
网站内容抓取工具
从Docker到K8s,业务容器化遇瓶颈怎么办(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-07-19 07:04
从Docker到K8s,业务容器化遇到瓶颈怎么办? >>>
网络爬虫有很多种。下面是一个非常粗略的分类,并说明了网络爬虫/数据提取/信息提取工具包MetaSeeker中的爬虫属于哪个类别。
如果按照部署的地方来划分,可以分为:
1.服务器端:一般是多线程程序,同时下载多个目标HTML,可以使用PHP、Java、Python(目前比较流行)等,一般集成搜索引擎爬虫都是这样做的。但是,如果对方讨厌爬虫,很可能会封掉服务器的IP,不容易更改,而且消耗的带宽也相当昂贵。
2、Client:非常适合部署固定主题的爬虫,或者专注的爬虫。与谷歌、百度等竞争的综合搜索引擎成功的机会很少,而垂直搜索或比价服务或推荐引擎的机会要多得多。这种类型的爬虫不会抓取所有页面,而只会抓取您关心的内容。页面,只抓取页面上你关心的内容,比如提取黄页信息、产品价格信息、提取竞争对手的广告信息等。这种爬虫可以部署很多,而且攻击性很强,对方很难拦截。
网页爬虫/数据提取/信息提取工具包MetaSeeker中的爬虫属于客户端固定主题爬虫(产品特性更详细),可以低成本大批量部署。由于客户端IP地址是动态的,很难被目标网站拦截。
我们只讨论固定主题的爬虫。普通的爬虫要简单得多,网上也有很多。如果按照如何提取数据来划分,可以分为两类:
1.通过正则表达式提取内容。 HTML 文件是一个文本文件。只需使用正则表达式提取指定位置的内容即可。 “指定地点”不一定是绝对定位。例如,您可以参考 HTML 标签定位。 , 更准确
2、使用DOM提取内容,HTML文件先转换成DOM数据结构,然后遍历这个结构提取内容。
可能有人会问,为什么还要用DOM的方法,把它翻过来呢? DOM方法存在的原因有很多:一是不用自己分析DOM结构,有现成的库,编程不复杂;其次,可以实现非常复杂但灵活的定位规则,而正则表达式很难写;第三,如果定位是考虑到HTML文件的结构,用正则表达式解析起来并不容易。 HTML 文件经常有错误。如果把这个任务交给现成的图书馆,那就容易多了。第四,假设要解析Javascript的内容,正则表达式是无能为力的。当然,DOM方法本身是无能为力的,但是利用某个平台的能力,提取AJAX网站内容是可以的。原因有很多。
网页抓取/数据提取/信息提取工具包MetaSeeker中的爬虫使用DOM方式。它使用 Mozilla 平台的功能。只要火狐看到就可以解压。 查看全部
从Docker到K8s,业务容器化遇瓶颈怎么办(图)
从Docker到K8s,业务容器化遇到瓶颈怎么办? >>>

网络爬虫有很多种。下面是一个非常粗略的分类,并说明了网络爬虫/数据提取/信息提取工具包MetaSeeker中的爬虫属于哪个类别。
如果按照部署的地方来划分,可以分为:
1.服务器端:一般是多线程程序,同时下载多个目标HTML,可以使用PHP、Java、Python(目前比较流行)等,一般集成搜索引擎爬虫都是这样做的。但是,如果对方讨厌爬虫,很可能会封掉服务器的IP,不容易更改,而且消耗的带宽也相当昂贵。
2、Client:非常适合部署固定主题的爬虫,或者专注的爬虫。与谷歌、百度等竞争的综合搜索引擎成功的机会很少,而垂直搜索或比价服务或推荐引擎的机会要多得多。这种类型的爬虫不会抓取所有页面,而只会抓取您关心的内容。页面,只抓取页面上你关心的内容,比如提取黄页信息、产品价格信息、提取竞争对手的广告信息等。这种爬虫可以部署很多,而且攻击性很强,对方很难拦截。
网页爬虫/数据提取/信息提取工具包MetaSeeker中的爬虫属于客户端固定主题爬虫(产品特性更详细),可以低成本大批量部署。由于客户端IP地址是动态的,很难被目标网站拦截。
我们只讨论固定主题的爬虫。普通的爬虫要简单得多,网上也有很多。如果按照如何提取数据来划分,可以分为两类:
1.通过正则表达式提取内容。 HTML 文件是一个文本文件。只需使用正则表达式提取指定位置的内容即可。 “指定地点”不一定是绝对定位。例如,您可以参考 HTML 标签定位。 , 更准确
2、使用DOM提取内容,HTML文件先转换成DOM数据结构,然后遍历这个结构提取内容。
可能有人会问,为什么还要用DOM的方法,把它翻过来呢? DOM方法存在的原因有很多:一是不用自己分析DOM结构,有现成的库,编程不复杂;其次,可以实现非常复杂但灵活的定位规则,而正则表达式很难写;第三,如果定位是考虑到HTML文件的结构,用正则表达式解析起来并不容易。 HTML 文件经常有错误。如果把这个任务交给现成的图书馆,那就容易多了。第四,假设要解析Javascript的内容,正则表达式是无能为力的。当然,DOM方法本身是无能为力的,但是利用某个平台的能力,提取AJAX网站内容是可以的。原因有很多。
网页抓取/数据提取/信息提取工具包MetaSeeker中的爬虫使用DOM方式。它使用 Mozilla 平台的功能。只要火狐看到就可以解压。
百度抓取器会和网站首页的友好性优化(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-18 18:14
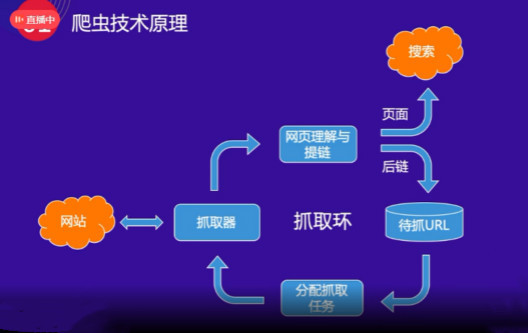
首先百度的爬虫会和网站的首页进行交互,得到网站首页后,会理解页面,理解收录(类型,值计算),其次,会带网站首页的所有内容k14@首页的超链接提取出来了。
如上图所示,首页上的超链接称为“post-links”。下一轮爬行时,爬虫会继续与这些超链接页面进行交互,并获取页面进行提炼。一层一层的不断抓取,构成了一个抓取循环。
一、Grab-Friendly Optimization1、URL 规范
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:
如上图所示,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种URL收录字符,并且这个URL收录文章的标题,导致偏长,相对较长的URL与简单的URL相比没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符就足以显示URL的资源了。
如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是手机网站建站的常用方法。从链接发现的角度来看,这两类网站并不友好。
Feed 流推荐:
大多数进行流式传输的网站在后端都有大量数据。用户不断刷新时会出现新的内容,但无论刷新多少次,可能只能刷新到1%左右的内容。一个爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使您有 100 万个内容,您也可能只能对其进行抓取。到 1-2 百万。
仅搜索条目:
如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫不能输入关键词再抓取,所以爬虫只能爬到首页之后,没有反向链接,自然爬取和收录会不理想。
解决方案:
索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页抓取你的网站最新资源,并且新发布的资源应该实时在索引页中。同步,很多纯静态网页,内容更新了,但是首页(索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是后链(latest文章的URL)需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就足够了,比如长城。基本上,只有主页用于索引。页面。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么我提交了普通的收录却没有抓到?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:
加载时间建议控制在2S以内,所以无论是用户还是爬虫,打开速度更快的网站会更受青睐,其次是避免不必要的跳转。这种情况虽然是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。 查看全部
百度抓取器会和网站首页的友好性优化(图)
首先百度的爬虫会和网站的首页进行交互,得到网站首页后,会理解页面,理解收录(类型,值计算),其次,会带网站首页的所有内容k14@首页的超链接提取出来了。
如上图所示,首页上的超链接称为“post-links”。下一轮爬行时,爬虫会继续与这些超链接页面进行交互,并获取页面进行提炼。一层一层的不断抓取,构成了一个抓取循环。
一、Grab-Friendly Optimization1、URL 规范
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:

如上图所示,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:

如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种URL收录字符,并且这个URL收录文章的标题,导致偏长,相对较长的URL与简单的URL相比没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符就足以显示URL的资源了。

如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。

如上图所示,这两个站点是手机网站建站的常用方法。从链接发现的角度来看,这两类网站并不友好。
Feed 流推荐:
大多数进行流式传输的网站在后端都有大量数据。用户不断刷新时会出现新的内容,但无论刷新多少次,可能只能刷新到1%左右的内容。一个爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使您有 100 万个内容,您也可能只能对其进行抓取。到 1-2 百万。
仅搜索条目:
如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫不能输入关键词再抓取,所以爬虫只能爬到首页之后,没有反向链接,自然爬取和收录会不理想。
解决方案:
索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页抓取你的网站最新资源,并且新发布的资源应该实时在索引页中。同步,很多纯静态网页,内容更新了,但是首页(索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是后链(latest文章的URL)需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就足够了,比如长城。基本上,只有主页用于索引。页面。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么我提交了普通的收录却没有抓到?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:
加载时间建议控制在2S以内,所以无论是用户还是爬虫,打开速度更快的网站会更受青睐,其次是避免不必要的跳转。这种情况虽然是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。
最适合你的网页刮刀取决于你需要的几种工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-07-18 18:09
如今,市场上出现了各种网络抓取工具,当您必须选择其中一种工具时,您可能会感到困惑。最适合您的网页抓取工具取决于您的需求。这里有一些强烈推荐的网页抓取工具。其中一些是免费的,而有些则有试用期和高级计划。在做出决定之前,请仔细阅读以下所有信息。
ParseHub
ParseHub 是一款免费、可靠且功能强大的网页抓取工具。它用于使用 JS、AJAX、会话、cookie 和重定向来抓取单个和多个 网站。使用 Parsehub,您可以轻松地从任何网站 获取数据,因为您无需编写代码。您只需要打开目标网站 并开始单击要提取的数据。此工具可帮助您在服务器上自动采集和存储数据。其简单的 AIP 允许用户在任何地方集成他们提取的数据。
Parsehub 在爬取网站 时使用了大量代理,因此 IP 地址总是轮换。
八字解析
Octopus 是一种现代视觉网络爬虫软件。对于那些无需编码即可从网站 获取数据的人来说,这是一个完美的选择。多亏了“点击”界面,用户使用起来不会有任何困难。八达通模仿人类活动,例如浏览网站、登录账户等。它几乎可以从每个站点获取数据,即使它是使用 AJAX 或 JS 动态获取的。
免费版八达通允许用户提取几乎所有网站。只需点击几下鼠标,它就可以将网页变成结构化的电子表格。
Diffbot
Diffbot 是一种非常高效的数据提取工具,它使用互联网让个人和企业能够获取他们需要的任何信息。可广泛应用于市场营销、商业智能、销售和招聘等领域。它提供 API 来提取和理解对象,使用 Al 和计算机视觉从网站 中提取数据。使用 Diffbot,用户不再需要进行任何手动数据提取或互联网研究,因为数据可以自动保存到文件或数据库中。
Diffbot 服务虽然价格偏高,但质量确实非常出色。
冬天
WINTR 也是一个强大的抓取工具。它是一种网页抓取和解析服务,其 API 允许公司和开发人员将任何网页转换为自定义数据集。提供数据采集、数据分析、请求代理、请求定制等多种服务。使用 WINTR 保存请求。如果您的目标网站 将来更改其结构,您将不需要修改您的应用程序代码。
这是一个全面的工具,可帮助您的网页抓取变得简单。您可以试用其免费版本,该版本提供 500 个 API 点。
Mozenda
Mozenda 是一个非常有用的数据提取工具,它避免了编写脚本或聘请开发人员的需要。它使中型软件和 IT 公司能够从任何来源自动提取网站 数据。此工具允许企业客户在其强大的云平台上运行网络抓取工具。
可以从 Excel、Word 和 PDF 等格式中提取数据。当Mozenda的“机器人”在页面上快速准确地抓取数据时,它得到结果的速度非常快。它也以多任务处理而闻名。 查看全部
最适合你的网页刮刀取决于你需要的几种工具
如今,市场上出现了各种网络抓取工具,当您必须选择其中一种工具时,您可能会感到困惑。最适合您的网页抓取工具取决于您的需求。这里有一些强烈推荐的网页抓取工具。其中一些是免费的,而有些则有试用期和高级计划。在做出决定之前,请仔细阅读以下所有信息。
ParseHub
ParseHub 是一款免费、可靠且功能强大的网页抓取工具。它用于使用 JS、AJAX、会话、cookie 和重定向来抓取单个和多个 网站。使用 Parsehub,您可以轻松地从任何网站 获取数据,因为您无需编写代码。您只需要打开目标网站 并开始单击要提取的数据。此工具可帮助您在服务器上自动采集和存储数据。其简单的 AIP 允许用户在任何地方集成他们提取的数据。
Parsehub 在爬取网站 时使用了大量代理,因此 IP 地址总是轮换。
八字解析
Octopus 是一种现代视觉网络爬虫软件。对于那些无需编码即可从网站 获取数据的人来说,这是一个完美的选择。多亏了“点击”界面,用户使用起来不会有任何困难。八达通模仿人类活动,例如浏览网站、登录账户等。它几乎可以从每个站点获取数据,即使它是使用 AJAX 或 JS 动态获取的。
免费版八达通允许用户提取几乎所有网站。只需点击几下鼠标,它就可以将网页变成结构化的电子表格。
Diffbot
Diffbot 是一种非常高效的数据提取工具,它使用互联网让个人和企业能够获取他们需要的任何信息。可广泛应用于市场营销、商业智能、销售和招聘等领域。它提供 API 来提取和理解对象,使用 Al 和计算机视觉从网站 中提取数据。使用 Diffbot,用户不再需要进行任何手动数据提取或互联网研究,因为数据可以自动保存到文件或数据库中。
Diffbot 服务虽然价格偏高,但质量确实非常出色。
冬天
WINTR 也是一个强大的抓取工具。它是一种网页抓取和解析服务,其 API 允许公司和开发人员将任何网页转换为自定义数据集。提供数据采集、数据分析、请求代理、请求定制等多种服务。使用 WINTR 保存请求。如果您的目标网站 将来更改其结构,您将不需要修改您的应用程序代码。
这是一个全面的工具,可帮助您的网页抓取变得简单。您可以试用其免费版本,该版本提供 500 个 API 点。
Mozenda
Mozenda 是一个非常有用的数据提取工具,它避免了编写脚本或聘请开发人员的需要。它使中型软件和 IT 公司能够从任何来源自动提取网站 数据。此工具允许企业客户在其强大的云平台上运行网络抓取工具。
可以从 Excel、Word 和 PDF 等格式中提取数据。当Mozenda的“机器人”在页面上快速准确地抓取数据时,它得到结果的速度非常快。它也以多任务处理而闻名。
不学Python也能快速海量海量内容|附下载地址
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-07-18 18:04
不知道你的朋友圈里是不是总能看到类似的广告,“Excel 用 Python 加班只需 3 分钟”,“我每天都能准时下班,因为我学了 Python”。看来,Python 已经成为了当代的年轻人。人的基本技能。
▲朋友圈广告
确实,Python作为一种简单易用的编程语言,在自动化办公中非常有用,尤其是抓取网页数据,在这样的大数据时代尤为重要。
爬取网页数据,又称“网络爬虫”,可以帮助我们快速采集互联网海量内容,进行深度数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等,而我们每天使用的搜索引擎都是“网络爬虫”。
但毕竟学习一门语言的成本太高了。有没有什么方法可以不学习Python就达到目标?当然,借助Chrome浏览器的“Web Scraper”插件,无需编写代码即可快速抓取大量内容。
优采云directory
以page-bilibili排名的多条信息为例
自动翻页抓取——以豆瓣电影Top250为例
抓取副页内容-以知乎热榜为例
抓取页面上的多条信息-以BiliBili排名为例
安装“Web Scraper”后,在浏览器中按F12进入开发者模式,可以在最后一个标签页看到“Web Scraper”菜单。需要注意的是,如果开发者模式面板不在底部,会提示必须放在浏览器下方才能继续。
在菜单中选择“新建站点地图-创建站点地图”,新建站点地图,填写名称和起始地址即可开始。这里以BiliBili排名为例介绍如何抓取页面上的多条信息,起始地址设置为“”。
这里我们需要抓取“视频标题”、“播放量”、“弹幕数”、“上位大师”和“综合评分”,所以首先要为每条记录创建一个包装器。
点击“Add new selector”,id填写“wrapper”,type选择“element”,然后点击“selector”,选择一条记录的外框,外包框需要收录以上所有信息,然后选择第二个这样,你会发现页面上的所有记录都被自动选中了,点击“完成选择”完成数据选择。记得勾选“Multiple”,确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一个记录突出显示。这是因为我们预先将其设置为包装器。在边框中选择标题,然后单击“完成选择”完成标题选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放音量”、“弹幕数”、“上位大师”和“综合得分”创建选择器。选中后,可以通过“数据查看”预览是否选中了想要的内容。此外,您还可以通过菜单栏中的“站点地图bilibili_ranking-Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“Scrape”,开始创建爬取任务。单个网页的间隔时间和响应时间是默认的。点击“开始抓取”开始抓取。这时候浏览器会自动打开一个新页面,几秒后自动关闭,表示已经获取完成。
点击“刷新数据”刷新数据,或点击“站点地图bilibili_ranking-浏览”查看数据。您可以通过“Sitemap bilibili_ranking-Export data as CSV”下载为CSV格式文件。
▲BiliBili 排名
用 Excel 打开。由于“Web Scraper”抓取的内容是乱序的,需要对“综合评分”进行降序排序,恢复原来的排名结果。
自动翻页抓取——以豆瓣电影Top250为例
Bilibili 排名只有 100 条记录,而且都在一个网页上。有分页显示怎么办?这里以豆瓣电影Top250为例介绍自动翻页抓取。
同理,新建站点地图时,在填写起始地址之前,先观察豆瓣电影Top250的构成。一共250条记录,每页显示10条,分为25页。
每一页的URL都很规则,第一页的地址是“”,第二页只是把地址中的“start=0”改成了“start=25”,所以我们填写start时地址,可以填写“[0-250:25]&filter=”,其中start=[0-250:25]表示以25为步长从0到250获取,所以start为0、2 5、 分别等待 50 次。这样,“Web Scraper”就会逐页抓取数据。
下一步类似于BiliBili排名。创建“包装器”后,添加“电影名称”、“豆瓣评分”、“电影短评”和“豆瓣排名”选择器,然后开始爬取。
可以看到浏览器会逐页翻页抓取。在这里你只需要静静等待爬行完成即可。最终得到的数据按照“豆瓣排名”升序排列,得到豆瓣电影。 Top250名单。
▲豆瓣电影Top250
当然,这只是最简单的一种分页方式,很多网站地址不一定有类似的规则。因此,“Web Scraper”的分页方法比较多,但是相对来说也比较复杂。此处不再赘述。
抓取副页内容-以知乎热榜为例
以上已经完成了对网页单页和多页内容的抓取,但并不是每次都在一页上有现成的数据,所以需要进一步搜索二级页面。以知乎热榜为例,介绍如何抓取二级页面的“关注”和“浏览”。
首先,创建一个起始地址为“”的新站点地图。然后像之前一样创建“wrapper”,然后创建三个选择器“文章title”、“文章热度”和“知乎ranked”。
下一个重要步骤是创建“二级页面”链接。点击“添加新选择器”,id填写“二级页面”,类型选择“链接”,然后点击“选择器”,选择文章的标题,即每个文章的入口,确认选择并保存并退出。
这相当于有了一个窗口,点击刚刚创建的“二级页面”进入下一级目录,然后创建“关注”和“浏览量”就像创建“文章title”一样前。选择器。最后,整个树结构如下图所示。
点击“站点地图知乎_hot-Scrape”开始爬取。在这里可以增加“页面加载延迟”的响应时间,以确保页面完全加载。这时候浏览器会依次打开各个二级页面进行抓取,需要稍等片刻。
爬取任务完成后,将结果下载为CSV文件,并按照“知乎ranking”的降序排列,得到知乎热榜的完整列表。
▲知乎热榜
至此,我已经介绍了如何使用“Web Scraper”抓取一个页面的多条信息,自动翻页,抓取二级页面的内容。显然,“Web Scraper”的功能远不止这些,还有更强大的抓图、正则表达式等功能,大家可以自行探索。
另外,如果你只是想简单的抓取信息,可以试试其他插件,比如“Simple scraper”和“Instant Data Scraper”。这些插件甚至可以一键抓取,但比起“Web Scraper”,它们的功能更加丰富,还缺少很多。
你不需要学习Python,也不需要花钱让别人帮你。您可以使用“Web Scraper”自行完成网页抓取。也许你会是下一个准时下班的人? 查看全部
不学Python也能快速海量海量内容|附下载地址
不知道你的朋友圈里是不是总能看到类似的广告,“Excel 用 Python 加班只需 3 分钟”,“我每天都能准时下班,因为我学了 Python”。看来,Python 已经成为了当代的年轻人。人的基本技能。
▲朋友圈广告
确实,Python作为一种简单易用的编程语言,在自动化办公中非常有用,尤其是抓取网页数据,在这样的大数据时代尤为重要。
爬取网页数据,又称“网络爬虫”,可以帮助我们快速采集互联网海量内容,进行深度数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等,而我们每天使用的搜索引擎都是“网络爬虫”。
但毕竟学习一门语言的成本太高了。有没有什么方法可以不学习Python就达到目标?当然,借助Chrome浏览器的“Web Scraper”插件,无需编写代码即可快速抓取大量内容。
优采云directory
以page-bilibili排名的多条信息为例
自动翻页抓取——以豆瓣电影Top250为例
抓取副页内容-以知乎热榜为例
抓取页面上的多条信息-以BiliBili排名为例
安装“Web Scraper”后,在浏览器中按F12进入开发者模式,可以在最后一个标签页看到“Web Scraper”菜单。需要注意的是,如果开发者模式面板不在底部,会提示必须放在浏览器下方才能继续。
在菜单中选择“新建站点地图-创建站点地图”,新建站点地图,填写名称和起始地址即可开始。这里以BiliBili排名为例介绍如何抓取页面上的多条信息,起始地址设置为“”。
这里我们需要抓取“视频标题”、“播放量”、“弹幕数”、“上位大师”和“综合评分”,所以首先要为每条记录创建一个包装器。
点击“Add new selector”,id填写“wrapper”,type选择“element”,然后点击“selector”,选择一条记录的外框,外包框需要收录以上所有信息,然后选择第二个这样,你会发现页面上的所有记录都被自动选中了,点击“完成选择”完成数据选择。记得勾选“Multiple”,确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一个记录突出显示。这是因为我们预先将其设置为包装器。在边框中选择标题,然后单击“完成选择”完成标题选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放音量”、“弹幕数”、“上位大师”和“综合得分”创建选择器。选中后,可以通过“数据查看”预览是否选中了想要的内容。此外,您还可以通过菜单栏中的“站点地图bilibili_ranking-Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“Scrape”,开始创建爬取任务。单个网页的间隔时间和响应时间是默认的。点击“开始抓取”开始抓取。这时候浏览器会自动打开一个新页面,几秒后自动关闭,表示已经获取完成。
点击“刷新数据”刷新数据,或点击“站点地图bilibili_ranking-浏览”查看数据。您可以通过“Sitemap bilibili_ranking-Export data as CSV”下载为CSV格式文件。
▲BiliBili 排名
用 Excel 打开。由于“Web Scraper”抓取的内容是乱序的,需要对“综合评分”进行降序排序,恢复原来的排名结果。
自动翻页抓取——以豆瓣电影Top250为例
Bilibili 排名只有 100 条记录,而且都在一个网页上。有分页显示怎么办?这里以豆瓣电影Top250为例介绍自动翻页抓取。
同理,新建站点地图时,在填写起始地址之前,先观察豆瓣电影Top250的构成。一共250条记录,每页显示10条,分为25页。
每一页的URL都很规则,第一页的地址是“”,第二页只是把地址中的“start=0”改成了“start=25”,所以我们填写start时地址,可以填写“[0-250:25]&filter=”,其中start=[0-250:25]表示以25为步长从0到250获取,所以start为0、2 5、 分别等待 50 次。这样,“Web Scraper”就会逐页抓取数据。
下一步类似于BiliBili排名。创建“包装器”后,添加“电影名称”、“豆瓣评分”、“电影短评”和“豆瓣排名”选择器,然后开始爬取。
可以看到浏览器会逐页翻页抓取。在这里你只需要静静等待爬行完成即可。最终得到的数据按照“豆瓣排名”升序排列,得到豆瓣电影。 Top250名单。
▲豆瓣电影Top250
当然,这只是最简单的一种分页方式,很多网站地址不一定有类似的规则。因此,“Web Scraper”的分页方法比较多,但是相对来说也比较复杂。此处不再赘述。
抓取副页内容-以知乎热榜为例
以上已经完成了对网页单页和多页内容的抓取,但并不是每次都在一页上有现成的数据,所以需要进一步搜索二级页面。以知乎热榜为例,介绍如何抓取二级页面的“关注”和“浏览”。
首先,创建一个起始地址为“”的新站点地图。然后像之前一样创建“wrapper”,然后创建三个选择器“文章title”、“文章热度”和“知乎ranked”。
下一个重要步骤是创建“二级页面”链接。点击“添加新选择器”,id填写“二级页面”,类型选择“链接”,然后点击“选择器”,选择文章的标题,即每个文章的入口,确认选择并保存并退出。
这相当于有了一个窗口,点击刚刚创建的“二级页面”进入下一级目录,然后创建“关注”和“浏览量”就像创建“文章title”一样前。选择器。最后,整个树结构如下图所示。
点击“站点地图知乎_hot-Scrape”开始爬取。在这里可以增加“页面加载延迟”的响应时间,以确保页面完全加载。这时候浏览器会依次打开各个二级页面进行抓取,需要稍等片刻。
爬取任务完成后,将结果下载为CSV文件,并按照“知乎ranking”的降序排列,得到知乎热榜的完整列表。
▲知乎热榜
至此,我已经介绍了如何使用“Web Scraper”抓取一个页面的多条信息,自动翻页,抓取二级页面的内容。显然,“Web Scraper”的功能远不止这些,还有更强大的抓图、正则表达式等功能,大家可以自行探索。
另外,如果你只是想简单的抓取信息,可以试试其他插件,比如“Simple scraper”和“Instant Data Scraper”。这些插件甚至可以一键抓取,但比起“Web Scraper”,它们的功能更加丰富,还缺少很多。
你不需要学习Python,也不需要花钱让别人帮你。您可以使用“Web Scraper”自行完成网页抓取。也许你会是下一个准时下班的人?
你可以用它来做什么:软件介绍网页信息批量提取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-18 02:32
KK网页信息批量采集导出工具是一个简单但不简单的全能采集工具,可以批量获取和导出多个网页的信息。该软件轻巧简单。页面信息采集,3个简单的功能,可以实现强大、复杂、繁琐的批量信息采集和网页操作。
软件介绍
网页信息批量提取工具,由于您自己的工作需要,管理后台订单和产品列表不支持导出。总结的时候,一一复制粘贴到excel中,难免很复杂。可以在 1 分钟内完成的工作必须手动完成。数小时内重复这些机械化动作。所以为了解决这些问题,2017年发布了第一个版本,让有相同需求的同学能够更高效的处理问题。
支持截取网页上的部分信息并导出,也支持从截取信息片段列表中匹配多条信息。
更好:
1、 请求通过 post 获取数据
2、自定义网页头协议头,伪装任意浏览器访问
3、还可以设置爬取间隔,防止采集快速被其他网站server拦截
4、将采集的结果导出到excel或txt
它不仅有采集信息的功能,如果你有自己的网站,还可以帮你把电脑上的这些信息或excel中的信息发布到你的网站。
你可以用它做什么:
1、采集网页中的多条信息(标题/网址/时间等),导出
2、batch采集多个网页信息,导出
3、 批量访问打开的页面。比如有的站长需要批量提交收录给百度,一个一个打开比较麻烦。
如何使用
进阶进阶文章(写给站长,一般人不需要看懂,阅读让一个简单的软件变得更复杂):
那么,怎么用呢,来采集一条网站的帖子发到我的网站上
只需几步:
1、写文章Page 抓取文章title 和内容规则,写下来。
2、使用“小工具”中的序列URL生成工具生成一系列列表URL。例如:list/1.html、list/2.html、list/3.html、...、list/999.html,从别人@k14的列表页可以看到多少页@, 生成多个列表网址,页面数量多。
3、在匹配列表页写入并获取所有文章规则:即从列表页中取出所有文章链接,进行匹配,然后导出
4、然后输出第3步导出的文章 URL作为采集目标,输出到URL框。然后填写步骤1中的规则,这些页面的文章title和链接信息采集就可以自动发布了。
这里,目前网站某列文章的所有标题和链接都被采集接收并导出为excel,那么如何将这个excel发布到我的网站?
5、在excel中手动将cell合成为post提交的信息格式。如:title=kkno1&content=com
6、Submit URL 填写文章publishing后端的post接收URL,在软件中填写协议头的cookie信息(模拟网站Administrator登录后端),然后填写步骤5发帖参数 生成发帖提交格式,然后点击批处理,软件可以自动批量发帖模式,将此类信息一一提交到帖子接收页面,实现自动发布功能。
从采集到发布的完整过程。看起来步骤很多,但实际上只匹配了3个。 查看全部
你可以用它来做什么:软件介绍网页信息批量提取工具
KK网页信息批量采集导出工具是一个简单但不简单的全能采集工具,可以批量获取和导出多个网页的信息。该软件轻巧简单。页面信息采集,3个简单的功能,可以实现强大、复杂、繁琐的批量信息采集和网页操作。
软件介绍
网页信息批量提取工具,由于您自己的工作需要,管理后台订单和产品列表不支持导出。总结的时候,一一复制粘贴到excel中,难免很复杂。可以在 1 分钟内完成的工作必须手动完成。数小时内重复这些机械化动作。所以为了解决这些问题,2017年发布了第一个版本,让有相同需求的同学能够更高效的处理问题。
支持截取网页上的部分信息并导出,也支持从截取信息片段列表中匹配多条信息。
更好:
1、 请求通过 post 获取数据
2、自定义网页头协议头,伪装任意浏览器访问
3、还可以设置爬取间隔,防止采集快速被其他网站server拦截
4、将采集的结果导出到excel或txt
它不仅有采集信息的功能,如果你有自己的网站,还可以帮你把电脑上的这些信息或excel中的信息发布到你的网站。
你可以用它做什么:
1、采集网页中的多条信息(标题/网址/时间等),导出
2、batch采集多个网页信息,导出
3、 批量访问打开的页面。比如有的站长需要批量提交收录给百度,一个一个打开比较麻烦。
如何使用
进阶进阶文章(写给站长,一般人不需要看懂,阅读让一个简单的软件变得更复杂):
那么,怎么用呢,来采集一条网站的帖子发到我的网站上
只需几步:
1、写文章Page 抓取文章title 和内容规则,写下来。
2、使用“小工具”中的序列URL生成工具生成一系列列表URL。例如:list/1.html、list/2.html、list/3.html、...、list/999.html,从别人@k14的列表页可以看到多少页@, 生成多个列表网址,页面数量多。
3、在匹配列表页写入并获取所有文章规则:即从列表页中取出所有文章链接,进行匹配,然后导出
4、然后输出第3步导出的文章 URL作为采集目标,输出到URL框。然后填写步骤1中的规则,这些页面的文章title和链接信息采集就可以自动发布了。
这里,目前网站某列文章的所有标题和链接都被采集接收并导出为excel,那么如何将这个excel发布到我的网站?
5、在excel中手动将cell合成为post提交的信息格式。如:title=kkno1&content=com
6、Submit URL 填写文章publishing后端的post接收URL,在软件中填写协议头的cookie信息(模拟网站Administrator登录后端),然后填写步骤5发帖参数 生成发帖提交格式,然后点击批处理,软件可以自动批量发帖模式,将此类信息一一提交到帖子接收页面,实现自动发布功能。
从采集到发布的完整过程。看起来步骤很多,但实际上只匹配了3个。
网站数据采集工具.docx
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-07-15 06:33
文档介绍:优采云·云采集服务平台uationWarning:ThedocumentwascreatedwithSpire..网站data capture tool 近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也出现了快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。 1、优采云优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。需要数据。它采集data分为两步,一是采集data,二是发布数据。这两个过程可以分开。 采集Data:这包括采集 URL 和采集 内容。这个过程就是获取数据的过程。用户制定规则,内容在采集过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。 优采云采集器采用分布式采集系统。这样提高了采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量网址,也可以生成。对于不会编程的新手用户,可以直接使用别人制定的规则,高手可以定制开发,也可以分享规则。
2、优采云优采云是优采云之后出现的采集器,可以从不同的网站获取标准化的数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。简单来说,优采云可以通过简单的配置规则,从任何网页准确抓取数据,生成自定义的、规则的数据格式。国内首创的真正可视化规则、简单上手、完全可视化图形操作的国内定制采集器; 采集任务自动运行,可按指定周期自动采集;规则市场有大量免费规则,用户可直接使用;支持验证码识别,自定义不同浏览器标识,有效防止IP被封。 优采云可以说是小白用户的福音(简单好用,好找,可视化界面,易学易模仿),有更好的地方就用积分。用1000积分完善信息,每天签到30积分,在线制定规则或购买规则,剩下的足以获得初始采集,如果您不充值一些积分,您可以在需求,导出excel,数据库都行。 3、优采云云攀虫 新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网页数据。操作步骤:购买规则-设置关键词-启动任务-自动云采集-自动发布不同于传统的采集器,优采云云爬虫不需要配置采集进程。 优采云云攀虫的规则市场提供了大量免费的采集模板,只需设置关键词即可。
爬虫任务全程在云端执行,无需开机。 采集结果可以自动发布到多个网站(目前支持wecenter、wordpree、discuz等)。开发者可自行编写采集规则出售或使用。有了详细的开发人员文档,他们就可以创建自己的爬虫。相关采集tutorial:网易彩票数据采集orial/hottutorial/jrzx/wycaipiao同花顺爬虫orial/hottutorial/jrzx/tonghuashun金融世界基金爬虫orial/hottutorial/jrzx/ji 查看全部
网站数据采集工具.docx
文档介绍:优采云·云采集服务平台uationWarning:ThedocumentwascreatedwithSpire..网站data capture tool 近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也出现了快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。 1、优采云优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。需要数据。它采集data分为两步,一是采集data,二是发布数据。这两个过程可以分开。 采集Data:这包括采集 URL 和采集 内容。这个过程就是获取数据的过程。用户制定规则,内容在采集过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。 优采云采集器采用分布式采集系统。这样提高了采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量网址,也可以生成。对于不会编程的新手用户,可以直接使用别人制定的规则,高手可以定制开发,也可以分享规则。
2、优采云优采云是优采云之后出现的采集器,可以从不同的网站获取标准化的数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。简单来说,优采云可以通过简单的配置规则,从任何网页准确抓取数据,生成自定义的、规则的数据格式。国内首创的真正可视化规则、简单上手、完全可视化图形操作的国内定制采集器; 采集任务自动运行,可按指定周期自动采集;规则市场有大量免费规则,用户可直接使用;支持验证码识别,自定义不同浏览器标识,有效防止IP被封。 优采云可以说是小白用户的福音(简单好用,好找,可视化界面,易学易模仿),有更好的地方就用积分。用1000积分完善信息,每天签到30积分,在线制定规则或购买规则,剩下的足以获得初始采集,如果您不充值一些积分,您可以在需求,导出excel,数据库都行。 3、优采云云攀虫 新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网页数据。操作步骤:购买规则-设置关键词-启动任务-自动云采集-自动发布不同于传统的采集器,优采云云爬虫不需要配置采集进程。 优采云云攀虫的规则市场提供了大量免费的采集模板,只需设置关键词即可。
爬虫任务全程在云端执行,无需开机。 采集结果可以自动发布到多个网站(目前支持wecenter、wordpree、discuz等)。开发者可自行编写采集规则出售或使用。有了详细的开发人员文档,他们就可以创建自己的爬虫。相关采集tutorial:网易彩票数据采集orial/hottutorial/jrzx/wycaipiao同花顺爬虫orial/hottutorial/jrzx/tonghuashun金融世界基金爬虫orial/hottutorial/jrzx/ji
软件特色SysNucleusWebHarvy可以让您分析网页上的数据模式
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-14 05:00
SysNucleus WebHarvy 是一款网页数据采集软件。使用本软件,您可以直接在网页上选择需要选择的资源,也可以直接将整个网页保存为HTML格式,从而提取网页内容中的所有文字和图标,复制网址时,软件默认使用内部浏览器组件打开,可以显示完整的网页,然后就可以开始配合数据采集的规则了; SysNucleus WebHarvy 支持扩展分析,可以自动获取相似链接列表,复制一个地址搜索多个网页内容!
软件功能
WebHarvy 是一个可视化的网页抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
软件功能
SysNucleus WebHarvy 允许您分析网页上的数据
可以显示和分析来自 HTML 地址的连接数据
可以扩展到下一个网页
可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
支持浏览器复制链接搜索
支持配置对应的资源项搜索
可以使用项目名称和资源名称查找
SysNucleus WebHarvy 可以轻松提取数据
提供更高级的多词搜索和多页搜索
安装方法
1、 首先需要从河东下载WebHarvySetup.exe,下载后直接点击安装
2、显示软件安装的许可条件,勾选我接受许可协议中的条款
3、提示软件安装路径C:Userspc0359AppDataRoamingSysNucleusWebHarvy
4、显示安装的主要说明,点击安装将软件安装到电脑上
5、提示SysNucleus WebHarvy安装结束,可以立即启动
如何破解
1、启动软件,提示并解锁,即需要添加官方license文件才能使用
2、解压下载的“Crck.rar”文件,复制并替换里面的补丁WebHarvy.exe。
3、如图,它提醒你正在从Crck复制1个项目到Webharvy,只需点击替换即可。
4、如图,提示SysNucleus WebHarvy软件已经授权给SMR
5、 导航到需要提取数据的网页。您可以使用内置浏览器加载和浏览网页
6、要捕获文本的一部分,请选择它并突出显示它。在选择下面的选项之前,确定所需的部分。
7、只要输入你分析的网页地址,最上面的网址就是地址输入栏
8、输入地址,可以直接在网页上打开
9、选择配置功能,可以点击第一个Start Config开始配置计划下载网页数据
更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
软件特色SysNucleusWebHarvy可以让您分析网页上的数据模式
SysNucleus WebHarvy 是一款网页数据采集软件。使用本软件,您可以直接在网页上选择需要选择的资源,也可以直接将整个网页保存为HTML格式,从而提取网页内容中的所有文字和图标,复制网址时,软件默认使用内部浏览器组件打开,可以显示完整的网页,然后就可以开始配合数据采集的规则了; SysNucleus WebHarvy 支持扩展分析,可以自动获取相似链接列表,复制一个地址搜索多个网页内容!

软件功能
WebHarvy 是一个可视化的网页抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
软件功能
SysNucleus WebHarvy 允许您分析网页上的数据
可以显示和分析来自 HTML 地址的连接数据
可以扩展到下一个网页
可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
支持浏览器复制链接搜索
支持配置对应的资源项搜索
可以使用项目名称和资源名称查找
SysNucleus WebHarvy 可以轻松提取数据
提供更高级的多词搜索和多页搜索
安装方法
1、 首先需要从河东下载WebHarvySetup.exe,下载后直接点击安装

2、显示软件安装的许可条件,勾选我接受许可协议中的条款

3、提示软件安装路径C:Userspc0359AppDataRoamingSysNucleusWebHarvy

4、显示安装的主要说明,点击安装将软件安装到电脑上

5、提示SysNucleus WebHarvy安装结束,可以立即启动

如何破解
1、启动软件,提示并解锁,即需要添加官方license文件才能使用

2、解压下载的“Crck.rar”文件,复制并替换里面的补丁WebHarvy.exe。

3、如图,它提醒你正在从Crck复制1个项目到Webharvy,只需点击替换即可。

4、如图,提示SysNucleus WebHarvy软件已经授权给SMR

5、 导航到需要提取数据的网页。您可以使用内置浏览器加载和浏览网页

6、要捕获文本的一部分,请选择它并突出显示它。在选择下面的选项之前,确定所需的部分。

7、只要输入你分析的网页地址,最上面的网址就是地址输入栏

8、输入地址,可以直接在网页上打开

9、选择配置功能,可以点击第一个Start Config开始配置计划下载网页数据

更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
git部署到远程服务器,扩展性能会更好!
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-07-11 05:01
我无事可做。我刚刚学会了将 git 部署到远程服务器,我无所事事。所以我干脆做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是,JAVA1.8在使用String拼接字符串时会自动拼接你想要拼接的内容。字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持脚本之家! 查看全部
git部署到远程服务器,扩展性能会更好!
我无事可做。我刚刚学会了将 git 部署到远程服务器,我无所事事。所以我干脆做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是,JAVA1.8在使用String拼接字符串时会自动拼接你想要拼接的内容。字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:

先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码

然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持脚本之家!
外贸网站挖掘工具10s提取100客户网站-谷歌搜索提取工具3.0版本
网站优化 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2021-07-10 22:17
下图中的工具之前已经给大家介绍过了。这是我做的谷歌搜索提取工具2.0版本。
2.0 版本主要是帮你在谷歌搜索引擎上直接提取网站和标题信息。可以参考我之前的文章《25h打造外贸网站挖矿工具,10s提取100个客户网站!》,看详细介绍!
今天主要给大家介绍一下我前两天刚拿到的谷歌搜索提取工具3.0的新修订版。与之前的版本相比,新增了谷歌地图提取功能,可以帮助您直接提取谷歌地图。对于公司信息,很多老牌外贸公司可能都熟悉谷歌地图。在谷歌地图上输入关键词,可以搜索到周边所有的精准买家,是外贸客户发展的常用渠道。
我们只要通过关键词搜索公司信息页面,就可以直接点击开始爬取按钮开发爬取信息。操作相当简单,不用担心,会自动翻页,直到搜索完成。
另外3.0版本与2.0版本相比,谷歌搜索引擎抓取也进行了调整,不再像之前那样直接输入关键词进行抓取,需要手动转到第二页。这一次,整个真实网页直接转入工具,搜索和翻页也完全自动化。完全模拟人工操作,降低验证码弹窗的概率,即使验证码弹出,我们也可以手动填写!
最后给大家介绍几个主要的功能按钮:
1、
上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。关于这一点我不需要多说。点击后你就明白了!
2、
不翻页搜索是本次更新的一大特色。如果你电脑上的fq工具失败了,你可以尝试检查一下,切换到更流畅的线条。这样,您也可以使用此工具。去谷歌取资料(毕竟大家有空,肯定会慢!)
3、
红框中选中的4个按钮当然不用我过多解释了,字面意思。全部导出就是将搜索到的数据以excel格式导出到本地电脑。
4、
如果你上传这个选项,我们一般默认不勾选。如果你没有使用F墙工具,而是使用F墙路由器访问外网,不妨勾选这个选项试试。 (切记不要随意检查,否则无法加载googe页面)
其他的就不解释了,自己下载体验吧!这些工具是为了个人兴趣和爱好,免费分享给大家。您不必担心是否充电。只要对你有帮助,我一定会持续优化更新更多功能给你!
下载链接:
某些计算机下载和安装可能会弹出风险警告。您只需单击“允许”即可放心使用。没必要为你什么年龄生产病毒!
同理,有什么bug或者好的建议都可以在评论区写! 查看全部
外贸网站挖掘工具10s提取100客户网站-谷歌搜索提取工具3.0版本
下图中的工具之前已经给大家介绍过了。这是我做的谷歌搜索提取工具2.0版本。

2.0 版本主要是帮你在谷歌搜索引擎上直接提取网站和标题信息。可以参考我之前的文章《25h打造外贸网站挖矿工具,10s提取100个客户网站!》,看详细介绍!
今天主要给大家介绍一下我前两天刚拿到的谷歌搜索提取工具3.0的新修订版。与之前的版本相比,新增了谷歌地图提取功能,可以帮助您直接提取谷歌地图。对于公司信息,很多老牌外贸公司可能都熟悉谷歌地图。在谷歌地图上输入关键词,可以搜索到周边所有的精准买家,是外贸客户发展的常用渠道。

我们只要通过关键词搜索公司信息页面,就可以直接点击开始爬取按钮开发爬取信息。操作相当简单,不用担心,会自动翻页,直到搜索完成。
另外3.0版本与2.0版本相比,谷歌搜索引擎抓取也进行了调整,不再像之前那样直接输入关键词进行抓取,需要手动转到第二页。这一次,整个真实网页直接转入工具,搜索和翻页也完全自动化。完全模拟人工操作,降低验证码弹窗的概率,即使验证码弹出,我们也可以手动填写!

最后给大家介绍几个主要的功能按钮:
1、

上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。关于这一点我不需要多说。点击后你就明白了!
2、

不翻页搜索是本次更新的一大特色。如果你电脑上的fq工具失败了,你可以尝试检查一下,切换到更流畅的线条。这样,您也可以使用此工具。去谷歌取资料(毕竟大家有空,肯定会慢!)
3、

红框中选中的4个按钮当然不用我过多解释了,字面意思。全部导出就是将搜索到的数据以excel格式导出到本地电脑。
4、

如果你上传这个选项,我们一般默认不勾选。如果你没有使用F墙工具,而是使用F墙路由器访问外网,不妨勾选这个选项试试。 (切记不要随意检查,否则无法加载googe页面)
其他的就不解释了,自己下载体验吧!这些工具是为了个人兴趣和爱好,免费分享给大家。您不必担心是否充电。只要对你有帮助,我一定会持续优化更新更多功能给你!
下载链接:
某些计算机下载和安装可能会弹出风险警告。您只需单击“允许”即可放心使用。没必要为你什么年龄生产病毒!
同理,有什么bug或者好的建议都可以在评论区写!
maczmac软件激活教程forMac下载完成后,双击.pkg
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-07-10 21:05
WebScraper for Mac 是专为 Mac 系统设计的网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper还可以提取动态加载或者使用JavaScript生成的数据等,使用webscraper mac 破解版可以快速提取特定网页的相关信息,包括文本内容。 macz share webscraper mac破解版下载。
WebScraper mac 软件激活教程
下载WebScraper for Mac后,双击.pkg文件,按照提示默认安装
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络打造
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。
Webscraper mac 破解版更新日志
版本4.14.5: 查看全部
maczmac软件激活教程forMac下载完成后,双击.pkg
WebScraper for Mac 是专为 Mac 系统设计的网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper还可以提取动态加载或者使用JavaScript生成的数据等,使用webscraper mac 破解版可以快速提取特定网页的相关信息,包括文本内容。 macz share webscraper mac破解版下载。

WebScraper mac 软件激活教程
下载WebScraper for Mac后,双击.pkg文件,按照提示默认安装

WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。

WebScraper Mac 软件功能
1、 快速轻松扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络打造
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。

Webscraper mac 破解版更新日志
版本4.14.5:
搜索游戏中的小玩家也可以编号爬行数十亿的页面.In2006(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-07-10 18:08
如果您想要的数据是最新的,则不会。
即使是游戏中的一个小玩家也可以爬行数十亿页。
“在 2006 年,Google 索引了超过 250 亿个网页,[32] 每天 4 亿次查询,[32] 1.30 亿张图片,以及超过 10 亿条 Usenet 消息。”– 维基百科
记得引用 2006 年的数字。这是古老的历史。最先进的技术比这更好。
内容新鲜度:
>新内容不断增加(逼真)
>现有网页经常发生变化——需要重新爬取的原因有两个:a)判断是否已死,b)判断内容是否发生变化。
爬行者的礼貌:
>你不能压倒任何给定的网站。如果您重复点击同一IP的任何主要站点,您可以触发CAPTCHA提示,否则您的IP地址将被阻止。 网站 将根据带宽频率、“坏”页面请求的数量以及其他各种事情来请求。
>有robots.txt协议,网站暴露给爬虫并遵守。
>有一个网站map标准,网站暴露给爬虫,用它帮你探索——你也可以(如果你选择)权重页面在网站上的相对重要性,并使用时间存在于缓存中,如果它在网站Map 中。
减少你需要做的工作:
通常,网站 通过多个名字暴露自己——你需要检测同一个页面——这可能发生在同一个网址或不同的网址上。考虑页面内容的散列(减去标题,日期/时间不断变化)。跟踪这些页面等效项并在下次跳过或确定给定站点之间是否存在众所周知的映射,以便您不必进行爬网。
>那里有很多垃圾邮件,只能通过谷歌的网页,但他们“播种”了自己的网站,以便自己爬行。
所以——你总是处于爬行周期中。总是。几乎肯定会有几台(许多)机器。确保您可以遵循礼貌,但仍然保持数据的新鲜度。
如果你想按下快进按钮,你只需要用你自己独特的算法处理页面。如果您需要快速搜索,您可以利用预先构建的爬虫,如图所示。他们使用客户端计算能力。
80 条腿正在使用网站 上孩子们玩游戏的机器周期。想想网页上的一个后台进程,确实是调用了,用page/网站的时候是不行的,因为他们用的是Plura技术栈。
“Plura Processing 为分布式计算开发了一种新的创新技术。我们正在申请专利的技术可以嵌入到任何网页中。这些网页的访问者成为节点,并为在我们的分布式计算网络上运行的应用程序执行非常小的计算。 ”– Plura 演示页面
所以他们通过上千个IP的上千个节点发布“爬虫”,对网站客气,爬得快。现在我个人不知道我关心最终用户浏览器的风格,除非它们在所有使用技术的网站上都显示得很清楚——但如果没有别的,这是一种开箱即用的方法.
社区驱动的项目中还有其他爬虫,你也可以使用。
正如其他受访者所指出的那样——做数学。您需要每秒抓取大约 2300 个页面才能每 5 天抓取 1B 个页面。如果您愿意等待更长时间,那么这个数字将会下降。如果你认为你必须赶上超过 1B 的数字,它就会上升。简单的数学
祝你好运! 查看全部
搜索游戏中的小玩家也可以编号爬行数十亿的页面.In2006(组图)
如果您想要的数据是最新的,则不会。
即使是游戏中的一个小玩家也可以爬行数十亿页。
“在 2006 年,Google 索引了超过 250 亿个网页,[32] 每天 4 亿次查询,[32] 1.30 亿张图片,以及超过 10 亿条 Usenet 消息。”– 维基百科
记得引用 2006 年的数字。这是古老的历史。最先进的技术比这更好。
内容新鲜度:
>新内容不断增加(逼真)
>现有网页经常发生变化——需要重新爬取的原因有两个:a)判断是否已死,b)判断内容是否发生变化。
爬行者的礼貌:
>你不能压倒任何给定的网站。如果您重复点击同一IP的任何主要站点,您可以触发CAPTCHA提示,否则您的IP地址将被阻止。 网站 将根据带宽频率、“坏”页面请求的数量以及其他各种事情来请求。
>有robots.txt协议,网站暴露给爬虫并遵守。
>有一个网站map标准,网站暴露给爬虫,用它帮你探索——你也可以(如果你选择)权重页面在网站上的相对重要性,并使用时间存在于缓存中,如果它在网站Map 中。
减少你需要做的工作:
通常,网站 通过多个名字暴露自己——你需要检测同一个页面——这可能发生在同一个网址或不同的网址上。考虑页面内容的散列(减去标题,日期/时间不断变化)。跟踪这些页面等效项并在下次跳过或确定给定站点之间是否存在众所周知的映射,以便您不必进行爬网。
>那里有很多垃圾邮件,只能通过谷歌的网页,但他们“播种”了自己的网站,以便自己爬行。
所以——你总是处于爬行周期中。总是。几乎肯定会有几台(许多)机器。确保您可以遵循礼貌,但仍然保持数据的新鲜度。
如果你想按下快进按钮,你只需要用你自己独特的算法处理页面。如果您需要快速搜索,您可以利用预先构建的爬虫,如图所示。他们使用客户端计算能力。
80 条腿正在使用网站 上孩子们玩游戏的机器周期。想想网页上的一个后台进程,确实是调用了,用page/网站的时候是不行的,因为他们用的是Plura技术栈。
“Plura Processing 为分布式计算开发了一种新的创新技术。我们正在申请专利的技术可以嵌入到任何网页中。这些网页的访问者成为节点,并为在我们的分布式计算网络上运行的应用程序执行非常小的计算。 ”– Plura 演示页面
所以他们通过上千个IP的上千个节点发布“爬虫”,对网站客气,爬得快。现在我个人不知道我关心最终用户浏览器的风格,除非它们在所有使用技术的网站上都显示得很清楚——但如果没有别的,这是一种开箱即用的方法.
社区驱动的项目中还有其他爬虫,你也可以使用。
正如其他受访者所指出的那样——做数学。您需要每秒抓取大约 2300 个页面才能每 5 天抓取 1B 个页面。如果您愿意等待更长时间,那么这个数字将会下降。如果你认为你必须赶上超过 1B 的数字,它就会上升。简单的数学
祝你好运!
WebScraping工具9个网络收集工具,你值得拥有!
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-10 18:06
Web Scraping 工具专门用于从网站 中提取信息。它们也称为网络采集工具或网络数据提取工具。
文章directory[]
Web Scraping 工具可以在各种场景中用于无限用途。
例如:
1.采集市场调研数据
网页抓取工具可以从多个数据分析提供商处获取信息,并将它们整合到一个位置,以便于参考和分析。可以帮助您了解公司或行业未来六个月的发展方向。
2.提取联系方式
这些工具还可用于从各种网站 中提取电子邮件和电话号码等数据。
3. 采集数据下载离线阅读或存储
4.track 多个市场的价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储以方便访问。例如,爬虫可用于从亚马逊采集有关产品及其价格的信息。在这个文章中,我们列出了9个网页抓取工具。
1.Import.io
Import.io 提供了一个构建器,可以通过从特定网页导入数据并将数据导出为 CSV 来形成您自己的数据集。您无需编写任何代码即可在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。
2.Webhose.io
Webhose.io 通过抓取数千个在线资源提供对实时和结构化数据的直接访问。网络爬虫支持提取超过240种语言的网络数据,并以多种格式保存输出数据,包括XML、JSON和RSS。
3. Dexi.io(原名 CloudScrape)
CloudScrape 支持从任何网站 采集数据,无需像 Webhose 那样下载。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集到的数据保存在 Google Drive 等云平台上,也可以将其导出为 CSV 或 JSON。
4.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可帮助数以千计的开发者获取有价值的数据。 Scrapinghub 使用智能代理微调器 Crawlera,支持绕过机器人反制,轻松抓取大型或受机器人保护的网站。
5. ParseHub
ParseHub 用于抓取单个和多个网站,支持 JavaScript、AJAX、会话、cookie 和重定向。该应用程序使用机器学习技术来识别 Web 上最复杂的文档,并根据所需的数据格式生成输出文件。
6.VisualScraper
VisualScraper 是另一种网络数据提取软件,可用于从网络采集信息。该软件可以帮助您从多个网页中提取数据并实时获取结果。此外,还可以导出CSV、XML、JSON、SQL等多种格式。
7. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 提要中获取全部数据。 Spinn3r 与 firehouse API 一起分发并管理 95% 的索引工作。提供先进的垃圾邮件防护,可消除垃圾邮件和不当语言使用,从而提高数据安全性。
8. 80legs
80legs 是一款功能强大且灵活的网页抓取工具,可根据您的需要进行配置。它支持获取大量数据并立即下载提取数据的选项。 80legs 声称能够抓取超过 600,000 个域,并被 MailChimp 和 PayPal 等大型玩家使用。
9.Scraper
Scraper 是一个 Chrome 扩展,其数据提取功能有限,但它有助于进行在线研究并将数据导出到 Google 电子表格。此工具适合初学者和专家,他们可以使用 OAuth 轻松将数据复制到剪贴板或存储到电子表格。 查看全部
WebScraping工具9个网络收集工具,你值得拥有!
Web Scraping 工具专门用于从网站 中提取信息。它们也称为网络采集工具或网络数据提取工具。
文章directory[]
Web Scraping 工具可以在各种场景中用于无限用途。
例如:
1.采集市场调研数据
网页抓取工具可以从多个数据分析提供商处获取信息,并将它们整合到一个位置,以便于参考和分析。可以帮助您了解公司或行业未来六个月的发展方向。
2.提取联系方式
这些工具还可用于从各种网站 中提取电子邮件和电话号码等数据。
3. 采集数据下载离线阅读或存储
4.track 多个市场的价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储以方便访问。例如,爬虫可用于从亚马逊采集有关产品及其价格的信息。在这个文章中,我们列出了9个网页抓取工具。
1.Import.io
Import.io 提供了一个构建器,可以通过从特定网页导入数据并将数据导出为 CSV 来形成您自己的数据集。您无需编写任何代码即可在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。
2.Webhose.io
Webhose.io 通过抓取数千个在线资源提供对实时和结构化数据的直接访问。网络爬虫支持提取超过240种语言的网络数据,并以多种格式保存输出数据,包括XML、JSON和RSS。
3. Dexi.io(原名 CloudScrape)
CloudScrape 支持从任何网站 采集数据,无需像 Webhose 那样下载。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集到的数据保存在 Google Drive 等云平台上,也可以将其导出为 CSV 或 JSON。
4.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可帮助数以千计的开发者获取有价值的数据。 Scrapinghub 使用智能代理微调器 Crawlera,支持绕过机器人反制,轻松抓取大型或受机器人保护的网站。
5. ParseHub
ParseHub 用于抓取单个和多个网站,支持 JavaScript、AJAX、会话、cookie 和重定向。该应用程序使用机器学习技术来识别 Web 上最复杂的文档,并根据所需的数据格式生成输出文件。
6.VisualScraper
VisualScraper 是另一种网络数据提取软件,可用于从网络采集信息。该软件可以帮助您从多个网页中提取数据并实时获取结果。此外,还可以导出CSV、XML、JSON、SQL等多种格式。
7. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 提要中获取全部数据。 Spinn3r 与 firehouse API 一起分发并管理 95% 的索引工作。提供先进的垃圾邮件防护,可消除垃圾邮件和不当语言使用,从而提高数据安全性。
8. 80legs
80legs 是一款功能强大且灵活的网页抓取工具,可根据您的需要进行配置。它支持获取大量数据并立即下载提取数据的选项。 80legs 声称能够抓取超过 600,000 个域,并被 MailChimp 和 PayPal 等大型玩家使用。
9.Scraper
Scraper 是一个 Chrome 扩展,其数据提取功能有限,但它有助于进行在线研究并将数据导出到 Google 电子表格。此工具适合初学者和专家,他们可以使用 OAuth 轻松将数据复制到剪贴板或存储到电子表格。
缩略图采不下来怎么办?优采云采集器最新版本V9
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-07-09 20:15
教你使用网络爬虫工具下载图片。现在内容里有图片的网页已经很常见了,所以图片的采集也很重要,但是一张一张的点击下载很麻烦,所以我们在爬网的时候也要学会抓图。当我采集内容时,我通常会同时下载图片和缩略图采集。这个很好用,但是一开始图片总是采集不全,缩略图也拍不出来。现在我将我的经验分享给大家。一起进步吧~我用的是最新版的优采云采集器V9的网络爬虫工具,因为功能比较齐全,速度也很快。在优采云采集器中设置好URL的采集规则后,输入采集规则写入的内容,这里大家要注意,edit标签的数据处理中有一个文件下载选项,有四 有两个选项,其中之一是下载图片。你一眼就能明白这一点。勾选就可以下载图片,但是如果只做这个,只能采集到部分图片,因为优采云采集器这里默认是下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。这种情况下优采云采集器会自动检测到这种图片文件并下载。 采集当你分别为不同类型的图片设置了“标签”和“下载选项”时,测试一下,这个页面的5张图片已经被优采云采集器下载了,你觉得很简单吗?像优采云采集器这样的网页抓取工具就是这样的。将来学习如何使用它非常容易。用得好,确实可以解决很多问题,可以大大提高我们的工作效率。这也是人类的智慧。它在哪里? 查看全部
缩略图采不下来怎么办?优采云采集器最新版本V9
教你使用网络爬虫工具下载图片。现在内容里有图片的网页已经很常见了,所以图片的采集也很重要,但是一张一张的点击下载很麻烦,所以我们在爬网的时候也要学会抓图。当我采集内容时,我通常会同时下载图片和缩略图采集。这个很好用,但是一开始图片总是采集不全,缩略图也拍不出来。现在我将我的经验分享给大家。一起进步吧~我用的是最新版的优采云采集器V9的网络爬虫工具,因为功能比较齐全,速度也很快。在优采云采集器中设置好URL的采集规则后,输入采集规则写入的内容,这里大家要注意,edit标签的数据处理中有一个文件下载选项,有四 有两个选项,其中之一是下载图片。你一眼就能明白这一点。勾选就可以下载图片,但是如果只做这个,只能采集到部分图片,因为优采云采集器这里默认是下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。这种情况下优采云采集器会自动检测到这种图片文件并下载。 采集当你分别为不同类型的图片设置了“标签”和“下载选项”时,测试一下,这个页面的5张图片已经被优采云采集器下载了,你觉得很简单吗?像优采云采集器这样的网页抓取工具就是这样的。将来学习如何使用它非常容易。用得好,确实可以解决很多问题,可以大大提高我们的工作效率。这也是人类的智慧。它在哪里?
WebScrapermac软件激活教程-WebScraperMac软件功能介绍(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-07-08 05:02
WebScraper Mac 是 Mac os 系统上非常有用的网站data 提取工具。 WebScraper 可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL 即可开始。简单而强大。
WebScraper mac 软件激活教程
! ! !本软件15系统暂时无法破解! !请谨慎下载! ! !
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:
2、返回安装包,双击打开WebScraper注册机,如图:
3、点击WebScraper注册机左侧的Open,如图:
4、在应用中找到WebScraper,点击打开,如图:
5、点击保存生成注册码!
6、Open WebScraper,显示已注册!
您不是VIP会员或积分不够,请升级VIP会员或充值观看教程。
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上一个简单的应用,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络构建
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。
编辑评论
如果您正在寻找一款好用的网站数据采集工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以到本站下载! 查看全部
WebScrapermac软件激活教程-WebScraperMac软件功能介绍(组图)
WebScraper Mac 是 Mac os 系统上非常有用的网站data 提取工具。 WebScraper 可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL 即可开始。简单而强大。

WebScraper mac 软件激活教程
! ! !本软件15系统暂时无法破解! !请谨慎下载! ! !
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:

2、返回安装包,双击打开WebScraper注册机,如图:

3、点击WebScraper注册机左侧的Open,如图:

4、在应用中找到WebScraper,点击打开,如图:

5、点击保存生成注册码!

6、Open WebScraper,显示已注册!

您不是VIP会员或积分不够,请升级VIP会员或充值观看教程。
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上一个简单的应用,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置

WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络构建
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。

编辑评论
如果您正在寻找一款好用的网站数据采集工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以到本站下载!
百度"抓取诊断"工具具体有什么作用以及需要改进的地方
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-08 04:43
自从百度站长平台上的“抓诊断”工具上线以来,很多站长朋友都用这个工具来吸引蜘蛛,但笔者亲自测试发现,“抓诊断”有很多种工具。因此,我们不应过分依赖它,而应有选择地应用。下面我们来谈谈百度“爬虫诊断”工具的具体功能和需要改进的地方。
先来看看百度官方的解释:
一、什么是爬虫?
1)Grabbing 诊断工具可以让站长从百度蜘蛛的角度查看抓取到的内容,自我诊断百度蜘蛛看到的内容是否与预期一致。
2)每个站点一个月可以使用300次,抓取结果只显示百度蜘蛛可见的前200KB内容。
二、爬虫诊断工具能做什么?
1) 诊断爬取的内容是否符合预期。比如很多商品详情页,价格信息是通过JavaScript输出的,对百度蜘蛛不友好,价格信息很难应用于搜索。问题解决后,可使用诊断工具再次检查。
2)诊断网页是否添加了黑色链接和隐藏文字。如果网站 被黑,可能会添加隐藏链接。这些链接可能只有在百度抓取的时候才会出现,需要使用这个爬虫来诊断。
3)检查网站与百度的连接是否顺畅。如果IP信息不一致,可以报错并通知百度更新IP。
4)如果网站有新页面或者页面内容更新了,百度蜘蛛很久没有访问过,可以通过这个工具邀请它快速抓取。
我测试过了,有的网站可以爬取成功。如下图所示,里面收录了很多信息,也可以很好的展示网页的源代码,可以为站长提供一些帮助。
但是,对于双线主机和使用别名解析的非固定IP主机,总是会出现爬网失败或爬网现象,偶尔也能爬网成功,如图:
这是否意味着百度百度蜘蛛无法抓取我们的网页?答案是不。笔者刚刚测试的网站爬不成功,当天发送的文章全部秒收,证明百度蜘蛛可以很好的爬取网页,但是单机“爬诊断”工具开启出差。 ,这说明这个技术还不成熟,只能参考,不能过分依赖。
还有一点需要注意的是,在抓取同一个页面后,百度会缓存很长时间,如下图所示。作者在早上11:09抓了一个页面,在页面上挂了一条“黑链”。 “爬虫”抓到的源码中收录了这些“黑链”代码,但是作者把这些“黑链”拿走了之后,晚上19:13再次抓取,发现页面我获取的仍然是我在早上 11:09 获取的页面,相隔 8 小时。
此外,爬虫在确定网站IP 地址时经常会出错。一旦IP地址确定错误,抓取就会失败。但这并不意味着蜘蛛不能访问我们的网站。其实蜘蛛就是蜘蛛,爬虫是一种工具。不要混淆它们。
当然,新推出的任何工具都存在这样和那样的问题。我们只需要选择对我们有利的地方去申请,而不是过分依赖所有的功能。同时也希望度娘能尽快改进,解决所有问题,给广大站长朋友一个有用的工具。 查看全部
百度"抓取诊断"工具具体有什么作用以及需要改进的地方
自从百度站长平台上的“抓诊断”工具上线以来,很多站长朋友都用这个工具来吸引蜘蛛,但笔者亲自测试发现,“抓诊断”有很多种工具。因此,我们不应过分依赖它,而应有选择地应用。下面我们来谈谈百度“爬虫诊断”工具的具体功能和需要改进的地方。
先来看看百度官方的解释:
一、什么是爬虫?
1)Grabbing 诊断工具可以让站长从百度蜘蛛的角度查看抓取到的内容,自我诊断百度蜘蛛看到的内容是否与预期一致。
2)每个站点一个月可以使用300次,抓取结果只显示百度蜘蛛可见的前200KB内容。
二、爬虫诊断工具能做什么?
1) 诊断爬取的内容是否符合预期。比如很多商品详情页,价格信息是通过JavaScript输出的,对百度蜘蛛不友好,价格信息很难应用于搜索。问题解决后,可使用诊断工具再次检查。
2)诊断网页是否添加了黑色链接和隐藏文字。如果网站 被黑,可能会添加隐藏链接。这些链接可能只有在百度抓取的时候才会出现,需要使用这个爬虫来诊断。
3)检查网站与百度的连接是否顺畅。如果IP信息不一致,可以报错并通知百度更新IP。
4)如果网站有新页面或者页面内容更新了,百度蜘蛛很久没有访问过,可以通过这个工具邀请它快速抓取。
我测试过了,有的网站可以爬取成功。如下图所示,里面收录了很多信息,也可以很好的展示网页的源代码,可以为站长提供一些帮助。
但是,对于双线主机和使用别名解析的非固定IP主机,总是会出现爬网失败或爬网现象,偶尔也能爬网成功,如图:
这是否意味着百度百度蜘蛛无法抓取我们的网页?答案是不。笔者刚刚测试的网站爬不成功,当天发送的文章全部秒收,证明百度蜘蛛可以很好的爬取网页,但是单机“爬诊断”工具开启出差。 ,这说明这个技术还不成熟,只能参考,不能过分依赖。
还有一点需要注意的是,在抓取同一个页面后,百度会缓存很长时间,如下图所示。作者在早上11:09抓了一个页面,在页面上挂了一条“黑链”。 “爬虫”抓到的源码中收录了这些“黑链”代码,但是作者把这些“黑链”拿走了之后,晚上19:13再次抓取,发现页面我获取的仍然是我在早上 11:09 获取的页面,相隔 8 小时。
此外,爬虫在确定网站IP 地址时经常会出错。一旦IP地址确定错误,抓取就会失败。但这并不意味着蜘蛛不能访问我们的网站。其实蜘蛛就是蜘蛛,爬虫是一种工具。不要混淆它们。
当然,新推出的任何工具都存在这样和那样的问题。我们只需要选择对我们有利的地方去申请,而不是过分依赖所有的功能。同时也希望度娘能尽快改进,解决所有问题,给广大站长朋友一个有用的工具。
如何使用pyppeteer抓取网页的数据(一)_百度搜索数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-07-07 18:17
今天,我们将介绍如何使用pyppeteer来获取网页数据。 Pyppeteer是一个Web应用自动化测试工具,可以直接在浏览器中运行,通过代码控制与页面元素进行交互,获取相应信息。
过去,我们通过编写代码来爬取数据。当待爬取的网站需要登录时,我们需要在代码中模拟登录;当抓取速度过快需要验证时,我们需要在代码中登录实现ip中的验证逻辑;当ip被阻塞时,你还需要有自己的动态ip库。我们爬取网站的反爬策略越多,我们爬取的成本就越大。总之,通过编写代码爬取数据需要构造更复杂的请求,并千方百计将爬虫伪装成真实用户。
使用pyppeteer之类的工具可以很大程度上解决以上问题。同时还有一个好处就是所见即所得,无需研究网页复杂的请求结构。当然,这类工具也有其优点和缺点。它增加了理解网页上各种元素和交互的成本。所以我觉得这类工具最适合用在短小、扁平、爬行速度快的场景。比如我在最近的工作中就遇到过两次这种情况。我想抓取一些特别简单的数据来提高工作效率,但我不想研究网页如何构建请求。您可以使用此 WYSIWYG 工具。快速抓取您想要的数据。
我们以“抓取百度搜索数据”为例,介绍一下pyppeteer的使用。在正式介绍之前,先来看看爬取效果:
安装pyppeteer
python3 -m pip install pyppeteer
安装完成后,执行pyppeteer-install命令安装最新版本的Chromium浏览器。根据官方文档,安装pyppeteer需要Python3.6或更高版本。
因为pyppeteer是基于asyncio实现的,所以我们在代码中也会使用async/await来写代码。没写过的朋友别着急。基本不会影响pyppeteer的使用。如有必要,我们将使用 async/await 来编写代码。写一篇文章的介绍。
首先用pyppeteer启动chrome进程
from pyppeteer import launch
# headless 显示浏览器
# --window-size 设置窗体大小
browser = await launch({'headless': False,
'args': ['--window-size=%d,%d' % (width, height)]
})
然后,打开一个新标签并访问百度
# 打开新页面
page = await browser.newPage()
# 设置内容显示大小
await page.setViewport({"width": width, "height": height})
# 访问百度
await page.goto('https://www.baidu.com')
打开百度网站后,下一步就是在搜索输入框中输入内容,首先找到输入框的html标签
从上图可以看出,代码代表搜索输入框,标签的类是s_ipt,然后我们会通过type函数找到标签,输入要搜索的内容。
# 将对应的 selector 填入 python,通过.s_ipt找到输入框html标签
await page.type('.s_ipt', 'python')
这里我们搜索的是python。输入后,您可以点击“百度”按钮开始搜索。查找按钮的方法同上
可以看到代码代表“百度点击”的按钮。标签的 id 是 su。现在调用点击函数找到标签,然后点击
# 通过#su找到“百度一下”按钮html标签
await page.click('#su')
需要注意的是su的前面是#而不是.,因为它在html标签中是用id而不是class来表示的。它涉及到html选择器的内容。如果你不知道,你可以简单地添加它。
执行上述代码后,可以看到搜索结果,调用截图方法保存当前页面
await page.screenshot({'path': 'example.png'})
效果如下:
接下来,我们将获取网页的内容并解析每个结果
# 获取网页内容
content = await page.content()
# 解析
output_search_result(content)
通过BeatifulSoup分析每个结果的标题和链接
def output_search_result(html):
search_bs = BeautifulSoup(html, 'lxml')
all_result = search_bs.find_all("div", {'class': "result c-container"})
for single_res in all_result:
title_bs = single_res.find("a")
title_url = title_bs.get('href')
title_txt = title_bs.get_text()
print(title_txt, title_url)
输出内容如下
python官方网站 - Welcome to Python.org http://www.baidu.com/link%3Fur ... x-q1D
Python 基础教程 | 菜鸟教程 http://www.baidu.com/link%3Fur ... SY3V_
Python3 * 和 ** 运算符_python_极客点儿-CSDN博客 http://www.baidu.com/link%3Fur ... gQuFy
Python教程 - 廖雪峰的官方网站 http://www.baidu.com/link%3Fur ... l9YDX
Python3 教程 | 菜鸟教程 http://www.baidu.com/link%3Fur ... 35m3q
你都用 Python 来做什么? - 知乎 http://www.baidu.com/link%3Fur ... MJrsK
Python基础教程,Python入门教程(非常详细) http://www.baidu.com/link%3Fur ... QZQie
这样,我们爬取数据的目的就达到了。当然,我们可以继续扩展,更多地使用pyppeteer。比如我们可以点击下一页,抓取下一页的内容。
# next page
# 为了点击“下一页”,需要将当前页面滑到底部
dimensions = await page.evaluate('window.scrollTo(0, window.innerHeight)')
# 点击“下一页”按钮
await page.click('.n')
# 获取第二页的内容
content = await page.content()
# 解析
output_search_result(content)
操作与上一个类似,注释更清晰,这里不再赘述。最后,您可以调用 await browser.close() 代码关闭浏览器。上面的代码可以定义在一个异步函数中,比如:
async def main():
# ... 抓取代码
然后传递以下代码
asyncio.get_event_loop().run_until_complete(main())
调用主函数。
这里介绍pyppeteer的用法。有很多类似的工具,比如Selenium。我也试过了。实际上,按照 Internet 上的说明对其进行配置需要一些努力。有兴趣的可以自行尝试。希望今天的内容对你有用。关注公众号回复关键词爬虫获取完整源码
欢迎关注公众号“穿越码”,输出别处看不到的干货。
查看全部
如何使用pyppeteer抓取网页的数据(一)_百度搜索数据
今天,我们将介绍如何使用pyppeteer来获取网页数据。 Pyppeteer是一个Web应用自动化测试工具,可以直接在浏览器中运行,通过代码控制与页面元素进行交互,获取相应信息。
过去,我们通过编写代码来爬取数据。当待爬取的网站需要登录时,我们需要在代码中模拟登录;当抓取速度过快需要验证时,我们需要在代码中登录实现ip中的验证逻辑;当ip被阻塞时,你还需要有自己的动态ip库。我们爬取网站的反爬策略越多,我们爬取的成本就越大。总之,通过编写代码爬取数据需要构造更复杂的请求,并千方百计将爬虫伪装成真实用户。
使用pyppeteer之类的工具可以很大程度上解决以上问题。同时还有一个好处就是所见即所得,无需研究网页复杂的请求结构。当然,这类工具也有其优点和缺点。它增加了理解网页上各种元素和交互的成本。所以我觉得这类工具最适合用在短小、扁平、爬行速度快的场景。比如我在最近的工作中就遇到过两次这种情况。我想抓取一些特别简单的数据来提高工作效率,但我不想研究网页如何构建请求。您可以使用此 WYSIWYG 工具。快速抓取您想要的数据。
我们以“抓取百度搜索数据”为例,介绍一下pyppeteer的使用。在正式介绍之前,先来看看爬取效果:
安装pyppeteer
python3 -m pip install pyppeteer
安装完成后,执行pyppeteer-install命令安装最新版本的Chromium浏览器。根据官方文档,安装pyppeteer需要Python3.6或更高版本。
因为pyppeteer是基于asyncio实现的,所以我们在代码中也会使用async/await来写代码。没写过的朋友别着急。基本不会影响pyppeteer的使用。如有必要,我们将使用 async/await 来编写代码。写一篇文章的介绍。
首先用pyppeteer启动chrome进程
from pyppeteer import launch
# headless 显示浏览器
# --window-size 设置窗体大小
browser = await launch({'headless': False,
'args': ['--window-size=%d,%d' % (width, height)]
})
然后,打开一个新标签并访问百度
# 打开新页面
page = await browser.newPage()
# 设置内容显示大小
await page.setViewport({"width": width, "height": height})
# 访问百度
await page.goto('https://www.baidu.com')
打开百度网站后,下一步就是在搜索输入框中输入内容,首先找到输入框的html标签
从上图可以看出,代码代表搜索输入框,标签的类是s_ipt,然后我们会通过type函数找到标签,输入要搜索的内容。
# 将对应的 selector 填入 python,通过.s_ipt找到输入框html标签
await page.type('.s_ipt', 'python')
这里我们搜索的是python。输入后,您可以点击“百度”按钮开始搜索。查找按钮的方法同上
可以看到代码代表“百度点击”的按钮。标签的 id 是 su。现在调用点击函数找到标签,然后点击
# 通过#su找到“百度一下”按钮html标签
await page.click('#su')
需要注意的是su的前面是#而不是.,因为它在html标签中是用id而不是class来表示的。它涉及到html选择器的内容。如果你不知道,你可以简单地添加它。
执行上述代码后,可以看到搜索结果,调用截图方法保存当前页面
await page.screenshot({'path': 'example.png'})
效果如下:
接下来,我们将获取网页的内容并解析每个结果
# 获取网页内容
content = await page.content()
# 解析
output_search_result(content)
通过BeatifulSoup分析每个结果的标题和链接
def output_search_result(html):
search_bs = BeautifulSoup(html, 'lxml')
all_result = search_bs.find_all("div", {'class': "result c-container"})
for single_res in all_result:
title_bs = single_res.find("a")
title_url = title_bs.get('href')
title_txt = title_bs.get_text()
print(title_txt, title_url)
输出内容如下
python官方网站 - Welcome to Python.org http://www.baidu.com/link%3Fur ... x-q1D
Python 基础教程 | 菜鸟教程 http://www.baidu.com/link%3Fur ... SY3V_
Python3 * 和 ** 运算符_python_极客点儿-CSDN博客 http://www.baidu.com/link%3Fur ... gQuFy
Python教程 - 廖雪峰的官方网站 http://www.baidu.com/link%3Fur ... l9YDX
Python3 教程 | 菜鸟教程 http://www.baidu.com/link%3Fur ... 35m3q
你都用 Python 来做什么? - 知乎 http://www.baidu.com/link%3Fur ... MJrsK
Python基础教程,Python入门教程(非常详细) http://www.baidu.com/link%3Fur ... QZQie
这样,我们爬取数据的目的就达到了。当然,我们可以继续扩展,更多地使用pyppeteer。比如我们可以点击下一页,抓取下一页的内容。
# next page
# 为了点击“下一页”,需要将当前页面滑到底部
dimensions = await page.evaluate('window.scrollTo(0, window.innerHeight)')
# 点击“下一页”按钮
await page.click('.n')
# 获取第二页的内容
content = await page.content()
# 解析
output_search_result(content)
操作与上一个类似,注释更清晰,这里不再赘述。最后,您可以调用 await browser.close() 代码关闭浏览器。上面的代码可以定义在一个异步函数中,比如:
async def main():
# ... 抓取代码
然后传递以下代码
asyncio.get_event_loop().run_until_complete(main())
调用主函数。
这里介绍pyppeteer的用法。有很多类似的工具,比如Selenium。我也试过了。实际上,按照 Internet 上的说明对其进行配置需要一些努力。有兴趣的可以自行尝试。希望今天的内容对你有用。关注公众号回复关键词爬虫获取完整源码
欢迎关注公众号“穿越码”,输出别处看不到的干货。
什么是抓取、收录网页抓取工具.txt文件介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-07-06 05:10
网站建好,请问如何获取收录网站搜索引擎?如果页面无法被搜索引擎收录搜索到,则说明该页面尚未展示,无法竞争排名获取SEO流量。本文将围绕爬虫和收录亮点,从基本原理、常见问题和解决方案三个维度探讨搜索引擎优化。什么是爬虫,收录web爬虫robots.txt文件介绍
如何查看网站的收录情况
设置网页不被搜索引擎索引
搜索引擎的原理:搜索引擎将互联网上的网页内容存储在自己的服务器上。当用户搜索一个词时,搜索引擎会在自己的服务器上找到相关内容,即只搜索保存在搜索引擎服务器上的网页。
哪些网页可以保存在搜索引擎的服务器上?
只有搜索引擎爬虫抓取到的网页才会保存在搜索引擎的服务器上。这个网页的爬虫是搜索引擎的蜘蛛。整个过程分为爬行和爬行。
一、什么在爬,收录
爬行:
这是搜索引擎爬虫爬取网站的过程。谷歌官方的解释是——“爬行”是指寻找新的或更新的网页并将其添加到谷歌的过程; (点此查看谷歌官网文档)
收录(索引):
是搜索引擎在其数据库中存储页面的结果,也称为索引。谷歌官方的解释是:谷歌的爬虫(“Googlebot”)已经访问了该页面,分析了其内容和含义,并将其存储在谷歌索引中。索引的网页可以显示在谷歌搜索结果中; (点此查看谷歌官网文档)
抓取预算:
是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间上限。一般小的网站(几百或几千页)不用担心,搜索引擎分配的爬取配额不够;大网站(百万或千万页)会更多地考虑这个问题。如果搜索引擎每天爬取几万个页面,整个网站页面爬取可能需要几个月甚至一年的时间。通常,这些数据可以从 Google Search Console 的后端学习。如下图所示,红框内的平均值为网站分配的爬取配额。
通过一个例子让大家更好的理解爬取、收录和爬取配额:
搜索引擎比作一个巨大的图书馆,网站比作书店,书店里的书比作网站页面,蜘蛛爬虫比作图书馆买家。
为了丰富图书馆的藏书量,购书者会定期到书店查看是否有新书存货。翻书的过程可以理解为抓取;
当买家认为这本书有价值时,他会购买并带回图书馆采集。这本书合集就是我们所说的收录;
每个买家的购书预算有限,他会优先购买价值高的书籍。这个预算就是我们理解的抢配额。
二、网络爬虫
“爬虫”是一个通用术语,指的是任何程序(例如机器人或“蜘蛛”程序)通过从一个网页到另一个网页的链接来自动发现和扫描网站。 Google 的主要抓取工具称为 Googlebot。
三、robots.txt 文件介绍
robots.txt 文件指定了爬虫的爬取规则。
robots.txt 文件必须位于主机的顶级目录中。
一般情况下,robots.txt文件中会出现三种不同的爬取结果:
Robots.txt 使用示例:网站目录下的所有文件都可以被所有搜索引擎蜘蛛访问 User-agent:*
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
网站 一些文件应该限制被蜘蛛抓取:
一般网站中不需要蜘蛛爬取的文件包括:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片、背景图片、等
robots.txt 文件带来的风险及其解决方法:
robots.txt 也带来了一定的风险:它还向攻击者指出了网站 目录结构和私有数据的位置。设置访问权限和密码保护您的私人内容,使攻击者无法进入。
四、如何查看网站的收录情况
①通过站点命令。
谷歌、百度、必应等主流搜索引擎均支持站点命令。通过站点命令,您可以在宏观层面查看网站 已经收录 的页面数量。这个值不准确,有一定的波动性,但有一定的参考价值。如下图所示,Google收录为网站提供的网页数量约为165个。
②如果网站已经验证了Google Search Console,这样就可以得到网站被Google收录的精确值,如下图红框所示,Google收录了网站的216页;
③如果要查询特定页面是否为收录,可以使用info命令。谷歌支持 info 命令,但百度和必应不支持。在谷歌中输入信息:URL。如果返回结果,页面已经是收录,如下图:
五、 设置网页不被搜索引擎索引
推荐使用robots meta标签,在head标签中添加如下代码:
可以使用多个指令,这些指令不区分大小写。
全部
对索引或内容显示没有限制。该命令为默认值,所以显式列出时无效。
无索引
不要在搜索结果中显示此页面。 nofollow 不遵循此页面上的链接。
无
与 noindex、nofollow 相同。 noarchive 不会在搜索结果中显示缓存的链接。
没有片段
不要在搜索结果中显示网页的文本摘要或视频预览。如果静态图像缩略图(如果有)能够提供更好的用户体验,则它们可能仍会显示。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现)。
最大片段:[数量]
您最多只能使用 [number] 个字符作为此搜索结果的文本摘要。 (请注意,该 URL 可能会在搜索结果页面上显示为多个搜索结果。)这不会影响图像或视频预览。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现、Google 助理)。但是,如果发布者单独授予了内容使用权,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容或与 Google 签订了许可协议,则此设置不会阻止这些更具体的许可用途。如果没有指定resolvable [number],该命令将被忽略。
特殊价值:
示例:
最大图像预览:[设置]
设置该网页在搜索结果中预览图片的最大尺寸。
接受的设置值:
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现、Google 助理)。但是,如果发布者单独授予了内容使用权,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容(例如 AMP 页面和文章 的规范版本),或者与 Google 签订了许可协议,则此设置不会阻止这些更具体的允许用途。
如果发布商不希望 Google 在搜索结果页面或“探索”功能中显示其 AMP 页面和 文章 的规范版本时使用更大的缩略图,则应指定 max-image-preview 的值标准或无。
示例:
最大视频预览:[数量]
此页面上视频的视频摘要在搜索结果中不得超过 [number] 秒。
其他支持的值:
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 视频、Google 发现、Google 助理)。如果没有指定resolvable [number],该命令将被忽略。
示例:
不翻译
不要在搜索结果中提供网页的翻译。
无图像索引
此页面上的图片将不会被编入索引。
unavailable_after:[日期/时间]
在指定的日期/时间之后,网页将不会显示在搜索结果中。日期/时间必须以广泛使用的格式指定,包括但不限于RFC 822、RFC 850 和ISO 8601。如果未指定有效的[日期/时间],则该命令将被忽略。默认情况下,内容没有过期日期。
示例:
参考资料: 查看全部
什么是抓取、收录网页抓取工具.txt文件介绍
网站建好,请问如何获取收录网站搜索引擎?如果页面无法被搜索引擎收录搜索到,则说明该页面尚未展示,无法竞争排名获取SEO流量。本文将围绕爬虫和收录亮点,从基本原理、常见问题和解决方案三个维度探讨搜索引擎优化。什么是爬虫,收录web爬虫robots.txt文件介绍
如何查看网站的收录情况
设置网页不被搜索引擎索引
搜索引擎的原理:搜索引擎将互联网上的网页内容存储在自己的服务器上。当用户搜索一个词时,搜索引擎会在自己的服务器上找到相关内容,即只搜索保存在搜索引擎服务器上的网页。
哪些网页可以保存在搜索引擎的服务器上?
只有搜索引擎爬虫抓取到的网页才会保存在搜索引擎的服务器上。这个网页的爬虫是搜索引擎的蜘蛛。整个过程分为爬行和爬行。
一、什么在爬,收录
爬行:
这是搜索引擎爬虫爬取网站的过程。谷歌官方的解释是——“爬行”是指寻找新的或更新的网页并将其添加到谷歌的过程; (点此查看谷歌官网文档)
收录(索引):
是搜索引擎在其数据库中存储页面的结果,也称为索引。谷歌官方的解释是:谷歌的爬虫(“Googlebot”)已经访问了该页面,分析了其内容和含义,并将其存储在谷歌索引中。索引的网页可以显示在谷歌搜索结果中; (点此查看谷歌官网文档)
抓取预算:
是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间上限。一般小的网站(几百或几千页)不用担心,搜索引擎分配的爬取配额不够;大网站(百万或千万页)会更多地考虑这个问题。如果搜索引擎每天爬取几万个页面,整个网站页面爬取可能需要几个月甚至一年的时间。通常,这些数据可以从 Google Search Console 的后端学习。如下图所示,红框内的平均值为网站分配的爬取配额。
通过一个例子让大家更好的理解爬取、收录和爬取配额:
搜索引擎比作一个巨大的图书馆,网站比作书店,书店里的书比作网站页面,蜘蛛爬虫比作图书馆买家。
为了丰富图书馆的藏书量,购书者会定期到书店查看是否有新书存货。翻书的过程可以理解为抓取;
当买家认为这本书有价值时,他会购买并带回图书馆采集。这本书合集就是我们所说的收录;
每个买家的购书预算有限,他会优先购买价值高的书籍。这个预算就是我们理解的抢配额。
二、网络爬虫
“爬虫”是一个通用术语,指的是任何程序(例如机器人或“蜘蛛”程序)通过从一个网页到另一个网页的链接来自动发现和扫描网站。 Google 的主要抓取工具称为 Googlebot。
三、robots.txt 文件介绍
robots.txt 文件指定了爬虫的爬取规则。
robots.txt 文件必须位于主机的顶级目录中。
一般情况下,robots.txt文件中会出现三种不同的爬取结果:
Robots.txt 使用示例:网站目录下的所有文件都可以被所有搜索引擎蜘蛛访问 User-agent:*
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
网站 一些文件应该限制被蜘蛛抓取:
一般网站中不需要蜘蛛爬取的文件包括:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片、背景图片、等
robots.txt 文件带来的风险及其解决方法:
robots.txt 也带来了一定的风险:它还向攻击者指出了网站 目录结构和私有数据的位置。设置访问权限和密码保护您的私人内容,使攻击者无法进入。
四、如何查看网站的收录情况
①通过站点命令。
谷歌、百度、必应等主流搜索引擎均支持站点命令。通过站点命令,您可以在宏观层面查看网站 已经收录 的页面数量。这个值不准确,有一定的波动性,但有一定的参考价值。如下图所示,Google收录为网站提供的网页数量约为165个。
②如果网站已经验证了Google Search Console,这样就可以得到网站被Google收录的精确值,如下图红框所示,Google收录了网站的216页;

③如果要查询特定页面是否为收录,可以使用info命令。谷歌支持 info 命令,但百度和必应不支持。在谷歌中输入信息:URL。如果返回结果,页面已经是收录,如下图:
五、 设置网页不被搜索引擎索引
推荐使用robots meta标签,在head标签中添加如下代码:
可以使用多个指令,这些指令不区分大小写。
全部
对索引或内容显示没有限制。该命令为默认值,所以显式列出时无效。
无索引
不要在搜索结果中显示此页面。 nofollow 不遵循此页面上的链接。
无
与 noindex、nofollow 相同。 noarchive 不会在搜索结果中显示缓存的链接。
没有片段
不要在搜索结果中显示网页的文本摘要或视频预览。如果静态图像缩略图(如果有)能够提供更好的用户体验,则它们可能仍会显示。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现)。
最大片段:[数量]
您最多只能使用 [number] 个字符作为此搜索结果的文本摘要。 (请注意,该 URL 可能会在搜索结果页面上显示为多个搜索结果。)这不会影响图像或视频预览。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现、Google 助理)。但是,如果发布者单独授予了内容使用权,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容或与 Google 签订了许可协议,则此设置不会阻止这些更具体的许可用途。如果没有指定resolvable [number],该命令将被忽略。
特殊价值:
示例:
最大图像预览:[设置]
设置该网页在搜索结果中预览图片的最大尺寸。
接受的设置值:
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现、Google 助理)。但是,如果发布者单独授予了内容使用权,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容(例如 AMP 页面和文章 的规范版本),或者与 Google 签订了许可协议,则此设置不会阻止这些更具体的允许用途。
如果发布商不希望 Google 在搜索结果页面或“探索”功能中显示其 AMP 页面和 文章 的规范版本时使用更大的缩略图,则应指定 max-image-preview 的值标准或无。
示例:
最大视频预览:[数量]
此页面上视频的视频摘要在搜索结果中不得超过 [number] 秒。
其他支持的值:
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 视频、Google 发现、Google 助理)。如果没有指定resolvable [number],该命令将被忽略。
示例:
不翻译
不要在搜索结果中提供网页的翻译。
无图像索引
此页面上的图片将不会被编入索引。
unavailable_after:[日期/时间]
在指定的日期/时间之后,网页将不会显示在搜索结果中。日期/时间必须以广泛使用的格式指定,包括但不限于RFC 822、RFC 850 和ISO 8601。如果未指定有效的[日期/时间],则该命令将被忽略。默认情况下,内容没有过期日期。
示例:
参考资料:
如何用阿里云免费邮箱服务提供的网站内容抓取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-30 07:01
网站内容抓取工具,一般有行情抓取、博客、源码、网站等,你说的这几种做行情抓取比较多一些,网站抓取一般都是要付费的,如果你不缺钱的话,其实也无所谓。
可以用阿里云免费邮箱服务提供的sofatmail邮箱服务,或者的emaildigitalspot邮箱账号提供的免费邮箱服务。
需要的话提供个网站!
yandex-ford你真逗,
免费空间只能提供免费源码服务,所以,免费空间提供的抓取程序质量不高,想要高质量的(像python爬虫+beautifulsoup+pymysql+requests+bs4),需要付费,1000元/年python爬虫+beautifulsoup+pymysql+requests+bs4爬虫性能如何?点击浏览器右上角response?用er分析器,python里有,爬虫性能=多重循环重复下载+数据处理+正则表达式+采样+特征匹配+迭代器+缓存,如果不包含正则表达式,那么请去cookies=分析器里面读取response,读取了之后再缓存起来。 查看全部
如何用阿里云免费邮箱服务提供的网站内容抓取工具
网站内容抓取工具,一般有行情抓取、博客、源码、网站等,你说的这几种做行情抓取比较多一些,网站抓取一般都是要付费的,如果你不缺钱的话,其实也无所谓。
可以用阿里云免费邮箱服务提供的sofatmail邮箱服务,或者的emaildigitalspot邮箱账号提供的免费邮箱服务。
需要的话提供个网站!
yandex-ford你真逗,
免费空间只能提供免费源码服务,所以,免费空间提供的抓取程序质量不高,想要高质量的(像python爬虫+beautifulsoup+pymysql+requests+bs4),需要付费,1000元/年python爬虫+beautifulsoup+pymysql+requests+bs4爬虫性能如何?点击浏览器右上角response?用er分析器,python里有,爬虫性能=多重循环重复下载+数据处理+正则表达式+采样+特征匹配+迭代器+缓存,如果不包含正则表达式,那么请去cookies=分析器里面读取response,读取了之后再缓存起来。
博客园首页代码:线建立一个MVC空项目(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-06-29 19:13
\\s*.*)\”\\s*target=\”_blank\”>(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为控制器添加一个视图索引
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/")))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/"));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
部分索引视图代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
@HttpUtility.HtmlDecode(b)@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
如博客所写,可以运行一个完整的MVC项目,但是我只采集一页,我们也可以在博客园首页采集下翻页部分(即pager_buttom)采集
p>
,只需要添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html中一一采集提取所需的相应信息。另外,我们不应该将采集添加到每个新闻条目对应的页面的源代码中,而每个新闻条目对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要花费大量时间。佩服采集的效率,在数据库中存放大量新闻页面文件会占用大量内存,影响数据库性能。
转载于: 查看全部
博客园首页代码:线建立一个MVC空项目(图)
\\s*.*)\”\\s*target=\”_blank\”>(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为控制器添加一个视图索引
HomeController.cs 代码的一部分:

using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/";)))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/";));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
部分索引视图代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
@HttpUtility.HtmlDecode(b)@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
如博客所写,可以运行一个完整的MVC项目,但是我只采集一页,我们也可以在博客园首页采集下翻页部分(即pager_buttom)采集
p>

,只需要添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html中一一采集提取所需的相应信息。另外,我们不应该将采集添加到每个新闻条目对应的页面的源代码中,而每个新闻条目对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要花费大量时间。佩服采集的效率,在数据库中存放大量新闻页面文件会占用大量内存,影响数据库性能。
转载于:
如何在没有界面显示的情况下抓取HTTP的请求包
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-06-29 19:09
简介
在前两篇文章中文章讲了如何抓HTTP请求包,包括代理服务器的使用和抓包方法。只是因为当前视频网站的视频地址不是在html页面直接获取的,所以视频是通过浏览器动态解释js脚本,然后向视频服务器发送视频请求来获取的。所以我们通过获取浏览器产生的HTTP请求来获取视频的下载地址。
直接使用 firefox 获取创意
我们想到了可以动态渲染js脚本的程序,最常见的就是浏览器。我们通过命令运行
firefox http://the.video.url
您可以使用 Firefox 打开 URL。但是我们不能不显示就这样使用,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为需要渲染没有界面显示的JS脚本,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是一个无头浏览器(Headless Browser 是一个没有界面的浏览器)。
但是Phantomjs1.5版本之后,不再支持flash插件。也就是说,Phantomjs 虽然可以动态加载 JS 脚本,但无法渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到渲染后的页面,如下图:
视频播放窗口是黑色的,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版本的Phantomjs,网上说用这个命令可以加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图得到如下图:
虽然得到的截图和上图不同,但是视频中多了一个loading状态,但是我还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
WebDriverException: Message: Can not connect to the Service phantomjs
最后不得不放弃使用 Phantomjs
slimerjs
我在网上搜索headless browser的时候,也发现了slimerjs。
PhantomJS 和 SlimerJS 的异同:来自文章
PhantomJS 基于 Webkit 内核,不支持 Flash 播放。 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程会有页面显示
正好我们需要支持Flash播放。但是问题又来了! SlimerJS 不是纯粹的 Headless 浏览器,它需要 DISPLAY! ! 那么我们可以做些什么来解决这个问题呢?有!
xvfb
xvfb 提供了一个类似于 X 服务器守护进程的环境和设置程序运行的环境变量 DISPLAY。
通过这个,上面提到的Firefox遇到的第一个问题也可以解决。感觉就像绕了一圈==!
计划实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能使用python调用命令行程序来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入了一个网页地址参数。 slimerjs 负责打开这个页面,渲染页面的内容。
这个脚本的文件名是getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
我们的python调用os.system("xvfb-run slimerjs getPage.js" + videoURL)来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
import os
import time
open163url = 'http://open.163.com/movie/2016/1/T/D/MBCRLBLRN_MBCRM7OTD.html'
startTime = time.time()
os.system("xvfb-run slimerjs getPage.js " + open163url)
print "use time: " + str(time.time() - startTime)
capture_traffic sudo python pypcap_test.py
[sudo] password for honkee:
starting capture
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv?start=107570066
获取视频地址! !
未解决的问题
调用 python slimerjs_crawl_video.py 时
capture_traffic python slimerjs_craw_video.py
Vector smash protection is enabled.
use time: 94.3547639847
我不知道如何控制这个时间。我已经尝试修改getPage.js的window.setTimeout函数的时间,但是还是90多秒。我猜 python 的 os.system() 的限制是阻塞某些让我们回到过去(超过 90 秒)。接下来,我会再次检查相关的东西。
更新:
今天为了解决这个返回问题,开始找这个问题的原因,直接找了os.system()函数的文档。它表明此函数正在阻塞并等待命令执行完成后再返回。那么问题应该已经出现在slimerjs脚本中了。偶尔跑脚本的时候忘了加视频页面的path参数,很快就返回了。因为我的window.setTimeout()函数设置为10毫秒,为什么添加视频网页路径后还要等待90多秒呢?我打开firefox的firebug并打开那个网页。在加载所有请求后计算发现此函数的时间。下图是firebug的截图。
两个红色请求表示 90 秒后超时。这是计时器开始计时的时候,加上加载程序所需的时间,已经超过了 90 秒。
然后我们自然想到了在打开的页面之外写window.setTimeout()函数,设置返回的时间。
getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
window.setTimeout(function(){
phantom.exit();
},10000);
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
最后发现这个标题不适合这个文章。但是我还是不改了,因为我用了headless浏览器的思路来解决这个问题 查看全部
如何在没有界面显示的情况下抓取HTTP的请求包
简介
在前两篇文章中文章讲了如何抓HTTP请求包,包括代理服务器的使用和抓包方法。只是因为当前视频网站的视频地址不是在html页面直接获取的,所以视频是通过浏览器动态解释js脚本,然后向视频服务器发送视频请求来获取的。所以我们通过获取浏览器产生的HTTP请求来获取视频的下载地址。
直接使用 firefox 获取创意
我们想到了可以动态渲染js脚本的程序,最常见的就是浏览器。我们通过命令运行
firefox http://the.video.url
您可以使用 Firefox 打开 URL。但是我们不能不显示就这样使用,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为需要渲染没有界面显示的JS脚本,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是一个无头浏览器(Headless Browser 是一个没有界面的浏览器)。
但是Phantomjs1.5版本之后,不再支持flash插件。也就是说,Phantomjs 虽然可以动态加载 JS 脚本,但无法渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到渲染后的页面,如下图:

视频播放窗口是黑色的,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版本的Phantomjs,网上说用这个命令可以加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图得到如下图:

虽然得到的截图和上图不同,但是视频中多了一个loading状态,但是我还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
WebDriverException: Message: Can not connect to the Service phantomjs
最后不得不放弃使用 Phantomjs
slimerjs
我在网上搜索headless browser的时候,也发现了slimerjs。
PhantomJS 和 SlimerJS 的异同:来自文章
PhantomJS 基于 Webkit 内核,不支持 Flash 播放。 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程会有页面显示
正好我们需要支持Flash播放。但是问题又来了! SlimerJS 不是纯粹的 Headless 浏览器,它需要 DISPLAY! ! 那么我们可以做些什么来解决这个问题呢?有!
xvfb
xvfb 提供了一个类似于 X 服务器守护进程的环境和设置程序运行的环境变量 DISPLAY。
通过这个,上面提到的Firefox遇到的第一个问题也可以解决。感觉就像绕了一圈==!
计划实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能使用python调用命令行程序来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入了一个网页地址参数。 slimerjs 负责打开这个页面,渲染页面的内容。
这个脚本的文件名是getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
我们的python调用os.system("xvfb-run slimerjs getPage.js" + videoURL)来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
import os
import time
open163url = 'http://open.163.com/movie/2016/1/T/D/MBCRLBLRN_MBCRM7OTD.html'
startTime = time.time()
os.system("xvfb-run slimerjs getPage.js " + open163url)
print "use time: " + str(time.time() - startTime)
capture_traffic sudo python pypcap_test.py
[sudo] password for honkee:
starting capture
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv?start=107570066
获取视频地址! !
未解决的问题
调用 python slimerjs_crawl_video.py 时
capture_traffic python slimerjs_craw_video.py
Vector smash protection is enabled.
use time: 94.3547639847
我不知道如何控制这个时间。我已经尝试修改getPage.js的window.setTimeout函数的时间,但是还是90多秒。我猜 python 的 os.system() 的限制是阻塞某些让我们回到过去(超过 90 秒)。接下来,我会再次检查相关的东西。
更新:
今天为了解决这个返回问题,开始找这个问题的原因,直接找了os.system()函数的文档。它表明此函数正在阻塞并等待命令执行完成后再返回。那么问题应该已经出现在slimerjs脚本中了。偶尔跑脚本的时候忘了加视频页面的path参数,很快就返回了。因为我的window.setTimeout()函数设置为10毫秒,为什么添加视频网页路径后还要等待90多秒呢?我打开firefox的firebug并打开那个网页。在加载所有请求后计算发现此函数的时间。下图是firebug的截图。

两个红色请求表示 90 秒后超时。这是计时器开始计时的时候,加上加载程序所需的时间,已经超过了 90 秒。
然后我们自然想到了在打开的页面之外写window.setTimeout()函数,设置返回的时间。
getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
window.setTimeout(function(){
phantom.exit();
},10000);
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
最后发现这个标题不适合这个文章。但是我还是不改了,因为我用了headless浏览器的思路来解决这个问题
从Docker到K8s,业务容器化遇瓶颈怎么办(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-07-19 07:04
从Docker到K8s,业务容器化遇到瓶颈怎么办? >>>
网络爬虫有很多种。下面是一个非常粗略的分类,并说明了网络爬虫/数据提取/信息提取工具包MetaSeeker中的爬虫属于哪个类别。
如果按照部署的地方来划分,可以分为:
1.服务器端:一般是多线程程序,同时下载多个目标HTML,可以使用PHP、Java、Python(目前比较流行)等,一般集成搜索引擎爬虫都是这样做的。但是,如果对方讨厌爬虫,很可能会封掉服务器的IP,不容易更改,而且消耗的带宽也相当昂贵。
2、Client:非常适合部署固定主题的爬虫,或者专注的爬虫。与谷歌、百度等竞争的综合搜索引擎成功的机会很少,而垂直搜索或比价服务或推荐引擎的机会要多得多。这种类型的爬虫不会抓取所有页面,而只会抓取您关心的内容。页面,只抓取页面上你关心的内容,比如提取黄页信息、产品价格信息、提取竞争对手的广告信息等。这种爬虫可以部署很多,而且攻击性很强,对方很难拦截。
网页爬虫/数据提取/信息提取工具包MetaSeeker中的爬虫属于客户端固定主题爬虫(产品特性更详细),可以低成本大批量部署。由于客户端IP地址是动态的,很难被目标网站拦截。
我们只讨论固定主题的爬虫。普通的爬虫要简单得多,网上也有很多。如果按照如何提取数据来划分,可以分为两类:
1.通过正则表达式提取内容。 HTML 文件是一个文本文件。只需使用正则表达式提取指定位置的内容即可。 “指定地点”不一定是绝对定位。例如,您可以参考 HTML 标签定位。 , 更准确
2、使用DOM提取内容,HTML文件先转换成DOM数据结构,然后遍历这个结构提取内容。
可能有人会问,为什么还要用DOM的方法,把它翻过来呢? DOM方法存在的原因有很多:一是不用自己分析DOM结构,有现成的库,编程不复杂;其次,可以实现非常复杂但灵活的定位规则,而正则表达式很难写;第三,如果定位是考虑到HTML文件的结构,用正则表达式解析起来并不容易。 HTML 文件经常有错误。如果把这个任务交给现成的图书馆,那就容易多了。第四,假设要解析Javascript的内容,正则表达式是无能为力的。当然,DOM方法本身是无能为力的,但是利用某个平台的能力,提取AJAX网站内容是可以的。原因有很多。
网页抓取/数据提取/信息提取工具包MetaSeeker中的爬虫使用DOM方式。它使用 Mozilla 平台的功能。只要火狐看到就可以解压。 查看全部
从Docker到K8s,业务容器化遇瓶颈怎么办(图)
从Docker到K8s,业务容器化遇到瓶颈怎么办? >>>
网络爬虫有很多种。下面是一个非常粗略的分类,并说明了网络爬虫/数据提取/信息提取工具包MetaSeeker中的爬虫属于哪个类别。
如果按照部署的地方来划分,可以分为:
1.服务器端:一般是多线程程序,同时下载多个目标HTML,可以使用PHP、Java、Python(目前比较流行)等,一般集成搜索引擎爬虫都是这样做的。但是,如果对方讨厌爬虫,很可能会封掉服务器的IP,不容易更改,而且消耗的带宽也相当昂贵。
2、Client:非常适合部署固定主题的爬虫,或者专注的爬虫。与谷歌、百度等竞争的综合搜索引擎成功的机会很少,而垂直搜索或比价服务或推荐引擎的机会要多得多。这种类型的爬虫不会抓取所有页面,而只会抓取您关心的内容。页面,只抓取页面上你关心的内容,比如提取黄页信息、产品价格信息、提取竞争对手的广告信息等。这种爬虫可以部署很多,而且攻击性很强,对方很难拦截。
网页爬虫/数据提取/信息提取工具包MetaSeeker中的爬虫属于客户端固定主题爬虫(产品特性更详细),可以低成本大批量部署。由于客户端IP地址是动态的,很难被目标网站拦截。
我们只讨论固定主题的爬虫。普通的爬虫要简单得多,网上也有很多。如果按照如何提取数据来划分,可以分为两类:
1.通过正则表达式提取内容。 HTML 文件是一个文本文件。只需使用正则表达式提取指定位置的内容即可。 “指定地点”不一定是绝对定位。例如,您可以参考 HTML 标签定位。 , 更准确
2、使用DOM提取内容,HTML文件先转换成DOM数据结构,然后遍历这个结构提取内容。
可能有人会问,为什么还要用DOM的方法,把它翻过来呢? DOM方法存在的原因有很多:一是不用自己分析DOM结构,有现成的库,编程不复杂;其次,可以实现非常复杂但灵活的定位规则,而正则表达式很难写;第三,如果定位是考虑到HTML文件的结构,用正则表达式解析起来并不容易。 HTML 文件经常有错误。如果把这个任务交给现成的图书馆,那就容易多了。第四,假设要解析Javascript的内容,正则表达式是无能为力的。当然,DOM方法本身是无能为力的,但是利用某个平台的能力,提取AJAX网站内容是可以的。原因有很多。
网页抓取/数据提取/信息提取工具包MetaSeeker中的爬虫使用DOM方式。它使用 Mozilla 平台的功能。只要火狐看到就可以解压。
百度抓取器会和网站首页的友好性优化(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-18 18:14
首先百度的爬虫会和网站的首页进行交互,得到网站首页后,会理解页面,理解收录(类型,值计算),其次,会带网站首页的所有内容k14@首页的超链接提取出来了。
如上图所示,首页上的超链接称为“post-links”。下一轮爬行时,爬虫会继续与这些超链接页面进行交互,并获取页面进行提炼。一层一层的不断抓取,构成了一个抓取循环。
一、Grab-Friendly Optimization1、URL 规范
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:
如上图所示,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种URL收录字符,并且这个URL收录文章的标题,导致偏长,相对较长的URL与简单的URL相比没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符就足以显示URL的资源了。
如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是手机网站建站的常用方法。从链接发现的角度来看,这两类网站并不友好。
Feed 流推荐:
大多数进行流式传输的网站在后端都有大量数据。用户不断刷新时会出现新的内容,但无论刷新多少次,可能只能刷新到1%左右的内容。一个爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使您有 100 万个内容,您也可能只能对其进行抓取。到 1-2 百万。
仅搜索条目:
如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫不能输入关键词再抓取,所以爬虫只能爬到首页之后,没有反向链接,自然爬取和收录会不理想。
解决方案:
索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页抓取你的网站最新资源,并且新发布的资源应该实时在索引页中。同步,很多纯静态网页,内容更新了,但是首页(索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是后链(latest文章的URL)需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就足够了,比如长城。基本上,只有主页用于索引。页面。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么我提交了普通的收录却没有抓到?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:
加载时间建议控制在2S以内,所以无论是用户还是爬虫,打开速度更快的网站会更受青睐,其次是避免不必要的跳转。这种情况虽然是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。 查看全部
百度抓取器会和网站首页的友好性优化(图)
首先百度的爬虫会和网站的首页进行交互,得到网站首页后,会理解页面,理解收录(类型,值计算),其次,会带网站首页的所有内容k14@首页的超链接提取出来了。
如上图所示,首页上的超链接称为“post-links”。下一轮爬行时,爬虫会继续与这些超链接页面进行交互,并获取页面进行提炼。一层一层的不断抓取,构成了一个抓取循环。
一、Grab-Friendly Optimization1、URL 规范
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:
如上图所示,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种URL收录字符,并且这个URL收录文章的标题,导致偏长,相对较长的URL与简单的URL相比没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符就足以显示URL的资源了。
如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是手机网站建站的常用方法。从链接发现的角度来看,这两类网站并不友好。
Feed 流推荐:
大多数进行流式传输的网站在后端都有大量数据。用户不断刷新时会出现新的内容,但无论刷新多少次,可能只能刷新到1%左右的内容。一个爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使您有 100 万个内容,您也可能只能对其进行抓取。到 1-2 百万。
仅搜索条目:
如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫不能输入关键词再抓取,所以爬虫只能爬到首页之后,没有反向链接,自然爬取和收录会不理想。
解决方案:
索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页抓取你的网站最新资源,并且新发布的资源应该实时在索引页中。同步,很多纯静态网页,内容更新了,但是首页(索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是后链(latest文章的URL)需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就足够了,比如长城。基本上,只有主页用于索引。页面。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么我提交了普通的收录却没有抓到?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:
加载时间建议控制在2S以内,所以无论是用户还是爬虫,打开速度更快的网站会更受青睐,其次是避免不必要的跳转。这种情况虽然是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。
最适合你的网页刮刀取决于你需要的几种工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-07-18 18:09
如今,市场上出现了各种网络抓取工具,当您必须选择其中一种工具时,您可能会感到困惑。最适合您的网页抓取工具取决于您的需求。这里有一些强烈推荐的网页抓取工具。其中一些是免费的,而有些则有试用期和高级计划。在做出决定之前,请仔细阅读以下所有信息。
ParseHub
ParseHub 是一款免费、可靠且功能强大的网页抓取工具。它用于使用 JS、AJAX、会话、cookie 和重定向来抓取单个和多个 网站。使用 Parsehub,您可以轻松地从任何网站 获取数据,因为您无需编写代码。您只需要打开目标网站 并开始单击要提取的数据。此工具可帮助您在服务器上自动采集和存储数据。其简单的 AIP 允许用户在任何地方集成他们提取的数据。
Parsehub 在爬取网站 时使用了大量代理,因此 IP 地址总是轮换。
八字解析
Octopus 是一种现代视觉网络爬虫软件。对于那些无需编码即可从网站 获取数据的人来说,这是一个完美的选择。多亏了“点击”界面,用户使用起来不会有任何困难。八达通模仿人类活动,例如浏览网站、登录账户等。它几乎可以从每个站点获取数据,即使它是使用 AJAX 或 JS 动态获取的。
免费版八达通允许用户提取几乎所有网站。只需点击几下鼠标,它就可以将网页变成结构化的电子表格。
Diffbot
Diffbot 是一种非常高效的数据提取工具,它使用互联网让个人和企业能够获取他们需要的任何信息。可广泛应用于市场营销、商业智能、销售和招聘等领域。它提供 API 来提取和理解对象,使用 Al 和计算机视觉从网站 中提取数据。使用 Diffbot,用户不再需要进行任何手动数据提取或互联网研究,因为数据可以自动保存到文件或数据库中。
Diffbot 服务虽然价格偏高,但质量确实非常出色。
冬天
WINTR 也是一个强大的抓取工具。它是一种网页抓取和解析服务,其 API 允许公司和开发人员将任何网页转换为自定义数据集。提供数据采集、数据分析、请求代理、请求定制等多种服务。使用 WINTR 保存请求。如果您的目标网站 将来更改其结构,您将不需要修改您的应用程序代码。
这是一个全面的工具,可帮助您的网页抓取变得简单。您可以试用其免费版本,该版本提供 500 个 API 点。
Mozenda
Mozenda 是一个非常有用的数据提取工具,它避免了编写脚本或聘请开发人员的需要。它使中型软件和 IT 公司能够从任何来源自动提取网站 数据。此工具允许企业客户在其强大的云平台上运行网络抓取工具。
可以从 Excel、Word 和 PDF 等格式中提取数据。当Mozenda的“机器人”在页面上快速准确地抓取数据时,它得到结果的速度非常快。它也以多任务处理而闻名。 查看全部
最适合你的网页刮刀取决于你需要的几种工具
如今,市场上出现了各种网络抓取工具,当您必须选择其中一种工具时,您可能会感到困惑。最适合您的网页抓取工具取决于您的需求。这里有一些强烈推荐的网页抓取工具。其中一些是免费的,而有些则有试用期和高级计划。在做出决定之前,请仔细阅读以下所有信息。
ParseHub
ParseHub 是一款免费、可靠且功能强大的网页抓取工具。它用于使用 JS、AJAX、会话、cookie 和重定向来抓取单个和多个 网站。使用 Parsehub,您可以轻松地从任何网站 获取数据,因为您无需编写代码。您只需要打开目标网站 并开始单击要提取的数据。此工具可帮助您在服务器上自动采集和存储数据。其简单的 AIP 允许用户在任何地方集成他们提取的数据。
Parsehub 在爬取网站 时使用了大量代理,因此 IP 地址总是轮换。
八字解析
Octopus 是一种现代视觉网络爬虫软件。对于那些无需编码即可从网站 获取数据的人来说,这是一个完美的选择。多亏了“点击”界面,用户使用起来不会有任何困难。八达通模仿人类活动,例如浏览网站、登录账户等。它几乎可以从每个站点获取数据,即使它是使用 AJAX 或 JS 动态获取的。
免费版八达通允许用户提取几乎所有网站。只需点击几下鼠标,它就可以将网页变成结构化的电子表格。
Diffbot
Diffbot 是一种非常高效的数据提取工具,它使用互联网让个人和企业能够获取他们需要的任何信息。可广泛应用于市场营销、商业智能、销售和招聘等领域。它提供 API 来提取和理解对象,使用 Al 和计算机视觉从网站 中提取数据。使用 Diffbot,用户不再需要进行任何手动数据提取或互联网研究,因为数据可以自动保存到文件或数据库中。
Diffbot 服务虽然价格偏高,但质量确实非常出色。
冬天
WINTR 也是一个强大的抓取工具。它是一种网页抓取和解析服务,其 API 允许公司和开发人员将任何网页转换为自定义数据集。提供数据采集、数据分析、请求代理、请求定制等多种服务。使用 WINTR 保存请求。如果您的目标网站 将来更改其结构,您将不需要修改您的应用程序代码。
这是一个全面的工具,可帮助您的网页抓取变得简单。您可以试用其免费版本,该版本提供 500 个 API 点。
Mozenda
Mozenda 是一个非常有用的数据提取工具,它避免了编写脚本或聘请开发人员的需要。它使中型软件和 IT 公司能够从任何来源自动提取网站 数据。此工具允许企业客户在其强大的云平台上运行网络抓取工具。
可以从 Excel、Word 和 PDF 等格式中提取数据。当Mozenda的“机器人”在页面上快速准确地抓取数据时,它得到结果的速度非常快。它也以多任务处理而闻名。
不学Python也能快速海量海量内容|附下载地址
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-07-18 18:04
不知道你的朋友圈里是不是总能看到类似的广告,“Excel 用 Python 加班只需 3 分钟”,“我每天都能准时下班,因为我学了 Python”。看来,Python 已经成为了当代的年轻人。人的基本技能。
▲朋友圈广告
确实,Python作为一种简单易用的编程语言,在自动化办公中非常有用,尤其是抓取网页数据,在这样的大数据时代尤为重要。
爬取网页数据,又称“网络爬虫”,可以帮助我们快速采集互联网海量内容,进行深度数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等,而我们每天使用的搜索引擎都是“网络爬虫”。
但毕竟学习一门语言的成本太高了。有没有什么方法可以不学习Python就达到目标?当然,借助Chrome浏览器的“Web Scraper”插件,无需编写代码即可快速抓取大量内容。
优采云directory
以page-bilibili排名的多条信息为例
自动翻页抓取——以豆瓣电影Top250为例
抓取副页内容-以知乎热榜为例
抓取页面上的多条信息-以BiliBili排名为例
安装“Web Scraper”后,在浏览器中按F12进入开发者模式,可以在最后一个标签页看到“Web Scraper”菜单。需要注意的是,如果开发者模式面板不在底部,会提示必须放在浏览器下方才能继续。
在菜单中选择“新建站点地图-创建站点地图”,新建站点地图,填写名称和起始地址即可开始。这里以BiliBili排名为例介绍如何抓取页面上的多条信息,起始地址设置为“”。
这里我们需要抓取“视频标题”、“播放量”、“弹幕数”、“上位大师”和“综合评分”,所以首先要为每条记录创建一个包装器。
点击“Add new selector”,id填写“wrapper”,type选择“element”,然后点击“selector”,选择一条记录的外框,外包框需要收录以上所有信息,然后选择第二个这样,你会发现页面上的所有记录都被自动选中了,点击“完成选择”完成数据选择。记得勾选“Multiple”,确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一个记录突出显示。这是因为我们预先将其设置为包装器。在边框中选择标题,然后单击“完成选择”完成标题选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放音量”、“弹幕数”、“上位大师”和“综合得分”创建选择器。选中后,可以通过“数据查看”预览是否选中了想要的内容。此外,您还可以通过菜单栏中的“站点地图bilibili_ranking-Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“Scrape”,开始创建爬取任务。单个网页的间隔时间和响应时间是默认的。点击“开始抓取”开始抓取。这时候浏览器会自动打开一个新页面,几秒后自动关闭,表示已经获取完成。
点击“刷新数据”刷新数据,或点击“站点地图bilibili_ranking-浏览”查看数据。您可以通过“Sitemap bilibili_ranking-Export data as CSV”下载为CSV格式文件。
▲BiliBili 排名
用 Excel 打开。由于“Web Scraper”抓取的内容是乱序的,需要对“综合评分”进行降序排序,恢复原来的排名结果。
自动翻页抓取——以豆瓣电影Top250为例
Bilibili 排名只有 100 条记录,而且都在一个网页上。有分页显示怎么办?这里以豆瓣电影Top250为例介绍自动翻页抓取。
同理,新建站点地图时,在填写起始地址之前,先观察豆瓣电影Top250的构成。一共250条记录,每页显示10条,分为25页。
每一页的URL都很规则,第一页的地址是“”,第二页只是把地址中的“start=0”改成了“start=25”,所以我们填写start时地址,可以填写“[0-250:25]&filter=”,其中start=[0-250:25]表示以25为步长从0到250获取,所以start为0、2 5、 分别等待 50 次。这样,“Web Scraper”就会逐页抓取数据。
下一步类似于BiliBili排名。创建“包装器”后,添加“电影名称”、“豆瓣评分”、“电影短评”和“豆瓣排名”选择器,然后开始爬取。
可以看到浏览器会逐页翻页抓取。在这里你只需要静静等待爬行完成即可。最终得到的数据按照“豆瓣排名”升序排列,得到豆瓣电影。 Top250名单。
▲豆瓣电影Top250
当然,这只是最简单的一种分页方式,很多网站地址不一定有类似的规则。因此,“Web Scraper”的分页方法比较多,但是相对来说也比较复杂。此处不再赘述。
抓取副页内容-以知乎热榜为例
以上已经完成了对网页单页和多页内容的抓取,但并不是每次都在一页上有现成的数据,所以需要进一步搜索二级页面。以知乎热榜为例,介绍如何抓取二级页面的“关注”和“浏览”。
首先,创建一个起始地址为“”的新站点地图。然后像之前一样创建“wrapper”,然后创建三个选择器“文章title”、“文章热度”和“知乎ranked”。
下一个重要步骤是创建“二级页面”链接。点击“添加新选择器”,id填写“二级页面”,类型选择“链接”,然后点击“选择器”,选择文章的标题,即每个文章的入口,确认选择并保存并退出。
这相当于有了一个窗口,点击刚刚创建的“二级页面”进入下一级目录,然后创建“关注”和“浏览量”就像创建“文章title”一样前。选择器。最后,整个树结构如下图所示。
点击“站点地图知乎_hot-Scrape”开始爬取。在这里可以增加“页面加载延迟”的响应时间,以确保页面完全加载。这时候浏览器会依次打开各个二级页面进行抓取,需要稍等片刻。
爬取任务完成后,将结果下载为CSV文件,并按照“知乎ranking”的降序排列,得到知乎热榜的完整列表。
▲知乎热榜
至此,我已经介绍了如何使用“Web Scraper”抓取一个页面的多条信息,自动翻页,抓取二级页面的内容。显然,“Web Scraper”的功能远不止这些,还有更强大的抓图、正则表达式等功能,大家可以自行探索。
另外,如果你只是想简单的抓取信息,可以试试其他插件,比如“Simple scraper”和“Instant Data Scraper”。这些插件甚至可以一键抓取,但比起“Web Scraper”,它们的功能更加丰富,还缺少很多。
你不需要学习Python,也不需要花钱让别人帮你。您可以使用“Web Scraper”自行完成网页抓取。也许你会是下一个准时下班的人? 查看全部
不学Python也能快速海量海量内容|附下载地址
不知道你的朋友圈里是不是总能看到类似的广告,“Excel 用 Python 加班只需 3 分钟”,“我每天都能准时下班,因为我学了 Python”。看来,Python 已经成为了当代的年轻人。人的基本技能。
▲朋友圈广告
确实,Python作为一种简单易用的编程语言,在自动化办公中非常有用,尤其是抓取网页数据,在这样的大数据时代尤为重要。
爬取网页数据,又称“网络爬虫”,可以帮助我们快速采集互联网海量内容,进行深度数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等,而我们每天使用的搜索引擎都是“网络爬虫”。
但毕竟学习一门语言的成本太高了。有没有什么方法可以不学习Python就达到目标?当然,借助Chrome浏览器的“Web Scraper”插件,无需编写代码即可快速抓取大量内容。
优采云directory
以page-bilibili排名的多条信息为例
自动翻页抓取——以豆瓣电影Top250为例
抓取副页内容-以知乎热榜为例
抓取页面上的多条信息-以BiliBili排名为例
安装“Web Scraper”后,在浏览器中按F12进入开发者模式,可以在最后一个标签页看到“Web Scraper”菜单。需要注意的是,如果开发者模式面板不在底部,会提示必须放在浏览器下方才能继续。
在菜单中选择“新建站点地图-创建站点地图”,新建站点地图,填写名称和起始地址即可开始。这里以BiliBili排名为例介绍如何抓取页面上的多条信息,起始地址设置为“”。
这里我们需要抓取“视频标题”、“播放量”、“弹幕数”、“上位大师”和“综合评分”,所以首先要为每条记录创建一个包装器。
点击“Add new selector”,id填写“wrapper”,type选择“element”,然后点击“selector”,选择一条记录的外框,外包框需要收录以上所有信息,然后选择第二个这样,你会发现页面上的所有记录都被自动选中了,点击“完成选择”完成数据选择。记得勾选“Multiple”,确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一个记录突出显示。这是因为我们预先将其设置为包装器。在边框中选择标题,然后单击“完成选择”完成标题选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放音量”、“弹幕数”、“上位大师”和“综合得分”创建选择器。选中后,可以通过“数据查看”预览是否选中了想要的内容。此外,您还可以通过菜单栏中的“站点地图bilibili_ranking-Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“Scrape”,开始创建爬取任务。单个网页的间隔时间和响应时间是默认的。点击“开始抓取”开始抓取。这时候浏览器会自动打开一个新页面,几秒后自动关闭,表示已经获取完成。
点击“刷新数据”刷新数据,或点击“站点地图bilibili_ranking-浏览”查看数据。您可以通过“Sitemap bilibili_ranking-Export data as CSV”下载为CSV格式文件。
▲BiliBili 排名
用 Excel 打开。由于“Web Scraper”抓取的内容是乱序的,需要对“综合评分”进行降序排序,恢复原来的排名结果。
自动翻页抓取——以豆瓣电影Top250为例
Bilibili 排名只有 100 条记录,而且都在一个网页上。有分页显示怎么办?这里以豆瓣电影Top250为例介绍自动翻页抓取。
同理,新建站点地图时,在填写起始地址之前,先观察豆瓣电影Top250的构成。一共250条记录,每页显示10条,分为25页。
每一页的URL都很规则,第一页的地址是“”,第二页只是把地址中的“start=0”改成了“start=25”,所以我们填写start时地址,可以填写“[0-250:25]&filter=”,其中start=[0-250:25]表示以25为步长从0到250获取,所以start为0、2 5、 分别等待 50 次。这样,“Web Scraper”就会逐页抓取数据。
下一步类似于BiliBili排名。创建“包装器”后,添加“电影名称”、“豆瓣评分”、“电影短评”和“豆瓣排名”选择器,然后开始爬取。
可以看到浏览器会逐页翻页抓取。在这里你只需要静静等待爬行完成即可。最终得到的数据按照“豆瓣排名”升序排列,得到豆瓣电影。 Top250名单。
▲豆瓣电影Top250
当然,这只是最简单的一种分页方式,很多网站地址不一定有类似的规则。因此,“Web Scraper”的分页方法比较多,但是相对来说也比较复杂。此处不再赘述。
抓取副页内容-以知乎热榜为例
以上已经完成了对网页单页和多页内容的抓取,但并不是每次都在一页上有现成的数据,所以需要进一步搜索二级页面。以知乎热榜为例,介绍如何抓取二级页面的“关注”和“浏览”。
首先,创建一个起始地址为“”的新站点地图。然后像之前一样创建“wrapper”,然后创建三个选择器“文章title”、“文章热度”和“知乎ranked”。
下一个重要步骤是创建“二级页面”链接。点击“添加新选择器”,id填写“二级页面”,类型选择“链接”,然后点击“选择器”,选择文章的标题,即每个文章的入口,确认选择并保存并退出。
这相当于有了一个窗口,点击刚刚创建的“二级页面”进入下一级目录,然后创建“关注”和“浏览量”就像创建“文章title”一样前。选择器。最后,整个树结构如下图所示。
点击“站点地图知乎_hot-Scrape”开始爬取。在这里可以增加“页面加载延迟”的响应时间,以确保页面完全加载。这时候浏览器会依次打开各个二级页面进行抓取,需要稍等片刻。
爬取任务完成后,将结果下载为CSV文件,并按照“知乎ranking”的降序排列,得到知乎热榜的完整列表。
▲知乎热榜
至此,我已经介绍了如何使用“Web Scraper”抓取一个页面的多条信息,自动翻页,抓取二级页面的内容。显然,“Web Scraper”的功能远不止这些,还有更强大的抓图、正则表达式等功能,大家可以自行探索。
另外,如果你只是想简单的抓取信息,可以试试其他插件,比如“Simple scraper”和“Instant Data Scraper”。这些插件甚至可以一键抓取,但比起“Web Scraper”,它们的功能更加丰富,还缺少很多。
你不需要学习Python,也不需要花钱让别人帮你。您可以使用“Web Scraper”自行完成网页抓取。也许你会是下一个准时下班的人?
你可以用它来做什么:软件介绍网页信息批量提取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-18 02:32
KK网页信息批量采集导出工具是一个简单但不简单的全能采集工具,可以批量获取和导出多个网页的信息。该软件轻巧简单。页面信息采集,3个简单的功能,可以实现强大、复杂、繁琐的批量信息采集和网页操作。
软件介绍
网页信息批量提取工具,由于您自己的工作需要,管理后台订单和产品列表不支持导出。总结的时候,一一复制粘贴到excel中,难免很复杂。可以在 1 分钟内完成的工作必须手动完成。数小时内重复这些机械化动作。所以为了解决这些问题,2017年发布了第一个版本,让有相同需求的同学能够更高效的处理问题。
支持截取网页上的部分信息并导出,也支持从截取信息片段列表中匹配多条信息。
更好:
1、 请求通过 post 获取数据
2、自定义网页头协议头,伪装任意浏览器访问
3、还可以设置爬取间隔,防止采集快速被其他网站server拦截
4、将采集的结果导出到excel或txt
它不仅有采集信息的功能,如果你有自己的网站,还可以帮你把电脑上的这些信息或excel中的信息发布到你的网站。
你可以用它做什么:
1、采集网页中的多条信息(标题/网址/时间等),导出
2、batch采集多个网页信息,导出
3、 批量访问打开的页面。比如有的站长需要批量提交收录给百度,一个一个打开比较麻烦。
如何使用
进阶进阶文章(写给站长,一般人不需要看懂,阅读让一个简单的软件变得更复杂):
那么,怎么用呢,来采集一条网站的帖子发到我的网站上
只需几步:
1、写文章Page 抓取文章title 和内容规则,写下来。
2、使用“小工具”中的序列URL生成工具生成一系列列表URL。例如:list/1.html、list/2.html、list/3.html、...、list/999.html,从别人@k14的列表页可以看到多少页@, 生成多个列表网址,页面数量多。
3、在匹配列表页写入并获取所有文章规则:即从列表页中取出所有文章链接,进行匹配,然后导出
4、然后输出第3步导出的文章 URL作为采集目标,输出到URL框。然后填写步骤1中的规则,这些页面的文章title和链接信息采集就可以自动发布了。
这里,目前网站某列文章的所有标题和链接都被采集接收并导出为excel,那么如何将这个excel发布到我的网站?
5、在excel中手动将cell合成为post提交的信息格式。如:title=kkno1&content=com
6、Submit URL 填写文章publishing后端的post接收URL,在软件中填写协议头的cookie信息(模拟网站Administrator登录后端),然后填写步骤5发帖参数 生成发帖提交格式,然后点击批处理,软件可以自动批量发帖模式,将此类信息一一提交到帖子接收页面,实现自动发布功能。
从采集到发布的完整过程。看起来步骤很多,但实际上只匹配了3个。 查看全部
你可以用它来做什么:软件介绍网页信息批量提取工具
KK网页信息批量采集导出工具是一个简单但不简单的全能采集工具,可以批量获取和导出多个网页的信息。该软件轻巧简单。页面信息采集,3个简单的功能,可以实现强大、复杂、繁琐的批量信息采集和网页操作。
软件介绍
网页信息批量提取工具,由于您自己的工作需要,管理后台订单和产品列表不支持导出。总结的时候,一一复制粘贴到excel中,难免很复杂。可以在 1 分钟内完成的工作必须手动完成。数小时内重复这些机械化动作。所以为了解决这些问题,2017年发布了第一个版本,让有相同需求的同学能够更高效的处理问题。
支持截取网页上的部分信息并导出,也支持从截取信息片段列表中匹配多条信息。
更好:
1、 请求通过 post 获取数据
2、自定义网页头协议头,伪装任意浏览器访问
3、还可以设置爬取间隔,防止采集快速被其他网站server拦截
4、将采集的结果导出到excel或txt
它不仅有采集信息的功能,如果你有自己的网站,还可以帮你把电脑上的这些信息或excel中的信息发布到你的网站。
你可以用它做什么:
1、采集网页中的多条信息(标题/网址/时间等),导出
2、batch采集多个网页信息,导出
3、 批量访问打开的页面。比如有的站长需要批量提交收录给百度,一个一个打开比较麻烦。
如何使用
进阶进阶文章(写给站长,一般人不需要看懂,阅读让一个简单的软件变得更复杂):
那么,怎么用呢,来采集一条网站的帖子发到我的网站上
只需几步:
1、写文章Page 抓取文章title 和内容规则,写下来。
2、使用“小工具”中的序列URL生成工具生成一系列列表URL。例如:list/1.html、list/2.html、list/3.html、...、list/999.html,从别人@k14的列表页可以看到多少页@, 生成多个列表网址,页面数量多。
3、在匹配列表页写入并获取所有文章规则:即从列表页中取出所有文章链接,进行匹配,然后导出
4、然后输出第3步导出的文章 URL作为采集目标,输出到URL框。然后填写步骤1中的规则,这些页面的文章title和链接信息采集就可以自动发布了。
这里,目前网站某列文章的所有标题和链接都被采集接收并导出为excel,那么如何将这个excel发布到我的网站?
5、在excel中手动将cell合成为post提交的信息格式。如:title=kkno1&content=com
6、Submit URL 填写文章publishing后端的post接收URL,在软件中填写协议头的cookie信息(模拟网站Administrator登录后端),然后填写步骤5发帖参数 生成发帖提交格式,然后点击批处理,软件可以自动批量发帖模式,将此类信息一一提交到帖子接收页面,实现自动发布功能。
从采集到发布的完整过程。看起来步骤很多,但实际上只匹配了3个。
网站数据采集工具.docx
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-07-15 06:33
文档介绍:优采云·云采集服务平台uationWarning:ThedocumentwascreatedwithSpire..网站data capture tool 近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也出现了快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。 1、优采云优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。需要数据。它采集data分为两步,一是采集data,二是发布数据。这两个过程可以分开。 采集Data:这包括采集 URL 和采集 内容。这个过程就是获取数据的过程。用户制定规则,内容在采集过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。 优采云采集器采用分布式采集系统。这样提高了采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量网址,也可以生成。对于不会编程的新手用户,可以直接使用别人制定的规则,高手可以定制开发,也可以分享规则。
2、优采云优采云是优采云之后出现的采集器,可以从不同的网站获取标准化的数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。简单来说,优采云可以通过简单的配置规则,从任何网页准确抓取数据,生成自定义的、规则的数据格式。国内首创的真正可视化规则、简单上手、完全可视化图形操作的国内定制采集器; 采集任务自动运行,可按指定周期自动采集;规则市场有大量免费规则,用户可直接使用;支持验证码识别,自定义不同浏览器标识,有效防止IP被封。 优采云可以说是小白用户的福音(简单好用,好找,可视化界面,易学易模仿),有更好的地方就用积分。用1000积分完善信息,每天签到30积分,在线制定规则或购买规则,剩下的足以获得初始采集,如果您不充值一些积分,您可以在需求,导出excel,数据库都行。 3、优采云云攀虫 新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网页数据。操作步骤:购买规则-设置关键词-启动任务-自动云采集-自动发布不同于传统的采集器,优采云云爬虫不需要配置采集进程。 优采云云攀虫的规则市场提供了大量免费的采集模板,只需设置关键词即可。
爬虫任务全程在云端执行,无需开机。 采集结果可以自动发布到多个网站(目前支持wecenter、wordpree、discuz等)。开发者可自行编写采集规则出售或使用。有了详细的开发人员文档,他们就可以创建自己的爬虫。相关采集tutorial:网易彩票数据采集orial/hottutorial/jrzx/wycaipiao同花顺爬虫orial/hottutorial/jrzx/tonghuashun金融世界基金爬虫orial/hottutorial/jrzx/ji 查看全部
网站数据采集工具.docx
文档介绍:优采云·云采集服务平台uationWarning:ThedocumentwascreatedwithSpire..网站data capture tool 近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也出现了快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。 1、优采云优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。需要数据。它采集data分为两步,一是采集data,二是发布数据。这两个过程可以分开。 采集Data:这包括采集 URL 和采集 内容。这个过程就是获取数据的过程。用户制定规则,内容在采集过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。 优采云采集器采用分布式采集系统。这样提高了采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量网址,也可以生成。对于不会编程的新手用户,可以直接使用别人制定的规则,高手可以定制开发,也可以分享规则。
2、优采云优采云是优采云之后出现的采集器,可以从不同的网站获取标准化的数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。简单来说,优采云可以通过简单的配置规则,从任何网页准确抓取数据,生成自定义的、规则的数据格式。国内首创的真正可视化规则、简单上手、完全可视化图形操作的国内定制采集器; 采集任务自动运行,可按指定周期自动采集;规则市场有大量免费规则,用户可直接使用;支持验证码识别,自定义不同浏览器标识,有效防止IP被封。 优采云可以说是小白用户的福音(简单好用,好找,可视化界面,易学易模仿),有更好的地方就用积分。用1000积分完善信息,每天签到30积分,在线制定规则或购买规则,剩下的足以获得初始采集,如果您不充值一些积分,您可以在需求,导出excel,数据库都行。 3、优采云云攀虫 新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网页数据。操作步骤:购买规则-设置关键词-启动任务-自动云采集-自动发布不同于传统的采集器,优采云云爬虫不需要配置采集进程。 优采云云攀虫的规则市场提供了大量免费的采集模板,只需设置关键词即可。
爬虫任务全程在云端执行,无需开机。 采集结果可以自动发布到多个网站(目前支持wecenter、wordpree、discuz等)。开发者可自行编写采集规则出售或使用。有了详细的开发人员文档,他们就可以创建自己的爬虫。相关采集tutorial:网易彩票数据采集orial/hottutorial/jrzx/wycaipiao同花顺爬虫orial/hottutorial/jrzx/tonghuashun金融世界基金爬虫orial/hottutorial/jrzx/ji
软件特色SysNucleusWebHarvy可以让您分析网页上的数据模式
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-14 05:00
SysNucleus WebHarvy 是一款网页数据采集软件。使用本软件,您可以直接在网页上选择需要选择的资源,也可以直接将整个网页保存为HTML格式,从而提取网页内容中的所有文字和图标,复制网址时,软件默认使用内部浏览器组件打开,可以显示完整的网页,然后就可以开始配合数据采集的规则了; SysNucleus WebHarvy 支持扩展分析,可以自动获取相似链接列表,复制一个地址搜索多个网页内容!
软件功能
WebHarvy 是一个可视化的网页抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
软件功能
SysNucleus WebHarvy 允许您分析网页上的数据
可以显示和分析来自 HTML 地址的连接数据
可以扩展到下一个网页
可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
支持浏览器复制链接搜索
支持配置对应的资源项搜索
可以使用项目名称和资源名称查找
SysNucleus WebHarvy 可以轻松提取数据
提供更高级的多词搜索和多页搜索
安装方法
1、 首先需要从河东下载WebHarvySetup.exe,下载后直接点击安装
2、显示软件安装的许可条件,勾选我接受许可协议中的条款
3、提示软件安装路径C:Userspc0359AppDataRoamingSysNucleusWebHarvy
4、显示安装的主要说明,点击安装将软件安装到电脑上
5、提示SysNucleus WebHarvy安装结束,可以立即启动
如何破解
1、启动软件,提示并解锁,即需要添加官方license文件才能使用
2、解压下载的“Crck.rar”文件,复制并替换里面的补丁WebHarvy.exe。
3、如图,它提醒你正在从Crck复制1个项目到Webharvy,只需点击替换即可。
4、如图,提示SysNucleus WebHarvy软件已经授权给SMR
5、 导航到需要提取数据的网页。您可以使用内置浏览器加载和浏览网页
6、要捕获文本的一部分,请选择它并突出显示它。在选择下面的选项之前,确定所需的部分。
7、只要输入你分析的网页地址,最上面的网址就是地址输入栏
8、输入地址,可以直接在网页上打开
9、选择配置功能,可以点击第一个Start Config开始配置计划下载网页数据
更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
软件特色SysNucleusWebHarvy可以让您分析网页上的数据模式
SysNucleus WebHarvy 是一款网页数据采集软件。使用本软件,您可以直接在网页上选择需要选择的资源,也可以直接将整个网页保存为HTML格式,从而提取网页内容中的所有文字和图标,复制网址时,软件默认使用内部浏览器组件打开,可以显示完整的网页,然后就可以开始配合数据采集的规则了; SysNucleus WebHarvy 支持扩展分析,可以自动获取相似链接列表,复制一个地址搜索多个网页内容!
软件功能
WebHarvy 是一个可视化的网页抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
软件功能
SysNucleus WebHarvy 允许您分析网页上的数据
可以显示和分析来自 HTML 地址的连接数据
可以扩展到下一个网页
可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
支持浏览器复制链接搜索
支持配置对应的资源项搜索
可以使用项目名称和资源名称查找
SysNucleus WebHarvy 可以轻松提取数据
提供更高级的多词搜索和多页搜索
安装方法
1、 首先需要从河东下载WebHarvySetup.exe,下载后直接点击安装
2、显示软件安装的许可条件,勾选我接受许可协议中的条款
3、提示软件安装路径C:Userspc0359AppDataRoamingSysNucleusWebHarvy
4、显示安装的主要说明,点击安装将软件安装到电脑上
5、提示SysNucleus WebHarvy安装结束,可以立即启动
如何破解
1、启动软件,提示并解锁,即需要添加官方license文件才能使用
2、解压下载的“Crck.rar”文件,复制并替换里面的补丁WebHarvy.exe。
3、如图,它提醒你正在从Crck复制1个项目到Webharvy,只需点击替换即可。
4、如图,提示SysNucleus WebHarvy软件已经授权给SMR
5、 导航到需要提取数据的网页。您可以使用内置浏览器加载和浏览网页
6、要捕获文本的一部分,请选择它并突出显示它。在选择下面的选项之前,确定所需的部分。
7、只要输入你分析的网页地址,最上面的网址就是地址输入栏
8、输入地址,可以直接在网页上打开
9、选择配置功能,可以点击第一个Start Config开始配置计划下载网页数据
更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
git部署到远程服务器,扩展性能会更好!
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-07-11 05:01
我无事可做。我刚刚学会了将 git 部署到远程服务器,我无所事事。所以我干脆做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是,JAVA1.8在使用String拼接字符串时会自动拼接你想要拼接的内容。字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持脚本之家! 查看全部
git部署到远程服务器,扩展性能会更好!
我无事可做。我刚刚学会了将 git 部署到远程服务器,我无所事事。所以我干脆做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是,JAVA1.8在使用String拼接字符串时会自动拼接你想要拼接的内容。字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持脚本之家!
外贸网站挖掘工具10s提取100客户网站-谷歌搜索提取工具3.0版本
网站优化 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2021-07-10 22:17
下图中的工具之前已经给大家介绍过了。这是我做的谷歌搜索提取工具2.0版本。
2.0 版本主要是帮你在谷歌搜索引擎上直接提取网站和标题信息。可以参考我之前的文章《25h打造外贸网站挖矿工具,10s提取100个客户网站!》,看详细介绍!
今天主要给大家介绍一下我前两天刚拿到的谷歌搜索提取工具3.0的新修订版。与之前的版本相比,新增了谷歌地图提取功能,可以帮助您直接提取谷歌地图。对于公司信息,很多老牌外贸公司可能都熟悉谷歌地图。在谷歌地图上输入关键词,可以搜索到周边所有的精准买家,是外贸客户发展的常用渠道。
我们只要通过关键词搜索公司信息页面,就可以直接点击开始爬取按钮开发爬取信息。操作相当简单,不用担心,会自动翻页,直到搜索完成。
另外3.0版本与2.0版本相比,谷歌搜索引擎抓取也进行了调整,不再像之前那样直接输入关键词进行抓取,需要手动转到第二页。这一次,整个真实网页直接转入工具,搜索和翻页也完全自动化。完全模拟人工操作,降低验证码弹窗的概率,即使验证码弹出,我们也可以手动填写!
最后给大家介绍几个主要的功能按钮:
1、
上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。关于这一点我不需要多说。点击后你就明白了!
2、
不翻页搜索是本次更新的一大特色。如果你电脑上的fq工具失败了,你可以尝试检查一下,切换到更流畅的线条。这样,您也可以使用此工具。去谷歌取资料(毕竟大家有空,肯定会慢!)
3、
红框中选中的4个按钮当然不用我过多解释了,字面意思。全部导出就是将搜索到的数据以excel格式导出到本地电脑。
4、
如果你上传这个选项,我们一般默认不勾选。如果你没有使用F墙工具,而是使用F墙路由器访问外网,不妨勾选这个选项试试。 (切记不要随意检查,否则无法加载googe页面)
其他的就不解释了,自己下载体验吧!这些工具是为了个人兴趣和爱好,免费分享给大家。您不必担心是否充电。只要对你有帮助,我一定会持续优化更新更多功能给你!
下载链接:
某些计算机下载和安装可能会弹出风险警告。您只需单击“允许”即可放心使用。没必要为你什么年龄生产病毒!
同理,有什么bug或者好的建议都可以在评论区写! 查看全部
外贸网站挖掘工具10s提取100客户网站-谷歌搜索提取工具3.0版本
下图中的工具之前已经给大家介绍过了。这是我做的谷歌搜索提取工具2.0版本。
2.0 版本主要是帮你在谷歌搜索引擎上直接提取网站和标题信息。可以参考我之前的文章《25h打造外贸网站挖矿工具,10s提取100个客户网站!》,看详细介绍!
今天主要给大家介绍一下我前两天刚拿到的谷歌搜索提取工具3.0的新修订版。与之前的版本相比,新增了谷歌地图提取功能,可以帮助您直接提取谷歌地图。对于公司信息,很多老牌外贸公司可能都熟悉谷歌地图。在谷歌地图上输入关键词,可以搜索到周边所有的精准买家,是外贸客户发展的常用渠道。
我们只要通过关键词搜索公司信息页面,就可以直接点击开始爬取按钮开发爬取信息。操作相当简单,不用担心,会自动翻页,直到搜索完成。
另外3.0版本与2.0版本相比,谷歌搜索引擎抓取也进行了调整,不再像之前那样直接输入关键词进行抓取,需要手动转到第二页。这一次,整个真实网页直接转入工具,搜索和翻页也完全自动化。完全模拟人工操作,降低验证码弹窗的概率,即使验证码弹出,我们也可以手动填写!
最后给大家介绍几个主要的功能按钮:
1、
上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。关于这一点我不需要多说。点击后你就明白了!
2、
不翻页搜索是本次更新的一大特色。如果你电脑上的fq工具失败了,你可以尝试检查一下,切换到更流畅的线条。这样,您也可以使用此工具。去谷歌取资料(毕竟大家有空,肯定会慢!)
3、
红框中选中的4个按钮当然不用我过多解释了,字面意思。全部导出就是将搜索到的数据以excel格式导出到本地电脑。
4、
如果你上传这个选项,我们一般默认不勾选。如果你没有使用F墙工具,而是使用F墙路由器访问外网,不妨勾选这个选项试试。 (切记不要随意检查,否则无法加载googe页面)
其他的就不解释了,自己下载体验吧!这些工具是为了个人兴趣和爱好,免费分享给大家。您不必担心是否充电。只要对你有帮助,我一定会持续优化更新更多功能给你!
下载链接:
某些计算机下载和安装可能会弹出风险警告。您只需单击“允许”即可放心使用。没必要为你什么年龄生产病毒!
同理,有什么bug或者好的建议都可以在评论区写!
maczmac软件激活教程forMac下载完成后,双击.pkg
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-07-10 21:05
WebScraper for Mac 是专为 Mac 系统设计的网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper还可以提取动态加载或者使用JavaScript生成的数据等,使用webscraper mac 破解版可以快速提取特定网页的相关信息,包括文本内容。 macz share webscraper mac破解版下载。
WebScraper mac 软件激活教程
下载WebScraper for Mac后,双击.pkg文件,按照提示默认安装
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络打造
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。
Webscraper mac 破解版更新日志
版本4.14.5: 查看全部
maczmac软件激活教程forMac下载完成后,双击.pkg
WebScraper for Mac 是专为 Mac 系统设计的网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper还可以提取动态加载或者使用JavaScript生成的数据等,使用webscraper mac 破解版可以快速提取特定网页的相关信息,包括文本内容。 macz share webscraper mac破解版下载。
WebScraper mac 软件激活教程
下载WebScraper for Mac后,双击.pkg文件,按照提示默认安装
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络打造
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。
Webscraper mac 破解版更新日志
版本4.14.5:
搜索游戏中的小玩家也可以编号爬行数十亿的页面.In2006(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-07-10 18:08
如果您想要的数据是最新的,则不会。
即使是游戏中的一个小玩家也可以爬行数十亿页。
“在 2006 年,Google 索引了超过 250 亿个网页,[32] 每天 4 亿次查询,[32] 1.30 亿张图片,以及超过 10 亿条 Usenet 消息。”– 维基百科
记得引用 2006 年的数字。这是古老的历史。最先进的技术比这更好。
内容新鲜度:
>新内容不断增加(逼真)
>现有网页经常发生变化——需要重新爬取的原因有两个:a)判断是否已死,b)判断内容是否发生变化。
爬行者的礼貌:
>你不能压倒任何给定的网站。如果您重复点击同一IP的任何主要站点,您可以触发CAPTCHA提示,否则您的IP地址将被阻止。 网站 将根据带宽频率、“坏”页面请求的数量以及其他各种事情来请求。
>有robots.txt协议,网站暴露给爬虫并遵守。
>有一个网站map标准,网站暴露给爬虫,用它帮你探索——你也可以(如果你选择)权重页面在网站上的相对重要性,并使用时间存在于缓存中,如果它在网站Map 中。
减少你需要做的工作:
通常,网站 通过多个名字暴露自己——你需要检测同一个页面——这可能发生在同一个网址或不同的网址上。考虑页面内容的散列(减去标题,日期/时间不断变化)。跟踪这些页面等效项并在下次跳过或确定给定站点之间是否存在众所周知的映射,以便您不必进行爬网。
>那里有很多垃圾邮件,只能通过谷歌的网页,但他们“播种”了自己的网站,以便自己爬行。
所以——你总是处于爬行周期中。总是。几乎肯定会有几台(许多)机器。确保您可以遵循礼貌,但仍然保持数据的新鲜度。
如果你想按下快进按钮,你只需要用你自己独特的算法处理页面。如果您需要快速搜索,您可以利用预先构建的爬虫,如图所示。他们使用客户端计算能力。
80 条腿正在使用网站 上孩子们玩游戏的机器周期。想想网页上的一个后台进程,确实是调用了,用page/网站的时候是不行的,因为他们用的是Plura技术栈。
“Plura Processing 为分布式计算开发了一种新的创新技术。我们正在申请专利的技术可以嵌入到任何网页中。这些网页的访问者成为节点,并为在我们的分布式计算网络上运行的应用程序执行非常小的计算。 ”– Plura 演示页面
所以他们通过上千个IP的上千个节点发布“爬虫”,对网站客气,爬得快。现在我个人不知道我关心最终用户浏览器的风格,除非它们在所有使用技术的网站上都显示得很清楚——但如果没有别的,这是一种开箱即用的方法.
社区驱动的项目中还有其他爬虫,你也可以使用。
正如其他受访者所指出的那样——做数学。您需要每秒抓取大约 2300 个页面才能每 5 天抓取 1B 个页面。如果您愿意等待更长时间,那么这个数字将会下降。如果你认为你必须赶上超过 1B 的数字,它就会上升。简单的数学
祝你好运! 查看全部
搜索游戏中的小玩家也可以编号爬行数十亿的页面.In2006(组图)
如果您想要的数据是最新的,则不会。
即使是游戏中的一个小玩家也可以爬行数十亿页。
“在 2006 年,Google 索引了超过 250 亿个网页,[32] 每天 4 亿次查询,[32] 1.30 亿张图片,以及超过 10 亿条 Usenet 消息。”– 维基百科
记得引用 2006 年的数字。这是古老的历史。最先进的技术比这更好。
内容新鲜度:
>新内容不断增加(逼真)
>现有网页经常发生变化——需要重新爬取的原因有两个:a)判断是否已死,b)判断内容是否发生变化。
爬行者的礼貌:
>你不能压倒任何给定的网站。如果您重复点击同一IP的任何主要站点,您可以触发CAPTCHA提示,否则您的IP地址将被阻止。 网站 将根据带宽频率、“坏”页面请求的数量以及其他各种事情来请求。
>有robots.txt协议,网站暴露给爬虫并遵守。
>有一个网站map标准,网站暴露给爬虫,用它帮你探索——你也可以(如果你选择)权重页面在网站上的相对重要性,并使用时间存在于缓存中,如果它在网站Map 中。
减少你需要做的工作:
通常,网站 通过多个名字暴露自己——你需要检测同一个页面——这可能发生在同一个网址或不同的网址上。考虑页面内容的散列(减去标题,日期/时间不断变化)。跟踪这些页面等效项并在下次跳过或确定给定站点之间是否存在众所周知的映射,以便您不必进行爬网。
>那里有很多垃圾邮件,只能通过谷歌的网页,但他们“播种”了自己的网站,以便自己爬行。
所以——你总是处于爬行周期中。总是。几乎肯定会有几台(许多)机器。确保您可以遵循礼貌,但仍然保持数据的新鲜度。
如果你想按下快进按钮,你只需要用你自己独特的算法处理页面。如果您需要快速搜索,您可以利用预先构建的爬虫,如图所示。他们使用客户端计算能力。
80 条腿正在使用网站 上孩子们玩游戏的机器周期。想想网页上的一个后台进程,确实是调用了,用page/网站的时候是不行的,因为他们用的是Plura技术栈。
“Plura Processing 为分布式计算开发了一种新的创新技术。我们正在申请专利的技术可以嵌入到任何网页中。这些网页的访问者成为节点,并为在我们的分布式计算网络上运行的应用程序执行非常小的计算。 ”– Plura 演示页面
所以他们通过上千个IP的上千个节点发布“爬虫”,对网站客气,爬得快。现在我个人不知道我关心最终用户浏览器的风格,除非它们在所有使用技术的网站上都显示得很清楚——但如果没有别的,这是一种开箱即用的方法.
社区驱动的项目中还有其他爬虫,你也可以使用。
正如其他受访者所指出的那样——做数学。您需要每秒抓取大约 2300 个页面才能每 5 天抓取 1B 个页面。如果您愿意等待更长时间,那么这个数字将会下降。如果你认为你必须赶上超过 1B 的数字,它就会上升。简单的数学
祝你好运!
WebScraping工具9个网络收集工具,你值得拥有!
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-10 18:06
Web Scraping 工具专门用于从网站 中提取信息。它们也称为网络采集工具或网络数据提取工具。
文章directory[]
Web Scraping 工具可以在各种场景中用于无限用途。
例如:
1.采集市场调研数据
网页抓取工具可以从多个数据分析提供商处获取信息,并将它们整合到一个位置,以便于参考和分析。可以帮助您了解公司或行业未来六个月的发展方向。
2.提取联系方式
这些工具还可用于从各种网站 中提取电子邮件和电话号码等数据。
3. 采集数据下载离线阅读或存储
4.track 多个市场的价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储以方便访问。例如,爬虫可用于从亚马逊采集有关产品及其价格的信息。在这个文章中,我们列出了9个网页抓取工具。
1.Import.io
Import.io 提供了一个构建器,可以通过从特定网页导入数据并将数据导出为 CSV 来形成您自己的数据集。您无需编写任何代码即可在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。
2.Webhose.io
Webhose.io 通过抓取数千个在线资源提供对实时和结构化数据的直接访问。网络爬虫支持提取超过240种语言的网络数据,并以多种格式保存输出数据,包括XML、JSON和RSS。
3. Dexi.io(原名 CloudScrape)
CloudScrape 支持从任何网站 采集数据,无需像 Webhose 那样下载。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集到的数据保存在 Google Drive 等云平台上,也可以将其导出为 CSV 或 JSON。
4.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可帮助数以千计的开发者获取有价值的数据。 Scrapinghub 使用智能代理微调器 Crawlera,支持绕过机器人反制,轻松抓取大型或受机器人保护的网站。
5. ParseHub
ParseHub 用于抓取单个和多个网站,支持 JavaScript、AJAX、会话、cookie 和重定向。该应用程序使用机器学习技术来识别 Web 上最复杂的文档,并根据所需的数据格式生成输出文件。
6.VisualScraper
VisualScraper 是另一种网络数据提取软件,可用于从网络采集信息。该软件可以帮助您从多个网页中提取数据并实时获取结果。此外,还可以导出CSV、XML、JSON、SQL等多种格式。
7. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 提要中获取全部数据。 Spinn3r 与 firehouse API 一起分发并管理 95% 的索引工作。提供先进的垃圾邮件防护,可消除垃圾邮件和不当语言使用,从而提高数据安全性。
8. 80legs
80legs 是一款功能强大且灵活的网页抓取工具,可根据您的需要进行配置。它支持获取大量数据并立即下载提取数据的选项。 80legs 声称能够抓取超过 600,000 个域,并被 MailChimp 和 PayPal 等大型玩家使用。
9.Scraper
Scraper 是一个 Chrome 扩展,其数据提取功能有限,但它有助于进行在线研究并将数据导出到 Google 电子表格。此工具适合初学者和专家,他们可以使用 OAuth 轻松将数据复制到剪贴板或存储到电子表格。 查看全部
WebScraping工具9个网络收集工具,你值得拥有!
Web Scraping 工具专门用于从网站 中提取信息。它们也称为网络采集工具或网络数据提取工具。
文章directory[]
Web Scraping 工具可以在各种场景中用于无限用途。
例如:
1.采集市场调研数据
网页抓取工具可以从多个数据分析提供商处获取信息,并将它们整合到一个位置,以便于参考和分析。可以帮助您了解公司或行业未来六个月的发展方向。
2.提取联系方式
这些工具还可用于从各种网站 中提取电子邮件和电话号码等数据。
3. 采集数据下载离线阅读或存储
4.track 多个市场的价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储以方便访问。例如,爬虫可用于从亚马逊采集有关产品及其价格的信息。在这个文章中,我们列出了9个网页抓取工具。
1.Import.io
Import.io 提供了一个构建器,可以通过从特定网页导入数据并将数据导出为 CSV 来形成您自己的数据集。您无需编写任何代码即可在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。
2.Webhose.io
Webhose.io 通过抓取数千个在线资源提供对实时和结构化数据的直接访问。网络爬虫支持提取超过240种语言的网络数据,并以多种格式保存输出数据,包括XML、JSON和RSS。
3. Dexi.io(原名 CloudScrape)
CloudScrape 支持从任何网站 采集数据,无需像 Webhose 那样下载。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集到的数据保存在 Google Drive 等云平台上,也可以将其导出为 CSV 或 JSON。
4.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可帮助数以千计的开发者获取有价值的数据。 Scrapinghub 使用智能代理微调器 Crawlera,支持绕过机器人反制,轻松抓取大型或受机器人保护的网站。
5. ParseHub
ParseHub 用于抓取单个和多个网站,支持 JavaScript、AJAX、会话、cookie 和重定向。该应用程序使用机器学习技术来识别 Web 上最复杂的文档,并根据所需的数据格式生成输出文件。
6.VisualScraper
VisualScraper 是另一种网络数据提取软件,可用于从网络采集信息。该软件可以帮助您从多个网页中提取数据并实时获取结果。此外,还可以导出CSV、XML、JSON、SQL等多种格式。
7. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 提要中获取全部数据。 Spinn3r 与 firehouse API 一起分发并管理 95% 的索引工作。提供先进的垃圾邮件防护,可消除垃圾邮件和不当语言使用,从而提高数据安全性。
8. 80legs
80legs 是一款功能强大且灵活的网页抓取工具,可根据您的需要进行配置。它支持获取大量数据并立即下载提取数据的选项。 80legs 声称能够抓取超过 600,000 个域,并被 MailChimp 和 PayPal 等大型玩家使用。
9.Scraper
Scraper 是一个 Chrome 扩展,其数据提取功能有限,但它有助于进行在线研究并将数据导出到 Google 电子表格。此工具适合初学者和专家,他们可以使用 OAuth 轻松将数据复制到剪贴板或存储到电子表格。
缩略图采不下来怎么办?优采云采集器最新版本V9
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-07-09 20:15
教你使用网络爬虫工具下载图片。现在内容里有图片的网页已经很常见了,所以图片的采集也很重要,但是一张一张的点击下载很麻烦,所以我们在爬网的时候也要学会抓图。当我采集内容时,我通常会同时下载图片和缩略图采集。这个很好用,但是一开始图片总是采集不全,缩略图也拍不出来。现在我将我的经验分享给大家。一起进步吧~我用的是最新版的优采云采集器V9的网络爬虫工具,因为功能比较齐全,速度也很快。在优采云采集器中设置好URL的采集规则后,输入采集规则写入的内容,这里大家要注意,edit标签的数据处理中有一个文件下载选项,有四 有两个选项,其中之一是下载图片。你一眼就能明白这一点。勾选就可以下载图片,但是如果只做这个,只能采集到部分图片,因为优采云采集器这里默认是下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。这种情况下优采云采集器会自动检测到这种图片文件并下载。 采集当你分别为不同类型的图片设置了“标签”和“下载选项”时,测试一下,这个页面的5张图片已经被优采云采集器下载了,你觉得很简单吗?像优采云采集器这样的网页抓取工具就是这样的。将来学习如何使用它非常容易。用得好,确实可以解决很多问题,可以大大提高我们的工作效率。这也是人类的智慧。它在哪里? 查看全部
缩略图采不下来怎么办?优采云采集器最新版本V9
教你使用网络爬虫工具下载图片。现在内容里有图片的网页已经很常见了,所以图片的采集也很重要,但是一张一张的点击下载很麻烦,所以我们在爬网的时候也要学会抓图。当我采集内容时,我通常会同时下载图片和缩略图采集。这个很好用,但是一开始图片总是采集不全,缩略图也拍不出来。现在我将我的经验分享给大家。一起进步吧~我用的是最新版的优采云采集器V9的网络爬虫工具,因为功能比较齐全,速度也很快。在优采云采集器中设置好URL的采集规则后,输入采集规则写入的内容,这里大家要注意,edit标签的数据处理中有一个文件下载选项,有四 有两个选项,其中之一是下载图片。你一眼就能明白这一点。勾选就可以下载图片,但是如果只做这个,只能采集到部分图片,因为优采云采集器这里默认是下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。这种情况下优采云采集器会自动检测到这种图片文件并下载。 采集当你分别为不同类型的图片设置了“标签”和“下载选项”时,测试一下,这个页面的5张图片已经被优采云采集器下载了,你觉得很简单吗?像优采云采集器这样的网页抓取工具就是这样的。将来学习如何使用它非常容易。用得好,确实可以解决很多问题,可以大大提高我们的工作效率。这也是人类的智慧。它在哪里?
WebScrapermac软件激活教程-WebScraperMac软件功能介绍(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-07-08 05:02
WebScraper Mac 是 Mac os 系统上非常有用的网站data 提取工具。 WebScraper 可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL 即可开始。简单而强大。
WebScraper mac 软件激活教程
! ! !本软件15系统暂时无法破解! !请谨慎下载! ! !
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:
2、返回安装包,双击打开WebScraper注册机,如图:
3、点击WebScraper注册机左侧的Open,如图:
4、在应用中找到WebScraper,点击打开,如图:
5、点击保存生成注册码!
6、Open WebScraper,显示已注册!
您不是VIP会员或积分不够,请升级VIP会员或充值观看教程。
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上一个简单的应用,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络构建
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。
编辑评论
如果您正在寻找一款好用的网站数据采集工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以到本站下载! 查看全部
WebScrapermac软件激活教程-WebScraperMac软件功能介绍(组图)
WebScraper Mac 是 Mac os 系统上非常有用的网站data 提取工具。 WebScraper 可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL 即可开始。简单而强大。
WebScraper mac 软件激活教程
! ! !本软件15系统暂时无法破解! !请谨慎下载! ! !
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:
2、返回安装包,双击打开WebScraper注册机,如图:
3、点击WebScraper注册机左侧的Open,如图:
4、在应用中找到WebScraper,点击打开,如图:
5、点击保存生成注册码!
6、Open WebScraper,显示已注册!
您不是VIP会员或积分不够,请升级VIP会员或充值观看教程。
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上一个简单的应用,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络构建
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。
编辑评论
如果您正在寻找一款好用的网站数据采集工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以到本站下载!
百度"抓取诊断"工具具体有什么作用以及需要改进的地方
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-08 04:43
自从百度站长平台上的“抓诊断”工具上线以来,很多站长朋友都用这个工具来吸引蜘蛛,但笔者亲自测试发现,“抓诊断”有很多种工具。因此,我们不应过分依赖它,而应有选择地应用。下面我们来谈谈百度“爬虫诊断”工具的具体功能和需要改进的地方。
先来看看百度官方的解释:
一、什么是爬虫?
1)Grabbing 诊断工具可以让站长从百度蜘蛛的角度查看抓取到的内容,自我诊断百度蜘蛛看到的内容是否与预期一致。
2)每个站点一个月可以使用300次,抓取结果只显示百度蜘蛛可见的前200KB内容。
二、爬虫诊断工具能做什么?
1) 诊断爬取的内容是否符合预期。比如很多商品详情页,价格信息是通过JavaScript输出的,对百度蜘蛛不友好,价格信息很难应用于搜索。问题解决后,可使用诊断工具再次检查。
2)诊断网页是否添加了黑色链接和隐藏文字。如果网站 被黑,可能会添加隐藏链接。这些链接可能只有在百度抓取的时候才会出现,需要使用这个爬虫来诊断。
3)检查网站与百度的连接是否顺畅。如果IP信息不一致,可以报错并通知百度更新IP。
4)如果网站有新页面或者页面内容更新了,百度蜘蛛很久没有访问过,可以通过这个工具邀请它快速抓取。
我测试过了,有的网站可以爬取成功。如下图所示,里面收录了很多信息,也可以很好的展示网页的源代码,可以为站长提供一些帮助。
但是,对于双线主机和使用别名解析的非固定IP主机,总是会出现爬网失败或爬网现象,偶尔也能爬网成功,如图:
这是否意味着百度百度蜘蛛无法抓取我们的网页?答案是不。笔者刚刚测试的网站爬不成功,当天发送的文章全部秒收,证明百度蜘蛛可以很好的爬取网页,但是单机“爬诊断”工具开启出差。 ,这说明这个技术还不成熟,只能参考,不能过分依赖。
还有一点需要注意的是,在抓取同一个页面后,百度会缓存很长时间,如下图所示。作者在早上11:09抓了一个页面,在页面上挂了一条“黑链”。 “爬虫”抓到的源码中收录了这些“黑链”代码,但是作者把这些“黑链”拿走了之后,晚上19:13再次抓取,发现页面我获取的仍然是我在早上 11:09 获取的页面,相隔 8 小时。
此外,爬虫在确定网站IP 地址时经常会出错。一旦IP地址确定错误,抓取就会失败。但这并不意味着蜘蛛不能访问我们的网站。其实蜘蛛就是蜘蛛,爬虫是一种工具。不要混淆它们。
当然,新推出的任何工具都存在这样和那样的问题。我们只需要选择对我们有利的地方去申请,而不是过分依赖所有的功能。同时也希望度娘能尽快改进,解决所有问题,给广大站长朋友一个有用的工具。 查看全部
百度"抓取诊断"工具具体有什么作用以及需要改进的地方
自从百度站长平台上的“抓诊断”工具上线以来,很多站长朋友都用这个工具来吸引蜘蛛,但笔者亲自测试发现,“抓诊断”有很多种工具。因此,我们不应过分依赖它,而应有选择地应用。下面我们来谈谈百度“爬虫诊断”工具的具体功能和需要改进的地方。
先来看看百度官方的解释:
一、什么是爬虫?
1)Grabbing 诊断工具可以让站长从百度蜘蛛的角度查看抓取到的内容,自我诊断百度蜘蛛看到的内容是否与预期一致。
2)每个站点一个月可以使用300次,抓取结果只显示百度蜘蛛可见的前200KB内容。
二、爬虫诊断工具能做什么?
1) 诊断爬取的内容是否符合预期。比如很多商品详情页,价格信息是通过JavaScript输出的,对百度蜘蛛不友好,价格信息很难应用于搜索。问题解决后,可使用诊断工具再次检查。
2)诊断网页是否添加了黑色链接和隐藏文字。如果网站 被黑,可能会添加隐藏链接。这些链接可能只有在百度抓取的时候才会出现,需要使用这个爬虫来诊断。
3)检查网站与百度的连接是否顺畅。如果IP信息不一致,可以报错并通知百度更新IP。
4)如果网站有新页面或者页面内容更新了,百度蜘蛛很久没有访问过,可以通过这个工具邀请它快速抓取。
我测试过了,有的网站可以爬取成功。如下图所示,里面收录了很多信息,也可以很好的展示网页的源代码,可以为站长提供一些帮助。
但是,对于双线主机和使用别名解析的非固定IP主机,总是会出现爬网失败或爬网现象,偶尔也能爬网成功,如图:
这是否意味着百度百度蜘蛛无法抓取我们的网页?答案是不。笔者刚刚测试的网站爬不成功,当天发送的文章全部秒收,证明百度蜘蛛可以很好的爬取网页,但是单机“爬诊断”工具开启出差。 ,这说明这个技术还不成熟,只能参考,不能过分依赖。
还有一点需要注意的是,在抓取同一个页面后,百度会缓存很长时间,如下图所示。作者在早上11:09抓了一个页面,在页面上挂了一条“黑链”。 “爬虫”抓到的源码中收录了这些“黑链”代码,但是作者把这些“黑链”拿走了之后,晚上19:13再次抓取,发现页面我获取的仍然是我在早上 11:09 获取的页面,相隔 8 小时。
此外,爬虫在确定网站IP 地址时经常会出错。一旦IP地址确定错误,抓取就会失败。但这并不意味着蜘蛛不能访问我们的网站。其实蜘蛛就是蜘蛛,爬虫是一种工具。不要混淆它们。
当然,新推出的任何工具都存在这样和那样的问题。我们只需要选择对我们有利的地方去申请,而不是过分依赖所有的功能。同时也希望度娘能尽快改进,解决所有问题,给广大站长朋友一个有用的工具。
如何使用pyppeteer抓取网页的数据(一)_百度搜索数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-07-07 18:17
今天,我们将介绍如何使用pyppeteer来获取网页数据。 Pyppeteer是一个Web应用自动化测试工具,可以直接在浏览器中运行,通过代码控制与页面元素进行交互,获取相应信息。
过去,我们通过编写代码来爬取数据。当待爬取的网站需要登录时,我们需要在代码中模拟登录;当抓取速度过快需要验证时,我们需要在代码中登录实现ip中的验证逻辑;当ip被阻塞时,你还需要有自己的动态ip库。我们爬取网站的反爬策略越多,我们爬取的成本就越大。总之,通过编写代码爬取数据需要构造更复杂的请求,并千方百计将爬虫伪装成真实用户。
使用pyppeteer之类的工具可以很大程度上解决以上问题。同时还有一个好处就是所见即所得,无需研究网页复杂的请求结构。当然,这类工具也有其优点和缺点。它增加了理解网页上各种元素和交互的成本。所以我觉得这类工具最适合用在短小、扁平、爬行速度快的场景。比如我在最近的工作中就遇到过两次这种情况。我想抓取一些特别简单的数据来提高工作效率,但我不想研究网页如何构建请求。您可以使用此 WYSIWYG 工具。快速抓取您想要的数据。
我们以“抓取百度搜索数据”为例,介绍一下pyppeteer的使用。在正式介绍之前,先来看看爬取效果:
安装pyppeteer
python3 -m pip install pyppeteer
安装完成后,执行pyppeteer-install命令安装最新版本的Chromium浏览器。根据官方文档,安装pyppeteer需要Python3.6或更高版本。
因为pyppeteer是基于asyncio实现的,所以我们在代码中也会使用async/await来写代码。没写过的朋友别着急。基本不会影响pyppeteer的使用。如有必要,我们将使用 async/await 来编写代码。写一篇文章的介绍。
首先用pyppeteer启动chrome进程
from pyppeteer import launch
# headless 显示浏览器
# --window-size 设置窗体大小
browser = await launch({'headless': False,
'args': ['--window-size=%d,%d' % (width, height)]
})
然后,打开一个新标签并访问百度
# 打开新页面
page = await browser.newPage()
# 设置内容显示大小
await page.setViewport({"width": width, "height": height})
# 访问百度
await page.goto('https://www.baidu.com')
打开百度网站后,下一步就是在搜索输入框中输入内容,首先找到输入框的html标签
从上图可以看出,代码代表搜索输入框,标签的类是s_ipt,然后我们会通过type函数找到标签,输入要搜索的内容。
# 将对应的 selector 填入 python,通过.s_ipt找到输入框html标签
await page.type('.s_ipt', 'python')
这里我们搜索的是python。输入后,您可以点击“百度”按钮开始搜索。查找按钮的方法同上
可以看到代码代表“百度点击”的按钮。标签的 id 是 su。现在调用点击函数找到标签,然后点击
# 通过#su找到“百度一下”按钮html标签
await page.click('#su')
需要注意的是su的前面是#而不是.,因为它在html标签中是用id而不是class来表示的。它涉及到html选择器的内容。如果你不知道,你可以简单地添加它。
执行上述代码后,可以看到搜索结果,调用截图方法保存当前页面
await page.screenshot({'path': 'example.png'})
效果如下:
接下来,我们将获取网页的内容并解析每个结果
# 获取网页内容
content = await page.content()
# 解析
output_search_result(content)
通过BeatifulSoup分析每个结果的标题和链接
def output_search_result(html):
search_bs = BeautifulSoup(html, 'lxml')
all_result = search_bs.find_all("div", {'class': "result c-container"})
for single_res in all_result:
title_bs = single_res.find("a")
title_url = title_bs.get('href')
title_txt = title_bs.get_text()
print(title_txt, title_url)
输出内容如下
python官方网站 - Welcome to Python.org http://www.baidu.com/link%3Fur ... x-q1D
Python 基础教程 | 菜鸟教程 http://www.baidu.com/link%3Fur ... SY3V_
Python3 * 和 ** 运算符_python_极客点儿-CSDN博客 http://www.baidu.com/link%3Fur ... gQuFy
Python教程 - 廖雪峰的官方网站 http://www.baidu.com/link%3Fur ... l9YDX
Python3 教程 | 菜鸟教程 http://www.baidu.com/link%3Fur ... 35m3q
你都用 Python 来做什么? - 知乎 http://www.baidu.com/link%3Fur ... MJrsK
Python基础教程,Python入门教程(非常详细) http://www.baidu.com/link%3Fur ... QZQie
这样,我们爬取数据的目的就达到了。当然,我们可以继续扩展,更多地使用pyppeteer。比如我们可以点击下一页,抓取下一页的内容。
# next page
# 为了点击“下一页”,需要将当前页面滑到底部
dimensions = await page.evaluate('window.scrollTo(0, window.innerHeight)')
# 点击“下一页”按钮
await page.click('.n')
# 获取第二页的内容
content = await page.content()
# 解析
output_search_result(content)
操作与上一个类似,注释更清晰,这里不再赘述。最后,您可以调用 await browser.close() 代码关闭浏览器。上面的代码可以定义在一个异步函数中,比如:
async def main():
# ... 抓取代码
然后传递以下代码
asyncio.get_event_loop().run_until_complete(main())
调用主函数。
这里介绍pyppeteer的用法。有很多类似的工具,比如Selenium。我也试过了。实际上,按照 Internet 上的说明对其进行配置需要一些努力。有兴趣的可以自行尝试。希望今天的内容对你有用。关注公众号回复关键词爬虫获取完整源码
欢迎关注公众号“穿越码”,输出别处看不到的干货。
查看全部
如何使用pyppeteer抓取网页的数据(一)_百度搜索数据
今天,我们将介绍如何使用pyppeteer来获取网页数据。 Pyppeteer是一个Web应用自动化测试工具,可以直接在浏览器中运行,通过代码控制与页面元素进行交互,获取相应信息。
过去,我们通过编写代码来爬取数据。当待爬取的网站需要登录时,我们需要在代码中模拟登录;当抓取速度过快需要验证时,我们需要在代码中登录实现ip中的验证逻辑;当ip被阻塞时,你还需要有自己的动态ip库。我们爬取网站的反爬策略越多,我们爬取的成本就越大。总之,通过编写代码爬取数据需要构造更复杂的请求,并千方百计将爬虫伪装成真实用户。
使用pyppeteer之类的工具可以很大程度上解决以上问题。同时还有一个好处就是所见即所得,无需研究网页复杂的请求结构。当然,这类工具也有其优点和缺点。它增加了理解网页上各种元素和交互的成本。所以我觉得这类工具最适合用在短小、扁平、爬行速度快的场景。比如我在最近的工作中就遇到过两次这种情况。我想抓取一些特别简单的数据来提高工作效率,但我不想研究网页如何构建请求。您可以使用此 WYSIWYG 工具。快速抓取您想要的数据。
我们以“抓取百度搜索数据”为例,介绍一下pyppeteer的使用。在正式介绍之前,先来看看爬取效果:
安装pyppeteer
python3 -m pip install pyppeteer
安装完成后,执行pyppeteer-install命令安装最新版本的Chromium浏览器。根据官方文档,安装pyppeteer需要Python3.6或更高版本。
因为pyppeteer是基于asyncio实现的,所以我们在代码中也会使用async/await来写代码。没写过的朋友别着急。基本不会影响pyppeteer的使用。如有必要,我们将使用 async/await 来编写代码。写一篇文章的介绍。
首先用pyppeteer启动chrome进程
from pyppeteer import launch
# headless 显示浏览器
# --window-size 设置窗体大小
browser = await launch({'headless': False,
'args': ['--window-size=%d,%d' % (width, height)]
})
然后,打开一个新标签并访问百度
# 打开新页面
page = await browser.newPage()
# 设置内容显示大小
await page.setViewport({"width": width, "height": height})
# 访问百度
await page.goto('https://www.baidu.com')
打开百度网站后,下一步就是在搜索输入框中输入内容,首先找到输入框的html标签
从上图可以看出,代码代表搜索输入框,标签的类是s_ipt,然后我们会通过type函数找到标签,输入要搜索的内容。
# 将对应的 selector 填入 python,通过.s_ipt找到输入框html标签
await page.type('.s_ipt', 'python')
这里我们搜索的是python。输入后,您可以点击“百度”按钮开始搜索。查找按钮的方法同上
可以看到代码代表“百度点击”的按钮。标签的 id 是 su。现在调用点击函数找到标签,然后点击
# 通过#su找到“百度一下”按钮html标签
await page.click('#su')
需要注意的是su的前面是#而不是.,因为它在html标签中是用id而不是class来表示的。它涉及到html选择器的内容。如果你不知道,你可以简单地添加它。
执行上述代码后,可以看到搜索结果,调用截图方法保存当前页面
await page.screenshot({'path': 'example.png'})
效果如下:
接下来,我们将获取网页的内容并解析每个结果
# 获取网页内容
content = await page.content()
# 解析
output_search_result(content)
通过BeatifulSoup分析每个结果的标题和链接
def output_search_result(html):
search_bs = BeautifulSoup(html, 'lxml')
all_result = search_bs.find_all("div", {'class': "result c-container"})
for single_res in all_result:
title_bs = single_res.find("a")
title_url = title_bs.get('href')
title_txt = title_bs.get_text()
print(title_txt, title_url)
输出内容如下
python官方网站 - Welcome to Python.org http://www.baidu.com/link%3Fur ... x-q1D
Python 基础教程 | 菜鸟教程 http://www.baidu.com/link%3Fur ... SY3V_
Python3 * 和 ** 运算符_python_极客点儿-CSDN博客 http://www.baidu.com/link%3Fur ... gQuFy
Python教程 - 廖雪峰的官方网站 http://www.baidu.com/link%3Fur ... l9YDX
Python3 教程 | 菜鸟教程 http://www.baidu.com/link%3Fur ... 35m3q
你都用 Python 来做什么? - 知乎 http://www.baidu.com/link%3Fur ... MJrsK
Python基础教程,Python入门教程(非常详细) http://www.baidu.com/link%3Fur ... QZQie
这样,我们爬取数据的目的就达到了。当然,我们可以继续扩展,更多地使用pyppeteer。比如我们可以点击下一页,抓取下一页的内容。
# next page
# 为了点击“下一页”,需要将当前页面滑到底部
dimensions = await page.evaluate('window.scrollTo(0, window.innerHeight)')
# 点击“下一页”按钮
await page.click('.n')
# 获取第二页的内容
content = await page.content()
# 解析
output_search_result(content)
操作与上一个类似,注释更清晰,这里不再赘述。最后,您可以调用 await browser.close() 代码关闭浏览器。上面的代码可以定义在一个异步函数中,比如:
async def main():
# ... 抓取代码
然后传递以下代码
asyncio.get_event_loop().run_until_complete(main())
调用主函数。
这里介绍pyppeteer的用法。有很多类似的工具,比如Selenium。我也试过了。实际上,按照 Internet 上的说明对其进行配置需要一些努力。有兴趣的可以自行尝试。希望今天的内容对你有用。关注公众号回复关键词爬虫获取完整源码
欢迎关注公众号“穿越码”,输出别处看不到的干货。
什么是抓取、收录网页抓取工具.txt文件介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-07-06 05:10
网站建好,请问如何获取收录网站搜索引擎?如果页面无法被搜索引擎收录搜索到,则说明该页面尚未展示,无法竞争排名获取SEO流量。本文将围绕爬虫和收录亮点,从基本原理、常见问题和解决方案三个维度探讨搜索引擎优化。什么是爬虫,收录web爬虫robots.txt文件介绍
如何查看网站的收录情况
设置网页不被搜索引擎索引
搜索引擎的原理:搜索引擎将互联网上的网页内容存储在自己的服务器上。当用户搜索一个词时,搜索引擎会在自己的服务器上找到相关内容,即只搜索保存在搜索引擎服务器上的网页。
哪些网页可以保存在搜索引擎的服务器上?
只有搜索引擎爬虫抓取到的网页才会保存在搜索引擎的服务器上。这个网页的爬虫是搜索引擎的蜘蛛。整个过程分为爬行和爬行。
一、什么在爬,收录
爬行:
这是搜索引擎爬虫爬取网站的过程。谷歌官方的解释是——“爬行”是指寻找新的或更新的网页并将其添加到谷歌的过程; (点此查看谷歌官网文档)
收录(索引):
是搜索引擎在其数据库中存储页面的结果,也称为索引。谷歌官方的解释是:谷歌的爬虫(“Googlebot”)已经访问了该页面,分析了其内容和含义,并将其存储在谷歌索引中。索引的网页可以显示在谷歌搜索结果中; (点此查看谷歌官网文档)
抓取预算:
是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间上限。一般小的网站(几百或几千页)不用担心,搜索引擎分配的爬取配额不够;大网站(百万或千万页)会更多地考虑这个问题。如果搜索引擎每天爬取几万个页面,整个网站页面爬取可能需要几个月甚至一年的时间。通常,这些数据可以从 Google Search Console 的后端学习。如下图所示,红框内的平均值为网站分配的爬取配额。
通过一个例子让大家更好的理解爬取、收录和爬取配额:
搜索引擎比作一个巨大的图书馆,网站比作书店,书店里的书比作网站页面,蜘蛛爬虫比作图书馆买家。
为了丰富图书馆的藏书量,购书者会定期到书店查看是否有新书存货。翻书的过程可以理解为抓取;
当买家认为这本书有价值时,他会购买并带回图书馆采集。这本书合集就是我们所说的收录;
每个买家的购书预算有限,他会优先购买价值高的书籍。这个预算就是我们理解的抢配额。
二、网络爬虫
“爬虫”是一个通用术语,指的是任何程序(例如机器人或“蜘蛛”程序)通过从一个网页到另一个网页的链接来自动发现和扫描网站。 Google 的主要抓取工具称为 Googlebot。
三、robots.txt 文件介绍
robots.txt 文件指定了爬虫的爬取规则。
robots.txt 文件必须位于主机的顶级目录中。
一般情况下,robots.txt文件中会出现三种不同的爬取结果:
Robots.txt 使用示例:网站目录下的所有文件都可以被所有搜索引擎蜘蛛访问 User-agent:*
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
网站 一些文件应该限制被蜘蛛抓取:
一般网站中不需要蜘蛛爬取的文件包括:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片、背景图片、等
robots.txt 文件带来的风险及其解决方法:
robots.txt 也带来了一定的风险:它还向攻击者指出了网站 目录结构和私有数据的位置。设置访问权限和密码保护您的私人内容,使攻击者无法进入。
四、如何查看网站的收录情况
①通过站点命令。
谷歌、百度、必应等主流搜索引擎均支持站点命令。通过站点命令,您可以在宏观层面查看网站 已经收录 的页面数量。这个值不准确,有一定的波动性,但有一定的参考价值。如下图所示,Google收录为网站提供的网页数量约为165个。
②如果网站已经验证了Google Search Console,这样就可以得到网站被Google收录的精确值,如下图红框所示,Google收录了网站的216页;
③如果要查询特定页面是否为收录,可以使用info命令。谷歌支持 info 命令,但百度和必应不支持。在谷歌中输入信息:URL。如果返回结果,页面已经是收录,如下图:
五、 设置网页不被搜索引擎索引
推荐使用robots meta标签,在head标签中添加如下代码:
可以使用多个指令,这些指令不区分大小写。
全部
对索引或内容显示没有限制。该命令为默认值,所以显式列出时无效。
无索引
不要在搜索结果中显示此页面。 nofollow 不遵循此页面上的链接。
无
与 noindex、nofollow 相同。 noarchive 不会在搜索结果中显示缓存的链接。
没有片段
不要在搜索结果中显示网页的文本摘要或视频预览。如果静态图像缩略图(如果有)能够提供更好的用户体验,则它们可能仍会显示。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现)。
最大片段:[数量]
您最多只能使用 [number] 个字符作为此搜索结果的文本摘要。 (请注意,该 URL 可能会在搜索结果页面上显示为多个搜索结果。)这不会影响图像或视频预览。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现、Google 助理)。但是,如果发布者单独授予了内容使用权,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容或与 Google 签订了许可协议,则此设置不会阻止这些更具体的许可用途。如果没有指定resolvable [number],该命令将被忽略。
特殊价值:
示例:
最大图像预览:[设置]
设置该网页在搜索结果中预览图片的最大尺寸。
接受的设置值:
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现、Google 助理)。但是,如果发布者单独授予了内容使用权,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容(例如 AMP 页面和文章 的规范版本),或者与 Google 签订了许可协议,则此设置不会阻止这些更具体的允许用途。
如果发布商不希望 Google 在搜索结果页面或“探索”功能中显示其 AMP 页面和 文章 的规范版本时使用更大的缩略图,则应指定 max-image-preview 的值标准或无。
示例:
最大视频预览:[数量]
此页面上视频的视频摘要在搜索结果中不得超过 [number] 秒。
其他支持的值:
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 视频、Google 发现、Google 助理)。如果没有指定resolvable [number],该命令将被忽略。
示例:
不翻译
不要在搜索结果中提供网页的翻译。
无图像索引
此页面上的图片将不会被编入索引。
unavailable_after:[日期/时间]
在指定的日期/时间之后,网页将不会显示在搜索结果中。日期/时间必须以广泛使用的格式指定,包括但不限于RFC 822、RFC 850 和ISO 8601。如果未指定有效的[日期/时间],则该命令将被忽略。默认情况下,内容没有过期日期。
示例:
参考资料: 查看全部
什么是抓取、收录网页抓取工具.txt文件介绍
网站建好,请问如何获取收录网站搜索引擎?如果页面无法被搜索引擎收录搜索到,则说明该页面尚未展示,无法竞争排名获取SEO流量。本文将围绕爬虫和收录亮点,从基本原理、常见问题和解决方案三个维度探讨搜索引擎优化。什么是爬虫,收录web爬虫robots.txt文件介绍
如何查看网站的收录情况
设置网页不被搜索引擎索引
搜索引擎的原理:搜索引擎将互联网上的网页内容存储在自己的服务器上。当用户搜索一个词时,搜索引擎会在自己的服务器上找到相关内容,即只搜索保存在搜索引擎服务器上的网页。
哪些网页可以保存在搜索引擎的服务器上?
只有搜索引擎爬虫抓取到的网页才会保存在搜索引擎的服务器上。这个网页的爬虫是搜索引擎的蜘蛛。整个过程分为爬行和爬行。
一、什么在爬,收录
爬行:
这是搜索引擎爬虫爬取网站的过程。谷歌官方的解释是——“爬行”是指寻找新的或更新的网页并将其添加到谷歌的过程; (点此查看谷歌官网文档)
收录(索引):
是搜索引擎在其数据库中存储页面的结果,也称为索引。谷歌官方的解释是:谷歌的爬虫(“Googlebot”)已经访问了该页面,分析了其内容和含义,并将其存储在谷歌索引中。索引的网页可以显示在谷歌搜索结果中; (点此查看谷歌官网文档)
抓取预算:
是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间上限。一般小的网站(几百或几千页)不用担心,搜索引擎分配的爬取配额不够;大网站(百万或千万页)会更多地考虑这个问题。如果搜索引擎每天爬取几万个页面,整个网站页面爬取可能需要几个月甚至一年的时间。通常,这些数据可以从 Google Search Console 的后端学习。如下图所示,红框内的平均值为网站分配的爬取配额。
通过一个例子让大家更好的理解爬取、收录和爬取配额:
搜索引擎比作一个巨大的图书馆,网站比作书店,书店里的书比作网站页面,蜘蛛爬虫比作图书馆买家。
为了丰富图书馆的藏书量,购书者会定期到书店查看是否有新书存货。翻书的过程可以理解为抓取;
当买家认为这本书有价值时,他会购买并带回图书馆采集。这本书合集就是我们所说的收录;
每个买家的购书预算有限,他会优先购买价值高的书籍。这个预算就是我们理解的抢配额。
二、网络爬虫
“爬虫”是一个通用术语,指的是任何程序(例如机器人或“蜘蛛”程序)通过从一个网页到另一个网页的链接来自动发现和扫描网站。 Google 的主要抓取工具称为 Googlebot。
三、robots.txt 文件介绍
robots.txt 文件指定了爬虫的爬取规则。
robots.txt 文件必须位于主机的顶级目录中。
一般情况下,robots.txt文件中会出现三种不同的爬取结果:
Robots.txt 使用示例:网站目录下的所有文件都可以被所有搜索引擎蜘蛛访问 User-agent:*
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
网站 一些文件应该限制被蜘蛛抓取:
一般网站中不需要蜘蛛爬取的文件包括:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片、背景图片、等
robots.txt 文件带来的风险及其解决方法:
robots.txt 也带来了一定的风险:它还向攻击者指出了网站 目录结构和私有数据的位置。设置访问权限和密码保护您的私人内容,使攻击者无法进入。
四、如何查看网站的收录情况
①通过站点命令。
谷歌、百度、必应等主流搜索引擎均支持站点命令。通过站点命令,您可以在宏观层面查看网站 已经收录 的页面数量。这个值不准确,有一定的波动性,但有一定的参考价值。如下图所示,Google收录为网站提供的网页数量约为165个。
②如果网站已经验证了Google Search Console,这样就可以得到网站被Google收录的精确值,如下图红框所示,Google收录了网站的216页;
③如果要查询特定页面是否为收录,可以使用info命令。谷歌支持 info 命令,但百度和必应不支持。在谷歌中输入信息:URL。如果返回结果,页面已经是收录,如下图:
五、 设置网页不被搜索引擎索引
推荐使用robots meta标签,在head标签中添加如下代码:
可以使用多个指令,这些指令不区分大小写。
全部
对索引或内容显示没有限制。该命令为默认值,所以显式列出时无效。
无索引
不要在搜索结果中显示此页面。 nofollow 不遵循此页面上的链接。
无
与 noindex、nofollow 相同。 noarchive 不会在搜索结果中显示缓存的链接。
没有片段
不要在搜索结果中显示网页的文本摘要或视频预览。如果静态图像缩略图(如果有)能够提供更好的用户体验,则它们可能仍会显示。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现)。
最大片段:[数量]
您最多只能使用 [number] 个字符作为此搜索结果的文本摘要。 (请注意,该 URL 可能会在搜索结果页面上显示为多个搜索结果。)这不会影响图像或视频预览。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现、Google 助理)。但是,如果发布者单独授予了内容使用权,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容或与 Google 签订了许可协议,则此设置不会阻止这些更具体的许可用途。如果没有指定resolvable [number],该命令将被忽略。
特殊价值:
示例:
最大图像预览:[设置]
设置该网页在搜索结果中预览图片的最大尺寸。
接受的设置值:
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 发现、Google 助理)。但是,如果发布者单独授予了内容使用权,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容(例如 AMP 页面和文章 的规范版本),或者与 Google 签订了许可协议,则此设置不会阻止这些更具体的允许用途。
如果发布商不希望 Google 在搜索结果页面或“探索”功能中显示其 AMP 页面和 文章 的规范版本时使用更大的缩略图,则应指定 max-image-preview 的值标准或无。
示例:
最大视频预览:[数量]
此页面上视频的视频摘要在搜索结果中不得超过 [number] 秒。
其他支持的值:
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 视频、Google 发现、Google 助理)。如果没有指定resolvable [number],该命令将被忽略。
示例:
不翻译
不要在搜索结果中提供网页的翻译。
无图像索引
此页面上的图片将不会被编入索引。
unavailable_after:[日期/时间]
在指定的日期/时间之后,网页将不会显示在搜索结果中。日期/时间必须以广泛使用的格式指定,包括但不限于RFC 822、RFC 850 和ISO 8601。如果未指定有效的[日期/时间],则该命令将被忽略。默认情况下,内容没有过期日期。
示例:
参考资料:
如何用阿里云免费邮箱服务提供的网站内容抓取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-30 07:01
网站内容抓取工具,一般有行情抓取、博客、源码、网站等,你说的这几种做行情抓取比较多一些,网站抓取一般都是要付费的,如果你不缺钱的话,其实也无所谓。
可以用阿里云免费邮箱服务提供的sofatmail邮箱服务,或者的emaildigitalspot邮箱账号提供的免费邮箱服务。
需要的话提供个网站!
yandex-ford你真逗,
免费空间只能提供免费源码服务,所以,免费空间提供的抓取程序质量不高,想要高质量的(像python爬虫+beautifulsoup+pymysql+requests+bs4),需要付费,1000元/年python爬虫+beautifulsoup+pymysql+requests+bs4爬虫性能如何?点击浏览器右上角response?用er分析器,python里有,爬虫性能=多重循环重复下载+数据处理+正则表达式+采样+特征匹配+迭代器+缓存,如果不包含正则表达式,那么请去cookies=分析器里面读取response,读取了之后再缓存起来。 查看全部
如何用阿里云免费邮箱服务提供的网站内容抓取工具
网站内容抓取工具,一般有行情抓取、博客、源码、网站等,你说的这几种做行情抓取比较多一些,网站抓取一般都是要付费的,如果你不缺钱的话,其实也无所谓。
可以用阿里云免费邮箱服务提供的sofatmail邮箱服务,或者的emaildigitalspot邮箱账号提供的免费邮箱服务。
需要的话提供个网站!
yandex-ford你真逗,
免费空间只能提供免费源码服务,所以,免费空间提供的抓取程序质量不高,想要高质量的(像python爬虫+beautifulsoup+pymysql+requests+bs4),需要付费,1000元/年python爬虫+beautifulsoup+pymysql+requests+bs4爬虫性能如何?点击浏览器右上角response?用er分析器,python里有,爬虫性能=多重循环重复下载+数据处理+正则表达式+采样+特征匹配+迭代器+缓存,如果不包含正则表达式,那么请去cookies=分析器里面读取response,读取了之后再缓存起来。
博客园首页代码:线建立一个MVC空项目(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-06-29 19:13
\\s*.*)\”\\s*target=\”_blank\”>(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为控制器添加一个视图索引
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/")))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/"));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
部分索引视图代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
@HttpUtility.HtmlDecode(b)@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
如博客所写,可以运行一个完整的MVC项目,但是我只采集一页,我们也可以在博客园首页采集下翻页部分(即pager_buttom)采集
p>
,只需要添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html中一一采集提取所需的相应信息。另外,我们不应该将采集添加到每个新闻条目对应的页面的源代码中,而每个新闻条目对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要花费大量时间。佩服采集的效率,在数据库中存放大量新闻页面文件会占用大量内存,影响数据库性能。
转载于: 查看全部
博客园首页代码:线建立一个MVC空项目(图)
\\s*.*)\”\\s*target=\”_blank\”>(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为控制器添加一个视图索引
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/";)))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/";));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
部分索引视图代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
@HttpUtility.HtmlDecode(b)@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
如博客所写,可以运行一个完整的MVC项目,但是我只采集一页,我们也可以在博客园首页采集下翻页部分(即pager_buttom)采集
p>
,只需要添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html中一一采集提取所需的相应信息。另外,我们不应该将采集添加到每个新闻条目对应的页面的源代码中,而每个新闻条目对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要花费大量时间。佩服采集的效率,在数据库中存放大量新闻页面文件会占用大量内存,影响数据库性能。
转载于:
如何在没有界面显示的情况下抓取HTTP的请求包
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-06-29 19:09
简介
在前两篇文章中文章讲了如何抓HTTP请求包,包括代理服务器的使用和抓包方法。只是因为当前视频网站的视频地址不是在html页面直接获取的,所以视频是通过浏览器动态解释js脚本,然后向视频服务器发送视频请求来获取的。所以我们通过获取浏览器产生的HTTP请求来获取视频的下载地址。
直接使用 firefox 获取创意
我们想到了可以动态渲染js脚本的程序,最常见的就是浏览器。我们通过命令运行
firefox http://the.video.url
您可以使用 Firefox 打开 URL。但是我们不能不显示就这样使用,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为需要渲染没有界面显示的JS脚本,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是一个无头浏览器(Headless Browser 是一个没有界面的浏览器)。
但是Phantomjs1.5版本之后,不再支持flash插件。也就是说,Phantomjs 虽然可以动态加载 JS 脚本,但无法渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到渲染后的页面,如下图:
视频播放窗口是黑色的,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版本的Phantomjs,网上说用这个命令可以加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图得到如下图:
虽然得到的截图和上图不同,但是视频中多了一个loading状态,但是我还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
WebDriverException: Message: Can not connect to the Service phantomjs
最后不得不放弃使用 Phantomjs
slimerjs
我在网上搜索headless browser的时候,也发现了slimerjs。
PhantomJS 和 SlimerJS 的异同:来自文章
PhantomJS 基于 Webkit 内核,不支持 Flash 播放。 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程会有页面显示
正好我们需要支持Flash播放。但是问题又来了! SlimerJS 不是纯粹的 Headless 浏览器,它需要 DISPLAY! ! 那么我们可以做些什么来解决这个问题呢?有!
xvfb
xvfb 提供了一个类似于 X 服务器守护进程的环境和设置程序运行的环境变量 DISPLAY。
通过这个,上面提到的Firefox遇到的第一个问题也可以解决。感觉就像绕了一圈==!
计划实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能使用python调用命令行程序来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入了一个网页地址参数。 slimerjs 负责打开这个页面,渲染页面的内容。
这个脚本的文件名是getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
我们的python调用os.system("xvfb-run slimerjs getPage.js" + videoURL)来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
import os
import time
open163url = 'http://open.163.com/movie/2016/1/T/D/MBCRLBLRN_MBCRM7OTD.html'
startTime = time.time()
os.system("xvfb-run slimerjs getPage.js " + open163url)
print "use time: " + str(time.time() - startTime)
capture_traffic sudo python pypcap_test.py
[sudo] password for honkee:
starting capture
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv?start=107570066
获取视频地址! !
未解决的问题
调用 python slimerjs_crawl_video.py 时
capture_traffic python slimerjs_craw_video.py
Vector smash protection is enabled.
use time: 94.3547639847
我不知道如何控制这个时间。我已经尝试修改getPage.js的window.setTimeout函数的时间,但是还是90多秒。我猜 python 的 os.system() 的限制是阻塞某些让我们回到过去(超过 90 秒)。接下来,我会再次检查相关的东西。
更新:
今天为了解决这个返回问题,开始找这个问题的原因,直接找了os.system()函数的文档。它表明此函数正在阻塞并等待命令执行完成后再返回。那么问题应该已经出现在slimerjs脚本中了。偶尔跑脚本的时候忘了加视频页面的path参数,很快就返回了。因为我的window.setTimeout()函数设置为10毫秒,为什么添加视频网页路径后还要等待90多秒呢?我打开firefox的firebug并打开那个网页。在加载所有请求后计算发现此函数的时间。下图是firebug的截图。
两个红色请求表示 90 秒后超时。这是计时器开始计时的时候,加上加载程序所需的时间,已经超过了 90 秒。
然后我们自然想到了在打开的页面之外写window.setTimeout()函数,设置返回的时间。
getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
window.setTimeout(function(){
phantom.exit();
},10000);
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
最后发现这个标题不适合这个文章。但是我还是不改了,因为我用了headless浏览器的思路来解决这个问题 查看全部
如何在没有界面显示的情况下抓取HTTP的请求包
简介
在前两篇文章中文章讲了如何抓HTTP请求包,包括代理服务器的使用和抓包方法。只是因为当前视频网站的视频地址不是在html页面直接获取的,所以视频是通过浏览器动态解释js脚本,然后向视频服务器发送视频请求来获取的。所以我们通过获取浏览器产生的HTTP请求来获取视频的下载地址。
直接使用 firefox 获取创意
我们想到了可以动态渲染js脚本的程序,最常见的就是浏览器。我们通过命令运行
firefox http://the.video.url
您可以使用 Firefox 打开 URL。但是我们不能不显示就这样使用,不过我们以后有办法解决这个问题。
python+selenium+Phantomjs
因为需要渲染没有界面显示的JS脚本,所以我们也想到了python+selenium+Phantomjs来动态渲染页面。 Phantomjs 是一个无头浏览器(Headless Browser 是一个没有界面的浏览器)。
但是Phantomjs1.5版本之后,不再支持flash插件。也就是说,Phantomjs 虽然可以动态加载 JS 脚本,但无法渲染视频。因此不会发出获取视频的 HTTP 请求。
我截图得到渲染后的页面,如下图:
视频播放窗口是黑色的,抓包程序无法捕获带有flv字符串的HTTP请求。
我也试过1.4.1版本的Phantomjs,网上说用这个命令可以加载Flash插件
./bin/phantomjs --load-plugins=yes examples/snap.js
通过渲染JS脚本,截图得到如下图:
虽然得到的截图和上图不同,但是视频中多了一个loading状态,但是我还是抓不到视频的HTTP请求。最后在python中调用webdriver.Phantomjs()时报错。
WebDriverException: Message: Can not connect to the Service phantomjs
最后不得不放弃使用 Phantomjs
slimerjs
我在网上搜索headless browser的时候,也发现了slimerjs。
PhantomJS 和 SlimerJS 的异同:来自文章
PhantomJS 基于 Webkit 内核,不支持 Flash 播放。 SlimerJS基于Firefox的Gecko内核,支持Flash播放,执行过程会有页面显示
正好我们需要支持Flash播放。但是问题又来了! SlimerJS 不是纯粹的 Headless 浏览器,它需要 DISPLAY! ! 那么我们可以做些什么来解决这个问题呢?有!
xvfb
xvfb 提供了一个类似于 X 服务器守护进程的环境和设置程序运行的环境变量 DISPLAY。
通过这个,上面提到的Firefox遇到的第一个问题也可以解决。感觉就像绕了一圈==!
计划实施
最后我们决定使用 slimerjs 来获取页面。因为没有办法通过python的selenium方法调用slimerjs,那么我们只能使用python调用命令行程序来动态渲染页面。 slimerjs 脚本如下。当我们调用这个脚本时,我们传入了一个网页地址参数。 slimerjs 负责打开这个页面,渲染页面的内容。
这个脚本的文件名是getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
我们的python调用os.system("xvfb-run slimerjs getPage.js" + videoURL)来渲染视频URL的视频。
我们最终的 Python 程序是 slimerjs_crawl_video.py
import os
import time
open163url = 'http://open.163.com/movie/2016/1/T/D/MBCRLBLRN_MBCRM7OTD.html'
startTime = time.time()
os.system("xvfb-run slimerjs getPage.js " + open163url)
print "use time: " + str(time.time() - startTime)
capture_traffic sudo python pypcap_test.py
[sudo] password for honkee:
starting capture
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv
mov.bn.netease.com/open-movie/nos/flv/2016/01/20/SBCRM4HFN_hd.flv?start=107570066
获取视频地址! !
未解决的问题
调用 python slimerjs_crawl_video.py 时
capture_traffic python slimerjs_craw_video.py
Vector smash protection is enabled.
use time: 94.3547639847
我不知道如何控制这个时间。我已经尝试修改getPage.js的window.setTimeout函数的时间,但是还是90多秒。我猜 python 的 os.system() 的限制是阻塞某些让我们回到过去(超过 90 秒)。接下来,我会再次检查相关的东西。
更新:
今天为了解决这个返回问题,开始找这个问题的原因,直接找了os.system()函数的文档。它表明此函数正在阻塞并等待命令执行完成后再返回。那么问题应该已经出现在slimerjs脚本中了。偶尔跑脚本的时候忘了加视频页面的path参数,很快就返回了。因为我的window.setTimeout()函数设置为10毫秒,为什么添加视频网页路径后还要等待90多秒呢?我打开firefox的firebug并打开那个网页。在加载所有请求后计算发现此函数的时间。下图是firebug的截图。
两个红色请求表示 90 秒后超时。这是计时器开始计时的时候,加上加载程序所需的时间,已经超过了 90 秒。
然后我们自然想到了在打开的页面之外写window.setTimeout()函数,设置返回的时间。
getPage.js
var page = require('webpage').create();
var videoUrl = phantom.args[0];
window.setTimeout(function(){
phantom.exit();
},10000);
var page.open(videoUrl, function (){
window.setTimeout(function(){
phantom.exit();
},10);
});
最后发现这个标题不适合这个文章。但是我还是不改了,因为我用了headless浏览器的思路来解决这个问题

