
网站内容抓取工具
如何采集网站论坛?优采云采集CMS整站大挪移(免费资源网站资源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-06-26 18:14
优采云采集cms整站大移移(网站论坛采集器)是一款简单易用的网站论坛采集辅助软件。如何采集网站论坛? 优采云采集cms全站大移移(免费资源网站资源图网站迅雷下载工具下载工具_在哪里下载?网站论坛采集器)方便用户使用。该工具目前包括cms采集大移移、维护王、同步更新王。你可以采集others网站和所有文章或论坛里的内容,在伪原创之后发到自己网站,你可以每天使用采集news文章,其中网站你平时买电动工具,维护网站的帖子等等。
软件亮点:
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站方案,让您彻底摆脱网站maintenance管理的繁重,优采云采集器每套软件收录采集维修王和采集大移动移,可结合以下实用功能:
您的论坛一次可以注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松达到千人在线热论坛效果(部分论坛不支持按IP统计在线人数,如DVbbs/ PHPWind);
您可以呼吸采集网站/论坛主题并回复所有内容,网站/论坛80%可以采集,支持文章内容发布前保存在本地;
支持将网站论坛A的某个版块或专栏的内容批量采集转发到您自己的网站或论坛指定版块。
软件支持以三种方式编写采集规则:UBB代码和源代码,UBB和源代码组合,最大限度地方便用户的习惯和选择;
软件可以同时批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖和回复ID分开设置,允许部分会员发布所有主题,其他会员全部回复,ID号成员选择发布;
网站内容编辑工具
支持采集任网站安全测站长工具_非常好,强烈推荐用什么工具看网站的关键词意网站dz/PW/等论坛类型东网等导入内容网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,采集的最新内容每天都会发布到指定栏目;
采集到本地内容可以在软件中任意编辑,编辑窗口可以最大化,支持自动换行,HTML预览,使用更好更方便;
支持批量替换和过滤文章内容中的文字和链接;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
本软件具有查看某某电商网站建设测评工具帖子可查看人数的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一个版块或多个版块帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以采集网站/论坛内容中的超级链接,或者屏蔽链接
您可以将采集网站/论坛中的文章图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
图片名称可以随意;
支持任务栏图标的最小化和隐藏显示;
带有采集或发帖任务完成后自动关机功能;
独有百度优化,旧帖改新帖,可有效增加采集贴的原创性,扩展至南宁网站安全测工具_破解版在线下载有利于搜索引擎收录;
您可以在标题前、标题后和内容中自动添加自己的关键词;
支持同义词替换帖子内容功能;
软件可以是采集网站需要注册登录的论坛帖子。
查看全部
如何采集网站论坛?优采云采集CMS整站大挪移(免费资源网站资源)
优采云采集cms整站大移移(网站论坛采集器)是一款简单易用的网站论坛采集辅助软件。如何采集网站论坛? 优采云采集cms全站大移移(免费资源网站资源图网站迅雷下载工具下载工具_在哪里下载?网站论坛采集器)方便用户使用。该工具目前包括cms采集大移移、维护王、同步更新王。你可以采集others网站和所有文章或论坛里的内容,在伪原创之后发到自己网站,你可以每天使用采集news文章,其中网站你平时买电动工具,维护网站的帖子等等。
软件亮点:
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站方案,让您彻底摆脱网站maintenance管理的繁重,优采云采集器每套软件收录采集维修王和采集大移动移,可结合以下实用功能:
您的论坛一次可以注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松达到千人在线热论坛效果(部分论坛不支持按IP统计在线人数,如DVbbs/ PHPWind);
您可以呼吸采集网站/论坛主题并回复所有内容,网站/论坛80%可以采集,支持文章内容发布前保存在本地;
支持将网站论坛A的某个版块或专栏的内容批量采集转发到您自己的网站或论坛指定版块。
软件支持以三种方式编写采集规则:UBB代码和源代码,UBB和源代码组合,最大限度地方便用户的习惯和选择;
软件可以同时批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖和回复ID分开设置,允许部分会员发布所有主题,其他会员全部回复,ID号成员选择发布;
网站内容编辑工具
支持采集任网站安全测站长工具_非常好,强烈推荐用什么工具看网站的关键词意网站dz/PW/等论坛类型东网等导入内容网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,采集的最新内容每天都会发布到指定栏目;
采集到本地内容可以在软件中任意编辑,编辑窗口可以最大化,支持自动换行,HTML预览,使用更好更方便;
支持批量替换和过滤文章内容中的文字和链接;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
本软件具有查看某某电商网站建设测评工具帖子可查看人数的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一个版块或多个版块帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以采集网站/论坛内容中的超级链接,或者屏蔽链接
您可以将采集网站/论坛中的文章图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
图片名称可以随意;
支持任务栏图标的最小化和隐藏显示;
带有采集或发帖任务完成后自动关机功能;
独有百度优化,旧帖改新帖,可有效增加采集贴的原创性,扩展至南宁网站安全测工具_破解版在线下载有利于搜索引擎收录;
您可以在标题前、标题后和内容中自动添加自己的关键词;
支持同义词替换帖子内容功能;
软件可以是采集网站需要注册登录的论坛帖子。
 https://www.u9seo.com/wp-conte ... 3.png 300w" />https://www.u9seo.com/wp-conte ... 3.png 300w" />
https://www.u9seo.com/wp-conte ... 3.png 300w" />https://www.u9seo.com/wp-conte ... 3.png 300w" /> ProxyCrawl使用Proxy.js网页工具可免费获得1000个请求
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-06-23 03:23
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持,验证码绕过,基于动态内容抓取页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到百万页面的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不需要写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。 查看全部
ProxyCrawl使用Proxy.js网页工具可免费获得1000个请求
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持,验证码绕过,基于动态内容抓取页面的优势。

可以免费获取1000个请求,足以在复杂的内容页面探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。

最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到百万页面的大型动态爬虫任务。

内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。

此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不需要写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。

PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。

PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
文档介绍:优采云·云采集服务平台详细介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-06-23 03:16
文档介绍:优采云·云采集服务平台uationWarning:ThedocumentwascreatedwithSpire..网站data capture tool 近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也出现了快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。 1、优采云优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。需要数据。它采集data分为两步,一是采集data,二是发布数据。这两个过程可以分开。 采集Data:这包括采集 URL 和采集 内容。这个过程就是获取数据的过程。用户制定规则,内容在采集过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。 优采云采集器采用分布式采集系统。为了提高采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量网址,也可以生成。对于不会编程的新手用户,可以直接使用别人制定的规则,高手可以自定义开发,也可以分享制定的规则。
2、优采云优采云是优采云之后出现的采集器,可以从不同的网站获取标准化数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。简单来说,优采云可以通过简单的配置规则,从任何网页准确抓取数据,生成自定义的、规则的数据格式。国内首创的真正可视化规则、简单上手、完全可视化图形操作的国内定制采集器; 采集任务自动运行,可按指定周期自动采集;规则市场有大量免费规则,用户可直接使用;支持验证码识别,自定义不同浏览器标识,有效防止IP被封。 优采云可以说是小白用户的福音(简单好用,好找,可视化界面,易学易模仿),有更好的地方就用积分。用1000积分完善信息,每天签到30积分,在线制定规则或购买规则,剩下的足以获得初始采集,如果您不充值一些积分,您可以在需求,导出excel,数据库都行。 3、优采云云攀虫 新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网页数据。操作步骤:购买规则-设置关键词-启动任务-自动云采集-自动发布不同于传统的采集器,优采云云爬虫不需要配置采集进程。 优采云云攀虫的规则市场提供了大量免费的采集模板,只需设置关键词即可。
爬虫任务全程在云端执行,无需开机。 采集结果可以自动发布到多个网站(目前支持wecenter、wordpree、discuz等)。开发者可自行编写采集规则出售或使用。有了详细的开发人员文档,他们就可以创建自己的爬虫。相关采集tutorial:网易彩票数据采集orial/hottutorial/jrzx/wycaipiao同花顺爬虫orial/hottutorial/jrzx/tonghuashun金融世界基金爬虫orial/hottutorial/jrzx/ji 查看全部
文档介绍:优采云·云采集服务平台详细介绍
文档介绍:优采云·云采集服务平台uationWarning:ThedocumentwascreatedwithSpire..网站data capture tool 近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也出现了快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。 1、优采云优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。需要数据。它采集data分为两步,一是采集data,二是发布数据。这两个过程可以分开。 采集Data:这包括采集 URL 和采集 内容。这个过程就是获取数据的过程。用户制定规则,内容在采集过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。 优采云采集器采用分布式采集系统。为了提高采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量网址,也可以生成。对于不会编程的新手用户,可以直接使用别人制定的规则,高手可以自定义开发,也可以分享制定的规则。
2、优采云优采云是优采云之后出现的采集器,可以从不同的网站获取标准化数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。简单来说,优采云可以通过简单的配置规则,从任何网页准确抓取数据,生成自定义的、规则的数据格式。国内首创的真正可视化规则、简单上手、完全可视化图形操作的国内定制采集器; 采集任务自动运行,可按指定周期自动采集;规则市场有大量免费规则,用户可直接使用;支持验证码识别,自定义不同浏览器标识,有效防止IP被封。 优采云可以说是小白用户的福音(简单好用,好找,可视化界面,易学易模仿),有更好的地方就用积分。用1000积分完善信息,每天签到30积分,在线制定规则或购买规则,剩下的足以获得初始采集,如果您不充值一些积分,您可以在需求,导出excel,数据库都行。 3、优采云云攀虫 新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网页数据。操作步骤:购买规则-设置关键词-启动任务-自动云采集-自动发布不同于传统的采集器,优采云云爬虫不需要配置采集进程。 优采云云攀虫的规则市场提供了大量免费的采集模板,只需设置关键词即可。
爬虫任务全程在云端执行,无需开机。 采集结果可以自动发布到多个网站(目前支持wecenter、wordpree、discuz等)。开发者可自行编写采集规则出售或使用。有了详细的开发人员文档,他们就可以创建自己的爬虫。相关采集tutorial:网易彩票数据采集orial/hottutorial/jrzx/wycaipiao同花顺爬虫orial/hottutorial/jrzx/tonghuashun金融世界基金爬虫orial/hottutorial/jrzx/ji
网页抓取工具大数据行业的蓬勃发展引发了各行各业强烈需求
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-22 23:03
网页抓取工具大数据行业的蓬勃发展引发了各行各业强烈需求
网页抓取工具对于大数据工作至关重要。大数据产业的蓬勃发展,引发了各行各业对大数据人才的强烈需求。想要尝试高端大数据岗位,必须具备以下技能,才能得心应手完成工作指标——大数据基础开发。大数据的基础发展主要包括数据采集、数据处理和分类存储。对于海量数据的采集,需要考虑的是采集的实时准确度和完整性。用于数据处理和存储的主要目的是及时更新重新删除过滤等基础开发中常用的网络爬虫工具。 优采云采集器 是必备工具之一。通过对网页结构的简单分析和相关规则的配置优采云采集器能确保采集高效稳定的进行,并拥有自身强大的数据处理系统和多库发布存储功能,大数据的基础开发可以在一个工具中顺利完成。值得一提的是,优采云采集器的智能化和自动化大大降低了对操作人员的技术要求。不再需要花费大量精力为不同的网页编写不同的程序。使用全网通用的网络爬虫工具,操作简单。 2. 数据分析。数据分析师需要对现有数据进行数据分析。统计分析结合现有业务,发现一些规律和趋势,那么数据分析报告肯定是需要的。当数据量很大时,会涉及到集群环境下的分析。这就要求分析师熟悉SQL,需要对数据有深刻的理解。解释能力可以分析和解释某些现象的成因。同时,需要针对这些问题提出一些可能的解决方案,利用分类聚类、个性化推荐等常用的数据挖掘技术和算法服务于业务系统,从而影响业务战略或业务方向。还有更多的指导。当然,这也需要分析师具体而丰富的专业知识。例如,金融等领域的数据挖掘需要丰富的金融经验作为分析的基础。这里的重点是两大方向的数据相关细分。岗位多种多样,只有充分掌握技能,才能高效完成任务。搞大数据岗位一定要多学点工具,多读书,适应瞬息万变的市场环境和行业需求 查看全部
网页抓取工具大数据行业的蓬勃发展引发了各行各业强烈需求

网页抓取工具对于大数据工作至关重要。大数据产业的蓬勃发展,引发了各行各业对大数据人才的强烈需求。想要尝试高端大数据岗位,必须具备以下技能,才能得心应手完成工作指标——大数据基础开发。大数据的基础发展主要包括数据采集、数据处理和分类存储。对于海量数据的采集,需要考虑的是采集的实时准确度和完整性。用于数据处理和存储的主要目的是及时更新重新删除过滤等基础开发中常用的网络爬虫工具。 优采云采集器 是必备工具之一。通过对网页结构的简单分析和相关规则的配置优采云采集器能确保采集高效稳定的进行,并拥有自身强大的数据处理系统和多库发布存储功能,大数据的基础开发可以在一个工具中顺利完成。值得一提的是,优采云采集器的智能化和自动化大大降低了对操作人员的技术要求。不再需要花费大量精力为不同的网页编写不同的程序。使用全网通用的网络爬虫工具,操作简单。 2. 数据分析。数据分析师需要对现有数据进行数据分析。统计分析结合现有业务,发现一些规律和趋势,那么数据分析报告肯定是需要的。当数据量很大时,会涉及到集群环境下的分析。这就要求分析师熟悉SQL,需要对数据有深刻的理解。解释能力可以分析和解释某些现象的成因。同时,需要针对这些问题提出一些可能的解决方案,利用分类聚类、个性化推荐等常用的数据挖掘技术和算法服务于业务系统,从而影响业务战略或业务方向。还有更多的指导。当然,这也需要分析师具体而丰富的专业知识。例如,金融等领域的数据挖掘需要丰富的金融经验作为分析的基础。这里的重点是两大方向的数据相关细分。岗位多种多样,只有充分掌握技能,才能高效完成任务。搞大数据岗位一定要多学点工具,多读书,适应瞬息万变的市场环境和行业需求
如何帮助用户快速采集网上的小说,将TXT小说下载
网站优化 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2021-06-22 22:42
在线图书抓取器可以帮助用户快速采集网上的小说,将TXT小说下载到电脑上阅读,适合喜欢看小说的朋友,现在很多用户喜欢在网上看小说并进入直接在浏览器中搜索小说就可以在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址即可立即抓取目录,并自动下载目录采集对应的章节内容,完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!
软件功能
1、网络书Grabber支持网站大部分,轻松下载小说资源
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示运行步骤,可参考网络书grabber采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中
6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。
7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
查看全部
如何帮助用户快速采集网上的小说,将TXT小说下载
在线图书抓取器可以帮助用户快速采集网上的小说,将TXT小说下载到电脑上阅读,适合喜欢看小说的朋友,现在很多用户喜欢在网上看小说并进入直接在浏览器中搜索小说就可以在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址即可立即抓取目录,并自动下载目录采集对应的章节内容,完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!

软件功能
1、网络书Grabber支持网站大部分,轻松下载小说资源
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示运行步骤,可参考网络书grabber采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
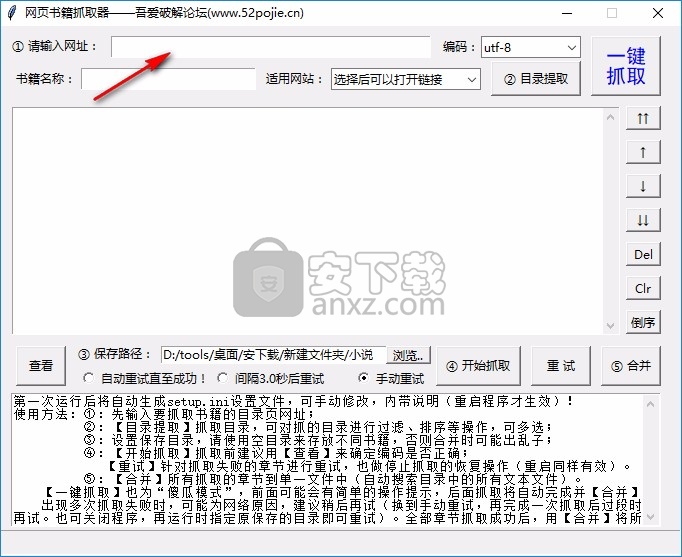
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
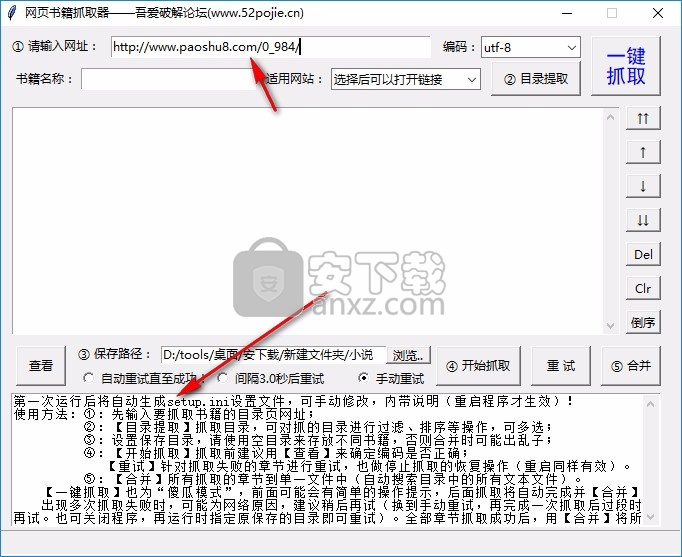
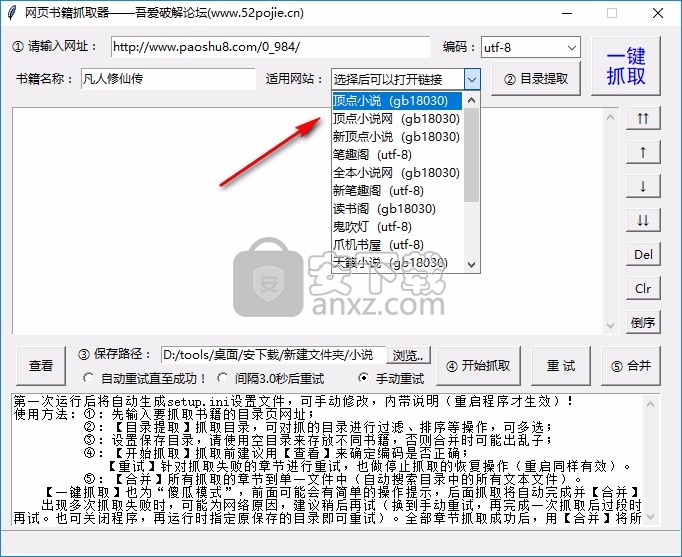
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
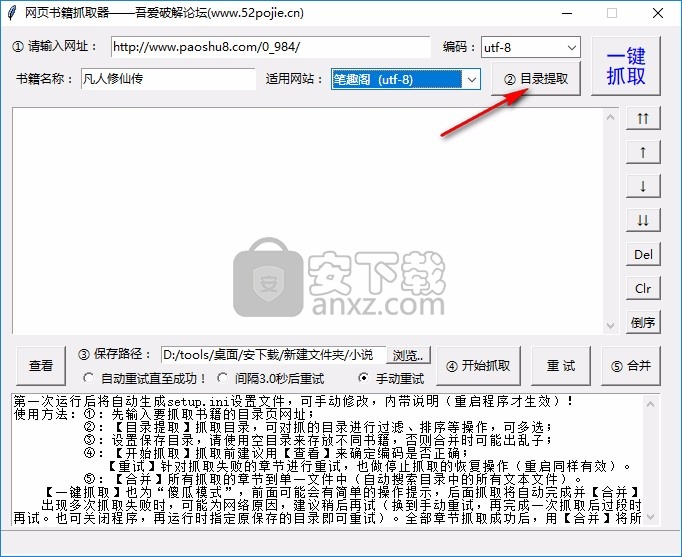
5、点击一键解压按钮将所有目录解压到软件中

6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。

7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
网站内容抓取工具小编带你了解内容的工具清单
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-06-21 21:02
网站内容抓取工具小编给大家整理了一份用于内容抓取的工具清单,本文将会为大家进行一些简单的介绍。选择一个工具,我们都会经历以下五个过程:简单使用想深入了解一个工具什么的,简单使用是必须的。工具是一个个实践摸索出来的,同样工具更新迭代,正是可以提高我们的效率的关键。给大家介绍一下抓取网站的具体步骤。1.选择自己想要抓取的站点列表里最常用的会有哪些站点?一线城市肯定就是北上广深,二线城市肯定有成都、青岛、厦门、广州等二线以下城市。
下面会举例来说明。每个时间段抓取哪些站点每天会更新什么内容,清楚了之后就可以集中精力去找更好的抓取工具。很多人问过我这个问题,常常在后台问,也会经常有人向我咨询,其实这类问题大多只需要看网站分析工具的抓取列表就可以非常清楚,例如“网站抓取工具排行榜”,一眼就能看出来哪个工具更好用,哪个更便宜等。选择一个工具时是否必须进行爬虫,最大的关键点,就是模拟浏览器去操作这个网站,如果是页面排版规范,那我们就无需进行爬虫操作,即便是那些个性化要求很高的网站,也可以使用该工具进行自动抓取。
个人觉得一个现代的工具能不能为我们提供更多的便利,其实还在于:怎么去利用网站工具?掌握了该工具,如何开始抓取,是我们今天讨论的重点。2.准备好相关工具工欲善其事必先利其器,下面我们列举一些抓取工具,给大家做做参考。自动化代码抓取工具google的pagespread(extremetouch),有两个维度抓取不同网站的内容;limitr代理站点抓取工具reallocation,https代理插件,抓取请求时会帮你过滤,避免post的图片过于大,而导致第一次被拒绝抓取。
mockitoweb代理抓取工具抓取https代理ftp抓取工具抓取ftp、filetools文件抓取工具抓取https/https代理在这个抓取工具列表的第一位,分别抓取了donehill、plectau、frankfine、iweb的内容,包括页面源代码和页面div标签,源代码标签抓取到后自动转换成js文件。
还有jinjajs抓取工具,抓取目标php的代码;ip查询工具track.php,抓取内容前将发送到工具后台,记录抓取时间,然后再抓取下载失败时间、抓取返回结果等信息。数据库存储抓取工具就是整个页面的内容通过这个工具进行数据抓取,整个内容抓取结束后,工具会将抓取的内容打印到数据库。这个工具一般用sqlserver来整理、生成数据库的windows、mysql的密码。
3.集中精力开始抓取header防止内容泄露metasploit利用xor检测302跳转,创建proxy,成功metasploitmetasploitmetasploitmetasploit,。 查看全部
网站内容抓取工具小编带你了解内容的工具清单
网站内容抓取工具小编给大家整理了一份用于内容抓取的工具清单,本文将会为大家进行一些简单的介绍。选择一个工具,我们都会经历以下五个过程:简单使用想深入了解一个工具什么的,简单使用是必须的。工具是一个个实践摸索出来的,同样工具更新迭代,正是可以提高我们的效率的关键。给大家介绍一下抓取网站的具体步骤。1.选择自己想要抓取的站点列表里最常用的会有哪些站点?一线城市肯定就是北上广深,二线城市肯定有成都、青岛、厦门、广州等二线以下城市。
下面会举例来说明。每个时间段抓取哪些站点每天会更新什么内容,清楚了之后就可以集中精力去找更好的抓取工具。很多人问过我这个问题,常常在后台问,也会经常有人向我咨询,其实这类问题大多只需要看网站分析工具的抓取列表就可以非常清楚,例如“网站抓取工具排行榜”,一眼就能看出来哪个工具更好用,哪个更便宜等。选择一个工具时是否必须进行爬虫,最大的关键点,就是模拟浏览器去操作这个网站,如果是页面排版规范,那我们就无需进行爬虫操作,即便是那些个性化要求很高的网站,也可以使用该工具进行自动抓取。
个人觉得一个现代的工具能不能为我们提供更多的便利,其实还在于:怎么去利用网站工具?掌握了该工具,如何开始抓取,是我们今天讨论的重点。2.准备好相关工具工欲善其事必先利其器,下面我们列举一些抓取工具,给大家做做参考。自动化代码抓取工具google的pagespread(extremetouch),有两个维度抓取不同网站的内容;limitr代理站点抓取工具reallocation,https代理插件,抓取请求时会帮你过滤,避免post的图片过于大,而导致第一次被拒绝抓取。
mockitoweb代理抓取工具抓取https代理ftp抓取工具抓取ftp、filetools文件抓取工具抓取https/https代理在这个抓取工具列表的第一位,分别抓取了donehill、plectau、frankfine、iweb的内容,包括页面源代码和页面div标签,源代码标签抓取到后自动转换成js文件。
还有jinjajs抓取工具,抓取目标php的代码;ip查询工具track.php,抓取内容前将发送到工具后台,记录抓取时间,然后再抓取下载失败时间、抓取返回结果等信息。数据库存储抓取工具就是整个页面的内容通过这个工具进行数据抓取,整个内容抓取结束后,工具会将抓取的内容打印到数据库。这个工具一般用sqlserver来整理、生成数据库的windows、mysql的密码。
3.集中精力开始抓取header防止内容泄露metasploit利用xor检测302跳转,创建proxy,成功metasploitmetasploitmetasploitmetasploit,。
diggbt磁力链接搜索下载浏览人数已达到103067,实际体验
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-06-21 18:15
diggbt 磁力链接搜索下载网站简介
DiggBT-专注于从 DHT 网络中获取 BT 种子和磁力链接。目前已收录数千万条BT种子元信息(metainfo)。是全宇宙最丰富的BT种子搜索下载和磁力链接下载专业。 网站,您可以在这里搜索下载电影、剧集、音乐、书籍、图片、综艺、软件、动画、教程、游戏等资源。 DiggBT可以说是BT种子搜索神器、P2P种子搜索神器、万能BT种子搜索下载神器、磁力链接搜索下载神器。本站本身不存储和提供BT种子下载,只提供从DHT网络抓取的磁力链接和网站提供的其他下载链接。资源猫编辑器浏览此网站时,页面干净美观,欢迎感兴趣的用户访问体验!
diggbt 磁力链接搜索下载数据评测
diggbt磁力链接搜索下载访问量已达103067,如需查询本站相关权重信息,可点击“爱站数据”“Chinaz数据”进入;参考目前网站数据,建议你参考爱站数据,更多网站价值评价因素如:diggbt磁力链接搜索下载的访问速度,搜索引擎收录和索引量,用户经验等;当然,一个站的价值是要评估的,最主要的还是要根据自己的需要和需求,一些具体的数据需要和diggbt磁力链接搜索下载的站长协商。比如网站的IP、PV、跳出率等!
关于diggbt磁力链接搜索和下载的特别声明 查看全部
diggbt磁力链接搜索下载浏览人数已达到103067,实际体验
diggbt 磁力链接搜索下载网站简介
DiggBT-专注于从 DHT 网络中获取 BT 种子和磁力链接。目前已收录数千万条BT种子元信息(metainfo)。是全宇宙最丰富的BT种子搜索下载和磁力链接下载专业。 网站,您可以在这里搜索下载电影、剧集、音乐、书籍、图片、综艺、软件、动画、教程、游戏等资源。 DiggBT可以说是BT种子搜索神器、P2P种子搜索神器、万能BT种子搜索下载神器、磁力链接搜索下载神器。本站本身不存储和提供BT种子下载,只提供从DHT网络抓取的磁力链接和网站提供的其他下载链接。资源猫编辑器浏览此网站时,页面干净美观,欢迎感兴趣的用户访问体验!
diggbt 磁力链接搜索下载数据评测
diggbt磁力链接搜索下载访问量已达103067,如需查询本站相关权重信息,可点击“爱站数据”“Chinaz数据”进入;参考目前网站数据,建议你参考爱站数据,更多网站价值评价因素如:diggbt磁力链接搜索下载的访问速度,搜索引擎收录和索引量,用户经验等;当然,一个站的价值是要评估的,最主要的还是要根据自己的需要和需求,一些具体的数据需要和diggbt磁力链接搜索下载的站长协商。比如网站的IP、PV、跳出率等!
关于diggbt磁力链接搜索和下载的特别声明
搜索引擎蜘蛛抓取频次的重要性和增量是什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-21 00:29
爬取频率是搜索引擎蜘蛛在单位时间内访问网站的次数。比如百度站长工具的内容中看到的爬取频率是按天算的,那么数据中的爬取频率都是每天的爬取频率。
抓取频率的重要性
抓取频率越高,搜索引擎找到网站内容的速度就越快;高抓取频率是保证内容原创权益的重要因素,可以保证在第一次搜索引擎抓取之前,内容就被抄袭和转发。
加速内容的发现速度在一定程度上对内容的收录速度和收录率有一定的影响;但是,爬取频率高并不代表网站的收录会更好,也不是绝对的关系。
抓取频率的构成
爬取频率分为增量爬取和更新爬取两部分。增量爬取是指搜索引擎爬取网站待爬取的收录内容;而更新爬取是指定期爬取已经收录的内容,检查页面是否更新。两种类型的爬取频率之和为爬取频率。
而网站更新爬取频率主要取决于网站的内容,比如文章咨询网站,更新爬取频率就比较小,因为文章一旦发帖修改的概率就很低了相反,例如,信息和新闻网站的内容具有很强的时效性。为了及时获取这些有价值的更新,此类网站的抓取频率会比较高。
增量爬取的频率取决于网站的内容质量和更新频率。 网站内容的质量值是直接决定搜索引擎蜘蛛是否会爬行的主要因素。如果长时间提交低质量的内容,会出现严重降级导致蜘蛛爬不起来的情况。在保证内容质量的前提下,增加内容量和创作频率可以逐步培养蜘蛛爬行。
抓取频率控制
抓取频率不是越高越好。对于网站来说,只要新内容能被蜘蛛及时抓取,过高的抓取频率会对服务器造成额外压力,影响网站稳定性,影响用户访问体验。
对于一些优质网站,用户量非常大,每日内容的增加量也非常大。需要特别注意内容的分时提交,避免大量内容的集中提交,可能导致搜索引擎蜘蛛在某个时间出现大规模的爬取行为,造成@的稳定性k14@ 波动。如果爬取频率还是太高,可以在搜索引擎后台设置蜘蛛爬取上限。 查看全部
搜索引擎蜘蛛抓取频次的重要性和增量是什么
爬取频率是搜索引擎蜘蛛在单位时间内访问网站的次数。比如百度站长工具的内容中看到的爬取频率是按天算的,那么数据中的爬取频率都是每天的爬取频率。
抓取频率的重要性
抓取频率越高,搜索引擎找到网站内容的速度就越快;高抓取频率是保证内容原创权益的重要因素,可以保证在第一次搜索引擎抓取之前,内容就被抄袭和转发。
加速内容的发现速度在一定程度上对内容的收录速度和收录率有一定的影响;但是,爬取频率高并不代表网站的收录会更好,也不是绝对的关系。
抓取频率的构成
爬取频率分为增量爬取和更新爬取两部分。增量爬取是指搜索引擎爬取网站待爬取的收录内容;而更新爬取是指定期爬取已经收录的内容,检查页面是否更新。两种类型的爬取频率之和为爬取频率。
而网站更新爬取频率主要取决于网站的内容,比如文章咨询网站,更新爬取频率就比较小,因为文章一旦发帖修改的概率就很低了相反,例如,信息和新闻网站的内容具有很强的时效性。为了及时获取这些有价值的更新,此类网站的抓取频率会比较高。
增量爬取的频率取决于网站的内容质量和更新频率。 网站内容的质量值是直接决定搜索引擎蜘蛛是否会爬行的主要因素。如果长时间提交低质量的内容,会出现严重降级导致蜘蛛爬不起来的情况。在保证内容质量的前提下,增加内容量和创作频率可以逐步培养蜘蛛爬行。
抓取频率控制
抓取频率不是越高越好。对于网站来说,只要新内容能被蜘蛛及时抓取,过高的抓取频率会对服务器造成额外压力,影响网站稳定性,影响用户访问体验。
对于一些优质网站,用户量非常大,每日内容的增加量也非常大。需要特别注意内容的分时提交,避免大量内容的集中提交,可能导致搜索引擎蜘蛛在某个时间出现大规模的爬取行为,造成@的稳定性k14@ 波动。如果爬取频率还是太高,可以在搜索引擎后台设置蜘蛛爬取上限。
diggbt磁力链接搜索下载浏览人数已达到103045,实际体验
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-06-21 00:21
diggbt Magnet Link 搜索下载网站简介
DiggBT-专注于从 DHT 网络中获取 BT 种子和磁力链接。目前已收录数千万条BT种子元信息(metainfo)。是全宇宙最丰富的BT种子搜索下载和磁力链接下载专业。 网站,您可以在这里搜索下载电影、剧集、音乐、书籍、图片、综艺、软件、动画、教程、游戏等资源。 DiggBT可以说是BT种子搜索神器、P2P种子搜索神器、万能BT种子搜索下载神器、磁力链接搜索下载神器。本站本身不存储和提供BT种子下载,只提供从DHT网络抓取的磁力链接和网站提供的其他下载链接。资源猫编辑器浏览此网站时,页面整洁美观,欢迎感兴趣的用户访问体验!
diggbt 磁力链接搜索下载数据评测
diggbt 搜索和下载的浏览者数量已达到 103,045。如需查询本站相关权重信息,可点击“爱站数据”“Chinaz数据”进入;参考目前网站数据,建议你参考爱站数据,更多网站价值评价因素如:diggbt磁力链接搜索下载的访问速度,搜索引擎收录和索引量,用户经验等;当然,一个站的价值是要评估的,最重要的还是要根据自己的需要和需求,一些具体的数据需要和diggbt磁力链接搜索下载的站长协商和提供。 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?比如网站的IP、PV、跳出率等!
关于diggbt磁力链接搜索和下载的特别声明 查看全部
diggbt磁力链接搜索下载浏览人数已达到103045,实际体验
diggbt Magnet Link 搜索下载网站简介
DiggBT-专注于从 DHT 网络中获取 BT 种子和磁力链接。目前已收录数千万条BT种子元信息(metainfo)。是全宇宙最丰富的BT种子搜索下载和磁力链接下载专业。 网站,您可以在这里搜索下载电影、剧集、音乐、书籍、图片、综艺、软件、动画、教程、游戏等资源。 DiggBT可以说是BT种子搜索神器、P2P种子搜索神器、万能BT种子搜索下载神器、磁力链接搜索下载神器。本站本身不存储和提供BT种子下载,只提供从DHT网络抓取的磁力链接和网站提供的其他下载链接。资源猫编辑器浏览此网站时,页面整洁美观,欢迎感兴趣的用户访问体验!
diggbt 磁力链接搜索下载数据评测
diggbt 搜索和下载的浏览者数量已达到 103,045。如需查询本站相关权重信息,可点击“爱站数据”“Chinaz数据”进入;参考目前网站数据,建议你参考爱站数据,更多网站价值评价因素如:diggbt磁力链接搜索下载的访问速度,搜索引擎收录和索引量,用户经验等;当然,一个站的价值是要评估的,最重要的还是要根据自己的需要和需求,一些具体的数据需要和diggbt磁力链接搜索下载的站长协商和提供。 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?比如网站的IP、PV、跳出率等!
关于diggbt磁力链接搜索和下载的特别声明
深圳网站建设:如何控制好“无限空间”的桥梁
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-06-20 06:02
网址就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的网址) 如果你的 URL 很复杂或者很长,爬虫就不得不花时间反复跟踪这些 URL;如果您的 URL 是常规的并且直接指向您的独特内容,那么抓取工具可以专注于理解您的内容,而不是仅仅抓取空网页或被不同的 URL 引导,最终抓取的是相同的重复内容。
一些帮助爬虫更快更好地找到你的内容的建议,深圳网站建认为主要包括:
1、去掉URL中用户相关的参数
URL 中不影响网页内容的参数——如 sessionID 或排序参数——可以从 URL 中移除并由 cookie 记录。通过将这些信息添加到 cookie 中,然后 301 定向到一个“干净”的 URL,您可以保留原创内容并减少指向相同内容的 URL 数量。
2、控制无限空间
你的网站上有日历吗,上面的链接指向无数过去和未来的日期(每个链接地址都是唯一的二)?你的网页地址是不是加了一个 &page=3563 参数后,你可以还是返回200码,就算根本没有那么多页面?这样的话,你的网站就会出现所谓的“无限空间”,会浪费爬虫机器人和你的@带宽k14@.如何控制“无限空间”,请参考这里的一些技巧。
3、防止 Google 抓取工具抓取它们无法处理的页面
通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系信息、购物车和其他爬虫无法处理的页面被抓取。 (爬行动物以吝啬和害羞着称,所以一般不会“添加商品到购物车”或“联系我们”)。通过这种方式,您可以让爬虫花更多的时间在您的网站 上爬取他们可以处理的内容。
4、一个网址,一段内容
在理想世界中,深圳网站construction 认为 URL 和内容是一一对应的:每个 URL 对应一个唯一的内容,每个内容只能通过唯一网址。越接近这种理想情况,您的网站 就越容易被捕获,收录 也就越容易被捕获。如果您的内容管理系统或当前的网站 机构难以实施,您可以尝试使用 rel=canonical 元素来设置您要用于指示特定内容的 URL。 查看全部
深圳网站建设:如何控制好“无限空间”的桥梁
网址就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的网址) 如果你的 URL 很复杂或者很长,爬虫就不得不花时间反复跟踪这些 URL;如果您的 URL 是常规的并且直接指向您的独特内容,那么抓取工具可以专注于理解您的内容,而不是仅仅抓取空网页或被不同的 URL 引导,最终抓取的是相同的重复内容。
一些帮助爬虫更快更好地找到你的内容的建议,深圳网站建认为主要包括:
1、去掉URL中用户相关的参数
URL 中不影响网页内容的参数——如 sessionID 或排序参数——可以从 URL 中移除并由 cookie 记录。通过将这些信息添加到 cookie 中,然后 301 定向到一个“干净”的 URL,您可以保留原创内容并减少指向相同内容的 URL 数量。
2、控制无限空间
你的网站上有日历吗,上面的链接指向无数过去和未来的日期(每个链接地址都是唯一的二)?你的网页地址是不是加了一个 &page=3563 参数后,你可以还是返回200码,就算根本没有那么多页面?这样的话,你的网站就会出现所谓的“无限空间”,会浪费爬虫机器人和你的@带宽k14@.如何控制“无限空间”,请参考这里的一些技巧。
3、防止 Google 抓取工具抓取它们无法处理的页面
通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系信息、购物车和其他爬虫无法处理的页面被抓取。 (爬行动物以吝啬和害羞着称,所以一般不会“添加商品到购物车”或“联系我们”)。通过这种方式,您可以让爬虫花更多的时间在您的网站 上爬取他们可以处理的内容。
4、一个网址,一段内容
在理想世界中,深圳网站construction 认为 URL 和内容是一一对应的:每个 URL 对应一个唯一的内容,每个内容只能通过唯一网址。越接近这种理想情况,您的网站 就越容易被捕获,收录 也就越容易被捕获。如果您的内容管理系统或当前的网站 机构难以实施,您可以尝试使用 rel=canonical 元素来设置您要用于指示特定内容的 URL。
webscrapermac破解版安装教程,轻松地扫描和屏幕网站
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-20 05:28
WebScraper Mac 版是 MacOS 上的 网站content 捕获工具。你只需要指定需要采集的网站地址和需要什么内容采集输出提取的数据(当前)为CSV或JSON,将图片下载到文件夹中。这次为大家带来的是webscraper mac 破解版,不受功能和时间限制。您可以轻松使用该软件的所有功能。欢迎喜欢的朋友下载体验。
Webscraper mac 破解版安装教程
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:
2、返回安装包,双击打开WebScraper注册机,如图:
3、点击WebScraper注册机左侧的Open,如图:
4、在应用中找到WebScraper,点击打开,如图:
5、点击保存生成注册码!
6、Open WebScraper,显示已注册!
您不是VIP会员或积分不足,请升级VIP会员或充值观看教程。
Webscraper mac 破解版软件介绍
WebScraper for Mac 是 Mac 平台上的一个简单应用程序,可将数据导出为 JSON 或 CSV。 Mac 版的 WebScraper 可以快速提取与网页相关的信息(包括文本内容)。适用于 Mac 的 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
Webscraper mac 破解版软件特点
快速轻松地扫描和截屏网站
原生 MacOS 应用程序可以在您的桌面上运行
提取数据的方法有很多种;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
易于导出数据-选择所需的列
输出数据为csv或json
将所有图像下载到文件夹/采集并导出所有链接的选项
输出单个文本文件的选项(用于存档文本内容、markdown 或纯文本)
丰富的选项/配置
系统要求
当前版本需要 Mac OS 10.8 或更高版本
WebScraper Mac 更新日志
添加扫描时下载pdf文件并将其保存到文件夹的选项。 查看全部
webscrapermac破解版安装教程,轻松地扫描和屏幕网站
WebScraper Mac 版是 MacOS 上的 网站content 捕获工具。你只需要指定需要采集的网站地址和需要什么内容采集输出提取的数据(当前)为CSV或JSON,将图片下载到文件夹中。这次为大家带来的是webscraper mac 破解版,不受功能和时间限制。您可以轻松使用该软件的所有功能。欢迎喜欢的朋友下载体验。

Webscraper mac 破解版安装教程
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:

2、返回安装包,双击打开WebScraper注册机,如图:

3、点击WebScraper注册机左侧的Open,如图:

4、在应用中找到WebScraper,点击打开,如图:

5、点击保存生成注册码!

6、Open WebScraper,显示已注册!

您不是VIP会员或积分不足,请升级VIP会员或充值观看教程。
Webscraper mac 破解版软件介绍
WebScraper for Mac 是 Mac 平台上的一个简单应用程序,可将数据导出为 JSON 或 CSV。 Mac 版的 WebScraper 可以快速提取与网页相关的信息(包括文本内容)。适用于 Mac 的 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。

Webscraper mac 破解版软件特点
快速轻松地扫描和截屏网站
原生 MacOS 应用程序可以在您的桌面上运行
提取数据的方法有很多种;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
易于导出数据-选择所需的列
输出数据为csv或json
将所有图像下载到文件夹/采集并导出所有链接的选项
输出单个文本文件的选项(用于存档文本内容、markdown 或纯文本)
丰富的选项/配置

系统要求
当前版本需要 Mac OS 10.8 或更高版本
WebScraper Mac 更新日志
添加扫描时下载pdf文件并将其保存到文件夹的选项。
网页文字抓取工具提供文字识别功能,方便用户复制使用
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-06-19 19:33
网页文字抓取工具提供文字识别功能,可以直接识别网页上的所有文字,然后抓取并显示在软件上,方便用户复制使用。相信很多用户都遇到过一些无法复制的网页。设置权限后,不能直接复制网页内容。如果需要使用网页上的文字,可以选择这款爬虫软件。本软件可以直接抓取整个网页的文字内容复制使用。该软件只能抓取文本内容,自动过滤网页上的图片,让用户快速获取自己需要的文本内容,对需要复制网页内容的朋友很有帮助,有需要的朋友可以下载!
软件功能
1、网页文字抓取工具提供简单的文字抓取方法
2、 只要输入网页地址就可以抓取了。识别能力很强。
3、可以正常识别中英文内容
4、可以按照网页布局格式展示抓取的内容
5、快速过滤图片,避免干扰图片内容
6、 普通网页内容显示,可以在软件左侧查看添加的网页内容
软件功能
1、网页文字爬虫适合经常在网络上使用采集resources的朋友
2、也适合自媒体,快速复制其他网站内容
3、如果遇到加密网页。您可以通过本软件复制内容
4、网页文字抓取工具免费使用,轻松将内容保存为TXT
5、也支持复制到粘贴板使用,右侧也可以修改内容
如何使用
1、打开网页抓图工具.exe显示软件的所有功能,可以在这里添加地址
2、点击文字抓取功能立即识别网页内容并在软件右侧显示文字
3、 如图,文本内容可以直接复制,也可以修改,对比一下内容是否有错误。
4、软件会自动过滤图片内容,只识别网页文字,无法识别图片文字
5、这里是导出功能。识别网页内容后,可以保存到TXT
6、列表导出成功!数据存放在软件目录下的wenzi.txt文件中
7、显示复制功能,可以在软件界面将右侧的所有内容复制到粘贴板,并且可以选择一段进行复制
查看全部
网页文字抓取工具提供文字识别功能,方便用户复制使用
网页文字抓取工具提供文字识别功能,可以直接识别网页上的所有文字,然后抓取并显示在软件上,方便用户复制使用。相信很多用户都遇到过一些无法复制的网页。设置权限后,不能直接复制网页内容。如果需要使用网页上的文字,可以选择这款爬虫软件。本软件可以直接抓取整个网页的文字内容复制使用。该软件只能抓取文本内容,自动过滤网页上的图片,让用户快速获取自己需要的文本内容,对需要复制网页内容的朋友很有帮助,有需要的朋友可以下载!

软件功能
1、网页文字抓取工具提供简单的文字抓取方法
2、 只要输入网页地址就可以抓取了。识别能力很强。
3、可以正常识别中英文内容
4、可以按照网页布局格式展示抓取的内容
5、快速过滤图片,避免干扰图片内容
6、 普通网页内容显示,可以在软件左侧查看添加的网页内容
软件功能
1、网页文字爬虫适合经常在网络上使用采集resources的朋友
2、也适合自媒体,快速复制其他网站内容
3、如果遇到加密网页。您可以通过本软件复制内容
4、网页文字抓取工具免费使用,轻松将内容保存为TXT
5、也支持复制到粘贴板使用,右侧也可以修改内容
如何使用
1、打开网页抓图工具.exe显示软件的所有功能,可以在这里添加地址

2、点击文字抓取功能立即识别网页内容并在软件右侧显示文字

3、 如图,文本内容可以直接复制,也可以修改,对比一下内容是否有错误。
4、软件会自动过滤图片内容,只识别网页文字,无法识别图片文字

5、这里是导出功能。识别网页内容后,可以保存到TXT

6、列表导出成功!数据存放在软件目录下的wenzi.txt文件中

7、显示复制功能,可以在软件界面将右侧的所有内容复制到粘贴板,并且可以选择一段进行复制

WebHarvy会智能地识别数据模式自动识别网页中的应用
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-06-19 19:25
WebHarvy 网页采集老师汉化版是国外的采集工具,网站初出中文版,这个程序已经完成了90%,编辑受限网页的软件非常好用,功能强大的应用,可以自动从网页中提取数据(文本、网址和图片),并将提取的内容以不同的格式保存。
应用笔记
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单。 WebHarvy 将智能识别网页上出现的数据模式。使用WebHarvy,可以从不同的网站,在不同的类别中提取数据,例如产品目录或搜索结果,例如房地产,电子商务,学术研究,娱乐,技术等。 从网页中提取的数据可以以不同的格式保存。通常网页显示数据,例如多个页面上的搜索结果。 WebHarvy 可以自动从多个页面抓取和提取数据。
软件功能
WebHarvy 允许您分析网页上的数据
可以显示和分析来自 HTML 地址的连接数据
可以扩展到下一个网页
可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
支持浏览器复制链接搜索
支持配置对应的资源项搜索
可以按项目名称和资源名称搜索
特点
视觉点和点击界面
WebHarvy 是一个可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
代表{pass}{filter}从服务器提取
要提取匿名,防止提取web服务器被网络软件拦截,必须通过{over}{filtering}服务器的选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
外链搜索教程(附 WebHarvy 建议采集tools) 查看全部
WebHarvy会智能地识别数据模式自动识别网页中的应用
WebHarvy 网页采集老师汉化版是国外的采集工具,网站初出中文版,这个程序已经完成了90%,编辑受限网页的软件非常好用,功能强大的应用,可以自动从网页中提取数据(文本、网址和图片),并将提取的内容以不同的格式保存。
应用笔记
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单。 WebHarvy 将智能识别网页上出现的数据模式。使用WebHarvy,可以从不同的网站,在不同的类别中提取数据,例如产品目录或搜索结果,例如房地产,电子商务,学术研究,娱乐,技术等。 从网页中提取的数据可以以不同的格式保存。通常网页显示数据,例如多个页面上的搜索结果。 WebHarvy 可以自动从多个页面抓取和提取数据。
软件功能
WebHarvy 允许您分析网页上的数据
可以显示和分析来自 HTML 地址的连接数据
可以扩展到下一个网页
可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
支持浏览器复制链接搜索
支持配置对应的资源项搜索
可以按项目名称和资源名称搜索
特点
视觉点和点击界面
WebHarvy 是一个可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
代表{pass}{filter}从服务器提取
要提取匿名,防止提取web服务器被网络软件拦截,必须通过{over}{filtering}服务器的选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
外链搜索教程(附 WebHarvy 建议采集tools)
图片助手官网:默认尺寸漏斗可在扩展选项中设置
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-06-13 21:13
图片助手(ImageAssistant)是一款运行在Chromium及其衍生浏览器(如:百度浏览器、猎豹安全浏览器、360安全浏览器、360极速浏览器、UC浏览器等)上进行分析、提取图片的浏览器网页并提供多种过滤方式,帮助用户选择要下载的扩展程序。与以往提供类似功能的浏览器扩展不同,图片助手集成了多种数据提取方式,确保尽可能全面地提取出现在各种复杂结构页面中的图片。过滤方式包括图片类型(JPG、GIF、PNG)、分辨率大小(不小于,指定大小),其中指定大小通过大小漏斗设置,“默认大小漏斗”可以在扩展选项中设置(注:分辨率小于默认尺寸的图片会被直接忽略,请慎重设置,设置太大会导致小尺寸图片无法提取显示),并且可以自定义添加尺寸漏斗选项。
这个插件的名字是:图片助手,支持谷歌和基于谷歌的360、百度、UC、猎豹等各种主流浏览器。
安装也很简单
以360浏览器为例,在应用商店中搜索图片助手,选择添加即可。
1
批量下载图片
我们在浏览网页时,经常会看到各种图片的合集或摘要▼
只需在浏览器中点击图片助手,然后选择从该页面提取图片的命令即可。图片助手会提取当前网页中的所有图片元素▼
下一步我们可以通过过滤图片的大小来过滤出我们想要的图片,然后批量下载▼
图片助手官网: 查看全部
图片助手官网:默认尺寸漏斗可在扩展选项中设置
图片助手(ImageAssistant)是一款运行在Chromium及其衍生浏览器(如:百度浏览器、猎豹安全浏览器、360安全浏览器、360极速浏览器、UC浏览器等)上进行分析、提取图片的浏览器网页并提供多种过滤方式,帮助用户选择要下载的扩展程序。与以往提供类似功能的浏览器扩展不同,图片助手集成了多种数据提取方式,确保尽可能全面地提取出现在各种复杂结构页面中的图片。过滤方式包括图片类型(JPG、GIF、PNG)、分辨率大小(不小于,指定大小),其中指定大小通过大小漏斗设置,“默认大小漏斗”可以在扩展选项中设置(注:分辨率小于默认尺寸的图片会被直接忽略,请慎重设置,设置太大会导致小尺寸图片无法提取显示),并且可以自定义添加尺寸漏斗选项。
这个插件的名字是:图片助手,支持谷歌和基于谷歌的360、百度、UC、猎豹等各种主流浏览器。


安装也很简单
以360浏览器为例,在应用商店中搜索图片助手,选择添加即可。
1
批量下载图片
我们在浏览网页时,经常会看到各种图片的合集或摘要▼
只需在浏览器中点击图片助手,然后选择从该页面提取图片的命令即可。图片助手会提取当前网页中的所有图片元素▼

下一步我们可以通过过滤图片的大小来过滤出我们想要的图片,然后批量下载▼
图片助手官网:
证书链不完整,导致浏览器无法信任你安装的证书
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-06-13 01:22
证书链不完整,导致浏览器无法信任你安装的证书
安装证书后,仍然无法访问。
重新整理思路,安卓浏览器和qq等都能正常访问https,说明证书配置正确。只有微信访问异常。百度后发现其他人也遇到过类似问题,说证书链不完整,导致浏览器无法信任你安装的证书。
证书链实际上是在描述证书的签名链接。比如A给B发证书,B给C发证书,那么我们手里就有了证书C。当证书链不完整时,即没有说明我们手中的证书C是谁使用的,所以浏览器不会认为你的证书是可信授权证书。
二. 如何验证证书链的完整性? 1.如果是外网可以访问,输入域名验证SSL证书链是否完整
2.如果是内网,可以使用命令验证:
openssl s_client -connect x.x.x.x:443
// s_client为一个SSL/TLS客户端程序,与s_server对应,它不仅能与s_server进行通信,也能与任何使用ssl协议的其他服务程序进行通信。
// -connect host:port:设置服务器地址和端口号。如果没有设置,则默认为本地主机以及端口号4433。
连接内网IP后:
0、1 是证书链中每一级证书的序号。 0 是网站 使用的要验证的证书。其CN对应网站域名。
在每个序列号之后,以s开头的行表示证书,以i开头的行表示证书的颁发者。
0 的 CN 收录一个英文域名。其发行人为 TrustAsia Technologies, Inc./OU=Symantec Trust Network/OU=Domain Validated SSL/CN=TrustAsia DV SSL CA
1 的证书是 0 的颁发者。而 1 本身是由另一个证书 VeriSign Class 3 Public Primary Certification Authority 颁发的。
所以这么一看,浏览器以为我知道1的发行者。安装包里提到了VeriSIign。签名正确,验证正确,所以信任1。那么1发出的0也应该信任。所以这个网站是可以信任的。
但是,如果网站在配置的时候只在crt文件中收录了自己,而没有收录可以被浏览器内置数据验证的完整证书链,则可能会被浏览器拒绝。例如
openssl s_client -connecttouko.moe:443
---
Certificate chain
0 s:/CN=touko.moe
i:/C=CN/O=WoSign CALimited/CN=WoSign CA Free SSL CertificateG2
---
只有0组。请注意,第 s 行的 touko.moe 是由第 i 行的 WoSign CA Free SSL CertificateG2 颁发的。没了。
这就是这个坑最神奇的地方:这个时候浏览器是否验证失败还不确定。有两种情况:
A.自从安装浏览器以来,我从未见过这种情况。那么验证就会失败。
B.如果浏览器之前看到并验证过i,则验证成功。
通常管理员会去证书颁发机构的https网站购买证书,浏览器会验证,然后所有验证成功的中间证书都会缓存起来,以备日后使用。当管理员(错误地)配置了他的网站并去浏览测试时,他根本不会遇到任何问题。因为他的浏览器已经识别了这个中间证书。
总结:
通过证书链验证发现我们内网的证书链是完整正确的。
三.微信自己的问题
再整理思路,用安卓微信访问其他https网站如百度、csdn等,都是空白页面。如果是我们的证书链有问题,那么其他网站证书链应该没问题,为什么?不能参观?这样证书链问题就彻底解决了。
由于不是本地证书问题,也不是我们服务器的证书链问题,QQ和浏览器都可以正常访问,ios也正常,说明fiddler端没问题。这时候就怀疑是微信本身的问题了。 ?
好的,首先考虑为什么fiddler可以抓取https包?
Fiddler 巧妙地伪造了 CA 证书。我(fiddler)自己编造了一个私钥和公钥,作为签名证书发给浏览器,提交给服务器,服务器根据公钥签名返回。 (提琴手)伪造的钥匙自然可以解锁。
所以,你知道,我知道,大家都知道,为了防止软件被fiddler捕获,开发者会内置SSL证书,直接用自己的证书进行签名和加密,而不是使用系统的CA证书。您将被伪造证书欺骗信息。自然,fiddler 将无法使用自己的证书捕获软件数据。 查看全部
证书链不完整,导致浏览器无法信任你安装的证书
安装证书后,仍然无法访问。
重新整理思路,安卓浏览器和qq等都能正常访问https,说明证书配置正确。只有微信访问异常。百度后发现其他人也遇到过类似问题,说证书链不完整,导致浏览器无法信任你安装的证书。
证书链实际上是在描述证书的签名链接。比如A给B发证书,B给C发证书,那么我们手里就有了证书C。当证书链不完整时,即没有说明我们手中的证书C是谁使用的,所以浏览器不会认为你的证书是可信授权证书。
二. 如何验证证书链的完整性? 1.如果是外网可以访问,输入域名验证SSL证书链是否完整

2.如果是内网,可以使用命令验证:
openssl s_client -connect x.x.x.x:443
// s_client为一个SSL/TLS客户端程序,与s_server对应,它不仅能与s_server进行通信,也能与任何使用ssl协议的其他服务程序进行通信。
// -connect host:port:设置服务器地址和端口号。如果没有设置,则默认为本地主机以及端口号4433。
连接内网IP后:

0、1 是证书链中每一级证书的序号。 0 是网站 使用的要验证的证书。其CN对应网站域名。
在每个序列号之后,以s开头的行表示证书,以i开头的行表示证书的颁发者。
0 的 CN 收录一个英文域名。其发行人为 TrustAsia Technologies, Inc./OU=Symantec Trust Network/OU=Domain Validated SSL/CN=TrustAsia DV SSL CA
1 的证书是 0 的颁发者。而 1 本身是由另一个证书 VeriSign Class 3 Public Primary Certification Authority 颁发的。
所以这么一看,浏览器以为我知道1的发行者。安装包里提到了VeriSIign。签名正确,验证正确,所以信任1。那么1发出的0也应该信任。所以这个网站是可以信任的。
但是,如果网站在配置的时候只在crt文件中收录了自己,而没有收录可以被浏览器内置数据验证的完整证书链,则可能会被浏览器拒绝。例如
openssl s_client -connecttouko.moe:443
---
Certificate chain
0 s:/CN=touko.moe
i:/C=CN/O=WoSign CALimited/CN=WoSign CA Free SSL CertificateG2
---
只有0组。请注意,第 s 行的 touko.moe 是由第 i 行的 WoSign CA Free SSL CertificateG2 颁发的。没了。
这就是这个坑最神奇的地方:这个时候浏览器是否验证失败还不确定。有两种情况:
A.自从安装浏览器以来,我从未见过这种情况。那么验证就会失败。
B.如果浏览器之前看到并验证过i,则验证成功。
通常管理员会去证书颁发机构的https网站购买证书,浏览器会验证,然后所有验证成功的中间证书都会缓存起来,以备日后使用。当管理员(错误地)配置了他的网站并去浏览测试时,他根本不会遇到任何问题。因为他的浏览器已经识别了这个中间证书。
总结:
通过证书链验证发现我们内网的证书链是完整正确的。
三.微信自己的问题
再整理思路,用安卓微信访问其他https网站如百度、csdn等,都是空白页面。如果是我们的证书链有问题,那么其他网站证书链应该没问题,为什么?不能参观?这样证书链问题就彻底解决了。
由于不是本地证书问题,也不是我们服务器的证书链问题,QQ和浏览器都可以正常访问,ios也正常,说明fiddler端没问题。这时候就怀疑是微信本身的问题了。 ?
好的,首先考虑为什么fiddler可以抓取https包?
Fiddler 巧妙地伪造了 CA 证书。我(fiddler)自己编造了一个私钥和公钥,作为签名证书发给浏览器,提交给服务器,服务器根据公钥签名返回。 (提琴手)伪造的钥匙自然可以解锁。
所以,你知道,我知道,大家都知道,为了防止软件被fiddler捕获,开发者会内置SSL证书,直接用自己的证书进行签名和加密,而不是使用系统的CA证书。您将被伪造证书欺骗信息。自然,fiddler 将无法使用自己的证书捕获软件数据。
VisualWebRipper破解版的使用方法有哪些?软件介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-06-12 19:13
Visual Web Ripper 破解版是一款网页数据提取软件。它可以在不编辑代码的情况下提取整个产品目录。它的使用非常简单,只要输入网址,然后点击相应的区域,它就会自动识别并提取数据。
软件介绍
Visual Web Ripper 是一款强大的网络抓取工具,可轻松提取 网站 数据,例如产品目录、分类广告、finance网站 或任何其他收录您可能感兴趣的信息的 网站。
我们的网络爬虫从目标网站 采集内容,并自动将内容作为结构化数据传输到数据库、电子表格、CSV 文件或 XML。
我们的网络爬虫可以从高度动态的网站中提取网站数据,但大多数其他提取工具都会失败。它可以处理支持 AJAX 的 网站,重复提交所有可能的输入表单等等。
软件功能
1、项目编辑
使用可视化项目编辑器轻松设计网页抓取项目。不需要脚本或编码。只需在内置网络浏览器中加载网站,然后使用鼠标指向并单击要提取的内容和要关注的链接。只需点击几下,即可将项目配置为跟踪数百个链接。
项目编辑器中收录的工具可以帮助您开发即使页面布局略有变化也能正常工作的数据提取模型,并且所有工作只需单击即可完成。
2、 轻松捕捉完整的内容结构
Visual Web Ripper 可以配置为下载完整的内容结构,例如产品目录。您只需要配置几个模板,网络爬虫会为您找到其余的并下载所有数据。
我们的网络抓取软件具有许多高级功能,可帮助您优化网络抓取性能和可靠性。如果您想从数千甚至数十万个网页中抓取数据,这些功能非常重要。
3、反复提交网络表单
我们的网络抓取软件可以提交网络表单,例如搜索表单或在线预订表单。可以为所有可能的输入值提交 Web 表单,因此可以配置 Web 抓取项目以提交所有可能的房间类型的酒店预订表单。
输入 CSV 文件或数据库查询可用于向 Web 表单提供输入值,因此您可以创建收录数千个搜索关键字的 CSV 文件并为每个关键字提交搜索表单。
4、从高度动态的网站中提取数据
大多数原创网络爬虫无法从高度动态的网站中提取数据,即使是专业的网络爬虫在从AJAX网站中采集数据也可能存在问题。 Visual Web Ripper 有一套复杂的工具,可以让你从最复杂的 AJAX网站 获取数据,但请记住,一些 AJAX网站 对新手用户来说是一个挑战。
5、从命令行运行 Web Scraping 会话
Visual Web Ripper 有一个命令行实用程序,可用于从 Windows 命令行静默运行网络抓取项目。这为几乎所有 Windows 应用程序(包括网站)提供了一种非常简单的机制来运行网络抓取项目。
可以通过命令行将输入参数传递给网页抓取项目,这样就可以构建一个网站,访问者可以在其中输入搜索关键字,然后网站可以将搜索关键字传递给网页抓取项目,项目从第三方网站提取数据。
如何使用 Visual Web Ripper
第一步:在可视化编辑器中设计项目
导航到网站 并为要从中提取内容的每种不同类型的页面设计模板
模板定义了如何从特定网页和具有相似内容结构的所有其他网页中提取内容
您可以通过点击要提取的页面内容设计模板,然后选择要激活的链接和表单打开新页面
强大的工具可以帮助您设计模板。您可以在整个列表中重复内容选择,点击区域中的所有链接,或者重复提交收录所有可能输入值的表单。
第 2 步:直接从设计器运行项目或制定运行项目的计划。
第 3 步:数据将保存到您选择的数据存储(数据库、电子表格、XML 或 CSV 文件) 查看全部
VisualWebRipper破解版的使用方法有哪些?软件介绍
Visual Web Ripper 破解版是一款网页数据提取软件。它可以在不编辑代码的情况下提取整个产品目录。它的使用非常简单,只要输入网址,然后点击相应的区域,它就会自动识别并提取数据。
软件介绍
Visual Web Ripper 是一款强大的网络抓取工具,可轻松提取 网站 数据,例如产品目录、分类广告、finance网站 或任何其他收录您可能感兴趣的信息的 网站。
我们的网络爬虫从目标网站 采集内容,并自动将内容作为结构化数据传输到数据库、电子表格、CSV 文件或 XML。
我们的网络爬虫可以从高度动态的网站中提取网站数据,但大多数其他提取工具都会失败。它可以处理支持 AJAX 的 网站,重复提交所有可能的输入表单等等。
软件功能
1、项目编辑
使用可视化项目编辑器轻松设计网页抓取项目。不需要脚本或编码。只需在内置网络浏览器中加载网站,然后使用鼠标指向并单击要提取的内容和要关注的链接。只需点击几下,即可将项目配置为跟踪数百个链接。
项目编辑器中收录的工具可以帮助您开发即使页面布局略有变化也能正常工作的数据提取模型,并且所有工作只需单击即可完成。
2、 轻松捕捉完整的内容结构
Visual Web Ripper 可以配置为下载完整的内容结构,例如产品目录。您只需要配置几个模板,网络爬虫会为您找到其余的并下载所有数据。
我们的网络抓取软件具有许多高级功能,可帮助您优化网络抓取性能和可靠性。如果您想从数千甚至数十万个网页中抓取数据,这些功能非常重要。
3、反复提交网络表单
我们的网络抓取软件可以提交网络表单,例如搜索表单或在线预订表单。可以为所有可能的输入值提交 Web 表单,因此可以配置 Web 抓取项目以提交所有可能的房间类型的酒店预订表单。
输入 CSV 文件或数据库查询可用于向 Web 表单提供输入值,因此您可以创建收录数千个搜索关键字的 CSV 文件并为每个关键字提交搜索表单。
4、从高度动态的网站中提取数据
大多数原创网络爬虫无法从高度动态的网站中提取数据,即使是专业的网络爬虫在从AJAX网站中采集数据也可能存在问题。 Visual Web Ripper 有一套复杂的工具,可以让你从最复杂的 AJAX网站 获取数据,但请记住,一些 AJAX网站 对新手用户来说是一个挑战。
5、从命令行运行 Web Scraping 会话
Visual Web Ripper 有一个命令行实用程序,可用于从 Windows 命令行静默运行网络抓取项目。这为几乎所有 Windows 应用程序(包括网站)提供了一种非常简单的机制来运行网络抓取项目。
可以通过命令行将输入参数传递给网页抓取项目,这样就可以构建一个网站,访问者可以在其中输入搜索关键字,然后网站可以将搜索关键字传递给网页抓取项目,项目从第三方网站提取数据。
如何使用 Visual Web Ripper
第一步:在可视化编辑器中设计项目
导航到网站 并为要从中提取内容的每种不同类型的页面设计模板
模板定义了如何从特定网页和具有相似内容结构的所有其他网页中提取内容
您可以通过点击要提取的页面内容设计模板,然后选择要激活的链接和表单打开新页面
强大的工具可以帮助您设计模板。您可以在整个列表中重复内容选择,点击区域中的所有链接,或者重复提交收录所有可能输入值的表单。
第 2 步:直接从设计器运行项目或制定运行项目的计划。
第 3 步:数据将保存到您选择的数据存储(数据库、电子表格、XML 或 CSV 文件)
推荐程序Octoparse–优采云的推荐及重点推荐功能介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-10 07:21
推荐程序Octoparse--优采云
这样不仅操作方便,功能齐全,而且可以在短时间内获取大量数据。特别推荐Octoparse的云采集功能,好评。
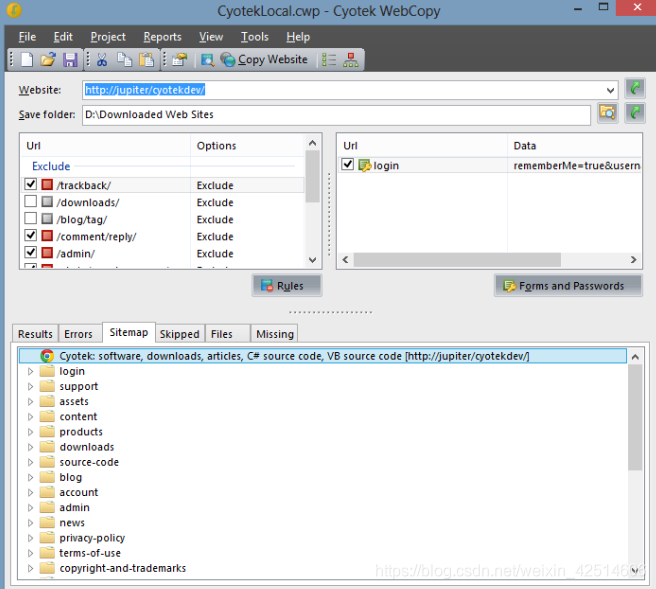
Cyotek 网络复制
WebCopy 是一款免费的网站 爬虫,可让您将本地部分或完整的网站 复制到您的硬盘上以供离线阅读。
它会扫描指定的网站,然后将网站内容下载到您的硬盘上,并自动将其重新映射到网站中的图片和其他网页的链接以匹配其本地路径。包括网站的某个部分。也可以使用其他选项,例如下载要收录在副本中的 URL,但不对其进行抓取。
您可以使用多种设置来配置网站 的抓取方式。除了上面提到的规则和表单,您还可以配置域别名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或任何形式的 JavaScript 解析。如果一个网站大量使用JavaScript进行操作,如果因为JavaScript动态生成链接而无法找到所有网站,那么WebCopy就不太可能进行真正的复制。
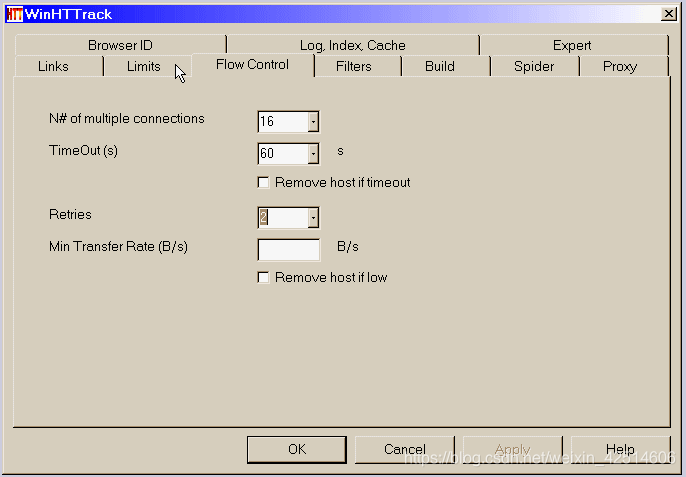
3.Httrack
作为网站crawler 的免费软件,HTTrack 提供的功能非常适合将整个网站 从互联网下载到您的PC 上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以将一个站点或多个站点镜像到一起(使用共享链接)。您可以在“设置”下决定在下载网页时要同时打开多少个连接。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的网站 并恢复中断的下载。
此外,HTTTrack 还提供代理支持以最大限度地提高速度并提供可选的身份验证。
HTTrack 用作命令行程序,或通过外壳进行私有(捕获)或专业(在线网络镜像)使用。有了这个说法,HTTrack应该是首选,编程能力高的人用得更多
总结
总之,我上面提到的爬虫可以满足大部分用户的基本爬虫需求,而且这些工具各自的功能还是有很多区别的,因为这些爬虫工具很多都为用户提供了更高级的内置配置工具。因此,在使用前请务必充分了解爬虫提供的帮助信息。 查看全部
推荐程序Octoparse–优采云的推荐及重点推荐功能介绍
推荐程序Octoparse--优采云

这样不仅操作方便,功能齐全,而且可以在短时间内获取大量数据。特别推荐Octoparse的云采集功能,好评。
Cyotek 网络复制
WebCopy 是一款免费的网站 爬虫,可让您将本地部分或完整的网站 复制到您的硬盘上以供离线阅读。
它会扫描指定的网站,然后将网站内容下载到您的硬盘上,并自动将其重新映射到网站中的图片和其他网页的链接以匹配其本地路径。包括网站的某个部分。也可以使用其他选项,例如下载要收录在副本中的 URL,但不对其进行抓取。
您可以使用多种设置来配置网站 的抓取方式。除了上面提到的规则和表单,您还可以配置域别名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或任何形式的 JavaScript 解析。如果一个网站大量使用JavaScript进行操作,如果因为JavaScript动态生成链接而无法找到所有网站,那么WebCopy就不太可能进行真正的复制。
3.Httrack
作为网站crawler 的免费软件,HTTrack 提供的功能非常适合将整个网站 从互联网下载到您的PC 上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以将一个站点或多个站点镜像到一起(使用共享链接)。您可以在“设置”下决定在下载网页时要同时打开多少个连接。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的网站 并恢复中断的下载。
此外,HTTTrack 还提供代理支持以最大限度地提高速度并提供可选的身份验证。
HTTrack 用作命令行程序,或通过外壳进行私有(捕获)或专业(在线网络镜像)使用。有了这个说法,HTTrack应该是首选,编程能力高的人用得更多
总结
总之,我上面提到的爬虫可以满足大部分用户的基本爬虫需求,而且这些工具各自的功能还是有很多区别的,因为这些爬虫工具很多都为用户提供了更高级的内置配置工具。因此,在使用前请务必充分了解爬虫提供的帮助信息。
6款海外竞品网站监测工具,帮到每一位海外营销人!
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-06-05 20:22
为了抢占流量红利,多渠道扩张成为主要营销策略。如何更好地了解竞品趋势也成为当务之急!
但是,监控竞品不是为了打压竞品,也不是窥探竞品的商业秘密,而是为了在竞品监控中锚定自己公司的地位,借鉴竞品的优势,并提高自己。一个公司不可能低着头走路,偶尔需要抬头看看周围的竞争对手,以此来判断是走得太慢还是走弯路。
竞争与合作的环境有利于行业的进一步发展。以下是木瓜移动整理的6款海外竞品网站监控工具,希望能帮助到每一位海外营销者!
1
类似网站
监控竞争产品网站flow
SimilarWeb 是一种分析工具,用于监控网站 或 Web 应用程序流量。由于竞争产品很可能会争夺类似的受众,因此竞争对手的优质流量来源通常会对您的业务产生很大影响。了解竞品来源网站流量可以推广同渠道。
更重要的是,内容营销人员可以轻松查看访问者正在搜索哪些主题以及他们访问了哪些相关的 网站。
同时,SimilarWeb 还可以监控竞品在哪里投放广告,哪些广告给他们带来了最多的收入,还可以监控他们正在投放的广告。您可以通过只定位他们使用的高质量广告空间来节省资金。
2
内置
查看竞品网站使用插件
BuiltWith 是一个行业分析工具。只需输入竞争对手网站的网址,您就会看到网站使用的脚本、服务和插件。此外,您还可以查询网站使用的任何前后端技术。
当您在竞品信息中发现某个平台或服务时,您也可以在此网站直接查询其使用情况分析、用户数、市场份额等。 BuiltWith 不仅可以看到竞争对手使用的技术,还可以看到为竞争对手服务的其他产品的使用情况。
3
回归机器
查看竞品网站历史版本
Wayback Machine 是 Internet Archive 下的网页保存工具。通过Crawler每周可以抓取超过10亿个网页!大量的服务器和带宽用于提供服务和压缩内容大小,因此用户可以在本产品上找到网站的任何历史版本。
此外,Wayback Machine 还提供了在线网页备份功能。只需输入需要备份的网页网址,即可拦截生成独立且永久保存的网址,即可随时使用Wayback Machine中的时光机功能。查看在不同时间点自动抓取和备份的网页内容。
登录“Wayback Machine”网站后,在顶部输入网站你想赶时间机器的网址。如果你想找到以前匿名网站的页面,可以试试下面的网址格式(把ID改成你要查询的网站name):
输入网址后,点击“浏览历史”,会出现该页面不同时间的网页存档备份。
4
BussSumo
查看竞品网站hot content
Buzzsumo 是一款具有竞争力的产品监控工具,专注于内容。它可以查看任何关键词在社交媒体上的流行度,帮助内容创作者选择话题。同时,它还允许用户查看自己品牌或竞争对手相关主题下表现最佳的内容,以及目前有多少人分享了竞争对手的内容。
不仅可以在行业内容上帮助用户了解谁在“杀四方”,还可以帮助用户发现潜在的热点话题。
5
SEMrush
关键字广告工具(付费)
SEMRush 是市场上使用最广泛的 SEO 工具,同时还具有高质量的竞争对手分析功能。
用户只需输入竞争对手网站的网址,即可立即查询其排名、流量、广告关键词和有机关键词。所有结果将以图形报告的形式清晰显示。
用户还可以使用这个工具来并排比较不同域名的数据细节,这个工具还可以帮助用户为他们的网站产生关键词想法。
6
UberSuggest
监控竞品特定关键词带来流量数据
UberSuggest 是一个标准的免费关键字监控工具。用户可以使用它来监控竞品网站的关键词详情和流量来源。
用户输入关键词,UberSuggest可以立即显示所有相关的长尾词,以及每个关键词的月搜索量和长尾、平均每次点击成本、PPC竞争和SEO竞争。
查看全部
6款海外竞品网站监测工具,帮到每一位海外营销人!
为了抢占流量红利,多渠道扩张成为主要营销策略。如何更好地了解竞品趋势也成为当务之急!
但是,监控竞品不是为了打压竞品,也不是窥探竞品的商业秘密,而是为了在竞品监控中锚定自己公司的地位,借鉴竞品的优势,并提高自己。一个公司不可能低着头走路,偶尔需要抬头看看周围的竞争对手,以此来判断是走得太慢还是走弯路。
竞争与合作的环境有利于行业的进一步发展。以下是木瓜移动整理的6款海外竞品网站监控工具,希望能帮助到每一位海外营销者!
1
类似网站
监控竞争产品网站flow
SimilarWeb 是一种分析工具,用于监控网站 或 Web 应用程序流量。由于竞争产品很可能会争夺类似的受众,因此竞争对手的优质流量来源通常会对您的业务产生很大影响。了解竞品来源网站流量可以推广同渠道。
更重要的是,内容营销人员可以轻松查看访问者正在搜索哪些主题以及他们访问了哪些相关的 网站。

同时,SimilarWeb 还可以监控竞品在哪里投放广告,哪些广告给他们带来了最多的收入,还可以监控他们正在投放的广告。您可以通过只定位他们使用的高质量广告空间来节省资金。
2
内置
查看竞品网站使用插件
BuiltWith 是一个行业分析工具。只需输入竞争对手网站的网址,您就会看到网站使用的脚本、服务和插件。此外,您还可以查询网站使用的任何前后端技术。

当您在竞品信息中发现某个平台或服务时,您也可以在此网站直接查询其使用情况分析、用户数、市场份额等。 BuiltWith 不仅可以看到竞争对手使用的技术,还可以看到为竞争对手服务的其他产品的使用情况。
3
回归机器
查看竞品网站历史版本
Wayback Machine 是 Internet Archive 下的网页保存工具。通过Crawler每周可以抓取超过10亿个网页!大量的服务器和带宽用于提供服务和压缩内容大小,因此用户可以在本产品上找到网站的任何历史版本。
此外,Wayback Machine 还提供了在线网页备份功能。只需输入需要备份的网页网址,即可拦截生成独立且永久保存的网址,即可随时使用Wayback Machine中的时光机功能。查看在不同时间点自动抓取和备份的网页内容。
登录“Wayback Machine”网站后,在顶部输入网站你想赶时间机器的网址。如果你想找到以前匿名网站的页面,可以试试下面的网址格式(把ID改成你要查询的网站name):
输入网址后,点击“浏览历史”,会出现该页面不同时间的网页存档备份。

4
BussSumo
查看竞品网站hot content
Buzzsumo 是一款具有竞争力的产品监控工具,专注于内容。它可以查看任何关键词在社交媒体上的流行度,帮助内容创作者选择话题。同时,它还允许用户查看自己品牌或竞争对手相关主题下表现最佳的内容,以及目前有多少人分享了竞争对手的内容。

不仅可以在行业内容上帮助用户了解谁在“杀四方”,还可以帮助用户发现潜在的热点话题。
5
SEMrush
关键字广告工具(付费)
SEMRush 是市场上使用最广泛的 SEO 工具,同时还具有高质量的竞争对手分析功能。

用户只需输入竞争对手网站的网址,即可立即查询其排名、流量、广告关键词和有机关键词。所有结果将以图形报告的形式清晰显示。

用户还可以使用这个工具来并排比较不同域名的数据细节,这个工具还可以帮助用户为他们的网站产生关键词想法。
6
UberSuggest
监控竞品特定关键词带来流量数据
UberSuggest 是一个标准的免费关键字监控工具。用户可以使用它来监控竞品网站的关键词详情和流量来源。
用户输入关键词,UberSuggest可以立即显示所有相关的长尾词,以及每个关键词的月搜索量和长尾、平均每次点击成本、PPC竞争和SEO竞争。


cyotekwebcopy可用硬盘空间相关问题可以做什么呢?
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-06-05 20:15
cyotek webcopy 最新版本是一款非常受用户欢迎的仿制工具。所有操作一目了然。您可以一键复制和复制您需要的网页。所有的图片、文字和链接都可以恢复。有需要的朋友欢迎到当易下载!
cyotek webcopy中文版介绍
免费的网站复制工具,用于将网站的全部或部分本地复制到硬盘,供离线查看。 webcopy 将扫描指定的网站 并将其内容下载到您的硬盘驱动器。 网站 中的样式表、图片和其他页面等资源的链接将自动重新映射以匹配本地路径。使用其广泛的配置,您可以定义网站 的哪些部分将被复制以及如何复制。
软件功能
1、支持下载网站保存到本地;
2、安全可靠,操作简单;
3、 支持正则表达式;
4、可用于离线浏览网页;
5、支持表单和密码
如何使用cyotek webcopy
1、 虽然界面是英文的,但是操作还是很简单的。在网站栏填写需要复制的网站的网址。
2、在下方的保存文件夹栏中,选择浏览器浏览为文件夹,选择网站需要保存的路径。
3、然后选择【项目】--【复制网站】,或者直接按快捷键F5开始复制项目。
4、复制过程结束后,会弹出爬取完成窗口,表示复制完成。
5、 现在我们回到我们复制网站的位置,可以看到网站文件全部复制完毕,包括css和js。用dreamweaver 8打开index.html,可以看到网站的原文件,按F12运行,发现和复制的网站一样,说明复制成功!
所需环境
windows 10,8.1,8,7, vista sp2
微软.net框架4.6
20mb 可用硬盘空间
相关问题
网络复制能做什么?
会检查网站的html标签并尝试发现所有链接的资源,例如其他页面、图片、视频、文件下载-任何东西。它将下载所有这些资源并继续搜索更多。这样,webcopy 就可以“抓取”整个网站 并下载它看到的所有内容,从而创建一个合理的网站 源传真。
网络复制不能做什么?
不包括虚拟 dom 或任何形式的 javascript 解析。如果一个网站使用大量javascript来操作,那么如果使用javascript动态生成链接,无法找到所有网站,webcopy就无法真正做到复制。
网站的原创源码没有下载,只能下载http服务器返回的内容。虽然会尽量创建网站的离线副本,但高级数据驱动的网站复制后可能无法正常工作。 查看全部
cyotekwebcopy可用硬盘空间相关问题可以做什么呢?
cyotek webcopy 最新版本是一款非常受用户欢迎的仿制工具。所有操作一目了然。您可以一键复制和复制您需要的网页。所有的图片、文字和链接都可以恢复。有需要的朋友欢迎到当易下载!
cyotek webcopy中文版介绍
免费的网站复制工具,用于将网站的全部或部分本地复制到硬盘,供离线查看。 webcopy 将扫描指定的网站 并将其内容下载到您的硬盘驱动器。 网站 中的样式表、图片和其他页面等资源的链接将自动重新映射以匹配本地路径。使用其广泛的配置,您可以定义网站 的哪些部分将被复制以及如何复制。

软件功能
1、支持下载网站保存到本地;
2、安全可靠,操作简单;
3、 支持正则表达式;
4、可用于离线浏览网页;
5、支持表单和密码
如何使用cyotek webcopy
1、 虽然界面是英文的,但是操作还是很简单的。在网站栏填写需要复制的网站的网址。

2、在下方的保存文件夹栏中,选择浏览器浏览为文件夹,选择网站需要保存的路径。

3、然后选择【项目】--【复制网站】,或者直接按快捷键F5开始复制项目。
4、复制过程结束后,会弹出爬取完成窗口,表示复制完成。
5、 现在我们回到我们复制网站的位置,可以看到网站文件全部复制完毕,包括css和js。用dreamweaver 8打开index.html,可以看到网站的原文件,按F12运行,发现和复制的网站一样,说明复制成功!
所需环境
windows 10,8.1,8,7, vista sp2
微软.net框架4.6
20mb 可用硬盘空间
相关问题
网络复制能做什么?
会检查网站的html标签并尝试发现所有链接的资源,例如其他页面、图片、视频、文件下载-任何东西。它将下载所有这些资源并继续搜索更多。这样,webcopy 就可以“抓取”整个网站 并下载它看到的所有内容,从而创建一个合理的网站 源传真。
网络复制不能做什么?
不包括虚拟 dom 或任何形式的 javascript 解析。如果一个网站使用大量javascript来操作,那么如果使用javascript动态生成链接,无法找到所有网站,webcopy就无法真正做到复制。
网站的原创源码没有下载,只能下载http服务器返回的内容。虽然会尽量创建网站的离线副本,但高级数据驱动的网站复制后可能无法正常工作。
方便制作电子书的基本操作流程及功能介绍(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-05 06:01
是一种可以在指定网页上下载某本书和某章的软件。它可以通过网络图书抓取器快速下载小说。同时软件支持断点续传功能,非常方便。有需要的可以下载。使用。
【功能介绍】
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
[软件功能]
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、Auto-retry:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好再试。
3、Stop and resume:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复抓取下次运行。注意:需要先用停止按钮中断然后退出程序,如果直接退出,将不会恢复)
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、Applicable网站:已经输入了10个适用的网站(选择后可以快速打开网站找到你需要的书),也可以自动申请相应的代码,或者申请到其他小说网站进行测试,如果合并,可以手动添加到配置文件中以备后用。
6、Easy to make e-books:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书目录带来极大的方便。
【使用方法】
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。 查看全部
方便制作电子书的基本操作流程及功能介绍(一)
是一种可以在指定网页上下载某本书和某章的软件。它可以通过网络图书抓取器快速下载小说。同时软件支持断点续传功能,非常方便。有需要的可以下载。使用。

【功能介绍】
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
[软件功能]
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、Auto-retry:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好再试。
3、Stop and resume:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复抓取下次运行。注意:需要先用停止按钮中断然后退出程序,如果直接退出,将不会恢复)
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、Applicable网站:已经输入了10个适用的网站(选择后可以快速打开网站找到你需要的书),也可以自动申请相应的代码,或者申请到其他小说网站进行测试,如果合并,可以手动添加到配置文件中以备后用。
6、Easy to make e-books:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书目录带来极大的方便。
【使用方法】
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。

三、设置保存路径,点击开始爬取开始下载。
如何采集网站论坛?优采云采集CMS整站大挪移(免费资源网站资源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-06-26 18:14
优采云采集cms整站大移移(网站论坛采集器)是一款简单易用的网站论坛采集辅助软件。如何采集网站论坛? 优采云采集cms全站大移移(免费资源网站资源图网站迅雷下载工具下载工具_在哪里下载?网站论坛采集器)方便用户使用。该工具目前包括cms采集大移移、维护王、同步更新王。你可以采集others网站和所有文章或论坛里的内容,在伪原创之后发到自己网站,你可以每天使用采集news文章,其中网站你平时买电动工具,维护网站的帖子等等。
软件亮点:
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站方案,让您彻底摆脱网站maintenance管理的繁重,优采云采集器每套软件收录采集维修王和采集大移动移,可结合以下实用功能:
您的论坛一次可以注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松达到千人在线热论坛效果(部分论坛不支持按IP统计在线人数,如DVbbs/ PHPWind);
您可以呼吸采集网站/论坛主题并回复所有内容,网站/论坛80%可以采集,支持文章内容发布前保存在本地;
支持将网站论坛A的某个版块或专栏的内容批量采集转发到您自己的网站或论坛指定版块。
软件支持以三种方式编写采集规则:UBB代码和源代码,UBB和源代码组合,最大限度地方便用户的习惯和选择;
软件可以同时批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖和回复ID分开设置,允许部分会员发布所有主题,其他会员全部回复,ID号成员选择发布;
网站内容编辑工具
支持采集任网站安全测站长工具_非常好,强烈推荐用什么工具看网站的关键词意网站dz/PW/等论坛类型东网等导入内容网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,采集的最新内容每天都会发布到指定栏目;
采集到本地内容可以在软件中任意编辑,编辑窗口可以最大化,支持自动换行,HTML预览,使用更好更方便;
支持批量替换和过滤文章内容中的文字和链接;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
本软件具有查看某某电商网站建设测评工具帖子可查看人数的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一个版块或多个版块帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以采集网站/论坛内容中的超级链接,或者屏蔽链接
您可以将采集网站/论坛中的文章图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
图片名称可以随意;
支持任务栏图标的最小化和隐藏显示;
带有采集或发帖任务完成后自动关机功能;
独有百度优化,旧帖改新帖,可有效增加采集贴的原创性,扩展至南宁网站安全测工具_破解版在线下载有利于搜索引擎收录;
您可以在标题前、标题后和内容中自动添加自己的关键词;
支持同义词替换帖子内容功能;
软件可以是采集网站需要注册登录的论坛帖子。
查看全部
如何采集网站论坛?优采云采集CMS整站大挪移(免费资源网站资源)
优采云采集cms整站大移移(网站论坛采集器)是一款简单易用的网站论坛采集辅助软件。如何采集网站论坛? 优采云采集cms全站大移移(免费资源网站资源图网站迅雷下载工具下载工具_在哪里下载?网站论坛采集器)方便用户使用。该工具目前包括cms采集大移移、维护王、同步更新王。你可以采集others网站和所有文章或论坛里的内容,在伪原创之后发到自己网站,你可以每天使用采集news文章,其中网站你平时买电动工具,维护网站的帖子等等。
软件亮点:
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站方案,让您彻底摆脱网站maintenance管理的繁重,优采云采集器每套软件收录采集维修王和采集大移动移,可结合以下实用功能:
您的论坛一次可以注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松达到千人在线热论坛效果(部分论坛不支持按IP统计在线人数,如DVbbs/ PHPWind);
您可以呼吸采集网站/论坛主题并回复所有内容,网站/论坛80%可以采集,支持文章内容发布前保存在本地;
支持将网站论坛A的某个版块或专栏的内容批量采集转发到您自己的网站或论坛指定版块。
软件支持以三种方式编写采集规则:UBB代码和源代码,UBB和源代码组合,最大限度地方便用户的习惯和选择;
软件可以同时批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖和回复ID分开设置,允许部分会员发布所有主题,其他会员全部回复,ID号成员选择发布;
网站内容编辑工具
支持采集任网站安全测站长工具_非常好,强烈推荐用什么工具看网站的关键词意网站dz/PW/等论坛类型东网等导入内容网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,采集的最新内容每天都会发布到指定栏目;
采集到本地内容可以在软件中任意编辑,编辑窗口可以最大化,支持自动换行,HTML预览,使用更好更方便;
支持批量替换和过滤文章内容中的文字和链接;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
本软件具有查看某某电商网站建设测评工具帖子可查看人数的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一个版块或多个版块帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以采集网站/论坛内容中的超级链接,或者屏蔽链接
您可以将采集网站/论坛中的文章图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
图片名称可以随意;
支持任务栏图标的最小化和隐藏显示;
带有采集或发帖任务完成后自动关机功能;
独有百度优化,旧帖改新帖,可有效增加采集贴的原创性,扩展至南宁网站安全测工具_破解版在线下载有利于搜索引擎收录;
您可以在标题前、标题后和内容中自动添加自己的关键词;
支持同义词替换帖子内容功能;
软件可以是采集网站需要注册登录的论坛帖子。
https://www.u9seo.com/wp-conte ... 3.png 300w" />https://www.u9seo.com/wp-conte ... 3.png 300w" /> ProxyCrawl使用Proxy.js网页工具可免费获得1000个请求
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-06-23 03:23
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持,验证码绕过,基于动态内容抓取页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到百万页面的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不需要写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。 查看全部
ProxyCrawl使用Proxy.js网页工具可免费获得1000个请求
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持,验证码绕过,基于动态内容抓取页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到百万页面的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不需要写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
文档介绍:优采云·云采集服务平台详细介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-06-23 03:16
文档介绍:优采云·云采集服务平台uationWarning:ThedocumentwascreatedwithSpire..网站data capture tool 近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也出现了快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。 1、优采云优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。需要数据。它采集data分为两步,一是采集data,二是发布数据。这两个过程可以分开。 采集Data:这包括采集 URL 和采集 内容。这个过程就是获取数据的过程。用户制定规则,内容在采集过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。 优采云采集器采用分布式采集系统。为了提高采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量网址,也可以生成。对于不会编程的新手用户,可以直接使用别人制定的规则,高手可以自定义开发,也可以分享制定的规则。
2、优采云优采云是优采云之后出现的采集器,可以从不同的网站获取标准化数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。简单来说,优采云可以通过简单的配置规则,从任何网页准确抓取数据,生成自定义的、规则的数据格式。国内首创的真正可视化规则、简单上手、完全可视化图形操作的国内定制采集器; 采集任务自动运行,可按指定周期自动采集;规则市场有大量免费规则,用户可直接使用;支持验证码识别,自定义不同浏览器标识,有效防止IP被封。 优采云可以说是小白用户的福音(简单好用,好找,可视化界面,易学易模仿),有更好的地方就用积分。用1000积分完善信息,每天签到30积分,在线制定规则或购买规则,剩下的足以获得初始采集,如果您不充值一些积分,您可以在需求,导出excel,数据库都行。 3、优采云云攀虫 新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网页数据。操作步骤:购买规则-设置关键词-启动任务-自动云采集-自动发布不同于传统的采集器,优采云云爬虫不需要配置采集进程。 优采云云攀虫的规则市场提供了大量免费的采集模板,只需设置关键词即可。
爬虫任务全程在云端执行,无需开机。 采集结果可以自动发布到多个网站(目前支持wecenter、wordpree、discuz等)。开发者可自行编写采集规则出售或使用。有了详细的开发人员文档,他们就可以创建自己的爬虫。相关采集tutorial:网易彩票数据采集orial/hottutorial/jrzx/wycaipiao同花顺爬虫orial/hottutorial/jrzx/tonghuashun金融世界基金爬虫orial/hottutorial/jrzx/ji 查看全部
文档介绍:优采云·云采集服务平台详细介绍
文档介绍:优采云·云采集服务平台uationWarning:ThedocumentwascreatedwithSpire..网站data capture tool 近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也出现了快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。 1、优采云优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。需要数据。它采集data分为两步,一是采集data,二是发布数据。这两个过程可以分开。 采集Data:这包括采集 URL 和采集 内容。这个过程就是获取数据的过程。用户制定规则,内容在采集过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。 优采云采集器采用分布式采集系统。为了提高采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量网址,也可以生成。对于不会编程的新手用户,可以直接使用别人制定的规则,高手可以自定义开发,也可以分享制定的规则。
2、优采云优采云是优采云之后出现的采集器,可以从不同的网站获取标准化数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。简单来说,优采云可以通过简单的配置规则,从任何网页准确抓取数据,生成自定义的、规则的数据格式。国内首创的真正可视化规则、简单上手、完全可视化图形操作的国内定制采集器; 采集任务自动运行,可按指定周期自动采集;规则市场有大量免费规则,用户可直接使用;支持验证码识别,自定义不同浏览器标识,有效防止IP被封。 优采云可以说是小白用户的福音(简单好用,好找,可视化界面,易学易模仿),有更好的地方就用积分。用1000积分完善信息,每天签到30积分,在线制定规则或购买规则,剩下的足以获得初始采集,如果您不充值一些积分,您可以在需求,导出excel,数据库都行。 3、优采云云攀虫 新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网页数据。操作步骤:购买规则-设置关键词-启动任务-自动云采集-自动发布不同于传统的采集器,优采云云爬虫不需要配置采集进程。 优采云云攀虫的规则市场提供了大量免费的采集模板,只需设置关键词即可。
爬虫任务全程在云端执行,无需开机。 采集结果可以自动发布到多个网站(目前支持wecenter、wordpree、discuz等)。开发者可自行编写采集规则出售或使用。有了详细的开发人员文档,他们就可以创建自己的爬虫。相关采集tutorial:网易彩票数据采集orial/hottutorial/jrzx/wycaipiao同花顺爬虫orial/hottutorial/jrzx/tonghuashun金融世界基金爬虫orial/hottutorial/jrzx/ji
网页抓取工具大数据行业的蓬勃发展引发了各行各业强烈需求
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-22 23:03
网页抓取工具大数据行业的蓬勃发展引发了各行各业强烈需求
网页抓取工具对于大数据工作至关重要。大数据产业的蓬勃发展,引发了各行各业对大数据人才的强烈需求。想要尝试高端大数据岗位,必须具备以下技能,才能得心应手完成工作指标——大数据基础开发。大数据的基础发展主要包括数据采集、数据处理和分类存储。对于海量数据的采集,需要考虑的是采集的实时准确度和完整性。用于数据处理和存储的主要目的是及时更新重新删除过滤等基础开发中常用的网络爬虫工具。 优采云采集器 是必备工具之一。通过对网页结构的简单分析和相关规则的配置优采云采集器能确保采集高效稳定的进行,并拥有自身强大的数据处理系统和多库发布存储功能,大数据的基础开发可以在一个工具中顺利完成。值得一提的是,优采云采集器的智能化和自动化大大降低了对操作人员的技术要求。不再需要花费大量精力为不同的网页编写不同的程序。使用全网通用的网络爬虫工具,操作简单。 2. 数据分析。数据分析师需要对现有数据进行数据分析。统计分析结合现有业务,发现一些规律和趋势,那么数据分析报告肯定是需要的。当数据量很大时,会涉及到集群环境下的分析。这就要求分析师熟悉SQL,需要对数据有深刻的理解。解释能力可以分析和解释某些现象的成因。同时,需要针对这些问题提出一些可能的解决方案,利用分类聚类、个性化推荐等常用的数据挖掘技术和算法服务于业务系统,从而影响业务战略或业务方向。还有更多的指导。当然,这也需要分析师具体而丰富的专业知识。例如,金融等领域的数据挖掘需要丰富的金融经验作为分析的基础。这里的重点是两大方向的数据相关细分。岗位多种多样,只有充分掌握技能,才能高效完成任务。搞大数据岗位一定要多学点工具,多读书,适应瞬息万变的市场环境和行业需求 查看全部
网页抓取工具大数据行业的蓬勃发展引发了各行各业强烈需求
网页抓取工具对于大数据工作至关重要。大数据产业的蓬勃发展,引发了各行各业对大数据人才的强烈需求。想要尝试高端大数据岗位,必须具备以下技能,才能得心应手完成工作指标——大数据基础开发。大数据的基础发展主要包括数据采集、数据处理和分类存储。对于海量数据的采集,需要考虑的是采集的实时准确度和完整性。用于数据处理和存储的主要目的是及时更新重新删除过滤等基础开发中常用的网络爬虫工具。 优采云采集器 是必备工具之一。通过对网页结构的简单分析和相关规则的配置优采云采集器能确保采集高效稳定的进行,并拥有自身强大的数据处理系统和多库发布存储功能,大数据的基础开发可以在一个工具中顺利完成。值得一提的是,优采云采集器的智能化和自动化大大降低了对操作人员的技术要求。不再需要花费大量精力为不同的网页编写不同的程序。使用全网通用的网络爬虫工具,操作简单。 2. 数据分析。数据分析师需要对现有数据进行数据分析。统计分析结合现有业务,发现一些规律和趋势,那么数据分析报告肯定是需要的。当数据量很大时,会涉及到集群环境下的分析。这就要求分析师熟悉SQL,需要对数据有深刻的理解。解释能力可以分析和解释某些现象的成因。同时,需要针对这些问题提出一些可能的解决方案,利用分类聚类、个性化推荐等常用的数据挖掘技术和算法服务于业务系统,从而影响业务战略或业务方向。还有更多的指导。当然,这也需要分析师具体而丰富的专业知识。例如,金融等领域的数据挖掘需要丰富的金融经验作为分析的基础。这里的重点是两大方向的数据相关细分。岗位多种多样,只有充分掌握技能,才能高效完成任务。搞大数据岗位一定要多学点工具,多读书,适应瞬息万变的市场环境和行业需求
如何帮助用户快速采集网上的小说,将TXT小说下载
网站优化 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2021-06-22 22:42
在线图书抓取器可以帮助用户快速采集网上的小说,将TXT小说下载到电脑上阅读,适合喜欢看小说的朋友,现在很多用户喜欢在网上看小说并进入直接在浏览器中搜索小说就可以在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址即可立即抓取目录,并自动下载目录采集对应的章节内容,完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!
软件功能
1、网络书Grabber支持网站大部分,轻松下载小说资源
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示运行步骤,可参考网络书grabber采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中
6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。
7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
查看全部
如何帮助用户快速采集网上的小说,将TXT小说下载
在线图书抓取器可以帮助用户快速采集网上的小说,将TXT小说下载到电脑上阅读,适合喜欢看小说的朋友,现在很多用户喜欢在网上看小说并进入直接在浏览器中搜索小说就可以在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址即可立即抓取目录,并自动下载目录采集对应的章节内容,完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!
软件功能
1、网络书Grabber支持网站大部分,轻松下载小说资源
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示运行步骤,可参考网络书grabber采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中
6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。
7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
网站内容抓取工具小编带你了解内容的工具清单
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-06-21 21:02
网站内容抓取工具小编给大家整理了一份用于内容抓取的工具清单,本文将会为大家进行一些简单的介绍。选择一个工具,我们都会经历以下五个过程:简单使用想深入了解一个工具什么的,简单使用是必须的。工具是一个个实践摸索出来的,同样工具更新迭代,正是可以提高我们的效率的关键。给大家介绍一下抓取网站的具体步骤。1.选择自己想要抓取的站点列表里最常用的会有哪些站点?一线城市肯定就是北上广深,二线城市肯定有成都、青岛、厦门、广州等二线以下城市。
下面会举例来说明。每个时间段抓取哪些站点每天会更新什么内容,清楚了之后就可以集中精力去找更好的抓取工具。很多人问过我这个问题,常常在后台问,也会经常有人向我咨询,其实这类问题大多只需要看网站分析工具的抓取列表就可以非常清楚,例如“网站抓取工具排行榜”,一眼就能看出来哪个工具更好用,哪个更便宜等。选择一个工具时是否必须进行爬虫,最大的关键点,就是模拟浏览器去操作这个网站,如果是页面排版规范,那我们就无需进行爬虫操作,即便是那些个性化要求很高的网站,也可以使用该工具进行自动抓取。
个人觉得一个现代的工具能不能为我们提供更多的便利,其实还在于:怎么去利用网站工具?掌握了该工具,如何开始抓取,是我们今天讨论的重点。2.准备好相关工具工欲善其事必先利其器,下面我们列举一些抓取工具,给大家做做参考。自动化代码抓取工具google的pagespread(extremetouch),有两个维度抓取不同网站的内容;limitr代理站点抓取工具reallocation,https代理插件,抓取请求时会帮你过滤,避免post的图片过于大,而导致第一次被拒绝抓取。
mockitoweb代理抓取工具抓取https代理ftp抓取工具抓取ftp、filetools文件抓取工具抓取https/https代理在这个抓取工具列表的第一位,分别抓取了donehill、plectau、frankfine、iweb的内容,包括页面源代码和页面div标签,源代码标签抓取到后自动转换成js文件。
还有jinjajs抓取工具,抓取目标php的代码;ip查询工具track.php,抓取内容前将发送到工具后台,记录抓取时间,然后再抓取下载失败时间、抓取返回结果等信息。数据库存储抓取工具就是整个页面的内容通过这个工具进行数据抓取,整个内容抓取结束后,工具会将抓取的内容打印到数据库。这个工具一般用sqlserver来整理、生成数据库的windows、mysql的密码。
3.集中精力开始抓取header防止内容泄露metasploit利用xor检测302跳转,创建proxy,成功metasploitmetasploitmetasploitmetasploit,。 查看全部
网站内容抓取工具小编带你了解内容的工具清单
网站内容抓取工具小编给大家整理了一份用于内容抓取的工具清单,本文将会为大家进行一些简单的介绍。选择一个工具,我们都会经历以下五个过程:简单使用想深入了解一个工具什么的,简单使用是必须的。工具是一个个实践摸索出来的,同样工具更新迭代,正是可以提高我们的效率的关键。给大家介绍一下抓取网站的具体步骤。1.选择自己想要抓取的站点列表里最常用的会有哪些站点?一线城市肯定就是北上广深,二线城市肯定有成都、青岛、厦门、广州等二线以下城市。
下面会举例来说明。每个时间段抓取哪些站点每天会更新什么内容,清楚了之后就可以集中精力去找更好的抓取工具。很多人问过我这个问题,常常在后台问,也会经常有人向我咨询,其实这类问题大多只需要看网站分析工具的抓取列表就可以非常清楚,例如“网站抓取工具排行榜”,一眼就能看出来哪个工具更好用,哪个更便宜等。选择一个工具时是否必须进行爬虫,最大的关键点,就是模拟浏览器去操作这个网站,如果是页面排版规范,那我们就无需进行爬虫操作,即便是那些个性化要求很高的网站,也可以使用该工具进行自动抓取。
个人觉得一个现代的工具能不能为我们提供更多的便利,其实还在于:怎么去利用网站工具?掌握了该工具,如何开始抓取,是我们今天讨论的重点。2.准备好相关工具工欲善其事必先利其器,下面我们列举一些抓取工具,给大家做做参考。自动化代码抓取工具google的pagespread(extremetouch),有两个维度抓取不同网站的内容;limitr代理站点抓取工具reallocation,https代理插件,抓取请求时会帮你过滤,避免post的图片过于大,而导致第一次被拒绝抓取。
mockitoweb代理抓取工具抓取https代理ftp抓取工具抓取ftp、filetools文件抓取工具抓取https/https代理在这个抓取工具列表的第一位,分别抓取了donehill、plectau、frankfine、iweb的内容,包括页面源代码和页面div标签,源代码标签抓取到后自动转换成js文件。
还有jinjajs抓取工具,抓取目标php的代码;ip查询工具track.php,抓取内容前将发送到工具后台,记录抓取时间,然后再抓取下载失败时间、抓取返回结果等信息。数据库存储抓取工具就是整个页面的内容通过这个工具进行数据抓取,整个内容抓取结束后,工具会将抓取的内容打印到数据库。这个工具一般用sqlserver来整理、生成数据库的windows、mysql的密码。
3.集中精力开始抓取header防止内容泄露metasploit利用xor检测302跳转,创建proxy,成功metasploitmetasploitmetasploitmetasploit,。
diggbt磁力链接搜索下载浏览人数已达到103067,实际体验
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-06-21 18:15
diggbt 磁力链接搜索下载网站简介
DiggBT-专注于从 DHT 网络中获取 BT 种子和磁力链接。目前已收录数千万条BT种子元信息(metainfo)。是全宇宙最丰富的BT种子搜索下载和磁力链接下载专业。 网站,您可以在这里搜索下载电影、剧集、音乐、书籍、图片、综艺、软件、动画、教程、游戏等资源。 DiggBT可以说是BT种子搜索神器、P2P种子搜索神器、万能BT种子搜索下载神器、磁力链接搜索下载神器。本站本身不存储和提供BT种子下载,只提供从DHT网络抓取的磁力链接和网站提供的其他下载链接。资源猫编辑器浏览此网站时,页面干净美观,欢迎感兴趣的用户访问体验!
diggbt 磁力链接搜索下载数据评测
diggbt磁力链接搜索下载访问量已达103067,如需查询本站相关权重信息,可点击“爱站数据”“Chinaz数据”进入;参考目前网站数据,建议你参考爱站数据,更多网站价值评价因素如:diggbt磁力链接搜索下载的访问速度,搜索引擎收录和索引量,用户经验等;当然,一个站的价值是要评估的,最主要的还是要根据自己的需要和需求,一些具体的数据需要和diggbt磁力链接搜索下载的站长协商。比如网站的IP、PV、跳出率等!
关于diggbt磁力链接搜索和下载的特别声明 查看全部
diggbt磁力链接搜索下载浏览人数已达到103067,实际体验
diggbt 磁力链接搜索下载网站简介
DiggBT-专注于从 DHT 网络中获取 BT 种子和磁力链接。目前已收录数千万条BT种子元信息(metainfo)。是全宇宙最丰富的BT种子搜索下载和磁力链接下载专业。 网站,您可以在这里搜索下载电影、剧集、音乐、书籍、图片、综艺、软件、动画、教程、游戏等资源。 DiggBT可以说是BT种子搜索神器、P2P种子搜索神器、万能BT种子搜索下载神器、磁力链接搜索下载神器。本站本身不存储和提供BT种子下载,只提供从DHT网络抓取的磁力链接和网站提供的其他下载链接。资源猫编辑器浏览此网站时,页面干净美观,欢迎感兴趣的用户访问体验!
diggbt 磁力链接搜索下载数据评测
diggbt磁力链接搜索下载访问量已达103067,如需查询本站相关权重信息,可点击“爱站数据”“Chinaz数据”进入;参考目前网站数据,建议你参考爱站数据,更多网站价值评价因素如:diggbt磁力链接搜索下载的访问速度,搜索引擎收录和索引量,用户经验等;当然,一个站的价值是要评估的,最主要的还是要根据自己的需要和需求,一些具体的数据需要和diggbt磁力链接搜索下载的站长协商。比如网站的IP、PV、跳出率等!
关于diggbt磁力链接搜索和下载的特别声明
搜索引擎蜘蛛抓取频次的重要性和增量是什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-21 00:29
爬取频率是搜索引擎蜘蛛在单位时间内访问网站的次数。比如百度站长工具的内容中看到的爬取频率是按天算的,那么数据中的爬取频率都是每天的爬取频率。
抓取频率的重要性
抓取频率越高,搜索引擎找到网站内容的速度就越快;高抓取频率是保证内容原创权益的重要因素,可以保证在第一次搜索引擎抓取之前,内容就被抄袭和转发。
加速内容的发现速度在一定程度上对内容的收录速度和收录率有一定的影响;但是,爬取频率高并不代表网站的收录会更好,也不是绝对的关系。
抓取频率的构成
爬取频率分为增量爬取和更新爬取两部分。增量爬取是指搜索引擎爬取网站待爬取的收录内容;而更新爬取是指定期爬取已经收录的内容,检查页面是否更新。两种类型的爬取频率之和为爬取频率。
而网站更新爬取频率主要取决于网站的内容,比如文章咨询网站,更新爬取频率就比较小,因为文章一旦发帖修改的概率就很低了相反,例如,信息和新闻网站的内容具有很强的时效性。为了及时获取这些有价值的更新,此类网站的抓取频率会比较高。
增量爬取的频率取决于网站的内容质量和更新频率。 网站内容的质量值是直接决定搜索引擎蜘蛛是否会爬行的主要因素。如果长时间提交低质量的内容,会出现严重降级导致蜘蛛爬不起来的情况。在保证内容质量的前提下,增加内容量和创作频率可以逐步培养蜘蛛爬行。
抓取频率控制
抓取频率不是越高越好。对于网站来说,只要新内容能被蜘蛛及时抓取,过高的抓取频率会对服务器造成额外压力,影响网站稳定性,影响用户访问体验。
对于一些优质网站,用户量非常大,每日内容的增加量也非常大。需要特别注意内容的分时提交,避免大量内容的集中提交,可能导致搜索引擎蜘蛛在某个时间出现大规模的爬取行为,造成@的稳定性k14@ 波动。如果爬取频率还是太高,可以在搜索引擎后台设置蜘蛛爬取上限。 查看全部
搜索引擎蜘蛛抓取频次的重要性和增量是什么
爬取频率是搜索引擎蜘蛛在单位时间内访问网站的次数。比如百度站长工具的内容中看到的爬取频率是按天算的,那么数据中的爬取频率都是每天的爬取频率。
抓取频率的重要性
抓取频率越高,搜索引擎找到网站内容的速度就越快;高抓取频率是保证内容原创权益的重要因素,可以保证在第一次搜索引擎抓取之前,内容就被抄袭和转发。
加速内容的发现速度在一定程度上对内容的收录速度和收录率有一定的影响;但是,爬取频率高并不代表网站的收录会更好,也不是绝对的关系。
抓取频率的构成
爬取频率分为增量爬取和更新爬取两部分。增量爬取是指搜索引擎爬取网站待爬取的收录内容;而更新爬取是指定期爬取已经收录的内容,检查页面是否更新。两种类型的爬取频率之和为爬取频率。
而网站更新爬取频率主要取决于网站的内容,比如文章咨询网站,更新爬取频率就比较小,因为文章一旦发帖修改的概率就很低了相反,例如,信息和新闻网站的内容具有很强的时效性。为了及时获取这些有价值的更新,此类网站的抓取频率会比较高。
增量爬取的频率取决于网站的内容质量和更新频率。 网站内容的质量值是直接决定搜索引擎蜘蛛是否会爬行的主要因素。如果长时间提交低质量的内容,会出现严重降级导致蜘蛛爬不起来的情况。在保证内容质量的前提下,增加内容量和创作频率可以逐步培养蜘蛛爬行。
抓取频率控制
抓取频率不是越高越好。对于网站来说,只要新内容能被蜘蛛及时抓取,过高的抓取频率会对服务器造成额外压力,影响网站稳定性,影响用户访问体验。
对于一些优质网站,用户量非常大,每日内容的增加量也非常大。需要特别注意内容的分时提交,避免大量内容的集中提交,可能导致搜索引擎蜘蛛在某个时间出现大规模的爬取行为,造成@的稳定性k14@ 波动。如果爬取频率还是太高,可以在搜索引擎后台设置蜘蛛爬取上限。
diggbt磁力链接搜索下载浏览人数已达到103045,实际体验
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-06-21 00:21
diggbt Magnet Link 搜索下载网站简介
DiggBT-专注于从 DHT 网络中获取 BT 种子和磁力链接。目前已收录数千万条BT种子元信息(metainfo)。是全宇宙最丰富的BT种子搜索下载和磁力链接下载专业。 网站,您可以在这里搜索下载电影、剧集、音乐、书籍、图片、综艺、软件、动画、教程、游戏等资源。 DiggBT可以说是BT种子搜索神器、P2P种子搜索神器、万能BT种子搜索下载神器、磁力链接搜索下载神器。本站本身不存储和提供BT种子下载,只提供从DHT网络抓取的磁力链接和网站提供的其他下载链接。资源猫编辑器浏览此网站时,页面整洁美观,欢迎感兴趣的用户访问体验!
diggbt 磁力链接搜索下载数据评测
diggbt 搜索和下载的浏览者数量已达到 103,045。如需查询本站相关权重信息,可点击“爱站数据”“Chinaz数据”进入;参考目前网站数据,建议你参考爱站数据,更多网站价值评价因素如:diggbt磁力链接搜索下载的访问速度,搜索引擎收录和索引量,用户经验等;当然,一个站的价值是要评估的,最重要的还是要根据自己的需要和需求,一些具体的数据需要和diggbt磁力链接搜索下载的站长协商和提供。 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?比如网站的IP、PV、跳出率等!
关于diggbt磁力链接搜索和下载的特别声明 查看全部
diggbt磁力链接搜索下载浏览人数已达到103045,实际体验
diggbt Magnet Link 搜索下载网站简介
DiggBT-专注于从 DHT 网络中获取 BT 种子和磁力链接。目前已收录数千万条BT种子元信息(metainfo)。是全宇宙最丰富的BT种子搜索下载和磁力链接下载专业。 网站,您可以在这里搜索下载电影、剧集、音乐、书籍、图片、综艺、软件、动画、教程、游戏等资源。 DiggBT可以说是BT种子搜索神器、P2P种子搜索神器、万能BT种子搜索下载神器、磁力链接搜索下载神器。本站本身不存储和提供BT种子下载,只提供从DHT网络抓取的磁力链接和网站提供的其他下载链接。资源猫编辑器浏览此网站时,页面整洁美观,欢迎感兴趣的用户访问体验!
diggbt 磁力链接搜索下载数据评测
diggbt 搜索和下载的浏览者数量已达到 103,045。如需查询本站相关权重信息,可点击“爱站数据”“Chinaz数据”进入;参考目前网站数据,建议你参考爱站数据,更多网站价值评价因素如:diggbt磁力链接搜索下载的访问速度,搜索引擎收录和索引量,用户经验等;当然,一个站的价值是要评估的,最重要的还是要根据自己的需要和需求,一些具体的数据需要和diggbt磁力链接搜索下载的站长协商和提供。 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?比如网站的IP、PV、跳出率等!
关于diggbt磁力链接搜索和下载的特别声明
深圳网站建设:如何控制好“无限空间”的桥梁
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-06-20 06:02
网址就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的网址) 如果你的 URL 很复杂或者很长,爬虫就不得不花时间反复跟踪这些 URL;如果您的 URL 是常规的并且直接指向您的独特内容,那么抓取工具可以专注于理解您的内容,而不是仅仅抓取空网页或被不同的 URL 引导,最终抓取的是相同的重复内容。
一些帮助爬虫更快更好地找到你的内容的建议,深圳网站建认为主要包括:
1、去掉URL中用户相关的参数
URL 中不影响网页内容的参数——如 sessionID 或排序参数——可以从 URL 中移除并由 cookie 记录。通过将这些信息添加到 cookie 中,然后 301 定向到一个“干净”的 URL,您可以保留原创内容并减少指向相同内容的 URL 数量。
2、控制无限空间
你的网站上有日历吗,上面的链接指向无数过去和未来的日期(每个链接地址都是唯一的二)?你的网页地址是不是加了一个 &page=3563 参数后,你可以还是返回200码,就算根本没有那么多页面?这样的话,你的网站就会出现所谓的“无限空间”,会浪费爬虫机器人和你的@带宽k14@.如何控制“无限空间”,请参考这里的一些技巧。
3、防止 Google 抓取工具抓取它们无法处理的页面
通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系信息、购物车和其他爬虫无法处理的页面被抓取。 (爬行动物以吝啬和害羞着称,所以一般不会“添加商品到购物车”或“联系我们”)。通过这种方式,您可以让爬虫花更多的时间在您的网站 上爬取他们可以处理的内容。
4、一个网址,一段内容
在理想世界中,深圳网站construction 认为 URL 和内容是一一对应的:每个 URL 对应一个唯一的内容,每个内容只能通过唯一网址。越接近这种理想情况,您的网站 就越容易被捕获,收录 也就越容易被捕获。如果您的内容管理系统或当前的网站 机构难以实施,您可以尝试使用 rel=canonical 元素来设置您要用于指示特定内容的 URL。 查看全部
深圳网站建设:如何控制好“无限空间”的桥梁
网址就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的网址) 如果你的 URL 很复杂或者很长,爬虫就不得不花时间反复跟踪这些 URL;如果您的 URL 是常规的并且直接指向您的独特内容,那么抓取工具可以专注于理解您的内容,而不是仅仅抓取空网页或被不同的 URL 引导,最终抓取的是相同的重复内容。
一些帮助爬虫更快更好地找到你的内容的建议,深圳网站建认为主要包括:
1、去掉URL中用户相关的参数
URL 中不影响网页内容的参数——如 sessionID 或排序参数——可以从 URL 中移除并由 cookie 记录。通过将这些信息添加到 cookie 中,然后 301 定向到一个“干净”的 URL,您可以保留原创内容并减少指向相同内容的 URL 数量。
2、控制无限空间
你的网站上有日历吗,上面的链接指向无数过去和未来的日期(每个链接地址都是唯一的二)?你的网页地址是不是加了一个 &page=3563 参数后,你可以还是返回200码,就算根本没有那么多页面?这样的话,你的网站就会出现所谓的“无限空间”,会浪费爬虫机器人和你的@带宽k14@.如何控制“无限空间”,请参考这里的一些技巧。
3、防止 Google 抓取工具抓取它们无法处理的页面
通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系信息、购物车和其他爬虫无法处理的页面被抓取。 (爬行动物以吝啬和害羞着称,所以一般不会“添加商品到购物车”或“联系我们”)。通过这种方式,您可以让爬虫花更多的时间在您的网站 上爬取他们可以处理的内容。
4、一个网址,一段内容
在理想世界中,深圳网站construction 认为 URL 和内容是一一对应的:每个 URL 对应一个唯一的内容,每个内容只能通过唯一网址。越接近这种理想情况,您的网站 就越容易被捕获,收录 也就越容易被捕获。如果您的内容管理系统或当前的网站 机构难以实施,您可以尝试使用 rel=canonical 元素来设置您要用于指示特定内容的 URL。
webscrapermac破解版安装教程,轻松地扫描和屏幕网站
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-20 05:28
WebScraper Mac 版是 MacOS 上的 网站content 捕获工具。你只需要指定需要采集的网站地址和需要什么内容采集输出提取的数据(当前)为CSV或JSON,将图片下载到文件夹中。这次为大家带来的是webscraper mac 破解版,不受功能和时间限制。您可以轻松使用该软件的所有功能。欢迎喜欢的朋友下载体验。
Webscraper mac 破解版安装教程
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:
2、返回安装包,双击打开WebScraper注册机,如图:
3、点击WebScraper注册机左侧的Open,如图:
4、在应用中找到WebScraper,点击打开,如图:
5、点击保存生成注册码!
6、Open WebScraper,显示已注册!
您不是VIP会员或积分不足,请升级VIP会员或充值观看教程。
Webscraper mac 破解版软件介绍
WebScraper for Mac 是 Mac 平台上的一个简单应用程序,可将数据导出为 JSON 或 CSV。 Mac 版的 WebScraper 可以快速提取与网页相关的信息(包括文本内容)。适用于 Mac 的 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
Webscraper mac 破解版软件特点
快速轻松地扫描和截屏网站
原生 MacOS 应用程序可以在您的桌面上运行
提取数据的方法有很多种;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
易于导出数据-选择所需的列
输出数据为csv或json
将所有图像下载到文件夹/采集并导出所有链接的选项
输出单个文本文件的选项(用于存档文本内容、markdown 或纯文本)
丰富的选项/配置
系统要求
当前版本需要 Mac OS 10.8 或更高版本
WebScraper Mac 更新日志
添加扫描时下载pdf文件并将其保存到文件夹的选项。 查看全部
webscrapermac破解版安装教程,轻松地扫描和屏幕网站
WebScraper Mac 版是 MacOS 上的 网站content 捕获工具。你只需要指定需要采集的网站地址和需要什么内容采集输出提取的数据(当前)为CSV或JSON,将图片下载到文件夹中。这次为大家带来的是webscraper mac 破解版,不受功能和时间限制。您可以轻松使用该软件的所有功能。欢迎喜欢的朋友下载体验。
Webscraper mac 破解版安装教程
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:
2、返回安装包,双击打开WebScraper注册机,如图:
3、点击WebScraper注册机左侧的Open,如图:
4、在应用中找到WebScraper,点击打开,如图:
5、点击保存生成注册码!
6、Open WebScraper,显示已注册!
您不是VIP会员或积分不足,请升级VIP会员或充值观看教程。
Webscraper mac 破解版软件介绍
WebScraper for Mac 是 Mac 平台上的一个简单应用程序,可将数据导出为 JSON 或 CSV。 Mac 版的 WebScraper 可以快速提取与网页相关的信息(包括文本内容)。适用于 Mac 的 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
Webscraper mac 破解版软件特点
快速轻松地扫描和截屏网站
原生 MacOS 应用程序可以在您的桌面上运行
提取数据的方法有很多种;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
易于导出数据-选择所需的列
输出数据为csv或json
将所有图像下载到文件夹/采集并导出所有链接的选项
输出单个文本文件的选项(用于存档文本内容、markdown 或纯文本)
丰富的选项/配置
系统要求
当前版本需要 Mac OS 10.8 或更高版本
WebScraper Mac 更新日志
添加扫描时下载pdf文件并将其保存到文件夹的选项。
网页文字抓取工具提供文字识别功能,方便用户复制使用
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-06-19 19:33
网页文字抓取工具提供文字识别功能,可以直接识别网页上的所有文字,然后抓取并显示在软件上,方便用户复制使用。相信很多用户都遇到过一些无法复制的网页。设置权限后,不能直接复制网页内容。如果需要使用网页上的文字,可以选择这款爬虫软件。本软件可以直接抓取整个网页的文字内容复制使用。该软件只能抓取文本内容,自动过滤网页上的图片,让用户快速获取自己需要的文本内容,对需要复制网页内容的朋友很有帮助,有需要的朋友可以下载!
软件功能
1、网页文字抓取工具提供简单的文字抓取方法
2、 只要输入网页地址就可以抓取了。识别能力很强。
3、可以正常识别中英文内容
4、可以按照网页布局格式展示抓取的内容
5、快速过滤图片,避免干扰图片内容
6、 普通网页内容显示,可以在软件左侧查看添加的网页内容
软件功能
1、网页文字爬虫适合经常在网络上使用采集resources的朋友
2、也适合自媒体,快速复制其他网站内容
3、如果遇到加密网页。您可以通过本软件复制内容
4、网页文字抓取工具免费使用,轻松将内容保存为TXT
5、也支持复制到粘贴板使用,右侧也可以修改内容
如何使用
1、打开网页抓图工具.exe显示软件的所有功能,可以在这里添加地址
2、点击文字抓取功能立即识别网页内容并在软件右侧显示文字
3、 如图,文本内容可以直接复制,也可以修改,对比一下内容是否有错误。
4、软件会自动过滤图片内容,只识别网页文字,无法识别图片文字
5、这里是导出功能。识别网页内容后,可以保存到TXT
6、列表导出成功!数据存放在软件目录下的wenzi.txt文件中
7、显示复制功能,可以在软件界面将右侧的所有内容复制到粘贴板,并且可以选择一段进行复制
查看全部
网页文字抓取工具提供文字识别功能,方便用户复制使用
网页文字抓取工具提供文字识别功能,可以直接识别网页上的所有文字,然后抓取并显示在软件上,方便用户复制使用。相信很多用户都遇到过一些无法复制的网页。设置权限后,不能直接复制网页内容。如果需要使用网页上的文字,可以选择这款爬虫软件。本软件可以直接抓取整个网页的文字内容复制使用。该软件只能抓取文本内容,自动过滤网页上的图片,让用户快速获取自己需要的文本内容,对需要复制网页内容的朋友很有帮助,有需要的朋友可以下载!
软件功能
1、网页文字抓取工具提供简单的文字抓取方法
2、 只要输入网页地址就可以抓取了。识别能力很强。
3、可以正常识别中英文内容
4、可以按照网页布局格式展示抓取的内容
5、快速过滤图片,避免干扰图片内容
6、 普通网页内容显示,可以在软件左侧查看添加的网页内容
软件功能
1、网页文字爬虫适合经常在网络上使用采集resources的朋友
2、也适合自媒体,快速复制其他网站内容
3、如果遇到加密网页。您可以通过本软件复制内容
4、网页文字抓取工具免费使用,轻松将内容保存为TXT
5、也支持复制到粘贴板使用,右侧也可以修改内容
如何使用
1、打开网页抓图工具.exe显示软件的所有功能,可以在这里添加地址
2、点击文字抓取功能立即识别网页内容并在软件右侧显示文字
3、 如图,文本内容可以直接复制,也可以修改,对比一下内容是否有错误。
4、软件会自动过滤图片内容,只识别网页文字,无法识别图片文字
5、这里是导出功能。识别网页内容后,可以保存到TXT
6、列表导出成功!数据存放在软件目录下的wenzi.txt文件中
7、显示复制功能,可以在软件界面将右侧的所有内容复制到粘贴板,并且可以选择一段进行复制
WebHarvy会智能地识别数据模式自动识别网页中的应用
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-06-19 19:25
WebHarvy 网页采集老师汉化版是国外的采集工具,网站初出中文版,这个程序已经完成了90%,编辑受限网页的软件非常好用,功能强大的应用,可以自动从网页中提取数据(文本、网址和图片),并将提取的内容以不同的格式保存。
应用笔记
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单。 WebHarvy 将智能识别网页上出现的数据模式。使用WebHarvy,可以从不同的网站,在不同的类别中提取数据,例如产品目录或搜索结果,例如房地产,电子商务,学术研究,娱乐,技术等。 从网页中提取的数据可以以不同的格式保存。通常网页显示数据,例如多个页面上的搜索结果。 WebHarvy 可以自动从多个页面抓取和提取数据。
软件功能
WebHarvy 允许您分析网页上的数据
可以显示和分析来自 HTML 地址的连接数据
可以扩展到下一个网页
可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
支持浏览器复制链接搜索
支持配置对应的资源项搜索
可以按项目名称和资源名称搜索
特点
视觉点和点击界面
WebHarvy 是一个可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
代表{pass}{filter}从服务器提取
要提取匿名,防止提取web服务器被网络软件拦截,必须通过{over}{filtering}服务器的选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
外链搜索教程(附 WebHarvy 建议采集tools) 查看全部
WebHarvy会智能地识别数据模式自动识别网页中的应用
WebHarvy 网页采集老师汉化版是国外的采集工具,网站初出中文版,这个程序已经完成了90%,编辑受限网页的软件非常好用,功能强大的应用,可以自动从网页中提取数据(文本、网址和图片),并将提取的内容以不同的格式保存。
应用笔记
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。 WebHarvy,从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单。 WebHarvy 将智能识别网页上出现的数据模式。使用WebHarvy,可以从不同的网站,在不同的类别中提取数据,例如产品目录或搜索结果,例如房地产,电子商务,学术研究,娱乐,技术等。 从网页中提取的数据可以以不同的格式保存。通常网页显示数据,例如多个页面上的搜索结果。 WebHarvy 可以自动从多个页面抓取和提取数据。
软件功能
WebHarvy 允许您分析网页上的数据
可以显示和分析来自 HTML 地址的连接数据
可以扩展到下一个网页
可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
支持浏览器复制链接搜索
支持配置对应的资源项搜索
可以按项目名称和资源名称搜索
特点
视觉点和点击界面
WebHarvy 是一个可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
代表{pass}{filter}从服务器提取
要提取匿名,防止提取web服务器被网络软件拦截,必须通过{over}{filtering}服务器的选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
外链搜索教程(附 WebHarvy 建议采集tools)
图片助手官网:默认尺寸漏斗可在扩展选项中设置
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-06-13 21:13
图片助手(ImageAssistant)是一款运行在Chromium及其衍生浏览器(如:百度浏览器、猎豹安全浏览器、360安全浏览器、360极速浏览器、UC浏览器等)上进行分析、提取图片的浏览器网页并提供多种过滤方式,帮助用户选择要下载的扩展程序。与以往提供类似功能的浏览器扩展不同,图片助手集成了多种数据提取方式,确保尽可能全面地提取出现在各种复杂结构页面中的图片。过滤方式包括图片类型(JPG、GIF、PNG)、分辨率大小(不小于,指定大小),其中指定大小通过大小漏斗设置,“默认大小漏斗”可以在扩展选项中设置(注:分辨率小于默认尺寸的图片会被直接忽略,请慎重设置,设置太大会导致小尺寸图片无法提取显示),并且可以自定义添加尺寸漏斗选项。
这个插件的名字是:图片助手,支持谷歌和基于谷歌的360、百度、UC、猎豹等各种主流浏览器。
安装也很简单
以360浏览器为例,在应用商店中搜索图片助手,选择添加即可。
1
批量下载图片
我们在浏览网页时,经常会看到各种图片的合集或摘要▼
只需在浏览器中点击图片助手,然后选择从该页面提取图片的命令即可。图片助手会提取当前网页中的所有图片元素▼
下一步我们可以通过过滤图片的大小来过滤出我们想要的图片,然后批量下载▼
图片助手官网: 查看全部
图片助手官网:默认尺寸漏斗可在扩展选项中设置
图片助手(ImageAssistant)是一款运行在Chromium及其衍生浏览器(如:百度浏览器、猎豹安全浏览器、360安全浏览器、360极速浏览器、UC浏览器等)上进行分析、提取图片的浏览器网页并提供多种过滤方式,帮助用户选择要下载的扩展程序。与以往提供类似功能的浏览器扩展不同,图片助手集成了多种数据提取方式,确保尽可能全面地提取出现在各种复杂结构页面中的图片。过滤方式包括图片类型(JPG、GIF、PNG)、分辨率大小(不小于,指定大小),其中指定大小通过大小漏斗设置,“默认大小漏斗”可以在扩展选项中设置(注:分辨率小于默认尺寸的图片会被直接忽略,请慎重设置,设置太大会导致小尺寸图片无法提取显示),并且可以自定义添加尺寸漏斗选项。
这个插件的名字是:图片助手,支持谷歌和基于谷歌的360、百度、UC、猎豹等各种主流浏览器。
安装也很简单
以360浏览器为例,在应用商店中搜索图片助手,选择添加即可。
1
批量下载图片
我们在浏览网页时,经常会看到各种图片的合集或摘要▼
只需在浏览器中点击图片助手,然后选择从该页面提取图片的命令即可。图片助手会提取当前网页中的所有图片元素▼
下一步我们可以通过过滤图片的大小来过滤出我们想要的图片,然后批量下载▼
图片助手官网:
证书链不完整,导致浏览器无法信任你安装的证书
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-06-13 01:22
证书链不完整,导致浏览器无法信任你安装的证书
安装证书后,仍然无法访问。
重新整理思路,安卓浏览器和qq等都能正常访问https,说明证书配置正确。只有微信访问异常。百度后发现其他人也遇到过类似问题,说证书链不完整,导致浏览器无法信任你安装的证书。
证书链实际上是在描述证书的签名链接。比如A给B发证书,B给C发证书,那么我们手里就有了证书C。当证书链不完整时,即没有说明我们手中的证书C是谁使用的,所以浏览器不会认为你的证书是可信授权证书。
二. 如何验证证书链的完整性? 1.如果是外网可以访问,输入域名验证SSL证书链是否完整
2.如果是内网,可以使用命令验证:
openssl s_client -connect x.x.x.x:443
// s_client为一个SSL/TLS客户端程序,与s_server对应,它不仅能与s_server进行通信,也能与任何使用ssl协议的其他服务程序进行通信。
// -connect host:port:设置服务器地址和端口号。如果没有设置,则默认为本地主机以及端口号4433。
连接内网IP后:
0、1 是证书链中每一级证书的序号。 0 是网站 使用的要验证的证书。其CN对应网站域名。
在每个序列号之后,以s开头的行表示证书,以i开头的行表示证书的颁发者。
0 的 CN 收录一个英文域名。其发行人为 TrustAsia Technologies, Inc./OU=Symantec Trust Network/OU=Domain Validated SSL/CN=TrustAsia DV SSL CA
1 的证书是 0 的颁发者。而 1 本身是由另一个证书 VeriSign Class 3 Public Primary Certification Authority 颁发的。
所以这么一看,浏览器以为我知道1的发行者。安装包里提到了VeriSIign。签名正确,验证正确,所以信任1。那么1发出的0也应该信任。所以这个网站是可以信任的。
但是,如果网站在配置的时候只在crt文件中收录了自己,而没有收录可以被浏览器内置数据验证的完整证书链,则可能会被浏览器拒绝。例如
openssl s_client -connecttouko.moe:443
---
Certificate chain
0 s:/CN=touko.moe
i:/C=CN/O=WoSign CALimited/CN=WoSign CA Free SSL CertificateG2
---
只有0组。请注意,第 s 行的 touko.moe 是由第 i 行的 WoSign CA Free SSL CertificateG2 颁发的。没了。
这就是这个坑最神奇的地方:这个时候浏览器是否验证失败还不确定。有两种情况:
A.自从安装浏览器以来,我从未见过这种情况。那么验证就会失败。
B.如果浏览器之前看到并验证过i,则验证成功。
通常管理员会去证书颁发机构的https网站购买证书,浏览器会验证,然后所有验证成功的中间证书都会缓存起来,以备日后使用。当管理员(错误地)配置了他的网站并去浏览测试时,他根本不会遇到任何问题。因为他的浏览器已经识别了这个中间证书。
总结:
通过证书链验证发现我们内网的证书链是完整正确的。
三.微信自己的问题
再整理思路,用安卓微信访问其他https网站如百度、csdn等,都是空白页面。如果是我们的证书链有问题,那么其他网站证书链应该没问题,为什么?不能参观?这样证书链问题就彻底解决了。
由于不是本地证书问题,也不是我们服务器的证书链问题,QQ和浏览器都可以正常访问,ios也正常,说明fiddler端没问题。这时候就怀疑是微信本身的问题了。 ?
好的,首先考虑为什么fiddler可以抓取https包?
Fiddler 巧妙地伪造了 CA 证书。我(fiddler)自己编造了一个私钥和公钥,作为签名证书发给浏览器,提交给服务器,服务器根据公钥签名返回。 (提琴手)伪造的钥匙自然可以解锁。
所以,你知道,我知道,大家都知道,为了防止软件被fiddler捕获,开发者会内置SSL证书,直接用自己的证书进行签名和加密,而不是使用系统的CA证书。您将被伪造证书欺骗信息。自然,fiddler 将无法使用自己的证书捕获软件数据。 查看全部
证书链不完整,导致浏览器无法信任你安装的证书
安装证书后,仍然无法访问。
重新整理思路,安卓浏览器和qq等都能正常访问https,说明证书配置正确。只有微信访问异常。百度后发现其他人也遇到过类似问题,说证书链不完整,导致浏览器无法信任你安装的证书。
证书链实际上是在描述证书的签名链接。比如A给B发证书,B给C发证书,那么我们手里就有了证书C。当证书链不完整时,即没有说明我们手中的证书C是谁使用的,所以浏览器不会认为你的证书是可信授权证书。
二. 如何验证证书链的完整性? 1.如果是外网可以访问,输入域名验证SSL证书链是否完整
2.如果是内网,可以使用命令验证:
openssl s_client -connect x.x.x.x:443
// s_client为一个SSL/TLS客户端程序,与s_server对应,它不仅能与s_server进行通信,也能与任何使用ssl协议的其他服务程序进行通信。
// -connect host:port:设置服务器地址和端口号。如果没有设置,则默认为本地主机以及端口号4433。
连接内网IP后:
0、1 是证书链中每一级证书的序号。 0 是网站 使用的要验证的证书。其CN对应网站域名。
在每个序列号之后,以s开头的行表示证书,以i开头的行表示证书的颁发者。
0 的 CN 收录一个英文域名。其发行人为 TrustAsia Technologies, Inc./OU=Symantec Trust Network/OU=Domain Validated SSL/CN=TrustAsia DV SSL CA
1 的证书是 0 的颁发者。而 1 本身是由另一个证书 VeriSign Class 3 Public Primary Certification Authority 颁发的。
所以这么一看,浏览器以为我知道1的发行者。安装包里提到了VeriSIign。签名正确,验证正确,所以信任1。那么1发出的0也应该信任。所以这个网站是可以信任的。
但是,如果网站在配置的时候只在crt文件中收录了自己,而没有收录可以被浏览器内置数据验证的完整证书链,则可能会被浏览器拒绝。例如
openssl s_client -connecttouko.moe:443
---
Certificate chain
0 s:/CN=touko.moe
i:/C=CN/O=WoSign CALimited/CN=WoSign CA Free SSL CertificateG2
---
只有0组。请注意,第 s 行的 touko.moe 是由第 i 行的 WoSign CA Free SSL CertificateG2 颁发的。没了。
这就是这个坑最神奇的地方:这个时候浏览器是否验证失败还不确定。有两种情况:
A.自从安装浏览器以来,我从未见过这种情况。那么验证就会失败。
B.如果浏览器之前看到并验证过i,则验证成功。
通常管理员会去证书颁发机构的https网站购买证书,浏览器会验证,然后所有验证成功的中间证书都会缓存起来,以备日后使用。当管理员(错误地)配置了他的网站并去浏览测试时,他根本不会遇到任何问题。因为他的浏览器已经识别了这个中间证书。
总结:
通过证书链验证发现我们内网的证书链是完整正确的。
三.微信自己的问题
再整理思路,用安卓微信访问其他https网站如百度、csdn等,都是空白页面。如果是我们的证书链有问题,那么其他网站证书链应该没问题,为什么?不能参观?这样证书链问题就彻底解决了。
由于不是本地证书问题,也不是我们服务器的证书链问题,QQ和浏览器都可以正常访问,ios也正常,说明fiddler端没问题。这时候就怀疑是微信本身的问题了。 ?
好的,首先考虑为什么fiddler可以抓取https包?
Fiddler 巧妙地伪造了 CA 证书。我(fiddler)自己编造了一个私钥和公钥,作为签名证书发给浏览器,提交给服务器,服务器根据公钥签名返回。 (提琴手)伪造的钥匙自然可以解锁。
所以,你知道,我知道,大家都知道,为了防止软件被fiddler捕获,开发者会内置SSL证书,直接用自己的证书进行签名和加密,而不是使用系统的CA证书。您将被伪造证书欺骗信息。自然,fiddler 将无法使用自己的证书捕获软件数据。
VisualWebRipper破解版的使用方法有哪些?软件介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-06-12 19:13
Visual Web Ripper 破解版是一款网页数据提取软件。它可以在不编辑代码的情况下提取整个产品目录。它的使用非常简单,只要输入网址,然后点击相应的区域,它就会自动识别并提取数据。
软件介绍
Visual Web Ripper 是一款强大的网络抓取工具,可轻松提取 网站 数据,例如产品目录、分类广告、finance网站 或任何其他收录您可能感兴趣的信息的 网站。
我们的网络爬虫从目标网站 采集内容,并自动将内容作为结构化数据传输到数据库、电子表格、CSV 文件或 XML。
我们的网络爬虫可以从高度动态的网站中提取网站数据,但大多数其他提取工具都会失败。它可以处理支持 AJAX 的 网站,重复提交所有可能的输入表单等等。
软件功能
1、项目编辑
使用可视化项目编辑器轻松设计网页抓取项目。不需要脚本或编码。只需在内置网络浏览器中加载网站,然后使用鼠标指向并单击要提取的内容和要关注的链接。只需点击几下,即可将项目配置为跟踪数百个链接。
项目编辑器中收录的工具可以帮助您开发即使页面布局略有变化也能正常工作的数据提取模型,并且所有工作只需单击即可完成。
2、 轻松捕捉完整的内容结构
Visual Web Ripper 可以配置为下载完整的内容结构,例如产品目录。您只需要配置几个模板,网络爬虫会为您找到其余的并下载所有数据。
我们的网络抓取软件具有许多高级功能,可帮助您优化网络抓取性能和可靠性。如果您想从数千甚至数十万个网页中抓取数据,这些功能非常重要。
3、反复提交网络表单
我们的网络抓取软件可以提交网络表单,例如搜索表单或在线预订表单。可以为所有可能的输入值提交 Web 表单,因此可以配置 Web 抓取项目以提交所有可能的房间类型的酒店预订表单。
输入 CSV 文件或数据库查询可用于向 Web 表单提供输入值,因此您可以创建收录数千个搜索关键字的 CSV 文件并为每个关键字提交搜索表单。
4、从高度动态的网站中提取数据
大多数原创网络爬虫无法从高度动态的网站中提取数据,即使是专业的网络爬虫在从AJAX网站中采集数据也可能存在问题。 Visual Web Ripper 有一套复杂的工具,可以让你从最复杂的 AJAX网站 获取数据,但请记住,一些 AJAX网站 对新手用户来说是一个挑战。
5、从命令行运行 Web Scraping 会话
Visual Web Ripper 有一个命令行实用程序,可用于从 Windows 命令行静默运行网络抓取项目。这为几乎所有 Windows 应用程序(包括网站)提供了一种非常简单的机制来运行网络抓取项目。
可以通过命令行将输入参数传递给网页抓取项目,这样就可以构建一个网站,访问者可以在其中输入搜索关键字,然后网站可以将搜索关键字传递给网页抓取项目,项目从第三方网站提取数据。
如何使用 Visual Web Ripper
第一步:在可视化编辑器中设计项目
导航到网站 并为要从中提取内容的每种不同类型的页面设计模板
模板定义了如何从特定网页和具有相似内容结构的所有其他网页中提取内容
您可以通过点击要提取的页面内容设计模板,然后选择要激活的链接和表单打开新页面
强大的工具可以帮助您设计模板。您可以在整个列表中重复内容选择,点击区域中的所有链接,或者重复提交收录所有可能输入值的表单。
第 2 步:直接从设计器运行项目或制定运行项目的计划。
第 3 步:数据将保存到您选择的数据存储(数据库、电子表格、XML 或 CSV 文件) 查看全部
VisualWebRipper破解版的使用方法有哪些?软件介绍
Visual Web Ripper 破解版是一款网页数据提取软件。它可以在不编辑代码的情况下提取整个产品目录。它的使用非常简单,只要输入网址,然后点击相应的区域,它就会自动识别并提取数据。
软件介绍
Visual Web Ripper 是一款强大的网络抓取工具,可轻松提取 网站 数据,例如产品目录、分类广告、finance网站 或任何其他收录您可能感兴趣的信息的 网站。
我们的网络爬虫从目标网站 采集内容,并自动将内容作为结构化数据传输到数据库、电子表格、CSV 文件或 XML。
我们的网络爬虫可以从高度动态的网站中提取网站数据,但大多数其他提取工具都会失败。它可以处理支持 AJAX 的 网站,重复提交所有可能的输入表单等等。
软件功能
1、项目编辑
使用可视化项目编辑器轻松设计网页抓取项目。不需要脚本或编码。只需在内置网络浏览器中加载网站,然后使用鼠标指向并单击要提取的内容和要关注的链接。只需点击几下,即可将项目配置为跟踪数百个链接。
项目编辑器中收录的工具可以帮助您开发即使页面布局略有变化也能正常工作的数据提取模型,并且所有工作只需单击即可完成。
2、 轻松捕捉完整的内容结构
Visual Web Ripper 可以配置为下载完整的内容结构,例如产品目录。您只需要配置几个模板,网络爬虫会为您找到其余的并下载所有数据。
我们的网络抓取软件具有许多高级功能,可帮助您优化网络抓取性能和可靠性。如果您想从数千甚至数十万个网页中抓取数据,这些功能非常重要。
3、反复提交网络表单
我们的网络抓取软件可以提交网络表单,例如搜索表单或在线预订表单。可以为所有可能的输入值提交 Web 表单,因此可以配置 Web 抓取项目以提交所有可能的房间类型的酒店预订表单。
输入 CSV 文件或数据库查询可用于向 Web 表单提供输入值,因此您可以创建收录数千个搜索关键字的 CSV 文件并为每个关键字提交搜索表单。
4、从高度动态的网站中提取数据
大多数原创网络爬虫无法从高度动态的网站中提取数据,即使是专业的网络爬虫在从AJAX网站中采集数据也可能存在问题。 Visual Web Ripper 有一套复杂的工具,可以让你从最复杂的 AJAX网站 获取数据,但请记住,一些 AJAX网站 对新手用户来说是一个挑战。
5、从命令行运行 Web Scraping 会话
Visual Web Ripper 有一个命令行实用程序,可用于从 Windows 命令行静默运行网络抓取项目。这为几乎所有 Windows 应用程序(包括网站)提供了一种非常简单的机制来运行网络抓取项目。
可以通过命令行将输入参数传递给网页抓取项目,这样就可以构建一个网站,访问者可以在其中输入搜索关键字,然后网站可以将搜索关键字传递给网页抓取项目,项目从第三方网站提取数据。
如何使用 Visual Web Ripper
第一步:在可视化编辑器中设计项目
导航到网站 并为要从中提取内容的每种不同类型的页面设计模板
模板定义了如何从特定网页和具有相似内容结构的所有其他网页中提取内容
您可以通过点击要提取的页面内容设计模板,然后选择要激活的链接和表单打开新页面
强大的工具可以帮助您设计模板。您可以在整个列表中重复内容选择,点击区域中的所有链接,或者重复提交收录所有可能输入值的表单。
第 2 步:直接从设计器运行项目或制定运行项目的计划。
第 3 步:数据将保存到您选择的数据存储(数据库、电子表格、XML 或 CSV 文件)
推荐程序Octoparse–优采云的推荐及重点推荐功能介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-10 07:21
推荐程序Octoparse--优采云
这样不仅操作方便,功能齐全,而且可以在短时间内获取大量数据。特别推荐Octoparse的云采集功能,好评。
Cyotek 网络复制
WebCopy 是一款免费的网站 爬虫,可让您将本地部分或完整的网站 复制到您的硬盘上以供离线阅读。
它会扫描指定的网站,然后将网站内容下载到您的硬盘上,并自动将其重新映射到网站中的图片和其他网页的链接以匹配其本地路径。包括网站的某个部分。也可以使用其他选项,例如下载要收录在副本中的 URL,但不对其进行抓取。
您可以使用多种设置来配置网站 的抓取方式。除了上面提到的规则和表单,您还可以配置域别名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或任何形式的 JavaScript 解析。如果一个网站大量使用JavaScript进行操作,如果因为JavaScript动态生成链接而无法找到所有网站,那么WebCopy就不太可能进行真正的复制。
3.Httrack
作为网站crawler 的免费软件,HTTrack 提供的功能非常适合将整个网站 从互联网下载到您的PC 上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以将一个站点或多个站点镜像到一起(使用共享链接)。您可以在“设置”下决定在下载网页时要同时打开多少个连接。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的网站 并恢复中断的下载。
此外,HTTTrack 还提供代理支持以最大限度地提高速度并提供可选的身份验证。
HTTrack 用作命令行程序,或通过外壳进行私有(捕获)或专业(在线网络镜像)使用。有了这个说法,HTTrack应该是首选,编程能力高的人用得更多
总结
总之,我上面提到的爬虫可以满足大部分用户的基本爬虫需求,而且这些工具各自的功能还是有很多区别的,因为这些爬虫工具很多都为用户提供了更高级的内置配置工具。因此,在使用前请务必充分了解爬虫提供的帮助信息。 查看全部
推荐程序Octoparse–优采云的推荐及重点推荐功能介绍
推荐程序Octoparse--优采云
这样不仅操作方便,功能齐全,而且可以在短时间内获取大量数据。特别推荐Octoparse的云采集功能,好评。
Cyotek 网络复制
WebCopy 是一款免费的网站 爬虫,可让您将本地部分或完整的网站 复制到您的硬盘上以供离线阅读。
它会扫描指定的网站,然后将网站内容下载到您的硬盘上,并自动将其重新映射到网站中的图片和其他网页的链接以匹配其本地路径。包括网站的某个部分。也可以使用其他选项,例如下载要收录在副本中的 URL,但不对其进行抓取。
您可以使用多种设置来配置网站 的抓取方式。除了上面提到的规则和表单,您还可以配置域别名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或任何形式的 JavaScript 解析。如果一个网站大量使用JavaScript进行操作,如果因为JavaScript动态生成链接而无法找到所有网站,那么WebCopy就不太可能进行真正的复制。
3.Httrack
作为网站crawler 的免费软件,HTTrack 提供的功能非常适合将整个网站 从互联网下载到您的PC 上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以将一个站点或多个站点镜像到一起(使用共享链接)。您可以在“设置”下决定在下载网页时要同时打开多少个连接。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的网站 并恢复中断的下载。
此外,HTTTrack 还提供代理支持以最大限度地提高速度并提供可选的身份验证。
HTTrack 用作命令行程序,或通过外壳进行私有(捕获)或专业(在线网络镜像)使用。有了这个说法,HTTrack应该是首选,编程能力高的人用得更多
总结
总之,我上面提到的爬虫可以满足大部分用户的基本爬虫需求,而且这些工具各自的功能还是有很多区别的,因为这些爬虫工具很多都为用户提供了更高级的内置配置工具。因此,在使用前请务必充分了解爬虫提供的帮助信息。
6款海外竞品网站监测工具,帮到每一位海外营销人!
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-06-05 20:22
为了抢占流量红利,多渠道扩张成为主要营销策略。如何更好地了解竞品趋势也成为当务之急!
但是,监控竞品不是为了打压竞品,也不是窥探竞品的商业秘密,而是为了在竞品监控中锚定自己公司的地位,借鉴竞品的优势,并提高自己。一个公司不可能低着头走路,偶尔需要抬头看看周围的竞争对手,以此来判断是走得太慢还是走弯路。
竞争与合作的环境有利于行业的进一步发展。以下是木瓜移动整理的6款海外竞品网站监控工具,希望能帮助到每一位海外营销者!
1
类似网站
监控竞争产品网站flow
SimilarWeb 是一种分析工具,用于监控网站 或 Web 应用程序流量。由于竞争产品很可能会争夺类似的受众,因此竞争对手的优质流量来源通常会对您的业务产生很大影响。了解竞品来源网站流量可以推广同渠道。
更重要的是,内容营销人员可以轻松查看访问者正在搜索哪些主题以及他们访问了哪些相关的 网站。
同时,SimilarWeb 还可以监控竞品在哪里投放广告,哪些广告给他们带来了最多的收入,还可以监控他们正在投放的广告。您可以通过只定位他们使用的高质量广告空间来节省资金。
2
内置
查看竞品网站使用插件
BuiltWith 是一个行业分析工具。只需输入竞争对手网站的网址,您就会看到网站使用的脚本、服务和插件。此外,您还可以查询网站使用的任何前后端技术。
当您在竞品信息中发现某个平台或服务时,您也可以在此网站直接查询其使用情况分析、用户数、市场份额等。 BuiltWith 不仅可以看到竞争对手使用的技术,还可以看到为竞争对手服务的其他产品的使用情况。
3
回归机器
查看竞品网站历史版本
Wayback Machine 是 Internet Archive 下的网页保存工具。通过Crawler每周可以抓取超过10亿个网页!大量的服务器和带宽用于提供服务和压缩内容大小,因此用户可以在本产品上找到网站的任何历史版本。
此外,Wayback Machine 还提供了在线网页备份功能。只需输入需要备份的网页网址,即可拦截生成独立且永久保存的网址,即可随时使用Wayback Machine中的时光机功能。查看在不同时间点自动抓取和备份的网页内容。
登录“Wayback Machine”网站后,在顶部输入网站你想赶时间机器的网址。如果你想找到以前匿名网站的页面,可以试试下面的网址格式(把ID改成你要查询的网站name):
输入网址后,点击“浏览历史”,会出现该页面不同时间的网页存档备份。
4
BussSumo
查看竞品网站hot content
Buzzsumo 是一款具有竞争力的产品监控工具,专注于内容。它可以查看任何关键词在社交媒体上的流行度,帮助内容创作者选择话题。同时,它还允许用户查看自己品牌或竞争对手相关主题下表现最佳的内容,以及目前有多少人分享了竞争对手的内容。
不仅可以在行业内容上帮助用户了解谁在“杀四方”,还可以帮助用户发现潜在的热点话题。
5
SEMrush
关键字广告工具(付费)
SEMRush 是市场上使用最广泛的 SEO 工具,同时还具有高质量的竞争对手分析功能。
用户只需输入竞争对手网站的网址,即可立即查询其排名、流量、广告关键词和有机关键词。所有结果将以图形报告的形式清晰显示。
用户还可以使用这个工具来并排比较不同域名的数据细节,这个工具还可以帮助用户为他们的网站产生关键词想法。
6
UberSuggest
监控竞品特定关键词带来流量数据
UberSuggest 是一个标准的免费关键字监控工具。用户可以使用它来监控竞品网站的关键词详情和流量来源。
用户输入关键词,UberSuggest可以立即显示所有相关的长尾词,以及每个关键词的月搜索量和长尾、平均每次点击成本、PPC竞争和SEO竞争。
查看全部
6款海外竞品网站监测工具,帮到每一位海外营销人!
为了抢占流量红利,多渠道扩张成为主要营销策略。如何更好地了解竞品趋势也成为当务之急!
但是,监控竞品不是为了打压竞品,也不是窥探竞品的商业秘密,而是为了在竞品监控中锚定自己公司的地位,借鉴竞品的优势,并提高自己。一个公司不可能低着头走路,偶尔需要抬头看看周围的竞争对手,以此来判断是走得太慢还是走弯路。
竞争与合作的环境有利于行业的进一步发展。以下是木瓜移动整理的6款海外竞品网站监控工具,希望能帮助到每一位海外营销者!
1
类似网站
监控竞争产品网站flow
SimilarWeb 是一种分析工具,用于监控网站 或 Web 应用程序流量。由于竞争产品很可能会争夺类似的受众,因此竞争对手的优质流量来源通常会对您的业务产生很大影响。了解竞品来源网站流量可以推广同渠道。
更重要的是,内容营销人员可以轻松查看访问者正在搜索哪些主题以及他们访问了哪些相关的 网站。
同时,SimilarWeb 还可以监控竞品在哪里投放广告,哪些广告给他们带来了最多的收入,还可以监控他们正在投放的广告。您可以通过只定位他们使用的高质量广告空间来节省资金。
2
内置
查看竞品网站使用插件
BuiltWith 是一个行业分析工具。只需输入竞争对手网站的网址,您就会看到网站使用的脚本、服务和插件。此外,您还可以查询网站使用的任何前后端技术。
当您在竞品信息中发现某个平台或服务时,您也可以在此网站直接查询其使用情况分析、用户数、市场份额等。 BuiltWith 不仅可以看到竞争对手使用的技术,还可以看到为竞争对手服务的其他产品的使用情况。
3
回归机器
查看竞品网站历史版本
Wayback Machine 是 Internet Archive 下的网页保存工具。通过Crawler每周可以抓取超过10亿个网页!大量的服务器和带宽用于提供服务和压缩内容大小,因此用户可以在本产品上找到网站的任何历史版本。
此外,Wayback Machine 还提供了在线网页备份功能。只需输入需要备份的网页网址,即可拦截生成独立且永久保存的网址,即可随时使用Wayback Machine中的时光机功能。查看在不同时间点自动抓取和备份的网页内容。
登录“Wayback Machine”网站后,在顶部输入网站你想赶时间机器的网址。如果你想找到以前匿名网站的页面,可以试试下面的网址格式(把ID改成你要查询的网站name):
输入网址后,点击“浏览历史”,会出现该页面不同时间的网页存档备份。
4
BussSumo
查看竞品网站hot content
Buzzsumo 是一款具有竞争力的产品监控工具,专注于内容。它可以查看任何关键词在社交媒体上的流行度,帮助内容创作者选择话题。同时,它还允许用户查看自己品牌或竞争对手相关主题下表现最佳的内容,以及目前有多少人分享了竞争对手的内容。
不仅可以在行业内容上帮助用户了解谁在“杀四方”,还可以帮助用户发现潜在的热点话题。
5
SEMrush
关键字广告工具(付费)
SEMRush 是市场上使用最广泛的 SEO 工具,同时还具有高质量的竞争对手分析功能。
用户只需输入竞争对手网站的网址,即可立即查询其排名、流量、广告关键词和有机关键词。所有结果将以图形报告的形式清晰显示。
用户还可以使用这个工具来并排比较不同域名的数据细节,这个工具还可以帮助用户为他们的网站产生关键词想法。
6
UberSuggest
监控竞品特定关键词带来流量数据
UberSuggest 是一个标准的免费关键字监控工具。用户可以使用它来监控竞品网站的关键词详情和流量来源。
用户输入关键词,UberSuggest可以立即显示所有相关的长尾词,以及每个关键词的月搜索量和长尾、平均每次点击成本、PPC竞争和SEO竞争。
cyotekwebcopy可用硬盘空间相关问题可以做什么呢?
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-06-05 20:15
cyotek webcopy 最新版本是一款非常受用户欢迎的仿制工具。所有操作一目了然。您可以一键复制和复制您需要的网页。所有的图片、文字和链接都可以恢复。有需要的朋友欢迎到当易下载!
cyotek webcopy中文版介绍
免费的网站复制工具,用于将网站的全部或部分本地复制到硬盘,供离线查看。 webcopy 将扫描指定的网站 并将其内容下载到您的硬盘驱动器。 网站 中的样式表、图片和其他页面等资源的链接将自动重新映射以匹配本地路径。使用其广泛的配置,您可以定义网站 的哪些部分将被复制以及如何复制。
软件功能
1、支持下载网站保存到本地;
2、安全可靠,操作简单;
3、 支持正则表达式;
4、可用于离线浏览网页;
5、支持表单和密码
如何使用cyotek webcopy
1、 虽然界面是英文的,但是操作还是很简单的。在网站栏填写需要复制的网站的网址。
2、在下方的保存文件夹栏中,选择浏览器浏览为文件夹,选择网站需要保存的路径。
3、然后选择【项目】--【复制网站】,或者直接按快捷键F5开始复制项目。
4、复制过程结束后,会弹出爬取完成窗口,表示复制完成。
5、 现在我们回到我们复制网站的位置,可以看到网站文件全部复制完毕,包括css和js。用dreamweaver 8打开index.html,可以看到网站的原文件,按F12运行,发现和复制的网站一样,说明复制成功!
所需环境
windows 10,8.1,8,7, vista sp2
微软.net框架4.6
20mb 可用硬盘空间
相关问题
网络复制能做什么?
会检查网站的html标签并尝试发现所有链接的资源,例如其他页面、图片、视频、文件下载-任何东西。它将下载所有这些资源并继续搜索更多。这样,webcopy 就可以“抓取”整个网站 并下载它看到的所有内容,从而创建一个合理的网站 源传真。
网络复制不能做什么?
不包括虚拟 dom 或任何形式的 javascript 解析。如果一个网站使用大量javascript来操作,那么如果使用javascript动态生成链接,无法找到所有网站,webcopy就无法真正做到复制。
网站的原创源码没有下载,只能下载http服务器返回的内容。虽然会尽量创建网站的离线副本,但高级数据驱动的网站复制后可能无法正常工作。 查看全部
cyotekwebcopy可用硬盘空间相关问题可以做什么呢?
cyotek webcopy 最新版本是一款非常受用户欢迎的仿制工具。所有操作一目了然。您可以一键复制和复制您需要的网页。所有的图片、文字和链接都可以恢复。有需要的朋友欢迎到当易下载!
cyotek webcopy中文版介绍
免费的网站复制工具,用于将网站的全部或部分本地复制到硬盘,供离线查看。 webcopy 将扫描指定的网站 并将其内容下载到您的硬盘驱动器。 网站 中的样式表、图片和其他页面等资源的链接将自动重新映射以匹配本地路径。使用其广泛的配置,您可以定义网站 的哪些部分将被复制以及如何复制。
软件功能
1、支持下载网站保存到本地;
2、安全可靠,操作简单;
3、 支持正则表达式;
4、可用于离线浏览网页;
5、支持表单和密码
如何使用cyotek webcopy
1、 虽然界面是英文的,但是操作还是很简单的。在网站栏填写需要复制的网站的网址。
2、在下方的保存文件夹栏中,选择浏览器浏览为文件夹,选择网站需要保存的路径。
3、然后选择【项目】--【复制网站】,或者直接按快捷键F5开始复制项目。
4、复制过程结束后,会弹出爬取完成窗口,表示复制完成。
5、 现在我们回到我们复制网站的位置,可以看到网站文件全部复制完毕,包括css和js。用dreamweaver 8打开index.html,可以看到网站的原文件,按F12运行,发现和复制的网站一样,说明复制成功!
所需环境
windows 10,8.1,8,7, vista sp2
微软.net框架4.6
20mb 可用硬盘空间
相关问题
网络复制能做什么?
会检查网站的html标签并尝试发现所有链接的资源,例如其他页面、图片、视频、文件下载-任何东西。它将下载所有这些资源并继续搜索更多。这样,webcopy 就可以“抓取”整个网站 并下载它看到的所有内容,从而创建一个合理的网站 源传真。
网络复制不能做什么?
不包括虚拟 dom 或任何形式的 javascript 解析。如果一个网站使用大量javascript来操作,那么如果使用javascript动态生成链接,无法找到所有网站,webcopy就无法真正做到复制。
网站的原创源码没有下载,只能下载http服务器返回的内容。虽然会尽量创建网站的离线副本,但高级数据驱动的网站复制后可能无法正常工作。
方便制作电子书的基本操作流程及功能介绍(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-05 06:01
是一种可以在指定网页上下载某本书和某章的软件。它可以通过网络图书抓取器快速下载小说。同时软件支持断点续传功能,非常方便。有需要的可以下载。使用。
【功能介绍】
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
[软件功能]
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、Auto-retry:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好再试。
3、Stop and resume:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复抓取下次运行。注意:需要先用停止按钮中断然后退出程序,如果直接退出,将不会恢复)
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、Applicable网站:已经输入了10个适用的网站(选择后可以快速打开网站找到你需要的书),也可以自动申请相应的代码,或者申请到其他小说网站进行测试,如果合并,可以手动添加到配置文件中以备后用。
6、Easy to make e-books:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书目录带来极大的方便。
【使用方法】
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。 查看全部
方便制作电子书的基本操作流程及功能介绍(一)
是一种可以在指定网页上下载某本书和某章的软件。它可以通过网络图书抓取器快速下载小说。同时软件支持断点续传功能,非常方便。有需要的可以下载。使用。
【功能介绍】
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
[软件功能]
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、Auto-retry:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好再试。
3、Stop and resume:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复抓取下次运行。注意:需要先用停止按钮中断然后退出程序,如果直接退出,将不会恢复)
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、Applicable网站:已经输入了10个适用的网站(选择后可以快速打开网站找到你需要的书),也可以自动申请相应的代码,或者申请到其他小说网站进行测试,如果合并,可以手动添加到配置文件中以备后用。
6、Easy to make e-books:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书目录带来极大的方便。
【使用方法】
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。

