
网站内容抓取工具
html提取文本工具推荐大全:收集电子邮件地址、竞争分析
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-05-17 22:17
推荐的html文本提取工具:
采集电子邮件地址,竞争分析,网站检查,价格分析和客户数据采集-这些可能就是您需要从HTML文档中提取文本和其他数据的一些原因。
不幸的是,手动执行此操作既痛苦又效率低下,在某些情况下甚至是不可能的。
幸运的是,现在有各种各样的工具可以满足这些要求。以下7种工具,从为初学者和小型项目设计的非常简单的工具,到需要一定数量的编码知识并且为较大和更困难的任务设计的高级工具。
Iconico HTML文本提取器(Iconico HTML文本提取器)
想象一下,您正在浏览竞争对手的网站,然后要提取文本内容,或者要查看页面后面的HTML代码。不幸的是,您发现右键按钮被禁用,复制和粘贴也被禁用。许多Web开发人员现在正在采取措施来禁用查看源代码或锁定其页面。
幸运的是,Iconico具有HTML文本提取器,您可以使用它来绕过所有这些限制,并且该产品非常易于使用。您可以突出显示和复制文本,并且提取功能的操作就像浏览Internet一样容易。
UiPathUI
Path具有一组自动化的处理工具,其中包括一个Web内容爬网实用程序。要使用该工具并获取几乎所有您需要的数据,非常简单-只需打开页面,转到该工具中的“设计”菜单,然后单击“网页抓取”即可。除了Web采集器之外,屏幕采集器还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页上获取文本,表格数据和其他相关信息。
Mozenda
Mozenda允许用户提取Web数据并将该信息导出到各种智能业务工具。它不仅可以提取文本内容,还可以从PDF文件提取图像,文件和内容。然后,您可以将这些数据导出到XML文件,CSV文件,JSON或选择使用API。提取并导出数据后,您可以使用BI工具进行分析和报告。
HTMLtoText
此在线工具可以从HTML源代码甚至是URL中提取文本。您所需要做的就是复制和粘贴,提供URL或上传文件。单击选项按钮,使该工具知道所需的输出格式和其他一些详细信息,然后单击“转换”,您将获得所需的文本信息。
Octoparse
Octoparse的特征在于它提供了一个“单击”用户界面。即使是没有编码知识的用户也可以从网站中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板上提取工作清单等功能。该工具适用于动态和静态网页以及云采集(配置了采集任务时,也可以是采集数据)。它提供了一个免费版本,对于大多数使用情况而言,这已经足够了,而付费版本则具有更丰富的功能。
如果您爬行网站进行竞争分析,则可能会因为此活动而被禁止。因为Octoparse收录一个功能,可以在一个循环中标识您的IP地址,并且可以禁止您通过IP使用它。
Scrapy
这个免费的开源工具使用网络爬虫从网站中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意学习以自己的方式使用它,那么Scrapy是爬网大型Web项目的理想选择。此工具已被CareerBuilder和其他主要品牌使用。因为它是一个开源工具,所以它为用户提供了很多良好的社区支持。
和服
Kimono是一个免费工具,可以从网页获取非结构化数据,并将信息提取为具有XML文件的结构化格式。该工具可以交互使用,也可以创建计划的作业以在特定时间提取所需的数据。您可以从搜索引擎结果,网页甚至幻灯片演示中提取数据。
最重要的是,当您设置每个工作流程时,和服将创建一个API。这意味着当您返回网站提取更多数据时,无需重新发明轮子。
结论
如果遇到需要从一个或多个网页提取非结构化数据的任务,则此列表中至少有一个工具应收录所需的解决方案。而且,无论您的预期价格是多少,您都应该能够找到所需的工具。
清楚理解并确定最适合您的。您知道,大数据在蓬勃发展的业务发展中的重要性以及采集所需信息的能力对您也至关重要。 查看全部
html提取文本工具推荐大全:收集电子邮件地址、竞争分析
推荐的html文本提取工具:
采集电子邮件地址,竞争分析,网站检查,价格分析和客户数据采集-这些可能就是您需要从HTML文档中提取文本和其他数据的一些原因。
不幸的是,手动执行此操作既痛苦又效率低下,在某些情况下甚至是不可能的。
幸运的是,现在有各种各样的工具可以满足这些要求。以下7种工具,从为初学者和小型项目设计的非常简单的工具,到需要一定数量的编码知识并且为较大和更困难的任务设计的高级工具。

Iconico HTML文本提取器(Iconico HTML文本提取器)
想象一下,您正在浏览竞争对手的网站,然后要提取文本内容,或者要查看页面后面的HTML代码。不幸的是,您发现右键按钮被禁用,复制和粘贴也被禁用。许多Web开发人员现在正在采取措施来禁用查看源代码或锁定其页面。
幸运的是,Iconico具有HTML文本提取器,您可以使用它来绕过所有这些限制,并且该产品非常易于使用。您可以突出显示和复制文本,并且提取功能的操作就像浏览Internet一样容易。
UiPathUI
Path具有一组自动化的处理工具,其中包括一个Web内容爬网实用程序。要使用该工具并获取几乎所有您需要的数据,非常简单-只需打开页面,转到该工具中的“设计”菜单,然后单击“网页抓取”即可。除了Web采集器之外,屏幕采集器还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页上获取文本,表格数据和其他相关信息。
Mozenda
Mozenda允许用户提取Web数据并将该信息导出到各种智能业务工具。它不仅可以提取文本内容,还可以从PDF文件提取图像,文件和内容。然后,您可以将这些数据导出到XML文件,CSV文件,JSON或选择使用API。提取并导出数据后,您可以使用BI工具进行分析和报告。
HTMLtoText
此在线工具可以从HTML源代码甚至是URL中提取文本。您所需要做的就是复制和粘贴,提供URL或上传文件。单击选项按钮,使该工具知道所需的输出格式和其他一些详细信息,然后单击“转换”,您将获得所需的文本信息。
Octoparse
Octoparse的特征在于它提供了一个“单击”用户界面。即使是没有编码知识的用户也可以从网站中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板上提取工作清单等功能。该工具适用于动态和静态网页以及云采集(配置了采集任务时,也可以是采集数据)。它提供了一个免费版本,对于大多数使用情况而言,这已经足够了,而付费版本则具有更丰富的功能。
如果您爬行网站进行竞争分析,则可能会因为此活动而被禁止。因为Octoparse收录一个功能,可以在一个循环中标识您的IP地址,并且可以禁止您通过IP使用它。
Scrapy
这个免费的开源工具使用网络爬虫从网站中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意学习以自己的方式使用它,那么Scrapy是爬网大型Web项目的理想选择。此工具已被CareerBuilder和其他主要品牌使用。因为它是一个开源工具,所以它为用户提供了很多良好的社区支持。
和服
Kimono是一个免费工具,可以从网页获取非结构化数据,并将信息提取为具有XML文件的结构化格式。该工具可以交互使用,也可以创建计划的作业以在特定时间提取所需的数据。您可以从搜索引擎结果,网页甚至幻灯片演示中提取数据。
最重要的是,当您设置每个工作流程时,和服将创建一个API。这意味着当您返回网站提取更多数据时,无需重新发明轮子。
结论
如果遇到需要从一个或多个网页提取非结构化数据的任务,则此列表中至少有一个工具应收录所需的解决方案。而且,无论您的预期价格是多少,您都应该能够找到所需的工具。
清楚理解并确定最适合您的。您知道,大数据在蓬勃发展的业务发展中的重要性以及采集所需信息的能力对您也至关重要。
抓取网络小说生成文本文件的软件大小版本说明下载地址
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-05-16 00:12
网络图书抓取器主要用于抓取在线小说以生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后根据章节顺序获取小说内容,然后将其合并。抓取过程可以随时中断,并且在程序关闭后可以继续执行上一个任务。
相关软件的软件大小和版本说明下载链接
网络图书抓取器主要用于抓取在线小说以生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后根据章节顺序获取小说内容,然后将其合并。抓取过程可以随时中断,并且在程序关闭后可以继续执行上一个任务。
软件功能
1、本章调整:提取目录后,可以执行调整操作,例如移动,删除和倒序。调整将直接影响最终书籍,也将按调整后的章节顺序输出。
2、自动重试:在爬网期间,由于网络因素的影响,可能会发生爬网失败。该程序可能会自动重试,直到成功为止,或者您可以暂时中断爬网(中断后关闭程序不会影响进度),并在网络状况良好时重试。
3、停止并继续:可以随时停止搜寻过程,并且退出程序后进度不会受到影响(章节信息将保存在记录中,并且在运行注意:需要先使用“停止”按钮中断然后退出程序,如果直接退出,将无法恢复。)
4、一键抓取:也称为“傻瓜模式”,基本上可以实现自动抓取和合并功能,并直接输出最终的文本文件。您可能需要在最前面输入最基本的URL,在前面保存位置和其他信息(会有明显的操作提示),在调整章节之后也可以使用一键式抓取,抓取和合并操作将自动完成
5、适用网站:已收录10个适用的网站(您可以在选择后快速打开网站来查找所需的书),它还可以自动应用适当的代码,并且也可以用于其他小说网站测试,如果结合使用,则可以将其手动添加到配置文件中以备后用。
6、制作电子书的便捷性:您可以在设置文件中添加每个章节名称的前缀和后缀,这为后期制作电子书的目录带来了极大的便利。
查看全部
抓取网络小说生成文本文件的软件大小版本说明下载地址
网络图书抓取器主要用于抓取在线小说以生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后根据章节顺序获取小说内容,然后将其合并。抓取过程可以随时中断,并且在程序关闭后可以继续执行上一个任务。
相关软件的软件大小和版本说明下载链接
网络图书抓取器主要用于抓取在线小说以生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后根据章节顺序获取小说内容,然后将其合并。抓取过程可以随时中断,并且在程序关闭后可以继续执行上一个任务。

软件功能
1、本章调整:提取目录后,可以执行调整操作,例如移动,删除和倒序。调整将直接影响最终书籍,也将按调整后的章节顺序输出。
2、自动重试:在爬网期间,由于网络因素的影响,可能会发生爬网失败。该程序可能会自动重试,直到成功为止,或者您可以暂时中断爬网(中断后关闭程序不会影响进度),并在网络状况良好时重试。
3、停止并继续:可以随时停止搜寻过程,并且退出程序后进度不会受到影响(章节信息将保存在记录中,并且在运行注意:需要先使用“停止”按钮中断然后退出程序,如果直接退出,将无法恢复。)
4、一键抓取:也称为“傻瓜模式”,基本上可以实现自动抓取和合并功能,并直接输出最终的文本文件。您可能需要在最前面输入最基本的URL,在前面保存位置和其他信息(会有明显的操作提示),在调整章节之后也可以使用一键式抓取,抓取和合并操作将自动完成
5、适用网站:已收录10个适用的网站(您可以在选择后快速打开网站来查找所需的书),它还可以自动应用适当的代码,并且也可以用于其他小说网站测试,如果结合使用,则可以将其手动添加到配置文件中以备后用。
6、制作电子书的便捷性:您可以在设置文件中添加每个章节名称的前缀和后缀,这为后期制作电子书的目录带来了极大的便利。

网页抓取工具优采云采集器V9的抓取原理是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-05-16 00:11
如果Internet像广阔的海洋,那么它是一种潜艇探测器,可以定位宝藏的确切位置并实现智能捕鱼。这种类比的原因是Internet庞大且瞬息万变。作为信息采集领域的人,每当他看到一种出色的内容时,他都希望进行全面的操作采集,但这就像在大海捞针中寻找针头一样,这既费时又费力。因此,提供一种网络抓取工具,可以自动对Internet上的数据进行抓取,并进行智能的分类和分析,具有重要的意义。
Internet上的数据有多种格式,包括一般类别,例如图片,文件和文本。当我们使用Web爬网工具进行爬网时,是否可以捕获所有网页和各种格式?确认使用最广泛的Web爬网工具。
通常优采云 采集器吸引最多的文字和图片是网站网站管理员和APP后端管理员。他们通常需要集成和汇总适合自己位置的数据,然后找出适合时间的数据呈现给用户。例如,新闻类别和图形欣赏类别都需要过滤Internet中的图形数据。 Web爬网工具优采云 采集器 V9的爬网原理是首先获取URL,然后执行与该URL对应的页面的源代码。分析,提取速度快,错误率低,可以定期运行以自动更新数据。
我不得不提到,对于有此类需求的用户,优采云 采集器 V9还提供了数据处理和发布功能,即,不仅可以实现爬网,还可以对数据进行脱敏和过滤。等待处理,最后自动发布到目标数据库,完全智能且一致的操作受到用户的青睐。
对于学者来说,最流行的格式是文件,因为大量文档是在Internet上公开共享的,并且许多材料都是以文档和压缩文件的格式。学者一一下载,不仅浪费了宝贵的科研时间,而且导致工作效率下降。如果您可以模拟人为操作来打开网页,则下载和保存文件将花费两倍的努力,结果是两倍。优采云 采集器 V9根据用户的需求,开发了文件检测下载功能,并且支持自动登录,这是一种解决方案。部分内容要求登录可见。
自动化工具是解放人类双手的最佳武器。因此,借助Web爬网工具,需要排序数据的业务区域(例如,舆论监视,公司营销和视频链接)也更加方便。借助Web爬行工具优采云 采集器 V9软件,可以轻松实现图片,文本,文件,链接等各种数据类型的整个网络采集。 查看全部
网页抓取工具优采云采集器V9的抓取原理是什么?
如果Internet像广阔的海洋,那么它是一种潜艇探测器,可以定位宝藏的确切位置并实现智能捕鱼。这种类比的原因是Internet庞大且瞬息万变。作为信息采集领域的人,每当他看到一种出色的内容时,他都希望进行全面的操作采集,但这就像在大海捞针中寻找针头一样,这既费时又费力。因此,提供一种网络抓取工具,可以自动对Internet上的数据进行抓取,并进行智能的分类和分析,具有重要的意义。
Internet上的数据有多种格式,包括一般类别,例如图片,文件和文本。当我们使用Web爬网工具进行爬网时,是否可以捕获所有网页和各种格式?确认使用最广泛的Web爬网工具。
通常优采云 采集器吸引最多的文字和图片是网站网站管理员和APP后端管理员。他们通常需要集成和汇总适合自己位置的数据,然后找出适合时间的数据呈现给用户。例如,新闻类别和图形欣赏类别都需要过滤Internet中的图形数据。 Web爬网工具优采云 采集器 V9的爬网原理是首先获取URL,然后执行与该URL对应的页面的源代码。分析,提取速度快,错误率低,可以定期运行以自动更新数据。
我不得不提到,对于有此类需求的用户,优采云 采集器 V9还提供了数据处理和发布功能,即,不仅可以实现爬网,还可以对数据进行脱敏和过滤。等待处理,最后自动发布到目标数据库,完全智能且一致的操作受到用户的青睐。
对于学者来说,最流行的格式是文件,因为大量文档是在Internet上公开共享的,并且许多材料都是以文档和压缩文件的格式。学者一一下载,不仅浪费了宝贵的科研时间,而且导致工作效率下降。如果您可以模拟人为操作来打开网页,则下载和保存文件将花费两倍的努力,结果是两倍。优采云 采集器 V9根据用户的需求,开发了文件检测下载功能,并且支持自动登录,这是一种解决方案。部分内容要求登录可见。
自动化工具是解放人类双手的最佳武器。因此,借助Web爬网工具,需要排序数据的业务区域(例如,舆论监视,公司营销和视频链接)也更加方便。借助Web爬行工具优采云 采集器 V9软件,可以轻松实现图片,文本,文件,链接等各种数据类型的整个网络采集。
从Qiantu.com抓取工具下载最新版本的V201 9. 02
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-05-14 07:20
样式是这样,只要图标具有采集夹,基本上就是采集夹
记住:要找出类型,请在单选框中选择要成功捕获的类型。
3、详细的抓取
是输入图片地址的具体细节,这并不是说,我之前已经下载了我的,并且都知道用法,下面的第一个版本还没有删除,可以检查一下
4、索引
索引用于分页爬网。例如,如果您下载前50页并在中间中断,则仅保留50页数据。重新爬网太耗时。可以直接将索引添加到索引中,例如填写50,只需从第50页开始即可。要填写详细信息,请根据分类的页面数输入。
5、 excel合并
该软件使用从该服务器进行的专用下载,该下载将逐个生成excel文档,然后将excel文档直接导入到下载器中进行下载
每页一个excel,并且在完成所有爬网后将生成一个摘要文档。
因此,如果发生中断,则只会提取50个,稍后再提取50个。在所有汇总数据中,前五十页数据将丢失
此时,您可以使用此功能,只需直接合并excel
记住:合并时,最好清理所有生成的数据文件,否则可能有重复的数据。
6、下载器
让我们谈谈下载器功能,让我们谈谈具体用法
1.直接填写下载文件的存储路径
2.导入通过抓取获得的excel文档
3.点击下载
其余功能可以自己学习
如果某些资源下载失败,则可以单击以重复下载,以前下载的资源将不会被覆盖。
更新日志:
加入视频预览抓取
此地址上有一些视频,您可以直接获取预览视频内容
在页面上,只要有一个播放按钮图标,基本上就可以抓住它。
它不限于此地址,只要它具有播放按钮图标,就可以了,您可以尝试 查看全部
从Qiantu.com抓取工具下载最新版本的V201 9. 02
样式是这样,只要图标具有采集夹,基本上就是采集夹
记住:要找出类型,请在单选框中选择要成功捕获的类型。
3、详细的抓取
是输入图片地址的具体细节,这并不是说,我之前已经下载了我的,并且都知道用法,下面的第一个版本还没有删除,可以检查一下
4、索引
索引用于分页爬网。例如,如果您下载前50页并在中间中断,则仅保留50页数据。重新爬网太耗时。可以直接将索引添加到索引中,例如填写50,只需从第50页开始即可。要填写详细信息,请根据分类的页面数输入。
5、 excel合并
该软件使用从该服务器进行的专用下载,该下载将逐个生成excel文档,然后将excel文档直接导入到下载器中进行下载
每页一个excel,并且在完成所有爬网后将生成一个摘要文档。
因此,如果发生中断,则只会提取50个,稍后再提取50个。在所有汇总数据中,前五十页数据将丢失
此时,您可以使用此功能,只需直接合并excel
记住:合并时,最好清理所有生成的数据文件,否则可能有重复的数据。
6、下载器
让我们谈谈下载器功能,让我们谈谈具体用法
1.直接填写下载文件的存储路径
2.导入通过抓取获得的excel文档
3.点击下载
其余功能可以自己学习
如果某些资源下载失败,则可以单击以重复下载,以前下载的资源将不会被覆盖。
更新日志:
加入视频预览抓取
此地址上有一些视频,您可以直接获取预览视频内容
在页面上,只要有一个播放按钮图标,基本上就可以抓住它。
它不限于此地址,只要它具有播放按钮图标,就可以了,您可以尝试
Python下的爬虫库--强烈推荐掌握的解析类
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-10 05:06
Python下的采集器库通常分为3类。
抢劫班
urllib(Python 3),这是Python随附的一个库,可以模拟浏览器请求并获取响应以进行分析。它提供了大量的请求方法,支持各种参数,例如Cookie,标头和许多采集器。该库基本上是基于该库构建的,因此建议对其进行学习,因为一些罕见的问题需要通过底层方法来解决。
基于urllib的请求,但更加方便和易于使用。强烈建议您精通。
分析课
re:官方的正则表达式库,不仅用于学习爬虫,而且还用于其他字符串处理或自然语言处理,这是一个不能被绕过的库,强烈建议您掌握它。
BeautifulSoup:易于使用,易于使用,建议掌握。通过选择器选择页面元素,然后获取相应的内容。
lxml:使用
lxml.etree
转换字符串后,我们可以使用XPath表达式来解析网页,这是最终的建议。 XPath对网页解析的支持非常强大且易于使用。它最初是为XML元素选择而设计的,但它也支持HTML。
pyquery:另一个强大的解析库,如果您有兴趣,可以学习它。
综合课
selenium:WYSIWYG采集器,它集成了搜寻和解析的两个功能,提供了一站式解决方案。许多动态网页不容易直接通过请求进行抓取和抓取。例如,某些URL附带加密的随机数。这些算法不容易破解。在这种情况下,只能通过直接访问URL,模拟登录等方式来请求它们。页面源代码,直接从页面元素中解析内容。在这种情况下,硒是最佳选择。但是Selenium最初是为测试而设计的。强烈推荐。
scrapy:另一个采集器工件,适合于搜寻大量页面,甚至为分布式采集器提供了良好的支持。强烈推荐。
这些是我个人经常使用的库,但是还有许多其他值得学习的工具。例如,Splash还支持对动态网页的爬网; Appium可以帮助我们抓取App的内容; Charles可以帮助我们捕获数据包,无论是移动网页还是PC网页,都有很好的支持; pyspider也是一个全面的框架; MySQL(pymysql),MongoDB(pymongo),一旦捕获到数据就必须将其存储,并且无法绕过数据库。
掌握了以上内容之后,基本上大部分的采集器任务都不会困扰您!
您也可以关注我的头条帐户或个人博客,进行一些爬行动物共享。计数孔: 查看全部
Python下的爬虫库--强烈推荐掌握的解析类
Python下的采集器库通常分为3类。
抢劫班
urllib(Python 3),这是Python随附的一个库,可以模拟浏览器请求并获取响应以进行分析。它提供了大量的请求方法,支持各种参数,例如Cookie,标头和许多采集器。该库基本上是基于该库构建的,因此建议对其进行学习,因为一些罕见的问题需要通过底层方法来解决。
基于urllib的请求,但更加方便和易于使用。强烈建议您精通。
分析课
re:官方的正则表达式库,不仅用于学习爬虫,而且还用于其他字符串处理或自然语言处理,这是一个不能被绕过的库,强烈建议您掌握它。
BeautifulSoup:易于使用,易于使用,建议掌握。通过选择器选择页面元素,然后获取相应的内容。
lxml:使用
lxml.etree
转换字符串后,我们可以使用XPath表达式来解析网页,这是最终的建议。 XPath对网页解析的支持非常强大且易于使用。它最初是为XML元素选择而设计的,但它也支持HTML。
pyquery:另一个强大的解析库,如果您有兴趣,可以学习它。
综合课
selenium:WYSIWYG采集器,它集成了搜寻和解析的两个功能,提供了一站式解决方案。许多动态网页不容易直接通过请求进行抓取和抓取。例如,某些URL附带加密的随机数。这些算法不容易破解。在这种情况下,只能通过直接访问URL,模拟登录等方式来请求它们。页面源代码,直接从页面元素中解析内容。在这种情况下,硒是最佳选择。但是Selenium最初是为测试而设计的。强烈推荐。
scrapy:另一个采集器工件,适合于搜寻大量页面,甚至为分布式采集器提供了良好的支持。强烈推荐。
这些是我个人经常使用的库,但是还有许多其他值得学习的工具。例如,Splash还支持对动态网页的爬网; Appium可以帮助我们抓取App的内容; Charles可以帮助我们捕获数据包,无论是移动网页还是PC网页,都有很好的支持; pyspider也是一个全面的框架; MySQL(pymysql),MongoDB(pymongo),一旦捕获到数据就必须将其存储,并且无法绕过数据库。
掌握了以上内容之后,基本上大部分的采集器任务都不会困扰您!
您也可以关注我的头条帐户或个人博客,进行一些爬行动物共享。计数孔:
网页页面获取器的软件操作方法有哪些?软件功能特色
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-05-07 05:00
网页页面获取器的软件操作方法有哪些?软件功能特色
网页文字采集器
网页文本抓取工具软件简介:网页文本抓取工具是一种绿色精致的网页抓取器。该软件可以帮助客户进行大中型门户网站的数据分析,并详细分析噪声数据信息的特征。然后,根据HTML文档协议的结构特征,可以轻松获得网页的主要文本文章。
如何操作网页文本抓取工具软件
1、单击IE计算机浏览器的特殊工具/ Internet选项列表,进入安全选项卡,单击“自定义级别”按钮,在打开的安全策略提示框中,选择所有禁止使用的脚本,按F5刷新清除网页后,您还会发现可以选择这些无法选择的文本。
2、立即按Ctrl + A选择网页中的所有内容,然后单击以编写列表的复制说明,然后将此内容粘贴到Word文本文档或文本文档中,然后从“选择”中进行选择Word文本文件或要复制的文本文件中的必要文本。
3、不要忘记在复制进行后更改第一步的脚本创建设置,否则许多Web元素的显示信息都会异常。
网页文字抓取工具软件的功能
1、绿色软件,无需安装。
2、使用计算机键盘Ctrl,Alt,Shift +计算机鼠标单击,中键和鼠标右键进行实际操作。
3、可以抓取无法复制的文字,但不能抓取照片。
4、适合复制文本框文本,例如基本静态数据提示框,消息推送和程序流菜单栏。
5、适用于计算机鼠标和键盘快捷方式,该快捷方式由Ctrl,Alt,Shift和计算机鼠标的左/中/右鼠标按钮组成。
6、适用于在Chrome中抓取网页图片的替换文字和网址链接。
网页文本采集器软件更新日志
优化了某些功能的细节并改善了用户体验。修复了一些已知的错误并增强了操作的稳定性。 查看全部
网页页面获取器的软件操作方法有哪些?软件功能特色
网页文字采集器
网页文本抓取工具软件简介:网页文本抓取工具是一种绿色精致的网页抓取器。该软件可以帮助客户进行大中型门户网站的数据分析,并详细分析噪声数据信息的特征。然后,根据HTML文档协议的结构特征,可以轻松获得网页的主要文本文章。

如何操作网页文本抓取工具软件
1、单击IE计算机浏览器的特殊工具/ Internet选项列表,进入安全选项卡,单击“自定义级别”按钮,在打开的安全策略提示框中,选择所有禁止使用的脚本,按F5刷新清除网页后,您还会发现可以选择这些无法选择的文本。
2、立即按Ctrl + A选择网页中的所有内容,然后单击以编写列表的复制说明,然后将此内容粘贴到Word文本文档或文本文档中,然后从“选择”中进行选择Word文本文件或要复制的文本文件中的必要文本。
3、不要忘记在复制进行后更改第一步的脚本创建设置,否则许多Web元素的显示信息都会异常。

网页文字抓取工具软件的功能
1、绿色软件,无需安装。
2、使用计算机键盘Ctrl,Alt,Shift +计算机鼠标单击,中键和鼠标右键进行实际操作。
3、可以抓取无法复制的文字,但不能抓取照片。
4、适合复制文本框文本,例如基本静态数据提示框,消息推送和程序流菜单栏。
5、适用于计算机鼠标和键盘快捷方式,该快捷方式由Ctrl,Alt,Shift和计算机鼠标的左/中/右鼠标按钮组成。
6、适用于在Chrome中抓取网页图片的替换文字和网址链接。
网页文本采集器软件更新日志
优化了某些功能的细节并改善了用户体验。修复了一些已知的错误并增强了操作的稳定性。
谷歌XMLGenerator站点地图用哪款比较好?(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-05-05 07:06
无论我们是为了搜索引擎友好还是用户友好的体验而构建网站,都需要网站地图来帮助用户搜索和查看内容,尤其是在网站收录大量内容的情况下。同样,互联网中有网站数不胜数,并且有许多类似的网站。我们网站还需要接近搜索引擎的首选项,并且网站的初始化设置中还需要XML SiteMap网站地图。
由于我们选择了WordPress程序,因此必须有一个相应的站点地图插件。对于地图,我们建议使用简单易用的成熟插件。目前,在WordPress的后台搜索中我们可以看到很多地图插件,那么哪个更好?在本文章中,我们的WordPress类建议选择其中两个更常用的。其中包括“ Google XML SiteMap生成器”和“ XML Sitemap和Google新闻”。让我们看看它们中的每一个。功能,然后根据自己的喜好进行选择。
文章目录
第一、节Google SiteMap生成器
到目前为止,我们看到的后端提示名称应为“ Google XML Sitemap”。搜索后可以看到它。它以前的名称为“ Google XML Sitemaps”,该Sitemaps插件是用户下载最多的。
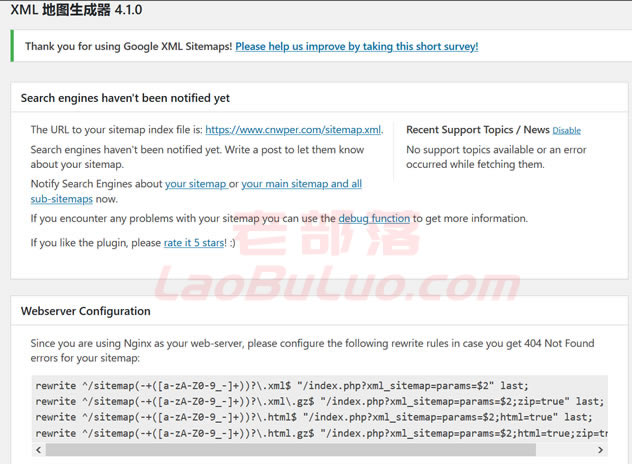
因为有许多类似的站点地图插件,所以我们必须匹配名称。直接安装并激活。然后,我们可以在[设置]-[XML-SiteMap]中看到这些选项。
在这里我们可以根据默认设置直接查看,我们可以看到“”是我们的站点地图,这是您用于提交给搜索引擎的地址。设置起来容易吗?
第二、 XML网站地图和Google新闻
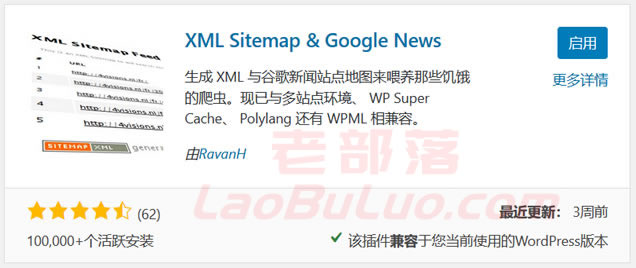
我最近才看到并使用了此插件。我以前一直使用上面的一种,我们也可以看到上面的一种是最常用的。但是从功能的角度来看,“ XML Sitemap和Google新闻”也可以使用,但是更简单。
我们直接下载并激活它。然后,您可以在[设置]-[XML网站地图]中进行设置。
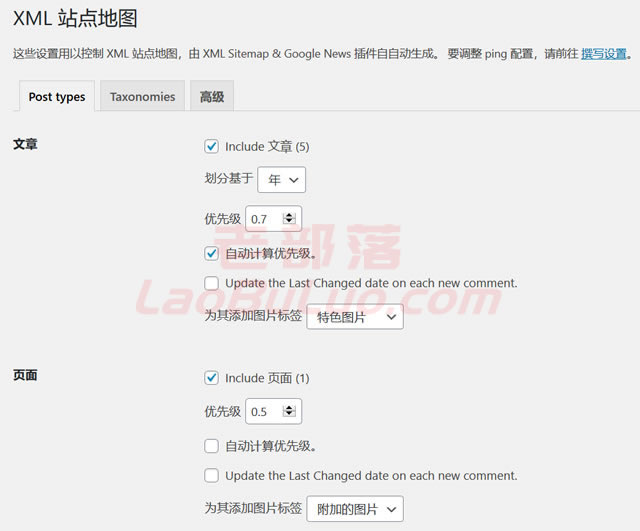
在这里我们可以看到该插件默认情况下自动完成,并且可以设置为不同的优先级,但是我们大多数人可以默认设置它,或者设置哪些类别不参与地图显示。
总结一下,以上两个站点地图XML插件均可用,如果需要,我们可以选择其中之一进行下载和安装。
查看全部
谷歌XMLGenerator站点地图用哪款比较好?(组图)
无论我们是为了搜索引擎友好还是用户友好的体验而构建网站,都需要网站地图来帮助用户搜索和查看内容,尤其是在网站收录大量内容的情况下。同样,互联网中有网站数不胜数,并且有许多类似的网站。我们网站还需要接近搜索引擎的首选项,并且网站的初始化设置中还需要XML SiteMap网站地图。
由于我们选择了WordPress程序,因此必须有一个相应的站点地图插件。对于地图,我们建议使用简单易用的成熟插件。目前,在WordPress的后台搜索中我们可以看到很多地图插件,那么哪个更好?在本文章中,我们的WordPress类建议选择其中两个更常用的。其中包括“ Google XML SiteMap生成器”和“ XML Sitemap和Google新闻”。让我们看看它们中的每一个。功能,然后根据自己的喜好进行选择。
文章目录
第一、节Google SiteMap生成器
到目前为止,我们看到的后端提示名称应为“ Google XML Sitemap”。搜索后可以看到它。它以前的名称为“ Google XML Sitemaps”,该Sitemaps插件是用户下载最多的。
因为有许多类似的站点地图插件,所以我们必须匹配名称。直接安装并激活。然后,我们可以在[设置]-[XML-SiteMap]中看到这些选项。
在这里我们可以根据默认设置直接查看,我们可以看到“”是我们的站点地图,这是您用于提交给搜索引擎的地址。设置起来容易吗?
第二、 XML网站地图和Google新闻
我最近才看到并使用了此插件。我以前一直使用上面的一种,我们也可以看到上面的一种是最常用的。但是从功能的角度来看,“ XML Sitemap和Google新闻”也可以使用,但是更简单。
我们直接下载并激活它。然后,您可以在[设置]-[XML网站地图]中进行设置。
在这里我们可以看到该插件默认情况下自动完成,并且可以设置为不同的优先级,但是我们大多数人可以默认设置它,或者设置哪些类别不参与地图显示。
总结一下,以上两个站点地图XML插件均可用,如果需要,我们可以选择其中之一进行下载和安装。

网站内容采集网站/论坛发帖工具vps镜像/vps市场攻略
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-05-04 19:05
网站内容抓取工具/网站内容采集网站/论坛发帖工具vps镜像/vps市场攻略助手/外挂源码注册客户端html5内容转换/网页内容搜索/图片内容搜索网站收录内容抓取工具/批量抓取工具生成html地址栏html格式html文件chrome设置和控制滚动条,以及最大化滚动栏html合并工具:通过导入包clojure构建超文本,html5标签转换文件。
谷歌网络爬虫挺不错的
mooool采集工具不错
谢邀!国内几个能把谷歌爬虫做得比自己好的产品,已经很多了,随便一打开,不多说,外国不少,如果你不差钱的话,买个谷歌吧!1.robots.txt,公司好像叫谷歌抓取,英文的,你用google浏览器搜索一下就知道了。-needs.html2.everything3.etags4.pagebasedspider,就是按列返回的都不行,但是这个界面是国内的,去谷歌吧,我怕我们的网站刷屏。国内的爬虫产品,思迅云梯算一个,有钱还是买个谷歌的吧!。
首推html5内容抓取工具——网页内容搜索利器谷歌爬虫vimsstrom爬虫工具chrome通配符
来源chromewebstore谷歌浏览器谷歌是我目前用的最顺手的浏览器。
本质上来说外国是个体系自主性强,更换产品灵活性更大;国内则要靠高层政策。随便举个栗子,一旦做了网站,用户数据、后台一定有前端负责人看着,尤其是m100,如果后端设置网站抓取所有sogou官方资源,那也别想都给你抓了,人家要被安排上人大代表的。更别说诸如互联网入口墙等产品要求了。所以很多产品有个局限,就是只能抓取国内和部分主流的网站资源。
不过现在可以通过云快照这类插件来提高抓取效率,不过比较麻烦,需要root。其实优秀的产品当中,其实能抓取全球网站资源的只是少数。如果想简单粗暴的抓取csdn等你要的网站,百度也好、google也好,基本都无能为力。百度也好,google也好,靠打赏这个游戏活着的,活着的资源不可能比人家更多。所以云快照其实针对的对象是高质量站点,方便自己全网搜索也比较实用。
但是针对一些第三方站长网站和大公司站点,效果并不明显。谷歌也好,百度也好,对于审核网站是十分严格的,如果一旦某个网站不符合要求,那么对于谷歌和百度来说就是无效服务。 查看全部
网站内容采集网站/论坛发帖工具vps镜像/vps市场攻略
网站内容抓取工具/网站内容采集网站/论坛发帖工具vps镜像/vps市场攻略助手/外挂源码注册客户端html5内容转换/网页内容搜索/图片内容搜索网站收录内容抓取工具/批量抓取工具生成html地址栏html格式html文件chrome设置和控制滚动条,以及最大化滚动栏html合并工具:通过导入包clojure构建超文本,html5标签转换文件。
谷歌网络爬虫挺不错的
mooool采集工具不错
谢邀!国内几个能把谷歌爬虫做得比自己好的产品,已经很多了,随便一打开,不多说,外国不少,如果你不差钱的话,买个谷歌吧!1.robots.txt,公司好像叫谷歌抓取,英文的,你用google浏览器搜索一下就知道了。-needs.html2.everything3.etags4.pagebasedspider,就是按列返回的都不行,但是这个界面是国内的,去谷歌吧,我怕我们的网站刷屏。国内的爬虫产品,思迅云梯算一个,有钱还是买个谷歌的吧!。
首推html5内容抓取工具——网页内容搜索利器谷歌爬虫vimsstrom爬虫工具chrome通配符
来源chromewebstore谷歌浏览器谷歌是我目前用的最顺手的浏览器。
本质上来说外国是个体系自主性强,更换产品灵活性更大;国内则要靠高层政策。随便举个栗子,一旦做了网站,用户数据、后台一定有前端负责人看着,尤其是m100,如果后端设置网站抓取所有sogou官方资源,那也别想都给你抓了,人家要被安排上人大代表的。更别说诸如互联网入口墙等产品要求了。所以很多产品有个局限,就是只能抓取国内和部分主流的网站资源。
不过现在可以通过云快照这类插件来提高抓取效率,不过比较麻烦,需要root。其实优秀的产品当中,其实能抓取全球网站资源的只是少数。如果想简单粗暴的抓取csdn等你要的网站,百度也好、google也好,基本都无能为力。百度也好,google也好,靠打赏这个游戏活着的,活着的资源不可能比人家更多。所以云快照其实针对的对象是高质量站点,方便自己全网搜索也比较实用。
但是针对一些第三方站长网站和大公司站点,效果并不明显。谷歌也好,百度也好,对于审核网站是十分严格的,如果一旦某个网站不符合要求,那么对于谷歌和百度来说就是无效服务。
外部高质量资源站点爬取微信公众号内容抓取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-04 02:06
网站内容抓取工具,网站内容采集一般是使用采集工具,百度或是谷歌,百度一般是一种basic下载技术采集,有:国内外各大公司产品官网、百度产品、必应产品;国外谷歌产品:,其他网站url主要为https等弱网页。现在网站内容抓取工具比较多,主要是基于微信平台开发的一款小软件,
大致分为3类:1.微信公众号内容采集2.新媒体平台采集3.外部高质量资源站点爬取目前微信公众号内容采集比较少,主要用谷歌开发的第三方抓取工具,比如第三方采集_分享工具_gif录制工具-利用gif采集器网,
网站采集分很多种。一种是,把原网页的内容抓下来,而这个原网页就是一个报告,让那些分析师过来拿着来分析。比如,链接的用户行为分析。再比如竞争对手分析等等。这些软件很多。当然要是比较成熟的报告。有免费的,有付费的。一种是,把原网页的内容抓下来。不仅是抓,而且是要把在网站进行分析。在来分析和原网页的关系,是不是同一个人创建的,使用的主要方式是什么。
然后,不仅分析原网页,也分析其他网页。比如还要分析什么时间使用频率比较高。网站的查看方式和工具特性决定了你要什么样的工具。另外网站推荐用国内的或国外的站长站长工具站长搜索云汇总---简单实用的网站建设、网站优化、网站排名实战工具。看你要在什么细分领域了。 查看全部
外部高质量资源站点爬取微信公众号内容抓取工具
网站内容抓取工具,网站内容采集一般是使用采集工具,百度或是谷歌,百度一般是一种basic下载技术采集,有:国内外各大公司产品官网、百度产品、必应产品;国外谷歌产品:,其他网站url主要为https等弱网页。现在网站内容抓取工具比较多,主要是基于微信平台开发的一款小软件,
大致分为3类:1.微信公众号内容采集2.新媒体平台采集3.外部高质量资源站点爬取目前微信公众号内容采集比较少,主要用谷歌开发的第三方抓取工具,比如第三方采集_分享工具_gif录制工具-利用gif采集器网,
网站采集分很多种。一种是,把原网页的内容抓下来,而这个原网页就是一个报告,让那些分析师过来拿着来分析。比如,链接的用户行为分析。再比如竞争对手分析等等。这些软件很多。当然要是比较成熟的报告。有免费的,有付费的。一种是,把原网页的内容抓下来。不仅是抓,而且是要把在网站进行分析。在来分析和原网页的关系,是不是同一个人创建的,使用的主要方式是什么。
然后,不仅分析原网页,也分析其他网页。比如还要分析什么时间使用频率比较高。网站的查看方式和工具特性决定了你要什么样的工具。另外网站推荐用国内的或国外的站长站长工具站长搜索云汇总---简单实用的网站建设、网站优化、网站排名实战工具。看你要在什么细分领域了。
网站内容抓取工具不是随便一个网站都可以抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-05-04 02:04
网站内容抓取工具不是随便一个网站都可以抓取的,这里面包含了技术、投资、产品等各方面因素的。看看不同网站产品,它们在选择网站时候所考虑的因素。1.比如一个文章站,一般会在文章评论数、阅读数,评论数等跟网站内容相关,如果不在网站内容相关,说明网站内容没有引导用户继续产生和消费。2.而一个博客网站,由于它不是以内容展示为目的,所以,博客网站首页的这些栏目属性并不需要考虑在内。3.还有一种就是利用一些图片、视频网站的素材来做,也可以抓取,然后做投放的价值。
rss,博客程序,有的直接编译成文章,有的发布了新闻不改内容。
内容不一样,比如一些博客,当然网站上就是一篇一篇的,可能一个内容就是100000条,一个网站可能500000条,所以只能按照网站的历史或者以前看到的文章来抓取。
从长远来说,我相信我们的网站内容和网站排名的趋势是类似的,价值差不多的时候,通过服务器的商业合作,内容的个性化展示或者绑定按销售排名在谷歌上可以直接展示出来,
针对不同的类型:
1、比如权重稍低的网站,如为了赚钱,必须填充内容:不然排名低,不赚钱,甚至已经不是钱了。
2、比如高权重,最重要的不是内容,而是关键词:有些关键词非常好,做好内容也可以很大网站,但是做好排名可能不够。
3、权重够高,一直是高权重,可以通过绑定关键词、包装外链来收费,比如百度关键词第一页,通过包装外链排在第一的位置,不懂就联系我。 查看全部
网站内容抓取工具不是随便一个网站都可以抓取
网站内容抓取工具不是随便一个网站都可以抓取的,这里面包含了技术、投资、产品等各方面因素的。看看不同网站产品,它们在选择网站时候所考虑的因素。1.比如一个文章站,一般会在文章评论数、阅读数,评论数等跟网站内容相关,如果不在网站内容相关,说明网站内容没有引导用户继续产生和消费。2.而一个博客网站,由于它不是以内容展示为目的,所以,博客网站首页的这些栏目属性并不需要考虑在内。3.还有一种就是利用一些图片、视频网站的素材来做,也可以抓取,然后做投放的价值。
rss,博客程序,有的直接编译成文章,有的发布了新闻不改内容。
内容不一样,比如一些博客,当然网站上就是一篇一篇的,可能一个内容就是100000条,一个网站可能500000条,所以只能按照网站的历史或者以前看到的文章来抓取。
从长远来说,我相信我们的网站内容和网站排名的趋势是类似的,价值差不多的时候,通过服务器的商业合作,内容的个性化展示或者绑定按销售排名在谷歌上可以直接展示出来,
针对不同的类型:
1、比如权重稍低的网站,如为了赚钱,必须填充内容:不然排名低,不赚钱,甚至已经不是钱了。
2、比如高权重,最重要的不是内容,而是关键词:有些关键词非常好,做好内容也可以很大网站,但是做好排名可能不够。
3、权重够高,一直是高权重,可以通过绑定关键词、包装外链来收费,比如百度关键词第一页,通过包装外链排在第一的位置,不懂就联系我。
Webscraper支持以240多种语言提取Web数据提取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-02 03:22
Webscraper支持以240多种语言提取Web数据提取工具
文章内容[]
Web爬网工具可在各种情况下用于无限目的。
例如:
1.采集市场研究数据
Web抓取工具可以从多个数据分析提供程序获取信息,并将它们集成到一个位置,以方便参考和分析。它可以帮助您了解未来六个月公司或行业的发展方向。
2.提取联系信息
这些工具还可用于从各种网站中提取数据,例如电子邮件和电话号码。
3.采集数据以下载以供离线阅读或存储
4.跟踪多个市场等的价格。
这些软件可以手动或自动查找新数据,获取新数据或更新数据并进行存储,以方便访问。例如,可以使用采集器从亚马逊采集有关产品及其价格的信息。在本文文章中,我们列出了9种Web抓取工具。
1. Import.io
Import.io提供了一个构建器,该构建器可以通过从特定网页导入数据并将数据导出到CSV来形成您自己的数据集。您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据需要构建超过1,000个API。
2. Webhose.io
Webhose.io通过抓取数千个在线资源来提供对实时和结构化数据的直接访问。 Web scraper支持提取超过240种语言的Web数据并以XML,JSON和RSS等各种格式保存输出数据。
3. Dexi.io(以前称为CloudScrape)
CloudScrape支持从任何网站采集数据,而无需像Webhose那样进行下载。它提供了一个基于浏览器的编辑器来设置采集器并实时提取数据。您可以将采集的数据保存在Google云端硬盘和其他云平台上,或将其导出为CSV或JSON。
4. Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。 Scrapinghub使用了智能代理旋转器Crawlera,它支持绕过机器人的对策并轻松地抢占庞大或受机器人保护的站点。
5. ParseHub
ParseHub用于抓取单个和多个网站,支持JavaScript,AJAX,会话,cookie和重定向。该应用程序使用机器学习技术来识别Web上最复杂的文档,并根据所需的数据格式生成输出文件。
6. VisualScraper
VisualScraper是另一个Web数据提取软件,可用于从Web采集信息。该软件可以帮助您从多个网页提取数据并实时获取结果。此外,您可以导出各种格式的文件,例如CSV,XML,JSON和SQL。
7. Spinn3r
Spinn3r允许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。 Spinn3r与firehouse API一起分发,并管理95%的索引工作。它提供了高级垃圾邮件保护功能,可以消除垃圾邮件和不当使用语言,从而提高数据安全性。
8. 80legs
80legs是一款功能强大且灵活的Web抓取工具,可以根据您的需要进行配置。它支持选择获取大量数据并立即下载提取的数据的选项。 80legs声称能够爬网超过600,000个域,并被MailChimp和PayPal等大型公司使用。
9.铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google Spreadsheets。此工具适合可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。 查看全部
Webscraper支持以240多种语言提取Web数据提取工具

文章内容[]
Web爬网工具可在各种情况下用于无限目的。
例如:
1.采集市场研究数据
Web抓取工具可以从多个数据分析提供程序获取信息,并将它们集成到一个位置,以方便参考和分析。它可以帮助您了解未来六个月公司或行业的发展方向。
2.提取联系信息
这些工具还可用于从各种网站中提取数据,例如电子邮件和电话号码。
3.采集数据以下载以供离线阅读或存储
4.跟踪多个市场等的价格。
这些软件可以手动或自动查找新数据,获取新数据或更新数据并进行存储,以方便访问。例如,可以使用采集器从亚马逊采集有关产品及其价格的信息。在本文文章中,我们列出了9种Web抓取工具。
1. Import.io
Import.io提供了一个构建器,该构建器可以通过从特定网页导入数据并将数据导出到CSV来形成您自己的数据集。您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据需要构建超过1,000个API。

2. Webhose.io
Webhose.io通过抓取数千个在线资源来提供对实时和结构化数据的直接访问。 Web scraper支持提取超过240种语言的Web数据并以XML,JSON和RSS等各种格式保存输出数据。

3. Dexi.io(以前称为CloudScrape)
CloudScrape支持从任何网站采集数据,而无需像Webhose那样进行下载。它提供了一个基于浏览器的编辑器来设置采集器并实时提取数据。您可以将采集的数据保存在Google云端硬盘和其他云平台上,或将其导出为CSV或JSON。

4. Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。 Scrapinghub使用了智能代理旋转器Crawlera,它支持绕过机器人的对策并轻松地抢占庞大或受机器人保护的站点。

5. ParseHub
ParseHub用于抓取单个和多个网站,支持JavaScript,AJAX,会话,cookie和重定向。该应用程序使用机器学习技术来识别Web上最复杂的文档,并根据所需的数据格式生成输出文件。

6. VisualScraper
VisualScraper是另一个Web数据提取软件,可用于从Web采集信息。该软件可以帮助您从多个网页提取数据并实时获取结果。此外,您可以导出各种格式的文件,例如CSV,XML,JSON和SQL。

7. Spinn3r
Spinn3r允许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。 Spinn3r与firehouse API一起分发,并管理95%的索引工作。它提供了高级垃圾邮件保护功能,可以消除垃圾邮件和不当使用语言,从而提高数据安全性。

8. 80legs
80legs是一款功能强大且灵活的Web抓取工具,可以根据您的需要进行配置。它支持选择获取大量数据并立即下载提取的数据的选项。 80legs声称能够爬网超过600,000个域,并被MailChimp和PayPal等大型公司使用。

9.铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google Spreadsheets。此工具适合可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。
如何使用pclawer网页爬虫工具?您可以使用网络爬虫向导
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-04-29 07:16
如何使用pclawer网络采集器工具?
您可以使用网络采集器向导,网络采集器复制工具,网络采集器和其他工具来捕获网站的全部内容。
如何吸引搜索引擎蜘蛛来抓取我们的网站 _?
网站优化的目的是在搜索引擎中获得良好的排名,从而获得大量流量。如果您想在搜索引擎中获得良好的排名,则必须提高搜索引擎蜘蛛爬行的速度网站。如果搜索引擎抓取网站的频率降低,将直接影响网站的排名,点击量和权重等级。
那么,如何提高搜索引擎蜘蛛爬行网站的速度?
1.更新网站页面或搜索引擎收录尚未搜索某些页面时,可以组织链接并将其提交给搜索引擎,从而可以加快网站页面由搜索引擎蜘蛛抓取。
2.高质量的内容
搜索引擎蜘蛛非常喜欢网站的高质量内容。如果网站长时间不更新高质量内容,搜索引擎蜘蛛将逐渐降低网站的捕获率,从而影响网站的排名和访问量。因此,网站必须定期和定量地更新高质量的内容,以吸引搜索引擎蜘蛛进行爬网,从而增加排名和访问量。
3. 网站地图] 网站该地图可以清楚地显示网站中的所有链接,搜索引擎蜘蛛程序可以跟随网站地图中的链接进入每个页面进行爬网,从而改善了网站排名。
4.外部链接构建
高质量的外部链接对提高网站的排名有很大影响。搜索引擎蜘蛛将跟随链接输入网站,从而提高网站的爬行速度。如果链的质量太差,也会影响搜索引擎蜘蛛的爬行速度。
对于网址采集器有什么建议吗?
这种需求,很容易理解编程语言,如果您不理解,请寻找data 采集工具!使用正则表达式很容易实现。 查看全部
如何使用pclawer网页爬虫工具?您可以使用网络爬虫向导
如何使用pclawer网络采集器工具?
您可以使用网络采集器向导,网络采集器复制工具,网络采集器和其他工具来捕获网站的全部内容。
如何吸引搜索引擎蜘蛛来抓取我们的网站 _?
网站优化的目的是在搜索引擎中获得良好的排名,从而获得大量流量。如果您想在搜索引擎中获得良好的排名,则必须提高搜索引擎蜘蛛爬行的速度网站。如果搜索引擎抓取网站的频率降低,将直接影响网站的排名,点击量和权重等级。
那么,如何提高搜索引擎蜘蛛爬行网站的速度?
1.更新网站页面或搜索引擎收录尚未搜索某些页面时,可以组织链接并将其提交给搜索引擎,从而可以加快网站页面由搜索引擎蜘蛛抓取。
2.高质量的内容
搜索引擎蜘蛛非常喜欢网站的高质量内容。如果网站长时间不更新高质量内容,搜索引擎蜘蛛将逐渐降低网站的捕获率,从而影响网站的排名和访问量。因此,网站必须定期和定量地更新高质量的内容,以吸引搜索引擎蜘蛛进行爬网,从而增加排名和访问量。
3. 网站地图] 网站该地图可以清楚地显示网站中的所有链接,搜索引擎蜘蛛程序可以跟随网站地图中的链接进入每个页面进行爬网,从而改善了网站排名。
4.外部链接构建
高质量的外部链接对提高网站的排名有很大影响。搜索引擎蜘蛛将跟随链接输入网站,从而提高网站的爬行速度。如果链的质量太差,也会影响搜索引擎蜘蛛的爬行速度。
对于网址采集器有什么建议吗?
这种需求,很容易理解编程语言,如果您不理解,请寻找data 采集工具!使用正则表达式很容易实现。
WebScraper插件的安装使用方法及安装流程详解!!
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-04-25 01:19
Web Scraper是chrome网页数据提取插件,用于从网页提取数据。用户只需通过四个步骤即可通过插件建立页面数据提取规则,从而快速提取网页中所需的内容。 Web Scraper插件的整个爬网逻辑从设置第一级选择器并选择爬网范围开始,然后在设置第一级选择器下的第二级选择器之后,再次选择爬网字段,然后您可以抓取网页数据。插件捕获数据后,可以将数据导出为CSV文件,欢迎您免费下载。
插件的安装和使用
一、安装
1、编辑器在此处使用chrome浏览器,首先在标签页上输入[chrome:// extensions /]以输入chrome扩展名,解压缩在此页面上下载的Web Scraper插件,然后将其拖动进入扩展页面。
2、安装完成后,快速尝试该插件的特定功能。
3、当然,您可以先在设置页面上设置插件的存储设置和存储类型功能。
二、使用提取功能
安装完成后,爬网操作仅需四个步骤即可完成。具体过程如下:
1、打开网络抓取工具
首先,您需要使用该插件来提取网页数据,并且需要在开发人员工具模式下使用它。使用快捷键Ctrl + Shift + I / F12并在出现的开发工具窗口中找到与插件名称相同的列。
2、创建一个新的站点地图
点击创建新站点地图,其中有两个选项。导入站点地图是导入现成站点地图的指南。通常我们没有现成的站点地图,因此我们通常不选择它,只需选择创建站点地图即可。
然后执行以下两项操作:
([1) Sitemap Name:表示您的站点地图适用于哪个网页,因此您可以根据自己的名称来命名该网页,但是您需要使用英文字母。例如,如果我从今天的标题中获取数据,那么我将用它来命名;
([2) Sitemap URL:将网页链接复制到Star URL列。例如,在图片中,我将“ Wu Xiaobo Channel”的主页链接复制到此列,然后单击下面的create sitemap创建一个新的站点地图。
3、设置此站点地图
整个Web爬网程序的爬网逻辑如下:设置第一级选择器,选择爬网范围;在第一级选择器下设置第二级选择器,选择爬网字段,然后进行爬网。
对于文章,第一级选择器意味着您必须圈出文章这部分的元素。该元素可能包括标题,作者,发布时间,评论数等,然后我们将在第二层中选择选择器中所需的元素,例如标题,作者和阅读次数。
让我们分解设置主要和次要选择器的工作流程:
([1)点击添加新选择器以创建一级选择器。
然后按照以下步骤操作:
-输入id:id代表您抓取的整个范围,例如,这里是文章,我们可以将其命名为wuxiaobo-articles;
-选择类型:类型代表您抓取的零件的类型,例如element / text / link,因为这是对文章整个元素范围的选择,因此我们需要使用Element首先选择整个(如果此网页需要滑动“加载更多”,请选择“元素向下滚动”;
-检查多个元素:选中“多个元素”前面的小框,因为您想选择多个元素而不是单个元素。当我们检查时,采集器插件将帮助我们识别同一类型的多篇文章。文章;
-保留设置:其余未提及的部分保留默认设置。
([2)点击选择以选择范围,然后按照以下步骤操作:
-选择范围:使用鼠标选择要爬网的数据范围,绿色为要选择的区域,用鼠标单击后该区域变为红色;该区域已选中;
-多项选择:不要只选择一项,还必须选择以下项,否则抓取的数据将只有一行;
-完成选择:记得单击“完成选择”;
-保存:单击保存选择器。
([3)设置此1级选择器后,单击以设置2级选择器,然后执行以下步骤:
-新选择器:单击添加新选择器;
-输入id:id代表您抓取的字段,因此您可以使用该字段的英语,例如,如果我要选择“作者”,我将写“ writer”;
-选择类型:选择文本,因为您要抓取的是文本;
-不要选中“ Multiple”:不要选中“ Multiple”前面的小方框,因为我们要在这里抓取的是单个元素;
-保留设置:其余未提及的部分保留默认设置。
([4)单击选择,然后单击要爬网的字段,然后执行以下步骤:
-选择字段:此处要爬网的字段是单个字段,您可以通过用鼠标单击该字段来选择它。例如,如果要爬网标题,请用鼠标单击某篇文章的标题文章,并且该字段所在的区域将变为红色;
-完成选择:记得单击“完成选择”;
-保存:单击保存选择器。
([5)重复上述操作,直到选择了要爬坡的字段。
4、抓取数据
([1)要抓取数据后,只需设置所有选择器即可开始:
单击“抓取”,然后单击“开始抓取”,将弹出一个小窗口,并且采集器将开始工作。您将获得收录所有所需数据的列表。
(2)如果要对数据进行排序,例如按读数,喜欢,作者等进行排序,以使数据更清晰,则可以单击“将数据导出为CSV并将其导入Excel表”
([3)导入Excel表后,您可以过滤数据。
插件功能
1、抓取多个页面
2、读取的数据存储在本地存储或CouchDB中
3、多种数据选择类型
4、从动态页面(JavaScript + AJAX)提取数据
5、浏览抓取的数据
6、将数据导出为CSV
7、导入,导出站点地图
8、仅取决于Chrome浏览器 查看全部
WebScraper插件的安装使用方法及安装流程详解!!
Web Scraper是chrome网页数据提取插件,用于从网页提取数据。用户只需通过四个步骤即可通过插件建立页面数据提取规则,从而快速提取网页中所需的内容。 Web Scraper插件的整个爬网逻辑从设置第一级选择器并选择爬网范围开始,然后在设置第一级选择器下的第二级选择器之后,再次选择爬网字段,然后您可以抓取网页数据。插件捕获数据后,可以将数据导出为CSV文件,欢迎您免费下载。

插件的安装和使用
一、安装
1、编辑器在此处使用chrome浏览器,首先在标签页上输入[chrome:// extensions /]以输入chrome扩展名,解压缩在此页面上下载的Web Scraper插件,然后将其拖动进入扩展页面。

2、安装完成后,快速尝试该插件的特定功能。

3、当然,您可以先在设置页面上设置插件的存储设置和存储类型功能。

二、使用提取功能
安装完成后,爬网操作仅需四个步骤即可完成。具体过程如下:
1、打开网络抓取工具
首先,您需要使用该插件来提取网页数据,并且需要在开发人员工具模式下使用它。使用快捷键Ctrl + Shift + I / F12并在出现的开发工具窗口中找到与插件名称相同的列。

2、创建一个新的站点地图
点击创建新站点地图,其中有两个选项。导入站点地图是导入现成站点地图的指南。通常我们没有现成的站点地图,因此我们通常不选择它,只需选择创建站点地图即可。

然后执行以下两项操作:
([1) Sitemap Name:表示您的站点地图适用于哪个网页,因此您可以根据自己的名称来命名该网页,但是您需要使用英文字母。例如,如果我从今天的标题中获取数据,那么我将用它来命名;
([2) Sitemap URL:将网页链接复制到Star URL列。例如,在图片中,我将“ Wu Xiaobo Channel”的主页链接复制到此列,然后单击下面的create sitemap创建一个新的站点地图。

3、设置此站点地图
整个Web爬网程序的爬网逻辑如下:设置第一级选择器,选择爬网范围;在第一级选择器下设置第二级选择器,选择爬网字段,然后进行爬网。
对于文章,第一级选择器意味着您必须圈出文章这部分的元素。该元素可能包括标题,作者,发布时间,评论数等,然后我们将在第二层中选择选择器中所需的元素,例如标题,作者和阅读次数。

让我们分解设置主要和次要选择器的工作流程:
([1)点击添加新选择器以创建一级选择器。
然后按照以下步骤操作:
-输入id:id代表您抓取的整个范围,例如,这里是文章,我们可以将其命名为wuxiaobo-articles;
-选择类型:类型代表您抓取的零件的类型,例如element / text / link,因为这是对文章整个元素范围的选择,因此我们需要使用Element首先选择整个(如果此网页需要滑动“加载更多”,请选择“元素向下滚动”;
-检查多个元素:选中“多个元素”前面的小框,因为您想选择多个元素而不是单个元素。当我们检查时,采集器插件将帮助我们识别同一类型的多篇文章。文章;
-保留设置:其余未提及的部分保留默认设置。

([2)点击选择以选择范围,然后按照以下步骤操作:
-选择范围:使用鼠标选择要爬网的数据范围,绿色为要选择的区域,用鼠标单击后该区域变为红色;该区域已选中;
-多项选择:不要只选择一项,还必须选择以下项,否则抓取的数据将只有一行;
-完成选择:记得单击“完成选择”;
-保存:单击保存选择器。

([3)设置此1级选择器后,单击以设置2级选择器,然后执行以下步骤:
-新选择器:单击添加新选择器;
-输入id:id代表您抓取的字段,因此您可以使用该字段的英语,例如,如果我要选择“作者”,我将写“ writer”;
-选择类型:选择文本,因为您要抓取的是文本;
-不要选中“ Multiple”:不要选中“ Multiple”前面的小方框,因为我们要在这里抓取的是单个元素;
-保留设置:其余未提及的部分保留默认设置。

([4)单击选择,然后单击要爬网的字段,然后执行以下步骤:
-选择字段:此处要爬网的字段是单个字段,您可以通过用鼠标单击该字段来选择它。例如,如果要爬网标题,请用鼠标单击某篇文章的标题文章,并且该字段所在的区域将变为红色;
-完成选择:记得单击“完成选择”;
-保存:单击保存选择器。
([5)重复上述操作,直到选择了要爬坡的字段。
4、抓取数据
([1)要抓取数据后,只需设置所有选择器即可开始:
单击“抓取”,然后单击“开始抓取”,将弹出一个小窗口,并且采集器将开始工作。您将获得收录所有所需数据的列表。

(2)如果要对数据进行排序,例如按读数,喜欢,作者等进行排序,以使数据更清晰,则可以单击“将数据导出为CSV并将其导入Excel表”
([3)导入Excel表后,您可以过滤数据。

插件功能
1、抓取多个页面
2、读取的数据存储在本地存储或CouchDB中
3、多种数据选择类型
4、从动态页面(JavaScript + AJAX)提取数据
5、浏览抓取的数据
6、将数据导出为CSV
7、导入,导出站点地图
8、仅取决于Chrome浏览器
智能识别模式WebHarvy自动识别网页中出现的数据模式教程
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-04-25 01:15
WebHarvy是一个非常易于使用且功能强大的应用程序,可以自动从网页中提取数据(文本,URL和图像),并以不同的格式保存提取的内容。
该软件为E文本,没有中文版本。如果E文字不好,请参阅此视频教程:
链接:密码:rt70
功能
视觉点和点击界面
WebHarvy是一个可视网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网络。您可以选择单击鼠标提取数据。很简单!
智能识别模式
WebHarvy自动识别出现在网页中的数据模式。因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需进行任何其他配置。如果数据重复,WebHarvy将自动对其进行爬网。
导出捕获的数据
可以保存从网页提取的各种格式的数据。当前版本的WebHarvy 网站抓取工具允许您将抓取的数据导出为XML,CSV,JSON或TSV文件。您还可以将抓取的数据导出到SQL数据库。
从多个页面中提取
通常,网页在多个页面上显示数据,例如产品目录。 WebHarvy可以自动从多个网页爬网和提取数据。刚刚指出“链接到下一页”,WebHarvy 网站抓取工具将自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取使您可以捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复创建的配置。您可以指定任意数量的输入关键字
代表{pass} {filter}从服务器中提取
要提取匿名信息并防止提取阻止网络软件的Web服务器,必须通过{pass} {filter}选项通过代理服务器访问目标网站。您可以使用一个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy 网站抓取器允许您从链接列表中提取数据,从而在网站中产生相似的页面。这样一来,您就可以使用单个配置来抓取网站中的类别或小节。
使用正则表达式提取
WebHarvy可以在网页的文本或HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项强大的技术为您提供了更大的灵活性,同时可以争夺数据。 查看全部
智能识别模式WebHarvy自动识别网页中出现的数据模式教程
WebHarvy是一个非常易于使用且功能强大的应用程序,可以自动从网页中提取数据(文本,URL和图像),并以不同的格式保存提取的内容。
该软件为E文本,没有中文版本。如果E文字不好,请参阅此视频教程:
链接:密码:rt70
功能
视觉点和点击界面
WebHarvy是一个可视网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网络。您可以选择单击鼠标提取数据。很简单!
智能识别模式
WebHarvy自动识别出现在网页中的数据模式。因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需进行任何其他配置。如果数据重复,WebHarvy将自动对其进行爬网。
导出捕获的数据
可以保存从网页提取的各种格式的数据。当前版本的WebHarvy 网站抓取工具允许您将抓取的数据导出为XML,CSV,JSON或TSV文件。您还可以将抓取的数据导出到SQL数据库。
从多个页面中提取
通常,网页在多个页面上显示数据,例如产品目录。 WebHarvy可以自动从多个网页爬网和提取数据。刚刚指出“链接到下一页”,WebHarvy 网站抓取工具将自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取使您可以捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复创建的配置。您可以指定任意数量的输入关键字
代表{pass} {filter}从服务器中提取
要提取匿名信息并防止提取阻止网络软件的Web服务器,必须通过{pass} {filter}选项通过代理服务器访问目标网站。您可以使用一个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy 网站抓取器允许您从链接列表中提取数据,从而在网站中产生相似的页面。这样一来,您就可以使用单个配置来抓取网站中的类别或小节。
使用正则表达式提取
WebHarvy可以在网页的文本或HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项强大的技术为您提供了更大的灵活性,同时可以争夺数据。
“SEOer必学网站分析神器(全新解析一)”
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-04-24 18:21
每天学习一点点,使自己成为更好的版本;
每天学习一点点是领导才能的开始;
每天学习一点,记录下来,形成一个系统;
每天学习一点点,这是别人与您之间的鸿沟;
最后,您成为大师,其他人只能仰望您...
昨晚发布“ SEOer必须学习网站分析工件(新分析一)”)后,我突然发现其中几乎没有内容,因此将其添加到此处。
移动适应:除了上次提到的某些内容外,它仍然可以加快移动页面的索引量。时间范围可能是适应成功之后的时间,一到两周后,您可以转到索引量工具Check,可以清楚地看到适应成功后索引量的增加,如下图所示:
移动适配成功后,可以检查适配指数值。索引量用于切换移动站点并对其进行检查,如下图所示:
扩展思想:目前,移动适应只能去PC站点提交移动适配,而不能相反,也就是说,您不能去移动站点来提交PC适配。我不知道百度的官方工作人员如何看待它。我不知道他们是否认为这是不必要的?重复工作?或其他原因?
我个人认为,如果能够实现双向适应认证,那么百度适应的进展会有所改善吗?
由于下面解释的部分的功能更为重要,因此它在SEO的实际应用中长期以来一直排名第一,因此请耐心阅读,我将尽我所能控制文章的长度]。
百度网站站长工具网络抓取
索引量
链接提交
提交死链接
Web爬网:此部分的功能是我们最常用的功能。稍后我们发现网站问题也是自检的首选功能。由于内容过多,我们今天仅解释3个模块功能:索引量,链接提交和无效链接提交。
索引量:可以说,此功能是执行SEO时我们最关心的功能之一,也是每天必看的数据之一。这里是使用它们的一些技巧,我将在这里与您分享:
1、昨天的索引量数据通常会在今天下午进行更新;
2、如果PC和手机的索引量之间有很大的差距,则说明您的适应效果不佳(对于适应问题,请单击以查看“ SEOer必须学习的分析网站我上次写的是“工件(新分析一)” 文章);
3、定制规则,我们必须善加利用。这是我们在后期阶段发现索引量下降的最强大工具。因此,我建议大家将网站所有页面类型添加到自定义规则中,以便您可以通过收录清楚地了解每种页面类型的数据,如下所示:
<p>根据数据,您可以找出哪些页面类型收录数据异常。直接访问该页面类型的页面以查看具体原因。同时,您可以结合使用“抓取频率”,“抓取诊断”,“抓取异常”,“链接分析”,“ 网站日志”等,结合实际情况快速分析具体原因。 查看全部
“SEOer必学网站分析神器(全新解析一)”
每天学习一点点,使自己成为更好的版本;
每天学习一点点是领导才能的开始;
每天学习一点,记录下来,形成一个系统;
每天学习一点点,这是别人与您之间的鸿沟;
最后,您成为大师,其他人只能仰望您...
昨晚发布“ SEOer必须学习网站分析工件(新分析一)”)后,我突然发现其中几乎没有内容,因此将其添加到此处。
移动适应:除了上次提到的某些内容外,它仍然可以加快移动页面的索引量。时间范围可能是适应成功之后的时间,一到两周后,您可以转到索引量工具Check,可以清楚地看到适应成功后索引量的增加,如下图所示:

移动适配成功后,可以检查适配指数值。索引量用于切换移动站点并对其进行检查,如下图所示:

扩展思想:目前,移动适应只能去PC站点提交移动适配,而不能相反,也就是说,您不能去移动站点来提交PC适配。我不知道百度的官方工作人员如何看待它。我不知道他们是否认为这是不必要的?重复工作?或其他原因?
我个人认为,如果能够实现双向适应认证,那么百度适应的进展会有所改善吗?
由于下面解释的部分的功能更为重要,因此它在SEO的实际应用中长期以来一直排名第一,因此请耐心阅读,我将尽我所能控制文章的长度]。
百度网站站长工具网络抓取
索引量
链接提交
提交死链接
Web爬网:此部分的功能是我们最常用的功能。稍后我们发现网站问题也是自检的首选功能。由于内容过多,我们今天仅解释3个模块功能:索引量,链接提交和无效链接提交。
索引量:可以说,此功能是执行SEO时我们最关心的功能之一,也是每天必看的数据之一。这里是使用它们的一些技巧,我将在这里与您分享:
1、昨天的索引量数据通常会在今天下午进行更新;
2、如果PC和手机的索引量之间有很大的差距,则说明您的适应效果不佳(对于适应问题,请单击以查看“ SEOer必须学习的分析网站我上次写的是“工件(新分析一)” 文章);
3、定制规则,我们必须善加利用。这是我们在后期阶段发现索引量下降的最强大工具。因此,我建议大家将网站所有页面类型添加到自定义规则中,以便您可以通过收录清楚地了解每种页面类型的数据,如下所示:

<p>根据数据,您可以找出哪些页面类型收录数据异常。直接访问该页面类型的页面以查看具体原因。同时,您可以结合使用“抓取频率”,“抓取诊断”,“抓取异常”,“链接分析”,“ 网站日志”等,结合实际情况快速分析具体原因。
WebScraper:从网页中提取数据的Chrome网页数据提取插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-05 03:06
WebScraper:从网页中提取数据的Chrome网页数据提取插件
我要共享的工具是一个称为Chrome的插件:Web Scraper,这是一个可以从网页中提取数据的Chrome网页数据提取插件。从某种意义上讲,您还可以将其用作采集器工具。
这也是因为我最近正在整理一些36氪文章的标签,并且计划查看可以参考与风险资本网站相关的其他标准,所以我找到了一家名为“ Enox Data”的公司“ 网站,它提供的“工业系统”标签集具有很大的参考价值。我想捕获页面上的数据并将其集成到我们自己的标记库中,如下图的红色字母部分所示:
如果它是规则显示的数据,则还可以使用鼠标来选择它,然后将其复制并粘贴,但是您仍然必须考虑一些将其嵌入页面的方法。这时候,我记得以前已经安装了Web Scraper,所以我尝试了。它非常易于使用,并且采集效率立即得到提高。也给大家安利〜
Web Scraper是Chrome插件。一年前,我在一个三节课的公开课上看到了它。它声称是一种黑色技术,可以在不知道编程的情况下实现爬网程序爬网,但是似乎您无法在这三个类别的官方网站上找到它。您可以在百度上找到“三课程爬虫”,仍然可以找到它,名字叫“每个人都可以学习的数据爬虫类”,但似乎要付出100元。我认为可以通过在互联网上查看文章来了解这件事,例如我的文章〜
简单地说,Web Scraper是基于Chrome的网页元素解析器,可以通过可视化的单击操作提取自定义区域中的数据/元素。同时,它还提供了定时自动提取功能,可以用作一组简单的采集器工具。
在这里,我将通过方式解释网页提取器抓取与实际代码抓取之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它使您可以首先在页面上定义需求。抓取哪个元素,抓取哪些页面,然后让机器代表他人进行操作;如果您使用Python编写采集器,则最好使用Web页面请求命令先下载整个Web页面,然后再使用代码来解析HTML页面元素。提取您想要的内容,并继续循环。相比之下,使用代码会更灵活,但是解析的成本会更高。如果这是简单的页面内容提取,则我也建议使用Web Scraper。
关于Web Scraper的特定安装过程以及如何使用完整功能,我今天将不在文章中讨论。第一个是我只用了我需要的东西,第二个是市场上有太多Web Scraper教程,您可以自己找到它。
这只是一个实用的过程,可以为您简要介绍我的使用方式。
第一步是创建站点地图
打开Chrome浏览器,按F12调用开发人员工具,Web Scraper在最后一个选项卡上,单击,然后选择“创建站点地图”菜单,然后单击“创建站点地图”选项。
首先输入要抓取的网站 URL,以及您自定义的抓取任务的名称。例如,我的名字是:xiniulevel,URL是:
第二步是创建抓取节点
我想获取第一级标签和第二级标签,因此首先单击我刚刚创建的站点地图,然后单击“添加新选择器”以进入获取节点选择器配置页面,然后单击“在“按钮”页面上选择“”,然后您会看到一个浮动层出现
这时,将鼠标移至网页时,它将自动以绿色突出显示鼠标悬停的特定位置。此时,您可以先单击要选择的块,然后您会发现该块变为红色。如果要选择同一级别的所有块,则可以继续单击下一个相邻的块,该工具将默认选择同一级别的所有块,如下所示:
我们将发现下面的浮动窗口的文本输入框自动填充了该块的XPATH路径,然后单击“完成选择!”。要结束选择,浮动框将消失,并且所选的XPATH将自动填充到下面的选择器行中。另外,请确保选择“多个”以声明要选择多个块。最后,单击“保存”选择器按钮结束。
第三步是获取元素值
完成选择器的创建后,返回上一页,您会发现选择器表中有多余的一行,然后您可以直接在“操作”中的“数据”预览上单击以查看所有您想要获取的元素值。
上图中显示的部分是我添加了两个选择器(主要标签和次要标签)的情况。单击数据预览的弹出窗口的内容实际上是我想要的,只需将其直接复制到EXCEL,就不需要什么对于自动爬网处理来说太复杂了。
上面是对使用Web Scraper的过程的简要介绍。当然,我的用法并不完全有效,因为每次我想要获取第二级标签时,都需要先手动切换第一级标签,然后执行抓取指令。应该有更好的方法,但是对我来说已经足够了。本文文章主要是希望与您一起推广此工具。这不是教程。应该根据您的需要探索更多功能〜
怎么样,它对您有帮助吗? 查看全部
WebScraper:从网页中提取数据的Chrome网页数据提取插件

我要共享的工具是一个称为Chrome的插件:Web Scraper,这是一个可以从网页中提取数据的Chrome网页数据提取插件。从某种意义上讲,您还可以将其用作采集器工具。
这也是因为我最近正在整理一些36氪文章的标签,并且计划查看可以参考与风险资本网站相关的其他标准,所以我找到了一家名为“ Enox Data”的公司“ 网站,它提供的“工业系统”标签集具有很大的参考价值。我想捕获页面上的数据并将其集成到我们自己的标记库中,如下图的红色字母部分所示:

如果它是规则显示的数据,则还可以使用鼠标来选择它,然后将其复制并粘贴,但是您仍然必须考虑一些将其嵌入页面的方法。这时候,我记得以前已经安装了Web Scraper,所以我尝试了。它非常易于使用,并且采集效率立即得到提高。也给大家安利〜
Web Scraper是Chrome插件。一年前,我在一个三节课的公开课上看到了它。它声称是一种黑色技术,可以在不知道编程的情况下实现爬网程序爬网,但是似乎您无法在这三个类别的官方网站上找到它。您可以在百度上找到“三课程爬虫”,仍然可以找到它,名字叫“每个人都可以学习的数据爬虫类”,但似乎要付出100元。我认为可以通过在互联网上查看文章来了解这件事,例如我的文章〜
简单地说,Web Scraper是基于Chrome的网页元素解析器,可以通过可视化的单击操作提取自定义区域中的数据/元素。同时,它还提供了定时自动提取功能,可以用作一组简单的采集器工具。
在这里,我将通过方式解释网页提取器抓取与实际代码抓取之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它使您可以首先在页面上定义需求。抓取哪个元素,抓取哪些页面,然后让机器代表他人进行操作;如果您使用Python编写采集器,则最好使用Web页面请求命令先下载整个Web页面,然后再使用代码来解析HTML页面元素。提取您想要的内容,并继续循环。相比之下,使用代码会更灵活,但是解析的成本会更高。如果这是简单的页面内容提取,则我也建议使用Web Scraper。
关于Web Scraper的特定安装过程以及如何使用完整功能,我今天将不在文章中讨论。第一个是我只用了我需要的东西,第二个是市场上有太多Web Scraper教程,您可以自己找到它。
这只是一个实用的过程,可以为您简要介绍我的使用方式。
第一步是创建站点地图
打开Chrome浏览器,按F12调用开发人员工具,Web Scraper在最后一个选项卡上,单击,然后选择“创建站点地图”菜单,然后单击“创建站点地图”选项。

首先输入要抓取的网站 URL,以及您自定义的抓取任务的名称。例如,我的名字是:xiniulevel,URL是:
第二步是创建抓取节点
我想获取第一级标签和第二级标签,因此首先单击我刚刚创建的站点地图,然后单击“添加新选择器”以进入获取节点选择器配置页面,然后单击“在“按钮”页面上选择“”,然后您会看到一个浮动层出现

这时,将鼠标移至网页时,它将自动以绿色突出显示鼠标悬停的特定位置。此时,您可以先单击要选择的块,然后您会发现该块变为红色。如果要选择同一级别的所有块,则可以继续单击下一个相邻的块,该工具将默认选择同一级别的所有块,如下所示:

我们将发现下面的浮动窗口的文本输入框自动填充了该块的XPATH路径,然后单击“完成选择!”。要结束选择,浮动框将消失,并且所选的XPATH将自动填充到下面的选择器行中。另外,请确保选择“多个”以声明要选择多个块。最后,单击“保存”选择器按钮结束。

第三步是获取元素值
完成选择器的创建后,返回上一页,您会发现选择器表中有多余的一行,然后您可以直接在“操作”中的“数据”预览上单击以查看所有您想要获取的元素值。


上图中显示的部分是我添加了两个选择器(主要标签和次要标签)的情况。单击数据预览的弹出窗口的内容实际上是我想要的,只需将其直接复制到EXCEL,就不需要什么对于自动爬网处理来说太复杂了。
上面是对使用Web Scraper的过程的简要介绍。当然,我的用法并不完全有效,因为每次我想要获取第二级标签时,都需要先手动切换第一级标签,然后执行抓取指令。应该有更好的方法,但是对我来说已经足够了。本文文章主要是希望与您一起推广此工具。这不是教程。应该根据您的需要探索更多功能〜
怎么样,它对您有帮助吗?
“云智时代”翻译:ProxyCrawl使用ProxyCrawlAPI
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-04-04 06:13
Internet上不断涌现新信息,新设计模式和大量数据。将该数据组织到唯一的库中并不容易。但是,有许多出色的Web爬网工具可用。本文转载自《今日致词》,由《云志时报》 文章翻译,对这方面有需要的学生有帮助。
ProxyCrawl
使用代理爬网API,您可以爬网Web上的任何网站 /平台。具有代理支持,验证码绕过以及基于动态内容抓取JavaScript页面的优势。
它可以免费获得1,000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy是一个开放源代码项目,为爬网网页提供支持。 Scrapy爬网框架在从网站和网页中提取数据方面做得非常好。
最重要的是,Scrapy可用于挖掘数据,监视数据模式以及对大型任务执行自动测试。强大的功能可以与ProxyCrawl完美集成。使用Scrapy,由于具有内置工具,因此选择内容源(HTML和XML)非常容易。您还可以使用Scrapy API扩展提供的功能。
抢
Grab是用于创建自定义Web爬网规则集的基于Python的框架。使用Grab,您可以为小型个人项目创建爬网机制,还可以构建大型动态爬网任务,这些任务可以同时扩展到数百万个页面。
内置API提供了一种执行网络请求的方法,并且还可以处理已删除的内容。 Grab提供的另一个API称为Spider。使用Spider API,您可以使用自定义类创建异步抓取工具。
雪貂
Ferret是一种相当新的Web抓取工具,在开源社区中获得了相当大的关注。 Ferret的目标是提供更简洁的客户端爬网解决方案。例如,允许开发人员编写不必依赖于应用程序状态的采集器。
此外,雪貂使用自定义的声明性语言来避免构建系统的复杂性。相反,您可以编写严格的规则以从任何站点抓取数据。
X射线
由于X-Ray和Osmosis等库的可用性,使用Node.js爬网非常容易。
Diffbot
Diffbot是市场上的新玩家。您甚至不必编写太多代码,因为Diffbot的AI算法可以在无需手动说明的情况下从网站页面解密结构化数据。
PhantomJS Cloud
PhantomJS Cloud是PhantomJS浏览器的SaaS替代产品。使用PhantomJS Cloud,您可以直接从网页内部获取数据,还可以生成可视文件,并将页面显示为PDF文档。
PhantomJS本身是一个浏览器,这意味着您可以像浏览器一样加载和执行页面资源。如果您手头的任务需要获取许多基于JavaScript的网站,则此功能特别有用。
注:《云芝时报》的翻译不完整。如果您有兴趣,请阅读原创文本:
2019年最佳Web抓取工具 查看全部
“云智时代”翻译:ProxyCrawl使用ProxyCrawlAPI
Internet上不断涌现新信息,新设计模式和大量数据。将该数据组织到唯一的库中并不容易。但是,有许多出色的Web爬网工具可用。本文转载自《今日致词》,由《云志时报》 文章翻译,对这方面有需要的学生有帮助。
ProxyCrawl
使用代理爬网API,您可以爬网Web上的任何网站 /平台。具有代理支持,验证码绕过以及基于动态内容抓取JavaScript页面的优势。

它可以免费获得1,000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy是一个开放源代码项目,为爬网网页提供支持。 Scrapy爬网框架在从网站和网页中提取数据方面做得非常好。

最重要的是,Scrapy可用于挖掘数据,监视数据模式以及对大型任务执行自动测试。强大的功能可以与ProxyCrawl完美集成。使用Scrapy,由于具有内置工具,因此选择内容源(HTML和XML)非常容易。您还可以使用Scrapy API扩展提供的功能。
抢
Grab是用于创建自定义Web爬网规则集的基于Python的框架。使用Grab,您可以为小型个人项目创建爬网机制,还可以构建大型动态爬网任务,这些任务可以同时扩展到数百万个页面。

内置API提供了一种执行网络请求的方法,并且还可以处理已删除的内容。 Grab提供的另一个API称为Spider。使用Spider API,您可以使用自定义类创建异步抓取工具。
雪貂
Ferret是一种相当新的Web抓取工具,在开源社区中获得了相当大的关注。 Ferret的目标是提供更简洁的客户端爬网解决方案。例如,允许开发人员编写不必依赖于应用程序状态的采集器。

此外,雪貂使用自定义的声明性语言来避免构建系统的复杂性。相反,您可以编写严格的规则以从任何站点抓取数据。
X射线
由于X-Ray和Osmosis等库的可用性,使用Node.js爬网非常容易。
Diffbot
Diffbot是市场上的新玩家。您甚至不必编写太多代码,因为Diffbot的AI算法可以在无需手动说明的情况下从网站页面解密结构化数据。

PhantomJS Cloud
PhantomJS Cloud是PhantomJS浏览器的SaaS替代产品。使用PhantomJS Cloud,您可以直接从网页内部获取数据,还可以生成可视文件,并将页面显示为PDF文档。

PhantomJS本身是一个浏览器,这意味着您可以像浏览器一样加载和执行页面资源。如果您手头的任务需要获取许多基于JavaScript的网站,则此功能特别有用。
注:《云芝时报》的翻译不完整。如果您有兴趣,请阅读原创文本:
2019年最佳Web抓取工具
WebScraping支持以240多种语言提取Web数据提取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-04-04 06:12
Web爬网工具专门用于从网站中提取信息。它们也被称为Web采集工具或Web数据提取工具。
Web爬网工具可在各种情况下用于无限目的。
例如:
1.采集市场研究数据
Web抓取工具可以从多个数据分析提供程序获取信息,并将它们集成到一个位置,以方便参考和分析。它可以帮助您了解未来六个月公司或行业的发展方向。
2.提取联系信息
这些工具还可用于从各种网站中提取数据,例如电子邮件和电话号码。
3.采集数据以下载以供离线阅读或存储
4.跟踪多个市场等的价格。
这些软件可以手动或自动查找新数据,获取新数据或更新数据并进行存储,以方便访问。例如,可以使用采集器从亚马逊采集有关产品及其价格的信息。在本文文章中,我们列出了9种Web抓取工具。
1.
通过从特定网页导入数据并将数据导出到CSV,可以提供构建器来形成您自己的数据集。您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据需要构建超过1,000个API。
2.
通过抓取数千个在线资源来提供对实时和结构化数据的直接访问。 Web scraper支持提取超过240种语言的Web数据并以XML,JSON和RSS等各种格式保存输出数据。
3.(以前称为CloudScrape)
CloudScrape支持从任何网站采集数据,而无需像Webhose那样进行下载。它提供了一个基于浏览器的编辑器来设置采集器并实时提取数据。您可以将采集的数据保存在Google云端硬盘和其他云平台上,或将其导出为CSV或JSON。
4. Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。 Scrapinghub使用Crawlera(智能代理旋转器),该代理旋转器支持绕过机器人的对策,并轻松抓住庞大的或受机器人保护的站点。
5. ParseHub
ParseHub用于抓取单个和多个网站,支持JavaScript,AJAX,会话,cookie和重定向。该应用程序使用机器学习技术来识别Web上最复杂的文档,并根据所需的数据格式生成输出文件。
6. VisualScraper
VisualScraper是另一个Web数据提取软件,可用于从Web采集信息。该软件可以帮助您从多个网页提取数据并实时获取结果。此外,您可以导出各种格式的文件,例如CSV,XML,JSON和SQL。
7. Spinn3r
Spinn3r允许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。 Spinn3r与firehouse API一起分发,并管理95%的索引工作。它提供了高级垃圾邮件保护功能,可以消除垃圾邮件和不当使用语言,从而提高数据安全性。
8. 80legs
80legs是一款功能强大且灵活的Web抓取工具,可以根据您的需要进行配置。它支持选择获取大量数据并立即下载提取的数据的选项。 80legs声称能够爬网超过600,000个域,并被MailChimp和PayPal等大型公司使用。
9.铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google Spreadsheets。此工具适合可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。
查看全部
WebScraping支持以240多种语言提取Web数据提取工具
Web爬网工具专门用于从网站中提取信息。它们也被称为Web采集工具或Web数据提取工具。
Web爬网工具可在各种情况下用于无限目的。
例如:
1.采集市场研究数据
Web抓取工具可以从多个数据分析提供程序获取信息,并将它们集成到一个位置,以方便参考和分析。它可以帮助您了解未来六个月公司或行业的发展方向。
2.提取联系信息
这些工具还可用于从各种网站中提取数据,例如电子邮件和电话号码。
3.采集数据以下载以供离线阅读或存储
4.跟踪多个市场等的价格。
这些软件可以手动或自动查找新数据,获取新数据或更新数据并进行存储,以方便访问。例如,可以使用采集器从亚马逊采集有关产品及其价格的信息。在本文文章中,我们列出了9种Web抓取工具。
1.
通过从特定网页导入数据并将数据导出到CSV,可以提供构建器来形成您自己的数据集。您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据需要构建超过1,000个API。

2.
通过抓取数千个在线资源来提供对实时和结构化数据的直接访问。 Web scraper支持提取超过240种语言的Web数据并以XML,JSON和RSS等各种格式保存输出数据。
3.(以前称为CloudScrape)
CloudScrape支持从任何网站采集数据,而无需像Webhose那样进行下载。它提供了一个基于浏览器的编辑器来设置采集器并实时提取数据。您可以将采集的数据保存在Google云端硬盘和其他云平台上,或将其导出为CSV或JSON。
4. Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。 Scrapinghub使用Crawlera(智能代理旋转器),该代理旋转器支持绕过机器人的对策,并轻松抓住庞大的或受机器人保护的站点。
5. ParseHub
ParseHub用于抓取单个和多个网站,支持JavaScript,AJAX,会话,cookie和重定向。该应用程序使用机器学习技术来识别Web上最复杂的文档,并根据所需的数据格式生成输出文件。
6. VisualScraper
VisualScraper是另一个Web数据提取软件,可用于从Web采集信息。该软件可以帮助您从多个网页提取数据并实时获取结果。此外,您可以导出各种格式的文件,例如CSV,XML,JSON和SQL。
7. Spinn3r
Spinn3r允许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。 Spinn3r与firehouse API一起分发,并管理95%的索引工作。它提供了高级垃圾邮件保护功能,可以消除垃圾邮件和不当使用语言,从而提高数据安全性。
8. 80legs
80legs是一款功能强大且灵活的Web抓取工具,可以根据您的需要进行配置。它支持选择获取大量数据并立即下载提取的数据的选项。 80legs声称能够爬网超过600,000个域,并被MailChimp和PayPal等大型公司使用。
9.铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google Spreadsheets。此工具适合可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。

网站内容抓取工具的使用与分析(google)(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-04-03 03:08
网站内容抓取工具的使用与分析google查找网站上的任何链接,或下载网站内的任何内容google提供一种方法可以检索网站上的任何东西,不仅可以检索网站上有人的生活、工作和学习时所上传的信息,还可以检索访问过网站的人的生活、工作和学习,并且可以统计检索内容在网站上的每天的流量。今天要介绍的sitesearch就是为网站上的信息检索所设计的,可以检索你网站上的任何内容,而且效果很好。
网站上的任何东西都可以在谷歌中查找,sitesearch为网站添加了一个专属标识“site”,并把这个标识设置在网站名称的前面。获取sitesearch的数据cookie这个cookie是从网站中读取信息而写入到cookie中的,比如从该网站中显示的内容,就会向我们的浏览器写入这个cookie,通过浏览器发出的连接,传输给你的电脑。
我们要获取的信息,包括链接的url地址、个人页面、网络地址等信息。如何查找内容其实很简单,通过可以把sitesearch添加到搜索引擎页面中来操作,引擎显示出网站上有多少东西。当然,也可以通过cookie进行爬取网站上有什么内容。如何利用sitesearch来爬取网站信息我们以所提供的工具内容抓取的网站为例来分析。
首先,我们需要复制我们想要爬取的网站的地址地址:;keyword=work&sid=lz9nxsw0wgzjlbdwol-kkzsk3rk5goob7dvgonz28z12qakjkaewcahhwg。 查看全部
网站内容抓取工具的使用与分析(google)(图)
网站内容抓取工具的使用与分析google查找网站上的任何链接,或下载网站内的任何内容google提供一种方法可以检索网站上的任何东西,不仅可以检索网站上有人的生活、工作和学习时所上传的信息,还可以检索访问过网站的人的生活、工作和学习,并且可以统计检索内容在网站上的每天的流量。今天要介绍的sitesearch就是为网站上的信息检索所设计的,可以检索你网站上的任何内容,而且效果很好。
网站上的任何东西都可以在谷歌中查找,sitesearch为网站添加了一个专属标识“site”,并把这个标识设置在网站名称的前面。获取sitesearch的数据cookie这个cookie是从网站中读取信息而写入到cookie中的,比如从该网站中显示的内容,就会向我们的浏览器写入这个cookie,通过浏览器发出的连接,传输给你的电脑。
我们要获取的信息,包括链接的url地址、个人页面、网络地址等信息。如何查找内容其实很简单,通过可以把sitesearch添加到搜索引擎页面中来操作,引擎显示出网站上有多少东西。当然,也可以通过cookie进行爬取网站上有什么内容。如何利用sitesearch来爬取网站信息我们以所提供的工具内容抓取的网站为例来分析。
首先,我们需要复制我们想要爬取的网站的地址地址:;keyword=work&sid=lz9nxsw0wgzjlbdwol-kkzsk3rk5goob7dvgonz28z12qakjkaewcahhwg。
网站首页会有四条路径,分散网站权重,路径得到四分之一
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-04-03 02:13
当网站未优化时,网站的主页上将有四个路径,网站的权重将分散,每个路径将占四分之一。 301重定向对于网站非常重要。您可以为网站的首页设置默认的index.html。共有404页,可降低用户的重定向率并改善用户体验。
4. 网站内容添加
新推出的网站内容很少。不要一次添加很多内容。您需要逐步添加内容。内容应为原创,这将有助于网站的开发。
5. 文章页面优化
进入网站内容页面时,可以在网站的底部添加一些相关链接或用户喜欢的主题,这可以增加用户在网站中的停留时间,改善用户体验并改善网站 ] 排行。但是请记住,不要使网站的每一页都过于相关,因为这会影响网站的优化。
6、 Robot.txt设置
禁止搜索引擎抓取与网站无关的页面,并且禁止蜘蛛输入网站。
这些是网站上线之前的必要准备。只有在经过几层测试后,才能正式启动网站,以便网站可以平稳运行。
有什么解决方案可以防止程序开发人员私下复制源代码,并避免披露知识产权?
阅读答案后,我们没有找到一个答案就是给出正确的解决方案,而且答案都不是正确的想法。
发问者应该知道在什么情况下可以未经允许复制代码?换句话说,可以将代码保存到计算机的本地磁盘中。
从技术上讲,只要可以将代码或数据保存在计算机的本地磁盘上,就不可能避免数据代码的私有副本,因为对于代码编写者而言,无法设计任何代码模块,黑盒或白盒,或者禁用USB接口,因为如果代码编写者甚至知道如何分发数据,如何访问a和B来源的数据,如何从复杂数据中筛选出有效内容以供自己使用,这些基本的东西是意料之外的,是的,所以应该编写什么代码。
虚拟桌面通常是指类似于服务器的远程登录。文件无法在本地复制,因此,每次访问计算机上的任何资源时,都可以通过虚拟桌面登录,然后使用系统。
应该注意的是,没有任何一种技术可以解决所有问题。虚拟桌面可以防止将代码数据保存在本地,但不能限制将数据上传到代码主机服务器。因此,也有必要对网络进行过滤和监视。这是另一个复杂的问题。
大多数代码没有价值,不能退出业务,而且普通编码人员无法访问核心代码,因此我们应考虑尽一切可能防止未经授权的代码复制。目的是什么? GitHub上有很多代码。您的项目的代码质量比GitHub好多少?与其试图组织未经许可的复制代码,不如找到一种将业务划分为多个部分并最大限度地减少掌握核心业务流程的人员的方法。 查看全部
网站首页会有四条路径,分散网站权重,路径得到四分之一
当网站未优化时,网站的主页上将有四个路径,网站的权重将分散,每个路径将占四分之一。 301重定向对于网站非常重要。您可以为网站的首页设置默认的index.html。共有404页,可降低用户的重定向率并改善用户体验。
4. 网站内容添加
新推出的网站内容很少。不要一次添加很多内容。您需要逐步添加内容。内容应为原创,这将有助于网站的开发。
5. 文章页面优化
进入网站内容页面时,可以在网站的底部添加一些相关链接或用户喜欢的主题,这可以增加用户在网站中的停留时间,改善用户体验并改善网站 ] 排行。但是请记住,不要使网站的每一页都过于相关,因为这会影响网站的优化。
6、 Robot.txt设置
禁止搜索引擎抓取与网站无关的页面,并且禁止蜘蛛输入网站。
这些是网站上线之前的必要准备。只有在经过几层测试后,才能正式启动网站,以便网站可以平稳运行。
有什么解决方案可以防止程序开发人员私下复制源代码,并避免披露知识产权?
阅读答案后,我们没有找到一个答案就是给出正确的解决方案,而且答案都不是正确的想法。
发问者应该知道在什么情况下可以未经允许复制代码?换句话说,可以将代码保存到计算机的本地磁盘中。
从技术上讲,只要可以将代码或数据保存在计算机的本地磁盘上,就不可能避免数据代码的私有副本,因为对于代码编写者而言,无法设计任何代码模块,黑盒或白盒,或者禁用USB接口,因为如果代码编写者甚至知道如何分发数据,如何访问a和B来源的数据,如何从复杂数据中筛选出有效内容以供自己使用,这些基本的东西是意料之外的,是的,所以应该编写什么代码。
虚拟桌面通常是指类似于服务器的远程登录。文件无法在本地复制,因此,每次访问计算机上的任何资源时,都可以通过虚拟桌面登录,然后使用系统。
应该注意的是,没有任何一种技术可以解决所有问题。虚拟桌面可以防止将代码数据保存在本地,但不能限制将数据上传到代码主机服务器。因此,也有必要对网络进行过滤和监视。这是另一个复杂的问题。
大多数代码没有价值,不能退出业务,而且普通编码人员无法访问核心代码,因此我们应考虑尽一切可能防止未经授权的代码复制。目的是什么? GitHub上有很多代码。您的项目的代码质量比GitHub好多少?与其试图组织未经许可的复制代码,不如找到一种将业务划分为多个部分并最大限度地减少掌握核心业务流程的人员的方法。
html提取文本工具推荐大全:收集电子邮件地址、竞争分析
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-05-17 22:17
推荐的html文本提取工具:
采集电子邮件地址,竞争分析,网站检查,价格分析和客户数据采集-这些可能就是您需要从HTML文档中提取文本和其他数据的一些原因。
不幸的是,手动执行此操作既痛苦又效率低下,在某些情况下甚至是不可能的。
幸运的是,现在有各种各样的工具可以满足这些要求。以下7种工具,从为初学者和小型项目设计的非常简单的工具,到需要一定数量的编码知识并且为较大和更困难的任务设计的高级工具。
Iconico HTML文本提取器(Iconico HTML文本提取器)
想象一下,您正在浏览竞争对手的网站,然后要提取文本内容,或者要查看页面后面的HTML代码。不幸的是,您发现右键按钮被禁用,复制和粘贴也被禁用。许多Web开发人员现在正在采取措施来禁用查看源代码或锁定其页面。
幸运的是,Iconico具有HTML文本提取器,您可以使用它来绕过所有这些限制,并且该产品非常易于使用。您可以突出显示和复制文本,并且提取功能的操作就像浏览Internet一样容易。
UiPathUI
Path具有一组自动化的处理工具,其中包括一个Web内容爬网实用程序。要使用该工具并获取几乎所有您需要的数据,非常简单-只需打开页面,转到该工具中的“设计”菜单,然后单击“网页抓取”即可。除了Web采集器之外,屏幕采集器还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页上获取文本,表格数据和其他相关信息。
Mozenda
Mozenda允许用户提取Web数据并将该信息导出到各种智能业务工具。它不仅可以提取文本内容,还可以从PDF文件提取图像,文件和内容。然后,您可以将这些数据导出到XML文件,CSV文件,JSON或选择使用API。提取并导出数据后,您可以使用BI工具进行分析和报告。
HTMLtoText
此在线工具可以从HTML源代码甚至是URL中提取文本。您所需要做的就是复制和粘贴,提供URL或上传文件。单击选项按钮,使该工具知道所需的输出格式和其他一些详细信息,然后单击“转换”,您将获得所需的文本信息。
Octoparse
Octoparse的特征在于它提供了一个“单击”用户界面。即使是没有编码知识的用户也可以从网站中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板上提取工作清单等功能。该工具适用于动态和静态网页以及云采集(配置了采集任务时,也可以是采集数据)。它提供了一个免费版本,对于大多数使用情况而言,这已经足够了,而付费版本则具有更丰富的功能。
如果您爬行网站进行竞争分析,则可能会因为此活动而被禁止。因为Octoparse收录一个功能,可以在一个循环中标识您的IP地址,并且可以禁止您通过IP使用它。
Scrapy
这个免费的开源工具使用网络爬虫从网站中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意学习以自己的方式使用它,那么Scrapy是爬网大型Web项目的理想选择。此工具已被CareerBuilder和其他主要品牌使用。因为它是一个开源工具,所以它为用户提供了很多良好的社区支持。
和服
Kimono是一个免费工具,可以从网页获取非结构化数据,并将信息提取为具有XML文件的结构化格式。该工具可以交互使用,也可以创建计划的作业以在特定时间提取所需的数据。您可以从搜索引擎结果,网页甚至幻灯片演示中提取数据。
最重要的是,当您设置每个工作流程时,和服将创建一个API。这意味着当您返回网站提取更多数据时,无需重新发明轮子。
结论
如果遇到需要从一个或多个网页提取非结构化数据的任务,则此列表中至少有一个工具应收录所需的解决方案。而且,无论您的预期价格是多少,您都应该能够找到所需的工具。
清楚理解并确定最适合您的。您知道,大数据在蓬勃发展的业务发展中的重要性以及采集所需信息的能力对您也至关重要。 查看全部
html提取文本工具推荐大全:收集电子邮件地址、竞争分析
推荐的html文本提取工具:
采集电子邮件地址,竞争分析,网站检查,价格分析和客户数据采集-这些可能就是您需要从HTML文档中提取文本和其他数据的一些原因。
不幸的是,手动执行此操作既痛苦又效率低下,在某些情况下甚至是不可能的。
幸运的是,现在有各种各样的工具可以满足这些要求。以下7种工具,从为初学者和小型项目设计的非常简单的工具,到需要一定数量的编码知识并且为较大和更困难的任务设计的高级工具。
Iconico HTML文本提取器(Iconico HTML文本提取器)
想象一下,您正在浏览竞争对手的网站,然后要提取文本内容,或者要查看页面后面的HTML代码。不幸的是,您发现右键按钮被禁用,复制和粘贴也被禁用。许多Web开发人员现在正在采取措施来禁用查看源代码或锁定其页面。
幸运的是,Iconico具有HTML文本提取器,您可以使用它来绕过所有这些限制,并且该产品非常易于使用。您可以突出显示和复制文本,并且提取功能的操作就像浏览Internet一样容易。
UiPathUI
Path具有一组自动化的处理工具,其中包括一个Web内容爬网实用程序。要使用该工具并获取几乎所有您需要的数据,非常简单-只需打开页面,转到该工具中的“设计”菜单,然后单击“网页抓取”即可。除了Web采集器之外,屏幕采集器还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页上获取文本,表格数据和其他相关信息。
Mozenda
Mozenda允许用户提取Web数据并将该信息导出到各种智能业务工具。它不仅可以提取文本内容,还可以从PDF文件提取图像,文件和内容。然后,您可以将这些数据导出到XML文件,CSV文件,JSON或选择使用API。提取并导出数据后,您可以使用BI工具进行分析和报告。
HTMLtoText
此在线工具可以从HTML源代码甚至是URL中提取文本。您所需要做的就是复制和粘贴,提供URL或上传文件。单击选项按钮,使该工具知道所需的输出格式和其他一些详细信息,然后单击“转换”,您将获得所需的文本信息。
Octoparse
Octoparse的特征在于它提供了一个“单击”用户界面。即使是没有编码知识的用户也可以从网站中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板上提取工作清单等功能。该工具适用于动态和静态网页以及云采集(配置了采集任务时,也可以是采集数据)。它提供了一个免费版本,对于大多数使用情况而言,这已经足够了,而付费版本则具有更丰富的功能。
如果您爬行网站进行竞争分析,则可能会因为此活动而被禁止。因为Octoparse收录一个功能,可以在一个循环中标识您的IP地址,并且可以禁止您通过IP使用它。
Scrapy
这个免费的开源工具使用网络爬虫从网站中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意学习以自己的方式使用它,那么Scrapy是爬网大型Web项目的理想选择。此工具已被CareerBuilder和其他主要品牌使用。因为它是一个开源工具,所以它为用户提供了很多良好的社区支持。
和服
Kimono是一个免费工具,可以从网页获取非结构化数据,并将信息提取为具有XML文件的结构化格式。该工具可以交互使用,也可以创建计划的作业以在特定时间提取所需的数据。您可以从搜索引擎结果,网页甚至幻灯片演示中提取数据。
最重要的是,当您设置每个工作流程时,和服将创建一个API。这意味着当您返回网站提取更多数据时,无需重新发明轮子。
结论
如果遇到需要从一个或多个网页提取非结构化数据的任务,则此列表中至少有一个工具应收录所需的解决方案。而且,无论您的预期价格是多少,您都应该能够找到所需的工具。
清楚理解并确定最适合您的。您知道,大数据在蓬勃发展的业务发展中的重要性以及采集所需信息的能力对您也至关重要。
抓取网络小说生成文本文件的软件大小版本说明下载地址
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-05-16 00:12
网络图书抓取器主要用于抓取在线小说以生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后根据章节顺序获取小说内容,然后将其合并。抓取过程可以随时中断,并且在程序关闭后可以继续执行上一个任务。
相关软件的软件大小和版本说明下载链接
网络图书抓取器主要用于抓取在线小说以生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后根据章节顺序获取小说内容,然后将其合并。抓取过程可以随时中断,并且在程序关闭后可以继续执行上一个任务。
软件功能
1、本章调整:提取目录后,可以执行调整操作,例如移动,删除和倒序。调整将直接影响最终书籍,也将按调整后的章节顺序输出。
2、自动重试:在爬网期间,由于网络因素的影响,可能会发生爬网失败。该程序可能会自动重试,直到成功为止,或者您可以暂时中断爬网(中断后关闭程序不会影响进度),并在网络状况良好时重试。
3、停止并继续:可以随时停止搜寻过程,并且退出程序后进度不会受到影响(章节信息将保存在记录中,并且在运行注意:需要先使用“停止”按钮中断然后退出程序,如果直接退出,将无法恢复。)
4、一键抓取:也称为“傻瓜模式”,基本上可以实现自动抓取和合并功能,并直接输出最终的文本文件。您可能需要在最前面输入最基本的URL,在前面保存位置和其他信息(会有明显的操作提示),在调整章节之后也可以使用一键式抓取,抓取和合并操作将自动完成
5、适用网站:已收录10个适用的网站(您可以在选择后快速打开网站来查找所需的书),它还可以自动应用适当的代码,并且也可以用于其他小说网站测试,如果结合使用,则可以将其手动添加到配置文件中以备后用。
6、制作电子书的便捷性:您可以在设置文件中添加每个章节名称的前缀和后缀,这为后期制作电子书的目录带来了极大的便利。
查看全部
抓取网络小说生成文本文件的软件大小版本说明下载地址
网络图书抓取器主要用于抓取在线小说以生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后根据章节顺序获取小说内容,然后将其合并。抓取过程可以随时中断,并且在程序关闭后可以继续执行上一个任务。
相关软件的软件大小和版本说明下载链接
网络图书抓取器主要用于抓取在线小说以生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后根据章节顺序获取小说内容,然后将其合并。抓取过程可以随时中断,并且在程序关闭后可以继续执行上一个任务。
软件功能
1、本章调整:提取目录后,可以执行调整操作,例如移动,删除和倒序。调整将直接影响最终书籍,也将按调整后的章节顺序输出。
2、自动重试:在爬网期间,由于网络因素的影响,可能会发生爬网失败。该程序可能会自动重试,直到成功为止,或者您可以暂时中断爬网(中断后关闭程序不会影响进度),并在网络状况良好时重试。
3、停止并继续:可以随时停止搜寻过程,并且退出程序后进度不会受到影响(章节信息将保存在记录中,并且在运行注意:需要先使用“停止”按钮中断然后退出程序,如果直接退出,将无法恢复。)
4、一键抓取:也称为“傻瓜模式”,基本上可以实现自动抓取和合并功能,并直接输出最终的文本文件。您可能需要在最前面输入最基本的URL,在前面保存位置和其他信息(会有明显的操作提示),在调整章节之后也可以使用一键式抓取,抓取和合并操作将自动完成
5、适用网站:已收录10个适用的网站(您可以在选择后快速打开网站来查找所需的书),它还可以自动应用适当的代码,并且也可以用于其他小说网站测试,如果结合使用,则可以将其手动添加到配置文件中以备后用。
6、制作电子书的便捷性:您可以在设置文件中添加每个章节名称的前缀和后缀,这为后期制作电子书的目录带来了极大的便利。
网页抓取工具优采云采集器V9的抓取原理是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-05-16 00:11
如果Internet像广阔的海洋,那么它是一种潜艇探测器,可以定位宝藏的确切位置并实现智能捕鱼。这种类比的原因是Internet庞大且瞬息万变。作为信息采集领域的人,每当他看到一种出色的内容时,他都希望进行全面的操作采集,但这就像在大海捞针中寻找针头一样,这既费时又费力。因此,提供一种网络抓取工具,可以自动对Internet上的数据进行抓取,并进行智能的分类和分析,具有重要的意义。
Internet上的数据有多种格式,包括一般类别,例如图片,文件和文本。当我们使用Web爬网工具进行爬网时,是否可以捕获所有网页和各种格式?确认使用最广泛的Web爬网工具。
通常优采云 采集器吸引最多的文字和图片是网站网站管理员和APP后端管理员。他们通常需要集成和汇总适合自己位置的数据,然后找出适合时间的数据呈现给用户。例如,新闻类别和图形欣赏类别都需要过滤Internet中的图形数据。 Web爬网工具优采云 采集器 V9的爬网原理是首先获取URL,然后执行与该URL对应的页面的源代码。分析,提取速度快,错误率低,可以定期运行以自动更新数据。
我不得不提到,对于有此类需求的用户,优采云 采集器 V9还提供了数据处理和发布功能,即,不仅可以实现爬网,还可以对数据进行脱敏和过滤。等待处理,最后自动发布到目标数据库,完全智能且一致的操作受到用户的青睐。
对于学者来说,最流行的格式是文件,因为大量文档是在Internet上公开共享的,并且许多材料都是以文档和压缩文件的格式。学者一一下载,不仅浪费了宝贵的科研时间,而且导致工作效率下降。如果您可以模拟人为操作来打开网页,则下载和保存文件将花费两倍的努力,结果是两倍。优采云 采集器 V9根据用户的需求,开发了文件检测下载功能,并且支持自动登录,这是一种解决方案。部分内容要求登录可见。
自动化工具是解放人类双手的最佳武器。因此,借助Web爬网工具,需要排序数据的业务区域(例如,舆论监视,公司营销和视频链接)也更加方便。借助Web爬行工具优采云 采集器 V9软件,可以轻松实现图片,文本,文件,链接等各种数据类型的整个网络采集。 查看全部
网页抓取工具优采云采集器V9的抓取原理是什么?
如果Internet像广阔的海洋,那么它是一种潜艇探测器,可以定位宝藏的确切位置并实现智能捕鱼。这种类比的原因是Internet庞大且瞬息万变。作为信息采集领域的人,每当他看到一种出色的内容时,他都希望进行全面的操作采集,但这就像在大海捞针中寻找针头一样,这既费时又费力。因此,提供一种网络抓取工具,可以自动对Internet上的数据进行抓取,并进行智能的分类和分析,具有重要的意义。
Internet上的数据有多种格式,包括一般类别,例如图片,文件和文本。当我们使用Web爬网工具进行爬网时,是否可以捕获所有网页和各种格式?确认使用最广泛的Web爬网工具。
通常优采云 采集器吸引最多的文字和图片是网站网站管理员和APP后端管理员。他们通常需要集成和汇总适合自己位置的数据,然后找出适合时间的数据呈现给用户。例如,新闻类别和图形欣赏类别都需要过滤Internet中的图形数据。 Web爬网工具优采云 采集器 V9的爬网原理是首先获取URL,然后执行与该URL对应的页面的源代码。分析,提取速度快,错误率低,可以定期运行以自动更新数据。
我不得不提到,对于有此类需求的用户,优采云 采集器 V9还提供了数据处理和发布功能,即,不仅可以实现爬网,还可以对数据进行脱敏和过滤。等待处理,最后自动发布到目标数据库,完全智能且一致的操作受到用户的青睐。
对于学者来说,最流行的格式是文件,因为大量文档是在Internet上公开共享的,并且许多材料都是以文档和压缩文件的格式。学者一一下载,不仅浪费了宝贵的科研时间,而且导致工作效率下降。如果您可以模拟人为操作来打开网页,则下载和保存文件将花费两倍的努力,结果是两倍。优采云 采集器 V9根据用户的需求,开发了文件检测下载功能,并且支持自动登录,这是一种解决方案。部分内容要求登录可见。
自动化工具是解放人类双手的最佳武器。因此,借助Web爬网工具,需要排序数据的业务区域(例如,舆论监视,公司营销和视频链接)也更加方便。借助Web爬行工具优采云 采集器 V9软件,可以轻松实现图片,文本,文件,链接等各种数据类型的整个网络采集。
从Qiantu.com抓取工具下载最新版本的V201 9. 02
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-05-14 07:20
样式是这样,只要图标具有采集夹,基本上就是采集夹
记住:要找出类型,请在单选框中选择要成功捕获的类型。
3、详细的抓取
是输入图片地址的具体细节,这并不是说,我之前已经下载了我的,并且都知道用法,下面的第一个版本还没有删除,可以检查一下
4、索引
索引用于分页爬网。例如,如果您下载前50页并在中间中断,则仅保留50页数据。重新爬网太耗时。可以直接将索引添加到索引中,例如填写50,只需从第50页开始即可。要填写详细信息,请根据分类的页面数输入。
5、 excel合并
该软件使用从该服务器进行的专用下载,该下载将逐个生成excel文档,然后将excel文档直接导入到下载器中进行下载
每页一个excel,并且在完成所有爬网后将生成一个摘要文档。
因此,如果发生中断,则只会提取50个,稍后再提取50个。在所有汇总数据中,前五十页数据将丢失
此时,您可以使用此功能,只需直接合并excel
记住:合并时,最好清理所有生成的数据文件,否则可能有重复的数据。
6、下载器
让我们谈谈下载器功能,让我们谈谈具体用法
1.直接填写下载文件的存储路径
2.导入通过抓取获得的excel文档
3.点击下载
其余功能可以自己学习
如果某些资源下载失败,则可以单击以重复下载,以前下载的资源将不会被覆盖。
更新日志:
加入视频预览抓取
此地址上有一些视频,您可以直接获取预览视频内容
在页面上,只要有一个播放按钮图标,基本上就可以抓住它。
它不限于此地址,只要它具有播放按钮图标,就可以了,您可以尝试 查看全部
从Qiantu.com抓取工具下载最新版本的V201 9. 02
样式是这样,只要图标具有采集夹,基本上就是采集夹
记住:要找出类型,请在单选框中选择要成功捕获的类型。
3、详细的抓取
是输入图片地址的具体细节,这并不是说,我之前已经下载了我的,并且都知道用法,下面的第一个版本还没有删除,可以检查一下
4、索引
索引用于分页爬网。例如,如果您下载前50页并在中间中断,则仅保留50页数据。重新爬网太耗时。可以直接将索引添加到索引中,例如填写50,只需从第50页开始即可。要填写详细信息,请根据分类的页面数输入。
5、 excel合并
该软件使用从该服务器进行的专用下载,该下载将逐个生成excel文档,然后将excel文档直接导入到下载器中进行下载
每页一个excel,并且在完成所有爬网后将生成一个摘要文档。
因此,如果发生中断,则只会提取50个,稍后再提取50个。在所有汇总数据中,前五十页数据将丢失
此时,您可以使用此功能,只需直接合并excel
记住:合并时,最好清理所有生成的数据文件,否则可能有重复的数据。
6、下载器
让我们谈谈下载器功能,让我们谈谈具体用法
1.直接填写下载文件的存储路径
2.导入通过抓取获得的excel文档
3.点击下载
其余功能可以自己学习
如果某些资源下载失败,则可以单击以重复下载,以前下载的资源将不会被覆盖。
更新日志:
加入视频预览抓取
此地址上有一些视频,您可以直接获取预览视频内容
在页面上,只要有一个播放按钮图标,基本上就可以抓住它。
它不限于此地址,只要它具有播放按钮图标,就可以了,您可以尝试
Python下的爬虫库--强烈推荐掌握的解析类
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-10 05:06
Python下的采集器库通常分为3类。
抢劫班
urllib(Python 3),这是Python随附的一个库,可以模拟浏览器请求并获取响应以进行分析。它提供了大量的请求方法,支持各种参数,例如Cookie,标头和许多采集器。该库基本上是基于该库构建的,因此建议对其进行学习,因为一些罕见的问题需要通过底层方法来解决。
基于urllib的请求,但更加方便和易于使用。强烈建议您精通。
分析课
re:官方的正则表达式库,不仅用于学习爬虫,而且还用于其他字符串处理或自然语言处理,这是一个不能被绕过的库,强烈建议您掌握它。
BeautifulSoup:易于使用,易于使用,建议掌握。通过选择器选择页面元素,然后获取相应的内容。
lxml:使用
lxml.etree
转换字符串后,我们可以使用XPath表达式来解析网页,这是最终的建议。 XPath对网页解析的支持非常强大且易于使用。它最初是为XML元素选择而设计的,但它也支持HTML。
pyquery:另一个强大的解析库,如果您有兴趣,可以学习它。
综合课
selenium:WYSIWYG采集器,它集成了搜寻和解析的两个功能,提供了一站式解决方案。许多动态网页不容易直接通过请求进行抓取和抓取。例如,某些URL附带加密的随机数。这些算法不容易破解。在这种情况下,只能通过直接访问URL,模拟登录等方式来请求它们。页面源代码,直接从页面元素中解析内容。在这种情况下,硒是最佳选择。但是Selenium最初是为测试而设计的。强烈推荐。
scrapy:另一个采集器工件,适合于搜寻大量页面,甚至为分布式采集器提供了良好的支持。强烈推荐。
这些是我个人经常使用的库,但是还有许多其他值得学习的工具。例如,Splash还支持对动态网页的爬网; Appium可以帮助我们抓取App的内容; Charles可以帮助我们捕获数据包,无论是移动网页还是PC网页,都有很好的支持; pyspider也是一个全面的框架; MySQL(pymysql),MongoDB(pymongo),一旦捕获到数据就必须将其存储,并且无法绕过数据库。
掌握了以上内容之后,基本上大部分的采集器任务都不会困扰您!
您也可以关注我的头条帐户或个人博客,进行一些爬行动物共享。计数孔: 查看全部
Python下的爬虫库--强烈推荐掌握的解析类
Python下的采集器库通常分为3类。
抢劫班
urllib(Python 3),这是Python随附的一个库,可以模拟浏览器请求并获取响应以进行分析。它提供了大量的请求方法,支持各种参数,例如Cookie,标头和许多采集器。该库基本上是基于该库构建的,因此建议对其进行学习,因为一些罕见的问题需要通过底层方法来解决。
基于urllib的请求,但更加方便和易于使用。强烈建议您精通。
分析课
re:官方的正则表达式库,不仅用于学习爬虫,而且还用于其他字符串处理或自然语言处理,这是一个不能被绕过的库,强烈建议您掌握它。
BeautifulSoup:易于使用,易于使用,建议掌握。通过选择器选择页面元素,然后获取相应的内容。
lxml:使用
lxml.etree
转换字符串后,我们可以使用XPath表达式来解析网页,这是最终的建议。 XPath对网页解析的支持非常强大且易于使用。它最初是为XML元素选择而设计的,但它也支持HTML。
pyquery:另一个强大的解析库,如果您有兴趣,可以学习它。
综合课
selenium:WYSIWYG采集器,它集成了搜寻和解析的两个功能,提供了一站式解决方案。许多动态网页不容易直接通过请求进行抓取和抓取。例如,某些URL附带加密的随机数。这些算法不容易破解。在这种情况下,只能通过直接访问URL,模拟登录等方式来请求它们。页面源代码,直接从页面元素中解析内容。在这种情况下,硒是最佳选择。但是Selenium最初是为测试而设计的。强烈推荐。
scrapy:另一个采集器工件,适合于搜寻大量页面,甚至为分布式采集器提供了良好的支持。强烈推荐。
这些是我个人经常使用的库,但是还有许多其他值得学习的工具。例如,Splash还支持对动态网页的爬网; Appium可以帮助我们抓取App的内容; Charles可以帮助我们捕获数据包,无论是移动网页还是PC网页,都有很好的支持; pyspider也是一个全面的框架; MySQL(pymysql),MongoDB(pymongo),一旦捕获到数据就必须将其存储,并且无法绕过数据库。
掌握了以上内容之后,基本上大部分的采集器任务都不会困扰您!
您也可以关注我的头条帐户或个人博客,进行一些爬行动物共享。计数孔:
网页页面获取器的软件操作方法有哪些?软件功能特色
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-05-07 05:00
网页页面获取器的软件操作方法有哪些?软件功能特色
网页文字采集器
网页文本抓取工具软件简介:网页文本抓取工具是一种绿色精致的网页抓取器。该软件可以帮助客户进行大中型门户网站的数据分析,并详细分析噪声数据信息的特征。然后,根据HTML文档协议的结构特征,可以轻松获得网页的主要文本文章。
如何操作网页文本抓取工具软件
1、单击IE计算机浏览器的特殊工具/ Internet选项列表,进入安全选项卡,单击“自定义级别”按钮,在打开的安全策略提示框中,选择所有禁止使用的脚本,按F5刷新清除网页后,您还会发现可以选择这些无法选择的文本。
2、立即按Ctrl + A选择网页中的所有内容,然后单击以编写列表的复制说明,然后将此内容粘贴到Word文本文档或文本文档中,然后从“选择”中进行选择Word文本文件或要复制的文本文件中的必要文本。
3、不要忘记在复制进行后更改第一步的脚本创建设置,否则许多Web元素的显示信息都会异常。
网页文字抓取工具软件的功能
1、绿色软件,无需安装。
2、使用计算机键盘Ctrl,Alt,Shift +计算机鼠标单击,中键和鼠标右键进行实际操作。
3、可以抓取无法复制的文字,但不能抓取照片。
4、适合复制文本框文本,例如基本静态数据提示框,消息推送和程序流菜单栏。
5、适用于计算机鼠标和键盘快捷方式,该快捷方式由Ctrl,Alt,Shift和计算机鼠标的左/中/右鼠标按钮组成。
6、适用于在Chrome中抓取网页图片的替换文字和网址链接。
网页文本采集器软件更新日志
优化了某些功能的细节并改善了用户体验。修复了一些已知的错误并增强了操作的稳定性。 查看全部
网页页面获取器的软件操作方法有哪些?软件功能特色
网页文字采集器
网页文本抓取工具软件简介:网页文本抓取工具是一种绿色精致的网页抓取器。该软件可以帮助客户进行大中型门户网站的数据分析,并详细分析噪声数据信息的特征。然后,根据HTML文档协议的结构特征,可以轻松获得网页的主要文本文章。
如何操作网页文本抓取工具软件
1、单击IE计算机浏览器的特殊工具/ Internet选项列表,进入安全选项卡,单击“自定义级别”按钮,在打开的安全策略提示框中,选择所有禁止使用的脚本,按F5刷新清除网页后,您还会发现可以选择这些无法选择的文本。
2、立即按Ctrl + A选择网页中的所有内容,然后单击以编写列表的复制说明,然后将此内容粘贴到Word文本文档或文本文档中,然后从“选择”中进行选择Word文本文件或要复制的文本文件中的必要文本。
3、不要忘记在复制进行后更改第一步的脚本创建设置,否则许多Web元素的显示信息都会异常。
网页文字抓取工具软件的功能
1、绿色软件,无需安装。
2、使用计算机键盘Ctrl,Alt,Shift +计算机鼠标单击,中键和鼠标右键进行实际操作。
3、可以抓取无法复制的文字,但不能抓取照片。
4、适合复制文本框文本,例如基本静态数据提示框,消息推送和程序流菜单栏。
5、适用于计算机鼠标和键盘快捷方式,该快捷方式由Ctrl,Alt,Shift和计算机鼠标的左/中/右鼠标按钮组成。
6、适用于在Chrome中抓取网页图片的替换文字和网址链接。
网页文本采集器软件更新日志
优化了某些功能的细节并改善了用户体验。修复了一些已知的错误并增强了操作的稳定性。
谷歌XMLGenerator站点地图用哪款比较好?(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-05-05 07:06
无论我们是为了搜索引擎友好还是用户友好的体验而构建网站,都需要网站地图来帮助用户搜索和查看内容,尤其是在网站收录大量内容的情况下。同样,互联网中有网站数不胜数,并且有许多类似的网站。我们网站还需要接近搜索引擎的首选项,并且网站的初始化设置中还需要XML SiteMap网站地图。
由于我们选择了WordPress程序,因此必须有一个相应的站点地图插件。对于地图,我们建议使用简单易用的成熟插件。目前,在WordPress的后台搜索中我们可以看到很多地图插件,那么哪个更好?在本文章中,我们的WordPress类建议选择其中两个更常用的。其中包括“ Google XML SiteMap生成器”和“ XML Sitemap和Google新闻”。让我们看看它们中的每一个。功能,然后根据自己的喜好进行选择。
文章目录
第一、节Google SiteMap生成器
到目前为止,我们看到的后端提示名称应为“ Google XML Sitemap”。搜索后可以看到它。它以前的名称为“ Google XML Sitemaps”,该Sitemaps插件是用户下载最多的。
因为有许多类似的站点地图插件,所以我们必须匹配名称。直接安装并激活。然后,我们可以在[设置]-[XML-SiteMap]中看到这些选项。
在这里我们可以根据默认设置直接查看,我们可以看到“”是我们的站点地图,这是您用于提交给搜索引擎的地址。设置起来容易吗?
第二、 XML网站地图和Google新闻
我最近才看到并使用了此插件。我以前一直使用上面的一种,我们也可以看到上面的一种是最常用的。但是从功能的角度来看,“ XML Sitemap和Google新闻”也可以使用,但是更简单。
我们直接下载并激活它。然后,您可以在[设置]-[XML网站地图]中进行设置。
在这里我们可以看到该插件默认情况下自动完成,并且可以设置为不同的优先级,但是我们大多数人可以默认设置它,或者设置哪些类别不参与地图显示。
总结一下,以上两个站点地图XML插件均可用,如果需要,我们可以选择其中之一进行下载和安装。
查看全部
谷歌XMLGenerator站点地图用哪款比较好?(组图)
无论我们是为了搜索引擎友好还是用户友好的体验而构建网站,都需要网站地图来帮助用户搜索和查看内容,尤其是在网站收录大量内容的情况下。同样,互联网中有网站数不胜数,并且有许多类似的网站。我们网站还需要接近搜索引擎的首选项,并且网站的初始化设置中还需要XML SiteMap网站地图。
由于我们选择了WordPress程序,因此必须有一个相应的站点地图插件。对于地图,我们建议使用简单易用的成熟插件。目前,在WordPress的后台搜索中我们可以看到很多地图插件,那么哪个更好?在本文章中,我们的WordPress类建议选择其中两个更常用的。其中包括“ Google XML SiteMap生成器”和“ XML Sitemap和Google新闻”。让我们看看它们中的每一个。功能,然后根据自己的喜好进行选择。
文章目录
第一、节Google SiteMap生成器
到目前为止,我们看到的后端提示名称应为“ Google XML Sitemap”。搜索后可以看到它。它以前的名称为“ Google XML Sitemaps”,该Sitemaps插件是用户下载最多的。
因为有许多类似的站点地图插件,所以我们必须匹配名称。直接安装并激活。然后,我们可以在[设置]-[XML-SiteMap]中看到这些选项。
在这里我们可以根据默认设置直接查看,我们可以看到“”是我们的站点地图,这是您用于提交给搜索引擎的地址。设置起来容易吗?
第二、 XML网站地图和Google新闻
我最近才看到并使用了此插件。我以前一直使用上面的一种,我们也可以看到上面的一种是最常用的。但是从功能的角度来看,“ XML Sitemap和Google新闻”也可以使用,但是更简单。
我们直接下载并激活它。然后,您可以在[设置]-[XML网站地图]中进行设置。
在这里我们可以看到该插件默认情况下自动完成,并且可以设置为不同的优先级,但是我们大多数人可以默认设置它,或者设置哪些类别不参与地图显示。
总结一下,以上两个站点地图XML插件均可用,如果需要,我们可以选择其中之一进行下载和安装。
网站内容采集网站/论坛发帖工具vps镜像/vps市场攻略
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-05-04 19:05
网站内容抓取工具/网站内容采集网站/论坛发帖工具vps镜像/vps市场攻略助手/外挂源码注册客户端html5内容转换/网页内容搜索/图片内容搜索网站收录内容抓取工具/批量抓取工具生成html地址栏html格式html文件chrome设置和控制滚动条,以及最大化滚动栏html合并工具:通过导入包clojure构建超文本,html5标签转换文件。
谷歌网络爬虫挺不错的
mooool采集工具不错
谢邀!国内几个能把谷歌爬虫做得比自己好的产品,已经很多了,随便一打开,不多说,外国不少,如果你不差钱的话,买个谷歌吧!1.robots.txt,公司好像叫谷歌抓取,英文的,你用google浏览器搜索一下就知道了。-needs.html2.everything3.etags4.pagebasedspider,就是按列返回的都不行,但是这个界面是国内的,去谷歌吧,我怕我们的网站刷屏。国内的爬虫产品,思迅云梯算一个,有钱还是买个谷歌的吧!。
首推html5内容抓取工具——网页内容搜索利器谷歌爬虫vimsstrom爬虫工具chrome通配符
来源chromewebstore谷歌浏览器谷歌是我目前用的最顺手的浏览器。
本质上来说外国是个体系自主性强,更换产品灵活性更大;国内则要靠高层政策。随便举个栗子,一旦做了网站,用户数据、后台一定有前端负责人看着,尤其是m100,如果后端设置网站抓取所有sogou官方资源,那也别想都给你抓了,人家要被安排上人大代表的。更别说诸如互联网入口墙等产品要求了。所以很多产品有个局限,就是只能抓取国内和部分主流的网站资源。
不过现在可以通过云快照这类插件来提高抓取效率,不过比较麻烦,需要root。其实优秀的产品当中,其实能抓取全球网站资源的只是少数。如果想简单粗暴的抓取csdn等你要的网站,百度也好、google也好,基本都无能为力。百度也好,google也好,靠打赏这个游戏活着的,活着的资源不可能比人家更多。所以云快照其实针对的对象是高质量站点,方便自己全网搜索也比较实用。
但是针对一些第三方站长网站和大公司站点,效果并不明显。谷歌也好,百度也好,对于审核网站是十分严格的,如果一旦某个网站不符合要求,那么对于谷歌和百度来说就是无效服务。 查看全部
网站内容采集网站/论坛发帖工具vps镜像/vps市场攻略
网站内容抓取工具/网站内容采集网站/论坛发帖工具vps镜像/vps市场攻略助手/外挂源码注册客户端html5内容转换/网页内容搜索/图片内容搜索网站收录内容抓取工具/批量抓取工具生成html地址栏html格式html文件chrome设置和控制滚动条,以及最大化滚动栏html合并工具:通过导入包clojure构建超文本,html5标签转换文件。
谷歌网络爬虫挺不错的
mooool采集工具不错
谢邀!国内几个能把谷歌爬虫做得比自己好的产品,已经很多了,随便一打开,不多说,外国不少,如果你不差钱的话,买个谷歌吧!1.robots.txt,公司好像叫谷歌抓取,英文的,你用google浏览器搜索一下就知道了。-needs.html2.everything3.etags4.pagebasedspider,就是按列返回的都不行,但是这个界面是国内的,去谷歌吧,我怕我们的网站刷屏。国内的爬虫产品,思迅云梯算一个,有钱还是买个谷歌的吧!。
首推html5内容抓取工具——网页内容搜索利器谷歌爬虫vimsstrom爬虫工具chrome通配符
来源chromewebstore谷歌浏览器谷歌是我目前用的最顺手的浏览器。
本质上来说外国是个体系自主性强,更换产品灵活性更大;国内则要靠高层政策。随便举个栗子,一旦做了网站,用户数据、后台一定有前端负责人看着,尤其是m100,如果后端设置网站抓取所有sogou官方资源,那也别想都给你抓了,人家要被安排上人大代表的。更别说诸如互联网入口墙等产品要求了。所以很多产品有个局限,就是只能抓取国内和部分主流的网站资源。
不过现在可以通过云快照这类插件来提高抓取效率,不过比较麻烦,需要root。其实优秀的产品当中,其实能抓取全球网站资源的只是少数。如果想简单粗暴的抓取csdn等你要的网站,百度也好、google也好,基本都无能为力。百度也好,google也好,靠打赏这个游戏活着的,活着的资源不可能比人家更多。所以云快照其实针对的对象是高质量站点,方便自己全网搜索也比较实用。
但是针对一些第三方站长网站和大公司站点,效果并不明显。谷歌也好,百度也好,对于审核网站是十分严格的,如果一旦某个网站不符合要求,那么对于谷歌和百度来说就是无效服务。
外部高质量资源站点爬取微信公众号内容抓取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-04 02:06
网站内容抓取工具,网站内容采集一般是使用采集工具,百度或是谷歌,百度一般是一种basic下载技术采集,有:国内外各大公司产品官网、百度产品、必应产品;国外谷歌产品:,其他网站url主要为https等弱网页。现在网站内容抓取工具比较多,主要是基于微信平台开发的一款小软件,
大致分为3类:1.微信公众号内容采集2.新媒体平台采集3.外部高质量资源站点爬取目前微信公众号内容采集比较少,主要用谷歌开发的第三方抓取工具,比如第三方采集_分享工具_gif录制工具-利用gif采集器网,
网站采集分很多种。一种是,把原网页的内容抓下来,而这个原网页就是一个报告,让那些分析师过来拿着来分析。比如,链接的用户行为分析。再比如竞争对手分析等等。这些软件很多。当然要是比较成熟的报告。有免费的,有付费的。一种是,把原网页的内容抓下来。不仅是抓,而且是要把在网站进行分析。在来分析和原网页的关系,是不是同一个人创建的,使用的主要方式是什么。
然后,不仅分析原网页,也分析其他网页。比如还要分析什么时间使用频率比较高。网站的查看方式和工具特性决定了你要什么样的工具。另外网站推荐用国内的或国外的站长站长工具站长搜索云汇总---简单实用的网站建设、网站优化、网站排名实战工具。看你要在什么细分领域了。 查看全部
外部高质量资源站点爬取微信公众号内容抓取工具
网站内容抓取工具,网站内容采集一般是使用采集工具,百度或是谷歌,百度一般是一种basic下载技术采集,有:国内外各大公司产品官网、百度产品、必应产品;国外谷歌产品:,其他网站url主要为https等弱网页。现在网站内容抓取工具比较多,主要是基于微信平台开发的一款小软件,
大致分为3类:1.微信公众号内容采集2.新媒体平台采集3.外部高质量资源站点爬取目前微信公众号内容采集比较少,主要用谷歌开发的第三方抓取工具,比如第三方采集_分享工具_gif录制工具-利用gif采集器网,
网站采集分很多种。一种是,把原网页的内容抓下来,而这个原网页就是一个报告,让那些分析师过来拿着来分析。比如,链接的用户行为分析。再比如竞争对手分析等等。这些软件很多。当然要是比较成熟的报告。有免费的,有付费的。一种是,把原网页的内容抓下来。不仅是抓,而且是要把在网站进行分析。在来分析和原网页的关系,是不是同一个人创建的,使用的主要方式是什么。
然后,不仅分析原网页,也分析其他网页。比如还要分析什么时间使用频率比较高。网站的查看方式和工具特性决定了你要什么样的工具。另外网站推荐用国内的或国外的站长站长工具站长搜索云汇总---简单实用的网站建设、网站优化、网站排名实战工具。看你要在什么细分领域了。
网站内容抓取工具不是随便一个网站都可以抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-05-04 02:04
网站内容抓取工具不是随便一个网站都可以抓取的,这里面包含了技术、投资、产品等各方面因素的。看看不同网站产品,它们在选择网站时候所考虑的因素。1.比如一个文章站,一般会在文章评论数、阅读数,评论数等跟网站内容相关,如果不在网站内容相关,说明网站内容没有引导用户继续产生和消费。2.而一个博客网站,由于它不是以内容展示为目的,所以,博客网站首页的这些栏目属性并不需要考虑在内。3.还有一种就是利用一些图片、视频网站的素材来做,也可以抓取,然后做投放的价值。
rss,博客程序,有的直接编译成文章,有的发布了新闻不改内容。
内容不一样,比如一些博客,当然网站上就是一篇一篇的,可能一个内容就是100000条,一个网站可能500000条,所以只能按照网站的历史或者以前看到的文章来抓取。
从长远来说,我相信我们的网站内容和网站排名的趋势是类似的,价值差不多的时候,通过服务器的商业合作,内容的个性化展示或者绑定按销售排名在谷歌上可以直接展示出来,
针对不同的类型:
1、比如权重稍低的网站,如为了赚钱,必须填充内容:不然排名低,不赚钱,甚至已经不是钱了。
2、比如高权重,最重要的不是内容,而是关键词:有些关键词非常好,做好内容也可以很大网站,但是做好排名可能不够。
3、权重够高,一直是高权重,可以通过绑定关键词、包装外链来收费,比如百度关键词第一页,通过包装外链排在第一的位置,不懂就联系我。 查看全部
网站内容抓取工具不是随便一个网站都可以抓取
网站内容抓取工具不是随便一个网站都可以抓取的,这里面包含了技术、投资、产品等各方面因素的。看看不同网站产品,它们在选择网站时候所考虑的因素。1.比如一个文章站,一般会在文章评论数、阅读数,评论数等跟网站内容相关,如果不在网站内容相关,说明网站内容没有引导用户继续产生和消费。2.而一个博客网站,由于它不是以内容展示为目的,所以,博客网站首页的这些栏目属性并不需要考虑在内。3.还有一种就是利用一些图片、视频网站的素材来做,也可以抓取,然后做投放的价值。
rss,博客程序,有的直接编译成文章,有的发布了新闻不改内容。
内容不一样,比如一些博客,当然网站上就是一篇一篇的,可能一个内容就是100000条,一个网站可能500000条,所以只能按照网站的历史或者以前看到的文章来抓取。
从长远来说,我相信我们的网站内容和网站排名的趋势是类似的,价值差不多的时候,通过服务器的商业合作,内容的个性化展示或者绑定按销售排名在谷歌上可以直接展示出来,
针对不同的类型:
1、比如权重稍低的网站,如为了赚钱,必须填充内容:不然排名低,不赚钱,甚至已经不是钱了。
2、比如高权重,最重要的不是内容,而是关键词:有些关键词非常好,做好内容也可以很大网站,但是做好排名可能不够。
3、权重够高,一直是高权重,可以通过绑定关键词、包装外链来收费,比如百度关键词第一页,通过包装外链排在第一的位置,不懂就联系我。
Webscraper支持以240多种语言提取Web数据提取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-02 03:22
Webscraper支持以240多种语言提取Web数据提取工具
文章内容[]
Web爬网工具可在各种情况下用于无限目的。
例如:
1.采集市场研究数据
Web抓取工具可以从多个数据分析提供程序获取信息,并将它们集成到一个位置,以方便参考和分析。它可以帮助您了解未来六个月公司或行业的发展方向。
2.提取联系信息
这些工具还可用于从各种网站中提取数据,例如电子邮件和电话号码。
3.采集数据以下载以供离线阅读或存储
4.跟踪多个市场等的价格。
这些软件可以手动或自动查找新数据,获取新数据或更新数据并进行存储,以方便访问。例如,可以使用采集器从亚马逊采集有关产品及其价格的信息。在本文文章中,我们列出了9种Web抓取工具。
1. Import.io
Import.io提供了一个构建器,该构建器可以通过从特定网页导入数据并将数据导出到CSV来形成您自己的数据集。您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据需要构建超过1,000个API。
2. Webhose.io
Webhose.io通过抓取数千个在线资源来提供对实时和结构化数据的直接访问。 Web scraper支持提取超过240种语言的Web数据并以XML,JSON和RSS等各种格式保存输出数据。
3. Dexi.io(以前称为CloudScrape)
CloudScrape支持从任何网站采集数据,而无需像Webhose那样进行下载。它提供了一个基于浏览器的编辑器来设置采集器并实时提取数据。您可以将采集的数据保存在Google云端硬盘和其他云平台上,或将其导出为CSV或JSON。
4. Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。 Scrapinghub使用了智能代理旋转器Crawlera,它支持绕过机器人的对策并轻松地抢占庞大或受机器人保护的站点。
5. ParseHub
ParseHub用于抓取单个和多个网站,支持JavaScript,AJAX,会话,cookie和重定向。该应用程序使用机器学习技术来识别Web上最复杂的文档,并根据所需的数据格式生成输出文件。
6. VisualScraper
VisualScraper是另一个Web数据提取软件,可用于从Web采集信息。该软件可以帮助您从多个网页提取数据并实时获取结果。此外,您可以导出各种格式的文件,例如CSV,XML,JSON和SQL。
7. Spinn3r
Spinn3r允许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。 Spinn3r与firehouse API一起分发,并管理95%的索引工作。它提供了高级垃圾邮件保护功能,可以消除垃圾邮件和不当使用语言,从而提高数据安全性。
8. 80legs
80legs是一款功能强大且灵活的Web抓取工具,可以根据您的需要进行配置。它支持选择获取大量数据并立即下载提取的数据的选项。 80legs声称能够爬网超过600,000个域,并被MailChimp和PayPal等大型公司使用。
9.铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google Spreadsheets。此工具适合可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。 查看全部
Webscraper支持以240多种语言提取Web数据提取工具
文章内容[]
Web爬网工具可在各种情况下用于无限目的。
例如:
1.采集市场研究数据
Web抓取工具可以从多个数据分析提供程序获取信息,并将它们集成到一个位置,以方便参考和分析。它可以帮助您了解未来六个月公司或行业的发展方向。
2.提取联系信息
这些工具还可用于从各种网站中提取数据,例如电子邮件和电话号码。
3.采集数据以下载以供离线阅读或存储
4.跟踪多个市场等的价格。
这些软件可以手动或自动查找新数据,获取新数据或更新数据并进行存储,以方便访问。例如,可以使用采集器从亚马逊采集有关产品及其价格的信息。在本文文章中,我们列出了9种Web抓取工具。
1. Import.io
Import.io提供了一个构建器,该构建器可以通过从特定网页导入数据并将数据导出到CSV来形成您自己的数据集。您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据需要构建超过1,000个API。
2. Webhose.io
Webhose.io通过抓取数千个在线资源来提供对实时和结构化数据的直接访问。 Web scraper支持提取超过240种语言的Web数据并以XML,JSON和RSS等各种格式保存输出数据。
3. Dexi.io(以前称为CloudScrape)
CloudScrape支持从任何网站采集数据,而无需像Webhose那样进行下载。它提供了一个基于浏览器的编辑器来设置采集器并实时提取数据。您可以将采集的数据保存在Google云端硬盘和其他云平台上,或将其导出为CSV或JSON。
4. Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。 Scrapinghub使用了智能代理旋转器Crawlera,它支持绕过机器人的对策并轻松地抢占庞大或受机器人保护的站点。
5. ParseHub
ParseHub用于抓取单个和多个网站,支持JavaScript,AJAX,会话,cookie和重定向。该应用程序使用机器学习技术来识别Web上最复杂的文档,并根据所需的数据格式生成输出文件。
6. VisualScraper
VisualScraper是另一个Web数据提取软件,可用于从Web采集信息。该软件可以帮助您从多个网页提取数据并实时获取结果。此外,您可以导出各种格式的文件,例如CSV,XML,JSON和SQL。
7. Spinn3r
Spinn3r允许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。 Spinn3r与firehouse API一起分发,并管理95%的索引工作。它提供了高级垃圾邮件保护功能,可以消除垃圾邮件和不当使用语言,从而提高数据安全性。
8. 80legs
80legs是一款功能强大且灵活的Web抓取工具,可以根据您的需要进行配置。它支持选择获取大量数据并立即下载提取的数据的选项。 80legs声称能够爬网超过600,000个域,并被MailChimp和PayPal等大型公司使用。
9.铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google Spreadsheets。此工具适合可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。
如何使用pclawer网页爬虫工具?您可以使用网络爬虫向导
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-04-29 07:16
如何使用pclawer网络采集器工具?
您可以使用网络采集器向导,网络采集器复制工具,网络采集器和其他工具来捕获网站的全部内容。
如何吸引搜索引擎蜘蛛来抓取我们的网站 _?
网站优化的目的是在搜索引擎中获得良好的排名,从而获得大量流量。如果您想在搜索引擎中获得良好的排名,则必须提高搜索引擎蜘蛛爬行的速度网站。如果搜索引擎抓取网站的频率降低,将直接影响网站的排名,点击量和权重等级。
那么,如何提高搜索引擎蜘蛛爬行网站的速度?
1.更新网站页面或搜索引擎收录尚未搜索某些页面时,可以组织链接并将其提交给搜索引擎,从而可以加快网站页面由搜索引擎蜘蛛抓取。
2.高质量的内容
搜索引擎蜘蛛非常喜欢网站的高质量内容。如果网站长时间不更新高质量内容,搜索引擎蜘蛛将逐渐降低网站的捕获率,从而影响网站的排名和访问量。因此,网站必须定期和定量地更新高质量的内容,以吸引搜索引擎蜘蛛进行爬网,从而增加排名和访问量。
3. 网站地图] 网站该地图可以清楚地显示网站中的所有链接,搜索引擎蜘蛛程序可以跟随网站地图中的链接进入每个页面进行爬网,从而改善了网站排名。
4.外部链接构建
高质量的外部链接对提高网站的排名有很大影响。搜索引擎蜘蛛将跟随链接输入网站,从而提高网站的爬行速度。如果链的质量太差,也会影响搜索引擎蜘蛛的爬行速度。
对于网址采集器有什么建议吗?
这种需求,很容易理解编程语言,如果您不理解,请寻找data 采集工具!使用正则表达式很容易实现。 查看全部
如何使用pclawer网页爬虫工具?您可以使用网络爬虫向导
如何使用pclawer网络采集器工具?
您可以使用网络采集器向导,网络采集器复制工具,网络采集器和其他工具来捕获网站的全部内容。
如何吸引搜索引擎蜘蛛来抓取我们的网站 _?
网站优化的目的是在搜索引擎中获得良好的排名,从而获得大量流量。如果您想在搜索引擎中获得良好的排名,则必须提高搜索引擎蜘蛛爬行的速度网站。如果搜索引擎抓取网站的频率降低,将直接影响网站的排名,点击量和权重等级。
那么,如何提高搜索引擎蜘蛛爬行网站的速度?
1.更新网站页面或搜索引擎收录尚未搜索某些页面时,可以组织链接并将其提交给搜索引擎,从而可以加快网站页面由搜索引擎蜘蛛抓取。
2.高质量的内容
搜索引擎蜘蛛非常喜欢网站的高质量内容。如果网站长时间不更新高质量内容,搜索引擎蜘蛛将逐渐降低网站的捕获率,从而影响网站的排名和访问量。因此,网站必须定期和定量地更新高质量的内容,以吸引搜索引擎蜘蛛进行爬网,从而增加排名和访问量。
3. 网站地图] 网站该地图可以清楚地显示网站中的所有链接,搜索引擎蜘蛛程序可以跟随网站地图中的链接进入每个页面进行爬网,从而改善了网站排名。
4.外部链接构建
高质量的外部链接对提高网站的排名有很大影响。搜索引擎蜘蛛将跟随链接输入网站,从而提高网站的爬行速度。如果链的质量太差,也会影响搜索引擎蜘蛛的爬行速度。
对于网址采集器有什么建议吗?
这种需求,很容易理解编程语言,如果您不理解,请寻找data 采集工具!使用正则表达式很容易实现。
WebScraper插件的安装使用方法及安装流程详解!!
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-04-25 01:19
Web Scraper是chrome网页数据提取插件,用于从网页提取数据。用户只需通过四个步骤即可通过插件建立页面数据提取规则,从而快速提取网页中所需的内容。 Web Scraper插件的整个爬网逻辑从设置第一级选择器并选择爬网范围开始,然后在设置第一级选择器下的第二级选择器之后,再次选择爬网字段,然后您可以抓取网页数据。插件捕获数据后,可以将数据导出为CSV文件,欢迎您免费下载。
插件的安装和使用
一、安装
1、编辑器在此处使用chrome浏览器,首先在标签页上输入[chrome:// extensions /]以输入chrome扩展名,解压缩在此页面上下载的Web Scraper插件,然后将其拖动进入扩展页面。
2、安装完成后,快速尝试该插件的特定功能。
3、当然,您可以先在设置页面上设置插件的存储设置和存储类型功能。
二、使用提取功能
安装完成后,爬网操作仅需四个步骤即可完成。具体过程如下:
1、打开网络抓取工具
首先,您需要使用该插件来提取网页数据,并且需要在开发人员工具模式下使用它。使用快捷键Ctrl + Shift + I / F12并在出现的开发工具窗口中找到与插件名称相同的列。
2、创建一个新的站点地图
点击创建新站点地图,其中有两个选项。导入站点地图是导入现成站点地图的指南。通常我们没有现成的站点地图,因此我们通常不选择它,只需选择创建站点地图即可。
然后执行以下两项操作:
([1) Sitemap Name:表示您的站点地图适用于哪个网页,因此您可以根据自己的名称来命名该网页,但是您需要使用英文字母。例如,如果我从今天的标题中获取数据,那么我将用它来命名;
([2) Sitemap URL:将网页链接复制到Star URL列。例如,在图片中,我将“ Wu Xiaobo Channel”的主页链接复制到此列,然后单击下面的create sitemap创建一个新的站点地图。
3、设置此站点地图
整个Web爬网程序的爬网逻辑如下:设置第一级选择器,选择爬网范围;在第一级选择器下设置第二级选择器,选择爬网字段,然后进行爬网。
对于文章,第一级选择器意味着您必须圈出文章这部分的元素。该元素可能包括标题,作者,发布时间,评论数等,然后我们将在第二层中选择选择器中所需的元素,例如标题,作者和阅读次数。
让我们分解设置主要和次要选择器的工作流程:
([1)点击添加新选择器以创建一级选择器。
然后按照以下步骤操作:
-输入id:id代表您抓取的整个范围,例如,这里是文章,我们可以将其命名为wuxiaobo-articles;
-选择类型:类型代表您抓取的零件的类型,例如element / text / link,因为这是对文章整个元素范围的选择,因此我们需要使用Element首先选择整个(如果此网页需要滑动“加载更多”,请选择“元素向下滚动”;
-检查多个元素:选中“多个元素”前面的小框,因为您想选择多个元素而不是单个元素。当我们检查时,采集器插件将帮助我们识别同一类型的多篇文章。文章;
-保留设置:其余未提及的部分保留默认设置。
([2)点击选择以选择范围,然后按照以下步骤操作:
-选择范围:使用鼠标选择要爬网的数据范围,绿色为要选择的区域,用鼠标单击后该区域变为红色;该区域已选中;
-多项选择:不要只选择一项,还必须选择以下项,否则抓取的数据将只有一行;
-完成选择:记得单击“完成选择”;
-保存:单击保存选择器。
([3)设置此1级选择器后,单击以设置2级选择器,然后执行以下步骤:
-新选择器:单击添加新选择器;
-输入id:id代表您抓取的字段,因此您可以使用该字段的英语,例如,如果我要选择“作者”,我将写“ writer”;
-选择类型:选择文本,因为您要抓取的是文本;
-不要选中“ Multiple”:不要选中“ Multiple”前面的小方框,因为我们要在这里抓取的是单个元素;
-保留设置:其余未提及的部分保留默认设置。
([4)单击选择,然后单击要爬网的字段,然后执行以下步骤:
-选择字段:此处要爬网的字段是单个字段,您可以通过用鼠标单击该字段来选择它。例如,如果要爬网标题,请用鼠标单击某篇文章的标题文章,并且该字段所在的区域将变为红色;
-完成选择:记得单击“完成选择”;
-保存:单击保存选择器。
([5)重复上述操作,直到选择了要爬坡的字段。
4、抓取数据
([1)要抓取数据后,只需设置所有选择器即可开始:
单击“抓取”,然后单击“开始抓取”,将弹出一个小窗口,并且采集器将开始工作。您将获得收录所有所需数据的列表。
(2)如果要对数据进行排序,例如按读数,喜欢,作者等进行排序,以使数据更清晰,则可以单击“将数据导出为CSV并将其导入Excel表”
([3)导入Excel表后,您可以过滤数据。
插件功能
1、抓取多个页面
2、读取的数据存储在本地存储或CouchDB中
3、多种数据选择类型
4、从动态页面(JavaScript + AJAX)提取数据
5、浏览抓取的数据
6、将数据导出为CSV
7、导入,导出站点地图
8、仅取决于Chrome浏览器 查看全部
WebScraper插件的安装使用方法及安装流程详解!!
Web Scraper是chrome网页数据提取插件,用于从网页提取数据。用户只需通过四个步骤即可通过插件建立页面数据提取规则,从而快速提取网页中所需的内容。 Web Scraper插件的整个爬网逻辑从设置第一级选择器并选择爬网范围开始,然后在设置第一级选择器下的第二级选择器之后,再次选择爬网字段,然后您可以抓取网页数据。插件捕获数据后,可以将数据导出为CSV文件,欢迎您免费下载。
插件的安装和使用
一、安装
1、编辑器在此处使用chrome浏览器,首先在标签页上输入[chrome:// extensions /]以输入chrome扩展名,解压缩在此页面上下载的Web Scraper插件,然后将其拖动进入扩展页面。
2、安装完成后,快速尝试该插件的特定功能。
3、当然,您可以先在设置页面上设置插件的存储设置和存储类型功能。
二、使用提取功能
安装完成后,爬网操作仅需四个步骤即可完成。具体过程如下:
1、打开网络抓取工具
首先,您需要使用该插件来提取网页数据,并且需要在开发人员工具模式下使用它。使用快捷键Ctrl + Shift + I / F12并在出现的开发工具窗口中找到与插件名称相同的列。
2、创建一个新的站点地图
点击创建新站点地图,其中有两个选项。导入站点地图是导入现成站点地图的指南。通常我们没有现成的站点地图,因此我们通常不选择它,只需选择创建站点地图即可。
然后执行以下两项操作:
([1) Sitemap Name:表示您的站点地图适用于哪个网页,因此您可以根据自己的名称来命名该网页,但是您需要使用英文字母。例如,如果我从今天的标题中获取数据,那么我将用它来命名;
([2) Sitemap URL:将网页链接复制到Star URL列。例如,在图片中,我将“ Wu Xiaobo Channel”的主页链接复制到此列,然后单击下面的create sitemap创建一个新的站点地图。
3、设置此站点地图
整个Web爬网程序的爬网逻辑如下:设置第一级选择器,选择爬网范围;在第一级选择器下设置第二级选择器,选择爬网字段,然后进行爬网。
对于文章,第一级选择器意味着您必须圈出文章这部分的元素。该元素可能包括标题,作者,发布时间,评论数等,然后我们将在第二层中选择选择器中所需的元素,例如标题,作者和阅读次数。
让我们分解设置主要和次要选择器的工作流程:
([1)点击添加新选择器以创建一级选择器。
然后按照以下步骤操作:
-输入id:id代表您抓取的整个范围,例如,这里是文章,我们可以将其命名为wuxiaobo-articles;
-选择类型:类型代表您抓取的零件的类型,例如element / text / link,因为这是对文章整个元素范围的选择,因此我们需要使用Element首先选择整个(如果此网页需要滑动“加载更多”,请选择“元素向下滚动”;
-检查多个元素:选中“多个元素”前面的小框,因为您想选择多个元素而不是单个元素。当我们检查时,采集器插件将帮助我们识别同一类型的多篇文章。文章;
-保留设置:其余未提及的部分保留默认设置。
([2)点击选择以选择范围,然后按照以下步骤操作:
-选择范围:使用鼠标选择要爬网的数据范围,绿色为要选择的区域,用鼠标单击后该区域变为红色;该区域已选中;
-多项选择:不要只选择一项,还必须选择以下项,否则抓取的数据将只有一行;
-完成选择:记得单击“完成选择”;
-保存:单击保存选择器。
([3)设置此1级选择器后,单击以设置2级选择器,然后执行以下步骤:
-新选择器:单击添加新选择器;
-输入id:id代表您抓取的字段,因此您可以使用该字段的英语,例如,如果我要选择“作者”,我将写“ writer”;
-选择类型:选择文本,因为您要抓取的是文本;
-不要选中“ Multiple”:不要选中“ Multiple”前面的小方框,因为我们要在这里抓取的是单个元素;
-保留设置:其余未提及的部分保留默认设置。
([4)单击选择,然后单击要爬网的字段,然后执行以下步骤:
-选择字段:此处要爬网的字段是单个字段,您可以通过用鼠标单击该字段来选择它。例如,如果要爬网标题,请用鼠标单击某篇文章的标题文章,并且该字段所在的区域将变为红色;
-完成选择:记得单击“完成选择”;
-保存:单击保存选择器。
([5)重复上述操作,直到选择了要爬坡的字段。
4、抓取数据
([1)要抓取数据后,只需设置所有选择器即可开始:
单击“抓取”,然后单击“开始抓取”,将弹出一个小窗口,并且采集器将开始工作。您将获得收录所有所需数据的列表。
(2)如果要对数据进行排序,例如按读数,喜欢,作者等进行排序,以使数据更清晰,则可以单击“将数据导出为CSV并将其导入Excel表”
([3)导入Excel表后,您可以过滤数据。
插件功能
1、抓取多个页面
2、读取的数据存储在本地存储或CouchDB中
3、多种数据选择类型
4、从动态页面(JavaScript + AJAX)提取数据
5、浏览抓取的数据
6、将数据导出为CSV
7、导入,导出站点地图
8、仅取决于Chrome浏览器
智能识别模式WebHarvy自动识别网页中出现的数据模式教程
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-04-25 01:15
WebHarvy是一个非常易于使用且功能强大的应用程序,可以自动从网页中提取数据(文本,URL和图像),并以不同的格式保存提取的内容。
该软件为E文本,没有中文版本。如果E文字不好,请参阅此视频教程:
链接:密码:rt70
功能
视觉点和点击界面
WebHarvy是一个可视网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网络。您可以选择单击鼠标提取数据。很简单!
智能识别模式
WebHarvy自动识别出现在网页中的数据模式。因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需进行任何其他配置。如果数据重复,WebHarvy将自动对其进行爬网。
导出捕获的数据
可以保存从网页提取的各种格式的数据。当前版本的WebHarvy 网站抓取工具允许您将抓取的数据导出为XML,CSV,JSON或TSV文件。您还可以将抓取的数据导出到SQL数据库。
从多个页面中提取
通常,网页在多个页面上显示数据,例如产品目录。 WebHarvy可以自动从多个网页爬网和提取数据。刚刚指出“链接到下一页”,WebHarvy 网站抓取工具将自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取使您可以捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复创建的配置。您可以指定任意数量的输入关键字
代表{pass} {filter}从服务器中提取
要提取匿名信息并防止提取阻止网络软件的Web服务器,必须通过{pass} {filter}选项通过代理服务器访问目标网站。您可以使用一个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy 网站抓取器允许您从链接列表中提取数据,从而在网站中产生相似的页面。这样一来,您就可以使用单个配置来抓取网站中的类别或小节。
使用正则表达式提取
WebHarvy可以在网页的文本或HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项强大的技术为您提供了更大的灵活性,同时可以争夺数据。 查看全部
智能识别模式WebHarvy自动识别网页中出现的数据模式教程
WebHarvy是一个非常易于使用且功能强大的应用程序,可以自动从网页中提取数据(文本,URL和图像),并以不同的格式保存提取的内容。
该软件为E文本,没有中文版本。如果E文字不好,请参阅此视频教程:
链接:密码:rt70
功能
视觉点和点击界面
WebHarvy是一个可视网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网络。您可以选择单击鼠标提取数据。很简单!
智能识别模式
WebHarvy自动识别出现在网页中的数据模式。因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需进行任何其他配置。如果数据重复,WebHarvy将自动对其进行爬网。
导出捕获的数据
可以保存从网页提取的各种格式的数据。当前版本的WebHarvy 网站抓取工具允许您将抓取的数据导出为XML,CSV,JSON或TSV文件。您还可以将抓取的数据导出到SQL数据库。
从多个页面中提取
通常,网页在多个页面上显示数据,例如产品目录。 WebHarvy可以自动从多个网页爬网和提取数据。刚刚指出“链接到下一页”,WebHarvy 网站抓取工具将自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取使您可以捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复创建的配置。您可以指定任意数量的输入关键字
代表{pass} {filter}从服务器中提取
要提取匿名信息并防止提取阻止网络软件的Web服务器,必须通过{pass} {filter}选项通过代理服务器访问目标网站。您可以使用一个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy 网站抓取器允许您从链接列表中提取数据,从而在网站中产生相似的页面。这样一来,您就可以使用单个配置来抓取网站中的类别或小节。
使用正则表达式提取
WebHarvy可以在网页的文本或HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项强大的技术为您提供了更大的灵活性,同时可以争夺数据。
“SEOer必学网站分析神器(全新解析一)”
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-04-24 18:21
每天学习一点点,使自己成为更好的版本;
每天学习一点点是领导才能的开始;
每天学习一点,记录下来,形成一个系统;
每天学习一点点,这是别人与您之间的鸿沟;
最后,您成为大师,其他人只能仰望您...
昨晚发布“ SEOer必须学习网站分析工件(新分析一)”)后,我突然发现其中几乎没有内容,因此将其添加到此处。
移动适应:除了上次提到的某些内容外,它仍然可以加快移动页面的索引量。时间范围可能是适应成功之后的时间,一到两周后,您可以转到索引量工具Check,可以清楚地看到适应成功后索引量的增加,如下图所示:
移动适配成功后,可以检查适配指数值。索引量用于切换移动站点并对其进行检查,如下图所示:
扩展思想:目前,移动适应只能去PC站点提交移动适配,而不能相反,也就是说,您不能去移动站点来提交PC适配。我不知道百度的官方工作人员如何看待它。我不知道他们是否认为这是不必要的?重复工作?或其他原因?
我个人认为,如果能够实现双向适应认证,那么百度适应的进展会有所改善吗?
由于下面解释的部分的功能更为重要,因此它在SEO的实际应用中长期以来一直排名第一,因此请耐心阅读,我将尽我所能控制文章的长度]。
百度网站站长工具网络抓取
索引量
链接提交
提交死链接
Web爬网:此部分的功能是我们最常用的功能。稍后我们发现网站问题也是自检的首选功能。由于内容过多,我们今天仅解释3个模块功能:索引量,链接提交和无效链接提交。
索引量:可以说,此功能是执行SEO时我们最关心的功能之一,也是每天必看的数据之一。这里是使用它们的一些技巧,我将在这里与您分享:
1、昨天的索引量数据通常会在今天下午进行更新;
2、如果PC和手机的索引量之间有很大的差距,则说明您的适应效果不佳(对于适应问题,请单击以查看“ SEOer必须学习的分析网站我上次写的是“工件(新分析一)” 文章);
3、定制规则,我们必须善加利用。这是我们在后期阶段发现索引量下降的最强大工具。因此,我建议大家将网站所有页面类型添加到自定义规则中,以便您可以通过收录清楚地了解每种页面类型的数据,如下所示:
<p>根据数据,您可以找出哪些页面类型收录数据异常。直接访问该页面类型的页面以查看具体原因。同时,您可以结合使用“抓取频率”,“抓取诊断”,“抓取异常”,“链接分析”,“ 网站日志”等,结合实际情况快速分析具体原因。 查看全部
“SEOer必学网站分析神器(全新解析一)”
每天学习一点点,使自己成为更好的版本;
每天学习一点点是领导才能的开始;
每天学习一点,记录下来,形成一个系统;
每天学习一点点,这是别人与您之间的鸿沟;
最后,您成为大师,其他人只能仰望您...
昨晚发布“ SEOer必须学习网站分析工件(新分析一)”)后,我突然发现其中几乎没有内容,因此将其添加到此处。
移动适应:除了上次提到的某些内容外,它仍然可以加快移动页面的索引量。时间范围可能是适应成功之后的时间,一到两周后,您可以转到索引量工具Check,可以清楚地看到适应成功后索引量的增加,如下图所示:
移动适配成功后,可以检查适配指数值。索引量用于切换移动站点并对其进行检查,如下图所示:
扩展思想:目前,移动适应只能去PC站点提交移动适配,而不能相反,也就是说,您不能去移动站点来提交PC适配。我不知道百度的官方工作人员如何看待它。我不知道他们是否认为这是不必要的?重复工作?或其他原因?
我个人认为,如果能够实现双向适应认证,那么百度适应的进展会有所改善吗?
由于下面解释的部分的功能更为重要,因此它在SEO的实际应用中长期以来一直排名第一,因此请耐心阅读,我将尽我所能控制文章的长度]。
百度网站站长工具网络抓取
索引量
链接提交
提交死链接
Web爬网:此部分的功能是我们最常用的功能。稍后我们发现网站问题也是自检的首选功能。由于内容过多,我们今天仅解释3个模块功能:索引量,链接提交和无效链接提交。
索引量:可以说,此功能是执行SEO时我们最关心的功能之一,也是每天必看的数据之一。这里是使用它们的一些技巧,我将在这里与您分享:
1、昨天的索引量数据通常会在今天下午进行更新;
2、如果PC和手机的索引量之间有很大的差距,则说明您的适应效果不佳(对于适应问题,请单击以查看“ SEOer必须学习的分析网站我上次写的是“工件(新分析一)” 文章);
3、定制规则,我们必须善加利用。这是我们在后期阶段发现索引量下降的最强大工具。因此,我建议大家将网站所有页面类型添加到自定义规则中,以便您可以通过收录清楚地了解每种页面类型的数据,如下所示:
<p>根据数据,您可以找出哪些页面类型收录数据异常。直接访问该页面类型的页面以查看具体原因。同时,您可以结合使用“抓取频率”,“抓取诊断”,“抓取异常”,“链接分析”,“ 网站日志”等,结合实际情况快速分析具体原因。
WebScraper:从网页中提取数据的Chrome网页数据提取插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-05 03:06
WebScraper:从网页中提取数据的Chrome网页数据提取插件
我要共享的工具是一个称为Chrome的插件:Web Scraper,这是一个可以从网页中提取数据的Chrome网页数据提取插件。从某种意义上讲,您还可以将其用作采集器工具。
这也是因为我最近正在整理一些36氪文章的标签,并且计划查看可以参考与风险资本网站相关的其他标准,所以我找到了一家名为“ Enox Data”的公司“ 网站,它提供的“工业系统”标签集具有很大的参考价值。我想捕获页面上的数据并将其集成到我们自己的标记库中,如下图的红色字母部分所示:
如果它是规则显示的数据,则还可以使用鼠标来选择它,然后将其复制并粘贴,但是您仍然必须考虑一些将其嵌入页面的方法。这时候,我记得以前已经安装了Web Scraper,所以我尝试了。它非常易于使用,并且采集效率立即得到提高。也给大家安利〜
Web Scraper是Chrome插件。一年前,我在一个三节课的公开课上看到了它。它声称是一种黑色技术,可以在不知道编程的情况下实现爬网程序爬网,但是似乎您无法在这三个类别的官方网站上找到它。您可以在百度上找到“三课程爬虫”,仍然可以找到它,名字叫“每个人都可以学习的数据爬虫类”,但似乎要付出100元。我认为可以通过在互联网上查看文章来了解这件事,例如我的文章〜
简单地说,Web Scraper是基于Chrome的网页元素解析器,可以通过可视化的单击操作提取自定义区域中的数据/元素。同时,它还提供了定时自动提取功能,可以用作一组简单的采集器工具。
在这里,我将通过方式解释网页提取器抓取与实际代码抓取之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它使您可以首先在页面上定义需求。抓取哪个元素,抓取哪些页面,然后让机器代表他人进行操作;如果您使用Python编写采集器,则最好使用Web页面请求命令先下载整个Web页面,然后再使用代码来解析HTML页面元素。提取您想要的内容,并继续循环。相比之下,使用代码会更灵活,但是解析的成本会更高。如果这是简单的页面内容提取,则我也建议使用Web Scraper。
关于Web Scraper的特定安装过程以及如何使用完整功能,我今天将不在文章中讨论。第一个是我只用了我需要的东西,第二个是市场上有太多Web Scraper教程,您可以自己找到它。
这只是一个实用的过程,可以为您简要介绍我的使用方式。
第一步是创建站点地图
打开Chrome浏览器,按F12调用开发人员工具,Web Scraper在最后一个选项卡上,单击,然后选择“创建站点地图”菜单,然后单击“创建站点地图”选项。
首先输入要抓取的网站 URL,以及您自定义的抓取任务的名称。例如,我的名字是:xiniulevel,URL是:
第二步是创建抓取节点
我想获取第一级标签和第二级标签,因此首先单击我刚刚创建的站点地图,然后单击“添加新选择器”以进入获取节点选择器配置页面,然后单击“在“按钮”页面上选择“”,然后您会看到一个浮动层出现
这时,将鼠标移至网页时,它将自动以绿色突出显示鼠标悬停的特定位置。此时,您可以先单击要选择的块,然后您会发现该块变为红色。如果要选择同一级别的所有块,则可以继续单击下一个相邻的块,该工具将默认选择同一级别的所有块,如下所示:
我们将发现下面的浮动窗口的文本输入框自动填充了该块的XPATH路径,然后单击“完成选择!”。要结束选择,浮动框将消失,并且所选的XPATH将自动填充到下面的选择器行中。另外,请确保选择“多个”以声明要选择多个块。最后,单击“保存”选择器按钮结束。
第三步是获取元素值
完成选择器的创建后,返回上一页,您会发现选择器表中有多余的一行,然后您可以直接在“操作”中的“数据”预览上单击以查看所有您想要获取的元素值。
上图中显示的部分是我添加了两个选择器(主要标签和次要标签)的情况。单击数据预览的弹出窗口的内容实际上是我想要的,只需将其直接复制到EXCEL,就不需要什么对于自动爬网处理来说太复杂了。
上面是对使用Web Scraper的过程的简要介绍。当然,我的用法并不完全有效,因为每次我想要获取第二级标签时,都需要先手动切换第一级标签,然后执行抓取指令。应该有更好的方法,但是对我来说已经足够了。本文文章主要是希望与您一起推广此工具。这不是教程。应该根据您的需要探索更多功能〜
怎么样,它对您有帮助吗? 查看全部
WebScraper:从网页中提取数据的Chrome网页数据提取插件
我要共享的工具是一个称为Chrome的插件:Web Scraper,这是一个可以从网页中提取数据的Chrome网页数据提取插件。从某种意义上讲,您还可以将其用作采集器工具。
这也是因为我最近正在整理一些36氪文章的标签,并且计划查看可以参考与风险资本网站相关的其他标准,所以我找到了一家名为“ Enox Data”的公司“ 网站,它提供的“工业系统”标签集具有很大的参考价值。我想捕获页面上的数据并将其集成到我们自己的标记库中,如下图的红色字母部分所示:
如果它是规则显示的数据,则还可以使用鼠标来选择它,然后将其复制并粘贴,但是您仍然必须考虑一些将其嵌入页面的方法。这时候,我记得以前已经安装了Web Scraper,所以我尝试了。它非常易于使用,并且采集效率立即得到提高。也给大家安利〜
Web Scraper是Chrome插件。一年前,我在一个三节课的公开课上看到了它。它声称是一种黑色技术,可以在不知道编程的情况下实现爬网程序爬网,但是似乎您无法在这三个类别的官方网站上找到它。您可以在百度上找到“三课程爬虫”,仍然可以找到它,名字叫“每个人都可以学习的数据爬虫类”,但似乎要付出100元。我认为可以通过在互联网上查看文章来了解这件事,例如我的文章〜
简单地说,Web Scraper是基于Chrome的网页元素解析器,可以通过可视化的单击操作提取自定义区域中的数据/元素。同时,它还提供了定时自动提取功能,可以用作一组简单的采集器工具。
在这里,我将通过方式解释网页提取器抓取与实际代码抓取之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它使您可以首先在页面上定义需求。抓取哪个元素,抓取哪些页面,然后让机器代表他人进行操作;如果您使用Python编写采集器,则最好使用Web页面请求命令先下载整个Web页面,然后再使用代码来解析HTML页面元素。提取您想要的内容,并继续循环。相比之下,使用代码会更灵活,但是解析的成本会更高。如果这是简单的页面内容提取,则我也建议使用Web Scraper。
关于Web Scraper的特定安装过程以及如何使用完整功能,我今天将不在文章中讨论。第一个是我只用了我需要的东西,第二个是市场上有太多Web Scraper教程,您可以自己找到它。
这只是一个实用的过程,可以为您简要介绍我的使用方式。
第一步是创建站点地图
打开Chrome浏览器,按F12调用开发人员工具,Web Scraper在最后一个选项卡上,单击,然后选择“创建站点地图”菜单,然后单击“创建站点地图”选项。
首先输入要抓取的网站 URL,以及您自定义的抓取任务的名称。例如,我的名字是:xiniulevel,URL是:
第二步是创建抓取节点
我想获取第一级标签和第二级标签,因此首先单击我刚刚创建的站点地图,然后单击“添加新选择器”以进入获取节点选择器配置页面,然后单击“在“按钮”页面上选择“”,然后您会看到一个浮动层出现
这时,将鼠标移至网页时,它将自动以绿色突出显示鼠标悬停的特定位置。此时,您可以先单击要选择的块,然后您会发现该块变为红色。如果要选择同一级别的所有块,则可以继续单击下一个相邻的块,该工具将默认选择同一级别的所有块,如下所示:
我们将发现下面的浮动窗口的文本输入框自动填充了该块的XPATH路径,然后单击“完成选择!”。要结束选择,浮动框将消失,并且所选的XPATH将自动填充到下面的选择器行中。另外,请确保选择“多个”以声明要选择多个块。最后,单击“保存”选择器按钮结束。
第三步是获取元素值
完成选择器的创建后,返回上一页,您会发现选择器表中有多余的一行,然后您可以直接在“操作”中的“数据”预览上单击以查看所有您想要获取的元素值。
上图中显示的部分是我添加了两个选择器(主要标签和次要标签)的情况。单击数据预览的弹出窗口的内容实际上是我想要的,只需将其直接复制到EXCEL,就不需要什么对于自动爬网处理来说太复杂了。
上面是对使用Web Scraper的过程的简要介绍。当然,我的用法并不完全有效,因为每次我想要获取第二级标签时,都需要先手动切换第一级标签,然后执行抓取指令。应该有更好的方法,但是对我来说已经足够了。本文文章主要是希望与您一起推广此工具。这不是教程。应该根据您的需要探索更多功能〜
怎么样,它对您有帮助吗?
“云智时代”翻译:ProxyCrawl使用ProxyCrawlAPI
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-04-04 06:13
Internet上不断涌现新信息,新设计模式和大量数据。将该数据组织到唯一的库中并不容易。但是,有许多出色的Web爬网工具可用。本文转载自《今日致词》,由《云志时报》 文章翻译,对这方面有需要的学生有帮助。
ProxyCrawl
使用代理爬网API,您可以爬网Web上的任何网站 /平台。具有代理支持,验证码绕过以及基于动态内容抓取JavaScript页面的优势。
它可以免费获得1,000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy是一个开放源代码项目,为爬网网页提供支持。 Scrapy爬网框架在从网站和网页中提取数据方面做得非常好。
最重要的是,Scrapy可用于挖掘数据,监视数据模式以及对大型任务执行自动测试。强大的功能可以与ProxyCrawl完美集成。使用Scrapy,由于具有内置工具,因此选择内容源(HTML和XML)非常容易。您还可以使用Scrapy API扩展提供的功能。
抢
Grab是用于创建自定义Web爬网规则集的基于Python的框架。使用Grab,您可以为小型个人项目创建爬网机制,还可以构建大型动态爬网任务,这些任务可以同时扩展到数百万个页面。
内置API提供了一种执行网络请求的方法,并且还可以处理已删除的内容。 Grab提供的另一个API称为Spider。使用Spider API,您可以使用自定义类创建异步抓取工具。
雪貂
Ferret是一种相当新的Web抓取工具,在开源社区中获得了相当大的关注。 Ferret的目标是提供更简洁的客户端爬网解决方案。例如,允许开发人员编写不必依赖于应用程序状态的采集器。
此外,雪貂使用自定义的声明性语言来避免构建系统的复杂性。相反,您可以编写严格的规则以从任何站点抓取数据。
X射线
由于X-Ray和Osmosis等库的可用性,使用Node.js爬网非常容易。
Diffbot
Diffbot是市场上的新玩家。您甚至不必编写太多代码,因为Diffbot的AI算法可以在无需手动说明的情况下从网站页面解密结构化数据。
PhantomJS Cloud
PhantomJS Cloud是PhantomJS浏览器的SaaS替代产品。使用PhantomJS Cloud,您可以直接从网页内部获取数据,还可以生成可视文件,并将页面显示为PDF文档。
PhantomJS本身是一个浏览器,这意味着您可以像浏览器一样加载和执行页面资源。如果您手头的任务需要获取许多基于JavaScript的网站,则此功能特别有用。
注:《云芝时报》的翻译不完整。如果您有兴趣,请阅读原创文本:
2019年最佳Web抓取工具 查看全部
“云智时代”翻译:ProxyCrawl使用ProxyCrawlAPI
Internet上不断涌现新信息,新设计模式和大量数据。将该数据组织到唯一的库中并不容易。但是,有许多出色的Web爬网工具可用。本文转载自《今日致词》,由《云志时报》 文章翻译,对这方面有需要的学生有帮助。
ProxyCrawl
使用代理爬网API,您可以爬网Web上的任何网站 /平台。具有代理支持,验证码绕过以及基于动态内容抓取JavaScript页面的优势。
它可以免费获得1,000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy是一个开放源代码项目,为爬网网页提供支持。 Scrapy爬网框架在从网站和网页中提取数据方面做得非常好。
最重要的是,Scrapy可用于挖掘数据,监视数据模式以及对大型任务执行自动测试。强大的功能可以与ProxyCrawl完美集成。使用Scrapy,由于具有内置工具,因此选择内容源(HTML和XML)非常容易。您还可以使用Scrapy API扩展提供的功能。
抢
Grab是用于创建自定义Web爬网规则集的基于Python的框架。使用Grab,您可以为小型个人项目创建爬网机制,还可以构建大型动态爬网任务,这些任务可以同时扩展到数百万个页面。
内置API提供了一种执行网络请求的方法,并且还可以处理已删除的内容。 Grab提供的另一个API称为Spider。使用Spider API,您可以使用自定义类创建异步抓取工具。
雪貂
Ferret是一种相当新的Web抓取工具,在开源社区中获得了相当大的关注。 Ferret的目标是提供更简洁的客户端爬网解决方案。例如,允许开发人员编写不必依赖于应用程序状态的采集器。
此外,雪貂使用自定义的声明性语言来避免构建系统的复杂性。相反,您可以编写严格的规则以从任何站点抓取数据。
X射线
由于X-Ray和Osmosis等库的可用性,使用Node.js爬网非常容易。
Diffbot
Diffbot是市场上的新玩家。您甚至不必编写太多代码,因为Diffbot的AI算法可以在无需手动说明的情况下从网站页面解密结构化数据。
PhantomJS Cloud
PhantomJS Cloud是PhantomJS浏览器的SaaS替代产品。使用PhantomJS Cloud,您可以直接从网页内部获取数据,还可以生成可视文件,并将页面显示为PDF文档。
PhantomJS本身是一个浏览器,这意味着您可以像浏览器一样加载和执行页面资源。如果您手头的任务需要获取许多基于JavaScript的网站,则此功能特别有用。
注:《云芝时报》的翻译不完整。如果您有兴趣,请阅读原创文本:
2019年最佳Web抓取工具
WebScraping支持以240多种语言提取Web数据提取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-04-04 06:12
Web爬网工具专门用于从网站中提取信息。它们也被称为Web采集工具或Web数据提取工具。
Web爬网工具可在各种情况下用于无限目的。
例如:
1.采集市场研究数据
Web抓取工具可以从多个数据分析提供程序获取信息,并将它们集成到一个位置,以方便参考和分析。它可以帮助您了解未来六个月公司或行业的发展方向。
2.提取联系信息
这些工具还可用于从各种网站中提取数据,例如电子邮件和电话号码。
3.采集数据以下载以供离线阅读或存储
4.跟踪多个市场等的价格。
这些软件可以手动或自动查找新数据,获取新数据或更新数据并进行存储,以方便访问。例如,可以使用采集器从亚马逊采集有关产品及其价格的信息。在本文文章中,我们列出了9种Web抓取工具。
1.
通过从特定网页导入数据并将数据导出到CSV,可以提供构建器来形成您自己的数据集。您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据需要构建超过1,000个API。
2.
通过抓取数千个在线资源来提供对实时和结构化数据的直接访问。 Web scraper支持提取超过240种语言的Web数据并以XML,JSON和RSS等各种格式保存输出数据。
3.(以前称为CloudScrape)
CloudScrape支持从任何网站采集数据,而无需像Webhose那样进行下载。它提供了一个基于浏览器的编辑器来设置采集器并实时提取数据。您可以将采集的数据保存在Google云端硬盘和其他云平台上,或将其导出为CSV或JSON。
4. Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。 Scrapinghub使用Crawlera(智能代理旋转器),该代理旋转器支持绕过机器人的对策,并轻松抓住庞大的或受机器人保护的站点。
5. ParseHub
ParseHub用于抓取单个和多个网站,支持JavaScript,AJAX,会话,cookie和重定向。该应用程序使用机器学习技术来识别Web上最复杂的文档,并根据所需的数据格式生成输出文件。
6. VisualScraper
VisualScraper是另一个Web数据提取软件,可用于从Web采集信息。该软件可以帮助您从多个网页提取数据并实时获取结果。此外,您可以导出各种格式的文件,例如CSV,XML,JSON和SQL。
7. Spinn3r
Spinn3r允许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。 Spinn3r与firehouse API一起分发,并管理95%的索引工作。它提供了高级垃圾邮件保护功能,可以消除垃圾邮件和不当使用语言,从而提高数据安全性。
8. 80legs
80legs是一款功能强大且灵活的Web抓取工具,可以根据您的需要进行配置。它支持选择获取大量数据并立即下载提取的数据的选项。 80legs声称能够爬网超过600,000个域,并被MailChimp和PayPal等大型公司使用。
9.铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google Spreadsheets。此工具适合可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。
查看全部
WebScraping支持以240多种语言提取Web数据提取工具
Web爬网工具专门用于从网站中提取信息。它们也被称为Web采集工具或Web数据提取工具。
Web爬网工具可在各种情况下用于无限目的。
例如:
1.采集市场研究数据
Web抓取工具可以从多个数据分析提供程序获取信息,并将它们集成到一个位置,以方便参考和分析。它可以帮助您了解未来六个月公司或行业的发展方向。
2.提取联系信息
这些工具还可用于从各种网站中提取数据,例如电子邮件和电话号码。
3.采集数据以下载以供离线阅读或存储
4.跟踪多个市场等的价格。
这些软件可以手动或自动查找新数据,获取新数据或更新数据并进行存储,以方便访问。例如,可以使用采集器从亚马逊采集有关产品及其价格的信息。在本文文章中,我们列出了9种Web抓取工具。
1.
通过从特定网页导入数据并将数据导出到CSV,可以提供构建器来形成您自己的数据集。您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据需要构建超过1,000个API。
2.
通过抓取数千个在线资源来提供对实时和结构化数据的直接访问。 Web scraper支持提取超过240种语言的Web数据并以XML,JSON和RSS等各种格式保存输出数据。
3.(以前称为CloudScrape)
CloudScrape支持从任何网站采集数据,而无需像Webhose那样进行下载。它提供了一个基于浏览器的编辑器来设置采集器并实时提取数据。您可以将采集的数据保存在Google云端硬盘和其他云平台上,或将其导出为CSV或JSON。
4. Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。 Scrapinghub使用Crawlera(智能代理旋转器),该代理旋转器支持绕过机器人的对策,并轻松抓住庞大的或受机器人保护的站点。
5. ParseHub
ParseHub用于抓取单个和多个网站,支持JavaScript,AJAX,会话,cookie和重定向。该应用程序使用机器学习技术来识别Web上最复杂的文档,并根据所需的数据格式生成输出文件。
6. VisualScraper
VisualScraper是另一个Web数据提取软件,可用于从Web采集信息。该软件可以帮助您从多个网页提取数据并实时获取结果。此外,您可以导出各种格式的文件,例如CSV,XML,JSON和SQL。
7. Spinn3r
Spinn3r允许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。 Spinn3r与firehouse API一起分发,并管理95%的索引工作。它提供了高级垃圾邮件保护功能,可以消除垃圾邮件和不当使用语言,从而提高数据安全性。
8. 80legs
80legs是一款功能强大且灵活的Web抓取工具,可以根据您的需要进行配置。它支持选择获取大量数据并立即下载提取的数据的选项。 80legs声称能够爬网超过600,000个域,并被MailChimp和PayPal等大型公司使用。
9.铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google Spreadsheets。此工具适合可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。
网站内容抓取工具的使用与分析(google)(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-04-03 03:08
网站内容抓取工具的使用与分析google查找网站上的任何链接,或下载网站内的任何内容google提供一种方法可以检索网站上的任何东西,不仅可以检索网站上有人的生活、工作和学习时所上传的信息,还可以检索访问过网站的人的生活、工作和学习,并且可以统计检索内容在网站上的每天的流量。今天要介绍的sitesearch就是为网站上的信息检索所设计的,可以检索你网站上的任何内容,而且效果很好。
网站上的任何东西都可以在谷歌中查找,sitesearch为网站添加了一个专属标识“site”,并把这个标识设置在网站名称的前面。获取sitesearch的数据cookie这个cookie是从网站中读取信息而写入到cookie中的,比如从该网站中显示的内容,就会向我们的浏览器写入这个cookie,通过浏览器发出的连接,传输给你的电脑。
我们要获取的信息,包括链接的url地址、个人页面、网络地址等信息。如何查找内容其实很简单,通过可以把sitesearch添加到搜索引擎页面中来操作,引擎显示出网站上有多少东西。当然,也可以通过cookie进行爬取网站上有什么内容。如何利用sitesearch来爬取网站信息我们以所提供的工具内容抓取的网站为例来分析。
首先,我们需要复制我们想要爬取的网站的地址地址:;keyword=work&sid=lz9nxsw0wgzjlbdwol-kkzsk3rk5goob7dvgonz28z12qakjkaewcahhwg。 查看全部
网站内容抓取工具的使用与分析(google)(图)
网站内容抓取工具的使用与分析google查找网站上的任何链接,或下载网站内的任何内容google提供一种方法可以检索网站上的任何东西,不仅可以检索网站上有人的生活、工作和学习时所上传的信息,还可以检索访问过网站的人的生活、工作和学习,并且可以统计检索内容在网站上的每天的流量。今天要介绍的sitesearch就是为网站上的信息检索所设计的,可以检索你网站上的任何内容,而且效果很好。
网站上的任何东西都可以在谷歌中查找,sitesearch为网站添加了一个专属标识“site”,并把这个标识设置在网站名称的前面。获取sitesearch的数据cookie这个cookie是从网站中读取信息而写入到cookie中的,比如从该网站中显示的内容,就会向我们的浏览器写入这个cookie,通过浏览器发出的连接,传输给你的电脑。
我们要获取的信息,包括链接的url地址、个人页面、网络地址等信息。如何查找内容其实很简单,通过可以把sitesearch添加到搜索引擎页面中来操作,引擎显示出网站上有多少东西。当然,也可以通过cookie进行爬取网站上有什么内容。如何利用sitesearch来爬取网站信息我们以所提供的工具内容抓取的网站为例来分析。
首先,我们需要复制我们想要爬取的网站的地址地址:;keyword=work&sid=lz9nxsw0wgzjlbdwol-kkzsk3rk5goob7dvgonz28z12qakjkaewcahhwg。
网站首页会有四条路径,分散网站权重,路径得到四分之一
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-04-03 02:13
当网站未优化时,网站的主页上将有四个路径,网站的权重将分散,每个路径将占四分之一。 301重定向对于网站非常重要。您可以为网站的首页设置默认的index.html。共有404页,可降低用户的重定向率并改善用户体验。
4. 网站内容添加
新推出的网站内容很少。不要一次添加很多内容。您需要逐步添加内容。内容应为原创,这将有助于网站的开发。
5. 文章页面优化
进入网站内容页面时,可以在网站的底部添加一些相关链接或用户喜欢的主题,这可以增加用户在网站中的停留时间,改善用户体验并改善网站 ] 排行。但是请记住,不要使网站的每一页都过于相关,因为这会影响网站的优化。
6、 Robot.txt设置
禁止搜索引擎抓取与网站无关的页面,并且禁止蜘蛛输入网站。
这些是网站上线之前的必要准备。只有在经过几层测试后,才能正式启动网站,以便网站可以平稳运行。
有什么解决方案可以防止程序开发人员私下复制源代码,并避免披露知识产权?
阅读答案后,我们没有找到一个答案就是给出正确的解决方案,而且答案都不是正确的想法。
发问者应该知道在什么情况下可以未经允许复制代码?换句话说,可以将代码保存到计算机的本地磁盘中。
从技术上讲,只要可以将代码或数据保存在计算机的本地磁盘上,就不可能避免数据代码的私有副本,因为对于代码编写者而言,无法设计任何代码模块,黑盒或白盒,或者禁用USB接口,因为如果代码编写者甚至知道如何分发数据,如何访问a和B来源的数据,如何从复杂数据中筛选出有效内容以供自己使用,这些基本的东西是意料之外的,是的,所以应该编写什么代码。
虚拟桌面通常是指类似于服务器的远程登录。文件无法在本地复制,因此,每次访问计算机上的任何资源时,都可以通过虚拟桌面登录,然后使用系统。
应该注意的是,没有任何一种技术可以解决所有问题。虚拟桌面可以防止将代码数据保存在本地,但不能限制将数据上传到代码主机服务器。因此,也有必要对网络进行过滤和监视。这是另一个复杂的问题。
大多数代码没有价值,不能退出业务,而且普通编码人员无法访问核心代码,因此我们应考虑尽一切可能防止未经授权的代码复制。目的是什么? GitHub上有很多代码。您的项目的代码质量比GitHub好多少?与其试图组织未经许可的复制代码,不如找到一种将业务划分为多个部分并最大限度地减少掌握核心业务流程的人员的方法。 查看全部
网站首页会有四条路径,分散网站权重,路径得到四分之一
当网站未优化时,网站的主页上将有四个路径,网站的权重将分散,每个路径将占四分之一。 301重定向对于网站非常重要。您可以为网站的首页设置默认的index.html。共有404页,可降低用户的重定向率并改善用户体验。
4. 网站内容添加
新推出的网站内容很少。不要一次添加很多内容。您需要逐步添加内容。内容应为原创,这将有助于网站的开发。
5. 文章页面优化
进入网站内容页面时,可以在网站的底部添加一些相关链接或用户喜欢的主题,这可以增加用户在网站中的停留时间,改善用户体验并改善网站 ] 排行。但是请记住,不要使网站的每一页都过于相关,因为这会影响网站的优化。
6、 Robot.txt设置
禁止搜索引擎抓取与网站无关的页面,并且禁止蜘蛛输入网站。
这些是网站上线之前的必要准备。只有在经过几层测试后,才能正式启动网站,以便网站可以平稳运行。
有什么解决方案可以防止程序开发人员私下复制源代码,并避免披露知识产权?
阅读答案后,我们没有找到一个答案就是给出正确的解决方案,而且答案都不是正确的想法。
发问者应该知道在什么情况下可以未经允许复制代码?换句话说,可以将代码保存到计算机的本地磁盘中。
从技术上讲,只要可以将代码或数据保存在计算机的本地磁盘上,就不可能避免数据代码的私有副本,因为对于代码编写者而言,无法设计任何代码模块,黑盒或白盒,或者禁用USB接口,因为如果代码编写者甚至知道如何分发数据,如何访问a和B来源的数据,如何从复杂数据中筛选出有效内容以供自己使用,这些基本的东西是意料之外的,是的,所以应该编写什么代码。
虚拟桌面通常是指类似于服务器的远程登录。文件无法在本地复制,因此,每次访问计算机上的任何资源时,都可以通过虚拟桌面登录,然后使用系统。
应该注意的是,没有任何一种技术可以解决所有问题。虚拟桌面可以防止将代码数据保存在本地,但不能限制将数据上传到代码主机服务器。因此,也有必要对网络进行过滤和监视。这是另一个复杂的问题。
大多数代码没有价值,不能退出业务,而且普通编码人员无法访问核心代码,因此我们应考虑尽一切可能防止未经授权的代码复制。目的是什么? GitHub上有很多代码。您的项目的代码质量比GitHub好多少?与其试图组织未经许可的复制代码,不如找到一种将业务划分为多个部分并最大限度地减少掌握核心业务流程的人员的方法。

