
网站内容抓取工具
推荐程序•Octoparse云采集功能云功能
网站优化 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-04-03 02:09
推荐程序
•Octoparse [1]-优采云
这不仅易于操作,功能完善,而且可以在短时间内获得大量数据。特别推荐并高度赞扬Octoparse的cloud 采集功能。
•Cyotek WebCopy [2]
WebCopy是免费的网站采集器,可让您将本地或完整的网站复制到硬盘上以供离线阅读。
它将扫描指定的网站,然后将网站的内容下载到您的硬盘驱动器,并自动将链接重新映射到网站中的图像和其他网页,以匹配其本地路径。包括网站的特定部分。其他选项也可用,例如下载要收录在副本中的URL,但不对其进行爬网。
您可以使用许多设置来配置网站的检索方法。除了上述规则和表格,您还可以配置域别名,用户代理字符串,默认文档等。
但是,WebCopy不包括虚拟DOM或任何形式的JavaScript解析。如果网站广泛使用JavaScript进行操作,并且由于使用JavaScript动态生成链接而无法发现所有网站,则WebCopy不太可能创建真实副本。
•Httrack [3]作为网站爬虫免费软件,HTTrack提供的功能非常适合将整个网站从Internet下载到您的PC。它提供适用于Windows,Linux,Sun Solaris和其他Unix系统的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。在“设置”下下载网页时,可以决定要同时打开多少个连接。您可以从整个目录中获取照片,文件,HTML代码,更新当前镜像网站并恢复中断的下载。
此外,HTTTrack还提供代理支持以最大程度地提高速度并提供可选的身份验证。
HTTrack用作命令行程序,或通过Shell专用(捕获)或专业(在线Web镜像)使用。有了这句话,HTTrack应该是首选,并且具有高级编程技能的人会更多地使用它。
摘要
简而言之,我上面提到的采集器可以满足大多数用户的基本搜寻需求,并且这些工具各自的功能仍然存在许多差异,因为其中许多采集器工具为用户提供了更高级的内置配置工具。因此,在使用前,请确保完全了解采集器提供的帮助信息。
参考
[1] Octoparse:[2] Cyotek WebCopy:[3] Httrack: 查看全部
推荐程序•Octoparse云采集功能云功能
推荐程序
•Octoparse [1]-优采云
这不仅易于操作,功能完善,而且可以在短时间内获得大量数据。特别推荐并高度赞扬Octoparse的cloud 采集功能。
•Cyotek WebCopy [2]
WebCopy是免费的网站采集器,可让您将本地或完整的网站复制到硬盘上以供离线阅读。
它将扫描指定的网站,然后将网站的内容下载到您的硬盘驱动器,并自动将链接重新映射到网站中的图像和其他网页,以匹配其本地路径。包括网站的特定部分。其他选项也可用,例如下载要收录在副本中的URL,但不对其进行爬网。
您可以使用许多设置来配置网站的检索方法。除了上述规则和表格,您还可以配置域别名,用户代理字符串,默认文档等。
但是,WebCopy不包括虚拟DOM或任何形式的JavaScript解析。如果网站广泛使用JavaScript进行操作,并且由于使用JavaScript动态生成链接而无法发现所有网站,则WebCopy不太可能创建真实副本。
•Httrack [3]作为网站爬虫免费软件,HTTrack提供的功能非常适合将整个网站从Internet下载到您的PC。它提供适用于Windows,Linux,Sun Solaris和其他Unix系统的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。在“设置”下下载网页时,可以决定要同时打开多少个连接。您可以从整个目录中获取照片,文件,HTML代码,更新当前镜像网站并恢复中断的下载。
此外,HTTTrack还提供代理支持以最大程度地提高速度并提供可选的身份验证。
HTTrack用作命令行程序,或通过Shell专用(捕获)或专业(在线Web镜像)使用。有了这句话,HTTrack应该是首选,并且具有高级编程技能的人会更多地使用它。
摘要
简而言之,我上面提到的采集器可以满足大多数用户的基本搜寻需求,并且这些工具各自的功能仍然存在许多差异,因为其中许多采集器工具为用户提供了更高级的内置配置工具。因此,在使用前,请确保完全了解采集器提供的帮助信息。
参考
[1] Octoparse:[2] Cyotek WebCopy:[3] Httrack:
Sitemap(站点地图)之标准xml文件格式与格式示例
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-04-02 22:02
Sitemap(站点地图)之标准xml文件格式与格式示例
提交站点地图
站点地图(站点地图)是一个文件,网站管理员可以通过该文件列出网站上的网页,并将网站内容的组织结构告知搜索引擎。
Shenma和其他搜索引擎的网络爬虫将读取此文件,以更智能地对网站的内容进行爬网
理想情况下,如果您的网站网页正确链接,神马的网络抓取工具将可以找到其中的大多数网页。即使这样,提交站点地图仍然可以帮助搜索引擎更有效地抓取网站,尤其是当网站满足以下条件之一时:
1. 网站是新创建的网站,对此网站的外部链接并不多。搜索引擎的Web爬网工具通过跟踪网页之间的链接来爬网网页。如果没有其他网站链接到您的网页,则可能找不到您的网页。
2. 网站非常大。在这种情况下,神马的网络抓取工具在抓取时可能会错过一些新的网页。
3. 网站中的大量内容页面彼此不相关或缺少有效链接。如果您的网站页面之间没有自然地相互引用,则可以在站点地图中列出这些页面,以确保搜索引擎不会错过您的页面。
请注意,神马搜索将按照正常过程分析和处理站点地图,但不能保证您提交的所有URL都会被爬网和建立索引,也不保证其在搜索结果中的排名。网站地图格式:
Shenma Search支持的Sitemap文件包括标准xml文件和索引xml文件。标准xml文件最多收录10,000个URL。如果URL超过10,000,则可以使用索引的xml文件。索引的xml文件限制为不超过三层。
标准xml文件格式的示例:
2014-05-01
每天
0. 5
2014-05-01
每天
0. 8
索引xml文件格式示例:
1.顶级站点地图格式 查看全部
Sitemap(站点地图)之标准xml文件格式与格式示例
提交站点地图
站点地图(站点地图)是一个文件,网站管理员可以通过该文件列出网站上的网页,并将网站内容的组织结构告知搜索引擎。
Shenma和其他搜索引擎的网络爬虫将读取此文件,以更智能地对网站的内容进行爬网
理想情况下,如果您的网站网页正确链接,神马的网络抓取工具将可以找到其中的大多数网页。即使这样,提交站点地图仍然可以帮助搜索引擎更有效地抓取网站,尤其是当网站满足以下条件之一时:
1. 网站是新创建的网站,对此网站的外部链接并不多。搜索引擎的Web爬网工具通过跟踪网页之间的链接来爬网网页。如果没有其他网站链接到您的网页,则可能找不到您的网页。
2. 网站非常大。在这种情况下,神马的网络抓取工具在抓取时可能会错过一些新的网页。
3. 网站中的大量内容页面彼此不相关或缺少有效链接。如果您的网站页面之间没有自然地相互引用,则可以在站点地图中列出这些页面,以确保搜索引擎不会错过您的页面。
请注意,神马搜索将按照正常过程分析和处理站点地图,但不能保证您提交的所有URL都会被爬网和建立索引,也不保证其在搜索结果中的排名。网站地图格式:
Shenma Search支持的Sitemap文件包括标准xml文件和索引xml文件。标准xml文件最多收录10,000个URL。如果URL超过10,000,则可以使用索引的xml文件。索引的xml文件限制为不超过三层。
标准xml文件格式的示例:
2014-05-01
每天
0. 5
2014-05-01
每天
0. 8
索引xml文件格式示例:
1.顶级站点地图格式
网站“抓取诊断”失败原因有哪些?怎么解决?
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-04-02 06:23
对于SEO人员来说,他们经常使用百度的官方工具来审查该网站,并检查网站的各项指标是否符合预期。其中,“爬网诊断”是网站管理员经常使用的工具。许多网站管理员说,在使用网站“提取诊断”时,经常会提示诊断失败,那么问题出在什么地方?
网站抓取诊断·概述
百度爬虫诊断工具的作用主要是从百度蜘蛛的角度了解网站的内容。反馈结果代表了Spider对网站内容的理解。通常网站爬行诊断失败,并且与百度蜘蛛的爬行有直接关系。
网站“抓取诊断”失败的原因是什么?
1、 Robots.txt被禁止
如果您阻止百度抓取网站 Robots.txt中的某个目录,则当您在该目录中生成内容时,百度将很难抓取该目录下的内容,并且抓取诊断也会提示失败出现。
2、 网站访问速度
许多网站管理员说,在本地测试中,我的网站返回了HTTP状态代码200,但是抓取诊断始终显示抓取正在进行中,没有反馈结果。
由于服务器线路不同,百度蜘蛛的爬网速度可能会有较长的延迟,这会导致爬网诊断在可以清晰访问时失败的问题。
遇到此问题时,您需要定期监视服务器的访问速度并进行网站打开速度优化。
3、 CDN缓存更新
我们知道更新CDN缓存需要花费时间。尽管您可以在管理平台的后台实时进行在线更新,但是由于不同服务提供商的技术不对称,通常会导致一定的时间延迟。
这势必会导致网站抓取失败。
4、跳转到抓取诊断
如果您更新旧内容并修改网站版本,并使用301或302进行重定向,由于配置错误,重定向次数过多,也会导致百度抓取失败的问题。
5、 DNS缓存
由于存在DNS缓存,当您在本地查询URL时,您可以正常访问它,但是当上述常见问题消除后,抓取诊断仍会提示失败,那么您需要更新本地DNS缓存,或使用代理IP进行审核网站都很容易访问。
网站关于“爬网诊断”的常见问题:
对于百度爬虫诊断工具,SEO顾问最常问的问题是:百度爬虫诊断是否有帮助收录?
从目前许多SEO人员的反馈结果来看,尚无合理的数据来支持它,可以证明爬行诊断工具对百度是有益的收录,但也许会对百度的快照产生一定的影响。更新。
摘要:网站“抓取诊断”失败的原因很多。除了参考官方提示外,您还需要自己一个人排除。以上内容仅供参考。
蝙蝠侠的IT转载需要授权! 查看全部
网站“抓取诊断”失败原因有哪些?怎么解决?
对于SEO人员来说,他们经常使用百度的官方工具来审查该网站,并检查网站的各项指标是否符合预期。其中,“爬网诊断”是网站管理员经常使用的工具。许多网站管理员说,在使用网站“提取诊断”时,经常会提示诊断失败,那么问题出在什么地方?

网站抓取诊断·概述
百度爬虫诊断工具的作用主要是从百度蜘蛛的角度了解网站的内容。反馈结果代表了Spider对网站内容的理解。通常网站爬行诊断失败,并且与百度蜘蛛的爬行有直接关系。
网站“抓取诊断”失败的原因是什么?
1、 Robots.txt被禁止
如果您阻止百度抓取网站 Robots.txt中的某个目录,则当您在该目录中生成内容时,百度将很难抓取该目录下的内容,并且抓取诊断也会提示失败出现。
2、 网站访问速度
许多网站管理员说,在本地测试中,我的网站返回了HTTP状态代码200,但是抓取诊断始终显示抓取正在进行中,没有反馈结果。
由于服务器线路不同,百度蜘蛛的爬网速度可能会有较长的延迟,这会导致爬网诊断在可以清晰访问时失败的问题。
遇到此问题时,您需要定期监视服务器的访问速度并进行网站打开速度优化。
3、 CDN缓存更新
我们知道更新CDN缓存需要花费时间。尽管您可以在管理平台的后台实时进行在线更新,但是由于不同服务提供商的技术不对称,通常会导致一定的时间延迟。
这势必会导致网站抓取失败。
4、跳转到抓取诊断
如果您更新旧内容并修改网站版本,并使用301或302进行重定向,由于配置错误,重定向次数过多,也会导致百度抓取失败的问题。
5、 DNS缓存
由于存在DNS缓存,当您在本地查询URL时,您可以正常访问它,但是当上述常见问题消除后,抓取诊断仍会提示失败,那么您需要更新本地DNS缓存,或使用代理IP进行审核网站都很容易访问。
网站关于“爬网诊断”的常见问题:
对于百度爬虫诊断工具,SEO顾问最常问的问题是:百度爬虫诊断是否有帮助收录?
从目前许多SEO人员的反馈结果来看,尚无合理的数据来支持它,可以证明爬行诊断工具对百度是有益的收录,但也许会对百度的快照产生一定的影响。更新。
摘要:网站“抓取诊断”失败的原因很多。除了参考官方提示外,您还需要自己一个人排除。以上内容仅供参考。
蝙蝠侠的IT转载需要授权!
互联网不断涌现出新的网页工具可供使用
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-04-02 01:08
新的信息,新的设计模式和大量的c不断在Internet上出现。将该数据组织到唯一的库中并不容易。但是,有许多出色的网络爬网工具可用。
1. ProxyCrawl
使用代理爬网API,您可以爬网Web上的任何网站 /平台。具有代理支持,验证码绕过以及基于动态内容抓取JavaScript页面的优势。
它可以免费获得1,000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2. Scrapy
Scrapy是一个开放源代码项目,为爬网网页提供支持。 Scrapy抓取框架出色地完成了从网站和网页中提取数据的工作。
最重要的是,Scrapy可用于挖掘数据,监视数据模式以及对大型任务执行自动测试。强大的功能可以与ProxyCrawl ***集成。使用Scrapy,由于具有内置工具,因此选择内容源(HTML和XML)非常容易。您还可以使用Scrapy API扩展提供的功能。
3.抓
Grab是用于创建自定义Web爬网规则集的基于Python的框架。使用Grab,可以为小型个人项目创建爬网机制,还可以构建大型动态爬网任务,这些任务可以同时扩展到数百万个页面。
内置API提供了一种执行网络请求的方法,还可以处理已删除的内容。 Grab提供的另一个API称为Spider。使用Spider API,您可以使用自定义类创建异步采集器。
4.雪貂
Ferret是一种相当新的Web抓取工具,在开源社区中获得了相当大的关注。 Ferret的目标是提供更简洁的客户端爬网解决方案。例如,允许开发人员编写不必依赖于应用程序状态的采集器。
此外,雪貂使用自定义的声明性语言来避免构建系统的复杂性。相反,您可以编写严格的规则以从任何站点抓取数据。
5. X射线
由于X-Ray和Osmosis等库的可用性,使用Node.js爬网非常容易。
6. Diffbot
Diffbot是市场上的新玩家。您甚至不必编写太多代码,因为Diffbot的AI算法可以在无需手动说明的情况下从网站页面解密结构化数据。
7. PhantomJS Cloud
PhantomJS Cloud是PhantomJS浏览器的SaaS替代产品。使用PhantomJS Cloud,您可以直接从网页内部获取数据,还可以生成可视文件,并将页面显示为PDF文档。
PhantomJS本身是一个浏览器,这意味着您可以像浏览器一样加载和执行页面资源。如果您手头的任务需要获取许多基于JavaScript的网站,则此功能特别有用。
[编辑推荐]
三大运营商的2018年运营数据,他们今年表现如何?分享有关将在2019年塑造数据中心行业的八种趋势的观点|物联网数据需要共享协议才能优雅地读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势 查看全部
互联网不断涌现出新的网页工具可供使用
新的信息,新的设计模式和大量的c不断在Internet上出现。将该数据组织到唯一的库中并不容易。但是,有许多出色的网络爬网工具可用。
1. ProxyCrawl
使用代理爬网API,您可以爬网Web上的任何网站 /平台。具有代理支持,验证码绕过以及基于动态内容抓取JavaScript页面的优势。

它可以免费获得1,000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2. Scrapy
Scrapy是一个开放源代码项目,为爬网网页提供支持。 Scrapy抓取框架出色地完成了从网站和网页中提取数据的工作。

最重要的是,Scrapy可用于挖掘数据,监视数据模式以及对大型任务执行自动测试。强大的功能可以与ProxyCrawl ***集成。使用Scrapy,由于具有内置工具,因此选择内容源(HTML和XML)非常容易。您还可以使用Scrapy API扩展提供的功能。
3.抓
Grab是用于创建自定义Web爬网规则集的基于Python的框架。使用Grab,可以为小型个人项目创建爬网机制,还可以构建大型动态爬网任务,这些任务可以同时扩展到数百万个页面。
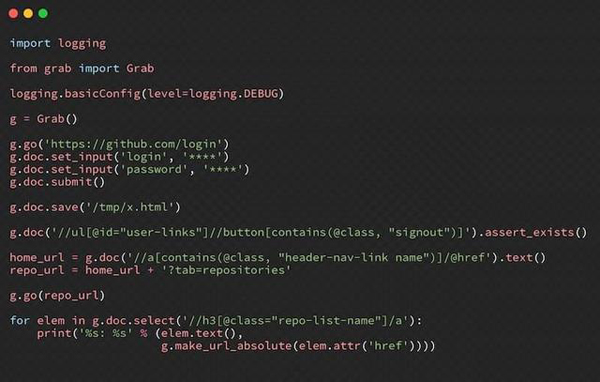
内置API提供了一种执行网络请求的方法,还可以处理已删除的内容。 Grab提供的另一个API称为Spider。使用Spider API,您可以使用自定义类创建异步采集器。
4.雪貂
Ferret是一种相当新的Web抓取工具,在开源社区中获得了相当大的关注。 Ferret的目标是提供更简洁的客户端爬网解决方案。例如,允许开发人员编写不必依赖于应用程序状态的采集器。
此外,雪貂使用自定义的声明性语言来避免构建系统的复杂性。相反,您可以编写严格的规则以从任何站点抓取数据。
5. X射线
由于X-Ray和Osmosis等库的可用性,使用Node.js爬网非常容易。
6. Diffbot
Diffbot是市场上的新玩家。您甚至不必编写太多代码,因为Diffbot的AI算法可以在无需手动说明的情况下从网站页面解密结构化数据。
7. PhantomJS Cloud
PhantomJS Cloud是PhantomJS浏览器的SaaS替代产品。使用PhantomJS Cloud,您可以直接从网页内部获取数据,还可以生成可视文件,并将页面显示为PDF文档。
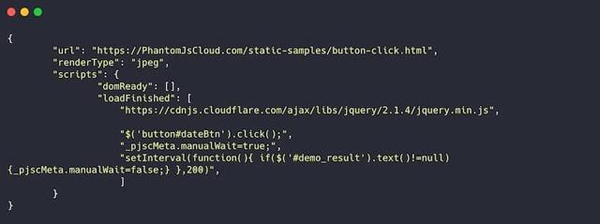
PhantomJS本身是一个浏览器,这意味着您可以像浏览器一样加载和执行页面资源。如果您手头的任务需要获取许多基于JavaScript的网站,则此功能特别有用。
[编辑推荐]
三大运营商的2018年运营数据,他们今年表现如何?分享有关将在2019年塑造数据中心行业的八种趋势的观点|物联网数据需要共享协议才能优雅地读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势
网页抓取工具EasyWeb功能特点及解决方案(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-03-31 06:14
网络爬网工具Easy Web是用于爬网网页的外部软件。网站管理员的朋友一定会使用它。您无需了解代码。它可以直接提取内容(文本,URL,图片,文件),并转换为多种格式。
软件说明
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单网站到复杂网站抓取内容。
但无需进行任何工作即可构建网络抓取项目。
在此页面上,我们将仅向您显示众所周知的功能。
使我们的网络采集器易于使用。
功能
1.轻松创建提取项目
对于任何用户而言,基于向导窗口创建新项目绝非易事。
项目安装向导将逐步指导您。
直到所有必要的任务完成。
以下是一些主要步骤:
第1步:输入一个起始URL,即起始页面,然后刷新屏幕即可加载该网页。
通常是指向报废产品列表的链接
第2步:输入关键词提交表单并获取结果。如果网站需要它,则在大多数情况下可以跳过此步骤;
第3步:在列表中选择一个项目,然后选择该项目的数据列的抓取效果;
第4步:选择下一页的URL来访问其他网页。
2.在多个线程中抓取数据
在网络争夺项目中,需要抓取成千上万的链接才能收获。
传统的刮板可能要花费您数小时或数天的时间。
但是,简单的Web提取可以同时运行多个线程来浏览多达24个不同的网页。
为了节省您的宝贵时间,请等待收获的结果。
因此,简单的Web提取可以利用系统的最佳性能。
旁边的动画图像显示了8个线程的提取。
3.从数据中加载各种提取的数据
一些高度动态的网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
这是事实,不仅是原创网页,而且是专业网络抓取工具所面临的挑战。
因为Web内容未嵌入HTML源中。
但是,简单的Web提取具有非常强大的技术。
甚至使新手都可以从网站类型的数据中获取数据。
此外,我们的网站抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如,联系人列表中的某些特定网站。
在这里,大多数网页抓取工具继续采集大量的重复信息。
很快就变得乏味。但是,请不要担心这个噩梦。
因为简单的Web提取具有避免它的聪明功能。
4.随时自动执行项目
通过一个简单的网络嵌入并自动运行调度程序。
您可以安排运行网络抓取项目,而无需任何操作。
计划的任务运行,并将抓取的结果导出到目的地。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
为确保仅保留新数据。
支持的时间表类型:
-在项目中每小时运行一次
-在项目中每天运行
-在特定时间运行项目
5.将数据导出为任何格式
我们最好的网络抓取工具支持多种格式以导出抓取的网站数据。
例如:CSV,访问权限,XML,HTML,SQL 等。
您还可以直接提交由它引起的任何类型的数据库目标。
通过ODBC连接。如果您的网站有提交表格。 查看全部
网页抓取工具EasyWeb功能特点及解决方案(一)
网络爬网工具Easy Web是用于爬网网页的外部软件。网站管理员的朋友一定会使用它。您无需了解代码。它可以直接提取内容(文本,URL,图片,文件),并转换为多种格式。

软件说明
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单网站到复杂网站抓取内容。
但无需进行任何工作即可构建网络抓取项目。
在此页面上,我们将仅向您显示众所周知的功能。
使我们的网络采集器易于使用。
功能
1.轻松创建提取项目
对于任何用户而言,基于向导窗口创建新项目绝非易事。
项目安装向导将逐步指导您。
直到所有必要的任务完成。
以下是一些主要步骤:
第1步:输入一个起始URL,即起始页面,然后刷新屏幕即可加载该网页。
通常是指向报废产品列表的链接
第2步:输入关键词提交表单并获取结果。如果网站需要它,则在大多数情况下可以跳过此步骤;
第3步:在列表中选择一个项目,然后选择该项目的数据列的抓取效果;
第4步:选择下一页的URL来访问其他网页。
2.在多个线程中抓取数据
在网络争夺项目中,需要抓取成千上万的链接才能收获。
传统的刮板可能要花费您数小时或数天的时间。
但是,简单的Web提取可以同时运行多个线程来浏览多达24个不同的网页。
为了节省您的宝贵时间,请等待收获的结果。
因此,简单的Web提取可以利用系统的最佳性能。
旁边的动画图像显示了8个线程的提取。
3.从数据中加载各种提取的数据
一些高度动态的网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
这是事实,不仅是原创网页,而且是专业网络抓取工具所面临的挑战。
因为Web内容未嵌入HTML源中。
但是,简单的Web提取具有非常强大的技术。
甚至使新手都可以从网站类型的数据中获取数据。
此外,我们的网站抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如,联系人列表中的某些特定网站。
在这里,大多数网页抓取工具继续采集大量的重复信息。
很快就变得乏味。但是,请不要担心这个噩梦。
因为简单的Web提取具有避免它的聪明功能。
4.随时自动执行项目
通过一个简单的网络嵌入并自动运行调度程序。
您可以安排运行网络抓取项目,而无需任何操作。
计划的任务运行,并将抓取的结果导出到目的地。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
为确保仅保留新数据。
支持的时间表类型:
-在项目中每小时运行一次
-在项目中每天运行
-在特定时间运行项目
5.将数据导出为任何格式
我们最好的网络抓取工具支持多种格式以导出抓取的网站数据。
例如:CSV,访问权限,XML,HTML,SQL 等。
您还可以直接提交由它引起的任何类型的数据库目标。
通过ODBC连接。如果您的网站有提交表格。
职场求职高效办公易企秀,100个在线h5制作工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-03-29 07:03
网站内容抓取工具汇总个性化个性化体验百度网盘pc手机端多种下载方式清爽不拖泥带水免费在线解压gif网址云端格式转换工具二维码扫描生成分享我的电脑链接到微信*使用很简单4快速批量下载工具h5网址导航快速学习,名家公开课,职场求职高效办公
易企秀,100个在线h5制作工具_微小宝|免费h5页面制作工具
bilibili
一丁引擎_搜索引擎,互联网短视频素材收集平台,找,
vidocity,
每天一条。
pc端,关键词搜索:用pc上快手做视频pc端,关键词搜索:用pc快手上爱奇艺做视频微信公众号搜索公众号名称:qualityhotvideo有人已经制作了一些,
视频下载器
网易云音乐用的,
给大家推荐五个比较好用的在线视频下载的平台视频下载器网:一度蜜视频下载器:专业的免费视频下载平台
最新在快手短视频上火了一位导师,给大家一个可以直接从一些小姐姐朋友圈偷窥到她所有的私人信息的平台,有兴趣的小伙伴可以去试试。点击这里进入下载链接:miko小姐姐(男友是真人)开直播了现在,你们也可以看到这位小姐姐,然后过一段时间,你会看到很多又有兴趣的小姐姐。支持多国语言,关注我的公众号:优沃移动;后台回复【视频】可以领取一个下载秘籍下载秘籍:文件夹内的个人微信号、个人手机号和验证方式都告诉你,不保证是最快最稳最安全,但我相信大家都是奔着安全和效率去的,而这份安全包括:程序和脚本的安全;注册私密小号,加到购物车。
解决你的很多疑惑,我相信很多小伙伴应该对从别人直播的个人微信号里偷窥购物车都是很纠结的,甚至以为里面有你所有的信息。在【老师】这里,我把关于购物车的所有秘密都告诉你,可以自行检验验证。有意者可以微信联系我一起成长,也可以加wx联系我领取视频下载秘籍。 查看全部
职场求职高效办公易企秀,100个在线h5制作工具
网站内容抓取工具汇总个性化个性化体验百度网盘pc手机端多种下载方式清爽不拖泥带水免费在线解压gif网址云端格式转换工具二维码扫描生成分享我的电脑链接到微信*使用很简单4快速批量下载工具h5网址导航快速学习,名家公开课,职场求职高效办公
易企秀,100个在线h5制作工具_微小宝|免费h5页面制作工具
bilibili
一丁引擎_搜索引擎,互联网短视频素材收集平台,找,
vidocity,
每天一条。
pc端,关键词搜索:用pc上快手做视频pc端,关键词搜索:用pc快手上爱奇艺做视频微信公众号搜索公众号名称:qualityhotvideo有人已经制作了一些,
视频下载器
网易云音乐用的,
给大家推荐五个比较好用的在线视频下载的平台视频下载器网:一度蜜视频下载器:专业的免费视频下载平台
最新在快手短视频上火了一位导师,给大家一个可以直接从一些小姐姐朋友圈偷窥到她所有的私人信息的平台,有兴趣的小伙伴可以去试试。点击这里进入下载链接:miko小姐姐(男友是真人)开直播了现在,你们也可以看到这位小姐姐,然后过一段时间,你会看到很多又有兴趣的小姐姐。支持多国语言,关注我的公众号:优沃移动;后台回复【视频】可以领取一个下载秘籍下载秘籍:文件夹内的个人微信号、个人手机号和验证方式都告诉你,不保证是最快最稳最安全,但我相信大家都是奔着安全和效率去的,而这份安全包括:程序和脚本的安全;注册私密小号,加到购物车。
解决你的很多疑惑,我相信很多小伙伴应该对从别人直播的个人微信号里偷窥购物车都是很纠结的,甚至以为里面有你所有的信息。在【老师】这里,我把关于购物车的所有秘密都告诉你,可以自行检验验证。有意者可以微信联系我一起成长,也可以加wx联系我领取视频下载秘籍。
远程办公的效率和质量,核心是自我管理的自驱力
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-03-28 04:00
1.之前说过
受这一流行病的影响,我相信大多数人仍在远离家乡的地方工作。首先,远程工作的最简单方法是拨打电话并发送微信。我们每天都这样做。后来,一系列工具(例如公司微信,各种在线会议工具,在线文档等)可以提高同事之间的协作效率,突破物理限制并在不上班的情况下创造价值。当您无法离线聚会时,请保持工作不间断。
但是在大多数情况下,内部协作办公室只能解决内部效率问题。对于大多数公司和企业主而言,办公室工作的目的是在外部与消费者和客户建立联系。为了真正地工作,有必要做生意。
换句话说,我认为远程办公的本质在于,除了允许每个人进行合作和共同努力(意义不只是纯粹的内部协作)之外,后续行动的真正价值还必须是外部的,并且让公司员工可以与外部消费者建立联系。
当然,我们今天的重点不在谈论远程办公。远程办公的效率和质量是自我管理的核心。
在日常工作中,无论是开发系学生,测试系学生还是运维维护系学生,必不可少的一些数据包捕获工具。今天,我将向您推荐4种采集器捕获工件。
2.让我们聊一聊:抓取数据包的原理
采集器的基本原理是模拟客户端(可以是浏览器或APP)以将HTTP请求发送到远程服务器。我们需要知道目标服务器的HOST,URI,请求方法,请求参数,请求标头和请求正文。网页网站可以通过Chrome浏览器找到此信息。但是对于APP采集器,似乎有些无奈。这时,我们必须借用一些数据包捕获工具,以帮助我们分析APP背后的秘密。数据包捕获的本质是引入额外的中间人代理层,如下图所示。
添加一个知识点。对于新手来说,有必要区分数据包捕获和采集器。两种不同的概念:数据包捕获是查看和分析网络请求,以及了解另一方的过程。爬网程序模拟网络请求。当您了解另一方时,您可以模拟用于请求数据的工具。两者相辅相成。首先,捕获并分析程序,然后对程序进行仿真。这是爬虫的开发过程,以达到您的爬虫的目的。
3.数据包捕获工件之一:提琴手
Fiddler是Windows平台上最好的可视数据包捕获工具,也是最著名的HTTP代理工具。它具有非常强大的功能。除了清楚地了解每个请求和响应之外,您还可以设置断点并修改请求数据并拦截响应内容。
从官方网站下载:
此外,您可以通过修改脚本来自定义规则并添加自己的特殊处理,但是由于它是用C#编写的,因此,如果要编写复杂的脚本,则需要了解C#。
过滤器功能允许您通过正则表达式规则显示您关心的请求。如果只需要捕获特定的网站数据,则此功能非常有用,可以删除很多干扰信息。
在Fiddler的左下角有一个名为QuickExec的命令行工具,使您可以直接输入命令,如上面的命令行说明所示。
常见命令是:
帮助:打开官方用法页面介绍,所有命令都会列出
cls:清除屏幕
选择:选择会话的命令
?. png:用于选择带有png后缀的图片
bpu:请求被拦截
@主持人突出显示该主持人的所有会话,例如@
=:等于指定的请求方法或突出显示状态代码,例如,输入:= 502
4.捕获工件2:查尔斯
Charles是跨平台的数据包捕获工具,也是macOS平台下最好的数据包捕获分析工具之一。它还提供了具有简单界面的GUI界面。基本功能包括HTTP和HTTPS请求数据包捕获,支持对于修改请求参数,最新的Charles 4还支持HTTP / 2。当然,它也支持Windows和Linux,但是此工具是收费的。免费试用30天,试用期结束后功能会受到限制。
Charles的当前最新版本为4. 5. 6,官方网站地址如下:
查尔斯在线破解工具:
查尔斯还经常用在一些简单的弱网络仿真工具中,打开Proxy-> Throttle Settings,界面如下:
PS:此外,用于模拟弱网络的常用工具有:Fiddler,FaceBook工具ATC弱网络模拟。
5.数据包捕获工件3:AnyProxy
AnyProxy是阿里巴巴的开源HTTP数据包捕获工具,基于NodeJS。优点是它支持二次开发并可以自定义请求处理逻辑。如果您可以编写JS,则需要同时进行一些自定义处理,那么AnyProxy非常适合。它支持HTTPS并提供GUI界面。 GitHub地址:
共同特点:
anyproxy的详细介绍:
6.数据包捕获工件四:mitmproxy
它不仅是跨平台的,而且还提供了一种命令行交互模式,这种模式非常(壮)客户(bi),并且是通过Python语言实现的。对于Pythoner来说,这无疑是一个很大的好处。 。 mitmproxy主要收录3个工具:
GitHub地址:
mitmproxy官方网站:
Mitmproxy文档介绍:
最后,作为分享,作者最常用的捕获工具是Charles和mitmproxy。 查看全部
远程办公的效率和质量,核心是自我管理的自驱力
1.之前说过
受这一流行病的影响,我相信大多数人仍在远离家乡的地方工作。首先,远程工作的最简单方法是拨打电话并发送微信。我们每天都这样做。后来,一系列工具(例如公司微信,各种在线会议工具,在线文档等)可以提高同事之间的协作效率,突破物理限制并在不上班的情况下创造价值。当您无法离线聚会时,请保持工作不间断。
但是在大多数情况下,内部协作办公室只能解决内部效率问题。对于大多数公司和企业主而言,办公室工作的目的是在外部与消费者和客户建立联系。为了真正地工作,有必要做生意。

换句话说,我认为远程办公的本质在于,除了允许每个人进行合作和共同努力(意义不只是纯粹的内部协作)之外,后续行动的真正价值还必须是外部的,并且让公司员工可以与外部消费者建立联系。
当然,我们今天的重点不在谈论远程办公。远程办公的效率和质量是自我管理的核心。
在日常工作中,无论是开发系学生,测试系学生还是运维维护系学生,必不可少的一些数据包捕获工具。今天,我将向您推荐4种采集器捕获工件。
2.让我们聊一聊:抓取数据包的原理
采集器的基本原理是模拟客户端(可以是浏览器或APP)以将HTTP请求发送到远程服务器。我们需要知道目标服务器的HOST,URI,请求方法,请求参数,请求标头和请求正文。网页网站可以通过Chrome浏览器找到此信息。但是对于APP采集器,似乎有些无奈。这时,我们必须借用一些数据包捕获工具,以帮助我们分析APP背后的秘密。数据包捕获的本质是引入额外的中间人代理层,如下图所示。

添加一个知识点。对于新手来说,有必要区分数据包捕获和采集器。两种不同的概念:数据包捕获是查看和分析网络请求,以及了解另一方的过程。爬网程序模拟网络请求。当您了解另一方时,您可以模拟用于请求数据的工具。两者相辅相成。首先,捕获并分析程序,然后对程序进行仿真。这是爬虫的开发过程,以达到您的爬虫的目的。
3.数据包捕获工件之一:提琴手
Fiddler是Windows平台上最好的可视数据包捕获工具,也是最著名的HTTP代理工具。它具有非常强大的功能。除了清楚地了解每个请求和响应之外,您还可以设置断点并修改请求数据并拦截响应内容。
从官方网站下载:

此外,您可以通过修改脚本来自定义规则并添加自己的特殊处理,但是由于它是用C#编写的,因此,如果要编写复杂的脚本,则需要了解C#。
过滤器功能允许您通过正则表达式规则显示您关心的请求。如果只需要捕获特定的网站数据,则此功能非常有用,可以删除很多干扰信息。

在Fiddler的左下角有一个名为QuickExec的命令行工具,使您可以直接输入命令,如上面的命令行说明所示。
常见命令是:
帮助:打开官方用法页面介绍,所有命令都会列出
cls:清除屏幕
选择:选择会话的命令
?. png:用于选择带有png后缀的图片
bpu:请求被拦截
@主持人突出显示该主持人的所有会话,例如@
=:等于指定的请求方法或突出显示状态代码,例如,输入:= 502
4.捕获工件2:查尔斯
Charles是跨平台的数据包捕获工具,也是macOS平台下最好的数据包捕获分析工具之一。它还提供了具有简单界面的GUI界面。基本功能包括HTTP和HTTPS请求数据包捕获,支持对于修改请求参数,最新的Charles 4还支持HTTP / 2。当然,它也支持Windows和Linux,但是此工具是收费的。免费试用30天,试用期结束后功能会受到限制。
Charles的当前最新版本为4. 5. 6,官方网站地址如下:

查尔斯在线破解工具:
查尔斯还经常用在一些简单的弱网络仿真工具中,打开Proxy-> Throttle Settings,界面如下:

PS:此外,用于模拟弱网络的常用工具有:Fiddler,FaceBook工具ATC弱网络模拟。
5.数据包捕获工件3:AnyProxy
AnyProxy是阿里巴巴的开源HTTP数据包捕获工具,基于NodeJS。优点是它支持二次开发并可以自定义请求处理逻辑。如果您可以编写JS,则需要同时进行一些自定义处理,那么AnyProxy非常适合。它支持HTTPS并提供GUI界面。 GitHub地址:

共同特点:
anyproxy的详细介绍:
6.数据包捕获工件四:mitmproxy
它不仅是跨平台的,而且还提供了一种命令行交互模式,这种模式非常(壮)客户(bi),并且是通过Python语言实现的。对于Pythoner来说,这无疑是一个很大的好处。 。 mitmproxy主要收录3个工具:
GitHub地址:

mitmproxy官方网站:
Mitmproxy文档介绍:
最后,作为分享,作者最常用的捕获工具是Charles和mitmproxy。
推荐程序•Octoparse云采集功能云功能
网站优化 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-04-03 02:09
推荐程序
•Octoparse [1]-优采云
这不仅易于操作,功能完善,而且可以在短时间内获得大量数据。特别推荐并高度赞扬Octoparse的cloud 采集功能。
•Cyotek WebCopy [2]
WebCopy是免费的网站采集器,可让您将本地或完整的网站复制到硬盘上以供离线阅读。
它将扫描指定的网站,然后将网站的内容下载到您的硬盘驱动器,并自动将链接重新映射到网站中的图像和其他网页,以匹配其本地路径。包括网站的特定部分。其他选项也可用,例如下载要收录在副本中的URL,但不对其进行爬网。
您可以使用许多设置来配置网站的检索方法。除了上述规则和表格,您还可以配置域别名,用户代理字符串,默认文档等。
但是,WebCopy不包括虚拟DOM或任何形式的JavaScript解析。如果网站广泛使用JavaScript进行操作,并且由于使用JavaScript动态生成链接而无法发现所有网站,则WebCopy不太可能创建真实副本。
•Httrack [3]作为网站爬虫免费软件,HTTrack提供的功能非常适合将整个网站从Internet下载到您的PC。它提供适用于Windows,Linux,Sun Solaris和其他Unix系统的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。在“设置”下下载网页时,可以决定要同时打开多少个连接。您可以从整个目录中获取照片,文件,HTML代码,更新当前镜像网站并恢复中断的下载。
此外,HTTTrack还提供代理支持以最大程度地提高速度并提供可选的身份验证。
HTTrack用作命令行程序,或通过Shell专用(捕获)或专业(在线Web镜像)使用。有了这句话,HTTrack应该是首选,并且具有高级编程技能的人会更多地使用它。
摘要
简而言之,我上面提到的采集器可以满足大多数用户的基本搜寻需求,并且这些工具各自的功能仍然存在许多差异,因为其中许多采集器工具为用户提供了更高级的内置配置工具。因此,在使用前,请确保完全了解采集器提供的帮助信息。
参考
[1] Octoparse:[2] Cyotek WebCopy:[3] Httrack: 查看全部
推荐程序•Octoparse云采集功能云功能
推荐程序
•Octoparse [1]-优采云
这不仅易于操作,功能完善,而且可以在短时间内获得大量数据。特别推荐并高度赞扬Octoparse的cloud 采集功能。
•Cyotek WebCopy [2]
WebCopy是免费的网站采集器,可让您将本地或完整的网站复制到硬盘上以供离线阅读。
它将扫描指定的网站,然后将网站的内容下载到您的硬盘驱动器,并自动将链接重新映射到网站中的图像和其他网页,以匹配其本地路径。包括网站的特定部分。其他选项也可用,例如下载要收录在副本中的URL,但不对其进行爬网。
您可以使用许多设置来配置网站的检索方法。除了上述规则和表格,您还可以配置域别名,用户代理字符串,默认文档等。
但是,WebCopy不包括虚拟DOM或任何形式的JavaScript解析。如果网站广泛使用JavaScript进行操作,并且由于使用JavaScript动态生成链接而无法发现所有网站,则WebCopy不太可能创建真实副本。
•Httrack [3]作为网站爬虫免费软件,HTTrack提供的功能非常适合将整个网站从Internet下载到您的PC。它提供适用于Windows,Linux,Sun Solaris和其他Unix系统的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。在“设置”下下载网页时,可以决定要同时打开多少个连接。您可以从整个目录中获取照片,文件,HTML代码,更新当前镜像网站并恢复中断的下载。
此外,HTTTrack还提供代理支持以最大程度地提高速度并提供可选的身份验证。
HTTrack用作命令行程序,或通过Shell专用(捕获)或专业(在线Web镜像)使用。有了这句话,HTTrack应该是首选,并且具有高级编程技能的人会更多地使用它。
摘要
简而言之,我上面提到的采集器可以满足大多数用户的基本搜寻需求,并且这些工具各自的功能仍然存在许多差异,因为其中许多采集器工具为用户提供了更高级的内置配置工具。因此,在使用前,请确保完全了解采集器提供的帮助信息。
参考
[1] Octoparse:[2] Cyotek WebCopy:[3] Httrack:
Sitemap(站点地图)之标准xml文件格式与格式示例
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-04-02 22:02
Sitemap(站点地图)之标准xml文件格式与格式示例
提交站点地图
站点地图(站点地图)是一个文件,网站管理员可以通过该文件列出网站上的网页,并将网站内容的组织结构告知搜索引擎。
Shenma和其他搜索引擎的网络爬虫将读取此文件,以更智能地对网站的内容进行爬网
理想情况下,如果您的网站网页正确链接,神马的网络抓取工具将可以找到其中的大多数网页。即使这样,提交站点地图仍然可以帮助搜索引擎更有效地抓取网站,尤其是当网站满足以下条件之一时:
1. 网站是新创建的网站,对此网站的外部链接并不多。搜索引擎的Web爬网工具通过跟踪网页之间的链接来爬网网页。如果没有其他网站链接到您的网页,则可能找不到您的网页。
2. 网站非常大。在这种情况下,神马的网络抓取工具在抓取时可能会错过一些新的网页。
3. 网站中的大量内容页面彼此不相关或缺少有效链接。如果您的网站页面之间没有自然地相互引用,则可以在站点地图中列出这些页面,以确保搜索引擎不会错过您的页面。
请注意,神马搜索将按照正常过程分析和处理站点地图,但不能保证您提交的所有URL都会被爬网和建立索引,也不保证其在搜索结果中的排名。网站地图格式:
Shenma Search支持的Sitemap文件包括标准xml文件和索引xml文件。标准xml文件最多收录10,000个URL。如果URL超过10,000,则可以使用索引的xml文件。索引的xml文件限制为不超过三层。
标准xml文件格式的示例:
2014-05-01
每天
0. 5
2014-05-01
每天
0. 8
索引xml文件格式示例:
1.顶级站点地图格式 查看全部
Sitemap(站点地图)之标准xml文件格式与格式示例
提交站点地图
站点地图(站点地图)是一个文件,网站管理员可以通过该文件列出网站上的网页,并将网站内容的组织结构告知搜索引擎。
Shenma和其他搜索引擎的网络爬虫将读取此文件,以更智能地对网站的内容进行爬网
理想情况下,如果您的网站网页正确链接,神马的网络抓取工具将可以找到其中的大多数网页。即使这样,提交站点地图仍然可以帮助搜索引擎更有效地抓取网站,尤其是当网站满足以下条件之一时:
1. 网站是新创建的网站,对此网站的外部链接并不多。搜索引擎的Web爬网工具通过跟踪网页之间的链接来爬网网页。如果没有其他网站链接到您的网页,则可能找不到您的网页。
2. 网站非常大。在这种情况下,神马的网络抓取工具在抓取时可能会错过一些新的网页。
3. 网站中的大量内容页面彼此不相关或缺少有效链接。如果您的网站页面之间没有自然地相互引用,则可以在站点地图中列出这些页面,以确保搜索引擎不会错过您的页面。
请注意,神马搜索将按照正常过程分析和处理站点地图,但不能保证您提交的所有URL都会被爬网和建立索引,也不保证其在搜索结果中的排名。网站地图格式:
Shenma Search支持的Sitemap文件包括标准xml文件和索引xml文件。标准xml文件最多收录10,000个URL。如果URL超过10,000,则可以使用索引的xml文件。索引的xml文件限制为不超过三层。
标准xml文件格式的示例:
2014-05-01
每天
0. 5
2014-05-01
每天
0. 8
索引xml文件格式示例:
1.顶级站点地图格式
网站“抓取诊断”失败原因有哪些?怎么解决?
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-04-02 06:23
对于SEO人员来说,他们经常使用百度的官方工具来审查该网站,并检查网站的各项指标是否符合预期。其中,“爬网诊断”是网站管理员经常使用的工具。许多网站管理员说,在使用网站“提取诊断”时,经常会提示诊断失败,那么问题出在什么地方?
网站抓取诊断·概述
百度爬虫诊断工具的作用主要是从百度蜘蛛的角度了解网站的内容。反馈结果代表了Spider对网站内容的理解。通常网站爬行诊断失败,并且与百度蜘蛛的爬行有直接关系。
网站“抓取诊断”失败的原因是什么?
1、 Robots.txt被禁止
如果您阻止百度抓取网站 Robots.txt中的某个目录,则当您在该目录中生成内容时,百度将很难抓取该目录下的内容,并且抓取诊断也会提示失败出现。
2、 网站访问速度
许多网站管理员说,在本地测试中,我的网站返回了HTTP状态代码200,但是抓取诊断始终显示抓取正在进行中,没有反馈结果。
由于服务器线路不同,百度蜘蛛的爬网速度可能会有较长的延迟,这会导致爬网诊断在可以清晰访问时失败的问题。
遇到此问题时,您需要定期监视服务器的访问速度并进行网站打开速度优化。
3、 CDN缓存更新
我们知道更新CDN缓存需要花费时间。尽管您可以在管理平台的后台实时进行在线更新,但是由于不同服务提供商的技术不对称,通常会导致一定的时间延迟。
这势必会导致网站抓取失败。
4、跳转到抓取诊断
如果您更新旧内容并修改网站版本,并使用301或302进行重定向,由于配置错误,重定向次数过多,也会导致百度抓取失败的问题。
5、 DNS缓存
由于存在DNS缓存,当您在本地查询URL时,您可以正常访问它,但是当上述常见问题消除后,抓取诊断仍会提示失败,那么您需要更新本地DNS缓存,或使用代理IP进行审核网站都很容易访问。
网站关于“爬网诊断”的常见问题:
对于百度爬虫诊断工具,SEO顾问最常问的问题是:百度爬虫诊断是否有帮助收录?
从目前许多SEO人员的反馈结果来看,尚无合理的数据来支持它,可以证明爬行诊断工具对百度是有益的收录,但也许会对百度的快照产生一定的影响。更新。
摘要:网站“抓取诊断”失败的原因很多。除了参考官方提示外,您还需要自己一个人排除。以上内容仅供参考。
蝙蝠侠的IT转载需要授权! 查看全部
网站“抓取诊断”失败原因有哪些?怎么解决?
对于SEO人员来说,他们经常使用百度的官方工具来审查该网站,并检查网站的各项指标是否符合预期。其中,“爬网诊断”是网站管理员经常使用的工具。许多网站管理员说,在使用网站“提取诊断”时,经常会提示诊断失败,那么问题出在什么地方?
网站抓取诊断·概述
百度爬虫诊断工具的作用主要是从百度蜘蛛的角度了解网站的内容。反馈结果代表了Spider对网站内容的理解。通常网站爬行诊断失败,并且与百度蜘蛛的爬行有直接关系。
网站“抓取诊断”失败的原因是什么?
1、 Robots.txt被禁止
如果您阻止百度抓取网站 Robots.txt中的某个目录,则当您在该目录中生成内容时,百度将很难抓取该目录下的内容,并且抓取诊断也会提示失败出现。
2、 网站访问速度
许多网站管理员说,在本地测试中,我的网站返回了HTTP状态代码200,但是抓取诊断始终显示抓取正在进行中,没有反馈结果。
由于服务器线路不同,百度蜘蛛的爬网速度可能会有较长的延迟,这会导致爬网诊断在可以清晰访问时失败的问题。
遇到此问题时,您需要定期监视服务器的访问速度并进行网站打开速度优化。
3、 CDN缓存更新
我们知道更新CDN缓存需要花费时间。尽管您可以在管理平台的后台实时进行在线更新,但是由于不同服务提供商的技术不对称,通常会导致一定的时间延迟。
这势必会导致网站抓取失败。
4、跳转到抓取诊断
如果您更新旧内容并修改网站版本,并使用301或302进行重定向,由于配置错误,重定向次数过多,也会导致百度抓取失败的问题。
5、 DNS缓存
由于存在DNS缓存,当您在本地查询URL时,您可以正常访问它,但是当上述常见问题消除后,抓取诊断仍会提示失败,那么您需要更新本地DNS缓存,或使用代理IP进行审核网站都很容易访问。
网站关于“爬网诊断”的常见问题:
对于百度爬虫诊断工具,SEO顾问最常问的问题是:百度爬虫诊断是否有帮助收录?
从目前许多SEO人员的反馈结果来看,尚无合理的数据来支持它,可以证明爬行诊断工具对百度是有益的收录,但也许会对百度的快照产生一定的影响。更新。
摘要:网站“抓取诊断”失败的原因很多。除了参考官方提示外,您还需要自己一个人排除。以上内容仅供参考。
蝙蝠侠的IT转载需要授权!
互联网不断涌现出新的网页工具可供使用
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-04-02 01:08
新的信息,新的设计模式和大量的c不断在Internet上出现。将该数据组织到唯一的库中并不容易。但是,有许多出色的网络爬网工具可用。
1. ProxyCrawl
使用代理爬网API,您可以爬网Web上的任何网站 /平台。具有代理支持,验证码绕过以及基于动态内容抓取JavaScript页面的优势。
它可以免费获得1,000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2. Scrapy
Scrapy是一个开放源代码项目,为爬网网页提供支持。 Scrapy抓取框架出色地完成了从网站和网页中提取数据的工作。
最重要的是,Scrapy可用于挖掘数据,监视数据模式以及对大型任务执行自动测试。强大的功能可以与ProxyCrawl ***集成。使用Scrapy,由于具有内置工具,因此选择内容源(HTML和XML)非常容易。您还可以使用Scrapy API扩展提供的功能。
3.抓
Grab是用于创建自定义Web爬网规则集的基于Python的框架。使用Grab,可以为小型个人项目创建爬网机制,还可以构建大型动态爬网任务,这些任务可以同时扩展到数百万个页面。
内置API提供了一种执行网络请求的方法,还可以处理已删除的内容。 Grab提供的另一个API称为Spider。使用Spider API,您可以使用自定义类创建异步采集器。
4.雪貂
Ferret是一种相当新的Web抓取工具,在开源社区中获得了相当大的关注。 Ferret的目标是提供更简洁的客户端爬网解决方案。例如,允许开发人员编写不必依赖于应用程序状态的采集器。
此外,雪貂使用自定义的声明性语言来避免构建系统的复杂性。相反,您可以编写严格的规则以从任何站点抓取数据。
5. X射线
由于X-Ray和Osmosis等库的可用性,使用Node.js爬网非常容易。
6. Diffbot
Diffbot是市场上的新玩家。您甚至不必编写太多代码,因为Diffbot的AI算法可以在无需手动说明的情况下从网站页面解密结构化数据。
7. PhantomJS Cloud
PhantomJS Cloud是PhantomJS浏览器的SaaS替代产品。使用PhantomJS Cloud,您可以直接从网页内部获取数据,还可以生成可视文件,并将页面显示为PDF文档。
PhantomJS本身是一个浏览器,这意味着您可以像浏览器一样加载和执行页面资源。如果您手头的任务需要获取许多基于JavaScript的网站,则此功能特别有用。
[编辑推荐]
三大运营商的2018年运营数据,他们今年表现如何?分享有关将在2019年塑造数据中心行业的八种趋势的观点|物联网数据需要共享协议才能优雅地读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势 查看全部
互联网不断涌现出新的网页工具可供使用
新的信息,新的设计模式和大量的c不断在Internet上出现。将该数据组织到唯一的库中并不容易。但是,有许多出色的网络爬网工具可用。
1. ProxyCrawl
使用代理爬网API,您可以爬网Web上的任何网站 /平台。具有代理支持,验证码绕过以及基于动态内容抓取JavaScript页面的优势。
它可以免费获得1,000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2. Scrapy
Scrapy是一个开放源代码项目,为爬网网页提供支持。 Scrapy抓取框架出色地完成了从网站和网页中提取数据的工作。
最重要的是,Scrapy可用于挖掘数据,监视数据模式以及对大型任务执行自动测试。强大的功能可以与ProxyCrawl ***集成。使用Scrapy,由于具有内置工具,因此选择内容源(HTML和XML)非常容易。您还可以使用Scrapy API扩展提供的功能。
3.抓
Grab是用于创建自定义Web爬网规则集的基于Python的框架。使用Grab,可以为小型个人项目创建爬网机制,还可以构建大型动态爬网任务,这些任务可以同时扩展到数百万个页面。
内置API提供了一种执行网络请求的方法,还可以处理已删除的内容。 Grab提供的另一个API称为Spider。使用Spider API,您可以使用自定义类创建异步采集器。
4.雪貂
Ferret是一种相当新的Web抓取工具,在开源社区中获得了相当大的关注。 Ferret的目标是提供更简洁的客户端爬网解决方案。例如,允许开发人员编写不必依赖于应用程序状态的采集器。
此外,雪貂使用自定义的声明性语言来避免构建系统的复杂性。相反,您可以编写严格的规则以从任何站点抓取数据。
5. X射线
由于X-Ray和Osmosis等库的可用性,使用Node.js爬网非常容易。
6. Diffbot
Diffbot是市场上的新玩家。您甚至不必编写太多代码,因为Diffbot的AI算法可以在无需手动说明的情况下从网站页面解密结构化数据。
7. PhantomJS Cloud
PhantomJS Cloud是PhantomJS浏览器的SaaS替代产品。使用PhantomJS Cloud,您可以直接从网页内部获取数据,还可以生成可视文件,并将页面显示为PDF文档。
PhantomJS本身是一个浏览器,这意味着您可以像浏览器一样加载和执行页面资源。如果您手头的任务需要获取许多基于JavaScript的网站,则此功能特别有用。
[编辑推荐]
三大运营商的2018年运营数据,他们今年表现如何?分享有关将在2019年塑造数据中心行业的八种趋势的观点|物联网数据需要共享协议才能优雅地读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势
网页抓取工具EasyWeb功能特点及解决方案(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-03-31 06:14
网络爬网工具Easy Web是用于爬网网页的外部软件。网站管理员的朋友一定会使用它。您无需了解代码。它可以直接提取内容(文本,URL,图片,文件),并转换为多种格式。
软件说明
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单网站到复杂网站抓取内容。
但无需进行任何工作即可构建网络抓取项目。
在此页面上,我们将仅向您显示众所周知的功能。
使我们的网络采集器易于使用。
功能
1.轻松创建提取项目
对于任何用户而言,基于向导窗口创建新项目绝非易事。
项目安装向导将逐步指导您。
直到所有必要的任务完成。
以下是一些主要步骤:
第1步:输入一个起始URL,即起始页面,然后刷新屏幕即可加载该网页。
通常是指向报废产品列表的链接
第2步:输入关键词提交表单并获取结果。如果网站需要它,则在大多数情况下可以跳过此步骤;
第3步:在列表中选择一个项目,然后选择该项目的数据列的抓取效果;
第4步:选择下一页的URL来访问其他网页。
2.在多个线程中抓取数据
在网络争夺项目中,需要抓取成千上万的链接才能收获。
传统的刮板可能要花费您数小时或数天的时间。
但是,简单的Web提取可以同时运行多个线程来浏览多达24个不同的网页。
为了节省您的宝贵时间,请等待收获的结果。
因此,简单的Web提取可以利用系统的最佳性能。
旁边的动画图像显示了8个线程的提取。
3.从数据中加载各种提取的数据
一些高度动态的网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
这是事实,不仅是原创网页,而且是专业网络抓取工具所面临的挑战。
因为Web内容未嵌入HTML源中。
但是,简单的Web提取具有非常强大的技术。
甚至使新手都可以从网站类型的数据中获取数据。
此外,我们的网站抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如,联系人列表中的某些特定网站。
在这里,大多数网页抓取工具继续采集大量的重复信息。
很快就变得乏味。但是,请不要担心这个噩梦。
因为简单的Web提取具有避免它的聪明功能。
4.随时自动执行项目
通过一个简单的网络嵌入并自动运行调度程序。
您可以安排运行网络抓取项目,而无需任何操作。
计划的任务运行,并将抓取的结果导出到目的地。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
为确保仅保留新数据。
支持的时间表类型:
-在项目中每小时运行一次
-在项目中每天运行
-在特定时间运行项目
5.将数据导出为任何格式
我们最好的网络抓取工具支持多种格式以导出抓取的网站数据。
例如:CSV,访问权限,XML,HTML,SQL 等。
您还可以直接提交由它引起的任何类型的数据库目标。
通过ODBC连接。如果您的网站有提交表格。 查看全部
网页抓取工具EasyWeb功能特点及解决方案(一)
网络爬网工具Easy Web是用于爬网网页的外部软件。网站管理员的朋友一定会使用它。您无需了解代码。它可以直接提取内容(文本,URL,图片,文件),并转换为多种格式。
软件说明
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单网站到复杂网站抓取内容。
但无需进行任何工作即可构建网络抓取项目。
在此页面上,我们将仅向您显示众所周知的功能。
使我们的网络采集器易于使用。
功能
1.轻松创建提取项目
对于任何用户而言,基于向导窗口创建新项目绝非易事。
项目安装向导将逐步指导您。
直到所有必要的任务完成。
以下是一些主要步骤:
第1步:输入一个起始URL,即起始页面,然后刷新屏幕即可加载该网页。
通常是指向报废产品列表的链接
第2步:输入关键词提交表单并获取结果。如果网站需要它,则在大多数情况下可以跳过此步骤;
第3步:在列表中选择一个项目,然后选择该项目的数据列的抓取效果;
第4步:选择下一页的URL来访问其他网页。
2.在多个线程中抓取数据
在网络争夺项目中,需要抓取成千上万的链接才能收获。
传统的刮板可能要花费您数小时或数天的时间。
但是,简单的Web提取可以同时运行多个线程来浏览多达24个不同的网页。
为了节省您的宝贵时间,请等待收获的结果。
因此,简单的Web提取可以利用系统的最佳性能。
旁边的动画图像显示了8个线程的提取。
3.从数据中加载各种提取的数据
一些高度动态的网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
这是事实,不仅是原创网页,而且是专业网络抓取工具所面临的挑战。
因为Web内容未嵌入HTML源中。
但是,简单的Web提取具有非常强大的技术。
甚至使新手都可以从网站类型的数据中获取数据。
此外,我们的网站抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如,联系人列表中的某些特定网站。
在这里,大多数网页抓取工具继续采集大量的重复信息。
很快就变得乏味。但是,请不要担心这个噩梦。
因为简单的Web提取具有避免它的聪明功能。
4.随时自动执行项目
通过一个简单的网络嵌入并自动运行调度程序。
您可以安排运行网络抓取项目,而无需任何操作。
计划的任务运行,并将抓取的结果导出到目的地。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
为确保仅保留新数据。
支持的时间表类型:
-在项目中每小时运行一次
-在项目中每天运行
-在特定时间运行项目
5.将数据导出为任何格式
我们最好的网络抓取工具支持多种格式以导出抓取的网站数据。
例如:CSV,访问权限,XML,HTML,SQL 等。
您还可以直接提交由它引起的任何类型的数据库目标。
通过ODBC连接。如果您的网站有提交表格。
职场求职高效办公易企秀,100个在线h5制作工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-03-29 07:03
网站内容抓取工具汇总个性化个性化体验百度网盘pc手机端多种下载方式清爽不拖泥带水免费在线解压gif网址云端格式转换工具二维码扫描生成分享我的电脑链接到微信*使用很简单4快速批量下载工具h5网址导航快速学习,名家公开课,职场求职高效办公
易企秀,100个在线h5制作工具_微小宝|免费h5页面制作工具
bilibili
一丁引擎_搜索引擎,互联网短视频素材收集平台,找,
vidocity,
每天一条。
pc端,关键词搜索:用pc上快手做视频pc端,关键词搜索:用pc快手上爱奇艺做视频微信公众号搜索公众号名称:qualityhotvideo有人已经制作了一些,
视频下载器
网易云音乐用的,
给大家推荐五个比较好用的在线视频下载的平台视频下载器网:一度蜜视频下载器:专业的免费视频下载平台
最新在快手短视频上火了一位导师,给大家一个可以直接从一些小姐姐朋友圈偷窥到她所有的私人信息的平台,有兴趣的小伙伴可以去试试。点击这里进入下载链接:miko小姐姐(男友是真人)开直播了现在,你们也可以看到这位小姐姐,然后过一段时间,你会看到很多又有兴趣的小姐姐。支持多国语言,关注我的公众号:优沃移动;后台回复【视频】可以领取一个下载秘籍下载秘籍:文件夹内的个人微信号、个人手机号和验证方式都告诉你,不保证是最快最稳最安全,但我相信大家都是奔着安全和效率去的,而这份安全包括:程序和脚本的安全;注册私密小号,加到购物车。
解决你的很多疑惑,我相信很多小伙伴应该对从别人直播的个人微信号里偷窥购物车都是很纠结的,甚至以为里面有你所有的信息。在【老师】这里,我把关于购物车的所有秘密都告诉你,可以自行检验验证。有意者可以微信联系我一起成长,也可以加wx联系我领取视频下载秘籍。 查看全部
职场求职高效办公易企秀,100个在线h5制作工具
网站内容抓取工具汇总个性化个性化体验百度网盘pc手机端多种下载方式清爽不拖泥带水免费在线解压gif网址云端格式转换工具二维码扫描生成分享我的电脑链接到微信*使用很简单4快速批量下载工具h5网址导航快速学习,名家公开课,职场求职高效办公
易企秀,100个在线h5制作工具_微小宝|免费h5页面制作工具
bilibili
一丁引擎_搜索引擎,互联网短视频素材收集平台,找,
vidocity,
每天一条。
pc端,关键词搜索:用pc上快手做视频pc端,关键词搜索:用pc快手上爱奇艺做视频微信公众号搜索公众号名称:qualityhotvideo有人已经制作了一些,
视频下载器
网易云音乐用的,
给大家推荐五个比较好用的在线视频下载的平台视频下载器网:一度蜜视频下载器:专业的免费视频下载平台
最新在快手短视频上火了一位导师,给大家一个可以直接从一些小姐姐朋友圈偷窥到她所有的私人信息的平台,有兴趣的小伙伴可以去试试。点击这里进入下载链接:miko小姐姐(男友是真人)开直播了现在,你们也可以看到这位小姐姐,然后过一段时间,你会看到很多又有兴趣的小姐姐。支持多国语言,关注我的公众号:优沃移动;后台回复【视频】可以领取一个下载秘籍下载秘籍:文件夹内的个人微信号、个人手机号和验证方式都告诉你,不保证是最快最稳最安全,但我相信大家都是奔着安全和效率去的,而这份安全包括:程序和脚本的安全;注册私密小号,加到购物车。
解决你的很多疑惑,我相信很多小伙伴应该对从别人直播的个人微信号里偷窥购物车都是很纠结的,甚至以为里面有你所有的信息。在【老师】这里,我把关于购物车的所有秘密都告诉你,可以自行检验验证。有意者可以微信联系我一起成长,也可以加wx联系我领取视频下载秘籍。
远程办公的效率和质量,核心是自我管理的自驱力
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-03-28 04:00
1.之前说过
受这一流行病的影响,我相信大多数人仍在远离家乡的地方工作。首先,远程工作的最简单方法是拨打电话并发送微信。我们每天都这样做。后来,一系列工具(例如公司微信,各种在线会议工具,在线文档等)可以提高同事之间的协作效率,突破物理限制并在不上班的情况下创造价值。当您无法离线聚会时,请保持工作不间断。
但是在大多数情况下,内部协作办公室只能解决内部效率问题。对于大多数公司和企业主而言,办公室工作的目的是在外部与消费者和客户建立联系。为了真正地工作,有必要做生意。
换句话说,我认为远程办公的本质在于,除了允许每个人进行合作和共同努力(意义不只是纯粹的内部协作)之外,后续行动的真正价值还必须是外部的,并且让公司员工可以与外部消费者建立联系。
当然,我们今天的重点不在谈论远程办公。远程办公的效率和质量是自我管理的核心。
在日常工作中,无论是开发系学生,测试系学生还是运维维护系学生,必不可少的一些数据包捕获工具。今天,我将向您推荐4种采集器捕获工件。
2.让我们聊一聊:抓取数据包的原理
采集器的基本原理是模拟客户端(可以是浏览器或APP)以将HTTP请求发送到远程服务器。我们需要知道目标服务器的HOST,URI,请求方法,请求参数,请求标头和请求正文。网页网站可以通过Chrome浏览器找到此信息。但是对于APP采集器,似乎有些无奈。这时,我们必须借用一些数据包捕获工具,以帮助我们分析APP背后的秘密。数据包捕获的本质是引入额外的中间人代理层,如下图所示。
添加一个知识点。对于新手来说,有必要区分数据包捕获和采集器。两种不同的概念:数据包捕获是查看和分析网络请求,以及了解另一方的过程。爬网程序模拟网络请求。当您了解另一方时,您可以模拟用于请求数据的工具。两者相辅相成。首先,捕获并分析程序,然后对程序进行仿真。这是爬虫的开发过程,以达到您的爬虫的目的。
3.数据包捕获工件之一:提琴手
Fiddler是Windows平台上最好的可视数据包捕获工具,也是最著名的HTTP代理工具。它具有非常强大的功能。除了清楚地了解每个请求和响应之外,您还可以设置断点并修改请求数据并拦截响应内容。
从官方网站下载:
此外,您可以通过修改脚本来自定义规则并添加自己的特殊处理,但是由于它是用C#编写的,因此,如果要编写复杂的脚本,则需要了解C#。
过滤器功能允许您通过正则表达式规则显示您关心的请求。如果只需要捕获特定的网站数据,则此功能非常有用,可以删除很多干扰信息。
在Fiddler的左下角有一个名为QuickExec的命令行工具,使您可以直接输入命令,如上面的命令行说明所示。
常见命令是:
帮助:打开官方用法页面介绍,所有命令都会列出
cls:清除屏幕
选择:选择会话的命令
?. png:用于选择带有png后缀的图片
bpu:请求被拦截
@主持人突出显示该主持人的所有会话,例如@
=:等于指定的请求方法或突出显示状态代码,例如,输入:= 502
4.捕获工件2:查尔斯
Charles是跨平台的数据包捕获工具,也是macOS平台下最好的数据包捕获分析工具之一。它还提供了具有简单界面的GUI界面。基本功能包括HTTP和HTTPS请求数据包捕获,支持对于修改请求参数,最新的Charles 4还支持HTTP / 2。当然,它也支持Windows和Linux,但是此工具是收费的。免费试用30天,试用期结束后功能会受到限制。
Charles的当前最新版本为4. 5. 6,官方网站地址如下:
查尔斯在线破解工具:
查尔斯还经常用在一些简单的弱网络仿真工具中,打开Proxy-> Throttle Settings,界面如下:
PS:此外,用于模拟弱网络的常用工具有:Fiddler,FaceBook工具ATC弱网络模拟。
5.数据包捕获工件3:AnyProxy
AnyProxy是阿里巴巴的开源HTTP数据包捕获工具,基于NodeJS。优点是它支持二次开发并可以自定义请求处理逻辑。如果您可以编写JS,则需要同时进行一些自定义处理,那么AnyProxy非常适合。它支持HTTPS并提供GUI界面。 GitHub地址:
共同特点:
anyproxy的详细介绍:
6.数据包捕获工件四:mitmproxy
它不仅是跨平台的,而且还提供了一种命令行交互模式,这种模式非常(壮)客户(bi),并且是通过Python语言实现的。对于Pythoner来说,这无疑是一个很大的好处。 。 mitmproxy主要收录3个工具:
GitHub地址:
mitmproxy官方网站:
Mitmproxy文档介绍:
最后,作为分享,作者最常用的捕获工具是Charles和mitmproxy。 查看全部
远程办公的效率和质量,核心是自我管理的自驱力
1.之前说过
受这一流行病的影响,我相信大多数人仍在远离家乡的地方工作。首先,远程工作的最简单方法是拨打电话并发送微信。我们每天都这样做。后来,一系列工具(例如公司微信,各种在线会议工具,在线文档等)可以提高同事之间的协作效率,突破物理限制并在不上班的情况下创造价值。当您无法离线聚会时,请保持工作不间断。
但是在大多数情况下,内部协作办公室只能解决内部效率问题。对于大多数公司和企业主而言,办公室工作的目的是在外部与消费者和客户建立联系。为了真正地工作,有必要做生意。
换句话说,我认为远程办公的本质在于,除了允许每个人进行合作和共同努力(意义不只是纯粹的内部协作)之外,后续行动的真正价值还必须是外部的,并且让公司员工可以与外部消费者建立联系。
当然,我们今天的重点不在谈论远程办公。远程办公的效率和质量是自我管理的核心。
在日常工作中,无论是开发系学生,测试系学生还是运维维护系学生,必不可少的一些数据包捕获工具。今天,我将向您推荐4种采集器捕获工件。
2.让我们聊一聊:抓取数据包的原理
采集器的基本原理是模拟客户端(可以是浏览器或APP)以将HTTP请求发送到远程服务器。我们需要知道目标服务器的HOST,URI,请求方法,请求参数,请求标头和请求正文。网页网站可以通过Chrome浏览器找到此信息。但是对于APP采集器,似乎有些无奈。这时,我们必须借用一些数据包捕获工具,以帮助我们分析APP背后的秘密。数据包捕获的本质是引入额外的中间人代理层,如下图所示。
添加一个知识点。对于新手来说,有必要区分数据包捕获和采集器。两种不同的概念:数据包捕获是查看和分析网络请求,以及了解另一方的过程。爬网程序模拟网络请求。当您了解另一方时,您可以模拟用于请求数据的工具。两者相辅相成。首先,捕获并分析程序,然后对程序进行仿真。这是爬虫的开发过程,以达到您的爬虫的目的。
3.数据包捕获工件之一:提琴手
Fiddler是Windows平台上最好的可视数据包捕获工具,也是最著名的HTTP代理工具。它具有非常强大的功能。除了清楚地了解每个请求和响应之外,您还可以设置断点并修改请求数据并拦截响应内容。
从官方网站下载:
此外,您可以通过修改脚本来自定义规则并添加自己的特殊处理,但是由于它是用C#编写的,因此,如果要编写复杂的脚本,则需要了解C#。
过滤器功能允许您通过正则表达式规则显示您关心的请求。如果只需要捕获特定的网站数据,则此功能非常有用,可以删除很多干扰信息。
在Fiddler的左下角有一个名为QuickExec的命令行工具,使您可以直接输入命令,如上面的命令行说明所示。
常见命令是:
帮助:打开官方用法页面介绍,所有命令都会列出
cls:清除屏幕
选择:选择会话的命令
?. png:用于选择带有png后缀的图片
bpu:请求被拦截
@主持人突出显示该主持人的所有会话,例如@
=:等于指定的请求方法或突出显示状态代码,例如,输入:= 502
4.捕获工件2:查尔斯
Charles是跨平台的数据包捕获工具,也是macOS平台下最好的数据包捕获分析工具之一。它还提供了具有简单界面的GUI界面。基本功能包括HTTP和HTTPS请求数据包捕获,支持对于修改请求参数,最新的Charles 4还支持HTTP / 2。当然,它也支持Windows和Linux,但是此工具是收费的。免费试用30天,试用期结束后功能会受到限制。
Charles的当前最新版本为4. 5. 6,官方网站地址如下:
查尔斯在线破解工具:
查尔斯还经常用在一些简单的弱网络仿真工具中,打开Proxy-> Throttle Settings,界面如下:
PS:此外,用于模拟弱网络的常用工具有:Fiddler,FaceBook工具ATC弱网络模拟。
5.数据包捕获工件3:AnyProxy
AnyProxy是阿里巴巴的开源HTTP数据包捕获工具,基于NodeJS。优点是它支持二次开发并可以自定义请求处理逻辑。如果您可以编写JS,则需要同时进行一些自定义处理,那么AnyProxy非常适合。它支持HTTPS并提供GUI界面。 GitHub地址:
共同特点:
anyproxy的详细介绍:
6.数据包捕获工件四:mitmproxy
它不仅是跨平台的,而且还提供了一种命令行交互模式,这种模式非常(壮)客户(bi),并且是通过Python语言实现的。对于Pythoner来说,这无疑是一个很大的好处。 。 mitmproxy主要收录3个工具:
GitHub地址:
mitmproxy官方网站:
Mitmproxy文档介绍:
最后,作为分享,作者最常用的捕获工具是Charles和mitmproxy。

