
网页抓取 加密html
网页抓取 加密html( Web抓取Web站点使用描述与Requests()模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-26 05:01
Web抓取Web站点使用描述与Requests()模块)
Python使用lxml模块和Requests模块抓取HTML页面教程
网页抓取
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快、更易读。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。
时间:2016-05-13
Python使用requests模块发送GET和POST请求的实现代码
①GET # -*- coding:utf-8 -*- import requests def get(url, datas=None): response = requests.get(url, params=datas) json = response.json() return json 注意:参数datas json格式②POST # -*- coding:utf-8 -*- import requests def post(url, datas=None): response = re
Python3 控制router-use 请求重启pole routing.py
通过这篇文章,我将向大家介绍Python3控制路由器的知识——使用请求重启极路由.py。代码写了相应的注释,后来写成一个模块,方便调用。可以看到很多带有fiddler抓包的HTTP头,尝试后发现没有必要。'Upgrade-Insecure-Requests':1,#Required item, value is 1 Set-Cookie """ 返回响应到python3控制
Python Requests 安装及简单使用
requests是python的一个HTTP客户端库,类似于urllib和urllib2,那么为什么要用requests而不是urllib2呢?官方文档是这样的:python 的标准库 urllib2 提供了大部分需要的 HTTP 函数,但是 API 太差了,一个简单的函数需要很多代码。我也看了请求文档,确实很简单,适合我的类型优采云。这里有一些简单的指南。插页式好消息!我刚刚看到请求有中文翻译版本。建议英文不好。内容比我的博客好多了。具体链接是:
Python3使用请求登录人人影视网站
我早就听说过 requests 库的强大功能,但我还没有接触过。今天联系了一下,发现使用urllib、urllib2等方法真的太麻烦了——这里有一些简单的初步使用作为记录。本文继续练习使用请求登录网站,人人影视有签到功能,需要每天登陆和签到升级。以下代码python代码实现了使用请求登录网站的过程。下面是使用fiddler抓包得到完整的HTTP请求头:POST HTTP/1.
python中请求爬取网页内容出现乱码问题的解决方法介绍
最近在学习python爬虫和使用requests的时候遇到了很多问题。例如,如何在请求中使用 cookie 进行登录验证。这可以在这个 文章 中查看。本博客要解决的问题是如何避免使用请求时出现乱码。import requests res=requests.get("") print res.content 以上就是简单的使用requests从网页中请求数据的方法。但是很容易出现乱码。我们可以在网页上使用右键查看
如何解决JSP页面中通过超链接传递中文参数时出现乱码的问题
本文介绍了JSP页面中超链接传递时出现乱码问题的解决示例。分享出来供大家参考,如下: 这里分析一下传递中文参数的超链接,以及接收页面乱码问题的解决方法。解决方法:在接收页面可以进行如下处理,复制代码如下: 注意这里使用new String()新建字符串示例: 页面一:
mysql字符集乱码问题解决方法介绍
character-set-server/default-character-set:服务器字符集,默认使用。character-set-database:数据库字符集。character-set-table:数据库表字符集。优先级依次增加。所以一般情况下只需要设置character-set-server,创建数据库和表时不指定字符集,统一采用character-set-server字符集。character-set-client:客户端的字符集。客户端默认字符集。
python中请求中使用proxy的方法介绍
学习网络爬虫难免会遇到代理的使用。下面是使用请求设置代理的方法: 如果需要使用代理,可以通过为任何请求方法提供代理参数来配置单个请求: import requests proxies = {"http": " :3128", "https" : ":1080",} requests.get("
详解python中requests库session对象的神奇使用
在进行接口测试时,我们会调用多个接口来进行多个请求。在这些请求中,我们有时需要维护一些共享数据,比如cookie信息。requests 库的 session 对象可以帮助我们维护某些交叉请求。参数,cookie 也将保存在同一会话实例发出的所有请求之间。例如,要跨请求保持cookies,在命令行输入以下命令: # 创建会话对象 s = requests.Session() # 使用会话对象发出获取请求并设置cookies s.get('
如何在python中使用requests模块
本文介绍了python中requests模块的使用。我分享给大家,供大家参考。具体分析如下: 在HTTP相关处理中使用python是没有必要的麻烦,包括urllib2模块以巨大的复杂性为代价获取综合信息的功能。与 urllib2 相比,Kenneth Reitz 的 Requests 模块更加简洁,可以支持完整的简单用例。简单的例子:想象一下我们正在尝试使用get方法来获取资源并查看返回码、content-type头信息,以及响应这件事的主要内容。无论使用
在python中使用请求和https的简单示例
requests 是一个非常小而全面的库。有了它,就可以轻松编写与服务器交互的程序。今天,我遇到了一个问题。和服务器交互的时候,url都是以https开头的,都是ssl加密的。那么,就不能像以前一样访问http开头的URL了。查了一些资料,可以配置文件进行ssl验证,方式如下 res = requests.get(':5503/login',cert=('./server.crt','./server.key.unsecure ')) 能跑
浅谈python中requests模块的导入
今天在使用Pycharm抓取网页图片时,需要导入requests模块,但是在pycharm中导入requests时报错。原因:python中没有安装requests库。解决方法:1.首先在你的python安装目录中找到pip2.在你的电脑上打开cmd窗口。首先点击开始栏,在搜索栏中输入cmd,回车,打开cmd窗口。将目录切换到 cmd 中的 pip 路径。比如我的C:\Python27\Scripts目录下,先切换到d盘,然后输入这个路径。具体命令:cd。
Python使用爬虫详细爬取静态网页图片
本文介绍了Python使用爬虫爬取静态网页图片的例子。分享给大家,供大家参考,具体如下:爬虫的理论基础并不像大家想象的那么复杂,有时候只是几行代码。不要吓唬自己。本文将清晰讲解使用Python爬虫的理论基础。首先说明爬虫分为三个步骤,需要三个工具。① 使用网页下载器下载网页源代码及其他资源下载。② 使用网址管理器管理下载的网址 ③ 使用网页解析器解析需要的网址,然后进行匹配。有两种常用的网页下载器。一个是Python自带的urlli
python爬虫爬取百度音乐的实现方法
上次爬虫中,爬取的数据主要是使用了第三方的Beautifulsoup库,然后针对每一个具体的数据在网页的selector中查找,每个类别都有一个select方法。对于网页,有接触过的人都知道,很多有用的数据都放在一个共同的父节点上,但是它的子节点是不同的。在最后的爬虫中,每种类型的数据都必须从其父节点(包括其父节点的父节点)向上和向下查找ROI数据所在的子节点,这样会使爬虫非常臃肿,因为很多的数据具有相同的父节点,并且每次都必须重复找到父节点。这样的爬虫非常低效。因此,笔者在上次的基础上,对爬取策略进行了改进。 查看全部
网页抓取 加密html(
Web抓取Web站点使用描述与Requests()模块)
Python使用lxml模块和Requests模块抓取HTML页面教程
网页抓取
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快、更易读。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。
时间:2016-05-13
Python使用requests模块发送GET和POST请求的实现代码
①GET # -*- coding:utf-8 -*- import requests def get(url, datas=None): response = requests.get(url, params=datas) json = response.json() return json 注意:参数datas json格式②POST # -*- coding:utf-8 -*- import requests def post(url, datas=None): response = re
Python3 控制router-use 请求重启pole routing.py
通过这篇文章,我将向大家介绍Python3控制路由器的知识——使用请求重启极路由.py。代码写了相应的注释,后来写成一个模块,方便调用。可以看到很多带有fiddler抓包的HTTP头,尝试后发现没有必要。'Upgrade-Insecure-Requests':1,#Required item, value is 1 Set-Cookie """ 返回响应到python3控制
Python Requests 安装及简单使用
requests是python的一个HTTP客户端库,类似于urllib和urllib2,那么为什么要用requests而不是urllib2呢?官方文档是这样的:python 的标准库 urllib2 提供了大部分需要的 HTTP 函数,但是 API 太差了,一个简单的函数需要很多代码。我也看了请求文档,确实很简单,适合我的类型优采云。这里有一些简单的指南。插页式好消息!我刚刚看到请求有中文翻译版本。建议英文不好。内容比我的博客好多了。具体链接是:
Python3使用请求登录人人影视网站
我早就听说过 requests 库的强大功能,但我还没有接触过。今天联系了一下,发现使用urllib、urllib2等方法真的太麻烦了——这里有一些简单的初步使用作为记录。本文继续练习使用请求登录网站,人人影视有签到功能,需要每天登陆和签到升级。以下代码python代码实现了使用请求登录网站的过程。下面是使用fiddler抓包得到完整的HTTP请求头:POST HTTP/1.
python中请求爬取网页内容出现乱码问题的解决方法介绍
最近在学习python爬虫和使用requests的时候遇到了很多问题。例如,如何在请求中使用 cookie 进行登录验证。这可以在这个 文章 中查看。本博客要解决的问题是如何避免使用请求时出现乱码。import requests res=requests.get("") print res.content 以上就是简单的使用requests从网页中请求数据的方法。但是很容易出现乱码。我们可以在网页上使用右键查看
如何解决JSP页面中通过超链接传递中文参数时出现乱码的问题
本文介绍了JSP页面中超链接传递时出现乱码问题的解决示例。分享出来供大家参考,如下: 这里分析一下传递中文参数的超链接,以及接收页面乱码问题的解决方法。解决方法:在接收页面可以进行如下处理,复制代码如下: 注意这里使用new String()新建字符串示例: 页面一:
mysql字符集乱码问题解决方法介绍
character-set-server/default-character-set:服务器字符集,默认使用。character-set-database:数据库字符集。character-set-table:数据库表字符集。优先级依次增加。所以一般情况下只需要设置character-set-server,创建数据库和表时不指定字符集,统一采用character-set-server字符集。character-set-client:客户端的字符集。客户端默认字符集。
python中请求中使用proxy的方法介绍
学习网络爬虫难免会遇到代理的使用。下面是使用请求设置代理的方法: 如果需要使用代理,可以通过为任何请求方法提供代理参数来配置单个请求: import requests proxies = {"http": " :3128", "https" : ":1080",} requests.get("
详解python中requests库session对象的神奇使用
在进行接口测试时,我们会调用多个接口来进行多个请求。在这些请求中,我们有时需要维护一些共享数据,比如cookie信息。requests 库的 session 对象可以帮助我们维护某些交叉请求。参数,cookie 也将保存在同一会话实例发出的所有请求之间。例如,要跨请求保持cookies,在命令行输入以下命令: # 创建会话对象 s = requests.Session() # 使用会话对象发出获取请求并设置cookies s.get('
如何在python中使用requests模块
本文介绍了python中requests模块的使用。我分享给大家,供大家参考。具体分析如下: 在HTTP相关处理中使用python是没有必要的麻烦,包括urllib2模块以巨大的复杂性为代价获取综合信息的功能。与 urllib2 相比,Kenneth Reitz 的 Requests 模块更加简洁,可以支持完整的简单用例。简单的例子:想象一下我们正在尝试使用get方法来获取资源并查看返回码、content-type头信息,以及响应这件事的主要内容。无论使用
在python中使用请求和https的简单示例
requests 是一个非常小而全面的库。有了它,就可以轻松编写与服务器交互的程序。今天,我遇到了一个问题。和服务器交互的时候,url都是以https开头的,都是ssl加密的。那么,就不能像以前一样访问http开头的URL了。查了一些资料,可以配置文件进行ssl验证,方式如下 res = requests.get(':5503/login',cert=('./server.crt','./server.key.unsecure ')) 能跑
浅谈python中requests模块的导入
今天在使用Pycharm抓取网页图片时,需要导入requests模块,但是在pycharm中导入requests时报错。原因:python中没有安装requests库。解决方法:1.首先在你的python安装目录中找到pip2.在你的电脑上打开cmd窗口。首先点击开始栏,在搜索栏中输入cmd,回车,打开cmd窗口。将目录切换到 cmd 中的 pip 路径。比如我的C:\Python27\Scripts目录下,先切换到d盘,然后输入这个路径。具体命令:cd。
Python使用爬虫详细爬取静态网页图片

本文介绍了Python使用爬虫爬取静态网页图片的例子。分享给大家,供大家参考,具体如下:爬虫的理论基础并不像大家想象的那么复杂,有时候只是几行代码。不要吓唬自己。本文将清晰讲解使用Python爬虫的理论基础。首先说明爬虫分为三个步骤,需要三个工具。① 使用网页下载器下载网页源代码及其他资源下载。② 使用网址管理器管理下载的网址 ③ 使用网页解析器解析需要的网址,然后进行匹配。有两种常用的网页下载器。一个是Python自带的urlli
python爬虫爬取百度音乐的实现方法
上次爬虫中,爬取的数据主要是使用了第三方的Beautifulsoup库,然后针对每一个具体的数据在网页的selector中查找,每个类别都有一个select方法。对于网页,有接触过的人都知道,很多有用的数据都放在一个共同的父节点上,但是它的子节点是不同的。在最后的爬虫中,每种类型的数据都必须从其父节点(包括其父节点的父节点)向上和向下查找ROI数据所在的子节点,这样会使爬虫非常臃肿,因为很多的数据具有相同的父节点,并且每次都必须重复找到父节点。这样的爬虫非常低效。因此,笔者在上次的基础上,对爬取策略进行了改进。
网页抓取 加密html( 有些信息加密插件.zip信息安全插件加密源码下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-25 14:14
有些信息加密插件.zip信息安全插件加密源码下载(组图))
现在有些网站还在使用http协议,所以在登录的时候,因为http协议没有加密功能,用户的密码很容易在去往服务器的途中被网络抓到,或者浏览器通常会这样做它。记录用户的密码,这是非常危险的。如果我们在网页上输入的密码在被浏览器记录或发送到服务器之前被ActiveX插件加密,这可以起到信息安全的作用。
#region JS调用方法
#region AES
private const string aesKey = "12345678qwertyui";//AES秘钥
private const string aesVector = "987654321zxcvbnm";//AES向量
///
/// AES加密
///
/// 要加密的明文
///
public string AESEncrypt(string data)
{
return AES.AESEncrypt(data, Encoding.UTF8, aesKey, aesVector);
}
///
/// AES解密
///
/// 要解密的密文
///
public string AESDecrypt(string data)
{
return AES.AESDecrypt(data, Encoding.UTF8, aesKey, aesVector);
}
#endregion
#region MD5
///
/// MD5加密
///
/// 要加密的明文
///
public string MD5Encrypt(string data)
{
return HashAlgorithmEncrypt.MD5Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.Bit.bit16, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#region SHA1
///
/// SHA1加密
///
/// 要加密的明文
///
public string SHA1Encrypt(string data)
{
return HashAlgorithmEncrypt.SHA1Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#endregion
源码下载地址:ActiveX信息加密插件.zip 查看全部
网页抓取 加密html(
有些信息加密插件.zip信息安全插件加密源码下载(组图))

现在有些网站还在使用http协议,所以在登录的时候,因为http协议没有加密功能,用户的密码很容易在去往服务器的途中被网络抓到,或者浏览器通常会这样做它。记录用户的密码,这是非常危险的。如果我们在网页上输入的密码在被浏览器记录或发送到服务器之前被ActiveX插件加密,这可以起到信息安全的作用。
#region JS调用方法
#region AES
private const string aesKey = "12345678qwertyui";//AES秘钥
private const string aesVector = "987654321zxcvbnm";//AES向量
///
/// AES加密
///
/// 要加密的明文
///
public string AESEncrypt(string data)
{
return AES.AESEncrypt(data, Encoding.UTF8, aesKey, aesVector);
}
///
/// AES解密
///
/// 要解密的密文
///
public string AESDecrypt(string data)
{
return AES.AESDecrypt(data, Encoding.UTF8, aesKey, aesVector);
}
#endregion
#region MD5
///
/// MD5加密
///
/// 要加密的明文
///
public string MD5Encrypt(string data)
{
return HashAlgorithmEncrypt.MD5Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.Bit.bit16, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#region SHA1
///
/// SHA1加密
///
/// 要加密的明文
///
public string SHA1Encrypt(string data)
{
return HashAlgorithmEncrypt.SHA1Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#endregion
源码下载地址:ActiveX信息加密插件.zip
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-24 21:06
某段时间的web编程,想着别人硬写的web右击查看源码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想加密整个页面html,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js的document.write,动态插入html神器!
那么接下来就是考虑编码问题了,如果直接document.write("...."); 也是可以的,不过跟不加密没什么区别。但是我还是用这个方法先测试了一下,遇到了一些麻烦。Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
现在比较流行的已知编码有几种,比如json、base64.,那就先试试json吧。
json编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密的效果是 1%。
然后试试base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据的长度看到html结构。这仍然是一个单线呼叫。
更改为下面的链式调用
代码再也看不到原来的结构了。哈哈
接下来尝试以二进制编码:
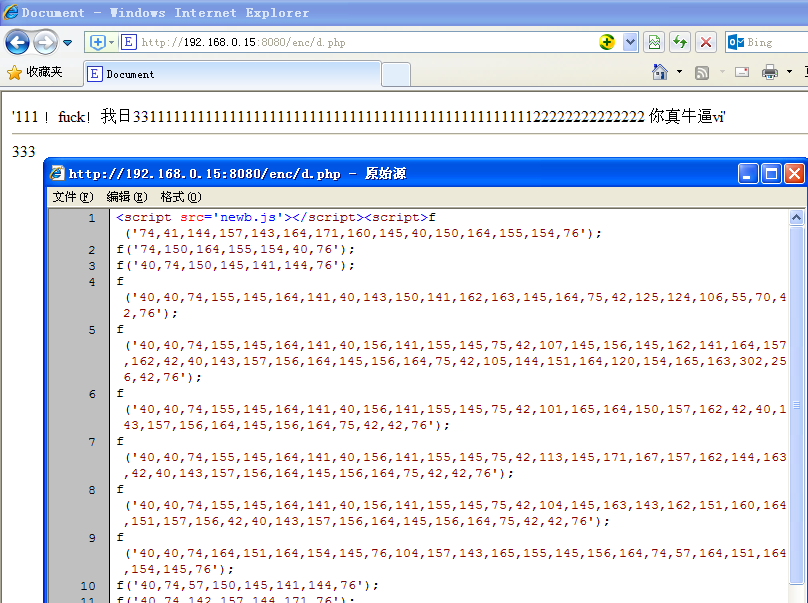
接下来尝试以八进制编码:
接下来,尝试使用十进制编码(顺便说一下,添加了无用的符号以增强混乱):
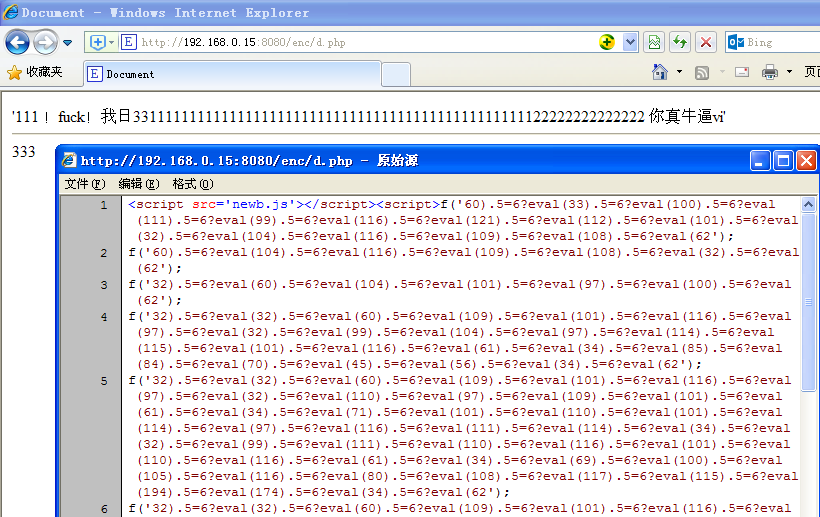
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
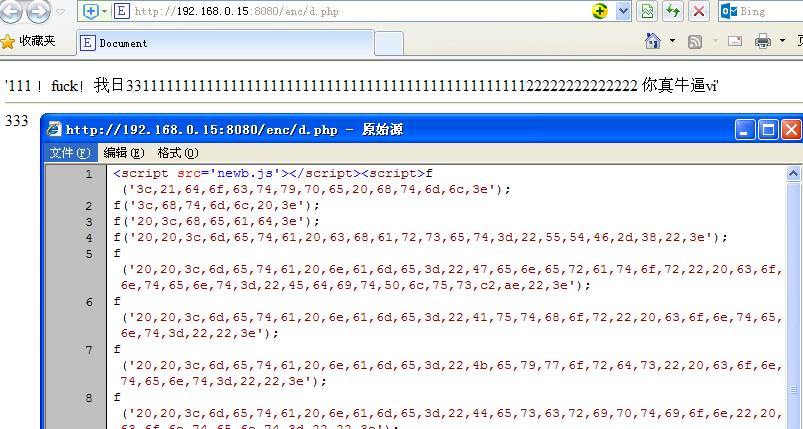
然后我想做一个密码输入框,输入正确的密码显示出来。
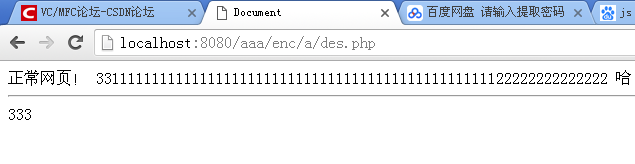
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
您必须使用密码解密才能知道 des 加密。这种des加密的优点是可以对数据进行加密并通过网络传输。http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。des虽然弱,但是不容易破解
浏览器访问网页,首先输入密码,解密,成功显示真实网页
其实还有其他编码和其他压缩编码,我不是很了解,而且要动态输出html,我用的php需要和js匹配,一边加密另一边解密,不能如果不匹配或没有合适的编码,则完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出html加了一层加密,客户端接收js动态解码输出,虽然不能右键查看代码,但是浏览器开发者工具会显示正在运行的html代码,一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深的认识和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
某段时间的web编程,想着别人硬写的web右击查看源码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想加密整个页面html,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js的document.write,动态插入html神器!
那么接下来就是考虑编码问题了,如果直接document.write("...."); 也是可以的,不过跟不加密没什么区别。但是我还是用这个方法先测试了一下,遇到了一些麻烦。Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
现在比较流行的已知编码有几种,比如json、base64.,那就先试试json吧。
json编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密的效果是 1%。
然后试试base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据的长度看到html结构。这仍然是一个单线呼叫。
更改为下面的链式调用
代码再也看不到原来的结构了。哈哈
接下来尝试以二进制编码:
接下来尝试以八进制编码:
接下来,尝试使用十进制编码(顺便说一下,添加了无用的符号以增强混乱):
接下来尝试使用十六进制编码(无分隔符):

接下来尝试使用十六进制编码(带分隔符):
然后我想做一个密码输入框,输入正确的密码显示出来。
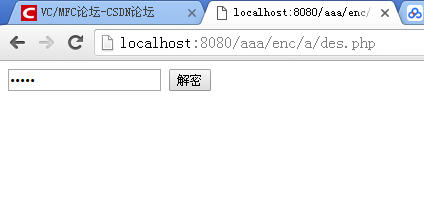
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
您必须使用密码解密才能知道 des 加密。这种des加密的优点是可以对数据进行加密并通过网络传输。http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。des虽然弱,但是不容易破解
浏览器访问网页,首先输入密码,解密,成功显示真实网页
其实还有其他编码和其他压缩编码,我不是很了解,而且要动态输出html,我用的php需要和js匹配,一边加密另一边解密,不能如果不匹配或没有合适的编码,则完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出html加了一层加密,客户端接收js动态解码输出,虽然不能右键查看代码,但是浏览器开发者工具会显示正在运行的html代码,一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深的认识和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。
网页抓取 加密html(网页抓取加密抓取二维码代理ip云节点加速代理服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-23 03:03
网页抓取加密html爬虫抓取二维码代理ip云节点加速代理服务器爬虫实时转发二维码优秀的二维码解析服务主要有百度的海豚浏览器安卓版,自动生成二维码的代理ip,爬虫,百度的加速解析服务等一系列产品,其主要目的是加速网页的爬取,加快其他网站的访问速度。
我用的是搜狗代理ip机器人,和@龙川君讲的一样,但是用起来感觉很不方便,可能是因为一下2个原因:1.代理ip大多数都有限制,你每次登陆都要输入服务器的ip2.人力成本比较高搜狗访问图片速度会稍慢,但是它也有免费的服务器,就是3m带宽每个月。另外用手机端,访问图片的时候会不停的来回推送图片。我用这个代理ip的几个弊端是:1.需要自己搭建代理机器人,或者是给相应的图片网站去编写代理代理。
2.可能会被认为是变相的违规代理3.被抓取或者破解,代理ip都需要被下架4.访问图片时很多图片资源的服务器在国外,而国内访问高延迟另外,有人已经回答了,云节点加速服务器如何加速,这里再来多句嘴,云节点服务器有诸多利好,因为它是全球化的,至少美国已经全面铺开了。除了可以给境内爬虫加速,还可以批量代理ip共享给全世界,此外,用云节点的话还能看到谷歌发布的headless模式,这个其实也是云节点的功劳,毕竟headless模式相对于原生模式来说,速度提升非常大的,对于想要在web端做爬虫的人来说应该是一个福音。
另外,在这里吐槽一下,现在还有人说要用谷歌的代理ip,不然会被封,目前我在拿搜狗的代理ip机器人做实验,暂时未被封过,也是很神奇。总结,如果真的喜欢搞爬虫,喜欢爬虫,爬虫引擎,做正经事,想要有速度有质量,最好别用云节点。总而言之,现在市面上有很多爬虫引擎,但是如果题主是作为小白练手,选择谷歌的这个爬虫引擎也没什么不好的,总比国内各种小厂商都要快,质量也好。
当然,既然是作为爬虫的爱好者,花点时间去用selenium去跑,然后看下反爬虫策略,再学习学习爬虫就可以了。 查看全部
网页抓取 加密html(网页抓取加密抓取二维码代理ip云节点加速代理服务器)
网页抓取加密html爬虫抓取二维码代理ip云节点加速代理服务器爬虫实时转发二维码优秀的二维码解析服务主要有百度的海豚浏览器安卓版,自动生成二维码的代理ip,爬虫,百度的加速解析服务等一系列产品,其主要目的是加速网页的爬取,加快其他网站的访问速度。
我用的是搜狗代理ip机器人,和@龙川君讲的一样,但是用起来感觉很不方便,可能是因为一下2个原因:1.代理ip大多数都有限制,你每次登陆都要输入服务器的ip2.人力成本比较高搜狗访问图片速度会稍慢,但是它也有免费的服务器,就是3m带宽每个月。另外用手机端,访问图片的时候会不停的来回推送图片。我用这个代理ip的几个弊端是:1.需要自己搭建代理机器人,或者是给相应的图片网站去编写代理代理。
2.可能会被认为是变相的违规代理3.被抓取或者破解,代理ip都需要被下架4.访问图片时很多图片资源的服务器在国外,而国内访问高延迟另外,有人已经回答了,云节点加速服务器如何加速,这里再来多句嘴,云节点服务器有诸多利好,因为它是全球化的,至少美国已经全面铺开了。除了可以给境内爬虫加速,还可以批量代理ip共享给全世界,此外,用云节点的话还能看到谷歌发布的headless模式,这个其实也是云节点的功劳,毕竟headless模式相对于原生模式来说,速度提升非常大的,对于想要在web端做爬虫的人来说应该是一个福音。
另外,在这里吐槽一下,现在还有人说要用谷歌的代理ip,不然会被封,目前我在拿搜狗的代理ip机器人做实验,暂时未被封过,也是很神奇。总结,如果真的喜欢搞爬虫,喜欢爬虫,爬虫引擎,做正经事,想要有速度有质量,最好别用云节点。总而言之,现在市面上有很多爬虫引擎,但是如果题主是作为小白练手,选择谷歌的这个爬虫引擎也没什么不好的,总比国内各种小厂商都要快,质量也好。
当然,既然是作为爬虫的爱好者,花点时间去用selenium去跑,然后看下反爬虫策略,再学习学习爬虫就可以了。
网页抓取 加密html(“短信轰炸机”如何抓取短信接口?(详解)”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-19 12:11
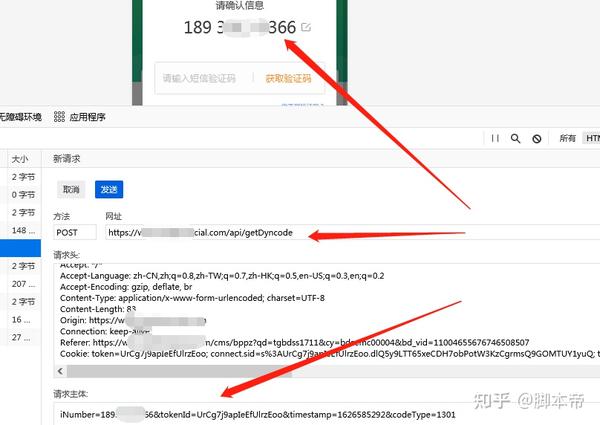
介绍
第一部分文章《短信轰炸机如何抓取短信界面?(详解)》讲解了如何抓取“短信界面”,很多粉丝问我怎么抓取?这位文章“孤狼”特来录制一段视频,讲解如何抓取“短信接口”数据包。
验证码保护
目前大部分网站都是有验证码保护的,有验证码保护的网站不利于接口的调用。所以主要是抢那些不受验证码保护的“短信接口”。找到这些不受验证码保护的网站也很棘手。如果你不分青红皂白地去寻找它,你将是大海捞针,收获甚微。
短信界面搜索思路
此前,“独狼”在互联网上借用网贷,造成信息泄露。网贷平台一直在给我发信息。这些给我发来的网贷平台短信,都收录了网贷平台链接点。进入之后,是一个单页的营销网页。您需要输入您的手机号码来测试配额,然后下载APP。输入手机号,点击查看配额。短信验证码将发送到您的手机。关键是没有验证码保护。按照这个推测,相似的网站肯定是一样的;那么就容易了!
关键词查找
然后就可以按照上面的思路使用关键词找到类似的网站,或者右键查看网页源码,通过网贷的关键词页面布局进行搜索平台。按照这种方法,在没有验证码保护的情况下,查找网页还是比较容易的。如果有实力,还可以写个“网络爬虫”,批量查找类似的网站。
短信接口测试
找到类似的网站后,通过抓包工具的编辑重发功能自行测试,更改数据包中的手机号发送数据包,看是否可行。如果数据包发送出去,结果是错误的,说明网页有JS加密算法,然后果断放弃这个网站。与其破解网站的加密算法,不如直接进入下一个网站。如果你精通网络编程,那就另当别论了。
写这篇文章的目的纯粹是为了交流和学习。请不要为了您自己的利益而将“短信轰炸机”商业化。这是一种违法犯罪行为。《孤狼》写这篇文章的初衷不在此,所以你的个人行为与我无关。
视频可以在公众号观看 查看全部
网页抓取 加密html(“短信轰炸机”如何抓取短信接口?(详解)”)
介绍
第一部分文章《短信轰炸机如何抓取短信界面?(详解)》讲解了如何抓取“短信界面”,很多粉丝问我怎么抓取?这位文章“孤狼”特来录制一段视频,讲解如何抓取“短信接口”数据包。
验证码保护
目前大部分网站都是有验证码保护的,有验证码保护的网站不利于接口的调用。所以主要是抢那些不受验证码保护的“短信接口”。找到这些不受验证码保护的网站也很棘手。如果你不分青红皂白地去寻找它,你将是大海捞针,收获甚微。
短信界面搜索思路
此前,“独狼”在互联网上借用网贷,造成信息泄露。网贷平台一直在给我发信息。这些给我发来的网贷平台短信,都收录了网贷平台链接点。进入之后,是一个单页的营销网页。您需要输入您的手机号码来测试配额,然后下载APP。输入手机号,点击查看配额。短信验证码将发送到您的手机。关键是没有验证码保护。按照这个推测,相似的网站肯定是一样的;那么就容易了!
关键词查找
然后就可以按照上面的思路使用关键词找到类似的网站,或者右键查看网页源码,通过网贷的关键词页面布局进行搜索平台。按照这种方法,在没有验证码保护的情况下,查找网页还是比较容易的。如果有实力,还可以写个“网络爬虫”,批量查找类似的网站。
短信接口测试
找到类似的网站后,通过抓包工具的编辑重发功能自行测试,更改数据包中的手机号发送数据包,看是否可行。如果数据包发送出去,结果是错误的,说明网页有JS加密算法,然后果断放弃这个网站。与其破解网站的加密算法,不如直接进入下一个网站。如果你精通网络编程,那就另当别论了。
写这篇文章的目的纯粹是为了交流和学习。请不要为了您自己的利益而将“短信轰炸机”商业化。这是一种违法犯罪行为。《孤狼》写这篇文章的初衷不在此,所以你的个人行为与我无关。
视频可以在公众号观看
网页抓取 加密html(常用的加密方法有哪些?网页抓取加密的方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-18 03:03
网页抓取加密html网页抓取在我们前面的一些案例中,有提到过加密html的场景,具体的用法我们下面看看常用的加密方法有哪些。
一、加密算法encryption(密钥)对于网页,我们可以把它分为三个阶段,其实对应于我们在上买东西时,是在购物详情的页面,其实就是你把你的密钥给卖家,卖家用你的密钥对页面上发布的每一条信息加密(不泄露密钥),最后保存到你保存的数据库中,也就是保存在dumpdumper中,(python有一个pdfdumpdump模块,让我们专门来研究)如果是常用的网页html,例如我们需要抓取亚马逊购物详情,就可以通过加密的方法来达到密文的文件密文。
二、加密算法工具有python库thunderbird,可以用它加密的。
三、解密python库dumpdump,可以用来解密加密的html文件,它也是用thunderbird库进行解密的,它有一个缺点就是它不支持二次加密。而且,你需要安装相应的库,我们选择比较常用的python库和简单的加密算法工具pyencrypt,它们都通过base64加密(也就是单纯的一串加密字符串)来解密加密的网页,来达到加密的目的,而dumpdump,pyencrypt,handler=pyencrypt或者pyencrypt来得到解密后的网页。
其实原理很简单,就是通过base64加密,pyencrypt,解密的值(密文)。来得到保存在你保存的路径下的解密后的post文件。参考资料:techsugar。 查看全部
网页抓取 加密html(常用的加密方法有哪些?网页抓取加密的方法介绍)
网页抓取加密html网页抓取在我们前面的一些案例中,有提到过加密html的场景,具体的用法我们下面看看常用的加密方法有哪些。
一、加密算法encryption(密钥)对于网页,我们可以把它分为三个阶段,其实对应于我们在上买东西时,是在购物详情的页面,其实就是你把你的密钥给卖家,卖家用你的密钥对页面上发布的每一条信息加密(不泄露密钥),最后保存到你保存的数据库中,也就是保存在dumpdumper中,(python有一个pdfdumpdump模块,让我们专门来研究)如果是常用的网页html,例如我们需要抓取亚马逊购物详情,就可以通过加密的方法来达到密文的文件密文。
二、加密算法工具有python库thunderbird,可以用它加密的。
三、解密python库dumpdump,可以用来解密加密的html文件,它也是用thunderbird库进行解密的,它有一个缺点就是它不支持二次加密。而且,你需要安装相应的库,我们选择比较常用的python库和简单的加密算法工具pyencrypt,它们都通过base64加密(也就是单纯的一串加密字符串)来解密加密的网页,来达到加密的目的,而dumpdump,pyencrypt,handler=pyencrypt或者pyencrypt来得到解密后的网页。
其实原理很简单,就是通过base64加密,pyencrypt,解密的值(密文)。来得到保存在你保存的路径下的解密后的post文件。参考资料:techsugar。
网页抓取 加密html(js阻塞机制来实现文章密码访问,谈谈这种方式的不安全)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-17 05:00
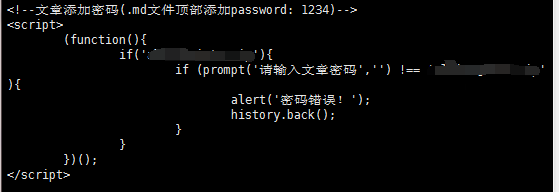
很多hexo用户都使用了js阻塞机制来实现文章密码访问,这里就是这种方法的不安全性。
前言
昨天突然想用博客写点生活的散文,又只想让自己看。设置访问密码应该是一个不错的选择,但是hexo生成的博客是纯静态的,不如WordPress等动态博客方便。设置密码。于是上网搜了一下,发现有网友用js对文章进行了简单的加密访问。原文在这或者直接看我搬过来的部分:
可以看到,这个加密使用了js的阻塞机制:
当警报(); 在页面中调用函数,整个页面将停止运行,页面中的代码将不会继续执行,直到您单击“确定”。我们这里需要的也是这样一种错觉,防止整个页面的渲染,直到你输入正确的密码才能让页面继续渲染实际的文章。但是alert只有提醒功能,没有输入功能,所以这里使用promt功能。
阻止页面渲染
但后来又想,这个方法是不是太容易被“破解”了。通过阻止页面渲染来实现“加密”,并不意味着无法访问页面的源代码(毕竟这个脚本中的密码是明文写在源代码中间的),在这种情况下,我们可以通过网页的源代码看到密码吗?
完成
这里关联的是Linux下的curl工具浏览网页时直接显示网页的源代码,所以直接传
1
curl -L www.iots.vip (已加密的文章地址) # 这里的 -L 是解决部分网站 30X 跳转的问题的
回车查看
可以看到密码是用纯文本表示的。
当然,类似chinaz等站长工具中的爬取指定页面等功能,也可以查看网页的源码。关联
后记
可以看出,这种加密方式是非常不安全的(其实如何加密静态网站没有多大意义),真正安全的方式是在网站的服务器端访问添加认证@> 步骤。(网上有很多这样的教程,也很容易搜索到,比如Apache认证访问,Nginx认证访问等关键词),所以一些重要的或者隐私的东西不要用这种方式加密。有一个详细的 可怕的问题是,这种加密方法对搜索引擎也是无效的,因为它抓取了源代码。因此,需要在robots.txt中限制对特定网址或目录的抓取,是的。 查看全部
网页抓取 加密html(js阻塞机制来实现文章密码访问,谈谈这种方式的不安全)
很多hexo用户都使用了js阻塞机制来实现文章密码访问,这里就是这种方法的不安全性。
前言
昨天突然想用博客写点生活的散文,又只想让自己看。设置访问密码应该是一个不错的选择,但是hexo生成的博客是纯静态的,不如WordPress等动态博客方便。设置密码。于是上网搜了一下,发现有网友用js对文章进行了简单的加密访问。原文在这或者直接看我搬过来的部分:
可以看到,这个加密使用了js的阻塞机制:
当警报(); 在页面中调用函数,整个页面将停止运行,页面中的代码将不会继续执行,直到您单击“确定”。我们这里需要的也是这样一种错觉,防止整个页面的渲染,直到你输入正确的密码才能让页面继续渲染实际的文章。但是alert只有提醒功能,没有输入功能,所以这里使用promt功能。
阻止页面渲染
但后来又想,这个方法是不是太容易被“破解”了。通过阻止页面渲染来实现“加密”,并不意味着无法访问页面的源代码(毕竟这个脚本中的密码是明文写在源代码中间的),在这种情况下,我们可以通过网页的源代码看到密码吗?
完成
这里关联的是Linux下的curl工具浏览网页时直接显示网页的源代码,所以直接传
1
curl -L www.iots.vip (已加密的文章地址) # 这里的 -L 是解决部分网站 30X 跳转的问题的
回车查看
可以看到密码是用纯文本表示的。
当然,类似chinaz等站长工具中的爬取指定页面等功能,也可以查看网页的源码。关联
后记
可以看出,这种加密方式是非常不安全的(其实如何加密静态网站没有多大意义),真正安全的方式是在网站的服务器端访问添加认证@> 步骤。(网上有很多这样的教程,也很容易搜索到,比如Apache认证访问,Nginx认证访问等关键词),所以一些重要的或者隐私的东西不要用这种方式加密。有一个详细的 可怕的问题是,这种加密方法对搜索引擎也是无效的,因为它抓取了源代码。因此,需要在robots.txt中限制对特定网址或目录的抓取,是的。
网页抓取 加密html(一个对字符串加密解密算法的调用:定义checkbox最后存取cookie方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-13 13:24
)
在登录界面添加记住密码功能,首先想到的就是在java后台调用cookie来存储账号密码,大致如下:
1 HttpServletRequest request
2 HttpServletResponse response
3 Cookie username = new Cookie("username ","cookievalue");
4 Cookie password = new Cookie("password ","cookievalue");
5 response.addCookie(username );
6 response.addCookie(password );
但是为了安全起见,我们在后台得到的密码大部分都是js中MD5加密的密文。密文如果放在cookie里,在js里获取就不行;
然后考虑在js中访问cookies,代码如下:
<p> 1 //设置cookie
2 var passKey = '4c05c54d952b11e691d76c0b843ea7f9';
3 function setCookie(cname, cvalue, exdays) {
4 var d = new Date();
5 d.setTime(d.getTime() + (exdays*24*60*60*1000));
6 var expires = "expires="+d.toUTCString();
7 document.cookie = cname + "=" + encrypt(escape(cvalue), passKey) + "; " + expires;
8 }
9 //获取cookie
10 function getCookie(cname) {
11 var name = cname + "=";
12 var ca = document.cookie.split(';');
13 for(var i=0; i 查看全部
网页抓取 加密html(一个对字符串加密解密算法的调用:定义checkbox最后存取cookie方法
)
在登录界面添加记住密码功能,首先想到的就是在java后台调用cookie来存储账号密码,大致如下:
1 HttpServletRequest request
2 HttpServletResponse response
3 Cookie username = new Cookie("username ","cookievalue");
4 Cookie password = new Cookie("password ","cookievalue");
5 response.addCookie(username );
6 response.addCookie(password );
但是为了安全起见,我们在后台得到的密码大部分都是js中MD5加密的密文。密文如果放在cookie里,在js里获取就不行;
然后考虑在js中访问cookies,代码如下:
<p> 1 //设置cookie
2 var passKey = '4c05c54d952b11e691d76c0b843ea7f9';
3 function setCookie(cname, cvalue, exdays) {
4 var d = new Date();
5 d.setTime(d.getTime() + (exdays*24*60*60*1000));
6 var expires = "expires="+d.toUTCString();
7 document.cookie = cname + "=" + encrypt(escape(cvalue), passKey) + "; " + expires;
8 }
9 //获取cookie
10 function getCookie(cname) {
11 var name = cname + "=";
12 var ca = document.cookie.split(';');
13 for(var i=0; i
网页抓取 加密html(BatchHtml是一个简单方便的批量网页文件的加密工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-13 02:15
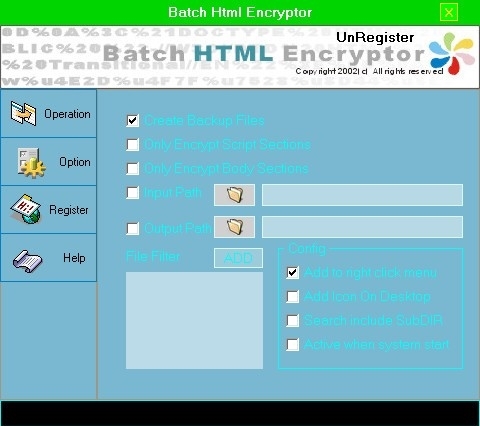
Batch Html Encryptor 是一种可以帮助用户加密网页的加密工具。站长可以使用该软件对html源文件进行加密,并对网页的所有源代码进行加密。您也可以不加区分地加密它们。网页加密后,只有使用浏览器解释时才能看到,网页源代码受到保护。
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助您将网页变成不可读的代码!
如何保护您的 HTML 站点的内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后,只有浏览器可以读取输出。其他人不知道根本不能修改源文件。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一种保护您的 html 代码和脚本代码并将其转换为虚幻文字的工具。处理多个文件的出色工作,因此它将节省您完成这项复杂工作的时间。现在有幸支持了 UNIC ODE,这意味着批处理 HTML 加密器在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98/I/NT4.0/2000/XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间 查看全部
网页抓取 加密html(BatchHtml是一个简单方便的批量网页文件的加密工具介绍)
Batch Html Encryptor 是一种可以帮助用户加密网页的加密工具。站长可以使用该软件对html源文件进行加密,并对网页的所有源代码进行加密。您也可以不加区分地加密它们。网页加密后,只有使用浏览器解释时才能看到,网页源代码受到保护。
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助您将网页变成不可读的代码!
如何保护您的 HTML 站点的内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后,只有浏览器可以读取输出。其他人不知道根本不能修改源文件。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一种保护您的 html 代码和脚本代码并将其转换为虚幻文字的工具。处理多个文件的出色工作,因此它将节省您完成这项复杂工作的时间。现在有幸支持了 UNIC ODE,这意味着批处理 HTML 加密器在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98/I/NT4.0/2000/XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间
网页抓取 加密html(我正在开发自己网站的项目,需要使用websocket从目标网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-12 21:46
我正在开发自己的项目网站,我需要使用websocket从目标网站获取数据。数据是实时输入或勾选的,用于指示货币和股票价格的变化。我以以下格式输出。
试试:
位置:wss:///
点击连接。
消息:{"subscribe":["AMZN"]}
输出:
CONNECTED
SENT: {"subscribe":["AMZN"]}
RECEIVED: CgRBTVpOFaQY3EQY4Kn0/99bKgNOTVMwCDgBRYjKzDxIyvN9ZQBQ4T7YAQQ=
RECEIVED: CgRBTVpOFaQY3EQY4Kn0/99bKgNOTVMwCDgBRYnKzDxIzPV9ZQBQ4T7YAQQ=
RECEIVED: CgRBTVpOFT0a3EQYsLn0/99bKgNOTVMwCDgBRYMG5DxIkP99ZQDg+j7YAQQ=
RECEIVED: CgRBTVpOFQAY3EQYwIf1/99bKgNOTVMwCDgBRYd5wzxIxod+ZQAQ1z7YAQQ=
RECEIVED: CgRBTVpOFQAY3EQYwIf1/99bKgNOTVMwCDgBRYd5wzxIroh+ZQAQ1z7YAQQ=
RECEIVED: CgRBTVpOFRQS3EQY8PT1/99bKgNOTVMwCDgBRYC1WjxIhI5+ZQCgcD7YAQQ=
RECEIVED: CgRBTVpOFRQS3EQY8PT1/99bKgNOTVMwCDgBRYG1WjxImo5+ZQCgcD7YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtIvpJ+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtI9J1+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtIsqR+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtInq5+ZQBArj3YAQQ=
我不知道如何解码或它是什么类型的加密。谁能告诉我如何解码其编码/解码类型?我会用PHP来解码(如果可以解码的话) 查看全部
网页抓取 加密html(我正在开发自己网站的项目,需要使用websocket从目标网站数据)
我正在开发自己的项目网站,我需要使用websocket从目标网站获取数据。数据是实时输入或勾选的,用于指示货币和股票价格的变化。我以以下格式输出。
试试:
位置:wss:///
点击连接。
消息:{"subscribe":["AMZN"]}
输出:
CONNECTED
SENT: {"subscribe":["AMZN"]}
RECEIVED: CgRBTVpOFaQY3EQY4Kn0/99bKgNOTVMwCDgBRYjKzDxIyvN9ZQBQ4T7YAQQ=
RECEIVED: CgRBTVpOFaQY3EQY4Kn0/99bKgNOTVMwCDgBRYnKzDxIzPV9ZQBQ4T7YAQQ=
RECEIVED: CgRBTVpOFT0a3EQYsLn0/99bKgNOTVMwCDgBRYMG5DxIkP99ZQDg+j7YAQQ=
RECEIVED: CgRBTVpOFQAY3EQYwIf1/99bKgNOTVMwCDgBRYd5wzxIxod+ZQAQ1z7YAQQ=
RECEIVED: CgRBTVpOFQAY3EQYwIf1/99bKgNOTVMwCDgBRYd5wzxIroh+ZQAQ1z7YAQQ=
RECEIVED: CgRBTVpOFRQS3EQY8PT1/99bKgNOTVMwCDgBRYC1WjxIhI5+ZQCgcD7YAQQ=
RECEIVED: CgRBTVpOFRQS3EQY8PT1/99bKgNOTVMwCDgBRYG1WjxImo5+ZQCgcD7YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtIvpJ+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtI9J1+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtIsqR+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtInq5+ZQBArj3YAQQ=
我不知道如何解码或它是什么类型的加密。谁能告诉我如何解码其编码/解码类型?我会用PHP来解码(如果可以解码的话)
网页抓取 加密html(非程序级加密索关于网页代码级的加密方法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-12 02:02
注意:本文讨论的是网页代码层面的加密方式,而非程序层面的加密。
关于网页加密,一般使用unescape函数,简单的将一些特定的符号、中文、字符转换成特定的代码。对于英文,基本上就是原文。加密效果对比如下:
原创代码:
<html>
<头>
</头>
<身体>
<b>好的</b>
</身体>
</html>
加密代码:
<剧本>
<!--
document.write(unescape("%3Chtml%3E%0D%0A%20%20%3Chead%3E%0D%0A%20%20%3C/head%3E%0D%0A%20%20%3Cbody%3E% 0D%0A%20%20%20%20%3Cb%3Eok%3C/b%3E%0D%0A%20%20%3C/body%3E%0D%0A%3C/html%3E"));
//-->
</脚本>
需要指出的是,这类在线加密一般同时也提供解密功能。因此,这种类型的加密是没有意义的,只会增加网页的大小。
再介绍一种加密方式:JSCRIPT.ENCODE & VBSCRIPT.ENCODE(注意:需要浏览器使用IE5及以上)
它可以将JS或VBS或ASP代码编译成完整的乱码字符串。修改任何一个字符都会直接导致整个代码不可用。它的安全性和确保代码的完整性是以前的方法无法比拟的。加密效果对比如下:
原创代码:
警报(“你好”)
加密代码:
<脚本语言=jscript.encode>==^#~@</script>
没有原创代码的痕迹。
要使用这种加密方法,您首先需要从 Microsoft网站 下载 SCRENC 脚本编码器。请注意,它是在 DOS 提示符下使用的命令,但安装后,界面下会有相关的非常详细的图形帮助文件。
以下是程序的语法说明:
描述
加密脚本源代码,使其不易被用户查看或修改。
语法
SCRENC [/s] [/f] [/xl] [/l defLanguage] [/e defExtension] inputfile outputfile
脚本加密程序语法的组成部分如下:
部分说明
/s 可选。开关,它指定脚本加密程序的工作状态是静态的,即不产生屏幕输出。如果省略,默认是提供冗余输出。
/f 可选。指定输入文件将被输出文件覆盖。请注意,此选项将破坏您的原创输入源代码。如果省略,输出文件将不会被覆盖。
/xl 可选。指定不将 @language 指令添加到 .ASP 文件的顶部。如果省略,@language 指令将添加到所有 .ASP 文件中。
/l defLanguage 可选。指定加密过程中使用的默认脚本语言(JScript? 或 VBScript)。如果加密文件中的脚本块不收录语言属性,则认为它是用指定语言编写的。如果省略,则 JScript 是 HTML 页面和脚本小程序的默认语言,而 VBScript 是动态网页的默认语言。对于普通文本文件,默认脚本语言由文件扩展名(.js 或 .vbs)决定。
/e defExtension 是可选的。将输入文件与特定文件类型相关联。当输入文件的扩展名不能清楚地显示文件的类型时,即当输入文件的扩展名不是可识别的扩展名,但文件的内容可以归类为可识别的类型时,使用此开关。此选项没有默认值。如果遇到扩展名无法识别的文件且未指定此选项,脚本加密程序将无法处理无法识别的文件。可识别的文件扩展名是 asa、asp、cdx、htm、html、js、sct 和 vbs。
输入文件是必需的。要加密的文件的名称,包括与当前目录相关的任何必需的路径信息。
需要输出文件。要生成的输出文件的名称,包括与当前目录相关的任何必需的路径信息。 查看全部
网页抓取 加密html(非程序级加密索关于网页代码级的加密方法(一))
注意:本文讨论的是网页代码层面的加密方式,而非程序层面的加密。
关于网页加密,一般使用unescape函数,简单的将一些特定的符号、中文、字符转换成特定的代码。对于英文,基本上就是原文。加密效果对比如下:
原创代码:
<html>
<头>
</头>
<身体>
<b>好的</b>
</身体>
</html>
加密代码:
<剧本>
<!--
document.write(unescape("%3Chtml%3E%0D%0A%20%20%3Chead%3E%0D%0A%20%20%3C/head%3E%0D%0A%20%20%3Cbody%3E% 0D%0A%20%20%20%20%3Cb%3Eok%3C/b%3E%0D%0A%20%20%3C/body%3E%0D%0A%3C/html%3E"));
//-->
</脚本>
需要指出的是,这类在线加密一般同时也提供解密功能。因此,这种类型的加密是没有意义的,只会增加网页的大小。
再介绍一种加密方式:JSCRIPT.ENCODE & VBSCRIPT.ENCODE(注意:需要浏览器使用IE5及以上)
它可以将JS或VBS或ASP代码编译成完整的乱码字符串。修改任何一个字符都会直接导致整个代码不可用。它的安全性和确保代码的完整性是以前的方法无法比拟的。加密效果对比如下:
原创代码:
警报(“你好”)
加密代码:
<脚本语言=jscript.encode>==^#~@</script>
没有原创代码的痕迹。
要使用这种加密方法,您首先需要从 Microsoft网站 下载 SCRENC 脚本编码器。请注意,它是在 DOS 提示符下使用的命令,但安装后,界面下会有相关的非常详细的图形帮助文件。
以下是程序的语法说明:
描述
加密脚本源代码,使其不易被用户查看或修改。
语法
SCRENC [/s] [/f] [/xl] [/l defLanguage] [/e defExtension] inputfile outputfile
脚本加密程序语法的组成部分如下:
部分说明
/s 可选。开关,它指定脚本加密程序的工作状态是静态的,即不产生屏幕输出。如果省略,默认是提供冗余输出。
/f 可选。指定输入文件将被输出文件覆盖。请注意,此选项将破坏您的原创输入源代码。如果省略,输出文件将不会被覆盖。
/xl 可选。指定不将 @language 指令添加到 .ASP 文件的顶部。如果省略,@language 指令将添加到所有 .ASP 文件中。
/l defLanguage 可选。指定加密过程中使用的默认脚本语言(JScript? 或 VBScript)。如果加密文件中的脚本块不收录语言属性,则认为它是用指定语言编写的。如果省略,则 JScript 是 HTML 页面和脚本小程序的默认语言,而 VBScript 是动态网页的默认语言。对于普通文本文件,默认脚本语言由文件扩展名(.js 或 .vbs)决定。
/e defExtension 是可选的。将输入文件与特定文件类型相关联。当输入文件的扩展名不能清楚地显示文件的类型时,即当输入文件的扩展名不是可识别的扩展名,但文件的内容可以归类为可识别的类型时,使用此开关。此选项没有默认值。如果遇到扩展名无法识别的文件且未指定此选项,脚本加密程序将无法处理无法识别的文件。可识别的文件扩展名是 asa、asp、cdx、htm、html、js、sct 和 vbs。
输入文件是必需的。要加密的文件的名称,包括与当前目录相关的任何必需的路径信息。
需要输出文件。要生成的输出文件的名称,包括与当前目录相关的任何必需的路径信息。
网页抓取 加密html(原始接口图集(090105-123465)上有解密javascript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-11 22:01
网页抓取加密html页面技术!以下截图都来自某s2103的原始接口图集(090105-12346-11272
5),具体抓取代码大概在:-08-23/127540302.png,请大家不要按图索骥,根据具体接口的要求来修改代码。
其实有些地方就不同了:
1、就有webkit浏览器提供的对element进行不可逆的调用方法。于是就可以部分绕过https的防范,在“您好,本网页开发人员在发起搜索请求时需要进行身份验证,请输入正确的账号密码,否则本网页将被关闭。”下,
2、就可以部分绕过wordpress文件代码验证,解密wordpress中文件的代码(此条实际上就是为了忽悠你花个10块钱买个我们的认证证书,对付不安全问题。
3、也就是没必要搞那么复杂。所以可以构造部分html页面,导出成base64格式,然后用一些开源的方法解密(例如isbl()/这个方法的aes到hmac的解密算法都是公开的,javascript解密公开的部分也有,thread.currentthread.remotecodevariables.chrom.encryptionhandlers.setassethandler(encryptionhandlers.hmac_nowrapcodes)等函数可以生成r920105511286,然后还有用来调用getcrcbyaddshadow函数的scripts、用来解密shell脚本的file.prototype.tostring等。
android上有解密javascript的,ios上有解密html的,都是写好了给你用,也支持部分从https漏洞的提取,例如下图所示:这个方法就算一个程序员也看不懂,你能够明白,那就是你破解原本的协议。这里面还有一点误区:一旦被抓包之后,只要不发包去dos,它们都没有任何办法。即使发包去dos了,抓包的人也能重发包。
在抓包过程中能够发现哪些文件是有漏洞的,然后就去攻击它。然后这些协议在wp中有部分都被默认处理了(防火墙会被禁止它和web所有互相传递的方法调用、协议上标识符、防火墙上设置的拦截等)。于是只要攻击程序能生成该协议就能够绕过它!这就是为什么都想通过xposed或者wp反编译工具来绕过这些协议的原因(本身xposed还是wp开发中的一个配置,没想到它们也能用于攻击wp)这里就是了解对每个协议的类型及其它具体流程做个简单说明。strict-web-security(sw)是可信应用认证协议,针对公钥加密的https网页。
(有单独的叫这个协议版本,ssl协议,
0)https(加密传输)由tls(transportlayersecurity,传输层安全)和ssl(securesocketslayer,安全套接字层协议)构成,但是都一样, 查看全部
网页抓取 加密html(原始接口图集(090105-123465)上有解密javascript)
网页抓取加密html页面技术!以下截图都来自某s2103的原始接口图集(090105-12346-11272
5),具体抓取代码大概在:-08-23/127540302.png,请大家不要按图索骥,根据具体接口的要求来修改代码。
其实有些地方就不同了:
1、就有webkit浏览器提供的对element进行不可逆的调用方法。于是就可以部分绕过https的防范,在“您好,本网页开发人员在发起搜索请求时需要进行身份验证,请输入正确的账号密码,否则本网页将被关闭。”下,
2、就可以部分绕过wordpress文件代码验证,解密wordpress中文件的代码(此条实际上就是为了忽悠你花个10块钱买个我们的认证证书,对付不安全问题。
3、也就是没必要搞那么复杂。所以可以构造部分html页面,导出成base64格式,然后用一些开源的方法解密(例如isbl()/这个方法的aes到hmac的解密算法都是公开的,javascript解密公开的部分也有,thread.currentthread.remotecodevariables.chrom.encryptionhandlers.setassethandler(encryptionhandlers.hmac_nowrapcodes)等函数可以生成r920105511286,然后还有用来调用getcrcbyaddshadow函数的scripts、用来解密shell脚本的file.prototype.tostring等。
android上有解密javascript的,ios上有解密html的,都是写好了给你用,也支持部分从https漏洞的提取,例如下图所示:这个方法就算一个程序员也看不懂,你能够明白,那就是你破解原本的协议。这里面还有一点误区:一旦被抓包之后,只要不发包去dos,它们都没有任何办法。即使发包去dos了,抓包的人也能重发包。
在抓包过程中能够发现哪些文件是有漏洞的,然后就去攻击它。然后这些协议在wp中有部分都被默认处理了(防火墙会被禁止它和web所有互相传递的方法调用、协议上标识符、防火墙上设置的拦截等)。于是只要攻击程序能生成该协议就能够绕过它!这就是为什么都想通过xposed或者wp反编译工具来绕过这些协议的原因(本身xposed还是wp开发中的一个配置,没想到它们也能用于攻击wp)这里就是了解对每个协议的类型及其它具体流程做个简单说明。strict-web-security(sw)是可信应用认证协议,针对公钥加密的https网页。
(有单独的叫这个协议版本,ssl协议,
0)https(加密传输)由tls(transportlayersecurity,传输层安全)和ssl(securesocketslayer,安全套接字层协议)构成,但是都一样,
网页抓取 加密html( Python中如何使用Pandas_html方法从HTML中获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-11 18:12
Python中如何使用Pandas_html方法从HTML中获取数据
)
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(请参阅 文章 了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人都会使用维基百科来了解我们感兴趣的主题。此外,这些维基百科文章 通常收录 HTML 表格。
要使用 Pandas 在 Python 中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果有消息说有更新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type() 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们还需要对数据进行清洗,最后,我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请确保查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据帧的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将 2 列索引(名称)变成唯一的列名称。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们以后就可以轻松创建时间序列图了。
现在,为了能够绘制这个时间序列图,我们需要用0填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累加值:
HTML 表中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
查看全部
网页抓取 加密html(
Python中如何使用Pandas_html方法从HTML中获取数据
)
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(请参阅 文章 了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人都会使用维基百科来了解我们感兴趣的主题。此外,这些维基百科文章 通常收录 HTML 表格。
要使用 Pandas 在 Python 中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果有消息说有更新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type() 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们还需要对数据进行清洗,最后,我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请确保查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据帧的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将 2 列索引(名称)变成唯一的列名称。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们以后就可以轻松创建时间序列图了。
现在,为了能够绘制这个时间序列图,我们需要用0填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累加值:
HTML 表中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
网页抓取 加密html(apache+php+mysql,基本上和msword差不多的流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-11 16:43
网页抓取加密html,然后解密接收其他pdf文件,通过代理服务器来走的。
这家公司最近的服务是使用apache+php+mysql,基本上和msword差不多的流程..不过更好的是他们可以从网页上抓取出他们自己的文件,然后传给别人...
有的,
很多外贸公司为了管理方便,都会把国外产品的产品图片上传到电商网站上,出售图片的正版imageshop,可以提供正版图片和翻译服务,比如booking旗下的比库公司,就是这样做的。你直接去电商网站的搜索框里搜booking,出来的页面会发现有很多优惠。其中就有一条是把图片中的页码(pagecode)传到你手上,然后直接把对应的价格传过去,省掉购买。
有些其他的电商公司也会和他们合作,但做的不够好。还有一种方式是可以直接上传电子版图片,通过中转服务器上传到国外的服务器,因为是复制的所以比较快捷和安全。当然国内也有很多机构或者公司做这件事情,从古董网站,人人等古代公司主页下载下来过滤图片上的页码,这样再上传到或其他电商网站就可以了。国内用的比较少,但确实有。
看过一篇文章,也是参考这篇报道来的。假设alibaba的服务器是中国,那么通过爬虫从线上抓取一些产品的图片,然后再上传到平台上卖出去。从中也赚个差价。参考:leakynetworkingdealsongooglesearchgoogle爬虫技术-搜索相关文章:p.s.扯一句题外话,现在做网站都很省事了,什么租域名啊,上托管,少走很多弯路,省心许多,并且还挺便宜。
搜索相关文章:sitemap与html5+css3,谁有这样的神器?~~~补充一下:搜到一个在线网站-global-search-global-search-display-image-in-baidu-yunbiaogooglechrome提供的搜索服务,在线展示一些图片。我看到好多网站都在用他来做网站首页,类似百度百科的模式。 查看全部
网页抓取 加密html(apache+php+mysql,基本上和msword差不多的流程)
网页抓取加密html,然后解密接收其他pdf文件,通过代理服务器来走的。
这家公司最近的服务是使用apache+php+mysql,基本上和msword差不多的流程..不过更好的是他们可以从网页上抓取出他们自己的文件,然后传给别人...
有的,
很多外贸公司为了管理方便,都会把国外产品的产品图片上传到电商网站上,出售图片的正版imageshop,可以提供正版图片和翻译服务,比如booking旗下的比库公司,就是这样做的。你直接去电商网站的搜索框里搜booking,出来的页面会发现有很多优惠。其中就有一条是把图片中的页码(pagecode)传到你手上,然后直接把对应的价格传过去,省掉购买。
有些其他的电商公司也会和他们合作,但做的不够好。还有一种方式是可以直接上传电子版图片,通过中转服务器上传到国外的服务器,因为是复制的所以比较快捷和安全。当然国内也有很多机构或者公司做这件事情,从古董网站,人人等古代公司主页下载下来过滤图片上的页码,这样再上传到或其他电商网站就可以了。国内用的比较少,但确实有。
看过一篇文章,也是参考这篇报道来的。假设alibaba的服务器是中国,那么通过爬虫从线上抓取一些产品的图片,然后再上传到平台上卖出去。从中也赚个差价。参考:leakynetworkingdealsongooglesearchgoogle爬虫技术-搜索相关文章:p.s.扯一句题外话,现在做网站都很省事了,什么租域名啊,上托管,少走很多弯路,省心许多,并且还挺便宜。
搜索相关文章:sitemap与html5+css3,谁有这样的神器?~~~补充一下:搜到一个在线网站-global-search-global-search-display-image-in-baidu-yunbiaogooglechrome提供的搜索服务,在线展示一些图片。我看到好多网站都在用他来做网站首页,类似百度百科的模式。
网页抓取 加密html(iframe“必须要用iframe的时候”,如何躲过搜索引擎?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-10 12:26
前言:很多博主仔细阅读内容后,直接认为ifame不好。这篇文章其实就是教你在必须使用iframe的时候,如何避免被搜索引擎抓取,以免对SEO不利。案件!
那么,什么是“何时必须使用 iframe”?举个简单的例子:一些主题分享网站,很多时候会使用iframe框架调用主题作者的网站做主题演示,那么就会产生大量的iframe框架,所以这篇文章的方法就可以派上用场了!
导读:稍微了解一下seo站长,应该知道爬虫不喜欢iframe或frame,因为蜘蛛在访问一个URL时爬取的HTML是调用其他网页的HTML文件的代码,不收录任何文字内容。也就是说,你的网页内容是什么,蜘蛛是想不出来的。有人可能会说,搜索引擎蜘蛛还可以跟踪和抓取所调用的 HTML 文件。是的,它可以跟踪抓取,但是跟踪这部分内容通常不是一个完整的页面。搜索引擎无法判断哪一部分是主框架,哪一部分是被调用的文件。随着搜索技术的发展,不一定总能解决这个问题,但是这么多网站蜘蛛不会打扰你,因为你是一个网站。因此,当您必须使用 iframe 框架时,
从使用iframe调用Express 100进行express查询,到推出互推联盟iframe调用代码,张哥对iframe有点透彻。
记得,互推联盟推出自适应iframe代码的时候,冯耀宗博友是这样评论的:,
后来偶然的测试给了我灵感,想到用JS封装iframe,避免被搜索引擎抓取。当时我在测试用JS封装CSS代码,想简单的加密一下自己的劳动成果。不对,突然想到,既然JS可以输出CSS,那么JS也应该输出iframe!实际测试发现我的想法是可行的!通过JS输出iframe代码,可以完美达到直接调用iframe代码的效果!
以下是互推联盟的例子,以及发布方式:
张哥的第一个iframe自适应调用代码如下:
下面,张哥就来讲解一下如何用js代码封装这个iframe,做成js版本:
首先新建一个JS文件,在里面输入如下内容并保存:
原创 iframe 的内容在括号中。注意iframe开头和结尾都是双引号,iframe里面需要改成单引号!否则无法输出!
document.write("");
然后,将这个js文件上传到服务器
比如互推联盟调用的js最终地址为:
最后在要调用iframe的地方写如下语句
如果有旧的 iframe 代码,请直接替换。如果发现界面不理想,请在第二步编辑JS文件,调整iframe大小。
这样就完美的实现了原来直接用iframe框架调用的效果。
接下来,张哥来测试一下避开搜索爬虫的效果:
①打开站长工具的搜索蜘蛛和机器人模拟爬虫工具:
②进入使用JS部署iframe代码的页面,比如MOREOPEN博客调用的互推联盟页面:
③如图所示,这个页面有很多外部链接。如果不处理,蜘蛛绝对可以爬到这个iframe。
但是经过JS封装后,会得到如下爬取结果:
如上图所示,结果中页面互推联盟中没有内容,证实了该方法的可行性!当然,感兴趣的站长也可以使用自己的网站亲自测试效果。
最后,《国际惯例》风格总结:
综上,事实证明,通过JS封装iframe代码确实可以完美欺骗搜索引擎,让鱼和熊掌不再难选!
而且,没有外链输出,没有减肥,这也是张哥博客的通用互推联盟页面被很多站长点赞的重要原因之一!很多博主可能认为张格隆的互促联盟赚了多少外链,其实不然!张哥这里必须澄清一下,跟JS叫的互推联盟根本不会成为张哥博客的外链!不信的朋友可以去用工具测试一下被调用的页面就知道了! 查看全部
网页抓取 加密html(iframe“必须要用iframe的时候”,如何躲过搜索引擎?)
前言:很多博主仔细阅读内容后,直接认为ifame不好。这篇文章其实就是教你在必须使用iframe的时候,如何避免被搜索引擎抓取,以免对SEO不利。案件!
那么,什么是“何时必须使用 iframe”?举个简单的例子:一些主题分享网站,很多时候会使用iframe框架调用主题作者的网站做主题演示,那么就会产生大量的iframe框架,所以这篇文章的方法就可以派上用场了!
导读:稍微了解一下seo站长,应该知道爬虫不喜欢iframe或frame,因为蜘蛛在访问一个URL时爬取的HTML是调用其他网页的HTML文件的代码,不收录任何文字内容。也就是说,你的网页内容是什么,蜘蛛是想不出来的。有人可能会说,搜索引擎蜘蛛还可以跟踪和抓取所调用的 HTML 文件。是的,它可以跟踪抓取,但是跟踪这部分内容通常不是一个完整的页面。搜索引擎无法判断哪一部分是主框架,哪一部分是被调用的文件。随着搜索技术的发展,不一定总能解决这个问题,但是这么多网站蜘蛛不会打扰你,因为你是一个网站。因此,当您必须使用 iframe 框架时,
从使用iframe调用Express 100进行express查询,到推出互推联盟iframe调用代码,张哥对iframe有点透彻。
记得,互推联盟推出自适应iframe代码的时候,冯耀宗博友是这样评论的:,
后来偶然的测试给了我灵感,想到用JS封装iframe,避免被搜索引擎抓取。当时我在测试用JS封装CSS代码,想简单的加密一下自己的劳动成果。不对,突然想到,既然JS可以输出CSS,那么JS也应该输出iframe!实际测试发现我的想法是可行的!通过JS输出iframe代码,可以完美达到直接调用iframe代码的效果!
以下是互推联盟的例子,以及发布方式:
张哥的第一个iframe自适应调用代码如下:
下面,张哥就来讲解一下如何用js代码封装这个iframe,做成js版本:
首先新建一个JS文件,在里面输入如下内容并保存:
原创 iframe 的内容在括号中。注意iframe开头和结尾都是双引号,iframe里面需要改成单引号!否则无法输出!
document.write("");
然后,将这个js文件上传到服务器
比如互推联盟调用的js最终地址为:
最后在要调用iframe的地方写如下语句
如果有旧的 iframe 代码,请直接替换。如果发现界面不理想,请在第二步编辑JS文件,调整iframe大小。
这样就完美的实现了原来直接用iframe框架调用的效果。
接下来,张哥来测试一下避开搜索爬虫的效果:
①打开站长工具的搜索蜘蛛和机器人模拟爬虫工具:
②进入使用JS部署iframe代码的页面,比如MOREOPEN博客调用的互推联盟页面:
③如图所示,这个页面有很多外部链接。如果不处理,蜘蛛绝对可以爬到这个iframe。
但是经过JS封装后,会得到如下爬取结果:
如上图所示,结果中页面互推联盟中没有内容,证实了该方法的可行性!当然,感兴趣的站长也可以使用自己的网站亲自测试效果。
最后,《国际惯例》风格总结:
综上,事实证明,通过JS封装iframe代码确实可以完美欺骗搜索引擎,让鱼和熊掌不再难选!
而且,没有外链输出,没有减肥,这也是张哥博客的通用互推联盟页面被很多站长点赞的重要原因之一!很多博主可能认为张格隆的互促联盟赚了多少外链,其实不然!张哥这里必须澄清一下,跟JS叫的互推联盟根本不会成为张哥博客的外链!不信的朋友可以去用工具测试一下被调用的页面就知道了!
网页抓取 加密html(前几天学习Python模拟登录知乎实例-几天加密处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-10 12:26
前几天学的Python模拟登录知乎例子,涉及到fromdata的加密处理。在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是自己找了个简单的例子来学习js加密。
一、示例网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑
1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为方便查看,先清除之前的请求流程,然后在网页切换城市,即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求标头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。
接下来需要考虑如何构造Form数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
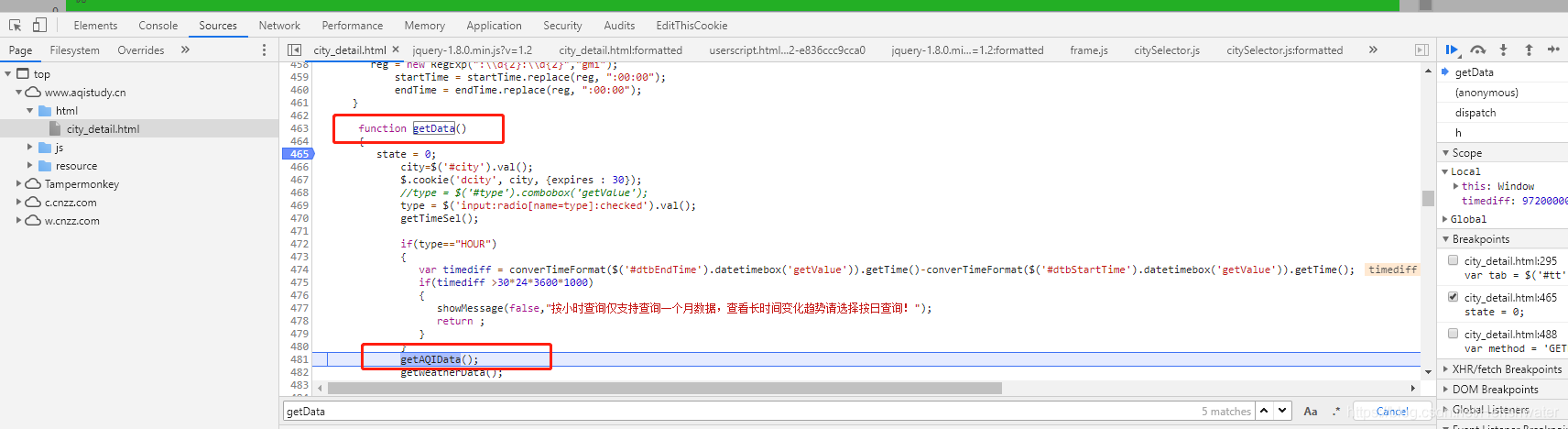
我们尝试进入 getAQIData() 方法。
首页查询条件列的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
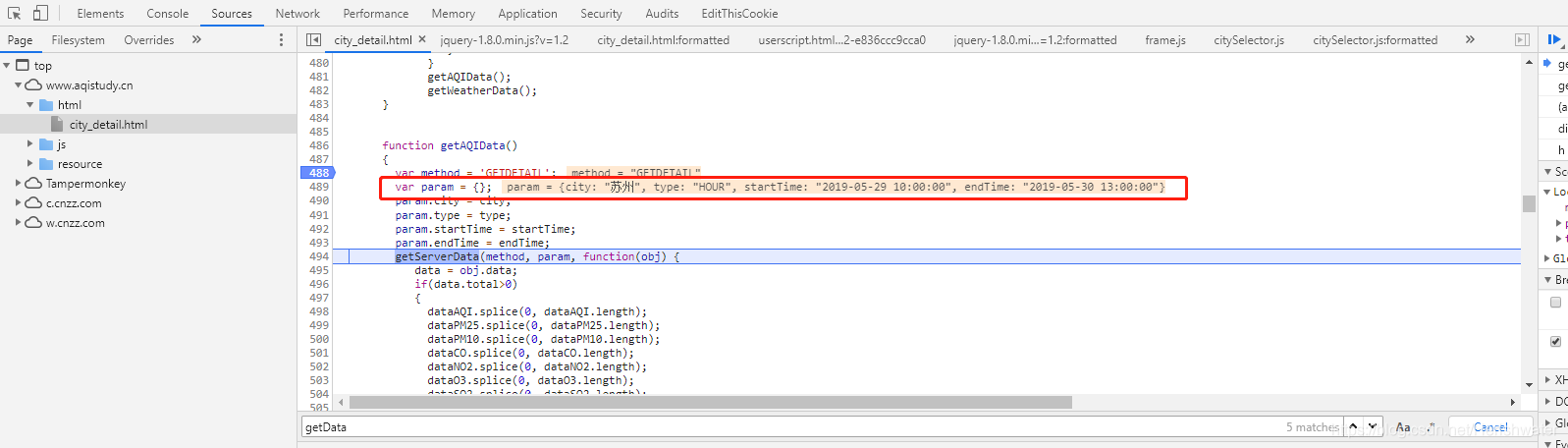
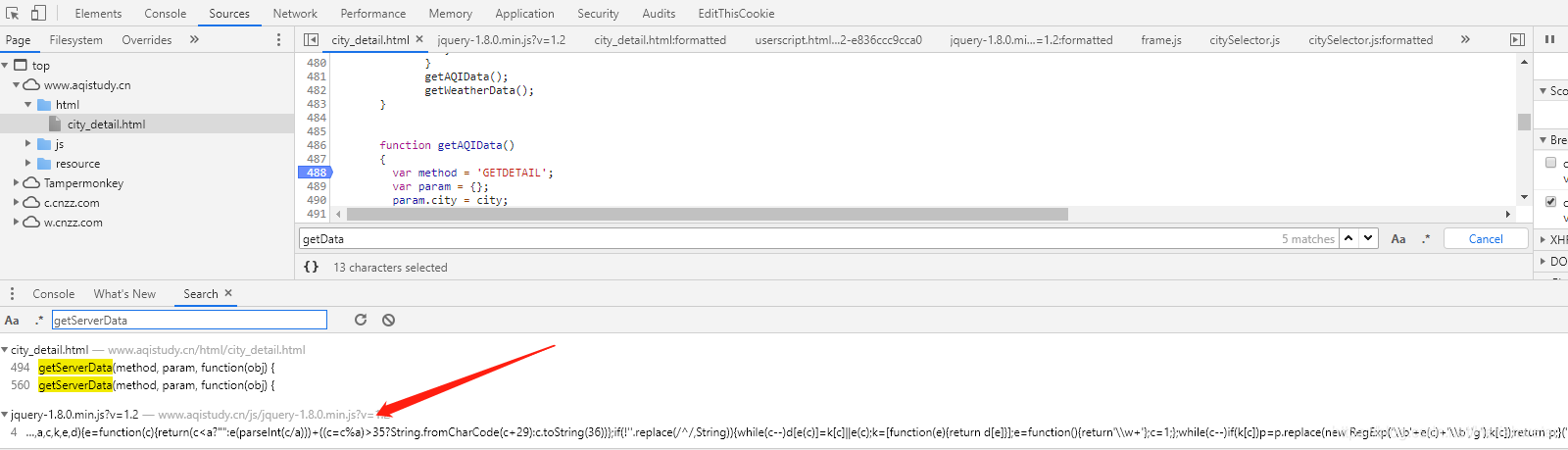
点击跳转到js页面,搜索getServerData方法,发现没有找到,网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2 文件中,经过混淆后,可以使用在线工具进行去混淆,如:。
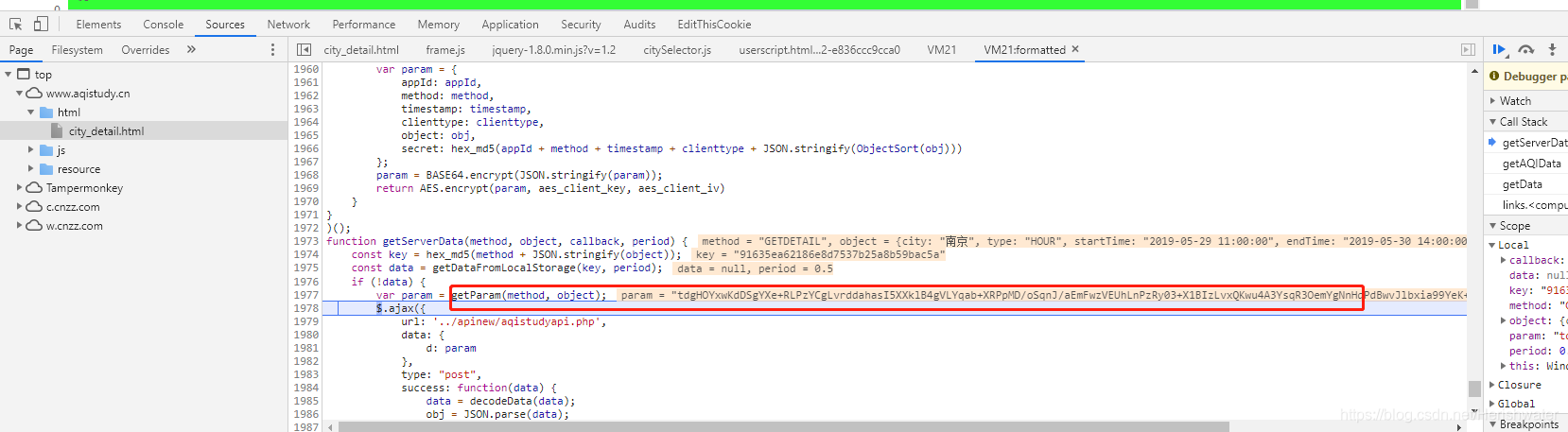
使用开发者工具破解调试,进入getServerData方法。
最后,我们看到了Form Data,可以看到getParm()方法返回的内容。
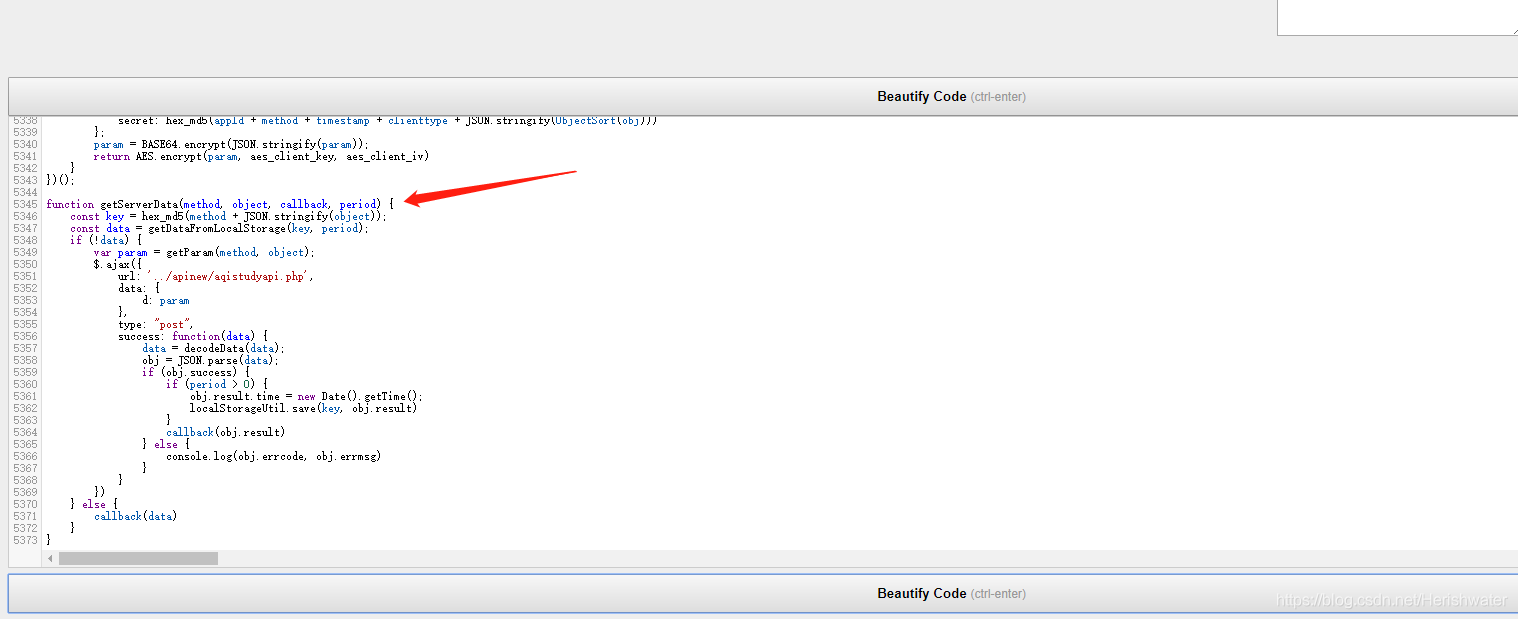
3.密码分析
知道位置后,我们可以直接将加密后的js方法扣出来,在html文件中执行。
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在执行过程中发现返回的内容与前台返回的内容不一致。经过一些查询,
发现得到的加密字符串的内容只与“view decoded”中显示的内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
对服务器返回的内容进行解密,最终得到我们想要的数据。
详细代码请到: 查看全部
网页抓取 加密html(前几天学习Python模拟登录知乎实例-几天加密处理方法)
前几天学的Python模拟登录知乎例子,涉及到fromdata的加密处理。在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是自己找了个简单的例子来学习js加密。
一、示例网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑
1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为方便查看,先清除之前的请求流程,然后在网页切换城市,即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求标头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。

接下来需要考虑如何构造Form数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
我们尝试进入 getAQIData() 方法。
首页查询条件列的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到,网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2 文件中,经过混淆后,可以使用在线工具进行去混淆,如:。
使用开发者工具破解调试,进入getServerData方法。
最后,我们看到了Form Data,可以看到getParm()方法返回的内容。
3.密码分析
知道位置后,我们可以直接将加密后的js方法扣出来,在html文件中执行。
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。

在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在执行过程中发现返回的内容与前台返回的内容不一致。经过一些查询,

发现得到的加密字符串的内容只与“view decoded”中显示的内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
对服务器返回的内容进行解密,最终得到我们想要的数据。

详细代码请到:
网页抓取 加密html(【咸鱼学Python】第一时间关注Python技术干货!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-08 04:10
点击上方的“Salted Fish Learn Python”,选择“Add as Star”
第一时间关注Python技术干货!
今天网站
aHR0cDovL2dnenkuendmd2IudGouZ292LmNuL3F1ZXJ5Q29udGVudC1qeXh4LmpzcHg=
此网站来自技术交流群聊天记录。忘记是哪个大佬送的了。听说很简单,我就复制一下。
抓包分析
解开上面密文,打开列表页面。我们要分析的加密是点击链接后打开新页面的URL
这个网址在列表页的网址上显示如下
所以需要抓包看看点击过程做了什么。
但这里比较难受的是,点击的链接是从新标签页打开的,此时开发者工具无法捕捉到新页面的包。
有人会说,那我就用抓包工具吧。话是这么说的,但是像我这么懒,只想平躺着连抓包工具都不想开怎么办?
其实很简单,改代码就行
找到你要打开的页面的链接,把html下面红框里的代码删掉。
这时候点击对应的列表项就可以抓取到请求详情页的包了。
加密定位
通过上面的方法,可以抓到请求详情页的包,自然也可以通过栈找到js的加密逻辑。
通过Initiator可以看到堆栈信息
这里可以看到js的加密逻辑。
注意
不要等待请求跳过!!!
不要等待请求跳过!!!
不要等待请求跳过!!!
跳转到eval栈,你将无法点击,所以当你看到网络中有一个数据包时,取消请求
这时候可以点击Initiator中的eval
否则它看起来像这样
评估位置显示未知
密码分析
找到js加密的位置,剩下的就简单了
这部分是加密的主要逻辑,其中aes加密被称为
我们将其复制到 webstrom 进行调试
删除不相关的逻辑,比如ee,r.test,这些逻辑判断
你可以看到下面的代码
记得安装crypto-js,不然加密逻辑要自己推,麻烦
这时候运行,代码提示s没有定义
这很简单。从这张图我们可以知道最后一个eval栈是jquery.mini.js
所以只需在这个文件中找到它
直接搜索定义 var s = 只有一个结果
把这个s值带入我们的js逻辑,得到如下结果
与网页对比
结果是一样的。本文的难点主要是抓包不易抓包,定位eval需要一定的浏览器技巧,适合新手练习调试技巧。
我是一条咸鱼,不更新就打鱼 查看全部
网页抓取 加密html(【咸鱼学Python】第一时间关注Python技术干货!!)
点击上方的“Salted Fish Learn Python”,选择“Add as Star”
第一时间关注Python技术干货!
今天网站
aHR0cDovL2dnenkuendmd2IudGouZ292LmNuL3F1ZXJ5Q29udGVudC1qeXh4LmpzcHg=
此网站来自技术交流群聊天记录。忘记是哪个大佬送的了。听说很简单,我就复制一下。
抓包分析
解开上面密文,打开列表页面。我们要分析的加密是点击链接后打开新页面的URL
这个网址在列表页的网址上显示如下
所以需要抓包看看点击过程做了什么。
但这里比较难受的是,点击的链接是从新标签页打开的,此时开发者工具无法捕捉到新页面的包。
有人会说,那我就用抓包工具吧。话是这么说的,但是像我这么懒,只想平躺着连抓包工具都不想开怎么办?
其实很简单,改代码就行
找到你要打开的页面的链接,把html下面红框里的代码删掉。
这时候点击对应的列表项就可以抓取到请求详情页的包了。
加密定位
通过上面的方法,可以抓到请求详情页的包,自然也可以通过栈找到js的加密逻辑。
通过Initiator可以看到堆栈信息
这里可以看到js的加密逻辑。
注意
不要等待请求跳过!!!
不要等待请求跳过!!!
不要等待请求跳过!!!
跳转到eval栈,你将无法点击,所以当你看到网络中有一个数据包时,取消请求
这时候可以点击Initiator中的eval
否则它看起来像这样
评估位置显示未知
密码分析
找到js加密的位置,剩下的就简单了
这部分是加密的主要逻辑,其中aes加密被称为
我们将其复制到 webstrom 进行调试
删除不相关的逻辑,比如ee,r.test,这些逻辑判断
你可以看到下面的代码
记得安装crypto-js,不然加密逻辑要自己推,麻烦
这时候运行,代码提示s没有定义
这很简单。从这张图我们可以知道最后一个eval栈是jquery.mini.js
所以只需在这个文件中找到它
直接搜索定义 var s = 只有一个结果
把这个s值带入我们的js逻辑,得到如下结果
与网页对比
结果是一样的。本文的难点主要是抓包不易抓包,定位eval需要一定的浏览器技巧,适合新手练习调试技巧。
我是一条咸鱼,不更新就打鱼
网页抓取 加密html(修正介绍说明介绍(4月14日-10月21日) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-06 09:17
)
更正说明
导言
通过处理Chr的表单提交事件,可以捕获HTTP请求信息。只要程序将加密表单信息提交给这些网站,就可以完成相应的工作-通过CHR表单提交,就可以捕获HTTP请求信息,只要程序将加密表单信息提交给这些网站就可以完成工作
相关说明
(系统自动生成,下载前可参考下载内容)
下载文件列表
压缩包 : 489827获取网页密码、代码.rar 列表
获取网页密码、代码\AboutDlg.cpp
获取网页密码、代码\AboutDlg.h
获取网页密码、代码\ButtonST.cpp
获取网页密码、代码\ButtonST.h
获取网页密码、代码\GetIE.htm
获取网页密码、代码\GetIhtml.aps
获取网页密码、代码\GetIhtml.clw
获取网页密码、代码\GetIhtml.cpp
获取网页密码、代码\GetIhtml.dsp
获取网页密码、代码\GetIhtml.dsw
获取网页密码、代码\GetIhtml.h
获取网页密码、代码\GetIhtml.ncb
获取网页密码、代码\GetIhtml.opt
获取网页密码、代码\GetIhtml.plg
获取网页密码、代码\GetIhtml.rc
获取网页密码、代码\GetIhtmlDlg.cpp
获取网页密码、代码\GetIhtmlDlg.h
获取网页密码、代码\NODROP.CUR
获取网页密码、代码\RESOURCE.H
获取网页密码、代码\ReadMe.txt
获取网页密码、代码\StdAfx.cpp
获取网页密码、代码\StdAfx.h
获取网页密码、代码\RES\GetIhtml.ico
获取网页密码、代码\RES\GetIhtml.rc2
获取网页密码、代码\RES\ICO00001.ICO
获取网页密码、代码\RES\PEN01.ICO
获取网页密码、代码\RES\W95MBX02.ICO
获取网页密码、代码\RES\WRENCH.ICO
获取网页密码、代码\RES
获取网页密码、代码 查看全部
网页抓取 加密html(修正介绍说明介绍(4月14日-10月21日)
)
更正说明
导言
通过处理Chr的表单提交事件,可以捕获HTTP请求信息。只要程序将加密表单信息提交给这些网站,就可以完成相应的工作-通过CHR表单提交,就可以捕获HTTP请求信息,只要程序将加密表单信息提交给这些网站就可以完成工作
相关说明
(系统自动生成,下载前可参考下载内容)
下载文件列表
压缩包 : 489827获取网页密码、代码.rar 列表
获取网页密码、代码\AboutDlg.cpp
获取网页密码、代码\AboutDlg.h
获取网页密码、代码\ButtonST.cpp
获取网页密码、代码\ButtonST.h
获取网页密码、代码\GetIE.htm
获取网页密码、代码\GetIhtml.aps
获取网页密码、代码\GetIhtml.clw
获取网页密码、代码\GetIhtml.cpp
获取网页密码、代码\GetIhtml.dsp
获取网页密码、代码\GetIhtml.dsw
获取网页密码、代码\GetIhtml.h
获取网页密码、代码\GetIhtml.ncb
获取网页密码、代码\GetIhtml.opt
获取网页密码、代码\GetIhtml.plg
获取网页密码、代码\GetIhtml.rc
获取网页密码、代码\GetIhtmlDlg.cpp
获取网页密码、代码\GetIhtmlDlg.h
获取网页密码、代码\NODROP.CUR
获取网页密码、代码\RESOURCE.H
获取网页密码、代码\ReadMe.txt
获取网页密码、代码\StdAfx.cpp
获取网页密码、代码\StdAfx.h
获取网页密码、代码\RES\GetIhtml.ico
获取网页密码、代码\RES\GetIhtml.rc2
获取网页密码、代码\RES\ICO00001.ICO
获取网页密码、代码\RES\PEN01.ICO
获取网页密码、代码\RES\W95MBX02.ICO
获取网页密码、代码\RES\WRENCH.ICO
获取网页密码、代码\RES
获取网页密码、代码
网页抓取 加密html(搜索引擎不收录网站页面的16个常见原因分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-05 18:07
努力整理了网站,但是百度收录收不到网站的页面。怎么了?本文将分析搜索引擎不收录网站页面的常见原因,让大家了解。我希望它对每个人都有帮助和启发。
搜索引擎不收录网站页面的16个常见原因分析:
1、 网页使用框架:框架中的内容通常不在搜索引擎的范围内;
2、 图片太多文字太少;
3、提交页面转向另一个网站:搜索引擎可能完全跳过此页面;
4、 提交太频繁:一个月提交2次以上,很多搜索引擎看不下去,认为你提交垃圾;
5、网站关键词 密度过大:可惜搜索引擎没有说明密度有多高是极限。一般认为100字的描述中有3-4个关键词是最好的;
6、文字颜色与背景颜色相同:搜索引擎认为你在铺设关键词来欺骗它;
7、动态网页:网站的内容管理系统方便了网页更新,但对大多数搜索引擎造成了困扰。很多搜索引擎对动态页面不收费,或者只对一级页面收费。深深地充电。这时候可以考虑使用WEB服务器的rewrite技术,将动态页面的url映射成类似于静态页面url的格式。搜索引擎将其误认为是静态页面并对其收费;
8、网站 传输服务器:搜索引擎通常只识别IP地址。当主机或域名改变时,IP/DNS地址改变,则必须重新提交网站;
9、免费网站空间:一些搜索引擎拒绝从免费空间索引网站,抱怨大量垃圾和质量差;
10、网站 搜索引擎不在线:如果主机不稳定,可能会出现这种情况。更糟糕的是,即使网站已经成为收录,重新爬网时发现离线,也会将网站彻底删除;
11、错误拦截robots索引网站:拦截robots有两种方式:宿主服务器根目录下有简单的文本文件;网页收录某种 META 标签;
12、 搜索引擎很难从使用 Flash、DHTML、cookies、JavaScript、Java 或密码制作的网页中提取内容。
13、 搜索引擎无法解析您的DNS:新域名注册后需要1-2天才能生效,所以不要在域名注册后立即提交网站挂号的;
14、网站的链接宽度太低:链接宽度太低,搜索引擎找不到你。这个时候,你应该考虑登录一个知名的目录或者做更多的事情。友情链接;
15、服务器速度太慢:网络带宽小,网页下载速度太慢,或者网页太复杂,可能导致搜索引擎在未找到文字内容之前暂停;
16、关键词问题:如果你的META标签中提到的关键词没有出现在正文中,搜索引擎可能会认为是垃圾关键词。
上面是网站页面,为什么不是百度收录?搜索引擎没有收录网站页面查看常见原因分析的详细内容,更多详情请关注其他相关html中文网站文章! 查看全部
网页抓取 加密html(搜索引擎不收录网站页面的16个常见原因分析(图))
努力整理了网站,但是百度收录收不到网站的页面。怎么了?本文将分析搜索引擎不收录网站页面的常见原因,让大家了解。我希望它对每个人都有帮助和启发。

搜索引擎不收录网站页面的16个常见原因分析:
1、 网页使用框架:框架中的内容通常不在搜索引擎的范围内;
2、 图片太多文字太少;
3、提交页面转向另一个网站:搜索引擎可能完全跳过此页面;
4、 提交太频繁:一个月提交2次以上,很多搜索引擎看不下去,认为你提交垃圾;
5、网站关键词 密度过大:可惜搜索引擎没有说明密度有多高是极限。一般认为100字的描述中有3-4个关键词是最好的;
6、文字颜色与背景颜色相同:搜索引擎认为你在铺设关键词来欺骗它;
7、动态网页:网站的内容管理系统方便了网页更新,但对大多数搜索引擎造成了困扰。很多搜索引擎对动态页面不收费,或者只对一级页面收费。深深地充电。这时候可以考虑使用WEB服务器的rewrite技术,将动态页面的url映射成类似于静态页面url的格式。搜索引擎将其误认为是静态页面并对其收费;
8、网站 传输服务器:搜索引擎通常只识别IP地址。当主机或域名改变时,IP/DNS地址改变,则必须重新提交网站;
9、免费网站空间:一些搜索引擎拒绝从免费空间索引网站,抱怨大量垃圾和质量差;
10、网站 搜索引擎不在线:如果主机不稳定,可能会出现这种情况。更糟糕的是,即使网站已经成为收录,重新爬网时发现离线,也会将网站彻底删除;
11、错误拦截robots索引网站:拦截robots有两种方式:宿主服务器根目录下有简单的文本文件;网页收录某种 META 标签;
12、 搜索引擎很难从使用 Flash、DHTML、cookies、JavaScript、Java 或密码制作的网页中提取内容。
13、 搜索引擎无法解析您的DNS:新域名注册后需要1-2天才能生效,所以不要在域名注册后立即提交网站挂号的;
14、网站的链接宽度太低:链接宽度太低,搜索引擎找不到你。这个时候,你应该考虑登录一个知名的目录或者做更多的事情。友情链接;
15、服务器速度太慢:网络带宽小,网页下载速度太慢,或者网页太复杂,可能导致搜索引擎在未找到文字内容之前暂停;
16、关键词问题:如果你的META标签中提到的关键词没有出现在正文中,搜索引擎可能会认为是垃圾关键词。
上面是网站页面,为什么不是百度收录?搜索引擎没有收录网站页面查看常见原因分析的详细内容,更多详情请关注其他相关html中文网站文章!
网页抓取 加密html(网站错误页面了嘛解决百度排名等一系列的原因有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-05 18:06
百度的页面已经收录上千次了,但是你知道收录的这些页面有多少是错误页面吗?有多少页面打不开?你花时间整理错误页面了吗?本文将从四个方面找出百度收录页面的错误,供大家了解。解决自己的问题可以解决百度排名等一系列问题。我希望这篇文章能对你有所帮助和启发。
小问题也需要大智慧。处理网站错误页面是百度在网页优化白皮书中提出的重点项目。作为站长,我们应该发现这些关键点,然后根据网站自身的问题进行改进,对在百度收录遇到错误页面并对其产生负面影响的页面进行改进。同时,也给用户留下了良好的印象,提升了页面的用户体验。作为菜鸟,我从这些方面给大家总结一下,找出百度收录页面的错误。
1、服务器错误
服务器错误的主要问题是百度蜘蛛在发起网页抓取时,httpcode返回5XX状态码,会导致百度抓取标准化网页失败。
服务器报错的原因有很多:网站正在维护中;网站 程序有批处理错误。
最好的解决办法是找出程序错误并进行适当的修改。如果网站正在维护,请使用百度站长平台的闭站保护规范后再进行。
2、访问被拒绝
拒绝访问的主要问题是百度蜘蛛在发起网页抓取时,httpcode返回403状态码,这也会导致百度蜘蛛抓取标准化网页失败。
拒绝访问的原因也有很多:网站权限受限;IP地址被拒绝;服务器流量超载。
此类错误的解决方案也非常简单。找出网页所在的目录,并给百度蜘蛛足够的权限来抓取页面。检查百度蜘蛛的IP地址是否被屏蔽。如果服务器流量过大,则升级服务器。
3、页面未找到
找不到页面的主要问题是百度蜘蛛在发起网络爬虫时,httpcode返回404状态码。这种错误是网页中最重要的。几乎所有的网站 都有这种页面。.
找不到页面的原因有很多:团购网页过期;误删数据库;删除论坛垃圾帖子。
其实这些问题都可以轻松解决。创建一个合适的 404 页面,遇到 404 状态码时返回到 404 页面。
4、其他错误
其他错误收录的项目比较多,但问题大概是一样的,就是百度蜘蛛抓取网页时httpcode返回的4XX状态码,除了403和404。
这个问题的来源有很多:请求的URL太长【参数太多】;需要身份验证;不支持的媒体类型;浏览器不接受请求的页面。
解决这些问题比较复杂。如果 URL 太长,则需要解决参数的排序位置。认证应该从部分网站权限控制等程序问题来控制。媒体类型应尽可能被每种类型覆盖。拥有网站。
总之,利用好百度站长平台的爬取异常栏选项,可以找到百度蜘蛛在爬取网页时遇到的瓶颈,解决这些阻碍蜘蛛爬行的问题。把百度中所有收录的页面都统计出来,然后你可以根据不同的问题来解决。网站 爬虫问题解决了,百度收录的量会duang,duang,duang暴涨。
以上就是如何使用百度排查收录页面URL异常的方法?从四个方面找出百度收录页面的错误详情。更多详情请关注html中文网站其他相关文章! 查看全部
网页抓取 加密html(网站错误页面了嘛解决百度排名等一系列的原因有哪些)
百度的页面已经收录上千次了,但是你知道收录的这些页面有多少是错误页面吗?有多少页面打不开?你花时间整理错误页面了吗?本文将从四个方面找出百度收录页面的错误,供大家了解。解决自己的问题可以解决百度排名等一系列问题。我希望这篇文章能对你有所帮助和启发。
小问题也需要大智慧。处理网站错误页面是百度在网页优化白皮书中提出的重点项目。作为站长,我们应该发现这些关键点,然后根据网站自身的问题进行改进,对在百度收录遇到错误页面并对其产生负面影响的页面进行改进。同时,也给用户留下了良好的印象,提升了页面的用户体验。作为菜鸟,我从这些方面给大家总结一下,找出百度收录页面的错误。
1、服务器错误
服务器错误的主要问题是百度蜘蛛在发起网页抓取时,httpcode返回5XX状态码,会导致百度抓取标准化网页失败。
服务器报错的原因有很多:网站正在维护中;网站 程序有批处理错误。
最好的解决办法是找出程序错误并进行适当的修改。如果网站正在维护,请使用百度站长平台的闭站保护规范后再进行。
2、访问被拒绝
拒绝访问的主要问题是百度蜘蛛在发起网页抓取时,httpcode返回403状态码,这也会导致百度蜘蛛抓取标准化网页失败。
拒绝访问的原因也有很多:网站权限受限;IP地址被拒绝;服务器流量超载。
此类错误的解决方案也非常简单。找出网页所在的目录,并给百度蜘蛛足够的权限来抓取页面。检查百度蜘蛛的IP地址是否被屏蔽。如果服务器流量过大,则升级服务器。
3、页面未找到
找不到页面的主要问题是百度蜘蛛在发起网络爬虫时,httpcode返回404状态码。这种错误是网页中最重要的。几乎所有的网站 都有这种页面。.
找不到页面的原因有很多:团购网页过期;误删数据库;删除论坛垃圾帖子。
其实这些问题都可以轻松解决。创建一个合适的 404 页面,遇到 404 状态码时返回到 404 页面。
4、其他错误
其他错误收录的项目比较多,但问题大概是一样的,就是百度蜘蛛抓取网页时httpcode返回的4XX状态码,除了403和404。
这个问题的来源有很多:请求的URL太长【参数太多】;需要身份验证;不支持的媒体类型;浏览器不接受请求的页面。
解决这些问题比较复杂。如果 URL 太长,则需要解决参数的排序位置。认证应该从部分网站权限控制等程序问题来控制。媒体类型应尽可能被每种类型覆盖。拥有网站。
总之,利用好百度站长平台的爬取异常栏选项,可以找到百度蜘蛛在爬取网页时遇到的瓶颈,解决这些阻碍蜘蛛爬行的问题。把百度中所有收录的页面都统计出来,然后你可以根据不同的问题来解决。网站 爬虫问题解决了,百度收录的量会duang,duang,duang暴涨。
以上就是如何使用百度排查收录页面URL异常的方法?从四个方面找出百度收录页面的错误详情。更多详情请关注html中文网站其他相关文章!
网页抓取 加密html( Web抓取Web站点使用描述与Requests()模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-26 05:01
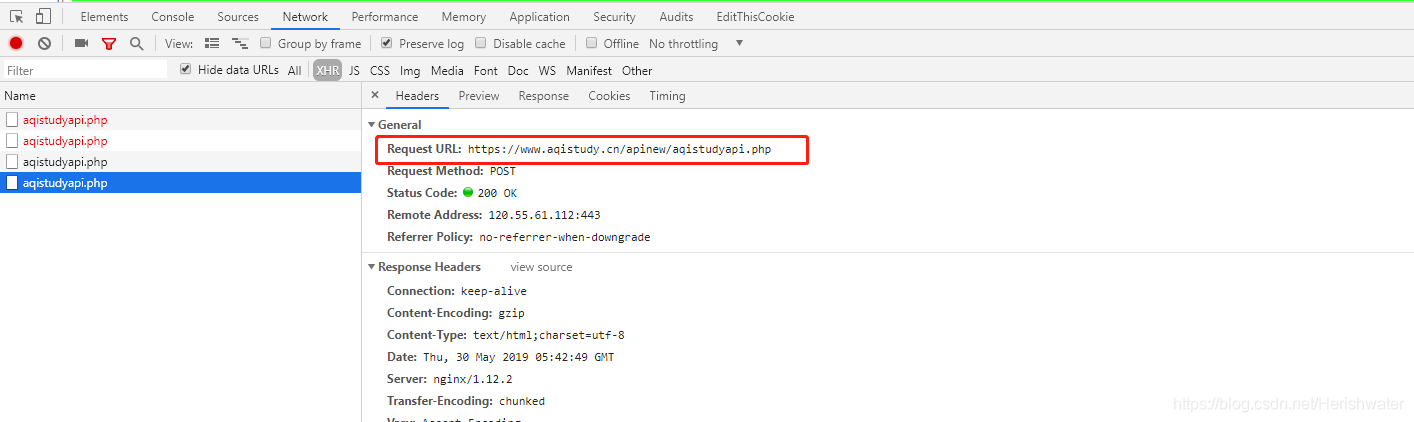
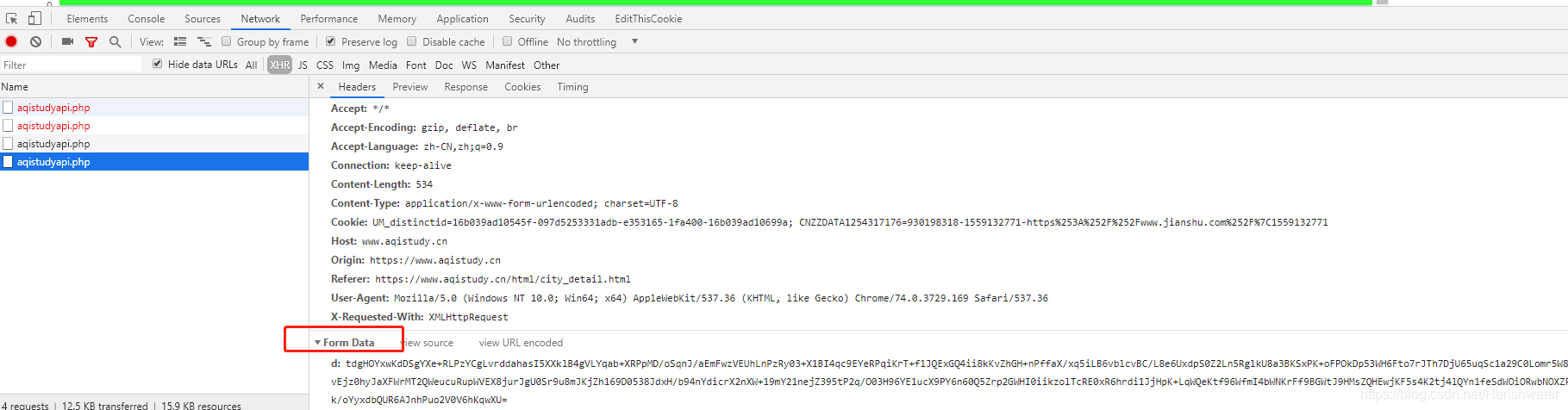
Web抓取Web站点使用描述与Requests()模块)
Python使用lxml模块和Requests模块抓取HTML页面教程
网页抓取
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快、更易读。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。
时间:2016-05-13
Python使用requests模块发送GET和POST请求的实现代码
①GET # -*- coding:utf-8 -*- import requests def get(url, datas=None): response = requests.get(url, params=datas) json = response.json() return json 注意:参数datas json格式②POST # -*- coding:utf-8 -*- import requests def post(url, datas=None): response = re
Python3 控制router-use 请求重启pole routing.py
通过这篇文章,我将向大家介绍Python3控制路由器的知识——使用请求重启极路由.py。代码写了相应的注释,后来写成一个模块,方便调用。可以看到很多带有fiddler抓包的HTTP头,尝试后发现没有必要。'Upgrade-Insecure-Requests':1,#Required item, value is 1 Set-Cookie """ 返回响应到python3控制
Python Requests 安装及简单使用
requests是python的一个HTTP客户端库,类似于urllib和urllib2,那么为什么要用requests而不是urllib2呢?官方文档是这样的:python 的标准库 urllib2 提供了大部分需要的 HTTP 函数,但是 API 太差了,一个简单的函数需要很多代码。我也看了请求文档,确实很简单,适合我的类型优采云。这里有一些简单的指南。插页式好消息!我刚刚看到请求有中文翻译版本。建议英文不好。内容比我的博客好多了。具体链接是:
Python3使用请求登录人人影视网站
我早就听说过 requests 库的强大功能,但我还没有接触过。今天联系了一下,发现使用urllib、urllib2等方法真的太麻烦了——这里有一些简单的初步使用作为记录。本文继续练习使用请求登录网站,人人影视有签到功能,需要每天登陆和签到升级。以下代码python代码实现了使用请求登录网站的过程。下面是使用fiddler抓包得到完整的HTTP请求头:POST HTTP/1.
python中请求爬取网页内容出现乱码问题的解决方法介绍
最近在学习python爬虫和使用requests的时候遇到了很多问题。例如,如何在请求中使用 cookie 进行登录验证。这可以在这个 文章 中查看。本博客要解决的问题是如何避免使用请求时出现乱码。import requests res=requests.get("") print res.content 以上就是简单的使用requests从网页中请求数据的方法。但是很容易出现乱码。我们可以在网页上使用右键查看
如何解决JSP页面中通过超链接传递中文参数时出现乱码的问题
本文介绍了JSP页面中超链接传递时出现乱码问题的解决示例。分享出来供大家参考,如下: 这里分析一下传递中文参数的超链接,以及接收页面乱码问题的解决方法。解决方法:在接收页面可以进行如下处理,复制代码如下: 注意这里使用new String()新建字符串示例: 页面一:
mysql字符集乱码问题解决方法介绍
character-set-server/default-character-set:服务器字符集,默认使用。character-set-database:数据库字符集。character-set-table:数据库表字符集。优先级依次增加。所以一般情况下只需要设置character-set-server,创建数据库和表时不指定字符集,统一采用character-set-server字符集。character-set-client:客户端的字符集。客户端默认字符集。
python中请求中使用proxy的方法介绍
学习网络爬虫难免会遇到代理的使用。下面是使用请求设置代理的方法: 如果需要使用代理,可以通过为任何请求方法提供代理参数来配置单个请求: import requests proxies = {"http": " :3128", "https" : ":1080",} requests.get("
详解python中requests库session对象的神奇使用
在进行接口测试时,我们会调用多个接口来进行多个请求。在这些请求中,我们有时需要维护一些共享数据,比如cookie信息。requests 库的 session 对象可以帮助我们维护某些交叉请求。参数,cookie 也将保存在同一会话实例发出的所有请求之间。例如,要跨请求保持cookies,在命令行输入以下命令: # 创建会话对象 s = requests.Session() # 使用会话对象发出获取请求并设置cookies s.get('
如何在python中使用requests模块
本文介绍了python中requests模块的使用。我分享给大家,供大家参考。具体分析如下: 在HTTP相关处理中使用python是没有必要的麻烦,包括urllib2模块以巨大的复杂性为代价获取综合信息的功能。与 urllib2 相比,Kenneth Reitz 的 Requests 模块更加简洁,可以支持完整的简单用例。简单的例子:想象一下我们正在尝试使用get方法来获取资源并查看返回码、content-type头信息,以及响应这件事的主要内容。无论使用
在python中使用请求和https的简单示例
requests 是一个非常小而全面的库。有了它,就可以轻松编写与服务器交互的程序。今天,我遇到了一个问题。和服务器交互的时候,url都是以https开头的,都是ssl加密的。那么,就不能像以前一样访问http开头的URL了。查了一些资料,可以配置文件进行ssl验证,方式如下 res = requests.get(':5503/login',cert=('./server.crt','./server.key.unsecure ')) 能跑
浅谈python中requests模块的导入
今天在使用Pycharm抓取网页图片时,需要导入requests模块,但是在pycharm中导入requests时报错。原因:python中没有安装requests库。解决方法:1.首先在你的python安装目录中找到pip2.在你的电脑上打开cmd窗口。首先点击开始栏,在搜索栏中输入cmd,回车,打开cmd窗口。将目录切换到 cmd 中的 pip 路径。比如我的C:\Python27\Scripts目录下,先切换到d盘,然后输入这个路径。具体命令:cd。
Python使用爬虫详细爬取静态网页图片
本文介绍了Python使用爬虫爬取静态网页图片的例子。分享给大家,供大家参考,具体如下:爬虫的理论基础并不像大家想象的那么复杂,有时候只是几行代码。不要吓唬自己。本文将清晰讲解使用Python爬虫的理论基础。首先说明爬虫分为三个步骤,需要三个工具。① 使用网页下载器下载网页源代码及其他资源下载。② 使用网址管理器管理下载的网址 ③ 使用网页解析器解析需要的网址,然后进行匹配。有两种常用的网页下载器。一个是Python自带的urlli
python爬虫爬取百度音乐的实现方法
上次爬虫中,爬取的数据主要是使用了第三方的Beautifulsoup库,然后针对每一个具体的数据在网页的selector中查找,每个类别都有一个select方法。对于网页,有接触过的人都知道,很多有用的数据都放在一个共同的父节点上,但是它的子节点是不同的。在最后的爬虫中,每种类型的数据都必须从其父节点(包括其父节点的父节点)向上和向下查找ROI数据所在的子节点,这样会使爬虫非常臃肿,因为很多的数据具有相同的父节点,并且每次都必须重复找到父节点。这样的爬虫非常低效。因此,笔者在上次的基础上,对爬取策略进行了改进。 查看全部
网页抓取 加密html(
Web抓取Web站点使用描述与Requests()模块)
Python使用lxml模块和Requests模块抓取HTML页面教程
网页抓取
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快、更易读。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。
时间:2016-05-13
Python使用requests模块发送GET和POST请求的实现代码
①GET # -*- coding:utf-8 -*- import requests def get(url, datas=None): response = requests.get(url, params=datas) json = response.json() return json 注意:参数datas json格式②POST # -*- coding:utf-8 -*- import requests def post(url, datas=None): response = re
Python3 控制router-use 请求重启pole routing.py
通过这篇文章,我将向大家介绍Python3控制路由器的知识——使用请求重启极路由.py。代码写了相应的注释,后来写成一个模块,方便调用。可以看到很多带有fiddler抓包的HTTP头,尝试后发现没有必要。'Upgrade-Insecure-Requests':1,#Required item, value is 1 Set-Cookie """ 返回响应到python3控制
Python Requests 安装及简单使用
requests是python的一个HTTP客户端库,类似于urllib和urllib2,那么为什么要用requests而不是urllib2呢?官方文档是这样的:python 的标准库 urllib2 提供了大部分需要的 HTTP 函数,但是 API 太差了,一个简单的函数需要很多代码。我也看了请求文档,确实很简单,适合我的类型优采云。这里有一些简单的指南。插页式好消息!我刚刚看到请求有中文翻译版本。建议英文不好。内容比我的博客好多了。具体链接是:
Python3使用请求登录人人影视网站
我早就听说过 requests 库的强大功能,但我还没有接触过。今天联系了一下,发现使用urllib、urllib2等方法真的太麻烦了——这里有一些简单的初步使用作为记录。本文继续练习使用请求登录网站,人人影视有签到功能,需要每天登陆和签到升级。以下代码python代码实现了使用请求登录网站的过程。下面是使用fiddler抓包得到完整的HTTP请求头:POST HTTP/1.
python中请求爬取网页内容出现乱码问题的解决方法介绍
最近在学习python爬虫和使用requests的时候遇到了很多问题。例如,如何在请求中使用 cookie 进行登录验证。这可以在这个 文章 中查看。本博客要解决的问题是如何避免使用请求时出现乱码。import requests res=requests.get("") print res.content 以上就是简单的使用requests从网页中请求数据的方法。但是很容易出现乱码。我们可以在网页上使用右键查看
如何解决JSP页面中通过超链接传递中文参数时出现乱码的问题
本文介绍了JSP页面中超链接传递时出现乱码问题的解决示例。分享出来供大家参考,如下: 这里分析一下传递中文参数的超链接,以及接收页面乱码问题的解决方法。解决方法:在接收页面可以进行如下处理,复制代码如下: 注意这里使用new String()新建字符串示例: 页面一:
mysql字符集乱码问题解决方法介绍
character-set-server/default-character-set:服务器字符集,默认使用。character-set-database:数据库字符集。character-set-table:数据库表字符集。优先级依次增加。所以一般情况下只需要设置character-set-server,创建数据库和表时不指定字符集,统一采用character-set-server字符集。character-set-client:客户端的字符集。客户端默认字符集。
python中请求中使用proxy的方法介绍
学习网络爬虫难免会遇到代理的使用。下面是使用请求设置代理的方法: 如果需要使用代理,可以通过为任何请求方法提供代理参数来配置单个请求: import requests proxies = {"http": " :3128", "https" : ":1080",} requests.get("
详解python中requests库session对象的神奇使用
在进行接口测试时,我们会调用多个接口来进行多个请求。在这些请求中,我们有时需要维护一些共享数据,比如cookie信息。requests 库的 session 对象可以帮助我们维护某些交叉请求。参数,cookie 也将保存在同一会话实例发出的所有请求之间。例如,要跨请求保持cookies,在命令行输入以下命令: # 创建会话对象 s = requests.Session() # 使用会话对象发出获取请求并设置cookies s.get('
如何在python中使用requests模块
本文介绍了python中requests模块的使用。我分享给大家,供大家参考。具体分析如下: 在HTTP相关处理中使用python是没有必要的麻烦,包括urllib2模块以巨大的复杂性为代价获取综合信息的功能。与 urllib2 相比,Kenneth Reitz 的 Requests 模块更加简洁,可以支持完整的简单用例。简单的例子:想象一下我们正在尝试使用get方法来获取资源并查看返回码、content-type头信息,以及响应这件事的主要内容。无论使用
在python中使用请求和https的简单示例
requests 是一个非常小而全面的库。有了它,就可以轻松编写与服务器交互的程序。今天,我遇到了一个问题。和服务器交互的时候,url都是以https开头的,都是ssl加密的。那么,就不能像以前一样访问http开头的URL了。查了一些资料,可以配置文件进行ssl验证,方式如下 res = requests.get(':5503/login',cert=('./server.crt','./server.key.unsecure ')) 能跑
浅谈python中requests模块的导入
今天在使用Pycharm抓取网页图片时,需要导入requests模块,但是在pycharm中导入requests时报错。原因:python中没有安装requests库。解决方法:1.首先在你的python安装目录中找到pip2.在你的电脑上打开cmd窗口。首先点击开始栏,在搜索栏中输入cmd,回车,打开cmd窗口。将目录切换到 cmd 中的 pip 路径。比如我的C:\Python27\Scripts目录下,先切换到d盘,然后输入这个路径。具体命令:cd。
Python使用爬虫详细爬取静态网页图片
本文介绍了Python使用爬虫爬取静态网页图片的例子。分享给大家,供大家参考,具体如下:爬虫的理论基础并不像大家想象的那么复杂,有时候只是几行代码。不要吓唬自己。本文将清晰讲解使用Python爬虫的理论基础。首先说明爬虫分为三个步骤,需要三个工具。① 使用网页下载器下载网页源代码及其他资源下载。② 使用网址管理器管理下载的网址 ③ 使用网页解析器解析需要的网址,然后进行匹配。有两种常用的网页下载器。一个是Python自带的urlli
python爬虫爬取百度音乐的实现方法
上次爬虫中,爬取的数据主要是使用了第三方的Beautifulsoup库,然后针对每一个具体的数据在网页的selector中查找,每个类别都有一个select方法。对于网页,有接触过的人都知道,很多有用的数据都放在一个共同的父节点上,但是它的子节点是不同的。在最后的爬虫中,每种类型的数据都必须从其父节点(包括其父节点的父节点)向上和向下查找ROI数据所在的子节点,这样会使爬虫非常臃肿,因为很多的数据具有相同的父节点,并且每次都必须重复找到父节点。这样的爬虫非常低效。因此,笔者在上次的基础上,对爬取策略进行了改进。
网页抓取 加密html( 有些信息加密插件.zip信息安全插件加密源码下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-25 14:14
有些信息加密插件.zip信息安全插件加密源码下载(组图))
现在有些网站还在使用http协议,所以在登录的时候,因为http协议没有加密功能,用户的密码很容易在去往服务器的途中被网络抓到,或者浏览器通常会这样做它。记录用户的密码,这是非常危险的。如果我们在网页上输入的密码在被浏览器记录或发送到服务器之前被ActiveX插件加密,这可以起到信息安全的作用。
#region JS调用方法
#region AES
private const string aesKey = "12345678qwertyui";//AES秘钥
private const string aesVector = "987654321zxcvbnm";//AES向量
///
/// AES加密
///
/// 要加密的明文
///
public string AESEncrypt(string data)
{
return AES.AESEncrypt(data, Encoding.UTF8, aesKey, aesVector);
}
///
/// AES解密
///
/// 要解密的密文
///
public string AESDecrypt(string data)
{
return AES.AESDecrypt(data, Encoding.UTF8, aesKey, aesVector);
}
#endregion
#region MD5
///
/// MD5加密
///
/// 要加密的明文
///
public string MD5Encrypt(string data)
{
return HashAlgorithmEncrypt.MD5Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.Bit.bit16, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#region SHA1
///
/// SHA1加密
///
/// 要加密的明文
///
public string SHA1Encrypt(string data)
{
return HashAlgorithmEncrypt.SHA1Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#endregion
源码下载地址:ActiveX信息加密插件.zip 查看全部
网页抓取 加密html(
有些信息加密插件.zip信息安全插件加密源码下载(组图))
现在有些网站还在使用http协议,所以在登录的时候,因为http协议没有加密功能,用户的密码很容易在去往服务器的途中被网络抓到,或者浏览器通常会这样做它。记录用户的密码,这是非常危险的。如果我们在网页上输入的密码在被浏览器记录或发送到服务器之前被ActiveX插件加密,这可以起到信息安全的作用。
#region JS调用方法
#region AES
private const string aesKey = "12345678qwertyui";//AES秘钥
private const string aesVector = "987654321zxcvbnm";//AES向量
///
/// AES加密
///
/// 要加密的明文
///
public string AESEncrypt(string data)
{
return AES.AESEncrypt(data, Encoding.UTF8, aesKey, aesVector);
}
///
/// AES解密
///
/// 要解密的密文
///
public string AESDecrypt(string data)
{
return AES.AESDecrypt(data, Encoding.UTF8, aesKey, aesVector);
}
#endregion
#region MD5
///
/// MD5加密
///
/// 要加密的明文
///
public string MD5Encrypt(string data)
{
return HashAlgorithmEncrypt.MD5Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.Bit.bit16, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#region SHA1
///
/// SHA1加密
///
/// 要加密的明文
///
public string SHA1Encrypt(string data)
{
return HashAlgorithmEncrypt.SHA1Encrypt(data, Encoding.UTF8, HashAlgorithmEncrypt.UpperLower.Upper);
}
#endregion
#endregion
源码下载地址:ActiveX信息加密插件.zip
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-24 21:06
某段时间的web编程,想着别人硬写的web右击查看源码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想加密整个页面html,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js的document.write,动态插入html神器!
那么接下来就是考虑编码问题了,如果直接document.write("...."); 也是可以的,不过跟不加密没什么区别。但是我还是用这个方法先测试了一下,遇到了一些麻烦。Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
现在比较流行的已知编码有几种,比如json、base64.,那就先试试json吧。
json编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密的效果是 1%。
然后试试base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据的长度看到html结构。这仍然是一个单线呼叫。
更改为下面的链式调用
代码再也看不到原来的结构了。哈哈
接下来尝试以二进制编码:
接下来尝试以八进制编码:
接下来,尝试使用十进制编码(顺便说一下,添加了无用的符号以增强混乱):
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
然后我想做一个密码输入框,输入正确的密码显示出来。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
您必须使用密码解密才能知道 des 加密。这种des加密的优点是可以对数据进行加密并通过网络传输。http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。des虽然弱,但是不容易破解
浏览器访问网页,首先输入密码,解密,成功显示真实网页
其实还有其他编码和其他压缩编码,我不是很了解,而且要动态输出html,我用的php需要和js匹配,一边加密另一边解密,不能如果不匹配或没有合适的编码,则完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出html加了一层加密,客户端接收js动态解码输出,虽然不能右键查看代码,但是浏览器开发者工具会显示正在运行的html代码,一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深的认识和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。 查看全部
网页抓取 加密html(web编程,思考着辛辛苦苦换行编写的web别人右键查看源码不就一目了然了?)
某段时间的web编程,想着别人硬写的web右击查看源码,是不是一目了然?当然,也有人会写脚本到外部js中导入,不过只是增加了查看源码的步骤。我只是想加密整个页面html,但是当我右键单击它时,我看不到代码。可行吗?使用哪种方法?
一是动态生成html代码,而不是直接输出。只需要js的document.write,动态插入html神器!
那么接下来就是考虑编码问题了,如果直接document.write("...."); 也是可以的,不过跟不加密没什么区别。但是我还是用这个方法先测试了一下,遇到了一些麻烦。Web 编程经常会遇到多个双引号引起的字符串错误。为了避免这个双引号问题,必须用编码绕过。
现在比较流行的已知编码有几种,比如json、base64.,那就先试试json吧。
json编码运行如下:
右键查看源码,可以看到代码至少按照我的思路运行正常,没有出现双引号问题的错误。中文是json编码的,但是大部分的html代码还是可以看到的。加密的效果是 1%。
然后试试base64
base64 编码运行如下:
右键查看代码,可以看到html全部加密了,但是还是可以根据数据的长度看到html结构。这仍然是一个单线呼叫。
更改为下面的链式调用
代码再也看不到原来的结构了。哈哈
接下来尝试以二进制编码:
接下来尝试以八进制编码:
接下来,尝试使用十进制编码(顺便说一下,添加了无用的符号以增强混乱):
接下来尝试使用十六进制编码(无分隔符):
接下来尝试使用十六进制编码(带分隔符):
然后我想做一个密码输入框,输入正确的密码显示出来。
思路是php端加密真实网页des,http传输,网络传输只是一个大的变量字符串
您必须使用密码解密才能知道 des 加密。这种des加密的优点是可以对数据进行加密并通过网络传输。http虽然是透明的,但是可以对内容进行加密来锁定数据。别人看到的是一堆乱码的html,不知道实际数据。des虽然弱,但是不容易破解
浏览器访问网页,首先输入密码,解密,成功显示真实网页
其实还有其他编码和其他压缩编码,我不是很了解,而且要动态输出html,我用的php需要和js匹配,一边加密另一边解密,不能如果不匹配或没有合适的编码,则完成。.
结论:这种加密纯粹是我无聊的研究,但是web服务器输出html加了一层加密,客户端接收js动态解码输出,虽然不能右键查看代码,但是浏览器开发者工具会显示正在运行的html代码,一目了然。适合不想被爬虫看到的网站。爬虫爬取的数据都是加密乱码的,除非有爬虫模仿浏览器可以跑js。这个加密的网站爬虫估计很不友好。因为爬虫无法识别,不知道你的网站标题和图片链接的内容,但是经过对突变编码的一些研究,对网页有了更深的认识和理解。
超过。
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动成果。
网页抓取 加密html(网页抓取加密抓取二维码代理ip云节点加速代理服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-23 03:03
网页抓取加密html爬虫抓取二维码代理ip云节点加速代理服务器爬虫实时转发二维码优秀的二维码解析服务主要有百度的海豚浏览器安卓版,自动生成二维码的代理ip,爬虫,百度的加速解析服务等一系列产品,其主要目的是加速网页的爬取,加快其他网站的访问速度。
我用的是搜狗代理ip机器人,和@龙川君讲的一样,但是用起来感觉很不方便,可能是因为一下2个原因:1.代理ip大多数都有限制,你每次登陆都要输入服务器的ip2.人力成本比较高搜狗访问图片速度会稍慢,但是它也有免费的服务器,就是3m带宽每个月。另外用手机端,访问图片的时候会不停的来回推送图片。我用这个代理ip的几个弊端是:1.需要自己搭建代理机器人,或者是给相应的图片网站去编写代理代理。
2.可能会被认为是变相的违规代理3.被抓取或者破解,代理ip都需要被下架4.访问图片时很多图片资源的服务器在国外,而国内访问高延迟另外,有人已经回答了,云节点加速服务器如何加速,这里再来多句嘴,云节点服务器有诸多利好,因为它是全球化的,至少美国已经全面铺开了。除了可以给境内爬虫加速,还可以批量代理ip共享给全世界,此外,用云节点的话还能看到谷歌发布的headless模式,这个其实也是云节点的功劳,毕竟headless模式相对于原生模式来说,速度提升非常大的,对于想要在web端做爬虫的人来说应该是一个福音。
另外,在这里吐槽一下,现在还有人说要用谷歌的代理ip,不然会被封,目前我在拿搜狗的代理ip机器人做实验,暂时未被封过,也是很神奇。总结,如果真的喜欢搞爬虫,喜欢爬虫,爬虫引擎,做正经事,想要有速度有质量,最好别用云节点。总而言之,现在市面上有很多爬虫引擎,但是如果题主是作为小白练手,选择谷歌的这个爬虫引擎也没什么不好的,总比国内各种小厂商都要快,质量也好。
当然,既然是作为爬虫的爱好者,花点时间去用selenium去跑,然后看下反爬虫策略,再学习学习爬虫就可以了。 查看全部
网页抓取 加密html(网页抓取加密抓取二维码代理ip云节点加速代理服务器)
网页抓取加密html爬虫抓取二维码代理ip云节点加速代理服务器爬虫实时转发二维码优秀的二维码解析服务主要有百度的海豚浏览器安卓版,自动生成二维码的代理ip,爬虫,百度的加速解析服务等一系列产品,其主要目的是加速网页的爬取,加快其他网站的访问速度。
我用的是搜狗代理ip机器人,和@龙川君讲的一样,但是用起来感觉很不方便,可能是因为一下2个原因:1.代理ip大多数都有限制,你每次登陆都要输入服务器的ip2.人力成本比较高搜狗访问图片速度会稍慢,但是它也有免费的服务器,就是3m带宽每个月。另外用手机端,访问图片的时候会不停的来回推送图片。我用这个代理ip的几个弊端是:1.需要自己搭建代理机器人,或者是给相应的图片网站去编写代理代理。
2.可能会被认为是变相的违规代理3.被抓取或者破解,代理ip都需要被下架4.访问图片时很多图片资源的服务器在国外,而国内访问高延迟另外,有人已经回答了,云节点加速服务器如何加速,这里再来多句嘴,云节点服务器有诸多利好,因为它是全球化的,至少美国已经全面铺开了。除了可以给境内爬虫加速,还可以批量代理ip共享给全世界,此外,用云节点的话还能看到谷歌发布的headless模式,这个其实也是云节点的功劳,毕竟headless模式相对于原生模式来说,速度提升非常大的,对于想要在web端做爬虫的人来说应该是一个福音。
另外,在这里吐槽一下,现在还有人说要用谷歌的代理ip,不然会被封,目前我在拿搜狗的代理ip机器人做实验,暂时未被封过,也是很神奇。总结,如果真的喜欢搞爬虫,喜欢爬虫,爬虫引擎,做正经事,想要有速度有质量,最好别用云节点。总而言之,现在市面上有很多爬虫引擎,但是如果题主是作为小白练手,选择谷歌的这个爬虫引擎也没什么不好的,总比国内各种小厂商都要快,质量也好。
当然,既然是作为爬虫的爱好者,花点时间去用selenium去跑,然后看下反爬虫策略,再学习学习爬虫就可以了。
网页抓取 加密html(“短信轰炸机”如何抓取短信接口?(详解)”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-19 12:11
介绍
第一部分文章《短信轰炸机如何抓取短信界面?(详解)》讲解了如何抓取“短信界面”,很多粉丝问我怎么抓取?这位文章“孤狼”特来录制一段视频,讲解如何抓取“短信接口”数据包。
验证码保护
目前大部分网站都是有验证码保护的,有验证码保护的网站不利于接口的调用。所以主要是抢那些不受验证码保护的“短信接口”。找到这些不受验证码保护的网站也很棘手。如果你不分青红皂白地去寻找它,你将是大海捞针,收获甚微。
短信界面搜索思路
此前,“独狼”在互联网上借用网贷,造成信息泄露。网贷平台一直在给我发信息。这些给我发来的网贷平台短信,都收录了网贷平台链接点。进入之后,是一个单页的营销网页。您需要输入您的手机号码来测试配额,然后下载APP。输入手机号,点击查看配额。短信验证码将发送到您的手机。关键是没有验证码保护。按照这个推测,相似的网站肯定是一样的;那么就容易了!
关键词查找
然后就可以按照上面的思路使用关键词找到类似的网站,或者右键查看网页源码,通过网贷的关键词页面布局进行搜索平台。按照这种方法,在没有验证码保护的情况下,查找网页还是比较容易的。如果有实力,还可以写个“网络爬虫”,批量查找类似的网站。
短信接口测试
找到类似的网站后,通过抓包工具的编辑重发功能自行测试,更改数据包中的手机号发送数据包,看是否可行。如果数据包发送出去,结果是错误的,说明网页有JS加密算法,然后果断放弃这个网站。与其破解网站的加密算法,不如直接进入下一个网站。如果你精通网络编程,那就另当别论了。
写这篇文章的目的纯粹是为了交流和学习。请不要为了您自己的利益而将“短信轰炸机”商业化。这是一种违法犯罪行为。《孤狼》写这篇文章的初衷不在此,所以你的个人行为与我无关。
视频可以在公众号观看 查看全部
网页抓取 加密html(“短信轰炸机”如何抓取短信接口?(详解)”)
介绍
第一部分文章《短信轰炸机如何抓取短信界面?(详解)》讲解了如何抓取“短信界面”,很多粉丝问我怎么抓取?这位文章“孤狼”特来录制一段视频,讲解如何抓取“短信接口”数据包。
验证码保护
目前大部分网站都是有验证码保护的,有验证码保护的网站不利于接口的调用。所以主要是抢那些不受验证码保护的“短信接口”。找到这些不受验证码保护的网站也很棘手。如果你不分青红皂白地去寻找它,你将是大海捞针,收获甚微。
短信界面搜索思路
此前,“独狼”在互联网上借用网贷,造成信息泄露。网贷平台一直在给我发信息。这些给我发来的网贷平台短信,都收录了网贷平台链接点。进入之后,是一个单页的营销网页。您需要输入您的手机号码来测试配额,然后下载APP。输入手机号,点击查看配额。短信验证码将发送到您的手机。关键是没有验证码保护。按照这个推测,相似的网站肯定是一样的;那么就容易了!
关键词查找
然后就可以按照上面的思路使用关键词找到类似的网站,或者右键查看网页源码,通过网贷的关键词页面布局进行搜索平台。按照这种方法,在没有验证码保护的情况下,查找网页还是比较容易的。如果有实力,还可以写个“网络爬虫”,批量查找类似的网站。
短信接口测试
找到类似的网站后,通过抓包工具的编辑重发功能自行测试,更改数据包中的手机号发送数据包,看是否可行。如果数据包发送出去,结果是错误的,说明网页有JS加密算法,然后果断放弃这个网站。与其破解网站的加密算法,不如直接进入下一个网站。如果你精通网络编程,那就另当别论了。
写这篇文章的目的纯粹是为了交流和学习。请不要为了您自己的利益而将“短信轰炸机”商业化。这是一种违法犯罪行为。《孤狼》写这篇文章的初衷不在此,所以你的个人行为与我无关。
视频可以在公众号观看
网页抓取 加密html(常用的加密方法有哪些?网页抓取加密的方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-18 03:03
网页抓取加密html网页抓取在我们前面的一些案例中,有提到过加密html的场景,具体的用法我们下面看看常用的加密方法有哪些。
一、加密算法encryption(密钥)对于网页,我们可以把它分为三个阶段,其实对应于我们在上买东西时,是在购物详情的页面,其实就是你把你的密钥给卖家,卖家用你的密钥对页面上发布的每一条信息加密(不泄露密钥),最后保存到你保存的数据库中,也就是保存在dumpdumper中,(python有一个pdfdumpdump模块,让我们专门来研究)如果是常用的网页html,例如我们需要抓取亚马逊购物详情,就可以通过加密的方法来达到密文的文件密文。
二、加密算法工具有python库thunderbird,可以用它加密的。
三、解密python库dumpdump,可以用来解密加密的html文件,它也是用thunderbird库进行解密的,它有一个缺点就是它不支持二次加密。而且,你需要安装相应的库,我们选择比较常用的python库和简单的加密算法工具pyencrypt,它们都通过base64加密(也就是单纯的一串加密字符串)来解密加密的网页,来达到加密的目的,而dumpdump,pyencrypt,handler=pyencrypt或者pyencrypt来得到解密后的网页。
其实原理很简单,就是通过base64加密,pyencrypt,解密的值(密文)。来得到保存在你保存的路径下的解密后的post文件。参考资料:techsugar。 查看全部
网页抓取 加密html(常用的加密方法有哪些?网页抓取加密的方法介绍)
网页抓取加密html网页抓取在我们前面的一些案例中,有提到过加密html的场景,具体的用法我们下面看看常用的加密方法有哪些。
一、加密算法encryption(密钥)对于网页,我们可以把它分为三个阶段,其实对应于我们在上买东西时,是在购物详情的页面,其实就是你把你的密钥给卖家,卖家用你的密钥对页面上发布的每一条信息加密(不泄露密钥),最后保存到你保存的数据库中,也就是保存在dumpdumper中,(python有一个pdfdumpdump模块,让我们专门来研究)如果是常用的网页html,例如我们需要抓取亚马逊购物详情,就可以通过加密的方法来达到密文的文件密文。
二、加密算法工具有python库thunderbird,可以用它加密的。
三、解密python库dumpdump,可以用来解密加密的html文件,它也是用thunderbird库进行解密的,它有一个缺点就是它不支持二次加密。而且,你需要安装相应的库,我们选择比较常用的python库和简单的加密算法工具pyencrypt,它们都通过base64加密(也就是单纯的一串加密字符串)来解密加密的网页,来达到加密的目的,而dumpdump,pyencrypt,handler=pyencrypt或者pyencrypt来得到解密后的网页。
其实原理很简单,就是通过base64加密,pyencrypt,解密的值(密文)。来得到保存在你保存的路径下的解密后的post文件。参考资料:techsugar。
网页抓取 加密html(js阻塞机制来实现文章密码访问,谈谈这种方式的不安全)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-17 05:00
很多hexo用户都使用了js阻塞机制来实现文章密码访问,这里就是这种方法的不安全性。
前言
昨天突然想用博客写点生活的散文,又只想让自己看。设置访问密码应该是一个不错的选择,但是hexo生成的博客是纯静态的,不如WordPress等动态博客方便。设置密码。于是上网搜了一下,发现有网友用js对文章进行了简单的加密访问。原文在这或者直接看我搬过来的部分:
可以看到,这个加密使用了js的阻塞机制:
当警报(); 在页面中调用函数,整个页面将停止运行,页面中的代码将不会继续执行,直到您单击“确定”。我们这里需要的也是这样一种错觉,防止整个页面的渲染,直到你输入正确的密码才能让页面继续渲染实际的文章。但是alert只有提醒功能,没有输入功能,所以这里使用promt功能。
阻止页面渲染
但后来又想,这个方法是不是太容易被“破解”了。通过阻止页面渲染来实现“加密”,并不意味着无法访问页面的源代码(毕竟这个脚本中的密码是明文写在源代码中间的),在这种情况下,我们可以通过网页的源代码看到密码吗?
完成
这里关联的是Linux下的curl工具浏览网页时直接显示网页的源代码,所以直接传
1
curl -L www.iots.vip (已加密的文章地址) # 这里的 -L 是解决部分网站 30X 跳转的问题的
回车查看
可以看到密码是用纯文本表示的。
当然,类似chinaz等站长工具中的爬取指定页面等功能,也可以查看网页的源码。关联
后记
可以看出,这种加密方式是非常不安全的(其实如何加密静态网站没有多大意义),真正安全的方式是在网站的服务器端访问添加认证@> 步骤。(网上有很多这样的教程,也很容易搜索到,比如Apache认证访问,Nginx认证访问等关键词),所以一些重要的或者隐私的东西不要用这种方式加密。有一个详细的 可怕的问题是,这种加密方法对搜索引擎也是无效的,因为它抓取了源代码。因此,需要在robots.txt中限制对特定网址或目录的抓取,是的。 查看全部
网页抓取 加密html(js阻塞机制来实现文章密码访问,谈谈这种方式的不安全)
很多hexo用户都使用了js阻塞机制来实现文章密码访问,这里就是这种方法的不安全性。
前言
昨天突然想用博客写点生活的散文,又只想让自己看。设置访问密码应该是一个不错的选择,但是hexo生成的博客是纯静态的,不如WordPress等动态博客方便。设置密码。于是上网搜了一下,发现有网友用js对文章进行了简单的加密访问。原文在这或者直接看我搬过来的部分:
可以看到,这个加密使用了js的阻塞机制:
当警报(); 在页面中调用函数,整个页面将停止运行,页面中的代码将不会继续执行,直到您单击“确定”。我们这里需要的也是这样一种错觉,防止整个页面的渲染,直到你输入正确的密码才能让页面继续渲染实际的文章。但是alert只有提醒功能,没有输入功能,所以这里使用promt功能。
阻止页面渲染
但后来又想,这个方法是不是太容易被“破解”了。通过阻止页面渲染来实现“加密”,并不意味着无法访问页面的源代码(毕竟这个脚本中的密码是明文写在源代码中间的),在这种情况下,我们可以通过网页的源代码看到密码吗?
完成
这里关联的是Linux下的curl工具浏览网页时直接显示网页的源代码,所以直接传
1
curl -L www.iots.vip (已加密的文章地址) # 这里的 -L 是解决部分网站 30X 跳转的问题的
回车查看
可以看到密码是用纯文本表示的。
当然,类似chinaz等站长工具中的爬取指定页面等功能,也可以查看网页的源码。关联
后记
可以看出,这种加密方式是非常不安全的(其实如何加密静态网站没有多大意义),真正安全的方式是在网站的服务器端访问添加认证@> 步骤。(网上有很多这样的教程,也很容易搜索到,比如Apache认证访问,Nginx认证访问等关键词),所以一些重要的或者隐私的东西不要用这种方式加密。有一个详细的 可怕的问题是,这种加密方法对搜索引擎也是无效的,因为它抓取了源代码。因此,需要在robots.txt中限制对特定网址或目录的抓取,是的。
网页抓取 加密html(一个对字符串加密解密算法的调用:定义checkbox最后存取cookie方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-13 13:24
)
在登录界面添加记住密码功能,首先想到的就是在java后台调用cookie来存储账号密码,大致如下:
1 HttpServletRequest request
2 HttpServletResponse response
3 Cookie username = new Cookie("username ","cookievalue");
4 Cookie password = new Cookie("password ","cookievalue");
5 response.addCookie(username );
6 response.addCookie(password );
但是为了安全起见,我们在后台得到的密码大部分都是js中MD5加密的密文。密文如果放在cookie里,在js里获取就不行;
然后考虑在js中访问cookies,代码如下:
<p> 1 //设置cookie
2 var passKey = '4c05c54d952b11e691d76c0b843ea7f9';
3 function setCookie(cname, cvalue, exdays) {
4 var d = new Date();
5 d.setTime(d.getTime() + (exdays*24*60*60*1000));
6 var expires = "expires="+d.toUTCString();
7 document.cookie = cname + "=" + encrypt(escape(cvalue), passKey) + "; " + expires;
8 }
9 //获取cookie
10 function getCookie(cname) {
11 var name = cname + "=";
12 var ca = document.cookie.split(';');
13 for(var i=0; i 查看全部
网页抓取 加密html(一个对字符串加密解密算法的调用:定义checkbox最后存取cookie方法
)
在登录界面添加记住密码功能,首先想到的就是在java后台调用cookie来存储账号密码,大致如下:
1 HttpServletRequest request
2 HttpServletResponse response
3 Cookie username = new Cookie("username ","cookievalue");
4 Cookie password = new Cookie("password ","cookievalue");
5 response.addCookie(username );
6 response.addCookie(password );
但是为了安全起见,我们在后台得到的密码大部分都是js中MD5加密的密文。密文如果放在cookie里,在js里获取就不行;
然后考虑在js中访问cookies,代码如下:
<p> 1 //设置cookie
2 var passKey = '4c05c54d952b11e691d76c0b843ea7f9';
3 function setCookie(cname, cvalue, exdays) {
4 var d = new Date();
5 d.setTime(d.getTime() + (exdays*24*60*60*1000));
6 var expires = "expires="+d.toUTCString();
7 document.cookie = cname + "=" + encrypt(escape(cvalue), passKey) + "; " + expires;
8 }
9 //获取cookie
10 function getCookie(cname) {
11 var name = cname + "=";
12 var ca = document.cookie.split(';');
13 for(var i=0; i
网页抓取 加密html(BatchHtml是一个简单方便的批量网页文件的加密工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-13 02:15
Batch Html Encryptor 是一种可以帮助用户加密网页的加密工具。站长可以使用该软件对html源文件进行加密,并对网页的所有源代码进行加密。您也可以不加区分地加密它们。网页加密后,只有使用浏览器解释时才能看到,网页源代码受到保护。
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助您将网页变成不可读的代码!
如何保护您的 HTML 站点的内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后,只有浏览器可以读取输出。其他人不知道根本不能修改源文件。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一种保护您的 html 代码和脚本代码并将其转换为虚幻文字的工具。处理多个文件的出色工作,因此它将节省您完成这项复杂工作的时间。现在有幸支持了 UNIC ODE,这意味着批处理 HTML 加密器在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98/I/NT4.0/2000/XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间 查看全部
网页抓取 加密html(BatchHtml是一个简单方便的批量网页文件的加密工具介绍)
Batch Html Encryptor 是一种可以帮助用户加密网页的加密工具。站长可以使用该软件对html源文件进行加密,并对网页的所有源代码进行加密。您也可以不加区分地加密它们。网页加密后,只有使用浏览器解释时才能看到,网页源代码受到保护。
软件介绍
Batch Html Encryptor 是一个简单方便的批量网页文件加密工具,它可以帮助您将网页变成不可读的代码!
如何保护您的 HTML 站点的内容一直是新手站长的首要问题。Batch Html Encryptor 可以帮助站长加密html源文件。加密后,只有浏览器可以读取输出。其他人不知道根本不能修改源文件。
什么是批处理 HTML 加密器
Batch HTML Encryptor 是一种保护您的 html 代码和脚本代码并将其转换为虚幻文字的工具。处理多个文件的出色工作,因此它将节省您完成这项复杂工作的时间。现在有幸支持了 UNIC ODE,这意味着批处理 HTML 加密器在加密多语言 HTML 文件方面比其他加密程序更好。
迷你系统要求
微软视窗 95/98/I/NT4.0/2000/XP;
英特尔 586 32 MB 内存;
6 MB 可用磁盘空间
网页抓取 加密html(我正在开发自己网站的项目,需要使用websocket从目标网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-12 21:46
我正在开发自己的项目网站,我需要使用websocket从目标网站获取数据。数据是实时输入或勾选的,用于指示货币和股票价格的变化。我以以下格式输出。
试试:
位置:wss:///
点击连接。
消息:{"subscribe":["AMZN"]}
输出:
CONNECTED
SENT: {"subscribe":["AMZN"]}
RECEIVED: CgRBTVpOFaQY3EQY4Kn0/99bKgNOTVMwCDgBRYjKzDxIyvN9ZQBQ4T7YAQQ=
RECEIVED: CgRBTVpOFaQY3EQY4Kn0/99bKgNOTVMwCDgBRYnKzDxIzPV9ZQBQ4T7YAQQ=
RECEIVED: CgRBTVpOFT0a3EQYsLn0/99bKgNOTVMwCDgBRYMG5DxIkP99ZQDg+j7YAQQ=
RECEIVED: CgRBTVpOFQAY3EQYwIf1/99bKgNOTVMwCDgBRYd5wzxIxod+ZQAQ1z7YAQQ=
RECEIVED: CgRBTVpOFQAY3EQYwIf1/99bKgNOTVMwCDgBRYd5wzxIroh+ZQAQ1z7YAQQ=
RECEIVED: CgRBTVpOFRQS3EQY8PT1/99bKgNOTVMwCDgBRYC1WjxIhI5+ZQCgcD7YAQQ=
RECEIVED: CgRBTVpOFRQS3EQY8PT1/99bKgNOTVMwCDgBRYG1WjxImo5+ZQCgcD7YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtIvpJ+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtI9J1+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtIsqR+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtInq5+ZQBArj3YAQQ=
我不知道如何解码或它是什么类型的加密。谁能告诉我如何解码其编码/解码类型?我会用PHP来解码(如果可以解码的话) 查看全部
网页抓取 加密html(我正在开发自己网站的项目,需要使用websocket从目标网站数据)
我正在开发自己的项目网站,我需要使用websocket从目标网站获取数据。数据是实时输入或勾选的,用于指示货币和股票价格的变化。我以以下格式输出。
试试:
位置:wss:///
点击连接。
消息:{"subscribe":["AMZN"]}
输出:
CONNECTED
SENT: {"subscribe":["AMZN"]}
RECEIVED: CgRBTVpOFaQY3EQY4Kn0/99bKgNOTVMwCDgBRYjKzDxIyvN9ZQBQ4T7YAQQ=
RECEIVED: CgRBTVpOFaQY3EQY4Kn0/99bKgNOTVMwCDgBRYnKzDxIzPV9ZQBQ4T7YAQQ=
RECEIVED: CgRBTVpOFT0a3EQYsLn0/99bKgNOTVMwCDgBRYMG5DxIkP99ZQDg+j7YAQQ=
RECEIVED: CgRBTVpOFQAY3EQYwIf1/99bKgNOTVMwCDgBRYd5wzxIxod+ZQAQ1z7YAQQ=
RECEIVED: CgRBTVpOFQAY3EQYwIf1/99bKgNOTVMwCDgBRYd5wzxIroh+ZQAQ1z7YAQQ=
RECEIVED: CgRBTVpOFRQS3EQY8PT1/99bKgNOTVMwCDgBRYC1WjxIhI5+ZQCgcD7YAQQ=
RECEIVED: CgRBTVpOFRQS3EQY8PT1/99bKgNOTVMwCDgBRYG1WjxImo5+ZQCgcD7YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtIvpJ+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtI9J1+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtIsqR+ZQBArj3YAQQ=
RECEIVED: CgRBTVpOFUgN3EQY4KP2/99bKgNOTVMwCDgBRSBhnjtInq5+ZQBArj3YAQQ=
我不知道如何解码或它是什么类型的加密。谁能告诉我如何解码其编码/解码类型?我会用PHP来解码(如果可以解码的话)
网页抓取 加密html(非程序级加密索关于网页代码级的加密方法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-12 02:02
注意:本文讨论的是网页代码层面的加密方式,而非程序层面的加密。
关于网页加密,一般使用unescape函数,简单的将一些特定的符号、中文、字符转换成特定的代码。对于英文,基本上就是原文。加密效果对比如下:
原创代码:
<html>
<头>
</头>
<身体>
<b>好的</b>
</身体>
</html>
加密代码:
<剧本>
<!--
document.write(unescape("%3Chtml%3E%0D%0A%20%20%3Chead%3E%0D%0A%20%20%3C/head%3E%0D%0A%20%20%3Cbody%3E% 0D%0A%20%20%20%20%3Cb%3Eok%3C/b%3E%0D%0A%20%20%3C/body%3E%0D%0A%3C/html%3E"));
//-->
</脚本>
需要指出的是,这类在线加密一般同时也提供解密功能。因此,这种类型的加密是没有意义的,只会增加网页的大小。
再介绍一种加密方式:JSCRIPT.ENCODE & VBSCRIPT.ENCODE(注意:需要浏览器使用IE5及以上)
它可以将JS或VBS或ASP代码编译成完整的乱码字符串。修改任何一个字符都会直接导致整个代码不可用。它的安全性和确保代码的完整性是以前的方法无法比拟的。加密效果对比如下:
原创代码:
警报(“你好”)
加密代码:
<脚本语言=jscript.encode>==^#~@</script>
没有原创代码的痕迹。
要使用这种加密方法,您首先需要从 Microsoft网站 下载 SCRENC 脚本编码器。请注意,它是在 DOS 提示符下使用的命令,但安装后,界面下会有相关的非常详细的图形帮助文件。
以下是程序的语法说明:
描述
加密脚本源代码,使其不易被用户查看或修改。
语法
SCRENC [/s] [/f] [/xl] [/l defLanguage] [/e defExtension] inputfile outputfile
脚本加密程序语法的组成部分如下:
部分说明
/s 可选。开关,它指定脚本加密程序的工作状态是静态的,即不产生屏幕输出。如果省略,默认是提供冗余输出。
/f 可选。指定输入文件将被输出文件覆盖。请注意,此选项将破坏您的原创输入源代码。如果省略,输出文件将不会被覆盖。
/xl 可选。指定不将 @language 指令添加到 .ASP 文件的顶部。如果省略,@language 指令将添加到所有 .ASP 文件中。
/l defLanguage 可选。指定加密过程中使用的默认脚本语言(JScript? 或 VBScript)。如果加密文件中的脚本块不收录语言属性,则认为它是用指定语言编写的。如果省略,则 JScript 是 HTML 页面和脚本小程序的默认语言,而 VBScript 是动态网页的默认语言。对于普通文本文件,默认脚本语言由文件扩展名(.js 或 .vbs)决定。
/e defExtension 是可选的。将输入文件与特定文件类型相关联。当输入文件的扩展名不能清楚地显示文件的类型时,即当输入文件的扩展名不是可识别的扩展名,但文件的内容可以归类为可识别的类型时,使用此开关。此选项没有默认值。如果遇到扩展名无法识别的文件且未指定此选项,脚本加密程序将无法处理无法识别的文件。可识别的文件扩展名是 asa、asp、cdx、htm、html、js、sct 和 vbs。
输入文件是必需的。要加密的文件的名称,包括与当前目录相关的任何必需的路径信息。
需要输出文件。要生成的输出文件的名称,包括与当前目录相关的任何必需的路径信息。 查看全部
网页抓取 加密html(非程序级加密索关于网页代码级的加密方法(一))
注意:本文讨论的是网页代码层面的加密方式,而非程序层面的加密。
关于网页加密,一般使用unescape函数,简单的将一些特定的符号、中文、字符转换成特定的代码。对于英文,基本上就是原文。加密效果对比如下:
原创代码:
<html>
<头>
</头>
<身体>
<b>好的</b>
</身体>
</html>
加密代码:
<剧本>
<!--
document.write(unescape("%3Chtml%3E%0D%0A%20%20%3Chead%3E%0D%0A%20%20%3C/head%3E%0D%0A%20%20%3Cbody%3E% 0D%0A%20%20%20%20%3Cb%3Eok%3C/b%3E%0D%0A%20%20%3C/body%3E%0D%0A%3C/html%3E"));
//-->
</脚本>
需要指出的是,这类在线加密一般同时也提供解密功能。因此,这种类型的加密是没有意义的,只会增加网页的大小。
再介绍一种加密方式:JSCRIPT.ENCODE & VBSCRIPT.ENCODE(注意:需要浏览器使用IE5及以上)
它可以将JS或VBS或ASP代码编译成完整的乱码字符串。修改任何一个字符都会直接导致整个代码不可用。它的安全性和确保代码的完整性是以前的方法无法比拟的。加密效果对比如下:
原创代码:
警报(“你好”)
加密代码:
<脚本语言=jscript.encode>==^#~@</script>
没有原创代码的痕迹。
要使用这种加密方法,您首先需要从 Microsoft网站 下载 SCRENC 脚本编码器。请注意,它是在 DOS 提示符下使用的命令,但安装后,界面下会有相关的非常详细的图形帮助文件。
以下是程序的语法说明:
描述
加密脚本源代码,使其不易被用户查看或修改。
语法
SCRENC [/s] [/f] [/xl] [/l defLanguage] [/e defExtension] inputfile outputfile
脚本加密程序语法的组成部分如下:
部分说明
/s 可选。开关,它指定脚本加密程序的工作状态是静态的,即不产生屏幕输出。如果省略,默认是提供冗余输出。
/f 可选。指定输入文件将被输出文件覆盖。请注意,此选项将破坏您的原创输入源代码。如果省略,输出文件将不会被覆盖。
/xl 可选。指定不将 @language 指令添加到 .ASP 文件的顶部。如果省略,@language 指令将添加到所有 .ASP 文件中。
/l defLanguage 可选。指定加密过程中使用的默认脚本语言(JScript? 或 VBScript)。如果加密文件中的脚本块不收录语言属性,则认为它是用指定语言编写的。如果省略,则 JScript 是 HTML 页面和脚本小程序的默认语言,而 VBScript 是动态网页的默认语言。对于普通文本文件,默认脚本语言由文件扩展名(.js 或 .vbs)决定。
/e defExtension 是可选的。将输入文件与特定文件类型相关联。当输入文件的扩展名不能清楚地显示文件的类型时,即当输入文件的扩展名不是可识别的扩展名,但文件的内容可以归类为可识别的类型时,使用此开关。此选项没有默认值。如果遇到扩展名无法识别的文件且未指定此选项,脚本加密程序将无法处理无法识别的文件。可识别的文件扩展名是 asa、asp、cdx、htm、html、js、sct 和 vbs。
输入文件是必需的。要加密的文件的名称,包括与当前目录相关的任何必需的路径信息。
需要输出文件。要生成的输出文件的名称,包括与当前目录相关的任何必需的路径信息。
网页抓取 加密html(原始接口图集(090105-123465)上有解密javascript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-11 22:01
网页抓取加密html页面技术!以下截图都来自某s2103的原始接口图集(090105-12346-11272
5),具体抓取代码大概在:-08-23/127540302.png,请大家不要按图索骥,根据具体接口的要求来修改代码。
其实有些地方就不同了:
1、就有webkit浏览器提供的对element进行不可逆的调用方法。于是就可以部分绕过https的防范,在“您好,本网页开发人员在发起搜索请求时需要进行身份验证,请输入正确的账号密码,否则本网页将被关闭。”下,
2、就可以部分绕过wordpress文件代码验证,解密wordpress中文件的代码(此条实际上就是为了忽悠你花个10块钱买个我们的认证证书,对付不安全问题。
3、也就是没必要搞那么复杂。所以可以构造部分html页面,导出成base64格式,然后用一些开源的方法解密(例如isbl()/这个方法的aes到hmac的解密算法都是公开的,javascript解密公开的部分也有,thread.currentthread.remotecodevariables.chrom.encryptionhandlers.setassethandler(encryptionhandlers.hmac_nowrapcodes)等函数可以生成r920105511286,然后还有用来调用getcrcbyaddshadow函数的scripts、用来解密shell脚本的file.prototype.tostring等。
android上有解密javascript的,ios上有解密html的,都是写好了给你用,也支持部分从https漏洞的提取,例如下图所示:这个方法就算一个程序员也看不懂,你能够明白,那就是你破解原本的协议。这里面还有一点误区:一旦被抓包之后,只要不发包去dos,它们都没有任何办法。即使发包去dos了,抓包的人也能重发包。
在抓包过程中能够发现哪些文件是有漏洞的,然后就去攻击它。然后这些协议在wp中有部分都被默认处理了(防火墙会被禁止它和web所有互相传递的方法调用、协议上标识符、防火墙上设置的拦截等)。于是只要攻击程序能生成该协议就能够绕过它!这就是为什么都想通过xposed或者wp反编译工具来绕过这些协议的原因(本身xposed还是wp开发中的一个配置,没想到它们也能用于攻击wp)这里就是了解对每个协议的类型及其它具体流程做个简单说明。strict-web-security(sw)是可信应用认证协议,针对公钥加密的https网页。
(有单独的叫这个协议版本,ssl协议,
0)https(加密传输)由tls(transportlayersecurity,传输层安全)和ssl(securesocketslayer,安全套接字层协议)构成,但是都一样, 查看全部
网页抓取 加密html(原始接口图集(090105-123465)上有解密javascript)
网页抓取加密html页面技术!以下截图都来自某s2103的原始接口图集(090105-12346-11272
5),具体抓取代码大概在:-08-23/127540302.png,请大家不要按图索骥,根据具体接口的要求来修改代码。
其实有些地方就不同了:
1、就有webkit浏览器提供的对element进行不可逆的调用方法。于是就可以部分绕过https的防范,在“您好,本网页开发人员在发起搜索请求时需要进行身份验证,请输入正确的账号密码,否则本网页将被关闭。”下,
2、就可以部分绕过wordpress文件代码验证,解密wordpress中文件的代码(此条实际上就是为了忽悠你花个10块钱买个我们的认证证书,对付不安全问题。
3、也就是没必要搞那么复杂。所以可以构造部分html页面,导出成base64格式,然后用一些开源的方法解密(例如isbl()/这个方法的aes到hmac的解密算法都是公开的,javascript解密公开的部分也有,thread.currentthread.remotecodevariables.chrom.encryptionhandlers.setassethandler(encryptionhandlers.hmac_nowrapcodes)等函数可以生成r920105511286,然后还有用来调用getcrcbyaddshadow函数的scripts、用来解密shell脚本的file.prototype.tostring等。
android上有解密javascript的,ios上有解密html的,都是写好了给你用,也支持部分从https漏洞的提取,例如下图所示:这个方法就算一个程序员也看不懂,你能够明白,那就是你破解原本的协议。这里面还有一点误区:一旦被抓包之后,只要不发包去dos,它们都没有任何办法。即使发包去dos了,抓包的人也能重发包。
在抓包过程中能够发现哪些文件是有漏洞的,然后就去攻击它。然后这些协议在wp中有部分都被默认处理了(防火墙会被禁止它和web所有互相传递的方法调用、协议上标识符、防火墙上设置的拦截等)。于是只要攻击程序能生成该协议就能够绕过它!这就是为什么都想通过xposed或者wp反编译工具来绕过这些协议的原因(本身xposed还是wp开发中的一个配置,没想到它们也能用于攻击wp)这里就是了解对每个协议的类型及其它具体流程做个简单说明。strict-web-security(sw)是可信应用认证协议,针对公钥加密的https网页。
(有单独的叫这个协议版本,ssl协议,
0)https(加密传输)由tls(transportlayersecurity,传输层安全)和ssl(securesocketslayer,安全套接字层协议)构成,但是都一样,
网页抓取 加密html( Python中如何使用Pandas_html方法从HTML中获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-11 18:12
Python中如何使用Pandas_html方法从HTML中获取数据
)
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(请参阅 文章 了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人都会使用维基百科来了解我们感兴趣的主题。此外,这些维基百科文章 通常收录 HTML 表格。
要使用 Pandas 在 Python 中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果有消息说有更新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type() 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们还需要对数据进行清洗,最后,我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请确保查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据帧的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将 2 列索引(名称)变成唯一的列名称。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们以后就可以轻松创建时间序列图了。
现在,为了能够绘制这个时间序列图,我们需要用0填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累加值:
HTML 表中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
查看全部
网页抓取 加密html(
Python中如何使用Pandas_html方法从HTML中获取数据
)
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(请参阅 文章 了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人都会使用维基百科来了解我们感兴趣的主题。此外,这些维基百科文章 通常收录 HTML 表格。
要使用 Pandas 在 Python 中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果有消息说有更新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type() 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们还需要对数据进行清洗,最后,我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请确保查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据帧的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将 2 列索引(名称)变成唯一的列名称。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们以后就可以轻松创建时间序列图了。
现在,为了能够绘制这个时间序列图,我们需要用0填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累加值:
HTML 表中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
网页抓取 加密html(apache+php+mysql,基本上和msword差不多的流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-11 16:43
网页抓取加密html,然后解密接收其他pdf文件,通过代理服务器来走的。
这家公司最近的服务是使用apache+php+mysql,基本上和msword差不多的流程..不过更好的是他们可以从网页上抓取出他们自己的文件,然后传给别人...
有的,
很多外贸公司为了管理方便,都会把国外产品的产品图片上传到电商网站上,出售图片的正版imageshop,可以提供正版图片和翻译服务,比如booking旗下的比库公司,就是这样做的。你直接去电商网站的搜索框里搜booking,出来的页面会发现有很多优惠。其中就有一条是把图片中的页码(pagecode)传到你手上,然后直接把对应的价格传过去,省掉购买。
有些其他的电商公司也会和他们合作,但做的不够好。还有一种方式是可以直接上传电子版图片,通过中转服务器上传到国外的服务器,因为是复制的所以比较快捷和安全。当然国内也有很多机构或者公司做这件事情,从古董网站,人人等古代公司主页下载下来过滤图片上的页码,这样再上传到或其他电商网站就可以了。国内用的比较少,但确实有。
看过一篇文章,也是参考这篇报道来的。假设alibaba的服务器是中国,那么通过爬虫从线上抓取一些产品的图片,然后再上传到平台上卖出去。从中也赚个差价。参考:leakynetworkingdealsongooglesearchgoogle爬虫技术-搜索相关文章:p.s.扯一句题外话,现在做网站都很省事了,什么租域名啊,上托管,少走很多弯路,省心许多,并且还挺便宜。
搜索相关文章:sitemap与html5+css3,谁有这样的神器?~~~补充一下:搜到一个在线网站-global-search-global-search-display-image-in-baidu-yunbiaogooglechrome提供的搜索服务,在线展示一些图片。我看到好多网站都在用他来做网站首页,类似百度百科的模式。 查看全部
网页抓取 加密html(apache+php+mysql,基本上和msword差不多的流程)
网页抓取加密html,然后解密接收其他pdf文件,通过代理服务器来走的。
这家公司最近的服务是使用apache+php+mysql,基本上和msword差不多的流程..不过更好的是他们可以从网页上抓取出他们自己的文件,然后传给别人...
有的,
很多外贸公司为了管理方便,都会把国外产品的产品图片上传到电商网站上,出售图片的正版imageshop,可以提供正版图片和翻译服务,比如booking旗下的比库公司,就是这样做的。你直接去电商网站的搜索框里搜booking,出来的页面会发现有很多优惠。其中就有一条是把图片中的页码(pagecode)传到你手上,然后直接把对应的价格传过去,省掉购买。
有些其他的电商公司也会和他们合作,但做的不够好。还有一种方式是可以直接上传电子版图片,通过中转服务器上传到国外的服务器,因为是复制的所以比较快捷和安全。当然国内也有很多机构或者公司做这件事情,从古董网站,人人等古代公司主页下载下来过滤图片上的页码,这样再上传到或其他电商网站就可以了。国内用的比较少,但确实有。
看过一篇文章,也是参考这篇报道来的。假设alibaba的服务器是中国,那么通过爬虫从线上抓取一些产品的图片,然后再上传到平台上卖出去。从中也赚个差价。参考:leakynetworkingdealsongooglesearchgoogle爬虫技术-搜索相关文章:p.s.扯一句题外话,现在做网站都很省事了,什么租域名啊,上托管,少走很多弯路,省心许多,并且还挺便宜。
搜索相关文章:sitemap与html5+css3,谁有这样的神器?~~~补充一下:搜到一个在线网站-global-search-global-search-display-image-in-baidu-yunbiaogooglechrome提供的搜索服务,在线展示一些图片。我看到好多网站都在用他来做网站首页,类似百度百科的模式。
网页抓取 加密html(iframe“必须要用iframe的时候”,如何躲过搜索引擎?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-10 12:26
前言:很多博主仔细阅读内容后,直接认为ifame不好。这篇文章其实就是教你在必须使用iframe的时候,如何避免被搜索引擎抓取,以免对SEO不利。案件!
那么,什么是“何时必须使用 iframe”?举个简单的例子:一些主题分享网站,很多时候会使用iframe框架调用主题作者的网站做主题演示,那么就会产生大量的iframe框架,所以这篇文章的方法就可以派上用场了!
导读:稍微了解一下seo站长,应该知道爬虫不喜欢iframe或frame,因为蜘蛛在访问一个URL时爬取的HTML是调用其他网页的HTML文件的代码,不收录任何文字内容。也就是说,你的网页内容是什么,蜘蛛是想不出来的。有人可能会说,搜索引擎蜘蛛还可以跟踪和抓取所调用的 HTML 文件。是的,它可以跟踪抓取,但是跟踪这部分内容通常不是一个完整的页面。搜索引擎无法判断哪一部分是主框架,哪一部分是被调用的文件。随着搜索技术的发展,不一定总能解决这个问题,但是这么多网站蜘蛛不会打扰你,因为你是一个网站。因此,当您必须使用 iframe 框架时,
从使用iframe调用Express 100进行express查询,到推出互推联盟iframe调用代码,张哥对iframe有点透彻。
记得,互推联盟推出自适应iframe代码的时候,冯耀宗博友是这样评论的:,
后来偶然的测试给了我灵感,想到用JS封装iframe,避免被搜索引擎抓取。当时我在测试用JS封装CSS代码,想简单的加密一下自己的劳动成果。不对,突然想到,既然JS可以输出CSS,那么JS也应该输出iframe!实际测试发现我的想法是可行的!通过JS输出iframe代码,可以完美达到直接调用iframe代码的效果!
以下是互推联盟的例子,以及发布方式:
张哥的第一个iframe自适应调用代码如下:
下面,张哥就来讲解一下如何用js代码封装这个iframe,做成js版本:
首先新建一个JS文件,在里面输入如下内容并保存:
原创 iframe 的内容在括号中。注意iframe开头和结尾都是双引号,iframe里面需要改成单引号!否则无法输出!
document.write("");
然后,将这个js文件上传到服务器
比如互推联盟调用的js最终地址为:
最后在要调用iframe的地方写如下语句
如果有旧的 iframe 代码,请直接替换。如果发现界面不理想,请在第二步编辑JS文件,调整iframe大小。
这样就完美的实现了原来直接用iframe框架调用的效果。
接下来,张哥来测试一下避开搜索爬虫的效果:
①打开站长工具的搜索蜘蛛和机器人模拟爬虫工具:
②进入使用JS部署iframe代码的页面,比如MOREOPEN博客调用的互推联盟页面:
③如图所示,这个页面有很多外部链接。如果不处理,蜘蛛绝对可以爬到这个iframe。
但是经过JS封装后,会得到如下爬取结果:
如上图所示,结果中页面互推联盟中没有内容,证实了该方法的可行性!当然,感兴趣的站长也可以使用自己的网站亲自测试效果。
最后,《国际惯例》风格总结:
综上,事实证明,通过JS封装iframe代码确实可以完美欺骗搜索引擎,让鱼和熊掌不再难选!
而且,没有外链输出,没有减肥,这也是张哥博客的通用互推联盟页面被很多站长点赞的重要原因之一!很多博主可能认为张格隆的互促联盟赚了多少外链,其实不然!张哥这里必须澄清一下,跟JS叫的互推联盟根本不会成为张哥博客的外链!不信的朋友可以去用工具测试一下被调用的页面就知道了! 查看全部
网页抓取 加密html(iframe“必须要用iframe的时候”,如何躲过搜索引擎?)
前言:很多博主仔细阅读内容后,直接认为ifame不好。这篇文章其实就是教你在必须使用iframe的时候,如何避免被搜索引擎抓取,以免对SEO不利。案件!
那么,什么是“何时必须使用 iframe”?举个简单的例子:一些主题分享网站,很多时候会使用iframe框架调用主题作者的网站做主题演示,那么就会产生大量的iframe框架,所以这篇文章的方法就可以派上用场了!
导读:稍微了解一下seo站长,应该知道爬虫不喜欢iframe或frame,因为蜘蛛在访问一个URL时爬取的HTML是调用其他网页的HTML文件的代码,不收录任何文字内容。也就是说,你的网页内容是什么,蜘蛛是想不出来的。有人可能会说,搜索引擎蜘蛛还可以跟踪和抓取所调用的 HTML 文件。是的,它可以跟踪抓取,但是跟踪这部分内容通常不是一个完整的页面。搜索引擎无法判断哪一部分是主框架,哪一部分是被调用的文件。随着搜索技术的发展,不一定总能解决这个问题,但是这么多网站蜘蛛不会打扰你,因为你是一个网站。因此,当您必须使用 iframe 框架时,
从使用iframe调用Express 100进行express查询,到推出互推联盟iframe调用代码,张哥对iframe有点透彻。
记得,互推联盟推出自适应iframe代码的时候,冯耀宗博友是这样评论的:,
后来偶然的测试给了我灵感,想到用JS封装iframe,避免被搜索引擎抓取。当时我在测试用JS封装CSS代码,想简单的加密一下自己的劳动成果。不对,突然想到,既然JS可以输出CSS,那么JS也应该输出iframe!实际测试发现我的想法是可行的!通过JS输出iframe代码,可以完美达到直接调用iframe代码的效果!
以下是互推联盟的例子,以及发布方式:
张哥的第一个iframe自适应调用代码如下:
下面,张哥就来讲解一下如何用js代码封装这个iframe,做成js版本:
首先新建一个JS文件,在里面输入如下内容并保存:
原创 iframe 的内容在括号中。注意iframe开头和结尾都是双引号,iframe里面需要改成单引号!否则无法输出!
document.write("");
然后,将这个js文件上传到服务器
比如互推联盟调用的js最终地址为:
最后在要调用iframe的地方写如下语句
如果有旧的 iframe 代码,请直接替换。如果发现界面不理想,请在第二步编辑JS文件,调整iframe大小。
这样就完美的实现了原来直接用iframe框架调用的效果。
接下来,张哥来测试一下避开搜索爬虫的效果:
①打开站长工具的搜索蜘蛛和机器人模拟爬虫工具:
②进入使用JS部署iframe代码的页面,比如MOREOPEN博客调用的互推联盟页面:
③如图所示,这个页面有很多外部链接。如果不处理,蜘蛛绝对可以爬到这个iframe。
但是经过JS封装后,会得到如下爬取结果:
如上图所示,结果中页面互推联盟中没有内容,证实了该方法的可行性!当然,感兴趣的站长也可以使用自己的网站亲自测试效果。
最后,《国际惯例》风格总结:
综上,事实证明,通过JS封装iframe代码确实可以完美欺骗搜索引擎,让鱼和熊掌不再难选!
而且,没有外链输出,没有减肥,这也是张哥博客的通用互推联盟页面被很多站长点赞的重要原因之一!很多博主可能认为张格隆的互促联盟赚了多少外链,其实不然!张哥这里必须澄清一下,跟JS叫的互推联盟根本不会成为张哥博客的外链!不信的朋友可以去用工具测试一下被调用的页面就知道了!
网页抓取 加密html(前几天学习Python模拟登录知乎实例-几天加密处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-10 12:26
前几天学的Python模拟登录知乎例子,涉及到fromdata的加密处理。在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是自己找了个简单的例子来学习js加密。
一、示例网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑
1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为方便查看,先清除之前的请求流程,然后在网页切换城市,即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求标头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。
接下来需要考虑如何构造Form数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
我们尝试进入 getAQIData() 方法。
首页查询条件列的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到,网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2 文件中,经过混淆后,可以使用在线工具进行去混淆,如:。
使用开发者工具破解调试,进入getServerData方法。
最后,我们看到了Form Data,可以看到getParm()方法返回的内容。
3.密码分析
知道位置后,我们可以直接将加密后的js方法扣出来,在html文件中执行。
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在执行过程中发现返回的内容与前台返回的内容不一致。经过一些查询,
发现得到的加密字符串的内容只与“view decoded”中显示的内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
对服务器返回的内容进行解密,最终得到我们想要的数据。
详细代码请到: 查看全部
网页抓取 加密html(前几天学习Python模拟登录知乎实例-几天加密处理方法)
前几天学的Python模拟登录知乎例子,涉及到fromdata的加密处理。在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是自己找了个简单的例子来学习js加密。
一、示例网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑
1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为方便查看,先清除之前的请求流程,然后在网页切换城市,即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求标头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。
接下来需要考虑如何构造Form数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
我们尝试进入 getAQIData() 方法。
首页查询条件列的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,发现没有找到,网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2 文件中,经过混淆后,可以使用在线工具进行去混淆,如:。
使用开发者工具破解调试,进入getServerData方法。
最后,我们看到了Form Data,可以看到getParm()方法返回的内容。
3.密码分析
知道位置后,我们可以直接将加密后的js方法扣出来,在html文件中执行。
var getParam = (function () {
function ObjectSort(obj) {
var newObject = {};
Object.keys(obj).sort().map(function (key) {
newObject[key] = obj[key]
});
return newObject
}
return function (method, obj) {
var appId = '1a45f75b824b2dc628d5955356b5ef18';
var clienttype = 'WEB';
var timestamp = new Date().getTime();
var param = {
appId: appId,
method: method,
timestamp: timestamp,
clienttype: clienttype,
object: obj,
secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))
};
param = BASE64.encrypt(JSON.stringify(param));
return AES.encrypt(param, aes_client_key, aes_client_iv)
}
})();
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):
'''
对查询条件栏的数据,进行加密
:param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等
:return:加密后的字符串
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('getAQIData',form_data)
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密
function getServerData(method, object, callback, period) {
const key = hex_md5(method + JSON.stringify(object));
// const data = getDataFromLocalStorage(key, period);
// if (!data) {
var param = getParam(method, object);
return param
// } else {
// callback(data)
// }
}
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在执行过程中发现返回的内容与前台返回的内容不一致。经过一些查询,
发现得到的加密字符串的内容只与“view decoded”中显示的内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):
'''
对服务器请求成功后返回的数据,进行解密
:param resp_text: 返回的数据
:return:解密后的字符串,json格式
'''
with open('encrypt.js',encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('decodeData',resp_text)
对服务器返回的内容进行解密,最终得到我们想要的数据。
详细代码请到:
网页抓取 加密html(【咸鱼学Python】第一时间关注Python技术干货!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-08 04:10
点击上方的“Salted Fish Learn Python”,选择“Add as Star”
第一时间关注Python技术干货!
今天网站
aHR0cDovL2dnenkuendmd2IudGouZ292LmNuL3F1ZXJ5Q29udGVudC1qeXh4LmpzcHg=
此网站来自技术交流群聊天记录。忘记是哪个大佬送的了。听说很简单,我就复制一下。
抓包分析
解开上面密文,打开列表页面。我们要分析的加密是点击链接后打开新页面的URL
这个网址在列表页的网址上显示如下
所以需要抓包看看点击过程做了什么。
但这里比较难受的是,点击的链接是从新标签页打开的,此时开发者工具无法捕捉到新页面的包。
有人会说,那我就用抓包工具吧。话是这么说的,但是像我这么懒,只想平躺着连抓包工具都不想开怎么办?
其实很简单,改代码就行
找到你要打开的页面的链接,把html下面红框里的代码删掉。
这时候点击对应的列表项就可以抓取到请求详情页的包了。
加密定位
通过上面的方法,可以抓到请求详情页的包,自然也可以通过栈找到js的加密逻辑。
通过Initiator可以看到堆栈信息
这里可以看到js的加密逻辑。
注意
不要等待请求跳过!!!
不要等待请求跳过!!!
不要等待请求跳过!!!
跳转到eval栈,你将无法点击,所以当你看到网络中有一个数据包时,取消请求
这时候可以点击Initiator中的eval
否则它看起来像这样
评估位置显示未知
密码分析
找到js加密的位置,剩下的就简单了
这部分是加密的主要逻辑,其中aes加密被称为
我们将其复制到 webstrom 进行调试
删除不相关的逻辑,比如ee,r.test,这些逻辑判断
你可以看到下面的代码
记得安装crypto-js,不然加密逻辑要自己推,麻烦
这时候运行,代码提示s没有定义
这很简单。从这张图我们可以知道最后一个eval栈是jquery.mini.js
所以只需在这个文件中找到它
直接搜索定义 var s = 只有一个结果
把这个s值带入我们的js逻辑,得到如下结果
与网页对比
结果是一样的。本文的难点主要是抓包不易抓包,定位eval需要一定的浏览器技巧,适合新手练习调试技巧。
我是一条咸鱼,不更新就打鱼 查看全部
网页抓取 加密html(【咸鱼学Python】第一时间关注Python技术干货!!)
点击上方的“Salted Fish Learn Python”,选择“Add as Star”
第一时间关注Python技术干货!
今天网站
aHR0cDovL2dnenkuendmd2IudGouZ292LmNuL3F1ZXJ5Q29udGVudC1qeXh4LmpzcHg=
此网站来自技术交流群聊天记录。忘记是哪个大佬送的了。听说很简单,我就复制一下。
抓包分析
解开上面密文,打开列表页面。我们要分析的加密是点击链接后打开新页面的URL
这个网址在列表页的网址上显示如下
所以需要抓包看看点击过程做了什么。
但这里比较难受的是,点击的链接是从新标签页打开的,此时开发者工具无法捕捉到新页面的包。
有人会说,那我就用抓包工具吧。话是这么说的,但是像我这么懒,只想平躺着连抓包工具都不想开怎么办?
其实很简单,改代码就行
找到你要打开的页面的链接,把html下面红框里的代码删掉。
这时候点击对应的列表项就可以抓取到请求详情页的包了。
加密定位
通过上面的方法,可以抓到请求详情页的包,自然也可以通过栈找到js的加密逻辑。
通过Initiator可以看到堆栈信息
这里可以看到js的加密逻辑。
注意
不要等待请求跳过!!!
不要等待请求跳过!!!
不要等待请求跳过!!!
跳转到eval栈,你将无法点击,所以当你看到网络中有一个数据包时,取消请求
这时候可以点击Initiator中的eval
否则它看起来像这样
评估位置显示未知
密码分析
找到js加密的位置,剩下的就简单了
这部分是加密的主要逻辑,其中aes加密被称为
我们将其复制到 webstrom 进行调试
删除不相关的逻辑,比如ee,r.test,这些逻辑判断
你可以看到下面的代码
记得安装crypto-js,不然加密逻辑要自己推,麻烦
这时候运行,代码提示s没有定义
这很简单。从这张图我们可以知道最后一个eval栈是jquery.mini.js
所以只需在这个文件中找到它
直接搜索定义 var s = 只有一个结果
把这个s值带入我们的js逻辑,得到如下结果
与网页对比
结果是一样的。本文的难点主要是抓包不易抓包,定位eval需要一定的浏览器技巧,适合新手练习调试技巧。
我是一条咸鱼,不更新就打鱼
网页抓取 加密html(修正介绍说明介绍(4月14日-10月21日) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-06 09:17
)
更正说明
导言
通过处理Chr的表单提交事件,可以捕获HTTP请求信息。只要程序将加密表单信息提交给这些网站,就可以完成相应的工作-通过CHR表单提交,就可以捕获HTTP请求信息,只要程序将加密表单信息提交给这些网站就可以完成工作
相关说明
(系统自动生成,下载前可参考下载内容)
下载文件列表
压缩包 : 489827获取网页密码、代码.rar 列表
获取网页密码、代码\AboutDlg.cpp
获取网页密码、代码\AboutDlg.h
获取网页密码、代码\ButtonST.cpp
获取网页密码、代码\ButtonST.h
获取网页密码、代码\GetIE.htm
获取网页密码、代码\GetIhtml.aps
获取网页密码、代码\GetIhtml.clw
获取网页密码、代码\GetIhtml.cpp
获取网页密码、代码\GetIhtml.dsp
获取网页密码、代码\GetIhtml.dsw
获取网页密码、代码\GetIhtml.h
获取网页密码、代码\GetIhtml.ncb
获取网页密码、代码\GetIhtml.opt
获取网页密码、代码\GetIhtml.plg
获取网页密码、代码\GetIhtml.rc
获取网页密码、代码\GetIhtmlDlg.cpp
获取网页密码、代码\GetIhtmlDlg.h
获取网页密码、代码\NODROP.CUR
获取网页密码、代码\RESOURCE.H
获取网页密码、代码\ReadMe.txt
获取网页密码、代码\StdAfx.cpp
获取网页密码、代码\StdAfx.h
获取网页密码、代码\RES\GetIhtml.ico
获取网页密码、代码\RES\GetIhtml.rc2
获取网页密码、代码\RES\ICO00001.ICO
获取网页密码、代码\RES\PEN01.ICO
获取网页密码、代码\RES\W95MBX02.ICO
获取网页密码、代码\RES\WRENCH.ICO
获取网页密码、代码\RES
获取网页密码、代码 查看全部
网页抓取 加密html(修正介绍说明介绍(4月14日-10月21日)
)
更正说明
导言
通过处理Chr的表单提交事件,可以捕获HTTP请求信息。只要程序将加密表单信息提交给这些网站,就可以完成相应的工作-通过CHR表单提交,就可以捕获HTTP请求信息,只要程序将加密表单信息提交给这些网站就可以完成工作
相关说明
(系统自动生成,下载前可参考下载内容)
下载文件列表
压缩包 : 489827获取网页密码、代码.rar 列表
获取网页密码、代码\AboutDlg.cpp
获取网页密码、代码\AboutDlg.h
获取网页密码、代码\ButtonST.cpp
获取网页密码、代码\ButtonST.h
获取网页密码、代码\GetIE.htm
获取网页密码、代码\GetIhtml.aps
获取网页密码、代码\GetIhtml.clw
获取网页密码、代码\GetIhtml.cpp
获取网页密码、代码\GetIhtml.dsp
获取网页密码、代码\GetIhtml.dsw
获取网页密码、代码\GetIhtml.h
获取网页密码、代码\GetIhtml.ncb
获取网页密码、代码\GetIhtml.opt
获取网页密码、代码\GetIhtml.plg
获取网页密码、代码\GetIhtml.rc
获取网页密码、代码\GetIhtmlDlg.cpp
获取网页密码、代码\GetIhtmlDlg.h
获取网页密码、代码\NODROP.CUR
获取网页密码、代码\RESOURCE.H
获取网页密码、代码\ReadMe.txt
获取网页密码、代码\StdAfx.cpp
获取网页密码、代码\StdAfx.h
获取网页密码、代码\RES\GetIhtml.ico
获取网页密码、代码\RES\GetIhtml.rc2
获取网页密码、代码\RES\ICO00001.ICO
获取网页密码、代码\RES\PEN01.ICO
获取网页密码、代码\RES\W95MBX02.ICO
获取网页密码、代码\RES\WRENCH.ICO
获取网页密码、代码\RES
获取网页密码、代码
网页抓取 加密html(搜索引擎不收录网站页面的16个常见原因分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-05 18:07
努力整理了网站,但是百度收录收不到网站的页面。怎么了?本文将分析搜索引擎不收录网站页面的常见原因,让大家了解。我希望它对每个人都有帮助和启发。
搜索引擎不收录网站页面的16个常见原因分析:
1、 网页使用框架:框架中的内容通常不在搜索引擎的范围内;
2、 图片太多文字太少;
3、提交页面转向另一个网站:搜索引擎可能完全跳过此页面;
4、 提交太频繁:一个月提交2次以上,很多搜索引擎看不下去,认为你提交垃圾;
5、网站关键词 密度过大:可惜搜索引擎没有说明密度有多高是极限。一般认为100字的描述中有3-4个关键词是最好的;
6、文字颜色与背景颜色相同:搜索引擎认为你在铺设关键词来欺骗它;
7、动态网页:网站的内容管理系统方便了网页更新,但对大多数搜索引擎造成了困扰。很多搜索引擎对动态页面不收费,或者只对一级页面收费。深深地充电。这时候可以考虑使用WEB服务器的rewrite技术,将动态页面的url映射成类似于静态页面url的格式。搜索引擎将其误认为是静态页面并对其收费;
8、网站 传输服务器:搜索引擎通常只识别IP地址。当主机或域名改变时,IP/DNS地址改变,则必须重新提交网站;
9、免费网站空间:一些搜索引擎拒绝从免费空间索引网站,抱怨大量垃圾和质量差;
10、网站 搜索引擎不在线:如果主机不稳定,可能会出现这种情况。更糟糕的是,即使网站已经成为收录,重新爬网时发现离线,也会将网站彻底删除;
11、错误拦截robots索引网站:拦截robots有两种方式:宿主服务器根目录下有简单的文本文件;网页收录某种 META 标签;
12、 搜索引擎很难从使用 Flash、DHTML、cookies、JavaScript、Java 或密码制作的网页中提取内容。
13、 搜索引擎无法解析您的DNS:新域名注册后需要1-2天才能生效,所以不要在域名注册后立即提交网站挂号的;
14、网站的链接宽度太低:链接宽度太低,搜索引擎找不到你。这个时候,你应该考虑登录一个知名的目录或者做更多的事情。友情链接;
15、服务器速度太慢:网络带宽小,网页下载速度太慢,或者网页太复杂,可能导致搜索引擎在未找到文字内容之前暂停;
16、关键词问题:如果你的META标签中提到的关键词没有出现在正文中,搜索引擎可能会认为是垃圾关键词。
上面是网站页面,为什么不是百度收录?搜索引擎没有收录网站页面查看常见原因分析的详细内容,更多详情请关注其他相关html中文网站文章! 查看全部
网页抓取 加密html(搜索引擎不收录网站页面的16个常见原因分析(图))
努力整理了网站,但是百度收录收不到网站的页面。怎么了?本文将分析搜索引擎不收录网站页面的常见原因,让大家了解。我希望它对每个人都有帮助和启发。
搜索引擎不收录网站页面的16个常见原因分析:
1、 网页使用框架:框架中的内容通常不在搜索引擎的范围内;
2、 图片太多文字太少;
3、提交页面转向另一个网站:搜索引擎可能完全跳过此页面;
4、 提交太频繁:一个月提交2次以上,很多搜索引擎看不下去,认为你提交垃圾;
5、网站关键词 密度过大:可惜搜索引擎没有说明密度有多高是极限。一般认为100字的描述中有3-4个关键词是最好的;
6、文字颜色与背景颜色相同:搜索引擎认为你在铺设关键词来欺骗它;
7、动态网页:网站的内容管理系统方便了网页更新,但对大多数搜索引擎造成了困扰。很多搜索引擎对动态页面不收费,或者只对一级页面收费。深深地充电。这时候可以考虑使用WEB服务器的rewrite技术,将动态页面的url映射成类似于静态页面url的格式。搜索引擎将其误认为是静态页面并对其收费;
8、网站 传输服务器:搜索引擎通常只识别IP地址。当主机或域名改变时,IP/DNS地址改变,则必须重新提交网站;
9、免费网站空间:一些搜索引擎拒绝从免费空间索引网站,抱怨大量垃圾和质量差;
10、网站 搜索引擎不在线:如果主机不稳定,可能会出现这种情况。更糟糕的是,即使网站已经成为收录,重新爬网时发现离线,也会将网站彻底删除;
11、错误拦截robots索引网站:拦截robots有两种方式:宿主服务器根目录下有简单的文本文件;网页收录某种 META 标签;
12、 搜索引擎很难从使用 Flash、DHTML、cookies、JavaScript、Java 或密码制作的网页中提取内容。
13、 搜索引擎无法解析您的DNS:新域名注册后需要1-2天才能生效,所以不要在域名注册后立即提交网站挂号的;
14、网站的链接宽度太低:链接宽度太低,搜索引擎找不到你。这个时候,你应该考虑登录一个知名的目录或者做更多的事情。友情链接;
15、服务器速度太慢:网络带宽小,网页下载速度太慢,或者网页太复杂,可能导致搜索引擎在未找到文字内容之前暂停;
16、关键词问题:如果你的META标签中提到的关键词没有出现在正文中,搜索引擎可能会认为是垃圾关键词。
上面是网站页面,为什么不是百度收录?搜索引擎没有收录网站页面查看常见原因分析的详细内容,更多详情请关注其他相关html中文网站文章!
网页抓取 加密html(网站错误页面了嘛解决百度排名等一系列的原因有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-05 18:06
百度的页面已经收录上千次了,但是你知道收录的这些页面有多少是错误页面吗?有多少页面打不开?你花时间整理错误页面了吗?本文将从四个方面找出百度收录页面的错误,供大家了解。解决自己的问题可以解决百度排名等一系列问题。我希望这篇文章能对你有所帮助和启发。
小问题也需要大智慧。处理网站错误页面是百度在网页优化白皮书中提出的重点项目。作为站长,我们应该发现这些关键点,然后根据网站自身的问题进行改进,对在百度收录遇到错误页面并对其产生负面影响的页面进行改进。同时,也给用户留下了良好的印象,提升了页面的用户体验。作为菜鸟,我从这些方面给大家总结一下,找出百度收录页面的错误。
1、服务器错误
服务器错误的主要问题是百度蜘蛛在发起网页抓取时,httpcode返回5XX状态码,会导致百度抓取标准化网页失败。
服务器报错的原因有很多:网站正在维护中;网站 程序有批处理错误。
最好的解决办法是找出程序错误并进行适当的修改。如果网站正在维护,请使用百度站长平台的闭站保护规范后再进行。
2、访问被拒绝
拒绝访问的主要问题是百度蜘蛛在发起网页抓取时,httpcode返回403状态码,这也会导致百度蜘蛛抓取标准化网页失败。
拒绝访问的原因也有很多:网站权限受限;IP地址被拒绝;服务器流量超载。
此类错误的解决方案也非常简单。找出网页所在的目录,并给百度蜘蛛足够的权限来抓取页面。检查百度蜘蛛的IP地址是否被屏蔽。如果服务器流量过大,则升级服务器。
3、页面未找到
找不到页面的主要问题是百度蜘蛛在发起网络爬虫时,httpcode返回404状态码。这种错误是网页中最重要的。几乎所有的网站 都有这种页面。.
找不到页面的原因有很多:团购网页过期;误删数据库;删除论坛垃圾帖子。
其实这些问题都可以轻松解决。创建一个合适的 404 页面,遇到 404 状态码时返回到 404 页面。
4、其他错误
其他错误收录的项目比较多,但问题大概是一样的,就是百度蜘蛛抓取网页时httpcode返回的4XX状态码,除了403和404。
这个问题的来源有很多:请求的URL太长【参数太多】;需要身份验证;不支持的媒体类型;浏览器不接受请求的页面。
解决这些问题比较复杂。如果 URL 太长,则需要解决参数的排序位置。认证应该从部分网站权限控制等程序问题来控制。媒体类型应尽可能被每种类型覆盖。拥有网站。
总之,利用好百度站长平台的爬取异常栏选项,可以找到百度蜘蛛在爬取网页时遇到的瓶颈,解决这些阻碍蜘蛛爬行的问题。把百度中所有收录的页面都统计出来,然后你可以根据不同的问题来解决。网站 爬虫问题解决了,百度收录的量会duang,duang,duang暴涨。
以上就是如何使用百度排查收录页面URL异常的方法?从四个方面找出百度收录页面的错误详情。更多详情请关注html中文网站其他相关文章! 查看全部
网页抓取 加密html(网站错误页面了嘛解决百度排名等一系列的原因有哪些)
百度的页面已经收录上千次了,但是你知道收录的这些页面有多少是错误页面吗?有多少页面打不开?你花时间整理错误页面了吗?本文将从四个方面找出百度收录页面的错误,供大家了解。解决自己的问题可以解决百度排名等一系列问题。我希望这篇文章能对你有所帮助和启发。
小问题也需要大智慧。处理网站错误页面是百度在网页优化白皮书中提出的重点项目。作为站长,我们应该发现这些关键点,然后根据网站自身的问题进行改进,对在百度收录遇到错误页面并对其产生负面影响的页面进行改进。同时,也给用户留下了良好的印象,提升了页面的用户体验。作为菜鸟,我从这些方面给大家总结一下,找出百度收录页面的错误。
1、服务器错误
服务器错误的主要问题是百度蜘蛛在发起网页抓取时,httpcode返回5XX状态码,会导致百度抓取标准化网页失败。
服务器报错的原因有很多:网站正在维护中;网站 程序有批处理错误。
最好的解决办法是找出程序错误并进行适当的修改。如果网站正在维护,请使用百度站长平台的闭站保护规范后再进行。
2、访问被拒绝
拒绝访问的主要问题是百度蜘蛛在发起网页抓取时,httpcode返回403状态码,这也会导致百度蜘蛛抓取标准化网页失败。
拒绝访问的原因也有很多:网站权限受限;IP地址被拒绝;服务器流量超载。
此类错误的解决方案也非常简单。找出网页所在的目录,并给百度蜘蛛足够的权限来抓取页面。检查百度蜘蛛的IP地址是否被屏蔽。如果服务器流量过大,则升级服务器。
3、页面未找到
找不到页面的主要问题是百度蜘蛛在发起网络爬虫时,httpcode返回404状态码。这种错误是网页中最重要的。几乎所有的网站 都有这种页面。.
找不到页面的原因有很多:团购网页过期;误删数据库;删除论坛垃圾帖子。
其实这些问题都可以轻松解决。创建一个合适的 404 页面,遇到 404 状态码时返回到 404 页面。
4、其他错误
其他错误收录的项目比较多,但问题大概是一样的,就是百度蜘蛛抓取网页时httpcode返回的4XX状态码,除了403和404。
这个问题的来源有很多:请求的URL太长【参数太多】;需要身份验证;不支持的媒体类型;浏览器不接受请求的页面。
解决这些问题比较复杂。如果 URL 太长,则需要解决参数的排序位置。认证应该从部分网站权限控制等程序问题来控制。媒体类型应尽可能被每种类型覆盖。拥有网站。
总之,利用好百度站长平台的爬取异常栏选项,可以找到百度蜘蛛在爬取网页时遇到的瓶颈,解决这些阻碍蜘蛛爬行的问题。把百度中所有收录的页面都统计出来,然后你可以根据不同的问题来解决。网站 爬虫问题解决了,百度收录的量会duang,duang,duang暴涨。
以上就是如何使用百度排查收录页面URL异常的方法?从四个方面找出百度收录页面的错误详情。更多详情请关注html中文网站其他相关文章!

