趣的内容。但这无疑损害了一些网站的利益,所以就会出现各种限制非客户端用户抓取网页的方法。本文提到的js加密cookie就是其中之一。
1、先看直接爬取的页面源码
<p>var x="hantom@@JgSe0upZ@@Path@02@GMT@f@@Sun@captcha@if@@@href@callP@@g@try@substr@DOMContentLoaded@as@@@Expires@@chars@@onreadystate
change@__jsl_clearance@new@0xFF@search@34@@window@@while@document@36@@@false@split@19@innerHTML@e@3D@8@function@location@setTimeout@attachEvent
@d@var@@0xEDB88320@length@2B@yF@addEventListener@@@charCodeAt@createElement@toLowerCase@@String@@cookie@1500@14@join@@@@__p@charAt@return@path
name@1559453654@Array@eval@@4@Jun@0@@catch@TmT2@@replace@@fromCharCode@@else@firstChild@@a@@FcG@oP@match@@WU@div@@reverse@challenge@06@toS
tring@RegExp@Oo4BUv@for@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@@https@1@2@@@@parseInt@FB@@932".replace(/@*$/,"").split("@"),
y="2b 39=26(){28('27.f=27.3e+27.1b.44(/[\\?|&]b-4l/,\\'\\')',35);1h.34='18=3f.5i|3l|'+(26(){2b e=[26(39){3d 39},26(e){3d e},
26(39){54(2b e=3l;e 查看全部
网页抓取 加密html(西部网盘不能解析了怎么构造这条cookie其中一种?)
有网友反映无法解析西部网盘。我确认网盘现在被限制爬取网页。网站 访问目前不稳定。根据情况,我们将尝试在下一个版本中修复它。
本来想用西部网盘写的,但是这个网盘打不开,先说彩虹云吧,一样的。
这个文章不是教程,所以会忽略一些内容
0、前言
无论是网盘分析还是各种网络爬虫,你都是先获取网页的源代码,然后再提取你感兴趣的内容。但这无疑损害了一些网站的利益,所以就会出现各种限制非客户端用户抓取网页的方法。本文提到的js加密cookie就是其中之一。
1、先看直接爬取的页面源码
<p>var x="hantom@@JgSe0upZ@@Path@02@GMT@f@@Sun@captcha@if@@@href@callP@@g@try@substr@DOMContentLoaded@as@@@Expires@@chars@@onreadystate
change@__jsl_clearance@new@0xFF@search@34@@window@@while@document@36@@@false@split@19@innerHTML@e@3D@8@function@location@setTimeout@attachEvent
@d@var@@0xEDB88320@length@2B@yF@addEventListener@@@charCodeAt@createElement@toLowerCase@@String@@cookie@1500@14@join@@@@__p@charAt@return@path
name@1559453654@Array@eval@@4@Jun@0@@catch@TmT2@@replace@@fromCharCode@@else@firstChild@@a@@FcG@oP@match@@WU@div@@reverse@challenge@06@toS
tring@RegExp@Oo4BUv@for@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@@@@https@1@2@@@@parseInt@FB@@932".replace(/@*$/,"").split("@"),
y="2b 39=26(){28('27.f=27.3e+27.1b.44(/[\\?|&]b-4l/,\\'\\')',35);1h.34='18=3f.5i|3l|'+(26(){2b e=[26(39){3d 39},26(e){3d e},
26(39){54(2b e=3l;e
网页抓取 加密html(网页爬虫工作时页面情况更加多样复杂(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-30 12:06
基本身份验证是一种登录身份验证方法,用于允许 Web 浏览器和其他客户端程序在请求时以用户名和密码的形式提供身份凭据。将用BASE64算法加密的“username+colon+password”字符串放入httprequest中的headerAuthorization中并发送给服务器。在发明 cookie 之前,HTTP 基本身份验证是处理 网站 登录最常用的方法。目前,一些安全性较高的网站仍在使用这种方法。
例子
1、需求说明:访问某个网站(内部涉及,不对外公布)。
2、分析过程:在浏览器中输入网址,看到如下页面。这时候就需要输入用户名和密码来获取需要的数据。否则将返回401错误码,并要求用户再次提供用户名和密码。另外,当使用fiddle抓取中间数据时,头部收录以下信息: 显然这是一个HTTP基本认证。
3、解决方案:这其实是一个post请求。与普通的post请求不同的是,每次请求数据时,都需要用BASE64对用户名和密码进行加密,并附加到请求头中。requests库提供了一个auth模块,专门用于处理HTTP认证,这样程序就不需要自己做加密处理了。具体代码如下:
知识点
http登录验证方式有很多种,其中应用最广泛的是基本验证和摘要验证。auth 模块还提供摘要验证处理方法。具体的使用方法我没有研究过。相关信息请咨询。
五、JavaScript 动态页面
前面介绍了静态页面和收录post表单网站的爬虫方法,比较简单。在实际做网络爬虫工作的时候,页面情况更加多样化和复杂。喜欢:
1、 网页收录javascript代码,需要渲染才能获取原创数据;
2、网站具有一定的反爬虫能力。有的cookies是客户端脚本执行JS后才生成的,requests模块无法执行JS代码。如果我们按照操作的第三部分发布表单,您会发现缺少一些cookie,导致请求被拒绝。在目前众所周知的网站反爬虫工作做得很好,很难找到一个简单的帖子形式。
这种网站爬虫有什么好的解决办法吗?
“Python+硒+第三方浏览器”。
例子
1、说明:登录微软官网,自动下载微软最近发布的iso文件。
2、分析过程:
(1)我们在使用python请求库获取服务端源码时,发现python获取的源码与浏览器渲染的场景不一样,Python获取了JS源码。如下图:
Python有第三方库PyV8,可以执行JS代码,但是执行效率低。此外,微软官网还涉及到JS加密的cookies。如果使用requests+Pyv8+BeautifulSoup这三个库组合,代码会显得臃肿凌乱。.
还有其他更简洁易懂的方式吗?
是的,硒。
(2)“Selenium+第三方浏览器”,允许浏览器自动加载页面,浏览器执行JS获取需要的数据,这样我们的python代码就不需要实现浏览器客户端的功能了可以说,“Selenium+第三方浏览器”构成了一个强大的网络爬虫,可以处理cookies、javascript等页面的抓取,第三方浏览器分为有界面(chrome)和无界面(PhantomJS),而界面浏览器是可以直接看到浏览器打开和跳转的过程,非界面浏览器会将网站加载到内存中执行页面上的JS,不会有图形界面。您可以根据自己的喜好或需要选择第三方浏览设备。
3、解决方法:使用“selenium + chrome”来完成需求。
(1)下载安装python的selenium库;
(2)下载chromeDriver到本地;
(3)使用webdriver api完成页面的操作。下面以完成微软官网登录为例。示例代码在初始化webdriver时设置网络代理,指定浏览器下载文件保存路径, 并让 chrome 提示下载进度等信息。
知识点
实例化webdriver时,可以通过参数设置浏览器,比如设置网络代理,保存浏览器下载文件的路径。如果不传递参数,则默认继承本地浏览器设置。如果在浏览器启动时设置了属性,则使用 ChromeOption 类。具体信息请参考chromedriver官网。
“Python+selenium+第三方浏览器”可以处理多种抓取场景,包括静态页面、帖子表单、JS。应用场景非常强大。使用selenium来操作浏览器模拟点击,可以省去我们很多的后顾之忧。无需担心“隐藏字段”、cookie 跟踪等问题,但这种方法对于收录验证码的网页的操作来说并不好处理。主要难点在于图像识别。
六、总结
本文主要根据每个网站的特点提供了不同的爬取方式,可以应对大量场景下的数据爬取。在实际工作中,最常用的是“静态页面”和“javascript动态页面”。当然,如果页面收录验证码,则需要借助图像识别工具进行处理。这种情况比较难处理,图像识别的准确率受图像内容的影响。
以下是一些个人总结。不知道大家有没有其他更好的方法?
如果你还有其他好的爬虫案例,欢迎在评论区留言,一起学习交流! 查看全部
网页抓取 加密html(网页爬虫工作时页面情况更加多样复杂(一)(组图))
基本身份验证是一种登录身份验证方法,用于允许 Web 浏览器和其他客户端程序在请求时以用户名和密码的形式提供身份凭据。将用BASE64算法加密的“username+colon+password”字符串放入httprequest中的headerAuthorization中并发送给服务器。在发明 cookie 之前,HTTP 基本身份验证是处理 网站 登录最常用的方法。目前,一些安全性较高的网站仍在使用这种方法。
例子
1、需求说明:访问某个网站(内部涉及,不对外公布)。
2、分析过程:在浏览器中输入网址,看到如下页面。这时候就需要输入用户名和密码来获取需要的数据。否则将返回401错误码,并要求用户再次提供用户名和密码。另外,当使用fiddle抓取中间数据时,头部收录以下信息: 显然这是一个HTTP基本认证。
3、解决方案:这其实是一个post请求。与普通的post请求不同的是,每次请求数据时,都需要用BASE64对用户名和密码进行加密,并附加到请求头中。requests库提供了一个auth模块,专门用于处理HTTP认证,这样程序就不需要自己做加密处理了。具体代码如下:
知识点
http登录验证方式有很多种,其中应用最广泛的是基本验证和摘要验证。auth 模块还提供摘要验证处理方法。具体的使用方法我没有研究过。相关信息请咨询。
五、JavaScript 动态页面
前面介绍了静态页面和收录post表单网站的爬虫方法,比较简单。在实际做网络爬虫工作的时候,页面情况更加多样化和复杂。喜欢:
1、 网页收录javascript代码,需要渲染才能获取原创数据;
2、网站具有一定的反爬虫能力。有的cookies是客户端脚本执行JS后才生成的,requests模块无法执行JS代码。如果我们按照操作的第三部分发布表单,您会发现缺少一些cookie,导致请求被拒绝。在目前众所周知的网站反爬虫工作做得很好,很难找到一个简单的帖子形式。
这种网站爬虫有什么好的解决办法吗?
“Python+硒+第三方浏览器”。
例子
1、说明:登录微软官网,自动下载微软最近发布的iso文件。
2、分析过程:
(1)我们在使用python请求库获取服务端源码时,发现python获取的源码与浏览器渲染的场景不一样,Python获取了JS源码。如下图:
Python有第三方库PyV8,可以执行JS代码,但是执行效率低。此外,微软官网还涉及到JS加密的cookies。如果使用requests+Pyv8+BeautifulSoup这三个库组合,代码会显得臃肿凌乱。.
还有其他更简洁易懂的方式吗?
是的,硒。
(2)“Selenium+第三方浏览器”,允许浏览器自动加载页面,浏览器执行JS获取需要的数据,这样我们的python代码就不需要实现浏览器客户端的功能了可以说,“Selenium+第三方浏览器”构成了一个强大的网络爬虫,可以处理cookies、javascript等页面的抓取,第三方浏览器分为有界面(chrome)和无界面(PhantomJS),而界面浏览器是可以直接看到浏览器打开和跳转的过程,非界面浏览器会将网站加载到内存中执行页面上的JS,不会有图形界面。您可以根据自己的喜好或需要选择第三方浏览设备。
3、解决方法:使用“selenium + chrome”来完成需求。
(1)下载安装python的selenium库;
(2)下载chromeDriver到本地;
(3)使用webdriver api完成页面的操作。下面以完成微软官网登录为例。示例代码在初始化webdriver时设置网络代理,指定浏览器下载文件保存路径, 并让 chrome 提示下载进度等信息。
知识点
实例化webdriver时,可以通过参数设置浏览器,比如设置网络代理,保存浏览器下载文件的路径。如果不传递参数,则默认继承本地浏览器设置。如果在浏览器启动时设置了属性,则使用 ChromeOption 类。具体信息请参考chromedriver官网。
“Python+selenium+第三方浏览器”可以处理多种抓取场景,包括静态页面、帖子表单、JS。应用场景非常强大。使用selenium来操作浏览器模拟点击,可以省去我们很多的后顾之忧。无需担心“隐藏字段”、cookie 跟踪等问题,但这种方法对于收录验证码的网页的操作来说并不好处理。主要难点在于图像识别。
六、总结
本文主要根据每个网站的特点提供了不同的爬取方式,可以应对大量场景下的数据爬取。在实际工作中,最常用的是“静态页面”和“javascript动态页面”。当然,如果页面收录验证码,则需要借助图像识别工具进行处理。这种情况比较难处理,图像识别的准确率受图像内容的影响。
以下是一些个人总结。不知道大家有没有其他更好的方法?
如果你还有其他好的爬虫案例,欢迎在评论区留言,一起学习交流!
网页抓取 加密html(西部网盘不能限制抓取网页源码的原因!上图框出的代码即为 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-26 23:14
)
有网友反映无法解析西部网盘。我确认网盘现在被限制爬取网页。网站 访问目前不稳定。根据情况,我们将尝试在下一个版本中修复它。
本来想用西部网盘写的,但是这个网盘打不开,先说彩虹云吧,一样的。
这个文章不是教程,所以会忽略一些内容
0、前言
无论是网盘分析还是各种网络爬虫,你都是先获取网页的源代码,然后再提取你感兴趣的内容。但这无疑损害了一些网站的利益,所以就会出现各种限制非客户端用户抓取网页的方法。本文提到的js加密cookie就是其中之一。
1、先看直接爬取的页面源码
就是上面的代码,它的作用是什么,你不能直接看到,因为它是加密的。
要执行上面的代码,eval函数是必不可少的。这是一个技巧。可以用return或者console.log等函数代替上面的eval打印出相关内容,可以看到上面代码的具体功能。
2、 懒得改了,直接说结果:上面的代码就是在浏览器中生成一个cookie。当访问网页时,它会首先检查cookie是否存在。如果它不存在,则表示您没有通过浏览器打开它。网页,会继续得到上面的代码,如果存在则正常返回结果。这就是为什么直接通过浏览器打开网页可以正常访问网页,却无法获取网页源代码的原因!
上图中框起来的代码是js动态生成的,这个cookie的__jsl_clearance可以在上面的js代码中找到!
3、这种情况怎么解决?
现在您了解了发生了什么,问题就很容易解决了。
思路:既然获取网页源码需要这个cookie,那我们就自己构造这个cookie,然后拿cookie来获取源码。
4、 问题的关键是如何构造这个cookie?
解决此类问题的一般方法是:
(1) 修改抓到的js代码(主要是用return代替eval函数,这里不再详细描述),使这段代码不执行eval,而是在后台执行,并返回解密后的代码片段
(2)解密后的js代码在后台再次执行获取cookie
(3) 携带这个cookie即可获取网页源码
彩虹云网盘经常更改cookie加密方式,导致早期版本的“网赚网盘下载助手工具”经常解析失败。现在看来西部网盘也会自带这套,不过问题不大!
查看全部
网页抓取 加密html(西部网盘不能限制抓取网页源码的原因!上图框出的代码即为
)
有网友反映无法解析西部网盘。我确认网盘现在被限制爬取网页。网站 访问目前不稳定。根据情况,我们将尝试在下一个版本中修复它。
本来想用西部网盘写的,但是这个网盘打不开,先说彩虹云吧,一样的。
这个文章不是教程,所以会忽略一些内容
0、前言
无论是网盘分析还是各种网络爬虫,你都是先获取网页的源代码,然后再提取你感兴趣的内容。但这无疑损害了一些网站的利益,所以就会出现各种限制非客户端用户抓取网页的方法。本文提到的js加密cookie就是其中之一。
1、先看直接爬取的页面源码
就是上面的代码,它的作用是什么,你不能直接看到,因为它是加密的。
要执行上面的代码,eval函数是必不可少的。这是一个技巧。可以用return或者console.log等函数代替上面的eval打印出相关内容,可以看到上面代码的具体功能。
2、 懒得改了,直接说结果:上面的代码就是在浏览器中生成一个cookie。当访问网页时,它会首先检查cookie是否存在。如果它不存在,则表示您没有通过浏览器打开它。网页,会继续得到上面的代码,如果存在则正常返回结果。这就是为什么直接通过浏览器打开网页可以正常访问网页,却无法获取网页源代码的原因!
上图中框起来的代码是js动态生成的,这个cookie的__jsl_clearance可以在上面的js代码中找到!
3、这种情况怎么解决?
现在您了解了发生了什么,问题就很容易解决了。
思路:既然获取网页源码需要这个cookie,那我们就自己构造这个cookie,然后拿cookie来获取源码。
4、 问题的关键是如何构造这个cookie?
解决此类问题的一般方法是:
(1) 修改抓到的js代码(主要是用return代替eval函数,这里不再详细描述),使这段代码不执行eval,而是在后台执行,并返回解密后的代码片段
(2)解密后的js代码在后台再次执行获取cookie
(3) 携带这个cookie即可获取网页源码
彩虹云网盘经常更改cookie加密方式,导致早期版本的“网赚网盘下载助手工具”经常解析失败。现在看来西部网盘也会自带这套,不过问题不大!
网页抓取 加密html(先理下需求,加密的目的是什么?加密到什么级别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-26 23:12
有些人一直在问如何做 HTML 加密混淆。其实,这是业内很多人都在研究的话题。
最近闲暇之余整理了一篇文章的文章,分享给大家。
我们先处理需求,加密的目的是什么?什么是加密级别?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全。加密将被破解,混淆将被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越多,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序的执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的有必要做这种源代码保护,我们还是要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
不要涉及到前端泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,很多代码不需要牺牲用户体验来保护。
但是一些前端代码涉及到终端用户的数据安全,这个时候我们还是要努力保护数据。
接下来,我们将详细分析几种方法。
不要把敏感数据放在前端
这听起来很废话,但它真的很重要。
一些开发者将用户的密码以明文形式存储在手机上,非常危险。
即使是原生开发,一旦手机root,也会造成数据泄露。更不用说HTML5开发了。
更好的做法是在手机上存储令牌而不是密码。这里有一篇文章文章专门介绍了这一点。建议参与登录的开发者仔细研究如何设计基于HTML5的APP登录功能和安全调用接口。(原则)
js、css压缩
压缩不是加密或混淆。但是,压缩后的js文件往往功能混乱。
js、css压缩是一个很常见的技术,我们经常看到各种框架的文件名都是xxx.min.js、xxx.min.css。
使用合适的 js 和 css 压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。完全没有害处。
最常用的混淆 js 的工具是 yahoo 的 YUI 混淆。单击 HBuilder 中的菜单工具-插件安装。里面有YUI compress,可以压缩js和css。
如果js和css比较大,建议发布前压缩一下。
HTML、js、css混淆
虽然压缩也会让人迷惑,但并不是为了让别人看不懂。混淆其实是为了让别人无法理解。
但是这样的混淆并不像压缩那样有利可图,而且会降低程序执行性能。
有的开发者不想在发布包解压后直接看到源码,所以这个时候可以使用混淆方案。
在网上搜索HTML很混乱,资料和工具很多。
原理类似,js代码变成乱串,然后用eval执行,HTML代码变成乱串,用document.write或者innerHTML执行,css也可以动态写在document.write中。
这些工具是免费的和商业的。一般来说,越商业化,去混淆就越难。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具,
其实你也可以根据原理自己写混淆算法。
混淆也是一项历史悠久的成熟技术。比如谷歌在保护gmail的前端代码的时候,也是通过混淆来保护的。
无论是压缩还是混淆,都是使用 grunt 进行发布的好方法。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上版本和iOS 支持webkit 远程调试。在HBuilder的教程中,也有关于如何使用chrome调试Android应用和使用safari调试iOS应用的教程。
在HBuilder开发的App中,manifest.json中plus-distribute下有一个debug标签,标记为false并打包。当这样的包在手机上运行时,webview 会阻塞浏览器的远程调试请求。
如果要调试,那就在打包前把debug改成true。
当然,有些Android rom 不是很规范,无法阻止调试。这是一个ROM错误。
专业的加密加固服务
由于Android的特殊性,出现了对apk的加固和脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有专业的公司如:爱加密,有免费的基础安全服务,也有收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。 查看全部
网页抓取 加密html(先理下需求,加密的目的是什么?加密到什么级别?)
有些人一直在问如何做 HTML 加密混淆。其实,这是业内很多人都在研究的话题。
最近闲暇之余整理了一篇文章的文章,分享给大家。
我们先处理需求,加密的目的是什么?什么是加密级别?我们可以为此牺牲什么?
我们知道,这个世界上没有绝对的安全。加密将被破解,混淆将被反混淆。
技术新手、开发者、黑客是完全不同的层次,不同层次的人防范的策略也不同。
预防越多,投资成本就越大,比如聘请专业的保安公司。
除了投资,我们还需要考虑程序的执行性能和用户体验。
加密的代码必须在运行时解密。混淆后,尤其是HTML混淆后,程序的执行性能会下降。
是否真的有必要做这种源代码保护,我们还是要慎重选择。
一般来说,前端代码负责用户体验,后端代码负责更安全的数据处理。
不要涉及到前端泄露太多机密信息,所以加密的意义不是特别大。
我很少在前端代码中看到值得保护的内容,比如高级算法,很多代码不需要牺牲用户体验来保护。
但是一些前端代码涉及到终端用户的数据安全,这个时候我们还是要努力保护数据。
接下来,我们将详细分析几种方法。
不要把敏感数据放在前端
这听起来很废话,但它真的很重要。
一些开发者将用户的密码以明文形式存储在手机上,非常危险。
即使是原生开发,一旦手机root,也会造成数据泄露。更不用说HTML5开发了。
更好的做法是在手机上存储令牌而不是密码。这里有一篇文章文章专门介绍了这一点。建议参与登录的开发者仔细研究如何设计基于HTML5的APP登录功能和安全调用接口。(原则)
js、css压缩
压缩不是加密或混淆。但是,压缩后的js文件往往功能混乱。
js、css压缩是一个很常见的技术,我们经常看到各种框架的文件名都是xxx.min.js、xxx.min.css。
使用合适的 js 和 css 压缩方案可以减小文件大小,提高加载速度,最重要的是还可以加快程序的执行性能。完全没有害处。
最常用的混淆 js 的工具是 yahoo 的 YUI 混淆。单击 HBuilder 中的菜单工具-插件安装。里面有YUI compress,可以压缩js和css。
如果js和css比较大,建议发布前压缩一下。
HTML、js、css混淆
虽然压缩也会让人迷惑,但并不是为了让别人看不懂。混淆其实是为了让别人无法理解。
但是这样的混淆并不像压缩那样有利可图,而且会降低程序执行性能。
有的开发者不想在发布包解压后直接看到源码,所以这个时候可以使用混淆方案。
在网上搜索HTML很混乱,资料和工具很多。
原理类似,js代码变成乱串,然后用eval执行,HTML代码变成乱串,用document.write或者innerHTML执行,css也可以动态写在document.write中。
这些工具是免费的和商业的。一般来说,越商业化,去混淆就越难。
这是一个免费的在线混淆工具
这是一个比较知名的商业工具,
其实你也可以根据原理自己写混淆算法。
混淆也是一项历史悠久的成熟技术。比如谷歌在保护gmail的前端代码的时候,也是通过混淆来保护的。
无论是压缩还是混淆,都是使用 grunt 进行发布的好方法。开发后一键调用grunt非常方便。
防止webkit远程调试,即防止浏览器控制台调试
Android4.4 及以上版本和iOS 支持webkit 远程调试。在HBuilder的教程中,也有关于如何使用chrome调试Android应用和使用safari调试iOS应用的教程。
在HBuilder开发的App中,manifest.json中plus-distribute下有一个debug标签,标记为false并打包。当这样的包在手机上运行时,webview 会阻塞浏览器的远程调试请求。
如果要调试,那就在打包前把debug改成true。
当然,有些Android rom 不是很规范,无法阻止调试。这是一个ROM错误。
专业的加密加固服务
由于Android的特殊性,出现了对apk的加固和脱壳行业,这也是业内常见的apk保护方案。
很多应用市场都提供加固服务,比如360手机助手的加固,
还有专业的公司如:爱加密,有免费的基础安全服务,也有收费的高级安全服务。
后记,一些非专业安全公司提供的所谓源代码加密服务,其实漏洞百出。
安全无小事,使用专业的安全服务产品更可靠。
网页抓取 加密html(官方文档多种加密方法汇总-百度文库的话,secrettable买)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-26 22:10
网页抓取加密html分析代码这个可以了解一下网络爬虫软件也是可以的,带正则、xpath等等吧。百度文库里面如果包含代码的话有很多渠道可以下载到,有免费的有付费的,
安装xpathregexp
python文档里可以搜搜
教你一招,在百度搜索里面,文章下面有"分享至朋友圈",点击"分享",在分享之前会弹出验证界面,验证后,
在想加密的网页下面比如
官方文档
多种加密方法加密方法汇总-百度文库
爬虫在百度的接口分为各种类型,比如:txt,html等等很多,想要加密的话主要是通过分析原文和接口返回的数据得出内容,再将其中的内容提取出来进行加密。
,
appstore搜索一下哈登文库,
有个叫kobo的写的一个python脚本能做到
网页可以抓取,至于原始数据什么的可以不用泄露,正常公司有保密方案。
百度文库的话,
secrettable
买本斯坦福大学《数据库原理》的解密版看看就懂了,百度文库也是这么干的,
可以试试公司推荐下国内哪家知名公司的对应接口,比如cmd下载上边这篇回答,资料够你下半年的了。至于这些数据怎么过滤,这就是工具的问题了,就像作业帮文章评论区那么多广告,如果那是seo发家的公司, 查看全部
网页抓取 加密html(官方文档多种加密方法汇总-百度文库的话,secrettable买)
网页抓取加密html分析代码这个可以了解一下网络爬虫软件也是可以的,带正则、xpath等等吧。百度文库里面如果包含代码的话有很多渠道可以下载到,有免费的有付费的,
安装xpathregexp
python文档里可以搜搜
教你一招,在百度搜索里面,文章下面有"分享至朋友圈",点击"分享",在分享之前会弹出验证界面,验证后,
在想加密的网页下面比如
官方文档
多种加密方法加密方法汇总-百度文库
爬虫在百度的接口分为各种类型,比如:txt,html等等很多,想要加密的话主要是通过分析原文和接口返回的数据得出内容,再将其中的内容提取出来进行加密。
,
appstore搜索一下哈登文库,
有个叫kobo的写的一个python脚本能做到
网页可以抓取,至于原始数据什么的可以不用泄露,正常公司有保密方案。
百度文库的话,
secrettable
买本斯坦福大学《数据库原理》的解密版看看就懂了,百度文库也是这么干的,
可以试试公司推荐下国内哪家知名公司的对应接口,比如cmd下载上边这篇回答,资料够你下半年的了。至于这些数据怎么过滤,这就是工具的问题了,就像作业帮文章评论区那么多广告,如果那是seo发家的公司,
网页抓取 加密html(基于http代理的抓包工具,直接抓html源码效果一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2021-09-23 17:08
网页抓取加密html代码本文中指出,采用了自动化抓取项目,开源的进程基于flask框架,结合正则表达式和正则表达式组合技巧就能轻松读取页面上的html代码,再在flask的session中完成对整个页面html的编译,最终解码成json代码。
看看flasksqlalchemyflask模板flask轮子,中间的连接服务器,根据数据源传回的数据返回抓取的数据,然后通过三种形式:htmlfiles/contents(html)nodejsvirtual_dom(nodejs的flask的wsgi服务端)至于数据加密那是基本上都要解密,但主要通过正则匹配和代理机制,所以还是比较简单的。
不过这一切的前提都是需要程序员熟悉几个比较有名的加密算法:dynamicencryptionaddressprotocolp2poriginmergerdereverythingbygod。
mongodb.
google搜一下airdrop这个关键词,
作为一个无组织无预算,最好又容易实现的项目,就是熟悉http请求本身加密的算法,
这个也不算项目。小型项目的话,可以自己编写shell脚本抓html代码,然后解析。
进行aes加密
看下这个,
自己写吧
看了看比较专业的博客,没太大帮助,其实没啥好的可用的抓html的方法,但是比较笨。如果是学生组织或者免费者,不妨试试:python抓包工具itchat:其实我也曾经准备找个爬虫的框架,我写过一个http代理抓包工具,分析我们需要抓取的html源码,然后编程显示出来.这个我知道基于http代理的抓包工具,有个sogou,安装chrome,打开f12调试工具,直接抓html源码.和抓网页源码效果一样,但代码量稍微多点.如果你是要爬免费的html可能网络服务器可以帮你把html转换成json,base64的方式返回.其实我知道的,想简单点的可以玩玩python写个爬虫抓个图片.。 查看全部
网页抓取 加密html(基于http代理的抓包工具,直接抓html源码效果一样)
网页抓取加密html代码本文中指出,采用了自动化抓取项目,开源的进程基于flask框架,结合正则表达式和正则表达式组合技巧就能轻松读取页面上的html代码,再在flask的session中完成对整个页面html的编译,最终解码成json代码。
看看flasksqlalchemyflask模板flask轮子,中间的连接服务器,根据数据源传回的数据返回抓取的数据,然后通过三种形式:htmlfiles/contents(html)nodejsvirtual_dom(nodejs的flask的wsgi服务端)至于数据加密那是基本上都要解密,但主要通过正则匹配和代理机制,所以还是比较简单的。
不过这一切的前提都是需要程序员熟悉几个比较有名的加密算法:dynamicencryptionaddressprotocolp2poriginmergerdereverythingbygod。
mongodb.
google搜一下airdrop这个关键词,
作为一个无组织无预算,最好又容易实现的项目,就是熟悉http请求本身加密的算法,
这个也不算项目。小型项目的话,可以自己编写shell脚本抓html代码,然后解析。
进行aes加密
看下这个,
自己写吧
看了看比较专业的博客,没太大帮助,其实没啥好的可用的抓html的方法,但是比较笨。如果是学生组织或者免费者,不妨试试:python抓包工具itchat:其实我也曾经准备找个爬虫的框架,我写过一个http代理抓包工具,分析我们需要抓取的html源码,然后编程显示出来.这个我知道基于http代理的抓包工具,有个sogou,安装chrome,打开f12调试工具,直接抓html源码.和抓网页源码效果一样,但代码量稍微多点.如果你是要爬免费的html可能网络服务器可以帮你把html转换成json,base64的方式返回.其实我知道的,想简单点的可以玩玩python写个爬虫抓个图片.。
网页抓取 加密html( 新的正确的识别Baiduspider移动ua的方法!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-22 08:07
新的正确的识别Baiduspider移动ua的方法!(一))
建立一个符合搜索引擎优化特征的网站友好抓取
爬行和收录是网站操作和优化的第一步。符合SEO特征的站点应该具有友好爬行的特征。以下是构建符合SEO特征的网站友好爬网的具体内容
请注意由“+”标识的网站!您需要修改标识方法。识别百度pider移动UA的新正确方法如下:
1.通过关键词“Android”或“mobile”进行识别,并将其判断为移动访问或捕获
2.via关键词“Baiduspider”/2.0,判定为百度爬虫
此外,需要强调的是,对于机器人,如果禁用的代理是Baiduspider,它将同时在PC和移动设备上生效。也就是说,无论是PC还是移动百度pider都不会抓取被阻止的对象。强调这一点的原因是,一些代码适应网站(相同的URL,当PC UA打开时,它是PC页面,当移动UA打开时,它是移动页面)希望通过设置机器人的代理阻止来实现仅允许移动Baiduspider抓取的目的。然而,这种方法是非常不可取的,因为PC和移动Baiduspider代理都是Baiduspider,这也是SEO优化需要考虑的
如何识别百度蜘蛛
百度蜘蛛是站长的主宾,但我们曾经遇到过站长的问题:我们如何判断疯狂抓取我们网站内容的蜘蛛是否是百度?事实上,站长可以通过DNS反检查IP来判断蜘蛛是否来自百度搜索引擎。不同平台的验证方法不同。例如,linux/Windows/OS下的验证方法如下:
1、在Linux平台上,您可以使用host IP命令反转IP,以确定抓取是否来自百度pider。百度风笛的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,它是冒充的
2、在windows平台或IBM OS/2平台上,可以使用NSLOOKUP IP命令反转IP,以确定抓取是否来自Baiduspider。打开命令处理器,输入NSLOOKUP xxx.xxx.xxx.xxx(IP地址)解析IP以确定爬网是否来自百度pider。百度pider的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,这是一种模仿
@在Mac OS平台上,您可以使用dig命令反转IP地址,以确定爬网是否来自百度pider。打开命令处理器,输入dig xxx.xxx.xxx.xxx(IP地址)解析IP以确定是否从百度pider获取。百度pider的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,这是一种模仿
什么是百度pider IP
即使很多站长知道如何判断百度蜘蛛,他们也会继续问“百度蜘蛛的IP是多少”。我们理解站长的意思。我们想把百度蜘蛛的IP加入白名单。我们只允许白名单下的IP捕获网站以避免被采集和其他行为
但我们不建议站长这样做。虽然百度蜘蛛确实有一个IP池,其中真正的IP是交换的,但我们不能保证IP池不会作为一个整体改变。因此,我们建议站长经常阅读日志,发现恶意蜘蛛后将其列入黑名单,以确保百度的正常捕获
同时,我们再次强调,通过IP区分百度蜘蛛的属性是非常荒谬的。所谓的“沙盒蜘蛛”、“降能蜘蛛”等根本不存在。SEO从业者需要记住
机器人书写法
机器人是网站与蜘蛛交流的重要渠道。该站点通过robots文件声明搜索引擎不希望成为收录的网站部分,或者指定搜索引擎只有收录特定部分。请注意,如果您的网站收录您不想被收录搜索的内容,您只需要使用robots.txt文件。如果您想要搜索引擎收录网站上的所有内容,请不要创建robots.txt文件,这是搜索引擎优化需要掌握的基本技能
Robots文件通常放在根目录中,并收录一个或多个记录。这些记录以空行分隔(Cr、Cr/NL或NL作为终止符)。每条记录的格式如下:
“:”
在此文件中,可以使用#进行注释。具体方法与UNIX中的约定相同。此文件中的记录通常以一行或多行user agent开始,然后是几行disallow和allow。详情如下:
用户代理:此项的值用于描述搜索引擎机器人的名称。在“robots.TXT”文件中,如果存在多个用户代理记录,则表示多个机器人将受到“robots.TXT”的限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.TXT”文件中,只能有一条记录,如“user agent:*”。如果在“robots.TXT”文件中添加了“user agent:somebot”和几个不允许和允许行,“somebot”名称仅受“user agent:somebot”后面的不允许和允许行的限制
不允许:此项的值用于描述不希望访问的一组URL。此值可以是完整路径或路径的非空前缀。机器人将不会访问以disallow item值开头的URL。例如,“disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“disallow:/help/”允许机器人访问/help.html、/helpabc.html和/help/index.html。“Disallow:”表示允许机器人访问此站点的所有URL网站. “/robots.TXT”文件中必须至少有一条不允许的记录。如果“/robots.TXT”不存在或是空文件,网站对所有搜索引擎robots打开
允许:此项的值用于描述要访问的一组URL。与“不允许”类似,此值可以是完整路径或路径的前缀。以值allow开头的URL允许机器人访问。例如,“允许:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。默认情况下,网站的所有URL都是允许的,因此allow通常与disallow一起使用,以允许访问某些网页并禁止访问所有其他URL
使用“*”和“$”:Baiduspider支持使用通配符“*”和“$”来模糊匹配URL
“*”匹配0个或多个任意字符
“$”与行终止符匹配
最后,需要注意的是,百度将严格遵守机器人的相关协议。请注意区分您不希望被捕获的目录或收录. 百度将准确地将用robots编写的文件与您不希望被捕获的目录进行匹配,收录或robots协议将不生效
robots需求使用表中robots.txt的写入方法是什么
robots.txt的编写方法是什么
上面提到了这么多理论,有没有一个简单的比较表来告诉我如何在什么需求场景下编写robots文件?是的:
禁止百度收录的其他方法,机器人除外
Meta robots标记是页面头部的标记之一,也是禁止搜索引擎索引页面内容的指令。目前,百度只支持nofollow和noarchive
禁止搜索引擎跟踪此页面上的链接
如果您不希望搜索引擎跟踪此页面上的链接,也不希望传递链接的权重,请将此元标记放在页面的以下部分:
如果你不想让百度跟踪某个特定的链接,并且百度也支持更精确的控制,请直接在链接上写上这个标记:sign
若要允许其他搜索引擎跟踪,但仅阻止百度跟踪您网页的链接,请将此元标记放在网页部分:
Noarchive:防止搜索引擎在搜索结果中显示网页快照
要防止所有搜索引擎显示您的网站快照,请将此元标记放置在页面的部分:
要允许其他搜索引擎显示快照,但仅阻止百度显示快照,请使用以下标签:
注意:此标志仅禁止百度显示页面快照。百度将继续为页面建立索引,并在搜索结果中显示页面摘要
使用机器人巧妙地避开蜘蛛黑洞
对于百度搜索引擎来说,蜘蛛黑洞是指网站以极低的成本创建大量参数过多、内容相似但URL不同的动态URL,就像一个无限圆形“黑洞”,诱捕蜘蛛。蜘蛛会浪费大量资源并抓取无效网页
例如,很多网站都有过滤功能,通过过滤功能生成的网页经常被搜索引擎抓取,其中很大一部分是检索价值和质量较低的网页。例如,“以500-1000之间的价格租房”,首先网站(包括实际情况)基本上没有相关资源。其次,站内用户和搜索引擎用户没有这种检索习惯。这类网页被搜索引擎抓取,搜索引擎只能占据网站有价值的抓取配额。如何避免这种情况
让我们以北京美团网为例,看看美团网是如何使用机器人巧妙地避开这个蜘蛛黑洞的:
对于普通的过滤结果 查看全部
网页抓取 加密html(
新的正确的识别Baiduspider移动ua的方法!(一))
建立一个符合搜索引擎优化特征的网站友好抓取
爬行和收录是网站操作和优化的第一步。符合SEO特征的站点应该具有友好爬行的特征。以下是构建符合SEO特征的网站友好爬网的具体内容
请注意由“+”标识的网站!您需要修改标识方法。识别百度pider移动UA的新正确方法如下:
1.通过关键词“Android”或“mobile”进行识别,并将其判断为移动访问或捕获
2.via关键词“Baiduspider”/2.0,判定为百度爬虫
此外,需要强调的是,对于机器人,如果禁用的代理是Baiduspider,它将同时在PC和移动设备上生效。也就是说,无论是PC还是移动百度pider都不会抓取被阻止的对象。强调这一点的原因是,一些代码适应网站(相同的URL,当PC UA打开时,它是PC页面,当移动UA打开时,它是移动页面)希望通过设置机器人的代理阻止来实现仅允许移动Baiduspider抓取的目的。然而,这种方法是非常不可取的,因为PC和移动Baiduspider代理都是Baiduspider,这也是SEO优化需要考虑的
如何识别百度蜘蛛
百度蜘蛛是站长的主宾,但我们曾经遇到过站长的问题:我们如何判断疯狂抓取我们网站内容的蜘蛛是否是百度?事实上,站长可以通过DNS反检查IP来判断蜘蛛是否来自百度搜索引擎。不同平台的验证方法不同。例如,linux/Windows/OS下的验证方法如下:
1、在Linux平台上,您可以使用host IP命令反转IP,以确定抓取是否来自百度pider。百度风笛的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,它是冒充的
2、在windows平台或IBM OS/2平台上,可以使用NSLOOKUP IP命令反转IP,以确定抓取是否来自Baiduspider。打开命令处理器,输入NSLOOKUP xxx.xxx.xxx.xxx(IP地址)解析IP以确定爬网是否来自百度pider。百度pider的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,这是一种模仿
@在Mac OS平台上,您可以使用dig命令反转IP地址,以确定爬网是否来自百度pider。打开命令处理器,输入dig xxx.xxx.xxx.xxx(IP地址)解析IP以确定是否从百度pider获取。百度pider的主机名以*格式命名。或*。百度.jp。如果不是*。或*。Baidu.jp,这是一种模仿
什么是百度pider IP
即使很多站长知道如何判断百度蜘蛛,他们也会继续问“百度蜘蛛的IP是多少”。我们理解站长的意思。我们想把百度蜘蛛的IP加入白名单。我们只允许白名单下的IP捕获网站以避免被采集和其他行为
但我们不建议站长这样做。虽然百度蜘蛛确实有一个IP池,其中真正的IP是交换的,但我们不能保证IP池不会作为一个整体改变。因此,我们建议站长经常阅读日志,发现恶意蜘蛛后将其列入黑名单,以确保百度的正常捕获
同时,我们再次强调,通过IP区分百度蜘蛛的属性是非常荒谬的。所谓的“沙盒蜘蛛”、“降能蜘蛛”等根本不存在。SEO从业者需要记住
机器人书写法
机器人是网站与蜘蛛交流的重要渠道。该站点通过robots文件声明搜索引擎不希望成为收录的网站部分,或者指定搜索引擎只有收录特定部分。请注意,如果您的网站收录您不想被收录搜索的内容,您只需要使用robots.txt文件。如果您想要搜索引擎收录网站上的所有内容,请不要创建robots.txt文件,这是搜索引擎优化需要掌握的基本技能
Robots文件通常放在根目录中,并收录一个或多个记录。这些记录以空行分隔(Cr、Cr/NL或NL作为终止符)。每条记录的格式如下:
“:”
在此文件中,可以使用#进行注释。具体方法与UNIX中的约定相同。此文件中的记录通常以一行或多行user agent开始,然后是几行disallow和allow。详情如下:
用户代理:此项的值用于描述搜索引擎机器人的名称。在“robots.TXT”文件中,如果存在多个用户代理记录,则表示多个机器人将受到“robots.TXT”的限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.TXT”文件中,只能有一条记录,如“user agent:*”。如果在“robots.TXT”文件中添加了“user agent:somebot”和几个不允许和允许行,“somebot”名称仅受“user agent:somebot”后面的不允许和允许行的限制
不允许:此项的值用于描述不希望访问的一组URL。此值可以是完整路径或路径的非空前缀。机器人将不会访问以disallow item值开头的URL。例如,“disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“disallow:/help/”允许机器人访问/help.html、/helpabc.html和/help/index.html。“Disallow:”表示允许机器人访问此站点的所有URL网站. “/robots.TXT”文件中必须至少有一条不允许的记录。如果“/robots.TXT”不存在或是空文件,网站对所有搜索引擎robots打开
允许:此项的值用于描述要访问的一组URL。与“不允许”类似,此值可以是完整路径或路径的前缀。以值allow开头的URL允许机器人访问。例如,“允许:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。默认情况下,网站的所有URL都是允许的,因此allow通常与disallow一起使用,以允许访问某些网页并禁止访问所有其他URL
使用“*”和“$”:Baiduspider支持使用通配符“*”和“$”来模糊匹配URL
“*”匹配0个或多个任意字符
“$”与行终止符匹配
最后,需要注意的是,百度将严格遵守机器人的相关协议。请注意区分您不希望被捕获的目录或收录. 百度将准确地将用robots编写的文件与您不希望被捕获的目录进行匹配,收录或robots协议将不生效
robots需求使用表中robots.txt的写入方法是什么
robots.txt的编写方法是什么
上面提到了这么多理论,有没有一个简单的比较表来告诉我如何在什么需求场景下编写robots文件?是的:
禁止百度收录的其他方法,机器人除外
Meta robots标记是页面头部的标记之一,也是禁止搜索引擎索引页面内容的指令。目前,百度只支持nofollow和noarchive
禁止搜索引擎跟踪此页面上的链接
如果您不希望搜索引擎跟踪此页面上的链接,也不希望传递链接的权重,请将此元标记放在页面的以下部分:
如果你不想让百度跟踪某个特定的链接,并且百度也支持更精确的控制,请直接在链接上写上这个标记:sign
若要允许其他搜索引擎跟踪,但仅阻止百度跟踪您网页的链接,请将此元标记放在网页部分:
Noarchive:防止搜索引擎在搜索结果中显示网页快照
要防止所有搜索引擎显示您的网站快照,请将此元标记放置在页面的部分:
要允许其他搜索引擎显示快照,但仅阻止百度显示快照,请使用以下标签:
注意:此标志仅禁止百度显示页面快照。百度将继续为页面建立索引,并在搜索结果中显示页面摘要
使用机器人巧妙地避开蜘蛛黑洞
对于百度搜索引擎来说,蜘蛛黑洞是指网站以极低的成本创建大量参数过多、内容相似但URL不同的动态URL,就像一个无限圆形“黑洞”,诱捕蜘蛛。蜘蛛会浪费大量资源并抓取无效网页
例如,很多网站都有过滤功能,通过过滤功能生成的网页经常被搜索引擎抓取,其中很大一部分是检索价值和质量较低的网页。例如,“以500-1000之间的价格租房”,首先网站(包括实际情况)基本上没有相关资源。其次,站内用户和搜索引擎用户没有这种检索习惯。这类网页被搜索引擎抓取,搜索引擎只能占据网站有价值的抓取配额。如何避免这种情况
让我们以北京美团网为例,看看美团网是如何使用机器人巧妙地避开这个蜘蛛黑洞的:
对于普通的过滤结果
网页抓取 加密html(软件介绍BatchHtml是一个网页加密工具,如何保护好自己的HTML站点内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-18 20:22
Batchhtmlencryptor是一个网页加密工具,可以帮助网站管理员加密HTML源文件。它不仅可以对整个网页的源代码进行加密,还可以对网页的源代码进行部分加密。只有在浏览器进行解释时,才能看到加密的网页
相关软件大小版本说明下载地址
Batch HTML encryptor是一种网页加密工具,可帮助网站管理员加密HTML源文件。它可以对整个网页的源代码进行加密,也可以对网页的源代码进行部分加密。只有在浏览器进行解释时,才能看到加密的网页
软件介绍
Batch HTML encryptor是一种简单方便的批量网页文件加密工具。它可以帮助你把网页变成不可读的代码
如何保护您的HTML网站内容一直是新手网站管理员的主要问题。批处理HTML加密程序可以帮助网站管理员加密HTML源文件。加密后,只有浏览器才能读取输出。其他人不知道源文件根本无法修改
什么是批处理HTML加密程序
Batch HTML encryptor是一种保护HTML代码和脚本代码并将其转换为虚幻文字的工具。在处理多个文件时,这是一项出色的工作,因此它将为您节省进行这项复杂工作的时间。现在它支持UNIC ode,这意味着批处理HTML加密程序在加密多语言HTML文件方面比其他加密程序工作得更好
微型系统要求
Microsoft Windows 95/98/I/NT4.0/2000/XP
英特尔586 32 MB内存
6 MB可用磁盘空间 查看全部
网页抓取 加密html(软件介绍BatchHtml是一个网页加密工具,如何保护好自己的HTML站点内容)
Batchhtmlencryptor是一个网页加密工具,可以帮助网站管理员加密HTML源文件。它不仅可以对整个网页的源代码进行加密,还可以对网页的源代码进行部分加密。只有在浏览器进行解释时,才能看到加密的网页
相关软件大小版本说明下载地址
Batch HTML encryptor是一种网页加密工具,可帮助网站管理员加密HTML源文件。它可以对整个网页的源代码进行加密,也可以对网页的源代码进行部分加密。只有在浏览器进行解释时,才能看到加密的网页
软件介绍
Batch HTML encryptor是一种简单方便的批量网页文件加密工具。它可以帮助你把网页变成不可读的代码
如何保护您的HTML网站内容一直是新手网站管理员的主要问题。批处理HTML加密程序可以帮助网站管理员加密HTML源文件。加密后,只有浏览器才能读取输出。其他人不知道源文件根本无法修改
什么是批处理HTML加密程序
Batch HTML encryptor是一种保护HTML代码和脚本代码并将其转换为虚幻文字的工具。在处理多个文件时,这是一项出色的工作,因此它将为您节省进行这项复杂工作的时间。现在它支持UNIC ode,这意味着批处理HTML加密程序在加密多语言HTML文件方面比其他加密程序工作得更好
微型系统要求
Microsoft Windows 95/98/I/NT4.0/2000/XP
英特尔586 32 MB内存
6 MB可用磁盘空间
网页抓取 加密html(几种加密和混淆的反垃圾邮件手段,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-09-18 20:19
邮箱中总是有很多垃圾邮件,这让我不得不重新检查网页上发布的电子邮件地址。为了避免垃圾邮件,我特意将@替换为#。也许十年前这是一个好方法,但随着神经网络和新的机器学习算法的发展,这种小方法也面临着失败的风险,因为它们大多修改电子邮件地址的“@”符号,通过正则表达式过滤和匹配特征值,例如,可疑电子邮件地址(如、)的特征仍然可以捕获电子邮件地址,因此我们需要在将电子邮件发布到HTML网页之前对其进行加密和混淆
接下来,我将介绍几种反垃圾邮件的加密和混淆方法作为示例
1.生成图片
使用传统的图灵测试验证码将阻止采集电子邮件地址生成图片。有许多方法可以通过使用机器无法识别的特征来区分他人和机器。除了高级Photoshop,您甚至可以使用系统带来的绘图工具。此外,如果你想偷懒,有一些在线工具可以帮助你,例如,排名前十的网站可以将你的电子邮件地址转换成图像
当然,生成图片并不是万无一失的。有理由相信,由于基于图片的验证码可以被机器识别和破解,因此基于相同技术的电子邮件地址将不再不可避免。特别是随着OCR技术的逐渐发展和成熟,采集程序可以对整个网页进行OCR,最终提取出所需的内容,因此,我们还需要将图片生成的电子邮件地址与噪音和干扰线混淆。有关详细信息,请参阅如何防止验证码被识别的相关内容
然而,经过这样的设计,我们的电子邮件地址对那些真正需要它的人变得不那么友好,人们更难获得准确的电子邮件地址
2、替换关键符号
我们知道许多爬虫通过@feature符号捕获电子邮件地址。正如我文章在开始时所说,用其他符号替换此符号将大大降低我们的电子邮件被捕获的概率。当然,这一点的缺点是,除非它给用户一个提示,否则需要解释这是一个电子邮件地址,例如John#或John{a},当然,智能电子邮件捕获软件可以自动免受这些技巧的影响。也可以通过判断域名来判断这是一个电子邮件地址。因此,用一个非常特殊的符号替换@也是一种生存方式。对于这种替换方法,更重要的是将电子邮件地址转换为一个句子,如的John,它似乎应该更安全,但它也给真正需要此电子邮件地址的用户带来了一点麻烦
3、使用JavaScript
JavaScript(简称JS)通常被用作嵌入web页面中的小脚本,以提供更丰富的交互和应用程序。我们通过JS混淆电子邮件地址,然后用document.write或innerHTML输出它。优点是大多数爬虫程序无法在网页中执行脚本。它们只擅长捕获静态文本,因此,不必担心电子邮件地址泄漏到爬虫程序。此外,对于最终用户,通过浏览器的解释,他们会看到一个完整的电子邮件地址,这具有良好的用户体验。但是,这种方法有一个致命的弱点,即如果用户的浏览器不支持脚本,电子邮件地址将无法正常显示,尽管这种情况很少见
一个典型的例子如下。当然,有很多不同的实现,比如PHP hide_uu我不会在这里介绍更多关于电子邮件的内容
var username = "john";
var hostname = "example.com";
document.write(username + "@" + hostname);
特别值得一提的是rot13算法的应用。Rot13转13位。在最终分析中,它将字母表的第一个位置连接成一个环,并将要编码的字母映射到要旋转的13位字母,如下图所示:
对于PHP,有一个函数str_;Rot13可以直接使用,然后根据其算法通过反转获得加密前的文本。通常使用以下JS代码:
document.write("Fraq n zrffntr".replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c=(c=c.charCodeAt(0)+13)?c:c-26);}));
上述代码将被解码为以下HTML:
Send a message
4、将HTML与CSS混淆
当然,除了使用JavaScript,我们还可以使用HTML或CSS的一些技巧来混淆HTML注释。HTML收录注释,不会通过浏览器呈现给最终用户。然后,我们可以充分利用此功能创建电子邮件地址,如下所示:
john@example.com
浏览器不会显示它,但足以混淆机器爬虫的爬行
同样,结合CSS显示:无,我们仍然可以得到以下类似方法的混淆:
jo@hn@@exam@ple.com
类似地,显示:没有一个CSS注定不会显示其中收录的文本,因此最终显示的也是完整的电子邮件地址
对于CSS,还有另一种避免爬行的方法,即使用CSS文本显示顺序的特征,例如:
moc.noitpecni@kcik
CSS代码如下所示:
.obfuscate { unicode-bidi: bidi-override; direction: rtl; }
首先,文本被我们颠倒了。如果你想还原它,你可以在没有JS帮助的情况下通过CSS再次将其反转,以获得正确的文本。当然,这种方法有一个缺陷,即用户选择复制电子邮件地址的顺序仍然是相反的
最后,在反垃圾邮件爬虫采集方法方面,我们充分发挥了网民的智慧,涌现出了各种优秀的实现方案。由于篇幅有限,我不一一介绍。事实上,没有绝对的安全。最安全的方法是没有电子邮件地址。你怎么说?也就是说,使用contact from可以让需要与您联系的人通过表单直接向您发送电子邮件,从而避免泄露电子邮件地址。在线联系人表单有很多开源代码。这是我博客考虑的最后一种方式。现在,您可以通过右上角的“关于我”找到此链接并向我发送消息 查看全部
网页抓取 加密html(几种加密和混淆的反垃圾邮件手段,你知道吗?)
邮箱中总是有很多垃圾邮件,这让我不得不重新检查网页上发布的电子邮件地址。为了避免垃圾邮件,我特意将@替换为#。也许十年前这是一个好方法,但随着神经网络和新的机器学习算法的发展,这种小方法也面临着失败的风险,因为它们大多修改电子邮件地址的“@”符号,通过正则表达式过滤和匹配特征值,例如,可疑电子邮件地址(如、)的特征仍然可以捕获电子邮件地址,因此我们需要在将电子邮件发布到HTML网页之前对其进行加密和混淆
接下来,我将介绍几种反垃圾邮件的加密和混淆方法作为示例
1.生成图片
使用传统的图灵测试验证码将阻止采集电子邮件地址生成图片。有许多方法可以通过使用机器无法识别的特征来区分他人和机器。除了高级Photoshop,您甚至可以使用系统带来的绘图工具。此外,如果你想偷懒,有一些在线工具可以帮助你,例如,排名前十的网站可以将你的电子邮件地址转换成图像
当然,生成图片并不是万无一失的。有理由相信,由于基于图片的验证码可以被机器识别和破解,因此基于相同技术的电子邮件地址将不再不可避免。特别是随着OCR技术的逐渐发展和成熟,采集程序可以对整个网页进行OCR,最终提取出所需的内容,因此,我们还需要将图片生成的电子邮件地址与噪音和干扰线混淆。有关详细信息,请参阅如何防止验证码被识别的相关内容
然而,经过这样的设计,我们的电子邮件地址对那些真正需要它的人变得不那么友好,人们更难获得准确的电子邮件地址
2、替换关键符号
我们知道许多爬虫通过@feature符号捕获电子邮件地址。正如我文章在开始时所说,用其他符号替换此符号将大大降低我们的电子邮件被捕获的概率。当然,这一点的缺点是,除非它给用户一个提示,否则需要解释这是一个电子邮件地址,例如John#或John{a},当然,智能电子邮件捕获软件可以自动免受这些技巧的影响。也可以通过判断域名来判断这是一个电子邮件地址。因此,用一个非常特殊的符号替换@也是一种生存方式。对于这种替换方法,更重要的是将电子邮件地址转换为一个句子,如的John,它似乎应该更安全,但它也给真正需要此电子邮件地址的用户带来了一点麻烦
3、使用JavaScript
JavaScript(简称JS)通常被用作嵌入web页面中的小脚本,以提供更丰富的交互和应用程序。我们通过JS混淆电子邮件地址,然后用document.write或innerHTML输出它。优点是大多数爬虫程序无法在网页中执行脚本。它们只擅长捕获静态文本,因此,不必担心电子邮件地址泄漏到爬虫程序。此外,对于最终用户,通过浏览器的解释,他们会看到一个完整的电子邮件地址,这具有良好的用户体验。但是,这种方法有一个致命的弱点,即如果用户的浏览器不支持脚本,电子邮件地址将无法正常显示,尽管这种情况很少见
一个典型的例子如下。当然,有很多不同的实现,比如PHP hide_uu我不会在这里介绍更多关于电子邮件的内容
var username = "john";
var hostname = "example.com";
document.write(username + "@" + hostname);
特别值得一提的是rot13算法的应用。Rot13转13位。在最终分析中,它将字母表的第一个位置连接成一个环,并将要编码的字母映射到要旋转的13位字母,如下图所示:
对于PHP,有一个函数str_;Rot13可以直接使用,然后根据其算法通过反转获得加密前的文本。通常使用以下JS代码:
document.write("Fraq n zrffntr".replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c=(c=c.charCodeAt(0)+13)?c:c-26);}));
上述代码将被解码为以下HTML:
Send a message
4、将HTML与CSS混淆
当然,除了使用JavaScript,我们还可以使用HTML或CSS的一些技巧来混淆HTML注释。HTML收录注释,不会通过浏览器呈现给最终用户。然后,我们可以充分利用此功能创建电子邮件地址,如下所示:
john@example.com
浏览器不会显示它,但足以混淆机器爬虫的爬行
同样,结合CSS显示:无,我们仍然可以得到以下类似方法的混淆:
jo@hn@@exam@ple.com
类似地,显示:没有一个CSS注定不会显示其中收录的文本,因此最终显示的也是完整的电子邮件地址
对于CSS,还有另一种避免爬行的方法,即使用CSS文本显示顺序的特征,例如:
moc.noitpecni@kcik
CSS代码如下所示:
.obfuscate { unicode-bidi: bidi-override; direction: rtl; }
首先,文本被我们颠倒了。如果你想还原它,你可以在没有JS帮助的情况下通过CSS再次将其反转,以获得正确的文本。当然,这种方法有一个缺陷,即用户选择复制电子邮件地址的顺序仍然是相反的
最后,在反垃圾邮件爬虫采集方法方面,我们充分发挥了网民的智慧,涌现出了各种优秀的实现方案。由于篇幅有限,我不一一介绍。事实上,没有绝对的安全。最安全的方法是没有电子邮件地址。你怎么说?也就是说,使用contact from可以让需要与您联系的人通过表单直接向您发送电子邮件,从而避免泄露电子邮件地址。在线联系人表单有很多开源代码。这是我博客考虑的最后一种方式。现在,您可以通过右上角的“关于我”找到此链接并向我发送消息
网页抓取 加密html(如何能够获取到指定网页的源码呢?的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-17 15:09
在C#中,我们如何能够获取到指定网页的源码呢?比如说我们要做一个文章抓取功能的小工具,这样的功能是必不可少的,小编自己做了一个能够获取网页源码的小工具,把主体代码共享出来,希望能给新手们一点帮助。
首先先看下面代码:
private string GetWebContent(string url)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse respone = (HttpWebResponse)request.GetResponse();
Stream stream = respone.GetResponseStream();
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
StreamReader streamReader = new StreamReader(stream, encoding);
return streamReader.ReadToEnd();
}
上面方法的功能是把传入参数(url地址)的网页源码返回给调用者,但这仅仅是所有源码,我们并不能从中剥离出网站标题,网站Body元素等,需要正确读到这些元素,我们还要进行下一步处理。
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
主要用来处理网站的不同编码,不同的网站有不同的编码,如果我们在读取时使用了错误的编码,那么返回结果中的所有汉字就成了乱码了,所以提供了一个供用户自己选择编码的功能,如果读取出源码是错误的,就可以使用另外一种编码再次尝试,ddlEncoding(ComboBox控件)提供了所有网站编码选择。
下面是处理GetWebContent(stringurl)方法返回的结果,以正确读取出网站的标题,body的元素。
private void button1_Click(object sender, EventArgs e)
{
try
{
if (this.txtUrl.Text.Trim().Length == 0)
{
("请输入主入口地址!");
}
else
{
//这里获取GetWebContent方法的结果
string webContent = GetWebContent(this.txtUrl.Text.Trim());
//声明一个WebBrowser
WebBrowser webBrowser = new WebBrowser();
webBrowser.Navigate("about:blank");
//将GetWebContent方法返回的结果转化为HtmlDocument,就可以正确处理网页中的元素了。
HtmlDocument htmlDoc = webBrowser.Document.OpenNew(true);
htmlDoc.Write(webContent);
//获取网页中Body中的Html代码
string outerHtml = htmlDoc.Body.OuterHtml;
//获取网页的标题
string outerTitle=htmlDoc.Title;
this.txtDocumentTitle.Text = outerTitle;
this.txtDocumentConent.Text = outerHtml;
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
通过上面两个步骤,我们就可以正确的读取指定网页中的各元素了,当然,实际处理时,可能还会遇到很多的问题,比如我们要获取源码的网站需要用户名与密码验证,但处理一般的网页还是足够了。我们还可以从获取到的源码中解析出A标签,然后再根据解析出的A标签继续读取源码,就可以实现自动抓取的功能了。 查看全部
网页抓取 加密html(如何能够获取到指定网页的源码呢?的小工具)
在C#中,我们如何能够获取到指定网页的源码呢?比如说我们要做一个文章抓取功能的小工具,这样的功能是必不可少的,小编自己做了一个能够获取网页源码的小工具,把主体代码共享出来,希望能给新手们一点帮助。
首先先看下面代码:
private string GetWebContent(string url)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse respone = (HttpWebResponse)request.GetResponse();
Stream stream = respone.GetResponseStream();
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
StreamReader streamReader = new StreamReader(stream, encoding);
return streamReader.ReadToEnd();
}
上面方法的功能是把传入参数(url地址)的网页源码返回给调用者,但这仅仅是所有源码,我们并不能从中剥离出网站标题,网站Body元素等,需要正确读到这些元素,我们还要进行下一步处理。
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
主要用来处理网站的不同编码,不同的网站有不同的编码,如果我们在读取时使用了错误的编码,那么返回结果中的所有汉字就成了乱码了,所以提供了一个供用户自己选择编码的功能,如果读取出源码是错误的,就可以使用另外一种编码再次尝试,ddlEncoding(ComboBox控件)提供了所有网站编码选择。
下面是处理GetWebContent(stringurl)方法返回的结果,以正确读取出网站的标题,body的元素。
private void button1_Click(object sender, EventArgs e)
{
try
{
if (this.txtUrl.Text.Trim().Length == 0)
{
("请输入主入口地址!");
}
else
{
//这里获取GetWebContent方法的结果
string webContent = GetWebContent(this.txtUrl.Text.Trim());
//声明一个WebBrowser
WebBrowser webBrowser = new WebBrowser();
webBrowser.Navigate("about:blank");
//将GetWebContent方法返回的结果转化为HtmlDocument,就可以正确处理网页中的元素了。
HtmlDocument htmlDoc = webBrowser.Document.OpenNew(true);
htmlDoc.Write(webContent);
//获取网页中Body中的Html代码
string outerHtml = htmlDoc.Body.OuterHtml;
//获取网页的标题
string outerTitle=htmlDoc.Title;
this.txtDocumentTitle.Text = outerTitle;
this.txtDocumentConent.Text = outerHtml;
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
通过上面两个步骤,我们就可以正确的读取指定网页中的各元素了,当然,实际处理时,可能还会遇到很多的问题,比如我们要获取源码的网站需要用户名与密码验证,但处理一般的网页还是足够了。我们还可以从获取到的源码中解析出A标签,然后再根据解析出的A标签继续读取源码,就可以实现自动抓取的功能了。
网页抓取 加密html(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-14 03:03
还有一个关于数据抓取的小研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎指正并补充哈哈!
方法一:直接抓取网页源码
优点:快。
缺点: 1、由于速度快,容易被服务器检测到,可能会限制当前ip爬取。对此,您可以尝试使用ip码来解决。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到一些大规模的网站抓取,如果登录后需要抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页完全静态,第一次加载网页后加载你要抓取的数据。涉及登录或权限操作的类似页面未加密或简单加密。
当然,如果你在这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于登录页面,我们如何获取登录页面背后的源代码?
首先要介绍一下,在session保存账户信息时,服务器是如何判断用户的身份的。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,服务器返回的 sessionId 会被接收并保存在 cookie 中。因此,我们可以用chrome浏览器打开勾选项,查看当前页面的jsessionId。下次用户访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
这里我搭建了一个简单的JSP登录页面,登录后的账号信息保存在服务器端会话中。
思考:1.登陆。2.登陆成功后获取cookies。 3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
Java 版本:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
Python 版本:
#encoding:utf-8
import urllib
import urllib2
data={'username':'admin','password':'123456'}
data=urllib.urlencode(data)
response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录
cookie = response.info()['set-cookie']//获得登录后的cookie
jsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionId
html = response.read()
if html=='error':
print('用户名密码错误!')
elif html=='success':
headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头
request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以清楚地看到python的优势。它将编写的代码量至少比 java 少一半。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好的控制底层。代码实现的缺点是不容易学习,需要的技术太多。因此,如果您是数据采集的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点:1、类似用户操作,不易被服务器检测到。
2.对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可以随时获取当前页面各个元素的最新状态。
缺点:1、速度稍慢。
这里有一些很好的模拟浏览器操作的库:
C#webbrower 控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以在dom模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit,等,或者直接调用页面js方法。
网页浏览器操作的C#代码:
webBrowser1.Navigate("https://localhost//index.html");//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们的浏览器系统,但我们需要确保浏览安装相应的驱动程序。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里给大家推荐一款后台浏览器,直接在cmd里面操作,没有界面,就是phantomjs。
这样我们就可以用python+selenium+phantomjs在不看界面的情况下模拟浏览器的操作了。由于phantomjs没有界面,所以会比普通浏览器快很多。
网上资料很多,一时无法解释,这里就不过多解释了,大家可以看看:
三、Fidderscript:
fdder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书,所以有时候,在爬取过程中,如果我们遇到安全证书错误,不妨打开fidder,让他给你提供一个证书,也许你离成功不远了。
比较强大的就是fidderscript,它可以在抓取请求后进行系统操作,比如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的抓取工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和Clike系列语法差不多,类库大都和c#一样,相信熟悉C#的同学会很快上手fiddlerscript。
附注: 查看全部
网页抓取 加密html(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
还有一个关于数据抓取的小研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎指正并补充哈哈!
方法一:直接抓取网页源码
优点:快。
缺点: 1、由于速度快,容易被服务器检测到,可能会限制当前ip爬取。对此,您可以尝试使用ip码来解决。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到一些大规模的网站抓取,如果登录后需要抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页完全静态,第一次加载网页后加载你要抓取的数据。涉及登录或权限操作的类似页面未加密或简单加密。
当然,如果你在这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于登录页面,我们如何获取登录页面背后的源代码?
首先要介绍一下,在session保存账户信息时,服务器是如何判断用户的身份的。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,服务器返回的 sessionId 会被接收并保存在 cookie 中。因此,我们可以用chrome浏览器打开勾选项,查看当前页面的jsessionId。下次用户访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
这里我搭建了一个简单的JSP登录页面,登录后的账号信息保存在服务器端会话中。
思考:1.登陆。2.登陆成功后获取cookies。 3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
Java 版本:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
Python 版本:
#encoding:utf-8
import urllib
import urllib2
data={'username':'admin','password':'123456'}
data=urllib.urlencode(data)
response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录
cookie = response.info()['set-cookie']//获得登录后的cookie
jsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionId
html = response.read()
if html=='error':
print('用户名密码错误!')
elif html=='success':
headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头
request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以清楚地看到python的优势。它将编写的代码量至少比 java 少一半。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好的控制底层。代码实现的缺点是不容易学习,需要的技术太多。因此,如果您是数据采集的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点:1、类似用户操作,不易被服务器检测到。
2.对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可以随时获取当前页面各个元素的最新状态。
缺点:1、速度稍慢。
这里有一些很好的模拟浏览器操作的库:
C#webbrower 控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以在dom模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit,等,或者直接调用页面js方法。
网页浏览器操作的C#代码:
webBrowser1.Navigate("https://localhost//index.html";);//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们的浏览器系统,但我们需要确保浏览安装相应的驱动程序。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里给大家推荐一款后台浏览器,直接在cmd里面操作,没有界面,就是phantomjs。
这样我们就可以用python+selenium+phantomjs在不看界面的情况下模拟浏览器的操作了。由于phantomjs没有界面,所以会比普通浏览器快很多。
网上资料很多,一时无法解释,这里就不过多解释了,大家可以看看:
三、Fidderscript:
fdder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书,所以有时候,在爬取过程中,如果我们遇到安全证书错误,不妨打开fidder,让他给你提供一个证书,也许你离成功不远了。
比较强大的就是fidderscript,它可以在抓取请求后进行系统操作,比如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的抓取工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和Clike系列语法差不多,类库大都和c#一样,相信熟悉C#的同学会很快上手fiddlerscript。
附注:
网页抓取 加密html(【魔兽世界】反爬与反反爬突破网站的一些经验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-14 03:02
防爬和防爬一直是相互博弈的游戏。路高一尺,魔道高一尺。知己知彼,百战不殆。想要突破网站的反爬机制,必须对当前的前端开发技术有深刻的了解,才能在这款游戏中生存。
我是爬行动物爱好者。最近在爬小说网站时,通过抓包分析,发现小说正文被加密,如图:
获取小说文本的响应数据
小说文本加密数据
根据字面意思可以看出,小说的文本是经过编码存储在Content key中的,但是这个字符编码无法显示和解码,所以确定它已经被加密了。这时候我们就来看看网页js代码分析和编码转换过程。但是一个网页有很多js代码,而且还经过编译、混淆和压缩,所以直接阅读整篇文章会很费力。因此,我们必须掌握一定的技巧,才能更有效地解决问题。
接下来分享一些我查看js代码的心得。
首先看请求地址,可以发现“index.php/Bookreader”是url的固定部分,
然后,我们按快捷键Ctrl+Shift+F进行搜索,结果如下
点击此结果定位位置
如您所见,此接口路径已分配给变量 getChapterContentAjaxUrl。接下来,搜索这个变量,看看它在哪里被调用。
根据经验,点击底部打开js代码页
看到这个代码逻辑,相信你已经明白了。本次POST请求成功后,返回json数据,然后对json的Content字段进行解码。在第754行,有一个函数“_decryptByBaseCode”来实现解码功能。函数,OK,看函数的具体实现。
在这个地方设置一个断点,在断点之后
点击F9一步步执行,跟踪进去
函数_decryptByBaseCode的实现代码
如你所见,这个解码逻辑很简单,将文本用反斜杠分割成数据,然后一一解码。
有两个函数 String.fromCharCode 和 parseInt。第一个是将int转换为unicode字符,第二个是根据指定的基数将字符串转换为int。这里他们使用 30 base 来编码 Encrypted。
所以这个功能可以用python实现。实现代码如下,
# 解码
def decrypt_by_basecode(text,base):
if not text:
return
# base=30
arrStr = []
arrText = text.split('\\')
for i in arrText:
if i:
s = chr(int(i,base))
arrStr.append(s)
objStr = ''.join(arrStr)
return objStr
写好解码函数后,我们可以在程序中调用这个接口,然后对小说内容进行解码。
通过上面的实战演示,你可以看到一个优秀的爬虫工程师,也是一个资深的前端工程师。
欢迎关注我的知乎account
@arckal 太阳
我会不定期分享一些技术经验。 ^_^ 查看全部
网页抓取 加密html(【魔兽世界】反爬与反反爬突破网站的一些经验)
防爬和防爬一直是相互博弈的游戏。路高一尺,魔道高一尺。知己知彼,百战不殆。想要突破网站的反爬机制,必须对当前的前端开发技术有深刻的了解,才能在这款游戏中生存。
我是爬行动物爱好者。最近在爬小说网站时,通过抓包分析,发现小说正文被加密,如图:
获取小说文本的响应数据
小说文本加密数据
根据字面意思可以看出,小说的文本是经过编码存储在Content key中的,但是这个字符编码无法显示和解码,所以确定它已经被加密了。这时候我们就来看看网页js代码分析和编码转换过程。但是一个网页有很多js代码,而且还经过编译、混淆和压缩,所以直接阅读整篇文章会很费力。因此,我们必须掌握一定的技巧,才能更有效地解决问题。
接下来分享一些我查看js代码的心得。
首先看请求地址,可以发现“index.php/Bookreader”是url的固定部分,
然后,我们按快捷键Ctrl+Shift+F进行搜索,结果如下
点击此结果定位位置
如您所见,此接口路径已分配给变量 getChapterContentAjaxUrl。接下来,搜索这个变量,看看它在哪里被调用。
根据经验,点击底部打开js代码页
看到这个代码逻辑,相信你已经明白了。本次POST请求成功后,返回json数据,然后对json的Content字段进行解码。在第754行,有一个函数“_decryptByBaseCode”来实现解码功能。函数,OK,看函数的具体实现。
在这个地方设置一个断点,在断点之后
点击F9一步步执行,跟踪进去
函数_decryptByBaseCode的实现代码
如你所见,这个解码逻辑很简单,将文本用反斜杠分割成数据,然后一一解码。
有两个函数 String.fromCharCode 和 parseInt。第一个是将int转换为unicode字符,第二个是根据指定的基数将字符串转换为int。这里他们使用 30 base 来编码 Encrypted。
所以这个功能可以用python实现。实现代码如下,
# 解码
def decrypt_by_basecode(text,base):
if not text:
return
# base=30
arrStr = []
arrText = text.split('\\')
for i in arrText:
if i:
s = chr(int(i,base))
arrStr.append(s)
objStr = ''.join(arrStr)
return objStr
写好解码函数后,我们可以在程序中调用这个接口,然后对小说内容进行解码。
通过上面的实战演示,你可以看到一个优秀的爬虫工程师,也是一个资深的前端工程师。
欢迎关注我的知乎account
@arckal 太阳
我会不定期分享一些技术经验。 ^_^
网页抓取 加密html(搜索引擎蜘蛛访问网站页面时的程序被称为蜘蛛(spider))
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-14 03:00
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人网站引蜘蛛。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度来说,都是用多只蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,不会被抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须具备不用任何软件查看网站日志的能力,而且你必须非常熟悉其代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址搜索下一个网页,这样循环下去,直到所有的网站 网页已被抓取。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。大约十个。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。就算能存储,下载还是有问题(按一台机器每秒下载20K计算,需要340个单元,机器不停下载一年才能完成所有网页的下载)。同时,由于数据量大,在提供搜索时也会影响效率。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而评价抓取重要性的主要依据是某个网页的链接深度。
由于无法抓取所有网页,部分网络蜘蛛为一些不太重要的网站设置了访问级别数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,网页我不会被访问,这也让网站之前的一些页面在搜索引擎上搜索到,其他部分搜索不到。
对于网站designers,扁平化的网站结构设计有助于搜索引擎抓取更多网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望搜索引擎可以搜索到他们的报告,但他们做不到自由。搜索者查看,所以需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限验证。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。名字的由来。
整个互联网网站是由相互链接组成的,也就是说,搜索引擎蜘蛛从任何一个页面开始,最终爬到所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了,所以蜘蛛只能通过某些方法抓取所有页面。据我了解,最简单的爬取策略有3种:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问被网络分析算法预测为“有用”的网页。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这种闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬,直到没有更多的链接在它前面,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二层进入页面的第二层找到的链接爬到三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是可以抓取所有页面。其实最大的搜索引擎只是爬取而收录了互联网的一小部分,当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了尽可能多地抓取用户信息,通常将深度优先和广度优先混用,这样可以照顾到尽可能多的网站,以及@的部分内页网站。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般情况下,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中从未见过的网址,从而访问其他网页并遍历网络。
其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,以遍历的方式爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要用于数据集合的日常维护和实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,我们在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。这方面需要解决的主要问题是什么?更好地处理动态网络数据问题(如Web2.0数据量不断增加等),更好地根据网页质量修正抓取策略问题。
四、database
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或360的网址收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则将其存储在数据库中以供访问(网站测期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并抓取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站,观察期间需要定期更新网站。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站持久化不更新,蜘蛛不会被光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。 .
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技巧足够高深,并且有了这个能力,你也可以试试。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的网站页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有页面,那我们就让它抓取重要页面,因为重要页面在索引中起着重要作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站被赋予了很高的权重。这种在网站页面上爬行的蜘蛛爬行深度更高,所以更多的内页会是收录。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要频繁爬取和爬取。 .
如果页面内容更新频繁,蜘蛛就会频繁的爬取爬行,那么页面上的新链接自然会被蜘蛛更快的跟踪和抓取,这就是为什么每天都要更新文章
3、import 链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道存在页。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛经常从对方网站爬到你网站,深度高。 查看全部
网页抓取 加密html(搜索引擎蜘蛛访问网站页面时的程序被称为蜘蛛(spider))
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人网站引蜘蛛。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度来说,都是用多只蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,不会被抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须具备不用任何软件查看网站日志的能力,而且你必须非常熟悉其代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址搜索下一个网页,这样循环下去,直到所有的网站 网页已被抓取。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。大约十个。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。就算能存储,下载还是有问题(按一台机器每秒下载20K计算,需要340个单元,机器不停下载一年才能完成所有网页的下载)。同时,由于数据量大,在提供搜索时也会影响效率。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而评价抓取重要性的主要依据是某个网页的链接深度。
由于无法抓取所有网页,部分网络蜘蛛为一些不太重要的网站设置了访问级别数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,网页我不会被访问,这也让网站之前的一些页面在搜索引擎上搜索到,其他部分搜索不到。
对于网站designers,扁平化的网站结构设计有助于搜索引擎抓取更多网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望搜索引擎可以搜索到他们的报告,但他们做不到自由。搜索者查看,所以需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限验证。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。名字的由来。
整个互联网网站是由相互链接组成的,也就是说,搜索引擎蜘蛛从任何一个页面开始,最终爬到所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了,所以蜘蛛只能通过某些方法抓取所有页面。据我了解,最简单的爬取策略有3种:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问被网络分析算法预测为“有用”的网页。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这种闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬,直到没有更多的链接在它前面,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二层进入页面的第二层找到的链接爬到三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是可以抓取所有页面。其实最大的搜索引擎只是爬取而收录了互联网的一小部分,当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了尽可能多地抓取用户信息,通常将深度优先和广度优先混用,这样可以照顾到尽可能多的网站,以及@的部分内页网站。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般情况下,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中从未见过的网址,从而访问其他网页并遍历网络。
其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,以遍历的方式爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要用于数据集合的日常维护和实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,我们在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。这方面需要解决的主要问题是什么?更好地处理动态网络数据问题(如Web2.0数据量不断增加等),更好地根据网页质量修正抓取策略问题。
四、database
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或360的网址收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则将其存储在数据库中以供访问(网站测期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并抓取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站,观察期间需要定期更新网站。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站持久化不更新,蜘蛛不会被光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。 .
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技巧足够高深,并且有了这个能力,你也可以试试。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的网站页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有页面,那我们就让它抓取重要页面,因为重要页面在索引中起着重要作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站被赋予了很高的权重。这种在网站页面上爬行的蜘蛛爬行深度更高,所以更多的内页会是收录。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要频繁爬取和爬取。 .
如果页面内容更新频繁,蜘蛛就会频繁的爬取爬行,那么页面上的新链接自然会被蜘蛛更快的跟踪和抓取,这就是为什么每天都要更新文章
3、import 链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道存在页。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛经常从对方网站爬到你网站,深度高。
网页抓取 加密html(最新发布的相关软件:正确的出山:保护保护您的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-13 15:03
近期发布的相关软件:
正确的 HRPT 几何图形 1.5.0.10_正确的 HRPT 几何图形 1.5.0.10 正确的 HTML 保护器 3.0_正确的 HTML 保护器 3.0
HTML 的保护将帮助您克隆、抄袭和加密垃圾邮件以防止您的网页
右键单击 HTML Protector 将帮助您加密网页、未经授权提取文本、图形、电子邮件、链接、JavaScript 和 VBScript 克隆、抄袭和垃圾邮件保护。
正确的神器出来了:保护您的网页免遭未经授权的信息、图像、文本、电子邮件地址、链接、JavaScript 和 VBScript 提取。加密HTML文件和源代码,拦截所有网站视频采集和电子邮件提取,用于采集垃圾邮件库。
您的访问者看不到更改,但它有助于避免在线抄袭和克隆,这在今天非常普遍。正确的 HTML 保护功能允许您收录或排除某些加密网页——例如,您只能保护电子邮件和图片加密方法。
这将有助于您的网站 保持较高的搜索引擎排名。高级选项可用于禁用鼠标右键、文本选择、页面打印和打印屏幕、页面缓存、IE 图片工具栏和智能标签、离线网页浏览和拖放
以下是“正确的 HTML 保护程序”的一些主要功能:
加密的HTML文件:保护从网站的网页中提取的信息,并使用6种加密方法保持较高的搜索引擎排名。
隐藏源代码之路:您的访问者将看不到这些更改,但任何人都无法阅读和窃取您的源代码。
防止克隆之路:防止他人使用您的文章、插图和照片、您的网页设计和脚本。
阻止垃圾邮件和病毒的方法:有专门的软件可以从互联网上提取电子邮件,有一天你会看到,商业信件垃圾邮件很难分割。此外,垃圾邮件提供了90F的所有病毒、木马和蠕虫。保护您和您的企业免于提取电子邮件。
路网站松土机座:您可能想屏蔽的软件用于自动保存您所有网站内容以备将来使用。
路障内容过滤器:您可能还需要阻止可以对访问者隐藏您的广告的内容过滤器。
道路维护搜索引擎的定位是使用选择性加密,以确保搜索引擎的高排名。
Road 易于使用:您不需要任何 HTML 或 Web 编程技能,只需将文件拖放到 protected_file.html 即可准备使用正确的 HTML 保护。
路由禁用动作(可选):禁用鼠标右键、文本选择、页面打印、打印屏幕、页面缓存、IE图像工具栏和智能标签、离线网页浏览和拖放。
限制:
Road Limited 为 15 天。 查看全部
网页抓取 加密html(最新发布的相关软件:正确的出山:保护保护您的网页)
近期发布的相关软件:
正确的 HRPT 几何图形 1.5.0.10_正确的 HRPT 几何图形 1.5.0.10 正确的 HTML 保护器 3.0_正确的 HTML 保护器 3.0
HTML 的保护将帮助您克隆、抄袭和加密垃圾邮件以防止您的网页
右键单击 HTML Protector 将帮助您加密网页、未经授权提取文本、图形、电子邮件、链接、JavaScript 和 VBScript 克隆、抄袭和垃圾邮件保护。
正确的神器出来了:保护您的网页免遭未经授权的信息、图像、文本、电子邮件地址、链接、JavaScript 和 VBScript 提取。加密HTML文件和源代码,拦截所有网站视频采集和电子邮件提取,用于采集垃圾邮件库。
您的访问者看不到更改,但它有助于避免在线抄袭和克隆,这在今天非常普遍。正确的 HTML 保护功能允许您收录或排除某些加密网页——例如,您只能保护电子邮件和图片加密方法。
这将有助于您的网站 保持较高的搜索引擎排名。高级选项可用于禁用鼠标右键、文本选择、页面打印和打印屏幕、页面缓存、IE 图片工具栏和智能标签、离线网页浏览和拖放
以下是“正确的 HTML 保护程序”的一些主要功能:
加密的HTML文件:保护从网站的网页中提取的信息,并使用6种加密方法保持较高的搜索引擎排名。
隐藏源代码之路:您的访问者将看不到这些更改,但任何人都无法阅读和窃取您的源代码。
防止克隆之路:防止他人使用您的文章、插图和照片、您的网页设计和脚本。
阻止垃圾邮件和病毒的方法:有专门的软件可以从互联网上提取电子邮件,有一天你会看到,商业信件垃圾邮件很难分割。此外,垃圾邮件提供了90F的所有病毒、木马和蠕虫。保护您和您的企业免于提取电子邮件。
路网站松土机座:您可能想屏蔽的软件用于自动保存您所有网站内容以备将来使用。
路障内容过滤器:您可能还需要阻止可以对访问者隐藏您的广告的内容过滤器。
道路维护搜索引擎的定位是使用选择性加密,以确保搜索引擎的高排名。
Road 易于使用:您不需要任何 HTML 或 Web 编程技能,只需将文件拖放到 protected_file.html 即可准备使用正确的 HTML 保护。
路由禁用动作(可选):禁用鼠标右键、文本选择、页面打印、打印屏幕、页面缓存、IE图像工具栏和智能标签、离线网页浏览和拖放。
限制:
Road Limited 为 15 天。
网页抓取 加密html(爬虫介绍三种常见的加密方式及其解决方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 470 次浏览 • 2021-09-12 07:14
在使用爬虫爬取网页数据的过程中,我们经常会发现目标网页返回的HTML源代码经过了不同编码方式的加密,导致我们无法正确定位到需要的元素。本文介绍了三种常见的加密方法及其解决方案,以说明编写爬虫时请求头的重要性。情况一、JS加密防爬
爬取影评数据()
要抓取网页,请求页面的最简单和最常见的方法是
此时返回的目标网页源代码为
通过网上检索信息,这种情况叫做JS加密,解决这个问题的方法也很简单,就是给爬虫添加请求头,比如
一般来说,网上大部分网页只需要在headers中添加User-Agent元素就可以正常抓取数据,但是有些网站已经添加了反抓取机制,所以我们需要添加相应的元素。比如这里的JS加密需要添加元素Cookies,返回源码如下:
情况二、language标签反爬
爬取猫眼电影的TOP100数据()
如上直接访问返回的源代码为
在不应用直接访问的情况下,目标网站服务器只会返回上图所示的无序英文,而不是我们在目标网站上看到的源代码。这时候还需要在请求头中添加元素Accept-Language如下:
此时返回的页面源代码为
Situation三、requests 库获取网页中文乱码处理
当我们请求一个网页时,得到的源代码是正常的上图所示的英文中文乱码,我们要明白目标网站返回给我们的源代码是经过加密的(不同的编码方式) ),这是我们默认的解码方法,不能再解释了。这时候,我们有两个解决方案:
1.打开target网站Developer界面,找到使用的编码方式,如下图:
编写爬虫时添加代码:
2.无论登陆页面使用哪种编码方式,都可以添加这行代码来破译:
总结
当我们发现请求页面的源代码与目标网站Developer接口不一致时,说明我们向目标网站发出的请求不完整或者返回的源代码需要进一步解释,但是不管遇到什么乱码,本文要强调的是,请求网页的源代码是从地面高层建筑爬取的第一步。我们都可以尽可能多地填写标题,避免不必要的时间和精力浪费。 查看全部
网页抓取 加密html(爬虫介绍三种常见的加密方式及其解决方法(图))
在使用爬虫爬取网页数据的过程中,我们经常会发现目标网页返回的HTML源代码经过了不同编码方式的加密,导致我们无法正确定位到需要的元素。本文介绍了三种常见的加密方法及其解决方案,以说明编写爬虫时请求头的重要性。情况一、JS加密防爬
爬取影评数据()
要抓取网页,请求页面的最简单和最常见的方法是
此时返回的目标网页源代码为
通过网上检索信息,这种情况叫做JS加密,解决这个问题的方法也很简单,就是给爬虫添加请求头,比如
一般来说,网上大部分网页只需要在headers中添加User-Agent元素就可以正常抓取数据,但是有些网站已经添加了反抓取机制,所以我们需要添加相应的元素。比如这里的JS加密需要添加元素Cookies,返回源码如下:
情况二、language标签反爬
爬取猫眼电影的TOP100数据()
如上直接访问返回的源代码为
在不应用直接访问的情况下,目标网站服务器只会返回上图所示的无序英文,而不是我们在目标网站上看到的源代码。这时候还需要在请求头中添加元素Accept-Language如下:
此时返回的页面源代码为
Situation三、requests 库获取网页中文乱码处理
当我们请求一个网页时,得到的源代码是正常的上图所示的英文中文乱码,我们要明白目标网站返回给我们的源代码是经过加密的(不同的编码方式) ),这是我们默认的解码方法,不能再解释了。这时候,我们有两个解决方案:
1.打开target网站Developer界面,找到使用的编码方式,如下图:
编写爬虫时添加代码:
2.无论登陆页面使用哪种编码方式,都可以添加这行代码来破译:
总结
当我们发现请求页面的源代码与目标网站Developer接口不一致时,说明我们向目标网站发出的请求不完整或者返回的源代码需要进一步解释,但是不管遇到什么乱码,本文要强调的是,请求网页的源代码是从地面高层建筑爬取的第一步。我们都可以尽可能多地填写标题,避免不必要的时间和精力浪费。
网页抓取 加密html(前端必须掌握的HTML5、选择器、JavaScript、加密爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-12 07:11
一、前端必须掌握HTML基础知识
5、选择器
在 CSS 中,我们使用 CSS 选择器来定位节点。比如下图中div节点的id如果是asideProfile,可以表示为#asideProfile,其中#以selection id开头,后面跟着id的名字。
另外,如果我们要选择一个类为side-box的节点,我们可以使用.aside-box,其中点“.”开始选择班级,然后是班级名称。
6、reptile 原理
互联网是一个大网,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬到这个就相当于访问了页面,获取了它的信息。节点之间的连接可以比作网页和网页之间的链接关系。
爬虫首先要做的就是获取网页,这里是获取网页的源代码。获得网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。
提取信息后,我们可以简单地将其保存为 TXT 文本或 JSON 文本,或者将其保存到数据库,例如 MySQL 和 MongoDB,或者将其保存到远程服务器。
7、JavaScript 渲染页面
现在越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原来的 HTML 代码只是一个空壳。
网页请求这个js文件。获取文件后,它会执行其中的JavaScript代码,JavaScript会改变HTML中的节点,向其中添加内容,最终得到完整的页面。
对于,可以使用selenium或者找到Ajax请求地址来解决。
8、加密
我们在爬网站的时候,经常会遇到各种类似加密的情况,比如:字体加密,结构参数加密,要爬就一定要知道怎么找到对应的js文件,研究这些参数是怎么回事建?现在越来越多的完整信息通过App展示。有的app在内部实现的时候会增加一些对代理的检查,比如绕过系统代理直接连接或者检测到使用了代理,直接拒绝连接。这需要考虑使用 Wireshark 和 Tcpdump 在较低级别的协议上捕获数据包。
之前的文章都会被反复整理整理。 查看全部
网页抓取 加密html(前端必须掌握的HTML5、选择器、JavaScript、加密爬取)
一、前端必须掌握HTML基础知识
5、选择器
在 CSS 中,我们使用 CSS 选择器来定位节点。比如下图中div节点的id如果是asideProfile,可以表示为#asideProfile,其中#以selection id开头,后面跟着id的名字。
另外,如果我们要选择一个类为side-box的节点,我们可以使用.aside-box,其中点“.”开始选择班级,然后是班级名称。
6、reptile 原理
互联网是一个大网,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬到这个就相当于访问了页面,获取了它的信息。节点之间的连接可以比作网页和网页之间的链接关系。
爬虫首先要做的就是获取网页,这里是获取网页的源代码。获得网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。
提取信息后,我们可以简单地将其保存为 TXT 文本或 JSON 文本,或者将其保存到数据库,例如 MySQL 和 MongoDB,或者将其保存到远程服务器。
7、JavaScript 渲染页面
现在越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原来的 HTML 代码只是一个空壳。
网页请求这个js文件。获取文件后,它会执行其中的JavaScript代码,JavaScript会改变HTML中的节点,向其中添加内容,最终得到完整的页面。
对于,可以使用selenium或者找到Ajax请求地址来解决。
8、加密
我们在爬网站的时候,经常会遇到各种类似加密的情况,比如:字体加密,结构参数加密,要爬就一定要知道怎么找到对应的js文件,研究这些参数是怎么回事建?现在越来越多的完整信息通过App展示。有的app在内部实现的时候会增加一些对代理的检查,比如绕过系统代理直接连接或者检测到使用了代理,直接拒绝连接。这需要考虑使用 Wireshark 和 Tcpdump 在较低级别的协议上捕获数据包。
之前的文章都会被反复整理整理。
网页抓取 加密html(Java的骚操作:方法调用完成小记录+11)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-12 07:10
当我们在页面上看到的是数据,而在 HTML 中,我们看到它是用字符加密的。当我们抓取整个 HTML 时,我们将抓取加密的内容。
示例:
其实在前端字符串加密中,可以根据请求查看使用的加密。
其实看到这个我就知道怎么解密了。我在互联网上搜索了很多。大部分都是用Python写的,但是我用的是Java,好无奈!
在这个请求的URL中,可以看到使用的加密是base64,后面是需要的key。但是每个页面的key都会变,所以只能查每个页面有没有这个东西;
纯属巧合。哈哈哈哈。 . . .
下面我们来看看Java的骚操作:
package com.cmcc.crawler.common;
import org.apache.commons.lang3.StringUtils;
import sun.font.Font2D;
import sun.font.Font2DHandle;
import sun.font.TrueTypeFont;
import sun.font.TrueTypeGlyphMapper;
import java.awt.*;
import java.awt.font.FontRenderContext;
import java.awt.font.GlyphVector;
import java.awt.geom.AffineTransform;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.util.Base64;
/**
* @NAME: zhaoxj
* @DESC: ..
* @DATE: 2021/3/12
* @TIME: 11:01
* @YEAR: 2021
* @MONTH: 03
**/
public class Base64Util {
//安居客字符解码
public static String decodeString(String key, String encodeString) {
try {
//base64解码,初始化字体
byte[] ss = Base64.getDecoder().decode(key);
InputStream inputStream = new ByteArrayInputStream(ss);
Font dynamicFont = Font.createFont(Font.TRUETYPE_FONT, inputStream);
FontRenderContext fontRenderContext = new FontRenderContext(new AffineTransform(), false, false);
GlyphVector glyphVector = dynamicFont.createGlyphVector(fontRenderContext, "");
//获取font中字形的映射关系,字段为private,使用反射
Class clazz = Font.class;
Field[] fs = clazz.getDeclaredFields();
Font2DHandle font2DHandle = null;
for (int i = 0; i < fs.length; i++) {
fs[i].setAccessible(true);// 将目标属性设置为可以访问
if (fs[i].getName().equals("font2DHandle")) {
font2DHandle = (Font2DHandle) fs[i].get(dynamicFont);
}
}
//得到映射关系
Font2D font2D = font2DHandle.font2D;
TrueTypeFont trueTypeFont = (TrueTypeFont) font2D;
TrueTypeGlyphMapper charToGlyphMapper = (TrueTypeGlyphMapper) trueTypeFont.getMapper();
//开始解密,encodeString为加密后的字符串
StringBuffer buffer = new StringBuffer();
char[] chars = encodeString.toCharArray();
for (int i = 0; i < chars.length; i++) {
buffer.append(charToGlyphMapper.charToGlyph(chars[i]) - 1);
}
return buffer.toString();
} catch (Exception e) {
e.printStackTrace();
}
return "";
}
}
方法调用
完整的小记录+1 查看全部
网页抓取 加密html(Java的骚操作:方法调用完成小记录+11)
当我们在页面上看到的是数据,而在 HTML 中,我们看到它是用字符加密的。当我们抓取整个 HTML 时,我们将抓取加密的内容。
示例:
其实在前端字符串加密中,可以根据请求查看使用的加密。
其实看到这个我就知道怎么解密了。我在互联网上搜索了很多。大部分都是用Python写的,但是我用的是Java,好无奈!
在这个请求的URL中,可以看到使用的加密是base64,后面是需要的key。但是每个页面的key都会变,所以只能查每个页面有没有这个东西;
纯属巧合。哈哈哈哈。 . . .
下面我们来看看Java的骚操作:
package com.cmcc.crawler.common;
import org.apache.commons.lang3.StringUtils;
import sun.font.Font2D;
import sun.font.Font2DHandle;
import sun.font.TrueTypeFont;
import sun.font.TrueTypeGlyphMapper;
import java.awt.*;
import java.awt.font.FontRenderContext;
import java.awt.font.GlyphVector;
import java.awt.geom.AffineTransform;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.util.Base64;
/**
* @NAME: zhaoxj
* @DESC: ..
* @DATE: 2021/3/12
* @TIME: 11:01
* @YEAR: 2021
* @MONTH: 03
**/
public class Base64Util {
//安居客字符解码
public static String decodeString(String key, String encodeString) {
try {
//base64解码,初始化字体
byte[] ss = Base64.getDecoder().decode(key);
InputStream inputStream = new ByteArrayInputStream(ss);
Font dynamicFont = Font.createFont(Font.TRUETYPE_FONT, inputStream);
FontRenderContext fontRenderContext = new FontRenderContext(new AffineTransform(), false, false);
GlyphVector glyphVector = dynamicFont.createGlyphVector(fontRenderContext, "");
//获取font中字形的映射关系,字段为private,使用反射
Class clazz = Font.class;
Field[] fs = clazz.getDeclaredFields();
Font2DHandle font2DHandle = null;
for (int i = 0; i < fs.length; i++) {
fs[i].setAccessible(true);// 将目标属性设置为可以访问
if (fs[i].getName().equals("font2DHandle")) {
font2DHandle = (Font2DHandle) fs[i].get(dynamicFont);
}
}
//得到映射关系
Font2D font2D = font2DHandle.font2D;
TrueTypeFont trueTypeFont = (TrueTypeFont) font2D;
TrueTypeGlyphMapper charToGlyphMapper = (TrueTypeGlyphMapper) trueTypeFont.getMapper();
//开始解密,encodeString为加密后的字符串
StringBuffer buffer = new StringBuffer();
char[] chars = encodeString.toCharArray();
for (int i = 0; i < chars.length; i++) {
buffer.append(charToGlyphMapper.charToGlyph(chars[i]) - 1);
}
return buffer.toString();
} catch (Exception e) {
e.printStackTrace();
}
return "";
}
}
方法调用
完整的小记录+1

