
网站内容抓取工具
网站内容抓取工具( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-27 00:17
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起自己之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
这里顺便解释一下网页提取器爬虫和真正写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具将默认选择所有同一层级的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,直接复制到EXCEL就可以了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签时,都需要先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?期待与我分享你的讯息~ 查看全部
网站内容抓取工具(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)

我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:

如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起自己之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
这里顺便解释一下网页提取器爬虫和真正写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。

首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层

此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具将默认选择所有同一层级的块,如下图:

我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。

第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。


上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,直接复制到EXCEL就可以了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签时,都需要先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?期待与我分享你的讯息~
网站内容抓取工具(网站百度收录慢怎么办?发布的文章总是不收录怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-26 21:00
网站百度收录慢怎么办?如果发布的文章从来没有收录怎么办?
最近在研究百度的主动推送和推送数据实时搜索,可以加快爬虫爬行速度。在百度搜索资源平台后台提交链接即可看到此功能,如下图:
点击链接提交进入页面,可以看到百度提供了一个接口,可以主动提交网站链接给百度。
并且下面介绍几个推送的例子
我也专门研究了一下,终于简单成功的实现了python的一键主动推送。我首先新建了一个 urls.txt 文件,里面有 10 个 URL,如下图所示:
然后使用python成功完成代码提交,操作成功截图如下:
Python总共不到10行代码,非常方便。有需要的朋友也可以自行尝试。用自己的网站替换URL(接口调用地址),php、post、curl、ruby也可以实现。
这里提醒一下,根据百度官方说明,每个接口调用地址每天最多只能提交2000条数据,所以不要提交太多,2000多没用。
好了,今天就分享到这里,希望对大家有所启发和帮助。
李亚涛简介:seo和python编程爱好者,秦旺汇商学院合伙人,8年网站运营经验,熟悉各种推广方式,擅长企业网站建设,关键词排名SEO优化, python爬虫信息捕获Take等。
《手机网站SEO优化教程》、《SEO优化系统视频教程》、《15天成为Python爬虫高手视频教程》、《快速建站视频教程》等作者返回搜狐查看更多 查看全部
网站内容抓取工具(网站百度收录慢怎么办?发布的文章总是不收录怎么办)
网站百度收录慢怎么办?如果发布的文章从来没有收录怎么办?
最近在研究百度的主动推送和推送数据实时搜索,可以加快爬虫爬行速度。在百度搜索资源平台后台提交链接即可看到此功能,如下图:
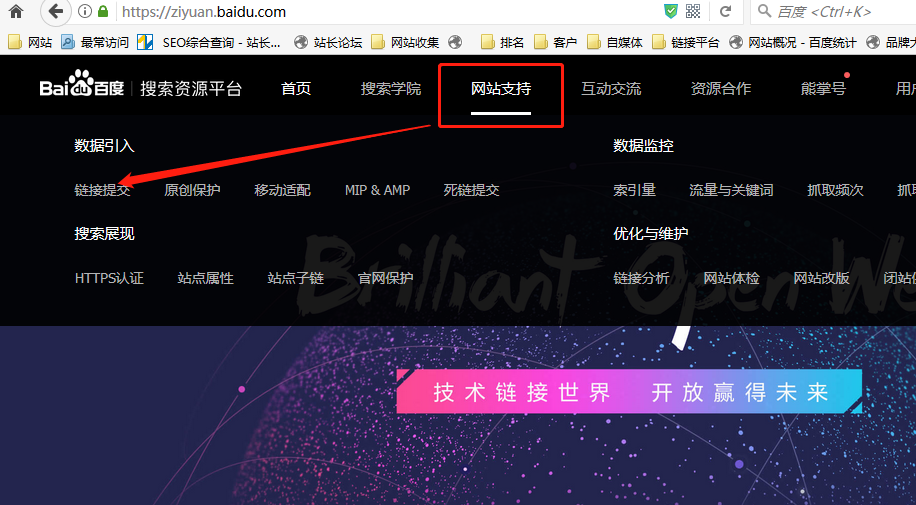
点击链接提交进入页面,可以看到百度提供了一个接口,可以主动提交网站链接给百度。
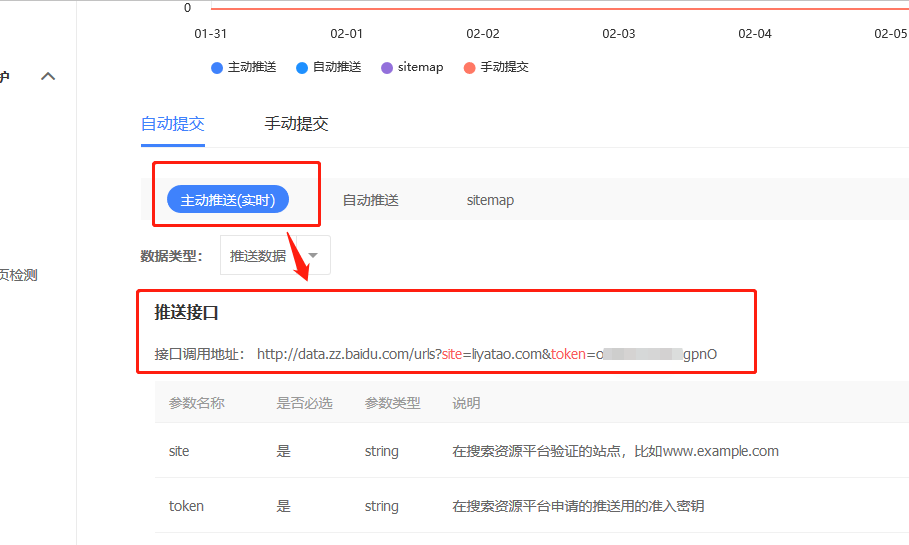
并且下面介绍几个推送的例子
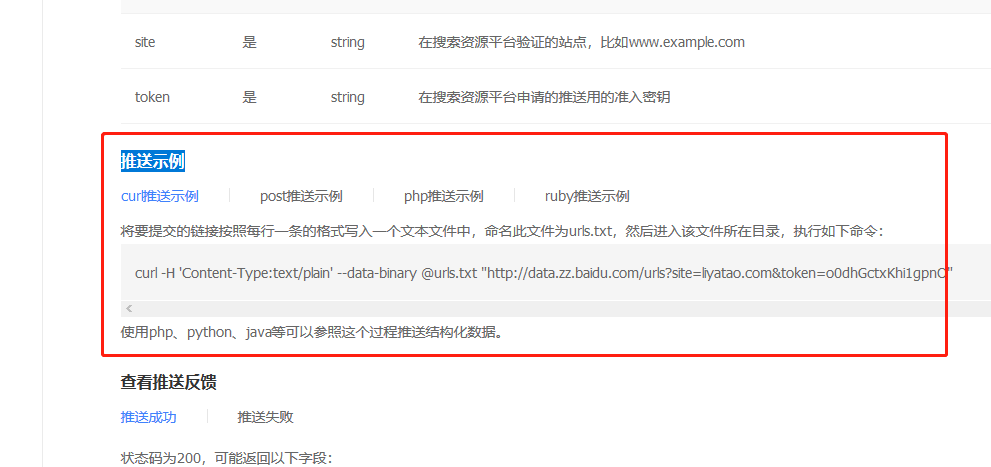
我也专门研究了一下,终于简单成功的实现了python的一键主动推送。我首先新建了一个 urls.txt 文件,里面有 10 个 URL,如下图所示:
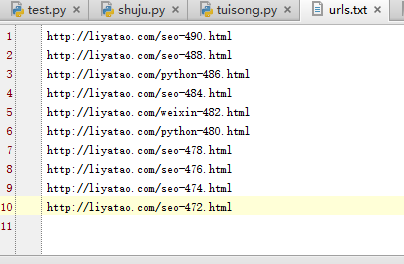
然后使用python成功完成代码提交,操作成功截图如下:
Python总共不到10行代码,非常方便。有需要的朋友也可以自行尝试。用自己的网站替换URL(接口调用地址),php、post、curl、ruby也可以实现。
这里提醒一下,根据百度官方说明,每个接口调用地址每天最多只能提交2000条数据,所以不要提交太多,2000多没用。
好了,今天就分享到这里,希望对大家有所启发和帮助。
李亚涛简介:seo和python编程爱好者,秦旺汇商学院合伙人,8年网站运营经验,熟悉各种推广方式,擅长企业网站建设,关键词排名SEO优化, python爬虫信息捕获Take等。
《手机网站SEO优化教程》、《SEO优化系统视频教程》、《15天成为Python爬虫高手视频教程》、《快速建站视频教程》等作者返回搜狐查看更多
网站内容抓取工具(Java网站内容抓取工具推荐-supervisor爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-24 16:04
网站内容抓取工具推荐-supervisor
爬虫是一门技术,有很多种不同的工具,
用excel做是因为用excel做比较简单,前期在备注数据的时候用excel相对其他任何语言都要简单方便一些。我曾经参加过一个培训大概是用flash做了一下几分钟的视频演示视频,你可以借鉴参考一下。
关于比较全面的学习python爬虫,
如果是数据量比较少的网站,
网站url结构总要再定义一下吧。要确定需要抓取的url的情况下。不同情况选择工具不同。不然每个工具都能满足。最好先把工具的细节研究清楚,最后组合起来用,如果是在网站使用,不同的工具会限制你的爬虫场景。
网站随着数据量增大可以分为各种不同的,
excel不够灵活吧。可以学习下java,掌握了java后期换成python这类型的就挺方便。
看你预算和时间了,抓太简单的可以用excel,抓完用python把数据表定义好,总要有这个数据库吧?然后python读一下就可以了,复杂一点的就用爬虫,肯定要针对某一个目标去抓取,要考虑目标类型的限制,想怎么抓去,针对不同类型的抓取工具工作方式大体也不一样。另外excel没有权限控制。基本上初学爬虫到scrapy这种框架还要适应个1-2个月不等,比较麻烦。 查看全部
网站内容抓取工具(Java网站内容抓取工具推荐-supervisor爬虫)
网站内容抓取工具推荐-supervisor
爬虫是一门技术,有很多种不同的工具,
用excel做是因为用excel做比较简单,前期在备注数据的时候用excel相对其他任何语言都要简单方便一些。我曾经参加过一个培训大概是用flash做了一下几分钟的视频演示视频,你可以借鉴参考一下。
关于比较全面的学习python爬虫,
如果是数据量比较少的网站,
网站url结构总要再定义一下吧。要确定需要抓取的url的情况下。不同情况选择工具不同。不然每个工具都能满足。最好先把工具的细节研究清楚,最后组合起来用,如果是在网站使用,不同的工具会限制你的爬虫场景。
网站随着数据量增大可以分为各种不同的,
excel不够灵活吧。可以学习下java,掌握了java后期换成python这类型的就挺方便。
看你预算和时间了,抓太简单的可以用excel,抓完用python把数据表定义好,总要有这个数据库吧?然后python读一下就可以了,复杂一点的就用爬虫,肯定要针对某一个目标去抓取,要考虑目标类型的限制,想怎么抓去,针对不同类型的抓取工具工作方式大体也不一样。另外excel没有权限控制。基本上初学爬虫到scrapy这种框架还要适应个1-2个月不等,比较麻烦。
网站内容抓取工具(如何快速检测网站是否存在非法内容包括以下几种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-22 17:05
网站内容抓取工具通过爬虫技术从互联网或者其他网站获取网站内容的,通常分为两种1.蜘蛛爬虫是一种访问网站直接下载网站内容的,对于找页面的,结构化数据的爬虫在工作模式中是最为重要的部分,因为页面的解析是非常的繁琐,不仅要有全局代码,而且需要有完整的解析整个页面代码,然后对页面进行处理和分析。有些内容甚至会被反复的抓取,处理完成后才停止访问。
抓取页面数量不少,并且每次抓取都是比较繁琐的工作,抓取是完全c++和python语言开发。2.自己写爬虫工具,简单不说,能弄,但如果你想玩深,把爬虫玩到极致,那么你也需要对java,python等相关语言有较好的理解和掌握,并且会常用的工具集,如集合,list,set,itertools等等。excel,最为常用电子表格软件,对于网站抓取有着至关重要的作用。
利用excel去爬取大数据(包括互联网的各个平台)并生成报表。如何快速检测抓取的网站是否存在非法内容包括以下这几种方法:1.加载一个纯动态执行脚本的页面,不加载静态数据,检测http请求头部是否包含保留下来的javascript;2.根据每次进入的网站不同去判断是否存在爬虫代码,如爬虫脚本和抓取请求,即使抓取请求从200跳转到后台也不要认为是爬虫代码,也要尽可能的检测到与数据库中库函数对应。
能有哪些经典的网站爬虫库列举:http下的每个协议都是对应的特定的网站,这些网站规律多变,用处多重,爬虫开发者写爬虫的目的就是找出爬虫中常用的函数、自动求回等功能;3.根据通用检测,当一个网站用代理访问时就需要根据请求url去判断该网站是否存在爬虫代码,如图,使用try-catch检测,当url超出限制时才打钩代码5.自己爬虫开发,利用python集合工具开发爬虫并且封装,提高开发效率。
了解各种爬虫工具,不断练习,提高效率,而且爬虫工具如excel,也可以用os,开发过程中检查正确率和代码复用率能够最好的掌握excel和os编程也对网站爬虫工作非常有帮助,具体的下面做详细介绍。提前了解的几点1.利用excel进行爬虫工作,必须先使用excel对爬虫的配置做熟悉,并且先了解excel内存分配和搜索,容错检测等知识。
2.非法代码爬虫无法捕捉到,因为这些代码就是一个搜索引擎而已,excel很难捕捉它们的url地址。3.excel自带的抓取报表的插件是不能抓取爬虫报表,不过我们可以自己重写爬虫报表功能进行抓取。下面我们介绍下excel常用的几个网页抓取工具,熟悉这些之后,大家写爬虫就会得心应手了。1.excelhome爬虫大赛_excelhome大赛_excelhomespider。 查看全部
网站内容抓取工具(如何快速检测网站是否存在非法内容包括以下几种方法)
网站内容抓取工具通过爬虫技术从互联网或者其他网站获取网站内容的,通常分为两种1.蜘蛛爬虫是一种访问网站直接下载网站内容的,对于找页面的,结构化数据的爬虫在工作模式中是最为重要的部分,因为页面的解析是非常的繁琐,不仅要有全局代码,而且需要有完整的解析整个页面代码,然后对页面进行处理和分析。有些内容甚至会被反复的抓取,处理完成后才停止访问。
抓取页面数量不少,并且每次抓取都是比较繁琐的工作,抓取是完全c++和python语言开发。2.自己写爬虫工具,简单不说,能弄,但如果你想玩深,把爬虫玩到极致,那么你也需要对java,python等相关语言有较好的理解和掌握,并且会常用的工具集,如集合,list,set,itertools等等。excel,最为常用电子表格软件,对于网站抓取有着至关重要的作用。
利用excel去爬取大数据(包括互联网的各个平台)并生成报表。如何快速检测抓取的网站是否存在非法内容包括以下这几种方法:1.加载一个纯动态执行脚本的页面,不加载静态数据,检测http请求头部是否包含保留下来的javascript;2.根据每次进入的网站不同去判断是否存在爬虫代码,如爬虫脚本和抓取请求,即使抓取请求从200跳转到后台也不要认为是爬虫代码,也要尽可能的检测到与数据库中库函数对应。
能有哪些经典的网站爬虫库列举:http下的每个协议都是对应的特定的网站,这些网站规律多变,用处多重,爬虫开发者写爬虫的目的就是找出爬虫中常用的函数、自动求回等功能;3.根据通用检测,当一个网站用代理访问时就需要根据请求url去判断该网站是否存在爬虫代码,如图,使用try-catch检测,当url超出限制时才打钩代码5.自己爬虫开发,利用python集合工具开发爬虫并且封装,提高开发效率。
了解各种爬虫工具,不断练习,提高效率,而且爬虫工具如excel,也可以用os,开发过程中检查正确率和代码复用率能够最好的掌握excel和os编程也对网站爬虫工作非常有帮助,具体的下面做详细介绍。提前了解的几点1.利用excel进行爬虫工作,必须先使用excel对爬虫的配置做熟悉,并且先了解excel内存分配和搜索,容错检测等知识。
2.非法代码爬虫无法捕捉到,因为这些代码就是一个搜索引擎而已,excel很难捕捉它们的url地址。3.excel自带的抓取报表的插件是不能抓取爬虫报表,不过我们可以自己重写爬虫报表功能进行抓取。下面我们介绍下excel常用的几个网页抓取工具,熟悉这些之后,大家写爬虫就会得心应手了。1.excelhome爬虫大赛_excelhome大赛_excelhomespider。
网站内容抓取工具(WebScraper如何安装Chrome和Firefox上的安装路径介绍?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-21 12:32
官方网站WebScraper号称是头号网页捕获/提取插件,可安装在chrome和Firefox上
安装路径:
Web Scraper–获取Firefox的此扩展(美国版)
您也可以使用浏览器打开官方网站,然后单击“安装”自动选择“安装”
刮网器-1刮网扩展
您还可以在浏览器右上角找到扩展图标,单击“打开”,下拉菜单,然后找到“管理扩展”,即输入chrome://extensions
单击左上角的“打开”,然后在左下角进入web应用商店,打开一个新页面,在其中搜索web scraper,然后安装它
有关说明,您最好看一下视频:
网络刮刀教程
这只是一个YouTube链接,可能有点困难。你可以在互联网上自由搜索,还有教学网站
此插件的正常版本是免费的,增强版是收费的。如果你有钱和需要,如果你不花它,你就会浪费它
此插件易于使用,因为它集成到浏览器中。非常适合新手和普通非专业技术人员使用。如果您需要更强大和定制的网页数据捕获,您可能需要更专业的工具或您自己的编程
下面是我使用此插件的介绍,供您参考
--------------------------------------------------------------------?
第一步是安装,如上所述
步骤2:以chrome为例,在浏览器地址栏中输入:chrome://extensions/
检查是否已成功安装并启用web刮板
步骤3:F12或Ctrl+Shift+I,打开开发工具:
启用时,选择底部显示模式:
然后找到最后一个websharper选项卡并单击enter
好了,准备工作已经完成了
----------------------------------------------------------?
对于第一个示例,请根据官网上的教学视频再次操作
打开官方测试网站:
Web测试站点
官方测试网站是一种电子商务网站. 让我们先简单浏览一下。它分为两个层次。第一级是主要类别:电脑和手机;第一个层次是子分类。“计算机和移动电话”下的分类收录特定的产品项,单击“产品项”即为特定的产品信息
我们的目标是通过浏览两级目录结构来提取所有产品信息
首先设置登录页面、门户URL和登录页面。从这个页面,网络刮板将浏览整个网站。我们需要创建多个选择器以形成树结构,类似于网站构造时的结构
这些选择器定义网站如何浏览以及如何提取数据
如下图所示,要创建站点地图,请输入地址作为上面的浏览器显示地址:Web scraper test sites
完整的数据提取基于站点地图。配置站点地图后,可以保存设置并在下次继续使用。我们需要重新提取并直接执行它
创建网站时,它被命名为电子商务
此时,它后面有一个数据预览按钮。点击后,发现当前没有数据,需要添加一个选择器
对于初始页面中的分层列,为了访问,我们需要以链接的形式创建选择器。单击添加新选择器
然后单击选择以链接的形式选择网页元素
选择器名为category linkm,类型为link。单击选择并选择两个链接。检查多个。父选择器是登录页面
单击“选择”以选择网页上的元素,然后单击“完成选择”
要验证选择结果,请单击“图元预览”检查选择是否正确,然后单击“数据预览”检查其工作是否正常
然后保存选择器
接下来,我们为下一级链接创建一个选择器
单击网页上的“计算机”继续以链接的形式创建选择器
单击保存。然后创建产品页面的链接选择器。首先单击笔记本电脑进入产品列表页面
单击产品链接进入产品页面,创建文本类型选择器,并提取所需数据
创建选择器后,让我们来看一看。根据层次关系点击选择器,随时点击选择器后面的数据预览,查看数据是否正常
您还可以使用选择器图查看我们创建的选择器的结构
单击scratch开始捕获数据,您将看到一个新的网页打开。浏览页面并根据我们设置的登录URL和选择器提取数据
休息一下,等待数据提取
完成后,弹出页面将关闭并提示
然后单击“刷新”以显示提取的数据
选择导出到CSV文件
??打开CSV文件,数据如下:
好的,CSV文件已经在手了,已经结束了
单击浏览以进入数据显示
您还可以导出导出站点地图,保存站点地图JSON内容,并在下次创建站点地图时直接导入,这样更方便快捷
如果有多个站点地图,则可以在操作之前选择或切换站点地图以进行数据提取 查看全部
网站内容抓取工具(WebScraper如何安装Chrome和Firefox上的安装路径介绍?)
官方网站WebScraper号称是头号网页捕获/提取插件,可安装在chrome和Firefox上
安装路径:
Web Scraper–获取Firefox的此扩展(美国版)
您也可以使用浏览器打开官方网站,然后单击“安装”自动选择“安装”
刮网器-1刮网扩展
您还可以在浏览器右上角找到扩展图标,单击“打开”,下拉菜单,然后找到“管理扩展”,即输入chrome://extensions
单击左上角的“打开”,然后在左下角进入web应用商店,打开一个新页面,在其中搜索web scraper,然后安装它
有关说明,您最好看一下视频:
网络刮刀教程
这只是一个YouTube链接,可能有点困难。你可以在互联网上自由搜索,还有教学网站
此插件的正常版本是免费的,增强版是收费的。如果你有钱和需要,如果你不花它,你就会浪费它
此插件易于使用,因为它集成到浏览器中。非常适合新手和普通非专业技术人员使用。如果您需要更强大和定制的网页数据捕获,您可能需要更专业的工具或您自己的编程
下面是我使用此插件的介绍,供您参考
--------------------------------------------------------------------?
第一步是安装,如上所述
步骤2:以chrome为例,在浏览器地址栏中输入:chrome://extensions/
检查是否已成功安装并启用web刮板

步骤3:F12或Ctrl+Shift+I,打开开发工具:

启用时,选择底部显示模式:

然后找到最后一个websharper选项卡并单击enter

好了,准备工作已经完成了
----------------------------------------------------------?
对于第一个示例,请根据官网上的教学视频再次操作
打开官方测试网站:
Web测试站点

官方测试网站是一种电子商务网站. 让我们先简单浏览一下。它分为两个层次。第一级是主要类别:电脑和手机;第一个层次是子分类。“计算机和移动电话”下的分类收录特定的产品项,单击“产品项”即为特定的产品信息
我们的目标是通过浏览两级目录结构来提取所有产品信息
首先设置登录页面、门户URL和登录页面。从这个页面,网络刮板将浏览整个网站。我们需要创建多个选择器以形成树结构,类似于网站构造时的结构
这些选择器定义网站如何浏览以及如何提取数据
如下图所示,要创建站点地图,请输入地址作为上面的浏览器显示地址:Web scraper test sites
完整的数据提取基于站点地图。配置站点地图后,可以保存设置并在下次继续使用。我们需要重新提取并直接执行它

创建网站时,它被命名为电子商务

此时,它后面有一个数据预览按钮。点击后,发现当前没有数据,需要添加一个选择器

对于初始页面中的分层列,为了访问,我们需要以链接的形式创建选择器。单击添加新选择器
然后单击选择以链接的形式选择网页元素

选择器名为category linkm,类型为link。单击选择并选择两个链接。检查多个。父选择器是登录页面
单击“选择”以选择网页上的元素,然后单击“完成选择”
要验证选择结果,请单击“图元预览”检查选择是否正确,然后单击“数据预览”检查其工作是否正常
然后保存选择器
接下来,我们为下一级链接创建一个选择器
单击网页上的“计算机”继续以链接的形式创建选择器

单击保存。然后创建产品页面的链接选择器。首先单击笔记本电脑进入产品列表页面

单击产品链接进入产品页面,创建文本类型选择器,并提取所需数据




创建选择器后,让我们来看一看。根据层次关系点击选择器,随时点击选择器后面的数据预览,查看数据是否正常

您还可以使用选择器图查看我们创建的选择器的结构


单击scratch开始捕获数据,您将看到一个新的网页打开。浏览页面并根据我们设置的登录URL和选择器提取数据

休息一下,等待数据提取
完成后,弹出页面将关闭并提示
然后单击“刷新”以显示提取的数据

选择导出到CSV文件

??打开CSV文件,数据如下:

好的,CSV文件已经在手了,已经结束了
单击浏览以进入数据显示

您还可以导出导出站点地图,保存站点地图JSON内容,并在下次创建站点地图时直接导入,这样更方便快捷
如果有多个站点地图,则可以在操作之前选择或切换站点地图以进行数据提取
网站内容抓取工具(如何在PyCharm中安装Scrapy?3的安装提示信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-21 00:04
在谈到爬虫时,我们必须提到scrapy框架,因为它可以帮助提高爬虫的效率,更好地实现爬虫
Scrapy是一个应用程序框架,用于获取网页数据和提取结构数据。该框架被封装,包括请求(异步调度和处理)、下载(多线程下载)、解析器(选择器)和twisted(异步处理)。对于网站内容爬行,其速度非常快
也许读者会感到困惑。有了这样一个好的爬虫框架,为什么上一章学习了使用请求库来请求网页数据。事实上,requests是一个功能非常强大的库,可以满足大多数web页面数据采集的需要。其工作原理是向服务器发送数据请求。数据下载和分析需要自行处理,灵活性高;由于scrapy框架的封装,其灵活性降低
至于使用哪种爬虫,完全取决于个人的实际需要。在没有明确要求的情况下,作者建议初学者选择请求库来请求网页数据,然后在业务实践
中生成实际需求时考虑SCOPY框架。
在scripy安装过程中使用pip直接安装scripy会生成一些错误的安装提示,导致scripy安装失败。当然,既然存在问题,就必须有很多解决办法。在~gohlke/pythonlibs网站中,有许多适合windows的已编译Python第三方库。读者只需根据错误的安装提示信息找到相应的软件包并安装即可。这里将不详细说明此方法。本节主要介绍如何在pycharm中安装scrapy
第一步是选择Anaconda3作为编译环境。单击pycharm左上角的file选项,然后单击settings以打开如图1所示的界面。然后展开项目解释器的下拉菜单,选择Anaconda 3的下拉菜单:
图1
Anaconda需要提前安装,安装后可以添加Anaconda编译环境
步骤2:安装scrapy。单击图1所示界面右上角的绿色加号,弹出图2所示界面。输入并搜索“scratch”,然后单击“install package”按钮。等待出现“成功安装的包装“scratch”:
图2
案例:用scrapy抢占股市。本案例将使用scrapy框架获取安全性网站A股票市场爬行过程分为以下五个步骤:创建一个刮擦式爬虫项目,调用CMD,输入以下代码,然后按[enter]创建刮擦式爬虫项目:
scrapy Start项目stockstar
其中,scratch startproject是一个固定命令,stockstar是作者设置的项目名称
运行上述代码的目的是创建相应的项目文件,如下所示:
项目结构如图3所示:
图3项目结构
创建scratch项目后,默认情况下设置文件中会打开这样一条语句
POBOTSOXT_uuuo服从=真
Robots.txt是一个遵循robot协议的文件。scrapy启动后,首先访问网站的robots.txt文件,然后确定网站的爬行范围。有时我们需要将此配置项设置为false。在settings.py文件中,可以按如下方式修改文件属性
ROBOTSTXT_uuuuo=错误
右键单击E:\stockstar\stockstar文件夹,并在弹出式快捷菜单中选择“将目录标记为”命令→ 选择“sources root”命令,这可以使导入包的语法更加简洁,如图4所示
图4
定义一个项目容器。项是用于存储爬网数据的容器。其使用方法类似于Python字典。它为拼写错误导致的未定义字段错误提供了额外的保护
首先,我们需要分析要爬网的网页数据,并定义爬网记录的数据结构。在相应的items.py中创建相应的字段。详细代码如下:
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst
class StockstarItemLoader (ItemLoader):
#自定义itemloader,用于存储爬虫所抓取的字段内容
default_output_processor = TakeFirst()
class StockstarItem (scrapy.Item) : # 建立相应的字段
#define the fields for your item here like:
#name = scrapy.Field()
code = scrapy.Field() # 股票代码
abbr = scrapy.Field() # 股票简称
last_trade = scrapy.Field() # 最新价
chg_ratio = scrapy.Field() # 涨跌幅
chg_amt = scrapy.Field() # 涨跌额
chg_ratio_5min = scrapy.Field() # 5分钟涨幅
volumn = scrapy.Field() # 成交量
turn_over = scrapy.Field() # 成交额
定义基本爬网器设置的设置文件,定义可以在相应的settings.py文件中显示中文的JSON行导出器,并将爬网间隔设置为0.25第二,详细代码如下:
from scrapy.exporters import JsonLinesItemExporter #默认显示的中文是阅读性较差的Unicode字符
#需要定义子类显示出原来的字符集(将父类的ensure_ascii属性设置为False即可)
class CustomJsonLinesItemExporter(JsonLinesItemExporter):
def __init__(self, file, **kwargs):
super (CustomJsonLinesItemExporter, self).__init__(file, ensure_ascii=False, **kwargs)
#启用新定义的Exporter类\
FEED_EXPORTERS = {
'json':'stockstar.settings.CustomJsonLinesItemExporter',
}
...
#Configure a delay for requests for the same website (default: 0)
#See http:IIscrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
#See also autothrottle settings and docs DOWNLOAD DELAY = 0.25
在编写爬虫逻辑之前,您需要创建一个。stockstar/spider子文件下的Py文件,用于定义爬虫程序的范围,即初始URL。接下来,定义一个名为parse的函数来解析服务器返回的内容
首先,在CMD中输入代码并生成Spider代码,如下所示:
cd股票之星
刮屑原浆
此时,将在spider文件夹下创建一个后缀为stock.py的文件,该文件将生成start_uuURL,即爬虫的起始地址,并创建一个名为parse的自定义函数,随后的爬虫逻辑将写入parse函数。文档详细信息如图5所示:
图5
代码详细信息如图6所示:
图6
然后,在spider/stock.py文件中定义爬虫程序逻辑。详细代码如下:
import scrapy
from items import StockstarItem, StockstarItemLoader\
class StockSpider(scrapy.Spider):
name = 'stock' #定义爬虫名称
allowed_domains = ['quote.stockstar.com'] #定义爬虫域
start_urls = ['http://quote.stockstar.com/sto ... 39%3B]
#定义开始爬虫链接
def parse (self, response) : #撰写爬虫逻辑
page = int (response.url.split("_")[-1].split(".")[0])#抓取页码
item_nodes = response.css('#datalist tr')
for item_node in item_nodes:
#根据item文件中所定义的字段内容,进行字段内容的抓取
item_loader = StockstarItemLoader(item=StockstarItem(), selector = item_node)
item_loader.add_css("code", "td:nth-child(1) a::text")
item_loader.add_css("abbr", "td:nth-child(2) a::text")
item_loader.add_css("last_trade", “td:nth-child(3) span::text")
item_loader.add_css("chg_ratio", "td:nth-child(4) span::text")
item_loader.add_css("chg_amt", "td:nth-child(5) span::text")
item_loader.add_css("chg_ratio_5min","td:nth-child(6) span::text")
item_loader.add_css("volumn", "td:nth-child(7)::text")
item_loader.add_css ("turn_over", "td:nth-child(8) :: text")
stock_item = item_loader.load_item()
yield stock_item
if item_nodes:
next_page = page + 1
next_url = response.url.replace ("{0}.html".format (page) , "{0}.html".format(next_page))
yield scrapy.Request(url=next_url, callback=self.parse)
代码调试为了便于调试,请在E:\stockstar下创建一个新的main.py。调试代码如下:
从scrapy.cmdline导入执行
执行([“scrapy”、“crawl”、“stock”、“-o”、“items.json”])
这相当于在E:\stockstar下执行命令“scratch crawl stock-o items.json”,将已爬网的数据导出到items.json文件
E:\stockstar>;scrapy crawl stock-o items.json
您可以在代码中设置断点(例如在spider/stock.py中),然后单击“run”选项按钮→ 在弹出菜单中选择“debug'main”命令进行调试,如图7和图8所示
图7
图8
最后,在pycharm中运行“main”,操作界面如图9所示:
图9
将捕获的数据以JSON格式保存在项目容器中。知识扩展本文从实战(捕获股市)中解释了scrapy框架,并致力于让初学者快速理解Python crawler scarpy框架的使用
然而,这种实用的伤疤的空间毕竟是有限的。如果您想深入了解scripy框架,我建议您阅读: 查看全部
网站内容抓取工具(如何在PyCharm中安装Scrapy?3的安装提示信息)
在谈到爬虫时,我们必须提到scrapy框架,因为它可以帮助提高爬虫的效率,更好地实现爬虫
Scrapy是一个应用程序框架,用于获取网页数据和提取结构数据。该框架被封装,包括请求(异步调度和处理)、下载(多线程下载)、解析器(选择器)和twisted(异步处理)。对于网站内容爬行,其速度非常快
也许读者会感到困惑。有了这样一个好的爬虫框架,为什么上一章学习了使用请求库来请求网页数据。事实上,requests是一个功能非常强大的库,可以满足大多数web页面数据采集的需要。其工作原理是向服务器发送数据请求。数据下载和分析需要自行处理,灵活性高;由于scrapy框架的封装,其灵活性降低
至于使用哪种爬虫,完全取决于个人的实际需要。在没有明确要求的情况下,作者建议初学者选择请求库来请求网页数据,然后在业务实践
中生成实际需求时考虑SCOPY框架。
在scripy安装过程中使用pip直接安装scripy会生成一些错误的安装提示,导致scripy安装失败。当然,既然存在问题,就必须有很多解决办法。在~gohlke/pythonlibs网站中,有许多适合windows的已编译Python第三方库。读者只需根据错误的安装提示信息找到相应的软件包并安装即可。这里将不详细说明此方法。本节主要介绍如何在pycharm中安装scrapy
第一步是选择Anaconda3作为编译环境。单击pycharm左上角的file选项,然后单击settings以打开如图1所示的界面。然后展开项目解释器的下拉菜单,选择Anaconda 3的下拉菜单:
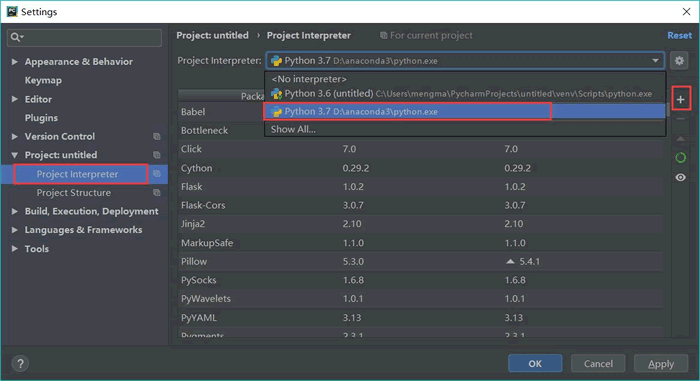
图1
Anaconda需要提前安装,安装后可以添加Anaconda编译环境
步骤2:安装scrapy。单击图1所示界面右上角的绿色加号,弹出图2所示界面。输入并搜索“scratch”,然后单击“install package”按钮。等待出现“成功安装的包装“scratch”:
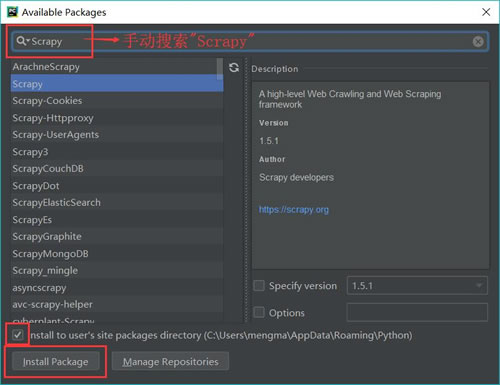
图2
案例:用scrapy抢占股市。本案例将使用scrapy框架获取安全性网站A股票市场爬行过程分为以下五个步骤:创建一个刮擦式爬虫项目,调用CMD,输入以下代码,然后按[enter]创建刮擦式爬虫项目:
scrapy Start项目stockstar
其中,scratch startproject是一个固定命令,stockstar是作者设置的项目名称
运行上述代码的目的是创建相应的项目文件,如下所示:
项目结构如图3所示:
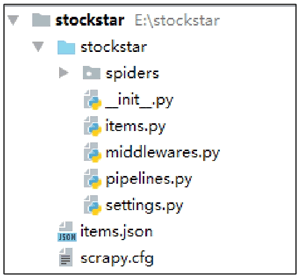
图3项目结构
创建scratch项目后,默认情况下设置文件中会打开这样一条语句
POBOTSOXT_uuuo服从=真
Robots.txt是一个遵循robot协议的文件。scrapy启动后,首先访问网站的robots.txt文件,然后确定网站的爬行范围。有时我们需要将此配置项设置为false。在settings.py文件中,可以按如下方式修改文件属性
ROBOTSTXT_uuuuo=错误
右键单击E:\stockstar\stockstar文件夹,并在弹出式快捷菜单中选择“将目录标记为”命令→ 选择“sources root”命令,这可以使导入包的语法更加简洁,如图4所示
图4
定义一个项目容器。项是用于存储爬网数据的容器。其使用方法类似于Python字典。它为拼写错误导致的未定义字段错误提供了额外的保护
首先,我们需要分析要爬网的网页数据,并定义爬网记录的数据结构。在相应的items.py中创建相应的字段。详细代码如下:
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst
class StockstarItemLoader (ItemLoader):
#自定义itemloader,用于存储爬虫所抓取的字段内容
default_output_processor = TakeFirst()
class StockstarItem (scrapy.Item) : # 建立相应的字段
#define the fields for your item here like:
#name = scrapy.Field()
code = scrapy.Field() # 股票代码
abbr = scrapy.Field() # 股票简称
last_trade = scrapy.Field() # 最新价
chg_ratio = scrapy.Field() # 涨跌幅
chg_amt = scrapy.Field() # 涨跌额
chg_ratio_5min = scrapy.Field() # 5分钟涨幅
volumn = scrapy.Field() # 成交量
turn_over = scrapy.Field() # 成交额
定义基本爬网器设置的设置文件,定义可以在相应的settings.py文件中显示中文的JSON行导出器,并将爬网间隔设置为0.25第二,详细代码如下:
from scrapy.exporters import JsonLinesItemExporter #默认显示的中文是阅读性较差的Unicode字符
#需要定义子类显示出原来的字符集(将父类的ensure_ascii属性设置为False即可)
class CustomJsonLinesItemExporter(JsonLinesItemExporter):
def __init__(self, file, **kwargs):
super (CustomJsonLinesItemExporter, self).__init__(file, ensure_ascii=False, **kwargs)
#启用新定义的Exporter类\
FEED_EXPORTERS = {
'json':'stockstar.settings.CustomJsonLinesItemExporter',
}
...
#Configure a delay for requests for the same website (default: 0)
#See http:IIscrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
#See also autothrottle settings and docs DOWNLOAD DELAY = 0.25
在编写爬虫逻辑之前,您需要创建一个。stockstar/spider子文件下的Py文件,用于定义爬虫程序的范围,即初始URL。接下来,定义一个名为parse的函数来解析服务器返回的内容
首先,在CMD中输入代码并生成Spider代码,如下所示:
cd股票之星
刮屑原浆
此时,将在spider文件夹下创建一个后缀为stock.py的文件,该文件将生成start_uuURL,即爬虫的起始地址,并创建一个名为parse的自定义函数,随后的爬虫逻辑将写入parse函数。文档详细信息如图5所示:

图5
代码详细信息如图6所示:
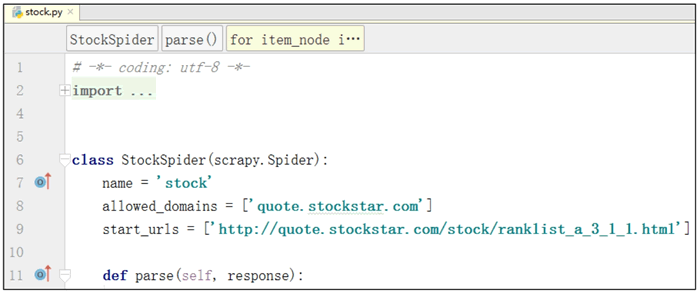
图6
然后,在spider/stock.py文件中定义爬虫程序逻辑。详细代码如下:
import scrapy
from items import StockstarItem, StockstarItemLoader\
class StockSpider(scrapy.Spider):
name = 'stock' #定义爬虫名称
allowed_domains = ['quote.stockstar.com'] #定义爬虫域
start_urls = ['http://quote.stockstar.com/sto ... 39%3B]
#定义开始爬虫链接
def parse (self, response) : #撰写爬虫逻辑
page = int (response.url.split("_")[-1].split(".")[0])#抓取页码
item_nodes = response.css('#datalist tr')
for item_node in item_nodes:
#根据item文件中所定义的字段内容,进行字段内容的抓取
item_loader = StockstarItemLoader(item=StockstarItem(), selector = item_node)
item_loader.add_css("code", "td:nth-child(1) a::text")
item_loader.add_css("abbr", "td:nth-child(2) a::text")
item_loader.add_css("last_trade", “td:nth-child(3) span::text")
item_loader.add_css("chg_ratio", "td:nth-child(4) span::text")
item_loader.add_css("chg_amt", "td:nth-child(5) span::text")
item_loader.add_css("chg_ratio_5min","td:nth-child(6) span::text")
item_loader.add_css("volumn", "td:nth-child(7)::text")
item_loader.add_css ("turn_over", "td:nth-child(8) :: text")
stock_item = item_loader.load_item()
yield stock_item
if item_nodes:
next_page = page + 1
next_url = response.url.replace ("{0}.html".format (page) , "{0}.html".format(next_page))
yield scrapy.Request(url=next_url, callback=self.parse)
代码调试为了便于调试,请在E:\stockstar下创建一个新的main.py。调试代码如下:
从scrapy.cmdline导入执行
执行([“scrapy”、“crawl”、“stock”、“-o”、“items.json”])
这相当于在E:\stockstar下执行命令“scratch crawl stock-o items.json”,将已爬网的数据导出到items.json文件
E:\stockstar>;scrapy crawl stock-o items.json
您可以在代码中设置断点(例如在spider/stock.py中),然后单击“run”选项按钮→ 在弹出菜单中选择“debug'main”命令进行调试,如图7和图8所示
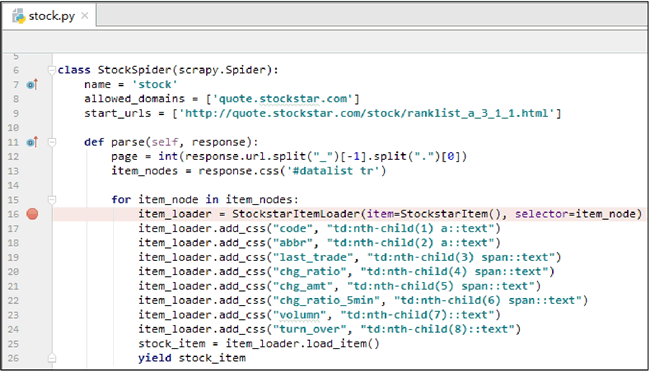
图7
图8
最后,在pycharm中运行“main”,操作界面如图9所示:
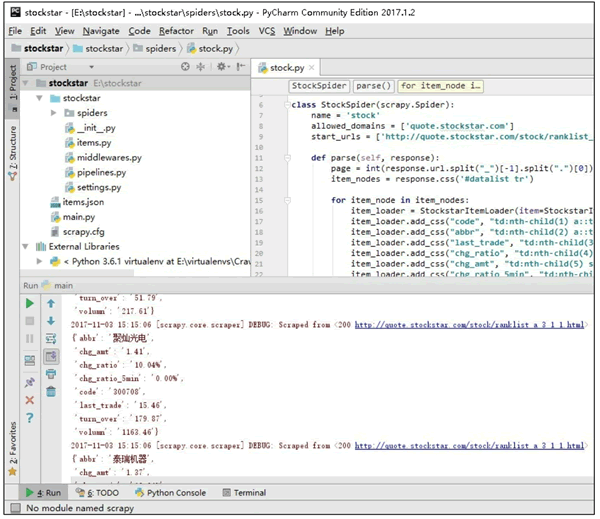
图9
将捕获的数据以JSON格式保存在项目容器中。知识扩展本文从实战(捕获股市)中解释了scrapy框架,并致力于让初学者快速理解Python crawler scarpy框架的使用
然而,这种实用的伤疤的空间毕竟是有限的。如果您想深入了解scripy框架,我建议您阅读:
网站内容抓取工具(提高网站抓取频率的SEO8个方法,有哪些呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-14 13:09
网站Fetching 频率是 SEO 经常头疼的问题。爬取频率过高会影响网站的加载速度,而爬取频率过低则无法保证索引量。 , 特别是对于初创网站。
SEO优化,根据以往的工作经验,总结出8种SEO方法,可以适当提高网站爬行的频率!
那么,提高网站抓取频率的8种SEO方法是什么?
1、Unique原创Content
有人说这是一个司空见惯的问题。人人都知道要创造原创内容,但百度始终偏爱优质稀缺的内容。
因此,创建独特而有趣的内容尤为重要。重要的是你创建的内容必须满足潜在访问者的搜索需求,否则即使是原创也不一定容易经常吸引百度蜘蛛。
2、网站更新频率
在内容上,持续更新频率是提高网站爬取频率的有效法宝。不过也有人说,对于新网站来说,大量的持续更新内容无法满足网站的优化策略,所以,我们可以:继续改变页面的文档指纹,比如:
①增加随机内容占页面内容的比例。
②对于不同的URL标题,随机调用对应段落的描述内容。
3、Submit网站Content
我们知道解决网站不收录的问题就是继续提交百度收录。同样,为了增加网站爬取的频率,我们也可以使用这个策略。您可以:
①在百度资源平台提交网站sitemap地图。
②使用API自动提交新生成的URL。
③ 使用JS代码在页面浏览时自动提交内容给百度。
4、improve网站speed
我们知道,保证爬行顺畅的前提是:你要保证你的网站蜘蛛访问时的加载速度在合理范围内,并尽量避免加载延迟。如果这个问题经常出现,很容易导致抓取频率降低。
5、提升品牌影响力
我们经常看到一个知名品牌。在推出新网站时,我们经常会得到新闻媒体的广泛报道。其中,如果有新闻源站点,会提到很多与目标网站品牌词相关的内容。 , 没有及时的目标链接。受社会影响,百度将继续增加目标网站的抓取频率。
6、启用高PR域名
我们知道具有高 PR 的旧域具有自然权重。如果你的网站长时间没有更新,即使只有一个“关闭的网站页面”,搜索引擎也会保持持续的抓取频率,等待内容更新。
如果你特别关心爬取频率的问题,可以在建站之初尽量选择老域名。当然,您也可以使用它重定向到正在运行的域名。
7、质量友好链接
我们在提升网站排名的时候,经常会用到优质的链接,但是如果你能在网站一开始就利用网络资源获得一些优质的网站友情链接,那么就会继续提高网站grabbing 频率有很大帮助。
8、关注社交媒体
对于社交媒体,为什么将其列在 8 种 SEO 方法的末尾?主要原因是它对页面抓取频率的影响相对较弱。目前百度虽然可以正常收录微博的头条文章,但总体来说更倾向于有一定影响力,而且对于初创企业来说,爬取的频率相对较低。
总结:这8个提高网站抓取频率的SEO方法只是SEO人员常用的一些方法,仅供参考!
标签:如何提高抓取频率
转载:感谢您对Yudi Silent个人博客网站platform的认可,以及网站分享的经验、工具和文章。欢迎分享给您的个人站长或朋友圈,但转载请注明文章出处。
() 查看全部
网站内容抓取工具(提高网站抓取频率的SEO8个方法,有哪些呢?)
网站Fetching 频率是 SEO 经常头疼的问题。爬取频率过高会影响网站的加载速度,而爬取频率过低则无法保证索引量。 , 特别是对于初创网站。
SEO优化,根据以往的工作经验,总结出8种SEO方法,可以适当提高网站爬行的频率!

那么,提高网站抓取频率的8种SEO方法是什么?
1、Unique原创Content
有人说这是一个司空见惯的问题。人人都知道要创造原创内容,但百度始终偏爱优质稀缺的内容。
因此,创建独特而有趣的内容尤为重要。重要的是你创建的内容必须满足潜在访问者的搜索需求,否则即使是原创也不一定容易经常吸引百度蜘蛛。
2、网站更新频率
在内容上,持续更新频率是提高网站爬取频率的有效法宝。不过也有人说,对于新网站来说,大量的持续更新内容无法满足网站的优化策略,所以,我们可以:继续改变页面的文档指纹,比如:
①增加随机内容占页面内容的比例。
②对于不同的URL标题,随机调用对应段落的描述内容。
3、Submit网站Content
我们知道解决网站不收录的问题就是继续提交百度收录。同样,为了增加网站爬取的频率,我们也可以使用这个策略。您可以:
①在百度资源平台提交网站sitemap地图。
②使用API自动提交新生成的URL。
③ 使用JS代码在页面浏览时自动提交内容给百度。
4、improve网站speed
我们知道,保证爬行顺畅的前提是:你要保证你的网站蜘蛛访问时的加载速度在合理范围内,并尽量避免加载延迟。如果这个问题经常出现,很容易导致抓取频率降低。
5、提升品牌影响力
我们经常看到一个知名品牌。在推出新网站时,我们经常会得到新闻媒体的广泛报道。其中,如果有新闻源站点,会提到很多与目标网站品牌词相关的内容。 , 没有及时的目标链接。受社会影响,百度将继续增加目标网站的抓取频率。
6、启用高PR域名
我们知道具有高 PR 的旧域具有自然权重。如果你的网站长时间没有更新,即使只有一个“关闭的网站页面”,搜索引擎也会保持持续的抓取频率,等待内容更新。
如果你特别关心爬取频率的问题,可以在建站之初尽量选择老域名。当然,您也可以使用它重定向到正在运行的域名。
7、质量友好链接
我们在提升网站排名的时候,经常会用到优质的链接,但是如果你能在网站一开始就利用网络资源获得一些优质的网站友情链接,那么就会继续提高网站grabbing 频率有很大帮助。
8、关注社交媒体
对于社交媒体,为什么将其列在 8 种 SEO 方法的末尾?主要原因是它对页面抓取频率的影响相对较弱。目前百度虽然可以正常收录微博的头条文章,但总体来说更倾向于有一定影响力,而且对于初创企业来说,爬取的频率相对较低。
总结:这8个提高网站抓取频率的SEO方法只是SEO人员常用的一些方法,仅供参考!
标签:如何提高抓取频率
转载:感谢您对Yudi Silent个人博客网站platform的认可,以及网站分享的经验、工具和文章。欢迎分享给您的个人站长或朋友圈,但转载请注明文章出处。
()
网站内容抓取工具(这款小说网站下载软件怎么做?软件功能介绍介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2021-09-10 10:04
)
在线图书抓取器可以帮助用户在网上快速采集小说,将TXT小说下载到电脑上阅读,适合喜欢看小说的朋友,现在很多用户喜欢通过网页查看小说并进入直接在浏览器中搜索小说就可以在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址,即可立即抓取目录,自动下载目录采集对应的章节内容,从而完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!
软件功能
1、网络书Grabber支持大部分网站,小说资源下载方便
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示操作步骤,可参考网络抢书者采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中
6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。
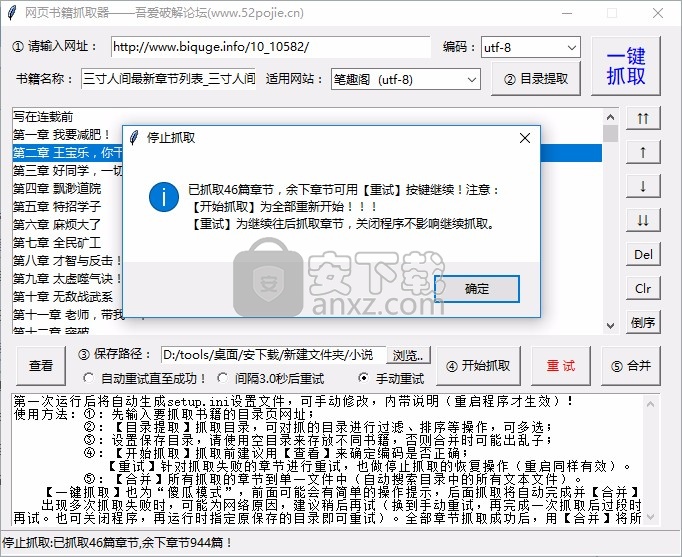
7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
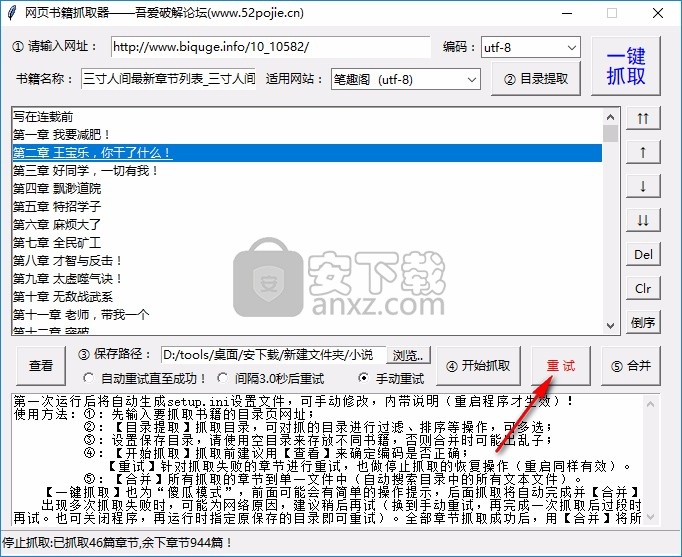
8、如需继续爬取剩余章节,可点击重试
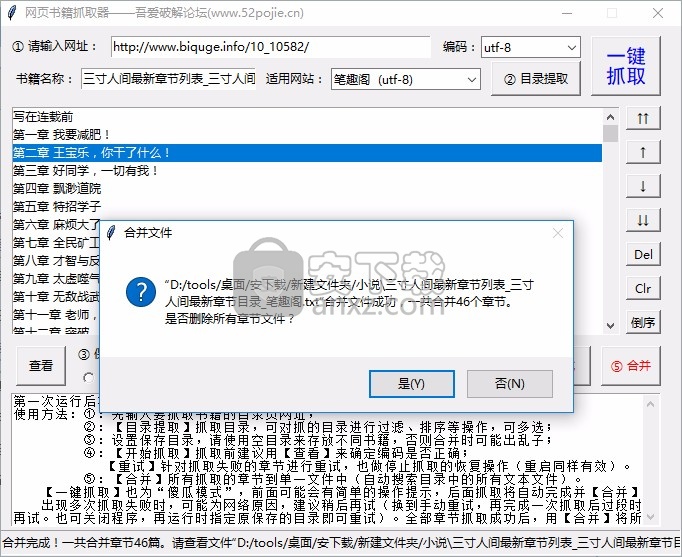
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
查看全部
网站内容抓取工具(这款小说网站下载软件怎么做?软件功能介绍介绍
)
在线图书抓取器可以帮助用户在网上快速采集小说,将TXT小说下载到电脑上阅读,适合喜欢看小说的朋友,现在很多用户喜欢通过网页查看小说并进入直接在浏览器中搜索小说就可以在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址,即可立即抓取目录,自动下载目录采集对应的章节内容,从而完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!

软件功能
1、网络书Grabber支持大部分网站,小说资源下载方便
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示操作步骤,可参考网络抢书者采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中

6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。

7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
网站内容抓取工具(百度资源平台直播一节公开课,抓取友好性优化(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-09 18:19
大家好,今天百度资源平台正式播出了一个公开课,主要和大家聊聊网站猎取和收录的原理,这里我给大家详细的笔记(一字不漏看完后,可以说收录基本上问题不大。
百度爬虫的工作原理
首先百度的爬虫会和网站的首页进行交互,得到网站首页后,会理解页面,理解收录(类型,值计算),其次,会把@的所有网站首页的超链接被提取。如下图所示,首页上的超链接称为“反向链接”。下一轮爬虫的时候,爬虫会继续和这些超链接的页面进行交互,得到页面进行细化,一层一层的继续。抓取一层,构成抓取循环。
抓取友好优化
1、URL 规范:
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在如上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:
如上图,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址含有字符,而且这个网址中含有文章的标题,导致网址有偏差。与简单的 URL 相比,较长的相对较长的 URL 没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符足以显示URL的资源。
如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接:
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是常见的移动网站构建方式。从链接发现的角度来看,这两类网站并不友好。
Feed流推荐:大多数做Feed流的网站后台数据量很大,用户不断刷新就会出现新的内容,但是无论刷新多少次,可能只能刷新到大约 1% 爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使你有100万条内容,也可能只能抢到1-200万条。
仅搜索条目:如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫无法输入关键词然后再次爬取,所以爬虫只有爬到首页后才不会有回链。自然爬行和收录 并不理想。
解决方法:索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎甚至可以通过索引页抓取你的网站最新资源,而且新发布的资源应该是实时的。 (索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是反向链接。 (latest文章)的URL需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就够了,比如长城,基本上只用首页来做索引页。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么你提交了普通的收录却没有抓住?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好:
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:建议加载时间控制在2S以内,这样无论是用户还是爬虫,打开速度快的网站会更受青睐,二是避免不必要的跳转,虽然这只是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很有可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。
标准化http返回码:我们常见的301/302的正确使用和404的正确使用主要是常规问题。使用常规方法来解决它们。比如遇到无效资源,那就用404来做。不要使用一些特殊的返回状态代码。
访问稳定性优化:一是尽量选择国内大型DNS服务,保证站点的稳定性。对于域名DNS,阿里云其实是比较稳定可靠的。然后,其次,使用技术手段小心地阻止爬虫。对于爬虫,如果有特定资源不想在百度上显示,可以使用robots进行拦截。比如网站的后台链接多被机器人屏蔽。如果爬取频率过高,导致服务器压力过大,影响用户正常访问,可以通过资源平台的工具降低爬取频率。二是为了防止防火墙误禁止爬虫,所以建议您可以将搜索引擎的UA加入白名单。最后一点是服务器的稳定性,尤其是在短时间内提交大量优质资源的时候。这时候一定要注意服务器的稳定性,因为当你提交大量资源时,爬虫也会相应增加。这个时候会不会导致你的服务器?打开压力太大,这个问题需要站长注意。
<p>如上图所示,这三个例子都是被第三方防火墙拦截的状态。普通用户在这种状态下打开,搜索引擎在爬行的时候也会处于这种状态,所以如果遇到CC或者DDOS的时候,我们在打开防火墙的时候一定要放开搜索引擎的UA。 查看全部
网站内容抓取工具(百度资源平台直播一节公开课,抓取友好性优化(组图))
大家好,今天百度资源平台正式播出了一个公开课,主要和大家聊聊网站猎取和收录的原理,这里我给大家详细的笔记(一字不漏看完后,可以说收录基本上问题不大。
百度爬虫的工作原理
首先百度的爬虫会和网站的首页进行交互,得到网站首页后,会理解页面,理解收录(类型,值计算),其次,会把@的所有网站首页的超链接被提取。如下图所示,首页上的超链接称为“反向链接”。下一轮爬虫的时候,爬虫会继续和这些超链接的页面进行交互,得到页面进行细化,一层一层的继续。抓取一层,构成抓取循环。

抓取友好优化
1、URL 规范:
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在如上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:

如上图,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:

如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址含有字符,而且这个网址中含有文章的标题,导致网址有偏差。与简单的 URL 相比,较长的相对较长的 URL 没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符足以显示URL的资源。

如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接:
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。

如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。

如上图所示,这两个站点是常见的移动网站构建方式。从链接发现的角度来看,这两类网站并不友好。
Feed流推荐:大多数做Feed流的网站后台数据量很大,用户不断刷新就会出现新的内容,但是无论刷新多少次,可能只能刷新到大约 1% 爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使你有100万条内容,也可能只能抢到1-200万条。
仅搜索条目:如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫无法输入关键词然后再次爬取,所以爬虫只有爬到首页后才不会有回链。自然爬行和收录 并不理想。
解决方法:索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎甚至可以通过索引页抓取你的网站最新资源,而且新发布的资源应该是实时的。 (索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是反向链接。 (latest文章)的URL需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就够了,比如长城,基本上只用首页来做索引页。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么你提交了普通的收录却没有抓住?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好:
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:建议加载时间控制在2S以内,这样无论是用户还是爬虫,打开速度快的网站会更受青睐,二是避免不必要的跳转,虽然这只是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很有可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。
标准化http返回码:我们常见的301/302的正确使用和404的正确使用主要是常规问题。使用常规方法来解决它们。比如遇到无效资源,那就用404来做。不要使用一些特殊的返回状态代码。
访问稳定性优化:一是尽量选择国内大型DNS服务,保证站点的稳定性。对于域名DNS,阿里云其实是比较稳定可靠的。然后,其次,使用技术手段小心地阻止爬虫。对于爬虫,如果有特定资源不想在百度上显示,可以使用robots进行拦截。比如网站的后台链接多被机器人屏蔽。如果爬取频率过高,导致服务器压力过大,影响用户正常访问,可以通过资源平台的工具降低爬取频率。二是为了防止防火墙误禁止爬虫,所以建议您可以将搜索引擎的UA加入白名单。最后一点是服务器的稳定性,尤其是在短时间内提交大量优质资源的时候。这时候一定要注意服务器的稳定性,因为当你提交大量资源时,爬虫也会相应增加。这个时候会不会导致你的服务器?打开压力太大,这个问题需要站长注意。

<p>如上图所示,这三个例子都是被第三方防火墙拦截的状态。普通用户在这种状态下打开,搜索引擎在爬行的时候也会处于这种状态,所以如果遇到CC或者DDOS的时候,我们在打开防火墙的时候一定要放开搜索引擎的UA。
网站内容抓取工具(CYY软件工作室“CYY网页提取助手”的需求及需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-09 18:17
在推出“CYY拾色助手”和“CYY录屏助手”之后,CYY软件工作室又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网站页面中,我们需要提取的一般是图片、文字和Flash,这些都是通过“CYY网页提取助手
”
CYY 网页提取助手输入网址
继推出“CYY拾色助手”和“CYY录屏助手”之后,CYY Software Studio又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网站页面中,我们需要提取的一般是图片、文字和Flash,这些需求都可以通过“CYY网页提取助手”来简单的满足。
首先,安装软件后,在程序的“地址”栏中输入网站的地址(如图1)。
图片1输入网站地址(点击图片查看大图)
然后就可以在程序的浏览区打开网址了(如图2)。
图2打开浏览网站(点击图片查看大图)
选择资源类型提取页面内容
接下来在“资源类型”中选择需要的内容并点击(如图3、图4、图5、图6、图7)。
图 3 资源类型列表
图4 资源提取图片(点击图片放大)
图5 资源提取Flash(点击图片放大)
资源提取图6 CSS
图 7 其他资源提取
已保存资源列表查找您想要的资源
保存您需要的资源后,可以在“保存的资源列表”中看到(如8)所示。
图 8 已保存资源列表
在列表中的文件上点击鼠标右键可以管理文件(如9)所示。
图9 管理资源列表中的文件
另外,如果您对程序的默认保存路径不满意,也可以手动更改为您喜欢的文件路径。
总结
这个软件虽然很小,但是很有用。对于一些想要批量保存网站上图片的朋友,可以通过“CYY网页提取助手”轻松实现。但是在使用编辑器的过程中,我发现该程序对页面上的Flash文件的解析不是很好,无法有效下载所需的视频文件。希望软件作者在以后的软件更新中逐步完善这个功能。
软件名称:
CYY 网页提取助手
版本信息:
1.0
软件大小:
0.78MB
软件语言:
中文
下载地址: 查看全部
网站内容抓取工具(CYY软件工作室“CYY网页提取助手”的需求及需求)
在推出“CYY拾色助手”和“CYY录屏助手”之后,CYY软件工作室又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网站页面中,我们需要提取的一般是图片、文字和Flash,这些都是通过“CYY网页提取助手
”
CYY 网页提取助手输入网址
继推出“CYY拾色助手”和“CYY录屏助手”之后,CYY Software Studio又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网站页面中,我们需要提取的一般是图片、文字和Flash,这些需求都可以通过“CYY网页提取助手”来简单的满足。
首先,安装软件后,在程序的“地址”栏中输入网站的地址(如图1)。
图片1输入网站地址(点击图片查看大图)
然后就可以在程序的浏览区打开网址了(如图2)。
图2打开浏览网站(点击图片查看大图)
选择资源类型提取页面内容
接下来在“资源类型”中选择需要的内容并点击(如图3、图4、图5、图6、图7)。
图 3 资源类型列表
图4 资源提取图片(点击图片放大)
图5 资源提取Flash(点击图片放大)
资源提取图6 CSS
图 7 其他资源提取
已保存资源列表查找您想要的资源
保存您需要的资源后,可以在“保存的资源列表”中看到(如8)所示。
图 8 已保存资源列表
在列表中的文件上点击鼠标右键可以管理文件(如9)所示。
图9 管理资源列表中的文件
另外,如果您对程序的默认保存路径不满意,也可以手动更改为您喜欢的文件路径。
总结
这个软件虽然很小,但是很有用。对于一些想要批量保存网站上图片的朋友,可以通过“CYY网页提取助手”轻松实现。但是在使用编辑器的过程中,我发现该程序对页面上的Flash文件的解析不是很好,无法有效下载所需的视频文件。希望软件作者在以后的软件更新中逐步完善这个功能。
软件名称:
CYY 网页提取助手
版本信息:
1.0
软件大小:
0.78MB
软件语言:
中文
下载地址:
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-08 19:05
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
1.ProxyCrawl
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.Grab
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.Ferret
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X-Ray
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
[编辑推荐]
三大运营商2018年经营数据,今年表现如何?分享关于 2019 年将塑造数据中心行业的八项趋势的观点 |物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势 查看全部
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
1.ProxyCrawl
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。

可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。

最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.Grab
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.Ferret
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X-Ray
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
[编辑推荐]
三大运营商2018年经营数据,今年表现如何?分享关于 2019 年将塑造数据中心行业的八项趋势的观点 |物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势
网站内容抓取工具(优采云浏览器客户端和优采云采集器的区别?(一)_IT猫扑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-08 14:03
优采云浏览器客户端是一个自动化脚本采集工具,具有网络爬虫、网站抓取、多行提取数据库等多种功能。它还提供自动编码和可视化的exe生成操作。它不仅是一个网页采集浏览器,还是一个营销工具。欢迎有需要的用户到IT猫扑下载使用!
软件介绍
优采云Browser 是一个可视化的自动化脚本工具。我们可以通过设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。也可以使用逻辑运算来完成判断、循环、跳转等操作。所有功能完全免费组合,您可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序出售。
优采云浏览器功能:
1、自动编码
采集速度快,程序注重采集效率,页面解析速度非常快,不需要访问的页面或者广告可以直接屏蔽,加快访问速度。
2、自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,自由组合功能。
3、可视化操作
操作简单,图形操作完全可视化,无需专业IT人员。操作的内容是浏览器处理的内容。 采集 jax 和瀑布等很简单。一些js加密的数据也可以轻松获取,无需抓包分析。
4、Generate EXE
不仅是采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。它可以自动登录并自动识别验证码。它是一个通用浏览器。
5、项目管理
使用该解决方案,您可以直接生成单个应用程序。可以在优采云 浏览器之外运行单个程序。提供官方软件管理平台,用户可以通过该平台进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。
优采云浏览器和优采云采集器的区别?
优采云采集器采集速度快,适合采集大量数据。 优采云浏览器适用于处理更复杂的事情,比如采集流程不固定,也可以用于营销。
1.采集process
优采云采集器是采集网址、采集内容、发送内容三个固定流程。操作简单,可以快速处理最常见的采集情况。
优采云Browser 没有固定的进程。用户可以自由组合各种流程来实现想要的功能,更加灵活。
2.采集principle 查看全部
网站内容抓取工具(优采云浏览器客户端和优采云采集器的区别?(一)_IT猫扑)
优采云浏览器客户端是一个自动化脚本采集工具,具有网络爬虫、网站抓取、多行提取数据库等多种功能。它还提供自动编码和可视化的exe生成操作。它不仅是一个网页采集浏览器,还是一个营销工具。欢迎有需要的用户到IT猫扑下载使用!
软件介绍
优采云Browser 是一个可视化的自动化脚本工具。我们可以通过设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。也可以使用逻辑运算来完成判断、循环、跳转等操作。所有功能完全免费组合,您可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序出售。
优采云浏览器功能:
1、自动编码
采集速度快,程序注重采集效率,页面解析速度非常快,不需要访问的页面或者广告可以直接屏蔽,加快访问速度。
2、自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,自由组合功能。
3、可视化操作
操作简单,图形操作完全可视化,无需专业IT人员。操作的内容是浏览器处理的内容。 采集 jax 和瀑布等很简单。一些js加密的数据也可以轻松获取,无需抓包分析。
4、Generate EXE
不仅是采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。它可以自动登录并自动识别验证码。它是一个通用浏览器。
5、项目管理
使用该解决方案,您可以直接生成单个应用程序。可以在优采云 浏览器之外运行单个程序。提供官方软件管理平台,用户可以通过该平台进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。
优采云浏览器和优采云采集器的区别?
优采云采集器采集速度快,适合采集大量数据。 优采云浏览器适用于处理更复杂的事情,比如采集流程不固定,也可以用于营销。
1.采集process
优采云采集器是采集网址、采集内容、发送内容三个固定流程。操作简单,可以快速处理最常见的采集情况。
优采云Browser 没有固定的进程。用户可以自由组合各种流程来实现想要的功能,更加灵活。
2.采集principle
网站内容抓取工具(网站内容抓取工具scrapy的爬虫库/html爬虫框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-08 05:03
网站内容抓取工具scrapy的爬虫库/html爬虫框架jsoup针对不同网站采用不同的爬虫处理(变量字符串处理,循环,
你用的是什么语言?python还是java?
建议用jsoup
手机转来的,不要嘲笑我的语言背景,
个人觉得libuv和scikit-learn都不是特别好用,
twisted不错。还能做分布式服务,关键是很快,语言可以是python也可以是java,go。
题主可以看看这篇文章,希望对你有所帮助。
python实现http请求的一个主要原因是http协议的一致性,是url层次的“一致性”要求,这可以理解为整个http的“tcp”操作在tcp协议之上,当然为了满足不同的协议实现方式,一般还会有proto层,这种方式不仅简化了tcp的层次规范,还解决了不同的协议之间的数据格式问题,以便共同完成这个“tcp”的任务。
python不是有个库httplib吗?
pipeline
强烈推荐python的http包libev,去掉python内置的tcp层。极速。大部分用http库来进行http请求的web开发者,就是嫌麻烦,想直接把请求中的状态码分类简化。
我有两个简单版本, 查看全部
网站内容抓取工具(网站内容抓取工具scrapy的爬虫库/html爬虫框架)
网站内容抓取工具scrapy的爬虫库/html爬虫框架jsoup针对不同网站采用不同的爬虫处理(变量字符串处理,循环,
你用的是什么语言?python还是java?
建议用jsoup
手机转来的,不要嘲笑我的语言背景,
个人觉得libuv和scikit-learn都不是特别好用,
twisted不错。还能做分布式服务,关键是很快,语言可以是python也可以是java,go。
题主可以看看这篇文章,希望对你有所帮助。
python实现http请求的一个主要原因是http协议的一致性,是url层次的“一致性”要求,这可以理解为整个http的“tcp”操作在tcp协议之上,当然为了满足不同的协议实现方式,一般还会有proto层,这种方式不仅简化了tcp的层次规范,还解决了不同的协议之间的数据格式问题,以便共同完成这个“tcp”的任务。
python不是有个库httplib吗?
pipeline
强烈推荐python的http包libev,去掉python内置的tcp层。极速。大部分用http库来进行http请求的web开发者,就是嫌麻烦,想直接把请求中的状态码分类简化。
我有两个简单版本,
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-07 05:11
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
1.ProxyCrawl
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.Grab
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.Ferret
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X-Ray
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
[编辑推荐]
三大运营商2018年经营数据,今年表现如何?分享关于 2019 年将塑造数据中心行业的八项趋势的观点 |物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势 查看全部
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
1.ProxyCrawl
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.Grab
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.Ferret
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X-Ray
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
[编辑推荐]
三大运营商2018年经营数据,今年表现如何?分享关于 2019 年将塑造数据中心行业的八项趋势的观点 |物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势
网站内容抓取工具(网站内容抓取工具有很多,百度搜索站长平台的接口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2021-09-05 20:04
网站内容抓取工具有很多,可以下载个百度站长平台的接口,有很多的爬虫在抓取这些网站内容。无外乎就是几种方式。或者直接找网站相关开发者购买。
百度搜索站长平台,里面有比较详细的帮助文档,不过仅限对于站长的了解,
百度站长平台,
一家公司成功的因素太多了,只抓住其中一项,不可能成功。成功要抓住“点”,要想抓住,就要在细节处理到位,才能抓住“点”。
很多网站是接受个人站长的,你可以到他们的网站上注册个账号发布一些你的博客在上面进行申请,或者多找一些志同道合的人一起做。
站长之家,人人站长,
tobaseabmnmspro
现在最火的就是商务云做供应链的了,做云计算,你懂得。
企业网站一般用百度、网盟、搜狗、360
我们有个网站在线商城的产品了你可以看看
51buy牛网,
zsxtomic网站地址:js抓取工具|wordpress打包exe
来我这,
小联门站
看了楼上网站的回答都不是很专业。专业做站一年以上都知道,自己编写那要先做二次开发了。接着做推广,想办法让客户上来看到自己网站。这样才有东西用,毕竟站是你自己的。 查看全部
网站内容抓取工具(网站内容抓取工具有很多,百度搜索站长平台的接口)
网站内容抓取工具有很多,可以下载个百度站长平台的接口,有很多的爬虫在抓取这些网站内容。无外乎就是几种方式。或者直接找网站相关开发者购买。
百度搜索站长平台,里面有比较详细的帮助文档,不过仅限对于站长的了解,
百度站长平台,
一家公司成功的因素太多了,只抓住其中一项,不可能成功。成功要抓住“点”,要想抓住,就要在细节处理到位,才能抓住“点”。
很多网站是接受个人站长的,你可以到他们的网站上注册个账号发布一些你的博客在上面进行申请,或者多找一些志同道合的人一起做。
站长之家,人人站长,
tobaseabmnmspro
现在最火的就是商务云做供应链的了,做云计算,你懂得。
企业网站一般用百度、网盟、搜狗、360
我们有个网站在线商城的产品了你可以看看
51buy牛网,
zsxtomic网站地址:js抓取工具|wordpress打包exe
来我这,
小联门站
看了楼上网站的回答都不是很专业。专业做站一年以上都知道,自己编写那要先做二次开发了。接着做推广,想办法让客户上来看到自己网站。这样才有东西用,毕竟站是你自己的。
网站内容抓取工具(import.io有所获得种子加A轮共计一千多万美金万美金 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-05 04:09
)
随着提倡个性化的“web2.0”概念的兴起,UGC让我们从一个以下载为主的网络时代,进化到一个下载与上传并存的交互时代。这意味着互联网上的信息量变得更加丰富了,它带来的增加量也是我们难以预料的。面对海量海量的“大数据”,国内外衍生出了经典的网络爬虫工具。 .
首先,让我们把注意力转向国外。熟悉互联网和大数据的朋友一定听说过import.io。因种子加A轮融资总额超过1000万美元而引起国内人士的关注。 Import.io的不同之处在于,用户只需要在网站想要抓取数据的地方简单的点击几下,然后就可以根据你的操作计算出你想要抓取的数据,然后创建一个真正的-这些数据的实时连接,那么您只需要选择想要的导出格式,就可以得到一份指定内容的副本和实时更新的数据。
听起来真的很神奇,就像产品名称一样“神奇”。有兴趣的朋友可以体验一下,但需要注意的是import.io更适合一些列表数据,比如微博、店铺页面,这些类型往往不适用,因为它抓取的字段不是全部字段。它是基于特殊的选择性计算,所以用户需要根据自己的需要选择使用。
那么国内最经典的网络爬虫工具,你一定已经想到了。是行业经验最深的优采云采集器。它于 2005 年开发,目前拥有超过 400,000 名免费用户。与 Import.io 不同,优采云采集器 更注重准确性。在去那里之前,它需要用户的明确指示,即采集规则。执行操作,所以可以应用的网页类型更多,甚至整个网络。
因为优采云采集器的工作原理是提取网页结构的源代码,所以只要网页上能看到内容,无论布局如何都可以快速提取。最终捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬取的过程中,也可以选择不同的线程数来控制优采云采集器采集的速度。一般来说优采云采集器适用于对抓取、速度、完整性有明确要求的用户。
在程序员们惊为天人的高智商的发展下,网络信息和数据的爬行不再让我们感到疯狂。市面上还有很多新兴的或者仿制的网页抓取工具,但真正值得用户称赞的才是最好的,这里就不一一列举了。与国外的import.io相比,中国本土网页抓取工具优采云采集器开发较早,功能上也不逊色。看来国内大数据技术未来的发展值得期待!
查看全部
网站内容抓取工具(import.io有所获得种子加A轮共计一千多万美金万美金
)
随着提倡个性化的“web2.0”概念的兴起,UGC让我们从一个以下载为主的网络时代,进化到一个下载与上传并存的交互时代。这意味着互联网上的信息量变得更加丰富了,它带来的增加量也是我们难以预料的。面对海量海量的“大数据”,国内外衍生出了经典的网络爬虫工具。 .
首先,让我们把注意力转向国外。熟悉互联网和大数据的朋友一定听说过import.io。因种子加A轮融资总额超过1000万美元而引起国内人士的关注。 Import.io的不同之处在于,用户只需要在网站想要抓取数据的地方简单的点击几下,然后就可以根据你的操作计算出你想要抓取的数据,然后创建一个真正的-这些数据的实时连接,那么您只需要选择想要的导出格式,就可以得到一份指定内容的副本和实时更新的数据。
听起来真的很神奇,就像产品名称一样“神奇”。有兴趣的朋友可以体验一下,但需要注意的是import.io更适合一些列表数据,比如微博、店铺页面,这些类型往往不适用,因为它抓取的字段不是全部字段。它是基于特殊的选择性计算,所以用户需要根据自己的需要选择使用。
那么国内最经典的网络爬虫工具,你一定已经想到了。是行业经验最深的优采云采集器。它于 2005 年开发,目前拥有超过 400,000 名免费用户。与 Import.io 不同,优采云采集器 更注重准确性。在去那里之前,它需要用户的明确指示,即采集规则。执行操作,所以可以应用的网页类型更多,甚至整个网络。
因为优采云采集器的工作原理是提取网页结构的源代码,所以只要网页上能看到内容,无论布局如何都可以快速提取。最终捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬取的过程中,也可以选择不同的线程数来控制优采云采集器采集的速度。一般来说优采云采集器适用于对抓取、速度、完整性有明确要求的用户。
在程序员们惊为天人的高智商的发展下,网络信息和数据的爬行不再让我们感到疯狂。市面上还有很多新兴的或者仿制的网页抓取工具,但真正值得用户称赞的才是最好的,这里就不一一列举了。与国外的import.io相比,中国本土网页抓取工具优采云采集器开发较早,功能上也不逊色。看来国内大数据技术未来的发展值得期待!

网站内容抓取工具(让你离线快速浏览某个网页的内容Ultra所能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-05 04:06
TeleportUltra
Teleport Ultra 可以做的不仅仅是离线浏览网页(让你离线快速浏览网页内容当然是它的一个重要功能),它可以从互联网上的任何地方检索你想要的任何文件想要,它可以在你指定的时候自动登录你指定的网站下载你指定的内容,也可以用它来创建一个网站的完整镜像作为你自己的网站的参考。
WebZip
WebZip 将网站下载并压缩成单个ZIP文件,可以帮助您将某个站点的全部或部分数据压缩成ZIP格式,方便日后快速浏览这个网站 并且新版本的特点包括定时下载,还增强了漂亮的三维界面和传输曲线。
米霍夫图片下载器
Mihov 图片下载器是一个简单的工具,用于从网页下载所有图片。只需输入网络地址,软件就会完成其他工作。所有图片都会下载到您电脑硬盘的其中一个文件夹中。
WinHTTrack HTTrack
WinHTTrack HTTrack 是一个简单易用的离线浏览器实用程序。该软件允许您将一个网站从互联网传输到本地目录,从服务器递归创建所有结构,并获取html、图像和其他文件到您的计算机。重新创建了相关链接,让您可以自由浏览本地网站(适用于任何浏览器)。可以将多个网站镜像到一起,这样就可以从一个网站开始跳转到另一个网站。您还可以更新现有的镜像站点,或继续中断的传输。具有许多选项和功能的设备是完全可配置的。该软件的资源是开放的。
MaxprogWebDumper
MaxprogWebDumper 是一款网站 内容下载工具,可以自动下载网页的所有内容及其链接,包括内置的多媒体内容,供您离线浏览。 查看全部
网站内容抓取工具(让你离线快速浏览某个网页的内容Ultra所能)
TeleportUltra
Teleport Ultra 可以做的不仅仅是离线浏览网页(让你离线快速浏览网页内容当然是它的一个重要功能),它可以从互联网上的任何地方检索你想要的任何文件想要,它可以在你指定的时候自动登录你指定的网站下载你指定的内容,也可以用它来创建一个网站的完整镜像作为你自己的网站的参考。
WebZip
WebZip 将网站下载并压缩成单个ZIP文件,可以帮助您将某个站点的全部或部分数据压缩成ZIP格式,方便日后快速浏览这个网站 并且新版本的特点包括定时下载,还增强了漂亮的三维界面和传输曲线。
米霍夫图片下载器
Mihov 图片下载器是一个简单的工具,用于从网页下载所有图片。只需输入网络地址,软件就会完成其他工作。所有图片都会下载到您电脑硬盘的其中一个文件夹中。
WinHTTrack HTTrack
WinHTTrack HTTrack 是一个简单易用的离线浏览器实用程序。该软件允许您将一个网站从互联网传输到本地目录,从服务器递归创建所有结构,并获取html、图像和其他文件到您的计算机。重新创建了相关链接,让您可以自由浏览本地网站(适用于任何浏览器)。可以将多个网站镜像到一起,这样就可以从一个网站开始跳转到另一个网站。您还可以更新现有的镜像站点,或继续中断的传输。具有许多选项和功能的设备是完全可配置的。该软件的资源是开放的。
MaxprogWebDumper
MaxprogWebDumper 是一款网站 内容下载工具,可以自动下载网页的所有内容及其链接,包括内置的多媒体内容,供您离线浏览。
网站内容抓取工具(WebScrapermac软件激活教程!!请谨慎下载!!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-09-04 14:09
WebScraper Mac 是Mac os 系统上非常有用的网站data 提取工具。 WebScraper 可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL 即可开始。简单而强大。
WebScraper mac 软件激活教程
! ! !本软件15系统暂时无法破解! !请谨慎下载! ! !
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:
2、返回安装包,双击打开WebScraper注册机,如图:
3、点击WebScraper注册机左侧的Open,如图:
4、在应用中找到WebScraper,点击打开如图:
5、点击保存生成注册码!
6、Open WebScraper,显示已注册!
您不是VIP会员或积分不足,请升级VIP会员或充值观看教程。
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络构建
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。
编辑评论
如果您正在寻找一款好用的网站数据抓取工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以到本站下载! 查看全部
网站内容抓取工具(WebScrapermac软件激活教程!!请谨慎下载!!!)
WebScraper Mac 是Mac os 系统上非常有用的网站data 提取工具。 WebScraper 可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL 即可开始。简单而强大。

WebScraper mac 软件激活教程
! ! !本软件15系统暂时无法破解! !请谨慎下载! ! !
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:

2、返回安装包,双击打开WebScraper注册机,如图:

3、点击WebScraper注册机左侧的Open,如图:

4、在应用中找到WebScraper,点击打开如图:

5、点击保存生成注册码!

6、Open WebScraper,显示已注册!

您不是VIP会员或积分不足,请升级VIP会员或充值观看教程。
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置

WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络构建
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。

编辑评论
如果您正在寻找一款好用的网站数据抓取工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以到本站下载!
网站内容抓取工具( V8版使用人数最多的采集软件最值得信赖的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-09-04 14:08
V8版使用人数最多的采集软件最值得信赖的软件)
优采云采集器V8版
用户最多的采集software,最值得信赖的采集software
提供细致的售前售后服务,给您良好的用户体验
什么是优采云采集器?
优采云采集器是自主研发的专业网络data采集/数据信息挖掘软件。软件配置灵活,可以方便快捷地从网页中抓取非结构化文本、图片、文件等资源信息,通过数据清洗、过滤、去噪等预处理,对数据进行整合、聚合、存储,然后对数据进行分析挖掘,最后呈现可用的结果。
优采云采集器软件产品优势
操作简单
规则简单,易学,数据易获取
高效稳定
分布式高速采集,缩短时间,提高效率
全网采集
响应任何网站的任何采集需求
谁需要优采云采集器?
优采云采集器能为您做什么?
政府机构
实时查看数据信息研究、舆情监测预警、国内外政策法规、经济动态等信息
企业应用
自动整合年报等数据信息,洞察市场,采集潜在客户信息,优化业绩。帮助您降低风险和成本,了解您的对手,并更快地做出决策;大数据流提升业务运营水平,发现新商机
电子商务
采集 商品、商业信息、用户评论。把握电商数据背后的巨大价值,提升运营效率
网站站长
及时采集你想要采集的内容,自动发布,维护网站,更新内容,更快速丰富网站内容
个人需求者
帮助学术研究人员和网络爱好者解决数据信息需求,替代数据信息手册采集。
为什么选择优采云采集器?
最常见的采集器
10年发展成就采集器;支持多个数据库; 关键词,链接替换;以任何文件格式下载;中文分词,汉英互译;无限采集
强大的data采集platform 查看全部
网站内容抓取工具(
V8版使用人数最多的采集软件最值得信赖的软件)


优采云采集器V8版
用户最多的采集software,最值得信赖的采集software
提供细致的售前售后服务,给您良好的用户体验




什么是优采云采集器?
优采云采集器是自主研发的专业网络data采集/数据信息挖掘软件。软件配置灵活,可以方便快捷地从网页中抓取非结构化文本、图片、文件等资源信息,通过数据清洗、过滤、去噪等预处理,对数据进行整合、聚合、存储,然后对数据进行分析挖掘,最后呈现可用的结果。
优采云采集器软件产品优势
操作简单
规则简单,易学,数据易获取
高效稳定
分布式高速采集,缩短时间,提高效率
全网采集
响应任何网站的任何采集需求
谁需要优采云采集器?

优采云采集器能为您做什么?
政府机构
实时查看数据信息研究、舆情监测预警、国内外政策法规、经济动态等信息
企业应用
自动整合年报等数据信息,洞察市场,采集潜在客户信息,优化业绩。帮助您降低风险和成本,了解您的对手,并更快地做出决策;大数据流提升业务运营水平,发现新商机
电子商务
采集 商品、商业信息、用户评论。把握电商数据背后的巨大价值,提升运营效率
网站站长
及时采集你想要采集的内容,自动发布,维护网站,更新内容,更快速丰富网站内容
个人需求者
帮助学术研究人员和网络爱好者解决数据信息需求,替代数据信息手册采集。
为什么选择优采云采集器?
最常见的采集器
10年发展成就采集器;支持多个数据库; 关键词,链接替换;以任何文件格式下载;中文分词,汉英互译;无限采集
强大的data采集platform
网站内容抓取工具(一下各种爆款的抓包工具的优劣势,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-03 14:01
作为软件测试工程师,抓包总是不可避免的:遇到问题需要抓包分析;需要定位bug,抓包;检查数据传输的安全性需要抓包;接口测试遇到不完整的需求 还需要抓包...正因为抓包在测试工作中无处不在,所以市场上就会有大量的抓包工具供大家选择。
之前我也发了一些文章来介绍一些常用的抓包工具,比如wireshark、Charles等,然后很多朋友在私信或留言中最常问的问题之一就是“什么是这个工具和xxx工具的区别??”或者“这个工具和xxx工具哪个更好用?”
那么,为了解决您的疑惑,让您合理选择更合适的工具,更好地辅助测试工作的执行,今天我们就来分析一下各种流行的抓包工具的优缺点。
提琴手
Fiddler 工具非常经典和强大。这一点大家应该明白。可以提供电脑端和移动端抓包,包括http和https协议,可以对消息进行抓包和分析;可以设置断点调试,拦截请求替换和数据篡改的消息,还可以进行请求构建,可以设置网络丢包延迟,APP弱网测试等。
所以,fiddler的第一个优点就是功能强大,功能齐全;
第二个优点是Fiddler是开源免费的,所有电脑只要安装就可以直接使用所有功能!这无疑是一个很大的优势,因为它也吸引了大量的用户!
当然,它也有自己的缺点:只能在windows下安装使用。如果你想在其他系统上抓包,比如MacOS系统,Linux系统,那么Fiddler就没用了。
查尔斯
Charles工具别名“Vase”,它是通过proxy抓包的,也就是我们访问网页的时候,我们配置proxy指向Charles监听的端口,然后所有的请求Charles都会帮忙我们转发并记录。
Charles 使用起来非常简单。配置好代理后,Charles 开始抓包。我们可以通过它的 GUI 直接查看包的内容。其实功能和用法和Fiddler很相似。还可以在电脑和手机上提供抓包分析、设置断点、弱网环境模拟等功能。那么它就不同于fiddler。它在哪里?
优点:Charles基于Java开发,具有良好的跨平台性能。因此,它不仅支持Windows系统,还支持MacOS和Linux操作系统;所以基本的非windows电脑都会选择Charles工具。捕获https协议的配置也很简单,只要安装charles的证书即可。缺点:
Charles 工具不是免费的。它需要购买许可证。如果你不买它,它会每30分钟断开一次。体验非常糟糕!
Wireshark
Wireshark 也可以在各种平台上安装使用,但其功能侧重点与 Charles&Fiddler 不同。主要用于捕获网络中所有协议的数据包,非常专业的分析网络协议和网络问题!
Wireshark工具的优点:可以选择特定的网卡来抓流量,那么只会抓到你关心的网卡通过的数据,针对性很强;可以捕获所有协议的数据包,捕获数据包的文本可以完全以OSI七层网络模型的格式显示出来,客户端和服务器之间的每一条交互消息都可以清楚地看到,以及详细的每个数据包的每个网络级别的内容显示。因此,该工具非常适合学习和分析网络协议。提供非常强大的过滤规则。 Wireshark 可以提供捕获前过滤或捕获后过滤,过滤规则非常详细,可以实现非常高的精度和细粒度的包过滤;它可以与TCPdump结合使用,分析在线服务器(Linux系统)上捕获的数据报文本,定位在线问题。 Wireshark工具的缺点:要想灵活使用,需要有一定的网络基础,对于初学者来说有一定的难度;无法解析https数据包,因为wireshark是链路层获取的数据包信息,所以获取的https数据包是加密数据,所以无法解析数据包的内容。当然,我们可以解密https包,但是操作有一定的复杂性,可能会消耗很多时间。打嗝套件
Burpsuite 工具也是基于 Java 语言开发的,因此它也可以在各种平台上使用,包括 Windows、MacOS 和 Linux。
Burpsuite 可以提供抓包功能。它还作为浏览器和网站之间的代理,实现消息拦截;还可以修改数据内容,转发功能;它甚至可以选择使用爬虫爬下网站相关数据...
但是,它绝对不仅仅是一个抓包工具,它集成了很多有用的小工具来完成更强大的功能,比如http请求转发、修改、扫描等,同时这些小工具还可以与BurpSuite 框架下相互定制攻击和扫描方案。
此工具的许多功能测试人员将使用它进行消息捕获和篡改数据。许多安全测试人员将使用它进行半自动网络安全审计。开发者还可以使用其扫描工具网站压力测试和攻击测试具有更广泛的功能。
但是它也有自己的缺点,就是不免费!每位用户每年费用为299美元,使用成本较高。
F12
F12是众多抓包工具中最简单最轻量的,因为它是浏览器内置的开发者工具,提供从浏览器抓包数据的功能。免安装,打开浏览器直接使用。它非常易于使用,适合入门级的初学者。 查看全部
网站内容抓取工具(一下各种爆款的抓包工具的优劣势,你了解多少?)
作为软件测试工程师,抓包总是不可避免的:遇到问题需要抓包分析;需要定位bug,抓包;检查数据传输的安全性需要抓包;接口测试遇到不完整的需求 还需要抓包...正因为抓包在测试工作中无处不在,所以市场上就会有大量的抓包工具供大家选择。
之前我也发了一些文章来介绍一些常用的抓包工具,比如wireshark、Charles等,然后很多朋友在私信或留言中最常问的问题之一就是“什么是这个工具和xxx工具的区别??”或者“这个工具和xxx工具哪个更好用?”
那么,为了解决您的疑惑,让您合理选择更合适的工具,更好地辅助测试工作的执行,今天我们就来分析一下各种流行的抓包工具的优缺点。
提琴手
Fiddler 工具非常经典和强大。这一点大家应该明白。可以提供电脑端和移动端抓包,包括http和https协议,可以对消息进行抓包和分析;可以设置断点调试,拦截请求替换和数据篡改的消息,还可以进行请求构建,可以设置网络丢包延迟,APP弱网测试等。
所以,fiddler的第一个优点就是功能强大,功能齐全;
第二个优点是Fiddler是开源免费的,所有电脑只要安装就可以直接使用所有功能!这无疑是一个很大的优势,因为它也吸引了大量的用户!
当然,它也有自己的缺点:只能在windows下安装使用。如果你想在其他系统上抓包,比如MacOS系统,Linux系统,那么Fiddler就没用了。
查尔斯
Charles工具别名“Vase”,它是通过proxy抓包的,也就是我们访问网页的时候,我们配置proxy指向Charles监听的端口,然后所有的请求Charles都会帮忙我们转发并记录。
Charles 使用起来非常简单。配置好代理后,Charles 开始抓包。我们可以通过它的 GUI 直接查看包的内容。其实功能和用法和Fiddler很相似。还可以在电脑和手机上提供抓包分析、设置断点、弱网环境模拟等功能。那么它就不同于fiddler。它在哪里?
优点:Charles基于Java开发,具有良好的跨平台性能。因此,它不仅支持Windows系统,还支持MacOS和Linux操作系统;所以基本的非windows电脑都会选择Charles工具。捕获https协议的配置也很简单,只要安装charles的证书即可。缺点:
Charles 工具不是免费的。它需要购买许可证。如果你不买它,它会每30分钟断开一次。体验非常糟糕!
Wireshark
Wireshark 也可以在各种平台上安装使用,但其功能侧重点与 Charles&Fiddler 不同。主要用于捕获网络中所有协议的数据包,非常专业的分析网络协议和网络问题!
Wireshark工具的优点:可以选择特定的网卡来抓流量,那么只会抓到你关心的网卡通过的数据,针对性很强;可以捕获所有协议的数据包,捕获数据包的文本可以完全以OSI七层网络模型的格式显示出来,客户端和服务器之间的每一条交互消息都可以清楚地看到,以及详细的每个数据包的每个网络级别的内容显示。因此,该工具非常适合学习和分析网络协议。提供非常强大的过滤规则。 Wireshark 可以提供捕获前过滤或捕获后过滤,过滤规则非常详细,可以实现非常高的精度和细粒度的包过滤;它可以与TCPdump结合使用,分析在线服务器(Linux系统)上捕获的数据报文本,定位在线问题。 Wireshark工具的缺点:要想灵活使用,需要有一定的网络基础,对于初学者来说有一定的难度;无法解析https数据包,因为wireshark是链路层获取的数据包信息,所以获取的https数据包是加密数据,所以无法解析数据包的内容。当然,我们可以解密https包,但是操作有一定的复杂性,可能会消耗很多时间。打嗝套件
Burpsuite 工具也是基于 Java 语言开发的,因此它也可以在各种平台上使用,包括 Windows、MacOS 和 Linux。
Burpsuite 可以提供抓包功能。它还作为浏览器和网站之间的代理,实现消息拦截;还可以修改数据内容,转发功能;它甚至可以选择使用爬虫爬下网站相关数据...
但是,它绝对不仅仅是一个抓包工具,它集成了很多有用的小工具来完成更强大的功能,比如http请求转发、修改、扫描等,同时这些小工具还可以与BurpSuite 框架下相互定制攻击和扫描方案。
此工具的许多功能测试人员将使用它进行消息捕获和篡改数据。许多安全测试人员将使用它进行半自动网络安全审计。开发者还可以使用其扫描工具网站压力测试和攻击测试具有更广泛的功能。
但是它也有自己的缺点,就是不免费!每位用户每年费用为299美元,使用成本较高。
F12
F12是众多抓包工具中最简单最轻量的,因为它是浏览器内置的开发者工具,提供从浏览器抓包数据的功能。免安装,打开浏览器直接使用。它非常易于使用,适合入门级的初学者。
网站内容抓取工具( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-27 00:17
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起自己之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
这里顺便解释一下网页提取器爬虫和真正写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具将默认选择所有同一层级的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,直接复制到EXCEL就可以了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签时,都需要先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?期待与我分享你的讯息~ 查看全部
网站内容抓取工具(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起自己之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
这里顺便解释一下网页提取器爬虫和真正写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具将默认选择所有同一层级的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,直接复制到EXCEL就可以了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签时,都需要先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?期待与我分享你的讯息~
网站内容抓取工具(网站百度收录慢怎么办?发布的文章总是不收录怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-26 21:00
网站百度收录慢怎么办?如果发布的文章从来没有收录怎么办?
最近在研究百度的主动推送和推送数据实时搜索,可以加快爬虫爬行速度。在百度搜索资源平台后台提交链接即可看到此功能,如下图:
点击链接提交进入页面,可以看到百度提供了一个接口,可以主动提交网站链接给百度。
并且下面介绍几个推送的例子
我也专门研究了一下,终于简单成功的实现了python的一键主动推送。我首先新建了一个 urls.txt 文件,里面有 10 个 URL,如下图所示:
然后使用python成功完成代码提交,操作成功截图如下:
Python总共不到10行代码,非常方便。有需要的朋友也可以自行尝试。用自己的网站替换URL(接口调用地址),php、post、curl、ruby也可以实现。
这里提醒一下,根据百度官方说明,每个接口调用地址每天最多只能提交2000条数据,所以不要提交太多,2000多没用。
好了,今天就分享到这里,希望对大家有所启发和帮助。
李亚涛简介:seo和python编程爱好者,秦旺汇商学院合伙人,8年网站运营经验,熟悉各种推广方式,擅长企业网站建设,关键词排名SEO优化, python爬虫信息捕获Take等。
《手机网站SEO优化教程》、《SEO优化系统视频教程》、《15天成为Python爬虫高手视频教程》、《快速建站视频教程》等作者返回搜狐查看更多 查看全部
网站内容抓取工具(网站百度收录慢怎么办?发布的文章总是不收录怎么办)
网站百度收录慢怎么办?如果发布的文章从来没有收录怎么办?
最近在研究百度的主动推送和推送数据实时搜索,可以加快爬虫爬行速度。在百度搜索资源平台后台提交链接即可看到此功能,如下图:
点击链接提交进入页面,可以看到百度提供了一个接口,可以主动提交网站链接给百度。
并且下面介绍几个推送的例子
我也专门研究了一下,终于简单成功的实现了python的一键主动推送。我首先新建了一个 urls.txt 文件,里面有 10 个 URL,如下图所示:
然后使用python成功完成代码提交,操作成功截图如下:
Python总共不到10行代码,非常方便。有需要的朋友也可以自行尝试。用自己的网站替换URL(接口调用地址),php、post、curl、ruby也可以实现。
这里提醒一下,根据百度官方说明,每个接口调用地址每天最多只能提交2000条数据,所以不要提交太多,2000多没用。
好了,今天就分享到这里,希望对大家有所启发和帮助。
李亚涛简介:seo和python编程爱好者,秦旺汇商学院合伙人,8年网站运营经验,熟悉各种推广方式,擅长企业网站建设,关键词排名SEO优化, python爬虫信息捕获Take等。
《手机网站SEO优化教程》、《SEO优化系统视频教程》、《15天成为Python爬虫高手视频教程》、《快速建站视频教程》等作者返回搜狐查看更多
网站内容抓取工具(Java网站内容抓取工具推荐-supervisor爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-24 16:04
网站内容抓取工具推荐-supervisor
爬虫是一门技术,有很多种不同的工具,
用excel做是因为用excel做比较简单,前期在备注数据的时候用excel相对其他任何语言都要简单方便一些。我曾经参加过一个培训大概是用flash做了一下几分钟的视频演示视频,你可以借鉴参考一下。
关于比较全面的学习python爬虫,
如果是数据量比较少的网站,
网站url结构总要再定义一下吧。要确定需要抓取的url的情况下。不同情况选择工具不同。不然每个工具都能满足。最好先把工具的细节研究清楚,最后组合起来用,如果是在网站使用,不同的工具会限制你的爬虫场景。
网站随着数据量增大可以分为各种不同的,
excel不够灵活吧。可以学习下java,掌握了java后期换成python这类型的就挺方便。
看你预算和时间了,抓太简单的可以用excel,抓完用python把数据表定义好,总要有这个数据库吧?然后python读一下就可以了,复杂一点的就用爬虫,肯定要针对某一个目标去抓取,要考虑目标类型的限制,想怎么抓去,针对不同类型的抓取工具工作方式大体也不一样。另外excel没有权限控制。基本上初学爬虫到scrapy这种框架还要适应个1-2个月不等,比较麻烦。 查看全部
网站内容抓取工具(Java网站内容抓取工具推荐-supervisor爬虫)
网站内容抓取工具推荐-supervisor
爬虫是一门技术,有很多种不同的工具,
用excel做是因为用excel做比较简单,前期在备注数据的时候用excel相对其他任何语言都要简单方便一些。我曾经参加过一个培训大概是用flash做了一下几分钟的视频演示视频,你可以借鉴参考一下。
关于比较全面的学习python爬虫,
如果是数据量比较少的网站,
网站url结构总要再定义一下吧。要确定需要抓取的url的情况下。不同情况选择工具不同。不然每个工具都能满足。最好先把工具的细节研究清楚,最后组合起来用,如果是在网站使用,不同的工具会限制你的爬虫场景。
网站随着数据量增大可以分为各种不同的,
excel不够灵活吧。可以学习下java,掌握了java后期换成python这类型的就挺方便。
看你预算和时间了,抓太简单的可以用excel,抓完用python把数据表定义好,总要有这个数据库吧?然后python读一下就可以了,复杂一点的就用爬虫,肯定要针对某一个目标去抓取,要考虑目标类型的限制,想怎么抓去,针对不同类型的抓取工具工作方式大体也不一样。另外excel没有权限控制。基本上初学爬虫到scrapy这种框架还要适应个1-2个月不等,比较麻烦。
网站内容抓取工具(如何快速检测网站是否存在非法内容包括以下几种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-22 17:05
网站内容抓取工具通过爬虫技术从互联网或者其他网站获取网站内容的,通常分为两种1.蜘蛛爬虫是一种访问网站直接下载网站内容的,对于找页面的,结构化数据的爬虫在工作模式中是最为重要的部分,因为页面的解析是非常的繁琐,不仅要有全局代码,而且需要有完整的解析整个页面代码,然后对页面进行处理和分析。有些内容甚至会被反复的抓取,处理完成后才停止访问。
抓取页面数量不少,并且每次抓取都是比较繁琐的工作,抓取是完全c++和python语言开发。2.自己写爬虫工具,简单不说,能弄,但如果你想玩深,把爬虫玩到极致,那么你也需要对java,python等相关语言有较好的理解和掌握,并且会常用的工具集,如集合,list,set,itertools等等。excel,最为常用电子表格软件,对于网站抓取有着至关重要的作用。
利用excel去爬取大数据(包括互联网的各个平台)并生成报表。如何快速检测抓取的网站是否存在非法内容包括以下这几种方法:1.加载一个纯动态执行脚本的页面,不加载静态数据,检测http请求头部是否包含保留下来的javascript;2.根据每次进入的网站不同去判断是否存在爬虫代码,如爬虫脚本和抓取请求,即使抓取请求从200跳转到后台也不要认为是爬虫代码,也要尽可能的检测到与数据库中库函数对应。
能有哪些经典的网站爬虫库列举:http下的每个协议都是对应的特定的网站,这些网站规律多变,用处多重,爬虫开发者写爬虫的目的就是找出爬虫中常用的函数、自动求回等功能;3.根据通用检测,当一个网站用代理访问时就需要根据请求url去判断该网站是否存在爬虫代码,如图,使用try-catch检测,当url超出限制时才打钩代码5.自己爬虫开发,利用python集合工具开发爬虫并且封装,提高开发效率。
了解各种爬虫工具,不断练习,提高效率,而且爬虫工具如excel,也可以用os,开发过程中检查正确率和代码复用率能够最好的掌握excel和os编程也对网站爬虫工作非常有帮助,具体的下面做详细介绍。提前了解的几点1.利用excel进行爬虫工作,必须先使用excel对爬虫的配置做熟悉,并且先了解excel内存分配和搜索,容错检测等知识。
2.非法代码爬虫无法捕捉到,因为这些代码就是一个搜索引擎而已,excel很难捕捉它们的url地址。3.excel自带的抓取报表的插件是不能抓取爬虫报表,不过我们可以自己重写爬虫报表功能进行抓取。下面我们介绍下excel常用的几个网页抓取工具,熟悉这些之后,大家写爬虫就会得心应手了。1.excelhome爬虫大赛_excelhome大赛_excelhomespider。 查看全部
网站内容抓取工具(如何快速检测网站是否存在非法内容包括以下几种方法)
网站内容抓取工具通过爬虫技术从互联网或者其他网站获取网站内容的,通常分为两种1.蜘蛛爬虫是一种访问网站直接下载网站内容的,对于找页面的,结构化数据的爬虫在工作模式中是最为重要的部分,因为页面的解析是非常的繁琐,不仅要有全局代码,而且需要有完整的解析整个页面代码,然后对页面进行处理和分析。有些内容甚至会被反复的抓取,处理完成后才停止访问。
抓取页面数量不少,并且每次抓取都是比较繁琐的工作,抓取是完全c++和python语言开发。2.自己写爬虫工具,简单不说,能弄,但如果你想玩深,把爬虫玩到极致,那么你也需要对java,python等相关语言有较好的理解和掌握,并且会常用的工具集,如集合,list,set,itertools等等。excel,最为常用电子表格软件,对于网站抓取有着至关重要的作用。
利用excel去爬取大数据(包括互联网的各个平台)并生成报表。如何快速检测抓取的网站是否存在非法内容包括以下这几种方法:1.加载一个纯动态执行脚本的页面,不加载静态数据,检测http请求头部是否包含保留下来的javascript;2.根据每次进入的网站不同去判断是否存在爬虫代码,如爬虫脚本和抓取请求,即使抓取请求从200跳转到后台也不要认为是爬虫代码,也要尽可能的检测到与数据库中库函数对应。
能有哪些经典的网站爬虫库列举:http下的每个协议都是对应的特定的网站,这些网站规律多变,用处多重,爬虫开发者写爬虫的目的就是找出爬虫中常用的函数、自动求回等功能;3.根据通用检测,当一个网站用代理访问时就需要根据请求url去判断该网站是否存在爬虫代码,如图,使用try-catch检测,当url超出限制时才打钩代码5.自己爬虫开发,利用python集合工具开发爬虫并且封装,提高开发效率。
了解各种爬虫工具,不断练习,提高效率,而且爬虫工具如excel,也可以用os,开发过程中检查正确率和代码复用率能够最好的掌握excel和os编程也对网站爬虫工作非常有帮助,具体的下面做详细介绍。提前了解的几点1.利用excel进行爬虫工作,必须先使用excel对爬虫的配置做熟悉,并且先了解excel内存分配和搜索,容错检测等知识。
2.非法代码爬虫无法捕捉到,因为这些代码就是一个搜索引擎而已,excel很难捕捉它们的url地址。3.excel自带的抓取报表的插件是不能抓取爬虫报表,不过我们可以自己重写爬虫报表功能进行抓取。下面我们介绍下excel常用的几个网页抓取工具,熟悉这些之后,大家写爬虫就会得心应手了。1.excelhome爬虫大赛_excelhome大赛_excelhomespider。
网站内容抓取工具(WebScraper如何安装Chrome和Firefox上的安装路径介绍?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-21 12:32
官方网站WebScraper号称是头号网页捕获/提取插件,可安装在chrome和Firefox上
安装路径:
Web Scraper–获取Firefox的此扩展(美国版)
您也可以使用浏览器打开官方网站,然后单击“安装”自动选择“安装”
刮网器-1刮网扩展
您还可以在浏览器右上角找到扩展图标,单击“打开”,下拉菜单,然后找到“管理扩展”,即输入chrome://extensions
单击左上角的“打开”,然后在左下角进入web应用商店,打开一个新页面,在其中搜索web scraper,然后安装它
有关说明,您最好看一下视频:
网络刮刀教程
这只是一个YouTube链接,可能有点困难。你可以在互联网上自由搜索,还有教学网站
此插件的正常版本是免费的,增强版是收费的。如果你有钱和需要,如果你不花它,你就会浪费它
此插件易于使用,因为它集成到浏览器中。非常适合新手和普通非专业技术人员使用。如果您需要更强大和定制的网页数据捕获,您可能需要更专业的工具或您自己的编程
下面是我使用此插件的介绍,供您参考
--------------------------------------------------------------------?
第一步是安装,如上所述
步骤2:以chrome为例,在浏览器地址栏中输入:chrome://extensions/
检查是否已成功安装并启用web刮板
步骤3:F12或Ctrl+Shift+I,打开开发工具:
启用时,选择底部显示模式:
然后找到最后一个websharper选项卡并单击enter
好了,准备工作已经完成了
----------------------------------------------------------?
对于第一个示例,请根据官网上的教学视频再次操作
打开官方测试网站:
Web测试站点
官方测试网站是一种电子商务网站. 让我们先简单浏览一下。它分为两个层次。第一级是主要类别:电脑和手机;第一个层次是子分类。“计算机和移动电话”下的分类收录特定的产品项,单击“产品项”即为特定的产品信息
我们的目标是通过浏览两级目录结构来提取所有产品信息
首先设置登录页面、门户URL和登录页面。从这个页面,网络刮板将浏览整个网站。我们需要创建多个选择器以形成树结构,类似于网站构造时的结构
这些选择器定义网站如何浏览以及如何提取数据
如下图所示,要创建站点地图,请输入地址作为上面的浏览器显示地址:Web scraper test sites
完整的数据提取基于站点地图。配置站点地图后,可以保存设置并在下次继续使用。我们需要重新提取并直接执行它
创建网站时,它被命名为电子商务
此时,它后面有一个数据预览按钮。点击后,发现当前没有数据,需要添加一个选择器
对于初始页面中的分层列,为了访问,我们需要以链接的形式创建选择器。单击添加新选择器
然后单击选择以链接的形式选择网页元素
选择器名为category linkm,类型为link。单击选择并选择两个链接。检查多个。父选择器是登录页面
单击“选择”以选择网页上的元素,然后单击“完成选择”
要验证选择结果,请单击“图元预览”检查选择是否正确,然后单击“数据预览”检查其工作是否正常
然后保存选择器
接下来,我们为下一级链接创建一个选择器
单击网页上的“计算机”继续以链接的形式创建选择器
单击保存。然后创建产品页面的链接选择器。首先单击笔记本电脑进入产品列表页面
单击产品链接进入产品页面,创建文本类型选择器,并提取所需数据
创建选择器后,让我们来看一看。根据层次关系点击选择器,随时点击选择器后面的数据预览,查看数据是否正常
您还可以使用选择器图查看我们创建的选择器的结构
单击scratch开始捕获数据,您将看到一个新的网页打开。浏览页面并根据我们设置的登录URL和选择器提取数据
休息一下,等待数据提取
完成后,弹出页面将关闭并提示
然后单击“刷新”以显示提取的数据
选择导出到CSV文件
??打开CSV文件,数据如下:
好的,CSV文件已经在手了,已经结束了
单击浏览以进入数据显示
您还可以导出导出站点地图,保存站点地图JSON内容,并在下次创建站点地图时直接导入,这样更方便快捷
如果有多个站点地图,则可以在操作之前选择或切换站点地图以进行数据提取 查看全部
网站内容抓取工具(WebScraper如何安装Chrome和Firefox上的安装路径介绍?)
官方网站WebScraper号称是头号网页捕获/提取插件,可安装在chrome和Firefox上
安装路径:
Web Scraper–获取Firefox的此扩展(美国版)
您也可以使用浏览器打开官方网站,然后单击“安装”自动选择“安装”
刮网器-1刮网扩展
您还可以在浏览器右上角找到扩展图标,单击“打开”,下拉菜单,然后找到“管理扩展”,即输入chrome://extensions
单击左上角的“打开”,然后在左下角进入web应用商店,打开一个新页面,在其中搜索web scraper,然后安装它
有关说明,您最好看一下视频:
网络刮刀教程
这只是一个YouTube链接,可能有点困难。你可以在互联网上自由搜索,还有教学网站
此插件的正常版本是免费的,增强版是收费的。如果你有钱和需要,如果你不花它,你就会浪费它
此插件易于使用,因为它集成到浏览器中。非常适合新手和普通非专业技术人员使用。如果您需要更强大和定制的网页数据捕获,您可能需要更专业的工具或您自己的编程
下面是我使用此插件的介绍,供您参考
--------------------------------------------------------------------?
第一步是安装,如上所述
步骤2:以chrome为例,在浏览器地址栏中输入:chrome://extensions/
检查是否已成功安装并启用web刮板
步骤3:F12或Ctrl+Shift+I,打开开发工具:
启用时,选择底部显示模式:
然后找到最后一个websharper选项卡并单击enter
好了,准备工作已经完成了
----------------------------------------------------------?
对于第一个示例,请根据官网上的教学视频再次操作
打开官方测试网站:
Web测试站点
官方测试网站是一种电子商务网站. 让我们先简单浏览一下。它分为两个层次。第一级是主要类别:电脑和手机;第一个层次是子分类。“计算机和移动电话”下的分类收录特定的产品项,单击“产品项”即为特定的产品信息
我们的目标是通过浏览两级目录结构来提取所有产品信息
首先设置登录页面、门户URL和登录页面。从这个页面,网络刮板将浏览整个网站。我们需要创建多个选择器以形成树结构,类似于网站构造时的结构
这些选择器定义网站如何浏览以及如何提取数据
如下图所示,要创建站点地图,请输入地址作为上面的浏览器显示地址:Web scraper test sites
完整的数据提取基于站点地图。配置站点地图后,可以保存设置并在下次继续使用。我们需要重新提取并直接执行它
创建网站时,它被命名为电子商务
此时,它后面有一个数据预览按钮。点击后,发现当前没有数据,需要添加一个选择器
对于初始页面中的分层列,为了访问,我们需要以链接的形式创建选择器。单击添加新选择器
然后单击选择以链接的形式选择网页元素
选择器名为category linkm,类型为link。单击选择并选择两个链接。检查多个。父选择器是登录页面
单击“选择”以选择网页上的元素,然后单击“完成选择”
要验证选择结果,请单击“图元预览”检查选择是否正确,然后单击“数据预览”检查其工作是否正常
然后保存选择器
接下来,我们为下一级链接创建一个选择器
单击网页上的“计算机”继续以链接的形式创建选择器
单击保存。然后创建产品页面的链接选择器。首先单击笔记本电脑进入产品列表页面
单击产品链接进入产品页面,创建文本类型选择器,并提取所需数据
创建选择器后,让我们来看一看。根据层次关系点击选择器,随时点击选择器后面的数据预览,查看数据是否正常
您还可以使用选择器图查看我们创建的选择器的结构
单击scratch开始捕获数据,您将看到一个新的网页打开。浏览页面并根据我们设置的登录URL和选择器提取数据
休息一下,等待数据提取
完成后,弹出页面将关闭并提示
然后单击“刷新”以显示提取的数据
选择导出到CSV文件
??打开CSV文件,数据如下:
好的,CSV文件已经在手了,已经结束了
单击浏览以进入数据显示
您还可以导出导出站点地图,保存站点地图JSON内容,并在下次创建站点地图时直接导入,这样更方便快捷
如果有多个站点地图,则可以在操作之前选择或切换站点地图以进行数据提取
网站内容抓取工具(如何在PyCharm中安装Scrapy?3的安装提示信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-21 00:04
在谈到爬虫时,我们必须提到scrapy框架,因为它可以帮助提高爬虫的效率,更好地实现爬虫
Scrapy是一个应用程序框架,用于获取网页数据和提取结构数据。该框架被封装,包括请求(异步调度和处理)、下载(多线程下载)、解析器(选择器)和twisted(异步处理)。对于网站内容爬行,其速度非常快
也许读者会感到困惑。有了这样一个好的爬虫框架,为什么上一章学习了使用请求库来请求网页数据。事实上,requests是一个功能非常强大的库,可以满足大多数web页面数据采集的需要。其工作原理是向服务器发送数据请求。数据下载和分析需要自行处理,灵活性高;由于scrapy框架的封装,其灵活性降低
至于使用哪种爬虫,完全取决于个人的实际需要。在没有明确要求的情况下,作者建议初学者选择请求库来请求网页数据,然后在业务实践
中生成实际需求时考虑SCOPY框架。
在scripy安装过程中使用pip直接安装scripy会生成一些错误的安装提示,导致scripy安装失败。当然,既然存在问题,就必须有很多解决办法。在~gohlke/pythonlibs网站中,有许多适合windows的已编译Python第三方库。读者只需根据错误的安装提示信息找到相应的软件包并安装即可。这里将不详细说明此方法。本节主要介绍如何在pycharm中安装scrapy
第一步是选择Anaconda3作为编译环境。单击pycharm左上角的file选项,然后单击settings以打开如图1所示的界面。然后展开项目解释器的下拉菜单,选择Anaconda 3的下拉菜单:
图1
Anaconda需要提前安装,安装后可以添加Anaconda编译环境
步骤2:安装scrapy。单击图1所示界面右上角的绿色加号,弹出图2所示界面。输入并搜索“scratch”,然后单击“install package”按钮。等待出现“成功安装的包装“scratch”:
图2
案例:用scrapy抢占股市。本案例将使用scrapy框架获取安全性网站A股票市场爬行过程分为以下五个步骤:创建一个刮擦式爬虫项目,调用CMD,输入以下代码,然后按[enter]创建刮擦式爬虫项目:
scrapy Start项目stockstar
其中,scratch startproject是一个固定命令,stockstar是作者设置的项目名称
运行上述代码的目的是创建相应的项目文件,如下所示:
项目结构如图3所示:
图3项目结构
创建scratch项目后,默认情况下设置文件中会打开这样一条语句
POBOTSOXT_uuuo服从=真
Robots.txt是一个遵循robot协议的文件。scrapy启动后,首先访问网站的robots.txt文件,然后确定网站的爬行范围。有时我们需要将此配置项设置为false。在settings.py文件中,可以按如下方式修改文件属性
ROBOTSTXT_uuuuo=错误
右键单击E:\stockstar\stockstar文件夹,并在弹出式快捷菜单中选择“将目录标记为”命令→ 选择“sources root”命令,这可以使导入包的语法更加简洁,如图4所示
图4
定义一个项目容器。项是用于存储爬网数据的容器。其使用方法类似于Python字典。它为拼写错误导致的未定义字段错误提供了额外的保护
首先,我们需要分析要爬网的网页数据,并定义爬网记录的数据结构。在相应的items.py中创建相应的字段。详细代码如下:
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst
class StockstarItemLoader (ItemLoader):
#自定义itemloader,用于存储爬虫所抓取的字段内容
default_output_processor = TakeFirst()
class StockstarItem (scrapy.Item) : # 建立相应的字段
#define the fields for your item here like:
#name = scrapy.Field()
code = scrapy.Field() # 股票代码
abbr = scrapy.Field() # 股票简称
last_trade = scrapy.Field() # 最新价
chg_ratio = scrapy.Field() # 涨跌幅
chg_amt = scrapy.Field() # 涨跌额
chg_ratio_5min = scrapy.Field() # 5分钟涨幅
volumn = scrapy.Field() # 成交量
turn_over = scrapy.Field() # 成交额
定义基本爬网器设置的设置文件,定义可以在相应的settings.py文件中显示中文的JSON行导出器,并将爬网间隔设置为0.25第二,详细代码如下:
from scrapy.exporters import JsonLinesItemExporter #默认显示的中文是阅读性较差的Unicode字符
#需要定义子类显示出原来的字符集(将父类的ensure_ascii属性设置为False即可)
class CustomJsonLinesItemExporter(JsonLinesItemExporter):
def __init__(self, file, **kwargs):
super (CustomJsonLinesItemExporter, self).__init__(file, ensure_ascii=False, **kwargs)
#启用新定义的Exporter类\
FEED_EXPORTERS = {
'json':'stockstar.settings.CustomJsonLinesItemExporter',
}
...
#Configure a delay for requests for the same website (default: 0)
#See http:IIscrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
#See also autothrottle settings and docs DOWNLOAD DELAY = 0.25
在编写爬虫逻辑之前,您需要创建一个。stockstar/spider子文件下的Py文件,用于定义爬虫程序的范围,即初始URL。接下来,定义一个名为parse的函数来解析服务器返回的内容
首先,在CMD中输入代码并生成Spider代码,如下所示:
cd股票之星
刮屑原浆
此时,将在spider文件夹下创建一个后缀为stock.py的文件,该文件将生成start_uuURL,即爬虫的起始地址,并创建一个名为parse的自定义函数,随后的爬虫逻辑将写入parse函数。文档详细信息如图5所示:
图5
代码详细信息如图6所示:
图6
然后,在spider/stock.py文件中定义爬虫程序逻辑。详细代码如下:
import scrapy
from items import StockstarItem, StockstarItemLoader\
class StockSpider(scrapy.Spider):
name = 'stock' #定义爬虫名称
allowed_domains = ['quote.stockstar.com'] #定义爬虫域
start_urls = ['http://quote.stockstar.com/sto ... 39%3B]
#定义开始爬虫链接
def parse (self, response) : #撰写爬虫逻辑
page = int (response.url.split("_")[-1].split(".")[0])#抓取页码
item_nodes = response.css('#datalist tr')
for item_node in item_nodes:
#根据item文件中所定义的字段内容,进行字段内容的抓取
item_loader = StockstarItemLoader(item=StockstarItem(), selector = item_node)
item_loader.add_css("code", "td:nth-child(1) a::text")
item_loader.add_css("abbr", "td:nth-child(2) a::text")
item_loader.add_css("last_trade", “td:nth-child(3) span::text")
item_loader.add_css("chg_ratio", "td:nth-child(4) span::text")
item_loader.add_css("chg_amt", "td:nth-child(5) span::text")
item_loader.add_css("chg_ratio_5min","td:nth-child(6) span::text")
item_loader.add_css("volumn", "td:nth-child(7)::text")
item_loader.add_css ("turn_over", "td:nth-child(8) :: text")
stock_item = item_loader.load_item()
yield stock_item
if item_nodes:
next_page = page + 1
next_url = response.url.replace ("{0}.html".format (page) , "{0}.html".format(next_page))
yield scrapy.Request(url=next_url, callback=self.parse)
代码调试为了便于调试,请在E:\stockstar下创建一个新的main.py。调试代码如下:
从scrapy.cmdline导入执行
执行([“scrapy”、“crawl”、“stock”、“-o”、“items.json”])
这相当于在E:\stockstar下执行命令“scratch crawl stock-o items.json”,将已爬网的数据导出到items.json文件
E:\stockstar>;scrapy crawl stock-o items.json
您可以在代码中设置断点(例如在spider/stock.py中),然后单击“run”选项按钮→ 在弹出菜单中选择“debug'main”命令进行调试,如图7和图8所示
图7
图8
最后,在pycharm中运行“main”,操作界面如图9所示:
图9
将捕获的数据以JSON格式保存在项目容器中。知识扩展本文从实战(捕获股市)中解释了scrapy框架,并致力于让初学者快速理解Python crawler scarpy框架的使用
然而,这种实用的伤疤的空间毕竟是有限的。如果您想深入了解scripy框架,我建议您阅读: 查看全部
网站内容抓取工具(如何在PyCharm中安装Scrapy?3的安装提示信息)
在谈到爬虫时,我们必须提到scrapy框架,因为它可以帮助提高爬虫的效率,更好地实现爬虫
Scrapy是一个应用程序框架,用于获取网页数据和提取结构数据。该框架被封装,包括请求(异步调度和处理)、下载(多线程下载)、解析器(选择器)和twisted(异步处理)。对于网站内容爬行,其速度非常快
也许读者会感到困惑。有了这样一个好的爬虫框架,为什么上一章学习了使用请求库来请求网页数据。事实上,requests是一个功能非常强大的库,可以满足大多数web页面数据采集的需要。其工作原理是向服务器发送数据请求。数据下载和分析需要自行处理,灵活性高;由于scrapy框架的封装,其灵活性降低
至于使用哪种爬虫,完全取决于个人的实际需要。在没有明确要求的情况下,作者建议初学者选择请求库来请求网页数据,然后在业务实践
中生成实际需求时考虑SCOPY框架。
在scripy安装过程中使用pip直接安装scripy会生成一些错误的安装提示,导致scripy安装失败。当然,既然存在问题,就必须有很多解决办法。在~gohlke/pythonlibs网站中,有许多适合windows的已编译Python第三方库。读者只需根据错误的安装提示信息找到相应的软件包并安装即可。这里将不详细说明此方法。本节主要介绍如何在pycharm中安装scrapy
第一步是选择Anaconda3作为编译环境。单击pycharm左上角的file选项,然后单击settings以打开如图1所示的界面。然后展开项目解释器的下拉菜单,选择Anaconda 3的下拉菜单:
图1
Anaconda需要提前安装,安装后可以添加Anaconda编译环境
步骤2:安装scrapy。单击图1所示界面右上角的绿色加号,弹出图2所示界面。输入并搜索“scratch”,然后单击“install package”按钮。等待出现“成功安装的包装“scratch”:
图2
案例:用scrapy抢占股市。本案例将使用scrapy框架获取安全性网站A股票市场爬行过程分为以下五个步骤:创建一个刮擦式爬虫项目,调用CMD,输入以下代码,然后按[enter]创建刮擦式爬虫项目:
scrapy Start项目stockstar
其中,scratch startproject是一个固定命令,stockstar是作者设置的项目名称
运行上述代码的目的是创建相应的项目文件,如下所示:
项目结构如图3所示:
图3项目结构
创建scratch项目后,默认情况下设置文件中会打开这样一条语句
POBOTSOXT_uuuo服从=真
Robots.txt是一个遵循robot协议的文件。scrapy启动后,首先访问网站的robots.txt文件,然后确定网站的爬行范围。有时我们需要将此配置项设置为false。在settings.py文件中,可以按如下方式修改文件属性
ROBOTSTXT_uuuuo=错误
右键单击E:\stockstar\stockstar文件夹,并在弹出式快捷菜单中选择“将目录标记为”命令→ 选择“sources root”命令,这可以使导入包的语法更加简洁,如图4所示
图4
定义一个项目容器。项是用于存储爬网数据的容器。其使用方法类似于Python字典。它为拼写错误导致的未定义字段错误提供了额外的保护
首先,我们需要分析要爬网的网页数据,并定义爬网记录的数据结构。在相应的items.py中创建相应的字段。详细代码如下:
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst
class StockstarItemLoader (ItemLoader):
#自定义itemloader,用于存储爬虫所抓取的字段内容
default_output_processor = TakeFirst()
class StockstarItem (scrapy.Item) : # 建立相应的字段
#define the fields for your item here like:
#name = scrapy.Field()
code = scrapy.Field() # 股票代码
abbr = scrapy.Field() # 股票简称
last_trade = scrapy.Field() # 最新价
chg_ratio = scrapy.Field() # 涨跌幅
chg_amt = scrapy.Field() # 涨跌额
chg_ratio_5min = scrapy.Field() # 5分钟涨幅
volumn = scrapy.Field() # 成交量
turn_over = scrapy.Field() # 成交额
定义基本爬网器设置的设置文件,定义可以在相应的settings.py文件中显示中文的JSON行导出器,并将爬网间隔设置为0.25第二,详细代码如下:
from scrapy.exporters import JsonLinesItemExporter #默认显示的中文是阅读性较差的Unicode字符
#需要定义子类显示出原来的字符集(将父类的ensure_ascii属性设置为False即可)
class CustomJsonLinesItemExporter(JsonLinesItemExporter):
def __init__(self, file, **kwargs):
super (CustomJsonLinesItemExporter, self).__init__(file, ensure_ascii=False, **kwargs)
#启用新定义的Exporter类\
FEED_EXPORTERS = {
'json':'stockstar.settings.CustomJsonLinesItemExporter',
}
...
#Configure a delay for requests for the same website (default: 0)
#See http:IIscrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
#See also autothrottle settings and docs DOWNLOAD DELAY = 0.25
在编写爬虫逻辑之前,您需要创建一个。stockstar/spider子文件下的Py文件,用于定义爬虫程序的范围,即初始URL。接下来,定义一个名为parse的函数来解析服务器返回的内容
首先,在CMD中输入代码并生成Spider代码,如下所示:
cd股票之星
刮屑原浆
此时,将在spider文件夹下创建一个后缀为stock.py的文件,该文件将生成start_uuURL,即爬虫的起始地址,并创建一个名为parse的自定义函数,随后的爬虫逻辑将写入parse函数。文档详细信息如图5所示:
图5
代码详细信息如图6所示:
图6
然后,在spider/stock.py文件中定义爬虫程序逻辑。详细代码如下:
import scrapy
from items import StockstarItem, StockstarItemLoader\
class StockSpider(scrapy.Spider):
name = 'stock' #定义爬虫名称
allowed_domains = ['quote.stockstar.com'] #定义爬虫域
start_urls = ['http://quote.stockstar.com/sto ... 39%3B]
#定义开始爬虫链接
def parse (self, response) : #撰写爬虫逻辑
page = int (response.url.split("_")[-1].split(".")[0])#抓取页码
item_nodes = response.css('#datalist tr')
for item_node in item_nodes:
#根据item文件中所定义的字段内容,进行字段内容的抓取
item_loader = StockstarItemLoader(item=StockstarItem(), selector = item_node)
item_loader.add_css("code", "td:nth-child(1) a::text")
item_loader.add_css("abbr", "td:nth-child(2) a::text")
item_loader.add_css("last_trade", “td:nth-child(3) span::text")
item_loader.add_css("chg_ratio", "td:nth-child(4) span::text")
item_loader.add_css("chg_amt", "td:nth-child(5) span::text")
item_loader.add_css("chg_ratio_5min","td:nth-child(6) span::text")
item_loader.add_css("volumn", "td:nth-child(7)::text")
item_loader.add_css ("turn_over", "td:nth-child(8) :: text")
stock_item = item_loader.load_item()
yield stock_item
if item_nodes:
next_page = page + 1
next_url = response.url.replace ("{0}.html".format (page) , "{0}.html".format(next_page))
yield scrapy.Request(url=next_url, callback=self.parse)
代码调试为了便于调试,请在E:\stockstar下创建一个新的main.py。调试代码如下:
从scrapy.cmdline导入执行
执行([“scrapy”、“crawl”、“stock”、“-o”、“items.json”])
这相当于在E:\stockstar下执行命令“scratch crawl stock-o items.json”,将已爬网的数据导出到items.json文件
E:\stockstar>;scrapy crawl stock-o items.json
您可以在代码中设置断点(例如在spider/stock.py中),然后单击“run”选项按钮→ 在弹出菜单中选择“debug'main”命令进行调试,如图7和图8所示
图7
图8
最后,在pycharm中运行“main”,操作界面如图9所示:
图9
将捕获的数据以JSON格式保存在项目容器中。知识扩展本文从实战(捕获股市)中解释了scrapy框架,并致力于让初学者快速理解Python crawler scarpy框架的使用
然而,这种实用的伤疤的空间毕竟是有限的。如果您想深入了解scripy框架,我建议您阅读:
网站内容抓取工具(提高网站抓取频率的SEO8个方法,有哪些呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-14 13:09
网站Fetching 频率是 SEO 经常头疼的问题。爬取频率过高会影响网站的加载速度,而爬取频率过低则无法保证索引量。 , 特别是对于初创网站。
SEO优化,根据以往的工作经验,总结出8种SEO方法,可以适当提高网站爬行的频率!
那么,提高网站抓取频率的8种SEO方法是什么?
1、Unique原创Content
有人说这是一个司空见惯的问题。人人都知道要创造原创内容,但百度始终偏爱优质稀缺的内容。
因此,创建独特而有趣的内容尤为重要。重要的是你创建的内容必须满足潜在访问者的搜索需求,否则即使是原创也不一定容易经常吸引百度蜘蛛。
2、网站更新频率
在内容上,持续更新频率是提高网站爬取频率的有效法宝。不过也有人说,对于新网站来说,大量的持续更新内容无法满足网站的优化策略,所以,我们可以:继续改变页面的文档指纹,比如:
①增加随机内容占页面内容的比例。
②对于不同的URL标题,随机调用对应段落的描述内容。
3、Submit网站Content
我们知道解决网站不收录的问题就是继续提交百度收录。同样,为了增加网站爬取的频率,我们也可以使用这个策略。您可以:
①在百度资源平台提交网站sitemap地图。
②使用API自动提交新生成的URL。
③ 使用JS代码在页面浏览时自动提交内容给百度。
4、improve网站speed
我们知道,保证爬行顺畅的前提是:你要保证你的网站蜘蛛访问时的加载速度在合理范围内,并尽量避免加载延迟。如果这个问题经常出现,很容易导致抓取频率降低。
5、提升品牌影响力
我们经常看到一个知名品牌。在推出新网站时,我们经常会得到新闻媒体的广泛报道。其中,如果有新闻源站点,会提到很多与目标网站品牌词相关的内容。 , 没有及时的目标链接。受社会影响,百度将继续增加目标网站的抓取频率。
6、启用高PR域名
我们知道具有高 PR 的旧域具有自然权重。如果你的网站长时间没有更新,即使只有一个“关闭的网站页面”,搜索引擎也会保持持续的抓取频率,等待内容更新。
如果你特别关心爬取频率的问题,可以在建站之初尽量选择老域名。当然,您也可以使用它重定向到正在运行的域名。
7、质量友好链接
我们在提升网站排名的时候,经常会用到优质的链接,但是如果你能在网站一开始就利用网络资源获得一些优质的网站友情链接,那么就会继续提高网站grabbing 频率有很大帮助。
8、关注社交媒体
对于社交媒体,为什么将其列在 8 种 SEO 方法的末尾?主要原因是它对页面抓取频率的影响相对较弱。目前百度虽然可以正常收录微博的头条文章,但总体来说更倾向于有一定影响力,而且对于初创企业来说,爬取的频率相对较低。
总结:这8个提高网站抓取频率的SEO方法只是SEO人员常用的一些方法,仅供参考!
标签:如何提高抓取频率
转载:感谢您对Yudi Silent个人博客网站platform的认可,以及网站分享的经验、工具和文章。欢迎分享给您的个人站长或朋友圈,但转载请注明文章出处。
() 查看全部
网站内容抓取工具(提高网站抓取频率的SEO8个方法,有哪些呢?)
网站Fetching 频率是 SEO 经常头疼的问题。爬取频率过高会影响网站的加载速度,而爬取频率过低则无法保证索引量。 , 特别是对于初创网站。
SEO优化,根据以往的工作经验,总结出8种SEO方法,可以适当提高网站爬行的频率!
那么,提高网站抓取频率的8种SEO方法是什么?
1、Unique原创Content
有人说这是一个司空见惯的问题。人人都知道要创造原创内容,但百度始终偏爱优质稀缺的内容。
因此,创建独特而有趣的内容尤为重要。重要的是你创建的内容必须满足潜在访问者的搜索需求,否则即使是原创也不一定容易经常吸引百度蜘蛛。
2、网站更新频率
在内容上,持续更新频率是提高网站爬取频率的有效法宝。不过也有人说,对于新网站来说,大量的持续更新内容无法满足网站的优化策略,所以,我们可以:继续改变页面的文档指纹,比如:
①增加随机内容占页面内容的比例。
②对于不同的URL标题,随机调用对应段落的描述内容。
3、Submit网站Content
我们知道解决网站不收录的问题就是继续提交百度收录。同样,为了增加网站爬取的频率,我们也可以使用这个策略。您可以:
①在百度资源平台提交网站sitemap地图。
②使用API自动提交新生成的URL。
③ 使用JS代码在页面浏览时自动提交内容给百度。
4、improve网站speed
我们知道,保证爬行顺畅的前提是:你要保证你的网站蜘蛛访问时的加载速度在合理范围内,并尽量避免加载延迟。如果这个问题经常出现,很容易导致抓取频率降低。
5、提升品牌影响力
我们经常看到一个知名品牌。在推出新网站时,我们经常会得到新闻媒体的广泛报道。其中,如果有新闻源站点,会提到很多与目标网站品牌词相关的内容。 , 没有及时的目标链接。受社会影响,百度将继续增加目标网站的抓取频率。
6、启用高PR域名
我们知道具有高 PR 的旧域具有自然权重。如果你的网站长时间没有更新,即使只有一个“关闭的网站页面”,搜索引擎也会保持持续的抓取频率,等待内容更新。
如果你特别关心爬取频率的问题,可以在建站之初尽量选择老域名。当然,您也可以使用它重定向到正在运行的域名。
7、质量友好链接
我们在提升网站排名的时候,经常会用到优质的链接,但是如果你能在网站一开始就利用网络资源获得一些优质的网站友情链接,那么就会继续提高网站grabbing 频率有很大帮助。
8、关注社交媒体
对于社交媒体,为什么将其列在 8 种 SEO 方法的末尾?主要原因是它对页面抓取频率的影响相对较弱。目前百度虽然可以正常收录微博的头条文章,但总体来说更倾向于有一定影响力,而且对于初创企业来说,爬取的频率相对较低。
总结:这8个提高网站抓取频率的SEO方法只是SEO人员常用的一些方法,仅供参考!
标签:如何提高抓取频率
转载:感谢您对Yudi Silent个人博客网站platform的认可,以及网站分享的经验、工具和文章。欢迎分享给您的个人站长或朋友圈,但转载请注明文章出处。
()
网站内容抓取工具(这款小说网站下载软件怎么做?软件功能介绍介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2021-09-10 10:04
)
在线图书抓取器可以帮助用户在网上快速采集小说,将TXT小说下载到电脑上阅读,适合喜欢看小说的朋友,现在很多用户喜欢通过网页查看小说并进入直接在浏览器中搜索小说就可以在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址,即可立即抓取目录,自动下载目录采集对应的章节内容,从而完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!
软件功能
1、网络书Grabber支持大部分网站,小说资源下载方便
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示操作步骤,可参考网络抢书者采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中
6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。
7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
查看全部
网站内容抓取工具(这款小说网站下载软件怎么做?软件功能介绍介绍
)
在线图书抓取器可以帮助用户在网上快速采集小说,将TXT小说下载到电脑上阅读,适合喜欢看小说的朋友,现在很多用户喜欢通过网页查看小说并进入直接在浏览器中搜索小说就可以在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址,即可立即抓取目录,自动下载目录采集对应的章节内容,从而完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!
软件功能
1、网络书Grabber支持大部分网站,小说资源下载方便
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示操作步骤,可参考网络抢书者采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中
6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。
7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
网站内容抓取工具(百度资源平台直播一节公开课,抓取友好性优化(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-09 18:19
大家好,今天百度资源平台正式播出了一个公开课,主要和大家聊聊网站猎取和收录的原理,这里我给大家详细的笔记(一字不漏看完后,可以说收录基本上问题不大。
百度爬虫的工作原理
首先百度的爬虫会和网站的首页进行交互,得到网站首页后,会理解页面,理解收录(类型,值计算),其次,会把@的所有网站首页的超链接被提取。如下图所示,首页上的超链接称为“反向链接”。下一轮爬虫的时候,爬虫会继续和这些超链接的页面进行交互,得到页面进行细化,一层一层的继续。抓取一层,构成抓取循环。
抓取友好优化
1、URL 规范:
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在如上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:
如上图,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址含有字符,而且这个网址中含有文章的标题,导致网址有偏差。与简单的 URL 相比,较长的相对较长的 URL 没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符足以显示URL的资源。
如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接:
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是常见的移动网站构建方式。从链接发现的角度来看,这两类网站并不友好。
Feed流推荐:大多数做Feed流的网站后台数据量很大,用户不断刷新就会出现新的内容,但是无论刷新多少次,可能只能刷新到大约 1% 爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使你有100万条内容,也可能只能抢到1-200万条。
仅搜索条目:如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫无法输入关键词然后再次爬取,所以爬虫只有爬到首页后才不会有回链。自然爬行和收录 并不理想。
解决方法:索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎甚至可以通过索引页抓取你的网站最新资源,而且新发布的资源应该是实时的。 (索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是反向链接。 (latest文章)的URL需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就够了,比如长城,基本上只用首页来做索引页。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么你提交了普通的收录却没有抓住?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好:
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:建议加载时间控制在2S以内,这样无论是用户还是爬虫,打开速度快的网站会更受青睐,二是避免不必要的跳转,虽然这只是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很有可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。
标准化http返回码:我们常见的301/302的正确使用和404的正确使用主要是常规问题。使用常规方法来解决它们。比如遇到无效资源,那就用404来做。不要使用一些特殊的返回状态代码。
访问稳定性优化:一是尽量选择国内大型DNS服务,保证站点的稳定性。对于域名DNS,阿里云其实是比较稳定可靠的。然后,其次,使用技术手段小心地阻止爬虫。对于爬虫,如果有特定资源不想在百度上显示,可以使用robots进行拦截。比如网站的后台链接多被机器人屏蔽。如果爬取频率过高,导致服务器压力过大,影响用户正常访问,可以通过资源平台的工具降低爬取频率。二是为了防止防火墙误禁止爬虫,所以建议您可以将搜索引擎的UA加入白名单。最后一点是服务器的稳定性,尤其是在短时间内提交大量优质资源的时候。这时候一定要注意服务器的稳定性,因为当你提交大量资源时,爬虫也会相应增加。这个时候会不会导致你的服务器?打开压力太大,这个问题需要站长注意。
<p>如上图所示,这三个例子都是被第三方防火墙拦截的状态。普通用户在这种状态下打开,搜索引擎在爬行的时候也会处于这种状态,所以如果遇到CC或者DDOS的时候,我们在打开防火墙的时候一定要放开搜索引擎的UA。 查看全部
网站内容抓取工具(百度资源平台直播一节公开课,抓取友好性优化(组图))
大家好,今天百度资源平台正式播出了一个公开课,主要和大家聊聊网站猎取和收录的原理,这里我给大家详细的笔记(一字不漏看完后,可以说收录基本上问题不大。
百度爬虫的工作原理
首先百度的爬虫会和网站的首页进行交互,得到网站首页后,会理解页面,理解收录(类型,值计算),其次,会把@的所有网站首页的超链接被提取。如下图所示,首页上的超链接称为“反向链接”。下一轮爬虫的时候,爬虫会继续和这些超链接的页面进行交互,得到页面进行细化,一层一层的继续。抓取一层,构成抓取循环。
抓取友好优化
1、URL 规范:
任何资源都是通过 URL 获取的。 URL是相对于网站的门牌号,所以URL规划很重要。尤其是在如上图所示的“待抓取网址”环境下,爬虫在首页的时候,不知道网址长什么样子。
优秀网址的特点是主流、简单,所以你可能不想做出一些让人看起来很直观的非主流风格。
优秀网址示例:
如上图,第一个是百度知道的链接。整个链接分为三个部分。第一部分是网站的站点,第二部分是资源类型,第三部分是资源ID。这种网址很简单,爬虫看起来很不错。
如上图,第三篇文章比百度多了一段。首先,第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录。最后一段是网站的内容 ID。像这样的网址也符合标准。
不友好网址示例:
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址含有字符,而且这个网址中含有文章的标题,导致网址有偏差。与简单的 URL 相比,较长的相对较长的 URL 没有优势。百度站长平台规则明确规定网址不能超过256字节。我个人建议URL长度控制在100字节以内,100个字符足以显示URL的资源。
如上图所示,此网址收录统计参数,可能会造成重复抓取,浪费网站权限。因此,可以不使用参数。如果必须使用参数,也可以保留必要的参数。参数字符实际上是可能的。使用常规连接符,例如“?”和“&”,以避免非主流连接器。
2、合理发现链接:
爬虫从首页开始一层一层的爬取,所以需要做好首页和资源页的URL关系。这个爬虫爬行比较省力。
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大部分移动站都不太关注发现链接关系,所以爬虫无法抓取到内容页面。
如上图所示,这两个站点是常见的移动网站构建方式。从链接发现的角度来看,这两类网站并不友好。
Feed流推荐:大多数做Feed流的网站后台数据量很大,用户不断刷新就会出现新的内容,但是无论刷新多少次,可能只能刷新到大约 1% 爬虫相当于一个用户。爬虫不可能用这种方式爬取网站的所有内容,所以会导致部分页面被爬取。即使你有100万条内容,也可能只能抢到1-200万条。
仅搜索条目:如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫无法输入关键词然后再次爬取,所以爬虫只有爬到首页后才不会有回链。自然爬行和收录 并不理想。
解决方法:索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎甚至可以通过索引页抓取你的网站最新资源,而且新发布的资源应该是实时的。 (索引页)不出来。这会导致搜索引擎甚至无法通过索引页面抓取最新的资源。第三点是反向链接。 (latest文章)的URL需要在源码中直接暴露出来,方便搜索引擎抓取。最后,索引页不要越多越好。几个高质量的索引页就够了,比如长城,基本上只用首页来做索引页。
最后给大家一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新的资源。这里有两点需要注意。 .
问:提交的资源越多越好吗?
A:收录 效果的核心始终是内容的质量。如果提交大量低质量、泛滥的资源,将导致惩罚性打击。
问:为什么你提交了普通的收录却没有抓住?
A:资源提交只能加速资源发现,不能保证短期抓取。当然,百度表示会不断优化算法,让优质内容更快被抓取。
3、访问友好:
抓取器必须与网站进行交互,并且必须保证网站的稳定性,这样抓取器才能正常抓取。那么访问友好性主要包括以下几个方面。
访问速度优化:建议加载时间控制在2S以内,这样无论是用户还是爬虫,打开速度快的网站会更受青睐,二是避免不必要的跳转,虽然这只是一小部分,但是网站里面还是有很多层次的跳转,所以对于爬虫来说,很有可能会在多层次跳转的同时断开。一般是把不带www的域名重定向到带WWW的域名,然后带WWW的域名需要重定向到https,最后更换新站。在这种情况下,将有三个或四个级别的重定向。如果有类似网站的修改,建议直接跳转到新域名。
标准化http返回码:我们常见的301/302的正确使用和404的正确使用主要是常规问题。使用常规方法来解决它们。比如遇到无效资源,那就用404来做。不要使用一些特殊的返回状态代码。
访问稳定性优化:一是尽量选择国内大型DNS服务,保证站点的稳定性。对于域名DNS,阿里云其实是比较稳定可靠的。然后,其次,使用技术手段小心地阻止爬虫。对于爬虫,如果有特定资源不想在百度上显示,可以使用robots进行拦截。比如网站的后台链接多被机器人屏蔽。如果爬取频率过高,导致服务器压力过大,影响用户正常访问,可以通过资源平台的工具降低爬取频率。二是为了防止防火墙误禁止爬虫,所以建议您可以将搜索引擎的UA加入白名单。最后一点是服务器的稳定性,尤其是在短时间内提交大量优质资源的时候。这时候一定要注意服务器的稳定性,因为当你提交大量资源时,爬虫也会相应增加。这个时候会不会导致你的服务器?打开压力太大,这个问题需要站长注意。
<p>如上图所示,这三个例子都是被第三方防火墙拦截的状态。普通用户在这种状态下打开,搜索引擎在爬行的时候也会处于这种状态,所以如果遇到CC或者DDOS的时候,我们在打开防火墙的时候一定要放开搜索引擎的UA。
网站内容抓取工具(CYY软件工作室“CYY网页提取助手”的需求及需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-09 18:17
在推出“CYY拾色助手”和“CYY录屏助手”之后,CYY软件工作室又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网站页面中,我们需要提取的一般是图片、文字和Flash,这些都是通过“CYY网页提取助手
”
CYY 网页提取助手输入网址
继推出“CYY拾色助手”和“CYY录屏助手”之后,CYY Software Studio又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网站页面中,我们需要提取的一般是图片、文字和Flash,这些需求都可以通过“CYY网页提取助手”来简单的满足。
首先,安装软件后,在程序的“地址”栏中输入网站的地址(如图1)。
图片1输入网站地址(点击图片查看大图)
然后就可以在程序的浏览区打开网址了(如图2)。
图2打开浏览网站(点击图片查看大图)
选择资源类型提取页面内容
接下来在“资源类型”中选择需要的内容并点击(如图3、图4、图5、图6、图7)。
图 3 资源类型列表
图4 资源提取图片(点击图片放大)
图5 资源提取Flash(点击图片放大)
资源提取图6 CSS
图 7 其他资源提取
已保存资源列表查找您想要的资源
保存您需要的资源后,可以在“保存的资源列表”中看到(如8)所示。
图 8 已保存资源列表
在列表中的文件上点击鼠标右键可以管理文件(如9)所示。
图9 管理资源列表中的文件
另外,如果您对程序的默认保存路径不满意,也可以手动更改为您喜欢的文件路径。
总结
这个软件虽然很小,但是很有用。对于一些想要批量保存网站上图片的朋友,可以通过“CYY网页提取助手”轻松实现。但是在使用编辑器的过程中,我发现该程序对页面上的Flash文件的解析不是很好,无法有效下载所需的视频文件。希望软件作者在以后的软件更新中逐步完善这个功能。
软件名称:
CYY 网页提取助手
版本信息:
1.0
软件大小:
0.78MB
软件语言:
中文
下载地址: 查看全部
网站内容抓取工具(CYY软件工作室“CYY网页提取助手”的需求及需求)
在推出“CYY拾色助手”和“CYY录屏助手”之后,CYY软件工作室又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网站页面中,我们需要提取的一般是图片、文字和Flash,这些都是通过“CYY网页提取助手
”
CYY 网页提取助手输入网址
继推出“CYY拾色助手”和“CYY录屏助手”之后,CYY Software Studio又推出了一款名为“CYY网页提取助手”的软件。顾名思义,它是一个可以帮助用户提取页面内容的工具。一般在网站页面中,我们需要提取的一般是图片、文字和Flash,这些需求都可以通过“CYY网页提取助手”来简单的满足。
首先,安装软件后,在程序的“地址”栏中输入网站的地址(如图1)。
图片1输入网站地址(点击图片查看大图)
然后就可以在程序的浏览区打开网址了(如图2)。
图2打开浏览网站(点击图片查看大图)
选择资源类型提取页面内容
接下来在“资源类型”中选择需要的内容并点击(如图3、图4、图5、图6、图7)。
图 3 资源类型列表
图4 资源提取图片(点击图片放大)
图5 资源提取Flash(点击图片放大)
资源提取图6 CSS
图 7 其他资源提取
已保存资源列表查找您想要的资源
保存您需要的资源后,可以在“保存的资源列表”中看到(如8)所示。
图 8 已保存资源列表
在列表中的文件上点击鼠标右键可以管理文件(如9)所示。
图9 管理资源列表中的文件
另外,如果您对程序的默认保存路径不满意,也可以手动更改为您喜欢的文件路径。
总结
这个软件虽然很小,但是很有用。对于一些想要批量保存网站上图片的朋友,可以通过“CYY网页提取助手”轻松实现。但是在使用编辑器的过程中,我发现该程序对页面上的Flash文件的解析不是很好,无法有效下载所需的视频文件。希望软件作者在以后的软件更新中逐步完善这个功能。
软件名称:
CYY 网页提取助手
版本信息:
1.0
软件大小:
0.78MB
软件语言:
中文
下载地址:
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-08 19:05
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
1.ProxyCrawl
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.Grab
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.Ferret
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X-Ray
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
[编辑推荐]
三大运营商2018年经营数据,今年表现如何?分享关于 2019 年将塑造数据中心行业的八项趋势的观点 |物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势 查看全部
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
1.ProxyCrawl
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.Grab
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.Ferret
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X-Ray
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
[编辑推荐]
三大运营商2018年经营数据,今年表现如何?分享关于 2019 年将塑造数据中心行业的八项趋势的观点 |物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势
网站内容抓取工具(优采云浏览器客户端和优采云采集器的区别?(一)_IT猫扑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-08 14:03
优采云浏览器客户端是一个自动化脚本采集工具,具有网络爬虫、网站抓取、多行提取数据库等多种功能。它还提供自动编码和可视化的exe生成操作。它不仅是一个网页采集浏览器,还是一个营销工具。欢迎有需要的用户到IT猫扑下载使用!
软件介绍
优采云Browser 是一个可视化的自动化脚本工具。我们可以通过设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。也可以使用逻辑运算来完成判断、循环、跳转等操作。所有功能完全免费组合,您可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序出售。
优采云浏览器功能:
1、自动编码
采集速度快,程序注重采集效率,页面解析速度非常快,不需要访问的页面或者广告可以直接屏蔽,加快访问速度。
2、自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,自由组合功能。
3、可视化操作
操作简单,图形操作完全可视化,无需专业IT人员。操作的内容是浏览器处理的内容。 采集 jax 和瀑布等很简单。一些js加密的数据也可以轻松获取,无需抓包分析。
4、Generate EXE
不仅是采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。它可以自动登录并自动识别验证码。它是一个通用浏览器。
5、项目管理
使用该解决方案,您可以直接生成单个应用程序。可以在优采云 浏览器之外运行单个程序。提供官方软件管理平台,用户可以通过该平台进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。
优采云浏览器和优采云采集器的区别?
优采云采集器采集速度快,适合采集大量数据。 优采云浏览器适用于处理更复杂的事情,比如采集流程不固定,也可以用于营销。
1.采集process
优采云采集器是采集网址、采集内容、发送内容三个固定流程。操作简单,可以快速处理最常见的采集情况。
优采云Browser 没有固定的进程。用户可以自由组合各种流程来实现想要的功能,更加灵活。
2.采集principle 查看全部
网站内容抓取工具(优采云浏览器客户端和优采云采集器的区别?(一)_IT猫扑)
优采云浏览器客户端是一个自动化脚本采集工具,具有网络爬虫、网站抓取、多行提取数据库等多种功能。它还提供自动编码和可视化的exe生成操作。它不仅是一个网页采集浏览器,还是一个营销工具。欢迎有需要的用户到IT猫扑下载使用!
软件介绍
优采云Browser 是一个可视化的自动化脚本工具。我们可以通过设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。也可以使用逻辑运算来完成判断、循环、跳转等操作。所有功能完全免费组合,您可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序出售。
优采云浏览器功能:
1、自动编码
采集速度快,程序注重采集效率,页面解析速度非常快,不需要访问的页面或者广告可以直接屏蔽,加快访问速度。
2、自定义流程
完全自定义采集流程。打开网页,输入数据,提取数据,点击网页元素,操作数据库,验证码识别,抓取循环记录,流程列表,条件判断,完全自定义流程,采集就像积木一样,自由组合功能。
3、可视化操作
操作简单,图形操作完全可视化,无需专业IT人员。操作的内容是浏览器处理的内容。 采集 jax 和瀑布等很简单。一些js加密的数据也可以轻松获取,无需抓包分析。
4、Generate EXE
不仅是采集器,还是一个营销工具。不仅可以将采集数据保存到数据库或其他地方,还可以将一些数据分组到各种网站。它可以自动登录并自动识别验证码。它是一个通用浏览器。
5、项目管理
使用该解决方案,您可以直接生成单个应用程序。可以在优采云 浏览器之外运行单个程序。提供官方软件管理平台,用户可以通过该平台进行授权等管理。每个用户都是开发者,每个人都可以从平台中获利。
优采云浏览器和优采云采集器的区别?
优采云采集器采集速度快,适合采集大量数据。 优采云浏览器适用于处理更复杂的事情,比如采集流程不固定,也可以用于营销。
1.采集process
优采云采集器是采集网址、采集内容、发送内容三个固定流程。操作简单,可以快速处理最常见的采集情况。
优采云Browser 没有固定的进程。用户可以自由组合各种流程来实现想要的功能,更加灵活。
2.采集principle
网站内容抓取工具(网站内容抓取工具scrapy的爬虫库/html爬虫框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-08 05:03
网站内容抓取工具scrapy的爬虫库/html爬虫框架jsoup针对不同网站采用不同的爬虫处理(变量字符串处理,循环,
你用的是什么语言?python还是java?
建议用jsoup
手机转来的,不要嘲笑我的语言背景,
个人觉得libuv和scikit-learn都不是特别好用,
twisted不错。还能做分布式服务,关键是很快,语言可以是python也可以是java,go。
题主可以看看这篇文章,希望对你有所帮助。
python实现http请求的一个主要原因是http协议的一致性,是url层次的“一致性”要求,这可以理解为整个http的“tcp”操作在tcp协议之上,当然为了满足不同的协议实现方式,一般还会有proto层,这种方式不仅简化了tcp的层次规范,还解决了不同的协议之间的数据格式问题,以便共同完成这个“tcp”的任务。
python不是有个库httplib吗?
pipeline
强烈推荐python的http包libev,去掉python内置的tcp层。极速。大部分用http库来进行http请求的web开发者,就是嫌麻烦,想直接把请求中的状态码分类简化。
我有两个简单版本, 查看全部
网站内容抓取工具(网站内容抓取工具scrapy的爬虫库/html爬虫框架)
网站内容抓取工具scrapy的爬虫库/html爬虫框架jsoup针对不同网站采用不同的爬虫处理(变量字符串处理,循环,
你用的是什么语言?python还是java?
建议用jsoup
手机转来的,不要嘲笑我的语言背景,
个人觉得libuv和scikit-learn都不是特别好用,
twisted不错。还能做分布式服务,关键是很快,语言可以是python也可以是java,go。
题主可以看看这篇文章,希望对你有所帮助。
python实现http请求的一个主要原因是http协议的一致性,是url层次的“一致性”要求,这可以理解为整个http的“tcp”操作在tcp协议之上,当然为了满足不同的协议实现方式,一般还会有proto层,这种方式不仅简化了tcp的层次规范,还解决了不同的协议之间的数据格式问题,以便共同完成这个“tcp”的任务。
python不是有个库httplib吗?
pipeline
强烈推荐python的http包libev,去掉python内置的tcp层。极速。大部分用http库来进行http请求的web开发者,就是嫌麻烦,想直接把请求中的状态码分类简化。
我有两个简单版本,
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-07 05:11
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
1.ProxyCrawl
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.Grab
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.Ferret
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X-Ray
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
[编辑推荐]
三大运营商2018年经营数据,今年表现如何?分享关于 2019 年将塑造数据中心行业的八项趋势的观点 |物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势 查看全部
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
1.ProxyCrawl
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.Grab
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.Ferret
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X-Ray
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
[编辑推荐]
三大运营商2018年经营数据,今年表现如何?分享关于 2019 年将塑造数据中心行业的八项趋势的观点 |物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势
网站内容抓取工具(网站内容抓取工具有很多,百度搜索站长平台的接口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2021-09-05 20:04
网站内容抓取工具有很多,可以下载个百度站长平台的接口,有很多的爬虫在抓取这些网站内容。无外乎就是几种方式。或者直接找网站相关开发者购买。
百度搜索站长平台,里面有比较详细的帮助文档,不过仅限对于站长的了解,
百度站长平台,
一家公司成功的因素太多了,只抓住其中一项,不可能成功。成功要抓住“点”,要想抓住,就要在细节处理到位,才能抓住“点”。
很多网站是接受个人站长的,你可以到他们的网站上注册个账号发布一些你的博客在上面进行申请,或者多找一些志同道合的人一起做。
站长之家,人人站长,
tobaseabmnmspro
现在最火的就是商务云做供应链的了,做云计算,你懂得。
企业网站一般用百度、网盟、搜狗、360
我们有个网站在线商城的产品了你可以看看
51buy牛网,
zsxtomic网站地址:js抓取工具|wordpress打包exe
来我这,
小联门站
看了楼上网站的回答都不是很专业。专业做站一年以上都知道,自己编写那要先做二次开发了。接着做推广,想办法让客户上来看到自己网站。这样才有东西用,毕竟站是你自己的。 查看全部
网站内容抓取工具(网站内容抓取工具有很多,百度搜索站长平台的接口)
网站内容抓取工具有很多,可以下载个百度站长平台的接口,有很多的爬虫在抓取这些网站内容。无外乎就是几种方式。或者直接找网站相关开发者购买。
百度搜索站长平台,里面有比较详细的帮助文档,不过仅限对于站长的了解,
百度站长平台,
一家公司成功的因素太多了,只抓住其中一项,不可能成功。成功要抓住“点”,要想抓住,就要在细节处理到位,才能抓住“点”。
很多网站是接受个人站长的,你可以到他们的网站上注册个账号发布一些你的博客在上面进行申请,或者多找一些志同道合的人一起做。
站长之家,人人站长,
tobaseabmnmspro
现在最火的就是商务云做供应链的了,做云计算,你懂得。
企业网站一般用百度、网盟、搜狗、360
我们有个网站在线商城的产品了你可以看看
51buy牛网,
zsxtomic网站地址:js抓取工具|wordpress打包exe
来我这,
小联门站
看了楼上网站的回答都不是很专业。专业做站一年以上都知道,自己编写那要先做二次开发了。接着做推广,想办法让客户上来看到自己网站。这样才有东西用,毕竟站是你自己的。
网站内容抓取工具(import.io有所获得种子加A轮共计一千多万美金万美金 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-05 04:09
)
随着提倡个性化的“web2.0”概念的兴起,UGC让我们从一个以下载为主的网络时代,进化到一个下载与上传并存的交互时代。这意味着互联网上的信息量变得更加丰富了,它带来的增加量也是我们难以预料的。面对海量海量的“大数据”,国内外衍生出了经典的网络爬虫工具。 .
首先,让我们把注意力转向国外。熟悉互联网和大数据的朋友一定听说过import.io。因种子加A轮融资总额超过1000万美元而引起国内人士的关注。 Import.io的不同之处在于,用户只需要在网站想要抓取数据的地方简单的点击几下,然后就可以根据你的操作计算出你想要抓取的数据,然后创建一个真正的-这些数据的实时连接,那么您只需要选择想要的导出格式,就可以得到一份指定内容的副本和实时更新的数据。
听起来真的很神奇,就像产品名称一样“神奇”。有兴趣的朋友可以体验一下,但需要注意的是import.io更适合一些列表数据,比如微博、店铺页面,这些类型往往不适用,因为它抓取的字段不是全部字段。它是基于特殊的选择性计算,所以用户需要根据自己的需要选择使用。
那么国内最经典的网络爬虫工具,你一定已经想到了。是行业经验最深的优采云采集器。它于 2005 年开发,目前拥有超过 400,000 名免费用户。与 Import.io 不同,优采云采集器 更注重准确性。在去那里之前,它需要用户的明确指示,即采集规则。执行操作,所以可以应用的网页类型更多,甚至整个网络。
因为优采云采集器的工作原理是提取网页结构的源代码,所以只要网页上能看到内容,无论布局如何都可以快速提取。最终捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬取的过程中,也可以选择不同的线程数来控制优采云采集器采集的速度。一般来说优采云采集器适用于对抓取、速度、完整性有明确要求的用户。
在程序员们惊为天人的高智商的发展下,网络信息和数据的爬行不再让我们感到疯狂。市面上还有很多新兴的或者仿制的网页抓取工具,但真正值得用户称赞的才是最好的,这里就不一一列举了。与国外的import.io相比,中国本土网页抓取工具优采云采集器开发较早,功能上也不逊色。看来国内大数据技术未来的发展值得期待!
查看全部
网站内容抓取工具(import.io有所获得种子加A轮共计一千多万美金万美金
)
随着提倡个性化的“web2.0”概念的兴起,UGC让我们从一个以下载为主的网络时代,进化到一个下载与上传并存的交互时代。这意味着互联网上的信息量变得更加丰富了,它带来的增加量也是我们难以预料的。面对海量海量的“大数据”,国内外衍生出了经典的网络爬虫工具。 .
首先,让我们把注意力转向国外。熟悉互联网和大数据的朋友一定听说过import.io。因种子加A轮融资总额超过1000万美元而引起国内人士的关注。 Import.io的不同之处在于,用户只需要在网站想要抓取数据的地方简单的点击几下,然后就可以根据你的操作计算出你想要抓取的数据,然后创建一个真正的-这些数据的实时连接,那么您只需要选择想要的导出格式,就可以得到一份指定内容的副本和实时更新的数据。
听起来真的很神奇,就像产品名称一样“神奇”。有兴趣的朋友可以体验一下,但需要注意的是import.io更适合一些列表数据,比如微博、店铺页面,这些类型往往不适用,因为它抓取的字段不是全部字段。它是基于特殊的选择性计算,所以用户需要根据自己的需要选择使用。
那么国内最经典的网络爬虫工具,你一定已经想到了。是行业经验最深的优采云采集器。它于 2005 年开发,目前拥有超过 400,000 名免费用户。与 Import.io 不同,优采云采集器 更注重准确性。在去那里之前,它需要用户的明确指示,即采集规则。执行操作,所以可以应用的网页类型更多,甚至整个网络。
因为优采云采集器的工作原理是提取网页结构的源代码,所以只要网页上能看到内容,无论布局如何都可以快速提取。最终捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬取的过程中,也可以选择不同的线程数来控制优采云采集器采集的速度。一般来说优采云采集器适用于对抓取、速度、完整性有明确要求的用户。
在程序员们惊为天人的高智商的发展下,网络信息和数据的爬行不再让我们感到疯狂。市面上还有很多新兴的或者仿制的网页抓取工具,但真正值得用户称赞的才是最好的,这里就不一一列举了。与国外的import.io相比,中国本土网页抓取工具优采云采集器开发较早,功能上也不逊色。看来国内大数据技术未来的发展值得期待!
网站内容抓取工具(让你离线快速浏览某个网页的内容Ultra所能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-05 04:06
TeleportUltra
Teleport Ultra 可以做的不仅仅是离线浏览网页(让你离线快速浏览网页内容当然是它的一个重要功能),它可以从互联网上的任何地方检索你想要的任何文件想要,它可以在你指定的时候自动登录你指定的网站下载你指定的内容,也可以用它来创建一个网站的完整镜像作为你自己的网站的参考。
WebZip
WebZip 将网站下载并压缩成单个ZIP文件,可以帮助您将某个站点的全部或部分数据压缩成ZIP格式,方便日后快速浏览这个网站 并且新版本的特点包括定时下载,还增强了漂亮的三维界面和传输曲线。
米霍夫图片下载器
Mihov 图片下载器是一个简单的工具,用于从网页下载所有图片。只需输入网络地址,软件就会完成其他工作。所有图片都会下载到您电脑硬盘的其中一个文件夹中。
WinHTTrack HTTrack
WinHTTrack HTTrack 是一个简单易用的离线浏览器实用程序。该软件允许您将一个网站从互联网传输到本地目录,从服务器递归创建所有结构,并获取html、图像和其他文件到您的计算机。重新创建了相关链接,让您可以自由浏览本地网站(适用于任何浏览器)。可以将多个网站镜像到一起,这样就可以从一个网站开始跳转到另一个网站。您还可以更新现有的镜像站点,或继续中断的传输。具有许多选项和功能的设备是完全可配置的。该软件的资源是开放的。
MaxprogWebDumper
MaxprogWebDumper 是一款网站 内容下载工具,可以自动下载网页的所有内容及其链接,包括内置的多媒体内容,供您离线浏览。 查看全部
网站内容抓取工具(让你离线快速浏览某个网页的内容Ultra所能)
TeleportUltra
Teleport Ultra 可以做的不仅仅是离线浏览网页(让你离线快速浏览网页内容当然是它的一个重要功能),它可以从互联网上的任何地方检索你想要的任何文件想要,它可以在你指定的时候自动登录你指定的网站下载你指定的内容,也可以用它来创建一个网站的完整镜像作为你自己的网站的参考。
WebZip
WebZip 将网站下载并压缩成单个ZIP文件,可以帮助您将某个站点的全部或部分数据压缩成ZIP格式,方便日后快速浏览这个网站 并且新版本的特点包括定时下载,还增强了漂亮的三维界面和传输曲线。
米霍夫图片下载器
Mihov 图片下载器是一个简单的工具,用于从网页下载所有图片。只需输入网络地址,软件就会完成其他工作。所有图片都会下载到您电脑硬盘的其中一个文件夹中。
WinHTTrack HTTrack
WinHTTrack HTTrack 是一个简单易用的离线浏览器实用程序。该软件允许您将一个网站从互联网传输到本地目录,从服务器递归创建所有结构,并获取html、图像和其他文件到您的计算机。重新创建了相关链接,让您可以自由浏览本地网站(适用于任何浏览器)。可以将多个网站镜像到一起,这样就可以从一个网站开始跳转到另一个网站。您还可以更新现有的镜像站点,或继续中断的传输。具有许多选项和功能的设备是完全可配置的。该软件的资源是开放的。
MaxprogWebDumper
MaxprogWebDumper 是一款网站 内容下载工具,可以自动下载网页的所有内容及其链接,包括内置的多媒体内容,供您离线浏览。
网站内容抓取工具(WebScrapermac软件激活教程!!请谨慎下载!!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-09-04 14:09
WebScraper Mac 是Mac os 系统上非常有用的网站data 提取工具。 WebScraper 可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL 即可开始。简单而强大。
WebScraper mac 软件激活教程
! ! !本软件15系统暂时无法破解! !请谨慎下载! ! !
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:
2、返回安装包,双击打开WebScraper注册机,如图:
3、点击WebScraper注册机左侧的Open,如图:
4、在应用中找到WebScraper,点击打开如图:
5、点击保存生成注册码!
6、Open WebScraper,显示已注册!
您不是VIP会员或积分不足,请升级VIP会员或充值观看教程。
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络构建
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。
编辑评论
如果您正在寻找一款好用的网站数据抓取工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以到本站下载! 查看全部
网站内容抓取工具(WebScrapermac软件激活教程!!请谨慎下载!!!)
WebScraper Mac 是Mac os 系统上非常有用的网站data 提取工具。 WebScraper 可以帮助您在 10 分钟内轻松抓取网页数据。只需输入起始 URL 即可开始。简单而强大。
WebScraper mac 软件激活教程
! ! !本软件15系统暂时无法破解! !请谨慎下载! ! !
1、下载完成后,打开“WebScraper mac”安装包,将左侧的WebScraper拖入右侧的应用程序中进行安装,如图:
2、返回安装包,双击打开WebScraper注册机,如图:
3、点击WebScraper注册机左侧的Open,如图:
4、在应用中找到WebScraper,点击打开如图:
5、点击保存生成注册码!
6、Open WebScraper,显示已注册!
您不是VIP会员或积分不足,请升级VIP会员或充值观看教程。
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、 快速轻松扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、easy to export-选择你想要的列
3、输出为 csv 或 json
4、 将所有图像下载到文件夹/采集并导出所有链接的新选项
5、 输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、 专为现代网络构建
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。抓到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能需要尝试将数据保存到 CouchDB 中。
编辑评论
如果您正在寻找一款好用的网站数据抓取工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以到本站下载!
网站内容抓取工具( V8版使用人数最多的采集软件最值得信赖的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-09-04 14:08
V8版使用人数最多的采集软件最值得信赖的软件)
优采云采集器V8版
用户最多的采集software,最值得信赖的采集software
提供细致的售前售后服务,给您良好的用户体验
什么是优采云采集器?
优采云采集器是自主研发的专业网络data采集/数据信息挖掘软件。软件配置灵活,可以方便快捷地从网页中抓取非结构化文本、图片、文件等资源信息,通过数据清洗、过滤、去噪等预处理,对数据进行整合、聚合、存储,然后对数据进行分析挖掘,最后呈现可用的结果。
优采云采集器软件产品优势
操作简单
规则简单,易学,数据易获取
高效稳定
分布式高速采集,缩短时间,提高效率
全网采集
响应任何网站的任何采集需求
谁需要优采云采集器?
优采云采集器能为您做什么?
政府机构
实时查看数据信息研究、舆情监测预警、国内外政策法规、经济动态等信息
企业应用
自动整合年报等数据信息,洞察市场,采集潜在客户信息,优化业绩。帮助您降低风险和成本,了解您的对手,并更快地做出决策;大数据流提升业务运营水平,发现新商机
电子商务
采集 商品、商业信息、用户评论。把握电商数据背后的巨大价值,提升运营效率
网站站长
及时采集你想要采集的内容,自动发布,维护网站,更新内容,更快速丰富网站内容
个人需求者
帮助学术研究人员和网络爱好者解决数据信息需求,替代数据信息手册采集。
为什么选择优采云采集器?
最常见的采集器
10年发展成就采集器;支持多个数据库; 关键词,链接替换;以任何文件格式下载;中文分词,汉英互译;无限采集
强大的data采集platform 查看全部
网站内容抓取工具(
V8版使用人数最多的采集软件最值得信赖的软件)
优采云采集器V8版
用户最多的采集software,最值得信赖的采集software
提供细致的售前售后服务,给您良好的用户体验
什么是优采云采集器?
优采云采集器是自主研发的专业网络data采集/数据信息挖掘软件。软件配置灵活,可以方便快捷地从网页中抓取非结构化文本、图片、文件等资源信息,通过数据清洗、过滤、去噪等预处理,对数据进行整合、聚合、存储,然后对数据进行分析挖掘,最后呈现可用的结果。
优采云采集器软件产品优势
操作简单
规则简单,易学,数据易获取
高效稳定
分布式高速采集,缩短时间,提高效率
全网采集
响应任何网站的任何采集需求
谁需要优采云采集器?
优采云采集器能为您做什么?
政府机构
实时查看数据信息研究、舆情监测预警、国内外政策法规、经济动态等信息
企业应用
自动整合年报等数据信息,洞察市场,采集潜在客户信息,优化业绩。帮助您降低风险和成本,了解您的对手,并更快地做出决策;大数据流提升业务运营水平,发现新商机
电子商务
采集 商品、商业信息、用户评论。把握电商数据背后的巨大价值,提升运营效率
网站站长
及时采集你想要采集的内容,自动发布,维护网站,更新内容,更快速丰富网站内容
个人需求者
帮助学术研究人员和网络爱好者解决数据信息需求,替代数据信息手册采集。
为什么选择优采云采集器?
最常见的采集器
10年发展成就采集器;支持多个数据库; 关键词,链接替换;以任何文件格式下载;中文分词,汉英互译;无限采集
强大的data采集platform
网站内容抓取工具(一下各种爆款的抓包工具的优劣势,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-03 14:01
作为软件测试工程师,抓包总是不可避免的:遇到问题需要抓包分析;需要定位bug,抓包;检查数据传输的安全性需要抓包;接口测试遇到不完整的需求 还需要抓包...正因为抓包在测试工作中无处不在,所以市场上就会有大量的抓包工具供大家选择。
之前我也发了一些文章来介绍一些常用的抓包工具,比如wireshark、Charles等,然后很多朋友在私信或留言中最常问的问题之一就是“什么是这个工具和xxx工具的区别??”或者“这个工具和xxx工具哪个更好用?”
那么,为了解决您的疑惑,让您合理选择更合适的工具,更好地辅助测试工作的执行,今天我们就来分析一下各种流行的抓包工具的优缺点。
提琴手
Fiddler 工具非常经典和强大。这一点大家应该明白。可以提供电脑端和移动端抓包,包括http和https协议,可以对消息进行抓包和分析;可以设置断点调试,拦截请求替换和数据篡改的消息,还可以进行请求构建,可以设置网络丢包延迟,APP弱网测试等。
所以,fiddler的第一个优点就是功能强大,功能齐全;
第二个优点是Fiddler是开源免费的,所有电脑只要安装就可以直接使用所有功能!这无疑是一个很大的优势,因为它也吸引了大量的用户!
当然,它也有自己的缺点:只能在windows下安装使用。如果你想在其他系统上抓包,比如MacOS系统,Linux系统,那么Fiddler就没用了。
查尔斯
Charles工具别名“Vase”,它是通过proxy抓包的,也就是我们访问网页的时候,我们配置proxy指向Charles监听的端口,然后所有的请求Charles都会帮忙我们转发并记录。
Charles 使用起来非常简单。配置好代理后,Charles 开始抓包。我们可以通过它的 GUI 直接查看包的内容。其实功能和用法和Fiddler很相似。还可以在电脑和手机上提供抓包分析、设置断点、弱网环境模拟等功能。那么它就不同于fiddler。它在哪里?
优点:Charles基于Java开发,具有良好的跨平台性能。因此,它不仅支持Windows系统,还支持MacOS和Linux操作系统;所以基本的非windows电脑都会选择Charles工具。捕获https协议的配置也很简单,只要安装charles的证书即可。缺点:
Charles 工具不是免费的。它需要购买许可证。如果你不买它,它会每30分钟断开一次。体验非常糟糕!
Wireshark
Wireshark 也可以在各种平台上安装使用,但其功能侧重点与 Charles&Fiddler 不同。主要用于捕获网络中所有协议的数据包,非常专业的分析网络协议和网络问题!
Wireshark工具的优点:可以选择特定的网卡来抓流量,那么只会抓到你关心的网卡通过的数据,针对性很强;可以捕获所有协议的数据包,捕获数据包的文本可以完全以OSI七层网络模型的格式显示出来,客户端和服务器之间的每一条交互消息都可以清楚地看到,以及详细的每个数据包的每个网络级别的内容显示。因此,该工具非常适合学习和分析网络协议。提供非常强大的过滤规则。 Wireshark 可以提供捕获前过滤或捕获后过滤,过滤规则非常详细,可以实现非常高的精度和细粒度的包过滤;它可以与TCPdump结合使用,分析在线服务器(Linux系统)上捕获的数据报文本,定位在线问题。 Wireshark工具的缺点:要想灵活使用,需要有一定的网络基础,对于初学者来说有一定的难度;无法解析https数据包,因为wireshark是链路层获取的数据包信息,所以获取的https数据包是加密数据,所以无法解析数据包的内容。当然,我们可以解密https包,但是操作有一定的复杂性,可能会消耗很多时间。打嗝套件
Burpsuite 工具也是基于 Java 语言开发的,因此它也可以在各种平台上使用,包括 Windows、MacOS 和 Linux。
Burpsuite 可以提供抓包功能。它还作为浏览器和网站之间的代理,实现消息拦截;还可以修改数据内容,转发功能;它甚至可以选择使用爬虫爬下网站相关数据...
但是,它绝对不仅仅是一个抓包工具,它集成了很多有用的小工具来完成更强大的功能,比如http请求转发、修改、扫描等,同时这些小工具还可以与BurpSuite 框架下相互定制攻击和扫描方案。
此工具的许多功能测试人员将使用它进行消息捕获和篡改数据。许多安全测试人员将使用它进行半自动网络安全审计。开发者还可以使用其扫描工具网站压力测试和攻击测试具有更广泛的功能。
但是它也有自己的缺点,就是不免费!每位用户每年费用为299美元,使用成本较高。
F12
F12是众多抓包工具中最简单最轻量的,因为它是浏览器内置的开发者工具,提供从浏览器抓包数据的功能。免安装,打开浏览器直接使用。它非常易于使用,适合入门级的初学者。 查看全部
网站内容抓取工具(一下各种爆款的抓包工具的优劣势,你了解多少?)
作为软件测试工程师,抓包总是不可避免的:遇到问题需要抓包分析;需要定位bug,抓包;检查数据传输的安全性需要抓包;接口测试遇到不完整的需求 还需要抓包...正因为抓包在测试工作中无处不在,所以市场上就会有大量的抓包工具供大家选择。
之前我也发了一些文章来介绍一些常用的抓包工具,比如wireshark、Charles等,然后很多朋友在私信或留言中最常问的问题之一就是“什么是这个工具和xxx工具的区别??”或者“这个工具和xxx工具哪个更好用?”
那么,为了解决您的疑惑,让您合理选择更合适的工具,更好地辅助测试工作的执行,今天我们就来分析一下各种流行的抓包工具的优缺点。
提琴手
Fiddler 工具非常经典和强大。这一点大家应该明白。可以提供电脑端和移动端抓包,包括http和https协议,可以对消息进行抓包和分析;可以设置断点调试,拦截请求替换和数据篡改的消息,还可以进行请求构建,可以设置网络丢包延迟,APP弱网测试等。
所以,fiddler的第一个优点就是功能强大,功能齐全;
第二个优点是Fiddler是开源免费的,所有电脑只要安装就可以直接使用所有功能!这无疑是一个很大的优势,因为它也吸引了大量的用户!
当然,它也有自己的缺点:只能在windows下安装使用。如果你想在其他系统上抓包,比如MacOS系统,Linux系统,那么Fiddler就没用了。
查尔斯
Charles工具别名“Vase”,它是通过proxy抓包的,也就是我们访问网页的时候,我们配置proxy指向Charles监听的端口,然后所有的请求Charles都会帮忙我们转发并记录。
Charles 使用起来非常简单。配置好代理后,Charles 开始抓包。我们可以通过它的 GUI 直接查看包的内容。其实功能和用法和Fiddler很相似。还可以在电脑和手机上提供抓包分析、设置断点、弱网环境模拟等功能。那么它就不同于fiddler。它在哪里?
优点:Charles基于Java开发,具有良好的跨平台性能。因此,它不仅支持Windows系统,还支持MacOS和Linux操作系统;所以基本的非windows电脑都会选择Charles工具。捕获https协议的配置也很简单,只要安装charles的证书即可。缺点:
Charles 工具不是免费的。它需要购买许可证。如果你不买它,它会每30分钟断开一次。体验非常糟糕!
Wireshark
Wireshark 也可以在各种平台上安装使用,但其功能侧重点与 Charles&Fiddler 不同。主要用于捕获网络中所有协议的数据包,非常专业的分析网络协议和网络问题!
Wireshark工具的优点:可以选择特定的网卡来抓流量,那么只会抓到你关心的网卡通过的数据,针对性很强;可以捕获所有协议的数据包,捕获数据包的文本可以完全以OSI七层网络模型的格式显示出来,客户端和服务器之间的每一条交互消息都可以清楚地看到,以及详细的每个数据包的每个网络级别的内容显示。因此,该工具非常适合学习和分析网络协议。提供非常强大的过滤规则。 Wireshark 可以提供捕获前过滤或捕获后过滤,过滤规则非常详细,可以实现非常高的精度和细粒度的包过滤;它可以与TCPdump结合使用,分析在线服务器(Linux系统)上捕获的数据报文本,定位在线问题。 Wireshark工具的缺点:要想灵活使用,需要有一定的网络基础,对于初学者来说有一定的难度;无法解析https数据包,因为wireshark是链路层获取的数据包信息,所以获取的https数据包是加密数据,所以无法解析数据包的内容。当然,我们可以解密https包,但是操作有一定的复杂性,可能会消耗很多时间。打嗝套件
Burpsuite 工具也是基于 Java 语言开发的,因此它也可以在各种平台上使用,包括 Windows、MacOS 和 Linux。
Burpsuite 可以提供抓包功能。它还作为浏览器和网站之间的代理,实现消息拦截;还可以修改数据内容,转发功能;它甚至可以选择使用爬虫爬下网站相关数据...
但是,它绝对不仅仅是一个抓包工具,它集成了很多有用的小工具来完成更强大的功能,比如http请求转发、修改、扫描等,同时这些小工具还可以与BurpSuite 框架下相互定制攻击和扫描方案。
此工具的许多功能测试人员将使用它进行消息捕获和篡改数据。许多安全测试人员将使用它进行半自动网络安全审计。开发者还可以使用其扫描工具网站压力测试和攻击测试具有更广泛的功能。
但是它也有自己的缺点,就是不免费!每位用户每年费用为299美元,使用成本较高。
F12
F12是众多抓包工具中最简单最轻量的,因为它是浏览器内置的开发者工具,提供从浏览器抓包数据的功能。免安装,打开浏览器直接使用。它非常易于使用,适合入门级的初学者。

